├── .DS_Store
├── MultiTrans.py
├── README.md
├── checkpoints
├── GMM_pretrained
│ └── gmm.txt
└── TOM_pretrained
│ └── tom.txt
├── cp_dataset.py
├── data
├── test_pairs.txt
├── test_pairs_same.txt
└── train_pairs.txt
├── grid.png
├── metrics
├── PerceptualSimilarity
│ ├── .gitignore
│ ├── Dockerfile
│ ├── LICENSE
│ ├── README.md
│ ├── data
│ │ ├── __init__.py
│ │ ├── base_data_loader.py
│ │ ├── custom_dataset_data_loader.py
│ │ ├── data_loader.py
│ │ ├── dataset
│ │ │ ├── __init__.py
│ │ │ ├── base_dataset.py
│ │ │ ├── jnd_dataset.py
│ │ │ └── twoafc_dataset.py
│ │ └── image_folder.py
│ ├── example_dists.txt
│ ├── imgs
│ │ ├── ex_dir0
│ │ │ ├── 0.png
│ │ │ └── 1.png
│ │ ├── ex_dir1
│ │ │ ├── 0.png
│ │ │ └── 1.png
│ │ ├── ex_dir_pair
│ │ │ ├── ex_p0.png
│ │ │ ├── ex_p1.png
│ │ │ └── ex_ref.png
│ │ ├── ex_p0.png
│ │ ├── ex_p1.png
│ │ ├── ex_ref.png
│ │ ├── example_dists.txt
│ │ └── fig1.png
│ ├── lpips
│ │ ├── __init__.py
│ │ ├── lpips.py
│ │ ├── pretrained_networks.py
│ │ ├── trainer.py
│ │ └── weights
│ │ │ ├── v0.0
│ │ │ ├── alex.pth
│ │ │ ├── squeeze.pth
│ │ │ └── vgg.pth
│ │ │ └── v0.1
│ │ │ ├── alex.pth
│ │ │ ├── squeeze.pth
│ │ │ └── vgg.pth
│ ├── lpips_1dir_allpairs.py
│ ├── lpips_2dirs.py
│ ├── lpips_2imgs.py
│ ├── lpips_loss.py
│ ├── requirements.txt
│ ├── scripts
│ │ ├── download_dataset.sh
│ │ ├── download_dataset_valonly.sh
│ │ ├── eval_valsets.sh
│ │ ├── train_test_metric.sh
│ │ ├── train_test_metric_scratch.sh
│ │ └── train_test_metric_tune.sh
│ ├── setup.py
│ ├── testLPIPS.sh
│ ├── test_dataset_model.py
│ ├── test_network.py
│ ├── train.py
│ └── util
│ │ ├── __init__.py
│ │ ├── html.py
│ │ ├── util.py
│ │ └── visualizer.py
├── getIS.py
├── getJS.py
├── getSSIM.py
└── inception_score.py
├── modules
├── __pycache__
│ ├── multihead_attention.cpython-36.pyc
│ ├── position_embedding.cpython-36.pyc
│ └── transformer.cpython-36.pyc
├── multihead_attention.py
├── position_embedding.py
└── transformer.py
├── networks.py
├── requirements.txt
├── test.py
├── train.py
└── visualization.py
/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/.DS_Store
--------------------------------------------------------------------------------
/MultiTrans.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 | import torch.nn.functional as F
4 |
5 | from einops import rearrange, repeat
6 | from einops.layers.torch import Rearrange
7 |
8 | from modules.transformer import TransformerEncoder
9 |
10 |
11 | class MULTModel(nn.Module):
12 | def __init__(self, img_H=256, img_W=192, patch_size = 32, dim = 1024):
13 | """
14 | """
15 | super(MULTModel, self).__init__()
16 |
17 | assert img_H % patch_size == 0, 'Image dimensions must be divisible by the patch size H.'
18 | assert img_W % patch_size == 0, 'Image dimensions must be divisible by the patch size W.'
19 |
20 | num_patches = (img_H // patch_size) * (img_W // patch_size) # (256 / 32) * (192 / 32) = 48
21 | patch_dim_22 = 22 * patch_size * patch_size # 22 * 32 * 32 = 22528
22 | patch_dim_3 = 3 * patch_size * patch_size # 3 * 32 * 32 = 3072
23 | patch_dim_1 = 1 * patch_size * patch_size # 1 * 32 * 32 = 1024
24 |
25 |
26 | self.to_patch_embedding_22 = nn.Sequential(
27 | # [B, 22, 256, 192] -> [B, 22, 8 * 32, 6 * 32] -> [B, 8 * 6, 32 * 32 * 22]
28 | Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size),
29 | # [B, 48, 32*32*22] -> [B, 48, 2048]
30 | nn.Linear(patch_dim_22, 11264),
31 | )
32 | self.to_patch_embedding_3 = nn.Sequential(
33 | # [B, 3, 256, 192] -> [B, 3, 8 * 32, 6 * 32] -> [B, 8 * 6, 32 * 32 * 3]
34 | Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size),
35 | # [B, 48, 3072] -> [B, 48, 1024]
36 | nn.Linear(patch_dim_3, dim),
37 | )
38 |
39 | self.to_patch_embedding_1 = nn.Sequential(
40 | # [B, 3, 256, 192] -> [B, 3, 8 * 32, 6 * 32] -> [B, 8 * 6, 32 * 32 * 3]
41 | Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size),
42 | # [B, 48, 3072] -> [B, 48, 1024]
43 | nn.Linear(patch_dim_1, dim),
44 | )
45 | # [B, 48, 32 * 32 * 26]
46 |
47 | self.backRearrange = nn.Sequential(Rearrange('b (h w) (p1 p2 c) -> b c (h p1) (w p2)', p1=patch_size, p2=patch_size, h=8, w=6))
48 |
49 | self.d_l, self.d_a, self.d_v = 1024, 1024, 1024
50 | combined_dim = self.d_l + self.d_a + self.d_v
51 |
52 | output_dim = 32 * 32 * 26
53 |
54 | self.num_heads = 8
55 | self.layers = 3
56 | self.attn_dropout = nn.Dropout(0.1)
57 | self.attn_dropout_a = nn.Dropout(0.0)
58 | self.attn_dropout_v = nn.Dropout(0.0)
59 | self.relu_dropout = nn.Dropout(0.1)
60 | self.embed_dropout = nn.Dropout(0.25)
61 | self.res_dropout = nn.Dropout(0.1)
62 | self.attn_mask = True
63 |
64 | # 2. Crossmodal Attentions
65 | # if self.lonly:
66 | self.trans_l_with_a = self.get_network(self_type='la')
67 | self.trans_l_with_v = self.get_network(self_type='lv')
68 | # if self.aonly:
69 | self.trans_a_with_l = self.get_network(self_type='al')
70 | self.trans_a_with_v = self.get_network(self_type='av')
71 | # if self.vonly:
72 | self.trans_v_with_l = self.get_network(self_type='vl')
73 | self.trans_v_with_a = self.get_network(self_type='va')
74 |
75 | # 3. Self Attentions (Could be replaced by LSTMs, GRUs, etc.)
76 | # [e.g., self.trans_x_mem = nn.LSTM(self.d_x, self.d_x, 1)
77 | self.trans_l_mem = self.get_network(self_type='l_mem', layers=3)
78 | self.trans_a_mem = self.get_network(self_type='a_mem', layers=3)
79 | self.trans_v_mem = self.get_network(self_type='v_mem', layers=3)
80 |
81 | # Projection layers
82 | self.proj1 = nn.Linear(6144, 6144)
83 | self.proj2 = nn.Linear(6144, 6144)
84 | self.out_layer = nn.Linear(6144, output_dim)
85 |
86 | self.projConv1 = nn.Conv1d(11264, 1024, kernel_size=1, padding=0, bias=False)
87 | self.projConv2 = nn.Conv1d(1024, 1024, kernel_size=1, padding=0, bias=False)
88 | self.projConv3 = nn.Conv1d(1024, 1024, kernel_size=1, padding=0, bias=False)
89 |
90 |
91 |
92 |
93 | def get_network(self, self_type='l', layers=-1):
94 | if self_type in ['l', 'al', 'vl']:
95 | embed_dim, attn_dropout = self.d_l, self.attn_dropout
96 | elif self_type in ['a', 'la', 'va']:
97 | embed_dim, attn_dropout = self.d_a, self.attn_dropout_a
98 | elif self_type in ['v', 'lv', 'av']:
99 | embed_dim, attn_dropout = self.d_v, self.attn_dropout_v
100 | elif self_type == 'l_mem':
101 | embed_dim, attn_dropout = self.d_l, self.attn_dropout
102 | elif self_type == 'a_mem':
103 | embed_dim, attn_dropout = self.d_a, self.attn_dropout
104 | elif self_type == 'v_mem':
105 | embed_dim, attn_dropout = self.d_v, self.attn_dropout
106 | else:
107 | raise ValueError("Unknown network type")
108 |
109 | return TransformerEncoder(embed_dim=embed_dim,
110 | num_heads=self.num_heads,
111 | layers=max(self.layers, layers),
112 | attn_dropout=attn_dropout,
113 | relu_dropout=self.relu_dropout,
114 | res_dropout=self.res_dropout,
115 | embed_dropout=self.embed_dropout,
116 | attn_mask=self.attn_mask)
117 |
118 |
119 | def forward(self, x1, x2, x3):
120 | # Input:
121 | # x1: [B, 22, 256, 192]
122 | # x2: [B, 3, 256, 192]
123 | # x3: [B, 1, 256, 192]
124 |
125 | # Step1: patch_embedding
126 | x1 = self.to_patch_embedding_22(x1) # [B, 22, 256, 192] -> [B, 48, 11264]
127 | x2 = self.to_patch_embedding_3(x2) # [B, 3, 256, 192] -> [B, 48, 1024]
128 | x3 = self.to_patch_embedding_1(x3) # [B, 1, 256, 192] -> [B, 48, 1024]
129 |
130 | # Step2: Project & 1D Conv & Permute
131 | # [B, 48, 1024] -> [B, 1024, 48]
132 | x1 = x1.transpose(1, 2) # [B, 11264, 48]
133 | x2 = x2.transpose(1, 2)
134 | x3 = x3.transpose(1, 2)
135 |
136 | # [1024]
137 | proj_x1 = self.projConv1(x1)
138 | proj_x2 = self.projConv2(x2)
139 | proj_x3 = self.projConv3(x3)
140 |
141 | # [48, B, 1024]
142 | proj_x1 = proj_x1.permute(2, 0, 1)
143 | proj_x2 = proj_x2.permute(2, 0, 1)
144 | proj_x3 = proj_x3.permute(2, 0, 1)
145 |
146 | # Self_att first [48, B, 1024]
147 | proj_x1_trans = self.trans_l_mem(proj_x1)
148 | proj_x2_trans = self.trans_a_mem(proj_x2)
149 | proj_x3_trans = self.trans_v_mem(proj_x3)
150 |
151 |
152 | # Step3: Cross Attention
153 | # (x3,x2) --> x1
154 | h_l_with_as = self.trans_l_with_a(proj_x1, proj_x2_trans, proj_x2_trans) # Dimension (L, N, d_l) [48, B, 1024]
155 | h_l_with_vs = self.trans_l_with_v(proj_x1, proj_x3_trans, proj_x3_trans) # Dimension (L, N, d_l) [48, B, 1024]
156 |
157 | cross1 = torch.cat([h_l_with_as, h_l_with_vs], 2) # [2048]
158 |
159 | # (x1, x3) --> x2
160 | h_a_with_ls = self.trans_a_with_l(proj_x2, proj_x1_trans, proj_x1_trans)
161 | h_a_with_vs = self.trans_a_with_v(proj_x2, proj_x3_trans, proj_x3_trans)
162 |
163 | cross2 = torch.cat([h_a_with_ls, h_a_with_vs], 2)
164 |
165 | # (x1,x2) --> x3
166 | h_v_with_ls = self.trans_v_with_l(proj_x3, proj_x1_trans, proj_x1_trans)
167 | h_v_with_as = self.trans_v_with_a(proj_x3, proj_x2_trans, proj_x2_trans)
168 |
169 | cross3 = torch.cat([h_v_with_ls, h_v_with_as], 2)
170 |
171 | # Combine by cat
172 | # 三个[48, B, 2048] -> [48, B, 6144]
173 | # last_hs = torch.cat([last_h_l, last_h_a, last_h_v], dim=1#[N,6144]
174 | last_hs = torch.cat([cross1, cross2, cross3], dim=2) #[48, B, 6144]
175 |
176 | # A residual block
177 | decompo_1 = self.proj1(last_hs)
178 | decompo_1_relu = F.relu(decompo_1)
179 | last_hs_proj = self.proj2(decompo_1_relu)
180 | last_hs_proj += last_hs
181 |
182 | # last_hs_proj = self.proj2(F.dropout(F.relu(self.proj1(last_hs)), p=self.out_dropout, training=self.training))
183 | # last_hs_proj += last_hs
184 |
185 | output = self.out_layer(last_hs_proj) # [48, B, 26624(26 * 32 * 32)]
186 | output = output.permute(1, 0, 2) # [B, 8 * 6, 32 * 32 * 26]
187 | output = self.backRearrange(output)
188 |
189 | return output
190 |
191 |
192 |
193 | if __name__ == '__main__':
194 | encoder = TransformerEncoder(300, 4, 2)
195 | x = torch.tensor(torch.rand(20, 2, 300))
196 | print(encoder(x).shape)
197 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 
2 | 
3 | 
4 | []((https://github.com/Amazingren/CIT/graphs/commit-activity))
5 | 
6 | 
7 |
8 | # Cloth Interactive Transformer (CIT)
9 |
10 | [Cloth Interactive Transformer for Virtual Try-On](https://arxiv.org/abs/2104.05519)
11 | [Bin Ren](https://scholar.google.com/citations?user=Md9maLYAAAAJ&hl=en)1, [Hao Tang](http://disi.unitn.it/~hao.tang/)1, Fanyang Meng2, Runwei Ding3, [Ling Shao](https://scholar.google.com/citations?user=z84rLjoAAAAJ&hl=en)4, [Philip H.S. Torr](https://scholar.google.com/citations?user=kPxa2w0AAAAJ&hl=en)5, [Nicu Sebe](https://scholar.google.com/citations?user=stFCYOAAAAAJ&hl=en)16.
12 | 1University of Trento, Italy,
13 | 2Peng Cheng Laboratory, China,
14 | 3Peking University Shenzhen Graduate School, China,
15 | 4Inception Institute of AI, UAE,
16 | 5University of Oxford, UK,
17 | 6Huawei Research Ireland, Ireland.
18 |
19 | The repository offers the official implementation of our paper in PyTorch.
20 | The code and pre-trained models are tested with pytorch 0.4.1, torchvision 0.2.1, opencv-python 4.1, and pillow 5.4 (Python 3.6).
21 |
22 | :t-rex:News!!! We have updated the pre-trained model(June 5th, 2021)!
23 |
24 | In the meantime, check out our recent paper [XingGAN](https://github.com/Ha0Tang/XingGAN) and [XingVTON](https://github.com/Ha0Tang/XingVTON).
25 |
26 | ## Usage
27 | This pipeline is a combination of consecutive training and testing of Cloth Interactive Transformer (CIT) Matching block based GMM and CIT Reasoning block based TOM. GMM generates the warped clothes according to the target human. Then, TOM blends the warped clothes outputs from GMM into the target human properties, to generate the final try-on output.
28 |
29 | 1) Install the requirements
30 | 2) Download/Prepare the dataset
31 | 3) Train the CIT Matching block based GMM network
32 | 4) Get warped clothes for training set with trained GMM network, and copy warped clothes & masks inside `data/train` directory
33 | 5) Train the CIT Reasoning block based TOM network
34 | 6) Test CIT Matching block based GMM for testing set
35 | 7) Get warped clothes for testing set, copy warped clothes & masks inside `data/test` directory
36 | 8) Test CIT Reasoning block based TOM testing set
37 |
38 | ## Installation
39 | This implementation is built and tested in PyTorch 0.4.1.
40 | Pytorch and torchvision are recommended to install with conda: `conda install pytorch=0.4.1 torchvision=0.2.1 -c pytorch`
41 |
42 | For all packages, run `pip install -r requirements.txt`
43 |
44 | ## Data Preparation
45 | For training/testing VITON dataset, our full and processed dataset is available here: https://1drv.ms/u/s!Ai8t8GAHdzVUiQQYX0azYhqIDPP6?e=4cpFTI. After downloading, unzip to your own data directory `./data/`.
46 |
47 | ## Training
48 | Run `python train.py` with your specific usage options for GMM and TOM stage.
49 |
50 | For example, GMM: ```python train.py --name GMM --stage GMM --workers 4 --save_count 5000 --shuffle```.
51 | Then run test.py for GMM network with the training dataset, which will generate the warped clothes and masks in "warp-cloth" and "warp-mask" folders inside the "result/GMM/train/" directory.
52 | Copy the "warp-cloth" and "warp-mask" folders into your data directory, for example inside "data/train" folder.
53 |
54 | Run TOM stage, ```python train.py --name TOM --stage TOM --workers 4 --save_count 5000 --shuffle```
55 |
56 | ## Evaluation
57 | We adopt four evaluation metrics in our work for evaluating the performance of the proposed XingVTON. There are Jaccard score (JS), structral similarity index measure (SSIM), learned perceptual image patch similarity (LPIPS), and Inception score (IS).
58 |
59 | Note that JS is used for the same clothing retry-on cases (with ground truth cases) in the first geometric matching stage, while SSIM and LPIPS are used for the same clothing retry-on cases (with ground truth cases) in the second try-on stage. In addition, IS is used for different clothing try-on (where no ground truth is available).
60 |
61 | ### For JS
62 | - Step1: Run```python test.py --name GMM --stage GMM --workers 4 --datamode test --data_list test_pairs_same.txt --checkpoint checkpoints/GMM_pretrained/gmm_final.pth```
63 | then the parsed segmentation area for current upper clothing is used as the reference image, accompanied with generated warped clothing mask then:
64 | - Step2: Run```python metrics/getJS.py```
65 |
66 | ### For SSIM
67 | After we run test.py for GMM network with the testibng dataset, the warped clothes and masks will be generated in "warp-cloth" and "warp-mask" folders inside the "result/GMM/test/" directory. Copy the "warp-cloth" and "warp-mask" folders into your data directory, for example inside "data/test" folder. Then:
68 | - Step1: Run TOM stage test ```python test.py --name TOM --stage TOM --workers 4 --datamode test --data_list test_pairs_same.txt --checkpoint checkpoints/TOM_pretrained/tom_final.pth```
69 | Then the original target human image is used as the reference image, accompanied with the generated retry-on image then:
70 | - Step2: Run ```python metrics/getSSIM.py```
71 |
72 | ### For LPIPS
73 | - Step1: You need to creat a new virtual enviriment, then install PyTorch 1.0+ and torchvision;
74 | - Step2: Run ```sh metrics/PerceptualSimilarity/testLPIPS.sh```;
75 |
76 | ### For IS
77 | - Step1: Run TOM stage test ```python test.py --name TOM --stage TOM --workers 4 --datamode test --data_list test_pairs.txt --checkpoint checkpoints/TOM_pretrained/tom_final.pth```
78 | - Step2: Run ```python metrics/getIS.py```
79 |
80 | ## Inference
81 | The pre-trained models are provided [here](https://drive.google.com/drive/folders/12SAalfaQ--osAIIEh-qE5TLOP_kJmIP8?usp=sharing). Download the pre-trained models and put them in this project (./checkpoints)
82 | Then just run the same step as Evaluation to test/inference our model.
83 |
84 | ## Acknowledgements
85 | This source code is inspired by [CP-VTON](https://github.com/sergeywong/cp-vton), [CP-VTON+](https://github.com/minar09/cp-vton-plus). We are extremely grateful for their public implementation.
86 |
87 | ## Citation
88 | If you use this code for your research, please consider giving a star :star: and citing our [paper](https://arxiv.org/abs/2104.05519) :t-rex::
89 |
90 | CIT
91 | ```
92 | @article{ren2021cloth,
93 | title={Cloth Interactive Transformer for Virtual Try-On},
94 | author={Ren, Bin and Tang, Hao and Meng, Fanyang and Ding, Runwei and Shao, Ling and Torr, Philip HS and Sebe, Nicu},
95 | journal={arXiv preprint arXiv:2104.05519},
96 | year={2021}
97 | }
98 | ```
99 |
100 |
101 | ## Contributions
102 | If you have any questions/comments/bug reports, feel free to open a github issue or pull a request or e-mail to the author Bin Ren ([bin.ren@unitn.it](bin.ren@unitn.it)).
--------------------------------------------------------------------------------
/checkpoints/GMM_pretrained/gmm.txt:
--------------------------------------------------------------------------------
1 | put the pre-trained gmm model here.
--------------------------------------------------------------------------------
/checkpoints/TOM_pretrained/tom.txt:
--------------------------------------------------------------------------------
1 | put the pre-trained tom model here.
--------------------------------------------------------------------------------
/cp_dataset.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | import torch
3 | import torch.utils.data as data
4 | import torchvision.transforms as transforms
5 |
6 | from PIL import Image
7 | from PIL import ImageDraw
8 |
9 | import os.path as osp
10 | import numpy as np
11 | import json
12 |
13 |
14 | class CPDataset(data.Dataset):
15 | """Dataset for CP-VTON+.
16 | """
17 |
18 | def __init__(self, opt):
19 | super(CPDataset, self).__init__()
20 | # base setting
21 | self.opt = opt
22 | self.root = opt.dataroot
23 | self.datamode = opt.datamode # train or test or self-defined
24 | self.stage = opt.stage # GMM or TOM
25 | self.data_list = opt.data_list
26 | self.fine_height = opt.fine_height
27 | self.fine_width = opt.fine_width
28 | self.radius = opt.radius
29 | self.data_path = osp.join(opt.dataroot, opt.datamode)
30 | self.transform = transforms.Compose([
31 | transforms.ToTensor(),
32 | transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
33 |
34 | # load data list
35 | im_names = []
36 | c_names = []
37 | with open(osp.join(opt.dataroot, opt.data_list), 'r') as f:
38 | for line in f.readlines():
39 | im_name, c_name = line.strip().split()
40 | im_names.append(im_name)
41 | c_names.append(c_name)
42 |
43 | self.im_names = im_names
44 | self.c_names = c_names
45 |
46 | def name(self):
47 | return "CPDataset"
48 |
49 | def __getitem__(self, index):
50 | c_name = self.c_names[index]
51 | im_name = self.im_names[index]
52 | if self.stage == 'GMM':
53 | c = Image.open(osp.join(self.data_path, 'cloth', c_name))
54 | cm = Image.open(osp.join(self.data_path, 'cloth-mask', c_name)).convert('L')
55 | else:
56 | c = Image.open(osp.join(self.data_path, 'warp-cloth', im_name)) # c_name, if that is used when saved
57 | cm = Image.open(osp.join(self.data_path, 'warp-mask', im_name)).convert('L') # c_name, if that is used when saved
58 |
59 | c = self.transform(c) # [-1,1]
60 | cm_array = np.array(cm)
61 | cm_array = (cm_array >= 128).astype(np.float32)
62 | cm = torch.from_numpy(cm_array) # [0,1]
63 | cm.unsqueeze_(0)
64 |
65 | # person image
66 | im = Image.open(osp.join(self.data_path, 'image', im_name))
67 | im = self.transform(im) # [-1,1]
68 |
69 | """
70 | LIP labels
71 |
72 | [(0, 0, 0), # 0=Background
73 | (128, 0, 0), # 1=Hat
74 | (255, 0, 0), # 2=Hair
75 | (0, 85, 0), # 3=Glove
76 | (170, 0, 51), # 4=SunGlasses
77 | (255, 85, 0), # 5=UpperClothes
78 | (0, 0, 85), # 6=Dress
79 | (0, 119, 221), # 7=Coat
80 | (85, 85, 0), # 8=Socks
81 | (0, 85, 85), # 9=Pants
82 | (85, 51, 0), # 10=Jumpsuits
83 | (52, 86, 128), # 11=Scarf
84 | (0, 128, 0), # 12=Skirt
85 | (0, 0, 255), # 13=Face
86 | (51, 170, 221), # 14=LeftArm
87 | (0, 255, 255), # 15=RightArm
88 | (85, 255, 170), # 16=LeftLeg
89 | (170, 255, 85), # 17=RightLeg
90 | (255, 255, 0), # 18=LeftShoe
91 | (255, 170, 0) # 19=RightShoe
92 | (170, 170, 50) # 20=Skin/Neck/Chest (Newly added after running dataset_neck_skin_correction.py)
93 | ]
94 | """
95 |
96 | # load parsing image
97 | parse_name = im_name.replace('.jpg', '.png')
98 | im_parse = Image.open(
99 | # osp.join(self.data_path, 'image-parse', parse_name)).convert('L')
100 | osp.join(self.data_path, 'image-parse-new', parse_name)).convert('L') # updated new segmentation
101 | parse_array = np.array(im_parse)
102 | im_mask = Image.open(
103 | osp.join(self.data_path, 'image-mask', parse_name)).convert('L')
104 | mask_array = np.array(im_mask)
105 |
106 | # parse_shape = (parse_array > 0).astype(np.float32) # CP-VTON body shape
107 | # Get shape from body mask (CP-VTON+)
108 | parse_shape = (mask_array > 0).astype(np.float32)
109 |
110 | if self.stage == 'GMM':
111 | parse_head = (parse_array == 1).astype(np.float32) + \
112 | (parse_array == 4).astype(np.float32) + \
113 | (parse_array == 13).astype(
114 | np.float32) # CP-VTON+ GMM input (reserved regions)
115 | else:
116 | parse_head = (parse_array == 1).astype(np.float32) + \
117 | (parse_array == 2).astype(np.float32) + \
118 | (parse_array == 4).astype(np.float32) + \
119 | (parse_array == 9).astype(np.float32) + \
120 | (parse_array == 12).astype(np.float32) + \
121 | (parse_array == 13).astype(np.float32) + \
122 | (parse_array == 16).astype(np.float32) + \
123 | (parse_array == 17).astype(
124 | np.float32) # CP-VTON+ TOM input (reserved regions)
125 |
126 | parse_cloth = (parse_array == 5).astype(np.float32) + \
127 | (parse_array == 6).astype(np.float32) + \
128 | (parse_array == 7).astype(np.float32) # upper-clothes labels
129 |
130 | # shape downsample
131 | parse_shape_ori = Image.fromarray((parse_shape*255).astype(np.uint8))
132 | parse_shape = parse_shape_ori.resize(
133 | (self.fine_width//16, self.fine_height//16), Image.BILINEAR)
134 | parse_shape = parse_shape.resize(
135 | (self.fine_width, self.fine_height), Image.BILINEAR)
136 | parse_shape_ori = parse_shape_ori.resize(
137 | (self.fine_width, self.fine_height), Image.BILINEAR)
138 | shape_ori = self.transform(parse_shape_ori) # [-1,1]
139 | shape = self.transform(parse_shape) # [-1,1]
140 | phead = torch.from_numpy(parse_head) # [0,1]
141 | # phand = torch.from_numpy(parse_hand) # [0,1]
142 | pcm = torch.from_numpy(parse_cloth) # [0,1]
143 |
144 | # upper cloth
145 | im_c = im * pcm + (1 - pcm) # [-1,1], fill 1 for other parts
146 | im_h = im * phead - (1 - phead) # [-1,1], fill -1 for other parts
147 |
148 | # load pose points
149 | pose_name = im_name.replace('.jpg', '_keypoints.json')
150 | with open(osp.join(self.data_path, 'pose', pose_name), 'r') as f:
151 | pose_label = json.load(f)
152 | pose_data = pose_label['people'][0]['pose_keypoints']
153 | pose_data = np.array(pose_data)
154 | pose_data = pose_data.reshape((-1, 3))
155 |
156 | point_num = pose_data.shape[0]
157 | pose_map = torch.zeros(point_num, self.fine_height, self.fine_width)
158 | r = self.radius
159 | im_pose = Image.new('L', (self.fine_width, self.fine_height))
160 | pose_draw = ImageDraw.Draw(im_pose)
161 | for i in range(point_num):
162 | one_map = Image.new('L', (self.fine_width, self.fine_height))
163 | draw = ImageDraw.Draw(one_map)
164 | pointx = pose_data[i, 0]
165 | pointy = pose_data[i, 1]
166 | if pointx > 1 and pointy > 1:
167 | draw.rectangle((pointx-r, pointy-r, pointx +
168 | r, pointy+r), 'white', 'white')
169 | pose_draw.rectangle(
170 | (pointx-r, pointy-r, pointx+r, pointy+r), 'white', 'white')
171 | one_map = self.transform(one_map)
172 | pose_map[i] = one_map[0]
173 |
174 | # just for visualization
175 | im_pose = self.transform(im_pose)
176 |
177 | # cloth-agnostic representation
178 | agnostic = torch.cat([shape, im_h, pose_map], 0)
179 |
180 | if self.stage == 'GMM':
181 | im_g = Image.open('grid.png')
182 | im_g = self.transform(im_g)
183 | else:
184 | im_g = ''
185 |
186 | pcm.unsqueeze_(0) # CP-VTON+
187 |
188 | result = {
189 | 'c_name': c_name, # for visualization
190 | 'im_name': im_name, # for visualization or ground truth
191 | 'cloth': c, # for input
192 | 'cloth_mask': cm, # for input
193 | 'image': im, # for visualization
194 | 'agnostic': agnostic, # for input
195 | 'parse_cloth': im_c, # for ground truth
196 | 'shape': shape, # for visualization
197 | 'head': im_h, # for visualization
198 | 'pose_image': im_pose, # for visualization
199 | 'grid_image': im_g, # for visualization
200 | 'parse_cloth_mask': pcm, # for CP-VTON+, TOM input
201 | 'shape_ori': shape_ori, # original body shape without resize
202 | }
203 |
204 | return result
205 |
206 | def __len__(self):
207 | return len(self.im_names)
208 |
209 |
210 | class CPDataLoader(object):
211 | def __init__(self, opt, dataset):
212 | super(CPDataLoader, self).__init__()
213 |
214 | if opt.shuffle:
215 | train_sampler = torch.utils.data.sampler.RandomSampler(dataset)
216 | else:
217 | train_sampler = None
218 |
219 | self.data_loader = torch.utils.data.DataLoader(
220 | dataset, batch_size=opt.batch_size, shuffle=(
221 | train_sampler is None),
222 | num_workers=opt.workers, pin_memory=True, sampler=train_sampler)
223 | self.dataset = dataset
224 | self.data_iter = self.data_loader.__iter__()
225 |
226 | def next_batch(self):
227 | try:
228 | batch = self.data_iter.__next__()
229 | except StopIteration:
230 | self.data_iter = self.data_loader.__iter__()
231 | batch = self.data_iter.__next__()
232 |
233 | return batch
234 |
235 |
236 | if __name__ == "__main__":
237 | print("Check the dataset for geometric matching module!")
238 |
239 | import argparse
240 | parser = argparse.ArgumentParser()
241 | parser.add_argument("--dataroot", default="data")
242 | parser.add_argument("--datamode", default="train")
243 | parser.add_argument("--stage", default="GMM")
244 | parser.add_argument("--data_list", default="train_pairs.txt")
245 | parser.add_argument("--fine_width", type=int, default=192)
246 | parser.add_argument("--fine_height", type=int, default=256)
247 | parser.add_argument("--radius", type=int, default=3)
248 | parser.add_argument("--shuffle", action='store_true',
249 | help='shuffle input data')
250 | parser.add_argument('-b', '--batch-size', type=int, default=4)
251 | parser.add_argument('-j', '--workers', type=int, default=1)
252 |
253 | opt = parser.parse_args()
254 | dataset = CPDataset(opt)
255 | data_loader = CPDataLoader(opt, dataset)
256 |
257 | print('Size of the dataset: %05d, dataloader: %04d'
258 | % (len(dataset), len(data_loader.data_loader)))
259 | first_item = dataset.__getitem__(0)
260 | first_batch = data_loader.next_batch()
261 |
262 | from IPython import embed
263 | embed()
264 |
--------------------------------------------------------------------------------
/grid.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/grid.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
2 |
3 | checkpoints/*
4 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM nvidia/cuda:9.0-base-ubuntu16.04
2 |
3 | LABEL maintainer="Seyoung Park "
4 |
5 | # This Dockerfile is forked from Tensorflow Dockerfile
6 |
7 | # Pick up some PyTorch gpu dependencies
8 | RUN apt-get update && apt-get install -y --no-install-recommends \
9 | build-essential \
10 | cuda-command-line-tools-9-0 \
11 | cuda-cublas-9-0 \
12 | cuda-cufft-9-0 \
13 | cuda-curand-9-0 \
14 | cuda-cusolver-9-0 \
15 | cuda-cusparse-9-0 \
16 | curl \
17 | libcudnn7=7.1.4.18-1+cuda9.0 \
18 | libfreetype6-dev \
19 | libhdf5-serial-dev \
20 | libpng12-dev \
21 | libzmq3-dev \
22 | pkg-config \
23 | python \
24 | python-dev \
25 | rsync \
26 | software-properties-common \
27 | unzip \
28 | && \
29 | apt-get clean && \
30 | rm -rf /var/lib/apt/lists/*
31 |
32 |
33 | # Install miniconda
34 | RUN apt-get update && apt-get install -y --no-install-recommends \
35 | wget && \
36 | MINICONDA="Miniconda3-latest-Linux-x86_64.sh" && \
37 | wget --quiet https://repo.continuum.io/miniconda/$MINICONDA && \
38 | bash $MINICONDA -b -p /miniconda && \
39 | rm -f $MINICONDA
40 | ENV PATH /miniconda/bin:$PATH
41 |
42 | # Install PyTorch
43 | RUN conda update -n base conda && \
44 | conda install pytorch torchvision cuda90 -c pytorch
45 |
46 | # Install PerceptualSimilarity dependencies
47 | RUN conda install numpy scipy jupyter matplotlib && \
48 | conda install -c conda-forge scikit-image && \
49 | apt-get install -y python-qt4 && \
50 | pip install opencv-python
51 |
52 | # For CUDA profiling, TensorFlow requires CUPTI. Maybe PyTorch needs this too.
53 | ENV LD_LIBRARY_PATH /usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
54 |
55 | # IPython
56 | EXPOSE 8888
57 |
58 | WORKDIR "/notebooks"
59 |
60 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/LICENSE:
--------------------------------------------------------------------------------
1 | Copyright (c) 2018, Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, Oliver Wang
2 | All rights reserved.
3 |
4 | Redistribution and use in source and binary forms, with or without
5 | modification, are permitted provided that the following conditions are met:
6 |
7 | * Redistributions of source code must retain the above copyright notice, this
8 | list of conditions and the following disclaimer.
9 |
10 | * Redistributions in binary form must reproduce the above copyright notice,
11 | this list of conditions and the following disclaimer in the documentation
12 | and/or other materials provided with the distribution.
13 |
14 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
15 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
16 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
17 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
18 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
19 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
20 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
21 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
22 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
23 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
24 |
25 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## Perceptual Similarity Metric and Dataset [[Project Page]](http://richzhang.github.io/PerceptualSimilarity/)
3 |
4 | **The Unreasonable Effectiveness of Deep Features as a Perceptual Metric**
5 | [Richard Zhang](https://richzhang.github.io/), [Phillip Isola](http://web.mit.edu/phillipi/), [Alexei A. Efros](http://www.eecs.berkeley.edu/~efros/), [Eli Shechtman](https://research.adobe.com/person/eli-shechtman/), [Oliver Wang](http://www.oliverwang.info/). In [CVPR](https://arxiv.org/abs/1801.03924), 2018.
6 |
7 | 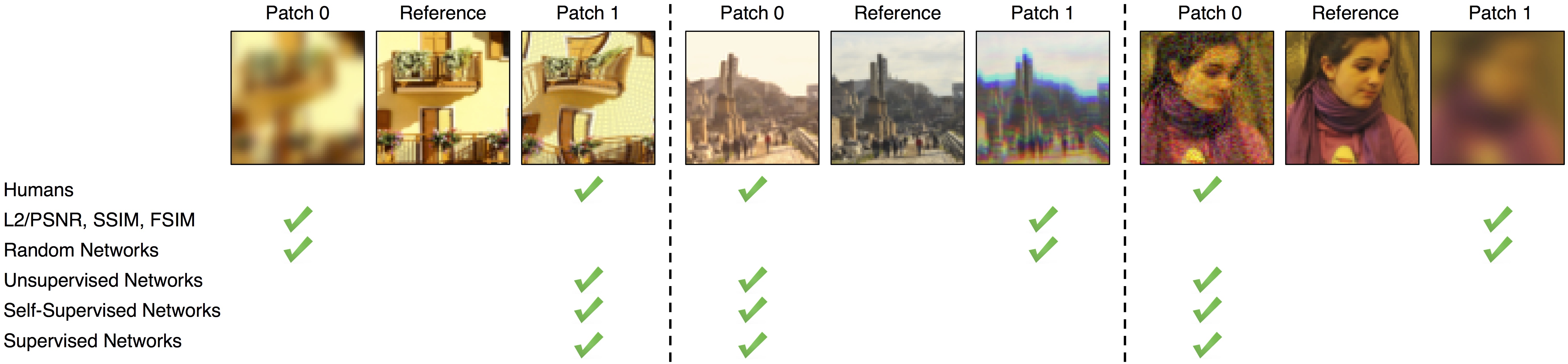 8 |
9 | ### Quick start
10 |
11 | Run `pip install lpips`. The following Python code is all you need.
12 |
13 | ```python
14 | import lpips
15 | loss_fn_alex = lpips.LPIPS(net='alex') # best forward scores
16 | loss_fn_vgg = lpips.LPIPS(net='vgg') # closer to "traditional" perceptual loss, when used for optimization
17 |
18 | import torch
19 | img0 = torch.zeros(1,3,64,64) # image should be RGB, IMPORTANT: normalized to [-1,1]
20 | img1 = torch.zeros(1,3,64,64)
21 | d = loss_fn_alex(img0, img1)
22 | ```
23 |
24 | More thorough information about variants is below. This repository contains our **perceptual metric (LPIPS)** and **dataset (BAPPS)**. It can also be used as a "perceptual loss". This uses PyTorch; a Tensorflow alternative is [here](https://github.com/alexlee-gk/lpips-tensorflow).
25 |
26 |
27 | **Table of Contents**
8 |
9 | ### Quick start
10 |
11 | Run `pip install lpips`. The following Python code is all you need.
12 |
13 | ```python
14 | import lpips
15 | loss_fn_alex = lpips.LPIPS(net='alex') # best forward scores
16 | loss_fn_vgg = lpips.LPIPS(net='vgg') # closer to "traditional" perceptual loss, when used for optimization
17 |
18 | import torch
19 | img0 = torch.zeros(1,3,64,64) # image should be RGB, IMPORTANT: normalized to [-1,1]
20 | img1 = torch.zeros(1,3,64,64)
21 | d = loss_fn_alex(img0, img1)
22 | ```
23 |
24 | More thorough information about variants is below. This repository contains our **perceptual metric (LPIPS)** and **dataset (BAPPS)**. It can also be used as a "perceptual loss". This uses PyTorch; a Tensorflow alternative is [here](https://github.com/alexlee-gk/lpips-tensorflow).
25 |
26 |
27 | **Table of Contents**
28 | 1. [Learned Perceptual Image Patch Similarity (LPIPS) metric](#1-learned-perceptual-image-patch-similarity-lpips-metric)
29 | a. [Basic Usage](#a-basic-usage) If you just want to run the metric through command line, this is all you need.
30 | b. ["Perceptual Loss" usage](#b-backpropping-through-the-metric)
31 | c. [About the metric](#c-about-the-metric)
32 | 2. [Berkeley-Adobe Perceptual Patch Similarity (BAPPS) dataset](#2-berkeley-adobe-perceptual-patch-similarity-bapps-dataset)
33 | a. [Download](#a-downloading-the-dataset)
34 | b. [Evaluation](#b-evaluating-a-perceptual-similarity-metric-on-a-dataset)
35 | c. [About the dataset](#c-about-the-dataset)
36 | d. [Train the metric using the dataset](#d-using-the-dataset-to-train-the-metric)
37 |
38 | ## (0) Dependencies/Setup
39 |
40 | ### Installation
41 | - Install PyTorch 1.0+ and torchvision fom http://pytorch.org
42 |
43 | ```bash
44 | pip install -r requirements.txt
45 | ```
46 | - Clone this repo:
47 | ```bash
48 | git clone https://github.com/richzhang/PerceptualSimilarity
49 | cd PerceptualSimilarity
50 | ```
51 |
52 | ## (1) Learned Perceptual Image Patch Similarity (LPIPS) metric
53 |
54 | Evaluate the distance between image patches. **Higher means further/more different. Lower means more similar.**
55 |
56 | ### (A) Basic Usage
57 |
58 | #### (A.I) Line commands
59 |
60 | Example scripts to take the distance between 2 specific images, all corresponding pairs of images in 2 directories, or all pairs of images within a directory:
61 |
62 | ```
63 | python lpips_2imgs.py -p0 imgs/ex_ref.png -p1 imgs/ex_p0.png --use_gpu
64 | python lpips_2dirs.py -d0 imgs/ex_dir0 -d1 imgs/ex_dir1 -o imgs/example_dists.txt --use_gpu
65 | python lpips_1dir_allpairs.py -d imgs/ex_dir_pair -o imgs/example_dists_pair.txt --use_gpu
66 | ```
67 |
68 | #### (A.II) Python code
69 |
70 | File [test_network.py](test_network.py) shows example usage. This snippet is all you really need.
71 |
72 | ```python
73 | import lpips
74 | loss_fn = lpips.LPIPS(net='alex')
75 | d = loss_fn.forward(im0,im1)
76 | ```
77 |
78 | Variables ```im0, im1``` is a PyTorch Tensor/Variable with shape ```Nx3xHxW``` (```N``` patches of size ```HxW```, RGB images scaled in `[-1,+1]`). This returns `d`, a length `N` Tensor/Variable.
79 |
80 | Run `python test_network.py` to take the distance between example reference image [`ex_ref.png`](imgs/ex_ref.png) to distorted images [`ex_p0.png`](./imgs/ex_p0.png) and [`ex_p1.png`](imgs/ex_p1.png). Before running it - which do you think *should* be closer?
81 |
82 | **Some Options** By default in `model.initialize`:
83 | - By default, `net='alex'`. Network `alex` is fastest, performs the best (as a forward metric), and is the default. For backpropping, `net='vgg'` loss is closer to the traditional "perceptual loss".
84 | - By default, `lpips=True`. This adds a linear calibration on top of intermediate features in the net. Set this to `lpips=False` to equally weight all the features.
85 |
86 | ### (B) Backpropping through the metric
87 |
88 | File [`lpips_loss.py`](lpips_loss.py) shows how to iteratively optimize using the metric. Run `python lpips_loss.py` for a demo. The code can also be used to implement vanilla VGG loss, without our learned weights.
89 |
90 | ### (C) About the metric
91 |
92 | **Higher means further/more different. Lower means more similar.**
93 |
94 | We found that deep network activations work surprisingly well as a perceptual similarity metric. This was true across network architectures (SqueezeNet [2.8 MB], AlexNet [9.1 MB], and VGG [58.9 MB] provided similar scores) and supervisory signals (unsupervised, self-supervised, and supervised all perform strongly). We slightly improved scores by linearly "calibrating" networks - adding a linear layer on top of off-the-shelf classification networks. We provide 3 variants, using linear layers on top of the SqueezeNet, AlexNet (default), and VGG networks.
95 |
96 | If you use LPIPS in your publication, please specify which version you are using. The current version is 0.1. You can set `version='0.0'` for the initial release.
97 |
98 | ## (2) Berkeley Adobe Perceptual Patch Similarity (BAPPS) dataset
99 |
100 | ### (A) Downloading the dataset
101 |
102 | Run `bash ./scripts/download_dataset.sh` to download and unzip the dataset into directory `./dataset`. It takes [6.6 GB] total. Alternatively, run `bash ./scripts/get_dataset_valonly.sh` to only download the validation set [1.3 GB].
103 | - 2AFC train [5.3 GB]
104 | - 2AFC val [1.1 GB]
105 | - JND val [0.2 GB]
106 |
107 | ### (B) Evaluating a perceptual similarity metric on a dataset
108 |
109 | Script `test_dataset_model.py` evaluates a perceptual model on a subset of the dataset.
110 |
111 | **Dataset flags**
112 | - `--dataset_mode`: `2afc` or `jnd`, which type of perceptual judgment to evaluate
113 | - `--datasets`: list the datasets to evaluate
114 | - if `--dataset_mode 2afc`: choices are [`train/traditional`, `train/cnn`, `val/traditional`, `val/cnn`, `val/superres`, `val/deblur`, `val/color`, `val/frameinterp`]
115 | - if `--dataset_mode jnd`: choices are [`val/traditional`, `val/cnn`]
116 |
117 | **Perceptual similarity model flags**
118 | - `--model`: perceptual similarity model to use
119 | - `lpips` for our LPIPS learned similarity model (linear network on top of internal activations of pretrained network)
120 | - `baseline` for a classification network (uncalibrated with all layers averaged)
121 | - `l2` for Euclidean distance
122 | - `ssim` for Structured Similarity Image Metric
123 | - `--net`: [`squeeze`,`alex`,`vgg`] for the `net-lin` and `net` models; ignored for `l2` and `ssim` models
124 | - `--colorspace`: choices are [`Lab`,`RGB`], used for the `l2` and `ssim` models; ignored for `net-lin` and `net` models
125 |
126 | **Misc flags**
127 | - `--batch_size`: evaluation batch size (will default to 1)
128 | - `--use_gpu`: turn on this flag for GPU usage
129 |
130 | An example usage is as follows: `python ./test_dataset_model.py --dataset_mode 2afc --datasets val/traditional val/cnn --model lpips --net alex --use_gpu --batch_size 50`. This would evaluate our model on the "traditional" and "cnn" validation datasets.
131 |
132 | ### (C) About the dataset
133 |
134 | The dataset contains two types of perceptual judgements: **Two Alternative Forced Choice (2AFC)** and **Just Noticeable Differences (JND)**.
135 |
136 | **(1) 2AFC** Evaluators were given a patch triplet (1 reference + 2 distorted). They were asked to select which of the distorted was "closer" to the reference.
137 |
138 | Training sets contain 2 judgments/triplet.
139 | - `train/traditional` [56.6k triplets]
140 | - `train/cnn` [38.1k triplets]
141 | - `train/mix` [56.6k triplets]
142 |
143 | Validation sets contain 5 judgments/triplet.
144 | - `val/traditional` [4.7k triplets]
145 | - `val/cnn` [4.7k triplets]
146 | - `val/superres` [10.9k triplets]
147 | - `val/deblur` [9.4k triplets]
148 | - `val/color` [4.7k triplets]
149 | - `val/frameinterp` [1.9k triplets]
150 |
151 | Each 2AFC subdirectory contains the following folders:
152 | - `ref`: original reference patches
153 | - `p0,p1`: two distorted patches
154 | - `judge`: human judgments - 0 if all preferred p0, 1 if all humans preferred p1
155 |
156 | **(2) JND** Evaluators were presented with two patches - a reference and a distorted - for a limited time. They were asked if the patches were the same (identically) or different.
157 |
158 | Each set contains 3 human evaluations/example.
159 | - `val/traditional` [4.8k pairs]
160 | - `val/cnn` [4.8k pairs]
161 |
162 | Each JND subdirectory contains the following folders:
163 | - `p0,p1`: two patches
164 | - `same`: human judgments: 0 if all humans thought patches were different, 1 if all humans thought patches were same
165 |
166 | ### (D) Using the dataset to train the metric
167 |
168 | See script `train_test_metric.sh` for an example of training and testing the metric. The script will train a model on the full training set for 10 epochs, and then test the learned metric on all of the validation sets. The numbers should roughly match the **Alex - lin** row in Table 5 in the [paper](https://arxiv.org/abs/1801.03924). The code supports training a linear layer on top of an existing representation. Training will add a subdirectory in the `checkpoints` directory.
169 |
170 | You can also train "scratch" and "tune" versions by running `train_test_metric_scratch.sh` and `train_test_metric_tune.sh`, respectively.
171 |
172 | ## Citation
173 |
174 | If you find this repository useful for your research, please use the following.
175 |
176 | ```
177 | @inproceedings{zhang2018perceptual,
178 | title={The Unreasonable Effectiveness of Deep Features as a Perceptual Metric},
179 | author={Zhang, Richard and Isola, Phillip and Efros, Alexei A and Shechtman, Eli and Wang, Oliver},
180 | booktitle={CVPR},
181 | year={2018}
182 | }
183 | ```
184 |
185 | ## Acknowledgements
186 |
187 | This repository borrows partially from the [pytorch-CycleGAN-and-pix2pix](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix) repository. The average precision (AP) code is borrowed from the [py-faster-rcnn](https://github.com/rbgirshick/py-faster-rcnn/blob/master/lib/datasets/voc_eval.py) repository. [Angjoo Kanazawa](https://github.com/akanazawa), [Connelly Barnes](http://www.connellybarnes.com/work/), [Gaurav Mittal](https://github.com/g1910), [wilhelmhb](https://github.com/wilhelmhb), [Filippo Mameli](https://github.com/mameli), [SuperShinyEyes](https://github.com/SuperShinyEyes), [Minyoung Huh](http://people.csail.mit.edu/minhuh/) helped to improve the codebase.
188 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/data/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/data/__init__.py
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/data/base_data_loader.py:
--------------------------------------------------------------------------------
1 |
2 | class BaseDataLoader():
3 | def __init__(self):
4 | pass
5 |
6 | def initialize(self):
7 | pass
8 |
9 | def load_data():
10 | return None
11 |
12 |
13 |
14 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/data/custom_dataset_data_loader.py:
--------------------------------------------------------------------------------
1 | import torch.utils.data
2 | from data.base_data_loader import BaseDataLoader
3 | import os
4 |
5 | def CreateDataset(dataroots,dataset_mode='2afc',load_size=64,):
6 | dataset = None
7 | if dataset_mode=='2afc': # human judgements
8 | from data.dataset.twoafc_dataset import TwoAFCDataset
9 | dataset = TwoAFCDataset()
10 | elif dataset_mode=='jnd': # human judgements
11 | from data.dataset.jnd_dataset import JNDDataset
12 | dataset = JNDDataset()
13 | else:
14 | raise ValueError("Dataset Mode [%s] not recognized."%self.dataset_mode)
15 |
16 | dataset.initialize(dataroots,load_size=load_size)
17 | return dataset
18 |
19 | class CustomDatasetDataLoader(BaseDataLoader):
20 | def name(self):
21 | return 'CustomDatasetDataLoader'
22 |
23 | def initialize(self, datafolders, dataroot='./dataset',dataset_mode='2afc',load_size=64,batch_size=1,serial_batches=True, nThreads=1):
24 | BaseDataLoader.initialize(self)
25 | if(not isinstance(datafolders,list)):
26 | datafolders = [datafolders,]
27 | data_root_folders = [os.path.join(dataroot,datafolder) for datafolder in datafolders]
28 | self.dataset = CreateDataset(data_root_folders,dataset_mode=dataset_mode,load_size=load_size)
29 | self.dataloader = torch.utils.data.DataLoader(
30 | self.dataset,
31 | batch_size=batch_size,
32 | shuffle=not serial_batches,
33 | num_workers=int(nThreads))
34 |
35 | def load_data(self):
36 | return self.dataloader
37 |
38 | def __len__(self):
39 | return len(self.dataset)
40 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/data/data_loader.py:
--------------------------------------------------------------------------------
1 | def CreateDataLoader(datafolder,dataroot='./dataset',dataset_mode='2afc',load_size=64,batch_size=1,serial_batches=True,nThreads=4):
2 | from data.custom_dataset_data_loader import CustomDatasetDataLoader
3 | data_loader = CustomDatasetDataLoader()
4 | # print(data_loader.name())
5 | data_loader.initialize(datafolder,dataroot=dataroot+'/'+dataset_mode,dataset_mode=dataset_mode,load_size=load_size,batch_size=batch_size,serial_batches=serial_batches, nThreads=nThreads)
6 | return data_loader
7 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/data/dataset/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/data/dataset/__init__.py
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/data/dataset/base_dataset.py:
--------------------------------------------------------------------------------
1 | import torch.utils.data as data
2 |
3 | class BaseDataset(data.Dataset):
4 | def __init__(self):
5 | super(BaseDataset, self).__init__()
6 |
7 | def name(self):
8 | return 'BaseDataset'
9 |
10 | def initialize(self):
11 | pass
12 |
13 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/data/dataset/jnd_dataset.py:
--------------------------------------------------------------------------------
1 | import os.path
2 | import torchvision.transforms as transforms
3 | from data.dataset.base_dataset import BaseDataset
4 | from data.image_folder import make_dataset
5 | from PIL import Image
6 | import numpy as np
7 | import torch
8 | from IPython import embed
9 |
10 | class JNDDataset(BaseDataset):
11 | def initialize(self, dataroot, load_size=64):
12 | self.root = dataroot
13 | self.load_size = load_size
14 |
15 | self.dir_p0 = os.path.join(self.root, 'p0')
16 | self.p0_paths = make_dataset(self.dir_p0)
17 | self.p0_paths = sorted(self.p0_paths)
18 |
19 | self.dir_p1 = os.path.join(self.root, 'p1')
20 | self.p1_paths = make_dataset(self.dir_p1)
21 | self.p1_paths = sorted(self.p1_paths)
22 |
23 | transform_list = []
24 | transform_list.append(transforms.Scale(load_size))
25 | transform_list += [transforms.ToTensor(),
26 | transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))]
27 |
28 | self.transform = transforms.Compose(transform_list)
29 |
30 | # judgement directory
31 | self.dir_S = os.path.join(self.root, 'same')
32 | self.same_paths = make_dataset(self.dir_S,mode='np')
33 | self.same_paths = sorted(self.same_paths)
34 |
35 | def __getitem__(self, index):
36 | p0_path = self.p0_paths[index]
37 | p0_img_ = Image.open(p0_path).convert('RGB')
38 | p0_img = self.transform(p0_img_)
39 |
40 | p1_path = self.p1_paths[index]
41 | p1_img_ = Image.open(p1_path).convert('RGB')
42 | p1_img = self.transform(p1_img_)
43 |
44 | same_path = self.same_paths[index]
45 | same_img = np.load(same_path).reshape((1,1,1,)) # [0,1]
46 |
47 | same_img = torch.FloatTensor(same_img)
48 |
49 | return {'p0': p0_img, 'p1': p1_img, 'same': same_img,
50 | 'p0_path': p0_path, 'p1_path': p1_path, 'same_path': same_path}
51 |
52 | def __len__(self):
53 | return len(self.p0_paths)
54 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/data/dataset/twoafc_dataset.py:
--------------------------------------------------------------------------------
1 | import os.path
2 | import torchvision.transforms as transforms
3 | from data.dataset.base_dataset import BaseDataset
4 | from data.image_folder import make_dataset
5 | from PIL import Image
6 | import numpy as np
7 | import torch
8 | # from IPython import embed
9 |
10 | class TwoAFCDataset(BaseDataset):
11 | def initialize(self, dataroots, load_size=64):
12 | if(not isinstance(dataroots,list)):
13 | dataroots = [dataroots,]
14 | self.roots = dataroots
15 | self.load_size = load_size
16 |
17 | # image directory
18 | self.dir_ref = [os.path.join(root, 'ref') for root in self.roots]
19 | self.ref_paths = make_dataset(self.dir_ref)
20 | self.ref_paths = sorted(self.ref_paths)
21 |
22 | self.dir_p0 = [os.path.join(root, 'p0') for root in self.roots]
23 | self.p0_paths = make_dataset(self.dir_p0)
24 | self.p0_paths = sorted(self.p0_paths)
25 |
26 | self.dir_p1 = [os.path.join(root, 'p1') for root in self.roots]
27 | self.p1_paths = make_dataset(self.dir_p1)
28 | self.p1_paths = sorted(self.p1_paths)
29 |
30 | transform_list = []
31 | transform_list.append(transforms.Scale(load_size))
32 | transform_list += [transforms.ToTensor(),
33 | transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))]
34 |
35 | self.transform = transforms.Compose(transform_list)
36 |
37 | # judgement directory
38 | self.dir_J = [os.path.join(root, 'judge') for root in self.roots]
39 | self.judge_paths = make_dataset(self.dir_J,mode='np')
40 | self.judge_paths = sorted(self.judge_paths)
41 |
42 | def __getitem__(self, index):
43 | p0_path = self.p0_paths[index]
44 | p0_img_ = Image.open(p0_path).convert('RGB')
45 | p0_img = self.transform(p0_img_)
46 |
47 | p1_path = self.p1_paths[index]
48 | p1_img_ = Image.open(p1_path).convert('RGB')
49 | p1_img = self.transform(p1_img_)
50 |
51 | ref_path = self.ref_paths[index]
52 | ref_img_ = Image.open(ref_path).convert('RGB')
53 | ref_img = self.transform(ref_img_)
54 |
55 | judge_path = self.judge_paths[index]
56 | # judge_img = (np.load(judge_path)*2.-1.).reshape((1,1,1,)) # [-1,1]
57 | judge_img = np.load(judge_path).reshape((1,1,1,)) # [0,1]
58 |
59 | judge_img = torch.FloatTensor(judge_img)
60 |
61 | return {'p0': p0_img, 'p1': p1_img, 'ref': ref_img, 'judge': judge_img,
62 | 'p0_path': p0_path, 'p1_path': p1_path, 'ref_path': ref_path, 'judge_path': judge_path}
63 |
64 | def __len__(self):
65 | return len(self.p0_paths)
66 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/data/image_folder.py:
--------------------------------------------------------------------------------
1 | ################################################################################
2 | # Code from
3 | # https://github.com/pytorch/vision/blob/master/torchvision/datasets/folder.py
4 | # Modified the original code so that it also loads images from the current
5 | # directory as well as the subdirectories
6 | ################################################################################
7 |
8 | import torch.utils.data as data
9 |
10 | from PIL import Image
11 | import os
12 | import os.path
13 |
14 | IMG_EXTENSIONS = [
15 | '.jpg', '.JPG', '.jpeg', '.JPEG',
16 | '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP',
17 | ]
18 |
19 | NP_EXTENSIONS = ['.npy',]
20 |
21 | def is_image_file(filename, mode='img'):
22 | if(mode=='img'):
23 | return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
24 | elif(mode=='np'):
25 | return any(filename.endswith(extension) for extension in NP_EXTENSIONS)
26 |
27 | def make_dataset(dirs, mode='img'):
28 | if(not isinstance(dirs,list)):
29 | dirs = [dirs,]
30 |
31 | images = []
32 | for dir in dirs:
33 | assert os.path.isdir(dir), '%s is not a valid directory' % dir
34 | for root, _, fnames in sorted(os.walk(dir)):
35 | for fname in fnames:
36 | if is_image_file(fname, mode=mode):
37 | path = os.path.join(root, fname)
38 | images.append(path)
39 |
40 | # print("Found %i images in %s"%(len(images),root))
41 | return images
42 |
43 | def default_loader(path):
44 | return Image.open(path).convert('RGB')
45 |
46 | class ImageFolder(data.Dataset):
47 | def __init__(self, root, transform=None, return_paths=False,
48 | loader=default_loader):
49 | imgs = make_dataset(root)
50 | if len(imgs) == 0:
51 | raise(RuntimeError("Found 0 images in: " + root + "\n"
52 | "Supported image extensions are: " + ",".join(IMG_EXTENSIONS)))
53 |
54 | self.root = root
55 | self.imgs = imgs
56 | self.transform = transform
57 | self.return_paths = return_paths
58 | self.loader = loader
59 |
60 | def __getitem__(self, index):
61 | path = self.imgs[index]
62 | img = self.loader(path)
63 | if self.transform is not None:
64 | img = self.transform(img)
65 | if self.return_paths:
66 | return img, path
67 | else:
68 | return img
69 |
70 | def __len__(self):
71 | return len(self.imgs)
72 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/ex_dir0/0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/ex_dir0/0.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/ex_dir0/1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/ex_dir0/1.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/ex_dir1/0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/ex_dir1/0.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/ex_dir1/1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/ex_dir1/1.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/ex_dir_pair/ex_p0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/ex_dir_pair/ex_p0.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/ex_dir_pair/ex_p1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/ex_dir_pair/ex_p1.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/ex_dir_pair/ex_ref.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/ex_dir_pair/ex_ref.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/ex_p0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/ex_p0.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/ex_p1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/ex_p1.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/ex_ref.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/ex_ref.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/example_dists.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/example_dists.txt
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/imgs/fig1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/imgs/fig1.png
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/lpips/__init__.py:
--------------------------------------------------------------------------------
1 |
2 | from __future__ import absolute_import
3 | from __future__ import division
4 | from __future__ import print_function
5 |
6 | import numpy as np
7 | import torch
8 | # from torch.autograd import Variable
9 |
10 | from lpips.trainer import *
11 | from lpips.lpips import *
12 |
13 | # class PerceptualLoss(torch.nn.Module):
14 | # def __init__(self, model='lpips', net='alex', spatial=False, use_gpu=False, gpu_ids=[0], version='0.1'): # VGG using our perceptually-learned weights (LPIPS metric)
15 | # # def __init__(self, model='net', net='vgg', use_gpu=True): # "default" way of using VGG as a perceptual loss
16 | # super(PerceptualLoss, self).__init__()
17 | # print('Setting up Perceptual loss...')
18 | # self.use_gpu = use_gpu
19 | # self.spatial = spatial
20 | # self.gpu_ids = gpu_ids
21 | # self.model = dist_model.DistModel()
22 | # self.model.initialize(model=model, net=net, use_gpu=use_gpu, spatial=self.spatial, gpu_ids=gpu_ids, version=version)
23 | # print('...[%s] initialized'%self.model.name())
24 | # print('...Done')
25 |
26 | # def forward(self, pred, target, normalize=False):
27 | # """
28 | # Pred and target are Variables.
29 | # If normalize is True, assumes the images are between [0,1] and then scales them between [-1,+1]
30 | # If normalize is False, assumes the images are already between [-1,+1]
31 |
32 | # Inputs pred and target are Nx3xHxW
33 | # Output pytorch Variable N long
34 | # """
35 |
36 | # if normalize:
37 | # target = 2 * target - 1
38 | # pred = 2 * pred - 1
39 |
40 | # return self.model.forward(target, pred)
41 |
42 | def normalize_tensor(in_feat,eps=1e-10):
43 | norm_factor = torch.sqrt(torch.sum(in_feat**2,dim=1,keepdim=True))
44 | return in_feat/(norm_factor+eps)
45 |
46 | def l2(p0, p1, range=255.):
47 | return .5*np.mean((p0 / range - p1 / range)**2)
48 |
49 | def psnr(p0, p1, peak=255.):
50 | return 10*np.log10(peak**2/np.mean((1.*p0-1.*p1)**2))
51 |
52 | def dssim(p0, p1, range=255.):
53 | from skimage.measure import compare_ssim
54 | return (1 - compare_ssim(p0, p1, data_range=range, multichannel=True)) / 2.
55 |
56 | def rgb2lab(in_img,mean_cent=False):
57 | from skimage import color
58 | img_lab = color.rgb2lab(in_img)
59 | if(mean_cent):
60 | img_lab[:,:,0] = img_lab[:,:,0]-50
61 | return img_lab
62 |
63 | def tensor2np(tensor_obj):
64 | # change dimension of a tensor object into a numpy array
65 | return tensor_obj[0].cpu().float().numpy().transpose((1,2,0))
66 |
67 | def np2tensor(np_obj):
68 | # change dimenion of np array into tensor array
69 | return torch.Tensor(np_obj[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
70 |
71 | def tensor2tensorlab(image_tensor,to_norm=True,mc_only=False):
72 | # image tensor to lab tensor
73 | from skimage import color
74 |
75 | img = tensor2im(image_tensor)
76 | img_lab = color.rgb2lab(img)
77 | if(mc_only):
78 | img_lab[:,:,0] = img_lab[:,:,0]-50
79 | if(to_norm and not mc_only):
80 | img_lab[:,:,0] = img_lab[:,:,0]-50
81 | img_lab = img_lab/100.
82 |
83 | return np2tensor(img_lab)
84 |
85 | def tensorlab2tensor(lab_tensor,return_inbnd=False):
86 | from skimage import color
87 | import warnings
88 | warnings.filterwarnings("ignore")
89 |
90 | lab = tensor2np(lab_tensor)*100.
91 | lab[:,:,0] = lab[:,:,0]+50
92 |
93 | rgb_back = 255.*np.clip(color.lab2rgb(lab.astype('float')),0,1)
94 | if(return_inbnd):
95 | # convert back to lab, see if we match
96 | lab_back = color.rgb2lab(rgb_back.astype('uint8'))
97 | mask = 1.*np.isclose(lab_back,lab,atol=2.)
98 | mask = np2tensor(np.prod(mask,axis=2)[:,:,np.newaxis])
99 | return (im2tensor(rgb_back),mask)
100 | else:
101 | return im2tensor(rgb_back)
102 |
103 | def load_image(path):
104 | if(path[-3:] == 'dng'):
105 | import rawpy
106 | with rawpy.imread(path) as raw:
107 | img = raw.postprocess()
108 | elif(path[-3:]=='bmp' or path[-3:]=='jpg' or path[-3:]=='png'):
109 | import cv2
110 | return cv2.imread(path)[:,:,::-1]
111 | else:
112 | img = (255*plt.imread(path)[:,:,:3]).astype('uint8')
113 |
114 | return img
115 |
116 | def rgb2lab(input):
117 | from skimage import color
118 | return color.rgb2lab(input / 255.)
119 |
120 | def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
121 | image_numpy = image_tensor[0].cpu().float().numpy()
122 | image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
123 | return image_numpy.astype(imtype)
124 |
125 | def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
126 | return torch.Tensor((image / factor - cent)
127 | [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
128 |
129 | def tensor2vec(vector_tensor):
130 | return vector_tensor.data.cpu().numpy()[:, :, 0, 0]
131 |
132 |
133 | def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
134 | # def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
135 | image_numpy = image_tensor[0].cpu().float().numpy()
136 | image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
137 | return image_numpy.astype(imtype)
138 |
139 | def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
140 | # def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
141 | return torch.Tensor((image / factor - cent)
142 | [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
143 |
144 |
145 |
146 | def voc_ap(rec, prec, use_07_metric=False):
147 | """ ap = voc_ap(rec, prec, [use_07_metric])
148 | Compute VOC AP given precision and recall.
149 | If use_07_metric is true, uses the
150 | VOC 07 11 point method (default:False).
151 | """
152 | if use_07_metric:
153 | # 11 point metric
154 | ap = 0.
155 | for t in np.arange(0., 1.1, 0.1):
156 | if np.sum(rec >= t) == 0:
157 | p = 0
158 | else:
159 | p = np.max(prec[rec >= t])
160 | ap = ap + p / 11.
161 | else:
162 | # correct AP calculation
163 | # first append sentinel values at the end
164 | mrec = np.concatenate(([0.], rec, [1.]))
165 | mpre = np.concatenate(([0.], prec, [0.]))
166 |
167 | # compute the precision envelope
168 | for i in range(mpre.size - 1, 0, -1):
169 | mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
170 |
171 | # to calculate area under PR curve, look for points
172 | # where X axis (recall) changes value
173 | i = np.where(mrec[1:] != mrec[:-1])[0]
174 |
175 | # and sum (\Delta recall) * prec
176 | ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
177 | return ap
178 |
179 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/lpips/lpips.py:
--------------------------------------------------------------------------------
1 |
2 | from __future__ import absolute_import
3 |
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.init as init
7 | from torch.autograd import Variable
8 | import numpy as np
9 | from . import pretrained_networks as pn
10 | import torch.nn
11 |
12 | import lpips
13 |
14 | def spatial_average(in_tens, keepdim=True):
15 | return in_tens.mean([2,3],keepdim=keepdim)
16 |
17 | def upsample(in_tens, out_HW=(64,64)): # assumes scale factor is same for H and W
18 | in_H, in_W = in_tens.shape[2], in_tens.shape[3]
19 | return nn.Upsample(size=out_HW, mode='bilinear', align_corners=False)(in_tens)
20 |
21 | # Learned perceptual metric
22 | class LPIPS(nn.Module):
23 | def __init__(self, pretrained=True, net='alex', version='0.1', lpips=True, spatial=False,
24 | pnet_rand=False, pnet_tune=False, use_dropout=True, model_path=None, eval_mode=True, verbose=True):
25 | # lpips - [True] means with linear calibration on top of base network
26 | # pretrained - [True] means load linear weights
27 |
28 | super(LPIPS, self).__init__()
29 | if(verbose):
30 | print('Setting up [%s] perceptual loss: trunk [%s], v[%s], spatial [%s]'%
31 | ('LPIPS' if lpips else 'baseline', net, version, 'on' if spatial else 'off'))
32 |
33 | self.pnet_type = net
34 | self.pnet_tune = pnet_tune
35 | self.pnet_rand = pnet_rand
36 | self.spatial = spatial
37 | self.lpips = lpips # false means baseline of just averaging all layers
38 | self.version = version
39 | self.scaling_layer = ScalingLayer()
40 |
41 | if(self.pnet_type in ['vgg','vgg16']):
42 | net_type = pn.vgg16
43 | self.chns = [64,128,256,512,512]
44 | elif(self.pnet_type=='alex'):
45 | net_type = pn.alexnet
46 | self.chns = [64,192,384,256,256]
47 | elif(self.pnet_type=='squeeze'):
48 | net_type = pn.squeezenet
49 | self.chns = [64,128,256,384,384,512,512]
50 | self.L = len(self.chns)
51 |
52 | self.net = net_type(pretrained=not self.pnet_rand, requires_grad=self.pnet_tune)
53 |
54 | if(lpips):
55 | self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
56 | self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
57 | self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
58 | self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
59 | self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
60 | self.lins = [self.lin0,self.lin1,self.lin2,self.lin3,self.lin4]
61 | if(self.pnet_type=='squeeze'): # 7 layers for squeezenet
62 | self.lin5 = NetLinLayer(self.chns[5], use_dropout=use_dropout)
63 | self.lin6 = NetLinLayer(self.chns[6], use_dropout=use_dropout)
64 | self.lins+=[self.lin5,self.lin6]
65 | self.lins = nn.ModuleList(self.lins)
66 |
67 | if(pretrained):
68 | if(model_path is None):
69 | import inspect
70 | import os
71 | model_path = os.path.abspath(os.path.join(inspect.getfile(self.__init__), '..', 'weights/v%s/%s.pth'%(version,net)))
72 |
73 | if(verbose):
74 | print('Loading model from: %s'%model_path)
75 | self.load_state_dict(torch.load(model_path, map_location='cpu'), strict=False)
76 |
77 | if(eval_mode):
78 | self.eval()
79 |
80 | def forward(self, in0, in1, retPerLayer=False, normalize=False):
81 | if normalize: # turn on this flag if input is [0,1] so it can be adjusted to [-1, +1]
82 | in0 = 2 * in0 - 1
83 | in1 = 2 * in1 - 1
84 |
85 | # v0.0 - original release had a bug, where input was not scaled
86 | in0_input, in1_input = (self.scaling_layer(in0), self.scaling_layer(in1)) if self.version=='0.1' else (in0, in1)
87 | outs0, outs1 = self.net.forward(in0_input), self.net.forward(in1_input)
88 | feats0, feats1, diffs = {}, {}, {}
89 |
90 | for kk in range(self.L):
91 | feats0[kk], feats1[kk] = lpips.normalize_tensor(outs0[kk]), lpips.normalize_tensor(outs1[kk])
92 | diffs[kk] = (feats0[kk]-feats1[kk])**2
93 |
94 | if(self.lpips):
95 | if(self.spatial):
96 | res = [upsample(self.lins[kk](diffs[kk]), out_HW=in0.shape[2:]) for kk in range(self.L)]
97 | else:
98 | res = [spatial_average(self.lins[kk](diffs[kk]), keepdim=True) for kk in range(self.L)]
99 | else:
100 | if(self.spatial):
101 | res = [upsample(diffs[kk].sum(dim=1,keepdim=True), out_HW=in0.shape[2:]) for kk in range(self.L)]
102 | else:
103 | res = [spatial_average(diffs[kk].sum(dim=1,keepdim=True), keepdim=True) for kk in range(self.L)]
104 |
105 | val = res[0]
106 | for l in range(1,self.L):
107 | val += res[l]
108 |
109 | # a = spatial_average(self.lins[kk](diffs[kk]), keepdim=True)
110 | # b = torch.max(self.lins[kk](feats0[kk]**2))
111 | # for kk in range(self.L):
112 | # a += spatial_average(self.lins[kk](diffs[kk]), keepdim=True)
113 | # b = torch.max(b,torch.max(self.lins[kk](feats0[kk]**2)))
114 | # a = a/self.L
115 | # from IPython import embed
116 | # embed()
117 | # return 10*torch.log10(b/a)
118 |
119 | if(retPerLayer):
120 | return (val, res)
121 | else:
122 | return val
123 |
124 |
125 | class ScalingLayer(nn.Module):
126 | def __init__(self):
127 | super(ScalingLayer, self).__init__()
128 | self.register_buffer('shift', torch.Tensor([-.030,-.088,-.188])[None,:,None,None])
129 | self.register_buffer('scale', torch.Tensor([.458,.448,.450])[None,:,None,None])
130 |
131 | def forward(self, inp):
132 | return (inp - self.shift) / self.scale
133 |
134 |
135 | class NetLinLayer(nn.Module):
136 | ''' A single linear layer which does a 1x1 conv '''
137 | def __init__(self, chn_in, chn_out=1, use_dropout=False):
138 | super(NetLinLayer, self).__init__()
139 |
140 | layers = [nn.Dropout(),] if(use_dropout) else []
141 | layers += [nn.Conv2d(chn_in, chn_out, 1, stride=1, padding=0, bias=False),]
142 | self.model = nn.Sequential(*layers)
143 |
144 | def forward(self, x):
145 | return self.model(x)
146 |
147 | class Dist2LogitLayer(nn.Module):
148 | ''' takes 2 distances, puts through fc layers, spits out value between [0,1] (if use_sigmoid is True) '''
149 | def __init__(self, chn_mid=32, use_sigmoid=True):
150 | super(Dist2LogitLayer, self).__init__()
151 |
152 | layers = [nn.Conv2d(5, chn_mid, 1, stride=1, padding=0, bias=True),]
153 | layers += [nn.LeakyReLU(0.2,True),]
154 | layers += [nn.Conv2d(chn_mid, chn_mid, 1, stride=1, padding=0, bias=True),]
155 | layers += [nn.LeakyReLU(0.2,True),]
156 | layers += [nn.Conv2d(chn_mid, 1, 1, stride=1, padding=0, bias=True),]
157 | if(use_sigmoid):
158 | layers += [nn.Sigmoid(),]
159 | self.model = nn.Sequential(*layers)
160 |
161 | def forward(self,d0,d1,eps=0.1):
162 | return self.model.forward(torch.cat((d0,d1,d0-d1,d0/(d1+eps),d1/(d0+eps)),dim=1))
163 |
164 | class BCERankingLoss(nn.Module):
165 | def __init__(self, chn_mid=32):
166 | super(BCERankingLoss, self).__init__()
167 | self.net = Dist2LogitLayer(chn_mid=chn_mid)
168 | # self.parameters = list(self.net.parameters())
169 | self.loss = torch.nn.BCELoss()
170 |
171 | def forward(self, d0, d1, judge):
172 | per = (judge+1.)/2.
173 | self.logit = self.net.forward(d0,d1)
174 | return self.loss(self.logit, per)
175 |
176 | # L2, DSSIM metrics
177 | class FakeNet(nn.Module):
178 | def __init__(self, use_gpu=True, colorspace='Lab'):
179 | super(FakeNet, self).__init__()
180 | self.use_gpu = use_gpu
181 | self.colorspace = colorspace
182 |
183 | class L2(FakeNet):
184 | def forward(self, in0, in1, retPerLayer=None):
185 | assert(in0.size()[0]==1) # currently only supports batchSize 1
186 |
187 | if(self.colorspace=='RGB'):
188 | (N,C,X,Y) = in0.size()
189 | value = torch.mean(torch.mean(torch.mean((in0-in1)**2,dim=1).view(N,1,X,Y),dim=2).view(N,1,1,Y),dim=3).view(N)
190 | return value
191 | elif(self.colorspace=='Lab'):
192 | value = lpips.l2(lpips.tensor2np(lpips.tensor2tensorlab(in0.data,to_norm=False)),
193 | lpips.tensor2np(lpips.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
194 | ret_var = Variable( torch.Tensor((value,) ) )
195 | if(self.use_gpu):
196 | ret_var = ret_var.cuda()
197 | return ret_var
198 |
199 | class DSSIM(FakeNet):
200 |
201 | def forward(self, in0, in1, retPerLayer=None):
202 | assert(in0.size()[0]==1) # currently only supports batchSize 1
203 |
204 | if(self.colorspace=='RGB'):
205 | value = lpips.dssim(1.*lpips.tensor2im(in0.data), 1.*lpips.tensor2im(in1.data), range=255.).astype('float')
206 | elif(self.colorspace=='Lab'):
207 | value = lpips.dssim(lpips.tensor2np(lpips.tensor2tensorlab(in0.data,to_norm=False)),
208 | lpips.tensor2np(lpips.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
209 | ret_var = Variable( torch.Tensor((value,) ) )
210 | if(self.use_gpu):
211 | ret_var = ret_var.cuda()
212 | return ret_var
213 |
214 | def print_network(net):
215 | num_params = 0
216 | for param in net.parameters():
217 | num_params += param.numel()
218 | print('Network',net)
219 | print('Total number of parameters: %d' % num_params)
220 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/lpips/pretrained_networks.py:
--------------------------------------------------------------------------------
1 | from collections import namedtuple
2 | import torch
3 | from torchvision import models as tv
4 |
5 | class squeezenet(torch.nn.Module):
6 | def __init__(self, requires_grad=False, pretrained=True):
7 | super(squeezenet, self).__init__()
8 | pretrained_features = tv.squeezenet1_1(pretrained=pretrained).features
9 | self.slice1 = torch.nn.Sequential()
10 | self.slice2 = torch.nn.Sequential()
11 | self.slice3 = torch.nn.Sequential()
12 | self.slice4 = torch.nn.Sequential()
13 | self.slice5 = torch.nn.Sequential()
14 | self.slice6 = torch.nn.Sequential()
15 | self.slice7 = torch.nn.Sequential()
16 | self.N_slices = 7
17 | for x in range(2):
18 | self.slice1.add_module(str(x), pretrained_features[x])
19 | for x in range(2,5):
20 | self.slice2.add_module(str(x), pretrained_features[x])
21 | for x in range(5, 8):
22 | self.slice3.add_module(str(x), pretrained_features[x])
23 | for x in range(8, 10):
24 | self.slice4.add_module(str(x), pretrained_features[x])
25 | for x in range(10, 11):
26 | self.slice5.add_module(str(x), pretrained_features[x])
27 | for x in range(11, 12):
28 | self.slice6.add_module(str(x), pretrained_features[x])
29 | for x in range(12, 13):
30 | self.slice7.add_module(str(x), pretrained_features[x])
31 | if not requires_grad:
32 | for param in self.parameters():
33 | param.requires_grad = False
34 |
35 | def forward(self, X):
36 | h = self.slice1(X)
37 | h_relu1 = h
38 | h = self.slice2(h)
39 | h_relu2 = h
40 | h = self.slice3(h)
41 | h_relu3 = h
42 | h = self.slice4(h)
43 | h_relu4 = h
44 | h = self.slice5(h)
45 | h_relu5 = h
46 | h = self.slice6(h)
47 | h_relu6 = h
48 | h = self.slice7(h)
49 | h_relu7 = h
50 | vgg_outputs = namedtuple("SqueezeOutputs", ['relu1','relu2','relu3','relu4','relu5','relu6','relu7'])
51 | out = vgg_outputs(h_relu1,h_relu2,h_relu3,h_relu4,h_relu5,h_relu6,h_relu7)
52 |
53 | return out
54 |
55 |
56 | class alexnet(torch.nn.Module):
57 | def __init__(self, requires_grad=False, pretrained=True):
58 | super(alexnet, self).__init__()
59 | alexnet_pretrained_features = tv.alexnet(pretrained=pretrained).features
60 | self.slice1 = torch.nn.Sequential()
61 | self.slice2 = torch.nn.Sequential()
62 | self.slice3 = torch.nn.Sequential()
63 | self.slice4 = torch.nn.Sequential()
64 | self.slice5 = torch.nn.Sequential()
65 | self.N_slices = 5
66 | for x in range(2):
67 | self.slice1.add_module(str(x), alexnet_pretrained_features[x])
68 | for x in range(2, 5):
69 | self.slice2.add_module(str(x), alexnet_pretrained_features[x])
70 | for x in range(5, 8):
71 | self.slice3.add_module(str(x), alexnet_pretrained_features[x])
72 | for x in range(8, 10):
73 | self.slice4.add_module(str(x), alexnet_pretrained_features[x])
74 | for x in range(10, 12):
75 | self.slice5.add_module(str(x), alexnet_pretrained_features[x])
76 | if not requires_grad:
77 | for param in self.parameters():
78 | param.requires_grad = False
79 |
80 | def forward(self, X):
81 | h = self.slice1(X)
82 | h_relu1 = h
83 | h = self.slice2(h)
84 | h_relu2 = h
85 | h = self.slice3(h)
86 | h_relu3 = h
87 | h = self.slice4(h)
88 | h_relu4 = h
89 | h = self.slice5(h)
90 | h_relu5 = h
91 | alexnet_outputs = namedtuple("AlexnetOutputs", ['relu1', 'relu2', 'relu3', 'relu4', 'relu5'])
92 | out = alexnet_outputs(h_relu1, h_relu2, h_relu3, h_relu4, h_relu5)
93 |
94 | return out
95 |
96 | class vgg16(torch.nn.Module):
97 | def __init__(self, requires_grad=False, pretrained=True):
98 | super(vgg16, self).__init__()
99 | vgg_pretrained_features = tv.vgg16(pretrained=pretrained).features
100 | self.slice1 = torch.nn.Sequential()
101 | self.slice2 = torch.nn.Sequential()
102 | self.slice3 = torch.nn.Sequential()
103 | self.slice4 = torch.nn.Sequential()
104 | self.slice5 = torch.nn.Sequential()
105 | self.N_slices = 5
106 | for x in range(4):
107 | self.slice1.add_module(str(x), vgg_pretrained_features[x])
108 | for x in range(4, 9):
109 | self.slice2.add_module(str(x), vgg_pretrained_features[x])
110 | for x in range(9, 16):
111 | self.slice3.add_module(str(x), vgg_pretrained_features[x])
112 | for x in range(16, 23):
113 | self.slice4.add_module(str(x), vgg_pretrained_features[x])
114 | for x in range(23, 30):
115 | self.slice5.add_module(str(x), vgg_pretrained_features[x])
116 | if not requires_grad:
117 | for param in self.parameters():
118 | param.requires_grad = False
119 |
120 | def forward(self, X):
121 | h = self.slice1(X)
122 | h_relu1_2 = h
123 | h = self.slice2(h)
124 | h_relu2_2 = h
125 | h = self.slice3(h)
126 | h_relu3_3 = h
127 | h = self.slice4(h)
128 | h_relu4_3 = h
129 | h = self.slice5(h)
130 | h_relu5_3 = h
131 | vgg_outputs = namedtuple("VggOutputs", ['relu1_2', 'relu2_2', 'relu3_3', 'relu4_3', 'relu5_3'])
132 | out = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3, h_relu5_3)
133 |
134 | return out
135 |
136 |
137 |
138 | class resnet(torch.nn.Module):
139 | def __init__(self, requires_grad=False, pretrained=True, num=18):
140 | super(resnet, self).__init__()
141 | if(num==18):
142 | self.net = tv.resnet18(pretrained=pretrained)
143 | elif(num==34):
144 | self.net = tv.resnet34(pretrained=pretrained)
145 | elif(num==50):
146 | self.net = tv.resnet50(pretrained=pretrained)
147 | elif(num==101):
148 | self.net = tv.resnet101(pretrained=pretrained)
149 | elif(num==152):
150 | self.net = tv.resnet152(pretrained=pretrained)
151 | self.N_slices = 5
152 |
153 | self.conv1 = self.net.conv1
154 | self.bn1 = self.net.bn1
155 | self.relu = self.net.relu
156 | self.maxpool = self.net.maxpool
157 | self.layer1 = self.net.layer1
158 | self.layer2 = self.net.layer2
159 | self.layer3 = self.net.layer3
160 | self.layer4 = self.net.layer4
161 |
162 | def forward(self, X):
163 | h = self.conv1(X)
164 | h = self.bn1(h)
165 | h = self.relu(h)
166 | h_relu1 = h
167 | h = self.maxpool(h)
168 | h = self.layer1(h)
169 | h_conv2 = h
170 | h = self.layer2(h)
171 | h_conv3 = h
172 | h = self.layer3(h)
173 | h_conv4 = h
174 | h = self.layer4(h)
175 | h_conv5 = h
176 |
177 | outputs = namedtuple("Outputs", ['relu1','conv2','conv3','conv4','conv5'])
178 | out = outputs(h_relu1, h_conv2, h_conv3, h_conv4, h_conv5)
179 |
180 | return out
181 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/lpips/trainer.py:
--------------------------------------------------------------------------------
1 |
2 | from __future__ import absolute_import
3 |
4 | import numpy as np
5 | import torch
6 | from torch import nn
7 | from collections import OrderedDict
8 | from torch.autograd import Variable
9 | from scipy.ndimage import zoom
10 | from tqdm import tqdm
11 | import lpips
12 | import os
13 |
14 |
15 | class Trainer():
16 | def name(self):
17 | return self.model_name
18 |
19 | def initialize(self, model='lpips', net='alex', colorspace='Lab', pnet_rand=False, pnet_tune=False, model_path=None,
20 | use_gpu=True, printNet=False, spatial=False,
21 | is_train=False, lr=.0001, beta1=0.5, version='0.1', gpu_ids=[0]):
22 | '''
23 | INPUTS
24 | model - ['lpips'] for linearly calibrated network
25 | ['baseline'] for off-the-shelf network
26 | ['L2'] for L2 distance in Lab colorspace
27 | ['SSIM'] for ssim in RGB colorspace
28 | net - ['squeeze','alex','vgg']
29 | model_path - if None, will look in weights/[NET_NAME].pth
30 | colorspace - ['Lab','RGB'] colorspace to use for L2 and SSIM
31 | use_gpu - bool - whether or not to use a GPU
32 | printNet - bool - whether or not to print network architecture out
33 | spatial - bool - whether to output an array containing varying distances across spatial dimensions
34 | is_train - bool - [True] for training mode
35 | lr - float - initial learning rate
36 | beta1 - float - initial momentum term for adam
37 | version - 0.1 for latest, 0.0 was original (with a bug)
38 | gpu_ids - int array - [0] by default, gpus to use
39 | '''
40 | self.use_gpu = use_gpu
41 | self.gpu_ids = gpu_ids
42 | self.model = model
43 | self.net = net
44 | self.is_train = is_train
45 | self.spatial = spatial
46 | self.model_name = '%s [%s]'%(model,net)
47 |
48 | if(self.model == 'lpips'): # pretrained net + linear layer
49 | self.net = lpips.LPIPS(pretrained=not is_train, net=net, version=version, lpips=True, spatial=spatial,
50 | pnet_rand=pnet_rand, pnet_tune=pnet_tune,
51 | use_dropout=True, model_path=model_path, eval_mode=False)
52 | elif(self.model=='baseline'): # pretrained network
53 | self.net = lpips.LPIPS(pnet_rand=pnet_rand, net=net, lpips=False)
54 | elif(self.model in ['L2','l2']):
55 | self.net = lpips.L2(use_gpu=use_gpu,colorspace=colorspace) # not really a network, only for testing
56 | self.model_name = 'L2'
57 | elif(self.model in ['DSSIM','dssim','SSIM','ssim']):
58 | self.net = lpips.DSSIM(use_gpu=use_gpu,colorspace=colorspace)
59 | self.model_name = 'SSIM'
60 | else:
61 | raise ValueError("Model [%s] not recognized." % self.model)
62 |
63 | self.parameters = list(self.net.parameters())
64 |
65 | if self.is_train: # training mode
66 | # extra network on top to go from distances (d0,d1) => predicted human judgment (h*)
67 | self.rankLoss = lpips.BCERankingLoss()
68 | self.parameters += list(self.rankLoss.net.parameters())
69 | self.lr = lr
70 | self.old_lr = lr
71 | self.optimizer_net = torch.optim.Adam(self.parameters, lr=lr, betas=(beta1, 0.999))
72 | else: # test mode
73 | self.net.eval()
74 |
75 | if(use_gpu):
76 | self.net.to(gpu_ids[0])
77 | self.net = torch.nn.DataParallel(self.net, device_ids=gpu_ids)
78 | if(self.is_train):
79 | self.rankLoss = self.rankLoss.to(device=gpu_ids[0]) # just put this on GPU0
80 |
81 | if(printNet):
82 | print('---------- Networks initialized -------------')
83 | networks.print_network(self.net)
84 | print('-----------------------------------------------')
85 |
86 | def forward(self, in0, in1, retPerLayer=False):
87 | ''' Function computes the distance between image patches in0 and in1
88 | INPUTS
89 | in0, in1 - torch.Tensor object of shape Nx3xXxY - image patch scaled to [-1,1]
90 | OUTPUT
91 | computed distances between in0 and in1
92 | '''
93 |
94 | return self.net.forward(in0, in1, retPerLayer=retPerLayer)
95 |
96 | # ***** TRAINING FUNCTIONS *****
97 | def optimize_parameters(self):
98 | self.forward_train()
99 | self.optimizer_net.zero_grad()
100 | self.backward_train()
101 | self.optimizer_net.step()
102 | self.clamp_weights()
103 |
104 | def clamp_weights(self):
105 | for module in self.net.modules():
106 | if(hasattr(module, 'weight') and module.kernel_size==(1,1)):
107 | module.weight.data = torch.clamp(module.weight.data,min=0)
108 |
109 | def set_input(self, data):
110 | self.input_ref = data['ref']
111 | self.input_p0 = data['p0']
112 | self.input_p1 = data['p1']
113 | self.input_judge = data['judge']
114 |
115 | if(self.use_gpu):
116 | self.input_ref = self.input_ref.to(device=self.gpu_ids[0])
117 | self.input_p0 = self.input_p0.to(device=self.gpu_ids[0])
118 | self.input_p1 = self.input_p1.to(device=self.gpu_ids[0])
119 | self.input_judge = self.input_judge.to(device=self.gpu_ids[0])
120 |
121 | self.var_ref = Variable(self.input_ref,requires_grad=True)
122 | self.var_p0 = Variable(self.input_p0,requires_grad=True)
123 | self.var_p1 = Variable(self.input_p1,requires_grad=True)
124 |
125 | def forward_train(self): # run forward pass
126 | self.d0 = self.forward(self.var_ref, self.var_p0)
127 | self.d1 = self.forward(self.var_ref, self.var_p1)
128 | self.acc_r = self.compute_accuracy(self.d0,self.d1,self.input_judge)
129 |
130 | self.var_judge = Variable(1.*self.input_judge).view(self.d0.size())
131 |
132 | self.loss_total = self.rankLoss.forward(self.d0, self.d1, self.var_judge*2.-1.)
133 |
134 | return self.loss_total
135 |
136 | def backward_train(self):
137 | torch.mean(self.loss_total).backward()
138 |
139 | def compute_accuracy(self,d0,d1,judge):
140 | ''' d0, d1 are Variables, judge is a Tensor '''
141 | d1_lt_d0 = (d1 %f' % (type,self.old_lr, lr))
197 | self.old_lr = lr
198 |
199 |
200 | def get_image_paths(self):
201 | return self.image_paths
202 |
203 | def save_done(self, flag=False):
204 | np.save(os.path.join(self.save_dir, 'done_flag'),flag)
205 | np.savetxt(os.path.join(self.save_dir, 'done_flag'),[flag,],fmt='%i')
206 |
207 |
208 | def score_2afc_dataset(data_loader, func, name=''):
209 | ''' Function computes Two Alternative Forced Choice (2AFC) score using
210 | distance function 'func' in dataset 'data_loader'
211 | INPUTS
212 | data_loader - CustomDatasetDataLoader object - contains a TwoAFCDataset inside
213 | func - callable distance function - calling d=func(in0,in1) should take 2
214 | pytorch tensors with shape Nx3xXxY, and return numpy array of length N
215 | OUTPUTS
216 | [0] - 2AFC score in [0,1], fraction of time func agrees with human evaluators
217 | [1] - dictionary with following elements
218 | d0s,d1s - N arrays containing distances between reference patch to perturbed patches
219 | gts - N array in [0,1], preferred patch selected by human evaluators
220 | (closer to "0" for left patch p0, "1" for right patch p1,
221 | "0.6" means 60pct people preferred right patch, 40pct preferred left)
222 | scores - N array in [0,1], corresponding to what percentage function agreed with humans
223 | CONSTS
224 | N - number of test triplets in data_loader
225 | '''
226 |
227 | d0s = []
228 | d1s = []
229 | gts = []
230 |
231 | for data in tqdm(data_loader.load_data(), desc=name):
232 | d0s+=func(data['ref'],data['p0']).data.cpu().numpy().flatten().tolist()
233 | d1s+=func(data['ref'],data['p1']).data.cpu().numpy().flatten().tolist()
234 | gts+=data['judge'].cpu().numpy().flatten().tolist()
235 |
236 | d0s = np.array(d0s)
237 | d1s = np.array(d1s)
238 | gts = np.array(gts)
239 | scores = (d0s=0.4.0
2 | torchvision>=0.2.1
3 | numpy>=1.14.3
4 | scipy>=1.0.1
5 | scikit-image>=0.13.0
6 | opencv>=2.4.11
7 | matplotlib>=1.5.1
8 | tqdm>=4.28.1
9 | jupyter
10 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/scripts/download_dataset.sh:
--------------------------------------------------------------------------------
1 |
2 | mkdir dataset
3 |
4 | # JND Dataset
5 | wget https://people.eecs.berkeley.edu/~rich.zhang/projects/2018_perceptual/dataset/jnd.tar.gz -O ./dataset/jnd.tar.gz
6 |
7 | mkdir dataset/jnd
8 | tar -xzf ./dataset/jnd.tar.gz -C ./dataset
9 | rm ./dataset/jnd.tar.gz
10 |
11 | # 2AFC Val set
12 | mkdir dataset/2afc/
13 | wget https://people.eecs.berkeley.edu/~rich.zhang/projects/2018_perceptual/dataset/twoafc_val.tar.gz -O ./dataset/twoafc_val.tar.gz
14 |
15 | mkdir dataset/2afc/val
16 | tar -xzf ./dataset/twoafc_val.tar.gz -C ./dataset/2afc
17 | rm ./dataset/twoafc_val.tar.gz
18 |
19 | # 2AFC Train set
20 | mkdir dataset/2afc/
21 | wget https://people.eecs.berkeley.edu/~rich.zhang/projects/2018_perceptual/dataset/twoafc_train.tar.gz -O ./dataset/twoafc_train.tar.gz
22 |
23 | mkdir dataset/2afc/train
24 | tar -xzf ./dataset/twoafc_train.tar.gz -C ./dataset/2afc
25 | rm ./dataset/twoafc_train.tar.gz
26 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/scripts/download_dataset_valonly.sh:
--------------------------------------------------------------------------------
1 |
2 | mkdir dataset
3 |
4 | # JND Dataset
5 | wget https://people.eecs.berkeley.edu/~rich.zhang/projects/2018_perceptual/dataset/jnd.tar.gz -O ./dataset/jnd.tar.gz
6 |
7 | mkdir dataset/jnd
8 | tar -xzf ./dataset/jnd.tar.gz -C ./dataset
9 | rm ./dataset/jnd.tar.gz
10 |
11 | # 2AFC Val set
12 | mkdir dataset/2afc/
13 | wget https://people.eecs.berkeley.edu/~rich.zhang/projects/2018_perceptual/dataset/twoafc_val.tar.gz -O ./dataset/twoafc_val.tar.gz
14 |
15 | mkdir dataset/2afc/val
16 | tar -xzf ./dataset/twoafc_val.tar.gz -C ./dataset/2afc
17 | rm ./dataset/twoafc_val.tar.gz
18 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/scripts/eval_valsets.sh:
--------------------------------------------------------------------------------
1 |
2 | python ./test_dataset_model.py --dataset_mode 2afc --model lpips --net alex --use_gpu --batch_size 50
3 |
4 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/scripts/train_test_metric.sh:
--------------------------------------------------------------------------------
1 |
2 | TRIAL=${1}
3 | NET=${2}
4 | mkdir checkpoints
5 | mkdir checkpoints/${NET}_${TRIAL}
6 | python ./train.py --use_gpu --net ${NET} --name ${NET}_${TRIAL}
7 | python ./test_dataset_model.py --use_gpu --net ${NET} --model_path ./checkpoints/${NET}_${TRIAL}/latest_net_.pth
8 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/scripts/train_test_metric_scratch.sh:
--------------------------------------------------------------------------------
1 |
2 | TRIAL=${1}
3 | NET=${2}
4 | mkdir checkpoints
5 | mkdir checkpoints/${NET}_${TRIAL}_scratch
6 | python ./train.py --from_scratch --train_trunk --use_gpu --net ${NET} --name ${NET}_${TRIAL}_scratch
7 | python ./test_dataset_model.py --from_scratch --train_trunk --use_gpu --net ${NET} --model_path ./checkpoints/${NET}_${TRIAL}_scratch/latest_net_.pth
8 |
9 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/scripts/train_test_metric_tune.sh:
--------------------------------------------------------------------------------
1 |
2 | TRIAL=${1}
3 | NET=${2}
4 | mkdir checkpoints
5 | mkdir checkpoints/${NET}_${TRIAL}_tune
6 | python ./train.py --train_trunk --use_gpu --net ${NET} --name ${NET}_${TRIAL}_tune
7 | python ./test_dataset_model.py --train_trunk --use_gpu --net ${NET} --model_path ./checkpoints/${NET}_${TRIAL}_tune/latest_net_.pth
8 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/setup.py:
--------------------------------------------------------------------------------
1 |
2 | import setuptools
3 | with open("README.md", "r") as fh:
4 | long_description = fh.read()
5 | setuptools.setup(
6 | name='lpips',
7 | version='0.1.2',
8 | author="Richard Zhang",
9 | author_email="rizhang@adobe.com",
10 | description="LPIPS Similarity metric",
11 | long_description=long_description,
12 | long_description_content_type="text/markdown",
13 | url="https://github.com/richzhang/PerceptualSimilarity",
14 | packages=['lpips'],
15 | package_data={'lpips': ['weights/v0.0/*.pth','weights/v0.1/*.pth']},
16 | include_package_data=True,
17 | classifiers=[
18 | "Programming Language :: Python :: 3",
19 | "License :: OSI Approved :: BSD License",
20 | "Operating System :: OS Independent",
21 | ],
22 | )
23 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/testLPIPS.sh:
--------------------------------------------------------------------------------
1 | CUDA_VISIBLE_DECIVES=1 python lpips_2dirs.py \
2 | -d0 PATH_of_your_project/result/TOM/test/try-on \
3 | -d1 PATH_of_your_project/data/test/image \
4 | -o ./example_dists.txt \
5 | --use_gpu
6 |
7 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/test_dataset_model.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import lpips
3 | from data import data_loader as dl
4 | import argparse
5 | from IPython import embed
6 |
7 | parser = argparse.ArgumentParser()
8 | parser.add_argument('--dataset_mode', type=str, default='2afc', help='[2afc,jnd]')
9 | parser.add_argument('--datasets', type=str, nargs='+', default=['val/traditional','val/cnn','val/superres','val/deblur','val/color','val/frameinterp'], help='datasets to test - for jnd mode: [val/traditional],[val/cnn]; for 2afc mode: [train/traditional],[train/cnn],[train/mix],[val/traditional],[val/cnn],[val/color],[val/deblur],[val/frameinterp],[val/superres]')
10 | parser.add_argument('--model', type=str, default='lpips', help='distance model type [lpips] for linearly calibrated net, [baseline] for off-the-shelf network, [l2] for euclidean distance, [ssim] for Structured Similarity Image Metric')
11 | parser.add_argument('--net', type=str, default='alex', help='[squeeze], [alex], or [vgg] for network architectures')
12 | parser.add_argument('--colorspace', type=str, default='Lab', help='[Lab] or [RGB] for colorspace to use for l2, ssim model types')
13 | parser.add_argument('--batch_size', type=int, default=50, help='batch size to test image patches in')
14 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
15 | parser.add_argument('--gpu_ids', type=int, nargs='+', default=[0], help='gpus to use')
16 | parser.add_argument('--nThreads', type=int, default=4, help='number of threads to use in data loader')
17 |
18 | parser.add_argument('--model_path', type=str, default=None, help='location of model, will default to ./weights/v[version]/[net_name].pth')
19 |
20 | parser.add_argument('--from_scratch', action='store_true', help='model was initialized from scratch')
21 | parser.add_argument('--train_trunk', action='store_true', help='model trunk was trained/tuned')
22 | parser.add_argument('--version', type=str, default='0.1', help='v0.1 is latest, v0.0 was original release')
23 |
24 | opt = parser.parse_args()
25 | if(opt.model in ['l2','ssim']):
26 | opt.batch_size = 1
27 |
28 | # initialize model
29 | trainer = lpips.Trainer()
30 | # trainer.initialize(model=opt.model,net=opt.net,colorspace=opt.colorspace,model_path=opt.model_path,use_gpu=opt.use_gpu)
31 | trainer.initialize(model=opt.model, net=opt.net, colorspace=opt.colorspace,
32 | model_path=opt.model_path, use_gpu=opt.use_gpu, pnet_rand=opt.from_scratch, pnet_tune=opt.train_trunk,
33 | version=opt.version, gpu_ids=opt.gpu_ids)
34 |
35 | if(opt.model in ['net-lin','net']):
36 | print('Testing model [%s]-[%s]'%(opt.model,opt.net))
37 | elif(opt.model in ['l2','ssim']):
38 | print('Testing model [%s]-[%s]'%(opt.model,opt.colorspace))
39 |
40 | # initialize data loader
41 | for dataset in opt.datasets:
42 | data_loader = dl.CreateDataLoader(dataset,dataset_mode=opt.dataset_mode, batch_size=opt.batch_size, nThreads=opt.nThreads)
43 |
44 | # evaluate model on data
45 | if(opt.dataset_mode=='2afc'):
46 | (score, results_verbose) = lpips.score_2afc_dataset(data_loader, trainer.forward, name=dataset)
47 | elif(opt.dataset_mode=='jnd'):
48 | (score, results_verbose) = lpips.score_jnd_dataset(data_loader, trainer.forward, name=dataset)
49 |
50 | # print results
51 | print(' Dataset [%s]: %.2f'%(dataset,100.*score))
52 |
53 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/test_network.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import lpips
3 | from IPython import embed
4 |
5 | use_gpu = False # Whether to use GPU
6 | spatial = True # Return a spatial map of perceptual distance.
7 |
8 | # Linearly calibrated models (LPIPS)
9 | loss_fn = lpips.LPIPS(net='alex', spatial=spatial) # Can also set net = 'squeeze' or 'vgg'
10 | # loss_fn = lpips.LPIPS(net='alex', spatial=spatial, lpips=False) # Can also set net = 'squeeze' or 'vgg'
11 |
12 | if(use_gpu):
13 | loss_fn.cuda()
14 |
15 | ## Example usage with dummy tensors
16 | dummy_im0 = torch.zeros(1,3,64,64) # image should be RGB, normalized to [-1,1]
17 | dummy_im1 = torch.zeros(1,3,64,64)
18 | if(use_gpu):
19 | dummy_im0 = dummy_im0.cuda()
20 | dummy_im1 = dummy_im1.cuda()
21 | dist = loss_fn.forward(dummy_im0,dummy_im1)
22 |
23 | ## Example usage with images
24 | ex_ref = lpips.im2tensor(lpips.load_image('./imgs/ex_ref.png'))
25 | ex_p0 = lpips.im2tensor(lpips.load_image('./imgs/ex_p0.png'))
26 | ex_p1 = lpips.im2tensor(lpips.load_image('./imgs/ex_p1.png'))
27 | if(use_gpu):
28 | ex_ref = ex_ref.cuda()
29 | ex_p0 = ex_p0.cuda()
30 | ex_p1 = ex_p1.cuda()
31 |
32 | ex_d0 = loss_fn.forward(ex_ref,ex_p0)
33 | ex_d1 = loss_fn.forward(ex_ref,ex_p1)
34 |
35 | if not spatial:
36 | print('Distances: (%.3f, %.3f)'%(ex_d0, ex_d1))
37 | else:
38 | print('Distances: (%.3f, %.3f)'%(ex_d0.mean(), ex_d1.mean())) # The mean distance is approximately the same as the non-spatial distance
39 |
40 | # Visualize a spatially-varying distance map between ex_p0 and ex_ref
41 | import pylab
42 | pylab.imshow(ex_d0[0,0,...].data.cpu().numpy())
43 | pylab.show()
44 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/train.py:
--------------------------------------------------------------------------------
1 | import torch.backends.cudnn as cudnn
2 | cudnn.benchmark=False
3 |
4 | import numpy as np
5 | import time
6 | import os
7 | import lpips
8 | from data import data_loader as dl
9 | import argparse
10 | from util.visualizer import Visualizer
11 | from IPython import embed
12 |
13 | parser = argparse.ArgumentParser()
14 | parser.add_argument('--datasets', type=str, nargs='+', default=['train/traditional','train/cnn','train/mix'], help='datasets to train on: [train/traditional],[train/cnn],[train/mix],[val/traditional],[val/cnn],[val/color],[val/deblur],[val/frameinterp],[val/superres]')
15 | parser.add_argument('--model', type=str, default='lpips', help='distance model type [lpips] for linearly calibrated net, [baseline] for off-the-shelf network, [l2] for euclidean distance, [ssim] for Structured Similarity Image Metric')
16 | parser.add_argument('--net', type=str, default='alex', help='[squeeze], [alex], or [vgg] for network architectures')
17 | parser.add_argument('--batch_size', type=int, default=50, help='batch size to test image patches in')
18 | parser.add_argument('--use_gpu', action='store_true', help='turn on flag to use GPU')
19 | parser.add_argument('--gpu_ids', type=int, nargs='+', default=[0], help='gpus to use')
20 |
21 | parser.add_argument('--nThreads', type=int, default=4, help='number of threads to use in data loader')
22 | parser.add_argument('--nepoch', type=int, default=5, help='# epochs at base learning rate')
23 | parser.add_argument('--nepoch_decay', type=int, default=5, help='# additional epochs at linearly learning rate')
24 | parser.add_argument('--display_freq', type=int, default=5000, help='frequency (in instances) of showing training results on screen')
25 | parser.add_argument('--print_freq', type=int, default=5000, help='frequency (in instances) of showing training results on console')
26 | parser.add_argument('--save_latest_freq', type=int, default=20000, help='frequency (in instances) of saving the latest results')
27 | parser.add_argument('--save_epoch_freq', type=int, default=1, help='frequency of saving checkpoints at the end of epochs')
28 | parser.add_argument('--display_id', type=int, default=0, help='window id of the visdom display, [0] for no displaying')
29 | parser.add_argument('--display_winsize', type=int, default=256, help='display window size')
30 | parser.add_argument('--display_port', type=int, default=8001, help='visdom display port')
31 | parser.add_argument('--use_html', action='store_true', help='save off html pages')
32 | parser.add_argument('--checkpoints_dir', type=str, default='checkpoints', help='checkpoints directory')
33 | parser.add_argument('--name', type=str, default='tmp', help='directory name for training')
34 |
35 | parser.add_argument('--from_scratch', action='store_true', help='model was initialized from scratch')
36 | parser.add_argument('--train_trunk', action='store_true', help='model trunk was trained/tuned')
37 | parser.add_argument('--train_plot', action='store_true', help='plot saving')
38 |
39 | opt = parser.parse_args()
40 | opt.save_dir = os.path.join(opt.checkpoints_dir,opt.name)
41 | if(not os.path.exists(opt.save_dir)):
42 | os.mkdir(opt.save_dir)
43 |
44 | # initialize model
45 | trainer = lpips.Trainer()
46 | trainer.initialize(model=opt.model, net=opt.net, use_gpu=opt.use_gpu, is_train=True,
47 | pnet_rand=opt.from_scratch, pnet_tune=opt.train_trunk, gpu_ids=opt.gpu_ids)
48 |
49 | # load data from all training sets
50 | data_loader = dl.CreateDataLoader(opt.datasets,dataset_mode='2afc', batch_size=opt.batch_size, serial_batches=False, nThreads=opt.nThreads)
51 | dataset = data_loader.load_data()
52 | dataset_size = len(data_loader)
53 | D = len(dataset)
54 | print('Loading %i instances from'%dataset_size,opt.datasets)
55 | visualizer = Visualizer(opt)
56 |
57 | total_steps = 0
58 | fid = open(os.path.join(opt.checkpoints_dir,opt.name,'train_log.txt'),'w+')
59 | for epoch in range(1, opt.nepoch + opt.nepoch_decay + 1):
60 | epoch_start_time = time.time()
61 | for i, data in enumerate(dataset):
62 | iter_start_time = time.time()
63 | total_steps += opt.batch_size
64 | epoch_iter = total_steps - dataset_size * (epoch - 1)
65 |
66 | trainer.set_input(data)
67 | trainer.optimize_parameters()
68 |
69 | if total_steps % opt.display_freq == 0:
70 | visualizer.display_current_results(trainer.get_current_visuals(), epoch)
71 |
72 | if total_steps % opt.print_freq == 0:
73 | errors = trainer.get_current_errors()
74 | t = (time.time()-iter_start_time)/opt.batch_size
75 | t2o = (time.time()-epoch_start_time)/3600.
76 | t2 = t2o*D/(i+.0001)
77 | visualizer.print_current_errors(epoch, epoch_iter, errors, t, t2=t2, t2o=t2o, fid=fid)
78 |
79 | for key in errors.keys():
80 | visualizer.plot_current_errors_save(epoch, float(epoch_iter)/dataset_size, opt, errors, keys=[key,], name=key, to_plot=opt.train_plot)
81 |
82 | if opt.display_id > 0:
83 | visualizer.plot_current_errors(epoch, float(epoch_iter)/dataset_size, opt, errors)
84 |
85 | if total_steps % opt.save_latest_freq == 0:
86 | print('saving the latest model (epoch %d, total_steps %d)' %
87 | (epoch, total_steps))
88 | trainer.save(opt.save_dir, 'latest')
89 |
90 | if epoch % opt.save_epoch_freq == 0:
91 | print('saving the model at the end of epoch %d, iters %d' %
92 | (epoch, total_steps))
93 | trainer.save(opt.save_dir, 'latest')
94 | trainer.save(opt.save_dir, epoch)
95 |
96 | print('End of epoch %d / %d \t Time Taken: %d sec' %
97 | (epoch, opt.nepoch + opt.nepoch_decay, time.time() - epoch_start_time))
98 |
99 | if epoch > opt.nepoch:
100 | trainer.update_learning_rate(opt.nepoch_decay)
101 |
102 | # trainer.save_done(True)
103 | fid.close()
104 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/util/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/metrics/PerceptualSimilarity/util/__init__.py
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/util/html.py:
--------------------------------------------------------------------------------
1 | import dominate
2 | from dominate.tags import *
3 | import os
4 |
5 |
6 | class HTML:
7 | def __init__(self, web_dir, title, image_subdir='', reflesh=0):
8 | self.title = title
9 | self.web_dir = web_dir
10 | # self.img_dir = os.path.join(self.web_dir, )
11 | self.img_subdir = image_subdir
12 | self.img_dir = os.path.join(self.web_dir, image_subdir)
13 | if not os.path.exists(self.web_dir):
14 | os.makedirs(self.web_dir)
15 | if not os.path.exists(self.img_dir):
16 | os.makedirs(self.img_dir)
17 | # print(self.img_dir)
18 |
19 | self.doc = dominate.document(title=title)
20 | if reflesh > 0:
21 | with self.doc.head:
22 | meta(http_equiv="reflesh", content=str(reflesh))
23 |
24 | def get_image_dir(self):
25 | return self.img_dir
26 |
27 | def add_header(self, str):
28 | with self.doc:
29 | h3(str)
30 |
31 | def add_table(self, border=1):
32 | self.t = table(border=border, style="table-layout: fixed;")
33 | self.doc.add(self.t)
34 |
35 | def add_images(self, ims, txts, links, width=400):
36 | self.add_table()
37 | with self.t:
38 | with tr():
39 | for im, txt, link in zip(ims, txts, links):
40 | with td(style="word-wrap: break-word;", halign="center", valign="top"):
41 | with p():
42 | with a(href=os.path.join(link)):
43 | img(style="width:%dpx" % width, src=os.path.join(im))
44 | br()
45 | p(txt)
46 |
47 | def save(self,file='index'):
48 | html_file = '%s/%s.html' % (self.web_dir,file)
49 | f = open(html_file, 'wt')
50 | f.write(self.doc.render())
51 | f.close()
52 |
53 |
54 | if __name__ == '__main__':
55 | html = HTML('web/', 'test_html')
56 | html.add_header('hello world')
57 |
58 | ims = []
59 | txts = []
60 | links = []
61 | for n in range(4):
62 | ims.append('image_%d.png' % n)
63 | txts.append('text_%d' % n)
64 | links.append('image_%d.png' % n)
65 | html.add_images(ims, txts, links)
66 | html.save()
67 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/util/util.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 |
3 | import numpy as np
4 | from PIL import Image
5 | import numpy as np
6 | import os
7 | import matplotlib.pyplot as plt
8 | import torch
9 |
10 | def load_image(path):
11 | if(path[-3:] == 'dng'):
12 | import rawpy
13 | with rawpy.imread(path) as raw:
14 | img = raw.postprocess()
15 | elif(path[-3:]=='bmp' or path[-3:]=='jpg' or path[-3:]=='png'):
16 | import cv2
17 | return cv2.imread(path)[:,:,::-1]
18 | else:
19 | img = (255*plt.imread(path)[:,:,:3]).astype('uint8')
20 |
21 | return img
22 |
23 | def save_image(image_numpy, image_path, ):
24 | image_pil = Image.fromarray(image_numpy)
25 | image_pil.save(image_path)
26 |
27 | def mkdirs(paths):
28 | if isinstance(paths, list) and not isinstance(paths, str):
29 | for path in paths:
30 | mkdir(path)
31 | else:
32 | mkdir(paths)
33 |
34 | def mkdir(path):
35 | if not os.path.exists(path):
36 | os.makedirs(path)
37 |
38 |
39 | def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
40 | # def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
41 | image_numpy = image_tensor[0].cpu().float().numpy()
42 | image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
43 | return image_numpy.astype(imtype)
44 |
45 | def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
46 | # def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
47 | return torch.Tensor((image / factor - cent)
48 | [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
49 |
--------------------------------------------------------------------------------
/metrics/PerceptualSimilarity/util/visualizer.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import os
3 | import time
4 | from . import util
5 | from . import html
6 | import matplotlib.pyplot as plt
7 | import math
8 | # from IPython import embed
9 |
10 | def zoom_to_res(img,res=256,order=0,axis=0):
11 | # img 3xXxX
12 | from scipy.ndimage import zoom
13 | zoom_factor = res/img.shape[1]
14 | if(axis==0):
15 | return zoom(img,[1,zoom_factor,zoom_factor],order=order)
16 | elif(axis==2):
17 | return zoom(img,[zoom_factor,zoom_factor,1],order=order)
18 |
19 | class Visualizer():
20 | def __init__(self, opt):
21 | # self.opt = opt
22 | self.display_id = opt.display_id
23 | # self.use_html = opt.is_train and not opt.no_html
24 | self.win_size = opt.display_winsize
25 | self.name = opt.name
26 | self.display_cnt = 0 # display_current_results counter
27 | self.display_cnt_high = 0
28 | self.use_html = opt.use_html
29 |
30 | if self.display_id > 0:
31 | import visdom
32 | self.vis = visdom.Visdom(port = opt.display_port)
33 |
34 | self.web_dir = os.path.join(opt.checkpoints_dir, opt.name, 'web')
35 | util.mkdirs([self.web_dir,])
36 | if self.use_html:
37 | self.img_dir = os.path.join(self.web_dir, 'images')
38 | print('create web directory %s...' % self.web_dir)
39 | util.mkdirs([self.img_dir,])
40 |
41 | # |visuals|: dictionary of images to display or save
42 | def display_current_results(self, visuals, epoch, nrows=None, res=256):
43 | if self.display_id > 0: # show images in the browser
44 | title = self.name
45 | if(nrows is None):
46 | nrows = int(math.ceil(len(visuals.items()) / 2.0))
47 | images = []
48 | idx = 0
49 | for label, image_numpy in visuals.items():
50 | title += " | " if idx % nrows == 0 else ", "
51 | title += label
52 | img = image_numpy.transpose([2, 0, 1])
53 | img = zoom_to_res(img,res=res,order=0)
54 | images.append(img)
55 | idx += 1
56 | if len(visuals.items()) % 2 != 0:
57 | white_image = np.ones_like(image_numpy.transpose([2, 0, 1]))*255
58 | white_image = zoom_to_res(white_image,res=res,order=0)
59 | images.append(white_image)
60 | self.vis.images(images, nrow=nrows, win=self.display_id + 1,
61 | opts=dict(title=title))
62 |
63 | if self.use_html: # save images to a html file
64 | for label, image_numpy in visuals.items():
65 | img_path = os.path.join(self.img_dir, 'epoch%.3d_cnt%.6d_%s.png' % (epoch, self.display_cnt, label))
66 | util.save_image(zoom_to_res(image_numpy, res=res, axis=2), img_path)
67 |
68 | self.display_cnt += 1
69 | self.display_cnt_high = np.maximum(self.display_cnt_high, self.display_cnt)
70 |
71 | # update website
72 | webpage = html.HTML(self.web_dir, 'Experiment name = %s' % self.name, reflesh=1)
73 | for n in range(epoch, 0, -1):
74 | webpage.add_header('epoch [%d]' % n)
75 | if(n==epoch):
76 | high = self.display_cnt
77 | else:
78 | high = self.display_cnt_high
79 | for c in range(high-1,-1,-1):
80 | ims = []
81 | txts = []
82 | links = []
83 |
84 | for label, image_numpy in visuals.items():
85 | img_path = 'epoch%.3d_cnt%.6d_%s.png' % (n, c, label)
86 | ims.append(os.path.join('images',img_path))
87 | txts.append(label)
88 | links.append(os.path.join('images',img_path))
89 | webpage.add_images(ims, txts, links, width=self.win_size)
90 | webpage.save()
91 |
92 | # save errors into a directory
93 | def plot_current_errors_save(self, epoch, counter_ratio, opt, errors,keys='+ALL',name='loss', to_plot=False):
94 | if not hasattr(self, 'plot_data'):
95 | self.plot_data = {'X':[],'Y':[], 'legend':list(errors.keys())}
96 | self.plot_data['X'].append(epoch + counter_ratio)
97 | self.plot_data['Y'].append([errors[k] for k in self.plot_data['legend']])
98 |
99 | # embed()
100 | if(keys=='+ALL'):
101 | plot_keys = self.plot_data['legend']
102 | else:
103 | plot_keys = keys
104 |
105 | if(to_plot):
106 | (f,ax) = plt.subplots(1,1)
107 | for (k,kname) in enumerate(plot_keys):
108 | kk = np.where(np.array(self.plot_data['legend'])==kname)[0][0]
109 | x = self.plot_data['X']
110 | y = np.array(self.plot_data['Y'])[:,kk]
111 | if(to_plot):
112 | ax.plot(x, y, 'o-', label=kname)
113 | np.save(os.path.join(self.web_dir,'%s_x')%kname,x)
114 | np.save(os.path.join(self.web_dir,'%s_y')%kname,y)
115 |
116 | if(to_plot):
117 | plt.legend(loc=0,fontsize='small')
118 | plt.xlabel('epoch')
119 | plt.ylabel('Value')
120 | f.savefig(os.path.join(self.web_dir,'%s.png'%name))
121 | f.clf()
122 | plt.close()
123 |
124 | # errors: dictionary of error labels and values
125 | def plot_current_errors(self, epoch, counter_ratio, opt, errors):
126 | if not hasattr(self, 'plot_data'):
127 | self.plot_data = {'X':[],'Y':[], 'legend':list(errors.keys())}
128 | self.plot_data['X'].append(epoch + counter_ratio)
129 | self.plot_data['Y'].append([errors[k] for k in self.plot_data['legend']])
130 | self.vis.line(
131 | X=np.stack([np.array(self.plot_data['X'])]*len(self.plot_data['legend']),1),
132 | Y=np.array(self.plot_data['Y']),
133 | opts={
134 | 'title': self.name + ' loss over time',
135 | 'legend': self.plot_data['legend'],
136 | 'xlabel': 'epoch',
137 | 'ylabel': 'loss'},
138 | win=self.display_id)
139 |
140 | # errors: same format as |errors| of plotCurrentErrors
141 | def print_current_errors(self, epoch, i, errors, t, t2=-1, t2o=-1, fid=None):
142 | message = '(ep: %d, it: %d, t: %.3f[s], ept: %.2f/%.2f[h]) ' % (epoch, i, t, t2o, t2)
143 | message += (', ').join(['%s: %.3f' % (k, v) for k, v in errors.items()])
144 |
145 | print(message)
146 | if(fid is not None):
147 | fid.write('%s\n'%message)
148 |
149 |
150 | # save image to the disk
151 | def save_images_simple(self, webpage, images, names, in_txts, prefix='', res=256):
152 | image_dir = webpage.get_image_dir()
153 | ims = []
154 | txts = []
155 | links = []
156 |
157 | for name, image_numpy, txt in zip(names, images, in_txts):
158 | image_name = '%s_%s.png' % (prefix, name)
159 | save_path = os.path.join(image_dir, image_name)
160 | if(res is not None):
161 | util.save_image(zoom_to_res(image_numpy,res=res,axis=2), save_path)
162 | else:
163 | util.save_image(image_numpy, save_path)
164 |
165 | ims.append(os.path.join(webpage.img_subdir,image_name))
166 | # txts.append(name)
167 | txts.append(txt)
168 | links.append(os.path.join(webpage.img_subdir,image_name))
169 | # embed()
170 | webpage.add_images(ims, txts, links, width=self.win_size)
171 |
172 | # save image to the disk
173 | def save_images(self, webpage, images, names, image_path, title=''):
174 | image_dir = webpage.get_image_dir()
175 | # short_path = ntpath.basename(image_path)
176 | # name = os.path.splitext(short_path)[0]
177 | # name = short_path
178 | # webpage.add_header('%s, %s' % (name, title))
179 | ims = []
180 | txts = []
181 | links = []
182 |
183 | for label, image_numpy in zip(names, images):
184 | image_name = '%s.jpg' % (label,)
185 | save_path = os.path.join(image_dir, image_name)
186 | util.save_image(image_numpy, save_path)
187 |
188 | ims.append(image_name)
189 | txts.append(label)
190 | links.append(image_name)
191 | webpage.add_images(ims, txts, links, width=self.win_size)
192 |
193 | # save image to the disk
194 | # def save_images(self, webpage, visuals, image_path, short=False):
195 | # image_dir = webpage.get_image_dir()
196 | # if short:
197 | # short_path = ntpath.basename(image_path)
198 | # name = os.path.splitext(short_path)[0]
199 | # else:
200 | # name = image_path
201 |
202 | # webpage.add_header(name)
203 | # ims = []
204 | # txts = []
205 | # links = []
206 |
207 | # for label, image_numpy in visuals.items():
208 | # image_name = '%s_%s.png' % (name, label)
209 | # save_path = os.path.join(image_dir, image_name)
210 | # util.save_image(image_numpy, save_path)
211 |
212 | # ims.append(image_name)
213 | # txts.append(label)
214 | # links.append(image_name)
215 | # webpage.add_images(ims, txts, links, width=self.win_size)
216 |
--------------------------------------------------------------------------------
/metrics/getIS.py:
--------------------------------------------------------------------------------
1 | import os
2 | from inception_score import get_inception_score
3 | from skimage.io import imread
4 |
5 | def test(generated_IMG_dir):
6 | print(generated_images_dir)
7 | print ("Loading image Pairs...")
8 |
9 | generated_images = []
10 | for img_nameG in os.listdir(generated_IMG_dir):
11 | imgG = imread(os.path.join(generated_IMG_dir, img_nameG))
12 | generated_images.append(imgG)
13 |
14 | print("#######IS########")
15 | print ("Compute inception score...")
16 | inception_score = get_inception_score(generated_images)
17 | print ("Inception score %s" % inception_score[0])
18 |
19 |
20 |
21 | if __name__ == "__main__":
22 | generated_images_dir = '/path to your CIT foder/result/TOM/test/try-on'
23 | test(generated_images_dir)
24 |
--------------------------------------------------------------------------------
/metrics/getJS.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import os
3 | from skimage.io import imread, imsave
4 | from sklearn.metrics import jaccard_score
5 |
6 |
7 | def computeJS(img1, img2):
8 | # Adjust the pixel value
9 | for row in range(256):
10 | for col in range(192):
11 | if img2[row][col] == 127:
12 | img2[row][col] = 0
13 |
14 | jaccard = jaccard_score(img2.flatten(), img1.flatten(), average='micro')
15 | return jaccard
16 |
17 |
18 | def JS_score(warpedMask_imgs, mask_onPerson_imgs):
19 | iou_score_list = []
20 | for warpedMask_img, mask_onPerson_img in zip(warpedMask_imgs, mask_onPerson_imgs):
21 | iou_score = computeJS(warpedMask_img, mask_onPerson_img)
22 | print(iou_score)
23 | iou_score_list.append(iou_score)
24 |
25 | return np.mean(iou_score_list)
26 |
27 |
28 | def test(warpedMask_dir, mask_onPerson_dir):
29 | print("Loading Images...")
30 | warpedMask_imgs = []
31 | for img_nameWM in os.listdir(warpedMask_dir):
32 | imgWM = imread(os.path.join(warpedMask_dir, img_nameWM))
33 | warpedMask_imgs.append(imgWM)
34 |
35 | mask_onPerson_imgs = []
36 | for img_nameOP in os.listdir(mask_onPerson_dir):
37 | imgOP = imread(os.path.join(mask_onPerson_dir, img_nameOP))
38 | mask_onPerson_imgs.append(imgOP)
39 |
40 | print("######JS######")
41 | Final_JS_score = JS_score(warpedMask_imgs, mask_onPerson_imgs)
42 | print("JS: %s " % Final_JS_score)
43 |
44 |
45 | if __name__ == "__main__":
46 | warpedMask_dir = '/path to your CIT foder/result/GMM/test/warp-mask'
47 | mask_onPerson_dir = '/path to your CIT foder/result/GMM/test/pcm'
48 |
49 | test(warpedMask_dir, mask_onPerson_dir)
50 |
51 |
52 |
--------------------------------------------------------------------------------
/metrics/getSSIM.py:
--------------------------------------------------------------------------------
1 | import os
2 | from skimage.io import imread, imsave
3 | from skimage.measure import compare_ssim
4 |
5 | import torch
6 | from torchvision import transforms
7 | import lpips
8 |
9 | import numpy as np
10 | import pandas as pd
11 |
12 | from tqdm import tqdm
13 | import re
14 |
15 |
16 | def ssim_score(generated_images, reference_images):
17 | ssim_score_list = []
18 | for reference_image, generated_image in zip(reference_images, generated_images):
19 | ssim = compare_ssim(reference_image, generated_image, gaussian_weights=True, sigma=1.5,
20 | use_sample_covariance=False, multichannel=True,
21 | data_range=generated_image.max() - generated_image.min())
22 | ssim_score_list.append(ssim)
23 | return np.mean(ssim_score_list)
24 |
25 |
26 | def test(generated_IMG_dir, reference_IMG_dir):
27 | print(generated_images_dir, reference_IMG_dir)
28 | print ("Loading image Pairs...")
29 |
30 | generated_images = []
31 | for img_nameG in os.listdir(generated_IMG_dir):
32 | imgG = imread(os.path.join(generated_IMG_dir, img_nameG))
33 | generated_images.append(imgG)
34 |
35 | reference_images = []
36 | for img_nameR in os.listdir(reference_IMG_dir):
37 | imgR = imread(os.path.join(reference_IMG_dir, img_nameR))
38 | reference_images.append(imgR)
39 |
40 | print("#####SSIM######")
41 | print ("Compute structured similarity score (SSIM)...")
42 | structured_score = ssim_score(generated_images, reference_images)
43 | print ("SSIM score %s" % structured_score)
44 |
45 |
46 |
47 | if __name__ == "__main__":
48 | generated_images_dir = '/path to your CIT foder/result/TOM/test/try-on'
49 | reference_images_dir = '/path to your CIT foder/data/test/image'
50 |
51 | test(generated_images_dir, reference_images_dir)
52 |
--------------------------------------------------------------------------------
/metrics/inception_score.py:
--------------------------------------------------------------------------------
1 | # Code derived from tensorflow/tensorflow/models/image/imagenet/classify_image.py
2 | from __future__ import absolute_import
3 | from __future__ import division
4 | from __future__ import print_function
5 |
6 | import os.path
7 | import sys
8 | import tarfile
9 |
10 | import numpy as np
11 | from six.moves import urllib
12 | import tensorflow as tf
13 | import glob
14 | import scipy.misc
15 | import math
16 | import sys
17 |
18 | MODEL_DIR = '~/models'
19 | DATA_URL = 'http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz'
20 | softmax = None
21 |
22 | # Call this function with list of images. Each of elements should be a
23 | # numpy array with values ranging from 0 to 255.
24 | def get_inception_score(images, splits=10):
25 | #assert(type(images) == list)
26 | assert(type(images[0]) == np.ndarray)
27 | assert(len(images[0].shape) == 3)
28 | assert(np.max(images[0]) > 10)
29 | assert(np.min(images[0]) >= 0.0)
30 | inps = []
31 | for img in images:
32 | img = img.astype(np.float32)
33 | inps.append(np.expand_dims(img, 0))
34 | bs = 10
35 | with tf.Session() as sess:
36 | preds = []
37 | n_batches = int(math.ceil(float(len(inps)) / float(bs)))
38 | for i in range(n_batches):
39 | sys.stdout.write(".")
40 | sys.stdout.flush()
41 | inp = inps[(i * bs):min((i + 1) * bs, len(inps))]
42 | inp = np.concatenate(inp, 0)
43 | pred = sess.run(softmax, {'ExpandDims:0': inp})
44 | preds.append(pred)
45 | preds = np.concatenate(preds, 0)
46 | scores = []
47 | for i in range(splits):
48 | part = preds[(i * preds.shape[0] // splits):((i + 1) * preds.shape[0] // splits), :]
49 | kl = part * (np.log(part) - np.log(np.expand_dims(np.mean(part, 0), 0)))
50 | kl = np.mean(np.sum(kl, 1))
51 | scores.append(np.exp(kl))
52 | return np.mean(scores), np.std(scores)
53 |
54 | # This function is called automatically.
55 | def _init_inception():
56 | global softmax
57 | if not os.path.exists(MODEL_DIR):
58 | os.makedirs(MODEL_DIR)
59 | filename = DATA_URL.split('/')[-1]
60 | filepath = os.path.join(MODEL_DIR, filename)
61 | if not os.path.exists(filepath):
62 | def _progress(count, block_size, total_size):
63 | sys.stdout.write('\r>> Downloading %s %.1f%%' % (
64 | filename, float(count * block_size) / float(total_size) * 100.0))
65 | sys.stdout.flush()
66 | filepath, _ = urllib.request.urlretrieve(DATA_URL, filepath, _progress)
67 | print()
68 | statinfo = os.stat(filepath)
69 | print('Succesfully downloaded', filename, statinfo.st_size, 'bytes.')
70 | tarfile.open(filepath, 'r:gz').extractall(MODEL_DIR)
71 | with tf.gfile.FastGFile(os.path.join(
72 | MODEL_DIR, 'classify_image_graph_def.pb'), 'rb') as f:
73 | graph_def = tf.GraphDef()
74 | graph_def.ParseFromString(f.read())
75 | _ = tf.import_graph_def(graph_def, name='')
76 | # Works with an arbitrary minibatch size.
77 | with tf.Session() as sess:
78 | pool3 = sess.graph.get_tensor_by_name('pool_3:0')
79 | ops = pool3.graph.get_operations()
80 | for op_idx, op in enumerate(ops):
81 | for o in op.outputs:
82 | shape = o.get_shape()
83 | shape = [s.value for s in shape]
84 | new_shape = []
85 | for j, s in enumerate(shape):
86 | if s == 1 and j == 0:
87 | new_shape.append(None)
88 | else:
89 | new_shape.append(s)
90 | o._shape = tf.TensorShape(new_shape)
91 | w = sess.graph.get_operation_by_name("softmax/logits/MatMul").inputs[1]
92 | logits = tf.matmul(tf.squeeze(pool3), w)
93 | softmax = tf.nn.softmax(logits)
94 |
95 | if softmax is None:
96 | _init_inception()
97 |
--------------------------------------------------------------------------------
/modules/__pycache__/multihead_attention.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/modules/__pycache__/multihead_attention.cpython-36.pyc
--------------------------------------------------------------------------------
/modules/__pycache__/position_embedding.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/modules/__pycache__/position_embedding.cpython-36.pyc
--------------------------------------------------------------------------------
/modules/__pycache__/transformer.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Amazingren/CIT/e7613e495cb60433fea28afd80d3cc70bcfa7ff1/modules/__pycache__/transformer.cpython-36.pyc
--------------------------------------------------------------------------------
/modules/multihead_attention.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 | from torch.nn import Parameter
4 | import torch.nn.functional as F
5 | import sys
6 |
7 | # Code adapted from the fairseq repo.
8 |
9 | class MultiheadAttention(nn.Module):
10 | """Multi-headed attention.
11 | See "Attention Is All You Need" for more details.
12 | """
13 |
14 | def __init__(self, embed_dim, num_heads, attn_dropout=0.,
15 | bias=True, add_bias_kv=False, add_zero_attn=False):
16 | super().__init__()
17 | self.embed_dim = embed_dim
18 | self.num_heads = num_heads
19 | self.attn_dropout = attn_dropout
20 | self.head_dim = embed_dim // num_heads
21 | assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
22 | self.scaling = self.head_dim ** -0.5
23 |
24 | self.in_proj_weight = Parameter(torch.Tensor(3 * embed_dim, embed_dim))
25 | self.register_parameter('in_proj_bias', None)
26 | if bias:
27 | self.in_proj_bias = Parameter(torch.Tensor(3 * embed_dim))
28 | self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
29 |
30 | if add_bias_kv:
31 | self.bias_k = Parameter(torch.Tensor(1, 1, embed_dim))
32 | self.bias_v = Parameter(torch.Tensor(1, 1, embed_dim))
33 | else:
34 | self.bias_k = self.bias_v = None
35 |
36 | self.add_zero_attn = add_zero_attn
37 |
38 | self.reset_parameters()
39 |
40 | def reset_parameters(self):
41 | nn.init.xavier_uniform_(self.in_proj_weight)
42 | nn.init.xavier_uniform_(self.out_proj.weight)
43 | if self.in_proj_bias is not None:
44 | nn.init.constant_(self.in_proj_bias, 0.)
45 | nn.init.constant_(self.out_proj.bias, 0.)
46 | if self.bias_k is not None:
47 | nn.init.xavier_normal_(self.bias_k)
48 | if self.bias_v is not None:
49 | nn.init.xavier_normal_(self.bias_v)
50 |
51 | def forward(self, query, key, value, attn_mask=None):
52 | """Input shape: Time x Batch x Channel
53 | Self-attention can be implemented by passing in the same arguments for
54 | query, key and value. Timesteps can be masked by supplying a T x T mask in the
55 | `attn_mask` argument. Padding elements can be excluded from
56 | the key by passing a binary ByteTensor (`key_padding_mask`) with shape:
57 | batch x src_len, where padding elements are indicated by 1s.
58 | """
59 | qkv_same = query.data_ptr() == key.data_ptr() == value.data_ptr()
60 | kv_same = key.data_ptr() == value.data_ptr()
61 |
62 | tgt_len, bsz, embed_dim = query.size()
63 | assert embed_dim == self.embed_dim
64 | assert list(query.size()) == [tgt_len, bsz, embed_dim]
65 | assert key.size() == value.size()
66 |
67 | aved_state = None
68 |
69 | if qkv_same:
70 | # self-attention
71 | q, k, v = self.in_proj_qkv(query)
72 | elif kv_same:
73 | # encoder-decoder attention
74 | q = self.in_proj_q(query)
75 |
76 | if key is None:
77 | assert value is None
78 | k = v = None
79 | else:
80 | k, v = self.in_proj_kv(key)
81 | else:
82 | q = self.in_proj_q(query)
83 | k = self.in_proj_k(key)
84 | v = self.in_proj_v(value)
85 | q = q * self.scaling
86 |
87 | if self.bias_k is not None:
88 | assert self.bias_v is not None
89 | k = torch.cat([k, self.bias_k.repeat(1, bsz, 1)])
90 | v = torch.cat([v, self.bias_v.repeat(1, bsz, 1)])
91 | if attn_mask is not None:
92 | attn_mask = torch.cat([attn_mask, attn_mask.new_zeros(attn_mask.size(0), 1)], dim=1)
93 |
94 | q = q.contiguous().view(tgt_len, bsz * self.num_heads, self.head_dim).transpose(0, 1)
95 | if k is not None:
96 | k = k.contiguous().view(-1, bsz * self.num_heads, self.head_dim).transpose(0, 1)
97 | if v is not None:
98 | v = v.contiguous().view(-1, bsz * self.num_heads, self.head_dim).transpose(0, 1)
99 |
100 | src_len = k.size(1)
101 |
102 | if self.add_zero_attn:
103 | src_len += 1
104 | k = torch.cat([k, k.new_zeros((k.size(0), 1) + k.size()[2:])], dim=1)
105 | v = torch.cat([v, v.new_zeros((v.size(0), 1) + v.size()[2:])], dim=1)
106 | if attn_mask is not None:
107 | attn_mask = torch.cat([attn_mask, attn_mask.new_zeros(attn_mask.size(0), 1)], dim=1)
108 |
109 | attn_weights = torch.bmm(q, k.transpose(1, 2))
110 | assert list(attn_weights.size()) == [bsz * self.num_heads, tgt_len, src_len]
111 |
112 | if attn_mask is not None:
113 | try:
114 | attn_weights += attn_mask.unsqueeze(0)
115 | except:
116 | print(attn_weights.shape)
117 | print(attn_mask.unsqueeze(0).shape)
118 | assert False
119 |
120 | attn_weights = F.softmax(attn_weights.float(), dim=-1).type_as(attn_weights)
121 | # attn_weights = F.relu(attn_weights)
122 | # attn_weights = attn_weights / torch.max(attn_weights)
123 | attn_weights = F.dropout(attn_weights, p=0.1, training=self.training)
124 |
125 | attn = torch.bmm(attn_weights, v)
126 | assert list(attn.size()) == [bsz * self.num_heads, tgt_len, self.head_dim]
127 |
128 | attn = attn.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
129 | attn = self.out_proj(attn)
130 |
131 | # average attention weights over heads
132 | attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
133 | attn_weights = attn_weights.sum(dim=1) / self.num_heads
134 | return attn, attn_weights
135 |
136 | def in_proj_qkv(self, query):
137 | return self._in_proj(query).chunk(3, dim=-1)
138 |
139 | def in_proj_kv(self, key):
140 | return self._in_proj(key, start=self.embed_dim).chunk(2, dim=-1)
141 |
142 | def in_proj_q(self, query, **kwargs):
143 | return self._in_proj(query, end=self.embed_dim, **kwargs)
144 |
145 | def in_proj_k(self, key):
146 | return self._in_proj(key, start=self.embed_dim, end=2 * self.embed_dim)
147 |
148 | def in_proj_v(self, value):
149 | return self._in_proj(value, start=2 * self.embed_dim)
150 |
151 | def _in_proj(self, input, start=0, end=None, **kwargs):
152 | weight = kwargs.get('weight', self.in_proj_weight)
153 | bias = kwargs.get('bias', self.in_proj_bias)
154 | weight = weight[start:end, :]
155 | if bias is not None:
156 | bias = bias[start:end]
157 | return F.linear(input, weight, bias)
158 |
--------------------------------------------------------------------------------
/modules/position_embedding.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import torch
4 | import torch.nn as nn
5 |
6 | # Code adapted from the fairseq repo.
7 |
8 | def make_positions(tensor, padding_idx, left_pad):
9 | """Replace non-padding symbols with their position numbers.
10 | Position numbers begin at padding_idx+1.
11 | Padding symbols are ignored, but it is necessary to specify whether padding
12 | is added on the left side (left_pad=True) or right side (left_pad=False).
13 | """
14 | max_pos = padding_idx + 1 + tensor.size(1)
15 | device = tensor.get_device()
16 | buf_name = f'range_buf_{device}'
17 | if not hasattr(make_positions, buf_name):
18 | setattr(make_positions, buf_name, tensor.new())
19 | setattr(make_positions, buf_name, getattr(make_positions, buf_name).type_as(tensor))
20 | if getattr(make_positions, buf_name).numel() < max_pos:
21 | torch.arange(padding_idx + 1, max_pos, out=getattr(make_positions, buf_name))
22 | mask = tensor.ne(padding_idx)
23 | positions = getattr(make_positions, buf_name)[:tensor.size(1)].expand_as(tensor)
24 | if left_pad:
25 | positions = positions - mask.size(1) + mask.long().sum(dim=1).unsqueeze(1)
26 | new_tensor = tensor.clone()
27 | return new_tensor.masked_scatter_(mask, positions[mask]).long()
28 |
29 |
30 | class SinusoidalPositionalEmbedding(nn.Module):
31 | """This module produces sinusoidal positional embeddings of any length.
32 | Padding symbols are ignored, but it is necessary to specify whether padding
33 | is added on the left side (left_pad=True) or right side (left_pad=False).
34 | """
35 |
36 | def __init__(self, embedding_dim, padding_idx=0, left_pad=0, init_size=128):
37 | super().__init__()
38 | self.embedding_dim = embedding_dim
39 | self.padding_idx = padding_idx
40 | self.left_pad = left_pad
41 | self.weights = dict() # device --> actual weight; due to nn.DataParallel :-(
42 | self.register_buffer('_float_tensor', torch.FloatTensor(1))
43 |
44 | @staticmethod
45 | def get_embedding(num_embeddings, embedding_dim, padding_idx=None):
46 | """Build sinusoidal embeddings.
47 | This matches the implementation in tensor2tensor, but differs slightly
48 | from the description in Section 3.5 of "Attention Is All You Need".
49 | """
50 | half_dim = embedding_dim // 2
51 | emb = math.log(10000) / (half_dim - 1)
52 | emb = torch.exp(torch.arange(half_dim, dtype=torch.float) * -emb)
53 | emb = torch.arange(num_embeddings, dtype=torch.float).unsqueeze(1) * emb.unsqueeze(0)
54 | emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1).view(num_embeddings, -1)
55 | if embedding_dim % 2 == 1:
56 | # zero pad
57 | emb = torch.cat([emb, torch.zeros(num_embeddings, 1)], dim=1)
58 | if padding_idx is not None:
59 | emb[padding_idx, :] = 0
60 | return emb
61 |
62 | def forward(self, input):
63 | """Input is expected to be of size [bsz x seqlen]."""
64 | bsz, seq_len = input.size()
65 | max_pos = self.padding_idx + 1 + seq_len
66 | device = input.get_device()
67 | if device not in self.weights or max_pos > self.weights[device].size(0):
68 | # recompute/expand embeddings if needed
69 | self.weights[device] = SinusoidalPositionalEmbedding.get_embedding(
70 | max_pos,
71 | self.embedding_dim,
72 | self.padding_idx,
73 | )
74 | self.weights[device] = self.weights[device].type_as(self._float_tensor)
75 | positions = make_positions(input, self.padding_idx, self.left_pad)
76 | return self.weights[device].index_select(0, positions.view(-1)).view(bsz, seq_len, -1).detach()
77 |
78 | def max_positions(self):
79 | """Maximum number of supported positions."""
80 | return int(1e5) # an arbitrary large number
--------------------------------------------------------------------------------
/modules/transformer.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 | import torch.nn.functional as F
4 | from modules.position_embedding import SinusoidalPositionalEmbedding
5 | from modules.multihead_attention import MultiheadAttention
6 | import math
7 |
8 |
9 | class TransformerEncoder(nn.Module):
10 | """
11 | Transformer encoder consisting of *args.encoder_layers* layers. Each layer
12 | is a :class:`TransformerEncoderLayer`.
13 | Args:
14 | embed_tokens (torch.nn.Embedding): input embedding
15 | num_heads (int): number of heads
16 | layers (int): number of layers
17 | attn_dropout (float): dropout applied on the attention weights
18 | relu_dropout (float): dropout applied on the first layer of the residual block
19 | res_dropout (float): dropout applied on the residual block
20 | attn_mask (bool): whether to apply mask on the attention weights
21 | """
22 |
23 | def __init__(self, embed_dim, num_heads, layers, attn_dropout=0.0, relu_dropout=0.0, res_dropout=0.0,
24 | embed_dropout=0.0, attn_mask=False):
25 | super().__init__()
26 | self.dropout = embed_dropout # Embedding dropout
27 | self.attn_dropout = attn_dropout
28 | self.embed_dim = embed_dim
29 | self.embed_scale = math.sqrt(embed_dim)
30 | self.embed_positions = SinusoidalPositionalEmbedding(embed_dim)
31 |
32 | self.attn_mask = attn_mask
33 |
34 | self.layers = nn.ModuleList([])
35 | for layer in range(layers):
36 | new_layer = TransformerEncoderLayer(embed_dim,
37 | num_heads=num_heads,
38 | attn_dropout=attn_dropout,
39 | relu_dropout=relu_dropout,
40 | res_dropout=res_dropout,
41 | attn_mask=attn_mask)
42 | self.layers.append(new_layer)
43 |
44 | self.register_buffer('version', torch.Tensor([2]))
45 | self.normalize = True
46 | if self.normalize:
47 | self.layer_norm = LayerNorm(embed_dim)
48 |
49 | def forward(self, x_in, x_in_k = None, x_in_v = None):
50 | """
51 | Args:
52 | x_in (FloatTensor): embedded input of shape `(src_len, batch, embed_dim)`
53 | x_in_k (FloatTensor): embedded input of shape `(src_len, batch, embed_dim)`
54 | x_in_v (FloatTensor): embedded input of shape `(src_len, batch, embed_dim)`
55 | Returns:
56 | dict:
57 | - **encoder_out** (Tensor): the last encoder layer's output of
58 | shape `(src_len, batch, embed_dim)`
59 | - **encoder_padding_mask** (ByteTensor): the positions of
60 | padding elements of shape `(batch, src_len)`
61 | """
62 | # embed tokens and positions
63 | x = self.embed_scale * x_in
64 | if self.embed_positions is not None:
65 | x += self.embed_positions(x_in.transpose(0, 1)[:, :, 0]).transpose(0, 1) # Add positional embedding
66 | x = F.dropout(x, p= 0.1, training=self.training)
67 |
68 | if x_in_k is not None and x_in_v is not None:
69 | # embed tokens and positions
70 | x_k = self.embed_scale * x_in_k
71 | x_v = self.embed_scale * x_in_v
72 | if self.embed_positions is not None:
73 | x_k += self.embed_positions(x_in_k.transpose(0, 1)[:, :, 0]).transpose(0, 1) # Add positional embedding
74 | x_v += self.embed_positions(x_in_v.transpose(0, 1)[:, :, 0]).transpose(0, 1) # Add positional embedding
75 | x_k = F.dropout(x_k, p=0.1, training=self.training)
76 | x_v = F.dropout(x_v, p=0.1, training=self.training)
77 |
78 | # encoder layers
79 | intermediates = [x]
80 | for layer in self.layers:
81 | if x_in_k is not None and x_in_v is not None:
82 | x = layer(x, x_k, x_v)
83 | else:
84 | x = layer(x)
85 | intermediates.append(x)
86 |
87 | if self.normalize:
88 | x = self.layer_norm(x)
89 |
90 | return x
91 |
92 | def max_positions(self):
93 | """Maximum input length supported by the encoder."""
94 | if self.embed_positions is None:
95 | return self.max_source_positions
96 | return min(self.max_source_positions, self.embed_positions.max_positions())
97 |
98 |
99 | class TransformerEncoderLayer(nn.Module):
100 | """Encoder layer block.
101 | In the original paper each operation (multi-head attention or FFN) is
102 | postprocessed with: `dropout -> add residual -> layernorm`. In the
103 | tensor2tensor code they suggest that learning is more robust when
104 | preprocessing each layer with layernorm and postprocessing with:
105 | `dropout -> add residual`. We default to the approach in the paper, but the
106 | tensor2tensor approach can be enabled by setting
107 | *args.encoder_normalize_before* to ``True``.
108 | Args:
109 | embed_dim: Embedding dimension
110 | """
111 |
112 | def __init__(self, embed_dim, num_heads=4, attn_dropout=0.1, relu_dropout=0.1, res_dropout=0.1,
113 | attn_mask=False):
114 | super().__init__()
115 | self.embed_dim = embed_dim
116 | self.num_heads = num_heads
117 |
118 | self.self_attn = MultiheadAttention(
119 | embed_dim=self.embed_dim,
120 | num_heads=self.num_heads,
121 | attn_dropout=attn_dropout
122 | )
123 | self.attn_mask = attn_mask
124 |
125 | self.relu_dropout = relu_dropout
126 | self.res_dropout = res_dropout
127 | self.normalize_before = True
128 |
129 | self.fc1 = Linear(self.embed_dim, 4*self.embed_dim) # The "Add & Norm" part in the paper
130 | self.fc2 = Linear(4*self.embed_dim, self.embed_dim)
131 | self.layer_norms = nn.ModuleList([LayerNorm(self.embed_dim) for _ in range(2)])
132 |
133 | def forward(self, x, x_k=None, x_v=None):
134 | """
135 | Args:
136 | x (Tensor): input to the layer of shape `(seq_len, batch, embed_dim)`
137 | encoder_padding_mask (ByteTensor): binary ByteTensor of shape
138 | `(batch, src_len)` where padding elements are indicated by ``1``.
139 | x_k (Tensor): same as x
140 | x_v (Tensor): same as x
141 | Returns:
142 | encoded output of shape `(batch, src_len, embed_dim)`
143 | """
144 | residual = x
145 | x = self.maybe_layer_norm(0, x, before=True)
146 | mask = buffered_future_mask(x, x_k) if self.attn_mask else None
147 | if x_k is None and x_v is None:
148 | x, _ = self.self_attn(query=x, key=x, value=x, attn_mask=mask)
149 | else:
150 | x_k = self.maybe_layer_norm(0, x_k, before=True)
151 | x_v = self.maybe_layer_norm(0, x_v, before=True)
152 | x, _ = self.self_attn(query=x, key=x_k, value=x_v, attn_mask=mask)
153 | x = F.dropout(x, p=0.1, training=self.training)
154 | x = residual + x
155 | x = self.maybe_layer_norm(0, x, after=True)
156 |
157 | residual = x
158 | x = self.maybe_layer_norm(1, x, before=True)
159 | x = F.relu(self.fc1(x))
160 | x = F.dropout(x, p=0.1, training=self.training)
161 | x = self.fc2(x)
162 | x = F.dropout(x, p=0.1, training=self.training)
163 | x = residual + x
164 | x = self.maybe_layer_norm(1, x, after=True)
165 | return x
166 |
167 | def maybe_layer_norm(self, i, x, before=False, after=False):
168 | assert before ^ after
169 | if after ^ self.normalize_before:
170 | return self.layer_norms[i](x)
171 | else:
172 | return x
173 |
174 | def fill_with_neg_inf(t):
175 | """FP16-compatible function that fills a tensor with -inf."""
176 | return t.float().fill_(float('-inf')).type_as(t)
177 |
178 |
179 | def buffered_future_mask(tensor, tensor2=None):
180 | dim1 = dim2 = tensor.size(0)
181 | if tensor2 is not None:
182 | dim2 = tensor2.size(0)
183 | future_mask = torch.triu(fill_with_neg_inf(torch.ones(dim1, dim2)), 1+abs(dim2-dim1))
184 | if tensor.is_cuda:
185 | future_mask = future_mask.cuda()
186 | return future_mask[:dim1, :dim2]
187 |
188 |
189 | def Linear(in_features, out_features, bias=True):
190 | m = nn.Linear(in_features, out_features, bias)
191 | nn.init.xavier_uniform_(m.weight)
192 | if bias:
193 | nn.init.constant_(m.bias, 0.)
194 | return m
195 |
196 |
197 | def LayerNorm(embedding_dim):
198 | m = nn.LayerNorm(embedding_dim)
199 | return m
200 |
201 |
202 | if __name__ == '__main__':
203 | encoder = TransformerEncoder(300, 4, 2)
204 | x = torch.tensor(torch.rand(20, 2, 300))
205 | print(encoder(x).shape)
206 |
--------------------------------------------------------------------------------
/networks.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | import torch
3 | import torch.nn as nn
4 | from torch.nn import init
5 | from torchvision import models
6 | import os
7 |
8 | import numpy as np
9 |
10 | from MultiTrans import MULTModel
11 |
12 | from modules.transformer import TransformerEncoder
13 |
14 |
15 | def weights_init_normal(m):
16 | classname = m.__class__.__name__
17 | if classname.find('Conv') != -1:
18 | init.normal_(m.weight.data, 0.0, 0.02)
19 | elif classname.find('Linear') != -1:
20 | init.normal(m.weight.data, 0.0, 0.02)
21 | elif classname.find('BatchNorm2d') != -1:
22 | init.normal_(m.weight.data, 1.0, 0.02)
23 | init.constant_(m.bias.data, 0.0)
24 |
25 |
26 | def weights_init_xavier(m):
27 | classname = m.__class__.__name__
28 | if classname.find('Conv') != -1:
29 | init.xavier_normal_(m.weight.data, gain=0.02)
30 | elif classname.find('Linear') != -1:
31 | init.xavier_normal_(m.weight.data, gain=0.02)
32 | elif classname.find('BatchNorm2d') != -1:
33 | init.normal_(m.weight.data, 1.0, 0.02)
34 | init.constant_(m.bias.data, 0.0)
35 |
36 |
37 | def weights_init_kaiming(m):
38 | classname = m.__class__.__name__
39 | if classname.find('Conv') != -1:
40 | init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
41 | elif classname.find('Linear') != -1:
42 | init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
43 | elif classname.find('BatchNorm2d') != -1:
44 | init.normal_(m.weight.data, 1.0, 0.02)
45 | init.constant_(m.bias.data, 0.0)
46 |
47 |
48 | def init_weights(net, init_type='normal'):
49 | print('initialization method [%s]' % init_type)
50 | if init_type == 'normal':
51 | net.apply(weights_init_normal)
52 | elif init_type == 'xavier':
53 | net.apply(weights_init_xavier)
54 | elif init_type == 'kaiming':
55 | net.apply(weights_init_kaiming)
56 | else:
57 | raise NotImplementedError(
58 | 'initialization method [%s] is not implemented' % init_type)
59 |
60 |
61 | class FeatureExtraction(nn.Module):
62 | def __init__(self, input_nc, ngf=64, n_layers=3, norm_layer=nn.BatchNorm2d, use_dropout=False):
63 | super(FeatureExtraction, self).__init__()
64 | downconv = nn.Conv2d(input_nc, ngf, kernel_size=4, stride=2, padding=1)
65 | model = [downconv, nn.ReLU(True), norm_layer(ngf)]
66 | for i in range(n_layers):
67 | in_ngf = 2**i * ngf if 2**i * ngf < 512 else 512
68 | out_ngf = 2**(i+1) * ngf if 2**i * ngf < 512 else 512
69 | downconv = nn.Conv2d(
70 | in_ngf, out_ngf, kernel_size=4, stride=2, padding=1)
71 | model += [downconv, nn.ReLU(True)]
72 | model += [norm_layer(out_ngf)]
73 | model += [nn.Conv2d(512, 512, kernel_size=3,
74 | stride=1, padding=1), nn.ReLU(True)]
75 | model += [norm_layer(512)]
76 | model += [nn.Conv2d(512, 512, kernel_size=3,
77 | stride=1, padding=1), nn.ReLU(True)]
78 |
79 | self.model = nn.Sequential(*model)
80 | init_weights(self.model, init_type='normal')
81 |
82 | def forward(self, x):
83 | return self.model(x)
84 |
85 |
86 | class FeatureL2Norm(torch.nn.Module):
87 | def __init__(self):
88 | super(FeatureL2Norm, self).__init__()
89 |
90 | def forward(self, feature):
91 | epsilon = 1e-6
92 | norm = torch.pow(torch.sum(torch.pow(feature, 2), 1) +
93 | epsilon, 0.5).unsqueeze(1).expand_as(feature)
94 | return torch.div(feature, norm)
95 |
96 |
97 | class FeatureCorrelation(nn.Module):
98 | def __init__(self):
99 | super(FeatureCorrelation, self).__init__()
100 |
101 | self.d_l, self.d_a, self.d_v = 192, 192, 192
102 | output_dim = 192
103 | self.num_heads = 8
104 | self.layers = 3
105 | self.attn_dropout = nn.Dropout(0.1)
106 | self.attn_dropout_a = nn.Dropout(0.0)
107 | self.attn_dropout_v = nn.Dropout(0.0)
108 | self.relu_dropout = nn.Dropout(0.1)
109 | self.embed_dropout = nn.Dropout(0.25)
110 | self.res_dropout = nn.Dropout(0.1)
111 | self.attn_mask = True
112 |
113 | # 2. Crossmodal Attentions
114 | # if self.lonly:
115 | self.trans_l_with_a = self.get_network(self_type='la')
116 | self.trans_l_with_v = self.get_network(self_type='lv')
117 | # if self.aonly:
118 | self.trans_a_with_l = self.get_network(self_type='al')
119 | self.trans_a_with_v = self.get_network(self_type='av')
120 | # if self.vonly:
121 | self.trans_v_with_l = self.get_network(self_type='vl')
122 | self.trans_v_with_a = self.get_network(self_type='va')
123 |
124 | # 3. Self Attentions
125 | self.trans_l_mem = self.get_network(self_type='l_mem', layers=3)
126 | self.trans_a_mem = self.get_network(self_type='a_mem', layers=3)
127 | self.trans_v_mem = self.get_network(self_type='v_mem', layers=3)
128 |
129 |
130 | self.projConv1 = nn.Conv1d(512, 512, kernel_size=1, padding=0, bias=False)
131 | self.projConv2 = nn.Conv1d(512, 512, kernel_size=1, padding=0, bias=False)
132 | self.out_layer1 = nn.Linear(192 * 2, output_dim)
133 |
134 |
135 | def get_network(self, self_type='l', layers=-1):
136 | if self_type in ['l', 'al', 'vl']:
137 | embed_dim, attn_dropout = self.d_l, self.attn_dropout
138 | elif self_type in ['a', 'la', 'va']:
139 | embed_dim, attn_dropout = self.d_a, self.attn_dropout_a
140 | elif self_type in ['v', 'lv', 'av']:
141 | embed_dim, attn_dropout = self.d_v, self.attn_dropout_v
142 | elif self_type == 'l_mem':
143 | # embed_dim, attn_dropout = 2*self.d_l, self.attn_dropout
144 | embed_dim, attn_dropout = self.d_l, self.attn_dropout
145 | elif self_type == 'a_mem':
146 | # embed_dim, attn_dropout = 2*self.d_a, self.attn_dropout
147 | embed_dim, attn_dropout = self.d_a, self.attn_dropout
148 | elif self_type == 'v_mem':
149 | embed_dim, attn_dropout = 2*self.d_v, self.attn_dropout
150 | else:
151 | raise ValueError("Unknown network type")
152 |
153 | return TransformerEncoder(embed_dim=embed_dim,
154 | num_heads=self.num_heads,
155 | layers=max(self.layers, layers),
156 | attn_dropout=attn_dropout,
157 | relu_dropout=self.relu_dropout,
158 | res_dropout=self.res_dropout,
159 | embed_dropout=self.embed_dropout,
160 | attn_mask=self.attn_mask)
161 |
162 | def forward(self, feature_A, feature_B):
163 | b, c, h, w = feature_A.size()
164 |
165 | feature_A = feature_A.transpose(2, 3).contiguous().view(b, c, h*w) # [B, 512, 16, 12] -> transpose(2, 3) -> [B, 512, 192]
166 | # feature_B = feature_B.view(b, c, h*w).transpose(1, 2) # [B, 512, 192] -> transpose(1, 2) -> [B, 192, 512]
167 | feature_B = feature_B.view(b, c, h*w) # [B, 512, 192]
168 |
169 | # [B, 512, 192]
170 | proj_x1 = self.projConv1(feature_A)
171 | proj_x2 = self.projConv2(feature_B)
172 |
173 | # [512, B, 192]
174 | proj_x1 = proj_x1.permute(1, 0, 2)
175 | proj_x2 = proj_x2.permute(1, 0, 2)
176 |
177 | # SelfTrans First # [512, B, 192]
178 | selfAtt_x1 = self.trans_l_mem(proj_x1)
179 | selfAtt_x2 = self.trans_l_mem(proj_x2)
180 |
181 | # Cross Trans
182 | transA = self.trans_l_with_a(selfAtt_x1, selfAtt_x2, selfAtt_x2)
183 | transB = self.trans_a_with_l(selfAtt_x2, selfAtt_x1, selfAtt_x1)
184 |
185 | # [512, B, 192 * 2]
186 | transAtt = torch.cat([transA, transB], 2)
187 | # [512, B, 192]
188 | transAtt = self.out_layer1(transAtt)
189 | # [B, 512, 192]
190 | transAtt = transAtt.permute(1, 0, 2)
191 |
192 | featureA_plus = feature_A + feature_A * torch.sigmoid(transAtt)
193 | featureB_plus = feature_B + feature_B * torch.sigmoid(transAtt)
194 |
195 | # perform matrix mult.
196 | feature_mul = torch.bmm(featureB_plus.transpose(1, 2), featureA_plus)
197 | correlation_tensor = feature_mul.view(
198 | b, h, w, h*w).transpose(2, 3).transpose(1, 2)
199 |
200 | return correlation_tensor
201 |
202 | class FeatureRegression(nn.Module):
203 | def __init__(self, input_nc=512, output_dim=6, use_cuda=True):
204 | super(FeatureRegression, self).__init__()
205 | self.conv = nn.Sequential(
206 | nn.Conv2d(input_nc, 512, kernel_size=4, stride=2, padding=1),
207 | nn.BatchNorm2d(512),
208 | nn.ReLU(inplace=True),
209 | nn.Conv2d(512, 256, kernel_size=4, stride=2, padding=1),
210 | nn.BatchNorm2d(256),
211 | nn.ReLU(inplace=True),
212 | nn.Conv2d(256, 128, kernel_size=3, padding=1),
213 | nn.BatchNorm2d(128),
214 | nn.ReLU(inplace=True),
215 | nn.Conv2d(128, 64, kernel_size=3, padding=1),
216 | nn.BatchNorm2d(64),
217 | nn.ReLU(inplace=True),
218 | )
219 | self.linear = nn.Linear(64 * 4 * 3, output_dim)
220 | self.tanh = nn.Tanh()
221 | if use_cuda:
222 | self.conv.cuda()
223 | self.linear.cuda()
224 | self.tanh.cuda()
225 |
226 | def forward(self, x):
227 | x = self.conv(x)
228 | x = x.view(x.size(0), -1)
229 | x = self.linear(x)
230 | x = self.tanh(x)
231 | return x
232 |
233 |
234 | class AffineGridGen(nn.Module):
235 | def __init__(self, out_h=256, out_w=192, out_ch=3):
236 | super(AffineGridGen, self).__init__()
237 | self.out_h = out_h
238 | self.out_w = out_w
239 | self.out_ch = out_ch
240 |
241 | def forward(self, theta):
242 | theta = theta.contiguous()
243 | batch_size = theta.size()[0]
244 | out_size = torch.Size(
245 | (batch_size, self.out_ch, self.out_h, self.out_w))
246 | return F.affine_grid(theta, out_size)
247 |
248 |
249 | class TpsGridGen(nn.Module):
250 | def __init__(self, out_h=256, out_w=192, use_regular_grid=True, grid_size=3, reg_factor=0, use_cuda=True):
251 | super(TpsGridGen, self).__init__()
252 | self.out_h, self.out_w = out_h, out_w
253 | self.reg_factor = reg_factor
254 | self.use_cuda = use_cuda
255 |
256 | # create grid in numpy
257 | self.grid = np.zeros([self.out_h, self.out_w, 3], dtype=np.float32)
258 | # sampling grid with dim-0 coords (Y)
259 | self.grid_X, self.grid_Y = np.meshgrid(
260 | np.linspace(-1, 1, out_w), np.linspace(-1, 1, out_h))
261 | # grid_X,grid_Y: size [1,H,W,1,1]
262 | self.grid_X = torch.FloatTensor(self.grid_X).unsqueeze(0).unsqueeze(3)
263 | self.grid_Y = torch.FloatTensor(self.grid_Y).unsqueeze(0).unsqueeze(3)
264 | if use_cuda:
265 | self.grid_X = self.grid_X.cuda()
266 | self.grid_Y = self.grid_Y.cuda()
267 |
268 | # initialize regular grid for control points P_i
269 | if use_regular_grid:
270 | axis_coords = np.linspace(-1, 1, grid_size)
271 | self.N = grid_size*grid_size
272 | P_Y, P_X = np.meshgrid(axis_coords, axis_coords)
273 | P_X = np.reshape(P_X, (-1, 1)) # size (N,1)
274 | P_Y = np.reshape(P_Y, (-1, 1)) # size (N,1)
275 | P_X = torch.FloatTensor(P_X)
276 | P_Y = torch.FloatTensor(P_Y)
277 | self.P_X_base = P_X.clone()
278 | self.P_Y_base = P_Y.clone()
279 | self.Li = self.compute_L_inverse(P_X, P_Y).unsqueeze(0)
280 | self.P_X = P_X.unsqueeze(2).unsqueeze(
281 | 3).unsqueeze(4).transpose(0, 4)
282 | self.P_Y = P_Y.unsqueeze(2).unsqueeze(
283 | 3).unsqueeze(4).transpose(0, 4)
284 | if use_cuda:
285 | self.P_X = self.P_X.cuda()
286 | self.P_Y = self.P_Y.cuda()
287 | self.P_X_base = self.P_X_base.cuda()
288 | self.P_Y_base = self.P_Y_base.cuda()
289 |
290 | def forward(self, theta):
291 | warped_grid = self.apply_transformation(
292 | theta, torch.cat((self.grid_X, self.grid_Y), 3))
293 |
294 | return warped_grid
295 |
296 | def compute_L_inverse(self, X, Y):
297 | N = X.size()[0] # num of points (along dim 0)
298 | # construct matrix K
299 | Xmat = X.expand(N, N)
300 | Ymat = Y.expand(N, N)
301 | P_dist_squared = torch.pow(
302 | Xmat-Xmat.transpose(0, 1), 2)+torch.pow(Ymat-Ymat.transpose(0, 1), 2)
303 | # make diagonal 1 to avoid NaN in log computation
304 | P_dist_squared[P_dist_squared == 0] = 1
305 | K = torch.mul(P_dist_squared, torch.log(P_dist_squared))
306 | # construct matrix L
307 | O = torch.FloatTensor(N, 1).fill_(1)
308 | Z = torch.FloatTensor(3, 3).fill_(0)
309 | P = torch.cat((O, X, Y), 1)
310 | L = torch.cat((torch.cat((K, P), 1), torch.cat(
311 | (P.transpose(0, 1), Z), 1)), 0)
312 | Li = torch.inverse(L)
313 | if self.use_cuda:
314 | Li = Li.cuda()
315 | return Li
316 |
317 | def apply_transformation(self, theta, points):
318 | if theta.dim() == 2:
319 | theta = theta.unsqueeze(2).unsqueeze(3)
320 | # points should be in the [B,H,W,2] format,
321 | # where points[:,:,:,0] are the X coords
322 | # and points[:,:,:,1] are the Y coords
323 |
324 | # input are the corresponding control points P_i
325 | batch_size = theta.size()[0]
326 | # split theta into point coordinates
327 | Q_X = theta[:, :self.N, :, :].squeeze(3)
328 | Q_Y = theta[:, self.N:, :, :].squeeze(3)
329 | Q_X = Q_X + self.P_X_base.expand_as(Q_X)
330 | Q_Y = Q_Y + self.P_Y_base.expand_as(Q_Y)
331 |
332 | # get spatial dimensions of points
333 | points_b = points.size()[0]
334 | points_h = points.size()[1]
335 | points_w = points.size()[2]
336 |
337 | # repeat pre-defined control points along spatial dimensions of points to be transformed
338 | P_X = self.P_X.expand((1, points_h, points_w, 1, self.N))
339 | P_Y = self.P_Y.expand((1, points_h, points_w, 1, self.N))
340 |
341 | # compute weigths for non-linear part
342 | W_X = torch.bmm(self.Li[:, :self.N, :self.N].expand(
343 | (batch_size, self.N, self.N)), Q_X)
344 | W_Y = torch.bmm(self.Li[:, :self.N, :self.N].expand(
345 | (batch_size, self.N, self.N)), Q_Y)
346 | # reshape
347 | # W_X,W,Y: size [B,H,W,1,N]
348 | W_X = W_X.unsqueeze(3).unsqueeze(4).transpose(
349 | 1, 4).repeat(1, points_h, points_w, 1, 1)
350 | W_Y = W_Y.unsqueeze(3).unsqueeze(4).transpose(
351 | 1, 4).repeat(1, points_h, points_w, 1, 1)
352 | # compute weights for affine part
353 | A_X = torch.bmm(self.Li[:, self.N:, :self.N].expand(
354 | (batch_size, 3, self.N)), Q_X)
355 | A_Y = torch.bmm(self.Li[:, self.N:, :self.N].expand(
356 | (batch_size, 3, self.N)), Q_Y)
357 | # reshape
358 | # A_X,A,Y: size [B,H,W,1,3]
359 | A_X = A_X.unsqueeze(3).unsqueeze(4).transpose(
360 | 1, 4).repeat(1, points_h, points_w, 1, 1)
361 | A_Y = A_Y.unsqueeze(3).unsqueeze(4).transpose(
362 | 1, 4).repeat(1, points_h, points_w, 1, 1)
363 |
364 | # compute distance P_i - (grid_X,grid_Y)
365 | # grid is expanded in point dim 4, but not in batch dim 0, as points P_X,P_Y are fixed for all batch
366 | points_X_for_summation = points[:, :, :, 0].unsqueeze(
367 | 3).unsqueeze(4).expand(points[:, :, :, 0].size()+(1, self.N))
368 | points_Y_for_summation = points[:, :, :, 1].unsqueeze(
369 | 3).unsqueeze(4).expand(points[:, :, :, 1].size()+(1, self.N))
370 |
371 | if points_b == 1:
372 | delta_X = points_X_for_summation-P_X
373 | delta_Y = points_Y_for_summation-P_Y
374 | else:
375 | # use expanded P_X,P_Y in batch dimension
376 | delta_X = points_X_for_summation - \
377 | P_X.expand_as(points_X_for_summation)
378 | delta_Y = points_Y_for_summation - \
379 | P_Y.expand_as(points_Y_for_summation)
380 |
381 | dist_squared = torch.pow(delta_X, 2)+torch.pow(delta_Y, 2)
382 | # U: size [1,H,W,1,N]
383 | dist_squared[dist_squared == 0] = 1 # avoid NaN in log computation
384 | U = torch.mul(dist_squared, torch.log(dist_squared))
385 |
386 | # expand grid in batch dimension if necessary
387 | points_X_batch = points[:, :, :, 0].unsqueeze(3)
388 | points_Y_batch = points[:, :, :, 1].unsqueeze(3)
389 | if points_b == 1:
390 | points_X_batch = points_X_batch.expand(
391 | (batch_size,)+points_X_batch.size()[1:])
392 | points_Y_batch = points_Y_batch.expand(
393 | (batch_size,)+points_Y_batch.size()[1:])
394 |
395 | points_X_prime = A_X[:, :, :, :, 0] + \
396 | torch.mul(A_X[:, :, :, :, 1], points_X_batch) + \
397 | torch.mul(A_X[:, :, :, :, 2], points_Y_batch) + \
398 | torch.sum(torch.mul(W_X, U.expand_as(W_X)), 4)
399 |
400 | points_Y_prime = A_Y[:, :, :, :, 0] + \
401 | torch.mul(A_Y[:, :, :, :, 1], points_X_batch) + \
402 | torch.mul(A_Y[:, :, :, :, 2], points_Y_batch) + \
403 | torch.sum(torch.mul(W_Y, U.expand_as(W_Y)), 4)
404 |
405 | return torch.cat((points_X_prime, points_Y_prime), 3)
406 |
407 | # Defines the Unet generator.
408 | # |num_downs|: number of downsamplings in UNet. For example,
409 | # if |num_downs| == 7, image of size 128x128 will become of size 1x1
410 | # at the bottleneck
411 |
412 |
413 | class UnetGenerator(nn.Module):
414 | def __init__(self, input_nc, output_nc, num_downs, ngf=64,
415 | norm_layer=nn.BatchNorm2d, use_dropout=False):
416 | super(UnetGenerator, self).__init__()
417 | # construct unet structure
418 | unet_block = UnetSkipConnectionBlock(
419 | ngf * 8, ngf * 8, input_nc=None, submodule=None, norm_layer=norm_layer, innermost=True)
420 | for i in range(num_downs - 5):
421 | unet_block = UnetSkipConnectionBlock(
422 | ngf * 8, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer, use_dropout=use_dropout)
423 | unet_block = UnetSkipConnectionBlock(
424 | ngf * 4, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
425 | unet_block = UnetSkipConnectionBlock(
426 | ngf * 2, ngf * 4, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
427 | unet_block = UnetSkipConnectionBlock(
428 | ngf, ngf * 2, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
429 | unet_block = UnetSkipConnectionBlock(
430 | output_nc, ngf, input_nc=input_nc, submodule=unet_block, outermost=True, norm_layer=norm_layer)
431 |
432 | self.model = unet_block
433 |
434 | self.multiTrans = MULTModel()
435 | self.gamma = nn.Parameter(torch.zeros(1))
436 | self.attconv = nn.Conv2d(26, 3, 1)
437 |
438 | def forward(self, input):
439 | agnostic_fea = input[:, 0:22, :, :]
440 | c_fea = input[:, 22:25, :, :]
441 | cm_fea = input[:, 25:26, :, :]
442 |
443 | multi_feature = self.multiTrans(agnostic_fea, c_fea, cm_fea).cuda()
444 | input = input + self.gamma * multi_feature
445 | transAttFea = self.attconv(multi_feature)
446 |
447 | return self.model(input), transAttFea
448 |
449 |
450 | # Defines the submodule with skip connection.
451 | # X -------------------identity---------------------- X
452 | # |-- downsampling -- |submodule| -- upsampling --|
453 | class UnetSkipConnectionBlock(nn.Module):
454 | def __init__(self, outer_nc, inner_nc, input_nc=None,
455 | submodule=None, outermost=False, innermost=False, norm_layer=nn.BatchNorm2d, use_dropout=False):
456 | super(UnetSkipConnectionBlock, self).__init__()
457 | self.outermost = outermost
458 | use_bias = norm_layer == nn.InstanceNorm2d
459 |
460 | if input_nc is None:
461 | input_nc = outer_nc
462 | downconv = nn.Conv2d(input_nc, inner_nc, kernel_size=4,
463 | stride=2, padding=1, bias=use_bias)
464 | downrelu = nn.LeakyReLU(0.2, True)
465 | downnorm = norm_layer(inner_nc)
466 | uprelu = nn.ReLU(True)
467 | upnorm = norm_layer(outer_nc)
468 |
469 | if outermost:
470 | upsample = nn.Upsample(scale_factor=2, mode='bilinear')
471 | upconv = nn.Conv2d(inner_nc * 2, outer_nc,
472 | kernel_size=3, stride=1, padding=1, bias=use_bias)
473 | down = [downconv]
474 | up = [uprelu, upsample, upconv, upnorm]
475 | model = down + [submodule] + up
476 | elif innermost:
477 | upsample = nn.Upsample(scale_factor=2, mode='bilinear')
478 | upconv = nn.Conv2d(inner_nc, outer_nc, kernel_size=3,
479 | stride=1, padding=1, bias=use_bias)
480 | down = [downrelu, downconv]
481 | up = [uprelu, upsample, upconv, upnorm]
482 | model = down + up
483 | else:
484 | upsample = nn.Upsample(scale_factor=2, mode='bilinear')
485 | upconv = nn.Conv2d(inner_nc*2, outer_nc, kernel_size=3,
486 | stride=1, padding=1, bias=use_bias)
487 | down = [downrelu, downconv, downnorm]
488 | up = [uprelu, upsample, upconv, upnorm]
489 |
490 | if use_dropout:
491 | model = down + [submodule] + up + [nn.Dropout(0.5)]
492 | else:
493 | model = down + [submodule] + up
494 |
495 | self.model = nn.Sequential(*model)
496 |
497 | def forward(self, x):
498 | if self.outermost:
499 | return self.model(x)
500 | else:
501 | return torch.cat([x, self.model(x)], 1)
502 |
503 |
504 | class Vgg19(nn.Module):
505 | def __init__(self, requires_grad=False):
506 | super(Vgg19, self).__init__()
507 | vgg_pretrained_features = models.vgg19(pretrained=True).features
508 | self.slice1 = torch.nn.Sequential()
509 | self.slice2 = torch.nn.Sequential()
510 | self.slice3 = torch.nn.Sequential()
511 | self.slice4 = torch.nn.Sequential()
512 | self.slice5 = torch.nn.Sequential()
513 | for x in range(2):
514 | self.slice1.add_module(str(x), vgg_pretrained_features[x])
515 | for x in range(2, 7):
516 | self.slice2.add_module(str(x), vgg_pretrained_features[x])
517 | for x in range(7, 12):
518 | self.slice3.add_module(str(x), vgg_pretrained_features[x])
519 | for x in range(12, 21):
520 | self.slice4.add_module(str(x), vgg_pretrained_features[x])
521 | for x in range(21, 30):
522 | self.slice5.add_module(str(x), vgg_pretrained_features[x])
523 | if not requires_grad:
524 | for param in self.parameters():
525 | param.requires_grad = False
526 |
527 | def forward(self, X):
528 | h_relu1 = self.slice1(X)
529 | h_relu2 = self.slice2(h_relu1)
530 | h_relu3 = self.slice3(h_relu2)
531 | h_relu4 = self.slice4(h_relu3)
532 | h_relu5 = self.slice5(h_relu4)
533 | out = [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5]
534 | return out
535 |
536 |
537 | class VGGLoss(nn.Module):
538 | def __init__(self, layids=None):
539 | super(VGGLoss, self).__init__()
540 | self.vgg = Vgg19()
541 | self.vgg.cuda()
542 | self.criterion = nn.L1Loss()
543 | self.weights = [1.0/32, 1.0/16, 1.0/8, 1.0/4, 1.0]
544 | self.layids = layids
545 |
546 | def forward(self, x, y):
547 | x_vgg, y_vgg = self.vgg(x), self.vgg(y)
548 | loss = 0
549 | if self.layids is None:
550 | self.layids = list(range(len(x_vgg)))
551 | for i in self.layids:
552 | loss += self.weights[i] * \
553 | self.criterion(x_vgg[i], y_vgg[i].detach())
554 | return loss
555 |
556 |
557 | class DT(nn.Module):
558 | def __init__(self):
559 | super(DT, self).__init__()
560 |
561 | def forward(self, x1, x2):
562 | dt = torch.abs(x1 - x2)
563 | return dt
564 |
565 |
566 | class DT2(nn.Module):
567 | def __init__(self):
568 | super(DT, self).__init__()
569 |
570 | def forward(self, x1, y1, x2, y2):
571 | dt = torch.sqrt(torch.mul(x1 - x2, x1 - x2) +
572 | torch.mul(y1 - y2, y1 - y2))
573 | return dt
574 |
575 |
576 | class GicLoss(nn.Module):
577 | def __init__(self, opt):
578 | super(GicLoss, self).__init__()
579 | self.dT = DT()
580 | self.opt = opt
581 |
582 | def forward(self, grid):
583 | Gx = grid[:, :, :, 0]
584 | Gy = grid[:, :, :, 1]
585 | Gxcenter = Gx[:, 1:self.opt.fine_height - 1, 1:self.opt.fine_width - 1]
586 | Gxup = Gx[:, 0:self.opt.fine_height - 2, 1:self.opt.fine_width - 1]
587 | Gxdown = Gx[:, 2:self.opt.fine_height, 1:self.opt.fine_width - 1]
588 | Gxleft = Gx[:, 1:self.opt.fine_height - 1, 0:self.opt.fine_width - 2]
589 | Gxright = Gx[:, 1:self.opt.fine_height - 1, 2:self.opt.fine_width]
590 |
591 | Gycenter = Gy[:, 1:self.opt.fine_height - 1, 1:self.opt.fine_width - 1]
592 | Gyup = Gy[:, 0:self.opt.fine_height - 2, 1:self.opt.fine_width - 1]
593 | Gydown = Gy[:, 2:self.opt.fine_height, 1:self.opt.fine_width - 1]
594 | Gyleft = Gy[:, 1:self.opt.fine_height - 1, 0:self.opt.fine_width - 2]
595 | Gyright = Gy[:, 1:self.opt.fine_height - 1, 2:self.opt.fine_width]
596 |
597 | dtleft = self.dT(Gxleft, Gxcenter)
598 | dtright = self.dT(Gxright, Gxcenter)
599 | dtup = self.dT(Gyup, Gycenter)
600 | dtdown = self.dT(Gydown, Gycenter)
601 |
602 | return torch.sum(torch.abs(dtleft - dtright) + torch.abs(dtup - dtdown))
603 |
604 |
605 | class GMM(nn.Module):
606 | """ Geometric Matching Module
607 | """
608 |
609 | def __init__(self, opt):
610 | super(GMM, self).__init__()
611 | self.extractionA = FeatureExtraction(
612 | 22, ngf=64, n_layers=3, norm_layer=nn.BatchNorm2d)
613 | self.extractionB = FeatureExtraction(
614 | 1, ngf=64, n_layers=3, norm_layer=nn.BatchNorm2d)
615 | self.l2norm = FeatureL2Norm()
616 | self.correlation = FeatureCorrelation()
617 | self.regression = FeatureRegression(
618 | input_nc=192, output_dim=2*opt.grid_size**2, use_cuda=True)
619 | self.gridGen = TpsGridGen(
620 | opt.fine_height, opt.fine_width, use_cuda=True, grid_size=opt.grid_size)
621 |
622 | def forward(self, inputA, inputB):
623 | featureA = self.extractionA(inputA)
624 | featureB = self.extractionB(inputB)
625 | featureA = self.l2norm(featureA)
626 | featureB = self.l2norm(featureB)
627 | correlation = self.correlation(featureA, featureB)
628 |
629 | theta = self.regression(correlation)
630 | grid = self.gridGen(theta)
631 | return grid, theta
632 |
633 |
634 | def save_checkpoint(model, save_path):
635 | if not os.path.exists(os.path.dirname(save_path)):
636 | os.makedirs(os.path.dirname(save_path))
637 |
638 | torch.save(model.cpu().state_dict(), save_path)
639 | model.cuda()
640 |
641 |
642 | def load_checkpoint(model, checkpoint_path):
643 | if not os.path.exists(checkpoint_path):
644 | return
645 | model.load_state_dict(torch.load(checkpoint_path))
646 | model.cuda()
647 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==0.4.1
2 | torchvision==0.2.1
3 | tensorboardX
4 | pillow==5.4
5 | numpy
6 | opencv-contrib-python
7 | scikit-image
8 | sklearn
9 | scipy
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | import argparse
7 | import os
8 | import time
9 | from cp_dataset import CPDataset, CPDataLoader
10 | from networks import GMM, UnetGenerator, load_checkpoint
11 |
12 | from tensorboardX import SummaryWriter
13 | from visualization import board_add_image, board_add_images, save_images
14 |
15 |
16 | def get_opt():
17 | parser = argparse.ArgumentParser()
18 |
19 | parser.add_argument("--name", default="GMM")
20 | # parser.add_argument("--name", default="TOM")
21 |
22 | parser.add_argument("--gpu_ids", default="")
23 | parser.add_argument('-j', '--workers', type=int, default=4)
24 | parser.add_argument('-b', '--batch-size', type=int, default=4)
25 |
26 | parser.add_argument("--dataroot", default="data")
27 |
28 | # parser.add_argument("--datamode", default="train")
29 | parser.add_argument("--datamode", default="test")
30 |
31 | parser.add_argument("--stage", default="GMM")
32 | # parser.add_argument("--stage", default="TOM")
33 |
34 | # parser.add_argument("--data_list", default="train_pairs.txt")
35 | parser.add_argument("--data_list", default="test_pairs_same.txt")
36 |
37 | parser.add_argument("--fine_width", type=int, default=192)
38 | parser.add_argument("--fine_height", type=int, default=256)
39 | parser.add_argument("--radius", type=int, default=5)
40 | parser.add_argument("--grid_size", type=int, default=5)
41 |
42 | parser.add_argument('--tensorboard_dir', type=str,
43 | default='tensorboard', help='save tensorboard infos')
44 |
45 | parser.add_argument('--result_dir', type=str,
46 | default='result', help='save result infos')
47 |
48 | parser.add_argument('--checkpoint', type=str, default='checkpoints/GMM/gmm_final.pth', help='model checkpoint for test')
49 |
50 | parser.add_argument("--display_count", type=int, default=1)
51 | parser.add_argument("--shuffle", action='store_true',
52 | help='shuffle input data')
53 |
54 | opt = parser.parse_args()
55 | return opt
56 |
57 |
58 | def test_gmm(opt, test_loader, model, board):
59 | model.cuda()
60 | model.eval()
61 |
62 | base_name = os.path.basename(opt.checkpoint)
63 | name = opt.name
64 | save_dir = os.path.join(opt.result_dir, name, opt.datamode)
65 | if not os.path.exists(save_dir):
66 | os.makedirs(save_dir)
67 | warp_cloth_dir = os.path.join(save_dir, 'warp-cloth')
68 | if not os.path.exists(warp_cloth_dir):
69 | os.makedirs(warp_cloth_dir)
70 | warp_mask_dir = os.path.join(save_dir, 'warp-mask')
71 | if not os.path.exists(warp_mask_dir):
72 | os.makedirs(warp_mask_dir)
73 | result_dir1 = os.path.join(save_dir, 'result_dir')
74 | if not os.path.exists(result_dir1):
75 | os.makedirs(result_dir1)
76 | overlayed_TPS_dir = os.path.join(save_dir, 'overlayed_TPS')
77 | if not os.path.exists(overlayed_TPS_dir):
78 | os.makedirs(overlayed_TPS_dir)
79 | warped_grid_dir = os.path.join(save_dir, 'warped_grid')
80 | if not os.path.exists(warped_grid_dir):
81 | os.makedirs(warped_grid_dir)
82 | im_pcm_dir = os.path.join(save_dir, 'pcm')
83 | if not os.path.exists(im_pcm_dir):
84 | os.makedirs(im_pcm_dir)
85 |
86 |
87 | for step, inputs in enumerate(test_loader.data_loader):
88 | iter_start_time = time.time()
89 |
90 | c_names = inputs['c_name']
91 | im_names = inputs['im_name']
92 | im = inputs['image'].cuda()
93 | im_pose = inputs['pose_image'].cuda()
94 | im_h = inputs['head'].cuda()
95 | shape = inputs['shape'].cuda()
96 | agnostic = inputs['agnostic'].cuda()
97 | c = inputs['cloth'].cuda()
98 | cm = inputs['cloth_mask'].cuda()
99 | im_c = inputs['parse_cloth'].cuda()
100 | im_g = inputs['grid_image'].cuda()
101 | shape_ori = inputs['shape_ori'] # original body shape without blurring
102 |
103 | pcm = inputs['parse_cloth_mask'].cuda()
104 |
105 | grid, theta = model(agnostic, cm)
106 | warped_cloth = F.grid_sample(c, grid, padding_mode='border')
107 | warped_mask = F.grid_sample(cm, grid, padding_mode='zeros')
108 | warped_grid = F.grid_sample(im_g, grid, padding_mode='zeros')
109 | overlay = 0.7 * warped_cloth + 0.3 * im
110 |
111 | visuals = [[im_h, shape, im_pose],
112 | [c, warped_cloth, im_c],
113 | [warped_grid, (warped_cloth+im)*0.5, im]]
114 |
115 | # save_images(warped_cloth, c_names, warp_cloth_dir)
116 | # save_images(warped_mask*2-1, c_names, warp_mask_dir)
117 | save_images(warped_cloth, im_names, warp_cloth_dir)
118 | save_images(warped_mask * 2 - 1, im_names, warp_mask_dir)
119 | save_images(shape_ori.cuda() * 0.2 + warped_cloth *
120 | 0.8, im_names, result_dir1)
121 | save_images(warped_grid, im_names, warped_grid_dir)
122 | save_images(overlay, im_names, overlayed_TPS_dir)
123 | save_images(pcm, im_names, im_pcm_dir)
124 |
125 | if (step+1) % opt.display_count == 0:
126 | board_add_images(board, 'combine', visuals, step+1)
127 | t = time.time() - iter_start_time
128 | print('step: %8d, time: %.3f' % (step+1, t), flush=True)
129 |
130 |
131 | def test_tom(opt, test_loader, model, board):
132 | model.cuda()
133 | model.eval()
134 |
135 | base_name = os.path.basename(opt.checkpoint)
136 | # save_dir = os.path.join(opt.result_dir, base_name, opt.datamode)
137 | save_dir = os.path.join(opt.result_dir, opt.name, opt.datamode)
138 | if not os.path.exists(save_dir):
139 | os.makedirs(save_dir)
140 | try_on_dir = os.path.join(save_dir, 'try-on')
141 | if not os.path.exists(try_on_dir):
142 | os.makedirs(try_on_dir)
143 | p_rendered_dir = os.path.join(save_dir, 'p_rendered')
144 | if not os.path.exists(p_rendered_dir):
145 | os.makedirs(p_rendered_dir)
146 | m_composite_dir = os.path.join(save_dir, 'm_composite')
147 | if not os.path.exists(m_composite_dir):
148 | os.makedirs(m_composite_dir)
149 | im_pose_dir = os.path.join(save_dir, 'im_pose')
150 | if not os.path.exists(im_pose_dir):
151 | os.makedirs(im_pose_dir)
152 | shape_dir = os.path.join(save_dir, 'shape')
153 | if not os.path.exists(shape_dir):
154 | os.makedirs(shape_dir)
155 | im_h_dir = os.path.join(save_dir, 'im_h')
156 | if not os.path.exists(im_h_dir):
157 | os.makedirs(im_h_dir) # for test data
158 |
159 |
160 |
161 | print('Dataset size: %05d!' % (len(test_loader.dataset)), flush=True)
162 | for step, inputs in enumerate(test_loader.data_loader):
163 | iter_start_time = time.time()
164 |
165 | im_names = inputs['im_name']
166 | im = inputs['image'].cuda()
167 | im_pose = inputs['pose_image']
168 | im_h = inputs['head']
169 | shape = inputs['shape']
170 |
171 | agnostic = inputs['agnostic'].cuda()
172 | c = inputs['cloth'].cuda()
173 | cm = inputs['cloth_mask'].cuda()
174 |
175 | # outputs = model(torch.cat([agnostic, c], 1)) # CP-VTON
176 | # outputs = model(torch.cat([agnostic, c, cm], 1)) # CP-VTON+
177 | outputs, transAttFea = model(torch.cat([agnostic, c, cm], 1)) # mTrans_Tryon
178 |
179 | p_rendered, m_composite = torch.split(outputs, 3, 1)
180 | # p_rendered = F.tanh(p_rendered)
181 | p_rendered = F.tanh(p_rendered) + p_rendered * F.sigmoid(transAttFea)
182 | m_composite = F.sigmoid(m_composite)
183 | p_tryon = c * m_composite + p_rendered * (1 - m_composite)
184 |
185 | visuals = [[im_h, shape, im_pose],
186 | [c, 2*cm-1, m_composite],
187 | [p_rendered, p_tryon, im]]
188 |
189 | save_images(p_tryon, im_names, try_on_dir)
190 | save_images(im_h, im_names, im_h_dir)
191 | save_images(shape, im_names, shape_dir)
192 | save_images(im_pose, im_names, im_pose_dir)
193 | save_images(m_composite, im_names, m_composite_dir)
194 | save_images(p_rendered, im_names, p_rendered_dir) # For test data
195 |
196 | if (step+1) % opt.display_count == 0:
197 | board_add_images(board, 'combine', visuals, step+1)
198 | t = time.time() - iter_start_time
199 | print('step: %8d, time: %.3f' % (step+1, t), flush=True)
200 |
201 |
202 | def main():
203 | opt = get_opt()
204 | print(opt)
205 | print("Start to test stage: %s, named: %s!" % (opt.stage, opt.name))
206 |
207 | # create dataset
208 | test_dataset = CPDataset(opt)
209 |
210 | # create dataloader
211 | test_loader = CPDataLoader(opt, test_dataset)
212 |
213 | # visualization
214 | if not os.path.exists(opt.tensorboard_dir):
215 | os.makedirs(opt.tensorboard_dir)
216 | board = SummaryWriter(log_dir=os.path.join(opt.tensorboard_dir, opt.name))
217 |
218 | # create model & test
219 | if opt.stage == 'GMM':
220 | model = GMM(opt)
221 | load_checkpoint(model, opt.checkpoint)
222 | with torch.no_grad():
223 | test_gmm(opt, test_loader, model, board)
224 | elif opt.stage == 'TOM':
225 | # model = UnetGenerator(25, 4, 6, ngf=64, norm_layer=nn.InstanceNorm2d) # CP-VTON
226 | model = UnetGenerator(26, 4, 6, ngf=64, norm_layer=nn.InstanceNorm2d) # CP-VTON+
227 | load_checkpoint(model, opt.checkpoint)
228 | with torch.no_grad():
229 | test_tom(opt, test_loader, model, board)
230 | else:
231 | raise NotImplementedError('Model [%s] is not implemented' % opt.stage)
232 |
233 | print('Finished test %s, named: %s!' % (opt.stage, opt.name))
234 |
235 |
236 | if __name__ == "__main__":
237 | main()
238 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | import argparse
7 | import os
8 | import time
9 | from cp_dataset import CPDataset, CPDataLoader
10 | from networks import GicLoss, GMM, UnetGenerator, VGGLoss, load_checkpoint, save_checkpoint
11 |
12 | from tensorboardX import SummaryWriter
13 | from visualization import board_add_image, board_add_images
14 |
15 |
16 | def get_opt():
17 | parser = argparse.ArgumentParser()
18 | parser.add_argument("--name", default="GMM")
19 |
20 | parser.add_argument("--gpu_ids", type=str, default="0")
21 | parser.add_argument('-j', '--workers', type=int, default=4)
22 | parser.add_argument('-b', '--batch-size', type=int, default=4)
23 |
24 | parser.add_argument("--dataroot", default="data")
25 |
26 | parser.add_argument("--datamode", default="train")
27 |
28 | parser.add_argument("--stage", default="GMM")
29 |
30 | parser.add_argument("--data_list", default="train_pairs.txt")
31 |
32 | parser.add_argument("--fine_width", type=int, default=192)
33 | parser.add_argument("--fine_height", type=int, default=256)
34 | parser.add_argument("--radius", type=int, default=5)
35 | parser.add_argument("--grid_size", type=int, default=5)
36 | parser.add_argument('--lr', type=float, default=0.0001,
37 | help='initial learning rate for adam')
38 | parser.add_argument('--tensorboard_dir', type=str,
39 | default='tensorboard', help='save tensorboard infos')
40 | parser.add_argument('--checkpoint_dir', type=str,
41 | default='checkpoints', help='save checkpoint infos')
42 | parser.add_argument('--checkpoint', type=str, default='',
43 | help='model checkpoint for initialization')
44 | parser.add_argument("--display_count", type=int, default=20)
45 | parser.add_argument("--save_count", type=int, default=5000)
46 | parser.add_argument("--keep_step", type=int, default=100000)
47 | parser.add_argument("--decay_step", type=int, default=100000)
48 | parser.add_argument("--shuffle", action='store_true',
49 | help='shuffle input data')
50 |
51 | opt = parser.parse_args()
52 | return opt
53 |
54 |
55 | def train_gmm(opt, train_loader, model, board):
56 | model = model.cuda()
57 |
58 | model.train()
59 |
60 | # criterion
61 | criterionL1 = nn.L1Loss()
62 | criterionL1_mask = nn.L1Loss()
63 | gicloss = GicLoss(opt)
64 | # optimizer
65 | optimizer = torch.optim.Adam(
66 | model.parameters(), lr=opt.lr, betas=(0.5, 0.999))
67 | scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda step: 1.0 -
68 | max(0, step - opt.keep_step) / float(opt.decay_step + 1))
69 |
70 | for step in range(opt.keep_step + opt.decay_step):
71 | iter_start_time = time.time()
72 | inputs = train_loader.next_batch()
73 |
74 | im = inputs['image'].cuda()
75 | im_pose = inputs['pose_image'].cuda()
76 | im_h = inputs['head'].cuda()
77 | shape = inputs['shape'].cuda()
78 | agnostic = inputs['agnostic'].cuda()
79 | c = inputs['cloth'].cuda()
80 | cm = inputs['cloth_mask'].cuda()
81 | im_c = inputs['parse_cloth'].cuda()
82 | im_g = inputs['grid_image'].cuda()
83 | pcm = inputs['parse_cloth_mask'].cuda()
84 |
85 |
86 |
87 | grid, theta = model(agnostic, cm) # can be added c too for new training
88 | #grid, theta = model(agnostic, torch.cat([c, cm], 1)) # can be added c too for new training
89 | warped_cloth = F.grid_sample(c, grid, padding_mode='border')
90 | warped_mask = F.grid_sample(cm, grid, padding_mode='zeros')
91 | warped_grid = F.grid_sample(im_g, grid, padding_mode='zeros')
92 |
93 | visuals = [[im_h, shape, im_pose],
94 | [c, warped_cloth, im_c],
95 | [warped_grid, (warped_cloth+im)*0.5, im]]
96 |
97 | Lwarp = criterionL1(warped_cloth, im_c) # loss for warped cloth
98 | Lwarp_mask = criterionL1_mask(warped_mask, pcm)
99 | # grid regularization loss
100 | Lgic = gicloss(grid)
101 | # 200x200 = 40.000 * 0.001
102 | Lgic = Lgic / (grid.shape[0] * grid.shape[1] * grid.shape[2])
103 |
104 | loss = Lwarp + 40 * Lgic # total GMM loss for B3 in CIT
105 | # loss = Lwarp + Lwarp_mask + 40 * Lgic # total GMM loss for B4 in CIT
106 |
107 |
108 | optimizer.zero_grad()
109 | loss.backward()
110 | optimizer.step()
111 |
112 | if (step+1) % opt.display_count == 0:
113 | board_add_images(board, 'combine', visuals, step+1)
114 | board.add_scalar('loss', loss.item(), step+1)
115 | board.add_scalar('40*Lgic', (40*Lgic).item(), step+1)
116 | board.add_scalar('Lwarp', Lwarp.item(), step+1)
117 | board.add_scalar('Lwarp_mask', Lwarp_mask.item(), step+1)
118 | t = time.time() - iter_start_time
119 | print('step: %8d, time: %.3f, loss: %4f, (40*Lgic): %.8f, Lwarp: %.6f, Lwarp_mask: %.6f' %
120 | (step+1, t, loss.item(), (40*Lgic).item(), Lwarp.item(), Lwarp_mask.item()), flush=True)
121 |
122 | if (step+1) % opt.save_count == 0:
123 | save_checkpoint(model, os.path.join(
124 | opt.checkpoint_dir, opt.name, 'step_%06d.pth' % (step+1)))
125 |
126 |
127 | def train_tom(opt, train_loader, model, board):
128 | model.cuda()
129 | model.train()
130 |
131 | # criterion
132 | criterionL1 = nn.L1Loss()
133 | criterionVGG = VGGLoss()
134 | criterionMask = nn.L1Loss()
135 |
136 | # optimizer
137 | optimizer = torch.optim.Adam(
138 | model.parameters(), lr=opt.lr, betas=(0.5, 0.999))
139 | scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda step: 1.0 -
140 | max(0, step - opt.keep_step) / float(opt.decay_step + 1))
141 |
142 | for step in range(opt.keep_step + opt.decay_step):
143 | iter_start_time = time.time()
144 | inputs = train_loader.next_batch()
145 |
146 | im = inputs['image'].cuda()
147 | im_pose = inputs['pose_image']
148 | im_h = inputs['head']
149 | shape = inputs['shape']
150 |
151 | agnostic = inputs['agnostic'].cuda()
152 | c = inputs['cloth'].cuda()
153 | cm = inputs['cloth_mask'].cuda()
154 | pcm = inputs['parse_cloth_mask'].cuda()
155 |
156 | # outputs = model(torch.cat([agnostic, c], 1)) # CP-VTON
157 | # outputs = model(torch.cat([agnostic, c, cm], 1)) # CP-VTON+
158 | outputs, transAttFea = model(torch.cat([agnostic, c, cm], 1)) # CIT
159 |
160 | p_rendered, m_composite = torch.split(outputs, 3, 1)
161 | # p_rendered = F.tanh(p_rendered) # CP-VTON+
162 | p_rendered = F.tanh(p_rendered) + p_rendered * F.sigmoid(transAttFea) # CIT
163 | m_composite = F.sigmoid(m_composite)
164 | p_tryon = c * m_composite + p_rendered * (1 - m_composite)
165 |
166 | """visuals = [[im_h, shape, im_pose],
167 | [c, cm*2-1, m_composite*2-1],
168 | [p_rendered, p_tryon, im]]""" # CP-VTON
169 |
170 | visuals = [[im_h, shape, im_pose],
171 | [c, pcm*2-1, m_composite*2-1],
172 | [p_rendered, p_tryon, im]] # CP-VTON+
173 |
174 | loss_l1 = criterionL1(p_tryon, im)
175 | loss_vgg = criterionVGG(p_tryon, im)
176 | # loss_mask = criterionMask(m_composite, cm) # CP-VTON
177 | loss_mask = criterionMask(m_composite, pcm) # CP-VTON+
178 | loss = loss_l1 + loss_vgg + loss_mask
179 | optimizer.zero_grad()
180 | loss.backward()
181 | optimizer.step()
182 |
183 | if (step+1) % opt.display_count == 0:
184 | board_add_images(board, 'combine', visuals, step+1)
185 | board.add_scalar('metric', loss.item(), step+1)
186 | board.add_scalar('L1', loss_l1.item(), step+1)
187 | board.add_scalar('VGG', loss_vgg.item(), step+1)
188 | board.add_scalar('MaskL1', loss_mask.item(), step+1)
189 | t = time.time() - iter_start_time
190 | print('step: %8d, time: %.3f, loss: %.4f, l1: %.4f, vgg: %.4f, mask: %.4f'
191 | % (step+1, t, loss.item(), loss_l1.item(),
192 | loss_vgg.item(), loss_mask.item()), flush=True)
193 |
194 | if (step+1) % opt.save_count == 0:
195 | save_checkpoint(model, os.path.join(
196 | opt.checkpoint_dir, opt.name, 'step_%06d.pth' % (step+1)))
197 |
198 |
199 | def main():
200 | opt = get_opt()
201 | print(opt)
202 | print("Start to train stage: %s, named: %s!" % (opt.stage, opt.name))
203 |
204 | # create dataset
205 | train_dataset = CPDataset(opt)
206 |
207 | # create dataloader
208 | train_loader = CPDataLoader(opt, train_dataset)
209 |
210 | # visualization
211 | if not os.path.exists(opt.tensorboard_dir):
212 | os.makedirs(opt.tensorboard_dir)
213 | board = SummaryWriter(log_dir=os.path.join(opt.tensorboard_dir, opt.name))
214 |
215 | # create model & train & save the final checkpoint
216 | if opt.stage == 'GMM':
217 | model = GMM(opt)
218 | if not opt.checkpoint == '' and os.path.exists(opt.checkpoint):
219 | load_checkpoint(model, opt.checkpoint)
220 | train_gmm(opt, train_loader, model, board)
221 | save_checkpoint(model, os.path.join(
222 | opt.checkpoint_dir, opt.name, 'gmm_final.pth'))
223 | elif opt.stage == 'TOM':
224 | # model = UnetGenerator(25, 4, 6, ngf=64, norm_layer=nn.InstanceNorm2d) # CP-VTON
225 | model = UnetGenerator(
226 | 26, 4, 6, ngf=64, norm_layer=nn.InstanceNorm2d) # CP-VTON+
227 | if not opt.checkpoint == '' and os.path.exists(opt.checkpoint):
228 | load_checkpoint(model, opt.checkpoint)
229 | train_tom(opt, train_loader, model, board)
230 | save_checkpoint(model, os.path.join(
231 | opt.checkpoint_dir, opt.name, 'tom_final.pth'))
232 | else:
233 | raise NotImplementedError('Model [%s] is not implemented' % opt.stage)
234 |
235 | print('Finished training %s, named: %s!' % (opt.stage, opt.name))
236 |
237 |
238 | if __name__ == "__main__":
239 | main()
240 |
--------------------------------------------------------------------------------
/visualization.py:
--------------------------------------------------------------------------------
1 | from tensorboardX import SummaryWriter
2 | import torch
3 | from PIL import Image
4 | import os
5 |
6 |
7 | def tensor_for_board(img_tensor):
8 | # map into [0,1]
9 | tensor = (img_tensor.clone()+1) * 0.5
10 | tensor.cpu().clamp(0, 1)
11 |
12 | if tensor.size(1) == 1:
13 | tensor = tensor.repeat(1, 3, 1, 1)
14 |
15 | return tensor
16 |
17 |
18 | def tensor_list_for_board(img_tensors_list):
19 | grid_h = len(img_tensors_list)
20 | grid_w = max(len(img_tensors) for img_tensors in img_tensors_list)
21 |
22 | batch_size, channel, height, width = tensor_for_board(
23 | img_tensors_list[0][0]).size()
24 | canvas_h = grid_h * height
25 | canvas_w = grid_w * width
26 | canvas = torch.FloatTensor(
27 | batch_size, channel, canvas_h, canvas_w).fill_(0.5)
28 | for i, img_tensors in enumerate(img_tensors_list):
29 | for j, img_tensor in enumerate(img_tensors):
30 | offset_h = i * height
31 | offset_w = j * width
32 | tensor = tensor_for_board(img_tensor)
33 | canvas[:, :, offset_h: offset_h + height,
34 | offset_w: offset_w + width].copy_(tensor)
35 |
36 | return canvas
37 |
38 |
39 | def board_add_image(board, tag_name, img_tensor, step_count):
40 | tensor = tensor_for_board(img_tensor)
41 |
42 | for i, img in enumerate(tensor):
43 | board.add_image('%s/%03d' % (tag_name, i), img, step_count)
44 |
45 |
46 | def board_add_images(board, tag_name, img_tensors_list, step_count):
47 | tensor = tensor_list_for_board(img_tensors_list)
48 |
49 | for i, img in enumerate(tensor):
50 | board.add_image('%s/%03d' % (tag_name, i), img, step_count)
51 |
52 |
53 | def save_images(img_tensors, img_names, save_dir):
54 | for img_tensor, img_name in zip(img_tensors, img_names):
55 | tensor = (img_tensor.clone()+1)*0.5 * 255
56 | tensor = tensor.cpu().clamp(0, 255)
57 |
58 | array = tensor.numpy().astype('uint8')
59 | if array.shape[0] == 1:
60 | array = array.squeeze(0)
61 | elif array.shape[0] == 3:
62 | array = array.swapaxes(0, 1).swapaxes(1, 2)
63 |
64 | Image.fromarray(array).save(os.path.join(save_dir, img_name))
65 |
--------------------------------------------------------------------------------