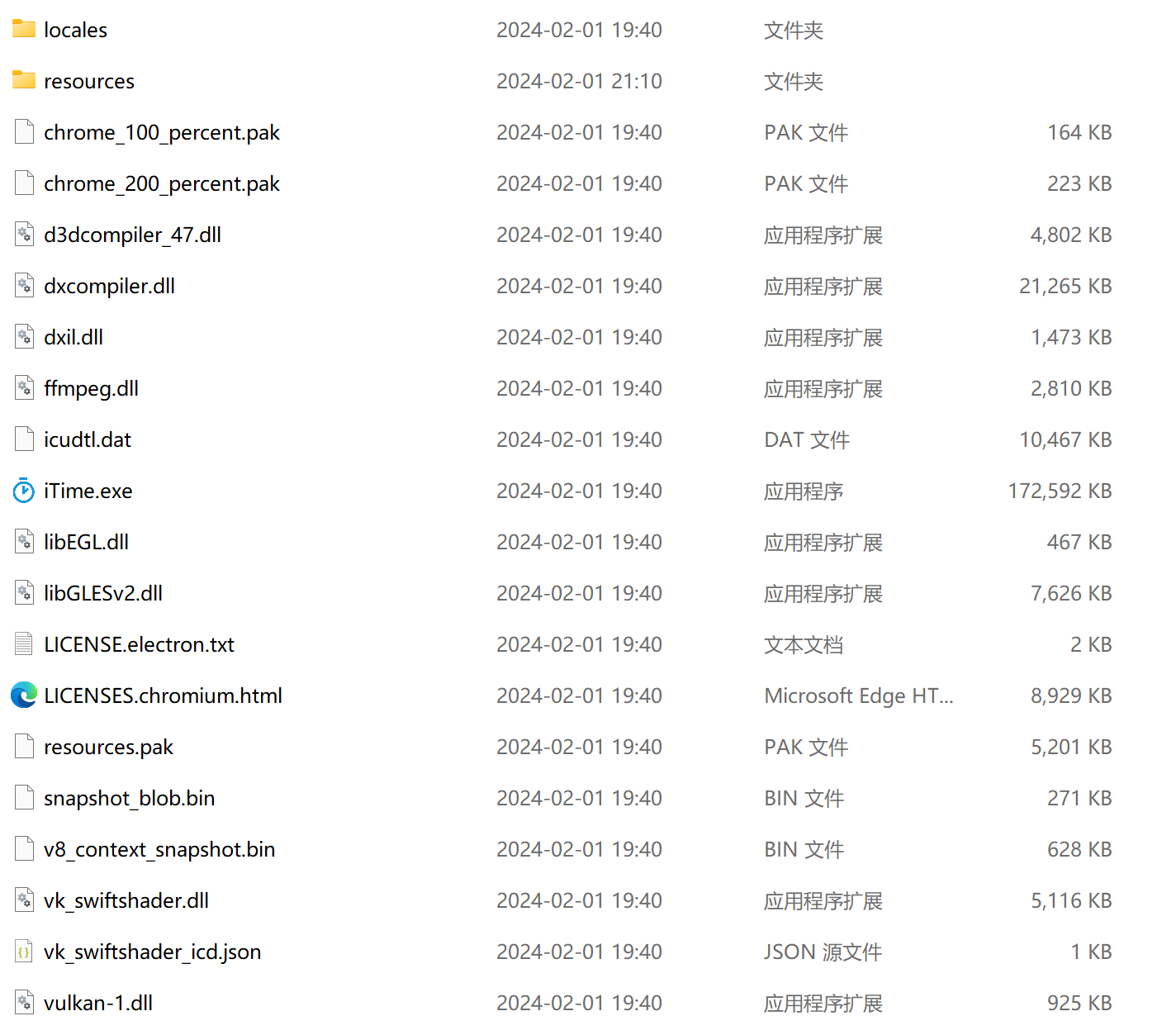
 162 |
163 | - 其中locales是多语言的配置,36MB,我的应用不需要多语言,因此把除中文的全部排除
164 | - 资源目录下是我们的asar归档文件,我的是40多M,有优化的空间但是不多,如优化代码,优化依赖项等
165 |
166 | 可以看asar文件中包含的是什么
167 |
168 | ```bash
169 | npm i -g asar # 下载插件
170 | asar extract app.asar ./app #解压asar文件
171 | ```
172 |
173 | - 两个许可证文件LICENSES.chromium和LICENSE.electron,我这里选择直接不要,优化了9MB
174 |
175 | 一共优化了45M,这个自己开发的话还是可以的,至少比网上的一些人才让把node_modules文件夹排除了有用点
176 |
177 | 需要自己在afterPack钩子后执行一个脚本,这个脚本返回一个异步函数负责删除那些不用的文件
178 |
179 | 在package.json里面添加这个配置项
180 |
181 | ```json
182 | "afterPack": "scripts/afterPack.js",
183 | ```
184 |
185 | files也要包含这个路径
186 |
187 | ```json
188 | "files": [
189 | "dist/**/*",
190 | "main.js",
191 | "preload/**/*",
192 | "package.json",
193 | "scripts/**/*"
194 | ],
195 | ```
196 |
197 | 脚本文件
198 |
199 | ```js
200 | const path = require("path");
201 | const fs = require("fs-extra"); // fs 的一个扩展
202 |
203 | module.exports = async (context) => {
204 | const unpackedDir = path.join(context.appOutDir, "locales");
205 |
206 | // 删除除 zh-CN.pak 之外的所有文件
207 | const files = await fs.readdir(unpackedDir);
208 | for (const file of files) {
209 | if (!file.endsWith("zh-CN.pak")) {
210 | await fs.remove(path.join(unpackedDir, file));
211 | }
212 | }
213 |
214 | // 删除特定的文件
215 | const filesToDelete = ["LICENSE.electron.txt", "LICENSES.chromium.html"];
216 |
217 | for (const fileName of filesToDelete) {
218 | const filePath = path.join(context.appOutDir, fileName);
219 | if (await fs.pathExists(filePath)) {
220 | await fs.remove(filePath);
221 | }
222 | }
223 | };
224 | ```
225 |
226 | 经过一系列操作,优化到了280MB。
227 |
228 | ## 最后
229 |
230 | electron-builder有三个钩子:`artifactBuildCompleted`、`afterPack`、`afterSign`,分别是构建完成、打包完成、签名完成、可以自动化构建流程。我这里还用到了构建完成,自动化命名构建文件(当然,手动命名也是可以的)。
231 |
232 | ```js
233 | const fs = require("fs");
234 | const path = require("path");
235 |
236 | module.exports = async function (params) {
237 | // 读取版本号
238 | const packageJson = require("../package.json");
239 | const version = packageJson.version;
240 | let artifact = params.file;
241 | let originFile = artifact;
242 |
243 | const ext = path.extname(artifact);
244 | // 处理版本号前缀,注意空格
245 | artifact = artifact.replace(` ${version}`, `-${version}`);
246 | let newName;
247 |
248 | if (ext === ".exe" && !artifact.includes("Setup")) {
249 | // 不用安装的程序
250 | newName = artifact.replace(/\.exe$/, "-windows-no-installer.exe");
251 | } else if (ext === ".exe") {
252 | // 常规安装包
253 | newName = artifact.replace(
254 | ` Setup-${version}.exe`,
255 | `-${version}-windows-installer.exe`
256 | );
257 | } else {
258 | newName = artifact;
259 | }
260 |
261 | // 重命名
262 | if (newName) {
263 | fs.renameSync(originFile, newName);
264 | }
265 | };
266 | ```
267 |
268 | 其他还有一些进阶语法,比如增量更新,有这种需求官网和stackoverflow、issues区都可以,其他的见仁见智吧,国内用的人还是不太多,有的回答API都废弃了,注意版本。
--------------------------------------------------------------------------------
/docs/Tutorial/vitepress.md:
--------------------------------------------------------------------------------
1 | # vitepress搭建并部署网站
2 |
3 | ## 前言
4 |
5 | 首先,明确一点,**不要轻易用最新的版本**!!!很多开源项目文档写的真的太简练了,个人觉得不太适合小白,给个QA区也好啊。最后我们在遇到问题的时候解决方案一般有三条:
6 |
7 | 1. 去网上搜索,看别人写的博客
8 | 2. 问gpt
9 | 3. 问别人(效率最低,特别是对于不会提问的同学)
10 |
11 | 对开源项目来说,还有两条
12 |
13 | 1. 去github的issues区看别人是否遇到过这种问题
14 | 2. 提issue
15 |
16 | 为什么说不要用最新版本,首先版本发布的最新,很多问题网上根本没有解决方案,特别是对于比较小众的开源项目。问GPT的话它的知识库都没更新到最新,也没法解决。至于github的issue区也只能碰运气。
17 |
18 | 到最后遇到问题你只能提issue,这个时候就得看负责维护这个项目团队的积极性了,vitepress团队还是很奈斯的,我今天两点提了个issue8分钟就回复了,也得益于美国跟咱这边有时差。
19 |
20 | 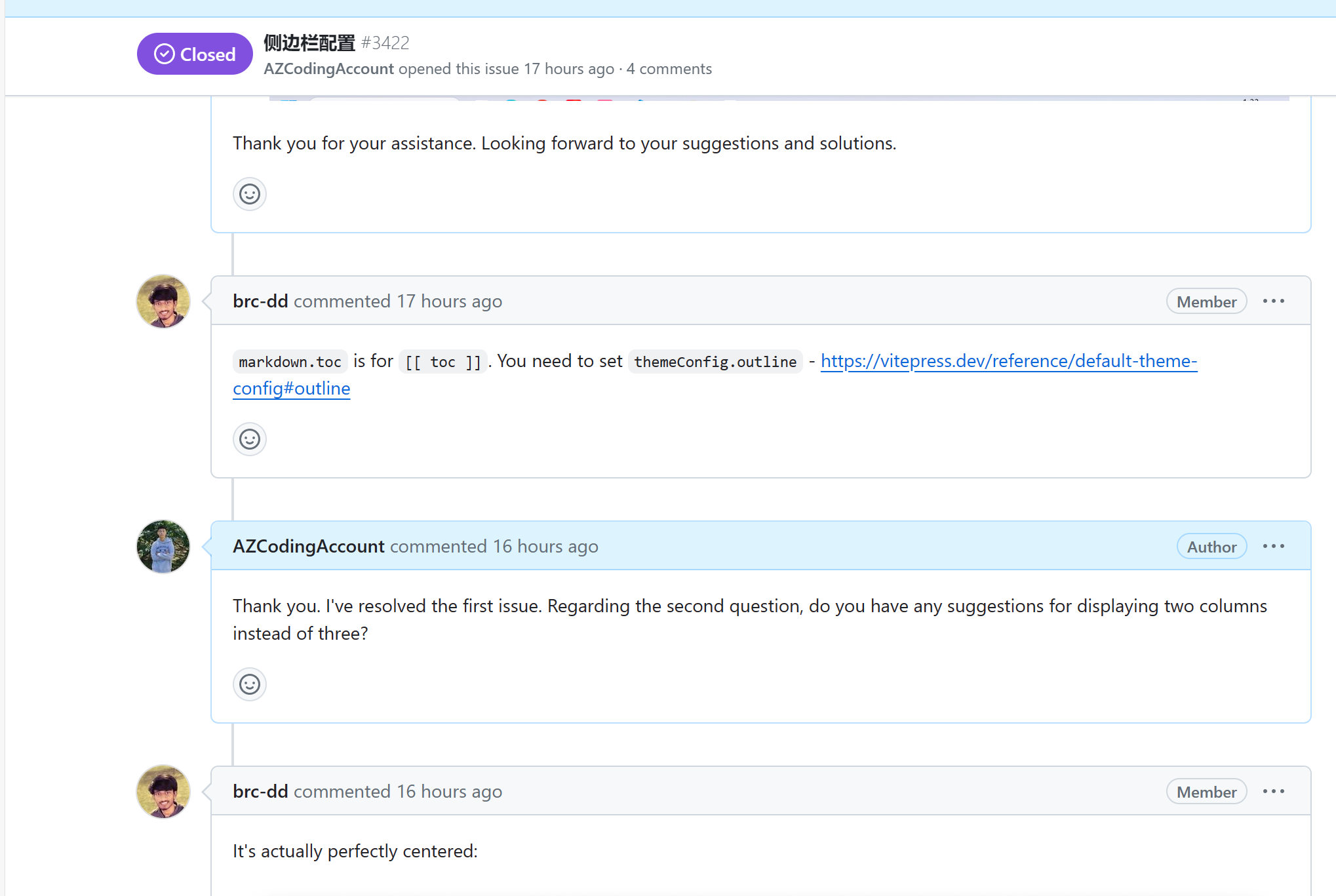
21 |
22 | ## 创建项目
23 |
24 | 话不多说,接下来开始我们的搭建步骤。对于开源项目,肯定是直接看官网和一些最佳实践了。
25 |
26 | vitepress官网地址:https://vitepress.dev/
27 |
28 | 模仿的最佳实践(B站一个UP主的):https://docs.zhengxinonly.com/
29 |
30 | **安装vitepress**
31 |
32 | 首先新建文件夹,打开cmd窗口
33 |
34 | ```sh
35 | pnpm add -D vitepress
36 | ```
37 |
38 | **初始化Vitepress**
39 |
40 | ```sh
41 | pnpm vitepress init
42 | ```
43 |
44 | 这是我的配置,简单介绍一下
45 |
46 | - 第一个是在当前根目录下创建vitepress项目
47 |
48 | - 站点标题和描述。后续可以在配置中改
49 | - 主题,建议选择第二个,个人觉得比较好看
50 | - 是否使用ts,我们个人学习就没必要ts了,主要还是我懒
51 | - 是否添加脚本到package.json,这个还是需要的,启动命令,打包命令这些都得用
52 |
53 |
162 |
163 | - 其中locales是多语言的配置,36MB,我的应用不需要多语言,因此把除中文的全部排除
164 | - 资源目录下是我们的asar归档文件,我的是40多M,有优化的空间但是不多,如优化代码,优化依赖项等
165 |
166 | 可以看asar文件中包含的是什么
167 |
168 | ```bash
169 | npm i -g asar # 下载插件
170 | asar extract app.asar ./app #解压asar文件
171 | ```
172 |
173 | - 两个许可证文件LICENSES.chromium和LICENSE.electron,我这里选择直接不要,优化了9MB
174 |
175 | 一共优化了45M,这个自己开发的话还是可以的,至少比网上的一些人才让把node_modules文件夹排除了有用点
176 |
177 | 需要自己在afterPack钩子后执行一个脚本,这个脚本返回一个异步函数负责删除那些不用的文件
178 |
179 | 在package.json里面添加这个配置项
180 |
181 | ```json
182 | "afterPack": "scripts/afterPack.js",
183 | ```
184 |
185 | files也要包含这个路径
186 |
187 | ```json
188 | "files": [
189 | "dist/**/*",
190 | "main.js",
191 | "preload/**/*",
192 | "package.json",
193 | "scripts/**/*"
194 | ],
195 | ```
196 |
197 | 脚本文件
198 |
199 | ```js
200 | const path = require("path");
201 | const fs = require("fs-extra"); // fs 的一个扩展
202 |
203 | module.exports = async (context) => {
204 | const unpackedDir = path.join(context.appOutDir, "locales");
205 |
206 | // 删除除 zh-CN.pak 之外的所有文件
207 | const files = await fs.readdir(unpackedDir);
208 | for (const file of files) {
209 | if (!file.endsWith("zh-CN.pak")) {
210 | await fs.remove(path.join(unpackedDir, file));
211 | }
212 | }
213 |
214 | // 删除特定的文件
215 | const filesToDelete = ["LICENSE.electron.txt", "LICENSES.chromium.html"];
216 |
217 | for (const fileName of filesToDelete) {
218 | const filePath = path.join(context.appOutDir, fileName);
219 | if (await fs.pathExists(filePath)) {
220 | await fs.remove(filePath);
221 | }
222 | }
223 | };
224 | ```
225 |
226 | 经过一系列操作,优化到了280MB。
227 |
228 | ## 最后
229 |
230 | electron-builder有三个钩子:`artifactBuildCompleted`、`afterPack`、`afterSign`,分别是构建完成、打包完成、签名完成、可以自动化构建流程。我这里还用到了构建完成,自动化命名构建文件(当然,手动命名也是可以的)。
231 |
232 | ```js
233 | const fs = require("fs");
234 | const path = require("path");
235 |
236 | module.exports = async function (params) {
237 | // 读取版本号
238 | const packageJson = require("../package.json");
239 | const version = packageJson.version;
240 | let artifact = params.file;
241 | let originFile = artifact;
242 |
243 | const ext = path.extname(artifact);
244 | // 处理版本号前缀,注意空格
245 | artifact = artifact.replace(` ${version}`, `-${version}`);
246 | let newName;
247 |
248 | if (ext === ".exe" && !artifact.includes("Setup")) {
249 | // 不用安装的程序
250 | newName = artifact.replace(/\.exe$/, "-windows-no-installer.exe");
251 | } else if (ext === ".exe") {
252 | // 常规安装包
253 | newName = artifact.replace(
254 | ` Setup-${version}.exe`,
255 | `-${version}-windows-installer.exe`
256 | );
257 | } else {
258 | newName = artifact;
259 | }
260 |
261 | // 重命名
262 | if (newName) {
263 | fs.renameSync(originFile, newName);
264 | }
265 | };
266 | ```
267 |
268 | 其他还有一些进阶语法,比如增量更新,有这种需求官网和stackoverflow、issues区都可以,其他的见仁见智吧,国内用的人还是不太多,有的回答API都废弃了,注意版本。
--------------------------------------------------------------------------------
/docs/Tutorial/vitepress.md:
--------------------------------------------------------------------------------
1 | # vitepress搭建并部署网站
2 |
3 | ## 前言
4 |
5 | 首先,明确一点,**不要轻易用最新的版本**!!!很多开源项目文档写的真的太简练了,个人觉得不太适合小白,给个QA区也好啊。最后我们在遇到问题的时候解决方案一般有三条:
6 |
7 | 1. 去网上搜索,看别人写的博客
8 | 2. 问gpt
9 | 3. 问别人(效率最低,特别是对于不会提问的同学)
10 |
11 | 对开源项目来说,还有两条
12 |
13 | 1. 去github的issues区看别人是否遇到过这种问题
14 | 2. 提issue
15 |
16 | 为什么说不要用最新版本,首先版本发布的最新,很多问题网上根本没有解决方案,特别是对于比较小众的开源项目。问GPT的话它的知识库都没更新到最新,也没法解决。至于github的issue区也只能碰运气。
17 |
18 | 到最后遇到问题你只能提issue,这个时候就得看负责维护这个项目团队的积极性了,vitepress团队还是很奈斯的,我今天两点提了个issue8分钟就回复了,也得益于美国跟咱这边有时差。
19 |
20 | 
21 |
22 | ## 创建项目
23 |
24 | 话不多说,接下来开始我们的搭建步骤。对于开源项目,肯定是直接看官网和一些最佳实践了。
25 |
26 | vitepress官网地址:https://vitepress.dev/
27 |
28 | 模仿的最佳实践(B站一个UP主的):https://docs.zhengxinonly.com/
29 |
30 | **安装vitepress**
31 |
32 | 首先新建文件夹,打开cmd窗口
33 |
34 | ```sh
35 | pnpm add -D vitepress
36 | ```
37 |
38 | **初始化Vitepress**
39 |
40 | ```sh
41 | pnpm vitepress init
42 | ```
43 |
44 | 这是我的配置,简单介绍一下
45 |
46 | - 第一个是在当前根目录下创建vitepress项目
47 |
48 | - 站点标题和描述。后续可以在配置中改
49 | - 主题,建议选择第二个,个人觉得比较好看
50 | - 是否使用ts,我们个人学习就没必要ts了,主要还是我懒
51 | - 是否添加脚本到package.json,这个还是需要的,启动命令,打包命令这些都得用
52 |
53 |  54 |
55 | 初始化成功后,使用vscode或webstorm打开文件夹,会看到这样一个目录。接下来简单介绍一下每个文件的含义
56 |
57 | - .vitepress,最核心的目录,
58 | - theme目录。自定义主题配置,css样式等
59 | - config.mjs。最核心的文件,各种配置导航栏、侧边栏、标题什么的都是在这里
60 | - node_modules。安装的依赖
61 | - api-examples.md和markdown-examples.md。官方给的两个示例
62 | - index.md。主页相关
63 | - package.json和pnpm-lock.yml。包管理工具需要用的
64 |
65 | 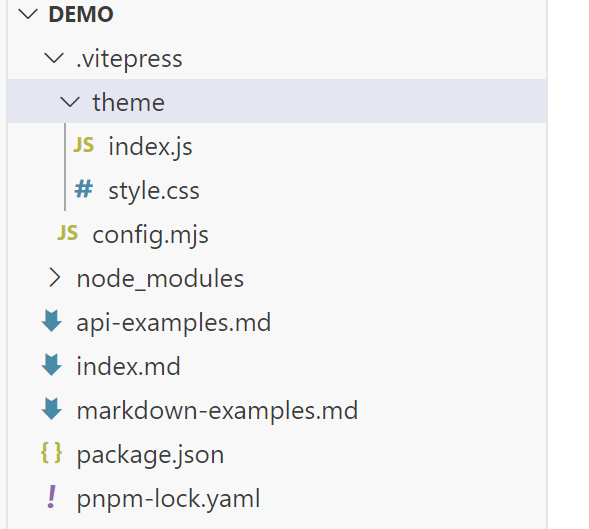
66 |
67 | **启动项目**
68 |
69 | ```sh
70 | pnpm run docs:dev
71 | ```
72 |
73 | 打开,看到这个,说明初始化成功
74 |
75 | 
76 |
77 | ## 自定义配置
78 |
79 | ### 美化主页
80 |
81 | 对于主页,我们自定义的内容有哪些?如下图,8个地方可以自定义。接下来就一一叙述这8个地方怎么自定义的。
82 |
83 | 
84 |
85 | 忘记了还有个页脚:
86 |
87 | 
88 |
89 | 9这个是直接配置footer,在`config.mjs defineConfig themeConfig`下面配置就可以了
90 |
91 | 
92 |
93 | 2-6是在index.md文件中自定义的。简单介绍一下对应关系
94 |
95 | `name<==>2` `text<==>3` `tagline<==>4` `actions<==>5` `features<==>6`
96 |
97 | 需要说明的是,对于5这两个按钮,是可以跳转的,**link指定路径**,比如/api-example就是在项目根目录下找api-example.md这个文件
98 |
99 |
54 |
55 | 初始化成功后,使用vscode或webstorm打开文件夹,会看到这样一个目录。接下来简单介绍一下每个文件的含义
56 |
57 | - .vitepress,最核心的目录,
58 | - theme目录。自定义主题配置,css样式等
59 | - config.mjs。最核心的文件,各种配置导航栏、侧边栏、标题什么的都是在这里
60 | - node_modules。安装的依赖
61 | - api-examples.md和markdown-examples.md。官方给的两个示例
62 | - index.md。主页相关
63 | - package.json和pnpm-lock.yml。包管理工具需要用的
64 |
65 | 
66 |
67 | **启动项目**
68 |
69 | ```sh
70 | pnpm run docs:dev
71 | ```
72 |
73 | 打开,看到这个,说明初始化成功
74 |
75 | 
76 |
77 | ## 自定义配置
78 |
79 | ### 美化主页
80 |
81 | 对于主页,我们自定义的内容有哪些?如下图,8个地方可以自定义。接下来就一一叙述这8个地方怎么自定义的。
82 |
83 | 
84 |
85 | 忘记了还有个页脚:
86 |
87 | 
88 |
89 | 9这个是直接配置footer,在`config.mjs defineConfig themeConfig`下面配置就可以了
90 |
91 | 
92 |
93 | 2-6是在index.md文件中自定义的。简单介绍一下对应关系
94 |
95 | `name<==>2` `text<==>3` `tagline<==>4` `actions<==>5` `features<==>6`
96 |
97 | 需要说明的是,对于5这两个按钮,是可以跳转的,**link指定路径**,比如/api-example就是在项目根目录下找api-example.md这个文件
98 |
99 | 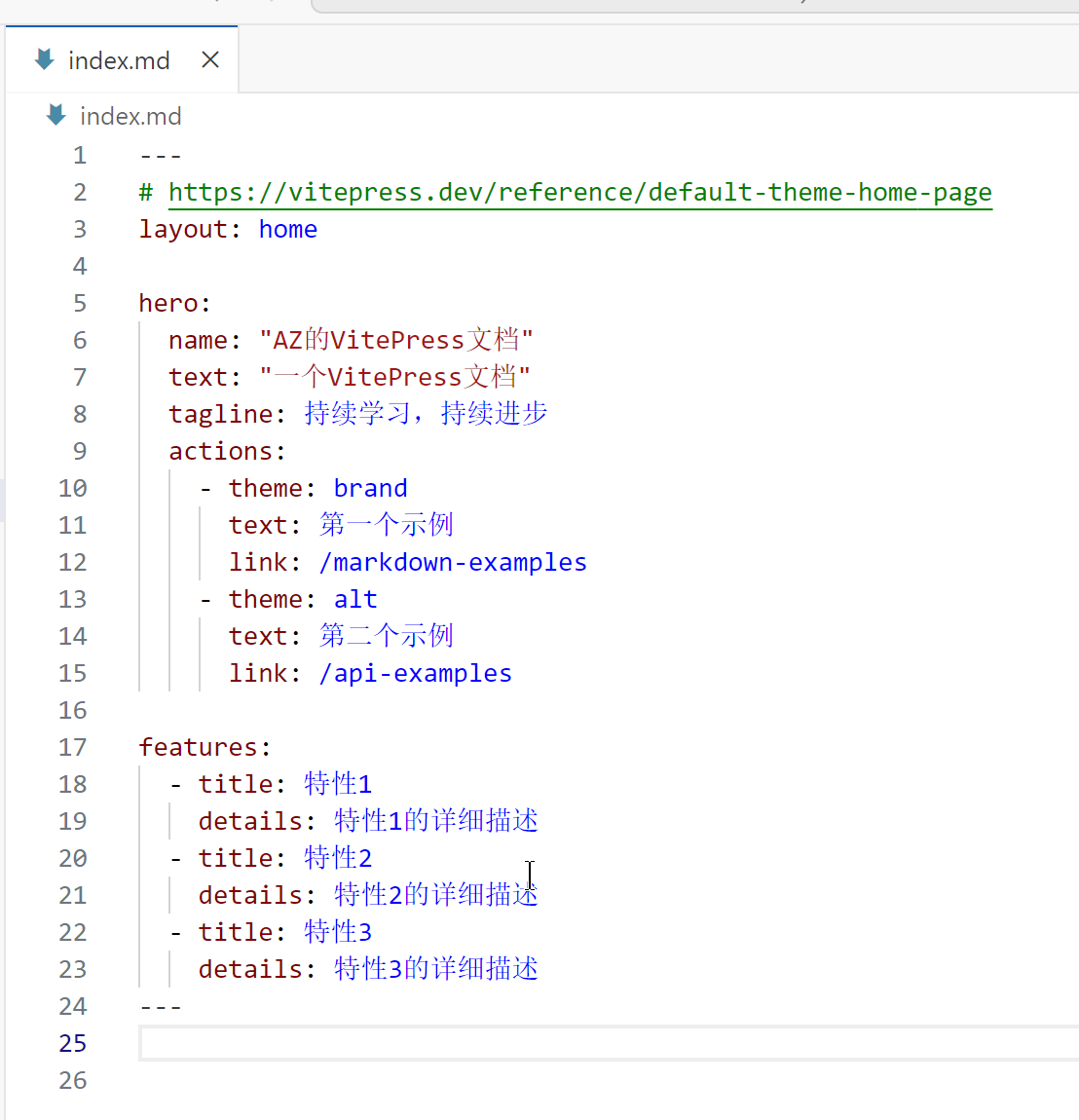 100 |
101 | 修改后的页面如下:
102 |
103 | 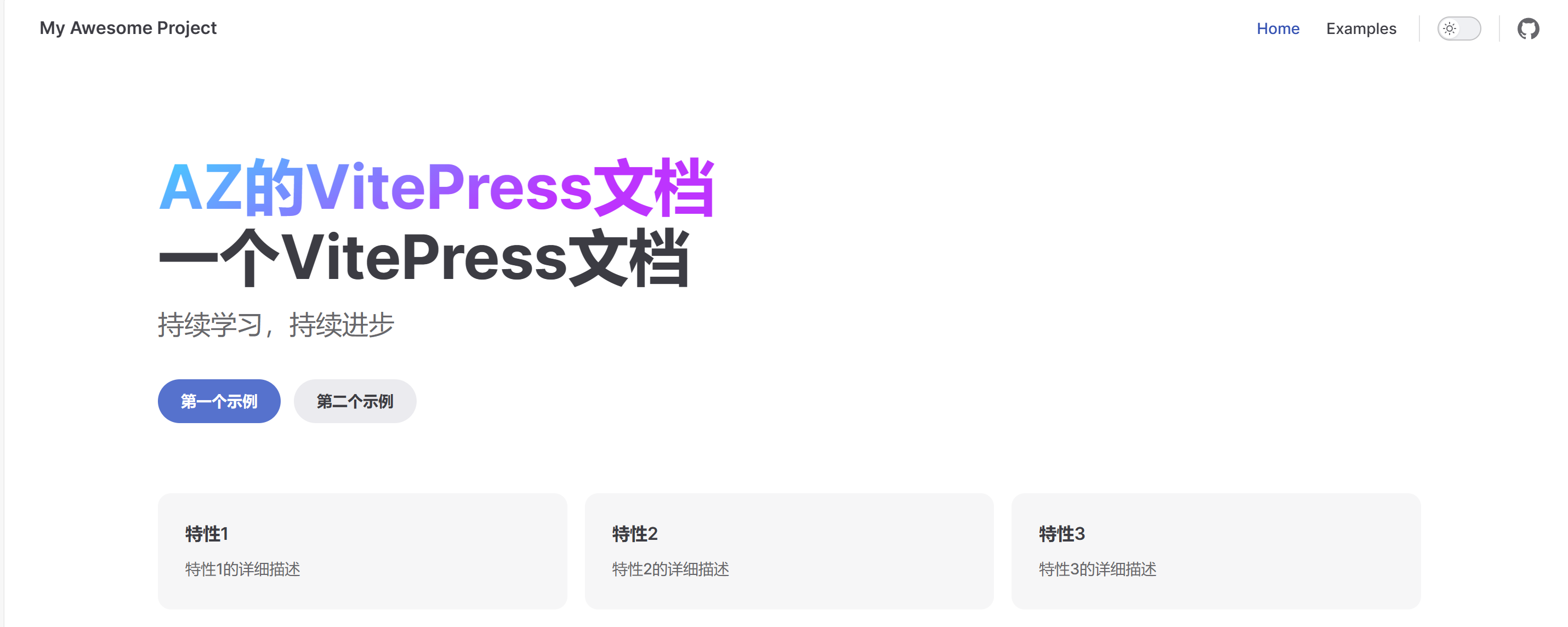
104 |
105 | 1、7、8这三个配置是在config.mjs中配置的
106 |
107 | 其中,title对应1,nav对应7,socialLinks对应8。description是SEO要用的,我们不用关注。
108 |
109 |
100 |
101 | 修改后的页面如下:
102 |
103 | 
104 |
105 | 1、7、8这三个配置是在config.mjs中配置的
106 |
107 | 其中,title对应1,nav对应7,socialLinks对应8。description是SEO要用的,我们不用关注。
108 |
109 | 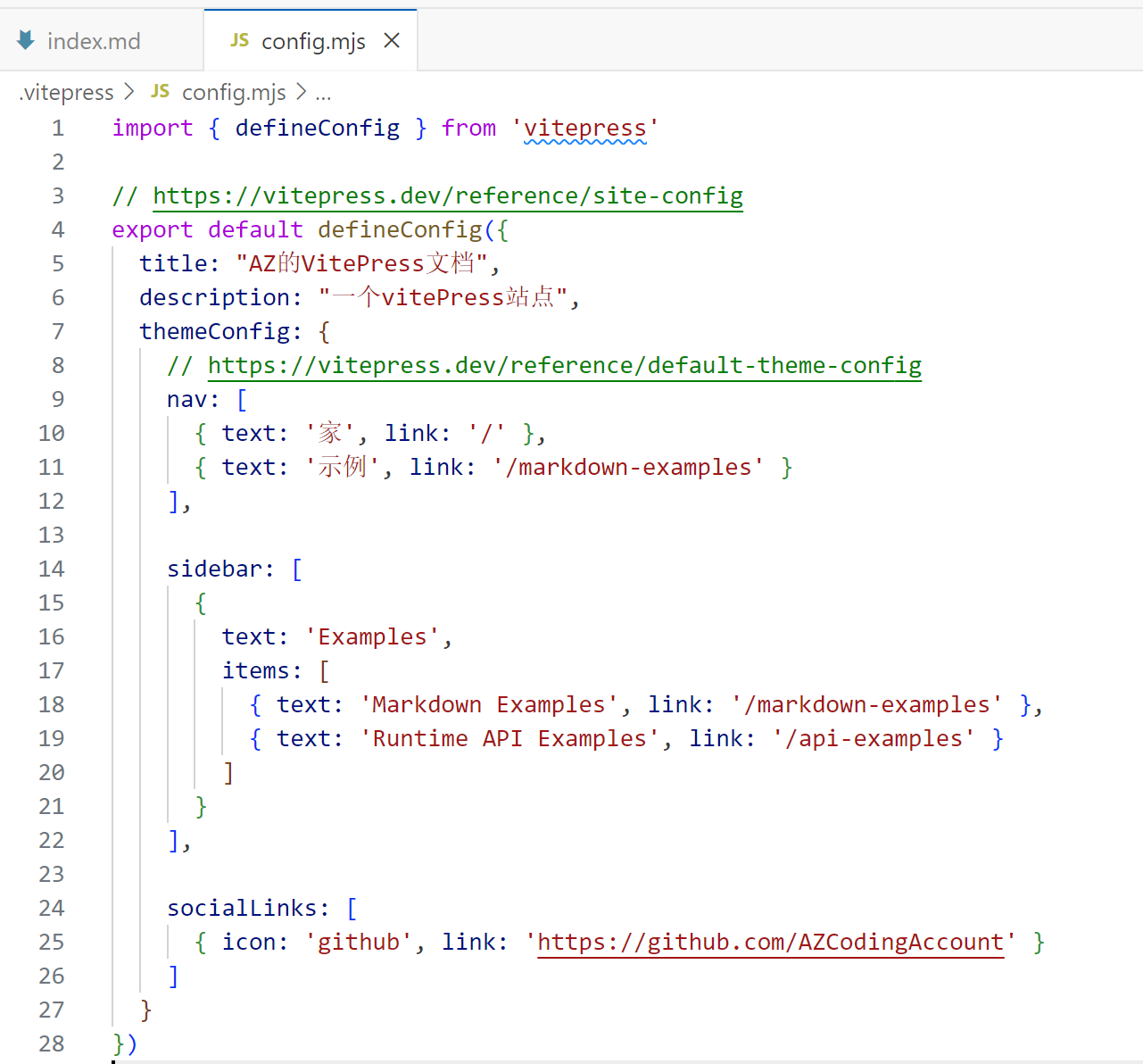 110 |
111 | 最后的结果是这样。
112 |
113 | 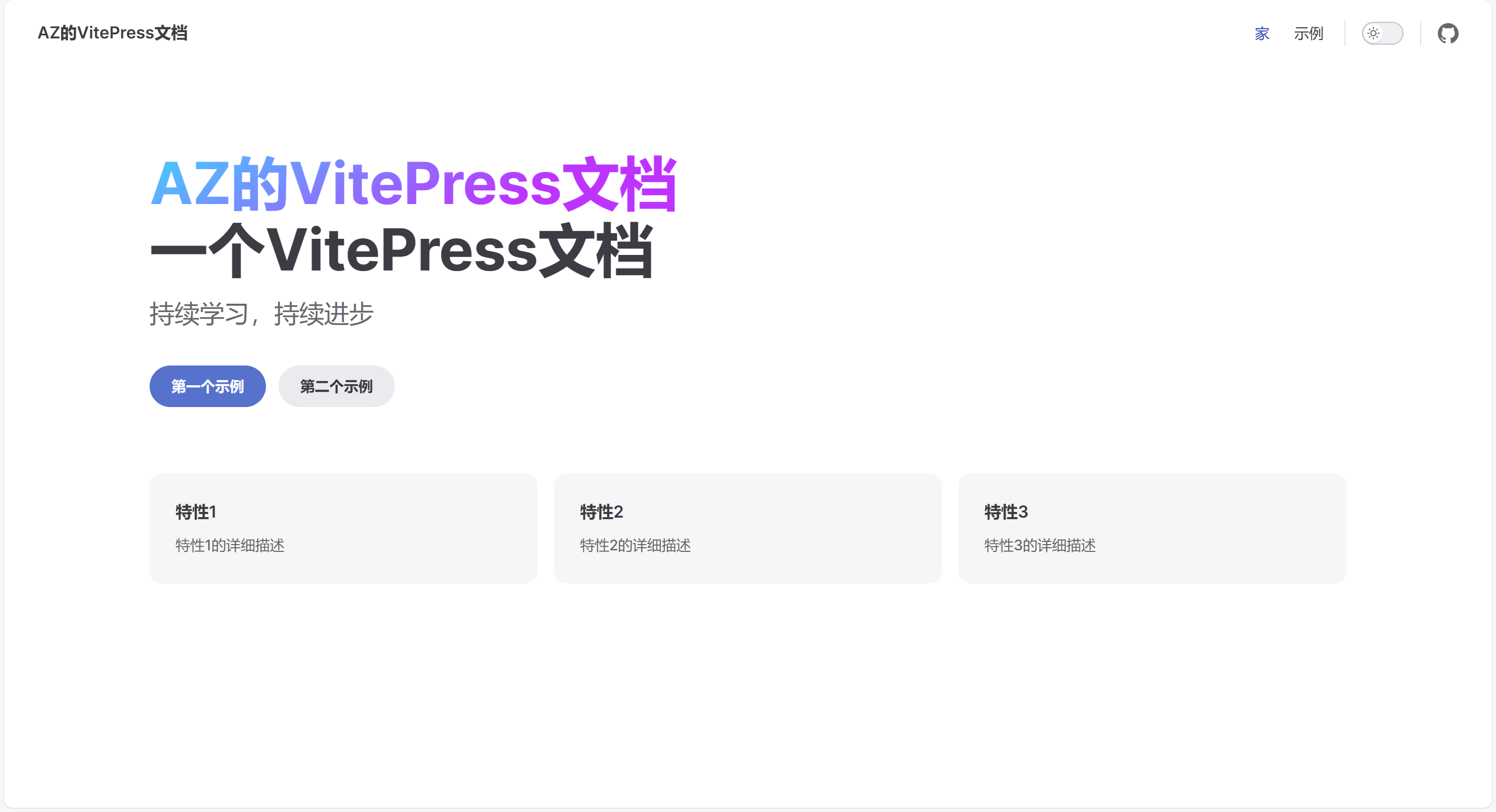
114 |
115 | ### 主页扩展
116 |
117 | 我们可能还想要对页面进行进一步美化,添加一些图标。可以去这个网站找图片https://www.iconfont.cn/
118 |
119 | 将找到的图片放在根目录下的public目录下。
120 |
121 |
110 |
111 | 最后的结果是这样。
112 |
113 | 
114 |
115 | ### 主页扩展
116 |
117 | 我们可能还想要对页面进行进一步美化,添加一些图标。可以去这个网站找图片https://www.iconfont.cn/
118 |
119 | 将找到的图片放在根目录下的public目录下。
120 |
121 | 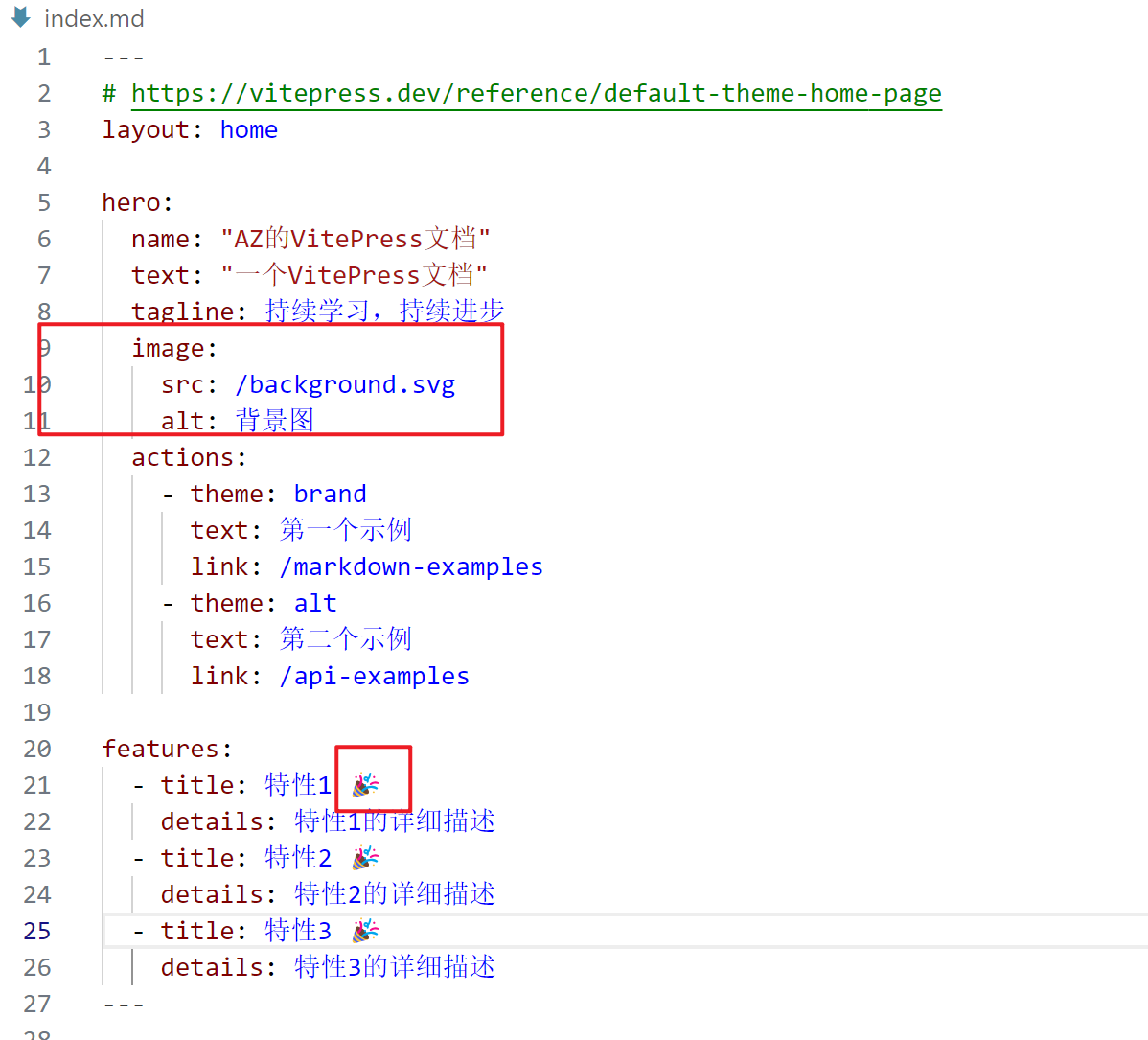 122 |
123 | 最后美化的效果如图:
124 |
125 | 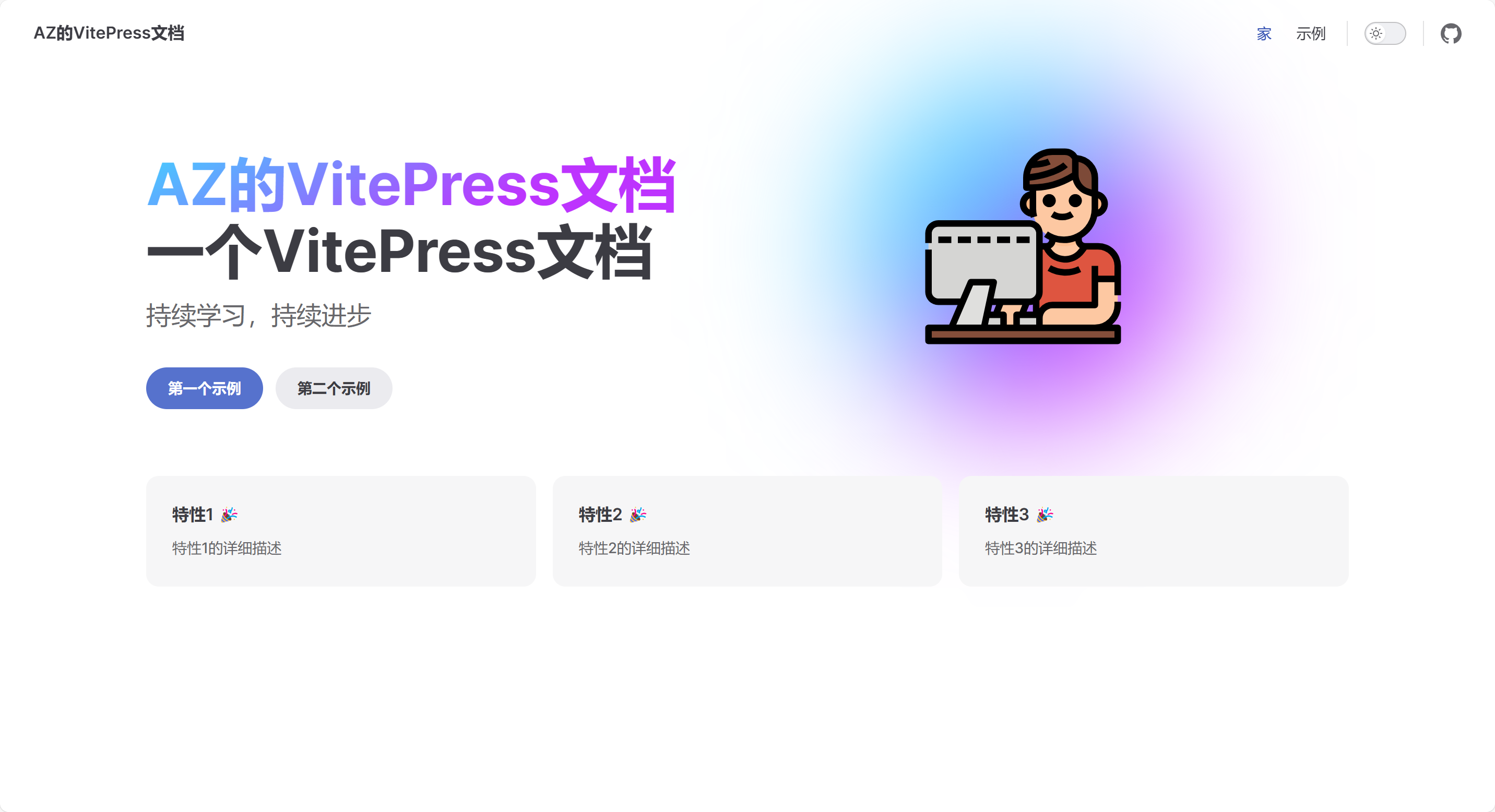
126 |
127 | **TODO:**
128 |
129 | - logo的配置是在config.mjs添加。(注意是themeConfig不是config)
130 |
131 | ```
132 | logo: "logo.svg", // 配置logo位置,public目录
133 | ```
134 |
135 | - vitepress原生支持国外的sociallink,如果是国内需要自行复制svg代码。如图:
136 |
137 | 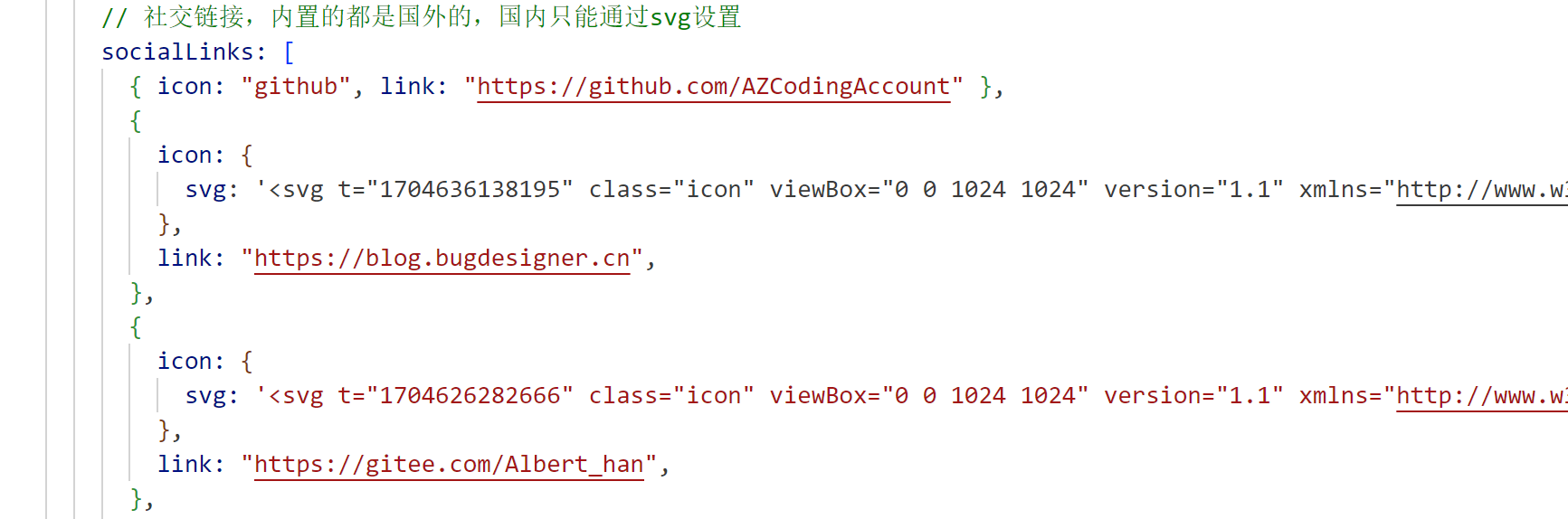
138 |
139 | - 添加搜索栏,config.mjs中的themeConfig(支持国际化需要进一步配置 )
140 |
141 | 
142 |
143 | ### 美化文章页
144 |
145 | 默认进来官方给的示例是三边栏的
146 |
147 | 左边是sidebar的配置,右边是显示的文章目录(默认显示一二级)。
148 |
149 | 
150 |
151 |
152 |
153 | 下面叙述这个是怎么配置的。sidebar可以是数组,也可以是对象。还是修改config.mjs
154 |
155 | 
156 |
157 | 最后的结果是这样
158 |
159 | 
160 |
161 | 右侧导航栏默认索引的是md文件的一二级标题,可能需要定义索引的标题级别和`On this page`这个说明。这个时候需要在config.mjs中配置下面这两个选项,`outlineTitle`用于替代On this page。`outline`定义展示的标题级别,这里定义2-6级
162 |
163 | 
164 |
165 | 最后美化后的文章目录是这样
166 |
167 | 
168 |
169 | **自动生成侧边栏**
170 |
171 | 我们使用这种配置时常常是一个目录有很多md文件,这些md文件所在的目录对应导航栏的一个选项。侧边栏的配置需要自己手写一个个路由映射到相应的文件上,那么有没有一个自动生成侧边栏的工具呢?根据一个目录下面的所有md文件自动生成路由,可以使用下面这个脚本
172 |
173 | ```js
174 | import path from "node:path";
175 | import fs from "node:fs";
176 |
177 | // 文件根目录
178 | const DIR_PATH = path.resolve();
179 | // 白名单,过滤不是文章的文件和文件夹
180 | const WHITE_LIST = [
181 | "index.md",
182 | ".vitepress",
183 | "node_modules",
184 | ".idea",
185 | "assets",
186 | ];
187 |
188 | // 判断是否是文件夹
189 | const isDirectory = (path) => fs.lstatSync(path).isDirectory();
190 |
191 | // 取差值
192 | const intersections = (arr1, arr2) =>
193 | Array.from(new Set(arr1.filter((item) => !new Set(arr2).has(item))));
194 |
195 | // 把方法导出直接使用
196 | function getList(params, path1, pathname) {
197 | // 存放结果
198 | const res = [];
199 | // 开始遍历params
200 | for (let file in params) {
201 | // 拼接目录
202 | const dir = path.join(path1, params[file]);
203 | // 判断是否是文件夹
204 | const isDir = isDirectory(dir);
205 | if (isDir) {
206 | // 如果是文件夹,读取之后作为下一次递归参数
207 | const files = fs.readdirSync(dir);
208 | res.push({
209 | text: params[file],
210 | collapsible: true,
211 | items: getList(files, dir, `${pathname}/${params[file]}`),
212 | });
213 | } else {
214 | // 获取名字
215 | const name = path.basename(params[file]);
216 | // 排除非 md 文件
217 | const suffix = path.extname(params[file]);
218 | if (suffix !== ".md") {
219 | continue;
220 | }
221 | res.push({
222 | text: name,
223 | link: `${pathname}/${name}`,
224 | });
225 | }
226 | }
227 | // 对name做一下处理,把后缀删除
228 | res.map((item) => {
229 | item.text = item.text.replace(/\.md$/, "");
230 | });
231 | return res;
232 | }
233 |
234 | export const set_sidebar = (pathname) => {
235 | // 获取pathname的路径
236 | const dirPath = path.join(DIR_PATH, pathname);
237 | // 读取pathname下的所有文件或者文件夹
238 | const files = fs.readdirSync(dirPath);
239 | // 过滤掉
240 | const items = intersections(files, WHITE_LIST);
241 | // getList 函数后面会讲到
242 | return getList(items, dirPath, pathname);
243 | };
244 | ```
245 |
246 | 使用时,需要导入函数名,
247 |
248 | ```js
249 | import { set_sidebar } from "../utils/auto-gen-sidebar.mjs"; // 改成自己的路径
250 | ```
251 |
252 | 直接使用。第一个/front-end/react常常是**nav的link**,这个set_sidebar传递的参数是相对于根路径的文件夹路径,返回的是每个文件夹中文件的名称和链接
253 |
254 | ```js
255 | sidebar: { "/front-end/react": set_sidebar("front-end/react") },
256 | ```
257 |
258 |
259 |
260 | ### 文章页扩展
261 |
262 | 当然,这样对一些项目的文档是非常合适的。但是如果我们需要记笔记的话有些繁琐,并且三边栏总感觉可以查阅的东西变少了。因此可以使用刚才说的自定义样式。将三边栏改成两边栏
263 |
264 | 在config.mjs中的themeConfig配置对象中配置
265 |
266 | ```js
267 | sidebar: false, // 关闭侧边栏
268 | aside: "left", // 设置右侧侧边栏在左侧显示
269 | ```
270 |
271 | 在.vitepress theme style.css中配置下面的css
272 |
273 | ```css
274 | /* 自定义侧边栏在最左边,右边撑满宽度 */
275 | .VPDoc .container {
276 | margin: 0 !important;
277 | }
278 | @media (min-width: 960px) {
279 | .VPDoc:not(.has-sidebar) .content {
280 | max-width: 1552px !important;
281 | }
282 | }
283 | .VPDoc.has-aside .content-container {
284 | max-width: 1488px !important;
285 | }
286 | @media (min-width: 960px) {
287 | .VPDoc:not(.has-sidebar) .container {
288 | display: flex;
289 | justify-content: center;
290 | max-width: 1562px !important;
291 | }
292 | }
293 | .aside-container {
294 | position: fixed;
295 | top: 0;
296 | padding-top: calc(
297 | var(--vp-nav-height) + var(--vp-layout-top-height, 0px) +
298 | var(--vp-doc-top-height, 0px) + 10px
299 | ) !important;
300 | width: 224px;
301 | height: 100vh;
302 | overflow-x: hidden;
303 | overflow-y: auto;
304 | scrollbar-width: none;
305 | }
306 |
307 | /* 自定义h2的间距 */
308 | .vp-doc h2 {
309 | margin: 0px 0 16px;
310 | padding-top: 24px;
311 | border: none;
312 | }
313 | ```
314 |
315 | 就可以将三栏样式改成双栏了(当然,上面的自定义css是我的偏好,根据实际情况可以修改),效果图如下
316 |
317 |
318 |
319 | 
320 |
321 | ### 美化地址栏icon
322 |
323 | 我们可能还需要修改浏览器地址栏的左边图标
324 |
325 | 
326 |
327 | 在`config.mjs defineConfig`下面直接配置即可
328 |
329 | ```js
330 | head: [["link", { rel: "icon", href: "/logo.svg" }]],
331 | ```
332 |
333 | ❗如果需要配置路径`base`,这个`href`也需要添加base路径作为前缀
334 |
335 | ### 设置搜索框
336 |
337 | 在`config.mjs defineConfig themeConfig`下面直接配置即可
338 |
339 | ```python
340 | // 设置搜索框的样式
341 | search: {
342 | provider: "local",
343 | options: {
344 | translations: {
345 | button: {
346 | buttonText: "搜索文档",
347 | buttonAriaLabel: "搜索文档",
348 | },
349 | modal: {
350 | noResultsText: "无法找到相关结果",
351 | resetButtonTitle: "清除查询条件",
352 | footer: {
353 | selectText: "选择",
354 | navigateText: "切换",
355 | },
356 | },
357 | },
358 | },
359 | },
360 | ```
361 |
362 |
363 |
364 | ## 使用Github Pages部署
365 |
366 | ### 部署步骤
367 |
368 | Github Pages专门用来托管静态内容,由于不需要服务器且基于git,支持CI/CD,成为很多静态网站比如博客、文档网站的很好的选择。下面介绍流程
369 |
370 | 1. 在github上创建仓库,如果没有Github账号,需要先注册一个。
371 |
372 | 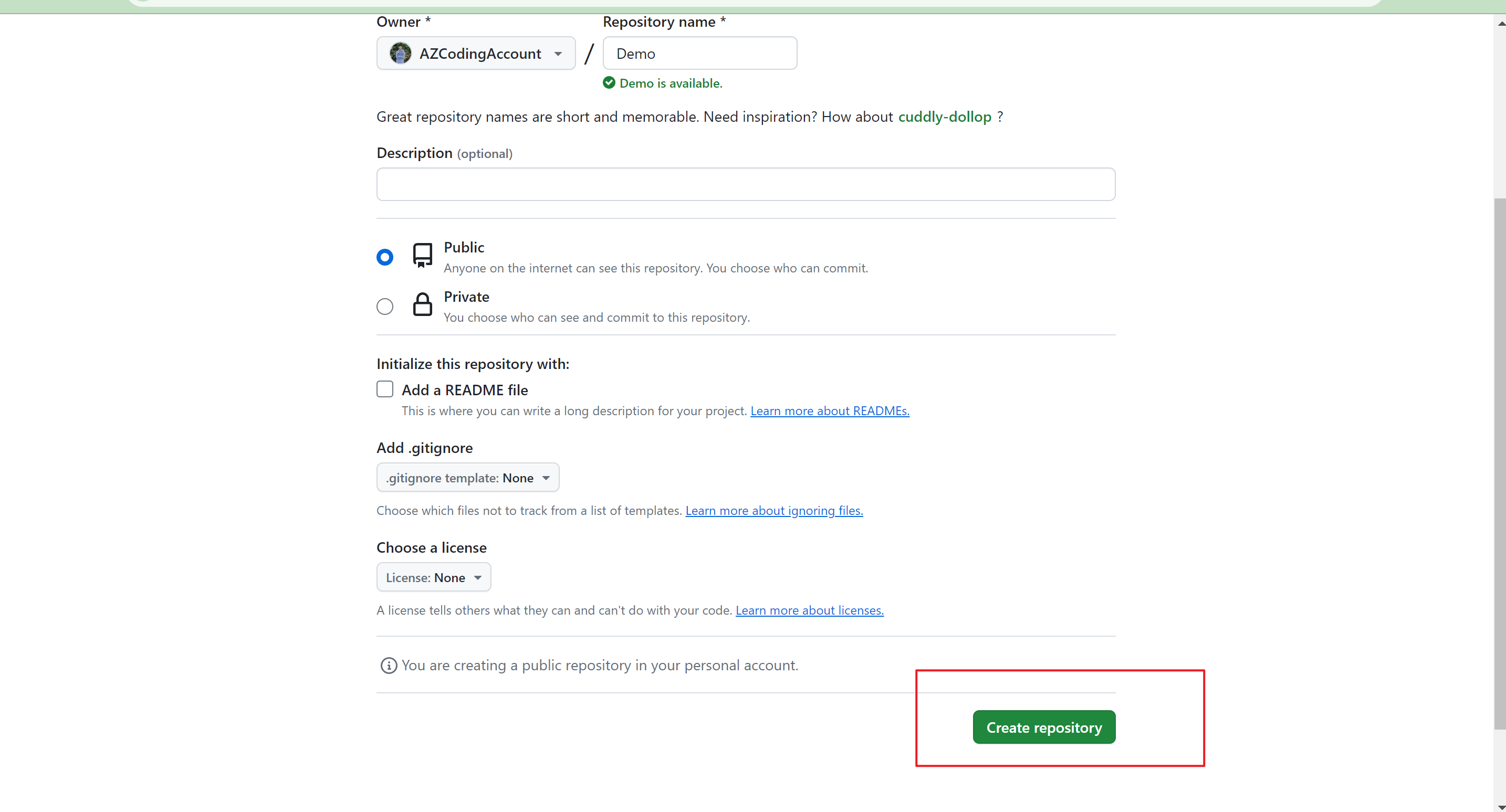
373 |
374 | 需要在config.mjs里面配置base,名称为github仓库名称,注意不要忘记改之前的icon
375 |
376 | ```js
377 | base: "/docs-demo/"
378 | ```
379 |
380 | 2. 初始化git仓库
381 |
382 | ```bash
383 | git init
384 | ```
385 |
386 | 3. 添加gitignore文件
387 |
388 | ```
389 | node_modules
390 | .DS_Store
391 | dist
392 | dist-ssr
393 | cache
394 | .cache
395 | .temp
396 | *.local
397 | ```
398 |
399 | 4. 添加本地所有文件到git仓库
400 |
401 | ```bash
402 | git add .
403 | ```
404 |
405 | 5. 创建第一次提交
406 |
407 | ```bash
408 | git commit -m "first commit"
409 | ```
410 |
411 | 6. 添加远程仓库地址到本地
412 |
413 | ```bash
414 | git remote add origin https://github.com/AZCodingAccount/Demo.git
415 | ```
416 |
417 | 7. 推送项目到github
418 |
419 | ```bash
420 | git push -u origin master
421 | ```
422 |
423 | 8. 选择github actions
424 |
425 | 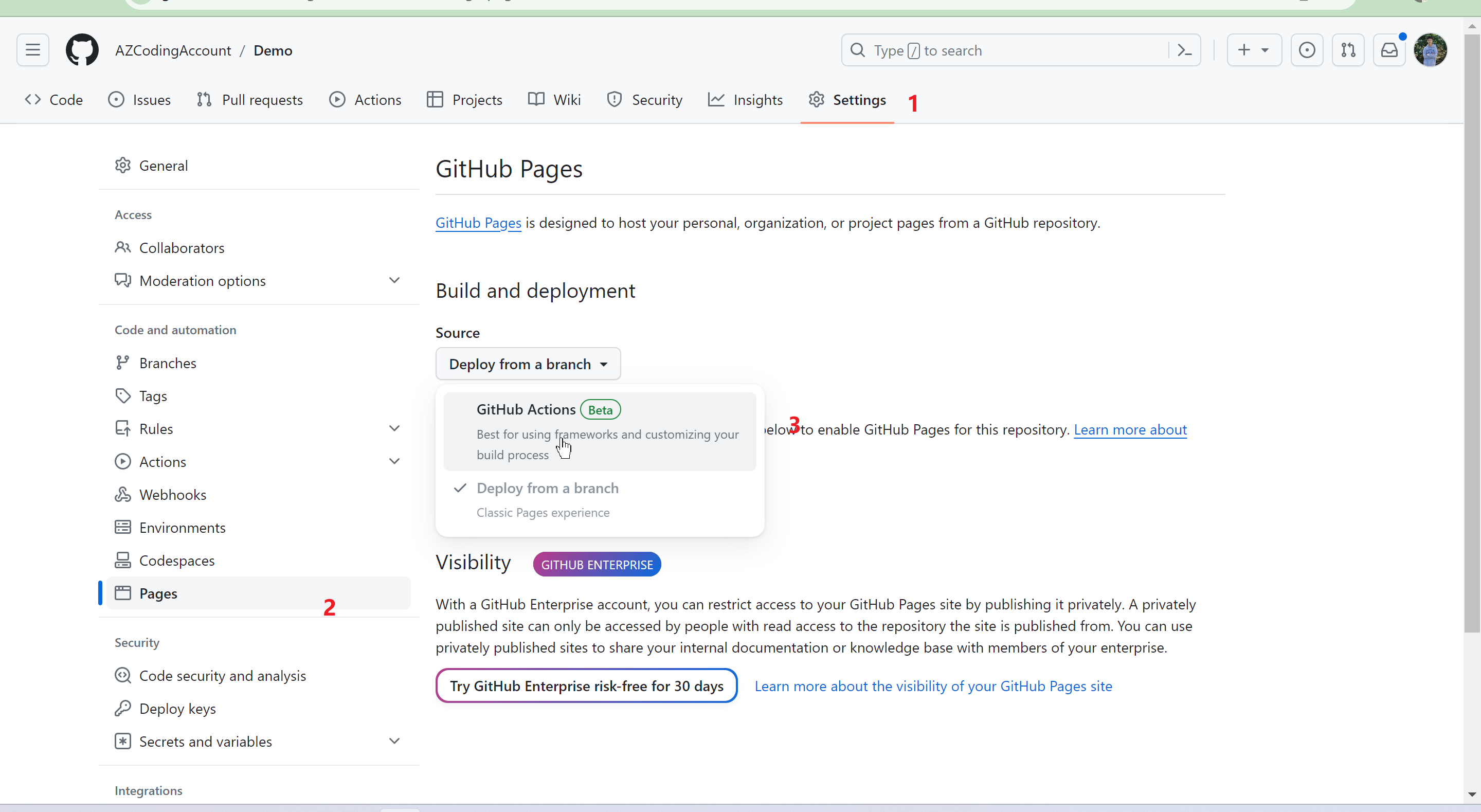
426 |
427 | 9. 设置工作流
428 |
429 | 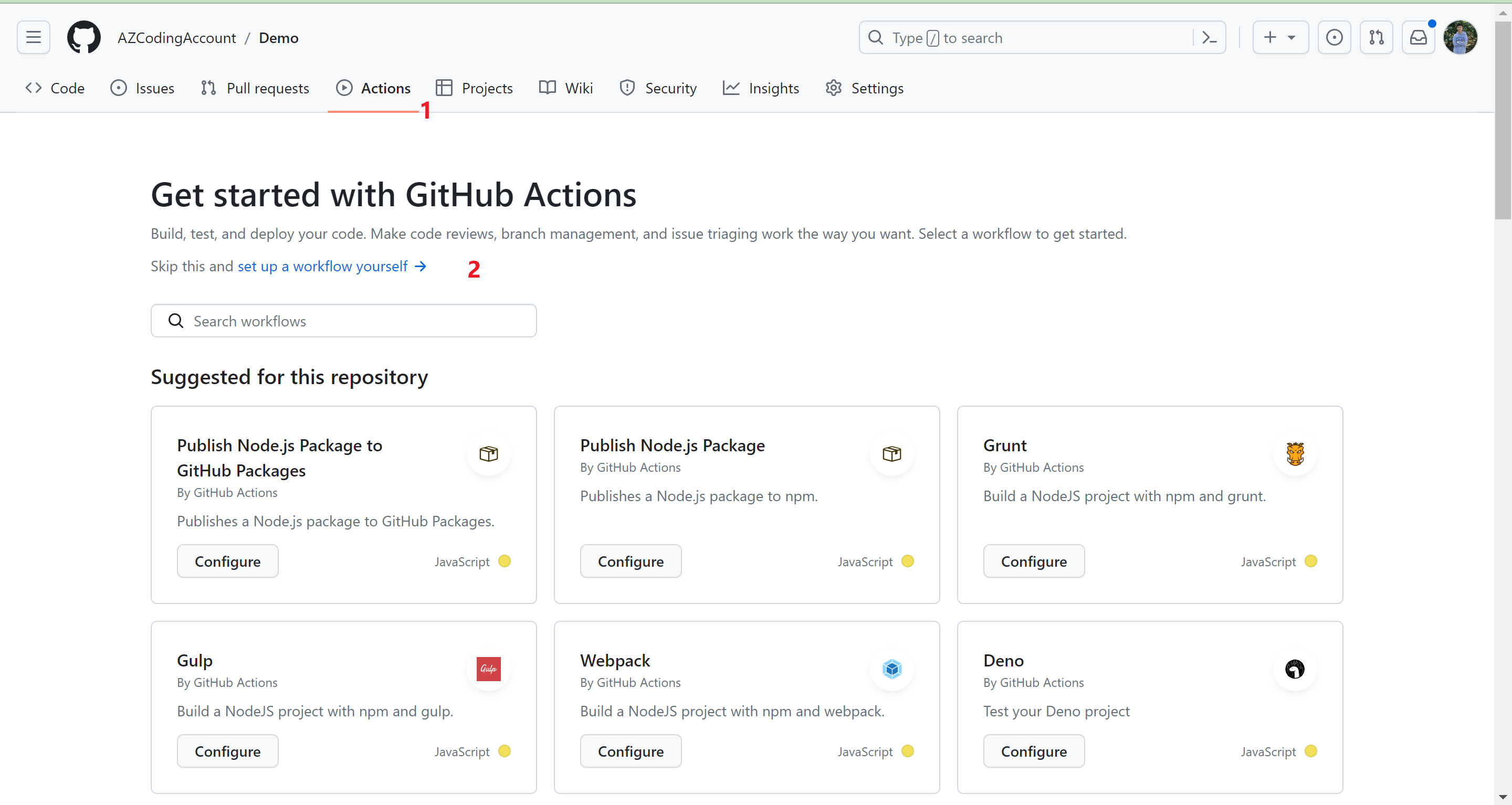
430 |
431 | 10. 重命名并设置deploy脚本
432 |
433 | 脚本文件:参考的vitepress官方文档:https://vitepress.dev/guide/deploy#github-pages
434 |
435 | ❗node版本和pnpm版本需要一致
436 |
437 | ❗对于npm的部署可以参考这个博客[GitHub Action一键部署个人博客 | Ahao (helloahao096.github.io)](https://helloahao096.github.io/helloahao/posts/GitHub Action一键部署个人博客.html)
438 |
439 | ❗需要注意项目的根目录(.vitepress所在的目录)
440 |
441 | ```yml
442 | name: Deploy VitePress site to Pages
443 |
444 | on:
445 | push:
446 | branches: [master]
447 |
448 | # 设置tokenn访问权限
449 | permissions:
450 | contents: read
451 | pages: write
452 | id-token: write
453 |
454 | # 只允许同时进行一次部署,跳过正在运行和最新队列之间的运行队列
455 | # 但是,不要取消正在进行的运行,因为我们希望允许这些生产部署完成
456 | concurrency:
457 | group: pages
458 | cancel-in-progress: false
459 |
460 | jobs:
461 | # 构建工作
462 | build:
463 | runs-on: ubuntu-latest
464 | steps:
465 | - name: Checkout
466 | uses: actions/checkout@v3
467 | with:
468 | fetch-depth: 0 # 如果未启用 lastUpdated,则不需要
469 | - name: Setup pnpm
470 | uses: pnpm/action-setup@v2 # 安装pnpm并添加到环境变量
471 | with:
472 | version: 8.6.12 # 指定需要的 pnpm 版本
473 | - name: Setup Node
474 | uses: actions/setup-node@v3
475 | with:
476 | node-version: 18
477 | cache: pnpm # 设置缓存
478 | - name: Setup Pages
479 | uses: actions/configure-pages@v3 # 在工作流程自动配置GithubPages
480 | - name: Install dependencies
481 | run: pnpm install # 安装依赖
482 | - name: Build with VitePress
483 | run: |
484 | pnpm run docs:build # 启动项目
485 | touch .nojekyll # 通知githubpages不要使用Jekyll处理这个站点,不知道为啥不生效,就手动搞了
486 | - name: Upload artifact
487 | uses: actions/upload-pages-artifact@v2 # 上传构建产物
488 | with:
489 | path: .vitepress/dist # 指定上传的路径,当前是根目录,如果是docs需要加docs/的前缀
490 |
491 | # 部署工作
492 | deploy:
493 | environment:
494 | name: github-pages
495 | url: ${{ steps.deployment.outputs.page_url }} # 从后续的输出中获取部署后的页面URL
496 | needs: build # 在build后面完成
497 | runs-on: ubuntu-latest # 运行在最新版本的ubuntu系统上
498 | name: Deploy
499 | steps:
500 | - name: Deploy to GitHub Pages
501 | id: deployment # 指定id
502 | uses: actions/deploy-pages@v2 # 将之前的构建产物部署到github pages中
503 |
504 | ```
505 |
506 |
507 |
508 | 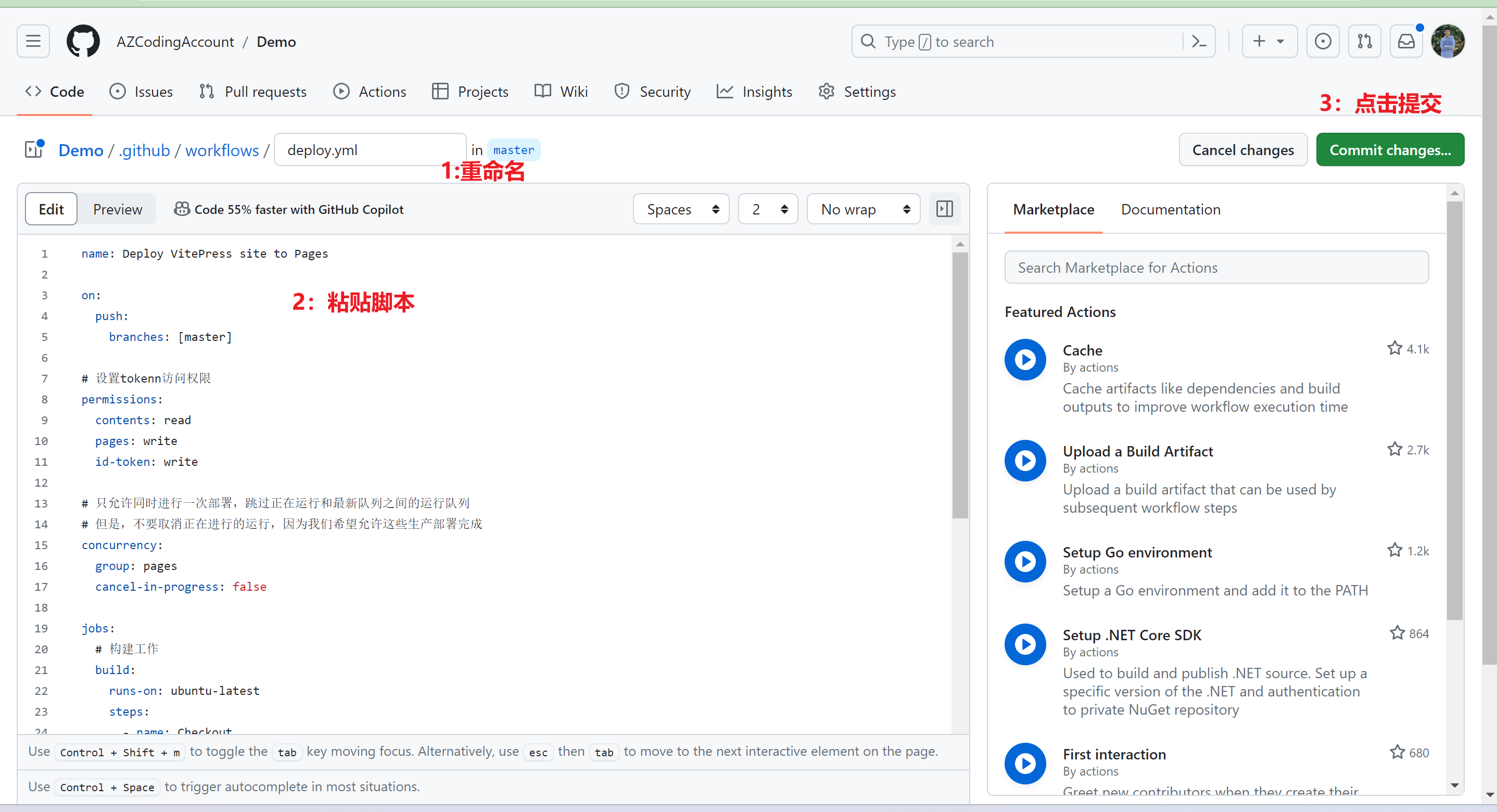
509 |
510 | 11. 点击确定,耐心等待15秒左右,就可以了,接下来查看我们的域名:
511 |
512 | 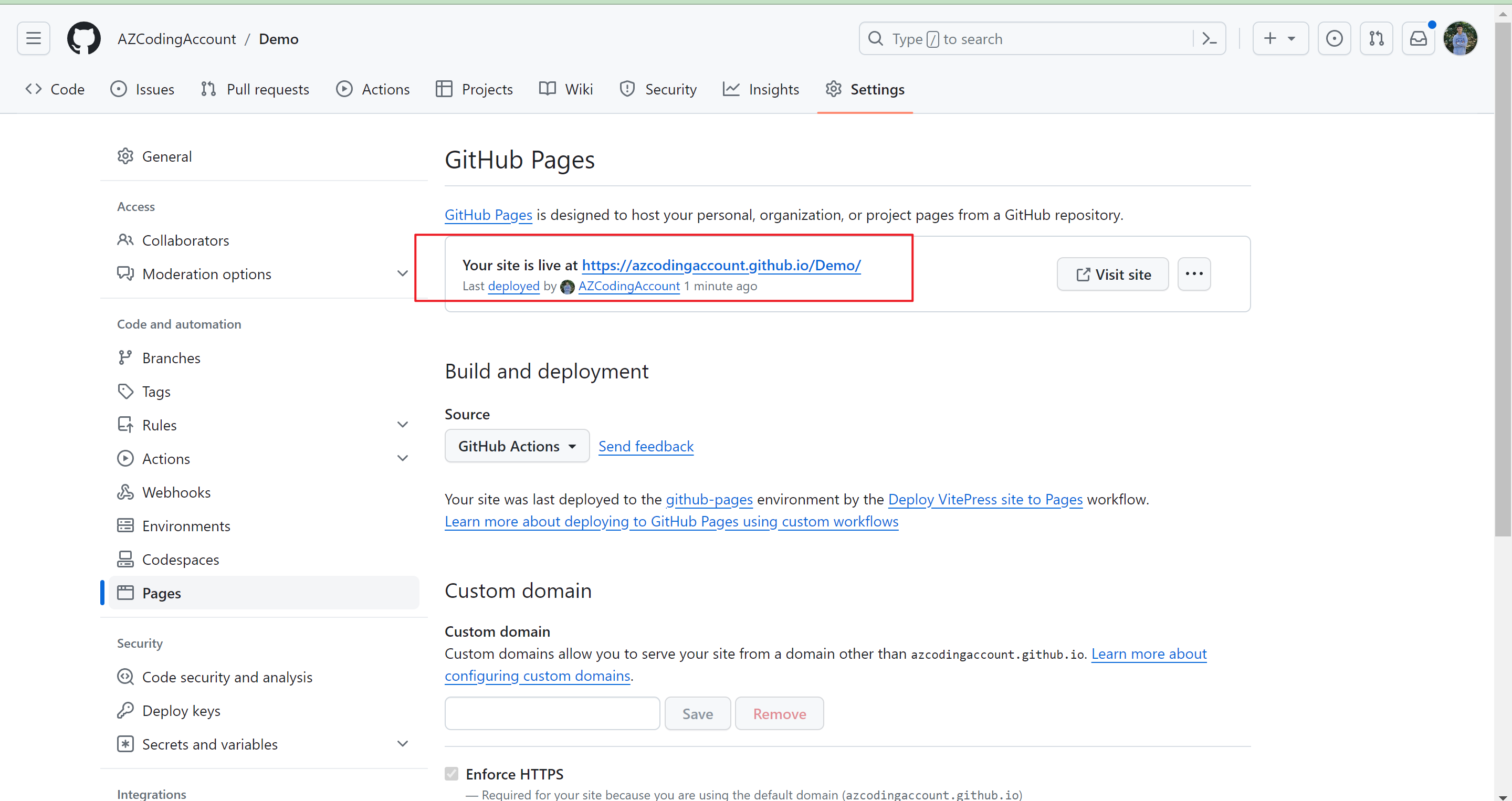
513 |
514 |
515 |
516 | 踩坑点:为啥下面的没有CSS样式呢?原因是因为没有.nojekyll这个文件,不然一些css会被忽略。添加一下再push就好了
517 |
518 | 
519 |
520 | 最后,就部署完毕了
521 |
522 | 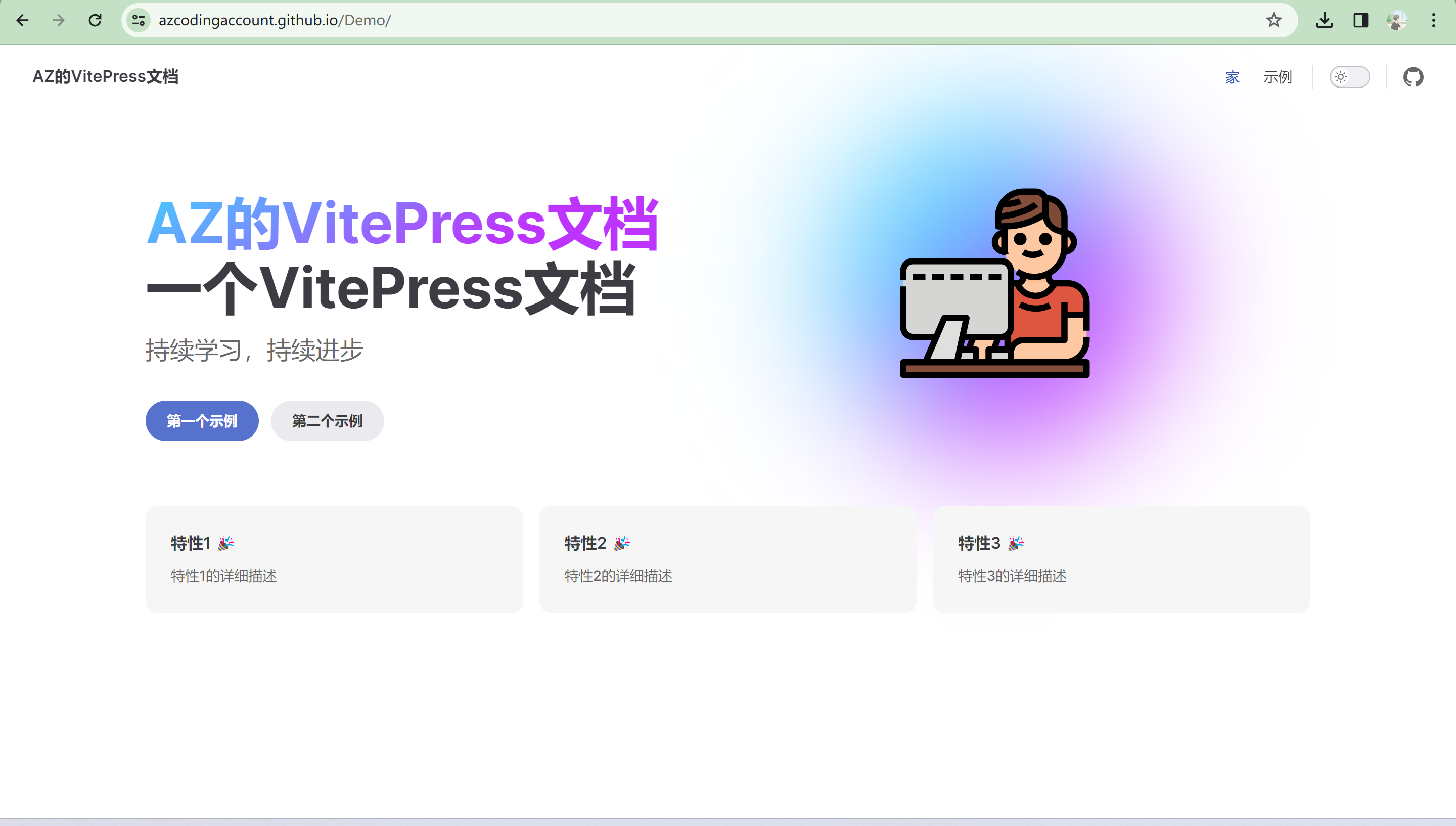
523 |
524 | ### 配置自定义域名
525 |
526 | 来自我的最佳实践,直接配置子域名,别配置4条A记录,没必要让所有都指向这个,一个域名能配置好几个网站。另外域名服务商只允许添加5条记录,多了就得加钱了。
527 |
528 | 在自己的域名服务商那里添加一条CNAME记录,直接指向自己的github分配的域名就好了,另外需要把这个base给注释掉(不然css文件和页面都找不到),等待分配完成。
529 |
530 | 
531 |
532 |
533 |
534 | ## 补充
535 |
536 | 如果你想要配置mermaid支持(这是一个可以使用md语法绘制流程图,饼状图的md扩展),需要按照下面的步骤操作。
537 | 安装
538 |
539 | ```bash
540 | npm i vitepress-plugin-mermaid mermaid -D
541 | ```
542 |
543 | 如果使用pnpm,还需要下面的配置改变pnpm的默认行为兼容插件
544 |
545 | ```bash
546 | pnpm install --shamefully-hoist
547 | # 或者在根目录新建.npmrc文件,配置
548 | shamefully-hoist=true
549 | ```
550 |
551 | 更改`.vitepress/config.mjs`配置项
552 |
553 | 1: 导入
554 |
555 | ```js
556 | import { withMermaid } from "vitepress-plugin-mermaid";
557 | ```
558 |
559 |
560 |
561 | 2: defineConfig—>withMermaid
562 |
563 |
122 |
123 | 最后美化的效果如图:
124 |
125 | 
126 |
127 | **TODO:**
128 |
129 | - logo的配置是在config.mjs添加。(注意是themeConfig不是config)
130 |
131 | ```
132 | logo: "logo.svg", // 配置logo位置,public目录
133 | ```
134 |
135 | - vitepress原生支持国外的sociallink,如果是国内需要自行复制svg代码。如图:
136 |
137 | 
138 |
139 | - 添加搜索栏,config.mjs中的themeConfig(支持国际化需要进一步配置 )
140 |
141 | 
142 |
143 | ### 美化文章页
144 |
145 | 默认进来官方给的示例是三边栏的
146 |
147 | 左边是sidebar的配置,右边是显示的文章目录(默认显示一二级)。
148 |
149 | 
150 |
151 |
152 |
153 | 下面叙述这个是怎么配置的。sidebar可以是数组,也可以是对象。还是修改config.mjs
154 |
155 | 
156 |
157 | 最后的结果是这样
158 |
159 | 
160 |
161 | 右侧导航栏默认索引的是md文件的一二级标题,可能需要定义索引的标题级别和`On this page`这个说明。这个时候需要在config.mjs中配置下面这两个选项,`outlineTitle`用于替代On this page。`outline`定义展示的标题级别,这里定义2-6级
162 |
163 | 
164 |
165 | 最后美化后的文章目录是这样
166 |
167 | 
168 |
169 | **自动生成侧边栏**
170 |
171 | 我们使用这种配置时常常是一个目录有很多md文件,这些md文件所在的目录对应导航栏的一个选项。侧边栏的配置需要自己手写一个个路由映射到相应的文件上,那么有没有一个自动生成侧边栏的工具呢?根据一个目录下面的所有md文件自动生成路由,可以使用下面这个脚本
172 |
173 | ```js
174 | import path from "node:path";
175 | import fs from "node:fs";
176 |
177 | // 文件根目录
178 | const DIR_PATH = path.resolve();
179 | // 白名单,过滤不是文章的文件和文件夹
180 | const WHITE_LIST = [
181 | "index.md",
182 | ".vitepress",
183 | "node_modules",
184 | ".idea",
185 | "assets",
186 | ];
187 |
188 | // 判断是否是文件夹
189 | const isDirectory = (path) => fs.lstatSync(path).isDirectory();
190 |
191 | // 取差值
192 | const intersections = (arr1, arr2) =>
193 | Array.from(new Set(arr1.filter((item) => !new Set(arr2).has(item))));
194 |
195 | // 把方法导出直接使用
196 | function getList(params, path1, pathname) {
197 | // 存放结果
198 | const res = [];
199 | // 开始遍历params
200 | for (let file in params) {
201 | // 拼接目录
202 | const dir = path.join(path1, params[file]);
203 | // 判断是否是文件夹
204 | const isDir = isDirectory(dir);
205 | if (isDir) {
206 | // 如果是文件夹,读取之后作为下一次递归参数
207 | const files = fs.readdirSync(dir);
208 | res.push({
209 | text: params[file],
210 | collapsible: true,
211 | items: getList(files, dir, `${pathname}/${params[file]}`),
212 | });
213 | } else {
214 | // 获取名字
215 | const name = path.basename(params[file]);
216 | // 排除非 md 文件
217 | const suffix = path.extname(params[file]);
218 | if (suffix !== ".md") {
219 | continue;
220 | }
221 | res.push({
222 | text: name,
223 | link: `${pathname}/${name}`,
224 | });
225 | }
226 | }
227 | // 对name做一下处理,把后缀删除
228 | res.map((item) => {
229 | item.text = item.text.replace(/\.md$/, "");
230 | });
231 | return res;
232 | }
233 |
234 | export const set_sidebar = (pathname) => {
235 | // 获取pathname的路径
236 | const dirPath = path.join(DIR_PATH, pathname);
237 | // 读取pathname下的所有文件或者文件夹
238 | const files = fs.readdirSync(dirPath);
239 | // 过滤掉
240 | const items = intersections(files, WHITE_LIST);
241 | // getList 函数后面会讲到
242 | return getList(items, dirPath, pathname);
243 | };
244 | ```
245 |
246 | 使用时,需要导入函数名,
247 |
248 | ```js
249 | import { set_sidebar } from "../utils/auto-gen-sidebar.mjs"; // 改成自己的路径
250 | ```
251 |
252 | 直接使用。第一个/front-end/react常常是**nav的link**,这个set_sidebar传递的参数是相对于根路径的文件夹路径,返回的是每个文件夹中文件的名称和链接
253 |
254 | ```js
255 | sidebar: { "/front-end/react": set_sidebar("front-end/react") },
256 | ```
257 |
258 |
259 |
260 | ### 文章页扩展
261 |
262 | 当然,这样对一些项目的文档是非常合适的。但是如果我们需要记笔记的话有些繁琐,并且三边栏总感觉可以查阅的东西变少了。因此可以使用刚才说的自定义样式。将三边栏改成两边栏
263 |
264 | 在config.mjs中的themeConfig配置对象中配置
265 |
266 | ```js
267 | sidebar: false, // 关闭侧边栏
268 | aside: "left", // 设置右侧侧边栏在左侧显示
269 | ```
270 |
271 | 在.vitepress theme style.css中配置下面的css
272 |
273 | ```css
274 | /* 自定义侧边栏在最左边,右边撑满宽度 */
275 | .VPDoc .container {
276 | margin: 0 !important;
277 | }
278 | @media (min-width: 960px) {
279 | .VPDoc:not(.has-sidebar) .content {
280 | max-width: 1552px !important;
281 | }
282 | }
283 | .VPDoc.has-aside .content-container {
284 | max-width: 1488px !important;
285 | }
286 | @media (min-width: 960px) {
287 | .VPDoc:not(.has-sidebar) .container {
288 | display: flex;
289 | justify-content: center;
290 | max-width: 1562px !important;
291 | }
292 | }
293 | .aside-container {
294 | position: fixed;
295 | top: 0;
296 | padding-top: calc(
297 | var(--vp-nav-height) + var(--vp-layout-top-height, 0px) +
298 | var(--vp-doc-top-height, 0px) + 10px
299 | ) !important;
300 | width: 224px;
301 | height: 100vh;
302 | overflow-x: hidden;
303 | overflow-y: auto;
304 | scrollbar-width: none;
305 | }
306 |
307 | /* 自定义h2的间距 */
308 | .vp-doc h2 {
309 | margin: 0px 0 16px;
310 | padding-top: 24px;
311 | border: none;
312 | }
313 | ```
314 |
315 | 就可以将三栏样式改成双栏了(当然,上面的自定义css是我的偏好,根据实际情况可以修改),效果图如下
316 |
317 |
318 |
319 | 
320 |
321 | ### 美化地址栏icon
322 |
323 | 我们可能还需要修改浏览器地址栏的左边图标
324 |
325 | 
326 |
327 | 在`config.mjs defineConfig`下面直接配置即可
328 |
329 | ```js
330 | head: [["link", { rel: "icon", href: "/logo.svg" }]],
331 | ```
332 |
333 | ❗如果需要配置路径`base`,这个`href`也需要添加base路径作为前缀
334 |
335 | ### 设置搜索框
336 |
337 | 在`config.mjs defineConfig themeConfig`下面直接配置即可
338 |
339 | ```python
340 | // 设置搜索框的样式
341 | search: {
342 | provider: "local",
343 | options: {
344 | translations: {
345 | button: {
346 | buttonText: "搜索文档",
347 | buttonAriaLabel: "搜索文档",
348 | },
349 | modal: {
350 | noResultsText: "无法找到相关结果",
351 | resetButtonTitle: "清除查询条件",
352 | footer: {
353 | selectText: "选择",
354 | navigateText: "切换",
355 | },
356 | },
357 | },
358 | },
359 | },
360 | ```
361 |
362 |
363 |
364 | ## 使用Github Pages部署
365 |
366 | ### 部署步骤
367 |
368 | Github Pages专门用来托管静态内容,由于不需要服务器且基于git,支持CI/CD,成为很多静态网站比如博客、文档网站的很好的选择。下面介绍流程
369 |
370 | 1. 在github上创建仓库,如果没有Github账号,需要先注册一个。
371 |
372 | 
373 |
374 | 需要在config.mjs里面配置base,名称为github仓库名称,注意不要忘记改之前的icon
375 |
376 | ```js
377 | base: "/docs-demo/"
378 | ```
379 |
380 | 2. 初始化git仓库
381 |
382 | ```bash
383 | git init
384 | ```
385 |
386 | 3. 添加gitignore文件
387 |
388 | ```
389 | node_modules
390 | .DS_Store
391 | dist
392 | dist-ssr
393 | cache
394 | .cache
395 | .temp
396 | *.local
397 | ```
398 |
399 | 4. 添加本地所有文件到git仓库
400 |
401 | ```bash
402 | git add .
403 | ```
404 |
405 | 5. 创建第一次提交
406 |
407 | ```bash
408 | git commit -m "first commit"
409 | ```
410 |
411 | 6. 添加远程仓库地址到本地
412 |
413 | ```bash
414 | git remote add origin https://github.com/AZCodingAccount/Demo.git
415 | ```
416 |
417 | 7. 推送项目到github
418 |
419 | ```bash
420 | git push -u origin master
421 | ```
422 |
423 | 8. 选择github actions
424 |
425 | 
426 |
427 | 9. 设置工作流
428 |
429 | 
430 |
431 | 10. 重命名并设置deploy脚本
432 |
433 | 脚本文件:参考的vitepress官方文档:https://vitepress.dev/guide/deploy#github-pages
434 |
435 | ❗node版本和pnpm版本需要一致
436 |
437 | ❗对于npm的部署可以参考这个博客[GitHub Action一键部署个人博客 | Ahao (helloahao096.github.io)](https://helloahao096.github.io/helloahao/posts/GitHub Action一键部署个人博客.html)
438 |
439 | ❗需要注意项目的根目录(.vitepress所在的目录)
440 |
441 | ```yml
442 | name: Deploy VitePress site to Pages
443 |
444 | on:
445 | push:
446 | branches: [master]
447 |
448 | # 设置tokenn访问权限
449 | permissions:
450 | contents: read
451 | pages: write
452 | id-token: write
453 |
454 | # 只允许同时进行一次部署,跳过正在运行和最新队列之间的运行队列
455 | # 但是,不要取消正在进行的运行,因为我们希望允许这些生产部署完成
456 | concurrency:
457 | group: pages
458 | cancel-in-progress: false
459 |
460 | jobs:
461 | # 构建工作
462 | build:
463 | runs-on: ubuntu-latest
464 | steps:
465 | - name: Checkout
466 | uses: actions/checkout@v3
467 | with:
468 | fetch-depth: 0 # 如果未启用 lastUpdated,则不需要
469 | - name: Setup pnpm
470 | uses: pnpm/action-setup@v2 # 安装pnpm并添加到环境变量
471 | with:
472 | version: 8.6.12 # 指定需要的 pnpm 版本
473 | - name: Setup Node
474 | uses: actions/setup-node@v3
475 | with:
476 | node-version: 18
477 | cache: pnpm # 设置缓存
478 | - name: Setup Pages
479 | uses: actions/configure-pages@v3 # 在工作流程自动配置GithubPages
480 | - name: Install dependencies
481 | run: pnpm install # 安装依赖
482 | - name: Build with VitePress
483 | run: |
484 | pnpm run docs:build # 启动项目
485 | touch .nojekyll # 通知githubpages不要使用Jekyll处理这个站点,不知道为啥不生效,就手动搞了
486 | - name: Upload artifact
487 | uses: actions/upload-pages-artifact@v2 # 上传构建产物
488 | with:
489 | path: .vitepress/dist # 指定上传的路径,当前是根目录,如果是docs需要加docs/的前缀
490 |
491 | # 部署工作
492 | deploy:
493 | environment:
494 | name: github-pages
495 | url: ${{ steps.deployment.outputs.page_url }} # 从后续的输出中获取部署后的页面URL
496 | needs: build # 在build后面完成
497 | runs-on: ubuntu-latest # 运行在最新版本的ubuntu系统上
498 | name: Deploy
499 | steps:
500 | - name: Deploy to GitHub Pages
501 | id: deployment # 指定id
502 | uses: actions/deploy-pages@v2 # 将之前的构建产物部署到github pages中
503 |
504 | ```
505 |
506 |
507 |
508 | 
509 |
510 | 11. 点击确定,耐心等待15秒左右,就可以了,接下来查看我们的域名:
511 |
512 | 
513 |
514 |
515 |
516 | 踩坑点:为啥下面的没有CSS样式呢?原因是因为没有.nojekyll这个文件,不然一些css会被忽略。添加一下再push就好了
517 |
518 | 
519 |
520 | 最后,就部署完毕了
521 |
522 | 
523 |
524 | ### 配置自定义域名
525 |
526 | 来自我的最佳实践,直接配置子域名,别配置4条A记录,没必要让所有都指向这个,一个域名能配置好几个网站。另外域名服务商只允许添加5条记录,多了就得加钱了。
527 |
528 | 在自己的域名服务商那里添加一条CNAME记录,直接指向自己的github分配的域名就好了,另外需要把这个base给注释掉(不然css文件和页面都找不到),等待分配完成。
529 |
530 | 
531 |
532 |
533 |
534 | ## 补充
535 |
536 | 如果你想要配置mermaid支持(这是一个可以使用md语法绘制流程图,饼状图的md扩展),需要按照下面的步骤操作。
537 | 安装
538 |
539 | ```bash
540 | npm i vitepress-plugin-mermaid mermaid -D
541 | ```
542 |
543 | 如果使用pnpm,还需要下面的配置改变pnpm的默认行为兼容插件
544 |
545 | ```bash
546 | pnpm install --shamefully-hoist
547 | # 或者在根目录新建.npmrc文件,配置
548 | shamefully-hoist=true
549 | ```
550 |
551 | 更改`.vitepress/config.mjs`配置项
552 |
553 | 1: 导入
554 |
555 | ```js
556 | import { withMermaid } from "vitepress-plugin-mermaid";
557 | ```
558 |
559 |
560 |
561 | 2: defineConfig—>withMermaid
562 |
563 |  564 |
565 | 3:根配置项下添加
566 |
567 | ```js
568 | mermaid: {
569 | // refer https://mermaid.js.org/config/setup/modules/mermaidAPI.html#mermaidapi-configuration-defaults for options
570 | },
571 | mermaidPlugin: {
572 | class: "mermaid my-class", // set additional css classes for parent container
573 | },
574 | ```
575 |
576 | 可以访问[插件官网](https://emersonbottero.github.io/vitepress-plugin-mermaid/guide/getting-started.html)和[mermaid官网](https://mermaid.js.org/config/setup/modules/mermaidAPI.html#mermaidapi-configuration-defaults for options)获取更多配置信息
577 |
--------------------------------------------------------------------------------
/docs/back-end/elasticsearch.md:
--------------------------------------------------------------------------------
1 | ## ElasticSearch
--------------------------------------------------------------------------------
/docs/back-end/integrate-tech.md:
--------------------------------------------------------------------------------
1 | # SpringBoot集成各种技术
2 |
3 | 演示一个小的Demo,拿过去就可以用,不用再查文档了,当然,还有一个java程序的模版。
4 |
5 | ## 集成ChatGPT
6 |
7 | ## 集成Ression
8 |
9 | ### Ression介绍
10 |
11 | 限流工具
12 |
13 | ### 代码实现
14 |
15 | ## 集成RabbitMQ
16 |
17 | ## 集成Redis
18 |
19 | ## 集成SpringTask
20 |
21 | ## 集成WebSocket
22 |
23 | ## 集成ES
24 |
25 |
--------------------------------------------------------------------------------
/docs/back-end/mybatis-plus.md:
--------------------------------------------------------------------------------
1 | # Mybatis-Plus
--------------------------------------------------------------------------------
/docs/back-end/rabbitmq.md:
--------------------------------------------------------------------------------
1 | ## rabbitmq
--------------------------------------------------------------------------------
/docs/back-end/springboot-template.md:
--------------------------------------------------------------------------------
1 | # SpringBoot项目模版
2 |
3 | 在做项目时候,常常需要有规范的项目目录、集成各种技术、甚至代码规范、接口命名、基础的CRUD等等,我之前做项目是去找之前的项目然后CV过来,后来发现都是机械性的重复工作。
4 |
5 | 可以专门集成一下项目的模版,这样CV肯定比从0开始快,写代码时候也有个参考。前端项目可以通过一些中台系统比如Arco design pro一键生成模版,但是后端还是自己写比较好,要集成的技术如下
6 |
7 | 模版:
8 |
9 | - 规范的目录结构
10 | - 登录注册代码模版,权限校验自定义注解
11 | - Redis序列化拦截器配置、操作Redis的CRUD代码
12 | - 规范的接口返回结构、全局异常处理
13 | - Swagger+Knife4j接口文档
14 | - SQL模版
15 |
16 | 技术集成
17 |
18 | - Junit5集成
19 | - EasyExcel集成
20 | - MP集成、分页拦截器
21 | - Hutool工具包集成
22 | - WebSocket集成
23 | - SpringTask定时任务
24 | - Redis分布式登录
25 | - Redission限流
26 | - ES搜索
27 | - RabbitMQ消息队列
28 | - DubboRPC框架
29 | - SpringCloudGateway网关
30 | - Nacos注册中心
31 |
32 | 部署
33 |
34 | - 后端跨域配置
35 |
36 | - Docker部署 脚本
37 |
38 | 下面贴一下Github地址,需要用直接克隆下来就可以
39 |
40 |
41 |
42 |
43 |
44 |
--------------------------------------------------------------------------------
/docs/front-end/react.md:
--------------------------------------------------------------------------------
1 | # React学习笔记
2 |
3 | 还是得记笔记,好记性不如烂笔头,之前学的React也仅限于会用,很多API的具体用法,原理还是忘,今年寒假4天把黑马出的React视频过一遍再做一个笔记。
4 |
5 | ## 初识React
6 |
7 | React是meta(原facebook)公司开源的前端框架,跟vue相似都是基于虚拟DOM的。但是相对vue而言有这些优势
8 |
9 | - 由于出现的比较早,社区资源更丰富,更流行
10 | - 大公司构建,稳定性和扩展性更好
11 | - 跟ts无缝集成
12 | - 个人觉得写起来自由度更高,更贴近js原生
13 |
14 | ## React入门
15 |
16 | diff算法是用于比较两个数据集之间的差异的算法,应用场景如更新虚拟DOM、版本控制系统Git
17 |
18 | uuid重复的概率使用生日悖论估计的话,1万亿条数据,生成的uuid重复的概率大概是9.4*10-14
19 |
20 | ### JSX是什么
21 |
22 | JSX全称JavaScript XML,是一种由meta(原facebook)公司推出的一个JS语法扩展,它允许开发者在js代码中写类似于HTML的标记语法,这种语法在React中应用广泛,浏览器不能识别JSX代码,需要通过如Babel这种构建工具编译以后使用。基本的用法是类似于
23 |
24 | ```jsx
25 | const titleText="Hello World";
26 | const title=
564 |
565 | 3:根配置项下添加
566 |
567 | ```js
568 | mermaid: {
569 | // refer https://mermaid.js.org/config/setup/modules/mermaidAPI.html#mermaidapi-configuration-defaults for options
570 | },
571 | mermaidPlugin: {
572 | class: "mermaid my-class", // set additional css classes for parent container
573 | },
574 | ```
575 |
576 | 可以访问[插件官网](https://emersonbottero.github.io/vitepress-plugin-mermaid/guide/getting-started.html)和[mermaid官网](https://mermaid.js.org/config/setup/modules/mermaidAPI.html#mermaidapi-configuration-defaults for options)获取更多配置信息
577 |
--------------------------------------------------------------------------------
/docs/back-end/elasticsearch.md:
--------------------------------------------------------------------------------
1 | ## ElasticSearch
--------------------------------------------------------------------------------
/docs/back-end/integrate-tech.md:
--------------------------------------------------------------------------------
1 | # SpringBoot集成各种技术
2 |
3 | 演示一个小的Demo,拿过去就可以用,不用再查文档了,当然,还有一个java程序的模版。
4 |
5 | ## 集成ChatGPT
6 |
7 | ## 集成Ression
8 |
9 | ### Ression介绍
10 |
11 | 限流工具
12 |
13 | ### 代码实现
14 |
15 | ## 集成RabbitMQ
16 |
17 | ## 集成Redis
18 |
19 | ## 集成SpringTask
20 |
21 | ## 集成WebSocket
22 |
23 | ## 集成ES
24 |
25 |
--------------------------------------------------------------------------------
/docs/back-end/mybatis-plus.md:
--------------------------------------------------------------------------------
1 | # Mybatis-Plus
--------------------------------------------------------------------------------
/docs/back-end/rabbitmq.md:
--------------------------------------------------------------------------------
1 | ## rabbitmq
--------------------------------------------------------------------------------
/docs/back-end/springboot-template.md:
--------------------------------------------------------------------------------
1 | # SpringBoot项目模版
2 |
3 | 在做项目时候,常常需要有规范的项目目录、集成各种技术、甚至代码规范、接口命名、基础的CRUD等等,我之前做项目是去找之前的项目然后CV过来,后来发现都是机械性的重复工作。
4 |
5 | 可以专门集成一下项目的模版,这样CV肯定比从0开始快,写代码时候也有个参考。前端项目可以通过一些中台系统比如Arco design pro一键生成模版,但是后端还是自己写比较好,要集成的技术如下
6 |
7 | 模版:
8 |
9 | - 规范的目录结构
10 | - 登录注册代码模版,权限校验自定义注解
11 | - Redis序列化拦截器配置、操作Redis的CRUD代码
12 | - 规范的接口返回结构、全局异常处理
13 | - Swagger+Knife4j接口文档
14 | - SQL模版
15 |
16 | 技术集成
17 |
18 | - Junit5集成
19 | - EasyExcel集成
20 | - MP集成、分页拦截器
21 | - Hutool工具包集成
22 | - WebSocket集成
23 | - SpringTask定时任务
24 | - Redis分布式登录
25 | - Redission限流
26 | - ES搜索
27 | - RabbitMQ消息队列
28 | - DubboRPC框架
29 | - SpringCloudGateway网关
30 | - Nacos注册中心
31 |
32 | 部署
33 |
34 | - 后端跨域配置
35 |
36 | - Docker部署 脚本
37 |
38 | 下面贴一下Github地址,需要用直接克隆下来就可以
39 |
40 |
41 |
42 |
43 |
44 |
--------------------------------------------------------------------------------
/docs/front-end/react.md:
--------------------------------------------------------------------------------
1 | # React学习笔记
2 |
3 | 还是得记笔记,好记性不如烂笔头,之前学的React也仅限于会用,很多API的具体用法,原理还是忘,今年寒假4天把黑马出的React视频过一遍再做一个笔记。
4 |
5 | ## 初识React
6 |
7 | React是meta(原facebook)公司开源的前端框架,跟vue相似都是基于虚拟DOM的。但是相对vue而言有这些优势
8 |
9 | - 由于出现的比较早,社区资源更丰富,更流行
10 | - 大公司构建,稳定性和扩展性更好
11 | - 跟ts无缝集成
12 | - 个人觉得写起来自由度更高,更贴近js原生
13 |
14 | ## React入门
15 |
16 | diff算法是用于比较两个数据集之间的差异的算法,应用场景如更新虚拟DOM、版本控制系统Git
17 |
18 | uuid重复的概率使用生日悖论估计的话,1万亿条数据,生成的uuid重复的概率大概是9.4*10-14
19 |
20 | ### JSX是什么
21 |
22 | JSX全称JavaScript XML,是一种由meta(原facebook)公司推出的一个JS语法扩展,它允许开发者在js代码中写类似于HTML的标记语法,这种语法在React中应用广泛,浏览器不能识别JSX代码,需要通过如Babel这种构建工具编译以后使用。基本的用法是类似于
23 |
24 | ```jsx
25 | const titleText="Hello World";
26 | const title={titleText}
; 27 | ``` 28 | 29 | 需要注意的是,大括号只能插入表达式而不能插入语句,函数、变量、模版字符串这些都可以,但是不能写如{a=1} 30 | 31 | ### 初始化React项目 32 | 33 | 使用CRA创建React项目。(当然使用Vite也是可以的) 34 | 35 | npx是npm的扩展,允许执行包中的命令而无需全局安装这些包,如果没有在执行过程中下载,执行命令完毕以后自动移除这个包。 36 | 37 | 使用npx初始化React项目的方式如下: 38 | 39 | ```bash 40 | npx create-react-app my-app 41 | ``` 42 | 43 | 使用pnpm初始化的命令(好像后面还会提示不兼容问题,还是用npx吧) 44 | 45 | ```bash 46 | pnpm create react-app my-app 47 | ``` 48 | 49 | 安装时候可能有点慢,三个包管理工具配置镜像源的命令 50 | 51 | ```bash 52 | npm config set registry https://registry.npmmirror.com 53 | pnpm config set registry https://registry.npmmirror.com 54 | yarn config set registry https://registry.npmmirror.com 55 | ``` 56 | 57 | ### jsx的简单使用 58 | 59 | **渲染列表** 60 | 61 | 返回使用小括号,不要使用中括号或者大括号 62 | 63 | 返回的是一个数组,react会自动解析渲染 64 | 65 | ```jsx 66 | const list = [ 67 | { name: "张三", age: 18 }, 68 | { name: "李四", age: 20 }, 69 | { name: "王五", age: 22 }, 70 | { name: "赵六", age: 24 }, 71 | ]; 72 | return ( 73 |
74 |
85 | );
86 | ```
87 |
88 | **条件渲染**
89 |
90 | ```jsx
91 | import { useState } from "react";
92 |
93 | const [isShow, setIsShow] = useState(false); // 控制内容显示隐藏
94 | const handleClick = () => {
95 | setIsShow(!isShow); // 修改状态
96 | };
97 | return (
98 | -
75 | {list.map((item, index) => {
76 | // 加上key是为了方便diff算法,规范是必须加
77 | return (
78 |
- 79 | 姓名:{item.name};年龄:{item.age} 80 | 81 | ); 82 | })} 83 |
99 | {/* {isShow &&
104 | );
105 | ```
106 |
107 | **条件渲染+函数调用**
108 |
109 | ```jsx
110 | const type = 1;
111 | const returnData = (type) => {
112 | if (type === 1) {
113 | return 应该展示的内容
} */}
100 | {/* 三目运算符 */}
101 | {isShow ? 应该展示的内容
: null}
102 |
103 | Hello 1
;
114 | } else if (type === 2) {
115 | return Hello 2
;
116 | }
117 | };
118 | return {type === 1 && returnData(type)}
; // type为1时才进行函数调用
119 | ```
120 |
121 | ## React基础
122 |
123 | ### 基础Hooks的使用
124 |
125 | #### useState
126 |
127 | 如果想要数据双向绑定的话,需要使用useState这个hook函数解构一个方法来修改状态(对于对象也是一样,一般都需要展开一下构建新对象赋值给原变量)
128 |
129 | 计时器案例
130 |
131 | ```jsx
132 | let [count, setCount] = useState(0);
133 | const handleDec = () => {
134 | setCount(--count);
135 | };
136 | const handleInc = () => {
137 | setCount(++count);
138 | };
139 | return (
140 |
141 |
142 | {count}
143 |
144 |
145 | );
146 | ```
147 |
148 | ! 实现样式控制,需要注意的是,对于多个单词的如font-size,bgc这种都需要使用驼峰
149 |
150 | **样式的扩展应用—classNames**
151 |
152 | 实际开发一般采用样式和代码分离,可以引入一个第三方库classNames,更方便的动态控制样式的显示隐藏
153 |
154 | github:[classNames](https://github.com/JedWatson/classnames)
155 |
156 | ```bash
157 | npm install classnames # 引入
158 | # 使用修改计数器案例
159 | # index.css
160 | .count-style{
161 | color: red;
162 | font-size: 25px;
163 | }
164 |
165 | # App.js
166 | import { useState } from "react";
167 | import classNames from "classnames";
168 | import "./index.css";
169 |
170 | function App() {
171 | let [count, setCount] = useState(0);
172 | const countClass = classNames({ "count-style": count > 5 }); # 静态属性直接在前面添加
173 | const handleDec = () => {
174 | setCount(--count);
175 | };
176 | const handleInc = () => {
177 | setCount(++count);
178 | };
179 | return (
180 |
181 |
182 | {count}
183 |
184 |
185 | );
186 | }
187 |
188 | export default App;
189 | ```
190 |
191 | #### useRef
192 |
193 | 这个hook函数可以获取ref对象,拿到ref对象(常和副作用钩子结合使用)以后,可以做一系列操作,比如说给输入框聚焦,获取输入框的值、设置输入框的值等。
194 |
195 | **发表评论案例**
196 |
197 | ```jsx
198 | let [comment, setComment] = useState("");
199 | const inputRef = useRef(); // 输入框对象
200 | const handlePublish = () => {
201 | console.dir(inputRef.current); // 打印输入框对象
202 | // 发表完成以后聚焦,展示内容(一般是绑定value属性,onChange事件)
203 | const value = inputRef.current.value;
204 | inputRef.current.value = ""; // 清空输入框
205 | setComment(value); // 更新显示值
206 | inputRef.current.focus(); // 聚焦
207 | };
208 | return (
209 |
210 | {/* 输入框和按钮 */}
211 |
216 |
217 | {/* 展示内容区域 */}
218 |
220 | );
221 | ```
222 |
223 | #### useEffect
224 |
225 | 这个hook函数用于不是由事件引起而是由渲染引起的操作,如刚进来或DOM更新发送AJAX请求,DOM更新以后要执行的操作等等。类似于Vue的watch和生命周期钩子的作用。
226 |
227 | **基础使用**
228 |
229 | ```jsx
230 | // 模拟特定依赖项更新向后端重新请求数据
231 | import { useEffect, useState } from "react";
232 |
233 | function App() {
234 | let [goodList, setGoodList] = useState([
235 | {
236 | name: "小飞棍",
237 | count: 11,
238 | },
239 | { name: "山竹醇", count: 500 },
240 | ]);
241 | const handleDelete = () => {
242 | console.log("发出删除数据的请求")
243 | setGoodList(goodList.filter((item) => item.name !== "山竹醇")); // 模拟删除并渲染
244 | };
245 | useEffect(() => {
246 | console.log("向后端重新请求数据");
247 | }, [goodList]);
248 | return (
249 | {comment}
219 |
250 | {goodList.map((item, index) => {
251 | return
255 | );
256 | }
257 | ```
258 |
259 | useEffect三个不同依赖项的执行时机对应关系
260 |
261 | | 依赖项 | 副作用函数执行时机 |
262 | | -------------- | ---------------------------------- |
263 | | 没有依赖项 | 组件初始渲染时和组件更新时执行 |
264 | | 空数组依赖 | 只在初始渲染时执行一次 |
265 | | 添加特定依赖项 | 组件初始渲染和特定依赖项变化时执行 |
266 |
267 | **清除副作用**
268 |
269 | 常用于定时器关闭、最后的收尾工作等,在回调函数中return一个函数
270 |
271 | ```jsx
272 | const Son = () => {
273 | // 渲染时候开启一个定时器
274 | useEffect(() => {
275 | let intervalId = setInterval(() => {
276 | console.log("定时器执行中~~~");
277 | }, 1000);
278 | // 清除副作用
279 | return () => {
280 | clearInterval(intervalId);
281 | };
282 | }, []);
283 | };
284 | function App() {
285 | let [isShow,setIsShow]=useState(true)
286 | return ({JSON.stringify(item)}
;
252 | })}
253 |
254 |
287 | {/* 控制组件是否卸载 */}
288 | {isShow&&
);
291 | }
292 | ```
293 |
294 |
295 |
296 | ### 组件通信
297 |
298 | #### 父传子
299 |
300 | **1:父组件传递数据,在子组件上绑定属性(属性名任意)**
301 |
302 | **2:子组件通过`props.属性名`接收数据**
303 |
304 | ```jsx
305 | // 父亲给孩子起名字
306 | const Son = (props) => {
307 | return 子组件——{props.name}
;
308 | };
309 |
310 | function App() {
311 | const pName = "这是父组件起的名字—张狗蛋";
312 | return (
313 |
314 | 父组件
315 | {/* 子组件通过name属性传递变量pName */}
316 |
318 | );
319 | }
320 | ```
321 |
322 | 还可以实现类似于vue的默认插槽的效果,(具名插槽通过jsx实现)。
323 |
324 | 在父组件的子组件标签内写入jsx,子组件可以通过`props.children`属性访问
325 |
326 | ```jsx
327 | const Son = (props) => {
328 | return (
329 |
330 | 我是子组件——{props.name}
331 |
{props.children} 332 |
333 | );
334 | };
335 |
336 | function App() {
337 | const pName = "这是父组件起的名字—张狗蛋";
338 | return (
339 | {props.children} 332 |
340 | 我是父组件
341 |
342 | {/* 子组件通过name传递变量pName */} 343 |
344 |
346 |
347 | );
348 | }
349 | ```
350 |
351 | !props可以传递任意类型的数据,包括jsx
352 |
353 | !props是只读对象,修改只能通过子传父
354 |
355 | #### 子传父
356 |
357 | **1:父组件传递一个属性,这个属性绑定父组件的一个回调方法**
358 |
359 | **2:子组件接收到这个方法,使用这个方法并进行传参**
360 |
361 | 子组件传参流程 onClick—>props.onGetName(sName)—>onGetName—>getName
362 |
363 | ```jsx
364 | // 父传子和子传父结合,父向子传递名字,子传父修改名字
365 | const Son = (props) => {
366 | const sName = "这是子组件的名字—AlbertZhang";
367 | return (
368 | 342 | {/* 子组件通过name传递变量pName */} 343 |
我是默认内容
345 |
369 | 我是子组件——{props.name}
370 | {/* 点击触发父组件传递过来的onGetName */}
371 |
372 |
373 | );
374 | };
375 |
376 | function App() {
377 | let [pName, setPName] = useState("这是父组件起的名字—张狗蛋"); // 使用这个钩子保证子组件响应式
378 | const getName = (sName) => {
379 | setPName(sName);
380 | };
381 | return (
382 | 372 |
383 | 我是父组件
384 |
385 | {/* 父组件通过传递onGetName属性,onGetName方法触发getName回调函数 */} 386 |
388 | );
389 | }
390 | ```
391 |
392 | !这里得父组件传递方法时不能加上(),不然Son组件渲染的时候这个就会直接调用
393 |
394 | #### 兄弟通信
395 |
396 | 1:子传父通过属性函数传参把消息传递给父组件
397 |
398 | 2:父传子通过属性变量把消息传递给子组件
399 |
400 | ```jsx
401 | // 给他兄弟起个名字 张二狗。useEffect函数是确保不要在渲染时候更改APP组件的状态
402 | const Son1 = ({ onGetName }) => {
403 | const name = "张二狗";
404 | // 组件挂载时执行一次
405 | useEffect(() => {
406 | onGetName(name); // 调用传参的函数
407 | }, [onGetName,name]);
408 | return null; // 只用于逻辑处理
409 | };
410 | const Son2 = (props) => {
411 | return 385 | {/* 父组件通过传递onGetName属性,onGetName方法触发getName回调函数 */} 386 |
兄弟组件起的名字—{props.name}
; // 渲染姓名
412 | };
413 | function App() {
414 | let [name, setName] = useState(""); // 存储姓名
415 | return (
416 |
417 | 父组件
418 | {/* 子传父 */}
419 | setName(sName)} />
420 | {/* 父传子 */}
421 |
423 | );
424 | }
425 | ```
426 |
427 | #### 爷孙通信
428 |
429 | **1:使用createContext方法创建一个上下文对象**
430 |
431 | **2:顶层组件通过Provider组件提供数据**
432 |
433 | **3:底层组件通过useContext钩子函数使用数据**
434 |
435 | ```jsx
436 | // 爷爷给孙子起名字
437 | import { createContext, useContext } from "react";
438 |
439 | const NameContext = createContext(); // 1. 创建上下文对象
440 | const Dad = () => {
441 | return (
442 |
443 | 我是儿子
444 |
446 | );
447 | };
448 | const Son = () => {
449 | const name = useContext(NameContext); // 3. 通过useContext使用数据
450 | return 我是孙子—{name}
;
451 | };
452 | function App() {
453 | const gName = "张爱国";
454 | return (
455 |
456 | {/* 2. 通过Provider组件提供数据 */}
457 |
458 | 我是爷爷
459 |
461 |
462 | );
463 | }
464 | ```
465 |
466 | ### Redux
467 |
468 | Redux是React配套的集中状态管理工具,它可以独立于React框架使用,但一般和React配合使用,类似于Vue里面的VueX。
469 |
470 | 为了简化Redux的配置,官方提供了RTK(Redux Toolkit)。
471 |
472 | #### 基础使用
473 |
474 | 安装RTK和react-redux
475 |
476 | ```bash
477 | npm i @reduxjs/toolkit react-redux
478 | ```
479 |
480 | **计数器案例**
481 |
482 | Redux的配置很繁琐,但是都是固定的,流程如下图
483 |
484 | ```mermaid
485 | graph LR
486 | A[创建子模块Store对象] -->B[在store/index.js中组合子模块]-->C[在src/index.js中使用Provider配置store]-->D[在组件中使用]
487 | ```
488 |
489 | 1:创建store—注意两个导出,一个导出actionCreater供组件使用、一个导出reducer供index里面组合
490 |
491 | ```js
492 | import { createSlice } from "@reduxjs/toolkit";
493 | const counterStore = createSlice({
494 | name: "counter",
495 | // 存储的状态
496 | initialState: {
497 | count: 0,
498 | },
499 | // 修改数据的同步方法
500 | reducers: {
501 | increment(state,action) {
502 | state.count+= action.payload;
503 | },
504 | decrement(state) {
505 | state.count --;
506 | },
507 | },
508 | });
509 |
510 | // 解构出创建action对象的函数
511 | const { increment, decrement } = counterStore.actions;
512 | // 获取reducer函数
513 | const counterReducer = counterStore.reducer;
514 | // 导出创建action对象的函数和reducer的值
515 | export { increment, decrement };
516 | export default counterReducer; // 用于全局挂载
517 | ```
518 |
519 | 2:在store/index.js中组合子模块—这个counter随便起,但是需要跟组件使用的时候对应
520 |
521 | ```jsx
522 | import { configureStore } from "@reduxjs/toolkit";
523 |
524 | import counterReducer from "./modules/CounterStore";
525 |
526 | // 创建根store组合子模块
527 | const store = configureStore({
528 | reducer: {
529 | counter: counterReducer,
530 | },
531 | });
532 |
533 | export default store;
534 | ```
535 |
536 | 3:在src/index.js中配置
537 |
538 | ```jsx
539 | import React from "react";
540 | import ReactDOM from "react-dom/client";
541 | import App from "./App";
542 | // 导入redux相关
543 | import store from "./store";
544 | import { Provider } from "react-redux";
545 |
546 | const root = ReactDOM.createRoot(document.getElementById("root"));
547 |
548 | // 将APP组件渲染到index.html中的id为root的根组件上面去
549 | root.render(
550 | // 使用redux
551 |
584 |
585 | 5 ? { color: "red", fontSize: "25px" } : {}}>
586 | {count}
587 |
588 |
589 |
590 |
591 | );
592 | }
593 |
594 | export default App;
595 |
596 | ```
597 |
598 | 关于回调函数传参的问题
599 |
600 | 当写 `onClick={handleInc(10)}` 时,实际上是在渲染时调用 `handleInc` 函数,并将返回值(如果有的话)设置为 `onClick` 事件的处理函数。如果 `handleInc` 直接调用了 `dispatch`,那么每次组件渲染时都会执行 `dispatch`,从而导致状态更新、组件重新渲染、再次调用 `dispatch`,形成一个无限循环。我们期望的是回调函数,采用函数柯里化技术
601 |
602 | **函数柯里化(Function Currying)技术**。函数柯里化是一种在函数式编程中常用的技术,允许你将一个接受多个参数的函数转换成一系列使用一个参数的函数。
603 |
604 | ```jsx
605 | // 改装之前
606 | function add(a, b, c) {
607 | return a + b + c;
608 | }
609 |
610 | const result = add(1, 2, 3); // 6
611 | // 改装后
612 | function curriedAdd(a) {
613 | return function(b) {
614 | return function(c) {
615 | return a + b + c;
616 | };
617 | };
618 | }
619 | const result = curriedAdd(1)(2)(3); // 6
620 |
621 | const curriedAdd = a => b => c => a + b + c; // 使用箭头函数简化,箭头函数会返回紧跟着箭头的第一个表达式的结果,如果不用{}包裹的情况下
622 | ```
623 |
624 | #### **异步调用**
625 |
626 | 异步调用需要改装store和原来的调用,也是固定格式。假如我们需要获取一个频道列表
627 |
628 | ChannelStore.js
629 |
630 | ```js
631 | import { createSlice } from "@reduxjs/toolkit";
632 |
633 | const channelStore = createSlice({
634 | name: "channel",
635 | initialState: {
636 | channelList: [],
637 | },
638 | reducers: {
639 | setChannels(state, action) {
640 | state.channelList = action.payload;
641 | },
642 | },
643 | });
644 |
645 | const { setChannels } = channelStore.actions;
646 | const url = "http://geek.itheima.net/v1_0/channels";
647 | const fetchChannelList = () => {
648 | return async (dispatch) => {
649 | const res = await fetch(url); // 浏览器自带请求api
650 | const channelList = await res.json();
651 | dispatch(setChannels(channelList.data.channels));
652 | };
653 | };
654 | const channelReducer = channelStore.reducer;
655 | export { fetchChannelList }; // 暴露出这个方法供组件使用
656 |
657 | export default channelReducer; // 暴露这个供index组合
658 | ```
659 |
660 | store/index.js注册
661 |
662 | ```js
663 | import { configureStore } from "@reduxjs/toolkit";
664 |
665 | import counterReducer from "./modules/CounterStore";
666 | import channelReducer from "./modules/ChannelStore";
667 |
668 | // 创建根store组合子模块
669 | const store = configureStore({
670 | reducer: {
671 | counter: counterReducer,
672 | channel: channelReducer,
673 | },
674 | });
675 |
676 | export default store;
677 | ```
678 |
679 | 组件使用
680 |
681 | ```jsx
682 | import { useDispatch, useSelector } from "react-redux";
683 | import { fetchChannelList } from "./store/modules/ChannelStore";
684 | import { useEffect } from "react";
685 |
686 | function App() {
687 | const dispatch = useDispatch();
688 | const { channelList } = useSelector((state) => state.channel);
689 | // 组件挂载时触发一下(这里根据需求何时触发)
690 | useEffect(() => {
691 | dispatch(fetchChannelList());
692 | }, [dispatch]);
693 |
694 | return (
695 |
696 |
702 | );
703 | }
704 |
705 | export default App;
706 | ```
707 |
708 | ### React Router
709 |
710 | ## React进阶
711 |
712 | ### 扩展hook函数
713 |
714 | ### 类组件
715 |
716 | ### zustand
717 |
718 | ## 项目实战
719 |
720 | ### 初始化
721 |
722 | ### 开发规范
723 |
724 | ### 注意点
725 |
726 |
--------------------------------------------------------------------------------
/docs/math-model/classify.md:
--------------------------------------------------------------------------------
1 | ## 分类模型
--------------------------------------------------------------------------------
/docs/math-model/data-ana.md:
--------------------------------------------------------------------------------
1 | ## pandas
2 |
3 | ## numpy
4 |
5 | ## matplotlib
--------------------------------------------------------------------------------
/docs/math-model/eval.md:
--------------------------------------------------------------------------------
1 | ## 评价类模型
--------------------------------------------------------------------------------
/docs/math-model/forecast.md:
--------------------------------------------------------------------------------
1 | ## 预测类模型
--------------------------------------------------------------------------------
/docs/math-model/optimize.md:
--------------------------------------------------------------------------------
1 | ## 优化类模型
--------------------------------------------------------------------------------
/docs/my-index/reason.md:
--------------------------------------------------------------------------------
1 | ## 建站原因 💡
2 |
3 | 早就想整一个自己的文档网站了,选择VitePress的原因有下面两个
4 |
5 | ### wp局限性 🔒
6 |
7 | 1. 之前使用wp搞了个博客,感觉是生态原因,国外市占率第一高的CMS我用的不咋惯,之前整个代码复制插件找半天也没配置好。还有一股神秘力量影响,每次进后台很慢,并且不知道为啥网站桌面端还经常访问不了(我服务器是国内的啊,可能哪个插件需要连外网?但是也不能影响我网站正常访问,有点奇怪)。
8 | 2. 还有一个问题是本来我用的就是kratos专门写博客的主题,再用其他的自己整学习成本有点太高,虽然wp有可视化拖拽的那种。本着技多不压身的原则,还是换一个框架,并且跟我技术栈有关联性吧,之所以选择VitePress而不是VuePress,主要是性能问题,vuepress是webpack打包的,有点慢。小尤都说让用vite了,都2024年了,咱不能开历史的倒车啊。
9 |
10 | ### 自身需要 👤
11 |
12 | 之前断断续续把前后端+爬虫的一些基础都学完了,网安也学了一部分。之前虽然还记笔记,但是记笔记实在太浪费时间了,后来学到框架就直接拿别人笔记过来看看。你问我说`webpack`、`css各种样式`、`js原型链`、`java的基础`、`vue组件通信的几种方式`、`mysql各种引擎的特性`、`node.js一些包的用法`,甚至git的命令都只会add,commit,push一把梭了。真的基本全忘了😢,虽然说用到直接搜,但是搜的时间也需要成本啊,况且面试时候面试官问你,你总不能说我先去搜搜,等我5分钟回来以后我再回答吧😂。
13 |
14 | 因此准备搞一个自己的知识库,也能让别人参考一下,以后学到或者复习到一门新的技术就整合到知识库里面,比如最近我在学react,把react的知识点就根据自己记一下,还有像高度复用的技术,**docker部署脚本**、**一些常见的配置(比如java长精度丢失)**、**一些正则**这些。
15 |
16 |
--------------------------------------------------------------------------------
/docs/net-sec/info-collect.md:
--------------------------------------------------------------------------------
1 | ## 信息搜集
--------------------------------------------------------------------------------
/docs/net-sec/intranet-pene.md:
--------------------------------------------------------------------------------
1 | ## 内网渗透
--------------------------------------------------------------------------------
/docs/net-sec/vul-reproduce.md:
--------------------------------------------------------------------------------
1 | ## 漏洞复现
--------------------------------------------------------------------------------
/docs/net-sec/web-aad.md:
--------------------------------------------------------------------------------
1 | ## web攻防
--------------------------------------------------------------------------------
/docs/python/base.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout:doc
3 | ---
4 |
5 | # Python
6 |
7 | 生成随机数:random.randint 是生成整数随机数(左右都包括),random.uniform 是生成小数随机数,random.rand 是 0-1 的随机数(包左不包右)
8 |
9 | 列表推导式:new_x_list=[x.append(1) for x in x_list]。简化书写,把后面循环的每一个变量传递给前面的变量
10 |
11 | 判断数据类型:isinstance(my_list , list)。返回一个 bool 类型的值
12 |
13 | - 对于 for 循环,while 循环,if 语句,函数等来说,python 使用缩进代表层次关系,如果你在缩进语句下加了一行不符合缩进规则的代码,则解释器会认为这行代码下面的代码不属于上面的层级
14 | - 如果双引号之间包括了双引号,就用单引号来代替。
15 | - 对 if key in dict.keys 是一个判断语句,有这种语法,一个元素是否在元组里面
16 | - 还有 if "/" not in title。这些语句都是数据容器常见的语法,在里面,不在里面
17 |
18 | ## python 基础语法
19 |
20 | ### 基础概念
21 |
22 | **字面量**:在代码中,被写下来的值,就叫做字面量,用于指示是什么让代码认出来的。例:123,“张晗”,[ ], ( ), { }
23 |
24 | **注释:**
25 |
26 | - 单行注释:快捷键 ctrl+/,#号加一个空格,例:# 这是单行注释
27 | - 多行注释:pycharm 无快捷键,例:""" 这是多行注释 """
28 |
29 | **变量:**记录数据用的量
30 |
31 | 注意:python 中变量声明方式为 name="张三",前面没有关键字
32 |
33 | **数据类型:**
34 |
35 | - 初步的数据类型有 int,string,float,bool
36 | - 查看数据类型使用 type()函数
37 | - 需要转换数据类型时使用 int(a)形式,类似与 Java 的强转但是 Java 是(int)a
38 |
39 | **标识符:**
40 |
41 | 标识符就是变量,方法名等,命名规范跟 Java 基本一致。命名规则:
42 |
43 | 1. 标识符只能由数字,字母,下划线,中文(不推荐)组成,命名时不能以数字和$开头
44 | 2. 对大小写敏感
45 | 3. 不能以关键字命名
46 | 4. 变量命名规范,见名知意,全部小写,各单词以下划线隔开
47 |
48 | **运算符:**
49 |
50 | - 算术运算符:+,-,\*,/,//,%,\*\*。其中//是取整除,如 9.0/2.0=4.0;两个星代表的是乘方
51 | - 赋值运算符:=,+=,-=,\*=,/=,//=,%=,\*\*=。用法不再赘述,简化运算
52 | - 比较运算符:==,!=,>,<,>=,<=。
53 | - 逻辑运算符:and,or,not
54 | - 按位运算符:<<,>>等等
55 |
56 | **字符串:**
57 |
58 | 字符串是每个编程语言的重点,python 主要注意:
59 |
60 | 1. 字符串的定义:单引号,双引号,三引号
61 |
62 | 2. 字符串的拼接:可以使用+号进行拼接,但是效率不高
63 |
64 | 3. 字符串在 print 语句中的表现
65 |
66 | - 字符串的格式化方法 format。利用"姓名是{name},年龄是{age}".format("张晗",19)
67 |
68 | - 使用 print()语句中的逗号,print("str1","str2")。这种方式输出的中间有空格
69 | - 使用+号拼接的方式,print("str1"+num1+"str2")
70 | - 使用占位符的形式,类似于 C 语言,print("这是字符串拼接%4.2f"%num),代表输出占四位,保留两位小数,输出的是 float 类型,常见的类型还有%d(decmical 十进制整数),%s(字符串)。如果值超过 1 个,就用()包裹,中间用,号隔开
71 | - 使用内嵌变量的方式,类似于 JS,print(f"这是内嵌变量的演示{num2}"),这个是原样输出,num2 也可以替换成表达式
72 |
73 | **数据输入:**采用 input 语句,函数内可以放占位文字,需要注意的是,用变量接收的都是字符串,需要手动强转成自己需要的类型
74 |
75 | ### 判断和循环
76 |
77 | #### if 语句
78 |
79 | if 语句的结构基本有三种,注意语法跟其他语言不太一样,语法如下
80 |
81 | - if-else 语句
82 | - elif 语句
83 | - if 语句的嵌套。我认为这个的应用场景是不用写 elif,层次感强一点,或者说第 n 层的嵌套语句中有很多个执行后也需要一起执行的代码时,我写的猜数字游戏。虽然我感觉还是没啥用。
84 |
85 | ```python
86 | # if-else语句
87 | a = 5
88 | if a > 10:
89 | print("a的值大于10")
90 | else:
91 | print("a的值小于等于10")
92 |
93 | # elif语句
94 | if "str1" == "str2":
95 | print("python亡了")
96 | elif "str1" == "str1 ":
97 | print("字符串用==号判断时忽略空格")
98 | else:
99 | print("字符串用==号判断时忽略空格")
100 |
101 | # if语句的嵌套
102 | a = 1
103 | b = 2
104 | c = 3
105 | if a < b:
106 | print("a已经小于b了")
107 | if a < c:
108 | print("a也小于c")
109 | else:
110 | print("a不小于b")
111 | ```
112 |
113 | #### while 循环
114 |
115 | while 循环语句的总体逻辑是跟其他编程语言一样的,就是语法有些差别,并且在构建状态机时,需要注意 python 里面的格式是 while True:,而不是 true。并且 while 语句也可以嵌套,格式就是缩进 4 个空格。
116 |
117 | ```python
118 | # 猜数字案例,while语句跟if语句的嵌套结合使用
119 | random_num = random.randint(1, 100)
120 | count = 1
121 | guess_num = int(input("请输入一个猜的数字:"))
122 | while 1:
123 | if guess_num == random_num:
124 | print(f"恭喜你,你在第{count}次猜中了")
125 | break
126 | else:
127 | if guess_num > random_num:
128 | print("大了")
129 | else:
130 | print("小了")
131 | count += 1
132 | guess_num = int(input("请输入一个猜的数字:"))
133 |
134 |
135 | # 利用while循环输出九九乘法表,while语句的嵌套
136 | # i控制行,j控制列
137 | i = 1
138 | while i <= 9:
139 | j = 1
140 | while j <= i:
141 | # \t制表符,让前面的对齐
142 | print(f"{j}*{i}={i * j}\t", end='')
143 | j += 1
144 | # 换行,把列值重置为1,把行值加1
145 | print()
146 | i += 1
147 | ```
148 |
149 | #### for 循环
150 |
151 | for 循环与 Java 语言不太相同,但是跟增强 for 类似,遍历元素,格式为 for x in str:这个 str 可以是字符串还有 range()函数,range 函数的调用是 range(0,20),就是 x 的值会一直从 0-19,左闭右开。
152 |
153 | **for-in 遍历的时候,那个 data 并不能改变原有的值**。比如说 for data in my_list:这个时候你再做任何操作都不影响 my_list 里面原来的值。
154 |
155 | for 循环可以跟 while 循环嵌套使用,对于 continue 和 break 关键字,和 Java 一致,以下是代码示例。
156 |
157 | 此外就是 print 语句中一些扩展知识:
158 |
159 | - 在代码中加入\t 制表符会代表代码自动会缩进一行,对于格式的对齐尤为重要
160 | - 如果 print()函数内不想自动换行,可以使用 print("str1",end='')
161 | - 在代码在可以加入\n 表示自动换行
162 | - print()语句单独使用表示换行
163 |
164 | ```python
165 | # for循环对字符个数计算
166 | s = "itheima is a brand of itcast"
167 | num_count = 0
168 | for x in s:
169 | if x == 'a':
170 | num_count += 1
171 | else:
172 | continue
173 | print(num_count)
174 |
175 |
176 | # for循环和while循环相互嵌套,输出九九乘法表
177 | # 定义控制行的变量
178 | row = 1
179 | while row <= 9:
180 | # 定义控制列的变量
181 | column = 1
182 | # column就代表每一列,row代表第n行
183 | # 相等于while里面的column<=row
184 | for column in range(1, row + 1):
185 | print(f"{column}*{row}={row * column}\t", end='')
186 | print()
187 | row += 1
188 | ```
189 |
190 | ### 函数
191 |
192 | 1. 函数就是为了简化程序代码,便于代码的重用性和简洁性所设计的。函数满足三个条件:提前写好的,可重用的,实现特定功能的代码段。
193 |
194 | 2. python 中的函数关键字是 def,弱类型语言,传参和返回参数都不用指定类型,由于作用域的关系,在函数体内部如果想要更改外部变量的值或者让外部代码访问到函数内的变量,只需要在函数中用 global 关键字修饰。
195 |
196 | 3. 对于函数的返回值,如果函数没有写 return 语句,返回值也是可以接收的,值为 None,类型为 NoneType,也可以手动返回 None。在变量初始化的时候,也是可以直接给初值为 None 的。代码如下
197 | 4. python 特别喜欢嵌套(if 语句,while 循环,for 循环),函数也可以嵌套,调用方式是在函数内部调用另一个函数是并发执行的,而非并行。调用函数的时候,要注意**函数代码一定要写在调用者上面**,不然程序访问不到函数就会报错。
198 |
199 | 代码如下:
200 |
201 | ```python
202 | # 带有参数和返回值的函数调用
203 | status = "张晗单身"
204 |
205 |
206 | def my_message(sex):
207 | global status
208 | if sex == "女生":
209 | status = "这个女生爱上了张晗"
210 | print("欢迎来到哈尔滨理工大学!\n您的导游是张晗")
211 | else:
212 | print("欢迎来到哈尔滨理工大学,请自行参观")
213 | # 如果是女生这个也可以不写,status变量已经被改变了;如果是男生就会返回None
214 | return status
215 |
216 |
217 | result = my_message("女生")
218 | print(result)
219 | ```
220 |
221 | #### 函数的拓展知识
222 |
223 | python 由于是弱类型加上一些其他的特性,真的是让我蛋疼,python 里面的语法特性简直了,以下是函数拓展的知识
224 |
225 | - 函数的多返回值。python 中的函数返回值可以返回多个**不同类型**的数据,不同数据之间用英文逗号分隔,在函数调用处接收的时候,用多个变量接收即可,中间用英文逗号分隔。
226 |
227 | - 函数的传参方式。
228 |
229 | - 位置参数。根据参数位置传递参数,就是普通的传参。
230 | - 关键字参数。根据键值对的形式传递参数,可以把最后一个形参利用 k=v 形式在实参传递时候写成第一个。在跟位置参数混合调用的时候,**一定要写在位置参数后面**,并且不要重复赋值,不会覆盖会直接报错。混合使用时候聊胜于无。
231 | - 缺省参数。不传递参数值的时候会使用默认的参数值,在函数定义时候,缺省参数一定要定义在最后面。格式为 age=11,gender="男"。
232 | - 不定长参数。普通不定长定义形参时候是\*args,在函数内想要处理的时候外面传入的参数被保存在元组中了,直接根据下标调用就可以。对于键值对不定长形参是\*\*args,(如 name="张晗")是存在了一个字典中,调用时候通过键调用就可以了。传递的时候 name="张三",age=19......
233 |
234 | - 函数作为参数传递和**lambda**匿名函数。
235 |
236 | - 函数作为参数传递。形参定义时候正常定义,不用加括号。调用时候函数名(args1,args2,...)调用就可以了。不同与传统传参的方式,传的是函数,是一段逻辑,之前传的是数据。
237 |
238 | - lambda 匿名函数是在函数调用时候需要一个函数作为参数传递的时候使用。避免重复定义,应用很广泛。lambda 格式为 lambda 形参 1,形参 2:函数体,会自动 return 值,并且不能换行。
239 |
240 | ```python
241 | # lambda匿名函数,参数值是函数
242 | def print_data(compute):
243 | data = compute(1, 2)
244 | print(data)
245 |
246 |
247 | # lambda格式为lambda 形参1,,形参2:函数体
248 | # 会自动return,不能换行。
249 | print_data(lambda x, y: x + y)
250 |
251 | ```
252 |
253 | ```python
254 | # 1:演示函数的多返回值
255 | def evaluate_looks(name):
256 | if name == "张晗":
257 | return "zhanghan is very handsome", "我给他的颜值打10分", 10
258 | else:
259 | return "你很丑", "我给你的颜值打0分", 0
260 |
261 |
262 | # 用三个参数接收数据
263 | is_handsome, evaluate, level = evaluate_looks("张晗")
264 | print(is_handsome)
265 | print(evaluate)
266 | print(level)
267 |
268 |
269 | # 2:函数的传参方式(关键字参数,缺省参数)
270 | def print_stu_info(name, age, gender, idol="张晗"):
271 | print(f"这个学生叫{name},性别是{gender},{age}岁了,偶像是{idol}")
272 |
273 |
274 | # 利用关键字参数给age赋值
275 | print_stu_info("张晗", 19, gender="男") # 这个学生叫张晗,性别是男,19岁了,偶像是张晗
276 |
277 |
278 | # 利用不定长参数传参
279 | def compute_add(*args):
280 | result = 0
281 | # 打印一下args的值和类型
282 | print(f"args的值是{args},数据类型是{type(args)}")
283 | # 传入的参数不确定,所以直接遍历元组
284 | for x in args:
285 | result += x
286 | return result
287 |
288 |
289 | # args的值是(1, 2, 3),数据类型是-
697 | {channelList.map((item) => {
698 | return
- {item.name} ; 699 | })} 700 |
s.strip(str) | 不传参的时候去除空格和换行符,传参的时候去除所有指定字符串 | 456 | | s.count(little_s) | 统计小串在大串中的出现次数 | 457 | | len(s) | 统计字符串的字符个数 | 458 | 459 | #### 序列的切片 460 | 461 | 序列的切片应该是 python 独有的功能了吧,非常好用。应用场景是截取指定字符串,反转字符串,range 函数里面也用了步长为负数的思想。 462 | 463 | 语法是:字符串/元组/列表[起始下标:结束下标:步长] 表示从序列中,从指定位置开始,到指定位置结束,得到一个新序列。 464 | 465 | 起始下标和结束下标可以留空,起始下标留空视为从头开始,结束下标留空表示截取到结尾 466 | 467 | 步长表示依次取元素的间隔。默认为 1,步长为 N,表示每次跳过 N-1 个元素取。步长为负数,表示反向取(开始下标和结束下标也要反向标记) 468 | 469 | ```python 470 | # 得到指定数据 471 | s="我是张晗,我很emo,浪费好多时间啊啊啊" 472 | 473 | # 得到ome这个数据 474 | # 倒着取的话从右边开始数,默认从0开始,步长为1是连续取 475 | new_s=s[11:8:-1] 476 | print(new_s) 477 | 478 | # 实现字符串的倒序 479 | # 需要注意字符串和元组都是不能更改的,所以处理结果是新的字符串 480 | reverse_s=s[::-1] 481 | print(reverse_s) 482 | 483 | ``` 484 | 485 | #### 集合 486 | 487 | 集合跟前面最大的不同是存取无序(不支持下标索引),集合也不允许重复元素,但是集合可以修改。 488 | 489 | 集合的字面量是{},定义空集合的方式是 my_set=set(),没有 my_set={},这是由于这个定义方式被字典占用了。 490 | 491 | 集合的常见方法如下: 492 | 493 | | 方法调用形式 | 方法作用 | 494 | | ---------------------------------- | ------------------------------------------------------------- | 495 | | my_set.add(ele) | 往集合中添加一个元素 | 496 | | my_set.remove(ele) | 移除集合内指定的元素 | 497 | | my_set.pop() | 从集合中随机取出一个元素 | 498 | | my_set.clear() | 清空集合 | 499 | | my_set1.difference(my_set2) | **得到一个新集合**,内容是两个集合的差集(A-B),原集合内容不变 | 500 | | my_set1.difference_update(my_set2) | 操作原理一样,只不过不再生成新集合,而是修改 my_set1(A=A-B) | 501 | | my_set1.union(my_set2) | **得到一个新集合**,内容是两个集合的和集,原集合内容不变(A+B) | 502 | | len(my_list) | 求集合的元素数量 | 503 | 504 | 代码演示: 505 | 506 | ```python 507 | # 定义两个集合 508 | my_set1 = {1, 2, 3, 4, 5} 509 | my_set2 = {1, 2, 3} 510 | difference = my_set1.difference(my_set2) 511 | union = my_set1.union(my_set2) 512 | # 求集合一的长度 513 | len = len(my_set1) 514 | # 两集合的差集是{4, 5},两集合的和集是{1, 2, 3, 4, 5} 515 | print(f"两集合的差集是{difference},两集合的和集是{union}") 516 | print(f"集合一的长度是{len}") 517 | # for循环遍历数据,遍历出来的是集合的元素 518 | for ele in my_set1: 519 | print(ele) 520 | 521 | ``` 522 | 523 | #### 字典 524 | 525 | 字典是基于键值对的数据容器。**字典中的 key 不能重复(重复添加会覆盖),并且模式是根据 key 检索 value,所以字典不支持下标索引,但是可以更改。** 526 | 527 | 由于可以嵌套使用的特点,导致字典的功能特别丰富,字典里面的 key 不能为字典,其余都可以。比如说存储学生信息的时候,用 key 存储学生姓名,对应的 value 存储以列表的形式再存储学生的年龄,成绩等等信息。 528 | 529 | 字典的字面量是{},跟集合的一样,但是中间格式需要是 key:value 的形式。定义空字典 my_dict={},my_dict=dict()。调用的时候用 my_dict[key]调用。 530 | 531 | | 操作 | 说明 | 532 | | ------------------ | ---------------------------------------------------------------------------------------- | 533 | | my_dict[key] | 获取指定 key 对应的 value 值 | 534 | | my_dict[key]=value | 添加或更新键值对 | 535 | | my_dict.pop(key) | 取出 key 对应的 value 并删除此 key 的键值对 | 536 | | my_dict.clear() | 清空字典 | 537 | | my_dict.keys() | 获取字典中的全部 key,可用于 for 循环遍历字典(存在一个
122 | 123 | **web_location** 124 | 125 | 全局搜这个的值,这个是在一个js文件中给参数赋值的,也是服务端生成的,应该直接带着就行,可能B站服务端会拿着这个地域做一些风控限制。https://s1.hdslb.com/bfs/static/player/main/core.d98a5476.js 126 | 127 |
128 | 129 | **w_rid** 130 | 131 | 重头戏: 132 | 133 | 这是逆向过程中的参数 134 | 135 | **数组不变和b不变** 136 | 137 | [46, 47, 18, 2, 53, 8, 23, 32, 15, 50, 10, 31, 58, 3, 45, 35, 27, 43, 5, 49, 33, 9, 42, 19, 29, 28, 14, 39, 12, 38, 41, 13, 37, 48, 7, 16, 24, 55, 40, 61, 26, 17, 0, 1, 60, 51, 30, 4, 22, 25, 54, 21, 56, 59, 6, 63, 57, 62, 11, 36, 20, 34, 44, 52] 138 | 139 | [46, 47, 18, 2, 53, 8, 23, 32, 15, 50, 10, 31, 58, 3, 45, 35, 27, 43, 5, 49, 33, 9, 42, 19, 29, 28, 14, 39, 12, 38, 41, 13, 37, 48, 7, 16, 24, 55, 40, 61, 26, 17, 0, 1, 60, 51, 30, 4, 22, 25, 54, 21, 56, 59, 6, 63, 57, 62, 11, 36, 20, 34, 44, 52] 140 | 141 | **n,其实是两个url处理后的字符,但是如果不登录,一直是固定的,没必要逆向了,但是我当时也是逆向了** 142 | 143 | ea1db124af3c7062474693fa704f4ff8 144 | 145 | ea1db124af3c7062474693fa704f4ff8 146 | 147 | https://api.bilibili.com/x/web-interface/nav:请求这个url得到img_url和sub_url,经过算法得到n 148 | 149 | ```js 150 | function d(e) { 151 | if (e || window.__NanoStaticHttpKey) { 152 | return "https://i0.hdslb.com/bfs/wbi/".concat("5a6f002d0bb14fc9848fc64157648ad4", ".png") 153 | } 154 | } 155 | 156 | 157 | function f(e) { 158 | if (e || window.__NanoStaticHttpKey) { 159 | return "https://i0.hdslb.com/bfs/wbi/".concat("0503a77b29d7409d9548fb44fe9daa1a", ".png") 160 | } 161 | } 162 | 163 | 164 | 165 | "https://i0.hdslb.com/bfs/wbi/4932caff0ff746eab6f01bf08b70ac45.png" 166 | 167 | // 就是先 168 | // 跟ip深度绑定的 169 | 170 | "img_url": "https://i0.hdslb.com/bfs/wbi/7cd084941338484aae1ad9425b84077c.png", 171 | "sub_url": "https://i0.hdslb.com/bfs/wbi/4932caff0ff746eab6f01bf08b70ac45.png" 172 | ``` 173 | 174 | 175 | 176 | **加密字符串** 177 | 178 | y:aid=325318514&cid=1381936481&web_location=1315873&wts=1703998861 179 | 180 | n:ea1db124af3c7062474693fa704f4ff8 181 | 182 | **n,其实是两个url经过一个小算法处理后的字符串,但是如果不登录,一直是固定的,没必要逆向了,但是我当时也是逆向了** 183 | 184 | 就是根据这个wts来生成不同的w_rid wts生成的逻辑:Date.now() / 1e3 185 | 186 | ()(t && t.asBytes )? r : (t && t.asString) ) ? a.bytesToString(r) : n.bytesToHex(r) &&运算符优先级大于?:, 187 | 188 | 因此这个运算结果是n.bytesToHex(r). 189 | 190 | 下面这个函数根据传进来的查询字符串和固定的值 191 | 192 | 思路是这样的,加密过程是拆分一下是这个,n.bytesToHex(n.wordsToBytes(s(123456))) 193 | 194 | s(123456)生成的这样一个数组[1791092075, -946928880, 1505655784, 1414671436]。是md5加密,16字节分成4个32位的整数,**猜测就是先进行md5加密,在转换成字节,在把字节转换成16进制。直接复现,发现结果一样,逆向成功。** 195 | 196 | 下面是这个函数,看不懂吧,没事我也看不懂,这些n里面的方法看起来应该是一个现成的库的,假设B站没有往里面掺自己的东西,直接复现就好了 197 | 198 | ```js 199 | e.exports = function(e, t) { 200 | if (null == e) 201 | throw new Error("Illegal argument " + e); 202 | var r = n.wordsToBytes(s(e, t)); 203 | return t && t.asBytes ? r : t && t.asString ? a.bytesToString(r) : n.bytesToHex(r) 204 | } 205 | 206 | 207 | 208 | 209 | s = function e(t, r) { 210 | t.constructor == String ? t = r && "binary" === r.encoding ? a.stringToBytes(t) : i.stringToBytes(t) : o(t) ? t = Array.prototype.slice.call(t, 0) : Array.isArray(t) || (t = t.toString()); 211 | for (var s = n.bytesToWords(t), u = 8 * t.length, c = 1732584193, l = -271733879, d = -1732584194, f = 271733878, p = 0; p < s.length; p++) 212 | s[p] = 16711935 & (s[p] << 8 | s[p] >>> 24) | 4278255360 & (s[p] << 24 | s[p] >>> 8); 213 | s[u >>> 5] |= 128 << u % 32, 214 | s[14 + (u + 64 >>> 9 << 4)] = u; 215 | var h = e._ff 216 | , y = e._gg 217 | , m = e._hh 218 | , g = e._ii; 219 | for (p = 0; p < s.length; p += 16) { 220 | var v = c 221 | , _ = l 222 | , E = d 223 | , b = f; 224 | c = h(c, l, d, f, s[p + 0], 7, -680876936), 225 | f = h(f, c, l, d, s[p + 1], 12, -389564586), 226 | d = h(d, f, c, l, s[p + 2], 17, 606105819), 227 | l = h(l, d, f, c, s[p + 3], 22, -1044525330), 228 | c = h(c, l, d, f, s[p + 4], 7, -176418897), 229 | f = h(f, c, l, d, s[p + 5], 12, 1200080426), 230 | d = h(d, f, c, l, s[p + 6], 17, -1473231341), 231 | l = h(l, d, f, c, s[p + 7], 22, -45705983), 232 | c = h(c, l, d, f, s[p + 8], 7, 1770035416), 233 | f = h(f, c, l, d, s[p + 9], 12, -1958414417), 234 | d = h(d, f, c, l, s[p + 10], 17, -42063), 235 | l = h(l, d, f, c, s[p + 11], 22, -1990404162), 236 | c = h(c, l, d, f, s[p + 12], 7, 1804603682), 237 | f = h(f, c, l, d, s[p + 13], 12, -40341101), 238 | d = h(d, f, c, l, s[p + 14], 17, -1502002290), 239 | c = y(c, l = h(l, d, f, c, s[p + 15], 22, 1236535329), d, f, s[p + 1], 5, -165796510), 240 | f = y(f, c, l, d, s[p + 6], 9, -1069501632), 241 | d = y(d, f, c, l, s[p + 11], 14, 643717713), 242 | l = y(l, d, f, c, s[p + 0], 20, -373897302), 243 | c = y(c, l, d, f, s[p + 5], 5, -701558691), 244 | f = y(f, c, l, d, s[p + 10], 9, 38016083), 245 | d = y(d, f, c, l, s[p + 15], 14, -660478335), 246 | l = y(l, d, f, c, s[p + 4], 20, -405537848), 247 | c = y(c, l, d, f, s[p + 9], 5, 568446438), 248 | f = y(f, c, l, d, s[p + 14], 9, -1019803690), 249 | d = y(d, f, c, l, s[p + 3], 14, -187363961), 250 | l = y(l, d, f, c, s[p + 8], 20, 1163531501), 251 | c = y(c, l, d, f, s[p + 13], 5, -1444681467), 252 | f = y(f, c, l, d, s[p + 2], 9, -51403784), 253 | d = y(d, f, c, l, s[p + 7], 14, 1735328473), 254 | c = m(c, l = y(l, d, f, c, s[p + 12], 20, -1926607734), d, f, s[p + 5], 4, -378558), 255 | f = m(f, c, l, d, s[p + 8], 11, -2022574463), 256 | d = m(d, f, c, l, s[p + 11], 16, 1839030562), 257 | l = m(l, d, f, c, s[p + 14], 23, -35309556), 258 | c = m(c, l, d, f, s[p + 1], 4, -1530992060), 259 | f = m(f, c, l, d, s[p + 4], 11, 1272893353), 260 | d = m(d, f, c, l, s[p + 7], 16, -155497632), 261 | l = m(l, d, f, c, s[p + 10], 23, -1094730640), 262 | c = m(c, l, d, f, s[p + 13], 4, 681279174), 263 | f = m(f, c, l, d, s[p + 0], 11, -358537222), 264 | d = m(d, f, c, l, s[p + 3], 16, -722521979), 265 | l = m(l, d, f, c, s[p + 6], 23, 76029189), 266 | c = m(c, l, d, f, s[p + 9], 4, -640364487), 267 | f = m(f, c, l, d, s[p + 12], 11, -421815835), 268 | d = m(d, f, c, l, s[p + 15], 16, 530742520), 269 | c = g(c, l = m(l, d, f, c, s[p + 2], 23, -995338651), d, f, s[p + 0], 6, -198630844), 270 | f = g(f, c, l, d, s[p + 7], 10, 1126891415), 271 | d = g(d, f, c, l, s[p + 14], 15, -1416354905), 272 | l = g(l, d, f, c, s[p + 5], 21, -57434055), 273 | c = g(c, l, d, f, s[p + 12], 6, 1700485571), 274 | f = g(f, c, l, d, s[p + 3], 10, -1894986606), 275 | d = g(d, f, c, l, s[p + 10], 15, -1051523), 276 | l = g(l, d, f, c, s[p + 1], 21, -2054922799), 277 | c = g(c, l, d, f, s[p + 8], 6, 1873313359), 278 | f = g(f, c, l, d, s[p + 15], 10, -30611744), 279 | d = g(d, f, c, l, s[p + 6], 15, -1560198380), 280 | l = g(l, d, f, c, s[p + 13], 21, 1309151649), 281 | c = g(c, l, d, f, s[p + 4], 6, -145523070), 282 | f = g(f, c, l, d, s[p + 11], 10, -1120210379), 283 | d = g(d, f, c, l, s[p + 2], 15, 718787259), 284 | l = g(l, d, f, c, s[p + 9], 21, -343485551), 285 | c = c + v >>> 0, 286 | l = l + _ >>> 0, 287 | d = d + E >>> 0, 288 | f = f + b >>> 0 289 | } 290 | return n.endian([c, l, d, f]) 291 | } 292 | ``` 293 | 294 | 295 | 296 | ```python 297 | import struct 298 | 299 | def s(input_string): 300 | """ 301 | 计算字符串的 MD5 散列,并返回四个整数值组成的数组。 302 | """ 303 | md5_hash = hashlib.md5(input_string.encode()) 304 | # 将 16 字节的 MD5 哈希分成四个 32 位的整数 305 | return list(struct.unpack('>4I', md5_hash.digest())) 306 | 307 | def words_to_bytes(words): 308 | """ 309 | 将整数数组转换为字节序列。 310 | """ 311 | # 每个整数转换为 4 字节 312 | return [byte for word in words for byte in struct.pack('>I', word)] 313 | 314 | def convert_md5(input_string, as_bytes=False, as_string=False): 315 | """ 316 | 根据选项返回 MD5 哈希的不同表示。 317 | """ 318 | # 计算 MD5 整数数组 319 | md5_words = s(input_string) 320 | 321 | if as_bytes: 322 | # 返回字节序列 323 | return words_to_bytes(md5_words) 324 | elif as_string: 325 | # 返回字符串表示(假设是 UTF-8 编码的字符串) 326 | return ''.join(chr(byte) for byte in words_to_bytes(md5_words)) 327 | else: 328 | # 返回十六进制表示 329 | return ''.join(f'{word:08x}' for word in md5_words) 330 | 331 | # 测试字符串 332 | test_string = 'aid=325318514&cid=1381936481&web_location=1315873&wts=1704001621ea1db124af3c7062474693fa704f4ff8' 333 | 334 | # 测试函数 335 | md5_as_bytes = convert_md5(test_string, as_bytes=True) 336 | md5_as_string = convert_md5(test_string, as_string=True) 337 | md5_as_hex = convert_md5(test_string) 338 | 339 | md5_as_bytes, md5_as_string, md5_as_hex 340 | ``` 341 | 342 |
343 | 344 | ### 请求体 345 | 346 | **cid** 347 | 348 | 跟w_aid一样,都是在第一个请求里面返回回来的。另外这个是跟视频绑定的,aid,cid 349 | 350 |
351 | 352 | **spmid** 353 | 354 | 跟上面那两个一样,都是跟视频深度绑定的,我猜想可能是存储到哪服务器的标识? 355 | 356 |
357 | 358 | **session** 359 | 360 | 这个是服务端随机生成的,看起来应该是md5那种的, 361 | 362 | main?oid=325318514&type=1&mode=3&pagination_str=%7B%22offset%22:%22%22%7D&plat=1&seek_rpid=&web_lo 363 | 364 | session是在这里返回的,使用正则拿到就行 365 | 366 | ### Cookie 367 | 368 | 前面也说了,cookie一般都是前面请求设置进去的,很少有生成的。这里直接找set_cookie的地方(看前面的请求) 369 | 370 | **buvid3、b_nut** 371 | 372 | 这个请求里面返回的https://www.bilibili.com/video/BV1aw41157V3 373 | 374 |
375 | **b_lsid、_uuid、sid** 376 | 377 | b_lsid和_uuid是客户端生成的,sid是https://api.bilibili.com/x/player/wbi/v2这个返回的 378 | 379 | b_lsid 380 | 381 | 下面的r就是我们的cookie,看到也是随机生成的,直接去python伪造就可以了,注意毫秒值伪造一下 382 | 383 | (0, l.G$)是函数o。(0, l.Q4)是函数a 384 | 385 | ```js 386 | t = (0, l.G$)(e.millisecond) , 387 | r = "".concat((0, l.Q4)(8), "_").concat(t) 388 | , a = function(e) { 389 | return Math.ceil(e).toString(16).toUpperCase() 390 | } 391 | 392 | , o = function(e) { 393 | for (var t = "", r = 0; r < e; r++) 394 | t += a(16 * Math.random()); 395 | return i(t, e) 396 | } 397 | s.Z.setCookie("b_lsid", r, 0, "current-domain") 398 | ``` 399 | 400 | 401 | 402 | _uuid:这个一看就是随机生成的,随机生成直接伪造就可以了,就是一个uuid+时间戳+后缀 403 | 404 | ```js 405 | var n = function() { 406 | var e = o(8) 407 | , t = o(4) 408 | , r = o(4) 409 | , n = o(4) 410 | , a = o(12) 411 | , s = (new Date).getTime(); 412 | return e + "-" + t + "-" + r + "-" + n + "-" + a + i((s % 1e5).toString(), 5) + "infoc" 413 | } 414 | , o = function(e) { 415 | for (var t = "", r = 0; r < e; r++) 416 | t += a(16 * Math.random()); 417 | return i(t, e) 418 | } 419 | , i = function(e, t) { 420 | var r = ""; 421 | if (e.length < t) 422 | for (var n = 0; n < t - e.length; n++) 423 | r += "0"; 424 | return r + e 425 | } 426 | ``` 427 | 428 | 429 | 430 | **buvid4、buvid_fp** 431 | 432 | 这个请求里面返回的https://api.bilibili.com/x/frontend/finger/spi。buvid4 433 | 434 | n是UA,o是cookie值 435 | 436 | o = u().x64hash128(n, 31); 437 | 438 | ## Python复现 439 | 440 | 上面都找到了,接下来就是写py代码复现了。需要注意的是,对有些参数的逆向有的可以扣代码、补环境。这里我统一都用py代码复现了。这个代码太长,我在这里就不提供了,移步github:https://github.com/AZCodingAccount/python-spider 441 | 442 | ❗这个仅仅是学习使用,投入应用是不可行的,因为我们这里没有登录,最多刷200-300个播放。另外提醒大家,尽量也不要刷自己视频,用心做视频才会有更多同学看! 443 | 444 | 445 | 446 | 447 | 448 | 449 | 450 | -------------------------------------------------------------------------------- /docs/spiders/dlt.md: -------------------------------------------------------------------------------- 1 | # 某练通逆向(附数据分析结果) 2 | 3 | ## 背景 4 | 5 | 背景是23年11月末时候有个人找到我说想打个省标,我问预算多少,我跟他要600,结果他跟我说别人都是200零基础问我200能不能打,我当时就震惊了,一年多没正经打过代练,现在代练行业都这么玩了吗? 6 | 7 | 正好当时在学APP逆向,由于跟dlt太熟悉了,我就把某代练通的搜索接口和分页查询接口给逆向了,这是当初21年我截的图,当然,现在已经不打单很久了。 8 | 9 | | | | 10 | | :----------------------------------------------------------: | :----------------------------------------------------------: | 11 | |
 |
|  |
12 |
13 | 但是一次只能爬取3000多条数据。后来想着攒到2万条时候再分析,结果12月事情太多了,各种比赛、考试、毕设中期检查、课设。实在是闲不下来,直到现在元旦才勉强有时间。
14 |
15 | 在B站也开了个python逆向的小坑,然后就花5个小时左右对所有数据整理了一下用Python的pandas和matplotlib简单分析可视化了一下。接下来就简单说一下逆向的思路和数据分析结果。
16 |
17 | ## 逆向思路
18 |
19 | 这个是讲原理的,不感兴趣的直接看数据分析结果就可以啦。
20 |
21 | ### 环境的选择
22 |
23 | 首先,搞APP逆向能用真机一定要用真机。原因我初步发现有两个
24 |
25 | 1. 有的APP会检测你的当前设备,检测到模拟器直接自动退出或者给你一个错误的包(代练通新版本就是直接退出)
26 | 2. APP主要设计就是在真机运行的,你模拟器可能别人开发者没有考虑到,会出现意料之外的问题。
27 |
28 | 但是我用的是模拟器,因为那时候还没买逆向手机,我买的是pixel4,安卓逆向和爬虫都是挺不错的。
29 |
30 | 这里去豌豆荚下载代练通旧版本就可以了,但是需要注意的是,如果有提示更新的选项。能用老版本就用老版本,我们是搞逆向的,他的新版本**加密肯定更难**了。如果强制让你更新,这个时候有两种情况,
31 |
32 | 1. 你去逆向这个APP,把这个弹弹窗的这个代码找到,给他删了或者更改掉。说实话,这个也不太简单,还需要过检测、签名绕过,如果不是逆向大佬,不要搞这个。
33 | 2. 假设你已经把这个APP给修改了,结果后端接口更新了,你还是拿不到数据,这个时候就只能老老实实更新了。
34 |
35 | 对于本案例,直接跳过更新就行,他不会让你强制更新。
36 |
37 | ### 逆向思路
38 |
39 | **抓包**
40 |
41 | 逆向第一步肯定是要抓包了,看看哪个请求是获取数据的。这里dlt有个坑,就是你直接配置代理抓包的时候是抓不到你想要的包的,有一些软件比如使用flutter开发的就不走这个代理,你需要用一些小工具。我这里使用socks droid+charles可以绕过这个检测,使用socks5一步到胃。
42 |
43 | ❗注意需要登录一下,不登录搜索接口不给你看。
44 |
45 | ❗对于分页查询接口,你又不能登录了,不然返回给你的数据很少。
46 |
47 | **分析请求进而逆向**
48 |
49 | 逆向一个APP或者网站的时候我们都需要明确自己的目的,这个APP或者网站里面有什么有价值的东西?比如抖音有评论接口,搜索接口,视频下载,得物,识货这种是查询接口。我这里目的是爬取**分页的订单数据**和**根据英雄名称搜索**
50 |
51 | 这里我就不说具体是哪个URL是发送请求的了,大家感兴趣自己去摸索,多踩踩坑,这样对自己的逆向技术也有帮助。
52 |
53 | 这个逆向还是非常简单的,非常适合新手小白,只有一个sign需要逆向,找到URL以后其他还有一些查询参数大家多点几下发一下请求就大概能知道这些参数是干嘛的了。
54 |
55 | **逆向工具**
56 |
57 | 我们都知道JS逆向中源代码是基本上都相当于脱光了站在我们面前,基本上不是特别变态的加密我们只要找都可以找到入口。但是APP这里怎么办呢?没有了开发者工具。
58 |
59 | 我这里采用的解决方案是**jadx**+**frida**直接一把梭。当然像jeb这种动态调试工具也可以用。
60 |
61 | 拿着我们刚刚找到的参数名和url去全局搜就可以,找到一些可能加密参数的方法用frida进行hook,看看程序过不过这个方法、输入参数和输出参数。就行了。这里分享一个小经验:
62 |
63 | 💡 `一般我们在开发时候都是会把url这种写成一个常量的,开发的规范要求,搜索的时候对常量注意点。基本没人会把URL写死在程序里面的`
64 |
65 | ### python完成业务逻辑
66 |
67 | 经过上面一系列混合双打,基本逆向过程就结束了,接下来就是py模拟发请求。这里就需要处理业务逻辑的东西了
68 |
69 | 对于根据英雄名称搜索,100多个英雄相信没人想写成一个数组搁那for循环遍历,也不优雅,那我们咋拿呢?直接去王者荣耀官网,这里尝试发一个请求,结果是没有返回完英雄,是动态加载的,使用**selenium**直接滑动一下就可以了
70 |
71 | ```python
72 | from selenium.webdriver import Chrome
73 | from selenium.webdriver.common.by import By
74 | from selenium.webdriver.chrome.options import Options
75 |
76 | # 这个类是获取王者荣耀英雄列表的
77 | heroes = []
78 |
79 |
80 | def get_heros_order():
81 | opt = Options()
82 | opt.add_argument("--headless") # 无头
83 | opt.add_argument('--disable-gpu')
84 | opt.add_argument("--window-size=4000,1600") # 设置窗口大小
85 |
86 | driver = Chrome(options=opt)
87 | driver.get("https://pvp.qq.com/web201605/herolist.shtml")
88 | driver.implicitly_wait(10) #等待
89 | lis = driver.find_elements(By.CSS_SELECTOR, ".herolist li")
90 | for li in lis:
91 | # 把数据存储到列表中
92 | heroes.append(li.text)
93 |
94 |
95 | get_heros_order()
96 |
97 | ```
98 |
99 | 拿到这个heros。其他就完事了。就是两个方法。前面思路都讲得很清楚了,**这个大家自己去逆向就可以了,我这里就不给代码了**。
100 |
101 | 逆向完毕还有一个存储到数据库的逻辑,当然也可以存储到**csv**文件或者**excel**中,我这里**mysql**用的比较熟就直接**mysql**了。给出我存储数据的逻辑的代码
102 |
103 | ```python
104 | import time
105 | from datetime import datetime
106 |
107 | import pymysql
108 |
109 | # 这个类是用来把数据存储到Mysql数据库的
110 | class MyDatabase:
111 |
112 | # 初始化数据库连接环境
113 | def __init__(self):
114 | self.db = pymysql.connect(host='localhost', user='root', password='123456', database='spidertestdb')
115 | self.cursor = self.db.cursor()
116 | self.create_table()
117 |
118 | # 这个数据库里面主要装爬取的所有数据,重复的也可以装
119 | def create_table(self):
120 | create_table_sql = """
121 | CREATE TABLE IF NOT EXISTS dailiantong_base (
122 | id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
123 | Title VARCHAR(10000) comment '标题',
124 | Price int comment '价格',
125 | Ensure1 int comment '安全保证金',
126 | Ensure2 int comment '效率保证金',
127 | TimeLimit int comment '时间限制',
128 | Creater VARCHAR(100) comment '发单人',
129 | Stamp DATETIME comment '发布时间',
130 | Zone VARCHAR(100) comment '游戏大区',
131 | UnitPrice int comment '单价',
132 | UserID VARCHAR(100) comment '发单人ID',
133 | SerialNo VARCHAR(100) comment '订单ID'
134 | )
135 | """
136 | # 这个数据库主要装按照英雄分类的时候爬取到的数据
137 | create_table_sql2="""
138 | CREATE TABLE IF NOT EXISTS heroes_table(
139 | id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
140 | hero VARCHAR(100) COMMENT '英雄名称',
141 | Title VARCHAR(10000) comment '标题',
142 | Price int comment '价格',
143 | Ensure1 int comment '安全保证金',
144 | Ensure2 int comment '效率保证金',
145 | TimeLimit int comment '时间限制',
146 | Creater VARCHAR(100) comment '发单人',
147 | Stamp DATETIME comment '发布时间',
148 | Zone VARCHAR(100) comment '游戏大区',
149 | UnitPrice int comment '单价',
150 | UserID VARCHAR(100) comment '发单人ID',
151 | SerialNo VARCHAR(100) comment '订单ID'
152 |
153 | )
154 | """
155 | self.cursor.execute(create_table_sql)
156 | self.cursor.execute(create_table_sql2)
157 | # 还有个表base_dailiantong用来装清洗过后的数据
158 |
159 |
160 | def save_data(self, datas):
161 | insert_sql = """
162 | INSERT INTO dailiantong_base (Title, Price, Ensure1, Ensure2, TimeLimit, Creater, Stamp, Zone, UnitPrice,UserID,SerialNo)
163 | VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s,%s,%s)
164 | """
165 | try:
166 | for data in datas["LevelOrderList"]:
167 | values = (
168 | data.get("Title", ""),
169 | data.get("Price", 0),
170 | data.get("Ensure1", 0),
171 | data.get("Ensure2", 0),
172 | data.get("TimeLimit", 0),
173 | data.get("Create", ""),
174 | datetime.fromtimestamp(data.get("Stamp", int(time.time())) + 255845872).strftime(
175 | '%Y-%m-%d %H:%M:%S'),
176 | data.get("Zone", ""),
177 | data.get("UnitPrice", 0),
178 | data.get("UserID", ""),
179 | data.get("SerialNo", "")
180 | )
181 | self.cursor.execute(insert_sql, values)
182 | self.db.commit()
183 | except Exception as e:
184 | print("插入数据时候出错了:", e)
185 | self.db.rollback()
186 |
187 | # 把英雄数据保存到数据库中
188 | def save_heroes_data(self, datas,search_str):
189 | insert_sql = """
190 | INSERT INTO heroes_table (hero,Title, Price, Ensure1, Ensure2, TimeLimit, Creater, Stamp, Zone, UnitPrice,UserID,SerialNo)
191 | VALUES (%s,%s, %s, %s, %s, %s, %s, %s, %s, %s,%s,%s)
192 | """
193 | try:
194 | for data in datas["LevelOrderList"]:
195 | values = (
196 | search_str,
197 | data.get("Title", ""),
198 | data.get("Price", 0),
199 | data.get("Ensure1", 0),
200 | data.get("Ensure2", 0),
201 | data.get("TimeLimit", 0),
202 | data.get("Create", ""),
203 | datetime.fromtimestamp(data.get("Stamp", int(time.time())) + 255845872).strftime(
204 | '%Y-%m-%d %H:%M:%S'),
205 | data.get("Zone", ""),
206 | data.get("UnitPrice", 0),
207 | data.get("UserID", ""),
208 | data.get("SerialNo", "")
209 | )
210 | self.cursor.execute(insert_sql, values)
211 | self.db.commit()
212 | except Exception as e:
213 | print("插入数据时候出错了:", e)
214 | self.db.rollback()
215 |
216 | # 关闭数据库连接
217 | def close(self):
218 | self.cursor.close()
219 | self.db.close()
220 |
221 | ```
222 |
223 | 最后数据分析的代码就不给出了,300多行实在是太多了,感兴趣直接去我Github仓库下就行https://github.com/AZCodingAccount/python-spider
224 |
225 | ## 数据分析结果
226 |
227 | ### 关于对英雄的分析结果
228 |
229 | 最受老板欢迎的10个英雄,瑶瑶公主居然才第8,你敢信?!!!
230 |
231 |
|
12 |
13 | 但是一次只能爬取3000多条数据。后来想着攒到2万条时候再分析,结果12月事情太多了,各种比赛、考试、毕设中期检查、课设。实在是闲不下来,直到现在元旦才勉强有时间。
14 |
15 | 在B站也开了个python逆向的小坑,然后就花5个小时左右对所有数据整理了一下用Python的pandas和matplotlib简单分析可视化了一下。接下来就简单说一下逆向的思路和数据分析结果。
16 |
17 | ## 逆向思路
18 |
19 | 这个是讲原理的,不感兴趣的直接看数据分析结果就可以啦。
20 |
21 | ### 环境的选择
22 |
23 | 首先,搞APP逆向能用真机一定要用真机。原因我初步发现有两个
24 |
25 | 1. 有的APP会检测你的当前设备,检测到模拟器直接自动退出或者给你一个错误的包(代练通新版本就是直接退出)
26 | 2. APP主要设计就是在真机运行的,你模拟器可能别人开发者没有考虑到,会出现意料之外的问题。
27 |
28 | 但是我用的是模拟器,因为那时候还没买逆向手机,我买的是pixel4,安卓逆向和爬虫都是挺不错的。
29 |
30 | 这里去豌豆荚下载代练通旧版本就可以了,但是需要注意的是,如果有提示更新的选项。能用老版本就用老版本,我们是搞逆向的,他的新版本**加密肯定更难**了。如果强制让你更新,这个时候有两种情况,
31 |
32 | 1. 你去逆向这个APP,把这个弹弹窗的这个代码找到,给他删了或者更改掉。说实话,这个也不太简单,还需要过检测、签名绕过,如果不是逆向大佬,不要搞这个。
33 | 2. 假设你已经把这个APP给修改了,结果后端接口更新了,你还是拿不到数据,这个时候就只能老老实实更新了。
34 |
35 | 对于本案例,直接跳过更新就行,他不会让你强制更新。
36 |
37 | ### 逆向思路
38 |
39 | **抓包**
40 |
41 | 逆向第一步肯定是要抓包了,看看哪个请求是获取数据的。这里dlt有个坑,就是你直接配置代理抓包的时候是抓不到你想要的包的,有一些软件比如使用flutter开发的就不走这个代理,你需要用一些小工具。我这里使用socks droid+charles可以绕过这个检测,使用socks5一步到胃。
42 |
43 | ❗注意需要登录一下,不登录搜索接口不给你看。
44 |
45 | ❗对于分页查询接口,你又不能登录了,不然返回给你的数据很少。
46 |
47 | **分析请求进而逆向**
48 |
49 | 逆向一个APP或者网站的时候我们都需要明确自己的目的,这个APP或者网站里面有什么有价值的东西?比如抖音有评论接口,搜索接口,视频下载,得物,识货这种是查询接口。我这里目的是爬取**分页的订单数据**和**根据英雄名称搜索**
50 |
51 | 这里我就不说具体是哪个URL是发送请求的了,大家感兴趣自己去摸索,多踩踩坑,这样对自己的逆向技术也有帮助。
52 |
53 | 这个逆向还是非常简单的,非常适合新手小白,只有一个sign需要逆向,找到URL以后其他还有一些查询参数大家多点几下发一下请求就大概能知道这些参数是干嘛的了。
54 |
55 | **逆向工具**
56 |
57 | 我们都知道JS逆向中源代码是基本上都相当于脱光了站在我们面前,基本上不是特别变态的加密我们只要找都可以找到入口。但是APP这里怎么办呢?没有了开发者工具。
58 |
59 | 我这里采用的解决方案是**jadx**+**frida**直接一把梭。当然像jeb这种动态调试工具也可以用。
60 |
61 | 拿着我们刚刚找到的参数名和url去全局搜就可以,找到一些可能加密参数的方法用frida进行hook,看看程序过不过这个方法、输入参数和输出参数。就行了。这里分享一个小经验:
62 |
63 | 💡 `一般我们在开发时候都是会把url这种写成一个常量的,开发的规范要求,搜索的时候对常量注意点。基本没人会把URL写死在程序里面的`
64 |
65 | ### python完成业务逻辑
66 |
67 | 经过上面一系列混合双打,基本逆向过程就结束了,接下来就是py模拟发请求。这里就需要处理业务逻辑的东西了
68 |
69 | 对于根据英雄名称搜索,100多个英雄相信没人想写成一个数组搁那for循环遍历,也不优雅,那我们咋拿呢?直接去王者荣耀官网,这里尝试发一个请求,结果是没有返回完英雄,是动态加载的,使用**selenium**直接滑动一下就可以了
70 |
71 | ```python
72 | from selenium.webdriver import Chrome
73 | from selenium.webdriver.common.by import By
74 | from selenium.webdriver.chrome.options import Options
75 |
76 | # 这个类是获取王者荣耀英雄列表的
77 | heroes = []
78 |
79 |
80 | def get_heros_order():
81 | opt = Options()
82 | opt.add_argument("--headless") # 无头
83 | opt.add_argument('--disable-gpu')
84 | opt.add_argument("--window-size=4000,1600") # 设置窗口大小
85 |
86 | driver = Chrome(options=opt)
87 | driver.get("https://pvp.qq.com/web201605/herolist.shtml")
88 | driver.implicitly_wait(10) #等待
89 | lis = driver.find_elements(By.CSS_SELECTOR, ".herolist li")
90 | for li in lis:
91 | # 把数据存储到列表中
92 | heroes.append(li.text)
93 |
94 |
95 | get_heros_order()
96 |
97 | ```
98 |
99 | 拿到这个heros。其他就完事了。就是两个方法。前面思路都讲得很清楚了,**这个大家自己去逆向就可以了,我这里就不给代码了**。
100 |
101 | 逆向完毕还有一个存储到数据库的逻辑,当然也可以存储到**csv**文件或者**excel**中,我这里**mysql**用的比较熟就直接**mysql**了。给出我存储数据的逻辑的代码
102 |
103 | ```python
104 | import time
105 | from datetime import datetime
106 |
107 | import pymysql
108 |
109 | # 这个类是用来把数据存储到Mysql数据库的
110 | class MyDatabase:
111 |
112 | # 初始化数据库连接环境
113 | def __init__(self):
114 | self.db = pymysql.connect(host='localhost', user='root', password='123456', database='spidertestdb')
115 | self.cursor = self.db.cursor()
116 | self.create_table()
117 |
118 | # 这个数据库里面主要装爬取的所有数据,重复的也可以装
119 | def create_table(self):
120 | create_table_sql = """
121 | CREATE TABLE IF NOT EXISTS dailiantong_base (
122 | id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
123 | Title VARCHAR(10000) comment '标题',
124 | Price int comment '价格',
125 | Ensure1 int comment '安全保证金',
126 | Ensure2 int comment '效率保证金',
127 | TimeLimit int comment '时间限制',
128 | Creater VARCHAR(100) comment '发单人',
129 | Stamp DATETIME comment '发布时间',
130 | Zone VARCHAR(100) comment '游戏大区',
131 | UnitPrice int comment '单价',
132 | UserID VARCHAR(100) comment '发单人ID',
133 | SerialNo VARCHAR(100) comment '订单ID'
134 | )
135 | """
136 | # 这个数据库主要装按照英雄分类的时候爬取到的数据
137 | create_table_sql2="""
138 | CREATE TABLE IF NOT EXISTS heroes_table(
139 | id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
140 | hero VARCHAR(100) COMMENT '英雄名称',
141 | Title VARCHAR(10000) comment '标题',
142 | Price int comment '价格',
143 | Ensure1 int comment '安全保证金',
144 | Ensure2 int comment '效率保证金',
145 | TimeLimit int comment '时间限制',
146 | Creater VARCHAR(100) comment '发单人',
147 | Stamp DATETIME comment '发布时间',
148 | Zone VARCHAR(100) comment '游戏大区',
149 | UnitPrice int comment '单价',
150 | UserID VARCHAR(100) comment '发单人ID',
151 | SerialNo VARCHAR(100) comment '订单ID'
152 |
153 | )
154 | """
155 | self.cursor.execute(create_table_sql)
156 | self.cursor.execute(create_table_sql2)
157 | # 还有个表base_dailiantong用来装清洗过后的数据
158 |
159 |
160 | def save_data(self, datas):
161 | insert_sql = """
162 | INSERT INTO dailiantong_base (Title, Price, Ensure1, Ensure2, TimeLimit, Creater, Stamp, Zone, UnitPrice,UserID,SerialNo)
163 | VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s,%s,%s)
164 | """
165 | try:
166 | for data in datas["LevelOrderList"]:
167 | values = (
168 | data.get("Title", ""),
169 | data.get("Price", 0),
170 | data.get("Ensure1", 0),
171 | data.get("Ensure2", 0),
172 | data.get("TimeLimit", 0),
173 | data.get("Create", ""),
174 | datetime.fromtimestamp(data.get("Stamp", int(time.time())) + 255845872).strftime(
175 | '%Y-%m-%d %H:%M:%S'),
176 | data.get("Zone", ""),
177 | data.get("UnitPrice", 0),
178 | data.get("UserID", ""),
179 | data.get("SerialNo", "")
180 | )
181 | self.cursor.execute(insert_sql, values)
182 | self.db.commit()
183 | except Exception as e:
184 | print("插入数据时候出错了:", e)
185 | self.db.rollback()
186 |
187 | # 把英雄数据保存到数据库中
188 | def save_heroes_data(self, datas,search_str):
189 | insert_sql = """
190 | INSERT INTO heroes_table (hero,Title, Price, Ensure1, Ensure2, TimeLimit, Creater, Stamp, Zone, UnitPrice,UserID,SerialNo)
191 | VALUES (%s,%s, %s, %s, %s, %s, %s, %s, %s, %s,%s,%s)
192 | """
193 | try:
194 | for data in datas["LevelOrderList"]:
195 | values = (
196 | search_str,
197 | data.get("Title", ""),
198 | data.get("Price", 0),
199 | data.get("Ensure1", 0),
200 | data.get("Ensure2", 0),
201 | data.get("TimeLimit", 0),
202 | data.get("Create", ""),
203 | datetime.fromtimestamp(data.get("Stamp", int(time.time())) + 255845872).strftime(
204 | '%Y-%m-%d %H:%M:%S'),
205 | data.get("Zone", ""),
206 | data.get("UnitPrice", 0),
207 | data.get("UserID", ""),
208 | data.get("SerialNo", "")
209 | )
210 | self.cursor.execute(insert_sql, values)
211 | self.db.commit()
212 | except Exception as e:
213 | print("插入数据时候出错了:", e)
214 | self.db.rollback()
215 |
216 | # 关闭数据库连接
217 | def close(self):
218 | self.cursor.close()
219 | self.db.close()
220 |
221 | ```
222 |
223 | 最后数据分析的代码就不给出了,300多行实在是太多了,感兴趣直接去我Github仓库下就行https://github.com/AZCodingAccount/python-spider
224 |
225 | ## 数据分析结果
226 |
227 | ### 关于对英雄的分析结果
228 |
229 | 最受老板欢迎的10个英雄,瑶瑶公主居然才第8,你敢信?!!!
230 |
231 | 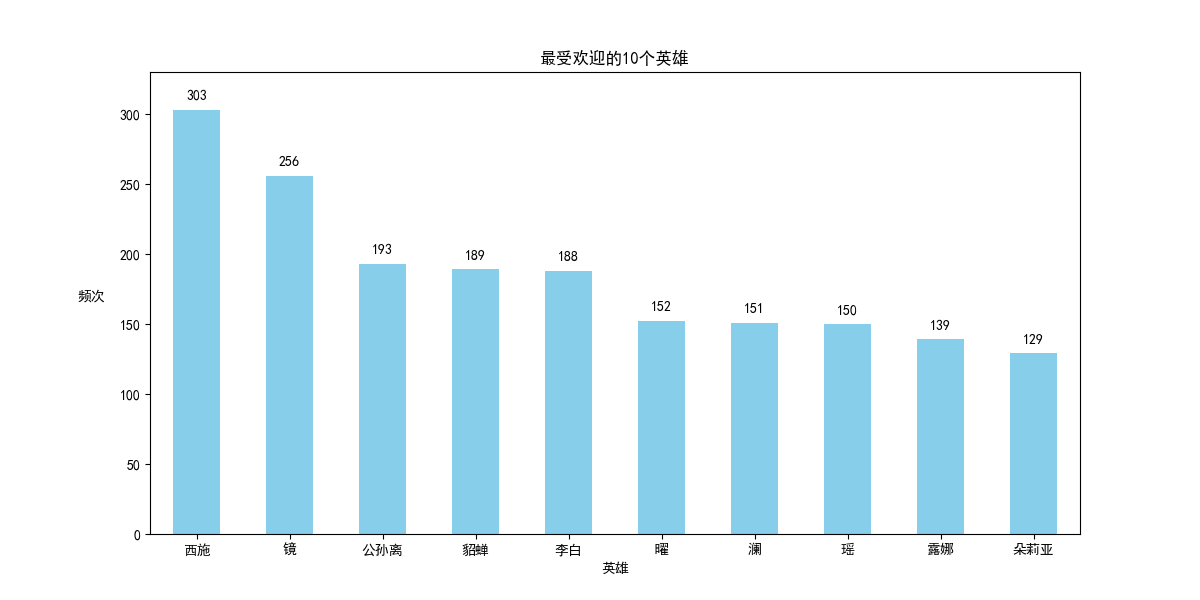 232 |
233 | 每单平均价格最高的几个英雄
234 |
235 | 老虎最高是没啥悬念的,让我没想到的是瑶瑶公主,朵莉亚居然都没上榜,镜第9名......。我猜测可能有人发了国服单一下子就把价格拉上去了?
236 |
237 |
232 |
233 | 每单平均价格最高的几个英雄
234 |
235 | 老虎最高是没啥悬念的,让我没想到的是瑶瑶公主,朵莉亚居然都没上榜,镜第9名......。我猜测可能有人发了国服单一下子就把价格拉上去了?
236 |
237 | 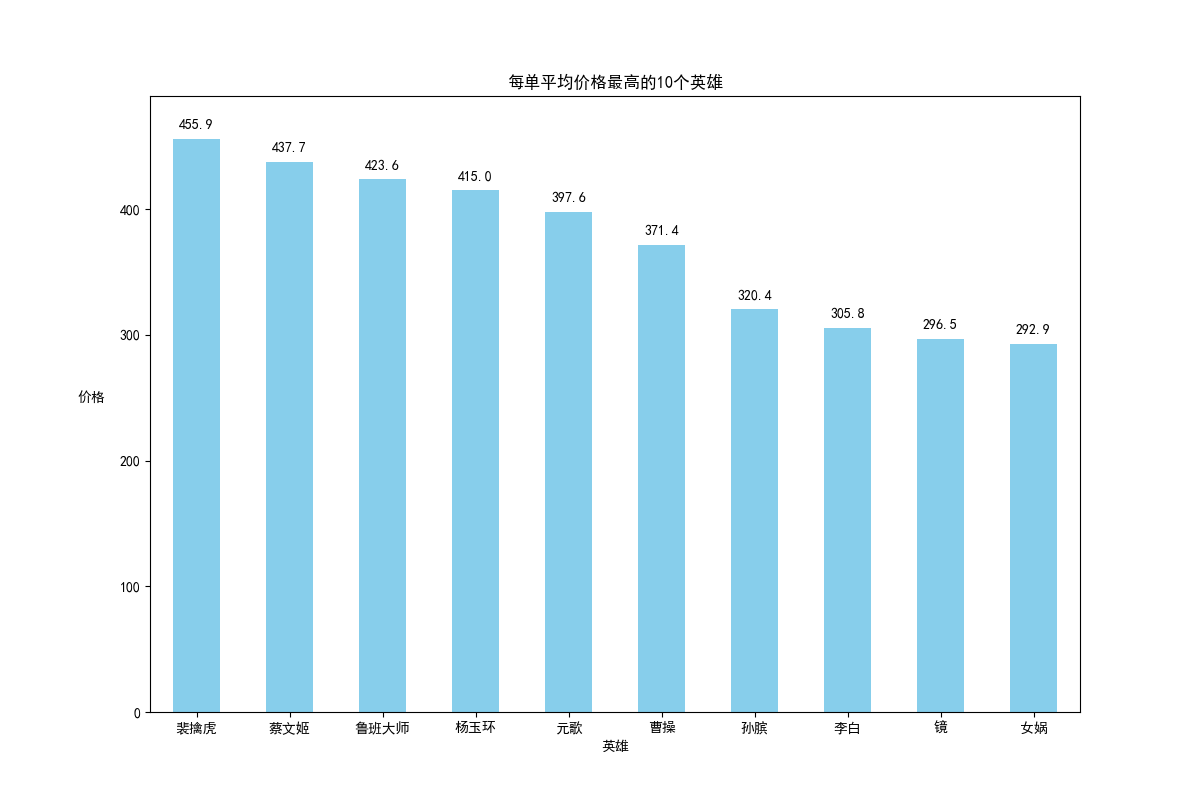 238 |
239 | ### 关于对所有订单的分析结果
240 |
241 | 样本数:**11364**个
242 |
243 | #### 游戏大区分布
244 |
245 | 还是安q傲立群雄,不过安卓微信居然才12.6%。安卓苹果也算是两足鼎立了。
246 |
247 | 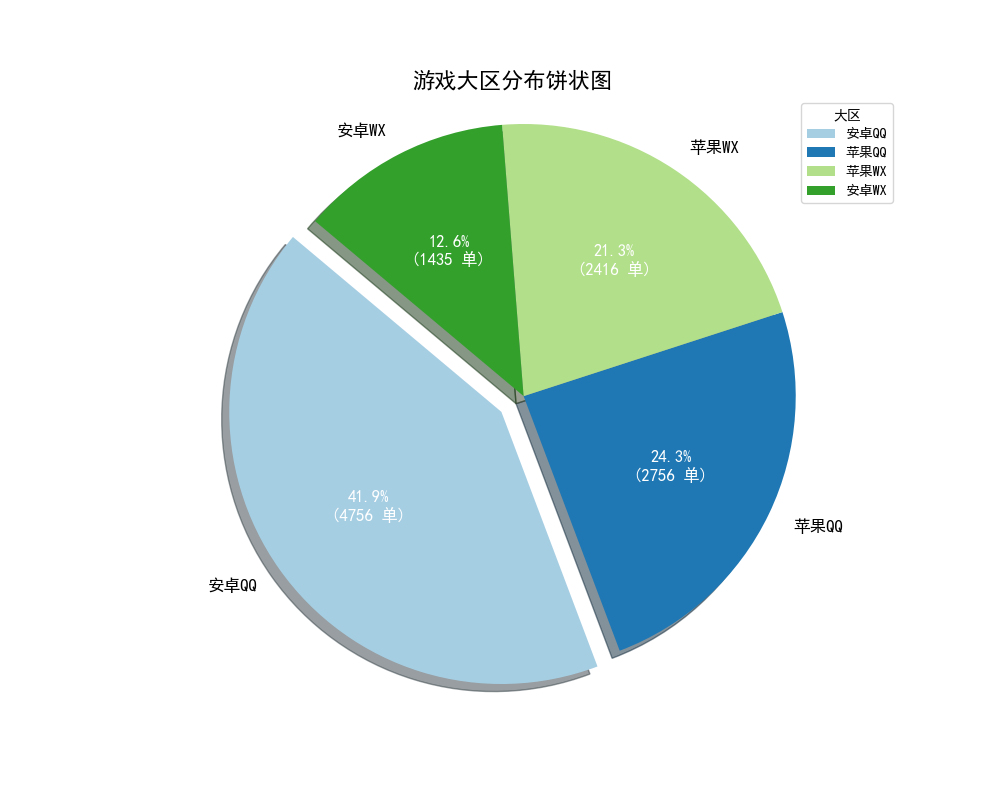
248 |
249 | #### 发单者和订单数的相关关系
250 |
251 | 这个图很明了了,0.5%的发单者发了50%的单子。我看了排名前几个的,第一个好像是淘宝来的,一共就一万多个单子,他发了1000多个。各种中间商抽成,真的比我国贫富差距还抽象啊
252 |
253 | 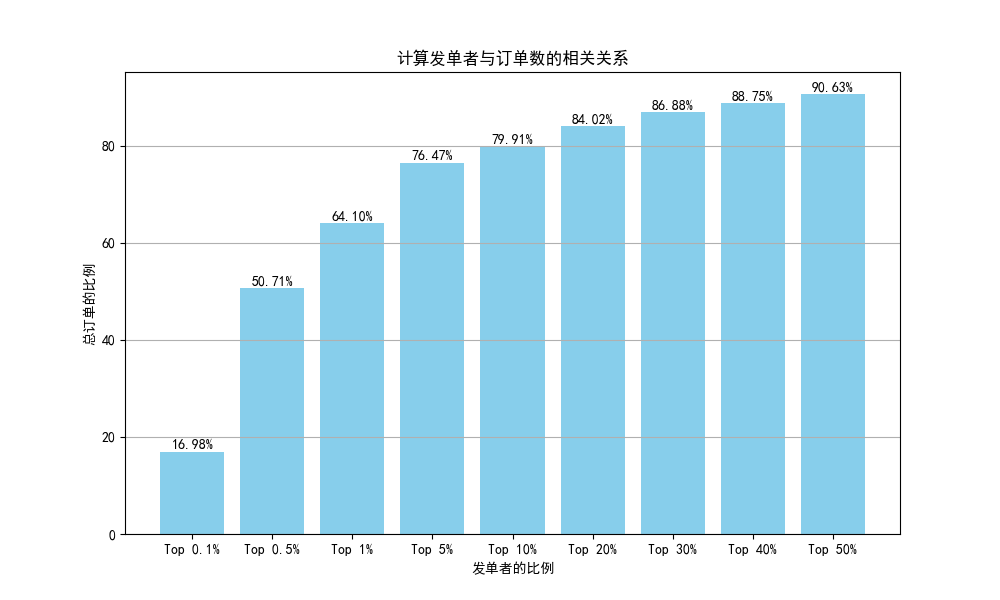
254 |
255 | #### 价格等的描述性统计
256 |
257 | 简单分析一下下面的图:
258 |
259 | - 标准差比平均值大好几倍,我们一般认为波动非常大,数据不稳定,在代练行业这个是正常的
260 | - 价格方面,每个单子的平均价格是在120左右、中位数在32左右,上四分位数是100, 说明低价的订单比较多。
261 | - 保证金方面,都没有太大的浮动。一般发单者也是喜欢设置两个保证金为差不多的价格
262 | - 时间限制方面,平均是在65个小时,上四分位数是72个小时,这个东西我们代练一般也不太看重。
263 |
264 | 
265 |
266 | #### 每个段位的价格问题
267 |
268 | 参与统计的数据集是一万一千多个,还是非常有参考价值的。
269 |
270 | - 一切尽在不言中,排位这么多的样本,这个应该是没人反对是偶然性了吧。这个我就不再分析了,都是聪明人。
271 |
272 | - 作为一个圈内人,我澄清一下,51星以上的基本就没有参考价值了。样本才53个。50星以下的26-51星,300多个样本,4块钱一颗星,进厂一个小时多少钱啊各位。
273 | - 另外巅峰赛的话现在也已经被各种中介搞的乌烟瘴气了,
274 |
275 | 最后大家可能会疑惑,为啥我统计了一万个样本,下面的才不到3000个呢。
276 |
277 | 1. 一个是因为我为了保证结果的准确性是使用正则提取这些星数的,只有符合我的标题格式的要求,我才会提取这个星数来计算平均价格。`宁可放过一千,不会错杀一个`
278 | 2. 还有就是我只是提取**固定区间**的数据,比如说有个单子是1-50星的,这个时候计算平均值时候你说把他放在哪个区间里面,所以我就把他舍去了。
279 |
280 | 
281 |
282 | ## 写在后面
283 |
284 | 真的,**做正确的事比正确的做事更重要**。永远都是**选择大于努力**。21年时候随便接个1500的单子一把都10块钱,再看看现在,还好王者荣耀代练我跑路跑的快。
--------------------------------------------------------------------------------
/docs/spiders/middle_exam.md:
--------------------------------------------------------------------------------
1 | # 河南考生中考移民大庆大家究竟在吵什么?我爬取了两万五千条抖音评论和近6年分数线并进行了数据分析
2 |
3 | ## 所涉及到的知识点
4 |
5 | **爬虫**
6 |
7 | - 爬虫基础
8 | 1. requests库的基本使用
9 | 2. pyquery库的基本使用
10 |
11 | - js逆向
12 |
13 | 1. js补环境(VMP还原)
14 |
15 | 2. execjs的使用
16 |
17 | **数据分析**
18 |
19 | - pandas的使用
20 |
21 | - numpy的使用
22 | - matplotlib的使用
23 | - 绘制组合条形图
24 | - 绘制词云图
25 | - 绘制折线图
26 | - 绘制柱状图
27 |
28 | **存储数据**
29 |
30 | - pymysql的基本使用
31 | - pymongo的基本使用
32 | - 存储到csv文件
33 |
34 | **小知识**
35 |
36 | - 复制请求的bash命令快速生成py代码
37 | - 快速编写windows脚本(以mongodb启动脚本为例)
38 |
39 | ## 数据爬取
40 |
41 | 数据来源:
42 |
43 | - 中国教育在线:https://www.eol.cn/e_html/gk/fsx/index.shtml
44 | - 抖音网页版:[发现更多精彩视频 - 抖音搜索 (douyin.com)](https://www.douyin.com/search/大庆回应河南中考生移民?publish_time=0&sort_type=1&source=tab_search&type=general)
45 |
46 | ### 爬取分数线相关数据
47 |
48 | 这个就是简单的爬取数据,点开这个网站,直接F12抓包。网站是用`jquery`写的,也没有异步加载,直接往一个页面上发送请求即可拿到返回的html页面。
49 |
50 | 在返回的html结构中就可以使用`pyquery`,`xpath`这种库来提取需要的数据了。
51 |
52 | ### 爬取评论数据
53 |
54 | 抖音这个网站当时也是研究了一天,也结合了网上的一些教程,比如K哥的手撸X-Bogus加密,最后成功的逆向出来了,本来想着还能搞个几k呢,谁想到老板跑路了。其实你只要拿着这个X-Bogus加密,就能拿到抖音很多东西了,比如`用户资料`,`用户视频信息`,`评论`什么的,一些自动化的还需要`bd-ticket-guard-client-data`。
55 |
56 | **X-Bogus逆向:**
57 |
58 | 这里我采用的是**补环境**,顾名思义,就是补一下js代码运行所需要的环境。找到加密入口,通过一些断点调试的方式找到加密的参数,把所有代码整个给扣下来,然后在python里面调用js代码,传递需要加密的参数,让js把加密后的数据给你返回即可。
59 |
60 | 可以参考这个教程:https://www.bilibili.com/video/BV1nw411t7dq/ ,两个小时讲的很适合小白,有基础的可以跳着看
61 |
62 | **剩下的参数**
63 |
64 | 对于剩下的参数,如果你需要自动化数据采集,比如根据关键字搜索后自动把这个关键字下面视频的所有评论都给采集出来,你可能还需要使用正则把`aweme_id`这种参数给逆向出来(一般是通过**正则**提取)。
65 |
66 | 但是我们这里就采集5条视频的两万五千条评论,我就手动赋值了,只需要修改分页查询的两个参数就可以愉快的进行爬取了。
67 |
68 | **写在后面**
69 |
70 | 本次我爬取的时候前前后后爬取了10万条评论,抖音没有进行风控,如果爬取的多了,比如几十万条几百万条,可能需要多个账号进行爬取。因为这里是学习目的,就不深入介绍了。
71 |
72 | ## 数据分析结果
73 |
74 | 参考的文章:
75 |
76 | - [为什么云南教育那么落后一本线却那么高 尤其是文科一本线达到560为全国第一? - 知乎 (zhihu.com)](https://www.zhihu.com/question/388542513)
77 | - [为什么没人说江西高考生难呢? - 知乎 (zhihu.com)](https://www.zhihu.com/question/406096847)
78 | - [2021高考共几套试卷,各省使用什么卷? - 知乎 (zhihu.com)](https://www.zhihu.com/question/463646951)
79 | - [2018年高考试卷使用版本划定 哪些省市使用全国卷_高考_新东方在线 (koolearn.com)](https://news.koolearn.com/20180605/1152565.html)
80 |
81 | ### 如何进行数据分析
82 |
83 | 很多同学拿到数据不知道怎么进行分析,我能给的建议是首先看你需要什么,第二看你拿到的数据能给你什么。分析的自由度是很大的,画什么图,用什么数据都是你自己决定的,多看看别人是怎么进行数据分析的。拿现在我们分析的举例子:
84 |
85 | **对分数线的分析**:我只是分析了一二本的前4名和后4名。扩展的是不是还有新高考省份的分数线?京津沪的分数线。
86 |
87 | **对评论的分析**:是不是可以对评论的人进行分类,看一下评论的性别分布和年龄分布。在B站的话可能还有等级分布
88 |
89 | ### 分数线分析
90 |
91 | 一图胜千言,首先是每个省份的可视化分析。
92 |
93 | 这里我的分析思路是这样的,我们之前拿到了每个省份近6年的分数线数据。这些数据**并不符合严格的规律**,分析自由度大了很多,当然提取数据的难度也大了很多。我分析的目的只是简单看一下各个省份分数线的分布,咱也不是专业人士,对于什么`艺术类`、`特招`、`自主招生`、`新高考`这些也并没有深入的了解,就不在这里班门弄斧了,就简单分析一下对于**2023年还在使用一本二本这些传统高考录取的省份进行一个分析。**
94 |
95 | 根据文理科和一二本进行分类,一共有4种组合,对每种组合分别分析**平均分数线**最高的4个省份和**平均分数线**最低的4个省份进行绘制折线图。
96 |
97 | **QA:**
98 |
99 | >Q: 为什么我使用平均分数线来对省份进行排序?
100 | >
101 | >A:选择的原因
102 | >
103 | >- 使用平均分数线分析起来相对简单,同时比单个年份的排序更有说服力
104 | >- 一般一个省份分数线高就会一直高下去,基本不会出现飞上枝头变凤凰这种情况,每年的差距应该不算很大。
105 | >
106 | >
107 | >
108 | >Q:每个省份不是对应有特定的I,II,III卷吗,这个可以忽略吗?
109 | >
110 | >A:显然是不建议忽略的。但是仍然忽略的原因如下
111 | >
112 | >1. 这里因为数据量较少(经过一二本的过滤只剩下了16个省份),如果再强行进行分类,可能会出现数据对照组较少难以解释的问题。
113 | >2. 选择II和III的省份近几年分数也相对比较低,跟卷I的省份比较也不会太大的影响分析结果。
114 |
115 | **明确一点,分数线高低并不直接代表高考的难易程度,任何事情都是相对的。**
116 |
117 | 举个例子:竞争压力大的省份过一本线70分可以上双一流,竞争压力小的省份过一本线30分可以上双一流。其中省内大学和省外大学又有差距。同时每个省份的评分标准也不尽相同
118 |
119 | >参与统计的省份(共16个):
120 | >
121 | >南方:江西、安徽、广西、四川、云南、贵州
122 | >
123 | >北方:河南、山西、内蒙古、陕西,甘肃,宁夏,青海,新疆、吉林、黑龙江
124 |
125 | #### **分数线排名**
126 |
127 | 1. 排名前4的分别是四川、云南、江西、河南
128 | 2. 排名后4的有宁夏、黑龙江、新疆、青海
129 |
130 | 2020年前的I卷和III卷难度差距较大,20年以后全国三张卷子更改成甲卷和乙卷,难度接近了。
131 |
132 | **排名前四的分析**:
133 |
134 | - 四川和云南使用三卷,分数高一点也正常,但是这么高的分数也足以看出他们的实力了。
135 | - 江西确实是直接一提的,同属一卷的情况下,分数线在20年之前遥遥领先河南,20年之后也是跟河南差不多的。
136 | - 从分数线看的话,河南的高考难度还好,并没有遥遥领先,可能是人多而高校招生人数是固定的,导致高校分数线在本省上浮从而上学难。
137 |
138 | **排名后四的分析**:
139 |
140 | - 从20年4个省份分数线开始极速暴跌,尤其是在2021年,新疆的一本分数线是405,与分数线最高的省份四川差了116分。可能是因为改用了全国卷的原因,在21年之前,新疆、宁夏、黑龙江使用卷III,由于教育改革,这三个省份开始使用全国乙卷(即与江西、安徽、河南等共用一套卷子)。
141 |
142 | 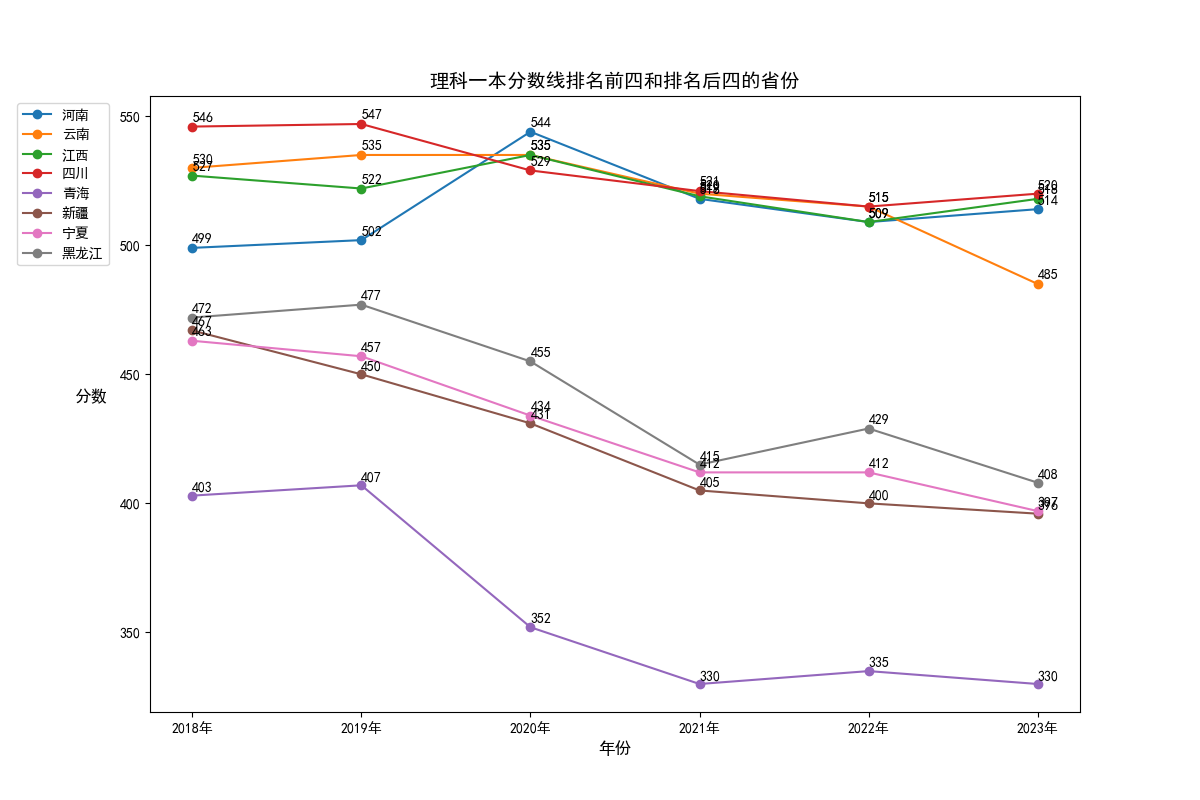
143 |
144 | 下面这几个图就不一一分析了:
145 |
146 |
238 |
239 | ### 关于对所有订单的分析结果
240 |
241 | 样本数:**11364**个
242 |
243 | #### 游戏大区分布
244 |
245 | 还是安q傲立群雄,不过安卓微信居然才12.6%。安卓苹果也算是两足鼎立了。
246 |
247 | 
248 |
249 | #### 发单者和订单数的相关关系
250 |
251 | 这个图很明了了,0.5%的发单者发了50%的单子。我看了排名前几个的,第一个好像是淘宝来的,一共就一万多个单子,他发了1000多个。各种中间商抽成,真的比我国贫富差距还抽象啊
252 |
253 | 
254 |
255 | #### 价格等的描述性统计
256 |
257 | 简单分析一下下面的图:
258 |
259 | - 标准差比平均值大好几倍,我们一般认为波动非常大,数据不稳定,在代练行业这个是正常的
260 | - 价格方面,每个单子的平均价格是在120左右、中位数在32左右,上四分位数是100, 说明低价的订单比较多。
261 | - 保证金方面,都没有太大的浮动。一般发单者也是喜欢设置两个保证金为差不多的价格
262 | - 时间限制方面,平均是在65个小时,上四分位数是72个小时,这个东西我们代练一般也不太看重。
263 |
264 | 
265 |
266 | #### 每个段位的价格问题
267 |
268 | 参与统计的数据集是一万一千多个,还是非常有参考价值的。
269 |
270 | - 一切尽在不言中,排位这么多的样本,这个应该是没人反对是偶然性了吧。这个我就不再分析了,都是聪明人。
271 |
272 | - 作为一个圈内人,我澄清一下,51星以上的基本就没有参考价值了。样本才53个。50星以下的26-51星,300多个样本,4块钱一颗星,进厂一个小时多少钱啊各位。
273 | - 另外巅峰赛的话现在也已经被各种中介搞的乌烟瘴气了,
274 |
275 | 最后大家可能会疑惑,为啥我统计了一万个样本,下面的才不到3000个呢。
276 |
277 | 1. 一个是因为我为了保证结果的准确性是使用正则提取这些星数的,只有符合我的标题格式的要求,我才会提取这个星数来计算平均价格。`宁可放过一千,不会错杀一个`
278 | 2. 还有就是我只是提取**固定区间**的数据,比如说有个单子是1-50星的,这个时候计算平均值时候你说把他放在哪个区间里面,所以我就把他舍去了。
279 |
280 | 
281 |
282 | ## 写在后面
283 |
284 | 真的,**做正确的事比正确的做事更重要**。永远都是**选择大于努力**。21年时候随便接个1500的单子一把都10块钱,再看看现在,还好王者荣耀代练我跑路跑的快。
--------------------------------------------------------------------------------
/docs/spiders/middle_exam.md:
--------------------------------------------------------------------------------
1 | # 河南考生中考移民大庆大家究竟在吵什么?我爬取了两万五千条抖音评论和近6年分数线并进行了数据分析
2 |
3 | ## 所涉及到的知识点
4 |
5 | **爬虫**
6 |
7 | - 爬虫基础
8 | 1. requests库的基本使用
9 | 2. pyquery库的基本使用
10 |
11 | - js逆向
12 |
13 | 1. js补环境(VMP还原)
14 |
15 | 2. execjs的使用
16 |
17 | **数据分析**
18 |
19 | - pandas的使用
20 |
21 | - numpy的使用
22 | - matplotlib的使用
23 | - 绘制组合条形图
24 | - 绘制词云图
25 | - 绘制折线图
26 | - 绘制柱状图
27 |
28 | **存储数据**
29 |
30 | - pymysql的基本使用
31 | - pymongo的基本使用
32 | - 存储到csv文件
33 |
34 | **小知识**
35 |
36 | - 复制请求的bash命令快速生成py代码
37 | - 快速编写windows脚本(以mongodb启动脚本为例)
38 |
39 | ## 数据爬取
40 |
41 | 数据来源:
42 |
43 | - 中国教育在线:https://www.eol.cn/e_html/gk/fsx/index.shtml
44 | - 抖音网页版:[发现更多精彩视频 - 抖音搜索 (douyin.com)](https://www.douyin.com/search/大庆回应河南中考生移民?publish_time=0&sort_type=1&source=tab_search&type=general)
45 |
46 | ### 爬取分数线相关数据
47 |
48 | 这个就是简单的爬取数据,点开这个网站,直接F12抓包。网站是用`jquery`写的,也没有异步加载,直接往一个页面上发送请求即可拿到返回的html页面。
49 |
50 | 在返回的html结构中就可以使用`pyquery`,`xpath`这种库来提取需要的数据了。
51 |
52 | ### 爬取评论数据
53 |
54 | 抖音这个网站当时也是研究了一天,也结合了网上的一些教程,比如K哥的手撸X-Bogus加密,最后成功的逆向出来了,本来想着还能搞个几k呢,谁想到老板跑路了。其实你只要拿着这个X-Bogus加密,就能拿到抖音很多东西了,比如`用户资料`,`用户视频信息`,`评论`什么的,一些自动化的还需要`bd-ticket-guard-client-data`。
55 |
56 | **X-Bogus逆向:**
57 |
58 | 这里我采用的是**补环境**,顾名思义,就是补一下js代码运行所需要的环境。找到加密入口,通过一些断点调试的方式找到加密的参数,把所有代码整个给扣下来,然后在python里面调用js代码,传递需要加密的参数,让js把加密后的数据给你返回即可。
59 |
60 | 可以参考这个教程:https://www.bilibili.com/video/BV1nw411t7dq/ ,两个小时讲的很适合小白,有基础的可以跳着看
61 |
62 | **剩下的参数**
63 |
64 | 对于剩下的参数,如果你需要自动化数据采集,比如根据关键字搜索后自动把这个关键字下面视频的所有评论都给采集出来,你可能还需要使用正则把`aweme_id`这种参数给逆向出来(一般是通过**正则**提取)。
65 |
66 | 但是我们这里就采集5条视频的两万五千条评论,我就手动赋值了,只需要修改分页查询的两个参数就可以愉快的进行爬取了。
67 |
68 | **写在后面**
69 |
70 | 本次我爬取的时候前前后后爬取了10万条评论,抖音没有进行风控,如果爬取的多了,比如几十万条几百万条,可能需要多个账号进行爬取。因为这里是学习目的,就不深入介绍了。
71 |
72 | ## 数据分析结果
73 |
74 | 参考的文章:
75 |
76 | - [为什么云南教育那么落后一本线却那么高 尤其是文科一本线达到560为全国第一? - 知乎 (zhihu.com)](https://www.zhihu.com/question/388542513)
77 | - [为什么没人说江西高考生难呢? - 知乎 (zhihu.com)](https://www.zhihu.com/question/406096847)
78 | - [2021高考共几套试卷,各省使用什么卷? - 知乎 (zhihu.com)](https://www.zhihu.com/question/463646951)
79 | - [2018年高考试卷使用版本划定 哪些省市使用全国卷_高考_新东方在线 (koolearn.com)](https://news.koolearn.com/20180605/1152565.html)
80 |
81 | ### 如何进行数据分析
82 |
83 | 很多同学拿到数据不知道怎么进行分析,我能给的建议是首先看你需要什么,第二看你拿到的数据能给你什么。分析的自由度是很大的,画什么图,用什么数据都是你自己决定的,多看看别人是怎么进行数据分析的。拿现在我们分析的举例子:
84 |
85 | **对分数线的分析**:我只是分析了一二本的前4名和后4名。扩展的是不是还有新高考省份的分数线?京津沪的分数线。
86 |
87 | **对评论的分析**:是不是可以对评论的人进行分类,看一下评论的性别分布和年龄分布。在B站的话可能还有等级分布
88 |
89 | ### 分数线分析
90 |
91 | 一图胜千言,首先是每个省份的可视化分析。
92 |
93 | 这里我的分析思路是这样的,我们之前拿到了每个省份近6年的分数线数据。这些数据**并不符合严格的规律**,分析自由度大了很多,当然提取数据的难度也大了很多。我分析的目的只是简单看一下各个省份分数线的分布,咱也不是专业人士,对于什么`艺术类`、`特招`、`自主招生`、`新高考`这些也并没有深入的了解,就不在这里班门弄斧了,就简单分析一下对于**2023年还在使用一本二本这些传统高考录取的省份进行一个分析。**
94 |
95 | 根据文理科和一二本进行分类,一共有4种组合,对每种组合分别分析**平均分数线**最高的4个省份和**平均分数线**最低的4个省份进行绘制折线图。
96 |
97 | **QA:**
98 |
99 | >Q: 为什么我使用平均分数线来对省份进行排序?
100 | >
101 | >A:选择的原因
102 | >
103 | >- 使用平均分数线分析起来相对简单,同时比单个年份的排序更有说服力
104 | >- 一般一个省份分数线高就会一直高下去,基本不会出现飞上枝头变凤凰这种情况,每年的差距应该不算很大。
105 | >
106 | >
107 | >
108 | >Q:每个省份不是对应有特定的I,II,III卷吗,这个可以忽略吗?
109 | >
110 | >A:显然是不建议忽略的。但是仍然忽略的原因如下
111 | >
112 | >1. 这里因为数据量较少(经过一二本的过滤只剩下了16个省份),如果再强行进行分类,可能会出现数据对照组较少难以解释的问题。
113 | >2. 选择II和III的省份近几年分数也相对比较低,跟卷I的省份比较也不会太大的影响分析结果。
114 |
115 | **明确一点,分数线高低并不直接代表高考的难易程度,任何事情都是相对的。**
116 |
117 | 举个例子:竞争压力大的省份过一本线70分可以上双一流,竞争压力小的省份过一本线30分可以上双一流。其中省内大学和省外大学又有差距。同时每个省份的评分标准也不尽相同
118 |
119 | >参与统计的省份(共16个):
120 | >
121 | >南方:江西、安徽、广西、四川、云南、贵州
122 | >
123 | >北方:河南、山西、内蒙古、陕西,甘肃,宁夏,青海,新疆、吉林、黑龙江
124 |
125 | #### **分数线排名**
126 |
127 | 1. 排名前4的分别是四川、云南、江西、河南
128 | 2. 排名后4的有宁夏、黑龙江、新疆、青海
129 |
130 | 2020年前的I卷和III卷难度差距较大,20年以后全国三张卷子更改成甲卷和乙卷,难度接近了。
131 |
132 | **排名前四的分析**:
133 |
134 | - 四川和云南使用三卷,分数高一点也正常,但是这么高的分数也足以看出他们的实力了。
135 | - 江西确实是直接一提的,同属一卷的情况下,分数线在20年之前遥遥领先河南,20年之后也是跟河南差不多的。
136 | - 从分数线看的话,河南的高考难度还好,并没有遥遥领先,可能是人多而高校招生人数是固定的,导致高校分数线在本省上浮从而上学难。
137 |
138 | **排名后四的分析**:
139 |
140 | - 从20年4个省份分数线开始极速暴跌,尤其是在2021年,新疆的一本分数线是405,与分数线最高的省份四川差了116分。可能是因为改用了全国卷的原因,在21年之前,新疆、宁夏、黑龙江使用卷III,由于教育改革,这三个省份开始使用全国乙卷(即与江西、安徽、河南等共用一套卷子)。
141 |
142 | 
143 |
144 | 下面这几个图就不一一分析了:
145 |
146 | 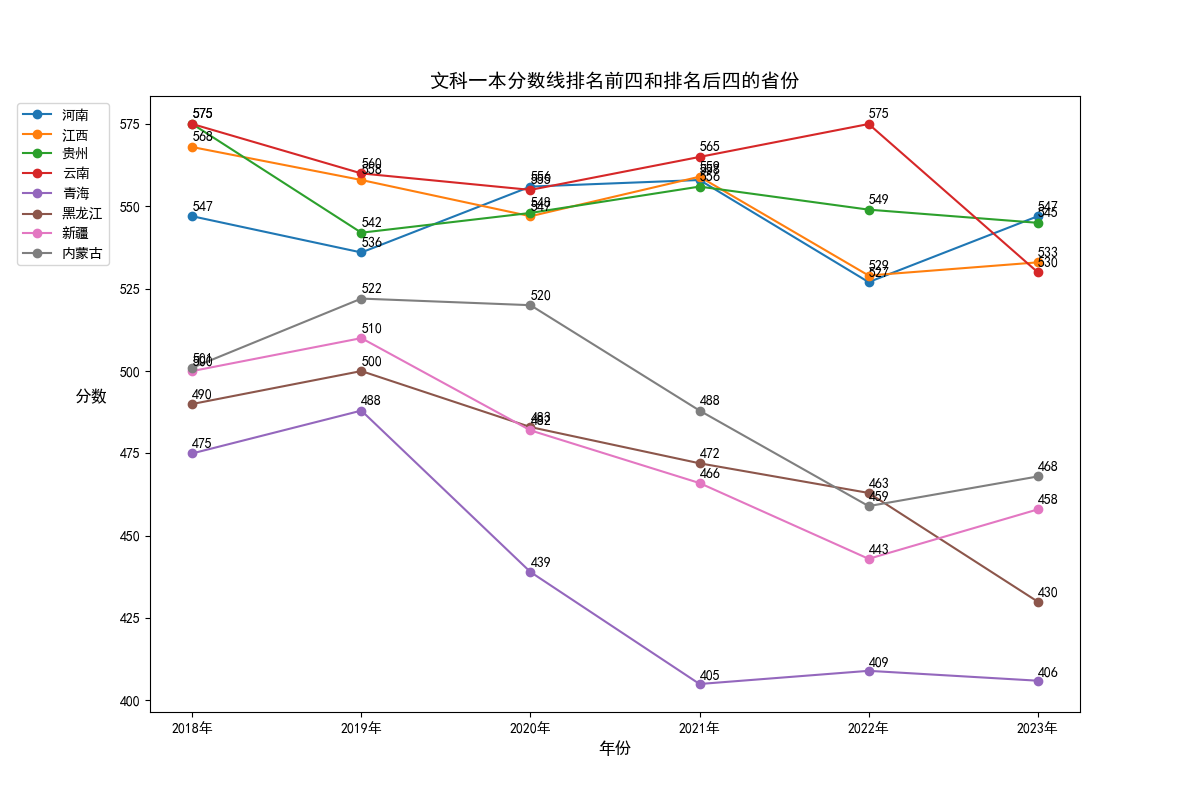 147 |
148 | 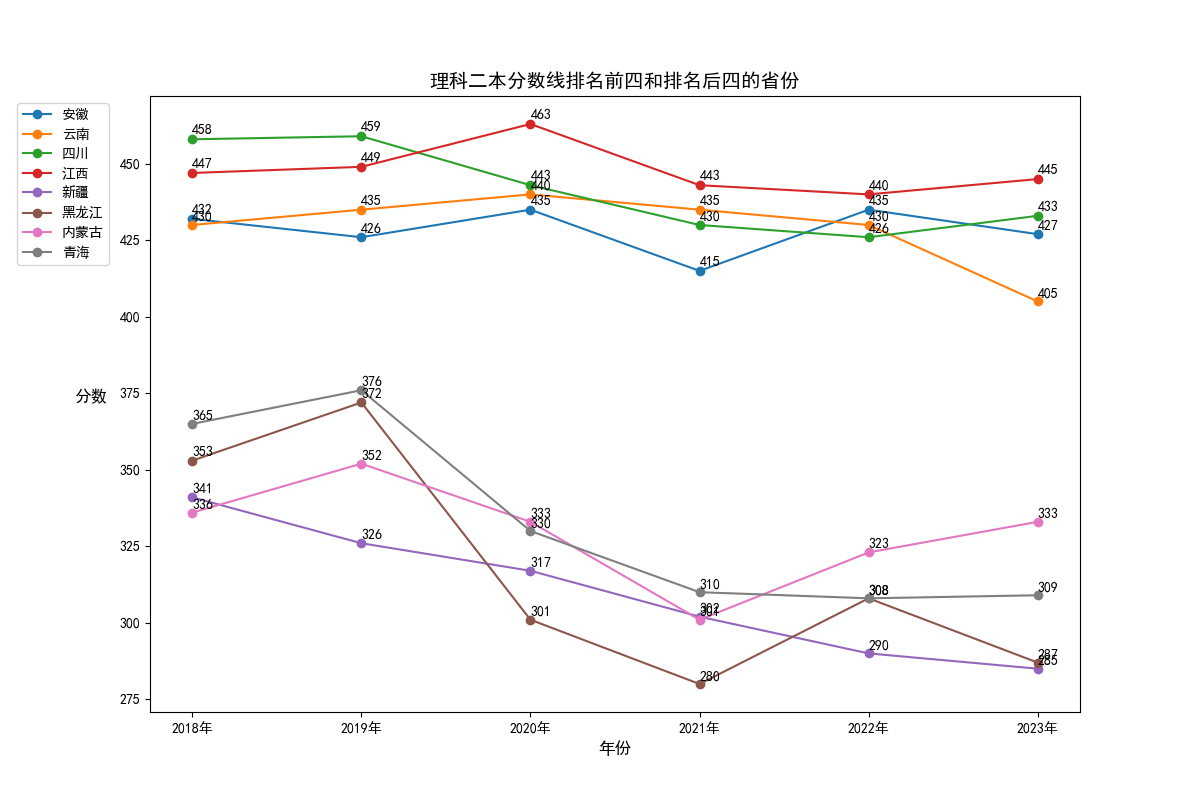
149 |
150 | 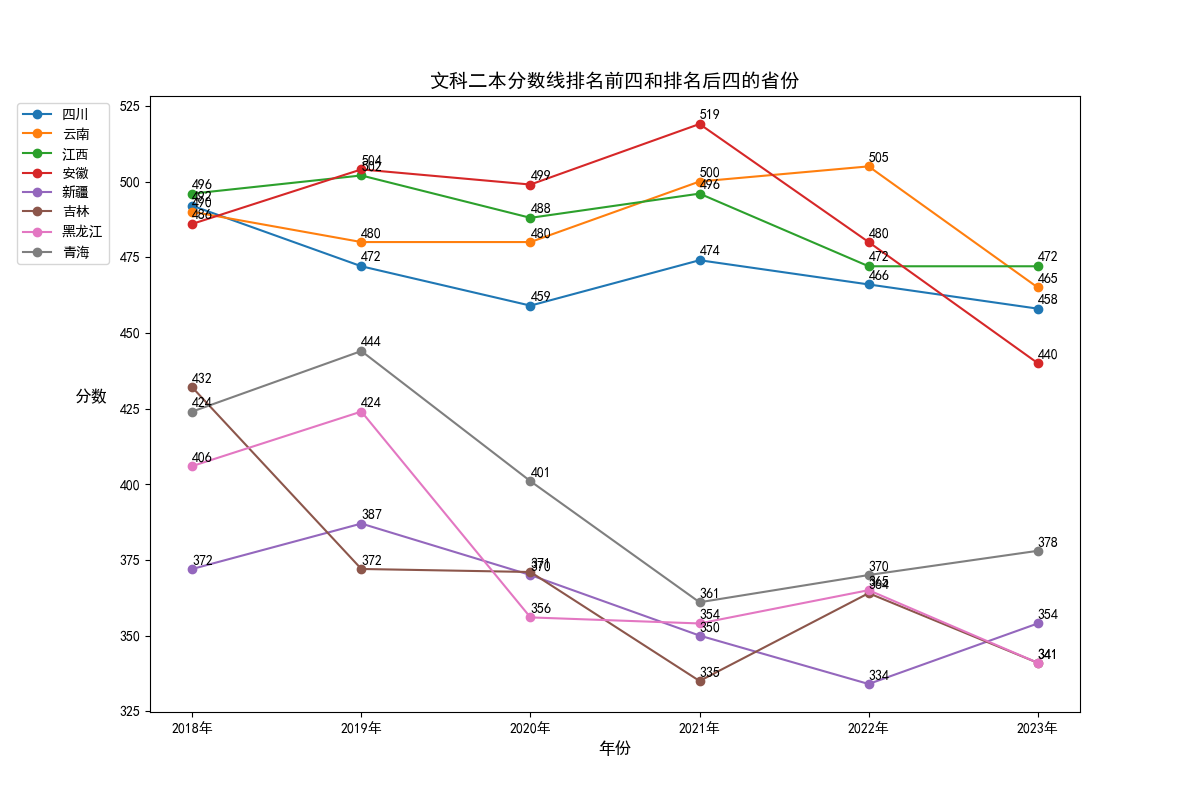
151 |
152 | #### 两省对比
153 |
154 | 我们是来探究河南移民大庆,我这里就把这两个省份简单抽出来做了一些比较。下面直接上图:
155 |
156 | 还是只分析理科的。
157 |
158 | - 在2021年(不含2021年)之前,由于两个省份卷子不同,所以其实可以看出河南并没有比黑龙江高出多少分,最高的一次在2020年,理科一本线高出了89分,理科二本线高出了117分。(这次可能是因为疫情原因)
159 | - 2021年以后,由于卷子统一,分数差距逐渐拉开,甚至在2023年,河南本科二批分数线高于黑龙江本科一批分数线1分,本科一批分数线高出黑龙江106分。本科二批分数线高出黑龙江122分。
160 |
161 | 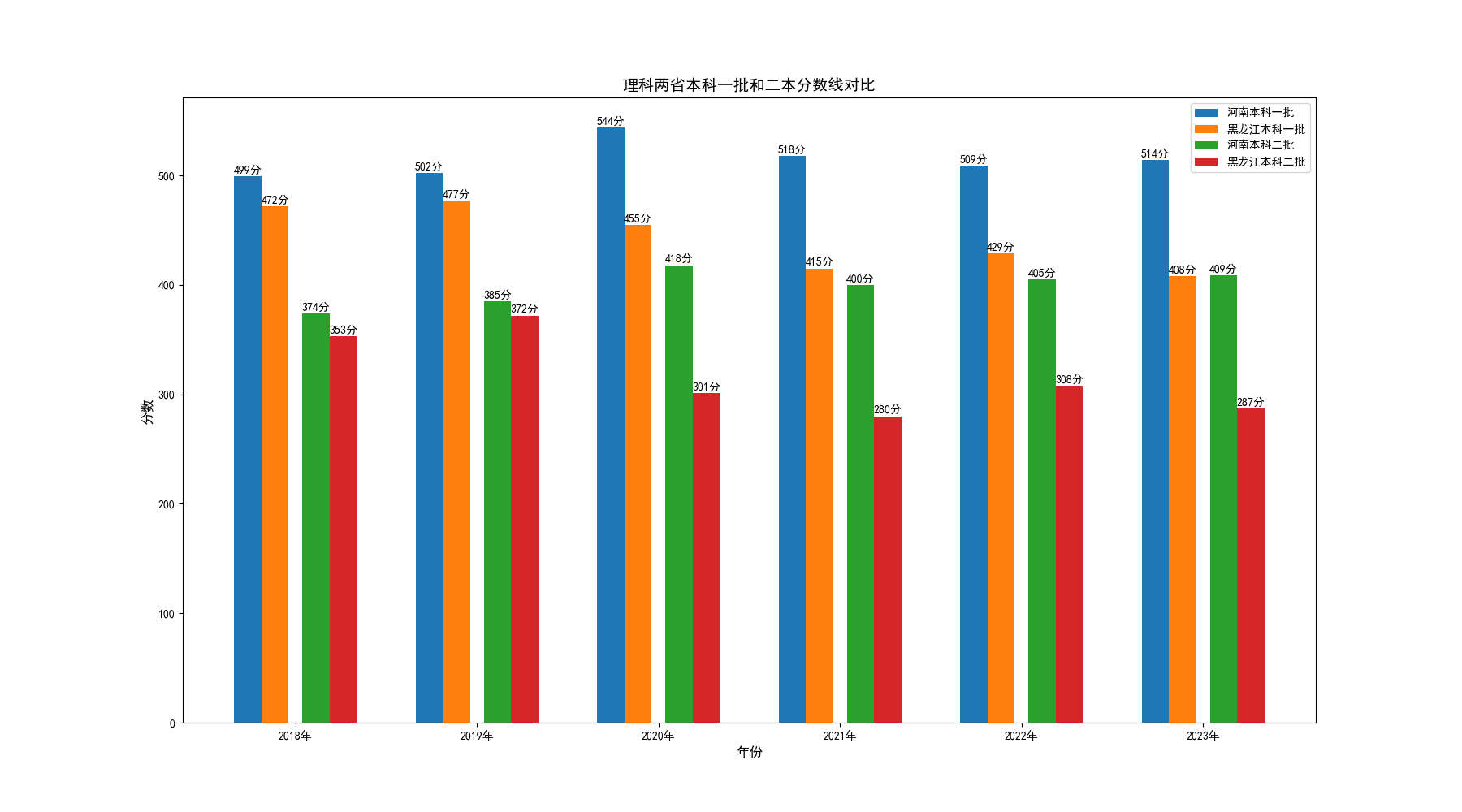
162 |
163 | 文科的也是一样,就不再赘述了
164 |
165 | 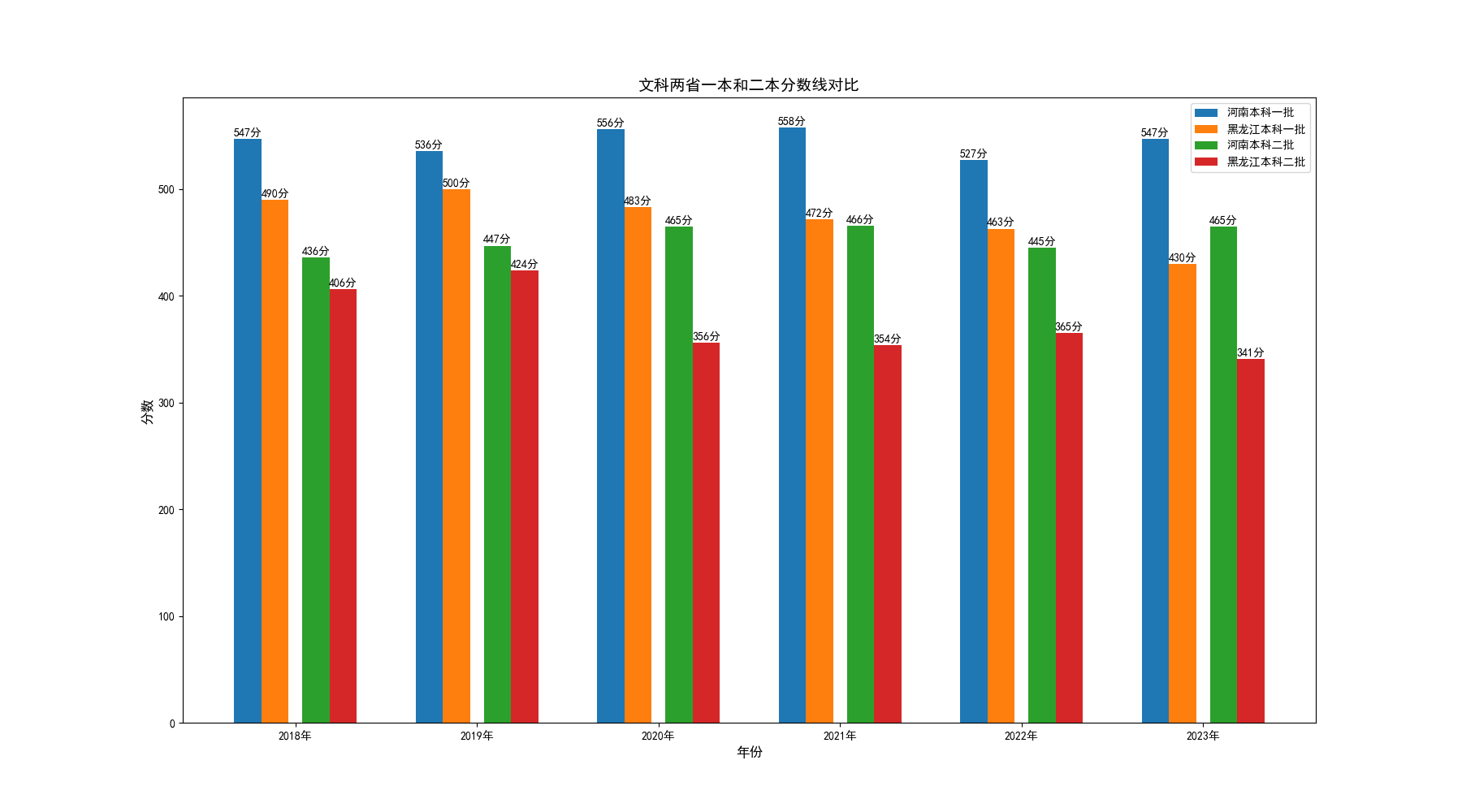
166 |
167 | ### 抖音评论分析
168 |
169 | 对评论来说,需要用到NLP技术,或者LDA分类。我对这方面的理解也仅限于调用一个别人的模型,可是这个评论属实有点......,别说模型了,连我有的都看不懂,要是手动打标记用一些机器学习模型再训练的话实在太浪费时间了。
170 |
171 | 所以我就想着调用一下GPT4的接口,让他帮我进行归类,我的prompt写的感觉够详细了,还是不太行,有的完全看不出来评论是冷嘲热讽的,如果每个评论调用一次接口,它的识别成功率可以达到60%-70%左右。但是如果每次评论我都调用一下接口,我的wallet也扛不住啊,因此就用模式匹配简单分析一下就可以了
172 |
173 | 可以看一下我的prompt:
174 |
175 | ```
176 | 我下面会给你一份csv文件,这个文件的text列是你所要分析的抖音评论
177 |
178 | 视频评论背景:
179 | 这个事件发生在最近,就在中国,中国的教育地域分布是非常不均的,教育公平是很多人都想达到的目标。其中河南高考的难度在中国是非常大的,而黑龙江却并没有那么大。这次事件的原委是有大量河南的家长把学生户籍迁移到黑龙江省大庆市,被大庆市的家长举报,认为侵犯了他们孩子的利益。这个事情在中国的抖音(国外的tiktok)平台引发了激烈的讨论。
180 |
181 | 给你的输入:
182 | 如前所述,这个输入的格式是一个csv文件。text列是我爬取的评论
183 |
184 | 你需要做的:
185 | 你需要识别不同评论的【深层】语义并把他们进行分类(需要结合视频评论的【特征】、【背景】、【以及隐含的含义】,来识别他们这个评论的含义)。分类的特征有12个:
186 | 1:支持河南考生移民
187 | 2:认为不能抢占黑龙江考生名额
188 |
189 | 3:认为河南高考分数太高
190 | 4:认为教育不平等,支持全国统一分数线
191 | 5:认为复读生太多
192 | 6: 认为河南好大学少
193 | 7:认为两者教育资源有差距,
194 |
195 | 8:认为河南生的多
196 | 9:攻击河南人
197 |
198 | 10: 谈到了西安
199 | 11:认为有人搞阴谋论,抹黑黑龙江和河南
200 | 12: 其他原因
201 |
202 | 分类的要求如下:根据你自己的模型训练集和上面的要求【精确】识别这些评论,你需要在上面11个选项中选择一个评论最可能的分类,(请注意,如果你实在无法识别评论的倾向,请把他们归类于其他原因)
203 |
204 | 补充说明:
205 | 不要简单的使用关键词匹配,你需要根据你的理解(即你的训练集)对每一个评论进行精确的分类。
206 |
207 | 在分类完成后,如果你可以返回csv文件,请提供一个csv文件,如果你不能返回文件,请严格按照下面的格式返回数据:
208 | cid,type
209 | 7323084537058886452,1
210 | 7323084537058886453,6
211 | ```
212 |
213 | #### 地域分析
214 |
215 | 可以看到来自河南的网民对这件事关注度最高,比例为**35.1%**,第二名就是山东,山河四省的核心成员,第三是陕西,我猜测是因为去年的西安事件,第四是黑龙江,河南—>黑龙江的,第五是江苏,这个应该是经济发达并且高考也不简单,所以应该也有关注度,第六个是河北,也是山河四省的核心成员。
216 |
217 | 话说 为啥山河四省的山西老铁没上榜,一家人没整整齐齐啊😂
218 |
219 | 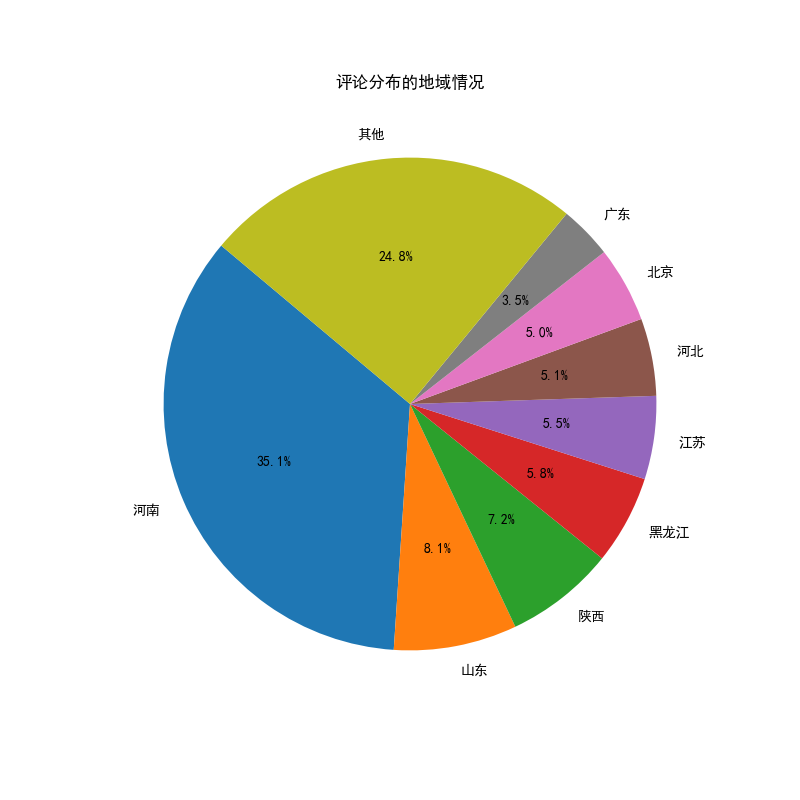
220 |
221 | #### 评论时间分析
222 |
223 | 2024-1-12号曝出来的,有80%(19804条)评论都是在当天评论的,2024-1-14号大家都不太关注了,仅仅3%不到,只有800个评论,热度还是蹭慢了🙁
224 |
225 | 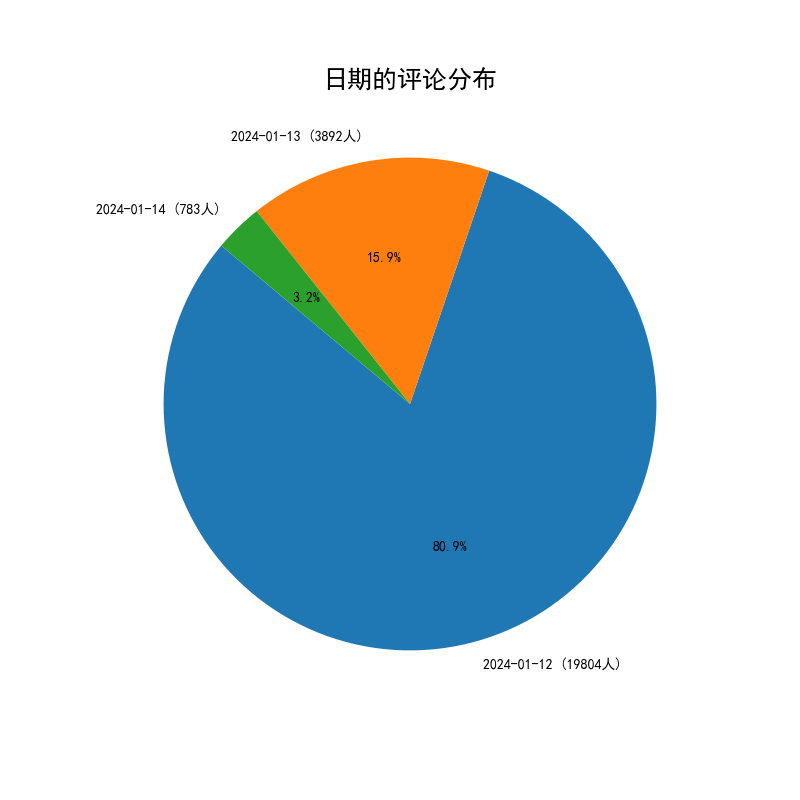
226 |
227 | #### 词云图分析
228 |
229 | 下面的词云图我做了一些过滤,把河南,黑龙江还有单字的这些给过滤出去了。下面简单看几个词分析一下。
230 |
231 | - **公平**、**高考**、**分数线**。这两个词应该是在强调教育不公平,高考难
232 |
233 | - **孩子**。父母之爱子,则为之计深远。这种意思
234 |
235 | - **全国统一**。应该是在呼吁全国统一考卷
236 |
237 | - **山河四省**。源自今年出圈的一个梗,在这次也有强调,应该也是在说山河四省高考难
238 |
239 | - **向阳而生**。一句话:`如果阳光不能均匀的撒在大地上,就不要责怪他们选择向阳而生!`
240 |
241 | - **西安**。应该是去年移民西安的事情
242 |
243 | - **为什么**、**河南人**、**他们**。这些词汇应该是在攻击河南人,比如这个评论:
244 |
245 | `这些人难道不是想享受好的教育资源后,去其他弱省钻空子吗,这么多年,怎么不见江苏,浙江这些教育强省的这种新闻,反倒是你们,去完西安,现在又去大庆。你们如果去江苏,浙江,山东,河北。我觉得还真没多少人这么说河南人[尬笑][尬笑][尬笑][尬笑]`
246 |
247 | 
248 |
249 |
250 |
251 | #### 归类分析
252 |
253 | 由于是经过模式匹配,自己添加正则,肯定有疏漏地方,一个匹配出来了2000个左右,10%, 这个参考价值并不是很大,但是也是有参考价值的。这里我们不谈比例,只谈多少人。上面的分类在prompt里面,
254 |
255 | 10对应的是**谈到了西安**
256 |
257 | 4对应的是认为**教育不平等,支持全国统一分数线,统一试卷**
258 |
259 | 7对应的是**教育资源差距**
260 |
261 | 5对应的是认为**复读生太多**
262 |
263 | 8对应的是**认为河南生的多,人多**
264 |
265 | 可以看到,谈到西安的评论占到了800个左右,大概是评论数的4%。统一分数线有600个评论提及,认为教育资源有差距的有500个评论,认为河南复读生多的有200个,认为河南人多的有190个。
266 |
267 | 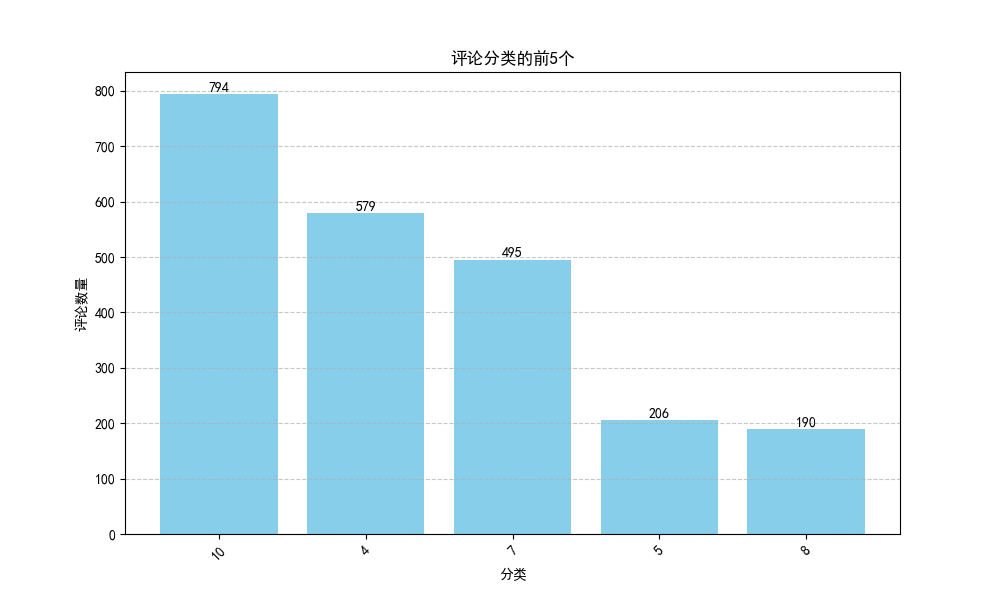
268 |
269 |
147 |
148 | 
149 |
150 | 
151 |
152 | #### 两省对比
153 |
154 | 我们是来探究河南移民大庆,我这里就把这两个省份简单抽出来做了一些比较。下面直接上图:
155 |
156 | 还是只分析理科的。
157 |
158 | - 在2021年(不含2021年)之前,由于两个省份卷子不同,所以其实可以看出河南并没有比黑龙江高出多少分,最高的一次在2020年,理科一本线高出了89分,理科二本线高出了117分。(这次可能是因为疫情原因)
159 | - 2021年以后,由于卷子统一,分数差距逐渐拉开,甚至在2023年,河南本科二批分数线高于黑龙江本科一批分数线1分,本科一批分数线高出黑龙江106分。本科二批分数线高出黑龙江122分。
160 |
161 | 
162 |
163 | 文科的也是一样,就不再赘述了
164 |
165 | 
166 |
167 | ### 抖音评论分析
168 |
169 | 对评论来说,需要用到NLP技术,或者LDA分类。我对这方面的理解也仅限于调用一个别人的模型,可是这个评论属实有点......,别说模型了,连我有的都看不懂,要是手动打标记用一些机器学习模型再训练的话实在太浪费时间了。
170 |
171 | 所以我就想着调用一下GPT4的接口,让他帮我进行归类,我的prompt写的感觉够详细了,还是不太行,有的完全看不出来评论是冷嘲热讽的,如果每个评论调用一次接口,它的识别成功率可以达到60%-70%左右。但是如果每次评论我都调用一下接口,我的wallet也扛不住啊,因此就用模式匹配简单分析一下就可以了
172 |
173 | 可以看一下我的prompt:
174 |
175 | ```
176 | 我下面会给你一份csv文件,这个文件的text列是你所要分析的抖音评论
177 |
178 | 视频评论背景:
179 | 这个事件发生在最近,就在中国,中国的教育地域分布是非常不均的,教育公平是很多人都想达到的目标。其中河南高考的难度在中国是非常大的,而黑龙江却并没有那么大。这次事件的原委是有大量河南的家长把学生户籍迁移到黑龙江省大庆市,被大庆市的家长举报,认为侵犯了他们孩子的利益。这个事情在中国的抖音(国外的tiktok)平台引发了激烈的讨论。
180 |
181 | 给你的输入:
182 | 如前所述,这个输入的格式是一个csv文件。text列是我爬取的评论
183 |
184 | 你需要做的:
185 | 你需要识别不同评论的【深层】语义并把他们进行分类(需要结合视频评论的【特征】、【背景】、【以及隐含的含义】,来识别他们这个评论的含义)。分类的特征有12个:
186 | 1:支持河南考生移民
187 | 2:认为不能抢占黑龙江考生名额
188 |
189 | 3:认为河南高考分数太高
190 | 4:认为教育不平等,支持全国统一分数线
191 | 5:认为复读生太多
192 | 6: 认为河南好大学少
193 | 7:认为两者教育资源有差距,
194 |
195 | 8:认为河南生的多
196 | 9:攻击河南人
197 |
198 | 10: 谈到了西安
199 | 11:认为有人搞阴谋论,抹黑黑龙江和河南
200 | 12: 其他原因
201 |
202 | 分类的要求如下:根据你自己的模型训练集和上面的要求【精确】识别这些评论,你需要在上面11个选项中选择一个评论最可能的分类,(请注意,如果你实在无法识别评论的倾向,请把他们归类于其他原因)
203 |
204 | 补充说明:
205 | 不要简单的使用关键词匹配,你需要根据你的理解(即你的训练集)对每一个评论进行精确的分类。
206 |
207 | 在分类完成后,如果你可以返回csv文件,请提供一个csv文件,如果你不能返回文件,请严格按照下面的格式返回数据:
208 | cid,type
209 | 7323084537058886452,1
210 | 7323084537058886453,6
211 | ```
212 |
213 | #### 地域分析
214 |
215 | 可以看到来自河南的网民对这件事关注度最高,比例为**35.1%**,第二名就是山东,山河四省的核心成员,第三是陕西,我猜测是因为去年的西安事件,第四是黑龙江,河南—>黑龙江的,第五是江苏,这个应该是经济发达并且高考也不简单,所以应该也有关注度,第六个是河北,也是山河四省的核心成员。
216 |
217 | 话说 为啥山河四省的山西老铁没上榜,一家人没整整齐齐啊😂
218 |
219 | 
220 |
221 | #### 评论时间分析
222 |
223 | 2024-1-12号曝出来的,有80%(19804条)评论都是在当天评论的,2024-1-14号大家都不太关注了,仅仅3%不到,只有800个评论,热度还是蹭慢了🙁
224 |
225 | 
226 |
227 | #### 词云图分析
228 |
229 | 下面的词云图我做了一些过滤,把河南,黑龙江还有单字的这些给过滤出去了。下面简单看几个词分析一下。
230 |
231 | - **公平**、**高考**、**分数线**。这两个词应该是在强调教育不公平,高考难
232 |
233 | - **孩子**。父母之爱子,则为之计深远。这种意思
234 |
235 | - **全国统一**。应该是在呼吁全国统一考卷
236 |
237 | - **山河四省**。源自今年出圈的一个梗,在这次也有强调,应该也是在说山河四省高考难
238 |
239 | - **向阳而生**。一句话:`如果阳光不能均匀的撒在大地上,就不要责怪他们选择向阳而生!`
240 |
241 | - **西安**。应该是去年移民西安的事情
242 |
243 | - **为什么**、**河南人**、**他们**。这些词汇应该是在攻击河南人,比如这个评论:
244 |
245 | `这些人难道不是想享受好的教育资源后,去其他弱省钻空子吗,这么多年,怎么不见江苏,浙江这些教育强省的这种新闻,反倒是你们,去完西安,现在又去大庆。你们如果去江苏,浙江,山东,河北。我觉得还真没多少人这么说河南人[尬笑][尬笑][尬笑][尬笑]`
246 |
247 | 
248 |
249 |
250 |
251 | #### 归类分析
252 |
253 | 由于是经过模式匹配,自己添加正则,肯定有疏漏地方,一个匹配出来了2000个左右,10%, 这个参考价值并不是很大,但是也是有参考价值的。这里我们不谈比例,只谈多少人。上面的分类在prompt里面,
254 |
255 | 10对应的是**谈到了西安**
256 |
257 | 4对应的是认为**教育不平等,支持全国统一分数线,统一试卷**
258 |
259 | 7对应的是**教育资源差距**
260 |
261 | 5对应的是认为**复读生太多**
262 |
263 | 8对应的是**认为河南生的多,人多**
264 |
265 | 可以看到,谈到西安的评论占到了800个左右,大概是评论数的4%。统一分数线有600个评论提及,认为教育资源有差距的有500个评论,认为河南复读生多的有200个,认为河南人多的有190个。
266 |
267 | 
268 |
269 | 270 | 271 | 根据上面的分析结果可以稍微得出一点结论: 272 | 273 | - 大家关注去年移民西安的事情 274 | - 支持全国统一分数线、统一试卷 275 | - 认为教育资源差距大 276 | 277 | ### 写在后面 278 | 279 | 今年哈尔滨爆火其实也让大家更了解了黑龙江。作为一个在黑龙江读了几年书的河南人,还是挺建议来这里的。原因 280 | 281 | - 反卷圣地,分数线上面也分析了,老师大部分很佛系,不会出现`不学习先死爹后死妈`的tagline。 282 | - 平常气候也非常宜人,冬暖(有暖气)夏凉很舒服 283 | - 至于景点和底蕴就不用我介绍了,抖音视频已经满天飞了。 284 | - 这里的人也很不错(不包括中介😡 ) 285 | 286 | 说回正题,调查结果出来了,好像是300多个人有100多人是河南的。 287 | 288 | 但是像这种中高考移民确实是不应该赞同的,首先,并不是鼓励大家仇富,这种能出来的要么家里有关系,要么家里有money,这不仅对黑龙江不公平,对河南考生不也相对不公平(短期大家可能觉得少了一个竞争对手)。但是你跑出来了那别人跑不跑呢?河南的跑了河北、山东的跑不跑呢?你出2w能跑别人是不是要出3w?大庆不让了是不是要去哈尔滨?哈尔滨不让了是不是要去齐齐哈尔?黑龙江不让了是不是要去青海🤔。归根结底还是不能说的问题 289 | 290 | >打个比喻,上游水闸开了,一直在下游建坝能解决问题吗?大家心知肚明。现在的问题是怎么关?或者怎么关小一点,这就轮到专家发力了。 291 | 292 | 并且也是真的对黑龙江考生不公平的,你在河南上学跑来黑龙江考试。举个栗子:河南考生5点起床9点放学**卷**16个小时,别人7点起床6点放学,你一天比本地考生多学5、6个小时,考试相对而言肯定不公平了。我一直认为中高考这种时间上的内卷是没有意义的,有那个时间多看看外面的世界,多去培养一些自己的兴趣爱好,不比你做100遍1+1强吗,但是这种机械劳动却被许多人奉为圭臬。 293 | 294 | 这个东西也是不可能有解,只要制度不改,那些高考大省是没有学校会去推崇素质教育的。 295 | 296 | **希望大家积极向上,怨天尤人没有用,还是努力提升自己。** 297 | 298 | >世界上只有一种真正的英雄主义,那就是在认清生活的真相以后依然热爱生活。 -------------------------------------------------------------------------------- /docs/tools/docker.md: -------------------------------------------------------------------------------- 1 | ## docker -------------------------------------------------------------------------------- /docs/tools/git.md: -------------------------------------------------------------------------------- 1 | ## git工作流 2 | 3 | ## git常用命令 -------------------------------------------------------------------------------- /docs/tools/iTime_docs.md: -------------------------------------------------------------------------------- 1 | # iTime软件使用说明书📄 2 | 3 | ## 软件介绍📘 4 | 5 | iTime🕰️ 是一款基于vue3+arco design+electron开发的桌面端效率应用,slogan是`让每一秒都刚刚好`🌟,意为提高您的效率,帮助您充分利用自己的每一秒。 6 | 7 | ## 功能介绍🔧 8 | 9 | 目前iTime有四个模块,分别是待办📝、倒计时⏳、番茄钟🍅、自定义设置⚙️,与这四个功能相辅相成的有**屏幕挂件**🖥️、**提示语音**🔊。下面将详细介绍这四个功能,**每个小功能之前都会有一个演示的gif动图** 10 | 11 | ### 待办功能📝 12 | 13 | 待办功能分为标准待办和自定义待办部分: 14 | 15 | 标准待办动图: 16 | 17 |
 18 |
19 | - 标准待办中,您每新增一个代办需要填写待办的**内容**✍️、**标签(可选)**🏷️、**提醒时间**⏰这三个部分,**时间**和**内容**是必需的,以便程序知道何时提醒您。
20 |
21 | 💡为了ui展示的合理性,建议您每个待办不要超过**5个**标签
22 |
23 | 自定义待办动图:
24 |
25 |
18 |
19 | - 标准待办中,您每新增一个代办需要填写待办的**内容**✍️、**标签(可选)**🏷️、**提醒时间**⏰这三个部分,**时间**和**内容**是必需的,以便程序知道何时提醒您。
20 |
21 | 💡为了ui展示的合理性,建议您每个待办不要超过**5个**标签
22 |
23 | 自定义待办动图:
24 |
25 |  26 |
27 | - 自定义待办中,您可以把待办当做一个便签📌,在富文本编辑器编辑好以后保存,去预览界面,右键发送待办挂件即可成为屏幕挂件。
28 |
29 | ### 倒计时功能⏳
30 |
31 |
26 |
27 | - 自定义待办中,您可以把待办当做一个便签📌,在富文本编辑器编辑好以后保存,去预览界面,右键发送待办挂件即可成为屏幕挂件。
28 |
29 | ### 倒计时功能⏳
30 |
31 |  32 |
33 | 倒计时器有三种使用方式:
34 |
35 | - 在软件主界面启动倒计时器
36 | - 左键双击全屏倒计时器
37 | - 右键双击发送倒计时器成为挂件
38 |
39 | ❗倒计时器的范围是**0.1-999**分钟。
40 |
41 | ❗您可以在获取焦点后按**R**键重置倒计时器
42 |
43 | ### 番茄钟功能🍅
44 |
45 |
32 |
33 | 倒计时器有三种使用方式:
34 |
35 | - 在软件主界面启动倒计时器
36 | - 左键双击全屏倒计时器
37 | - 右键双击发送倒计时器成为挂件
38 |
39 | ❗倒计时器的范围是**0.1-999**分钟。
40 |
41 | ❗您可以在获取焦点后按**R**键重置倒计时器
42 |
43 | ### 番茄钟功能🍅
44 |
45 |  46 |
47 | ℹ️:上述gif番茄钟时间参数是为了方便开发时设置的参数、实际并不暴露给定范围外的接口
48 |
49 | 与倒计时器类似,也支持上述三种方式使用番茄钟。番茄钟了解链接:[番茄钟如何提高效率](https://www.zhihu.com/question/330121574)
50 |
51 | - 在软件主界面启动倒计时器
52 | - 左键双击全屏倒计时器
53 | - 右键双击发送倒计时器成为挂件
54 |
55 | ℹ️ 番茄钟可以自定义`长休息`🌴、`短休息`☕、`专注时间`⏲️、`轮数`🔄4个选项,稍后会介绍。
56 |
57 | ### 自定义设置⚙️
58 |
59 | 我们暴露出了一些接口供用户自定义,包含**全局快捷键设置**⌨️、**挂件位置设置**📍、**提示语音设置**🔊、**待办列表项设置**🗃️、**番茄钟参数设置**🕒、**番茄钟与计时器背景图设置**🖼️,下面详细介绍:
60 |
61 |
46 |
47 | ℹ️:上述gif番茄钟时间参数是为了方便开发时设置的参数、实际并不暴露给定范围外的接口
48 |
49 | 与倒计时器类似,也支持上述三种方式使用番茄钟。番茄钟了解链接:[番茄钟如何提高效率](https://www.zhihu.com/question/330121574)
50 |
51 | - 在软件主界面启动倒计时器
52 | - 左键双击全屏倒计时器
53 | - 右键双击发送倒计时器成为挂件
54 |
55 | ℹ️ 番茄钟可以自定义`长休息`🌴、`短休息`☕、`专注时间`⏲️、`轮数`🔄4个选项,稍后会介绍。
56 |
57 | ### 自定义设置⚙️
58 |
59 | 我们暴露出了一些接口供用户自定义,包含**全局快捷键设置**⌨️、**挂件位置设置**📍、**提示语音设置**🔊、**待办列表项设置**🗃️、**番茄钟参数设置**🕒、**番茄钟与计时器背景图设置**🖼️,下面详细介绍:
60 |
61 | 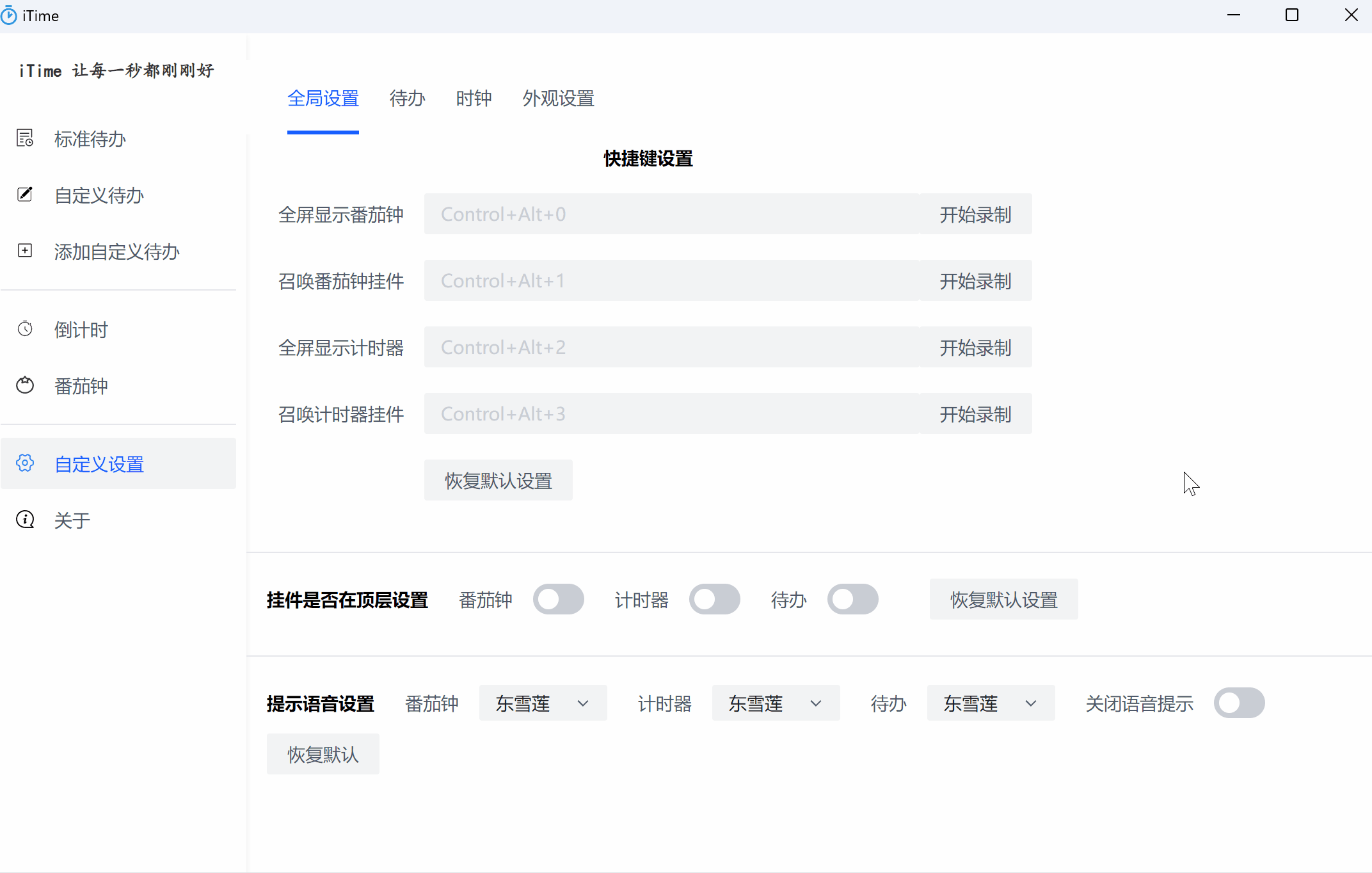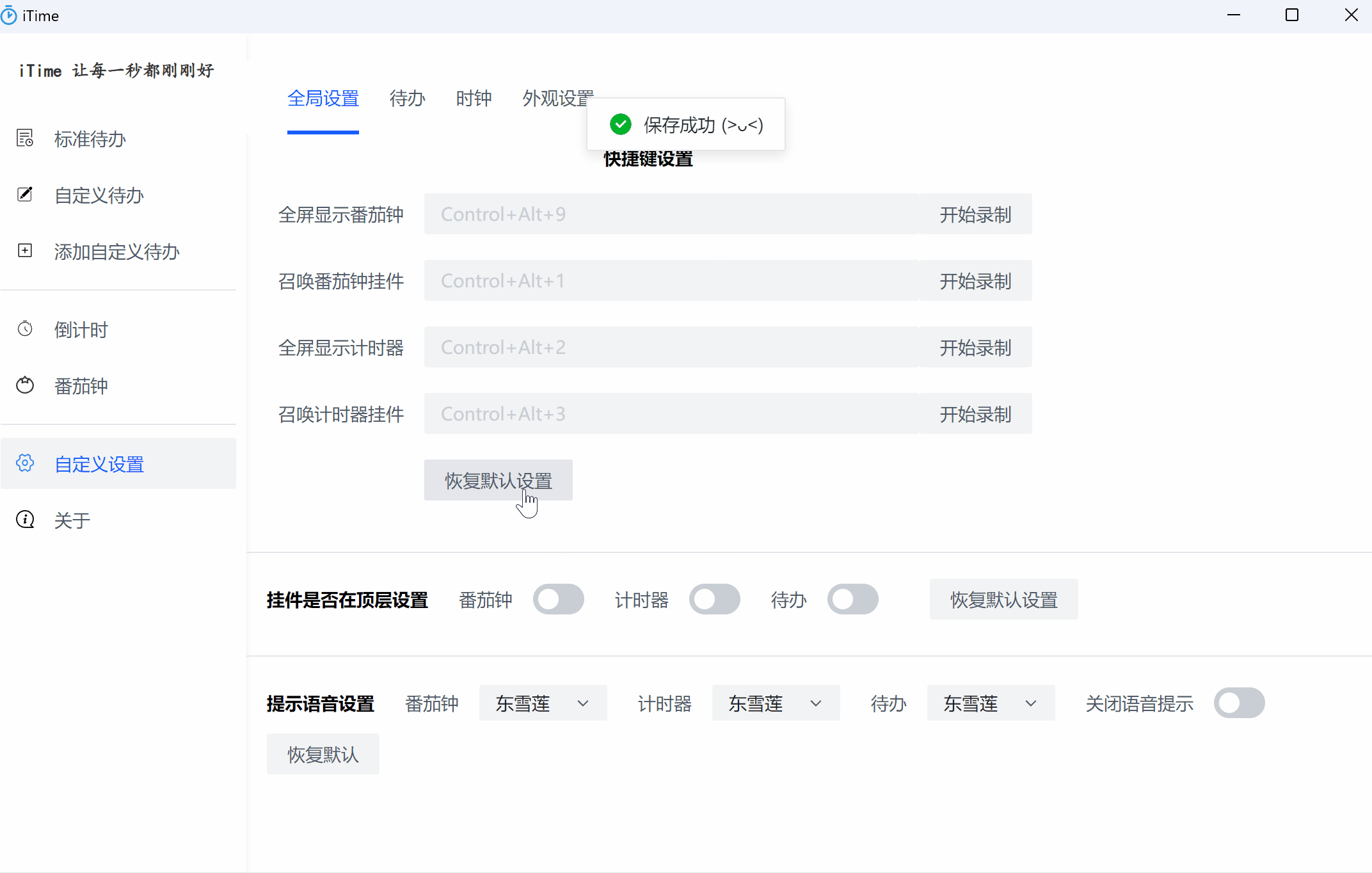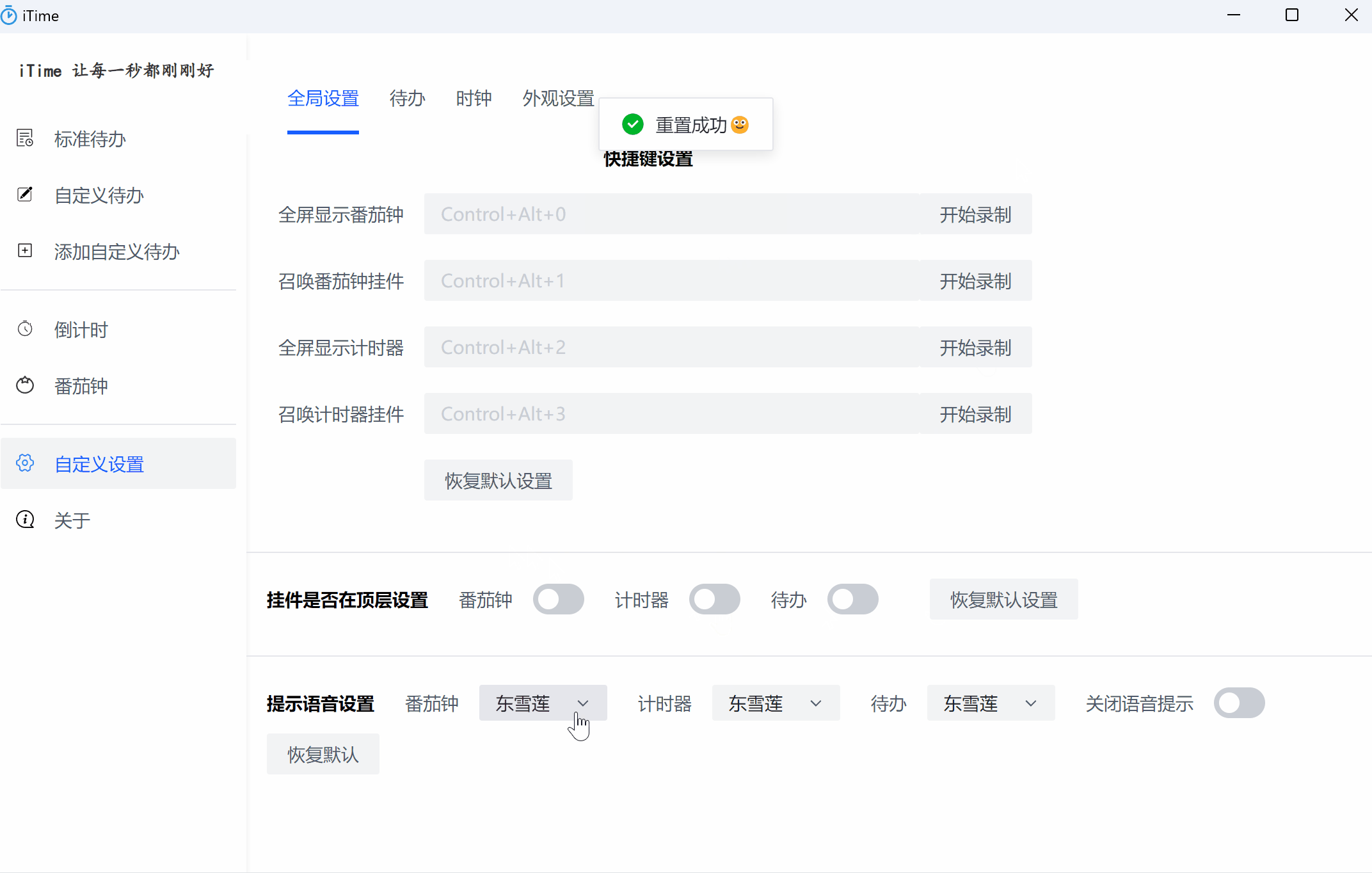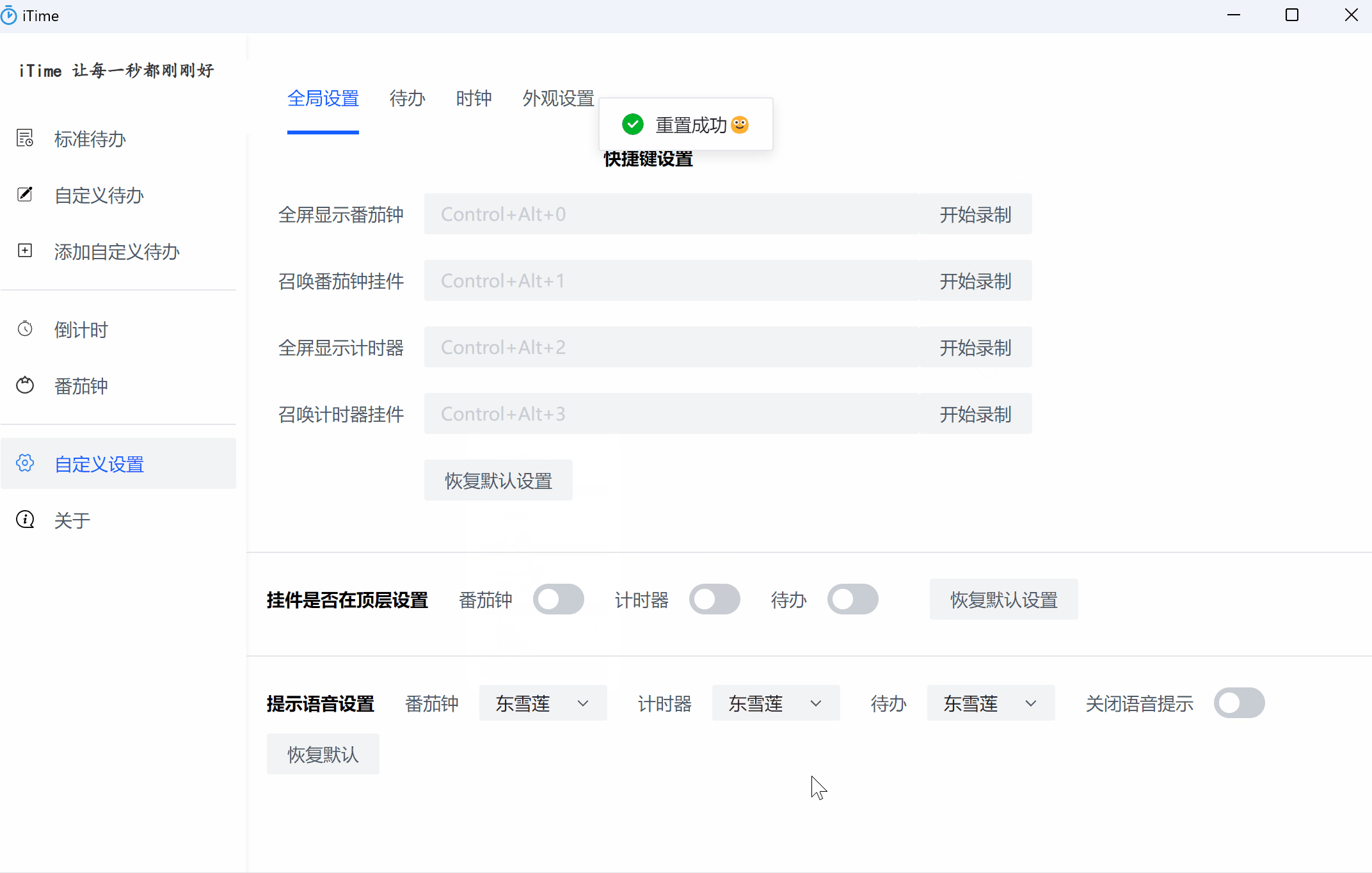 62 |
63 | - 全局快捷键设置⌨️。自定义快捷键全屏显示番茄钟、召唤番茄钟挂件、全屏显示计时器、召唤计时器挂件4个功能。
64 | - 挂件是否在顶层设置🔝。如果选择顶层,那么挂件将一直悬浮在屏幕上,三个挂件可以设置是否在顶层。
65 | - 提示语音设置🔊。在番茄钟、计时器、待办达到一定条件后软件会播放提示语音,您可以自定义提示语音的AI角色和是否开启提示语音。
66 |
67 |
62 |
63 | - 全局快捷键设置⌨️。自定义快捷键全屏显示番茄钟、召唤番茄钟挂件、全屏显示计时器、召唤计时器挂件4个功能。
64 | - 挂件是否在顶层设置🔝。如果选择顶层,那么挂件将一直悬浮在屏幕上,三个挂件可以设置是否在顶层。
65 | - 提示语音设置🔊。在番茄钟、计时器、待办达到一定条件后软件会播放提示语音,您可以自定义提示语音的AI角色和是否开启提示语音。
66 |
67 |  68 |
69 | - 待办列表项设置🗃️。您可以自定义有序列表和无序列表前面显示的图标。
70 |
71 |
68 |
69 | - 待办列表项设置🗃️。您可以自定义有序列表和无序列表前面显示的图标。
70 |
71 |  72 |
73 | 番茄钟参数设置🕒。如前所述、您可以在一定范围内自定义番茄钟的4个参数。
74 |
75 | - 番茄钟和计时器背景图设置🖼️。默认情况下桌面挂件的样式是半透明的灰色。您可以自定义全屏的背景图和挂件的背景图。
76 |
77 | ## 快捷键介绍⌨️
78 |
79 | ### 待办📝
80 |
81 | 标准待办中**Ctrl/Command+Alt+Enter**调出添加待办窗口。
82 |
83 | 自定义代办中富文本编辑器选项:
84 |
85 | - **\"-"+空格**➡️ 无序列表
86 | - **1+“.“**➡️ 有序列表
87 | - **Ctrl/Command+B**➡️ 将选中文本加粗
88 | - **Ctrl/Command+I**➡️ 将选中文本斜体
89 | - **Ctrl/Command+U**➡️ 将选中文本加下划线
90 |
91 | 自定义代办中操作选项:
92 |
93 | - **Ctrl/Command+Alt+Enter**调出确认窗口
94 | - 标题窗口+**Enter**即可添加
95 |
96 | ### 定时器&番茄钟⏲️
97 |
98 | **全局快捷键⌨️**
99 |
100 | - **Ctrl/Command+Alt+0**全屏番茄钟
101 | - **Ctrl/Command+Alt+9**召唤番茄钟挂件
102 | - **Ctrl/Command+Alt+8**全屏计时器
103 | - **Ctrl/Command+Alt+7**召唤计时器挂件
104 |
105 | **组件快捷键⚡**
106 |
107 | - **F**全屏
108 | - 全屏模式按**F**退出
109 | - **A**添加挂件
110 | - 挂件模式下按**E**删除挂件
111 |
112 | **鼠标设置🖱️**
113 |
114 | - **左键双击背景**全屏
115 | - **右键双击背景**添加挂件
116 | - 全屏模式下**左键双击背景**退出
117 | - 挂件模式下**左键双击时间**删除挂件
118 |
119 | ## 语音内容🔊
120 |
121 | 我们采用内置音频的方式来提醒,软件不需连接互联网
122 |
123 | | 事件 | 语音内容 |
124 | | ------------ | -------------------------------- |
125 | | 番茄钟短休息 | 时间到了,短短的休息一会儿吧 |
126 | | 番茄钟长休息 | 你太棒了,接下来是长休息时间 |
127 | | 番茄钟专注 | 好了,开始专注吧 |
128 | | 倒计时过半 | 时间已经过去一半了 |
129 | | 倒计时结束 | 倒计时结束了 |
130 | | 待办提醒 | 您现在有计划的安排,提醒您一下哈 |
131 |
132 | 这些提示的英文版本
133 |
134 | | 事件 | 语音内容 |
135 | | ------------ | ------------------------------------------ |
136 | | 番茄钟短休息 | Take a short break, time's up. |
137 | | 番茄钟长休息 | You're doing great, time for a long break. |
138 | | 番茄钟专注 | Alright, time to focus. |
139 | | 倒计时过半 | Half the time has passed. |
140 | | 倒计时结束 | The countdown is over. |
141 | | 待办提醒 | You have scheduled tasks, just a reminder. |
142 |
143 |
--------------------------------------------------------------------------------
/docs/tools/icons.md:
--------------------------------------------------------------------------------
1 | # 写文档常用的一些图标
2 |
3 | unicode字符集为我们内置了许多图标,可以访问官网看所有的图标https://www.unicode.org/emoji/charts/full-emoji-list.html。
4 |
5 | 然而这些图标太多了,一个解决方法是可以看最近流行的图标[表情符号频率 – Unicode](https://home.unicode.org/emoji/emoji-frequency/),但是这样找还是比较麻烦,所以我这里就整理了一下写md文档常用的一些图标。
6 |
7 | > ❗合理的使用图标可以让文档更具有可读性,但要确保见名知意,不要过度使用。
8 |
9 | ## 内容图标
10 |
11 | 1. ⚠️ **Warning:** 这是一个警告信息。
12 | 2. ℹ️ **Info:** 这里是一些额外的信息。
13 | 3. ❗ **Important:** 这是一个重要提示。
14 | 4. 💡 **Tip:** 这是一个有用的提示。
15 | 5. 📝 **Note:** 这是一个备注或注释。
16 |
17 | ## 开源项目必备
18 |
19 | 1. 🚀 **rocket:** 火箭
20 | 2. 🎉**colour bar**:彩带
21 | 3. 🎯**focus**:专注
22 | 4. 💪**fist**: 力量
23 | 5. 🌟**star** :星星
24 | 6. 🛠️ **Setup:** 用于说明设置或安装过程。(或者工具)
25 | 7. 🔒 **Security:** 强调安全性相关的特性或提示。
26 | 8. ⚙️ **Configuration:** 指向配置文件或配置步骤。
27 | 9. 📊 **Metrics:** 展示项目的状态或性能指标。
28 | 10. 📦 **Package:** 提到与包管理或发行版相关的内容。
29 | 11. 🐛 **Bug Fix:** 指出已解决的错误或已知问题。
30 | 12. ✨ **Enhancement:** 强调新功能或改进。
31 | 13. 📚 **Documentation:** 指向项目的文档或说明。
32 | 14. 🧪 **Testing:** 与测试相关的代码或说明。
33 | 15. 🔄 **Update:** 标记更新或版本迭代。
34 | 16. 🗂️ **File Structure:** 描述项目的文件组织。
35 | 17. 🏗️ **Architecture:** 描述系统架构或高层设计。
36 | 18. 🌐 **Web:** 专用于Web开发或相关技术的提示。
37 | 19. 🤝 **Contribution:** 邀请他人贡献代码或参与项目。
38 | 20. 👀 **Review:** 请求审查或提醒审查相关事项。
39 | 21. 📘 **introduction:**介绍
40 | 22. 🌍 **i18n:**国际化
41 | 23. ❓ **question:**用来表示问题或询问,可以用在探究原因的上下文中。
42 | 24. 🔍 **magnifying glass:**放大镜,象征搜索或调查,可以用来表示寻找原因。
43 | 25. 🏋️♂️ **man lifting:** 举重运动员,象征着努力和坚持。
44 | 26. 🧗 **man climbing:**攀岩者,代表攀登和克服困难的努力。
45 | 27. 💭 **thought balloon:**想法气泡,用来表示思考中的想法或幻想。
46 | 28. 🧠 **brain:**大脑,象征智力和思考过程。
47 | 29. ☁️ **cloud:** 云,表示云计算和云服务。
48 | 30. 🧭 - 罗盘,象征导向或指引,可以用于指示方向或引导来源。
49 | 31. 🔗 - 链接符号,表示来源是通过链接或互联网连接的。
50 | 32. 🔜 - “即将”箭头符号,直接表示即将发生的事件。
51 | 33. 🪄 魔法棒,代表创造和变化
52 | 34. ✨ 闪光点,代表灵感和创意—引申为新功能
53 | 35. 📄 文档,表示文档
54 |
55 | ## 平时的图标
56 |
57 | 1. 🖼️ 背景图
58 | 2. 🍅 番茄钟
59 | 3. 🔊 声音
60 | 4. ⚙️ 设置
61 | 5. **👤** 个人信息图标
62 | 6. 🤖 机器人,代表人工智能、机器学习或自动化。
63 | 7. ⏳ - 沙漏,象征时间的流逝,适用于表示等待或过渡期。
64 | 8. 📅 - 日历,适用于表示特定的日期或时间规划。
65 | 9. 🕒 - 时钟,显示特定的时间(例如三点钟)。
66 |
67 | ## 微表情
68 |
69 | 1. 😂 - 笑哭
70 | 2. 😊 - 高兴/满足
71 | 3. 😁 - 笑脸/开心
72 | 4. 😢 - 哭泣
73 | 5. 🤔 - 思考
74 | 6. 🙂 - 微笑
75 | 7. 🙁 - 轻微不开心
76 | 8. 😍 - 热爱
77 | 9. 😎 - 戴着太阳镜的酷脸
78 | 10. 😴 - 睡觉
79 | 11. 😮 - 惊讶
80 | 12. 😡 - 生气
81 | 13. 😱 - 恐惧
82 | 14. 🧐 - 带着放大镜的脸,象征研究和查找信息。
83 | 15. 😏 - 得意/调皮
84 | 16. 😌 - 安心/满足
85 | 17. 😭 - 大哭/非常伤心
86 | 18. 🥰 - 拥抱的脸/表达爱和亲近
87 |
88 | ## 颜文字
89 |
90 | 哭泣:(。•́︿•̀。)
91 |
92 | 开心:\^_^ (˃ᴗ˂) ٩(◕‿◕。)۶ (^-^)ノ
93 |
94 | 悲伤/失望:(T_T) (╥_╥) (。•́︿•̀。) (。╯︵╰。)
95 |
96 | 可爱/萌:(≧ω≦) (。♥‿♥。) (✿◠‿◠)
97 |
98 |
99 |
100 | 持续更新......
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
--------------------------------------------------------------------------------
/docs/tools/linux-commands.md:
--------------------------------------------------------------------------------
1 | # Linux常用命令
--------------------------------------------------------------------------------
/docs/tools/tips.md:
--------------------------------------------------------------------------------
1 | ## 小tips
2 |
3 | ### 包命名
4 |
5 | 为什么Android或者Java的这些包习惯都叫com.xxx.xxx?
6 |
7 | 因为域名在全球是唯一的,我们常常的命名习惯是域名反写+项目名,这样可以保证包的唯一性,因此maven仓库、发布安卓或者桌面应用不会存在潜在的命名冲突问题,同时也见名知义
8 |
9 | 为什么包名全小写?
10 |
11 | 第一个原因是命名规范和惯例问题,第二个原因是第一个原因的一个具象化windows大小写不敏感,Linux大小写敏感,如果使用驼峰之类的命名法,会导致命名冲突(比如MySQLwindows就不区分大小写,但是Linux又区分了)
12 |
13 | 比如我在开发的一个项目叫iTime,我的域名是bugdesigner.cn,可以命名成**cn.bugdesigner.itime**
14 |
15 | ### 分辨率
16 |
17 | 在开发时候
18 |
19 | ### MySQL建表
20 |
21 | 为什么使用varchar的时候喜欢使用varchar(255)?
22 |
23 | 因为,在Mysql5.0.3之前,varchar的最大长度是255字符,这是由于长度前缀使用了一个字节存储长度信息。但是在5.0.3版本以后,varchar的最大长度是65535字节,如果超过了255,那么长度位就需要两个字节来存储。事实上,在超过255以后,使用65535还是256,对于空间的占用基本没有区别了,但是一般还是2的倍数有助于稍微提升性能。节省空间只需要记住255这个时间点即可
24 |
25 | 需要注意的是,对于Mysql4.1版本以后,varchar(n)中的n代表字符数而非字节数,这就意味着汉字并不需要根据字符集换算。比如:
26 |
27 | >假设字段类型为varchar(255),业务需求需要存储汉字,使用utf8mb4编码且存储满后,占用的空间是255*4+1=1024字节。(Mysql8.0以后默认编码集是utf8mb4)
28 |
29 |
30 |
31 | ### Restful命名规则
32 |
33 | 目前的HTTP API接口设计基本都是Get、Post一把梭。随之衍生的就是不清晰不规范,一般开发的时候还是推荐遵循Restful风格,主要规定是**URL标识资源路径、方法标识操作**。
34 |
35 | 1. 使用名词而非动词。如添加用户传统方式是`POST`: `/user/update`、restful就是`PUT` : `/users`
36 |
37 | 2. 使用复数形式。保持直观性和一致性,如`/users`而非`/user`
38 |
39 | 3. 使用路径标识资源层级关系。
40 |
41 | >除了对单一资源的简单操作,往往还需要进行一些复杂操作,比如查询某一特定用户的订单、某一用户加入队伍等,用到了层级关系。URL如:
42 | >
43 | >- /users/{userId}/orders (GET) /users/{userId}标明主资源为用户、orders为与用户关联的子资源(订单)、GET表示查询与用户关联的订单
44 | >- /teams/{teamId}/members (POST) /teams/{teamId}标明是主资源为队伍、members表示操作的队伍的成员、POST表示添加成员
45 | >- /users/matches (GET) 匹配推荐的用户伙伴列表
46 |
47 | 4. 资源列表的查询使用查询字符串。如`/users?role=admin` 表示查询所有管理员用户
48 |
49 | 5. 尽量保证简单。路径参数{id}在Restful API中非常常用,因为其比路径参数更加清晰。在其他时候如获取个人信息也不用传递个人id,因为这个id一般都是在session|token|jwt中存储
50 |
51 |
52 |
53 | ### 单例模式的双检锁实现
54 |
55 | 为了性能要求,我们常常需要单例模式进行对象的创建。但是在多线情况下,还是会创建多个对象,带来一定程度下的性能损耗,单例模式中**相对高大上**的一个方法双检锁可以解决这个问题
56 |
57 | ```java
58 | public class MetaManager {
59 | private static volatile Meta meta; // 保证线程内存共享,不重复初始化
60 |
61 | public static Meta getMetaobject() {
62 | if (meta == null) {
63 | synchronized (MetaManager.class) {
64 | if (meta == null) {
65 | meta = initMeta(); // 一个初始化方法
66 | }
67 | }
68 | }
69 | return meta;
70 | }
71 |
72 | private static Meta initMeta() {
73 | // 初始化 Meta 对象的逻辑
74 | return new Meta();
75 | }
76 | }
77 | ```
78 |
79 | 会有一个疑问,为什么锁不加在外面,还需要外层进行判断呢?
80 |
81 | 这个是因为性能开销的缘故,在每次调用`getMetaObject`时,如果加在最外层,在已经初始化完成以后,还是变成同步方法,降低性能。在外层判断`meta`对象以后,如果已经被初始化,可以**直接退出而不需要等待锁**
82 |
83 |
84 |
85 | ### 开发中保证代码健壮性的常见习惯
86 |
87 | 健壮性,可移植性,可扩展性是软件开发的常见原则。
88 |
89 | 1. 用户输入的参数做校验
90 | 2. 完善异常处理,比如银行转账异常一定要有错误日志或者告警
91 | 3. 调用第三方API有重试机制
92 | 4. 有降级处理,如果参数错误或系统宕机了有兜底的策略
93 |
94 |
95 |
96 | ### 常见的设计模式
97 |
98 | 学术上定义分为创建型、结构型、行为型。合理的运用设计模式
99 |
100 | - 单例模式
101 |
102 | > 避免重复创建对象,优化性能
103 |
104 | - 策略模式
105 |
106 | > 根据不同的情况定义不同的策略,类似于switch-case。如OJ系统中根据不同编程语言分配时间和空间
107 |
108 | - 模版方法模式
109 |
110 | > 不同情况但是有标准固定的工作流,每一步可以抽象成一个方法,但不要重复计算。如在不同系统复制文件并处理都是标准的几步,在实现时继承模版的步骤,可以选择性的修改某一步(即重写方法)。
111 |
112 | - 命令模式
113 |
114 | > 命令行程序的开发。遥控器遥控电视案例。
115 |
116 | - 代理模式
117 |
118 | > 在业务流程中间又加了一层。打日志、参数校验。卖手机送盆
119 |
120 | - 适配器模式
121 |
122 | > 调用其他系统API,需要对不同参数做适配。
123 |
124 | - 建造者模式
125 |
126 | > 构建复杂对象时,逐步指定创建的类型和内容,分离构造过程和表示。Java给对象属性赋值
127 |
128 |
129 |
130 | ## 算法篇
131 |
132 | ### Hash表中的链表拆分和索引计算
133 |
134 | 索引计算时,给定一个hash值,假定哈希函数为hash与数组长度的余数,余数即为索引。有两种方式,一种是位运算,一种是直接取余
135 |
136 | 位运算的公式为hash值&(数组长度-1)。
137 |
138 | 例如:
139 |
140 | hash值为17,数组长度为8。位运算的过程为
141 |
142 | 00010001&
143 |
144 | 00000111
145 |
146 | 因为位运算的规则是**与1运算保留位、与0运算均为0**,因此上述17&7的结果应该是00000001,即为1,这样可以更加高级且高效的求解余数。`规律是保留原二进制的后n位,n=log2(数组长度)`
147 |
148 | ---
149 |
150 | 链表拆分部分也是应用到了位运算。链表拆分是哈希表在数组长度不够动态扩容时触发的,由于之前链表的部分节点根据哈希函数重新计算后是可以分配到哈希表的不同数组槽中。在默认的JDK实现中(即负载因子固定),固定是a、b两个链表
151 |
152 | hash&旧数组长度=0时该节点的链表不变、hash&旧数组长度!=0时节点挂载位置为arr[i+旧数组长度]
153 |
154 | 为什么=0?假设hash值一个为1,一个为17,数组长度从8->16
155 |
156 | n=5 00010000(16)跟下面的两个二进制数字按位与
157 |
158 | 00000001 结果为 00000000
159 |
160 | 00010001 结果为 00010000
161 |
162 | 上面这两个hash按位与时候保留的是倒数第n位的数字,如果倒数第n位=0,代表hash值小于原数组长度,反之大于原数组。对于大于原数组长度的节点,当然可以给他分配到扩容后的数组槽中。`其中n=log2(新数组长度)+1`
163 |
164 |
165 |
166 | 当然,上面的都可以使用直接求余来计算,但是位运算相对性能高一点且B格更高。并且位运算需要满足特定条件,比如**数组长度必须是2的倍数、扩容时遵循JDK的扩容逻辑**。
167 |
--------------------------------------------------------------------------------
/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | # https://vitepress.dev/reference/default-theme-home-page
3 | layout: home
4 |
5 | hero:
6 | name: "AlbertZhang的文档站"
7 | text: "构建知识库"
8 | tagline: 好记性不如烂笔头
9 | image:
10 | src: /background.svg
11 | alt: 背景图
12 | actions:
13 | - theme: brand
14 | text: 建站原因
15 | link: /docs/my-index/reason
16 |
17 | features:
18 | - title: 💡 小建议
19 | details: 选择永远大于努力
20 | - title: 🧗 努力
21 | details: 如果做一件事就努力把它做好
22 | - title: 🤔 思考
23 | details: 学会思考,不要人云亦云
24 | ---
25 |
26 |
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "devDependencies": {
3 | "mermaid": "^10.8.0",
4 | "vitepress": "1.0.0-rc.35",
5 | "vitepress-plugin-mermaid": "^2.0.16"
6 | },
7 | "scripts": {
8 | "docs:dev": "vitepress dev",
9 | "docs:build": "vitepress build",
10 | "docs:preview": "vitepress preview"
11 | },
12 | "dependencies": {
13 | "@mdit-vue/plugin-toc": "^2.0.0",
14 | "markdown-it": "^14.0.0",
15 | "markdown-it-anchor": "^8.6.7"
16 | }
17 | }
--------------------------------------------------------------------------------
/public/background.svg:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/public/logo.svg:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/utils/auto-gen-sidebar.mjs:
--------------------------------------------------------------------------------
1 | import path from "node:path";
2 | import fs from "node:fs";
3 |
4 | // 文件根目录
5 | const DIR_PATH = path.resolve();
6 | // 白名单,过滤不是文章的文件和文件夹
7 | const WHITE_LIST = [
8 | "index.md",
9 | ".vitepress",
10 | "node_modules",
11 | ".idea",
12 | "assets",
13 | ];
14 |
15 | // 判断是否是文件夹
16 | const isDirectory = (path) => fs.lstatSync(path).isDirectory();
17 |
18 | // 取差值
19 | const intersections = (arr1, arr2) =>
20 | Array.from(new Set(arr1.filter((item) => !new Set(arr2).has(item))));
21 |
22 | // 把方法导出直接使用
23 | function getList(params, path1, pathname) {
24 | // 存放结果
25 | const res = [];
26 | // 开始遍历params
27 | for (let file in params) {
28 | // 拼接目录
29 | const dir = path.join(path1, params[file]);
30 | // 判断是否是文件夹
31 | const isDir = isDirectory(dir);
32 | if (isDir) {
33 | // 如果是文件夹,读取之后作为下一次递归参数
34 | const files = fs.readdirSync(dir);
35 | res.push({
36 | text: params[file],
37 | collapsible: true,
38 | items: getList(files, dir, `${pathname}/${params[file]}`),
39 | });
40 | } else {
41 | // 获取名字
42 | const name = path.basename(params[file]);
43 | // 排除非 md 文件
44 | const suffix = path.extname(params[file]);
45 | if (suffix !== ".md") {
46 | continue;
47 | }
48 | res.push({
49 | text: name,
50 | link: `${pathname}/${name}`,
51 | });
52 | }
53 | }
54 | // 对name做一下处理,把后缀删除
55 | res.map((item) => {
56 | item.text = item.text.replace(/\.md$/, "");
57 | });
58 | return res;
59 | }
60 |
61 | export const set_sidebar = (pathname) => {
62 | // 获取pathname的路径
63 | const dirPath = path.join(DIR_PATH, pathname);
64 | // 读取pathname下的所有文件或者文件夹
65 | const files = fs.readdirSync(dirPath);
66 | // 过滤掉
67 | const items = intersections(files, WHITE_LIST);
68 | // getList 函数后面会讲到
69 | return getList(items, dirPath, pathname);
70 | };
71 |
--------------------------------------------------------------------------------
72 |
73 | 番茄钟参数设置🕒。如前所述、您可以在一定范围内自定义番茄钟的4个参数。
74 |
75 | - 番茄钟和计时器背景图设置🖼️。默认情况下桌面挂件的样式是半透明的灰色。您可以自定义全屏的背景图和挂件的背景图。
76 |
77 | ## 快捷键介绍⌨️
78 |
79 | ### 待办📝
80 |
81 | 标准待办中**Ctrl/Command+Alt+Enter**调出添加待办窗口。
82 |
83 | 自定义代办中富文本编辑器选项:
84 |
85 | - **\"-"+空格**➡️ 无序列表
86 | - **1+“.“**➡️ 有序列表
87 | - **Ctrl/Command+B**➡️ 将选中文本加粗
88 | - **Ctrl/Command+I**➡️ 将选中文本斜体
89 | - **Ctrl/Command+U**➡️ 将选中文本加下划线
90 |
91 | 自定义代办中操作选项:
92 |
93 | - **Ctrl/Command+Alt+Enter**调出确认窗口
94 | - 标题窗口+**Enter**即可添加
95 |
96 | ### 定时器&番茄钟⏲️
97 |
98 | **全局快捷键⌨️**
99 |
100 | - **Ctrl/Command+Alt+0**全屏番茄钟
101 | - **Ctrl/Command+Alt+9**召唤番茄钟挂件
102 | - **Ctrl/Command+Alt+8**全屏计时器
103 | - **Ctrl/Command+Alt+7**召唤计时器挂件
104 |
105 | **组件快捷键⚡**
106 |
107 | - **F**全屏
108 | - 全屏模式按**F**退出
109 | - **A**添加挂件
110 | - 挂件模式下按**E**删除挂件
111 |
112 | **鼠标设置🖱️**
113 |
114 | - **左键双击背景**全屏
115 | - **右键双击背景**添加挂件
116 | - 全屏模式下**左键双击背景**退出
117 | - 挂件模式下**左键双击时间**删除挂件
118 |
119 | ## 语音内容🔊
120 |
121 | 我们采用内置音频的方式来提醒,软件不需连接互联网
122 |
123 | | 事件 | 语音内容 |
124 | | ------------ | -------------------------------- |
125 | | 番茄钟短休息 | 时间到了,短短的休息一会儿吧 |
126 | | 番茄钟长休息 | 你太棒了,接下来是长休息时间 |
127 | | 番茄钟专注 | 好了,开始专注吧 |
128 | | 倒计时过半 | 时间已经过去一半了 |
129 | | 倒计时结束 | 倒计时结束了 |
130 | | 待办提醒 | 您现在有计划的安排,提醒您一下哈 |
131 |
132 | 这些提示的英文版本
133 |
134 | | 事件 | 语音内容 |
135 | | ------------ | ------------------------------------------ |
136 | | 番茄钟短休息 | Take a short break, time's up. |
137 | | 番茄钟长休息 | You're doing great, time for a long break. |
138 | | 番茄钟专注 | Alright, time to focus. |
139 | | 倒计时过半 | Half the time has passed. |
140 | | 倒计时结束 | The countdown is over. |
141 | | 待办提醒 | You have scheduled tasks, just a reminder. |
142 |
143 |
--------------------------------------------------------------------------------
/docs/tools/icons.md:
--------------------------------------------------------------------------------
1 | # 写文档常用的一些图标
2 |
3 | unicode字符集为我们内置了许多图标,可以访问官网看所有的图标https://www.unicode.org/emoji/charts/full-emoji-list.html。
4 |
5 | 然而这些图标太多了,一个解决方法是可以看最近流行的图标[表情符号频率 – Unicode](https://home.unicode.org/emoji/emoji-frequency/),但是这样找还是比较麻烦,所以我这里就整理了一下写md文档常用的一些图标。
6 |
7 | > ❗合理的使用图标可以让文档更具有可读性,但要确保见名知意,不要过度使用。
8 |
9 | ## 内容图标
10 |
11 | 1. ⚠️ **Warning:** 这是一个警告信息。
12 | 2. ℹ️ **Info:** 这里是一些额外的信息。
13 | 3. ❗ **Important:** 这是一个重要提示。
14 | 4. 💡 **Tip:** 这是一个有用的提示。
15 | 5. 📝 **Note:** 这是一个备注或注释。
16 |
17 | ## 开源项目必备
18 |
19 | 1. 🚀 **rocket:** 火箭
20 | 2. 🎉**colour bar**:彩带
21 | 3. 🎯**focus**:专注
22 | 4. 💪**fist**: 力量
23 | 5. 🌟**star** :星星
24 | 6. 🛠️ **Setup:** 用于说明设置或安装过程。(或者工具)
25 | 7. 🔒 **Security:** 强调安全性相关的特性或提示。
26 | 8. ⚙️ **Configuration:** 指向配置文件或配置步骤。
27 | 9. 📊 **Metrics:** 展示项目的状态或性能指标。
28 | 10. 📦 **Package:** 提到与包管理或发行版相关的内容。
29 | 11. 🐛 **Bug Fix:** 指出已解决的错误或已知问题。
30 | 12. ✨ **Enhancement:** 强调新功能或改进。
31 | 13. 📚 **Documentation:** 指向项目的文档或说明。
32 | 14. 🧪 **Testing:** 与测试相关的代码或说明。
33 | 15. 🔄 **Update:** 标记更新或版本迭代。
34 | 16. 🗂️ **File Structure:** 描述项目的文件组织。
35 | 17. 🏗️ **Architecture:** 描述系统架构或高层设计。
36 | 18. 🌐 **Web:** 专用于Web开发或相关技术的提示。
37 | 19. 🤝 **Contribution:** 邀请他人贡献代码或参与项目。
38 | 20. 👀 **Review:** 请求审查或提醒审查相关事项。
39 | 21. 📘 **introduction:**介绍
40 | 22. 🌍 **i18n:**国际化
41 | 23. ❓ **question:**用来表示问题或询问,可以用在探究原因的上下文中。
42 | 24. 🔍 **magnifying glass:**放大镜,象征搜索或调查,可以用来表示寻找原因。
43 | 25. 🏋️♂️ **man lifting:** 举重运动员,象征着努力和坚持。
44 | 26. 🧗 **man climbing:**攀岩者,代表攀登和克服困难的努力。
45 | 27. 💭 **thought balloon:**想法气泡,用来表示思考中的想法或幻想。
46 | 28. 🧠 **brain:**大脑,象征智力和思考过程。
47 | 29. ☁️ **cloud:** 云,表示云计算和云服务。
48 | 30. 🧭 - 罗盘,象征导向或指引,可以用于指示方向或引导来源。
49 | 31. 🔗 - 链接符号,表示来源是通过链接或互联网连接的。
50 | 32. 🔜 - “即将”箭头符号,直接表示即将发生的事件。
51 | 33. 🪄 魔法棒,代表创造和变化
52 | 34. ✨ 闪光点,代表灵感和创意—引申为新功能
53 | 35. 📄 文档,表示文档
54 |
55 | ## 平时的图标
56 |
57 | 1. 🖼️ 背景图
58 | 2. 🍅 番茄钟
59 | 3. 🔊 声音
60 | 4. ⚙️ 设置
61 | 5. **👤** 个人信息图标
62 | 6. 🤖 机器人,代表人工智能、机器学习或自动化。
63 | 7. ⏳ - 沙漏,象征时间的流逝,适用于表示等待或过渡期。
64 | 8. 📅 - 日历,适用于表示特定的日期或时间规划。
65 | 9. 🕒 - 时钟,显示特定的时间(例如三点钟)。
66 |
67 | ## 微表情
68 |
69 | 1. 😂 - 笑哭
70 | 2. 😊 - 高兴/满足
71 | 3. 😁 - 笑脸/开心
72 | 4. 😢 - 哭泣
73 | 5. 🤔 - 思考
74 | 6. 🙂 - 微笑
75 | 7. 🙁 - 轻微不开心
76 | 8. 😍 - 热爱
77 | 9. 😎 - 戴着太阳镜的酷脸
78 | 10. 😴 - 睡觉
79 | 11. 😮 - 惊讶
80 | 12. 😡 - 生气
81 | 13. 😱 - 恐惧
82 | 14. 🧐 - 带着放大镜的脸,象征研究和查找信息。
83 | 15. 😏 - 得意/调皮
84 | 16. 😌 - 安心/满足
85 | 17. 😭 - 大哭/非常伤心
86 | 18. 🥰 - 拥抱的脸/表达爱和亲近
87 |
88 | ## 颜文字
89 |
90 | 哭泣:(。•́︿•̀。)
91 |
92 | 开心:\^_^ (˃ᴗ˂) ٩(◕‿◕。)۶ (^-^)ノ
93 |
94 | 悲伤/失望:(T_T) (╥_╥) (。•́︿•̀。) (。╯︵╰。)
95 |
96 | 可爱/萌:(≧ω≦) (。♥‿♥。) (✿◠‿◠)
97 |
98 |
99 |
100 | 持续更新......
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
--------------------------------------------------------------------------------
/docs/tools/linux-commands.md:
--------------------------------------------------------------------------------
1 | # Linux常用命令
--------------------------------------------------------------------------------
/docs/tools/tips.md:
--------------------------------------------------------------------------------
1 | ## 小tips
2 |
3 | ### 包命名
4 |
5 | 为什么Android或者Java的这些包习惯都叫com.xxx.xxx?
6 |
7 | 因为域名在全球是唯一的,我们常常的命名习惯是域名反写+项目名,这样可以保证包的唯一性,因此maven仓库、发布安卓或者桌面应用不会存在潜在的命名冲突问题,同时也见名知义
8 |
9 | 为什么包名全小写?
10 |
11 | 第一个原因是命名规范和惯例问题,第二个原因是第一个原因的一个具象化windows大小写不敏感,Linux大小写敏感,如果使用驼峰之类的命名法,会导致命名冲突(比如MySQLwindows就不区分大小写,但是Linux又区分了)
12 |
13 | 比如我在开发的一个项目叫iTime,我的域名是bugdesigner.cn,可以命名成**cn.bugdesigner.itime**
14 |
15 | ### 分辨率
16 |
17 | 在开发时候
18 |
19 | ### MySQL建表
20 |
21 | 为什么使用varchar的时候喜欢使用varchar(255)?
22 |
23 | 因为,在Mysql5.0.3之前,varchar的最大长度是255字符,这是由于长度前缀使用了一个字节存储长度信息。但是在5.0.3版本以后,varchar的最大长度是65535字节,如果超过了255,那么长度位就需要两个字节来存储。事实上,在超过255以后,使用65535还是256,对于空间的占用基本没有区别了,但是一般还是2的倍数有助于稍微提升性能。节省空间只需要记住255这个时间点即可
24 |
25 | 需要注意的是,对于Mysql4.1版本以后,varchar(n)中的n代表字符数而非字节数,这就意味着汉字并不需要根据字符集换算。比如:
26 |
27 | >假设字段类型为varchar(255),业务需求需要存储汉字,使用utf8mb4编码且存储满后,占用的空间是255*4+1=1024字节。(Mysql8.0以后默认编码集是utf8mb4)
28 |
29 |
30 |
31 | ### Restful命名规则
32 |
33 | 目前的HTTP API接口设计基本都是Get、Post一把梭。随之衍生的就是不清晰不规范,一般开发的时候还是推荐遵循Restful风格,主要规定是**URL标识资源路径、方法标识操作**。
34 |
35 | 1. 使用名词而非动词。如添加用户传统方式是`POST`: `/user/update`、restful就是`PUT` : `/users`
36 |
37 | 2. 使用复数形式。保持直观性和一致性,如`/users`而非`/user`
38 |
39 | 3. 使用路径标识资源层级关系。
40 |
41 | >除了对单一资源的简单操作,往往还需要进行一些复杂操作,比如查询某一特定用户的订单、某一用户加入队伍等,用到了层级关系。URL如:
42 | >
43 | >- /users/{userId}/orders (GET) /users/{userId}标明主资源为用户、orders为与用户关联的子资源(订单)、GET表示查询与用户关联的订单
44 | >- /teams/{teamId}/members (POST) /teams/{teamId}标明是主资源为队伍、members表示操作的队伍的成员、POST表示添加成员
45 | >- /users/matches (GET) 匹配推荐的用户伙伴列表
46 |
47 | 4. 资源列表的查询使用查询字符串。如`/users?role=admin` 表示查询所有管理员用户
48 |
49 | 5. 尽量保证简单。路径参数{id}在Restful API中非常常用,因为其比路径参数更加清晰。在其他时候如获取个人信息也不用传递个人id,因为这个id一般都是在session|token|jwt中存储
50 |
51 |
52 |
53 | ### 单例模式的双检锁实现
54 |
55 | 为了性能要求,我们常常需要单例模式进行对象的创建。但是在多线情况下,还是会创建多个对象,带来一定程度下的性能损耗,单例模式中**相对高大上**的一个方法双检锁可以解决这个问题
56 |
57 | ```java
58 | public class MetaManager {
59 | private static volatile Meta meta; // 保证线程内存共享,不重复初始化
60 |
61 | public static Meta getMetaobject() {
62 | if (meta == null) {
63 | synchronized (MetaManager.class) {
64 | if (meta == null) {
65 | meta = initMeta(); // 一个初始化方法
66 | }
67 | }
68 | }
69 | return meta;
70 | }
71 |
72 | private static Meta initMeta() {
73 | // 初始化 Meta 对象的逻辑
74 | return new Meta();
75 | }
76 | }
77 | ```
78 |
79 | 会有一个疑问,为什么锁不加在外面,还需要外层进行判断呢?
80 |
81 | 这个是因为性能开销的缘故,在每次调用`getMetaObject`时,如果加在最外层,在已经初始化完成以后,还是变成同步方法,降低性能。在外层判断`meta`对象以后,如果已经被初始化,可以**直接退出而不需要等待锁**
82 |
83 |
84 |
85 | ### 开发中保证代码健壮性的常见习惯
86 |
87 | 健壮性,可移植性,可扩展性是软件开发的常见原则。
88 |
89 | 1. 用户输入的参数做校验
90 | 2. 完善异常处理,比如银行转账异常一定要有错误日志或者告警
91 | 3. 调用第三方API有重试机制
92 | 4. 有降级处理,如果参数错误或系统宕机了有兜底的策略
93 |
94 |
95 |
96 | ### 常见的设计模式
97 |
98 | 学术上定义分为创建型、结构型、行为型。合理的运用设计模式
99 |
100 | - 单例模式
101 |
102 | > 避免重复创建对象,优化性能
103 |
104 | - 策略模式
105 |
106 | > 根据不同的情况定义不同的策略,类似于switch-case。如OJ系统中根据不同编程语言分配时间和空间
107 |
108 | - 模版方法模式
109 |
110 | > 不同情况但是有标准固定的工作流,每一步可以抽象成一个方法,但不要重复计算。如在不同系统复制文件并处理都是标准的几步,在实现时继承模版的步骤,可以选择性的修改某一步(即重写方法)。
111 |
112 | - 命令模式
113 |
114 | > 命令行程序的开发。遥控器遥控电视案例。
115 |
116 | - 代理模式
117 |
118 | > 在业务流程中间又加了一层。打日志、参数校验。卖手机送盆
119 |
120 | - 适配器模式
121 |
122 | > 调用其他系统API,需要对不同参数做适配。
123 |
124 | - 建造者模式
125 |
126 | > 构建复杂对象时,逐步指定创建的类型和内容,分离构造过程和表示。Java给对象属性赋值
127 |
128 |
129 |
130 | ## 算法篇
131 |
132 | ### Hash表中的链表拆分和索引计算
133 |
134 | 索引计算时,给定一个hash值,假定哈希函数为hash与数组长度的余数,余数即为索引。有两种方式,一种是位运算,一种是直接取余
135 |
136 | 位运算的公式为hash值&(数组长度-1)。
137 |
138 | 例如:
139 |
140 | hash值为17,数组长度为8。位运算的过程为
141 |
142 | 00010001&
143 |
144 | 00000111
145 |
146 | 因为位运算的规则是**与1运算保留位、与0运算均为0**,因此上述17&7的结果应该是00000001,即为1,这样可以更加高级且高效的求解余数。`规律是保留原二进制的后n位,n=log2(数组长度)`
147 |
148 | ---
149 |
150 | 链表拆分部分也是应用到了位运算。链表拆分是哈希表在数组长度不够动态扩容时触发的,由于之前链表的部分节点根据哈希函数重新计算后是可以分配到哈希表的不同数组槽中。在默认的JDK实现中(即负载因子固定),固定是a、b两个链表
151 |
152 | hash&旧数组长度=0时该节点的链表不变、hash&旧数组长度!=0时节点挂载位置为arr[i+旧数组长度]
153 |
154 | 为什么=0?假设hash值一个为1,一个为17,数组长度从8->16
155 |
156 | n=5 00010000(16)跟下面的两个二进制数字按位与
157 |
158 | 00000001 结果为 00000000
159 |
160 | 00010001 结果为 00010000
161 |
162 | 上面这两个hash按位与时候保留的是倒数第n位的数字,如果倒数第n位=0,代表hash值小于原数组长度,反之大于原数组。对于大于原数组长度的节点,当然可以给他分配到扩容后的数组槽中。`其中n=log2(新数组长度)+1`
163 |
164 |
165 |
166 | 当然,上面的都可以使用直接求余来计算,但是位运算相对性能高一点且B格更高。并且位运算需要满足特定条件,比如**数组长度必须是2的倍数、扩容时遵循JDK的扩容逻辑**。
167 |
--------------------------------------------------------------------------------
/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | # https://vitepress.dev/reference/default-theme-home-page
3 | layout: home
4 |
5 | hero:
6 | name: "AlbertZhang的文档站"
7 | text: "构建知识库"
8 | tagline: 好记性不如烂笔头
9 | image:
10 | src: /background.svg
11 | alt: 背景图
12 | actions:
13 | - theme: brand
14 | text: 建站原因
15 | link: /docs/my-index/reason
16 |
17 | features:
18 | - title: 💡 小建议
19 | details: 选择永远大于努力
20 | - title: 🧗 努力
21 | details: 如果做一件事就努力把它做好
22 | - title: 🤔 思考
23 | details: 学会思考,不要人云亦云
24 | ---
25 |
26 |
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "devDependencies": {
3 | "mermaid": "^10.8.0",
4 | "vitepress": "1.0.0-rc.35",
5 | "vitepress-plugin-mermaid": "^2.0.16"
6 | },
7 | "scripts": {
8 | "docs:dev": "vitepress dev",
9 | "docs:build": "vitepress build",
10 | "docs:preview": "vitepress preview"
11 | },
12 | "dependencies": {
13 | "@mdit-vue/plugin-toc": "^2.0.0",
14 | "markdown-it": "^14.0.0",
15 | "markdown-it-anchor": "^8.6.7"
16 | }
17 | }
--------------------------------------------------------------------------------
/public/background.svg:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/public/logo.svg:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/utils/auto-gen-sidebar.mjs:
--------------------------------------------------------------------------------
1 | import path from "node:path";
2 | import fs from "node:fs";
3 |
4 | // 文件根目录
5 | const DIR_PATH = path.resolve();
6 | // 白名单,过滤不是文章的文件和文件夹
7 | const WHITE_LIST = [
8 | "index.md",
9 | ".vitepress",
10 | "node_modules",
11 | ".idea",
12 | "assets",
13 | ];
14 |
15 | // 判断是否是文件夹
16 | const isDirectory = (path) => fs.lstatSync(path).isDirectory();
17 |
18 | // 取差值
19 | const intersections = (arr1, arr2) =>
20 | Array.from(new Set(arr1.filter((item) => !new Set(arr2).has(item))));
21 |
22 | // 把方法导出直接使用
23 | function getList(params, path1, pathname) {
24 | // 存放结果
25 | const res = [];
26 | // 开始遍历params
27 | for (let file in params) {
28 | // 拼接目录
29 | const dir = path.join(path1, params[file]);
30 | // 判断是否是文件夹
31 | const isDir = isDirectory(dir);
32 | if (isDir) {
33 | // 如果是文件夹,读取之后作为下一次递归参数
34 | const files = fs.readdirSync(dir);
35 | res.push({
36 | text: params[file],
37 | collapsible: true,
38 | items: getList(files, dir, `${pathname}/${params[file]}`),
39 | });
40 | } else {
41 | // 获取名字
42 | const name = path.basename(params[file]);
43 | // 排除非 md 文件
44 | const suffix = path.extname(params[file]);
45 | if (suffix !== ".md") {
46 | continue;
47 | }
48 | res.push({
49 | text: name,
50 | link: `${pathname}/${name}`,
51 | });
52 | }
53 | }
54 | // 对name做一下处理,把后缀删除
55 | res.map((item) => {
56 | item.text = item.text.replace(/\.md$/, "");
57 | });
58 | return res;
59 | }
60 |
61 | export const set_sidebar = (pathname) => {
62 | // 获取pathname的路径
63 | const dirPath = path.join(DIR_PATH, pathname);
64 | // 读取pathname下的所有文件或者文件夹
65 | const files = fs.readdirSync(dirPath);
66 | // 过滤掉
67 | const items = intersections(files, WHITE_LIST);
68 | // getList 函数后面会讲到
69 | return getList(items, dirPath, pathname);
70 | };
71 |
--------------------------------------------------------------------------------