├── file
├── C++面试题集锦.pdf
├── 20200415.md
├── linux命令.md
├── 20200412.md
├── 阿里面试真题解析之进程线程的区别.md
├── 字节面试真题解析之协程.md
├── 百度面试真题解析之Zero Copy技术.md
├── 阿里面试真题解析之并发安全的map.md
├── 阿里面试真题解析之互斥锁和自旋锁相关问题.md
├── 阿里面试真题解析之内存对齐.md
├── 腾讯面试真题解析之epoll.md
├── 20200302.md
├── 阿里面试真题解析之C++相关问题.md
├── 20200301.md
├── 20200515.md
├── 20200413.md
├── 20200305.md
├── 20200226.md
├── other.md
├── 20200320.md
├── c++笔记.md
├── 20200227.md
└── 20200228.md
├── .idea
├── IE.iml
├── encodings.xml
├── vcs.xml
├── misc.xml
└── modules.xml
├── CMakeLists.txt
├── main.cpp
├── time_heap.h
├── test.cpp
├── README.md
└── time_heap.cpp
/file/C++面试题集锦.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/834810071/IE/HEAD/file/C++面试题集锦.pdf
--------------------------------------------------------------------------------
/.idea/IE.iml:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/.idea/encodings.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/file/20200415.md:
--------------------------------------------------------------------------------
1 | ### [快手C++基础架构凉经](https://www.nowcoder.com/discuss/401870?type=0&order=0&pos=7&page=1)
2 |
3 | #### 1.写出short类型-1的十六进制表示(0xffff)
4 |
5 | #### 2.虚拟地址、逻辑地址、物理地址区别与联系
6 |
7 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | cmake_minimum_required(VERSION 3.13)
2 | project(IE)
3 |
4 | set(CMAKE_CXX_STANDARD 14)
5 |
6 | set(lib
7 | test.cpp
8 | time_heap.cpp
9 | time_heap.h)
10 |
11 | add_library(Lib ${lib})
12 |
13 | add_executable(IE main.cpp)
14 | add_executable(test test.cpp)
15 | add_executable(epoll epoll源码注释.c)
16 |
17 | target_link_libraries(IE Lib pthread)
18 | target_link_libraries(test Lib pthread)
--------------------------------------------------------------------------------
/main.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include
5 | #include
6 | #include
7 | #include
8 |
9 | using namespace std;
10 |
11 |
12 | int main()
13 | {
14 | string str;
15 | cin >> str;
16 | if (str.length() >= 100)
17 | {
18 | cout << " " << endl;
19 | return 0;
20 | }
21 | unordered_set s;
22 |
23 | for (int i = 0; i < str.length(); ++i)
24 | {
25 | if (s.count(str[i]))
26 | {
27 | cout << str[i] << endl;
28 | return 0;
29 | }
30 | else
31 | {
32 | s.insert(str[i]);
33 | }
34 | }
35 | cout << " " << endl;
36 | return 0;
37 | }
--------------------------------------------------------------------------------
/file/linux命令.md:
--------------------------------------------------------------------------------
1 | **history** : 历史命令
2 |
3 | **ctrl + p**: 前一个历史命令
4 |
5 | **ctrl + n** : 下一个历史命令
6 |
7 | **ctrl + h** :删除光标前字符
8 |
9 | **ctrl + d** : 删除光标所在字符
10 |
11 | **ctrl + a** : 移动到行首
12 |
13 | **ctrl + e**: 移动到行尾
14 |
15 | **cd** : 目录切 换
16 |
17 | * **cd -** : 在相邻的两个目录互相切换
18 | * **cd ~**: home 目录
19 |
20 | **ls**: 目录查看
21 |
22 | **$**:代表普通用户
23 |
24 | **#** : 超级用户
25 |
26 | * **exit** : 退出
27 |
28 | **mkdir** : 创建目录
29 |
30 | * **make -p name ** : 创建嵌套目录
31 |
32 | **touch** **echo** **vi** : 创建文件
33 |
34 | **rmdir** : 删除空目录
35 |
36 | **rm -rf** : 删除目录
37 |
38 | * **rm -ri** : 删除时给提示
39 |
40 | **cp**: 拷贝文件
41 |
42 | * 文件存在会覆盖
43 | * **cp -r** : 递归拷贝目录
44 |
45 | **cat** : 查看文件内容
46 |
47 | **more** : 查看文件内容
48 |
49 | * 空格翻页 : 只能往后看
50 |
51 | **less** : 查看文件内容
52 |
53 | * **ctrl + p** : 向前翻页
54 |
55 | **head** : 查看前几行
56 |
57 | **tail** : 查看后几行
58 |
59 | **ln**: 创建硬链接
60 |
61 | **ln -s**: 创建软链接
62 |
63 | **wc** : 查看文件信息
64 |
65 | **od**: 查看二进制文件信息
66 |
67 | **du** : 查看目录大小
68 |
69 | **df** : 查看磁盘信息
70 |
71 | **chmod**:查看和修改文件权限
72 |
73 | **chgrp**: 修改文件所属的组
74 |
75 | **find 查找目录 -name "文件名"** : 查找文件名
76 |
77 | **find 查找目录 -size 文件大小** : 查找文件名
78 |
79 | * -10k : < 10k
80 | * +10k: > 10k
81 |
82 | **grep -r "查找的内容" 查找路径** : 按文件内容查找
83 |
84 | **mount 设备名字 挂载位置** : 挂载u盘
85 |
86 | **sudo fdisk -l** : 查看硬盘设备
87 |
--------------------------------------------------------------------------------
/file/20200412.md:
--------------------------------------------------------------------------------
1 | ### [2019 秋招 C++ 个人面经集合(包含 cvte、BIGO、老虎、网易、拼夕夕等)](https://leetcode-cn.com/circle/article/kqWT9f/)
2 |
3 | ### 1. KMP
4 |
5 | 参考:[字符串匹配的KMP算法]([http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html](http://www.ruanyifeng.com/blog/2013/05/Knuth–Morris–Pratt_algorithm.html))
6 |
7 | [从头到尾彻底理解KMP](https://blog.csdn.net/v_JULY_v/article/details/7041827)
8 |
9 | #### 2. 函数传值的方式?
10 |
11 | * 按值传递(pass by value) value
12 | * 地址传递(pass by pointer) *value
13 | * 引用传递(pass by reference) &value
14 |
15 | #### 3.[C++ 内存分区,未初始化的全局变量放在哪?](https://blog.csdn.net/jirryzhang/article/details/79518408)[如果编译了在二进制文件里会有他的位置吗?](https://blog.csdn.net/qq_38880380/article/details/79459195)
16 |
17 | C语言在内存中一共分为如下几个区域,分别是:
18 |
19 | 1. 内存栈区: 存放局部变量名;
20 | 2. 内存堆区: 存放new或者malloc出来的对象;
21 | 3. 常数区: 存放局部变量或者全局变量的值;
22 | 4. 静态区: 用于存放全局变量或者静态变量;
23 | 5. 代码区:二进制代码。
24 | 知道如上一些内存分配机制,有助于我们理解指针的概念。
25 |
26 | C/C++不提供垃圾回收机制,因此需要对堆中的数据进行及时销毁,防止内存泄漏,使用free和delete销毁new和malloc申请的堆内存,而栈内存是动态释放。
27 |
28 | 全局变量、静态局部变量保存在全局数据区,初始化的和未初始化的分别保存在一起;
29 |
30 | 普通局部变量保存在堆栈中;
31 |
32 |
33 | **全局变量和局部变量初始化与不初始化的区别**
34 | 即int x 和 int x=0的区别。
35 |
36 | int x =0; 跟 int x; 的效果看起来是一样的。但其实这里面的差别很大,强烈建议大家所有的全局变量都要初始化,他们的主要差别如下:
37 |
38 | 编译器在编译的时候针对这两种情况会产生两种符号放在目标文件的符号表中,对于初始化的,叫强符号,未初始化的,叫弱符号。连接器在连接目标文件的时候,如果遇到两个重名符号,会有以下处理规
39 | 则:
40 | 1、如果有多个重名的强符号,则报错。
41 | 2、如果有一个强符号,多个弱符号,则以强符号为准。
42 | 3、如果没有强符号,但有多个重名的弱符号,则任选一个弱符号。
--------------------------------------------------------------------------------
/time_heap.h:
--------------------------------------------------------------------------------
1 | //
2 | // Created by jxq on 20-4-7.
3 | //
4 |
5 | #ifndef IE_TIME_HEAP_H
6 | #define IE_TIME_HEAP_H
7 |
8 | #pragma once
9 |
10 | #include
11 | #include
12 | #include
13 | #include
14 |
15 | const int BUFFER_SIZE = 64;
16 |
17 | class heap_timer;
18 |
19 | //用户数据,绑定socket和定时器
20 | struct client_data
21 | {
22 | sockaddr_in address;
23 | int sockfd;
24 | char buf[BUFFER_SIZE];
25 | heap_timer *timer;
26 | };
27 |
28 | //定时器
29 | class heap_timer
30 | {
31 | public:
32 | heap_timer(int delay)
33 | {
34 | expire = time(NULL) + delay;
35 | }
36 | public:
37 | time_t expire;//定时器生效绝对时间
38 | void (*cb_func)(client_data*); //定时器回调函数
39 | client_data* user_data;//客户端数据
40 | };
41 |
42 | //时间堆
43 | class time_heap
44 | {
45 | public:
46 | //构造之一:初始化一个大小为cap的空堆
47 | time_heap(int cap);
48 | //构造之二:用已用数组来初始化堆
49 | time_heap(heap_timer** init_array,int size,int capacity);
50 | //销毁时间堆
51 | ~time_heap();
52 | //添加定时器timer
53 | int add_timer(heap_timer *timer);
54 | //删除定时器timer
55 | void del_timer(heap_timer *timer);
56 | //获得顶部的定时器
57 | heap_timer * top()const;
58 | //删除顶部的定时器
59 | void pop_timer();
60 | //心跳函数
61 | void tick();
62 | //堆是否为空
63 | bool empty()const;
64 | //最小堆的下操作,
65 | //确保堆数组中认第hole个节点作为根的子树拥有最小堆性质
66 | void percolate_down(int hole);
67 |
68 | //将堆数组容量扩大1倍
69 | void resize();
70 | private:
71 | heap_timer **array; //堆数组
72 | int capacity; //堆数组的空量
73 | int cur_size; //堆数组当前包含元素个数
74 | };
75 |
76 |
77 | #endif //IE_TIME_HEAP_H
78 |
--------------------------------------------------------------------------------
/test.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include
5 | #include
6 | #include
7 |
8 | using namespace std;
9 |
10 | class A
11 | {
12 | public:
13 | A(int l) : l(l)
14 | {
15 |
16 | }
17 | A(int v, int l) : val(v), l(l)
18 | {
19 |
20 | }
21 | int val;
22 | int l;
23 |
24 | };
25 |
26 | bool cmp(A a, A b)
27 | {
28 | if (a.val == b.val)
29 | {
30 | return a.l < b.l;
31 | }
32 | return a.val > b.val;
33 | }
34 |
35 | int main()
36 | {
37 | int len;
38 | cin >> len;
39 | vector arr;
40 | string lens, vs;
41 | cin >> lens;
42 | cin >> vs;
43 | int s = 0;
44 | for (int i = 0; i < lens.size(); ++i)
45 | {
46 | if (lens[i] == ',')
47 | {
48 | arr.push_back(A(atoi(lens.substr(s, i).c_str())));
49 | s = i+1;
50 | }
51 | }
52 | arr.push_back(A(atoi(lens.substr(s).c_str())));
53 | s = 0;
54 | int t = 0;
55 | for (int i = 0; i < vs.size(); ++i)
56 | {
57 | if (vs[i] == ',')
58 | {
59 | arr[t++].val = atoi(vs.substr(s).c_str());
60 | s = i+1;
61 | }
62 | }
63 | arr[t++].val = atoi(vs.substr(s).c_str());
64 |
65 | int res = 0;
66 | sort(arr.begin(), arr.end(), cmp);
67 | int cur = len;
68 | for (int i = 0; i < arr.size(); ++i)
69 | {
70 | if (arr[i].l <= cur)
71 | {
72 | cur -= arr[i].l;
73 | res += arr[i].val;
74 | }
75 | else
76 | {
77 | break;
78 | }
79 | }
80 | cout << res << endl;
81 | return 0;
82 | }
--------------------------------------------------------------------------------
/file/阿里面试真题解析之进程线程的区别.md:
--------------------------------------------------------------------------------
1 | # 前言
2 |
3 | 我们都知道进程是系统进行资源分配和调度的一个独立单位。线程是进程的一个实体,是CPU调度的基本单位。线程自己基本上不拥有系统资源,但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。由于线程比进程更小,基本上不拥有系统资源,线程上下文切换比进程上下文切换要快得多,所以线程调度的开销就会小得多,从而可以显著提高系统资源的利用率和吞吐量。**但是对于为什么线程上下文切换比进程要快以及进程线程上下文切换到底做了哪些事情大多数人并不是特别清楚。**本节将结合阿里面试真题,对线程和进程的区别做一个总结。
4 |
5 | # 进程
6 |
7 | 进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。进程一般由**程序,数据集合和进程控制块**三部分组成。
8 |
9 | # 线程
10 |
11 | 线程是操作系统调度的最小单位。一个进程可以包含多个线程,每个线程可以看做一个独立的逻辑流,线程也称为轻量级进程。在Linux下其实原本并没有线程的概念,线程和进程对于操作系统都是一样的调度,都有具有自己独立的task_struct(进程描述符),也都有自己独立的pid,但是线程可以共享同一内存地址空间、代码段、全局变量、同一打开文件集合等等。
12 |
13 | # 进程切换的开销
14 |
15 | 开销分成两种:
16 |
17 | 1.直接开销
18 |
19 | 2.间接开销
20 |
21 | ### 直接开销:
22 |
23 | 1. **切换页表全局目录**
24 | 2. 切换**内核态堆栈**
25 | 3. 切换硬件上下文:寄存器当中的数据
26 | 4. 刷新TLB
27 | 5. 执行操作系统调度器的代码
28 |
29 | ### **间接开销:**
30 |
31 | 间接开销指的是由于切换到一个新进程后,各种缓存对于新的进程而言未命中的概率非常大。进程如果跨CPU调度,那么之前的TLB、L1、L2、L3缓存因为运行的进程已经变了,缓存所带来的空间局部性和时间局部性的优势失效,当前缓存起来的代码、数据失效。这将导致新进程需要重新从内存当中获取数据和代码,并将其缓存起来。从而导致穿透到内存的**IO**会变多,由于CPU和内存读取速度的差异很大,这部分带来的开销也非常大。
32 |
33 | ####
34 |
35 | # 线程切换的开销
36 |
37 | **线程切换和进程切换之间的主要区别在于**:
38 |
39 | 1. 在线程切换期间,虚拟内存空间保持不变。
40 | 2. 进程切换期间,TLB会被刷新,从而使内存访问在一段时间内变得更加昂贵。
41 |
42 | ####
43 |
44 | # 进程线程的本质区别
45 |
46 | 1.进程**更安全**,一个进程完全不会影响另外的进程。
47 |
48 | 2.进程间通信比线程间**通信的性能差**很多。
49 |
50 | 3.线程切换开销更低。
51 |
52 | ####
53 |
54 | # 阿里面试真题
55 |
56 | ### 1.进程切换开销有哪些?
57 |
58 | 答:分为直接开销和间接开销 (具体答案参见上文)
59 |
60 | 解析:此处考察的不仅仅是书本上简单的上下文切换开销,需要对直接开销和间接开销的具体内容有比较好的理解,尤其需要回答出缓存失效带来的额外开销,此问题属于对计算机体系结构的考察。
61 |
62 | ### 2.线程共享哪些进程的资源?
63 |
64 | 答: 1.进程代码段 ; 2.进程的公有数据; 3.进程打开的**文件描述符;** 4.信号的处理器; 5.进程的当前目录;6.进程用户ID与进程组ID。
65 |
66 | ### 3.线程独立的资源有哪些?
67 |
68 | 答:1.线程ID;2.寄存器组的值;3.线程栈;4.错误返回码;5.线程的信号屏蔽码;6.线程的优先级。
69 |
70 | ### 4.说一说你知道的多线程和多进程的场景?
71 |
72 | 答:多进程场景比如 Nginx,一个 Master 多个 Worker,进程间只进行有限的通信,并不传递数据,每个进程使用IO多路复用去管理事件,是一个典型的多进程场景。
73 |
74 | 多线程场景比如一些web server,每到达一个请求使用一个线程去处理请求,在链接数量不大的情况下,比进程开销低很多,还可以使用线程池去优化创建和销毁线程的开销。
75 |
76 | ### 5.除了进程和线程你还知道哪些概念?
77 |
78 | 答:协程。协程是用户级线程,比如Golang当中原生支持协程概念,在用户空态去调度协程,维护和操作系统线程的多对多的关系。
79 |
80 | # 总结
81 |
82 | 1.多线程之间堆内存共享,线程间通信可以直接基于共享内存来实现,比多进程之间通信更轻量。
83 |
84 | 2.多线程之间切换**不需要切换虚拟内存空间、文件描述符**等,所以线程的上下文切换也比多进程轻量。
85 |
86 | 3.由于进程之间空间相互独立,多进程比多线程更安全,一个进程基本上不会影响另外一个进程。
87 |
88 | 4.一般不同任务间需要大量的通信,使用多线程的场景比多进程多。但是多进程有更高的容错性,一个进程的崩溃不会导致整个系统的崩溃,在任务安全性较高的情况下,采用多进程。
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # IE [Typera软件阅读]
2 |
3 | 面经记录 -- 见[file](https://github.com/834810071/IE/tree/master/file)文件夹
4 |
5 | [个人牛客面经记录](https://www.nowcoder.com/profile/8447408/myDiscussPost)
6 |
7 | ```java
8 | 面试官一来我啪的就站起来了,很快啊!然后上来就是手写二分查找,两个有序队列实现堆栈,两数之和,
9 | 我全都写完了啊,写完了以后自然是传统面试以点到为止,后面几道求空间复杂度和时间复杂度算法就没做了,
10 | 因为几道题,按传统答题点到为止我已经不会做了。
11 |
12 | 面试官说他是乱出的,他可不是乱出的啊,数据结构,算法分析,训练有素,
13 | 后来他说他以前是阿里p8,看来是有备而来!面试官不讲武德,来,骗!来,偷袭!我工作一年多的菜狗,这好吗,这不好,
14 | 我劝这位面试官耗子尾汁,好好反思,以后不要再犯这要的聪明,小聪明啊。
15 |
16 | 面试要以和为贵,不要搞-窝里斗~ 谢谢朋友们!
17 | ```
18 |
19 | 推荐: [C/C++ 技术面试基础知识总结,包括语言、程序库、数据结构、算法、系统、网络、链接装载库等知识及面试经验、招聘、内推等信息。](https://github.com/huihut/interview)
20 |
21 | [后台开发相关知识](https://github.com/twomonkeyclub/BackEnd)
22 |
23 | [计算机基础(计算机网络/操作系统/数据库/Git...)面试问题全面总结,包含详细的follow-up question以及答案;全部采用【问题+追问+答案】的形式,即拿即用,直击互联网大厂面试rocket;可用于模拟面试、面试前复习、短期内快速备战面试...](https://github.com/wolverinn/Waking-Up)
24 |
25 | [面试常见问题汇总](https://github.com/Making-It/CS_Review)
26 |
27 | [2020 grinninggringrinninggringrinning 秋招笔试面试合集,以及2019届公司真题模拟题集 & 附上自己的后端指南,computermortar_board包括(C/C++基础、数据结构、算法、操作系统computer、计算机网络、MySQL、shell(ps:sed、awk、grep))](https://github.com/Apriluestc/2020)
28 |
29 | [笔试面试知识整理](https://github.com/HIT-Alibaba/interview)
30 |
31 | [MeiK](https://meik2333.com/posts)
32 |
33 | [专注于分享算法,计算机基础(包括计算机网络,操作系统,MySQL等),无论是应付面试,还是提升自己地内功,这里都能帮到你](https://github.com/iamshuaidi/algo-basic)
34 |
35 | [Learning](https://github.com/loversgzl/Learning)
36 |
37 | [c++](https://github.com/WhiteNotWolf/Skill-Notes)
38 |
39 | [「Java学习+面试指南」一份涵盖大部分Java程序员所需要掌握的核心知识。准备 Java 面试,首选 JavaGuide!](https://github.com/Snailclimb/JavaGuide)
40 |
41 | [C/C++学习,后端开发进阶指南。](https://github.com/balloonwj/CppGuide)
42 |
43 | [《互联网面试笔记》收集和分析互联网常见面试题,并将这些面试知识整理成文方便大家查阅。主要是面向java程序员,但基础知识部分不同语言程序员(c,c++,python等)都可以参考。---持续更新中, 欢迎编辑~](https://github.com/zhengjianglong915/note-of-interview)
44 |
45 | [后端架构师技术图谱](https://github.com/xingshaocheng/architect-awesome)
46 |
47 | [从Java基础、JavaWeb基础到常用的框架再到面试题都有完整的教程,几乎涵盖了Java后端必备的知识点](https://github.com/ZhongFuCheng3y/3y)
48 |
49 | [C++那些事](https://github.com/Light-City/CPlusPlusThings)
50 |
51 | [【Java面试+Java学习指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。](https://github.com/AobingJava/JavaFamily)
52 |
53 | [About
54 | 涵盖C++ Primer 5th、 effective C++ 、 STL api和demos C++ 基础知识与理论、 智能指针、C++11、 Git教程 Linux命令 Unix操作系统(进程、线程、内存管理、信号)计算机网络、 数据结构(排序、查找)、数据库、、C++对象模型、 设计模式、算法(《剑指offer》、leetcode、lintcode、hihocoder、《王道程序员求职宝典》)、面试题、嵌入式相关等](https://github.com/yzhu798/CodingInterviewsNotes)
55 |
56 | [fullstack tutorial 2020,后台技术栈/架构师之路/全栈开发社区,春招/秋招/校招/面试](https://github.com/frank-lam/fullstack-tutorial)
57 |
--------------------------------------------------------------------------------
/file/字节面试真题解析之协程.md:
--------------------------------------------------------------------------------
1 | # 前言
2 |
3 | 在第12节当中我们介绍了面试当中常考的进程和线程相关的问题,除了进程和线程之外,协程相关的问题在面试当中出现的频次越来越高,尤其是在一些使用Golang作为主要后端开发语言的大厂当中。本节我将以字节面试真题为例讲解协程相关知识。
4 |
5 | # 并发模型
6 |
7 | 要理解协程的出现,首先需要了解网络服务器并发模型有哪些:
8 |
9 | ### **1.简单多线程模型**:
10 |
11 | 该模型采用一个连接一个线程的模式,对于每一个连接都需要一个单独的线程去处理业务逻辑。
12 |
13 | ### **2.半同步半异步模**型:
14 |
15 | 单独一个IO线程来异步处理各种网络IO,比如使用IO多路复用技术。同时使用线程池来同步处理每个请求,业务逻辑部分交给线程池当中的工作线程处理。
16 |
17 | ### **3.全异步模型**:
18 |
19 | 该模型在网络IO部分和业务逻辑处理部分都是异步的,不会因为IO而导致程序阻塞,通过一个线程就处理所有的任务,由于避免了多线程的开销问题,能够**最大程度利用计算机的性能**,但是将给程序员带来编程的巨大困难,因为业务逻辑的编写将非常难以理解。
20 |
21 | # 协程
22 |
23 | **我们知道线程可以看做轻量级进程,而协程简单来说可以看做更轻量级的线程。**不同的语言有不同的协程实现,比如Golang原生支持协程,Python的Greenlet,C++的第三方库libgo等等。如同一个进程可以拥有多个线程,一个线程也可以拥有多个协程。如同线程是进程的一种优化,协程也可以看做线程的进一步优化。
24 |
25 | ### **协程内存开销:**
26 |
27 | 以Golang为例,协程初始化创建的时候为其分配的栈有2KB,而线程栈一般为8M左右。如果对每个连接创建一个协程去处理,100万并发请求只需要2G内存,而如果用线程模型则需要8T,所以对于相同的内存而言,使用协程可以支持的并发量比线程多很多。
28 |
29 | ### **协程的实现:**
30 |
31 | 以Golang为例,会在启动用户main函数之前启动runtime等几个协程。简单来说,runtime会维护用户级协程和操作系统线程的多对多的映射关系,Golang抽象出G,P,M的概念,将协程的调度完全实现在用户态的runtime当中:
32 |
33 | M: Machine,简单理解为操作系统线程;
34 |
35 | G: Goroutine,协程;
36 |
37 | P: Processor,处理器抽象,协调多个个G在某一个M上执行。
38 |
39 | 有兴趣的话可以去看看Golang在协程方面的设计和实现。
40 |
41 | # 字节跳动面试真题解析
42 |
43 | ### 1.协程的切换在什么时候?
44 |
45 | 答:1.当Golang当中协程在执行一些阻塞调用,例如网络IO,磁盘IO函数会发生协程切换;
46 |
47 | 2.Golang当中协程的切换时间片是10ms,当协程连续执行超过10ms时会被runtime调度器切换;
48 |
49 | 3.当协程主动交出执行权限时也会发生协程切换,比如协程主动sleep。
50 |
51 | 分析:该问题是考察对于协程切换的理解,协程切换和操作系统线程切换有所不同,线程的切换由操作系统在内核态切换,同时操作系统支持时间片以及优先级调度,但是协程并不支持优先级调度。
52 |
53 | ### 2.如何实现协程的自动切换?说出你的想法。
54 |
55 | 答:可以使用任务队列维护协程和操作系统线程的映射关系,封装各种io函数,当这些封装的函数被程序使用的时候,内部使用操作系统的异步io函数,当异步io函数表示阻塞时,将当前协程放入任务队列,切换执行任务其他可执行的协程。
56 |
57 | 分析:这个问题是一个发散性问题,如果不了解协程实现可以通过类比的方式进行回答,言之有理即可。
58 |
59 | ### 3.Golang当中的协程是占用一个CPU还是会被调度到不同的CPU?
60 |
61 | 答:会被调度到不同的CPU。
62 |
63 | 分析:协程和线程是多对多的关系,一个协程的运行实际还是会绑定到一个操作系统线程,而线程的调度是操作系统决定的,任何一个线程在没有特殊限制的情况下可能会被调度到任何一个CPU上运行,而协程和线程是由runtime动态绑定的,所以协程也可能在任何一个CPU上运行。
64 |
65 | ### 4.协程和线程的区别?
66 |
67 | 答:1.线程是操作系统调度的最小单元,线程是由操作系统调度。但是操作系统对于协程是无感知的,协程的调度 是在用户态而非由操作系统在内核态调度。
68 |
69 | 2.相比创建一个线程而言,创建一个协程的开销非常小。
70 |
71 | 3.协程之间的切换开销相比线程间切换开销低很多。
72 |
73 | 4.协程比线程支持更大的并发量。
74 |
75 | 5.协程不支持抢占,因为操作系统有时间片概念,所以线程是支持优先级和抢占的,但是协程是在用户态实 现,协程是非抢占式调度。在任务调度上,协程是弱于线程的。
76 |
77 | 分析:本题属于概念性问题,回答全面即可。
78 |
79 | ### 5.**协程适合哪些场景?**
80 |
81 | 答:协程适合以下特点的场景
82 |
83 | 1.高并发场景:每秒钟需要处理成千上万的用户请求;
84 |
85 | 2.高网络IO场景:服务经常需要从其它机器获取数据,进行网络IO;
86 |
87 | 3.低计算场景:CPU密集型计算比较少。
88 |
89 | 分析:本题考查协程的应用场景。无论是网络IO,还是磁盘IO,远远慢于CPU的操作速度,所以往往需要CPU去等待IO操作完成。同步IO下系统需要切换线程,但是由于大量的线程切换带来了大量的性能的浪费,尤其是IO密集型的程序。而异步IO可以减少线程切换带来性能损失,但是编程模式并不符合人类思维。所以使用协程既可以解决线程切换开销大的问题,也可以符合人类编程的思维。
90 |
91 | ### 6.说一说你对于协程的理解?
92 |
93 | 答:由于现在系统的并发量越来越大,一开始的简单多线程模型已经不能很好的应对高并发场景,因为线程的切换开销已经成为了瓶颈。由于epoll的出现,IO多路复用的并发模式可以极大的提升系统的性能,但是这种IO多路复用的方式虽然提升的运行效率但是对于程序员而言这种编程模型非常难以理解,开发效率低且代码调试困难。此时协程就成了2者的一种折中方案,协程解决了操作系统线程切换和创建销毁开销大的问题,同时又可以以简单的编程模式开发,提升系统的效率的同时也没有降低太多编程难度。
94 |
95 | 分析:本题也是发散性问题,对一个概念的理解,我认为从其产生的原因和其能够解决的问题这两个角度进行回答是比较合适的。
96 |
97 | # 总结
98 |
99 | 本节总结了协程的概念,结合我在面试字节跳动过程当中遇到的问题进行解答。
--------------------------------------------------------------------------------
/file/百度面试真题解析之Zero Copy技术.md:
--------------------------------------------------------------------------------
1 | # 前言
2 |
3 | 在我秋招面试过程当中,关于Zero Copy的问题一共出现了3次。对于一个程序员来说,当一个问题出现了3次那么就需要重视和总结,事不过三。本节我会对Zero Copy做一个介绍,并结合百度面试真题进行解析。
4 |
5 | ####
6 |
7 | # 系统级IO
8 |
9 | 要理解Zero Copy技术的出现,首先需要知道什么是系统级IO。Linux系统级IO分为:
10 |
11 | 1.标准IO库
12 |
13 | 2.IO系统调用
14 |
15 | 3.网络IO库
16 |
17 | ### **IO系统调用**:
18 |
19 | Linux标准访问文件方式是通过两个系统调用实现的:read()和write(),这两个系统调用在**用户态都是没有缓冲**。当用户进程使用read 和 write 读写Linux的文件时,进程会从用户态进入内核态,通过I/O操作读取文件中的数据。
20 |
21 | **read ():**
22 |
23 | ```c
24 | ssize_t read(int fd, void * buf, size_t count);
25 | ```
26 |
27 | read()会把参数fd所指的文件传送count 个字节到buf 指针所指的内存中。
28 |
29 | **write():**
30 |
31 | ```c
32 | ssize_t write (int fd, const void * buf, size_t count);
33 | ```
34 |
35 | write()会把参数buf所指的内存写入count个字节到参数放到所指的文件内。
36 |
37 | 举例来说,要写入数据到文件上时,内核先将数据写入到内核中所设的缓冲当中;假如这个缓冲储存器的长度是100字节,调用系统函数write时,假设每次要写入的数据的长度为10个字节,那么你几要调用10次write函数才能将内核缓冲区写满;此时数据还是在缓冲区,并没有写入到磁盘,缓冲区满了之后,才真正进行实际上的IO操作,将数据写入磁盘。因为内存和磁盘读取速度的巨大差异,采用内核缓存可以减少磁盘IO的次数,提升磁盘IO的效率。
38 |
39 | ### **标准IO库:**
40 |
41 | 标准IO库是基于IO系统调用实现的,优化了对系统调用的使用方式。引入标准IO库有以下几个原因:
42 |
43 | 1.因为IO系统调用的使用方式非常底层,需要指定读写的count以及buf,使用比较麻烦,所以标准IO库对IO系统调用进行封装。
44 |
45 | 2.因为read 和 write 等底层系统调用需要在**用户态**和**内核态**之间切换,如果每次读写的数据很少,那么切换带来的开销将大大降低IO的效率,所以标准IO库在用户态也引入了缓冲机制,提升了性能。
46 |
47 | 3.IO系统调用在不同的操作系统之间是不能通用的,但是标准IO库在不同的平台几乎是一致的,这就增强了可移植性。
48 |
49 | **常见的标准IO库函数:**
50 |
51 | fopen、fclose、fwrite、fread、ffulsh、fseek等等。
52 |
53 | #### ** **
54 |
55 | # **Zero-Copy**
56 |
57 | 零拷贝技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时**节省CPU周期和内存带宽**。举例来说,如果要从磁盘当中读取一个文件并通过网络发送它,传统方式下每个读/写周期都需要复制两次数据和切换两次上下文,而**数据的复制都需要依靠CPU**。
58 |
59 | ### 1.Linux 2.1内核引入**sendfile函数**:
60 |
61 | sendfile通过一次系统调用完成了文件的传送,通过sendfile发送文件只需要一次系统调用,当调用sendfile时数据的拷贝路径如下:
62 |
63 | 第一次拷贝:将数据从磁盘读取到内核缓冲区中;
64 |
65 | 第二次拷贝:将数据从内核缓冲区拷贝到socket buffer中;
66 |
67 | 第三次拷贝:将数据从socket buffer拷贝到网卡设备中发送;
68 |
69 | ### **2.Linux2.4 内核对sendfile做了进一步的改进:**
70 |
71 | 改进后的数据拷贝处理路径如下:
72 |
73 | 第一次拷贝:将文件从磁盘拷贝到内核缓冲区中,不再将内核缓冲区的数据拷贝到socket buffer,而是向socket buffer中写入当前要发送的数据在内核缓冲区中的位置和偏移量;
74 |
75 | 第二次拷贝:根据socket buffer中的位置和偏移量,直接将内核缓冲区的数据copy到网卡设备中;
76 |
77 | ####
78 |
79 | # 百度面试真题
80 |
81 | 现在有一个用户需要**读取磁盘文件上的内容然后将其通过网络**发送出去,假设使用IO系统调用read/write
82 |
83 | ### 1.这个过程当中,数据经过几次拷贝?
84 |
85 | 答:在这个过程中经历了4次数据copy的过程,路径如下:
86 |
87 | 第一次数据拷贝:调用read时,文件从磁盘拷贝到了内核缓冲区;
88 |
89 | 第二次数据拷贝:数据从内核缓冲区拷贝到用户内存缓冲区;
90 |
91 | 第三次数据拷贝:调用write时,将用户内存缓冲区的数据内容拷贝到内核模式下的socket的buffer中;
92 |
93 | 第四次数据拷贝:最后将内核模式下的socket buffer的数据拷贝到网卡设备中;
94 |
95 | ### 2.这个过程当中,出现了几次用户态和内核态的切换?
96 |
97 | 答:在这个过程中经历了4次用户态和内核态的切换:
98 |
99 | 第一次切换:调用read时用户态切换到内核态;
100 |
101 | 第二次切换:read调用返回,内核态切换回用户态;
102 |
103 | 第三次切换:调用write时用户态切换到内核态;
104 |
105 | 第四次切换:write返回时内核态切换到用户态;
106 |
107 | ### 3.这个过程当中,需要几次系统调用?
108 |
109 | 答:这个过程当中经历了2次系统调用,分别是read和write系统调用。
110 |
111 | ### 4.有什么方法可以优化这个过程?
112 |
113 | 答:使用zero copy,避免数据在用户态的拷贝以及减少系统调用次数。
114 |
115 | # 结论
116 |
117 | 每次IO请求,内核态和用户态的切换开销以及数据的拷贝开销会严重降低性能,所以Zero-Copy技术可以来去掉用户态多余的数据拷贝,大大提高了应用程序的性能,并且减少了内核态和用户态的上下文的切换。对于Zero-copy需要记住以下2点:
118 |
119 | 1. Zero-copy可以将读取磁盘文件网络传输的上下文切换的次数从4次降低到2次;数据拷贝次数从4次降低到2次;
120 | 2. Zero-copy是针对内核来说,数据在内核模式下是无拷贝过程,并不是指整个过程数据没有拷贝。
--------------------------------------------------------------------------------
/file/阿里面试真题解析之并发安全的map.md:
--------------------------------------------------------------------------------
1 | # 前言
2 |
3 | 秋招面阿里的时候被问到一个这样的问题:
4 |
5 | > 平时你使用过map么?是并发安全的么?如何实现一个并发安全的map? 考虑过效率么?
6 |
7 | 相信大家平时使用最多的结构就是各种hash map了,无论哪种语言都有自身提供的实现,比如Java当中的HashMap,Golang当中的Sync.Map等等。在技术面试当中,对于hash Map实现的考察非常频繁。本文将从阿里的面试真题切入,结合相关代码简要的介绍几种实现并发安全的map的方法。
8 |
9 | # 阿里面试真题再现:
10 |
11 | ### 1.普通的map是并发安全的么?
12 |
13 | 答:不是并发安全的,在并发访问的过程当中会出现竞争,导致数据不一致。
14 |
15 | ### 2.unordered_map 和 map的区别?
16 |
17 | 答:unordered_map是基于哈希实现的,查找和插入开销都是O(1),而map是基于红黑树实现的,查找和插入的开销都是O(logn)。
18 |
19 | ### 3.如何实现一个并发安全的map?
20 |
21 | 答:1.封装读写锁实现;
22 |
23 | 2.分段锁实现;
24 |
25 | 3.读写分离实现;
26 |
27 | 解析:
28 |
29 | #### **方法1**:通过将读写锁和非并发安全的map封装在一起,实现一个并发安全的map结构。
30 |
31 | 如下面go语言的一个简单的实现,将一个并发不安全的map和一个读写锁结合,对于读写操作的接口进行封装。
32 |
33 | ```go
34 | type MyMap struct {
35 | sync.RWMutex
36 | mp map[interface{}]interface{}
37 | ...
38 | }
39 |
40 | func (m *MyMap) Read(key interface{}) interface{} {
41 | m.RLock()
42 | value := m.mp[key]
43 | m.RUnlock()
44 | return value
45 | }
46 |
47 | func (m *MyMap) Write(key, value interface{}) {
48 | m.Lock()
49 | m.mp[key] = value
50 | m.Unlock()
51 | }
52 | ```
53 |
54 | 优势:
55 |
56 | 1. 实现简单,几行代码就可以实现。
57 | 2. 并发量很小,或者竞争使用map的情况较少时对性能的影响并不大。
58 |
59 | 缺点:
60 |
61 | 锁的粒度太大。举例来说,线程A调用Write方法写key1的时候锁住了map,此时线程B调用Read方法,读取和key1不相关的key2时就会被阻塞。当并发量增大时,该方案带来的线程阻塞等待的开销会很大,在高并发情况下就需要进行优化。
62 |
63 | #### **方法2:** **锁分段技术**
64 |
65 | 相比方法1使用全局锁的方式,锁分段技术将数据分段存储,给每一段数据配一把锁。实现思路:当线程需要读取map当中某个key的时候,线程不会对整个map进行加锁操作,而是先通过hash取模来找到该key存放在哪一个分段中,然后对这个分段进行加锁,因为每一段数据使用不同的锁,所以对该分段加锁不会阻塞其他分段的读写。分段锁的设计目的是细化锁的粒度,减少线程间锁竞争的次数,从而可以有效的提高并发访问效率。
66 |
67 | 举例来说,分段锁实现的map的主要逻辑如下:
68 |
69 | ```go
70 | type MyConcurrentMap []*Shard
71 |
72 | // 分片Shard
73 | type Shard struct {
74 | items map[string]interface{}
75 | mu sync.RWMutex
76 | }
77 |
78 | //根据给定的key获取其对应的段
79 | func (m MyConcurrentMap) GetShard(key string) *Shared {
80 | h := hash(key) //对key求hash code
81 | return m[h%SHARD_COUNT]//SHARD_COUNT为预设的Shard的个数
82 |
83 | }
84 |
85 | //Set方法
86 | func (m MyConcurrentMap) Set(key string, value interface{}) {
87 | shard := m.GetShard(key)
88 | shard.mu.Lock()
89 | shard.items[key] = value
90 | shard.Unlock()
91 | }
92 |
93 | //Get方法
94 | func (m MyConcurrentMap) Get(key string) (interface{}, bool) {
95 | shard := m.GetShard(key)
96 | shard.mu.RLock()
97 | val, ok := shard.items[key]
98 | shard.mu.RUnlock()
99 | return val, ok
100 | }
101 | ```
102 |
103 | 优势:
104 |
105 | 相比方法1,并发访问效率有很大提升。
106 |
107 | 缺点:
108 |
109 | 对于map扩缩容时比较麻烦,因为shard的个数需要预先设定。
110 |
111 | #### **方法3**:**读写分离+原子操作**
112 |
113 | sync.Map是Golang1.9引入的并发安全的map,以下代码节选自sync.Map的实现:
114 |
115 | ```go
116 | //sync.Map的实现
117 | type Map struct {
118 | mu Mutex
119 | read atomic.Value // readOnly
120 | dirty map[interface{}]*entry
121 | misses int
122 | }
123 | ```
124 |
125 | 上述结构当中,read 只提供读,dirty 负责写。read 主要用于实现无锁操作,而 dirty 的操作是由 Mutex来保护。简单来说就是,当从map当中读取数据时会先从read当中读取数据,如果read当中可以获取该数据则无锁读取,当无法从read当中读取到时则从dirty当中加锁读取。该方案也是为了减少加锁操作,提升并发访问的效率,具体的实现可以看sync.Map的源码,这里篇幅有限不再赘述。
126 |
127 | 优势:
128 |
129 | 1. 通过冗余的两个数据结构(read、dirty),减少频繁加锁对性能的影响。**典型的空间换时间的做法。**
130 | 2. 将锁的粒度更加的细小到数据的状态上,减少锁操作。
131 | 3. 更好的拓展性,没有分段锁在扩缩容时的烦恼。
132 |
133 | 缺点:
134 |
135 | sync.Map的实现方式并不适用于大量写出现的场景,原因:
136 |
137 | - 大量的写会导致read当中读取不到数据,从而加锁读dirty,性能退化。
138 | - 大量写会导致read的miss不断提升,**导致dirty不断提升为read,导致性能下降
139 | **
140 |
141 | ###
142 |
143 | ### 4.如何考虑并发读写map的效率?
144 |
145 | 答:具体的场景需要具体分析,一般来说需要先分析对于map的使用场景,是读多写少还是更新多但是创建少,可以对不同的场景进行特殊的优化。一般常用的技巧就是减小锁的粒度,使用无锁操作代替加锁的方式,使用读写分离的方式等等。
--------------------------------------------------------------------------------
/file/阿里面试真题解析之互斥锁和自旋锁相关问题.md:
--------------------------------------------------------------------------------
1 | # 前言
2 |
3 | 在多处理器系统环境中需要保护资源避免由于并发带来的资源访问竞争导致的问题,就需要互斥访问,也就是需要引入锁的机制。只有获取了锁的进程才能访问资源。互斥锁和自旋锁是两种代表性的锁。在实际面试当中对于锁相关的问题出现的频率较高,一般涉及到并发访问,线程安全,线程同步相关问题就会问到互斥锁和自旋锁。本文将先对互斥锁和自旋锁的作用,实现以及使用场景做一个重点分析,然后例举6道我在面试阿里时的真题进行分析。
4 |
5 | # 多线程并发访问问题
6 |
7 | 当多个线程并发访问共享资源时,有可能产生并发访问的安全性问题,可能会导致共享资源被破坏,导致非预期的结果。比如C++ STL当中的vector,map等等都是非并发安全的容器。如果想要解决并发访问的安全性问题就需要引入线程同步机制。
8 |
9 | 线程间同步指的是:当有一个线程在对共享资源进行操作时,其他线程都不可以对这个资源进行操作,直到该线程完成操作。简单来说,就是线程之间需要达到协同一致。
10 |
11 | 一般线程间同步机制有:共享内存,信号量机制,锁机制,信号机制等等。其中对于锁的使用是最普遍的方式。
12 |
13 | # **互斥锁:**
14 |
15 | ### **互斥锁的作用:**
16 |
17 | 互斥锁是为实现保护共享资源而提出一种锁机制。采用互斥锁保护临界区,防止竞争条件出现。当某个线程无法获取互斥锁时,该线程会被挂起,当其他线程释放互斥锁后,操作系统会唤醒被挂起在这个锁上的线程,让其运行。
18 |
19 | ### **互斥锁的实现:**
20 |
21 | 在Linux下互斥锁的实现是通过futex这个基础组件。
22 |
23 | 互斥锁加锁解锁开销很大,需要从用户态切换到内核态,上下文切换以及涉及缓存的更新等等。通常很多同步操作发生的时候并没有竞争的产生,此时上述开销就没有必要。考虑到这个因素,futex通过用户空间的共享内存以及原子操作,在共享的资源不存在竞争的时候,不会进行系统调用而是只有当竞争出现的情况下再进行系统调用陷入内核。进程或者线程在没有竞争的情况下可以立刻获取锁。具体来说,futex的优化方式如下:
24 |
25 | futex将同步过程分为两个部分,一部分由内核完成,一部分由用户态完成;如果同步时没有竞争发生,那么完全在用户态处理;否则,进入内核态进行处理。**减少系统调用的次数,来提高系统的性能是一种合理的优化方式。**
26 |
27 | ### **互斥锁的使用场景:**
28 |
29 | 1. 解决线程安全问题,一次只能一个线程访问被保护的资源。
30 | 2. 被保护资源需要睡眠,那么可以使用互斥锁。
31 |
32 | # **自旋锁:**
33 |
34 | ### **自旋锁的作用:**
35 |
36 | 自旋锁也是为实现保护共享资源而提出一种锁机制。自旋锁不会引起调用线程阻塞,如果自旋锁已经被别的线程持有,调用线程就一直循环检测是否该自旋锁已经被释放。
37 |
38 | ### **自旋锁的特点**:
39 |
40 | 1. 线程不会阻塞,不会在内核态和用户态之间进行切换。
41 | 2. 消耗 CPU: 因为自旋锁会不断的去检测是否可以获得锁,会一直处于这样的循环当中,这个逻辑的处理过程消耗的 CPU相对其实际功能来说是浪费的。
42 |
43 | ### **自旋锁的实现:**
44 |
45 | CAS(compare and swap) 是实现自旋锁的基础。CAS 的实现基于硬件平台的指令。
46 |
47 | **CAS**涉及到三个操作数:
48 |
49 | - 需要读写的内存值 value1
50 | - 进行比较的值 value2
51 | - 拟写入的新值 value3
52 |
53 | 当且仅当 value1 的值等于 value2时,CAS通过原子方式用新值value3来更新value1的值,否则不会执行任何操作。可以理解为线程会不停的执行一个while循环进行CAS操作,直到达成条件。
54 |
55 | ### **自旋锁的使用场景:**
56 |
57 | 1. 如果预计线程持有锁的时间比较短,相比使用互斥锁两次上下文切换的开销而言,自旋锁消耗的CPU更少的情况下,那么使用自旋锁比互斥锁更高效。
58 | 2. 如果代码当中经常需要加锁但是实际情况下产生竞争的情况比较少此时可以使用自旋锁进行优化。
59 | 3. 被保护的共享资源需要在中断上下文访问,就必须使用自旋锁。
60 |
61 | # 原子操作
62 |
63 | ### **原子操作的作用:**
64 |
65 | 原子操作是不可被中断的一个或者一系列操作,原子操作可以避免操作被进程/线程的调度打断,原子操作的过程当中不会出现上下文的切换,保证操作的完整性。同时在多处理器的环境下,原子操作也保证了多处理器之间对内存访问的原子性。
66 |
67 | ### **原子操作的实现:**
68 |
69 | 原子操作主要是通过硬件操作的方式实现。**在x86 平台上,CPU提供了在指令执行期间对**总线加锁的手段,通过将总线锁住,保证其他CPU无法在同一时刻操作内存,从而保证操作的原子性。同时由于缓存的存在,原子操作也需要缓存锁来提供复杂内存情况下的实现。
70 |
71 | # 阿里面试真题
72 |
73 | ### **问题1:你知道哪些锁?**
74 |
75 | 答:互斥锁,自旋锁,读写锁,行锁,表锁,乐观锁,悲观锁。
76 |
77 | 互斥锁:实现互斥操作最简单的方案
78 |
79 | 自旋锁:无锁操作,比较耗费CPU
80 |
81 | 读写锁:适合读多写少的场景
82 |
83 | 行锁:数据库当中细粒度的一种锁实现,只锁一行数据,锁粒度相对较低
84 |
85 | 表锁:数据库当中粗粒度的一种锁实现,锁整张表,锁粒度较大
86 |
87 | 乐观锁:当线程去获取数据的时候,乐观地认为别的线程不会修改数据,不对对数据加锁。在更新数据的时候会去通过数据的version(版本号)来判断,如果数据被修改了就拒绝更新。
88 |
89 | 悲观锁:当线程去获取数据的时候,悲观地以为别的线程会去修改数据,所以线程每次获取数据的时候都会加锁。
90 |
91 | 解析:在回答有哪些锁的时候,可以同时对每种锁的特点和作用进行介绍;如果对某些锁的实现有比较深入的了解,可以做更多的介绍,比如以某种语言下某种锁的具体实现方式,特点以及优缺点等等。
92 |
93 |
94 |
95 | ### **问题2:锁的作用是什么?**
96 |
97 | 答:锁的作用是为了控制并发访问的安全性。
98 |
99 | 解析:为了避免由于并发带来的资源访问竞争导致的问题,就需要互斥访问,所以需要引入锁机制。
100 |
101 | ### **问题3:自旋锁和互斥锁的使用场景的区别是什么?**
102 |
103 | 答:互斥锁使用场景:被保护资源需要睡眠,那么只能使用互斥锁或者信号量,不能使用自旋锁。
104 |
105 | 自旋锁使用场景:锁的持有时间非常短或者被保护的共享资源需要在中断上下文访问。
106 |
107 | ### **问题4:如何提升并发访问当中锁的性能?**
108 |
109 | 答:有以下几种方案:
110 |
111 | 1. 减小锁的粒度:比如锁分段技术
112 | 2. 减少锁持有的时间
113 | 3. 可以使用自旋锁或者原子操作优化使用互斥锁的地方
114 | 4. 读多写少的情况下可以使用特定功能的锁比如读写锁优化互斥锁
115 | 5. 读写分离,对读和写的操作采用分离的方式实现
116 |
117 | 解析:一般在问到Java当中HashMap的实现,Golang当中Sync.Map的实现时,就是对并发访问当中提升锁的性能方式的考察。
118 |
119 |
120 |
121 | ### **问题5:分布式场景下一般使用什么样的锁?**
122 |
123 | 答:可以使用分布式锁,比如使用ETCD来做分布式锁。
124 |
125 | 解析:分布式锁一般使用版本号和watch机制去实现。
126 |
127 | ### **问题6:互斥锁的开销有哪些?**
128 |
129 | 答: 线程(进程)在申请锁时,从用户态切换到内核态,申请到锁之后从内核态返回用户态,这个过程会产生两次上下文切换;线程(进程)在使用完资源后释放锁,从用户态切换到内核态,操作系统会唤醒阻塞等待锁的其他进程,线程(进程)返回用户态,这个过程也会产生两次上下文的切换;而进程上下文切换又包含直接消耗和间接消耗:
130 |
131 | 1. 直接消耗包括CPU寄存器保存和加载
132 | 2. 间接消耗包括TLB的刷新等等
133 |
134 | # 总结
135 |
136 | 互斥锁的使用是非常重量级的,在一些可以满足自旋锁使用的场景可以使用自旋锁可以优化性能!理解自旋锁和互斥锁的使用场景,也有助于优化并发访问的性能。
--------------------------------------------------------------------------------
/file/阿里面试真题解析之内存对齐.md:
--------------------------------------------------------------------------------
1 | # 前言
2 |
3 | 阿里的面试非常的喜欢问体系结构相关的问题。比如我在秋招面阿里云polardb团队终面当中被问到的这个问题:
4 |
5 | > 你知道什么是内存对齐以及为什么要内存对齐么?
6 |
7 | 相信大家都思考或者看到过这个问题,看似离我们平时写代码很远的细节却能考察出我们对计算机体系结构的了解,这也是为什么在阿里的面试当中会出现这个问题的原因。接下来我将会通过几个例子讲解我对内存对齐的理解,然后以阿里面试真题为例对内存对齐相关问题进行解析。
8 |
9 | ####
10 |
11 | # 内存对齐
12 |
13 | 内存对齐:**编译器**将程序中的每个“数据单元”安排在适当的位置上。
14 |
15 | 简单理解:按照**某种规则**将我们定义的结构体成员放在合适的地址偏移位置上存储。
16 |
17 | **举一个例子:**
18 |
19 | ```c++
20 | //32位系统
21 | #include
22 | using namespace std;
23 |
24 | struct{
25 | int x;
26 | char y;
27 | }s;
28 |
29 | int main()
30 | {
31 | cout << sizeof(s) << endl;
32 | return 0;
33 | }
34 | ```
35 |
36 | **问题:上述代码的输出是多少?**
37 |
38 | 答案:8
39 |
40 | 
41 |
42 | 为什么要额外的3字节去填充这个结构体?一个原本5字节的结构现在变成8 字节,几乎扩大了 2 倍的存储空间,这样的空间开销是否值得?又是什么样的原因导致这样的设计?
43 |
44 | ####
45 |
46 | # 内存对齐的原因
47 |
48 | ### 1.内存以**字节为单位**:
49 |
50 | 内存是以字节为单位存储,但是处理器并不会按照一个字节为单位去存取内存。处理器存取内存是块为单位,块的大小可以是2,4,8,16字节大小,这样的存取单位称为**内存存取粒度**。如果在64位的机器上,不论CPU是要读取第0个字节还是要读取第1个字节,在硬件上传输的信号都是一样的。因为它都会把地址0到地址7,这8个字节全部读到CPU,只是当我们是需要读取第0个字节时,丢掉后面7个字节,当我们是需要读取第1个字节,丢掉第1个和后面6个字节。所以对于计算机硬件来说,内存只能通过特定的对齐地址进行访问。
51 |
52 | ### 2.**内存存取效率:**
53 |
54 | 从内存存取效率方面考虑,内存对齐的情况下可以提升CPU存取内存的效率。比如有一个整型变量(4 字节),现在有一块内存单元: 地址从 0~7。这个整型变量从 地址为 1 的位置开始占据了 1,2,3,4 这 4 个字节。 现在处理器需要读取这个整型变量。假设处理器是 4 字节 4 字节的读取,所以从 0 开始读读取 0,1,2,3发现并没有读完整这个变量,那么需要再读一次,读取 4,5,6,7。然后对两次读取的结果进行处理,提取出 1,2,3,4 地址的内容。需要**两次**访问内存,同时通过一些**逻辑计算**才能得到最终的结果。如果进行内存对齐,将这个整型变量放在从0开始的地址存放,那么CPU只需要一次内存读取,并且没有额外的逻辑计算。可见内存对齐之后存取的效率提升了1倍。
55 |
56 | ####
57 |
58 | # 面试真题
59 |
60 | ### **1.C++当中一个空的结构体或者类的对象的大小是多少?**
61 |
62 | 答案: 空的类或者结构体的大小是1个字节,因为C++当中每个实例在内存中都有一个独一无二的地址,为了达到这个目的,编译器往往会给一个空类隐含的加一个字节,这样空类在实例化后在内存得到了独一无二的地址。
63 |
64 | ### 2.结构体成员的声明顺序会影响结构体的大小么?比如下面两个结构体A,B他们大小是多少?
65 |
66 | ```cpp
67 | struct A // sizeof (A) == 12
68 | {
69 | char b;
70 | int a;
71 | char c;
72 | };
73 | struct B // sizeof (B) == 8
74 | {
75 | char b;
76 | char c;
77 | int a;
78 | };
79 | ```
80 |
81 | 答案:成员声明顺序会影响结构体大小。
82 |
83 | ### 3.内存对齐的作用是什么?
84 |
85 | 答案:提升性能:减少CPU读取内存的次数,提升程序执行的**效率**
86 |
87 | 
88 |
89 | 上图是CPU和几种存储之间的存取速度在这30多年的发展对比(图片来自CMU的深入理解计算机系统课程)。内存就是上述的DRAM存储,CPU的速度和内存 的速度之间差距接近1000倍,3个数量级的差距。可见如果能够减少对内存的读取次数可以极大的提升程序的执 行效率。**移植原因:**有的硬件体系不支持非对齐内存地址的电路系统.当遇到非对齐内存地址的存取时,它将抛出一个异常,可能导致程序崩溃。
90 |
91 | ### 4.内存对齐的原则是什么?
92 |
93 | 答:三原则:
94 |
95 | 1. 结构体变量的**起始地址**能够被其最宽的成员大小整除;
96 | 2. 结构体每个成员相对于**起始地址的偏移**能够被其**自身大小整除**,如果不能则在**前一个成员后面**补充空白字节;
97 | 3. 结构体总体大小能够**被最宽的成员的大小**整除,如不能则在**后面**补充空白字节;
98 |
99 | 分析:编译器在编译的时候是可以指定对齐大小的,实际使用的有效对齐其实是取指定大小和自身大小的最小值,一般默认的对齐大小是4。可以通过预编译命令#pragma pack(n)。除了上述3原则之外还有其他的对齐规则:计算机体系结构当中缓存是很重要的一环,CPU不是直接读取内存而是读取缓存:高速缓冲存储器。其作用是为了更好的利用局部性原理,减少CPU访问主存的次数。因为存取内存相对存取缓存是慢很多的,cache也可以看做是一种空间换时间的做法。实际读取内存的是缓存。所以内存对齐有的时候还需要考虑缓存更新的读取策略,一些规则如下:
100 |
101 | 1.对较大结构体进行cache line对齐:Cache与内存交换的最小单位为cache line。一个cache line大小以64字节为例。当我们的结构体大小没有与64字节对齐时,一个结构体可能就要占用比原本需要更多的cache line,同时还会带来**错误共享**问题,大家可以自行google。
102 |
103 | 2.对只读字段和读写字段分离对齐: 只读字段和读写字段分离对齐的目的是为了让只读字段和读写字段分别存储在缓存的不同cache line中,使得读写字段的淘汰尽量少的影响只读字段,因为只读字段不会被改变所以应该尽量少的被缓存换出。
104 |
105 | ### 5.什么是指令乱序?
106 |
107 | 答:从编译器的角度其实是对我们写的代码的一种优化,按照机器的角度讲一些指令代码执行顺序进行改变,优化程序实际执行的效率。
108 |
109 | 分析:之所以出现编译器乱序优化是因为**编译器能在很大范围内进行代码分析,**从而做出更优的执行策略,可以充分利用处理器的乱序执行功能。
110 |
111 | 指令乱序的问题:编译器优化产生的指令乱序可能会导致多线程程序产生意外的结果。
112 |
113 | 6.如何解决指令乱序问题?
114 |
115 | 答:**内存屏障。**
116 |
117 | 分析:内存屏障,是一类同步指令,是对内存随机访问的操作中的一个同步点。此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。因为指令乱序执行的存在,就需要内存屏障保证程序执行的可靠。
118 |
119 | # 总结
120 |
121 | **通过填充字段padding使得结构体大小与机器字倍数对齐是一种常见的做法。**显然内存对齐是会浪费一些空间的。但是这种空间上得浪费却可以减少存取的时间。这是典型的一种以空间换时间的做法。在内存越来越便宜的今天,这一点点的空间上的浪费就不算什么了。**因为访问内存的速度对于处理来说是非常非常的慢, 内存访问速率对于现在 CPU 来说越来越跟不上, 额外的内存访问无疑是浪费 CPU的。**本节简要介绍了内存对齐的概念并结合我在面试阿里云过程当中遇到的问题进行解答。
--------------------------------------------------------------------------------
/time_heap.cpp:
--------------------------------------------------------------------------------
1 | //
2 | // Created by jxq on 20-4-7.
3 | //
4 |
5 | #include "time_heap.h"
6 |
7 | time_heap::time_heap(int cap):capacity(cap),cur_size(0)
8 | {
9 | //创建数组
10 | array = new heap_timer*[capacity];
11 | if(!array)
12 | {
13 | fprintf(stderr,"init heap faild");
14 | return ;
15 | }
16 | for(int i=0;i=0;--i)
47 | {
48 | percolate_down(i);
49 | }
50 | }
51 | }
52 |
53 |
54 | time_heap::~time_heap()
55 | {
56 | for(int i=0;i= capacity)
70 | {
71 | resize();
72 | }
73 |
74 | ////新插入一个元素,当前堆大小加1, hole是新建空穴的位置
75 | int hole = cur_size++;
76 | int parent = 0;
77 | //对从空穴到根节点的路径上的所有节点执行上虑操作
78 | for(;hole>0;hole=parent)
79 | {
80 | parent = (hole-1)/2;
81 |
82 | if(array[parent]->expire <= timer->expire)
83 | {
84 | break;
85 | }
86 | array[hole] = array[parent];
87 | }
88 | array[hole] = timer;
89 | return 0;
90 | }
91 |
92 | void time_heap::del_timer(heap_timer* timer)
93 | {
94 | if(!timer)
95 | return ;
96 | timer->cb_func = NULL;
97 | }
98 |
99 | heap_timer* time_heap::top()const
100 | {
101 | if(empty())
102 | {
103 | return NULL;
104 | }
105 | return array[0];
106 | }
107 |
108 | void time_heap::pop_timer()
109 | {
110 | if(empty())
111 | {
112 | return ;
113 | }
114 | if(array[0])
115 | {
116 | delete array[0];
117 | //将原来的堆顶元素替换为堆数组中最后一个元素
118 | array[0] = array[--cur_size];
119 |
120 | //对新的堆顶元素执行以下操作
121 | percolate_down(0);
122 | }
123 |
124 | }
125 |
126 |
127 | void time_heap::tick()
128 | {
129 | heap_timer *tmp = array[0];
130 | time_t cur = time(NULL);
131 | //循环处理定时器
132 | while(!empty())
133 | {
134 | if(!tmp)
135 | {
136 | break;
137 | }
138 | //如果堆顶定时没有到期,则退出循环
139 | if(tmp->expire > cur)
140 | {
141 | break;
142 | }
143 | //否则执行堆顶定时器中的回调函数
144 | if(array[0]->cb_func)
145 | {
146 | array[0]->cb_func(array[0]->user_data);
147 | }
148 | //删除堆顶元素,同时生成新的堆顶定时器
149 | pop_timer();
150 | tmp = array[0];
151 | }
152 | }
153 |
154 |
155 | void time_heap::percolate_down(int hole)
156 | {
157 | heap_timer *tmp = array[hole];
158 | int child = 0;
159 | for(;((hole*2)+1) <= (cur_size-1);hole = child)
160 | {
161 | child = hole*2+1; // 左子树
162 | if(child < (cur_size-1) && array[child+1]->expire < array[child]->expire)
163 | {
164 | ++child;
165 | }
166 |
167 | if(array[child]->expire < tmp->expire)
168 | {
169 | array[hole] = array[child];
170 | }
171 | else
172 | {
173 | /* code */
174 | break;
175 | }
176 |
177 | }
178 | array[hole] = tmp;
179 | }
180 |
181 |
182 | void time_heap::resize()
183 | {
184 | heap_timer **tmp = new heap_timer*[2* capacity];
185 | for(int i=0;i<(2*capacity);i++)
186 | {
187 | tmp[i] = NULL;
188 | }
189 |
190 | if(!tmp)
191 | {
192 | fprintf(stderr,"resize() faild");
193 | return ;
194 | }
195 |
196 | capacity = 2*capacity;
197 | for(int i=0;i
33 |
34 | int select(int nfds,fd_set *readset,fd_set *writeset,fd_set *exceptset, struct timeval *timeout);
35 | ```
36 |
37 | nfds参数指定被监听的文件描述符的总数;readset,writeset,exceptset参数分别是可读,可写和异常事件对应的文件描述符集合;而fd_set结构体由一个整形数组组成,该数组每一位标记了一个文件描述符,该数组的上限有宏FD_SETSIZE指定;timeout是select的超时时间。
38 |
39 | **select机制的缺点**
40 |
41 | 1. 每次调用select,都需要把监听的文件描述符集合fd_set从用户态拷贝到内核态,从算法角度来说就是O(n)的时间开销。
42 | 2. 每次调用select调用返回之后都需要遍历所有文件描述符,判断哪些文件描述符有读写事件发生,这也是O(n)的时间开销。
43 | 3. 内核对被监控的文件描述符集合大小做了限制,并且这个是通过宏控制的,大小不可改变(限制为1024)。
44 |
45 | # poll
46 |
47 | 1997年出现了poll系统调用,和select类似,poll也是在指定时间内监听多个文件描述符。
48 |
49 | 函数原型:
50 |
51 | ```c
52 | #include
53 | int poll(struct pollfd *fds, nfds_t nfds, int timeout);
54 | ```
55 |
56 | 优化:poll改变了文件描述符集合的描述方式,通过一个pollfd数组向内核传递需要关注的事件,没有描述符个数的限制.
57 |
58 | ```c
59 | typedef struct pollfd {
60 | int fd;
61 | short events;
62 | short revents;
63 | } pollfd_t;
64 | ```
65 |
66 | ####
67 |
68 | # epoll
69 |
70 | Linux2.6内核实现了epoll,函数原型如下:
71 |
72 | ```c
73 | #include
74 |
75 | int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
76 | ```
77 |
78 | epoll是Linux特有的I/O复用函数。对于select的几个问题,epoll的优化策略如下:
79 |
80 | 1.epoll使用一个文件描述符管理多个描述符,将用户关心的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间只需一次拷贝,不用每次调用都重复传入文件描述符集合。
81 |
82 | 2.在epoll_wait函数返回时,无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入就绪队列的描述符集合就行,这样就避免了无效的遍历。
83 |
84 | 简单来说,在用户进程通过epoll_ctl系统调用向内核注册需要监听的事件,使用epoll_wait开启I/O多路复用,epoll为每个文件描述符指定一个回调函数,当设备就绪,就会调用这个回调函数,而这个回调函数会把就绪的文件描述符加入一个就绪链表,唤醒等待在这个epoll_wait上的进程,用户进程只需要遍历这个就绪链表就可以进行下一步处理。同时内核通过红黑树的结构存储这些文件描述符,提升查找的效率。
85 |
86 | ####
87 |
88 | # 腾讯面试真题
89 |
90 | ### 1.说一下epoll的好处
91 |
92 | 答:epoll解决了select和poll在文件描述符集合拷贝和遍历上的问题,能够在一个进程当中监听多个文件描述符,并且十分高效。
93 |
94 | ### 2.epoll和select之间的区别?
95 |
96 | 答:1.epoll不需要每次调用的时候都在用户态和内核态拷贝文件描述符集合,而select需要。
97 |
98 | 2.epoll在内核态通过红黑树和回调的方式处理文件描述符,返回时只需要遍历就绪链表即可,而select通过数 组的方式处理,每次需要遍历整个数组判断哪些文件描述符就绪。
99 |
100 | 3.epoll使用maxevents参数指定最多监听的文件描述符的个数,最多可以到达系统允许打开的最大文件描述 符个数,而select允许监听的最大文件描述符熟练有限制。
101 |
102 | 4.epoll可以工作在高效的ET模式,而select只能工作在相对低效的LT模式。
103 |
104 | 5.epoll使用的是回调的方式将就绪文件描述符插入就绪链表,返回时用户只需要O(1)的时间开销寻找就绪事 件,而select采用轮询的方式,需要O(n)的时间开销。
105 |
106 | ### 3.epoll需要在用户态和内核态拷贝数据么?
107 |
108 | 答:在注册监听事件时从用户态将数据传入内核态;当返回时需要将就绪队列的内容拷贝到用户空间。
109 |
110 | ### 4.epoll的实现知道么?在内核当中是什么样的数据结构进行存储,每个操作的时间复杂度是多少?
111 |
112 | 答:在内核当中是以红黑树的方式组织监听的事件,查询开销是O(logn)。采用回调的方式检测就绪事件,时间复杂的位O(1);
113 |
114 | ### 5.epoll的水平触发和边沿触发有什么区别?
115 |
116 | 答:**水平触发(Level Trigger):是eopll的**默认工作模式,当epoll_wait检测到某文件描述符上有事件发生,并通知应用程序之后,应用程序可以不立即处理该事件,当下次调用epoll_wait时,epoll_wait还会再次向应用程序通知此事件,直到该事件被应用程序处理。
117 |
118 | 边缘触发(Edge Trigger): 当epoll_wait检测到某文件描述符上有事件发生,并通知应用程序之后,应用程序必须立即处理该事件。如果应用程序不处理,下次调用epoll_wait时,epoll_wait不会再次通知此事件。
119 |
120 | ET模式很大程度上减少了epoll事件被重复触发的次数,因此效率比LT模式下高。
121 |
122 | ### 6.什么是EPOLLONESHOT事件?
123 |
124 | 答:注册了EPOLLONESHOT事件的文件描述符,操作系统只能触发该文件描述符上注册的最多一个就绪事件,并且只触发一次。该处理方式保证了当一个线程正在处理该文件描述符上的就绪事件时,其他线程无法操作该文件描述符。
125 |
126 | # 总结
127 |
128 | epoll的出现是由于历史的原因,在十几年前前并发量不大的情况下select和poll已经可以解决那时的问题,而随着并发量越来越大,select和poll就暴露出设计的问题,从而一步一步优化,这也是符合程序设计的思路,先解决当前问题,再考虑优化。三者对比总结如下:
129 |
130 | | 系统调用 | select | poll | epoll |
131 | | ---------------------------------- | ---------------------------------- | ---------------------------------- | ------------------------------------------ |
132 | | 查找就绪文件描述符的操作时间复杂的 | O(n) | O(n) | O(1) |
133 | | 最大支持的文件描述符数量 | 有最大限制一般为1024 | 最多可达系统文件描述符上限 | 最多可达系统文件描述符上限 |
134 | | 工作模式 | LT | LT | LT,ET |
135 | | 效率对比 | 调用时需要O(n)的文件描述符集合拷贝 | 调用时需要O(n)的文件描述符集合拷贝 | 只在添加描述符时拷贝,调用无需额外拷贝开销 |
136 |
137 | 本节主要介绍了epoll和select,poll的区别,并结合腾讯的面试真题对epoll相关问题进行解答。
--------------------------------------------------------------------------------
/file/20200302.md:
--------------------------------------------------------------------------------
1 | ## [vivo面试(软件工程师(后端方向))](https://www.nowcoder.com/discuss/197881)
2 |
3 | ### 1. 线程池
4 |
5 | ## 基础概念
6 |
7 | **线程池:** 当进行并行的任务作业操作时,线程的建立与销毁的开销是,阻碍性能进步的关键,因此线程池,由此产生。使用多个线程,无限制循环等待队列,进行计算和操作。帮助快速降低和减少性能损耗。
8 |
9 | ## 线程池的组成
10 |
11 | 1. 线程池管理器:初始化和创建线程,启动和停止线程,调配任务;管理线程池
12 | 2. 工作线程:线程池中等待并执行分配的任务
13 | 3. 任务接口:添加任务的接口,以提供工作线程调度任务的执行。
14 | 4. 任务队列:用于存放没有处理的任务,提供一种缓冲机制,同时具有调度功能,高优先级的任务放在队列前面
15 |
16 | 参考:[C++线程池](https://wangpengcheng.github.io/2019/05/17/cplusplus_theadpool/)
17 |
18 | ### 2. hashmap
19 |
20 |
21 |
22 | 
23 |
24 | 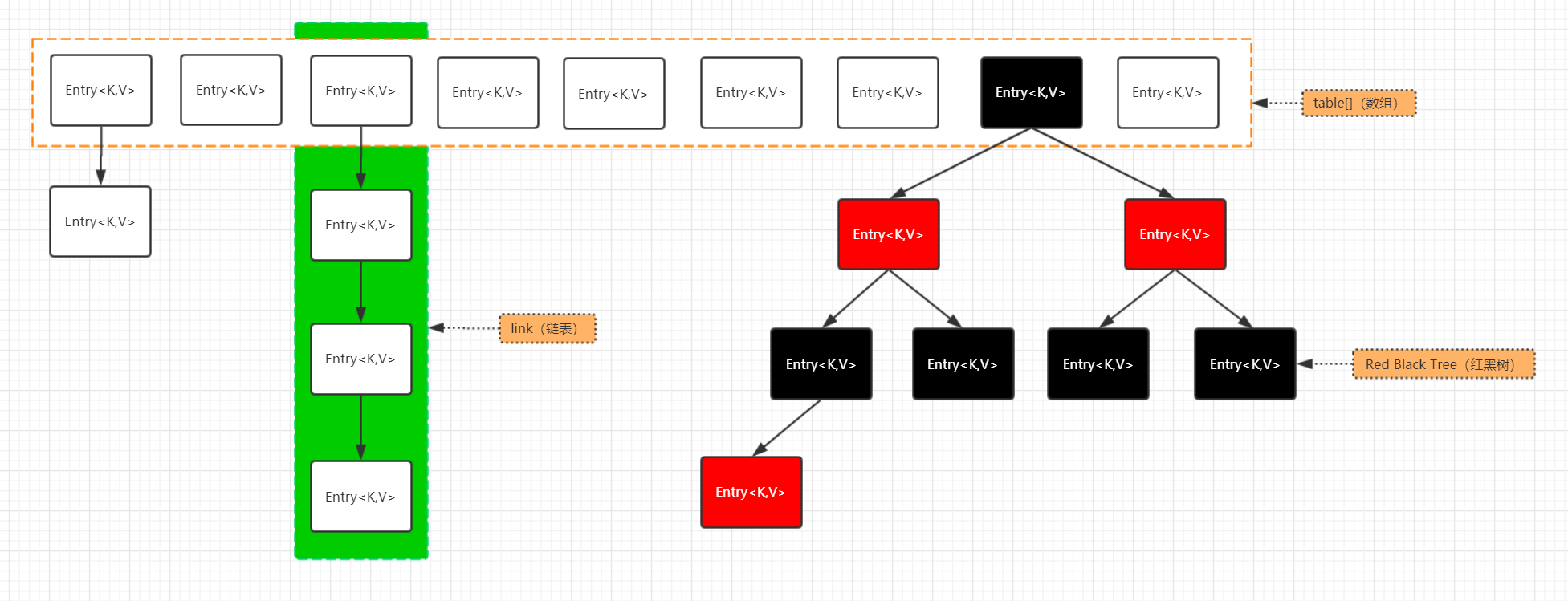
25 |
26 | **HashMap由数组加链表组成的,数组是HashMap的哈希桶,链表则是为解决哈希碰撞而存在的,如果定位到的数组位置不含链表(即哈希桶中只有一个Entry),那么对于查找,添加等操作很快,仅需一次寻址即可(数组根据下标寻址,速度很快);如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,也需遍历链表,然后通过key对象的equals方法逐一比较查找。所以,性能考虑,HashMap中的链表出现越少,性能就会越好。(其实也就是key的哈希值越离散,Entry就会尽可能的均匀分布,出现链表的概率也就越低)**
27 |
28 | 参考:[HashMap的底层实现]([https://lushunjian.github.io/blog/2019/01/02/HashMap%E7%9A%84%E5%BA%95%E5%B1%82%E5%AE%9E%E7%8E%B0/](https://lushunjian.github.io/blog/2019/01/02/HashMap的底层实现/))
29 |
30 | ### [3. 三次握手+四次挥手]([https://interview.huihut.com/#/?id=tcp-%e4%b8%89%e6%ac%a1%e6%8f%a1%e6%89%8b%e5%bb%ba%e7%ab%8b%e8%bf%9e%e6%8e%a5](https://interview.huihut.com/#/?id=tcp-三次握手建立连接))
31 |
32 | ##### [TCP 三次握手建立连接](https://interview.huihut.com/#/?id=tcp-三次握手建立连接)
33 |
34 | 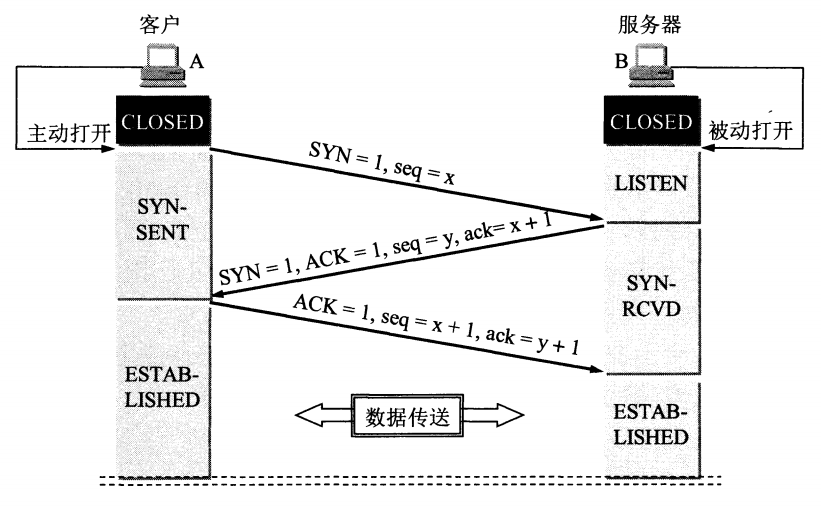
35 |
36 | 【TCP 建立连接全过程解释】
37 |
38 | 1. 客户端发送 SYN 给服务器,说明客户端请求建立连接;
39 | 2. 服务端收到客户端发的 SYN,并回复 SYN+ACK 给客户端(同意建立连接);
40 | 3. 客户端收到服务端的 SYN+ACK 后,回复 ACK 给服务端(表示客户端收到了服务端发的同意报文);
41 | 4. 服务端收到客户端的 ACK,连接已建立,可以数据传输。
42 |
43 | ##### [TCP 为什么要进行三次握手?](https://interview.huihut.com/#/?id=tcp-为什么要进行三次握手?)
44 |
45 | 【答案一】因为信道不可靠,而 TCP 想在不可靠信道上建立可靠地传输,那么三次通信是理论上的最小值。(而 UDP 则不需建立可靠传输,因此 UDP 不需要三次握手。)
46 |
47 | ##### [TCP 四次挥手释放连接](https://interview.huihut.com/#/?id=tcp-四次挥手释放连接)
48 |
49 | 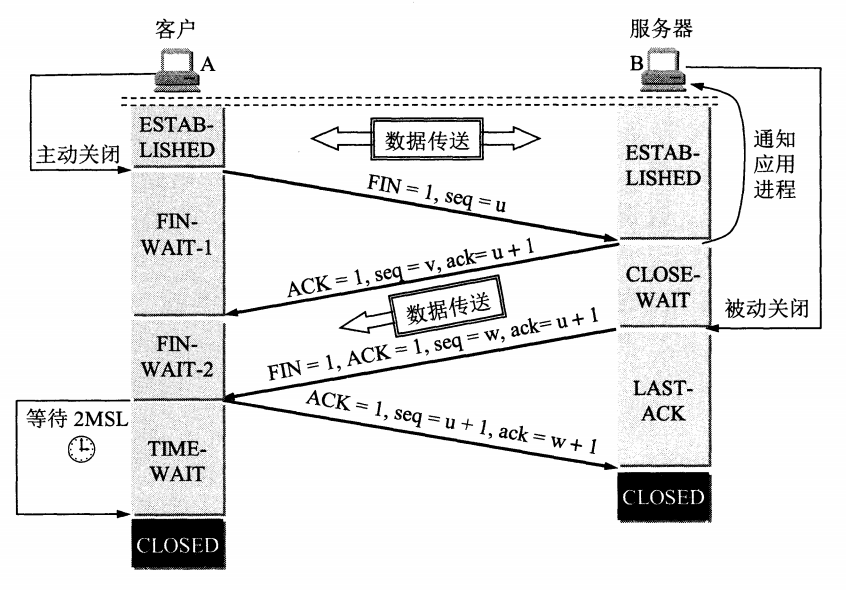
50 |
51 | 【TCP 释放连接全过程解释】
52 |
53 | 1. 客户端发送 FIN 给服务器,说明客户端不必发送数据给服务器了(请求释放从客户端到服务器的连接);
54 | 2. 服务器接收到客户端发的 FIN,并回复 ACK 给客户端(同意释放从客户端到服务器的连接);
55 | 3. 客户端收到服务端回复的 ACK,此时从客户端到服务器的连接已释放(但服务端到客户端的连接还未释放,并且客户端还可以接收数据);
56 | 4. 服务端继续发送之前没发完的数据给客户端;
57 | 5. 服务端发送 FIN+ACK 给客户端,说明服务端发送完了数据(请求释放从服务端到客户端的连接,就算没收到客户端的回复,过段时间也会自动释放);
58 | 6. 客户端收到服务端的 FIN+ACK,并回复 ACK 给客户端(同意释放从服务端到客户端的连接);
59 | 7. 服务端收到客户端的 ACK 后,释放从服务端到客户端的连接。
60 |
61 | ##### [TCP 为什么要进行四次挥手?](https://interview.huihut.com/#/?id=tcp-为什么要进行四次挥手?)
62 |
63 | 【问题一】TCP 为什么要进行四次挥手? / 为什么 TCP 建立连接需要三次,而释放连接则需要四次?
64 |
65 | 【答案一】因为 TCP 是全双工模式,客户端请求关闭连接后,客户端向服务端的连接关闭(一二次挥手),服务端继续传输之前没传完的数据给客户端(数据传输),服务端向客户端的连接关闭(三四次挥手)。所以 TCP 释放连接时服务器的 ACK 和 FIN 是分开发送的(中间隔着数据传输),而 TCP 建立连接时服务器的 ACK 和 SYN 是一起发送的(第二次握手),所以 TCP 建立连接需要三次,而释放连接则需要四次。
66 |
67 | 【问题二】为什么 TCP 连接时可以 ACK 和 SYN 一起发送,而释放时则 ACK 和 FIN 分开发送呢?(ACK 和 FIN 分开是指第二次和第三次挥手)
68 |
69 | 【答案二】因为客户端请求释放时,服务器可能还有数据需要传输给客户端,因此服务端要先响应客户端 FIN 请求(服务端发送 ACK),然后数据传输,传输完成后,服务端再提出 FIN 请求(服务端发送 FIN);而连接时则没有中间的数据传输,因此连接时可以 ACK 和 SYN 一起发送。
70 |
71 | 【问题三】为什么客户端释放最后需要 TIME-WAIT 等待 2MSL 呢?
72 |
73 | 【答案三】
74 |
75 | 1. 为了保证客户端发送的最后一个 ACK 报文能够到达服务端。若未成功到达,则服务端超时重传 FIN+ACK 报文段,客户端再重传 ACK,并重新计时。
76 | 2. 防止已失效的连接请求报文段出现在本连接中。TIME-WAIT 持续 2MSL 可使本连接持续的时间内所产生的所有报文段都从网络中消失,这样可使下次连接中不会出现旧的连接报文段。
77 |
78 |
79 |
80 | ### 4.有两个场景,一个是计算密集型服务,一个是I/O密集型服务,分别设计两个线程池,哪个要设计线程池更大些?线程池设计多大合适?
81 |
82 | * 对于cpu密集型的任务来说,线程数等于cpu数是最好的了,
83 | * 对于I/O密集型的任务来说,线程数等于IO任务数是最佳的. **多**
84 | * **在处理I/O密集型任务的时候,线程数大于当前核数的情况下确实会更快的处理完任务;**
85 | * **在处理CPU密集型任务的时候,线程数保持和当前核数一致的情况下也确实会更快的处理完任务。**
86 |
87 | ### 5. mysql的内联接和外联接的区别?
88 |
89 | - 内连接(inner join): 只连接匹配的行
90 |
91 | - 左外连接(left join): 包含左边表的全部行(不管右边的表中是否存在与它们匹配的行),以及右边表中全部匹配的行
92 |
93 | - 右外连接(right join): 包含右边表的全部行(不管左边的表中是否存在与它们匹配的行),以及左边表中全部匹配的行
94 |
95 | ```sql
96 | 例子:
97 | a表 id name b表 id job parent_id
98 | 1 张3 1 23 1
99 | 2 李四 2 34 2
100 | 3 王武 3 34 4
101 |
102 | a.id同parent_id 存在关系
103 |
104 | 内连接
105 | select a.*,b.* from a inner join b on a.id=b.parent_id
106 |
107 | 结果是
108 | 1 张3 1 23 1
109 | 2 李四 2 34 2
110 |
111 | 左连接
112 | select a.*,b.* from a left join b on a.id=b.parent_id
113 |
114 | 结果是
115 | 1 张3 1 23 1
116 | 2 李四 2 34 2
117 | 3 王武 null
118 |
119 | 右连接
120 | select a.*,b.* from a right join b on a.id=b.parent_id
121 |
122 | 结果是
123 | 1 张3 1 23 1
124 | 2 李四 2 34 2
125 | null 3 34 4
126 |
127 | 完全连接
128 | select a.*,b.* from a full join b on a.id=b.parent_id
129 |
130 | 结果是
131 | 1 张3 1 23 1
132 | 2 李四 2 34 2
133 | null 3 34 4
134 | 3 王武 null
135 | ```
136 |
137 |
138 |
139 | 参考:[SQL 左外连接,右外连接,全连接,内连接](https://www.cnblogs.com/youzhangjin/archive/2009/05/22/1486982.html)
140 |
141 | ### 6. linux查看占用某个端口的进程号的命令
142 |
143 | linux 下查看进程占用端口:
144 | (1)查看程序对应的进程号: **ps -ef | grep 进程名字**
145 |
146 | (2)查看进程号所占用的端口号:**netstat -nltp | grep 进程号**
147 |
148 | ubuntu :查看进程占用端口号:netstat -anp | grep pid
149 |
150 | **linux 下查看端口号所使用的进程号:**
151 | (1)使用 lsof 命令:**lsof -i:端口号**
152 |
153 | ### 7. linux中tar -zxvf中zxvf各代表什么含义?
154 |
155 | * -z: 支持gzip解压文件
156 | * -x: 从压缩文件中提取文件
157 | * -v: 显示操作过程
158 | * -f: 指定压缩文件
--------------------------------------------------------------------------------
/file/阿里面试真题解析之C++相关问题.md:
--------------------------------------------------------------------------------
1 | # 前言
2 |
3 | 阿里虽然是国内Java的第一大厂但是并非所有的业务都是由Java支撑,很多服务和中下层的存储,计算,网络服务,大规模的分布式任务都是由C++编写。在阿里所有部门当中对C++考察最深的可能就是阿里云。在此我将以我今年实习和秋招面试阿里云的真题进行分析,通过真题对面试当中遇到的C++问题进行解答。
4 |
5 |
6 |
7 | # C++面试重点
8 |
9 | 我本人是以C++作为主编程语言。C++是后台开发以及基础架构方向使用较多的语言之一。在我所有的面试当中,对于C++语言的考察主要集中在以下几点:
10 | 1.STL 容器相关实现
11 | 2.C++新特性的了解
12 | 3.多态和虚函数的实现
13 | 4.指针的使用
14 |
15 | # 阿里面试真题再现
16 |
17 | ### **问题1:**现在假设有一个编译好的C++程序,编译没有错误,但是运行时报错,报错如下:你正在调用一个纯虚函数(Pure virtual function call error),请问导致这个错误的原因可能是什么?
18 |
19 | 答:纯虚函数调用错误一般由以下几种原因导致:
20 |
21 | 1. 从基类构造函数直接调用虚函数。
22 | 2. 从基类析构函数直接调用虚函数。
23 | 3. 从基类构造函数间接调用虚函数。
24 | 4. 从基类析构函数间接调用虚函数。
25 | 5. 通过悬空指针调用虚函数。
26 |
27 | 其中1,2编译器会检测到此类错误。3,4,5编译器无法检测出此类情况,会在运行时报错。
28 |
29 | 直接调用指的是函数内部直接调用虚函数,间接调用指的是函数内部调用其他的非虚函数内部直接或间接调用了虚函数。
30 |
31 |
32 |
33 | **解析:**
34 |
35 | **首先对关键知识点进行回顾:虚函数表,对象构造和析构过程**
36 |
37 | **虚函数表vtbl:**
38 |
39 | 1. 编译器在**编译时期**为每个带虚函数的类创建一份虚函数表
40 | 2. 实例化对象时, 编译器自动将类对象的虚表指针指向这个虚函数表
41 |
42 | **构造一个派生类对象的过程:**
43 |
44 | 1.构造基类部分:
45 |
46 | 1. 将实例的虚表指针指向基类的vtbl
47 | 2. 构造基类的成员变量
48 | 3. 执行基类的构造函数函数体
49 |
50 | 2.递归构造派生类部分:
51 |
52 | 1. 将实例的虚表指针指向派生类vtbl
53 | 2. 构造派生类的成员变量
54 | 3. 执行派生类的构造函数体
55 |
56 | **析构一个派生类对象的过程:**
57 |
58 | 1.递归析构派生类部分:
59 |
60 | 1. 将实例的虚表指针指向派生类vtbl
61 | 2. 执行派生类的析构函数体
62 | 3. 析构派生类的成员变量
63 |
64 | 2.析构基类部分:
65 |
66 | 1. 将实例的虚表指针指向基类的vtbl
67 | 2. 执行基类的析构函数函数体
68 | 3. 析构基类的成员变量
69 |
70 | 由以上可知在构造函数和析构函数执行函数体过程时,实例的虚表指针指向的是构造函数和析构函数本身所属的那部分的类的虚函数表,此时执行的虚函数都实际调用的是该类本身的虚函数,所以如果在基类的析构或者构造函数当中调用虚函数且该虚函数本身在基类当中是纯虚函数那么就会出现纯虚函数调用。
71 |
72 | 可以运行如下代码进行验证:
73 |
74 | ```c++
75 | #include
76 | using namespace std;
77 |
78 | class Parent {
79 | public:
80 | virtual void virtualFunc() = 0;
81 | void helper() {
82 | virtualFunc();
83 | }
84 | virtual ~Parent(){
85 | helper();
86 | }
87 | };
88 |
89 | class Child : public Parent{
90 | public:
91 | void virtualFunc() {
92 | cout << "Child" << endl;
93 | }
94 | virtual ~Child(){}
95 | };
96 |
97 |
98 | int main() {
99 |
100 | Child child;
101 | return 0;
102 | }
103 | ```
104 |
105 | 运行时报错:libc++abi.dylib: Pure virtual function called!
106 |
107 | **通过悬空指针调用虚函数:**
108 |
109 | 悬空指针:指针最初指向的内存已经被释放了的一种指针, 访问"不安全可控"的内存区域将导致未定义的行为。
110 |
111 | 如下代码显示了悬空指针调用虚函数的典型案例:
112 |
113 | ```c++
114 | #include
115 | using namespace std;
116 |
117 | class Parent {
118 | public:
119 | virtual void virtualFunc() = 0;
120 | void testFunc(){};
121 | virtual ~Parent(){
122 | testFunc();
123 | };
124 | };
125 |
126 | class Child : public Parent{
127 | public:
128 | virtual void virtualFunc() {
129 | cout << "Child-VirtualFunc-call" << endl;
130 | }
131 | virtual ~Child(){};
132 | };
133 |
134 |
135 | int main() {
136 |
137 | Parent* child = new Child();
138 | Parent* p = child;
139 | //p此时可以成功的调用Child的virtualFunc输出"Child-VirtualFunc-call"
140 | p->virtualFunc();
141 | delete child;
142 | //在delete child之后p就是一个悬空指针
143 | p->virtualFunc();
144 |
145 | return 0;
146 | }
147 | ```
148 |
149 | 上述代码当中,p指向一个前对象,该对象已经被delete。根据C++标准,它是“未定义的”:意味着任何事情都可能发生:程序可能崩溃,或者继续运行,行为可能因编译器而异,或因计算机而异,或运行时不同。有几种常见的可能性:
150 |
151 | - 内存可能被标记为已释放。任何访问它的尝试都将立即标记为使用了悬空指针。
152 | - 内存可能被故意加密。释放后,内存管理系统可能会将类似垃圾的值写入内存。
153 | - 内存可能会被重用。如果在删除对象和使用悬空指针之间执行了其他代码,则内存分配系统可能已经从旧对象使用的部分或全部内存中创建了一个新对象。如果幸运的话,这看起来就像垃圾,程序立即崩溃。否则,该程序可能会在某个时间之后崩溃。
154 | - 内存可能完全保留,没有变化。
155 |
156 | 最后一种情况就是此时对象的虚表指针指向的是基类的虚函数表,此时调用的是纯虚函数。
157 |
158 |
159 |
160 | ### **问题2:**是先构造父类的虚表指针还是先构造父类的成员?
161 |
162 | 答:由问题1解析可知先构造虚表指针再构造成员变量。
163 |
164 | 对于本类来说:先设定本类虚表指针->执行初始化列表->调用成员变量构造函数->执行本身构造函数体
165 |
166 | ### **问题3**:在构造实例过程当中一部分是初始化列表一部分是在函数体内,你能说一下这些的顺序是什么?差别是什么和this指针构造的顺序
167 |
168 | 答:初始化列表当中的先初始化,然后才是函数体内代码被执行。构造函数本身也只是一个函数,执行构造函数时所有成员其实都已经初始化完成。this指针属于对象,初始化列表在构造函数之前执行,在对象还没有构造完成前,使用this指针,编译器无法识别。所以this指针在初始化列表当中不应当使用,在构造函数体内部可以使用。
169 |
170 | 解析:构造函数的执行可以分成两个阶段:
171 |
172 | - 初始化阶段:所有类类型的成员都会在初始化阶段初始化,即使该成员没有出现在构造函数的初始化列表中。
173 | - 计算赋值阶段:一般用于执行构造函数体内的赋值操作。
174 |
175 | 可以使用如下代码进行验证:
176 |
177 | ```c++
178 | #include
179 | using namespace std;
180 |
181 | class Test1 {
182 | public:
183 | Test1(){
184 | cout << "Construct Test1" << endl;
185 | }
186 | Test1& operator = (const Test1& t1) {
187 | cout << "Assignment for Test1" << endl;
188 | this->a = t1.a;
189 | return *this;
190 | }
191 | int a ;
192 | };
193 |
194 | class Test2 {
195 | public:
196 | Test1 test1;
197 | Test2(Test1 &t1) {
198 | cout << "构造函数体开始" << endl;
199 | test1 = t1 ;
200 | cout << "构造函数体结束" << endl;
201 | }
202 | };
203 |
204 | int main() {
205 | Test1 t1;
206 | Test2 test(t1);
207 | return 0;
208 | }
209 | ```
210 |
211 | 输出:
212 |
213 | ```
214 | Construct Test1
215 | Construct Test1
216 | 构造函数体开始
217 | assignment for Test1
218 | 构造函数体结束
219 | ```
220 |
221 | 可以看出Test2在构造函数体执行之前已经使用了Test1的默认构造函数初始化好了t1。
222 |
223 | ### **问题4**:初始化列表的写法和顺序有没有什么关系?
224 |
225 | 答:成员初始化的顺序和它们在类定义中出现的顺序一致,构造函数初始值列表中的前后位置不会影响实际的初始化顺序。当数据成员是 const 、引用,或者属于某种未提供默认构造函数的类类型的话,就必须通过构造函数的初始值列表为这些成员提供初始值,否则就会引发错误。
226 |
227 | ### **问题5**:如果父类有一个虚函数叫func_A,子类也实现这个函数,在子类的构造函数当中去调用这个func_A,运行的是谁的实现?
228 |
229 | 答:运行的是子类的实现。因为子类构造函数调用的时候对象的虚表指针指向的是子类的虚函数表,因为子类实现了func_A所以调用的是子类自己的func_A。
230 |
231 | ### **问题6**:虚表指针和构造函数体那个先被构造?
232 |
233 | 答:虚表指针先构造。
234 |
235 | ### **问题7**:c++运行构造函数的时候虚函数表被构造出来了么?
236 |
237 | 答:构造出来了。因为虚函数表是在编译时由编译器创建,在运行时肯定已经创建完成。
238 |
239 | ### **问题8**:在普通的函数当中调用虚函数和在构造函数当中调用虚函数有什么区别?
240 |
241 | 答:普调函数当中调用虚函数是希望运行时多态。而在构造函数当中不应该去调用虚函数因为构造函数当中调用的就是本类型当中的虚函数,无法达到运行时多态的作用。
242 |
243 | ### **问题9**:成员变量,虚函数表指针的位置是怎么排布?
244 |
245 | 答:如果一个类带有虚函数,那么该类实例对象的内存布局如下:首先是一个虚函数指针,接下来是该类的成员变量,按照成员在类当中声明的顺序排布,整体对象的大小由于内存对齐会有空白补齐。其次如果基类没有虚函数但是子类含有虚函数此时内存子类对象的内存排布也是先虚函数表指针再各个成员。如果将子类指针转换成基类指针此时编译器会根据偏移做转换。
246 |
247 | 可以使用如下代码验证:
248 |
249 | ```c++
250 | #include
251 | using namespace std;
252 |
253 | class Parent{
254 | public:
255 | int a;
256 | int b;
257 | };
258 |
259 | class Child:public Parent{
260 | public:
261 | virtual void test(){}
262 | int c;
263 | };
264 |
265 | int main() {
266 | Child c = Child();
267 | Parent p = Child();
268 | cout << sizeof(c) << endl;//24
269 | cout << sizeof(p) << endl;//8
270 |
271 | Child* cc = new Child();
272 | Parent* pp = cc;
273 | cout << cc << endl;//0x7fbe98402a50
274 | cout << pp << endl;//0x7fbe98402a58
275 | cout << &(cc->a) << endl;//0x7fbe98402a58
276 | cout << &(cc->b) << endl;//0x7fbe98402a5c
277 | cout << &(cc->c) << endl;//0x7fbe98402a60
278 | return 0;
279 | }
280 | ```
281 |
282 | 输出:
283 |
284 | ```
285 | 24
286 | 8
287 | 0x7fbe98402a50
288 | 0x7fbe98402a58
289 | 0x7fbe98402a58
290 | 0x7fbe98402a5c
291 | 0x7fbe98402a60
292 | ```
293 |
294 | 我的测试环境是64位,所以指针为8个字节。转换之后pp和cc相差一个虚表指针的偏移。
295 |
296 | # 总结
297 |
298 | 阿里考察C++的问题集中在以下几点:
299 |
300 | 1. 虚函数的实现
301 | 2. 虚函数使用出现的问题原因
302 | 3. 带有虚函数的类对象的构造和析构过程
303 | 4. 对象的内存布局
304 | 5. 虚函数的缺点:相比普通函数,虚函数调用需要2次跳转,会降低CPU缓存的命中率。运行时绑定,编译器不好优化。
--------------------------------------------------------------------------------
/file/20200301.md:
--------------------------------------------------------------------------------
1 | ## [vivo提前批武汉站C++后端面经](https://www.nowcoder.com/discuss/197908)
2 |
3 | ### 1. linux中查询一个文件第三列并按顺序显示
4 |
5 | ```
6 | cat filename | awk '{print $1 }' // 第一列
7 | cat filename | awk 'NR==1' // 第一行
8 | ```
9 |
10 | ### 2.const,static,volatile
11 |
12 | ### [const](https://interview.huihut.com/#/?id=const)
13 |
14 | #### [作用](https://interview.huihut.com/#/?id=作用)
15 |
16 | 1. 修饰变量,说明该变量不可以被改变;
17 | 2. 修饰指针,分为指向常量的指针和指针常量;
18 | 3. 常量引用,经常用于形参类型,即避免了拷贝,又避免了函数对值的修改;
19 | 4. 修饰成员函数,说明该成员函数内不能修改成员变量。
20 | 5. 指向常量的指针:const int * a;int const *a; 常量指针int *const a;
21 |
22 | ### [static](https://interview.huihut.com/#/?id=static)
23 |
24 | #### [作用](https://interview.huihut.com/#/?id=作用-1)
25 |
26 | 1. 修饰普通变量,修改变量的存储区域和生命周期,使变量存储在静态区,在 main 函数运行前就分配了空间,如果有初始值就用初始值初始化它,如果没有初始值系统用默认值初始化它。
27 | 2. 修饰普通函数,表明函数的作用范围,仅在定义该函数的文件内才能使用。在多人开发项目时,为了防止与他人命名空间里的函数重名,可以将函数定位为 static。
28 | 3. 修饰成员变量,修饰成员变量使所有的对象只保存一个该变量,而且不需要生成对象就可以访问该成员。
29 | 4. 修饰成员函数,修饰成员函数使得不需要生成对象就可以访问该函数,但是在 static 函数内不能访问非静态成员。
30 |
31 | ### [volatile](https://interview.huihut.com/#/?id=volatile)
32 |
33 | ```cpp
34 | volatile int i = 10;
35 | ```
36 |
37 | - **不可优化性.** volatile 关键字是一种类型修饰符,用它声明的类型变量表示不可以被某些编译器未知的因素(操作系统、硬件、其它线程等)更改。所以使用 volatile 告诉编译器不应对这样的对象进行优化。
38 | - **易变性.**volatile 关键字声明的变量,每次访问时都必须从内存中取出值(没有被 volatile 修饰的变量,可能由于编译器的优化,从 CPU 寄存器中取值)
39 | - const 可以是 volatile (如只读的状态寄存器)
40 | - 指针可以是 volatile
41 |
42 | ### 3. 内存对齐
43 |
44 | ### 一、什么是内存对齐
45 |
46 | **内存对齐(Memory alignment)**,也叫字节对齐。
47 |
48 | 现代计算机中内存空间都是按照 byte 划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,这就是所谓的内存对齐。
49 |
50 | ### 二、为什么要内存对齐
51 |
52 | 之所以要内存对齐,有两方面的原因:
53 |
54 | - **平台原因**:各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。————- 比如,有些架构的CPU在访问 一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐。
55 | - **性能原因**:内存对齐可以提高存取效率。————- 比如,有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit数据。
56 |
57 | 参考:[C/C++内存对齐](https://songlee24.github.io/2014/09/20/memory-alignment/)
58 |
59 | ### 4.模板的编译过程
60 |
61 | 当编译器遇到一个template时,不能够立马为他产生机器代码,它必须等到template被指定某种类型。也就是说,函数模板和类模板的完整定义将出现在template被使用的每一个角落.
62 |
63 | 对于不同的编译器,其对模板的编译和链接技术也会有所不同,其中一个常用的技术称之为Smart,其基本原理如下:
64 |
65 | 1. 模板编译时,以每个cpp文件为编译单位,实例化该文件中的函数模板和类模板
66 | 2. 链接器在链接每个目标文件时,会检测是否存在相同的实例;有存在相同的实例版本,则删除一个重复的实例,保证模板实例化没有重复存在。
67 |
68 | 
69 |
70 | ### 5. 多线程常用的函数
71 |
72 | * 创建线程
73 |
74 | ```cpp
75 | #include
76 | pthread_create (thread, attr, start_routine, arg)
77 | ```
78 |
79 | * 终止线程
80 |
81 | ```c
82 | #include
83 | pthread_exit (status)
84 | ```
85 |
86 | * 连接和分离
87 |
88 | ```c
89 | pthread_join (threadid, status)
90 | pthread_detach (threadid)
91 | ```
92 |
93 | * ```c
94 | pthread_t pthread_self(void);
95 | ```
96 |
97 | * ```c
98 | int pthread_cancel(pthread_t thread);
99 | ```
100 |
101 | ### 6. 线程锁
102 |
103 | 线程之间的锁有:**互斥锁**、**条件锁**、**自旋锁**、**读写锁**、**递归锁**、**原子锁**
104 |
105 | * 互斥锁:互斥锁用于控制多个线程对他们之间共享资源互斥访问的一个信号量。
106 |
107 | ```c
108 | #include
109 | pthread_mutex_init(pthread_mutex_t* mutex, const pthread_mutexattr_t* mutexattr);
110 | pthread_mutex_destroy(pthread_mutex_t* mutex);
111 | pthread_mutex_lock(pthread_mutex_t* mutex);
112 | pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
113 | pthread_mutex_unlock(pthread_mutex_t* mutex);
114 | ```
115 |
116 | * 条件锁:条件锁就是所谓的条件变量,某一个线程因为某个条件为满足时可以使用条件变量使改程序处于阻塞状态。一旦条件满足以“信号量”的方式唤醒一个因为该条件而被阻塞的线程。
117 |
118 | ```c
119 | #include
120 | pthread_cond_init(pthread_cond_t* condition, const pthread_condattr_t* condattr);
121 | pthread_cond_destroy(pthread_cond_t* condition);
122 | pthread_cond_wait(pthread_cond_t* cond, pthread_mutex_t* mutex);
123 | pthread_cond_t condition = PTHREAD_COND_INITIALIZER
124 | ```
125 |
126 | * 自旋锁:假设我们有一个两个处理器core1和core2计算机,现在在这台计算机上运行的程序中有两个线程:T1和T2分别在处理器core1和core2上运行,两个线程之间共享着一个资源。
127 |
128 | 首先我们说明互斥锁的工作原理,**互斥锁是是一种sleep-waiting的锁**。假设线程T1获取互斥锁并且正在core1上运行时,此时线程T2也想要获取互斥锁(pthread_mutex_lock),但是由于T1正在使用互斥锁使得T2被阻塞。当T2处于阻塞状态时,T2被放入到等待队列中去,处理器core2会去处理其他任务而不必一直等待(忙等)。也就是说处理器不会因为线程阻塞而空闲着,它去处理其他事务去了。
129 |
130 | 而自旋锁就不同了,**自旋锁是一种busy-waiting的锁**。也就是说,如果T1正在使用自旋锁,而T2也去申请这个自旋锁,此时T2肯定得不到这个自旋锁。与互斥锁相反的是,此时运行T2的处理器core2会一直不断地循环检查锁是否可用(自旋锁请求),直到获取到这个自旋锁为止。
131 |
132 | ```c
133 | #include
134 | spin_lock_init(spinlock_t *x);
135 | spin_lock(x);
136 | spin_unlock(x);
137 | spin_trylock(x);
138 | spin_is_locked(x);
139 | ```
140 |
141 | * 读写锁
142 |
143 | ```c
144 | #include
145 | int pthread_rwlock_init(pthread_rwlock_t* rwlock, const pthread_rwlockattr_t* attr);
146 | int pthread_rwlock_rdlock(pthread_rwlock_t* rwlock);
147 | int pthread_rwlock_wrlock(pthread_rwlock_t* rwlock);
148 | int pthread_rwlock_unlock(pthread_rwlock_t* rwlock);
149 | int pthread_rwlock_destroy(pthread_rwlock_t* rwlock);
150 | ```
151 |
152 | 参考:[c++线程中的几种锁](https://blog.csdn.net/bian_qing_quan11/article/details/73734157)
153 |
154 | [多线程编程之读写锁](https://blog.csdn.net/lovecodeless/article/details/24968369)
155 |
156 | ### [7.单例模式]([https://github.com/twomonkeyclub/BackEnd/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/%E5%9F%BA%E6%9C%AC%E6%89%8B%E5%86%99%E4%BB%A3%E7%A0%81/%E5%8D%95%E4%BE%8B%E6%A8%A1%E5%BC%8F.cpp](https://github.com/twomonkeyclub/BackEnd/blob/master/计算机基础知识/基本手写代码/单例模式.cpp))
157 |
158 | ```c
159 | #include
160 |
161 | using namespace std;
162 |
163 | class single{
164 | private:
165 | static single* p;
166 | single(){}
167 | ~single(){}
168 |
169 | public:
170 | static single* getinstance();
171 |
172 | };
173 | single* single::p = new single();
174 | single* single::getinstance(){
175 | return p;
176 | }
177 |
178 | int main(){
179 |
180 | single *p1 = single::getinstance();
181 | single *p2 = single::getinstance();
182 |
183 | if (p1 == p2)
184 | cout << "same" << endl;
185 |
186 | system("pause");
187 | return 0;
188 | }
189 | ```
190 |
191 |
192 |
193 | ```c
194 | class Singleton{
195 | public:
196 | // 注意返回的是引用。
197 | static Singleton& getInstance(){
198 | static Singleton m_instance; //局部静态变量
199 | return m_instance;
200 | }
201 | private:
202 | Singleton(); //私有构造函数,不允许使用者自己生成对象
203 | Singleton(const Singleton& other);
204 | };
205 | ```
206 |
207 |
208 |
209 | ```c
210 |
211 | class Lock
212 | {
213 | private:
214 | CCriticalSection m_cs;
215 | public:
216 | Lock(CCriticalSection cs) : m_cs(cs)
217 | {
218 | m_cs.Lock();
219 | }
220 | ~Lock()
221 | {
222 | m_cs.Unlock();
223 | }
224 | };
225 |
226 | class Singleton
227 | {
228 | private:
229 | Singleton();
230 | Singleton(const Singleton &);
231 | Singleton& operator = (const Singleton &);
232 |
233 | public:
234 | static Singleton *Instantialize();
235 | static Singleton *pInstance;
236 | static CCriticalSection cs;
237 | };
238 |
239 | Singleton* Singleton::pInstance = 0;
240 |
241 | Singleton* Singleton::Instantialize()
242 | {
243 | if(pInstance == NULL)
244 | { //double check
245 | Lock lock(cs); //用lock实现线程安全,用资源管理类,实现异常安全
246 | //使用资源管理类,在抛出异常的时候,资源管理类对象会被析构,析构总是发生的无论是因为异常抛出还是语句块结束。
247 | if(pInstance == NULL)
248 | {
249 | pInstance = new Singleton();
250 | }
251 | }
252 | return pInstance;
253 | }
254 | ```
255 |
256 | 参考:[设计模式之单例模式(c++版)](https://segmentfault.com/a/1190000015950693)
257 |
258 | [C++中的单例模式](https://blog.csdn.net/Hackbuteer1/article/details/7460019)
--------------------------------------------------------------------------------
/file/20200515.md:
--------------------------------------------------------------------------------
1 | ### [1. 三次握手及其对应的函数](https://blog.csdn.net/yigui3542/article/details/81099255)
2 |
3 |
4 |
5 | 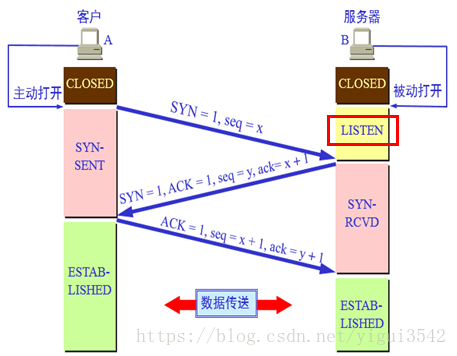
6 |
7 | 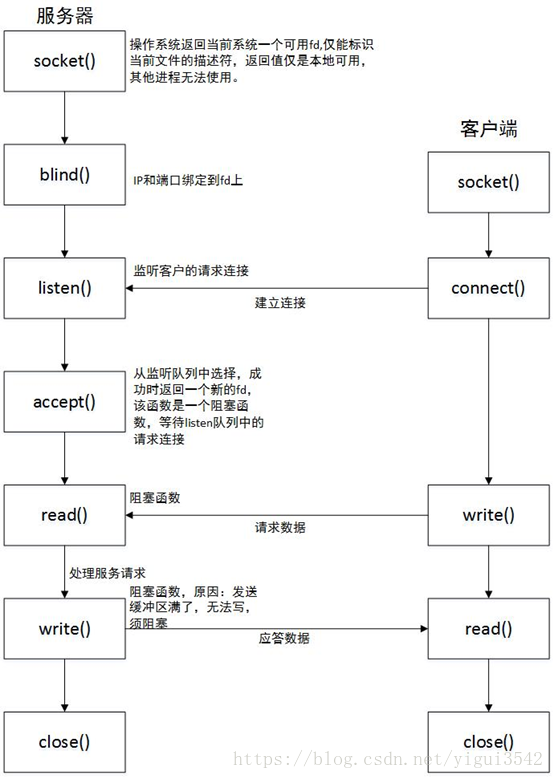
8 |
9 | 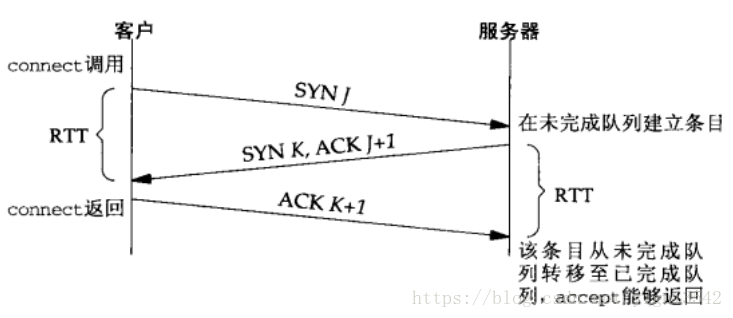
10 |
11 | 
12 |
13 | 1.客户端调用connect()函数,此时客户端会向服务端发送SYN
14 |
15 | 2.服务端收到SYN后,会从listen()函数返回SYN+ACK
16 |
17 | 3.客户端收到connect()函数的返回,之后向服务端发送最后一个ACK
18 |
19 | 4.服务端收到最后一个ACK以后,将该连接请求从未完成连接队列放入已完成连接队列中,等待accept()从该队列中取出
20 |
21 | ### [2.HTTP与TCP的区别和联系](https://blog.csdn.net/u013485792/article/details/52100533)
22 |
23 | **1、TCP连接**
24 | 手机能够使用联网功能是因为手机底层实现了TCP/IP协议,可以使手机终端通过无线网络建立TCP连接。TCP协议可以对上层网络提供接口,使上层网络数据的传输建立在“无差别”的网络之上。
25 | 建立起一个TCP连接需要经过“三次握手”:
26 |
27 | * 第一次握手:客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
28 | * 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
29 | * 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
30 | 握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。理想状态下,TCP连接一旦建立,在通信双方中的任何一方主动关闭连 接之前,TCP 连接都将被一直保持下去。断开连接时服务器和客户端均可以主动发起断开TCP连接的请求,断开过程需要经过“四次握手”(过程就不细写 了,就是服务器和客户端交互,最终确定断开)
31 |
32 | **2、HTTP连接**
33 | HTTP协议即超文本传送协议(Hypertext Transfer Protocol ),是Web联网的基础,也是手机联网常用的协议之一,HTTP协议是建立在TCP协议之上的一种应用。
34 | **HTTP连接最显著的特点是客户端发送的每次请求都需要服务器回送响应,在请求结束后,会主动释放连接。从建立连接到关闭连接的过程称为“一次连接”。**
35 | 1)在HTTP 1.0中,客户端的每次请求都要求建立一次单独的连接,在处理完本次请求后,就自动释放连接。
36 |
37 | 2)在HTTP 1.1中则可以在一次连接中处理多个请求,并且多个请求可以重叠进行,不需要等待一个请求结束后再发送下一个请求。
38 |
39 | 由于HTTP在每次请求结束后都会主动释放连接,因此HTTP连接是一种“短连接”,要保持客户端程序的在线状态,需要不断地向服务器发起连接请求。通常的 做法是即时不需要获得任何数据,客户端也保持每隔一段固定的时间向服务器发送一次“保持连接”的请求,服务器在收到该请求后对客户端进行回复,表明知道客 户端“在线”。若服务器长时间无法收到客户端的请求,则认为客户端“下线”,若客户端长时间无法收到服务器的回复,则认为网络已经断开。
40 |
41 | * ### TCP就是单纯建立连接,不涉及任何我们需要请求的实际数据,简单的传输。http是用来收发数据,即实际应用上来的。
42 |
43 | 三、总结
44 |
45 | * TCP是底层通讯协议,定义的是数据传输和连接方式的规范;
46 | * HTTP是应用层协议,定义的是传输数据的内容的规范;
47 | * HTTP协议中的数据是利用TCP协议传输的,所以支持HTTP也就一定支持TCP ;
48 | * HTTP支持的是www服务 而TCP/IP是协议, 是Internet国际互联网络的基础,是网络中使用的基本的通信协议。
49 | * TCP/IP实际上是一组协议,它包括上百个各种功能的协议,如:远程登录、文件传输和电子邮件等,而TCP协议和IP协议是保证数据完整传输的两个基本的重要协议。通常说TCP/IP是Internet协议族,而不单单是TCP和IP。
50 |
51 | ### [3 中间人攻击](https://www.jianshu.com/p/a825de42ccbc)
52 |
53 | **1、SSL证书欺骗攻击**
54 |
55 | * 伪造证书
56 |
57 | **2 SSL剥离攻击(SSLStrip)**
58 |
59 | * 中间人攻击者在劫持了客户端与服务端的HTTP会话后,将HTTP页面里面所有的 https:// 超链接都换成 http:// ,用户在点击相应的链接时,是使用HTTP协议来进行访问
60 |
61 | **3 针对SSL算法进行攻击**
62 |
63 | ### [4. 读写锁的几种实现方式-互斥量,信号量,条件变量](https://blog.csdn.net/juzihongle1/article/details/78014999)
64 |
65 | 1. 直接使用读写锁
66 |
67 | ```c
68 | #include
69 |
70 | pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER; // 定义和初始化读写锁
71 |
72 | 写模式:
73 | pthread_rwlock_wrlock(&rwlock); // 加写锁
74 | 写写写...
75 | pthread_rwlock_unlock(&rwlock); // 解锁
76 |
77 | 读模式:
78 | pthread_rwlock_rdlock(&rwlock); // 加读锁
79 | 读读读...
80 | pthread_rwlock_unlock(&rwlock); // 解锁
81 | ```
82 |
83 | 2. 用条件变量实现读写锁 (条件变量 + 互斥锁 + 两个变量记录读/写数量)
84 |
85 | ```c
86 | #include
87 |
88 | pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; // 定义和初始化互斥锁
89 | pthread_cond_t cond = PTHREAD_COND_INITIALIZER; // 定义和初始化条件变量
90 | int w = 0, r = 0;
91 |
92 | 写模式
93 | pthread_mutex_lock(&mutex); // 枷锁
94 | while (w != 0 || r > 0)
95 | {
96 | pthread_cond_wait(&cond, &mutex); // 等待条件变量成立
97 | }
98 | w = 1;
99 | pthread_mutex_unlock(&mutex); // 解锁
100 |
101 | 写写写...
102 |
103 | pthread_mutex_lock(&mutex); // 枷锁
104 | w = 0;
105 | pthread_cond_broadcast(&cond); // 唤醒其他因条件变量而产生阻塞
106 | pthread_mutex_unlock(&mutex); // 解锁
107 |
108 |
109 | 读模式
110 | pthread_mutex_lock(&mutex); // 枷锁
111 | while (w != 0)
112 | {
113 | pthread_cond_wait(&cond, mutex);
114 | }
115 | ++r;
116 | pthread_mutex_unlock(&mutex);
117 |
118 | 读读读...
119 |
120 | pthread_mutex_lock(&mutex);
121 | --r;
122 | if (r == 0)
123 | {
124 | pthread_cond_broadcast(&cond); // 唤醒
125 | }
126 | pthread_mutex_unlock(&mutex);
127 | ```
128 |
129 | ```c
130 | mutex m_mutex;
131 | condition_variable m_cond;
132 | int w = 0, r = 0;
133 |
134 | 写模式
135 | m_mutex.lock();// 枷锁
136 | while (w != 0 || r > 0)
137 | {
138 | m_cond.wait(m_mutex); // 等待条件变量成立
139 | }
140 | w = 1;
141 | m_mutex.unlock(); // 解锁
142 |
143 | 写写写...
144 |
145 | m_mutex.lock();// 枷锁
146 | w = 0;
147 | m_cond.notify_all(); // 唤醒其他因条件变量而产生阻塞
148 | m_mutex.unlock(); // 解锁
149 |
150 |
151 | 读模式
152 | m_mutex.lock(); // 枷锁
153 | while (w != 0)
154 | {
155 | m_cond.wait(m_mutex);
156 | }
157 | ++r;
158 | m_mutex.unlock();
159 |
160 | 读读读...
161 |
162 | m_mutex.lock();
163 | --r;
164 | if (r == 0)
165 | {
166 | m_cond.notify_all(); // 唤醒
167 | }
168 | m_mutex.unlock();
169 | ```
170 |
171 | 3. 互斥锁 (两个互斥锁 + 一个记录读数量变量)
172 |
173 | ```c
174 | #include
175 | pthread_mutex_t r_mutex = PTHREAD_MUTEX_INITIALIZER;
176 | pthread_mutex_t w_mutex = PTHREAD_MUTEX_INITIALIZER;
177 | int r = 0; // 记录读者个数
178 |
179 | 写模式
180 | pthread_mutex_lock(&w_mutex);
181 | 写写写...
182 | pthread_mutex_unlock(&w_mutex);
183 |
184 | 读模式
185 | pthread_mutex_lock(&r_mutex);
186 | if (r == 0)
187 | {
188 | pthread_mutex_lock(&w_mutex);
189 | }
190 | ++r;
191 | pthread_mutex_unlock(&r_mutex);
192 |
193 | 读读读
194 |
195 | pthread_mutex_lock(&r_lock);
196 | --r;
197 | if (r == 0)
198 | {
199 | pthread_mutex_unlock(&w_mutex);
200 | }
201 | pthrad_mutex_unlock(&r_lock);
202 | ```
203 |
204 | ```c
205 | mutex r_mutex;
206 | mutex w_mutex;
207 | int r = 0; // 记录读者个数
208 |
209 | 写模式
210 | w_mutex.lock();
211 | 写写写...
212 | w_mutex.unlock();
213 |
214 | 读模式
215 | r_mutex.lock();
216 | if (r == 0)
217 | {
218 | w_mutex.lock();
219 | }
220 | ++r;
221 | r_mutex.unlock();
222 |
223 | 读读读
224 |
225 | r_mutex.lock();
226 | --r;
227 | if (r == 0)
228 | {
229 | w_mutex.unlock();
230 | }
231 | r_mutex.unlock();
232 | ```
233 |
234 | 4. 信号量 (两个信号量 + 一个记录读数量变量)
235 |
236 | ```c
237 | #include
238 |
239 | sem_t r_sem; // 定义信号量
240 | sem_init(&r_sem, 0, 1); // 初始化信号量
241 |
242 | sem_t w_sem;
243 | sem_init(&w_sem, 0, 1);
244 | int r = 0;
245 |
246 | 写模式
247 | sem_wait(&w_sem);
248 | 写写写
249 | sem_post(&w_sem);
250 |
251 | 读模式
252 | sem_wait(&r_sem);
253 | if (r == 0)
254 | {
255 | sem_wait(&w_sem);
256 | }
257 | ++r;
258 | sem_post(&r_sem);
259 | 读读读...
260 | sem_wait(&r_sem);
261 | --r;
262 | if (r == 0)
263 | {
264 | sem_post(&w_sem);
265 | }
266 | sem_post(&r_sem);
267 | ```
268 |
269 | ### [5. 数据库建表语句](https://zhuanlan.zhihu.com/p/55372544)
270 |
271 | ```sql
272 | CREATE TABLE t1(
273 | id int not null,
274 | name char(20),
275 | primary key(id, name)
276 | );
277 | insert into t1(id, name) values(10, "hello");
278 | delete from t1 where 范围
279 | update table set field = value where ...
280 | 选择:select * from table1 where 范围
281 | 插入:insert into table1(field1,field2) values(value1,value2)
282 | 删除:delete from table1 where 范围
283 | 更新:update table1 set field1=value1 where 范围
284 | 查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料!
285 | 排序:select * from table1 order by field1,field2 [desc]
286 | 总数:select count as totalcount from table1
287 | 求和:select sum(field1) as sumvalue from table1
288 | 平均:select avg(field1) as avgvalue from table1
289 | 最大:select max(field1) as maxvalue from table1
290 | 最小:select min(field1) as minvalue from table1
291 | ```
292 |
293 | ### [6.链接过程](https://www.ibm.com/developerworks/cn/linux/l-dynlink/index.html)
294 |
295 | * 链接器主要是将有关的目标文件彼此相连接生成可加载、可执行的目标文件。链接器的核心工作就是符号表解析和重定位
296 | * 符号解析:当一个模块使用了在该模块中没有定义过的函数或全局变量时,编译器生成的符号表会标记出所有这样的函数或全局变量,而链接器的责任就是要到别的模块中去查找它们的定义,如果没有找到合适的定义或者找到的合适的定义不唯一,符号解析都无法正常完成。
297 | * 重定位:编译器在编译生成目标文件时,通常都使用从零开始的相对地址。然而,在链接过程中,链接器将从一个指定的地址开始,根据输入的目标文件的顺序以段为单位将它们一个接一个的拼装起来。除了目标文件的拼装之外,在重定位的过程中还完成了两个任务:一是生成最终的符号表;二是对代码段中的某些位置进行修改,所有需要修改的位置都由编译器生成的重定位表指出。
298 |
299 | ### 7. 进程切换
300 |
301 | * 切换页全局目录以安装一个新的地址空间
302 | * 切换内核态堆栈和硬件上下文,因为硬件上下文提供了内核执行新进程所需要的所有信息,包含CPU寄存器
303 |
304 | ### 8. const常量和define宏定义区别
305 |
306 | * 编译器处理方式不同
307 | * define宏是在预处理阶段展开
308 | * const常量是编译运行阶段使用
309 | * 类型和安全检查不同
310 | * define宏没有类型,不做任何类型检查,仅仅是展开。
311 | * const常量有具体的类型,在编译阶段会执行类型检查。
312 | * 存储方式不同
313 | * define宏仅仅是展开,有多少地方使用,就展开多少次,不会分配内存。(宏定义不分配内存,**变量定义**分配内存。)
314 | * const常量会在内存中分配(可以是堆中也可以是栈中)
315 | * const 可以节省空间,避免不必要的内存分配
316 |
--------------------------------------------------------------------------------
/file/20200413.md:
--------------------------------------------------------------------------------
1 | ### [快手 基础架构实习1,2,3面 hr面 面经](https://www.nowcoder.com/discuss/165835?type=0&order=0&pos=12&page=1)
2 |
3 | #### 1. c++智能指针说一下 ,几个智能指针的使用场景和区别
4 |
5 | C++里面的四个智能指针: auto_ptr, shared_ptr, weak_ptr, unique_ptr 其中后三个是c++11支持,并且第一个已经被11弃用。
6 |
7 | 为什么要使用智能指针:
8 |
9 | 智能指针的作用是管理一个指针,因为存在以下这种情况:申请的空间在函数结束时忘记释放,造成内存泄漏。使用智能指针可以很大程度上的避免这个问题,因为智能指针就是一个类,当超出了类的作用域是,类会自动调用析构函数,析构函数会自动释放资源。所以智能指针的作用原理就是在函数结束时自动释放内存空间,不需要手动释放内存空间。
10 |
11 |
12 |
13 | \1. auto_ptr(c++98的方案,cpp11已经抛弃)
14 |
15 | 采用所有权模式。
16 |
17 | ```c
18 | auto_ptr< string> p1 (new string ("I reigned lonely as a cloud.”));
19 | auto_ptr p2;
20 | p2 = p1; //auto_ptr不会报错.
21 | ```
22 |
23 | 此时不会报错,p2剥夺了p1的所有权,但是当程序运行时访问p1将会报错。所以auto_ptr的缺点是:存在潜在的内存崩溃问题!
24 |
25 |
26 |
27 | \2. unique_ptr(替换auto_ptr)
28 |
29 | unique_ptr实现独占式拥有或严格拥有概念,保证同一时间内只有一个智能指针可以指向该对象。它对于避免资源泄露(例如“以new创建对象后因为发生异常而忘记调用delete”)特别有用。
30 |
31 | 采用所有权模式,还是上面那个例子
32 |
33 | ```c
34 | unique_ptr p3 (``new` `string (``"auto"``)); ``//#4``unique_ptr p4; ``//#5``p4 = p3;``//此时会报错!!
35 | ```
36 |
37 |
38 |
39 | 编译器认为p4=p3非法,避免了p3不再指向有效数据的问题。因此,unique_ptr比auto_ptr更安全。
40 |
41 | 另外unique_ptr还有更聪明的地方:当程序试图将一个 unique_ptr 赋值给另一个时,如果源 unique_ptr 是个临时右值,编译器允许这么做;如果源 unique_ptr 将存在一段时间,编译器将禁止这么做,比如:
42 |
43 | ```c
44 | unique_ptr pu1(new string ("hello world"));
45 | unique_ptr pu2;
46 | pu2 = pu1; // #1 not allowed
47 | unique_ptr pu3;
48 | pu3 = unique_ptr(new string ("You")); // #2 allowed
49 | ```
50 |
51 |
52 |
53 | 其中#1留下悬挂的unique_ptr(pu1),这可能导致危害。而#2不会留下悬挂的unique_ptr,因为它调用 unique_ptr 的构造函数,该构造函数创建的临时对象在其所有权让给 pu3 后就会被销毁。这种随情况而已的行为表明,unique_ptr 优于允许两种赋值的auto_ptr 。
54 |
55 | 注:如果确实想执行类似与#1的操作,要安全的重用这种指针,可给它赋新值。C++有一个标准库函数std::move(),让你能够将一个unique_ptr赋给另一个。例如:
56 |
57 | ```c
58 | unique_ptr ps1, ps2;
59 | ps1 = demo("hello");
60 | ps2 = move(ps1);
61 | ps1 = demo("alexia");
62 | cout << *ps2 << *ps1 << endl;
63 | ```
64 |
65 |
66 |
67 | \3. shared_ptr
68 |
69 | shared_ptr实现共享式拥有概念。多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。从名字share就可以看出了资源可以被多个指针共享,它使用计数机制来表明资源被几个指针共享。可以通过成员函数use_count()来查看资源的所有者个数。除了可以通过new来构造,还可以通过传入auto_ptr, unique_ptr,weak_ptr来构造。当我们调用release()时,当前指针会释放资源所有权,计数减一。当计数等于0时,资源会被释放。
70 |
71 | shared_ptr 是为了解决 auto_ptr 在对象所有权上的局限性(auto_ptr 是独占的), 在使用引用计数的机制上提供了可以共享所有权的智能指针。
72 |
73 | 成员函数:
74 |
75 | use_count 返回引用计数的个数
76 |
77 | unique 返回是否是独占所有权( use_count 为 1)
78 |
79 | swap 交换两个 shared_ptr 对象(即交换所拥有的对象)
80 |
81 | reset 放弃内部对象的所有权或拥有对象的变更, 会引起原有对象的引用计数的减少
82 |
83 | get 返回内部对象(指针), 由于已经重载了()方法, 因此和直接使用对象是一样的.如 shared_ptr sp(new int(1)); sp 与 sp.get()是等价的
84 |
85 |
86 |
87 | \4. weak_ptr
88 |
89 | weak_ptr 是一种不控制对象生命周期的智能指针, 它指向一个 shared_ptr 管理的对象. 进行该对象的内存管理的是那个强引用的 shared_ptr. weak_ptr只是提供了对管理对象的一个访问手段。weak_ptr 设计的目的是为配合 shared_ptr 而引入的一种智能指针来协助 shared_ptr 工作, 它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造, 它的构造和析构不会引起引用记数的增加或减少。weak_ptr是用来解决shared_ptr相互引用时的死锁问题,如果说两个shared_ptr相互引用,那么这两个指针的引用计数永远不可能下降为0,资源永远不会释放。它是对对象的一种弱引用,不会增加对象的引用计数,和shared_ptr之间可以相互转化,shared_ptr可以直接赋值给它,它可以通过调用lock函数来获得shared_ptr。
90 |
91 | ```c
92 | class B;
93 | class A
94 | {
95 | public:
96 | shared_ptr pb_;
97 | ~A()
98 | {
99 | cout<<"A delete\n";
100 | }
101 | };
102 | class B
103 | {
104 | public:
105 | shared_ptr pa_;
106 | ~B()
107 | {
108 | cout<<"B delete\n";
109 | }
110 | };
111 | void fun()
112 | {
113 | shared_ptr pb(new B());
114 | shared_ptr pa(new A());
115 | pb->pa_ = pa;
116 | pa->pb_ = pb;
117 | cout<pb_->print(); 英文pb_是一个weak_ptr,应该先把它转化为shared_ptr,如:shared_ptr p = pa->pb_.lock(); p->print();
130 |
131 | #### [2.智能指针之间的转换](https://www.jianshu.com/p/92459fc683fc)
132 |
133 | ```c
134 | #include
135 | #include
136 | #include
137 | #include
138 |
139 | class Base {
140 | public:
141 | Base(){}
142 | virtual ~Base() {}
143 | };
144 |
145 | class D : public Base {
146 | public:
147 | D(){}
148 | virtual ~D() {}
149 | };
150 |
151 | int main()
152 | {
153 | // derived class to base class
154 | D* d1 = new D();
155 | Base* b1 = d1;
156 | //
157 | std::shared_ptr d2 = std::make_shared();
158 | std::shared_ptr b2 = d2;
159 |
160 | boost::shared_ptr d3 = boost::make_shared();
161 | boost::shared_ptr b3 = d3;
162 |
163 | /*
164 | * dynamic cast maybe failed. and return null;
165 | *
166 | */
167 | D* d11 = dynamic_cast(b1); //succ
168 | D* d12 = static_cast(b1); //succ
169 |
170 | typedef std::shared_ptr d_ptr;
171 | // std::shared_ptr d21 = dynamic_cast(b2); //compile error
172 | std::shared_ptr d22 = std::dynamic_pointer_cast(b2);
173 |
174 | typedef boost::shared_ptr d_b_ptr;
175 | // boost::shared_ptr d31 = dynamic_cast(b3); //compile error
176 | boost::shared_ptr d32 = boost::dynamic_pointer_cast(b3);
177 | return 0;
178 | }
179 | ```
180 |
181 | #### 3.如何将unique_ptr赋值给shared_ptr
182 |
183 | ```c
184 | #include
185 | #include
186 |
187 | using namespace std;
188 |
189 | int main()
190 | {
191 | unique_ptr a(new int(1));
192 | shared_ptr b(a.get()); // get 返回内部对象指针
193 | cout << *b << endl;
194 | return 0;
195 | }
196 | ```
197 |
198 | #### 4.使用map存放的是指针会不会出现内存泄漏 如何避免
199 |
200 | 手动删除 / 智能指针
201 |
202 | 参考:[STL释放指针元素时造成的内存泄露](https://imzlp.me/posts/50773/)
203 |
204 | #### 5.一个裸指针分别初始化2个智能指针会出现什么问题?
205 |
206 | * unique_ptr :引起程序崩溃
207 | * shared_ptr : succ,但是use_count是都是1,之后会存在内存崩溃的问题
208 |
209 | 参考:[使用 C++11 智能指针时要避开的 10 大错误](https://blog.csdn.net/yixianfeng41/article/details/56298957)
210 |
211 | #### 6.std::move
212 |
213 | * 实现了移动语义[移动拷贝函数 + 移动赋值函数]和完美转发[参数类型为右值引用]
214 | * 模版 + 右值引用[引用折叠原理] + 强制类型抓换 + 返回右值引用 实现
215 |
216 | 参考: [c++ 之 std::move 原理实现与用法总结](https://blog.csdn.net/p942005405/article/details/84644069)
217 |
218 | [c++11std-move使用与原理]([https://wendeng.github.io/2019/05/14/c++%E5%9F%BA%E7%A1%80/c++11std-move%E4%BD%BF%E7%94%A8%E4%B8%8E%E5%8E%9F%E7%90%86/](https://wendeng.github.io/2019/05/14/c++基础/c++11std-move使用与原理/))
219 |
220 | [详解C++11中移动语义(std::move)和完美转发(std::forward)](http://shaoyuan1943.github.io/2016/03/26/explain-move-forward/)
221 |
222 | #### [7.tcp和udp之间的区别]([https://github.com/twomonkeyclub/BackEnd/tree/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C#TCPUDP%E7%9A%84%E5%8C%BA%E5%88%AB%E5%92%8C%E5%BA%94%E7%94%A8%E5%9C%BA%E6%99%AF](https://github.com/twomonkeyclub/BackEnd/tree/master/计算机基础知识/计算机网络#TCPUDP的区别和应用场景))
223 |
224 | TCP,全称:传输控制协议,面向连接的安全的流式传输协议 UDP,全称:用户数据报协议,面向无连接的不安全的报式传输协议
225 |
226 | - 连接
227 | - TCP是面向连接的传输层协议,即传输数据之前必须先建立好连接。
228 | - UDP无连接。
229 | - 服务对象
230 | - TCP是点对点的两点间服务,即一条TCP连接只能有两个端点
231 | - UDP支持一对一,一对多,多对一,多对多的交互通信。
232 | - 可靠性
233 | - TCP是可靠交付:无差错,不丢失,不重复,按序到达。
234 | - UDP是尽最大努力交付,不保证可靠交付。
235 | - 拥塞控制,流量控制
236 | - TCP有拥塞控制和流量控制保证数据传输的安全性。
237 | - UDP没有拥塞控制,网络拥塞不会影响源主机的发送效率。
238 | - 报文长度
239 | - TCP是动态报文长度,即TCP报文长度是根据接收方的窗口大小和当前网络拥塞情况决定的,流式传输
240 | - UDP面向报文,不合并,不拆分,保留上面(应用层)传下来报文的边界,直接传输报文。
241 | - 首部开销
242 | - TCP首部开销大,首部20个字节。
243 | - UDP首部开销小,8字节。(源端口,目的端口,UDP数据报长度,检验和,每个字段两个字节)
244 |
245 | ### 应用场景
246 |
247 | - 要求通信数据完整性,则应该选用TCP协议(如文件传输、重要状态的更新,登录数据传输等)
248 | - 要求通信实时性,使用 UDP 协议(如视频传输,通话,屏幕共享软件)
249 |
250 | #### 8.基于udp如何实现稳定传输?有什么办法实现?
251 |
252 | UDP它不属于连接型协议,因而具有资源消耗小,处理速度快的优点,所以通常主要用于音频、视频和普通数据在传送时使用UDP较多。因而它们即使丢失一两个数据包,也不会对接收的结果产生较大的影响。
253 | 传输层无法保证数据的可靠性的传输,只能通过应用层来进行实现了。实现的方式可以参照tcp可靠性传输的方式,只是实现不在传输层,实现转移到了应用层。
254 | **实现确认机制,重传机制,窗口确认机制。**
255 | 如果你不利用linux协议栈以及上层socket机制。自己通过抓包和发包的方式去实现可靠性传输,那么必须要实现的功能就如下所示:
256 | 简单来讲,要使用UDP来构建可靠的面向连接的数据传输,就要实现类似于TCP协议的
257 |
258 | **超时重传(定时器)**
259 |
260 | **有序接受 (添加包序号)将数据包进行编号,按照包的顺序接收并存储。**
261 |
262 | **应答确认 (Seq/Ack应答机制)**
263 |
264 | **滑动窗口流量控制等机制 (滑动窗口协议)**
265 |
266 | 等于说要在传输层的上一层(或者直接在应用层)实现TCP协议的可靠数据传输机制,比如使用UDP数据包+序列号,UDP数据包+时间戳等方法。
267 |
268 | 参考:[网络基础------如何让UDP实现可靠性传输](https://blog.csdn.net/daboluo521/article/details/80726867)
269 |
270 | #### [12.编程题:使用2个mutex实现读写锁](https://blog.csdn.net/ojshilu/article/details/25244389)
271 |
272 | ```c
273 | int readers = 0;
274 | mutex r_mutex;
275 | mutex w_mutex;
276 |
277 | void write_lock()
278 | {
279 | w_mutex.lock();
280 | }
281 | void write_unlock()
282 | {
283 | w_mutex.unlock();
284 | }
285 | void read_lock()
286 | {
287 | r_mutex.lock();
288 | if (readers == 0)
289 | {
290 | w_mutex.lock();
291 | }
292 | readers++;
293 | r_mutex.unlock();
294 | }
295 | void read_unlock()
296 | {
297 | r_mutex.lock();
298 | --readers;
299 | if (readers == 0)
300 | {
301 | w_mutex.unlock();
302 | }
303 | r_mutex.unlock();
304 | }
305 | ```
306 |
307 | #### [13.rr级别下如何解决幻读(next-key-lock)](https://juejin.im/post/5c7912eee51d4547222f5d3c)
308 |
309 | * MVCC : 增加两个隐藏列, 创建版本号 删除版本号
310 | * next-key lock :Reacord Lock[单个行记录上的锁] + Gap Lock[间隙所,锁定一个范围]
311 |
312 | #### [14.主键索引和非主键索引](https://www.jianshu.com/p/f3a1e17a4df6)
313 |
314 | 例如下表(其实就是上面的表中增加了一个k字段),且ID是主键。
315 |
316 | 
317 |
318 | k
319 |
320 | 主键索引和非主键索引的示意图如下:
321 |
322 | 
323 |
324 | 结构对比
325 |
326 | 其中R代表一整行的值。
327 |
328 | 由图看出,主键索引和非主键索引的区别是:非主键索引的叶子节点存放的是**主键的值**,而主键索引的叶子节点存放的是**整行数据**。非主键索引也被称为**二级索引**,而主键索引也被称为**聚簇索引**。
329 |
330 | 1️⃣根据这两种结构进行查询,看看区别:
331 |
332 | 1. 如果查询语句是 `select * from table where ID = 100`,即主键查询的方式,则只需要搜索 ID 这棵 B+树。
333 | 2. 如果查询语句是 `select * from table where k = 1`,即非主键的查询方式,则先搜索k索引树,得到ID=100,再到ID索引树搜索一次,这个过程也被称为回表。
334 |
335 | 2️⃣聚集索引和非聚集索引的区别:
336 |
337 | 1. 聚集索引表示表中存储的数据按照索引的顺序存储,检索效率比非聚集索引高,但对数据更新影响较大。(比如主键索引)
338 | 2. 非聚集索引表示数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据的存储位置。非聚集索引检索效率比聚集索引低,但对数据更新影响较小。
339 |
340 | #### [15. 分布式事务](https://juejin.im/post/5b5a0bf9f265da0f6523913b)
341 |
342 | * 在数据库之上通过某种手段,实现支持跨数据库的事务支持,这也就是大家常说的“分布式事务”。
343 | * CAP的含义:
344 | - C:Consistency 一致性 同一数据的多个副本是否实时相同。
345 | - A:Availability 可用性 可用性:一定时间内 & 系统返回一个明确的结果 则称为该系统可用。
346 | - P:Partition tolerance 分区容错性 将同一服务分布在多个系统中,从而保证某一个系统宕机,仍然有其他系统提供相同的服务。
347 |
348 | 参考: [常用的分布式事务解决方案](https://juejin.im/post/5aa3c7736fb9a028bb189bca#heading-5)
349 |
350 | #### 16.**数据库自增id,当id值大于MAXINT时,数据库如何做**
351 |
352 | * big int unsigned
353 |
354 | #### [17. 前缀索引](https://www.cnblogs.com/studyzy/p/4310653.html)
355 |
356 | * 前缀索引说白了就是对文本的前几个字符(具体是几个字符在建立索引时指定)建立索引,这样建立起来的索引更小,所以查询更快
357 |
358 | #### [18.联合索引、最左匹配原则](https://segmentfault.com/a/1190000015416513)
359 |
360 | * 联合索引 test_col1_col2_col3 实际建立了(col1)、(col1,col2)、(col,col2,col3)三个索引。
361 |
362 | 参考: [MySql创建联合索引](https://blog.csdn.net/Connie1451/article/details/80528238)
363 |
364 |
--------------------------------------------------------------------------------
/file/20200305.md:
--------------------------------------------------------------------------------
1 | ## [ 我的C++后台研发学习路线总结](https://www.nowcoder.com/discuss/197611)
2 |
3 | ### 1. 进程和线程的区别
4 |
5 | - 进程是cpu资源分配的最小单位,线程是cpu调度的最小单位。
6 | - 进程有独立的系统资源或地址空间,而同一进程内的线程共享进程的大部分系统资源,包括堆、代码段、数据段,每个线程只拥有一些在运行中必不可少的私有属性,比如线程Id,栈、寄存器、程序计数器PC(或者说IP)。
7 | - 一个进程崩溃,不会对其他进程产生影响;而一个线程崩溃,会让同一进程内的其他线程也宕掉。
8 | - 进程在创建、销毁时开销比较大,而线程比较小。进程创建的时候需要分配虚拟地址空间等系统资源,而销毁的的时候需要释放系统资源;线程只需要创建栈,栈指针,程序计数器,通用目的寄存器和条件码等,不需要创建独立的虚拟地址空间。
9 | - 进程切换开销比较打,线程比较小。进程切换需要分两步:切换页目录、刷新TLB以使用新的地址空间;切换内核栈和硬件上下文(寄存器);而同一进程的线程间逻辑地址空间是一样的,不需要切换页目录、刷新TLB。
10 | - 进程间通信比较复杂,而同一进程的线程由于共享代码段和数据段,所以通信比较容易。
11 |
12 | ### [2.**协程**]([https://github.com/twomonkeyclub/BackEnd/tree/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F#%E5%8D%8F%E7%A8%8B](https://github.com/twomonkeyclub/BackEnd/tree/master/计算机基础知识/操作系统#协程))
13 |
14 | ### 协程概述
15 |
16 | - 协程是轻量级线程,拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。
17 | - 协程能保留上一次调用时的状态,即所有局部状态的一个特定组合,每次过程重入时,就相当于进入上一次调用的状态。
18 |
19 | ### 协程和线程的区别
20 |
21 | - 协程最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
22 | - 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
23 |
24 | ### 应用场景
25 |
26 | - I/O 密集型任务。
27 |
28 | > - 这一点与多线程有些类似,但协程调用是在一个线程内进行的,是单线程,切换的开销小,因此效率上略高于多线程。
29 | > - 当程序在执行 I/O 时操作时,CPU 是空闲的,此时可以充分利用 CPU 的时间片来处理其他任务。在单线程中,一个函数调用,一般是从函数的第一行代码开始执行,结束于 return 语句、异常或者函数执行(也可以认为是隐式地返回了 None )。
30 | > - 有了协程,我们在函数的执行过程中,如果遇到了耗时的 I/O 操作,函数可以临时让出控制权,让 CPU 执行其他函数,等 I/O 操作执行完毕以后再收回控制权。
31 |
32 | ## 总结:
33 |
34 | 三种调度的技术虽然有相似的地方,但并不冲突。
35 |
36 | 进程调度可以很好的控制资源分配,线程调度让进程内部不因某个操作阻塞而整体阻塞。协程则是在用户态来优化程序,让程序员以写同步代码的方式写出异步代码般的效率。
37 |
38 | 参考:[**进程,线程,协程**](https://yq.aliyun.com/articles/53673)
39 |
40 | ### [3. 为什么需要三次握手](https://blog.csdn.net/xifeijian/article/details/12777187)
41 |
42 | 在谢希仁著《计算机网络》第四版中讲“三次握手”的目的是“**为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误**”。在另一部经典的《计算机网络》一书中讲“三次握手”的目的是为了解决“**网络中存在延迟的重复分组**”的问题。这两种不用的表述其实阐明的是同一个问题。
43 | 谢希仁版《计算机网络》中的例子是这样的,“**已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了**。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。”。**主要目的防止server端一直等待,浪费资源**。
44 |
45 | ### [4.Time_wait]([https://github.com/twomonkeyclub/BackEnd/tree/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C#TIME-WAIT%E7%8A%B6%E6%80%81%E5%8F%8A2MSL%E6%97%B6%E9%97%B4](https://github.com/twomonkeyclub/BackEnd/tree/master/计算机基础知识/计算机网络#TIME-WAIT状态及2MSL时间))
46 |
47 | - 四次挥手期间,客户端和服务器端都可主动释放连接,谁主动释放,谁将进入TIME_WAIT状态
48 | - MSL是最长报文寿命,一般为2分钟,2MSL即4分钟
49 | - 为什么TIME-WAIT状态必须等待2MSL时间?
50 | - **保证最后一次挥手报文能到B,能进行超时重传。**若B收不到A的ACK报文,则B会超时重传FIN+ACK,A会在2MSL时间内收到重传报文段,然后发送ACK,重新启动2MSL计时器
51 | - 2MSL后,本次连接的所有报文都会消失,不会影响下一次连接。
52 |
53 | ### [5.**平衡二叉树**]([https://interview.huihut.com/#/?id=%e4%ba%8c%e5%8f%89%e6%a0%91](https://interview.huihut.com/#/?id=二叉树))
54 |
55 | * 平衡二叉树是**二叉排序树**,每一个结点左右子树高度之差的绝对值不超过1
56 |
57 | 
58 |
59 | 参考:[平衡二叉树]([https://github.com/twomonkeyclub/BackEnd/tree/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84#%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91](https://github.com/twomonkeyclub/BackEnd/tree/master/计算机基础知识/数据结构#平衡二叉树))
60 |
61 | ### 5.快速排序和堆排序
62 |
63 | ### [排序](https://interview.huihut.com/#/?id=排序)
64 |
65 | | 排序算法 | 平均时间复杂度 | 最差时间复杂度 | 空间复杂度 | 数据对象稳定性 |
66 | | ------------------------------------------------------------ | -------------- | -------------- | ---------- | -------------------- |
67 | | [冒泡排序](https://interview.huihut.com/#/Algorithm/BubbleSort.h) | O(n2) | O(n2) | O(1) | 稳定 |
68 | | [选择排序](https://interview.huihut.com/#/Algorithm/SelectionSort.h) | O(n2) | O(n2) | O(1) | 数组不稳定、链表稳定 |
69 | | [插入排序](https://interview.huihut.com/#/Algorithm/InsertSort.h) | O(n2) | O(n2) | O(1) | 稳定 |
70 | | [快速排序](https://interview.huihut.com/#/Algorithm/QuickSort.h) | O(n*log2n) | O(n2) | O(log2n) | 不稳定 |
71 | | [堆排序](https://interview.huihut.com/#/Algorithm/HeapSort.cpp) | O(n*log2n) | O(n*log2n) | O(1) | 不稳定 |
72 | | [归并排序](https://interview.huihut.com/#/Algorithm/MergeSort.h) | O(n*log2n) | O(n*log2n) | O(n) | 稳定 |
73 | | [希尔排序](https://interview.huihut.com/#/Algorithm/ShellSort.h) | O(n*log2n) | O(n2) | O(1) | 不稳定 |
74 | | [计数排序](https://interview.huihut.com/#/Algorithm/CountSort.cpp) | O(n+m) | O(n+m) | O(n+m) | 稳定 |
75 | | [桶排序](https://interview.huihut.com/#/Algorithm/BucketSort.cpp) | O(n) | O(n) | O(m) | 稳定 |
76 | | [基数排序](https://interview.huihut.com/#/Algorithm/RadixSort.h) | O(k*n) | O(n2) | | 稳定 |
77 |
78 | ### 6. TCP协议和IP协议有什么关系
79 |
80 | **IP协议** : ip协议位于网络层,IP 协议的作用是把各种数据包传送给对方。而要保证确实传送到对方那里,则需要满足各类条件。其中两个重要的条件是 IP 地址和 MAC地址(Media Access Control Address)。
81 |
82 | IP 地址指明了节点被分配到的地址,MAC 地址是指网卡所属的固定地址。IP 地址可以和 MAC 地址进行配对。IP 地址可变换,但 MAC地址基本上不会更改。使用 ARP 协议凭借 MAC 地址进行通信
83 |
84 | **TCP协议**:TCP 位于传输层,提供可靠的字节流服务。
85 |
86 | ### 7.TCP如何保证传输的可靠性
87 |
88 | 1. 数据包校验
89 | 2. 对失序数据包重新排序(TCP报文具有序列号)
90 | 3. 丢弃重复数据
91 | 4. 应答机制:接收方收到数据之后,会发送一个确认(通常延迟几分之一秒);
92 | 5. 超时重发:发送方发出数据之后,启动一个定时器,超时未收到接收方的确认,则重新发送这个数据;
93 | 6. 流量控制:确保接收端能够接收发送方的数据而不会缓冲区溢出
94 |
95 | ### 8.TCP和HTTP的关系,HTTP还可以基于什么传输
96 |
97 | * **TPC协议是传输层协议,主要解决数据如何在网络中传输,而HTTP是应用层协议,主要解决如何包装数据。**
98 |
99 | * HTTP 是基于 TCP/IP 协议的[**应用层协议**](http://www.ruanyifeng.com/blog/2012/05/internet_protocol_suite_part_i.html)。。
100 |
101 | ### [9.HTTP和HTTPS]([https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md#HTTP%E5%92%8CHTTPS%E6%9C%89%E4%BB%80%E4%B9%88%E5%8C%BA%E5%88%AB](https://github.com/wolverinn/Waking-Up/blob/master/Computer Network.md#HTTP和HTTPS有什么区别))
102 |
103 | 1. 端口不同:HTTP使用的是80端口,HTTPS使用443端口;
104 | 2. HTTP(超文本传输协议)信息是明文传输,HTTPS运行在SSL(Secure Socket Layer)之上,添加了加密和认证机制,更加安全;
105 | 3. HTTPS由于加密解密会带来更大的CPU和内存开销;
106 | 4. HTTPS通信需要证书,一般需要向证书颁发机构(CA)购买
107 |
108 | 参考:[HTTP和HTTPS的区别]([https://github.com/twomonkeyclub/BackEnd/tree/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C#HTTP%E5%92%8CHTTPS%E7%9A%84%E5%8C%BA%E5%88%AB](https://github.com/twomonkeyclub/BackEnd/tree/master/计算机基础知识/计算机网络#HTTP和HTTPS的区别))
109 |
110 | ### 10.加密算法有哪些,如何理解MD5
111 |
112 | 参考:[浅谈常见的七种加密算法及实现](https://juejin.im/post/5b48b0d7e51d4519962ea383)
113 |
114 | [MD5加密算法流程](https://blog.csdn.net/u010347226/article/details/77400012)
115 |
116 | ### 11.**Linux如何创建空文件,创建目录指令,find如何查找用户名为work的文件**
117 |
118 | * 创建文件 touch name
119 | * 创建目录 mkdir name
120 | * 查找 find [目录] -name [文件名]
121 |
122 | 参考:[Linux下各种查找命令(find, grep, which, whereis, locate)](https://blog.csdn.net/wzzfeitian/article/details/40985549)
123 |
124 | ### 12.**短连接和长连接,聊天室是采取哪种连接方式**
125 |
126 | **长连接:** 客户端和服务端建立连接后不进行断开,之后客户端再次访问这个服务器上的内容时,继续使用这一条连接通道。
127 |
128 | **短连接:** 客户端和服务端建立连接,发送完数据后立马断开连接。下次要取数据,需要再次建立连接。
129 |
130 | 短连接:适用于网页浏览等数据刷新频度较低的场景。
131 |
132 | 长连接:适用于客户端和服务端通信频繁的场景,例如聊天室,实时游戏等。
133 |
134 | ### 13.服务器的架构和实现
135 |
136 | ### [14. http里面列举几个消息头,最常用的消息头](https://itbilu.com/other/relate/EJ3fKUwUx.html)
137 |
138 | ### [15.GET和POST幂等性,为什么POST不幂等?](https://blog.csdn.net/qq_33082731/article/details/74230813)
139 |
140 | * 幂等性概念:幂等通俗来说是指不管进行多少次重复操作,都是实现相同的结果。
141 |
142 | * GET,PUT,DELETE都是幂等操作,而POST不是,以下进行分析:
143 |
144 | * 首先GET请求很好理解,对资源做查询多次,此实现的结果都是一样的。
145 | PUT请求的幂等性可以这样理解,将A修改为B,它第一次请求值变为了B,再进行多次此操作,最终的结果还是B,与一次执行的结果是一样的,所以PUT是幂等操作。
146 | 同理可以理解DELETE操作,第一次将资源删除后,后面多次进行此删除请求,最终结果是一样的,将资源删除掉了。
147 |
148 | * POST不是幂等操作,因为一次请求添加一份新资源,二次请求则添加了两份新资源,多次请求会产生不同的结果,因此POST不是幂等操作。
149 |
150 | ### 16. IO分流
151 |
152 | * fork: 父子进程
153 |
154 | * ```c
155 | #include
156 | int dup(int fildes);
157 | int dup2(int fildes, int fildes2);
158 | ```
159 |
160 | 复制一份文件描述符。
161 |
162 | ### 17. UTF8和GB2312的区别
163 |
164 | UTF8: 英文1个字节,中文3个字节。
165 |
166 | GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示
167 |
168 | GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换:
169 |
170 | GBK、GB2312--Unicode--UTF8
171 |
172 | UTF8--Unicode--GBK、GB2312
173 |
174 | utf8是对unicode字符集进行编码的一种编码方式。
175 |
176 | 简单从功能上说:
177 |
178 | 1、GBK通常指GB2312编码,只支持简体中文字
179 |
180 | 2、utf通常指UTF-8,支持简体中文字、繁体中文字、英文、日文、韩文等语言(支持文字更广)
181 |
182 | 3、通常国内使用utf-8和gb2312,看自己需求选择
183 |
184 | ### 18.进程栈和线程栈的区别
185 |
186 | 总结:
187 |
188 | (1)进程栈大小时执行时确定的,与编译链接无关
189 |
190 | (2)进程栈大小是随机确认的,至少比线程栈要大,但不会超过2倍
191 |
192 | (3)线程栈是固定大小的,可以使用ulimit -a 查看,使用ulimit -s 修改,每个线程都有独立的栈区
193 |
194 | (4) 线程栈的空间开辟在所属进程的堆区,线程与其所属的进程共享进程的用户空间,所以线程栈之间可以互访。
195 |
196 | (5)线程栈的起始地址和大小存放在pthread_attr_t 中,栈的大小不是用来判断是否越界,而是用来初始化避免栈溢出的缓冲区的大小。
197 |
198 | ### [19.**malloc的内存分配方式**](https://blog.csdn.net/u012658346/article/details/51154615)
199 |
200 | 它有一个将可用的内存块连接为一个长长的列表的所谓**空闲链表**。
201 | 调用malloc函数时,它**沿连接表寻找一个大到足以满足用户请求所需要的内存块**。然后,**将该内存块一分为二**(一块的大小与用户请求的大小相等,另一块的大小就是剩下的字节)。接下来,将分配给用户的那块内存传给用户,并将剩下的那块(如果有的话)返回到连接表上。
202 | 调用free函数时,**它将用户释放的内存块连接到空闲链上**。到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。于是,malloc函数请求延时,并开始在空闲链上翻箱倒柜地检查各内存片段,对它们进行整理,**将相邻的小空闲块合并成较大的内存块**。
203 |
204 | 参考:[[malloc的内存分配原理](https://www.cnblogs.com/alantu2018/p/8460804.html)](https://www.cnblogs.com/alantu2018/p/8460804.html)
205 |
206 | ### [20.二叉树找公共祖先,只有root节点和两个节点指针](https://blog.csdn.net/xyzbaihaiping/article/details/52122885)
207 |
208 |
209 |
210 | ```c
211 | BinaryNode* GetLastCommonAncestor(BinaryNode* root, BinaryNode* node1, BinaryNode* node2)
212 | {
213 | if (root == NULL || node1 == NULL || node2 == NULL)
214 | return NULL;
215 | if (node1 == root || node2 == root)
216 | return root;
217 |
218 | BinaryNode* cur = NULL;
219 |
220 | BinaryNode* left_lca = GetLastCommonAncestor(root->_left, node1, node2);
221 | BinaryNode* right_lca = GetLastCommonAncestor(root->_right, node1, node2);
222 | if (left_lca && right_lca)
223 | return root;
224 | if (left_lca == NULL)
225 | return right_lca;
226 | else
227 | return left_lca;
228 | }
229 | ```
230 | ### 21.**emplace / empalce_front / emplace_back**
231 |
232 | **当调用push或insert成员函数时,我们将元素类型的对象传递给它们,这些对象被拷贝到容器中**。**而当我们调用一个emplace成员函数时,则是将参数传递给元素类型的构造函数**。
233 |
234 | **emplace相关函数可以减少内存拷贝和移动。当插入rvalue,它节约了一次move构造,当插入lvalue,它节约了一次copy构造。**
235 |
236 | ` emplace` 最大的作用是避免产生不必要的临时变量
237 |
238 | ### [22.模版特化](https://blog.csdn.net/thefutureisour/article/details/7964682/)
239 |
240 | 模板为什么要特化,因为编译器认为,对于特定的类型,如果你能对某一功能更好的实现,那么就该听你的。
241 |
242 | 模板分为类模板与函数模板,特化分为全特化与偏特化。全特化就是限定死模板实现的具体类型,偏特化就是如果这个模板有多个类型,那么只限定其中的一部分。
243 |
244 | ### **[23. 定位内存泄露](http://www.cnblogs.com/skynet/archive/2011/02/20/1959162.html)**
245 |
246 | * 静态分析,mtrace
247 | * 相关命令 ps top
248 | * ps -aux | grep -E 'programe1|PID'
249 | * 动态分析,memwatch valgrind工具
250 |
251 | ### [24. 数据流的中位数](https://blog.csdn.net/summer2day/article/details/92795926)
252 |
253 | ```c
254 | class MedianFinder {
255 | public:
256 | /** initialize your data structure here. */
257 | MedianFinder() {
258 |
259 | }
260 |
261 | void addNum(int num) {
262 | if(maxHeap.empty()){
263 | maxHeap.push(num);
264 | return;
265 | }
266 | if(num1)
271 | {
272 | minHeap.push(maxHeap.top());
273 | maxHeap.pop();
274 | }
275 | }
276 | else
277 | {
278 | minHeap.push(num);
279 | if(minHeap.size()>maxHeap.size())
280 | {
281 | maxHeap.push(minHeap.top());
282 | minHeap.pop();
283 | }
284 | }
285 |
286 |
287 |
288 | }
289 |
290 | double findMedian() {
291 | if(minHeap.size()==maxHeap.size())
292 | return (minHeap.top()+maxHeap.top())/2.0;
293 | return maxHeap.top();
294 | }
295 | private:
296 | priority_queue,less> maxHeap;//大顶堆
297 | priority_queue,greater> minHeap;//小顶堆
298 | };
299 |
300 | /**
301 | * Your MedianFinder object will be instantiated and called as such:
302 | * MedianFinder* obj = new MedianFinder();
303 | * obj->addNum(num);
304 | * double param_2 = obj->findMedian();
305 | */
306 | ```
307 |
308 | ### [25.**C语言如何处理返回值?**](https://blog.csdn.net/hixiaogui/article/details/79864641)
309 |
310 | 一般来说,函数在返回返回值的时候汇编代码一般都会将待返回的值放入eax寄存器暂存,接着再调用mov指令将eax中返回值写入对应的变量中。
311 |
312 | 下面三中情况可以返回指针:
313 |
314 | 1)函数中存储了静态局部变量,可以通过返回静态局部变量的地址,来修改静态局部变量的值。如下面函数
315 |
316 | ```cpp
317 | char *fun_1()
318 | {
319 | static char name[]="jack";
320 | return name;
321 | }
322 | ```
323 |
324 | (2)函数返回一个const修饰的常量,也可以通过返回它地址在主函数中访问
325 |
326 | ```c
327 | char *fun_2()
328 | {
329 | char *p="alice";
330 | return p;
331 | }
332 | ```
333 |
334 | ### 26.**命名管道和无名管道**
335 |
336 |
--------------------------------------------------------------------------------
/file/20200226.md:
--------------------------------------------------------------------------------
1 | ## [字节跳动rust/c++实习面经](https://www.nowcoder.com/discuss/201045)
2 |
3 | ### [1.合并k个有序数组](https://leetcode-cn.com/problems/merge-k-sorted-lists/)
4 |
5 | ```c
6 | // 效率不高
7 | /**
8 |
9 | * Definition for singly-linked list.
10 | * struct ListNode {
11 | * int val;
12 | * ListNode *next;
13 | * ListNode(int x) : val(x), next(NULL) {}
14 | * };
15 | */
16 | class Solution {
17 | public:
18 | ListNode* mergeKLists(vector& lists) {
19 | ListNode* res = nullptr;
20 | if (lists.size() == 0) {
21 | return res;
22 | }
23 |
24 | for (int i = 0; i < lists.size(); ++i) {
25 | res = merge(res, lists[i]);
26 | }
27 | return res;
28 | }
29 |
30 | ListNode* merge(ListNode* l, ListNode* r) {
31 | ListNode* res = new ListNode(0);
32 | ListNode* cur = res;
33 | while (l && r) {
34 | if (l->val >= r->val) {
35 | cur->next = r;
36 | cur = cur->next;
37 | r = r->next;
38 | } else {
39 | cur->next = l;
40 | cur = cur->next;
41 | l = l->next;
42 | }
43 | }
44 | while (r) {
45 | cur->next = r;
46 | cur = cur->next;
47 | r = r->next;
48 | }
49 |
50 | while (l) {
51 | cur->next = l;
52 | cur = cur->next;
53 | l = l->next;
54 | }
55 | return res->next;
56 | }
57 | };
58 | ```
59 |
60 | ```c
61 | // 分治法
62 | class Solution {
63 | public:
64 | ListNode* mergeKLists(vector& lists) {
65 | if (lists.empty()) return NULL;
66 | int n = lists.size();
67 | while (n > 1) {
68 | int k = (n + 1) / 2;
69 | for (int i = 0; i < n / 2; ++i) {
70 | lists[i] = mergeTwoLists(lists[i], lists[i + k]);
71 | }
72 | n = k;
73 | }
74 | return lists[0];
75 | }
76 | ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
77 | ListNode *dummy = new ListNode(-1), *cur = dummy;
78 | while (l1 && l2) {
79 | if (l1->val < l2->val) {
80 | cur->next = l1;
81 | l1 = l1->next;
82 | } else {
83 | cur->next = l2;
84 | l2 = l2->next;
85 | }
86 | cur = cur->next;
87 | }
88 | if (l1) cur->next = l1;
89 | if (l2) cur->next = l2;
90 | return dummy->next;
91 | }
92 | };
93 | ```
94 |
95 | ## [2.一个整数分解为多个不同的数之和,有几种分法](https://www.cnblogs.com/ibilllee/p/7655317.html)
96 |
97 | ```c
98 | 此类问题有如下几种形态:
99 |
100 | 1. 将n划分成若干正整数之和的划分数。
101 | 2. 将n划分成k个正整数之和的划分数。
102 | 3. 将n划分成最大数不超过k的划分数。
103 | 4. 将n划分成若干奇正整数之和的划分数。
104 | 5. 将n划分成若干不同整数之和的划分数。
105 |
106 |
107 |
108 | 1:将n划分成若干正整数的划分数
109 |
110 | (1):划分数可以存在相同的数
111 |
112 | 那么,设dp[n][m]表示整数 n 的划分中,每个数不大于 m 的划分数。
113 |
114 | 则划分数可以分为两种情况:
115 | a.划分中每个数都小于 m,相当于每个数不大于 m- 1, 故划分数为 dp[n][m-1]
116 | b.划分中有一个数为 m. 那就在 n中减去 m ,剩下的就相当于把 n-m 进行划分, 故划分数为 dp[n-m][m]
117 |
118 | 总递推式:dp[n][m]=dp[n][m-1]+dp[n-m][m]
119 |
120 | (2):划分数不可以存在相同的数
121 |
122 | 若还是设成同样的状态,从(1)可以看出,a条件是不会改变的,而b条件中,n-m后由于不存在重复,则划分数变为dp[n-m][m-1]
123 |
124 | 总递推式:dp[n][m]=dp[n][m-1]+dp[n-m][m-1]
125 |
126 |
127 |
128 | 2:将n划分成k个正整数的划分数
129 |
130 | 设dp[i][k]为,把i分成k分的划分法
131 |
132 | 那么也有两种情况:
133 |
134 | a.n份中不包括1的情况,那么每份中都可以拿出1来,即为dp[i-k][k]
135 |
136 | b.n份中起码有1个1的情况,那么把这个1去掉,变为dp[i-1][k-1]
137 |
138 | 总递推式:dp[i][k]=dp[i-k][k]+dp[i-1][k-1]
139 |
140 |
141 |
142 | 3:将n划分成若干奇数的划分数
143 |
144 | 设g[i][j]:将i划分成j个偶数
145 |
146 | f[i][j]:将i划分成j个奇数
147 |
148 | 对于偶数来讲,为f[i-j][j]中的共j个数,每个加1,则变成偶数。
149 |
150 | 对于奇数来讲,为g[i-j][j]中的共j个数,每个加1,则变成奇数;且还有新加入的1,则为f[i-1][j-1]
151 |
152 | 所以递推式为:g[i][j]=f[i-j][j] , f[i][j]=f[i-1][j-1] + g[i-j][j]
153 | ```
154 |
155 | ```c
156 | #define nmax 51
157 | int num[nmax][nmax]; //将i划分为不大于j的个数
158 | int num1[nmax][nmax]; //将i划分为不大于j的不同的数
159 | int num2[nmax][nmax]; //将i划分为j个数
160 | int f[nmax][nmax]; //将i划分为j个奇数
161 | int g[nmax][nmax]; //将i划分为j个偶数
162 | void init() {
163 | int i, j;
164 | for (i = 0; i < nmax; i++) {
165 | num[i][0] = 0, num[0][i] = 0, num1[i][0] = 0, num1[0][i] = 0, num2[i][0] =
166 | 0, num2[0][i] = 0;
167 | }
168 | for (i = 1; i < nmax; i++) {
169 | for (j = 1; j < nmax; j++) {
170 | if (i < j) {
171 | num[i][j] = num[i][i];
172 | num1[i][j] = num1[i][i];
173 | num2[i][j] = 0;
174 | } else if (i == j) {
175 | num[i][j] = num[i][j - 1] + 1;
176 | num1[i][j] = num1[i][j - 1] + 1;
177 | num2[i][j] = 1;
178 |
179 | } else {
180 | num[i][j] = num[i][j - 1] + num[i - j][j];
181 | num1[i][j] = num1[i][j - 1] + num1[i - j][j - 1];
182 | num2[i][j] = num2[i - 1][j - 1] + num2[i - j][j];
183 | }
184 | }
185 | }
186 | f[0][0] = 1, g[0][0] = 1;
187 | for (i = 1; i < nmax; i++) {
188 | for (j = 1; j <= i; j++) {
189 | g[i][j] = f[i - j][j];
190 | f[i][j] = f[i - 1][j - 1] + g[i - j][j];
191 | }
192 | }
193 | }
194 | ```
195 |
196 | **参考**: [将一个整数划分为多个正整数之和](https://blog.csdn.net/woniu317/article/details/39250403)
197 |
198 | ## 3.介绍一下cpp的智能指针
199 |
200 | ### [智能指针](https://interview.huihut.com/#/?id=智能指针)
201 |
202 | #### [C++ 标准库(STL)中](https://interview.huihut.com/#/?id=c-标准库(stl)中)
203 |
204 | 头文件:`#include `
205 |
206 | #### [C++ 98](https://interview.huihut.com/#/?id=c-98)
207 |
208 | ```cpp
209 | std::auto_ptr ps (new std::string(str));
210 | ```
211 |
212 | #### [C++ 11](https://interview.huihut.com/#/?id=c-11)
213 |
214 | 1. shared_ptr
215 | 2. unique_ptr
216 | 3. weak_ptr
217 | 4. auto_ptr(被 C++11 弃用)
218 |
219 | - Class shared_ptr 实现共享式拥有(shared ownership)概念。多个智能指针指向相同对象,该对象和其相关资源会在 “最后一个 reference 被销毁” 时被释放。为了在结构较复杂的情景中执行上述工作,标准库提供 weak_ptr、bad_weak_ptr 和 enable_shared_from_this 等辅助类。
220 | - Class unique_ptr 实现独占式拥有(exclusive ownership)或严格拥有(strict ownership)概念,保证同一时间内只有一个智能指针可以指向该对象。你可以移交拥有权。它对于避免内存泄漏(resource leak)——如 new 后忘记 delete ——特别有用。
221 |
222 | ##### [shared_ptr](https://interview.huihut.com/#/?id=shared_ptr)
223 |
224 | 多个智能指针可以共享同一个对象,对象的最末一个拥有着有责任销毁对象,并清理与该对象相关的所有资源。
225 |
226 | - 支持定制型删除器(custom deleter),可防范 Cross-DLL 问题(对象在动态链接库(DLL)中被 new 创建,却在另一个 DLL 内被 delete 销毁)、自动解除互斥锁
227 |
228 | ##### [weak_ptr](https://interview.huihut.com/#/?id=weak_ptr)
229 |
230 | weak_ptr 允许你共享但不拥有某对象,一旦最末一个拥有该对象的智能指针失去了所有权,任何 weak_ptr 都会自动成空(empty)。因此,在 default 和 copy 构造函数之外,weak_ptr 只提供 “接受一个 shared_ptr” 的构造函数。
231 |
232 | - 可打破环状引用(cycles of references,两个其实已经没有被使用的对象彼此互指,使之看似还在 “被使用” 的状态)的问题
233 |
234 | ##### [unique_ptr](https://interview.huihut.com/#/?id=unique_ptr)
235 |
236 | unique_ptr 是 C++11 才开始提供的类型,是一种在异常时可以帮助避免资源泄漏的智能指针。采用独占式拥有,意味着可以确保一个对象和其相应的资源同一时间只被一个 pointer 拥有。一旦拥有着被销毁或编程 empty,或开始拥有另一个对象,先前拥有的那个对象就会被销毁,其任何相应资源亦会被释放。
237 |
238 | - unique_ptr 用于取代 auto_ptr
239 |
240 | ##### [auto_ptr](https://interview.huihut.com/#/?id=auto_ptr)
241 |
242 | 被 c++11 弃用,原因是缺乏语言特性如 “针对构造和赋值” 的 `std::move` 语义,以及其他瑕疵。
243 |
244 | ##### [auto_ptr 与 unique_ptr 比较](https://interview.huihut.com/#/?id=auto_ptr-与-unique_ptr-比较)
245 |
246 | - auto_ptr 可以赋值拷贝,复制拷贝后所有权转移;unqiue_ptr 无拷贝赋值语义,但实现了`move` 语义;
247 | - auto_ptr 对象不能管理数组(析构调用 `delete`),unique_ptr 可以管理数组(析构调用 `delete[]` );
248 |
249 | **参考**: [c++ 智能指针用法详解](https://www.cnblogs.com/TenosDoIt/p/3456704.html)
250 |
251 | ### [4. std::move](https://blog.csdn.net/p942005405/article/details/84644069)
252 |
253 | std::move是将对象的状态或者所有权从一个对象转移到另一个对象,只是转移,没有内存的搬迁或者内存拷贝所以可以提高利用效率,改善性能.。
254 |
255 | ```c
256 | template
257 | typename remove_reference::type&& move(T&& t)
258 | {
259 | return static_cast::type&&>(t);
260 | }
261 | ```
262 |
263 | 原型定义中的原理实现:
264 | 首先,函数参数T&&是一个指向模板类型参数的右值引用,通过引用折叠,此参数可以与任何类型的实参匹配(可以传递左值或右值,这是std::move主要使用的两种场景)。关于引用折叠如下:
265 |
266 | ```c
267 | 公式一)X& &、X&& &、X& &&都折叠成X&,用于处理左值
268 | string s("hello");
269 | std::move(s) => std::move(string& &&) => 折叠后 std::move(string& )
270 | 此时:T的类型为string&
271 | typename remove_reference::type为string
272 | 整个std::move被实例化如下
273 | string&& move(string& t) //t为左值,移动后不能在使用t
274 | {
275 | //通过static_cast将string&强制转换为string&&
276 | return static_cast(t);
277 | }
278 | ```
279 |
280 |
281 |
282 | ```C
283 | 公式二)X&& &&折叠成X&&,用于处理右值
284 | std::move(string("hello")) => std::move(string&&)
285 | //此时:T的类型为string
286 | // remove_reference::type为string
287 | //整个std::move被实例如下
288 | string&& move(string&& t) //t为右值
289 | {
290 | return static_cast(t); //返回一个右值引用
291 | }
292 | ```
293 |
294 |
295 |
296 | 简单来说,右值经过T&&传递类型保持不变还是右值,而左值经过T&&变为普通的左值引用.
297 |
298 | ②对于static_cast<>的使用注意:任何具有明确定义的类型转换,只要不包含底层const,都可以使用static_cast。
299 |
300 | ```C
301 | double d = 1;
302 | void* p = &d;
303 | double *dp = static_cast p; //正确
304 |
305 | const char *cp = "hello";
306 | char *q = static_cast(cp); //错误:static不能去掉const性质
307 | static_cast(cp); //正确
308 | ```
309 |
310 |
311 |
312 | ③对于remove_reference是通过类模板的部分特例化进行实现的,其实现代码如下
313 |
314 | ```C
315 | //原始的,最通用的版本
316 | template struct remove_reference{
317 | typedef T type; //定义T的类型别名为type
318 | };
319 |
320 | //部分版本特例化,将用于左值引用和右值引用
321 | template struct remove_reference //左值引用
322 | { typedef T type; }
323 |
324 | template struct remove_reference //右值引用
325 | { typedef T type; }
326 |
327 | //举例如下,下列定义的a、b、c三个变量都是int类型
328 | int i;
329 | remove_refrence::type a; //使用原版本,
330 | remove_refrence::type b; //左值引用特例版本
331 | remove_refrence::type b; //右值引用特例版本
332 | ```
333 |
334 | **总结:**
335 | std::move实现,首先,通过右值引用传递模板实现,利用引用折叠原理将右值经过T&&传递类型保持不变还是右值,而左值经过T&&变为普通的左值引用,以保证模板可以传递任意实参,且保持类型不变。然后我们通过static_cast<>进行强制类型转换返回T&&右值引用,而static_cast之所以能使用类型转换,是通过remove_refrence::type模板移除T&&,T&的引用,获取具体体类型T。
336 |
337 | ### 5. extern c
338 |
339 | ### [extern "C"](https://interview.huihut.com/#/?id=extern-quotcquot)
340 |
341 | - 被 extern 限定的函数或变量是 extern 类型的
342 | - 被 `extern "C"` 修饰的变量和函数是按照 C 语言方式编译和链接的
343 |
344 | `extern "C"` 的作用是让 C++ 编译器将 `extern "C"` 声明的代码当作 C 语言代码处理,可以避免 C++ 因符号修饰导致代码不能和C语言库中的符号进行链接的问题。
345 |
346 | extern "C" 使用
347 |
348 | ```cpp
349 | #ifdef __cplusplus
350 | extern "C" {
351 | #endif
352 |
353 | void *memset(void *, int, size_t);
354 |
355 | #ifdef __cplusplus
356 | }
357 | #endif
358 | ```
359 |
360 | 参考:[C++项目中的extern "C" {}](https://www.cnblogs.com/skynet/archive/2010/07/10/1774964.html)
361 |
362 | ### 6. TCP的重传机制
363 |
364 | 参考: [浅谈TCP(1):状态机与重传机制]([https://monkeysayhi.github.io/2018/03/07/%E6%B5%85%E8%B0%88TCP%EF%BC%881%EF%BC%89%EF%BC%9A%E7%8A%B6%E6%80%81%E6%9C%BA%E4%B8%8E%E9%87%8D%E4%BC%A0%E6%9C%BA%E5%88%B6/](https://monkeysayhi.github.io/2018/03/07/浅谈TCP(1):状态机与重传机制/))
365 |
366 | [TCP 的那些事儿(上)](https://coolshell.cn/articles/11564.html)
367 |
368 | [TCP的超时重传机制与拥塞避免](https://blog.csdn.net/ahafg/article/details/51058467)
369 |
370 | [TCP重传机制](https://blog.csdn.net/lishanmin11/article/details/77001506)
371 |
372 | [TCP-IP详解:超时重传机制](https://blog.csdn.net/wdscq1234/article/details/52476231)
373 |
374 | [TCP-IP详解:SACK选项(Selective Acknowledgment)](https://blog.csdn.net/wdscq1234/article/details/52503315)
375 |
376 | ### [7. TCP的拥塞控制](https://zhuanlan.zhihu.com/p/37379780)
377 |
378 | ##### [概念](https://interview.huihut.com/#/?id=概念-4)
379 |
380 | 拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。
381 |
382 | ##### [方法](https://interview.huihut.com/#/?id=方法-1)
383 |
384 | - 慢开始( slow-start )
385 | - 拥塞避免( congestion avoidance )
386 | - 快重传( fast retransmit )
387 | - 快恢复( fast recovery )
388 |
389 | TCP的拥塞控制图
390 |
391 | 
392 |
393 | 
394 |
395 | 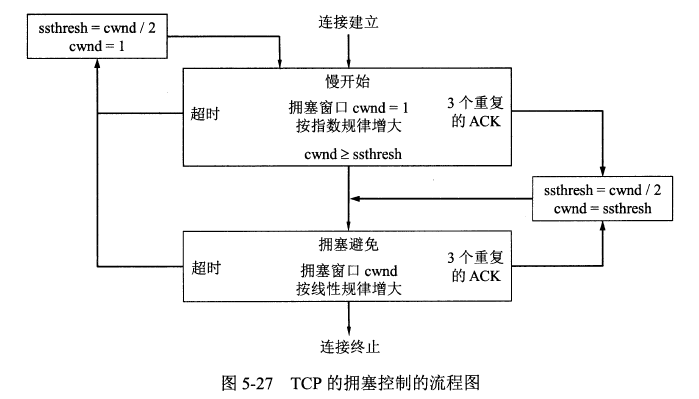
396 |
397 | ### [8.cookie和session]([https://github.com/twomonkeyclub/BackEnd/tree/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C#cookie%E5%92%8Csession](https://github.com/twomonkeyclub/BackEnd/tree/master/计算机基础知识/计算机网络#cookie和session))
398 |
399 | HTTP协议作为无状态协议,对于HTTP协议而言,无状态指每次request请求之前是相互独立的,当前请求并不会记录它的上一次请求信息,如何将上下文请求进行关联呢?**客户端(不同的浏览器)记录用户的状态通过cookie,服务器端(不同的网站)记录用户的状态通过session。**
400 |
401 | ### cookie
402 |
403 | #### **工作流程**
404 |
405 | - 客户端请求服务器端,服务器端产生cookie响应头,随响应报文发送给客户端,客户端将cookie文本保存起来
406 | - 下次客户端再次请求服务端时,会产生cookie请求头,将之前服务器发送的cookie信息,再发送给服务器,服务器就可以根据cookie信息跟踪客户端的状态。
407 |
408 | #### **基础知识**
409 |
410 | Cookie总是保存在客户端中,按在客户端中的存储位置,可分为内存Cookie和硬盘Cookie,它是服务器端存放在本地机器中的数据,随每一个请求发送给服务器,由于Cookie在客户端,所以可以编辑伪造,不是十分安全。
411 |
412 | - 非持久cookie
413 | - 内存Cookie由浏览器维护,保存在内存中,浏览器关闭后就消失了,其存在时间是短暂的。
414 | - 持久cookie
415 | - 硬盘Cookie保存在硬盘里,有一个过期时间(客户端cookie设置的时间),除非用户手工清理或到了过期时间,硬盘Cookie不会被删除,其存在时间是长期的。
416 |
417 | ### session
418 |
419 | #### **工作流程**
420 |
421 | - 当用户第一次访问站点时,服务器端为用户创建一个sessionID,这就是针对这个用户的唯一标识,每一个访问的用户都会得到一个自己独有的session ID,这个session ID会存放在响应头里的cookie中,之后发送给客户端。这样客户端就会拥有一个该站点给他的session ID。
422 | - 当用户第二次访问该站点时,浏览器会带着本地存放的cookie(里面存有上次得到的session ID)随着请求一起发送到服务器,服务端接到请求后会检测是否有session ID,如果有就会找到响应的session文件,把其中的信息读取出来;如果没有就跟第一次一样再创建个新的。
423 |
424 | #### **基础知识**
425 |
426 | session是存放在服务器里的,所以session 里的东西不断增加会增加服务器的负担,我们会把一些重要的东西放在session里,不太重要的放在客户端cookie里
427 |
428 | - session失效
429 | - 服务器(非正常)关闭时
430 | - session过期/失效(默认30分钟)
431 | - 问题:时间的起算点 从何时开始计算30分钟?从不操作服务器端的资源开始计时(例如:当你访问淘宝页面时,点开页面不动,第29分钟再动一下页面,就得重新计时30分钟;当过了30分钟,就失效了。)
432 | - 手动销毁session
433 | - sessionID的传递方式
434 | - 通过cookie传递
435 | - 当cookie禁用后,可以通过url传递
436 | - 不同场景下的session
437 | - 当在同一个浏览器中同时打开多个标签,发送同一个请求或不同的请求,仍是同一个session;
438 | - 当不在同一个窗口中打开相同的浏览器时(打开多个相同的浏览器),发送请求,仍是同一个session;
439 | - 当使用不同的浏览器时,发送请求,即使发送相同的请求,是不同的session;
440 | - 当把当前某个浏览器的窗口全关闭,再打开,发起相同的请求时,是不同的session。
441 |
442 | ### 区别
443 |
444 | - cookie数据存放在客户的浏览器上,session数据放在服务器上。
445 | - cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。
446 | - session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie。
447 | - 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
448 | - 可以考虑将登陆信息等重要信息存放为session,其他信息如果需要保留,可以放在cookie中。
449 |
450 |
--------------------------------------------------------------------------------
/file/other.md:
--------------------------------------------------------------------------------
1 | ### 面经
2 |
3 | [面经答案整理一](https://meik2333.com/posts/interview1/)
4 |
5 | [面经答案整理二](https://meik2333.com/posts/interview2/)
6 |
7 | [面经答案整理三](https://meik2333.com/posts/interview3/)
8 |
9 | [面经答案整理四](https://meik2333.com/posts/interview4/)
10 |
11 | [计算机网络之面试常考](https://www.nowcoder.com/discuss/1937?type=2&order=0&pos=14&page=2)
12 |
13 | [笔试/面试](https://www.cnblogs.com/webary/tag/笔试%2F面试/)
14 |
15 | [C++后台腾讯WXG实习面经(已拿offer](https://mp.weixin.qq.com/s?__biz=MzU2MTkwMTE4Nw==&mid=2247487932&idx=2&sn=ded87785e7135b9220b592f5a46ab0fa&chksm=fc70ea50cb076346d5d2e773b8633efcb21c60797701648dc34a7ca7ef11e3d6d9ac726d30ae&scene=0&xtrack=1&exportkey=AwpO52UZEKdtSMWLjKDyzjg%3D&pass_ticket=dTP4vQHP4GUGbmiafBk5ZMDwx7EUGJqQfsyKHD0ZVGrDGDNnH6%2Fu3VZP49jLlrk1#rd)
16 |
17 | [常见的C++面试题——附答案](https://mp.weixin.qq.com/s?__biz=MzU3Njc5OTg4Mw==&mid=2247484846&idx=1&sn=7a8a09cd7d3140acf0ffd4c631b989a2&chksm=fd0f104aca78995c761a5280792519b3bb7e3f5c5c01e87e02e3286c5cbe960411827b2abb9c&scene=0&xtrack=1&exportkey=A16tmwpXISfT5%2FY00jD13QY%3D&pass_ticket=dTP4vQHP4GUGbmiafBk5ZMDwx7EUGJqQfsyKHD0ZVGrDGDNnH6%2Fu3VZP49jLlrk1#rd)
18 |
19 | [[c/c++后台开发面经系列]2 京东面经(含答案)](https://mp.weixin.qq.com/s?__biz=MzI3NzcwNjY3NQ==&mid=2247483872&idx=1&sn=4d245efe694f0e5ba94962b2e036964a&chksm=eb63633cdc14ea2aaba00a2b2df16af03270dc3a89c532468af634a7002cef6c58d680136fa6&scene=0&xtrack=1&exportkey=A%2F%2FTVSrrOIxSNlEQSOpieZo%3D&pass_ticket=dTP4vQHP4GUGbmiafBk5ZMDwx7EUGJqQfsyKHD0ZVGrDGDNnH6%2Fu3VZP49jLlrk1#rd)
20 |
21 | [[c/c++后台开发面经系列]1 深信服面经](https://mp.weixin.qq.com/s?__biz=MzI3NzcwNjY3NQ==&mid=2247483865&idx=1&sn=972e503e479a0d5f6c03eaf448df58fb&chksm=eb636305dc14ea13a39862f7a3b3a4f7978f99c524cbc51734757b7f0abb567d830cfb1c9b47&mpshare=1&scene=24&srcid=&sharer_sharetime=1582703245730&sharer_shareid=ad083dfbb456b99720581c2315ccd358&exportkey=A9mx%2FfqiFyv5xG3%2BPcds1ic%3D&pass_ticket=dTP4vQHP4GUGbmiafBk5ZMDwx7EUGJqQfsyKHD0ZVGrDGDNnH6%2Fu3VZP49jLlrk1#rd)
22 |
23 | [[c/c++后台开发面经系列]3 bigo/映客面经(含答案)](https://mp.weixin.qq.com/s?__biz=MzI3NzcwNjY3NQ==&mid=2247483877&idx=1&sn=804195185b646bc311899c52bd5555fa&chksm=eb636339dc14ea2fa6f049ad1845b7edd510213e2d71c16d7bee7e6d6a3778ba2c9bf0a74682&scene=0&xtrack=1&exportkey=A6TiDl%2B4ZzcJb%2FxZFKSMNcU%3D&pass_ticket=dTP4vQHP4GUGbmiafBk5ZMDwx7EUGJqQfsyKHD0ZVGrDGDNnH6%2Fu3VZP49jLlrk1#rd)
24 |
25 | [[c/c++后台开发面经系列]4 Zoom面经(含答案)](https://mp.weixin.qq.com/s?__biz=MzI3NzcwNjY3NQ==&mid=2247483910&idx=1&sn=3f3228c1faaecd193b62d74ac3ca1dae&chksm=eb6360dadc14e9cc3f9036026c5d1fde21b377611fed6933050ce023bcf38c609462861b5ce7&scene=0&xtrack=1&exportkey=A3x9YvG0AEl%2FOPD5PDku5hE%3D&pass_ticket=dTP4vQHP4GUGbmiafBk5ZMDwx7EUGJqQfsyKHD0ZVGrDGDNnH6%2Fu3VZP49jLlrk1#rd)
26 |
27 | [一位小哥哥的腾讯后台开发面经 - 无答案](https://mp.weixin.qq.com/s?__biz=Mzg4MTA5MDE3OQ==&mid=2247483752&idx=1&sn=7213ef6c0e9a86df120d562aed855e09&chksm=cf6a0a84f81d8392d719b57f442f3ef849142083314171c8983d401ef82a5b196ad7798bc3d2&scene=0&xtrack=1&exportkey=A2g5CYp5BhdPdn4KMYI9EhU%3D&pass_ticket=dTP4vQHP4GUGbmiafBk5ZMDwx7EUGJqQfsyKHD0ZVGrDGDNnH6%2Fu3VZP49jLlrk1#rd)
28 |
29 | [2021 腾讯暑期实习,我竟因这样的题目挂掉了](https://mp.weixin.qq.com/s?__biz=MzA5MzY4NTQwMA==&mid=2651016941&idx=4&sn=5b420834883ea297767e1cdb123a39e2&chksm=8badfd1abcda740c54ce081f8e577dca2fcc62bc3d63841958767a82b45bef2dbe28850302b6&scene=0&xtrack=1&exportkey=A8HulOqxzDItt7yVF%2FjxNmE%3D&pass_ticket=dTP4vQHP4GUGbmiafBk5ZMDwx7EUGJqQfsyKHD0ZVGrDGDNnH6%2Fu3VZP49jLlrk1#rd)
30 |
31 | [C++面试宝典](https://www.nowcoder.com/tutorial/93/8ba2828006dd42879f3a9029eabde9f1)
32 |
33 | [你们需要的C++面试题来了](https://mp.weixin.qq.com/s?__biz=MzIwODI3NDk4Mg==&mid=2247485013&idx=2&sn=b70948b45ae104a4feb1f6905412bc84&chksm=9704d51ca0735c0a48b4f3f191df6d6aa84232b406a5a35f1543b7c8ef6df4a8630b2d30583a&scene=0&xtrack=1&exportkey=A3gpgx0Xe2gAGxbfIw1lsLw%3D&pass_ticket=kghR2tZybuDSjhJ1DdKw9NBpn26hHHLSL9y9bABXnDHI2hiILChfPaQf%2BjzyxPLx#rd)
34 |
35 | [腾讯C++后台开发面试笔试知识点参考笔记](https://mp.weixin.qq.com/s?__biz=MzA3MTU1MzMzNQ==&mid=2247485008&idx=1&sn=2096030cab1403fe4dcfe44278f770f1&chksm=9f2a9e08a85d171e8d1a6d37b8f5121d885ad415ca26c7b4a0df81c593e815776482cd01f964&scene=0&xtrack=1&exportkey=A37Q8hqDbNHctFNz26WZq48%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
36 |
37 | [我的2016笔试面试经验(送给下一届的学弟学妹们) ](https://www.nowcoder.com/discuss/18460)
38 |
39 | ---
40 |
41 | ### 知识点
42 |
43 | [红黑树](https://www.jianshu.com/p/e136ec79235c)
44 |
45 | [浏览器输入 URL 回车之后发生了什么?](https://mp.weixin.qq.com/s?__biz=MzIwNTc4NTEwOQ==&mid=2247487993&idx=2&sn=4d0e85664acf3f9b8e52ca657d4624c4&chksm=972ac083a05d49953c252befc538267d4c9e0250d28eb1a1408c6618717b4a990da9c15fb328&scene=0&xtrack=1&exportkey=A9B0A77uTco6vfW0%2FB94qvc%3D&pass_ticket=Q6IAjSjKVqZKcjHGt21AZGcwOAi3MHzOXrR78xxoMxdxrp64M%2FKX48msfsKs5Wck#rd)
46 |
47 | [漫画:美团面试题(TOPK:求第K个最大的元素)](https://mp.weixin.qq.com/s?__biz=Mzg2NzA4MTkxNQ==&mid=2247487187&idx=2&sn=00e34b16b1dbaf97ece7c6d9e796a933&chksm=ce404507f937cc11fd77e1164abc8c97b753e1bd6d572fd781c172369adc85f534bb4560f67d&scene=0&xtrack=1&exportkey=A7bjM43mqBeyS42%2BcogAAgU%3D&pass_ticket=Q6IAjSjKVqZKcjHGt21AZGcwOAi3MHzOXrR78xxoMxdxrp64M%2FKX48msfsKs5Wck#rd)
48 |
49 | [漫画:BAT必考题目 (最小的k个数)](https://mp.weixin.qq.com/s?__biz=MzI2NjI5MzU2Nw==&mid=2247484287&idx=1&sn=c7207c765c363e0f1e97c5fb58b1bfd5&chksm=ea911b2fdde69239971cf26b206e7d52c79b4be73792f42107b12737b3490c4d788402327547&scene=21#wechat_redirect)
50 |
51 | [腾讯面试题04.进程和线程的区别?](https://blog.csdn.net/mxsgoden/article/details/8821936)
52 |
53 | [拜托,别问我什么各种Tree了,干就完事!](https://mp.weixin.qq.com/s?__biz=MzI3NzcwNjY3NQ==&mid=2247483940&idx=1&sn=0c9b346ad35e0cd6b9c58b82a73bd5f9&chksm=eb6360f8dc14e9ee146bef73a0ffd6469b2b4599510d16a1038022b9e05aec526e02ec1ae4ab&scene=0&xtrack=1&exportkey=A9cinI1wvSa8f8lTlgf8Qk8%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
54 |
55 | [详解linux虚拟内存原理](https://mp.weixin.qq.com/s?__biz=MzU4NDM4MjA1Mg==&mid=2247484296&idx=1&sn=5e44aee6d9df11fe4420d48dea8e24d6&chksm=fd9be083caec69952cabedaf50ab07d3b72279188ad3c12df0c9f52350da7988dc401127dc6c&scene=0&xtrack=1&exportkey=A5v3Jy7jiUsFxmo%2BHJcw%2FXg%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
56 |
57 | [linux内存分配管理](https://mp.weixin.qq.com/s?__biz=MzU4NDM4MjA1Mg==&mid=2247484310&idx=1&sn=16d0d531877f4be9a44aca1ad832bec8&chksm=fd9be09dcaec698bb0d8e42cb8ccc7da71db34c1b6806544debb1e8835a9c284834a18297ce5&scene=0&xtrack=1&exportkey=A5HHjutf4PdQhWzBXQKW41s%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
58 |
59 | [二叉树问题太复杂?「三步走」方法解决它!](https://mp.weixin.qq.com/s?__biz=MzA5ODk3ODA4OQ==&mid=2648167191&idx=1&sn=6d8ce02aaf7376f94eee022ac2324568&chksm=88aa2351bfddaa470552469d23d6cb2da4191a242cee66a36b143a2722021ac3566abb60ac09&scene=0&xtrack=1&exportkey=A9s4RMf2ZuzgrMPyL2jQB7E%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
60 |
61 | [今天就盘计算机网络,跟帅地快速过一遍计算机网络!](https://mp.weixin.qq.com/s?__biz=Mzg2NzA4MTkxNQ==&mid=2247487231&idx=1&sn=2514355ae23974cc14dc18f13ff311c6&chksm=ce40452bf937cc3d1cb8af348376d7457ef61d03ca6e625c0adb9dfc3537a745b11641d0d91e&scene=0&xtrack=1&exportkey=A1I%2F21V6fztjYVdDSOIGLn0%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
62 |
63 | [我和面试官之间关于操作系统的一场对弈!写了很久,看完你就可以盘面试官了](https://mp.weixin.qq.com/s?__biz=Mzg2NzA4MTkxNQ==&mid=2247487214&idx=1&sn=38cbbd83ca62ecdcf6d476735d5f613d&chksm=ce40453af937cc2c842520ccb16f8a4309f6976c4bc5452cdccc24d8cd741bbeb37e854046f0&scene=0&xtrack=1&exportkey=A1a%2FU5g649%2FZL1DiHeBvWCQ%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
64 |
65 | [看完这篇 HTTPS,和面试官扯皮就没问题了](https://mp.weixin.qq.com/s?__biz=MzUyNjQxNjYyMg==&mid=2247487830&idx=2&sn=11257effafffe416cd13a035ad6f2fcf&chksm=fa0e7ed7cd79f7c1d8cdbddd53ab83faa39f2d05b16d2f7a120b065ce8862ca44f18392328db&scene=0&xtrack=1&exportkey=AyvwXSQRpFjsqTdY8dLbKho%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
66 |
67 | [15分钟读懂进程线程、同步异步、阻塞非阻塞、并发并行,太实用了!](https://mp.weixin.qq.com/s?__biz=MzI2OTQxMTM4OQ==&mid=2247491984&idx=2&sn=641c384c3d9e4f30e7e6f7627684aee3&chksm=eae214c2dd959dd40b8f45a1be2ca930cc5d0a7d1d7959ef40c362fda97851933082f3ab1ad9&scene=0&xtrack=1&exportkey=A%2FyV%2BKohNaveXFhIf27sml4%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
68 |
69 | [最小堆定时器](https://mp.weixin.qq.com/s?__biz=MzU4NDM4MjA1Mg==&mid=2247484288&idx=1&sn=f24f887db875acb138d29d0cd4701bb0&chksm=fd9be08bcaec699da0aa570fe610ee2c1e62638ea0a2a3859cdfb3fdd0cf293cdc63bace2a27&scene=0&xtrack=1&exportkey=Axb6szzXA0q9jC2C%2B2iEVM8%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
70 |
71 | [Linux 系统调用和库函数的区别](https://mp.weixin.qq.com/s?__biz=MzIwODI3NDk4Mg==&mid=2247484795&idx=2&sn=9a59f4883ff9448c7a43ed3532b6c008&chksm=9704d632a0735f244fc3f5228d3c84ceaa49d9ebffd8c561c4b681614e64c3b3c3ca72d12995&scene=0&xtrack=1&exportkey=AxguwZ7LZ%2F9QJWotr2aadoE%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
72 |
73 | [数据库的初恋](https://mp.weixin.qq.com/s?__biz=MzI3NzcwNjY3NQ==&mid=2247483920&idx=1&sn=24a8c66417bf27c8d6d479617bd594b3&chksm=eb6360ccdc14e9da78931d42ba6448aa9630199183e6d4062522889d9c5074bd70090a8886f1&scene=0&xtrack=1&exportkey=AwNe6e%2B6X%2FPXeguoRDkUED4%3D&pass_ticket=YEO6O2qMY479vaEeH%2F1jtKRHGizQVnmYjkbhHP74kD%2FNPsG4S1qid5Z9wEaSzGqb#rd)
74 |
75 | [面试常考点:http和https的区别与联系](https://blog.csdn.net/xionghuixionghui/article/details/68569282)
76 |
77 | [HTTP与TCP的区别和联系](https://blog.csdn.net/u013485792/article/details/52100533)
78 |
79 | [Linux进程总结](https://mp.weixin.qq.com/s?__biz=MzI4MDEwNzAzNg==&mid=2649446675&idx=1&sn=540075dd25c7874a5f06957b989cbddc&chksm=f3a27860c4d5f1760f5bbe88bfb59513cb648a2a9bbfb6a29fffa17a3da2d514574bbbea2ba7&scene=0&xtrack=1&exportkey=A%2FuT%2B9QeC2gSgDAjlYYzBDs%3D&pass_ticket=QDl6Sz47X44kCfE%2FMsekc0cHQRQX2zN3l1PTg8Rt2sy6e2lickrTcMTN%2Bi21XScq#rd)
80 |
81 | [浅谈Linux内存管理那些事儿](https://mp.weixin.qq.com/s?__biz=MzI2MTcxNjg5OA==&mid=2247484009&idx=1&sn=08cd17746acda15da3f521eae3c0bc45&chksm=ea576ca4dd20e5b22e7d46989da5c4c07b78f8e6186efd03f462b6cd938f4fdeccdf14005ce9&scene=0&xtrack=1&exportkey=AxaFVMXQU9Fy9YbBqhi5Yt0%3D&pass_ticket=QDl6Sz47X44kCfE%2FMsekc0cHQRQX2zN3l1PTg8Rt2sy6e2lickrTcMTN%2Bi21XScq#rd)
82 |
83 | [[TCP 的那些事儿](https://www.cnblogs.com/sunsky303/p/10643263.html)]
84 |
85 | [SQL查询语句练习题](https://zhuanlan.zhihu.com/p/55372544)
86 |
87 | [[数据库](https://www.cnblogs.com/HHHzhihao/p/12609845.html)]
88 |
89 | [详解布隆过滤器的原理,使用场景和注意事项](https://zhuanlan.zhihu.com/p/43263751)
90 |
91 | [全网最透彻HTTPS(面试常问)](https://mp.weixin.qq.com/s?__biz=MzAwNDA2OTM1Ng==&mid=2453141883&idx=2&sn=3b93d3bed05ec0094a0cae77bf1cc82c&chksm=8cf2dbf8bb8552ee286c4799b30d3847a641760142e50234b12bd042f9d238b3291c161b5996&scene=0&xtrack=1&exportkey=AxsVX61UrEai8MMLL1KCneM%3D&pass_ticket=bkectU6wcfZcFKygAq6y4ReQosvMHt3K8G1aeEFKElgCtRMM0R8I2zae2dJBNUDd#rd)
92 |
93 | [深入理解CAP理论和适用场景](https://mp.weixin.qq.com/s?__biz=MzI3ODg2OTY1OQ==&mid=2247486544&idx=2&sn=19bb73ec60a0cb0854142d93858b9376&chksm=eb512fa4dc26a6b2cc79f6863f14a127d11592cb9cd7f9ab847ef5a038eac59fe65c042ce240&scene=0&xtrack=1&exportkey=AwpeAbJ%2F7yB9l6is%2F7UtVpo%3D&pass_ticket=bkectU6wcfZcFKygAq6y4ReQosvMHt3K8G1aeEFKElgCtRMM0R8I2zae2dJBNUDd#rd)
94 |
95 | [C++ STL库](https://blog.nowcoder.net/n/95824efb636f4442a440cc0acc929c79)
96 |
97 | [面试资料-C++](https://blog.nowcoder.net/n/597b7119c7ff40308fc6f9b59fdb041d?from=sx21)
98 |
99 | [牛客网](https://docs.qq.com/sheet/DQWRqeGJmQ1N1WEl5?c=A1A0AT0&tab=cdv9ja)
100 |
101 | [五种常见IO模型介绍](https://mp.weixin.qq.com/s/rVTI-1J5a0rhy0RvPZXHXg)
102 |
103 | [Linux面试题(2020最新版)](https://mp.weixin.qq.com/s/GAsIxGoS_XPr089pZGL16w)
104 |
105 | [C++面试题](http://www.mianshigee.com/job/C-plus-plus/p1)
106 |
107 | [LeetCode 例题精讲 | 15 最长公共子序列:二维动态规划的解法](https://mp.weixin.qq.com/s/dHIeiIQWAeynmYSq9IdqJg)
108 |
109 | [IP 基础知识“全家桶”,45 张图一套带走](https://mp.weixin.qq.com/s/qydIO7NDfFTYs4-ZZlfgRg)
110 |
111 | [C语言与C++面试知识总结](https://mp.weixin.qq.com/s/GPM_-nyWubcPjXV8Ug93qw)
112 |
113 | [炸裂!万字长文拿下HTTP 我在字节跳动等你!](https://mp.weixin.qq.com/s/HFOU2zfpRTGRRiW2NwohaQ)
114 |
115 | [分析 HTTP,TCP 的长连接和短连接以及 sock](https://mp.weixin.qq.com/s/KUVZrP_ytSaaRW5bQQjcSw)
116 |
117 | [Java并发和多线程基础面试题大集合](https://mp.weixin.qq.com/s/pIVf97W4DuAPNxq6zgRvsQ)
118 |
119 | [c++11新特性,所有知识点都在这了!](https://mp.weixin.qq.com/s/EyKZE_MbZ-KLB3myZpzCbw)
120 |
121 | [[别被脱裤系列]2 还没深入数据库就浅出了](https://mp.weixin.qq.com/s/KnkktFsKOw9xMuMieciEog)
122 |
123 | [面试系列之C++的对象布局【建议收藏】](https://mp.weixin.qq.com/s/y5ts0o0-ESrw4_-i4CHfjQ)
124 |
125 | [写给程序员的 MySQL 面试高频 100 问,看完吊打面试官!](https://mp.weixin.qq.com/s/mXTLt53s5iv0YNPOq4Y6uQ)
126 |
127 | [彻底理解 IO多路复用](https://mp.weixin.qq.com/s/LBZOOs7T2ZFCkKsT1VXK-g)
128 |
129 | [后端服务中的定时器设计](https://mp.weixin.qq.com/s/t33b-KRq-nPsZG65ycABgw)
130 |
131 | [epoll LT 模式和 ET 模式详解](https://mp.weixin.qq.com/s/n5qp8hX-LXdO1NgQt22EKA)
132 |
133 | [SQL | 44道经典 SQL 笔试题与答案解析](https://mp.weixin.qq.com/s/E5P9XjsG27iO4OsZpkYPEw)
134 |
135 |
136 | [高并发基石|深入理解IO复用技术之epoll](https://mp.weixin.qq.com/s/ZL45TOUvuCaAGslrNdA5OA)
137 |
138 | [这篇高并发服务模型大科普,内部分享时被老大表扬了](https://mp.weixin.qq.com/s/yXMgpAhz3JhtCtutMQnXvQ)
139 |
140 | [大厂面试爱问的「调度算法」,20 张图一举拿下](https://mp.weixin.qq.com/s/JWj6_BF9Xc84kQcyx6Nf_g)
141 |
142 | [揭开高性能服务器底层面纱](https://mp.weixin.qq.com/s/iFtVNi0ec3wterrLJd3Lgw)
143 |
144 | [42图揭秘,「后端技术学些啥」](https://mp.weixin.qq.com/s/bWgX8ZoQj-ZZAigiiRHzAw)
145 |
146 | [138 张图带你 MySQL 入门](https://mp.weixin.qq.com/s/LePDgnothGCnOLoxNVRQKQ)
147 |
148 | [纯干货|史上最全的技术岗面试笔记—数据库篇(下)](https://mp.weixin.qq.com/s/TzEhG0RAimmjYruqXNOznw)
149 |
150 | [纯干货|史上最全的技术岗面试笔记——数据库篇(上)](https://mp.weixin.qq.com/s/9EUhiZQ_yHXuX82msGkPAg)
151 |
152 | [姗姗来迟的Redis分布式锁](https://mp.weixin.qq.com/s/Z_xriP-jc2Bnmdcm0l5xzg)
153 |
154 | [Linux 进程间通信方式(管道、命名管道、消息队列、信号量、共享内存、套接字)](https://mp.weixin.qq.com/s/qtH16MhPli-e7Cp53zHTEg)
155 |
156 | [五分钟学算法:什么是堆?](https://mp.weixin.qq.com/s/7GeO8jjg1QUG_ofJznOsCQ)
157 |
158 | [高并发基石|深入理解IO复用技术之epoll](https://mp.weixin.qq.com/s/FKvEnf8rMgRM3k934oko4A)
159 |
160 | [100 个网络基础知识普及,看完成半个网络高手!(文末附PDF版本)](https://mp.weixin.qq.com/s/9t-7fcMCxDdwSwrs0hlU_g)
161 |
162 | [高频面试题-如何交换两个变量值?](https://mp.weixin.qq.com/s/pSJe2t8MgKCxOvwqDgbyuw)
163 |
164 | [硬核!16000 字 Redis 面试知识点总结,建议收藏!](https://mp.weixin.qq.com/s/bHeTlrCeM-MXvcr2xcV0ow)
165 |
166 | [8000+字总结:一文搞定 UDP 和 TCP 高频面试题!](https://mp.weixin.qq.com/s/Hda0LCYAKTvwfUMMm_i4Ng)
167 |
168 | [网络编程-数据结构与函数详解](https://mp.weixin.qq.com/s/S7xo9GupiFov0Djsl1S-OA)
169 |
170 | [校招必看硬核干货:C++怎么学才能进大厂](https://mp.weixin.qq.com/s/GGG10XQLP2QhX_1EThlgkg)
171 |
172 | [字节跳动的面试题.pdf](https://mp.weixin.qq.com/s/_CVIqVVmc53mZaMfs7Yd1A)
173 |
174 | [高性能服务器开发 2019 年原创汇总](https://mp.weixin.qq.com/s/FfXAsHGEZrivnyB6EKdP2g)
175 |
176 | [C++后台腾讯WXG实习面经(已拿offer)](https://mp.weixin.qq.com/s/JY-ZIRcGbypCA3ew5bQteQ)
177 |
178 | [零基础,SQL语句大全,所有的SQL都在这里](https://mp.weixin.qq.com/s/gLRAdFzlSLQlSgr2L0glbw)
179 |
180 | [单例模式很简单?但是你真的能写对吗?](https://mp.weixin.qq.com/s/ipZUOMhjKxXLb1S8o1-G6Q)
181 |
182 | [你该知道的C++四种显式类型转换](https://mp.weixin.qq.com/s/dOYQn1a6SSrLlXKExS3O5A)
183 |
184 | [《吊打面试官》系列-秒杀系统设计](https://mp.weixin.qq.com/s/z2S1EjWQDwKm5Ud36IenNw)
185 |
186 | [《吊打面试官》之Redis基础—这是我看过超有条理的面试文章了](https://mp.weixin.qq.com/s/d6pixN-wrC3zf0V6Llhl8Q)
187 |
188 | [精心整理了20道操作系统高频面试题(建议收藏)](https://mp.weixin.qq.com/s/kXZEgpj6krym2Pxk6O1EGA)
189 |
190 | [100 道 Linux 笔试题,能拿90分以上的都去了BAT](https://mp.weixin.qq.com/s/K6mBj-Zlr_9_LwpU5X8W6Q)
191 |
192 | [一文彻底搞懂cookie和session](https://mp.weixin.qq.com/s/Zg7GY3diBTrviRFWQFoo-A)
193 |
194 | [你们要的C++面试题答案来了--基础篇](https://mp.weixin.qq.com/s/NmJQ0tEk78rSvxAWzO6cRw)
195 |
196 | [聊一聊字节跳动的面试](https://mp.weixin.qq.com/s/73FO63_ydKhuKTWUSCS3TQ)
197 |
198 | [你们要的C++面试题答案来了--基础篇](https://mp.weixin.qq.com/s/YRo5Lm9pbbZnjY1DQfW6yw)
199 |
200 | [面试环节:在浏览器输入 URL 回车之后发生了什么?(超详细版)](https://mp.weixin.qq.com/s/CF_i7Q-dHokD1GXeBYScFA)
201 |
202 | [GDB调试入门,看这篇就够了](https://mp.weixin.qq.com/s/7HGDy91SLRLM-6uWRzM78w)
203 |
204 | [干货 | 非科班C++后台实习面经](https://mp.weixin.qq.com/s/u_5a64BldXeWQgDhlmyUig)
205 |
206 | [面经 | 附答案的蚂蚁金服面经分享](https://mp.weixin.qq.com/s/QFIDulDjkopG9CeleUAH8g)
207 |
208 | [【BATJ面试必会】Jvm 虚拟机篇](https://mp.weixin.qq.com/s/mo_pQ5Q1o4c-_fPcii3mrg)
209 |
210 | [BATJ面试必会之Java IO 篇](https://mp.weixin.qq.com/s/jgC5cUwQtOZQgi0pLzoqxw)
211 |
212 | [BATJ面试必会之 Spring 篇(一)](https://mp.weixin.qq.com/s/Y7Y1NHnv5oECt6-VpviQxw)
213 |
214 | [BATJ面试必会之 Java 容器篇](https://mp.weixin.qq.com/s/W1dx2gOuLY0nd6gq71BwDA)
215 |
216 | ---
217 |
218 | ### LeetCode
219 |
220 | [深度剖析头条面试真题 | 二叉树那点事儿](https://mp.weixin.qq.com/s/JMO-0j6mxUXtrs3VzfWuYg)
221 |
222 | [Leecode题解 :4.Median of Two Sorted Arrays](https://mp.weixin.qq.com/s/g3-_zLFMRFoCUXhfQmSYFQ)
223 |
224 | [BFS 算法框架套路详解](https://mp.weixin.qq.com/s/WH_XGm1-w5882PnenymZ7g)
225 |
226 | [LeetCode 例题精讲 | 12 岛屿问题:网格结构中的 DFS](https://mp.weixin.qq.com/s?__biz=MzA5ODk3ODA4OQ==&mid=2648167208&idx=1&sn=d8118c7c0e0f57ea2bdd8aa4d6ac7ab7&chksm=88aa236ebfddaa78a6183cf6dcf88f82c5ff5efb7f5c55d6844d9104b307862869eb9032bd1f&scene=0&xtrack=1&exportkey=A4c9MaejeYrCco4FmGEPPsc%3D&pass_ticket=diGeb3cAaGn%2FticqnwUFCqXTUjzbYgGkUqF7EtM7PzKkPLbkgfrd%2FUb9iwC4edIY#rd)
227 |
228 | [经典动态规划:完全背包问题](https://mp.weixin.qq.com/s?__biz=MzAxODQxMDM0Mw==&mid=2247485124&idx=1&sn=52068c8000b90a7a972dbd04658d79b7&chksm=9bd7f8ccaca071da66d3c9e567ab49b27c711db154c2f297f55fcd7c3c1156afa37b0ad60555&scene=0&xtrack=1&exportkey=AxJGZaR6Zn0%2BTdF3TOdT4xU%3D&pass_ticket=diGeb3cAaGn%2FticqnwUFCqXTUjzbYgGkUqF7EtM7PzKkPLbkgfrd%2FUb9iwC4edIY#rd)
229 |
230 | [LeetCode 例题精讲 | 15 最长公共子序列:二维动态规划的解法](https://mp.weixin.qq.com/s/dHIeiIQWAeynmYSq9IdqJg)
231 |
--------------------------------------------------------------------------------
/file/20200320.md:
--------------------------------------------------------------------------------
1 | ### [2019暑期实习面经](https://www.nowcoder.com/discuss/189431)
2 |
3 | ### [1.select poll epoll 区别以及各自的应用场景]()
4 |
5 | **select的几大缺点:**
6 |
7 | - 每次调用 **select** 函数,都需要把 fd 集合从用户态拷贝到内核态,这个开销在 fd 较多时会很大,同时每次调用 **select** 函数都需要在内核遍历传递进来的所有 fd,这个开销在 fd 较多时也很大;
8 | - 单个进程能够监视的文件描述符的数量存在最大限制,在 Linux 上一般为 1024,可以通过修改宏定义然后重新编译内核的方式提升这一限制,这样非常麻烦而且效率低下;
9 | - **select** 函数在每次调用之前都要对传入参数进行重新设定,这样做比较麻烦而且会降低性能。
10 |
11 | **poll** 与 **select** 相比具有如下优点:
12 |
13 | - **poll** 不要求开发者计算最大文件描述符加 1 的大小;
14 | - 相比于 **select**,**poll** 在处理大数目的文件描述符的时候速度更快;
15 | - **poll** 没有最大连接数的限制,原因是它是基于链表来存储的;
16 | - 在调用 **poll** 函数时,只需要对参数进行一次设置就好了。
17 |
18 | select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
19 |
20 | **当监测的fd数目较小,且各个fd都比较活跃,建议使用select或者poll**
21 |
22 | **当监测的fd数目非常大,成千上万,且单位时间只有其中的一部分fd处于就绪状态,这个时候使用epoll能够明显提升性能,比如ngix web服务器就是使用epoll实现的。**
23 |
24 |
25 |
26 | ```c
27 | select
28 | select是最早出现的方式:
29 |
30 | 它可监控的文件描述符数量最多是1024个,
31 | 每次进行调用都要将全部描述符从应用进程缓冲区复制到内核缓冲区中,
32 | 返回的结果中不会具体声明哪些描述符已经就绪,还需要进行轮询查找
33 | poll
34 | poll
35 | 监控描述符的数量没有了限制,但其他缺点和select一样
36 |
37 | epoll
38 | epoll
39 |
40 | 没有监控数量限制
41 | 只需要将描述符从进程缓冲区向内核缓冲区拷贝一次
42 | 不需要轮询查询哪些就绪,epoll返回后直接告诉进程哪些描述符已经就绪
43 | epoll仅仅适用于linux OS
44 |
45 | 1. select 应用场景
46 | select 的 timeout 参数精度为 1ns,而 poll 和 epoll 为 1ms,因此 select 更加适用于实时性要求比较高的场景,比如核反应堆的控制。
47 |
48 | select 可移植性更好,几乎被所有主流平台所支持。
49 |
50 | 2. poll 应用场景
51 | poll 没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用 poll 而不是 select。
52 |
53 | 3. epoll 应用场景
54 | 只需要运行在 Linux 平台上,有大量的描述符需要同时轮询,并且这些连接最好是长连接。
55 |
56 | 需要同时监控小于 1000 个描述符,就没有必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势。
57 |
58 | 需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率。并且 epoll 的描述符存储在内
59 | ```
60 |
61 | ### [2. shared_ptr线程安全](https://blog.csdn.net/Solstice/article/details/8547547)
62 |
63 | **因为 shared_ptr 有两个数据成员,读写操作不能原子化**
64 |
65 | **如果要从多个线程读写同一个 shared_ptr 对象,那么需要加锁**
66 |
67 | **引用计数**指的是,所有管理同一个裸指针(raw pointer)的shared_ptr,都共享一个引用计数器,每当一个shared_ptr被赋值(或拷贝构造)给其它shared_ptr时,这个共享的引用计数器就加1,当一个shared_ptr析构或者被用于管理其它裸指针时,这个引用计数器就减1,如果此时发现引用计数器为0,那么说明它是管理这个指针的最后一个shared_ptr了,于是我们释放指针指向的资源
68 |
69 | 在底层实现中,这个引用计数器保存在某个内部类型里(这个类型中还包含了deleter,它控制了指针的释放策略,默认情况下就是普通的delete操作),而这个内部类型对象在shared_ptr第一次构造时以指针的形式保存在shared_ptr中。shared_ptr重载了赋值运算符,在赋值和拷贝构造另一个shared_ptr时,这个指针被另一个shared_ptr共享。在引用计数归零时,这个内部类型指针与shared_ptr管理的资源一起被释放。此外,为了保证线程安全性,引用计数器的加1,减1操作都是原子操作,它保证shared_ptr由多个线程共享时不会爆掉。
70 |
71 | 用shared_ptr,不用new
72 | 使用weak_ptr来打破循环引用
73 | 用make_shared来生成shared_ptr
74 | 用enable_shared_from_this来使一个类能获取自身的shared_ptr
75 |
76 | ### 3.STL 迭代器
77 |
78 | 1. 对于序列式容器(如vector,deque),序列式容器就是数组式容器,删除当前的iterator会使后面所有元素的iterator都失效。这是因为vetor,deque使用了连续分配的内存,删除一个元素导致后面所有的元素会向前移动一个位置。所以不能使用erase(iter++)的方式,还好**erase方法可以返回下一个有效的iterator。**
79 |
80 | 2. vector是一个顺序容器,在内存中是一块连续的内存,当删除一个元素后,内存中的数据会发生移动,以保证数据的紧凑。所以删除一个数据后,其他数据的地址发生了变化,之前获取的迭代器根据原有的信息就访问不到正确的数据。
81 |
82 | 3. 对于关联容器(如map, set,multimap,multiset),删除当前的iterator,仅仅会使当前的iterator失效,只要在erase时,递增当前iterator即可。这是因为map之类的容器,使用了红黑树来实现,插入、删除一个结点不会对其他结点造成影响。erase迭代器只是被删元素的迭代器失效,但是返回值为void,所以要采用erase(iter++)的方式删除迭代器。
83 |
84 | map是关联容器,以红黑树或者平衡二叉树组织数据,虽然删除了一个元素,整棵树也会调整,以符合红黑树或者二叉树的规范,但是单个节点在内存中的地址没有变化,变化的是各节点之间的指向关系。
85 |
86 | 总结:迭代器失效分三种情况考虑,也是非三种数据结构考虑,分别为数组型,链表型,树型数据结构。
87 |
88 | **数组型数据结构**:该数据结构的元素是分配在连续的内存中,insert和erase操作,都会使得删除点和插入点之后的元素挪位置,所以,插入点和删除掉之后的迭代器全部失效,也就是说insert(*iter)(或erase(*iter)),然后在iter++,是没有意义的。解决方法:erase(*iter)的返回值是下一个有效迭代器的值。 iter =cont.erase(iter);
89 |
90 | **链表型数据结构**:对于list型的数据结构,使用了不连续分配的内存,删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.解决办法两种,erase(*iter)会返回下一个有效迭代器的值,或者erase(iter++).
91 |
92 | **树形数据结构**: 使用红黑树来存储数据,插入不会使得任何迭代器失效;删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.erase迭代器只是被删元素的迭代器失效,但是返回值为void,所以要采用erase(iter++)的方式删除迭代器。
93 |
94 | ### [4.虚继承的实现原理](https://www.nowcoder.com/questionTerminal/638f798ac0da4a89a0c3e893f62d5376)
95 |
96 | 作用:为了解决从不同途径继承来的同名的数据成员在内存中有不同的拷贝造成数据不一致问题,将共同基类设置为虚基类。
97 |
98 | 这时从不同的路径继承过来的同名数据成员在内存中就只有一个拷贝,同一个函数名也只有一个映射。这样不仅就解决 了二义性问题,也节省了内存,避免了数据不一致的问题。
99 |
100 | 底层实现原理:底层实现原理与编译器相关,一般通过**虚基类指针**实现,即各对象中只保存一份父类的对象,多继承时**通过虚基类指针引用该公共对象**,从而避免菱形继承中的二义性问题。
101 |
102 | ### 5. memory order内存序
103 |
104 | c++11提供了六种内存序供选择,分别为:
105 |
106 | ```
107 | typedef enum memory_order {
108 | memory_order_relaxed,
109 | memory_order_consume,
110 | memory_order_acquire,
111 | memory_order_release,
112 | memory_order_acq_rel,
113 | memory_order_seq_cst
114 | } memory_order;
115 | ```
116 |
117 | 之前在场景2中,因为指令的重排导致了意料之外的错误,通过使用原子变量并选择合适内存序,可以解决这个问题。下面先来看看这几种内存序
118 |
119 | ## memory_order_release/memory_order_acquire
120 |
121 | 内存序选项用来作为原子量成员函数的参数,memory_order_release用于store操作,memory_order_acquire用于load操作,这里我们把使用了memory_order_release的调用称之为release操作。从逻辑上可以这样理解:release操作可以阻止这个调用之前的读写操作被重排到后面去,而acquire操作则可以保证调用之后的读写操作不会重排到前面来。听起来有种很绕的感觉,还是以一个例子来解释:假设flag为一个 atomic特化的bool 原子量,a为一个int变量,并且有如下时序的操作:
122 |
123 | | step | thread A | thread B |
124 | | :--: | :------------------------------------: | :------------------------------------------: |
125 | | 1 | a = 1 | |
126 | | 2 | flag.store(true, memory_order_release) | |
127 | | 3 | | if( true == flag.load(memory_order_acquire)) |
128 | | 4 | | assert(a == 1) |
129 |
130 | 实际上这就是把我们上文场景2中的flag变量换成了原子量,并用其成员函数进行读写。在这种情况下的逻辑顺序上,step1不会跑到step2后面去,step4不会跑到step3前面去。这样一来,实际上我们就已经保证了当读取到flag为true的时候a一定已经被写入为1了,场景2得到了解决。换一种比较严谨的描述方式可以总结为:
131 |
132 | - 对于同一个原子量,release操作前的写入,一定对随后acquire操作后的读取可见。
133 |
134 | 这两种内存序是需要配对使用的,这也是将他们放在一起介绍的原因。还有一点需要注意的是:只有对同一个原子量进行操作才会有上面的保证,比如step3如果是读取了另一个原子量flag2,是不能保证读取到a的值为1的。
135 |
136 | ## memory_order_release/memory_order_consume
137 |
138 | memory_order_release还可以和memory_order_consume搭配使用。memory_order_release操作的作用没有变化,而memory_order_consume用于load操作,我们简称为consume操作,comsume操作防止在其后对原子变量有依赖的操作被重排到前面去。这种情况下:
139 |
140 | - 对于同一个原子变量,release操作所依赖的写入,一定对随后consume操作后依赖于该原子变量的操作可见。
141 |
142 | 这个组合比上一种更宽松,comsume只阻止对这个原子量有依赖的操作重拍到前面去,而非像aquire一样全部阻止。将上面的例子稍加改造来展示这种内存序,假设flag为一个 atomic特化的bool 原子量,a为一个int变量,b、c各为一个bool变量,并且有如下时序的操作:
143 |
144 | | step | thread A | thread B |
145 | | :--: | :---------------------------------: | :--------------------------------------------: |
146 | | 1 | b = true | |
147 | | 2 | a = 1 | |
148 | | 3 | flag.store(b, memory_order_release) | |
149 | | 4 | | while (!(c = flag.load(memory_order_consume))) |
150 | | 5 | | assert(a == 1) |
151 | | 6 | | assert(c == true) |
152 | | 7 | | assert(b == true) |
153 |
154 | step4使得c依赖于flag,当step4线程B读取到flag的值为true的时候,由于flag依赖于b,b在之前的写入是可见的,此时b一定为true,所以step6、step7的断言一定会成功。而且这种依赖关系具有传递性,假如b又依赖与另一个变量d,则d在之前的写入同样对step4之后的操作可见。那么a呢?很遗憾在这种内存序下a并不能得到保证,step5的断言可能会失败。
155 |
156 | ## memory_order_acq_rel
157 |
158 | 这个选项看名字就很像release和acquire的结合体,实际上它的确兼具两者的特性。这个操作用于“读取-修改-写回”这一类既有读取又有修改的操作,例如CAS操作。可以将这个操作在内存序中的作用想象为将release操作和acquire操作捆在一起,因此任何读写操作的重拍都不能跨越这个调用。依然以一个例子来说明,flag为一个 atomic特化的bool 原子量,a、c各为一个int变量,b为一个bool变量,并且刚好按如下顺序执行:
159 |
160 | | step | thread A | thread B |
161 | | :--: | :------------------------------------------: | :----------------------------------------------------------: |
162 | | 1 | a = 1 | |
163 | | 2 | flag.store(true, memory_order_release) | |
164 | | 3 | | b = true |
165 | | 4 | | c = 2 |
166 | | 5 | | while (!flag.compare_exchange_weak(b, false, memory_order_acq_rel)) {b = true} |
167 | | 6 | | assert(a == 1) |
168 | | 7 | if (false == flag.load(memory_order_acquire) | |
169 | | 8 | assert(c == 2) | |
170 |
171 | 由于memory_order_acq_rel同时具有memory_order_release与memory_order_acquire的作用,因此step2可以和step5组合成上面提到的release/acquire组合,因此step6的断言一定会成功,而step5又可以和step7组成release/acquire组合,step8的断言同样一定会成功。
172 |
173 | ## memory_order_seq_cst
174 |
175 | 这个内存序是各个成员函数的内存序默认选项,如果不选择内存序则默认使用memory_order_seq_cst。这是一个“美好”的选项,如果对原子变量的操作都是使用的memory_order_seq_cst内存序,则多线程行为相当于是这些操作都以一种特定顺序被一个线程执行,在哪个线程观察到的对这些原子量的操作都一样。同时,任何使用该选项的写操作都相当于release操作,任何读操作都相当于acquire操作,任何“读取-修改-写回”这一类的操作都相当于使用memory_order_acq_rel的操作。
176 |
177 | ## memory_order_relaxed
178 |
179 | 这个选项如同其名字,比较松散,它仅仅只保证其成员函数操作本身是原子不可分割的,但是对于顺序性不做任何保证。
180 |
181 | 参考:[C++11的原子量与内存序浅析](https://www.cnblogs.com/FateTHarlaown/p/8919235.html)
182 |
183 | [C++11 中的内存模型](https://tyzual.com/2019/02/11/mem-order/)
184 |
185 | [C++11的6种内存序](https://blog.csdn.net/qq_22660775/article/details/88800782)
186 |
187 | ### 6.lock-free & wait-free
188 |
189 | **lock-free**:需要取得锁的线程在有限步骤或时间内内就可以成功(多数线程都会成功,一些可能失败,比wait-free语义稍弱)
190 |
191 | **wait-free**:需要取得锁的线程在有限步骤或时间内内就可以成功(任意线程都会成功,语义更加强烈)
192 |
193 | **(1)wait-free:不管OS如何调度线程,每个线程始终在做有用的事情。**
194 |
195 | **(2)lock-free:不管OS如何调度线程,至少有一个线程在做有用的事情。**
196 |
197 | **总结**
198 |
199 | (1)无锁化并一定能带来高性能,但一定能保证一件事情在确定的时间内完成;
200 |
201 | (2)使用无锁化会带来两个问题:性能和crash;
202 |
203 | (3)面对无锁化使用的性能问题:采用规避原则,尽可能多核少共享内存资源,少同时操作一个资源;
204 |
205 | (4)面对无锁化crash问题,分析了原因是指令重排序,引入了memory_order,制定相应的模型规定指令的执行先后顺序,将多核指令cacheline。
206 |
207 | (5)临界区较大一定上锁,小临界区尽可能用原子指令。
208 |
209 | 对于lock-free算法,如果任何时刻一个操作该数据结构的线程被挂起,其他线程仍然可以访问数据结构并完成相应工作。
210 |
211 | wait-free首先是一个lock-free算法,但是进行了加强,线程在有限步内需要完成相应工作。
212 |
213 | Lock-Free: 任意时刻至少一个线程在干活
214 |
215 | Wait-Free: 任意时刻所有的线程都在干活
216 |
217 | ### 7.backlog的作用,编程中应该设置为多大
218 |
219 | ```CQL
220 | int listen(int sockfd, int backlog)
221 | ```
222 |
223 | **已完成的连接队列**(`ESTABLISHED`)与**未完成连接队列**(`SYN_RCVD`)之和的上限。
224 |
225 | 
226 |
227 | 
228 |
229 | 参考:[[backlog参数对TCP连接建立的影响](https://segmentfault.com/a/1190000019252960)](https://segmentfault.com/a/1190000019252960)
230 |
231 | [浅谈tcp socket的backlog参数](https://www.cnblogs.com/qiumingcheng/p/9492962.html)
232 |
233 | ### 8.[mysql中innodb和myisam的区别](https://www.nowcoder.com/tutorial/93/8ac75a692a3b4b0a868796b9f008bc2c),[行锁的实现原理](https://lanjingling.github.io/2015/10/10/mysql-hangsuo/)
234 |
235 | 1)事务:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持,提供事务支持已经外部键等高级数据库功能。
236 |
237 | 2)性能:MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快。
238 |
239 | 3)行数保存:InnoDB 中不保存表的具体行数,也就是说,执行select count() fromtable时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count()语句包含where条件时,两种表的操作是一样的。
240 |
241 | 4)索引存储:对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。MyISAM支持全文索引(FULLTEXT)、压缩索引,InnoDB不支持。
242 |
243 | MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少。能加载更多索引,而Innodb是索引和数据是紧密捆绑的,没有使用压缩从而会造成Innodb比MyISAM体积庞大不小。
244 |
245 | InnoDB存储引擎被完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB存储它的表&索引在一个表空间中,表空间可以包含数个文件(或原始磁盘分区)。这与MyISAM表不同,比如在MyISAM表中每个表被存在分离的文件中。InnoDB 表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上。
246 |
247 | 5)服务器数据备份:InnoDB必须导出SQL来备份,LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用。
248 |
249 | MyISAM应对错误编码导致的数据恢复速度快。MyISAM的数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
250 |
251 | InnoDB是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。
252 |
253 | 6)锁的支持:MyISAM只支持表锁。InnoDB支持表锁、行锁 行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。
254 |
255 | **InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。** InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
256 |
257 | 参考:[MySQL 表锁和行锁机制](https://juejin.im/entry/5a55c7976fb9a01cba42786f)
258 |
259 | ### 9.redis可以做什么
260 |
261 | 通常局限点来说,Redis也以消息队列的形式存在,作为内嵌的List存在,满足实时的高并发需求。而通常在一个电商类型的数据处理过程之中,有关商品,热销,推荐排序的队列,通常存放在Redis之中,期间也包扩Storm对于Redis列表的读取和更新。
262 |
263 | ### 10. 内存池概念
264 |
265 | 当 创建大量消耗小内存的对象时,频繁调用new/malloc会导致大量的内存碎片,致使效率降低。内存池的概念就是预先在内存中申请一定数量的,大小相等 的内存块留作备用,当有新的内存需求时,就先从内存池中分配内存给这个需求,不够了之后再申请新的内存。这样做最显著的优势就是能够减少内存碎片,提升效率。
266 |
267 | 参考:[STL分配器内存池](https://www.nowcoder.com/tutorial/93/8f140fa03c084299a77459dc4be31c95)
268 |
269 | ### 11. vector deque
270 |
271 | 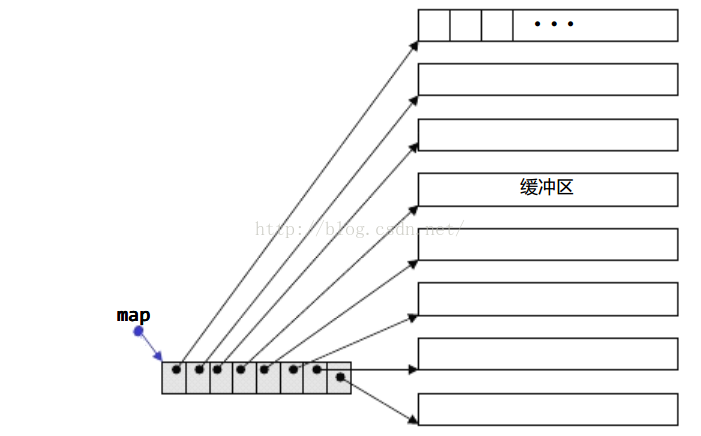
272 |
273 | 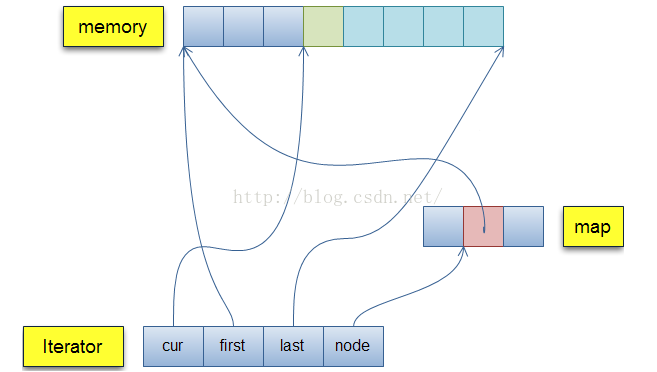
274 |
275 | 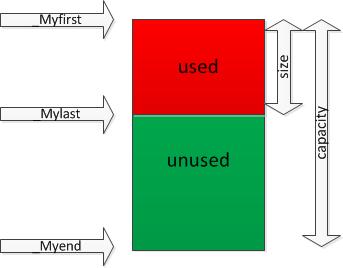
276 |
277 | ### [12.数据结构堆](https://juejin.im/post/59fc75f76fb9a0452206dd15#heading-1)
278 |
279 | 堆的特性:
280 |
281 | - **必须是[完全二叉树](http://www.jianshu.com/p/5c9e773344b4)**
282 | - **用数组实现**
283 | - 任一结点的值是其子树所有结点的最大值或最小值
284 | - 最大值时,称为“最大堆”,也称大顶堆;
285 | - 最小值时,称为“最小堆”,也称小顶堆
286 |
287 | - heap[1]表示堆顶;
288 |
289 | - 如果一个有中间结点是i,那么它的左孩子的下标就是2*i,右孩子的下标就是2*i+1,父亲是2*i
290 |
291 | - 如果一个结点i,1 <= i <= heap_size/2 那么它有孩子; heap_size/2 < i <= heap_size 则结点i为叶子结点
292 |
293 | - **pop**
294 |
295 | - 正确的做法是将根结点(第一个元素)与最后一个结点(最后一个元素)进行交换,删除最后一个元素,然后再根结点进行一次向下调整。
296 |
297 | - push
298 |
299 | - 向上调整:(调整孩子结点child)再来看向上调整,就简单的多了。找到你想调整的结点child,找出它的父亲结点parent,比较两个的大小,若child < parent,不操作。若child > parent, 则交换两个的值,然后令child的下标 = parent的下标。重复以上操作,直到child的下标 <= 0(说明到达根结点)。
300 |
301 |
302 |
303 | 
304 |
305 | ### 13. 析构函数可以抛出异常吗
306 |
307 | **从语法上来说,析构函数可以抛出异常,但从逻辑上和风险控制上,析构函数中不要抛出异常,因为栈展开容易导致资源泄露和程序崩溃,所以别让异常逃离析构函数。**
308 |
309 | 1)如果析构函数抛出异常,则**异常点之后的程序不会执行**,如果析构函数在异常点之后执行了某些必要的动作比如释放某些资源,则这些动作不会执行,会造成诸如资源泄漏的问题。
310 |
311 | 2)通常异常发生时,c++的机制会调用已经构造对象的析构函数来释放资源,此时若析构函数本身也抛出异常,则前一个异常尚未处理,又有新的异常,会造成程序崩溃的问题。
312 |
313 | ### [14.进程虚拟地址空间布局](https://www.cnblogs.com/clover-toeic/p/3754433.html)
314 |
315 |
316 |
317 | 
318 |
319 | 用户进程部分分段存储内容如下表所示(按地址递减顺序):
320 |
321 | | **名称** | **存储内容** |
322 | | -------- | ----------------------------------------- |
323 | | 栈 | 局部变量、函数参数、返回地址等 |
324 | | 堆 | 动态分配的内存 |
325 | | BSS段 | 未初始化或初值为0的全局变量和静态局部变量 |
326 | | 数据段 | 已初始化且初值非0的全局变量和静态局部变量 |
327 | | 代码段 | 可执行代码、字符串字面值、只读变量 |
328 |
329 | ### [15.进程间通信IPC (InterProcess Communication)](https://www.jianshu.com/p/c1015f5ffa74)
330 |
331 | ### [16.支持并发读写的队列](https://blog.csdn.net/mymodian9612/article/details/53608084)
332 |
333 | ### 17[【面试题】野指针的成因,危害以及避免方法?](https://www.cnblogs.com/asking/p/9460965.html)
334 |
335 | ### [18. 多线程程序内存布局](https://blog.csdn.net/songchuwang1868/article/details/90143633)
336 |
337 |
338 |
339 | 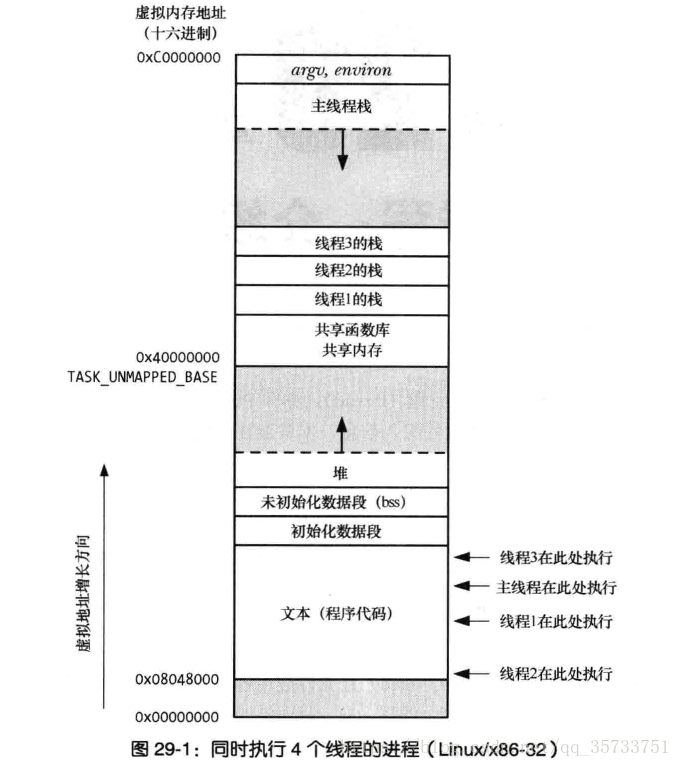
340 |
341 | ### [19. Apache与Nginx](https://blog.csdn.net/u013074465/article/details/44993863)
342 |
343 | Apache与Nginx的性能谁更高效,取决于其服务器的并发策略以及其面对的场景:
344 |
345 | 并发策略:
346 |
347 | 我们目前使用的 **Apache是基于\**一个线程处理一个请求的非阻塞IO并发策略\**** 。这种方式允许一个进程中通过多个线程来处理多个连接,其中每个线程处理一个连接。Apache使用其worker模块实现这种方式,目的是减少perfork模式中太多进程的开销,使得apache可以支持更多的并发连接。
348 |
349 | 至于,非阻塞IO的实现,是通过一个子进程负责accept(),一旦接收到连接后,便将任务分配给适当worker的线程。
350 |
351 | 由于apache的线程使用的是内核进程调度器管理的轻量级进程,因此与perfork模式比较,进程上下文切换的开销依然存在,性能提升不是很明显。
352 |
353 | **Nginx使用的是\**一个进程处理多个连接、非阻塞IO模式\**** ,这种模式最特别的是设计了独立的listener进程,专门负责接收新的连接,再分配给各个worker,当然为了减少任务调度的开销,一般都是由worker进程来进行接收。
354 |
355 | 而IO模型层面,***\*Nginx选择epoll\**,此方式高效主要在于其基于事件的就绪通知机制**,在高连接数的场景下,epoll通知方式更具优势。另外,epoll方式只关注活跃连接,而不像select方式需要扫描所有的文件描述符,这样在大量连接的场景下,epoll方式优势会更加明显。
356 |
357 | epoll在多连接并发处理以及管理这两方面,都较于select具有很大的优势。这也正是高并发、高连接的互联网网站大量使用Nginx服务器的原因所在。
358 |
359 | ### 20.线程栈的大小,能调整吗?代码中怎么调整?
360 |
361 | 8M [ulimits -s]
362 |
363 | pthread_attr_setstacksize();
364 |
365 | ```CQL
366 | #include
367 |
368 | int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize);
369 | int pthread_attr_getstacksize(const pthread_attr_t *attr, size_t *stacksize);
370 |
371 | ```
372 |
373 | ### [21.TCP中已有SO_KEEPALIVE选项,为什么还要在应用层加入心跳包机制?](https://blog.csdn.net/gettogetto/article/details/76736371)
374 |
375 | 因为TCP协议中的SO_KEEPALIVE有几个致命的缺陷:
376 |
377 | 1. keepalive只能检测连接是否存活,不能检测连接是否可用。比如服务器因为负载过高导致无法响应请求但是连接仍然存在,此时keepalive无法判断连接是否可用。
378 | 2. 如果TCP连接中的另一方因为停电突然断网,我们并不知道连接断开,此时发送数据失败会进行重传,由于重传包的优先级要高于keepalive的数据包,因此keepalive的数据包无法发送出去。只有在长时间的重传失败之后我们才能判断此连接断开了。
379 |
380 | 
--------------------------------------------------------------------------------
/file/c++笔记.md:
--------------------------------------------------------------------------------
1 | #### 1.构造函数生成的顺序
2 |
3 | 建立派生类对象时,3种构造函数分别是a(基类的构造函数)、b(成员对象的构造函数)、c(派生类的构造函数)这3种构造函数的调用顺序为:
4 | A. abc
5 | B. acb
6 | C. cab
7 | D. cba
8 |
9 | 答案是**A**,b的意思应该是父类在子类中还有一个对象作为子类的成员,然后就是这样的构造函数的顺序
10 |
11 | 2.运算符重载
12 |
13 | 如果友元函数重载一个运算符时,其参数表中没有任何参数则说明该运算符是:
14 | A.一元运算符
15 | B.二元运算符
16 | C.选项A)和选项B)都可能
17 | D.重载错误
18 |
19 | 答案是D,友元函数重载时,参数列表为1,说明是1元,为2说明是2元
20 | 成员函数重载时,参数列表为空,是一元,参数列表是1,为2元
21 |
22 |
23 |
24 | 3.为什么不使用#define而使用const和inline
25 | 一.#define是预处理,比如#define AS 1.653 ,可能AS不会进入记号表,如果出错,可能出现的错误提示是1.653而不是AS
26 | 二.define不会做类型检查(容易出错),const拥有类型,会执行相应的类型检查
27 | define仅仅是宏替换,不占用内存,而const会占用内存
28 | const内存效率更高,编译器可能将const变量保存在符号表中,而不会分配存储空间,这使得它成
29 | 为一个编译期间的常量,没有存储和读取的操作
30 | 当使用#define定义一个简单的函数时,强烈建议使用内联函数替换!
31 | 内联函数和宏的区别在于,宏是由预处理器对宏进行替代,而内联函数是
32 | 通过编译器控制来实现的。而且内联函数是真正的函数,只是在需要用到的时
33 | 候,内联函数像宏一样的展开,所以取消了函数的参数压栈,减少了调用的开
34 | 销。
35 |
36 |
37 | 4.explicit:阻止执行隐式类型转换(以下借用百度百科)
38 |
39 |
40 | explicit构造函数是用来防止隐式转换的。请看下面的代码:
41 | class Test1
42 | {
43 | public:
44 | Test1(int n)
45 | {
46 | num=n;
47 | }//普通构造函数
48 | private:
49 | int num;
50 | };
51 | class Test2
52 | {
53 | public:
54 | explicit Test2(int n)
55 | {
56 | num=n;
57 | }//explicit(显式)构造函数
58 | private:
59 | int num;
60 | };
61 | int main()
62 | {
63 | Test1 t1=12;//隐式调用其构造函数,成功
64 | Test2 t2=12;//编译错误,不能隐式调用其构造函数
65 | Test2 t2(12);//显式调用成功
66 | return 0;
67 | }
68 | Test1的构造函数带一个int型的参数,代码23行会隐式转换成调用Test1的这个构造函数。
69 | 而Test2的构造函数被声明为explicit(显式),这表示不能通过隐式转换来调用这个构造函数,因此代码24行会出现编译错误。
70 | 普通构造函数能够被隐式调用。而explicit构造函数只能被显式调用。
71 |
72 |
73 |
74 | 5.拷贝构造函数的使用:(只有一个参数,而且要为引用,不然会造成无限的复制构造)
75 | class Widget{
76 | public:
77 | Widget(); //default构造函数
78 | Widget(const Widget& rhs); //拷贝构造函数
79 | Widget& operator=(const Widget& rhs);//拷贝赋值符
80 | };
81 | Widget w1; //调用default构造函数
82 | Widget w2(w1); //调用拷贝构造函数
83 | w1=w2; //调用拷贝赋值符
84 | Widget w3=w2; //调用拷贝构造函数
85 |
86 |
87 |
88 | 6.类型转换:
89 | 公有派生类对象可以被当作基类的对象使用,反之则不可.
90 | 一.派生类的对象可以隐含转换为基类对象;
91 | 二.派生类的对象可以初始化基本的引用
92 | 三.派生类的指针可以隐含转换为基类的指针.
93 | 通过基类对象名,指针只能使用从基类继承的成员
94 |
95 |
96 | 7.#include
97 | using namespace std;
98 |
99 | class A
100 | {
101 | public:
102 | int m;
103 | int* p;
104 | };
105 |
106 | int main()
107 | {
108 | A s;
109 | s.m = 10;
110 | cout << s.m << endl; //10
111 | s.p = &s.m;
112 | *s.p = 5;//!!!
113 | cout << s.m << endl; //5
114 | return 0;
115 | }
116 |
117 |
118 | 8.若函数参数为引用,则函数将不再为传入的实参建立拷贝,
119 | 结果直接作用在实参上,是c++提供的一种跨函数传值的手段。
120 | 这里同时加了const防止更改实参,
121 | 则只是省去了函数建立拷贝的步骤,应该是为了提升运行效率,去掉&不会影响程序结构。
122 |
123 |
124 |
125 | 9.std::string str,str可以被修改,而且会调用拷贝构造函数。
126 | std::sring& str,str可以被修改,但不会调用拷贝构造函数。
127 | const::string str ,str不能被修改,但会调用拷贝构造函数。
128 | const::string& str,str不能被修改,而且也不会调用拷贝构造函数。
129 |
130 |
131 | 10.深拷贝与浅拷贝
132 | 简单的来说就是,在有指针的情况下,浅拷贝只是增
133 | 加了一个指针指向已经存在的内存,而深拷贝就是增
134 | 加一个指针并且申请一个新的内存,使这个增加的指
135 | 针指向这个新的内存.
136 | 采用深拷贝的情况下,释放内存的时候就不会出现在浅拷贝时重复释放同一内存的错误!
137 |
138 |
139 |
140 | 11.this指针隐含于每一个非静态成员函数中
141 | 每个对象调用函数时,会先把对象的地址传给this指针,然后通过this指针来调用
142 |
143 |
144 | 12.
145 | 1、在类的定义中进行的,只有const 且 static 且 integral 的变量。
146 | 2、在类的构造函数初始化列表中, 包括const对象和Reference对象。
147 | 3、在类的定义之外初始化的,包括static变量。因为它是属于类的唯一变量。
148 | 4、普通的变量可以在构造函数的内部,通过赋值方式进行。当然这样效率不高。
149 |
150 |
151 |
152 | 13.static:
153 | 1.当一个进程的全局变量被声明为static之后,它的中文名叫静态全局变量。
154 | 静态全局变量和其他的全局变量的存储地点并没有区别,都是在.data段(已初始化
155 | )或者.bss段(未初始化)内,但是它只在定义它的源文件内有效,其他源文件无法访问它
156 | 。所以,普通全局变量穿上static外衣后,它就变成了新娘,已心有所属,
157 | 只能被定义它的源文件(新郎)中的变量或函数访问。
158 |
159 |
160 |
161 |
162 | 14.
163 | 重载为成员函数:
164 | 前置单目运算符,重载函数没有形参
165 | 后置++运算符,重载函数需要有一个int形参
166 | //前置单目运算符重载
167 | Clock& operator ++ ();
168 | //后置单目运算符重载
169 | Clock operator ++ (int);
170 |
171 |
172 | 15.虚函数不能为内联函数,而且并且是非静态的函数,因为静态的是属于类的,
173 | 不是属于对象的,而虚函数就是要被对象操作,在类里声明,类外定义,因为虚函
174 | 数是要动态绑定,就是要在运行时候处理,而内联函数是在编译时候就处理
175 |
176 | 构造函数不能是虚函数
177 | 析构函数可以是虚函数
178 | 虚函数一般不声明为内联函数,因为对虚函数的调用需要动态绑定,而对内联函
179 | 数的处理是静态的
180 |
181 | 如果派生类和基类函数都一样,那么派生类就算不加virtual也会被视为虚函数
182 |
183 | 16.为什么需要虚析构函数:
184 | 假设基类对象指针指向派生类成员对象,
185 | 那么如果不把基类和派生类的析构函数加virtual
186 | 那么就会只析构基类的所分配的空间,不会析构派生类的所分配的空间
187 |
188 |
189 |
190 |
191 | 17.cout << sizeof("\x0012") << endl;
192 | cout << sizeof("hello") << endl;
193 | 输出 2和6
194 |
195 | cout << sizeof("\48") << endl; 3 "'\"后面是跟8进制,但是有个8,超过了8,所以"\4"是一个字符,8是一个字符
196 | cout << sizeof("\048") << endl; 3
197 | cout << sizeof("\048\48") << endl; 5
198 |
199 | cout<=指定长>源长,则将源串全部拷贝到目标串,连同'\0'
184 | 如果指定长<源长,则将截取源串中按指定长度拷贝到目标字符串,不包括'\0'
185 | 如果指定长>目标长,错误!
186 |
187 | ```
188 |
189 | strncpy 比起 strcpy 来说,添加了缓冲区长度的限制,可以防止缓冲区溢出。
190 | 明显是 strncpy 更安全。
191 | ```
192 |
193 | * 1、什么是栈溢出和栈内存溢出?
194 |
195 | 2、什么是堆溢出?
196 |
197 | 3、栈和堆有什么区别?
198 |
199 | ### 一、 栈溢出(StackOverflowError)
200 |
201 | 栈是线程私有的,它的生命周期与线程相同,程序调用的每个方法在执行的时候都会创建一个栈帧,用来存储局部变量表,操作数栈,动态链接等信息。局部变量表又包含基本数据类型,对象引用类型(局部变量表编译器完成,运行期间不会变化)。
202 |
203 | 所谓栈溢出就是**创建的栈帧超过了栈的深度**。那么一般来说有以下几种可能:
204 |
205 | 1、程序出现了死循环;
206 |
207 | 2、函数调用层次太深。函数递归调用时,系统要在栈中不断保存函数调用时的现场和产生的变量,如果递归调用太深,就会造成栈溢出,这时递归无法返回。再有,当函数调用层次过深时也可能导致栈无法容纳这些调用的返回地址而造成栈溢出。
208 |
209 | 3、指针/数组非法访问。指针保存了一个非法的地址,通过这样的指针访问所指向的地址时会产生内存访问错误。看下面的代码。
210 |
211 | ```c
212 | int f(int x) {
213 | int a[9];
214 | a[10] = x;
215 | }
216 | ```
217 |
218 | *这个就是栈溢出,x 被写到了不应该写的地方。在特定编译模式下,这个 x 的内容就会覆盖f 原来的返回地址。也就是原本应该返回到调用位置的 f 函数,返回到了 x 指向的位置。一般情况下程序会就此崩溃。但是如果 x 被有意指向一段恶意代码,这段恶意代码就会被执行。*
219 |
220 | *堆溢出相对比较复杂,因为各种环境堆的实现都不完全相同。但是程序管理堆必须有额外的数据来标记堆的各种信息。堆内存如果发生上面那样的赋值的话就有可能破坏堆的逻辑结构。进而修改原本无法访问的数据。*
221 |
222 | ```c
223 | int g(char *s, int n) {
224 | char a[10];
225 | memcpy(a, s, n);
226 | }
227 | ```
228 |
229 | *这个是栈溢出比较真实一点的例子,如果传入的数据长度大于 10 就会造成溢出,进而改变g 的返回地址。只要事先在特定地址写入恶意代码,代码就会被执行。*
230 |
231 | *堆溢出执行恶意代码的一种情况是通过过长的数据破坏堆结构,使下次申请能得到保存某些特定函数指针的位置,然后进行修改。* 引用自网络。
232 |
233 | 我们知道,在一次函数调用中,栈中将被依次压入:参数,返回地址,EBP。如果函数有局部变量,接下来,就在栈中开辟相应的空间以构造变量。
234 |
235 | **内存溢出**是由于没被引用的对象(垃圾)过多造成 JVM 没有及时回收,造成的内存溢出。如果出现这种现象可行代码排查。
236 |
237 | **何时发生栈内存溢出?**
238 | 对于一台服务器而言,每一个用户请求,都会产生一个线程来处理这个请求,每一个线程对应着一个栈,栈会分配内存,此时如果请求过多,这时候内存不够了,就会发生栈内存溢出。
239 |
240 | **什么时候会发生栈溢出?**
241 | 栈溢出是指不断的调用方法,不断的压栈,最终超出了栈允许的栈深度,就会发生栈溢出,比如递归操作没有终止,死循环。
242 |
243 | **帮助记忆:**
244 |
245 | 可以把内存比作是一个大箱子,栈是一个小箱子,栈溢出是指小箱子装不下了;而栈内存溢出是大箱子在也装不下小箱子了。
246 |
247 | 栈空间不足时,需要分下面两种情况处理:
248 |
249 | - 线程请求的栈深度大于虚拟机所允许的最大深度,将抛出 StackOverflowError
250 | - 虚拟机在扩展栈深度时无法申请到足够的内存空间,将抛出 OutOfMemberError
251 |
252 | ##### 程序中的数据在内存中的存放方式有以下几种:
253 |
254 | 1、**栈(也可以成为堆栈)区**:由编译器自动分配并且释放,该区域一般存放函数的参数值,局部变量值等,当函数运行结束并且返回时,所有的函数参数和局部变量都会被操作系统自动回收。
255 |
256 | 2、**堆区**:一般由程序员分配及释放,若程序员不释放,程序结束时可能由操作系统自动回收。
257 |
258 | 3、**寄存器区**:用来保存栈顶指针和指令指针
259 |
260 | 4、**全局(静态)区**:全局变量和静态变量是存储在一块的。初始化的全局变量和静态变量在一块区域,未初始化的全局变量和静态变量在相邻的另一块区域。程序结束后由系统释放。
261 |
262 | 5、**文字常量区**:存放常量字符串,程序结束后由系统释放。
263 |
264 | 6、**程序代码区**:存放函数体的二进制代码。
265 |
266 | ### 二、堆溢出
267 |
268 | 所谓堆溢出,heap space 表示堆空间,堆中主要存储的是对象。如果不断的 new 对象则会导致堆中的空间溢出。
269 |
270 | ### 三、栈和堆的不同点
271 |
272 | | | 栈 | 堆 |
273 | | -------------------------- | :----------------------------------------------------------: | -----------------------------------------------------------: |
274 | | 内存申请和释放方式上的不同 | 由系统自动分配,例如声明一个局部变量int a;那么系统就会自动在栈中为变量a开辟内存空间,函数结束时变量a占的空间会被系统自动回收 | 需要程序员自己申请,因此也需要指明变量大小。例如使用new操作符申请:int *a=new int;那么系统就会在堆区分配一个大小为4Byte的内存空间。使用delete操作符释放:delete a;这样就释放了在堆区分配的空间 |
275 | | 系统响应的不同 | 只有在栈的空间大于申请的空间,系统才会为程序提供内存,否则将会提示overflow,也就是`栈溢出(申请空间大于栈空间)` | 操作系统中有一个记录空闲内存地址的链表,当我们在堆上申请空间后,将在空闲链表中找到符合申请大小的空间节点,该节点会被系统从链表中删除,然后分配给程序符合大小的内存空间,多余的空间会回收到空闲链表中。如果不停地申请空间确没有使用delete释放,会造成内存不停的增长,这就是所谓的`内存泄漏(由于程序员的失误,没有对在堆区申请的内存进行释放)` |
276 | | 空间大小的不同 | 在windows下,栈是一块连续的内存区域,其大小是在编译时就确定的常数vs2010 可以在项目中右键–属性窗口—链接器—系统—堆栈保留大小,这里可以更改栈的大小,默认是1M的大小 | 堆是不连续的区域,由链表串联起来。这些串联起来不连续的空间就组成了堆。堆的上限是由系统的有效虚拟内存来决定的。 |
277 | | 执行效率的不同 | 由系统分配,速度快,但是程序员不能对其进行操作 | 由程序员分配内存,由于机制上的缘故,效率慢,容易产生内存碎片,但是使用方便 |
278 | | 执行函数时的不同 | 由于栈是先入后出的特点,所以局部变量和代码入栈的顺序和代码表现的顺序正好相反,比如说:函数的参数都是从右到左的入栈顺序。`栈有一个特点:数据不断入栈,它的内存地址就会不断减小` | 同“系统响应的不同” |
279 |
280 | 总结:
281 | 栈的内存小,效率高,存储的数据局部有效,超出局部就消失。
282 |
283 | 堆可存储空间大,灵活性高,但容易产生碎片,效率低。
284 |
285 | **一个更加详细的例子:**
286 |
287 | 一、预备知识—程序的内存分配
288 |
289 | 一个由C/C++编译的程序占用的内存分为以下几个部分
290 | 1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
291 | 2、堆区(heap) — 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
292 | 3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的 全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域,程序结束后由系统释放。
293 | 4、文字常量区 —常量字符串就是放在这里的。程序结束后由系统释放
294 | 5、程序代码区—存放函数体的二进制代码。
295 |
296 | 二、例子程序
297 |
298 | 这是一个前辈写的,非常详细
299 |
300 | ```c
301 | #include
302 | using namespace std;
303 | int a = 0; //全局初始化区
304 | char *p1; //全局未初始化区
305 | int main() {
306 | int b; //栈
307 | char s[] = "abc"; //栈
308 | char *p2; //栈
309 | char *p3 = "123456"; //123456/0在常量区,p3在栈上。
310 | static int c =0; //全局(静态)初始化区
311 | p1 = (char *)malloc(10);
312 | p2 = (char *)malloc(20);
313 | /*
314 | 分配得来得 10 和 20 字节的区域就在堆区。
315 | strcpy(p1, "123456"); 123456/0放在常量区,
316 | 编译器可能会将它与p3所指向的"123456" 优化成一个地方。
317 | */
318 | return 0;
319 | }
320 | ```
321 |
322 | 参考: [浅谈堆溢出与栈溢出]([https://rongweihe.github.io/2019/07/30/%E6%B5%85%E8%B0%88%E5%A0%86%E6%BA%A2%E5%87%BA%E4%B8%8E%E6%A0%88%E6%BA%A2%E5%87%BA/](https://rongweihe.github.io/2019/07/30/浅谈堆溢出与栈溢出/))
323 |
324 | ### 5. 硬链接和软链接的区别
325 |
326 | - 硬链接: 与普通文件没什么不同,`inode` 都指向同一个文件在硬盘中的区块
327 | - 软链接: 保存了其代表的文件的绝对路径,是另外一种文件,在硬盘上有独立的区块,访问时替换自身路径。
328 |
329 | ##### 图 1. 通过文件名打开文件
330 |
331 | 
332 |
333 | ##### 图 2. 软链接的访问
334 |
335 | 
336 |
337 | 硬链接存在以下几点特性:
338 |
339 | - 文件有相同的 inode 及 data block;
340 | - 只能对已存在的文件进行创建;
341 | - 不能交叉文件系统进行硬链接的创建;
342 | - 不能对目录进行创建,只可对文件创建;
343 | - 删除一个硬链接文件并不影响其他有相同 inode 号的文件。
344 |
345 | 软链接存在以下几点特性:
346 |
347 | - 软链接有自己的文件属性及权限等;
348 | - 可对不存在的文件或目录创建软链接;
349 | - 软链接可交叉文件系统;
350 | - 软链接可对文件或目录创建;
351 | - 创建软链接时,链接计数 i_nlink 不会增加;
352 | - 删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
353 |
354 | 参考:[5分钟让你明白“软链接”和“硬链接”的区别](https://www.jianshu.com/p/dde6a01c4094)
355 |
356 | [硬链接与软链接的联系与区别](https://www.ibm.com/developerworks/cn/linux/l-cn-hardandsymb-links/index.html)
357 |
358 | ### [6. 输入URL到显示网页的过程](https://segmentfault.com/a/1190000006879700)
359 |
360 | ```c
361 | 总体来说分为以下几个过程:
362 |
363 | 1.DNS解析
364 |
365 | 2.TCP连接
366 |
367 | 3.发送HTTP请求
368 |
369 | 4.服务器处理请求并返回HTTP报文
370 |
371 | 5.浏览器解析渲染页面
372 |
373 | 6.连接结束
374 |
375 | 链接:https://www.nowcoder.com/questionTerminal/f09d6db0077d4731ac5b34607d4431ee
376 | 来源:牛客网
377 |
378 | 事件顺序
379 |
380 | (1) 浏览器获取输入的域名www.baidu.com
381 |
382 | (2) 浏览器向DNS请求解析www.baidu.com的IP地址
383 |
384 | (3) 域名系统DNS解析出百度服务器的IP地址
385 |
386 | (4) 浏览器与该服务器建立TCP连接(默认端口号80)
387 |
388 | (5) 浏览器发出HTTP请求,请求百度首页
389 |
390 | (6) 服务器通过HTTP响应把首页文件发送给浏览器
391 |
392 | (7) TCP连接释放
393 |
394 | (8) 浏览器将首页文件进行解析,并将Web页显示给用户。
395 |
396 | 涉及到的协议
397 |
398 | (1) 应用层:HTTP(WWW访问协议),DNS(域名解析服务)
399 |
400 | (2) 传输层:TCP(为HTTP提供可靠的数据传输),UDP(DNS使用UDP传输)
401 |
402 | (3) 网络层:IP(IP数据数据包传输和路由选择),ICMP(提供网络传输过程中的差错检测),ARP(将本机的默认网关IP地址映射成物理MAC地址)
403 | ```
404 |
405 | 呈现引擎开始工作,基本流程如下(以webkit为例)
406 |
407 | - 通过HTML解析器解析HTML文档,构建一个DOM Tree,同时通过CSS解析器解析HTML中存在的CSS,构建Style Rules,两者结合形成一个Attachment。
408 |
409 | - 通过Attachment构造出一个呈现树(Render Tree)
410 |
411 | - Render Tree构建完毕,进入到布局阶段(layout/reflow),将会为每个阶段分配一个应出现在屏幕上的确切坐标。
412 |
413 | - 最后将全部的节点遍历绘制出来后,一个页面就展现出来了。
414 |
415 | 
416 |
417 | 参考:[从输入url到页面展现发生了什么?](https://segmentfault.com/a/1190000013522717)
418 |
419 | [浏览器键入URL后的访问流程]([https://github.com/twomonkeyclub/BackEnd/tree/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C#%E6%B5%8F%E8%A7%88%E5%99%A8%E9%94%AE%E5%85%A5URL%E5%90%8E%E7%9A%84%E8%AE%BF%E9%97%AE%E6%B5%81%E7%A8%8B](https://github.com/twomonkeyclub/BackEnd/tree/master/计算机基础知识/计算机网络#浏览器键入URL后的访问流程))
420 |
421 | ### 7.快排的思想?如何优化?平均情况?最坏情况?
422 |
423 | **采用分治法,将数组分为两部分,并递归调用。**
424 |
425 | 快速排序算法是一种基于交换的高效的排序算法,它采用了 **分治法** 的思想:
426 |
427 | 1. 从数列中取出一个数作为基准数(枢轴,pivot)。
428 | 2. 将数组进行划分(partition),将比基准数大的元素都移至枢轴右边,将小于等于基准数的元素都移至枢轴左边。
429 | 3. 再对左右的子区间重复第二步的划分操作,直至每个子区间只有一个元素。
430 |
431 | 优化: ***\*三数取中+插排+聚集相等元素\****
432 |
433 | **平均运行时间是O(NlogN);但最坏情形性能为O(N2)**
434 |
435 | ```java
436 | // 定义接口
437 | interface Sorter {
438 | /**
439 | * 将数组按升序排序
440 | */
441 | int[] sort(int[] arr);
442 |
443 | /**
444 | * 交换数组arr中的第i个位置和第j个位置的关键字
445 | */
446 | default void swap(int[] arr, int i, int j) {
447 | int tmp = arr[i];
448 | arr[i] = arr[j];
449 | arr[j] = tmp;
450 | }
451 | }
452 |
453 | // 未优化的快速排序
454 | class QuickSorter implements Sorter {
455 |
456 | @Override
457 | public int[] sort(int[] arr) {
458 | quickSort(arr, 0, arr.length - 1);
459 | return arr;
460 | }
461 |
462 | /**
463 | * 对数组arr[low...high]的子序列作快速排序,使之有序
464 | */
465 | protected void quickSort(int[] arr, int low, int high) {
466 | int pivotLoc; // 记录枢轴(pivot)所在位置
467 | if (low < high) {
468 | pivotLoc = partition(arr, low, high); // 将arr[low...high]一分为二,并返回枢轴位置
469 |
470 | quickSort(arr, low, pivotLoc - 1);// 递归遍历arr[low...pivotLoc-1]
471 | quickSort(arr, pivotLoc + 1, high); // 递归遍历arr[pivotLoc+1...high]
472 | }
473 | }
474 |
475 | /**
476 | * 在arr[low...high]选定pivot=arr[low]作为枢轴(中间位置),将arr[low...high]分成两部分,
477 | * 前半部分的子序列的记录均小于pivot,后半部分的记录均大于pivot;最后返回pivot的位置
478 | */
479 | protected int partition(int[] arr, int low, int high) {
480 | int pivot;
481 | pivot = arr[low]; // 将arr[low]作为枢轴
482 | while (low < high) { // 从数组的两端向中间扫描 // A
483 | while (low < high && arr[high] >= pivot) { // B
484 | high--;
485 | }
486 | swap(arr, low, high); // 将比枢轴pivot小的元素交换到低位 // C
487 | while (low < high && arr[low] <= pivot) { //D
488 | low++;
489 | }
490 | swap(arr, low, high); // 将比枢轴pivot大的元素交换到高位 // E
491 | }
492 | return low; // 返回一趟下来后枢轴pivot所在的位置
493 | }
494 | }
495 | ```
496 |
497 | 参考: [三种快速排序以及快速排序的优化](https://blog.csdn.net/insistGoGo/article/details/7785038)
498 |
499 | [快速排序实现及优化 | DualPivotQuicksort](https://www.sczyh30.com/posts/Algorithm/algorithm-quicksort/)
500 |
501 | [排序--快速排序及其优化](https://www.jianshu.com/p/bc62a66be82c)
502 |
503 | ### 8. 中断
504 |
505 | 1、为什么有中断?
506 |
507 | 处理器需要管理很多硬件,不可能每次等到这个硬件完毕再去下一个,也不好挨个轮询问。
508 |
509 | ->中断:硬件在需要的时候主动向处理器发出信号
510 |
511 | 中断随时产生,处理器随时被打断,不考虑处理器时钟同步,非常任性。
512 |
513 | 2、中断本质上是电信号。
514 |
515 | 1. 中断由硬件设备(比如键盘)产生,然后送入**中断控制器**的输入引脚。
516 | 2. 中断控制器的另一端与处理器相连,接收一个中断后,就会给处理器发送电信号;
517 | 3. 处理器收到信号,就会中断自己当前任务,转去处理中断,然后通知操作系统已经产生中断。
518 | 4. 由操作系统处理中断。
519 |
520 | Linux 内核需要对连接到计算机上的所有硬件设备进行管理,毫无疑问这是它的份内事。如果要管理这些设备,首先得和它们互相通信才行,一般有两种方案可实现这种功能:
521 |
522 | 1. **轮询(\*polling\*)** 让内核定期对设备的状态进行查询,然后做出相应的处理;
523 | 2. **中断(\*interrupt\*)** 让硬件在需要的时候向内核发出信号(变内核主动为硬件主动)。
524 |
525 | [中断的处理过程有以下几步构成:](https://juejin.im/post/5d615c35e51d4561fd6cb501)
526 |
527 | 1. **关中断**。CPU关闭中断,即不再接受其他**外部**中断请求。
528 | 2. **保存断点**。将发生中断处的指令地址压入堆栈,以使中断处理完后能正确的返回(注意,有可能保存中断处的指令地址,也有可能是中断处的指令的下一条指令的地址,具体情况视中断的类型)。
529 | 3. **识别中断源**。CPU识别中断的来源,确定中断类型号,从而找到相应的中断处理程序的入口地址
530 | 4. (以上三步一般由处理中断的硬件电路完成)**保存现场**。将发生中断处的有关寄存器(中断服务程序要使用的寄存器)以及标志寄存器的内容压入堆栈。
531 | 5. **执行中断服务程序**。转到中断服务程序入口开始执行,可在适时时刻重新开放中断,以便允许响应较高优先级的外部中断。
532 | 6. (后三步一般软件,即中断处理程序完成)**恢复现场并返回**。把“保护现场”时压入堆栈的信息弹回寄存器,然后执行中断返回指令,从而返回主程序继续运行。(IRET指令,无操作数,从栈顶弹出3个字,分别送入IP、CS和FLAGS寄存器)
533 |
534 | 参考:[[Linux概念学习]6 中断和中断处理](https://zhuanlan.zhihu.com/p/53640307)
535 |
536 | [Linux 内核中断内幕](https://www.ibm.com/developerworks/cn/linux/l-cn-linuxkernelint/index.html)
537 |
538 | [Linux中断内幕]([https://r00tk1ts.github.io/2017/12/21/Linux%E4%B8%AD%E6%96%AD%E5%86%85%E5%B9%95/#IDT%E5%88%9D%E5%A7%8B%E5%8C%96](https://r00tk1ts.github.io/2017/12/21/Linux中断内幕/#IDT初始化))
539 |
540 | ### 9.[内存泄漏](https://blog.csdn.net/weixin_36343850/article/details/77856051)和内存溢出的区别?
541 |
542 | [内存溢出](https://link.jianshu.com?t=http://51code.com/)out of memory,是指程序在为自身申请内存时,没有足够的内存空间供自己使用,出现out of memory;比如你为程序申请了一个integer,但是只给它存了long才能存下的数,就是内存溢出。内存溢出就是你要求被分配的内存超出了系统能给你的内存,系统不能满足你的需求,于是产生溢出。
543 |
544 | [内存泄露](https://link.jianshu.com?t=http://51code.com/)memory leak,是指程序在申请内存后,无法释放已经申请到的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
545 |
546 | memory leak会最终会导致out of memory!
547 |
548 | 内存泄漏是指你向系统申请分配内存进行使用(new),可是使用完了以后却不归还(delete),结果你申请到的那块内存你自己也不能再访问(也许你把它的地址给弄丢了),而系统也不能再次将它分配给需要的程序。一个盘子用尽各种方法只能装4个果子,你装了5个,结果掉倒地上不能吃了。这就是溢出!比方说栈,[栈](https://link.jianshu.com?t=http://51code.com/)满时再做进栈必定产生空间溢出,叫上溢,栈空时再做退栈也产生空间溢出,称为下溢。就是分配的内存不足以放下数据项序列,称为内存溢出.
549 |
550 | ### [10.哈希是什么?哈希冲突是什么?如何解决?]([https://github.com/twomonkeyclub/BackEnd/tree/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84#%E5%93%88%E5%B8%8C%E8%A1%A8](https://github.com/twomonkeyclub/BackEnd/tree/master/计算机基础知识/数据结构#哈希表))
551 |
552 | **哈希**:通过某种特定的函数、算法将要检索的项与用来检索的索引关联起来,生成一种便于搜索的数据结构。
553 |
554 | **哈希冲突**: 假设hash表的大小为9(即有9个槽),现在要把一串数据存到表里:5,28,19,15,20,33,12,17,10
555 |
556 | 简单计算一下:hash(5)=5, 所以数据5应该放在hash表的第5个槽里;hash(28)=1,所以数据28应该放在hash表的第1个槽里;hash(19)=1,也就是说,数据19也应该放在hash表的第1个槽里——于是就造成了碰撞(也称为冲突,collision)。
557 |
558 | **解决冲突**: 1.[ 链地址法:链地址法的基本思想是,为每个 Hash 值建立一个单链表,当发生冲突时,将记录插入到链表中。](https://hit-alibaba.github.io/interview/basic/algo/Hash-Table.html)
559 |
560 | 2. 开放地址法 :当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止。
561 |
562 | 3. 再哈希法
563 |
564 | 4. 建立公共溢出区
565 |
566 | ---
567 |
568 |
569 |
570 | hash 是通过某种函数将值映射到某个位置,从而能够进行快速的查找。这个函数叫散列函数,存储数据的数据结构叫散列表。
571 |
572 | 解决 hash 冲突的办法主要有:
573 |
574 | - 开放定址法:当要插入的数据冲突的时候,通过某种方式(线行探查法、平方探查法、双散列函数探查法)去重新尝试插入。
575 | - 链地址法:散列函数的结果位置并不直接存储数据,而是存储一条链表的地址,如果有冲突的数据,那么直接添加到链表后即可。
576 | - 再哈希法:指定多个哈希函数,当某个函数冲突时,更换函数重新哈希。
577 | - 建立公共溢出区:将溢出的数据统一放入公共溢出区
578 |
579 | Java 中的 HashMap 底层实现是链地址法 + 红黑树,当某一个位置的冲突个数不超过 7 个时链表顺序存储,超过 7 个后转化为红黑树。
580 |
581 | 在不冲突的情况下,只需要通过散列函数找到对应的位置即可获得数据,因此时间复杂度最优可以达到 O(1)。
582 |
583 | ### [11. 进程间同步方式有哪些?](https://blog.csdn.net/wuhuagu_wuhuaguo/article/details/78591330)
584 |
585 | 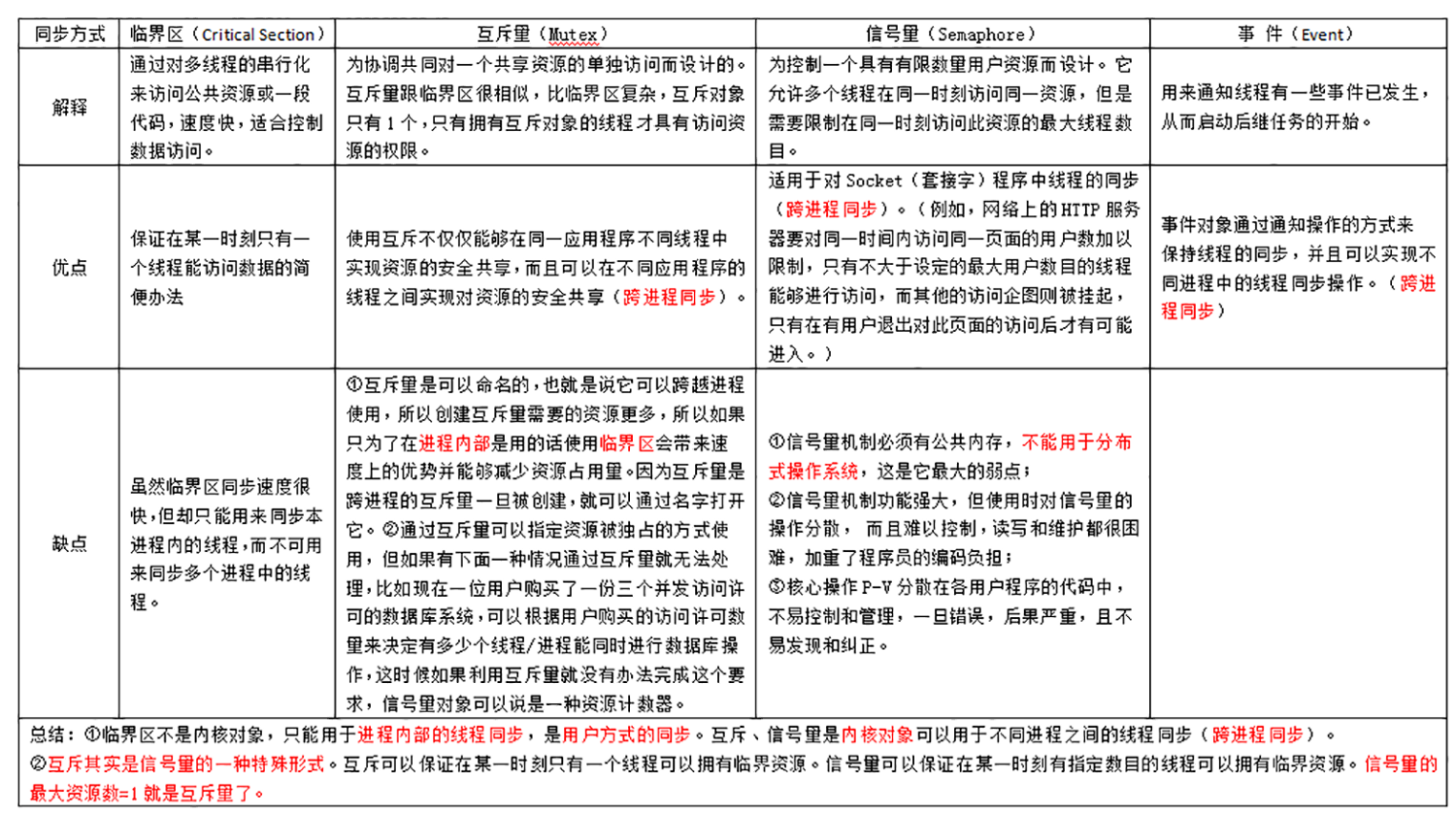
586 |
587 | ### 12.如何检查上亿条URL中是否有重复的URL?
588 |
589 | 将文件通过哈希函数成多个小的文件,由于哈希函数所有重复的URL只可能在同一个文件中,在每个文件中利用一个哈希表做次数统计。就能找到重复的URL。这时候要注意的就是给了多少内存,我们要根据文件大小结合内存大小决定要分割多少文件。
590 |
--------------------------------------------------------------------------------
/file/20200228.md:
--------------------------------------------------------------------------------
1 | ## [CVTE C++实习生 一面面经](https://www.nowcoder.com/discuss/199864)
2 |
3 | ### [1. 空类占用内存大小](https://blog.csdn.net/u013203733/article/details/73868734)
4 |
5 | ```c
6 | class CBase
7 | {
8 | };
9 | sizeof(CBase)=1;
10 |
11 | 为什么空的什么都没有是1呢?
12 | c++要求每个实例在内存中都有独一无二的地址。//注意这句话!!!!!!!!!!
13 | 空类也会被实例化,所以编译器会给空类隐含的添加一个字节,这样空类实例化之后就有了独一无二的地址了。所以空类的sizeof为1。
14 |
15 | 总结:
16 |
17 | 空的类是会占用内存空间的,而且大小是1,原因是C++要求每个实例在内存中都有独一无二的地址。
18 |
19 | (一)类内部的成员变量:
20 |
21 | 普通的变量:是要占用内存的,但是要注意对齐原则(这点和struct类型很相似)。static修饰的静态变量:不占用内容,原因是编译器将其放在全局变量区。
22 |
23 |
24 | (二)类内部的成员函数:普通函数:不占用内存。虚函数:要占用4个字节,用来指定虚函数的虚拟函数表的入口地址。所以一个类的虚函数所占用的地址是不变的,和虚函数的个数是没有关系的。
25 | ```
26 |
27 | ### 2. 动态多态的实现
28 |
29 | - 静态多态(运算符重载、函数重载)
30 |
31 | - 动态多态(继承、虚函数)
32 |
33 | - #### [静态多态(编译期/早绑定)](https://interview.huihut.com/#/?id=静态多态(编译期早绑定))
34 |
35 | 函数重载
36 |
37 | ```cpp
38 | class A
39 | {
40 | public:
41 | void do(int a);
42 | void do(int a, int b);
43 | };
44 | ```
45 |
46 | #### [动态多态(运行期/晚绑定)](https://interview.huihut.com/#/?id=动态多态(运行期期晚绑定))
47 |
48 | - 虚函数:用 virtual 修饰成员函数,使其成为虚函数
49 |
50 | **注意:**
51 |
52 | - 普通函数(非类成员函数)不能是虚函数
53 | - 静态函数(static)不能是虚函数
54 | - 构造函数不能是虚函数(因为在调用构造函数时,虚表指针并没有在对象的内存空间中,必须要构造函数调用完成后才会形成虚表指针)
55 | - 内联函数不能是表现多态性时的虚函数,解释见:[虚函数(virtual)可以是内联函数(inline)吗?](https://github.com/huihut/interview#虚函数virtual可以是内联函数inline吗)
56 |
57 | 动态多态使用
58 |
59 | ```cpp
60 | class Shape // 形状类
61 | {
62 | public:
63 | virtual double calcArea()
64 | {
65 | ...
66 | }
67 | virtual ~Shape();
68 | };
69 | class Circle : public Shape // 圆形类
70 | {
71 | public:
72 | virtual double calcArea();
73 | ...
74 | };
75 | class Rect : public Shape // 矩形类
76 | {
77 | public:
78 | virtual double calcArea();
79 | ...
80 | };
81 | int main()
82 | {
83 | Shape * shape1 = new Circle(4.0);
84 | Shape * shape2 = new Rect(5.0, 6.0);
85 | shape1->calcArea(); // 调用圆形类里面的方法
86 | shape2->calcArea(); // 调用矩形类里面的方法
87 | delete shape1;
88 | shape1 = nullptr;
89 | delete shape2;
90 | shape2 = nullptr;
91 | return 0;
92 | }
93 | ```
94 |
95 | 参考:[静态多态和动态多态]([https://github.com/twomonkeyclub/BackEnd/tree/master/%E5%9F%BA%E7%A1%80%E8%AF%AD%E8%A8%80/C%2B%2B%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1#%E9%9D%99%E6%80%81%E5%A4%9A%E6%80%81%E5%92%8C%E5%8A%A8%E6%80%81%E5%A4%9A%E6%80%81](https://github.com/twomonkeyclub/BackEnd/tree/master/基础语言/C%2B%2B面向对象#静态多态和动态多态))
96 |
97 | ### 3. c++11 容器
98 |
99 | ### [STL 容器](https://interview.huihut.com/#/?id=stl-容器)
100 |
101 |
102 |
103 | | 容器 | 底层数据结构 | 时间复杂度 | 有无序 | 可不可重复 | 其他 |
104 | | ------------------------------------------------------------ | ----------------- | --------------------------------------------------------- | ------ | ---------- | ------------------------------------------------------------ |
105 | | [array](https://github.com/huihut/interview/tree/master/STL#array) | 数组 | 随机读改 O(1) | 无序 | 可重复 | 支持随机访问 |
106 | | [vector](https://github.com/huihut/interview/tree/master/STL#vector) | 数组 | 随机读改、尾部插入、尾部删除 O(1) 头部插入、头部删除 O(n) | 无序 | 可重复 | 支持随机访问 |
107 | | [deque](https://github.com/huihut/interview/tree/master/STL#deque) | 双端队列 | 头尾插入、头尾删除 O(1) | 无序 | 可重复 | 一个中央控制器 + 多个缓冲区,支持首尾快速增删,支持随机访问 |
108 | | [forward_list](https://github.com/huihut/interview/tree/master/STL#forward_list) | 单向链表 | 插入、删除 O(1) | 无序 | 可重复 | 不支持随机访问 |
109 | | [list](https://github.com/huihut/interview/tree/master/STL#list) | 双向链表 | 插入、删除 O(1) | 无序 | 可重复 | 不支持随机访问 |
110 | | [stack](https://github.com/huihut/interview/tree/master/STL#stack) | deque / list | 顶部插入、顶部删除 O(1) | 无序 | 可重复 | deque 或 list 封闭头端开口,不用 vector 的原因应该是容量大小有限制,扩容耗时 |
111 | | [queue](https://github.com/huihut/interview/tree/master/STL#queue) | deque / list | 尾部插入、头部删除 O(1) | 无序 | 可重复 | deque 或 list 封闭头端开口,不用 vector 的原因应该是容量大小有限制,扩容耗时 |
112 | | [priority_queue](https://github.com/huihut/interview/tree/master/STL#priority_queue) | vector + max-heap | 插入、删除 O(log2n) | 有序 | 可重复 | vector容器+heap处理规则 |
113 | | [set](https://github.com/huihut/interview/tree/master/STL#set) | 红黑树 | 插入、删除、查找 O(log2n) | 有序 | 不可重复 | |
114 | | [multiset](https://github.com/huihut/interview/tree/master/STL#multiset) | 红黑树 | 插入、删除、查找 O(log2n) | 有序 | 可重复 | |
115 | | [map](https://github.com/huihut/interview/tree/master/STL#map) | 红黑树 | 插入、删除、查找 O(log2n) | 有序 | 不可重复 | |
116 | | [multimap](https://github.com/huihut/interview/tree/master/STL#multimap) | 红黑树 | 插入、删除、查找 O(log2n) | 有序 | 可重复 | |
117 | | [unordered_set](https://github.com/huihut/interview/tree/master/STL#unordered_set) | 哈希表 | 插入、删除、查找 O(1) 最差 O(n) | 无序 | 不可重复 | |
118 | | [unordered_multiset](https://github.com/huihut/interview/tree/master/STL#unordered_multiset) | 哈希表 | 插入、删除、查找 O(1) 最差 O(n) | 无序 | 可重复 | |
119 | | [unordered_map](https://github.com/huihut/interview/tree/master/STL#unordered_map) | 哈希表 | 插入、删除、查找 O(1) 最差 O(n) | 无序 | 不可重复 | |
120 | | [unordered_multimap](https://github.com/huihut/interview/tree/master/STL#unordered_multimap) | 哈希表 | 插入、删除、查找 O(1) 最差 O(n) | 无序 | 可重复 | |
121 |
122 | ### 4. 二叉树 红黑树
123 |
124 | - 二叉树定义
125 | - n个结点的有限集合,该集合为空集,或者一个根节点和两棵互不相交的、分别称为根节点的左子树和右子树的二叉树组成
126 | - 满二叉树
127 | - 一棵二叉树中所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上
128 | - 完全二叉树
129 | - 一棵有n个结点的二叉树按层序编号,编号为i的结点与同样深度的满二叉树中编号为i的结点在二叉树中位置完全相同
130 | - 二叉树的性质
131 | - 非空二叉树第 i 层最多 2^(i-1) 个结点 (i >= 1)
132 | - 深度为 k 的二叉树最多 2^k - 1 个结点 (k >= 1)
133 | - 度为 0 的结点数为 n0,度为 2 的结点数为 n2,则 n0 = n2 + 1
134 | - 有 n 个结点的完全二叉树深度 k = ⌊ log2(n) ⌋ + 1
135 | - 对于含 n 个结点的完全二叉树中编号为 i (1 <= i <= n) 的结点
136 | - 若 i = 1,为根,否则双亲为 ⌊ i / 2 ⌋
137 | - 若 2i > n,则 i 结点没有左孩子,否则孩子编号为 2i
138 | - 若 2i + 1 > n,则 i 结点没有右孩子,否则孩子编号为 2i + 1
139 |
140 | ## [红黑树](https://www.cnblogs.com/yangecnu/p/Introduce-Red-Black-Tree.html)
141 |
142 | - 红黑树,一种二叉查找树,但在每个结点上增加一个存储位表示结点的颜色,可以是Red或Black。
143 | 通过对任何一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有一条路径会比其他路径长出俩倍,因而是接近平衡的。
144 | - 查找时间复杂度O(logn),插入和删除时间复杂度O(logn)
145 | - 红黑树的五个性质(性质没法解释),红黑树是这样的树!!!
146 |
147 | > - 每个结点非红即黑
148 | > - 根结点为黑色
149 | > - 每个叶结点(叶结点即实际叶子结点的NULL指针或NULL结点)都是黑的;
150 | > - 若结点为红色,其子节点一定是黑色(没有连续的红结点)
151 | > - 对于每个结点,从该结点到其后代叶结点的简单路径上,均包含相同数目的黑色结点(叶子结点要补充两个NULL结点)
152 | > - 有了五条性质,才有一个结论:**通过任意一条从根到叶子简单路径上颜色的约束,红黑树保证最长路径不超过最短路径的二倍,因而近似平衡**。
153 |
154 | - 平衡树和红黑树的区别
155 |
156 | - **AVL树是高度平衡的**,频繁的插入和删除,会引起频繁的调整以重新平衡,导致效率下降
157 | - **红黑树不是高度平衡的**,算是一种折中,插入最多两次旋转,删除最多三次旋转,调整时新插入的都是红色。
158 |
159 | - 为什么红黑树的插入、删除和查找如此高效?
160 |
161 | - 插入、删除和查找操作与树的高度成正比,因此如果平衡二叉树不会频繁的调整以重新平衡,那它肯定是最快的,但它需要频繁调整以保证平衡
162 | - 红黑树算是一种折中,保证最长路径不超过最短路径的二倍,这种情况下插入最多两次旋转,删除最多三次旋转,因此比平衡二叉树高效。
163 |
164 | - 红黑树为什么要保证每条路径上黑色结点数目一致?
165 |
166 | - 为了保证红黑树保证最长路径不超过最短路径的二倍
167 |
168 | - 假设一个红黑树T,其到叶节点的最短路径肯定全部是黑色节点(共B个),最长路径肯定有相同个黑色节点(性质5:黑色节点的数量是相等),另外会多几个红色节点。性质4(红色节点必须有两个黑色儿子节点)能保证不会再现两个连续的红色节点。所以最长的路径长度应该是2B个节点,其中B个红色,B个黑色。
169 |
170 | 
171 |
172 | 参考:[2-3树与红黑树](https://riteme.site/blog/2016-3-12/2-3-tree-and-red-black-tree.html#_4)
173 |
174 | ### [4.tcp黏包问题]([https://interview.huihut.com/#/?id=tcp-%e9%bb%8f%e5%8c%85%e9%97%ae%e9%a2%98](https://interview.huihut.com/#/?id=tcp-黏包问题))
175 |
176 | ##### [原因](https://interview.huihut.com/#/?id=原因-2)
177 |
178 | TCP 是一个基于字节流的传输服务(UDP 基于报文的),“流” 意味着 TCP 所传输的数据是没有边界的。所以可能会出现两个数据包黏在一起的情况。
179 |
180 | 1发送端需要等缓冲区满才发送出去,造成粘包
181 |
182 | 2接收方不及时接收缓冲区的包,造成多个包接收
183 |
184 | ##### [解决](https://interview.huihut.com/#/?id=解决)
185 |
186 | - 发送定长包。如果每个消息的大小都是一样的,那么在接收对等方只要累计接收数据,直到数据等于一个定长的数值就将它作为一个消息。
187 | - 包头加上包体长度。包头是定长的 4 个字节,说明了包体的长度。接收对等方先接收包头长度,依据包头长度来接收包体。
188 | - 在数据包之间设置边界,如添加特殊符号 `\r\n` 标记。FTP 协议正是这么做的。但问题在于如果数据正文中也含有 `\r\n`,则会误判为消息的边界。
189 | - 使用更加复杂的应用层协议。
190 |
191 | ### 5. 工厂模式
192 |
193 | 工厂模式的两个最重要的功能:
194 |
195 | * 定义创建对象的接口,封装了对象的创建;
196 | * 使得具体化类的工作延迟到了子类中。
197 |
198 | 简单工厂模式(Simple Factory),工厂方法模式(Factory Method),抽象工厂模式(Abstract Factory)。
199 |
200 | **简单工厂**
201 | 具体情形:有一个肥皂厂,生产各种肥皂,有舒肤佳,夏士莲,娜爱斯等。给这个肥皂厂建模。
202 |
203 | UML图如下:
204 |
205 | 
206 |
207 |
208 |
209 | 对于简单设计模式的结构图,我们可以很清晰的看到它的组成:
210 | 1) 工厂类角色:这是本模式的核心,含有一定的商业逻辑和判断逻辑。
211 | 2) 抽象产品角色:它一般是具体产品继承的父类或者实现的接口。
212 | 3) 具体产品角色:工厂类所创建的对象就是此角色的实例。
213 | 简单设计模式存在的目的很简单:定义一个用于创建对象的接口。
214 |
215 | 缺点:对修改不封闭,新增加产品您要修改工厂。违法了鼎鼎大名的开闭法则(OCP)。
216 |
217 | 代码实现:
218 |
219 | ```cpp
220 | #include
221 | using namespace std;
222 | enum PRODUCTTYPE {SFJ,XSL,NAS};
223 | class soapBase
224 | {
225 | public:
226 | virtual ~soapBase(){};
227 | virtual void show() = 0;
228 | };
229 |
230 | class SFJSoap:public soapBase
231 | {
232 | public:
233 | void show() {cout<<"SFJ Soap!"<show();
275 | soapBase* pSoap2 = factory.creatSoap(XSL);
276 | pSoap2->show();
277 | soapBase* pSoap3 = factory.creatSoap(NAS);
278 | pSoap3->show();
279 | delete pSoap1;
280 | delete pSoap2;
281 | delete pSoap3;
282 | return 0;
283 | }
284 | ```
285 |
286 | **工厂方法模式**
287 | 具体情形:最近莫名肥皂需求激增!! 于是要独立每个生产线,每个生产线只生产一种肥皂。
288 |
289 | UML图如下:
290 |
291 | 
292 |
293 | 其实这才是真正的工厂模式,简单工厂模式只能算是“坑爹版”的工厂模式。我们能很容易看出工厂方法模式和简单工厂模式的区别之处。工厂方法模式的应用并不是只是为了封装对象的创建,而是要把对象的创建放到子类中实现:Factory中只是提供了对象创建的接口,其实现将放在Factory的子类ConcreteFactory中进行。
294 | 对于工厂方法模式的组成:
295 | 1)抽象工厂角色: 这是工厂方法模式的核心,它与应用程序无关。是具体工厂角色必须实现的接口或者必须继承的父类。
296 | 2)具体工厂角色:它含有和具体业务逻辑有关的代码。由应用程序调用以创建对应的具体产品的对象。
297 | 3)抽象产品角色:它是具体产品继承的父类或者是实现的接口。
298 | 4)具体产品角色:具体工厂角色所创建的对象就是此角色的实例。
299 |
300 | 缺点:每增加一种产品,就需要增加一个对象的工厂。如果这家公司发展迅速,推出了很多新的处理器核,那么就要开设相应的新工厂。在C++实现中,就是要定义一个个的工厂类。显然,相比简单工厂模式,工厂方法模式需要更多的类定义。
301 |
302 | 代码实现:
303 |
304 | ```c
305 |
306 | #include
307 | using namespace std;
308 | enum SOAPTYPE {SFJ,XSL,NAS};
309 |
310 | class soapBase
311 | {
312 | public:
313 | virtual ~soapBase(){};
314 | virtual void show() = 0;
315 | };
316 |
317 | class SFJSoap:public soapBase
318 | {
319 | public:
320 | void show() {cout<<"SFJ Soap!"<show();
375 | XSLFactory factory2;
376 | soapBase* pSoap2 = factory2.creatSoap();
377 | pSoap2->show();
378 | NASFactory factory3;
379 | soapBase* pSoap3 = factory3.creatSoap();
380 | pSoap3->show();
381 | delete pSoap1;
382 | delete pSoap2;
383 | delete pSoap3;
384 | return 0;
385 | }
386 | ```
387 |
388 | **抽象工厂模式**
389 | 具体情形:这个肥皂厂发现搞牙膏也很赚钱,决定做牙膏。牙膏有高档低档,肥皂也是。现在搞两个厂房,一个生产低档的牙膏和肥皂,一个生产高档的牙膏和肥皂。
390 |
391 | 比如,厂房一生产中华牙膏、娜爱斯肥皂,厂房二生产黑人牙膏和舒肤佳牙膏
392 |
393 | UML图如下:
394 |
395 | 
396 |
397 | 对于上面的结构图,可以看出抽象工厂模式,比前两者更为的复杂和一般性,抽象工厂模式和工厂方法模式的区别就在于需要创建对象的复杂程度上。
398 | 抽象工厂模式:给客户端提供一个接口,可以创建多个产品族中的产品对象 ,而且使用抽象工厂模式还要满足一下条件:
399 | 1)系统中有多个产品族,而系统一次只可能消费其中一族产品。
400 | 2)同属于同一个产品族的产品以其使用。
401 |
402 | 抽象工厂模式的组成(和工厂方法模式一样):
403 | 1)抽象工厂角色:这是工厂方法模式的核心,它与应用程序无关。是具体工厂角色必须实现的接口或者必须继承的父类。
404 | 2)具体工厂角色:它含有和具体业务逻辑有关的代码。由应用程序调用以创建对应的具体产品的对象。
405 | 3)抽象产品角色:它是具体产品继承的父类或者是实现的接口。
406 | 4)具体产品角色:具体工厂角色所创建的对象就是此角色的实例。
407 |
408 | 代码实现
409 |
410 |
411 |
412 | ```c
413 |
414 | #include
415 | using namespace std;
416 | enum SOAPTYPE {SFJ,XSL,NAS};
417 | enum TOOTHTYPE {HR,ZH};
418 |
419 | class SoapBase
420 | {
421 | public:
422 | virtual ~SoapBase(){};
423 | virtual void show() = 0;
424 | };
425 |
426 | class SFJSoap:public SoapBase
427 | {
428 | public:
429 | void show() {cout<<"SFJ Soap!"<show();
502 | pToothpaste1->show();
503 |
504 | SoapBase *pSoap2 = NULL;
505 | ToothBase *pToothpaste2 = NULL;
506 | pSoap2 = factory2.creatSoap();
507 | pToothpaste2 = factory2.creatToothpaste();
508 | pSoap2->show();
509 | pToothpaste2->show();
510 |
511 | delete pSoap1;
512 | delete pSoap2;
513 | delete pToothpaste1;
514 | delete pToothpaste2;
515 |
516 | return 0;
517 | }
518 | ```
519 |
520 | 参考:[三种工厂模式的C++实现](https://blog.csdn.net/silangquan/article/details/20492293)
521 |
522 | ### 6. OSI参考模型分为几层?每层都有什么协议
523 |
524 | | 分层 | 作用 | 协议 |
525 | | ---------- | --------------------------------------------------- | --------------------------------------------------- |
526 | | 物理层 | 通过媒介传输比特,确定机械及电气规范(比特 Bit) | RJ45、CLOCK、IEEE802.3(中继器,集线器) |
527 | | 数据链路层 | 将比特组装成帧和点到点的传递(帧 Frame) | PPP、FR、HDLC、VLAN、MAC(网桥,交换机) |
528 | | 网络层 | 负责数据包从源到宿的传递和网际互连(包 Packet) | IP、ICMP、ARP、RARP、OSPF、IPX、RIP、IGRP(路由器) |
529 | | 运输层 | 提供端到端的可靠报文传递和错误恢复( 段Segment) | TCP、UDP、SPX |
530 | | 会话层 | 建立、管理和终止会话(会话协议数据单元 SPDU) | NFS、SQL、NETBIOS、RPC |
531 | | 表示层 | 对数据进行翻译、加密和压缩(表示协议数据单元 PPDU) | JPEG、MPEG、ASII |
532 | | 应用层 | 允许访问OSI环境的手段(应用协议数据单元 APDU) | FTP、DNS、Telnet、SMTP、HTTP、WWW、NFS |
533 |
534 | ### [7. TCP和UDP]([https://github.com/twomonkeyclub/BackEnd/tree/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C#TCPUDP%E7%9A%84%E5%8C%BA%E5%88%AB%E5%92%8C%E5%BA%94%E7%94%A8%E5%9C%BA%E6%99%AF](https://github.com/twomonkeyclub/BackEnd/tree/master/计算机基础知识/计算机网络#TCPUDP的区别和应用场景))
535 |
536 | 协议:
537 |
538 | - TCP(Transmission Control Protocol,传输控制协议)
539 | - UDP(User Datagram Protocol,用户数据报协议)
540 |
541 | * TCP,全称:传输控制协议,面向连接的安全的流式传输协议
542 | * UDP,全称:用户数据报协议,面向无连接的不安全的报式传输协议
543 |
544 | - 连接
545 | - TCP是面向连接的传输层协议,即传输数据之前必须先建立好连接。
546 | - UDP无连接。
547 | - 服务对象
548 | - TCP是点对点的两点间服务,即一条TCP连接只能有两个端点
549 | - UDP支持一对一,一对多,多对一,多对多的交互通信。
550 | - 可靠性
551 | - TCP是可靠交付:无差错,不丢失,不重复,按序到达。
552 | - UDP是尽最大努力交付,不保证可靠交付。
553 | - 拥塞控制,流量控制
554 | - TCP有拥塞控制和流量控制保证数据传输的安全性。
555 | - UDP没有拥塞控制,网络拥塞不会影响源主机的发送效率。
556 | - 报文长度
557 | - TCP是动态报文长度,即TCP报文长度是根据接收方的窗口大小和当前网络拥塞情况决定的,流式传输
558 | - UDP面向报文,不合并,不拆分,保留上面(应用层)传下来报文的边界,直接传输报文。
559 | - 首部开销
560 | - TCP首部开销大,首部20个字节。
561 | - UDP首部开销小,8字节。(源端口,目的端口,UDP数据报长度,检验和,每个字段两个字节)
562 |
563 | ### 应用场景
564 |
565 | - 要求通信数据完整性,则应该选用TCP协议(如文件传输、重要状态的更新,登录数据传输等)
566 | - 要求通信实时性,使用 UDP 协议(如视频传输,通话,屏幕共享软件)
567 |
568 | ### 8. 一个空类编译器会自动生成哪些函数
569 |
570 | 当空类Empty_one定义一个对象时Empty_one pt;sizeof(pt)仍是为1,但编译器会生成**6个成员函数**:一个缺省的构造函数、一个拷贝构造函数、一个析构函数、一个赋值运算符、两个取址运算符。
571 |
572 | ```c
573 | class Empty
574 | {};
575 | ```
576 |
577 | 等价于:
578 |
579 | ```c
580 | class Empty
581 | {
582 | public:
583 | Empty(); //缺省构造函数
584 | Empty(const Empty &rhs); //拷贝构造函数
585 | ~Empty(); //析构函数
586 | Empty& operator=(const Empty &rhs); //赋值运算符
587 | Empty* operator&(); //取址运算符
588 | const Empty* operator&() const; //取址运算符(const版本)
589 | };
590 | ```
591 |
592 | ### 9. 类静态成员函数的特点
593 |
594 | 静态成员函数
595 |
596 | - 静态成员函数可以直接访问静态成员变量,不能直接访问普通成员变量,但可以通过参数传递的方式访问
597 | - 普通成员函数可以访问普通成员变量,也可以访问静态成员变量
598 | - 静态成员函数没有this指针。非静态数据成员为对象单独维护,但静态成员函数为共享函数,无法区分是哪个对象,因此不能直接访问普通变量成员,也没有this指针。
599 |
600 | (1)出现在类体外的函数不能指定关键字static;
601 |
602 | (2)静态成员之间可以互相访问,包括静态成员函数访问静态数据成员和访问静态成员函数;
603 |
604 | (3)非静态成员函数可以任意地访问静态成员函数和静态数据成员;
605 |
606 | (4)静态成员函数不能访问非静态成员函数和非静态数据成员;
607 |
608 | (5)由于没有this指针的额外开销,因此静态成员函数与类的全局函数相比,速度上会有少许的增长;
609 |
610 | (6)调用静态成员函数,可以用成员访问操作符(.)和(->)为一个类的对象或指向类对象的指调用静态成员函数
611 |
612 | **C++中,静态成员函数不能被声明为virtual函数。**
613 |
614 | **静态成员函数也不能被声明为const和volatile.**
615 |
616 | **虚函数的调用关系:this -> vptr -> vtable ->virtual function**
617 |
618 | 参考:[静态成员变量与静态成员函数]([https://github.com/twomonkeyclub/BackEnd/tree/master/%E5%9F%BA%E7%A1%80%E8%AF%AD%E8%A8%80/C%2B%2B%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1#%E9%9D%99%E6%80%81%E6%88%90%E5%91%98%E5%8F%98%E9%87%8F%E4%B8%8E%E9%9D%99%E6%80%81%E6%88%90%E5%91%98%E5%87%BD%E6%95%B0](https://github.com/twomonkeyclub/BackEnd/tree/master/基础语言/C%2B%2B面向对象#静态成员变量与静态成员函数))
619 |
620 | ### 10.C++多态是怎么体现的,派生类的内存分布,多重继承的虚函数表有几个?
621 |
622 | C++ 多态分类及实现:
623 |
624 | 1. 重载多态(Ad-hoc Polymorphism,编译期):函数重载、运算符重载
625 | 2. 子类型多态(Subtype Polymorphism,运行期):虚函数
626 | 3. 参数多态性(Parametric Polymorphism,编译期):类模板、函数模板
627 | 4. 强制多态(Coercion Polymorphism,编译期/运行期):基本类型转换、自定义类型转换
628 |
629 | 
630 |
631 | 
632 |
633 | 
634 |
635 | 参考:[图说C++对象模型:对象内存布局详解](https://www.cnblogs.com/QG-whz/p/4909359.html)
636 |
637 | 多重继承会有多个虚函数表,几重继承,就会有几个虚函数表。
638 |
639 | ### 11. 拷贝构造函数以及深拷贝和浅拷贝的区别
640 |
641 | 拷贝构造函数的参数必须加const,因为防止修改,本来就是用现有的对象初始化新的对象。
642 |
643 | - 拷贝构造函数的使用时机
644 | - 使用已经创建好的对象初始化新对象 `A a; A b = a; A c(a); b = c;//b = c不是初始化,调用赋值运算符`
645 | - 以值传递的方式来给函数参数传值
646 | - 以值方式返回局部对象(不常用,一般不返回局部对象)
647 | - 深拷贝和浅拷贝 只有当对象的成员属性在堆区开辟空间内存时,才会涉及深浅拷贝,如果仅仅是在栈区开辟内存,则默认的拷贝构造函数和析构函数就可以满足要求。
648 | - **浅拷贝**:使用默认拷贝构造函数,拷贝过程中是按字节复制的,对于指针型成员变量只复制指针本身,而不复制指针所指向的目标,因此涉及堆区开辟内存时,会将两个成员属性指向相同的内存空间,从而在释放时导致内存空间被多次释放,使得程序down掉。
649 | - **浅拷贝的问题**:当出现类的等号赋值时,系统会调用默认的拷贝函数——即浅拷贝,它能够完成成员的一一复制。当数据成员中没有指针时,浅拷贝是可行的。但当数据成员中有指针时,如果采用简单的浅拷贝,则两类中的两个指针将指向同一个地址,当对象快结束时,会调用两次free函数,指向的内存空间已经被释放掉,再次free会报错;另外,一片空间被两个不同的子对象共享了,只要其中的一个子对象改变了其中的值,那另一个对象的值也跟着改变了所以,这时,必须采用深拷贝
650 | - **深拷贝**:自定义拷贝构造函数,在堆内存中另外申请空间来储存数据,从而解决指针悬挂的问题。**需要注意自定义析构函数中应该释放掉申请的内存**
651 |
652 | 我们在定义类或者结构体,这些结构的时候,最后都重写拷贝函数,避免浅拷贝这类不易发现但后果严重的错误产生。
653 |
654 | ### 12.vector扩容的方式及底层实现方法
655 |
656 | **扩容原理概述**
657 |
658 | * 新增元素:Vector通过一个连续的数组存放元素,如果集合已满,在新增数据的时候,就要分配一块更大的内存,将原来的数据复制过来,释放之前的内存,在插入新增的元素;
659 | * 对vector的任何操作,一旦引起空间重新配置,指向原vector的所有迭代器就都失效了 ;
660 | * 初始时刻vector的capacity为0,塞入第一个元素后capacity增加为1;
661 | * 不同的编译器实现的扩容方式不一样,VS2015中以1.5倍扩容,GCC以2倍扩容。
662 |
663 | ### 总结
664 |
665 | 1. vector在push_back以成倍增长可以在均摊后达到O(1)的事件复杂度,相对于增长指定大小的O(n)时间复杂度更好。
666 | 2. 为了防止申请内存的浪费,现在使用较多的有2倍与1.5倍的增长方式,而1.5倍的增长方式可以更好的实现对内存的重复利用,因为更好。
667 | 3. 
668 |
669 | 4. 函数**clear()**删除储存在vector中的所有元素. 如果vector的元素是一些object, 则它将为当前储存的每个元素调用它们各自的析构函数(destructor). 然而, 如果vector储存的是指向对象的指针, 此函数并不会调用到对应的析构函数.
670 | 5. **“vector 的 clear 不影响 capacity , 你应该 swap 一个空的 vector。”**
671 |
672 | ```c
673 | #include
674 | #include
675 | using namespace std;
676 | int main()
677 | {
678 | vector v;
679 | v.push_back(1);
680 | v.push_back(2);
681 | v.push_back(3);
682 | v.push_back(4);
683 | v.push_back(5);
684 |
685 | cout << "size:" << v.size() << endl;
686 | cout << "capacity:" << v.capacity() << endl;
687 |
688 | vector().swap(v);
689 | cout << "after swap size:" << v.size() << endl;
690 | cout << "after swap capacity:" << v.capacity() << endl;
691 | return 0;
692 | }
693 | //输出:
694 | size:5
695 | capacity:6
696 | after swap size:0
697 | after swap capacity:0
698 | ```
699 |
700 |
701 |
702 | ### 13.linux文件系统包含哪些种类,ext文件系统用什么数据结构实现的
703 |
704 | Linux系统核心可以支持十多种文件系统类型:JFS、 **ReiserFS**、**ext**、**ext2**、**ext3**、**ISO9660**、XFS、Minx、MSDOS、UMSDOS、**VFAT**、**NTFS**、HPFS、**NFS**、 SMB、SysV、PROC等。
705 |
706 | 参考:[文件系统](http://math.ecnu.edu.cn/~jypan/Teaching/Linux/Linux08/lect04_FileSystem.pdf)
707 |
708 | ### 14 new
709 |
710 | #### [new、delete](https://interview.huihut.com/#/?id=new、delete)
711 |
712 | 1. new / new[]:完成两件事,先底层调用 malloc 分配了内存,然后调用构造函数(创建对象)。
713 | 2. delete/delete[]:也完成两件事,先调用析构函数(清理资源),然后底层调用 free 释放空间。
714 | 3. new 在申请内存时会自动计算所需字节数,而 malloc 则需我们自己输入申请内存空间的字节数。
715 |
716 | ### 15 二叉树的非递归实现
717 |
718 | 中序:
719 |
720 | ```c
721 |
722 | void InOrderWithoutRecursion1(BTNode* root)
723 | {
724 | //空树
725 | if (root == NULL)
726 | return;
727 | //树非空
728 | BTNode* p = root;
729 | stack s;
730 | while (!s.empty() || p)
731 | {
732 | //一直遍历到左子树最下边,边遍历边保存根节点到栈中
733 | while (p)
734 | {
735 | s.push(p);
736 | p = p->lchild;
737 | }
738 | //当p为空时,说明已经到达左子树最下边,这时需要出栈了
739 | if (!s.empty())
740 | {
741 | p = s.top();
742 | s.pop();
743 | cout << setw(4) << p->data;
744 | //进入右子树,开始新的一轮左子树遍历(这是递归的自我实现)
745 | p = p->rchild;
746 | }
747 | }
748 | }
749 | ```
750 |
751 | 前序
752 |
753 | ```c
754 |
755 | void PreOrderWithoutRecursion1(BTNode* root)
756 | {
757 | if (root == NULL)
758 | return;
759 | BTNode* p = root;
760 | stack s;
761 | while (!s.empty() || p)
762 | {
763 | //边遍历边打印,并存入栈中,以后需要借助这些根节点(不要怀疑这种说法哦)进入右子树
764 | while (p)
765 | {
766 | cout << setw(4) << p->data;
767 | s.push(p);
768 | p = p->lchild;
769 | }
770 | //当p为空时,说明根和左子树都遍历完了,该进入右子树了
771 | if (!s.empty())
772 | {
773 | p = s.top();
774 | s.pop();
775 | p = p->rchild;
776 | }
777 | }
778 | cout << endl;
779 | }
780 | ```
781 |
782 | 后序
783 |
784 | ```c
785 | //后序遍历
786 | void PostOrderWithoutRecursion(BTNode* root)
787 | {
788 | if (root == NULL)
789 | return;
790 | stack s;
791 | //pCur:当前访问节点,pLastVisit:上次访问节点
792 | BTNode* pCur, *pLastVisit;
793 | //pCur = root;
794 | pCur = root;
795 | pLastVisit = NULL;
796 | //先把pCur移动到左子树最下边
797 | while (pCur)
798 | {
799 | s.push(pCur);
800 | pCur = pCur->lchild;
801 | }
802 | while (!s.empty())
803 | {
804 | //走到这里,pCur都是空,并已经遍历到左子树底端(看成扩充二叉树,则空,亦是某棵树的左孩子)
805 | pCur = s.top();
806 | s.pop();
807 | //一个根节点被访问的前提是:无右子树或右子树已被访问过
808 | if (pCur->rchild == NULL || pCur->rchild == pLastVisit)
809 | {
810 | cout << setw(4) << pCur->data;
811 | //修改最近被访问的节点
812 | pLastVisit = pCur;
813 | }
814 | /*这里的else语句可换成带条件的else if:
815 | else if (pCur->lchild == pLastVisit)//若左子树刚被访问过,则需先进入右子树(根节点需再次入栈)
816 | 因为:上面的条件没通过就一定是下面的条件满足。仔细想想!
817 | */
818 | else
819 | {
820 | //根节点再次入栈
821 | s.push(pCur);
822 | //进入右子树,且可肯定右子树一定不为空
823 | pCur = pCur->rchild;
824 | while (pCur)
825 | {
826 | s.push(pCur);
827 | pCur = pCur->lchild;
828 | }
829 | }
830 | }
831 | cout << endl;
832 | }
833 | ```
834 |
835 | 参考:[二叉树前序、中序、后序遍历非递归写法的透彻解析](https://blog.csdn.net/zhangxiangDavaid/article/details/37115355)
--------------------------------------------------------------------------------