├── .gitignore
├── C0uci.bat
├── LICENSE.txt
├── data
└── model
│ ├── model_best_config.json
│ └── model_best_weight.h5
├── model.png
├── readme.md
├── requirements.txt
└── src
└── chess_zero
├── agent
├── api_chess.py
├── model_chess.py
└── player_chess.py
├── config.py
├── configs
├── distributed.py
├── mini.py
└── normal.py
├── env
└── chess_env.py
├── lib
├── data_helper.py
├── logger.py
├── model_helper.py
└── tf_util.py
├── manager.py
├── play_game
└── uci.py
├── run.py
├── stacktracer.py
└── worker
├── evaluate.py
├── optimize.py
├── self_play.py
└── sl.py
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea
2 | .python-version
3 | *.mdl
4 | *.png
5 | *.pyc
6 | __pycache__
7 | .DS_Store
8 | *.pkl
9 | *.csv
10 | *.gz
11 | /data/
12 | .ipynb_checkpoints/
13 | tmp/
14 | tmp.*
15 | .env
16 | *.bin
17 | /bin/
18 | /keys/*
19 | video/*
20 | *.h5
21 | logs/
22 | *.sh
--------------------------------------------------------------------------------
/C0uci.bat:
--------------------------------------------------------------------------------
1 | python src/chess_zero/run.py uci
--------------------------------------------------------------------------------
/LICENSE.txt:
--------------------------------------------------------------------------------
1 | Copyright (c) 2017 Samuel Gravan (part of the code is due to Ken Morishita)
2 |
3 | Permission is hereby granted, free of charge, to any person obtaining
4 | a copy of this software and associated documentation files (the
5 | "Software"), to deal in the Software without restriction, including
6 | without limitation the rights to use, copy, modify, merge, publish,
7 | distribute, sublicense, and/or sell copies of the Software, and to
8 | permit persons to whom the Software is furnished to do so, subject to
9 | the following conditions:
10 |
11 | The above copyright notice and this permission notice shall be
12 | included in all copies or substantial portions of the Software.
13 |
14 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
15 | EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
16 | MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
17 | NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
18 | LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
19 | OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
20 | WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
21 |
--------------------------------------------------------------------------------
/data/model/model_best_config.json:
--------------------------------------------------------------------------------
1 | {"name": "chess_model", "layers": [{"name": "input_1", "class_name": "InputLayer", "config": {"batch_input_shape": [null, 18, 8, 8], "dtype": "float32", "sparse": false, "name": "input_1"}, "inbound_nodes": []}, {"name": "input_conv-5-256", "class_name": "Conv2D", "config": {"name": "input_conv-5-256", "trainable": true, "filters": 256, "kernel_size": [5, 5], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["input_1", 0, 0, {}]]]}, {"name": "input_batchnorm", "class_name": "BatchNormalization", "config": {"name": "input_batchnorm", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["input_conv-5-256", 0, 0, {}]]]}, {"name": "input_relu", "class_name": "Activation", "config": {"name": "input_relu", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["input_batchnorm", 0, 0, {}]]]}, {"name": "res1_conv1-3-256", "class_name": "Conv2D", "config": {"name": "res1_conv1-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["input_relu", 0, 0, {}]]]}, {"name": "res1_batchnorm1", "class_name": "BatchNormalization", "config": {"name": "res1_batchnorm1", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res1_conv1-3-256", 0, 0, {}]]]}, {"name": "res1_relu1", "class_name": "Activation", "config": {"name": "res1_relu1", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res1_batchnorm1", 0, 0, {}]]]}, {"name": "res1_conv2-3-256", "class_name": "Conv2D", "config": {"name": "res1_conv2-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res1_relu1", 0, 0, {}]]]}, {"name": "res1_batchnorm2", "class_name": "BatchNormalization", "config": {"name": "res1_batchnorm2", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res1_conv2-3-256", 0, 0, {}]]]}, {"name": "res1_add", "class_name": "Add", "config": {"name": "res1_add", "trainable": true}, "inbound_nodes": [[["input_relu", 0, 0, {}], ["res1_batchnorm2", 0, 0, {}]]]}, {"name": "res1_relu2", "class_name": "Activation", "config": {"name": "res1_relu2", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res1_add", 0, 0, {}]]]}, {"name": "res2_conv1-3-256", "class_name": "Conv2D", "config": {"name": "res2_conv1-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res1_relu2", 0, 0, {}]]]}, {"name": "res2_batchnorm1", "class_name": "BatchNormalization", "config": {"name": "res2_batchnorm1", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res2_conv1-3-256", 0, 0, {}]]]}, {"name": "res2_relu1", "class_name": "Activation", "config": {"name": "res2_relu1", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res2_batchnorm1", 0, 0, {}]]]}, {"name": "res2_conv2-3-256", "class_name": "Conv2D", "config": {"name": "res2_conv2-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res2_relu1", 0, 0, {}]]]}, {"name": "res2_batchnorm2", "class_name": "BatchNormalization", "config": {"name": "res2_batchnorm2", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res2_conv2-3-256", 0, 0, {}]]]}, {"name": "res2_add", "class_name": "Add", "config": {"name": "res2_add", "trainable": true}, "inbound_nodes": [[["res1_relu2", 0, 0, {}], ["res2_batchnorm2", 0, 0, {}]]]}, {"name": "res2_relu2", "class_name": "Activation", "config": {"name": "res2_relu2", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res2_add", 0, 0, {}]]]}, {"name": "res3_conv1-3-256", "class_name": "Conv2D", "config": {"name": "res3_conv1-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res2_relu2", 0, 0, {}]]]}, {"name": "res3_batchnorm1", "class_name": "BatchNormalization", "config": {"name": "res3_batchnorm1", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res3_conv1-3-256", 0, 0, {}]]]}, {"name": "res3_relu1", "class_name": "Activation", "config": {"name": "res3_relu1", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res3_batchnorm1", 0, 0, {}]]]}, {"name": "res3_conv2-3-256", "class_name": "Conv2D", "config": {"name": "res3_conv2-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res3_relu1", 0, 0, {}]]]}, {"name": "res3_batchnorm2", "class_name": "BatchNormalization", "config": {"name": "res3_batchnorm2", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res3_conv2-3-256", 0, 0, {}]]]}, {"name": "res3_add", "class_name": "Add", "config": {"name": "res3_add", "trainable": true}, "inbound_nodes": [[["res2_relu2", 0, 0, {}], ["res3_batchnorm2", 0, 0, {}]]]}, {"name": "res3_relu2", "class_name": "Activation", "config": {"name": "res3_relu2", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res3_add", 0, 0, {}]]]}, {"name": "res4_conv1-3-256", "class_name": "Conv2D", "config": {"name": "res4_conv1-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res3_relu2", 0, 0, {}]]]}, {"name": "res4_batchnorm1", "class_name": "BatchNormalization", "config": {"name": "res4_batchnorm1", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res4_conv1-3-256", 0, 0, {}]]]}, {"name": "res4_relu1", "class_name": "Activation", "config": {"name": "res4_relu1", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res4_batchnorm1", 0, 0, {}]]]}, {"name": "res4_conv2-3-256", "class_name": "Conv2D", "config": {"name": "res4_conv2-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res4_relu1", 0, 0, {}]]]}, {"name": "res4_batchnorm2", "class_name": "BatchNormalization", "config": {"name": "res4_batchnorm2", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res4_conv2-3-256", 0, 0, {}]]]}, {"name": "res4_add", "class_name": "Add", "config": {"name": "res4_add", "trainable": true}, "inbound_nodes": [[["res3_relu2", 0, 0, {}], ["res4_batchnorm2", 0, 0, {}]]]}, {"name": "res4_relu2", "class_name": "Activation", "config": {"name": "res4_relu2", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res4_add", 0, 0, {}]]]}, {"name": "res5_conv1-3-256", "class_name": "Conv2D", "config": {"name": "res5_conv1-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res4_relu2", 0, 0, {}]]]}, {"name": "res5_batchnorm1", "class_name": "BatchNormalization", "config": {"name": "res5_batchnorm1", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res5_conv1-3-256", 0, 0, {}]]]}, {"name": "res5_relu1", "class_name": "Activation", "config": {"name": "res5_relu1", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res5_batchnorm1", 0, 0, {}]]]}, {"name": "res5_conv2-3-256", "class_name": "Conv2D", "config": {"name": "res5_conv2-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res5_relu1", 0, 0, {}]]]}, {"name": "res5_batchnorm2", "class_name": "BatchNormalization", "config": {"name": "res5_batchnorm2", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res5_conv2-3-256", 0, 0, {}]]]}, {"name": "res5_add", "class_name": "Add", "config": {"name": "res5_add", "trainable": true}, "inbound_nodes": [[["res4_relu2", 0, 0, {}], ["res5_batchnorm2", 0, 0, {}]]]}, {"name": "res5_relu2", "class_name": "Activation", "config": {"name": "res5_relu2", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res5_add", 0, 0, {}]]]}, {"name": "res6_conv1-3-256", "class_name": "Conv2D", "config": {"name": "res6_conv1-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res5_relu2", 0, 0, {}]]]}, {"name": "res6_batchnorm1", "class_name": "BatchNormalization", "config": {"name": "res6_batchnorm1", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res6_conv1-3-256", 0, 0, {}]]]}, {"name": "res6_relu1", "class_name": "Activation", "config": {"name": "res6_relu1", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res6_batchnorm1", 0, 0, {}]]]}, {"name": "res6_conv2-3-256", "class_name": "Conv2D", "config": {"name": "res6_conv2-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res6_relu1", 0, 0, {}]]]}, {"name": "res6_batchnorm2", "class_name": "BatchNormalization", "config": {"name": "res6_batchnorm2", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res6_conv2-3-256", 0, 0, {}]]]}, {"name": "res6_add", "class_name": "Add", "config": {"name": "res6_add", "trainable": true}, "inbound_nodes": [[["res5_relu2", 0, 0, {}], ["res6_batchnorm2", 0, 0, {}]]]}, {"name": "res6_relu2", "class_name": "Activation", "config": {"name": "res6_relu2", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res6_add", 0, 0, {}]]]}, {"name": "res7_conv1-3-256", "class_name": "Conv2D", "config": {"name": "res7_conv1-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res6_relu2", 0, 0, {}]]]}, {"name": "res7_batchnorm1", "class_name": "BatchNormalization", "config": {"name": "res7_batchnorm1", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res7_conv1-3-256", 0, 0, {}]]]}, {"name": "res7_relu1", "class_name": "Activation", "config": {"name": "res7_relu1", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res7_batchnorm1", 0, 0, {}]]]}, {"name": "res7_conv2-3-256", "class_name": "Conv2D", "config": {"name": "res7_conv2-3-256", "trainable": true, "filters": 256, "kernel_size": [3, 3], "strides": [1, 1], "padding": "same", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res7_relu1", 0, 0, {}]]]}, {"name": "res7_batchnorm2", "class_name": "BatchNormalization", "config": {"name": "res7_batchnorm2", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["res7_conv2-3-256", 0, 0, {}]]]}, {"name": "res7_add", "class_name": "Add", "config": {"name": "res7_add", "trainable": true}, "inbound_nodes": [[["res6_relu2", 0, 0, {}], ["res7_batchnorm2", 0, 0, {}]]]}, {"name": "res7_relu2", "class_name": "Activation", "config": {"name": "res7_relu2", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["res7_add", 0, 0, {}]]]}, {"name": "value_conv-1-4", "class_name": "Conv2D", "config": {"name": "value_conv-1-4", "trainable": true, "filters": 4, "kernel_size": [1, 1], "strides": [1, 1], "padding": "valid", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res7_relu2", 0, 0, {}]]]}, {"name": "policy_conv-1-2", "class_name": "Conv2D", "config": {"name": "policy_conv-1-2", "trainable": true, "filters": 2, "kernel_size": [1, 1], "strides": [1, 1], "padding": "valid", "data_format": "channels_first", "dilation_rate": [1, 1], "activation": "linear", "use_bias": false, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["res7_relu2", 0, 0, {}]]]}, {"name": "value_batchnorm", "class_name": "BatchNormalization", "config": {"name": "value_batchnorm", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["value_conv-1-4", 0, 0, {}]]]}, {"name": "policy_batchnorm", "class_name": "BatchNormalization", "config": {"name": "policy_batchnorm", "trainable": true, "axis": 1, "momentum": 0.99, "epsilon": 0.001, "center": true, "scale": true, "beta_initializer": {"class_name": "Zeros", "config": {}}, "gamma_initializer": {"class_name": "Ones", "config": {}}, "moving_mean_initializer": {"class_name": "Zeros", "config": {}}, "moving_variance_initializer": {"class_name": "Ones", "config": {}}, "beta_regularizer": null, "gamma_regularizer": null, "beta_constraint": null, "gamma_constraint": null}, "inbound_nodes": [[["policy_conv-1-2", 0, 0, {}]]]}, {"name": "value_relu", "class_name": "Activation", "config": {"name": "value_relu", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["value_batchnorm", 0, 0, {}]]]}, {"name": "policy_relu", "class_name": "Activation", "config": {"name": "policy_relu", "trainable": true, "activation": "relu"}, "inbound_nodes": [[["policy_batchnorm", 0, 0, {}]]]}, {"name": "value_flatten", "class_name": "Flatten", "config": {"name": "value_flatten", "trainable": true}, "inbound_nodes": [[["value_relu", 0, 0, {}]]]}, {"name": "policy_flatten", "class_name": "Flatten", "config": {"name": "policy_flatten", "trainable": true}, "inbound_nodes": [[["policy_relu", 0, 0, {}]]]}, {"name": "value_dense", "class_name": "Dense", "config": {"name": "value_dense", "trainable": true, "units": 256, "activation": "relu", "use_bias": true, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["value_flatten", 0, 0, {}]]]}, {"name": "policy_out", "class_name": "Dense", "config": {"name": "policy_out", "trainable": true, "units": 1968, "activation": "softmax", "use_bias": true, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["policy_flatten", 0, 0, {}]]]}, {"name": "value_out", "class_name": "Dense", "config": {"name": "value_out", "trainable": true, "units": 1, "activation": "tanh", "use_bias": true, "kernel_initializer": {"class_name": "VarianceScaling", "config": {"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": {"class_name": "L1L2", "config": {"l1": 0.0, "l2": 9.999999747378752e-05}}, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}, "inbound_nodes": [[["value_dense", 0, 0, {}]]]}], "input_layers": [["input_1", 0, 0]], "output_layers": [["policy_out", 0, 0], ["value_out", 0, 0]]}
--------------------------------------------------------------------------------
/data/model/model_best_weight.h5:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Akababa/Chess-Zero/90a5aad05656131506239388557b9f60d16235a3/data/model/model_best_weight.h5
--------------------------------------------------------------------------------
/model.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Akababa/Chess-Zero/90a5aad05656131506239388557b9f60d16235a3/model.png
--------------------------------------------------------------------------------
/readme.md:
--------------------------------------------------------------------------------
1 | About
2 | =====
3 |
4 | Chess reinforcement learning by [AlphaGo Zero](https://deepmind.com/blog/alphago-zero-learning-scratch/) methods.
5 |
6 | This project is based on these main resources:
7 | 1) DeepMind's Oct 19th publication: [Mastering the Game of Go without Human Knowledge](https://www.nature.com/articles/nature24270.epdf?author_access_token=VJXbVjaSHxFoctQQ4p2k4tRgN0jAjWel9jnR3ZoTv0PVW4gB86EEpGqTRDtpIz-2rmo8-KG06gqVobU5NSCFeHILHcVFUeMsbvwS-lxjqQGg98faovwjxeTUgZAUMnRQ).
8 | 2) The great Reversi development of the DeepMind ideas that @mokemokechicken did in his repo: https://github.com/mokemokechicken/reversi-alpha-zero
9 | 3) DeepMind just released a new version of AlphaGo Zero (named now AlphaZero) where they master chess from scratch:
10 | https://arxiv.org/pdf/1712.01815.pdf. In fact, in chess AlphaZero outperformed Stockfish after just 4 hours (300k steps) Wow!
11 |
12 | See the [wiki](https://github.com/Akababa/Chess-Zero/wiki) for more details.
13 |
14 | Note: This project is still under construction!!
15 |
16 | Environment
17 | -----------
18 |
19 | * Python 3.6.3
20 | * tensorflow-gpu: 1.3.0
21 | * Keras: 2.0.8
22 |
23 | ### Results so far
24 |
25 | Using supervised learning on about 10k games, I trained a model (7 residual blocks of 256 filters) to a guesstimate of 1200 elo with 1200 sims/move. One of the strengths of MCTS is it scales quite well with computing power.
26 |
27 | Here you can see an example of a game I (white, ~2000 elo) played against the model in this repo (black):
28 |
29 | 
30 |
31 | Modules
32 | -------
33 |
34 | ### Supervised Learning
35 |
36 | I've done a supervised learning new pipeline step (to use those human games files "PGN" we can find in internet as play-data generator).
37 | This SL step was also used in the first and original version of AlphaGo and maybe chess is a some complex game that we have to pre-train first the policy model before starting the self-play process (i.e., maybe chess is too much complicated for a self training alone).
38 |
39 | To use the new SL process is as simple as running in the beginning instead of the worker "self" the new worker "sl".
40 | Once the model converges enough with SL play-data we just stop the worker "sl" and start the worker "self" so the model will start improving now due to self-play data.
41 |
42 | ```bash
43 | python src/chess_zero/run.py sl
44 | ```
45 | If you want to use this new SL step you will have to download big PGN files (chess files) and paste them into the `data/play_data` folder ([FICS](http://ficsgames.org/download.html) is a good source of data). You can also use the [SCID program](http://scid.sourceforge.net/) to filter by headers like player ELO, game result and more.
46 |
47 | **To avoid overfitting, I recommend using data sets of at least 3000 games and running at most 3-4 epochs.**
48 |
49 | ### Reinforcement Learning
50 |
51 | This AlphaGo Zero implementation consists of three workers: `self`, `opt` and `eval`.
52 |
53 | * `self` is Self-Play to generate training data by self-play using BestModel.
54 | * `opt` is Trainer to train model, and generate next-generation models.
55 | * `eval` is Evaluator to evaluate whether the next-generation model is better than BestModel. If better, replace BestModel.
56 |
57 |
58 | ### Distributed Training
59 |
60 | Now it's possible to train the model in a distributed way. The only thing needed is to use the new parameter:
61 |
62 | * `--type distributed`: use mini config for testing, (see `src/chess_zero/configs/distributed.py`)
63 |
64 | So, in order to contribute to the distributed team you just need to run the three workers locally like this:
65 |
66 | ```bash
67 | python src/chess_zero/run.py self --type distributed (or python src/chess_zero/run.py sl --type distributed)
68 | python src/chess_zero/run.py opt --type distributed
69 | python src/chess_zero/run.py eval --type distributed
70 | ```
71 |
72 | ### GUI
73 | * `uci` launches the Universal Chess Interface, for use in a GUI.
74 |
75 | To set up ChessZero with a GUI, point it to `C0uci.bat` (or rename to .sh).
76 | For example, this is screenshot of the random model using Arena's self-play feature:
77 | 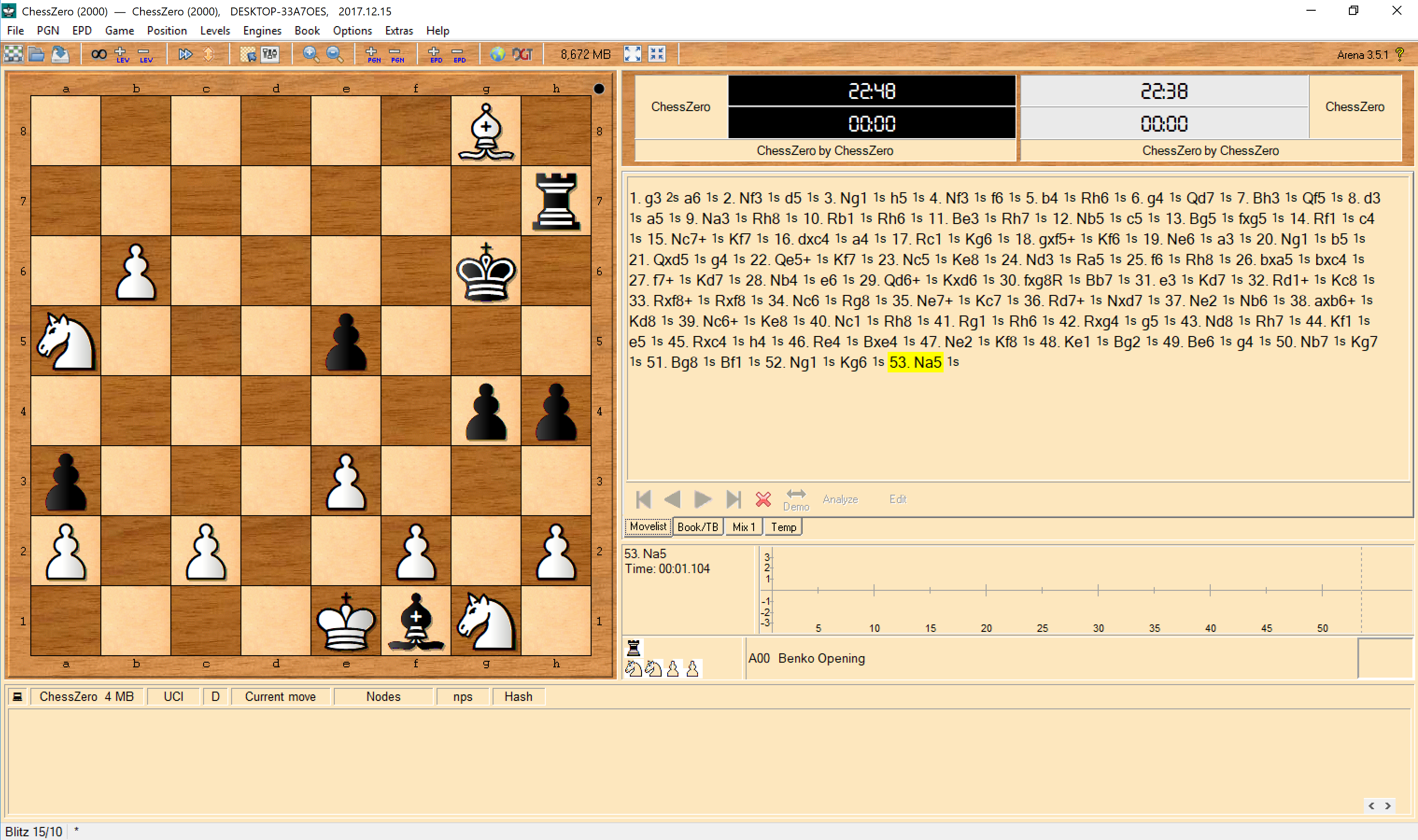
78 |
79 | Data
80 | -----
81 |
82 | * `data/model/model_best_*`: BestModel.
83 | * `data/model/next_generation/*`: next-generation models.
84 | * `data/play_data/play_*.json`: generated training data.
85 | * `logs/main.log`: log file.
86 |
87 | If you want to train the model from the beginning, delete the above directories.
88 |
89 | How to use
90 | ==========
91 |
92 | Setup
93 | -------
94 | ### install libraries
95 | ```bash
96 | pip install -r requirements.txt
97 | ```
98 |
99 | If you want to use GPU,
100 |
101 | ```bash
102 | pip install tensorflow-gpu
103 | ```
104 |
105 | Make sure Keras is using Tensorflow and you have Python 3.6.3+.
106 |
107 |
108 | Basic Usage
109 | ------------
110 |
111 | For training model, execute `Self-Play`, `Trainer` and `Evaluator`.
112 |
113 |
114 | Self-Play
115 | --------
116 |
117 | ```bash
118 | python src/chess_zero/run.py self
119 | ```
120 |
121 | When executed, Self-Play will start using BestModel.
122 | If the BestModel does not exist, new random model will be created and become BestModel.
123 |
124 | ### options
125 | * `--new`: create new BestModel
126 | * `--type mini`: use mini config for testing, (see `src/chess_zero/configs/mini.py`)
127 |
128 | Trainer
129 | -------
130 |
131 | ```bash
132 | python src/chess_zero/run.py opt
133 | ```
134 |
135 | When executed, Training will start.
136 | A base model will be loaded from latest saved next-generation model. If not existed, BestModel is used.
137 | Trained model will be saved every epoch.
138 |
139 | ### options
140 | * `--type mini`: use mini config for testing, (see `src/chess_zero/configs/mini.py`)
141 | * `--total-step`: specify total step(mini-batch) numbers. The total step affects learning rate of training.
142 |
143 | Evaluator
144 | ---------
145 |
146 | ```bash
147 | python src/chess_zero/run.py eval
148 | ```
149 |
150 | When executed, Evaluation will start.
151 | It evaluates BestModel and the latest next-generation model by playing about 200 games.
152 | If next-generation model wins, it becomes BestModel.
153 |
154 | ### options
155 | * `--type mini`: use mini config for testing, (see `src/chess_zero/configs/mini.py`)
156 |
157 |
158 | Tips and Memory
159 | ====
160 |
161 | GPU Memory
162 | ----------
163 |
164 | Usually the lack of memory cause warnings, not error.
165 | If error happens, try to change `vram_frac` in `src/configs/mini.py`,
166 |
167 | ```python
168 | self.vram_frac = 1.0
169 | ```
170 |
171 | Smaller batch_size will reduce memory usage of `opt`.
172 | Try to change `TrainerConfig#batch_size` in `MiniConfig`.
173 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | tensorflow-gpu
2 | keras
3 | profilehooks
4 | numpy
5 | pyperclip
6 | python-chess
7 | ujson
8 | h5py
--------------------------------------------------------------------------------
/src/chess_zero/agent/api_chess.py:
--------------------------------------------------------------------------------
1 | from multiprocessing import connection, Pipe
2 | import time
3 | from threading import Thread
4 |
5 | import numpy as np
6 |
7 | from chess_zero.config import Config
8 |
9 |
10 | class ChessModelAPI:
11 | # noinspection PyUnusedLocal
12 | def __init__(self, config: Config, agent_model): # ChessModel
13 | self.agent_model = agent_model
14 | self.pipes = []
15 |
16 | def start(self):
17 | prediction_worker = Thread(target=self.predict_batch_worker, name="prediction_worker")
18 | prediction_worker.daemon = True
19 | prediction_worker.start()
20 |
21 | def get_pipe(self):
22 | me, you = Pipe()
23 | self.pipes.append(me)
24 | return you
25 |
26 | def predict_batch_worker(self):
27 | while True:
28 | ready = connection.wait(self.pipes,timeout=0.001)
29 | if not ready:
30 | continue
31 | data, result_pipes = [], []
32 | for pipe in ready:
33 | while pipe.poll():
34 | data.append(pipe.recv())
35 | result_pipes.append(pipe)
36 | # print(f"predicting {len(result_pipes)} items")
37 | data = np.asarray(data, dtype=np.float32)
38 | policy_ary, value_ary = self.agent_model.model.predict_on_batch(data)
39 | for pipe, p, v in zip(result_pipes, policy_ary, value_ary):
40 | pipe.send((p, float(v)))
41 |
--------------------------------------------------------------------------------
/src/chess_zero/agent/model_chess.py:
--------------------------------------------------------------------------------
1 | import ftplib
2 | import hashlib
3 | import json
4 | import os
5 | from logging import getLogger
6 |
7 | from keras.engine.topology import Input
8 | from keras.engine.training import Model
9 | from keras.layers.convolutional import Conv2D
10 | from keras.layers.core import Activation, Dense, Flatten
11 | from keras.layers.merge import Add
12 | from keras.layers.normalization import BatchNormalization
13 | from keras.regularizers import l2
14 |
15 | from chess_zero.agent.api_chess import ChessModelAPI
16 | from chess_zero.config import Config
17 |
18 | # noinspection PyPep8Naming
19 |
20 | logger = getLogger(__name__)
21 |
22 |
23 | class ChessModel:
24 | def __init__(self, config: Config):
25 | self.config = config
26 | self.model = None # type: Model
27 | self.digest = None
28 | self.api = None
29 |
30 | def get_pipes(self, num = 1):
31 | if self.api is None:
32 | self.api = ChessModelAPI(self.config, self)
33 | self.api.start()
34 | return [self.api.get_pipe() for _ in range(num)]
35 |
36 | def build(self):
37 | mc = self.config.model
38 | in_x = x = Input((18, 8, 8))
39 |
40 | # (batch, channels, height, width)
41 | x = Conv2D(filters=mc.cnn_filter_num, kernel_size=mc.cnn_first_filter_size, padding="same",
42 | data_format="channels_first", use_bias=False, kernel_regularizer=l2(mc.l2_reg),
43 | name="input_conv-"+str(mc.cnn_first_filter_size)+"-"+str(mc.cnn_filter_num))(x)
44 | x = BatchNormalization(axis=1, name="input_batchnorm")(x)
45 | x = Activation("relu", name="input_relu")(x)
46 |
47 | for i in range(mc.res_layer_num):
48 | x = self._build_residual_block(x, i + 1)
49 |
50 | res_out = x
51 |
52 | # for policy output
53 | x = Conv2D(filters=2, kernel_size=1, data_format="channels_first", use_bias=False, kernel_regularizer=l2(mc.l2_reg),
54 | name="policy_conv-1-2")(res_out)
55 | x = BatchNormalization(axis=1, name="policy_batchnorm")(x)
56 | x = Activation("relu", name="policy_relu")(x)
57 | x = Flatten(name="policy_flatten")(x)
58 | # no output for 'pass'
59 | policy_out = Dense(self.config.n_labels, kernel_regularizer=l2(mc.l2_reg), activation="softmax", name="policy_out")(x)
60 |
61 |
62 | # for value output
63 | x = Conv2D(filters=4, kernel_size=1, data_format="channels_first", use_bias=False, kernel_regularizer=l2(mc.l2_reg),
64 | name="value_conv-1-4")(res_out)
65 | x = BatchNormalization(axis=1, name="value_batchnorm")(x)
66 | x = Activation("relu",name="value_relu")(x)
67 | x = Flatten(name="value_flatten")(x)
68 | x = Dense(mc.value_fc_size, kernel_regularizer=l2(mc.l2_reg), activation="relu", name="value_dense")(x)
69 | value_out = Dense(1, kernel_regularizer=l2(mc.l2_reg), activation="tanh", name="value_out")(x)
70 |
71 | self.model = Model(in_x, [policy_out, value_out], name="chess_model")
72 |
73 | def _build_residual_block(self, x, index):
74 | mc = self.config.model
75 | in_x = x
76 | res_name = "res"+str(index)
77 | x = Conv2D(filters=mc.cnn_filter_num, kernel_size=mc.cnn_filter_size, padding="same",
78 | data_format="channels_first", use_bias=False, kernel_regularizer=l2(mc.l2_reg),
79 | name=res_name+"_conv1-"+str(mc.cnn_filter_size)+"-"+str(mc.cnn_filter_num))(x)
80 | x = BatchNormalization(axis=1, name=res_name+"_batchnorm1")(x)
81 | x = Activation("relu",name=res_name+"_relu1")(x)
82 | x = Conv2D(filters=mc.cnn_filter_num, kernel_size=mc.cnn_filter_size, padding="same",
83 | data_format="channels_first", use_bias=False, kernel_regularizer=l2(mc.l2_reg),
84 | name=res_name+"_conv2-"+str(mc.cnn_filter_size)+"-"+str(mc.cnn_filter_num))(x)
85 | x = BatchNormalization(axis=1, name="res"+str(index)+"_batchnorm2")(x)
86 | x = Add(name=res_name+"_add")([in_x, x])
87 | x = Activation("relu", name=res_name+"_relu2")(x)
88 | return x
89 |
90 | @staticmethod
91 | def fetch_digest(weight_path):
92 | if os.path.exists(weight_path):
93 | m = hashlib.sha256()
94 | with open(weight_path, "rb") as f:
95 | m.update(f.read())
96 | return m.hexdigest()
97 |
98 | def load(self, config_path, weight_path):
99 | mc = self.config.model
100 | resources = self.config.resource
101 | if mc.distributed and config_path == resources.model_best_config_path:
102 | try:
103 | logger.debug("loading model from server")
104 | ftp_connection = ftplib.FTP(resources.model_best_distributed_ftp_server,
105 | resources.model_best_distributed_ftp_user,
106 | resources.model_best_distributed_ftp_password)
107 | ftp_connection.cwd(resources.model_best_distributed_ftp_remote_path)
108 | ftp_connection.retrbinary("RETR model_best_config.json", open(config_path, 'wb').write)
109 | ftp_connection.retrbinary("RETR model_best_weight.h5", open(weight_path, 'wb').write)
110 | ftp_connection.quit()
111 | except:
112 | pass
113 | if os.path.exists(config_path) and os.path.exists(weight_path):
114 | logger.debug(f"loading model from {config_path}")
115 | with open(config_path, "rt") as f:
116 | self.model = Model.from_config(json.load(f))
117 | self.model.load_weights(weight_path)
118 | self.model._make_predict_function()
119 | self.digest = self.fetch_digest(weight_path)
120 | logger.debug(f"loaded model digest = {self.digest}")
121 | #print(self.model.summary)
122 | return True
123 | else:
124 | logger.debug(f"model files does not exist at {config_path} and {weight_path}")
125 | return False
126 |
127 | def save(self, config_path, weight_path):
128 | logger.debug(f"save model to {config_path}")
129 | with open(config_path, "wt") as f:
130 | json.dump(self.model.get_config(), f)
131 | self.model.save_weights(weight_path)
132 | self.digest = self.fetch_digest(weight_path)
133 | logger.debug(f"saved model digest {self.digest}")
134 |
135 | mc = self.config.model
136 | resources = self.config.resource
137 | if mc.distributed and config_path == resources.model_best_config_path:
138 | try:
139 | logger.debug("saving model to server")
140 | ftp_connection = ftplib.FTP(resources.model_best_distributed_ftp_server,
141 | resources.model_best_distributed_ftp_user,
142 | resources.model_best_distributed_ftp_password)
143 | ftp_connection.cwd(resources.model_best_distributed_ftp_remote_path)
144 | fh = open(config_path, 'rb')
145 | ftp_connection.storbinary('STOR model_best_config.json', fh)
146 | fh.close()
147 |
148 | fh = open(weight_path, 'rb')
149 | ftp_connection.storbinary('STOR model_best_weight.h5', fh)
150 | fh.close()
151 | ftp_connection.quit()
152 | except:
153 | pass
154 |
--------------------------------------------------------------------------------
/src/chess_zero/agent/player_chess.py:
--------------------------------------------------------------------------------
1 | from collections import defaultdict
2 | from concurrent.futures import ThreadPoolExecutor
3 | from logging import getLogger
4 | from threading import Lock
5 |
6 | import chess
7 | import numpy as np
8 |
9 | from chess_zero.config import Config
10 | from chess_zero.env.chess_env import ChessEnv, Winner
11 |
12 | #from chess_zero.play_game.uci import info
13 |
14 | logger = getLogger(__name__)
15 |
16 | # these are from AGZ nature paper
17 | class VisitStats:
18 | def __init__(self):
19 | self.a = defaultdict(ActionStats)
20 | self.sum_n = 0
21 |
22 | class ActionStats:
23 | def __init__(self):
24 | self.n = 0
25 | self.w = 0
26 | self.q = 0
27 |
28 | class ChessPlayer:
29 | # dot = False
30 | def __init__(self, config: Config, pipes=None, play_config=None, dummy=False):
31 | self.moves = []
32 |
33 | self.config = config
34 | self.play_config = play_config or self.config.play
35 | self.labels_n = config.n_labels
36 | self.labels = config.labels
37 | self.move_lookup = {chess.Move.from_uci(move): i for move, i in zip(self.labels, range(self.labels_n))}
38 | if dummy:
39 | return
40 |
41 | self.pipe_pool = pipes
42 | self.node_lock = defaultdict(Lock)
43 |
44 | def reset(self):
45 | self.tree = defaultdict(VisitStats)
46 |
47 | def deboog(self, env):
48 | print(env.testeval())
49 |
50 | state = state_key(env)
51 | my_visit_stats = self.tree[state]
52 | stats = []
53 | for action, a_s in my_visit_stats.a.items():
54 | moi = self.move_lookup[action]
55 | stats.append(np.asarray([a_s.n, a_s.w, a_s.q, a_s.p, moi]))
56 | stats = np.asarray(stats)
57 | a = stats[stats[:,0].argsort()[::-1]]
58 |
59 | for s in a:
60 | print(f'{self.labels[int(s[4])]:5}: '
61 | f'n: {s[0]:3.0f} '
62 | f'w: {s[1]:7.3f} '
63 | f'q: {s[2]:7.3f} '
64 | f'p: {s[3]:7.5f}')
65 |
66 | def action(self, env, can_stop = True) -> str:
67 | self.reset()
68 |
69 | # for tl in range(self.play_config.thinking_loop):
70 | root_value, naked_value = self.search_moves(env)
71 | policy = self.calc_policy(env)
72 | my_action = int(np.random.choice(range(self.labels_n), p = self.apply_temperature(policy, env.num_halfmoves)))
73 | #print(naked_value)
74 | #self.deboog(env)
75 | if can_stop and self.play_config.resign_threshold is not None and \
76 | root_value <= self.play_config.resign_threshold \
77 | and env.num_halfmoves > self.play_config.min_resign_turn:
78 | # noinspection PyTypeChecker
79 | return None
80 | else:
81 | self.moves.append([env.observation, list(policy)])
82 | return self.config.labels[my_action]
83 |
84 | def search_moves(self, env) -> (float, float):
85 | # if ChessPlayer.dot == False:
86 | # import stacktracer
87 | # stacktracer.trace_start("trace.html")
88 | # ChessPlayer.dot = True
89 |
90 | futures = []
91 | with ThreadPoolExecutor(max_workers=self.play_config.search_threads) as executor:
92 | for _ in range(self.play_config.simulation_num_per_move):
93 | futures.append(executor.submit(self.search_my_move,env=env.copy(),is_root_node=True))
94 |
95 | vals = [f.result() for f in futures]
96 | #vals=[self.search_my_move(env.copy(),True) for _ in range(self.play_config.simulation_num_per_move)]
97 |
98 | return np.max(vals), vals[0] # vals[0] is kind of racy
99 |
100 | def search_my_move(self, env: ChessEnv, is_root_node=False) -> float:
101 | """
102 | Q, V is value for this Player(always white).
103 | P is value for the player of next_player (black or white)
104 | :return: leaf value
105 | """
106 | if env.done:
107 | if env.winner == Winner.draw:
108 | return 0
109 | # assert env.whitewon != env.white_to_move # side to move can't be winner!
110 | return -1
111 |
112 | state = state_key(env)
113 |
114 | with self.node_lock[state]:
115 | if state not in self.tree:
116 | leaf_p, leaf_v = self.expand_and_evaluate(env)
117 | self.tree[state].p = leaf_p
118 | return leaf_v # I'm returning everything from the POV of side to move
119 | #assert state in self.tree
120 |
121 | # SELECT STEP
122 | action_t = self.select_action_q_and_u(env, is_root_node)
123 |
124 | virtual_loss = self.play_config.virtual_loss
125 |
126 | my_visit_stats = self.tree[state]
127 | my_stats = my_visit_stats.a[action_t]
128 |
129 | my_visit_stats.sum_n += virtual_loss
130 | my_stats.n += virtual_loss
131 | my_stats.w += -virtual_loss
132 | my_stats.q = my_stats.w / my_stats.n
133 |
134 | env.step(action_t.uci())
135 | leaf_v = self.search_my_move(env) # next move from enemy POV
136 | leaf_v = -leaf_v
137 |
138 | # BACKUP STEP
139 | # on returning search path
140 | # update: N, W, Q
141 | with self.node_lock[state]:
142 | my_visit_stats.sum_n += -virtual_loss + 1
143 | my_stats.n += -virtual_loss + 1
144 | my_stats.w += virtual_loss + leaf_v
145 | my_stats.q = my_stats.w / my_stats.n
146 |
147 | return leaf_v
148 |
149 | def expand_and_evaluate(self, env) -> (np.ndarray, float):
150 | """ expand new leaf, this is called only once per state
151 | this is called with state locked
152 | insert P(a|s), return leaf_v
153 | """
154 | state_planes = env.canonical_input_planes()
155 |
156 | leaf_p, leaf_v = self.predict(state_planes)
157 | # these are canonical policy and value (i.e. side to move is "white")
158 |
159 | if not env.white_to_move:
160 | leaf_p = Config.flip_policy(leaf_p) # get it back to python-chess form
161 | #np.testing.assert_array_equal(Config.flip_policy(Config.flip_policy(leaf_p)), leaf_p)
162 |
163 | return leaf_p, leaf_v
164 |
165 | def predict(self, state_planes):
166 | pipe = self.pipe_pool.pop()
167 | pipe.send(state_planes)
168 | ret = pipe.recv()
169 | self.pipe_pool.append(pipe)
170 | return ret
171 |
172 | #@profile
173 | def select_action_q_and_u(self, env, is_root_node) -> chess.Move:
174 | # this method is called with state locked
175 | state = state_key(env)
176 |
177 | my_visitstats = self.tree[state]
178 |
179 | if my_visitstats.p is not None: #push p to edges
180 | tot_p = 1e-8
181 | for mov in env.board.legal_moves:
182 | mov_p = my_visitstats.p[self.move_lookup[mov]]
183 | my_visitstats.a[mov].p = mov_p
184 | tot_p += mov_p
185 | for a_s in my_visitstats.a.values():
186 | a_s.p /= tot_p
187 | my_visitstats.p = None
188 |
189 | xx_ = np.sqrt(my_visitstats.sum_n + 1) # sqrt of sum(N(s, b); for all b)
190 |
191 | e = self.play_config.noise_eps
192 | c_puct = self.play_config.c_puct
193 | dir_alpha = self.play_config.dirichlet_alpha
194 |
195 | best_s = -999
196 | best_a = None
197 |
198 | for action, a_s in my_visitstats.a.items():
199 | p_ = a_s.p
200 | if is_root_node:
201 | p_ = (1-e) * p_ + e * np.random.dirichlet([dir_alpha])
202 | b = a_s.q + c_puct * p_ * xx_ / (1 + a_s.n)
203 | if b > best_s:
204 | best_s = b
205 | best_a = action
206 |
207 | return best_a
208 |
209 | def apply_temperature(self, policy, turn):
210 | tau = np.power(self.play_config.tau_decay_rate, turn + 1)
211 | if tau < 0.1:
212 | tau = 0
213 | if tau == 0:
214 | action = np.argmax(policy)
215 | ret = np.zeros(self.labels_n)
216 | ret[action] = 1.0
217 | return ret
218 | else:
219 | ret = np.power(policy, 1/tau)
220 | ret /= np.sum(ret)
221 | return ret
222 |
223 | def calc_policy(self, env):
224 | """calc π(a|s0)
225 | :return:
226 | """
227 | state = state_key(env)
228 | my_visitstats = self.tree[state]
229 | policy = np.zeros(self.labels_n)
230 | for action, a_s in my_visitstats.a.items():
231 | policy[self.move_lookup[action]] = a_s.n
232 |
233 | policy /= np.sum(policy)
234 | return policy
235 |
236 | def sl_action(self, observation, my_action, weight=1):
237 | policy = np.zeros(self.labels_n)
238 |
239 | k = self.move_lookup[chess.Move.from_uci(my_action)]
240 | policy[k] = weight
241 |
242 | self.moves.append([observation, list(policy)])
243 | return my_action
244 |
245 | def finish_game(self, z):
246 | """
247 | :param self:
248 | :param z: win=1, lose=-1, draw=0
249 | :return:
250 | """
251 | for move in self.moves: # add this game winner result to all past moves.
252 | move += [z]
253 |
254 | def state_key(env: ChessEnv) -> str:
255 | fen = env.board.fen().rsplit(' ', 1) # drop the move clock
256 | return fen[0]
--------------------------------------------------------------------------------
/src/chess_zero/config.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 |
4 |
5 | class PlayWithHumanConfig:
6 | def __init__(self):
7 | self.simulation_num_per_move = 1200
8 | self.threads_multiplier = 2
9 | self.c_puct = 1 # lower = prefer mean action value
10 | self.noise_eps = 0
11 | self.tau_decay_rate = 0 # start deterministic mode
12 | self.resign_threshold = None
13 |
14 | def update_play_config(self, pc):
15 | """
16 | :param PlayConfig pc:
17 | :return:
18 | """
19 | pc.simulation_num_per_move = self.simulation_num_per_move
20 | pc.search_threads *= self.threads_multiplier
21 | pc.c_puct = self.c_puct
22 | pc.noise_eps = self.noise_eps
23 | pc.tau_decay_rate = self.tau_decay_rate
24 | pc.resign_threshold = self.resign_threshold
25 | pc.max_game_length = 999999
26 |
27 |
28 | class Options:
29 | new = False
30 |
31 |
32 | class ResourceConfig:
33 | def __init__(self):
34 | self.project_dir = os.environ.get("PROJECT_DIR", _project_dir())
35 | self.data_dir = os.environ.get("DATA_DIR", _data_dir())
36 |
37 | self.model_dir = os.environ.get("MODEL_DIR", os.path.join(self.data_dir, "model"))
38 | self.model_best_config_path = os.path.join(self.model_dir, "model_best_config.json")
39 | self.model_best_weight_path = os.path.join(self.model_dir, "model_best_weight.h5")
40 |
41 | self.model_best_distributed_ftp_server = "alpha-chess-zero.mygamesonline.org"
42 | self.model_best_distributed_ftp_user = "2537576_chess"
43 | self.model_best_distributed_ftp_password = "alpha-chess-zero-2"
44 | self.model_best_distributed_ftp_remote_path = "/alpha-chess-zero.mygamesonline.org/"
45 |
46 | self.next_generation_model_dir = os.path.join(self.model_dir, "next_generation")
47 | self.next_generation_model_dirname_tmpl = "model_%s"
48 | self.next_generation_model_config_filename = "model_config.json"
49 | self.next_generation_model_weight_filename = "model_weight.h5"
50 |
51 | self.play_data_dir = os.path.join(self.data_dir, "play_data")
52 | self.play_data_filename_tmpl = "play_%s.json"
53 |
54 | self.log_dir = os.path.join(self.project_dir, "logs")
55 | self.main_log_path = os.path.join(self.log_dir, "main.log")
56 |
57 | def create_directories(self):
58 | dirs = [self.project_dir, self.data_dir, self.model_dir, self.play_data_dir, self.log_dir,
59 | self.next_generation_model_dir]
60 | for d in dirs:
61 | if not os.path.exists(d):
62 | os.makedirs(d)
63 |
64 | def flipped_uci_labels():
65 | def repl(x):
66 | return "".join([(str(9 - int(a)) if a.isdigit() else a) for a in x])
67 |
68 | return [repl(x) for x in create_uci_labels()]
69 |
70 |
71 | def create_uci_labels():
72 | labels_array = []
73 | letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
74 | numbers = ['1', '2', '3', '4', '5', '6', '7', '8']
75 | promoted_to = ['q', 'r', 'b', 'n']
76 |
77 | for l1 in range(8):
78 | for n1 in range(8):
79 | destinations = [(t, n1) for t in range(8)] + \
80 | [(l1, t) for t in range(8)] + \
81 | [(l1 + t, n1 + t) for t in range(-7, 8)] + \
82 | [(l1 + t, n1 - t) for t in range(-7, 8)] + \
83 | [(l1 + a, n1 + b) for (a, b) in
84 | [(-2, -1), (-1, -2), (-2, 1), (1, -2), (2, -1), (-1, 2), (2, 1), (1, 2)]]
85 | for (l2, n2) in destinations:
86 | if (l1, n1) != (l2, n2) and l2 in range(8) and n2 in range(8):
87 | move = letters[l1] + numbers[n1] + letters[l2] + numbers[n2]
88 | labels_array.append(move)
89 | for l1 in range(8):
90 | l = letters[l1]
91 | for p in promoted_to:
92 | labels_array.append(l + '2' + l + '1' + p)
93 | labels_array.append(l + '7' + l + '8' + p)
94 | if l1 > 0:
95 | l_l = letters[l1 - 1]
96 | labels_array.append(l + '2' + l_l + '1' + p)
97 | labels_array.append(l + '7' + l_l + '8' + p)
98 | if l1 < 7:
99 | l_r = letters[l1 + 1]
100 | labels_array.append(l + '2' + l_r + '1' + p)
101 | labels_array.append(l + '7' + l_r + '8' + p)
102 | return labels_array
103 |
104 |
105 | class Config:
106 | labels = create_uci_labels()
107 | n_labels = int(len(labels))
108 | flipped_labels = flipped_uci_labels()
109 | unflipped_index = None
110 |
111 | def __init__(self, config_type="mini"):
112 | self.opts = Options()
113 | self.resource = ResourceConfig()
114 |
115 | if config_type == "mini":
116 | import chess_zero.configs.mini as c
117 | elif config_type == "normal":
118 | import chess_zero.configs.normal as c
119 | elif config_type == "distributed":
120 | import chess_zero.configs.distributed as c
121 | else:
122 | raise RuntimeError(f"unknown config_type: {config_type}")
123 | self.model = c.ModelConfig()
124 | self.play = c.PlayConfig()
125 | self.play_data = c.PlayDataConfig()
126 | self.trainer = c.TrainerConfig()
127 | self.eval = c.EvaluateConfig()
128 | self.labels = Config.labels
129 | self.n_labels = Config.n_labels
130 | self.flipped_labels = Config.flipped_labels
131 |
132 | @staticmethod
133 | def flip_policy(pol):
134 | return np.asarray([pol[ind] for ind in Config.unflipped_index])
135 |
136 |
137 | Config.unflipped_index = [Config.labels.index(x) for x in Config.flipped_labels]
138 |
139 |
140 | # print(Config.labels)
141 | # print(Config.flipped_labels)
142 |
143 |
144 | def _project_dir():
145 | d = os.path.dirname
146 | return d(d(d(os.path.abspath(__file__))))
147 |
148 |
149 | def _data_dir():
150 | return os.path.join(_project_dir(), "data")
--------------------------------------------------------------------------------
/src/chess_zero/configs/distributed.py:
--------------------------------------------------------------------------------
1 | class EvaluateConfig:
2 | def __init__(self):
3 | self.game_num = 400
4 | self.replace_rate = 0.55
5 | self.play_config = PlayConfig()
6 | self.play_config.simulation_num_per_move = 200
7 | self.play_config.thinking_loop = 1
8 | self.play_config.c_puct = 1
9 | self.play_config.change_tau_turn = 0
10 | self.play_config.noise_eps = 0
11 | self.evaluate_latest_first = True
12 |
13 |
14 | class PlayDataConfig:
15 | def __init__(self):
16 | self.sl_nb_game_in_file = 100
17 | self.nb_game_in_file = 100
18 | self.max_file_num = 200
19 |
20 |
21 | class PlayConfig:
22 | def __init__(self):
23 | self.simulation_num_per_move = 200
24 | self.thinking_loop = 1
25 | self.logging_thinking = False
26 | self.c_puct = 1.5
27 | self.noise_eps = 0.25
28 | self.dirichlet_alpha = 0.3
29 | self.change_tau_turn = 10
30 | self.virtual_loss = 3
31 | self.prediction_queue_size = 16
32 | self.search_threads = 16
33 | self.prediction_worker_sleep_sec = 0.00001
34 | self.wait_for_expanding_sleep_sec = 0.000001
35 | self.resign_threshold = -0.8
36 | self.min_resign_turn = 5
37 | self.average_chess_movements = 50
38 |
39 |
40 | class TrainerConfig:
41 | def __init__(self):
42 | self.batch_size = 2048
43 | self.epoch_to_checkpoint = 1
44 | self.start_total_steps = 0
45 | self.save_model_steps = 2000
46 | self.load_data_steps = 1000
47 | self.loss_weights = [1.0, 1.0] # prevent value overfit in SL
48 |
49 |
50 | class ModelConfig:
51 | cnn_filter_num = 256
52 | cnn_filter_size = 3
53 | res_layer_num = 7
54 | l2_reg = 1e-4
55 | value_fc_size = 256
56 | distributed = True
57 |
--------------------------------------------------------------------------------
/src/chess_zero/configs/mini.py:
--------------------------------------------------------------------------------
1 | class EvaluateConfig:
2 | def __init__(self):
3 | self.vram_frac = 1.0
4 | self.game_num = 50
5 | self.replace_rate = 0.55
6 | self.play_config = PlayConfig()
7 | self.play_config.simulation_num_per_move = 200
8 | self.play_config.thinking_loop = 1
9 | self.play_config.c_puct = 1 # lower = prefer mean action value
10 | self.play_config.tau_decay_rate = 0.6 # I need a better distribution...
11 | self.play_config.noise_eps = 0
12 | self.evaluate_latest_first = True
13 | self.max_game_length = 1000
14 |
15 |
16 | class PlayDataConfig:
17 | def __init__(self):
18 | self.min_elo_policy = 500 # 0 weight
19 | self.max_elo_policy = 1800 # 1 weight
20 | self.sl_nb_game_in_file = 250
21 | self.nb_game_in_file = 50
22 | self.max_file_num = 150
23 |
24 |
25 | class PlayConfig:
26 | def __init__(self):
27 | self.max_processes = 3
28 | self.search_threads = 16
29 | self.vram_frac = 1.0
30 | self.simulation_num_per_move = 100
31 | self.thinking_loop = 1
32 | self.logging_thinking = False
33 | self.c_puct = 1.5
34 | self.noise_eps = 0.25
35 | self.dirichlet_alpha = 0.3
36 | self.tau_decay_rate = 0.99
37 | self.virtual_loss = 3
38 | self.resign_threshold = -0.8
39 | self.min_resign_turn = 5
40 | self.max_game_length = 1000
41 |
42 |
43 | class TrainerConfig:
44 | def __init__(self):
45 | self.min_data_size_to_learn = 0
46 | self.cleaning_processes = 5 # RAM explosion...
47 | self.vram_frac = 1.0
48 | self.batch_size = 384 # tune this to your gpu memory
49 | self.epoch_to_checkpoint = 1
50 | self.dataset_size = 100000
51 | self.start_total_steps = 0
52 | self.save_model_steps = 25
53 | self.load_data_steps = 100
54 | self.loss_weights = [1.25, 1.0] # [policy, value] prevent value overfit in SL
55 |
56 |
57 | class ModelConfig:
58 | cnn_filter_num = 256
59 | cnn_first_filter_size = 5
60 | cnn_filter_size = 3
61 | res_layer_num = 7
62 | l2_reg = 1e-4 # GO TO JSON TO SET THIS!!!! I don't have much worry for overfitting with only 1-2 epochs/dataset
63 | value_fc_size = 256
64 | distributed = False
65 | input_depth = 18
--------------------------------------------------------------------------------
/src/chess_zero/configs/normal.py:
--------------------------------------------------------------------------------
1 | class EvaluateConfig:
2 | def __init__(self):
3 | self.game_num = 400
4 | self.replace_rate = 0.55
5 | self.play_config = PlayConfig()
6 | self.play_config.simulation_num_per_move = 200
7 | self.play_config.thinking_loop = 1
8 | self.play_config.c_puct = 1
9 | self.play_config.change_tau_turn = 0
10 | self.play_config.noise_eps = 0
11 | self.evaluate_latest_first = True
12 |
13 |
14 | class PlayDataConfig:
15 | def __init__(self):
16 | self.sl_nb_game_in_file = 100
17 | self.nb_game_in_file = 100
18 | self.max_file_num = 200
19 |
20 |
21 | class PlayConfig:
22 | def __init__(self):
23 | self.simulation_num_per_move = 200
24 | self.thinking_loop = 1
25 | self.logging_thinking = False
26 | self.c_puct = 1.5
27 | self.noise_eps = 0.25
28 | self.dirichlet_alpha = 0.3
29 | self.change_tau_turn = 10
30 | self.virtual_loss = 3
31 | self.prediction_queue_size = 16
32 | self.search_threads = 16
33 | self.prediction_worker_sleep_sec = 0.00001
34 | self.wait_for_expanding_sleep_sec = 0.000001
35 | self.resign_threshold = -0.8
36 | self.min_resign_turn = 5
37 | self.average_chess_movements = 50
38 |
39 |
40 | class TrainerConfig:
41 | def __init__(self):
42 | self.batch_size = 2048
43 | self.epoch_to_checkpoint = 1
44 | self.start_total_steps = 0
45 | self.save_model_steps = 2000
46 | self.load_data_steps = 1000
47 | self.loss_weights = [1.0, 1.0] # prevent value overfit in SL
48 |
49 |
50 | class ModelConfig:
51 | cnn_filter_num = 256
52 | cnn_filter_size = 3
53 | res_layer_num = 7
54 | l2_reg = 1e-4
55 | value_fc_size = 256
56 | distributed = False
57 |
--------------------------------------------------------------------------------
/src/chess_zero/env/chess_env.py:
--------------------------------------------------------------------------------
1 | import enum
2 | import chess.pgn
3 | import numpy as np
4 | import copy
5 |
6 | from logging import getLogger
7 |
8 | logger = getLogger(__name__)
9 |
10 | # noinspection PyArgumentList
11 | Winner = enum.Enum("Winner", "black white draw")
12 |
13 | # input planes
14 | # noinspection SpellCheckingInspection
15 | pieces_order = 'KQRBNPkqrbnp' # 12x8x8
16 | castling_order = 'KQkq' # 4x8x8
17 | # fifty-move-rule # 1x8x8
18 | # en en_passant # 1x8x8
19 |
20 | ind = {pieces_order[i]: i for i in range(12)}
21 |
22 | class ChessEnv:
23 |
24 | def __init__(self):
25 | self.board = None
26 | self.num_halfmoves = 0
27 | self.winner = None # type: Winner
28 | self.resigned = False
29 | self.result = None
30 |
31 | def reset(self):
32 | self.board = chess.Board()
33 | self.num_halfmoves = 0
34 | self.winner = None
35 | self.resigned = False
36 | return self
37 |
38 | def update(self, board):
39 | self.board = chess.Board(board)
40 | self.winner = None
41 | self.resigned = False
42 | return self
43 |
44 | @property
45 | def done(self):
46 | return self.winner is not None
47 |
48 | @property
49 | def white_won(self):
50 | return self.winner == Winner.white
51 |
52 | @property
53 | def white_to_move(self):
54 | return self.board.turn == chess.WHITE
55 |
56 | def step(self, action: str, check_over = True):
57 | """
58 | :param action:
59 | :param check_over:
60 | :return:
61 | """
62 | if check_over and action is None:
63 | self._resign()
64 | return
65 |
66 | self.board.push_uci(action)
67 |
68 | self.num_halfmoves += 1
69 |
70 | if check_over and self.board.result(claim_draw=True) != "*":
71 | self._game_over()
72 |
73 | def _game_over(self):
74 | if self.winner is None:
75 | self.result = self.board.result(claim_draw = True)
76 | if self.result == '1-0':
77 | self.winner = Winner.white
78 | elif self.result == '0-1':
79 | self.winner = Winner.black
80 | else:
81 | self.winner = Winner.draw
82 |
83 | def _resign(self):
84 | self.resigned = True
85 | if self.white_to_move: # WHITE RESIGNED!
86 | self.winner = Winner.black
87 | self.result = "0-1"
88 | else:
89 | self.winner = Winner.white
90 | self.result = "1-0"
91 |
92 | def adjudicate(self):
93 | score = self.testeval(absolute = True)
94 | if abs(score) < 0.01:
95 | self.winner = Winner.draw
96 | self.result = "1/2-1/2"
97 | elif score > 0:
98 | self.winner = Winner.white
99 | self.result = "1-0"
100 | else:
101 | self.winner = Winner.black
102 | self.result = "0-1"
103 |
104 | def ending_average_game(self):
105 | self.winner = Winner.draw
106 | self.result = "1/2-1/2"
107 |
108 | def copy(self):
109 | env = copy.copy(self)
110 | env.board = copy.copy(self.board)
111 | return env
112 |
113 | def render(self):
114 | print("\n")
115 | print(self.board)
116 | print("\n")
117 |
118 | @property
119 | def observation(self):
120 | return self.board.fen()
121 |
122 | def deltamove(self, fen_next):
123 | moves = list(self.board.legal_moves)
124 | for mov in moves:
125 | self.board.push(mov)
126 | fee = self.board.fen()
127 | self.board.pop()
128 | if fee == fen_next:
129 | return mov.uci()
130 | return None
131 |
132 | def replace_tags(self):
133 | return replace_tags_board(self.board.fen())
134 |
135 | def canonical_input_planes(self):
136 | return canon_input_planes(self.board.fen())
137 |
138 | def testeval(self, absolute=False) -> float:
139 | return testeval(self.board.fen(), absolute)
140 |
141 | def testeval(fen, absolute = False) -> float:
142 | piece_vals = {'K': 3, 'Q': 14, 'R': 5,'B': 3.25,'N': 3,'P': 1} # somehow it doesn't know how to keep its queen
143 | ans = 0.0
144 | tot = 0
145 | for c in fen.split(' ')[0]:
146 | if not c.isalpha():
147 | continue
148 | #assert c.upper() in piece_vals
149 | if c.isupper():
150 | ans += piece_vals[c]
151 | tot += piece_vals[c]
152 | else:
153 | ans -= piece_vals[c.upper()]
154 | tot += piece_vals[c.upper()]
155 | v = ans/tot
156 | if not absolute and is_black_turn(fen):
157 | v = -v
158 | assert abs(v) < 1
159 | return np.tanh(v * 3) # arbitrary
160 |
161 | def check_current_planes(realfen, planes):
162 | cur = planes[0:12]
163 | assert cur.shape == (12, 8, 8)
164 | fakefen = ["1"] * 64
165 | for i in range(12):
166 | for rank in range(8):
167 | for file in range(8):
168 | if cur[i][rank][file] == 1:
169 | assert fakefen[rank * 8 + file] == '1'
170 | fakefen[rank * 8 + file] = pieces_order[i]
171 |
172 | castling = planes[12:16]
173 | fiftymove = planes[16][0][0]
174 | ep = planes[17]
175 |
176 | castlingstring = ""
177 | for i in range(4):
178 | if castling[i][0][0] == 1:
179 | castlingstring += castling_order[i]
180 |
181 | if len(castlingstring) == 0:
182 | castlingstring = '-'
183 |
184 | epstr = "-"
185 | for rank in range(8):
186 | for file in range(8):
187 | if ep[rank][file] == 1:
188 | epstr = coord_to_alg((rank, file))
189 |
190 | realfen = maybe_flip_fen(realfen, flip=is_black_turn(realfen))
191 | realparts = realfen.split(' ')
192 | assert realparts[1] == 'w'
193 | assert realparts[2] == castlingstring
194 | assert realparts[3] == epstr
195 | assert int(realparts[4]) == fiftymove
196 | # realparts[5] is the fifty-move clock, discard that
197 | return "".join(fakefen) == replace_tags_board(realfen)
198 |
199 | def canon_input_planes(fen):
200 | fen = maybe_flip_fen(fen, is_black_turn(fen))
201 | return all_input_planes(fen)
202 |
203 | def all_input_planes(fen):
204 | current_aux_planes = aux_planes(fen)
205 |
206 | history_both = to_planes(fen)
207 |
208 | ret = np.vstack((history_both, current_aux_planes))
209 | assert ret.shape == (18, 8, 8)
210 | return ret
211 |
212 | def maybe_flip_fen(fen, flip = False):
213 | if not flip:
214 | return fen
215 | foo = fen.split(' ')
216 | rows = foo[0].split('/')
217 | def swapcase(a):
218 | if a.isalpha():
219 | return a.lower() if a.isupper() else a.upper()
220 | return a
221 | def swapall(aa):
222 | return "".join([swapcase(a) for a in aa])
223 | return "/".join( [swapall(row) for row in reversed(rows)] ) \
224 | + " " + ('w' if foo[1]=='b' else 'b') \
225 | + " " + "".join( sorted( swapall(foo[2]) ) ) \
226 | + " " + foo[3] + " " + foo[4] + " " + foo[5]
227 |
228 | def aux_planes(fen):
229 | foo = fen.split(' ')
230 |
231 | en_passant = np.zeros((8, 8), dtype=np.float32)
232 | if foo[3] != '-':
233 | eps = alg_to_coord(foo[3])
234 | en_passant[eps[0]][eps[1]] = 1
235 |
236 | fifty_move_count = int(foo[4])
237 | fifty_move = np.full((8,8), fifty_move_count, dtype=np.float32)
238 |
239 | castling = foo[2]
240 | auxiliary_planes = [np.full((8,8), int('K' in castling), dtype=np.float32),
241 | np.full((8,8), int('Q' in castling), dtype=np.float32),
242 | np.full((8,8), int('k' in castling), dtype=np.float32),
243 | np.full((8,8), int('q' in castling), dtype=np.float32),
244 | fifty_move,
245 | en_passant]
246 |
247 | ret = np.asarray(auxiliary_planes, dtype=np.float32)
248 | assert ret.shape == (6,8,8)
249 | return ret
250 |
251 | # FEN board is like this:
252 | # a8 b8 .. h8
253 | # a7 b7 .. h7
254 | # .. .. .. ..
255 | # a1 b1 .. h1
256 | #
257 | # FEN string is like this:
258 | # 0 1 .. 7
259 | # 8 9 .. 15
260 | # .. .. .. ..
261 | # 56 57 .. 63
262 |
263 | # my planes are like this:
264 | # 00 01 .. 07
265 | # 10 11 .. 17
266 | # .. .. .. ..
267 | # 70 71 .. 77
268 | #
269 |
270 | def alg_to_coord(alg):
271 | rank = 8 - int(alg[1]) # 0-7
272 | file = ord(alg[0]) - ord('a') # 0-7
273 | return rank, file
274 |
275 | def coord_to_alg(coord):
276 | letter = chr(ord('a') + coord[1])
277 | number = str(8 - coord[0])
278 | return letter + number
279 |
280 | def to_planes(fen):
281 | board_state = replace_tags_board(fen)
282 | pieces_both = np.zeros(shape = (12, 8, 8), dtype=np.float32)
283 | for rank in range(8):
284 | for file in range(8):
285 | v = board_state[rank * 8 + file]
286 | if v.isalpha():
287 | pieces_both[ind[v]][rank][file] = 1
288 | assert pieces_both.shape == (12, 8, 8)
289 | return pieces_both
290 |
291 | def replace_tags_board(board_san):
292 | board_san = board_san.split(" ")[0]
293 | board_san = board_san.replace("2", "11")
294 | board_san = board_san.replace("3", "111")
295 | board_san = board_san.replace("4", "1111")
296 | board_san = board_san.replace("5", "11111")
297 | board_san = board_san.replace("6", "111111")
298 | board_san = board_san.replace("7", "1111111")
299 | board_san = board_san.replace("8", "11111111")
300 | return board_san.replace("/", "")
301 |
302 | def is_black_turn(fen):
303 | return fen.split(" ")[1] == 'b'
--------------------------------------------------------------------------------
/src/chess_zero/lib/data_helper.py:
--------------------------------------------------------------------------------
1 | import os
2 | import ujson
3 | from datetime import datetime
4 | from glob import glob
5 | from logging import getLogger
6 |
7 | import chess
8 | import pyperclip
9 | from chess_zero.config import ResourceConfig
10 |
11 | logger = getLogger(__name__)
12 |
13 |
14 | def pretty_print(env, colors):
15 | new_pgn = open("test3.pgn", "at")
16 | game = chess.pgn.Game.from_board(env.board)
17 | game.headers["Result"] = env.result
18 | game.headers["White"], game.headers["Black"] = colors
19 | game.headers["Date"] = datetime.now().strftime("%Y.%m.%d")
20 | new_pgn.write(str(game) + "\n\n")
21 | new_pgn.close()
22 | pyperclip.copy(env.board.fen())
23 |
24 |
25 | def find_pgn_files(directory, pattern='*.pgn'):
26 | dir_pattern = os.path.join(directory, pattern)
27 | files = list(sorted(glob(dir_pattern)))
28 | return files
29 |
30 |
31 | def get_game_data_filenames(rc: ResourceConfig):
32 | pattern = os.path.join(rc.play_data_dir, rc.play_data_filename_tmpl % "*")
33 | files = list(sorted(glob(pattern)))
34 | return files
35 |
36 |
37 | def get_next_generation_model_dirs(rc: ResourceConfig):
38 | dir_pattern = os.path.join(rc.next_generation_model_dir, rc.next_generation_model_dirname_tmpl % "*")
39 | dirs = list(sorted(glob(dir_pattern)))
40 | return dirs
41 |
42 |
43 | def write_game_data_to_file(path, data):
44 | try:
45 | with open(path, "wt") as f:
46 | ujson.dump(data, f)
47 | except Exception as e:
48 | print(e)
49 |
50 |
51 | def read_game_data_from_file(path):
52 | try:
53 | with open(path, "rt") as f:
54 | return ujson.load(f)
55 | except Exception as e:
56 | print(e)
57 |
58 | # def conv_helper(path):
59 | # with open(path, "rt") as f:
60 | # data = json.load(f)
61 | # with open(path, "wb") as f:
62 | # pickle.dump(data, f)
63 |
64 | # def convert_json_to_pickle():
65 | # import os
66 | # files = [x for x in os.listdir() if x.endswith(".json")]
67 | # from concurrent.futures import ProcessPoolExecutor
68 | # with ProcessPoolExecutor(max_workers=6) as executor:
69 | # executor.map(conv_helper,files)
70 |
--------------------------------------------------------------------------------
/src/chess_zero/lib/logger.py:
--------------------------------------------------------------------------------
1 | from logging import StreamHandler, basicConfig, DEBUG, getLogger, Formatter
2 |
3 |
4 | def setup_logger(log_filename):
5 | format_str = '%(asctime)s@%(name)s %(levelname)s # %(message)s'
6 | basicConfig(filename=log_filename, level=DEBUG, format=format_str)
7 | stream_handler = StreamHandler()
8 | stream_handler.setFormatter(Formatter(format_str))
9 | getLogger().addHandler(stream_handler)
10 |
11 |
12 | if __name__ == '__main__':
13 | setup_logger("aa.log")
14 | logger = getLogger("test")
15 | logger.info("OK")
16 |
--------------------------------------------------------------------------------
/src/chess_zero/lib/model_helper.py:
--------------------------------------------------------------------------------
1 | from logging import getLogger
2 |
3 | logger = getLogger(__name__)
4 |
5 |
6 | def load_best_model_weight(model):
7 | """
8 | :param chess_zero.agent.model.ChessModel model:
9 | :return:
10 | """
11 | return model.load(model.config.resource.model_best_config_path, model.config.resource.model_best_weight_path)
12 |
13 |
14 | def save_as_best_model(model):
15 | """
16 |
17 | :param chess_zero.agent.model.ChessModel model:
18 | :return:
19 | """
20 | return model.save(model.config.resource.model_best_config_path, model.config.resource.model_best_weight_path)
21 |
22 |
23 | def reload_best_model_weight_if_changed(model):
24 | """
25 |
26 | :param chess_zero.agent.model.ChessModel model:
27 | :return:
28 | """
29 | if model.config.model.distributed:
30 | return load_best_model_weight(model)
31 | else:
32 | logger.debug("start reload the best model if changed")
33 | digest = model.fetch_digest(model.config.resource.model_best_weight_path)
34 | if digest != model.digest:
35 | return load_best_model_weight(model)
36 |
37 | logger.debug("the best model is not changed")
38 | return False
39 |
--------------------------------------------------------------------------------
/src/chess_zero/lib/tf_util.py:
--------------------------------------------------------------------------------
1 | def set_session_config(per_process_gpu_memory_fraction=None, allow_growth=None):
2 | """
3 |
4 | :param allow_growth: When necessary, reserve memory
5 | :param float per_process_gpu_memory_fraction: specify GPU memory usage as 0 to 1
6 |
7 | :return:
8 | """
9 | import tensorflow as tf
10 | import keras.backend as k
11 |
12 | config = tf.ConfigProto(
13 | gpu_options=tf.GPUOptions(
14 | per_process_gpu_memory_fraction=per_process_gpu_memory_fraction,
15 | allow_growth=allow_growth,
16 | )
17 | )
18 | sess = tf.Session(config=config)
19 | k.set_session(sess)
20 |
--------------------------------------------------------------------------------
/src/chess_zero/manager.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | from logging import getLogger,disable
4 |
5 | from .lib.logger import setup_logger
6 | from .config import Config
7 |
8 | logger = getLogger(__name__)
9 |
10 | CMD_LIST = ['self', 'opt', 'eval', 'sl', 'uci']
11 |
12 |
13 | def create_parser():
14 | parser = argparse.ArgumentParser()
15 | parser.add_argument("cmd", help="what to do", choices=CMD_LIST)
16 | parser.add_argument("--new", help="run from new best model", action="store_true")
17 | parser.add_argument("--type", help="use normal setting", default="mini")
18 | parser.add_argument("--total-step", help="set TrainerConfig.start_total_steps", type=int)
19 | return parser
20 |
21 |
22 | def setup(config: Config, args):
23 | config.opts.new = args.new
24 | if args.total_step is not None:
25 | config.trainer.start_total_steps = args.total_step
26 | config.resource.create_directories()
27 | setup_logger(config.resource.main_log_path)
28 |
29 |
30 | def start():
31 | parser = create_parser()
32 | args = parser.parse_args()
33 | config_type = args.type
34 |
35 | if args.cmd == 'uci':
36 | disable(999999) # plz don't interfere with uci
37 |
38 | config = Config(config_type=config_type)
39 | setup(config, args)
40 |
41 | logger.info(f"config type: {config_type}")
42 |
43 | if args.cmd == 'self':
44 | from .worker import self_play
45 | return self_play.start(config)
46 | elif args.cmd == 'opt':
47 | from .worker import optimize
48 | return optimize.start(config)
49 | elif args.cmd == 'eval':
50 | from .worker import evaluate
51 | return evaluate.start(config)
52 | elif args.cmd == 'sl':
53 | from .worker import sl
54 | return sl.start(config)
55 | elif args.cmd == 'uci':
56 | from .play_game import uci
57 | return uci.start(config)
58 |
--------------------------------------------------------------------------------
/src/chess_zero/play_game/uci.py:
--------------------------------------------------------------------------------
1 | import sys
2 | from logging import getLogger
3 |
4 | from chess_zero.agent.player_chess import ChessPlayer
5 | from chess_zero.config import Config, PlayWithHumanConfig
6 | from chess_zero.env.chess_env import ChessEnv
7 |
8 | logger = getLogger(__name__)
9 |
10 |
11 | # noinspection SpellCheckingInspection,SpellCheckingInspection,SpellCheckingInspection,SpellCheckingInspection,SpellCheckingInspection,SpellCheckingInspection
12 | def start(config: Config):
13 |
14 | PlayWithHumanConfig().update_play_config(config.play)
15 |
16 | me_player = None
17 | env = ChessEnv().reset()
18 |
19 | while True:
20 | line=input()
21 | words=line.rstrip().split(" ",1)
22 | if words[0] == "uci":
23 | print("id name ChessZero")
24 | print("id author ChessZero")
25 | print("uciok")
26 | elif words[0]=="isready":
27 | if not me_player:
28 | me_player = get_player(config)
29 | print("readyok")
30 | elif words[0]=="ucinewgame":
31 | env.reset()
32 | elif words[0]=="position":
33 | words=words[1].split(" ",1)
34 | if words[0]=="startpos":
35 | env.reset()
36 | else:
37 | fen = words[0]
38 | for _ in range(5):
39 | words = words[1].split(' ',1)
40 | fen += " " + words[0]
41 | env.update(fen)
42 | #print(maybe_flip_fen(fen,True))
43 | if len(words) > 1:
44 | words = words[1].split(" ",1)
45 | if words[0]=="moves":
46 | for w in words[1].split(" "):
47 | env.step(w, False)
48 | elif words[0]=="go":
49 | if not me_player:
50 | me_player = get_player(config)
51 | action = me_player.action(env, False)
52 | print(f"bestmove {action}")
53 | elif words[0]=="stop":
54 | pass #lol
55 | elif words[0]=="quit":
56 | break
57 |
58 | def get_player(config):
59 | from chess_zero.agent.model_chess import ChessModel
60 | from chess_zero.lib.model_helper import load_best_model_weight
61 | model = ChessModel(config)
62 | if not load_best_model_weight(model):
63 | raise RuntimeError("Best model not found!")
64 | return ChessPlayer(config, model.get_pipes(config.play.search_threads))
65 |
66 | def info(depth,move, score):
67 | print(f"info score cp {int(score*100)} depth {depth} pv {move}")
68 | sys.stdout.flush()
--------------------------------------------------------------------------------
/src/chess_zero/run.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import multiprocessing as mp
4 |
5 | _PATH_ = os.path.dirname(os.path.dirname(__file__))
6 |
7 |
8 | if _PATH_ not in sys.path:
9 | sys.path.append(_PATH_)
10 |
11 |
12 | if __name__ == "__main__":
13 | mp.set_start_method('spawn')
14 | sys.setrecursionlimit(10000)
15 | from chess_zero import manager
16 | manager.start()
--------------------------------------------------------------------------------
/src/chess_zero/stacktracer.py:
--------------------------------------------------------------------------------
1 | """Stack tracer for multi-threaded applications.
2 |
3 |
4 | Usage:
5 |
6 | import stacktracer
7 | stacktracer.start_trace("trace.html",interval=5,auto=True) # Set auto flag to always update file!
8 | ....
9 | stacktracer.stop_trace()
10 | """
11 |
12 |
13 |
14 | import sys
15 | import traceback
16 | from pygments import highlight
17 | from pygments.formatters import HtmlFormatter
18 | from pygments.lexers import PythonLexer
19 |
20 |
21 | # Taken from http://bzimmer.ziclix.com/2008/12/17/python-thread-dumps/
22 |
23 | def stacktraces():
24 | code = []
25 | for threadId, stack in sys._current_frames().items():
26 | code.append("\n# ThreadID: %s" % threadId)
27 | for filename, lineno, name, line in traceback.extract_stack(stack):
28 | code.append('File: "%s", line %d, in %s' % (filename, lineno, name))
29 | if line:
30 | code.append(" %s" % (line.strip()))
31 |
32 | return highlight("\n".join(code), PythonLexer(), HtmlFormatter(
33 | full=False,
34 | # style="native",
35 | noclasses=True,
36 | ))
37 |
38 |
39 | # This part was made by nagylzs
40 | import os
41 | import time
42 | import threading
43 |
44 | class TraceDumper(threading.Thread):
45 | """Dump stack traces into a given file periodically."""
46 | def __init__(self,fpath,interval,auto):
47 | """
48 | @param fpath: File path to output HTML (stack trace file)
49 | @param auto: Set flag (True) to update trace continuously.
50 | Clear flag (False) to update only if file not exists.
51 | (Then delete the file to force update.)
52 | @param interval: In seconds: how often to update the trace file.
53 | """
54 | assert(interval>0.1)
55 | self.auto = auto
56 | self.interval = interval
57 | self.fpath = os.path.abspath(fpath)
58 | self.stop_requested = threading.Event()
59 | threading.Thread.__init__(self)
60 |
61 | def run(self):
62 | while not self.stop_requested.isSet():
63 | time.sleep(self.interval)
64 | if self.auto or not os.path.isfile(self.fpath):
65 | self.stacktraces()
66 |
67 | def stop(self):
68 | self.stop_requested.set()
69 | self.join()
70 | try:
71 | if os.path.isfile(self.fpath):
72 | os.unlink(self.fpath)
73 | except:
74 | pass
75 |
76 | def stacktraces(self):
77 | fout = open(self.fpath,"w")
78 | try:
79 | fout.write(stacktraces())
80 | finally:
81 | fout.close()
82 |
83 |
84 | _tracer = None
85 | def trace_start(fpath,interval=5,auto=True):
86 | """Start tracing into the given file."""
87 | global _tracer
88 | if _tracer is None:
89 | _tracer = TraceDumper(fpath,interval,auto)
90 | _tracer.setDaemon(True)
91 | _tracer.start()
92 | else:
93 | raise Exception("Already tracing to %s"%_tracer.fpath)
94 |
95 | def trace_stop():
96 | """Stop tracing."""
97 | global _tracer
98 | if _tracer is None:
99 | raise Exception("Not tracing, cannot stop.")
100 | else:
101 | _trace.stop()
102 | _trace = None
--------------------------------------------------------------------------------
/src/chess_zero/worker/evaluate.py:
--------------------------------------------------------------------------------
1 | import os
2 | from concurrent.futures import ProcessPoolExecutor, as_completed
3 | from logging import getLogger
4 | from multiprocessing import Manager
5 | from time import sleep
6 |
7 | from chess_zero.agent.model_chess import ChessModel
8 | from chess_zero.agent.player_chess import ChessPlayer
9 | from chess_zero.config import Config
10 | from chess_zero.env.chess_env import ChessEnv, Winner
11 | from chess_zero.lib.data_helper import get_next_generation_model_dirs, pretty_print
12 | from chess_zero.lib.model_helper import save_as_best_model, load_best_model_weight
13 |
14 | logger = getLogger(__name__)
15 |
16 | def start(config: Config):
17 | #tf_util.set_session_config(config.play.vram_frac)
18 | return EvaluateWorker(config).start()
19 |
20 | class EvaluateWorker:
21 | def __init__(self, config: Config):
22 | """
23 | :param config:
24 | """
25 | self.config = config
26 | self.play_config = config.eval.play_config
27 | self.current_model = self.load_current_model()
28 | self.m = Manager()
29 | self.cur_pipes = self.m.list([self.current_model.get_pipes(self.play_config.search_threads) for _ in range(self.play_config.max_processes)])
30 |
31 | def start(self):
32 | while True:
33 | ng_model, model_dir = self.load_next_generation_model()
34 | logger.debug(f"start evaluate model {model_dir}")
35 | ng_is_great = self.evaluate_model(ng_model)
36 | if ng_is_great:
37 | logger.debug(f"New Model become best model: {model_dir}")
38 | save_as_best_model(ng_model)
39 | self.current_model = ng_model
40 | self.move_model(model_dir) # i lost my models because of this :(
41 |
42 | def evaluate_model(self, ng_model):
43 | ng_pipes = self.m.list([ng_model.get_pipes(self.play_config.search_threads) for _ in range(self.play_config.max_processes)])
44 |
45 | futures = []
46 | with ProcessPoolExecutor(max_workers=self.play_config.max_processes) as executor:
47 | for game_idx in range(self.config.eval.game_num):
48 | fut = executor.submit(play_game, self.config, cur=self.cur_pipes, ng=ng_pipes, current_white=(game_idx % 2 == 0))
49 | futures.append(fut)
50 |
51 | results = []
52 | for fut in as_completed(futures):
53 | # ng_score := if ng_model win -> 1, lose -> 0, draw -> 0.5
54 | ng_score, env, current_white = fut.result()
55 | results.append(ng_score)
56 | win_rate = sum(results) / len(results)
57 | game_idx = len(results)
58 | logger.debug(f"game {game_idx:3}: ng_score={ng_score:.1f} as {'black' if current_white else 'white'} "
59 | f"{'by resign ' if env.resigned else ' '}"
60 | f"win_rate={win_rate*100:5.1f}% "
61 | f"{env.board.fen().split(' ')[0]}")
62 |
63 | colors = ("current_model", "ng_model")
64 | if not current_white:
65 | colors = reversed(colors)
66 | pretty_print(env, colors)
67 |
68 | if len(results)-sum(results) >= self.config.eval.game_num * (1-self.config.eval.replace_rate):
69 | logger.debug(f"lose count reach {results.count(0)} so give up challenge")
70 | return False
71 | if sum(results) >= self.config.eval.game_num * self.config.eval.replace_rate:
72 | logger.debug(f"win count reach {results.count(1)} so change best model")
73 | return True
74 |
75 | win_rate = sum(results) / len(results)
76 | logger.debug(f"winning rate {win_rate*100:.1f}%")
77 | return win_rate >= self.config.eval.replace_rate
78 |
79 | def move_model(self, model_dir):
80 | rc = self.config.resource
81 | # config_path = os.path.join(model_dir, rc.next_generation_model_config_filename)
82 | # weight_path = os.path.join(model_dir, rc.next_generation_model_weight_filename)
83 | # os.remove(config_path)
84 | # os.remove(weight_path)
85 | new_dir = os.path.join(rc.next_generation_model_dir, "copies", model_dir.name)
86 | os.rename(model_dir, new_dir)
87 |
88 | def load_current_model(self):
89 | model = ChessModel(self.config)
90 | load_best_model_weight(model)
91 | return model
92 |
93 | def load_next_generation_model(self):
94 | rc = self.config.resource
95 | while True:
96 | dirs = get_next_generation_model_dirs(self.config.resource)
97 | if dirs:
98 | break
99 | logger.info("There is no next generation model to evaluate")
100 | sleep(60)
101 | model_dir = dirs[-1] if self.config.eval.evaluate_latest_first else dirs[0]
102 | config_path = os.path.join(model_dir, rc.next_generation_model_config_filename)
103 | weight_path = os.path.join(model_dir, rc.next_generation_model_weight_filename)
104 | model = ChessModel(self.config)
105 | model.load(config_path, weight_path)
106 | return model, model_dir
107 |
108 | def play_game(config, cur, ng, current_white: bool) -> (float, ChessEnv, bool):
109 | cur_pipes = cur.pop()
110 | ng_pipes = ng.pop()
111 | env = ChessEnv().reset()
112 |
113 | current_player = ChessPlayer(config, pipes=cur_pipes, play_config=config.eval.play_config)
114 | ng_player = ChessPlayer(config, pipes=ng_pipes, play_config=config.eval.play_config)
115 | if current_white:
116 | white, black = current_player, ng_player
117 | else:
118 | white, black = ng_player, current_player
119 |
120 | while not env.done:
121 | if env.white_to_move:
122 | action = white.action(env)
123 | else:
124 | action = black.action(env)
125 | env.step(action)
126 | if env.num_halfmoves >= config.eval.max_game_length:
127 | env.adjudicate()
128 |
129 | if env.winner == Winner.draw:
130 | ng_score = 0.5
131 | elif env.white_won == current_white:
132 | ng_score = 0
133 | else:
134 | ng_score = 1
135 | cur.append(cur_pipes)
136 | ng.append(ng_pipes)
137 | return ng_score, env, current_white
--------------------------------------------------------------------------------
/src/chess_zero/worker/optimize.py:
--------------------------------------------------------------------------------
1 | import os
2 | from collections import deque
3 | from concurrent.futures import ProcessPoolExecutor
4 | from datetime import datetime
5 | from logging import getLogger
6 | from time import sleep
7 | from random import shuffle
8 |
9 | import numpy as np
10 |
11 | from chess_zero.agent.model_chess import ChessModel
12 | from chess_zero.config import Config
13 | from chess_zero.env.chess_env import canon_input_planes, is_black_turn, testeval
14 | from chess_zero.lib.data_helper import get_game_data_filenames, read_game_data_from_file, get_next_generation_model_dirs
15 | from chess_zero.lib.model_helper import load_best_model_weight
16 |
17 | from keras.optimizers import Adam
18 | from keras.callbacks import TensorBoard
19 | logger = getLogger(__name__)
20 |
21 |
22 | def start(config: Config):
23 | #tf_util.set_session_config(config.trainer.vram_frac)
24 | return OptimizeWorker(config).start()
25 |
26 |
27 | class OptimizeWorker:
28 | def __init__(self, config: Config):
29 | self.config = config
30 | self.model = None # type: ChessModel
31 | self.loaded_filenames = set()
32 | self.loaded_data = deque(maxlen=self.config.trainer.dataset_size) # this should just be a ring buffer i.e. queue of length 500,000 in AZ
33 | self.dataset = deque(),deque(),deque()
34 | self.executor = ProcessPoolExecutor(max_workers=config.trainer.cleaning_processes)
35 |
36 | def start(self):
37 | self.model = self.load_model()
38 | self.training()
39 |
40 | def training(self):
41 | self.compile_model()
42 | self.filenames = deque(get_game_data_filenames(self.config.resource))
43 | shuffle(self.filenames)
44 | last_load_data_step = last_save_step = total_steps = self.config.trainer.start_total_steps
45 |
46 | while True:
47 | self.fill_queue()
48 | # if self.dataset_size < self.config.trainer.min_data_size_to_learn:
49 | # logger.info(f"dataset_size={self.dataset_size} is less than {self.config.trainer.min_data_size_to_learn}")
50 | # sleep(60)
51 | # self.fill_queue()
52 | # continue
53 | #self.update_learning_rate(total_steps)
54 | steps = self.train_epoch(self.config.trainer.epoch_to_checkpoint)
55 | total_steps += steps
56 | #if last_save_step + self.config.trainer.save_model_steps < total_steps:
57 | self.save_current_model()
58 | last_save_step = total_steps
59 | a,b,c=self.dataset
60 | while len(a) > self.config.trainer.dataset_size/2:
61 | a.popleft()
62 | b.popleft()
63 | c.popleft()
64 | # if last_load_data_step + self.config.trainer.load_data_steps < total_steps:
65 | # self.fill_queue()
66 | # last_load_data_step = total_steps
67 |
68 | def train_epoch(self, epochs):
69 | tc = self.config.trainer
70 | state_ary, policy_ary, value_ary = self.collect_all_loaded_data()
71 | tensorboard_cb = TensorBoard(log_dir="./logs", batch_size=tc.batch_size, histogram_freq=1)
72 | self.model.model.fit(state_ary, [policy_ary, value_ary],
73 | batch_size=tc.batch_size,
74 | epochs=epochs,
75 | shuffle=True,
76 | validation_split=0.02,
77 | callbacks=[tensorboard_cb])
78 | steps = (state_ary.shape[0] // tc.batch_size) * epochs
79 | return steps
80 |
81 | def compile_model(self):
82 | opt = Adam() #SGD(lr=2e-1, momentum=0.9) # Adam better?
83 | losses = ['categorical_crossentropy', 'mean_squared_error'] # avoid overfit for supervised
84 | self.model.model.compile(optimizer=opt, loss=losses, loss_weights=self.config.trainer.loss_weights)
85 |
86 | def save_current_model(self):
87 | rc = self.config.resource
88 | model_id = datetime.now().strftime("%Y%m%d-%H%M%S.%f")
89 | model_dir = os.path.join(rc.next_generation_model_dir, rc.next_generation_model_dirname_tmpl % model_id)
90 | os.makedirs(model_dir, exist_ok=True)
91 | config_path = os.path.join(model_dir, rc.next_generation_model_config_filename)
92 | weight_path = os.path.join(model_dir, rc.next_generation_model_weight_filename)
93 | self.model.save(config_path, weight_path)
94 |
95 | def fill_queue(self):
96 | futures = deque()
97 | with ProcessPoolExecutor(max_workers=self.config.trainer.cleaning_processes) as executor:
98 | for _ in range(self.config.trainer.cleaning_processes):
99 | if len(self.filenames) == 0:
100 | break
101 | filename = self.filenames.popleft()
102 | logger.debug(f"loading data from {filename}")
103 | futures.append(executor.submit(load_data_from_file,filename))
104 | while futures and len(self.dataset[0]) < self.config.trainer.dataset_size:
105 | for x,y in zip(self.dataset,futures.popleft().result()):
106 | x.extend(y)
107 | if len(self.filenames) > 0:
108 | filename = self.filenames.popleft()
109 | logger.debug(f"loading data from {filename}")
110 | futures.append(executor.submit(load_data_from_file,filename))
111 |
112 | def collect_all_loaded_data(self):
113 | state_ary,policy_ary,value_ary=self.dataset
114 |
115 | state_ary1 = np.asarray(state_ary, dtype=np.float32)
116 | policy_ary1 = np.asarray(policy_ary, dtype=np.float32)
117 | value_ary1 = np.asarray(value_ary, dtype=np.float32)
118 | return state_ary1, policy_ary1, value_ary1
119 |
120 |
121 | def load_model(self):
122 | model = ChessModel(self.config)
123 | rc = self.config.resource
124 |
125 | dirs = get_next_generation_model_dirs(rc)
126 | if not dirs:
127 | logger.debug("loading best model")
128 | if not load_best_model_weight(model):
129 | raise RuntimeError("Best model can not loaded!")
130 | else:
131 | latest_dir = dirs[-1]
132 | logger.debug("loading latest model")
133 | config_path = os.path.join(latest_dir, rc.next_generation_model_config_filename)
134 | weight_path = os.path.join(latest_dir, rc.next_generation_model_weight_filename)
135 | model.load(config_path, weight_path)
136 | return model
137 | # def unload_data_of_file(self, filename):
138 | # logger.debug(f"removing data about {filename} from training set")
139 | # self.loaded_filenames.remove(filename)
140 | # if filename in self.loaded_data:
141 | # del self.loaded_data[filename]
142 |
143 | def load_data_from_file(filename):
144 | data = read_game_data_from_file(filename)
145 | return convert_to_cheating_data(data) ### HERE, use with SL
146 |
147 |
148 | def convert_to_cheating_data(data):
149 | """
150 | :param data: format is SelfPlayWorker.buffer
151 | :return:
152 | """
153 | state_list = []
154 | policy_list = []
155 | value_list = []
156 | for state_fen, policy, value in data:
157 |
158 | state_planes = canon_input_planes(state_fen)
159 | #assert check_current_planes(state_fen, state_planes)
160 |
161 | if is_black_turn(state_fen):
162 | policy = Config.flip_policy(policy)
163 |
164 | # assert len(policy) == 1968
165 | # assert state_planes.dtype == np.float32
166 | # assert state_planes.shape == (18, 8, 8) #print(state_planes.shape)
167 |
168 | move_number = int(state_fen.split(' ')[5])
169 | value_certainty = min(5, move_number)/5 # reduces the noise of the opening... plz train faster
170 | sl_value = value*value_certainty + testeval(state_fen, False)*(1-value_certainty)
171 |
172 | state_list.append(state_planes)
173 | policy_list.append(policy)
174 | value_list.append(sl_value)
175 |
176 | return np.asarray(state_list, dtype=np.float32), np.asarray(policy_list, dtype=np.float32), np.asarray(value_list, dtype=np.float32)
--------------------------------------------------------------------------------
/src/chess_zero/worker/self_play.py:
--------------------------------------------------------------------------------
1 | import os
2 | from collections import deque
3 | from concurrent.futures import ProcessPoolExecutor
4 | from datetime import datetime
5 | from logging import getLogger
6 | from multiprocessing import Manager
7 | from threading import Thread
8 | from time import time
9 |
10 | from chess_zero.agent.model_chess import ChessModel
11 | from chess_zero.agent.player_chess import ChessPlayer
12 | from chess_zero.config import Config
13 | from chess_zero.env.chess_env import ChessEnv, Winner
14 | from chess_zero.lib.data_helper import get_game_data_filenames, write_game_data_to_file, pretty_print
15 | from chess_zero.lib.model_helper import load_best_model_weight, save_as_best_model, \
16 | reload_best_model_weight_if_changed
17 |
18 | logger = getLogger(__name__)
19 |
20 | def start(config: Config):
21 | return SelfPlayWorker(config).start()
22 |
23 |
24 | # noinspection PyAttributeOutsideInit
25 | class SelfPlayWorker:
26 | def __init__(self, config: Config):
27 | """
28 | :param config:
29 | """
30 | self.config = config
31 | self.current_model = self.load_model()
32 | self.m = Manager()
33 | self.cur_pipes = self.m.list([self.current_model.get_pipes(self.config.play.search_threads) for _ in range(self.config.play.max_processes)])
34 |
35 | def start(self):
36 | self.buffer = []
37 |
38 | futures = deque()
39 | with ProcessPoolExecutor(max_workers=self.config.play.max_processes) as executor:
40 | for game_idx in range(self.config.play.max_processes):
41 | futures.append(executor.submit(self_play_buffer, self.config, cur=self.cur_pipes))
42 | game_idx = 0
43 | while True:
44 | game_idx += 1
45 | start_time = time()
46 | env, data = futures.popleft().result()
47 | print(f"game {game_idx:3} time={time() - start_time:5.1f}s "
48 | f"halfmoves={env.num_halfmoves:3} {env.winner:12} "
49 | f"{'by resign ' if env.resigned else ' '}")
50 |
51 | pretty_print(env, ("current_model", "current_model"))
52 | self.buffer += data
53 | if (game_idx % self.config.play_data.nb_game_in_file) == 0:
54 | self.flush_buffer()
55 | reload_best_model_weight_if_changed(self.current_model)
56 | futures.append(executor.submit(self_play_buffer, self.config, cur=self.cur_pipes)) # Keep it going
57 |
58 | if len(data) > 0:
59 | self.flush_buffer()
60 |
61 | def load_model(self):
62 | model = ChessModel(self.config)
63 | if self.config.opts.new or not load_best_model_weight(model):
64 | model.build()
65 | save_as_best_model(model)
66 | return model
67 |
68 | def flush_buffer(self):
69 | rc = self.config.resource
70 | game_id = datetime.now().strftime("%Y%m%d-%H%M%S.%f")
71 | path = os.path.join(rc.play_data_dir, rc.play_data_filename_tmpl % game_id)
72 | logger.info(f"save play data to {path}")
73 | thread = Thread(target = write_game_data_to_file, args=(path, self.buffer))
74 | thread.start()
75 | self.buffer = []
76 |
77 | def remove_play_data(self):
78 | return
79 | files = get_game_data_filenames(self.config.resource)
80 | if len(files) < self.config.play_data.max_file_num:
81 | return
82 | for i in range(len(files) - self.config.play_data.max_file_num):
83 | os.remove(files[i])
84 |
85 |
86 | def self_play_buffer(config, cur) -> (ChessEnv, list):
87 | pipes = cur.pop() # borrow
88 | env = ChessEnv().reset()
89 |
90 | white = ChessPlayer(config, pipes=pipes)
91 | black = ChessPlayer(config, pipes=pipes)
92 |
93 | while not env.done:
94 | if env.white_to_move:
95 | action = white.action(env)
96 | else:
97 | action = black.action(env)
98 | env.step(action)
99 | if env.num_halfmoves >= config.play.max_game_length:
100 | env.adjudicate()
101 |
102 | if env.winner == Winner.white:
103 | black_win = -1
104 | elif env.winner == Winner.black:
105 | black_win = 1
106 | else:
107 | black_win = 0
108 |
109 | black.finish_game(black_win)
110 | white.finish_game(-black_win)
111 |
112 | data = []
113 | for i in range(len(white.moves)):
114 | data.append(white.moves[i])
115 | if i < len(black.moves):
116 | data.append(black.moves[i])
117 |
118 | cur.append(pipes)
119 | return env, data
--------------------------------------------------------------------------------
/src/chess_zero/worker/sl.py:
--------------------------------------------------------------------------------
1 | import os
2 | import re
3 | from concurrent.futures import ProcessPoolExecutor, as_completed
4 | from datetime import datetime
5 | from logging import getLogger
6 | from threading import Thread
7 | from time import time
8 |
9 | import chess.pgn
10 |
11 | from chess_zero.agent.player_chess import ChessPlayer
12 | from chess_zero.config import Config
13 | from chess_zero.env.chess_env import ChessEnv, Winner
14 | from chess_zero.lib.data_helper import write_game_data_to_file, find_pgn_files
15 |
16 | logger = getLogger(__name__)
17 |
18 | TAG_REGEX = re.compile(r"^\[([A-Za-z0-9_]+)\s+\"(.*)\"\]\s*$")
19 |
20 |
21 | def start(config: Config):
22 | return SupervisedLearningWorker(config).start()
23 |
24 |
25 | class SupervisedLearningWorker:
26 | def __init__(self, config: Config):
27 | """
28 | :param config:
29 | """
30 | self.config = config
31 | self.buffer = []
32 |
33 | def start(self):
34 | self.buffer = []
35 | # noinspection PyAttributeOutsideInit
36 | self.idx = 0
37 | start_time = time()
38 | with ProcessPoolExecutor(max_workers=7) as executor:
39 | games = self.get_games_from_all_files()
40 | for res in as_completed([executor.submit(get_buffer, self.config, game) for game in games]): #poisoned reference (memleak)
41 | self.idx += 1
42 | env, data = res.result()
43 | self.save_data(data)
44 | end_time = time()
45 | logger.debug(f"game {self.idx:4} time={(end_time - start_time):.3f}s "
46 | f"halfmoves={env.num_halfmoves:3} {env.winner:12}"
47 | f"{' by resign ' if env.resigned else ' '}"
48 | f"{env.observation.split(' ')[0]}")
49 | start_time = end_time
50 |
51 | if len(self.buffer) > 0:
52 | self.flush_buffer()
53 |
54 | def get_games_from_all_files(self):
55 | files = find_pgn_files(self.config.resource.play_data_dir)
56 | print (files)
57 | games = []
58 | for filename in files:
59 | games.extend(get_games_from_file(filename))
60 | print("done reading")
61 | return games
62 |
63 | def save_data(self, data):
64 | self.buffer += data
65 | if self.idx % self.config.play_data.sl_nb_game_in_file == 0:
66 | self.flush_buffer()
67 |
68 | def flush_buffer(self):
69 | rc = self.config.resource
70 | game_id = datetime.now().strftime("%Y%m%d-%H%M%S.%f")
71 | path = os.path.join(rc.play_data_dir, rc.play_data_filename_tmpl % game_id)
72 | logger.info(f"save play data to {path}")
73 | thread = Thread(target = write_game_data_to_file, args=(path, self.buffer))
74 | thread.start()
75 | self.buffer = []
76 |
77 | def get_games_from_file(filename):
78 | pgn = open(filename, errors='ignore')
79 | offsets = list(chess.pgn.scan_offsets(pgn))
80 | n = len(offsets)
81 | print(f"found {n} games")
82 | games = []
83 | for offset in offsets:
84 | pgn.seek(offset)
85 | games.append(chess.pgn.read_game(pgn))
86 | return games
87 |
88 | def clip_elo_policy(config, elo):
89 | return min(1, max(0, elo - config.play_data.min_elo_policy) / config.play_data.max_elo_policy)
90 | # 0 until min_elo, 1 after max_elo, linear in between
91 |
92 | def get_buffer(config, game) -> (ChessEnv, list):
93 | env = ChessEnv().reset()
94 | white = ChessPlayer(config, dummy = True)
95 | black = ChessPlayer(config, dummy = True)
96 | result = game.headers["Result"]
97 | white_elo, black_elo = int(game.headers["WhiteElo"]), int(game.headers["BlackElo"])
98 | white_weight = clip_elo_policy(config, white_elo)
99 | black_weight = clip_elo_policy(config, black_elo)
100 |
101 | actions = []
102 | while not game.is_end():
103 | game = game.variation(0)
104 | actions.append(game.move.uci())
105 | k = 0
106 | while not env.done and k < len(actions):
107 | if env.white_to_move:
108 | action = white.sl_action(env.observation, actions[k], weight= white_weight) #ignore=True
109 | else:
110 | action = black.sl_action(env.observation, actions[k], weight= black_weight) #ignore=True
111 | env.step(action, False)
112 | k += 1
113 |
114 | if not env.board.is_game_over() and result != '1/2-1/2':
115 | env.resigned = True
116 | if result == '1-0':
117 | env.winner = Winner.white
118 | black_win = -1
119 | elif result == '0-1':
120 | env.winner = Winner.black
121 | black_win = 1
122 | else:
123 | env.winner = Winner.draw
124 | black_win = 0
125 |
126 | black.finish_game(black_win)
127 | white.finish_game(-black_win)
128 |
129 | data = []
130 | for i in range(len(white.moves)):
131 | data.append(white.moves[i])
132 | if i < len(black.moves):
133 | data.append(black.moves[i])
134 |
135 | return env, data
--------------------------------------------------------------------------------