├── README.md
├── ✍ 文章
├── 18张图揭秘高性能Linux服务器内存池技术是如何实现的.md
├── 5 useful tools to detect memory leaks with examples.md
├── 59问:内存管理.md
├── C++ 实现高性能内存池.md
├── C++中内存管理之new、delete.md
├── Linux 内存占用分析的几个方法,你知道几个?.md
├── Linux: large-memory management histories.md
├── Linux中的内存管理机制.md
├── Linux虚拟内存管理,MMU机制,原来如此.md
├── Looking at kmalloc() and the SLUB Memory Allocator.md
├── Memory Management in OS: Contiguous, Swapping, Fragmentation.md
├── Memory Management in Operating System.md
├── Nginx 内存池管理.md
├── Operating System - Memory Management.md
├── Virtual Memory in OS: What is, Demand Paging, Advantages.md
├── Why Do We Need Virtual Memory?.md
├── glibc2.23 ptmalloc 原理概述.md
├── linux 内核(5.4.81)—内存管理模块源码分析.md
├── linux内存管理---详解.md
├── malloc和free的实现原理解析.md
├── 【性能优化】高效内存池的设计与实现.md
├── 一文了解,Linux内存管理,malloc、free 实现原理.md
├── 一文带你了解,虚拟内存、内存分页、分段、段页式内存管理.md
├── 一文让你看懂内存与CPU之间的关系.md
├── 为什么linux需要虚拟内存.md
├── 内存泄漏的在线排查.md
├── 内存碎片之外部碎片与内部碎片.md
├── 内存管理-内核态内存映射.md
├── 内存管理-物理内存空间管理.md
├── 内存管理-用户态内存映射.md
├── 内存管理之内存映射.md
├── 内存管理之内核空间和用户空间.md
├── 内存管理之分页.md
├── 内存管理系列一:启动简介.md
├── 内存管理系列七:slub初始化.md
├── 内存管理系列三:MMU前CPU初始化及打开MMU.md
├── 内存管理系列九:slub申请内存.md
├── 内存管理系列二十一:内存回收入口.md
├── 内存管理系列二十二:内存回收核心流程.md
├── 内存管理系列二十:内存压缩算法之数据同步.md
├── 内存管理系列二:创建启动阶段的页表.md
├── 内存管理系列五:alloc_pages从伙伴系统申请空间简易流程.md
├── 内存管理系列八:slub创建.md
├── 内存管理系列六:伙伴系统之buffered_rmqueue.md
├── 内存管理系列十一:slub销毁.md
├── 内存管理系列十七:内存池.md
├── 内存管理系列十三:VMA操作.md
├── 内存管理系列十九:内存压缩算法.md
├── 内存管理系列十二:vmalloc内存机制.md
├── 内存管理系列十五:do_page_fault缺页中断.md
├── 内存管理系列十八:内存回收之LRU链表.md
├── 内存管理系列十六:反向映射RMAP.md
├── 内存管理系列十四:brk.md
├── 内存管理系列十:slub回收.md
├── 内存管理系列四:setup_arch简介(内存管理初始化).md
├── 内存管理(一):硬件原理 和 分页管理.md
├── 内存管理(三):进程的内存消耗和泄漏.md
├── 内存管理(二):内存的动态申请和释放.md
├── 内存管理(五):其他工程问题以及调优.md
├── 内存管理(四):内存与IO的交换.md
├── 图解 Linux 内存性能优化核心思想.md
├── 多核心Linux内核路径优化的不二法门之-slab与伙伴系统.md
├── 尽情阅读,技术进阶,详解mmap原理.md
├── 常用寄存器总结.md
├── 浅谈Linux内存管理机制.md
├── 深入浅出linux内存管理(一).md
├── 深入浅出linux内存管理(二).md
├── 深入理解 Linux 内存子系统.md
├── 深入理解 glibc malloc:内存分配器实现原理.md
├── 虚拟地址空间——MMU.md
└── 进程的虚拟内存空间.md
├── 内存管理-用户态内存映射.md
├── 内存管理知识点总结.pdf
└── 📁论文
├── ARM的虚拟内存管理技术的研究.caj
├── C语言的内存漏洞分析与研究.pdf
├── FreeRTOS内存管理方案的分析与改进.pdf
├── Linux Memory Management.pdf
├── Linux内存管理分析与研究.pdf
├── Linux内存管理的设计与实现.pdf
├── Linux内核中内存池的实现及应用.pdf
├── Linux内核中动态内存检测机制的研究.pdf
├── Linux内核伙伴系统分析.pdf
├── Linux内核内存池实现研究.pdf
├── Linux实时内存的研究与实现.pdf
├── Linux操作系统内核分析与研究.pdf
├── Memory Management 101: Introduction to Memory Management in Linux.pdf
├── Memory Management in Linux.pdf
├── Memory Management.pdf
├── NUMA架构内多个节点间访存延时平衡的内存分配策略.pdf
├── Nginx Slab算法研究.pdf
├── TCP_IP协议栈的轻量级多线程实现.caj
├── Understanding the Linux Understanding the Linux.pdf
├── VC中利用内存映射文件实现进程间通信的方法.pdf
├── Virtual Memory Management Techniques in 2.6 Kernel and Challenges.pdf
├── Visual C 中利用内存映射文件在进程之间共享数据.pdf
├── 《Linux Physical Memory Page Allocation》.pdf
├── 一个内存分配器的设计和实现.pdf
├── 一种Linux内存管理机制.pdf
├── 一种TLB结构优化方法.pdf
├── 一种优化的伙伴系统存储管理算法设计.pdf
├── 一种基于虚拟机的动态内存泄露检测方法.pdf
├── 一种提高Linux内存管理实时性的设计方案.pdf
├── 一种改进的Linux内存分配机制.pdf
├── 一种改进的伙伴系统内存管理方法.pdf
├── 一种跨平台内存池的设计与实现.pdf
├── 一种高效的池式内存管理器的设计.pdf
├── 云计算平台中多虚拟机内存协同优化策略研.pdf
├── 云计算平台中多虚拟机内存协同优化策略研究.pdf
├── 内存管理机制的高效实现研究.pdf
├── 分页存储管理系统中内存有效访问时间的计算.pdf
├── 利用内存映射连续性提高TLB地址覆盖范围的技术评测.pdf
├── 动态内存分配器研究综述.pdf
├── 动态存储管理机制的改进及实现.pdf
├── 基于C 的高效内存池的设计与实现.pdf
├── 基于C 自定义内存分配器的实现.pdf
├── 基于Linux内核的动态内存管理机制的实现.pdf
├── 基于Linux内核页表构建内核隔离空间的研究及实现.pdf
├── 基于RDMA和NVM的大数据系统一致性协议研究.pdf
├── 基于RDMA高速网络的高性能分布式系统.pdf
├── 基于RelayFS的内核态内存泄露的检测和跟踪.pdf
├── 基于linux用户态可自控缓冲区管理设计与实现.pdf
├── 基于multimap映射的动态内存分配算法探究.pdf
├── 基于云计算虚拟化平台的内存管理研究.pdf
├── 基于内存池的空间数据调度算法.pdf
├── 多核系统内存管理算法的研究.pdf
├── 实时系统内存管理方案的设计与实现.pdf
├── 对linux伙伴系统及其反碎片机制的研究.pdf
├── 嵌入式实时系统动态内存分配管理器的设计与实现.pdf
├── 并发数据结构及其在动态内存管理中的应用.pdf
├── 应用协同的进程组内存管理支撑技术.pdf
├── 支持高性能IPC的内存管理策略研究.pdf
├── 有效的C 内存泄露检测方法.pdf
├── 浅析伙伴系统的分配与回收.pdf
├── 用户态内存管理关键技术研究.pdf
├── 申威处理器页表结构Cache的优化研究与实现.pdf
├── 虚拟化系统中的内存管理优化.pdf
├── 面向Linux内核空间的内存分配隔离方法的研究与实现.pdf
└── 页面分配器的研究与实现.pdf
/✍ 文章/18张图揭秘高性能Linux服务器内存池技术是如何实现的.md:
--------------------------------------------------------------------------------
1 | 大家生活中肯定都有这样的经验,那就是大众化的产品都比较便宜,但便宜的大众产品就是一个词,普通;而可以定制的产品一般都价位不凡,这种定制的产品注定不会在大众中普及,因此定制产品就是一个词,独特。
2 |
3 | 有的同学可能会有疑问,你不是要聊技术吗?怎么又说起消费了?
4 |
5 | 原来技术也有大众货以及定制品。
6 |
7 |
8 |
9 | **通用 VS 定制**
10 |
11 | 作为程序员(C/C++)我们知道申请内存使用的是malloc,malloc其实就是一个通用的大众货,什么场景下都可以用,**但是什么场景下都可以用就意味着什么场景下都不会有很高的性能**。
12 |
13 | 
14 |
15 | malloc性能不高的原因一在于其没有为特定场景做优化,除此之外还在于malloc看似简单,但是其调用过程是很复杂的,一次malloc的调用过程可能需要经过操作系统的配合才能完成。
16 |
17 | 那么调用malloc时底层都发生了什么呢?简单来说会有这样典型的几个步骤:
18 |
19 | 1. malloc开始搜索空闲内存块,如果能找到一块大小合适的就分配出去
20 | 2. 如果malloc找不到一块合适的空闲内存,那么调用brk等系统调用扩大堆区从而获得更多的空闲内存
21 | 3. malloc调用brk后开始转入内核态,此时操作系统中的虚拟内存系统开始工作,扩大进程的堆区,注意额外扩大的这一部分内存仅仅是虚拟内存,操作系统并没有为此分配真正的物理内存
22 | 4. brk执行结束后返回到malloc,从内核态切换到用户态,malloc找到一块合适的空闲内存后返回
23 |
24 | 
25 |
26 | 以上就是一次内存申请的完整过程,我们可以看到,**一次内存申请过程其实是非常复杂的,**关于这个问题的详细讨论你可以参考这里。
27 |
28 | 既然每次分配内存都要经过这么复杂的过程,**那么如果程序大量使用malloc申请内存那么该程序注定无法获得高性能**。
29 |
30 | 幸好,除了大众货的malloc,我们还可以私人定制,也就是针对特定场景自己来维护内存申请和分配,**这就是高性能高并发必备的内存池技术**。
31 |
32 |
33 |
34 |
35 | ##### **内存池技术有什么特殊的吗?**
36 |
37 | 有的同学可能会说,等等,那malloc和这里提到的内存池技术有什么区别呢?
38 |
39 | 第一个区别在于我们所说的malloc其实是标准库的一部分,位于标准库这一层;而内存池是应用程序的一部分。
40 |
41 | 
42 |
43 | 其次在于定位,我们自己实现的malloc其实也是定位**通用性**的,通用性的内存分配器设计实现往往比较复杂,但是内存池技术就不一样了,**内存池技术专用于某个特定场景**,以此优化程序性能,但内存池技术的通用性是很差的,在一种场景下有很高性能的内存池基本上没有办法在其它场景也能获得高性能,甚至根本就不能用于其它场景,这就是内存池这种技术的定位。
44 |
45 | 
46 |
47 | 那么内存池技术是怎样优化性能的呢?
48 |
49 |
50 |
51 |
52 | ##### **内存池技术原理**
53 |
54 | 简单来说,内存池技术一次性获取到大块内存,然后在其之上自己管理内存的申请和释放,这样就**绕过了标准库以及操作系统**:
55 |
56 | 
57 |
58 | 也就是说,通过内存池,一次内存的申请再也不用去绕一大圈了。
59 |
60 | 除此之外,我们可以根据特定的使用模式来进一步优化,比如在服务器端,每次用户请求需要创建的对象可能就那几种,那么这时我们就可以在自己的内存池上**提前创建**出这些对象,当业务逻辑需要时就从内存池中申请已经创建好的对象,使用完毕后还回内存池。
61 |
62 | 因此我们可以看到,这种为某些应用场景定制的内存池相比通用的比如malloc内存分配器会有大的优势。
63 |
64 | 接下来我们就着手实现一个。
65 |
66 |
67 |
68 |
69 | ##### **实现内存池的考虑**
70 |
71 | 值得注意的是,内存池实际上有很多的实现方法,在这里我们还是以服务器端编程为例来说明。
72 |
73 | 假设你的服务器程序非常简单,处理用户请求时只使用一种对象(数据结构),那么最简单的就是我们提前申请出一堆来,使用的时候拿出一个,使用完后还回去:
74 |
75 | 
76 |
77 | 怎么样,足够简单吧!这样的内存池只能分配特定对象(数据结构),当然这样的内存池需要自己维护哪些对象是已经被分配出去的,哪些是还没有被使用的。
78 |
79 | 但是,在这里我们可以实现一个稍微复杂一些的,那就是可以申请不同大小的内存,而且由于是服务器端编程,那么一次用户请求过程中我们只申请内存,只有当用户请求处理完毕后**一次性释放所有内存**,从而将内存申请释放的开销降低到最小。
80 |
81 | 因此,你可以看到,内存池的设计都是针对特定场景的。
82 |
83 | 现在,有了初步的设计,接下来就是细节了。
84 |
85 |
86 |
87 |
88 | ##### **数据结构**
89 |
90 | 为了能够分配大小可变的对象,显然我们需要管理空闲内存块,我们可以用一个链表把所有内存块链接起来,然后使用一个指针来记录当前空闲内存块的位置,如图所示:
91 |
92 | 
93 |
94 | 从图中我们可以看到,有两个空闲内存块,空闲内存之间使用链表链接起来,每个内存块都是前一个的2倍,也就是说,当内存池中的空闲内存不足以分配时我们就向malloc申请内存,只不过其大小是前一个的2倍:
95 |
96 | 
97 |
98 | 其次,我们有一个指针free_ptr,指向接下来的空闲内存块起始位置,当向内存池分配内存时找到free_ptr并判断当前内存池剩余空闲是否足够就可以了,有就分配出去并修改free_ptr,否则向malloc再次成倍申请内存。
99 |
100 | 从这里的设计可以看出,我们的内存池其实是不会提供类似free这样的内存释放函数的,如果要释放内存,那么会一次性将整个内存池释放掉,这一点和通用的内存分配器是不一样。
101 |
102 | 现在,我们可以分配内存了,还有一个问题是所有内存池设计不得不考虑的,那就是线程安全,这个话题你可以参考这里。
103 |
104 |
105 |
106 |
107 | ##### **线程安全**
108 |
109 | 显然,内存池不应该局限在单线程场景,那我们的内存池要怎样实现线程安全呢?
110 |
111 | 有的同学可能会说这还不简单,直接给内存池一把锁保护就可以了。
112 |
113 | 
114 |
115 | 这种方法是不是可行呢?还是那句话,It depends,要看情况。
116 |
117 | 如果你的程序有大量线程申请释放内存,那么这种方案下锁的竞争将会非常激烈,线程这样的场景下使用该方案不会有很好的性能。
118 |
119 | 那么还有没有一种更好的办法吗?答案是肯定的。
120 |
121 |
122 |
123 |
124 | ##### **线程局部存储**
125 |
126 | 既然多线程使用线程池存在竞争问题,那么干脆我们为每个线程维护一个内存池就好了,这样多线程间就不存在竞争问题了。
127 |
128 | 那么我们该怎样为每个线程维护一个内存池呢?
129 |
130 | 线程局部存储,Thread Local Storage正是用于解决这一类问题的,什么是线程局部存储呢?
131 |
132 | 简单说就是,我们可以创建一个全局变量,因此所有线程都可以使用该全局变量,但与此同时,我们将该全局变量声明为线程私有存储,那么这时虽然所有线程依然看似使用同一个全局变量,但该全局变量在每个线程中都有自己的副本,**变量指向的值是线程私有的**,相互之间不会干扰。
133 |
134 | 
135 |
136 | 关于线程局部存储,可以参考这里。
137 |
138 | 假设这个全局变量是一个整数,变量名字为global_value,初始值为100,那么当线程A将global_value修改为200时,线程B看到的global_value的值依然为100,只有线程A看到的global_value为200,这就是线程局部存储的作用。
139 |
140 |
141 |
142 |
143 | ##### **线程局部存储+内存池**
144 |
145 | 有了线程局部存储问题就简单了,我们可以将内存池声明为线程局部存储,这样每个线程都只会操作属于自己的内存池,这样就再也不会有锁竞争问题了。
146 |
147 | 
148 |
149 | 注意,虽然这里给出了线程局部存储的设计,但并不是说加锁的方案就比不上线程局部存储方案,还是那句话,一切要看使用场景,如果加锁的方案够用,那么我们就没有必要绞尽脑汁的去用其它方案,因为加锁的方案更简单,代码也更容易维护。
150 |
151 | 还需要提醒的是,这里只是给出了内存池的一种实现方法,并不是说所有内存池都要这么设计,内存池可以简单也可复杂,一切要看实际场景,这一点也需要注意。
152 |
153 |
154 |
155 |
156 | ##### **其它内存池形式**
157 |
158 | 到目前为止我们给出了两种内存池的设计方法,第一种是提前创建出一堆需要的对象(数据结构),自己维护好哪些对象(数据结构)可用哪些已被分配;第二种可以申请任意大小的内存空间,使用过程中只申请不释放,最后一次性释放。这两种内存池天然适用于服务器端编程。
159 |
160 | 最后我们再来介绍一种内存池实现技术,这种内存池会提前申请出一大段内存,然后将这一大段内存切分为大小相同的小内存块:
161 |
162 | 
163 |
164 | 然后我们自己来维护这些被切分出来的小内存块哪些是空闲的哪些是已经被分配的,比如我们可以使用栈这种数据结构,最初把所有空闲内存块地址push到栈中,分配内存是就pop出来一个,用户使用完毕后再push回栈里。
165 |
166 | 
167 |
168 | 从这里的设计我们可以看出,这种内存池有一个限制,这个限制就是说**程序申请的最大内存不能超过这里内存块的大小**,否则不足以装下用户数据,这需要我们对程序所涉及的业务非常了解才可以。
169 |
170 | 用户申请到内存后根据需要将其塑造成特定对象(数据结构)。
171 |
172 | 关于线程安全的问题,可以同样采用线程局部存储的方式来实现:
173 |
174 | 
175 |
176 |
177 |
178 |
179 | ##### **一个有趣的问题**
180 |
181 | 除了线程安全,这里还有一个非常有趣的问题,那就是如果线程A申请的对象被线程B拿去释放,我们的内存池该怎么处理呢?
182 |
183 | 这个问题之所以有趣是因为我们**必须知道该内存属于哪个线程的局部存储,但申请的内存本身并不能告诉你这样的信息**。
184 |
185 | 有的同学可能会说这还不简单,不就是一个指针到另一个指针的映射吗,直接用map之类存起来就好了,但问题并没有这么简单,原因就在于如果我们切分的内存块很小,那么会存在大量内存块,这就需要存储大量的映射关系,有没有办法改进呢?
186 |
187 | 改进方法是这样的,一般来说,我们申请到的大段内存其实是会按照特定大小进行内存对齐,我们假设总是按照4K字节对齐,那么该大段内存的起始地址后12个bit(4K = 2^12)为总是0,比如地址0x9abcd**000**,同时我们也假设申请到的大段内存大小也是4K:
188 |
189 | 
190 |
191 | 那么我们就能知道该大段内存中的各个小内存块起始地址除了后12个bit位外都是一样的:
192 |
193 | 
194 |
195 | 这样拿到任意一个内存的地址我们就能知道对应的大段内存的起始地址,只需要简单的将后12个bit置为0即可,有了大段内存的起始地址剩下的就简单了,我们可以在大段内存中的最后保存对应的线程局部存储信息:
196 |
197 | 
198 |
199 | **这样我们对任意一个内存块地址进行简单的位运算就可以得到对应的线程局部存储信息**,大大减少了维护映射信息对内存的占用。
200 |
201 |
202 |
203 |
204 | ##### **总结**
205 |
206 | 内存池是高性能服务器中常见的一种优化技术,在这里我们介绍了三种实现方法,值得注意的是,内存池实现没有统一标准,一切都要根据具体场景定制,因此我们可以看到内存池设计是有针对性的,当然其反面就是不具备通用性。
207 |
208 | 希望本文对大家理解内存池有所帮助。
209 |
--------------------------------------------------------------------------------
/✍ 文章/Linux中的内存管理机制.md:
--------------------------------------------------------------------------------
1 | 程序在运行时所有的数据结构的分配都是在堆和栈上进行的,而堆和栈都是建立在内存之上。内存作为现代计算机运行的核心,CPU可以直接访问的通用存储只有内存和处理器内置的寄存器,所有的代码都需要装载到内存之后才能让CPU通过指令寄存器找到相应的地址进行访问。
2 |
3 | ## 地址空间和MMU
4 |
5 | 内存管理单元(MMU)是硬件提供的最底层的内存管理机制,是CPU的一部分,用来管理内存的控制线路,提供把虚拟地址映射为物理地址的能力。
6 |
7 | 在x86体系结构下,CPU对内存的寻址都是通过分段方式进行的。其工作流程为:CPU生成逻辑地址并交给分段单元。分段单元为每个逻辑地址生成一个线性地址。然后线性地址交给分页单元,以生成内存的物理地址。因此也就是分段和分页单元组成了内存管理单元(MMU)。
8 |
9 | 
10 |
11 | 其中: + 虚拟地址:在段中的偏移地址 + 线性地址:在某个段中“基地址+偏移地址”得出的地址 + 物理地址:在x86中,MMU还提供了分页机制,假如没有开启分页机制,那么线性地址就等于物理地址;否则还需要经过分页机制换算后线性地址才能转换成物理地址。 一个段是由“基地址+段界限(该段长度)+类型”组成,主要确定了段的起始地址,段的界限长度和确定段的属性如是否可读、可写、段的基本粒度单位、表述该段是数据段还是代码段等。 分段允许进程的物理地址空间是非连续的,分页则是提供这一优势的另外一种内存管理方案,并且**分页避免了外部碎片和紧缩,分段却不可以**。在x86体系中MMU支持多级的分页模型,主要分为以下三种情况: 1. 32为系统分为2级分页模型 2. 32位系统开启了物理地址扩展模式(PAE),则分为3级分页模型 3. 64位系统分为4级分页模型 80x86的分页机制由CR0中的PG位开启,若PG=0则禁用分页机制,也就是直接将线性地址作为物理地址。32位的线性地址主要分为三个部分:
12 |
13 | 
14 |
15 | * 22-31位指向页目录表中的某一项,页目录表中的每一项存有4子节地址指向页表。所以页表目录大小为4 * 210 = 4K
16 | * 12-21位指向页表中的某一项,页表大小与页目录表相同为4K
17 | * 一个物理页为4K,刚好0-11位指向页表中的偏移,一个页表刚好4K(212)
18 |
19 | 页表和页目录表可以存放在内存的任何地方,当分页机制开启后,需要让CR3寄存器指向页目录表的起始地址。
20 |
21 | > CR0-CR4这五个寄存器为系统内的控制寄存器,与分页机制密切相关。
22 | > CR0控制寄存器是一些特殊的寄存器,可以控制CPU的一些重要特性;
23 | > CR1是未定义的控制寄存器,供将来使用;
24 | > CR2是页故障线性地址寄存器,保存最后一次出现页故障的全32位线性地址;
25 | > CR3是页目录基址寄存器,保存页目录表的物理地址(页目录表总是放在4k为单位的存储器边界上,因此其低12位总为0不起作用,即使写上内容也不会被理会)
26 | > CR4在Pentium系列(包括486后期版本)处理器中才出现,处理事务包括何时启用虚拟8086模式等。
27 |
28 | ### Linux中的分段与分页
29 |
30 | MMU在保护模式下分段数据主要定义在GDT中。
31 |
32 | ```c
33 | //arch/x86/kernel/cpu/common.c
34 |
35 | DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = { .gdt = {
36 | ...
37 | [GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xc09a, 0, 0xfffff), //代码段
38 | [GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff), //数据段
39 | [GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xc0fa, 0, 0xfffff),
40 | [GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f2, 0, 0xfffff),
41 | ...
42 | } };
43 | EXPORT_PER_CPU_SYMBOL_GPL(gdt_page);
44 | ```
45 |
46 | 通过代码可知道这些段的基地址都是0,界限为4G。说明Linux只定义了一个段,并没有真正利用分段机制。
47 |
48 | Linux中只用了一个段,而且基地址从0开始,那么在程序中使用的虚地址就是线性地址了。Linux为了兼容64位、32位及其PAE扩展情况,在代码中通过4级分页机制来做兼容。
49 |
50 | ## Linux的内存分配与管理
51 |
52 | 在32位的x86设备中,Linux为每个进程分配的虚拟地址空间都是0-4GB,其中
53 |
54 | * 0-3GB用于用户态使用
55 | * 3GB-3GB+896MB映射到物理地址的0-896MB处,作为内核态地址空间
56 | * 3GB+896MB-4GB之间的128MB空间用于vmalloc保留区域,该区域用于kmalloc、kmap固定地址映射等功能,可以让内核访问高端物理地址空间
57 |
58 | 
59 |
60 | Linux中进程的地址空间由mm_struct来描述,一个进程只会有一个mm_struct。系统中的内核态是共享的,不会发生缺页中断或者访问用户进程空间,所以内核线程的task_struct->mm为NULL。
61 |
62 | 页表的分配分为两个部分:
63 |
64 | 1、内核页表,也就是在系统启动中,最后会在paging_init函数中,把ZONE_DMA和ZONE_NORMAL区域的物理页面与虚拟地址空间的3GB-3GB+896MB进行直接映射
65 | 2、内核高端地址和用户态地址,都是通过MMU机制修改线性地址(虚拟地址)和物理地址的映射关系,然后刷新页表缓存来达到的
66 |
67 | > 物理内存中ZONE_DMA的范围是0-16MB,该区域的物理页面专门供IO设备的DMA使用,之所以要单独管理DMA的物理页面,是因为DMA使用物理地址访问内存不经过MMU,并且需要连续的缓冲区。为了能够提供物理上的连续缓冲区,必须从物理地址专门划分出一段区域用于DMA。 ZONE_NORMAL的范围是16MB-896MB,该区域的物理页面是内核能够直接使用的。 ZONE_HIGHMEM的范围是896MB-结束,该区域即高端内存,内核不能直接使用。
68 |
69 | ### 伙伴系统
70 | 对于物理内存经过频繁地申请和释放后会产生外部碎片,Linux通过伙伴系统来解决外部碎片的问题。
71 |
72 | 满足:
73 | 1.具有相同的大小;
74 | 2.物理地址连续条件的两个块为伙伴。主要实现思路位伙伴系统在申请内存的时候让最小的块满足申请的需求,在归还的时候,尽量让连续的小块内存伙伴合并成大块,降低外部碎片出现的可能性。
75 |
76 | 在Linux系统中伙伴系统维护了11个块链表,每个块链表分别包含了大小为20-211个连续的物理页。对1024个页的最大请求对应着4MB大小的连续RAM块。每个快的第一个页框的物理地址就是该块大小的整数倍。如大小为16个页框的块,其起始地址为16×212(212=4KB这是一个页的大小)的倍数。
77 |
78 | 系统在初始化的时候把内各节点各区域都释放到伙伴系统中,每个区域还维护了per-cpu高速缓存来处理单页的分配,各个区域都通过伙伴算法进行物理内存的分配。
79 |
80 | ### slab分配器
81 |
82 | Linux系统通过伙伴算法解决了外部碎片的问题,此外还提供了slab分配器来处理内部碎片的问题。slab分配器也是一种内存预分配机制,是一种空间换时间的做法,并且其假定从slab分配器中获得的内存都是比页还小的小内存块。
83 |
84 | 
85 |
86 | slab的设计思想就是把若干的页框合在一起形成一大存储块——slab,并在这个slab中只存储同一类数据,这样就可以在这个slab内部打破页的界限,以该类型数据的大小来定义分配粒度,存放多个数据,这样就可以尽可能地减少页内碎片了。在Linux中,多个存储同类数据的slab的集合叫做一类对象的缓冲区——cache。注意,这不是硬件的那个cache,只是借用这个名词而已。
87 |
88 | Linux中slab的可分为以下三种状态:
89 |
90 | 1、slabs_full:该链表中slab已经完全分配出去
91 | 2、slabs_free:该链表中的slab都是空闲可分配状态
92 | 3、labs_partial:该链表中的slab部分已经被分配出去了
93 |
94 | 其中slab代表物理地址连续的内存块,由1-N个物理页面组成,在一个slab中可以分配多个object对象。
95 |
96 | slab的优点:
97 |
98 | * 内核通常依赖于对小对象的分配,它们会在系统生命周期内进行无数次分配。slab 缓存分配器通过对类似大小的对象进行缓存而提供这种功能,从而避免了常见的碎片问题;
99 | * slab 分配器还支持通用对象的初始化,从而避免了为同一目的而对一个对象重复进行初始化;
100 | * slab 分配器还可以支持硬件缓存对齐和着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能。
101 |
102 | slab的缺点:
103 |
104 | * 较多复杂的队列管理。在slab分配器中存在众多的队列,例如针对处理器的本地缓存队列,slab中空闲队列,每个slab处于一个特定状态的队列之中。
105 | * slab管理数据和队列的存储开销比较大。每个slab需要一个struct slab数据结构和一个管理者kmem_bufctl_t型的数组。当对象体积较小时,该数组将造成较大的开销(比如对象大小为32字节时,将浪费1/8空间)。同时,缓冲区针对节点和处理器的队列也会浪费不少内存。
106 | * 缓冲区回收、性能调试调优比较复杂。
107 |
108 |
109 | ### 内核态内存管理
110 |
111 | 根据之前的的Linux的内存管理机制,即伙伴系统和slab分配器。对于内核态的内存分配主要通过函数kmalloc和vmalloc完成。
112 |
113 | 
114 |
115 | 其中kmalloc函数可以为内核申请连续物理地址的内存空间,由于kmalloc是基于slab分配器实现的,所以比较适合较小块的内存申请。kmalloc函数的调用过程为:`kmalloc->__kmalloc->__do_kmalloc`,其中`__do_kmalloc`的实现主要分为两步:
116 |
117 | 1、通过`kmalloc_slab`找到一个合适的`kmem_cache`缓存
118 | 2、通过`slab_alloc`向slab分配器申请对象内存空间
119 |
120 | Linux提供的vmalloc函数可以获得连续的虚拟空间,但是其物理内存不一定连续。vmalloc函数的调用过程为:`vmalloc->__vmalloc_node_flags->__vmalloc_node->__vmalloc_node_range`。其中`__vmalloc_node_range`函数也分为两步:
121 |
122 | 1、通过`__get_vm_area_node`分配一个可用的虚拟地址空间
123 | 2、`__vmalloc_node_range`通过`alloc_pages`一页一页申请物理内存,再为刚才申请的虚拟地址空间分配物理页表映射
124 |
125 |
126 |
--------------------------------------------------------------------------------
/✍ 文章/Linux虚拟内存管理,MMU机制,原来如此.md:
--------------------------------------------------------------------------------
1 | ## MMU
2 |
3 | 现代操作系统普遍采用虚拟内存管理(Virtual Memory Management)机制,这需要处理器中的MMU(Memory Management Unit,内存管理单元)提供支持。
4 |
5 | 首先引入 PA 和 VA 两个概念。
6 |
7 | ## PA
8 |
9 | 如果处理器没有MMU,或者有MMU但没有启用,CPU执行单元发出的内存地址将直接传到芯片引脚上,被内存芯片(以下称为物理内存,以便与虚拟内存区分)接收,这称为PA(Physical Address,以下简称PA),如下图所示。
10 |
11 | 
12 |
13 |
14 | ## VA
15 | 如果处理器启用了MMU,CPU执行单元发出的内存地址将被MMU截获,从CPU到MMU的地址称为虚拟地址(Virtual Address,以下简称VA),而MMU将这个地址翻译成另一个地址发到CPU芯片的外部地址引脚上,也就是将VA映射成PA,如下图所示。
16 |
17 | 
18 |
19 | 如果是32位处理器,则内地址总线是32位的,与CPU执行单元相连(图中只是示意性地画了4条地址线),而经过MMU转换之后的外地址总线则不一定是32位的。也就是说,虚拟地址空间和物理地址空间是独立的,32位处理器的虚拟地址空间是4GB,而物理地址空间既可以大于也可以小于4GB。
20 |
21 | MMU将VA映射到PA是以页(Page)为单位的,32位处理器的页尺寸通常是4KB。例如,MMU可以通过一个映射项将VA的一页0xb7001000~0xb7001fff映射到PA的一页0x2000~0x2fff,如果CPU执行单元要访问虚拟地址0xb7001008,则实际访问到的物理地址是0x2008。物理内存中的页称为物理页面或者页帧(Page Frame)。虚拟内存的哪个页面映射到物理内存的哪个页帧是通过页表(Page Table)来描述的,页表保存在物理内存中,MMU会查找页表来确定一个VA应该映射到什么PA。
22 |
23 | ## 进程地址空间
24 |
25 | 
26 |
27 | x86平台的虚拟地址空间是0x0000 0000~0xffff ffff,大致上前3GB(0x0000 0000~0xbfff ffff)是用户空间,后1GB(0xc000 0000~0xffff ffff)是内核空间。
28 |
29 | Text Segmest 和 Data Segment
30 |
31 | * Text Segment,包含.text段、.rodata段、.plt段等。是从/bin/bash加载到内存的,访问权限为r-x。
32 | * Data Segment,包含.data段、.bss段等。也是从/bin/bash加载到内存的,访问权限为rw-。
33 |
34 | ## 堆和栈
35 |
36 | * 堆(heap):堆说白了就是电脑内存中的剩余空间,malloc函数动态分配内存是在这里分配的。在动态分配内存时堆空间是可以向高地址增长的。堆空间的地址上限称为Break,堆空间要向高地址增长就要抬高Break,映射新的虚拟内存页面到物理内存,这是通过系统调用brk实现的,malloc函数也是调用brk向内核请求分配内存的。
37 | * 栈(stack):栈是一个特定的内存区域,其中高地址的部分保存着进程的环境变量和命令行参数,低地址的部分保存函数栈帧,栈空间是向低地址增长的,但显然没有堆空间那么大的可供增长的余地,因为实际的应用程序动态分配大量内存的并不少见,但是有几十层深的函数调用并且每层调用都有很多局部变量的非常少见。
38 |
39 | 如果写程序的时候没有注意好内存的分配问题,在堆和栈这两个地方可能产生以下几种问题:
40 |
41 | 1、内存泄露:如果你在一个函数里通过 malloc 在堆里申请了一块空间,并在栈里声明一个指针变量保存它,那么当该函数结束时,该函数的成员变量将会被释放,包括这个指针变量,那么这块空间也就找不回来了,也就无法得到释放。久而久之,可能造成下面的内存泄露问题。
42 | 2、栈溢出:如果你放太多数据到栈中(例如大型的结构体和数组),那么就可能会造成“栈溢出”(Stack Overflow)问题,程序也将会终止。为了避免这个问题,在声明这类变量时应使用 malloc 申请堆的空间。
43 | 3、野指针 和 段错误:如果一个指针所指向的空间已经被释放,此时再试图用该指针访问已经被释放了的空间将会造成“段错误”(Segment Fault)问题。此时指针已经变成野指针,应该及时手动将野指针置空。
44 |
45 | ## 虚拟内存管理的作用
46 |
47 | 1、虚拟内存管理可以控制物理内存的访问权限。物理内存本身是不限制访问的,任何地址都可以读写,而操作系统要求不同的页面具有不同的访问权限,这是利用CPU模式和MMU的内存保护机制实现的。
48 | 2、虚拟内存管理最主要的作用是让每个进程有独立的地址空间。所谓独立的地址空间是指,不同进程中的同一个VA被MMU映射到不同的PA,并且在某一个进程中访问任何地址都不可能访问到另外一个进程的数据,这样使得任何一个进程由于执行错误指令或恶意代码导致的非法内存访问都不会意外改写其它进程的数据,不会影响其它进程的运行,从而保证整个系统的稳定性。另一方面,每个进程都认为自己独占整个虚拟地址空间,这样链接器和加载器的实现会比较容易,不必考虑各进程的地址范围是否冲突。
49 |
50 | 
51 |
52 | 3、VA到PA的映射会给分配和释放内存带来方便,物理地址不连续的几块内存可以映射成虚拟地址连续的一块内存。比如要用malloc分配一块很大的内存空间,虽然有足够多的空闲物理内存,却没有足够大的连续空闲内存,这时就可以分配多个不连续的物理页面而映射到连续的虚拟地址范围。
53 |
54 | 
55 |
56 | 4、一个系统如果同时运行着很多进程,为各进程分配的内存之和可能会大于实际可用的物理内存,虚拟内存管理使得这种情况下各进程仍然能够正常运行。因为各进程分配的只不过是虚拟内存的页面,这些页面的数据可以映射到物理页面,也可以临时保存到磁盘上而不占用物理页面,在磁盘上临时保存虚拟内存页面的可能是一个磁盘分区,也可能是一个磁盘文件,称为交换设备(Swap Device)。当物理内存不够用时,将一些不常用的物理页面中的数据临时保存到交换设备,然后这个物理页面就认为是空闲的了,可以重新分配给进程使用,这个过程称为换出(Page out)。如果进程要用到被换出的页面,就从交换设备再加载回物理内存,这称为换入(Page in)。换出和换入操作统称为换页(Paging),因此:\[\mbox{系统中可分配的内存总量} = \mbox{物理内存的大小} + \mbox{交换设备的大小}\]
57 |
58 | 如下图所示。第一张图是换出,将物理页面中的数据保存到磁盘,并解除地址映射,释放物理页面。第二张图是换入,从空闲的物理页面中分配一个,将磁盘暂存的页面加载回内存,并建立地址映射。
59 |
60 | 
61 |
62 | ## malloc 和 free
63 |
64 | C标准库函数malloc可以在堆空间动态分配内存,它的底层通过brk系统调用向操作系统申请内存。动态分配的内存用完之后可以用free释放,更准确地说是归还给malloc,这样下次调用malloc时这块内存可以再次被分配。
65 |
66 | ```c
67 | #include
68 |
69 | void *malloc(size_t size);
70 | 返回值:成功返回所分配内存空间的首地址,出错返回NULL
71 |
72 | void free(void *ptr);
73 | ```
74 |
75 | malloc的参数size表示要分配的字节数,如果分配失败(可能是由于系统内存耗尽)则返回NULL。由于malloc函数不知道用户拿到这块内存要存放什么类型的数据,所以返回通用指针void *,用户程序可以转换成其它类型的指针再访问这块内存。malloc函数保证它返回的指针所指向的地址满足系统的对齐要求,例如在32位平台上返回的指针一定对齐到4字节边界,以保证用户程序把它转换成任何类型的指针都能用。
76 | 动态分配的内存用完之后可以用free释放掉,传给free的参数正是先前malloc返回的内存块首地址。
77 |
78 | **示例**
79 |
80 | ```c
81 | #include
82 | #include
83 | #include
84 |
85 | typedef struct {
86 | int number;
87 | char *msg;
88 | } unit_t;
89 |
90 | int main(void)
91 | {
92 | unit_t *p = malloc(sizeof(unit_t));
93 |
94 | if (p == NULL) {
95 | printf("out of memory\n");
96 | exit(1);
97 | }
98 | p->number = 3;
99 | p->msg = malloc(20);
100 | strcpy(p->msg, "Hello world!");
101 | printf("number: %d\nmsg: %s\n", p->number, p->msg);
102 | free(p->msg);
103 | free(p);
104 | p = NULL;
105 |
106 | return 0;
107 | }
108 | ```
109 |
110 | **说明**
111 |
112 | * `unit_t *p = malloc(sizeof(unit_t))`;这一句,等号右边是`void *`类型,等号左边是`unit_t *`类型,编译器会做隐式类型转换,我们讲过`void *`类型和任何指针类型之间可以相互隐式转换。
113 | * 虽然内存耗尽是很不常见的错误,但写程序要规范,malloc之后应该判断是否成功。以后要学习的大部分系统函数都有成功的返回值和失败的返回值,每次调用系统函数都应该判断是否成功。
114 | * `free(p)`;之后,p所指的内存空间是归还了,但是p的值并没有变,因为从free的函数接口来看根本就没法改变p的值,p现在指向的内存空间已经不属于用户,换句话说,p成了野指针,为避免出现野指针,我们应该在`free(p)`;之后手动置`p = NULL`;。
115 | * 应该先`free(p->msg)`,再`free(p)`。如果先`free(p)`,p成了野指针,就不能再通过`p->msg`访问内存了。
116 |
117 | ## 内存泄漏
118 |
119 | 如果一个程序长年累月运行(例如网络服务器程序),并且在循环或递归中调用malloc分配内存,则必须有free与之配对,分配一次就要释放一次,否则每次循环都分配内存,分配完了又不释放,就会慢慢耗尽系统内存,这种错误称为内存泄漏(Memory Leak)。另外,malloc返回的指针一定要保存好,只有把它传给free才能释放这块内存,如果这个指针丢失了,就没有办法free这块内存了,也会造成内存泄漏。例如:
120 |
121 | ```c
122 | void foo(void)
123 | {
124 | char *p = malloc(10);
125 | ...
126 | }
127 | ```
128 |
129 | foo函数返回时要释放局部变量p的内存空间,它所指向的内存地址就丢失了,这10个字节也就没法释放了。内存泄漏的Bug很难找到,因为它不会像访问越界一样导致程序运行错误,少量内存泄漏并不影响程序的正确运行,大量的内存泄漏会使系统内存紧缺,导致频繁换页,不仅影响当前进程,而且把整个系统都拖得很慢。
130 |
131 | 关于malloc和free还有一些特殊情况。malloc(0)这种调用也是合法的,也会返回一个非NULL的指针,这个指针也可以传给free释放,但是不能通过这个指针访问内存。free(NULL)也是合法的,不做任何事情,但是free一个野指针是不合法的,例如先调用malloc返回一个指针p,然后连着调用两次free§;,则后一次调用会产生运行时错误。
132 |
--------------------------------------------------------------------------------
/✍ 文章/Virtual Memory in OS: What is, Demand Paging, Advantages.md:
--------------------------------------------------------------------------------
1 | ## What is Virtual Memory?
2 |
3 | **Virtual Memory** is a storage mechanism which offers user an illusion of having a very big main memory. It is done by treating a part of secondary memory as the main memory. In Virtual memory, the user can store processes with a bigger size than the available main memory.
4 |
5 | Therefore, instead of loading one long process in the main memory, the OS loads the various parts of more than one process in the main memory. Virtual memory is mostly implemented with demand paging and demand segmentation.
6 |
7 | In this Operating system tutorial, you will learn:
8 |
9 | - [What is Virtual Memory?](https://www.guru99.com/virtual-memory-in-operating-system.html#1)
10 | - [How Virtual Memory Works?](https://www.guru99.com/virtual-memory-in-operating-system.html#2)
11 | - [What is Demand Paging?](https://www.guru99.com/virtual-memory-in-operating-system.html#3)
12 | - [Types of Page replacement methods](https://www.guru99.com/virtual-memory-in-operating-system.html#4)
13 | - [FIFO Page Replacement](https://www.guru99.com/virtual-memory-in-operating-system.html#5)
14 | - [Optimal Algorithm](https://www.guru99.com/virtual-memory-in-operating-system.html#6)
15 | - [LRU Page Replacement](https://www.guru99.com/virtual-memory-in-operating-system.html#7)
16 | - [Advantages of Virtual Memory](https://www.guru99.com/virtual-memory-in-operating-system.html#8)
17 | - [Disadvantages of Virtual Memory](https://www.guru99.com/virtual-memory-in-operating-system.html#9)
18 |
19 | ## Why Need Virtual Memory?
20 |
21 | Here, are reasons for using virtual memory:
22 |
23 | - Whenever your computer doesn’t have space in the physical memory it writes what it needs to remember to the hard disk in a swap file as virtual memory.
24 | - If a computer running Windows needs more memory/RAM, then installed in the system, it uses a small portion of the hard drive for this purpose.
25 |
26 | ## How Virtual Memory Works?
27 |
28 | In the modern world, virtual memory has become quite common these days. It is used whenever some pages require to be loaded in the main memory for the execution, and the memory is not available for those many pages.
29 |
30 | So, in that case, instead of preventing pages from entering in the main memory, the OS searches for the RAM space that are minimum used in the recent times or that are not referenced into the secondary memory to make the space for the new pages in the main memory.
31 |
32 | Let’s understand virtual memory management with the help of one example.
33 |
34 | ### For example:
35 |
36 | Let’s assume that an OS requires 300 MB of memory to store all the running programs. However, there’s currently only 50 MB of available physical memory stored on the RAM.
37 |
38 | - The OS will then set up 250 MB of virtual memory and use a program called the Virtual Memory Manager(VMM) to manage that 250 MB.
39 | - So, in this case, the VMM will create a file on the hard disk that is 250 MB in size to store extra memory that is required.
40 | - The OS will now proceed to address memory as it considers 300 MB of real memory stored in the RAM, even if only 50 MB space is available.
41 | - It is the job of the VMM to manage 300 MB memory even if just 50 MB of real memory space is available.
42 |
43 | ## What is Demand Paging?
44 |
45 | 
46 |
47 | A demand paging mechanism is very much similar to a paging system with swapping where processes stored in the secondary memory and pages are loaded only on demand, not in advance.
48 |
49 | So, when a context switch occurs, the OS never copy any of the old program’s pages from the disk or any of the new program’s pages into the main memory. Instead, it will start executing the new program after loading the first page and fetches the program’s pages, which are referenced.
50 |
51 | During the program execution, if the program references a page that may not be available in the main memory because it was swapped, then the processor considers it as an invalid memory reference. That’s because the page fault and transfers send control back from the program to the OS, which demands to store page back into the memory.
52 |
53 | ## Types of Page Replacement Methods
54 |
55 | Here, are some important Page replacement methods
56 |
57 | - FIFO
58 | - Optimal Algorithm
59 | - LRU Page Replacement
60 |
61 | ## FIFO Page Replacement
62 |
63 | FIFO (First-in-first-out) is a simple implementation method. In this method, memory selects the page for a replacement that has been in the virtual address of the memory for the longest time.
64 |
65 | ### Features:
66 |
67 | - Whenever a new page loaded, the page recently comes in the memory is removed. So, it is easy to decide which page requires to be removed as its identification number is always at the FIFO stack.
68 | - The oldest page in the main memory is one that should be selected for replacement first.
69 |
70 | ## Optimal Algorithm
71 |
72 | The optimal page replacement method selects that page for a replacement for which the time to the next reference is the longest.
73 |
74 | ### Features:
75 |
76 | - Optimal algorithm results in the fewest number of page faults. This algorithm is difficult to implement.
77 | - An optimal page-replacement algorithm method has the lowest page-fault rate of all algorithms. This algorithm exists and which should be called MIN or OPT.
78 | - Replace the page which unlike to use for a longer period of time. It only uses the time when a page needs to be used.
79 |
80 | ## LRU Page Replacement
81 |
82 | The full form of LRU is the Least Recently Used page. This method helps OS to find page usage over a short period of time. This algorithm should be implemented by associating a counter with an even- page.
83 |
84 | ### How does it work?
85 |
86 | - Page, which has not been used for the longest time in the main memory, is the one that will be selected for replacement.
87 | - Easy to implement, keep a list, replace pages by looking back into time.
88 |
89 | ### Features:
90 |
91 | - The LRU replacement method has the highest count. This counter is also called aging registers, which specify their age and how much their associated pages should also be referenced.
92 | - The page which hasn’t been used for the longest time in the main memory is the one that should be selected for replacement.
93 | - It also keeps a list and replaces pages by looking back into time.
94 |
95 | ### Fault rate
96 |
97 | Fault rate is a frequency with which a designed system or component fails. It is expressed in failures per unit of time. It is denoted by the Greek letter ? (lambda).
98 |
99 | ## Advantages of Virtual Memory
100 |
101 | Here, are pros/benefits of using Virtual Memory:
102 |
103 | - Virtual memory helps to gain speed when only a particular segment of the program is required for the execution of the program.
104 | - It is very helpful in implementing a multiprogramming environment.
105 | - It allows you to run more applications at once.
106 | - It helps you to fit many large programs into smaller programs.
107 | - Common data or code may be shared between memory.
108 | - Process may become even larger than all of the physical memory.
109 | - Data / code should be read from disk whenever required.
110 | - The code can be placed anywhere in physical memory without requiring relocation.
111 | - More processes should be maintained in the main memory, which increases the effective use of CPU.
112 | - Each page is stored on a disk until it is required after that, it will be removed.
113 | - It allows more applications to be run at the same time.
114 | - There is no specific limit on the degree of multiprogramming.
115 | - Large programs should be written, as virtual address space available is more compared to physical memory.
116 |
117 | ## Disadvantages of Virtual Memory
118 |
119 | Here, are drawbacks/cons of using virtual memory:
120 |
121 | - Applications may run slower if the system is using virtual memory.
122 | - Likely takes more time to switch between applications.
123 | - Offers lesser hard drive space for your use.
124 | - It reduces system stability.
125 | - It allows larger applications to run in systems that don’t offer enough physical RAM alone to run them.
126 | - It doesn’t offer the same performance as RAM.
127 | - It negatively affects the overall performance of a system.
128 | - Occupy the storage space, which may be used otherwise for long term data storage.
129 |
130 | ## Summary:
131 |
132 | - Virtual Memory is a storage mechanism which offers user an illusion of having a very big main memory.
133 | - Virtual memory is needed whenever your computer doesn’t have space in the physical memory
134 | - A demand paging mechanism is very much similar to a paging system with swapping where processes stored in the secondary memory and pages are loaded only on demand, not in advance.
135 | - Important Page replacement methods are 1) FIFO 2) Optimal Algorithm 3) LRU Page Replacement.
136 | - In FIFO (First-in-first-out) method, memory selects the page for a replacement that has been in the virtual address of the memory for the longest time.
137 | - The optimal page replacement method selects that page for a replacement for which the time to the next reference is the longest.
138 | - LRU method helps OS to find page usage over a short period of time.
139 | - Virtual memory helps to gain speed when only a particular segment of the program is required for the execution of the program.
140 | - Applications may run slower if the system is using virtual memory.
141 |
--------------------------------------------------------------------------------
/✍ 文章/Why Do We Need Virtual Memory?.md:
--------------------------------------------------------------------------------
1 | ## 1. Overview
2 |
3 | In this tutorial, we’ll learn about the virtual memory concept in operating systems (OS). **We’ll examine the problems that form the main motivation for the creation of virtual memory.** Finally, we’ll explain the purpose of using this feature in an OS.
4 |
5 | ## 2. Motivation
6 |
7 | Computers are designed to be able to execute many programs, each operating on different amounts of data. Operating systems are expected to exploit better computer resources, guaranteeing fast and efficient processing.
8 |
9 | Three main problems cause the processing to be slow in terms of time and consumed memory. Since we store data in bytes in the disk, the CPU must load the needed data into RAM when executing programs.
10 |
11 | While being executed, an OS allows a program to use a certain range of addresses from RAM. Suppose this space is  bits, which means an expected RAM size of  (Exabyte) is required here.
12 |
13 | Now let’s assume that the OS already reserved a portion of it (), but the computer has less memory than the required RAM. **Trying to use addresses that are out of range will crash the computer.**
14 |
15 | Furthermore, it’s not feasible for an OS to have the capacity of such a large RAM: 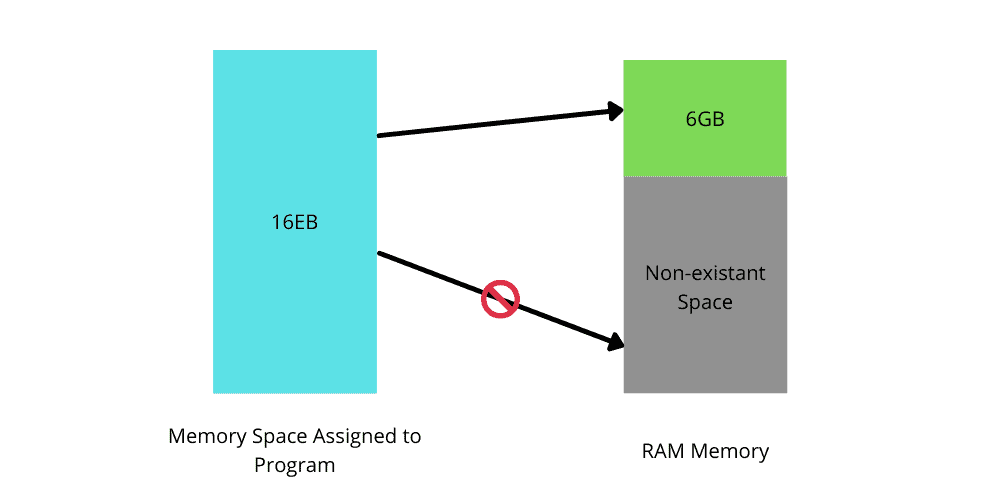
16 |
17 | When executing multiple programs simultaneously, an OS will assign each one of them a continuous partition of RAM, allowing them to be processed at the same time. Now let’s assume that two programs finished their execution. If the space freed up by the two programs is not [continuous](https://en.wikipedia.org/wiki/Continuous_memory), and not enough for other programs to run, the RAM will have holes in different places. **This results in** **[memory fragmentation](https://en.wikipedia.org/wiki/Fragmentation_(computing)):**
18 |
19 | 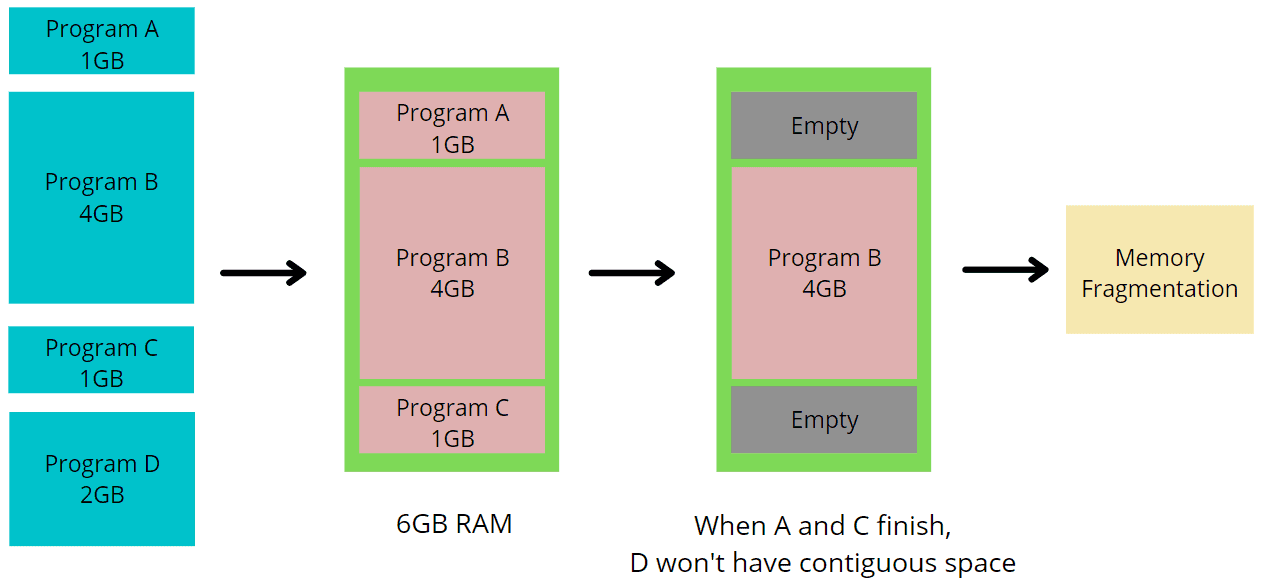
20 |
21 | Since many programs are executed simultaneously, more than one program can access the same case of memory. **To change their value, these programs can collide with each other, corrupt the memory, or crash the system.** The figure below shows how data can be easily corrupted when accessed by multiple programs: 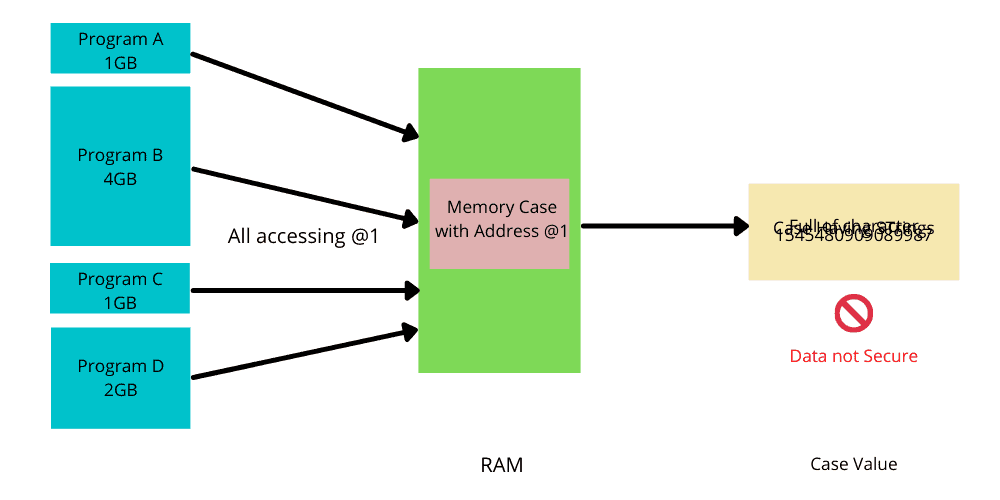
22 |
23 | ## 3. Introduction to Virtual Memory
24 |
25 | **Virtual Memory is a technique aiming to solve memory’s physical shortages by using the secondary memory so that an OS considers it as a part of the main memory.** Virtual memory is temporary memory. The size of the virtual memory storage depends on the addressing scheme used by an OS and the available secondary memory.
26 |
27 | Virtual memory maps program addresses into RAM addresses. If no more space is available, these addresses will be mapped into the disk:
28 |
29 | 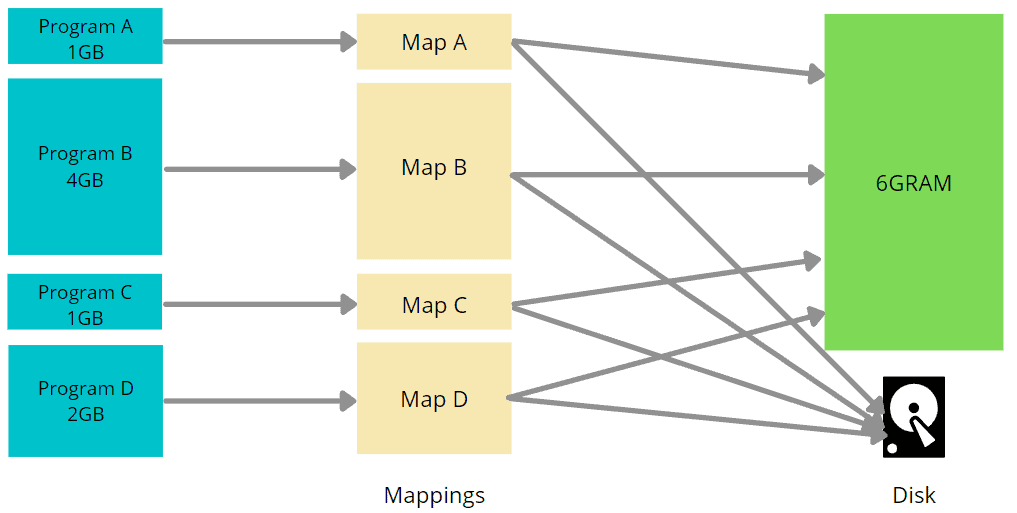
30 |
31 | **The main advantage of virtual memory is that an OS can load programs larger than its physical memory.** It makes an impression to the users that the computer has unlimited memory. It also provides [memory protection](https://en.wikipedia.org/wiki/Memory_protection).
32 |
33 | In order to realize the mapping operations, virtual memory needs to use [page tables and translations](https://www.baeldung.com/cs/virtual-memory). Page Tables are a data structure that stores page tables known as page table entry (PTE). Page tables’ goal is to map virtual addresses to physical addresses. It is a contiguous block and the smallest unit of virtual memory.
34 |
35 | Creating memory pages consists of partitioning them into [equal-sized frames](https://en.wikipedia.org/wiki/Page_(computer_memory)). Each frame refers to each physical address frame number, a frame offset, or an absolute address.
36 |
37 | The translation is the process of transforming a virtual address to a physical address using page tables: 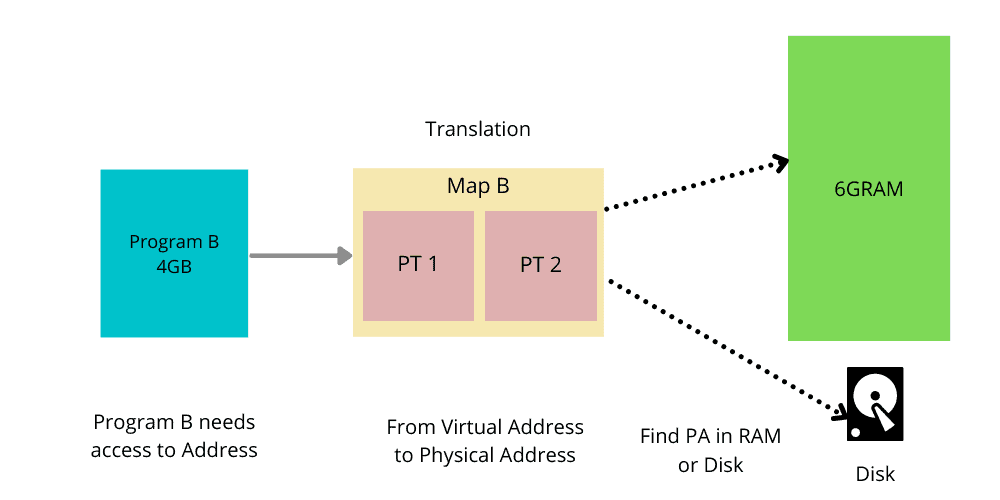
38 |
39 | **To make the process of reading data faster, virtual memory can use [cache memory](https://en.wikipedia.org/wiki/CPU_cache).** Since physical caches don’t guarantee a fast process, we use virtual caches. The CPU is directly connected to the cache, and it looks up the virtual addresses in it while avoiding translation. Translation will occur only if an address isn’t found. Eventually, each program has its own virtual cache:
40 |
41 | 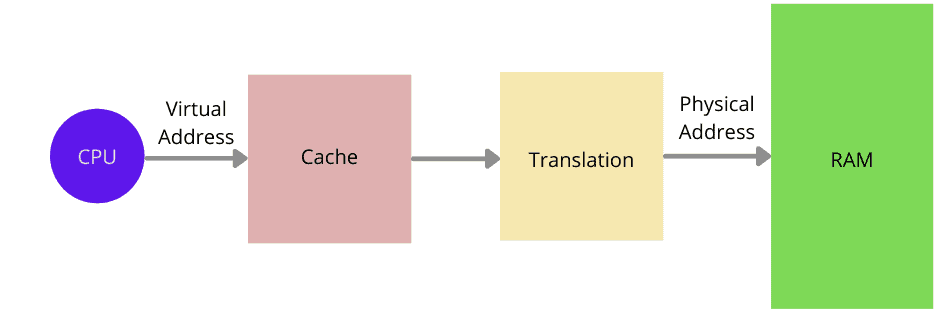
42 |
43 | ## 4. Why Do We Need Virtual Memory?
44 |
45 | Virtual memory plays an important role in a modern-day OS. This section will discuss some of the crucial reasons why an OS needs to use virtual memory.
46 |
47 | ### 4.1. Memory Space Problem
48 |
49 | **Virtual memory makes it easy to share code; therefore, we don’t have to keep several copies of the same code.** With virtual memory, different virtual addresses can map to the same location in the physical memory. Consequently, we don’t have to store multiple copies of the same code in the main memory.
50 |
51 | RAM is very costly. As a result, the use of a very large RAM is not a feasible solution to alleviate any need for storage allocation. **Assigning a virtual memory for each program and mapping addresses to the disk eliminates space problems.**
52 |
53 | In the case of a binary file, when we load them in an OS, each function reserves a fixed address in the main memory. **If virtual memory doesn’t exist, we can’t load more than one program in the main memory.** This means that without virtual memory, we can only run one program at a time. This is because each program might have to use different functions that may point to the same addresses in RAM.
54 |
55 | ### 4.2. Data Security
56 |
57 | **Another important issue is data security.** In general, a program can guess another program’s physical address and gain access to sensitive and secret data.
58 |
59 | If an OS uses the virtual memory technique, even if some programs have to access the same address, they all have different mappings. This ensures that they will access different addresses in the RAM or the disk. This is how virtual memory enables data security.
60 |
61 | **It also provides position independence to the data.** We can store data at any position in the main memory.
62 |
63 | ### 4.3. Memory Fragmentation and Errors
64 |
65 | **Virtual memory facilitates each program with its own mapping.** The data space won’t have to be continuous, and each program can store data wherever it wants.
66 |
67 | **It also facilitates debugging and provides options for checking various features, like unallocated memory and null pointers.**
68 |
69 | Let’s assume that two or more applications are running in an OS at the same time. All of these applications use the direct addresses of RAM. If one of the applications results in an error, like [memory error](https://en.wikipedia.org/wiki/Out_of_memory), while running, this could destroy and take down the other applications.
70 |
71 | Some physical devices, like video RAM, might reserve some memory addresses prior, depending on the hardware used in the computer. If the OS starts loading programs without knowing the reserved addresses, the OS may read and write to the reserved addresses. This can result in physically breaking the plugged-in devices. Virtual memory helps the OS to avoid these issues.
72 |
73 | ## 5. Conclusion
74 |
75 | In this article, we discussed virtual memory in detail. We started our discussion by describing some of the motivations for using virtual memory in OS. Then we gave a general overview of the virtual memory concept. Finally, we explained why we need virtual memory in OS.
76 |
--------------------------------------------------------------------------------
/✍ 文章/一文了解,Linux内存管理,malloc、free 实现原理.md:
--------------------------------------------------------------------------------
1 | ## malloc / free 简介
2 |
3 | ```c
4 | void *malloc(size_t size)
5 | void free(void *ptr)
6 | ```
7 | `malloc` 分配指定大小的内存空间,返回一个指向该空间的指针。大小以字节为单位。返回 `void*` 指针,需要强制类型转换后才能引用其中的值。
8 | `free` 释放一个由 `malloc` 所分配的内存空间。`ptr` 指向一个要释放内存的内存块,该指针应当是之前调用 `malloc` 的返回值。
9 |
10 | 使用示例:
11 |
12 | ```c
13 | int* ptr;
14 | ptr = (int*)malloc(10 * sizeof(int)); /* 进行强制类型转换 */
15 | free(ptr);
16 | ```
17 |
18 | ## 动态内存分配的系统调用:`brk / sbrk`
19 |
20 | 动态分配的内存都在堆中,堆从低地址向高地址增长:
21 |
22 | 
23 |
24 | Linux 提供了两个系统调用 `brk` 和 `sbrk`:
25 |
26 | ```c
27 | int brk(void *addr);
28 | void *sbrk(intptr_t increment);
29 | ```
30 |
31 | `brk` 用于返回堆的顶部地址;`sbrk` 用于扩展堆,通过参数 `increment` 指定要增加的大小,如果扩展成功,返回 `brk` 的旧值。如果 `increment` 为零,返回 `brk` 的当前值。
32 |
33 | 我们不会直接通过 `brk` 或 `sbrk` 来分配堆内存,而是先通过 `sbrk` 扩展堆,将这部分空闲内存空间作为缓冲池,然后通过 `malloc / free` 管理缓冲池中的内存。这是一种池化思想,能够避免频繁的系统调用,提高程序性能。
34 |
35 | ## malloc / free 实现思路
36 |
37 | `malloc` 使用空闲链表组织堆中的空闲区块,空闲链表有时也用双向链表实现。每个空闲区块都有一个相同的首部,称为“内存控制块” `mem_control_block`,其中记录了空闲区块的元信息,比如指向下一个分配块的指针、当前分配块的长度、或者当前区块是否已经被分配出去。这个首部对于程序是不可见的,`malloc `返回的是紧跟在首部后面的地址,即可用空间的起始地址。
38 |
39 | `malloc` 分配时会搜索空闲链表,根据匹配原则,找到一个大于等于所需空间的空闲区块,然后将其分配出去,返回这部分空间的指针。如果没有这样的内存块,则向操作系统申请扩展堆内存。注意,返回的指针是从可用空间开始的,而不是从首部开始的:
40 |
41 | 
42 |
43 | malloc 所实际使用的内存匹配算法有很多,执行时间和内存消耗各有不同。到底使用哪个匹配算法,取决于实现。常见的内存匹配算法有:
44 |
45 | * 最佳适应法
46 | * 最差适应法
47 | * 首次适应法
48 | * 下一个适应法
49 |
50 | free 会将区块重新插入到空闲链表中。free 只接受一个指针,却可以释放恰当大小的内存,这是因为在分配的区域的首部保存了该区域的大小。
51 |
52 | ## malloc 的实现方式一:显式空闲链表 + 整块分配
53 |
54 | malloc 的实现方式有很多种。最简单的方法是使用一个链表来管理所有已分配和未分配的内存块,在每个内存块的首部记录当前块的大小、当前区块是否已经被分配出去。首部对应这样的结构体:
55 |
56 | ```c
57 | struct mem_control_block {
58 | int is_available; // 是否可用(如果还没被分配出去,就是 1)
59 | int size; // 实际空间的大小
60 | };
61 | ```
62 |
63 | 使用首次适应法进行分配:遍历整个链表,找到第一个未被分配、大小合适的内存块;如果没有这样的内存块,则向操作系统申请扩展堆内存。
64 |
65 | 下面是这种实现方式的代码:
66 |
67 | ```c
68 | int has_initialized = 0; // 初始化标志
69 | void *managed_memory_start; // 指向堆底(内存块起始位置)
70 | void *last_valid_address; // 指向堆顶
71 |
72 | void malloc_init() {
73 | // 这里不向操作系统申请堆空间,只是为了获取堆的起始地址
74 | last_valid_address = sbrk(0);
75 | managed_memory_start = last_valid_address;
76 | has_initialized = 1;
77 | }
78 |
79 | void *malloc(long numbytes) {
80 | void *current_location; // 当前访问的内存位置
81 | struct mem_control_block *current_location_mcb; // 只是作了一个强制类型转换
82 | void *memory_location; // 这是要返回的内存位置。初始时设为
83 | // 0,表示没有找到合适的位置
84 | if (!has_initialized) {
85 | malloc_init();
86 | }
87 | // 要查找的内存必须包含内存控制块,所以需要调整 numbytes 的大小
88 | numbytes = numbytes + sizeof(struct mem_control_block);
89 | // 初始时设为 0,表示没有找到合适的位置
90 | memory_location = 0;
91 | /* Begin searching at the start of managed memory */
92 | // 从被管理内存的起始位置开始搜索
93 | // managed_memory_start 是在 malloc_init 中通过 sbrk() 函数设置的
94 | current_location = managed_memory_start;
95 | while (current_location != last_valid_address) {
96 | // current_location 是一个 void 指针,用来计算地址;
97 | // current_location_mcb 是一个具体的结构体类型
98 | // 这两个实际上是一个含义
99 | current_location_mcb = (struct mem_control_block *)current_location;
100 | if (current_location_mcb->is_available) {
101 | if (current_location_mcb->size >= numbytes) {
102 | // 找到一个可用、大小适合的内存块
103 | current_location_mcb->is_available = 0; // 设为不可用
104 | memory_location = current_location; // 设置内存地址
105 | break;
106 | }
107 | }
108 | // 否则,当前内存块不可用或过小,移动到下一个内存块
109 | current_location = current_location + current_location_mcb->size;
110 | }
111 | // 循环结束,没有找到合适的位置,需要向操作系统申请更多内存
112 | if (!memory_location) {
113 | // 扩展堆
114 | sbrk(numbytes);
115 | // 新的内存的起始位置就是 last_valid_address 的旧值
116 | memory_location = last_valid_address;
117 | // 将 last_valid_address 后移 numbytes,移动到整个内存的最右边界
118 | last_valid_address = last_valid_address + numbytes;
119 | // 初始化内存控制块 mem_control_block
120 | current_location_mcb = memory_location;
121 | current_location_mcb->is_available = 0;
122 | current_location_mcb->size = numbytes;
123 | }
124 | // 最终,memory_location 保存了大小为 numbyte的内存空间,
125 | // 并且在空间的开始处包含了一个内存控制块,记录了元信息
126 | // 内存控制块对于用户而言应该是透明的,因此返回指针前,跳过内存分配块
127 | memory_location = memory_location + sizeof(struct mem_control_block);
128 | // 返回内存块的指针
129 | return memory_location;
130 | }
131 | ```
132 |
133 | 对应的free实现:
134 |
135 | ```c
136 | void free(void *ptr) { // ptr 是要回收的空间
137 | struct mem_control_block *free;
138 | free = ptr - sizeof(struct mem_control_block); // 找到该内存块的控制信息的地址
139 | free->is_available = 1; // 该空间置为可用
140 | return;
141 | }
142 | ```
143 |
144 | 这种方法的缺点是:
145 |
146 | 1、已分配和未分配的内存块位于同一个链表中,每次分配都需要从头到尾遍历
147 | 2、采用首次适应法,内存块会被整体分配,容易产生较多内部碎片
148 |
149 | ## malloc 的实现方式二:显式空闲链表 + 按需分配
150 |
151 | 这种实现方式维护一个空闲块链表,只包含未分配的内存块。malloc 分配时会搜索空闲链表,找到第一个大于等于所需空间的空闲区块,然后从该区块的尾部取出所需要的空间,剩余空间还是存在空闲链表中;如果该区块的剩余部分不足以放下首部信息,则直接将其从空闲链表摘除。最后返回这部分空间的指针。
152 | 下面是这种实现方式的几个示例:
153 |
154 | 
155 |
156 | 
157 |
158 | 
159 |
160 | 通过 free 释放内存时,会将内存块加入到空闲链表中,并将前后相邻的空闲内存合并,这时使用双向链表管理空闲链表就很有用了。
161 |
162 | 和第一种方式相比,这种方式的优点主要是:
163 | * 空闲链表中只包含未被分配的内存块,节省遍历开销
164 | * 只分配必须大小的空间,避免内存浪费
165 |
166 | 这种方式的缺点是:多次调用 malloc 后,空闲内存被切成很多的小内存片段,产生较多外部碎片,会导致用户在申请内存使用时,找不到足够大的内存空间。这时需要进行内存整理,将连续的空闲内存合并,但是这会降低函数性能。
167 |
168 | 注意:内存紧凑在这里一般是不可用的,因为这会改变之前 malloc 返回的空间的地址。
169 |
170 | ## malloc 的实现方式三:分离的空闲链表
171 |
172 | 上面的两种分配方法,分配时间都和空闲块的数量成线性关系。
173 |
174 | 另一种实现方式是分离存储,即维护多个空闲链表,其中每个链表中的块有大致相等或者相同的大小。一般常见的是根据 2 的幂来划分块大小。分配时,可以直接在某个空闲链表里搜索合适的块。如果没有找到合适的块与之匹配,就搜索下一个链表,以此类推。
175 |
176 | ### 简单分离存储
177 |
178 | 每个大小类的空闲链表包含大小相等的块。分配时,从某个空闲链表取下一块,或者向操作系统请求内存片并分割成大小相等的块,形成新的链表。释放时,只需要简单的将块插入到相应空闲链表的前面。
179 |
180 | 优点一是分配和释放只需要在链表头进行操作,都是常数时间,二是因为每个块大小都是固定的,所以只需要一个 next 指针,不需要额外的控制信息,节省空间。缺点是容易造成内部碎片和外部碎片。内部碎片显而易见,因为每个块都是整体分配的,不会被分割。外部碎片在这样的模式下很容易产生:应用频繁地申请和释放较小大小的内存块,由于这些内存块不会合并,所以系统维护了大量小内存块形成的空闲链表,而没有多余空间来分配大内存块,导致产生外部碎片。
181 |
182 | ### 分离适配
183 | 这种方法同样维护了多个空闲链表,只不过每个链表中的块是大致相等的大小,比如每个链表中的块大小范围可能是:
184 |
185 | * 1
186 | * 2
187 | * 3~4
188 | * 5~8
189 | * …
190 | * 1025~2048
191 | * 2049~4096
192 | * 4097~∞
193 |
194 | 在分配的时候,需要先根据申请内存的大小选择适当的空闲链表,然后遍历该链表,根据匹配算法(如首次适应)寻找合适的块。如果找到一个块,将其分割(可选),并将剩余部分插入到适当的空闲链表中。如果找不到合适的块,则查找下一个更大的大小类的空闲链表,以此类推,直到找到或者向操作系统申请额外的堆内存。在释放一个块时,合并前后相邻的空闲块,并将结果放到相应的空闲链表中。
195 |
196 | 分离适配方法是一种常见的选择,C 标准库中提供的 GNU malloc 包就是采用的这种方法。这种方法既快速,对内存的使用也很有效率。由于搜索被限制在堆的某个部分而不是整个堆,所以搜索时间减少了。内存利用率也得到了改善,避免大量内部碎片和外部碎片。
197 |
198 | ### 伙伴系统
199 |
200 | 伙伴系统是分离适配的一种特例。它的每个大小类的空闲链表包含大小相等的块,并且大小都是 2 的幂。最开始时,全局只有一个大小为 2m2m 字的空闲块,2m2m 是堆的大小。
201 |
202 | 假设分配的块的大小都是 2 的幂,为了分配一个大小为 2k2k 的块,需要找到大小恰好是 2k2k 的空闲块。如果找到,则整体分配。如果没有找到,则将刚好比它大的块分割成两块,每个剩下的半块(也叫做伙伴)被放置在相应的空闲链表中,以此类推,直到得到大小恰好是 2k2k 的空闲块。释放一个大小为 2k2k 的块时,将其与空闲的伙伴合并,得到新的更大的块,以此类推,直到伙伴已分配时停止合并。
203 |
204 | 伙伴系统分配器的主要优点是它的快速搜索和快速合并。主要缺点是要求块大小为 2 的幂可能导致显著的内部碎片。因此,伙伴系统分配器不适合通用目的的工作负载。然而,对于某些特定应用的工作负载,其中块大小预先知道是 2 的幂,伙伴系统分配器就很有吸引力了。
205 |
206 | ### tcmalloc
207 |
208 | tcmalloc 是 Google 开发的内存分配器,全称 Thread-Caching Malloc,即线程缓存的 malloc,实现了高效的多线程内存管理。
209 |
210 | tcmalloc 主要利用了池化思想来管理内存分配。对于每个线程,都有自己的私有缓存池,内部包含若干个不同大小的内存块。对于一些小容量的内存申请,可以使用线程的私有缓存;私有缓存不足或大容量内存申请时再从全局缓存中进行申请。在线程内分配时不需要加锁,因此在多线程的情况下可以大大提高分配效率。
211 |
212 | ## 总结
213 | malloc 使用链表管理内存块。malloc 有多种实现方式,在不同场景下可能会使用不同的匹配算法。
214 |
215 | malloc 分配的空间中包含一个首部来记录控制信息,因此它分配的空间要比实际需要的空间大一些。这个首部对用户而言是透明的,malloc 返回的是紧跟在首部后面的地址,即可用空间的起始地址。
216 |
217 | malloc 分配的函数应该是字对齐的。在 32 位模式中,malloc 返回的块总是 8 的倍数。在 64 位模式中,该地址总是 16 的倍数。最简单的方式是先让堆的起始位置字对齐,然后始终分配字大小倍数的内存。
218 |
219 | malloc 只分配几种固定大小的内存块,可以减少外部碎片,简化对齐实现,降低管理成本。
220 |
221 | free 只需要传递一个指针就可以释放内存,空间大小可以从首部读取。
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
--------------------------------------------------------------------------------
/✍ 文章/为什么linux需要虚拟内存.md:
--------------------------------------------------------------------------------
1 | 操作系统中的CPU和主存都是稀缺资源,所有运行在当前操作系统的进程会共享系统中的CPU和内存资源,操作系统会使用CPU调度器分配CPU事件并引入虚拟内存管理物理内存。
2 |
3 | 虚拟内存是操作系统物理内存和进程之间的中间层,它为进程隐藏了物理内存这一概念,为进程提供了更加简洁和易用的接口以及更加复杂的功能。
4 |
5 |
6 |
7 | 
8 |
9 | 早期的操作系统中,进程会直接使用目标内存的物理地址直接访问主存中的内容,然而现代的操作系统都引入了虚拟内存,进程持有的虚拟地址会经过内存管理单元(MMU)的转换为物理地址,然后通过物理地址访问内存
10 |
11 | 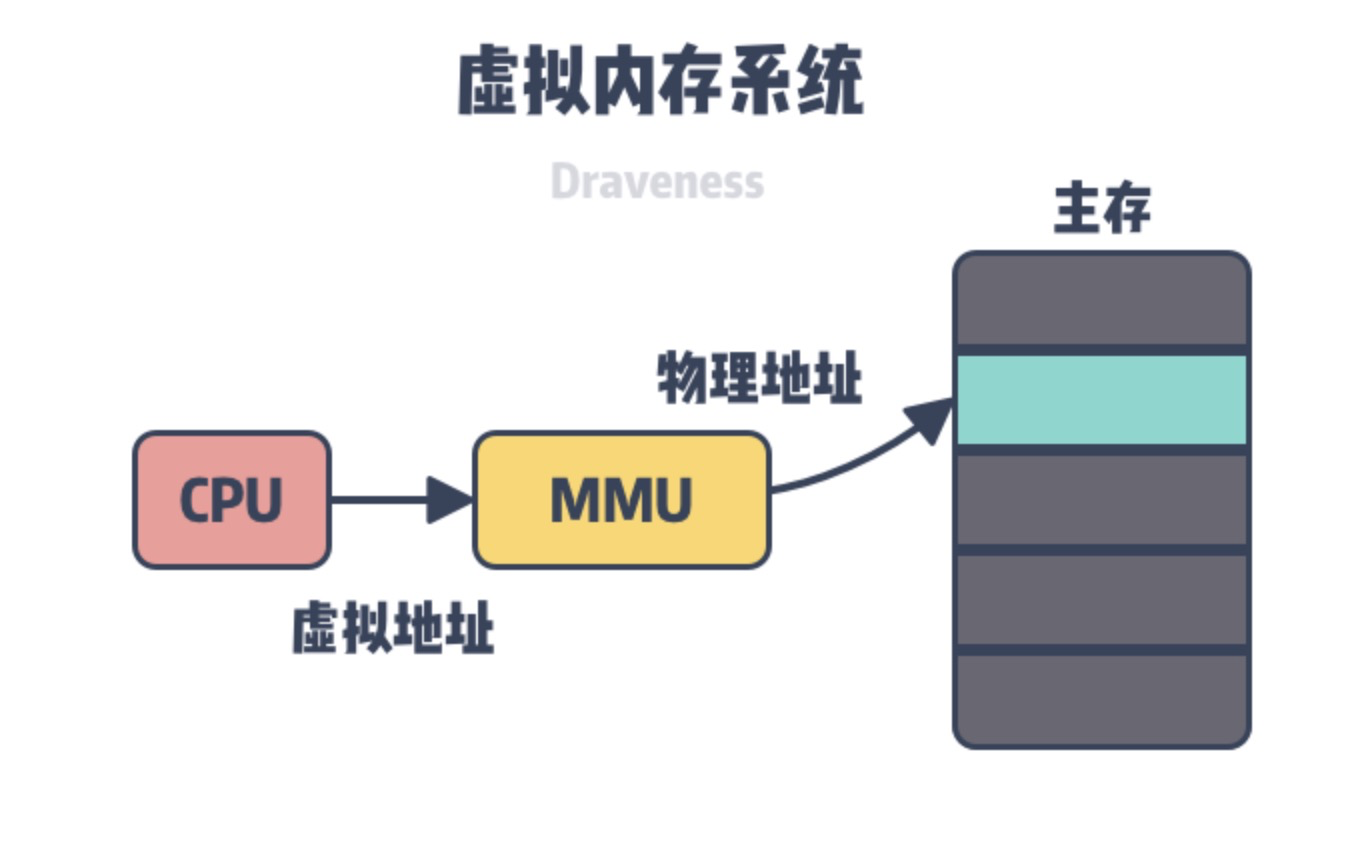
12 |
13 | 主存是相对比较稀缺的资源,虽然顺序读取只比磁盘快1各数量级,但是它能提供极快的随机访问速度,从内存上随机读取数据的速度是磁盘的100000倍。
14 |
15 | 操作系统以页作为单位管理内存,当进程发现需要访问的数据不在内存时,操作系统会以页的方式加载到内存中,这个过程是MMU完成的。
16 |
17 | 虚拟内存起到了以下三个非常关键的作用:
18 |
19 | - 虚拟内存可以利用磁盘起到缓存的作用,提高进程访问指定内存的速度。
20 | - 虚拟内存可以为进程提供独立的内存空间,简化程序的链接、加载过程并通过动态库共享内存。
21 |
22 | - 虚拟内存可以控制进程对物理内存的访问,隔离不同进程的访问权限,提高系统的安全性。
23 |
24 |
25 |
26 | ## 缓存
27 |
28 | 我们可以把虚拟内存看作是磁盘上的一片空间,当这片空间的一部分访问比较频繁时,这部分数据会以页为单位缓存到主存中以加速CPU访问数据的性能,虚拟内存利用空间较大的磁盘存储作为内存并是使用主存缓存进行加速,**让上层认为操作系统的内存很大而且很快,然而区域很大的磁盘并不快,而很快的内存也并不大。**
29 |
30 | 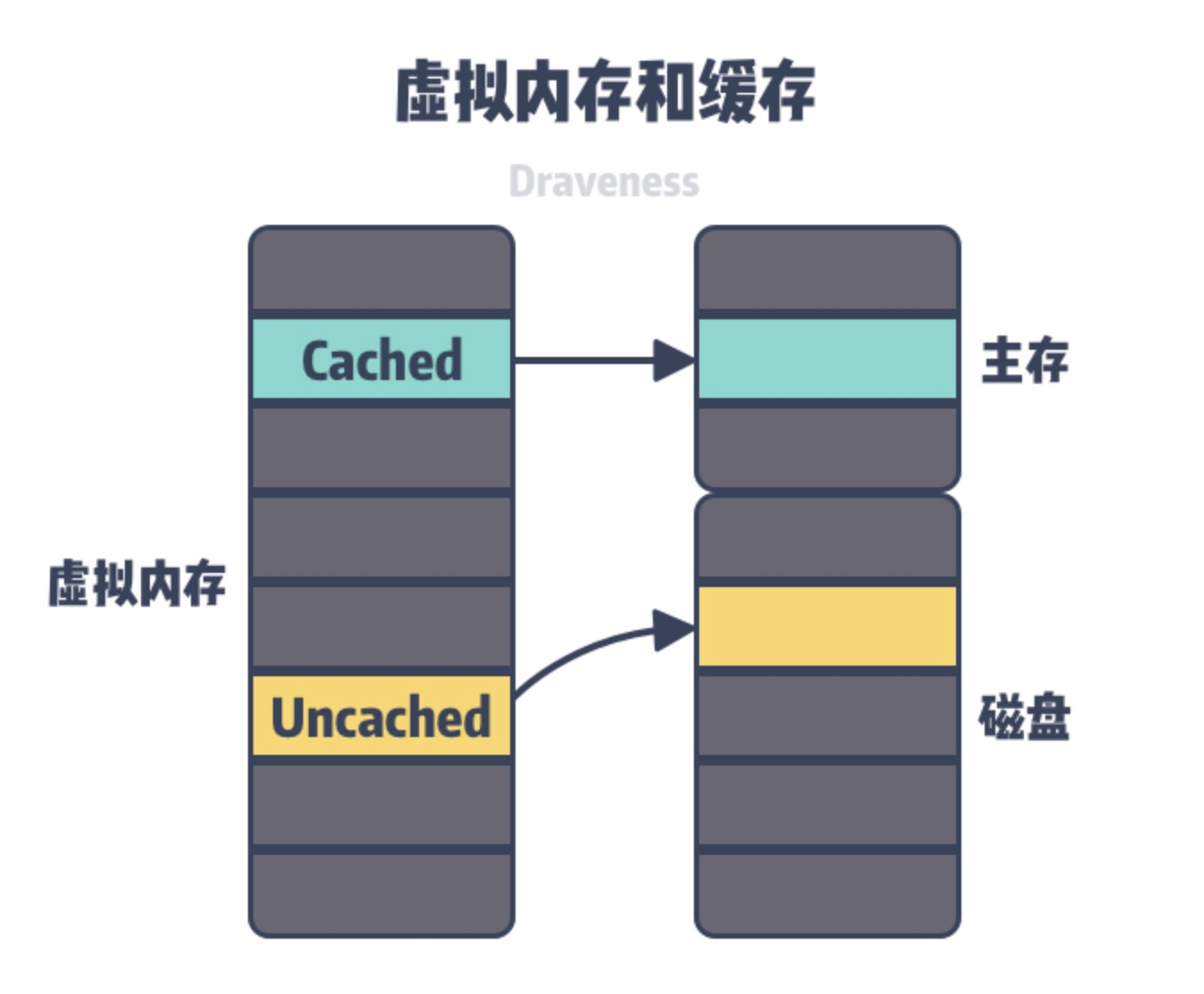
31 |
32 | 虚拟内存中的虚拟页可能处于以下三中状况——未分配、未缓存和已缓存,其中未分配的内存页事没有被进程申请使用的,也就是空闲的虚拟内存,不占用虚拟内存磁盘的任何空间,未缓存和已缓存的内存页分别表示已经加载到主存中的内存页和仅加载到磁盘中的内存页。
33 |
34 | 当用户程序访问未被缓存的虚拟页时候=,硬件就会触发缺页中断,在部分情况下,被访问的页面已经加载到物理内存中,但是用户程序的页表并不存在该对应关系,这时候我们只需要在页表中建立虚拟内存到物理内存的关系;在其他情况下,操作系统需要把磁盘上未被缓存的虚拟页加载到物理内存中。
35 |
36 | 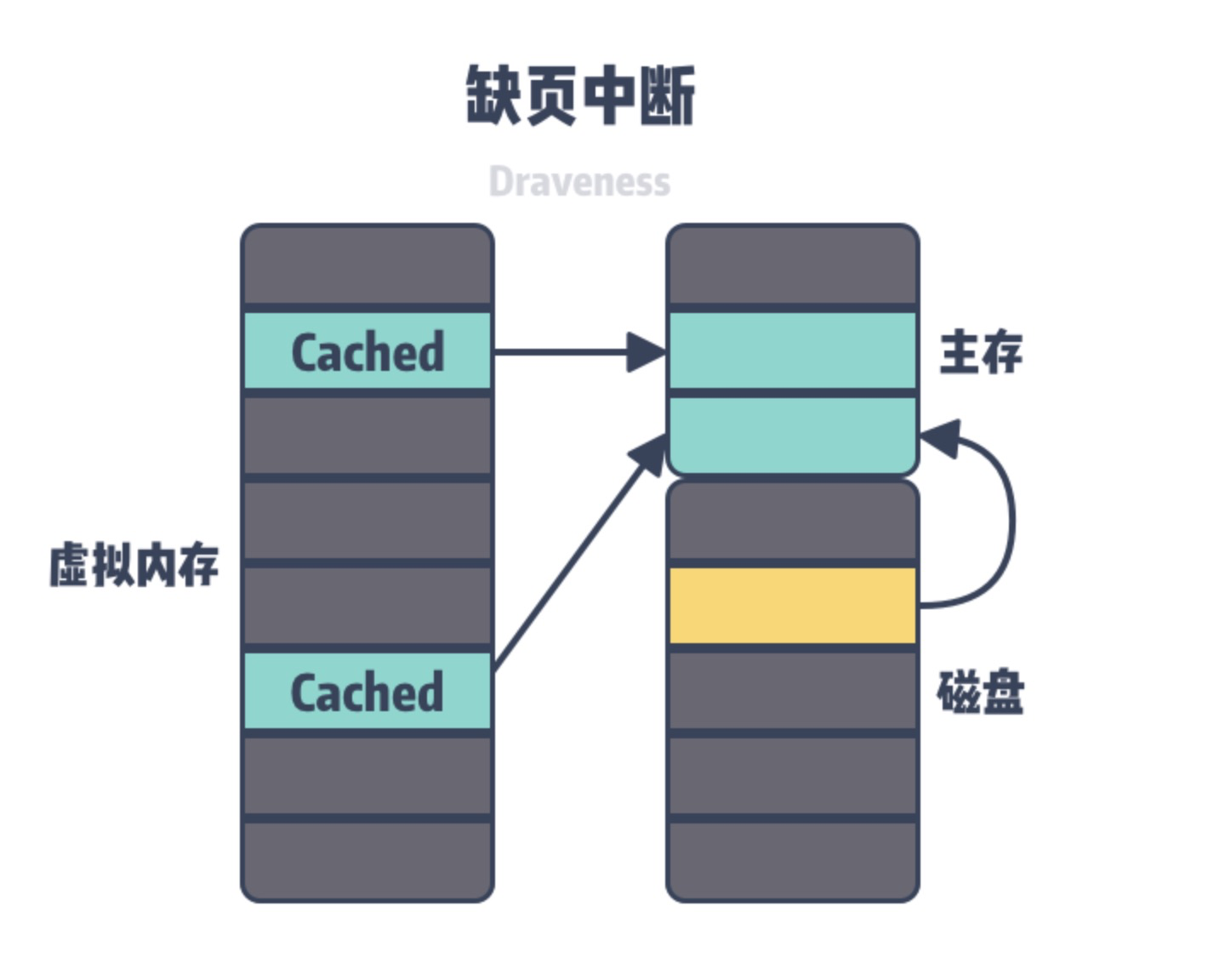
37 |
38 | 因为主内存的空间是有限的,当主内存中不包含可以使用的空间时,操作系统会选择合适的物理内存驱除回磁盘,为新的内存让出位置,选择待驱除的页的过程在操作系统中叫做页面替换。缺页中断和页面替换都是操作系统调页算法的一部分。
39 |
40 | ## 内存管理
41 |
42 | 虚拟内存可以为正在运行的进程提供独立的内存空间,制造一种每个进程的内存都是独立的假象。在64位的操作系统上,每个进程都由256TiB的内存空间,内核和用户空间分别占128TiB。�因为每个进程的虚拟内存空间是完全独立的。
43 |
44 | 虚拟内存只是操作系统中的逻辑结构,应用程序最终还是需要访问物理内存或磁盘上的内容,因为操作系统加了一个虚拟内存的中间层,所以我们也需要为进程实现地址翻译器,实现从虚拟地址到物理地址的转换,页表是虚拟内存系统中重要的数据结构,每一个进程的页表中都存储了从虚拟内存到物理内存的映射关系,为了存储64位系统中128TiB虚拟内存的映射数据,Linux在2.6.10中引入了四层的页表来辅助虚拟地址的转换,在4.11中引入了五层的页表结构。
45 |
46 | 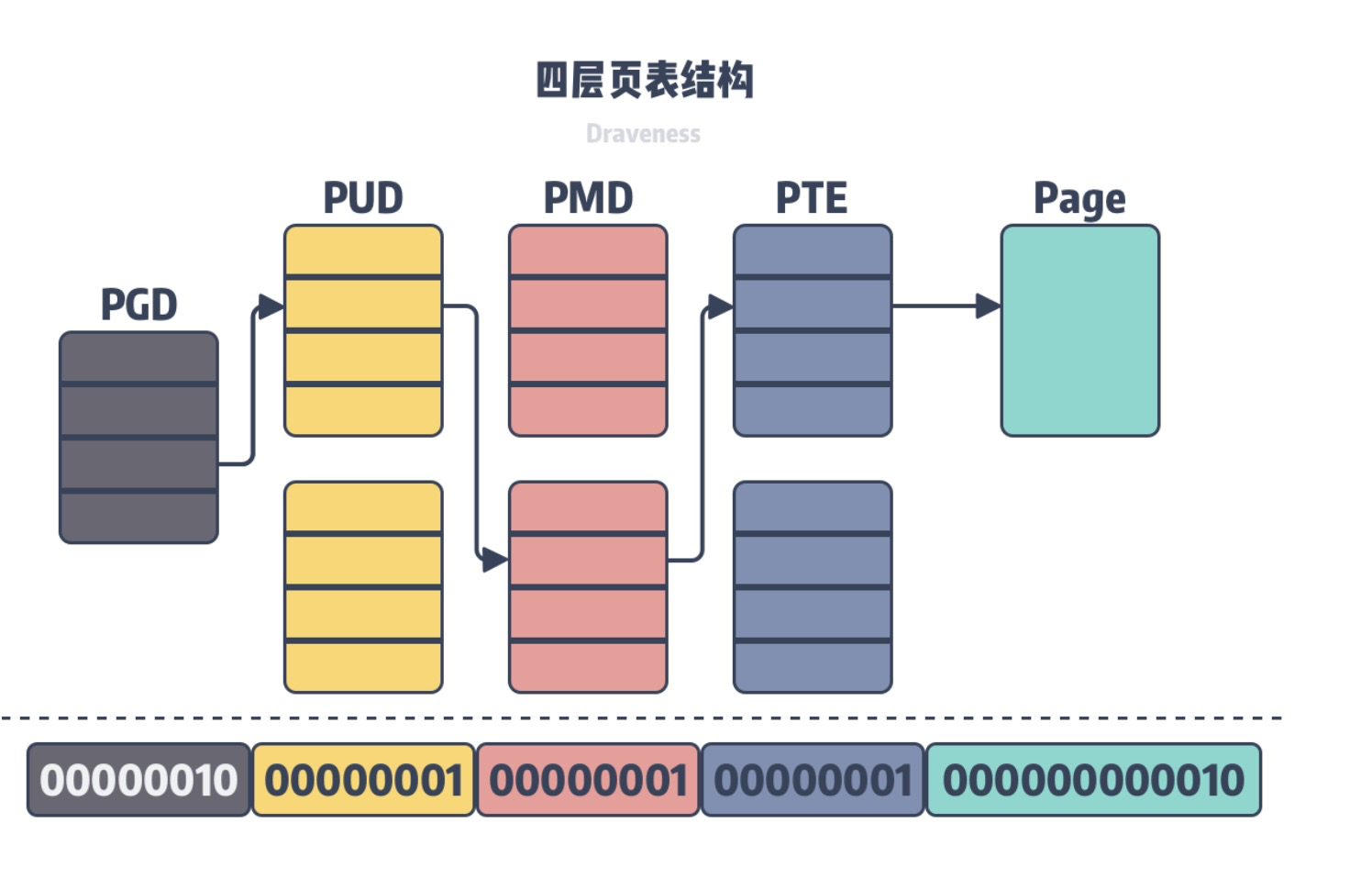
47 |
48 | 在上图所示的四层页表结构中,操作系统会使用最低的12位作为页面的偏移量,剩下的32位会分四组分别表示当前层级在上一层的索引,所有的虚拟地址都可以用上述的多层页表查找到对应的物理地址。
49 |
50 | 所以多个进程可以通过虚拟内存共享物理内存。在Linux中调用fork的时候,实际上只复制了父进程的页表。父子进程会通过不同的页表指向相同的物理内存。
51 |
52 | 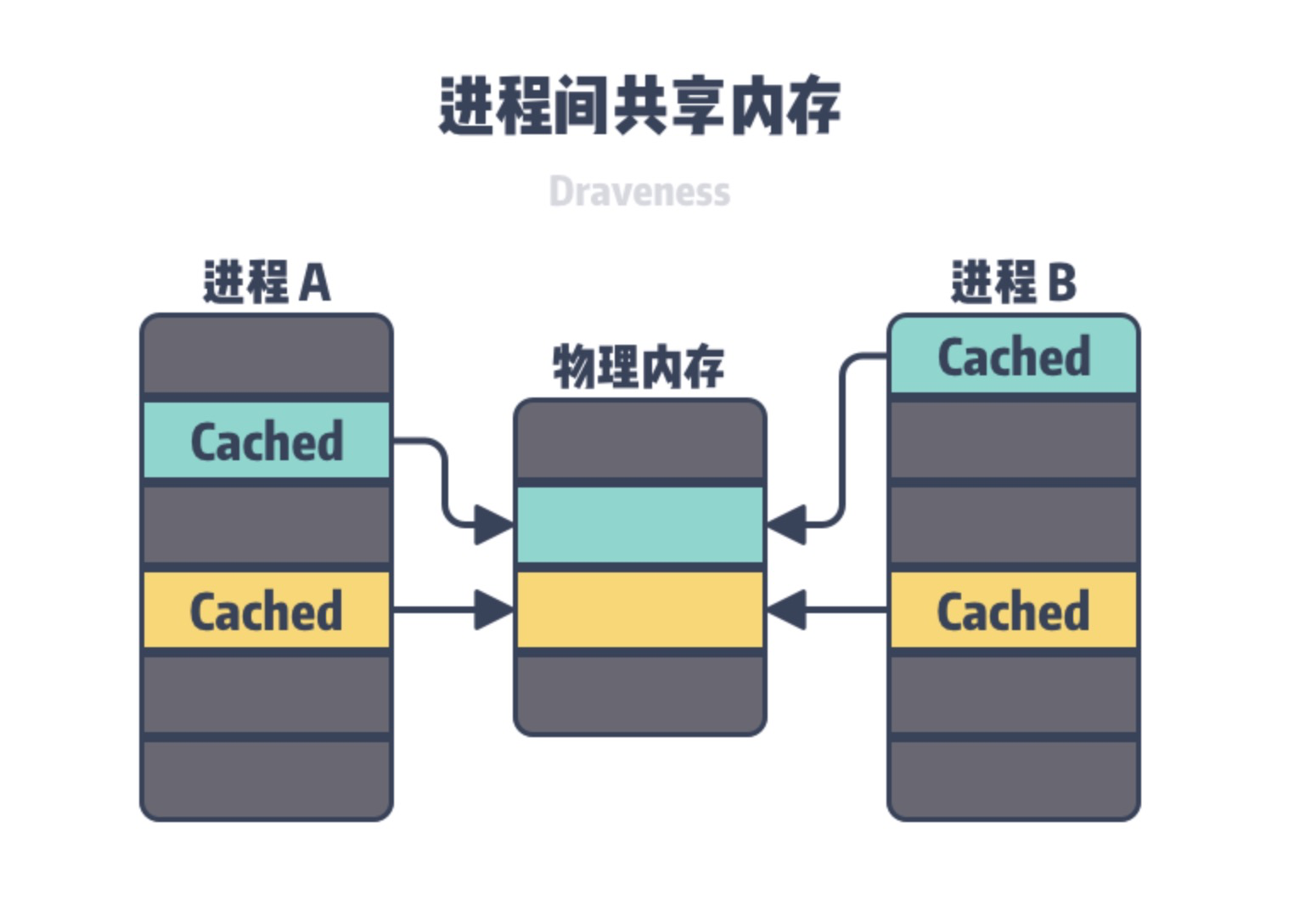
53 |
54 | 虚拟内存不仅可以在fork时用于共享进程的物理内存,提供写时复制的机制。还能共享一些常见的动态库减少物理内存的占用、所有的进程都可能调用相同的操作系统内核代码,而C语言也会调用相同的标准库。
55 |
56 | 除了能够共享内存之外,独立的虚拟内存空间也会简化内存的分配过程,当用户程序向操作系统申请堆内存时,操作系统可以分配几个连续的虚拟页,但是这些虚拟页对应到物理内存中不连续的页。
57 |
58 | ## 内存保护
59 |
60 | 操作系统中的用户程序不应该修改只读的代码段,也不应该读取或修改内核中的代码和数据结构或者访问私有的的以及其他的进程的内存,如果无法对用户程序的内存访问进行限制,攻击者就可以访问和修改其他进程的内存影响系统的安全。
61 |
62 | 如果每一个进程都持有独立的虚拟空间,那么虚拟内存中页表可以理解为进程和物理页的连接表,其中可以存储进程和物理页之间的访问关系,包括读权限、写权限和执行权限:
63 |
64 | 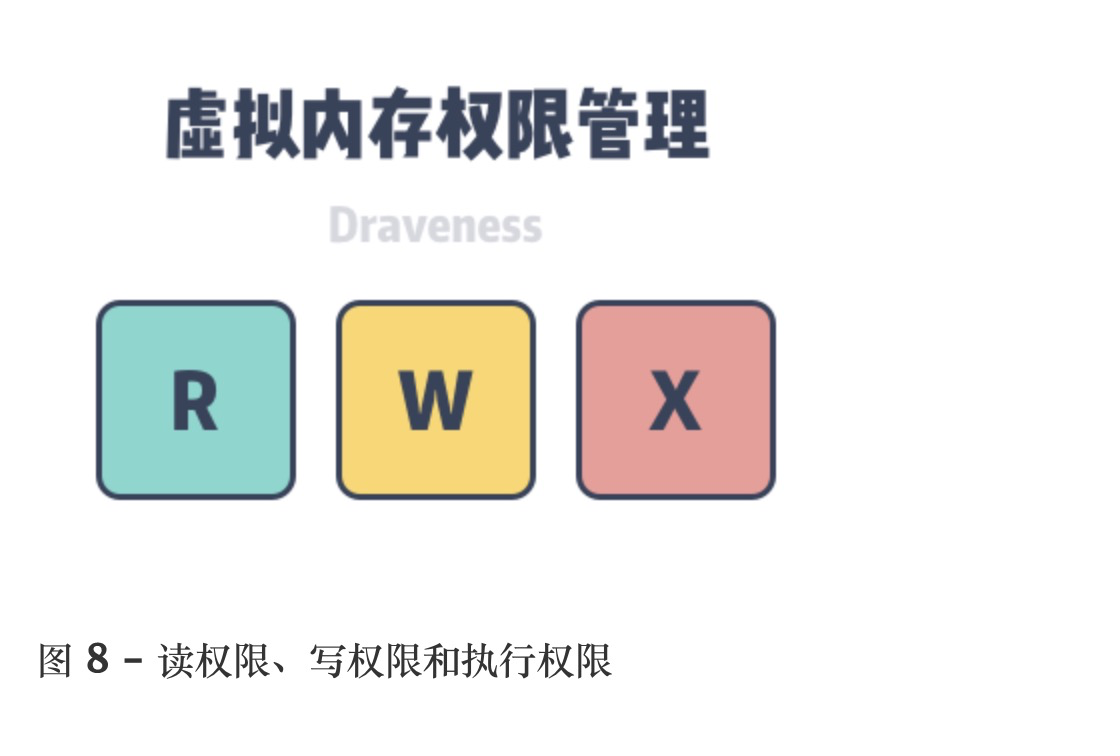
65 |
66 | MMU可以决定当前进程是否是否有权限访问目标的物理内存,这样我们就最终将权限管理的功能全部收敛到虚拟内存系统中。
67 |
68 | # 总结
69 |
70 | Linux中为什么需要虚拟内存:
71 |
72 | - 虚拟内存可以结合磁盘和物理内存的优势为进程提供看起来速度足够块并且容量足够大的存储
73 | - 虚拟内存可以为进程提供独立的内存空间并引入多层的页表结构将虚拟内存翻译为物理内存,进程之间可以互相共享物理内存减少开销,也能简化程序的链接、装载以及内存分配过程
74 |
75 | - 虚拟内存可以控制进程对物理内存的访问、隔离不同进程的访问权限,提高系统的安全性
76 |
77 |
--------------------------------------------------------------------------------
/✍ 文章/内存碎片之外部碎片与内部碎片.md:
--------------------------------------------------------------------------------
1 | “内存碎片”描述了一个系统中所有不可用的空闲内存。这些资源之所以仍然未被使用,是因为负责分配内存的分配器使这些内存无法使用,原因在于空闲内存以小而不连续方式出现在不同的位置,内存分配器无法将这些内存利用起来分配给新的进程。由于分配方法决定内存碎片是否是一个问题,因此内存分配器在保证空闲资源可用性方面扮演着重要的角色。
2 |
3 | ## 内部碎片与外部碎片
4 |
5 | ### 内部碎片
6 |
7 |
8 |
9 | [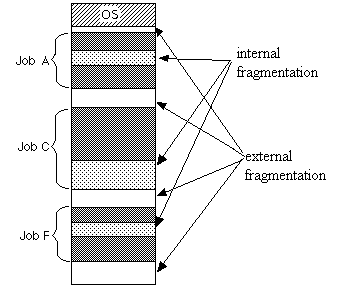](https://jacktang816.github.io/img/unix/memoryFragmentation/internalFragmentation.gif)
10 |
11 | 内部碎片是由于系统分配给进程的空间大于其所申请的大小,处于(操作系统分配的用于装载某一进程的内存)区域内部或页面内部的存储块,占有这些区域或页面的进程并不使用这个存储块。而在进程占有这块存储块时,系统无法利用它。直到进程释放它,或进程结束时,系统才有可能利用这个存储块。
12 |
13 |
14 |
15 | ### 外部碎片
16 |
17 |
18 |
19 | [](https://jacktang816.github.io/img/unix/memoryFragmentation/externalFragmentation.gif)
20 |
21 | 外部碎片指的是还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域,即处于任何两个已分配区域或页面之间的空闲存储块。这些存储块的总和可以满足当前申请的长度要求,但是由于它们的地址不连续或其他原因,使得系统无法满足当前申请。
22 |
23 |
24 |
25 | ## 内存碎片产生的原因
26 |
27 | - 内部碎片的产生
28 | 因为所有的内存分配必须起始于可被 4、8 或 16 整除(视处理器体系结构而定)的地址或者因为MMU的分页机制的限制,决定内存分配算法仅能把预定大小的内存块分配给客户。假设当某个客户请求一个 43 字节的内存块时,因为没有适合大小的内存,所以它可能会获得 44字节、48字节等稍大一点的字节,因此由所需大小四舍五入而产生的多余空间就叫内部碎片。
29 | - 外部碎片的产生
30 | 频繁的分配与回收物理页面会导致大量的、连续且小的页面块夹杂在已分配的页面中间,就会产生外部碎片。假设有一块一共有100个单位的连续空闲内存空间,范围是0-99。如果你从中申请一块内存,如10个单位,那么申请出来的内存块就为0-9区间。这时候你继续申请一块内存,比如说5个单位大,第二块得到的内存块就应该为10-14区间。如果你把第一块内存块释放,然后再申请一块大于10个单位的内存块,比如说20个单位。因为刚被释放的内存块不能满足新的请求,所以只能从15开始分配出20个单位的内存块。现在整个内存空间的状态是0-9空闲,10-14被占用,15-24被占用,25-99空闲。其中0-9就是一个内存碎片了。如果10-14一直被占用,而以后申请的空间都大于10个单位,那么0-9就永远用不上了,变成外部碎片。
31 |
32 | ## 内存分配方式
33 |
34 | ### 连续分配
35 |
36 | 首先讲连续分配方式。连续分配方式出现的时间比较早,曾广泛应用于20世纪60~70年代的OS中,但是它至今仍然在内存管理方式中占有一席之地,原因在于它实现起来比较方便,所需的硬件支持最少。连续分配方式又可细分为四种:单一连续分配、固定分区分配、动态分区分配和动态重定位分区分配。
37 |
38 | 其中**固定分区分配方式**,因为分区固定,所以缺乏灵活性,即当程序太小时,会造成内存空间的浪费(内部碎片);程序太大时,一个分区又不足以容纳,致使程序无法运行。但尽管如此,当一台计算机去控制多个相同对象的时候,由于这些对象内存大小相同,所以完全可以采用这种内存管理方式,而且是最高效的。这里我们可以看出存储器管理机制的多面性:即没有那种存储器管理机制是完全没有用的,在适合的场合下,一种被认为最不合理的分配方案却可能称为最高效的分配方案。一切都要从实际问题出发,进行设计。
39 |
40 | 为了解决固定分区分配方式的缺乏灵活性,出现了**动态分配方式**。动态分配方式采用一些寻表的方式,查找能符合程序需要的空闲内存分区。但代价是增加了系统运行的开销,而且内存空闲表本身是一个文件,必然会占用一部分宝贵的内存资源,而且有些算法还会增加**内存碎片**。
41 |
42 | **可重定位分区分配**通过对程序实现成定位,从而可以将内存块进行搬移,将小块拼成大块,将小空闲“紧凑”成大空闲,腾出较大的内存以容纳新的程序进程。但是拼凑过程的开销较大。
43 |
44 | ### 基本分页存储管理方式
45 |
46 | 连续分配方式会形成许多“碎片”,虽然可以通过“紧凑”方式将许多碎片拼接成可用的大块空间,但须为之付出很大开销。所以提出了“离散分配方式”的想法。如果离散分配的基本单位是页,则称为分页管理方式;如果离散分配的基本单位是段,则称为分段管理方式。
47 |
48 | 分页存储管理是将一个进程的逻辑地址空间分成若干个大小相等的片,称为页面或页,并为各页加以编号,从0开始,如第0页、第1页等。相应地,也把内存空间分成与页面相同大小的若干个存储块,称为(物理)块或页框(frame),也同样为它们加以编号,如0#块、1#块等等。在为进程分配内存时,以块为单位将进程中的若干个页分别装入到多个可以不相邻接的物理块中。**由于进程的最后一页经常装不满一块而形成了不可利用的碎片,称之为“页内碎片”。**
49 |
50 | 在分页系统中,允许将进程的各个页离散地存储在内存不同的物理块中,但系统应能保证进程的正确运行,即能在内存中找到每个页面所对应的物理块。为此,系统又为每个进程建立了一张**页面映射表**,简称页表。在进程地址空间内的所有页,依次在页表中有一页表项,其中记录了相应页在内存中对应的物理块号。在配置了页表后,进程执行时,通过查找该表,即可找到每页在内存中的物理块号。可见,页表的**作用是实现从页号到物理块号的地址映射(逻辑地址向物理地址的映射)**。
51 |
52 | 页表的功能可由一组专门的寄存器来实现。由于寄存器成本较高,且大多数现代计算机的页表又很大,使页表项总数可达几千甚至几十万个,显然这些页表项不可能都用寄存器来实现,因此,页表大多驻留在内存中。因为一个进程可以通过它的PCB来时时保存自己的状态,等到CPU要处理它的时候才将PCB交给寄存器,所以,系统中虽然可以运行多个进程,但也只需要一个页表寄存器就可以了。
53 |
54 | 由于页表是存放在内存中的,这使得CPU在每存取一个数据时,都要两次访问内存。为了提高地址变换速度,在地址变化机构中增设了一个具有并行查询能力的缓冲寄存器,又称为“联想寄存器”(TLB)。
55 |
56 | 在单级页表的基础上,为了适应非常大的逻辑地址空间,出现了两级和多级页表,但是,他们的原理和单级页表是一样的,只不过为了适应地址变换层次的增加,需要在地址变换机构中增设外层的页表寄存器。
57 |
58 | ### 基本分段存储管理方式
59 |
60 | 分段存储管理方式的目的,主要是为了满足用户(程序员)在编程和使用上多方面的要求,其中有些要求是其他几种存储管理方式所难以满足的。因此,这种存储管理方式已成为当今所有存储管理方式的基础。
61 |
62 | (1)方便编程:通常,用户把自己的作业按照逻辑关系划分为若干个段,每个段都是从0开始编址,并有自己的名字和长度。因此,希望要访问的逻辑地址是由段名(段号)和段内偏移量(段内地址)决定的。
63 |
64 | (2)信息共享:分页系统中的“页”只是存放信息的物理单位(块),并无完整的意义,不便于实现共享;然而段却是信息的逻辑单位。由此可知,为了实现段的共享,希望存储器管理能与用户程序分段的组织方式相适应。
65 |
66 | (3)信息保护:信息保护同样是对信息的逻辑单位进行保护,因此,分段管理方式能更有效和方便的实现信息保护功能。
67 |
68 | (4)动态增长:在实际应用中,往往有些段,特别是数据段,在使用过程中会不断地增长,而事先又无法确切地知道数据段会增长到多大。前面的几种存储管理方式都难以应付这种动态增长的情况,分段存储管理方式能较好的解决这一问题。
69 |
70 | (5)动态链接:动态链接是指在作业运行之前,并不把几个目标程序段链接起来。要运行时,先将主程序所对应的目标程序装入内存并启动运行,当运行过程中又需要调用某段时,才将该段(目标程序)调入内存并进行链接。可见,动态链接也要求以段作为管理的单位。
71 |
72 | #### 分页和分段的主要区别
73 |
74 | 分页和分段系统都采用离散分配方式,且都要通过地址映射机构来实现地址变换。但在概念上两者完全不同,主要表现在3个方面:
75 |
76 | (1)页是信息的物理单位,分页是为实现离散分配方式,**消减外部碎片**,提高内存的利用率(没有外部碎片)。分页仅仅是由于系统管理的需要而不是用户的需要。段则是信息的逻辑单位,它含有一组其意义相对完整的信息。分段的目的是为了更好的满足用户的需要。
77 |
78 | (2)页的大小固定且由系统决定,由系统把逻辑地址划分为页号和页内地址两部分,是由机器硬件实现的,因而在系统中只能有一种大小的页面;而**段的长度不固定**,决定于用户所编写的程序,通常由编译程序在对源程序进行编译时,根据信息的性质来划分。
79 |
80 | (3)分页的作业地址空间是一维的,即单一的线性地址空间,程序员只需利用一个记忆符,即可表示一个地址;而分段的作业地址空间是二维的,程序员在标识一个地址时,既需给出段名,又需给出段内地址。
81 |
82 | ### 段页式存储管理方式
83 |
84 | 前面所介绍的分页和分段存储管理方式都各有优缺点。分页系统能有效地提高内存利用率,而分段系统则能很好地满足用户需求。我们希望能够把两者的优点结合,于是出现了段页式存储管理方式。
85 |
86 | 段页式系统的基本原理是分段和分页原理的结合,即先将用户程序分成若干个段,再把每个段分成若干个页,并为每一个段赋予一个段名。在段页式系统中,地址结构由段号、段内页号和页内地址三部分所组成。和前两种存储管理方式相同,段页式存储管理方式同样需要增设联想寄存器(TLB)。
87 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理系列一:启动简介.md:
--------------------------------------------------------------------------------
1 | > 本系列所有文章转载自:https://pzh2386034.github.io/Black-Jack/
2 | > 在bootloader将控制权交给linux kernel前,需要完成下面几个动作
3 |
4 | - 初始化系统中ram,并将ram信息告知kernel
5 | - 准备好device tree blob, 并将首地址写到x0寄存器
6 | - 解压内核(option)
7 | - MMU=off, D-cache=off
8 |
9 | ### 介绍几个关于内核位置的宏,在启动过程中,经常会用到
10 |
11 | - `#define __PHYS_OFFSET (KERNEL_START - TEXT_OFFSET)` : kernel space 首地址
12 | - `KERNEL_START: _text=PAGE_OFFSET + TEXT_OFFSET` : kernel开始运行的虚拟地址(内核正文段开始的虚拟地址)
13 | - `TEXT_OFFSET` : 内核正文地址距离kernel space首地址的偏移量
14 | 1. 对于arm32,该空间一般为32kb(0x8000),用于保存内核页表(process id = 0的pgd), 以及bootloader和kernel间参数传递
15 | 2. 对于arm64, 该空间一般为512kb(0x80000)
16 | - `PAGE_OFFSET` : 目前看和`__PHYS_OFFSET`一样,均表示kernel space首地址
17 |
18 | ## 启动代码分析
19 |
20 | ## 常见arm指令
21 |
22 | - `ldr: ldr r0, [r1]`r0=* r1;将r1指向的内容存入r0
23 | 1. `ldr r0 0x12345678` : 把0x12345678这个地址中的值存放到r0中, r0=*(0x12345678)
24 | 2. `ldr r0, =0x12345678`: 此时ldr是个伪指令,功能类似mov,r0=0x12345678
25 | - `str`:`str r0 [r1, #4]`\* (r1+4) = r0;将r0中内容存入r1+4中的地址
26 | 1. .macro str_l, src, sym, tmp
27 | 2. adrp \tmp \sym
28 | 3. str \src, [\tmp, :lo12:\sym]
29 | - `str`: `str r0 [r1] , #4` *r1=r0; r1=r1+4; 将r0中内容存入r1中的地址,并将新地址r1+8存入r1
30 | - adr: 小范围地址读取指令,将基于pc相对偏移的地址值读取到寄存器中(距离pc 1m以内)
31 | 1. 原理:将符号的21位偏移,加上pc,结果写入到寄存器中
32 | - adr_l: 将符号地址转变为运行时地址(通过pc relative offset形式)
33 | 1. .macro ldr_l, dst, sym
34 | 2. adrp \dst, \sym
35 | 3. ldr \dst, [\dst, :lo12:\sym]
36 | - `adrp`: 以页为单位的大范围地址读取指令,通过该指令可以获得符号的物理地址,当然是page对齐的
37 | - `mrs`: 处理器模式切换指令,从指定寄存器读取到临时寄存器
38 | - `msr`: 写模式到指定寄存器
39 | - `bic`: `bic x0, x0, #0xF000 0000 0000 0000`: 位清除,将x0的高4位清除
40 | - `rsb`: `rsb x0, x0, #123`: x0=1280-x0
41 | - `ldp,stp`: load/store pair; `ldp x8, x2, [x0, #0x10]` : x0 += 0x10, x8 = *(x0), x2 = *(x0 + 0x8); `stp x9, x8, [x4]` : *(x4) = x9, *(x4 + 8) = x9;
42 | - `b,bl,blx,bx`: 分别为跳转指令, 带返回值的跳转指令, 带返回和状态切换的跳转指令, 带状态切换的跳转指令
43 |
44 | ## head.s中入口函数stext
45 |
46 | ```assembly
47 | ENTRY(stext)
48 | bl preserve_boot_args //(1)根据arm64规范,保存x0-x3寄存器;在setup_arch函数中会访问boot_args进行校验
49 | bl el2_setup // Drop to EL1, w20=cpu_boot_mode, (2)判断启动模式为EL1或是EL2,EL2表示支持虚拟化,KVM模块可以顺利启动
50 | adrp x24, __PHYS_OFFSET //将__PHYS_OFFSET保存到x24中
51 | bl set_cpu_boot_mode_flag //见下一篇解释
52 |
53 | bl __vet_fdt //对bootloader传递给kernel的fdt参数进行校验;1. 是否8字节对齐;2. 是否在kernel space的前512M内
54 | bl __create_page_tables // x25=TTBR0, x26=TTBR1, 见下一篇解释
55 | /*
56 | * The following calls CPU setup code, see arch/arm64/mm/proc.S for
57 | * details.
58 | * On return, the CPU will be ready for the MMU to be turned on and
59 | * the TCR will have been set.
60 | */
61 | ldr x27, =__mmap_switched // address to jump to after
62 | // MMU has been enabled
63 | adr_l lr, __enable_mmu // return (PIC) address
64 | b __cpu_setup // initialise processor
65 | ENDPROC(stext)
66 | ```
67 |
68 | ## preserve_boot_args
69 |
70 | ```assembly
71 | /*
72 | * Preserve the arguments passed by the bootloader in x0 .. x3
73 | * 保存x0-x3寄存器,是为了符合arm64规范:x0必须为dtb物理地址,x1-x3必须为0
74 | * 在setup_arch函数中会访问boot_args并进行校验
75 | */
76 | preserve_boot_args:
77 | mov x21, x0 // x21=FDT, 将dtb的地址暂存在x21中
78 |
79 | adr_l x0, boot_args // record the contents of, 将boot_args首地址保存在x0中
80 | stp x21, x1, [x0] // x0 .. x3 at kernel entry, 将x21,x1分别保存在boot_args[0], boot_args[1]
81 | stp x2, x3, [x0, #16] //将x2,x3分别保存在boot_args[2], boot_args[3]
82 |
83 | dmb sy // needed before dc ivac with
84 | // MMU off
85 |
86 | add x1, x0, #0x20 // 4 x 8 bytes, 将boot_args非参数首地址赋给x1,即x0是boot_args这段memory的首地址,x1是末尾的地址
87 | b __inval_cache_range // tail call, 将x0, x1地址段对应的cacheline设定为无效
88 | ENDPROC(preserve_boot_args)
89 | ```
90 |
91 | ## el2_setup
92 |
93 | ```unix-assembly
94 | /*
95 | * end early head section, begin head code that is also used for
96 | * hotplug and needs to have the same protections as the text region
97 | */
98 | .section ".text","ax"
99 | /*
100 | * If we're fortunate enough to boot at EL2, ensure that the world is
101 | * sane before dropping to EL1.
102 | *
103 | * Returns either BOOT_CPU_MODE_EL1 or BOOT_CPU_MODE_EL2 in x20 if
104 | * booted in EL1 or EL2 respectively.
105 | * 判断cpu模式,只拿部分为例
106 | */
107 | ENTRY(el2_setup)
108 | mrs x0, CurrentEL
109 | cmp x0, #CurrentEL_EL2 //判断是否处于EL2
110 | b.ne 1f //如果不是,则跳转到1f
111 | mrs x0, sctlr_el2 //从sctlr_el2读取模式到寄存器
112 | CPU_BE( orr x0, x0, #(1 << 25) ) // Set the EE bit for EL2
113 | CPU_LE( bic x0, x0, #(1 << 25) ) // Clear the EE bit for EL2
114 | msr sctlr_el2, x0
115 | b 2f
116 | 1: mrs x0, sctlr_el1 //执行到这,说明为EL1模式
117 | CPU_BE( orr x0, x0, #(3 << 24) ) // Set the EE and E0E bits for EL1
118 | CPU_LE( bic x0, x0, #(3 << 24) ) // Clear the EE and E0E bits for EL1
119 | msr sctlr_el1, x0
120 | mov w20, #BOOT_CPU_MODE_EL1 // This cpu booted in EL1
121 | isb
122 | ret
123 | .........
124 | ENDPROC(el2_setup)
125 | ```
126 |
127 | ## set_cpu_boot_mode_flag
128 |
129 | ```unix-assembly
130 | /*
131 | * Sets the __boot_cpu_mode flag depending on the CPU boot mode passed
132 | * in x20. See arch/arm64/include/asm/virt.h for more info.
133 | * 执行完el2_setup后,w20保存了exception level
134 | * 分析__boot_cpu_mode的定义,可以有如下结论:
135 | * 1. 如果cpu启动的时候是EL1 mode,会修改变量__boot_cpu_mode A域,将其修改为BOOT_CPU_MODE_EL1
136 | * 2. 如果cpu启动的时候是EL2 mode,会修改变量__boot_cpu_mode B域,将其修改为BOOT_CPU_MODE_EL2
137 | * ENTRY(__boot_cpu_mode)
138 | * .long BOOT_CPU_MODE_EL2--------A
139 | * .long BOOT_CPU_MODE_EL1--------B
140 | */
141 | ENTRY(set_cpu_boot_mode_flag)
142 | adr_l x1, __boot_cpu_mode
143 | cmp w20, #BOOT_CPU_MODE_EL2
144 | b.ne 1f
145 | add x1, x1, #4 //el1模式走这里,修改x1的地址为B域
146 | 1: str w20, [x1] // This CPU has booted in EL1, *x1=w20;
147 | dmb sy
148 | dc ivac, x1 // Invalidate potentially stale cache line
149 | ret
150 | ENDPROC(set_cpu_boot_mode_flag)
151 | ```
152 |
153 | ## __vet_fdt
154 |
155 | ```unix-assembly
156 | /*
157 | * Determine validity of the x21 FDT pointer.
158 | * The dtb must be 8-byte aligned and live in the first 512M of memory.
159 | * 见document/boot.txt要求
160 | * 在512m内是为了在保证kernel space的首地址和fdt首地址在一个pud entry中
161 | */
162 | __vet_fdt:
163 | tst x21, #0x7 //校验x21是否为8字节对齐
164 | b.ne 1f
165 | cmp x21, x24 //是否在小于kernel space的首地址
166 | b.lt 1f
167 | mov x0, #(1 << 29)
168 | add x0, x0, x24
169 | cmp x21, x0
170 | b.ge 1f //是否大于kernel space首地址+512M
171 | ret
172 | 1:
173 | mov x21, #0 //fdt地址有误,清零
174 | ret
175 | ENDPROC(__vet_fdt)
176 | ```
177 |
178 | 参考文档:
179 |
180 | 1. Documentation/arm64/booting.txt
181 | 2. http://www.wowotech.net/armv8a_arch/arm64_initialize_1.html
182 | 3. https://www.jianshu.com/p/4b68f45065c6
183 |
184 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理系列七:slub初始化.md:
--------------------------------------------------------------------------------
1 | ## 前沿
2 |
3 | ### 往篇回顾
4 |
5 | 在前两篇中,主要介绍了alloc_pages正常情况下,如果从伙伴系统获得内存;简单来说有如下几步:
6 |
7 | - 正常情况下,alloc_pages->get_page_from_freelist会使用low阀值遍历zonelist尝试分配, 分两次遍历,首先尝试只从preferred_zone所在node中的zone分配;
8 | 1. 如果某个zone检查水位不足,则会触发起进行内存回收zone_reclaim后,再尝试检查其水位是否符合要求;
9 | - 在get_page_from_freelist中,如果某个zone经过区间、水位校验通过后调用buffered_rmqueue申请内存;
10 | - 在buffered_rmqueue会区分order
11 | 1. order=0,尝试从CPU缓存中分配, 如果CPU缓存中没有空闲内存,则使用rmqueue_bulk从伙伴系统中申请bulk个order=0的空闲内存;
12 | 2. order>0, 尝试从zone的伙伴系统中分配内存__rmqueue(), 从free_list[order]开始找空闲内存(__rmqueue_smallest),找不到则尝试更高一阶,直到找到为止;
13 | - 如果使用__rmqueue()从free_list中获取空闲页失败,则调用__rmqueue_fallback从migratetype的fallback列表中依次尝试分配;
14 | 1. 为了反碎片,从备用mirgratetype中获取到的内存会首先尝试移动到希望的mirgratype;
15 | 2. 从备用mirgratetype获取内存,是从高阶order=10到低阶进行尝试的;这种机制应该也是为了反碎片;
16 | - 如果以上都没有成功,则会进行第二次get_page_from_freelist, 这次尝试所有zonelist中的zone;
17 | - 如果第二次遍历zonelist也失败,则会触发慢速分配__alloc_pages_slowpath,并修改水位阀值为min;
18 |
19 | ### slub简介
20 |
21 | #### 与slab的比较
22 |
23 | - slub来源于slab,slab对于小内存分配管理有不错的表现;但是对于大型的NUMA系统,slab的管理开销会成倍增大,导致异常臃肿;
24 | - slub摒弃了slab的一些管理数据,以及着色概念(为了避免CPU硬件高速缓存频繁换入换出,在一个kmem_cache中的slab的前端空闲区域嵌入空闲偏移);
25 | - node结点对应的 kmem_cache_node->colour_next * kmem_cache->colour_off 就得到了偏移量(kmem_cache.colour_off * kmem_cache.node[NODE_ID].colour_next);
26 | - colour_next++,当colour_next等于kmem_cache中的colour时,colour_next置0(kmem_cache.node[NODE_ID].colour_next++);
27 | - slab根据状态划分了3个链表–full,partial和free. slub分配器做了简化,去掉了free链表,对于空闲的slab,slub分配器选择直接将其释放;
28 | - 在NUMA架构上,slub分配器较slab做了简化;
29 |
30 | ### 本篇主要内容
31 |
32 | > 本篇主要分析slub分配器初始化过程,该阶段的主要任务是初始化用于kmalloc的gerneral cache:struct kmem_cache *kmalloc_caches[KMALLOC_SHIFT_HIGH + 1];其中KMALLOC_SHIFT_HIGH=14
33 |
34 | ## 代码分析
35 |
36 | ### size_index数组及kmem_caches数据关系
37 |
38 | - size_index数组中存储的是gerneral cache的编号;
39 | - 要根据Object size大小来定位合适的gerneral cache,直接用size/8 - 1;
40 | 1. 例如:size=48 ===> 对应size_index的下标=49/8-1=5;
41 | 2. size_index[5] == 6, 对应kmem_cache[6], 其中的slub size 为 64;
42 | 3. 即:如果你要申请一个object size=49的slub,真正给你返回的是一个object size=64的slub;
43 | - linux在Mem_init()函数中完成bootmem到伙伴系统的转移后,随即开始slub初始化
44 |
45 | ### kmem_cache_init
46 |
47 | ```c
48 | start_kernel->mm_init()->kmem_cache_init
49 |
50 | /*
51 | * 1. 通过create_boot_cache创建"kmem_cache", "kmem_cache_node" slab,后续结构体struct kmem_cache, struct kmem_cache_node的内存申请都会分别通过这两个slab完成;
52 | * 2. register_hotmemory_notifier()注册热插拔内存内核通知链回调函数用于热插拔内存处理?
53 | * 3. 完成"kmem_cache", "kmem_cache_node" slab创建后,要刷新各个node中slab的相应指针;
54 | * 4. 在create_kmalloc_caches完成 size_index和kmem_caches的映射,并对kmem_cache结构体指针用create_kmalloc_caches创建slab, 进行初始化;
55 | * 5. 置slab_state=up;
56 | */
57 | void __init kmem_cache_init(void)
58 | {
59 | //声明静态变量,存储临时kmem_cache管理结构
60 | static __initdata struct kmem_cache boot_kmem_cache,
61 | boot_kmem_cache_node;
62 |
63 | if (debug_guardpage_minorder())
64 | slub_max_order = 0;
65 |
66 | kmem_cache_node = &boot_kmem_cache_node;
67 | kmem_cache = &boot_kmem_cache;
68 | /*
69 | * 创建一个slub, size: sizeof(struct kmem_cache_node), name: "kmem_cache_node", 置引用次数refcount=-1
70 | * 其中核心函数__kmem_cache_create在下一篇中分析,其关键作用是把kmem_cache结构初始化
71 | * 申请slub缓冲区,管理数据放在临时结构体中
72 | */
73 | create_boot_cache(kmem_cache_node, "kmem_cache_node",
74 | sizeof(struct kmem_cache_node), SLAB_HWCACHE_ALIGN);
75 | /* 注册热插拔内存内核通知链回调函数用于热插拔内存处理,注册到memory_chain上 */
76 | register_hotmemory_notifier(&slab_memory_callback_nb);
77 |
78 | /* 将初始化进度改为PARTIAL,表示已经可以分配struct kmem_cache_node */
79 | slab_state = PARTIAL;
80 |
81 | create_boot_cache(kmem_cache, "kmem_cache",
82 | offsetof(struct kmem_cache, node) +
83 | nr_node_ids * sizeof(struct kmem_cache_node *),
84 | SLAB_HWCACHE_ALIGN);
85 | /*
86 | * boot_kmem_cache和boot_kmem_cache_node中的内容拷贝到新申请的对象中,并修正其余node slab中相关指针
87 | * 从而完成了struct kmem_cache和struct kmem_cache_node管理结构的bootstrap(自引导)
88 | */
89 | kmem_cache = bootstrap(&boot_kmem_cache);
90 |
91 | kmem_cache_node = bootstrap(&boot_kmem_cache_node);
92 |
93 | /* Now we can use the kmem_cache to allocate kmalloc slabs */
94 | create_kmalloc_caches(0);
95 |
96 | #ifdef CONFIG_SMP
97 | /* 注册内核通知链回调函数,注册到cpu_chain上 */
98 | register_cpu_notifier(&slab_notifier);
99 | #endif
100 |
101 | pr_info("SLUB: HWalign=%d, Order=%d-%d, MinObjects=%d, CPUs=%d, Nodes=%d\n",
102 | cache_line_size(),
103 | slub_min_order, slub_max_order, slub_min_objects,
104 | nr_cpu_ids, nr_node_ids);
105 | }
106 | ```
107 |
108 | ### bootstrap
109 |
110 | ```c
111 | /*
112 | * 从刚才挂在临时结构的缓冲区中申请kmem_cache的kmem_cache,并将管理数据拷贝到新申请的内存中
113 | * 将临时kmem_cache向最终kmem_cache迁移,并修正其余node slab中相关指针,使其指向最终kmem_cache
114 | */
115 | static struct kmem_cache * __init bootstrap(struct kmem_cache *static_cache)
116 | {
117 | int node;
118 | /*
119 | * kmem_cache_zalloc()->kmem_cache_alloc()->slab_alloc(), slab_alloc函数后面会分析
120 | * 为create_boot_cache()初始化创建的kmem_cache申请slub空间
121 | */
122 | struct kmem_cache *s = kmem_cache_zalloc(kmem_cache, GFP_NOWAIT);
123 | struct kmem_cache_node *n;
124 | /* 将bootstrap()入参的kmem_cache结构数据memcpy()至申请的空间中 */
125 | memcpy(s, static_cache, kmem_cache->object_size);
126 |
127 | /*
128 | * 刷新cpu的slab信息
129 | */
130 | __flush_cpu_slab(s, smp_processor_id());
131 | /*
132 | * 要将新的kmem_cache地址刷新到各个内存管理节点node的slab中
133 | * 通过for_each_kmem_cache_node()遍历各个内存管理节点node,获取各个节点的kmem_cache_node,如果不为空:
134 | * 遍历其中部分满的slab链表,修正每个slab指向kmem_cache的指针;
135 | * 如果开启debug,则对满的slab链表也遍历
136 | */
137 | for_each_kmem_cache_node(s, node, n) {
138 | struct page *p;
139 |
140 | list_for_each_entry(p, &n->partial, lru)
141 | p->slab_cache = s;
142 |
143 | #ifdef CONFIG_SLUB_DEBUG
144 | list_for_each_entry(p, &n->full, lru)
145 | p->slab_cache = s;
146 | #endif
147 | }
148 | slab_init_memcg_params(s);
149 | /* 将kmem_cache添加到全局slab_caches链表中 */
150 | list_add(&s->list, &slab_caches);
151 | return s;
152 | }
153 | ```
154 |
155 | ### create_kmalloc_caches
156 |
157 | ```c
158 | /*
159 | * 1. 根据KMALLOC_MIN_SIZE大小,对size_index全局数组中数据进行改变
160 | * 对于slub分配算法而言,KMALLOC_MIN_SIZE为1 << KMALLOC_SHIFT_LOW,其中KMALLOC_SHIFT_LOW为3,则KMALLOC_MIN_SIZE为8
161 | * 因此size_index中数据不会改变
162 | * 2. 循环调用 create_kmalloc_cache 初始化 kmalloc_caches 结构体数组====>到这,完成了size_index和kmalloc_caches的映射
163 | * 3. 创建完后,将slab_state置为up
164 | * 4. 将kmem_cache的name成员进行初始化
165 | * 5. 如果配置了CONFIG_ZONE_DMA, 则初始化创建kmalloc_dma_caches
166 | */
167 | void __init create_kmalloc_caches(unsigned long flags)
168 | {
169 | int i;
170 |
171 | /* 保证kmalloc允许的最小对象大小不能大于256,且该值必须是2的整数幂 */
172 | BUILD_BUG_ON(KMALLOC_MIN_SIZE > 256 ||
173 | (KMALLOC_MIN_SIZE & (KMALLOC_MIN_SIZE - 1)));
174 | /* 对大小在8byte与KMALLOC_MIN_SIZE之间的对象,将其在size_index数组的索引设置为KMALLOC_SHIFT_LOW */
175 | for (i = 8; i < KMALLOC_MIN_SIZE; i += 8) {
176 | int elem = size_index_elem(i);
177 |
178 | if (elem >= ARRAY_SIZE(size_index))
179 | break;
180 | size_index[elem] = KMALLOC_SHIFT_LOW;
181 | }
182 |
183 | if (KMALLOC_MIN_SIZE >= 64) {
184 | /* KMALLOC_MIN_SIZE=8,不会进入该分支 */
185 | for (i = 64 + 8; i <= 96; i += 8)
186 | size_index[size_index_elem(i)] = 7;
187 |
188 | }
189 |
190 | if (KMALLOC_MIN_SIZE >= 128) {
191 | /* KMALLOC_MIN_SIZE=8,不会进入该分支 */
192 | for (i = 128 + 8; i <= 192; i += 8)
193 | size_index[size_index_elem(i)] = 8;
194 | }
195 | /*
196 | * 循环调用 create_kmalloc_cache 初始化 kmalloc_caches 结构体数组
197 | * KMALLOC_SHIFT_HIGH=12,但是size_index最大只到7阶,高阶的怎么处理?
198 | * create_kmalloc_cache:
199 | * 1. 通过kmem_cache_zalloc申请一个kmem_cache对象
200 | * 2. 通过create_boot_cache()创建slab
201 | * 3. 将创建的slab添加到slab_caches中
202 | */
203 | for (i = KMALLOC_SHIFT_LOW; i <= KMALLOC_SHIFT_HIGH; i++) {
204 | if (!kmalloc_caches[i]) {
205 | kmalloc_caches[i] = create_kmalloc_cache(NULL,
206 | 1 << i, flags);
207 | }
208 | if (KMALLOC_MIN_SIZE <= 32 && !kmalloc_caches[1] && i == 6)
209 | kmalloc_caches[1] = create_kmalloc_cache(NULL, 96, flags);
210 |
211 | if (KMALLOC_MIN_SIZE <= 64 && !kmalloc_caches[2] && i == 7)
212 | kmalloc_caches[2] = create_kmalloc_cache(NULL, 192, flags);
213 | }
214 |
215 | /* Kmalloc array is now usable */
216 | slab_state = UP;
217 | /* 将kmem_cache的name成员进行初始化 */
218 | for (i = 0; i <= KMALLOC_SHIFT_HIGH; i++) {
219 | struct kmem_cache *s = kmalloc_caches[i];
220 | char *n;
221 |
222 | if (s) {
223 | n = kasprintf(GFP_NOWAIT, "kmalloc-%d", kmalloc_size(i));
224 |
225 | BUG_ON(!n);
226 | s->name = n;
227 | }
228 | }
229 |
230 | #ifdef CONFIG_ZONE_DMA
231 | for (i = 0; i <= KMALLOC_SHIFT_HIGH; i++) {
232 | struct kmem_cache *s = kmalloc_caches[i];
233 |
234 | if (s) {
235 | int size = kmalloc_size(i);
236 | char *n = kasprintf(GFP_NOWAIT,
237 | "dma-kmalloc-%d", size);
238 |
239 | BUG_ON(!n);
240 | kmalloc_dma_caches[i] = create_kmalloc_cache(n,
241 | size, SLAB_CACHE_DMA | flags);
242 | }
243 | }
244 | #endif
245 | }
246 | #endif /* !CONFIG_SLOB */
247 | ```
248 |
249 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理系列三:MMU前CPU初始化及打开MMU.md:
--------------------------------------------------------------------------------
1 | > 上一篇中,详细分析了MMU打开前,为MMU打开后能正常启动linux kernel进行了3块区域的section map; 本篇聚焦为打开MMU而进行的CPU初始化, 主要内容:
2 |
3 | - cache和TLB处理
4 | - memory attributes lookup table的创建
5 | - SCTLR_EL1、TCR_EL1的设定(详细见参考资料)
6 |
7 | ## 首先介绍icache, dcache
8 |
9 | ### icache: 指令cache(instruction cache)
10 |
11 | - 由cp15协处理器中控制寄存器1的第12位控制,一般在MMU开启之后被使用
12 | - icache一般有512个entry,每个16 bytes;如果miss cache, 则从内存中读取指令,且触发`8-word linefill`, 将该指令所在区域8 word写进某个entry
13 |
14 | ### dcache: 数据cache
15 |
16 | - ARM dcache架构由cache存储器和写缓冲器(write-buffer)组成,其中写缓冲器是CACHE按照FIFO原则向主存写的缓冲处理器
17 | - 一般来说CACHEABILITY和BUFFERABILITY都是可以配置的,所以,一块存储区域可以配置成下面4种方式:NCNB CNB NCB CB(例: ip map都采用NCNB)
18 | - DCaches使用的是虚拟地址,它的大小是16KB,它被分成512行(entry), 每行8个字(8 words,32Bits)。每行有两个修改标志位(dirty bits),第一个标志位标识前4个字,第二个标志位标识后4个字,同时每行中还有一个TAG 地址(标签地址)和一个valid bit
19 |
20 | ## memory type
21 |
22 | 在上一篇中,我们主要分析了新建slub的过程,入口函数是`kmem_cache_create`,主要内容如下:
6 |
7 | - 首先搜索现有的slub,看看有没有可以重用的,如果有就给合适的slub再取一个别名,refcount+1,然后返回;
8 | - 如果无法找到合适的可复用slub,则通过`do_kmem_cache_create`新建一个slub;
9 | - 新建slub其实并没有为其从伙伴系统申请内存,全部内容围绕这初始化管理结构体kmem_cache进行,主要动作是如下4个:
10 | 1. 申请管理结构体kmem_cache内存;
11 | 2. 根据传入参数size、flag以及系统全局变量`slub_min_objects`, `slub_max_order`通过碎片最小原则确定内存order;
12 | 3. 初始化kmem_cache;
13 | 4. 通过`init_kmem_cache_nodes`及`init_kmem_cache_cpus`申请内存,初始化后挂到kmem_cache响应成员变量上;
14 |
15 | ### 本篇主要内容
16 |
17 | > 在完成kmem create后,使用`kmem_cache_alloc`申请slub对象的流程,简单来说步骤如下:
18 |
19 | ## 代码分析
20 |
21 | ### slab_alloc_node
22 |
23 | slub内存申请入口函数: kmem_cache_alloc; 外层函数都比较简单,直接看内存的slab_alloc_node
24 |
25 | ```c
26 | kmem_cache_alloc()-->slab_alloc()-->slab_alloc_node()
27 | /*
28 | * 1. 通过cpu_slab->tid来防止多线程重入导致当前获取的cpu_slab已经不是最新状态
29 | * 2. 如果cpu_slab->freelist不为空 则尝试从freelist中快速分配
30 | * 3. 否则进入__slab_alloc慢速分配
31 | */
32 | static __always_inline void *slab_alloc_node(struct kmem_cache *s,
33 | gfp_t gfpflags, int node, unsigned long addr)
34 | {
35 | void **object;
36 | struct kmem_cache_cpu *c;
37 | struct page *page;
38 | unsigned long tid;
39 |
40 | s = slab_pre_alloc_hook(s, gfpflags);
41 | if (!s)
42 | return NULL;
43 | redo:
44 | /*
45 | * 1. 获取tid
46 | * 2. 通过__this_cpu_ptr()获取当前CPU的kmem_cache_cpu结构
47 | * tid的作用是防止多线程操作导致获取到的slub不是最新状态
48 | */
49 | do {
50 | tid = this_cpu_read(s->cpu_slab->tid);
51 | c = raw_cpu_ptr(s->cpu_slab);
52 | } while (IS_ENABLED(CONFIG_PREEMPT) &&
53 | unlikely(tid != READ_ONCE(c->tid)));
54 |
55 | /*
56 | * 上面这段注释说明了tid及barrier()的作用,中文解释见附录
57 | * barrier:内存屏障
58 | */
59 | barrier();
60 |
61 |
62 | object = c->freelist;
63 | page = c->page;
64 | /* 判断当前CPU的slab空闲列表是否为空或者当前slab使用内存页面与管理节点是否不匹配 */
65 | if (unlikely(!object || !node_match(page, node))) {
66 | /* 进入慢速分配 */
67 | object = __slab_alloc(s, gfpflags, node, addr, c);
68 | stat(s, ALLOC_SLOWPATH);
69 | } else {
70 | /* 进入快速分配,获取slub中空闲对象地址 */
71 | void *next_object = get_freepointer_safe(s, object);
72 |
73 | /* 使用this_cpu_cmpxchg_double()原子指令操作更新freelist,tid
74 | * this_cpu_cmpxchg_double是一个内核常用函数,可以单独百度搜索其作用:
75 | * 1. 检测 s->cpu_slab->freelist==object && s->cpu_slab->tid==tid
76 | * 2. 成功则,更新s->cpu_slab->freelist, s->cpu_slab->tid
77 | * 3. 否则,返回失败
78 | */
79 | if (unlikely(!this_cpu_cmpxchg_double(
80 | s->cpu_slab->freelist, s->cpu_slab->tid,
81 | object, tid,
82 | next_object, next_tid(tid)))) {
83 | /* 获取空闲对象失败,则经note_cmpxchg_failure()记录日志后重回redo标签再次尝试分配 */
84 | note_cmpxchg_failure("slab_alloc", s, tid);
85 | goto redo;
86 | }
87 | /* 刷新结构体数据 */
88 | prefetch_freepointer(s, next_object);
89 | stat(s, ALLOC_FASTPATH);
90 | }
91 | /* 如果有__GFP_ZERO,则刷新内存 */
92 | if (unlikely(gfpflags & __GFP_ZERO) && object)
93 | memset(object, 0, s->object_size);
94 |
95 | slab_post_alloc_hook(s, gfpflags, object);
96 |
97 | return object;
98 | }
99 | ```
100 |
101 | ### __slab_alloc
102 |
103 | ```c
104 | /*
105 | * 1. new_slab中会依次尝试从cpu_slab->partial链表,kmem_cache_node->partial链表尝试分配
106 | * 2. 如果上面两个地方都失败了,则只能尝试从伙伴系统中再次申请slab
107 | */
108 | static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
109 | unsigned long addr, struct kmem_cache_cpu *c)
110 | {
111 | void *freelist;
112 | struct page *page;
113 | unsigned long flags;
114 | /* 关闭本CPU中断 */
115 | local_irq_save(flags);
116 | #ifdef CONFIG_PREEMPT
117 | /*
118 | * We may have been preempted and rescheduled on a different
119 | * cpu before disabling interrupts. Need to reload cpu area
120 | * pointer.
121 | */
122 | c = this_cpu_ptr(s->cpu_slab);
123 | #endif
124 | /* slab内存的page指针,指向正在使用的slab的页帧, 如果page为空,则重新申请slub */
125 | page = c->page;
126 | if (!page)
127 | goto new_slab;
128 | redo:
129 | /* 如果节点不匹配就通过deactivate_slab()去激活cpu本地slab? */
130 | if (unlikely(!node_match(page, node))) {
131 | int searchnode = node;
132 |
133 | if (node != NUMA_NO_NODE && !node_present_pages(node))
134 | searchnode = node_to_mem_node(node);
135 |
136 | if (unlikely(!node_match(page, searchnode))) {
137 | stat(s, ALLOC_NODE_MISMATCH);
138 | deactivate_slab(s, page, c->freelist);
139 | c->page = NULL;
140 | c->freelist = NULL;
141 | goto new_slab;
142 | }
143 | }
144 |
145 | /* 通过pfmemalloc_match()判断当前页面属性是否为pfmemalloc? 如果不是则同样去激活 */
146 | if (unlikely(!pfmemalloc_match(page, gfpflags))) {
147 | /*
148 | * 1. 将cpu_slab的freelist全部释放回page->freelist
149 | * 2. 根据page(slab)的状态进行不同操作:
150 | * 如果该slab有部分空闲对象,则将page移到kmem_cache_node的partial队列;
151 | * 如果该slab全部空闲,则直接释放该slab;
152 | * 如果该slab全部占用,而且开启了CONFIG_SLUB_DEBUG编译选项,则将page移到full队列;
153 | * 3. page的状态也从frozen改变为unfrozen(frozen代表slab在cpu_slub,unfroze代表在partial队列或者full队列)
154 | */
155 | deactivate_slab(s, page, c->freelist);
156 | c->page = NULL;
157 | c->freelist = NULL;
158 | goto new_slab;
159 | }
160 |
161 | /* must check again c->freelist in case of cpu migration or IRQ */
162 | freelist = c->freelist;
163 | if (freelist)
164 | goto load_freelist;
165 | /* 通过get_freelist()从页面中获取空闲队列 */
166 | freelist = get_freelist(s, page);
167 | /* 获取空闲队列失败,此时则需要创建新的slab,否则更新统计信息进入load_freelist分支取得对象并返回 */
168 | if (!freelist) {
169 | c->page = NULL;
170 | stat(s, DEACTIVATE_BYPASS);
171 | goto new_slab;
172 | }
173 | /* 更新统计信息进入load_freelist分支取得对象并返回 */
174 | stat(s, ALLOC_REFILL);
175 |
176 | load_freelist:
177 | /*
178 | * 把对象从空闲队列中取出,并更新数据信息,然后恢复中断使能,返回对象地址
179 | */
180 | VM_BUG_ON(!c->page->frozen);
181 | c->freelist = get_freepointer(s, freelist);
182 | c->tid = next_tid(c->tid);
183 | local_irq_restore(flags);
184 | return freelist;
185 |
186 | new_slab:
187 | /* partial不为空则从partial中取出,然后跳转回redo重试分配 */
188 | if (c->partial) {
189 | page = c->page = c->partial;
190 | c->partial = page->next;
191 | stat(s, CPU_PARTIAL_ALLOC);
192 | c->freelist = NULL;
193 | goto redo;
194 | }
195 | /* 如果partial为空,意味着当前所有的slab都已经满负荷使用,那么则需使用new_slab_objects()创建新的slab
196 | * 该函数中,首先通过get_partial()获取存在空闲对象的slab并将对象返回;
197 | * 继而通过new_slab()创建slab,如果创建好slab后,将空闲对象链表摘下并返回
198 | */
199 | freelist = new_slab_objects(s, gfpflags, node, &c);
200 |
201 | if (unlikely(!freelist)) {
202 | /* 记录日志后使能中断并返回NULL表示申请失败 */
203 | slab_out_of_memory(s, gfpflags, node);
204 | local_irq_restore(flags);
205 | return NULL;
206 | }
207 |
208 | page = c->page;
209 | /* 判断是否未开启调试且页面属性匹配pfmemalloc */
210 | if (likely(!kmem_cache_debug(s) && pfmemalloc_match(page, gfpflags)))
211 | goto load_freelist;
212 |
213 | /* 若开启调试并且调试初始化失败,则返回创建新的slab */
214 | if (kmem_cache_debug(s) &&
215 | !alloc_debug_processing(s, page, freelist, addr))
216 | goto new_slab; /* Slab failed checks. Next slab needed */
217 | /* deactivate_slab()去激活该page,使能中断并返回 */
218 | deactivate_slab(s, page, get_freepointer(s, freelist));
219 | c->page = NULL;
220 | c->freelist = NULL;
221 | local_irq_restore(flags);
222 | return freelist;
223 | }
224 | ```
225 |
226 | ### new_slab
227 |
228 | ```c
229 | /*
230 | * 申请新的slub
231 | *
232 | */
233 | static struct page *new_slab(struct kmem_cache *s, gfp_t flags, int node)
234 | {
235 | struct page *page;
236 | void *start;
237 | void *p;
238 | int order;
239 | int idx;
240 |
241 | if (unlikely(flags & GFP_SLAB_BUG_MASK)) {
242 | pr_emerg("gfp: %u\n", flags & GFP_SLAB_BUG_MASK);
243 | BUG();
244 | }
245 | /*
246 | * 1. 通过allocate_slab_page从伙伴系统申请内存,如果申请失败则降低要求,以kmem_cache->min中阶数申请
247 | * 2. 如果开启了kmemcheck检测功能,则需要申请相同数量的shadow page,并初始化其数据
248 | * 3. 分配成功则刷新page->objects数量
249 | */
250 | page = allocate_slab(s,
251 | flags & (GFP_RECLAIM_MASK | GFP_CONSTRAINT_MASK), node);
252 | if (!page)
253 | goto out;
254 |
255 | order = compound_order(page);
256 | inc_slabs_node(s, page_to_nid(page), page->objects);
257 | page->slab_cache = s;
258 | __SetPageSlab(page);
259 | if (page_is_pfmemalloc(page))
260 | SetPageSlabPfmemalloc(page);
261 |
262 | start = page_address(page);
263 |
264 | if (unlikely(s->flags & SLAB_POISON))
265 | memset(start, POISON_INUSE, PAGE_SIZE << order);
266 |
267 | kasan_poison_slab(page);
268 |
269 | for_each_object_idx(p, idx, s, start, page->objects) {
270 | setup_object(s, page, p);
271 | if (likely(idx < page->objects))
272 | set_freepointer(s, p, p + s->size);
273 | else
274 | set_freepointer(s, p, NULL);
275 | }
276 |
277 | page->freelist = start;
278 | page->inuse = page->objects;
279 | page->frozen = 1;
280 | out:
281 | return page;
282 | }
283 | ```
284 |
285 | ## 附录
286 |
287 | ### barrier、tid起到的作用
288 |
289 | - 局部变量tid和object、page在cpu看来没有任何依赖关系;
290 | - 因此编译器和CPU的乱序执行都可能会导致先write object、page再write tid;
291 | - 实际必须先write tid,原因是:
292 |
293 | 假设先写object、page,此时线程thread1被thread2抢占,而thread2恰好在当前CPU上执行了slab_alloc_node,那么c->tid、c->freelist、c->page将被更新,再切回thread1设置局部变量tid = c->tid,随后执行cmpxchg时必将成功,因为 tid == c->tid,而此时thread1的object和page明显不是最新, tid也就发挥不了应有的作用;
294 |
295 | 而假设先写tid,此时线程thread1被thread2抢占,而thread2恰好在当前CPU上执行了slab_alloc_node,那么c->tid、c->freelist、c->page将被更新,再切回thread1设置局部变量object和page,随后执行cmpxchg时必将失败,因为 tid != c->tid,然后此时我只需要goto redo即可;
296 |
297 | ## 参考资料
298 |
299 | [slub源码分析](https://www.jeanleo.com/2018/09/07/【linux内存源码分析】slub分配算法(4)/)
300 |
301 | [图解slub,slub结构体描述](http://www.wowotech.net/memory_management/426.html)
302 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理系列十一:slub销毁.md:
--------------------------------------------------------------------------------
1 | ## 前沿
2 |
3 | ### 往篇回顾
4 |
5 | > 在上一篇中,主要看了slub释放的代码流程,入口函数是`kmem_cache_free`,主要内容如下:
6 |
7 | 待补充!
8 |
9 | ## 代码分析
10 |
11 | ### kmem_cache_destroy
12 |
13 | ```c
14 | void kmem_cache_destroy(struct kmem_cache *s)
15 | {
16 | struct kmem_cache *c, *c2;
17 | LIST_HEAD(release);
18 | bool need_rcu_barrier = false;
19 | bool busy = false;
20 |
21 | BUG_ON(!is_root_cache(s));
22 |
23 | get_online_cpus();
24 | get_online_mems();
25 |
26 | mutex_lock(&slab_mutex);
27 |
28 | s->refcount--;
29 | if (s->refcount)
30 | goto out_unlock;/* 如果引用不为0,则不释放该slub */
31 | /* 引用==0,释放slub,关键函数为do_kmem_cache_shutdown */
32 | for_each_memcg_cache_safe(c, c2, s) {
33 | if (do_kmem_cache_shutdown(c, &release, &need_rcu_barrier))
34 | busy = true;
35 | }
36 |
37 | if (!busy)
38 | do_kmem_cache_shutdown(s, &release, &need_rcu_barrier);
39 |
40 | out_unlock:
41 | mutex_unlock(&slab_mutex);
42 |
43 | put_online_mems();
44 | put_online_cpus();
45 |
46 | do_kmem_cache_release(&release, need_rcu_barrier);
47 | }
48 | ```
49 |
50 | ### do_kmem_cache_shutdown
51 |
52 | ```c
53 | static int do_kmem_cache_shutdown(struct kmem_cache *s,
54 | struct list_head *release, bool *need_rcu_barrier)
55 | {
56 | /* 销毁slub核心函数:__kmem_cache_shutdown->kmem_cache_close */
57 | if (__kmem_cache_shutdown(s) != 0) {
58 | printk(KERN_ERR "kmem_cache_destroy %s: "
59 | "Slab cache still has objects\n", s->name);
60 | dump_stack();
61 | return -EBUSY;
62 | }
63 |
64 | if (s->flags & SLAB_DESTROY_BY_RCU)
65 | *need_rcu_barrier = true;
66 |
67 | #ifdef CONFIG_MEMCG_KMEM
68 | if (!is_root_cache(s))
69 | list_del(&s->memcg_params.list);
70 | #endif
71 | /* 成功后,将slub从slab_cache中删除 */
72 | list_move(&s->list, release);
73 | return 0;
74 | }
75 | ```
76 |
77 | ### kmem_cache_close
78 |
79 | ```c
80 | /*
81 | * Release all resources used by a slab cache.
82 | */
83 | static inline int kmem_cache_close(struct kmem_cache *s)
84 | {
85 | int node;
86 | struct kmem_cache_node *n;
87 | /* 释放本地CPU的缓存区,即kmem_cache_cpu管理的缓存区空间 */
88 | flush_all(s);
89 | /* 遍历各节点,get_node()获取节点下的kmem_cache_node管理结构 */
90 | for_each_kmem_cache_node(s, node, n) {
91 | /* 释放各个node中的半满队列 */
92 | free_partial(s, n);
93 | /* 如果nr_partial非0,则说明有异常;销毁失败 */
94 | if (n->nr_partial || slabs_node(s, node))
95 | return 1;
96 | }
97 | /* 将kmem_cache的每CPU缓存管理kmem_cache_cpu通过free_percpu()归还给系统 */
98 | free_percpu(s->cpu_slab);
99 | /* 将每node管理结构体kmem_cache_node归还系统 */
100 | free_kmem_cache_nodes(s);
101 | return 0;
102 | }
103 | ```
104 |
105 | ### flush_all
106 |
107 | ```c
108 | /*
109 | * on_each_cpu_cond任务是遍历所有cpu,执行作为入参传入的函数has_cpu_slab
110 | * 判断各个cpu上的资源是否存在,存在则通过flush_cpu_slab对该cpu上的资源进行释放
111 | */
112 | static void flush_all(struct kmem_cache *s)
113 | {
114 | on_each_cpu_cond(has_cpu_slab, flush_cpu_slab, s, 1, GFP_ATOMIC);
115 | }
116 | ```
117 |
118 | ### on_each_cpu_cond
119 |
120 | ```c
121 | /*
122 | * cond_func: 钩子函数,用于根据调用者传入的CPU信息参数来判断是否需要打断该CPU以执行入参func的操作
123 | * has_cpu_slab:判断cpu是否有缓冲区,有则返回true;即需要CPU被打断去执行本地缓存释放动作
124 | * smp_call_func_t func: 任务函数
125 | * info: 入参
126 | * gfp_flags:申请cpumask空间的标识
127 | */
128 | void on_each_cpu_cond(bool (*cond_func)(int cpu, void *info),
129 | smp_call_func_t func, void *info, bool wait,
130 | gfp_t gfp_flags)
131 | {
132 | cpumask_var_t cpus;
133 | int cpu, ret;
134 |
135 | might_sleep_if(gfp_flags & __GFP_WAIT);
136 | /* 申请cpumask空间 */
137 | if (likely(zalloc_cpumask_var(&cpus, (gfp_flags|__GFP_NOWARN)))) {
138 | /* 禁止抢占内核 */
139 | preempt_disable();
140 | /* 遍历各个CPU,根据cond_func()判断是否需要对该CPU进行打断处理,如果需要则cpumask_set_cpu()对该CPU进行标志 */
141 | for_each_online_cpu(cpu)
142 | if (cond_func(cpu, info))
143 | cpumask_set_cpu(cpu, cpus);
144 | /* 打断各个标志位对应的CPU去执行func()的操作 */
145 | on_each_cpu_mask(cpus, func, info, wait);
146 | /* 完了将会恢复抢占,释放cpumask空间 */
147 | preempt_enable();
148 | free_cpumask_var(cpus);
149 | } else {
150 | /*
151 | * zalloc_cpumask_var()申请不到空间,将会逐个处理器进行打断再进行处理,其最终功能和作用与申请到空间的情况都是一致的
152 | */
153 | preempt_disable();
154 | for_each_online_cpu(cpu)
155 | if (cond_func(cpu, info)) {
156 | ret = smp_call_function_single(cpu, func,
157 | info, wait);
158 | WARN_ON_ONCE(ret);
159 | }
160 | preempt_enable();
161 | }
162 | }
163 | ```
164 |
165 | ### __flush_cpu_slab
166 |
167 | flush_cpu_slab()->__flush_cpu_slab()
168 |
169 | ```c
170 | /* 将本地CPU的缓存区进行释放 */
171 | static inline void __flush_cpu_slab(struct kmem_cache *s, int cpu)
172 | {
173 | /* 首先获取本地CPU的kmem_cache_cpu管理结构 */
174 | struct kmem_cache_cpu *c = per_cpu_ptr(s->cpu_slab, cpu);
175 |
176 | if (likely(c)) {
177 | /*
178 | * 如果本地CPU存在缓存区占用, 则通过flush_slab()释放本地缓存区
179 | * 其主要通过deactivate_slab()去激活本地缓存区;即释放
180 | */
181 | if (c->page)
182 | flush_slab(s, c);
183 | /* 本地CPU半满缓存列表进行释放 */
184 | unfreeze_partials(s, c);
185 | }
186 | }
187 | ```
188 |
189 | ### deactivate_slab
190 |
191 | ```c
192 | /*
193 | * Remove the cpu slab
194 | */
195 | static void deactivate_slab(struct kmem_cache *s, struct page *page,
196 | void *freelist)
197 | {
198 | enum slab_modes { M_NONE, M_PARTIAL, M_FULL, M_FREE };
199 | struct kmem_cache_node *n = get_node(s, page_to_nid(page));
200 | int lock = 0;
201 | enum slab_modes l = M_NONE, m = M_NONE;
202 | void *nextfree;
203 | int tail = DEACTIVATE_TO_HEAD;
204 | struct page new;
205 | struct page old;
206 | /* 如果不为空,则该CPU的slub对象被其它CPU释放了, 将会更新统计同时设置tail标识为DEACTIVATE_TO_TAIL */
207 | if (page->freelist) {
208 | stat(s, DEACTIVATE_REMOTE_FREES);
209 | tail = DEACTIVATE_TO_TAIL;
210 | }
211 | /* 如果为空,意味着该缓存区的对象已经全部分配到了CPU的kmem_cache_cpu中freelist链表中 */
212 | /*
213 | * 1. 通过while循环遍历CPU上的freelist链表get_greepointer()获取空闲对象
214 | * 2. 通过内部的do-while循环,借用__cmpxchg_double_slab()比较交换将对象以插入缓存区页面的freelist空闲链表头的方式归还回去
215 | * 3. 目标:当页面还处于冻结状态,将会释放每CPU的所有可用对象回到缓冲区的空闲列表中
216 | */
217 | while (freelist && (nextfree = get_freepointer(s, freelist))) {
218 | void *prior;
219 | unsigned long counters;
220 |
221 | do {
222 | prior = page->freelist;
223 | counters = page->counters;
224 | set_freepointer(s, freelist, prior);
225 | new.counters = counters;
226 | new.inuse--;
227 | VM_BUG_ON(!new.frozen);
228 |
229 | } while (!__cmpxchg_double_slab(s, page,
230 | prior, counters,
231 | freelist, new.counters,
232 | "drain percpu freelist"));
233 |
234 | freelist = nextfree;
235 | }
236 |
237 | /*
238 | * Stage two: Ensure that the page is unfrozen while the
239 | * list presence reflects the actual number of objects
240 | * during unfreeze.
241 | *
242 | * We setup the list membership and then perform a cmpxchg
243 | * with the count. If there is a mismatch then the page
244 | * is not unfrozen but the page is on the wrong list.
245 | *
246 | * Then we restart the process which may have to remove
247 | * the page from the list that we just put it on again
248 | * because the number of objects in the slab may have
249 | * changed.
250 | */
251 | redo:
252 | /* 将缓冲区的freeelist以及counters信息存到临时old结构中以备后用 */
253 | old.freelist = page->freelist;
254 | old.counters = page->counters;
255 | VM_BUG_ON(!old.frozen);
256 |
257 | /* Determine target state of the slab */
258 | new.counters = old.counters;
259 | if (freelist) {
260 | /* 把前面步骤一未被归还的那个对象归还到缓冲区中,同时更新new信息,此时new.freelist持有该缓存区的所有空闲对象 */
261 | new.inuse--;
262 | set_freepointer(s, freelist, old.freelist);
263 | new.freelist = freelist;
264 | } else
265 | new.freelist = old.freelist;
266 | /* 将临时缓冲区状态设置为非冻结 */
267 | new.frozen = 0;
268 |
269 | if (!new.inuse && n->nr_partial >= s->min_partial)
270 | /* 该slab缓存区中无对象被使用(!new.inuse),且部分满slab个数大于最小值,意味着该缓存区需要被销毁 */
271 | m = M_FREE;
272 | else if (new.freelist) {
273 | /* freelist不为空,仅使用了部分对象,则标识m为M_PARTIAL */
274 | m = M_PARTIAL;
275 | if (!lock) {
276 | lock = 1;
277 | /*
278 | * Taking the spinlock removes the possiblity
279 | * that acquire_slab() will see a slab page that
280 | * is frozen
281 | */
282 | spin_lock(&n->list_lock);
283 | }
284 | } else {
285 | /* freelist为空,仅使用了部分对象,则标识m为M_PARTIAL */
286 | m = M_FULL;
287 | if (kmem_cache_debug(s) && !lock) {
288 | lock = 1;
289 | /*
290 | * This also ensures that the scanning of full
291 | * slabs from diagnostic functions will not see
292 | * any frozen slabs.
293 | */
294 | spin_lock(&n->list_lock);
295 | }
296 | }
297 | /*
298 | * 判断上一次的缓存区状态l与接下来的操作状态m是否一致,不一致则意味着需要发生变更
299 | * 其将会先判断l的状态为M_PARTIAL或M_FULL,继而采取对应的remove_partial()或remove_full()链表摘除操作
300 | */
301 | if (l != m) {
302 |
303 | if (l == M_PARTIAL)
304 |
305 | remove_partial(n, page);
306 |
307 | else if (l == M_FULL)
308 |
309 | remove_full(s, n, page);
310 |
311 | if (m == M_PARTIAL) {
312 |
313 | add_partial(n, page, tail);
314 | stat(s, tail);
315 |
316 | } else if (m == M_FULL) {
317 |
318 | stat(s, DEACTIVATE_FULL);
319 | add_full(s, n, page);
320 |
321 | }
322 | }
323 |
324 | l = m;
325 | /*
326 | * 判断自redo到此,缓存区是否发生过对象操作变更,如果没发生过的话,将会把new暂存的空闲对象挂载到缓存区中以及更新counters
327 | * 否则将会跳转回redo标签重新执行前面的操作
328 | */
329 | if (!__cmpxchg_double_slab(s, page,
330 | old.freelist, old.counters,
331 | new.freelist, new.counters,
332 | "unfreezing slab"))
333 | goto redo;
334 |
335 | if (lock)
336 | spin_unlock(&n->list_lock);
337 |
338 | if (m == M_FREE) {
339 | stat(s, DEACTIVATE_EMPTY);
340 | discard_slab(s, page);
341 | stat(s, FREE_SLAB);
342 | }
343 | }
344 | ```
345 |
346 | ## 参考资料
347 |
348 | [slub释放](https://www.jeanleo.com/2018/09/08/【linux内存源码分析】slub分配算法(6)/)
349 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理系列十七:内存池.md:
--------------------------------------------------------------------------------
1 | ## 前沿
2 |
3 | ### 往篇回顾
4 |
5 | > 在上一篇中,着重分析了匿名页RMAP的机制及建立过程
6 |
7 | - 在malloc触发缺页中断、写时复制等场景下产生匿名页面的同时建立新页的RMAP,主要有下面几个步骤
8 | 1. 通过anon_vma_prepare()创建新页对应vma的av,avc;并使用anon_vma_chain_link初始化结构体数据,建立该vma的RMAP基础框架
9 | 2. 从Buddy sys中申请到新页面后,使用`page_add_new_anon_rmap`为该页面添加RMAP;主要处理struct page,struct av,struct avc成员变量初始化
10 | - 在fork后,要更新进程的RMAP框架,要让页面能反向找到子进程,关键子进程对父进程各个vma的复制
11 | 1. 在`dup_mmap()`函数中,遍历所有父进程所有非VM_DONTCOPY的vma,使用`anon_vma_fork`复制对应的子进程vma
12 | 2. 在`anon_vma_fork`中首先使用`anon_vma_clone`对挂在vma->anon_vma_chain中的所有avc进行复制,并使用anon_vma_chain_link使复制的avc加入子进程RMAP,当然要加入父进程的av红黑树
13 | 3. 在avc的复制后,在`anon_vma_fork`再建立完全属于子进程的av,avc
14 |
15 | ### 匿名页的诞生
16 |
17 | - malloc/mmap(共享)分配内存,发生缺页中断,调用`do_anonymous_page()`产生匿名页面
18 | - 发生写时复制,缺页中断出现写保护错误
19 | 1. `do_wp_page()`: fork后访问页面触发、页面swap in触发的写时复制
20 | 2. `do_cow_page()`: 共享文件匿名页(do_fault_page->do_cow_page)
21 | - do_swap_page(),从swap分去读回数据时会新分配匿名页
22 | - 迁移页面
23 |
24 | ### 内核内存池简介
25 |
26 | - 内存池是用于预先申请一些内存用于备用,当系统内存不足无法从伙伴系统和slab中获取内存时,会从内存池中获取预留的那些内存;
27 | - 内核里使用mempool_create()创建一个内存池,使用mempool_destroy()销毁一个内存池,使用mempool_alloc()申请内存和mempool_free()释放内存
28 |
29 | ### 本篇主要内容
30 |
31 | > 内核内存池的使用流程分析
32 |
33 | ## 代码分析
34 |
35 | ### mempool_create_node
36 |
37 | mempool_create->mempool_create_node
38 |
39 | ```c
40 | /*
41 | * 新建一个mempool,需要用户自己传入内存申请及释放函数
42 | * 初始化mempool_t管理结构体,过程清晰简单
43 | */
44 | mempool_t *mempool_create_node(int min_nr, mempool_alloc_t *alloc_fn,
45 | mempool_free_t *free_fn, void *pool_data,
46 | gfp_t gfp_mask, int node_id)
47 | {
48 | mempool_t *pool;
49 | pool = kzalloc_node(sizeof(*pool), gfp_mask, node_id);
50 | if (!pool)
51 | return NULL;
52 | pool->elements = kmalloc_node(min_nr * sizeof(void *),
53 | gfp_mask, node_id);
54 | if (!pool->elements) {
55 | kfree(pool);
56 | return NULL;
57 | }
58 | spin_lock_init(&pool->lock);
59 | pool->min_nr = min_nr;
60 | pool->pool_data = pool_data;
61 | init_waitqueue_head(&pool->wait);
62 | pool->alloc = alloc_fn;
63 | pool->free = free_fn;
64 |
65 | /*
66 | * First pre-allocate the guaranteed number of buffers.
67 | */
68 | while (pool->curr_nr < pool->min_nr) {
69 | void *element;
70 | /* 调用pool->alloc函数min_nr次 */
71 | element = pool->alloc(gfp_mask, pool->pool_data);
72 | /* 如果申请不到element,则直接销毁此内存池 */
73 | if (unlikely(!element)) {
74 | mempool_destroy(pool);
75 | return NULL;
76 | }
77 | /* 添加到elements指针数组中 */
78 | add_element(pool, element);
79 | }
80 | /* 返回内存池结构体 */
81 | return pool;
82 | }
83 | ```
84 |
85 | ### mempool_destroy
86 |
87 | ```c
88 | /*
89 | * 销毁一个内存池
90 | * 初始化mempool_t管理结构体
91 | */
92 | void mempool_destroy(mempool_t *pool)
93 | {
94 | while (pool->curr_nr) {
95 | /* 销毁elements数组中的所有对象 */
96 | void *element = remove_element(pool);
97 | pool->free(element, pool->pool_data);
98 | }
99 | /* 销毁elements指针数组 */
100 | kfree(pool->elements);
101 | /* 销毁内存池结构体 */
102 | kfree(pool);
103 | }
104 | ```
105 |
106 | ### mempool_alloc
107 |
108 | ```c
109 | /*
110 | * 从mempool_t中申请内存:
111 | * 1. 首先从pool->pool_data中申请元素对象(即从伙伴系统、slub cache中申请)
112 | * 2. 再尝试从mempool中申请
113 | * 3. mempool申请失败,且分配允许等待;则进程加入pool->wait等待队列
114 | a. 在init_wait中初始化wait_queue_t wait结构体
115 | b. 在prepare_to_wait中将本进程的wait结构体加入pool->wait
116 | c. 在io_schedule_timeout中本进入睡眠状态5s,并触发进程调度
117 | * 4. 在finish_wait中触发本进程恢复执行,并再次执行1,2,3,4尝试分配内存
118 | */
119 | void * mempool_alloc(mempool_t *pool, gfp_t gfp_mask)
120 | {
121 | void *element;
122 | unsigned long flags;
123 | wait_queue_t wait;
124 | gfp_t gfp_temp;
125 |
126 | VM_WARN_ON_ONCE(gfp_mask & __GFP_ZERO);
127 | /* 如果有__GFP_WAIT标志,则会先阻塞,切换进程 */
128 | might_sleep_if(gfp_mask & __GFP_WAIT);
129 | /* 不使用预留内存 */
130 | gfp_mask |= __GFP_NOMEMALLOC; /* don't allocate emergency reserves */
131 | /* 分配页时如果失败则返回,不进行重试 */
132 | gfp_mask |= __GFP_NORETRY; /* don't loop in __alloc_pages */
133 | /* 分配失败不提供警告 */
134 | gfp_mask |= __GFP_NOWARN; /* failures are OK */
135 | /* gfp_temp等于gfp_mask去除__GFP_WAIT和__GFP_IO的其他标志 */
136 | gfp_temp = gfp_mask & ~(__GFP_WAIT|__GFP_IO);
137 |
138 | repeat_alloc:
139 | /* 使用内存池中的alloc函数进行分配对象,实际上就是从伙伴系统或者slab缓冲区获取内存对象 */
140 | element = pool->alloc(gfp_temp, pool->pool_data);
141 | /* 在内存富足的情况下,一般是能够获取到内存的 */
142 | if (likely(element != NULL))
143 | return element;
144 | /* 在内存不足的情况,造成从伙伴系统或slab缓冲区获取内存失败,则会执行到这 */
145 | /* 给内存池上锁,获取后此段临界区禁止中断和抢占 */
146 | spin_lock_irqsave(&pool->lock, flags);
147 | /* 如果当前内存池中有空闲数量,就是初始化时获取的内存数量保存在curr_nr中 */
148 | if (likely(pool->curr_nr)) {
149 | /* 从内存池中获取内存对象 */
150 | element = remove_element(pool);
151 | spin_unlock_irqrestore(&pool->lock, flags);
152 | /* 写内存屏障,保证之前的写操作已经完成 */
153 | smp_wmb();
154 | /* 用于debug */
155 | kmemleak_update_trace(element);
156 | return element;
157 | }
158 |
159 | /* 这里是内存池中也没有空闲内存对象的时候进行的操作 */
160 | /* gfp_temp != gfp_mask说明传入的gfp_mask允许阻塞等待,但是之前已经阻塞等待过了,所以这里立即重新获取一次 */
161 | if (gfp_temp != gfp_mask) {
162 | spin_unlock_irqrestore(&pool->lock, flags);
163 | gfp_temp = gfp_mask;
164 | goto repeat_alloc;
165 | }
166 |
167 | /* 传入的参数gfp_mask不允许阻塞等待,分配不到内存则直接退出 */
168 | if (!(gfp_mask & __GFP_WAIT)) {
169 | spin_unlock_irqrestore(&pool->lock, flags);
170 | return NULL;
171 | }
172 |
173 | /* Let's wait for someone else to return an element to @pool */
174 | init_wait(&wait);
175 | /* 将当前进程wait结构体加入到内存池的等待队列中,并把状态设置为只有wake_up信号才能唤醒的状态
176 | * 1. 当内存池有新释放内存时,会主动唤醒(wake_up)等待队列中的第一个进程
177 | * 2. 等待超时,定时器自动唤醒
178 | */
179 | prepare_to_wait(&pool->wait, &wait, TASK_UNINTERRUPTIBLE);
180 |
181 | spin_unlock_irqrestore(&pool->lock, flags);
182 |
183 | /*
184 | * FIXME: this should be io_schedule(). The timeout is there as a
185 | * workaround for some DM problems in 2.6.18.
186 | */
187 | /* 阻塞等待5秒 */
188 | io_schedule_timeout(5*HZ);
189 | /* 从内存池的等待队列删除此进程 */
190 | finish_wait(&pool->wait, &wait);
191 | /* 跳转到repeat_alloc,重新尝试获取内存对象 */
192 | goto repeat_alloc;
193 | }
194 | ```
195 |
196 | ### mempool_free
197 |
198 | ```c
199 | /*
200 | * 释放内存
201 | * 1. 如果内存池中水位低于min_nr,则将释放的内存加入内存池中,并wake_up wait队列中任务
202 | * 2. 否则直接释放内存
203 | */
204 | void mempool_free(void *element, mempool_t *pool)
205 | {
206 | unsigned long flags;
207 | /* 传入的对象为空,则直接退出 */
208 | if (unlikely(element == NULL))
209 | return;
210 |
211 | /* 读内存屏障 */
212 | smp_rmb();
213 |
214 | /* pool->curr_nr < pool->min_nr,优先把释放的对象加入到内存池空闲数组中 */
215 | if (unlikely(pool->curr_nr < pool->min_nr)) {
216 | spin_lock_irqsave(&pool->lock, flags);
217 | if (likely(pool->curr_nr < pool->min_nr)) {
218 | add_element(pool, element);
219 | spin_unlock_irqrestore(&pool->lock, flags);
220 | /* 唤醒(default_wake_function)等待队列中的第一个进程 */
221 | wake_up(&pool->wait);
222 | return;
223 | }
224 | spin_unlock_irqrestore(&pool->lock, flags);
225 | }
226 | /* 直接调用释放函数 */
227 | pool->free(element, pool->pool_data);
228 | }
229 | ```
230 |
231 | ### 内核中mempool例子可以搜索mempool_create函数被调用的地方
232 |
233 | ## 附录
234 |
235 | ### mempool_s
236 |
237 | ```c
238 | typedef struct mempool_s {
239 | spinlock_t lock;
240 | /* 最大元素个数,也是初始个数
241 | * 当内存池被创建时,会调用alloc函数申请此变量相应数量的slab放到elements指向的指针数组中
242 | */
243 | int min_nr;
244 | int curr_nr; /* 当前元素个数 */
245 | /* 指向一个数组,在mempool_create中会分配内存,数组中保存指向元素指针 */
246 | void **elements;
247 | /* 内存池的拥有者的私有数据结构,当元素是slab中的对象时,这里保存的是slab缓存描述符 */
248 | void *pool_data;
249 | /* 当元素是slab中的对象时,会使用方法mempool_alloc_slab()和mempool_free_slab() */
250 | /* 分配一个元素的方法 */
251 | mempool_alloc_t *alloc;
252 | /* 释放一个元素的方法 */
253 | mempool_free_t *free;
254 | /* 当内存池为空时使用的等待队列
255 | * 当内存池中空闲内存对象为空时,获取函数会将当前进程阻塞,直到超时或者有空闲内存对象时才会唤醒 */
256 | wait_queue_head_t wait;
257 | } mempool_t;
258 | ```
259 |
260 | ## 参考资料
261 |
262 | [tolimit-内存池](https://www.cnblogs.com/tolimit/p/5266575.html)
263 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理系列十三:VMA操作.md:
--------------------------------------------------------------------------------
1 | ## 前沿
2 |
3 | ### 往篇回顾
4 |
5 | > 在上两篇中,主要分析了vmalloc模块初始化、vmalloc申请内存、vmalloc内存释放的过程
6 |
7 | - 在kernel_start()->mm_init()函数中会调用vmalloc_init()进行模块初始化;主要有个任务:
8 | 1. 初始化各个cpu中vmalloc的管理结构vmap_block_queue、vfree_deferred,目前并未看到作用是什么;
9 | 2. 将挂在全局链表`vm_struct *vmlist`中的vmalloc区通过__insert_vmap_area()插入`vmap_area_root`红黑树及链表中;
10 | - 通过vmalloc申请非连续物理内存主要有如下几步:
11 | 1. 首先通过__get_vm_area_node()向slub系统为管理结构体申请内存;
12 | 2. 在alloc_vmap_area()通过查询红黑树、链表找到vmalloc合适的虚拟内存区,并将该区域插入红黑树、链表中;
13 | 3. 通过__vmalloc_area_node()为area分配管理page数组,并向伙伴系统申请物理空间,并使用map_vm_area()将物理地址和虚拟地址进行映射;
14 | - 由于所有进程共享内核地址空间,内核中所有vm_struct放在一起,通过vm_struct->next链成表;
15 | - vmalloc区的具体地址映射信息抽成一个结构vmap_area,该结构在内核通过红黑树(vmap_area_root)和双向链表(vmap_area_list)管理;
16 |
17 | ### VMA简介
18 |
19 | - 进程的虚拟内存空间(管理结构体struct mm_struct)按功能分为如下几部分: stack, mmap, heap, bbs segment, data segment, text segment; 均由VMA管理, 每块虚拟内存对应一个管理结构体[vm_area_struct](https://pzh2386034.github.io/Black-Jack/linux-memory/2019/09/05/ARM64内存管理十三-VMA操作/#vm_area_struct);
20 | - 类似内核vmalloc,VMA也是有一颗红黑树,一个链表来管理;
21 | - 当使用malloc()->brk()向系统请求一些内存时,内核仅仅更新堆的VMA,真正分配物理页帧在发生缺页中断时,系统调用do_page_fault();
22 |
23 | ### 本篇主要内容
24 |
25 | > vmalloc是内核的虚拟内存申请工具;而对于用户态的虚拟内存管理,则主要依赖VMA模块
26 |
27 | ## 代码分析
28 |
29 | ### find_vma
30 |
31 | ```c
32 | /* Look up the first VMA which satisfies addr < vm_end, NULL if none.
33 | * struct mm_struct是描述进程内存管理的核心数据结构
34 | * 首先尝试从vma cache中查找,再从进程红黑树中查找
35 | * 1. 快速查找:首先从4槽位 per-thread VMA 缓存hash表中进行查找;
36 | * 2. 慢速查找:从进程红黑树中查找到合适VMA后,通过vmacache_update()更新到vmacache
37 | * 当释放VMA时,必须使所有线程的VMA cache无效,否则后续VMA查找将可能指向空指针
38 | */
39 | struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr)
40 | {
41 | struct rb_node *rb_node;
42 | struct vm_area_struct *vma;
43 |
44 | /*
45 | * 首先从vma cache中查找,如果addr在某个vma地址范围内,则直接返回该vma
46 | * 其中有一个关键函数vmacache_valid,关联一个严重的内存提权漏洞CVE-2018-17182,见附录资料
47 | * vmacache_find:主要为了解决释放VMA后,为使高速缓存无效,避免遍历所有线程的VMA,防止出现性能问题
48 | */
49 | vma = vmacache_find(mm, addr);
50 | if (likely(vma))
51 | return vma;
52 |
53 | rb_node = mm->mm_rb.rb_node;
54 | vma = NULL;
55 |
56 | while (rb_node) {
57 | struct vm_area_struct *tmp;
58 |
59 | tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb);
60 |
61 | if (tmp->vm_end > addr) {
62 | vma = tmp;
63 | if (tmp->vm_start <= addr)
64 | break;
65 | rb_node = rb_node->rb_left;
66 | } else
67 | rb_node = rb_node->rb_right;
68 | }
69 |
70 | if (vma)/* 将新找到的vma更新到vma cache中 */
71 | vmacache_update(addr, vma);
72 | return vma;
73 | }
74 | ```
75 |
76 | ### insert_vm_struct
77 |
78 | ```c
79 | /*
80 | * 在线性区对象链表和内存描述符的红黑树中插入一个vm
81 | * mm: 指定进程内存描述符;vma:要插入的vm_area_struct对象地址
82 | * 1. 利用find_vma_links()寻找出将要插入的节点位置,及前驱,父节点
83 | * 2. 利用__vma_link_list()和__vma_link_rb()将结点分别插入链表和红黑树中,vma_link()是其前端函数
84 | * 3. 若线性区用于文件映射,那么利用__vma_link_file()处理,暂不讨论
85 | * 4. 线性区计数+1
86 | */
87 | int insert_vm_struct(struct mm_struct *mm, struct vm_area_struct *vma)
88 | {
89 | struct vm_area_struct *prev;
90 | struct rb_node **rb_link, *rb_parent;
91 |
92 | /*
93 | * The vm_pgoff of a purely anonymous vma should be irrelevant
94 | * until its first write fault, when page's anon_vma and index
95 | * are set. But now set the vm_pgoff it will almost certainly
96 | * end up with (unless mremap moves it elsewhere before that
97 | * first wfault), so /proc/pid/maps tells a consistent story.
98 | *
99 | * By setting it to reflect the virtual start address of the
100 | * vma, merges and splits can happen in a seamless way, just
101 | * using the existing file pgoff checks and manipulations.
102 | * Similarly in do_mmap_pgoff and in do_brk.
103 | */
104 | if (!vma->vm_file) {
105 | BUG_ON(vma->anon_vma);
106 | vma->vm_pgoff = vma->vm_start >> PAGE_SHIFT;
107 | }
108 | /* 找到vma插入点 */
109 | if (find_vma_links(mm, vma->vm_start, vma->vm_end,
110 | &prev, &rb_link, &rb_parent))
111 | return -ENOMEM;
112 | if ((vma->vm_flags & VM_ACCOUNT) &&
113 | security_vm_enough_memory_mm(mm, vma_pages(vma)))
114 | return -ENOMEM;
115 | /* 实际执行vma插入动作 */
116 | vma_link(mm, vma, prev, rb_link, rb_parent);
117 | return 0;
118 | }
119 | ```
120 |
121 | ### insert_vm_struct
122 |
123 | ```c
124 | /*
125 | * 当一个新建的VMA区域加入进程时,内核会试图将这个新区域与已存在的区域进行合并,vma合并条件:
126 | * 1. 新区域之前的prve区域终于地址是否与新区域地址重合
127 | * 2. 新区域结束地址是否与其之后的next区域起始地址重合
128 | * 3. 然后再检查要合并的区域是否有相同的标志
129 | * 4. 如果合并区域均映射了磁盘文件,则还要检查其映射文件是否相同,以及文件内的偏移量是否连续
130 | */
131 | struct vm_area_struct *vma_merge(struct mm_struct *mm,
132 | struct vm_area_struct *prev, unsigned long addr,
133 | unsigned long end, unsigned long vm_flags,
134 | struct anon_vma *anon_vma, struct file *file,
135 | pgoff_t pgoff, struct mempolicy *policy)
136 | {
137 | pgoff_t pglen = (end - addr) >> PAGE_SHIFT;
138 | struct vm_area_struct *area, *next;
139 | int err;
140 |
141 | /* VM_SPECIAL标志指定了该区域不能和其他区域合并,因此立即返回NULL */
142 | if (vm_flags & VM_SPECIAL)
143 | return NULL;
144 |
145 | if (prev)
146 | next = prev->vm_next;
147 | else
148 | next = mm->mmap;
149 | area = next;
150 | if (next && next->vm_end == end) /* cases 6, 7, 8 */
151 | next = next->vm_next;
152 |
153 | /*
154 | * Can it merge with the predecessor? prev->vm_end == addr
155 | * can_vma_merge_after 判断两者的标志和映射文件等是否相同
156 | */
157 | if (prev && prev->vm_end == addr &&
158 | mpol_equal(vma_policy(prev), policy) &&
159 | can_vma_merge_after(prev, vm_flags,
160 | anon_vma, file, pgoff)) {
161 | /*
162 | * OK, it can. Can we now merge in the successor as well? end == next->vm_start
163 | */
164 | if (next && end == next->vm_start &&
165 | mpol_equal(policy, vma_policy(next)) &&
166 | can_vma_merge_before(next, vm_flags,
167 | anon_vma, file, pgoff+pglen) &&
168 | is_mergeable_anon_vma(prev->anon_vma,
169 | next->anon_vma, NULL)) {
170 | /* cases 1, 6 */
171 | err = vma_adjust(prev, prev->vm_start,
172 | next->vm_end, prev->vm_pgoff, NULL);
173 | } else /* cases 2, 5, 7 */
174 | err = vma_adjust(prev, prev->vm_start,
175 | end, prev->vm_pgoff, NULL);
176 | if (err)
177 | return NULL;
178 | khugepaged_enter_vma_merge(prev, vm_flags);
179 | return prev;
180 | }
181 |
182 | /*
183 | * Can this new request be merged in front of next?
184 | */
185 | if (next && end == next->vm_start &&
186 | mpol_equal(policy, vma_policy(next)) &&
187 | can_vma_merge_before(next, vm_flags,
188 | anon_vma, file, pgoff+pglen)) {
189 | if (prev && addr < prev->vm_end) /* case 4 */
190 | err = vma_adjust(prev, prev->vm_start,
191 | addr, prev->vm_pgoff, NULL);
192 | else /* cases 3, 8 */
193 | err = vma_adjust(area, addr, next->vm_end,
194 | next->vm_pgoff - pglen, NULL);
195 | if (err)
196 | return NULL;
197 | khugepaged_enter_vma_merge(area, vm_flags);
198 | return area;
199 | }
200 |
201 | return NULL;
202 | }
203 | ```
204 |
205 | ## 附录
206 |
207 | ### vm_area_struct
208 |
209 | ```c
210 | /*
211 | * This struct defines a memory VMM memory area. There is one of these
212 | * per VM-area/task. A VM area is any part of the process virtual memory
213 | * space that has a special rule for the page-fault handlers (ie a shared
214 | * library, the executable area etc).
215 | */
216 | struct vm_area_struct {
217 | /* The first cache line has the info for VMA tree walking. */
218 |
219 | unsigned long vm_start; /* Our start address within vm_mm. */
220 | unsigned long vm_end; /* The first byte after our end address
221 | within vm_mm. */
222 |
223 | /* linked list of VM areas per task, sorted by address */
224 | struct vm_area_struct *vm_next, *vm_prev;
225 |
226 | struct rb_node vm_rb;
227 |
228 | /*
229 | * Largest free memory gap in bytes to the left of this VMA.
230 | * Either between this VMA and vma->vm_prev, or between one of the
231 | * VMAs below us in the VMA rbtree and its ->vm_prev. This helps
232 | * get_unmapped_area find a free area of the right size.
233 | */
234 | unsigned long rb_subtree_gap;
235 |
236 | /* Second cache line starts here. */
237 |
238 | struct mm_struct *vm_mm; /* 指向VMA所属进程的struct mm_struct结构. */
239 | pgprot_t vm_page_prot; /* VMA访问权限. */
240 | unsigned long vm_flags; /* VMA标志位. */
241 |
242 | /*
243 | * For areas with an address space and backing store,
244 | * linkage into the address_space->i_mmap interval tree.
245 | */
246 | struct {
247 | struct rb_node rb;
248 | unsigned long rb_subtree_last;
249 | } shared;
250 |
251 | /*
252 | * A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
253 | * list, after a COW of one of the file pages. A MAP_SHARED vma
254 | * can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
255 | * or brk vma (with NULL file) can only be in an anon_vma list.
256 | */
257 | struct list_head anon_vma_chain; /* 用于管理RMAP反向映射 */
258 | struct anon_vma *anon_vma; /* 用于管理RMAP反向映射 */
259 |
260 | /* VMA操作函数合集,常用于文件映射. */
261 | const struct vm_operations_struct *vm_ops;
262 |
263 | /* Information about our backing store: */
264 | unsigned long vm_pgoff; /* 指定文件映射的偏移量,单位是页面 */
265 | struct file * vm_file; /* 描述一个被映射的文件. */
266 | void * vm_private_data; /* was vm_pte (shared mem) */
267 |
268 | #ifndef CONFIG_MMU
269 | struct vm_region *vm_region; /* NOMMU mapping region */
270 | #endif
271 | #ifdef CONFIG_NUMA
272 | struct mempolicy *vm_policy; /* NUMA policy for the VMA */
273 | #endif
274 | };
275 | ```
276 |
277 | ## 参考资料
278 |
279 | [VMA,进程虚拟空间简介](https://linux.cn/article-9393-1.html)
280 |
281 | [vma_merge函数分析](http://edsionte.com/techblog/archives/3586)
282 |
283 | [CVE-2018-17182 VMA-UFA 提权漏洞原理](https://www.360zhijia.com/anquan/423092.html)
284 |
285 | [CVE-2018-17182 VMA-UFA 提权漏洞](https://www.anquanke.com/post/id/161632)
286 |
287 | [CVE-2018-17182 VMA-UFA 提权漏洞利用code](https://github.com/jas502n/CVE-2018-17182)
288 |
289 | [find_vma导致系能问题](http://www.trueeyu.com/2015/04/15/findvma/)
290 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理系列十八:内存回收之LRU链表.md:
--------------------------------------------------------------------------------
1 | ## 前沿
2 |
3 | ### 往篇回顾
4 |
5 | > 在上一篇中,主要分析了内存池的实现、运行机制;内存池实际是一个最后的内存资源储存池,本身还是依赖于现有的伙伴系统或者slub系统
6 |
7 | - 主要涉及`mempool_create`, `mempool_destroy`, `mempool_alloc`, `mempool_free`这几个函数;
8 | - 重点在内存申请的时候,首先从自定义的mempool->alloc尝试分配,失败后再从内存池中获取;
9 | - 如果内存池也分配失败,则会自行加入mempool->wait队列中,并将本进程自动睡眠等待有空闲内存或者时间截止被唤醒;
10 |
11 | ### 内存回收简述
12 |
13 | - 当linux系统内存压力就大时,就会对系统的每个压力大的zone(最新的linux动向逐渐转向按node回收)进程内存回收,内存回收主要是针对匿名页和文件页进行的
14 | - 内存回收主要有两个方面: 释放页;将页回写到swap区,再释放内存页
15 | 1. 进程堆栈,数据段使用的匿名页:存放swap区
16 | 2. 进程代码段映射的可执行文件的文件页:直接释放
17 | 3. 打开文件进行读写使用的文件页:如果页中数据与文件数据不一致,则回写到磁盘对应的文件页,如果一致则释放
18 | 4. 进行文件映射mmap共享内存时使用的页:如果页中数据与文件数据不一致,则进行回写到磁盘对应文件中,如果一致,则直接释放
19 | 5. 进行匿名mmap共享内存时使用的页:存放到swap分区中
20 | 6. 进行shmem共享内存时使用的页:存放到swap分区中
21 |
22 | ### lru链表分类
23 |
24 | - LRU_INACTIVE_ANON:称为非活动匿名页lru链表,此链表中保存的是此zone中所有最近没被访问过的并且可以存放到swap分区的页描述符,在此链表中的页描述符的PG_active标志为0
25 | - LRU_ACTIVE_ANON:称为活动匿名页lru链表,此链表中保存的是此zone中所有最近被访问过的并且可以存放到swap分区的页描述符,此链表中的页描述符的PG_active标志为1
26 | - LRU_INACTIVE_FILE:称为非活动文件页lru链表,此链表中保存的是此zone中所有最近没被访问过的文件页的页描述符,此链表中的页描述符的PG_active标志为0
27 | - LRU_ACTIVE_FILE:称为活动文件页lru链表,此链表中保存的是此zone中所有最近被访问过的文件页的页描述符,此链表中的页描述符的PG_active标志为1
28 | - LRU_UNEVICTABLE:此链表中保存的是此zone中所有禁止换出的页的描述符, 一般是被mlock锁定
29 |
30 | ### lru缓存
31 |
32 | - 在多核环境下,在同时需要对lru链表进行修改时,锁的竞争会非常频繁,因此内核提供了一个[lru缓存](https://pzh2386034.github.io/Black-Jack/linux-memory/2019/09/30/ARM64内存管理十八-内存回收之LRU链表/#pagevec)机制,用以减少锁的竞争频率
33 | - [lru缓存](https://pzh2386034.github.io/Black-Jack/linux-memory/2019/09/30/ARM64内存管理十八-内存回收之LRU链表/#pagevec)是按照要对lru操作的类型纬度定义的,对lru链表的操作主要有以下几种:
34 | 1. 将不处于lru链表的新页放入到lru链表中, 对应`static DEFINE_PER_CPU(struct pagevec, lru_add_pvec)`
35 | 2. 将非活动lru链表中的页移动到非活动lru链表尾部(活动页不需要这样做,后面说明), 对应`static DEFINE_PER_CPU(struct pagevec, lru_rotate_pvecs)`
36 | 3. 将处于活动lru链表尾部的页移动到非活动lru链表, 对应`static DEFINE_PER_CPU(struct pagevec, lru_deactivate_pvecs)`
37 | 4. 将处于非活动lru链表的页移动到活动lru链表头, 对应`static DEFINE_PER_CPU(struct pagevec, activate_page_pvecs)`
38 | 5. 将页从lru链表中移除(不需要依赖lru)
39 | - 由于4中lru缓冲链表都是cpu级别的;而目前lru的5种链表都是zone级别的,因此在一个页加入lru缓存前,必须设置好页的属性,才能配合lru缓存进行工作
40 |
41 | ### 本篇主要内容
42 |
43 | > 对于整个内存回收来说,lru链表是关键中的关键,实际上整个内存回收,做的事情就是处理LRU(Least Recently Used)链表的收缩,所以这篇文章就先说说系统的lru链表
44 |
45 | ## LRU基本操作代码分析
46 |
47 | ### 新页加入lru链表
48 |
49 | #### __lru_cache_add
50 |
51 | > 当需要将一个新页加入到lru链表中,必须先加入到当前CPU的`lru_add_pvec`缓存中
52 |
53 | ```c
54 | /* 加入到lru_add_pvec缓存中 */
55 | static void __lru_cache_add(struct page *page)
56 | {
57 | /* 获取此CPU的lru缓存 */
58 | struct pagevec *pvec = &get_cpu_var(lru_add_pvec);
59 | /* page->_count++
60 | * 在页从lru缓存移动到lru链表时,这些页的page->_count会--
61 | */
62 | page_cache_get(page);
63 | /* 检查LRU缓存是否已满 */
64 | if (!pagevec_space(pvec))
65 | /* 满则将此lru缓存中的页放到lru链表中,核心转移函数:__pagevec_lru_add_fn */
66 | __pagevec_lru_add(pvec);
67 | /* 将page加入到此cpu的lru缓存中,注意
68 | * 加入pagevec实际上只是将pagevec中的pages数组中的某个指针指向此页
69 | * 如果此页原本属于lru链表,那么现在实际还是在原来的lru链表中
70 | */
71 | pagevec_add(pvec, page);
72 | put_cpu_var(lru_add_pvec);
73 | }
74 | ```
75 |
76 | #### __lru_cache_add
77 |
78 | ```c
79 | /* 将lru_add缓存中的页加入到lru链表中 */
80 | static void __pagevec_lru_add_fn(struct page *page, struct lruvec *lruvec,
81 | void *arg)
82 | {
83 | /* 判断此页是否是page cache页(映射文件的页) */
84 | int file = page_is_file_cache(page);
85 | /* 是否是活跃的页, 判断page的PG_active标志
86 | * 1. 置位,则将此页加入到活动lru链表中
87 | * 2. 没置位,则加入到非活动lru链表中
88 | */
89 | int active = PageActive(page);
90 | /* 获取page所在的lru链表,里面会检测是映射页还是文件页,并且检查PG_active,最后能得出该page应该放到哪个lru链表中
91 | * 1. PG_unevictable置位,则加入到LRU_UNEVICTABLE链表中
92 | * 2. 如果PG_swapbacked置位,则加入到匿名页lru链表,否则加入到文件页lru链表
93 | * 3. PG_active置位,则加入到活动lru链表,否则加入到非活动lru链表
94 | */
95 | enum lru_list lru = page_lru(page);
96 |
97 | VM_BUG_ON_PAGE(PageLRU(page), page);
98 |
99 | SetPageLRU(page);
100 | /*
101 | * 将page加入到对应lru链表头部中:
102 | * 1. 获取页的数量,如果支持透明大叶,会是多个页
103 | * 2. 通过mem_cgroup_update_lru_size更新lruvec中lru类型的链表的page num
104 | * 3. 加入对应lru链表头部,更新统计
105 | */
106 | add_page_to_lru_list(page, lruvec, lru);
107 | /* 更新lruvec中的reclaim_stat */
108 | update_page_reclaim_stat(lruvec, file, active);
109 | trace_mm_lru_insertion(page, lru);
110 | }
111 | ```
112 |
113 | ### 将处于非活动链表中的页移动到非活动链表尾部
114 |
115 | > 当一个脏页需要回收时,系统首先会将页异步回写到swap或磁盘对应文件中,再通过`rotate_reclaimable_page`将页移动到非活动lru链表尾部
116 |
117 | #### rotate_reclaimable_page
118 |
119 | ```c
120 | void rotate_reclaimable_page(struct page *page)
121 | {
122 | /* 此页加入到非活动lru链表尾部的条件 */
123 | if (!PageLocked(page) && !PageDirty(page) && !PageActive(page) &&
124 | !PageUnevictable(page) && PageLRU(page)) {
125 | struct pagevec *pvec;
126 | unsigned long flags;
127 | /* page->_count++,因为这里会加入到lru_rotate_pvecs这个lru缓存中
128 | * lru缓存中的页移动到lru时,会对移动的页page->_count--
129 | */
130 | page_cache_get(page);
131 | local_irq_save(flags);/* 禁止中断 */
132 | /* 获取当前CPU的lru_rotate_pvecs缓存 */
133 | pvec = this_cpu_ptr(&lru_rotate_pvecs);
134 | if (!pagevec_add(pvec, page))
135 | /* lru_rotate_pvecs缓存已满,将当前缓存中的页加入到非活动lru链表尾部
136 | * 转移核心函数:pagevec_move_tail_fn
137 | */
138 | pagevec_move_tail(pvec);
139 | local_irq_restore(flags);/* 重新开启中断 */
140 | }
141 | }
142 | ```
143 |
144 | #### pagevec_move_tail_fn
145 |
146 | ```c
147 | /*
148 | * 将lru缓存pvec中的页移动到非活动lru链表尾部操作的回调函数
149 | * 这些页原本就属于非活动lru链表
150 | */
151 | static void pagevec_move_tail_fn(struct page *page, struct lruvec *lruvec,
152 | void *arg)
153 | {
154 | int *pgmoved = arg;
155 |
156 | if (PageLRU(page) && !PageActive(page) && !PageUnevictable(page)) {
157 | /* 获取页应该放入匿名页lru链表还是文件页lru链表,通过页的PG_swapbacked标志判断 */
158 | enum lru_list lru = page_lru_base_type(page);
159 | /* 加入到对应的非活动lru链表尾部 */
160 | list_move_tail(&page->lru, &lruvec->lists[lru]);
161 | (*pgmoved)++;
162 | }
163 | }
164 | ```
165 |
166 | ### 将活动lru链表中的页加入到非活动lru链表中
167 |
168 | > 文件系统主动将一些没有被进程映射的页进行释放时,会讲一些活动lru链表的页移动到非活动lru链表中;内存回收过程中并不会使用这种方式;
169 |
170 | #### deactivate_file_page
171 |
172 | ```c
173 | void deactivate_file_page(struct page *page)
174 | {
175 | /* 如果页被锁在内存中禁止换出,则跳出 */
176 | if (PageUnevictable(page))
177 | return;
178 | /*page->count==1 说明此页没有进程映射*/
179 | if (likely(get_page_unless_zero(page))) {
180 | /* 获取本cpu的deactivate缓存链表 */
181 | struct pagevec *pvec = &get_cpu_var(lru_deactivate_file_pvecs);
182 | /* 将page加入deactivate链表后如果链表满了,则触发lru_deactivate_file_fn函数,将lru缓存中页放到lru链表中 */
183 | if (!pagevec_add(pvec, page))
184 | pagevec_lru_move_fn(pvec, lru_deactivate_file_fn, NULL);
185 | put_cpu_var(lru_deactivate_file_pvecs);
186 | }
187 | }
188 | ```
189 |
190 | #### lru_deactivate_file_fn
191 |
192 | ```c
193 | static void lru_deactivate_file_fn(struct page *page, struct lruvec *lruvec,
194 | void *arg)
195 | {
196 | int lru, file;
197 | bool active;
198 | /*此页不在lru中,不处理此页*/
199 | if (!PageLRU(page))
200 | return;
201 | /*此页被锁定,则不处理此页*/
202 | if (PageUnevictable(page))
203 | return;
204 |
205 | /* 有进程映射了此页,不处理 */
206 | if (page_mapped(page))
207 | return;
208 | /*获取页的活动标志 */
209 | active = PageActive(page);
210 | /* 根据页的PG_swapbacked判断此页是否需要依赖swap分区 */
211 | file = page_is_file_cache(page);
212 | /* 获取此页需要加入匿名页或者文件页lru链表,也是通过PG_swapbacked标志判断 */
213 | lru = page_lru_base_type(page);
214 | /* 从活动lru链表中删除 */
215 | del_page_from_lru_list(page, lruvec, lru + active);
216 | /* 清除PG_active和PG_referenced */
217 | ClearPageActive(page);
218 | ClearPageReferenced(page);
219 | /* 加到非活动页lru链表头部 */
220 | add_page_to_lru_list(page, lruvec, lru);
221 | /* 如果此页当前正在回写或者是脏页 */
222 | if (PageWriteback(page) || PageDirty(page)) {
223 | /*
224 | * PG_reclaim could be raced with end_page_writeback
225 | * It can make readahead confusing. But race window
226 | * is _really_ small and it's non-critical problem.
227 | */
228 | /* 则设置此页需要回收 */
229 | SetPageReclaim(page);
230 | } else {
231 | /* 如果此页是干净的,并且非活动的,则将此页移动到非活动lru链表尾部
232 | * 因为此页回收起来更简单,不用回写
233 | */
234 | list_move_tail(&page->lru, &lruvec->lists[lru]);
235 | __count_vm_event(PGROTATED);
236 | }
237 |
238 | if (active)
239 | __count_vm_event(PGDEACTIVATE);
240 | update_page_reclaim_stat(lruvec, file, 0);
241 | }
242 | ```
243 |
244 | ### 将非活动lru链表页加入到活动lru链表
245 |
246 | 使用场景:
247 |
248 | - 非活动页被标记为活动页后,要加入到活动lru链表中
249 |
250 | #### activate_page
251 |
252 | ```c
253 | void activate_page(struct page *page)
254 | {
255 | /* 该页要在lru链表中,非活动页,没有被锁定 */
256 | if (PageLRU(page) && !PageActive(page) && !PageUnevictable(page)) {
257 | struct pagevec *pvec = &get_cpu_var(activate_page_pvecs);
258 |
259 | page_cache_get(page);
260 | if (!pagevec_add(pvec, page))
261 | pagevec_lru_move_fn(pvec, __activate_page, NULL);
262 | put_cpu_var(activate_page_pvecs);
263 | }
264 | }
265 | ```
266 |
267 | #### __activate_page
268 |
269 | ```c
270 | static void __activate_page(struct page *page, struct lruvec *lruvec,
271 | void *arg)
272 | {
273 | if (PageLRU(page) && !PageActive(page) && !PageUnevictable(page)) {
274 | /*是否为文件页*/
275 | int file = page_is_file_cache(page);
276 | /*获取lru类型*/
277 | int lru = page_lru_base_type(page);
278 | /*将此页从lru链表中移除*/
279 | del_page_from_lru_list(page, lruvec, lru);
280 | /*设置page的PG_active标志,说明此页已经在lru链表中*/
281 | SetPageActive(page);
282 | /*获取lru最终所属链表*/
283 | lru += LRU_ACTIVE;
284 | /*将此页加入到活动页lru链表头*/
285 | add_page_to_lru_list(page, lruvec, lru);
286 | trace_mm_lru_activate(page);
287 |
288 | __count_vm_event(PGACTIVATE);
289 | /* 更新lruvec中zone_reclaim_stat->recent_scanned[file]++和zone_reclaim_stat->recent_rotated[file]++ */
290 | update_page_reclaim_stat(lruvec, file, 1);
291 | }
292 | }
293 | ```
294 |
295 | ## 附录
296 |
297 | #### pagevec
298 |
299 | ```c
300 | struct pagevec {
301 | /* 当前数量 */
302 | unsigned long nr;
303 | unsigned long cold;
304 | /* 指针数组,每一项都可以指向一个页描述符,默认大小是14 */
305 | struct page *pages[PAGEVEC_SIZE];
306 | };
307 | ```
308 |
309 | #### lruvec
310 |
311 | \``` c++ /* lru链表描述符,主要有5个双向链表 */ struct lruvec { /* 5个lru双向链表头 */ struct list_head lists[NR_LRU_LISTS]; struct zone_reclaim_stat reclaim_stat; #ifdef CONFIG_MEMCG /* 所属zone */ struct zone *zone; #endif };
312 |
313 | ## 参考资料
314 |
315 | [tolimit-lru链表](https://www.cnblogs.com/tolimit/p/5447448.html)
316 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理系列十:slub回收.md:
--------------------------------------------------------------------------------
1 | ## 前沿
2 |
3 | ### 往篇回顾
4 |
5 | > 在上一篇中,我们主要分析了申请slub内存的过程,入口函数是`kmem_cache_alloc`,主要内容如下:
6 |
7 | - kmem_cache刚刚建立,还没有任何对象可供分配,此时只能从伙伴系统分配一个slab;
8 | - 如果正在使用的slab有free obj,那么就直接分配即可,这种是最简单快捷的;
9 | - 随着正在使用的slab中obj的一个个分配出去,最终会无obj可分配,此时per cpu partial链表中有可用slab用于分配,那么就会从per cpu partial链表中取下一个slab用于分配obj;
10 | - 如果per cpu partial链表也为空,此时发现per node partial链表中有可用slab用于分配,那么就会从per node partial链表中取下一个slab用于分配obj;
11 | - 最后还是不行只能从伙伴系统再申请一个slab;
12 |
13 | ### 本篇主要内容
14 |
15 | > 前面分析了Slub分配算法的缓存区创建及对象分配,现继续分配算法的对象回收,入口函数`kmem_cache_free`
16 |
17 | ## 代码分析
18 |
19 | ### kmem_cache_free
20 |
21 | ```c
22 | void kmem_cache_free(struct kmem_cache *s, void *x)
23 | {
24 | /* 用于获取回收对象的kmem_cache */
25 | s = cache_from_obj(s, x);
26 | if (!s)
27 | return;
28 | /* 用于将对象回收 */
29 | slab_free(s, virt_to_head_page(x), x, _RET_IP_);
30 | /* 对对象的回收做轨迹跟踪 */
31 | trace_kmem_cache_free(_RET_IP_, x);
32 | }
33 | ```
34 |
35 | ### slab_free
36 |
37 | ```c
38 | static __always_inline void slab_free(struct kmem_cache *s,
39 | struct page *page, void *x, unsigned long addr)
40 | {
41 | void **object = (void *)x;
42 | struct kmem_cache_cpu *c;
43 | unsigned long tid;
44 | /* 释放处理钩子调用处理,主要是用于去注册kmemleak中的对象? */
45 | slab_free_hook(s, x);
46 |
47 | redo:
48 | /*
49 | * 如果目前执行代码的CPU,要释放的缓冲区所属的CPU不是同一个(通过tid判断);
50 | * 则不停循环等待抢占;等待切换到同一个CPU,否则this_cpu_cmpxchg_double会失败;
51 | */
52 | do {
53 | tid = this_cpu_read(s->cpu_slab->tid);
54 | c = raw_cpu_ptr(s->cpu_slab);
55 | } while (IS_ENABLED(CONFIG_PREEMPT) &&
56 | unlikely(tid != READ_ONCE(c->tid)));
57 |
58 | /* Same with comment on barrier() in slab_alloc_node() */
59 | barrier();
60 | /* 如果当前释放的对象与本地CPU的缓存区相匹配,设置该对象尾随的空闲对象指针数据 */
61 | if (likely(page == c->page)) {
62 | set_freepointer(s, object, c->freelist);
63 | /* 快速归还对象? */
64 | if (unlikely(!this_cpu_cmpxchg_double(
65 | s->cpu_slab->freelist, s->cpu_slab->tid,
66 | c->freelist, tid,
67 | object, next_tid(tid)))) {
68 |
69 | note_cmpxchg_failure("slab_free", s, tid);
70 | goto redo;
71 | }
72 | stat(s, FREE_FASTPATH);
73 | } else
74 | /* 否则通过慢速通道释放对象 */
75 | __slab_free(s, page, x, addr);
76 |
77 | }
78 | ```
79 |
80 | ### __slab_free
81 |
82 | ```c
83 | static void __slab_free(struct kmem_cache *s, struct page *page,
84 | void *x, unsigned long addr)
85 | {
86 | void *prior;
87 | void **object = (void *)x;
88 | int was_frozen;
89 | struct page new;
90 | unsigned long counters;
91 | struct kmem_cache_node *n = NULL;
92 | unsigned long uninitialized_var(flags);
93 |
94 | stat(s, FREE_SLOWPATH);
95 | /*
96 | *判断是否开启调试,如果开启
97 | * 1. 通过free_debug_processing进行调试检测
98 | * 2. 获取经检验过的合法的kmem_cache_node节点缓冲区管理结构
99 | */
100 | if (kmem_cache_debug(s) &&
101 | !(n = free_debug_processing(s, page, x, addr, &flags)))
102 | return;
103 |
104 | do {
105 | if (unlikely(n)) {
106 | /* 释放在free_debug_processing中加的锁 */
107 | spin_unlock_irqrestore(&n->list_lock, flags);
108 | n = NULL;
109 | }
110 | /* 获取缓冲区的信息以及设置对象末尾的空闲对象指针,同时更新缓冲区中对象使用数 */
111 | prior = page->freelist;
112 | counters = page->counters;
113 | set_freepointer(s, object, prior);/* 设置对象末尾空闲对象指针? */
114 | new.counters = counters;
115 | was_frozen = new.frozen;
116 | new.inuse--;
117 | /*
118 | * 如果缓冲区中被使用的对象为0或者空闲队列为空,且缓冲区未处于冻结态(即缓冲区未处于每CPU对象缓存中):
119 | * 该释放的对象是缓冲区中最后一个被使用的对象,对象释放之后的缓冲区是可以被释放回伙伴管理算法的
120 | */
121 | if ((!new.inuse || !prior) && !was_frozen) {
122 |
123 | if (kmem_cache_has_cpu_partial(s) && !prior) {
124 |
125 | /*
126 | * 每CPU存在partial半满队列同时空闲队列不为空
127 | * 那么该缓冲区将会设置frozen标识,用于后期将其放置到每CPU的partial队列中
128 | */
129 | new.frozen = 1;
130 |
131 | } else { /* 该缓冲区将会从链表中移出 */
132 | /* 获取节点缓冲区管理结构 */
133 | n = get_node(s, page_to_nid(page));
134 | /*
135 | * Speculatively acquire the list_lock.
136 | * If the cmpxchg does not succeed then we may
137 | * drop the list_lock without any processing.
138 | *
139 | * Otherwise the list_lock will synchronize with
140 | * other processors updating the list of slabs.
141 | */
142 | spin_lock_irqsave(&n->list_lock, flags);
143 |
144 | }
145 | }
146 |
147 | } while (!cmpxchg_double_slab(s, page,
148 | prior, counters,
149 | object, new.counters,
150 | "__slab_free"));/* 通过cmpxchg_double_slab()将对象释放 */
151 |
152 | if (likely(!n)) {
153 |
154 | /*
155 | * 如果刚冻结该缓冲区,则把该缓冲区put_cpu_partial()挂入到每CPU的partial队列中
156 | */
157 | if (new.frozen && !was_frozen) {
158 | put_cpu_partial(s, page, 1);
159 | stat(s, CPU_PARTIAL_FREE);
160 | }
161 | /*
162 | * 该缓冲区本来就是冻结的
163 | */
164 | if (was_frozen)
165 | stat(s, FREE_FROZEN);
166 | return;
167 | }
168 | /*
169 | * 如果缓冲区无对象被使用,且节点的半满slab缓冲区数量超过了最小临界点,则该页面将需要被释放掉
170 | * 跳转至slab_empty执行缓冲区释放操作
171 | */
172 | if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
173 | goto slab_empty;
174 |
175 | /*
176 | * 如果本来缓冲区链表都被使用,释放后处于半满状态
177 | * 其将从full链表中remove_full()移出,并add_partial()添加至半满partial队列中
178 | */
179 | if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) {
180 | if (kmem_cache_debug(s))
181 | remove_full(s, n, page);
182 | add_partial(n, page, DEACTIVATE_TO_TAIL);
183 | stat(s, FREE_ADD_PARTIAL);
184 | }
185 | /* 释放中断锁并恢复中断环境 */
186 | spin_unlock_irqrestore(&n->list_lock, flags);
187 | return;
188 |
189 | slab_empty:
190 | if (prior) {
191 | /* 如果缓冲区非空,则从partial链表中删除 */
192 | remove_partial(n, page);
193 | stat(s, FREE_REMOVE_PARTIAL);
194 | } else {
195 | /* Slab must be on the full list */
196 | remove_full(s, n, page);
197 | }
198 |
199 | spin_unlock_irqrestore(&n->list_lock, flags);
200 | stat(s, FREE_SLAB);
201 | discard_slab(s, page);
202 | }
203 | static noinline struct kmem_cache_node *free_debug_processing(
204 | struct kmem_cache *s, struct page *page, void *object,
205 | unsigned long addr, unsigned long *flags)
206 | {
207 | struct kmem_cache_node *n = get_node(s, page_to_nid(page));
208 |
209 | spin_lock_irqsave(&n->list_lock, *flags);
210 | slab_lock(page);
211 | /* 检查slab的kmem_cache与page中的slab信息是否匹配,如果不匹配,可能发生了破坏或者数据不符 */
212 | if (!check_slab(s, page))
213 | goto fail;
214 | /* 检查对象地址的合法性,表示地址确切地为某对象的首地址,而非对象的中间位置 */
215 | if (!check_valid_pointer(s, page, object)) {
216 | slab_err(s, page, "Invalid object pointer 0x%p", object);
217 | goto fail;
218 | }
219 | /* on_freelist()检测该对象是否已经被释放,避免造成重复释放置 */
220 | if (on_freelist(s, page, object)) {
221 | object_err(s, page, object, "Object already free");
222 | goto fail;
223 | }
224 | /* check_object()主要是根据内存标识SLAB_RED_ZONE及SLAB_POISON的设置,对对象空间进行完整性检测 */
225 | if (!check_object(s, page, object, SLUB_RED_ACTIVE))
226 | goto out;
227 | /* 确保用户传入的kmem_cache与页面所属的kmem_cache类型是匹配的,否则将记录错误日志 */
228 | if (unlikely(s != page->slab_cache)) {
229 | if (!PageSlab(page)) {
230 | slab_err(s, page, "Attempt to free object(0x%p) "
231 | "outside of slab", object);
232 | } else if (!page->slab_cache) {
233 | pr_err("SLUB : no slab for object 0x%p.\n",
234 | object);
235 | dump_stack();
236 | } else
237 | object_err(s, page, object,
238 | "page slab pointer corrupt.");
239 | goto fail;
240 | }
241 | /* 如果设置了SLAB_STORE_USER标识,将记录对象释放的track信息 */
242 | if (s->flags & SLAB_STORE_USER)
243 | set_track(s, object, TRACK_FREE, addr);
244 | /* trace()记录对象的轨迹信息,同时还init_object()将重新初始化对象 */
245 | trace(s, page, object, 0);
246 | init_object(s, object, SLUB_RED_INACTIVE);
247 | out:
248 | slab_unlock(page);
249 | /*
250 | * Keep node_lock to preserve integrity
251 | * until the object is actually freed
252 | */
253 | return n;
254 |
255 | fail:
256 | slab_unlock(page);
257 | spin_unlock_irqrestore(&n->list_lock, *flags);
258 | slab_fix(s, "Object at 0x%p not freed", object);
259 | return NULL;
260 | }
261 | ```
262 |
263 | ### discard_slab
264 |
265 | ```c
266 | static void discard_slab(struct kmem_cache *s, struct page *page)
267 | {
268 | /* 更新统计信息 */
269 | dec_slabs_node(s, page_to_nid(page), page->objects);
270 | /* 释放缓冲区 */
271 | free_slab(s, page);
272 | }
273 | ```
274 |
275 | ### __free_slab
276 |
277 | ```c
278 | static void __free_slab(struct kmem_cache *s, struct page *page)
279 | {
280 | /* 获取页面阶数转而获得释放的页面数 */
281 | int order = compound_order(page);
282 | int pages = 1 << order;
283 | /* 对该slab缓冲区进行一次检测,主要是检测是否有内存破坏以记录相关信息 */
284 | if (kmem_cache_debug(s)) {
285 | void *p;
286 |
287 | slab_pad_check(s, page);
288 | for_each_object(p, s, page_address(page),
289 | page->objects)
290 | check_object(s, page, p, SLUB_RED_INACTIVE);
291 | }
292 | /* 释放影子内存 */
293 | kmemcheck_free_shadow(page, compound_order(page));
294 | /* 修改内存页面的状态 */
295 | mod_zone_page_state(page_zone(page),
296 | (s->flags & SLAB_RECLAIM_ACCOUNT) ?
297 | NR_SLAB_RECLAIMABLE : NR_SLAB_UNRECLAIMABLE,
298 | -pages);
299 | /* 清除页面的slab信息 */
300 | __ClearPageSlabPfmemalloc(page);
301 | __ClearPageSlab(page);
302 |
303 | page_mapcount_reset(page);
304 | if (current->reclaim_state)
305 | current->reclaim_state->reclaimed_slab += pages;
306 | /* 将内存释放回伙伴系统,在伙伴系统内存释放中再分析 */
307 | __free_pages(page, order);
308 | /* 释放memcg中的页面处理 */
309 | memcg_uncharge_slab(s, order);
310 | }
311 | ```
312 |
313 | ## 参考资料
314 |
315 | [slub释放](https://www.jeanleo.com/2018/09/07/【linux内存源码分析】slub分配算法(5)/)
316 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理(一):硬件原理 和 分页管理.md:
--------------------------------------------------------------------------------
1 | ### 前言
2 | 内存管理相对复杂,涉及到硬件和软件,从微机原理到应用程序到内核。比如,硬件上的cache,CPU如何去寻址内存,页表, DMA,IOMMU。 软件上,要知道底层怎么分配内存,怎么管理内存,应用程序怎么申请内存。
3 |
4 | 常见的误解包括:
5 |
6 | 对free命令 cache和buffer的理解。
7 | 1、应用程序申请10M内存,申请成功其实并没有分配。内存其实是边写边拿。代码段有10M,并不是真的内存里占了10M。
8 | 2、内存管理学习难,一是网上的资料不准确,二是学习时执行代码,具有欺骗性。看到的东西不一定真实,要想理解必须陷入Linux本身。
9 |
10 | 学习时,不要过快陷入太多细节,而要先对整个流程整个框架理解。
11 |
12 | 先理清楚脉络和主干,从硬件到最底层内存的分配算法,-->到内核的内存分配算法,-->应用程序与内核的交互,-->到内存如何做磁盘的缓存, --> 内存如何和磁盘替换。
13 |
14 | 再动手实践demo。
15 |
16 | ### 硬件原理 和 分页管理
17 | 本文主要让大家理解内存管理最底层的buddy算法,内存为什么要分成多个Zone?
18 |
19 | * CPU寻址内存,虚拟地址、物理地址
20 | * MMU 以及RWX权限、kernel和user模式权限
21 | * 内存的zone: DMA、Normal和HIGHMEM
22 | * Linux内存管理Buddy算法
23 | * 连续内存分配器(CMA)
24 |
25 | 内存分页
26 |
27 | 
28 |
29 | CPU 一旦开启MMU,MMU是个硬件。CPU就只知道虚拟地址了。如果地址是32位,0x12345670 。
30 |
31 | 假设MMU的管理是把每一页的内存分成4K,那么其中的670是页内偏移,作为d;0x12345 是页号,作为p。通过虚拟地址去查对应的物理地址,用0x12345去查一张页表,页表(Page table)本身在内存。
32 |
33 | 硬件里有寄存器,记录页表的基地址,每次进程切换时,寄存器就会更新一次,因为每个进程的页表不同。
34 |
35 | CPU一旦访问虚拟地址,通过页表查到页表项,页表项记录对应的物理地址。
36 |
37 | 总结:一旦开启MMU,CPU只能看到虚拟地址,MMU才能看到物理地址。
38 | 虚拟地址是指针,物理地址是个整数。内存中的一切均通过虚拟地址来访问。
39 | ```
40 | typedef u64 phys_addr_t;
41 | ```
42 | 去内存里读取页表会比较慢,CPU里有个高速单元tlb,它是页表的高速缓存。CPU就不需要在内存里读页表,直接在tlb中读取,从虚拟地址到物理地址的映射。如果tlb中读取不到,才回到内存里读取页表映射,并且在tlb中命中。
43 |
44 | 虚拟地址:0x12345 670 --> 1M
45 |
46 | 物理地址:1M+670 MMU去访问这个物理地址。
47 |
48 | 内存的映射以页为单位。
49 | ### 页表(Page table)记录的页权限
50 | cpu虚拟地址,mmu根据cpu请求的虚拟地址,访问页表,查得物理地址。
51 |
52 | 每个MMU中的页表项,除了有虚拟地址到物理地址的映射之外,还可以标注这个页的 RWX权限和 kernel和user模式权限(用户空间,内核空间读取地址的权限),它们是内存管理两个的非常重要的权限。
53 |
54 | 一是,这一页地址的RWX权限 ,标记这4k地址的权限。一般用来做保护。
55 |
56 | Pagefault,是CPU提供的功能。两种情况会出现Pagefault,一是,CPU通过虚拟地址没有查到对应的物理地址。二是,MMU没有访问物理地址的权限。
57 |
58 | MPU,memory protection unit.
59 |
60 | 二是,MMU的页表项中,还可以标注这一页的地址:可以在内核态访问,还是只能在用户态访问。用户一般映射到0~3G,只有当CPU陷入到内核模式,才可以访问3G以上地址。
61 |
62 | 程序在用户态运行,处于CPU非特权模式,不能访问特权模式才能访问的内存。内核运行在CPU的特权模式,从用户态陷入到内核态,发送 软中断指令,CPU进行切环,x86从3环切到0环,到一个固定的地址去执行。软件就从非特权模式,跳到特权模式去执行。
63 |
64 | MMU,能把某一段地址指定为只有特权模式才能够访问,会把内核空间3G以上的页表项里的每一行,指定为只有CPU 0环才能访问。应用程序没有陷入到内核态,是无法访问内核态的东西。
65 |
66 | intel的漏洞meltdown,就是让用户可以在用户态读到内核态的东西。
67 |
68 | meltdown 攻击原理: 基于时间的 旁路攻击 side-channel
69 |
70 | 李小璐买汉堡的故事 --> 安全的基于时间的旁路攻击技巧。
71 |
72 | 比如试探用户名,密码。比如一个软件比较傻,每次第一个字母就不对,就不对比第2个字母了。那我每次26个字母实验换一次,看哪个字母反弹地最慢,就证明是这个字母的密码。
73 |
74 | 密码是abc, 我敲了d,那么第一个字母就不对,软件这个时候如果快速的返回出错,我知道首字母不是d,我可以实验出来首字母是a,然后接着一个个字母实,就可以把密码试探出来了。类似地原理。。
75 |
76 | 下面的这个例子,演示 page table记录的RWX权限的作用
77 |
78 | 
79 |
80 | 页表的权限,RWX权限,和 用户空间,内核空间读取的权限。
81 |
82 | ### 内存分Zone
83 | 下面解释内存为什么分Zone? DMA zone.
84 |
85 | 
86 |
87 | 内存的分Zone,全都是物理地址的概念。内存条,被分为三个Zone。
88 |
89 | 分DMA Zone的原因,是DMA引擎的缺陷。DMA引擎 可以直接访问内存空间的地址,但不一定能够访问到所有的内存,访问内存时会存在一定的限制。
90 |
91 | 当CPU 和DMA同时访问内存时,硬件上会有仲裁器,选择优先级高的去访问内存。
92 |
93 | 为什么要切DMA zone?
94 | DMA Zone的大小,是由硬件决定的。访问不到更高的内存。
95 |
96 | 什么叫做 normal zone? highmem zone?
97 |
98 | highmem和lowmem 都是指的内存条,在虚拟地址空间,只能称为highmem,lowmem映射区。
99 |
100 | 如上图,内存虚拟地址空间0~4G,3~4G是内核空间的虚拟地址,0-3G 是用户空间的虚拟地址。
101 |
102 | 内核空间,访问任何一片内存都要虚拟地址。Linux为了简化内存访问,开机就把lowmem的物理地址一一映射到虚拟地址。highmem 地址包括了 normal + DMA。
103 |
104 | 
105 |
106 | lowmem是开机就直接映射好的内存,CPU访问这片内存,也是通过3G以上的虚拟地址。这段地址的虚拟地址和物理地址是直接线性映射,通过linux的两个api (phys_to_virt / virt_to_phys)在虚拟和物理之间进行映射, highmem 不能直接用。
107 |
108 | 内核空间一般不使用highmem,内核一般使用kmalloc在lowmem申请内存,使用 kmmap在highmem 申请内存。lowmem 映射了,并不代表被内核使用掉了,只是不需要重建页表。内核使用lowmem内存,同样是要申请。 应用程序一样可以申请 lowmem 和highmem。
109 |
110 | 总结:
111 | 内存分highmem zone的原因,地址空间整体不够。
112 | DMA zone产生的原因,硬件DMA引擎的访问缺陷。
113 |
114 | 
115 |
116 | ### 硬件层的内存管理- buddy算法
117 |
118 | 每个zone都会使用buddy算法,把所有的空闲页面变成2的n次方进行管理。
119 |
120 | /proc/buddyinfo
121 |
122 | 通过/proc/buddyinfo,可以看出空闲内存的情况
123 |
124 | 
125 |
126 | CPU寻址内存的方法:通过MMU提供的虚拟地址到物理地址的映射访问。
127 |
128 | 如何处理内存碎片
129 |
130 | 
131 |
132 | X86 linux 内核有一个线程 compaction, 会进行内存碎片整理,会尽量移出大内存。
133 |
134 | CMA:continuous memory allocation
135 |
136 | 内核把虚拟地址 指向新的物理地址,让应用程序毫无知觉情况,把64M内存腾出来给DMA。当用DMA的api申请内存,会走到CMA。在dts中指定哪块区域做CMA。
137 |
138 | Documentation/devicetree/bindings
139 |
140 | reserved-memory/reserved-memory.txt
141 |
142 | dma_alloc_coherent
143 |
144 | **CMA, iommu,**
145 |
146 | CMA主要是给需要连续内存的DMA用的。但是为了避免DMA不用的时候浪费,才在DMA不用的时候给可移动的页面用。不能移动的页面,不能从CMA里面拿。所以主要是APP和文件的page cache的内存,才可以在CMA区域拿。
147 |
148 | 这样当DMA想拿CMA区域的时候,要么移走,要么抛弃。总之,必须保证DMA需要这片CMA区域的时候,之前占着CMA的统统滚蛋。
149 |
150 | 不具备滚蛋能力的内存,不能从CMA区域申请。你申请也滚蛋不了,待会DMA上来用的时候,DMA就完蛋了。
151 |
152 | 要搞清楚CMA的真正房东是那些需要连续内存的DMA,其他的人都只是租客。DMA要住的时候,租客必须走。哪个房东会把房子租给一辈子都不准备走的人?内核绝大多数情况下的内存申请,都是无法走的。应用走起来很容易,改下页面就行了。
153 |
154 | CMA和不可移动之间,没有任何交集。CMA唯一的好处是,房东不住的时候,免得房子空置。
155 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理(三):进程的内存消耗和泄漏.md:
--------------------------------------------------------------------------------
1 | ## 进程的内存消耗和泄漏
2 | * 进程的VMA
3 | * 进程内存消耗的4个概念: vss、rss、pss和uss
4 | * page fault的几种可能性, major 和 minor
5 | * 应用内存泄漏的界定方法
6 | * 应用内存泄漏的检测方法:valgrind 和 addresssanitizer
7 |
8 | 本节重点阐述 Linux的应用程序究竟消耗了多少内存?
9 |
10 | 一是,看到的内存消耗,并不是一定是真的消耗。
11 |
12 | 二是,Linux存在大量的内存共享的情况。
13 | 动态链接库的特点:代码段共享内存,数据段写时拷贝。
14 | 把一个应用程序跑两个进程,这两个进程的代码段也是共享的。
15 |
16 | 当我们评估进程消耗多少内存时,就是指在用户空间消耗的内存,即虚拟地址在0~3G的部分,对应的物理地址内存。内核空间的内存消耗属于内核,系统调用申请了很多内存,这些内存是不属于进程消耗的。
17 |
18 | ### 进程的虚拟地址空间VMA
19 |
20 | 
21 |
22 | task_struct里面有个mm_struct指针, 它代表进程的内存资源。pgd,代表 页表的地址; mmap 指向vm_area_struct 链表。 vm_area_struct 的每一段代表进程的一个虚拟地址空间。vma的每一段,都可能是可执行程序的某个数据段、某个代码段,堆、或栈。一个进程的虚拟地址,是在0~3G之间任意分布的。
23 |
24 | 
25 |
26 | 上图 提供三种方式,看到进程的VMA空间。
27 |
28 | pmap 3474
29 |
30 | 基地址,size, 权限,
31 |
32 | 通过以上的方式,可以看到进程的虚拟地址空间,分布在0~3G,任意一小段一小段分布的。
33 |
34 | 应用程序运行起来,就是一堆各种各样的VMA。VMA对应着 堆、栈、代码段、数据段、等,不在任何段里的虚拟地址空间,被认为是非法的。
35 |
36 | 
37 |
38 | 当指针访问地址时,落在一个非法的地址,即不在任何一个VMA区域。相当于访问一个非法的地址,这些虚拟地址没有对应的物理地址。应用程序收到page fault,查看原因,访问非法位置,返回segv。
39 |
40 | 在VMA的东西,不等于在内存。调malloc申请了100M内存,立马会多出一个100M的 VMA,代表这段vma区域有r+w权限。
41 |
42 | **应用程序访问内存,必须落在一个VMA里。其次,落在一个VMA里也不一定对。把100M的堆申请出来,100M内存页全部映射为0页。页表里每一页写的只读,页表和硬件对应,MMU只查页表。而在页表项中指向物理地址的权限是只读,所以在任何时候,去写其中任何一页,硬件都会发生缺页中断。**
43 |
44 | **Linux 内核在缺页中断的处理程序,通过MMU寄存器读出发生page fault的地址和原因。发现此时page fault的原因是写一个页表里记录只读的物理地址,而vma记录的虚拟地址又是r+w,此时,linux会申请一页内存。同时把页表中的权限改为r+w。**
45 |
46 | 总结:
47 | Linux 内核通过VMA管理进程每一段虚拟地址空间和权限。一旦发生page fault,如果没有落在任何一个vma区域,会干掉。
48 |
49 | VMA的起始地址+size,用来限定程序访问的地址是否合法。VMA中每一段的权限,是来界定访问这段地址是否使用正确的方式访问。
50 |
51 | 把所有的vma加起来,构成进程的虚拟地址空间,但这并不代表进程真实耗费的内存。拿到之后才是真实耗费的内存,RSS。耗费的虚拟内存,是VSS。
52 |
53 | ### page fault的几种可能性
54 |
55 | 
56 |
57 | 1、申请堆内存vma,第一次写,页表里的权限是R ,发生page fault,linux会去申请一页内存,此时把页表权限设置为 R+W。
58 | 2、内存访问落在空白非法区域,程序收到segv段错误。
59 | 3、代码段在VMA记录是R+X,此时如果对代码段执行写,程序会收到segv段错误。
60 |
61 | #### minor 和major 缺页
62 |
63 | 缺页,分为两种情况:主缺页 和次缺页。
64 |
65 | 主缺页 和次缺页,区别就是 申请内存时,是否需要读硬盘。前者需要。
66 |
67 | 如上图第4种情况,在代码段里执行时,出现缺页。linux申请一页内存,而且要从硬盘中读取代码段的内容,此时产生了IO,称为 major缺页。
68 |
69 | 无论是代码段还是堆,都是边执行边产生缺页中断,申请实际的内存给代码段,且从硬盘中读取代码段的内容到内存。这个过程时间比较长。
70 |
71 | minor: malloc的内存,产生缺页中断。去申请一页内存,没有产生IO的行为。major缺页处理时间,远大于minor。
72 |
73 | 
74 |
75 | ### vss、rss、pss和uss的区别
76 |
77 | 
78 |
79 | ```
80 | VSS - Virtual Set Size
81 | RSS - Resident Set Size
82 | PSS - Proportional Set Size
83 | USS - Unique Set Size
84 | ASAN - AddressSanitizer
85 | LSAN - LeakSanitizer
86 | ```
87 |
88 | 如上图,中间是一根内存条。三个进程分别是1044,1045,1054, 每一个进程对应一个page table,页表项记录虚拟地址如何往物理地址转换。硬件里的寄存器,记录页表的物理地址。当linux做进程上下文切换时,页表也跟着一起切换。
89 |
90 | 
91 |
92 | 三个进程都需要使用libc的代码段。
93 | VSS = 1 +2 +3
94 | RSS = 4 +5 +6
95 | PSS= 4/3 + 5/2 + 6 比例化的
96 | USS= 6 独占且驻留的
97 |
98 | 工具:smem ,查看进程使用内存的情况。
99 | 一般来讲,进程使用的内存量,还是看PSS,强调公平性。看内存泄漏看USS 就好了。
100 |
101 | ### 内存泄漏 界定和检测方法
102 | 界定:连续多点采样法,随着时间越久,进程耗费内存越多。
103 |
104 | 主要由内存申请和释放不是成对引起。RSS/USS曲线,
105 |
106 | 观察方法:使用smem工具查看多次进程使用内存,USS使用量。
107 |
108 | 检查工具:
109 | 1、valgrind ,会跑一个虚拟机,运行时检查进程的内存行为。会放慢程序的速度。不需要重新编译程序。
110 | 2、addressanitizer,需要重新编译程序。编译时加参数,-fsanitize
111 | gcc 4.9才支持,只会放慢程序速度2~3倍。
112 |
113 |
114 |
115 |
116 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理(二):内存的动态申请和释放.md:
--------------------------------------------------------------------------------
1 | ## 内存的动态申请和释放
2 |
3 | 内核空间 和用户空间申请的内存最终和buddy怎么交互?以及在页表映射上的区别?虚拟地址到物理地址,什么时候开始映射?
4 |
5 | ### Buddy的问题
6 | 分配的粒度太大
7 | buddy算法把空闲页面分成1,2,4页,buddy算法会明确知道哪一页内存空闲还是被占用?
8 |
9 | 4k,8k,16k
10 |
11 | 无论是在应用还是内核,都需要申请很小的内存。
12 |
13 | 从buddy要到的内存,会进行slab切割。
14 |
15 | ### slab原理:
16 | 比如在内核中申请8字节的内存,buddy分配4K,分成很多个小的8个字节,每个都是一个object。
17 |
18 | slab,slub,slob 是slab机制的三种不同实现算法。
19 |
20 | Linux 会针对一些常规的小的内存申请,数据结构,会做slab申请。
21 |
22 | cat /proc/slabinfo 可以看到内核空间小块内存的申请情况,也是slab分配的情况。
23 |
24 | :每个slab一共可以分出多少个obj,
25 | :还可以分配多少个obj,
26 | < pagesperslab>:每个slab对应多少个pages,
27 | < objperslab>:每个slab可以分出多少个object,
28 | < objsize>:每个obj多大,
29 |
30 | slab主要分为两类:
31 |
32 | 一、常用数据结构像 nfsd_drc, UDPv6,TCPv6 ,这些经常申请和释放的数据结构。比如,存在TCPv6的slab,之后申请 TCPv6 数据结构时,会通过这个slab来申请。
33 |
34 | 
35 |
36 | 二、常规的小内存申请,做的slab。例如 kmalloc-32,kmalloc-64, kmalloc-96, kmalloc-128
37 |
38 | 
39 |
40 | 
41 |
42 | 注意,slab申请和分配的都是只针对内核空间,与用户空间申请分配内存无关。用户空间的malloc和free调用的是libc。
43 |
44 | slab和buddy的关系?
45 | 1、slab的内存来自于buddy。slab相当于二级管理器。
46 | 2、slab和buddy在算法上,级别是对等的。
47 |
48 | 两者都是内存分配器,buddy是把内存条分成多个Zone来管理分配,slab是把从buddy拿到的内存,进行管理分配。
49 |
50 | 同理,malloc 和free也不找buddy拿内存。 malloc 和free不是系统调用,只是c库中的函数。
51 |
52 | ### mallopt
53 | 在C库中有一个api是mallopt,可以控制一系列的选项。
54 |
55 | 
56 |
57 | M_TRIM_THRESHOLD:控制c库把内存还给内核的阈值。
58 | -1UL 代表最大的正整数。
59 |
60 | 此处代表应用程序把内存还给c库后,c库并不把内存还给内核。
61 |
62 | <\do your RT-thing>
63 | 程序在此处申请内存,都不需要再和内核交互了,此时程序的实时性比较高。
64 |
65 | ### kmalloc vs. vmalloc/ioremap
66 |
67 | 内存空间: 内存+寄存器
68 |
69 | register --> LDR/STR
70 |
71 | 所有内存空间的东西,CPU去访问,都要通过虚拟地址。
72 | CPU --> virt --> mmu --> phys
73 |
74 | cpu请求虚拟地址,mmu根据cpu请求的虚拟地址,查页表得物理地址。
75 |
76 | buddy算法,管理这一页的使用情况。
77 |
78 | 两个虚拟地址可以映射到同一个物理地址。
79 |
80 | 
81 |
82 | 页表 -> 数组,
83 |
84 | 任何一个虚拟地址,都可以用地址的高20位,作为页表的行号去读对应的页表项。而低12位,是指页内偏移。(由于一页是4K,2^12 足够描述)
85 |
86 | kmalloc 和 vmalloc 申请的内存,有什么区别?
87 | 答:申请之后,是否还要去改页表。一般情况,kmalloc申请内存,不需要再去改页表。同一张页表,几个虚拟地址可以同时映射到同一个物理地址。
88 |
89 | 寄存器,通过ioremap往vmalloc区域,进行映射。然后改进程的虚拟地址页表。
90 |
91 | 总结:所有的页,最底层都是用buddy算法进行管理,用虚拟地址找物理地址。理解内存分配和映射的区别,无论是lowmem还是highmem 都可以被vmalloc拿走,也可能被用户拿走,只不过拿走之后,还要把虚拟地址往物理地址再映射一遍。但如果是被kmalloc拿走,一般指低端内存,就不需要再改进程的页表。因为这部分低端内存,已经做好了虚实映射。
92 | ```
93 | cat /proc/vmallocinfo |grep ioremap
94 | ```
95 | 可以看到寄存器中的哪个区域,被映射到哪个虚拟地址。
96 |
97 | vmalloc区域主要用来,vmalloc申请的内存从这里找虚拟地址 和 寄存器的ioremap映射。
98 |
99 | ### Linux内存分配的lazy行为
100 |
101 | Linux总是以最lazy的方式,给应用程序分配内存。
102 |
103 | 
104 |
105 | malloc 100M内存成功时,其实并没有真实拿到。只有当100M内存中的任何一页,被写一次的时候,才成功。
106 |
107 | vss:虚拟地址空间。 rss:常驻内存空间
108 |
109 | malloc 100M内存成功时,Linux把100M内存全部以只读的形式,映射到一个全部清0的页面。
110 |
111 | 当应用程序写100M中每一页任意字节时,会发出page fault。 linux 内核收到缺页中断后,从硬件寄存器中读取到,包括缺页中断发生的原因和虚拟地址。Linux从内存条申请一页内存,执行cow,把页面重新拷贝到新申请的页表,再把进程页表中的虚拟地址,指向一个新的物理地址,权限也被改成R+W。
112 |
113 | 调用brk 把8k变成 16k。
114 |
115 | 针对应用程序的堆、代码、栈、等,会使用lazy分配机制,只有当写内存页时,才会真实请求内存分配页表。但,当内核使用kmalloc申请内存时,就真实的分配相应的内存,不使用lazy机制。
116 |
117 | ### 内存OOM
118 |
119 | 当真实去写内存时,应用程序并不能拿到真实的内存时。Linux启动OOM,linux在运行时,会对每一个进程进行out-of-memory打分。打分主要基于,耗费的内存。耗费的内存越多,打分越高。
120 |
121 | ```
122 | cat /proc//oom_score
123 | ```
124 |
125 | demo:
126 |
127 | ```c
128 | #include
129 | #include
130 | #include
131 | int main(int argc, char **argv)
132 | {
133 | int max = -1;
134 | int mb = 0;
135 | char *buffer;
136 | int i;
137 | #define SIZE 2000
138 | unsigned int *p = malloc(1024 * 1024 * SIZE);
139 | printf("malloc buffer: %p\n", p);
140 | for (i = 0; i < 1024 * 1024 * (SIZE/sizeof(int)); i++) {
141 | p[i] = 123;
142 | if ((i & 0xFFFFF) == 0) {
143 | printf("%dMB written\n", i >> 18);
144 | usleep(100000);
145 | }
146 | }
147 | pause();
148 | return 0;
149 | }
150 | ```
151 |
152 | 设定条件:
153 |
154 | 总内存1G
155 | 1、swapoff -a 关掉swap交换
156 | 2、echo 1 > /proc/sys/vm/overcommit_memory
157 | 3、内核不去评估系统还有多少空闲内存
158 |
159 | Linux进行OOM打分,主要是看耗费内存情况,此外还会参考用户权限,比如root权限,打分会减少30分。
160 |
161 | 还有OOM打分因子:/proc/pid/oom_score_adj (加减)和 /proc/pid/oom_adj (乘除)。
162 |
163 | 
164 |
165 | ### 总结:
166 | 1、slab的作用,针对在内核空间小内存分配,和常用数据结构的申请。
167 | 2、同样的二次分配器,在用户空间是C库。malloc和free的时候,内存不一定从buddy分配和还给buddy。
168 | 3、kmalloc,vmalloc 和malloc的区别
169 |
170 | * kmalloc:申请内存,一般在低端内存区。申请到时,内存已经映射过了,不需要再去改进程的页表。所以,申请到的物理页是连续的。
171 | * vmalloc:申请内存,申请到就拿到内存,并且已经修改了进程页表的虚拟地址到物理地址的映射。vmalloc()申请的内存并不保证物理地址的连续。
172 | * 用户空间的malloc:申请内存,申请到并没有拿到,写的时候才去拿到。拿到之后,才去改页表。申请成功,页表只读,只有到写时,发生page fault,才去buddy拿内存。
173 | * kmalloc和vmalloc针对内核空间,malloc针对用户空间。这些内存,可以来自任何一个Zone。
174 | * 无论是kmalloc,vmalloc还是用户空间的malloc,都可以使用内存条的不同Zone,无论是highmem zone、lowmem zone 和 DMA zone。
175 |
176 | 4、如果在从buddy拿不到内存时,会触发Linux对所有进程进行OOM打分。当Linux出现内存耗尽,就kill一个oom score 最高的那个进程。oom_score,可以根据 oom_adj (-17~25)。
177 |
178 | 安卓的程序,不停的调整前台和后台进程oom_score,当被切换到后台时,oom_score会被调整的比较大。以保证前台的进程不容易因为oom而kill掉。
179 |
180 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理(五):其他工程问题以及调优.md:
--------------------------------------------------------------------------------
1 | ## 其他工程问题以及调优
2 | * DMA和cache一致性
3 | * 内存的cgroup
4 | * memcg子系统分析
5 | * 性能方面的调优: page in/out, swap in/out
6 | * Dirty ratio的一些设置
7 | * swappiness
8 |
9 | ### DMA和cache一致性
10 |
11 | 
12 |
13 | 工程中,DMA可以直接在内存和外设进行数据搬移,而CPU访问内存时要经过MMU。DMA访问不到CPU内部的cache,所以会出现cache不一致的问题。因为CPU读写内存时,如果在cache中命中,就不会再访问内存。
14 |
15 | 当CPU 写memory时,cache有两种算法:write_back ,write_through。一般都采用write_back。cache的硬件,使用LRU算法,把cache中的数据替换到磁盘。
16 |
17 | 
18 |
19 | cache一致性问题,主要靠以上两类api来解决这个问题。一致性DMA缓冲区api,和流式DMA映射api。CPU通过MMU访问DMA区域,在页表项中可以配置这片区域是否带cache。
20 |
21 | 现代的SoC,DMA引擎可以自动维护cache的同步。
22 |
23 | ### 内存的cgroup
24 | 进程分group,内存也分group。
25 |
26 | 进程调度时,把一组进程加到一个cgroup,控制这一组进程的CPU权重和最大CPU占用率。在/sys/fs/cgroup/memory创建一个目录,把进程放到这个group。可以限制某个group下的进程不用swap,每个group的swapiness都可以配置。
27 |
28 | 比如,当你把某个group下的swapiness设置为0,那么这个group下进程的匿名页就不允许交换了。
29 | /proc/sys/vm/swapiness是控制全局的swap特性,不影响加到group中的进程。
30 |
31 | 也可以控制每个group的最大内存消耗为200M,当这个group下进程使用的内存达到200M,就oom。
32 |
33 | demo: 演示用memory cgroup来限制进程group内存资源消耗的方法
34 |
35 | ```
36 | swapoff -a
37 | echo 1 > /proc/sys/vm/overcommit_memory # 进程申请多少资源,内核都允许
38 |
39 | root@whale:/sys/fs/cgroup/memory# mkdir A
40 | root@whale:/sys/fs/cgroup/memory# cd A
41 | root@whale:/sys/fs/cgroup/memory/A# echo $((200*1024*1024)) > memory.limit_in_bytes
42 |
43 | cgexec -g memory:A ./a.out
44 |
45 |
46 | [ 560.618666] Memory cgroup out of memory: Kill process 5062 (a.out) score 977 or sacrifice child
47 | [ 560.618817] Killed process 5062 (a.out) total-vm:2052084kB, anon-rss:204636kB, file-rss:1240kB
48 | ```
49 |
50 | ### memory cgroup子系统分析
51 | memcg v1的参数有25个, 通过数据结构 res_counter 来计算。
52 |
53 | ```
54 | ~~~
55 | /* * The core object. the cgroup that wishes to account for some
56 | * resource may include this counter into its structures and use
57 | * the helpers described beyond */
58 |
59 | struct res_counter {
60 | unsigned long long usage; /* * 目前资源消费的级别 */
61 | unsigned long long max_usage; /* *从counter创建的最大使用值 */
62 | unsigned long long limit; /* * 不能超过的使用限制 */
63 | unsigned long long soft_limit; /* * 可以超过使用的限制 */
64 | unsigned long long failcnt; /* * 尝试消费资源的失败数 */
65 | spinlock_t lock; /* * the lock to protect all of the above.
66 | * the routines below consider this to be IRQ-safe */
67 | struct res_counter *parent; /* * Parent counter, used for hierarchial resource accounting */
68 | };
69 | ```
70 | 内存的使用量 mem_cgroup_usage 通过递归RSS和page cache之和来计算。
71 |
72 | struct mem_cgroup是负责内存 cgroup 的结构
73 |
74 | ```c
75 | struct mem_cgroup {
76 | struct cgroup_subsys_state css; // 通过css关联cgroup.
77 | struct res_counter res; // mem统计变量
78 | res_counter memsw; // mem+sw的和
79 | struct res_counter kmem; // 内核内存统计量 ...
80 | }
81 | ```
82 | 这些参数的入口都在mm/memcontrol.c下,比如说memory.usage_in_bytes的读取调用的是mem_cgroup_read函数, 统计的入口是mem_cgroup_charge_common(),如果统计值超过限制就会在cgroup内进行回收。调用者分别是缺页时调用的mem_cgroup_newpage_charge和 page cache相关的mem_cgroup_cache_charge。
83 |
84 | 当进程进入缺页异常的时候就会分配具体的物理内存,当物理内存使用超过高水平线以后,换页daemon(kswapd)就会被唤醒用于把内存交换到交换空间以腾出内存,当内存恢复至高水平线以后换页daemon进入睡眠。
85 |
86 | 缺页异常的入口是 __do_fault,
87 |
88 | RSS在page_fault的时候记录,page cache是插入到inode的radix-tree中才记录的。
89 | RSS在完全unmap的时候减少计数,page cache的page在离开inode的radix-tree才减少计数。
90 | 即使RSS完全unmap,也就是被kswapd给换出,可能作为SwapCache存留在系统中,除非不作为SwapCache,不然还是会被计数。
91 | 一个换入的page不会马上计数,只有被map的时候才会,当进行换页的时候,会预读一些不属于当前进程的page,而不是通过page fault,所以不在换入的时候计数。
92 |
93 | ### 脏页写回的“时空”控制
94 |
95 | 
96 |
97 | “脏页”:当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。
98 |
99 | 通过时间(dirty_expire_centisecs)和比例,控制Linux脏页返回。
100 |
101 | dirty_expire_centisecs:当Linux中脏页的时间到达dirty_expire_centisecs,无论脏页的数量多少,必须立即写回。通过在后台启动进程,进行脏页写回。
102 | 默认时间设置为30s。
103 |
104 | dirty_ratio,dirty_background_ratio 基于空间的脏页写回控制。
105 | 不能让内存中存在太多空间的脏页。如果一个进程在循环调用write,当达到dirty_background_ratio后,后台进程就开始写回脏页。默认值5%。当达到第2个阈值dirty_ratio时,应用进程被阻塞。当内存中的脏页在两个阈值之间时,应用程序是不会阻塞。
106 |
107 | ### 内存何时回收:水位控制
108 | 脏页写回不是 内存回收。
109 |
110 | 脏页写回:是保证在内存不在磁盘的数据不要太多。
111 | 水位控制:是指内存何时开始回收。
112 |
113 | 
114 |
115 | 由/pro/sys/vm/min_free_kbytes 控制,根据内存大小算出来的平方根。
116 | pf_mem_alloc,允许内存达到低水位以下,还可以继续申请。内存的回收,在最低水位以上就开始回收。
117 |
118 | 
119 |
120 | 每个Zone都有自己的三个水位,最小的水位是根据min_free_kbytes控制。5/4min_free_kbytes =low 3/2min_free_kbytes =high ,
121 | Zone的最小内存达到5/4的low 水位,Linux开始后台回收内存。直到达到6/4的high水位,开始不回收。
122 | 当Zone的最小内存达到min水位,应用程序的写会直接阻塞。
123 |
124 | 实时操作系统,
125 |
126 | 
127 |
128 | 当你要开始回收内存时,回收比例通过swappiness越大,越倾向于回收匿名页;swappiness越小,越倾向于回收file-backed的页面。
129 | 当把cgroup中的swapiness设置为0,就不回收匿名页了。
130 | 当你的应用会经常去访问数据malloc的内存,需要把swapiness设置小。dirty的设置,水位的设置都没有一个标准,要看应用使用内存的情况而定。
131 |
132 | getdelays工具:用来评估应用等待CPU,内存,IO,的时间。
133 | linux/Documents/accounting
134 |
135 | 
136 |
137 | CONFIG_TASK_DELAY_ACCT=y
138 | CONFIG_TASKSTATS=y
139 |
140 | vmstat 可以展现给定时间间隔的服务器的状态值,包括Linux的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。
141 | ```
142 | vmstat 1
143 | ```
144 | Documents/sysctl/vm.txt 中有所有参数最细节的描述。
145 |
146 |
--------------------------------------------------------------------------------
/✍ 文章/内存管理(四):内存与IO的交换.md:
--------------------------------------------------------------------------------
1 | ## 内存与I/O的交换
2 | 堆、栈、代码段是否常驻内存?本文主要介绍两类不同的页面,以及这两类页面如何在内存和磁盘间进行交换?以及内存和磁盘的颠簸行为- swaping,和硬盘的swap分区。
3 |
4 | ### page cache
5 |
6 | **file-backed的页面**:(有文件背景的页面,比如代码段、比如read/write方法读写的文件、比如mmap读写的文件;他们有对应的硬盘文件,因此如果要交换,可以直接和硬盘对应的文件进行交换),此部分页面进page cache。
7 |
8 | **匿名页**:匿名页,如stack,heap,CoW后的数据段等;他们没有对应的硬盘文件,因此如果要交换,只能交换到虚拟内存-swapfile或者Linux的swap硬盘分区),此部分页面,如果系统内存不充分,可以被swap到swapfile或者硬盘的swap分区。
9 |
10 | 
11 |
12 | 内核通过两种方式打开硬盘的文件,**任何时候打开文件,Linux会申请一个page cache,然后把文件读到page cache里。**page cache 是内存针对硬盘的缓存。
13 |
14 | Linux读写文件有两种方式:read/write 和 mmap
15 |
16 | 1)read/write: read会把内核空间的page cache,往用户空间的buffer拷贝。
17 | 参数 fd, buffer, size ,write只是把用户空间的buffer拷贝到内核空间的page cache。
18 |
19 | 2)mmap:可以避免内核空间到用户空间拷贝的过程,直接把文件映射成一个虚拟地址指针,指向linux内核申请的page cache。也就知道page cache和硬盘里文件的对应关系。
20 |
21 | 参数 fd,
22 |
23 | 文件对于应用程序,只是一部分内存。Linux使用write写文件,只是把文件写进内存,并没有sync。而内存的数据和硬盘交换的功能去完成。
24 |
25 | ELF可执行程序的头部会记录,从xxx到xxx是代码段。把代码段映射到虚拟地址,0~3 G, 权限是RX。这段地址映射到内核空间的page cache, 这段page cache又映射到可执行程序。
26 |
27 | page cache,会根据LRU算法(最近最少使用)进行替换。
28 |
29 | demo演示 page cache会多大程度影响程序执行时间。
30 |
31 | ```
32 | echo 3 > /proc/sys/vm/drop_caches
33 | time python hello.py
34 | \time -v python hello.py
35 |
36 | root@whale:/home/gzzhangyi2015# \time -v python hello.py
37 | Hello World! Love, Python
38 | Command being timed: "python hello.py"
39 | User time (seconds): 0.01
40 | System time (seconds): 0.00
41 | Percent of CPU this job got: 40%
42 | Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.03
43 | Average shared text size (kbytes): 0
44 | Average unshared data size (kbytes): 0
45 | Average stack size (kbytes): 0
46 | Average total size (kbytes): 0
47 | Maximum resident set size (kbytes): 6544
48 | Average resident set size (kbytes): 0
49 | Major (requiring I/O) page faults: 10
50 | Minor (reclaiming a frame) page faults: 778
51 | Voluntary context switches: 54
52 | Involuntary context switches: 9
53 | Swaps: 0
54 | File system inputs: 6528
55 | File system outputs: 0
56 | Socket messages sent: 0
57 | Socket messages received: 0
58 | Signals delivered: 0
59 | Page size (bytes): 4096
60 | Exit status: 0
61 |
62 | root@whale:/home/gzzhangyi2015# \time -v python hello.py
63 | Hello World! Love, Python
64 | Command being timed: "python hello.py"
65 | User time (seconds): 0.01
66 | System time (seconds): 0.00
67 | Percent of CPU this job got: 84%
68 | Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.01
69 | Average shared text size (kbytes): 0
70 | Average unshared data size (kbytes): 0
71 | Average stack size (kbytes): 0
72 | Average total size (kbytes): 0
73 | Maximum resident set size (kbytes): 6624
74 | Average resident set size (kbytes): 0
75 | Major (requiring I/O) page faults: 0
76 | Minor (reclaiming a frame) page faults: 770
77 | Voluntary context switches: 1
78 | Involuntary context switches: 4
79 | Swaps: 0
80 | File system inputs: 0
81 | File system outputs: 0
82 | Socket messages sent: 0
83 | Socket messages received: 0
84 | Signals delivered: 0
85 | Page size (bytes): 4096
86 | Exit status: 0
87 | ```
88 |
89 | 总结:Linux有两种方式读取文件,不管以何种方式读文件,都会产生page cache 。
90 |
91 | ### free命令的详细解释
92 |
93 | ```
94 | total used free shared buffers cached
95 | Mem: 49537244 1667532 47869712 146808 21652 421268
96 | -/+ buffers/cache: 1224612 48312632
97 | Swap: 4194300 0 4194300
98 | ```
99 |
100 | 
101 |
102 | buffers/cache都是文件系统的缓存,当访问ext3/ext4,fat等文件系统中的文件,产生cache。当直接访问裸分区(/dev/sdax)时,产生buffer。
103 |
104 | 访问裸分区的用户,主要是应用程序直接打开 or 文件系统本身。dd命令 or 硬盘备份 or sd卡,会访问裸分区,产生的缓存就是buffer。而ext4文件系统把硬盘当作裸分区。
105 |
106 | buffer和cache没有本质的区别,只是背景的区别。
107 |
108 | -/+ buffer/cache 的公式
109 | used buffers/cache = used - buffers - cached
110 | free buffers/cache = free + buffers + cached
111 |
112 | 新版free
113 | available参数:评估出有多少空闲内存给应用程序使用,free + 可回收的。
114 |
115 | 
116 |
117 | ### File-backed和Anonymous page
118 |
119 | * File-backed映射把进程的虚拟地址空间映射到files
120 | * 比如 代码段
121 | * 比如 mmap一个字体文件
122 |
123 | * Anonymous映射是进程的虚拟地址空间没有映射到任何file
124 | * Stack
125 | * Heap
126 | * CoW pages
127 |
128 | anonymous pages(没有任何文件背景)分配一个swapfile文件或者一个swap分区,来进行交换到磁盘的动作。
129 |
130 | read/write和 mmap 本质上都是有文件背景的映射,把进程的虚拟地址空间映射到files。在内存中的副本,只是一个page cache。是page cache就有可能被踢出内存。CPU 内部的cache,当访问新的内存时,也会被踢出cache。
131 |
132 | demo:演示进程的代码段是如何被踢出去的?
133 |
134 | ```
135 | pidof firefox
136 | cat /proc//smaps
137 |
138 | 运行 oom.c
139 |
140 | ```
141 | ### swap以及zRAM
142 |
143 | 数据段,在未写过时,有文件背景。在写过之后,变成没有文件背景,就被当作匿名页。linux把swap分区,当作匿名页的文件背景。
144 | ```
145 | swap(v.),内存和硬盘之间的颠簸行为。
146 | swap(n.),swap分区和swap文件,当作内存中匿名页的交换背景。在windows内,被称作虚拟内存。pagefile.sys
147 | ```
148 | ### 页面回收和LRU
149 |
150 | 
151 |
152 | 回收匿名页和 回收有文件背景的页面。
153 | 后台慢慢回收:通过kswapd进程,回收到高水位(high)时,才停止回收。从low -> high
154 | 直接回收:当水位达到min水位,会在两种页面同时进行回收,回收比例通过swappiness越大,越倾向于回收匿名页;swappiness越小,越倾向于回收file-backed的页面。当然,它们的回收方法都是一样的LRU算法。
155 |
156 | ### Linux Page Replacement
157 |
158 | 用LRU算法来进行swap和page cache的页面替换。
159 |
160 | 
161 |
162 | ```
163 | 现在cache的大小是4页,前四次,1,2,3,4文件被一次使用,注意第七次,5文件被使用,系统评估最近最少被使用的文件是3,那么不好意思,3被swap出去,5加载进来,依次类推。
164 |
165 | 所以LRU可能会触发page cache或者anonymous页与对应文件的数据交换。
166 | ```
167 |
168 | ### 嵌入式系统的zRAM
169 |
170 | 
171 |
172 | zRAM: 用内存来做swap分区。从内存中开辟一小段出来,模拟成硬盘分区,做交换分区,交换匿名页,自带透明压缩功能。当应用程序往zRAM写数据时,会自动把匿名页进行压缩。当应用程序访问匿名页时,内存页表里不命中,发生page fault(major)。从zRAM中把匿名页透明解压出来,还到内存。
173 |
174 |
--------------------------------------------------------------------------------
/✍ 文章/图解 Linux 内存性能优化核心思想.md:
--------------------------------------------------------------------------------
1 | 今天分享一篇**内存性能优化**的文章,文章用了大量精美的图深入浅出地分析了Linux内核slab性能优化的**核心思想**,**slab**是Linux内核小对象内存分配最重要的算法,文章分析了内存分配的各种性能问题(在不同的场景下面),并给出了这些问题的优化方案,这个对我们实现**高性能内存池算法**,或以后遇到内存性能问题的时候,有一定的启发,值得我们学习。
2 |
3 |
4 |
5 | **Linux内核的slab**来自一种很简单的思想,即事先准备好一些会频繁分配,释放的数据结构。然而标准的slab实现太复杂且维护开销巨大,因此便分化出了更加小巧的slub,因此本文讨论的就是slub,后面所有提到slab的地方,指的都是slub。另外又由于本文主要描述内核优化方面的内容,因此想了解slab细节以及代码实现的请查看源码。
6 |
7 |
8 |
9 | ### 单CPU上单纯的slab
10 |
11 | 下图给出了单CPU上slab在分配和释放对象时的情景序列:
12 |
13 |
14 |
15 | 
16 |
17 |
18 |
19 | 可以看出,非常之简单,而且完全达到了slab设计之初的目标。
20 |
21 | ### 扩展到多核心CPU****
22 |
23 | 现在我们简单的将上面的模型扩展到多核心CPU,同样差不多的分配序列如下图所示:
24 |
25 | 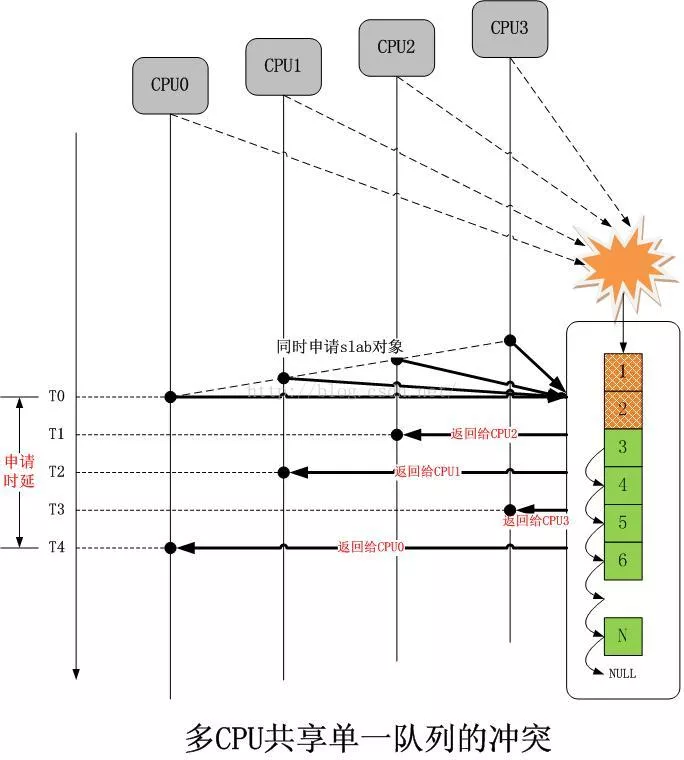
26 |
27 | 我们看到,在只有单一slab的时候,如果多个CPU同时分配对象,冲突是不可避免的,解决冲突的几乎是唯一的办法就是加锁排队,然而这将大大增加延迟,我们看到,申请单一对象的整个时延从T0开始,到T4结束,这太久了。
28 |
29 |
30 |
31 | 多CPU无锁化并行化操作的直接思路-复制给每个CPU一套相同的数据结构。不二法门就是增加“每CPU变量”。对于slab而言,可以扩展成下面的样子:
32 |
33 |
34 |
35 | 
36 |
37 | 如果以为这么简单就结束了,那这就太没有意义了。
38 |
39 | ### 问题
40 |
41 | ### 首先,我们来看一个简单的问题,如果单独的某个CPU的slab缓存没有对象可分配了,但是其它CPU的slab缓存仍有大量空闲对象的情况,如下图所示:
42 |
43 |
44 |
45 | 
46 |
47 |
48 |
49 | 这是可能的,因为对单独一种slab的需求是和该CPU上执行的进程/线程紧密相关的,比如如果CPU0只处理网络,那么它就会对skb等数据结构有大量的需求,对于上图最后引出的问题,如果我们选择从伙伴系统中分配一个新的page(或者pages,取决于对象大小以及slab cache的order),那么久而久之就会造成slab在CPU间分布的不均衡,更可能会因此吃掉大量的物理内存,这都是不希望看到的。
50 |
51 |
52 |
53 | 在继续之前,首先要明确的是,我们需要在CPU间均衡slab,并且这些必须靠slab内部的机制自行完成,这个和进程在CPU间负载均衡是完全不同的,对进程而言,拥有一个核心调度机制,比如基于时间片,或者虚拟时钟的步进速率等,但是对于slab,完全取决于使用者自身,只要对象仍然在使用,就不能剥夺使用者继续使用的权利,除非使用者自己释放。因此slab的负载均衡必须设计成合作型的,而不是抢占式的。
54 |
55 |
56 |
57 | 好了。现在我们知道,从伙伴系统重新分配一个page(s)并不是一个好主意,它应该是最终的决定,在执行它之前,首先要试一下别的路线。
58 |
59 |
60 |
61 | 现在,我们引出第二个问题,如下图所示:
62 |
63 | 
64 |
65 |
66 |
67 | 谁也不能保证分配slab对象的CPU和释放slab对象的CPU是同一个CPU,谁也不能保证一个CPU在一个slab对象的生命周期内没有分配新的page(s),这期间的复杂操作谁也没有规定。这些问题该怎么解决呢?事实上,理解了这些问题是怎么解决的,一个slab框架就彻底理解了。
68 |
69 | ### 问题的解决-分层slab cache
70 |
71 | 无级变速总是让人向往。如果一个CPU的slab缓存满了,直接去抢同级别的别的CPU的slab缓存被认为是一种鲁莽且不道义的做法。那么为何不设置另外一个slab缓存,获取它里面的对象不像直接获取CPU的slab缓存那么简单且直接,但是难度却又不大,只是稍微增加一点消耗,这不是很好吗?
72 |
73 |
74 |
75 | 事实上,**CPU的L1,L2,L3 cache**不就是这个方案设计的吗?这事实上已经成为cache设计的不二法门。这个**设计思想**同样作用于slab,就是Linux内核的slub实现,现在可以给出概念和解释了。
76 |
77 | 1. **Linux kernel slab cache**:一个分为3层的对象cache模型。
78 | 2. **Level 1 slab cache**:一个空闲对象链表,每个CPU一个的独享cache,分配释放对象无需加锁。
79 | 3. **Level 2 slab cache**:一个空闲对象链表,每个CPU一个的共享page(s) cache,分配释放对象时仅需要锁住该page(s),与Level 1 slab cache互斥,不互相包容。
80 | 4. **Level 3 slab cache**:一个page(s)链表,每个NUMA NODE的所有CPU共享的cache,单位为page(s),获取后被提升到对应CPU的Level 1 slab cache,同时该page(s)作为Level 2的共享page(s)存在。
81 | 5. **共享page(s)**:该page(s)被一个或者多个CPU占有,每一个CPU在该page(s)上都可以拥有互相不充图的空闲对象链表,该page(s)拥有一个唯一的Level 2 slab cache空闲链表,该链表与上述一个或多个Level 1 slab cache空闲链表亦不冲突,多个CPU获取该Level 2 slab cache时必须争抢,获取后可以将该链表提升成自己的Level 1 slab cache。
82 |
83 |
84 |
85 | 该**slab cache**的图示如下:
86 |
87 |
88 |
89 | 
90 |
91 | 其行为如下图所示:
92 |
93 | 
94 |
95 | ### 2个场景****
96 |
97 | 对于常规的对象分配过程,下图展示了其细节:
98 |
99 | 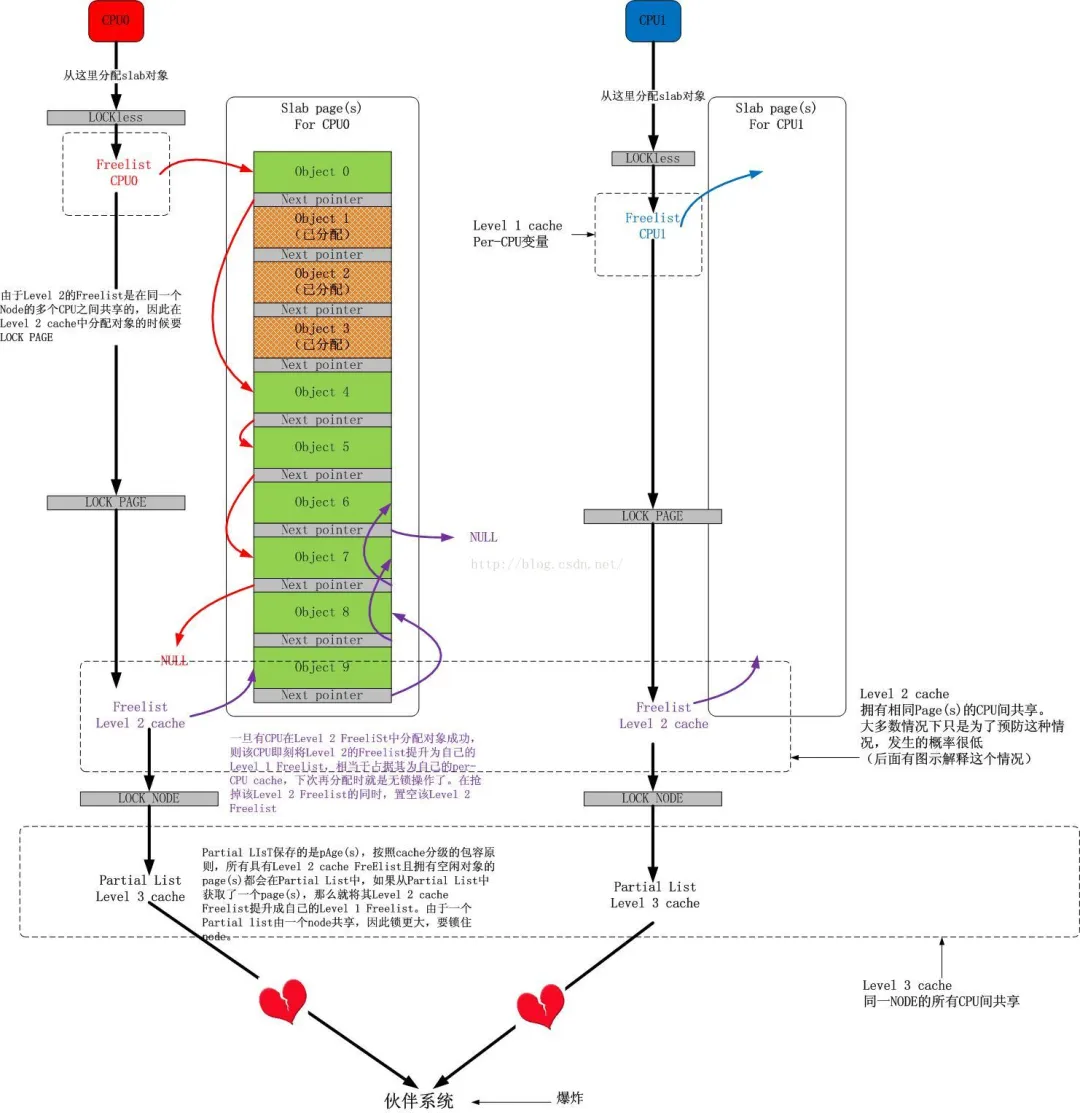
100 |
101 | 事实上,对于多个CPU共享一个page(s)的情况,还可以有另一种玩法,如下图所示:
102 |
103 | 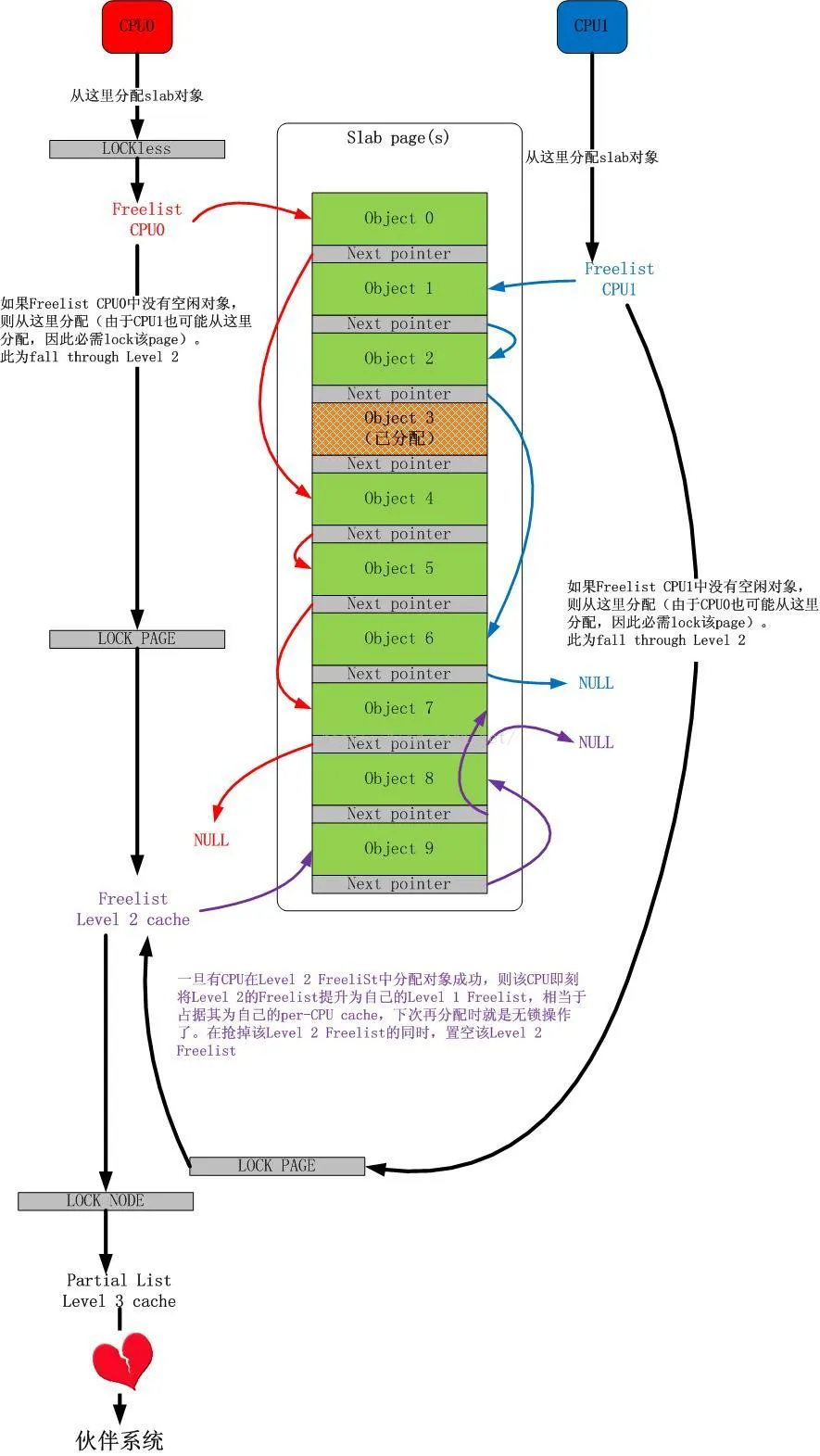
104 |
105 | ### 伙伴系统
106 |
107 | 前面我们简短的体会了Linux内核的slab设计,不宜过长,太长了不易理解.但是最后,如果Level 3也没有获取page(s),那么最终会落到终极的伙伴系统,伙伴系统是为了防内存分配碎片化的,所以它尽可能地做两件事:
108 |
109 | 1. **尽量分配尽可能大的内存**
110 | 2. **尽量合并连续的小块内存成一块大内存**
111 |
112 | 我们可以通过下面的图解来理解上面的原则:
113 |
114 | 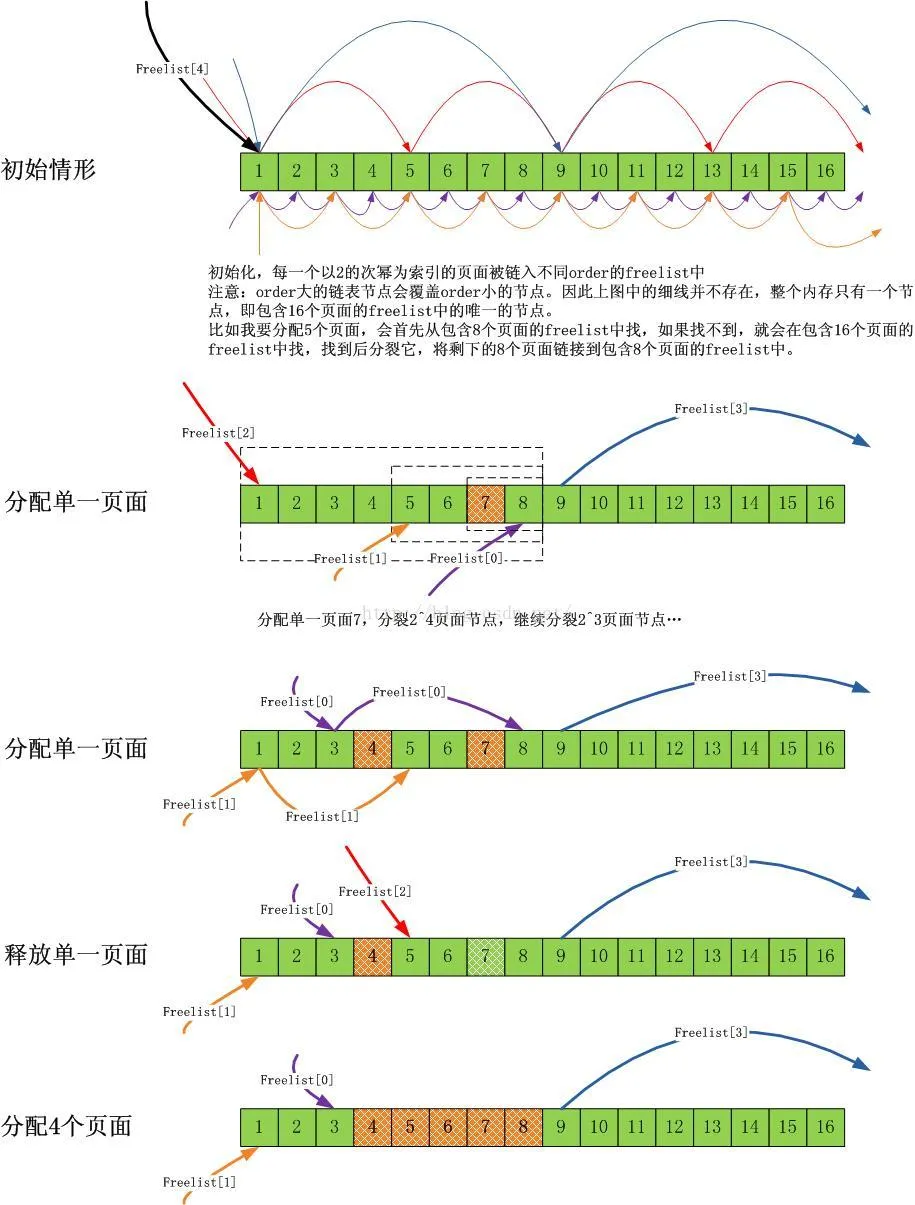
115 |
116 | 注意,本文是关于优化的,不是伙伴系统的科普,所以我假设大家已经理解了伙伴系统。
117 |
118 |
119 |
120 | 鉴于slab缓存对象大多数都是不超过1个页面的小结构(不仅仅slab系统,超过1个页面的内存需求相比1个页面的内存需求,很少),因此会有大量的针对1个页面的内存分配需求。
121 |
122 |
123 |
124 | 从伙伴系统的分配原理可知,如果持续大量分配单一页面,会有大量的order大于0的页面分裂成单一页面,在单核心CPU上,这不是问题,但是在多核心CPU上,由于每一个CPU都会进行此类分配,而伙伴系统的分裂,合并操作会涉及大量的链表操作,这个锁开销是巨大的,因此需要优化!
125 |
126 |
127 |
128 | Linux内核对伙伴系统针对单一页面的分配需求采取的批量分配“每CPU单一页面缓存”的方式!每一个CPU拥有一个单一页面缓存池,需要单一页面的时候,可以无需加锁从当前CPU对应的页面池中获取页面。而当池中页面不足时,系统会批量从伙伴系统中拉取一堆页面到池中,反过来,在单一页面释放的时候,会择优将其释放到每CPU的单一页面缓存中。
129 |
130 |
131 |
132 | 为了维持“每CPU单一页面缓存”中页面的数量不会太多或太少(太多会影响伙伴系统,太少会影响CPU的需求),系统保持了两个值,当缓存页面数量低于low值的时候,便从伙伴系统中批量获取页面到池中,而当缓存页面数量大于high的时候,便会释放一些页面到伙伴系统中。
133 |
134 | ### 小结
135 |
136 | 多CPU操作系统内核中,关键的开销就是锁的开销。我认为这是一开始的设计导致的,因为一开始,多核CPU并没有出现,单核CPU上的共享保护几乎都是可以用“禁中断”,“禁抢占”来简单实现的,到了多核时代,操作系统同样简单平移到了新的平台,因此同步操作是在单核的基础上后来添加的。
137 |
138 |
139 |
140 | 简单来讲,目前的主流操作系统都是在单核年代创造出来的,因此它们都是顺应单核环境的,对于多核环境,可能它们一开始的设计就有问题。
141 |
142 |
143 |
144 | 不管怎么说,优化操作的不二法门就是禁止或者尽量减少锁的操作。随之而来的思路就是为共享的关键数据结构创建"**每CPU的缓存**“,而这类缓存分为两种类型:
145 |
146 | **1. 数据通路缓存**
147 |
148 | 比如路由表之类的数据结构,你可以用RCU锁来保护,当然如果为每一个CPU都创建一个本地路由表缓存,也是不错的,现在的问题是何时更新它们,因为所有的缓存都是平级的,因此一种批量同步的机制是必须的。
149 |
150 | **2. 管理机制缓存**
151 |
152 | 比如slab对象缓存这类,其生命周期完全取决于使用者,因此不存在同步问题,然而却存在管理问题。采用分级cache的思想是好的,这个非常类似于CPU的L1/L2/L3缓存,采用这种平滑的开销逐渐增大,容量逐渐增大的机制,并配合以设计良好的换入/换出等算法,效果是非常明显的。
153 |
154 |
--------------------------------------------------------------------------------
/✍ 文章/多核心Linux内核路径优化的不二法门之-slab与伙伴系统.md:
--------------------------------------------------------------------------------
1 | Linux内核的slab来自一种很简单的思想,即事先准备好一些会频繁分配,释放的数据结构。然而标准的slab实现太复杂且维护开销巨大,因此便分化 出了更加小巧的slub,因此本文讨论的就是slub,后面所有提到slab的地方,指的都是slub。另外又由于本文主要描述内核优化方面的内容,并不 是基本原理介绍,因此想了解slab细节以及代码实现的请自行百度或者看源码。
2 |
3 | ## 单CPU上单纯的slab
4 |
5 | 下图给出了单CPU上slab在分配和释放对象时的情景序列:
6 |
7 | 
8 |
9 | 可以看出,非常之简单,而且完全达到了slab设计之初的目标。
10 |
11 | ## 扩展到多核心CPU
12 |
13 | 现在我们简单的将上面的模型扩展到多核心CPU,同样差不多的分配序列如下图所示:
14 |
15 | 
16 |
17 | 我们看到,在只有单一slab的时候,如果多个CPU同时分配对象,冲突是不可避免的,解决冲突的几乎是唯一的办法就是加锁排队,然而这将大大增加延迟,我们看到,申请单一对象的整个时延从T0开始,到T4结束,这太久了。
18 |
19 | 多CPU无锁化并行化操作的直接思路-复制给每个CPU一套相同的数据结构。
20 |
21 | 不二法门就是增加“每CPU变量”。对于slab而言,可以扩展成下面的样子:
22 |
23 | 
24 |
25 | 如果以为这么简单就结束了,那这就太没有意义了。
26 |
27 | ## 问题
28 |
29 | 首先,我们来看一个简单的问题,如果单独的某个CPU的slab缓存没有对象可分配了,但是其它CPU的slab缓存仍有大量空闲对象的情况,如下图所示:
30 |
31 | 
32 |
33 | 这 是可能的,因为对单独一种slab的需求是和该CPU上执行的进程/线程紧密相关的,比如如果CPU0只处理网络,那么它就会对skb等数据结构有大量的 需求,对于上图最后引出的问题,如果我们选择从伙伴系统中分配一个新的page(或者pages,取决于对象大小以及slab cache的order),那么久而久之就会造成slab在CPU间分布的不均衡,更可能会因此吃掉大量的物理内存,这都是不希望看到的。
34 |
35 | 在继续之前,首先要明确的是,我们需要在CPU间均衡slab,并且这些必须靠slab内部的机制自行完成,这个和进程在CPU间负载均衡是完全不同的, 对进程而言,拥有一个核心调度机制,比如基于时间片,或者虚拟时钟的步进速率等,但是对于slab,完全取决于使用者自身,只要对象仍然在使用,就不能剥 夺使用者继续使用的权利,除非使用者自己释放。因此slab的负载均衡必须设计成合作型的,而不是抢占式的。
36 |
37 | 好了。现在我们知道,从伙伴系统重新分配一个page(s)并不是一个好主意,它应该是最终的决定,在执行它之前,首先要试一下别的路线。
38 |
39 | 现在,我们引出第二个问题,如下图所示:
40 |
41 | 
42 |
43 | 谁也不能保证分配slab对象的CPU和释放slab对象的CPU是同一个CPU,谁也不能保证一个CPU在一个slab对象的生命周期内没有分配新的 page(s),这期间的复杂操作谁也没有规定。这些问题该怎么解决呢?事实上,理解了这些问题是怎么解决的,一个slab框架就彻底理解了。
44 |
45 | ## 问题的解决-分层slab cache
46 |
47 | 无级变速总是让人向往。
48 |
49 | 如果一个CPU的slab缓存满了,直接去抢同级别的别的CPU的slab缓存被认为是一种鲁莽且不道义的做法。那么为何不设置另外一个slab缓存,获 取它里面的对象不像直接获取CPU的slab缓存那么简单且直接,但是难度却又不大,只是稍微增加一点消耗,这不是很好吗?事实上,CPU的 L1,L2,L3 cache不就是这个方案设计的吗?这事实上已经成为cache设计的不二法门。这个设计思想同样作用于slab,就是Linux内核的slub实现。
50 | 现在可以给出概念和解释了。
51 |
52 | * Linux kernel slab cache:一个分为3层的对象cache模型。
53 | * Level 1 slab cache:一个空闲对象链表,每个CPU一个的独享cache,分配释放对象无需加锁。
54 | * Level 2 slab cache:一个空闲对象链表,每个CPU一个的共享page(s) cache,分配释放对象时仅需要锁住该page(s),与Level 1 slab cache互斥,不互相包容。
55 | * Level 3 slab cache:一个page(s)链表,每个NUMA NODE的所有CPU共享的cache,单位为page(s),获取后被提升到对应CPU的Level 1 slab cache,同时该page(s)作为Level 2的共享page(s)存在。
56 | * 共享page(s):该page(s)被一个或者多个CPU占 有,每一个CPU在该page(s)上都可以拥有互相不充图的空闲对象链表,该page(s)拥有一个唯一的Level 2 slab cache空闲链表,该链表与上述一个或多个Level 1 slab cache空闲链表亦不冲突,多个CPU获取该Level 2 slab cache时必须争抢,获取后可以将该链表提升成自己的Level 1 slab cache。
57 |
58 | 该slab cache的图示如下:
59 |
60 | 
61 |
62 | 其行为如下图所示:
63 |
64 | 
65 |
66 | ## 2个场景
67 |
68 | 对于常规的对象分配过程,下图展示了其细节:
69 |
70 | 
71 |
72 | 事实上,对于多个CPU共享一个page(s)的情况,还可以有另一种玩法,如下图所示:
73 |
74 | 
75 |
76 | ## 伙伴系统
77 |
78 | 前面我们简短的体会了Linux内核的slab设计,不宜过长,太长了不易理解.但是最后,如果Level 3也没有获取page(s),那么最终会落到终极的伙伴系统。
79 |
80 | 伙伴系统是为了防内存分配碎片化的,所以它尽可能地做两件事:
81 |
82 | **1).尽量分配尽可能大的内存**
83 | **2).尽量合并连续的小块内存成一块大内存**
84 |
85 | 我们可以通过下面的图解来理解上面的原则:
86 |
87 | 
88 |
89 | 注意,本文是关于优化的,不是伙伴系统的科普,所以我假设大家已经理解了伙伴系统。
90 |
91 | 鉴于slab缓存对象大多数都是不超过1个页面的小结构(不仅仅slab系统,超过1个页面的内存需求相比1个页面的内存需求,很少),因此会有大量的针 对1个页面的内存分配需求。从伙伴系统的分配原理可知,如果持续大量分配单一页面,会有大量的order大于0的页面分裂成单一页面,在单核心CPU上, 这不是问题,但是在多核心CPU上,由于每一个CPU都会进行此类分配,而伙伴系统的分裂,合并操作会涉及大量的链表操作,这个锁开销是巨大的,因此需要 优化!
92 |
93 | Linux内核对伙伴系统针对单一页面的分配需求采取的批量分配“每CPU单一页面缓存”的方式!
94 |
95 | 每一个CPU拥有一个单一页面缓存池,需要单一页面的时候,可以无需加锁从当前CPU对应的页面池中获取页面。而当池中页面不足时,系统会批量从伙伴系统中拉取一堆页面到池中,反过来,在单一页面释放的时候,会择优将其释放到每CPU的单一页面缓存中。
96 |
97 | 为了维持“每CPU单一页面缓存”中页面的数量不会太多或太少(太多会影响伙伴系统,太少会影响CPU的需求),系统保持了两个值,当缓存页面数量低于 low值的时候,便从伙伴系统中批量获取页面到池中,而当缓存页面数量大于high的时候,便会释放一些页面到伙伴系统中。
98 |
99 | ## 小结
100 |
101 | 多 CPU操作系统内核中,关键的开销就是锁的开销。我认为这是一开始的设计导致的,因为一开始,多核CPU并没有出现,单核CPU上的共享保护几乎都是可以 用“禁中断”,“禁抢占”来简单实现的,到了多核时代,操作系统同样简单平移到了新的平台,因此同步操作是在单核的基础上后来添加的。简单来讲,目前的主 流操作系统都是在单核年代创造出来的,因此它们都是顺应单核环境的,对于多核环境,可能它们一开始的设计就有问题。
102 |
103 | 不管怎么说,优化操作的不二法门就是禁止或者尽量减少锁的操作。随之而来的思路就是为共享的关键数据结构创建"每CPU的缓存“,而这类缓存分为两种类型:
104 |
105 | 1).数据通路缓存。
106 | 比如路由表之类的数据结构,你可以用RCU锁来保护,当然如果为每一个CPU都创建一个本地路由表缓存,也是不错的,现在的问题是何时更新它们,因为所有的缓存都是平级的,因此一种批量同步的机制是必须的。
107 | 2).管理机制缓存。
108 | 比 如slab对象缓存这类,其生命周期完全取决于使用者,因此不存在同步问题,然而却存在管理问题。采用分级cache的思想是好的,这个非常类似于CPU 的L1/L2/L3缓存,采用这种平滑的开销逐渐增大,容量逐渐增大的机制,并配合以设计良好的换入/换出等算法,效果是非常明显的。
109 |
--------------------------------------------------------------------------------
/✍ 文章/尽情阅读,技术进阶,详解mmap原理.md:
--------------------------------------------------------------------------------
1 | ## 1. 一句话概括mmap
2 |
3 | mmap的作用,在应用这一层,是让你把文件的某一段,当作内存一样来访问。将文件映射到物理内存,将进程虚拟空间映射到那块内存。
4 |
5 | 这样,进程不仅能像访问内存一样读写文件,多个进程映射同一文件,还能保证虚拟空间映射到同一块物理内存,达到内存共享的作用。
6 |
7 | ## 2. 虚拟内存?虚拟空间?
8 |
9 | 其实是一个概念,前一篇对于这个词没有确切的定义,现在定义一下:
10 |
11 | 虚拟空间就是进程看到的所有地址组成的空间,虚拟空间是某个进程对分配给它的所有物理地址(已经分配的和将会分配的)的重新映射。
12 |
13 | 而虚拟内存,为啥叫虚拟内存,是因为它就不是真正的内存,是假的,因为它是由地址组成的空间,所以在这里,使用虚拟空间这个词更加确切和易懂。(不过虚拟内存这个词也不算错)
14 |
15 | ### 2.1 虚拟空间原理
16 |
17 | #### 2.1.1物理内存
18 |
19 | 首先,物理地址实际上也不是连续的,通常是包含作为主存的DRAM和IO寄存器
20 |
21 | 
22 |
23 | 以前的CPU(如X86)是为IO划分单独的地址空间,所以不能用直接访问内存的方式(如指针)IO,只能用专门的方法(in/read/out/write)诸如此类。
24 |
25 | 现在的CPU利用PCI总线将IO寄存器映射到物理内存,所以出现了基于内存访问的IO。
26 |
27 | 还有一点补充的,就如同进程空间有一块内核空间一样,物理内存也会有极小一部分是不能访问的,为内核所用。
28 |
29 | ### 2.1.2三个总线
30 |
31 | 这里再补充下三个总线的知识,即:地址总线、数据总线、控制总线
32 | * 地址总线,用来传输地址
33 | * 数据总线,用来传输数据
34 | * 控制总线,用来传输命令
35 |
36 | 比如CPU通过控制总线发送读取命令,同时用地址总线发送要读取的数据虚地址,经过MMU后到内存
37 |
38 | 内存通过数据总线将数据传输给CPU。
39 |
40 | 虚拟地址的空间和指令集的地址长度有关,不一定和物理地址长度一致,比如现在的64位处理器,从VA角度看来,可以访问64位的地址,但地址总线长度只有48位,所以你可以访问一个位于2^52这个位置的地址。
41 |
42 | #### 2.1.3虚拟内存地址转换(虚地址转实地址)
43 |
44 | 上面已经明确了虚拟内存是虚拟空间,即地址的集合这一概念。基于此,来说说原理。
45 |
46 | 如果还记得操作系统课程里面提到的虚地址,那么这个虚地址就是虚拟空间的地址了,虚地址通过转换得到实地址,转换方式课程内也讲得很清楚,虚地址头部包含了页号(段地址和段大小,看存储模式:页存储、段存储,段页式),剩下部分是偏移量,经过MMU转换成实地址。
47 |
48 | 
49 |
50 | 存储方式
51 |
52 | 
53 |
54 | 如图则是页式存储动态地址变换的方式
55 |
56 | 虚拟地址头部为页号通过查询页表得到物理页号,假设一页时1K,那么页号*偏移量就得到物理地址
57 |
58 | 
59 |
60 | 如图所示,段式存储
61 |
62 | 虚拟地址头部为段号,段表中找到段基地址加上偏移量得到实地址
63 |
64 | 
65 |
66 | 段页式结合两者,如图所示。
67 |
68 | ## 3. mmap映射
69 |
70 | 至此,如果对虚拟空间已经了解了,那么接下来,作为coder,应该自动把虚拟空间无视掉,因为Linux的目的也是要让更多额进程能享用内存,又不让进程做麻烦的事情,是将虚拟空间和MMU都透明化,让进程(和coder)只需要管对内存怎样使用。
71 |
72 | 所以现在开始不再强调虚拟空间了。
73 |
74 | mmap就是将文件映射到内存上,进程直接对内存进行读写,然后就会反映到磁盘上。
75 |
76 | 
77 |
78 | * 虚拟空间获取到一段连续的地址
79 | * 在没有读写的时候,这个地址指向不存在的地方(所以,上图中起始地址和终止地址是还没分配给进程的)
80 | * 好了,根据偏移量,进程要读文件数据了,数据占在两个页当中(物理内存着色部分)
81 | * 这时,进程开始使用内存了,所以OS给这两个页分配了内存(即缺页异常)(其余部分还是没有分配)
82 | * 然后刚分配的页内是空的,所以再将相同偏移量的文件数据拷贝到物理内存对应页上。
83 |
--------------------------------------------------------------------------------
/✍ 文章/常用寄存器总结.md:
--------------------------------------------------------------------------------
1 | 80386寄存器共有34个寄存器,可分为7类,它们是通用寄存器,指令指针和标志寄存器,段寄存器,系统地址寄存器,控制寄存器、调试和测试寄存器。我们经常碰到的是前四类寄存器,也是我这篇文章总结的重点。
2 |
3 | ## 通用寄存器
4 |
5 | [](https://jacktang816.github.io/img/unix/register/register80386.gif)
6 |
7 | 80386寄存器有8个32位通用寄存器这8个通用寄存器都是由8088/8086/80286的相应的16位通用寄存器扩展成32位而得。名字分别是:EAX,EBX,ECX,EDX,ESI,EDI,EBP,ESP。**每个32位的通用寄存器的低16位可以单独使用**,对应于8088/8086/80286的相应16位通用寄存器作用相同。同时,EAX,EBX,ECX,EDX四个寄存器的低16位AX,BX,CX,DX还可以继续分为各高8位,低8位寄存器单独使用,例如AX可以分为AH和AL,每个都是8位寄存器。
8 |
9 | 这8个为通用寄存器,说明它们的用处不止一个。它们通常**既可以保存逻辑和算术运算中的那个操作数,也可以保存地址运算中的操作数。**
10 |
11 | 下面说介绍一下在c程序和系统调用时,这些寄存器的用法:
12 |
13 | ```c
14 | #include
15 | int sum(int x, int y)
16 | {
17 | int accum = 0;
18 | int t;
19 | t = x + y;
20 | accum += t;
21 | return accum;
22 | }
23 |
24 | int main( int argc, char **argv)
25 | {
26 | int x = 1, y = 2;
27 | int result = sum( x, y );
28 | printf("\nresult = %d\n", result);
29 | return 0;
30 | }
31 | ```
32 |
33 | 在函数调用和系统调用时,需要先将参数压入栈,然后被调用函数再从相应的寄存器获取参数值,存储在被调用函数的栈中,所以被调用函数对参数做出的改变并不会修改主函数的数值,因为他们在不同的栈中。函数的参数存入栈的顺序是从右到左,如果是调用函数sum(x,y),则是先将y压入栈,然后再将x压入栈。
34 |
35 | 对于寄存器而言,**c程序和系统调用的参数则必须按顺序放到寄存器 ebx,ecx,edx,esi,edi 中,而函数调用的参数操作是从右到左,所以最后一个参数放入esi,倒数第二个参数存入edi等以此类推。**对于上述的例子main函数调用sum(x,y),main函数将y存入esi,x存入edi。然后sum函数内部从esi和edi获取参数值。
36 |
37 | **而eax在函数调用中,经常用来存储函数的返回值**。上述例子中,sum函数将值存入eax寄存器中,main函数再从eax寄存器获取返回值。对于fork函数返回两个值,也可以通过eax来理解,当内核调度父进程时,键pid存入eax寄存器,当内核调度子进程时,将0存入eax寄存器。
38 |
39 | esp寄存器为栈顶寄存器,并且始终指向栈顶。
40 |
41 | ebp寄存器为**基址寄存器**,其实就是每个函数栈的栈底寄存器,通过这个基址寄存器,再加上偏移量,即可获取参数以及局部变量的值。
42 |
43 | ## 指令指针寄存器和标志寄存器
44 |
45 | **EIP为指令指针寄存器**,是32位寄存器,低16位称为IP,用于兼容16为CPU,其内容是下一条要取入CPU的指令在内存中的偏移地址。当程序刚运行时,系统把EIP清零,每取入一条指令,EIP自动增加相应的字节数,指向下一条指令。
46 |
47 | [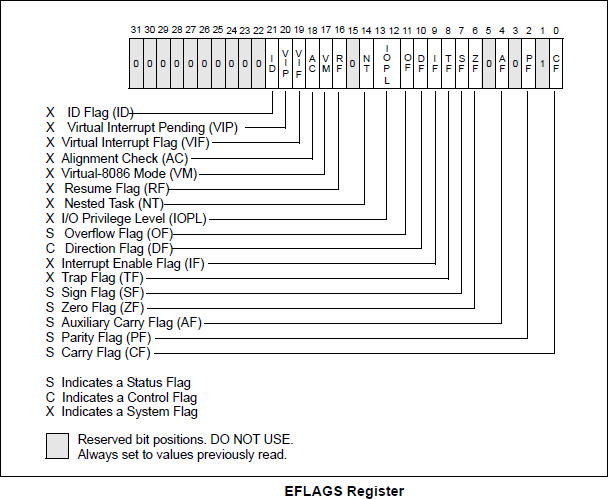](https://jacktang816.github.io/img/unix/register/EFLAGS.png)
48 |
49 | **EFLAGS也是为标志寄存器**,低16位称为FLAGS,与16位CPU的标志寄存器同名,同作用。可分为3类:状态标志,控制标志和系统标志,简述如下:
50 |
51 | AF——辅助进位标志。若该位置位时,表示最低有效的4位向高位产生了进位或借位,则该标志位主要用于BCD算术运算。
52 |
53 | CF——进位标志。当该位置位,表示8位或16位或32位数的算术操作产生了进位或借位。进行多字节数的加、减时要使用该标志。循环移位指令也影响进位标志。
54 |
55 | PF——奇偶标志。主要用于数据通讯应用程序中,当该位置位时,表示结果数据位中有偶数个1,可以检查数据传送中是否出现错误。
56 |
57 | SF——符号标志。该位置位时表示结果的最高位(符号位)为1。对于带符号数,该位为1表示负数,该位为0表示正数。
58 |
59 | ZF——零标志。当该位置位时,表示操作的结果为0。
60 |
61 | DF——方向标志。用于控制数据串操作指令中的地址变化方向。DF为0时,SI/DI或ESI/EDI为自动增量,地址从低向高变化,DF为1,SI/DI或ESI/EDI为自动减量,地址从高向低变化。
62 |
63 | IF——中断允许标志。该位置1时允许响应外部可屏蔽中断(INTR),该位复位时禁止响应外部可屏蔽中断。IF不影响非屏蔽外部中断(NMI)或内部产生的中断。
64 |
65 | OF——溢出标志。若该位置位表示此次运算发生了溢出,即作为带符号数运算,其结果值超出目的单位所能表示的数值范围。这时目的单位的内容对带符号数没有意义。
66 |
67 | TF——陷阱标志。当该位置位时,把处理器置成供调试的单步方式。在这种方式中,每条指令执行后CPU自动产生一个内部中断,使调试者可以观察程序中该条指令执行的情况。
68 |
69 | NT——嵌套任务标志。用来表示当前的任务是否嵌套在另一任务内,当该位置1时,表示当前的任务有一个有效的链连接到前一个任务(被嵌套),如果执行IRET指令,则转换到前一个任务。
70 |
71 | IOPL——输入/输出特权级标志,用于定义允许执行输入/输出指令的I/O特权级的数值。
72 |
73 | RF——恢复标志。它是与调试寄存器的断点一起使用的标志,当该位置1时,即使遇到断点或调试故障,也不产生异常中断1。在成功地执行每条指令时,RF将自动复位。
74 |
75 | VM——虚拟8086方式标志。当该位置位时,CPU工作在虚拟8086模式(简称为拟86模式),在这种模式下运行8086的程序就好象是在8086CPU上运行一样。
76 |
77 | AC——对准检查标志。这是80486新定义的标志位。该位置位时,如果进行未对准的地址访问,则产生异常中断17。所谓未对准的地址访问,是指访问字数据时为奇地址,访问双字数据时不是4的倍数地址,访问8字节数据时,不是8的倍数的地址。对准检查在特权级为0,1,2时无效,只有在特权级3时有效。
78 |
79 | s—状态标志;c—控制标志;x—系统标
80 |
81 | ## 段寄存器
82 |
83 | 可能在刚接触汇编时,会觉得段寄存器存储的就是程序每个段的基地址,在了解了linux虚拟地址转为物理地址之后,我才知道原来**段描述符存储的并不是段基地址,而是存储了在段描述符表的索引以及一些属性。**
84 |
85 | **80386有6个段寄存器,分别是CS,DS,SS,ES,FS和GS,是16位寄存器**。前4个段寄存器的名称与8088/8086相同,在实地址方式下使用方式也和8088/8086相同。80386又增加了FS与GS,主要为了减轻对DS段和ES段的压力。
86 |
87 | 这些16位段寄存器存放的并不是段基地址,而是存储了在段描述符表的索引,D3-D15位是索引值,D0-D1位是优先级(RPL)用于特权检查,D2位是描述符表引用指示位TI,TI=0指示从全局描述表GDT中读取描述符,TI=1指示从局部描述符中LDT中读取描述符。这些信息总称段选择器(段选择子).
88 |
89 | ## 系统地址寄存器
90 |
91 | 这些寄存器是我写这篇文章最主要的原因,因为这些寄存器在汇编代码中很少见,而在理解地址转换又是那么重要。
92 |
93 | **系统地址寄存器有四个,用来存储操作系统需要的保护信息和地址转换表信息、定义目前正在执行任务的环境、地址空间和中断向量空间。**
94 |
95 | - GDTR 48位全局描述符表寄存器,用于保存全局描述符表的32位基地址和全局描述符表的16位界限(全局描述符表最大为 216216 字节,共216/8=8K216/8=8K个全局描述符)。GDT表里面的每一项都表明一个段的信息,或者是一个LDT表的相关信息。其实一个LDT表也是一个段。所以也可以说GDT表的每一项都描述一个段。就像一个文件夹下面可以有文件,也可以有文件夹一样,GDT表里面既可以有段描述符,也可以有LDT的表。
96 | - IDTR 48位中断描述符表寄存器,用于保存中断描述符表的32位基地址和中断描述符表的16位界限(中断描述符表最大为 216216 字节,共216/8=8K216/8=8K个中断描述符)。
97 | - LDTR 16位局部描述符表寄存器,用于保存局部描述符表的选择符。一旦16位的选择符(也叫选择子)放入LDTR,CPU会自动将选择符所指定的局部描述符装入64位的局部描述符寄存器中。
98 | - TR 16位任务状态段寄存器,用于保存任务状态段(TSS)的16位选择符。与LDTR类似,一旦16位的选择符放入TR,CPU会自动将该选择符所指定的任务描述符装入64位的任务描述符寄存器中。 注:TSS是一个段,所以在GDT中有对应的表项描述。
99 |
100 | 所以LDTR和TR寄存器分别是局部描述符表的选择符和任务状态段选择符,它们需要到GDT表格中找到各自的描述符才能定位到各自的表格,所以可以把这两个寄存器看作是和cs,ds等段寄存器一样,局部描述符表和任务状态段看作是一个段。
101 |
--------------------------------------------------------------------------------
/✍ 文章/浅谈Linux内存管理机制.md:
--------------------------------------------------------------------------------
1 | ## 活学活用
2 |
3 | OOM Killer 在 Linux 系统里如果内存不足时,会杀死一个正在运行的进程来释放一些内存。
4 |
5 | Linux 里的程序都是调用 malloc() 来申请内存,如果内存不足,直接 malloc() 返回失败就可以,为什么还要去杀死正在运行的进程呢?Linux允许进程申请超过实际物理内存上限的内存。因为 malloc() 申请的是内存的虚拟地址,系统只是给了程序一个地址范围,由于没有写入数据,所以程序并没有得到真正的物理内存。物理内存只有程序真的往这个地址写入数据的时候,才会分配给程序。
6 |
7 | 
8 |
9 | ## 内存管理
10 |
11 | 对于内存的访问,用户态的进程使用虚拟地址,内核的也基本都是使用虚拟地址
12 |
13 | ## 物理内存空间布局
14 |
15 | 
16 |
17 | ## 虚拟内存与物理内存的映射
18 |
19 | 
20 |
21 | ## 进程“独占”虚拟内存及虚拟内存划分
22 |
23 | 为了保证操作系统的稳定性和安全性。用户程序不可以直接访问硬件资源,如果用户程序需要访问硬件资源,必须调用操作系统提供的接口,这个调用接口的过程也就是系统调用。每一次系统调用都会存在两个内存空间之间的相互切换,通常的网络传输也是一次系统调用,通过网络传输的数据先是从内核空间接收到远程主机的数据,然后再从内核空间复制到用户空间,供用户程序使用。这种从内核空间到用户空间的数据复制很费时,虽然保住了程序运行的安全性和稳定性,但是牺牲了一部分的效率。
24 |
25 | 如何分配用户空间和内核空间的比例也是一个问题,是更多地分配给用户空间供用户程序使用,还是首先保住内核有足够的空间来运行。在当前的Windows 32位操作系统中,默认用户空间:内核空间的比例是1:1,而在32位Linux系统中的默认比例是3:1(3GB用户空间、1GB内核空间)(这里只是地址空间,映射到物理地址,可没有某个物理地址的内存只能存储内核态数据或用户态数据的说法)。
26 |
27 | 
28 |
29 | 
30 |
31 | 左右两侧均表示虚拟地址空间,左侧以描述内核空间为主,右侧以描述用户空间为主。
32 |
33 | 
34 |
35 | 在内核里面也会有内核的代码,同样有 Text Segment、Data Segment 和 BSS Segment,别忘了内核代码也是 ELF 格式的。
36 |
37 | **在代码上的体现**
38 |
39 | ```c
40 | // 持有task_struct 便可以访问进程在内存中的所有数据
41 | struct task_struct {
42 | ...
43 | struct mm_struct *mm;
44 | struct mm_struct *active_mm;
45 | ...
46 | void *stack; // 指向内核栈的指针
47 | }
48 | ```
49 |
50 | 内核使用内存描述符mm_struct来表示进程的地址空间,该描述符表示着进程所有地址空间的信息
51 |
52 | 
53 |
54 | 在用户态,进程觉着整个空间是它独占的,没有其他进程存在。但是到了内核里面,无论是从哪个进程进来的,看到的都是同一个内核空间,看到的都是同一个进程列表。虽然内核栈是各用个的,但是如果想知道的话,还是能够知道每个进程的内核栈在哪里的。所以,如果要访问一些公共的数据结构,需要进行锁保护。
55 |
56 | 
57 |
58 | ## 地址空间内的栈
59 |
60 | 栈是主要用途就是支持函数调用。
61 |
62 | 大多数的处理器架构,都有实现硬件栈。有专门的栈指针寄存器,以及特定的硬件指令来完成 入栈/出栈 的操作。
63 |
64 | ### 用户栈和内核栈的切换
65 |
66 | 内核在创建进程的时候,在创建task_struct的同时,会为进程创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当进程在用户空间运行时,cpu堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;当进程在内核空间时,cpu堆栈指针寄存器里面的内容是内核栈空间地址,使用内核栈。
67 |
68 | 当进程因为中断或者系统调用而陷入内核态之行时,进程所使用的堆栈也要从用户栈转到内核栈。
69 |
70 | 如何相互切换呢?
71 |
72 | 进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态执行时,在内核态执行的最后,将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
73 |
74 | 那么,我们知道从内核转到用户态时用户栈的地址是在陷入内核的时候保存在内核栈里面的,但是在陷入内核的时候,我们是如何知道内核栈的地址的呢?
75 |
76 | 关键在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为,一旦进程从内核态返回到用户态后,内核栈中保存的信息无效,会全部恢复。因此,每次进程从用户态陷入内核的时候得到的内核栈都是空的,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
77 |
78 | ### 为什么需要单独的进程内核栈?
79 |
80 | 内核地址空间所有进程空闲,但内核栈却不共享。为什么需要单独的进程内核栈?因为同时可能会有多个进程在内核运行。
81 |
82 | 所有进程运行的时候,都可能通过系统调用陷入内核态继续执行。假设第一个进程 A 陷入内核态执行的时候,需要等待读取网卡的数据,主动调用 schedule() 让出 CPU;此时调度器唤醒了另一个进程 B,碰巧进程 B 也需要系统调用进入内核态。那问题就来了,如果内核栈只有一个,那进程 B 进入内核态的时候产生的压栈操作,必然会破坏掉进程 A 已有的内核栈数据;一但进程 A 的内核栈数据被破坏,很可能导致进程 A 的内核态无法正确返回到对应的用户态了。
83 |
84 | 进程内核栈在进程创建的时候,通过 slab 分配器从 thread_info_cache 缓存池中分配出来,其大小为 THREAD_SIZE,一般来说是一个页大小 4K;
85 |
86 | ### 进程切换带来的用户栈切换和内核栈切换
87 |
88 | ```c
89 | // 持有task_struct 便可以访问进程在内存中的所有数据
90 | struct task_struct {
91 | ...
92 | struct mm_struct *mm;
93 | struct mm_struct *active_mm;
94 | ...
95 | void *stack; // 指向内核栈的指针
96 | }
97 | ```
98 |
99 | 从进程 A 切换到进程 B,用户栈要不要切换呢?当然要,在切换内存空间的时候就切换了,每个进程的用户栈都是独立的,都在内存空间里面。
100 |
101 | 那内核栈呢?已经在 __switch_to 里面切换了,也就是将 current_task 指向当前的 task_struct。里面的 void *stack 指针,指向的就是当前的内核栈。
102 |
103 | 内核栈的栈顶指针呢?在 __switch_to_asm 里面已经切换了栈顶指针,并且将栈顶指针在 __switch_to加载到了 TSS 里面。
104 |
105 | 用户栈的栈顶指针呢?如果当前在内核里面的话,它当然是在内核栈顶部的 pt_regs 结构里面呀。当从内核返回用户态运行的时候,pt_regs 里面有所有当时在用户态的时候运行的上下文信息,就可以开始运行了。
106 |
107 | 主线程的用户栈和一般现成的线程栈
108 |
109 | 
110 |
111 | 对应着jvm 一个线程一个栈
112 |
113 | ### 中断栈
114 |
115 | 中断有点类似于我们经常说的事件驱动编程,而这个事件通知机制是怎么实现的呢,硬件中断的实现通过一个导线和 CPU 相连来传输中断信号,软件上会有特定的指令,例如执行系统调用创建线程的指令,而 CPU 每执行完一个指令,就会检查中断寄存器中是否有中断,如果有就取出然后执行该中断对应的处理程序。
116 |
117 | 当系统收到中断事件后,进行中断处理的时候,也需要中断栈来支持函数调用。由于系统中断的时候,系统当然是处于内核态的,所以中断栈是可以和内核栈共享的。但是具体是否共享,这和具体处理架构密切相关。ARM 架构就没有独立的中断栈。
118 |
119 | ## 内存管理的进程和硬件背景
120 |
121 | ### 页表的位置
122 |
123 | 每个进程都有独立的地址空间,为了这个进程独立完成映射,每个进程都有独立的进程页表,这个页表的最顶级的 pgd 存放在 task_struct 中的 mm_struct 的 pgd 变量里面。
124 |
125 | 在一个进程新创建的时候,会调用 fork,对于内存的部分会调用 copy_mm,里面调用 dup_mm。
126 |
127 | ```c
128 | // Allocate a new mm structure and copy contents from the mm structure of the passed in task structure.
129 | static struct mm_struct *dup_mm(struct task_struct *tsk){
130 | struct mm_struct *mm, *oldmm = current->mm;
131 | mm = allocate_mm();
132 | memcpy(mm, oldmm, sizeof(*mm));
133 | if (!mm_init(mm, tsk, mm->user_ns))
134 | goto fail_nomem;
135 | err = dup_mmap(mm, oldmm);
136 | return mm;
137 | }
138 | ```
139 |
140 | 除了创建一个新的 mm_struct,并且通过memcpy将它和父进程的弄成一模一样之外,我们还需要调用 mm_init 进行初始化。接下来,mm_init 调用 mm_alloc_pgd,分配全局页目录项,赋值给mm_struct 的 pdg 成员变量。
141 |
142 | ```c
143 | static inline int mm_alloc_pgd(struct mm_struct *mm){
144 | mm->pgd = pgd_alloc(mm);
145 | return 0;
146 | }
147 | ```
148 |
149 | 一个进程的虚拟地址空间包含用户态和内核态两部分。为了从虚拟地址空间映射到物理页面,页表也分为用户地址空间的页表和内核页表。在内核里面,映射靠内核页表,这里内核页表会拷贝一份到进程的页表
150 |
151 | 如果是用户态进程页表,会有 mm_struct 指向进程顶级目录 pgd,对于内核来讲,也定义了一个 mm_struct,指向 swapper_pg_dir(指向内核最顶级的目录 pgd)。
152 |
153 | ```c
154 | struct mm_struct init_mm = {
155 | .mm_rb = RB_ROOT,
156 | // pgd 页表最顶级目录
157 | .pgd = swapper_pg_dir,
158 | .mm_users = ATOMIC_INIT(2),
159 | .mm_count = ATOMIC_INIT(1),
160 | .mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
161 | .page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
162 | .mmlist = LIST_HEAD_INIT(init_mm.mmlist),
163 | .user_ns = &init_user_ns,
164 | INIT_MM_CONTEXT(init_mm)
165 | };
166 |
167 | ```
168 |
169 | ### 页表的应用
170 |
171 | 一个进程 fork 完毕之后,有了内核页表(内核初始化时即弄好了内核页表, 所有进程共享),有了自己顶级的 pgd,但是对于用户地址空间来讲,还完全没有映射过(用户空间页表一开始是不完整的,只有最顶级目录pgd这个“光杆司令”)。这需要等到这个进程在某个 CPU 上运行,并且对内存访问的那一刻了
172 |
173 | 当这个进程被调度到某个 CPU 上运行的时候,要调用 context_switch 进行上下文切换。对于内存方面的切换会调用 switch_mm_irqs_off,这里面会调用 load_new_mm_cr3。
174 |
175 | cr3 是 CPU 的一个寄存器,它会指向当前进程的顶级 pgd。如果 CPU 的指令要访问进程的虚拟内存,它就会自动从cr3 里面得到 pgd 在物理内存的地址,然后根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据。
176 |
177 | 这里需要注意两点。第一点,cr3 里面存放当前进程的顶级 pgd,这个是硬件的要求。cr3 里面需要存放 pgd 在物理内存的地址,不能是虚拟地址。第二点,用户进程在运行的过程中,访问虚拟内存中的数据,会被 cr3 里面指向的页表转换为物理地址后,才在物理内存中访问数据,这个过程都是在用户态运行的,地址转换的过程无需进入内核态。
178 |
179 | 
180 |
181 | 这就可以解释,为什么页表数据在 task_struct 的mm_struct里却又 可以融入硬件地址翻译机制了。
182 |
183 | ### 通过缺页中断来“填充”页表
184 |
185 | 内存管理并不直接分配物理内存,只有等你真正用的那一刻才会开始分配。只有访问虚拟内存的时候,发现没有映射多物理内存,页表也没有创建过,才触发缺页异常。进入内核调用 do_page_fault,一直调用到 __handle_mm_fault,__handle_mm_fault 调用 pud_alloc 和 pmd_alloc,来创建相应的页目录项,最后调用 handle_pte_fault 来创建页表项。
186 |
187 | ```c
188 | static noinline void
189 | __do_page_fault(struct pt_regs *regs, unsigned long error_code,
190 | unsigned long address){
191 | struct vm_area_struct *vma;
192 | struct task_struct *tsk;
193 | struct mm_struct *mm;
194 | tsk = current;
195 | mm = tsk->mm;
196 | // 判断缺页是否发生在内核
197 | if (unlikely(fault_in_kernel_space(address))) {
198 | if (vmalloc_fault(address) >= 0)
199 | return;
200 | }
201 | ......
202 | // 找到待访问地址所在的区域 vm_area_struct
203 | vma = find_vma(mm, address);
204 | ......
205 | fault = handle_mm_fault(vma, address, flags);
206 | ......
207 |
208 | static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
209 | unsigned int flags){
210 | struct vm_fault vmf = {
211 | .vma = vma,
212 | .address = address & PAGE_MASK,
213 | .flags = flags,
214 | .pgoff = linear_page_index(vma, address),
215 | .gfp_mask = __get_fault_gfp_mask(vma),
216 | };
217 | struct mm_struct *mm = vma->vm_mm;
218 | pgd_t *pgd;
219 | p4d_t *p4d;
220 | int ret;
221 | pgd = pgd_offset(mm, address);
222 | p4d = p4d_alloc(mm, pgd, address);
223 | ......
224 | vmf.pud = pud_alloc(mm, p4d, address);
225 | ......
226 | vmf.pmd = pmd_alloc(mm, vmf.pud, address);
227 | ......
228 | return handle_pte_fault(&vmf);
229 | }
230 | ```
231 |
232 | 以handle_pte_fault 的一种场景 do_anonymous_page为例:先通过 pte_alloc 分配一个页表项,然后通过 alloc_zeroed_user_highpage_movable 分配一个页,接下来要调用 mk_pte,将页表项指向新分配的物理页,set_pte_at 会将页表项塞到页表里面。
233 |
234 | ```c
235 | static int do_anonymous_page(struct vm_fault *vmf){
236 | struct vm_area_struct *vma = vmf->vma;
237 | struct mem_cgroup *memcg;
238 | struct page *page;
239 | int ret = 0;
240 | pte_t entry;
241 | ......
242 | if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
243 | return VM_FAULT_OOM;
244 | ......
245 | page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
246 | ......
247 | entry = mk_pte(page, vma->vm_page_prot);
248 | if (vma->vm_flags & VM_WRITE)
249 | entry = pte_mkwrite(pte_mkdirty(entry));
250 | vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
251 | &vmf->ptl);
252 | ......
253 | set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
254 | ......
255 | }
256 |
257 | ```
258 |
--------------------------------------------------------------------------------
/✍ 文章/深入浅出linux内存管理(一).md:
--------------------------------------------------------------------------------
1 | - 前言
2 | - linux 虚拟内存系统
3 | - 虚拟寻址
4 | - 多级页表
5 | - 内存映射
6 |
7 | ### 前言
8 |
9 | 最近断断续续补充了一些linux内存管理的知识。包括之前看 nginx 源码,看 tcmalloc 原理也有一些心得。对于内存管理这个话题也有了一些浅薄的见解。现在针对 linux 下的内存管理这个话题做一个整理,整合一些目前学到的内存管理相关知识。
10 |
11 | 本文涉及操作系统层面的内存管理原理,同时也包括现在主流的内存管理方式,并结合一些优秀的开源项目来针对不同场景的内存管理去理解。在开始之前,我们需要先提出几个问题,以便更有深度的思考。
12 |
13 | 1. 什么是内存管理? 为什么要进行内存管理?
14 | 2. 当前有哪些主流的内存管理方式?
15 | 3. 不同场景下应该如何做好内存管理 ?
16 | 4. 如何衡量内存管理的效率?
17 |
18 | 现在,先回到初学者的状态,带着以上的问题一步步去解决这些疑问。
19 |
20 | ### linux 虚拟内存系统
21 |
22 | #### 虚拟寻址
23 |
24 | 说到 linux 内存管理,必然要谈一谈 linux 的虚拟内存系统。我们先从操作系统最底层的内存组织原理开始,一步一步往应用层去理解。
25 |
26 | 首先,大家都是知道,整个计算机最基本的体系结构就是 CPU+内存。CPU负责计算,内存负责存储临时的计算数据。当然实际模型比这个要复杂的多。那么现在就涉及一个寻址的问题,也就是CPU需要获取内存的数据,如何进行内存寻址?
27 |
28 | 假设我们的内存被组织成一个字节数组,每个字节都有唯一的物理地址,按照这种方式,CPU访问内存最简单的就是使用物理寻址。
29 |
30 | 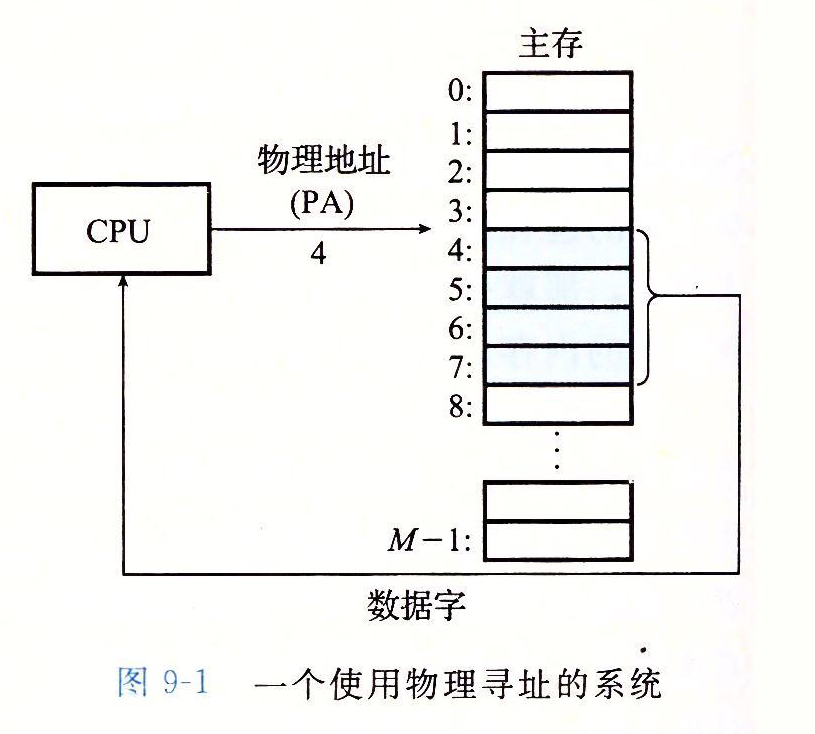
31 |
32 | 物理寻址有很多问题,一个是进程之间不隔离的问题,如果多个进程同时运行,怎么能保证进程A不越权访问进程B的内存呢?一个是内存划分的问题,没有一种有效的方式可以最大效率的满足的各个进程对内存的使用。当然物理寻址方式更加简单粗暴,现在一些嵌入式系统也采用物理寻址方式。这不是我们当前讨论范围,因为现代操作系统基本都采用另一种寻址方式——虚拟寻址。
33 |
34 | 由虚拟寻址又引申出另一个概念——虚拟内存空间。
35 |
36 | 由虚拟地址组织起来的虚拟内存是一个抽象概念,它使得每个进程都独占的使用整个主存。每个进程看到的内存都是一致的,这个进程的内存空间叫做虚拟地址空间。
37 |
38 | 这样说可能很不好理解。我们举个例子。
39 |
40 | 首先从CPU到磁盘有多级缓存,从上至下分别是寄存器,L1/L2/L3(SRAM) 高速缓存,DRAM,磁盘。
41 |
42 | 
43 |
44 | DRAM 呢就是我们最熟悉的内存。比如一台笔记本内存是16GB,DRAM就是16GB。这16GB是实实在在的物理内存大小。但是对于每个进程就不一样了。每个进程都有一个虚拟内存空间,这个虚拟内存空间的大小是多少呢? 对于32 位操作系统,是4GB。
45 |
46 | 为什么是4GB呢?
47 |
48 | 这个大小其实是机器的字长决定的。因为CPU和内存之间传送数据是通过系统总线实现的,系统总线每次传输单元是一个字。在32位系统上,1个字=32位=4个字节。1个字可以表示的最大范围是 0~2^32,我们用16进制来表示地址的话,1个字可以表示的最大地址就是 0xFFFFFFFF,也就是虚拟内存空间的寻址范围是 0~0xFFFFFFFF,也就是4GB。
49 |
50 | 那么对于一个32位操作系统,16G内存的计算机来说,每个进程的虚拟内存空间都是4GB大小,这些进程共同使用DRAM=16G的物理内存。当然对于64位操作系统,进程的虚拟内存空间就远远不止4GB了,而是 2^64 = 128TB 大小。这个暂时不予讨论,我们只关注32位系统下的。
51 |
52 | 现在既然每个进程都有4GB的虚拟空间,而实际的物理内存又只有16G,那就要考虑如何将这些进程的虚拟内存映射到物理内存上。
53 |
54 | 上文提到的虚拟寻址就是如何根据一个虚拟空间的地址,获取到实际的物理内存地址。
55 |
56 | 负责虚拟地址到物理地址的转换的是一个叫做MMU( memory manage unit , 虚拟内存管理单元) 的硬件。
57 |
58 | 每当CPU需要访问物理内存时,都会产生一个虚拟地址,这个虚拟地址被 MMU 翻译成物理内存地址。为了方便地址的管理和调用,linux 将内存分成页,一页的大小是4KB,不管是虚拟内存还是物理内存,管理和调度的单元都是以页为单位进行的,每一页已分配的虚拟内存都对应着一页物理内存。此时虚拟内存空间的页,我们叫做虚拟页 VP(Vistural Page), 物理内存的页叫做物理页 PP(Physical Page),物理页又叫页帧。
59 |
60 | MMU 并不存储这个映射关系,这个映射关系存储在一个叫做页表(Page Table)的地方, 页表是一个结构为PTE(Page Table Entry) 的数组。每一个PTE都存储了一个虚拟页到物理页的映射。
61 |
62 | 接下来我们需要知道 PTE 的内容。根据虚拟页是否分配了物理页和是否缓存的角度来区分虚拟内存页的话,分为3种虚拟内存页:
63 |
64 | 1. 未分配物理页
65 | 2. 已分配物理页,且已缓存。
66 |
67 | 1. 已分配物理页,但未缓存。
68 | 为了区分上述3种情况,在一个PTE中有一个有效标志位和一个指向物理内存的地址。其中有效标志位,用于表明是否缓存在DRAM中。
69 | 如果地址为空,表示没有为虚拟页分配对应的物理页。
70 | 如果有效位为1,则表示物理内存页已分配且已缓存,此时地址指向DRAM中物理内存页的地址。
71 | 如果有效位为0,则表示物理内存页已分配但缓存未命中。
72 | 
73 |
74 | 如图所示是8个虚拟页和4个物理页。其中4个虚拟页VP1,VP2,VP7,VP4都被缓存在DRAM中,其地址都不为空,且有效位为1。VP0和VP5 的地址是空的,表示还没有分配,VP3,VP6虽然分配了地址,但是有效位为0,表示没有被缓存。
75 |
76 | 上述页表一般是缓存在L1 cache 中的,而MMU到 L1 cache 所需的指令周期也很长,所以MMU自己也做了一个小缓存,叫做翻译后备缓冲器TLB((translation Lookaside buffer)。当MMU需要将虚拟内存地址转换为DRAM中的内存地址时,此时先查TLB,如果缓存命中直接就得到了DRAM中的地址,否则就需要到页表中去查。
77 |
78 | 查询页表,找到当前虚拟页对应的PTE,然后根据PTE的有效标志位判断DRAM中是否有缓存,
79 |
80 | 如果有缓存则直接根据地址去DRAM中获取数据。如果DRAM缓存不命中,此时将触发一个缺页异常。
81 |
82 | 缺页异常将程序的控制权转移给一个缺页异常程序,缺页异常程序从DRAM中选择一个牺牲页(如果牺牲页被修改过,会将牺牲页回写入磁盘),同时将所需页面从磁盘复制到DRAM中,替换掉牺牲页。
83 |
84 | 当然上述换页之后,PTE中的有效标志位也会随之更新。
85 |
86 | 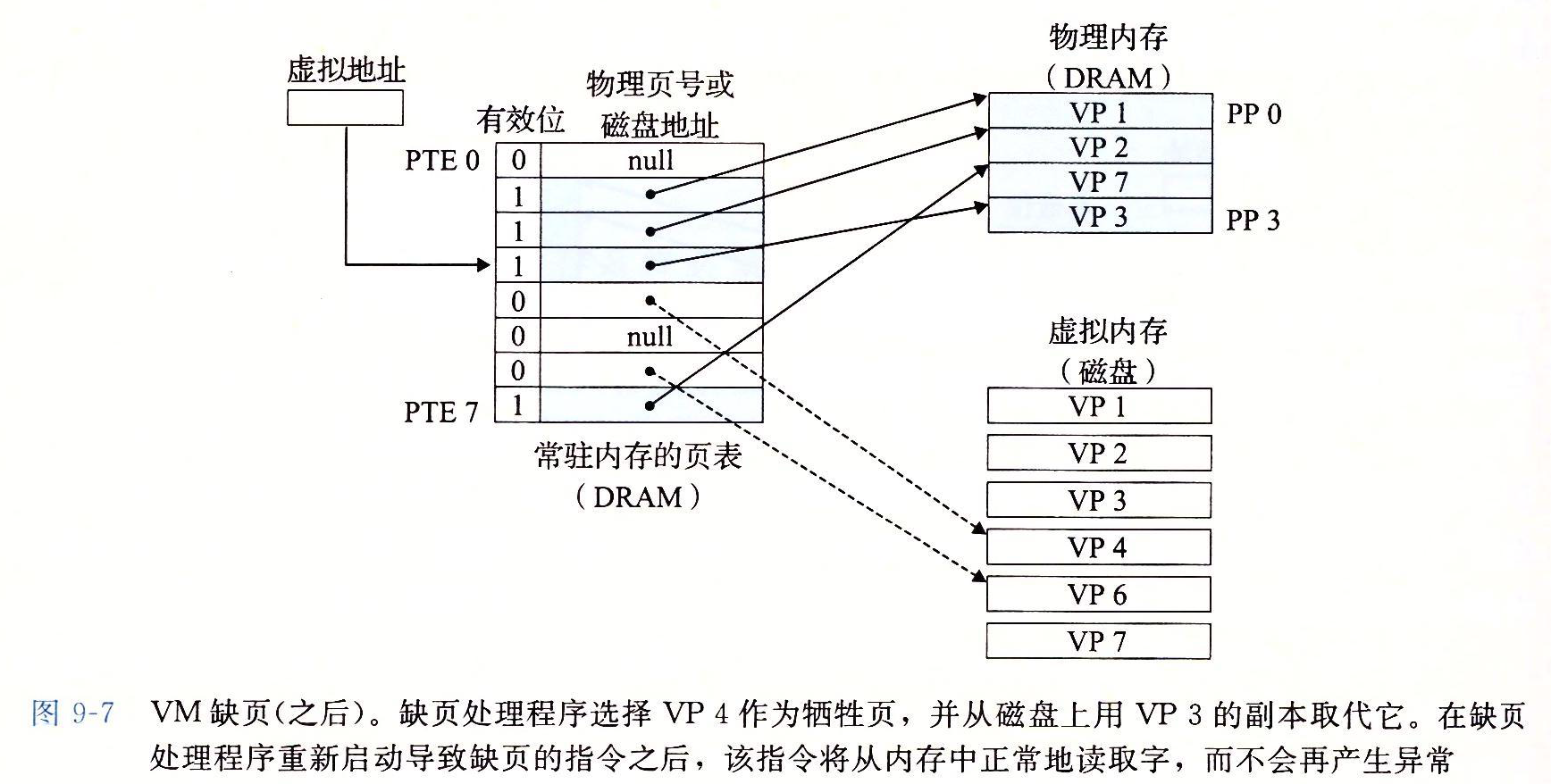
87 |
88 | 这种设计方式会导致程序的性能降低吗?可能会有人疑问,每个进程都拥有4GB的虚拟内存,但是实际的物理内存却只有16GB,也就是 DRAM中缓存的物理页是远远小于进程中使用的虚拟页的,会不会频繁的出现缺页异常。实际上,由于程序的局部性原理,进程总是趋向于在一个较小的活动页面集合上工作,这个工作集合或者说常驻集合,在第一次访问的时候被 cache 到 DRAM 中之后,后续都会命中缓存。只有当的这个常驻集合大于物理内存的时候,才会产生不断的换页,此时就是内存不够用了。需要优化程序的性能。
89 |
90 | 接下来我们继续讨论 PTE,实际上PTE不仅仅只有一个有效标志位。还记得之前程序隔离的问题吗?如何保证进程A不会访问进程B的虚拟页,如何保证用户态不会访问内核态的虚拟页?答案还是在 PTE里。
91 |
92 | 
93 |
94 | 比如上图中PTE添加了3个许可位。SUP表示进程是否必须运行在内核模式才能访问该页。SUP为1 的页在用户态是无法访问的。同时还有读权限和写权限。当某个指令进行越权访问时,CPU就会触发一个段错误。
95 |
96 | 一般来说,PTE可以实现以下的功能:
97 |
98 | 1. 每个进程的代码段所在页是不可修改的
99 | 2. 内核的代码和数据结构所在页也是不可修改的
100 |
101 | 1. 进程不能读写其他进程的私有内存页
102 | 2. 进程间通信可以通过设置进程间共享页来实现。即允许多个进程对某一页进行读写。
103 |
104 | #### 多级页表
105 |
106 | 说完了PTE,接下来再看看页表。我们先算一算对于32位系统,页表有多大,一页4KB,虚拟内存空间是4GB,也就是有4GB/4KB = 10^6 个页,假设一个 PTE 大小是4个字节,页表的大小也达到了 4GB/4KB* 4Byte = 4MB。由于页表是缓存在 L1 里的。4MB可不是个小数目。
107 |
108 | 更麻烦的是,如果是64 位系统,虚拟内存空间是128 TB 。页表的大小将指数增长。
109 |
110 | 页表多了也会非常浪费资源,而实际上一个进程虽然有4GB的虚拟内存空间,但大部分进程都不会用满4GB,这就导致很多页表项都是空的。为了压缩页表,就需要使用多级页表,将页按层次的组织。
111 |
112 | 以2级页表为例,2级页表每1024页为一个单位,由最上层的1级页表索引,1级页表的每个PTE将不再代表1页,而是1024页,也就是4MB。
113 |
114 | 如果1级页表的PTE为空,表示接下来的4MB内存都是空的,只有PTE中任意一页不为空的时候,才会指向2级页表。
115 |
116 |
117 |
118 | 这种组织方式就类似一颗树或一个跳表结构一样,基于底层的4KB页建立多级索引。
119 |
120 | #### 内存映射
121 |
122 | 讲完了虚拟寻址的过程,接下来我们需要了解进程是如何和虚拟内存空间相关联的。当然,原理上是通过页的方式,但是我们需要更进一步的了解这个关联过程。
123 |
124 | 首先祭出一张大家都非常熟悉的图,就是32位系统下的进程空间分布。
125 |
126 | 
127 |
128 | 最上面的1GB是内核内存空间,用户态无法访问。
129 |
130 | 内核空间向下随机偏移一个值就是栈空间的起始地址。栈是向下生长的,栈空间最大是8M。
131 |
132 | 然后再偏移一个随机值,就是共享内存映射区域的起始地址。同时堆空间向上增长,与共享内存区域相对增长直到耗尽所有可用的区域。
133 |
134 | 随机偏移是为了防止缓冲区溢出的攻击,毕竟如果每次栈和堆和 mmap 的起始地址都固定的话,非常容易受到攻击。
135 |
136 | 接着在代码层面,linux 为每个进程都对应了一个结构体 task_struct。
137 |
138 | 
139 |
140 | 可以看到 mmp 指向一个 vm_area_struct 的链表,每个 vm_area_struct 都描述了进程空间中的一个区域。一个具体的区域包括以下字段:
141 |
142 | - vm_start :起始地址。
143 | - vm_end : 结束地址。
144 |
145 | - vm_prot : 该区域所在页的读写权限。
146 | - vm_flags : 是共享的还是私有的。
147 |
148 | - vm_next : 下一个区域结构。
149 |
150 | 有了区域的概念,我们再仔细回顾一下缺页异常的处理:
151 |
152 | 当 MMU 试图寻址一个虚拟地址A时,发现不在 DRAM中,于是触发一个缺页异常。接着缺页异常处理程序将执行以下步骤:
153 |
154 | 1. A 是否合法?也就是在不在已有的区域内?此时处理程序需要遍历整个区域链表,看 A 是不是在 vm_start ~ vm_end 中。如果 A 不合法,此时就会触发一个段错误(Segment Fault)。进程退出。当然实际linux为了提高查找效率额外用一颗树来组织这些区域。这点暂时不表。
155 | 2. 当A 的地址合法之后,接下来判断访问是否合法,也就是是否有读写的权限?有些区域只有只读权限,有些区域只能由内核访问,任何越权访问的行为会触发一个保护异常。进程终止。
156 |
157 | 1. 当地址合法,访问也合法之后,就会向之前提到的那样,从 DRAM 中找一个牺牲页,然后淘汰,换上新的页。
158 |
159 | 以下就是整个缺页异常的处理过程。
160 |
161 | 
162 |
163 | 有了区域的概念,现在再说下内存映射。内存映射指的是 linux 可以将进程中的区域和一个磁盘对象关联起来,来初始化这个区域的内容。
164 |
165 | 这个关联的对象分为2种:
166 |
167 | 1. linux 系统中普通文件。
168 | 2. 匿名文件。这种情况也叫请求二进制0的页。
169 |
170 | 当程序启动,可执行文件被加载到内存中,就是第一种情况,而我们在堆上或共享内存区域去申请一块可用内存,就属于第二种情况。
171 |
172 | 根据映射对象的访问性质呢,又可以分为2种类型——私有对象和共享对象。
173 |
174 | 比如很多进程会共享相同的内核代码,这一部分公共代码映射的就是共享对象。
175 |
176 | 内存映射有以下几个好处:
177 |
178 | 1. 共享对象的映射减少了浪费,被共享的对象避免了在每个进程间都拷贝一份副本。
179 | 2. 共享对象可以实现进程间的通信。通过多个进程同时读写同一个虚拟内存区域,可以进行通信。
180 |
181 | 下图展示了一个进程被加载到内存中的时候,不同区域与私有对象和共享对象的映射关系
182 |
183 | 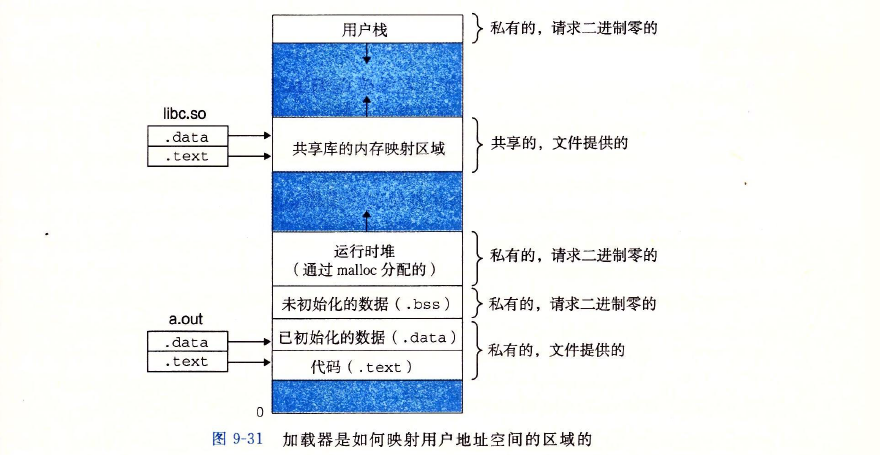
184 |
185 | 讲完了进程地址空间的映射关系,接下来说一说与实际开发相关的内存管理API。
186 |
187 | 写过C的都知道,在C里面进行内存的分配和释放是用的标准库的API `malloc() / free()`
188 |
189 | `malloc/free` 实际上并不是系统调用,而是linux系统库 glibc 标准库函数。linux 提供的真正的申请内存的函数是 `brk()/mmap()` 。
190 |
191 | ```plain
192 | #include
193 | int brk( const void *addr);
194 | ```
195 |
196 | 上述两个函数的作用都是扩展 heap 的上界 brk
197 |
198 | brk()的参数设置为新的 brk 上界地址,成功返回1,失败返回 0;
199 |
200 | 当然,在标准库里还有一个
201 |
202 | ```plain
203 | void* sbrk ( intptr_t incr );
204 | ```
205 |
206 | sbrk()的参数为申请内存的大小,返回heap新的上界brk的地址。
207 |
208 | brk 函数是用于 heap 区域内存的申请。共享内存区域是通过另一个函数来分配的:
209 |
210 | ```plain
211 | #include
212 | void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
213 | int munmap(void *addr, size_t length);
214 | ```
215 |
216 | mmap分为2种用法:
217 |
218 | 一种是映射此盘文件到内存中,动态链接库就是用这种方式加载的。比如 dlopen() 等等。
219 |
220 | 一种是匿名映射,向映射区申请一块内存。 比如 malloc 。
221 |
222 | 这里使用 mmap 的内存映射和上述的内存映射是一样的,只是一个是用户级的内存映射和内核级的内存映射。
223 |
--------------------------------------------------------------------------------
/✍ 文章/深入浅出linux内存管理(二).md:
--------------------------------------------------------------------------------
1 | - c 内存管理
2 | - Glibc 的 ptmalloc
3 | - unsorted bin
4 | - small bin
5 | - large bin
6 | - Fast Bins
7 | - mmaped chunk
8 | - Google 的 tcmalloc
9 | - small object 的分配
10 | - large object 的分配
11 | - span
12 | - 对象释放和重分配
13 | - central free list
14 | - GC
15 |
16 | ## c 内存管理
17 |
18 | 有了上述的基础理论知识,我们现在继续讨论 malloc / free 这一组函数。
19 |
20 | 既然 malloc 是对系统调用的封装,那么每次 malloc 都会经过系统调用去申请内存吗?
21 |
22 | 一次系统调用的过程就是,保存当前进程用户态的调用栈,然后切换到内核态,调用完毕再切换回用户态,每一次系统调用需要保存调用栈,恢复调用栈。如果有大量的系统调用,将耗费大量的CPU资源在内核态和用户态的切换上,明显降低CPU的利用率。
23 |
24 | 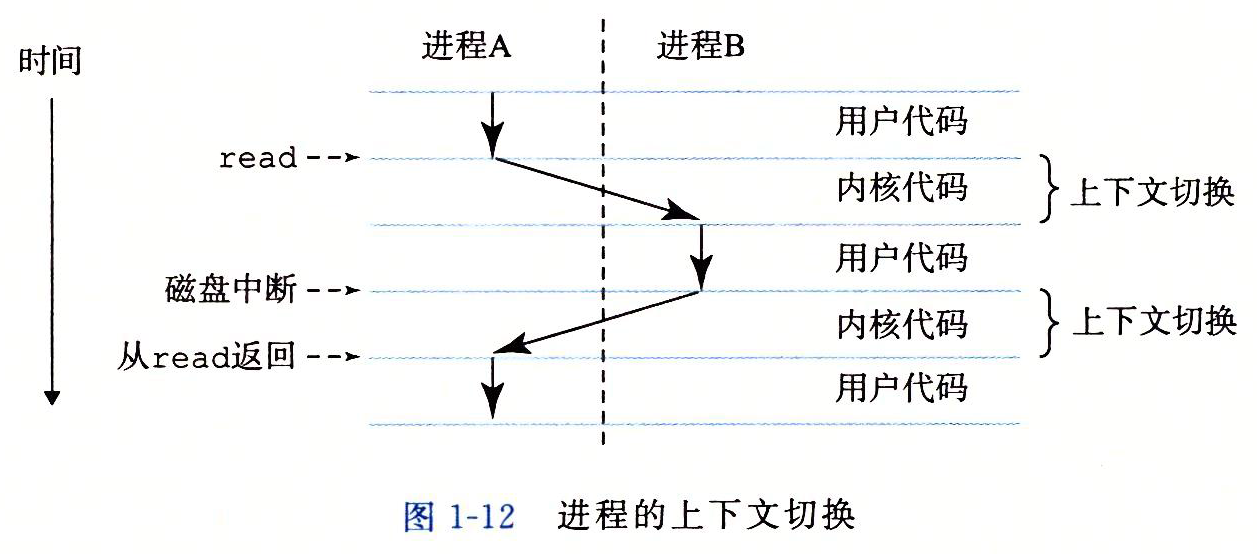
25 |
26 | 为了降低系统调用的频率,我们可以选择将申请的内存缓存起来,每次调用多申请一些内存,释放也不立刻还给操作系统,而是等待下次申请再次复用。
27 |
28 | 针对这种情况,衍生出了很多的内存管理方案,包括linux 自带的glibc 中的 ptmalloc , Google 的 tcmalloc ,FaceBook 的 jemalloc。
29 |
30 | ### Glibc 的 ptmalloc
31 |
32 | ptmalloc 的内存分配器中在最早的版本时一个进程只有一个主分配区,在多线程的情况下,锁的争用非常激烈,严重影响了 malloc 的分配效率,于是ptmalloc根据系统对分配区的争用情况动态增加非主分配区的数量,分配区的数量一旦增加,就不会再减少。1个进程的内存分配区域包括 1个主分配区+N个非主分配区。
33 |
34 | 主分配区可以访问进程的heap区域和 mmap 映射区域,也就是主分配区可以使用 brk 和 mmap 申请内存。
35 |
36 | 而非主分配区只能访问的 mmap映射区域,非主分配区每次使用mmap()向操作系统“批发”HEAP_MAX_SIZE(32位系统上默认为1MB,64位系统默认为64MB)大小的虚拟内存,当用户向非主分配区请求分配内存时再切割成小块“零售”出去。
37 |
38 | 当某一线程需要调用malloc()分配内存空间时,该线程先查看线程私有变量中是否已经存在一个分配区,如果存在,尝试对该分配区加锁,如果加锁成功,使用该分配区分配内存,如果失败,该线程搜索循环链表试图获得一个没有加锁的分配区。如果所有的分配区都已经加锁,那么malloc()会开辟一个新的分配区,把该分配区加入到全局分配区循环链表并加锁,然后使用该分配区进行分配内存操作。在释放操作中,线程同样试图获得待释放内存块所在分配区的锁,如果该分配区正在被别的线程使用,则需要等待直到其他线程释放该分配区的互斥锁之后才可以进行释放操作。
39 |
40 | 申请小块内存时会产生很多内存碎片,ptmalloc在整理时也需要对分配区做加锁操作。每个加锁操作大概需要5~10个cpu指令,而且程序线程很多的情况下,锁等待的时间就会延长,导致malloc性能下降。一次加锁操作需要消耗100ns左右,正是锁的缘故,导致ptmalloc在多线程竞争情况下性能远远落后于tcmalloc。最新版的ptmalloc对锁进行了优化,加入了PER_THREAD和ATOMIC_FASTBINS优化,但默认编译不会启用该优化,这两个对锁的优化应该能够提升多线程内存的分配的效率。
41 |
42 | ptmalloc 管理内存不是以页为单位的,而是 chunk。chunk 以双向链表的形式组织。
43 |
44 | 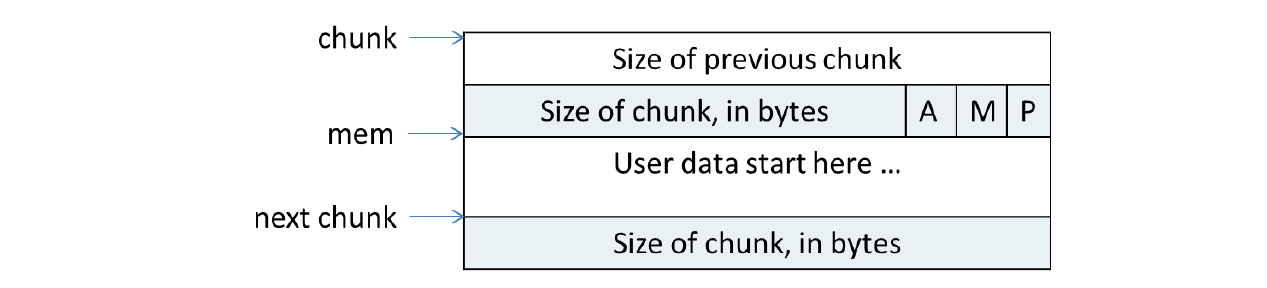
45 |
46 | 一个 chunk 有3个标志位,A | M | P
47 |
48 | - P : 前一个块是否可用,0 表示前一个块空闲可用,此时 prev_size 才有效。通过 prev_size, 程序可以计算出前一个块的起始地址。
49 | - M : 表示内存是从 mmap 申请的还是从 heap 申请的
50 |
51 | - A :表示该chunk属于主分配区或者非主分配区
52 |
53 | 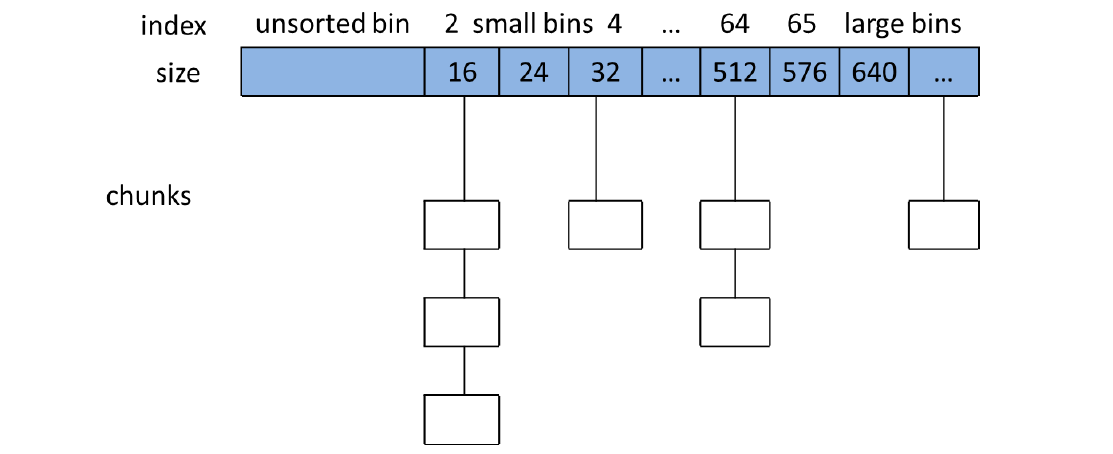
54 |
55 | #### unsorted bin
56 |
57 | 数组中的第一个为unsorted bin。Unsorted bin可以看作是small bins和large bins的cache,Unsorted bin 中的空闲chunk不排序,分配时,如果在unsorted bin中没有合适的chunk,就会把unsorted bin中的所有chunk分别加入到所属的bin中,然后再在bin中分配合适的chunk。 如果被用户释放的chunk大于max_fast,或者fast bins中的空闲chunk合并后,这些chunk首先会被放到unsorted bin队列中。
58 |
59 | #### small bin
60 |
61 | 数组中从2开始编号的前64个bin称为 small bins,同一个small bin中的chunk具有相同的大小。两个相邻的small bin中的chunk大小相差8bytes。small bins中的chunk按照最近使用顺序进行排列,最后释放的chunk被链接到链表的头部,而申请chunk是从链表尾部开始,也就是最近不使用的优先分配,这样每一个chunk 都有相同的机会被ptmalloc选中。
62 |
63 | #### large bin
64 |
65 | Small bins后面的bin被称作 large bins。large bins中的每一个bin分别包含了一个给定范围内的chunk,其中的chunk按大小序排列。相同大小的chunk同样按照最近使用顺序排列。ptmalloc使用“smallest-first,best-fit”原则在空闲large bins中查找合适的chunk。
66 |
67 | #### Fast Bins
68 |
69 | 一般的情况是,程序在运行时会经常需要申请和释放一些较小的内存空间。当分配器合并了相邻的几个小的chunk之后,也许马上就会有另一个小块内存的请求,这样分配器又需要从大的空闲内存中切分出一块,这样无疑是比较低效的,故而,ptmalloc中在分配过程中引入了fast bins,不大于max_fast (默认值为64B)的chunk被释放后,首先会被放到 fast bins 中,fast bins中的chunk并不改变它的使用标志P。这样也就无法将它们合并,当需要给用户分配的chunk小于或等于max_fast时,ptmalloc首先会在fast bins中查找相应的空闲块,然后才会去查找bins中的空闲chunk。在某个特定的时候,ptmalloc会遍历fast bins中的chunk,将相邻的空闲chunk进行合并,并将合并后的chunk加入unsorted bin中,然后再将usorted bin里的chunk加入bins中。
70 |
71 | fast bins 相当于 small bins 的一个缓冲区。
72 |
73 | #### mmaped chunk
74 |
75 | 当需要分配的chunk足够大,而且fast bins和bins都不能满足要求,甚至top chunk本身也不能满足分配需求时,ptmalloc会使用mmap来直接使用内存映射来将页映射到进程空间。这样分配的chunk在被free时将直接解除映射,于是就将内存归还给了操作系统,再次对这样的内存区的引用将导致segmentation fault错误。这样的chunk也不会包含在任何bin中。
76 |
77 | 从分配内存的大小来看:
78 |
79 | unsorted bin 是 bins 的缓冲区
80 |
81 | fast Bins 是 small bins 的缓冲区
82 |
83 | small bins < large bins < top chunk < mmaped chunk
84 |
85 | small bins 和 large bins 的分界线是 64B
86 |
87 | large bins 和 top chunk 的分界线是 512B
88 |
89 | top chunk 和 mmaped chunk 的分界线是 128KB
90 |
91 | 分配算法概述,以32系统为例,64位系统类似。
92 |
93 | - 小于等于64字节:用pool算法,最近不使用的优先分配。也就是从 small bins 中分配。
94 | - 64到512字节之间:从 large bins 分配,在最佳匹配算法分配和pool算法分配中取一种合适的。也就是
95 |
96 | - 大于等于512字节:用最佳匹配算法分配。
97 | - 大于等于mmap分配阈值(默认值128KB):根据设置的mmap的分配策略进行分配,如果没有开启mmap分配阈值的动态调整机制,大于等于128KB就直接调用mmap
98 |
99 | 下面简单总结下 malloc 的过程。
100 |
101 | 一个进程启动之后,
102 |
103 | 1. 第一次分配内存时,一般情况下只存在一个主分配区,但也有可能从父进程那里继承来了多个非主分配区,在这里主要讨论主分配区的情况。brk值等于start_brk,所以实际上heap大小为0,top chunk大小也是0。这时,如果不增加heap大小,就不能满足任何分配要求。所以,若用户的请求的内存大小小于mmap分配阈值,则ptmalloc会初始heap。然后在heap中分配空间给用户,以后的分配就基于这个heap进行。若第一次用户的请求就大于mmap分配阈值,则ptmalloc直接使用mmap()分配一块内存给用户,而heap也就没有被初始化,直到用户第一次请求小于mmap分配阈值的内存分配。
104 | 2. 非第一次分配,ptmalloc
105 |
106 | 1. 1. 首先会查找fast bins,
107 | 2. 如果不能找到匹配的 chunk,则查找small bins。
108 |
109 | 1. 1. 若还是不行,合并fast bins,把chunk加入unsorted bin,在unsorted bin中查找,
110 | 2. 若还是不行,把unsorted bin中的chunk全加入large bins中,并查找large bins。
111 |
112 | 1. 1. 在fast bins和small bins中的查找都需要精确匹配,而在large bins中查找时,则遵循“smallest-first,best-fit”的原则,不需要精确匹配。
113 | 2. 若以上方法都失败了,则ptmalloc会考虑使用top chunk。
114 |
115 | 1. 1. 若top chunk也不能满足分配要求。而且所需chunk大小大于mmap分配阈值,则使用mmap进行分配。否则增加heap,增大top chunk。以满足分配要求。
116 |
117 | free 的过程:
118 |
119 | ptmalloc的内存收缩是从top chunk开始,如果与top chunk相邻的那个chunk在我们NoSql的内存池中没有释放,top chunk以下的空闲内存都无法返回给系统,即使这些空闲内存有几十个G也不行。
120 |
121 | ### Google 的 tcmalloc
122 |
123 | google 的 tcmalloc 比 ptmalloc 的设计就简单多了。
124 |
125 | 为了优化多线程对锁的争用,整个内存分配区分为 thread cache 和 central heap
126 |
127 | 同时将内存对象分为大对象和小对象,以32K为界。
128 |
129 | 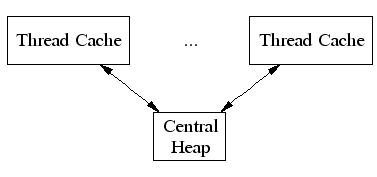
130 |
131 | #### small object 的分配
132 |
133 | 每个线程都有私有的thread cache ,当申请小块内存的时候,会优先分配 thread cache 中的内存,thread cache 的内存以数组+链表的形式组织起来。
134 |
135 | 如下图每一个class 表示一个定长大小的内存块。8字节,16字节,32字节,跟 ptmalloc 里的 small bins 差不多。
136 |
137 | 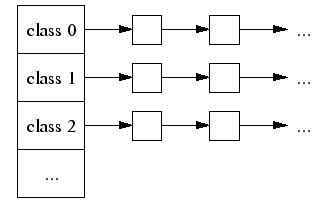
138 |
139 | 小内存(<=32K)的分配过程如下:
140 |
141 | 1. 先将需要申请的内存适配到合适的 class 中,比如 7字节的内存申请,将从 class=8字节的链表上申请。
142 | 2. 如果链表不为空,返回链条头部的内存块。
143 |
144 | 1. 如果链表空,从 central heap 中批发的一块内存,然后切成当前 class 大小的小内存,放到这个class对应的链表中,然后返回最近使用的一块内存,也就是链表头。
145 | 2. 如果 central heap 也是空的,从central page allocator. 那里分配一块内存,然后切成当前 class 的大小,放到 central heap 里,再按照步骤3,给 thread local 分配内存。
146 |
147 | #### large object 的分配
148 |
149 | central heap 中大内存的组织形式以 page 为单位,1page=4K,类似上面的 small bins 和 class 的形式,也是数组+链表。只是链表的元素变成了 page* K 大小的页。数组的大小是 256, 每个 entry 是 kPages大小的链表入口。K<=255。
150 |
151 | 
152 |
153 | 大内存(>32K)的分配过程如下:
154 |
155 | 大于 32 K的内存分配,最终都会适配成 4K 的倍数来分配,比如需要5K,就会分配8K。
156 |
157 | 1. 先将需要申请的内存适配到合适的 class 中,先找到适配的链表。
158 | 2. 如果链表不为空,返回链表头。
159 |
160 | 1. 如果适配的pages 所在的链表为空,继续遍历下一个链表,比如8K的链表为空,此时遍历16K的链表去找。
161 | 2. 如果找到了,比如16K的,此时剩下的内存就会插到合适的链表中,对于5K来说,需要返回对方8K,然后将剩余的8K插入8K的链表中。
162 |
163 | 1. 如果最终 255K 的链表也没有内存,就要从操作系统申请内存了, 用 sbrk,brk,mmap 之类的方式。
164 |
165 | #### span
166 |
167 | tcmalloc 的heap管理是以 page 为单位的,为了管理这些 page,引入了 span 的概念。span 是一组 **连续的** page,类似于操作系统底层用多级页表来管理的方式一样。上文中的 kPage 的数组,kPage 就是大小不同的 span。span 可以被分配也可以被释放。
168 |
169 | span被释放时,就会变成多个page,插入到上述的 central heap 的链表中。
170 |
171 | span被分配时,要么是一块大内存分配给了应用层,要么是被用于切成小块的pages 插入到 central Heap 中。
172 |
173 | 由于 span 是一组 **连续的** page,因此span 和 page 的关联通过一个 central array 来记录。给所有的 page 编号,central array 就是整个pages 数组,如下图,span a 和 2个page 关联,span b 和一个page 关联,span c 和 5 个page 关联。
174 |
175 | 
176 |
177 | 一个32位的系统有 2^20 个 4K的 pages。因此这个 central array 的大小是 4MB 。还记得操作系统中用于虚拟地址到物理地址映射的页表的大小吗?如果不使用多级页表,页表大小也是 4K,这里的 central array 与页表异曲同工。
178 |
179 | 当然在 64 位系统上,会使用 3 层的基数树来管理 pages,此时的虚拟内存空间已经达到 256 TB。
180 |
181 | #### 对象释放和重分配
182 |
183 | 一个对象释放的过程:
184 |
185 | 1. 先计算 page 的编号,这个应该可以根据地址值算出。
186 | 2. 然后根据 central array 找到这个 page 对应的 span, span 中包含了该对象的大小信息,是 small object 还是 large object。
187 |
188 | 1. 如果是 small object , span 会有对应的 size-class 信息,那就把它插入到 thread cache 的 size-class 中。当然 thread cache 的大小上限是 2MB,如果超过这个值,会启动GC机制,将无用的 object 移到 central free list 中。
189 | 2. 如果是 large object ,span 中会有这个 object 所包含的 pages numbers 范围,比如 [p,q],此时会在 central array 的 p-1 and q+1 范围内也找依照有没有一样是 free 的pages ,有的话,全部合并,归还到 central heap 中。
190 |
191 | #### central free list
192 |
193 | 上文提到了的 small object 会还到 central free list 中。
194 |
195 | thread cache 中的 每一个 size-class 都会对应一个 central free list。这个 central free list 是所有 thread cache 共用的。每个 central free list 保存着一组 spans,每个 span 下有一个链表,保存着 free objects。
196 |
197 | 当 object 需要重新分配的时候,可以直接从 central free list 的某个span上分配一个 free object.。如果所有span 的链表都是空的,就从 central Heap 分配了。
198 |
199 | 当一个 object 被释放到 central free list 的时候,会添加到对应的 span的list 中。如果链表长度跟 span 里的small object 数一样,这个 span 就会完全被释放并放回到 central heap 中。
200 |
201 | #### GC
202 |
203 | thread cache 达到 2MB 时会触发GC。
204 |
205 | GC时会遍历所有的 central free list, 并把一些 objects 从 central free list 移到 central list。
206 |
207 | 被移动的 objects 数取决于一个参数 L (per-list low-water-mark)。
208 |
209 | L 记录了从上次GC开始,central free lists 的最小长度。L 可以作为历史记录来预测将来可能使用的 list 长度。需要移到 central free list 的 object 数 = L/2 。
210 |
211 | 这个算法有一个很好的特性,当一个线程停止的时候,所占用的内存是某个值的时候,所有这个大小的 objects 都会被移到 central free list,给其他的线程复用.
212 |
--------------------------------------------------------------------------------
/✍ 文章/虚拟地址空间——MMU.md:
--------------------------------------------------------------------------------
1 | ### 虚拟内存
2 |
3 | 虚拟内存就是在你电脑的物理内存不够用时把一部分硬盘空间作为内存来使用,这部分硬盘空间就叫作虚拟内存。
4 |
5 | 硬盘传输的速度要比内存传输速度慢的多,所以虚拟内存比物理内存的效率要慢得多。
6 |
7 | 断电后数据丢失。
8 |
9 | ### 虚拟地址空间
10 |
11 | 虚拟地址空间是一个非常抽象的概念,先根据字面意思进行解释:
12 |
13 | - 它可以用来加载程序数据(数据可能被加载到物理内存上,空间不够就加载到虚拟内存中)
14 | - 它对应着一段连续的内存地址,起始位置为 0。
15 |
16 | - 之所以说虚拟是因为这个起始的 0 地址是被虚拟出来的, 不是物理内存的 0 地址。
17 |
18 | 虚拟地址空间的大小也由操作系统决定,32位的操作系统虚拟地址空间的大小为 2^32 字节,也就是 4G,64 位的操作系统虚拟地址空间大小为 2^64 字节,这是一个非常大的数,感兴趣可以自己计算一下。
19 |
20 | 关于虚拟4G内存的描述和解析:
21 |
22 | 一个进程用到的虚拟地址是由内存区域表来管理的,实际用不了4G。而用到的内存区域,会通过页表映射到物理内存。
23 |
24 | 所以每个进程都可以使用同样的虚拟内存地址而不冲突,因为它们的物理地址实际上是不同的。内核用的是3G以上的1G虚拟内存地址,其中896M是直接映射到物理地址的,128M按需映射896M以上的所谓高位内存。各进程使用的是同一个内核。
25 |
26 | 首先要分清“可以寻址”和“实际使用”的区别。
27 |
28 | 其实我们讲的每个进程都有4G虚拟地址空间,讲的都是“可以寻址”4G,意思是虚拟地址的0-3G对于一个进程的用户态和内核态来说是可以访问的,而3-4G是只有进程的内核态可以访问的。并不是说这个进程会用满这些空间。
29 |
30 | 其次,所谓“独立拥有的虚拟地址”是指对于每一个进程,都可以访问自己的0-4G的虚拟地址。虚拟地址是“虚拟”的,需要转化为“真实”的物理地址。
31 |
32 | 好比你有你的地址簿,我有我的地址簿。你和我的地址簿都有1、2、3、4页,但是每页里面的实际内容是不一样的,我的地址簿第1页写着3你的地址簿第1页写着4,对于你、我自己来说都是用第1页(虚拟),实际上用的分别是第3、4页(物理),不冲突。
33 |
34 | 内核用的896M虚拟地址是直接映射的,意思是只要把虚拟地址减去一个偏移量(3G)就等于物理地址。同样,这里指的还是寻址,实际使用前还是要分配内存。而且896M只是个最大值。如果物理内存小,内核能使用(分配)的可用内存也小。
35 |
36 |
37 |
38 | 进程的虚拟地址空间分为用户区(0~3G)和内核区(3~4G), 其中内核区是受保护的, 用户是不能够对其进行读写操作的;
39 |
40 | **内核区对于所有进程是共享的;系统中所有进程对应的虚拟地址空间的内核区都会映射到同一块物理内存上(系统内核只有一个)。**
41 |
42 | 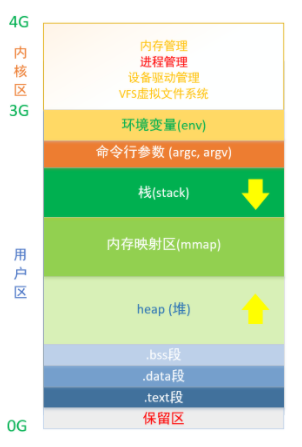
43 |
44 | 虚拟地址空间中用户区地址范围是 0~3G,里边分为多个区块:
45 |
46 | - **保留区**: 位于虚拟地址空间的最底部,未赋予物理地址。任何对它的引用都是非法的,程序中的空指针(NULL)指向的就是这块内存地址。
47 | - **.text段**: 代码段也称正文段或文本段,通常用于存放程序的执行代码 (即 CPU 执行的机器指令),代码段一般情况下是只读的,这是对执行代码的一种保护机制。
48 |
49 | - **.data段**: 数据段通常用于存放程序中已初始化且初值不为 0 的全局变量和静态变量。数据段属于静态内存分配 (静态存储区),可读可写。
50 | - .**bss段**: 未初始化以及初始为 0 的全局变量和静态变量,操作系统会将这些未初始化变量初始化为 0
51 |
52 | - **堆(heap)**:用于存放进程运行时动态分配的内存。
53 |
54 | - - 堆中内容是匿名的,不能按名字直接访问,只能通过指针间接访问。
55 | - 堆向高地址扩展 (即 “向上生长”),是不连续的内存区域。这是由于系统用链表来存储空闲内存地址,自然不连续,而链表从低地址向高地址遍历。
56 |
57 | - **内存映射区(mmap)**:作为内存映射区加载磁盘文件,或者加载程序运作过程中需要调用的动态库。
58 | - **栈(stack)**: 存储函数内部声明的非静态局部变量,函数参数,函数返回地址等信息,栈内存由编译器自动分配释放。栈和堆相反地址 “向下生长”,分配的内存是连续的。
59 |
60 | - **命令行参数**:存储进程执行的时候传递给 main() 函数的参数,argc,argv [],env[]
61 | - **环境变量**: 存储和进行相关的环境变量,比如:工作路径,进程所有者等信息
62 |
63 | ### 内存管理单元MMU
64 |
65 | MMU位于CPU内,作用:
66 |
67 | - 程序中使用的地址均是虚拟内存地址,进程中的数据是如何进出入到物理内存中的呢?
68 | - **MMU完成虚拟内存到物理内存的映射,即虚拟地址映射为物理地址;**
69 |
70 | - **流水线中预取指令取到的地址是虚拟地址,需要MMU转换以及设置访问权限**
71 |
72 | **MMU采用分页机制(即按页来划分物理内存)**
73 |
74 | **用MMU的是**:Windows、MacOS、Linux、Android;
75 |
76 | **不用MMU的是**:FreeRTOS、VxWorks、UCOS……
77 |
78 | 与此相对应的:CPU也可以分成两类,带MMU的、不带MMU的。
79 |
80 | **带MMU的是**:Cortex-A系列、ARM9、ARM11系列;
81 |
82 | **不带MMU的是**:Cortex-M系列……(STM32是M系列,没有MMU,不能运行Linux,只能运行一些UCOS、FreeRTOS等等)。
83 |
84 | 虚拟地址和物理地址的映射关系存储在页表中,而现在页表又是分级的
85 |
86 | **页表**:
87 |
88 | 实现从页号到物理块号的地址映射。
89 |
90 | 逻辑地址转换成物理地址的过程是:用页号p去检索页表,从页表中得到该页的物理块号,把它装入物理[地址寄存器](https://baike.baidu.com/item/地址寄存器)中。同时,将页内地址d直接送入物理[地址寄存器](https://baike.baidu.com/item/地址寄存器)的块内地址字段中。这样,物理[地址寄存器](https://baike.baidu.com/item/地址寄存器)中的内容就是由二者拼接成的实际访问内存的地址,从而完成了从[逻辑地址](https://baike.baidu.com/item/逻辑地址)到物理地址的转换。
91 |
92 | **TLB快表**:
93 |
94 | TLB是MMU中的一块高速缓存,也是一种Cache.
95 |
96 | TLB就是页表的Cache,其中存储了当前最可能被访问到的页表项,其内容是部分页表项的一个副本。只有在TLB无法完成地址翻译任务时,才会到内存中查询页表,这样就减少了页表查询导致的处理器性能下降。
97 |
98 | **如果没有TLB,则每次取数据都需要两次访问内存,即查页表获得物理地址和取数据.**
99 |
100 |
101 |
102 | 虚拟地址空间以**页**为单位进行划分,而相应的物理地址空间也被划分,其使用的单位称为**页帧**,页帧和页必须保持相同,因为**内存与外部存储器之间的传输是以页为单位进行传输的**。例如,MMU可以通过一个映射项将VA的一页0xb70010000xb7001fff映射到PA的一页0x20000x2fff,如果CPU执行单元要访问虚拟地址0xb7001008,则实际访问到的物理地址是0x2008。
103 |
104 | 虚拟内存的哪个页面映射到物理内存的哪个页帧是通过**页表(Page Table)**来描述的,页表保存在**物理内存中**,**MMU会查找页表来确定一个VA应该映射到什么PA。**
105 |
106 | - **内存访问级别的设置和修改(内存保护)**,在完成映射的同时,会设置CPU访问该段内存的访问级别(3,2,1,0 Linux只有用户空间3,内核空间0),
107 |
108 | 如图:
109 |
110 | ro表示read only
111 |
112 | 0和3表示访问级别
113 |
114 | 程序运行了两次,产生两个独立的进程,因此虚拟地址空间不一样
115 |
116 | 两个进程共用一个内核区,映射一份(图中也要通过MMU映射,懒得话而已)即可,其中**两个进程的PCB不一样**
117 |
118 | 用户区需要单独映射
119 |
120 | 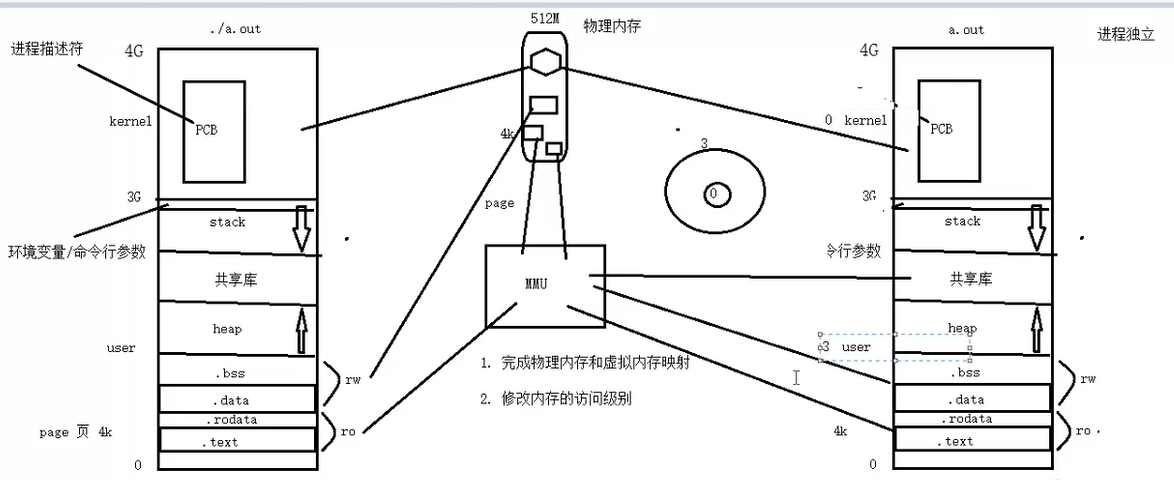
121 |
122 | #### MMU执行过程
123 |
124 | OS和MMU是这样配合的:
125 |
126 | 1. 操作系统在初始化或分配、释放内存时会执行一些指令在物理内存中填写页表,然后用指令设置MMU,告诉MMU页表在物理内存中的什么位置。
127 | 2. 设置好之后,CPU每次执行访问内存的指令都会自动引发MMU做查表和地址转换操作,地址转换操作由硬件自动完成,不需要用指令控制MMU去做。
128 |
129 | 我们在程序中使用的变量和函数都有各自的地址,在程序被编译后,这些地址就成了指令中的地址,指令中的地址就成了CPU执行单元发出的内存地址,所以在启用MMU的情况下, 程序中使用的地址均是**虚拟内存地址**,都会引发MMU进行查表和地址转换操作。(注意理解这句话)
130 |
131 | ### 内存保护机制
132 |
133 | #### 中断和异常
134 |
135 | - 中断由外部设备产生,而 异常由CPU内部产生的
136 | - 中断产生与CPU当前执行的指令无关,而异常是由于当前执行的指令出现问题导致的g
137 |
138 | 处理器一般有**用户模式(User Mode)**和**特权模式(privileged Mode)**之分。操作系统可以在页表中设置每个页表访问权限,有些页表不可以访问,有些页表只能在特权模式下访问,有些页表在用户模式和特权模式下都可以访问,同时,访问权限又分为**可读**、**可写**和**可执行**三种。这样设定之后,当CPU要访问一个VA(Virtual Address)时,**MMU**会检查CPU当前处于用户模式还是特权模式,访问内存的目的是读数据、写数据还是取指令执行,**如果与操作系统设定的权限相符,则允许访问,把VA转换成PA,否则不允许执行,产生异常(Exception)**。
139 |
140 |
141 |
142 | **在正常情况下处理器在用户模式执行用户程序,在中断或异常情况下处理器切换到特权模式执行内核程序,处理完中断或异常之后再返回用户模式继续执行用户程序。**
143 |
144 | **段错误**我们已经遇到过很多次了,它是这样产生的:
145 |
146 | 1. 用户程序要访问的一个虚拟机地址,经MMU检查无权访问。
147 | 2. MMU产生一个异常,CPU从用户模式切换到特权模式,跳转到内核代码中执行异常服务程序。
148 |
149 | 1. 内核把这个异常解释为段错误,把引发异常的进程终止掉。
150 |
151 | ### 用户空间与内核通信方式有哪些?
152 |
153 | 1)系统调用。用户空间进程通过系统调用进入内核空间,访问指定的内核空间数据;
154 |
155 | 2)共享映射区mmap。在代码中调用接口,实现内核空间与用户空间的地址映射,在实时性要求很高的项目中为首选,省去拷贝数据的时间等资源,但缺点是不好控制;
156 |
157 | 3)驱动程序。用户空间进程可以使用封装后的系统调用接口访问驱动设备节点,以和运行在内核空间的驱动程序通信;
158 |
159 | 4)copy_to_user()、copy_from_user(),是在驱动程序中调用接口,实现用户空间与内核空间的数据拷贝操作,应用于实时性要求不高的项目中。
160 |
--------------------------------------------------------------------------------
/内存管理知识点总结.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/内存管理知识点总结.pdf
--------------------------------------------------------------------------------
/📁论文/ARM的虚拟内存管理技术的研究.caj:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/ARM的虚拟内存管理技术的研究.caj
--------------------------------------------------------------------------------
/📁论文/C语言的内存漏洞分析与研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/C语言的内存漏洞分析与研究.pdf
--------------------------------------------------------------------------------
/📁论文/FreeRTOS内存管理方案的分析与改进.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/FreeRTOS内存管理方案的分析与改进.pdf
--------------------------------------------------------------------------------
/📁论文/Linux Memory Management.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Linux Memory Management.pdf
--------------------------------------------------------------------------------
/📁论文/Linux内存管理分析与研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Linux内存管理分析与研究.pdf
--------------------------------------------------------------------------------
/📁论文/Linux内存管理的设计与实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Linux内存管理的设计与实现.pdf
--------------------------------------------------------------------------------
/📁论文/Linux内核中内存池的实现及应用.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Linux内核中内存池的实现及应用.pdf
--------------------------------------------------------------------------------
/📁论文/Linux内核中动态内存检测机制的研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Linux内核中动态内存检测机制的研究.pdf
--------------------------------------------------------------------------------
/📁论文/Linux内核伙伴系统分析.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Linux内核伙伴系统分析.pdf
--------------------------------------------------------------------------------
/📁论文/Linux内核内存池实现研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Linux内核内存池实现研究.pdf
--------------------------------------------------------------------------------
/📁论文/Linux实时内存的研究与实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Linux实时内存的研究与实现.pdf
--------------------------------------------------------------------------------
/📁论文/Linux操作系统内核分析与研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Linux操作系统内核分析与研究.pdf
--------------------------------------------------------------------------------
/📁论文/Memory Management 101: Introduction to Memory Management in Linux.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Memory Management 101: Introduction to Memory Management in Linux.pdf
--------------------------------------------------------------------------------
/📁论文/Memory Management in Linux.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Memory Management in Linux.pdf
--------------------------------------------------------------------------------
/📁论文/Memory Management.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Memory Management.pdf
--------------------------------------------------------------------------------
/📁论文/NUMA架构内多个节点间访存延时平衡的内存分配策略.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/NUMA架构内多个节点间访存延时平衡的内存分配策略.pdf
--------------------------------------------------------------------------------
/📁论文/Nginx Slab算法研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Nginx Slab算法研究.pdf
--------------------------------------------------------------------------------
/📁论文/TCP_IP协议栈的轻量级多线程实现.caj:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/TCP_IP协议栈的轻量级多线程实现.caj
--------------------------------------------------------------------------------
/📁论文/Understanding the Linux Understanding the Linux.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Understanding the Linux Understanding the Linux.pdf
--------------------------------------------------------------------------------
/📁论文/VC中利用内存映射文件实现进程间通信的方法.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/VC中利用内存映射文件实现进程间通信的方法.pdf
--------------------------------------------------------------------------------
/📁论文/Virtual Memory Management Techniques in 2.6 Kernel and Challenges.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Virtual Memory Management Techniques in 2.6 Kernel and Challenges.pdf
--------------------------------------------------------------------------------
/📁论文/Visual C 中利用内存映射文件在进程之间共享数据.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/Visual C 中利用内存映射文件在进程之间共享数据.pdf
--------------------------------------------------------------------------------
/📁论文/《Linux Physical Memory Page Allocation》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/《Linux Physical Memory Page Allocation》.pdf
--------------------------------------------------------------------------------
/📁论文/一个内存分配器的设计和实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/一个内存分配器的设计和实现.pdf
--------------------------------------------------------------------------------
/📁论文/一种Linux内存管理机制.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/一种Linux内存管理机制.pdf
--------------------------------------------------------------------------------
/📁论文/一种TLB结构优化方法.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/一种TLB结构优化方法.pdf
--------------------------------------------------------------------------------
/📁论文/一种优化的伙伴系统存储管理算法设计.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/一种优化的伙伴系统存储管理算法设计.pdf
--------------------------------------------------------------------------------
/📁论文/一种基于虚拟机的动态内存泄露检测方法.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/一种基于虚拟机的动态内存泄露检测方法.pdf
--------------------------------------------------------------------------------
/📁论文/一种提高Linux内存管理实时性的设计方案.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/一种提高Linux内存管理实时性的设计方案.pdf
--------------------------------------------------------------------------------
/📁论文/一种改进的Linux内存分配机制.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/一种改进的Linux内存分配机制.pdf
--------------------------------------------------------------------------------
/📁论文/一种改进的伙伴系统内存管理方法.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/一种改进的伙伴系统内存管理方法.pdf
--------------------------------------------------------------------------------
/📁论文/一种跨平台内存池的设计与实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/一种跨平台内存池的设计与实现.pdf
--------------------------------------------------------------------------------
/📁论文/一种高效的池式内存管理器的设计.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/一种高效的池式内存管理器的设计.pdf
--------------------------------------------------------------------------------
/📁论文/云计算平台中多虚拟机内存协同优化策略研.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/云计算平台中多虚拟机内存协同优化策略研.pdf
--------------------------------------------------------------------------------
/📁论文/云计算平台中多虚拟机内存协同优化策略研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/云计算平台中多虚拟机内存协同优化策略研究.pdf
--------------------------------------------------------------------------------
/📁论文/内存管理机制的高效实现研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/内存管理机制的高效实现研究.pdf
--------------------------------------------------------------------------------
/📁论文/分页存储管理系统中内存有效访问时间的计算.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/分页存储管理系统中内存有效访问时间的计算.pdf
--------------------------------------------------------------------------------
/📁论文/利用内存映射连续性提高TLB地址覆盖范围的技术评测.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/利用内存映射连续性提高TLB地址覆盖范围的技术评测.pdf
--------------------------------------------------------------------------------
/📁论文/动态内存分配器研究综述.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/动态内存分配器研究综述.pdf
--------------------------------------------------------------------------------
/📁论文/动态存储管理机制的改进及实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/动态存储管理机制的改进及实现.pdf
--------------------------------------------------------------------------------
/📁论文/基于C 的高效内存池的设计与实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/基于C 的高效内存池的设计与实现.pdf
--------------------------------------------------------------------------------
/📁论文/基于C 自定义内存分配器的实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/基于C 自定义内存分配器的实现.pdf
--------------------------------------------------------------------------------
/📁论文/基于Linux内核的动态内存管理机制的实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/基于Linux内核的动态内存管理机制的实现.pdf
--------------------------------------------------------------------------------
/📁论文/基于Linux内核页表构建内核隔离空间的研究及实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/基于Linux内核页表构建内核隔离空间的研究及实现.pdf
--------------------------------------------------------------------------------
/📁论文/基于RDMA和NVM的大数据系统一致性协议研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/基于RDMA和NVM的大数据系统一致性协议研究.pdf
--------------------------------------------------------------------------------
/📁论文/基于RDMA高速网络的高性能分布式系统.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/基于RDMA高速网络的高性能分布式系统.pdf
--------------------------------------------------------------------------------
/📁论文/基于RelayFS的内核态内存泄露的检测和跟踪.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/基于RelayFS的内核态内存泄露的检测和跟踪.pdf
--------------------------------------------------------------------------------
/📁论文/基于linux用户态可自控缓冲区管理设计与实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/基于linux用户态可自控缓冲区管理设计与实现.pdf
--------------------------------------------------------------------------------
/📁论文/基于multimap映射的动态内存分配算法探究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/基于multimap映射的动态内存分配算法探究.pdf
--------------------------------------------------------------------------------
/📁论文/基于云计算虚拟化平台的内存管理研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/基于云计算虚拟化平台的内存管理研究.pdf
--------------------------------------------------------------------------------
/📁论文/基于内存池的空间数据调度算法.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/基于内存池的空间数据调度算法.pdf
--------------------------------------------------------------------------------
/📁论文/多核系统内存管理算法的研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/多核系统内存管理算法的研究.pdf
--------------------------------------------------------------------------------
/📁论文/实时系统内存管理方案的设计与实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/实时系统内存管理方案的设计与实现.pdf
--------------------------------------------------------------------------------
/📁论文/对linux伙伴系统及其反碎片机制的研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/对linux伙伴系统及其反碎片机制的研究.pdf
--------------------------------------------------------------------------------
/📁论文/嵌入式实时系统动态内存分配管理器的设计与实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/嵌入式实时系统动态内存分配管理器的设计与实现.pdf
--------------------------------------------------------------------------------
/📁论文/并发数据结构及其在动态内存管理中的应用.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/并发数据结构及其在动态内存管理中的应用.pdf
--------------------------------------------------------------------------------
/📁论文/应用协同的进程组内存管理支撑技术.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/应用协同的进程组内存管理支撑技术.pdf
--------------------------------------------------------------------------------
/📁论文/支持高性能IPC的内存管理策略研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/支持高性能IPC的内存管理策略研究.pdf
--------------------------------------------------------------------------------
/📁论文/有效的C 内存泄露检测方法.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/有效的C 内存泄露检测方法.pdf
--------------------------------------------------------------------------------
/📁论文/浅析伙伴系统的分配与回收.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/浅析伙伴系统的分配与回收.pdf
--------------------------------------------------------------------------------
/📁论文/用户态内存管理关键技术研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/用户态内存管理关键技术研究.pdf
--------------------------------------------------------------------------------
/📁论文/申威处理器页表结构Cache的优化研究与实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/申威处理器页表结构Cache的优化研究与实现.pdf
--------------------------------------------------------------------------------
/📁论文/虚拟化系统中的内存管理优化.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/虚拟化系统中的内存管理优化.pdf
--------------------------------------------------------------------------------
/📁论文/面向Linux内核空间的内存分配隔离方法的研究与实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/面向Linux内核空间的内存分配隔离方法的研究与实现.pdf
--------------------------------------------------------------------------------
/📁论文/页面分配器的研究与实现.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/0voice/kernel_memory_management/e7c9010eb1f449a1abbac9bfdd2ba660b6dc46ff/📁论文/页面分配器的研究与实现.pdf
--------------------------------------------------------------------------------