├── README.md
├── framework
├── vSphere体系架构.md
├── 网络虚拟化.md
├── 虚拟化架构、特点及优势.md
└── 虚拟地址的理解.md
├── papers
├── 01_Emerging_Virtualization_Technology.pdf
├── 02_HYPERVISOR_FOR_VIRTUALIZATION_IN_PRIVATE_CLOUD.pdf
├── 03_Secure_Virtualization_for_Cloud_Environment_Using_Hypervisor-based_Technology.pdf
├── 04_OPERATING_SYSTEM_VIRTUALIZATION_IN_THE_EDUCATION_OF_COMPUTER_SCIENCE_STUDENTS.pdf
├── 05_Virtualization_Technologies_and_Cloud_Securityadvantages,issues,and_perspectives.pdf
├── 06_Xen_and_the_Art_of_Virtualization.pdf
├── 07_Analysis_of_Virtualization_Technologies_for_High_Performance_Computing_Environments.pdf
├── 08_Research_on_Cloud_Computing_Based_on_Storage_Virtualization_in_Data_Center.pdf
├── 09_Architecture_for_Technology_Transformation.pdf
├── 10_A_Study_On_Virtualization_Techniques_And_Challenges_In_Cloud_Computing.pdf
├── 11_Virtual_Machine_Security_Guidelines_Version_1.0.pdf
├── 12_Comparative_Performance_Analysis_of_the_Virtualization_Technologies_in_Cloud_Computing.pdf
├── 13_Improving_Business_Performance_by_Employing_VirtualizationTechnology_A_Case_Study_in_the_Financial_Sector.pdf
├── 14_Consolidation_Using_Oracle's_SPARCVirtualization_Technologies.pdf
├── 15-Development_of_a_virtualization_systems_architecture_course_for_t.pdf
├── 16_Educational_Infrastructure_Using_Virtualization_Technologies_Experience_at_Kaunas_University_of_Technology.pdf
├── 17_Comparative_Study_of_Virtual_Machine_Software_Packages_with_Real_Operating_System.pdf
├── 18_Dell_EMC_Unity_Virtualization_Integration.pdf
├── 19_A_Study_On_Virtualization_And_Virtual_Machines.pdf
├── 20_Review_on_Virtualization_for_Cloud_Computing.pdf
├── 21_A_Survey_on_Virtualization_and_Hypervisor-based_Technology_in_Cloud_Computing_Environment.pdf
├── 22_STUDY_ON_VIRTUALIZATION_TECHNOLOGY_AND_ITS_IMPORTANCE_IN_CLOUD_COMPUTING_ENVIRONMENT.pdf
├── 23_Research_on_the_Virtualization_Technology_in_Cloud_Computing_Environment.pdf
├── 24_Research_and_Development_on_Network_Virtualization_Technologies_in_Japan.pdf
├── 25_Eliminate_Software_Development_and_Testing_Constraints_with_Service_Virtualization.pdf
├── 26_Network_Virtualization_A_Data_Plane_Perspective.pdf
├── 27_A_taxonomy_of_virtualization_technologies.pdf
├── 28_Network_Functions_Virtualisation.pdf
├── 29_Recommendations_of_the_National_Institute_of_Standards_and_Technology.pdf
├── 30_Big_Data_Virtualization_Why_and_How.pdf
├── 31_Server_Virtualization_Technology_and_ltsLatest_Trends.pdf
├── 32_Virtualization_Technologies_for_Cars_Solutions_to_increase_safety_and_security_of_vehicular_ECUs.pdf
├── 33_Virtualization_and_Future_Technologies.pdf
├── 34_Virtualization_and_the_Computer_Architecture.pdf
├── 35_Virtualization_Introduction_QSM_White_Paper.pdf
├── 36_Security_Implications_of_Different_Virtualization_Approaches_for_Secure_Cyber_Architectures.pdf
├── 37_Server_Virtualization_A_Step_Toward_Cost_Efficiency_and_Business_Agility.pdf
├── 38_Performance_Implications_of_Virtualization.pdf
├── 39_State-of-the-Art_of_Virtualization,_its_Security_Threats_and_Deployment_Models.pdf
├── 40_HMI_&_Virtualization_in_Process_Automation.pdf
├── 41_Terra_A_Virtual_Machine-Based_Platform_for_Trusted_Computing.pdf
├── 42_Research_on_Virtualization_Technology_for_Real-time_Reconfigurable_Systems.pdf
├── 43_A_Survey_on_Virtualization_Technologies.pdf
├── 44_Intel_Virtualization_Technology.pdf
├── 45_EXPERIENCES_WITH_VIRTUALIZATION_TECHNOLOGY_IN_EDUCATION.pdf
├── 46_VIRTUALIZATION_IN_CLOUD_COMPUTING.pdf
├── 47_Systematic_Study_of_Virtualization.pdf
├── 48_Virtualization_in_Cloud_Computing__Developments_and_Trends.pdf
├── 49_Virtualization_Overview.pdf
├── 50_ArcGIS_Pro_Virtualization.pdf
├── 51_Intel®_Virtualization_Technology(VT)_in_Converged_Application_Platforms.pdf
├── 52_Virtualization_Technology_Whitepaper-Infrastructure_to_Perform_Static_Tools_and_Binary_Analysis.pdf
├── 53_A_Survey_on_Virtual_Machine_Security.pdf
├── 54_Intel®_Virtualization_Technology_Hardware_Support_for_Efficient_Processor_Virtualization.pdf
├── 55_Network_functions_virtualization.pdf
├── 56_BEYOND_VIRTUALIZATION_The_MontaVista_Approach_to_Multi-core_SoC_Resource_Allocation_and_Control.pdf
├── 57_A_PRINCIPLED_TECHNOLOGIES_WHITE_PAPER.pdf
├── 58_Data_Virtualization–Flexible_Technology_for_the_Agile_Enterprise.pdf
├── 59_Top_5_Things_You_Need_in_a_Virtualization_Management_Solution.pdf
├── 60_The_IBM_Advantage_for_Implementing_the_Virtualization_Reference_Architecture.pdf
└── README.md
├── product
├── KVM简介及安装.md
├── OpenStack介绍及原理.md
├── OpenStack知识体系.md
├── P8整理的OpenStack构架,希望能帮助到你.md
├── Xen虚拟化详解.md
├── vmm执行基本流程.md
├── 操作系统级虚拟化实现.md
├── 系统级虚拟化实现.md
├── 虚拟化技术.md
├── 虚拟化技术概要之VMM结构.md
├── 虚拟化的必要性.md
└── 软件模拟虚拟化、全虚拟化、半虚拟化、硬件辅助虚拟化和容器.md
├── vedio
└── README.md
└── virtualization_type
├── README.md
├── cpu_virtualization
├── CPU的三种虚拟化机制.md
└── CPU虚拟化.md
├── io_virtualization
├── IO虚拟化.md
├── IO虚拟化三种形式.md
├── IO虚拟化基本原理.md
└── IO虚拟化面临的问题及解决方案.md
├── memory_virtualization
├── KVM内存虚拟化.md
├── 内存虚拟化-shadow实现.md
├── 内存虚拟化.md
└── 内存虚拟化影子页表技术和EPT技术.md
├── storage_virtualization
├── Neutron实现网络虚拟化.md
├── 什么是文件虚拟化(File Virtualization)
├── 在Linux平台使用mhVTL虚拟化磁带库.md
├── 块虚拟化.md
├── 基于主机的虚拟化存储应用及注意事项.md
├── 带内虚拟化和带外虚拟化.md
├── 文件系统虚拟化解决方案.md
├── 磁盘虚拟化.md
└── 详解存储子系统的虚拟化.md
├── 全虚拟化和半虚拟化.md
├── 虚拟化之四种网络模型.md
├── 虚拟化五种类型.md
├── 虚拟化技术.md
├── 虚拟化技术分类.md
├── 虚拟化架构图.md
└── 虚拟化的分类
/framework/vSphere体系架构.md:
--------------------------------------------------------------------------------
1 | # vSphere 体系架构
2 |
3 | ## 1. vSphere 体系
4 |
5 | 
6 |
7 | 
8 |
9 | ### 1.1 VMware vSphere 6组件
10 | #### 1.1.1 VMware ESXi
11 | vSphere 早期版本存在ESX,ESX:虚拟机平台管理程序,ESX包含了一个VMware Kernel(虚拟化管理内核)和一个命令行式的Service Console(服务控制台)(vSphere 4.1将是最后一个包含ESX版本的平台,其后续版本仅将包含ESXi)
12 | ESXi(又名vSphere Hypervisor):基本功能同ESX,但ESXi仅保留管理内核(VMKernel)以及VMM而不再包含服务控制台(用vCLI 或 PowerCLI替代其大部分功能),所以体积很小,可安装在嵌入式设备如U盘上。
13 |
14 | #### 1.1.2 VMware vCenter Server
15 | 虚拟化平台管理中心控制系统,有windows和linux版,
16 |
17 | #### 1.1.3 vSphere Update Manager
18 | vSphere环境升级,打补丁的工具,
19 |
20 | #### 1.1.4 VMware vSphere Client和vSphere Web Client
21 | vSphere客户端,
22 |
23 | #### 1.1.5 vRealize Orchestrator(原名vCenter Orchestrator)
24 | 自动化引擎,建立工作流的工具---任务编排器
25 |
26 | #### 1.1.6 VMware Data Protection
27 | 数据保护-----备份虚拟机
28 |
29 | #### 1.1.7 vSphere with Operations Management(单独购买或购买套件)
30 | 监控和管理的工具
31 |
32 | ### 1.2 产品与特性
33 | #### 1.2.1 VMware ESXi
34 | #### 1.2.2 VMware vCenter Server
35 | #### 1.2.3 vSphere Update Manager
36 | #### 1.2.4 VMware vSphere Client and vSphere Web Client
37 | #### 1.2.5 VMware vShield Zones
38 | #### 1.2.6 VMware vCenter Orchestrator
39 | #### 1.2.7 vSphere Virtual Symmetric Multi-Processing
40 | #### 1.2.8 vSphere vMotion and Storage vMotion
41 | #### 1.2.9 vSphere Distributed Resource Scheduler
42 | #### 1.2.10 vSphere Storage DRS
43 | #### 1.2.11 Storage I/O Control and Network I/O Control
44 | #### 1.2.12 Profile-Driven Storage
45 | #### 1.2.13 vSphere High Availability
46 | #### 1.2.14 vSphere Fault Tolerance
47 | #### 1.2.15 vSphere Storage APIs(应用程序接口)for Data Protection and VMware Data Recovery
48 |
49 | ### 1.3 必须使用vCenter Server才能支持的特性
50 | #### 1.3.1 virtual machine templates(虚拟机模版)
51 | #### 1.3.2 role-based access controls (基于角色的访问控制)
52 | #### 1.3.3 fine-grained resource allocation controls (粒度的资源关联控制)
53 | #### 1.3.4 VMware Vmotion (在线迁移)
54 | #### 1.3.5 VMware Distributed Resource Scheduler (分布式资源调度)
55 | #### 1.3.6 VMware High Availability (高可用性)
56 | #### 1.3.7 VMware Fault Tolerance (容错)
57 | #### 1.3.8 Enhanced VMotion Compatibility (EVC) (增强vMotion兼容性)
58 | #### 1.3.9 Host profiles (主机脚本)
59 | #### 1.3.10 vNetwork Distributed Switches (分布式交换机)
60 | #### 1.3.11 Storage and Network I/O Control (存储和网络I/O控制)
61 | #### 1.3.12 Sphere Storage DRS (存储分布式资源调度)
62 |
63 |
64 | VMware虚拟化拓扑图:
65 |
66 |
67 | 
68 |
69 | ## 2. 传统架构VS虚拟化
70 | 6.0与5.5版本的对比:
71 |
72 |
73 | 
74 |
75 |
76 | 传统物理基础架构: 虚拟化架构:
77 |
78 |
79 | 
80 |
81 |
82 |
83 | 
84 |
85 |
86 |
87 | 
88 |
89 |
90 |
91 | 
92 |
93 |
94 |
95 | 
96 |
97 |
98 |
99 | 
100 |
101 |
102 |
103 | 
104 |
105 |
106 |
107 | 
108 |
109 |
110 |
111 | 
112 |
113 | ## 3. 虚拟化的优势
114 | ### 3.1 虚拟化优点:
115 | 优点1:提高硬件整合率:虚拟化使得低利用率的服务器负载整合到一台服务器,安全可靠地达到很高的硬件利用率
116 | 优点2:快速部署服务器
117 | 优点3:降低整体投资成本(TCO)将不同应用负载虚拟化使得用户可以大大减少服务器的数量典型的平均整合比率在8:1到15:1
118 | 优点4:节能降耗
119 | 优点5:提高了系统可用性物理主机被虚拟化后,计算资源均被池化。当资源池里一个节点发生故障时,运行在其上的虚拟机将自动迁移到健康的物理主机上。
120 |
121 | ## 4. VMware vSphere 方案概览
122 | ### 4.1 基于vSphere的虚拟数据中心基础架构
123 | vSphere 可加快现有数据中心向云计算的转变,同时还支持兼容的公有云服务,从而为业界唯一的混合云模式奠定了基础。vSphere,许多群体称之为“ESXi”,即底层虚拟化管理程序体系结构的名称,这是一种采用尖端技术的裸机虚拟化管理程序。
124 | vSphere 是市场上最先进的虚拟化管理程序,具有许多独特的功能和特性,其中包括:
125 | #### 1.4.1.1 磁盘空间占用量小,因此可以缩小受攻击面并减少补丁程序数量
126 | #### 1.4.1.2 不依赖操作系统,并采用加强型驱动程序
127 | #### 1.4.1.3 具备高级内存管理功能,能够消除重复内存页或压缩内存页
128 | #### 1.4.1.4 通过集成式的集群文件系统提供高级存储管理功能
129 | #### 1.4.1.5 高I/O可扩展性可消除I/O瓶颈
130 |
131 | 
132 |
133 | 基于VMware vSphere 的虚拟数据中心由基本物理构建块(例如x86 虚拟化服务器、存储器网络和阵列、IP 网络、管理服务器和桌面客户端)组成。
134 |
135 | ### 4.2 vSphere 数据中心的物理拓扑
136 | 
137 |
138 | vSphere 数据中心拓扑包括下列组件:
139 | #### 1.4.2.6 计算服务器:ESXi主机群,在祼机上运行ESXi 的业界标准 x86 服务器。ESXi 软件为虚拟机提供资源,并运行虚拟机。每台计算服务器在虚拟环境中均称为独立主机。可以将许多配置相似的x86 服务器组合在一起,并与相同的网络和存储子系统连接,以便提供虚拟环境中的资源集合(称为群集)。
140 | #### 1.4.2.7 存储网络和阵列光纤通道:SAN 阵列、iSCSI SAN 阵列和 NAS 阵列是广泛应用的存储技术,VMware vSphere支持这些技术以满足不同数据中心的存储需求。
141 | #### 1.4.2.8 IP 网络:每台计算服务器都可以有多个物理网络适配器,为整个VMware vSphere 数据中心提供高带宽和可靠的网络连接。
142 | #### 1.4.2.9 vCenter Server: vCenter Server 为数据中心提供一个单一控制点
143 | #### 1.4.2.10 管理客户端:这些界面包括VMware vSphere Client (vSphere Client)、vSphere Web Client(用于通过 Web 浏览器访问)或 vSphere Command-Line Interface (vSphere CLI)。
144 |
145 | ### 4.3 ESXi架构和组件
146 | 如下图所示,从体系结构来说ESXi包含虚拟化层和虚拟机,而虚拟化层有两个重要组成部分:虚拟化管理程序VMkernel和虚拟机监视器VMM(守护进程)。ESXi主机可以通过vSphere Client、vCLI、API/SDK和CIM接口接入管理。
147 | 1. VMkernel 是虚拟化的核心和推动力,由VMware 开发并提供与其他操作系统提供的功能类似的某些功能,如进程创建和控制、信令、文件系统和进程线程。VMkernel控制和管理服务器的实际资源,它用资源管理器排定VM顺序,为它们动态分配CPU时间、内存和磁盘及网络访问。它还包含了物理服务器各种组件的设备驱动器——例如,网卡和磁盘控制卡、VMFS文件系统和虚拟交换机。VMkernel 专用于支持运行多个虚拟机及提供如下核心功能:
148 | 资源调度----->CPU、内存
149 | I/O 堆栈----->网卡、存储
150 | 设备驱动程序------>网卡等
151 |
152 | 2. 每个 ESXi 主机的关键组件是一个称为VMM 的进程(守护进程)。对于每个已开启的虚拟机,将在VMkernel中运行一个 VMM。虚拟机开始运行时,控制权将转交给VMM,然后由 VMM 依次执行虚拟机发出的指令。VMkernel 将设置系统状态,以便VMM 可以直接在硬件上运行。然而,虚拟机中的操作系统并不了解此次控制权转交,而会认为自己是在硬件上运行。VMM 使虚拟机可以像物理机一样运行,而同时仍与主机和其他虚拟机保持隔离。因此,如果单台虚拟机崩溃,主机本身以及主机上的其他虚拟机将不受任何影响。
153 |
154 | ### 4.4 虚拟机的组件:操作系统、VMware Tools 以及虚拟资源和硬件。
155 | #### 1.4.4.1 操作系统
156 | 虚拟机与所有标准x86 操作系统和应用程序完全兼容。在一台物理主机的不同虚拟机里,可以根据应用需求同时运行不同的x86操作系统,彼此之间不会冲突,且对x86操作系统无需进行任何修改。
157 | #### 1.4.4.2 Vmware Tools
158 | VMware Tools 是一套实用程序,能够提高虚拟机的客户操作系统的性能,并改善对虚拟机的管理。VMwareTools 服务是一项在客户操作系统内执行各种功能的服务。该服务在客户操作系统启动时自动启动。该服务可执行的功能包括:
159 |
160 | ①将消息从 ESXi 主机传送到客户操作系统。
161 | ②向ESXi主机发送心跳信号,使其知道客户操作系统正在运行。
162 | ③实现客户操作系统与主机操作系统之间的时间同步。
163 | ④在虚拟机中运行脚本并执行命令。
164 | ⑤为使用 VMware VIX API 创建的与客户操作系统绑定的调用提供支持,除Mac OS X 客户操作系统外。
165 | ⑥允许指针在 Windows 客户操作系统的客户机和Workstation 之间自由移动。
166 | ⑦帮助创建 Windows 客户操作系统中由特定备份应用程序使用的快照。
167 | ⑧在客户操作系统中安装 VMware Tools 后,它还会提供 VMware 设备驱动程序,包括 SVGA 显示驱动程序、用于某些客户操作系统的 vmxnet 网络连接驱动程序、用于某些客户操作系统的 BusLogic SCSI 或 LSI Logic驱动程序、用于在虚拟机之间进行有效内存分配的内存控制驱动程序、用于将 I/O 置于静默状态(使用VMware Data Recovery 或 VMware vStorage API for Data Recovery)以进行备份的同步驱动程序、用于实现文件夹共享的内核模块以及 VMware 鼠标驱动程序。
168 | ⑨各种驱动程序:
169 |
170 | ### 4.3 虚拟硬件
171 | 每个虚拟机都有虚拟硬件,这些虚拟硬件在所安装的客户操作系统及其应用中显示为物理硬件。每个客户操作系统都能识别出常规硬件设备,但它并不知道这些设备实际上是虚拟设备。虚拟机具有统一的硬件(少数选项可以由系统管理员控制)。统一硬件使得虚拟机可以跨vSphere 主机进行迁移
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
--------------------------------------------------------------------------------
/framework/网络虚拟化.md:
--------------------------------------------------------------------------------
1 | # 网络虚拟化
2 |
3 | ## 前言
4 |
5 | 网络虚拟化相对计算、存储虚拟化来说是比较抽象的,以我们在学校书本上学的那点网络知识来理解网络虚拟化可能是不够的。
6 | 在我们的印象中,网络就是由各种网络设备(如交换机、路由器)相连组成的一个网状结构,世界上的任何两个人都可以通过网络建立起连接。
7 | 带着这样一种思路去理解网络虚拟化可能会感觉云里雾里——这样一个庞大的网络如何实现虚拟化?
8 | 其实,网络虚拟化更多关注的是数据中心网络、主机网络这样比较「细粒度」的网络,所谓细粒度,是相对来说的,是深入到某一台物理主机之上的网络结构来谈的。
9 | 如果把传统的网络看作「宏观网络」的话,那网络虚拟化关注的就是「微观网络」。网络虚拟化的目的,是要节省物理主机的网卡设备资源。从资源这个角度去理解,可能会比较好理解一点。
10 |
11 | ## 传统网络架构
12 | 在传统网络环境中,一台物理主机包含一个或多个网卡(NIC),要实现与其他物理主机之间的通信,需要通过自身的 NIC 连接到外部的网络设施,如交换机上,如下图所示。
13 |
14 |
15 |
16 | 
17 |
18 |
19 | 这种架构下,为了对应用进行隔离,往往是将一个应用部署在一台物理设备上,这样会存在两个问题,1)是某些应用大部分情况可能处于空闲状态,2)是当应用增多的时候,只能通过增加物理设备来解决扩展性问题。不管怎么样,这种架构都会对物理资源造成极大的浪费。
20 |
21 | ## 虚拟化网络架构
22 | 为了解决这个问题,可以借助虚拟化技术对一台物理资源进行抽象,将一张物理网卡虚拟成多张虚拟网卡(vNIC),通过虚拟机来隔离不同的应用。
23 | 这样对于上面的问题 1),可以利用虚拟化层 Hypervisor 的调度技术,将资源从空闲的应用上调度到繁忙的应用上,达到资源的合理利用;针对问题 2),可以根据物理设备的资源使用情况进行横向扩容,除非设备资源已经用尽,否则没有必要新增设备。这种架构如下所示。
24 |
25 |
26 |
27 | 
28 |
29 |
30 |
31 | 其中虚拟机与虚拟机之间的通信,由虚拟交换机完成,虚拟网卡和虚拟交换机之间的链路也是虚拟的链路,整个主机内部构成了一个虚拟的网络,如果虚拟机之间涉及到三层的网络包转发,则又由另外一个角色——虚拟路由器来完成。
32 | 一般,这一整套虚拟网络的模块都可以独立出去,由第三方来完成,如其中比较出名的一个解决方案就是 Open vSwitch(OVS)。
33 | OVS 的优势在于它基于 SDN 的设计原则,方便虚拟机集群的控制与管理,另外就是它分布式的特性,可以「透明」地实现跨主机之间的虚拟机通信,如下是跨主机启用 OVS 通信的图示。
34 |
35 |
36 | 
37 |
38 |
39 | 总结下来,网络虚拟化主要解决的是虚拟机构成的网络通信问题,完成的是各种网络设备的虚拟化,如网卡、交换设备、路由设备等。
40 |
41 | ## Linux 下网络设备虚拟化的几种形式
42 | 为了完成虚拟机在同主机和跨主机之间的通信,需要借助某种“桥梁”来完成用户态到内核态(Guest 到 Host)的数据传输,这种桥梁的角色就是由虚拟的网络设备来完成,上面介绍了一个第三方的开源方案——OVS,它其实是一个融合了各种虚拟网络设备的集大成者,是一个产品级的解决方案。
43 | 但 Linux 本身由于虚拟化技术的演进,也集成了一些虚拟网络设备的解决方案,主要有以下几种:
44 |
45 | ### (1)TAP/TUN/VETH
46 | TAP/TUN 是 Linux 内核实现的一对虚拟网络设备,TAP 工作在二层,TUN 工作在三层。Linux 内核通过 TAP/TUN 设备向绑定该设备的用户空间程序发送数据,反之,用户空间程序也可以像操作物理网络设备那样,向 TAP/TUN 设备发送数据。
47 | 基于 TAP 驱动,即可实现虚拟机 vNIC 的功能,虚拟机的每个 vNIC 都与一个 TAP 设备相连,vNIC 之于 TAP 就如同 NIC 之于 eth。
48 | 当一个 TAP 设备被创建时,在 Linux 设备文件目录下会生成一个对应的字符设备文件,用户程序可以像打开一个普通文件一样对这个文件进行读写。
49 | 比如,当对这个 TAP 文件执行 write 操作时,相当于 TAP 设备收到了数据,并请求内核接受它,内核收到数据后将根据网络配置进行后续处理,处理过程类似于普通物理网卡从外界收到数据。当用户程序执行 read 请求时,相当于向内核查询 TAP 设备是否有数据要发送,有的话则发送,从而完成 TAP 设备的数据发送。
50 | TUN 则属于网络中三层的概念,数据收发过程和 TAP 是类似的,只不过它要指定一段 IPv4 地址或 IPv6 地址,并描述其相关的配置信息,其数据处理过程也是类似于普通物理网卡收到三层 IP 报文数据。
51 | VETH 设备总是成对出现,一端连着内核协议栈,另一端连着另一个设备,一个设备收到内核发送的数据后,会发送到另一个设备上去,这种设备通常用于容器中两个 namespace 之间的通信。
52 |
53 | ### (2)Bridge#
54 | Bridge 也是 Linux 内核实现的一个工作在二层的虚拟网络设备,但不同于 TAP/TUN 这种单端口的设备,Bridge 实现为多端口,本质上是一个虚拟交换机,具备和物理交换机类似的功能。
55 | Bridge 可以绑定其他 Linux 网络设备作为从设备,并将这些从设备虚拟化为端口,当一个从设备被绑定到 Bridge 上时,就相当于真实网络中的交换机端口上插入了一根连有终端的网线。
56 | 如下图所示,Bridge 设备 br0 绑定了实际设备 eth0 和 虚拟设备设备 tap0/tap1,当这些从设备接收到数据时,会发送给 br0 ,br0 会根据 MAC 地址与端口的映射关系进行转发。
57 |
58 |
59 | 
60 |
61 |
62 | 因为 Bridge 工作在二层,所以绑定到它上面的从设备 eth0、tap0、tap1 均不需要设 IP,但是需要为 br0 设置 IP,因为对于上层路由器来说,这些设备位于同一个子网,需要一个统一的 IP 将其加入路由表中。
63 | 这里有人可能会有疑问,Bridge 不是工作在二层吗,为什么会有 IP 的说法?其实 Bridge 虽然工作在二层,但它只是 Linux 网络设备抽象的一种,能设 IP 也不足为奇。
64 | 对于实际设备 eth0 来说,本来它是有自己的 IP 的,但是绑定到 br0 之后,其 IP 就失效了,就和 br0 共享一个 IP 网段了,在设路由表的时候,就需要将 br0 设为目标网段的地址。
65 |
66 | ## 总结
67 | 传统网络架构到虚拟化的网络架构,可以看作是宏观网络到微观网络的过渡
68 | TAP/TUN/VETH、Bridge 这些虚拟的网络设备是 Linux 为了实现网络虚拟化而实现的网络设备模块,很多的云开源项目的网络功能都是基于这些技术做的,比如 Neutron、Docker network 等。
69 | OVS 是一个开源的成熟的产品级分布式虚拟交换机,基于 SDN 的思想,被大量应用在生产环境中。
70 |
--------------------------------------------------------------------------------
/framework/虚拟化架构、特点及优势.md:
--------------------------------------------------------------------------------
1 | # 虚拟化架构、特点及优势
2 |
3 | # 1. 虚拟化架构
4 |
5 | 根据在整个系统中的位置不同,虚拟化架构分为以下几种:
6 | * 寄居虚拟化架构
7 | * 裸金属虚拟化架构
8 | * 操作系统虚拟化架构
9 | * 混合虚拟化架构
10 |
11 | 1) 寄居虚拟化架构
12 | 寄居虚拟化架构指在宿主操作系统之上安装和运行虚拟化程序,依赖于宿主操作系统对设备的支持和物理资源的管理。(类似 Vmware Workstation 的程序)
13 | 
14 |
15 | 2) 裸金属虚拟化架构
16 | 裸金属虚拟化架构指直接在硬件上面安装虚拟化软件,再在其上安装操作系统和应用,依赖虚拟层内核和服务器控制台进行管理。
17 | 
18 |
19 | 3) 操作系统虚拟化架构
20 | 操作系统虚拟化架构在操作系统层面增加虚拟服务器功能。操作系统虚拟化架构把单个的操作系统划分为多个容器,使用容器管理器来进行管理。
21 | 宿主操作系统负责在多个虚拟服务器(即容器)之间分配硬件资源,并且让这些服务器彼此独立。
22 |
23 | 4) 混合虚拟化架构
24 | 混合虚拟化架构将一个内核级驱动器插入到宿主操作系统内核。这个驱动器作为虚拟硬件管理器来协调虚拟机和宿主操作系统之间的硬件访问。
25 | 
26 |
27 | # 2. 虚拟化特点
28 | 虚拟化具有以下特点:
29 | * 分区:对物理机分区,可实现在单一物理机上同时运行多个虚拟机。
30 | * 隔离:同一物理机上多个虚拟机相互隔离。
31 | * 封装:整个虚拟机执行环境封装在独立文件中。
32 | * 独立:虚拟机无须修改,可运行在任何物理机上。
33 |
--------------------------------------------------------------------------------
/framework/虚拟地址的理解.md:
--------------------------------------------------------------------------------
1 | # 虚拟地址的理解
2 |
3 | 在进入正题前先来谈谈操作系统内存管理机制的发展历程,了解这些有利于我们更好的理解目前操作系统的内存管理机制。
4 |
5 | ## 1. 早期的内存分配机制
6 |
7 | 在 早期的计算机中,要运行一个程序,会把这些程序全都装入内存,程序都是直接运行在内存上的,也就是说程序中访问的内存地址都是实际的物理内存地址。当计算机同时运行多个程序时,必须保证这些程序用到的内存总量要小于计算机实际物理内存的大小。那当程序同时运行多个程序时,操作系统是如何为这些程序分配内存 的呢?下面通过实例来说明当时的内存分配方法:
8 |
9 | 某台计算机总的内存大小是 128M ,现在同时运行两个程序 A 和 B , A 需占用内存 10M , B 需占用内存 110 。计算机在给程序分配内存时会采取这样的方法:先将内存中的前 10M 分配给程序 A ,接着再从内存中剩余的 118M 中划分出 110M 分配给程序 B 。这种分配方法可以保证程序 A 和程序 B 都能运行,但是这种简单的内存分配策略问题很多。
10 |
11 | 
12 | 图1 早期的内存分配方法
13 |
14 | * 问题 1 :进程地址空间不隔离。由于程序都是直接访问物理内存,所以恶意程序可以随意修改别的进程的内存数据,以达到破坏的目的。有些非恶意的,但是有 bug 的程序也可能不小心修改了其它程序的内存数据,就会导致其它程序的运行出现异常。这种情况对用户来说是无法容忍的,因为用户希望使用计算机的时候,其中一个任务失败了,至少不能影响其它的任务。
15 | * 问题 2 :内存使用效率低。在 A 和 B 都运行的情况下,如果用户又运行了程序 C ,而程序 C 需要 20M 大小的内存才能运行,而此时系统只剩下 8M 的空间可供使用,所以此时系统必须在已运行的程序中选择一个将该程序的数据暂时拷贝到硬盘上,释放出部分空间来供程序 C 使用,然后再将程序 C 的数据全部装入内存中运行。可以想象得到,在这个过程中,有大量的数据在装入装出,导致效率十分低下。
16 | * 问题 3 :程序运行的地址不确定。当内存中的剩余空间可以满足程序 C 的要求后,操作系统会在剩余空间中随机分配一段连续的 20M 大小的空间给程序 C 使用,因为是随机分配的,所以程序运行的地址是不确定的。
17 |
18 | ## 2. 分段
19 |
20 | 为 了解决上述问题,人们想到了一种变通的方法,就是增加一个中间层,利用一种间接的地址访问方法访问物理内存。按照这种方法,程序中访问的内存地址不再是实际的物理内存地址,而是一个虚拟地址,然后由操作系统将这个虚拟地址映射到适当的物理内存地址上。这样,只要操作系统处理好虚拟地址到物理内存地址的映 射,就可以保证不同的程序最终访问的内存地址位于不同的区域,彼此没有重叠,就可以达到内存地址空间隔离的效果。
21 | 当创建一个进程时,操作系统会为该进程分配一个 4GB 大小的虚拟进程地址空间。之所以是 4GB ,是因为在 32 位的操作系统中,一个指针长度是 4 字节,而 4 字节指针的寻址能力是从 0x00000000~0xFFFFFFFF ,最大值 0xFFFFFFFF 表示的即为 4GB 大小的容量。与虚拟地址空间相对的,还有一个物理地址空间,这个地址空间对应的是真实的物理内存。如果你的计算机上安装了 512M 大小的内存,那么这个物理地址空间表示的范围是 0x00000000~0x1FFFFFFF 。当操作系统做虚拟地址到物理地址映射时,只能映射到这一范围,操作系统也只会映射到这一范围。当进程创建时,每个进程都会有一个自己的 4GB 虚拟地址空间。要注意的是这个 4GB 的地址空间是“虚拟”的,并不是真实存在的,而且每个进程只能访问自己虚拟地址空间中的数据,无法访问别的进程中的数据,通过这种方法实现了进程间的地址隔离。那是不是这 4GB 的虚拟地址空间应用程序可以随意使用呢?很遗憾,在 Windows 系统下,这个虚拟地址空间被分成了 4 部分: NULL 指针区、用户区、 64KB 禁入区、内核区。应用程序能使用的只是用户区而已,大约 2GB 左右 ( 最大可以调整到 3GB) 。内核区为 2GB ,内核区保存的是系统线程调度、内存管理、设备驱动等数据,这部分数据供所有的进程共享,但应用程序是不能直接访问的。
22 |
23 | 人们之所以要创建一个虚拟地址空间,目的是为了解决进程地址空间隔离的问题。但程序要想执行,必须运行在真实的内存上,所以,必须在虚拟地址与物理地址间建立一种映射关系。这样,通过映射机制,当程序访问虚拟地址空间上的某个地址值时,就相当于访问了物理地址空间中的另一个值。人们想到了一种分段 (Sagmentation) 的方法,它的思想是在虚拟地址空间和物理地址空间之间做一一映射。比如说虚拟地址空间中某个10M 大小的空间映射到物理地址空间中某个10M 大小的空间,可以多对一,就是说可虚拟地址的多个10M大小的空间可以映射到相同的物理地址空间的某个10M。这种思想理解起来并不难,操作系统保证不同进程的地址空间被映射到物理地址空间中不同的区域上,这样每个进程最终访问到的
24 | 物理地址空间都是彼此分开的。通过这种方式,就实现了进程间的地址隔离。还是以实例说明,假设有两个进程 A 和 B ,进程 A 所需内存大小为 10M ,其虚拟地址空间分布在 0x00000000 到 0x00A00000 ,进程 B 所需内存为 100M ,其虚拟地址空间分布为 0x00000000 到 0x06400000 。那么按照分段的映射方法,进程 A 在物理内存上映射区域为 0x00100000 到 0x00B00000 ,,进程 B 在物理内存上映射区域为 0x00C00000 到 0x07000000 。于是进程 A 和进程 B 分别被映射到了不同的内存区间,彼此互不重叠,实现了地址隔离。从应用程序的角度看来,进程 A 的地址空间就是分布在 0x00000000 到 0x00A00000 ,在做开发时,开发人员只需访问这段区间上的地址即可。应用程序并不关心进程 A 究竟被映射到物理内存的那块区域上了,所以程序的运行地址也就是相当于说是确定的了。 图二显示的是分段方式
25 | 的内存映射方法。
26 |
27 | 
28 |
29 | 图2 分段方式的内存映射方法
30 |
31 | 这种分段的映射方法虽然解决了上述中的问题一和问题三,但并没能解决问题二,即内存的使用效率问题。在分段的映射方法中,每次换入换出内存的都是整个程序,这样会造成大量的磁盘访问操作,导致效率低下。所以这种映射方法还是稍显粗糙,粒度比较大。实际上,程序的运行有局部性特点,在某个时间段内,程序只是访 问程序的一小部分数据,也就是说,程序的大部分数据在一个时间段内都不会被用到。基于这种情况,人们想到了粒度更小的内存分割和映射方法,这种方法就是分页 (Paging) 。
32 |
33 | ## 3. 分页
34 |
35 | 分页的基本方法是,将地址空间分成许多的页。每页的大小由 CPU 决定,然后由操作系统选择页的大小。目前 Inter 系列的 CPU 支持 4KB 或 4MB 的页大小,而 PC 上目前都选择使用 4KB 。按这种选择, 4GB 虚拟地址空间共可以分成 1048576 个页, 512M 的物理内存可以分为 131072 个页。显然虚拟空间的页数要比物理空间的页数多得多。
36 |
37 | 在分段的方法中,每次程序运行时总是把程序全部装入内存,而分页的方法则有所不同。分页的思想是程序运行时用到哪页就为哪页分配内存,没用到的页暂时保留在硬盘上。当用到这些页时再在物理地址空间中为这些页分配内存,然后建立虚拟地址空间中的页和刚分配的物理内存页间的映射。
38 |
39 | 下面通过介绍一个可执行文件的装载过程来说明分页机制的实现方法。一个可执行文件 (PE 文件 ) 其实就是一些编译链接好的数据和指令的集合,它也会被分成很多页,在 PE 文件执行的过程中,它往内存中装载的单位就是页。当一个 PE 文件被执行时,操作系统会先为该程序创建一个 4GB 的进程虚拟地址空间。前面介绍过,虚拟地址空间只是一个中间层而已,它的功能是利用一种映射机制将虚拟地址空间映射到物理地址空间,所以,创建 4GB 虚拟地址空间其实并不是要真的创建空间,只是要创建那种映射机制所需要的数据结构而已,这种数据结构就是页目和页表。
40 |
41 | 当创建完虚拟地址空间所需要的数据结构后,进程开始读取 PE 文件的第一页。在 PE 文件的第一页包含了 PE 文件头和段表等信息,进程根据文件头和段表等信息,将 PE 文件中所有的段一一映射到虚拟地址空间中相应的页 (PE 文件中的段的长度都是页长的整数倍 ) 。这时 PE 文件的真正指令和数据还没有被装入内存中,操作系统只是根据 PE 文件的头部等信息建立了 PE 文件和进程虚拟地址空间中页的映射关系而已。当 CPU 要访问程序中用到的某个虚拟地址时,当 CPU 发现该地址并没有相相关联的物理地址时, CPU 认为该虚拟地址所在的页面是个空页面, CPU 会认为这是个页错误 (Page Fault) , CPU 也就知道了操作系统还未给该 PE 页面分配内存, CPU 会将控制权交还给操作系统。操作系统于是为该 PE 页面在物理空间中分配一个页面,然后再将这个物理页面与虚拟空间中的虚拟页面映射起来,然后将控制权再还给进程,进程从刚才发生页错误的位置重新开始执行。由于此时已为 PE 文件的那个页面分配了内存,所以就不会发生页错误了。随着程序的执行,页错误会不断地产生,操作系统也会为进程分配相应的物理页面来满足进程执行的需求。
42 |
43 | 分页方法的核心思想就是当可执行文件执行到第 x 页时,就为第 x 页分配一个内存页 y ,然后再将这个内存页添加到进程虚拟地址空间的映射表中 , 这个映射表就相当于一个 y=f(x) 函数。应用程序通过这个映射表就可以访问到 x 页关联的 y 页了。
44 |
45 | # 总结:
46 | 32 位的CPU 的寻址空间是4G , 所以虚拟内存的最大值为4G , 而windows 操作系统把这4G 分成2 部分, 即2G 的用户空间和2G 的系统空间, 系统空间是各个进程所共享的, 他存放的是操作系统及一些内核对象等, 而用户空间是分配给各个进程使用的, 用户空间包括用: 程序代码和数据, 堆, 共享库, 栈。
47 |
--------------------------------------------------------------------------------
/papers/01_Emerging_Virtualization_Technology.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/01_Emerging_Virtualization_Technology.pdf
--------------------------------------------------------------------------------
/papers/02_HYPERVISOR_FOR_VIRTUALIZATION_IN_PRIVATE_CLOUD.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/02_HYPERVISOR_FOR_VIRTUALIZATION_IN_PRIVATE_CLOUD.pdf
--------------------------------------------------------------------------------
/papers/03_Secure_Virtualization_for_Cloud_Environment_Using_Hypervisor-based_Technology.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/03_Secure_Virtualization_for_Cloud_Environment_Using_Hypervisor-based_Technology.pdf
--------------------------------------------------------------------------------
/papers/04_OPERATING_SYSTEM_VIRTUALIZATION_IN_THE_EDUCATION_OF_COMPUTER_SCIENCE_STUDENTS.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/04_OPERATING_SYSTEM_VIRTUALIZATION_IN_THE_EDUCATION_OF_COMPUTER_SCIENCE_STUDENTS.pdf
--------------------------------------------------------------------------------
/papers/05_Virtualization_Technologies_and_Cloud_Securityadvantages,issues,and_perspectives.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/05_Virtualization_Technologies_and_Cloud_Securityadvantages,issues,and_perspectives.pdf
--------------------------------------------------------------------------------
/papers/06_Xen_and_the_Art_of_Virtualization.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/06_Xen_and_the_Art_of_Virtualization.pdf
--------------------------------------------------------------------------------
/papers/07_Analysis_of_Virtualization_Technologies_for_High_Performance_Computing_Environments.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/07_Analysis_of_Virtualization_Technologies_for_High_Performance_Computing_Environments.pdf
--------------------------------------------------------------------------------
/papers/08_Research_on_Cloud_Computing_Based_on_Storage_Virtualization_in_Data_Center.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/08_Research_on_Cloud_Computing_Based_on_Storage_Virtualization_in_Data_Center.pdf
--------------------------------------------------------------------------------
/papers/09_Architecture_for_Technology_Transformation.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/09_Architecture_for_Technology_Transformation.pdf
--------------------------------------------------------------------------------
/papers/10_A_Study_On_Virtualization_Techniques_And_Challenges_In_Cloud_Computing.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/10_A_Study_On_Virtualization_Techniques_And_Challenges_In_Cloud_Computing.pdf
--------------------------------------------------------------------------------
/papers/11_Virtual_Machine_Security_Guidelines_Version_1.0.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/11_Virtual_Machine_Security_Guidelines_Version_1.0.pdf
--------------------------------------------------------------------------------
/papers/12_Comparative_Performance_Analysis_of_the_Virtualization_Technologies_in_Cloud_Computing.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/12_Comparative_Performance_Analysis_of_the_Virtualization_Technologies_in_Cloud_Computing.pdf
--------------------------------------------------------------------------------
/papers/13_Improving_Business_Performance_by_Employing_VirtualizationTechnology_A_Case_Study_in_the_Financial_Sector.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/13_Improving_Business_Performance_by_Employing_VirtualizationTechnology_A_Case_Study_in_the_Financial_Sector.pdf
--------------------------------------------------------------------------------
/papers/14_Consolidation_Using_Oracle's_SPARCVirtualization_Technologies.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/14_Consolidation_Using_Oracle's_SPARCVirtualization_Technologies.pdf
--------------------------------------------------------------------------------
/papers/15-Development_of_a_virtualization_systems_architecture_course_for_t.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/15-Development_of_a_virtualization_systems_architecture_course_for_t.pdf
--------------------------------------------------------------------------------
/papers/16_Educational_Infrastructure_Using_Virtualization_Technologies_Experience_at_Kaunas_University_of_Technology.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/16_Educational_Infrastructure_Using_Virtualization_Technologies_Experience_at_Kaunas_University_of_Technology.pdf
--------------------------------------------------------------------------------
/papers/17_Comparative_Study_of_Virtual_Machine_Software_Packages_with_Real_Operating_System.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/17_Comparative_Study_of_Virtual_Machine_Software_Packages_with_Real_Operating_System.pdf
--------------------------------------------------------------------------------
/papers/18_Dell_EMC_Unity_Virtualization_Integration.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/18_Dell_EMC_Unity_Virtualization_Integration.pdf
--------------------------------------------------------------------------------
/papers/19_A_Study_On_Virtualization_And_Virtual_Machines.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/19_A_Study_On_Virtualization_And_Virtual_Machines.pdf
--------------------------------------------------------------------------------
/papers/20_Review_on_Virtualization_for_Cloud_Computing.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/20_Review_on_Virtualization_for_Cloud_Computing.pdf
--------------------------------------------------------------------------------
/papers/21_A_Survey_on_Virtualization_and_Hypervisor-based_Technology_in_Cloud_Computing_Environment.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/21_A_Survey_on_Virtualization_and_Hypervisor-based_Technology_in_Cloud_Computing_Environment.pdf
--------------------------------------------------------------------------------
/papers/22_STUDY_ON_VIRTUALIZATION_TECHNOLOGY_AND_ITS_IMPORTANCE_IN_CLOUD_COMPUTING_ENVIRONMENT.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/22_STUDY_ON_VIRTUALIZATION_TECHNOLOGY_AND_ITS_IMPORTANCE_IN_CLOUD_COMPUTING_ENVIRONMENT.pdf
--------------------------------------------------------------------------------
/papers/23_Research_on_the_Virtualization_Technology_in_Cloud_Computing_Environment.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/23_Research_on_the_Virtualization_Technology_in_Cloud_Computing_Environment.pdf
--------------------------------------------------------------------------------
/papers/24_Research_and_Development_on_Network_Virtualization_Technologies_in_Japan.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/24_Research_and_Development_on_Network_Virtualization_Technologies_in_Japan.pdf
--------------------------------------------------------------------------------
/papers/25_Eliminate_Software_Development_and_Testing_Constraints_with_Service_Virtualization.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/25_Eliminate_Software_Development_and_Testing_Constraints_with_Service_Virtualization.pdf
--------------------------------------------------------------------------------
/papers/26_Network_Virtualization_A_Data_Plane_Perspective.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/26_Network_Virtualization_A_Data_Plane_Perspective.pdf
--------------------------------------------------------------------------------
/papers/27_A_taxonomy_of_virtualization_technologies.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/27_A_taxonomy_of_virtualization_technologies.pdf
--------------------------------------------------------------------------------
/papers/28_Network_Functions_Virtualisation.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/28_Network_Functions_Virtualisation.pdf
--------------------------------------------------------------------------------
/papers/29_Recommendations_of_the_National_Institute_of_Standards_and_Technology.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/29_Recommendations_of_the_National_Institute_of_Standards_and_Technology.pdf
--------------------------------------------------------------------------------
/papers/30_Big_Data_Virtualization_Why_and_How.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/30_Big_Data_Virtualization_Why_and_How.pdf
--------------------------------------------------------------------------------
/papers/31_Server_Virtualization_Technology_and_ltsLatest_Trends.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/31_Server_Virtualization_Technology_and_ltsLatest_Trends.pdf
--------------------------------------------------------------------------------
/papers/32_Virtualization_Technologies_for_Cars_Solutions_to_increase_safety_and_security_of_vehicular_ECUs.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/32_Virtualization_Technologies_for_Cars_Solutions_to_increase_safety_and_security_of_vehicular_ECUs.pdf
--------------------------------------------------------------------------------
/papers/33_Virtualization_and_Future_Technologies.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/33_Virtualization_and_Future_Technologies.pdf
--------------------------------------------------------------------------------
/papers/34_Virtualization_and_the_Computer_Architecture.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/34_Virtualization_and_the_Computer_Architecture.pdf
--------------------------------------------------------------------------------
/papers/35_Virtualization_Introduction_QSM_White_Paper.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/35_Virtualization_Introduction_QSM_White_Paper.pdf
--------------------------------------------------------------------------------
/papers/36_Security_Implications_of_Different_Virtualization_Approaches_for_Secure_Cyber_Architectures.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/36_Security_Implications_of_Different_Virtualization_Approaches_for_Secure_Cyber_Architectures.pdf
--------------------------------------------------------------------------------
/papers/37_Server_Virtualization_A_Step_Toward_Cost_Efficiency_and_Business_Agility.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/37_Server_Virtualization_A_Step_Toward_Cost_Efficiency_and_Business_Agility.pdf
--------------------------------------------------------------------------------
/papers/38_Performance_Implications_of_Virtualization.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/38_Performance_Implications_of_Virtualization.pdf
--------------------------------------------------------------------------------
/papers/39_State-of-the-Art_of_Virtualization,_its_Security_Threats_and_Deployment_Models.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/39_State-of-the-Art_of_Virtualization,_its_Security_Threats_and_Deployment_Models.pdf
--------------------------------------------------------------------------------
/papers/40_HMI_&_Virtualization_in_Process_Automation.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/40_HMI_&_Virtualization_in_Process_Automation.pdf
--------------------------------------------------------------------------------
/papers/41_Terra_A_Virtual_Machine-Based_Platform_for_Trusted_Computing.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/41_Terra_A_Virtual_Machine-Based_Platform_for_Trusted_Computing.pdf
--------------------------------------------------------------------------------
/papers/42_Research_on_Virtualization_Technology_for_Real-time_Reconfigurable_Systems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/42_Research_on_Virtualization_Technology_for_Real-time_Reconfigurable_Systems.pdf
--------------------------------------------------------------------------------
/papers/43_A_Survey_on_Virtualization_Technologies.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/43_A_Survey_on_Virtualization_Technologies.pdf
--------------------------------------------------------------------------------
/papers/44_Intel_Virtualization_Technology.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/44_Intel_Virtualization_Technology.pdf
--------------------------------------------------------------------------------
/papers/45_EXPERIENCES_WITH_VIRTUALIZATION_TECHNOLOGY_IN_EDUCATION.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/45_EXPERIENCES_WITH_VIRTUALIZATION_TECHNOLOGY_IN_EDUCATION.pdf
--------------------------------------------------------------------------------
/papers/46_VIRTUALIZATION_IN_CLOUD_COMPUTING.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/46_VIRTUALIZATION_IN_CLOUD_COMPUTING.pdf
--------------------------------------------------------------------------------
/papers/47_Systematic_Study_of_Virtualization.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/47_Systematic_Study_of_Virtualization.pdf
--------------------------------------------------------------------------------
/papers/48_Virtualization_in_Cloud_Computing__Developments_and_Trends.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/48_Virtualization_in_Cloud_Computing__Developments_and_Trends.pdf
--------------------------------------------------------------------------------
/papers/49_Virtualization_Overview.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/49_Virtualization_Overview.pdf
--------------------------------------------------------------------------------
/papers/50_ArcGIS_Pro_Virtualization.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/50_ArcGIS_Pro_Virtualization.pdf
--------------------------------------------------------------------------------
/papers/51_Intel®_Virtualization_Technology(VT)_in_Converged_Application_Platforms.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/51_Intel®_Virtualization_Technology(VT)_in_Converged_Application_Platforms.pdf
--------------------------------------------------------------------------------
/papers/52_Virtualization_Technology_Whitepaper-Infrastructure_to_Perform_Static_Tools_and_Binary_Analysis.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/52_Virtualization_Technology_Whitepaper-Infrastructure_to_Perform_Static_Tools_and_Binary_Analysis.pdf
--------------------------------------------------------------------------------
/papers/53_A_Survey_on_Virtual_Machine_Security.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/53_A_Survey_on_Virtual_Machine_Security.pdf
--------------------------------------------------------------------------------
/papers/54_Intel®_Virtualization_Technology_Hardware_Support_for_Efficient_Processor_Virtualization.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/54_Intel®_Virtualization_Technology_Hardware_Support_for_Efficient_Processor_Virtualization.pdf
--------------------------------------------------------------------------------
/papers/55_Network_functions_virtualization.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/55_Network_functions_virtualization.pdf
--------------------------------------------------------------------------------
/papers/56_BEYOND_VIRTUALIZATION_The_MontaVista_Approach_to_Multi-core_SoC_Resource_Allocation_and_Control.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/56_BEYOND_VIRTUALIZATION_The_MontaVista_Approach_to_Multi-core_SoC_Resource_Allocation_and_Control.pdf
--------------------------------------------------------------------------------
/papers/57_A_PRINCIPLED_TECHNOLOGIES_WHITE_PAPER.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/57_A_PRINCIPLED_TECHNOLOGIES_WHITE_PAPER.pdf
--------------------------------------------------------------------------------
/papers/58_Data_Virtualization–Flexible_Technology_for_the_Agile_Enterprise.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/58_Data_Virtualization–Flexible_Technology_for_the_Agile_Enterprise.pdf
--------------------------------------------------------------------------------
/papers/59_Top_5_Things_You_Need_in_a_Virtualization_Management_Solution.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/59_Top_5_Things_You_Need_in_a_Virtualization_Management_Solution.pdf
--------------------------------------------------------------------------------
/papers/60_The_IBM_Advantage_for_Implementing_the_Virtualization_Reference_Architecture.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/Introduce_to_virtualization/484f02f54d9eb016bb9807846e527f9d40c11306/papers/60_The_IBM_Advantage_for_Implementing_the_Virtualization_Reference_Architecture.pdf
--------------------------------------------------------------------------------
/papers/README.md:
--------------------------------------------------------------------------------
1 | #
2 |
--------------------------------------------------------------------------------
/product/KVM简介及安装.md:
--------------------------------------------------------------------------------
1 | # KVM简介及安装
2 |
3 | ## 1. KVM 介绍
4 |
5 | ### 1.1 虚拟化简史
6 | 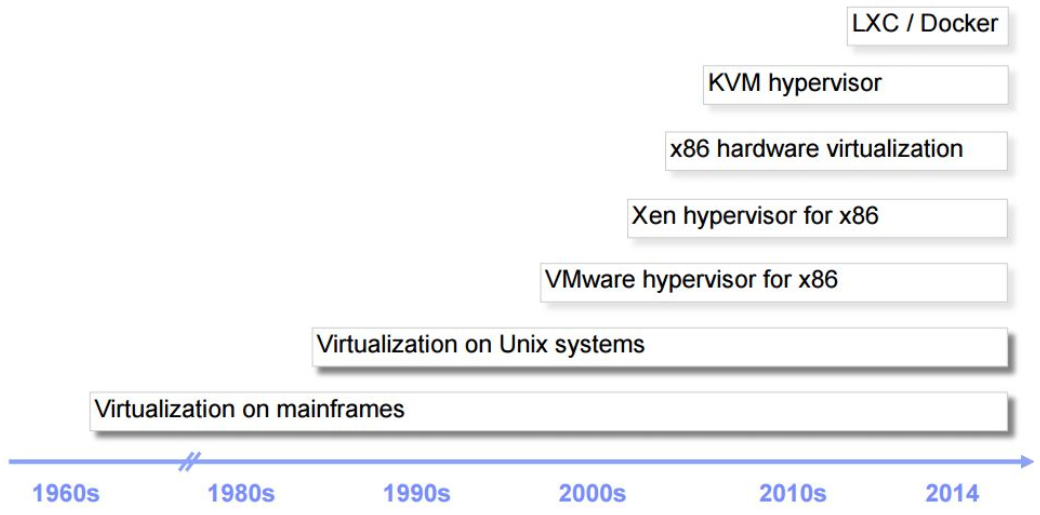
7 |
8 | 其中,KVM 全称是 基于内核的虚拟机(Kernel-based Virtual Machine),它是Linux 的一个内核模块,该内核模块使得 Linux 变成了一个 Hypervisor:
9 |
10 | 它由 Quramnet 开发,该公司于 2008年被 Red Hat 收购。
11 | 它支持 x86 (32 and 64 位), s390, Powerpc 等 CPU。
12 | 它从 Linux 2.6.20 起就作为一模块被包含在 Linux 内核中。
13 | 它需要支持虚拟化扩展的 CPU。
14 | 它是完全开源的。官网。
15 | 本文介绍的是基于 X86 CPU 的 KVM。
16 |
17 | ### 1.2 KVM 架构
18 |
19 | KVM 是基于虚拟化扩展(Intel VT 或者 AMD-V)的 X86 硬件的开源的 Linux 原生的全虚拟化解决方案。KVM 中,虚拟机被实现为常规的 Linux 进程,由标准 Linux 调度程序进行调度;虚机的每个虚拟 CPU 被实现为一个常规的 Linux 线程。这使得 KMV 能够使用 Linux 内核的已有功能。
20 | 但是,KVM 本身不执行任何硬件模拟,需要用户空间程序通过 /dev/kvm 接口设置一个客户机虚拟服务器的地址空间,向它提供模拟 I/O,并将它的视频显示映射回宿主的显示屏。目前这个应用程序是 QEMU。
21 |
22 | Linux 上的用户空间、内核空间和虚机:
23 | 
24 |
25 | * Guest:客户机系统,包括CPU(vCPU)、内存、驱动(Console、网卡、I/O 设备驱动等),被 KVM 置于一种受限制的 CPU 模式下运行。
26 | * KVM:运行在内核空间,提供 CPU 和内存的虚级化,以及客户机的 I/O 拦截。Guest 的 I/O 被 KVM 拦截后,交给 QEMU 处理。
27 | * QEMU:修改过的被 KVM 虚机使用的 QEMU 代码,运行在用户空间,提供硬件 I/O 虚拟化,通过 IOCTL /dev/kvm 设备和 KVM 交互。
28 |
29 | #### KVM 是实现拦截虚机的 I/O 请求的原理:
30 |
31 | 现代 CPU 本身实现了对特殊指令的截获和重定向的硬件支持,甚至新硬件会提供额外的资源来帮助软件实现对关键硬件资源的虚拟化从而提高性能。以 X86 平台为例,支持虚拟化技术的 CPU 带有特别优化过的指令集来控制虚拟化过程。通过这些指令集,VMM 很容易将客户机置于一种受限制的模式下运行,一旦客户机试图访问物理资源,硬件会暂停客户机运行,将控制权交回给 VMM 处理。VMM 还可以利用硬件的虚级化增强机制,将客户机在受限模式下对一些特定资源的访问,完全由硬件重定向到 VMM 指定的虚拟资源,整个过程不需要暂停客户机的运行和 VMM 的参与。由于虚拟化硬件提供全新的架构,支持操作系统直接在上面运行,无需进行二进制转换,减少了相关的性能开销,极大简化了VMM的设计,使得VMM性能更加强大。从 2005 年开始,Intel 在其处理器产品线中推广 Intel Virtualization Technology 即 IntelVT 技术。
32 |
33 | #### QEMU-KVM:
34 |
35 | 其实 QEMU 原本不是 KVM 的一部分,它自己就是一个纯软件实现的虚拟化系统,所以其性能低下。但是,QEMU 代码中包含整套的虚拟机实现,包括处理器虚拟化,内存虚拟化,以及 KVM需要使用到的虚拟设备模拟(网卡、显卡、存储控制器和硬盘等)。 为了简化代码,KVM 在 QEMU 的基础上做了修改。VM 运行期间,QEMU 会通过 KVM 模块提供的系统调用进入内核,由 KVM 负责将虚拟机置于处理的特殊模式运行。当虚机进行 I/O 操作时,KVM 会从上次系统调用出口处返回 QEMU,由 QEMU 来负责解析和模拟这些设备。 从 QEMU 角度看,也可以说是 QEMU 使用了 KVM 模块的虚拟化功能,为自己的虚机提供了硬件虚拟化加速。除此以外,虚机的配置和创建、虚机运行所依赖的虚拟设备、虚机运行时的用户环境和交互,以及一些虚机的特定技术比如动态迁移,都是 QEMU 自己实现的。
36 |
37 | #### KVM:
38 | KVM 内核模块在运行时按需加载进入内核空间运行。KVM 本身不执行任何设备模拟,需要 QEMU 通过 /dev/kvm 接口设置一个 GUEST OS 的地址空间,向它提供模拟的 I/O 设备,并将它的视频显示映射回宿主机的显示屏。它是KVM 虚机的核心部分,其主要功能是初始化 CPU 硬件,打开虚拟化模式,然后将虚拟客户机运行在虚拟机模式下,并对虚机的运行提供一定的支持。以在 Intel 上运行为例,KVM 模块被加载的时候,它:
39 | 1. 首先初始化内部的数据结构;
40 | 2. 做好准备后,KVM 模块检测当前的 CPU,然后打开 CPU 控制及存取 CR4 的虚拟化模式开关,并通过执行 VMXON 指令将宿主操作系统置于虚拟化模式的根模式;
41 | 3. 最后,KVM 模块创建特殊设备文件 /dev/kvm 并等待来自用户空间的指令。
42 |
43 | 接下来的虚机的创建和运行将是 QEMU 和 KVM 相互配合的过程。两者的通信接口主要是一系列针对特殊设备文件 /dev/kvm 的 IOCTL 调用。其中最重要的是创建虚机。它可以理解成KVM 为了某个特定的虚机创建对应的内核数据结构,同时,KVM 返回一个文件句柄来代表所创建的虚机。
44 |
45 | 针对该句柄的调用可以对虚机做相应地管理,比如创建用户空间虚拟地址和客户机物理地址、真实物理地址之间的映射关系,再比如创建多个 vCPU。KVM 为每一个 vCPU 生成对应的文件句柄,对其相应地 IOCTL 调用,就可以对vCPU进行管理。其中最重要的就是“执行虚拟处理器”。通过它,虚机在 KVM 的支持下,被置于虚拟化模式的非根模式下,开始执行二进制指令。在非根模式下,所有敏感的二进制指令都被CPU捕捉到,CPU 在保存现场之后自动切换到根模式,由 KVM 决定如何处理。
46 |
47 | 除了 CPU 的虚拟化,内存虚拟化也由 KVM 实现。实际上,内存虚拟化往往是一个虚机实现中最复杂的部分。CPU 中的内存管理单元 MMU 是通过页表的形式将程序运行的虚拟地址转换成实际物理地址。在虚拟机模式下,MMU 的页表则必须在一次查询的时候完成两次地址转换。因为除了将客户机程序的虚拟地址转换了客户机的物理地址外,还要将客户机物理地址转化成真实物理地址。
48 |
49 | ## 2. KVM 的功能列表
50 |
51 | KVM 所支持的功能包括:
52 | * 支持 CPU 和 memory 超分(Overcommit)
53 | * 支持半虚拟化 I/O (virtio)
54 | * 支持热插拔 (cpu,块设备、网络设备等)
55 | * 支持对称多处理(Symmetric Multi-Processing,缩写为 SMP )
56 | * 支持实时迁移(Live Migration)
57 | * 支持 PCI 设备直接分配和 单根 I/O 虚拟化 (SR-IOV)
58 | * 支持 内核同页合并 (KSM )
59 | * 支持 NUMA (Non-Uniform Memory Access,非一致存储访问结构 )
60 |
61 | ## 3. KVM 工具集合
62 |
63 | * libvirt:操作和管理KVM虚机的虚拟化 API,使用 C 语言编写,可以由 Python,Ruby, Perl, PHP, Java 等语言调用。可以操作包括 KVM,vmware,XEN,Hyper-v, LXC 等在内的多种 Hypervisor。
64 | * Virsh:基于 libvirt 的 命令行工具 (CLI)
65 | * Virt-Manager:基于 libvirt 的 GUI 工具
66 | * virt-v2v:虚机格式迁移工具
67 | * virt-* 工具:包括 Virt-install (创建KVM虚机的命令行工具), Virt-viewer (连接到虚机屏幕的工具),Virt-clone(虚机克隆工具),virt-top 等
68 | * sVirt:安全工具
69 |
70 | ## 4. RedHat Linux KVM 安装
71 |
72 | RedHat 有两款产品提供 KVM 虚拟化:
73 | * Red Hat Enterprise Linux:适用于小的环境,提供数目较少的KVM虚机。最新的版本包括 6.5 和 7.0.
74 | * Red Hat Enterprise Virtualization (RHEV):提供企业规模的KVM虚拟化环境,包括更简单的管理、HA,性能优化和其它高级功能。最新的版本是 3.0.
75 |
76 | RedHat Linux KVM:
77 | * KVM 由 libvirt API 和基于该 API的一组工具进行管理和控制
78 | * KVM 支持系统资源超分,包括内存和CPU的超分。RedHat Linux 最多支持物理 CPU 内核总数的10倍数目的虚拟CPU,但是不支持在一个虚机上分配超过物理CPU内核总数的虚拟CPU。
79 | 支持 KSM (Kenerl Same-page Merging 内核同页合并)
80 |
81 | RedHat Linux KVM 有如下两种安装方式:
82 |
83 | ### 4.1 在安装 RedHat Linux 时安装 KVM
84 |
85 | 选择安装类型为 Virtualizaiton Host :
86 | 
87 |
88 | 可以选择具体的 KVM 客户端、平台和工具:
89 | 
90 |
91 | ### 4.2 在已有的 RedHat Linux 中安装 KVM
92 |
93 | 这种安装方式要求该系统已经被注册,否则会报错:
94 |
95 | ```C
96 | [root@rh65 ~]# yum install qemu-kvm qemu-img
97 | Loaded plugins: product-id, refresh-packagekit, security, subscription-manager
98 | This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
99 | Setting up Install Process
100 | Nothing to do
101 | ```
102 |
103 | 你至少需要安装 qemu-kvm qemu-img 这两个包。
104 |
105 | ```C
106 | # yum install qemu-kvm qemu-img
107 | ```
108 |
109 | 你还可以安装其它工具包:
110 | ```C
111 | # yum install virt-manager libvirt libvirt-python python-virtinst libvirt-client
112 | ```
113 |
114 | ### 4.3 QEMU/KVM 代码下载编译安装
115 | #### 4.3.1 QEMU/KVM 的代码结构
116 | QEMU/KVM 的代码包括几个部分:
117 | * (1)KVM 内核模块是 Linux 内核的一部分。通常 Linux 比较新的发行版(2.6.20+)都包含了 KVM 内核,也可以从这里得到。比如在我的RedHat 6.5 上:
118 | ```C
119 | [root@rh65 isoimages]# uname -r
120 | 2.6.32-431.el6.x86_64
121 | [root@rh65 isoimages]# modprobe -l | grep kvm
122 | kernel/arch/x86/kvm/kvm.ko
123 | kernel/arch/x86/kvm/kvm-intel.ko
124 | kernel/arch/x86/kvm/kvm-amd.ko
125 | ```
126 | * (2)用户空间的工具即 qemu-kvm。qemu-kvm 是 KVM 项目从 QEMU 新拉出的一个分支(看这篇文章)。在 QEMU 1.3 版本之前,QEMU 和 QEMU-KVM 是有区别的,但是从 2012 年底 GA 的 QEMU 1.3 版本开始,两者就完全一样了。
127 | * (3)Linux Guest OS virtio 驱动,也是较新的Linux 内核的一部分了。
128 | * (4)Windows Guest OS virtio 驱动,可以从这里下载。
129 |
130 | #### 4.3.2 安装 QEMU
131 |
132 | RedHat 6.5 上自带的 QEMU 太老,0.12.0 版本,最新版本都到了 2.* 了。
133 | * (1). 参考 这篇文章,将 RedHat 6.5 的 ISO 文件当作本地源
134 |
135 | ```C
136 | mount -o loop soft/rhel-server-6.4-x86_64-dvd.iso /mnt/rhel6/
137 |
138 | vim /etc/fstab
139 | => /root/isoimages/soft/RHEL6.5-20131111.0-Server-x86_64-DVD1.iso /mnt/rhel6 iso9660 ro,loop
140 | [root@rh65 qemu-2.3.0]# cat /etc/yum.repos.d/local.repo
141 | [local]
142 | name=local
143 | baseurl=file:///mnt/rhel6/
144 | enabled=1
145 | gpgcjeck=0
146 |
147 |
148 | yum clean all
yum update
149 |
150 | ```
151 |
152 | * (2). 安装依赖包包
153 | ```C
154 | yum install gcc
155 | yum install autoconf
156 | yum install autoconf automake libtool
157 | yum install -y glib*
158 | yum install zlib*
159 | ```
160 |
161 | * (3). 从 http://wiki.qemu.org/Download 下载代码,上传到我的编译环境 RedHat 6.5.
162 | ```C
163 | tar -jzvf qemu-2.3.0.tar.bz2
164 | cd qemu-2.3.0
165 | ./configure
166 | make -j 4
167 | make install
168 | ```
169 |
170 | * (4). 安装完成
171 | ```C
172 | [root@rh65 qemu-2.3.0]# /usr/local/bin/qemu-x86_64 -version
173 | qemu-x86_64 version 2.3.0, Copyright (c) 2003-2008 Fabrice Bellard
174 | ```
175 |
176 | * (5). 为方便起见,创建一个link
177 | ```C
178 | ln -s /usr/bin/qemu-system-x86_64 /usr/bin/qemu-kvm
179 | ```
180 |
181 | #### 4.3.3 安装 libvirt
182 | 可以从 libvirt 官网下载安装包。最新的版本是 0.10.2.
183 |
184 | ## 5. 创建 KVM 虚机的几种方式
185 | ### 5.1 使用 virt-install 命令
186 | ```C
187 | virt-install \
188 | --name=guest1-rhel5-64 \
189 | --file=/var/lib/libvirt/images/guest1-rhel5-64.dsk \
190 | --file-size=8 \
191 | --nonsparse --graphics spice \
192 | --vcpus=2 --ram=2048 \
193 | --location=http://example1.com/installation_tree/RHEL5.6-Serverx86_64/os \
194 | --network bridge=br0 \
195 | --os-type=linux \
196 | --os-variant=rhel5.4
197 | ```
198 |
199 | ### 5.2 使用 virt-manager 工具
200 | 
201 |
202 | 使用 VMM GUI 创建的虚机的xml 定义文件在 /etc/libvirt/qemu/ 目录中。
203 |
204 | ### 5.3 使用 qemu-img 和 qemu-kvm 命令行方式安装
205 | (1)创建一个空的qcow2格式的镜像文件
206 | ```C
207 | qemu-img create -f qcow2 windows-master.qcow2 10G
208 | ```
209 | (2)启动一个虚机,将系统安装盘挂到 cdrom,安装操作系统
210 | ```C
211 | qemu-kvm -hda windows-master.qcow2 -m 512 -boot d -cdrom /home/user/isos/en_winxp_pro_with_sp2.iso
212 | ```
213 |
214 | (3)现在你就拥有了一个带操作系统的镜像文件。你可以以它为模板创建新的镜像文件。使用模板的好处是,它会被设置为只读所以可以免于破坏。
215 | ```C
216 | qemu-img create -b windows-master.qcow2 -f qcow2 windows-clone.qcow2
217 | ```
218 |
219 | (4)你可以在新的镜像文件上启动虚机了
220 | ```C
221 | qemu-kvm -hda windows-clone.qcow2 -m 400
222 | ```
223 |
224 | ### 5.4 通过 OpenStack Nova 使用 libvirt API 通过编程方式来创建虚机
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 |
239 |
240 |
241 |
242 |
243 |
244 |
245 |
246 |
247 |
248 |
249 |
250 |
251 |
252 |
253 |
254 |
--------------------------------------------------------------------------------
/product/OpenStack介绍及原理.md:
--------------------------------------------------------------------------------
1 | # OpenStack介绍及原理
2 |
3 | ## 什么是openstack
4 | OpenStack 是一系列开源工具(或开源项目)的组合,主要使用池化虚拟资源来构建和管理私有云及公共云。其中的六个项目主要负责处理核心云计算服务,包括计算、网络、存储、身份和镜像服务。还有另外十多个可选项目,用户可把它们捆绑打包,用来创建独特、可部署的云架构。
5 |
6 | ## 云计算模式
7 | 1. IaaS:基础设施即服务(个人比较习惯的):用户通过网络获取虚机、存储、网络,然后用户根据自己的需求操作获取的资源
8 | 2. PaaS:平台即服务:将软件研发平台作为一种服务, 如Eclipse/Java编程平台,服务商提供编程接口/运行平台等
9 | 3. SaaS:软件即服务 :将软件作为一种服务通过网络提供给用户,如web的电子邮件、HR系统、订单管理系统、客户关系系统等。用户无需购买软件,而是向提供商租用基于web的软件,来管理企业经营活动
10 |
11 | ## OpenStack 中有哪些项目?
12 | OpenStack 架构由大量开源项目组成。其中包含 6 个稳定可靠的核心服务,用于处理计算、网络、存储、身份和镜像; 同时,还为用户提供了十多种开发成熟度各异的可选服务。OpenStack 的 6 个核心服务主要担纲系统的基础架构,其余项目则负责管理控制面板、编排、裸机部署、信息传递、容器及统筹管理等操作。
13 |
14 | * keystone:Keystone 认证所有 OpenStack 服务并对其进行授权。同时,它也是所有服务的端点目录。
15 | * glance:Glance 可存储和检索多个位置的虚拟机磁盘镜像。
16 | * nova:是一个完整的 OpenStack 计算资源管理和访问工具,负责处理规划、创建和删除操作。
17 | * neutron:Neutron 能够连接其他 OpenStack 服务并连接网络。
18 | * dashboard:web管理界面
19 | * Swift: 是一种高度容错的对象存储服务,使用 RESTful API 来存储和检索非结构数据对象。
20 | * Cinder 通过自助服务 API 访问持久块存储。
21 | * Ceilometer:计费
22 | * Heat:编排
23 |
24 | OpenStack基本架构
25 | 
26 |
27 | 通过消息队列和数据库,各个组件可以相互调用,互相通信。每个项目都有各自的特性,大而全的架构并非适合每一个用户,如Glance在最早的A、B版本中并没有实际出现应用,Nova可以脱离镜像服务独立运行。当用户的云计算规模大到需要管理多种镜像时,才需要像Glance这样的组件。
28 |
29 | OpenStack的逻辑架构
30 |
31 | 
32 |
33 | Openstack创建实例的流程
34 | 1. 通过登录界面dashboard或命令行CLI通过RESTful API向keystone获取认证信息。
35 | 2. keystone通过用户请求认证信息,并生成auth-token返回给对应的认证请求。
36 |
37 | 
38 |
39 | 3. 然后携带auth-token通过RESTful API向nova-api发送一个boot instance的请求。
40 |
41 | 
42 |
43 | 4. nova-api接受请求后向keystone发送认证请求,查看token是否为有效用户和token。
44 | 5. keystone验证token是否有效,将结果返回给nova-api。
45 |
46 | 
47 |
48 | 6. 通过认证后nova-api和数据库通讯,初始化新建虚拟机的数据库记录。
49 | 
50 |
51 |
52 |
53 |
54 |
--------------------------------------------------------------------------------
/product/OpenStack知识体系.md:
--------------------------------------------------------------------------------
1 | # OpenStack知识体系
2 |
3 | ## 第1章:OpenStack介绍
4 | * OpenStack定义
5 | * OpenStack架构
6 |
7 | ## 第2章:OpenStack实验环境部署
8 | * 安装方法与工具概述
9 | * 实验环境安装
10 |
11 | ## 第3章:验证授权与服务编目-Keystone
12 | * Keystone原理
13 | * 什么是Keystone?
14 | * Keystone的主要功能
15 | * Keystone的概念
16 | * 示例:Keystone与其它服务交互的流程
17 | * 实验:
18 | * 启用启动服务器后,DevStack的启动
19 | * 通过图形界面的Horizon访问Openstack
20 | * 通过命令行访问Openstack
21 | * 通过REST API访问OpenStack
22 | * 管理项目、用户、角色
23 |
24 | ## 第4章:镜像服务-Glance
25 | * 什么是Image
26 | * Glance原理
27 | * Glance体系结构
28 | * Glace支持的镜像格式和容器
29 | * 镜像的属性、权限与状态
30 | * 制作镜像的思路
31 | * 实验:
32 | * 考察现有镜像(GUI、CLI)
33 | * 上传新的镜像(GUI、CLI)
34 | * 修改镜像属性(仅能用CLI)
35 | * 删除镜像
36 |
37 | ## 第5章:计算服务-Nova
38 | * Nova原理
39 | * Nova体系结构
40 | * Nova组件功能与交互流程
41 | * 实例类型
42 | * 计算节点的选择调度与Driver架构
43 | * 实验:
44 | * 实例创建与控制
45 | * 实例的操作(GUI、CLI)
46 | * 启动与关闭
47 | * 重新启动
48 | * 锁定与解锁
49 | * 暂停与挂起
50 | * 大小调整
51 | * 废弃与取回
52 | * 删除
53 |
54 | ## 第6章:块存储服务-Cinder
55 | * 创建实例时存储的选项
56 | * Cinder原理
57 | * Cinder体系结构
58 | * Cinder组件交互流程
59 | * Cinder的调度算法
60 | * Cinder-volume的Driver架构
61 | * 实验:
62 | * 创建卷
63 | * 连接卷到实例
64 | * 分离卷
65 | * 扩展卷
66 | * 卷的快照
67 | * 删除卷
68 | * NFS Volume Provider
69 |
70 | ## 第7章:网络服务-Neutron(基础)
71 | * Neutron原理:
72 | * 概述与功能
73 | * 基本概念与架构
74 | * Neutron Server分层模型
75 | * ML2 Core Plugin与Agent
76 | * Service Plugin与Agent
77 | * 实验:
78 | * 配置Linuxbridge
79 | * 创建Local Nertwork(Linuxbridge)
80 | * 创建Flat Nertwork(Linuxbridge)
81 | * 配置DHCP Agent
82 | * 创建VLAN Network(Linuxbridge)
83 | * 创建Routing (Linuxbridge)
84 |
85 |
--------------------------------------------------------------------------------
/product/P8整理的OpenStack构架,希望能帮助到你.md:
--------------------------------------------------------------------------------
1 | # P8整理的OpenStack构架,希望能帮助到你
2 |
3 | ## 1. OpenStack介绍
4 | OpenStack既是一个社区,也是一个项目和一个开源软件,提供开放源码软件,建立公共和私有云,它提供了一个部署云的操作平台或工具集,其宗旨在于:帮助组织运行为虚拟计算或存储服务的云,为公有云、私有云,也为大云、小云提供可扩展的、灵活的云计算。
5 | OpenStackd开源项目由社区维护,包括OpenStack计算(代号为Nova),OpenStack对象存储(代号为Swift),并OpenStack镜像服务(代号Glance)的集合。 OpenStack提供了一个操作平台,或工具包,用于编排云。
6 |
7 | 下面列出Openstack的详细构架图
8 | 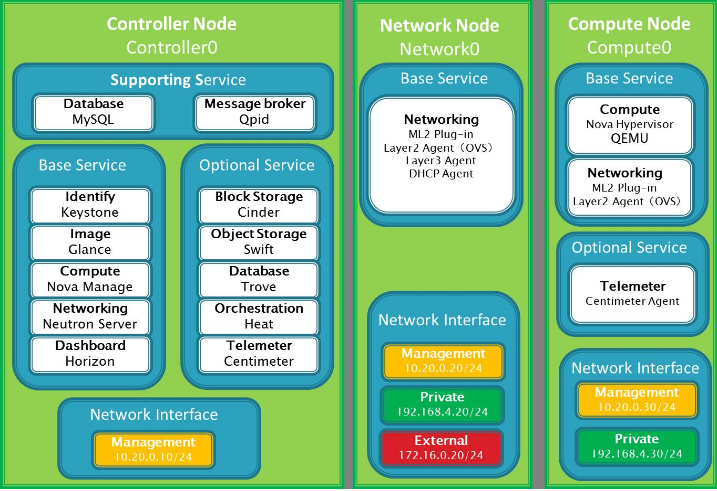
9 |
10 |
11 | Openstack的网络拓扑结构图
12 | 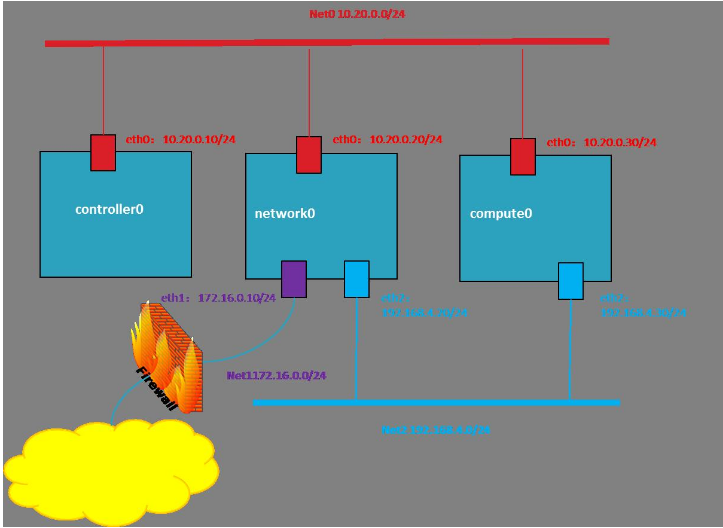
13 |
14 |
15 | [500篇关于虚拟化的经典资料,含CPU虚拟化,磁盘虚拟化,内存虚拟化,IO虚拟化](https://github.com/0voice/Introduce_to_virtualization)
16 |
17 | 整个OpenStack是由控制节点,计算节点,网络节点,存储节点四大部分组成。(这四个节点也可以安装在一台机器上,单机部署)
18 | 其中:
19 | * 控制节点负责对其余节点的控制,包含虚拟机建立,迁移,网络分配,存储分配等等
20 | * 计算节点负责虚拟机运行
21 | * 网络节点负责对外网络与内网络之间的通信
22 | * 存储节点负责对虚拟机的额外存储管理等等
23 |
24 | ## 2. 控制节点架构:
25 | 控制节点包括以下服务
26 | * 管理支持服务
27 | * 基础管理服务
28 | * 扩展管理服务
29 |
30 | ### 1. 管理支持服务包含MySQL与Qpid两个服务
31 | MySQL:数据库作为基础/扩展服务产生的数据存放的地方
32 | Qpid:消息代理(也称消息中间件)为其他各种服务之间提供了统一的消息通信服务
33 |
34 | ### 2. 基础管理服务包含Keystone,Glance,Nova,Neutron,Horizon五个服务
35 | Keystone:认证管理服务,提供了其余所有组件的认证信息/令牌的管理,创建,修改等等,使用MySQL作为统一的数据库
36 | Glance:镜像管理服务,提供了对虚拟机部署的时候所能提供的镜像的管理,包含镜像的导入,格式,以及制作相应的模板
37 | Nova:计算管理服务,提供了对计算节点的Nova的管理,使用Nova-API进行通信
38 | Neutron:网络管理服务,提供了对网络节点的网络拓扑管理,同时提供Neutron在Horizon的管理面板
39 | Horizon:控制台服务,提供了以Web的形式对所有节点的所有服务的管理,通常把该服务称为DashBoard
40 |
41 | ### 3. 扩展管理服务包含Cinder,Swift,Trove,Heat,Centimeter五个服务
42 | Cinder:提供管理存储节点的Cinder相关,同时提供Cinder在Horizon中的管理面板
43 | Swift:提供管理存储节点的Swift相关,同时提供Swift在Horizon中的管理面板
44 | Trove:提供管理数据库节点的Trove相关,同时提供Trove在Horizon中的管理面板
45 | Heat:提供了基于模板来实现云环境中资源的初始化,依赖关系处理,部署等基本操作,也可以解决自动收缩,负载均衡等高级特性。
46 | Centimeter:提供对物理资源以及虚拟资源的监控,并记录这些数据,对该数据进行分析,在一定条件下触发相应动作控制节点一般来说只需要一个网络端口用于通信/管理各个节点
47 |
48 | ## 3. 网络节点架构
49 | 网络节点仅包含Neutron服务
50 | Neutron:负责管理私有网段与公有网段的通信,以及管理虚拟机网络之间的通信/拓扑,管理虚拟机之上的防火等等
51 | 网络节点包含三个网络端口
52 | eth0:用于与控制节点进行通信
53 | eth1:用于与除了控制节点之外的计算/存储节点之间的通信
54 | eth2:用于外部的虚拟机与相应网络之间的通信
55 |
56 | ## 4. 计算节点架构
57 | 计算节点包含Nova,Neutron,Telemeter三个服务
58 |
59 | * 1. 基础服务
60 | Nova:提供虚拟机的创建,运行,迁移,快照等各种围绕虚拟机的服务,并提供API与控制节点对接,由控制节点下发任务
61 | Neutron:提供计算节点与网络节点之间的通信服务
62 |
63 | * 2. 扩展服务
64 | Telmeter:提供计算节点的监控代理,将虚拟机的情况反馈给控制节点,是Centimeter的代理服务
65 | 计算节点包含最少两个网络端口
66 | eth0:与控制节点进行通信,受控制节点统一调配
67 | eth1:与网络节点,存储节点进行通信
68 |
69 | ## 5. 存储节点架构
70 | 存储节点包含Cinder,Swift等服务
71 | Cinder:块存储服务,提供相应的块存储,简单来说,就是虚拟出一块磁盘,可以挂载到相应的虚拟机之上,不受文件系统等因素影响,对虚拟机来说,这个操作就像是新加了一块硬盘,可以完成对磁盘的任何操作,包括挂载,卸载,格式化,转换文件系统等等操作,大多应用于虚拟机空间不足的情况下的空间扩容等等
72 | Swift:对象存储服务,提供相应的对象存储,简单来说,就是虚拟出一块磁盘空间,可以在这个空间当中存放文件,也仅仅只能存放文件,不能进行格式化,转换文件系统,大多应用于云磁盘/文件
73 | 存储节点包含最少两个网络接口
74 | eth0:与控制节点进行通信,接受控制节点任务,受控制节点统一调配
75 | eth1:与计算/网络节点进行通信,完成控制节点下发的各类任务
76 |
77 | ## 6. Openstack的各个组件作用及关系
78 | Openstack发展至今,总共集成了下面几个组件:
79 | * Nova - 计算服务
80 | * Neutron-网络服务
81 | * Swift - 对象存储服务
82 | * Cinder-块存储服务
83 | * Glance - 镜像服务
84 | * Keystone - 认证服务
85 | * Horizon - UI服务
86 | * Ceilometer-监控服务
87 | * Heat-集群服务
88 | * Trove-数据库服务
89 |
90 | 组件间的关系图如下:
91 | 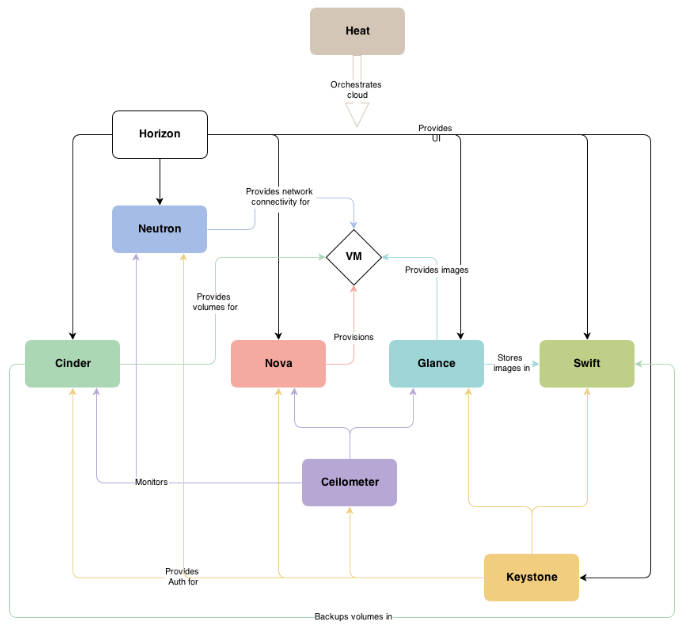
92 |
93 |
94 | ## 7. 重要组件介绍
95 | ### 7.1 OpenStack认证服务(Keystone)
96 | Keystone为所有的OpenStack组件提供认证和访问策略服务,它依赖自身REST(基于Identity API)系统进行工作,主要对(但不限于)Swift、Glance、Nova等进行认证与授权。事实上,授权通过对动作消息来源者请求的合法性进行鉴定。下图显示了身份认证服务流程:
97 |
98 | 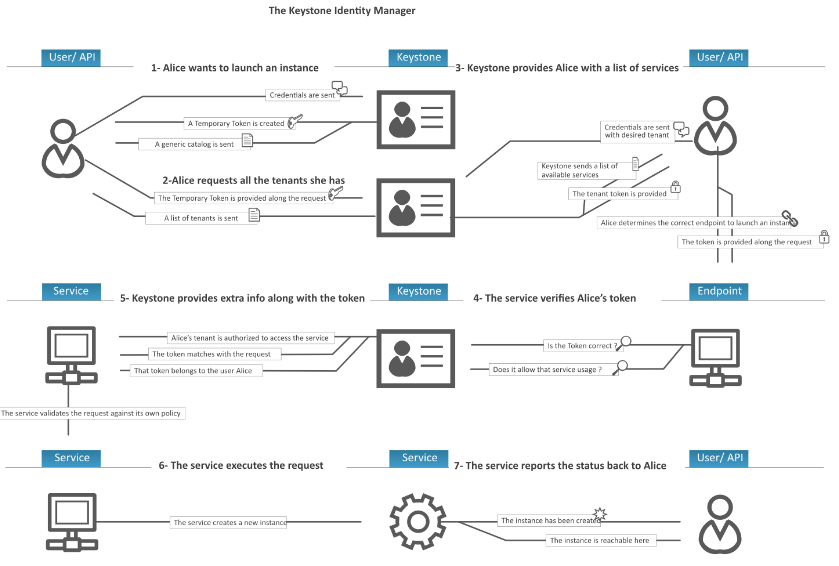
99 |
100 |
101 | Keystone采用两种授权方式,一种基于用户名/密码,另一种基于令牌(Token)。
102 |
103 | 除此之外,Keystone提供以下三种服务:
104 | * 令牌服务:含有授权用户的授权信息
105 | * 目录服务:含有用户合法操作的可用服务列表
106 | * 策略服务:利用Keystone具体指定用户或群组某些访问权限
107 |
108 | keystone认证服务注意点:
109 |
110 | 服务入口:如Nova、Swift和Glance一样每个OpenStack服务都拥有一个指定的端口和专属的URL,我们称其为入口(endpoints)。
111 |
112 | 区位:在某个数据中心,一个区位具体指定了一处物理位置。在典型的云架构中,如果不是所有的服务都访问分布式数据中心或服务器的话,则也称其为区位。
113 |
114 | 用户:Keystone授权使用者
115 | > PS:代表一个个体,OpenStack以用户的形式来授权服务给它们。用户拥有证书(credentials),且可能分配给一个或多个租户。经过验证后,会为每个单独的租户提供一个特定的令牌。
116 | 服务:总体而言,任何通过Keystone进行连接或管理的组件都被称为服务。举个例子,我们可以称Glance为Keystone的服务。
117 | 角色:为了维护安全限定,就云内特定用户可执行的操作而言,该用户关联的角色是非常重要的。
118 | > PS:一个角色是应用于某个租户的使用权限集合,以允许某个指定用户访问或使用特定操作。角色是使用权限的逻辑分组,它使得通用的权限可以简单地分组并绑定到与某个指定租户相关的用户。
119 | 租间:租间指的是具有全部服务入口并配有特定成员角色的一个项目。
120 | > PS:一个租间映射到一个Nova的“project-id”,在对象存储中,一个租间可以有多个容器。根据不同的安装方式,一个租间可以代表一个客户、帐号、组织或项目。
121 |
122 | ### 7.2 OpenStack计算设施----Nova
123 | Nova是OpenStack计算的弹性控制器。OpenStack云实例生命期所需的各种动作都将由Nova进行处理和支撑,这就意味着Nova以管理平台的身份登场,负责管理整个云的计算资源、网络、授权及测度。虽然Nova本身并不提供任何虚拟能力,但是它将使用libvirt API与虚拟机的宿主机进行交互。Nova通过Web服务API来对外提供处理接口,而且这些接口与Amazon的Web服务接口是兼容的。
124 |
125 | 功能及特点:
126 | * 实例生命周期管理
127 | * 计算资源管理
128 | * 网络与授权管理
129 | * 基于REST的API
130 | * 异步连续通信
131 | * 支持各种宿主:Xen、XenServer/XCP、KVM、UML、VMware vSphere及Hyper-V
132 |
133 | Nova弹性云(OpenStack计算部件)包含以下主要部分:
134 | * API Server(nova-api)
135 | * 消息队列(rabbit-mq server)
136 | * 运算工作站(nova-compute)
137 | * 网络控制器(nova-network)
138 | * 卷管理(nova-volume)
139 | * 调度器(nova-scheduler)
140 |
141 | 解释如下:
142 | 1. API服务器(nova-api)
143 | API服务器提供了云设施与外界交互的接口,它是外界用户对云实施管理的唯一通道。通过使用web服务来调用各种EC2的API,接着API服务器便通过消息队列把请求送达至云内目标设施进行处理。作为对EC2-api的替代,用户也可以使用OpenStack的原生API,我们把它叫做“OpenStack API”。
144 |
145 | 2. 消息队列(Rabbit MQ Server)
146 | OpenStack内部在遵循AMQP(高级消息队列协议)的基础上采用消息队列进行通信。Nova对请求应答进行异步调用,当请求接收后便则立即触发一个回调。由于使用了异步通信,不会有用户的动作被长置于等待状态。例如,启动一个实例或上传一份镜像的过程较为耗时,API调用就将等待返回结果而不影响其它操作,在此异步通信起到了很大作用,使整个系统变得更加高效。
147 |
148 | 3. 调度器(nova-scheduler)
149 | 调度器负责把nova-API调用送达给目标。调度器以名为“nova-schedule”的守护进程方式运行,并根据调度算法从可用资源池中恰当地选择运算服务器。有很多因素都可以影响调度结果,比如负载、内存、子节点的远近、CPU架构等等。强大的是nova调度器采用的是可插入式架构。
150 |
151 | 目前nova调度器使用了几种基本的调度算法:
152 | * 随机化:主机随机选择可用节点;
153 | * 可用化:与随机相似,只是随机选择的范围被指定;
154 | * 简单化:应用这种方式,主机选择负载最小者来运行实例。负载数据可以从别处获得,如负载均衡服务器。
155 |
156 | 4. 运算工作站(nova-compute)
157 | 运算工作站的主要任务是管理实例的整个生命周期。他们通过消息队列接收请求并执行,从而对实例进行各种操作。在典型实际生产环境下,会架设许多运算工作站,根据调度算法,一个实例可以在可用的任意一台运算工作站上部署。
158 |
159 | 5. 网络控制器(nova-network)
160 | 网络控制器处理主机的网络配置,例如IP地址分配,配置项目VLAN,设定安全群组以及为计算节点配置网络。
161 |
162 | 6. 卷工作站(nova-volume)
163 | 卷工作站管理基于LVM的 实例卷,它能够为一个实例创建、删除、附加卷,也可以从一个实例中分离卷。卷管理为何如此重要?因为它提供了一种保持实例持续存储的手段,比如当结束一个 实例后,根分区如果是非持续化的,那么对其的任何改变都将丢失。可是,如果从一个实例中将卷分离出来,或者为这个实例附加上卷的话,即使实例被关闭,数据 仍然保存其中。这些数据可以通过将卷附加到原实例或其他实例的方式而重新访问。
164 |
165 | 因此,为了日后访问,重要数据务必要写入卷中。这种应用对于数据服务器实例的存储而言,尤为重要。
166 |
167 | ### 7.3 OpenStack镜像服务器----Glance
168 | OpenStack镜像服务器是一套虚拟机镜像发现、注册、检索系统,我们可以将镜像存储到以下任意一种存储中:
169 | * 本地文件系统(默认)
170 | * S3直接存储
171 | * S3对象存储(作为S3访问的中间渠道)
172 | * OpenStack对象存储等等。
173 |
174 | 功能及特点:
175 | 提供镜像相关服务。
176 |
177 | Glance构件:
178 | 1. Glance-API:
179 | 主要负责接收响应镜像管理命令的Restful请求,分析消息请求信息并分发其所带的命令(如新增,删除,更新等)。默认绑定端口是9292。
180 | 2. Glance-Registry:
181 | 主要负责接收响应镜像元数据命令的Restful请求。分析消息请求信息并分发其所带的命令(如获取元数据,更新元数据等)。默认绑定的端口是9191。
182 |
183 | ### 7.4 OpenStack存储设施----Swift
184 | Swift为OpenStack提供一种分布式、持续虚拟对象存储,它类似于Amazon Web Service的S3简单存储服务。Swift具有跨节点百级对象的存储能力。Swift内建冗余和失效备援管理,也能够处理归档和媒体流,特别是对大数据(千兆字节)和大容量(多对象数量)的测度非常高效。
185 |
186 | swift功能及特点:
187 | * 海量对象存储
188 | * 大文件(对象)存储
189 | * 数据冗余管理
190 | * 归档能力-----处理大数据集
191 | * 为虚拟机和云应用提供数据容器
192 | * 处理流媒体
193 | * 对象安全存储
194 | * 备份与归档
195 | * 良好的可伸缩性
196 |
197 | * Swift组件
198 | * Swift账户
199 | * Swift容器
200 | * Swift对象
201 | * Swift代理
202 | * Swift RING
203 |
204 | #### Swift代理服务器
205 | 用户都是通过Swift-API与代理服务器进行交互,代理服务器正是接收外界请求的门卫,它检测合法的实体位置并路由它们的请求。
206 | 此外,代理服务器也同时处理实体失效而转移时,故障切换的实体重复路由请求。
207 |
208 | #### Swift对象服务器
209 | 对象服务器是一种二进制存储,它负责处理本地存储中的对象数据的存储、检索和删除。对象都是文件系统中存放的典型的二进制文件,具有扩展文件属性的元数据(xattr)。
210 |
211 | 注意:xattr格式被Linux中的ext3/4,XFS,Btrfs,JFS和ReiserFS所支持,但是并没有有效测试证明在XFS,JFS,ReiserFS,Reiser4和ZFS下也同样能运行良好。不过,XFS被认为是当前最好的选择。
212 |
213 | #### Swift容器服务器
214 | 容器服务器将列出一个容器中的所有对象,默认对象列表将存储为SQLite文件(译者注:也可以修改为MySQL,安装中就是以MySQL为例)。容器服务器也会统计容器中包含的对象数量及容器的存储空间耗费。
215 |
216 | #### Swift账户服务器
217 | 账户服务器与容器服务器类似,将列出容器中的对象。
218 |
219 | #### Ring(索引环)
220 | Ring容器记录着Swift中物理存储对象的位置信息,它是真实物理存储位置的实体名的虚拟映射,类似于查找及定位不同集群的实体真实物理位置的索引服务。这里所谓的实体指账户、容器、对象,它们都拥有属于自己的不同的Rings。
221 |
222 | ### 7.5 OpenStack管理的Web接口----Horizon
223 | Horizon是一个用以管理、控制OpenStack服务的Web控制面板,它可以管理实例、镜像、创建密匙对,对实例添加卷、操作Swift容器等。除此之外,用户还可以在控制面板中使用终端(console)或VNC直接访问实例。
224 |
225 | 总之,Horizon具有如下一些特点:
226 | * 实例管理:创建、终止实例,查看终端日志,VNC连接,添加卷等
227 | * 访问与安全管理:创建安全群组,管理密匙对,设置浮动IP等
228 | * 偏好设定:对虚拟硬件模板可以进行不同偏好设定
229 | * 镜像管理:编辑或删除镜像
230 | 查看服务目录
231 | * 管理用户、配额及项目用途
232 | * 用户管理:创建用户等
233 | * 卷管理:创建卷和快照
234 | * 对象存储处理:创建、删除容器和对象
235 | 为项目下载环境变量
236 |
--------------------------------------------------------------------------------
/product/Xen虚拟化详解.md:
--------------------------------------------------------------------------------
1 | # Xen虚拟化详解
2 |
3 | ## 1. Xen虚拟化模型
4 |
5 | ### 1.1 Xen相关概念
6 | Xen是由剑桥大学计算机实验室开发的一个开源项目。是一个直接运行在计算机硬件之上的用以替代操作系统的软件层,它能够在计算机硬件上并发的运行多个客户操作系统(Guest OS)。目前已经在开源社区中得到了极大的推动。
7 | Xen支持x86、x86-64、安腾( Itanium)、Power PC和ARM多种处理器,因此Xen可以在大量的计算设备上运行,目前Xen支持Linux、NetBSD、FreeBSD、Solaris、 Windows和其他常用的操作系统作为客户操作系统在其管理程序上运行。硬件之上
8 | Xen只对CPU和mem进行驱动,对IO没有驱动,
9 | Linux对新型IO设备的驱动能力,没有Windows强,应为硬件厂商,首先会开发Windows版本的驱动。
10 |
11 | 第一安装好的Guest的作用:
12 | 1. 管理其他Guest的接口
13 | 2. 提供驱动IO程序
14 |
15 | 其他Guest使用CPU和内存向Xen Hypervisor请求,使用IO设备,向domain 0发起请求。
16 | IO设备的模拟,Qemu实现
17 | 图Xen架构:
18 | 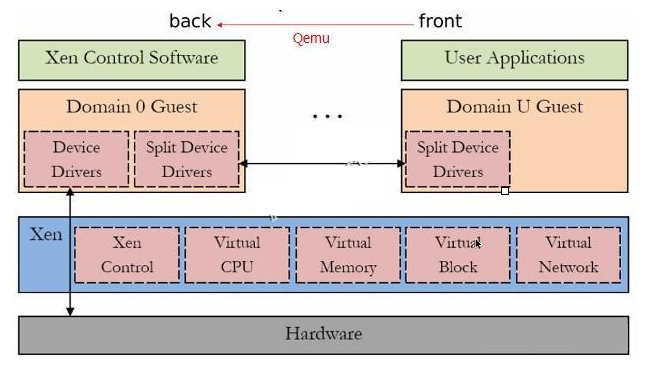
19 |
20 | Domain 0:Privileged Domain //特权虚拟机:Dom0;特权域 直接驱动IO硬件设备;与DomU交互;Linux-2.6.37内核开始直接运行在Dom0上;
21 | 修改过的Linux kernel,运行在Hypervisor之上。
22 | Domain 0 在Xen中担任管理员的角色,它负责管理其他虚拟客户机。
23 | 在Domain 0中包含两个驱动程序,用于支持其他客户虚拟机对于网络和硬盘的访问请求。这两个驱动分别是Network Backend Driver和Block Backend Driver。
24 | Network Backend Driver直接与本地的网络硬件进行通信,用于处理来自Domain U客户机的所有关于网络的虚拟机请求。根据Domain U发出的请求Block Backend Driver直接与本地的存储设备进行通信然后,将数据读写到存储设备上。
25 | 图Dom-0
26 | 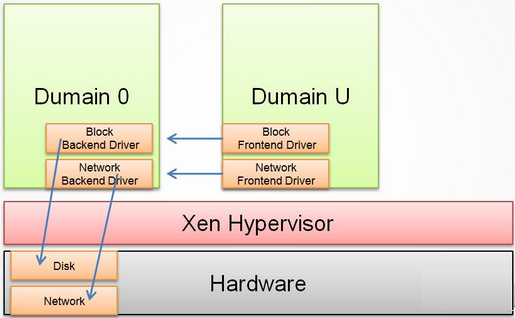
27 |
28 | Domain U :Unprivileged Domain //非特权域 其他虚拟机;直接驱动IO硬件设备;Linux-2.6.24+内核开始支持
29 | 无论是半虚拟化Domain U还是完全虚拟化Domain U,作为客户虚拟机系统,Domain U在Xen Hypervisor上运行并行的存在多个,他们之间相互独立,每个Domain U都拥有自己所能操作的虚拟资源(如:内存,磁盘等)。而且允许单独一个Domain U进行重启和关机操作而不影响其他Domain U。
30 | 图Dom-u
31 | 
32 |
33 | Xen Hypervisor:虚拟化技术通过在现有平台(机器)上添加一层薄的虚拟机监控程序(Virtual Machine Monitor,简称 VMM)软件而实现对系统的虚拟化,如虚拟处理器,虚拟内存管理器(MMU)和虚拟 I/O 系统等。虚拟机监控程序又被称之为监管程序(Hypervisor)。
34 | 控制虚拟机,并进行CPU和mem的分配。 Xen Hypervisor不负责处理诸如网络、外部存储设备、视频或其他通用的I/O处理。
35 |
36 | ### 1.2 Xen虚拟化类型
37 | 半虚拟化:
38 | 半虚拟化(Paravirtualization)有些资料称为“超虚拟化”,简称为PV,Guest Os知道自己运行在Xen Hypervisor上而不是硬件上。同时也可以识别出其他运行在相同环境中的客户虚拟机。
39 | 需要修改Guest.Kernel,不需要修改Guest上的Application
40 | 图半-1-2
41 |
42 | 
43 |
44 |
45 | 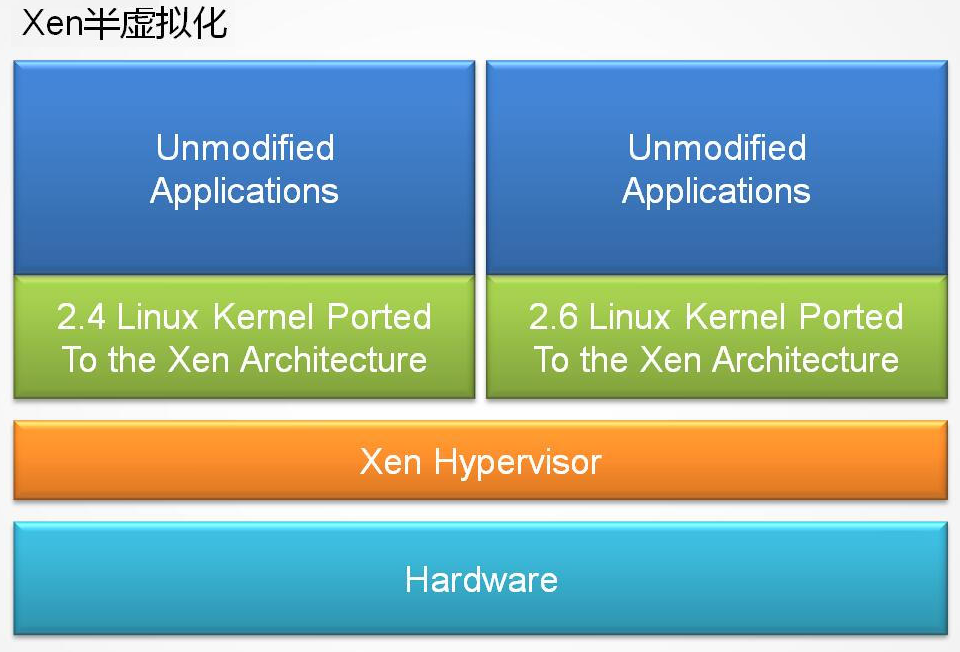
46 |
47 | 全虚拟化:
48 | 完全虚拟化(Hardware Virtual Machine)又称“硬件虚拟化”,简称HVM,Guest OS任务自己运行在硬件上,无法感知其他Guest OS
49 | 在Xen Hypervisor运行的完全虚拟化虚拟机,所运行的操作系统都是标准的操作系统,即:无需任何修改的操作系统版本。同时也需要提供特殊的硬件设备。
50 | Xen上虚拟的Windows虚拟机必须采用完全虚拟化技术。
51 | 图全-2-1
52 | 
53 |
54 | 
55 |
56 | ### 1.3 PV-HVM
57 | CPU全虚拟化,IO半虚拟化
58 | 为了提高性能,完全虚拟化的Guests可以使用特殊的半虚拟设备驱动程序(PVHVM或PV-on-HVM驱动)。这些驱动程序在HVM环境下优化的PV驱动,模拟的磁盘和网络IO旁路运行,从而让你的PV在HVM中有更好的性能。
59 | 注意:Xen项目PV(半虚拟化)的Guest自动使用PV驱动;不需要这些驱动,因为已经使用优化的驱动程序。PVHVM只会在HVM(全虚拟化)Guest中需要
60 | 图P-1-2
61 | 
62 |
63 | 
64 |
65 | ## 2. Xen的体系架构和运行机制
66 |
67 | ### 2.1 Xen体系架构
68 | Xen 的 VMM ( Xen Hyperviso ) 位于操作系统和硬件之间,负责为上层运行的操作系统内核提供虚拟化的硬件资源,负责管理和分配这些资源,并确保上层虚拟机(称为域 Domain)之间的相互隔离。Xen采用混合模式,因而设定了一个特权域用以辅助Xen管理其他的域,并提供虚拟的资源服务,该特权域称为Domain 0,而其余的域则称为Domain U。
69 | Xen向Domain提供了一个抽象层,其中包含了管理和虚拟硬件的API。Domain 0内部包含了真实的设备驱动(原生设备驱动),可直接访问物理硬件,负责与 Xen 提供的管理 API 交互,并通过用户模式下的管理工具来管理 Xen 的虚拟机环境。
70 | Xen2.0之后,引入了分离设备驱动模式。该模式在每个用户域中建立前端(front end)设备,在特权域(Dom0)中建立后端(back end)设备。所有的用户域操作系统像使用普通设备一样向前端设备发送请求,而前端设备通过IO请求描述符(IO descripror ring)和设备通道(device channel)将这些请求以及用户域的身份信息发送到处于特权域中的后端设备。这种体系将控制信息传递和数据传递分开处理。
71 | 在Xen体系结构设计中,后端设别运行的特权域被赋予一个特有的名字---隔离设备域(Isolation Device Domain, IDD),而在实际设计中,IDD 就处在Dom0中。所有的真实硬件访问都由特权域的后端设备调用本地设备驱动 (native device drive)发起。前端设备的设计十分简单,只需要完成数据的转发操作,由于它们不是真实的设备驱动程序,所以也不用进行请求调度操作。而运行在IDD中 的后端设备,可以利用Linux的现有设备驱动来完成硬件访问,需要增加的只是IO请求的桥接功能---能完成任务的分发和回送。
72 |
73 | 图2-1
74 | 
75 |
76 | ### 2.2 不同虚拟技术的运行机制
77 | 半虚拟化技术:
78 | 采用半虚拟化技术的虚拟机操作系统能够识别到自己是运行在Xen Hypervisor而非直接运行于硬件之上,并且也可以识别到在相同的机器上运行的其他虚拟机系统。而且运行的操作系统都需要进行相应的修改。
79 | 半虚拟化客户机(Domain U PV Guests)包含两个用于操作网络和磁盘的驱动程序,PV Network Driver 和PV Block Driver。
80 | PV Network Driver负责为Domain U提供网络访问功能。PV Block Driver负责为Domain U提供磁盘操作功能。
81 | 图3-1
82 | 
83 |
84 | 完全虚拟化技术:
85 | 完全虚拟化客户机(Domain U HVM Guests)运行的是标准版本的操作系统,因此其操作系统中不存在半虚拟化驱动程序(PV Driver),但是在每个完全虚拟化客户机都会在Domain 0中存在一个特殊的精灵程序,称作:Qemu-DM,Qemu-DM帮助完全虚拟化客户机(Domain U HVM Guest)获取网络和磁盘的访问操作。
86 | 完全虚拟化客户机必须和在普通硬件环境下一样进行初始化,所以需要在其中加入一个特殊的软件Xen virtual firmware,来模拟操作系统启动时所需要的BIOS。
87 |
88 | 图3-2
89 | 
90 |
91 | ### 2.3 Domain 管理和控制
92 | Linux精灵程序分类为“管理”和“控制”两大类。这些服务支撑着整个虚拟环境的管理和控制操作,并且存在于Domain 0虚拟机中。
93 | 注:为了清晰的描述Xen的运行流程,画图时将精灵程序放在Domain 0外部来描述,但事实上所有精灵程序都存在于Domain 0 之中
94 | XenD)
95 | Xend精灵线程是一个Python应用程序,它作为Xen环境的系统管理员。它利用Libxenctrl类库向Xen Hypervisor发出请求。
96 | 所有Xend处理的请求都是由XM工具使用XML RPC接口发送过来的。
97 | 图3-3
98 | 
99 |
100 | Xm)
101 | 用于将用户输入通过XML RPC接口传递到Xend中的命令行工具。
102 |
103 | Xenstored)
104 | Xenstored精灵程序用于维护注册信息,这些信息包括内存和在连接Domain 0和所有其他Domain U之间的事件通道。Domain 0虚拟机利用这些注册信息来与系统中其他虚拟机建立设备通道,即帮助Domain U虚拟机访问硬件资源。
105 |
106 | Libxenctrl)
107 | Libxenctrl是C程序类库,用于让Xend具有通过Domain 0与Xen Hypervisor进行交互的能力。在Domain 0中存在一个特殊的驱动程序称作privcmd,它将请求发送给Hypervisor。
108 |
109 | 图3-4
110 | 
111 | qemu-DM)
112 | 在Xen环境下,每个完全虚拟化虚拟机都需要拥有自己的Qemu精灵程序。Qemu-DM处理在Xen环境下完全虚拟化客户机所能允许执行的所有关于网络 和磁盘请求和操作。Qemu程序必须存在于Hypervisor之外同时又需要访问网络和I/O,所以Qemu-DM必须存在于Domain 0 中(参见前面章节对Domain 0 的描述)。
113 | 未来版本的Xen中,一种新的工具Stub-DM将会提供一系列对所有完全虚拟化客户机都可用的服务,以此来替代需要在每个虚拟机上都生成一个Qemu的逻辑。
114 |
115 | Xen Virtual Firmware)
116 | Xen Virtual Firmware是被嵌入到所有完全虚拟化客户机中的虚拟的BIOS系统,来确保所有客户操作系统在正常启动操作中接收到标准的启动指令集并提供标准的软件兼容环境。
117 |
118 | ### 2.4 半虚拟化环境下Domain 0与Domain U通信
119 | Xen Hypervisor不负责处理网络和磁盘请求,因此半虚拟化客户机(Domain U PV)必须通过Domain 0 与Xen Hypervisor进行通信,从而完成网络和磁盘的操作请求。下面以半虚拟化客户机(Domain U PV)执行向本地磁盘写入数据为例描述Domain 0与Domain U PV的交互过程。
120 | 半虚拟化客户机(Domain U PV)的PV Block Driver接收到要向本地磁盘写入数据的请求,然后通过Xen Hypervisor将与Domain 0共享的本地内存中的数据写入到本地磁盘中。在Domain 0 和半虚拟化Domain U之间存在事件通道,这个通道允许它们之间通过存在于Xen Hypervisor内的异步中断来进行通信。Domain 0将会接收到一个来自于Xen Hypervisor的系统中断,并触发Domain 0中的Block Backend驱动程序去访问本地系统内容,并从与半虚拟化客户机的共享内存中读取适合的数据块。从共享内存中读取的数据随后被写入到本地磁盘的指定位置中。
121 |
122 |
123 | 上图中所显示的事件通道是直接连接Domain 0 和Domain U PV是为了清晰和简单的描述系统是如何运行的。但事实上,事件通道(Event Channel)运行于Xen Hypervisor中,并在Xenstored中注册特定的系统中断,以此来让Domain 0 和Domain U PV能够通过本地内存快速的共享信息。
124 | 图3-6
125 | 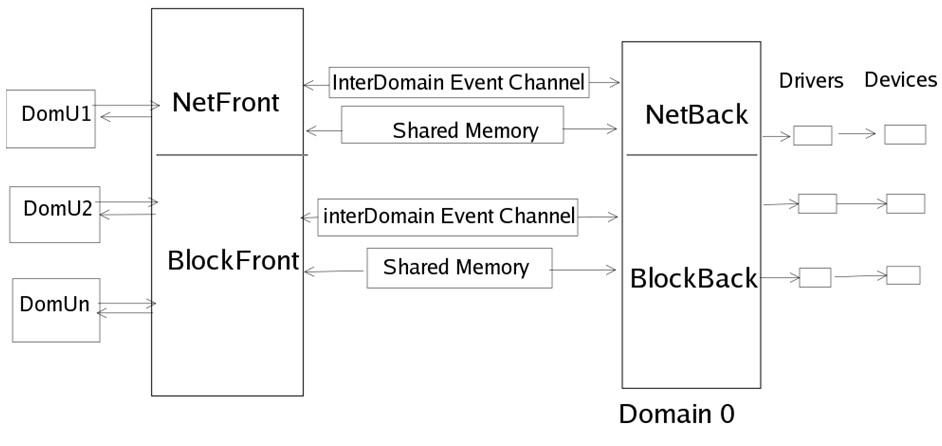
126 |
127 | ## 3. Xen的网络架构
128 | ### 3.1 Xen支持三种网络工作模式
129 | Bridge模式
130 | Xend启动时流程:
131 | * 1) 创建虚拟网桥 xenbr0。
132 | * 2) 停止物理网卡 eth0。
133 | * 3) 物理网卡 eth0 的 MAC 地址和 IP 地址被复制到虚拟网卡 veth0。
134 | * 4) 物理网卡 eth0 重命名为 peth0。
135 | * 5) Veth0 重命名为 eth0。
136 | * 6) Peth0 的 MAC 地址更改( FE:FF:FF:FF:FF:FF ),ARP 功能关闭。
137 | * 7) 连接 peth0、vif0.0 到网桥 xenbr0
138 | * 8) 启动 peth0、vif0.0、xenbr0
139 |
140 | Domain U 启动时的流程:
141 | * 1) vif.0 连接到 xenbr0
142 | * 2) 启动vif.0
143 |
144 | Route 模式
145 | Xend启动时的流程:
146 | * 1) 开启Domain 0的IP Forward。
147 | Domain U启动时的流程:
148 | * 1) 创建 vif.0 ,dom U eth0的IP地址被拷贝到vif。
149 | * 2) 启动 vif.0。
150 | * 3) 为domU的配置文件中指向虚拟接口vif.0分配的IP地址增加静态路由。
151 |
152 | NAT模式
153 | NAT 模式会使用虚拟局域网 virbr0
154 |
155 | ### 3.2 Xen Domain U Guests 发送数据包处理流程
156 | 图4-2
157 | 
158 |
159 | ### 3.3 Xen中虚拟网卡与物理网卡之间的关系
160 | 安装了Xen的Linux机器,在Dom 0中能看到以下几类网卡(网络接口设备 ):
161 | (X ,Y都为数字)
162 | pethY
163 | ethY
164 | xenbrY
165 | virbrY
166 | vifX.Y(X为DomaiID,Y表示该虚拟网卡是该Domain的第几块虚拟网卡)
167 | vethY (一般在Xend启动完成以后就不存在了)
168 | 图4-3
169 | 
170 |
171 |
172 |
173 |
174 | 原文作者: MT_IT
175 |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
--------------------------------------------------------------------------------
/product/vmm执行基本流程.md:
--------------------------------------------------------------------------------
1 | # vmm执行基本流程
2 | ```C
3 | `vmm_test_begin(testcase_name,vmm_env,"Test Case Name String") ;
4 | env.build() ;
5 | env.reset_dut() ;
6 | env.start() ;
7 | env.wait_for_end() ;
8 | env.report() ;
9 | `vmm_test_end(testcase_name);
10 | ```
11 |
12 | 参考文献:http://www.testbench.in/VM_09_VMM_TEST.html
13 | vmm_test is introduced in vmm 1.1.
14 |
15 | To know the vmm version which you are using, use this command
16 | vcs -R -sverilog -ntb_opts dtm
17 | +incdir+$VMM_HOME/sv $VMM_HOME/sv/vmm_versions.sv
18 |
19 | vmm_test is used for compiling all the testcases in one compilation. The simulation of each testcase is done individually. Traditionally for each testcase, compile and simulation are done per testcase file. With this new approach, which dose compilation only once, will save lot of cup.
20 | Generally each testcase can be divided into two parts.
21 |
22 | ## (S)Procedural code part.
23 | The procedural code part (like passing the above new constrained transaction definition to some atomic generator, calling the env methods etc) has to be defined between these macros. vmm provides 2 macros to define testcase procedural part.
24 | ```C
25 | `vmm_test_begin(testcase_name,vmm_env,"Test Case Name String")
26 | `vmm_test_env(testcase_name)
27 | ```
28 |
29 | ## (S)Declarative code part.
30 | The declarative part( like new constrained transacting definition) is defined outside these macros.
31 |
32 | Writing A Testcase
33 |
34 | Let us see an example of writing a testcase.
35 | Inside the testcase, we will define a new transaction and pass this transaction to the atomic generator.
36 |
37 |
38 | ## (S) Declarative part:
39 | 1) Define all the declarative code.
40 |
41 | ```C
42 | class constrained_tran extends pcie_transaction;
43 |
44 | // Add some constraints
45 | // Change some method definitions
46 |
47 | end class
48 | ```
49 |
50 | 2) Define a handle to the above object.
51 |
52 | constrained_tran c_tran_obj;
53 |
54 | ## (S) Procedural part:
55 |
56 | Use a `vmm_test_begin . There are 3 arguments to macro.
57 | The first argument is the name of the testcase class and will also be used as the name of the testcase in the global testcase registry.
58 | The second argument is the name of the environment class that will be used to execute the testcase. A data member of that type named "env" will be defined and assigned, ready to be used.
59 | The third argument is a string documenting the purpose of the test.
60 |
61 | ```C
62 | `vmm_test_begin(test_1,vmm_env,"Test_1")
63 | ```
64 |
65 | In this testcase, we want to pass the c_tran_obj object. The steps t pass the c_tran_obj as per the vmm_env is
66 |
67 | ```C
68 | env.build();
69 | c_tran_obj = new(" ");
70 | env.atomic_gen.randomized_obj = c_tran_obj;
71 | ```
72 |
73 | Start the vmm_env execution.
74 |
75 | ```C
76 | env.run();
77 | ```
78 |
79 | Now use `vmm_test_end to define the end of the testcase. The argument to this is the testcase name.
80 |
81 | ```C
82 | `vmm_test_end(test_1)
83 | ```
84 |
85 | Following is the full testcase source code which we discussed above.
86 |
87 | ## (S) Testcase source code
88 |
89 | ```C
90 | class constrained_tran extends pcie_transaction;
91 |
92 | end class
93 | ```
94 |
95 | constrained_tran c_tran_obj
96 |
97 | ```C
98 | `vmm_test_begin(test_1,vmm_env,"Test_1")
99 | $display(" Start of Testcase : Test_1 ");
100 | env.build();
101 | c_tran_obj = new(" ");
102 | env.atomic_gen.randomized_obj = c_tran_obj;
103 | env.run();
104 | $display(" End of Testcase : Test_1 ");
105 | `vmm_test_end(test_1)
106 | ```
107 |
108 | Like this you can write many testcases in separate file or single file.
109 |
110 | Example Of Using Vmm_test
111 |
112 |
113 | Now we will implement 3 simple testcases and a main testcase which will be used for selecting any one of the 3 testcases.
114 |
115 |
116 | ## (S) testcase_1
117 |
118 | Write this testcase in a testcase_1.sv file
119 |
120 | ```C
121 | // Define all the declarative code hear. I done have anything to show you.
122 | //
123 | // class constrained_tran extends pcie_transaction;
124 | //
125 | // end class
126 | //
127 | // constrained_tran c_tran_obj
128 |
129 | `vmm_test_begin(test_1,vmm_env,"Test_1")
130 | $display(" Start of Testcase : Test_1 ");
131 | // This is procedural part. You can call build method.
132 | env.build();
133 |
134 | // You can pass the above created transaction to atomic gen.
135 | // c_tran_obj = new(" ");
136 | // env.atomic_gen.randomized_obj = c_tran_obj;
137 | //
138 | //
139 |
140 | env.run();
141 | $display(" End of Testcase : Test_1 ");
142 | `vmm_test_end(test_1)
143 | ```
144 |
145 | ## (S)testcase_2
146 | Write this testcase in a testcase_2.sv file
147 |
148 | ```C
149 | `vmm_test_begin(test_2,vmm_env,"Test_2")
150 | $display(" Start of Testcase : Test_2 ");
151 | // Do something like this ....
152 | env.build();
153 | // like this ....
154 | env.run();
155 | $display(" End of Testcase : Test_2 ");
156 | `vmm_test_end(test_2)
157 | ```
158 |
159 | ## (S)testcase_3
160 |
161 | Write this testcase in a testcase_3.sv file
162 |
163 | ```C
164 | `vmm_test_begin(test_3,vmm_env,"Test_3")
165 | $display(" Start of Testcase : Test_3 ");
166 | // Do something like this ....
167 | env.build();
168 | // like this ....
169 | env.run();
170 | $display(" End of Testcase : Test_3 ");
171 | `vmm_test_end(test_3)
172 | ```
173 |
174 | ## (S)main testcase
175 |
176 | Now we will write the main testcase. This doesn't have any test scenario, it is only used for handling the above 3 testcases.
177 |
178 | This should be written in program block.
179 |
180 | 1) First include all the above testcases inside the program block.
181 | ```C
182 | `include "testcase_1.sv"
183 | `include "testcase_2.sv"
184 | `include "testcase_3.sv"
185 | ```
186 |
187 | 2) Define env class object.
188 | ```C
189 | vmm_env env = new();
190 | ```
191 |
192 | As I dont have a custom env class to show, I used vmm_env. You can use your custom defined env.
193 |
194 | 3) In the initial block call the run() method of vmm_test_registry class and pass the above env object as argument. This run method of vmm_test_registry is a static method, so there is no need to create an object of this class.
195 |
196 | ```C
197 | vmm_test_registry::run(env);
198 | ```
199 |
200 | ## (S) Main testcase source code
201 | ```C
202 | `include "vmm.sv"
203 | program main();
204 |
205 | `include "testcase_1.sv"
206 | `include "testcase_2.sv"
207 | `include "testcase_3.sv"
208 |
209 | vmm_env env;
210 |
211 | initial
212 | begin
213 | $display(" START OF TEST CASE ");
214 | env = new();
215 | vmm_test_registry::run(env);
216 | $display(" START OF TEST CASE ");
217 | end
218 |
219 |
220 | endprogram
221 | ```
222 |
223 | Now compile the above code using command.
224 |
225 | vcs -sverilog main_testcase.sv +incdir+$VMM_HOME/sv
226 |
227 | Now simulate the above compiled code.
228 |
229 | To simulate , just do ./simv and see the log.
230 | You can see the list of the testcases. This simulation will not ececute any testcase.
231 |
232 | ## (S)LOG
233 |
234 | START OF TEST CASE
235 | *FATAL*[FAILURE] on vmm_test_registry(class) at 0:
236 | No test was selected at runtime using +vmm_test=.
237 | Available tests are:
238 | 0) Default : Default testcase that simply calls env::run()
239 | 1) test_1 : Test_1
240 | 2) test_2 : Test_2
241 | 3) test_3 : Test_3
242 |
243 | To run testcase_1 use ./simv +vmm_test=test_1
244 |
245 | ## (S)LOG
246 |
247 | START OF TEST CASE
248 | Normal[NOTE] on vmm_test_registry(class) at 0:
249 | Running test "test_1"...
250 | Start of Testcase : Test_1
251 | Simulation PASSED on /./ (/./) at 0 (0 warnings, 0 demoted errors & 0 demoted warnings)
252 | End of Testcase : Test_1
253 | START OF TEST CASE
254 |
255 | Simillarly to run testcase_2 ./simv +vmm_test=test_2
256 |
257 |
258 | ## (S)LOG
259 |
260 | START OF TEST CASE
261 | Normal[NOTE] on vmm_test_registry(class) at 0:
262 | Running test "test_2"...
263 | Start of Testcase : Test_2
264 | Simulation PASSED on /./ (/./) at 0 (0 warnings, 0 demoted errors & 0 demoted warnings)
265 | End of Testcase : Test_2
266 | START OF TEST CASE
267 |
268 | You can also call the Default testcase, which just calls the env::run()
269 |
270 | ./simv +vmm_test=Default
271 |
272 | ## (S)LOG
273 |
274 | START OF TEST CASE
275 | Normal[NOTE] on vmm_test_registry(class) at 0:
276 | Running test "Default"...
277 | Simulation PASSED on /./ (/./) at 0 (0 warnings, 0 demoted errors & 0 demoted warnings)
278 | START OF TEST CASE
279 |
280 | ## (S) Download the source code
281 |
282 | vmm_test.tar
283 | Browse the code in vmm_test.tar
284 |
285 | ## (S) Command to compile
286 | vcs -sverilog -ntb_opts dtm +incdir+$VMM_HOME/sv main_testcase.sv
287 |
288 | ## (S) Commands to simulate testcases
289 | ./simv
290 | ./simv +vmm_test=Default
291 | ./simv +vmm_test=test_1
292 | ./simv +vmm_test=test_2
293 | ./simv +vmm_test=test_3
294 |
295 |
296 |
297 |
298 |
299 |
300 |
301 |
302 |
303 |
304 |
305 |
306 |
307 |
308 |
309 |
310 |
311 |
312 |
313 |
314 |
--------------------------------------------------------------------------------
/product/操作系统级虚拟化实现.md:
--------------------------------------------------------------------------------
1 | # 操作系统级虚拟化实现
2 |
3 | ## 1.2 操作系统级虚拟化实现
4 | ### 1.2.1 chroot
5 | 容器的概念始于 1979 年的 UNIX chroot,它是一个 UNIX 操作系统上的系统调用,用于将一个进程及其子进程的根目录改变到文件系统中的一个新位置,让这些进程只能访问到该目录。这个功能的想法是为每个进程提供独立的磁盘空间。其后在 1982年,它被加入到了 BSD 系统中。
6 |
7 | ### 1.2.2 LXC
8 | LXC 的意思是 LinuX Containers,它是第一个最完善的 Linux 容器管理器的实现方案,是通过 cgroups 和 Linux 名字空间namespace实现的。LXC 存在于 liblxc 库中,提供了各种编程语言的 API 实现,包括 Python3、Python2、Lua、Go、Ruby 和 Haskell 等。与其它容器技术不同的是, LXC 可以工作在普通的 Linux 内核上,而不需要增加补丁。现在 LXC project 是由 Canonical 公司赞助并托管的。
9 |
10 | ### 1.2.3 Docker
11 | Docker 是到现在为止最流行和使用广泛的容器管理系统。它最初是一个叫做 dotCloud 的 PaaS 服务公司的内部项目,后来该公司改名为 Docker。Docker 开始阶段使用的也是 LXC ,之后采用自己开发的 libcontainer 替代了它。不像其它的容器平台,Docker 引入了一整个管理容器的生态系统,这包括高效、分层的容器镜像模型、全局和本地的容器注册库、清晰的 REST API、命令行等等。稍后的阶段, Docker 推动实现了一个叫做 Docker Swarm 的容器集群管理方案。
12 |
13 | ### 1.2.4 Linux VServer
14 | Linux-VServer 也是一个操作系统级虚拟化解决方案。Linux-VServer 对 Linux 内核进行虚拟化,这样多个用户空间环境—又称为 Virtual Private Server(VPS) 就可以单独运行,而不需要互相了解。Linux-VServer 通过修改 Linux 内核实现用户空间的隔离。
15 | Linux-VServer 也使用了 chroot 来为每个 VPS 隔离 root 目录。虽然 chroot 允许指定新 root 目录,但还是需要其他一些功能(称为 Chroot-Barrier)来限制 VPS 脱离其隔离的 root 目录回到上级目录。给定一个隔离的 root 目录之后,每个 VPS 就可以拥有自己的用户列表和 root 密码。
16 | 2.4 和 2.6 版本的 Linux 内核支持 Linux-VServer,它可以运行于很多平台之上,包括 x86、x86-64、SPARC、MIPS、ARM 和 PowerPC。
17 |
18 | ### 1.2.5 Virtuozzo/OpenVZ
19 | Virtuozzo是SWsoft公司(目前SWsoft已经改名为Parallels)的操作系统虚拟化软件的命名,Virtuozzo是商业解决方案,而OpenVZ是以Virtuozzo为基础的开源项目,它们采用的也是操作系统级虚拟化技术。OpenVZ 类似于 Linux-VServer,它通过对 Linux 内核进行补丁来提供虚拟化、隔离、资源管理和状态检查。每个 OpenVZ 容器都有一套隔离的文件系统、用户及用户组等。
20 |
--------------------------------------------------------------------------------
/product/系统级虚拟化实现.md:
--------------------------------------------------------------------------------
1 | ## 1.1 系统级虚拟化实现
2 | ### 1.1.1 VMware
3 | VMware是x86 虚拟化软件的主流广商之一。VMware的5位创始人中的3位曾在斯坦福大学研究操作系统虚拟化,项目包括SimOS系统模拟器和Disco虚拟机监控器。1998年,他们与另外两位创始人共同创建了VMware 公司,总部位于美国加州Palo Alto。
4 | VMware提供一系列的虚拟化产品,产品的应用领域从服务器到桌面。下面是VMware主要产品的简介,包括VMware ESX、VMware Server和VMware Workstation。
5 | VMware ESX Server是VMware的旗舰产品,后续版本改称VMware vSphere。ESX Server基于Hypervisor模型,在性能和安全性方面都得到了优化,是一款面向企业级应用的产品。VMware ESX Server支持完全虚拟化,可以运行Windows 、Linux、Solaris和Novell Netware等客户机操作系统。VMware ESX Server也支持类虚拟化,可以运行Linux 2. 6. 21 以上的客户机操作系统。ESX Server的早期版本采用软件虚拟化的方式,基于Binary Translation技术。自ESX Server 3开始采用硬件虚拟化的技术,支持Intel VT技术和AMD-V技术。
6 | VMware Server之前叫VMware GSX Server,是VMware面向服务器端的入门级产品。VMware Server采用了宿主模型,宿主机操作系统可以是Windows或者Linux。VMware Server的功能与ESX Server类似,但是在性能和安全性上与ESX Server有所差距。VMware Server也有自己的优点,由于采用了宿主模型,因此VMware Server支持的硬件种类要比ESX Server多。
7 | VMware Workstation是VMware面向桌面的主打产品。与VMware Server类似,VMware Workstation也是基于宿主模型,宿主机操作系统可以是Windows或者Linux。VMware Workstation也支持完全虚拟化,可以运行Windows、Linux、Solaris、Novell Netware和FreeBSD等客户机操作系统。与VMware Server不同, VMware Workstation专门针对桌面应用做了优化,如为虚拟机分配USB设备,为虚拟机显卡进行3D加速等。
8 |
9 | ### 1.1.2 Microsoft
10 | 微软在虚拟化产品方面起步比VMware晚,但是在认识到虚拟化的重要性之后,微软通过外部收购和内部开发,推出了一系列虚拟化产品,目前已经形成了比较完整的虚拟化产品线。微软的虚拟化产品涵盖了服务器虚拟化(Hyper-V)和桌面虚拟化(Virtual PC)。
11 | Virtual PC是而向桌面的虚拟化产品,最早由Connectix公司开发,后来该产品被微软公司收购。Virtual PC是基于宿主模型的虚拟机产品,宿主机操作系统是Windows。早期版本也采用软件虚拟化方式,基于Binary Translation技术。之后版本已经支持硬件虚拟化技术。
12 | Windows Server 2008是微软推出的服务器操作系统,其中一项重要的新功能是虚拟化功能。其虚拟化架构采用的是混合模型,重要组件之一Hyper-V作为Hypervisor运行在最底层,Server 2008本身作为特权操作系统运行在Hyper-V之上。Server 2008采用硬件虚拟化技术,必须运行在支持Intel VT技术或者AMD-V 技术的处理器上。
13 |
14 | ### 1.1.3 Xen
15 | Xen是一款基于GPL授权方式的开源虚拟机软件。Xen起源于英国剑桥大学Ian Pratt领导的一个研究项目,之后,Xen独立出来成为一个社区驱动的开源软件项目。Xen社区吸引了许多公司和科研院所的开发者加入,发展非常迅速。之后,Ian成立了XenSource公司进行Xen的商业化应用,并且推出了基于Xen的产品Xen Server。2007年,Ctrix公司收购了XenSource公司,继续推广Xen的商业化应用,Xen开源项目本身则被独立到www.xen.org。
16 | 从技术角度来说,Xen基于混合模型,特权操作系统( 在Xen中称作Domain 0)可以是Linux、Solaris以及NetBSD,理论上,其他操作系统也可以移植作为Xen的特权操作系统。Xen最初的虚拟化思路是类虚拟化,通过修改Linux内核,实现处理器和内存的虚拟化,通过引入I/O的前端驱动/后端驱动(front / backend)架构实现设备的类虚拟化。之后也支持了完全虚拟化和硬件虚拟化技术。
17 |
18 | ### 1.1.4 KVM
19 | KVM(Kernel-based Virtual Machine)也是一款基于GPL授权方式的开源虚拟机软件。KVM 最早由Qumranet公司开发,在2006年出现在Linux内核的邮件列表上,并于2007年被集成到了Linux 2.6.20内核中,成为内核的一部分。
20 | KVM支持硬件虚拟化方法,并结合QEMU来提供设备虚拟化。KVM的特点在于和Linux内核结合得非常好,而且和Xen一样,作为开源软件,KVM的移植性也很好。
21 |
22 | ### 1.1.5 Oracle VM VirtualBox
23 | VirtualBox是一款开源虚拟机软件,类似于VMware Workstation。VirtualBox 是由德国Innotek公司开发,由Sun Microsystems公司出品的软件,使用Qt编写,在 Sun 被 Oracle 收购后正式更名成 Oracle VM VirtualBox。Innotek 以 GNU General Public License (GPL) 释出 VirtualBox。用户可以在VirtualBox上安装并且执行Solaris、Windows、DOS、Linux、BSD等系统作为客户端操作系统。现在由甲骨文公司进行开发,是甲骨文公司VM虚拟化平台技术的一部分。
24 |
25 | ### 1.1.6 Bochs
26 | Bochs 是一个 x86 计算机仿真器,它在很多平台上(包括 x86、PowerPC、Alpha、SPARC 和 MIPS)都可以移植和运行。使 Bochs 不仅可以对处理器进行仿真,还可以对整个计算机进行仿真,包括计算机的外围设备,比如键盘、鼠标、视频图像硬件、网卡(NIC)等。
27 | Bochs 可以配置作为一个老式的 Intel® 386 或其后继处理器使用,例如 486、Pentium、Pentium Pro 或 64 位处理器。它甚至还可以对一些可选的图形指令进行仿真,例如 MMX 和 3DNow。
28 |
29 | ### 1.1.7 QEMU
30 | QEMU是一套由Fabrice Bellard所编写的模拟处理器的自由软件。它与Bochs,PearPC近似,但其具有某些后两者所不具备的特性,如高速度及跨平台的特性,qemu可以虚拟出不同架构的虚拟机,如在x86平台上可以虚拟出power机器。kqemu为qemu的加速器,经由kqemu这个开源的加速器,QEMU能模拟至接近真实电脑的速度。
31 | QEMU本身可以不依赖于KVM,但是如果有 KVM的存在并且硬件(处理器)支持比如Intel VT功能,那么QEMU在对处理器虚拟化这一块可以利用KVM提供的功能来提升性能。换言之,KVM缺乏设备虚拟化以及相应的用户空间管理虚拟机的工具,所以它借用了QEMU的代码并加以精简,连同KVM一起构成了一个完整的虚拟化解决方案,不妨称之为:KVM+QEMU。
32 |
--------------------------------------------------------------------------------
/product/虚拟化技术.md:
--------------------------------------------------------------------------------
1 | # 虚拟化技术
2 | 虚拟化指通过虚拟技术,将一台物理主机,虚拟成多个逻辑主机,每个逻辑主机上运行不同的操作系统和应用程序,且互不干扰,从而显著提升计算机的工作效率。
3 |
4 | * 虚拟化前
5 | * 每台主机一个操作系统
6 | * 在同一台主机运行多个应用程序,有时候会产生冲突
7 | * 资源利用率低
8 | * 硬件成本高昂
9 |
10 | * 虚拟化后
11 | * 打破了操作系统和硬件的相互依赖
12 | * 通过封装到虚拟机的技术,管理操作系统和应用程序为单一整体
13 | * 强大的安全和故障隔离
14 | * 虚拟机是独立于硬件的,它能在硬件上运行
15 |
--------------------------------------------------------------------------------
/product/虚拟化技术概要之VMM结构.md:
--------------------------------------------------------------------------------
1 | # 虚拟化技术概要之VMM结构
2 |
3 | ## 1. 概述
4 |
5 | 当前主流的 VMM (Virtual Machine Monitor)
6 | 实现结构可以分为三类:
7 |
8 | 宿主模型 (OS-hosted VMMs)
9 | Hypervisor 模型 (Hypervisor
10 | VMMs)
11 | 混合模型 (Hybrid VMMs)
12 |
13 | ## 2. 宿主模型
14 |
15 | 
16 |
17 | 该结构的 VMM,物理资源由 Host OS (Windows, Linux etc.) 管理
18 | 实际的虚拟化功能由
19 | VMM 提供,其通常是 Host OS 的独立内核模块(有的实现还含用户进程,如负责 I/O 虚拟化的用户态设备模型)
20 | VMM 通过调用 Host OS
21 | 的服务来获得资源,实现 CPU,内存和 I/O 设备的虚拟化
22 | VMM 创建出 VM 后,通常将 VM 作为 Host OS
23 | 的一个进程参与调度
24 |
25 | 如上图所示,VMM 模块负责 CPU 和内存虚拟化,由 ULM 请求 Host OS 设备驱动,实现 I/O
26 | 设备的虚拟化。
27 |
28 | **优点**:可以充分利用现有 OS 的设备驱动,VMM 无需自己实现大量的设备驱动,轻松实现 I/O
29 | 设备的虚拟化。
30 | **缺点**:因资源受 Host OS 控制,VMM 需调用 Host OS
31 | 的服务来获取资源进行虚拟化,其效率和功能会受到一定影响。
32 |
33 | 采用该结构的 VMM 有:VMware Workstation, VMWare
34 | Server (GSX), Virtual PC, Virtual Server, KVM(早期)
35 |
36 |
37 | 3. Hypervisor 模型
38 | 
39 |
40 | 该结构中,VMM 可以看作一个为虚拟化而生的完整 OS,掌控有所有资源(CPU,内存,I/O 设备)
41 | VMM
42 | 承担管理资源的重任,其还需向上提供 VM 用于运行 Guest OS,因此 VMM
43 | 还负责虚拟环境的创建和管理。
44 |
45 | 优点:因 VMM
46 | 同时具有物理资源的管理功能和虚拟化功能,故虚拟化的效率会较高;安全性方面,VM 的安全只依赖于 VMM 的安全
47 | 缺点:因
48 | VMM 完全拥有物理资源,因此,VMM 需要进行物理资源的管理,包括设备的驱动,而设备驱动的开发工作量是很大的,这对 VMM
49 | 是个很大的挑战。
50 |
51 | 采用该结构的 VMM 有:VMWare ESX Server, WindRiver Hypervisor,
52 | KVM(后期)
53 |
54 | 4. 混合模型
55 | 该结构是上述两种模式的混合体,VMM 依然位于最底层,拥有所有物理资源,但 VMM 会主动让出大部分 I/O 设备的控制权,将它们交由一个运行在特权 VM 上的特权 OS 来控制。
56 | VMM
57 | 只负责 CPU 和内存的虚拟化,I/O 设备的虚拟化由 VMM 和特权 OS 共同完成:
58 | 
59 |
60 | 优点:可利用现有 OS 的 I/O 设备驱动;VMM 直接控制 CPU
61 | 和内存等物理资源,虚拟化效率较高;若对特权 OS 的权限控制得当,虚拟机的安全性只依赖于 VMM。
62 | 缺点:因特权 OS
63 | 运行于 VM 上,当需要特权 OS 提供服务时,VMM 需要切换到特权 OS,这里面就产生上下文切换的开销。
64 |
65 | 采用该结构的 VMM 有:Xen,
66 | SUN Logical Domain
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
--------------------------------------------------------------------------------
/product/虚拟化的必要性.md:
--------------------------------------------------------------------------------
1 | # 虚拟化的必要性
2 |
3 | 
4 |
5 |
6 |
--------------------------------------------------------------------------------
/product/软件模拟虚拟化、全虚拟化、半虚拟化、硬件辅助虚拟化和容器.md:
--------------------------------------------------------------------------------
1 | # 软件模拟虚拟化、全虚拟化、半虚拟化、硬件辅助虚拟化和容器
2 |
3 | ## 虚拟化技术
4 | 虚拟化指通过虚拟技术,将一台物理主机,虚拟成多个逻辑主机,每个逻辑主机上运行不同的操作系统和应用程序,且互不干扰,从而显著提升计算机的工作效率。
5 |
6 | ## 虚拟化前
7 | * 每台主机一个操作系统
8 | * 在同一台主机运行多个应用程序,有时候会产生冲突
9 | * 资源利用率低
10 | * 硬件成本高昂
11 |
12 | ## 虚拟化后
13 | * 打破了操作系统和硬件的相互依赖
14 | * 通过封装到虚拟机的技术,管理操作系统和应用程序为单一整体
15 | * 强大的安全和故障隔离
16 | * 虚拟机是独立于硬件的,它能在硬件上运行
17 |
--------------------------------------------------------------------------------
/vedio/README.md:
--------------------------------------------------------------------------------
1 | #
2 |
--------------------------------------------------------------------------------
/virtualization_type/README.md:
--------------------------------------------------------------------------------
1 | ## 虚拟化架构
2 | ### 全虚拟化架构
3 |
4 | 
5 |
6 | 客户机操作系统不宿主机操作系统的限制
7 |
8 | ### 操作系统层的虚拟化
9 |
10 | 
11 |
12 | 客户机操作系统必须要和宿主机操作系统保持一致
13 |
14 | ### 平台虚拟化(硬件虚拟化)
15 |
16 | 无需安装宿主机操作系统,客户机操作系统可以随意进行安装
17 |
18 | 
19 |
20 | ### Hypervisor
21 | Hypervisor是一种运行在物理服务器和操作系统之间的中间软件层,可允许多个操作系统和应用共享一套基础物理硬件,因此也可以看作是虚拟环境中的“元”操作系统,他可以协调访问服务器上的所有的物理设备和虚拟机,也叫虚拟机监视器。Hypervisor是所有虚拟化技术的核心。当服务器启动并执行Hypervisor时,他会给每一台虚拟机分配适量的内存、CPU、网络和磁盘,并加载所有虚拟机的客户操作系统。常见的产品有Vmware、KVM、Xen等。
22 |
23 |
--------------------------------------------------------------------------------
/virtualization_type/cpu_virtualization/CPU虚拟化.md:
--------------------------------------------------------------------------------
1 | # CPU虚拟化
2 |
3 | ## 1. 基于二进制翻译的全虚拟化(Full Virtualization with Binary Translation)
4 |
5 | 
6 |
7 | 客户操作系统运行在 Ring 1,它在执行特权指令时,会触发异常(CPU的机制,没权限的指令会触发异常),然后 VMM 捕获这个异常,在异常里面做翻译,模拟,最后返回到客户操作系统内,客户操作系统认为自己的特权指令工作正常,继续运行。但是这个性能损耗,就非常的大,简单的一条指令,执行完,了事,现在却要通过复杂的异常处理过程。
8 |
9 | 异常 “捕获(trap)-翻译(handle)-模拟(emulate)” 过程:
10 |
11 | 
12 |
13 | ### 2. 超虚拟化(或者半虚拟化/操作系统辅助虚拟化 Paravirtualization)
14 |
15 | 半虚拟化的思想就是, 修改操作系统内核,替换掉不能虚拟化的指令, 通过超级调用(hypercall )直接和底层的虚拟化层hypervisor 来通讯 ,hypervisor 同时也提供了超级调用接口来满足其他关键内核操作,比如内存管理、中断和时间保持。
16 |
17 | 这种做法省去了全虚拟化中的捕获和模拟,大大提高了效率。所以像XEN这种半虚拟化技术,客户机操作系统都是有一个专门的定制内核版本,和x86、mips、arm这些内核版本等价。这样以来,就不会有捕获异常、翻译、模拟的过程了,性能损耗非常低。这就是XEN这种半虚拟化架构的优势。这也是为什么XEN只支持虚拟化Linux,无法虚拟化windows原因,微软不改代码啊。
18 |
19 | 
20 |
21 | ### 3. 硬件辅助的虚拟化
22 |
23 | 2005年后,CPU厂商Intel 和 AMD 开始支持虚拟化了。 Intel 引入了 Intel-VT (Virtualization Technology)技术。 这种 CPU,有 VMX root operation 和 VMX non-root operation两种模式,两种模式都支持Ring 0 ~ Ring 3 共 4 个运行级别。这样,VMM 可以运行在 VMX root operation模式下,客户OS运行在VMX non-root operation模式下。
24 |
25 | 
26 |
27 | 而且两种操作模式可以互相转换。运行在 VMX root operation 模式下的 VMM 通过显式调用 VMLAUNCH 或 VMRESUME 指令切换到 VMX non-root operation 模式,硬件自动加载 Guest OS 的上下文,于是 Guest OS 获得运行,这种转换称为 VM entry。Guest OS 运行过程中遇到需要 VMM 处理的事件,例如外部中断或缺页异常,或者主动调用 VMCALL 指令调用 VMM 的服务的时候(与系统调用类似),硬件自动挂起 Guest OS,切换到 VMX root operation 模式,恢复 VMM 的运行,这种转换称为 VM exit。VMX root operation 模式下软件的行为与在没有 VT-x 技术的处理器上的行为基本一致;而VMX non-root operation 模式则有很大不同,最主要的区别是此时运行某些指令或遇到某些事件时,发生 VM exit。
28 |
29 | 也就说,硬件这层就做了些区分,这样全虚拟化下,那些靠“捕获异常-翻译-模拟”的实现就不需要了。而且CPU厂商,支持虚拟化的力度越来越大,靠硬件辅助的全虚拟化技术的性能逐渐逼近半虚拟化,再加上全虚拟化不需要修改客户操作系统这一优势,全虚拟化技术应该是未来的发展趋势。
30 |
--------------------------------------------------------------------------------
/virtualization_type/io_virtualization/IO虚拟化.md:
--------------------------------------------------------------------------------
1 | # KVM I/O虚拟化
2 |
3 | I/O虚拟化包括管理虚拟设备和共享的物理硬件之间I/O请求的路由选择。目前,实现I/O虚拟化有三种方式:I/O全虚拟化、I/O半虚拟化和I/O透传。
4 |
5 | 
6 |
7 | * 全虚拟化:宿主机截获客户机对I/O设备的访问请求,然后通过软件模拟真实的硬件。这种方式对客户机而言非常透明,无需考虑底层硬件的情况,不需要修改操作系统。
8 | * 半虚拟化:通过前端驱动/后端驱动模拟实现I/O虚拟化。客户机中的驱动程序为前端,宿主机提供的与客户机通信的驱动程序为后端。前端驱动将客户机的请求通过与宿主机间的特殊通信机制发送给后端驱动,后端驱动在处理完请求后再发送给物理驱动。
9 | * IO透传:直接把物理设备分配给虚拟机使用,这种方式需要硬件平台具备I/O透传技术,例如Intel VT-d技术。它能获得近乎本地的性能,并且CPU开销不高。
10 |
11 | DPDK支持半虚拟化的前端virtio和后端vhost,并且对前后端都有性能加速的设计。而对于I/O透传,DPDK可以直接在客户机里使用,就像在宿主机里,直接接管物理设备,进行操作。
12 |
13 | ## 1. I/O透传
14 | I/O透传带来的好处是高性能,几乎可以获得本机的性能,这个主要是因为Intel®VT-d的技术支持,在执行IO操作时大量减少甚至避免VM-Exit陷入到宿主机中。目前只有PCI和PCI-e设备支持Intel®VT-d技术。可以配合SR-IOV使用,让一个网卡生成多个独立的虚拟网卡,把这些虚拟网卡分配给每一个客户机,可以获得相对好的性能。
15 |
16 | ## VT-d
17 | VT-d主要给宿主机软件提供了以下的功能:
18 |
19 | * I/O设备的分配:可以灵活地把I/O设备分配给虚拟机,把对虚拟机的保护和隔离的特性扩展到IO的操作上来。
20 | * DMA重映射:可以支持来自设备DMA的地址翻译转换。
21 | * 中断重映射:可以支持来自设备或者外部中断控制器的中断的隔离和路由到对应的虚拟机。
22 | * 可靠性:记录并报告DMA和中断的错误给系统软件,否则的话可能会破坏内存或影响虚拟机的隔离。
23 |
24 | ## SR-IOV
25 | SR-IOV技术是由PCI-SIG制定的一套硬件虚拟化规范,全称是Single Root IO Virtualization(单根IO虚拟化)。SR-IOV规范主要用于网卡(NIC)、磁盘阵列控制器(RAID controller)和光纤通道主机总线适配器(Fibre Channel Host Bus Adapter,FC HBA),使数据中心达到更高的效率。SR-IOV架构中,一个I/O设备支持最多256个虚拟功能,同时将每个功能的硬件成本降至最低。SR-IOV引入了两个功能类型:
26 |
27 | * PF(Physical Function,物理功能):这是支持SR-IOV扩展功能的PCIe功能,主要用于配置和管理SR-IOV,拥有所有的PCIe设备资源。PF在系统中不能被动态地创建和销毁(PCI Hotplug除外)。
28 | * VF(Virtual Function,虚拟功能):“精简”的PCIe功能,包括数据迁移必需的资源,以及经过谨慎精简的配置资源集,可以通过PF创建和销毁。
29 |
30 | 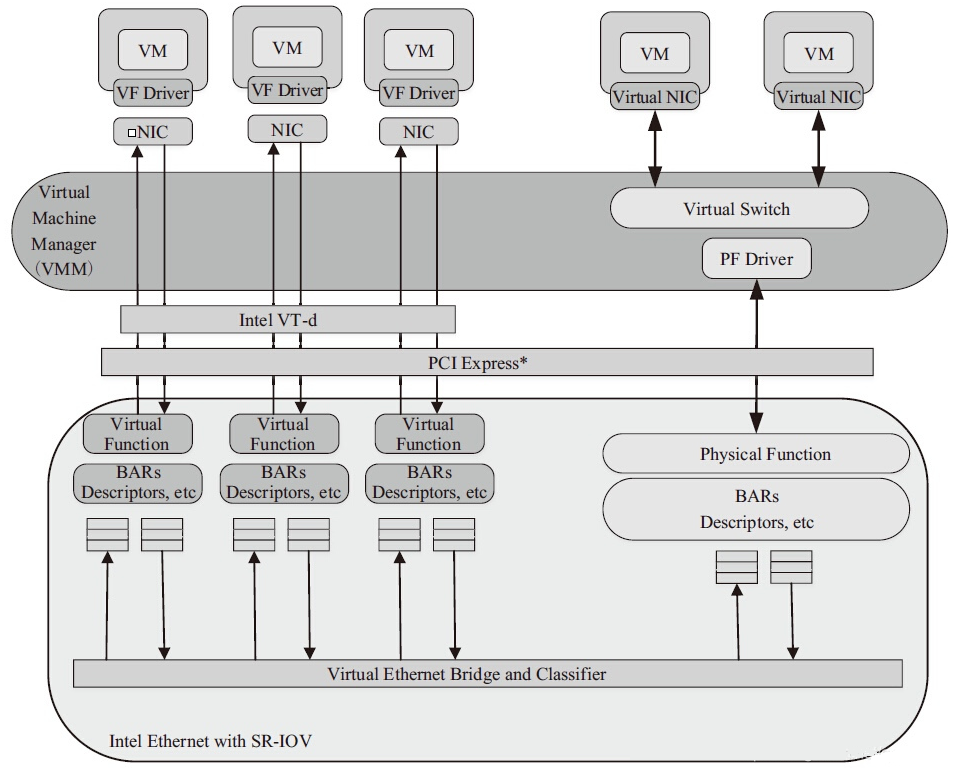
31 |
32 | ## 2. virtio
33 | 在客户机操作系统中实现的前端驱动程序一般直接叫Virtio,在宿主机实现的后端驱动程序目前常用的叫vhost。与宿主机纯软件模拟I/O(如e1000、rtl8139)设备相比,virtio可以获得很好的I/O性能。但其缺点是必须要客户机安装特定的virtio驱动使其知道是运行在虚拟化环境中。
34 |
35 | 
36 |
37 | 常见的virtio设备
38 |
39 | 
40 |
41 | ### Virtio网络设备Linux内核驱动设计
42 |
43 | Virtio网络设备Linux内核驱动主要包括三个层次:底层PCI-e设备层,中间Virtio虚拟队列层,上层网络设备层。
44 |
45 | 
46 |
47 | 
48 |
49 | 
50 |
51 | ### DPDK用户空间virtio设备的优化
52 | DPDK用户空间驱动和Linux内核驱动相比,主要不同点在于DPDK只暂时实现了Virtio网卡设备,所以整个构架和优化上面可以暂时只考虑网卡设备的应用场景。
53 |
54 | * 关于单帧mbuf的网络包收发优化:固定了可用环表表项与描述符表项的映射,即可用环表所有表项head_idx指向固定的vring描述符表位置(对于接收过程,可用环表0->描述符表0,1->1,…,255->255的固定映射;对于发送过程,0->128,1->129,…127->255,128->128,129->129,…255->255的固定映射,描述符表0127指向mbuf的数据区域,描述符表128255指向virtio net header的空间),对可用环表的更新只需要更新环表自身的指针。固定的可用环表除了能够避免不同核之间的CACHE迁移,也节省了vring描述符的分配和释放操作,并为使用SIMD指令进行进一步加速提供了便利。
55 | * Indirect特性在网络包发送中的支持:如前面介绍,发送的包至少需要两个描述符。通过支持indirect特性,任何一个要发送的包,无论单帧还是巨型帧(巨型帧的介绍见6.6.1节)都只需要一个描述符,该描述符指向一块驱动程序额外分配的间接描述符表的内存区域。
56 |
57 | 
58 |
59 | ## 3. vhost
60 | virtio-net的后端驱动经历过从virtio-net后端,到内核态vhost-net,再到用户态vhost-user的演进过程。
61 |
62 | ### 3.1 virtio-net
63 | virtio-net后端驱动的最基本要素是虚拟队列机制、消息通知机制和中断机制。虚拟队列机制连接着客户机和宿主机的数据交互。消息通知机制主要用于从客户机到宿主机的消息通知。中断机制主要用于从宿主机到客户机的中断请求和处理。
64 |
65 | 
66 |
67 | 性能瓶颈主要存在于数据通道和消息通知路径这两块:
68 |
69 | * 数据通道是从Tap设备到Qemu的报文拷贝和Qemu到客户机的报文拷贝,两次报文拷贝导致报文接收和发送上的性能瓶颈。
70 | * 消息通知路径是当报文到达Tap设备时内核发出并送到Qemu的通知消息,然后Qemu利用IOCTL向KVM请求中断,KVM发送中断到客户机。
71 |
72 | ### 3.2 vhost-net
73 | vhost-net技术对virtio-net进行了优化,在内核中加入了vhost-net.ko模块,使得对网络数据可以在内核态得到处理。vhost-net通过卸载virtio-net在报文收发处理上的工作,使Qemu从virtio-net的虚拟队列工作中解放出来,减少上下文切换和数据包拷贝,进而提高报文收发的性能。除此以外,宿主机上的vhost-net模块还需要承担报文到达和发送消息通知及中断的工作。
74 |
75 | 
76 |
77 | 报文接收仍然包括数据通路和消息通知路径两个方面:
78 |
79 | * 数据通路是从Tap设备接收数据报文,通过vhost-net模块把该报文拷贝到虚拟队列中的数据区,从而使客户机接收报文。
80 | * 消息通路是当报文从Tap设备到达vhost-net时,通过KVM模块向客户机发送中断,通知客户机接收报文。
81 |
82 | ### 3.3 vhost-user
83 | Linux内核态的vhost-net模块需要在内核态完成报文拷贝和消息处理,这会给报文处理带来一定的性能损失,因此用户态的vhost应运而生。用户态vhost采用了共享内存技术,通过共享的虚拟队列来完成报文传输和控制,大大降低了vhost和virtio-net之间的数据传输成本。
84 |
85 | 1. 数据通路不再涉及内核,直接通过共享内存发送给用户态应用(如DPDK,OVS)
86 | 2. 消息通路通过Unix Domain Socket实现
87 |
88 | 
89 |
90 | DPDK vhost同时支持Linux virtio-net驱动和DPDK virtio PMD驱动的前端。
91 |
92 | ## 4 DPDK vhost
93 | DPDK vhost支持vhost-cuse(用户态字符设备)和vhost-user(用户态socket服务)两种消息机制,它负责为客户机中的virtio-net创建、管理和销毁vhost设备。
94 |
95 | 当使用vhost-user时,首先需要在系统中创建一个Unix domain socket server,用于处理Qemu发送给vhost的消息,其消息机制如图所示。
96 |
97 | 
98 |
99 | DPDK的vhost有两种封装形式:vhost lib和vhost PMD。vhost lib实现了用户态的vhost驱动供vhost应用程序调用,而vhost PMD则对vhost lib进行了封装,将其抽象成一个虚拟端口,可以使用标准端口的接口来进行管理和报文收发。
100 |
101 | DPDK示例程序vhost-switch是基于vhost lib的一个用户态以太网交换机的实现,可以完成在virtio-net设备和物理网卡之间的报文交换。还使用了虚拟设备队列(VMDQ)技术来减少交换过程中的软件开销,该技术在网卡上实现了报文处理分类的任务,大大减轻了处理器的负担。
102 |
103 | ## 三种方案对比
104 |
105 | 
106 |
107 | 
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 | 原文地址: https://feisky.gitbooks.io/sdn/content/dpdk/io-virtualization.html
119 |
120 |
121 |
122 |
--------------------------------------------------------------------------------
/virtualization_type/io_virtualization/IO虚拟化三种形式.md:
--------------------------------------------------------------------------------
1 | # I/O虚拟化三种形式
2 |
3 | ## I/O 全虚拟化
4 | 这种方式比较好理解,简单来说,就是通过纯软件的形式来模拟虚拟机的 I/O 请求。以 qemu-kvm 来举例,内核中的 kvm 模块负责截获 I/O 请求,然后通过事件通知告知给用户空间的设备模型 qemu,qemu 负责完成本次 I/O 请求的模拟。更具体的内容可以翻阅前文。
5 |
6 | 
7 |
8 | ### 优点:
9 | 不需要对操作系统做修改,也不需要改驱动程序,因此这种方式对于多种虚拟化技术的「可移植性」和「兼容性」比较好。
10 |
11 | ### 缺点:
12 | 纯软件形式模拟,自然性能不高,另外,虚拟机发出的 I/O 请求需要虚拟机和 VMM 之间的多次交互,产生大量的上下文切换,造成巨大的开销。
13 |
14 | ## I/O 半虚拟化
15 | 针对 I/O 全虚拟化纯软件模拟性能不高这一点,I/O 半虚拟化前进了一步。它提供了一种机制,使得 Guest 端与 Host 端可以建立连接,直接通信,摒弃了截获模拟这种方式,从而获得较高的性能。
16 |
17 | 值得注意的有两点:1)采用 I/O 环机制,使得 Guest 端和 Host 端可以共享内存,减少了虚拟机与 VMM 之间的交互;2)采用事件和回调的机制来实现 Guest 与 Host VMM 之间的通信。这样,在进行中断处理时,就可以直接采用事件和回调机制,无需进行上下文切换,减少了开销。
18 |
19 | 要实现这种方式, Guest 端和 Host 端需要采用类似于 C/S 的通信方式建立连接,这也就意味着要修改 Guest 和 Host 端操作系统内核相应的代码,使之满足这样的要求。为了描述方便,我们统称 Guest 端为前端,Host 端为后端。
20 |
21 | 
22 |
23 | 前后端通常采用的实现方式是驱动的方式,即前后端分别构建通信的驱动模块,前端实现在内核的驱动程序中,后端实现在 qemu 中,然后前后端之间采用共享内存的方式传递数据。关于这方面一个比较好的开源实现是 virtio,后面会有专门的文章来讲述之。
24 |
25 | ### 优点:
26 | 性能较 I/O 全虚拟化有了较大的提升
27 |
28 | ### 缺点:
29 | 要修改操作系统内核以及驱动程序,因此会存在移植性和适用性方面的问题,导致其使用受限。
30 |
31 | ## I/O 直通或透传技术
32 |
33 | 上面两种虚拟化方式,还是从软件层面上来实现,性能自然不会太高。最好的提高性能的方式还是从硬件上来解决。如果让虚拟机独占一个物理设备,像宿主机一样使用物理设备,那无疑性能是最好的。
34 |
35 | I/O 直通技术就是提出来完成这样一件事的。它通过硬件的辅助可以让虚拟机直接访问物理设备,而不需要通过 VMM 或被 VMM 所截获。
36 |
37 | 由于多个虚拟机直接访问物理设备,会涉及到内存的访问,而内存又是共享的,那怎么来隔离各个虚拟机对内存的访问呢,这里就要用到一门技术——IOMMU,简单说,IOMMU 就是用来隔离虚拟机对内存资源访问的。
38 |
39 | I/O 直通技术需要硬件支持才能完成,这方面首选是 Intel 的 VT-d 技术,它通过对芯片级的改造来达到这样的要求,这种方式固然对性能有着质的提升,不需要修改操作系统,移植性也好。
40 |
41 | 但该方式也是有一定限制的,这种方式仅限于物理资源丰富的机器,因为这种方式仅仅能满足一个设备分配给一个虚拟机,一旦一个设备被虚拟机占用了,其他虚拟机时无法使用该设备的。
42 |
43 | 
44 |
45 | 为了解决这个问题,使一个物理设备能被更多的虚拟机所共享。学术界和工业界都对此作了大量的改进,PCI-SIG 发布了 SR-IOV (Single Root I/O Virtualizmion) 规范,其中详细阐述了硬件供应商在多个虚拟机中如何共享单个 I/O 设备硬件。
46 |
47 | SR-IOV标准定义了设备原生共享所需的「软硬件支持」。硬件支持包括芯片组对 SR-IOV 设备的识别,为保证对设备的安全、隔离访问还需要北桥芯片的 VT-d 支持,为保证虚拟机有独立的内存空间,CPU 要支持 IOMMU。软件方面,VMM 将驱动管理权限交给 Guest,Guest 操作系统必须支持 SR-IOV 功能。
48 |
49 | SR-IOV 单独引入了两种软件实体功能:
50 |
51 | * PF(physical function):包含轻量级的 PCIe 功能,负责管理 SR-IOV 设备的特殊驱动,其主要功能是为 Guest 提供设备访问功能和全局贡献资源配置的功能。
52 |
53 | * VF(virtual function):包含轻量级的 PCIe 功能。其功能包含三个方面:向虚拟机操作系统提供的接口;数据的发送、接收功能;与 PF 进行通信,完成全局相关操作。
54 |
55 | 每个 SR-IOV 设备都可有一个物理功能 PF,并且每个 PF 最多可有 64,000 个与其关联的虚拟功能 VF。
56 |
57 | 一般,Guest 通过物理功能 PF 驱动发现设备的 SR-IOV 功能后将包括发送、接收队列在内的物理资源依据 VF 数目划分成多个子集,然后 PF 驱动将这些资源子集抽象成 VF 设备,这样,VF 设备就可以通过某种通信机制分配给虚拟机了。
58 |
59 | 
60 |
61 | 尽管 I/O 直通技术消除了虚拟机 I/O 中 VMM 干预引起的额外开销,但在 I/O 操作中 I/O 设备会产生大量的中断,出于安全等因素考虑,虚拟机无法直接处理中断,因此中断请求需要由 VMM 安全、隔离地路由至合适的虚拟机。所以,其实实际使用中,都是软硬件虚拟化方式结合使用的。
62 |
63 |
64 |
--------------------------------------------------------------------------------
/virtualization_type/io_virtualization/IO虚拟化基本原理.md:
--------------------------------------------------------------------------------
1 | # I/O虚拟化基本原理
2 |
3 | ## 概述
4 | 从处理器的角度看,外设是通过一组I/O资源(端口I/O或者是MMIO)来进行访问的,所以设备的相关虚拟化被称为I/O虚拟化。其思想就是 VMM截获客户操作系统对设备的访问请求,然后通过软件的方式来模拟真实设备的效果。基于设备类型的多样化,I/O虚拟化的方式和特点纷繁复杂。
5 |
6 | ### 一个完整的系统虚拟化方案在I/O虚拟化方面需要处理以下几块
7 | * 虚拟芯片组
8 | * 虚拟PCI总线布局,主要是通过虚拟化PCI配置空间,为客户机操作系统呈现虚拟的或是直接分配使用的设备。
9 | * 虚拟系统设备,例如PIC、IO-APIC、PIT和RTC等。
10 | * 虚拟基本的输入输出设备,例如显卡、网卡和硬盘等。
11 |
12 | ### I/O虚拟化主要包含以下几个方面的虚拟化
13 | * I/O端口寄存器
14 | * MMIO寄存器
15 | * 中断
16 |
17 | ## I/O虚拟化
18 | 下面具体的描述IO虚拟化需要做的工作
19 |
20 | ### 设备发现
21 | 设备发现就是要让VMM提供一种方式,来让客户机操作系统发现虚拟设备,这样客户机操作系统才能加载相关的驱动程序,这是IO虚拟化的第一步。设备发现取决于被虚拟的设备类型。
22 |
23 | #### 模拟一个所处物理总线的设备,这其中包含如下两种类型。
24 |
25 | * 1)模拟一个所处总线类型是不可枚举的物理设备,而且该设备本身所属的资源是硬编码固定下来的。比如ISA设备、PS/2键盘、鼠标、RTC及传统 IDE控制器。对于这类设备,驱动程序会通过设备特定的方式来检测设备是否存在,例如读取特定端口的状态信息。对于这类设备的发现,VMM在给定端口进行 正确的模拟就可以了,即截获客户机对该端口的访问,模拟出结果交给客户机。
26 | * 2)模拟一个所处总线类型是可枚举的物理设备,而且相关设备资源是软件可配置的,比如PCI设备。由于PCI总线是通过PCI配置空间定义一套完备 的设备发现方式,并且运行系统软件通过PCI配置空间的一些字段对给定PCI设备进行资源的配置,例如允许或禁止I/O端口和MMIO,设置I/O和 MMIO的起始地址等。所以VMM仅模拟自身的逻辑是不够的,必须进一步模拟PCI总线的行为,包括拓扑关系和设备特定的配置空间内容,以便让客户机操作 系统发现这类虚拟设备。
27 |
28 | #### 模拟一个完全虚拟的设备
29 |
30 | 这种情况下,没有一个现实中的规范与之对应,这种虚拟设备所处的总线类型完全由VMM自行决定,VMM可以选择将虚拟设备挂在PCI总线上,也可以完全自定义一套新的虚拟总线协议,这样的话客户机操作系统必须加装新的总线驱动。
31 |
32 | ### 访问截获
33 | 虚拟设备被客户机操作系统发现后,客户机操作系统中的驱动会按照接口定义访问这个虚拟设备。此时VMM必须截获驱动对虚拟设备的访问,并进行模拟。
34 |
35 | #### 非直接分配给客户机操作系统的设备
36 |
37 | * 对于端口I/O,IO指令本身是特权指令,处于低特权的客户机访问端口I/O会抛出异常,从而陷入到VMM中,交给设备模拟器进行模拟。
38 | * 对于MMIO,VMM把映射到该MMIO的页表设为无效,客户机访问MMIO时会抛出缺页异常,从而陷入到VMM中,交给设备模拟器进行模拟。
39 | * 对于中断,VMM需要提供一种机制,供设备模拟器在 接收到物理中断并需要触发中断时,可以通知到虚拟中断逻辑,然后由虚拟中断逻辑模拟一个虚拟中断的注入。
40 |
41 | #### 直接分配给客户机操作系统的设备
42 |
43 | * 对于端口I/O,可以直接让客户机访问。
44 | * 对于MMIO,也可以直接让客户机进行映射访问。
45 | * 对于中断,VMM物理中断处理函数接收到物理中断后,辨认出中断源属于哪个客户机,直接通知该客户机的虚拟中断逻辑。
46 |
47 | ### 设备模拟
48 | 上一步中我们已经多次提到,下面分类介绍下设备模拟。
49 |
50 | #### 基于软件的全虚拟化
51 |
52 | 虚拟设备与现实设备具有完全一样的接口定义。这种情况下,VMM的设备模拟器需要仔细研究现实设备的接口定义和内部设计规范,然后以软件的方式模拟 真实逻辑电路来满足每个接口的定义和效果。现实设备具有哪些资源,设备模拟器就需要呈现出同样的资源。这种情况下,客户机操作系统原有的驱动程序无需修改 就能驱动虚拟设备。设备访问过程中,VMM通过截获驱动程序对设备的访问进行模拟。
53 |
54 | 举例:qemu VMware Workstation
55 |
56 | #### 半虚拟化
57 |
58 | 给客户机操作系统提供一个特定的驱动程序(称为前端),VMM中的模拟程序称为后端,前端将请求通过VMM提供的通信机制直接发送给后端,后端处理 完请求后再发回通知给前者。与传统设备驱动程序流程(前一种方式)比较,传统设备程序为了完成一次操作要涉及到多个寄存器的操作,使得VMM要截获每个寄 存器访问并进行相应的模拟,就会导致多次上下文切换。这种方式能很大程度的减少上下文切换的频率,提供更大的优化空间。
59 |
60 | 举例:xen virtio (virtio接下来我会继续研究,主要包括virtio框架、virtio前端驱动、后端实现方式及原理、前端后端共享内存的方式)
61 |
62 | #### 基于硬件的直接分配(实际上已经不是设备模拟了)
63 |
64 | 直接将物理设备分配给客户机操作系统,由客户机操作系统直接访问目标设备。这种情况下实际上不存在设备模拟,客户机直接通过原有的驱动操作真实硬件。这种方式从性能上说是最优的,但这种方式需要比较多的硬件资源。
65 | 基于硬件的直接分配还有一种方式,硬件本身支持虚拟化,本身可以向不同的虚拟机提供独立的硬件支持,设备本身支持多个虚拟机同时访问。比如SR-IOV。(这种方式接下来我会继续研究)
66 |
67 | 举例:intel vt-d SR-IOV
68 |
69 | 一个VMM中,常常是多种虚拟化方式并存。
70 |
71 | #### 不同的IO虚拟化方式对比
72 |
73 |
74 | ### 设备共享
75 |
76 | 设备虚拟化中,有些设备可以被软件模拟器完全用软件的方式模拟而不用接触实际物理设备,比如CMOS,而有些设备需要设备模拟进一步请求物理硬件的帮助。一般输入输出类设备,如鼠标、键盘、显卡、硬盘、网卡。这些设备都涉及到从真实设备上获取输入或者输出到真实设备上。
77 |
78 | 
79 |
80 | 对于多个客户机,每个客户机拥有自己的设备模拟器,多个设备模拟器需要共享同一个物理设备,这种情况下,VMM中的真实设备的驱动程序需要同时接收并处理多个客户或进程的请求,达到物理资源的复用。
81 |
--------------------------------------------------------------------------------
/virtualization_type/io_virtualization/IO虚拟化面临的问题及解决方案.md:
--------------------------------------------------------------------------------
1 | # I/O虚拟化面临的问题及解决方案
2 |
3 | ## I/O虚拟化的难点
4 | 在讨论用于虚拟化的系统级别的硬件解决方案之前,我们需要确定驱动这些功能的动机。 要理解这些问题,我们必须认识到,以某种方式与I/O进行通信
5 | 虚拟化环境是一个悖论。 我们希望在沙盒环境中运行一个操作系统,而该操作系统不会在虚拟环境之外运行该系统。 但是I/O不能忽略外部环境,因为它正在与该环境通信。 因此,可以理解地虚拟化I/O成为一个难题。 因此,从哲学问题出发,虚拟化的目标是什么?I/O如何适应该目标? 在我看来,这是提供一种托管环境来托管VM,从而改善整体用户体验。 为了实现此目标,理想情况下,我们希望VM中的I/O具有以下属性:
6 |
7 | 1. 来宾有权访问在本机环境中将使用的相同I/O设备。
8 | 2. 来宾操作系统不能影响其他来宾的I/O操作或内存。
9 | 3. 对来宾操作系统的软件更改必须最少。
10 | 4. 来宾操作系统需要能够从硬件故障或VM迁移中恢复。
11 | 5. 来宾OS上的I / O操作应具有与本机运行类似的性能。
12 |
13 | 在此列表中,我们可以看到列表中的几个项目如何与列表中的其他项目竞争。 因此,最终解决方案将需要根据特定用例进行权衡。 现在,带着这些目标,让我们看一下实现I/O虚拟化的各种技术以及所面临的问题。
14 |
15 | ## 仿真或半虚拟设备
16 | 实施完全虚拟化时,最简单的选择之一是让客户机OS在主机上模拟虚拟设备。 来宾与该虚拟设备进行通信,并且管理程序会检测到来宾的通信。 这可以通过捕获设备访问权限或对某些内存页面的权限来完成。 系统管理程序了解来宾OS在虚拟设备上的操作,并在物理设备上执行相应的操作。 该技术称为托管或拆分I/O。
17 |
18 | 
19 |
20 | 该技术的优势在于,由于每个调用都通过管理程序,因此管理程序可以提供所需的功能。 例如,管理程序可以跟踪设备当前正在等待的每个I/O操作。 类似地,简化了限制来宾影响其他来宾的过程,因为所有物理设备访问均由管理程序管理。 但是此技术具有很高的CPU开销。 数据需要多次复制,通过多个I/O堆栈进行处理等。使用半虚拟化可以提高性能。 在这种情况下,操作系统中的设备驱动程序将通过管理程序实现ABI。 设备驱动程序与虚拟机管理程序接口,并且虚拟机管理程序直接与物理设备通信,如下图所示。
21 |
22 | 
23 |
24 | 该技术通过类似的控制提供了更好的性能,但是仍然存在相当大的性能开销,例如在捕获到管理程序时。 下图显示了IBM在KVM中使用仿真IDE控制器与IBM virtio-blk半虚拟化设备驱动程序所观察到的差异。
25 |
26 | 
27 |
28 | 在查看此开销时,请务必记住,它与用例密切相关。 CPU约束的基准测试对I/O虚拟化不会表现出太大的敏感性。 另外,对于I/O繁重的基准测试,此开销可能会很大。 作为示例,用于求解线性方程组的共轭梯度方法在用户模式下花费了大约70%的CPU周期,并在参与磁盘I/O的管理程序内核中花费了剩余时间。
29 |
30 | ## 直通I/O
31 |
32 | 直通I/O通过重新映射来宾页表直接写入物理设备来大大提高性能。 这消除了为每个操作捕获到虚拟机监控程序的大部分开销。 这种技术使大量的I/O处理达到了接近本机的速度。
33 |
34 | 
35 |
36 | 要使用此技术有效地虚拟化I/O,需要解决几个问题。 考虑来宾使用DMA访问与设备通信的情况。 在这种情况下,我们需要考虑以下问题。
37 |
38 | ## 隔离
39 | 虚拟化的目标是对来宾操作系统进行沙箱处理,以防止其访问其他来宾操作系统的数据。 我们通过添加第二阶段翻译在来宾中进行此操作。 但是,DMA设备在物理地址上运行,并且不知道第二阶段的转换。 因此,如果为来宾提供了对DMA设备的不受限制的访问权限,则它可以读取或写入内存中的任何物理地址,并破坏其他来宾的内存。 因此,需要建立一种保护机制,以确保设备仅将来自特定来宾的DMA请求定向到与该来宾关联的内存。 此外,一个以上的访客可能需要访问同一设备。 该设备需要能够区分来自不同设备的访问,并正确地重定向它们。
40 |
41 | ## 实际地址
42 | 为了完成DMA事务,客户机OS需要为设备提供内存中的正确物理地址以查找数据。 但是访客不知道数据的物理地址,只有中间的物理地址(IPA)实际上是虚拟地址。 为了使DMA访问正常工作,设备必须能够将IPA转换为正确的物理地址。
43 |
44 | ## 连续内存块
45 | 仅给设备提供正确的PA不能解决该问题。 设备期望DMA目标区域位于内存的连续区域中。 在虚拟环境中,无法保证。 系统管理程序可以以不超过4K的块分配不连续的访客页面。 因此,设备必须能够对整个DMA区域执行此转换。
46 |
47 | ## 较大地址空间中的32位设备
48 | 此问题类似于上一篇文章中讨论的在64位主机上使用32位来宾的问题。 系统可能具有无法访问较新系统的完整较大地址空间的较旧设备。 使用这些设备的DMA超出其正常可寻址范围时,必须进行地址转换。
49 |
50 | ## 硬体支援
51 | 上面提到的问题很难用软件解决,需要硬件解决方案将设备地址正确映射到正确的客户。 大多数平台都为此提供了硬件解决方案。 此机制称为IO内存管理单元的IOMMU 。 英特尔称其实施为VT-d,AMD称其实施为AMD-Vi,ARM称其实施为SystemMMU。 IOMMU的基本思想很简单。 地址转换单元放在来宾OS可以使用的任何设备之间。 当管理程序为访客OS设置第二阶段页面表以访问设备时,它也将设置IOMMU。 与核心中的走道相似,地址翻译非常昂贵。 因此,实现TLB可以减少地址转换的开销。
52 |
53 | 
54 |
55 | 显示系统MMU可以放置位置的示例系统。 与设备的事务通过系统MMU进行翻译。
56 |
57 | ## 系统MMU
58 |
59 | ARM系统MMU用不同的转换上下文编程。 通过与预期流进行匹配,它将每个事务映射到相应的上下文。 根据上下文,系统MMU可能会绕过转换,导致故障或执行转换。 ARM体系结构中的System MMU提供了完整的2阶段翻译支持(如上一篇文章中所述),并且根据上下文,我们可以进行第一阶段翻译或第二阶段翻译。 为了执行转换,系统MMU具有类似于TTBR的寄存器和每个上下文的其他控制寄存器。
60 |
61 | 系统MMU在其转换过程中或未设置上下文时也可能会收到故障。 根据故障的类型以及系统MMU的配置方式,它可能会采取某些措施。 翻译错误会触发中断。 这为虚拟机管理程序提供了处理中断并重新启动转换的机会,以便它可以完成。 系统MMU也可以将BUSERROR发送给适当的请求者。 存在综合症寄存器以简化诊断和解决问题的过程。
62 |
63 | System MMU的某些优势甚至不需要虚拟化。 由于系统MMU使每个设备都能执行VA到PA的转换,因此驱动程序可以在用户空间中使用VA执行I / O操作。 权限检查和转换映射可以确保一个用户应用程序不会破坏另一应用程序的内存。 这将消除当前所需的内核陷阱,从而进一步减少I / O开销。 另一个问题是处理连续内存。 许多操作导致非常大的DMA访问,而OS无法将其分配给单个内存块。 当前,它们需要被拆分成多个DMA请求,或者需要通过复杂的DMA分散收集操作来执行。 系统MMU使设备可以通过基于连续VA而不是分段PA的DMA进行通信。 这既减少了CPU开销,又简化了软件和设备。
64 |
65 | 应该注意的是,系统MMU是平台的一部分,而不是核心体系结构的一部分。 这意味着它仅影响驱动程序。 因此,许多功能都是实现定义的。 例如,用于匹配流并将其映射到上下文的位是实现定义的。 由于没有用户代码知道系统的这一部分,因此对系统MMU体系结构的更改将不需要那么多的旧代码问题。
66 |
67 | 因此,使用这些技术,系统管理程序可以根据用例提供虚拟化I / O的适当实现。 到此结束本系列有关虚拟化的第三部分。 本系列文章将在下一篇文章中继续,讨论虚拟化的用例,尤其是ARM在移动领域针对的用例。
68 |
69 | 有关更多信息,请查看以下资源。
70 |
71 | * http://xpgc.vicp.net/course/svt/TechDoc/ch12-IOArchitecturesForVirtualization.pdf
72 | * http://nowlab.cse.ohio-state.edu/NOW/dissertations/huang.pdf
73 | * http://www.ibm.com/developerworks/linux/library/l-virtio/
74 | * http://pic.dhe.ibm.com/infocenter/lnxinfo/v3r0m0/topic/liaat/liaatbestpractices_pdf.pdf
75 | * http://www.mulix.org/lectures/xen-iommu/xen-io.pdf
76 | * http://developer.amd.com/wordpress/media/2012/10/IOMMU-ben-yehuda.pdf
77 | * http://www.arm.com/files/pdf/System-MMU-Whitepaper-v8.0.pdf
78 | * http://software.intel.com/zh-CN/articles/intel-virtualization-technology-for-directed-io-vt-d-enhancing-intel-platforms-for-efficiency-virtualization-of-io-devices
79 | * http://support.amd.com/us/Processor_TechDocs/48882.pdf
80 |
81 |
82 | 原文作者: 程序员大本营
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
--------------------------------------------------------------------------------
/virtualization_type/memory_virtualization/KVM内存虚拟化.md:
--------------------------------------------------------------------------------
1 | # KVM 内存虚拟化
2 |
3 | ## 1 内存虚拟化的概念
4 |
5 | 除了 CPU 虚拟化,另一个关键是内存虚拟化,通过内存虚拟化共享物理系统内存,动态分配给虚拟机。虚拟机的内存虚拟化很象现在的操作系统支持的虚拟内存方式,应用程序看到邻近的内存地址空间,这个地址空间无需和下面的物理机器内存直接对应,操作系统保持着虚拟页到物理页的映射。现在所有的 x86 CPU 都包括了一个称为内存管理的模块MMU(Memory Management Unit)和 TLB(Translation Lookaside Buffer),通过MMU和TLB来优化虚拟内存的性能。
6 |
7 | KVM 实现客户机内存的方式是,利用mmap系统调用,在QEMU主线程的虚拟地址空间中申明一段连续的大小的空间用于客户机物理内存映射。
8 |
9 | 
10 | (图片来源 HVA 同下面的 MA,GPA 同下面的 PA,GVA 同下面的 VA)
11 |
12 | 在有两个虚机的情况下,情形是这样的:
13 |
14 | 
15 |
16 | 可见,KVM 为了在一台机器上运行多个虚拟机,需要增加一个新的内存虚拟化层,也就是说,必须虚拟 MMU 来支持客户操作系统,来实现 VA -> PA -> MA 的翻译。客户操作系统继续控制虚拟地址到客户内存物理地址的映射 (VA -> PA),但是客户操作系统不能直接访问实际机器内存,因此VMM 需要负责映射客户物理内存到实际机器内存 (PA -> MA)。
17 |
18 | VMM 内存虚拟化的实现方式:
19 | * 软件方式:通过软件实现内存地址的翻译,比如 Shadow page table (影子页表)技术
20 | * 硬件实现:基于 CPU 的辅助虚拟化功能,比如 AMD 的 NPT 和 Intel 的 EPT 技术
21 |
22 | * 影子页表技术:
23 | 
24 |
25 |
26 | ## 2 KVM 内存虚拟化
27 |
28 | KVM 中,虚机的物理内存即为 qemu-kvm 进程所占用的内存空间。KVM 使用 CPU 辅助的内存虚拟化方式。在 Intel 和 AMD 平台,其内存虚拟化的实现方式分别为:
29 | * AMD 平台上的 NPT (Nested Page Tables) 技术
30 | * Intel 平台上的 EPT (Extended Page Tables)技术
31 | EPT 和 NPT采用类似的原理,都是作为 CPU 中新的一层,用来将客户机的物理地址翻译为主机的物理地址。关于 EPT, Intel 官方文档中的技术如下
32 | 
33 |
34 | EPT的好处是,它的两阶段记忆体转换,特点就是将 Guest Physical Address → System Physical Address,VMM不用再保留一份 SPT (Shadow Page Table),以及以往还得经过 SPT 这个转换过程。除了降低各部虚拟机器在切换时所造成的效能损耗外,硬体指令集也比虚拟化软体处理来得可靠与稳定。
35 |
36 | ## 3 KSM (Kernel SamePage Merging 或者 Kernel Shared Memory)
37 |
38 | KSM 在 Linux 2.6.32 版本中被加入到内核中。
39 |
40 | ## 3.1 原理
41 |
42 | 其原理是,KSM 作为内核中的守护进程(称为 ksmd)存在,它定期执行页面扫描,识别副本页面并合并副本,释放这些页面以供它用。因此,在多个进程中,Linux将内核相似的内存页合并成一个内存页。这个特性,被KVM用来减少多个相似的虚拟机的内存占用,提高内存的使用效率。由于内存是共享的,所以多个虚拟机使用的内存减少了。这个特性,对于虚拟机使用相同镜像和操作系统时,效果更加明显。但是,事情总是有代价的,使用这个特性,都要增加内核开销,用时间换空间。所以为了提高效率,可以将这个特性关闭。
43 |
44 | ## 3.2 好处
45 | 其好处是,在运行类似的客户机操作系统时,通过 KSM,可以节约大量的内存,从而可以实现更多的内存超分,运行更多的虚机。
46 |
47 | ## 3.3 合并过程
48 |
49 | (1)初始状态:
50 | 
51 |
52 | (2)合并后:
53 | 
54 |
55 | (3)Guest 1 写内存后:
56 | 
57 |
58 | ## 4 KVM Huge Page Backed Memory (巨页内存技术)
59 |
60 | 这是KVM虚拟机的又一个优化技术.。Intel 的 x86 CPU 通常使用4Kb内存页,当是经过配置,也能够使用巨页(huge page): (4MB on x86_32, 2MB on x86_64 and x86_32 PAE)
61 |
62 | 使用巨页,KVM的虚拟机的页表将使用更少的内存,并且将提高CPU的效率。最高情况下,可以提高20%的效率!
63 |
64 | 使用方法,需要三部:
65 |
66 | ```C
67 | mkdir /dev/hugepages
68 | mount -t hugetlbfs hugetlbfs /dev/hugepages
69 | ```
70 | * 保留一些内存给巨页
71 | ```C
72 | sysctl vm.nr_hugepages=2048 (使用 x86_64 系统时,这相当于从物理内存中保留了2048 x 2M = 4GB 的空间来给虚拟机使用)
73 | ```
74 | * 给 kvm 传递参数 hugepages
75 | ```C
76 | qemu-kvm - qemu-kvm -mem-path /dev/hugepages
77 | ```
78 | 也可以在配置文件里加入:
79 |
80 |
81 |
82 | 验证方式,当虚拟机正常启动以后,在物理机里查看:
83 | ```C
84 | cat /proc/meminfo |grep -i hugepages
85 | ```
86 | 老外的一篇文档,他使用的是libvirt方式,先让libvirtd进程使用hugepages空间,然后再分配给虚拟机。
87 |
88 |
89 |
90 |
91 | 原文作者: SammyLiu
92 |
93 |
94 |
95 |
96 |
97 |
--------------------------------------------------------------------------------
/virtualization_type/memory_virtualization/内存虚拟化-shadow实现.md:
--------------------------------------------------------------------------------
1 | # 内存虚拟化-shadow实现
2 |
3 | ## 1. 虚拟化目的
4 | * 提供给虚机从 零地址开始的连续物理内存空间视图
5 | * 虚机之间隔离及共享内存资源
6 |
7 | ## 2. 概念阐述
8 | 地址空间和物理内存空间:地址空间可以理解为地址域,比如32bit CPU,能访问的地址空间是2 ^ 32 = 4G,这是地址空间,但是我可以只插1G内存。即使插4G内存,有一部分地址空间还要划分给mmio使用,物理内存占用整个地址空间的一部分,它俩并不是一个慨念。在虚拟化环境中,虚机和物理机都有自己的地址空间
9 | * GVA (Guest Virtual Address),虚机虚拟地址
10 | * GPA(Guest Physical Address),虚机物理地址
11 | * HVA(Host Virtual Address),物理机虚拟地址
12 | * HPA(Host Physical Address),物理机物理地址
13 |
14 | ## 3. 内存虚拟化软件实现
15 | 虚机OS维护的是GVA->GPA的映射,为了实现从客户机物理地址GPA到VMM(Virtual Machine Manager)物理地址HPA,VMM为每个虚机维护了一张从GPA->HPA地映射表。虚机维护的GVA->GPA页表是没有真正写入CR3的,VMM会截获CR3装载指令或TLB操作指令,然后根据上面两张表,VMM为每一个进程维护一个GVA->HPA的页表,并将页表基地址真正写入CR3。这个过程中,也利用了MMU的一大好处,可以将不连续地物理地址空间提供给虚机,并且虚机以为是连续的。通过上面地操作,每个虚机都有了从 零地址开始的连续物理内存空间视图。
16 |
17 | ### 3.1 影子页表(Shadow Page Table)
18 | 虚机维护的虚拟内页表完成了GVA->GPA的映射,如果将该页表的基地址装入CR3中,必然会出现问题。影子页表的解决方法是由VMM维护的影子页表实现GVA->HPA的地址映射。如下图:
19 |
20 | 
21 |
22 | 虚实物理地址翻译表又由VMM维护,通过这些转换关系,最终提现在影子页表中,并将影子页表装载在CR3中。
23 |
24 | 影子页表是被物理MMU装载使用的页表,VMM为每个虚机中的每个页表(每个进程都有自己的页表)都维护了一套影子页表,影子页表在地址转换时能够直接将GVA->HPA,不会引入额外的开销。另外,影子页表的结构不一定与虚机内的页表结构相同,比如可以在64位宿主机上运行32位虚机。
25 |
26 | 刷新TLB场景:
27 |
28 | * 在x86平台,写入CR3,如果CR3内容不变,那么写入CR3的这个动作相当于无效整个TLB
29 | * 写入不同的CR3,相当于进程切换,TLB内容也会无效
30 | * 修改页表项,由于页表项被更改了,此时也需要刷新TLB。但此时一般不需要操作整个TLB,一般用INVLPG操作
31 |
32 | 影子页表的关键就在于VMM如何捕获虚机对虚机内页表的操作。对于CR3写入及INVLPG操作,都属于特权指令,VMM能够捕获,但是虚机如果直接修改虚机内部页表,实现起来比较复杂。
33 |
34 | 影子页表性能评估
35 |
36 | * 时间:大多数情况下,影子页表可以直接将GVA->HPA,所以时间上来讲,虽然与非虚拟化环境有一定差距,不过还算可以
37 | * 空间:需要为每个虚机内部的每个页表都维护一个与之对应的影子页表,开销很大
38 |
39 | ## 4. KVM shadow实现
40 | 这里讨论的是VT-x + shadow page实现方式,对于没有VT-x的情况纯软件内存虚拟化过于久远,不做讨论。
41 |
42 | 在虚机刚启动时(64位虚机),虚拟内部模式转换过程是 实地址模式(rmode) -> 保护模式(pmode) -> IA32-e模式(x64),这里面先不去管如何实现模式切换及切换过程中内存虚拟化实现方式的改变,先只关注在IA32-e模式下如何实现内存虚拟化,后面会单独讲解虚机在模式切换过程中具体实现。在正式介绍shadow具体实现前,先简单了解下MMU如何实现映射的(如果不了解MMU映射实现,最好先查些相关资料),为方便理解,后面讨论得映射页大小均为4KB。
43 |
44 | INTEL文档中给出的地址:
45 |
46 | 
47 |
48 | 整个页表映射结构如下:
49 |
50 | 
51 |
52 | 对于虚机内部页表实现的功能是GVA->GPA的映射,这个页表基地址是不能写入CR3的,原因如下:
53 |
54 | * 每个虚机的内存空间都是从0开始的连续地址,如果都直接写入CR3,必然会冲突。另外,如果虚机可以直接访问到物理机地址,也没有安全性可言
55 | * GPA并不是与HPA直接对应,需要通过KVM维护的映射关系将GPA转换为HPA,写入到shadow页表中去
56 | *
57 | 下面图说明了,虚机内页表和影子页表的关系,为了说明简单,这里不会像上面画出那么多页表项
58 |
59 | 
60 |
61 | 上图描述了SPT(shadow page table)是如何根据GPT(guest page table)实现映射的,在虚机内部,看到的物理地址都是GPA,前面说了,虚机页表是不能直接写入CR3的,真正生效的是SPT。SPT的目的只有一个,就是将GVA映射成HPA,那么HPA是怎么来的呢?首先遍历虚机页表,获取GVA映射的GPA,然后通过kvm slot,获取GPA对应的HPA,进而在shadow中建立GVA->HPA的映射。对于上图,有以下几点需要注意:
62 |
63 | * 为了便于理解,这里虚机和VMM都采用ia32-e模式,页表均为4级,page size 4KB
64 | * shadow页表是在KVM中分配的,并不占用虚机GPA范围内空间,而且对于shadow页表的在VMM中地址也没有限定。shadow的目的就是将GVA映射成HPA
65 | * 由于虚机内每个进程都有自己的页表,所以每个进程都需要维护一套SPT与其GPT对应
66 |
67 | ### 4.1 shadow页表建立
68 | 虚机启动时涉及到处理器模式转换,rmod->pmod->x64,在rmod和pmod模式下,虽然虚机内没有开启页表,但是此时也要为虚机分配一个SPT,只不过此时的SPT没有GPT与之对应,也不需要通过GVA寻找GPA,因为虚机内没有开启分页模式,此时访问的地址都是GPA。在pmode下,虚机内部会初始化虚GPT,然后设置CR3(vm_exit),开启分页模式。此时,有了GPT,现在需要建立SPT。SPT的建立在mmu_alloc_roots函数中实现,起初SPT只有PML4一级,且PML4E为空。当虚机产生因为产生page fault而vm_exit时,会判断是由于GPT引起的page fault,还是由于SPT引起的page fault,当前只讨论SPT引起的page fault。如果SPT引起page fault,那么就需要walk GPT,找到发生异常地址GVA对应的GPA,在根据GPA拿到HPA,然后在shadow中建立GVA到HPA映射。
69 |
70 | 上面仅仅讨论了SPT从无到有的过程,其实还有很多情况,比如SPTE的access和dirty位如何同步给GPTE、GPTE清除了DIRTY又如何同步给SPTE、GPTE更改了如何同步给SPTE等等。归根结底,要做的就是虚机页表和shadow页表的同步,最理想情况就是时刻保持同步,假设GPTE改变了映射,那么SPTE也应该改变。SPTE中dirty或access位变了,那么也要同步给GPTE。下面就针对各个情况来讨论页表同步的实现,这里先不讲具体代码实现,先理清处理流程,代码自然就看懂了。
71 |
72 | #### 4.1.1 page table entry的同步
73 | 这里先不考虑access和dirty的同步,先就看映射关系的变化。依然假定虚机页表已经建立好,但是这里需要注意,虚机的页表也是虚机的物理地址空间,所以对虚机页表访问也需要shadow page table,当前进程页表的初始化是由其它进程在内核态完成的,那么问题来了,最开始页表是怎么初始化的。答案就是在rmod和pmode模式初始化的,也就是前面说得那个只有SPT,没有GPT的状态。现在考虑的是虚机进程页表已经建立好,如何建立shadow页表的,见下图:
74 |
75 | 
76 |
77 | 对上图做下简要说明:
78 |
79 | 1. 初始状态,虚机初始化了页表,不过此时的SPTE为空
80 |
81 | 2. 当实际访问的过程中,会使用SPTE作为页表,由于此时页表为空,虚机会因为产生page fault而vm_exit,这里简单说下,虚机产生page fault时,是否会vm_exit是由于vmcs中的EXCEPTION_BITMAP域决定的,比如具有EPT功能时,虚机page fault就无需vm_exit。而对于没有EPT情况,是需要vm_exit。当产生vm_exit时,handle_exception中判断,如果是由于page fault引起的,就会调用FNAME(page_fault)来处理,进而处理shadow缺页情况。
82 |
83 | 3. 上图中每有一个虚机页表,都有一个shadow页表与之对应,而每一个shadow页表都有一个struct kvm_mmu_page来描述,这里有个关键成员就是gfn,这个值就是当前shadow页表对应的虚机页表在guest os中的GPA。具体作用下面会讲到。同时,所有的struct kvm_mmu_page结构会以gfn为键值,维护在mmu_page_hash链式哈希中。
84 |
85 | 4. SPT一级级建立好,最后一级的SPTE中对应的就是GPA对应的HPA,这样便可以访问了
86 |
87 | 上面讲述了当shadow中从无到有的过程,但是GPT在虚机内可能是变化的,所以就涉及GPT和SPT的同步,现在讲述几个同步case
88 |
89 | Case1:
90 |
91 | 针对一些没有SPT与之对应的GPT,如果GPT被修改了,此时如何处理。结论就是不需要管,结合下图说明:
92 |
93 | 
94 |
95 | 首先,对于guest os,一旦开启分页模式后,访问任何物理地址都需要经过MMU页表翻译,包括页表本身。图中我现在要修改粉色的页表(标注为"修改页表"),简称粉页表,也就是说要写粉页表对应的GPA。在修改粉页表的过程中,是通过其它页表来访问的粉页表,其它页表需要shadow page table,而粉页表此时可以没有shadow page table,针对这种情况,即使粉页表修改了,也可以不需要同步,因为本身没有shadow page table,也没有同步目标啊。由于没有SPT,所以当需要访问粉页表对应的GPA时,必然page fault,此时会建立shadow page table,这时自然会根据粉页表最新内容创建SPT。注:所谓的同步,就是在不断处理SPT和GPT之间的关系,保证两者表述一致
96 |
97 | case2:
98 |
99 | 就是SPT和GPT本身是同步的,但是GPT修改了,如何同步给SPT。结合下图说明:
100 |
101 | 
102 |
103 | 下面简述下这个图描述的整个流程:
104 | 1.首先,对于guest os,一旦开启分页模式后,访问任何物理地址都需要经过MMU页表翻译,包括页表本身。图中我现在要修改粉色的页表(标注为"修改页表"),简称粉页表,也就是说要写粉页表对应的GPA。所以,此时我需要建立能够访问到粉页表HPA的shadow page table,在建立的最后的spte时,会做一个检查,如果这个粉页表的GPA和mmu_page_hash表中的某一个struct kvm_mmu_page成员的gfn相等,那就说明现在我要访问的GPA是一个虚机页表,并且已经有shadow page table和这个GPA页表关联上,那么既然GPA修改了,对应的shadow page table也要修改,所以struct kvm_mmu_page的unsync会置位,用于后面同步使用。总结一下就是说,在建立shadow page table时候,会看虚机访问的GPA是否和mmu_page_hash表中的某一个struct kvm_mmu_page成员的gfn相等,那么就需要置位unsync。因为相等的话,说明存在shadow page table和guset page table关联着,需要同步。如果mmu_page_hash表中不存在任何struct kvm_mmu_page成员的gfn与该GPA相等,那么即使要访问的GPA是虚机页表,也不存在shadow page table,所以不需要同步,此时和case1场景一样。对于代码中的一些写保护设定,也是为了及时设置unsync状态。这里面讨论的是最后一级页表,对于非最后一级的页表一直都是写保护的,处理方式比上面描述的简单,读者直接看代码即可。
105 |
106 | #### 4.1.2 access、dirty位同步
107 | 针对SPTE和GPTE中access、dirty的同步。无论是虚机kernel、还是vmm kernel,LRU算法会根据access和dirty标记进行物理页管理。所以当SPTE、和GPTE出现不同步时,要及时同步。造成不同步的原因主要有以下两种:
108 |
109 | * 问题1
110 |
111 | 因为虚机实际使用的是SPTE页表,所以当访问page或者写page时,硬件会自动对SPTE中的access和dirty置位,而虚机在做LRU算法时,依赖与GPTE中的access和dirty位,所以需要将SPTE同步给GPTE
112 |
113 | 针对上面的问题,access和dirty实现方式略有不同。但是同步时机都是相同的,对于SPTE同步给GPTE,都是在FNAME(page_fault)中实现。先看dirty,上面4.1中讲了,shadow最开始时候是空的,如果虚机执行了写操作,且GPT已经初始化好了,后面在讨论问题时,都假设GPT已经初始化好了(因为虚机本身page fault的处理和虚拟化实现关系不大),由于shadow为空,此时写操作必然page fault,然后为其建立shadow页表,同时,将access、dirty同步到GPTE。如果虚机读操作,那么会将SPTE设置为写保护,同时GPTE access置位。
114 |
115 | * 问题2
116 |
117 | 虚机会对GPTE中的access和dirty做清除操作,此时也需要将SPTE感知(为了还原到问题1的场景进而对GPTE再次置位)
118 |
119 | 当虚机内部清除access、dirty时,会调用INVLPG,此时虚机会vm_exit,在FNAME(invlpg)中会根据会清除spte,清除spte保证一个原则,那就是可以还原到问题1中的状态,能够为再次同步GPTE做准备。为了加速访问,这里会进行预取操作,如果GPTE access为1,那么会进行预取,dirty为0的话,那么会将SPTE设置为只读。如果GPTE access为0,则不预取了,为了产生page fault而同步access。
120 |
121 | 针对上面两个问题,主要考虑两点,一个是同步时机、另一个是同步方法。同步时机两个,分别是FNAME(page_fault),FNAME(invlpg)。同步方法对于access和dirty略有不通,dirty位可以通过写保护同步,而同步access需要清空SPTE实现。
122 |
123 |
124 |
125 | 原文作者: hx_op
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
--------------------------------------------------------------------------------
/virtualization_type/memory_virtualization/内存虚拟化.md:
--------------------------------------------------------------------------------
1 | # 内存虚拟化
2 |
3 | 
4 |
5 | 大型操作系统(比如Linux)的内存管理的内容是很丰富的,而内存的虚拟化技术在OS内存管理的基础上又叠加了一层复杂性,比如我们常说的虚拟内存(virtual memory),如果使用虚拟内存的OS是运行在虚拟机中的,那么需要对虚拟内存再进行虚拟化,也就是vitualizing virtualized memory。本文将仅从“内存地址转换”和“内存回收”两个方面探讨内存虚拟化技术。
6 |
7 | 【虚拟机内存地址转换】
8 |
9 | 在Linux这种使用虚拟地址的OS中,虚拟地址经过page table转换可得到物理地址(参考这篇文章):
10 |
11 | 
12 |
13 | 如果这个操作系统是运行在虚拟机上的,那么这只是一个中间的物理地址(Intermediate Phyical Address - IPA),需要经过VMM/hypervisor的转换,才能得到最终的物理地址(Host Phyical Address - HPA)。从VMM的角度,guest VM中的虚拟地址就成了GVA(Guest Virtual Address),IPA就成了GPA(Guest Phyical Address)。
14 |
15 | 
16 |
17 | 可见,如果使用VMM,并且guest VM中的程序使用虚拟地址(如果guest VM中运行的是不支持虚拟地址的RTOS,则在虚拟机层面不需要地址转换),那么就需要两次地址转换。
18 |
19 | 
20 |
21 | 但是传统的IA32架构从硬件上只支持一次地址转换,即由CR3寄存器指向进程第一级页表的首地址,通过MMU查询进程的各级页表,获得物理地址。
22 |
23 |
24 | >软件实现 - 影子页表
25 |
26 |
27 | 为了支持GVA->GPA->HPA的两次转换,可以计算出GVA->HPA的映射关系,将其写入一个单独的影子页表(sPT - shadow Page Table)。在一个运行Linux的guest VM中,每个进程有一个由内核维护的页表,用于GVA->GPA的转换,这里我们把它称作gPT(guest Page Table)。
28 |
29 | VMM层的软件会将gPT本身使用的物理页面设为write protected的,那么每当gPT有变动的时候(比如添加或删除了一个页表项),就会产生被VMM截获的page fault异常,之后VMM需要重新计算GVA->HPA的映射,更改sPT中对应的页表项。可见,这种纯软件的方法虽然能够解决问题,但是其存在两个缺点:
30 |
31 | * 实现较为复杂,需要为每个guest VM中的每个进程的gPT都维护一个对应的sPT,增加了内存的开销。
32 | * VMM使用的截获方法增多了page fault和trap/vm-exit的数量,加重了CPU的负担。
33 |
34 | 在一些场景下,这种影子页表机制造成的开销可以占到整个VMM软件负载的75%。
35 |
36 | 
37 |
38 | > 硬件辅助 - EPT/NPT
39 |
40 | 为此,各大CPU厂商相继推出了硬件辅助的内存虚拟化技术,比如Intel的EPT(Extended Page Table)和AMD的NPT(Nested Page Table),它们都能够从硬件上同时支持GVA->GPA和GPA->HPA的地址转换的技术。
41 |
42 | GVA->GPA的转换依然是通过查找gPT页表完成的,而GPA->HPA的转换则通过查找nPT页表来实现,每个guest VM有一个由VMM维护的nPT。其实,EPT/NPT就是一种扩展的MMU(以下称EPT/NPT MMU),它可以交叉地查找gPT和nPT两个页表:
43 |
44 | 
45 |
46 |
47 | 假设gPT和nPT都是4级页表,那么EPT/NPT MMU完成一次地址转换的过程是这样的(不考虑TLB):
48 |
49 | 首先它会查找guest VM中CR3寄存器(gCR3)指向的PML4页表,由于gCR3中存储的地址是GPA,因此CPU需要查找nPT来获取gCR3的GPA对应的HPA。nPT的查找和前面文章讲的页表查找方法是一样的,这里我们称一次nPT的查找过程为一次nested walk。
50 |
51 | 
52 |
53 | 如果在nPT中没有找到,则产生EPT violation异常(可理解为VMM层的page fault)。如果找到了,也就是获得了PML4页表的物理地址后,就可以用GVA中的bit位子集作为PML4页表的索引,得到PDPE页表的GPA。接下来又是通过一次nested walk进行PDPE页表的GPA->HPA转换,然后重复上述过程,依次查找PD和PE页表,最终获得该GVA对应的HPA。
54 |
55 | 
56 |
57 | 不同于影子页表是一个进程需要一个sPT,EPT/NPT MMU解耦了GVA->GPA转换和GPA->HPA转换之间的依赖关系,一个VM只需要一个nPT,减少了内存开销。如果guest VM中发生了page fault,可直接由guest OS处理,不会产生vm-exit,减少了CPU的开销。可以说,EPT/NPT MMU这种硬件辅助的内存虚拟化技术解决了纯软件实现存在的两个问题。
58 |
59 | > EPT/NPT MMU优化
60 |
61 | 事实上,EPT/NPT MMU作为传统MMU的扩展,自然也是有TLB的,它在查找gPT和nPT之前,会先去查找自己的TLB(前面为了描述的方便省略了这一步)。但这里的TLB存储的并不是一个GVA->GPA的映射关系,也不是一个GPA->HPA的映射关系,而是最终的转换结果,也就是GVA->HPA的映射。
62 |
63 | 不同的进程可能会有相同的虚拟地址,为了避免进程切换的时候flush所有的TLB,可通过给TLB entry加上一个标识进程的PCID/ASID的tag来区分(参考这篇文章)。同样地,不同的guest VM也会有相同的GVA,为了flush的时候有所区分,需要再加上一个标识虚拟机的tag,这个tag在ARM体系中被叫做VMID,在Intel体系中则被叫做VPID。
64 |
65 | 
66 |
67 | 在最坏的情况下(也就是TLB完全没有命中),gPT中的每一级转换都需要一次nested walk【1】,而每次nested walk需要4次内存访问,因此5次nested walk总共需要 [公式] 次内存访问(就像一个5x5的二维矩阵一样):
68 |
69 | 
70 |
71 | 虽然这24次内存访问都是由硬件自动完成的,不需要软件的参与,但是内存访问的速度毕竟不能与CPU的运行速度同日而语,而且内存访问还涉及到对总线的争夺,次数自然是越少越好。
72 |
73 | 要想减少内存访问次数,要么是增大EPT/NPT TLB的容量,增加TLB的命中率,要么是减少gPT和nPT的级数。gPT是为guest VM中的进程服务的,通常采用4KB粒度的页,那么在64位系统下使用4级页表是非常合适的(参考这篇文章)。
74 |
75 | 而nPT是为guset VM服务的,对于划分给一个VM的内存,粒度不用太小。64位的x86_64支持2MB和1GB的large page,假设创建一个VM的时候申请的是2G物理内存,那么只需要给这个VM分配2个1G的large pages就可以了(这2个large pages不用相邻,但large page内部的物理内存是连续的),这样nPT只需要2级(nPML4和nPDPE)。
76 |
77 | 如果现在物理内存中确实找不到2个连续的1G内存区域,那么就退而求其次,使用2MB的large page,这样nPT就是3级(nPML4, nPDPE和nPD)。
78 |
79 | 下文将介绍从guest VM回收内存的技术。
80 |
81 | 注【1】:这里区分一个英文表达,stage和level,查找gPT的转换过程被称作stage 1,查找nPT的转换过程被称作stage 2,而gPT和nPT自身都是由multi-level的页表组成。
82 |
83 | 参考:
84 |
85 | [AMD-V™ Nested Paging](https://link.zhihu.com/?target=http%3A//developer.amd.com/wordpress/media/2012/10/NPT-WP-1%25201-final-TM.pdf)
86 |
87 | [Performance Evaluation of Intel EPT Hardware Assist](https://link.zhihu.com/?target=https%3A//www.vmware.com/pdf/Perf_ESX_Intel-EPT-eval.pdf)
88 |
89 |
90 | 原文作者: 兰新宇
91 |
92 |
93 |
94 |
95 |
96 |
97 |
--------------------------------------------------------------------------------
/virtualization_type/memory_virtualization/内存虚拟化影子页表技术和EPT技术.md:
--------------------------------------------------------------------------------
1 | # 内存虚拟化影子页表技术和EPT技术
2 |
3 | 虚拟化分为软件虚拟化和硬件虚拟化,而且遵循 intercept 和 virtualize 的规律。
4 |
5 | 内存虚拟化也分为基于软件的内存虚拟化和硬件辅助的内存虚拟化,其中,常用的基于软件的内存虚拟化技术为「影子页表」技术,硬件辅助内存虚拟化技术为 Intel 的 EPT(Extend Page Table,扩展页表)技术。
6 |
7 | ## 常规软件内存虚拟化
8 | 虚拟机本质上是 Host 机上的一个进程,按理说应该可以使用 Host 机的虚拟地址空间,但由于在虚拟化模式下,虚拟机处于非 Root 模式,无法直接访问 Root 模式下的 Host 机上的内存。
9 | 这个时候就需要 VMM 的介入,VMM 需要 intercept (截获)虚拟机的内存访问指令,然后 virtualize(模拟)Host 上的内存,相当于 VMM 在虚拟机的虚拟地址空间和 Host 机的虚拟地址空间中间增加了一层,即虚拟机的物理地址空间,也可以看作是 Qemu 的虚拟地址空间(稍微有点绕,但记住一点,虚拟机是由 Qemu 模拟生成的就比较清楚了)。
10 | 所以,内存软件虚拟化的目标就是要将虚拟机的虚拟地址(Guest Virtual Address, GVA)转化为 Host 的物理地址(Host Physical Address, HPA),中间要经过虚拟机的物理地址(Guest Physical Address, GPA)和 Host 虚拟地址(Host Virtual Address)的转化,即:
11 | ```C
12 | GVA -> GPA -> HVA -> HPA
13 | ```
14 |
15 | 其中前两步由虚拟机的系统页表完成,中间两步由 VMM 定义的映射表(由数据结构 kvm_memory_slot 记录)完成,它可以将连续的虚拟机物理地址映射成非连续的 Host 机虚拟地址,后面两步则由 Host 机的系统页表完成。如下图所示。
16 |
17 | 
18 |
19 | 这样做得目的有两个:
20 | 1. 提供给虚拟机一个从零开始的连续的物理内存空间。
21 | 2. 在各虚拟机之间有效隔离、调度以及共享内存资源。
22 |
23 | ## 影子页表技术
24 | 接上图,我们可以看到,传统的内存虚拟化方式,虚拟机的每次内存访问都需要 VMM 介入,并由软件进行多次地址转换,其效率是非常低的。因此才有了影子页表技术和 EPT 技术。
25 |
26 | 影子页表简化了地址转换的过程,实现了 Guest 虚拟地址空间到 Host 物理地址空间的直接映射。
27 |
28 | 要实现这样的映射,必须为 Guest 的系统页表设计一套对应的影子页表,然后将影子页表装入 Host 的 MMU 中,这样当 Guest 访问 Host 内存时,就可以根据 MMU 中的影子页表映射关系,完成 GVA 到 HPA 的直接映射。而维护这套影子页表的工作则由 VMM 来完成。
29 |
30 | 由于 Guest 中的每个进程都有自己的虚拟地址空间,这就意味着 VMM 要为 Guest 中的每个进程页表都维护一套对应的影子页表,当 Guest 进程访问内存时,才将该进程的影子页表装入 Host 的 MMU 中,完成地址转换。
31 |
32 | 我们也看到,这种方式虽然减少了地址转换的次数,但本质上还是纯软件实现的,效率还是不高,而且 VMM 承担了太多影子页表的维护工作,设计不好。
33 |
34 | 为了改善这个问题,就提出了基于硬件的内存虚拟化方式,将这些繁琐的工作都交给硬件来完成,从而大大提高了效率。
35 |
36 | ## EPT 技术
37 |
38 | 这方面 Intel 和 AMD 走在了最前面,Intel 的 EPT 和 AMD 的 NPT 是硬件辅助内存虚拟化的代表,两者在原理上类似,本文重点介绍一下 EPT 技术。
39 |
40 | 如下图是 EPT 的基本原理图示,EPT 在原有 CR3 页表地址映射的基础上,引入了 EPT 页表来实现另一层映射,这样,GVA->GPA->HPA 的两次地址转换都由硬件来完成。
41 |
42 | 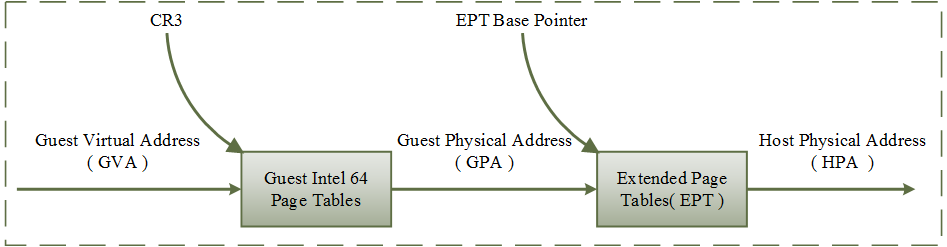
43 |
44 |
45 | 这里举一个小例子来说明整个地址转换的过程。假设现在 Guest 中某个进程需要访问内存,CPU 首先会访问 Guest 中的 CR3 页表来完成 GVA 到 GPA 的转换,如果 GPA 不为空,则 CPU 接着通过 EPT 页表来实现 GPA 到 HPA 的转换(实际上,CPU 会首先查看硬件 EPT TLB 或者缓存,如果没有对应的转换,才会进一步查看 EPT 页表),如果 HPA 为空呢,则 CPU 会抛出 EPT Violation 异常由 VMM 来处理。
46 |
47 | 如果 GPA 地址为空,即缺页,则 CPU 产生缺页异常,注意,这里,如果是软件实现的方式,则会产生 VM-exit,但是硬件实现方式,并不会发生 VM-exit,而是按照一般的缺页中断处理,这种情况下,也就是交给 Guest 内核的中断处理程序处理。
48 |
49 | 在中断处理程序中会产生 EXIT_REASON_EPT_VIOLATION,Guest 退出,VMM 截获到该异常后,分配物理地址并建立 GVA 到 HPA 的映射,并保存到 EPT 中,这样在下次访问的时候就可以完成从 GVA 到 HPA 的转换了。
50 |
51 | ## 总结
52 | 内存虚拟化经历从虚拟内存,到传统软件辅助虚拟化,影子页表,再到硬件辅助虚拟化,EPT 技术的进化,效率越来越高。
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
--------------------------------------------------------------------------------
/virtualization_type/storage_virtualization/Neutron实现网络虚拟化.md:
--------------------------------------------------------------------------------
1 | # Neutron实现网络虚拟化
2 |
3 | ## 1. 云计算时代数据中心物理网络的问题
4 | 数据中心虚拟化成为了趋势,最典型的场景莫过于:对数据中心的服务器进行虚拟化,来提高资源利用率,同时降低单位能耗。
5 | 但是,随着数据中心虚拟化程度的不断提高、虚拟化服务器规模的不断扩大,带来了巨大的管理压力。===>这正是云计算诞生的原因。
6 | 在大规模虚拟化的基础上,实现了自动化管理和集中化管理,就是云计算的基本模型。
7 |
8 | 云计算的超大规模加上其特有的服务模式带来了诸多亟需解决的问题,这些问题中,首当其冲的就是网络问题
9 |
10 | 我们需要从两个角度去看:
11 | * 数据中心现有的物理网络,无法承载云计算机的超大规模
12 | (详见1.1小节)
13 | * 数据中心现有的物理网络,无法满足云计算SDN的要求
14 | (详见1.2小节)
15 |
16 | ### 1.1 数据中心现有的物理网络,无法承载云计算机的超大规模
17 | 互联网行业数据中心的基本特征就是服务器的规模偏大。进入云计算时代后,其业务特征变得更加复杂,包括:虚拟化支持、多业务承载、资源灵活调度等(如图1所示)。与此同时,互联网云计算的规模不但没有缩减,反而更加庞大。这就给云计算的网络带来了巨大的压力。
18 |
19 | 
20 | 图1. 互联网云计算的业务特点
21 |
22 | #### 大容量的MAC表项和ARP表项
23 | 虚拟化会导致更大的MAC表项。假设一个互联网云计算中心的服务器有5000台,按照1:20的比例进行虚拟化,则有10万个虚拟机。通常每个虚拟机会配置两个业务网口,这样这个云计算中心就有20万个虚拟网口,对应的就是需要20万个MAC地址和IP地址。云计算要求资源灵活调度,业务资源任意迁移。也就是说任意一个虚拟机可以在整个云计算网络中任意迁移。这就要求全网在一个统一的二层网络中。全网任意交换机都有可能学习到全网所有的MAC表项。与此对应的则是,目前业界主流的接入交换机的MAC表项只有32K,基本无法满足互联网云计算的需求。另外,网关需要记录全网所有主机、所有网口的ARP信息。这就需要网关设备的有效ARP表项超过20万。大部分的网关设备芯片都不具备这种能力。
24 |
25 | #### 4K VLAN Trunk问题
26 | 传统的大二层网络支持任意VLAN的虚拟机迁移到网络的任意位置,一般有两种方式。方式一:虚拟机迁移后,通过自动化网络管理平台动态的在虚拟机对应的所有端口上下发VLAN配置;同时,还需要动态删除迁移前虚拟机对应所有端口上的VLAN配置。这种方式的缺点是实现非常复杂,同时自动化管理平台对多厂商设备还面临兼容性的问题,所以很难实现。方式二:在云计算网络上静态配置VLAN,在所有端口上配置VLAN trunk all。这种方式的优点是非常简单,是目前主流的应用方式。但这也带来了巨大的问题:任一VLAN内如果出现广播风暴,则全网所有VLAN内的虚拟机都会受到风暴影响,出现业务中断。
27 |
28 | #### 4K VLAN上限问题
29 | 云计算网络中有可能出现多租户需求。如果租户及业务的数量规模超出VLAN的上限(4K),则无法支撑客户的需求。
30 |
31 | #### 虚拟机迁移网络依赖问题
32 | VM迁移需要在同一个二层域内,基于IP子网的区域划分限制了二层网络连通性的规模。
33 |
34 | ### 1.2 数据中心现有的物理网络,无法满足云计算SDN的要求
35 | 站着使用角度去考虑,比如我们使用阿里云
36 | * 一方面:每个申请阿里云的人或组织都是一个独立的租户,而每个申请者自以为自己独享的网络资源,实际上是与其他申请者共享阿里云的物理网络,这就需要阿里云做好租户与租户直接的隔离,这是一个很重要的方面,显然,数据中心现有的物理网络无法满足需求: 数据中心现有的物理网络是固定的,需要手动配置的,单一的。
37 | * 另一方面:就是自服务,试想,我们作为阿里云的使用者,完全可以构建自己的网络环境,这就需要云环境对租户提供API,从而满足租户基于云计算虚拟出来的网络之上来设计、部署租户自己需要的网络架构。
38 | 所以总结下来,云计算SDN的需求无非两点:
39 | 1. 租户“共享同一套物理网络”并且一定要实现“互相隔离”
40 | 2. 自服务
41 |
42 | ### 1.3 小结
43 | 总结1.1和1.2:
44 | 1. 其实很明显的可以看出来,无论是1.1还是1.2的问题,都指向了同一点:数据中心现有的物理网络好使,不够6。如何解决呢?
45 | 2. 简答地说,就是在数据中心现有的物理网络基础之上叠加一层我们自己的虚拟网络
46 |
47 | ## 2. 如何解决问题:Neutron实现网络虚拟化
48 |
49 | ### 2.1 Neutron组件介绍
50 |
51 | neutron包含组件:
52 | * neutron-server
53 | * neutron-plugin
54 | * neutron-agent
55 |
56 | 
57 |
58 | neutron各组件功能介绍:
59 |
60 | 1. Neutron-server可以理解为一个专门用来接收Neutron REST API调用的服务器,然后负责将不同的rest api分发到不同的neutron-plugin上。
61 | 2. Neutron-plugin可以理解为不同网络功能实现的入口,各个厂商可以开发自己的plugin。Neutron-plugin接收neutron-server分发过来的REST API,向neutron database完成一些信息的注册,然后将具体要执行的业务操作和参数通知给自身对应的neutron agent。
62 | 3. Neutron-agent可以直观地理解为neutron-plugin在设备上的代理,接收相应的neutron-plugin通知的业务操作和参数,并转换为具体的设备级操作,以指导设备的动作。当设备本地发生问题时,neutron-agent会将情况通知给neutron-plugin。
63 | 4. Neutron database,顾名思义就是Neutron的数据库,一些业务相关的参数都存在这里。
64 | 5. Network provider,即为实际执行功能的网络设备,一般为虚拟交换机(OVS或者Linux Bridge)。
65 |
66 |
67 | neutron-plugin分为core-plugin和service-plugin两类。
68 | Core-plugin,Neutron中即为ML2(Modular Layer 2),负责管理L2的网络连接。ML2中主要包括network、subnet、port三类核心资源,对三类资源进行操作的REST API被neutron-server看作Core API,由Neutron原生支持。其中:
69 |
70 | 
71 |
72 | Service-plugin,即为除core-plugin以外其它的plugin,包括l3 router、firewall、loadbalancer、VPN、metering等等,主要实现L3-L7的网络服务。这些plugin要操作的资源比较丰富,对这些资源进行操作的REST API被neutron-server看作Extension API,需要厂家自行进行扩展。
73 | “Neutron对Quantum的插件机制进行了优化,将各个厂商L2插件中独立的数据库实现提取出来,作为公共的ML2插件存储租户的业务需求,使得厂商可以专注于L2设备驱动的实现,而ML2作为总控可以协调多厂商L2设备共同运行”。在Quantum中,厂家都是开发各自的Service-plugin,不能兼容而且开发重复度很高,于是在Neutron中就为设计了ML2机制,使得各厂家的L2插件完全变成了可插拔的,方便了L2中network资源扩展与使用。
74 |
75 | (注意,以前厂商开发的L2 plugin跟ML2都存在于neutron/plugins目录下,而可插拔的ML2设备驱动则存在于neutron/plugins/ml2/drivers目录下)
76 |
77 | ML2作为L2的总控,其实现包括Type和Mechanism两部分,每部分又分为Manager和Driver。Type指的是L2网络的类型(如Flat、VLAN、VxLAN等),与厂家实现无关。Mechanism则是各个厂家自己设备机制的实现,如下图所示。当然有ML2,对应的就可以有ML3,不过在Neutron中L3的实现只负责路由的功能,传统路由器中的其他功能(如Firewalls、LB、VPN)都被独立出来实现了,因此暂时还没有看到对ML3的实际需求。
78 |
79 | 
80 |
81 | 一般而言,neutron-server和各neutron-plugin部署在控制节点或者网络节点上,而neutron agent则部署在网络节点上和计算节点上。我们先来分析控制端neutron-server和neutron-plugin的工作,然后再分析设备端neutron-agent的工作。
82 |
83 | neutron新进展(dragon flow): https://www.ustack.com/blog/neutron-dragonflow/
84 |
85 | ### 2.2 Neturon网络虚拟化简介
86 |
87 | 想要了解openstack的虚拟化网络,必先知道承载openstack虚拟化网络的物理网络
88 |
89 | 在实际的数据中心中,与openstack相关的物理网络可以分为三层:
90 |
91 | 1. OpenStack Cloud network:OpenStack 架构的网络
92 | 2. 机房intranet (external network):数据中心所管理的的公司网(Intranet) ,虚机使用的 Floating IP 是这个网络的地址的一部分。
93 | 3. 以及真正的外部网络即 Internet:由各大电信运营商所管理的公共网络,使用公共IP。
94 |
95 | External 网络和Internet 之间是数据中心的 Uplink 路由器,它负责通过 NAT 来进行两个网络之间的IP地址(即 floating IP 和 Internet/Public IP)转换,因此,这部分的控制不在 OpenStack 控制之下,我们无需关心它。
96 |
97 | openstack架构的网络--->机房的网络external-----(NAT)--->外网internet
98 |
99 | openstack架构的网络又可细分为以下几种(下述指的仍然是物理网络):
100 |
101 | 1. 管理网络:包含api网络(public给外部用,admin给管理员用-是内部ip,internal给内部用-是内部ip)
102 | 2. 数据网络
103 | 3. 存储网络
104 | 4. IDRAC网络
105 | 5. PXE网络
106 |
107 | 数据网络主要用于vm之间的通信,这部分是neutron所实现网络虚拟化的核心,neutron基于该物理网络之上,来实现满足多租户要求的虚拟网络和服务。
108 |
109 | Neutron 提供的网络虚拟化能力包括:
110 |
111 | 1. 二层到七层网络的虚拟化:L2(virtual switch)、L3(virtual Router 和 LB)、L4-7(virtual Firewall )等
112 | 2. 网络连通性:二层网络和三层网络
113 | 3. 租户隔离性
114 | 4. 网络安全性
115 | 5. 网络扩展性
116 | 6. REST API
117 | 7. 更高级的服务,包括 LBaaS,FWaaS,VPNaaS 等。具体以后再慢慢分析。
118 |
119 | Neutron主要为租户提供虚拟的
120 | 1. 交换机(switch)
121 | 2. 网络(L2 network)和子网(subnet),
122 | 3. 路由器(router)
123 | 4. 端口(port)
124 |
125 | ### 2.3 构建大二层网络:虚拟交换机(switch)+物理交换机
126 |
127 | 1. 什么是二层网络?
128 | 二层指的是数据链路层,计算机与计算机之间的通信采用的是基于以太网协议广播的方式,请参考http://www.cnblogs.com/linhaifeng/articles/5937962.html
129 |
130 | 2. 什么是大二层网络?
131 | 大二层的概念指的是openstack中所有的vm都处于一个大的二层网络中,大二层也可以被想象成一堆二层交换机串联到一起。
132 |
133 | 3. 为什么要构建大二层网络?
134 | 构建大二层网络的目的就是为了满足vm可以迁移到全网的任意位置。二层无需网关,无需路由,因而资源调用更加灵活,反之,如果所有vm不在一个大二层中,那么vm迁移到另外一个位置(另外一个网络中),则需要我们人为地指定网关,添加路由策略,然而这还只是针对一台vm的迁移,要满足所有的vm的动态迁移,再去指定网关、路由等就不现实了。
135 |
136 | 4. 如何构建大二层网络?
137 | 一些列二层设备串联起来,组成一个大二层网络,在openstack中二层设备分为:物理的二层设备和虚拟机的二层设备
138 | 虚拟的二层设备又分为:
139 | * 1. Neutron 默认采用的 开源Open vSwitch 创建的虚机交换机
140 | * 2. Linux bridge。
141 |
142 | 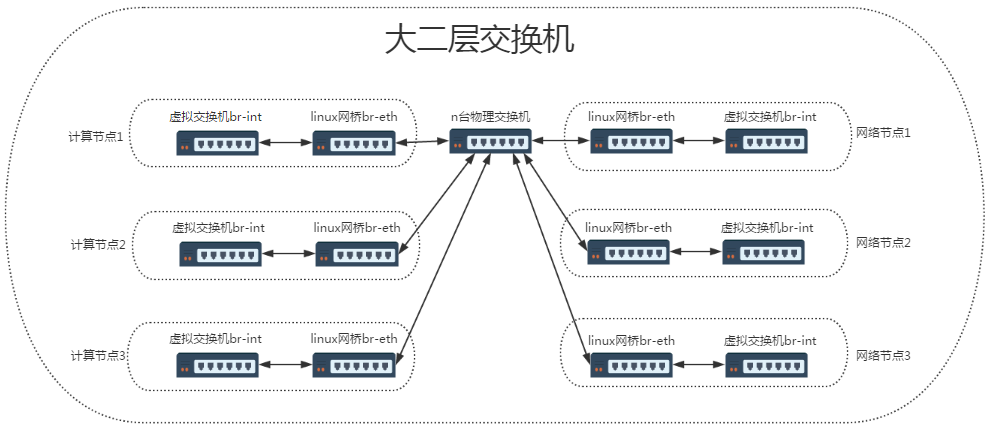
143 |
144 |
145 | 需要特别强调的是:
146 | 1. 大二层网络是由虚拟二层设备和物理二层设备共同组成的;
147 | 2. 而这里面所有的二层设备合在一起相当于一个大的交换机;
148 | 3. 大二层网络是在计算节点或者网络节点启动时就会建立,而后期用户建立的网络,都是在此网络的基础之上进行逻辑划分,用户每新建一个网络都被分配相应的段ID(相当于vlan id)
149 |
150 | ### 2.4 大二层网络创建完毕后,用户如何使用?->网络(L2 network)、子网(subnet)
151 | 云平台在构建完毕后,即在物理节点都正常启动后,大二层网络也就创建好了,对用户来说,此时相当于一台大的二层交换机摆在面前,即用户创建网络就是把整个大二层网络当成一个交换机
152 | 然后用户需要做的是基于该网络划分自己的vlan,即建立一个l2 network,
153 | 例如:用户(例如demo用户)可以在自己的project下创建网络(L2 network),该网络就是在大二层的基础上划分出来的,是一个隔离的二层网段。类似于物理网络世界中的虚拟 LAN (VLAN),每建立一个l2 network,都会被分配一个段ID,该段ID标识一个广播域,这个ID是被随机分配的,除非使用管理员身份在管理员菜单下,才可以手动指定该ID
154 | 那么就让我们在demo租户下以demo用户身份创建demo-net网络:
155 |
156 | 
157 |
158 | 以admin用户登录,这样才能看到新建网络demo-net的段ID,其实此时demo-net仅仅只是一种逻辑上划分
159 |
160 | 
161 |
162 | 补充:使用管理员身份在管理员菜单下,创建网络可以手动指定段ID
163 |
164 | 
165 |
166 | 子网是一组 IPv4 或 IPv6 地址以及与其有关联的配置。它是一个地址池,OpenStack 可从中向虚拟机 (VM) 分配 IP 地址。每个子网指定为一个无类别域间路由 (Classless Inter-Domain Routing) 范围,必须与一个网络相关联。除了子网之外,租户还可以指定一个网关、一个域名系统 (DNS) 名称服务器列表,以及一组主机路由。这个子网上的 VM 实例随后会自动继承该配置。
167 |
168 | 在 OpenStack Kilo 版本之前,用户需要自己输入 CIDR。Kilo 版本中实现了这个 Blueprint,使得 Neutron 能够从用户指定的 CIDR Pool 中自动分配 CIDR。
169 |
170 | 
171 |
172 | 
173 |
174 | 查看新建子网的信息
175 |
176 | 
177 |
178 |
179 | 创建的结果:就好比我们拿来一台“交换机”分出了一个VLAN.
180 | 注:在AWS中,该概念对应其 Subnet 概念。AWS 对 Subnet 的数目有一定的限制,默认地每个 VPC 内最多只能创建 200 个 Subnet。从CIDR角度看,一个 VPC 有一个比较大的网段,其中的每个 Subnet 分别拥有一个较小的网段。这种做法和OpenStack 有区别,OpenStack 中创建网络时不需要指定 CIDR。
181 | 在建立了子网后,会在网络节点上新增一个名称空间用来运行dhcp-agent专门为demo-net下的demo-subnet分配ip
182 |
183 | * demo-net有一个段ID:51
184 | * demo-subnet有网络ID:a603fd2c-35ef-46de-b9c4-da48680eb27d
185 | * 连接dhcp-agent的端口网络ID:a603fd2c-35ef-46de-b9c4-da48680eb27d
186 |
187 | 
188 |
189 | 对应大二层网络上的变化为:在网络节点上新增dhcp-agent,在网络节点上的br-int新增端口,该端口的属于demo-net,及属于段ID:51
190 | ps:新建子网后,便会网络节点新增dhcp-agent(解释一下:图中虚拟机是新建虚拟机后才有的)
191 |
192 | 
193 |
194 | 
195 |
196 | 在demo-net新增一个子网的话,不会新增dhcp-agent,会新增地址池
197 |
198 | 
199 |
200 | 总结:
201 |
202 | DHCP 服务是网络环境中必须有的。Neutron 提供基于 Dnamasq (轻型的dns和dhcp服务)实现的虚机 DHCP 服务,向租户网络内的虚机动态分配固定 IP 地址。它具有以下特性:
203 |
204 | 一个网络可以有多个运行在不同物理网络节点上的 DHCP Agent,同时向网络内的虚机提供服务
205 | 一个 DHCP Agent 只属于一个网络,在网络节点上运行在一个 network namespace 内
206 | 网络内的子网共享该 DHCP Agent
207 |
208 | 在demo-net以及demo-subnet建立成功后,就可以新建虚拟机连接到demo-net了,相当于同一个vlan中的俩台虚拟机,二层互通
209 | 此处我们新建vm1和vm2,网络拓扑如下
210 |
211 | 
212 |
213 | 按照同样的套路创建demo-net1,它与demo-net是隔离的
214 | 
215 |
216 | 对应大二层网络的端口连接连接
217 | 
218 |
219 | 这里所谓的隔离,可以理解为几个含义:
220 | * 1. 每个网络使用自己的 DHCP Agent,每个 DHCP Agent 在一个 Network namespace 内
221 | * 2. 不同网络内的IP地址可以重复(overlapping)
222 | * 3. 跨网络的子网之间的流量必须走 L3 Virtual Router
223 |
224 | ### 2.5 虚拟机路由器(Vitual Router)
225 | 要想让demo-net1上的vm3与demo-net上的vm2通信,用户必须建立连接这两个网络的路由器router
226 |
227 | 
228 |
229 | 添加接口
230 |
231 | 
232 |
233 | 查看网络拓扑
234 |
235 | 
236 |
237 | 对应大二层网络的变化
238 |
239 | 测试来自demo-net的vm2:172.16.45.6与demo-net1的vm3:172.16.18.3的连通性
240 |
241 | 
242 |
243 | 要想连接外网,需要用管理员身份,创建与外部网络绑定的网络,然后将demo租户下的test-router的网关指定为该网络
244 |
245 | 
246 |
247 | 
248 |
249 | 网络拓扑
250 |
251 | 
252 |
253 | 测试:
254 |
255 | 
256 |
257 | 总结:一个 Virtual router 提供不同网段之间的 IP 包路由功能,由 Nuetron L3 agent 负责管理。
258 |
259 | ### 2.6 端口(Port)
260 |
261 | 一个 Port 代表虚拟网络交换机(logical network switch)上的一个虚机交换端口(virtual switch port)。虚机的网卡(VIF - Virtual Interface)会被连接到 port 上。当虚机的 VIF 连接到 Port 后,这个 vNIC 就会拥有 MAC 地址和 IP 地址。Port 的 IP 地址是从 subnet 中分配的。
262 |
263 | ## 3. 实现网络虚拟化的关键:如何构建虚拟的大二层网络
264 |
265 | 根据创建网络的用户的权限,Neutron L2 network 可以分为:
266 |
267 | * Provider network:管理员创建的和物理网络有直接映射关系的虚拟网络。
268 |
269 | 
270 |
271 | 
272 |
273 | * Tenant network:租户普通用户创建的网络,物理网络对创建者透明,其配置由 Neutron根据管理员在系统中的配置决定。
274 |
275 | 
276 |
277 | 虚机可以直接挂接到 provider network 或者 tenant network 上 “VMs can attach directly to both tenant and provider networks, and to networks with any provider:network_type value, assuming their tenant owns the network or its shared.”。
278 |
279 | 根据网络的类型,Neutron L2 network 可以分为:
280 | * Flat network:基于不使用 VLAN 的物理网络实现的虚拟网络。每个物理网络最多只能实现一个虚拟网络。
281 | * local network(本地网络):一个只允许在本服务器内通信的虚拟网络,不知道跨服务器的通信。主要用于单节点上测试。
282 | * VLAN network(虚拟局域网) :基于物理 VLAN 网络实现的虚拟网络。共享同一个物理网络的多个 VLAN 网络是相互隔离的,甚至可以使用重叠的 IP 地址空间。每个支持 VLAN network 的物理网络可以被视为一个分离的 VLAN trunk,它使用一组独占的 VLAN ID。有效的 VLAN ID 范围是 1 到 4094。
283 | * GRE network (通用路由封装网络):一个使用 GRE 封装网络包的虚拟网络。GRE 封装的数据包基于 IP 路由表来进行路由,因此 GRE network 不和具体的物理网络绑定。
284 | * VXLAN network(虚拟可扩展网络):基于 VXLAN 实现的虚拟网络。同 GRE network 一样, VXLAN network 中 IP 包的路由也基于 IP 路由表,也不和具体的物理网络绑定。
285 |
286 | 注:在AWS中,该概念对应 VPC 概念。AWS 对 VPC 的数目有一定的限制,比如每个账户在每个 region 上默认最多只能创建 5 个VPC,通过特别的要求最多可以创建 100 个。
287 |
288 | L2 network之Provider与Tenant的区别
289 |
290 | * Provider network 是由 Admin 用户创建的,而 Tenant network 是由 tenant 普通用户创建的。
291 | * Provider network 和物理网络的某段直接映射,比如对应某个 VLAN,因此需要预先在物理网络中做相应的配置。而 tenant network 是虚拟化的网络,Neutron 需要负责其路由等三层功能。
292 | * 对 Flat 和 VLAN 类型的网络来说,只有 Provider network 才有意义。即使是这种类型的 tenant network,其本质上也是对应于一个实际的物理段。
293 | * 对 GRE 和 VXLAN 类型的网络来说,只有 tenant network 才有意义,因为它本身不依赖于具体的物理网络,只是需要物理网络提供 IP 和 组播即可。
294 | * Provider network 根据 admin 用户输入的物理网络参数创建;而 tenant work 由 tenant 普通用户创建,Neutron 根据其网络配置来选择具体的配置,包括网络类型,物理网络和 segmentation_id。
295 | * 创建 Provider network 时允许使用不在配置项范围内的 segmentation_id。
296 |
297 | ### 3.2 依赖物理的二层来建立虚拟的大二层(vlan模式)
298 | 物理的二层指的是:物理网络是二层网络,基于以太网协议的广播方式进行通信
299 | 虚拟的二层指的是:neutron实现的虚拟的网络也是二层网络(openstack的vm机所用的网络必须是大二层),也是基于以太网协议的广播方式进行通信,但毫无疑问的是该虚拟网络依赖于物理的二层网络
300 | 物理二层+虚拟二层的典型代表:vlan网络模式,点击进入详解
301 |
302 | ### 3.3 依赖物理的三层来建立虚拟的大二层(gre模块与vxlan模式)
303 | 物理的三层指的是:物理网络是三层网络,基于ip路由的方式进行通信
304 | 虚拟的二层指的是:neutron实现的虚拟的网络仍然是二层网络(openstack的vm机所用的网络必须是大二层),仍然是基于以太网协议的广播方式进行通信,但毫无疑问的是该虚拟网络依赖于物理的三层网络,这有点类似于VPN的概念,根本原理就是将私网的包封装起来,最终打上隧道的ip地址传输。
305 | 物理三层+虚拟二层的典型代表:gre模式与vxlan模式,点击进入详解
306 |
307 |
308 |
309 |
310 |
311 |
312 |
313 |
314 |
315 |
316 |
317 |
318 |
319 |
320 |
321 |
322 |
323 |
324 |
325 |
326 |
327 |
328 |
329 |
330 |
331 |
332 |
333 |
334 |
335 |
336 |
337 |
338 |
339 |
340 |
341 |
342 |
343 |
344 |
345 |
346 |
347 |
348 |
349 |
350 |
351 |
352 |
--------------------------------------------------------------------------------
/virtualization_type/storage_virtualization/什么是文件虚拟化(File Virtualization):
--------------------------------------------------------------------------------
1 | # 什么是文件虚拟化(File Virtualization)?
2 |
3 | 文件虚拟化(File Virtualization)是在文件服务器和访问这些文件服务器的客户机之间创建一个抽象层。一旦应用,文件虚拟化层管理跨服务器的文件和文件系统,允许管理员向客户机提供一个所有服务器的逻辑文件挂接。这台服务器继续托管文件数据和元数据。
4 | 虽然这种安排好想象不必要地增加了IT开销,但是,文件虚拟化提供了一些关键的优势,包括一个全局命名空间用来给网络文件服务器上的文件加索引。此外,这种虚拟文件存储整合允许文件服务器之间共享访问存储容量。文件服务器之间实施的数据迁移对于最终用户和应用程序都是透明的。这在分层次的存储基础设施中是理想的。简言之,文件虚拟化允许企业访问网络文件服务器上隔离的存储容量并且在上面进行无缝的文件迁移。
5 | 文件虚拟化可以部署为一台设备或者一台运行文件虚拟化软件的现成的服务器。这种选择基本上是根据成本以及有关的管理和破坏水平确定的。最常用的部署选择是设备。这种设备有四种不同的架构:带外、带内、这两者的结合和分离路径(Split-Path)。
6 | 并为所有的文件虚拟化部署从长远看是成功的。有些机构也许会退回(撤销)他们的部署。这对于文件服务器和网络附加存储平台来说是一个破坏性非常大的过程。在极端的情况下,退回可能需要机构卸载数据、删除文件虚拟化层,然后重新格式化和重新装载全部数据。经销商通常能够帮助识别潜在的退回问题,提供减轻破坏的建议。用户在一般部署之前通常要测试其退回的程序。
7 | 文件虚拟化受到可伸缩性的限制。可伸缩性包括文件系统、文件、服务器或者输入/输出性能。文件虚拟化平台还必须要兼容当前的基础设施。这样,它就能够与现有的存储系统和交换机一起工作。要防止出现潜在的问题,文件虚拟化平台应该经常进行适当的可伸缩性和兼容性测试。
8 |
--------------------------------------------------------------------------------
/virtualization_type/storage_virtualization/在Linux平台使用mhVTL虚拟化磁带库.md:
--------------------------------------------------------------------------------
1 | # 在Linux平台使用mhVTL虚拟化磁带库
2 |
3 | ## 1. 查看磁带库设备相关信息。
4 |
5 | ```C
6 | [root@centos1 opt]# lsscsi -g
7 | [0:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sda /dev/sg0
8 | [1:0:0:0] mediumx STK L700 0104 - /dev/sg9
9 | [1:0:1:0] tape IBM ULT3580-TD5 0104 /dev/st0 /dev/sg1
10 | [1:0:2:0] tape IBM ULT3580-TD5 0104 /dev/st1 /dev/sg2
11 | [1:0:3:0] tape IBM ULT3580-TD4 0104 /dev/st2 /dev/sg3
12 | [1:0:4:0] tape IBM ULT3580-TD4 0104 /dev/st3 /dev/sg4
13 | [1:0:8:0] mediumx STK L80 0104 - /dev/sg10
14 | [1:0:9:0] tape STK T10000B 0104 /dev/st4 /dev/sg5
15 | [1:0:10:0] tape STK T10000B 0104 /dev/st5 /dev/sg6
16 | [1:0:11:0] tape STK T10000B 0104 /dev/st6 /dev/sg7
17 | [1:0:12:0] tape STK T10000B 0104 /dev/st7 /dev/sg8
18 | ```
19 |
20 | 一般磁带库有两个机械手(sg),八个驱动器(st),多个插槽(slot),插槽中的磁带被放入了驱动之后才能被正常的读写,每盘磁带读写完毕,或读写满了需要手动更换下一盘磁带。
21 |
22 | ## 2. 装载磁带操作。
23 |
24 | 装载磁带命令格式:mtx -f load
25 |
26 | ### 1). 查看sg9机械手状态:
27 | ```C
28 | [root@centos1 ~]# mtx -f /dev/sg9 status
29 | Storage Changer /dev/sg9:4 Drives, 43 Slots ( 4 Import/Export )
30 | Data Transfer Element 0:Empty
31 | Data Transfer Element 1:Empty
32 | Data Transfer Element 2:Empty
33 | Data Transfer Element 3:Empty
34 | Storage Element 1:Full :VolumeTag=E01001L4
35 | Storage Element 2:Full :VolumeTag=E01002L4
36 | Storage Element 3:Full :VolumeTag=E01003L4
37 | Storage Element 4:Full :VolumeTag=E01004L4
38 | Storage Element 5:Full :VolumeTag=E01005L4
39 | Storage Element 6:Full :VolumeTag=E01006L4
40 | Storage Element 7:Full :VolumeTag=E01007L4
41 | Storage Element 8:Full :VolumeTag=E01008L4
42 | Storage Element 9:Full :VolumeTag=E01009L4
43 | Storage Element 10:Full :VolumeTag=E01010L4
44 | Storage Element 11:Full :VolumeTag=E01011L4
45 | Storage Element 12:Full :VolumeTag=E01012L4
46 | Storage Element 13:Full :VolumeTag=E01013L4
47 | Storage Element 14:Full :VolumeTag=E01014L4
48 | Storage Element 15:Full :VolumeTag=E01015L4
49 | Storage Element 16:Full :VolumeTag=E01016L4
50 | Storage Element 17:Full :VolumeTag=E01017L4
51 | Storage Element 18:Full :VolumeTag=E01018L4
52 | Storage Element 19:Full :VolumeTag=E01019L4
53 | Storage Element 20:Full :VolumeTag=E01020L4
54 | Storage Element 21:Empty
55 | Storage Element 22:Full :VolumeTag=CLN101L4
56 | Storage Element 23:Full :VolumeTag=CLN102L5
57 | Storage Element 24:Empty
58 | Storage Element 25:Empty
59 | Storage Element 26:Empty
60 | Storage Element 27:Empty
61 | Storage Element 28:Empty
62 | Storage Element 29:Empty
63 | Storage Element 30:Full :VolumeTag=F01030L5
64 | Storage Element 31:Full :VolumeTag=F01031L5
65 | Storage Element 32:Full :VolumeTag=F01032L5
66 | Storage Element 33:Full :VolumeTag=F01033L5
67 | Storage Element 34:Full :VolumeTag=F01034L5
68 | Storage Element 35:Full :VolumeTag=F01035L5
69 | Storage Element 36:Full :VolumeTag=F01036L5
70 | Storage Element 37:Full :VolumeTag=F01037L5
71 | Storage Element 38:Full :VolumeTag=F01038L5
72 | Storage Element 39:Full :VolumeTag=F01039L5
73 | Storage Element 40 IMPORT/EXPORT:Empty
74 | Storage Element 41 IMPORT/EXPORT:Empty
75 | Storage Element 42 IMPORT/EXPORT:Empty
76 | Storage Element 43 IMPORT/EXPORT:Empty
77 | ```
78 | 4个驱动器中没有磁带。
79 |
80 | ### 2). 将磁带从39号插槽装入0号驱动器:
81 | ```C
82 | [root@centos1 ~]# mtx -f /dev/sg9 load 39 0
83 | [root@centos1 ~]# mtx -f /dev/sg9 status
84 | Storage Changer /dev/sg9:4 Drives, 43 Slots ( 4 Import/Export )
85 | Data Transfer Element 0:Full (Storage Element 39 Loaded):VolumeTag = F01039L5
86 | Data Transfer Element 1:Empty
87 | Data Transfer Element 2:Empty
88 | Data Transfer Element 3:Empty
89 | .....
90 | ```
91 | 成功将39号槽位的磁带装入0号磁带驱动器。
92 |
93 | ### 3). 检查0号驱动器里磁带的状态:
94 | ```C
95 | [root@centos1 ~]# mt -f /dev/st0 status
96 | SCSI 2 tape drive:
97 | File number=0, block number=0, partition=0.
98 | Tape block size 0 bytes. Density code 0x58 (no translation).
99 | Soft error count since last status=0
100 | General status bits on (41010000):
101 | BOT ONLINE IM_REP_EN
102 | ```
103 |
104 | ### 4). 检查0号驱动器中磁头的位置:
105 | ```C
106 | [root@centos1 ~]# mt -f /dev/st0 tell
107 | At block 0.
108 | ```
109 |
110 | ### 5). 向磁带中写入数据:
111 | ```C
112 | [root@centos1 ~]# ls
113 | anaconda-ks.cfg Desktop install.log install.log.syslog
114 | [root@centos1 ~]# tar -cvf /dev/st0 Desktop
115 | Desktop/
116 | [root@centos1 ~]# mt -f /dev/st0 tell
117 | At block 0.
118 | ```
119 | st打头的表示写入完成后会自动倒带,下次写入会覆盖之前的数据。
120 | ```C
121 | [root@centos1 ~]# tar -cvf /dev/nst0 Desktop
122 | Desktop/
123 | [root@centos1 ~]# mt -f /dev/st0 tell
124 | At block 2.
125 | ```
126 | nst打头的表示写入完成后不会自动倒带。
127 |
128 | ## 3. 卸载磁带库操作。
129 |
130 | 将磁带从0号驱动器拔出放入39号插槽:
131 | ```C
132 | [root@centos1 ~]# mtx -f /dev/sg9 unload 39 0
133 | Unloading Data Transfer Element into Storage Element 39...done
134 | ```
135 |
136 | 以上是一些简单的基本操作。
137 |
138 |
139 | 原文作者: 尛样儿
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
--------------------------------------------------------------------------------
/virtualization_type/storage_virtualization/块虚拟化.md:
--------------------------------------------------------------------------------
1 | # 块虚拟化过程
2 |
3 | 存储系统采用了块虚拟化技术,实现了存储池中资源的动态分配和扩展,提升了存储池中数据的读写响应速度,缩短了硬盘故障后的重构时间。
4 |
5 | 块虚拟化过程如图1所示。
6 |
7 | 图1 块虚拟化过程
8 |
9 | 
10 |
11 | 1. 存储系统所有硬盘划分为多个硬盘域。虚拟机业务中SAS硬盘用于安装虚拟机操作系统,NL-SAS和SATA硬盘用于存储业务数据。一个硬盘域里可以创建多个存储池。
12 | 2. 存储系统将各存储层的存储介质划分为固定大小的CHUNK。
13 | 3. 每一个存储层的CHUNK按照用户在DeviceManager上设置的“RAID策略”和“热备策略”组成CHUNK group和热备空间。
14 | 4. 存储系统按照用户在DeviceManager管理界面上设置的“数据迁移粒度”将CHUNK group划分为更小的Extent,它是组成thick LUN的最小单位。
15 | 5. 当用户创建thin LUN时,存储系统还会在Extent的基础上再进行更细粒度的划分(Grain),并以Grain为单位映射到thin LUN,从而实现对存储的精细化管理。
16 |
--------------------------------------------------------------------------------
/virtualization_type/storage_virtualization/基于主机的虚拟化存储应用及注意事项.md:
--------------------------------------------------------------------------------
1 | # 基于主机的虚拟化存储应用及注意事项
2 |
3 | 虚拟存储化技术可以简化企业的存储模型,提高灵活性并支持异构的存储环境,被越来越多的企业所接受并采用。根据虚拟化技术部署方式的不同,可以分为基于主机的虚拟化技术、基于存储设备的虚拟化技术等等。不同的技术对应于企业不同的应用场合。笔者在这里简要介绍一下基于主机的虚拟化存储应用的场合以及相关注意事项。抛砖引玉,希望能够给各位管理员带来一定的帮助。
4 |
5 | ## 一、基于主机的虚拟化存储应用模型。
6 |
7 | 简单的说,基于主机的虚拟化存储应用模型指的就是存储产品与服务器是一体的。此时虚拟化存储的应用通过特定的软件在主机服务器上完成,经过虚拟化的存储空间可以跨越多个异构的磁盘阵列。换句话说,此时的服务器其实有四个层次组成。最上面的一个层次为应用软件层次,如视频监控系统。第二个层次为操作系统层次,如Linux操作系统或者Windows操作系统。第三个层次为虚拟化管理软件层次,如Windows操作系统的自带卷管理器。第四个层次为物理存储产品层次,如硬盘或者磁带等等。基于主机的虚拟化存储应用模型,指的就是这几个层次都处在同一台应用服务器上。
8 |
9 | 目前很多企业都是建立在这个应用模型之上的。通过这种模型,企业既可以享受虚拟化存储技术所带来的收益,如提高灵活性、扩大存储空间等等,同时又不需要大的投入。故这种基于主机的虚拟化存储应用很受大众的欢迎。
10 |
11 | ## 二、基于主机的虚拟化存储应用场合。
12 |
13 | 那么在什么时候可以使用这个存储应用模型呢?如果从广义上来说,在任何情况下都可以使用这个应用模型。而从狭义的角度讲,如结合性能、存储空间等角度来说,那么企业如果需要单个主机服务器(或者群集服务器)访问多个磁盘阵列的时候,可以采用这个基于主机的虚拟化存储模型。
14 |
15 | 如企业现在有一个文件服务器,为了优化文件服务器的性能,扩大存储空间,需要其能够像多个磁盘阵列中存储、读取数据文件。如此不仅可以实现磁盘之间的负载均衡,提高文件访问的效率;而且不同磁盘阵列之间还可以实现数据的冗余校验,提高数据的安全性。此时就可以通过基于主机的虚拟化存储应用。另外,如果企业现在的磁盘阵列是异构的,即磁盘阵列是不同的类型或者所采用的存储介质是不同的,这个模型也支持。支持异构的存储介质正式虚拟化存储应用的一大特色。
16 |
17 | ## 三、基于主机的虚拟化存储实现方式及注意事项。
18 |
19 | 从上面第一点的分析中可以看出,基于主机的虚拟化存储技术其核心就是位于第三层的“虚拟化存储技术管理软件”。在现实应用中,这个软件通常是有操作系统下的逻辑卷管理软件来实现。如Windows操作系统下面的自动卷管理软件。此外现在市场上也有了独立的虚拟卷管理软件,如IBM 的Tivloli等等。不过从笔者的经验来看,还是采用操作系统自带的卷管理软件为好。在兼容性、性能上面都比较优越,而且还是免费的。通过这些软件可以在操作系统与存储设备之间建立一个虚拟层。通过这个虚拟层,可以将存储设备组成逻辑磁盘与逻辑卷。
20 |
21 | 从功能上来说,这个逻辑卷跟Windows操作系统下的动态硬盘很类似。动态硬盘技术就是将一块硬盘分割成多个逻辑卷。而采用逻辑卷的最大好处就在于磁盘容量的管理。如可以不用格式化,就可以调整各个逻辑卷的大小。不过如果光用动态磁盘技术的话,只能够组合一块硬盘。如果想要将多块硬盘组合成一块逻辑磁盘,那么还需要其他技术,如磁盘阵列或者虚拟化存储管理软件的在支持。如果单从逻辑卷的管理上,就跟动态磁盘很类似。
22 |
23 | 在部署基于主机的虚拟化存储应用的时候,主要是要考虑磁盘的空间规划。虽然每个逻辑卷的大小可以动态的调整,但是需要注意的是,由于主机空间的限制,没有足够大的空间来放置很多硬盘,故对于存储空间的总量需要预先规划。然后再根据后续的需要,来调整各个逻辑卷的大小。另外需要注意的是,由于基于主机的虚拟化存储应用其自身的实现方法决定了在性能上要比其他应用模型要差一点。对于这个问题笔者在下面会详细的阐述。这里先跟用户提一个醒。对于性能要求特别高或者用户并发访问数量特别多的企业,可能不适合这个方案。因为性能跟不上。
24 |
25 | ## 四、基于主机的虚拟化存储优劣分析。
26 |
27 | 基于主机的虚拟化存储其优点笔者认为主要有三方面,分别为投资成本低、稳定性高、支持异构的存储系统。现在大部分操作系统,如Windows或者Linux等常见的主机服务器系统,都自带有卷管理软件。也就是说,如果企业要实现基于主机的虚拟化存储应用,基本上不需要额外的购买商业软件。利用操作系统自带的软件就可以实现。所以相比购买那些商业的虚拟化存储产品,部署成本要低的多。其次虚拟层与文件系统都处于主机服务器上,两者紧密结合,不仅可以实现存储容量的灵活管理,而且逻辑卷和文件系统都可以在不停机的情况下(跟动态磁盘技术类似)对其容量进行动态的调整。故其稳定性比较高。支持异构的存储系统就不用多说了,这是虚拟化存储的最大特点之一。
28 |
29 | 不过虽然基于主机的虚拟化存储有以上提到的三大优点,不过其也有致命伤。其中最大的致命伤就在于性能。与其他虚拟化技术相比,如于基于存储设备的虚拟化存储应用相比,这个基于主机的虚拟化存储应用在性能上表现不是很好。这是这个模型的先天性缺陷,很难克服。这个性能的不佳主要是有两个原因造成的。一是虚拟卷管理软件与主机部署在一起,会占用主机服务器的资源,故会影响整台主机服务器的运行性能。虽然可以通过提高整台服务器的硬件性能来消除这个负面影响,但是往往这个投资成本比较高。有时候投资成本甚至比“基于存储设备的虚拟化存储应用”还要高出许多。二是这个模型是基于文件系统实现的,也就是说文件系统与虚拟层紧密的结合在一起。这带来了两面性。如上所示,一方面这两者紧密结合,方便了逻辑卷容量的管理,提高了这个应用模型的灵活性。另一方面,在性能上打了折扣。众所周知,基于特定文件系统的虚拟化应用在性能上表现的并不是很理想。与基于裸机的虚拟化应用相比,性能要逊色一点。
30 |
31 | 由于这些缺陷是基于主机的虚拟化存储应用模型的先天性缺陷,很难通过其他技术来解决,或者说不值得这么做。这也在很大程度上限制了这个模型的应用范围。一般来说,如果企业对于存储的性能要求比较高,或者用户数量比较多。如基于互联网的邮箱系统(像163等提供邮件服务的机构),就不适合采用这个模型。但是如果用户比较少,如一般企业内部自用的邮箱服务器,则这个基于主机的虚拟化存储应用模型在性能上已经可以满足企业的需求了。
32 |
33 | 总之,在使用这个基于主机的虚拟化存储应用模型的时候,要扬长避短。在合时的场合使用这个虚拟化存储模型,往往可以提到事半功倍的作用。
34 |
--------------------------------------------------------------------------------
/virtualization_type/storage_virtualization/带内虚拟化和带外虚拟化.md:
--------------------------------------------------------------------------------
1 | # 带内虚拟化和带外虚拟化
2 |
3 | 所谓带内即In Band,是指控制信令和数据走的是同一条路线。所谓控制信令,就是说用来控制实际数据流向和行为的数据。典型的控制信 令,比如IP网络中的各种IP路由协议所产生的数据包,它们利用实际数据线路进行传输,从而达到各个设备之间的路由统一,这就是带内的概 念。
4 |
5 | 带外即Out Band,是指控制信令和实际数据走的不是同一条路,控制信令走单独的通路,受到“优待”。 带内和带外,只是一种叫法而已,在电话信令中,带内和带外是用“共路”和“随路”这两个词来描述的。共路信令指的是控制信令和实际数据
6 |
7 | 走相同的线路;随路信令则指二者走不同的线路,信令单独走一条线路。随路又可以称作“旁路”,因为它是单独一条路。 明白了上面这些概念,用户就可以理解所谓“带内虚拟化”和“带外虚拟化”的概念了。 带内虚拟化,就是说进行虚拟化动作的设备,是直接横插在发起者和目标路径之间的,斩断了二者之间的通路,执行中介操作,发起者看
8 |
9 | 不到目标,而只能看到经过虚拟化的虚拟目标。所以在带内虚拟化方式下,数据流一定会经过路径上的所有设备,即所有设备是串联在同一条 路径上的,虚拟化设备插入这条路径中,作为一个“泵”,经过它的时候就被虚拟化了。
10 |
11 | 带外虚拟化,则是在这个路径旁另起一条路径,也就是所谓旁路。用这条路径来走控制信号,而实际数据还是由发起者直接走向目标。但 是这些数据流是受控制信令所控制的,也就是发起者必须先“咨询”旁路上的虚拟化设备,经过“提示”或者“授权”之后,才可以根据虚拟化设备发 来的“指示”直接向目标请求数据。带外虚拟化方式中,数据通路和信令通路是并联的。
12 |
13 | 带内虚拟化的例子非常多,目前的虚拟化引擎几乎都是带内虚拟化。IBM的SVC(San Volume Controller)、Netapp的V-series、HDS公司 的USP系列等,它们都是带内虚拟化引擎。
14 |
15 | ## 带外虚拟化系统 SanFS
16 |
17 | 带外虚拟化的一个典型的例子,是IBM公司的SanFS系统。图14-2显示了SanFS的基本架构。
18 |
19 | SanFS其实根本没有什么高深的地方,说白了,SanFS就是一个网络上的文件系统,也就是说,常规的文件系统都是运行在主机服务器上 的,而SanFS将它搬到了网络上,用一台专门的设备来处理文件系统逻辑。
20 |
21 | 然而,这个“网络上的文件系统”却绝对不是“网络文件系统”。网络文件系统是典型的带内虚拟化方式,因为网络文件系统对上层屏蔽了底层 卷,只给上层提供一个目录访问接口,上层看不到网络文件系统底层的卷,只能看到目录。而SanFS架构中,上层既能看到文件系统目录,又 能看到底层卷(LUN),如图1所示。
22 |
23 |
24 |
25 | 图1中,左边的服务器是一台普通的服务器,右边是一台使用SanFS文件系统的服务器。右边的服务器上的文件系统已经被搬到了外 面,即运行在一台SanFS控制器上,这个控制器与服务器都接入一台以太网交换机。当虚拟目录层需要与文件系统层通信的时候,通信路径不 再是内存,而是以太网了。由于文件系统已经被搬出主机,所以任何与文件系统的通信都要被重定向到外部,并且需要用特定的格式,将请求 通过以太网发送到SanFS控制器,以及从控制器接受相应的回应,所以在使用SanFS的服务器主机上,必须安装SanFS管理软件(或者叫做 SanFS代理)。
26 |
27 | 下面用几个实例来说明SanFS是如何作用的。 实例 1
28 |
29 | 服务器运行Windows 2003操作系统,使用SanFS作为文件系统的卷的盘符为“S”盘。在Windows中双击盘符S,此时VFS虚拟目录层便会发 起与SanFS控制器的通信,因为需要获取盘符S根目录下的文件和目录列表。所以VFS调用SanFS代理程序,通过以太网络向SanFS控制器发 送请求,请求S根目录的文件列表,SanFS控制器收到请求之后,将列表通过以太网发送给SanFS代理,代理再传递给VFS,随即就可以在窗 口中看到文件和目录列表了。
30 |
31 |
32 | ## 实例 1.1
33 |
34 | 某时刻,某应用程序要向S盘根目录下写入一个大小为1MB的文件。VFS收到这个请求之后,立即向SanFS控制器发送请求,SanFS控制 器收到请求之后,计算出应该使用卷上的哪些空闲块,将这些空闲块的LBA号码列表以及一些其他必要信息通过以太网传送到服务器。服务器 上的SanFS收到这些信息后,便调用操作系统相关模块,将应用的数据从服务器的内存中直接向下写入对应卷的LBA地址上。
35 |
36 | SanFS系统是一个典型的带外虚拟化系统,服务器主机虽然可以看到底层卷,但是管理这个卷的文件系统,却没有运行在主机上,而是运 行在主机之外。主机与这个文件系统之间通过前端以太网通信,收到文件系统的指示之后,主机才按照指示将数据直接写入卷。
37 |
38 | SanFS究竟有何意义呢?SanFS是不是有点多此一举呢?放着主机内存这么好的风水宝地不用,却自己跑出去单独运行,和别人通信还得 忍受以太网的低速度(相对内存来说),这是何苦呢?煞费苦心的SanFS当然有自己的算盘,这么做的原因如下。
39 |
40 | 将文件系统逻辑从主机中剥离出来,降低主机的负担。 既然将文件系统从主机剥离出来,为何不干脆做成NAS呢?NAS同样也是将文件系统搬移出主机。答案是因为向NAS传输数据,走的是以
41 |
42 | 太网,速度相对FC SAN要慢。所以SanFS的设计是只有元数据的数据流走以太网,实际数据依然由主机自行通过SAN网络写入盘阵等存储设 备。这样就加快了数据的传输速度,比NAS有优势。
43 |
44 | 其实SanFS一个最大的特点,就是支持多台主机共享同一个卷,即同一时刻可以由多台主机共同读写(注意是读写)同一个SanFS卷。这 也是SanFS最大的卖点。共享同一个LUN的所有主机,都与SanFS控制器通信以获得访问权限,所以SanFS干脆就自己单独占用一台专用设 备,放在网络上,也就是SanFS控制器,这样可以让所有主机方便地与它连接。
45 |
46 |
47 | ## 2 SanFS与 NAS的异同
48 |
49 | SanFS与网络文件系统究竟有何不同呢
50 |
51 |
52 | 显然,NAS(网络文件系统)与SanFS是截然不同的。主机向NAS写入数据,其实要经历两次写的过程,第一次写是主机将数据通过以太 网发送给NAS的时候,第二次写是NAS将收到的数据写入自己的硬盘(本地磁盘或者SAN上的LUN卷)。而SanFS只写入一次数据,而且是通 过FC SAN,而不是相对慢速的以太网。
53 |
54 |
55 | ## 3 轮回和嵌套虚拟化
56 |
57 | 以太网在传统上是用来承载IP的,但是有一些技术是将以太网承载到IP之上的,比如VPLS。VPLS属于一种极端**的协议杂交方式。它 嵌套了多次,也轮回了多次。
58 |
59 | VPLS可以说是对以太网VLAN技术的一种上层扩展。传统VLAN使用VLAN标签来区分不同的域,VPLS则可以直接通过用不同的IP来封装 以太网头来区分各个以太网域。
60 |
61 | 这个技术也从一个侧面表明了TCP/IP在当今网络通信领域所不可动摇的绝对地位。
62 |
--------------------------------------------------------------------------------
/virtualization_type/storage_virtualization/文件系统虚拟化解决方案.md:
--------------------------------------------------------------------------------
1 | # Enigma Virtual Box - 文件系统虚拟化解决方案
2 |
3 | Enigma Virtual Box是软件虚拟化工具,它可以将多个文件封装到应用程序主文件,从而制作成为单执行文件exe
4 |
5 | 下载地址:https://enigmaprotector.com/en/downloads.html
6 |
7 | 
8 |
9 | 操作流程:
10 |
11 | ①选择需封包的exe程序,并设置封包后单个exe文件的路径和名称
12 | 
13 |
14 | ②添加执行的相关依赖库,请确保依赖库完整
15 |
16 | 
17 |
18 | ③ 点击OK,再运点击Process运行
19 |
20 | 
21 |
22 | 则在输出目录可以看到单个可执行exe文件。
23 |
24 | (如有必要,可先对程序进行混淆,再打包)
25 |
--------------------------------------------------------------------------------
/virtualization_type/storage_virtualization/磁盘虚拟化.md:
--------------------------------------------------------------------------------
1 | # 磁盘虚拟化
2 |
3 | ## 1 磁盘虚拟化简介
4 | QEMU-KVM 提供磁盘虚拟化,从虚拟机角度看其自身拥有的磁盘即是实际的物理磁盘。实际上,虚拟机读写的磁盘数据保存在 host 上的物理磁盘。
5 | QEMU-KVM 主要有如下几种方式虚拟磁盘:
6 | * 本地存储虚拟机镜像文件。
7 | * host 上物理磁盘或磁盘分区。
8 | * LVM(Logical Volume Management),逻辑分区。
9 | * NFS(Network File System),网络文件系统。
10 | * GFS(Gluster File System),分布式文件系统。
11 |
12 | ## 2 磁盘虚拟化配置
13 | 本节针对常用的虚拟磁盘方式进行介绍,包括本地存储虚拟机镜像文件和 LVM 逻辑分区:
14 |
15 | ### 2.1 本地存储镜像
16 | 本地存储镜像文件,首先需要在本地创建镜像文件,然后指定本地镜像文件为虚拟机的磁盘。
17 | 通过 qemu-img 命令创建镜像文件,qemu-img 是编译安装完 QEMU 即默认自带的软件程序,常用的 qemu-img 选项有 create 和 info,create 用来创建镜像 img,info 用来查看镜像信息:
18 |
19 | ```C
20 | [lianhua@host ~]$ time qemu-img create -f raw lianhua_demo.img -o preallocation=off 10G
21 | Formatting 'lianhua_demo.img', fmt=raw size=10737418240 preallocation=off
22 |
23 | real 0m0.040s
24 | user 0m0.015s
25 | sys 0m0.015s
26 |
27 | [lianhua@host ~]$ qemu-img info lianhua_demo.img
28 | image: lianhua_demo.img
29 | file format: raw
30 | virtual size: 10G (10737418240 bytes)
31 | disk size: 0
32 | ```
33 |
34 | 如上所示,创建了一个名为 lianhua_demo.img 的格式为 raw 的镜像,该镜像大小为 10G。但是,使用 info 查看镜像信息时,镜像的实际大小为 0(disk size)。这是由于 raw 格式的镜像可以指定自己为稀疏文件,如果是稀疏文件,那么只在写数据到镜像的时候才会真正为其分配空间。
35 |
36 | qemu-img 的 preallocation 选项可以指定是否预分配空间,它有三个值,off/full 和 falloc。off 表示禁止预分配空间;full 表示为镜像预分配空间,预分配的方式是给镜像逐字节写 0;falloc 表示预分配磁盘空间给镜像文件,但不往镜像文件中写数据。比较上述三种分配方式,如下:
37 |
38 | ```C
39 | [lianhua@host ~]$ time qemu-img create -f raw lianhua_demo_full.img -o preallocation=full 10G
40 | Formatting 'lianhua_demo_on.img', fmt=raw size=10737418240 preallocation=full
41 |
42 | real 0m22.955s
43 | user 0m0.013s
44 | sys 0m8.930s
45 | [lianhua@host ~]$ time qemu-img create -f raw lianhua_demo_falloc.img -o preallocation=falloc 10G
46 | Formatting 'lianhua_demo_falloc.img', fmt=raw size=10737418240 preallocation=falloc
47 |
48 | real 0m8.256s
49 | user 0m0.008s
50 | sys 0m8.114s
51 |
52 | [lianhua@host ~]$ du -h lianhua_demo*.img
53 | 11G lianhua_demo_falloc.img
54 | 0 lianhua_demo.img
55 | 11G lianhua_demo_full.img
56 | ```
57 |
58 | 镜像格式有多种,除了 raw 外,还有常用的磁盘格式 qcow2,vdi 等。
59 | 镜像分配完磁盘空间后,使用 qemu-kvm 创建虚拟机,并且将镜像文件作为虚拟机的磁盘,命令如下:
60 |
61 | ```C
62 | [lianhua@host ~]$ /usr/libexec/qemu-kvm -m 1024 -smp 2 -hda lianhua_demo_falloc.img -monitor stdio
63 | WARNING: Image format was not specified for 'lianhua_demo_falloc.img' and probing guessed raw.
64 | Automatically detecting the format is dangerous for raw images, write operations on block 0 will be restricted.
65 | Specify the 'raw' format explicitly to remove the restrictions.
66 | QEMU 2.6.0 monitor - type 'help' for more information
67 | (qemu) VNC server running on '::1;5900'
68 |
69 | (qemu) info pci
70 | Bus 0, device 0, function 0:
71 | Host bridge: PCI device 8086:1237
72 | id ""
73 | Bus 0, device 1, function 1:
74 | IDE controller: PCI device 8086:7010
75 | BAR4: I/O at 0xc040 [0xc04f].
76 | id ""
77 | Bus 0, device 1, function 3:
78 | Bridge: PCI device 8086:7113
79 | IRQ 9.
80 | id ""
81 | Bus 0, device 3, function 0:
82 | Ethernet controller: PCI device 8086:100e
83 | IRQ 11.
84 | BAR0: 32 bit memory at 0xfebc0000 [0xfebdffff].
85 | BAR1: I/O at 0xc000 [0xc03f].
86 | BAR6: 32 bit memory at 0xffffffffffffffff [0x0003fffe].
87 | id ""
88 | ```
89 |
90 | 可以看出,镜像在虚拟机中的 pci 号为 00:01:1,且该设备为 IDE 设备。qemu-kvm 的 -hda 选项将镜像文件作为虚拟机的第一个 IDE 设备,在虚拟机中表现为 /dev/hda 设备或 /dev/sda 设备(驱动不同,表现的设备名称不同),更多磁盘选项配置可以查看 qemu-kvm 的 man 文档。
91 |
92 | ### 2.2 LVM 逻辑分区
93 | LVM 逻辑分区,首先需要使用 LVM 创建 volume,然后将此 volume attach 到虚拟机上作为虚拟机的磁盘。
94 |
95 | 在 OpenStack 平台上创建 LVM volume,如下:
96 | ```C
97 | [root@host ~]# pvdisplay
98 | --- Physical volume ---
99 | PV Name /dev/loop2
100 | VG Name cinder-volumes
101 | PV Size 602.34 GiB / not usable 4.00 MiB
102 | Allocatable yes
103 | PE Size 4.00 MiB
104 | Total PE 154199
105 | Free PE 146519
106 | Allocated PE 7680
107 | PV UUID pTkQ5Z-zNdc-LRrn-qWAX-13D6-bhbG-DdcGFD
108 |
109 | [root@host ~]# vgdisplay
110 | --- Volume group ---
111 | VG Name cinder-volumes
112 | System ID
113 | Format lvm2
114 | Metadata Areas 1
115 | Metadata Sequence No 1447
116 | VG Access read/write
117 | VG Status resizable
118 | MAX LV 0
119 | Cur LV 2
120 | Open LV 2
121 | Max PV 0
122 | Cur PV 1
123 | Act PV 1
124 | VG Size 602.34 GiB
125 | PE Size 4.00 MiB
126 | Total PE 154199
127 | Alloc PE / Size 7680 / 30.00 GiB
128 | Free PE / Size 146519 / 572.34 GiB
129 | VG UUID Mrrh1r-qKQw-bCgW-0WXi-d5Bd-OiVV-cTBrg5
130 |
131 | [root@host ~]# lvdisplay
132 | --- Logical volume ---
133 | LV Path /dev/cinder-volumes/volume-c34555f0-fd26-42fe-a3b2-86098b590be2
134 | LV Name volume-c34555f0-fd26-42fe-a3b2-86098b590be2
135 | VG Name cinder-volumes
136 | LV UUID n81Af6-cWEe-LvAm-wjA3-vgKD-RxgV-qMtIq6
137 | LV Write Access read/write
138 | LV Creation host, time host.localdomain, 2020-08-02 00:47:30 +0800
139 | LV Status available
140 | # open 1
141 | LV Size 26.00 GiB
142 | Current LE 6656
143 | Segments 1
144 | Allocation inherit
145 | Read ahead sectors auto
146 | - currently set to 8192
147 | Block device 253:0
148 | ```
149 |
150 | (看这里详细了解 LVM)
151 |
152 | volume 创建成功后将 volume attach 到虚拟机上作为虚拟机的磁盘:
153 | ```C
154 | [root@host ~]# openstack volume list
155 | +--------------------------------------+--------------------------------------------+--------+------+---------------------------------------------+
156 | | ID | Display Name | Status | Size | Attached to |
157 | +--------------------------------------+--------------------------------------------+--------+------+---------------------------------------------+
158 | | c34555f0-fd26-42fe-a3b2-86098b590be2 | lianhua-vm1-vol | in-use | 26 | Attached to lianhua-vm1-vol on /dev/vdb |
159 | +--------------------------------------+--------------------------------------------+--------+------+---------------------------------------------+
160 | ```
161 |
162 | volume attach 到虚拟机上,在虚拟机中的磁盘设备名为 /dev/vdb。进入虚拟机,查看该磁盘设备的详细信息:
163 | ```C
164 | [root@lianhua-vm1:/home/robot]
165 | # fdisk -l | grep vdb
166 | Disk /dev/vdb: 26 GiB, 27917287424 bytes, 54525952 sectors
167 |
168 | [root@lianhua-vm1:/home/robot]
169 | # lspci
170 | ...
171 | 00:0b.0 SCSI storage controller: Red Hat, Inc. Virtio block device
172 |
173 | [root@lianhua-vm1:/home/robot]
174 | # lspci -s 00:0b.0 -vvv
175 | 00:0b.0 SCSI storage controller: Red Hat, Inc. Virtio block device
176 | Subsystem: Red Hat, Inc. Device 0002
177 | Physical Slot: 11
178 | Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+
179 | Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- SERR-
189 | BAR=0 offset=00000000 size=00000000
190 | Capabilities: [70] Vendor Specific Information: VirtIO: Notify
191 | BAR=4 offset=00003000 size=00001000 multiplier=00000004
192 | Capabilities: [60] Vendor Specific Information: VirtIO: DeviceCfg
193 | BAR=4 offset=00002000 size=00001000
194 | Capabilities: [50] Vendor Specific Information: VirtIO: ISR
195 | BAR=4 offset=00001000 size=00001000
196 | Capabilities: [40] Vendor Specific Information: VirtIO: CommonCfg
197 | BAR=4 offset=00000000 size=00001000
198 | Kernel driver in use: virtio-pci
199 | ```
200 |
201 | 不同于 -hda 指定的磁盘设备,这里的磁盘设备名以 vd 开头,这是因为它们是通过 virtio 半虚拟化方式分配的磁盘设备,从上例可以看出磁盘设备 vdb 的 pci 号为 00:0b:0,其使用的驱动为 virtio-pci。
202 |
203 | 在 libvirt XML 文件的 devices 标签下定义 disk, 实现使用 virtio 半虚拟化方式分配磁盘设备:
204 |
205 | ```C
206 |
207 |
208 |
209 |
210 | c34555f0-fd26-42fe-a3b2-86098b590be2
211 |
212 |
213 |
214 | 同理,也可以在 qemu-kvm 的 device 和 drive 选项下指定 virtio-blk-pci 参数实现 virtio 半虚拟化方式分配磁盘设备:
215 |
216 | ```C
217 | [root@host 2177d777-2a46-4e5b-ac92-ba7ad27e21a3]# /usr/libexec/qemu-kvm -m 1024 -smp 2 -device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x6,drive=drive-virtio-disk0,id=virtio-disk0,bootindex=1 -drive file=/var/lib/nova/instances/2177d777-2a46-4e5b-ac92-ba7ad27e21a3/disk.config,format=raw,if=none,id=drive-ide0-0-0,readonly=on,cache=none -monitor stdio
218 | ```
219 |
220 | ## 3 磁盘虚拟化环境部署
221 | 根据上两节的描述,部署一个简单的环境实现磁盘虚拟化及磁盘文件共享,部署环境如下:
222 | * 使用 virtio 半虚拟化方式指定镜像文件实现磁盘虚拟化,虚拟出的磁盘设备名为 vda。
223 | * 使用 virtio 半虚拟化方式指定 volume 实现磁盘虚拟化,虚拟出的磁盘设备名为 vdb。
224 | * 在虚拟机内部使用 LVM 分割磁盘设备 vdb 为 lv volume,并将 volume 指定为文件系统。
225 | * 使用 NFS 方式共享虚拟机的文件系统。
226 |
227 | 示意图如下:
228 | 
229 |
230 | 1) 查看 virtio 的 libvirt XML 配置:
231 |
232 | ```C
233 |
234 | /usr/libexec/qemu-kvm
235 |
236 |
237 |
238 |
239 |
240 |
241 |
242 |
243 |
244 |
245 | c34555f0-fd26-42fe-a3b2-86098b590be2
246 |
247 |
248 |
249 |
250 | vda 磁盘设备所使用的镜像文件为 /var/lib/nova/instances/2177d777-2a46-4e5b-ac92-ba7ad27e21a3/disk,它在虚拟机的磁盘设备名为 /dev/vda,且 pci 号为 00:06:0。
251 | 使用 qemu-info 查看 disk 镜像文件:
252 | ```
253 |
254 | ```C
255 | [root@host 2177d777-2a46-4e5b-ac92-ba7ad27e21a3]# qemu-img info disk
256 | image: disk
257 | file format: qcow2
258 | virtual size: 40G (42949672960 bytes)
259 | disk size: 1.7G
260 | cluster_size: 65536
261 | backing file: /var/lib/nova/instances/_base/52968ae0bfbfeef835844ee0b97be5e45d382e4c
262 | Format specific information:
263 | compat: 1.1
264 | lazy refcounts: false
265 | refcount bits: 16
266 | corrupt: false
267 | ```
268 |
269 | 可以看出,disk 分配的虚拟磁盘容量为 40G,而它现在占的磁盘空间是 1.7G。
270 |
271 | vdb 为 volume 分配的磁盘设备,在虚拟机中的磁盘设备名为 /dev/vdb,且 pci 号为 00:0b:0。
272 |
273 | 进入虚拟机查看磁盘设备是否分配:
274 |
275 | ```C
276 | [root@lianhua-vm1:/home/robot]
277 | # fdisk -l | grep vd
278 | Disk /dev/vda: 40 GiB, 42949672960 bytes, 83886080 sectors # 这里 vda 的磁盘容量为 40G
279 | /dev/vda1 * 2048 83886046 83883999 40G 83 Linux
280 | Disk /dev/vdb: 26 GiB, 27917287424 bytes, 54525952 sectors
281 |
282 | [root@lianhua-vm1:/home/robot]
283 | # lspci | grep block
284 | 00:06.0 SCSI storage controller: Red Hat, Inc. Virtio block device
285 | 00:0b.0 SCSI storage controller: Red Hat, Inc. Virtio block device
286 | ```
287 |
288 | 虚拟机中成功分配磁盘设备,且从 vda 中分出磁盘分区 vda1 给操作系统的文件系统使用。
289 |
290 | 2) 查看虚拟机内磁盘设备 vdb 分割的 lv volume:
291 | ```C
292 | [root@lianhua-vm1:/home/robot]
293 | # pvdisplay
294 | --- Physical volume ---
295 | PV Name /dev/vdb
296 | VG Name lianhua-vm1-vol
297 | PV Size 26.00 GiB / not usable 4.00 MiB
298 | Allocatable yes
299 | PE Size 4.00 MiB
300 | Total PE 6655
301 | Free PE 1405
302 | Allocated PE 5250
303 | PV UUID OqdKmO-PspN-0ZKe-M0l4-0vGD-cY7k-VjZvTJ
304 |
305 | [root@lianhua-vm1:/home/robot]
306 | # vgdisplay
307 | --- Volume group ---
308 | VG Name lianhua-vm1-vol
309 | System ID
310 | Format lvm2
311 | Metadata Areas 1
312 | Metadata Sequence No 7
313 | VG Access read/write
314 | VG Status resizable
315 | MAX LV 0
316 | Cur LV 6
317 | Open LV 6
318 | Max PV 0
319 | Cur PV 1
320 | Act PV 1
321 | VG Size <26.00 GiB
322 | PE Size 4.00 MiB
323 | Total PE 6655
324 | Alloc PE / Size 5250 / <20.51 GiB
325 | Free PE / Size 1405 / <5.49 GiB
326 | VG UUID JcVrao-YnJ7-mRpK-8Rxc-i07i-WVH4-aVgAoD
327 |
328 | [root@lianhua-vm1:/home/robot]
329 | # lvdisplay
330 | --- Logical volume ---
331 | LV Path /dev/lianhua-vm1-vol/provider_sys
332 | LV Name provider_sys
333 | VG Name lianhua-vm1-vol
334 | LV UUID C6byt7-5cby-h2RT-xcLg-OJU0-Qq1E-27G6jB
335 | LV Write Access read/write
336 | LV Creation host, time lianhua-vm1, 2020-08-02 00:50:11 +0800
337 | LV Status available
338 | # open 1
339 | LV Size <9.77 GiB
340 | Current LE 2500
341 | Segments 1
342 | Allocation inherit
343 | Read ahead sectors auto
344 | - currently set to 256
345 | Block device 252:0
346 |
347 | --- Logical volume ---
348 | LV Path /dev/lianhua-vm1-vol/provider_lianhua
349 | LV Name provider_lianhua
350 | VG Name lianhua-vm1-vol
351 | LV UUID vfeZg8-PKVR-kKxv-yidf-rQqp-A7De-CvXqws
352 | LV Write Access read/write
353 | LV Creation host, time lianhua-vm1, 2020-08-02 00:50:11 +0800
354 | LV Status available
355 | # open 1
356 | LV Size 4.88 GiB
357 | Current LE 1250
358 | Segments 1
359 | Allocation inherit
360 | Read ahead sectors auto
361 | - currently set to 256
362 | Block device 252:1
363 |
364 | --- Logical volume ---
365 | LV Path /dev/lianhua-vm1-vol/provider_log
366 | LV Name provider_log
367 | VG Name lianhua-vm1-vol
368 | LV UUID mHdD60-QjSy-sRlz-GLmK-CFIM-l42c-QGthXa
369 | LV Write Access read/write
370 | LV Creation host, time lianhua-vm1, 2020-08-02 00:50:12 +0800
371 | LV Status available
372 | # open 1
373 | LV Size 1000.00 MiB
374 | Current LE 250
375 | Segments 1
376 | Allocation inherit
377 | Read ahead sectors auto
378 | - currently set to 256
379 | Block device 252:2
380 | ```
381 |
382 | 3) 指定 lv 的文件系统为 log/sys/lianhua,并且通过 NFS 的方式共享文件系统:
383 |
384 | ```C
385 | [root@lianhua-vm1:/home/robot]
386 | # df -h
387 | Filesystem Size Used Avail Use% Mounted on
388 | /dev/vda1 40G 7.0G 31G 19% /
389 | /dev/mapper/lianhua-vm1-vol-provider_sys 9.1G 37M 8.6G 1% /mnt/sys
390 | /dev/mapper/lianhua-vm1-vol-provider_lianhua 4.6G 20M 4.3G 1% /mnt/lianhua
391 | /dev/mapper/lianhua-vm1-vol-provider_log 922M 18M 838M 3% /mnt/log
392 | ```
393 |
394 | (看这里详细了解 NFS)
395 |
396 | 进入 VM2 查看文件系统是否共享成功:
397 |
398 | ```C
399 | [root@lianhua-vm2:/mnt/log]
400 | # ls
401 | [root@lianhua-vm2:/mnt/log]
402 | # mkdir lianhua
403 | [root@lianhua-vm2:/mnt/log]
404 | # ls
405 | lianhua
406 |
407 | [root@lianhua-vm1:/mnt/log]
408 | # ls
409 | lianhua
410 | ```
411 |
412 | 文件共享成功,环境部署完毕。
413 |
414 |
415 | 原文作者: 乱舞春秋
416 |
--------------------------------------------------------------------------------
/virtualization_type/storage_virtualization/详解存储子系统的虚拟化.md:
--------------------------------------------------------------------------------
1 | # 详解存储子系统的虚拟化
2 |
3 | 随着存储虚拟化技术的越发成熟,存储虚拟化在企业中的应用越来越广。下面我们来介绍一下与存储虚拟化关系最近的计算机的存储子系统的虚拟化,看看存储子系统是怎么抽象虚拟的。
4 | 存储子系统的元素包括:磁盘、磁盘控制器、存储网络、磁盘阵列、卷管理层、目录虚拟层。具体看下面详细介绍。
5 |
6 | 1. 的虚拟化
7 | 磁盘控制器的工作就是根据驱动程序发来的磁盘读写信息,向磁盘发送scsi指令和数据。这个不减的虚拟化是大家最常用的虚拟化方式,raid就是典型代表,控制器将磁盘组成raid阵列模式,在此基础上,虚拟出多了lun ,通告给主机驱动。
8 |
9 | 2. 存储网络的虚拟化
10 | 目前存储系统,网络化已经非常彻底,从磁盘到磁盘控制器,从磁盘阵控制器到主机总线适配器,都已经潜入了网络化元素。网络的虚拟化,并不只是镜像,比如某些n节点的lun合并成一个池,然后动态的从这个池中再划分出虚拟lun,向发起者报告等。
11 |
12 | 3. 虚拟化
13 | 磁盘阵列简单的说就是将大量磁盘进行组织管理,抽象虚拟,最终形成虚拟的逻辑磁盘,最后通过和主机适配器通信,将这些逻辑磁盘呈现给主机。
14 |
15 | 4. 文件系统
16 | 文件系统是对磁盘块的虚拟、抽象、组织和管理。用户只要访问一个个的文件,就等于访问了磁盘扇区。
17 |
18 | 5. 卷管理器
19 | 卷管理器是指运行在应用主机上的功能模块。负责底层物理磁盘或者lun的收集和再分配。而经过磁盘阵控制器虚拟化之后生存的lun提交给主机使用,主机可以对这些lun进行再次的抽象和虚拟,也就是通常所说的重复虚拟化。
20 |
21 | 6. 目录虚拟层
22 | 不管是熟悉的windows系统,还是unix系统,还是linux系统,都有一个虚拟目录结构。这个虚拟目录能够增强灵活性,而这样做使用户更容易操作。
23 | 我们上面所描述的子系统的虚拟化只是虚拟存储平台的简单介绍。而为企业虚拟环境规划存储系统是个挑战,尤其是对于拥有独立服务器和存储团队的组织来说更是如此。不过虚拟化所给用户带来的好处和便利却是明显的,虚拟化在不同企业都有很好的应用,也值得企业去进行存储虚拟化。
24 |
--------------------------------------------------------------------------------
/virtualization_type/全虚拟化和半虚拟化.md:
--------------------------------------------------------------------------------
1 | # 全虚拟化和半虚拟化
2 |
3 | ## 1. 完全虚拟化(Full Virtualization) 需要跑在宿主机之上
4 | 全虚拟化也成为原始虚拟化技术,该模型使用虚拟机协调guest操作系统和原始硬件,VMM在guest操作系统和裸硬件之间用于工作协调,一些受保护指令必须由Hypervisor(虚拟机管理程序)来捕获处理。
5 | guest执行特权级操作,只能通过Hypervisor来处理。例如,guest执行 shutdown -h now,这条指令将会被Hypervisor所捕获到,因此不会真正的被CPU执行,而是被Hypervisor协调执行,从而关闭了虚拟机guest,而不是这个物理机上的OS
6 |
7 | 代表作品:Vmware Workstation, KVM
8 |
9 | ## 2:半虚拟化(Para Virtualization)直接跑在硬件之上
10 | 半虚拟化是另一种类似于全虚拟化的技术,它使用Hypervisor分享存取底层的硬件,但是它的guest操作系统集成了虚拟化方面的代码。
11 |
12 | 代表作品:Xen, VMware vSphere,Huawei FusionSphere
13 |
--------------------------------------------------------------------------------
/virtualization_type/虚拟化之四种网络模型.md:
--------------------------------------------------------------------------------
1 | # KVM虚拟化之四种网络模型
2 |
3 | ## 1. 四种网络模型简要说明:
4 | ### 1.1 隔离模型
5 | 该模型的特点是宿主机上的所有虚拟机之间可以组建网络,但是虚拟机无法与宿主机进行通信,也无法与其他网络的主机或其他宿主机上的虚拟机进行通信;相当于将虚拟机只是连接到一个交换机上,而这个交换机是在宿主机上虚拟出来的,即我们通常所说的网桥设备
6 |
7 | ### 1.2 路由模型
8 | 该模型的特点是在隔离模型的基础上,在宿主机开启了ip路由转发功能,此时的宿主机相当于路由器,完成虚拟机与宿主机的数据报文转发。因此,虚拟机可以宿主机的物理网卡进行通信,但是无法与宿主机之外的主机进行通信,因为宿主机没有对源地址转换,报文可以送到外部主机,但是外部主机无法回应。
9 |
10 | ### 1.3 NAT模型
11 | 该模型的特点是当虚拟机需要与外部进行通信时,需要将源IP地址转换为物理网卡的IP地址,这样外部主机接收到报文后可以正确的将响应报文发送给目标IP地址(宿主机的物理网卡IP地址),因此,实现虚拟机与外部的通信;
12 |
13 | 注意:该模型仅仅是实现了源地址转换,实现虚拟机与外部网络的通信,但那是外部网络无法访问虚拟机,如果要实现,则需要在宿主机做目标地址转换。
14 |
15 | ### 1.4 桥接模型
16 | 该模型的特点是通过创建一个虚拟网卡,为该虚拟机网卡分配可以访问外部网络的IP地址;此时的物理网卡相当于一台交换机设备;虚拟机可以分配与外部网络通信的IP地址实现与外部网络的通信;此时,虚拟机相当于宿主机所在的局域网内单独的一台主机,它宿主机的地位是同等的,没有依存关系。
17 |
18 | ## 2. 前期准备
19 | ### 2.1 环境说明
20 | 本次测试在VMware workstation 12版本的虚拟机环境中进行,注意开启cpu虚拟化功能;
21 | 网络适配器使用仅主机模型,共享主机网络的internet。
22 | OS:centos-6.5_x86-64
23 | eth0: 10.241.96.176/24
24 | 采用kvm部署虚拟机,磁盘映像文件使用 cirros-0.3.5-x86_64-disk.img
25 |
26 | ### 2.2 安装qemu-kvm及解决依赖关系
27 | ```C
28 | ## 装载kvm模块:
29 | [root@C65-201 ~]# modprobe kvm
30 | [root@C65-201 ~]# modprobe kvm-intel
31 |
32 | ## 安装qemu-kvm、bridge-utils
33 | [root@C65-201 ~]# yum install qemu-kvm bridge-utils
34 |
35 | ## 确保CPU支持HVM
36 | [root@C65-201 ~]# grep -E --color=auto "(vmx|svm)" /proc/cpuinfo
37 | ```
38 |
39 | ## 3. 隔离模型
40 |
41 | ### 3.1 隔离模型中的虚拟机网络
42 | > 同一宿主机中,虚拟机如何与宿主机中的网桥通信?
43 |
44 | 隔离模型中的虚拟机无法与宿主机的物理网卡通信,但是可以与宿主机中的网桥通信;
45 | 图中VM表示虚拟机,每个虚拟机的网卡包含前半段和后半段;前半段vNIC在虚拟机上,后半段VIF在宿主机上。图中虚拟机中vNIC网卡对应的后半段为VIF网卡,VM虚拟机中发往vNIF网卡的数据报文都会发往后半段网卡VIF;
46 |
47 | > 同一宿主机中,虚拟机如何与虚拟机通信?
48 |
49 | 图中br-in是宿主机上的桥设备,也称之为Virtual Switch或者Bridge;在隔离模型中,相当于一个二层的虚拟交换机,要想实现同一宿主机中的虚拟机互相通信,需要满足几个条件:
50 |
51 | * 1)需要在宿主机中创建一个Bridge,图中为br-in
52 | * 2)需要互相通信的每个虚拟机的前半段IP地址必须在同一网段内;
53 | * 3)需要互相通信的每个虚拟机的后半段网卡VIF网卡设备添加至br-in这个桥设备n桥。
54 |
55 | 注意:如果要实现同网段虚拟机不能通信,即虚拟机之间隔离,则需要创建不同的网桥,并将虚拟机的后半段添加至不同的网桥设备,即可实现隔离。
56 |
57 | > 虚拟机如何与宿主机的物理网卡通信?
58 |
59 | 隔离模型中的虚拟机无法与宿主机的物理网卡通信。
60 |
61 | > 虚拟机如何与外部网络通信?
62 |
63 | 隔离模型中的虚拟机无法与外部进行通信。
64 |
65 | ### 3.2 使用qemu-kvm创建虚拟机并实现隔离模型
66 | #### 3.2.1 创建br-in网桥
67 | ```C
68 | ## 创建网桥
69 | [root@C65-201 ~]# brctl addbr br-in
70 |
71 | ## 查看网桥
72 | [root@C65-201 ~]# brctl show
73 | bridge name bridge id STP enabled interfaces
74 | br-in 8000.000000000000 no
75 |
76 | ## 激活网桥,使之为启动状态
77 | [root@C65-201 ~]# ip link set br-in up
78 | ```
79 |
80 | #### 3.2.2 创建脚本qemu-ifup
81 | 创建虚拟机并启动时,通过qemu-kvm命令的启动参数,添加VM的前半段网卡,后半段网卡指定ifname参数自动创建,但是需要手动激活并且添加至桥br-in中;通常这部分操作由qemu-ifup这额脚本完成。
82 | ```C
83 | [root@kvm ~]# vim /etc/qemu-ifup
84 | #!/bin/bash
85 | BRIDGE=br-in
86 | if [ -n $1 ]; then
87 | ip link set $1 up
88 | sleep 1
89 | brctl addif $BRIDGE $1
90 | [ $? -eq 0 ] && exit 0 || exit 1
91 | else
92 | echo "Error: no interface specified."
93 | exit 1
94 | fi
95 | ```
96 |
97 | 保存后给该脚本添加执行权限并检查语法
98 | ```C
99 | [root@C65-201 ~]# chmod +x /etc/qemu-ifup # 添加执行权限
100 | [root@C65-201 ~]# bash -n /etc/qemu-ifup # 检查语法是否有误
101 | ```
102 |
103 | 当虚拟机停止时,虚拟机网卡的后半段会自动从宿主机中down掉,所以不需要编写down脚本
104 |
105 | #### 3.2.3 创建第一个虚拟机guest01并启动
106 | ```C
107 | ## 创建guest01并启动
108 | [root@C65-201 ~]# qemu-kvm -name guest01 -m 128 -smp 1 --drive file=/images/kvm/guest01.img,if=virtio,media=disk -net nic,model=virtio,macaddr=52:54:00:11:22:aa -net tap,ifname=vif1.0,script=/etc/qemu-ifup -daemonize
109 |
110 | ## 配置guest01的ip地址
111 | # ip addr add 10.0.1.1/24 dev eth0
112 | ```
113 |
114 | #### 3.2.4 创建第二个虚拟机guest02并启动
115 | ```C
116 | ## 创建guest02并启动
117 | [root@C65-201 ~]# qemu-kvm -name guest02 -m 128 -smp 1 --drive file=/images/kvm/guest02.img,if=virtio,media=disk -net nic,model=virtio,macaddr=52:54:00:11:22:bb -net tap,ifname=vif2.0,script=/etc/qemu-ifup -daemonize
118 |
119 | ## 配置guest02的ip地址
120 | # ip addr add 10.0.1.2/24 dev eth0
121 | ```
122 |
123 | #### 3.2.5 通信测试
124 | 在宿主机上查看桥设备,可以看到两台虚拟机的网卡后半段都已经添加至br-in网桥中了
125 |
126 | 
127 |
128 | 测试guest01和guest02之间的通信
129 |
130 | 
131 |
132 | 测试宿主机访问虚拟机
133 |
134 | 
135 |
136 | 根据以上结果,虚拟机与虚拟机之间可以访问,宿主机无法访问虚拟机,实现了隔离模型
137 |
138 | ## 4. 路由模型
139 |
140 | 
141 |
142 | ### 4.1 路由模型模型中的虚拟机网络
143 | > 同一宿主机中,虚拟机如何与宿主机中的网桥通信?
144 |
145 | 路由模型中的虚拟机与宿主机的网桥的通信机制,参考隔离模型
146 |
147 | > 同一宿主机中,虚拟机如何与虚拟机通信?
148 |
149 | 路由模型中的虚拟机与虚拟机的通信机制,参考隔离模型
150 |
151 | > 虚拟机如何与宿主机的物理网卡通信?
152 |
153 | 路由模型中的虚拟机要与宿主机的物理网卡进行通信,要满足以下几个条件:
154 |
155 | * 1) 宿主机必须在内核打开IP转发功能,即net.ipv4.ip_forward = 1;
156 | * 2) 宿主机中的网桥br-in需要添加一个与虚拟机同网段的IP地址;
157 | * 3) 虚拟机需要添加一条路由,下一跳地址设置为网桥br-in的ip;
158 |
159 | > 虚拟机如何与外部网络通信?
160 |
161 | 路由模型中的虚拟机无法与外部进行通信;因为虚拟机发送到外部网络的主机时,源地址内网地址,内网地址无法与外部直接通信,且没有对源地址转换为物理网卡的IP地址,因此,外部网络发送的响应报文中的目标地址为虚拟机的IP地址时,无法到达宿主机的物理网卡,故虚拟机无法收到响应报文。
162 |
163 | ### 4.2 使用qemu-kvm创建虚拟机并实现路由模型
164 | #### 4.2.1 创建脚本qemu-rtup和qemu-rtdown
165 | 创建虚拟机并启动时,通过qemu-kvm命令的启动参数,添加VM的前半段网卡,后半段网卡指定ifname参数自动创建,但是需要手动激活并且添加至桥br-in中;通常这部分操作由qemu-rtup这额脚本完成;关闭虚拟机时由qemu-rtdown完成移除后半段网卡等;
166 | ```C
167 | ## 添加VM的前半段网卡脚本
168 | [root@C65-201 ~]# vim /etc/qemu-rtup
169 | #!/bin/bash
170 | bridge="br-in"
171 | ifaddr=192.168.1.254 # 网桥br-in的IP地址
172 | checkbr() {
173 | if brctl show | grep -i "^$1"; then
174 | return 0
175 | else
176 | return 1
177 | fi
178 | }
179 | initbr() {
180 | brctl addbr $bridge
181 | ip link set $bridge up
182 | ip addr add $ifaddr/24 dev $bridge
183 | }
184 | enable_ip_forward() {
185 | sysctl -w net.ipv4.ip_forward=1
186 | }
187 | setup_rt() {
188 | checkbr $bridge
189 | if [ $? -eq 1 ]; then
190 | initbr
191 | enable_ip_forward
192 | fi
193 | }
194 |
195 | if [ -n "$1" ]; then
196 | setup_rt
197 | ip link set $1 up
198 | brctl addif $bridge $1
199 | exit 0
200 | else
201 | echo "Error: no interface specified."
202 | exit 1
203 | fi
204 |
205 | ## 删除VM的后半段网卡脚本
206 | [root@C65-201 ~]# vim /etc/qemu-rtdown
207 | #!/bin/bash
208 |
209 | bridge="br-in"
210 |
211 | isalone_bridge() {
212 | if ! brctl show | awk "/^$bridge/{print \$4}" | grep "[^[:space:]]" &> /dev/null; then
213 | ip link set $bridge down
214 | brctl delbr $bridge
215 | fi
216 |
217 | }
218 | if [ -n "$1" ];then
219 | ip link set $1 down
220 | brctl delif $bridge $1
221 | isalone_bridge
222 | exit 0
223 | else
224 | echo "Error: no interface specified."
225 | exit 1
226 | fi
227 |
228 | ## 保存后给该脚本添加执行权限并检查语法
229 | [root@C65-201 ~]# chmod +x /etc/{qemu-rtup,qemu-rtdown} # 添加执行权限
230 | [root@C65-201 ~]# bash -n /etc/qemu-rtup # 检查语法是否有误
231 | [root@C65-201 ~]# bash -n /etc/qemu-rtdown # 检查语法是否有误
232 | ```
233 |
234 | #### 4.2.2 创建第一个虚拟机guest01并启动
235 | ```C
236 | ## 创建guest01并启动
237 | [root@C65-201 ~]# qemu-kvm -name guest01 -m 128 -smp 1 --drive file=/images/kvm/guest01.img,if=virtio,media=disk -net nic,model=virtio,macaddr=52:54:00:11:22:aa -net tap,ifname=vif1.0,script=/etc/qemu-rtup,downscript=/etc/qemu-rtdown -daemonize
238 |
239 | ## 在guest01配置其ip地址
240 | # ip addr add 192.168.1.1/24 dev eth0
241 |
242 | ## 给guest01添加路由
243 | # ip route add default via 192.168.1.254
244 | ```
245 |
246 | #### 4.2.3 创建第二个虚拟机guest02并启动
247 | ```C
248 | ## 创建guest02并启动
249 | [root@C65-201 ~]# qemu-kvm -name guest02 -m 128 -smp 1 --drive file=/images/kvm/guest02.img,if=virtio,media=disk -net nic,model=virtio,macaddr=52:54:00:11:22:bb -net tap,ifname=vif2.0,script=/etc/qemu-rtup,downscript=/etc/qemu-rtdown -daemonize
250 |
251 | ## 在guest02配置其ip地址
252 | # ip addr add 192.168.1.2/24 dev eth0
253 |
254 |
255 | ## 给guest02添加路由
256 | # ip route add default via 192.168.1.254
257 | ```
258 |
259 | #### 4.2.4 通信测试
260 | 
261 |
262 | 
263 |
264 | 无法与外部网络的主机进行通信
265 |
266 | 
267 |
268 | 根据以上结果,虚拟机与宿主机之间可以互相访问,但无法与外部网络通信,实现了路由模型
269 |
270 | ## 5. NAT模型
271 |
272 | 
273 |
274 | ### 5.1 NAT模型中的虚拟机网络
275 | NAT模型与路由模型的通信机制基本一致,唯一不同的就是,NAT模型可以使虚拟机直接与外部网络进行通信;即只需要在NAT模型中,在宿主机SNAT地址转换,将虚拟机的源地址IP转换为物理网卡的IP地址,发送报文至外部网络的主机;外部网络的主机收到报文后构建的响应报文的目标IP地址,为宿主机的物理网卡的IP地址,而后宿主机在将报文发送至虚拟机,实现了虚拟机与外部网络的通信。
276 |
277 | ### 5.2 使用qemu-kvm创建虚拟机并实现NAT模型
278 | #### 5.2.1 创建脚本qemu-natup和qemu-natdown
279 | 创建虚拟机并启动时,通过qemu-kvm命令的启动参数,添加VM的前半段网卡,后半段网卡指定ifname参数自动创建,但是需要手动激活并且添加至桥br-in中;通常这部分操作由qemu-natup这额脚本完成;关闭虚拟机时由qemu-natdown完成移除后半段网卡、删除nat规则等;
280 |
281 | ```C
282 | ## 添加脚本
283 | [root@C65-201 ~]# vim /etc/qemu-natup
284 | #!/bin/bash
285 | bridge="br-in"
286 | net="192.168.1.0/24"
287 | ifaddr=192.168.1.254
288 |
289 | checkbr() {
290 | if brctl show | grep -i "^$1"; then
291 | return 0
292 | else
293 | return 1
294 | fi
295 | }
296 |
297 | initbr() {
298 | brctl addbr $bridge
299 | ip link set $bridge up
300 | ip addr add $ifaddr dev $bridge
301 | }
302 |
303 | enable_ip_forward() {
304 | sysctl -w net.ipv4.ip_forward=1
305 | }
306 |
307 | setup_nat() {
308 | checkbr $bridge
309 | if [ $? -eq 1 ]; then
310 | initbr
311 | enable_ip_forward
312 | iptables -t nat -A POSTROUTING -s $net ! -d $net -j MASQUERADE
313 | fi
314 | }
315 |
316 | if [ -n "$1" ]; then
317 | setup_nat
318 | ip link set $1 up
319 | brctl addif $bridge $1
320 | exit 0
321 | else
322 | echo "Error: no interface specified."
323 | exit 1
324 | fi
325 |
326 | ## 删除脚本
327 | [root@C65-201 ~]# vim /etc/qemu-natdown
328 | #!/bin/bash
329 | bridge="br-in"
330 | remove_rule() {
331 | iptables -t nat -F
332 | }
333 |
334 | isalone_bridge() {
335 | if ! brctl show | awk "/^$bridge/{print \$4}" | grep "[^[:space:]]" &> /dev/null; then
336 | ip link set $bridge down
337 | brctl delbr $bridge
338 | remove_rule
339 | fi
340 | }
341 |
342 | if [ -n "$1" ];then
343 | ip link set $1 down
344 | brctl delif $bridge $1
345 | isalone_bridge
346 | exit 0
347 | else
348 | echo "Error: no interface specified."
349 | exit 1
350 | fi
351 |
352 |
353 |
354 | ## 保存后给该脚本添加执行权限并检查语法
355 | [root@C65-201 ~]# chmod +x /etc/{qemu-natup,qemu-natdown} # 添加执行权限
356 | [root@C65-201 ~]# bash -n /etc/qemu-natup # 检查语法是否有误
357 | [root@C65-201 ~]# bash -n /etc/qemu-natdown # 检查语法是否有误
358 | ```
359 |
360 | #### 5.2.2 创建第一个虚拟机guest01并启动
361 | ```C
362 | ## 创建guest01并启动
363 | [root@C65-201 ~]# qemu-kvm -name guest01 -m 128 -smp 1 --drive file=/images/kvm/guest01.img,if=virtio,media=disk -net nic,model=virtio,macaddr=52:54:00:11:22:aa -net tap,ifname=vif1.0,script=/etc/qemu-natup,downscript=/etc/qemu-natdown -daemonize
364 |
365 | ## 在guest01配置其ip地址
366 | # ip addr add 192.168.1.1/24 dev eth0
367 |
368 | ## 给guest01添加路由
369 | # ip route add default via 192.168.1.254
370 | ```
371 |
372 | #### 5.2.3 创建第二个虚拟机guest02并启动
373 | ```C
374 | ## 创建guest02并启动
375 | [root@C65-201 ~]# qemu-kvm -name guest02 -m 128 -smp 1 --drive file=/images/kvm/guest02.img,if=virtio,media=disk -net nic,model=virtio,macaddr=52:54:00:11:22:bb -net tap,ifname=vif2.0,script=/etc/qemu-natup,downscript=/etc/qemu-natdown -daemonize
376 |
377 | ## 在guest02配置其ip地址
378 | # ip addr add 192.168.1.2/24 dev eth0
379 |
380 | ## 给guest02添加路由
381 | # ip route add default via 192.168.1.254
382 | ```
383 |
384 | #### 5.2.4 通信测试
385 |
386 | 
387 |
388 | 
389 |
390 | 
391 |
392 | 根据以上结果,虚拟机与宿主机之间可以互相访问,也可以与外部网络通信,实现了NAT模型
393 |
394 | ## 6. 桥接模型
395 |
396 | 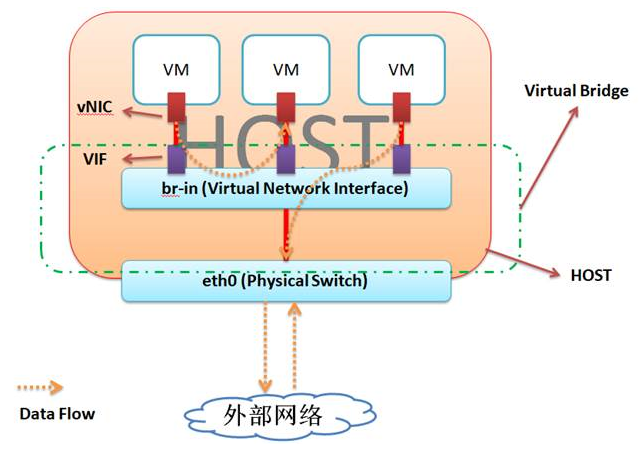
397 |
398 | ### 6.1 桥接模型中的虚拟机网络
399 | #### 桥接模型不同于隔离模型、路由模型和NAT模型;在模型下,宿主机会虚拟出一块网卡作为该宿主机的通信网卡,而宿主机的物理网卡则成为桥接设备(也可称为交换机),此时,虚拟机相当于宿主机所在的局域网内单独的一台主机,它宿主机的地位是同等的,没有依存关系。
400 |
401 | ### 6.2 使用qemu-kvm创建虚拟机并实现桥接模型
402 | #### 6.2.1 创建br-in网桥并将eth0添加至br-in桥
403 |
404 | ```C
405 | ## 为宿主机创建虚拟网卡,并将物理网卡eth0作为桥设备
406 | [root@C65-201 ~]# cd /etc/sysconfig/network-scripts/
407 | [root@C65-201 network-scripts]# cp ifcfg-eth0 ifcfg-br-in
408 |
409 | ##修改br-in
410 | [root@C65-201 network-scripts]# vim ifcfg-br-in
411 | DEVICE=br-in
412 | TYPE=Bridge
413 | ONBOOT=yes
414 | NM_CONTROLLED=yes
415 | BOOTPROTO=static
416 | IPADDR=10.241.96.176
417 | NETMASK=255.255.255.0
418 | GATEWAY=10.241.96.1
419 | DNS1=10.241.96.1
420 |
421 | ## 修改eth0
422 | [root@C65-201 network-scripts]# vim ifcfg-eth0
423 | DEVICE=eth0
424 | HWADDR=00:0C:29:64:9C:CD
425 | TYPE=Ethernet
426 | UUID=62a2f66a-754e-4c46-810c-fd23abff3d5a
427 | ONBOOT=yes
428 | BRIDGE=br-in
429 | NM_CONTROLLED=yes
430 | BOOTPROTO=static
431 |
432 | ## 重启网络服务
433 | [root@C65-201 network-scripts]# service network restart
434 | ```
435 |
436 | 查看ip
437 |
438 | 
439 |
440 | 查看桥设备
441 |
442 | 
443 |
444 | 此时,物理网卡eth0已经添加至br-in中
445 |
446 | #### 6.2.2 创建脚本qemu-ifup
447 |
448 | 该脚本与隔离模型的qemu-ifup脚本一致,参照3.2.2即可
449 |
450 | #### 6.2.3 创建虚拟机guest01并启动
451 | ```C
452 | ## 创建guest01并启动
453 | [root@C65-201 ~]# qemu-kvm -name guest01 -m 128 -smp 1 --drive file=/images/kvm/guest01.img,if=virtio,media=disk -net nic,model=virtio,macaddr=52:54:00:11:22:aa -net tap,ifname=vif1.0,script=/etc/qemu-ifup -daemonize
454 |
455 | ## 在guest01配置其ip地址
456 | # ip addr add 10.241.96.90/24 dev eth0
457 |
458 | ## 在guest01添加路由
459 | # ip route add default via 10.241.96.1
460 | ```
461 |
462 | #### 6.2.4 通信测试
463 |
464 | 
465 |
466 | 以上是KVM最简单的四种网络模型,在生产环境中使用的最多的是桥接模型,但是桥接模型的安全性是最低的,因为虚拟机直接暴露给了外部网络;而现在的容器技术中,NAT网络模型使用的较多,比如docker
467 |
468 |
469 |
470 |
471 |
472 |
473 |
474 |
475 |
476 |
477 |
478 |
479 |
480 |
481 |
482 | 原文作者: ccschan
483 |
484 |
485 |
486 |
487 |
488 |
489 |
490 |
491 |
492 |
493 |
494 |
495 |
496 |
497 |
498 |
499 |
500 |
501 |
502 |
503 |
504 |
505 |
506 |
507 |
508 |
509 |
510 |
511 |
512 |
513 |
514 |
515 |
516 |
517 |
518 |
519 |
520 |
521 |
522 |
523 |
524 |
525 |
--------------------------------------------------------------------------------
/virtualization_type/虚拟化五种类型.md:
--------------------------------------------------------------------------------
1 | # 虚拟化五种类型
2 |
3 | ## CPU虚拟化
4 |
5 | 虚拟化在计算机方面通常是指计算元件在虚拟的基础上而不是真实的基础上运行。虚拟化技术可以扩大硬件的容量,简化软件的重新配置过程。简单说来,CPU的虚拟化技术就是单CPU模拟多CPU并行,允许一个平台同时运行多个操作系统,并且应用程序都可以在相互独立的空间内运行而互不影响,从而显著提高计算机的工作效率。
6 |
7 | 纯软件虚拟化解决方案存在很多限制。“客户”操作系统很多情况下是通过VMM(Virtual Machine Monitor,虚拟机监视器)来与硬件进行通信,由VMM来决定其对系统上所有虚拟机的访问。(注意,大多数处理器和内存访问独立于VMM,只在发生特定事件时才会涉及VMM,如页面错误。)在纯软件虚拟化解决方案中,VMM在软件套件中的位置是传统意义上操作系统所处的位茫。如处理器、内存、存储、显卡和网卡等)的接口,模拟硬件环境。这种转换必然会增加系统的复杂性。
8 |
9 | CPU的虚拟化技术是一种硬件方案,支持虚拟技术的CPU带有特别优化过的指令集来控制虚拟过程,通过这些指令集,VMM会很容易提高性能,相比软件的虚拟实现方式会很大程度上提高性能。虚拟化技术可提供基于芯片的功能,借助兼容VMM软件能够改进纯软件解决方案。由于虚拟化硬件可提供全新的架构,支持操作系统直接在上面运行,从而无需进行二进制转换,减少了相关的性能开销,极大简化了VMM设计,进而使VMM能够按通用标准进行编写,性能更加强大。另外,在纯软件VMM中,目前缺少对64位客户操作系统的支持,而随着64位处理器的不断普及,这一严重缺点也日益突出。而CPU的虚拟化技术除支持广泛的传统操作系统之外,还支持64位客户操作系统。
10 |
11 | 虚拟化技术是一套解决方案。完整的情况需要CPU、主板芯片组、BIOS和软件的支持,例如VMM软件或者某些操作系统本身。即使只是CPU支持虚拟化技术,在配合VMM的软件情况下,也会比完全不支持虚拟化技术的系统有更好的性能。
12 |
13 | 两大CPU巨头英特尔和AMD都想方设法在虚拟化领域中占得先机,但是AMD的虚拟化技术在时间上要比英特尔落后几个月。英特尔自2005年末开始便在其处理器产品线中推广应用英特尔Virtualization Technology(Intel VT)虚拟化技术。目前,英特尔已经发布了具有Intel VT虚拟化技术的一系列处理器产品,包括桌面平台的Pentium 4 6X2系列、Pentium D 9X0系列和Pentium EE 9XX系列,还有Core Duo系列和Core Solo系列中的部分产品,以及服务器/工作站平台上的Xeon LV系列、Xeon 5000系列、Xeon 5100系列、Xeon MP 7000系列以及Itanium 2 9000系列;同时绝大多数的Intel下一代主流处理器,包括Merom核心移动处理器,Conroe核心桌面处理器,Woodcrest核心服务器处理器,以及基于Montecito核心的Itanium 2高端服务器处理器都将支持Intel VT虚拟化技术。
14 |
15 | 而AMD方面也已经发布了支持AMD Virtualization Technology(AMD VT)虚拟化技术的一系列处理器产品,包括Socket S1接口的Turion 64 X2系列以及Socket AM2接口的Athlon 64 X2系列和Athlon 64 FX系列等等,并且绝大多数的AMD下一代主流处理器,包括即将发布的Socket F接口的Opteron都将支持AMD VT虚拟化技术。
16 |
17 |
18 |
19 |
20 | ## 网络虚拟化
21 |
22 | 网络虚拟化是目前业界关于虚拟化细分领域界定最不明确,存在争议较多的一个概念。微软眼中的“网络虚拟化”,是指虚拟专用网络 (VPN)。VPN对网络连接的概念进行了抽象,允许远程用户访问组织的内部网络,就像物理上连接到该网络一样。网络虚拟化可以帮助保护 IT环境,防止来自 Internet 的威胁,同时使用户能够快速安全的访问应用程序和数据。
23 |
24 | 但是网络巨头思科(Cisco)不那么认为。出身、成名且目前称霸于网络的思科公司,当然在对IT未来的考虑上以网络为核心。它认为在理论上,网络虚拟化能将任何基于服务的传统客户端/服务器安置到“网络上”。那么,这意味着可以让路由器和交换机执行更多的服务,自然,思科在业界的重要性和生意额都将大幅增加。思科表示网络虚拟化由三个部分组成: 访问控制、路径提取,以及服务优势。从思科的产品规划图上看,该公司的路由器和交换机将拥有诸如安全、存储、VoIP、移动和应用等功能。 对思科而言,他们的战略是通过扩大网络基础设备的销售来持续产生盈利。 而对用户来讲,这能帮助他们提高网络设备的价值,并调整原有的网络基础设备。
25 |
26 | 对于网络阵营的另一巨头,3Com公司在网络虚拟化方面的动作比思科更大。3Com的路由器中可以插入一张工作卡。该卡上带有一套全功能的Linux服务器,可以和路由器中枢相连。在这个Linux服务器中,你可以安装诸如sniffer、VoIP、安全应用等等。此外,该公司还计划未来在Linux卡上运行VMware,以让用户运行Windows Server。3Com的这个开源网络虚拟化活动名为3Com ON(又名开放式网络)。
27 |
28 | 当然,王婆卖瓜自卖自夸,思科与3Com自己的一厢情愿决不能作为网络虚拟化大旗真正升起的标志,现在,网络虚拟化依然处于初期的萌芽阶段,但在人类网络信息化飞速需求的现在,我们有理由相信它的突破和成长将是飞速的。
29 |
30 |
31 |
32 |
33 | ## 服务器虚拟化
34 |
35 | 与网络虚拟化不同,服务器虚拟化却是虚拟化技术最早细分出来的子领域。根据2006年2月Forrester Research的调查,全球范围的企业对服务器虚拟化的认知率达到了75%。三分之一的企业已经在使用或者准备部署服务器虚拟化。这个产生于20世纪60年代的技术日益显示出其重要价值。由于服务器虚拟化发展时间长,应用广泛,所以很多时候人们几乎把服务器虚拟化等同于虚拟化。
36 |
37 | 关于服务器虚拟化的概念,各个厂商有自己不同的定义,然而其核心思想是一致的,即它是一种方法,能够通过区分资源的优先次序并随时随地能将服务器资源分配给最需要它们的工作负载来简化管理和提高效率,从而减少为单个工作负载峰值而储备的资源。
38 |
39 | 似乎与所有颠覆性技术一样,服务器虚拟化技术先是悄然出现,然后突然迸发,最终因为节省能源的合并计划而得到了认可。如今,许多公司使用虚拟技术来提高硬件资源的利用率,进行灾难恢复、提高办公自动化水平。本组文章分别从服务器、存储、应用程序和桌面虚拟化技术三个角度介绍了如何消除物理硬件的限制。
40 |
41 | 有了虚拟化技术,用户可以动态启用虚拟服务器(又叫虚拟机),每个服务器实际上可以让操作系统(以及在上面运行的任何应用程序)误以为虚拟机就是实际硬件。运行多个虚拟机还可以充分发挥物理服务器的计算潜能,迅速应对数据中心不断变化的需求。
42 |
43 | 虚拟化概念并不是新概念。早在20世纪70年代,大型计算机就一直在同时运行多个操作系统实例,每个实例也彼此独立。不过直到最近,软硬件方面的进步才使得虚拟化技术有可能出现在基于行业标准的大众化x86服务器上。
44 |
45 | 微软于2004年底宣布了其Virtual Server 2005计划。与其他服务器虚拟化技术一样,Virtual Server 2005允许用户对服务器进行分区,以使这些服务器能够支持多个操作系统和应用。计划于2005年面市的Virtual Server建立在去年年初时通过购买Connectix而获得的技术基础之上,该软件可以在Windows、Linux和Mac OS服务器及工作站上运行。
46 |
47 | 微软宣布Windows Server 2008发行版将包括虚拟化服务器(WSV)的测试版在内,Windows Server 2008是微软最新的服务器操作系统,可在一个服务器上虚拟化多种操作系统,如Windows、Linux 等等。服务器操作系统内置的虚拟化技术和更加简单灵活的授权策略,获得前所未有的易用性优势并降低成本。借助Terminal Services Gateway 和 Terminal Services RemoteApp ,可轻松进行远程访问并与本地桌面应用程序进行集成,还可实现在无需 VPN 的情况下,安全无缝地部署应用程序。
48 |
49 | 另外,在服务器虚拟化技术方面走得比较靠前的应该是IBM和HP等服务器厂商。今年以来,这两家公司在虚拟化领域也非常积极,在最新的RISC架构服务器及最新版的操作系统中,都嵌入了虚拟化技术。
50 |
51 | 先说说IBM,早在p690服务器和AIX 5L操作系统首次公布的时候,IBM就宣布在其动态逻辑分区(LPAR)技术的支持下,一个系统内可独立的运行多个分区,每个分区运行独立的操作系统。这时候的分区,是以CPU为“颗粒”的。
52 |
53 | 到去年发布p5服务器时,IBM大张旗鼓地扯出了虚拟技术的大旗。不过,与以前相比,在虚拟化技术的帮助下, IBM最新的微分区技术打破了分区上以CPU为“颗粒”的限制,可以将单个CPU划分为10个微分区,从而创建和运行比物理处理器数量更多的分区。IBM 同时宣布,新版操作系统AIX 5.3可以支持1/10 CPU颗粒的微分区。
54 |
55 | 今年,IBM进一步拓展了其服务器虚拟技术的范畴,推出了由操作系统、系统技术和系统服务三部分组成的服务器虚拟引擎。其中,操作系统涉及AIX、 i5/OS、z/OS和Linux,其技术宗旨是单台服务器内运行多种操作系统、在异构IT基础架构中以统一的方式实现资源的共享和管理以及管理非IBM 操作系统平台;系统技术包括微分区、vLan、虚拟I/O、Hypervisor等;而系统服务则包括一个服务器系统服务套件和一个存储系统服务套间。在服务器系统服务套间中,包括硬件监督模块VE console虚拟引擎控制台,可以利用两个主要的功能模块Launchpad和Health Center,监控资源的健康状态、进行问题诊断和系统管理;另外还包括硬件管理模块IBM Direction Multiplatform(DCM)整合系统管理。
56 |
57 | 同时,IBM还推出了应用虚拟工具套件,包括应用监督模块Enterprise Workload Management企业负载管理器(EWLM),可以在异构环境下自动管理分布式企业级系统,根据业务优先级将IT服务分类,并设立相应的性能目标,并根据这些性能目标,提供端到端的性能分析和评估,通过分析,EWLM自动按照应用拓扑调整网络路由。与EWLM相配合的是一个应用管理模块Tivoli Provisioning Manger(TPM),该模块与EWLM配合,可以实现系统部署和配置步骤的自动化,为IT系统的自动部署、资源分配和启用提供解决方案。
58 |
59 | 对于HP,我们最熟悉的就是HP提供三个层次的虚拟化解决方案。其中,部件虚拟化可以优化不同类型IT资源的利用,如服务器、存储和网络资源,包括分区、集群、工作负载管理和应用虚拟化;集成虚拟化可以把优化多个部件的虚拟化方法结合在一起,自动调度资源满足服务水平协议(SLO),包括虚拟服务器环境、连续访问存储专用服务器等;而完全虚拟化可以优化所有异构资源、使得资源供应能够实时满足业务需求。
60 |
61 | HP-UX 下的分区连续技术能够把服务器划分成物理或逻辑独立的分区,为优化资源利用、提高服务器的可用性提供坚实的基础。
62 |
63 | 硬件分区 (nPars)--HP nPars 是单个服务器中的硬件分区。nPars 根据服务器类型最多提供 16 个硬件分区、完全的硬件和软件隔离能力以及在一个服务器上运行多个OS实例。
64 |
65 | 虚拟分区 (vPars)--HP vPars 具有在一个系统或硬件分区内实现执行多个OS实例的独特特性。每个 vPar 能够拥有规定的内存量、一个或多个物理内存区域、一个规定的CPU池、服务器内一个或多个I/O 卡。vPars 能够使用软件命令动态地创立和修改。因此,每个应用能够在性能最大、OS配置要求得到满足的环境中运行。
66 |
67 | 资源分区--进程资源管理软件(PRM) 能够动态地以多种方式把系统资源 (CPU, 内存和磁盘 I/O)分配给客户的应用,分配的方式可以是根据份额、百分比和处理器组 (pSets)。 pSets 允许在服务器上创立处理器组,而应用或用户可以被分配到在规定的pSet 上运行。
68 |
69 |
70 |
71 |
72 |
73 | ## 存储虚拟化
74 |
75 | 随着信息业务的不断运行和发展,存储系统网络平台已经成为一个核心平台,大量高价值数据积淀下来,围绕这些数据的应用对平台的要求也越来越高,不光是在存储容量上,还包括数据访问性能、数据传输性能、数据管理能力、存储扩展能力等等多个方面。可以说,存储网络平台的综合性能的优劣,将直接影响到整个系统的正常运行。因为这个原因,虚拟化技术又一子领域——虚拟存储技术,应运而生。
76 |
77 | 其实虚拟化技术并不是一件很新的技术,它的发展,应该说是随着计算机技术的发展而发展起来的,最早是始于70年代。由于当时的存储容量,特别是内存容量成本非常高、容量也很小,对于大型应用程序或多程序应用就受到了很大的限制。为了克服这样的限制,人们就采用了虚拟存储的技术,最典型的应用就是虚拟内存技术。
78 |
79 | 随着计算机技术以及相关信息处理技术的不断发展,人们对存储的需求越来越大。这样的需求刺激了各种新技术的出现,比如磁盘性能越来越好、容量越来越大。但是在大量的大中型信息处理系统中,单个磁盘是不能满足需要,这样的情况下存储虚拟化技术就发展起来了。在这个发展过程中也由几个阶段和几种应用。首先是磁盘条带集(RAID,可带容错)技术,将多个物理磁盘通过一定的逻辑关系集合起来,成为一个大容量的虚拟磁盘。而随着数据量不断增加和对数据可用性要求的不断提高,又一种新的存储技术应运而生,那就是存储区域网络(SAN)技术。
80 |
81 | SAN的广域化则旨在将存储设备实现成为一种公用设施,任何人员、任何主机都可以随时随地获取各自想要的数据。目前讨论比较多的包括iSCSI、FC Over IP 等技术,由于一些相关的标准还没有最终确定,但是存储设备公用化、存储网络广域化是一个不可逆转的潮流。
82 |
83 | 所谓虚拟存储,就是把多个存储介质模块(如硬盘、RAID)通过一定的手段集中管理起来,所有的存储模块在一个存储池(Storage Pool)中得到统一管理,从主机和工作站的角度,看到就不是多个硬盘,而是一个分区或者卷,就好象是一个超大容量(如1T以上)的硬盘。这种可以将多种、多个存储设备统一管理起来,为使用者提供大容量、高数据传输性能的存储系统,就称之为虚拟存储。
84 |
85 |
86 |
87 |
88 | ## 应用虚拟化
89 |
90 | 前面几种虚拟化技术,主要还专注于对硬件平台资源的虚拟优化分配,随着IT应用的日益广泛,应用虚拟化作为虚拟化家族的明日之星登上了历史舞台。2006年7月由Forrester咨询公司在美国对各种不同行业的高层IT管理人员所做的一项研究显示,当今的机构现在将应用虚拟化当作是业务上的一个必由之路,而不是一个IT决策。据统计,全世界目前至少有超过18万个机构在利用应用虚拟化技术进行集中IT管理、加强安全性和减少总体成本。
91 |
92 | 尽管在过去十年间虚拟技术有了迅速的发展,但现实情况是,当需要使用应用系统的时候,我们仍然把自己的思维局限在电脑机箱之内。从键盘、鼠标、麦克风或扫描仪接收用户输入的设备,通常也是处理和存储数据、通过对显示器、打印机和扬声器的输出来进行响应的同一设备。然而,随着虚拟化概念的发展和变化,“应用虚拟化”成为一个正在迅速发展的市场。
93 |
94 | 何为应用虚拟化?
95 |
96 | 简单来讲,应用虚拟化技术使机构能够用更少的投入做更多的事情,并最终节省经费。这样,企业决策者就能够在IT开销与业务需求之间达成更好的平衡——由运营成本降低所节省的经费可以重新投入到能够推动增长的业务领域中。
97 |
98 | 从技术角度来讲,应用虚拟化可以简单描述为“以IT应用客户端集中部署平台为核心,以对最终用户透明的方式完全使用户的应用和数据在平台上统一计算和运行,并最终让用户获得与本地访问应用同样的应用感受和计算结果。”
99 |
100 | 虚拟化背后的主要推动力是基础设施各方面的猛烈增长,同时伴随着IT硬件和应用的大量增加。而且,IT系统正在变得越来越大,分布越来越广,并且更加复杂,因而难以管理,但要求加强IT控制的业务和监管压力却在继续增大。这听起来可能很专业,但对业务决策者来说却很中听,因为应用虚拟化正在帮助解决当今机构所面临的很多推动力方面的问题——提高业务效率、增强员工移动性、遵守安全与监管规定、向新兴市场拓展、业务外包、以及业务连续性等等。
101 |
102 | 在可能实现的一系列利益当中,应用虚拟化技术能帮助企业解决三个关键方面的问题——安全性、性能和成本。从安全角度来讲,应用虚拟化从其设计本身来看是安全的。采用客户-服务器端应用,数据安全面临风险。IT人员不仅必须应对数据的存放、打印和操控环境,而且还必须考虑数据在网络内和网络外如何迁移,并保证知识产权不会泄露,电脑病毒也不会潜入。启动应用虚拟化项目后,一个公司的所有系统和数据都被整合到了一起,从而几乎消除了在设备层面上数据被盗或数据丢失的风险。性能改善对很多公司来说是另一个吸引人的因素。因为客户-服务器端应用依靠网络来传输流量,所以它们会为网络增添带宽消耗问题。这种问题困扰着很多企业,反过来又会降低应用系统的性能。应用虚拟化技术可以将各种应用系统集中起来,只有一个通过网络传送的虚拟界面。这样可以保证在极低的带宽上实现高性能,而不管设备、网络和地点如何。所以在业务扩张或合并的情况下,企业能够在几分钟或几小时时间内让新用户上网,而不像过去那样需要几个星期或几个月。因此,容易理解为什么应用虚拟化是很多所谓的“业务流程外包”公司所欢迎的一种方式。
103 |
104 | 个人计算设备和操作系统的繁多使得客户-服务器端应用的测试、调试和客户定制开发成本高昂且耗费时间。采用应用虚拟化技术之后,将不需要在每个用户的桌面上部署和管理多个软件客户端系统,所有应用客户端系统都将一次性地部署在数据中心的一台专用服务器上,这台服务器就放在应用服务器的前面。客户也将不需要通过网络向每个用户发送实际的数据,只有虚拟的客户端界面(屏幕图像更新、按键、鼠标移动等等)被实际传送并显示在用户的电脑上。这个过程对最终用户是一目了然的,最终用户的感觉好像是实际的客户端软件正在他的桌面上运行一样。
105 |
106 | 客户-服务器端应用要求在每个用户的电脑上安装客户端软件,从而导致更高的成本,因为需要在分布式网络上管理这些软件的部署、补丁和升级。这个问题随着用户登录到每个新应用系统的需求量呈增长趋势,因为IT部门需要在每个用户的桌面上部署另一个独特的客户端设备。即便在最讲究战术的接入服务场景中,应用虚拟化可以带来的成本效益也是相当诱人的。通过将IT系统的管理集中起来,企业能够同时实现各种不同的效益——从带宽成本节约到提高IT效率和员工生产力以及延长陈旧的或当前的系统的寿命等等。
107 |
108 | 目前,应用虚拟化能够展现给用户最直接的功能还是远程应用交付,或者叫远程接入,应用虚拟化领域,从全球看,走在最前沿的厂商还是Citrix(思杰),其推出的应用虚拟化平台Citrix交付中心(Citrix Delivery Center),即Citrix应用交付基础架构解决方案正在逐步进行中国全面本地化的进程。国内最具实力的应用虚拟化领导厂商极通科技,也在2008年7月向全球推出极通EWEBS 2008应用虚拟化系统,该产品在EWEBS 2008中采用了极通科技独创的AIP(Application Integration Protocol)技术,把应用程序的输入输出逻辑(应用程序界面)与计算逻辑指令隔离开来,在用户访问EWEBS服务器发布的应用时,在EWEBS 服务器上会为用户开设独立的会话,占用独立的内存空间,应用程序的计算逻辑指令在这个会话空间中运行,应用程序的界面会通过AIP协议传送到用户计算机上,用户计算机只需要通过网络把键盘、鼠标及其他外设的操作传送到服务器端,从服务器端接收变化的应用程序界面,并且在用户端显示出来就可以获得在本地运行应用一样的访问感受,最终实现用户客户端使用人员不受终端设备和网络带宽的限制,在任何时间、任何地点、使用任何设备、采用任何网络连接,都能够高效、安全地访问EWEBS服务器(集群)上的各种应用软件。
109 |
110 |
--------------------------------------------------------------------------------
/virtualization_type/虚拟化技术.md:
--------------------------------------------------------------------------------
1 | # 软件模拟虚拟化、全虚拟化、半虚拟化、硬件辅助虚拟化和容器
2 |
3 | 目前虚拟化技术有软件模拟、全虚拟化(使用二进制翻译)、半虚拟化(操作系统辅助)、硬件辅助虚拟化和容器虚拟化这几种。
4 |
5 | ## 1. 软件模拟
6 | 软件模拟是通过软件完全模拟cpu、芯片组、磁盘、网卡等计算机硬件:
7 |
8 | 
9 |
10 | 因为是软件模拟,所以理论上可以模拟任何硬件,但是非常低效,一般只用于研究测试的场景,典型的有QEMU。
11 |
12 | ## 2. 全虚拟化
13 | x86平台指令集分为4个特权模式:Ring0 、Ring1、Ring2、Ring3、OS工作在Ring0级别,应用软件工作在Ring3级别,驱动程序工作在Ring1和Ring2。
14 |
15 | 
16 |
17 | 如何将虚拟机越级的指令使用进行隔离,1998年VMware首次找到了解决办法,通过虚拟化引擎,捕获虚拟机的指令,并进行处理,即全虚拟化方案。
18 | 在全虚拟化的情况下,VMM工作在Ring 0 ,Guest OS工作在Ring 1 ,应用程序工作在Ring 3,可是这时候Guest OS是不知道自己工作在虚拟机里的,认为自己还是工作在Ring 0 ,所以它还是按照Ring 0级别产特权生指令,Guest OS产生的每一条指令都会被VMM截取,并翻译成宿主机平台的指令,然后交给实际的物理平台执行,由于每一条指令都需要这么翻译一下,所以这种虚拟化性能比较差。
19 |
20 | 
21 |
22 | ## 3. 半虚拟化**
23 | 半虚拟化是对Guest OS做相应修改,以便和VMM协同运作。在硬件辅助虚拟化兴起之前,半虚拟化性能胜过全虚拟化。在半虚拟化情况下,Guest OS知道自己并不是直接运行在硬件资源上,而是运行在虚拟化环境里,工作在非Ring 0,那么它原先在物理机上执行的一些特权指令,就会修改成其他方式(超级调用),这种方式是可以和VMM约定好的,半虚拟化不需要VMM层进行二进制翻译,所以性能较好,但是实现比较麻烦(要修改OS内核代码),典型的半虚拟化技术有xen。
24 |
25 | 
26 |
27 | ## 4. 硬件辅助虚拟化**
28 | 2005年,Intel推出了硬件辅助虚拟化方案,对CPU指令进行改造,即VT-x,VT-x提供了两种操作模式:VMX root operation和VMX non-root operation,VMM运行在 VMX root operation,虚拟机运行在VMX non-root operation。在绝大多数情况下,客户机在此模式下运行与原生系统在非虚拟化环境中运行性能一样,不需要像全虚拟化那样每条指令都要先翻译再执行;在少数必要的时候,某些客户机指令的运行才需要被VMM截获并做相应处理。这种方案因为是基于硬件的,所以效率非常高。
29 |
30 | 
31 |
32 | 现在不仅CPU指令有硬件虚拟化方案,I/O通信也有硬件解决方案,称为VT-d;网络通信的称为VT-c。
33 |
34 | ## 5. 容器虚拟化
35 | 容器虚拟化是基于CGroups、Namespace等技术将进程进行隔离,每个进程就像一台独立的虚拟机,拥有自己被隔离出来的资源,也有自己的根目录、独立的进程编号、被隔离的内存空间。基于容器的虚拟化可以实现在单一内核上运行多个实例。目前热门的容器虚拟化技术Docker,Docker可以将一个开发环境进行打包,很方便在另一个系统上运行起来。
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 | 原文作者: -光光-
49 |
--------------------------------------------------------------------------------
/virtualization_type/虚拟化技术分类.md:
--------------------------------------------------------------------------------
1 | # 虚拟化技术的分类及介绍
2 |
3 | ## 目录
4 |
5 | * 摘要
6 |
7 | * 1 引言
8 | * 2 虚拟化技术的分类
9 | * 2.1 不同抽象层次的虚拟化技术
10 | * 2.1.1 硬件抽象层上的虚拟化
11 | * 2.1.2 操作系统层上的虚拟化
12 | * 2.1.3 库函数层上的虚拟化
13 | * 2.1.4 编程语言层上的虚拟化
14 | * 2.2 系统级虚拟化
15 | * 2.2.1 可虚拟化架构和不可虚拟化架构
16 | * 2.2.2 按照实现方法分类
17 | * 2.2.3 按照实现结构分类
18 | * 2.3 操作系统级虚拟化
19 | * 3 典型虚拟化技术实现及其特点
20 | * 3.1 系统级虚拟化实现
21 | * 3.1.1 VMware
22 | * 3.1.2 Microsoft
23 | * 3.1.3 Xen
24 | * 3.1.4 KVM
25 | * 3.1.5 Oracle VM VirtualBox
26 | * 3.1.6 Bochs
27 | * 3.1.7 QEMU
28 | * 3.2 操作系统级虚拟化实现
29 | * 3.2.1 chroot
30 | * 3.2.2 LXC
31 | * 3.2.3 Docker
32 | * 3.2.4 Linux VServer
33 | * 3.2.5 Virtuozzo/OpenVZ
34 | * 参考文献
35 |
36 | ## 摘要
37 |
38 | 虚拟化是云计算系统中的一种基础技术,可以说当前一个云计算服务必定是构建在虚拟化的基础上的。本文首先介绍了不同抽象层次的虚拟化技术,之后对应用广泛的系统级虚拟化和操作系统级虚拟化进行了更详细的分类和描述,最后介绍了各种典型虚拟化方案的具体实现。
39 |
40 | ## 1 引言
41 |
42 | 虚拟化是计算机系统中的一个重要概念,基本上每个计算机系统都提供一个给上层软件的界面,从处理器提供的基本指令集到很多中间件系统提供的巨大的应用程序界面集。虚拟化本质上是扩展或替换一个现存界面来模仿另一个系统的行为,其对计算机系统的重要性主要体现在以下几个方面。
43 |
44 | 相比高层软件(比如中间件和应用软件),硬件和底层系统软件变化得比较快,也就是说,我们面对的一种情况是旧有软件的维护跟不上下层平台更新的步伐。通过移植旧有软件的底层接口到新平台,可使得一大类的现有软件可以立刻在新平台上工作。
45 |
46 | 在服务器机器上,一个组织为它提供的每个服务都分配一台虚拟机,接着,将虚拟机以最佳方式分配到物理服务器上。与进程不同,虚拟机能很简单地迁移到其他物理机器上,这增加了管理服务器基础设施的灵活性。这个方法能潜在地减少服务器计算机的投资并减少能量消耗,后者是大型服务器中心的关键问题。
47 |
48 | 虚拟化技术和云计算的提供极为相关。云计算采用了这样一个模型,即作为一个服务,提供云上创建的存储、计算和高层对象。所提供的服务覆盖从诸如物理体系结构等的底层方面(基础设施即服务IaaS)到诸如软件平台(平台即服务PaaS),再到任意应用层次的服务(软件即服务SaaS)。云服务的提供被虚拟化技术直接驱动,允许为云的用户提供一个或多个虚拟机,供用户自己使用。
49 |
50 | 分布式应用的需求也激发虚拟化解决方案的开发者去以很少的开销创建和销毁虚拟机。在可能需要动态地请求资源的应用中,这是必要的。例如对于多人在线游戏或分布式多媒体应用,通过采用合适的资源分配策略满足虚拟机服务质量需求,能提升对这样的应用的支持度。
51 |
52 | 另一个好处是,在单台计算机上提供对几个不同操作系统环境的便利访问,虚拟化可用于在一种物理体系结构上提供多种操作系统类型。
53 |
54 | 虚拟化技术起始于IBM370体系结构,它的VM操作系统能为运行在同一计算机上的不同程序提供几个完整的虚拟机。最近,人们对虚拟化的兴趣大增,有许多研究项目和商业系统为商用PC、服务器和云基础设施提供虚拟化解决方案。
55 |
56 |
57 |
58 | ## 2 虚拟化技术的分类
59 |
60 | 现代计算机系统是一个庞大的整体,整个系统的复杂性是不言而喻的。因而,整个计算机系统被分成了多个自下而上的层次,每一个层次都向上一层次呈现一个抽象,并且每一层只需知道下层抽象的接口,而不需要了解其内部运作机制。这样以层的方式抽象资源的好处是每一层只需要考虑本层设计以及与相邻层间的相互交互,从而大大降低了系统设计的复杂性,提高了软件的移植性。
61 |
62 | 本质上,虚拟化就是由位于下层的软件模块,通过向上一层软件模块提供一个与它原先所期待的运行环境完全一致的接口的方法,抽象出一个虚拟的软件或硬件接口,使得上层软件可以直接运行在虚拟的环境上。虚拟化可以发生在现代计算机系统的各个层次上,不同层次的虚拟化会带来不同的虚拟化概念。
63 |
64 | 如前文所述,虚拟化技术起源于上世纪70年代的IBM370体系,经过四十余年的发展,当前存在诸多实现在不同层次的虚拟化技术,原理不尽相同,且每一种技术都相当复杂。在本文中,将通过不同的角度对目前存在的较流行的虚拟化技术进行分类,并对其原理进行初步介绍,旨在对纷繁复杂的虚拟化技术有个整体认识及厘清不同虚拟化技术之间的相互关系。
65 |
66 |
67 |
68 | ### 2.1 不同抽象层次的虚拟化技术
69 |
70 | 在介绍各种虚拟化概念之前,先介绍虚拟化中的两个重要名词。在虚拟化中,物理资源通常有一个定语称为宿主(Host),而虚拟出来的资源通常有一个定语称为客户(Guest)。
71 |
72 | 在计算机系统中,从底层至高层依次可分为:硬件层、操作系统层、函数库层、应用程序层,在对某层实施虚拟化时,该层和上一层之间的接口不发生变化,而只变化该层的实现方式。从使用虚拟资源的Guest的角度来看,虚拟化可发生在上述四层中的任一层。应当注意,在对Guest的某一层进行虚拟化时,并未对Host在哪一层实现它作出要求,这一点是时常引起混淆的地方。
73 |
74 |
75 |
76 | #### 2.1.1 硬件抽象层上的虚拟化
77 |
78 | 硬件抽象层上的虚拟化是指通过虚拟硬件抽象层来实现虚拟机,为客户机操作系统呈现和物理硬件相同或相近的硬件抽象层,又称为指令集级虚拟化,实现在此层的虚拟化粒度是最小的。
79 |
80 | 实现在此层的虚拟化技术可以对整个计算机系统进行虚拟,即可将一台物理计算机系统虚拟化为一台或多台虚拟计算机系统,故又可称作系统级虚拟化。每个虚拟计算机系统(简称为虚拟机)都拥有自己的虚拟硬件(如CPU、内存和设备等),来提供一个独立的虚拟机执行环境。每个虚拟机中的操作系统可以完全不同,并且它们的执行环境是完全独立的。由于客户机操作系统所能看到的是硬件抽象层,因此,客户机操作系统的行为和在物理平台上没有什么区别。
81 |
82 |
83 |
84 | #### 2.1.2 操作系统层上的虚拟化
85 |
86 | 操作系统层上的虚拟化是指操作系统的内核可以提供多个互相隔离的用户态实例。这些用户态实例(经常被称为容器)对于它的用户来说就像是一台真实的计算机,有自己独立的文件系统、网络、系统设置和库函数等。
87 |
88 | 由于这是操作系统内核主动提供的虚拟化,因此操作系统层上的虚拟化通常非常高效,它的虚拟化资源和性能开销非常小,也不需要有硬件的特殊支持。但它的灵活性相对较小,每个容器中的操作系统通常必须是同一种操作系统。另外,操作系统层上的虚拟化虽然为用户态实例间提供了比较强的隔离性,但其粒度是比较粗的。
89 |
90 |
91 |
92 | #### 2.1.3 库函数层上的虚拟化
93 |
94 | 操作系统通常会通过应用级的库函数提供给应用程序一组服务,例如文件操作服务、时间操作服务等。这些库函数可以隐藏操作系统内部的一些细节,使得应用程序编程更为简单。不同的操作系统库函数有着不同的服务接口,例如Linux的服务接口是不同于Windows的。库函数层上的虚拟化就是通过虚拟化操作系统的应用级库函数的服务接口,使得应用程序不需要修改,就可以在不同的操作系统中无缝运行,从而提高系统间的互操作性。
95 |
96 | 例如,Wine就是在Linux上模拟了Windows的库函数接口,使得一个Windows应用程序能够在Linux上正常运行。
97 |
98 |
99 |
100 | #### 2.1.4 编程语言层上的虚拟化
101 |
102 | 另一大类编程语言层上的虚拟机称为语言级虚拟机,例如JVM(Java Virtual Machine)和微软的CLR(Common Language Runtime)。这一类虚拟机运行的是进程级的作业,所不同的是这些程序所针对的不是一个硬件上存在的体系结构,而是一个虚拟体系结构。这些程序的代码首先被编译为针对其虚拟体系结构的中间代码,再由虚拟机的运行时支持系统翻译为硬件的机器语言进行执行。
103 |
104 |
105 |
106 | ### 2.2 系统级虚拟化
107 |
108 | 系统级虚拟化即硬件抽象层上的虚拟化、指令集级虚拟化,是最早被提出和研究的一种虚拟化技术,当前存在多种此种技术的具体实现方案,在介绍它们之前,有必要先了解实现系统级虚拟化可采取的途径。
109 |
110 | 在每台虚拟机中都有属于它的虚拟硬件,通过虚拟化层的模拟,虚拟机中的操作系统认为自己仍然是独占一个系统在运行,这个虚拟化层被称为虚拟机监控器(Virtual Machine Monitor,VMM)。VMM对物理资源的虚拟可以归结为三个主要任务:处理器虚拟化、内存虚拟化和I/O虚拟化。其中,处理器虚拟化是VMM中最核心的部分,因为访问内存或进行I/O本身就是通过一些指令来实现的。
111 |
112 |
113 |
114 | #### 2.2.1 可虚拟化架构和不可虚拟化架构
115 |
116 | 在系统级虚拟化中,虚拟计算机系统和物理计算机系统可以是两个完全不同ISA(Instruction Set Architecture,指令集架构)的系统,例如,可以在一个x86的物理计算机上运行一个安腾的虚拟计算机。但是,不同的ISA使得虚拟机的每一条指令都需要在物理机上模拟执行,从而造成性能上的极大下降。
117 |
118 | 显然,相同体系结构的系统虚拟化通常会有比较好的性能,并且VMM实现起来也会比较简单。这种情况下虚拟机的大部分指令可以在处理器上直接运行,只有那些与硬件资源关系密切的敏感指令才会由VMM进行处理。此时面前的一个问题是,要能将这些敏感指令很好地筛选出来。但事实上,某些处理器在设计之初并没有充分考虑虚拟化的需求,导致没有办法识别出所有的敏感指令,因而不具备一个完备的可虚拟化结构。
119 |
120 | 大多数的现代计算机体系结构都有两个或两个以上的特权级,用来分隔系统软件和应用软件。系统中有一些操作和管理关键系统资源的指令会被定为特权指令,这些指令只有在最高特权级上才能够正确执行。如果在非最高特权级上运行,特权指令会引发一个异常,处理器会陷入到最高特权级,交由系统软件来处理。
121 |
122 | 在x86架构中,所有的特权指令都是敏感指令,然而并不是所有的敏感指令都是特权指令。
123 |
124 | 为了VMM可以完全控制系统资源,它不允许虚拟机上操作系统直接执行敏感指令。如果一个系统上所有敏感指令都是特权指令,则能够用一个很简单的方法来实现一个虚拟环境:将VMM运行在系统的最高特权级上,而将客户机操作系统运行在非最高特权级上,当客户机操作系统因执行敏感指令而陷入到VMM时,VMM模拟执行引起异常的敏感指令,这种方法被称为“陷入再模拟”。
125 |
126 | 总而言之,判断一个架构是否可虚拟化,其核心就在于该结构对敏感指令的支持上。如果一个架构中所有敏感指令都是特权指令,则称其为可虚拟化架构,否则称为不可虚拟化架构。
127 |
128 |
129 |
130 | #### 2.2.2 按照实现方法分类
131 |
132 | 系统级虚拟化有许多不同的具体实现方案,按照实现方法的不同,可划分为如下几个类别。
133 |
134 | ##### (1)仿真(Emulation)
135 |
136 | 我们已经知道,通过陷入再模拟敏感指令的执行来实现虚拟机的方法是有前提条件的:所有的敏感指令必须都是特权指令。如果一个体系结构上存在敏感指令不属于特权指令,那么其就存在虚拟化漏洞,可以采用一些方法来填补或避免这些漏洞。最简单直接的方法是,所有指令都采用模拟来实现,就是取一条指令,就模拟出这条指令执行的效果。这种方法称作仿真。
137 |
138 | 仿真是最复杂的虚拟化实现技术,使用仿真方法,可以在一个x86处理器上运行为PowerPC设计的操作系统,这在其它的虚拟化方案中是无法实现的。甚至可以运行多个虚拟机,每个虚拟机仿真一个不同的处理器。此外,这种方法不需要对宿主操作系统的特殊支持,虚拟机可以完全作为应用层程序运行。
139 |
140 | 正如前面提到的,使用仿真方法的主要问题是速度会非常慢。由于每条指令都必须在底层硬件上进行仿真,因此速度减慢100倍的情况也并不稀奇。若要实现高度保真的仿真,包括周期精度、CPU的缓存行为等,实际速度差距甚至可能会达到1000倍之多。
141 |
142 | 使用这种方式的典型实现是Bochs。
143 |
144 | ##### (2)完全虚拟化(Full Virtualization)
145 |
146 | 在客户操作系统看来,完全虚拟化的虚拟平台和现实平台是一样的,客户机操作系统察觉不到是运行在一个虚拟平台上,这样的虚拟平台可以运行现有的操作系统,无须对操作系统进行任何修改,因此这种方式被称为完全虚拟化。
147 |
148 | 进一步说,客户机的行为是通过执行反映出来的,因此VMM需要能够正确处理所有可能的指令。在实现方式上,以x86架构为例,完全虚拟化经历了两个阶段:软件辅助的完全虚拟化和硬件辅助的完全虚拟化。
149 |
150 | ①软件实现的完全虚拟化
151 |
152 | 在x86虚拟化技术的早期,没有在硬件层次上对虚拟化提供支持,因此完全虚拟化只能通过软件实现。一个典型的做法是二进制代码翻译(Binary Translation)。
153 |
154 | 二进制代码翻译的思想是,通过扫描并修改客户机的二进制代码,将难以虚拟化的指令转化为支持虚拟化的指令。VMM通常会对操作系统的二进制代码进行扫描,一旦发现需要处理的指令,就将其翻译成为支持虚拟化的指令块(Cache Block)。这些指令块可以与VMM合作访问受限的虚拟资源,或者显式地触发异常让VMM进一步处理。
155 |
156 | 这种技术虽然能够实现完全虚拟化,但很难在架构上保证其完整性。因此,x86厂商在硬件上加入了对虚拟化的支持,从而在硬件架构上实现了虚拟化。
157 |
158 | ②硬件辅助完全虚拟化
159 |
160 | 可以预料,如果硬件本身加入足够的虚拟化功能,可以截获操作系统对敏感指令的执行或者对敏感资源的访问,从而通过异常的方式报告给VMM,这样就解决了虚拟化的问题。硬件虚拟化时一种完备的虚拟化方法,因而内存和外设的访问本身也是由指令来承载,对处理器指令级别的截获就意味着VMM可以模拟一个与真实主机完全一样的环境。
161 |
162 | Intel的VT-x和AMD的AMD-V是这一方向的代表。以VT-x为例,其在处理器上引入了一个新的执行模式用于运行虚拟机,当虚拟机执行在这个特殊模式中时,它仍然面对的是一套完整的处理器寄存器集合和执行环境,只是任何敏感操作都会被处理器截获并报告给VMM。
163 |
164 | 在当前的系统级虚拟化解决方案中,全虚拟化应用得非常普遍,典型的有知名的产品有VirtualBox、KVM、VMware Workstation和VMware ESX(它在其4.0版,被改名为VMware vSphere)、Xen(也支持全虚拟化)。
165 |
166 | ##### (3)类虚拟化(Para-Virtualization)
167 |
168 | 这样的虚拟平台需要对所运行的客户机操作系统进行或多或少的修改使之适应虚拟环境,因此客户机操作系统知道其运行在虚拟平台上,并且会去主动适应。这种方式被称为类虚拟化,有时也称作半虚拟化。另外,值得指出的是,一个VMM可以既提供完全虚拟化的虚拟平台,又提供类虚拟化的虚拟平台。
169 |
170 | 类虚拟化是通过在源代码级别修改指令以回避虚拟化漏洞的方式来使VMM 能够对物理资源实现虚拟化。上面谈到x86 存在一些难以虚拟化的指令,完全虚拟化通过Binary Translation在二进制代码级别上来避免虚拟化漏洞。类虚拟化采取的是另一种思路,即修改操作系统内核的代码,使得操作系统内核完全避免这些难以虚拟化的指令。
171 |
172 | 既然内核代码已经需要修改,类虚拟化进一步可以被用于优化I/O。也就是说,类虚拟化不是去模拟真实世界中的设备,因为太多的寄存器模拟会降低性能.相反,类虚拟化可以自定义出高度优化的协议I/O。这种I/O协议完全基于事务,可以达到近似物理机的速度。
173 |
174 | 这种虚拟技术以Xen为代表,微软的Hyper-V所采用技术和Xen类似,也可以把Hyper-V归属于半虚拟化。
175 |
176 |
177 |
178 | #### 2.2.3 按照实现结构分类
179 |
180 | 在系统级虚拟化的实现中,VMM是一个关键角色,前面已介绍过VMM的组成部分。从Host实现VMM的角度出发,还可以将当前主流的虚拟化技术按照实现结构分为如下三类。
181 |
182 | ##### Hypervisor模型
183 | Hypervisor这个术语是在 20 世纪 70 年代出现的,在早期计算机界,操作系统被称为Supervisor,因而能够在其他操作系统上运行的操作系统被称为 Hypervisor。
184 |
185 | 在Hypervisor模型中,VMM首先可以被看做是一个完备的操作系统,不过和传统操作系统不同的是,VMM是为虚拟化而设计的,因此还具备虚拟化功能。从架构上来看,首先,所有的物理资源如处理器、内存和I/O设备等都归VMM所有,因此,VMM承担着管理物理资源的责任;其次,VMM需要向上提供虚拟机用于运行客户机操作系统,因此,VMM还负责虚拟环境的创建和管理。
186 |
187 | 由于VMM同时具备物理资源的管理功能和虚拟化功能,因此,物理资源虚拟化的效率会更高一些。在安全方面,虚拟机的安全只依赖于VMM的安全。Hypervisor模型在拥有虚拟化高效率的同时也有其缺点。由于VMM完全拥有物理资源,因此,VMM需要进行物理资源的管理,包括设备的驱动。我们知道,设备驱动开发的工作量是很大的。因此,对于Hypervisor模型来说这是个很大的挑战。事实上,在实际的产品中,基于Hypervisor模型的VMM通常会根据产品定位,有选择地挑选一些I/O设备来支持,而不是支持所有的I/O设备。
188 |
189 | 采用这种模型的典型是面向企业级应用的VMware vSphere。
190 |
191 |
192 |
193 | ##### 宿主模型
194 | 与Hypervisor模型不同。在宿主模型中,物理资源由宿主机操作系统管理。宿主机操作系统是传统操作系统,如Windows 、Linux等,这些传统操作系统并不是为虚拟化而设计的,因此本身并不具备虚拟化功能,实际的虚拟化功能由VMM来提供。VMM通常是宿主机操作系统独立的内核模块,有些实现中还包括用户态进程,如负责I/O虚拟化的用户态设备模型。 VMM通过调用宿主机操作系统的服务来获得资源, 实现处理器、内存和I/O设备的虚拟化。VMM创建出虚拟机之后,通常将虚拟机作为宿主机操作系统的一个进程参与调度。
195 |
196 | 宿主模型的优缺点和Hypervisor模型恰好相反。宿主模型最大的优点是可以充分利用现有操作系统的设备驱动程序,VMM无须为各类I/O设备重新实现驱动程序,可以专注于物理资源的虚拟化。考虑到I/O设备种类繁多,千变万化, 设备驱动程序开发的工作量非常大,因此,这个优点意义重大。此外,宿主模型也可以利用宿主机操作系统的其他功能,例如调度和电源管理等,这些都不需要VMM重新实现就可以直接使用。
197 |
198 | 宿主模型当然也有缺点,由于物理资源由宿主机操作系统控制,VMM得要调用宿主机操作系统的服务来获取资源进行虚拟化,而那些系统服务在设计开发之初并没有考虑虚拟化的支持,因此,VMM虚拟化的效率和功能会受到一定影响。此外,在安全方面,由于VMM是宿主机操作系统内核的一部分,因此,如果宿主机操作系统内核是不安全的,那么,VMM也是不安全的,相应地运行在虚拟机之上的客户机操作系统也是不安全的。换言之,虚拟机的安全不仅依赖于VMM的安全,也依赖于宿主机操作系统的安全。
199 |
200 | 采用这种模型的典型是KVM、VirtualBox和VMware Workstation。
201 |
202 | ##### 混合模型
203 | 混合模型是上述两种模式的汇合体。VMM依然位于最低层,拥有所有的物理资源。与Hypervisor模式不同的是,VMM 会主动让出大部分I/O设备的控制权,将它们交由一个运行在特权虚拟机中的特权操作系统控制。相应地,VMM 虚拟化的职责也被分担.处理器和内存的虚拟化依然由VMM来完成,而I/O的虚拟化则由VMM和特权操作系统共同合作来完成。
204 |
205 | I/O设备虚拟化由VMM和特权操作系统共同完成,因此,设备模型模块位于特权操作系统中,并且通过相应的通信机制与VMM合作。
206 |
207 | 混合模型集中了上述两种模型的优点。 VMM可以利用现有操作系统的I/O设备驱动程序,不需要另外开发。VMM直接控制处理器、内存等物理资源,虚拟化的效率也比较高。
208 |
209 | 在安全方面,如果对特权操作系统的权限控制得当,虚拟机的安全性只依赖于VMM。当然,混合模型也存在缺点。由于特权操作系统运行在虚拟机上,当需要特权操作系统提供服务时,VMM需要切换到特权操作系统,这里面就产生上下文切换的开销。当切换比较频繁时,上下文切换的开销会造成性能的明显下降。出于性能方面的考虑,很多功能还是必须在VMM 中实现,如调度程序和电源管理等。
210 |
211 | 采用这种模型的典型是Xen。
212 |
213 |
214 |
215 | ### 2.3 操作系统级虚拟化
216 |
217 | 在操作系统虚拟化技术中,每个节点上只有唯一的系统内核,不虚拟任何硬件设备。通过使用操作系统提供的功能,多个虚拟环境之间可以相互隔离。通常所说的容器(Container)技术,如目前为止最流行的容器系统Docker,即属于操作系统级虚拟化。此外,在不同的场景中,隔离出的虚拟环境也被称作虚拟环境(即VE,Virtual Environment)或虚拟专用服务器(即VPS,Virtual Private Server)。
218 |
219 | 以容器技术为例,它有自己独特的优点,它的出现,一方面解决了传统操作系统所忽视和缺乏的应用程序间的独立性问题,另一方面,它避免了相对笨重的系统级虚拟化,是一种轻量级的虚拟化解决方案。
220 |
221 | 操作系统领域一直以来面临的一个主要挑战来自于应用程序间存在的相互独立性和资源互操作性之间的矛盾,即每个应用程序都希望能运行在一个相对独立的系统环境下,不受到其他程序的干扰,同时又能以方便快捷的方式与其他程序交换和共享系统资源。当前通用操作系统更强调程序间的互操作性,而缺乏对程序间相对独立性的有效支持,然而对于许多分布式系统如Web服务、数据库、游戏平台等应用领域,提供高效的资源互操作同保持程序间的相对独立性具有同等重要的意义。
222 |
223 | 主流虚拟化产品VMware和Xen等均采用Hypervisor模型(Xen采用的混合模型与Hypervisor模型差别不大,可统称为Hypervisor模型)。该模型通过将应用程序运行在多个不同虚拟机内,实现对上层应用程序的隔离。但由于Hypervisor 模型倾向于每个虚拟机都拥有一份相对独立的系统资源,以提供更为完全的独立性,这种策略造成处于不同虚拟机内的应用程序间实现互操作非常困难。例如, 即使是运行在同一台物理机器上,如果处于不同虚拟机内,那么应用程序间仍然只能通过网络进行数据交换,而非共享内存或者文件。而如果使用容器技术,由于各容器共享同一个宿主操作系统,能够在满足基本的独立性需求的同时提供高效的系统资源共享支持。
224 |
225 | 容器技术还可以更高效地使用系统资源,由于容器不需要进行硬件虚拟以及运行完整操作系统等额外开销,相比虚拟机技术,一个相同配置的主机,往往可以运行更多数量的应用。此外,容器还具有更快速的启动时间,传统的虚拟机技术启动应用服务往往需要数分钟,而对于容器由于,直接运行于宿主内核,无需启动完整的操作系统,因此可以做到秒级、甚至毫秒级的启动时间,大大的节约了应用开发、测试、部署的时间。
226 |
227 |
228 |
229 | ## 3 典型虚拟化技术实现及其特点
230 |
231 | ### 3.1 系统级虚拟化实现
232 |
233 | #### 3.1.1 VMware
234 |
235 | VMware是x86 虚拟化软件的主流广商之一。VMware的5位创始人中的3位曾在斯坦福大学研究操作系统虚拟化,项目包括SimOS系统模拟器和Disco虚拟机监控器。1998年,他们与另外两位创始人共同创建了VMware 公司,总部位于美国加州Palo Alto。
236 |
237 | VMware提供一系列的虚拟化产品,产品的应用领域从服务器到桌面。下面是VMware主要产品的简介,包括VMware ESX、VMware Server和VMware Workstation。
238 |
239 | VMware ESX Server是VMware的旗舰产品,后续版本改称VMware vSphere。ESX Server基于Hypervisor模型,在性能和安全性方面都得到了优化,是一款面向企业级应用的产品。VMware ESX Server支持完全虚拟化,可以运行Windows 、Linux、Solaris和Novell Netware等客户机操作系统。VMware ESX Server也支持类虚拟化,可以运行Linux 2. 6. 21 以上的客户机操作系统。ESX Server的早期版本采用软件虚拟化的方式,基于Binary Translation技术。自ESX Server 3开始采用硬件虚拟化的技术,支持Intel VT技术和AMD-V技术。
240 |
241 | VMware Server之前叫VMware GSX Server,是VMware面向服务器端的入门级产品。VMware Server采用了宿主模型,宿主机操作系统可以是Windows或者Linux。VMware Server的功能与ESX Server类似,但是在性能和安全性上与ESX Server有所差距。VMware Server也有自己的优点,由于采用了宿主模型,因此VMware Server支持的硬件种类要比ESX Server多。
242 |
243 | VMware Workstation是VMware面向桌面的主打产品。与VMware Server类似,VMware Workstation也是基于宿主模型,宿主机操作系统可以是Windows或者Linux。VMware Workstation也支持完全虚拟化,可以运行Windows、Linux、Solaris、Novell Netware和FreeBSD等客户机操作系统。与VMware Server不同, VMware Workstation专门针对桌面应用做了优化,如为虚拟机分配USB设备,为虚拟机显卡进行3D加速等。
244 |
245 |
246 |
247 | #### 3.1.2 Microsoft
248 |
249 | 微软在虚拟化产品方面起步比VMware晚,但是在认识到虚拟化的重要性之后,微软通过外部收购和内部开发,推出了一系列虚拟化产品,目前已经形成了比较完整的虚拟化产品线。微软的虚拟化产品涵盖了服务器虚拟化(Hyper-V)和桌面虚拟化(Virtual PC)。
250 |
251 | Virtual PC是而向桌面的虚拟化产品,最早由Connectix公司开发,后来该产品被微软公司收购。Virtual PC是基于宿主模型的虚拟机产品,宿主机操作系统是Windows。早期版本也采用软件虚拟化方式,基于Binary Translation技术。之后版本已经支持硬件虚拟化技术。
252 |
253 | Windows Server 2008是微软推出的服务器操作系统,其中一项重要的新功能是虚拟化功能。其虚拟化架构采用的是混合模型,重要组件之一Hyper-V作为Hypervisor运行在最底层,Server 2008本身作为特权操作系统运行在Hyper-V之上。Server 2008采用硬件虚拟化技术,必须运行在支持Intel VT技术或者AMD-V 技术的处理器上。
254 |
255 |
256 |
257 | #### 3.1.3 Xen
258 |
259 | Xen是一款基于GPL授权方式的开源虚拟机软件。Xen起源于英国剑桥大学Ian Pratt领导的一个研究项目,之后,Xen独立出来成为一个社区驱动的开源软件项目。Xen社区吸引了许多公司和科研院所的开发者加入,发展非常迅速。之后,Ian成立了XenSource公司进行Xen的商业化应用,并且推出了基于Xen的产品Xen Server。2007年,Ctrix公司收购了XenSource公司,继续推广Xen的商业化应用,Xen开源项目本身则被独立到http://www.xen.org。
260 |
261 | 从技术角度来说,Xen基于混合模型,特权操作系统( 在Xen中称作Domain 0)可以是Linux、Solaris以及NetBSD,理论上,其他操作系统也可以移植作为Xen的特权操作系统。Xen最初的虚拟化思路是类虚拟化,通过修改Linux内核,实现处理器和内存的虚拟化,通过引入I/O的前端驱动/后端驱动(front / backend)架构实现设备的类虚拟化。之后也支持了完全虚拟化和硬件虚拟化技术。
262 |
263 |
264 |
265 | #### 3.1.4 KVM
266 |
267 | KVM(Kernel-based Virtual Machine)也是一款基于GPL授权方式的开源虚拟机软件。KVM 最早由Qumranet公司开发,在2006年出现在Linux内核的邮件列表上,并于2007年被集成到了Linux 2.6.20内核中,成为内核的一部分。
268 |
269 | KVM支持硬件虚拟化方法,并结合QEMU来提供设备虚拟化。KVM的特点在于和Linux内核结合得非常好,而且和Xen一样,作为开源软件,KVM的移植性也很好。
270 |
271 |
272 |
273 | #### 3.1.5 Oracle VM VirtualBox
274 |
275 | VirtualBox是一款开源虚拟机软件,类似于VMware Workstation。VirtualBox 是由德国Innotek公司开发,由Sun Microsystems公司出品的软件,使用Qt编写,在 Sun 被 Oracle 收购后正式更名成 Oracle VM VirtualBox。Innotek 以 GNU General Public License (GPL) 释出 VirtualBox。用户可以在VirtualBox上安装并且执行Solaris、Windows、DOS、Linux、BSD等系统作为客户端操作系统。现在由甲骨文公司进行开发,是甲骨文公司VM虚拟化平台技术的一部分。
276 |
277 |
278 |
279 | #### 3.1.6 Bochs
280 |
281 | Bochs 是一个 x86 计算机仿真器,它在很多平台上(包括 x86、PowerPC、Alpha、SPARC 和 MIPS)都可以移植和运行。使 Bochs 不仅可以对处理器进行仿真,还可以对整个计算机进行仿真,包括计算机的外围设备,比如键盘、鼠标、视频图像硬件、网卡(NIC)等。
282 |
283 | Bochs 可以配置作为一个老式的 Intel® 386 或其后继处理器使用,例如 486、Pentium、Pentium Pro 或 64 位处理器。它甚至还可以对一些可选的图形指令进行仿真,例如 MMX 和 3DNow。
284 |
285 |
286 |
287 | #### 3.1.7 QEMU
288 |
289 | QEMU是一套由Fabrice Bellard所编写的模拟处理器的自由软件。它与Bochs,PearPC近似,但其具有某些后两者所不具备的特性,如高速度及跨平台的特性,qemu可以虚拟出不同架构的虚拟机,如在x86平台上可以虚拟出power机器。kqemu为qemu的加速器,经由kqemu这个开源的加速器,QEMU能模拟至接近真实电脑的速度。
290 |
291 | QEMU本身可以不依赖于KVM,但是如果有 KVM的存在并且硬件(处理器)支持比如Intel VT功能,那么QEMU在对处理器虚拟化这一块可以利用KVM提供的功能来提升性能。换言之,KVM缺乏设备虚拟化以及相应的用户空间管理虚拟机的工具,所以它借用了QEMU的代码并加以精简,连同KVM一起构成了一个完整的虚拟化解决方案,不妨称之为:KVM+QEMU。
292 |
293 |
294 |
295 | ### 3.2 操作系统级虚拟化实现
296 |
297 | #### 3.2.1 chroot
298 |
299 | 容器的概念始于 1979 年的 UNIX chroot,它是一个 UNIX 操作系统上的系统调用,用于将一个进程及其子进程的根目录改变到文件系统中的一个新位置,让这些进程只能访问到该目录。这个功能的想法是为每个进程提供独立的磁盘空间。其后在 1982年,它被加入到了 BSD 系统中。
300 |
301 |
302 |
303 | #### 3.2.2 LXC
304 |
305 | LXC 的意思是 LinuX Containers,它是第一个最完善的 Linux 容器管理器的实现方案,是通过 cgroups 和 Linux 名字空间namespace实现的。LXC 存在于 liblxc 库中,提供了各种编程语言的 API 实现,包括 Python3、Python2、Lua、Go、Ruby 和 Haskell 等。与其它容器技术不同的是, LXC 可以工作在普通的 Linux 内核上,而不需要增加补丁。现在 LXC project 是由 Canonical 公司赞助并托管的。
306 |
307 |
308 |
309 | #### 3.2.3 Docker
310 |
311 | Docker 是到现在为止最流行和使用广泛的容器管理系统。它最初是一个叫做 dotCloud 的 PaaS 服务公司的内部项目,后来该公司改名为 Docker。Docker 开始阶段使用的也是 LXC ,之后采用自己开发的 libcontainer 替代了它。不像其它的容器平台,Docker 引入了一整个管理容器的生态系统,这包括高效、分层的容器镜像模型、全局和本地的容器注册库、清晰的 REST API、命令行等等。稍后的阶段, Docker 推动实现了一个叫做 Docker Swarm 的容器集群管理方案。
312 |
313 |
314 |
315 | #### 3.2.4 Linux VServer
316 |
317 | Linux-VServer 也是一个操作系统级虚拟化解决方案。Linux-VServer 对 Linux 内核进行虚拟化,这样多个用户空间环境—又称为 Virtual Private Server(VPS) 就可以单独运行,而不需要互相了解。Linux-VServer 通过修改 Linux 内核实现用户空间的隔离。
318 |
319 | Linux-VServer 也使用了 chroot 来为每个 VPS 隔离 root 目录。虽然 chroot 允许指定新 root 目录,但还是需要其他一些功能(称为 Chroot-Barrier)来限制 VPS 脱离其隔离的 root 目录回到上级目录。给定一个隔离的 root 目录之后,每个 VPS 就可以拥有自己的用户列表和 root 密码。
320 |
321 | 2.4 和 2.6 版本的 Linux 内核支持 Linux-VServer,它可以运行于很多平台之上,包括 x86、x86-64、SPARC、MIPS、ARM 和 PowerPC。
322 |
323 |
324 |
325 | #### 3.2.5 Virtuozzo/OpenVZ
326 |
327 | Virtuozzo是SWsoft公司(目前SWsoft已经改名为Parallels)的操作系统虚拟化软件的命名,Virtuozzo是商业解决方案,而OpenVZ是以Virtuozzo为基础的开源项目,它们采用的也是操作系统级虚拟化技术。OpenVZ 类似于 Linux-VServer,它通过对 Linux 内核进行补丁来提供虚拟化、隔离、资源管理和状态检查。每个 OpenVZ 容器都有一套隔离的文件系统、用户及用户组等。
328 |
329 | ## 参考文献
330 |
331 | 1. ] 金海, 廖小飞. 面向计算系统的虚拟化技术J]. 中国基础科学, 2008, 10(6):12-18.
332 | 2. ] 英特尔开源软件技术中心. 系统虚拟化M]. 清华大学出版社, 2009.
333 | 3. ] GeorgeCoulouris, 库鲁里斯, 金蓓弘,等. 分布式系统:分布式系统概念与设计M]. 机械工业出版社, 2013
334 | 4. ] Andrew S. Tanenbaum, Maarten van Steen. 分布式系统原理与范型M]. 清华大学出版社, 2004.
335 | 5. ] Barham P, Dragovic B, Fraser K, et al. Virtual machine monitors: Xen and the art of virtualizationJ]. Symposium on Operating System Principles, 2003, 36(August):164--177.
336 | 6. ] Qumranet A K, Qumranet Y K, Qumranet D L, et al. kvm: the Linux virtual machine monitorJ]. Proc Linux Symposium, 2007.
337 | 7. ] Adams K, Agesen O. A comparison of software and hardware techniques for x86 virtualizationC]// ACM, 2006:2-13.
338 | 8. ] Uhlig R, Neiger G, Rodgers D, et al. Intel virtualization technologyJ]. Computer, 2005, 38(5):48-56.
339 | 9. ] Garfinkel T, Rosenblum M. A Virtual Machine Introspection Based Architecture for Intrusion DetectionJ]. Proceedings of the Network & Distributed Systems Security Symposium, 2003:191--206.
340 |
341 | 原文作者: doubleXnine
342 |
--------------------------------------------------------------------------------
/virtualization_type/虚拟化架构图.md:
--------------------------------------------------------------------------------
1 | # 虚拟化架构图
2 |
3 | ## 虚拟化架构
4 | ### 全虚拟化架构
5 |
6 | 
7 |
8 | 客户机操作系统不宿主机操作系统的限制
9 |
10 | ### 操作系统层的虚拟化
11 |
12 | 
13 |
14 | 客户机操作系统必须要和宿主机操作系统保持一致
15 |
16 | ### 平台虚拟化(硬件虚拟化)
17 |
18 | 无需安装宿主机操作系统,客户机操作系统可以随意进行安装
19 |
20 | 
21 |
22 | ### Hypervisor
23 | Hypervisor是一种运行在物理服务器和操作系统之间的中间软件层,可允许多个操作系统和应用共享一套基础物理硬件,因此也可以看作是虚拟环境中的“元”操作系统,他可以协调访问服务器上的所有的物理设备和虚拟机,也叫虚拟机监视器。Hypervisor是所有虚拟化技术的核心。当服务器启动并执行Hypervisor时,他会给每一台虚拟机分配适量的内存、CPU、网络和磁盘,并加载所有虚拟机的客户操作系统。常见的产品有Vmware、KVM、Xen等。
24 |
--------------------------------------------------------------------------------
/virtualization_type/虚拟化的分类:
--------------------------------------------------------------------------------
1 | # 虚拟化的分类
2 |
3 | ## 1. 按应用分类
4 | A. 操作系统虚拟化——Vmware的vSphere、workstation;微软的Windows Server with Hyper-v、Virtual PC;IBM的Power VM、zVM;Citrix的Xen
5 | B. 应用程序虚拟化——微软的APP-V;Citrix的Xen APP等
6 | C. 桌面虚拟化——微软的MED-V、VDI;Citrix的Xen Desktop;Vmware的 Vmware view;IBM的Virtual Infrastructure Access等
7 | D. 存储虚拟化、网络虚拟化等
8 |
9 | ## 2. 按照应用模式分类
10 | A. 一对多:其中将一个物理服务器划分为多个虚拟服务器。这是典型的服务器整合模式。
11 | B. 多对一:其中整合了多个虚拟服务器,并将它们作为一个资源池。这是典型的网格计算模式。
12 | C. 多对多:将前两种模式结合在一起。
13 |
14 | ## 3. 按硬件资源调用模式分类
15 | A. 全虚拟化——虚拟操作系统与底层硬件完全隔离,由中间的Hypervisor层转化虚拟客户操作系统对底层硬件的调用代码,全虚拟化无需更改客户端操作系统,兼容性好。典型代表是VMare WorkStation、ESX Server早期版本、Microsoft Vitrual Server
16 | B. 半虚拟化——在虚拟客户操作系统中加入特定的虚拟化指令,通过这些指令可以直接通过Hypervisor层调用硬件资源,免除有hypervisor层转换指令的性能开销。半虚拟化的典型代表Microsoft Hyper-V;Vmware的vSphere
17 | C. 硬件辅助虚拟化——在CPU中加入了新的指令集和处理器运行模式,完成虚拟操作系统对硬件资源的直接调用。典型技术是Intel VT、AMD-V
18 |
19 | ## 4. 按运行平台分类
20 | A. X86平台——由于X86体系结构服务器的蓬勃发展,基于X86体系的虚拟化技术也有了很大的进步,目前比较流行的基于X86体系的虚拟厂商有VMware Microsoft、Citrix、IBM System x系列服务器
21 | B. 非X86平台——非X86平台的虚拟化鼻祖是IBM公司,早在20世纪60年代,IBM就在大型机上实现了虚拟化的商用,目前IBM的虚拟化技术包括大型机的System z系列服务器,中小企业应用的System p系列服务器;HP 的虚拟服务器环境(virtual Server Environment,VSE)以及虚拟 vPar、nPartition 和 Integrity 虚拟机(IVM);Sun的SPARC平台的xVM等,这些都是非X86平台虚拟化的重要力量。
22 |
--------------------------------------------------------------------------------