19 | 【点击展开】怎么实现按顺序输出怎么输出?
20 |
21 |
22 |
23 |
24 | 将var改为let
25 |
26 | ```javascript
27 | for (let i = 0; i < 5; i++) {
28 | setTimeout(function (i) {
29 | console.log(i);
30 | },1000)
31 | }
32 | ```
33 |
34 | 立即执行函数
35 |
36 | ```javascript
37 | for (var i = 0; i < 5; i++) {
38 | (function (i) {
39 | setTimeout(function () {
40 | console.log(i);
41 | },1000)
42 | })(i)
43 | }
44 | ```
45 |
46 | bind
47 |
48 | ```javascript
49 | for (var i = 0; i < 5; i++) {
50 | setTimeout(function (i) {
51 | console.log(i);
52 | }.bind(this,i),1000)
53 | }
54 | ```
55 |
56 | call(bind返回的是函数,而call、apply是立即调用,所以写法要变化)
57 |
58 | ```javascript
59 | for (var i = 0; i < 5; i++) {
60 | setTimeout(function (i) {
61 | return function () {
62 | console.log(i);
63 | }
64 | }.call(this,i),1000)
65 | }
66 | ```
67 |
68 | apply
69 |
70 | ```javascript
71 | for (var i = 0; i < 5; i++) {
72 | setTimeout(function (i) {
73 | return function () {
74 | console.log(i);
75 | }
76 | }.apply(this,[i]),1000)
77 | }
78 | ```
79 |
80 | 闭包
81 |
82 | ```javascript
83 | for (var i = 0; i < 5; i++) {
84 | function f(){
85 | var j = i;
86 | return function () {
87 | setTimeout(function () {
88 | console.log(j);
89 | },1000)
90 | }
91 | }
92 | f()();
93 | }
94 | ```
95 |
96 | setTimeout第三个参数
97 |
98 | ```javascript
99 | for (var i = 0; i < 5; i++) {
100 | setTimeout(function (i) {
101 | console.log(i);
102 | }, 1000,i)
103 | }
104 | ```
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 | ## 连等赋值a=b=c
113 |
114 | ```
115 | var a = {n:1};
116 | a.x = a = {n:2};
117 | console.log(a.x); // 为什么输出undefined?
118 | ```
119 |
120 | 首先可以确定,连续赋值是从右至左永远只取等号右边的表达式结果赋值到等号左侧。
121 |
122 | - 1、在执行前,会先将a和a.x中的a的引用地址都取出来,此值他们都指向{n:1}
123 | - 2、在内存中创建一个新对象{n:2}
124 | - 3、执行a={n:2},将a的引用从指向{n:1}改为指向新的{n:2}
125 | - 4、执行a.x=a,此时a已经指向了新对象,而a.x因为在执行前保留了原引用,所以a.x的a依然指向原先的{n:1}对象,所以给原对象新增一个属性x,内容为{n:2}也就是现在a
126 | - 5、语句执行结束,原对象由{n:1}变成{n:1,x:{n:2}},而原对象因为无人再引用他,所以被GC回收,当前a指向新对象{n:2}
127 | - 6、再执行a.x,自然就是undefined了
128 |
129 | **尽量不要使用JS的连续赋值操作**
130 |
131 | ## 代码实现浏览器事件循环event-loop
132 |
133 | 思路:
134 |
135 | - 主线程=>微任务=>宏任务
136 | - 遇setTimeout、setInterval放入到宏任务中
137 | - new Promise构造函数的内容作为主线程,遇到resolve()则把then的内容放入到微任务中,构造函数中resolve()后的内容继续执行
138 | - async关键字将函数封装成Promise,函数里遇到await则相当于对应的异步函数转化为new Promise构造函数,依据上面的规则判断
139 |
140 | ```javascript
141 | async function async1(){
142 | console.log('async1 start')
143 | await async2()
144 | console.log('async1 end')
145 | }
146 |
147 | async function async2(){
148 | console.log('async2')
149 | }
150 |
151 | console.log('script start')
152 |
153 | setTimeout(function(){
154 | console.log('setTimeOut')
155 | }, 0)
156 |
157 | async1()
158 |
159 | new Promise(function(resolve){
160 | console.log('promise1')
161 | resolve()
162 | }).then(function(){
163 | console.log('promise2')
164 | })
165 |
166 | console.log('script end')
167 |
168 | //script start
169 | //async1 start
170 | //async2
171 | //promise1
172 | //script end
173 | //async1 end
174 | //promise2
175 | //setTimeOut
176 | ```
177 |
--------------------------------------------------------------------------------
/docs/experience/questions.md:
--------------------------------------------------------------------------------
1 | #### 1. 简历上*了解*、*熟悉*、*精通*是一种怎样的界定标准?
2 |
3 | - “**了解”**:是指只是上过课或看过书,没做过实际项目。
4 | - “**熟悉**”:应该占据了简历中描述技能的掌握程度的大部分,已经使用某项技术有较长时间,通过查阅相关文档可以独立解决大部分问题。对于毕业应届生而言,毕业设计所用到的技能可以用“熟悉”,对于已经工作过的,项目开发中所用到的技能也可以成为熟悉。
5 | - “**精通**”:如果对一项技术得心应手,在项目开发中,当同学请教这个领域的问题的时候,我们都有信心也有能力解决的时候,才可以说精通.
6 |
7 | #### 2. 哪些招聘网站值得推荐?
8 |
9 | - **牛客网**:互联网招聘首推,讨论区有大量大厂内推机会不间断。
10 | - **Boss直聘**、**拉勾网**:小公司很多,有很多比较不错的岗位,也有相应的面试机会。
11 | - **脉脉**:能跟很多hr,技术官1对1沟通,善于利用这个平台也能早就机会。
12 |
13 | #### 3. 如何才能拿到大厂的实习Offer?
14 | #### 4. 如何才能拿到大厂的正式校招offer?
15 | #### 5. 如何才能拿到大厂的社招offer?
16 | #### 6. 怎么引导面试官提问你擅长的知识点?
17 | #### 7. 如何选择公司部门和事业群?
18 | #### 8. 大厂对数据结构和算法要求到什么程度?
19 |
20 | "要求不高,但是更倾向于招算法娴熟的"。大厂在面试过程中都会考算法,尤其是字节跳动,就算是前端,基本上每轮面试必问算法,你会遇到力扣middle级别甚至hard级别的。
21 |
22 | #### 9. 怎么提高数据结构和算法能力?
23 |
24 | 当你对数据结构和算法有了一个整体的认知之后,就可以开始练习了。
25 | 注意,一定是**分类练习**!**分类练习**!**分类练习**!重要的事情说三遍。我曾见过非常多的同学带着一腔热血就开始刷题了,从leetcode第一题开始,刚开始往往非常有动力,可能还会发个朋友圈或者空间动态什么的😅,然后就没有然后了。
26 | 因为前几题非常简单,可能会给你一定的自信,但是,按序号来的话,很快就会遇到hard。或者有的人,干脆只刷简单,先把所有的简单刷完。但是,这样盲目的刷题,效果是非常差的,有可能你坚持下来,刷了几百道,也能有点效果,但是整个过程可能非常慢,而且效果远远没有分类练习要好。
27 | 所谓分类练习,即按每种类别练习,例如:这段时间只练习二叉树的题目,后面开始练习回溯算法的题目。在开始练习之前,你往往还需要对这种具体的类别进行一个详细的了解,对其具体的定义、相关的概念和应用、可能出现的题目类型进行梳理,然后再开始。
28 |
29 | 刷题"力扣"是首选,可以针对性的刷自己薄弱的方向,要做到读题后能知道这是哪种题型。如"动态规划、贪心"等等。
30 |
31 | 最次最次,也要把《剑指offer》刷两遍,掌握十大排序算法和基本的数据结构(二叉树、链表、栈、队列)
32 |
33 | #### 10. 如果对方问到岗时间,怎么应对?
34 | 剑谱:人挪活,树挪死,你这个应该是日常实习,你应该说:春节后大概率可以过去实习的,先面试在说,拿到了去不了的话,就说学校事情走不开等等’.主要是积累面试经验,这个在互联网行业内很常见.
35 |
36 | #### 11. 遇到提问不会的内容怎么办?
37 | 就告诉面试官,我会这个相似的,BalaBala……
38 |
39 | #### 12. 应届生在面试的时候如何谈薪资?
40 | 因为没有经验,很怕在面试时候要求的薪资会被hr减分,从而错失一个工作机会,但是不聊薪资又很被动。
41 |
42 | 如果HR开了一个薪资你不满意,可以尝试性发问:“这个薪资确实离我的预期有点小偏差,不知有无可能帮忙争取一下到xxx,当然我肯定不希望我的这个需求让您的工作产生为难,毕竟相比薪资来讲我还是更看重咱们公司的机会。”这样说HR立马就会明白你什么意思,同时又避免了尴尬。
43 |
44 | #### 13. HR面有哪些需要注意的地方?
45 | 袋鼠云实习hr:*反正我师姐对于候选人昨天聊了一个,说人蛮聪明,但是对自己投的岗位和公司都不了解,并且在海投简历,然后拒绝了。*
46 |
47 | #### 14. 面试官会提问React源码的东西,我应该花精力去读源码吗?
48 | 如果你是为了面试而读源码,不必。同样的精力不如多看几篇面经,进行实战并理解原理。
49 |
50 | 如果你是为了"听起来很专家"而读源码,不必。收益极低,不如带着目的性去总结某一部分源码的设计理念。
51 |
52 | #### 15. 像牛客有很多内推码、内推私人邮箱,怎么利用?
53 | 牛客讨论区有很多内推码,但是不要发了邮件就万事大吉了,很多情况下,你可简历可能压根就没被投递出去,所以,一定要多"麻烦"别人,机会是把握在自己手中的。
54 |
55 | #### 16. 每次面试前需要准备什么?
56 | 不管是视频面试、电话面试还是现场面试,面试之前一定要先把所面公司的情况基本了解一遍,特别是对于中小企业,海投不明白公司业务,可能hr面就被刷下来。
57 |
58 | #### 17. node有必要深入学习吗?
59 |
60 | 非常必要!我在面试美团、阿里、腾讯等大厂的时候,面试官都会提到"会使用node吗",重要性你自己掂量掂量
61 |
62 | #### 18. 怎么才能确定哪些是自己必须掌握的知识点?
63 |
64 | 一份漂亮的简历让你通过初筛,简历上"技能栏"的所有角落,你都要经得起提问。
65 |
66 | #### 19. 视频面试时面试官能看到我的屏幕吗?
67 |
68 | 比如牛客视频面试,你鼠标跳出页面对方是知道的,看不到你屏幕内容,但是知道你跳出去了。所以,不要耍小动作,认真理解和记忆这些知识点,未来的自己会感谢曾经努力的你的💪。
69 |
70 | #### 20. 什么是前端素养?
71 |
72 | 素养就是,你要会设计模式、软件设计原则、IEEE754等等,大厂会问,比如快手。
73 |
74 | #### 21. 前端技能树优先级
75 |
76 | JS第一,其他全是其次。如果你JS还有"怕被问到"的地方,赶快去补习把!!!
77 |
78 | #### 22. 寒假/暑期/日常实习的区别
79 |
80 | [寒假实习,暑期实习,日常实习究竟有什么区别?!](https://www.nowcoder.com/discuss/361127)
81 |
82 | #### 23. 一些面试过程中专业术语是什么意思?
83 |
84 | |缩写|解释|
85 | |-|-|
86 | |offer|录取通知书,一般是邮件发送的pdf文件|
87 | |HC|计划招聘的人员数量|
88 | |HR|专门负责人力资源的人,一般负责最后一面和入职流程,主要考察候选人软素质,有的HR(如阿里)有一票否决权|
89 | |oc|offer call代表着HR给你打电话告诉你被录取了,到这里就稳了|
90 | |om|offer mail代表着HR给你发offer邮件,正式录取的分界线|
91 | |tql|太强了。常见于交流群中,表示感叹!|
92 | |WXG/CDG/IEG/CSIG/PCG/TEG|都是腾讯的事业群缩写|
93 | |花名|常见于阿里系,公司内部互相称呼的名字|
94 | |双非|非985非211|
95 |
96 | #### 24. 春招时间段是什么?
97 | #### 25. 秋招时间段是什么?
98 | 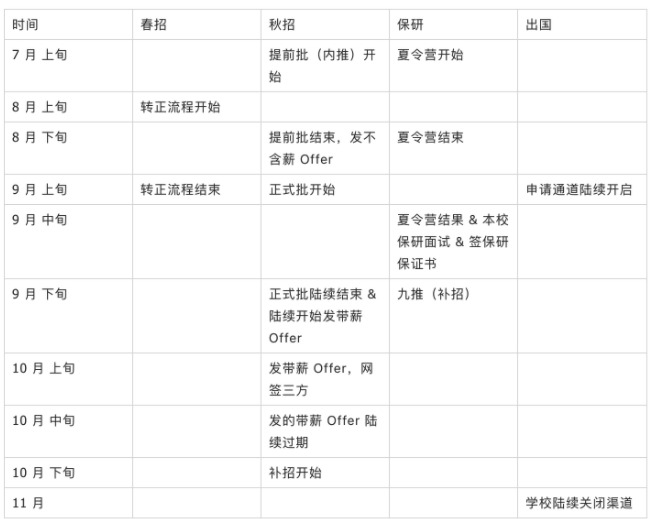
99 |
100 | #### 26. BAT前端技术哪家强?
101 |
102 | #### 27. 你还有其他公司在面试吗/你拿到其他公司的offer了吗
103 |
104 | 有。
105 |
106 | 1. 说2-3个公司,不宜过多。
107 | 2. 一定要说同行业或者同等级的,这样面试官认为你方向明确
108 | 3. 夸他!表示这家公司是第一选择。大公司夸制度完善,前景好。小公司夸挑战性,工作节奏利于成长。
109 |
110 | #### 28. 你为什么离职?
111 |
112 | 1. 为什么离职
113 | 1. 不要说压力大,会被认为工作能力弱,工作效率低
114 | 2. 不要说在上级
115 | 2. 为什么来这里
116 |
117 | [解密国内BAT等大厂前端技术体系-完结篇](https://juejin.im/post/5e02c0896fb9a0160770ae9e)
118 |
119 | #### 101. 面试有那么难吗?
120 | 
121 |
--------------------------------------------------------------------------------
/docs/browser/questions.md:
--------------------------------------------------------------------------------
1 |
2 | ## 响应式布局怎么实现
3 |
4 | 1. **使用设备的宽度作为视图宽度并禁止初始的缩放**
5 |
6 | > arr[j]){
157 | //将最小的数的下标保存
158 | minIndex=j;
159 | }
160 | }
161 | //将最小值与基准值交换
162 | tempNum = arr[minIndex];
163 | arr[minIndex] = arr[i];
164 | arr[i] = tempNum;
165 | }
166 | return arr;
167 | };
168 | ```
169 |
170 | #### 时间复杂度O(n^2)
171 | 从动画上我们能很轻易地看出,循环运行次数和问题规模的关系是:
172 |
173 | 循环执行次数 =(n-1)+(n-2)+……+2+1= n(n-1)/ 2=`(1/2)n^2 + (1/2)n`
174 |
175 | 所以复杂度O(n^2)
176 |
177 | #### 稳定性:不稳定
178 | 举个例子,序列5 8 5 2 9,我们知道第一遍选择第1个元素5会和2交换,那么原序列中两个5的相对前后顺序就被破坏了,所以选择排序是一个不稳定的排序算法。
179 |
180 | ### 插入排序
181 | 插入排序虽然没有冒泡和选择那么简单粗暴,但是也是比较好理解的一种排序方式了。他就像我们平常打扑克时“整理起手牌”的动作。顺序遍历每一个数,将当前数和之前的数依次比较,并插入到之前到正确位置。
182 | #### 思路
183 | 1. 标识当前判断的元素。
184 | 2. 遍历数组中每一个数,并执行步骤3
185 | 3. 对于每一个数,都比较和前一个相邻值的大小,如果源值小,则不是当前插入的位置,继续向前比较,一直比较到源值大的那个位置,插入进去。如果一直比对到arr[0]的位置仍是源值小,则直接插入到最前面。
186 | #### 动画演示
187 | 
188 | #### 代码实现
189 | ```javascript
190 | /**
191 | * 插入排序
192 | * tip:就想玩扑克牌的时候整理顺序一样
193 | * @param {Array} arr 传入一个数组,按照从小到大排序
194 | * @returns {Array} 返回排序后的数组
195 | */
196 | let insertionSort=(arr)=>{
197 | let length = arr.length;
198 | //current为本次循环中源位置的值
199 | let current,preIndex;
200 | for (let i = 1; i < length; i++) {
201 | //preIndex为相邻的前一个下标
202 | preIndex = i-1;
203 | current=arr[i];
204 | //元素向后移动
205 | while (preIndex>=0&&arr[preIndex]>current){
206 | arr[preIndex+1] = arr[preIndex];
207 | preIndex--;
208 | }
209 | //插入
210 | arr[preIndex+1] = current;
211 | }
212 | return arr;
213 | };
214 | ```
215 | #### 时间复杂度O(n^2)
216 | 最坏情况是,原数组是降序排列,则`次数=n(n-1)/2`;对于最好情况来说本身就是正序,也就不必专门向前插入了,省了一层循环,那直接O(n)就行了。
217 |
218 | 但是还是最坏情况比较有参考意义,所以还是O(n^2)。因而,插入排序不适合对于数据量比较大的排序应用。但是,如果需要排序的数据量很小,例如,量级小于千,那么插入排序还是一个不错的选择。
219 |
220 | #### 稳定性:稳定
221 | 每次插入到前面的小值之后,就算遇到相等的值,也是放到之后,所以相等元素的前后顺序没有改变,所以插入排序是稳定的。
222 |
223 | ### 希尔排序
224 | 希尔排序是插入排序的升级版,先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序(最后一次插入排序即是正常的直接插入排序,但此时因为已经基本有序,排序会很快)。
225 |
226 | 希尔排序优点是:间隔大的时候移动次数少,间隔小的时候移动距离短,所以总体来说比插入排序要优良,美中不足的是该排序是不稳定的。
227 |
228 | > 大家可以先看看这个,大概了解一下什么是希尔排序:
229 | >
230 | > [希尔排序真人版视频](https://v.youku.com/v_show/id_XNTA3NDUxMjcy.html)
231 |
232 |
233 | #### 思路
234 | 1. 设置增量gap,每次循环递减到之前到一半
235 | 2. 基于每层循环的gap值,每次遍历都进行一次插入排序_insert()
236 | 3. 执行每层都_insert,进行分组插入排序
237 | 4. 直到gap==1时,即为常规插入排序,也即是最后一轮循环
238 | #### 动画演示
239 | 
240 | #### 代码实现
241 | ```javascript
242 | /**
243 | * 希尔排序
244 | * tip:插入排序的升级版
245 | * @param {Array} arr 传入一个数组,按照从小到大排序
246 | * @returns {Array} 返回排序后的数组
247 | */
248 | let shellSort = (arr) => {
249 | let N = arr.length;
250 | //开始分组,初始状态,增量(gap)为数组长度的一半,当递减到增量为1时,即是最后一次排序
251 | for (let gap = Math.floor(N / 2); gap >= 1; gap = Math.floor(gap / 2)) {
252 | //对各个分组进行插入排序
253 | for (let i = gap; i < N; i++) {
254 | //将arr[i]插入到正确对位置上
255 | _insert(arr, gap, i);
256 | }
257 | }
258 | return arr;
259 | };
260 | /**
261 | * 希尔排序中将arr[i]插入到正确到位置上
262 | *(即插入排序,带有增量)
263 | * arr[i]所在到分组是:...arr[i-2*gap],arr[i-gap],arr[i],arr[i+gap],arr[i+2*gap]...当
264 | * @param arr 需要进行插入排序对数组
265 | * @param gap 增量
266 | * @param i 指定位置的下标
267 | */
268 | let _insert = (arr, gap, i) => {
269 | let inserted = arr[i], j;
270 | //插入的时候分组插入(组内元素两两相隔gap)
271 | for (j = i - gap; j >= 0 && inserted < arr[j]; j -= gap) {
272 | arr[j + gap] = arr[j];
273 | }
274 | arr[j + gap] = inserted;
275 | };
276 | ```
277 | #### 时间复杂度O(nlog^2 n)
278 | 步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作。算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为1进行排序。当步长为1时,算法变为普通插入排序,这就保证了数据一定会被排序。
279 |
280 | Donald Shell最初建议步长选择为n/2,并且对步长取半直到步长达到1。虽然这样取可以比O(n^2)类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。
281 |
282 | 
283 |
284 | 已知的最好步长序列是由Sedgewick提出的(1, 5, 19, 41, 109,...),他的这研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序要快,甚至在小数组中比快速排序和堆排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
285 |
286 | 另一个在大数组中表现优异的步长序列是(斐波那契数列除去0和1将剩余的数以黄金分割比的两倍的幂进行运算得到的数列):(1, 9, 34, 182, 836, 4025, 19001, 90358, 428481, 2034035, 9651787, 45806244, 217378076, 1031612713,…)
287 |
288 | 参考链接:[维基百科](https://zh.wikipedia.org/wiki/%E5%B8%8C%E5%B0%94%E6%8E%92%E5%BA%8F)
289 |
290 | #### 稳定性:不稳定
291 | 由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以shell排序是不稳定的。
292 |
293 | ### 归并排序
294 | 归并排序是建立在归并操作上的一种有效的排序算法,是分治法的一个经典应用。
295 |
296 | 所谓**分治**,将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之。
297 |
298 | 
299 |
300 | #### 思路
301 | 1. 申请空间,使其为两个已经排序序列之和,该空间用来存放合并后的序列;
302 | 2. 设定两个指针,最初位置分别为两个已经排序的序列的起始位置;
303 | 3. 比较两个指针所指向的元素,选择相对较小的放到合并空间,并移动指针到下一位置;
304 | 4. 重复3步骤直到某一指针达到序列尾;
305 | 5. 将另一序列剩下的元素直接复制到合并序列尾;
306 | #### 动画演示
307 |
308 | 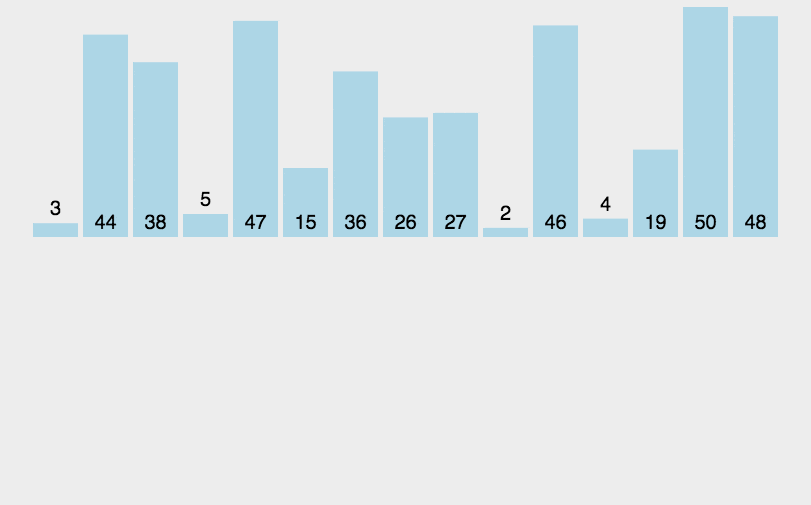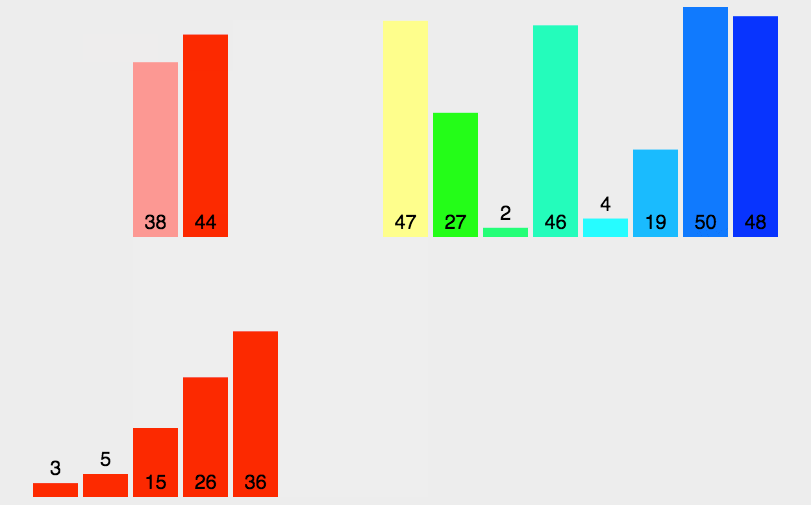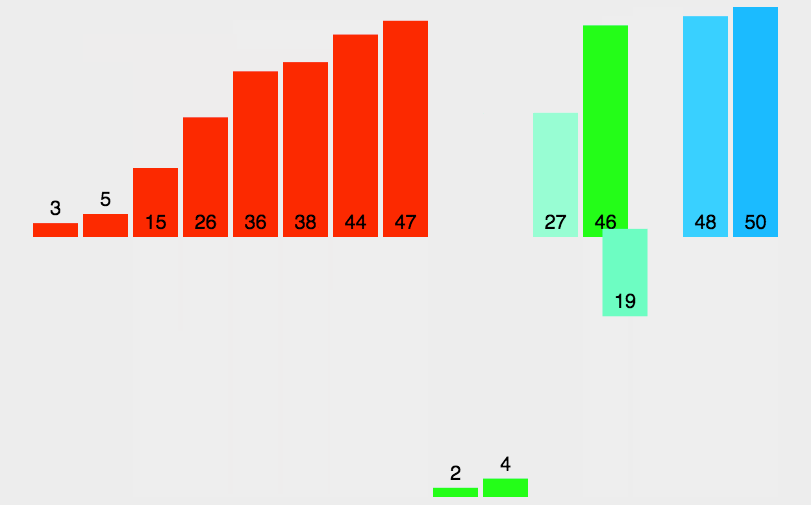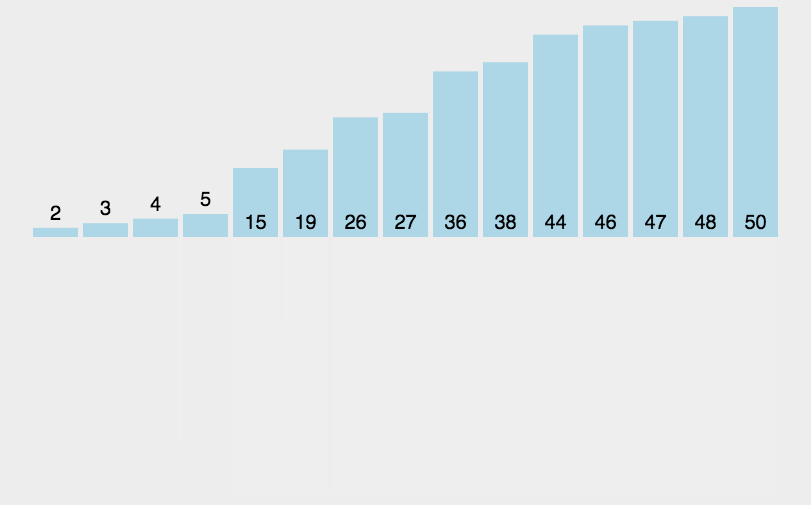
309 |
310 | 
311 |
312 | #### 代码实现
313 | ```javascript
314 | /**
315 | * 归并排序
316 | *
317 | * @param {Array} arr 传入一个数组,按照从小到大排序
318 | * @returns {Array} 返回排序后的数组
319 | */
320 | let mergeSort = (arr) => {
321 | let len = arr.length;
322 | if (len < 2) {
323 | return arr;
324 | }
325 | let middle = Math.floor(len / 2),
326 | left = arr.slice(0, middle),
327 | right = arr.slice(middle);
328 |
329 | return _merge(mergeSort(left), mergeSort(right));
330 | };
331 |
332 | /**
333 | * 合并(归并)两个数组
334 | * @param left
335 | * @param right
336 | * @returns {[]}
337 | * @private
338 | */
339 | let _merge = (left, right) => {
340 | //合并空间
341 | let result = [];
342 | while (left.length && right.length) {
343 | if (left[0] <= right[0]) {
344 | //移除left的第一个元素,并且添加到合并空间中
345 | result.push(left.shift());
346 | }else{
347 | //移除right到第一个元素,并且添加到合并空间中
348 | result.push(right.shift());
349 | }
350 | }
351 | //假如左数组还有剩余,则把左数组增加到合并空间中
352 | while (left.length){
353 | result.push(left.shift());
354 | }
355 | //假如右数组还有剩余,则把右数组增加到合并空间中
356 | while (right.length){
357 | result.push(right.shift());
358 | }
359 | return result;
360 | };
361 | ```
362 | #### 时间复杂度O(nlogn)
363 | 归并的时间复杂度分析:主要是考虑两个函数的时间花销,一、数组划分函数mergeSort();二、有序数组归并函数_merge();
364 |
365 | 简单的分析下元素长度为n的归并排序所消耗的时间 T[n]:调用mergeSort()函数划分两部分,那每一小部分排序好所花时间则为T[n/2],而最后把这两部分有序的数组合并成一个有序的数组_merge()函数所花的时间为 O(n);
366 |
367 | 公式:`T[n] = 2T[n/2] + O(n)`
368 |
369 | 公式就不仔细推导了,可以[参考链接](http://blog.csdn.net/yuzhihui_no1/article/details/44198701#t2)
370 |
371 | 所以得出的结果为:`T[n] = O( nlogn )`
372 |
373 | 从另一个角度思考,假设解决最后的子问题用时为常数c,则对于n个待排序记录来说整个问题的规模为cn。
374 |
375 | 
376 |
377 | 从这个递归树可以看出,第一层时间代价为cn,第二层时间代价为cn/2+cn/2=cn…..每一层代价都是cn,总共有logn层。所以总的时间代价为cn*(logn).时间复杂度是O(nlogn)。
378 |
379 |
380 | #### 稳定性:稳定
381 | 归并排序是稳定的排序.即相等的元素的顺序不会改变。即是原数组有相等数字,在排序成新数组后,也会保持着之前到相等数字的前后位置。
382 |
383 |
384 | ---
385 | **更新中ing**
386 |
387 |
388 | ### 快速排序
389 | 1. 算法步骤
390 | - 从数列中挑出一个元素,称为 "基准"(pivot);
391 |
392 | - 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
393 |
394 | - 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
395 |
396 | ```javascript
397 | function quickSort(arr, left, right) {
398 | var len = arr.length,
399 | partitionIndex,
400 | left = typeof left != 'number' ? 0 : left,
401 | right = typeof right != 'number' ? len - 1 : right;
402 |
403 | if (left < right) {
404 | partitionIndex = partition(arr, left, right);
405 | quickSort(arr, left, partitionIndex-1);
406 | quickSort(arr, partitionIndex+1, right);
407 | }
408 | return arr;
409 | }
410 |
411 | function partition(arr, left ,right) { // 分区操作
412 | var pivot = left, // 设定基准值(pivot)
413 | index = pivot + 1;
414 | for (var i = index; i <= right; i++) {
415 | if (arr[i] < arr[pivot]) {
416 | swap(arr, i, index);
417 | index++;
418 | }
419 | }
420 | swap(arr, pivot, index - 1);
421 | return index-1;
422 | }
423 |
424 | function swap(arr, i, j) {
425 | var temp = arr[i];
426 | arr[i] = arr[j];
427 | arr[j] = temp;
428 | }
429 |
430 | let arr = [2,43,2,32,55,1,-6,-77,5,434];
431 | console.log(quickSort(arr,0,arr.length-1));
432 |
433 | ```
434 |
435 |
436 | ### 堆排序
437 | ### 计数排序
438 | ### 桶排序
439 | ### 基数排序
440 |
--------------------------------------------------------------------------------
/docs/javascript/questions.md:
--------------------------------------------------------------------------------
1 |
2 | 说句真心话,一切博文和专栏都不如红宝书《JavaScript高级程序设计》和犀牛书《JavaScript权威指南》,这两本书将会伴随你一生的前端生涯,**选一本**,**吃透它**,从此前端之路有条不紊!
3 |
4 | ## ES6新语法,包含es7、es8、es9更新的语法
5 |
6 | - `let`声明变量,`const`声明常量,let声明的变量在未声明前不允许使用,即“暂时性死区”。
7 | - 解构赋值
8 | - 模版字符串、字符串被for…of遍历
9 | - 字符串的正则
10 | - Number的二进制前缀0b/0B和八进制前缀0o/0O
11 | - 数组的map、forEach等便利方法,另外Array.from()可以将类似数组的对象和可以遍历的对象转化为数组;Array.of()将一组值转化为数组
12 | - 函数参数设置默认值、箭头函数、扩展运算符(...)
13 | - Object.assign()合并对象
14 | - Symbol
15 | - Promise
16 | - Set:类似于数组,成员值唯一
17 | - Map:键值对数据结构
18 | - Proxy和Reflect。Proxy用于对编程语言编程,对外界对访问进行过滤和改写。Reflect是为了代替Object操作对象提供的新API,比如异常情况下Object.defineProperty会抛出错误,而Reflect.defineProperty会返回false
19 | - Iterator和for...of循环
20 | - Generator/yield用于异步编程
21 | - async与await。async是Generator的语法糖,完全可以看作多个异步操作,包装成的一个Promise对象,而await命令就是内部then命令的语法糖。
22 | - class
23 | - 模块化(Module),主要由export 和 import组成。
24 | - 修饰器(Decorator)
25 |
26 | ## 箭头函数和普通函数的区别
27 |
28 | 1、没有自己的this、super、arguments和new.target绑定。
29 | 2、不能使用new来调用。
30 | 3、没有原型对象。
31 | 4、不可以改变this的绑定。
32 | 5、形参名称不能重复。
33 |
34 | 箭头函数中没有this绑定,必须通过查找作用域链来决定其值。
35 |
36 | 如果箭头函数被非箭头函数包含,则this绑定的是最近一层非箭头函数的this,否则this的值则被设置为全局对象。
37 |
38 | ## Promise.all和Promise.race
39 |
40 | Promise.all可以将多个Promise实例包装成一个新的Promise实例。同时,成功和失败的返回值是不同的,成功的时候返回的是一个结果数组,而失败的时候则返回最先被reject失败状态的值。
41 |
42 | Promise.race就是赛跑的意思,意思就是说,Promise.race([p1, p2, p3])里面哪个结果获得的快,就返回那个结果,不管结果本身是成功状态还是失败状态。
43 |
44 | race场景: 给异步请求设定一个超时时间.
45 |
46 | ## 跨域原理,解决方案
47 |
48 | [跨域参考链接](https://segmentfault.com/a/1190000011145364)
49 |
50 | 浏览器的“同源策略”会导致跨域,其中同源是指“协议、域名、端口”都相同。
51 |
52 | 跨域解决方案
53 |
54 | 1. **通过jsonp跨域**
55 |
56 | jsonp原理:静态文件不受同源政策影响,我可以返回一个script里面有一个回调函数,函数的里面是我要的东西。
57 |
58 | 2. **document.domain + iframe跨域**
59 |
60 | 此方案仅限主域相同,子域不同的跨域应用场景。
61 |
62 | 实现原理:两个页面都通过js强制设置document.domain为基础主域,就实现了同域。
63 |
64 | 3. **location.hash + iframe**
65 |
66 | 实现原理: a欲与b跨域相互通信,通过中间页c来实现。 三个页面,不同域之间利用iframe的location.hash传值,相同域之间直接js访问来通信。
67 |
68 | 具体实现:A域:a.html -> B域:b.html -> A域:c.html,a与b不同域只能通过hash值单向通信,b与c也不同域也只能单向通信,但c与a同域,所以c可通过parent.parent访问a页面所有对象。
69 |
70 | 4. **window.name + iframe跨域**
71 |
72 | window.name属性的独特之处:name值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。
73 |
74 | 通过iframe的src属性由外域转向本地域,跨域数据即由iframe的window.name从外域传递到本地域。这个就巧妙地绕过了浏览器的跨域访问限制,但同时它又是安全操作。
75 |
76 | 5. **postMessage跨域**
77 |
78 | postMessage是HTML5 XMLHttpRequest Level 2中的API,且是为数不多可以跨域操作的window属性之一,它可用于解决以下方面的问题:
79 |
80 |
81 | - 页面和其打开的新窗口的数据传递
82 | - 多窗口之间消息传递
83 | - 页面与嵌套的iframe消息传递
84 | - 上面三个场景的跨域数据传递
85 |
86 | 用法:postMessage(data,origin)方法接受两个参数
87 |
88 | data: html5规范支持任意基本类型或可复制的对象,但部分浏览器只支持字符串,所以传参时最好用JSON.stringify()序列化。
89 |
90 | origin: 协议+主机+端口号,也可以设置为"*",表示可以传递给任意窗口,如果要指定和当前窗口同源的话设置为"/"。
91 |
92 | 6. **跨域资源共享(CORS)**
93 |
94 | **为什么选择CORS?** 因为jsonp只支持get请求,但我们还有post请求,CORS就满足了我的要求。服务端设置响应头中的Access-Control-Allow-Origin为对应的域名。
95 |
96 | - (必须)Access-Control-Allow-Origin: *
97 | - (可选)Access-Control-Allow-Credentials: true//表示允许是否发送cookie,默认情况下cookie不包含cros请求中
98 | - (可选)Access-Control-Expose-Headers: name//携带上制定响应头的字段
99 |
100 | 如果CORS请求了非简单请求,还会带来进行option的问题
101 |
102 | 7. **nginx代理跨域**
103 |
104 | ##### nginx反向代理接口跨域
105 |
106 | 浏览器跨域访问js、css、img等常规静态资源被同源策略许可,但iconfont字体文件(eot|otf|ttf|woff|svg)例外,此时可在nginx的静态资源服务器中加入以下配置。
107 |
108 | ```
109 | location / {
110 | add_header Access-Control-Allow-Origin *;
111 | }
112 | ```
113 | ##### nginx配置解决iconfont跨域
114 |
115 | 跨域原理: 同源策略是浏览器的安全策略,不是HTTP协议的一部分。服务器端调用HTTP接口只是使用HTTP协议,不会执行JS脚本,不需要同源策略,也就不存在跨越问题。
116 |
117 | 实现思路:通过nginx配置一个代理服务器(域名与domain1相同,端口不同)做跳板机,反向代理访问domain2接口,并且可以顺便修改cookie中domain信息,方便当前域cookie写入,实现跨域登录。
118 |
119 | 8. **nodejs中间件代理跨域**
120 |
121 | node中间件实现跨域代理,原理大致与nginx相同,都是通过启一个代理服务器,实现数据的转发,也可以通过设置cookieDomainRewrite参数修改响应头中cookie中域名,实现当前域的cookie写入,方便接口登录认证。
122 |
123 | 9. **WebSocket协议跨域**
124 |
125 | WebSocket protocol是HTML5一种新的协议。它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是server push技术的一种很好的实现。
126 |
127 | 原生WebSocket API使用起来不太方便,我们使用Socket.io,它很好地封装了webSocket接口,提供了更简单、灵活的接口,也对不支持webSocket的浏览器提供了向下兼容。
128 |
129 | ## 简单请求和非简单请求,Option请求
130 |
131 | 浏览器将CORS请求分成两类:简单请求(simple request)和非简单请求(not-so-simple request)。
132 |
133 | - 请求方法是以下三种方法之一:
134 | - HEAD
135 | - GET
136 | - POST
137 | - HTTP的头信息不超出以下几种字段:
138 | - Accept//客户端或代理能够处理的媒体类型
139 | - Accept-Language//优先的语言(中文、英文……)
140 | - Content-Language// 实体主体的自然语言
141 | - Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain
142 |
143 | 凡是不同时满足上面两个条件,就属于非简单请求。
144 |
145 | - 对于简单请求,在头信息里加一个Origin字段(协议 + 域名 + 端口),直接请求,
146 | - 对于非简单请求,需要先用options请求“预检”,
147 |
148 | 预检的请求头里有两个字段:
149 | - Access-Control-Request-Method//列出浏览器的CORS请求会用到哪些HTTP方法
150 | - Access-Control-Request-Headers//浏览器CORS请求会额外发送的头信息字段
151 |
152 | 服务器收到"预检"请求以后,检查了Origin、Access-Control-Request-Method和Access-Control-Request-Headers字段以后,确认允许跨源请求,就可以做出回应。如果服务器否定了"预检"请求,会返回一个正常的HTTP回应,但是没有任何CORS相关的头信息字段。这时,浏览器就会认定,服务器不同意预检请求,因此触发一个错误,被XMLHttpRequest对象的onerror回调函数捕获。
153 |
154 |
155 | ## 原型链✨
156 |
157 | 绝大部分函数都有一个`prototype`属性,含义是**函数的原型对象**,所有被创建的对象都可以访问原型对象的属性和方法。在new的过程中,会将函数的prototype赋值给对象的`__proto__`属性,当访问一个对象的属性的时候,如果对象内部不存在这个属性,就从`__proto__`所指的父对象寻找,一直找到终点null,通过`__proto__`属性连接的这条链就是原型链。
158 |
159 | > 原型链最顶端:`Object.prototype.__proto__=null`
160 |
161 |
162 | ## new一个对象发生了什么?
163 |
164 | 三步:
165 |
166 | 1. 创建以这个函数为原型的空对象;
167 |
168 | 2. 将函数的`prototype`赋值给对象的`__proto__`属性;
169 |
170 | 3. 将对象作为函数的this传进去,如果有return就返回return里面的内容,如果没有就创建这个对象。
171 |
172 | ## 基本类型和引用类型
173 |
174 | **基本类型:**
175 |
176 | `String`、`Boolean`、`Number`、`Null`、`Undefined`、`Symbol`、`BigInt`。
177 |
178 | `Symbol`可以用来创建唯一常量。
179 |
180 | - 基本类型的值不能被方法来改变,只能通过赋值的方式来改变,所谓“赋值”就是“指针指向的改变”,
181 | - 基本数据类型的值不能添加方法和属性
182 | - 一个变量向另一个变量赋值,是会在变量对象上创建新值,把新值复制到新变量分配到位置上,两个变量独立且不互相影响
183 | - 基本数据类型的比较是值的比较
184 | - 基本数据类型是存放在栈区的,变量的标识符和变量的值
185 |
186 | **引用类型:**
187 |
188 | 引用类型统称为Object 类型,细分的话包括Object 类型、Array 类型、Date 类型、RegExp 类型、Function 类型
189 |
190 | - 引用类型的值是可以改变的
191 | - 引用类型可以添加属性和方法
192 | - 引用类型的值是按照引用访问的,当从一个变量向另一个变量赋值引用类型的值时,同样也会将储存在变量中的对象的值复制一份放到为新变量分配的空间中.引用类型保存在变量中的是对象在堆内存中的地址,所以,与基本数据类型的简单赋值不同,这个值的副本实际上是一个指针,而这个指针指向存储在堆内存的一个对象.那么赋值操作后,两个变量都保存了同一个对象地址,而这两个地址指向了同一个对象.因此,改变其中任何一个变量,都会互相影响
193 | - 引用类型的比较是引用的比较
194 | - 引用类型的值是同时保存在栈区和堆区中的
195 |
196 | **补充:基本包装类型**
197 |
198 | 字符串是基本类型,按理说不该有方法,但我们可以调用split()等等方法,主要是因为ECMAScript还提供了三个特殊的引用类型**Boolean**,**String**,**Number**.我们称这三个特殊的引用类型为**基本包装类型**,也叫**包装对象**.
199 |
200 | 也就是说当读取string,boolean和number这三个基本数据类型的时候,后台就会创建一个对应的基本包装类型对象,从而让我们能够调用一些方法来操作这些数据,最后再销毁基本包装类型的实例。正因为有这个销毁的动作,所以基本数据类型不可以添加属性和方法,
201 |
202 | **生存周期**:
203 | 对象的生存期,使用new操作符创建的引用类型的实例,在执行流离开当前作用域之前都是一直保存在内存中;而自动创建的基本包装类型的对象,则只存在于一行代码的执行瞬间,然后立即被销毁
204 |
205 | ## 装箱和拆箱
206 |
207 | **装箱:**
208 | 基本数据类型转换为对应的引用类型的操作
209 |
210 | - **隐式装箱:** 在基本数据类型调用一些方法时,后台会创建对应的基本包装类型实例来操作,最后再销毁,这个过程就是个装箱。
211 | - **显式装箱:** 当我们显式得把字符串传入new String()时就是显式装箱
212 |
213 | **拆箱:**
214 |
215 | 拆箱就和装箱相反,是指把引用类型转换成基本的数据类型,JS标准规定了ToPrimitive用于拆箱转换。
216 |
217 | ## ToPrimitive
218 |
219 | ToPrimitive 算法在执行时,会被传递一个参数 hint,表示这是一个什么类型的运算(也可以叫运算的期望值),根据这个 hint 参数,ToPrimitive 算法来决定内部的执行逻辑。
220 |
221 | - ToPrimitive如果传入的hint为基本数据类型,则直接返回;Number先调用valueOf(),String先调用toString()。
222 | - 若两属性均无,或没有返回基本类型,则会产生类型错误 TypeError: Cannot convert object to primitive value
223 |
224 | ## 作用域
225 | 在ES5中,只有函数作用域和全局作用域。
226 |
227 | 在ES6中,let和const拥有了块级作用域{}。
228 |
229 | ## 事件循环、宏任务和微任务
230 |
231 | 浏览器端事件循环中的异步队列有两种:macro(宏任务)队列和 micro(微任务)队列。
232 |
233 | - 常见的 macro-task 比如:setTimeout、setInterval、script(整体代码)、 I/O 操作、UI 渲染等。
234 | - 常见的 micro-task 比如: new Promise().then(回调)、MutationObserver(html5新特性,提供了监视对DOM树所做更改的能力) 等。
235 |
236 | 当某个宏任务执行完后,会查看是否有微任务队列。如果有,先执行微任务队列中的所有任务,如果没有,会读取宏任务队列中排在最前的任务,执行宏任务的过程中,遇到微任务,依次加入微任务队列。执行栈空后,再次读取微任务队列里的任务,依次类推。
237 |
238 | ## this的指向问题
239 |
240 | this在函数里:函数的拥有者默认绑定this
241 | 例如在对象的方法,this指向对象
242 |
243 | 如果要判断一个运行中函数的 this 绑定, 就需要找到这个函数的直接调用位置。 找到之后
244 | 就可以顺序应用下面这四条规则来判断 this 的绑定对象。
245 |
246 | 1. new 调用:绑定到新创建的对象,注意:显示return函数或对象,返回值不是新创建的对象,而是显式返回的函数或对象。
247 | 2. call 或者 apply( 或者 bind) 调用:严格模式下,绑定到指定的第一个参数。非严格模式下,null和undefined,指向全局对象(浏览器中是window),其余值指向被new Object()包装的对象。
248 | 3. 对象上的函数调用:绑定到那个对象。
249 | 4. 普通函数调用: 在严格模式下绑定到 undefined,否则绑定到全局对象。
250 | ES6 中的箭头函数:不会使用上文的四条标准的绑定规则, 而是根据当前的词法作用域来决定this, 具体来说, 箭头函数会继承外层函数,调用的 this 绑定( 无论 this 绑定到什么),没有外层函数,则是绑定到全局对象(浏览器中是window)。 这其实和 ES6 之前代码中的 self = this 机制一样。
251 |
252 | DOM事件函数:一般指向绑定事件的DOM元素,但有些情况绑定到全局对象(比如IE6~IE8的attachEvent)。
253 |
254 | ## apply,call,bind区别
255 |
256 | 三者都是用于改变函数体内this的指向,但是bind与apply和call的最大的区别是:bind不会立即调用,而是返回一个新函数,称为绑定函数,其内的this指向为创建它时传入bind的第一个参数,而传入bind的第二个及以后的参数作为原函数的参数来调用原函数。
257 |
258 | apply和call都是为了改变某个函数运行时的上下文而存在的(就是为了改变函数内部this的指向);apply和call的调用返回函数执行结果;
259 |
260 | 如果使用apply或call方法,那么this指向他们的第一个参数,apply的第二个参数是一个参数数组,call的第二个及其以后的参数都是数组里面的元素,就是说要全部列举出来;
261 | ## 解释下变量提升✨
262 |
263 | JS引擎的工作方式是,先解析代码,获取所有被声明的变量,再一行一行运行,所有变量的声明语句会被提升带代码的头部,这叫做变量提升(hoisting)。
264 |
265 | ```javascript
266 | console.log(a);//undefined
267 | var a = 1;
268 | ```
269 |
270 | 代码的实际执行顺序是这样的:
271 |
272 | ```javascript
273 | var a;
274 | console.log(a);
275 | a=1;
276 | ```
277 | ## 声明一个函数有几种方式,有什么区别
278 |
279 | **函数式声明**
280 |
281 | ```
282 | //ES5
283 | funciton name(){}
284 | function (){}//匿名函数
285 | //ES6
286 | ()=>{}
287 | ```
288 |
289 | **函数表达式(函数字面量)**
290 |
291 | ```
292 | let fun = function(){}
293 | let fun = ()=>{}
294 | let fun = function name(){}
295 |
296 | (function name(){})()
297 | ```
298 |
299 | **Function构造**
300 |
301 | let fun = new Function('arg1','arg2','alert(arg1+","+arg2)')
302 |
303 |
304 | **区别**:
305 |
306 | - 构造函数需要被解析两次,第一次解析js代码,第二次解析传入构造函数的字符串,影响性能。
307 | - 基于变量提升和函数提升的机制,函数的声明优先级更高,会直接提升当前作用域的顶端,然后表达式和变量按顺序执行。
308 |
309 | ## 理解闭包吗?✨
310 |
311 | ?> 这个问题是在问:闭包是什么?闭包有什么作用?
312 |
313 | 闭包的关键是函数有自己的作用域,这个作用域的寿命可可以存活的比函数本身还要长。
314 |
315 | 闭包:"有权访问另一个函数作用域中变量的函数"(来自红宝书)
316 |
317 | 闭包的最大作用是“隐藏变量”,一大特性是**内部函数总是可以访问外部函数中声明的参数和变量,甚至在其外部函数被返回(寿终正寝)之后**,比如可以利用闭包访问私有变量。
318 |
319 | 缺点也很明显:
320 | - 常驻内存,增加内存使用量
321 | - 使用不当造成内存泄漏。
322 |
323 | **写个闭包:**
324 |
325 | ```javascript
326 | function fun(){
327 | var num = 1;
328 | return function () {
329 | console.log(++num)
330 | }
331 | }
332 |
333 | var count = fun()
334 | count()//2
335 | count()//3
336 | count()//4
337 | ```
338 |
339 | ## 作用域链理解吗?
340 |
341 | > 区别于原型链,作用域链是为了访问**变量**而存在的链,原型链是为了访问**对象的属性**而存在的链。
342 |
343 | 专业回答:JS在执行的过程中会创建**可执行上下文**,可执行上下文的词法环境中含有外部词法环境的引用,通过这个引用可以获取到外部词法环境的变量的声明,这些引用串联起来会一直指向全局的词法环境,因此形成了作用域链。
344 |
345 | 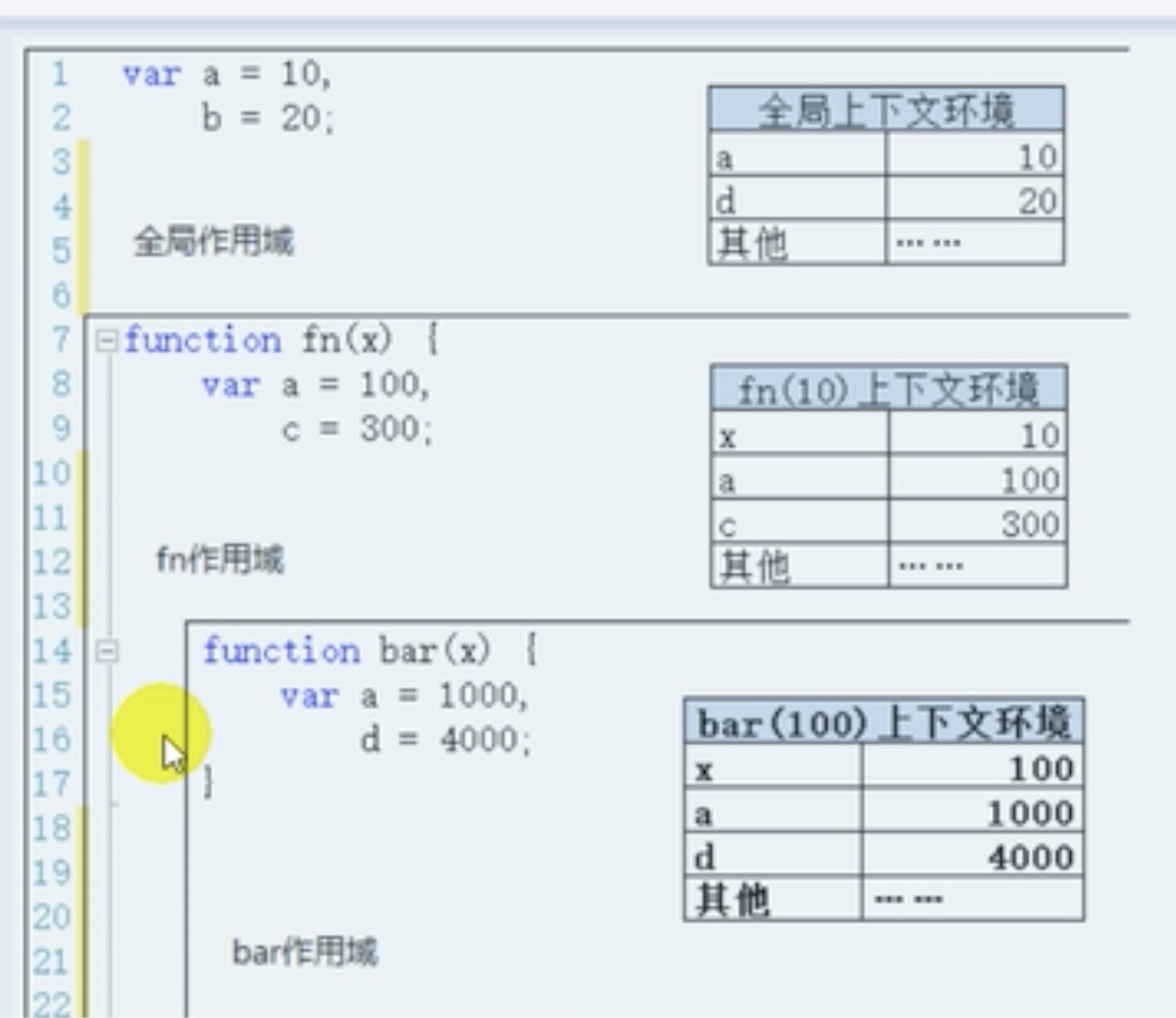
346 | > 通俗理解:按照我们的常规思路,其实完全可以把“作用域”和“执行上下文环境”当作一个东西来理解,毕竟只是概念性的东西,不用过多深究。真实情况下“作用域”是在函数定义的时候存在的,而“执行上下文环境”是JS执行之前确定的,从内到外查找变量,找不到就向外层去找同名变量,这种作用域产生的“由内向外”的过程就是作用域链。
347 |
348 | ## Module模块化的意义
349 |
350 | - 解决命名冲突,防止全局变量的污染
351 | - 管理文件依赖
352 | - 保护私有属性
353 | - 易于代码的扩展和维护
354 |
355 | ## 前端模块化有几种
356 |
357 | ES6(ES2017)之前,前端模块规范有三种: CommandJS、AMD和CMD
358 |
359 | CommandJS用在服务端模块化规范,AMD和CMD用在浏览器模块化规范
360 |
361 | ES6之后,就可以直接食用import和export来实现模块化
362 |
363 |
364 | CommandJS:同步加载---NodeJS
365 | AMD:提前执行(异步加载,回调执行)---RequireJS
366 | CMD:延迟执行(运行时按需加载,顺序执行)---SeaJS
367 |
368 |
369 | ## ES6模块和CommonJS模块有什么区别?
370 | CommonJS是对模块的浅拷贝,可以改变require引入的变量,是node广泛使用的模块化机制。
371 |
372 | ES6模块是对模块的引用,通过import引入的是只读状态,不允许修改只读变量的值。
373 |
374 | CommonJS模块是对象,运行时加载,ES6模块不是对象,编译时加载。
375 |
376 | ## 聊一聊BigInt
377 | 但即将加入标准的基本类型,它是为了解决超过Number的最大安全数字就会出现计算不准确的情况。
378 |
379 | 声明方法是,"阿拉伯数字+n",如`let b = 10n`;
380 |
381 | > 不建议BigInt和Number进行转换,因为会损失精度。
382 |
383 | ## null和undefined有什么区别?
384 | - null表示“没有对象”,即该处不应该有值
385 | - undefined表示“缺少值”,此处应该有一个值,只是没有定义
386 |
387 | ## 轮询和长轮询
388 |
389 | 轮询:客户端定时向服务器发送请求,服务器接收到请求后马上返回响应信息并关闭连接。
390 |
391 | 长轮询:客户端向服务器发送请求,服务器接收到请求之后并不马上响应,等待资源更新时再响应并关闭连接。
392 |
393 | 轮询请求大半无用,浪费带宽,适用于中小项目。
394 |
395 | 长轮询看起来美好,但占用服务器资源,用于实时性比较高的项目,比如WebQQ。
396 |
397 | ## map、reduce、foreach、filter区别
398 |
399 | - foreach按顺序传入每个值,不返回内容
400 | - reduce,将每个值从第二个参数中获取,在第一个参数中保存
401 | - filter过滤器,只返回符合条件的值
402 | - map按顺序传入每个值,return的值改变当前值
403 |
404 | filter和map是返回新数组,reduce返回结果值,foreach不返回
405 |
406 | ## 深拷贝和浅拷贝
407 |
408 | - 浅拷贝(shallow copy):只复制指向某个对象的指针,而不复制对象本身,新旧对象共享一块内存;
409 | - 深拷贝(deep copy):复制并创建一个一摸一样的对象,不共享内存,修改新对象,旧对象保持不变。
410 |
411 | ## Object.assign()是深拷贝还是浅拷贝
412 |
413 | 当对象中只有一级属性,没有二级属性的时候,此方法为深拷贝,但是对象中有对象的时候,此方法,在二级属性以后就是浅拷贝。
414 |
415 | ## ==和===和Obejct.is()的区别
416 |
417 | 三者都用于相等性比较:
418 |
419 | - ==比较宽松,会自动转化数据类型,含义是“值相等”
420 | - ===严格相等,要求值和数据类型都相等
421 | - Object.is(v1,v2)是ES6新语法,传入两个被比较的元素,返回布尔值。类似于===,但有点区别。
422 |
423 | ```javascript
424 |
425 | +0 === -0 //true
426 | NaN === NaN // false
427 | Object.is(+0, -0) // false
428 | Object.is(NaN, NaN) // true
429 |
430 | ```
431 | ## ==隐式转化
432 |
433 | 如果双等号两边有下列情形,则会依次发生这样的判定转化:
434 |
435 | - **其中一个是布尔**:布尔=>数值(false->0、true->1)
436 | - **一个字符串一个数值**:字符串=>数值
437 | - **一个是对象另一个不是**:调用对象的valueOf()方法,如果不是基本类型,基于返回值再调用ToPrimitive算法,这是一个内部的转化为基本类型值的算法,得到了基本类型值再基于前面的规则进行比较。
438 | - **两个都是对象:** 如果他们指向同一个对象,则返回true,否则返回false
439 | - null===undefined//true
440 | - **如果包含NaN:**如果有一个是NaN,甚至NaN==NaN都返回false,而NaN!=NaN返回true
441 |
442 | >例题:
443 | >
444 | >[]==![]//true
445 | >
446 | >- !运算符的优先级大于 ==,会将后面的值转化为布尔值。即![]变成!Boolean([]), 也就是!true,也就是false。
447 | >- 实际上是对比 [] == false;
448 | >- 运用上面的顺序,false是布尔值,所以转化为数值Number(flase), 为0。
449 | >- 对比[] == 0;
450 | >- 满足第三条规则[] 是对象(数组也属于对象),0不是对象。所以ToPrimitive([])是""
451 | >- 对比"" == 0;
452 | >- 满足第二条规则,"" 是字符串,0是数值,对比Number("") == 0, 也就是 0 == 0,结果为true
453 | >- 所以得出 [] == ![]为true
454 |
455 | ## js垃圾回收和内存管理
456 |
457 | 关键:标记清除、V8 新生代和老生代内存、新生代 From 空间和 To 空间的逻辑和好处(拾荒者算法更快+内存碎片)、内存泄露
458 |
459 | JS的垃圾回收机制是为了以防内存泄漏。变量生命周期结束后会被释放内存,全局变量的生命周期持续到浏览器关闭页面,局部变量的生命周期在函数执行后就结束了。
460 |
461 | > 内存泄漏的含义就是当已经不需要某块内存时这块内存还存在着,垃圾回收机制就是间歇的不定期的寻找到不再使用的变量,并释放掉它们所指向的内存。
462 |
463 | js垃圾回收有两种方式:**标记清除**、**引用计数**
464 |
465 | **标记清除**:
466 |
467 | - 标记阶段:垃圾回收器从根对象开始遍历,每一个可以从根对象访问到的对象都会被添加一个可到达对象的标识。
468 | - 清除阶段:垃圾回收器会对堆内存从头到尾进行线性遍历,如果有对象没有被标识为可到达对象,那么就将对应的内存回收,并清除可到达对象的标识,以便下次垃圾回收。
469 |
470 | **引用计数**:
471 |
472 | 低版本的IE使用这种方式,但常常会引起内存泄露。原理是跟踪一个值的引用次数,当声明一个变量并将一个引用类型赋值给该变量时引用次数就是1,同一个值又被赋给另一个变量,引用次数+1,包含这个值当引用的变量取得新值,则引用次数-1,当垃圾回收器下次运行时,就会释放那些引用次数0的值占用的内存。
473 |
474 | 内存泄漏:循环引用指的是对象A中包含一个指向对象B的指针,而对象B中也包含一个指向对象A的引用。
475 | ```
476 | function problem(){
477 | var objectA = new Object();
478 | var objectB = new Object();
479 |
480 | objectA.someOtherObject = objectB;
481 | objectB.anotherObject = objectA;
482 | }
483 | ```
484 |
485 | ## js如何判断数据类型。如何判断数组
486 | **typeof**(不可以)
487 |
488 | typeof [] === "object"
489 | typeof Null === "object"
490 |
491 | **instanceof**
492 |
493 | 检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上。
494 |
495 | ```
496 | const a = [],b={};
497 | console.log(a instanceof Array);//true
498 | console.log(a instanceof Object);//true,在数组的原型链上也能找到Object构造函数
499 | console.log(b instanceof Array);//false
500 | ```
501 |
502 | **constructor**
503 |
504 | ```
505 | const a = [];
506 | console.log(a.constructor);//function Array(){ [native code] }
507 | ```
508 |
509 | 但不能保证constructor属性被改写的情况。
510 |
511 | **Object.toString()和call/apply改写isArray**
512 |
513 | 除了对象之外,其他的数据类型的toString返回的都是内容的字符串,只有对象的toString方法会返回对象的类型,可以通过call/appy改变toString的执行上下文。
514 |
515 | ```
516 | const isArray = (something)=>{
517 | return Object.prototype.toString.call(something) === '[object Array]';
518 | }
519 |
520 | cosnt a = [];
521 | const b = {};
522 | isArray(a);//true
523 | isArray(b);//false
524 | ```
525 |
526 | **Array.isArray()**最靠谱
527 |
528 | ```
529 | const a = [];
530 | const b = {};
531 | Array.isArray(a);//true
532 | Array.isArray(b);//false
533 | ```
534 |
535 | ## 事件委托
536 |
537 | 事件委托就是利用事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。
538 |
539 | 事件委托的好处
540 |
541 | - 只绑定一次事件,无频繁访问DOM,性能较高
542 | - 当有新DOM生成时,无需重复绑定事件,代码清晰简洁
543 |
544 | (联想到React的合成事件)
545 |
546 | ## 前端发送请求的多种方法fetch/ajax/axios
547 |
548 | **Ajax**:
549 |
550 | 异步网络请求。区别于传统web开发中采用的同步方式。
551 |
552 | Ajax带来的最大影响就是页面可以无刷新的请求数据。以往,页面表单提交数据,在用户点击完”submit“按钮后,页面会强制刷新一下,体验十分不友好。
553 |
554 | ```javascript
555 | var request = new XMLHttpRequest(); // 创建XMLHttpRequest对象
556 |
557 | //ajax是异步的,设置回调函数
558 | request.onreadystatechange = function () { // 状态发生变化时,函数被回调
559 | if (request.readyState === 4) { // 成功完成
560 | // 判断响应状态码
561 | if (request.status === 200) {
562 | // 成功,通过responseText拿到响应的文本:
563 | return success(request.responseText);
564 | } else {
565 | // 失败,根据响应码判断失败原因:
566 | return fail(request.status);
567 | }
568 | } else {
569 | // HTTP请求还在继续...
570 | }
571 | }
572 |
573 | // 发送请求:
574 | request.open('GET', '/api/categories');
575 | request.setRequestHeader("Content-Type", "application/json") //设置请求头
576 | request.send();//到这一步,请求才正式发出
577 | ```
578 |
579 | **axios**:
580 |
581 | axios不是一种新的技术,axios 是一个基于Promise 用于浏览器和 nodejs 的 HTTP 客户端,本质上也是对原生XHR的封装,只不过它是Promise的实现版本,符合最新的ES规范,
582 |
583 | > 实际上,axios可以用在浏览器和 node.js 中是因为,它会自动判断当前环境是什么,如果是浏览器,就会基于XMLHttpRequests实现axios。如果是node.js环境,就会基于node内置核心模块http实现axios
584 | >
585 | 有以下特点:
586 |
587 | - 从浏览器中创建 XMLHttpRequests
588 | - 从 node.js 创建 http 请求
589 | - 支持 Promise API
590 | - 拦截请求和响应
591 | - 转换请求数据和响应数据
592 | - 取消请求
593 | - 自动转换 JSON 数据
594 | - 客户端支持防御 CSRF/XSRF
595 |
596 | **fetch**:
597 |
598 | fetch是前端发展的一种新技术产物。Fetch API提供了访问和操控HTTP流的js接口,例如请求和响应。它还提供了一个全局 fetch()方法,该方法提供了一种简单,合理的方式来跨网络异步获取资源。
599 |
600 | fetch() 会返回一个 promise。然后我们用then()方法编写处理函数来处理promise中异步返回的结果。处理函数会接收fetch promise的返回值,这是一个 Response 对象。
601 |
602 | 在使用fetch的时候需要注意:
603 |
604 | - 接受到错误状态码时,Promise还是resolve(但是会将 resolve 的返回值的 ok 属性设置为 false )仅当网络故障时或请求被阻止时,才会标记为 reject。
605 | - 默认情况下,fetch 不会从服务端发送或接收任何 cookies, 如果站点依赖于用户 session,则会导致未经认证的请求(要发送 cookies,必须设置 credentials 选项)。
606 |
607 | fetch代表着更先进的技术方向,但是目前兼容性不是很好,在项目中使用的时候得慎重。
608 |
609 | **缺点:**
610 |
611 | 虽然fetch比XHR有极大的提高,特别是它在Service Worker中的集成,但是 Fetch 现在还没有方法中止一个请求,除非使用实验性功能, AbortController 和 AbortSignal,这是个通用的API 来通知 中止 事件。另外用 Fetch 不能监测上传进度。如果需要的话,还是使用axios
612 |
613 | ```javascript
614 | fetch('http://example.com/movies.json')
615 | .then(function(response) {
616 | return response.json();
617 | })
618 | .then(function(myJson) {
619 | console.log(myJson);
620 | });
621 | ```
622 |
623 | **另外还有JQuery,request封装了网络请求**
624 |
625 | ## 什么是同步和异步
626 |
627 | 我们可以通俗理解为异步就是一个任务分成两段,先执行第一段,然后转而执行其他任务,等做好了准备,再回过头执行第二段。排在异步任务后面的代码,不用等待异步任务结束会马上运行,也就是说,异步任务不具有”堵塞“效应。不连续的执行,就叫做异步。相应地,连续的执行,就叫做同步
628 |
629 | "异步模式"非常重要。在浏览器端,耗时很长的操作都应该异步执行,避免浏览器失去响应,最好的例子就是Ajax操作。在服务器端,"异步模式"甚至是唯一的模式,因为执行环境是单线程的,如果允许同步执行所有http请求,服务器性能会急剧下降,很快就会失去响应。
630 |
631 | ## js中实现异步编程的六种方案
632 |
633 | #### 回调函数
634 |
635 | 回调是一个简单的函数,它作为参数传递给另一个函数,并且在事件发生的时候会执行。在 JavaScript中,函数可以赋值给一个变量,作为其他函数的参数。
636 |
637 | 回调函数的优点是简单、容易理解和实现,缺点是不利于代码的阅读和维护,各个部分之间高度耦合,使得程序结构混乱、流程难以追踪(尤其是多个回调函数嵌套的情况),而且每个任务只能指定一个回调函数。此外它不能使用 try catch 捕获错误,不能直接 return。
638 |
639 | #### 事件监听
640 |
641 | 这种方式下,异步任务的执行不取决于代码的顺序,而取决于某个事件是否发生。
642 |
643 | 这种方法的优点是比较容易理解,可以绑定多个事件,每个事件可以指定多个回调函数,而且可以"去耦合",有利于实现模块化。缺点是整个程序都要变成事件驱动型,运行流程会变得很不清晰。
644 |
645 | #### 发布订阅
646 |
647 | 我们假定,存在一个"信号中心",某个任务执行完成,就向信号中心"发布"(publish)一个信号,其他任务可以向信号中心"订阅"(subscribe)这个信号,从而知道什么时候自己可以开始执行。这就叫做"发布/订阅模式"(publish-subscribe pattern)
648 |
649 | #### Promise
650 |
651 | **Promise的三种状态:**
652 |
653 | - Pending----Promise对象实例创建时候的初始状态
654 | - Fulfilled----可以理解为成功的状态
655 | - Rejected----可以理解为失败的状态
656 |
657 | 这个promise一旦从等待状态变成为其他状态就永远不能更改状态了
658 |
659 | promise的链式调用:
660 |
661 | - 每次调用返回的都是一个新的Promise实例(这就是then可用链式调用的原因)
662 | - 如果then中返回的是一个结果的话会把这个结果传递下一次then中的成功回调
663 | - 如果then中出现异常,会走下一个then的失败回调
664 | - 在then中使用了return,那么return的值会被Promise.resolve() 包装
665 | - then中可以不传递参数,如果不传递会透到下一个then中
666 | - catch 会捕获到没有捕获的异常
667 |
668 | #### 生成器Generators/ yield
669 |
670 | Generator 函数是 ES6 提供的一种异步编程解决方案,语法行为与传统函数完全不同,Generator 最大的特点就是可以控制函数的执行。
671 |
672 | - 语法上,首先可以把它理解成,Generator 函数是一个状态机,封装了多个内部状态。
673 | - Generator 函数除了状态机,还是一个遍历器对象生成函数。
674 | - 可暂停函数, yield可暂停,next方法可启动,每次返回的是yield后的表达式结果。
675 | - yield表达式本身没有返回值,或者说总是返回undefined。next方法可以带一个参数,该参数就会被当作上一个yield表达式的返回值。
676 |
677 | ```javascript
678 | function *foo(x) {
679 | let y = 2 * (yield (x + 1))
680 | let z = yield (y / 3)
681 | return (x + y + z)
682 | }
683 | let it = foo(5)
684 | console.log(it.next()) // => {value: 6, done: false}
685 | console.log(it.next(12)) // => {value: 8, done: false}
686 | console.log(it.next(13)) // => {value: 42, done: true}
687 | ```
688 |
689 | 手动迭代Generator 函数很麻烦,而实际开发一般会配合 co 库去使用。co是一个为Node.js和浏览器打造的基于生成器的流程控制工具,借助于Promise,你可以使用更加优雅的方式编写非阻塞代码。
690 |
691 | #### async/await
692 |
693 | - async/await是基于Promise实现的,它不能用于普通的回调函数。
694 | - async/await与Promise一样,是非阻塞的。
695 | - async/await使得异步代码看起来像同步代码,写法优雅,处理 then 的调用链,能够更清晰准确的写出代码
696 |
697 | ## async/await比Generator好在哪
698 |
699 | - 内置执行器。Generator 函数的执行必须靠执行器,所以才有了 co 函数库,而 async 函数自带执行器。也就是说,async 函数的执行,与普通函数一模一样,只要一行。
700 | - 更广的适用性。 co 函数库约定,yield 命令后面只能是 Thunk 函数或 Promise 对象,而 async 函数的 await 命令后面,可以跟 Promise 对象和原始类型的值(数值、字符串和布尔值,但这时等同于同步操作)。
701 | - 更好的语义。 async 和 await,比起星号和 yield,语义更清楚了。async 表示函数里有异步操作,await 表示紧跟在后面的表达式需要等待结果。
702 |
703 | ## 浏览器实现提供的通信手段
704 |
705 | [各种浏览器通信测试网站](https://alienzhou.github.io/cross-tab-communication)
706 |
707 | |通信手段|常用场景|同源同 Tab|同源跨 Tab|跨域|
708 | |-|-|-|-|-|
709 | |`SessionStorage`|单页面临时状态|✔️|||
710 | |`Web Workers`|独立线程,复杂计算|✔️|||
711 | |`ServiceWorker`|独立线程,离线/弱网|✔️|||
712 | |`Shared Workers`|多标签页共享的线程|✔️|✔️||
713 | |`BroadcastChannel API`|多标签页广播通信|✔️|✔️||
714 | |`localStorage`|长期本地存储|✔️|✔️||
715 | |`IndexedDB`|大量结构化数据存储|✔️|✔️||
716 | |`cookies`|用户身份认证、会话持久化|✔️|✔️||
717 | |`postMessage`|不同窗口间安全通信|✔️|✔️|✔️|
718 | |`WebSocket`|C/S双向通信|✔️|✔️|✔️|
719 | |`CORS+Fetch/XMLHttpRequest`|跨域常用解决方案|✔️|✔️|✔️|
720 | |`JSONP`|get 跨域|✔️|✔️|✔️|
721 | |`WebRTC`|C/C的P2P通信|✔️|✔️|✔️|
722 |
723 |
724 | ## localStorage和sessionStorage
725 |
726 |
727 | localStorage和sessionStorage一样都是用来存储客户端临时信息的对象。
728 |
729 | - localStorage生命周期是永久,这意味着除非用户主动在浏览器上清除localStorage信息,否则这些信息将永远存在。
730 | - sessionStorage生命周期为当前窗口或标签页,一旦窗口或标签页被永久关闭了,那么所有通过sessionStorage存储的数据也就被清空了。
731 |
732 | 不同浏览器无法共享localStorage或sessionStorage中的信息。相同浏览器的不同页面间可以共享相同的 localStorage(页面属于相同域名和端口),但是不同页面或标签页间无法共享sessionStorage的信息。这里需要注意的是,页面及标签页仅指顶级窗口,如果一个标签页包含多个iframe标签且他们属于同源页面,那么他们之间是可以共享sessionStorage的。
733 |
734 | 使用时使用相同的API:
735 |
736 | - localStorage.setItem('myCat', 'Tom');
737 | - let cat = localStorage.getItem('myCat');
738 | - localStorage.removeItem('myCat');
739 | - localStorage.clear();// 移除所有
740 |
741 | localStorage的除了get的API都会触发storage事件,可以利用这个来做不同标签页的通信,比如多个页面的购物车数据同步。
742 |
743 | ## cookie和session的区别
744 |
745 | Cookie与Session都能够进行会话跟踪,普通状况下二者均能够满足需求
746 |
747 | - cookie数据存放在客户的浏览器(客户端)上,session数据放在服务器上,但是服务端的session的实现对客户端的cookie有依赖关系的;
748 | - cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,考虑到安全应当使用session;
749 | - session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能。考虑到减轻服务器性能方面,应当使用COOKIE;
750 | - 单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能超过3K;
751 |
752 | ## 冒泡和捕获
753 | **冒泡:**
754 |
755 | 微软提出了事件冒泡的事件流,事件会从最内层的元素开始发生,一直向上传播,直到document对象。p元素上发生click事件的顺序应该是p -> body -> html -> document
756 |
757 | **捕获:**
758 |
759 | 网景提出了事件捕获的事件流,事件冒泡相反,事件会从最外层开始发生,直到最具体的元素。p元素上发生click事件的顺序应该是document -> html -> body -> div -> p
760 |
761 | W3C制定了统一的标准,**先捕获再冒泡**。
762 |
763 | 可以通过addEventListener()的第三个参数来确定捕获还是冒泡,第一个参数是要绑定的事件,第二个参数是回调函数,第三个参数默认是false,代表**事件冒泡阶段**调用事件处理函数,如果设置成true,则在**事件捕获阶段**调用处理函数。
764 |
765 | 在浏览器中,如果父子元素**都设置了捕获和冒泡**的输出,当点击子元素时:
766 |
767 | - 先捕获父元素
768 | - 子元素输出先注册的事件,如果是捕获先输出捕获,如果是冒泡先输出冒泡
769 | - 在输出父元素的冒泡事件
770 |
771 | **阻止冒泡和捕获:**
772 | event.stopPropagation(); 以阻止事件的继续传播。
773 |
774 | ## ECMAScript 新特性&&常用
775 |
776 | ECMAScript 2022:
777 | Array.at(-1)从后向前取
778 |
779 | ECMAScript 2021:
780 | - Promise.any()和AggregateError
781 | - 逻辑赋值运算符 (&&=, ||=, ??=)
782 | - 数字字面量中使用下划线(_)作为分隔符,以增加可读性
783 |
784 | ES 2020:
785 | - 新的逻辑操作符??,只有当左侧的表达式结果为 null 或者 undefined 时,才会返回右侧的表达式。
786 | - BigInt
787 | - Promise.allSettled()
788 | - 查询嵌套结构时,允许a?.b的语法,避开报错或特殊处理
789 |
790 | ES 2021:
791 | - Object.fromEntries(ECMAScript 2019):该方法把键值对列表转换为一个对象
792 |
--------------------------------------------------------------------------------
/docs/javascript/write-code.md:
--------------------------------------------------------------------------------
1 |
2 | 手撸代码不仅考察代码逻辑,还考察格式规范,这个注意一下。
3 |
4 |
5 | ## 实现生物上的S型增长曲线
6 |
7 | **美团点评**
8 |
9 | 面试官:"在实现动画的过程中,想要控制某些动画速度先快后慢,假如说现在要自定义一个速度曲线,应该怎么实现?比如**先慢速增加,再快速增加,再慢速增加**"
10 |
11 | 我提到了动画的`animation-timing-function`,大概就是类似`linear`、`ease`、`ease-in-out`……这种,不过意思是要实现定制化
12 |
13 | 思路:曲线其实就是"sin(t)"的变形,然后取中间一部分
14 | 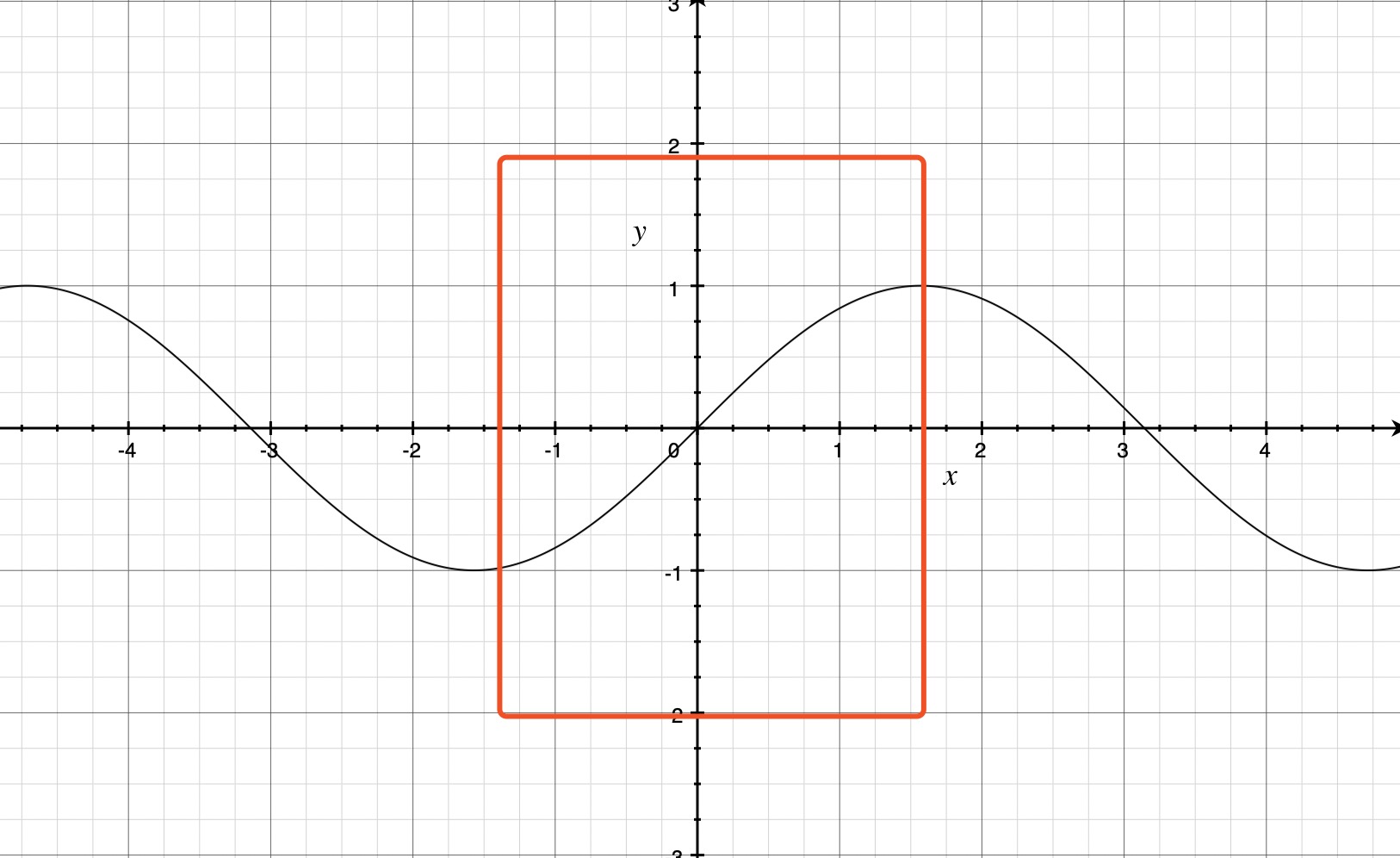
15 |
16 | 以便于调节单位长度的变化,我们最好将曲线变形成这样:
17 | 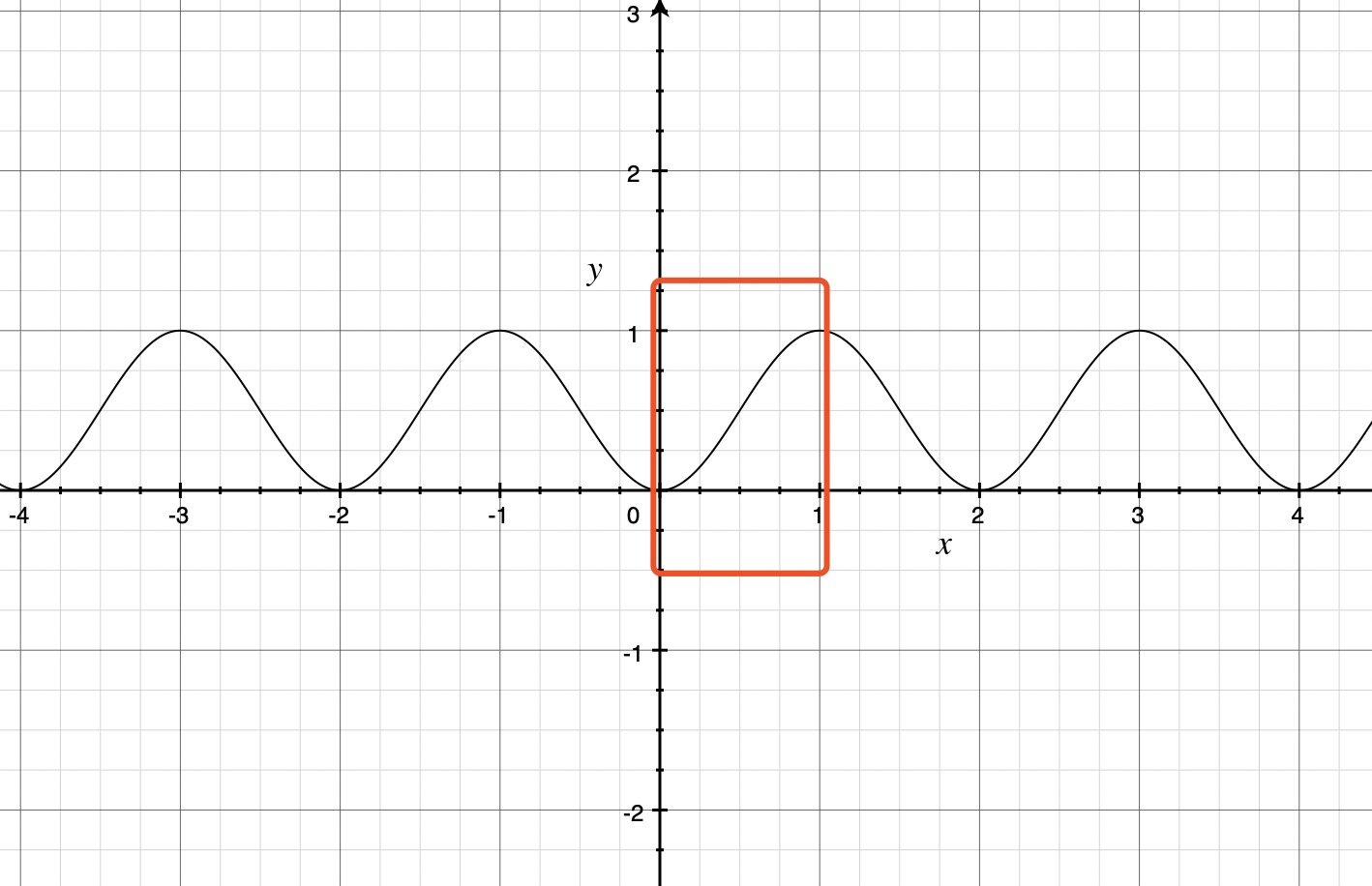
18 |
19 | 我已经将函数变形完成,公式如下:(这里将3.14=Math.PI)突然懵逼的小伙伴还请复习三角函数知识。
20 |
21 | 
22 |
23 | 转化为代码:
24 |
25 | ```javascript
26 | function l(x) {
27 | let {sin,PI} = Math;
28 | let y = 0.5*((sin(PI*x-PI/2.0)+1));
29 | return y;
30 | }
31 | ```
32 |
33 | 传入{0-1},按照速度曲线变化,输出{0-1}
34 |
35 | ## 深拷贝
36 |
37 | 百度二面
38 |
39 | 注意JSON.parse(JSON.stringify(json));这个
40 |
41 | ```javascript
42 |
43 | // 深拷贝
44 | // 局限性:循环引用,不能处理无原型链的对象
45 | let deepCopy = (obj: any): any => {
46 | if (obj === null) return null
47 | let clone = Object.assign({}, obj)
48 | // 拷贝属性
49 | Object.keys(obj).forEach(k => {
50 | // 特殊对象还是需要特殊处理,需要拷贝更多,需要添加更多
51 | if (typeof obj[k] === 'function') {
52 | clone[k] = obj[k].bind(clone)
53 | } else if (obj[k] instanceof RegExp) {
54 | clone[k] = new RegExp(obj[k])
55 | } else if (obj[k] instanceof Date) {
56 | clone[k] = new Date(obj[k])
57 | } else if (obj[k] instanceof Set) {
58 | clone[k] = new Set(deepCopy(Array.from(obj[k])))
59 | } else if (obj[k] instanceof Map) {
60 | clone[k] = new Map(deepCopy(Array.from(obj[k])))
61 | } else if (typeof obj[k] === 'object') {
62 | clone[k] = deepCopy(obj[k])
63 | } else {
64 | clone[k] = obj[k]
65 | }
66 | })
67 |
68 | if (Array.isArray(obj)) {
69 | clone.length = obj.length
70 | return Array.from(clone)
71 | }
72 | }
73 |
74 |
75 | ```
76 |
77 | ## 数组乱序
78 |
79 | 百度二面
80 |
81 | ```javascript
82 |
83 | let arr = [1,2,3,4,4,5,6,7,7,5,5,2,3];
84 |
85 | //方法一:sort随机排序
86 | function fun(arr){
87 | arr.sort(()=>)
88 | }
89 |
90 | /**
91 | * 方法二:随机交换每个下表值
92 | * @param arr
93 | * @returns {*}
94 | */
95 | function fun(arr) {
96 |
97 | let len = arr.length;
98 | for (let i = 0; i < len; i++) {
99 | let handleIndex = Math.floor(Math.random() * len);
100 |
101 | let temp = arr[i];
102 | arr[i] = arr[handleIndex];
103 | arr[handleIndex] = temp;
104 | temp = arr[i];
105 | }
106 |
107 | return arr;
108 | }
109 |
110 | console.log(fun(arr));
111 |
112 | ```
113 |
114 | ## 数组去重
115 |
116 | ```javascript
117 | let arr = [1, 2, 3, 4, 5, 5, 3, 2, 1];
118 |
119 | function removeRepeat(arr) {
120 | let newArr = [];
121 |
122 | //排序数组
123 | arr.sort();
124 |
125 | //当前值
126 | let curr = null;
127 |
128 | for (let i = 0; i < arr.length; i++) {
129 | if (curr===arr[i]){
130 | continue;
131 | }
132 |
133 | curr = arr[i];
134 | newArr.push(arr[i]);
135 | }
136 | return newArr;
137 | }
138 |
139 | console.log(removeRepeat(arr));
140 | ```
141 |
142 | ## 数组扁平化
143 |
144 | ```javascript
145 | let arr = [1, 2, 3, [4, 5], [6, [7, 8]],];
146 |
147 | //方法一:flat扁平化数组,默认为1
148 | console.log(arr.flat(Infinity));
149 |
150 | //方法二:递归
151 | function fun(arr){
152 | let newArr = [];
153 | arr.forEach(value => {
154 | if (Array.isArray(value)){
155 | newArr = newArr.concat(fun(value));
156 | }else {
157 | newArr =newArr.concat(value);
158 | }
159 | });
160 | return newArr;
161 | }
162 | console.log(fun(arr));
163 |
164 | //方法三:toString()
165 | //实现到Array上
166 | Array.prototype.f2=function(){
167 | let arr=this;
168 | return arr.toString().split(',')
169 | }
170 | console.log(f2(arr));
171 |
172 |
173 | ```
174 |
175 | ## 手撸继承
176 |
177 | 创建一个 Person 类,其包含公有属性 name 和私有属性 age 以及公有方法 setAge ;创建一个 Teacher 类,使其继承 Person ,并包含私有属性 studentCount 和私有方法 setStudentCount
178 |
179 | ```javascript
180 |
181 | const [Person, Teacher] = (function () {
182 | const _age = Symbol('_age');
183 |
184 | const _studentCount = Symbol('_studentCount');
185 | const _setStudentCount = Symbol('_setStudentCount');
186 |
187 |
188 | class Person {
189 | constructor(name, age) {
190 | this.name = name;
191 | this[_age] = age;
192 | }
193 |
194 | setAge(age) {
195 | this[_age] = age;
196 | }
197 | }
198 |
199 | class Teacher extends Person{
200 | constructor(name,age,studentCount){
201 | super(name,age);
202 | this[_studentCount] = studentCount;
203 | }
204 |
205 | /**
206 | * 私有方法,设置学生数量
207 | * @param studentCount
208 | */
209 | [_setStudentCount](studentCount){
210 | this[_studentCount] = studentCount;
211 | }
212 |
213 | setCount(count){
214 | this[_setStudentCount](count);
215 | }
216 |
217 | }
218 |
219 | return [Person, Teacher];
220 | })();
221 |
222 | const p = new Person('初始名字',0);
223 | const t = new Teacher('老师',24,55);
224 |
225 | ```
226 |
227 | 其实未来js是可以使用#来实现私有属性和私有方法的,截止2020年4月,这个提案已经被审核到[stage3](https://github.com/tc39/proposal-private-methods)阶段,即作为候选的完善阶段。
228 |
229 | ## 实现Promise
230 |
231 | **第一版 Promise:能保存回调方法**
232 |
233 | 思路是在 .then() 方法中, 将 fullfill 和 reject 结果的回调函数保存下来, 然后在异步方法中调用. 因为是异步调用, 根据 event-loop 的原理, promiseAsyncFunc().then(fulfillCallback, rejectCallback) 传入的 callback 在异步调用结束时一定是已经赋值过了.
234 |
235 | ```javascript
236 | // Promise 形式的异步方法定义
237 | var promiseAsyncFunc = function() {
238 | var fulfillCallback
239 | var rejectCallback
240 |
241 | setTimeout(() => {
242 | var randomNumber = Math.random()
243 | if (randomNumber > 0.5) fulfillCallback(randomNumber)
244 | else rejectCallback(randomNumber)
245 | }, 1000)
246 | return {
247 | then: function(_fulfillCallback, _rejectCallback) {
248 | fulfillCallback = _fulfillCallback
249 | rejectCallback = _rejectCallback
250 | }
251 | }
252 | }
253 |
254 | // Promise 形式的异步方法调用
255 | promiseAsyncFunc().then(fulfillCallback, rejectCallback)
256 |
257 | ```
258 |
259 |
260 | 【点击展开】更高级的实现Promise的方法
261 |
262 | **第二版 Promise:实构造函数:**
263 |
264 | 当前我们的实现 Promise 中,异步逻辑代码和 Promise 的代码是杂糅在一起的,让我们将其区分开:
265 |
266 | 定义一个新方法 ownPromise() 用于创建 Promise,并在promiseAsyncFunc() 中暴露出 fulfill 和 reject 接口方便异步代码去调用。
267 |
268 | ```javascript
269 | var promiseAsyncFunc = function() {
270 | var fulfillCallback
271 | var rejectCallback
272 |
273 | return {
274 | fulfill: function(value) {
275 | if (fulfillCallback && typeof fulfillCallback === 'function') {
276 | fulfillCallback(value)
277 | }
278 | },
279 | reject: function(err) {
280 | if (rejectCallback && typeof rejectCallback === 'function') {
281 | rejectCallback(err)
282 | }
283 | },
284 | promise: {
285 | then: function(_fulfillCallback, _rejectCallback) {
286 | fulfillCallback = _fulfillCallback
287 | rejectCallback = _rejectCallback
288 | }
289 | }
290 | }
291 | }
292 |
293 | let ownPromise = function(asyncCall) {
294 | let defer = promiseAsyncFunc()
295 | asyncCall(defer.fulfill, defer.reject)
296 | return defer.promise
297 | }
298 |
299 | // Promise 形式的异步方法调用
300 | ownPromise(function(fulfill, reject) {
301 | setTimeout(() => {
302 | var randomNumber = Math.random()
303 | if (randomNumber > 0.5) fulfill(randomNumber)
304 | else reject(randomNumber)
305 | }, 1000)
306 | })
307 |
308 | ```
309 |
310 | **第三版 Promise: 支持状态管理**
311 |
312 | 为了实现规范中对于 Promise 状态变化的要求, 我们需要为 Promise 加入状态管理, 可以利用 Symbol 来表示状态常量
313 |
314 | 为了判断 Promise 的状态, 我们加入了 fulfill 和 reject 两个方法。并在其中判断 promise 当前状态。如果不是 pending 状态则直接 return(因为 Promise 状态只可能改变一次)。
315 |
316 | 要实现这样的规范:
317 |
318 | - 只允许改变一次状态
319 | - 只能从 pending => fulfilled 或 pending => rejected
320 |
321 | ```javascript
322 | const PENDING = Symbol('pending')
323 | const FULFILLED = Symbol('fulfilled')
324 | const REJECTED = Symbol('rejected')
325 |
326 | // Promise 形式的异步方法定义
327 | var promiseAsyncFunc = function() {
328 | var status = PENDING
329 | var fulfillCallback
330 | var rejectCallback
331 |
332 | return {
333 | fulfill: function(value) {
334 | if (status !== PENDING) return
335 | if (typeof fulfillCallback === 'function') {
336 | fulfillCallback(value)
337 | status = FULFILLED
338 | }
339 | },
340 | reject(error) {
341 | if (status !== PENDING) return
342 | if (typeof rejectCallback === 'function') {
343 | rejectCallback(error)
344 | status = REJECTED
345 | }
346 | },
347 | promise: {
348 | then: function(_fulfillCallback, _rejectCallback) {
349 | fulfillCallback = _fulfillCallback
350 | rejectCallback = _rejectCallback
351 | }
352 | }
353 | }
354 | }
355 |
356 | let ownPromise = function(asyncCall) {
357 | let defer = promiseAsyncFunc()
358 | asyncCall(defer.fulfill, defer.reject)
359 | return defer.promise
360 | }
361 |
362 | // Promise 形式的异步方法调用
363 | ownPromise(function(fulfill, reject) {
364 | setTimeout(() => {
365 | var randomNumber = Math.random()
366 | if (randomNumber > 0.5) fulfill(randomNumber)
367 | else reject(randomNumber)
368 | }, 1000)
369 | }).then(data => console.log(data), err => console.log(err))
370 | ```
371 |
372 |
373 |
374 |
375 | ## Promise.all()
376 | promise.all 是解决并发问题的,多个异步并发获取最终的结果(如果有一个失败则失败)。
377 |
378 | ```javascript
379 | Promise.all = function(values) {
380 | if (!Array.isArray(values)) {
381 | const type = typeof values;
382 | return new TypeError(`TypeError: ${type} ${values} is not iterable`)
383 | }
384 |
385 | return new Promise((resolve, reject) => {
386 | let resultArr = [];
387 | let orderIndex = 0;
388 | const processResultByKey = (value, index) => {
389 | resultArr[index] = value;
390 | if (++orderIndex === values.length) {
391 | resolve(resultArr)
392 | }
393 | }
394 | for (let i = 0; i < values.length; i++) {
395 | let value = values[i];
396 | if (value && typeof value.then === 'function') {
397 | value.then((value) => {
398 | processResultByKey(value, i);
399 | }, reject);
400 | } else {
401 | processResultByKey(value, i);
402 | }
403 | }
404 | });
405 | }
406 |
407 | ```
408 | ## Promise.race()
409 |
410 | Promise.race 用来处理多个请求,采用最快的(谁先完成用谁的)。
411 |
412 | ```
413 | Promise.race = function(promises) {
414 | return new Promise((resolve, reject) => {
415 | // 一起执行就是for循环
416 | for (let i = 0; i < promises.length; i++) {
417 | let val = promises[i];
418 | if (val && typeof val.then === 'function') {
419 | val.then(resolve, reject);
420 | } else { // 普通值
421 | resolve(val)
422 | }
423 | }
424 | });
425 | }
426 |
427 | ```
428 |
429 |
430 | ## 防抖和节流
431 |
432 | 防抖:在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时。适用于:输入框联想,防止多次点击提交按钮。
433 | 节流:规定在一个单位时间内,只能触发一次函数。如果这个单位时间内触发多次函数,只有一次生效。适用于:浏览器resize、onscroll。
434 |
435 | ```javascript
436 | // 防抖函数
437 | const debounce = (fn, delay) => {
438 | let timer = null;
439 | return (...args) => {
440 | clearTimeout(timer);
441 | timer = setTimeout(() => {
442 | fn.apply(this, args);
443 | }, delay);
444 | };
445 | };
446 |
447 |
448 | // 节流函数
449 | const throttle = (fn, delay = 500) => {
450 | let flag = true;
451 | return (...args) => {
452 | if (!flag) return;
453 | flag = false;
454 | setTimeout(() => {
455 | fn.apply(this, args);
456 | flag = true;
457 | }, delay);
458 | };
459 | };
460 |
461 | ```
462 |
463 | 防抖节流演示:
464 |
465 |
466 |
467 | ## 实现new操作符
468 |
469 | ```javascript
470 | /**
471 | * 模拟实现 new 操作符
472 | * @param {Function} ctor [构造函数]
473 | * @return {Object|Function|Regex|Date|Error} [返回结果]
474 | */
475 | function newOperator(ctor){
476 | if(typeof ctor !== 'function'){
477 | throw 'newOperator function the first param must be a function';
478 | }
479 | // ES6 new.target 是指向构造函数
480 | newOperator.target = ctor;
481 | // 1.创建一个全新的对象,
482 | // 2.并且执行[[Prototype]]链接
483 | // 4.通过`new`创建的每个对象将最终被`[[Prototype]]`链接到这个函数的`prototype`对象上。
484 | var newObj = Object.create(ctor.prototype);
485 | // ES5 arguments转成数组 当然也可以用ES6 [...arguments], Aarry.from(arguments);
486 | // 除去ctor构造函数的其余参数
487 | var argsArr = [].slice.call(arguments, 1);
488 | // 3.生成的新对象会绑定到函数调用的`this`。
489 | // 获取到ctor函数返回结果
490 | var ctorReturnResult = ctor.apply(newObj, argsArr);
491 | // 小结4 中这些类型中合并起来只有Object和Function两种类型 typeof null 也是'object'所以要不等于null,排除null
492 | var isObject = typeof ctorReturnResult === 'object' && ctorReturnResult !== null;
493 | var isFunction = typeof ctorReturnResult === 'function';
494 | if(isObject || isFunction){
495 | return ctorReturnResult;
496 | }
497 | // 5.如果函数没有返回对象类型`Object`(包含`Functoin`, `Array`, `Date`, `RegExg`, `Error`),那么`new`表达式中的函数调用会自动返回这个新的对象。
498 | return newObj;
499 | }
500 | ```
501 |
502 | ## 实现bind
503 |
504 | **简单版本**:
505 |
506 | ```javascript
507 | Function.prototype.myBind = function(thisArg) {
508 | if (typeof this !== 'function') {
509 | return;
510 | }
511 | let _self = this;
512 | let args = Array.prototype.slice.call(arguments, 1)
513 | let fnBound = function () {
514 | // 检测 New
515 | // 如果当前函数的this指向的是构造函数中的this 则判定为new 操作
516 | let _this = this instanceof _self ? this : thisArg;
517 | return _self.apply(_this, args.concat(Array.prototype.slice.call(arguments)));
518 | }
519 | // 为了完成 new操作 需要原型链接
520 | fnBound.prototype = this.prototype;
521 | return fnBound;
522 | }
523 |
524 |
525 | ```
526 |
527 |
528 | 【点击展开】更高级的实现bind()的方法
529 |
530 |
531 | **bind高级版本:**
532 |
533 | ```javascript
534 | // 第三版 实现new调用
535 | Function.prototype.bindFn = function bind(thisArg){
536 | if(typeof this !== 'function'){
537 | throw new TypeError(this + ' must be a function');
538 | }
539 | // 存储调用bind的函数本身
540 | var self = this;
541 | // 去除thisArg的其他参数 转成数组
542 | var args = [].slice.call(arguments, 1);
543 | var bound = function(){
544 | // bind返回的函数 的参数转成数组
545 | var boundArgs = [].slice.call(arguments);
546 | var finalArgs = args.concat(boundArgs);
547 | // new 调用时,其实this instanceof bound判断也不是很准确。es6 new.target就是解决这一问题的。
548 | if(this instanceof bound){
549 | // 这里是实现上文描述的 new 的第 1, 2, 4 步
550 | // 1.创建一个全新的对象
551 | // 2.并且执行[[Prototype]]链接
552 | // 4.通过`new`创建的每个对象将最终被`[[Prototype]]`链接到这个函数的`prototype`对象上。
553 | // self可能是ES6的箭头函数,没有prototype,所以就没必要再指向做prototype操作。
554 | if(self.prototype){
555 | // ES5 提供的方案 Object.create()
556 | // bound.prototype = Object.create(self.prototype);
557 | // 但 既然是模拟ES5的bind,那浏览器也基本没有实现Object.create()
558 | // 所以采用 MDN ployfill方案 https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Object/create
559 | function Empty(){}
560 | Empty.prototype = self.prototype;
561 | bound.prototype = new Empty();
562 | }
563 | // 这里是实现上文描述的 new 的第 3 步
564 | // 3.生成的新对象会绑定到函数调用的`this`。
565 | var result = self.apply(this, finalArgs);
566 | // 这里是实现上文描述的 new 的第 5 步
567 | // 5.如果函数没有返回对象类型`Object`(包含`Functoin`, `Array`, `Date`, `RegExg`, `Error`),
568 | // 那么`new`表达式中的函数调用会自动返回这个新的对象。
569 | var isObject = typeof result === 'object' && result !== null;
570 | var isFunction = typeof result === 'function';
571 | if(isObject || isFunction){
572 | return result;
573 | }
574 | return this;
575 | }
576 | else{
577 | // apply修改this指向,把两个函数的参数合并传给self函数,并执行self函数,返回执行结果
578 | return self.apply(thisArg, finalArgs);
579 | }
580 | };
581 | return bound;
582 | }
583 | ```
584 |
585 |
586 |
587 |
588 |
589 | ## 实现apply和call方法
590 |
591 | **简单的ES6实现call**
592 |
593 | ```javascript
594 | /**
595 | * @description 使用ES6函数的rest参数和数组的扩展运算符实现call方法
596 | * @param {Object} context call方法一个指定的this值
597 | * @param {Object, String, Number, Boolean} context call方法一个指定的this值
598 | * @returns {Object, String, Number, Boolean} 返回调用函数的值
599 | */
600 | Function.prototype.call = function(context, ...args) {
601 | // 使用ES6函数的rest参数(形式为...变量名),args是数组
602 | // context为null的时候,context为window
603 | var context = context || window
604 | // 获取调用call的函数
605 | context.fn = this
606 | // 使用ES6扩展运算符(...)执行函数,返回结果
607 | var result = context.fn(...args)
608 | // 删除fn属性
609 | delete context.fn
610 | // 返回结果
611 | return result;
612 | }
613 | ```
614 |
615 | **使用ES3实现call**:
616 |
617 | ```javascript
618 |
619 | /**
620 | * @description 使用ES3实现call方法
621 | * @param {Object} context call方法一个指定的this值
622 | * @returns {Object, String, Number, Boolean} 返回调用函数的值
623 | */
624 | Function.prototype.call = function (context) {
625 | // context为null的时候,context为window
626 | var context = context || window
627 | // 获取调用call的函数
628 | context.fn = this
629 | // 获取call方法的不定长参数
630 | var args = []
631 | for(var i = 1, len = arguments.length; i < len; i++) {
632 | args.push('arguments[' + i + ']')
633 | }
634 | // 运行fn函数并返回结果,
635 | // eval(string)通过计算string得到的值
636 | var result = eval('context.fn(' + args +')')
637 | // 删除fn属性
638 | delete context.fn
639 | // 返回结果
640 | return result;
641 | }
642 | /**
643 | * @description 测试call方法
644 | * @param {Number} c,d 函数的参宿
645 | * @returns {Number} 返回add函数的计算结果
646 | */
647 | function add(c, d){
648 | return this.a + this.b + c + d
649 | }
650 | var o = {a:1, b:3}
651 | add.call(o, 5, 7) // 16
652 |
653 | ```
654 |
655 | **ES6实现apply**:
656 |
657 | ```javascript
658 | /**
659 | * @description 使用ES6数组的扩展运算符实现apply方法
660 | * @param {Object} context apply方法一个指定的this值
661 | * @param {Array} arr apply方法传递给调用函数的参数
662 | * @returns {Object, String, Number, Boolean} 返回调用函数的值
663 | */
664 | Function.prototype.apply = function(context, arr) {
665 | // context为null的时候,context为window
666 | var context = context || window
667 | // 获取调用apply的函数
668 | context.fn = this
669 | // 使用ES6扩展运算符(...)执行函数,返回结果
670 | var result = context.fn(...arr)
671 | // 删除fn属性
672 | delete context.fn
673 | // 返回结果
674 | return result
675 | }
676 | ```
677 |
678 | **ES3实现apply**:
679 |
680 | ```javascript
681 | /**
682 | * @description 使用ES3实现apply方法
683 | * @param {Object} context apply方法一个指定的this值
684 | * @param {Array} arr apply方法传递给调用函数的参数
685 | * @returns {Object, String, Number, Boolean} 返回调用函数的值
686 | */
687 | Function.prototype.apply= function (context, arr) {
688 | // context为null的时候,context为window
689 | var context = context || window
690 | // 获取调用apply的函数
691 | context.fn = this
692 | var result
693 | // 判断apply是否只有一个参数
694 | if (!arr) {
695 | // 执行函数
696 | result = context.fn();
697 | } else {
698 | // 获取参数
699 | var args = [];
700 | for (var i = 0, len = arr.length; i < len; i++) {
701 | args.push('arr[' + i + ']');
702 | }
703 | // 执行函数
704 | result = eval('context.fn(' + args + ')')
705 | }
706 | // 删除fn属性
707 | delete context.fn
708 | // 返回结果
709 | return result;
710 | }
711 | /**
712 | * @description 测试apply方法
713 | * @param {Number} c,d 函数的参宿
714 | * @returns {Number} 返回add函数的计算结果
715 | */
716 | function add(c, d){
717 | return this.a + this.b + c + d
718 | }
719 | var o = {a:1, b:3}
720 | add.apply(o, [5, 7]) // 16
721 | ```
722 |
723 |
724 | 【点击展开】更高级的实现apply()和call()的方法
725 |
726 |
727 | **apply**
728 |
729 | ```javascript
730 | // 浏览器环境 非严格模式
731 | function getGlobalObject(){
732 | return this;
733 | }
734 | function generateFunctionCode(argsArrayLength){
735 | var code = 'return arguments[0][arguments[1]](';
736 | for(var i = 0; i < argsArrayLength; i++){
737 | if(i > 0){
738 | code += ',';
739 | }
740 | code += 'arguments[2][' + i + ']';
741 | }
742 | code += ')';
743 | // return arguments[0][arguments[1]](arg1, arg2, arg3...)
744 | return code;
745 | }
746 | Function.prototype.applyFn = function apply(thisArg, argsArray){ // `apply` 方法的 `length` 属性是 `2`。
747 | // 1.如果 `IsCallable(func)` 是 `false`, 则抛出一个 `TypeError` 异常。
748 | if(typeof this !== 'function'){
749 | throw new TypeError(this + ' is not a function');
750 | }
751 | // 2.如果 argArray 是 null 或 undefined, 则
752 | // 返回提供 thisArg 作为 this 值并以空参数列表调用 func 的 [[Call]] 内部方法的结果。
753 | if(typeof argsArray === 'undefined' || argsArray === null){
754 | argsArray = [];
755 | }
756 | // 3.如果 Type(argArray) 不是 Object, 则抛出一个 TypeError 异常 .
757 | if(argsArray !== new Object(argsArray)){
758 | throw new TypeError('CreateListFromArrayLike called on non-object');
759 | }
760 | if(typeof thisArg === 'undefined' || thisArg === null){
761 | // 在外面传入的 thisArg 值会修改并成为 this 值。
762 | // ES3: thisArg 是 undefined 或 null 时它会被替换成全局对象 浏览器里是window
763 | thisArg = getGlobalObject();
764 | }
765 | // ES3: 所有其他值会被应用 ToObject 并将结果作为 this 值,这是第三版引入的更改。
766 | thisArg = new Object(thisArg);
767 | var __fn = '__' + new Date().getTime();
768 | // 万一还是有 先存储一份,删除后,再恢复该值
769 | var originalVal = thisArg[__fn];
770 | // 是否有原始值
771 | var hasOriginalVal = thisArg.hasOwnProperty(__fn);
772 | thisArg[__fn] = this;
773 | // 9.提供 `thisArg` 作为 `this` 值并以 `argList` 作为参数列表,调用 `func` 的 `[[Call]]` 内部方法,返回结果。
774 | // ES6版
775 | // var result = thisArg[__fn](...args);
776 | var code = generateFunctionCode(argsArray.length);
777 | var result = (new Function(code))(thisArg, __fn, argsArray);
778 | delete thisArg[__fn];
779 | if(hasOriginalVal){
780 | thisArg[__fn] = originalVal;
781 | }
782 | return result;
783 | };
784 | ```
785 |
786 | **call**
787 |
788 |
789 | ```javascript
790 | Function.prototype.callFn = function call(thisArg){
791 | var argsArray = [];
792 | var argumentsLength = arguments.length;
793 | for(var i = 0; i < argumentsLength - 1; i++){
794 | // argsArray.push(arguments[i + 1]);
795 | argsArray[i] = arguments[i + 1];
796 | }
797 | console.log('argsArray:', argsArray);
798 | return this.applyFn(thisArg, argsArray);
799 | }
800 | ```
801 |
802 |
803 |
804 |
805 | ## 大数相加
806 |
807 | ```javascript
808 | function addBigNum(a,b){
809 | let res = ''
810 | loc = 0
811 | a = a.split('')
812 | b = b.split('')
813 | while(a.length || b.length || loc){
814 | //~~把字符串转换为数字,用~~而不用parseInt,是因为~~可以将undefined转换为0,当a或b数组超限,不用再判断undefined
815 | //注意这里的+=,每次都加了loc本身,loc为true,相当于加1,loc为false,相当于加0
816 | loc += ~~a.pop() + ~~b.pop()
817 | //字符串连接,将个位加到res头部
818 | res = (loc % 10) + res
819 | //当个位数和大于9,产生进位,需要往res头部继续加1,此时loc变为true,true + 任何数字,true会被转换为1
820 | loc = loc > 9
821 | }
822 | return res.replace(/^0+/,'')
823 | }
824 |
825 | ```
826 | ## 大数相乘
827 |
828 | 时间复杂度O(n^2)
829 |
830 | ```
831 | const multiply = (num1, num2) => {
832 | const len1 = num1.length;
833 | const len2 = num2.length;
834 | const pos = new Array(len1 + len2).fill(0);
835 |
836 | for (let i = len1 - 1; i >= 0; i--) {
837 | const n1 = +num1[i];
838 | for (let j = len2 - 1; j >= 0; j--) {
839 | const n2 = +num2[j];
840 | const multi = n1 * n2;
841 | const sum = pos[i + j + 1] + multi;
842 |
843 | pos[i + j + 1] = sum % 10;
844 | pos[i + j] += sum / 10 | 0;
845 | }
846 | }
847 | while (pos[0] == 0) {
848 | pos.shift();
849 | }
850 | return pos.length ? pos.join('') : '0';
851 | };
852 |
853 | ```
854 |
855 | ## 函数链式调用/自调用
856 |
857 | 实现:
858 | - add(1)(2)(3).print()//6
859 | - add(1)(2)(3)//6
860 | - add(1)(2)//3
861 |
862 |
863 | 思路:
864 |
865 | 创建闭包,将变量保存在内存中,如果直接输出,则重写toString()返回结果;如果通过print()则写成函数属性
866 |
867 | ```javascript
868 | function add(num){
869 | let total = num
870 |
871 | function _add (n) {
872 | total += n
873 | return _add
874 | }
875 |
876 | // 直接返回最终结果
877 | _add.toString=function () {
878 | return total
879 | }
880 |
881 | // 通过print()返回最终结果
882 | _add.print = function () {
883 | return total
884 | }
885 |
886 | return _add
887 | }
888 |
889 | console.log(add(1)(2)(3).print())//6
890 | console.log(add(1)(2)(3))//6
891 | console.log(add(1)(2))//3
892 | ```
893 | ## 实现一个axios
894 |
895 | **思路:**
896 | axios还是属于 XMLHttpRequest, 因此需要实现一个ajax。或者基于http 。还需要一个promise对象来对结果进行处理。
897 |
898 | `myAxios.js`
899 |
900 | ```javascript
901 | class Axios {
902 | constructor() {
903 |
904 | }
905 |
906 | request(config) {
907 | return new Promise(resolve => {
908 | const {url = '', method = 'get', data = {}} = config;
909 | // 发送ajax请求
910 | const xhr = new XMLHttpRequest();
911 | xhr.open(method, url, true);
912 | xhr.onload = function() {
913 | console.log(xhr.responseText)
914 | resolve(xhr.responseText);
915 | }
916 | xhr.send(data);
917 | })
918 | }
919 | }
920 |
921 | // 最终导出axios的方法,即实例的request方法
922 | function CreateAxiosFn() {
923 | let axios = new Axios();
924 | let req = axios.request.bind(axios);
925 | return req;
926 | }
927 |
928 | // 得到最后的全局变量axios
929 | let axios = CreateAxiosFn();
930 |
931 | ```
932 |
933 | 然后可以在html上进行测试
934 |
935 | ```html
936 | //index.html
937 |
938 |
939 |
940 |
951 |
952 | ```
953 |
954 |
955 | ## 观察者模式
956 |
957 | 观察者直接订阅目标,当目标触发事件时,通知观察者进行更新
958 |
959 | 简单实现
960 |
961 | ```javascript
962 | class Observer {
963 | constructor(name) {
964 | this.name = name;
965 | }
966 |
967 | update() {
968 | console.log(`${this.name} update`)
969 | }
970 | }
971 |
972 | class subject {
973 | constructor() {
974 | this.subs = [];
975 | }
976 |
977 | add(observer) {
978 | this.subs.push(observer);
979 | }
980 |
981 | notify() {
982 | this.subs.forEach(item => {
983 | item.update();
984 | });
985 | }
986 | }
987 |
988 | const sub = new subject();
989 | const ob1 = new Observer('ob1');
990 | const ob2 = new Observer('ob2');
991 |
992 | // 观察者订阅目标
993 | sub.add(ob1);
994 | sub.add(ob2);
995 |
996 | // 目标触发事件
997 | sub.notify();
998 | ```
999 | ## 手写发布者-订阅者模式
1000 |
1001 | 发布订阅模式通过一个调度中心进行处理,使得订阅者和发布者分离开来,互不干扰。
1002 |
1003 | 简单实现:
1004 |
1005 | ```javascript
1006 | class Event {
1007 | constructor() {
1008 | this.lists = new Map();
1009 | }
1010 |
1011 | on(type, fn) {
1012 | if (!this.lists.get(type)) {
1013 | this.lists.set(type, []);
1014 | }
1015 |
1016 | this.lists.get(type).push(fn);
1017 | }
1018 |
1019 | emit(type, ...args) {
1020 | const arr = this.lists.get(type);
1021 | arr && arr.forEach(fn => {
1022 | fn.apply(null, args);
1023 | });
1024 | }
1025 | }
1026 |
1027 | const ev = new Event();
1028 |
1029 | // 订阅
1030 | ev.on('msg', (msg) => console.log(msg));
1031 |
1032 | // 发布
1033 | ev.emit('msg', '发布');
1034 | ```
1035 |
1036 | 另一种实现:
1037 |
1038 | ```javascript
1039 | // 事件对象
1040 | let eventEmitter = {};
1041 |
1042 | // 缓存列表,存放 event 及 fn
1043 | eventEmitter.list = {};
1044 |
1045 | // 订阅
1046 | eventEmitter.on = function (event, fn) {
1047 | let _this = this;
1048 | // 如果对象中没有对应的 event 值,也就是说明没有订阅过,就给 event 创建个缓存列表
1049 | // 如有对象中有相应的 event 值,把 fn 添加到对应 event 的缓存列表里
1050 | (_this.list[event] || (_this.list[event] = [])).push(fn);
1051 | return _this;
1052 | };
1053 |
1054 | // 发布
1055 | eventEmitter.emit = function () {
1056 | let _this = this;
1057 | // 第一个参数是对应的 event 值,直接用数组的 shift 方法取出
1058 | let event = [].shift.call(arguments),
1059 | fns = [..._this.list[event]];
1060 | // 如果缓存列表里没有 fn 就返回 false
1061 | if (!fns || fns.length === 0) {
1062 | return false;
1063 | }
1064 | // 遍历 event 值对应的缓存列表,依次执行 fn
1065 | fns.forEach(fn => {
1066 | fn.apply(_this, arguments);
1067 | });
1068 | return _this;
1069 | };
1070 |
1071 | function user1 (content) {
1072 | console.log('用户1订阅了:', content);
1073 | };
1074 |
1075 | function user2 (content) {
1076 | console.log('用户2订阅了:', content);
1077 | };
1078 |
1079 | // 订阅
1080 | eventEmitter.on('article', user1);
1081 | eventEmitter.on('article', user2);
1082 |
1083 | // 发布
1084 | eventEmitter.emit('article', 'Javascript 发布-订阅模式');
1085 |
1086 | /*
1087 | 用户1订阅了: Javascript 发布-订阅模式
1088 | 用户2订阅了: Javascript 发布-订阅模式
1089 | */
1090 | ```
1091 |
1092 | ## 手撸一个事件机制
1093 |
1094 | **关键词:发布-订阅模式**
1095 |
1096 | 其实核心就是维护一个对象,对象的 key 存的是事件 type,对应的 value 为触发相应 type 的回调函数,即 listeners,然后 trigger 时遍历通知,即 forEach 进行回调执行。
1097 |
1098 | ```javascript
1099 | class EventTarget {
1100 | constructor() {
1101 | this.listeners = {}; // 储存事件的对象
1102 | }
1103 |
1104 | // 注册事件的回调函数
1105 | on(type, callback) {
1106 | if (!this.listeners[type]) this.listeners[type] = []; // 如果是第一次监听该事件,则初始化数组
1107 | this.listeners[type].push(callback);
1108 | }
1109 | // 注册事件的回调函数,只执行一次
1110 | once(type, callback) {
1111 | if (!this.listeners[type]) this.listeners[type] = [];
1112 | callback._once = true; // once 只触发一次,触发后 off 即可
1113 | this.listeners[type].push(callback);
1114 | }
1115 | // 删除一个回调函数
1116 | off(type, callback) {
1117 | const listeners = this.listeners[type];
1118 | if (Array.isArray(listeners)) {
1119 | // filter 返回新的数组,会每次对 this.listeners[type] 分配新的空间
1120 | // this.listeners[type] = listeners.filter(l => l !== callback);
1121 | const index = listeners.indexOf(callback); // 根据 type 取消对应的回调
1122 | this.listeners[type].splice(index, 1); // 用 splice 要好些,直接操作原数组
1123 |
1124 | if (this.listeners[type].length === 0) delete this.listeners[type]; // 如果回调为空,删除对该事件的监听
1125 | }
1126 | }
1127 | // 触发注册的事件回调函数执行
1128 | trigger(event) {
1129 | const { type } = event; // type 为必传属性
1130 | if (!type) throw new Error('没有要触发的事件!');
1131 |
1132 | const listeners = this.listeners[type]; // 判断是否之前对该事件进行监听了
1133 | if (!listeners) throw new Error(`没有对象监听 ${type} 事件!`);
1134 |
1135 | if (!event.target) event.target = this;
1136 |
1137 | listeners.forEach(l => {
1138 | l(event);
1139 | if (l._once) this.off(type, l); // 如果通过 once 监听,执行一次后取消
1140 | });
1141 | }
1142 | }
1143 |
1144 | // 测试
1145 | function handleMessage(event) {
1146 | console.log(`message received: ${ event.message }`);
1147 | }
1148 |
1149 | function handleMessage2(event) {
1150 | console.log(`message2 received: ${ event.message }`);
1151 | }
1152 |
1153 | const target = new EventTarget();
1154 |
1155 | target.on('message', handleMessage);
1156 | target.on('message', handleMessage2);
1157 | target.trigger({ type: 'message', message: 'hello custom event' }); // 打印 message,message2
1158 |
1159 | target.off('message', handleMessage);
1160 | target.trigger({ type: 'message', message: 'off the event' }); // 只打印 message2
1161 |
1162 | target.once('words', handleMessage);
1163 | target.trigger({ type: 'words', message: 'hello2 once event' }); // 打印 words
1164 | target.trigger({ type: 'words', message: 'hello2 once event' }); // 报错:没有对象监听 words 事件!
1165 | ```
1166 |
1167 | ## 实现一个sleep函数
1168 |
1169 | ```javascript
1170 | //Promise
1171 | const sleep = time => {
1172 | return new Promise(resolve => setTimeout(resolve,time))
1173 | }
1174 | sleep(1000).then(()=>{
1175 | console.log(1)
1176 | })
1177 |
1178 | //Generator
1179 | function* sleepGenerator(time) {
1180 | yield new Promise(function(resolve,reject){
1181 | setTimeout(resolve,time);
1182 | })
1183 | }
1184 | sleepGenerator(1000).next().value.then(()=>{console.log(1)})
1185 |
1186 | //async
1187 | function sleep(time) {
1188 | return new Promise(resolve => setTimeout(resolve,time))
1189 | }
1190 | async function output() {
1191 | let out = await sleep(1000);
1192 | console.log(1);
1193 | return out;
1194 | }
1195 | output();
1196 |
1197 | //ES5
1198 | function sleep(callback,time) {
1199 | if(typeof callback === 'function')
1200 | setTimeout(callback,time)
1201 | }
1202 |
1203 | function output(){
1204 | console.log(1);
1205 | }
1206 | sleep(output,1000);
1207 | ```
1208 |
1209 | ## 实现add(1)(2,3)(1)//6函数
1210 |
1211 | ```javascript
1212 | function add(){
1213 | let args = [...arguments];
1214 | let addfun = function(){
1215 | args.push(...arguments);
1216 | return addfun;
1217 | }
1218 | addfun.toString = function(){
1219 | return args.reduce((a,b)=>{
1220 | return a + b;
1221 | });
1222 | }
1223 | return addfun;
1224 | }
1225 |
1226 | add(1); // 1
1227 | add(1)(2); // 3
1228 | add(1)(2)(3); // 6
1229 | add(1)(2, 3); // 6
1230 | add(1, 2)(3); // 6
1231 | add(1, 2, 3); // 6
1232 | ```
1233 |
1234 | ## 控制最大(请求)并发数量
1235 |
1236 | 假设最大并发数是n,那就通过`n--`发n个异步请求,同时将任务数组arr传进去,并通过shift()取arr首元素,虽然异步调用的顺序不同,但操作的是同一个数组,然后将元素进行处理之后,判断当前数组是否为空,否则按照上面的方法进行递归,知道数组为空为止。
1237 |
1238 | ```javascript
1239 | /**
1240 | * @params list {Array} - 要迭代的数组
1241 | * @params limit {Number} - 并发数量控制数
1242 | * @params asyncHandle {Function} - 对`list`的每一个项的处理函数,参数为当前处理项,必须 return 一个Promise来确定是否继续进行迭代
1243 | * @return {Promise} - 返回一个 Promise 值来确认所有数据是否迭代完成
1244 | */
1245 | let mapLimit = (list, limit, asyncHandle) => {
1246 | let recursion = (arr) => {
1247 | return asyncHandle(arr.shift()).then(() => {
1248 | if (arr.length !== 0) return recursion(arr) // 数组还未迭代完,递归继续进行迭代
1249 | else return 'finish'
1250 | })
1251 | }
1252 |
1253 | let listCopy = [].concat(list)
1254 | let asyncList = [] // 正在进行的所有并发异步操作
1255 | while (limit--) {
1256 | asyncList.push(recursion(listCopy))
1257 | }
1258 | return Promise.all(asyncList) // 所有并发异步操作都完成后,本次并发控制迭代完成
1259 | }
1260 | ```
1261 |
1262 | 以下是手动测试
1263 |
1264 | ```
1265 | let list = [1, 2, 3, 4, 5,4,333,222,122,23,54,64]
1266 | let limit = 3//限制的并发数量
1267 | let count = 0//记数当前并发量
1268 |
1269 | let callback = (curItem) => {
1270 | return new Promise(resolve => {
1271 | count++
1272 | setTimeout(() => {
1273 | console.log(curItem, '当前并发量:', count--)
1274 | resolve()
1275 | }, Math.random() * 5000)
1276 | })
1277 | }
1278 |
1279 | mapLimit(list, limit, callback)
1280 | //完成之后
1281 | .then(()=>{
1282 | console.log('所有并发执行完成')
1283 | })
1284 | ```
1285 |
1286 | ## 实现instanceof
1287 |
1288 | instanceof 运算符用于检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上。
1289 |
1290 | ```javascript
1291 | //instanceof的使用方法
1292 | function Car() {}
1293 | const benz = new Car();
1294 | console.log(benz instanceof Car);//true
1295 | console.log(auto instanceof Object);//true
1296 | ```
1297 |
1298 | 实现instance_of(L,R)
1299 |
1300 | ```javascript
1301 | function instance_of(L, R) {//L 表示左表达式,R 表示右表达式
1302 | var O = R.prototype; // 取 R 的显示原型
1303 | L = L.__proto__; // 取 L 的隐式原型
1304 | while (true) {
1305 | if (L === null)
1306 | return false;
1307 | if (O === L) // 当 O 显式原型 严格等于 L隐式原型 时,返回true
1308 | return true;
1309 | L = L.__proto__;
1310 | }
1311 | }
1312 | ```
1313 |
1314 | ## 手写一个jsonp
1315 |
1316 | ```javascript
1317 | //根据指定的URL发送一个JSONP请求
1318 | //然后把解析得到的响应数据传递给回调函数
1319 | //在URL中添加一个名为jsonp的查询参数,用于指定该请求的回调函数的名称
1320 | function getJSONP(url, callback) { //为本次请求创建一个唯一的回调函数名称
1321 | var cbnum = "cb" + getJSONP.counter++; //每次自增计数器
1322 | var cbname = "getJSONP." + cbnum; //作为JSONP函数的属性
1323 | //将回调函数名称以表单编码的形式添加到URL的查询部分中
1324 | //使用jsonp作为参数名,一些支持JSONP的服务
1325 | //可能使用其他的参数名,比如callback
1326 | if (url.indexOf("?") === -1) //URL没有查询部分
1327 | url += "?jsonp=" + cbname; //作为查询部分添加参数
1328 | else //否则
1329 | url += "&jsonp=" + cbname; //作为新的参数添加它
1330 | //创建script元素用于发送请求
1331 | var script = document.createElement("script"); //定义将被脚本执行的回调函数
1332 | getJSONP[cbnum] = function (response) {
1333 | try {
1334 | callback(response); //处理响应数据
1335 | } finally { //即使回调函数或响应抛出错误
1336 | delete getJSONP[cbnum]; //删除该函数
1337 | script.parentNode.removeChild(script); //移除script元素
1338 | }
1339 | }; //立即触发HTTP请求
1340 | script.src = url; //设置脚本的URL
1341 | document.body.appendChild(script); //把它添加到文档中
1342 | }
1343 | getJSONP.counter = 0; //用于创建唯一回调函数名称的计数器
1344 | ```
1345 |
--------------------------------------------------------------------------------
 2 |
3 | # 前端高频面试精粹
4 | ### 持续更新中……(8.8W+字 )
5 | - 本文档是作者苏一恒(Junking) 校招以来的面试总结,旨在应对前端高频面试问题,精炼话术,以不变应万变。如果本文能为您得到帮助,请给予支持!
6 |
7 | [](https://github.com/827652549/my-book) [](https://github.com/827652549/my-book)
8 |
9 | ### 种树最好的时间是十年前,其次是现在
10 |
11 | [GitHub](
2 |
3 | # 前端高频面试精粹
4 | ### 持续更新中……(8.8W+字 )
5 | - 本文档是作者苏一恒(Junking) 校招以来的面试总结,旨在应对前端高频面试问题,精炼话术,以不变应万变。如果本文能为您得到帮助,请给予支持!
6 |
7 | [](https://github.com/827652549/my-book) [](https://github.com/827652549/my-book)
8 |
9 | ### 种树最好的时间是十年前,其次是现在
10 |
11 | [GitHub](