├── .gitattributes
├── .gitignore
├── .gitmodules
├── Dockerfile
├── Dockerfile-for-Mainland-China
├── LICENSE
├── README-zh.md
├── README.md
├── assets
├── favicon.ico
├── gitconfig-cn
└── tensorboard-example.png
├── config
├── default.toml
├── lora.toml
├── presets
│ └── example.toml
└── sample_prompts.txt
├── gui.py
├── huggingface
├── accelerate
│ └── default_config.yaml
└── hub
│ └── version.txt
├── install-cn.ps1
├── install.bash
├── install.ps1
├── interrogate.ps1
├── logs
└── .keep
├── mikazuki
├── app
│ ├── __init__.py
│ ├── api.py
│ ├── application.py
│ ├── config.py
│ ├── models.py
│ └── proxy.py
├── global.d.ts
├── hook
│ ├── i18n.json
│ └── sitecustomize.py
├── launch_utils.py
├── log.py
├── process.py
├── schema
│ ├── dreambooth.ts
│ ├── flux-lora.ts
│ ├── lora-basic.ts
│ ├── lora-master.ts
│ ├── lumina2-lora.ts
│ ├── sd3-lora.ts
│ └── shared.ts
├── scripts
│ ├── fix_scripts_python_executable_path.py
│ └── torch_check.py
├── tagger
│ ├── dbimutils.py
│ ├── format.py
│ └── interrogator.py
├── tasks.py
├── tsconfig.json
└── utils
│ ├── devices.py
│ ├── tk_window.py
│ └── train_utils.py
├── output
└── .keep
├── requirements.txt
├── resize.ps1
├── run.ipynb
├── run_gui.ps1
├── run_gui.sh
├── run_gui_cn.sh
├── scripts
├── dev
│ ├── .gitignore
│ ├── COMMIT_ID
│ ├── LICENSE.md
│ ├── README-ja.md
│ ├── README.md
│ ├── XTI_hijack.py
│ ├── _typos.toml
│ ├── fine_tune.py
│ ├── finetune
│ │ ├── blip
│ │ │ ├── blip.py
│ │ │ ├── med.py
│ │ │ ├── med_config.json
│ │ │ └── vit.py
│ │ ├── clean_captions_and_tags.py
│ │ ├── hypernetwork_nai.py
│ │ ├── make_captions.py
│ │ ├── make_captions_by_git.py
│ │ ├── merge_captions_to_metadata.py
│ │ ├── merge_dd_tags_to_metadata.py
│ │ ├── prepare_buckets_latents.py
│ │ └── tag_images_by_wd14_tagger.py
│ ├── flux_minimal_inference.py
│ ├── flux_train.py
│ ├── flux_train_control_net.py
│ ├── flux_train_network.py
│ ├── gen_img.py
│ ├── gen_img_diffusers.py
│ ├── library
│ │ ├── __init__.py
│ │ ├── adafactor_fused.py
│ │ ├── attention_processors.py
│ │ ├── config_util.py
│ │ ├── custom_offloading_utils.py
│ │ ├── custom_train_functions.py
│ │ ├── deepspeed_utils.py
│ │ ├── device_utils.py
│ │ ├── flux_models.py
│ │ ├── flux_train_utils.py
│ │ ├── flux_utils.py
│ │ ├── huggingface_util.py
│ │ ├── hypernetwork.py
│ │ ├── ipex
│ │ │ ├── __init__.py
│ │ │ ├── attention.py
│ │ │ ├── diffusers.py
│ │ │ ├── gradscaler.py
│ │ │ └── hijacks.py
│ │ ├── lpw_stable_diffusion.py
│ │ ├── model_util.py
│ │ ├── original_unet.py
│ │ ├── sai_model_spec.py
│ │ ├── sd3_models.py
│ │ ├── sd3_train_utils.py
│ │ ├── sd3_utils.py
│ │ ├── sdxl_lpw_stable_diffusion.py
│ │ ├── sdxl_model_util.py
│ │ ├── sdxl_original_control_net.py
│ │ ├── sdxl_original_unet.py
│ │ ├── sdxl_train_util.py
│ │ ├── slicing_vae.py
│ │ ├── strategy_base.py
│ │ ├── strategy_flux.py
│ │ ├── strategy_sd.py
│ │ ├── strategy_sd3.py
│ │ ├── strategy_sdxl.py
│ │ ├── train_util.py
│ │ └── utils.py
│ ├── networks
│ │ ├── check_lora_weights.py
│ │ ├── control_net_lllite.py
│ │ ├── control_net_lllite_for_train.py
│ │ ├── convert_flux_lora.py
│ │ ├── dylora.py
│ │ ├── extract_lora_from_dylora.py
│ │ ├── extract_lora_from_models.py
│ │ ├── flux_extract_lora.py
│ │ ├── flux_merge_lora.py
│ │ ├── lora.py
│ │ ├── lora_diffusers.py
│ │ ├── lora_fa.py
│ │ ├── lora_flux.py
│ │ ├── lora_interrogator.py
│ │ ├── lora_sd3.py
│ │ ├── merge_lora.py
│ │ ├── merge_lora_old.py
│ │ ├── oft.py
│ │ ├── oft_flux.py
│ │ ├── resize_lora.py
│ │ ├── sdxl_merge_lora.py
│ │ └── svd_merge_lora.py
│ ├── pytest.ini
│ ├── requirements.txt
│ ├── sd3_minimal_inference.py
│ ├── sd3_train.py
│ ├── sd3_train_network.py
│ ├── sdxl_gen_img.py
│ ├── sdxl_minimal_inference.py
│ ├── sdxl_train.py
│ ├── sdxl_train_control_net.py
│ ├── sdxl_train_control_net_lllite.py
│ ├── sdxl_train_control_net_lllite_old.py
│ ├── sdxl_train_network.py
│ ├── sdxl_train_textual_inversion.py
│ ├── setup.py
│ ├── tools
│ │ ├── cache_latents.py
│ │ ├── cache_text_encoder_outputs.py
│ │ ├── canny.py
│ │ ├── convert_diffusers20_original_sd.py
│ │ ├── convert_diffusers_to_flux.py
│ │ ├── detect_face_rotate.py
│ │ ├── latent_upscaler.py
│ │ ├── merge_models.py
│ │ ├── merge_sd3_safetensors.py
│ │ ├── original_control_net.py
│ │ ├── resize_images_to_resolution.py
│ │ └── show_metadata.py
│ ├── train_control_net.py
│ ├── train_controlnet.py
│ ├── train_db.py
│ ├── train_network.py
│ ├── train_textual_inversion.py
│ └── train_textual_inversion_XTI.py
└── stable
│ ├── .gitignore
│ ├── COMMIT_ID
│ ├── LICENSE.md
│ ├── README-ja.md
│ ├── README.md
│ ├── XTI_hijack.py
│ ├── _typos.toml
│ ├── fine_tune.py
│ ├── finetune
│ ├── blip
│ │ ├── blip.py
│ │ ├── med.py
│ │ ├── med_config.json
│ │ └── vit.py
│ ├── clean_captions_and_tags.py
│ ├── hypernetwork_nai.py
│ ├── make_captions.py
│ ├── make_captions_by_git.py
│ ├── merge_captions_to_metadata.py
│ ├── merge_dd_tags_to_metadata.py
│ ├── prepare_buckets_latents.py
│ └── tag_images_by_wd14_tagger.py
│ ├── gen_img.py
│ ├── gen_img_diffusers.py
│ ├── library
│ ├── __init__.py
│ ├── adafactor_fused.py
│ ├── attention_processors.py
│ ├── config_util.py
│ ├── custom_train_functions.py
│ ├── deepspeed_utils.py
│ ├── device_utils.py
│ ├── huggingface_util.py
│ ├── hypernetwork.py
│ ├── ipex
│ │ ├── __init__.py
│ │ ├── attention.py
│ │ ├── diffusers.py
│ │ ├── gradscaler.py
│ │ └── hijacks.py
│ ├── lpw_stable_diffusion.py
│ ├── model_util.py
│ ├── original_unet.py
│ ├── sai_model_spec.py
│ ├── sdxl_lpw_stable_diffusion.py
│ ├── sdxl_model_util.py
│ ├── sdxl_original_unet.py
│ ├── sdxl_train_util.py
│ ├── slicing_vae.py
│ ├── train_util.py
│ └── utils.py
│ ├── networks
│ ├── check_lora_weights.py
│ ├── control_net_lllite.py
│ ├── control_net_lllite_for_train.py
│ ├── dylora.py
│ ├── extract_lora_from_dylora.py
│ ├── extract_lora_from_models.py
│ ├── lora.py
│ ├── lora_diffusers.py
│ ├── lora_fa.py
│ ├── lora_interrogator.py
│ ├── merge_lora.py
│ ├── merge_lora_old.py
│ ├── oft.py
│ ├── resize_lora.py
│ ├── sdxl_merge_lora.py
│ └── svd_merge_lora.py
│ ├── requirements.txt
│ ├── sdxl_gen_img.py
│ ├── sdxl_minimal_inference.py
│ ├── sdxl_train.py
│ ├── sdxl_train_control_net_lllite.py
│ ├── sdxl_train_control_net_lllite_old.py
│ ├── sdxl_train_network.py
│ ├── sdxl_train_textual_inversion.py
│ ├── setup.py
│ ├── tools
│ ├── cache_latents.py
│ ├── cache_text_encoder_outputs.py
│ ├── canny.py
│ ├── convert_diffusers20_original_sd.py
│ ├── detect_face_rotate.py
│ ├── latent_upscaler.py
│ ├── merge_models.py
│ ├── original_control_net.py
│ ├── resize_images_to_resolution.py
│ └── show_metadata.py
│ ├── train_controlnet.py
│ ├── train_db.py
│ ├── train_network.py
│ ├── train_textual_inversion.py
│ └── train_textual_inversion_XTI.py
├── sd-models
└── put stable diffusion model here.txt
├── svd_merge.ps1
├── tagger.ps1
├── tagger.sh
├── tensorboard.ps1
├── train.ipynb
├── train.ps1
├── train.sh
├── train_by_toml.ps1
└── train_by_toml.sh
/.gitattributes:
--------------------------------------------------------------------------------
1 | *.ps1 text eol=crlf
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .vscode
2 | .idea
3 |
4 | venv
5 | __pycache__
6 |
7 | output/*
8 | !output/.keep
9 |
10 | assets/config.json
11 |
12 | py310
13 | python
14 | git
15 | wd14_tagger_model
16 |
17 | train/*
18 | logs/*
19 | sd-models/*
20 | toml/autosave/*
21 | config/autosave/*
22 | config/presets/test*.toml
23 |
24 | !sd-models/put stable diffusion model here.txt
25 | !logs/.keep
26 |
27 | tests/
28 |
29 | huggingface/hub/models*
30 | huggingface/hub/version_diffusers_cache.txt
--------------------------------------------------------------------------------
/.gitmodules:
--------------------------------------------------------------------------------
1 | [submodule "frontend"]
2 | path = frontend
3 | url = https://github.com/hanamizuki-ai/lora-gui-dist
4 | [submodule "mikazuki/dataset-tag-editor"]
5 | path = mikazuki/dataset-tag-editor
6 | url = https://github.com/Akegarasu/dataset-tag-editor
7 |
--------------------------------------------------------------------------------
/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM nvcr.io/nvidia/pytorch:24.07-py3
2 |
3 | EXPOSE 28000
4 |
5 | ENV TZ=Asia/Shanghai
6 | RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone && apt update && apt install python3-tk -y
7 |
8 | RUN mkdir /app
9 |
10 | WORKDIR /app
11 | RUN git clone --recurse-submodules https://github.com/Akegarasu/lora-scripts
12 |
13 | WORKDIR /app/lora-scripts
14 | RUN pip install xformers==0.0.27.post2 --no-deps && pip install -r requirements.txt
15 |
16 | WORKDIR /app/lora-scripts/scripts
17 | RUN pip install -r requirements.txt
18 |
19 | WORKDIR /app/lora-scripts
20 |
21 | CMD ["python", "gui.py", "--listen"]
--------------------------------------------------------------------------------
/Dockerfile-for-Mainland-China:
--------------------------------------------------------------------------------
1 | FROM nvcr.io/nvidia/pytorch:24.07-py3
2 |
3 | EXPOSE 28000
4 |
5 | ENV TZ=Asia/Shanghai
6 | RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone && apt update && apt install python3-tk -y
7 |
8 | RUN mkdir /app
9 |
10 | WORKDIR /app
11 | RUN git clone --recurse-submodules https://github.com/Akegarasu/lora-scripts
12 |
13 | WORKDIR /app/lora-scripts
14 |
15 | # 设置 Python pip 软件包国内镜像代理
16 | RUN pip config set global.index-url 'https://pypi.tuna.tsinghua.edu.cn/simple' && \
17 | pip config set install.trusted-host 'pypi.tuna.tsinghua.edu.cn'
18 |
19 | # 初次安装依赖
20 | RUN pip install xformers==0.0.27.post2 --no-deps && pip install -r requirements.txt
21 |
22 | # 更新 训练程序 stable 版本依赖
23 | WORKDIR /app/lora-scripts/scripts/stable
24 | RUN pip install -r requirements.txt
25 |
26 | # 更新 训练程序 dev 版本依赖
27 | WORKDIR /app/lora-scripts/scripts/dev
28 | RUN pip install -r requirements.txt
29 |
30 | WORKDIR /app/lora-scripts
31 |
32 | # 修正运行报错以及底包缺失的依赖
33 | # ref
34 | # - https://soulteary.com/2024/01/07/fix-opencv-dependency-errors-opencv-fixer.html
35 | # - https://blog.csdn.net/qq_50195602/article/details/124188467
36 | RUN pip install opencv-fixer==0.2.5 && python -c "from opencv_fixer import AutoFix; AutoFix()" \
37 | pip install opencv-python-headless && apt install ffmpeg libsm6 libxext6 libgl1 -y
38 |
39 | CMD ["python", "gui.py", "--listen"]
--------------------------------------------------------------------------------
/README-zh.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |

4 |
5 | # SD-Trainer
6 |
7 | _✨ 享受 Stable Diffusion 训练! ✨_
8 |
9 |
12 |
13 |  14 |
15 |
16 |
14 |
15 |
16 |  17 |
18 |
19 |
17 |
18 |
19 |  20 |
21 |
22 |
20 |
21 |
22 |  23 |
24 |
23 |
24 |
25 |
26 |
27 | 下载
28 | ·
29 | 文档
30 | ·
31 | 中文README
32 |
33 |
34 | LoRA-scripts(又名 SD-Trainer)
35 |
36 | LoRA & Dreambooth 训练图形界面 & 脚本预设 & 一键训练环境,用于 [kohya-ss/sd-scripts](https://github.com/kohya-ss/sd-scripts.git)
37 |
38 | ## ✨新特性: 训练 WebUI
39 |
40 | Stable Diffusion 训练工作台。一切集成于一个 WebUI 中。
41 |
42 | 按照下面的安装指南安装 GUI,然后运行 `run_gui.ps1`(Windows) 或 `run_gui.sh`(Linux) 来启动 GUI。
43 |
44 | 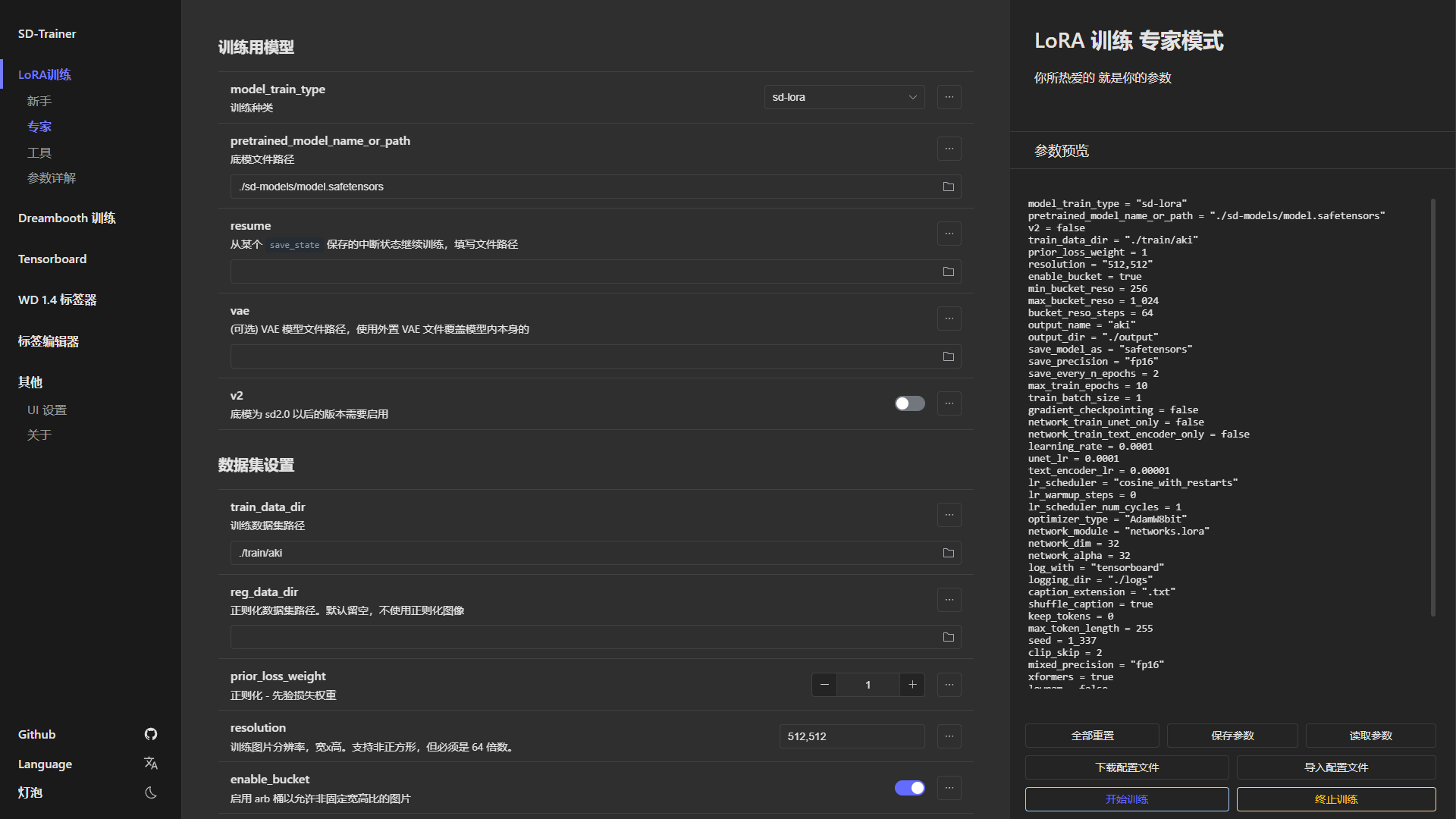
45 |
46 | | Tensorboard | WD 1.4 标签器 | 标签编辑器 |
47 | | ------------ | ------------ | ------------ |
48 | | 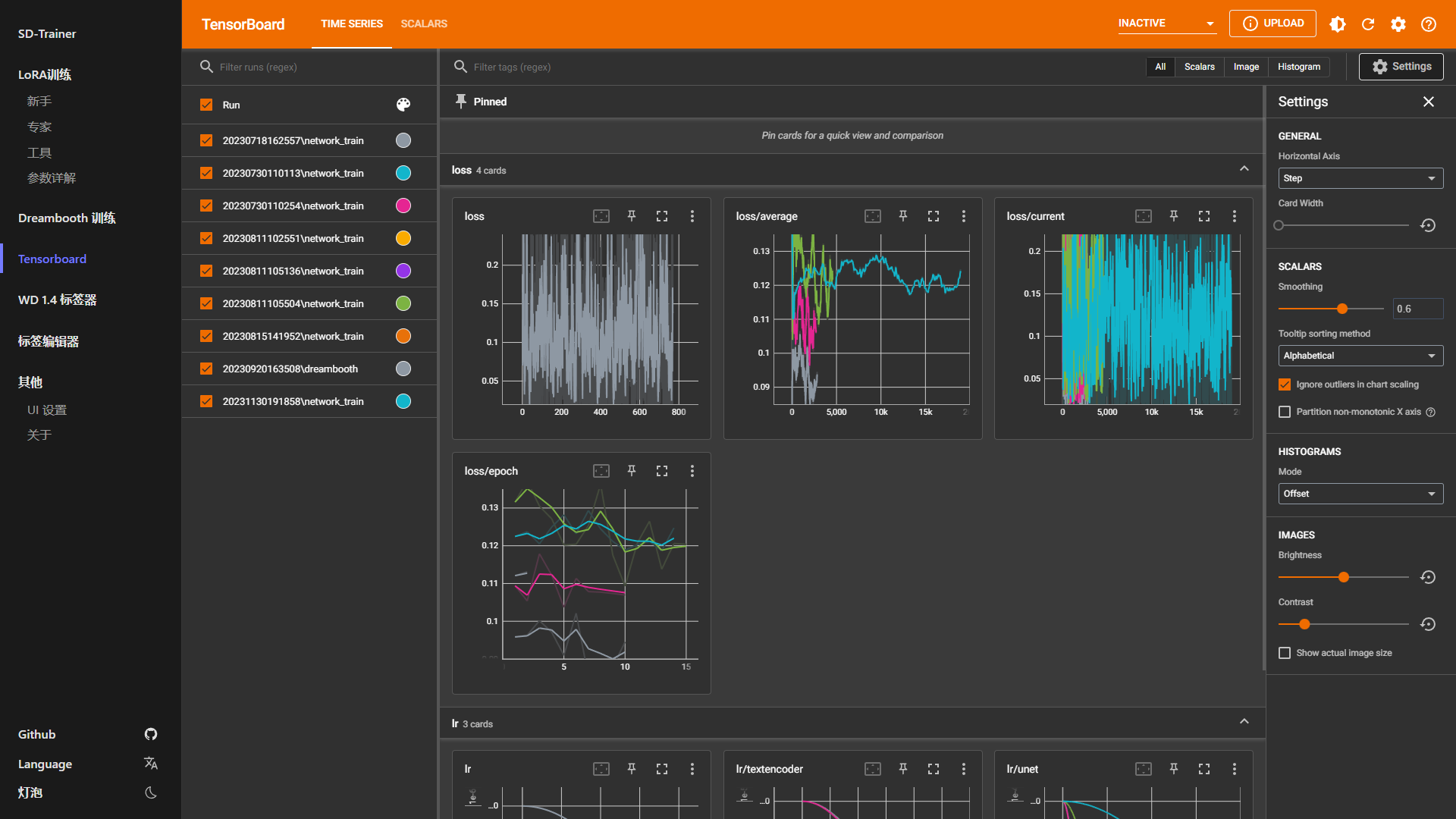 | 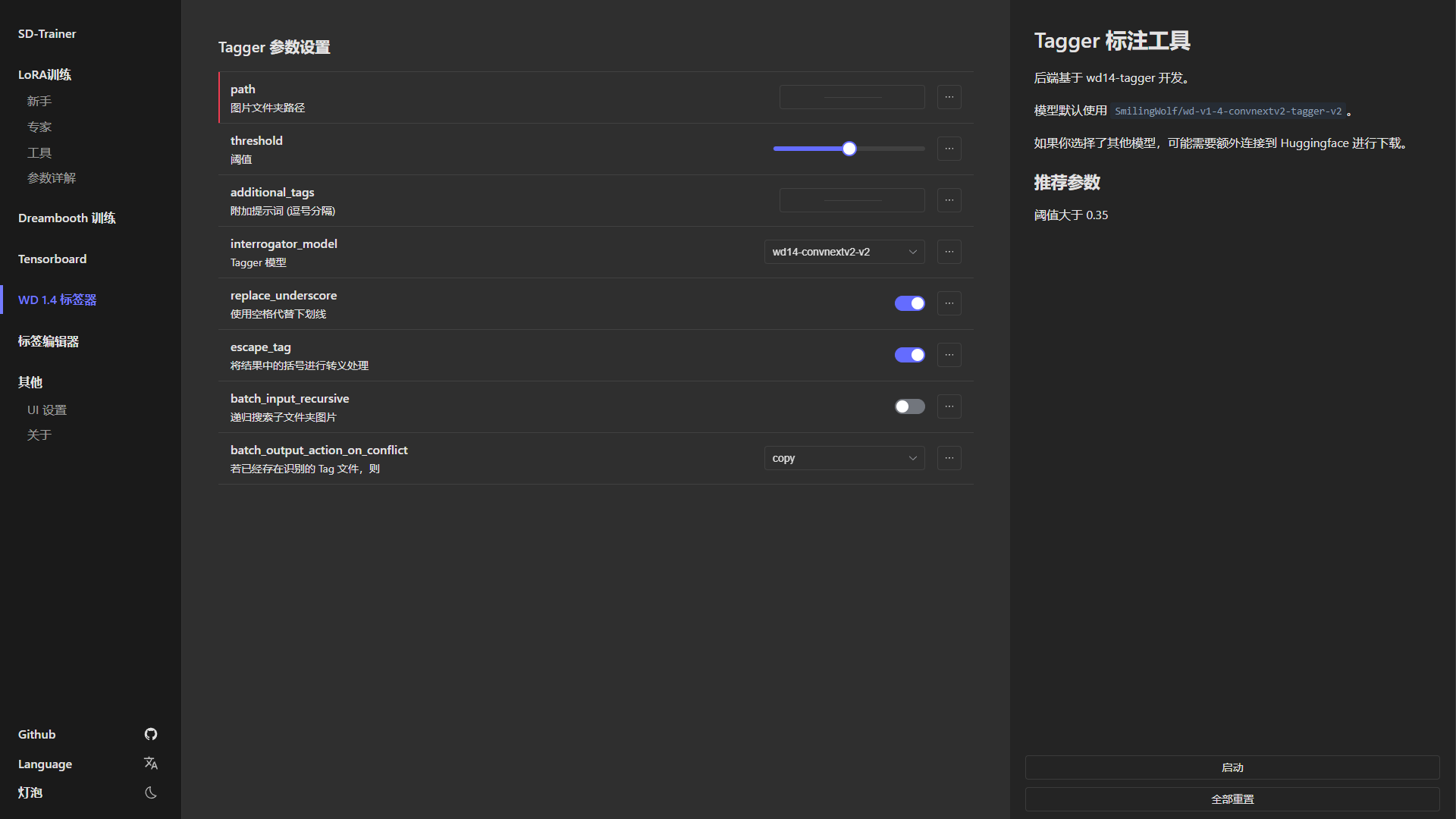 | 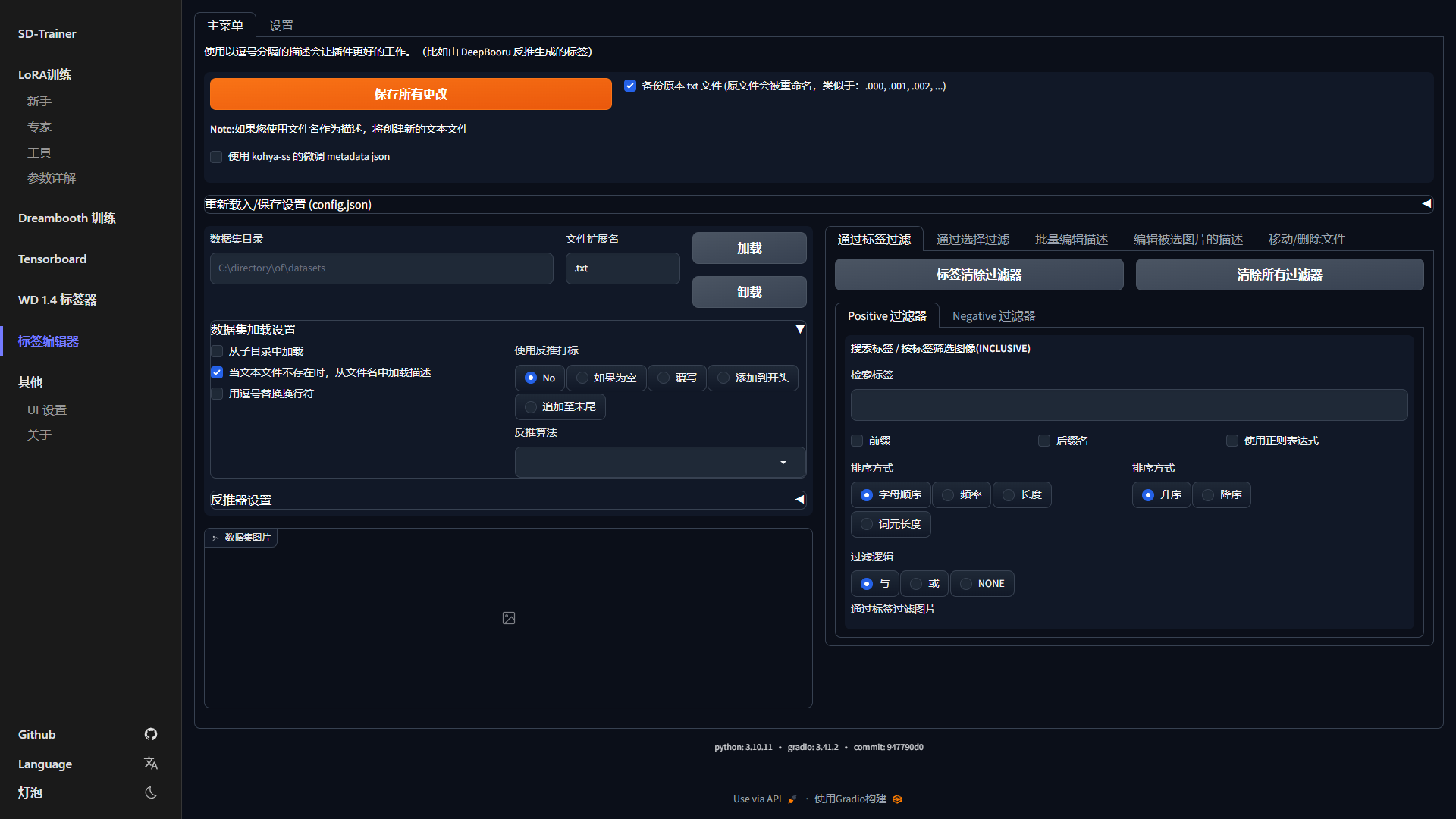 |
49 |
50 |
51 | # 使用方法
52 |
53 | ### 必要依赖
54 |
55 | Python 3.10 和 Git
56 |
57 | ### 克隆带子模块的仓库
58 |
59 | ```sh
60 | git clone --recurse-submodules https://github.com/Akegarasu/lora-scripts
61 | ```
62 |
63 | ## ✨ SD-Trainer GUI
64 |
65 | ### Windows
66 |
67 | #### 安装
68 |
69 | 运行 `install-cn.ps1` 将自动为您创建虚拟环境并安装必要的依赖。
70 |
71 | #### 训练
72 |
73 | 运行 `run_gui.ps1`,程序将自动打开 [http://127.0.0.1:28000](http://127.0.0.1:28000)
74 |
75 | ### Linux
76 |
77 | #### 安装
78 |
79 | 运行 `install.bash` 将创建虚拟环境并安装必要的依赖。
80 |
81 | #### 训练
82 |
83 | 运行 `bash run_gui.sh`,程序将自动打开 [http://127.0.0.1:28000](http://127.0.0.1:28000)
84 |
85 | ### Docker
86 |
87 | #### 编译镜像
88 |
89 | ```bash
90 | # 国内镜像优化版本
91 | # 其中 akegarasu_lora-scripts:latest 为镜像及其 tag 名,根据镜像托管服务商实际进行修改
92 | docker build -t akegarasu_lora-scripts:latest -f Dockfile-for-Mainland-China .
93 | docker push akegarasu_lora-scripts:latest
94 | ```
95 |
96 | #### 使用镜像
97 |
98 | > 提供一个本人已打包好并推送到 `aliyuncs` 上的镜像,此镜像压缩归档大小约 `10G` 左右,请耐心等待拉取。
99 |
100 | ```bash
101 | docker run --gpus all -p 28000:28000 -p 6006:6006 registry.cn-hangzhou.aliyuncs.com/go-to-mirror/akegarasu_lora-scripts:latest
102 | ```
103 |
104 | 或者使用 `docker-compose.yaml` 。
105 |
106 | ```yaml
107 | services:
108 | lora-scripts:
109 | container_name: lora-scripts
110 | build:
111 | context: .
112 | dockerfile: Dockerfile-for-Mainland-China
113 | image: "registry.cn-hangzhou.aliyuncs.com/go-to-mirror/akegarasu_lora-scripts:latest"
114 | ports:
115 | - "28000:28000"
116 | - "6006:6006"
117 | # 共享本地文件夹(请根据实际修改)
118 | #volumes:
119 | # - "/data/srv/lora-scripts:/app/lora-scripts"
120 | # 共享 comfyui 大模型
121 | # - "/data/srv/comfyui/models/checkpoints:/app/lora-scripts/sd-models/comfyui"
122 | # 共享 sd-webui 大模型
123 | # - "/data/srv/stable-diffusion-webui/models/Stable-diffusion:/app/lora-scripts/sd-models/sd-webui"
124 | environment:
125 | - HF_HOME=huggingface
126 | - PYTHONUTF8=1
127 | security_opt:
128 | - "label=type:nvidia_container_t"
129 | runtime: nvidia
130 | deploy:
131 | resources:
132 | reservations:
133 | devices:
134 | - driver: nvidia
135 | device_ids: ['0']
136 | capabilities: [gpu]
137 | ```
138 |
139 | 关于容器使用 GPU 相关依赖安装问题,请自行搜索查阅资料解决。
140 |
141 | ## 通过手动运行脚本的传统训练方式
142 |
143 | ### Windows
144 |
145 | #### 安装
146 |
147 | 运行 `install.ps1` 将自动为您创建虚拟环境并安装必要的依赖。
148 |
149 | #### 训练
150 |
151 | 编辑 `train.ps1`,然后运行它。
152 |
153 | ### Linux
154 |
155 | #### 安装
156 |
157 | 运行 `install.bash` 将创建虚拟环境并安装必要的依赖。
158 |
159 | #### 训练
160 |
161 | 训练
162 |
163 | 脚本 `train.sh` **不会** 为您激活虚拟环境。您应该先激活虚拟环境。
164 |
165 | ```sh
166 | source venv/bin/activate
167 | ```
168 |
169 | 编辑 `train.sh`,然后运行它。
170 |
171 | #### TensorBoard
172 |
173 | 运行 `tensorboard.ps1` 将在 http://localhost:6006/ 启动 TensorBoard
174 |
175 | ## 程序参数
176 |
177 | | 参数名称 | 类型 | 默认值 | 描述 |
178 | |------------------------------|-------|--------------|-------------------------------------------------|
179 | | `--host` | str | "127.0.0.1" | 服务器的主机名 |
180 | | `--port` | int | 28000 | 运行服务器的端口 |
181 | | `--listen` | bool | false | 启用服务器的监听模式 |
182 | | `--skip-prepare-environment` | bool | false | 跳过环境准备步骤 |
183 | | `--disable-tensorboard` | bool | false | 禁用 TensorBoard |
184 | | `--disable-tageditor` | bool | false | 禁用标签编辑器 |
185 | | `--tensorboard-host` | str | "127.0.0.1" | 运行 TensorBoard 的主机 |
186 | | `--tensorboard-port` | int | 6006 | 运行 TensorBoard 的端口 |
187 | | `--localization` | str | | 界面的本地化设置 |
188 | | `--dev` | bool | false | 开发者模式,用于禁用某些检查 |
189 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | # SD-Trainer
6 |
7 | _✨ Enjoy Stable Diffusion Train! ✨_
8 |
9 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 | Download
28 | ·
29 | Documents
30 | ·
31 | 中文README
32 |
33 |
34 | LoRA-scripts (a.k.a SD-Trainer)
35 |
36 | LoRA & Dreambooth training GUI & scripts preset & one key training environment for [kohya-ss/sd-scripts](https://github.com/kohya-ss/sd-scripts.git)
37 |
38 | ## ✨NEW: Train WebUI
39 |
40 | The **REAL** Stable Diffusion Training Studio. Everything in one WebUI.
41 |
42 | Follow the installation guide below to install the GUI, then run `run_gui.ps1`(windows) or `run_gui.sh`(linux) to start the GUI.
43 |
44 | 
45 |
46 | | Tensorboard | WD 1.4 Tagger | Tag Editor |
47 | | ------------ | ------------ | ------------ |
48 | |  |  |  |
49 |
50 |
51 | # Usage
52 |
53 | ### Required Dependencies
54 |
55 | Python 3.10 and Git
56 |
57 | ### Clone repo with submodules
58 |
59 | ```sh
60 | git clone --recurse-submodules https://github.com/Akegarasu/lora-scripts
61 | ```
62 |
63 | ## ✨ SD-Trainer GUI
64 |
65 | ### Windows
66 |
67 | #### Installation
68 |
69 | Run `install.ps1` will automatically create a venv for you and install necessary deps.
70 | If you are in China mainland, please use `install-cn.ps1`
71 |
72 | #### Train
73 |
74 | run `run_gui.ps1`, then program will open [http://127.0.0.1:28000](http://127.0.0.1:28000) automanticlly
75 |
76 | ### Linux
77 |
78 | #### Installation
79 |
80 | Run `install.bash` will create a venv and install necessary deps.
81 |
82 | #### Train
83 |
84 | run `bash run_gui.sh`, then program will open [http://127.0.0.1:28000](http://127.0.0.1:28000) automanticlly
85 |
86 | ## Legacy training through run script manually
87 |
88 | ### Windows
89 |
90 | #### Installation
91 |
92 | Run `install.ps1` will automatically create a venv for you and install necessary deps.
93 |
94 | #### Train
95 |
96 | Edit `train.ps1`, and run it.
97 |
98 | ### Linux
99 |
100 | #### Installation
101 |
102 | Run `install.bash` will create a venv and install necessary deps.
103 |
104 | #### Train
105 |
106 | Training script `train.sh` **will not** activate venv for you. You should activate venv first.
107 |
108 | ```sh
109 | source venv/bin/activate
110 | ```
111 |
112 | Edit `train.sh`, and run it.
113 |
114 | #### TensorBoard
115 |
116 | Run `tensorboard.ps1` will start TensorBoard at http://localhost:6006/
117 |
118 | ## Program arguments
119 |
120 | | Parameter Name | Type | Default Value | Description |
121 | |-------------------------------|-------|---------------|--------------------------------------------------|
122 | | `--host` | str | "127.0.0.1" | Hostname for the server |
123 | | `--port` | int | 28000 | Port to run the server |
124 | | `--listen` | bool | false | Enable listening mode for the server |
125 | | `--skip-prepare-environment` | bool | false | Skip the environment preparation step |
126 | | `--disable-tensorboard` | bool | false | Disable TensorBoard |
127 | | `--disable-tageditor` | bool | false | Disable tag editor |
128 | | `--tensorboard-host` | str | "127.0.0.1" | Host to run TensorBoard |
129 | | `--tensorboard-port` | int | 6006 | Port to run TensorBoard |
130 | | `--localization` | str | | Localization settings for the interface |
131 | | `--dev` | bool | false | Developer mode to disale some checks |
132 |
--------------------------------------------------------------------------------
/assets/favicon.ico:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Akegarasu/lora-scripts/e0f5194815203093659d6ec280b9362b9792c070/assets/favicon.ico
--------------------------------------------------------------------------------
/assets/gitconfig-cn:
--------------------------------------------------------------------------------
1 | [url "https://jihulab.com/Akegarasu/lora-scripts"]
2 | insteadOf = https://github.com/Akegarasu/lora-scripts
3 |
4 | [url "https://jihulab.com/Akegarasu/sd-scripts"]
5 | insteadOf = https://github.com/Akegarasu/sd-scripts
6 |
7 | [url "https://jihulab.com/affair3547/sd-scripts"]
8 | insteadOf = https://github.com/kohya-ss/sd-scripts.git
9 |
10 | [url "https://jihulab.com/affair3547/lora-gui-dist"]
11 | insteadOf = https://github.com/hanamizuki-ai/lora-gui-dist
12 |
13 | [url "https://jihulab.com/Akegarasu/dataset-tag-editor"]
14 | insteadOf = https://github.com/Akegarasu/dataset-tag-editor
15 |
--------------------------------------------------------------------------------
/assets/tensorboard-example.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Akegarasu/lora-scripts/e0f5194815203093659d6ec280b9362b9792c070/assets/tensorboard-example.png
--------------------------------------------------------------------------------
/config/default.toml:
--------------------------------------------------------------------------------
1 | [model]
2 | v2 = false
3 | v_parameterization = false
4 | pretrained_model_name_or_path = "./sd-models/model.ckpt"
5 |
6 | [dataset]
7 | train_data_dir = "./train/input"
8 | reg_data_dir = ""
9 | prior_loss_weight = 1
10 | cache_latents = true
11 | shuffle_caption = true
12 | enable_bucket = true
13 |
14 | [additional_network]
15 | network_dim = 32
16 | network_alpha = 16
17 | network_train_unet_only = false
18 | network_train_text_encoder_only = false
19 | network_module = "networks.lora"
20 | network_args = []
21 |
22 | [optimizer]
23 | unet_lr = 1e-4
24 | text_encoder_lr = 1e-5
25 | optimizer_type = "AdamW8bit"
26 | lr_scheduler = "cosine_with_restarts"
27 | lr_warmup_steps = 0
28 | lr_restart_cycles = 1
29 |
30 | [training]
31 | resolution = "512,512"
32 | train_batch_size = 1
33 | max_train_epochs = 10
34 | noise_offset = 0.0
35 | keep_tokens = 0
36 | xformers = true
37 | lowram = false
38 | clip_skip = 2
39 | mixed_precision = "fp16"
40 | save_precision = "fp16"
41 |
42 | [sample_prompt]
43 | sample_sampler = "euler_a"
44 | sample_every_n_epochs = 1
45 |
46 | [saving]
47 | output_name = "output_name"
48 | save_every_n_epochs = 1
49 | save_n_epoch_ratio = 0
50 | save_last_n_epochs = 499
51 | save_state = false
52 | save_model_as = "safetensors"
53 | output_dir = "./output"
54 | logging_dir = "./logs"
55 | log_prefix = "output_name"
56 |
57 | [others]
58 | min_bucket_reso = 256
59 | max_bucket_reso = 1024
60 | caption_extension = ".txt"
61 | max_token_length = 225
62 | seed = 1337
63 |
--------------------------------------------------------------------------------
/config/lora.toml:
--------------------------------------------------------------------------------
1 | [model_arguments]
2 | v2 = false
3 | v_parameterization = false
4 | pretrained_model_name_or_path = "./sd-models/model.ckpt"
5 |
6 | [dataset_arguments]
7 | train_data_dir = "./train/aki"
8 | reg_data_dir = ""
9 | resolution = "512,512"
10 | prior_loss_weight = 1
11 |
12 | [additional_network_arguments]
13 | network_dim = 32
14 | network_alpha = 16
15 | network_train_unet_only = false
16 | network_train_text_encoder_only = false
17 | network_module = "networks.lora"
18 | network_args = []
19 |
20 | [optimizer_arguments]
21 | unet_lr = 1e-4
22 | text_encoder_lr = 1e-5
23 |
24 | optimizer_type = "AdamW8bit"
25 | lr_scheduler = "cosine_with_restarts"
26 | lr_warmup_steps = 0
27 | lr_restart_cycles = 1
28 |
29 | [training_arguments]
30 | train_batch_size = 1
31 | noise_offset = 0.0
32 | keep_tokens = 0
33 | min_bucket_reso = 256
34 | max_bucket_reso = 1024
35 | caption_extension = ".txt"
36 | max_token_length = 225
37 | seed = 1337
38 | xformers = true
39 | lowram = false
40 | max_train_epochs = 10
41 | resolution = "512,512"
42 | clip_skip = 2
43 | mixed_precision = "fp16"
44 |
45 | [sample_prompt_arguments]
46 | sample_sampler = "euler_a"
47 | sample_every_n_epochs = 5
48 |
49 | [saving_arguments]
50 | output_name = "output_name"
51 | save_every_n_epochs = 1
52 | save_state = false
53 | save_model_as = "safetensors"
54 | output_dir = "./output"
55 | logging_dir = "./logs"
56 | log_prefix = ""
57 | save_precision = "fp16"
58 |
59 | [others]
60 | cache_latents = true
61 | shuffle_caption = true
62 | enable_bucket = true
--------------------------------------------------------------------------------
/config/presets/example.toml:
--------------------------------------------------------------------------------
1 | # 模板显示的信息
2 | [metadata]
3 | name = "中分辨率训练" # 模板名称
4 | version = "0.0.1" # 模板版本
5 | author = "秋叶" # 模板作者
6 | # train_type 参数可以设置 lora-basic,lora-master,flux-lora 等内容。用于过滤显示的。不填就全部显示
7 | # train_type = ""
8 | description = "这是一个样例模板,提高训练分辨率。如果你想加入自己的模板,可以按照 config/presets 中的文件,修改后前往 Github 发起 PR"
9 |
10 | # 模板配置内容。请只填写修改了的内容,未修改无需填写。
11 | [data]
12 | resolution = "768,768"
13 | enable_bucket = true
14 | min_bucket_reso = 256
15 | max_bucket_reso = 2048
16 | bucket_no_upscale = true
--------------------------------------------------------------------------------
/config/sample_prompts.txt:
--------------------------------------------------------------------------------
1 | (masterpiece, best quality:1.2), 1girl, solo, --n lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, --w 512 --h 768 --l 7 --s 24 --d 1337
--------------------------------------------------------------------------------
/gui.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import locale
3 | import os
4 | import platform
5 | import subprocess
6 | import sys
7 |
8 | from mikazuki.launch_utils import (base_dir_path, catch_exception, git_tag,
9 | prepare_environment, check_port_avaliable, find_avaliable_ports)
10 | from mikazuki.log import log
11 |
12 | parser = argparse.ArgumentParser(description="GUI for stable diffusion training")
13 | parser.add_argument("--host", type=str, default="127.0.0.1")
14 | parser.add_argument("--port", type=int, default=28000, help="Port to run the server on")
15 | parser.add_argument("--listen", action="store_true")
16 | parser.add_argument("--skip-prepare-environment", action="store_true")
17 | parser.add_argument("--skip-prepare-onnxruntime", action="store_true")
18 | parser.add_argument("--disable-tensorboard", action="store_true")
19 | parser.add_argument("--disable-tageditor", action="store_true")
20 | parser.add_argument("--disable-auto-mirror", action="store_true")
21 | parser.add_argument("--tensorboard-host", type=str, default="127.0.0.1", help="Port to run the tensorboard")
22 | parser.add_argument("--tensorboard-port", type=int, default=6006, help="Port to run the tensorboard")
23 | parser.add_argument("--localization", type=str)
24 | parser.add_argument("--dev", action="store_true")
25 |
26 |
27 | @catch_exception
28 | def run_tensorboard():
29 | log.info("Starting tensorboard...")
30 | subprocess.Popen([sys.executable, "-m", "tensorboard.main", "--logdir", "logs",
31 | "--host", args.tensorboard_host, "--port", str(args.tensorboard_port)])
32 |
33 |
34 | @catch_exception
35 | def run_tag_editor():
36 | log.info("Starting tageditor...")
37 | cmd = [
38 | sys.executable,
39 | base_dir_path() / "mikazuki/dataset-tag-editor/scripts/launch.py",
40 | "--port", "28001",
41 | "--shadow-gradio-output",
42 | "--root-path", "/proxy/tageditor"
43 | ]
44 | if args.localization:
45 | cmd.extend(["--localization", args.localization])
46 | else:
47 | l = locale.getdefaultlocale()[0]
48 | if l and l.startswith("zh"):
49 | cmd.extend(["--localization", "zh-Hans"])
50 | subprocess.Popen(cmd)
51 |
52 |
53 | def launch():
54 | log.info("Starting SD-Trainer Mikazuki GUI...")
55 | log.info(f"Base directory: {base_dir_path()}, Working directory: {os.getcwd()}")
56 | log.info(f"{platform.system()} Python {platform.python_version()} {sys.executable}")
57 |
58 | if not args.skip_prepare_environment:
59 | prepare_environment(disable_auto_mirror=args.disable_auto_mirror)
60 |
61 | if not check_port_avaliable(args.port):
62 | avaliable = find_avaliable_ports(30000, 30000+20)
63 | if avaliable:
64 | args.port = avaliable
65 | else:
66 | log.error("port finding fallback error")
67 |
68 | log.info(f"SD-Trainer Version: {git_tag(base_dir_path())}")
69 |
70 | os.environ["MIKAZUKI_HOST"] = args.host
71 | os.environ["MIKAZUKI_PORT"] = str(args.port)
72 | os.environ["MIKAZUKI_TENSORBOARD_HOST"] = args.tensorboard_host
73 | os.environ["MIKAZUKI_TENSORBOARD_PORT"] = str(args.tensorboard_port)
74 | os.environ["MIKAZUKI_DEV"] = "1" if args.dev else "0"
75 |
76 | if args.listen:
77 | args.host = "0.0.0.0"
78 | args.tensorboard_host = "0.0.0.0"
79 |
80 | if not args.disable_tageditor:
81 | run_tag_editor()
82 |
83 | if not args.disable_tensorboard:
84 | run_tensorboard()
85 |
86 | import uvicorn
87 | log.info(f"Server started at http://{args.host}:{args.port}")
88 | uvicorn.run("mikazuki.app:app", host=args.host, port=args.port, log_level="error", reload=args.dev)
89 |
90 |
91 | if __name__ == "__main__":
92 | args, _ = parser.parse_known_args()
93 | launch()
94 |
--------------------------------------------------------------------------------
/huggingface/accelerate/default_config.yaml:
--------------------------------------------------------------------------------
1 | command_file: null
2 | commands: null
3 | compute_environment: LOCAL_MACHINE
4 | deepspeed_config: {}
5 | distributed_type: 'NO'
6 | downcast_bf16: 'no'
7 | dynamo_backend: 'NO'
8 | fsdp_config: {}
9 | gpu_ids: all
10 | machine_rank: 0
11 | main_process_ip: null
12 | main_process_port: null
13 | main_training_function: main
14 | megatron_lm_config: {}
15 | mixed_precision: fp16
16 | num_machines: 1
17 | num_processes: 1
18 | rdzv_backend: static
19 | same_network: true
20 | tpu_name: null
21 | tpu_zone: null
22 | use_cpu: false
23 |
--------------------------------------------------------------------------------
/huggingface/hub/version.txt:
--------------------------------------------------------------------------------
1 | 1
--------------------------------------------------------------------------------
/install-cn.ps1:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Akegarasu/lora-scripts/e0f5194815203093659d6ec280b9362b9792c070/install-cn.ps1
--------------------------------------------------------------------------------
/install.bash:
--------------------------------------------------------------------------------
1 | #!/usr/bin/bash
2 |
3 | script_dir="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
4 | create_venv=true
5 |
6 | while [ -n "$1" ]; do
7 | case "$1" in
8 | --disable-venv)
9 | create_venv=false
10 | shift
11 | ;;
12 | *)
13 | shift
14 | ;;
15 | esac
16 | done
17 |
18 | if $create_venv; then
19 | echo "Creating python venv..."
20 | python3 -m venv venv
21 | source "$script_dir/venv/bin/activate"
22 | echo "active venv"
23 | fi
24 |
25 | echo "Installing torch & xformers..."
26 |
27 | cuda_version=$(nvidia-smi | grep -oiP 'CUDA Version: \K[\d\.]+')
28 |
29 | if [ -z "$cuda_version" ]; then
30 | cuda_version=$(nvcc --version | grep -oiP 'release \K[\d\.]+')
31 | fi
32 | cuda_major_version=$(echo "$cuda_version" | awk -F'.' '{print $1}')
33 | cuda_minor_version=$(echo "$cuda_version" | awk -F'.' '{print $2}')
34 |
35 | echo "CUDA Version: $cuda_version"
36 |
37 |
38 | if (( cuda_major_version >= 12 )); then
39 | echo "install torch 2.7.0+cu128"
40 | pip install torch==2.7.0+cu128 torchvision==0.22.0+cu128 --extra-index-url https://download.pytorch.org/whl/cu128
41 | pip install --no-deps xformers==0.0.30 --extra-index-url https://download.pytorch.org/whl/cu128
42 | elif (( cuda_major_version == 11 && cuda_minor_version >= 8 )); then
43 | echo "install torch 2.4.0+cu118"
44 | pip install torch==2.4.0+cu118 torchvision==0.19.0+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
45 | pip install --no-deps xformers==0.0.27.post2+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
46 | elif (( cuda_major_version == 11 && cuda_minor_version >= 6 )); then
47 | echo "install torch 1.12.1+cu116"
48 | pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
49 | # for RTX3090+cu113/cu116 xformers, we need to install this version from source. You can also try xformers==0.0.18
50 | pip install --upgrade git+https://github.com/facebookresearch/xformers.git@0bad001ddd56c080524d37c84ff58d9cd030ebfd
51 | pip install triton==2.0.0.dev20221202
52 | elif (( cuda_major_version == 11 && cuda_minor_version >= 2 )); then
53 | echo "install torch 1.12.1+cu113"
54 | pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu116
55 | pip install --upgrade git+https://github.com/facebookresearch/xformers.git@0bad001ddd56c080524d37c84ff58d9cd030ebfd
56 | pip install triton==2.0.0.dev20221202
57 | else
58 | echo "Unsupported cuda version:$cuda_version"
59 | exit 1
60 | fi
61 |
62 | echo "Installing deps..."
63 |
64 | cd "$script_dir" || exit
65 | pip install --upgrade -r requirements.txt
66 |
67 | echo "Install completed"
68 |
--------------------------------------------------------------------------------
/install.ps1:
--------------------------------------------------------------------------------
1 | $Env:HF_HOME = "huggingface"
2 |
3 | if (!(Test-Path -Path "venv")) {
4 | Write-Output "Creating venv for python..."
5 | python -m venv venv
6 | }
7 | .\venv\Scripts\activate
8 |
9 | Write-Output "Installing deps..."
10 |
11 | pip install torch==2.7.0+cu128 torchvision==0.22.0+cu128 --extra-index-url https://download.pytorch.org/whl/cu128
12 | pip install -U -I --no-deps xformers==0.0.30 --extra-index-url https://download.pytorch.org/whl/cu128
13 | pip install --upgrade -r requirements.txt
14 |
15 | Write-Output "Install completed"
16 | Read-Host | Out-Null ;
17 |
--------------------------------------------------------------------------------
/interrogate.ps1:
--------------------------------------------------------------------------------
1 | # LoRA interrogate script by @bdsqlsz
2 |
3 | $v2 = 0 # load Stable Diffusion v2.x model / Stable Diffusion 2.x模型读取
4 | $sd_model = "./sd-models/sd_model.safetensors" # Stable Diffusion model to load: ckpt or safetensors file | 读取的基础SD模型, 保存格式 cpkt 或 safetensors
5 | $model = "./output/LoRA.safetensors" # LoRA model to interrogate: ckpt or safetensors file | 需要调查关键字的LORA模型, 保存格式 cpkt 或 safetensors
6 | $batch_size = 64 # batch size for processing with Text Encoder | 使用 Text Encoder 处理时的批量大小,默认16,推荐64/128
7 | $clip_skip = 1 # use output of nth layer from back of text encoder (n>=1) | 使用文本编码器倒数第 n 层的输出,n 可以是大于等于 1 的整数
8 |
9 |
10 | # Activate python venv
11 | .\venv\Scripts\activate
12 |
13 | $Env:HF_HOME = "huggingface"
14 | $ext_args = [System.Collections.ArrayList]::new()
15 |
16 | if ($v2) {
17 | [void]$ext_args.Add("--v2")
18 | }
19 |
20 | # run interrogate
21 | accelerate launch --num_cpu_threads_per_process=8 "./scripts/stable/networks/lora_interrogator.py" `
22 | --sd_model=$sd_model `
23 | --model=$model `
24 | --batch_size=$batch_size `
25 | --clip_skip=$clip_skip `
26 | $ext_args
27 |
28 | Write-Output "Interrogate finished"
29 | Read-Host | Out-Null ;
30 |
--------------------------------------------------------------------------------
/logs/.keep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Akegarasu/lora-scripts/e0f5194815203093659d6ec280b9362b9792c070/logs/.keep
--------------------------------------------------------------------------------
/mikazuki/app/__init__.py:
--------------------------------------------------------------------------------
1 | from . import application
2 |
3 | app = application.app
--------------------------------------------------------------------------------
/mikazuki/app/application.py:
--------------------------------------------------------------------------------
1 | import asyncio
2 | import mimetypes
3 | import os
4 | import sys
5 | import webbrowser
6 | from contextlib import asynccontextmanager
7 |
8 | from fastapi import FastAPI
9 | from fastapi.middleware.cors import CORSMiddleware
10 | from fastapi.responses import FileResponse
11 | from fastapi.staticfiles import StaticFiles
12 | from starlette.exceptions import HTTPException
13 |
14 | from mikazuki.app.config import app_config
15 | from mikazuki.app.api import load_schemas, load_presets
16 | from mikazuki.app.api import router as api_router
17 | # from mikazuki.app.ipc import router as ipc_router
18 | from mikazuki.app.proxy import router as proxy_router
19 | from mikazuki.utils.devices import check_torch_gpu
20 |
21 | mimetypes.add_type("application/javascript", ".js")
22 | mimetypes.add_type("text/css", ".css")
23 |
24 |
25 | class SPAStaticFiles(StaticFiles):
26 | async def get_response(self, path: str, scope):
27 | try:
28 | return await super().get_response(path, scope)
29 | except HTTPException as ex:
30 | if ex.status_code == 404:
31 | return await super().get_response("index.html", scope)
32 | else:
33 | raise ex
34 |
35 |
36 | async def app_startup():
37 | app_config.load_config()
38 |
39 | await load_schemas()
40 | await load_presets()
41 | await asyncio.to_thread(check_torch_gpu)
42 |
43 | if sys.platform == "win32" and os.environ.get("MIKAZUKI_DEV", "0") != "1":
44 | webbrowser.open(f'http://{os.environ["MIKAZUKI_HOST"]}:{os.environ["MIKAZUKI_PORT"]}')
45 |
46 |
47 | @asynccontextmanager
48 | async def lifespan(app: FastAPI):
49 | await app_startup()
50 | yield
51 |
52 |
53 | app = FastAPI(lifespan=lifespan)
54 | app.include_router(proxy_router)
55 |
56 |
57 | cors_config = os.environ.get("MIKAZUKI_APP_CORS", "")
58 | if cors_config != "":
59 | if cors_config == "1":
60 | cors_config = ["http://localhost:8004", "*"]
61 | else:
62 | cors_config = cors_config.split(";")
63 | app.add_middleware(
64 | CORSMiddleware,
65 | allow_origins=cors_config,
66 | allow_credentials=True,
67 | allow_methods=["*"],
68 | allow_headers=["*"],
69 | )
70 |
71 |
72 | @app.middleware("http")
73 | async def add_cache_control_header(request, call_next):
74 | response = await call_next(request)
75 | response.headers["Cache-Control"] = "max-age=0"
76 | return response
77 |
78 | app.include_router(api_router, prefix="/api")
79 | # app.include_router(ipc_router, prefix="/ipc")
80 |
81 |
82 | @app.get("/")
83 | async def index():
84 | return FileResponse("./frontend/dist/index.html")
85 |
86 |
87 | @app.get("/favicon.ico", response_class=FileResponse)
88 | async def favicon():
89 | return FileResponse("assets/favicon.ico")
90 |
91 | app.mount("/", SPAStaticFiles(directory="frontend/dist", html=True), name="static")
92 |
--------------------------------------------------------------------------------
/mikazuki/app/config.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | from pathlib import Path
4 | from mikazuki.log import log
5 |
6 | class Config:
7 |
8 | def __init__(self, path: str):
9 | self.path = path
10 | self._stored = {}
11 | self._default = {
12 | "last_path": "",
13 | "saved_params": {}
14 | }
15 | self.lock = False
16 |
17 | def load_config(self):
18 | log.info(f"Loading config from {self.path}")
19 | if not os.path.exists(self.path):
20 | self._stored = self._default
21 | self.save_config()
22 | return
23 |
24 | try:
25 | with open(self.path, "r", encoding="utf-8") as f:
26 | self._stored = json.load(f)
27 | except Exception as e:
28 | log.error(f"Error loading config: {e}")
29 | self._stored = self._default
30 | return
31 |
32 | def save_config(self):
33 | try:
34 | with open(self.path, "w", encoding="utf-8") as f:
35 | json.dump(self._stored, f, indent=4, ensure_ascii=False)
36 | except Exception as e:
37 | log.error(f"Error saving config: {e}")
38 |
39 | def __getitem__(self, key):
40 |
41 | return self._stored.get(key, None)
42 |
43 | def __setitem__(self, key, value):
44 | self._stored[key] = value
45 |
46 |
47 | app_config = Config(Path(__file__).parents[2].absolute() / "assets" / "config.json")
48 |
--------------------------------------------------------------------------------
/mikazuki/app/models.py:
--------------------------------------------------------------------------------
1 | from pydantic import BaseModel, Field
2 | from typing import List, Optional, Union, Dict, Any
3 |
4 |
5 | class TaggerInterrogateRequest(BaseModel):
6 | path: str
7 | interrogator_model: str = Field(
8 | default="wd14-convnextv2-v2"
9 | )
10 | threshold: float = Field(
11 | default=0.35,
12 | ge=0,
13 | le=1
14 | )
15 | additional_tags: str = ""
16 | exclude_tags: str = ""
17 | escape_tag: bool = True
18 | batch_input_recursive: bool = False
19 | batch_output_action_on_conflict: str = "ignore"
20 | replace_underscore: bool = True
21 | replace_underscore_excludes: str = Field(
22 | default="0_0, (o)_(o), +_+, +_-, ._., _, <|>_<|>, =_=, >_<, 3_3, 6_9, >_o, @_@, ^_^, o_o, u_u, x_x, |_|, ||_||"
23 | )
24 |
25 |
26 | class APIResponse(BaseModel):
27 | status: str
28 | message: Optional[str]
29 | data: Optional[Dict]
30 |
31 |
32 | class APIResponseSuccess(APIResponse):
33 | status: str = "success"
34 |
35 |
36 | class APIResponseFail(APIResponse):
37 | status: str = "fail"
38 |
--------------------------------------------------------------------------------
/mikazuki/app/proxy.py:
--------------------------------------------------------------------------------
1 | import asyncio
2 | import os
3 |
4 | import httpx
5 | import starlette
6 | import websockets
7 | from fastapi import APIRouter, Request, WebSocket
8 | from httpx import ConnectError
9 | from starlette.background import BackgroundTask
10 | from starlette.requests import Request
11 | from starlette.responses import PlainTextResponse, StreamingResponse
12 |
13 | from mikazuki.log import log
14 |
15 | router = APIRouter()
16 |
17 |
18 | def reverse_proxy_maker(url_type: str, full_path: bool = False):
19 | if url_type == "tensorboard":
20 | host = os.environ.get("MIKAZUKI_TENSORBOARD_HOST", "127.0.0.1")
21 | port = os.environ.get("MIKAZUKI_TENSORBOARD_PORT", "6006")
22 | elif url_type == "tageditor":
23 | host = os.environ.get("MIKAZUKI_TAGEDITOR_HOST", "127.0.0.1")
24 | port = os.environ.get("MIKAZUKI_TAGEDITOR_PORT", "28001")
25 |
26 | client = httpx.AsyncClient(base_url=f"http://{host}:{port}/", proxies={}, trust_env=False, timeout=360)
27 |
28 | async def _reverse_proxy(request: Request):
29 | if full_path:
30 | url = httpx.URL(path=request.url.path, query=request.url.query.encode("utf-8"))
31 | else:
32 | url = httpx.URL(
33 | path=request.path_params.get("path", ""),
34 | query=request.url.query.encode("utf-8")
35 | )
36 | rp_req = client.build_request(
37 | request.method, url,
38 | headers=request.headers.raw,
39 | content=request.stream() if request.method != "GET" else None
40 | )
41 | try:
42 | rp_resp = await client.send(rp_req, stream=True)
43 | except ConnectError:
44 | return PlainTextResponse(
45 | content="The requested service not started yet or service started fail. This may cost a while when you first time startup\n请求的服务尚未启动或启动失败。若是第一次启动,可能需要等待一段时间后再刷新网页。",
46 | status_code=502
47 | )
48 | return StreamingResponse(
49 | rp_resp.aiter_raw(),
50 | status_code=rp_resp.status_code,
51 | headers=rp_resp.headers,
52 | background=BackgroundTask(rp_resp.aclose),
53 | )
54 |
55 | return _reverse_proxy
56 |
57 |
58 | async def proxy_ws_forward(ws_a: WebSocket, ws_b: websockets.WebSocketClientProtocol):
59 | while True:
60 | try:
61 | data = await ws_a.receive_text()
62 | await ws_b.send(data)
63 | except starlette.websockets.WebSocketDisconnect as e:
64 | break
65 | except Exception as e:
66 | log.error(f"Error when proxy data client -> backend: {e}")
67 | break
68 |
69 |
70 | async def proxy_ws_reverse(ws_a: WebSocket, ws_b: websockets.WebSocketClientProtocol):
71 | while True:
72 | try:
73 | data = await ws_b.recv()
74 | await ws_a.send_text(data)
75 | except websockets.exceptions.ConnectionClosedOK as e:
76 | break
77 | except Exception as e:
78 | log.error(f"Error when proxy data backend -> client: {e}")
79 | break
80 |
81 |
82 | @router.websocket("/proxy/tageditor/queue/join")
83 | async def websocket_a(ws_a: WebSocket):
84 | # for temp use
85 | ws_b_uri = "ws://127.0.0.1:28001/queue/join"
86 | await ws_a.accept()
87 | async with websockets.connect(ws_b_uri, timeout=360, ping_timeout=None) as ws_b_client:
88 | fwd_task = asyncio.create_task(proxy_ws_forward(ws_a, ws_b_client))
89 | rev_task = asyncio.create_task(proxy_ws_reverse(ws_a, ws_b_client))
90 | await asyncio.gather(fwd_task, rev_task)
91 |
92 | router.add_route("/proxy/tensorboard/{path:path}", reverse_proxy_maker("tensorboard"), ["GET", "POST"])
93 | router.add_route("/font-roboto/{path:path}", reverse_proxy_maker("tensorboard", full_path=True), ["GET", "POST"])
94 | router.add_route("/proxy/tageditor/{path:path}", reverse_proxy_maker("tageditor"), ["GET", "POST"])
95 |
--------------------------------------------------------------------------------
/mikazuki/global.d.ts:
--------------------------------------------------------------------------------
1 | interface Window {
2 | __MIKAZUKI__: any;
3 | }
4 |
5 | type Dict = {
6 | [key in K]: T;
7 | };
8 |
9 | declare const kSchema: unique symbol;
10 |
11 | declare namespace Schemastery {
12 | type From = X extends string | number | boolean ? SchemaI : X extends SchemaI ? X : X extends typeof String ? SchemaI : X extends typeof Number ? SchemaI : X extends typeof Boolean ? SchemaI : X extends typeof Function ? SchemaI any> : X extends Constructor ? SchemaI : never;
13 | type TypeS1 = X extends SchemaI ? S : never;
14 | type Inverse = X extends SchemaI ? (arg: Y) => void : never;
15 | type TypeS = TypeS1>;
16 | type TypeT = ReturnType>;
17 | type Resolve = (data: any, schema: SchemaI, options?: Options, strict?: boolean) => [any, any?];
18 | type IntersectS = From extends SchemaI ? S : never;
19 | type IntersectT = Inverse> extends ((arg: infer T) => void) ? T : never;
20 | type TupleS = X extends readonly [infer L, ...infer R] ? [TypeS?, ...TupleS] : any[];
21 | type TupleT = X extends readonly [infer L, ...infer R] ? [TypeT?, ...TupleT] : any[];
22 | type ObjectS = {
23 | [K in keyof X]?: TypeS | null;
24 | } & Dict;
25 | type ObjectT = {
26 | [K in keyof X]: TypeT;
27 | } & Dict;
28 | type Constructor = new (...args: any[]) => T;
29 | interface Static {
30 | (options: Partial>): SchemaI;
31 | new (options: Partial>): SchemaI;
32 | prototype: SchemaI;
33 | resolve: Resolve;
34 | from(source?: X): From;
35 | extend(type: string, resolve: Resolve): void;
36 | any(): SchemaI;
37 | never(): SchemaI;
38 | const(value: T): SchemaI;
39 | string(): SchemaI;
40 | number(): SchemaI;
41 | natural(): SchemaI;
42 | percent(): SchemaI;
43 | boolean(): SchemaI;
44 | date(): SchemaI;
45 | bitset(bits: Partial>): SchemaI;
46 | function(): SchemaI any>;
47 | is(constructor: Constructor): SchemaI;
48 | array(inner: X): SchemaI[], TypeT[]>;
49 | dict = SchemaI>(inner: X, sKey?: Y): SchemaI, TypeS>, Dict, TypeT>>;
50 | tuple(list: X): SchemaI, TupleT>;
51 | object(dict: X): SchemaI, ObjectT>;
52 | union(list: readonly X[]): SchemaI, TypeT>;
53 | intersect(list: readonly X[]): SchemaI, IntersectT>;
54 | transform(inner: X, callback: (value: TypeS) => T, preserve?: boolean): SchemaI, T>;
55 | }
56 | interface Options {
57 | autofix?: boolean;
58 | }
59 | interface Meta {
60 | default?: T extends {} ? Partial : T;
61 | required?: boolean;
62 | disabled?: boolean;
63 | collapse?: boolean;
64 | badges?: {
65 | text: string;
66 | type: string;
67 | }[];
68 | hidden?: boolean;
69 | loose?: boolean;
70 | role?: string;
71 | extra?: any;
72 | link?: string;
73 | description?: string | Dict;
74 | comment?: string;
75 | pattern?: {
76 | source: string;
77 | flags?: string;
78 | };
79 | max?: number;
80 | min?: number;
81 | step?: number;
82 | }
83 |
84 | interface Schemastery {
85 | (data?: S | null, options?: Schemastery.Options): T;
86 | new(data?: S | null, options?: Schemastery.Options): T;
87 | [kSchema]: true;
88 | uid: number;
89 | meta: Schemastery.Meta;
90 | type: string;
91 | sKey?: SchemaI;
92 | inner?: SchemaI;
93 | list?: SchemaI[];
94 | dict?: Dict;
95 | bits?: Dict;
96 | callback?: Function;
97 | value?: T;
98 | refs?: Dict;
99 | preserve?: boolean;
100 | toString(inline?: boolean): string;
101 | toJSON(): SchemaI;
102 | required(value?: boolean): SchemaI;
103 | hidden(value?: boolean): SchemaI;
104 | loose(value?: boolean): SchemaI;
105 | role(text: string, extra?: any): SchemaI;
106 | link(link: string): SchemaI;
107 | default(value: T): SchemaI;
108 | comment(text: string): SchemaI;
109 | description(text: string): SchemaI;
110 | disabled(value?: boolean): SchemaI;
111 | collapse(value?: boolean): SchemaI;
112 | deprecated(): SchemaI;
113 | experimental(): SchemaI;
114 | pattern(regexp: RegExp): SchemaI;
115 | max(value: number): SchemaI;
116 | min(value: number): SchemaI;
117 | step(value: number): SchemaI;
118 | set(key: string, value: SchemaI): SchemaI;
119 | push(value: SchemaI): SchemaI;
120 | simplify(value?: any): any;
121 | i18n(messages: Dict): SchemaI;
122 | extra(key: K, value: Schemastery.Meta[K]): SchemaI;
123 | }
124 |
125 | }
126 |
127 | type SchemaI = Schemastery.Schemastery;
128 |
129 | declare const Schema: Schemastery.Static
130 |
131 | declare const SHARED_SCHEMAS: Dict
132 |
133 | declare function UpdateSchema(origin: Record, modify?: Record, toDelete?: string[]): Record;
134 |
--------------------------------------------------------------------------------
/mikazuki/hook/i18n.json:
--------------------------------------------------------------------------------
1 | {
2 | "指定エポックまでのステップ数": "指定 epoch 之前的步数",
3 | "学習開始": "训练开始",
4 | "学習画像の数×繰り返し回数": "训练图像数量×重复次数",
5 | "正則化画像の数": "正则化图像数量",
6 | "正則化画像の数×繰り返し回数": "正则化图像数量×重复次数",
7 | "1epochのバッチ数": "每个 epoch 的 batch 数",
8 | "バッチサイズ": "batch 大小",
9 | "学習率": "学习率",
10 | "勾配を合計するステップ数": "梯度累积步数",
11 | "学習率の減衰率": "学习率衰减率",
12 | "学習ステップ数": "训练步数"
13 | }
--------------------------------------------------------------------------------
/mikazuki/hook/sitecustomize.py:
--------------------------------------------------------------------------------
1 |
2 |
3 | _origin_print = print
4 |
5 |
6 | def i18n_print(data, *args, **kwargs):
7 | _origin_print(data, *args, **kwargs)
8 | _origin_print("i18n_print")
9 |
10 |
11 | __builtins__["print"] = i18n_print
12 |
--------------------------------------------------------------------------------
/mikazuki/log.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 |
4 | log = logging.getLogger('sd-trainer')
5 | log.setLevel(logging.DEBUG)
6 |
7 | try:
8 | from rich.console import Console
9 | from rich.logging import RichHandler
10 | from rich.pretty import install as pretty_install
11 | from rich.theme import Theme
12 |
13 | console = Console(
14 | log_time=True,
15 | log_time_format='%H:%M:%S-%f',
16 | theme=Theme(
17 | {
18 | 'traceback.border': 'black',
19 | 'traceback.border.syntax_error': 'black',
20 | 'inspect.value.border': 'black',
21 | }
22 | ),
23 | )
24 | pretty_install(console=console)
25 | rh = RichHandler(
26 | show_time=True,
27 | omit_repeated_times=False,
28 | show_level=True,
29 | show_path=False,
30 | markup=False,
31 | rich_tracebacks=True,
32 | log_time_format='%H:%M:%S-%f',
33 | level=logging.INFO,
34 | console=console,
35 | )
36 | rh.set_name(logging.INFO)
37 | while log.hasHandlers() and len(log.handlers) > 0:
38 | log.removeHandler(log.handlers[0])
39 | log.addHandler(rh)
40 |
41 | except ModuleNotFoundError:
42 | pass
43 |
44 |
--------------------------------------------------------------------------------
/mikazuki/process.py:
--------------------------------------------------------------------------------
1 |
2 | import asyncio
3 | import os
4 | import sys
5 | from typing import Optional
6 |
7 | from mikazuki.app.models import APIResponse
8 | from mikazuki.log import log
9 | from mikazuki.tasks import tm
10 | from mikazuki.launch_utils import base_dir_path
11 |
12 |
13 | def run_train(toml_path: str,
14 | trainer_file: str = "./scripts/train_network.py",
15 | gpu_ids: Optional[list] = None,
16 | cpu_threads: Optional[int] = 2):
17 | log.info(f"Training started with config file / 训练开始,使用配置文件: {toml_path}")
18 | args = [
19 | sys.executable, "-m", "accelerate.commands.launch", # use -m to avoid python script executable error
20 | "--num_cpu_threads_per_process", str(cpu_threads), # cpu threads
21 | "--quiet", # silence accelerate error message
22 | trainer_file,
23 | "--config_file", toml_path,
24 | ]
25 |
26 | customize_env = os.environ.copy()
27 | customize_env["ACCELERATE_DISABLE_RICH"] = "1"
28 | customize_env["PYTHONUNBUFFERED"] = "1"
29 | customize_env["PYTHONWARNINGS"] = "ignore::FutureWarning,ignore::UserWarning"
30 |
31 | if gpu_ids:
32 | customize_env["CUDA_VISIBLE_DEVICES"] = ",".join(gpu_ids)
33 | log.info(f"Using GPU(s) / 使用 GPU: {gpu_ids}")
34 |
35 | if len(gpu_ids) > 1:
36 | args[3:3] = ["--multi_gpu", "--num_processes", str(len(gpu_ids))]
37 | if sys.platform == "win32":
38 | customize_env["USE_LIBUV"] = "0"
39 | args[3:3] = ["--rdzv_backend", "c10d"]
40 |
41 | if not (task := tm.create_task(args, customize_env)):
42 | return APIResponse(status="error", message="Failed to create task / 无法创建训练任务")
43 |
44 | def _run():
45 | try:
46 | task.execute()
47 | result = task.communicate()
48 | if result.returncode != 0:
49 | log.error(f"Training failed / 训练失败")
50 | else:
51 | log.info(f"Training finished / 训练完成")
52 | except Exception as e:
53 | log.error(f"An error occurred when training / 训练出现致命错误: {e}")
54 |
55 | coro = asyncio.to_thread(_run)
56 | asyncio.create_task(coro)
57 |
58 | return APIResponse(status="success", message=f"Training started / 训练开始 ID: {task.task_id}")
59 |
--------------------------------------------------------------------------------
/mikazuki/schema/flux-lora.ts:
--------------------------------------------------------------------------------
1 | Schema.intersect([
2 | Schema.object({
3 | model_train_type: Schema.string().default("flux-lora").disabled().description("训练种类"),
4 | pretrained_model_name_or_path: Schema.string().role('filepicker', { type: "model-file" }).default("./sd-models/model.safetensors").description("Flux 模型路径"),
5 | ae: Schema.string().role('filepicker', { type: "model-file" }).description("AE 模型文件路径"),
6 | clip_l: Schema.string().role('filepicker', { type: "model-file" }).description("clip_l 模型文件路径"),
7 | t5xxl: Schema.string().role('filepicker', { type: "model-file" }).description("t5xxl 模型文件路径"),
8 | resume: Schema.string().role('filepicker', { type: "folder" }).description("从某个 `save_state` 保存的中断状态继续训练,填写文件路径"),
9 | }).description("训练用模型"),
10 |
11 | Schema.object({
12 | timestep_sampling: Schema.union(["sigma", "uniform", "sigmoid", "shift"]).default("sigmoid").description("时间步采样"),
13 | sigmoid_scale: Schema.number().step(0.001).default(1.0).description("sigmoid 缩放"),
14 | model_prediction_type: Schema.union(["raw", "additive", "sigma_scaled"]).default("raw").description("模型预测类型"),
15 | discrete_flow_shift: Schema.number().step(0.001).default(1.0).description("Euler 调度器离散流位移"),
16 | loss_type: Schema.union(["l1", "l2", "huber", "smooth_l1"]).default("l2").description("损失函数类型"),
17 | guidance_scale: Schema.number().step(0.01).default(1.0).description("CFG 引导缩放"),
18 | t5xxl_max_token_length: Schema.number().step(1).description("T5XXL 最大 token 长度(不填写使用自动)"),
19 | train_t5xxl: Schema.boolean().default(false).description("训练 T5XXL(不推荐)"),
20 | }).description("Flux 专用参数"),
21 |
22 | Schema.object(
23 | UpdateSchema(SHARED_SCHEMAS.RAW.DATASET_SETTINGS, {
24 | resolution: Schema.string().default("768,768").description("训练图片分辨率,宽x高。支持非正方形,但必须是 64 倍数。"),
25 | enable_bucket: Schema.boolean().default(true).description("启用 arb 桶以允许非固定宽高比的图片"),
26 | min_bucket_reso: Schema.number().default(256).description("arb 桶最小分辨率"),
27 | max_bucket_reso: Schema.number().default(2048).description("arb 桶最大分辨率"),
28 | bucket_reso_steps: Schema.number().default(64).description("arb 桶分辨率划分单位,FLUX 需大于 64"),
29 | })
30 | ).description("数据集设置"),
31 |
32 | // 保存设置
33 | SHARED_SCHEMAS.SAVE_SETTINGS,
34 |
35 | Schema.object({
36 | max_train_epochs: Schema.number().min(1).default(20).description("最大训练 epoch(轮数)"),
37 | train_batch_size: Schema.number().min(1).default(1).description("批量大小, 越高显存占用越高"),
38 | gradient_checkpointing: Schema.boolean().default(true).description("梯度检查点"),
39 | gradient_accumulation_steps: Schema.number().min(1).default(1).description("梯度累加步数"),
40 | network_train_unet_only: Schema.boolean().default(true).description("仅训练 U-Net"),
41 | network_train_text_encoder_only: Schema.boolean().default(false).description("仅训练文本编码器"),
42 | }).description("训练相关参数"),
43 |
44 | // 学习率&优化器设置
45 | SHARED_SCHEMAS.LR_OPTIMIZER,
46 |
47 | Schema.intersect([
48 | Schema.object({
49 | network_module: Schema.union(["networks.lora_flux", "networks.oft_flux", "lycoris.kohya"]).default("networks.lora_flux").description("训练网络模块"),
50 | network_weights: Schema.string().role('filepicker').description("从已有的 LoRA 模型上继续训练,填写路径"),
51 | network_dim: Schema.number().min(1).default(2).description("网络维度,常用 4~128,不是越大越好, 低dim可以降低显存占用"),
52 | network_alpha: Schema.number().min(1).default(16).description("常用值:等于 network_dim 或 network_dim*1/2 或 1。使用较小的 alpha 需要提升学习率"),
53 | network_dropout: Schema.number().step(0.01).default(0).description('dropout 概率 (与 lycoris 不兼容,需要用 lycoris 自带的)'),
54 | scale_weight_norms: Schema.number().step(0.01).min(0).description("最大范数正则化。如果使用,推荐为 1"),
55 | network_args_custom: Schema.array(String).role('table').description('自定义 network_args,一行一个'),
56 | enable_base_weight: Schema.boolean().default(false).description('启用基础权重(差异炼丹)'),
57 | }).description("网络设置"),
58 |
59 | // lycoris 参数
60 | SHARED_SCHEMAS.LYCORIS_MAIN,
61 | SHARED_SCHEMAS.LYCORIS_LOKR,
62 |
63 | SHARED_SCHEMAS.NETWORK_OPTION_BASEWEIGHT,
64 | ]),
65 |
66 | // 预览图设置
67 | SHARED_SCHEMAS.PREVIEW_IMAGE,
68 |
69 | // 日志设置
70 | SHARED_SCHEMAS.LOG_SETTINGS,
71 |
72 | // caption 选项
73 | // FLUX 去除 max_token_length
74 | Schema.object(UpdateSchema(SHARED_SCHEMAS.RAW.CAPTION_SETTINGS, {}, ["max_token_length"])).description("caption(Tag)选项"),
75 |
76 | // 噪声设置
77 | SHARED_SCHEMAS.NOISE_SETTINGS,
78 |
79 | // 数据增强
80 | SHARED_SCHEMAS.DATA_ENCHANCEMENT,
81 |
82 | // 其他选项
83 | SHARED_SCHEMAS.OTHER,
84 |
85 | // 速度优化选项
86 | Schema.object(
87 | UpdateSchema(SHARED_SCHEMAS.RAW.PRECISION_CACHE_BATCH, {
88 | fp8_base: Schema.boolean().default(true).description("对基础模型使用 FP8 精度"),
89 | fp8_base_unet: Schema.boolean().description("仅对 U-Net 使用 FP8 精度(CLIP-L不使用)"),
90 | sdpa: Schema.boolean().default(true).description("启用 sdpa"),
91 | cache_text_encoder_outputs: Schema.boolean().default(true).description("缓存文本编码器的输出,减少显存使用。使用时需要关闭 shuffle_caption"),
92 | cache_text_encoder_outputs_to_disk: Schema.boolean().default(true).description("缓存文本编码器的输出到磁盘"),
93 | }, ["xformers"])
94 | ).description("速度优化选项"),
95 |
96 | // 分布式训练
97 | SHARED_SCHEMAS.DISTRIBUTED_TRAINING
98 | ]);
99 |
--------------------------------------------------------------------------------
/mikazuki/schema/lora-basic.ts:
--------------------------------------------------------------------------------
1 | Schema.intersect([
2 | Schema.object({
3 | pretrained_model_name_or_path: Schema.string().role('filepicker', {type: "model-file"}).default("./sd-models/model.safetensors").description("底模文件路径"),
4 | }).description("训练用模型"),
5 |
6 | Schema.object({
7 | train_data_dir: Schema.string().role('filepicker', { type: "folder", internal: "train-dir" }).default("./train/aki").description("训练数据集路径"),
8 | reg_data_dir: Schema.string().role('filepicker', { type: "folder", internal: "train-dir" }).description("正则化数据集路径。默认留空,不使用正则化图像"),
9 | resolution: Schema.string().default("512,512").description("训练图片分辨率,宽x高。支持非正方形,但必须是 64 倍数。"),
10 | }).description("数据集设置"),
11 |
12 | Schema.object({
13 | output_name: Schema.string().default("aki").description("模型保存名称"),
14 | output_dir: Schema.string().default("./output").role('filepicker', { type: "folder" }).description("模型保存文件夹"),
15 | save_every_n_epochs: Schema.number().default(2).description("每 N epoch(轮)自动保存一次模型"),
16 | }).description("保存设置"),
17 |
18 | Schema.object({
19 | max_train_epochs: Schema.number().min(1).default(10).description("最大训练 epoch(轮数)"),
20 | train_batch_size: Schema.number().min(1).default(1).description("批量大小"),
21 | }).description("训练相关参数"),
22 |
23 | Schema.intersect([
24 | Schema.object({
25 | unet_lr: Schema.string().default("1e-4").description("U-Net 学习率"),
26 | text_encoder_lr: Schema.string().default("1e-5").description("文本编码器学习率"),
27 | lr_scheduler: Schema.union([
28 | "cosine",
29 | "cosine_with_restarts",
30 | "constant",
31 | "constant_with_warmup",
32 | ]).default("cosine_with_restarts").description("学习率调度器设置"),
33 | lr_warmup_steps: Schema.number().default(0).description('学习率预热步数'),
34 | }).description("学习率与优化器设置"),
35 | Schema.union([
36 | Schema.object({
37 | lr_scheduler: Schema.const('cosine_with_restarts'),
38 | lr_scheduler_num_cycles: Schema.number().default(1).description('重启次数'),
39 | }),
40 | Schema.object({}),
41 | ]),
42 | Schema.object({
43 | optimizer_type: Schema.union([
44 | "AdamW8bit",
45 | "Lion",
46 | ]).default("AdamW8bit").description("优化器设置"),
47 | })
48 | ]),
49 |
50 | Schema.intersect([
51 | Schema.object({
52 | enable_preview: Schema.boolean().default(false).description('启用训练预览图'),
53 | }).description('训练预览图设置'),
54 |
55 | Schema.union([
56 | Schema.object({
57 | enable_preview: Schema.const(true).required(),
58 | sample_prompts: Schema.string().role('textarea').default(window.__MIKAZUKI__.SAMPLE_PROMPTS_DEFAULT).description(window.__MIKAZUKI__.SAMPLE_PROMPTS_DESCRIPTION),
59 | sample_sampler: Schema.union(["ddim", "pndm", "lms", "euler", "euler_a", "heun", "dpm_2", "dpm_2_a", "dpmsolver", "dpmsolver++", "dpmsingle", "k_lms", "k_euler", "k_euler_a", "k_dpm_2", "k_dpm_2_a"]).default("euler_a").description("生成预览图所用采样器"),
60 | sample_every_n_epochs: Schema.number().default(2).description("每 N 个 epoch 生成一次预览图"),
61 | }),
62 | Schema.object({}),
63 | ]),
64 | ]),
65 |
66 | Schema.intersect([
67 | Schema.object({
68 | network_weights: Schema.string().role('filepicker', { type: "model-file", internal: "model-saved-file" }).description("从已有的 LoRA 模型上继续训练,填写路径"),
69 | network_dim: Schema.number().min(8).max(256).step(8).default(32).description("网络维度,常用 4~128,不是越大越好, 低dim可以降低显存占用"),
70 | network_alpha: Schema.number().min(1).default(32).description(
71 | "常用值:等于 network_dim 或 network_dim*1/2 或 1。使用较小的 alpha 需要提升学习率。"
72 | ),
73 | }).description("网络设置"),
74 | ]),
75 |
76 | Schema.object({
77 | shuffle_caption: Schema.boolean().default(true).description("训练时随机打乱 tokens"),
78 | keep_tokens: Schema.number().min(0).max(255).step(1).default(0).description("在随机打乱 tokens 时,保留前 N 个不变"),
79 | }).description("caption 选项"),
80 |
81 | Schema.object({
82 | mixed_precision: Schema.union(["no", "fp16", "bf16"]).default("fp16").description("混合精度, RTX30系列以后也可以指定`bf16`"),
83 | no_half_vae: Schema.boolean().description("不使用半精度 VAE,当出现 NaN detected in latents 报错时使用"),
84 | xformers: Schema.boolean().default(true).description("启用 xformers"),
85 | cache_latents: Schema.boolean().default(true).description("缓存图像 latent, 缓存 VAE 输出以减少 VRAM 使用")
86 | }).description("速度优化选项"),
87 | ]);
88 |
--------------------------------------------------------------------------------
/mikazuki/schema/lora-master.ts:
--------------------------------------------------------------------------------
1 | Schema.intersect([
2 | Schema.intersect([
3 | Schema.object({
4 | model_train_type: Schema.union(["sd-lora", "sdxl-lora"]).default("sd-lora").description("训练种类"),
5 | pretrained_model_name_or_path: Schema.string().role('filepicker', { type: "model-file" }).default("./sd-models/model.safetensors").description("底模文件路径"),
6 | resume: Schema.string().role('filepicker', { type: "folder" }).description("从某个 `save_state` 保存的中断状态继续训练,填写文件路径"),
7 | vae: Schema.string().role('filepicker', { type: "model-file" }).description("(可选) VAE 模型文件路径,使用外置 VAE 文件覆盖模型内本身的"),
8 | }).description("训练用模型"),
9 |
10 | Schema.union([
11 | Schema.object({
12 | model_train_type: Schema.const("sd-lora"),
13 | v2: Schema.boolean().default(false).description("底模为 sd2.0 以后的版本需要启用"),
14 | }),
15 | Schema.object({}),
16 | ]),
17 |
18 | Schema.union([
19 | Schema.object({
20 | model_train_type: Schema.const("sd-lora"),
21 | v2: Schema.const(true).required(),
22 | v_parameterization: Schema.boolean().default(false).description("v-parameterization 学习"),
23 | scale_v_pred_loss_like_noise_pred: Schema.boolean().default(false).description("缩放 v-prediction 损失(与v-parameterization配合使用)"),
24 | }),
25 | Schema.object({}),
26 | ]),
27 | ]),
28 |
29 | // 数据集设置
30 | Schema.object(SHARED_SCHEMAS.RAW.DATASET_SETTINGS).description("数据集设置"),
31 |
32 | // 保存设置
33 | SHARED_SCHEMAS.SAVE_SETTINGS,
34 |
35 | Schema.object({
36 | max_train_epochs: Schema.number().min(1).default(10).description("最大训练 epoch(轮数)"),
37 | train_batch_size: Schema.number().min(1).default(1).description("批量大小, 越高显存占用越高"),
38 | gradient_checkpointing: Schema.boolean().default(false).description("梯度检查点"),
39 | gradient_accumulation_steps: Schema.number().min(1).description("梯度累加步数"),
40 | network_train_unet_only: Schema.boolean().default(false).description("仅训练 U-Net 训练SDXL Lora时推荐开启"),
41 | network_train_text_encoder_only: Schema.boolean().default(false).description("仅训练文本编码器"),
42 | }).description("训练相关参数"),
43 |
44 | // 学习率&优化器设置
45 | SHARED_SCHEMAS.LR_OPTIMIZER,
46 |
47 | Schema.intersect([
48 | Schema.object({
49 | network_module: Schema.union(["networks.lora", "networks.dylora", "networks.oft", "lycoris.kohya"]).default("networks.lora").description("训练网络模块"),
50 | network_weights: Schema.string().role('filepicker').description("从已有的 LoRA 模型上继续训练,填写路径"),
51 | network_dim: Schema.number().min(1).default(32).description("网络维度,常用 4~128,不是越大越好, 低dim可以降低显存占用"),
52 | network_alpha: Schema.number().min(1).default(32).description("常用值:等于 network_dim 或 network_dim*1/2 或 1。使用较小的 alpha 需要提升学习率"),
53 | network_dropout: Schema.number().step(0.01).default(0).description('dropout 概率 (与 lycoris 不兼容,需要用 lycoris 自带的)'),
54 | scale_weight_norms: Schema.number().step(0.01).min(0).description("最大范数正则化。如果使用,推荐为 1"),
55 | network_args_custom: Schema.array(String).role('table').description('自定义 network_args,一行一个'),
56 | enable_block_weights: Schema.boolean().default(false).description('启用分层学习率训练(只支持网络模块 networks.lora)'),
57 | enable_base_weight: Schema.boolean().default(false).description('启用基础权重(差异炼丹)'),
58 | }).description("网络设置"),
59 |
60 | // lycoris 参数
61 | SHARED_SCHEMAS.LYCORIS_MAIN,
62 | SHARED_SCHEMAS.LYCORIS_LOKR,
63 |
64 | // dylora 参数
65 | SHARED_SCHEMAS.NETWORK_OPTION_DYLORA,
66 |
67 | // 分层学习率参数
68 | SHARED_SCHEMAS.NETWORK_OPTION_BLOCK_WEIGHTS,
69 |
70 | SHARED_SCHEMAS.NETWORK_OPTION_BASEWEIGHT,
71 | ]),
72 |
73 | // 预览图设置
74 | SHARED_SCHEMAS.PREVIEW_IMAGE,
75 |
76 | // 日志设置
77 | SHARED_SCHEMAS.LOG_SETTINGS,
78 |
79 | // caption 选项
80 | Schema.object(SHARED_SCHEMAS.RAW.CAPTION_SETTINGS).description("caption(Tag)选项"),
81 |
82 | // 噪声设置
83 | SHARED_SCHEMAS.NOISE_SETTINGS,
84 |
85 | // 数据增强
86 | SHARED_SCHEMAS.DATA_ENCHANCEMENT,
87 |
88 | // 其他选项
89 | SHARED_SCHEMAS.OTHER,
90 |
91 | // 速度优化选项
92 | Schema.object(SHARED_SCHEMAS.RAW.PRECISION_CACHE_BATCH).description("速度优化选项"),
93 |
94 | // 分布式训练
95 | SHARED_SCHEMAS.DISTRIBUTED_TRAINING
96 | ]);
97 |
--------------------------------------------------------------------------------
/mikazuki/schema/lumina2-lora.ts:
--------------------------------------------------------------------------------
1 | //使用sd-script的配置
2 | Schema.intersect([
3 | Schema.object({
4 | model_train_type: Schema.string().default("lumina-lora").disabled().description("训练种类"),
5 | pretrained_model_name_or_path: Schema.string().role('filepicker', { type: "model-file" }).default("./sd-models/model.safetensors").description("Lumina 模型路径"),
6 | ae: Schema.string().role('filepicker', { type: "model-file" }).description("AE 模型文件路径"),
7 | gemma2: Schema.string().role('filepicker', { type: "model-file" }).description("gemma2 模型文件路径"),
8 | resume: Schema.string().role('filepicker', { type: "folder" }).description("从某个 `save_state` 保存的中断状态继续训练,填写文件路径"),
9 | }).description("训练用模型"),
10 |
11 | Schema.object({
12 | timestep_sampling: Schema.union(["sigma", "uniform", "sigmoid", "shift", "nextdit_shift"]).default("nextdit_shift").description("时间步采样"),
13 | sigmoid_scale: Schema.number().step(0.001).default(1.0).description("sigmoid 缩放"),
14 | model_prediction_type: Schema.union(["raw", "additive", "sigma_scaled"]).default("raw").description("模型预测类型"),
15 | discrete_flow_shift: Schema.number().step(0.001).default(3.185).description("Euler 调度器离散流位移"),
16 | //loss_type: Schema.union(["l1", "l2", "huber", "smooth_l1"]).default("l2").description("损失函数类型"),
17 | guidance_scale: Schema.number().step(0.01).default(1.0).description("CFG 引导缩放"),
18 | use_flash_attn: Schema.boolean().default(false).description("是否使用 Flash Attention"),
19 | cfg_trunc: Schema.number().step(0.01).default(0.25).description("CFG 截断"),
20 | renorm_cfg: Schema.number().step(0.01).default(1.0).description("重归一化 CFG"),
21 | system_prompt: Schema.string().default("You are an assistant designed to generate high-quality images based on user prompts. ").description("Gemma2b的系统提示"),
22 | }).description("Lumina 专用参数"),
23 |
24 | Schema.object(
25 | UpdateSchema(SHARED_SCHEMAS.RAW.DATASET_SETTINGS, {
26 | resolution: Schema.string().default("1024,1024").description("训练图片分辨率,宽x高。支持非正方形,但必须是 64 倍数。"),
27 | enable_bucket: Schema.boolean().default(true).description("启用 arb 桶以允许非固定宽高比的图片"),
28 | min_bucket_reso: Schema.number().default(256).description("arb 桶最小分辨率"),
29 | max_bucket_reso: Schema.number().default(2048).description("arb 桶最大分辨率"),
30 | bucket_reso_steps: Schema.number().default(64).description("arb 桶分辨率划分单位"),
31 | })
32 | ).description("数据集设置"),
33 |
34 | // 保存设置
35 | SHARED_SCHEMAS.SAVE_SETTINGS,
36 |
37 | Schema.object({
38 | max_train_epochs: Schema.number().min(1).default(10).description("最大训练 epoch(轮数)"),
39 | train_batch_size: Schema.number().min(1).default(2).description("批量大小, 越高显存占用越高"),
40 | gradient_checkpointing: Schema.boolean().default(true).description("梯度检查点"),
41 | gradient_accumulation_steps: Schema.number().min(1).default(1).description("梯度累加步数"),
42 | network_train_unet_only: Schema.boolean().default(true).description("仅训练 U-Net"),
43 | network_train_text_encoder_only: Schema.boolean().default(false).description("仅训练文本编码器"),
44 | }).description("训练相关参数"),
45 |
46 | // 学习率&优化器设置
47 | SHARED_SCHEMAS.LR_OPTIMIZER,
48 |
49 | Schema.intersect([
50 | Schema.object({
51 | network_module: Schema.union(["networks.lora_lumina", "networks.oft_lumina", "lycoris.kohya"]).default("networks.lora_lumina").description("训练网络模块"),
52 | network_weights: Schema.string().role('filepicker').description("从已有的 LoRA 模型上继续训练,填写路径"),
53 | network_dim: Schema.number().min(1).default(16).description("网络维度,常用 4~128,不是越大越好, 低dim可以降低显存占用"),
54 | network_alpha: Schema.number().min(1).default(8).description("常用值:等于 network_dim 或 network_dim*1/2 或 1。使用较小的 alpha 需要提升学习率"),
55 | network_dropout: Schema.number().step(0.01).default(0).description('dropout 概率 (与 lycoris 不兼容,需要用 lycoris 自带的)'),
56 | scale_weight_norms: Schema.number().step(0.01).min(0).default(1.0).description("最大范数正则化。如果使用,推荐为 1"),
57 | network_args_custom: Schema.array(String).role('table').description('自定义 network_args,一行一个'),
58 | enable_base_weight: Schema.boolean().default(false).description('启用基础权重(差异炼丹)'),
59 | }).description("网络设置"),
60 |
61 | // lycoris 参数
62 | SHARED_SCHEMAS.LYCORIS_MAIN,
63 | SHARED_SCHEMAS.LYCORIS_LOKR,
64 |
65 | SHARED_SCHEMAS.NETWORK_OPTION_BASEWEIGHT,
66 | ]),
67 |
68 | // 预览图设置
69 | SHARED_SCHEMAS.PREVIEW_IMAGE,
70 |
71 | // 日志设置
72 | SHARED_SCHEMAS.LOG_SETTINGS,
73 |
74 | // caption 选项
75 | Schema.object(UpdateSchema(SHARED_SCHEMAS.RAW.CAPTION_SETTINGS, {}, ["max_token_length"])).description("caption(Tag)选项"),
76 |
77 | // 噪声设置
78 | SHARED_SCHEMAS.NOISE_SETTINGS,
79 |
80 | // 数据增强
81 | SHARED_SCHEMAS.DATA_ENCHANCEMENT,
82 |
83 | // 其他选项
84 | SHARED_SCHEMAS.OTHER,
85 |
86 | // 速度优化选项
87 | Schema.object(
88 | UpdateSchema(SHARED_SCHEMAS.RAW.PRECISION_CACHE_BATCH, {
89 | fp8_base: Schema.boolean().default(false).description("对基础模型使用 FP8 精度"), // lumina 默认为 false
90 | fp8_base_unet: Schema.boolean().default(false).description("仅对 U-Net 使用 FP8 精度(CLIP-L不使用)"), // lumina 默认为 false
91 | sdpa: Schema.boolean().default(true).description("启用 sdpa"), // 脚本中未明确指定,但通常建议开启
92 | cache_text_encoder_outputs: Schema.boolean().default(true).description("缓存文本编码器的输出,减少显存使用。使用时需要关闭 shuffle_caption"),
93 | cache_text_encoder_outputs_to_disk: Schema.boolean().default(true).description("缓存文本编码器的输出到磁盘"),
94 | }, ["xformers"])
95 | ).description("速度优化选项"),
96 |
97 | // 分布式训练
98 | SHARED_SCHEMAS.DISTRIBUTED_TRAINING
99 | ]);
--------------------------------------------------------------------------------
/mikazuki/schema/sd3-lora.ts:
--------------------------------------------------------------------------------
1 | Schema.intersect([
2 | Schema.object({
3 | model_train_type: Schema.string().default("sd3-lora").disabled().description("训练种类"),
4 | pretrained_model_name_or_path: Schema.string().role('filepicker', { type: "model-file" }).default("./sd-models/model.safetensors").description("SD3 模型路径"),
5 | clip_l: Schema.string().role('filepicker', { type: "model-file" }).description("clip_l 模型文件路径"),
6 | clip_g: Schema.string().role('filepicker', { type: "model-file" }).description("clip_g 模型文件路径"),
7 | t5xxl: Schema.string().role('filepicker', { type: "model-file" }).description("t5xxl 模型文件路径"),
8 | resume: Schema.string().role('filepicker', { type: "folder" }).description("从某个 `save_state` 保存的中断状态继续训练,填写文件路径"),
9 | }).description("训练用模型"),
10 |
11 | Schema.object({
12 | t5xxl_max_token_length: Schema.number().step(1).description("T5XXL 最大 token 长度(不填写使用自动)"),
13 | train_t5xxl: Schema.boolean().default(false).description("训练 T5XXL(不推荐)"),
14 | }).description("SD3 专用参数"),
15 |
16 | Schema.object(
17 | UpdateSchema(SHARED_SCHEMAS.RAW.DATASET_SETTINGS, {
18 | resolution: Schema.string().default("768,768").description("训练图片分辨率,宽x高。支持非正方形,但必须是 64 倍数。"),
19 | enable_bucket: Schema.boolean().default(true).description("启用 arb 桶以允许非固定宽高比的图片"),
20 | min_bucket_reso: Schema.number().default(256).description("arb 桶最小分辨率"),
21 | max_bucket_reso: Schema.number().default(2048).description("arb 桶最大分辨率"),
22 | bucket_reso_steps: Schema.number().default(64).description("arb 桶分辨率划分单位"),
23 | })
24 | ).description("数据集设置"),
25 |
26 | // 保存设置
27 | SHARED_SCHEMAS.SAVE_SETTINGS,
28 |
29 | Schema.object({
30 | max_train_epochs: Schema.number().min(1).default(20).description("最大训练 epoch(轮数)"),
31 | train_batch_size: Schema.number().min(1).default(1).description("批量大小, 越高显存占用越高"),
32 | gradient_checkpointing: Schema.boolean().default(true).description("梯度检查点"),
33 | gradient_accumulation_steps: Schema.number().min(1).default(1).description("梯度累加步数"),
34 | network_train_unet_only: Schema.boolean().default(true).description("仅训练 U-Net"),
35 | network_train_text_encoder_only: Schema.boolean().default(false).description("仅训练文本编码器"),
36 | }).description("训练相关参数"),
37 |
38 | // 学习率&优化器设置
39 | SHARED_SCHEMAS.LR_OPTIMIZER,
40 |
41 | Schema.intersect([
42 | Schema.object({
43 | network_module: Schema.union(["networks.lora_sd3", "lycoris.kohya"]).default("networks.lora_sd3").description("训练网络模块"),
44 | network_weights: Schema.string().role('filepicker').description("从已有的 LoRA 模型上继续训练,填写路径"),
45 | network_dim: Schema.number().min(1).default(4).description("网络维度,常用 4~128,不是越大越好, 低dim可以降低显存占用"),
46 | network_alpha: Schema.number().min(1).default(1).description("常用值:等于 network_dim 或 network_dim*1/2 或 1。使用较小的 alpha 需要提升学习率"),
47 | network_args_custom: Schema.array(String).role('table').description('自定义 network_args,一行一个'),
48 | enable_base_weight: Schema.boolean().default(false).description('启用基础权重(差异炼丹)'),
49 | }).description("网络设置"),
50 |
51 | // lycoris 参数
52 | SHARED_SCHEMAS.LYCORIS_MAIN,
53 | SHARED_SCHEMAS.LYCORIS_LOKR,
54 |
55 | SHARED_SCHEMAS.NETWORK_OPTION_BASEWEIGHT,
56 | ]),
57 |
58 | // 预览图设置
59 | SHARED_SCHEMAS.PREVIEW_IMAGE,
60 |
61 | // 日志设置
62 | SHARED_SCHEMAS.LOG_SETTINGS,
63 |
64 | // caption 选项
65 | // FLUX 去除 max_token_length
66 | Schema.object(UpdateSchema(SHARED_SCHEMAS.RAW.CAPTION_SETTINGS, {}, ["max_token_length"])).description("caption(Tag)选项"),
67 |
68 | // 噪声设置
69 | SHARED_SCHEMAS.NOISE_SETTINGS,
70 |
71 | // 数据增强
72 | SHARED_SCHEMAS.DATA_ENCHANCEMENT,
73 |
74 | // 其他选项
75 | SHARED_SCHEMAS.OTHER,
76 |
77 | // 速度优化选项
78 | Schema.object(
79 | UpdateSchema(SHARED_SCHEMAS.RAW.PRECISION_CACHE_BATCH, {
80 | fp8_base: Schema.boolean().default(true).description("对基础模型使用 FP8 精度"),
81 | fp8_base_unet: Schema.boolean().description("仅对 U-Net 使用 FP8 精度(CLIP-L不使用)"),
82 | sdpa: Schema.boolean().default(true).description("启用 sdpa"),
83 | cache_text_encoder_outputs: Schema.boolean().default(true).description("缓存文本编码器的输出,减少显存使用。使用时需要关闭 shuffle_caption"),
84 | cache_text_encoder_outputs_to_disk: Schema.boolean().default(true).description("缓存文本编码器的输出到磁盘"),
85 | }, ["xformers"])
86 | ).description("速度优化选项"),
87 |
88 | // 分布式训练
89 | SHARED_SCHEMAS.DISTRIBUTED_TRAINING
90 | ]);
91 |
--------------------------------------------------------------------------------
/mikazuki/scripts/fix_scripts_python_executable_path.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import re
4 | from pathlib import Path
5 |
6 | py_path = sys.executable
7 | scripts_path = Path(sys.executable).parent
8 |
9 | if scripts_path.name != "Scripts":
10 | print("Seems your env not venv, do you want to continue? [y/n]")
11 | sure = input()
12 | if sure != "y":
13 | sys.exit(1)
14 |
15 | scripts_list = os.listdir(scripts_path)
16 |
17 | for script in scripts_list:
18 | if not script.endswith(".exe") or script in ["python.exe", "pythonw.exe"]:
19 | continue
20 |
21 | with open(os.path.join(scripts_path, script), "rb+") as f:
22 | s = f.read()
23 | spl = re.split(b'(#!.*python\.exe)', s)
24 | if len(spl) == 3:
25 | spl[1] = bytes(b"#!"+sys.executable.encode())
26 | f.seek(0)
27 | f.write(b''.join(spl))
28 | print(f"fixed {script}")
--------------------------------------------------------------------------------
/mikazuki/scripts/torch_check.py:
--------------------------------------------------------------------------------
1 | import sys
2 |
3 | def check_torch_gpu():
4 | try:
5 | import torch
6 | print(f'Torch {torch.__version__}')
7 | if torch.cuda.is_available():
8 | if torch.version.cuda:
9 | print(
10 | f'Torch backend: nVidia CUDA {torch.version.cuda} cuDNN {torch.backends.cudnn.version() if torch.backends.cudnn.is_available() else "N/A"}')
11 | for device in [torch.cuda.device(i) for i in range(torch.cuda.device_count())]:
12 | print(f'Torch detected GPU: {torch.cuda.get_device_name(device)} VRAM {round(torch.cuda.get_device_properties(device).total_memory / 1024 / 1024)} Arch {torch.cuda.get_device_capability(device)} Cores {torch.cuda.get_device_properties(device).multi_processor_count}')
13 | else:
14 | print("Torch is not able to use GPU, please check your torch installation.\n Use --skip-prepare-environment to disable this check")
15 | except Exception as e:
16 | print(f'Could not load torch: {e}')
17 | sys.exit(1)
18 |
19 | check_torch_gpu()
--------------------------------------------------------------------------------
/mikazuki/tagger/dbimutils.py:
--------------------------------------------------------------------------------
1 | # DanBooru IMage Utility functions
2 |
3 | import cv2
4 | import numpy as np
5 | from PIL import Image
6 |
7 |
8 | def smart_imread(img, flag=cv2.IMREAD_UNCHANGED):
9 | if img.endswith(".gif"):
10 | img = Image.open(img)
11 | img = img.convert("RGB")
12 | img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
13 | else:
14 | img = cv2.imread(img, flag)
15 | return img
16 |
17 |
18 | def smart_24bit(img):
19 | if img.dtype is np.dtype(np.uint16):
20 | img = (img / 257).astype(np.uint8)
21 |
22 | if len(img.shape) == 2:
23 | img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
24 | elif img.shape[2] == 4:
25 | trans_mask = img[:, :, 3] == 0
26 | img[trans_mask] = [255, 255, 255, 255]
27 | img = cv2.cvtColor(img, cv2.COLOR_BGRA2BGR)
28 | return img
29 |
30 |
31 | def make_square(img, target_size):
32 | old_size = img.shape[:2]
33 | desired_size = max(old_size)
34 | desired_size = max(desired_size, target_size)
35 |
36 | delta_w = desired_size - old_size[1]
37 | delta_h = desired_size - old_size[0]
38 | top, bottom = delta_h // 2, delta_h - (delta_h // 2)
39 | left, right = delta_w // 2, delta_w - (delta_w // 2)
40 |
41 | color = [255, 255, 255]
42 | new_im = cv2.copyMakeBorder(
43 | img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color
44 | )
45 | return new_im
46 |
47 |
48 | def smart_resize(img, size):
49 | # Assumes the image has already gone through make_square
50 | if img.shape[0] > size:
51 | img = cv2.resize(img, (size, size), interpolation=cv2.INTER_AREA)
52 | elif img.shape[0] < size:
53 | img = cv2.resize(img, (size, size), interpolation=cv2.INTER_CUBIC)
54 | return img
55 |
--------------------------------------------------------------------------------
/mikazuki/tagger/format.py:
--------------------------------------------------------------------------------
1 | import re
2 | import hashlib
3 |
4 | from typing import Dict, Callable, NamedTuple
5 | from pathlib import Path
6 |
7 |
8 | class Info(NamedTuple):
9 | path: Path
10 | output_ext: str
11 |
12 |
13 | def hash(i: Info, algo='sha1') -> str:
14 | try:
15 | hash = hashlib.new(algo)
16 | except ImportError:
17 | raise ValueError(f"'{algo}' is invalid hash algorithm")
18 |
19 | # TODO: is okay to hash large image?
20 | with open(i.path, 'rb') as file:
21 | hash.update(file.read())
22 |
23 | return hash.hexdigest()
24 |
25 |
26 | pattern = re.compile(r'\[([\w:]+)\]')
27 |
28 | # all function must returns string or raise TypeError or ValueError
29 | # other errors will cause the extension error
30 | available_formats: Dict[str, Callable] = {
31 | 'name': lambda i: i.path.stem,
32 | 'extension': lambda i: i.path.suffix[1:],
33 | 'hash': hash,
34 |
35 | 'output_extension': lambda i: i.output_ext
36 | }
37 |
38 |
39 | def format(match: re.Match, info: Info) -> str:
40 | matches = match[1].split(':')
41 | name, args = matches[0], matches[1:]
42 |
43 | if name not in available_formats:
44 | return match[0]
45 |
46 | return available_formats[name](info, *args)
47 |
--------------------------------------------------------------------------------
/mikazuki/tasks.py:
--------------------------------------------------------------------------------
1 | import subprocess
2 | import sys
3 | import os
4 | import threading
5 | import uuid
6 | from enum import Enum
7 | from typing import Dict, List
8 | from subprocess import Popen, PIPE, TimeoutExpired, CalledProcessError, CompletedProcess
9 | import psutil
10 |
11 | from mikazuki.log import log
12 |
13 | try:
14 | import msvcrt
15 | import _winapi
16 | _mswindows = True
17 | except ModuleNotFoundError:
18 | _mswindows = False
19 |
20 |
21 | def kill_proc_tree(pid, including_parent=True):
22 | parent = psutil.Process(pid)
23 | children = parent.children(recursive=True)
24 | for child in children:
25 | child.kill()
26 | gone, still_alive = psutil.wait_procs(children, timeout=5)
27 | if including_parent:
28 | parent.kill()
29 | parent.wait(5)
30 |
31 |
32 | class TaskStatus(Enum):
33 | CREATED = 0
34 | RUNNING = 1
35 | FINISHED = 2
36 | TERMINATED = 3
37 |
38 |
39 | class Task:
40 | def __init__(self, task_id, command, environ=None):
41 | self.task_id = task_id
42 | self.lock = threading.Lock()
43 | self.command = command
44 | self.status = TaskStatus.CREATED
45 | self.environ = environ or os.environ
46 |
47 | def communicate(self, input=None, timeout=None):
48 | try:
49 | stdout, stderr = self.process.communicate(input, timeout=timeout)
50 | except TimeoutExpired as exc:
51 | self.process.kill()
52 | if _mswindows:
53 | exc.stdout, exc.stderr = self.process.communicate()
54 | else:
55 | self.process.wait()
56 | raise
57 | except:
58 | self.process.kill()
59 | raise
60 | retcode = self.process.poll()
61 | self.status = TaskStatus.FINISHED
62 | return CompletedProcess(self.process.args, retcode, stdout, stderr)
63 |
64 | def wait(self):
65 | self.process.wait()
66 | self.status = TaskStatus.FINISHED
67 |
68 | def execute(self):
69 | self.status = TaskStatus.RUNNING
70 | self.process = subprocess.Popen(self.command, env=self.environ)
71 |
72 | def terminate(self):
73 | try:
74 | kill_proc_tree(self.process.pid, False)
75 | except Exception as e:
76 | log.error(f"Error when killing process: {e}")
77 | return
78 | finally:
79 | self.status = TaskStatus.TERMINATED
80 |
81 |
82 | class TaskManager:
83 | def __init__(self, max_concurrent=1) -> None:
84 | self.max_concurrent = max_concurrent
85 | self.tasks: Dict[Task] = {}
86 |
87 | def create_task(self, command: List[str], environ):
88 | running_tasks = [t for _, t in self.tasks.items() if t.status == TaskStatus.RUNNING]
89 | if len(running_tasks) >= self.max_concurrent:
90 | log.error(
91 | f"Unable to create a task because there are already {len(running_tasks)} tasks running, reaching the maximum concurrent limit. / 无法创建任务,因为已经有 {len(running_tasks)} 个任务正在运行,已达到最大并发限制。")
92 | return None
93 | task_id = str(uuid.uuid4())
94 | task = Task(task_id=task_id, command=command, environ=environ)
95 | self.tasks[task_id] = task
96 | # task.execute() # breaking change
97 | log.info(f"Task {task_id} created")
98 | return task
99 |
100 | def add_task(self, task_id: str, task: Task):
101 | self.tasks[task_id] = task
102 |
103 | def terminate_task(self, task_id: str):
104 | if task_id in self.tasks:
105 | task = self.tasks[task_id]
106 | task.terminate()
107 |
108 | def wait_for_process(self, task_id: str):
109 | if task_id in self.tasks:
110 | task: Task = self.tasks[task_id]
111 | task.wait()
112 |
113 | def dump(self) -> List[Dict]:
114 | return [
115 | {
116 | "id": task.task_id,
117 | "status": task.status.name,
118 | }
119 | for task in self.tasks.values()
120 | ]
121 |
122 |
123 | tm = TaskManager()
124 |
--------------------------------------------------------------------------------
/mikazuki/tsconfig.json:
--------------------------------------------------------------------------------
1 | {
2 | "compilerOptions": {
3 | "target": "ES2020",
4 | "module": "commonjs",
5 | },
6 | "include": [
7 | "**/*.ts"
8 | ],
9 | }
--------------------------------------------------------------------------------
/mikazuki/utils/devices.py:
--------------------------------------------------------------------------------
1 | from mikazuki.log import log
2 | from packaging.version import Version
3 |
4 | available_devices = []
5 | printable_devices = []
6 |
7 |
8 | def check_torch_gpu():
9 | try:
10 | import torch
11 | log.info(f'Torch {torch.__version__}')
12 | if not torch.cuda.is_available():
13 | log.error("Torch is not able to use GPU, please check your torch installation.\n Use --skip-prepare-environment to disable this check")
14 | log.error("!!!Torch 无法使用 GPU,您无法正常开始训练!!!\n您的显卡可能并不支持,或是 torch 安装有误。请检查您的 torch 安装。")
15 | if "cpu" in torch.__version__:
16 | log.error("You are using torch CPU, please install torch GPU version by run install script again.")
17 | log.error("!!!您正在使用 CPU 版本的 torch,无法正常开始训练。请重新运行安装脚本!!!")
18 | return
19 |
20 | if Version(torch.__version__) < Version("2.3.0"):
21 | log.warning("Torch version is lower than 2.3.0, which may not be able to train FLUX model properly. Please re-run the installation script (install.ps1 or install.bash) to upgrade Torch.")
22 | log.warning("!!!Torch 版本低于 2.3.0,将无法正常训练 FLUX 模型。请考虑重新运行安装脚本以升级 Torch!!!")
23 | log.warning("!!!若您正在使用训练包,请直接下载最新训练包!!!")
24 |
25 | if torch.version.cuda:
26 | log.info(
27 | f'Torch backend: nVidia CUDA {torch.version.cuda} cuDNN {torch.backends.cudnn.version() if torch.backends.cudnn.is_available() else "N/A"}')
28 | elif torch.version.hip:
29 | log.info(f'Torch backend: AMD ROCm HIP {torch.version.hip}')
30 |
31 | devices = [torch.cuda.device(i) for i in range(torch.cuda.device_count())]
32 |
33 | for pos, device in enumerate(devices):
34 | name = torch.cuda.get_device_name(device)
35 | memory = torch.cuda.get_device_properties(device).total_memory
36 | available_devices.append(device)
37 | printable_devices.append(f"GPU {pos}: {name} ({round(memory / (1024**3))} GB)")
38 | log.info(
39 | f'Torch detected GPU: {name} VRAM {round(memory / 1024 / 1024)} Arch {torch.cuda.get_device_capability(device)} Cores {torch.cuda.get_device_properties(device).multi_processor_count}')
40 | except Exception as e:
41 | log.error(f'Could not load torch: {e}')
42 |
--------------------------------------------------------------------------------
/mikazuki/utils/tk_window.py:
--------------------------------------------------------------------------------
1 | import os
2 | from mikazuki.log import log
3 | try:
4 | import tkinter
5 | from tkinter.filedialog import askdirectory, askopenfilename
6 | except ImportError:
7 | tkinter = None
8 | askdirectory = None
9 | askopenfilename = None
10 | log.warning("tkinter not found, file selector will not work.")
11 |
12 | last_dir = ""
13 |
14 |
15 | def tk_window():
16 | window = tkinter.Tk()
17 | window.wm_attributes('-topmost', 1)
18 | window.withdraw()
19 |
20 |
21 | def open_file_selector(
22 | initialdir="",
23 | title="Select a file",
24 | filetypes="*") -> str:
25 | global last_dir
26 | if last_dir != "":
27 | initialdir = last_dir
28 | elif initialdir == "":
29 | initialdir = os.getcwd()
30 | try:
31 | tk_window()
32 | filename = askopenfilename(
33 | initialdir=initialdir, title=title,
34 | filetypes=filetypes
35 | )
36 | last_dir = os.path.dirname(filename)
37 | return filename
38 | except:
39 | return ""
40 |
41 |
42 | def open_directory_selector(initialdir) -> str:
43 | global last_dir
44 | if last_dir != "":
45 | initialdir = last_dir
46 | elif initialdir == "":
47 | initialdir = os.getcwd()
48 | try:
49 | tk_window()
50 | directory = askdirectory(
51 | initialdir=initialdir
52 | )
53 | last_dir = directory
54 | return directory
55 | except:
56 | return ""
57 |
--------------------------------------------------------------------------------
/output/.keep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Akegarasu/lora-scripts/e0f5194815203093659d6ec280b9362b9792c070/output/.keep
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | accelerate==0.33.0
2 | transformers==4.44.0
3 | diffusers[torch]==0.25.0
4 | ftfy==6.1.1
5 | # albumentations==1.3.0
6 | opencv-python==4.8.1.78
7 | einops==0.7.0
8 | pytorch-lightning==1.9.0
9 | bitsandbytes==0.46.0
10 | lion-pytorch==0.1.2
11 | schedulefree==1.4
12 | pytorch-optimizer==3.5.0
13 | prodigy-plus-schedule-free==1.9.0
14 | prodigyopt==1.1.2
15 | tensorboard==2.10.1
16 | safetensors==0.4.4
17 | prodigy-plus-schedule-free
18 | # gradio==3.16.2
19 | altair==4.2.2
20 | easygui==0.98.3
21 | toml==0.10.2
22 | voluptuous==0.13.1
23 | huggingface-hub==0.24.5
24 | # for Image utils
25 | imagesize==1.4.1
26 | # for T5XXL tokenizer (SD3/FLUX)
27 | sentencepiece==0.2.0
28 | # for ui
29 | rich==13.7.0
30 | pandas
31 | scipy
32 | requests
33 | pillow
34 | numpy==1.26.4
35 | # <=2.0.0
36 | gradio==3.44.2
37 | fastapi==0.95.1
38 | uvicorn==0.22.0
39 | wandb==0.16.2
40 | httpx==0.24.1
41 | # extra
42 | open-clip-torch==2.20.0
43 | lycoris-lora==2.1.0.post3
44 | dadaptation==3.1
45 |
--------------------------------------------------------------------------------
/resize.ps1:
--------------------------------------------------------------------------------
1 | # LoRA resize script by @bdsqlsz
2 |
3 | $save_precision = "fp16" # precision in saving, default float | 保存精度, 可选 float、fp16、bf16, 默认 float
4 | $new_rank = 4 # dim rank of output LoRA | dim rank等级, 默认 4
5 | $model = "./output/lora_name.safetensors" # original LoRA model path need to resize, save as cpkt or safetensors | 需要调整大小的模型路径, 保存格式 cpkt 或 safetensors
6 | $save_to = "./output/lora_name_new.safetensors" # output LoRA model path, save as ckpt or safetensors | 输出路径, 保存格式 cpkt 或 safetensors
7 | $device = "cuda" # device to use, cuda for GPU | 使用 GPU跑, 默认 CPU
8 | $verbose = 1 # display verbose resizing information | rank变更时, 显示详细信息
9 | $dynamic_method = "" # Specify dynamic resizing method, --new_rank is used as a hard limit for max rank | 动态调节大小,可选"sv_ratio", "sv_fro", "sv_cumulative",默认无
10 | $dynamic_param = "" # Specify target for dynamic reduction | 动态参数,sv_ratio模式推荐1~2, sv_cumulative模式0~1, sv_fro模式0~1, 比sv_cumulative要高
11 |
12 |
13 | # Activate python venv
14 | .\venv\Scripts\activate
15 |
16 | $Env:HF_HOME = "huggingface"
17 | $ext_args = [System.Collections.ArrayList]::new()
18 |
19 | if ($verbose) {
20 | [void]$ext_args.Add("--verbose")
21 | }
22 |
23 | if ($dynamic_method) {
24 | [void]$ext_args.Add("--dynamic_method=" + $dynamic_method)
25 | }
26 |
27 | if ($dynamic_param) {
28 | [void]$ext_args.Add("--dynamic_param=" + $dynamic_param)
29 | }
30 |
31 | # run resize
32 | accelerate launch --num_cpu_threads_per_process=8 "./scripts/networks/resize_lora.py" `
33 | --save_precision=$save_precision `
34 | --new_rank=$new_rank `
35 | --model=$model `
36 | --save_to=$save_to `
37 | --device=$device `
38 | $ext_args
39 |
40 | Write-Output "Resize finished"
41 | Read-Host | Out-Null ;
42 |
--------------------------------------------------------------------------------
/run.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "id": "5e35269a-ec20-41a3-93a6-da798c3a8401",
6 | "metadata": {},
7 | "source": [
8 | "# LoRA Train UI: SD-Trainer\n",
9 | "\n",
10 | "LoRA Training UI By [Akegarasu](https://github.com/Akegarasu)\n",
11 | "User Guide:https://github.com/Akegarasu/lora-scripts/blob/main/README.md\n",
12 | "\n",
13 | "LoRA 训练 By [秋葉aaaki@bilibili](https://space.bilibili.com/12566101)\n",
14 | "使用方法:https://www.bilibili.com/read/cv24050162/"
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "id": "12c2a3d0-9aec-4680-9b8a-cb02cac48de6",
20 | "metadata": {},
21 | "source": [
22 | "### Run | 运行"
23 | ]
24 | },
25 | {
26 | "cell_type": "code",
27 | "execution_count": null,
28 | "id": "7ae0678f-69df-4a12-a0bc-1325e52e9122",
29 | "metadata": {},
30 | "outputs": [],
31 | "source": [
32 | "import sys\n",
33 | "!export HF_HOME=huggingface && $sys.executable gui.py --host 0.0.0.0"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "id": "99edaa2b-9ba2-4fde-9b2e-af5dc8bf7062",
39 | "metadata": {},
40 | "source": [
41 | "## Update | 更新"
42 | ]
43 | },
44 | {
45 | "cell_type": "markdown",
46 | "metadata": {},
47 | "source": [
48 | "### Github"
49 | ]
50 | },
51 | {
52 | "cell_type": "code",
53 | "execution_count": null,
54 | "metadata": {},
55 | "outputs": [],
56 | "source": [
57 | "!git pull && git submodule init && git submodule update"
58 | ]
59 | },
60 | {
61 | "cell_type": "markdown",
62 | "metadata": {},
63 | "source": [
64 | "### 国内镜像加速"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": null,
70 | "metadata": {},
71 | "outputs": [],
72 | "source": [
73 | "!export GIT_CONFIG_GLOBAL=./assets/gitconfig-cn && export GIT_TERMINAL_PROMPT=false && git pull && git submodule init && git submodule update"
74 | ]
75 | }
76 | ],
77 | "metadata": {
78 | "kernelspec": {
79 | "display_name": "Python 3 (ipykernel)",
80 | "language": "python",
81 | "name": "python3"
82 | },
83 | "language_info": {
84 | "codemirror_mode": {
85 | "name": "ipython",
86 | "version": 3
87 | },
88 | "file_extension": ".py",
89 | "mimetype": "text/x-python",
90 | "name": "python",
91 | "nbconvert_exporter": "python",
92 | "pygments_lexer": "ipython3",
93 | "version": "3.10.8"
94 | }
95 | },
96 | "nbformat": 4,
97 | "nbformat_minor": 5
98 | }
99 |
--------------------------------------------------------------------------------
/run_gui.ps1:
--------------------------------------------------------------------------------
1 | $Env:HF_HOME = "huggingface"
2 | $Env:PYTHONUTF8 = "1"
3 |
4 | if (Test-Path -Path "venv\Scripts\activate") {
5 | Write-Host -ForegroundColor green "Activating virtual environment..."
6 | .\venv\Scripts\activate
7 | }
8 | elseif (Test-Path -Path "python\python.exe") {
9 | Write-Host -ForegroundColor green "Using python from python folder..."
10 | $py_path = (Get-Item "python").FullName
11 | $env:PATH = "$py_path;$env:PATH"
12 | }
13 | else {
14 | Write-Host -ForegroundColor Blue "No virtual environment found, using system python..."
15 | }
16 |
17 | python gui.py
--------------------------------------------------------------------------------
/run_gui.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | export HF_HOME=huggingface
4 | export PYTHONUTF8=1
5 |
6 | python gui.py "$@"
7 |
8 |
--------------------------------------------------------------------------------
/run_gui_cn.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | source "./venv/bin/activate"
4 |
5 | export HF_HOME=huggingface
6 | export HF_ENDPOINT=https://hf-mirror.com
7 | export PIP_INDEX_URL="https://pypi.tuna.tsinghua.edu.cn/simple"
8 | export PYTHONUTF8=1
9 |
10 | python gui.py "$@"
11 |
12 |
13 |
--------------------------------------------------------------------------------
/scripts/dev/.gitignore:
--------------------------------------------------------------------------------
1 | logs
2 | __pycache__
3 | wd14_tagger_model
4 | venv
5 | *.egg-info
6 | build
7 | .vscode
8 | wandb
9 |
--------------------------------------------------------------------------------
/scripts/dev/COMMIT_ID:
--------------------------------------------------------------------------------
1 | 6364379f17d50add1696b0672f39c25c08a006b6
--------------------------------------------------------------------------------
/scripts/dev/README-ja.md:
--------------------------------------------------------------------------------
1 | ## リポジトリについて
2 | Stable Diffusionの学習、画像生成、その他のスクリプトを入れたリポジトリです。
3 |
4 | [README in English](./README.md) ←更新情報はこちらにあります
5 |
6 | 開発中のバージョンはdevブランチにあります。最新の変更点はdevブランチをご確認ください。
7 |
8 | FLUX.1およびSD3/SD3.5対応はsd3ブランチで行っています。それらの学習を行う場合はsd3ブランチをご利用ください。
9 |
10 | GUIやPowerShellスクリプトなど、より使いやすくする機能が[bmaltais氏のリポジトリ](https://github.com/bmaltais/kohya_ss)で提供されています(英語です)のであわせてご覧ください。bmaltais氏に感謝します。
11 |
12 | 以下のスクリプトがあります。
13 |
14 | * DreamBooth、U-NetおよびText Encoderの学習をサポート
15 | * fine-tuning、同上
16 | * LoRAの学習をサポート
17 | * 画像生成
18 | * モデル変換(Stable Diffision ckpt/safetensorsとDiffusersの相互変換)
19 |
20 | ## 使用法について
21 |
22 | * [学習について、共通編](./docs/train_README-ja.md) : データ整備やオプションなど
23 | * [データセット設定](./docs/config_README-ja.md)
24 | * [SDXL学習](./docs/train_SDXL-en.md) (英語版)
25 | * [DreamBoothの学習について](./docs/train_db_README-ja.md)
26 | * [fine-tuningのガイド](./docs/fine_tune_README_ja.md):
27 | * [LoRAの学習について](./docs/train_network_README-ja.md)
28 | * [Textual Inversionの学習について](./docs/train_ti_README-ja.md)
29 | * [画像生成スクリプト](./docs/gen_img_README-ja.md)
30 | * note.com [モデル変換スクリプト](https://note.com/kohya_ss/n/n374f316fe4ad)
31 |
32 | ## Windowsでの動作に必要なプログラム
33 |
34 | Python 3.10.6およびGitが必要です。
35 |
36 | - Python 3.10.6: https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
37 | - git: https://git-scm.com/download/win
38 |
39 | Python 3.10.x、3.11.x、3.12.xでも恐らく動作しますが、3.10.6でテストしています。
40 |
41 | PowerShellを使う場合、venvを使えるようにするためには以下の手順でセキュリティ設定を変更してください。
42 | (venvに限らずスクリプトの実行が可能になりますので注意してください。)
43 |
44 | - PowerShellを管理者として開きます。
45 | - 「Set-ExecutionPolicy Unrestricted」と入力し、Yと答えます。
46 | - 管理者のPowerShellを閉じます。
47 |
48 | ## Windows環境でのインストール
49 |
50 | スクリプトはPyTorch 2.1.2でテストしています。PyTorch 2.2以降でも恐らく動作します。
51 |
52 | (なお、python -m venv~の行で「python」とだけ表示された場合、py -m venv~のようにpythonをpyに変更してください。)
53 |
54 | PowerShellを使う場合、通常の(管理者ではない)PowerShellを開き以下を順に実行します。
55 |
56 | ```powershell
57 | git clone https://github.com/kohya-ss/sd-scripts.git
58 | cd sd-scripts
59 |
60 | python -m venv venv
61 | .\venv\Scripts\activate
62 |
63 | pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu118
64 | pip install --upgrade -r requirements.txt
65 | pip install xformers==0.0.23.post1 --index-url https://download.pytorch.org/whl/cu118
66 |
67 | accelerate config
68 | ```
69 |
70 | コマンドプロンプトでも同一です。
71 |
72 | 注:`bitsandbytes==0.44.0`、`prodigyopt==1.0`、`lion-pytorch==0.0.6` は `requirements.txt` に含まれるようになりました。他のバージョンを使う場合は適宜インストールしてください。
73 |
74 | この例では PyTorch および xfomers は2.1.2/CUDA 11.8版をインストールします。CUDA 12.1版やPyTorch 1.12.1を使う場合は適宜書き換えください。たとえば CUDA 12.1版の場合は `pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu121` および `pip install xformers==0.0.23.post1 --index-url https://download.pytorch.org/whl/cu121` としてください。
75 |
76 | PyTorch 2.2以降を用いる場合は、`torch==2.1.2` と `torchvision==0.16.2` 、および `xformers==0.0.23.post1` を適宜変更してください。
77 |
78 | accelerate configの質問には以下のように答えてください。(bf16で学習する場合、最後の質問にはbf16と答えてください。)
79 |
80 | ```txt
81 | - This machine
82 | - No distributed training
83 | - NO
84 | - NO
85 | - NO
86 | - all
87 | - fp16
88 | ```
89 |
90 | ※場合によって ``ValueError: fp16 mixed precision requires a GPU`` というエラーが出ることがあるようです。この場合、6番目の質問(
91 | ``What GPU(s) (by id) should be used for training on this machine as a comma-separated list? [all]:``)に「0」と答えてください。(id `0`のGPUが使われます。)
92 |
93 | ## アップグレード
94 |
95 | 新しいリリースがあった場合、以下のコマンドで更新できます。
96 |
97 | ```powershell
98 | cd sd-scripts
99 | git pull
100 | .\venv\Scripts\activate
101 | pip install --use-pep517 --upgrade -r requirements.txt
102 | ```
103 |
104 | コマンドが成功すれば新しいバージョンが使用できます。
105 |
106 | ## 謝意
107 |
108 | LoRAの実装は[cloneofsimo氏のリポジトリ](https://github.com/cloneofsimo/lora)を基にしたものです。感謝申し上げます。
109 |
110 | Conv2d 3x3への拡大は [cloneofsimo氏](https://github.com/cloneofsimo/lora) が最初にリリースし、KohakuBlueleaf氏が [LoCon](https://github.com/KohakuBlueleaf/LoCon) でその有効性を明らかにしたものです。KohakuBlueleaf氏に深く感謝します。
111 |
112 | ## ライセンス
113 |
114 | スクリプトのライセンスはASL 2.0ですが(Diffusersおよびcloneofsimo氏のリポジトリ由来のものも同様)、一部他のライセンスのコードを含みます。
115 |
116 | [Memory Efficient Attention Pytorch](https://github.com/lucidrains/memory-efficient-attention-pytorch): MIT
117 |
118 | [bitsandbytes](https://github.com/TimDettmers/bitsandbytes): MIT
119 |
120 | [BLIP](https://github.com/salesforce/BLIP): BSD-3-Clause
121 |
122 | ## その他の情報
123 |
124 | ### LoRAの名称について
125 |
126 | `train_network.py` がサポートするLoRAについて、混乱を避けるため名前を付けました。ドキュメントは更新済みです。以下は当リポジトリ内の独自の名称です。
127 |
128 | 1. __LoRA-LierLa__ : (LoRA for __Li__ n __e__ a __r__ __La__ yers、リエラと読みます)
129 |
130 | Linear 層およびカーネルサイズ 1x1 の Conv2d 層に適用されるLoRA
131 |
132 | 2. __LoRA-C3Lier__ : (LoRA for __C__ olutional layers with __3__ x3 Kernel and __Li__ n __e__ a __r__ layers、セリアと読みます)
133 |
134 | 1.に加え、カーネルサイズ 3x3 の Conv2d 層に適用されるLoRA
135 |
136 | デフォルトではLoRA-LierLaが使われます。LoRA-C3Lierを使う場合は `--network_args` に `conv_dim` を指定してください。
137 |
138 |
143 |
144 | ### 学習中のサンプル画像生成
145 |
146 | プロンプトファイルは例えば以下のようになります。
147 |
148 | ```
149 | # prompt 1
150 | masterpiece, best quality, (1girl), in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
151 |
152 | # prompt 2
153 | masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n (low quality, worst quality), bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
154 | ```
155 |
156 | `#` で始まる行はコメントになります。`--n` のように「ハイフン二個+英小文字」の形でオプションを指定できます。以下が使用可能できます。
157 |
158 | * `--n` Negative prompt up to the next option.
159 | * `--w` Specifies the width of the generated image.
160 | * `--h` Specifies the height of the generated image.
161 | * `--d` Specifies the seed of the generated image.
162 | * `--l` Specifies the CFG scale of the generated image.
163 | * `--s` Specifies the number of steps in the generation.
164 |
165 | `( )` や `[ ]` などの重みづけも動作します。
166 |
--------------------------------------------------------------------------------
/scripts/dev/_typos.toml:
--------------------------------------------------------------------------------
1 | # Files for typos
2 | # Instruction: https://github.com/marketplace/actions/typos-action#getting-started
3 |
4 | [default.extend-identifiers]
5 | ddPn08="ddPn08"
6 |
7 | [default.extend-words]
8 | NIN="NIN"
9 | parms="parms"
10 | nin="nin"
11 | extention="extention" # Intentionally left
12 | nd="nd"
13 | shs="shs"
14 | sts="sts"
15 | scs="scs"
16 | cpc="cpc"
17 | coc="coc"
18 | cic="cic"
19 | msm="msm"
20 | usu="usu"
21 | ici="ici"
22 | lvl="lvl"
23 | dii="dii"
24 | muk="muk"
25 | ori="ori"
26 | hru="hru"
27 | rik="rik"
28 | koo="koo"
29 | yos="yos"
30 | wn="wn"
31 | hime="hime"
32 |
33 |
34 | [files]
35 | extend-exclude = ["_typos.toml", "venv"]
36 |
--------------------------------------------------------------------------------
/scripts/dev/finetune/blip/med_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "architectures": [
3 | "BertModel"
4 | ],
5 | "attention_probs_dropout_prob": 0.1,
6 | "hidden_act": "gelu",
7 | "hidden_dropout_prob": 0.1,
8 | "hidden_size": 768,
9 | "initializer_range": 0.02,
10 | "intermediate_size": 3072,
11 | "layer_norm_eps": 1e-12,
12 | "max_position_embeddings": 512,
13 | "model_type": "bert",
14 | "num_attention_heads": 12,
15 | "num_hidden_layers": 12,
16 | "pad_token_id": 0,
17 | "type_vocab_size": 2,
18 | "vocab_size": 30524,
19 | "encoder_width": 768,
20 | "add_cross_attention": true
21 | }
22 |
--------------------------------------------------------------------------------
/scripts/dev/finetune/hypernetwork_nai.py:
--------------------------------------------------------------------------------
1 | # NAI compatible
2 |
3 | import torch
4 |
5 |
6 | class HypernetworkModule(torch.nn.Module):
7 | def __init__(self, dim, multiplier=1.0):
8 | super().__init__()
9 |
10 | linear1 = torch.nn.Linear(dim, dim * 2)
11 | linear2 = torch.nn.Linear(dim * 2, dim)
12 | linear1.weight.data.normal_(mean=0.0, std=0.01)
13 | linear1.bias.data.zero_()
14 | linear2.weight.data.normal_(mean=0.0, std=0.01)
15 | linear2.bias.data.zero_()
16 | linears = [linear1, linear2]
17 |
18 | self.linear = torch.nn.Sequential(*linears)
19 | self.multiplier = multiplier
20 |
21 | def forward(self, x):
22 | return x + self.linear(x) * self.multiplier
23 |
24 |
25 | class Hypernetwork(torch.nn.Module):
26 | enable_sizes = [320, 640, 768, 1280]
27 | # return self.modules[Hypernetwork.enable_sizes.index(size)]
28 |
29 | def __init__(self, multiplier=1.0) -> None:
30 | super().__init__()
31 | self.modules = []
32 | for size in Hypernetwork.enable_sizes:
33 | self.modules.append((HypernetworkModule(size, multiplier), HypernetworkModule(size, multiplier)))
34 | self.register_module(f"{size}_0", self.modules[-1][0])
35 | self.register_module(f"{size}_1", self.modules[-1][1])
36 |
37 | def apply_to_stable_diffusion(self, text_encoder, vae, unet):
38 | blocks = unet.input_blocks + [unet.middle_block] + unet.output_blocks
39 | for block in blocks:
40 | for subblk in block:
41 | if 'SpatialTransformer' in str(type(subblk)):
42 | for tf_block in subblk.transformer_blocks:
43 | for attn in [tf_block.attn1, tf_block.attn2]:
44 | size = attn.context_dim
45 | if size in Hypernetwork.enable_sizes:
46 | attn.hypernetwork = self
47 | else:
48 | attn.hypernetwork = None
49 |
50 | def apply_to_diffusers(self, text_encoder, vae, unet):
51 | blocks = unet.down_blocks + [unet.mid_block] + unet.up_blocks
52 | for block in blocks:
53 | if hasattr(block, 'attentions'):
54 | for subblk in block.attentions:
55 | if 'SpatialTransformer' in str(type(subblk)) or 'Transformer2DModel' in str(type(subblk)): # 0.6.0 and 0.7~
56 | for tf_block in subblk.transformer_blocks:
57 | for attn in [tf_block.attn1, tf_block.attn2]:
58 | size = attn.to_k.in_features
59 | if size in Hypernetwork.enable_sizes:
60 | attn.hypernetwork = self
61 | else:
62 | attn.hypernetwork = None
63 | return True # TODO error checking
64 |
65 | def forward(self, x, context):
66 | size = context.shape[-1]
67 | assert size in Hypernetwork.enable_sizes
68 | module = self.modules[Hypernetwork.enable_sizes.index(size)]
69 | return module[0].forward(context), module[1].forward(context)
70 |
71 | def load_from_state_dict(self, state_dict):
72 | # old ver to new ver
73 | changes = {
74 | 'linear1.bias': 'linear.0.bias',
75 | 'linear1.weight': 'linear.0.weight',
76 | 'linear2.bias': 'linear.1.bias',
77 | 'linear2.weight': 'linear.1.weight',
78 | }
79 | for key_from, key_to in changes.items():
80 | if key_from in state_dict:
81 | state_dict[key_to] = state_dict[key_from]
82 | del state_dict[key_from]
83 |
84 | for size, sd in state_dict.items():
85 | if type(size) == int:
86 | self.modules[Hypernetwork.enable_sizes.index(size)][0].load_state_dict(sd[0], strict=True)
87 | self.modules[Hypernetwork.enable_sizes.index(size)][1].load_state_dict(sd[1], strict=True)
88 | return True
89 |
90 | def get_state_dict(self):
91 | state_dict = {}
92 | for i, size in enumerate(Hypernetwork.enable_sizes):
93 | sd0 = self.modules[i][0].state_dict()
94 | sd1 = self.modules[i][1].state_dict()
95 | state_dict[size] = [sd0, sd1]
96 | return state_dict
97 |
--------------------------------------------------------------------------------
/scripts/dev/finetune/merge_captions_to_metadata.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import json
3 | from pathlib import Path
4 | from typing import List
5 | from tqdm import tqdm
6 | import library.train_util as train_util
7 | import os
8 | from library.utils import setup_logging
9 |
10 | setup_logging()
11 | import logging
12 |
13 | logger = logging.getLogger(__name__)
14 |
15 |
16 | def main(args):
17 | assert not args.recursive or (
18 | args.recursive and args.full_path
19 | ), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
20 |
21 | train_data_dir_path = Path(args.train_data_dir)
22 | image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
23 | logger.info(f"found {len(image_paths)} images.")
24 |
25 | if args.in_json is None and Path(args.out_json).is_file():
26 | args.in_json = args.out_json
27 |
28 | if args.in_json is not None:
29 | logger.info(f"loading existing metadata: {args.in_json}")
30 | metadata = json.loads(Path(args.in_json).read_text(encoding="utf-8"))
31 | logger.warning("captions for existing images will be overwritten / 既存の画像のキャプションは上書きされます")
32 | else:
33 | logger.info("new metadata will be created / 新しいメタデータファイルが作成されます")
34 | metadata = {}
35 |
36 | logger.info("merge caption texts to metadata json.")
37 | for image_path in tqdm(image_paths):
38 | caption_path = image_path.with_suffix(args.caption_extension)
39 | caption = caption_path.read_text(encoding="utf-8").strip()
40 |
41 | if not os.path.exists(caption_path):
42 | caption_path = os.path.join(image_path, args.caption_extension)
43 |
44 | image_key = str(image_path) if args.full_path else image_path.stem
45 | if image_key not in metadata:
46 | metadata[image_key] = {}
47 |
48 | metadata[image_key]["caption"] = caption
49 | if args.debug:
50 | logger.info(f"{image_key} {caption}")
51 |
52 | # metadataを書き出して終わり
53 | logger.info(f"writing metadata: {args.out_json}")
54 | Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding="utf-8")
55 | logger.info("done!")
56 |
57 |
58 | def setup_parser() -> argparse.ArgumentParser:
59 | parser = argparse.ArgumentParser()
60 | parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
61 | parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
62 | parser.add_argument(
63 | "--in_json",
64 | type=str,
65 | help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)",
66 | )
67 | parser.add_argument(
68 | "--caption_extention",
69 | type=str,
70 | default=None,
71 | help="extension of caption file (for backward compatibility) / 読み込むキャプションファイルの拡張子(スペルミスしていたのを残してあります)",
72 | )
73 | parser.add_argument(
74 | "--caption_extension", type=str, default=".caption", help="extension of caption file / 読み込むキャプションファイルの拡張子"
75 | )
76 | parser.add_argument(
77 | "--full_path",
78 | action="store_true",
79 | help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)",
80 | )
81 | parser.add_argument(
82 | "--recursive",
83 | action="store_true",
84 | help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す",
85 | )
86 | parser.add_argument("--debug", action="store_true", help="debug mode")
87 |
88 | return parser
89 |
90 |
91 | if __name__ == "__main__":
92 | parser = setup_parser()
93 |
94 | args = parser.parse_args()
95 |
96 | # スペルミスしていたオプションを復元する
97 | if args.caption_extention is not None:
98 | args.caption_extension = args.caption_extention
99 |
100 | main(args)
101 |
--------------------------------------------------------------------------------
/scripts/dev/finetune/merge_dd_tags_to_metadata.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import json
3 | from pathlib import Path
4 | from typing import List
5 | from tqdm import tqdm
6 | import library.train_util as train_util
7 | import os
8 | from library.utils import setup_logging
9 |
10 | setup_logging()
11 | import logging
12 |
13 | logger = logging.getLogger(__name__)
14 |
15 |
16 | def main(args):
17 | assert not args.recursive or (
18 | args.recursive and args.full_path
19 | ), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
20 |
21 | train_data_dir_path = Path(args.train_data_dir)
22 | image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
23 | logger.info(f"found {len(image_paths)} images.")
24 |
25 | if args.in_json is None and Path(args.out_json).is_file():
26 | args.in_json = args.out_json
27 |
28 | if args.in_json is not None:
29 | logger.info(f"loading existing metadata: {args.in_json}")
30 | metadata = json.loads(Path(args.in_json).read_text(encoding="utf-8"))
31 | logger.warning("tags data for existing images will be overwritten / 既存の画像のタグは上書きされます")
32 | else:
33 | logger.info("new metadata will be created / 新しいメタデータファイルが作成されます")
34 | metadata = {}
35 |
36 | logger.info("merge tags to metadata json.")
37 | for image_path in tqdm(image_paths):
38 | tags_path = image_path.with_suffix(args.caption_extension)
39 | tags = tags_path.read_text(encoding="utf-8").strip()
40 |
41 | if not os.path.exists(tags_path):
42 | tags_path = os.path.join(image_path, args.caption_extension)
43 |
44 | image_key = str(image_path) if args.full_path else image_path.stem
45 | if image_key not in metadata:
46 | metadata[image_key] = {}
47 |
48 | metadata[image_key]["tags"] = tags
49 | if args.debug:
50 | logger.info(f"{image_key} {tags}")
51 |
52 | # metadataを書き出して終わり
53 | logger.info(f"writing metadata: {args.out_json}")
54 | Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding="utf-8")
55 |
56 | logger.info("done!")
57 |
58 |
59 | def setup_parser() -> argparse.ArgumentParser:
60 | parser = argparse.ArgumentParser()
61 | parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
62 | parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
63 | parser.add_argument(
64 | "--in_json",
65 | type=str,
66 | help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)",
67 | )
68 | parser.add_argument(
69 | "--full_path",
70 | action="store_true",
71 | help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)",
72 | )
73 | parser.add_argument(
74 | "--recursive",
75 | action="store_true",
76 | help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す",
77 | )
78 | parser.add_argument(
79 | "--caption_extension",
80 | type=str,
81 | default=".txt",
82 | help="extension of caption (tag) file / 読み込むキャプション(タグ)ファイルの拡張子",
83 | )
84 | parser.add_argument("--debug", action="store_true", help="debug mode, print tags")
85 |
86 | return parser
87 |
88 |
89 | if __name__ == "__main__":
90 | parser = setup_parser()
91 |
92 | args = parser.parse_args()
93 | main(args)
94 |
--------------------------------------------------------------------------------
/scripts/dev/library/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Akegarasu/lora-scripts/e0f5194815203093659d6ec280b9362b9792c070/scripts/dev/library/__init__.py
--------------------------------------------------------------------------------
/scripts/dev/library/adafactor_fused.py:
--------------------------------------------------------------------------------
1 | import math
2 | import torch
3 | from transformers import Adafactor
4 |
5 | # stochastic rounding for bfloat16
6 | # The implementation was provided by 2kpr. Thank you very much!
7 |
8 | def copy_stochastic_(target: torch.Tensor, source: torch.Tensor):
9 | """
10 | copies source into target using stochastic rounding
11 |
12 | Args:
13 | target: the target tensor with dtype=bfloat16
14 | source: the target tensor with dtype=float32
15 | """
16 | # create a random 16 bit integer
17 | result = torch.randint_like(source, dtype=torch.int32, low=0, high=(1 << 16))
18 |
19 | # add the random number to the lower 16 bit of the mantissa
20 | result.add_(source.view(dtype=torch.int32))
21 |
22 | # mask off the lower 16 bit of the mantissa
23 | result.bitwise_and_(-65536) # -65536 = FFFF0000 as a signed int32
24 |
25 | # copy the higher 16 bit into the target tensor
26 | target.copy_(result.view(dtype=torch.float32))
27 |
28 | del result
29 |
30 |
31 | @torch.no_grad()
32 | def adafactor_step_param(self, p, group):
33 | if p.grad is None:
34 | return
35 | grad = p.grad
36 | if grad.dtype in {torch.float16, torch.bfloat16}:
37 | grad = grad.float()
38 | if grad.is_sparse:
39 | raise RuntimeError("Adafactor does not support sparse gradients.")
40 |
41 | state = self.state[p]
42 | grad_shape = grad.shape
43 |
44 | factored, use_first_moment = Adafactor._get_options(group, grad_shape)
45 | # State Initialization
46 | if len(state) == 0:
47 | state["step"] = 0
48 |
49 | if use_first_moment:
50 | # Exponential moving average of gradient values
51 | state["exp_avg"] = torch.zeros_like(grad)
52 | if factored:
53 | state["exp_avg_sq_row"] = torch.zeros(grad_shape[:-1]).to(grad)
54 | state["exp_avg_sq_col"] = torch.zeros(grad_shape[:-2] + grad_shape[-1:]).to(grad)
55 | else:
56 | state["exp_avg_sq"] = torch.zeros_like(grad)
57 |
58 | state["RMS"] = 0
59 | else:
60 | if use_first_moment:
61 | state["exp_avg"] = state["exp_avg"].to(grad)
62 | if factored:
63 | state["exp_avg_sq_row"] = state["exp_avg_sq_row"].to(grad)
64 | state["exp_avg_sq_col"] = state["exp_avg_sq_col"].to(grad)
65 | else:
66 | state["exp_avg_sq"] = state["exp_avg_sq"].to(grad)
67 |
68 | p_data_fp32 = p
69 | if p.dtype in {torch.float16, torch.bfloat16}:
70 | p_data_fp32 = p_data_fp32.float()
71 |
72 | state["step"] += 1
73 | state["RMS"] = Adafactor._rms(p_data_fp32)
74 | lr = Adafactor._get_lr(group, state)
75 |
76 | beta2t = 1.0 - math.pow(state["step"], group["decay_rate"])
77 | update = (grad**2) + group["eps"][0]
78 | if factored:
79 | exp_avg_sq_row = state["exp_avg_sq_row"]
80 | exp_avg_sq_col = state["exp_avg_sq_col"]
81 |
82 | exp_avg_sq_row.mul_(beta2t).add_(update.mean(dim=-1), alpha=(1.0 - beta2t))
83 | exp_avg_sq_col.mul_(beta2t).add_(update.mean(dim=-2), alpha=(1.0 - beta2t))
84 |
85 | # Approximation of exponential moving average of square of gradient
86 | update = Adafactor._approx_sq_grad(exp_avg_sq_row, exp_avg_sq_col)
87 | update.mul_(grad)
88 | else:
89 | exp_avg_sq = state["exp_avg_sq"]
90 |
91 | exp_avg_sq.mul_(beta2t).add_(update, alpha=(1.0 - beta2t))
92 | update = exp_avg_sq.rsqrt().mul_(grad)
93 |
94 | update.div_((Adafactor._rms(update) / group["clip_threshold"]).clamp_(min=1.0))
95 | update.mul_(lr)
96 |
97 | if use_first_moment:
98 | exp_avg = state["exp_avg"]
99 | exp_avg.mul_(group["beta1"]).add_(update, alpha=(1 - group["beta1"]))
100 | update = exp_avg
101 |
102 | if group["weight_decay"] != 0:
103 | p_data_fp32.add_(p_data_fp32, alpha=(-group["weight_decay"] * lr))
104 |
105 | p_data_fp32.add_(-update)
106 |
107 | # if p.dtype in {torch.float16, torch.bfloat16}:
108 | # p.copy_(p_data_fp32)
109 |
110 | if p.dtype == torch.bfloat16:
111 | copy_stochastic_(p, p_data_fp32)
112 | elif p.dtype == torch.float16:
113 | p.copy_(p_data_fp32)
114 |
115 |
116 | @torch.no_grad()
117 | def adafactor_step(self, closure=None):
118 | """
119 | Performs a single optimization step
120 |
121 | Arguments:
122 | closure (callable, optional): A closure that reevaluates the model
123 | and returns the loss.
124 | """
125 | loss = None
126 | if closure is not None:
127 | loss = closure()
128 |
129 | for group in self.param_groups:
130 | for p in group["params"]:
131 | adafactor_step_param(self, p, group)
132 |
133 | return loss
134 |
135 |
136 | def patch_adafactor_fused(optimizer: Adafactor):
137 | optimizer.step_param = adafactor_step_param.__get__(optimizer)
138 | optimizer.step = adafactor_step.__get__(optimizer)
139 |
--------------------------------------------------------------------------------
/scripts/dev/library/deepspeed_utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import argparse
3 | import torch
4 | from accelerate import DeepSpeedPlugin, Accelerator
5 |
6 | from .utils import setup_logging
7 |
8 | setup_logging()
9 | import logging
10 |
11 | logger = logging.getLogger(__name__)
12 |
13 |
14 | def add_deepspeed_arguments(parser: argparse.ArgumentParser):
15 | # DeepSpeed Arguments. https://huggingface.co/docs/accelerate/usage_guides/deepspeed
16 | parser.add_argument("--deepspeed", action="store_true", help="enable deepspeed training")
17 | parser.add_argument("--zero_stage", type=int, default=2, choices=[0, 1, 2, 3], help="Possible options are 0,1,2,3.")
18 | parser.add_argument(
19 | "--offload_optimizer_device",
20 | type=str,
21 | default=None,
22 | choices=[None, "cpu", "nvme"],
23 | help="Possible options are none|cpu|nvme. Only applicable with ZeRO Stages 2 and 3.",
24 | )
25 | parser.add_argument(
26 | "--offload_optimizer_nvme_path",
27 | type=str,
28 | default=None,
29 | help="Possible options are /nvme|/local_nvme. Only applicable with ZeRO Stage 3.",
30 | )
31 | parser.add_argument(
32 | "--offload_param_device",
33 | type=str,
34 | default=None,
35 | choices=[None, "cpu", "nvme"],
36 | help="Possible options are none|cpu|nvme. Only applicable with ZeRO Stage 3.",
37 | )
38 | parser.add_argument(
39 | "--offload_param_nvme_path",
40 | type=str,
41 | default=None,
42 | help="Possible options are /nvme|/local_nvme. Only applicable with ZeRO Stage 3.",
43 | )
44 | parser.add_argument(
45 | "--zero3_init_flag",
46 | action="store_true",
47 | help="Flag to indicate whether to enable `deepspeed.zero.Init` for constructing massive models."
48 | "Only applicable with ZeRO Stage-3.",
49 | )
50 | parser.add_argument(
51 | "--zero3_save_16bit_model",
52 | action="store_true",
53 | help="Flag to indicate whether to save 16-bit model. Only applicable with ZeRO Stage-3.",
54 | )
55 | parser.add_argument(
56 | "--fp16_master_weights_and_gradients",
57 | action="store_true",
58 | help="fp16_master_and_gradients requires optimizer to support keeping fp16 master and gradients while keeping the optimizer states in fp32.",
59 | )
60 |
61 |
62 | def prepare_deepspeed_args(args: argparse.Namespace):
63 | if not args.deepspeed:
64 | return
65 |
66 | # To avoid RuntimeError: DataLoader worker exited unexpectedly with exit code 1.
67 | args.max_data_loader_n_workers = 1
68 |
69 |
70 | def prepare_deepspeed_plugin(args: argparse.Namespace):
71 | if not args.deepspeed:
72 | return None
73 |
74 | try:
75 | import deepspeed
76 | except ImportError as e:
77 | logger.error(
78 | "deepspeed is not installed. please install deepspeed in your environment with following command. DS_BUILD_OPS=0 pip install deepspeed"
79 | )
80 | exit(1)
81 |
82 | deepspeed_plugin = DeepSpeedPlugin(
83 | zero_stage=args.zero_stage,
84 | gradient_accumulation_steps=args.gradient_accumulation_steps,
85 | gradient_clipping=args.max_grad_norm,
86 | offload_optimizer_device=args.offload_optimizer_device,
87 | offload_optimizer_nvme_path=args.offload_optimizer_nvme_path,
88 | offload_param_device=args.offload_param_device,
89 | offload_param_nvme_path=args.offload_param_nvme_path,
90 | zero3_init_flag=args.zero3_init_flag,
91 | zero3_save_16bit_model=args.zero3_save_16bit_model,
92 | )
93 | deepspeed_plugin.deepspeed_config["train_micro_batch_size_per_gpu"] = args.train_batch_size
94 | deepspeed_plugin.deepspeed_config["train_batch_size"] = (
95 | args.train_batch_size * args.gradient_accumulation_steps * int(os.environ["WORLD_SIZE"])
96 | )
97 | deepspeed_plugin.set_mixed_precision(args.mixed_precision)
98 | if args.mixed_precision.lower() == "fp16":
99 | deepspeed_plugin.deepspeed_config["fp16"]["initial_scale_power"] = 0 # preventing overflow.
100 | if args.full_fp16 or args.fp16_master_weights_and_gradients:
101 | if args.offload_optimizer_device == "cpu" and args.zero_stage == 2:
102 | deepspeed_plugin.deepspeed_config["fp16"]["fp16_master_weights_and_grads"] = True
103 | logger.info("[DeepSpeed] full fp16 enable.")
104 | else:
105 | logger.info(
106 | "[DeepSpeed]full fp16, fp16_master_weights_and_grads currently only supported using ZeRO-Offload with DeepSpeedCPUAdam on ZeRO-2 stage."
107 | )
108 |
109 | if args.offload_optimizer_device is not None:
110 | logger.info("[DeepSpeed] start to manually build cpu_adam.")
111 | deepspeed.ops.op_builder.CPUAdamBuilder().load()
112 | logger.info("[DeepSpeed] building cpu_adam done.")
113 |
114 | return deepspeed_plugin
115 |
116 |
117 | # Accelerate library does not support multiple models for deepspeed. So, we need to wrap multiple models into a single model.
118 | def prepare_deepspeed_model(args: argparse.Namespace, **models):
119 | # remove None from models
120 | models = {k: v for k, v in models.items() if v is not None}
121 |
122 | class DeepSpeedWrapper(torch.nn.Module):
123 | def __init__(self, **kw_models) -> None:
124 | super().__init__()
125 | self.models = torch.nn.ModuleDict()
126 |
127 | for key, model in kw_models.items():
128 | if isinstance(model, list):
129 | model = torch.nn.ModuleList(model)
130 | assert isinstance(
131 | model, torch.nn.Module
132 | ), f"model must be an instance of torch.nn.Module, but got {key} is {type(model)}"
133 | self.models.update(torch.nn.ModuleDict({key: model}))
134 |
135 | def get_models(self):
136 | return self.models
137 |
138 | ds_model = DeepSpeedWrapper(**models)
139 | return ds_model
140 |
--------------------------------------------------------------------------------
/scripts/dev/library/device_utils.py:
--------------------------------------------------------------------------------
1 | import functools
2 | import gc
3 |
4 | import torch
5 | try:
6 | # intel gpu support for pytorch older than 2.5
7 | # ipex is not needed after pytorch 2.5
8 | import intel_extension_for_pytorch as ipex # noqa
9 | except Exception:
10 | pass
11 |
12 |
13 | try:
14 | HAS_CUDA = torch.cuda.is_available()
15 | except Exception:
16 | HAS_CUDA = False
17 |
18 | try:
19 | HAS_MPS = torch.backends.mps.is_available()
20 | except Exception:
21 | HAS_MPS = False
22 |
23 | try:
24 | HAS_XPU = torch.xpu.is_available()
25 | except Exception:
26 | HAS_XPU = False
27 |
28 |
29 | def clean_memory():
30 | gc.collect()
31 | if HAS_CUDA:
32 | torch.cuda.empty_cache()
33 | if HAS_XPU:
34 | torch.xpu.empty_cache()
35 | if HAS_MPS:
36 | torch.mps.empty_cache()
37 |
38 |
39 | def clean_memory_on_device(device: torch.device):
40 | r"""
41 | Clean memory on the specified device, will be called from training scripts.
42 | """
43 | gc.collect()
44 |
45 | # device may "cuda" or "cuda:0", so we need to check the type of device
46 | if device.type == "cuda":
47 | torch.cuda.empty_cache()
48 | if device.type == "xpu":
49 | torch.xpu.empty_cache()
50 | if device.type == "mps":
51 | torch.mps.empty_cache()
52 |
53 |
54 | @functools.lru_cache(maxsize=None)
55 | def get_preferred_device() -> torch.device:
56 | r"""
57 | Do not call this function from training scripts. Use accelerator.device instead.
58 | """
59 | if HAS_CUDA:
60 | device = torch.device("cuda")
61 | elif HAS_XPU:
62 | device = torch.device("xpu")
63 | elif HAS_MPS:
64 | device = torch.device("mps")
65 | else:
66 | device = torch.device("cpu")
67 | print(f"get_preferred_device() -> {device}")
68 | return device
69 |
70 |
71 | def init_ipex():
72 | """
73 | Apply IPEX to CUDA hijacks using `library.ipex.ipex_init`.
74 |
75 | This function should run right after importing torch and before doing anything else.
76 |
77 | If xpu is not available, this function does nothing.
78 | """
79 | try:
80 | if HAS_XPU:
81 | from library.ipex import ipex_init
82 |
83 | is_initialized, error_message = ipex_init()
84 | if not is_initialized:
85 | print("failed to initialize ipex:", error_message)
86 | else:
87 | return
88 | except Exception as e:
89 | print("failed to initialize ipex:", e)
90 |
--------------------------------------------------------------------------------
/scripts/dev/library/huggingface_util.py:
--------------------------------------------------------------------------------
1 | from typing import Union, BinaryIO
2 | from huggingface_hub import HfApi
3 | from pathlib import Path
4 | import argparse
5 | import os
6 | from library.utils import fire_in_thread
7 | from library.utils import setup_logging
8 | setup_logging()
9 | import logging
10 | logger = logging.getLogger(__name__)
11 |
12 | def exists_repo(repo_id: str, repo_type: str, revision: str = "main", token: str = None):
13 | api = HfApi(
14 | token=token,
15 | )
16 | try:
17 | api.repo_info(repo_id=repo_id, revision=revision, repo_type=repo_type)
18 | return True
19 | except:
20 | return False
21 |
22 |
23 | def upload(
24 | args: argparse.Namespace,
25 | src: Union[str, Path, bytes, BinaryIO],
26 | dest_suffix: str = "",
27 | force_sync_upload: bool = False,
28 | ):
29 | repo_id = args.huggingface_repo_id
30 | repo_type = args.huggingface_repo_type
31 | token = args.huggingface_token
32 | path_in_repo = args.huggingface_path_in_repo + dest_suffix if args.huggingface_path_in_repo is not None else None
33 | private = args.huggingface_repo_visibility is None or args.huggingface_repo_visibility != "public"
34 | api = HfApi(token=token)
35 | if not exists_repo(repo_id=repo_id, repo_type=repo_type, token=token):
36 | try:
37 | api.create_repo(repo_id=repo_id, repo_type=repo_type, private=private)
38 | except Exception as e: # とりあえずRepositoryNotFoundErrorは確認したが他にあると困るので
39 | logger.error("===========================================")
40 | logger.error(f"failed to create HuggingFace repo / HuggingFaceのリポジトリの作成に失敗しました : {e}")
41 | logger.error("===========================================")
42 |
43 | is_folder = (type(src) == str and os.path.isdir(src)) or (isinstance(src, Path) and src.is_dir())
44 |
45 | def uploader():
46 | try:
47 | if is_folder:
48 | api.upload_folder(
49 | repo_id=repo_id,
50 | repo_type=repo_type,
51 | folder_path=src,
52 | path_in_repo=path_in_repo,
53 | )
54 | else:
55 | api.upload_file(
56 | repo_id=repo_id,
57 | repo_type=repo_type,
58 | path_or_fileobj=src,
59 | path_in_repo=path_in_repo,
60 | )
61 | except Exception as e: # RuntimeErrorを確認済みだが他にあると困るので
62 | logger.error("===========================================")
63 | logger.error(f"failed to upload to HuggingFace / HuggingFaceへのアップロードに失敗しました : {e}")
64 | logger.error("===========================================")
65 |
66 | if args.async_upload and not force_sync_upload:
67 | fire_in_thread(uploader)
68 | else:
69 | uploader()
70 |
71 |
72 | def list_dir(
73 | repo_id: str,
74 | subfolder: str,
75 | repo_type: str,
76 | revision: str = "main",
77 | token: str = None,
78 | ):
79 | api = HfApi(
80 | token=token,
81 | )
82 | repo_info = api.repo_info(repo_id=repo_id, revision=revision, repo_type=repo_type)
83 | file_list = [file for file in repo_info.siblings if file.rfilename.startswith(subfolder)]
84 | return file_list
85 |
--------------------------------------------------------------------------------
/scripts/dev/library/ipex/diffusers.py:
--------------------------------------------------------------------------------
1 | from functools import wraps
2 | import torch
3 | import diffusers # pylint: disable=import-error
4 |
5 | # pylint: disable=protected-access, missing-function-docstring, line-too-long
6 |
7 |
8 | # Diffusers FreeU
9 | original_fourier_filter = diffusers.utils.torch_utils.fourier_filter
10 | @wraps(diffusers.utils.torch_utils.fourier_filter)
11 | def fourier_filter(x_in, threshold, scale):
12 | return_dtype = x_in.dtype
13 | return original_fourier_filter(x_in.to(dtype=torch.float32), threshold, scale).to(dtype=return_dtype)
14 |
15 |
16 | # fp64 error
17 | class FluxPosEmbed(torch.nn.Module):
18 | def __init__(self, theta: int, axes_dim):
19 | super().__init__()
20 | self.theta = theta
21 | self.axes_dim = axes_dim
22 |
23 | def forward(self, ids: torch.Tensor) -> torch.Tensor:
24 | n_axes = ids.shape[-1]
25 | cos_out = []
26 | sin_out = []
27 | pos = ids.float()
28 | for i in range(n_axes):
29 | cos, sin = diffusers.models.embeddings.get_1d_rotary_pos_embed(
30 | self.axes_dim[i],
31 | pos[:, i],
32 | theta=self.theta,
33 | repeat_interleave_real=True,
34 | use_real=True,
35 | freqs_dtype=torch.float32,
36 | )
37 | cos_out.append(cos)
38 | sin_out.append(sin)
39 | freqs_cos = torch.cat(cos_out, dim=-1).to(ids.device)
40 | freqs_sin = torch.cat(sin_out, dim=-1).to(ids.device)
41 | return freqs_cos, freqs_sin
42 |
43 |
44 | def ipex_diffusers(device_supports_fp64=False, can_allocate_plus_4gb=False):
45 | diffusers.utils.torch_utils.fourier_filter = fourier_filter
46 | if not device_supports_fp64:
47 | diffusers.models.embeddings.FluxPosEmbed = FluxPosEmbed
48 |
--------------------------------------------------------------------------------
/scripts/dev/networks/check_lora_weights.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import torch
4 | from safetensors.torch import load_file
5 | from library.utils import setup_logging
6 | setup_logging()
7 | import logging
8 | logger = logging.getLogger(__name__)
9 |
10 | def main(file):
11 | logger.info(f"loading: {file}")
12 | if os.path.splitext(file)[1] == ".safetensors":
13 | sd = load_file(file)
14 | else:
15 | sd = torch.load(file, map_location="cpu")
16 |
17 | values = []
18 |
19 | keys = list(sd.keys())
20 | for key in keys:
21 | if "lora_up" in key or "lora_down" in key or "lora_A" in key or "lora_B" in key or "oft_" in key:
22 | values.append((key, sd[key]))
23 | print(f"number of LoRA modules: {len(values)}")
24 |
25 | if args.show_all_keys:
26 | for key in [k for k in keys if k not in values]:
27 | values.append((key, sd[key]))
28 | print(f"number of all modules: {len(values)}")
29 |
30 | for key, value in values:
31 | value = value.to(torch.float32)
32 | print(f"{key},{str(tuple(value.size())).replace(', ', '-')},{torch.mean(torch.abs(value))},{torch.min(torch.abs(value))}")
33 |
34 |
35 | def setup_parser() -> argparse.ArgumentParser:
36 | parser = argparse.ArgumentParser()
37 | parser.add_argument("file", type=str, help="model file to check / 重みを確認するモデルファイル")
38 | parser.add_argument("-s", "--show_all_keys", action="store_true", help="show all keys / 全てのキーを表示する")
39 |
40 | return parser
41 |
42 |
43 | if __name__ == "__main__":
44 | parser = setup_parser()
45 |
46 | args = parser.parse_args()
47 |
48 | main(args.file)
49 |
--------------------------------------------------------------------------------
/scripts/dev/networks/extract_lora_from_dylora.py:
--------------------------------------------------------------------------------
1 | # Convert LoRA to different rank approximation (should only be used to go to lower rank)
2 | # This code is based off the extract_lora_from_models.py file which is based on https://github.com/cloneofsimo/lora/blob/develop/lora_diffusion/cli_svd.py
3 | # Thanks to cloneofsimo
4 |
5 | import argparse
6 | import math
7 | import os
8 | import torch
9 | from safetensors.torch import load_file, save_file, safe_open
10 | from tqdm import tqdm
11 | from library import train_util, model_util
12 | import numpy as np
13 | from library.utils import setup_logging
14 | setup_logging()
15 | import logging
16 | logger = logging.getLogger(__name__)
17 |
18 | def load_state_dict(file_name):
19 | if model_util.is_safetensors(file_name):
20 | sd = load_file(file_name)
21 | with safe_open(file_name, framework="pt") as f:
22 | metadata = f.metadata()
23 | else:
24 | sd = torch.load(file_name, map_location="cpu")
25 | metadata = None
26 |
27 | return sd, metadata
28 |
29 |
30 | def save_to_file(file_name, model, metadata):
31 | if model_util.is_safetensors(file_name):
32 | save_file(model, file_name, metadata)
33 | else:
34 | torch.save(model, file_name)
35 |
36 |
37 | def split_lora_model(lora_sd, unit):
38 | max_rank = 0
39 |
40 | # Extract loaded lora dim and alpha
41 | for key, value in lora_sd.items():
42 | if "lora_down" in key:
43 | rank = value.size()[0]
44 | if rank > max_rank:
45 | max_rank = rank
46 | logger.info(f"Max rank: {max_rank}")
47 |
48 | rank = unit
49 | split_models = []
50 | new_alpha = None
51 | while rank < max_rank:
52 | logger.info(f"Splitting rank {rank}")
53 | new_sd = {}
54 | for key, value in lora_sd.items():
55 | if "lora_down" in key:
56 | new_sd[key] = value[:rank].contiguous()
57 | elif "lora_up" in key:
58 | new_sd[key] = value[:, :rank].contiguous()
59 | else:
60 | # なぜかscaleするとおかしくなる……
61 | # this_rank = lora_sd[key.replace("alpha", "lora_down.weight")].size()[0]
62 | # scale = math.sqrt(this_rank / rank) # rank is > unit
63 | # logger.info(key, value.size(), this_rank, rank, value, scale)
64 | # new_alpha = value * scale # always same
65 | # new_sd[key] = new_alpha
66 | new_sd[key] = value
67 |
68 | split_models.append((new_sd, rank, new_alpha))
69 | rank += unit
70 |
71 | return max_rank, split_models
72 |
73 |
74 | def split(args):
75 | logger.info("loading Model...")
76 | lora_sd, metadata = load_state_dict(args.model)
77 |
78 | logger.info("Splitting Model...")
79 | original_rank, split_models = split_lora_model(lora_sd, args.unit)
80 |
81 | comment = metadata.get("ss_training_comment", "")
82 | for state_dict, new_rank, new_alpha in split_models:
83 | # update metadata
84 | if metadata is None:
85 | new_metadata = {}
86 | else:
87 | new_metadata = metadata.copy()
88 |
89 | new_metadata["ss_training_comment"] = f"split from DyLoRA, rank {original_rank} to {new_rank}; {comment}"
90 | new_metadata["ss_network_dim"] = str(new_rank)
91 | # new_metadata["ss_network_alpha"] = str(new_alpha.float().numpy())
92 |
93 | model_hash, legacy_hash = train_util.precalculate_safetensors_hashes(state_dict, metadata)
94 | metadata["sshs_model_hash"] = model_hash
95 | metadata["sshs_legacy_hash"] = legacy_hash
96 |
97 | filename, ext = os.path.splitext(args.save_to)
98 | model_file_name = filename + f"-{new_rank:04d}{ext}"
99 |
100 | logger.info(f"saving model to: {model_file_name}")
101 | save_to_file(model_file_name, state_dict, new_metadata)
102 |
103 |
104 | def setup_parser() -> argparse.ArgumentParser:
105 | parser = argparse.ArgumentParser()
106 |
107 | parser.add_argument("--unit", type=int, default=None, help="size of rank to split into / rankを分割するサイズ")
108 | parser.add_argument(
109 | "--save_to",
110 | type=str,
111 | default=None,
112 | help="destination base file name: ckpt or safetensors file / 保存先のファイル名のbase、ckptまたはsafetensors",
113 | )
114 | parser.add_argument(
115 | "--model",
116 | type=str,
117 | default=None,
118 | help="DyLoRA model to resize at to new rank: ckpt or safetensors file / 読み込むDyLoRAモデル、ckptまたはsafetensors",
119 | )
120 |
121 | return parser
122 |
123 |
124 | if __name__ == "__main__":
125 | parser = setup_parser()
126 |
127 | args = parser.parse_args()
128 | split(args)
129 |
--------------------------------------------------------------------------------
/scripts/dev/networks/lora_interrogator.py:
--------------------------------------------------------------------------------
1 |
2 |
3 | from tqdm import tqdm
4 | from library import model_util
5 | import library.train_util as train_util
6 | import argparse
7 | from transformers import CLIPTokenizer
8 |
9 | import torch
10 | from library.device_utils import init_ipex, get_preferred_device
11 | init_ipex()
12 |
13 | import library.model_util as model_util
14 | import lora
15 | from library.utils import setup_logging
16 | setup_logging()
17 | import logging
18 | logger = logging.getLogger(__name__)
19 |
20 | TOKENIZER_PATH = "openai/clip-vit-large-patch14"
21 | V2_STABLE_DIFFUSION_PATH = "stabilityai/stable-diffusion-2" # ここからtokenizerだけ使う
22 |
23 | DEVICE = get_preferred_device()
24 |
25 |
26 | def interrogate(args):
27 | weights_dtype = torch.float16
28 |
29 | # いろいろ準備する
30 | logger.info(f"loading SD model: {args.sd_model}")
31 | args.pretrained_model_name_or_path = args.sd_model
32 | args.vae = None
33 | text_encoder, vae, unet, _ = train_util._load_target_model(args,weights_dtype, DEVICE)
34 |
35 | logger.info(f"loading LoRA: {args.model}")
36 | network, weights_sd = lora.create_network_from_weights(1.0, args.model, vae, text_encoder, unet)
37 |
38 | # text encoder向けの重みがあるかチェックする:本当はlora側でやるのがいい
39 | has_te_weight = False
40 | for key in weights_sd.keys():
41 | if 'lora_te' in key:
42 | has_te_weight = True
43 | break
44 | if not has_te_weight:
45 | logger.error("This LoRA does not have modules for Text Encoder, cannot interrogate / このLoRAはText Encoder向けのモジュールがないため調査できません")
46 | return
47 | del vae
48 |
49 | logger.info("loading tokenizer")
50 | if args.v2:
51 | tokenizer: CLIPTokenizer = CLIPTokenizer.from_pretrained(V2_STABLE_DIFFUSION_PATH, subfolder="tokenizer")
52 | else:
53 | tokenizer: CLIPTokenizer = CLIPTokenizer.from_pretrained(TOKENIZER_PATH) # , model_max_length=max_token_length + 2)
54 |
55 | text_encoder.to(DEVICE, dtype=weights_dtype)
56 | text_encoder.eval()
57 | unet.to(DEVICE, dtype=weights_dtype)
58 | unet.eval() # U-Netは呼び出さないので不要だけど
59 |
60 | # トークンをひとつひとつ当たっていく
61 | token_id_start = 0
62 | token_id_end = max(tokenizer.all_special_ids)
63 | logger.info(f"interrogate tokens are: {token_id_start} to {token_id_end}")
64 |
65 | def get_all_embeddings(text_encoder):
66 | embs = []
67 | with torch.no_grad():
68 | for token_id in tqdm(range(token_id_start, token_id_end + 1, args.batch_size)):
69 | batch = []
70 | for tid in range(token_id, min(token_id_end + 1, token_id + args.batch_size)):
71 | tokens = [tokenizer.bos_token_id, tid, tokenizer.eos_token_id]
72 | # tokens = [tid] # こちらは結果がいまひとつ
73 | batch.append(tokens)
74 |
75 | # batch_embs = text_encoder(torch.tensor(batch).to(DEVICE))[0].to("cpu") # bos/eosも含めたほうが差が出るようだ [:, 1]
76 | # clip skip対応
77 | batch = torch.tensor(batch).to(DEVICE)
78 | if args.clip_skip is None:
79 | encoder_hidden_states = text_encoder(batch)[0]
80 | else:
81 | enc_out = text_encoder(batch, output_hidden_states=True, return_dict=True)
82 | encoder_hidden_states = enc_out['hidden_states'][-args.clip_skip]
83 | encoder_hidden_states = text_encoder.text_model.final_layer_norm(encoder_hidden_states)
84 | encoder_hidden_states = encoder_hidden_states.to("cpu")
85 |
86 | embs.extend(encoder_hidden_states)
87 | return torch.stack(embs)
88 |
89 | logger.info("get original text encoder embeddings.")
90 | orig_embs = get_all_embeddings(text_encoder)
91 |
92 | network.apply_to(text_encoder, unet, True, len(network.unet_loras) > 0)
93 | info = network.load_state_dict(weights_sd, strict=False)
94 | logger.info(f"Loading LoRA weights: {info}")
95 |
96 | network.to(DEVICE, dtype=weights_dtype)
97 | network.eval()
98 |
99 | del unet
100 |
101 | logger.info("You can ignore warning messages start with '_IncompatibleKeys' (LoRA model does not have alpha because trained by older script) / '_IncompatibleKeys'の警告は無視して構いません(以前のスクリプトで学習されたLoRAモデルのためalphaの定義がありません)")
102 | logger.info("get text encoder embeddings with lora.")
103 | lora_embs = get_all_embeddings(text_encoder)
104 |
105 | # 比べる:とりあえず単純に差分の絶対値で
106 | logger.info("comparing...")
107 | diffs = {}
108 | for i, (orig_emb, lora_emb) in enumerate(zip(orig_embs, tqdm(lora_embs))):
109 | diff = torch.mean(torch.abs(orig_emb - lora_emb))
110 | # diff = torch.mean(torch.cosine_similarity(orig_emb, lora_emb, dim=1)) # うまく検出できない
111 | diff = float(diff.detach().to('cpu').numpy())
112 | diffs[token_id_start + i] = diff
113 |
114 | diffs_sorted = sorted(diffs.items(), key=lambda x: -x[1])
115 |
116 | # 結果を表示する
117 | print("top 100:")
118 | for i, (token, diff) in enumerate(diffs_sorted[:100]):
119 | # if diff < 1e-6:
120 | # break
121 | string = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens([token]))
122 | print(f"[{i:3d}]: {token:5d} {string:<20s}: {diff:.5f}")
123 |
124 |
125 | def setup_parser() -> argparse.ArgumentParser:
126 | parser = argparse.ArgumentParser()
127 |
128 | parser.add_argument("--v2", action='store_true',
129 | help='load Stable Diffusion v2.x model / Stable Diffusion 2.xのモデルを読み込む')
130 | parser.add_argument("--sd_model", type=str, default=None,
131 | help="Stable Diffusion model to load: ckpt or safetensors file / 読み込むSDのモデル、ckptまたはsafetensors")
132 | parser.add_argument("--model", type=str, default=None,
133 | help="LoRA model to interrogate: ckpt or safetensors file / 調査するLoRAモデル、ckptまたはsafetensors")
134 | parser.add_argument("--batch_size", type=int, default=16,
135 | help="batch size for processing with Text Encoder / Text Encoderで処理するときのバッチサイズ")
136 | parser.add_argument("--clip_skip", type=int, default=None,
137 | help="use output of nth layer from back of text encoder (n>=1) / text encoderの後ろからn番目の層の出力を用いる(nは1以上)")
138 |
139 | return parser
140 |
141 |
142 | if __name__ == '__main__':
143 | parser = setup_parser()
144 |
145 | args = parser.parse_args()
146 | interrogate(args)
147 |
--------------------------------------------------------------------------------
/scripts/dev/pytest.ini:
--------------------------------------------------------------------------------
1 | [pytest]
2 | minversion = 6.0
3 | testpaths =
4 | tests
5 | filterwarnings =
6 | ignore::DeprecationWarning
7 | ignore::UserWarning
8 | ignore::FutureWarning
9 |
--------------------------------------------------------------------------------
/scripts/dev/requirements.txt:
--------------------------------------------------------------------------------
1 | accelerate==0.33.0
2 | transformers==4.44.0
3 | diffusers[torch]==0.25.0
4 | ftfy==6.1.1
5 | # albumentations==1.3.0
6 | opencv-python==4.8.1.78
7 | einops==0.7.0
8 | pytorch-lightning==1.9.0
9 | bitsandbytes==0.44.0
10 | lion-pytorch==0.0.6
11 | schedulefree==1.4
12 | pytorch-optimizer==3.5.0
13 | prodigy-plus-schedule-free==1.9.0
14 | prodigyopt==1.1.2
15 | tensorboard
16 | safetensors==0.4.4
17 | # gradio==3.16.2
18 | altair==4.2.2
19 | easygui==0.98.3
20 | toml==0.10.2
21 | voluptuous==0.13.1
22 | huggingface-hub==0.24.5
23 | # for Image utils
24 | imagesize==1.4.1
25 | numpy<=2.0
26 | # for BLIP captioning
27 | # requests==2.28.2
28 | # timm==0.6.12
29 | # fairscale==0.4.13
30 | # for WD14 captioning (tensorflow)
31 | # tensorflow==2.10.1
32 | # for WD14 captioning (onnx)
33 | # onnx==1.15.0
34 | # onnxruntime-gpu==1.17.1
35 | # onnxruntime==1.17.1
36 | # for cuda 12.1(default 11.8)
37 | # onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/
38 |
39 | # this is for onnx:
40 | # protobuf==3.20.3
41 | # open clip for SDXL
42 | # open-clip-torch==2.20.0
43 | # For logging
44 | rich==13.7.0
45 | # for T5XXL tokenizer (SD3/FLUX)
46 | sentencepiece==0.2.0
47 | # for kohya_ss library
48 | -e .
49 |
--------------------------------------------------------------------------------
/scripts/dev/sdxl_train_textual_inversion.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | from typing import Optional, Union
4 |
5 | import regex
6 |
7 | import torch
8 | from library.device_utils import init_ipex
9 |
10 | init_ipex()
11 |
12 | from library import sdxl_model_util, sdxl_train_util, strategy_sd, strategy_sdxl, train_util
13 | import train_textual_inversion
14 |
15 |
16 | class SdxlTextualInversionTrainer(train_textual_inversion.TextualInversionTrainer):
17 | def __init__(self):
18 | super().__init__()
19 | self.vae_scale_factor = sdxl_model_util.VAE_SCALE_FACTOR
20 | self.is_sdxl = True
21 |
22 | def assert_extra_args(self, args, train_dataset_group: Union[train_util.DatasetGroup, train_util.MinimalDataset], val_dataset_group: Optional[train_util.DatasetGroup]):
23 | super().assert_extra_args(args, train_dataset_group, val_dataset_group)
24 | sdxl_train_util.verify_sdxl_training_args(args, supportTextEncoderCaching=False)
25 |
26 | train_dataset_group.verify_bucket_reso_steps(32)
27 | if val_dataset_group is not None:
28 | val_dataset_group.verify_bucket_reso_steps(32)
29 |
30 | def load_target_model(self, args, weight_dtype, accelerator):
31 | (
32 | load_stable_diffusion_format,
33 | text_encoder1,
34 | text_encoder2,
35 | vae,
36 | unet,
37 | logit_scale,
38 | ckpt_info,
39 | ) = sdxl_train_util.load_target_model(args, accelerator, sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, weight_dtype)
40 |
41 | self.load_stable_diffusion_format = load_stable_diffusion_format
42 | self.logit_scale = logit_scale
43 | self.ckpt_info = ckpt_info
44 |
45 | return sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, [text_encoder1, text_encoder2], vae, unet
46 |
47 | def get_tokenize_strategy(self, args):
48 | return strategy_sdxl.SdxlTokenizeStrategy(args.max_token_length, args.tokenizer_cache_dir)
49 |
50 | def get_tokenizers(self, tokenize_strategy: strategy_sdxl.SdxlTokenizeStrategy):
51 | return [tokenize_strategy.tokenizer1, tokenize_strategy.tokenizer2]
52 |
53 | def get_latents_caching_strategy(self, args):
54 | latents_caching_strategy = strategy_sd.SdSdxlLatentsCachingStrategy(
55 | False, args.cache_latents_to_disk, args.vae_batch_size, args.skip_cache_check
56 | )
57 | return latents_caching_strategy
58 |
59 | def get_text_encoding_strategy(self, args):
60 | return strategy_sdxl.SdxlTextEncodingStrategy()
61 |
62 | def call_unet(self, args, accelerator, unet, noisy_latents, timesteps, text_conds, batch, weight_dtype):
63 | noisy_latents = noisy_latents.to(weight_dtype) # TODO check why noisy_latents is not weight_dtype
64 |
65 | # get size embeddings
66 | orig_size = batch["original_sizes_hw"]
67 | crop_size = batch["crop_top_lefts"]
68 | target_size = batch["target_sizes_hw"]
69 | embs = sdxl_train_util.get_size_embeddings(orig_size, crop_size, target_size, accelerator.device).to(weight_dtype)
70 |
71 | # concat embeddings
72 | encoder_hidden_states1, encoder_hidden_states2, pool2 = text_conds
73 | vector_embedding = torch.cat([pool2, embs], dim=1).to(weight_dtype)
74 | text_embedding = torch.cat([encoder_hidden_states1, encoder_hidden_states2], dim=2).to(weight_dtype)
75 |
76 | noise_pred = unet(noisy_latents, timesteps, text_embedding, vector_embedding)
77 | return noise_pred
78 |
79 | def sample_images(
80 | self, accelerator, args, epoch, global_step, device, vae, tokenizers, text_encoders, unet, prompt_replacement
81 | ):
82 | sdxl_train_util.sample_images(
83 | accelerator, args, epoch, global_step, device, vae, tokenizers, text_encoders, unet, prompt_replacement
84 | )
85 |
86 | def save_weights(self, file, updated_embs, save_dtype, metadata):
87 | state_dict = {"clip_l": updated_embs[0], "clip_g": updated_embs[1]}
88 |
89 | if save_dtype is not None:
90 | for key in list(state_dict.keys()):
91 | v = state_dict[key]
92 | v = v.detach().clone().to("cpu").to(save_dtype)
93 | state_dict[key] = v
94 |
95 | if os.path.splitext(file)[1] == ".safetensors":
96 | from safetensors.torch import save_file
97 |
98 | save_file(state_dict, file, metadata)
99 | else:
100 | torch.save(state_dict, file)
101 |
102 | def load_weights(self, file):
103 | if os.path.splitext(file)[1] == ".safetensors":
104 | from safetensors.torch import load_file
105 |
106 | data = load_file(file)
107 | else:
108 | data = torch.load(file, map_location="cpu")
109 |
110 | emb_l = data.get("clip_l", None) # ViT-L text encoder 1
111 | emb_g = data.get("clip_g", None) # BiG-G text encoder 2
112 |
113 | assert (
114 | emb_l is not None or emb_g is not None
115 | ), f"weight file does not contains weights for text encoder 1 or 2 / 重みファイルにテキストエンコーダー1または2の重みが含まれていません: {file}"
116 |
117 | return [emb_l, emb_g]
118 |
119 |
120 | def setup_parser() -> argparse.ArgumentParser:
121 | parser = train_textual_inversion.setup_parser()
122 | sdxl_train_util.add_sdxl_training_arguments(parser, support_text_encoder_caching=False)
123 | return parser
124 |
125 |
126 | if __name__ == "__main__":
127 | parser = setup_parser()
128 |
129 | args = parser.parse_args()
130 | train_util.verify_command_line_training_args(args)
131 | args = train_util.read_config_from_file(args, parser)
132 |
133 | trainer = SdxlTextualInversionTrainer()
134 | trainer.train(args)
135 |
--------------------------------------------------------------------------------
/scripts/dev/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 |
3 | setup(name = "library", packages = find_packages())
--------------------------------------------------------------------------------
/scripts/dev/tools/canny.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import cv2
3 |
4 | import logging
5 | from library.utils import setup_logging
6 | setup_logging()
7 | logger = logging.getLogger(__name__)
8 |
9 | def canny(args):
10 | img = cv2.imread(args.input)
11 | img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
12 |
13 | canny_img = cv2.Canny(img, args.thres1, args.thres2)
14 | # canny_img = 255 - canny_img
15 |
16 | cv2.imwrite(args.output, canny_img)
17 | logger.info("done!")
18 |
19 |
20 | def setup_parser() -> argparse.ArgumentParser:
21 | parser = argparse.ArgumentParser()
22 | parser.add_argument("--input", type=str, default=None, help="input path")
23 | parser.add_argument("--output", type=str, default=None, help="output path")
24 | parser.add_argument("--thres1", type=int, default=32, help="thres1")
25 | parser.add_argument("--thres2", type=int, default=224, help="thres2")
26 |
27 | return parser
28 |
29 |
30 | if __name__ == '__main__':
31 | parser = setup_parser()
32 |
33 | args = parser.parse_args()
34 | canny(args)
35 |
--------------------------------------------------------------------------------
/scripts/dev/tools/show_metadata.py:
--------------------------------------------------------------------------------
1 | import json
2 | import argparse
3 | from safetensors import safe_open
4 | from library.utils import setup_logging
5 | setup_logging()
6 | import logging
7 | logger = logging.getLogger(__name__)
8 |
9 | parser = argparse.ArgumentParser()
10 | parser.add_argument("--model", type=str, required=True)
11 | args = parser.parse_args()
12 |
13 | with safe_open(args.model, framework="pt") as f:
14 | metadata = f.metadata()
15 |
16 | if metadata is None:
17 | logger.error("No metadata found")
18 | else:
19 | # metadata is json dict, but not pretty printed
20 | # sort by key and pretty print
21 | print(json.dumps(metadata, indent=4, sort_keys=True))
22 |
23 |
24 |
--------------------------------------------------------------------------------
/scripts/dev/train_controlnet.py:
--------------------------------------------------------------------------------
1 | from library.utils import setup_logging
2 |
3 | setup_logging()
4 | import logging
5 |
6 | logger = logging.getLogger(__name__)
7 |
8 |
9 | from library import train_util
10 | from train_control_net import setup_parser, train
11 |
12 | if __name__ == "__main__":
13 | logger.warning(
14 | "The module 'train_controlnet.py' is deprecated. Please use 'train_control_net.py' instead"
15 | " / 'train_controlnet.py'は非推奨です。代わりに'train_control_net.py'を使用してください。"
16 | )
17 | parser = setup_parser()
18 |
19 | args = parser.parse_args()
20 | train_util.verify_command_line_training_args(args)
21 | args = train_util.read_config_from_file(args, parser)
22 |
23 | train(args)
24 |
--------------------------------------------------------------------------------
/scripts/stable/.gitignore:
--------------------------------------------------------------------------------
1 | logs
2 | __pycache__
3 | wd14_tagger_model
4 | venv
5 | *.egg-info
6 | build
7 | .vscode
8 | wandb
9 |
--------------------------------------------------------------------------------
/scripts/stable/COMMIT_ID:
--------------------------------------------------------------------------------
1 | 8f4ee8fc343b047965cd8976fca65c3a35b7593a
--------------------------------------------------------------------------------
/scripts/stable/README-ja.md:
--------------------------------------------------------------------------------
1 | ## リポジトリについて
2 | Stable Diffusionの学習、画像生成、その他のスクリプトを入れたリポジトリです。
3 |
4 | [README in English](./README.md) ←更新情報はこちらにあります
5 |
6 | 開発中のバージョンはdevブランチにあります。最新の変更点はdevブランチをご確認ください。
7 |
8 | FLUX.1およびSD3/SD3.5対応はsd3ブランチで行っています。それらの学習を行う場合はsd3ブランチをご利用ください。
9 |
10 | GUIやPowerShellスクリプトなど、より使いやすくする機能が[bmaltais氏のリポジトリ](https://github.com/bmaltais/kohya_ss)で提供されています(英語です)のであわせてご覧ください。bmaltais氏に感謝します。
11 |
12 | 以下のスクリプトがあります。
13 |
14 | * DreamBooth、U-NetおよびText Encoderの学習をサポート
15 | * fine-tuning、同上
16 | * LoRAの学習をサポート
17 | * 画像生成
18 | * モデル変換(Stable Diffision ckpt/safetensorsとDiffusersの相互変換)
19 |
20 | ## 使用法について
21 |
22 | * [学習について、共通編](./docs/train_README-ja.md) : データ整備やオプションなど
23 | * [データセット設定](./docs/config_README-ja.md)
24 | * [SDXL学習](./docs/train_SDXL-en.md) (英語版)
25 | * [DreamBoothの学習について](./docs/train_db_README-ja.md)
26 | * [fine-tuningのガイド](./docs/fine_tune_README_ja.md):
27 | * [LoRAの学習について](./docs/train_network_README-ja.md)
28 | * [Textual Inversionの学習について](./docs/train_ti_README-ja.md)
29 | * [画像生成スクリプト](./docs/gen_img_README-ja.md)
30 | * note.com [モデル変換スクリプト](https://note.com/kohya_ss/n/n374f316fe4ad)
31 |
32 | ## Windowsでの動作に必要なプログラム
33 |
34 | Python 3.10.6およびGitが必要です。
35 |
36 | - Python 3.10.6: https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
37 | - git: https://git-scm.com/download/win
38 |
39 | Python 3.10.x、3.11.x、3.12.xでも恐らく動作しますが、3.10.6でテストしています。
40 |
41 | PowerShellを使う場合、venvを使えるようにするためには以下の手順でセキュリティ設定を変更してください。
42 | (venvに限らずスクリプトの実行が可能になりますので注意してください。)
43 |
44 | - PowerShellを管理者として開きます。
45 | - 「Set-ExecutionPolicy Unrestricted」と入力し、Yと答えます。
46 | - 管理者のPowerShellを閉じます。
47 |
48 | ## Windows環境でのインストール
49 |
50 | スクリプトはPyTorch 2.1.2でテストしています。PyTorch 2.2以降でも恐らく動作します。
51 |
52 | (なお、python -m venv~の行で「python」とだけ表示された場合、py -m venv~のようにpythonをpyに変更してください。)
53 |
54 | PowerShellを使う場合、通常の(管理者ではない)PowerShellを開き以下を順に実行します。
55 |
56 | ```powershell
57 | git clone https://github.com/kohya-ss/sd-scripts.git
58 | cd sd-scripts
59 |
60 | python -m venv venv
61 | .\venv\Scripts\activate
62 |
63 | pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu118
64 | pip install --upgrade -r requirements.txt
65 | pip install xformers==0.0.23.post1 --index-url https://download.pytorch.org/whl/cu118
66 |
67 | accelerate config
68 | ```
69 |
70 | コマンドプロンプトでも同一です。
71 |
72 | 注:`bitsandbytes==0.44.0`、`prodigyopt==1.0`、`lion-pytorch==0.0.6` は `requirements.txt` に含まれるようになりました。他のバージョンを使う場合は適宜インストールしてください。
73 |
74 | この例では PyTorch および xfomers は2.1.2/CUDA 11.8版をインストールします。CUDA 12.1版やPyTorch 1.12.1を使う場合は適宜書き換えください。たとえば CUDA 12.1版の場合は `pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu121` および `pip install xformers==0.0.23.post1 --index-url https://download.pytorch.org/whl/cu121` としてください。
75 |
76 | PyTorch 2.2以降を用いる場合は、`torch==2.1.2` と `torchvision==0.16.2` 、および `xformers==0.0.23.post1` を適宜変更してください。
77 |
78 | accelerate configの質問には以下のように答えてください。(bf16で学習する場合、最後の質問にはbf16と答えてください。)
79 |
80 | ```txt
81 | - This machine
82 | - No distributed training
83 | - NO
84 | - NO
85 | - NO
86 | - all
87 | - fp16
88 | ```
89 |
90 | ※場合によって ``ValueError: fp16 mixed precision requires a GPU`` というエラーが出ることがあるようです。この場合、6番目の質問(
91 | ``What GPU(s) (by id) should be used for training on this machine as a comma-separated list? [all]:``)に「0」と答えてください。(id `0`のGPUが使われます。)
92 |
93 | ## アップグレード
94 |
95 | 新しいリリースがあった場合、以下のコマンドで更新できます。
96 |
97 | ```powershell
98 | cd sd-scripts
99 | git pull
100 | .\venv\Scripts\activate
101 | pip install --use-pep517 --upgrade -r requirements.txt
102 | ```
103 |
104 | コマンドが成功すれば新しいバージョンが使用できます。
105 |
106 | ## 謝意
107 |
108 | LoRAの実装は[cloneofsimo氏のリポジトリ](https://github.com/cloneofsimo/lora)を基にしたものです。感謝申し上げます。
109 |
110 | Conv2d 3x3への拡大は [cloneofsimo氏](https://github.com/cloneofsimo/lora) が最初にリリースし、KohakuBlueleaf氏が [LoCon](https://github.com/KohakuBlueleaf/LoCon) でその有効性を明らかにしたものです。KohakuBlueleaf氏に深く感謝します。
111 |
112 | ## ライセンス
113 |
114 | スクリプトのライセンスはASL 2.0ですが(Diffusersおよびcloneofsimo氏のリポジトリ由来のものも同様)、一部他のライセンスのコードを含みます。
115 |
116 | [Memory Efficient Attention Pytorch](https://github.com/lucidrains/memory-efficient-attention-pytorch): MIT
117 |
118 | [bitsandbytes](https://github.com/TimDettmers/bitsandbytes): MIT
119 |
120 | [BLIP](https://github.com/salesforce/BLIP): BSD-3-Clause
121 |
122 | ## その他の情報
123 |
124 | ### LoRAの名称について
125 |
126 | `train_network.py` がサポートするLoRAについて、混乱を避けるため名前を付けました。ドキュメントは更新済みです。以下は当リポジトリ内の独自の名称です。
127 |
128 | 1. __LoRA-LierLa__ : (LoRA for __Li__ n __e__ a __r__ __La__ yers、リエラと読みます)
129 |
130 | Linear 層およびカーネルサイズ 1x1 の Conv2d 層に適用されるLoRA
131 |
132 | 2. __LoRA-C3Lier__ : (LoRA for __C__ olutional layers with __3__ x3 Kernel and __Li__ n __e__ a __r__ layers、セリアと読みます)
133 |
134 | 1.に加え、カーネルサイズ 3x3 の Conv2d 層に適用されるLoRA
135 |
136 | デフォルトではLoRA-LierLaが使われます。LoRA-C3Lierを使う場合は `--network_args` に `conv_dim` を指定してください。
137 |
138 |
143 |
144 | ### 学習中のサンプル画像生成
145 |
146 | プロンプトファイルは例えば以下のようになります。
147 |
148 | ```
149 | # prompt 1
150 | masterpiece, best quality, (1girl), in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
151 |
152 | # prompt 2
153 | masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n (low quality, worst quality), bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
154 | ```
155 |
156 | `#` で始まる行はコメントになります。`--n` のように「ハイフン二個+英小文字」の形でオプションを指定できます。以下が使用可能できます。
157 |
158 | * `--n` Negative prompt up to the next option.
159 | * `--w` Specifies the width of the generated image.
160 | * `--h` Specifies the height of the generated image.
161 | * `--d` Specifies the seed of the generated image.
162 | * `--l` Specifies the CFG scale of the generated image.
163 | * `--s` Specifies the number of steps in the generation.
164 |
165 | `( )` や `[ ]` などの重みづけも動作します。
166 |
--------------------------------------------------------------------------------
/scripts/stable/_typos.toml:
--------------------------------------------------------------------------------
1 | # Files for typos
2 | # Instruction: https://github.com/marketplace/actions/typos-action#getting-started
3 |
4 | [default.extend-identifiers]
5 | ddPn08="ddPn08"
6 |
7 | [default.extend-words]
8 | NIN="NIN"
9 | parms="parms"
10 | nin="nin"
11 | extention="extention" # Intentionally left
12 | nd="nd"
13 | shs="shs"
14 | sts="sts"
15 | scs="scs"
16 | cpc="cpc"
17 | coc="coc"
18 | cic="cic"
19 | msm="msm"
20 | usu="usu"
21 | ici="ici"
22 | lvl="lvl"
23 | dii="dii"
24 | muk="muk"
25 | ori="ori"
26 | hru="hru"
27 | rik="rik"
28 | koo="koo"
29 | yos="yos"
30 | wn="wn"
31 | hime="hime"
32 |
33 |
34 | [files]
35 | extend-exclude = ["_typos.toml", "venv"]
36 |
--------------------------------------------------------------------------------
/scripts/stable/finetune/blip/med_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "architectures": [
3 | "BertModel"
4 | ],
5 | "attention_probs_dropout_prob": 0.1,
6 | "hidden_act": "gelu",
7 | "hidden_dropout_prob": 0.1,
8 | "hidden_size": 768,
9 | "initializer_range": 0.02,
10 | "intermediate_size": 3072,
11 | "layer_norm_eps": 1e-12,
12 | "max_position_embeddings": 512,
13 | "model_type": "bert",
14 | "num_attention_heads": 12,
15 | "num_hidden_layers": 12,
16 | "pad_token_id": 0,
17 | "type_vocab_size": 2,
18 | "vocab_size": 30524,
19 | "encoder_width": 768,
20 | "add_cross_attention": true
21 | }
22 |
--------------------------------------------------------------------------------
/scripts/stable/finetune/hypernetwork_nai.py:
--------------------------------------------------------------------------------
1 | # NAI compatible
2 |
3 | import torch
4 |
5 |
6 | class HypernetworkModule(torch.nn.Module):
7 | def __init__(self, dim, multiplier=1.0):
8 | super().__init__()
9 |
10 | linear1 = torch.nn.Linear(dim, dim * 2)
11 | linear2 = torch.nn.Linear(dim * 2, dim)
12 | linear1.weight.data.normal_(mean=0.0, std=0.01)
13 | linear1.bias.data.zero_()
14 | linear2.weight.data.normal_(mean=0.0, std=0.01)
15 | linear2.bias.data.zero_()
16 | linears = [linear1, linear2]
17 |
18 | self.linear = torch.nn.Sequential(*linears)
19 | self.multiplier = multiplier
20 |
21 | def forward(self, x):
22 | return x + self.linear(x) * self.multiplier
23 |
24 |
25 | class Hypernetwork(torch.nn.Module):
26 | enable_sizes = [320, 640, 768, 1280]
27 | # return self.modules[Hypernetwork.enable_sizes.index(size)]
28 |
29 | def __init__(self, multiplier=1.0) -> None:
30 | super().__init__()
31 | self.modules = []
32 | for size in Hypernetwork.enable_sizes:
33 | self.modules.append((HypernetworkModule(size, multiplier), HypernetworkModule(size, multiplier)))
34 | self.register_module(f"{size}_0", self.modules[-1][0])
35 | self.register_module(f"{size}_1", self.modules[-1][1])
36 |
37 | def apply_to_stable_diffusion(self, text_encoder, vae, unet):
38 | blocks = unet.input_blocks + [unet.middle_block] + unet.output_blocks
39 | for block in blocks:
40 | for subblk in block:
41 | if 'SpatialTransformer' in str(type(subblk)):
42 | for tf_block in subblk.transformer_blocks:
43 | for attn in [tf_block.attn1, tf_block.attn2]:
44 | size = attn.context_dim
45 | if size in Hypernetwork.enable_sizes:
46 | attn.hypernetwork = self
47 | else:
48 | attn.hypernetwork = None
49 |
50 | def apply_to_diffusers(self, text_encoder, vae, unet):
51 | blocks = unet.down_blocks + [unet.mid_block] + unet.up_blocks
52 | for block in blocks:
53 | if hasattr(block, 'attentions'):
54 | for subblk in block.attentions:
55 | if 'SpatialTransformer' in str(type(subblk)) or 'Transformer2DModel' in str(type(subblk)): # 0.6.0 and 0.7~
56 | for tf_block in subblk.transformer_blocks:
57 | for attn in [tf_block.attn1, tf_block.attn2]:
58 | size = attn.to_k.in_features
59 | if size in Hypernetwork.enable_sizes:
60 | attn.hypernetwork = self
61 | else:
62 | attn.hypernetwork = None
63 | return True # TODO error checking
64 |
65 | def forward(self, x, context):
66 | size = context.shape[-1]
67 | assert size in Hypernetwork.enable_sizes
68 | module = self.modules[Hypernetwork.enable_sizes.index(size)]
69 | return module[0].forward(context), module[1].forward(context)
70 |
71 | def load_from_state_dict(self, state_dict):
72 | # old ver to new ver
73 | changes = {
74 | 'linear1.bias': 'linear.0.bias',
75 | 'linear1.weight': 'linear.0.weight',
76 | 'linear2.bias': 'linear.1.bias',
77 | 'linear2.weight': 'linear.1.weight',
78 | }
79 | for key_from, key_to in changes.items():
80 | if key_from in state_dict:
81 | state_dict[key_to] = state_dict[key_from]
82 | del state_dict[key_from]
83 |
84 | for size, sd in state_dict.items():
85 | if type(size) == int:
86 | self.modules[Hypernetwork.enable_sizes.index(size)][0].load_state_dict(sd[0], strict=True)
87 | self.modules[Hypernetwork.enable_sizes.index(size)][1].load_state_dict(sd[1], strict=True)
88 | return True
89 |
90 | def get_state_dict(self):
91 | state_dict = {}
92 | for i, size in enumerate(Hypernetwork.enable_sizes):
93 | sd0 = self.modules[i][0].state_dict()
94 | sd1 = self.modules[i][1].state_dict()
95 | state_dict[size] = [sd0, sd1]
96 | return state_dict
97 |
--------------------------------------------------------------------------------
/scripts/stable/finetune/merge_captions_to_metadata.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import json
3 | from pathlib import Path
4 | from typing import List
5 | from tqdm import tqdm
6 | import library.train_util as train_util
7 | import os
8 | from library.utils import setup_logging
9 |
10 | setup_logging()
11 | import logging
12 |
13 | logger = logging.getLogger(__name__)
14 |
15 |
16 | def main(args):
17 | assert not args.recursive or (
18 | args.recursive and args.full_path
19 | ), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
20 |
21 | train_data_dir_path = Path(args.train_data_dir)
22 | image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
23 | logger.info(f"found {len(image_paths)} images.")
24 |
25 | if args.in_json is None and Path(args.out_json).is_file():
26 | args.in_json = args.out_json
27 |
28 | if args.in_json is not None:
29 | logger.info(f"loading existing metadata: {args.in_json}")
30 | metadata = json.loads(Path(args.in_json).read_text(encoding="utf-8"))
31 | logger.warning("captions for existing images will be overwritten / 既存の画像のキャプションは上書きされます")
32 | else:
33 | logger.info("new metadata will be created / 新しいメタデータファイルが作成されます")
34 | metadata = {}
35 |
36 | logger.info("merge caption texts to metadata json.")
37 | for image_path in tqdm(image_paths):
38 | caption_path = image_path.with_suffix(args.caption_extension)
39 | caption = caption_path.read_text(encoding="utf-8").strip()
40 |
41 | if not os.path.exists(caption_path):
42 | caption_path = os.path.join(image_path, args.caption_extension)
43 |
44 | image_key = str(image_path) if args.full_path else image_path.stem
45 | if image_key not in metadata:
46 | metadata[image_key] = {}
47 |
48 | metadata[image_key]["caption"] = caption
49 | if args.debug:
50 | logger.info(f"{image_key} {caption}")
51 |
52 | # metadataを書き出して終わり
53 | logger.info(f"writing metadata: {args.out_json}")
54 | Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding="utf-8")
55 | logger.info("done!")
56 |
57 |
58 | def setup_parser() -> argparse.ArgumentParser:
59 | parser = argparse.ArgumentParser()
60 | parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
61 | parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
62 | parser.add_argument(
63 | "--in_json",
64 | type=str,
65 | help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)",
66 | )
67 | parser.add_argument(
68 | "--caption_extention",
69 | type=str,
70 | default=None,
71 | help="extension of caption file (for backward compatibility) / 読み込むキャプションファイルの拡張子(スペルミスしていたのを残してあります)",
72 | )
73 | parser.add_argument(
74 | "--caption_extension", type=str, default=".caption", help="extension of caption file / 読み込むキャプションファイルの拡張子"
75 | )
76 | parser.add_argument(
77 | "--full_path",
78 | action="store_true",
79 | help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)",
80 | )
81 | parser.add_argument(
82 | "--recursive",
83 | action="store_true",
84 | help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す",
85 | )
86 | parser.add_argument("--debug", action="store_true", help="debug mode")
87 |
88 | return parser
89 |
90 |
91 | if __name__ == "__main__":
92 | parser = setup_parser()
93 |
94 | args = parser.parse_args()
95 |
96 | # スペルミスしていたオプションを復元する
97 | if args.caption_extention is not None:
98 | args.caption_extension = args.caption_extention
99 |
100 | main(args)
101 |
--------------------------------------------------------------------------------
/scripts/stable/finetune/merge_dd_tags_to_metadata.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import json
3 | from pathlib import Path
4 | from typing import List
5 | from tqdm import tqdm
6 | import library.train_util as train_util
7 | import os
8 | from library.utils import setup_logging
9 |
10 | setup_logging()
11 | import logging
12 |
13 | logger = logging.getLogger(__name__)
14 |
15 |
16 | def main(args):
17 | assert not args.recursive or (
18 | args.recursive and args.full_path
19 | ), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
20 |
21 | train_data_dir_path = Path(args.train_data_dir)
22 | image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
23 | logger.info(f"found {len(image_paths)} images.")
24 |
25 | if args.in_json is None and Path(args.out_json).is_file():
26 | args.in_json = args.out_json
27 |
28 | if args.in_json is not None:
29 | logger.info(f"loading existing metadata: {args.in_json}")
30 | metadata = json.loads(Path(args.in_json).read_text(encoding="utf-8"))
31 | logger.warning("tags data for existing images will be overwritten / 既存の画像のタグは上書きされます")
32 | else:
33 | logger.info("new metadata will be created / 新しいメタデータファイルが作成されます")
34 | metadata = {}
35 |
36 | logger.info("merge tags to metadata json.")
37 | for image_path in tqdm(image_paths):
38 | tags_path = image_path.with_suffix(args.caption_extension)
39 | tags = tags_path.read_text(encoding="utf-8").strip()
40 |
41 | if not os.path.exists(tags_path):
42 | tags_path = os.path.join(image_path, args.caption_extension)
43 |
44 | image_key = str(image_path) if args.full_path else image_path.stem
45 | if image_key not in metadata:
46 | metadata[image_key] = {}
47 |
48 | metadata[image_key]["tags"] = tags
49 | if args.debug:
50 | logger.info(f"{image_key} {tags}")
51 |
52 | # metadataを書き出して終わり
53 | logger.info(f"writing metadata: {args.out_json}")
54 | Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding="utf-8")
55 |
56 | logger.info("done!")
57 |
58 |
59 | def setup_parser() -> argparse.ArgumentParser:
60 | parser = argparse.ArgumentParser()
61 | parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
62 | parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
63 | parser.add_argument(
64 | "--in_json",
65 | type=str,
66 | help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)",
67 | )
68 | parser.add_argument(
69 | "--full_path",
70 | action="store_true",
71 | help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)",
72 | )
73 | parser.add_argument(
74 | "--recursive",
75 | action="store_true",
76 | help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す",
77 | )
78 | parser.add_argument(
79 | "--caption_extension",
80 | type=str,
81 | default=".txt",
82 | help="extension of caption (tag) file / 読み込むキャプション(タグ)ファイルの拡張子",
83 | )
84 | parser.add_argument("--debug", action="store_true", help="debug mode, print tags")
85 |
86 | return parser
87 |
88 |
89 | if __name__ == "__main__":
90 | parser = setup_parser()
91 |
92 | args = parser.parse_args()
93 | main(args)
94 |
--------------------------------------------------------------------------------
/scripts/stable/library/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Akegarasu/lora-scripts/e0f5194815203093659d6ec280b9362b9792c070/scripts/stable/library/__init__.py
--------------------------------------------------------------------------------
/scripts/stable/library/adafactor_fused.py:
--------------------------------------------------------------------------------
1 | import math
2 | import torch
3 | from transformers import Adafactor
4 |
5 | @torch.no_grad()
6 | def adafactor_step_param(self, p, group):
7 | if p.grad is None:
8 | return
9 | grad = p.grad
10 | if grad.dtype in {torch.float16, torch.bfloat16}:
11 | grad = grad.float()
12 | if grad.is_sparse:
13 | raise RuntimeError("Adafactor does not support sparse gradients.")
14 |
15 | state = self.state[p]
16 | grad_shape = grad.shape
17 |
18 | factored, use_first_moment = Adafactor._get_options(group, grad_shape)
19 | # State Initialization
20 | if len(state) == 0:
21 | state["step"] = 0
22 |
23 | if use_first_moment:
24 | # Exponential moving average of gradient values
25 | state["exp_avg"] = torch.zeros_like(grad)
26 | if factored:
27 | state["exp_avg_sq_row"] = torch.zeros(grad_shape[:-1]).to(grad)
28 | state["exp_avg_sq_col"] = torch.zeros(grad_shape[:-2] + grad_shape[-1:]).to(grad)
29 | else:
30 | state["exp_avg_sq"] = torch.zeros_like(grad)
31 |
32 | state["RMS"] = 0
33 | else:
34 | if use_first_moment:
35 | state["exp_avg"] = state["exp_avg"].to(grad)
36 | if factored:
37 | state["exp_avg_sq_row"] = state["exp_avg_sq_row"].to(grad)
38 | state["exp_avg_sq_col"] = state["exp_avg_sq_col"].to(grad)
39 | else:
40 | state["exp_avg_sq"] = state["exp_avg_sq"].to(grad)
41 |
42 | p_data_fp32 = p
43 | if p.dtype in {torch.float16, torch.bfloat16}:
44 | p_data_fp32 = p_data_fp32.float()
45 |
46 | state["step"] += 1
47 | state["RMS"] = Adafactor._rms(p_data_fp32)
48 | lr = Adafactor._get_lr(group, state)
49 |
50 | beta2t = 1.0 - math.pow(state["step"], group["decay_rate"])
51 | update = (grad ** 2) + group["eps"][0]
52 | if factored:
53 | exp_avg_sq_row = state["exp_avg_sq_row"]
54 | exp_avg_sq_col = state["exp_avg_sq_col"]
55 |
56 | exp_avg_sq_row.mul_(beta2t).add_(update.mean(dim=-1), alpha=(1.0 - beta2t))
57 | exp_avg_sq_col.mul_(beta2t).add_(update.mean(dim=-2), alpha=(1.0 - beta2t))
58 |
59 | # Approximation of exponential moving average of square of gradient
60 | update = Adafactor._approx_sq_grad(exp_avg_sq_row, exp_avg_sq_col)
61 | update.mul_(grad)
62 | else:
63 | exp_avg_sq = state["exp_avg_sq"]
64 |
65 | exp_avg_sq.mul_(beta2t).add_(update, alpha=(1.0 - beta2t))
66 | update = exp_avg_sq.rsqrt().mul_(grad)
67 |
68 | update.div_((Adafactor._rms(update) / group["clip_threshold"]).clamp_(min=1.0))
69 | update.mul_(lr)
70 |
71 | if use_first_moment:
72 | exp_avg = state["exp_avg"]
73 | exp_avg.mul_(group["beta1"]).add_(update, alpha=(1 - group["beta1"]))
74 | update = exp_avg
75 |
76 | if group["weight_decay"] != 0:
77 | p_data_fp32.add_(p_data_fp32, alpha=(-group["weight_decay"] * lr))
78 |
79 | p_data_fp32.add_(-update)
80 |
81 | if p.dtype in {torch.float16, torch.bfloat16}:
82 | p.copy_(p_data_fp32)
83 |
84 |
85 | @torch.no_grad()
86 | def adafactor_step(self, closure=None):
87 | """
88 | Performs a single optimization step
89 |
90 | Arguments:
91 | closure (callable, optional): A closure that reevaluates the model
92 | and returns the loss.
93 | """
94 | loss = None
95 | if closure is not None:
96 | loss = closure()
97 |
98 | for group in self.param_groups:
99 | for p in group["params"]:
100 | adafactor_step_param(self, p, group)
101 |
102 | return loss
103 |
104 | def patch_adafactor_fused(optimizer: Adafactor):
105 | optimizer.step_param = adafactor_step_param.__get__(optimizer)
106 | optimizer.step = adafactor_step.__get__(optimizer)
107 |
--------------------------------------------------------------------------------
/scripts/stable/library/deepspeed_utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import argparse
3 | import torch
4 | from accelerate import DeepSpeedPlugin, Accelerator
5 |
6 | from .utils import setup_logging
7 |
8 | setup_logging()
9 | import logging
10 |
11 | logger = logging.getLogger(__name__)
12 |
13 |
14 | def add_deepspeed_arguments(parser: argparse.ArgumentParser):
15 | # DeepSpeed Arguments. https://huggingface.co/docs/accelerate/usage_guides/deepspeed
16 | parser.add_argument("--deepspeed", action="store_true", help="enable deepspeed training")
17 | parser.add_argument("--zero_stage", type=int, default=2, choices=[0, 1, 2, 3], help="Possible options are 0,1,2,3.")
18 | parser.add_argument(
19 | "--offload_optimizer_device",
20 | type=str,
21 | default=None,
22 | choices=[None, "cpu", "nvme"],
23 | help="Possible options are none|cpu|nvme. Only applicable with ZeRO Stages 2 and 3.",
24 | )
25 | parser.add_argument(
26 | "--offload_optimizer_nvme_path",
27 | type=str,
28 | default=None,
29 | help="Possible options are /nvme|/local_nvme. Only applicable with ZeRO Stage 3.",
30 | )
31 | parser.add_argument(
32 | "--offload_param_device",
33 | type=str,
34 | default=None,
35 | choices=[None, "cpu", "nvme"],
36 | help="Possible options are none|cpu|nvme. Only applicable with ZeRO Stage 3.",
37 | )
38 | parser.add_argument(
39 | "--offload_param_nvme_path",
40 | type=str,
41 | default=None,
42 | help="Possible options are /nvme|/local_nvme. Only applicable with ZeRO Stage 3.",
43 | )
44 | parser.add_argument(
45 | "--zero3_init_flag",
46 | action="store_true",
47 | help="Flag to indicate whether to enable `deepspeed.zero.Init` for constructing massive models."
48 | "Only applicable with ZeRO Stage-3.",
49 | )
50 | parser.add_argument(
51 | "--zero3_save_16bit_model",
52 | action="store_true",
53 | help="Flag to indicate whether to save 16-bit model. Only applicable with ZeRO Stage-3.",
54 | )
55 | parser.add_argument(
56 | "--fp16_master_weights_and_gradients",
57 | action="store_true",
58 | help="fp16_master_and_gradients requires optimizer to support keeping fp16 master and gradients while keeping the optimizer states in fp32.",
59 | )
60 |
61 |
62 | def prepare_deepspeed_args(args: argparse.Namespace):
63 | if not args.deepspeed:
64 | return
65 |
66 | # To avoid RuntimeError: DataLoader worker exited unexpectedly with exit code 1.
67 | args.max_data_loader_n_workers = 1
68 |
69 |
70 | def prepare_deepspeed_plugin(args: argparse.Namespace):
71 | if not args.deepspeed:
72 | return None
73 |
74 | try:
75 | import deepspeed
76 | except ImportError as e:
77 | logger.error(
78 | "deepspeed is not installed. please install deepspeed in your environment with following command. DS_BUILD_OPS=0 pip install deepspeed"
79 | )
80 | exit(1)
81 |
82 | deepspeed_plugin = DeepSpeedPlugin(
83 | zero_stage=args.zero_stage,
84 | gradient_accumulation_steps=args.gradient_accumulation_steps,
85 | gradient_clipping=args.max_grad_norm,
86 | offload_optimizer_device=args.offload_optimizer_device,
87 | offload_optimizer_nvme_path=args.offload_optimizer_nvme_path,
88 | offload_param_device=args.offload_param_device,
89 | offload_param_nvme_path=args.offload_param_nvme_path,
90 | zero3_init_flag=args.zero3_init_flag,
91 | zero3_save_16bit_model=args.zero3_save_16bit_model,
92 | )
93 | deepspeed_plugin.deepspeed_config["train_micro_batch_size_per_gpu"] = args.train_batch_size
94 | deepspeed_plugin.deepspeed_config["train_batch_size"] = (
95 | args.train_batch_size * args.gradient_accumulation_steps * int(os.environ["WORLD_SIZE"])
96 | )
97 | deepspeed_plugin.set_mixed_precision(args.mixed_precision)
98 | if args.mixed_precision.lower() == "fp16":
99 | deepspeed_plugin.deepspeed_config["fp16"]["initial_scale_power"] = 0 # preventing overflow.
100 | if args.full_fp16 or args.fp16_master_weights_and_gradients:
101 | if args.offload_optimizer_device == "cpu" and args.zero_stage == 2:
102 | deepspeed_plugin.deepspeed_config["fp16"]["fp16_master_weights_and_grads"] = True
103 | logger.info("[DeepSpeed] full fp16 enable.")
104 | else:
105 | logger.info(
106 | "[DeepSpeed]full fp16, fp16_master_weights_and_grads currently only supported using ZeRO-Offload with DeepSpeedCPUAdam on ZeRO-2 stage."
107 | )
108 |
109 | if args.offload_optimizer_device is not None:
110 | logger.info("[DeepSpeed] start to manually build cpu_adam.")
111 | deepspeed.ops.op_builder.CPUAdamBuilder().load()
112 | logger.info("[DeepSpeed] building cpu_adam done.")
113 |
114 | return deepspeed_plugin
115 |
116 |
117 | # Accelerate library does not support multiple models for deepspeed. So, we need to wrap multiple models into a single model.
118 | def prepare_deepspeed_model(args: argparse.Namespace, **models):
119 | # remove None from models
120 | models = {k: v for k, v in models.items() if v is not None}
121 |
122 | class DeepSpeedWrapper(torch.nn.Module):
123 | def __init__(self, **kw_models) -> None:
124 | super().__init__()
125 | self.models = torch.nn.ModuleDict()
126 |
127 | for key, model in kw_models.items():
128 | if isinstance(model, list):
129 | model = torch.nn.ModuleList(model)
130 | assert isinstance(
131 | model, torch.nn.Module
132 | ), f"model must be an instance of torch.nn.Module, but got {key} is {type(model)}"
133 | self.models.update(torch.nn.ModuleDict({key: model}))
134 |
135 | def get_models(self):
136 | return self.models
137 |
138 | ds_model = DeepSpeedWrapper(**models)
139 | return ds_model
140 |
--------------------------------------------------------------------------------
/scripts/stable/library/device_utils.py:
--------------------------------------------------------------------------------
1 | import functools
2 | import gc
3 |
4 | import torch
5 |
6 | try:
7 | HAS_CUDA = torch.cuda.is_available()
8 | except Exception:
9 | HAS_CUDA = False
10 |
11 | try:
12 | HAS_MPS = torch.backends.mps.is_available()
13 | except Exception:
14 | HAS_MPS = False
15 |
16 | try:
17 | import intel_extension_for_pytorch as ipex # noqa
18 |
19 | HAS_XPU = torch.xpu.is_available()
20 | except Exception:
21 | HAS_XPU = False
22 |
23 |
24 | def clean_memory():
25 | gc.collect()
26 | if HAS_CUDA:
27 | torch.cuda.empty_cache()
28 | if HAS_XPU:
29 | torch.xpu.empty_cache()
30 | if HAS_MPS:
31 | torch.mps.empty_cache()
32 |
33 |
34 | def clean_memory_on_device(device: torch.device):
35 | r"""
36 | Clean memory on the specified device, will be called from training scripts.
37 | """
38 | gc.collect()
39 |
40 | # device may "cuda" or "cuda:0", so we need to check the type of device
41 | if device.type == "cuda":
42 | torch.cuda.empty_cache()
43 | if device.type == "xpu":
44 | torch.xpu.empty_cache()
45 | if device.type == "mps":
46 | torch.mps.empty_cache()
47 |
48 |
49 | @functools.lru_cache(maxsize=None)
50 | def get_preferred_device() -> torch.device:
51 | r"""
52 | Do not call this function from training scripts. Use accelerator.device instead.
53 | """
54 | if HAS_CUDA:
55 | device = torch.device("cuda")
56 | elif HAS_XPU:
57 | device = torch.device("xpu")
58 | elif HAS_MPS:
59 | device = torch.device("mps")
60 | else:
61 | device = torch.device("cpu")
62 | print(f"get_preferred_device() -> {device}")
63 | return device
64 |
65 |
66 | def init_ipex():
67 | """
68 | Apply IPEX to CUDA hijacks using `library.ipex.ipex_init`.
69 |
70 | This function should run right after importing torch and before doing anything else.
71 |
72 | If IPEX is not available, this function does nothing.
73 | """
74 | try:
75 | if HAS_XPU:
76 | from library.ipex import ipex_init
77 |
78 | is_initialized, error_message = ipex_init()
79 | if not is_initialized:
80 | print("failed to initialize ipex:", error_message)
81 | else:
82 | return
83 | except Exception as e:
84 | print("failed to initialize ipex:", e)
85 |
--------------------------------------------------------------------------------
/scripts/stable/library/huggingface_util.py:
--------------------------------------------------------------------------------
1 | from typing import Union, BinaryIO
2 | from huggingface_hub import HfApi
3 | from pathlib import Path
4 | import argparse
5 | import os
6 | from library.utils import fire_in_thread
7 | from library.utils import setup_logging
8 | setup_logging()
9 | import logging
10 | logger = logging.getLogger(__name__)
11 |
12 | def exists_repo(repo_id: str, repo_type: str, revision: str = "main", token: str = None):
13 | api = HfApi(
14 | token=token,
15 | )
16 | try:
17 | api.repo_info(repo_id=repo_id, revision=revision, repo_type=repo_type)
18 | return True
19 | except:
20 | return False
21 |
22 |
23 | def upload(
24 | args: argparse.Namespace,
25 | src: Union[str, Path, bytes, BinaryIO],
26 | dest_suffix: str = "",
27 | force_sync_upload: bool = False,
28 | ):
29 | repo_id = args.huggingface_repo_id
30 | repo_type = args.huggingface_repo_type
31 | token = args.huggingface_token
32 | path_in_repo = args.huggingface_path_in_repo + dest_suffix if args.huggingface_path_in_repo is not None else None
33 | private = args.huggingface_repo_visibility is None or args.huggingface_repo_visibility != "public"
34 | api = HfApi(token=token)
35 | if not exists_repo(repo_id=repo_id, repo_type=repo_type, token=token):
36 | try:
37 | api.create_repo(repo_id=repo_id, repo_type=repo_type, private=private)
38 | except Exception as e: # とりあえずRepositoryNotFoundErrorは確認したが他にあると困るので
39 | logger.error("===========================================")
40 | logger.error(f"failed to create HuggingFace repo / HuggingFaceのリポジトリの作成に失敗しました : {e}")
41 | logger.error("===========================================")
42 |
43 | is_folder = (type(src) == str and os.path.isdir(src)) or (isinstance(src, Path) and src.is_dir())
44 |
45 | def uploader():
46 | try:
47 | if is_folder:
48 | api.upload_folder(
49 | repo_id=repo_id,
50 | repo_type=repo_type,
51 | folder_path=src,
52 | path_in_repo=path_in_repo,
53 | )
54 | else:
55 | api.upload_file(
56 | repo_id=repo_id,
57 | repo_type=repo_type,
58 | path_or_fileobj=src,
59 | path_in_repo=path_in_repo,
60 | )
61 | except Exception as e: # RuntimeErrorを確認済みだが他にあると困るので
62 | logger.error("===========================================")
63 | logger.error(f"failed to upload to HuggingFace / HuggingFaceへのアップロードに失敗しました : {e}")
64 | logger.error("===========================================")
65 |
66 | if args.async_upload and not force_sync_upload:
67 | fire_in_thread(uploader)
68 | else:
69 | uploader()
70 |
71 |
72 | def list_dir(
73 | repo_id: str,
74 | subfolder: str,
75 | repo_type: str,
76 | revision: str = "main",
77 | token: str = None,
78 | ):
79 | api = HfApi(
80 | token=token,
81 | )
82 | repo_info = api.repo_info(repo_id=repo_id, revision=revision, repo_type=repo_type)
83 | file_list = [file for file in repo_info.siblings if file.rfilename.startswith(subfolder)]
84 | return file_list
85 |
--------------------------------------------------------------------------------
/scripts/stable/networks/check_lora_weights.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import torch
4 | from safetensors.torch import load_file
5 | from library.utils import setup_logging
6 | setup_logging()
7 | import logging
8 | logger = logging.getLogger(__name__)
9 |
10 | def main(file):
11 | logger.info(f"loading: {file}")
12 | if os.path.splitext(file)[1] == ".safetensors":
13 | sd = load_file(file)
14 | else:
15 | sd = torch.load(file, map_location="cpu")
16 |
17 | values = []
18 |
19 | keys = list(sd.keys())
20 | for key in keys:
21 | if "lora_up" in key or "lora_down" in key or "lora_A" in key or "lora_B" in key or "oft_" in key:
22 | values.append((key, sd[key]))
23 | print(f"number of LoRA modules: {len(values)}")
24 |
25 | if args.show_all_keys:
26 | for key in [k for k in keys if k not in values]:
27 | values.append((key, sd[key]))
28 | print(f"number of all modules: {len(values)}")
29 |
30 | for key, value in values:
31 | value = value.to(torch.float32)
32 | print(f"{key},{str(tuple(value.size())).replace(', ', '-')},{torch.mean(torch.abs(value))},{torch.min(torch.abs(value))}")
33 |
34 |
35 | def setup_parser() -> argparse.ArgumentParser:
36 | parser = argparse.ArgumentParser()
37 | parser.add_argument("file", type=str, help="model file to check / 重みを確認するモデルファイル")
38 | parser.add_argument("-s", "--show_all_keys", action="store_true", help="show all keys / 全てのキーを表示する")
39 |
40 | return parser
41 |
42 |
43 | if __name__ == "__main__":
44 | parser = setup_parser()
45 |
46 | args = parser.parse_args()
47 |
48 | main(args.file)
49 |
--------------------------------------------------------------------------------
/scripts/stable/networks/extract_lora_from_dylora.py:
--------------------------------------------------------------------------------
1 | # Convert LoRA to different rank approximation (should only be used to go to lower rank)
2 | # This code is based off the extract_lora_from_models.py file which is based on https://github.com/cloneofsimo/lora/blob/develop/lora_diffusion/cli_svd.py
3 | # Thanks to cloneofsimo
4 |
5 | import argparse
6 | import math
7 | import os
8 | import torch
9 | from safetensors.torch import load_file, save_file, safe_open
10 | from tqdm import tqdm
11 | from library import train_util, model_util
12 | import numpy as np
13 | from library.utils import setup_logging
14 | setup_logging()
15 | import logging
16 | logger = logging.getLogger(__name__)
17 |
18 | def load_state_dict(file_name):
19 | if model_util.is_safetensors(file_name):
20 | sd = load_file(file_name)
21 | with safe_open(file_name, framework="pt") as f:
22 | metadata = f.metadata()
23 | else:
24 | sd = torch.load(file_name, map_location="cpu")
25 | metadata = None
26 |
27 | return sd, metadata
28 |
29 |
30 | def save_to_file(file_name, model, metadata):
31 | if model_util.is_safetensors(file_name):
32 | save_file(model, file_name, metadata)
33 | else:
34 | torch.save(model, file_name)
35 |
36 |
37 | def split_lora_model(lora_sd, unit):
38 | max_rank = 0
39 |
40 | # Extract loaded lora dim and alpha
41 | for key, value in lora_sd.items():
42 | if "lora_down" in key:
43 | rank = value.size()[0]
44 | if rank > max_rank:
45 | max_rank = rank
46 | logger.info(f"Max rank: {max_rank}")
47 |
48 | rank = unit
49 | split_models = []
50 | new_alpha = None
51 | while rank < max_rank:
52 | logger.info(f"Splitting rank {rank}")
53 | new_sd = {}
54 | for key, value in lora_sd.items():
55 | if "lora_down" in key:
56 | new_sd[key] = value[:rank].contiguous()
57 | elif "lora_up" in key:
58 | new_sd[key] = value[:, :rank].contiguous()
59 | else:
60 | # なぜかscaleするとおかしくなる……
61 | # this_rank = lora_sd[key.replace("alpha", "lora_down.weight")].size()[0]
62 | # scale = math.sqrt(this_rank / rank) # rank is > unit
63 | # logger.info(key, value.size(), this_rank, rank, value, scale)
64 | # new_alpha = value * scale # always same
65 | # new_sd[key] = new_alpha
66 | new_sd[key] = value
67 |
68 | split_models.append((new_sd, rank, new_alpha))
69 | rank += unit
70 |
71 | return max_rank, split_models
72 |
73 |
74 | def split(args):
75 | logger.info("loading Model...")
76 | lora_sd, metadata = load_state_dict(args.model)
77 |
78 | logger.info("Splitting Model...")
79 | original_rank, split_models = split_lora_model(lora_sd, args.unit)
80 |
81 | comment = metadata.get("ss_training_comment", "")
82 | for state_dict, new_rank, new_alpha in split_models:
83 | # update metadata
84 | if metadata is None:
85 | new_metadata = {}
86 | else:
87 | new_metadata = metadata.copy()
88 |
89 | new_metadata["ss_training_comment"] = f"split from DyLoRA, rank {original_rank} to {new_rank}; {comment}"
90 | new_metadata["ss_network_dim"] = str(new_rank)
91 | # new_metadata["ss_network_alpha"] = str(new_alpha.float().numpy())
92 |
93 | model_hash, legacy_hash = train_util.precalculate_safetensors_hashes(state_dict, metadata)
94 | metadata["sshs_model_hash"] = model_hash
95 | metadata["sshs_legacy_hash"] = legacy_hash
96 |
97 | filename, ext = os.path.splitext(args.save_to)
98 | model_file_name = filename + f"-{new_rank:04d}{ext}"
99 |
100 | logger.info(f"saving model to: {model_file_name}")
101 | save_to_file(model_file_name, state_dict, new_metadata)
102 |
103 |
104 | def setup_parser() -> argparse.ArgumentParser:
105 | parser = argparse.ArgumentParser()
106 |
107 | parser.add_argument("--unit", type=int, default=None, help="size of rank to split into / rankを分割するサイズ")
108 | parser.add_argument(
109 | "--save_to",
110 | type=str,
111 | default=None,
112 | help="destination base file name: ckpt or safetensors file / 保存先のファイル名のbase、ckptまたはsafetensors",
113 | )
114 | parser.add_argument(
115 | "--model",
116 | type=str,
117 | default=None,
118 | help="DyLoRA model to resize at to new rank: ckpt or safetensors file / 読み込むDyLoRAモデル、ckptまたはsafetensors",
119 | )
120 |
121 | return parser
122 |
123 |
124 | if __name__ == "__main__":
125 | parser = setup_parser()
126 |
127 | args = parser.parse_args()
128 | split(args)
129 |
--------------------------------------------------------------------------------
/scripts/stable/networks/lora_interrogator.py:
--------------------------------------------------------------------------------
1 |
2 |
3 | from tqdm import tqdm
4 | from library import model_util
5 | import library.train_util as train_util
6 | import argparse
7 | from transformers import CLIPTokenizer
8 |
9 | import torch
10 | from library.device_utils import init_ipex, get_preferred_device
11 | init_ipex()
12 |
13 | import library.model_util as model_util
14 | import lora
15 | from library.utils import setup_logging
16 | setup_logging()
17 | import logging
18 | logger = logging.getLogger(__name__)
19 |
20 | TOKENIZER_PATH = "openai/clip-vit-large-patch14"
21 | V2_STABLE_DIFFUSION_PATH = "stabilityai/stable-diffusion-2" # ここからtokenizerだけ使う
22 |
23 | DEVICE = get_preferred_device()
24 |
25 |
26 | def interrogate(args):
27 | weights_dtype = torch.float16
28 |
29 | # いろいろ準備する
30 | logger.info(f"loading SD model: {args.sd_model}")
31 | args.pretrained_model_name_or_path = args.sd_model
32 | args.vae = None
33 | text_encoder, vae, unet, _ = train_util._load_target_model(args,weights_dtype, DEVICE)
34 |
35 | logger.info(f"loading LoRA: {args.model}")
36 | network, weights_sd = lora.create_network_from_weights(1.0, args.model, vae, text_encoder, unet)
37 |
38 | # text encoder向けの重みがあるかチェックする:本当はlora側でやるのがいい
39 | has_te_weight = False
40 | for key in weights_sd.keys():
41 | if 'lora_te' in key:
42 | has_te_weight = True
43 | break
44 | if not has_te_weight:
45 | logger.error("This LoRA does not have modules for Text Encoder, cannot interrogate / このLoRAはText Encoder向けのモジュールがないため調査できません")
46 | return
47 | del vae
48 |
49 | logger.info("loading tokenizer")
50 | if args.v2:
51 | tokenizer: CLIPTokenizer = CLIPTokenizer.from_pretrained(V2_STABLE_DIFFUSION_PATH, subfolder="tokenizer")
52 | else:
53 | tokenizer: CLIPTokenizer = CLIPTokenizer.from_pretrained(TOKENIZER_PATH) # , model_max_length=max_token_length + 2)
54 |
55 | text_encoder.to(DEVICE, dtype=weights_dtype)
56 | text_encoder.eval()
57 | unet.to(DEVICE, dtype=weights_dtype)
58 | unet.eval() # U-Netは呼び出さないので不要だけど
59 |
60 | # トークンをひとつひとつ当たっていく
61 | token_id_start = 0
62 | token_id_end = max(tokenizer.all_special_ids)
63 | logger.info(f"interrogate tokens are: {token_id_start} to {token_id_end}")
64 |
65 | def get_all_embeddings(text_encoder):
66 | embs = []
67 | with torch.no_grad():
68 | for token_id in tqdm(range(token_id_start, token_id_end + 1, args.batch_size)):
69 | batch = []
70 | for tid in range(token_id, min(token_id_end + 1, token_id + args.batch_size)):
71 | tokens = [tokenizer.bos_token_id, tid, tokenizer.eos_token_id]
72 | # tokens = [tid] # こちらは結果がいまひとつ
73 | batch.append(tokens)
74 |
75 | # batch_embs = text_encoder(torch.tensor(batch).to(DEVICE))[0].to("cpu") # bos/eosも含めたほうが差が出るようだ [:, 1]
76 | # clip skip対応
77 | batch = torch.tensor(batch).to(DEVICE)
78 | if args.clip_skip is None:
79 | encoder_hidden_states = text_encoder(batch)[0]
80 | else:
81 | enc_out = text_encoder(batch, output_hidden_states=True, return_dict=True)
82 | encoder_hidden_states = enc_out['hidden_states'][-args.clip_skip]
83 | encoder_hidden_states = text_encoder.text_model.final_layer_norm(encoder_hidden_states)
84 | encoder_hidden_states = encoder_hidden_states.to("cpu")
85 |
86 | embs.extend(encoder_hidden_states)
87 | return torch.stack(embs)
88 |
89 | logger.info("get original text encoder embeddings.")
90 | orig_embs = get_all_embeddings(text_encoder)
91 |
92 | network.apply_to(text_encoder, unet, True, len(network.unet_loras) > 0)
93 | info = network.load_state_dict(weights_sd, strict=False)
94 | logger.info(f"Loading LoRA weights: {info}")
95 |
96 | network.to(DEVICE, dtype=weights_dtype)
97 | network.eval()
98 |
99 | del unet
100 |
101 | logger.info("You can ignore warning messages start with '_IncompatibleKeys' (LoRA model does not have alpha because trained by older script) / '_IncompatibleKeys'の警告は無視して構いません(以前のスクリプトで学習されたLoRAモデルのためalphaの定義がありません)")
102 | logger.info("get text encoder embeddings with lora.")
103 | lora_embs = get_all_embeddings(text_encoder)
104 |
105 | # 比べる:とりあえず単純に差分の絶対値で
106 | logger.info("comparing...")
107 | diffs = {}
108 | for i, (orig_emb, lora_emb) in enumerate(zip(orig_embs, tqdm(lora_embs))):
109 | diff = torch.mean(torch.abs(orig_emb - lora_emb))
110 | # diff = torch.mean(torch.cosine_similarity(orig_emb, lora_emb, dim=1)) # うまく検出できない
111 | diff = float(diff.detach().to('cpu').numpy())
112 | diffs[token_id_start + i] = diff
113 |
114 | diffs_sorted = sorted(diffs.items(), key=lambda x: -x[1])
115 |
116 | # 結果を表示する
117 | print("top 100:")
118 | for i, (token, diff) in enumerate(diffs_sorted[:100]):
119 | # if diff < 1e-6:
120 | # break
121 | string = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens([token]))
122 | print(f"[{i:3d}]: {token:5d} {string:<20s}: {diff:.5f}")
123 |
124 |
125 | def setup_parser() -> argparse.ArgumentParser:
126 | parser = argparse.ArgumentParser()
127 |
128 | parser.add_argument("--v2", action='store_true',
129 | help='load Stable Diffusion v2.x model / Stable Diffusion 2.xのモデルを読み込む')
130 | parser.add_argument("--sd_model", type=str, default=None,
131 | help="Stable Diffusion model to load: ckpt or safetensors file / 読み込むSDのモデル、ckptまたはsafetensors")
132 | parser.add_argument("--model", type=str, default=None,
133 | help="LoRA model to interrogate: ckpt or safetensors file / 調査するLoRAモデル、ckptまたはsafetensors")
134 | parser.add_argument("--batch_size", type=int, default=16,
135 | help="batch size for processing with Text Encoder / Text Encoderで処理するときのバッチサイズ")
136 | parser.add_argument("--clip_skip", type=int, default=None,
137 | help="use output of nth layer from back of text encoder (n>=1) / text encoderの後ろからn番目の層の出力を用いる(nは1以上)")
138 |
139 | return parser
140 |
141 |
142 | if __name__ == '__main__':
143 | parser = setup_parser()
144 |
145 | args = parser.parse_args()
146 | interrogate(args)
147 |
--------------------------------------------------------------------------------
/scripts/stable/requirements.txt:
--------------------------------------------------------------------------------
1 | accelerate==0.30.0
2 | transformers==4.44.0
3 | diffusers[torch]==0.25.0
4 | ftfy==6.1.1
5 | # albumentations==1.3.0
6 | opencv-python==4.8.1.78
7 | einops==0.7.0
8 | pytorch-lightning==1.9.0
9 | bitsandbytes==0.44.0
10 | prodigyopt==1.0
11 | lion-pytorch==0.0.6
12 | tensorboard
13 | safetensors==0.4.2
14 | # gradio==3.16.2
15 | altair==4.2.2
16 | easygui==0.98.3
17 | toml==0.10.2
18 | voluptuous==0.13.1
19 | huggingface-hub==0.24.5
20 | # for Image utils
21 | imagesize==1.4.1
22 | # for BLIP captioning
23 | # requests==2.28.2
24 | # timm==0.6.12
25 | # fairscale==0.4.13
26 | # for WD14 captioning (tensorflow)
27 | # tensorflow==2.10.1
28 | # for WD14 captioning (onnx)
29 | # onnx==1.15.0
30 | # onnxruntime-gpu==1.17.1
31 | # onnxruntime==1.17.1
32 | # for cuda 12.1(default 11.8)
33 | # onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/
34 |
35 | # this is for onnx:
36 | # protobuf==3.20.3
37 | # open clip for SDXL
38 | # open-clip-torch==2.20.0
39 | # For logging
40 | rich==13.7.0
41 | # for kohya_ss library
42 | -e .
43 |
--------------------------------------------------------------------------------
/scripts/stable/sdxl_train_textual_inversion.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 |
4 | import regex
5 |
6 | import torch
7 | from library.device_utils import init_ipex
8 | init_ipex()
9 |
10 | from library import sdxl_model_util, sdxl_train_util, train_util
11 |
12 | import train_textual_inversion
13 |
14 |
15 | class SdxlTextualInversionTrainer(train_textual_inversion.TextualInversionTrainer):
16 | def __init__(self):
17 | super().__init__()
18 | self.vae_scale_factor = sdxl_model_util.VAE_SCALE_FACTOR
19 | self.is_sdxl = True
20 |
21 | def assert_extra_args(self, args, train_dataset_group):
22 | super().assert_extra_args(args, train_dataset_group)
23 | sdxl_train_util.verify_sdxl_training_args(args, supportTextEncoderCaching=False)
24 |
25 | train_dataset_group.verify_bucket_reso_steps(32)
26 |
27 | def load_target_model(self, args, weight_dtype, accelerator):
28 | (
29 | load_stable_diffusion_format,
30 | text_encoder1,
31 | text_encoder2,
32 | vae,
33 | unet,
34 | logit_scale,
35 | ckpt_info,
36 | ) = sdxl_train_util.load_target_model(args, accelerator, sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, weight_dtype)
37 |
38 | self.load_stable_diffusion_format = load_stable_diffusion_format
39 | self.logit_scale = logit_scale
40 | self.ckpt_info = ckpt_info
41 |
42 | return sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, [text_encoder1, text_encoder2], vae, unet
43 |
44 | def load_tokenizer(self, args):
45 | tokenizer = sdxl_train_util.load_tokenizers(args)
46 | return tokenizer
47 |
48 | def get_text_cond(self, args, accelerator, batch, tokenizers, text_encoders, weight_dtype):
49 | input_ids1 = batch["input_ids"]
50 | input_ids2 = batch["input_ids2"]
51 | with torch.enable_grad():
52 | input_ids1 = input_ids1.to(accelerator.device)
53 | input_ids2 = input_ids2.to(accelerator.device)
54 | encoder_hidden_states1, encoder_hidden_states2, pool2 = train_util.get_hidden_states_sdxl(
55 | args.max_token_length,
56 | input_ids1,
57 | input_ids2,
58 | tokenizers[0],
59 | tokenizers[1],
60 | text_encoders[0],
61 | text_encoders[1],
62 | None if not args.full_fp16 else weight_dtype,
63 | accelerator=accelerator,
64 | )
65 | return encoder_hidden_states1, encoder_hidden_states2, pool2
66 |
67 | def call_unet(self, args, accelerator, unet, noisy_latents, timesteps, text_conds, batch, weight_dtype):
68 | noisy_latents = noisy_latents.to(weight_dtype) # TODO check why noisy_latents is not weight_dtype
69 |
70 | # get size embeddings
71 | orig_size = batch["original_sizes_hw"]
72 | crop_size = batch["crop_top_lefts"]
73 | target_size = batch["target_sizes_hw"]
74 | embs = sdxl_train_util.get_size_embeddings(orig_size, crop_size, target_size, accelerator.device).to(weight_dtype)
75 |
76 | # concat embeddings
77 | encoder_hidden_states1, encoder_hidden_states2, pool2 = text_conds
78 | vector_embedding = torch.cat([pool2, embs], dim=1).to(weight_dtype)
79 | text_embedding = torch.cat([encoder_hidden_states1, encoder_hidden_states2], dim=2).to(weight_dtype)
80 |
81 | noise_pred = unet(noisy_latents, timesteps, text_embedding, vector_embedding)
82 | return noise_pred
83 |
84 | def sample_images(self, accelerator, args, epoch, global_step, device, vae, tokenizer, text_encoder, unet, prompt_replacement):
85 | sdxl_train_util.sample_images(
86 | accelerator, args, epoch, global_step, device, vae, tokenizer, text_encoder, unet, prompt_replacement
87 | )
88 |
89 | def save_weights(self, file, updated_embs, save_dtype, metadata):
90 | state_dict = {"clip_l": updated_embs[0], "clip_g": updated_embs[1]}
91 |
92 | if save_dtype is not None:
93 | for key in list(state_dict.keys()):
94 | v = state_dict[key]
95 | v = v.detach().clone().to("cpu").to(save_dtype)
96 | state_dict[key] = v
97 |
98 | if os.path.splitext(file)[1] == ".safetensors":
99 | from safetensors.torch import save_file
100 |
101 | save_file(state_dict, file, metadata)
102 | else:
103 | torch.save(state_dict, file)
104 |
105 | def load_weights(self, file):
106 | if os.path.splitext(file)[1] == ".safetensors":
107 | from safetensors.torch import load_file
108 |
109 | data = load_file(file)
110 | else:
111 | data = torch.load(file, map_location="cpu")
112 |
113 | emb_l = data.get("clip_l", None) # ViT-L text encoder 1
114 | emb_g = data.get("clip_g", None) # BiG-G text encoder 2
115 |
116 | assert (
117 | emb_l is not None or emb_g is not None
118 | ), f"weight file does not contains weights for text encoder 1 or 2 / 重みファイルにテキストエンコーダー1または2の重みが含まれていません: {file}"
119 |
120 | return [emb_l, emb_g]
121 |
122 |
123 | def setup_parser() -> argparse.ArgumentParser:
124 | parser = train_textual_inversion.setup_parser()
125 | # don't add sdxl_train_util.add_sdxl_training_arguments(parser): because it only adds text encoder caching
126 | # sdxl_train_util.add_sdxl_training_arguments(parser)
127 | return parser
128 |
129 |
130 | if __name__ == "__main__":
131 | parser = setup_parser()
132 |
133 | args = parser.parse_args()
134 | train_util.verify_command_line_training_args(args)
135 | args = train_util.read_config_from_file(args, parser)
136 |
137 | trainer = SdxlTextualInversionTrainer()
138 | trainer.train(args)
139 |
--------------------------------------------------------------------------------
/scripts/stable/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 |
3 | setup(name = "library", packages = find_packages())
--------------------------------------------------------------------------------
/scripts/stable/tools/canny.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import cv2
3 |
4 | import logging
5 | from library.utils import setup_logging
6 | setup_logging()
7 | logger = logging.getLogger(__name__)
8 |
9 | def canny(args):
10 | img = cv2.imread(args.input)
11 | img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
12 |
13 | canny_img = cv2.Canny(img, args.thres1, args.thres2)
14 | # canny_img = 255 - canny_img
15 |
16 | cv2.imwrite(args.output, canny_img)
17 | logger.info("done!")
18 |
19 |
20 | def setup_parser() -> argparse.ArgumentParser:
21 | parser = argparse.ArgumentParser()
22 | parser.add_argument("--input", type=str, default=None, help="input path")
23 | parser.add_argument("--output", type=str, default=None, help="output path")
24 | parser.add_argument("--thres1", type=int, default=32, help="thres1")
25 | parser.add_argument("--thres2", type=int, default=224, help="thres2")
26 |
27 | return parser
28 |
29 |
30 | if __name__ == '__main__':
31 | parser = setup_parser()
32 |
33 | args = parser.parse_args()
34 | canny(args)
35 |
--------------------------------------------------------------------------------
/scripts/stable/tools/show_metadata.py:
--------------------------------------------------------------------------------
1 | import json
2 | import argparse
3 | from safetensors import safe_open
4 | from library.utils import setup_logging
5 | setup_logging()
6 | import logging
7 | logger = logging.getLogger(__name__)
8 |
9 | parser = argparse.ArgumentParser()
10 | parser.add_argument("--model", type=str, required=True)
11 | args = parser.parse_args()
12 |
13 | with safe_open(args.model, framework="pt") as f:
14 | metadata = f.metadata()
15 |
16 | if metadata is None:
17 | logger.error("No metadata found")
18 | else:
19 | # metadata is json dict, but not pretty printed
20 | # sort by key and pretty print
21 | print(json.dumps(metadata, indent=4, sort_keys=True))
22 |
23 |
24 |
--------------------------------------------------------------------------------
/sd-models/put stable diffusion model here.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Akegarasu/lora-scripts/e0f5194815203093659d6ec280b9362b9792c070/sd-models/put stable diffusion model here.txt
--------------------------------------------------------------------------------
/svd_merge.ps1:
--------------------------------------------------------------------------------
1 | # LoRA svd_merge script by @bdsqlsz
2 |
3 | $save_precision = "fp16" # precision in saving, default float | 保存精度, 可选 float、fp16、bf16, 默认 和源文件相同
4 | $precision = "float" # precision in merging (float is recommended) | 合并时计算精度, 可选 float、fp16、bf16, 推荐float
5 | $new_rank = 4 # dim rank of output LoRA | dim rank等级, 默认 4
6 | $models = "./output/modelA.safetensors ./output/modelB.safetensors" # original LoRA model path need to resize, save as cpkt or safetensors | 需要合并的模型路径, 保存格式 cpkt 或 safetensors,多个用空格隔开
7 | $ratios = "1.0 -1.0" # ratios for each model / LoRA模型合并比例,数量等于模型数量,多个用空格隔开
8 | $save_to = "./output/lora_name_new.safetensors" # output LoRA model path, save as ckpt or safetensors | 输出路径, 保存格式 cpkt 或 safetensors
9 | $device = "cuda" # device to use, cuda for GPU | 使用 GPU跑, 默认 CPU
10 | $new_conv_rank = 0 # Specify rank of output LoRA for Conv2d 3x3, None for same as new_rank | Conv2d 3x3输出,没有默认同new_rank
11 |
12 | # Activate python venv
13 | .\venv\Scripts\activate
14 |
15 | $Env:HF_HOME = "huggingface"
16 | $Env:XFORMERS_FORCE_DISABLE_TRITON = "1"
17 | $ext_args = [System.Collections.ArrayList]::new()
18 |
19 | [void]$ext_args.Add("--models")
20 | foreach ($model in $models.Split(" ")) {
21 | [void]$ext_args.Add($model)
22 | }
23 |
24 | [void]$ext_args.Add("--ratios")
25 | foreach ($ratio in $ratios.Split(" ")) {
26 | [void]$ext_args.Add([float]$ratio)
27 | }
28 |
29 | if ($new_conv_rank) {
30 | [void]$ext_args.Add("--new_conv_rank=" + $new_conv_rank)
31 | }
32 |
33 | # run svd_merge
34 | accelerate launch --num_cpu_threads_per_process=8 "./scripts/stable/networks/svd_merge_lora.py" `
35 | --save_precision=$save_precision `
36 | --precision=$precision `
37 | --new_rank=$new_rank `
38 | --save_to=$save_to `
39 | --device=$device `
40 | $ext_args
41 |
42 | Write-Output "SVD Merge finished"
43 | Read-Host | Out-Null ;
44 |
--------------------------------------------------------------------------------
/tagger.ps1:
--------------------------------------------------------------------------------
1 | # tagger script by @bdsqlsz
2 |
3 | # Train data path
4 | $train_data_dir = "./input" # input images path | 图片输入路径
5 | $repo_id = "SmilingWolf/wd-v1-4-swinv2-tagger-v2" # model repo id from huggingface |huggingface模型repoID
6 | $model_dir = "" # model dir path | 本地模型文件夹路径
7 | $batch_size = 4 # batch size in inference 批处理大小,越大越快
8 | $max_data_loader_n_workers = 0 # enable image reading by DataLoader with this number of workers (faster) | 0最快
9 | $thresh = 0.35 # concept thresh | 最小识别阈值
10 | $general_threshold = 0.35 # general threshold | 总体识别阈值
11 | $character_threshold = 0.1 # character threshold | 人物姓名识别阈值
12 | $remove_underscore = 0 # remove_underscore | 下划线转空格,1为开,0为关
13 | $undesired_tags = "" # no need tags | 排除标签
14 | $recursive = 0 # search for images in subfolders recursively | 递归搜索下层文件夹,1为开,0为关
15 | $frequency_tags = 0 # order by frequency tags | 从大到小按识别率排序标签,1为开,0为关
16 |
17 |
18 | # Activate python venv
19 | .\venv\Scripts\activate
20 |
21 | $Env:HF_HOME = "huggingface"
22 | $Env:XFORMERS_FORCE_DISABLE_TRITON = "1"
23 | $ext_args = [System.Collections.ArrayList]::new()
24 |
25 | if ($repo_id) {
26 | [void]$ext_args.Add("--repo_id=" + $repo_id)
27 | }
28 |
29 | if ($model_dir) {
30 | [void]$ext_args.Add("--model_dir=" + $model_dir)
31 | }
32 |
33 | if ($batch_size) {
34 | [void]$ext_args.Add("--batch_size=" + $batch_size)
35 | }
36 |
37 | if ($max_data_loader_n_workers) {
38 | [void]$ext_args.Add("--max_data_loader_n_workers=" + $max_data_loader_n_workers)
39 | }
40 |
41 | if ($general_threshold) {
42 | [void]$ext_args.Add("--general_threshold=" + $general_threshold)
43 | }
44 |
45 | if ($character_threshold) {
46 | [void]$ext_args.Add("--character_threshold=" + $character_threshold)
47 | }
48 |
49 | if ($remove_underscore) {
50 | [void]$ext_args.Add("--remove_underscore")
51 | }
52 |
53 | if ($undesired_tags) {
54 | [void]$ext_args.Add("--undesired_tags=" + $undesired_tags)
55 | }
56 |
57 | if ($recursive) {
58 | [void]$ext_args.Add("--recursive")
59 | }
60 |
61 | if ($frequency_tags) {
62 | [void]$ext_args.Add("--frequency_tags")
63 | }
64 |
65 | # run tagger
66 | accelerate launch --num_cpu_threads_per_process=8 "./scripts/stable/finetune/tag_images_by_wd14_tagger.py" `
67 | $train_data_dir `
68 | --thresh=$thresh `
69 | --caption_extension .txt `
70 | $ext_args
71 |
72 | Write-Output "Tagger finished"
73 | Read-Host | Out-Null ;
74 |
--------------------------------------------------------------------------------
/tagger.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # tagger script by @bdsqlsz
3 | # Train data path
4 | train_data_dir="./input" # input images path | 图片输入路径
5 | repo_id="SmilingWolf/wd-v1-4-swinv2-tagger-v2" # model repo id from huggingface |huggingface模型repoID
6 | model_dir="" # model dir path | 本地模型文件夹路径
7 | batch_size=12 # batch size in inference 批处理大小,越大越快
8 | max_data_loader_n_workers=0 # enable image reading by DataLoader with this number of workers (faster) | 0最快
9 | thresh=0.35 # concept thresh | 最小识别阈值
10 | general_threshold=0.35 # general threshold | 总体识别阈值
11 | character_threshold=0.1 # character threshold | 人物姓名识别阈值
12 | remove_underscore=0 # remove_underscore | 下划线转空格,1为开,0为关
13 | undesired_tags="" # no need tags | 排除标签
14 | recursive=0 # search for images in subfolders recursively | 递归搜索下层文件夹,1为开,0为关
15 | frequency_tags=0 # order by frequency tags | 从大到小按识别率排序标签,1为开,0为关
16 |
17 |
18 | # ============= DO NOT MODIFY CONTENTS BELOW | 请勿修改下方内容 =====================
19 |
20 | export HF_HOME="huggingface"
21 | export TF_CPP_MIN_LOG_LEVEL=3
22 | extArgs=()
23 |
24 | if [ -n "$repo_id" ]; then
25 | extArgs+=( "--repo_id=$repo_id" )
26 | fi
27 |
28 | if [ -n "$model_dir" ]; then
29 | extArgs+=( "--model_dir=$model_dir" )
30 | fi
31 |
32 | if [[ $batch_size -ne 0 ]]; then
33 | extArgs+=( "--batch_size=$batch_size" )
34 | fi
35 |
36 | if [ -n "$max_data_loader_n_workers" ]; then
37 | extArgs+=( "--max_data_loader_n_workers=$max_data_loader_n_workers" )
38 | fi
39 |
40 | if [ -n "$general_threshold" ]; then
41 | extArgs+=( "--general_threshold=$general_threshold" )
42 | fi
43 |
44 | if [ -n "$character_threshold" ]; then
45 | extArgs+=( "--character_threshold=$character_threshold" )
46 | fi
47 |
48 | if [ "$remove_underscore" -eq 1 ]; then
49 | extArgs+=( "--remove_underscore" )
50 | fi
51 |
52 | if [ -n "$undesired_tags" ]; then
53 | extArgs+=( "--undesired_tags=$undesired_tags" )
54 | fi
55 |
56 | if [ "$recursive" -eq 1 ]; then
57 | extArgs+=( "--recursive" )
58 | fi
59 |
60 | if [ "$frequency_tags" -eq 1 ]; then
61 | extArgs+=( "--frequency_tags" )
62 | fi
63 |
64 |
65 | # run tagger
66 | accelerate launch --num_cpu_threads_per_process=8 "./scripts/stable/finetune/tag_images_by_wd14_tagger.py" \
67 | $train_data_dir \
68 | --thresh=$thresh \
69 | --caption_extension .txt \
70 | ${extArgs[@]}
71 |
--------------------------------------------------------------------------------
/tensorboard.ps1:
--------------------------------------------------------------------------------
1 | $Env:TF_CPP_MIN_LOG_LEVEL = "3"
2 |
3 | .\venv\Scripts\activate
4 | tensorboard --logdir=logs
--------------------------------------------------------------------------------
/train.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {
7 | "pycharm": {
8 | "name": "#%%\n"
9 | }
10 | },
11 | "outputs": [],
12 | "source": [
13 | "# Train data path | 设置训练用模型、图片\n",
14 | "pretrained_model = \"./sd-models/model.ckpt\" # base model path | 底模路径\n",
15 | "train_data_dir = \"./train/aki\" # train dataset path | 训练数据集路径\n",
16 | "\n",
17 | "# Train related params | 训练相关参数\n",
18 | "resolution = \"512,512\" # image resolution w,h. 图片分辨率,宽,高。支持非正方形,但必须是 64 倍数。\n",
19 | "batch_size = 1 # batch size\n",
20 | "max_train_epoches = 10 # max train epoches | 最大训练 epoch\n",
21 | "save_every_n_epochs = 2 # save every n epochs | 每 N 个 epoch 保存一次\n",
22 | "network_dim = 32 # network dim | 常用 4~128,不是越大越好\n",
23 | "network_alpha= 32 # network alpha | 常用与 network_dim 相同的值或者采用较小的值,如 network_dim的一半 防止下溢。默认值为 1,使用较小的 alpha 需要提升学习率。\n",
24 | "clip_skip = 2 # clip skip | 玄学 一般用 2\n",
25 | "train_unet_only = 0 # train U-Net only | 仅训练 U-Net,开启这个会牺牲效果大幅减少显存使用。6G显存可以开启\n",
26 | "train_text_encoder_only = 0 # train Text Encoder only | 仅训练 文本编码器\n",
27 | "\n",
28 | "# Learning rate | 学习率\n",
29 | "lr = \"1e-4\"\n",
30 | "unet_lr = \"1e-4\"\n",
31 | "text_encoder_lr = \"1e-5\"\n",
32 | "lr_scheduler = \"cosine_with_restarts\" # \"linear\", \"cosine\", \"cosine_with_restarts\", \"polynomial\", \"constant\", \"constant_with_warmup\"\n",
33 | "\n",
34 | "# Output settings | 输出设置\n",
35 | "output_name = \"aki\" # output model name | 模型保存名称\n",
36 | "save_model_as = \"safetensors\" # model save ext | 模型保存格式 ckpt, pt, safetensors"
37 | ]
38 | },
39 | {
40 | "cell_type": "code",
41 | "execution_count": null,
42 | "metadata": {
43 | "pycharm": {
44 | "name": "#%%\n"
45 | }
46 | },
47 | "outputs": [],
48 | "source": [
49 | "!accelerate launch --num_cpu_threads_per_process=8 \"./scripts/train_network.py\" \\\n",
50 | " --enable_bucket \\\n",
51 | " --pretrained_model_name_or_path=$pretrained_model \\\n",
52 | " --train_data_dir=$train_data_dir \\\n",
53 | " --output_dir=\"./output\" \\\n",
54 | " --logging_dir=\"./logs\" \\\n",
55 | " --resolution=$resolution \\\n",
56 | " --network_module=networks.lora \\\n",
57 | " --max_train_epochs=$max_train_epoches \\\n",
58 | " --learning_rate=$lr \\\n",
59 | " --unet_lr=$unet_lr \\\n",
60 | " --text_encoder_lr=$text_encoder_lr \\\n",
61 | " --network_dim=$network_dim \\\n",
62 | " --network_alpha=$network_alpha \\\n",
63 | " --output_name=$output_name \\\n",
64 | " --lr_scheduler=$lr_scheduler \\\n",
65 | " --train_batch_size=$batch_size \\\n",
66 | " --save_every_n_epochs=$save_every_n_epochs \\\n",
67 | " --mixed_precision=\"fp16\" \\\n",
68 | " --save_precision=\"fp16\" \\\n",
69 | " --seed=\"1337\" \\\n",
70 | " --cache_latents \\\n",
71 | " --clip_skip=$clip_skip \\\n",
72 | " --prior_loss_weight=1 \\\n",
73 | " --max_token_length=225 \\\n",
74 | " --caption_extension=\".txt\" \\\n",
75 | " --save_model_as=$save_model_as \\\n",
76 | " --xformers --shuffle_caption --use_8bit_adam"
77 | ]
78 | }
79 | ],
80 | "metadata": {
81 | "kernelspec": {
82 | "display_name": "Python 3",
83 | "language": "python",
84 | "name": "python3"
85 | },
86 | "language_info": {
87 | "name": "python",
88 | "version": "3.10.7 (tags/v3.10.7:6cc6b13, Sep 5 2022, 14:08:36) [MSC v.1933 64 bit (AMD64)]"
89 | },
90 | "orig_nbformat": 4,
91 | "vscode": {
92 | "interpreter": {
93 | "hash": "675b13e958f0d0236d13cdfe08a1df3882cae564fa23a2e7e5eb1f2c6c632b02"
94 | }
95 | }
96 | },
97 | "nbformat": 4,
98 | "nbformat_minor": 2
99 | }
100 |
--------------------------------------------------------------------------------
/train_by_toml.ps1:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Akegarasu/lora-scripts/e0f5194815203093659d6ec280b9362b9792c070/train_by_toml.ps1
--------------------------------------------------------------------------------
/train_by_toml.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # LoRA train script by @Akegarasu
3 |
4 | config_file="./config/default.toml" # config file | 使用 toml 文件指定训练参数
5 | sample_prompts="./config/sample_prompts.txt" # prompt file for sample | 采样 prompts 文件, 留空则不启用采样功能
6 |
7 | sdxl=0 # train sdxl LoRA | 训练 SDXL LoRA
8 | multi_gpu=0 # multi gpu | 多显卡训练 该参数仅限在显卡数 >= 2 使用
9 |
10 | # ============= DO NOT MODIFY CONTENTS BELOW | 请勿修改下方内容 =====================
11 |
12 | export HF_HOME="huggingface"
13 | export TF_CPP_MIN_LOG_LEVEL=3
14 | export PYTHONUTF8=1
15 |
16 | extArgs=()
17 | launchArgs=()
18 |
19 | if [[ $multi_gpu == 1 ]]; then
20 | launchArgs+=("--multi_gpu")
21 | launchArgs+=("--num_processes=2")
22 | fi
23 |
24 | # run train
25 | if [[ $sdxl == 1 ]]; then
26 | script_name="sdxl_train_network.py"
27 | else
28 | script_name="train_network.py"
29 | fi
30 |
31 | python -m accelerate.commands.launch "${launchArgs[@]}" --num_cpu_threads_per_process=8 "./scripts/$script_name" \
32 | --config_file="$config_file" \
33 | --sample_prompts="$sample_prompts" \
34 | "${extArgs[@]}"
35 |
--------------------------------------------------------------------------------