├── Code-15
├── README.md
├── 第01讲:必知必会,掌握 HTTP 基本原理.md
├── 第02讲:夯实根基,Web 网页基础.md
├── 第03讲:原理探究,了解爬虫的基本原理.md
├── 第04讲:基础探究,Session 与 Cookies.md
├── 第05讲:多路加速,了解多线程基本原理.md
├── 第06讲:多路加速,了解多进程基本原理.md
├── 第08讲:解析无所不能的正则表达式.md
├── 第09讲:爬虫解析利器 PyQuery 的使用.md
├── 第10讲:高效存储 MongoDB 的用法.md
├── 第11讲:Reqeusts + PyQuery + PyMongo 基本案例实战.md
├── 第12讲:Ajax 的原理和解析.md
├── 第13讲:Ajax 爬取案例实战.md
├── 第14讲:Selenium 的基本使用.md
├── 第15讲:Selenium 爬取实战.md
├── 第16讲:异步爬虫的原理和解析.md
├── 第17讲:aiohttp 异步爬虫实战.md
├── 第18讲:爬虫神器 Pyppeteer 的使用.md
├── 第20讲:代理的基本原理和用法.md
├── 第21讲:提高利用效率,代理池的搭建和使用.md
├── 第22讲:验证码反爬虫的基本原理.md
├── 第23讲:利用资源,学会用打码平台处理验证码.md
├── 第24讲:更智能的深度学习处理验证码.md
├── 第25讲:你有权限吗?解析模拟登录基本原理.md
├── 第26讲:模拟登录爬取实战案例.md
├── 第27讲:令人抓狂的 JavaScript 混淆技术.md
├── 第30讲:App 爬虫是什么?.md
└── 第31讲:抓包利器 Charles 的使用.md
/Code-15:
--------------------------------------------------------------------------------
1 | import logging
2 | from selenium import webdriver
3 | from selenium.webdriver.support.wait import WebDriverWait
4 | from selenium.webdriver.support import expected_conditions as EC
5 | from selenium.webdriver.common.by import By
6 | from selenium.common.exceptions import TimeoutException
7 |
8 | logging.basicConfig(level=logging.INFO,
9 | format='%(asctime)s - %(levelname)s: %(message)s')
10 | INDEX_URL = 'https://dynamic2.scrape.cuiqingcai.com/page/{page}'
11 | TIME_OUT = 10
12 | TOTAL_PAGE = 10
13 | browser = webdriver.Chrome()
14 | wait = WebDriverWait(browser, TIME_OUT)
15 |
16 | # 启动Chrome的Headless模式
17 | options=webdriver.ChromeOptions()
18 | options.add_argument('--headless')
19 | browser=webdriver.Chrome(options=options)
20 |
21 | def scrape_page(url, condition, locator):
22 | logging.info('scraping %s', url)
23 | try:
24 | browser.get(url)
25 | wait.until(condition(locator))
26 | except TimeoutException:
27 | logging.error('error occurred while scraping %s', url, exc_info=True)
28 |
29 | def scrape_index(page):
30 | url = INDEX_URL.format(page=page)
31 | scrape_page(url, condition=EC.visibility_of_all_elements_located,
32 | locator=(By.CSS_SELECTOR, '#index .item'))
33 |
34 | from urllib.parse import urljoin
35 | def parse_index():
36 | elements = browser.find_elements_by_css_selector('#index .item .name')
37 | for element in elements:
38 | href = element.get_attribute('href')
39 | yield urljoin(INDEX_URL, href)
40 |
41 | def scrapy_detail(url):
42 | scrape_page(url,condition=EC.visibility_of_element_located,locator=(By.TAG_NAME,'h2'))
43 |
44 | def parse_detail():
45 | url=browser.current_url
46 | name=browser.find_element_by_tag_name('h2').text
47 | categories=[ element.text for element in browser.find_elements_by_css_selector('.categories button span')]
48 | cover=browser.find_element_by_css_selector('.cover').get_attribute('src')
49 | score=browser.find_element_by_class_name('score').text
50 | drama=browser.find_element_by_css_selector('.drama p').text
51 | return {
52 | 'url':url,
53 | 'name':name,
54 | 'categories':categories,
55 | 'cover':cover,
56 | 'score':score,
57 | 'drama':drama
58 | }
59 |
60 | from os import makedirs
61 | from os.path import exists
62 | import json
63 | RESULTS_DIR='results2'
64 | exists(RESULTS_DIR) or makedirs(RESULTS_DIR)
65 |
66 | def save_data(data):
67 | name = data.get('name')
68 | data_path = f'{RESULTS_DIR}/{name}.json'
69 | json.dump(data, open(data_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=2)
70 |
71 |
72 | def main():
73 | try:
74 | for page in range(1, TOTAL_PAGE + 1):
75 | scrape_index(page)
76 | detail_urls = parse_index()
77 | for detail_url in list(detail_urls):
78 | logging.info('get detail url %s',detail_url)
79 | scrapy_detail(detail_url)
80 | detail_data=parse_detail()
81 | logging.info('details data %s', detail_data)
82 | save_data(detail_data)
83 | finally:
84 | browser.close()
85 |
86 | if __name__ == '__main__':
87 | main()
88 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 52讲轻松搞定爬虫
2 |
3 | 作者:崔庆才
4 |
5 | 资料来源于:https://kaiwu.lagou.com/course/courseInfo.htm?sid=&courseId=46#/detail/pc?id=1663
6 |
7 | 官网已经全部更新结束。
8 |
9 | 欢迎大家支持正版!
10 |
11 |
12 |
--------------------------------------------------------------------------------
/第01讲:必知必会,掌握 HTTP 基本原理.md:
--------------------------------------------------------------------------------
1 | 本课时我们会详细讲解 HTTP 的基本原理,以及了解在浏览器中输入 URL 到获取网页内容之间发生了什么。了解了这些内容,有助于我们进一步掌握爬虫的基本原理。
2 |
3 | #### URI 和 URL
4 | 首先,我们来了解一下 URI 和 URL,URI 的全称为 Uniform Resource Identifier,即统一资源标志符,URL 的全称为 Universal Resource Locator,即统一资源定位符。
5 |
6 | 举例来说,[https://github.com/favicon.ico](https://github.com/favicon.ico]),它是一个 URL,也是一个 URI。即有这样的一个图标资源,我们用 URL/URI 来唯一指定了它的访问方式,这其中包括了访问协议 HTTPS、访问路径(即根目录)和资源名称 favicon.ico。通过这样一个链接,我们便可以从互联网上找到这个资源,这就是 URL/URI。
7 |
8 |
9 |
10 | URL 是 URI 的子集,也就是说每个 URL 都是 URI,但不是每个 URI 都是 URL。那么,什么样的 URI 不是 URL 呢?URI 还包括一个子类叫作 URN,它的全称为 Universal Resource Name,即统一资源名称。
11 |
12 |
13 |
14 | URN 只命名资源而不指定如何定位资源,比如 urn:isbn:0451450523 指定了一本书的 ISBN,可以唯一标识这本书,但是没有指定到哪里定位这本书,这就是 URN。URL、URN 和 URI 的关系可以用图表示。
15 | 
16 | 但是在目前的互联网,URN 的使用非常少,几乎所有的 URI 都是 URL,所以一般的网页链接我们可以称之为 URL,也可以称之为 URI,我个人习惯称之为 URL。
17 |
18 | #### 超文本
19 |
20 | 接下来,我们再了解一个概念 —— 超文本,其英文名称叫作 Hypertext,我们在浏览器里看到的网页就是超文本解析而成的,其网页源代码是一系列 HTML 代码,里面包含了一系列标签,比如 img 显示图片,p 指定显示段落等。浏览器解析这些标签后,便形成了我们平常看到的网页,而网页的源代码 HTML 就可以称作超文本。
21 |
22 |
23 |
24 | 例如,我们在 Chrome 浏览器里面打开任意一个页面,如淘宝首页,右击任一地方并选择 “检查” 项(或者直接按快捷键 F12),即可打开浏览器的开发者工具,这时在 Elements 选项卡即可看到当前网页的源代码,这些源代码都是超文本,如图所示。
25 | 
26 | #### HTTP 和 HTTPS
27 |
28 | 在淘宝的首页 [https://www.taobao.com/](https://www.taobao.com/) 中,URL 的开头会有 http 或 https,这个就是访问资源需要的协议类型,有时我们还会看到 ftp、sftp、smb 开头的 URL,那么这里的 ftp、sftp、smb 都是指的**协议类型**。在爬虫中,我们抓取的页面通常就是 http 或 https 协议的,我们在这里首先来了解一下这两个协议的含义。
29 |
30 |
31 |
32 | HTTP 的全称是 Hyper Text Transfer Protocol,中文名叫作**超文本传输协议**,HTTP 协议是用于从网络传输超文本数据到本地浏览器的传送协议,它能保证高效而准确地传送超文本文档。HTTP 由万维网协会(World Wide Web Consortium)和 Internet 工作小组 IETF(Internet Engineering Task Force)共同合作制定的规范,目前广泛使用的是 HTTP 1.1 版本。
33 |
34 |
35 |
36 | HTTPS 的全称是 Hyper Text Transfer Protocol over Secure Socket Layer,是以安全为目标的 HTTP 通道,简单讲是 HTTP 的安全版,即 HTTP 下加入 SSL 层,简称为 HTTPS。
37 |
38 |
39 |
40 | HTTPS 的安全基础是 SSL,因此通过它传输的内容都是**经过 SSL 加密**的,它的主要作用可以分为两种:
41 |
42 | * 建立一个信息安全通道,来保证数据传输的安全。
43 |
44 | * 确认网站的真实性,凡是使用了 HTTPS 的网站,都可以通过点击浏览器地址栏的锁头标志来查看网站认证之后的真实信息,也可以通过 CA 机构颁发的安全签章来查询。
45 |
46 | 现在越来越多的网站和 App 都已经向 HTTPS 方向发展。例如:
47 |
48 | * 苹果公司强制所有 iOS App 在 2017 年 1 月 1 日 前全部改为使用 HTTPS 加密,否则 App 就无法在应用商店上架。
49 |
50 | * 谷歌从 2017 年 1 月推出的 Chrome 56 开始,对未进行 HTTPS 加密的网址链接亮出风险提示,即在地址栏的显著位置提醒用户 “此网页不安全”。
51 |
52 | * 腾讯微信小程序的官方需求文档要求后台使用 HTTPS 请求进行网络通信,不满足条件的域名和协议无法请求。
53 |
54 | 因此,HTTPS 已经已经是大势所趋。
55 | #### HTTP 请求过程
56 |
57 | 我们在浏览器中输入一个 URL,回车之后便可以在浏览器中观察到页面内容。实际上,这个过程是**浏览器向网站所在的服务器发送了一个请求**,**网站服务器接收到这个请求后进行处理和解析,然后返回对应的响应,接着传回给浏览器**。响应里包含了页面的源代码等内容,浏览器再对其进行解析,便将网页呈现了出来,传输模型如图所示。
58 | 
59 | 此处客户端即代表我们自己的 PC 或手机浏览器,服务器即要访问的网站所在的服务器。
60 |
61 |
62 |
63 | 为了更直观地说明这个过程,这里用 Chrome 浏览器的开发者模式下的 Network 监听组件来做下演示,它可以显示访问当前请求网页时发生的所有网络请求和响应。
64 |
65 |
66 |
67 | 打开 Chrome 浏览器,右击并选择 “检查” 项,即可打开浏览器的开发者工具。这里访问百度 [http://www.baidu.com/](http://www.baidu.com/),输入该 URL 后回车,观察这个过程中发生了怎样的网络请求。可以看到,在 Network 页面下方出现了一个个的条目,其中一个条目就代表一次发送请求和接收响应的过程,如图所示。
68 | 
69 | 我们先观察第一个网络请求,即 [www.baidu.com](www.baidu.com),其中各列的含义如下。
70 |
71 | * 第一列 Name:请求的名称,一般会将 URL 的最后一部分内容当作名称。
72 |
73 | * 第二列 Status:响应的状态码,这里显示为 **200,代表响应是正常的**。通过状态码,我们可以判断发送了请求之后是否得到了正常的响应。
74 |
75 | * 第三列 Type:请求的文档类型。这里为 document,代表我们这次请求的是一个 HTML 文档,内容就是一些 HTML 代码。
76 |
77 | * 第四列 Initiator:**请求源**。用来标记请求是由哪个对象或进程发起的。
78 |
79 | * 第五列 Size:**从服务器下载的文件和请求的资源大小**。如果是从缓存中取得的资源,则该列会显示 from cache。
80 |
81 | * 第六列 Time:发起请求到获取响应所用的总时间。
82 |
83 | * 第七列 Waterfall:网络请求的可视化瀑布流。
84 |
85 | 我们点击这个条目即可看到其更详细的信息,如图所示。
86 | 
87 | 首先是 General 部分,Request URL 为请求的 URL,Request Method 为请求的方法,Status Code 为响应状态码,Remote Address 为远程服务器的地址和端口,Referrer Policy 为 Referrer 判别策略。
88 |
89 |
90 |
91 | 再继续往下,可以看到,有 Response Headers 和 Request Headers,这分别代表响应头和请求头。请求头里带有许多请求信息,例如浏览器标识、Cookies、Host 等信息,这是请求的一部分,服务器会根据请求头内的信息判断请求是否合法,进而作出对应的响应。图中看到的 Response Headers 就是响应的一部分,例如其中包含了服务器的类型、文档类型、日期等信息,浏览器接受到响应后,会解析响应内容,进而呈现网页内容。
92 |
93 |
94 |
95 | 下面我们分别来介绍一下请求和响应都包含哪些内容。
96 | #### 请求
97 |
98 | 请求,由客户端向服务端发出,可以分为 4 部分内容:**请求方法**(Request Method)、**请求的网址**(Request URL)、**请求头**(Request Headers)、**请求体**(Request Body)。
99 |
100 | ##### 请求方法
101 |
102 | 常见的请求方法有两种:GET 和 POST。
103 |
104 |
105 |
106 | **在浏览器中直接输入 URL 并回车,这便发起了一个 GET 请求**,请求的参数会直接包含到 URL 里。例如,在百度中搜索 Python,这就是一个 GET 请求,链接为 [https://www.baidu.com/s?wd=Python](https://www.baidu.com/s?wd=Python),其中 URL 中包含了请求的参数信息,这里参数 wd 表示要搜寻的关键字。**POST 请求大多在表单提交时发起**。比如,对于一个登录表单,输入用户名和密码后,点击 “登录” 按钮,这通常会发起一个 POST 请求,其数据通常以表单的形式传输,而不会体现在 URL 中。
107 |
108 |
109 |
110 | ##### GET 和 POST 请求方法有如下区别。
111 |
112 | * GET 请求中的参数包含在 URL 里面,数据可以在 URL 中看到,而 POST 请求的 URL 不会包含这些数据,数据都是通过表单形式传输的,会包含在请求体中。
113 |
114 | * GET 请求提交的数据最多只有 1024 字节,而 POST 请求没有限制。
115 |
116 | 一般来说,登录时,需要提交用户名和密码,其中包含了敏感信息,**使用 GET 方式请求的话,密码就会暴露在 URL 里面,造成密码泄露**,所以这里最好以 POST 方式发送。上传文件时,由于文件内容比较大,也会选用 POST 方式。
117 |
118 |
119 |
120 | 我们平常遇到的绝大部分请求都是 GET 或 POST 请求,另外还有一些请求方法,如 HEAD、PUT、DELETE、OPTIONS、CONNECT、TRACE 等,我们简单将其总结为下表。
121 | 
122 | 请求的网址本表参考:[http://www.runoob.com/http/http-methods.html](http://www.runoob.com/http/http-methods.html)
123 |
124 |
125 |
126 | 请求的网址,即统一资源定位符 URL,它可以唯一确定我们想请求的资源。
127 | ##### 请求头
128 |
129 | **请求头,用来说明服务器要使用的附加信息,比较重要的信息有 Cookie、Referer、User-Agent 等**。下面简要说明一些常用的头信息。
130 |
131 | * Accept:请求报头域,用于指定客户端可接受哪些类型的信息。
132 |
133 | * Accept-Language:指定客户端可接受的语言类型。
134 |
135 | * Accept-Encoding:指定客户端可接受的内容编码。
136 |
137 | * Host:用于指定请求资源的主机 IP 和端口号,其内容为请求 URL 的原始服务器或网关的位置。从 HTTP 1.1 版本开始,请求必须包含此内容。
138 |
139 | * Cookie:也常用复数形式 Cookies,这是**网站为了辨别用户进行会话跟踪而存储在用户本地的数据。它的主要功能是维持当前访问会话**。例如,我们输入用户名和密码成功登录某个网站后,服务器会用会话保存登录状态信息,后面我们每次刷新或请求该站点的其他页面时,会发现都是登录状态,这就是 Cookies 的功劳。Cookies 里有信息标识了我们所对应的服务器的会话,每次浏览器在请求该站点的页面时,都会在请求头中加上 Cookies 并将其发送给服务器,服务器通过 Cookies 识别出是我们自己,并且查出当前状态是登录状态,所以返回结果就是登录之后才能看到的网页内容。
140 |
141 | * Referer:此内容用来标识这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应的处理,如做来源统计、防盗链处理等。
142 |
143 | * User-Agent:简称 UA,它是一个特殊的字符串头,**可以使服务器识别客户使用的操作系统及版本、浏览器及版本等信息**。在做爬虫时加上此信息,可以伪装为浏览器;如果不加,很可能会被识别出为爬虫。
144 |
145 | * Content-Type:也叫互联网媒体类型(Internet Media Type)或者 MIME 类型,在 HTTP 协议消息头中,它用来表示具体请求中的媒体类型信息。例如,text/html 代表 HTML 格式,image/gif 代表 GIF 图片,application/json 代表 JSON 类型,更多对应关系可以查看此对照表:[http://tool.oschina.net/commons](http://tool.oschina.net/commons)。
146 |
147 | 因此,请求头是请求的重要组成部分,在写爬虫时,大部分情况下都需要设定请求头。
148 | ##### 请求体
149 |
150 | 请求体一般承载的内容是 POST 请求中的表单数据,而对于 GET 请求,请求体则为空。
151 |
152 | 例如,这里我登录 GitHub 时捕获到的请求和响应如图所示。
153 | 
154 | 登录之前,我们填写了用户名和密码信息,提交时这些内容就会以表单数据的形式提交给服务器,此时需要注意 Request Headers 中指定 Content-Type 为 *application/x-www-form-urlencoded*。只有设置 Content-Type 为 *application/x-www-form-urlencoded*,才会以表单数据的形式提交。另外,我们也可以将 Content-Type 设置为 *application/json* 来提交 JSON 数据,或者设置为 *multipart/form-data* 来上传文件。
155 |
156 |
157 | 表格中列出了 Content-Type 和 POST 提交数据方式的关系。
158 | 
159 | #### 响应
160 |
161 | 响应,由服务端返回给客户端,可以分为三部分:**响应状态码**(Response Status Code)、**响应头**(Response Headers)和**响应体**(Response Body)。
162 | ##### 响应状态码
163 |
164 | 响应状态码表示服务器的响应状态,如 **200 代表服务器正常响应,404 代表页面未找到,500 代表服务器内部发生错误**。在爬虫中,我们可以根据状态码来判断服务器响应状态,如状态码为 200,则证明成功返回数据,再进行进一步的处理,否则直接忽略。下表列出了常见的错误代码及错误原因。
165 | 
166 | **响应头包含了服务器对请求的应答信息,如 Content-Type、Server、Set-Cookie 等。下面简要说明一些常用的头信息。响应头**
167 |
168 | * Date:标识响应产生的时间。
169 |
170 | * Last-Modified:指定资源的最后修改时间。
171 |
172 | * Content-Encoding:指定响应内容的编码。
173 |
174 | * Server:包含服务器的信息,比如名称、版本号等。
175 |
176 | * Content-Type:文档类型,指定返回的数据类型是什么,如 text/html 代表返回 HTML 文档,application/x-javascript 则代表返回 JavaScript 文件,image/jpeg 则代表返回图片。
177 |
178 | * Set-Cookie:设置 Cookies。响应头中的 Set-Cookie 告诉浏览器需要将此内容放在 Cookies 中,下次请求携带 Cookies 请求。
179 |
180 | * Expires:指定响应的过期时间,可以使代理服务器或浏览器将加载的内容更新到缓存中。如果再次访问时,就可以直接从缓存中加载,降低服务器负载,缩短加载时间。
181 | ##### 响应体
182 |
183 | 最重要的当属响应体的内容了。响应的正文数据都在响应体中,比如请求网页时,它的响应体就是网页的 HTML 代码;请求一张图片时,它的响应体就是图片的二进制数据。我们做爬虫请求网页后,要解析的内容就是响应体,如图所示。
184 | 
185 | 在浏览器开发者工具中点击 **Preview**,就可以看到网页的源代码,也就是响应体的内容,它**是解析的目标**。
186 |
187 |
188 | 在做爬虫时,我们主要通过响应体得到网页的源代码、JSON 数据等,然后从中做相应内容的提取。
189 |
190 | 好了,今天的内容就全部讲完了,本课时中,我们了解了 HTTP 的基本原理,大概了解了访问网页时背后的请求和响应过程。本课时涉及的知识点需要好好掌握,后面分析网页请求时会经常用到。
191 |
--------------------------------------------------------------------------------
/第02讲:夯实根基,Web 网页基础.md:
--------------------------------------------------------------------------------
1 | 当我们用浏览器访问网站时,页面各不相同,那么你有没有想过它为何会呈现成这个样子呢?本课时,我们就来讲解网页的基本组成、结构和节点等内容。
2 | #### 网页的组成
3 |
4 | 首先,我们来了解网页的基本组成,网页可以分为三大部分:HTML、CSS 和 JavaScript。
5 |
6 |
7 |
8 | 如果把网页比作一个人的话,**HTML 相当于骨架,JavaScript 相当于肌肉,CSS 相当于皮肤**,三者结合起来才能形成一个完整的网页。下面我们来分别介绍一下这三部分的功能。
9 | #### HTML
10 |
11 | HTML 是用来描述网页的一种语言,其全称叫作 Hyper Text Markup Language,即超文本标记语言。
12 |
13 |
14 | 我们浏览的网页包括文字、按钮、图片和视频等各种复杂的元素,其基础架构就是 HTML。**不同类型的元素通过不同类型的标签来表示**,如图片用 img 标签表示,视频用 video 标签表示,段落用 p 标签表示,它们之间的布局又常通过布局标签 **div 嵌套组合**而成,各种标签通过不同的排列和嵌套就可以形成网页的框架。
15 |
16 |
17 |
18 | 我们在 Chrome 浏览器中打开百度,右击并选择 “检查” 项(或按 F12 键),打开开发者模式,这时在 Elements 选项卡中即可看到网页的源代码,如图所示。
19 | 
20 | 这就是 HTML,整个网页就是由各种标签嵌套组合而成的。这些标签定义的节点元素相互嵌套和组合形成了复杂的层次关系,就形成了网页的架构。
21 | #### CSS
22 |
23 | 虽然 **HTML 定义了网页的结构**,但是只有 HTML 页面的布局并不美观,可能只是简单的节点元素的排列,为了让网页看起来更好看一些,这里就需要借助 CSS 了。
24 |
25 |
26 |
27 | CSS,全称叫作 Cascading Style Sheets,即**层叠样式表**。“层叠” 是指当在 HTML 中引用了数个样式文件,并且样式发生冲突时,浏览器能依据层叠顺序处理。**“样式” 指网页中文字大小、颜色、元素间距、排列等格式**。
28 |
29 |
30 |
31 | CSS 是目前唯一的网页页面排版样式标准,有了它的帮助,页面才会变得更为美观。
32 |
33 |
34 |
35 | 图的右侧即为 CSS,例如:
36 |
37 | ```css
38 | #head_wrapper.s-ps-islite .s-p-top {
39 |
40 | position: absolute;
41 |
42 | bottom: 40px;
43 |
44 | width: 100%;
45 |
46 | height: 181px;
47 | ```
48 | 这就是一个 CSS 样式。大括号前面是一个 CSS 选择器。此选择器的作用是首先选中 id 为 head_wrapper 且 class 为 s-ps-islite 的节点,然后再选中其内部的 class 为 s-p-top 的节点。
49 |
50 |
51 |
52 | 大括号内部写的就是一条条样式规则,例如 position 指定了这个元素的布局方式为绝对布局,bottom 指定元素的下边距为 40 像素,width 指定了宽度为 100% 占满父元素,height 则指定了元素的高度。
53 |
54 |
55 |
56 | 也就是说,我们将位置、宽度、高度等样式配置统一写成这样的形式,然后用大括号括起来,接着在开头再加上 CSS 选择器,这就代表这个样式对 CSS 选择器选中的元素生效,元素就会根据此样式来展示了。
57 |
58 |
59 |
60 | 在网页中,一般会统一定义整个网页的样式规则,并写入 CSS 文件中(其后缀为 css)。在 HTML 中,只需要用 link 标签即可引入写好的 CSS 文件,这样整个页面就会变得美观、优雅。
61 | #### JavaScript
62 |
63 | JavaScript,简称 JS,是一种**脚本语言**。HTML 和 CSS 配合使用,提供给用户的只是一种静态信息,缺乏交互性。我们在网页里可能会看到一些**交互和动画效果**,如下载进度条、提示框、轮播图等,这通常就是 JavaScript 的功劳。**它的出现使得用户与信息之间不只是一种浏览与显示的关系,而是实现了一种实时、动态、交互的页面功能**。
64 |
65 |
66 |
67 | JavaScript 通常也是以单独的文件形式加载的,后缀为 js,在 HTML 中通过 script 标签即可引入,例如:
68 |
69 | ```javascript
70 | <script src="jquery2.1.0.js"></script>
71 | ```
72 | 综上所述,HTML 定义了网页的内容和结构,CSS 描述了网页的布局,JavaScript 定义了网页的行为。
73 |
74 | #### 网页的结构
75 |
76 | 了解了网页的基本组成,我们再用一个例子来感受下 HTML 的基本结构。新建一个文本文件,名称可以自取,后缀为 html,内容如下:
77 |
78 | ```css
79 | <!DOCTYPE html>
80 | <html>
81 | <head>
82 | <meta charset="UTF-8">
83 | <title>This is a Demo</title>
84 | </head>
85 | <body>
86 | <div id="container">
87 | <div class="wrapper">
88 | <h2 class="title">Hello World</h2>
89 | <p class="text">Hello, this is a paragraph.</p>
90 | </div>
91 | </div>
92 | </body>
93 | </html>
94 | ```
95 | 这就是一个最简单的 HTML 实例。开头用 DOCTYPE 定义了文档类型,其次最外层是 html 标签,最后还有对应的结束标签来表示闭合,其内部是 head 标签和 body 标签,分别代表网页头和网页体,它们也需要结束标签。
96 |
97 |
98 |
99 | head 标签内定义了一些页面的配置和引用,如:,它指定了网页的编码为 UTF-8。title 标签则定义了网页的标题,会显示在网页的选项卡中,不会显示在正文中。body 标签内则是在网页正文中显示的内容。
100 |
101 |
102 |
103 | div 标签定义了网页中的区块,它的 id 是 container,这是一个非常常用的属性,且 id 的内容在网页中是唯一的,我们可以通过它来获取这个区块。然后在此区块内又有一个 div 标签,它的 class 为 wrapper,这也是一个非常常用的属性,经常与 CSS 配合使用来设定样式。
104 |
105 |
106 |
107 | 然后此区块内部又有一个 h2 标签,这代表一个二级标题。另外,还有一个 p 标签,这代表一个段落。在这两者中直接写入相应的内容即可在网页中呈现出来,它们也有各自的 class 属性。
108 |
109 |
110 |
111 | 将代码保存后,在浏览器中打开该文件,可以看到如图所示的内容。
112 | 
113 | 可以看到,在选项卡上显示了 This is a Demo 字样,这是我们在 head 中的 title 里定义的文字。而网页正文是 body 标签内部定义的各个元素生成的,可以看到这里显示了二级标题和段落。
114 |
115 |
116 |
117 | 这个实例便是网页的一般结构。一个网页的标准形式是 html 标签内嵌套 head 和 body 标签,head 内定义网页的配置和引用,body 内定义网页的正文。
118 | #### 节点树及节点间的关系
119 | 在 HTML 中,所有标签定义的内容都是节点,它们构成了一个 HTML DOM 树。
120 |
121 |
122 |
123 | 我们先看下什么是 DOM。DOM 是 W3C(万维网联盟)的标准,其英文全称 Document Object Model,即文档对象模型。它定义了访问 HTML 和 XML 文档的标准:
124 |
125 | W3C 文档对象模型(DOM)是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。
126 |
127 | W3C DOM 标准被分为 3 个不同的部分:
128 |
129 | * 核心 DOM - 针对任何结构化文档的标准模型
130 |
131 | * XML DOM - 针对 XML 文档的标准模型
132 |
133 | * HTML DOM - 针对 HTML 文档的标准模型
134 |
135 | 根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:
136 |
137 | * 整个文档是一个文档节点
138 |
139 | * 每个 HTML 元素是元素节点
140 |
141 | * HTML 元素内的文本是文本节点
142 |
143 | * 每个 HTML 属性是属性节点
144 |
145 | * 注释是注释节点
146 |
147 | HTML DOM 将 HTML 文档视作树结构,这种结构被称为节点树,如图所示。
148 | 
149 | 通过 HTML DOM,树中的所有节点均可通过 JavaScript 访问,所有 HTML 节点元素均可被修改,也可以被创建或删除。
150 |
151 |
152 |
153 | 节点树中的节点彼此拥有层级关系。我们常用父(parent)、子(child)和兄弟(sibling)等术语描述这些关系。父节点拥有子节点,同级的子节点被称为兄弟节点。
154 |
155 |
156 |
157 | 在节点树中,顶端节点称为根(root)。除了根节点之外,每个节点都有父节点,同时可拥有任意数量的子节点或兄弟节点。图中展示了节点树以及节点之间的关系。
158 | 
159 | 本段参考 W3SCHOOL,链接:[http://www.w3school.com.cn/htmldom/dom_nodes.asp](http://www.w3school.com.cn/htmldom/dom_nodes.asp)
160 | #### 选择器
161 |
162 | 我们知道网页由一个个节点组成,CSS 选择器会根据不同的节点设置不同的样式规则,那么怎样来定位节点呢?
163 |
164 |
165 |
166 | 在 CSS 中,我们使用 CSS 选择器来定位节点。例如,上例中 div 节点的 id 为 container,那么就可以表示为 #container,其中 **# 开头代表选择 id**,其后紧跟 id 的名称。
167 |
168 |
169 |
170 | 另外,如果我们想选择 class 为 wrapper 的节点,便可以使用 .wrapper,这里**以点“.”开头代表选择 class**,其后紧跟 class 的名称。另外,还有一种选择方式,那就是根据标签名筛选,例如想选择二级标题,直接用 h2 即可。这是最常用的 3 种表示,分别是根据 id、class、标签名筛选,请牢记它们的写法。
171 |
172 |
173 |
174 | 另外,CSS 选择器还支持嵌套选择,各个选择器之间加上空格分隔开便可以代表嵌套关系,如 **#container .wrapper p 则代表先选择 id 为 container 的节点,然后选中其内部的 class 为 wrapper 的节点,然后再进一步选中其内部的 p 节点**。
175 |
176 |
177 |
178 | 另外,如果不加空格,则代表并列关系,如 div#container .wrapper p.text 代表先选择 id 为 container 的 div 节点,然后选中其内部的 class 为 wrapper 的节点,再进一步选中其内部的 class 为 text 的 p 节点。这就是 CSS 选择器,其筛选功能还是非常强大的。
179 |
180 |
181 |
182 | 另外,CSS 选择器还有一些其他语法规则,具体如表所示。因为表中的内容非常的多,我就不在一一介绍,课下你可以参考文字内容详细理解掌握这部分知识。
183 | 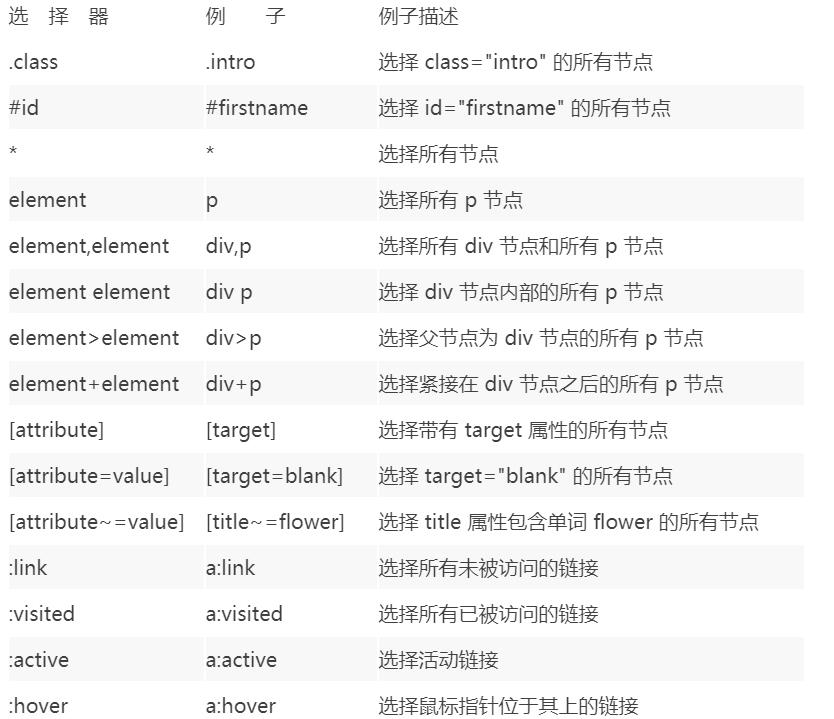
184 | 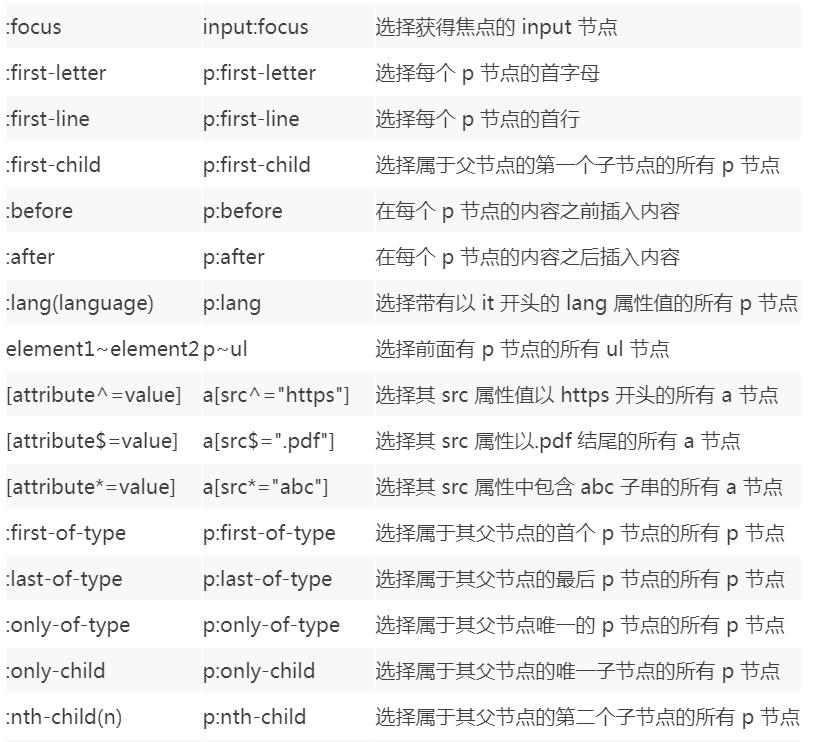
185 | 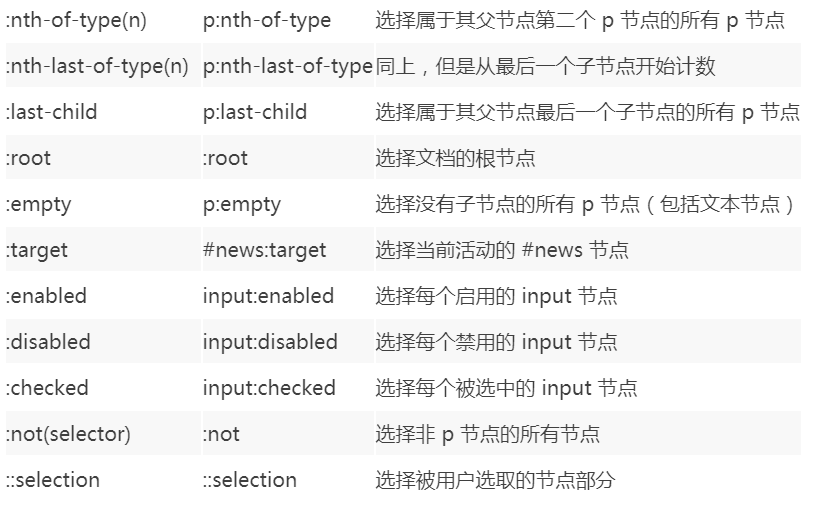
186 | 另外,还有一种比较常用的选择器是 **XPath**,这种选择方式后面会详细介绍。
187 |
188 |
189 |
190 | 本课时的内容就全部讲完了,在本课时中我们介绍了网页的基本结构和节点间的关系,了解了这些内容后,我们才有更加清晰的思路去解析和提取网页内容。
191 |
--------------------------------------------------------------------------------
/第03讲:原理探究,了解爬虫的基本原理.md:
--------------------------------------------------------------------------------
1 | 我们可以把互联网比作一张大网,而爬虫(即网络爬虫)便是在网上爬行的蜘蛛。如果把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,获取了其信息。可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛通过一个节点后,可以顺着节点连线继续爬行到达下一个节点,即通过一个网页继续获取后续的网页,这样整个网的节点便可以被蜘蛛全部爬行到,网站的数据就可以被抓取下来了。
2 | #### 爬虫概述
3 |
4 | 简单来说,爬虫就是获取网页并提取和保存信息的自动化程序,下面概要介绍一下。
5 |
6 |
7 | #### 获取网页
8 | 爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。
9 |
10 | 源代码里包含了网页的部分有用信息,所以只要把源代码获取下来,就可以从中提取想要的信息了。
11 |
12 | 前面讲了请求和响应的概念,向网站的服务器发送一个请求,返回的响应体便是网页源代码。所以,最关键的部分就是构造一个请求并发送给服务器,然后接收到响应并将其解析出来,那么这个流程怎样实现呢?总不能手工去截取网页源码吧?
13 |
14 | 不用担心,Python提供了许多库来帮助我们实现这个操作,如urllib、requests等。我们可以用这些库来帮助我们实现HTTP请求操作,请求和响应都可以用类库提供的数据结构来表示,得到响应之后只需要解析数据结构中的 Body 部分即可,即得到网页的源代码,这样我们可以用程序来实现获取网页的过程了。
15 |
16 |
17 | #### 提取信息
18 | 获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。首先,最通用的方法便是采用**正则表达式**提取,这是一个万能的方法,但是在构造正则表达式时比较复杂且容易出错。
19 |
20 | 另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS选择器或XPath来提取网页信息的库,如BeautifulSoup、pyquery、lxml等。使用这些库,我们可以高效快速地从中提取网页信息,如节点的属性、文本值等。
21 |
22 | 提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理清晰,以便我们后续处理和分析数据。
23 |
24 | #### 保存数据
25 | 提取信息后,我们一般会将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保存为**TXT文本或JSON文本**,也可以保存到**数据库**,如MySQL和MongoDB,还可保存至远程服务器,如借助 SFTP 进行操作等。
26 | #### 自动化程序
27 | 说到自动化程序,意思是说爬虫可以代替人来完成这些操作。首先,我们手工当然可以提取这些信息,但是当量特别大或者想快速获取大量数据的话,肯定还是要借助程序。爬虫就是代替我们来完成这份爬取工作的自动化程序,它可以在抓取过程中进行各种异常处理、错误重试等操作,确保爬取持续高效地运行。
28 | #### 能抓怎样的数据
29 | 在网页中我们能看到各种各样的信息,最常见的便是常规网页,它们对应着HTML代码,而最常抓取的便是HTML源代码。
30 |
31 | 另外,可能有些网页返回的不是 HTML 代码,而是一个 **JSON 字符串**(其中 API 接口大多采用这样的形式),这种格式的数据方便传输和解析,它们同样可以抓取,而且数据提取更加方便。
32 |
33 | 此外,我们还可以看到各种二进制数据,如图片、视频和音频等。利用爬虫,我们可以将这些**二进制数据抓取**下来,然后保存成对应的文件名。
34 |
35 | 另外,还可以看到各种扩展名的文件,如 CSS、JavaScript 和配置文件等,这些其实也是最普通的文件,只要在浏览器里面可以访问到,就可以将其抓取下来。
36 |
37 | 上述内容其实都对应各自的 URL,是基于 HTTP 或 HTTPS 协议的,只要是这种数据,爬虫都可以抓取。
38 |
39 | #### JavaScript 渲染页面
40 | 有时候,我们在用urllib或requests抓取网页时,得到的源代码实际和浏览器中看到的**不一样**。
41 |
42 | 这是一个非常常见的问题。现在网页越来越多地采用Ajax、前端模块化工具来构建,整个网页可能都是由 JavaScript 渲染出来的,也就是说原始的 HTML 代码就是一个空壳,例如:
43 | 
44 | **body 节点里面只有一个 id 为 container 的节点,但是需要注意在 body 节点后引入了 app.js,它便负责整个网站的渲染。**
45 |
46 | 在浏览器中打开这个页面时,首先会加载这个HTML内容,接着浏览器会发现其中引入了一个app.js文件,然后便会接着去请求这个文件,获取到该文件后,便会执行其中的JavaScript代码,而 JavaScript 则会改变 HTML 中的节点,向其添加内容,最后得到完整的页面。
47 |
48 | 但是在用 urllib 或 requests 等库请求当前页面时,我们得到的只是这个 HTML 代码,它不会帮助我们去继续加载这个 JavaScript 文件,这样也就看不到浏览器中的内容了。
49 |
50 | 这也解释了为什么有时我们得到的源代码和浏览器中看到的不一样。
51 |
52 | 因此,使用基本HTTP请求库得到的源代码可能跟浏览器中的页面源代码不太一样。对于这样的情况,我们可以分析其后台Ajax接口,也可使用Selenium、Splash这样的库来实现模拟 JavaScript 渲染。
53 |
54 | 后面,我们会详细介绍如何采集 JavaScript 渲染的网页。本节介绍了爬虫的一些基本原理,这可以帮助我们在后面编写爬虫时更加得心应手。
55 |
56 |
57 |
58 |
59 |
--------------------------------------------------------------------------------
/第04讲:基础探究,Session 与 Cookies.md:
--------------------------------------------------------------------------------
1 | 我们在浏览网站的过程中,经常会遇到需要登录的情况,而有些网页只有登录之后才可以访问,而且登录之后可以连续访问很多次网站,但是有时候过一段时间就需要重新登录。
2 |
3 | 还有一些网站,在打开浏览器时就自动登录了,而且很长时间都不会失效,这种情况又是为什么?其实这里面涉及 **Session** 和 **Cookies** 的相关知识,本节就来揭开它们的神秘面纱。
4 |
5 | #### 静态网页和动态网页
6 |
7 | 在开始介绍它们之前,我们需要先了解一下静态网页和动态网页的概念。这里还是前面的示例代码,内容如下:
8 | 
9 |
10 | 这是最基本的HTML代码,我们将其保存为一个.html文件,然后把它放在某台具有固定公网IP的主机上,主机上装上Apache或Nginx等服务器,这样这台主机就可以作为服务器了,其他人便可以通过访问服务器看到这个页面,这就搭建了一个最简单的网站。
11 |
12 | 这种网页的内容是HTML代码编写的,文字、图片等内容均通过写好的HTML代码来指定,这种页面叫作**静态网页**。它加载速度快,编写简单,但是存在很大的缺陷,如**可维护性差**,不能根据URL灵活多变地显示内容等。例如,我们想要给这个网页的 URL 传入一个 name 参数,让其在网页中显示出来,是无法做到的。
13 |
14 | 因此,动态网页应运而生,它可以**动态解析URL中参数的变化**,关联数据库并动态呈现不同的页面内容,非常灵活多变。我们现在遇到的大多数网站都是动态网站,它们不再是一个简单的 HTML,而是可能由 JSP、PHP、Python 等语言编写的,其功能比静态网页强大和丰富太多了。
15 |
16 | 此外,动态网站还可以实现用户登录和注册的功能。再回到开头来看提到的问题,很多页面是需要登录之后才可以查看的。按照一般的逻辑来说,输入用户名和密码登录之后,肯定是拿到了一种类似凭证的东西,有了它,我们才能保持登录状态,才能访问登录之后才能看到的页面。
17 |
18 | 那么,这种神秘的凭证到底是什么呢?其实它就是 Session 和 Cookies 共同产生的结果,下面我们来一探究竟。
19 |
20 | #### 无状态 HTTP
21 |
22 | 在了解 Session 和 Cookies 之前,我们还需要了解 HTTP 的一个特点,叫作无状态。
23 |
24 | HTTP 的无状态是指 HTTP 协议对事务处理是没有记忆能力的,也就是说服务器不知道客户端是什么状态。
25 |
26 | 当我们向服务器发送请求后,服务器解析此请求,然后返回对应的响应,服务器负责完成这个过程,而且这个过程是完全独立的,服务器不会记录前后状态的变化,也就是缺少状态记录。
27 |
28 | 这意味着如果后续需要处理前面的信息,则必须重传,这也导致需要额外传递一些前面的重复请求,才能获取后续响应,然而这种效果显然不是我们想要的。为了保持前后状态,我们肯定不能将前面的请求全部重传一次,这太浪费资源了,对于这种需要用户登录的页面来说,更是棘手。
29 |
30 | 这时两个用于保持 HTTP 连接状态的技术就出现了,它们分别是 **Session** 和 **Cookies**。**Session 在服务端,也就是网站的服务器,用来保存用户的 Session 信息**;**Cookies 在客户端,也可以理解为浏览器端,有了 Cookies,浏览器在下次访问网页时会自动附带上它发送给服务器,服务器通过识别 Cookies 并鉴定出是哪个用户,然后再判断用户是否是登录状态,进而返回对应的响应。**
31 |
32 | 我们可以理解为 Cookies 里面保存了登录的凭证,有了它,只需要在下次请求携带 Cookies 发送请求而不必重新输入用户名、密码等信息重新登录了。
33 |
34 | 因此在爬虫中,有时候处理需要登录才能访问的页面时,我们一般会直接将登录成功后获取的 Cookies 放在请求头里面直接请求,而不必重新模拟登录。
35 |
36 | 好了,了解 Session 和 Cookies 的概念之后,我们在来详细剖析它们的原理。
37 |
38 | #### Session
39 | Session,中文称之为会话,其本身的含义是指**有始有终的一系列动作 / 消息**。比如,打电话时,从拿起电话拨号到挂断电话这中间的一系列过程可以称为一个 Session。
40 |
41 | 而在 Web 中,Session 对象用来存储特定用户 Session 所需的属性及配置信息。这样,当用户在应用程序的 Web 页之间跳转时,存储在 Session 对象中的变量将不会丢失,而是在整个用户 Session 中一直存在下去。当用户请求来自应用程序的 Web 页时,如果该用户还没有 Session,则 Web 服务器将自动创建一个 Session 对象。当 Session 过期或被放弃后,服务器将终止该 Session。
42 |
43 | #### Cookies
44 | Cookies 指某些网站为了辨别用户身份、进行 Session 跟踪而存储在用户本地终端上的数据。
45 | #### Session 维持
46 | 那么,我们怎样利用 Cookies 保持状态呢?当客户端第一次请求服务器时,服务器会返回一个响应头中带有 Set-Cookie 字段的响应给客户端,用来标记是哪一个用户,客户端浏览器会把 Cookies 保存起来。当浏览器下一次再请求该网站时,浏览器会把此 Cookies 放到请求头一起提交给服务器,Cookies 携带了 Session ID 信息,服务器检查该 Cookies 即可找到对应的 Session 是什么,然后再判断 Session 来以此来辨认用户状态。
47 |
48 | 在成功登录某个网站时,服务器会告诉客户端设置哪些 Cookies 信息,在后续访问页面时客户端会把 Cookies 发送给服务器,服务器再找到对应的 Session 加以判断。如果 Session 中的某些设置登录状态的变量是有效的,那就证明用户处于登录状态,此时返回登录之后才可以查看的网页内容,浏览器再进行解析便可以看到了。
49 |
50 | 反之,如果传给服务器的 Cookies 是无效的,或者 Session 已经过期了,我们将不能继续访问页面,此时可能会收到错误的响应或者跳转到登录页面重新登录。
51 |
52 | 所以,**Cookies 和 Session 需要配合,一个处于客户端,一个处于服务端,二者共同协作**,就实现了登录 Session 控制。
53 |
54 | #### 属性结构
55 |
56 | 接下来,我们来看看 Cookies 都有哪些内容。这里以知乎为例,在浏览器开发者工具中打开 Application 选项卡,然后在左侧会有一个 Storage 部分,最后一项即为 Cookies,将其点开,如图所示,这些就是 Cookies。
57 | 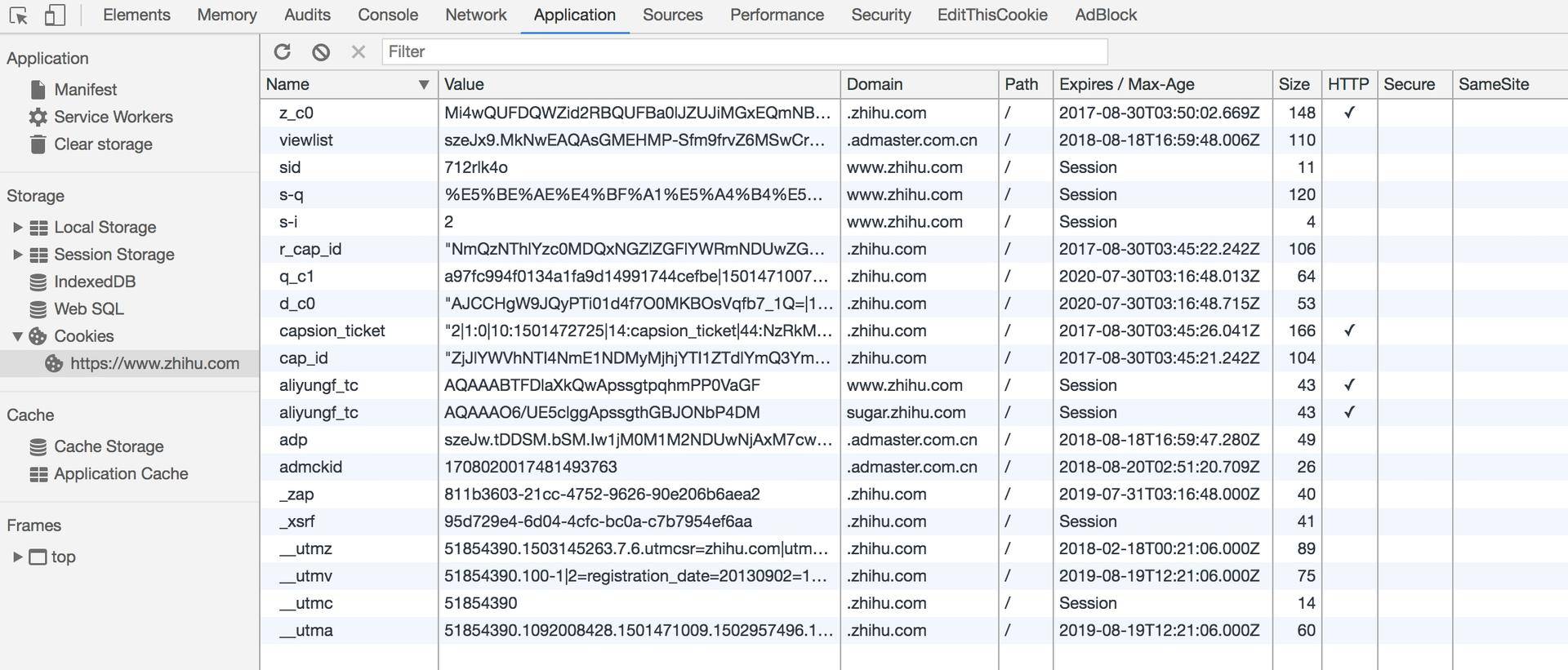
58 | 可以看到,这里有很多条目,其中每个条目可以称为 Cookie。它有如下几个属性。
59 |
60 | * Name,即该 Cookie 的名称。Cookie 一旦创建,名称便不可更改。
61 | * Value,即该 Cookie 的值。如果值为 Unicode 字符,需要为字符编码。如果值为二进制数据,则需要使用 BASE64 编码。
62 | * Max Age,即该 Cookie 失效的时间,单位秒,也常和 Expires 一起使用,通过它可以计算出其有效时间。Max Age 如果为正数,则该 Cookie 在 Max Age 秒之后失效。如果为负数,则关闭浏览器时 Cookie 即失效,浏览器也不会以任何形式保存该 Cookie。
63 | * Path,即该 Cookie 的使用路径。如果设置为 /path/,则只有路径为 /path/ 的页面可以访问该 Cookie。如果设置为 /,则本域名下的所有页面都可以访问该 Cookie。
64 | * Domain,即可以访问该 Cookie 的域名。例如如果设置为 .zhihu.com,则所有以 zhihu.com,结尾的域名都可以访问该 Cookie。
65 | * Size 字段,即此 Cookie 的大小。
66 | * Http 字段,即 Cookie 的 httponly 属性。若此属性为 true,则只有在 HTTP Headers 中会带有此 Cookie 的信息,而不能通过 document.cookie 来访问此 Cookie。
67 | * Secure,即该 Cookie 是否仅被使用安全协议传输。安全协议。安全协议有 HTTPS、SSL 等,在网络上传输数据之前先将数据加密。默认为 false。
68 | #### 会话 Cookie 和持久 Cookie
69 |
70 | 从表面意思来说,会话 Cookie 就是把 Cookie 放在浏览器内存里,浏览器在关闭之后该 Cookie 即失效;**持久 Cookie 则会保存到客户端的硬盘中**,下次还可以继续使用,用于长久保持用户登录状态。
71 |
72 | 其实严格来说,没有会话 Cookie 和持久 Cookie 之 分,只是由 Cookie 的 Max Age 或 Expires 字段决定了过期的时间。
73 |
74 | 因此,**一些持久化登录的网站其实就是把 Cookie 的有效时间和 Session 有效期设置得比较长**,下次我们再访问页面时仍然携带之前的 Cookie,就可以直接保持登录状态。
75 |
76 | #### 常见误区
77 | 在谈论 Session 机制的时候,常常听到这样一种误解 ——“只要关闭浏览器,Session 就消失了”。可以想象一下会员卡的例子,除非顾客主动对店家提出销卡,否则店家绝对不会轻易删除顾客的资料。对 Session 来说,也是一样,除非程序通知服务器删除一个 Session,否则服务器会一直保留。比如,**程序一般都是在我们做注销操作时才去删除 Session**。
78 |
79 | 但是当我们关闭浏览器时,浏览器不会主动在关闭之前通知服务器它将要关闭,所以服务器根本不会有机会知道浏览器已经关闭。之所以会有这种错觉,是因为大部分网站都使用会话 Cookie 来保存 Session ID 信息,而关闭浏览器后 Cookies 就消失了,再次连接服务器时,也就无法找到原来的 Session 了。如果服务器设置的 Cookies 保存到硬盘上,或者使用某种手段改写浏览器发出的 HTTP 请求头,把原来的 Cookies 发送给服务器,则再次打开浏览器,仍然能够找到原来的 Session ID,依旧还是可以保持登录状态的。
80 |
81 | 而且恰恰是由于关闭浏览器不会导致 Session 被删除,这就需要服务器为 Session 设置一个失效时间,当距离客户端上一次使用 Session 的时间超过这个失效时间时,服务器就可以认为客户端已经停止了活动,才会把 Session 删除以节省存储空间。
82 |
83 |
84 |
85 |
86 |
--------------------------------------------------------------------------------
/第05讲:多路加速,了解多线程基本原理.md:
--------------------------------------------------------------------------------
1 | 我们知道,在一台计算机中,我们可以同时打开许多软件,比如同时浏览网页、听音乐、打字等等,看似非常正常。但仔细想想,为什么计算机可以做到这么多软件同时运行呢?这就涉及到计算机中的两个重要概念:**多进程和多线程了**。
2 |
3 | 同样,在编写爬虫程序的时候,为了提高爬取效率,我们可能想同时运行多个爬虫任务。这里同样需要涉及多进程和多线程的知识。
4 |
5 | 本课时,我们就先来了解一下多线程的基本原理,以及在 Python 中如何实现多线程。
6 |
7 | #### 多线程的含义
8 |
9 | 说起多线程,就不得不先说什么是线程。然而想要弄明白什么是线程,又不得不先说什么是进程。
10 |
11 | 进程我们可以理解为是一个可以独立运行的程序单位,比如打开一个浏览器,这就开启了一个浏览器进程;打开一个文本编辑器,这就开启了一个文本编辑器进程。但一个进程中是可以同时处理很多事情的,比如在浏览器中,我们可以在多个选项卡中打开多个页面,有的页面在播放音乐,有的页面在播放视频,有的网页在播放动画,它们可以同时运行,互不干扰。为什么能同时做到同时运行这么多的任务呢?这里就需要引出线程的概念了,其实这一个个任务,实际上就对应着一个个线程的执行。
12 |
13 | 而进程呢?它就是线程的集合,进程就是由一个或多个线程构成的,**线程是操作系统进行运算调度的最小单位,是进程中的一个最小运行单元**。比如上面所说的浏览器进程,其中的播放音乐就是一个线程,播放视频也是一个线程,当然其中还有很多其他的线程在同时运行,这些线程的并发或并行执行最后使得整个浏览器可以同时运行这么多的任务。
14 |
15 | 了解了线程的概念,多线程就很容易理解了,多线程就是一个进程中同时执行多个线程,前面所说的浏览器的情景就是典型的多线程执行。
16 |
17 | #### 并发和并行
18 | 说到多进程和多线程,这里就需要再讲解两个概念,那就是并发和并行。我们知道,一个程序在计算机中运行,其底层是处理器通过运行一条条的指令来实现的。
19 |
20 | 并发,英文叫作 concurrency。它是指同一时刻只能有一条指令执行,但是多个线程的对应的指令被快速轮换地执行。比如一个处理器,它先执行线程 A 的指令一段时间,再执行线程 B 的指令一段时间,再切回到线程 A 执行一段时间。
21 |
22 | 由于处理器执行指令的速度和切换的速度非常非常快,人完全感知不到计算机在这个过程中有多个线程切换上下文执行的操作,这就使得宏观上看起来多个线程在同时运行。但微观上只是这个处理器在连续不断地在多个线程之间切换和执行,每个线程的执行一定会占用这个处理器一个时间片段,同一时刻,其实只有一个线程在执行。
23 |
24 | 并行,英文叫作 parallel。它是指同一时刻,有多条指令在多个处理器上同时执行,并行必须要依赖于多个处理器。不论是从宏观上还是微观上,多个线程都是在同一时刻一起执行的。
25 |
26 | **并行只能在多处理器系统中存在**,如果我们的计算机处理器只有一个核,那就不可能实现并行。而**并发在单处理器和多处理器系统中都是可以存在的,因为仅靠一个核,就可以实现并发**。
27 |
28 | 举个例子,比如系统处理器需要同时运行多个线程。如果系统处理器只有一个核,那它只能通过并发的方式来运行这些线程。如果系统处理器有多个核,当一个核在执行一个线程时,另一个核可以执行另一个线程,这样这两个线程就实现了并行执行,当然其他的线程也可能和另外的线程处在同一个核上执行,它们之间就是并发执行。具体的执行方式,就取决于操作系统的调度了。
29 |
30 | #### 多线程适用场景
31 |
32 | 在一个程序进程中,有一些操作是比较耗时或者需要等待的,比如等待数据库的查询结果的返回,等待网页结果的响应。如果使用单线程,处理器必须要等到这些操作完成之后才能继续往下执行其他操作,而这个线程在等待的过程中,处理器明显是可以来执行其他的操作的。**如果使用多线程,处理器就可以在某个线程等待的时候,去执行其他的线程**,**从而从整体上提高执行效率**。
33 |
34 | 像上述场景,线程在执行过程中很多情况下是需要等待的。比如网络爬虫就是一个非常典型的例子,爬虫在向服务器发起请求之后,有一段时间必须要等待服务器的响应返回,这种任务就属于 IO 密集型任务。对于这种任务,如果我们启用多线程,处理器就可以在某个线程等待的过程中去处理其他的任务,从而**提高整体的爬取效率**。
35 |
36 | 但并不是所有的任务都是 IO 密集型任务,还有一种任务叫作**计算密集型任务**,也可以称之为 **CPU 密集型任务**。顾名思义,就是任务的运行一直需要处理器的参与。此时如果我们开启了多线程,一个处理器从一个计算密集型任务切换到切换到另一个计算密集型任务上去,处理器依然不会停下来,始终会忙于计算,这样并不会节省总体的时间,因为需要处理的任务的计算总量是不变的。如果线程数目过多,反而还会在线程切换的过程中多耗费一些时间,整体效率会变低。
37 |
38 | 所以,如果任务不全是计算密集型任务,我们可以使用多线程来提高程序整体的执行效率。尤其对于网络爬虫这种 IO 密集型任务来说,使用多线程会大大提高程序整体的爬取效率。
39 |
40 | #### Python 实现多线程
41 |
42 | 在 Python 中,实现多线程的模块叫作 `threading`,是 Python 自带的模块。下面我们来了解下使用` threading` 实现多线程的方法。
43 |
44 | #### Thread 直接创建子线程
45 | 首先,我们可以使用 `Thread` 类来创建一个线程,创建时需要指定 `target` 参数为运行的方法名称,如果被调用的方法需要传入额外的参数,则可以通过 `Thread `的 `args` 参数来指定。示例如下:
46 | 
47 | 运行结果如下:
48 | ```python
49 | Threading MainThread is running
50 | Threading Thread-1 is running
51 | Threading Thread-1 sleep 1s
52 | Threading Thread-2 is running
53 | Threading Thread-2 sleep 5s
54 | Threading MainThread is ended
55 | Threading Thread-1 is ended
56 | Threading Thread-2 is ended
57 | ```
58 | 在这里我们首先声明了一个方法,叫作 `target`,它接收一个参数为 `second`,通过方法的实现可以发现,这个方法其实就是执行了一个 time.sleep 休眠操作,`second` 参数就是休眠秒数,其前后都 print 了一些内容,其中线程的名字我们通过 `threading.current_thread().name` 来获取出来,如果是主线程的话,其值就是 MainThread,如果是子线程的话,其值就是 Thread-*。
59 |
60 | 然后我们通过 Thead 类新建了两个线程,target 参数就是刚才我们所定义的方法名,args 以列表的形式传递。两次循环中,这里 i 分别就是 1 和 5,这样两个线程就分别休眠 1 秒和 5 秒,声明完成之后,我们调用 start 方法即可开始线程的运行。
61 |
62 | 观察结果我们可以发现,这里一共产生了三个线程,分别是主线程 MainThread 和两个子线程 Thread-1、Thread-2。另外我们观察到,主线程首先运行结束,紧接着 Thread-1、Thread-2 才接连运行结束,分别间隔了 1 秒和 4 秒。这说明**主线程并没有等待子线程运行完毕才结束运行**,而是直接退出了,有点不符合常理。
63 |
64 | 如果我们想要主线程等待子线程运行完毕之后才退出,可以让每个子线程对象都调用下 `join` 方法,实现如下:
65 | 
66 | 运行结果如下:
67 | ```python
68 | Threading MainThread is running
69 | Threading Thread-1 is running
70 | Threading Thread-1 sleep 1s
71 | Threading Thread-2 is running
72 | Threading Thread-2 sleep 5s
73 | Threading Thread-1 is ended
74 | Threading Thread-2 is ended
75 | Threading MainThread is ended
76 | ```
77 | 这样,主线程必须等待子线程都运行结束,主线程才继续运行并结束。
78 | #### 继承 Thread 类创建子线程
79 | 另外,我们也可以通过继承 Thread 类的方式创建一个线程,该线程需要执行的方法写在类的 run 方法里面即可。上面的例子的等价改写为:
80 | 
81 | 运行结果如下:
82 |
83 | ```python
84 | Threading MainThread is running
85 | Threading Thread-1 is running
86 | Threading Thread-1 sleep 1s
87 | Threading Thread-2 is running
88 | Threading Thread-2 sleep 5s
89 | Threading Thread-1 is ended
90 | Threading Thread-2 is ended
91 | Threading MainThread is ended
92 | ```
93 | 可以看到,两种实现方式,其运行效果是相同的。
94 | #### 守护线程
95 | 在线程中有一个叫作守护线程的概念,**如果一个线程被设置为守护线程,那么意味着这个线程是“不重要”的**,这意味着,如果主线程结束了而该守护线程还没有运行完,那么它将会被强制结束。在 Python 中我们可以通过 `setDaemon `方法来将某个线程设置为守护线程。
96 |
97 | 示例如下:
98 | 
99 | 在这里我们通过 setDaemon 方法将 t2 设置为了守护线程,这样主线程在运行完毕时,t2 线程会随着线程的结束而结束。
100 |
101 | 运行结果如下:
102 | ```python
103 | Threading MainThread is running
104 | Threading Thread-1 is running
105 | Threading Thread-1 sleep 2s
106 | Threading Thread-2 is running
107 | Threading Thread-2 sleep 5s
108 | Threading MainThread is ended
109 | Threading Thread-1 is ended
110 | ```
111 | 可以看到,我们没有看到 Thread-2 打印退出的消息,Thread-2 随着主线程的退出而退出了。
112 |
113 | 不过细心的你可能会发现,这里并没有调用 join 方法,如果我们让 t1 和 t2 都调用 join 方法,主线程就会仍然等待各个子线程执行完毕再退出,不论其是否是守护线程。
114 |
115 | #### 互斥锁
116 | 在一个进程中的多个线程是共享资源的,比如在一个进程中,有一个全局变量 count 用来计数,现在我们声明多个线程,每个线程运行时都给 count 加 1,让我们来看看效果如何,代码实现如下:
117 | 
118 | 图片给的代码没有进行缩进,正确缩进之后代码如下:
119 | ```python
120 | import threading
121 | import time
122 |
123 | count=0
124 |
125 | class MyThread(threading.Thread):
126 |
127 | def __init__(self):
128 | threading.Thread.__init__(self)
129 | def run(self):
130 | global count
131 | temp=count+1
132 | time.sleep(0.001)
133 | count=temp
134 |
135 | threads=[]
136 | for _ in range(1000):
137 | thread=MyThread()
138 | thread.start()
139 | threads.append(thread)
140 | for thread in threads:
141 | thread.join()
142 | print('Final count{}:'.format(count))
143 | ```
144 | 在这里,我们声明了 1000 个线程,每个线程都是现取到当前的全局变量 count 值,然后休眠一小段时间,然后对 count 赋予新的值。
145 |
146 | 那这样,按照常理来说,最终的 count 值应该为 1000。但其实不然,我们来运行一下看看。
147 |
148 | 运行结果如下:
149 |
150 | Final count: 69
151 |
152 | 最后的结果居然只有 69,而且多次运行或者换个环境运行结果是不同的。
153 |
154 | 这是为什么呢?因为 count 这个值是共享的,每个线程都可以在执行 temp = count 这行代码时拿到当前 count 的值,但是这些线程中的一些线程可能是并发或者并行执行的,这就导致不同的线程拿到的可能是同一个 count 值,最后导致有些线程的 count 的加 1 操作并没有生效,导致最后的结果偏小。
155 |
156 | 所以,如果多个线程同时对某个数据进行读取或修改,就会出现不可预料的结果。为了避免这种情况,我们需要对多个线程进行同步,要实现同步,我们可以对需要操作的数据进行加锁保护,这里就需要用到 threading.Lock 了。
157 |
158 | 加锁保护是什么意思呢?就是说,某个线程在对数据进行操作前,需要先加锁,这样其他的线程发现被加锁了之后,就无法继续向下执行,会一直等待锁被释放,只有加锁的线程把锁释放了,其他的线程才能继续加锁并对数据做修改,修改完了再释放锁。这样可以确保同一时间只有一个线程操作数据,多个线程不会再同时读取和修改同一个数据,这样最后的运行结果就是对的了。
159 |
160 | 我们可以将代码修改为如下内容:
161 | 
162 | 在这里我们声明了一个 lock 对象,其实就是 threading.Lock 的一个实例,然后在 run 方法里面,获取 count 前先加锁,修改完 count 之后再释放锁,这样多个线程就不会同时获取和修改 count 的值了。
163 |
164 | 运行结果如下:
165 | ```python
166 | Final count: 1000
167 | ```
168 | 这样运行结果就正常了。
169 |
170 | 关于 Python 多线程的内容,这里暂且先介绍这些,关于 theading 更多的使用方法,如信号量、队列等,可以参考官方文档:https://docs.python.org/zh-cn/3.7/library/threading.html#module-threading。
171 |
172 | #### Python 多线程的问题
173 |
174 | 由于 Python 中 GIL 的限制,**导致不论是在单核还是多核条件下,在同一时刻只能运行一个线程**,导致 Python 多线程无法发挥多核并行的优势。
175 |
176 | GIL 全称为 **Global Interpreter Lock**,中文翻译为全局解释器锁,其最初设计是出于数据安全而考虑的。
177 |
178 | 在 Python 多线程下,每个线程的执行方式如下:
179 | * 获取 GIL
180 | * 执行对应线程的代码
181 | * 释放 GIL
182 |
183 | 可见,某个线程想要执行,必须先拿到 GIL,我们可以把 GIL 看作是通行证,并且在一个 Python 进程中,GIL 只有一个。拿不到通行证的线程,就不允许执行。这样就会导致,即使是多核条件下,一个 Python 进程下的多个线程,同一时刻也只能执行一个线程。
184 |
185 | 不过对于爬虫这种 IO 密集型任务来说,这个问题影响并不大。而对于计算密集型任务来说,由于 GIL 的存在,多线程总体的运行效率相比可能反而比单线程更低。
186 |
187 |
--------------------------------------------------------------------------------
/第06讲:多路加速,了解多进程基本原理.md:
--------------------------------------------------------------------------------
1 | 在上一课时我们了解了多线程的基本概念,同时我们也提到,Python 中的**多线程**是不能很好发挥多核优势的,如果想要发挥多核优势,最好还是使用**多进程**。
2 |
3 | 那么本课时我们就来了解下多进程的基本概念和用 Python 实现多进程的方法。
4 | #### 多进程的含义
5 |
6 | 进程(Process)是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位。
7 |
8 | 顾名思义,多进程就是启用多个进程同时运行。由于进程是线程的集合,而且进程是由一个或多个线程构成的,所以**多进程的运行意味着有大于或等于进程数量的线程在运行**。
9 | #### Python 多进程的优势
10 |
11 | 通过上一课时我们知道,由于进程中 GIL 的存在,Python 中的多线程并不能很好地发挥多核优势,一个进程中的多个线程,在同一时刻只能有一个线程运行。
12 |
13 | 而对于多进程来说,每个进程都有属于自己的 GIL,所以,在多核处理器下,多进程的运行是不会受 GIL 的影响的。因此,多进程能更好地发挥多核的优势。
14 |
15 | 当然,对于爬虫这种 IO 密集型任务来说,多线程和多进程影响差别并不大。对于计算密集型任务来说,Python 的多进程相比多线程,其多核运行效率会有成倍的提升。
16 |
17 | 总的来说,Python 的多进程整体来看是比多线程更有优势的。所以,在条件允许的情况下,能用多进程就尽量用多进程。
18 |
19 | 不过值得注意的是,由于进程是系统进行资源分配和调度的一个独立单位,所以**各个进程之间的数据是无法共享的**,如多个进程无法共享一个全局变量,进程之间的数据共享需要有单独的机制来实现,这在后面也会讲到。
20 |
21 | #### 多进程的实现
22 |
23 | 在 Python 中也有内置的库来实现多进程,它就是 `multiprocessing`。
24 |
25 | `multiprocessing` 提供了一系列的组件,如 `Process`(进程)、`Queue`(队列)、`Semaphore`(信号量)、`Pipe`(管道)、`Lock`(锁)、`Pool`(进程池)等,接下来让我们来了解下它们的使用方法。
26 | ##### 直接使用 Process 类
27 |
28 | 在 multiprocessing 中,每一个进程都用一个 Process 类来表示。它的 API 调用如下:
29 |
30 | > Process([group [, target [, name [, args [, kwargs]]]]])
31 | >
32 | * target 表示调用对象,你可以传入方法的名字。
33 | * args 表示被调用对象的位置参数元组,比如 target 是函数 func,他有两个参数 m,n,那么 args 就传入 [m, n] 即可。
34 | * kwargs 表示调用对象的字典。
35 | * name 是别名,相当于给这个进程取一个名字。
36 | * group 分组。
37 |
38 | 我们先用一个实例来感受一下:
39 | 
40 | 这是一个实现多进程最基础的方式:通过创建 Process 来新建一个子进程,其中 target 参数传入方法名,args 是方法的参数,是以元组的形式传入,其和被调用的方法 process 的参数是一一对应的。
41 |
42 | 注意:这里 args 必须要是一个元组**加粗样式**,如果只有一个参数,那也要在元组第一个元素后面加一个逗号,如果没有逗号则和单个元素本身没有区别,无法构成元组,导致参数传递出现问题。
43 |
44 | 创建完进程之后,我们通过调用 start 方法即可启动进程了。运行结果如下:
45 | ```python
46 | Process: 0
47 | Process: 1
48 | Process: 2
49 | Process: 3
50 | Process: 4
51 | ```
52 | 可以看到,我们运行了 5 个子进程,每个进程都调用了 process 方法。process 方法的 index 参数通过 Process 的 args 传入,分别是 0~4 这 5 个序号,最后打印出来,5 个子进程运行结束。
53 |
54 | 由于**进程是 Python 中最小的资源分配单元**,因此这些进程和线程不同,**各个进程之间的数据是不会共享**的,每启动一个进程,都会独立分配资源。
55 |
56 | 另外,在当前 CPU 核数足够的情况下,这些不同的进程会分配给不同的 CPU 核来运行,实现真正的并行执行。
57 |
58 | `multiprocessing` 还提供了几个比较有用的方法,如我们可以通过 `cpu_count` 的方法来获取当前机器 CPU 的核心数量,通过 `active_children` 方法获取当前还在运行的所有进程。
59 |
60 | 下面通过一个实例来看一下:
61 | 
62 | ```python
63 | CPU number: 8
64 | Child process name: Process-5 id: 73595
65 | Child process name: Process-2 id: 73592
66 | Child process name: Process-3 id: 73593
67 | Child process name: Process-4 id: 73594
68 | Process Ended
69 | Process: 1
70 | Process: 2
71 | Process: 3
72 | Process: 4
73 | ```
74 | 在上面的例子中我们通过 `cpu_count` 成功获取了 CPU 核心的数量:8 个,当然不同的机器结果可能不同。
75 |
76 | 另外我们还通过 `active_children `获取到了当前正在活跃运行的进程列表。然后我们遍历了每个进程,并将它们的名称和进程号打印出来了,这里进程号直接使用 pid 属性即可获取,进程名称直接通过 name 属性即可获取。
77 |
78 | 以上我们就完成了多进程的创建和一些基本信息的获取。
79 | ##### 继承 Process 类
80 | 在上面的例子中,我们创建进程是直接使用 `Process` 这个类来创建的,这是一种创建进程的方式。不过,创建进程的方式不止这一种,同样,我们也可以像线程 `Thread` 一样来通过继承的方式创建一个进程类,进程的基本操作我们在子类的 run 方法中实现即可。
81 |
82 | 通过一个实例来看一下:
83 | 
84 | 我们首先声明了一个构造方法,这个方法接收一个 loop 参数,代表循环次数,并将其设置为全局变量。在 run 方法中,又使用这个 loop 变量循环了 loop 次并**打印了当前的进程号和循环次数**。
85 |
86 | 在调用时,我们用 range 方法得到了 2、3、4 三个数字,并把它们分别初始化了 MyProcess 进程,然后调用 start 方法将进程启动起来。
87 |
88 | 注意:这里进程的执行逻辑需要在 run 方法中实现,启动进程需要调用 start 方法,调用之后 run 方法便会执行。
89 |
90 | 运行结果如下:
91 |
92 | ```python
93 | Pid: 73667 LoopCount: 0
94 | Pid: 73668 LoopCount: 0
95 | Pid: 73669 LoopCount: 0
96 | Pid: 73667 LoopCount: 1
97 | Pid: 73668 LoopCount: 1
98 | Pid: 73669 LoopCount: 1
99 | Pid: 73668 LoopCount: 2
100 | Pid: 73669 LoopCount: 2
101 | Pid: 73669 LoopCount: 3
102 | ```
103 | 可以看到,三个进程分别打印出了 2、3、4 条结果,即进程 73667 打印了 2 次 结果,进程 73668 打印了 3 次结果,进程 73669 打印了 4 次结果。
104 |
105 | 注意,这里的进程 **pid 代表进程号**,不同机器、不同时刻运行结果可能不同。
106 |
107 | 通过上面的方式,我们也非常方便地实现了一个进程的定义。为了复用方便,我们可以把一些方法写在每个进程类里封装好,在使用时直接初始化一个进程类运行即可。
108 | ##### 守护进程
109 |
110 | 在多进程中,同样存在守护进程的概念,**如果一个进程被设置为守护进程,当父进程结束后,子进程会自动被终止**,我们可以通过设置 `daemon `属性来控制是否为守护进程。
111 |
112 | 还是原来的例子,增加了 deamon 属性的设置:
113 | 
114 | 运行结果如下:
115 | ```python
116 | Main Process ended
117 | ```
118 | 结果很简单,因为主进程没有做任何事情,直接输出一句话结束,所以在这时也直接终止了子进程的运行。
119 |
120 | 这样可以有效防止无控制地生成子进程。这样的写法可以让我们在主进程运行结束后无需额外担心子进程是否关闭,避免了独立子进程的运行。
121 |
122 | ##### 进程等待
123 | 上面的运行效果其实不太符合我们预期:主进程运行结束时,子进程(守护进程)也都退出了,**子进程什么都没来得及执行**。
124 |
125 | 能不能让所有子进程都执行完了然后再结束呢?当然是可以的,只需要加入 join 方法即可,我们可以将代码改写如下:
126 | 
127 | 运行结果如下:
128 | ```python
129 | Pid: 40866 LoopCount: 0
130 | Pid: 40867 LoopCount: 0
131 | Pid: 40868 LoopCount: 0
132 | Pid: 40866 LoopCount: 1
133 | Pid: 40867 LoopCount: 1
134 | Pid: 40868 LoopCount: 1
135 | Pid: 40867 LoopCount: 2
136 | Pid: 40868 LoopCount: 2
137 | Pid: 40868 LoopCount: 3
138 | Main Process ended
139 | ```
140 | 在调用 start 和 join 方法后,父进程就可以等待所有子进程都执行完毕后,再打印出结束的结果。
141 |
142 | 默认情况下,join 是无限期的。也就是说,如果有子进程没有运行完毕,主进程会一直等待。这种情况下,如果子进程出现问题陷入了死循环,主进程也会无限等待下去。怎么解决这个问题呢?可以给 join 方法传递一个超时参数,代表最长等待秒数。如果子进程没有在这个指定秒数之内完成,会被强制返回,主进程不再会等待。也就是说这个参数设置了主进程等待该子进程的最长时间。
143 |
144 | 例如这里我们传入 1,代表最长等待 1 秒,代码改写如下:
145 | 
146 | 运行结果如下:
147 | ```python
148 | Pid: 40970 LoopCount: 0
149 | Pid: 40971 LoopCount: 0
150 | Pid: 40970 LoopCount: 1
151 | Pid: 40971 LoopCount: 1
152 | Main Process ended
153 | ```
154 | 可以看到,有的子进程本来要运行 3 秒,结果运行 1 秒就被强制返回了,由于是守护进程,该子进程被终止了。
155 |
156 | 到这里,我们就了解了守护进程、进程等待和超时设置的用法。
157 | ##### 终止进程
158 |
159 | 当然,终止进程不止有守护进程这一种做法,我们也可以通过 `terminate` 方法来终止某个子进程,另外我们还可以通过 `is_alive`方法判断进程是否还在运行。
160 |
161 | 下面我们来看一个实例:
162 | 
163 | 在上面的例子中,我们用 Process 创建了一个进程,接着调用 `start` 方法启动这个进程,然后调用 `terminate` 方法将进程终止,最后调用` join` 方法。
164 |
165 | 另外,在进程运行不同的阶段,我们还通过 `is_alive` 方法判断当前进程是否还在运行。
166 |
167 | 运行结果如下:
168 | 
169 | 这里有一个值得注意的地方,在调用 `terminate` 方法之后,我们用 `is_alive` 方法获取进程的状态发现依然还是运行状态。在调用 `join` 方法之后,`is_alive` 方法获取进程的运行状态才变为终止状态。
170 |
171 | 所以,在调用 `terminate` 方法之后,记得要调用一下` join` 方法,这里调用 `join` 方法可以为进程提供时间来更新对象状态,用来反映出最终的进程终止效果。
172 | ##### 进程互斥锁
173 |
174 | 在上面的一些实例中,我们可能会遇到如下的运行结果:
175 | ```python
176 | Pid: 73993 LoopCount: 0
177 | Pid: 73993 LoopCount: 1
178 | Pid: 73994 LoopCount: 0Pid: 73994 LoopCount: 1
179 | Pid: 73994 LoopCount: 2
180 | Pid: 73995 LoopCount: 0
181 | Pid: 73995 LoopCount: 1
182 | Pid: 73995 LoopCount: 2
183 | Pid: 73995 LoopCount: 3
184 | Main Process ended
185 | ```
186 | 我们发现,有的输出结果没有换行。这是什么原因造成的呢?
187 |
188 | 这种情况是由**多个进程并行执行导致的**,两个进程同时进行了输出,结果第一个进程的换行没有来得及输出,第二个进程就输出了结果,导致最终输出没有换行。
189 |
190 | 那如何来避免这种问题?如果我们能保证,多个进程运行期间的任一时间,只能一个进程输出,其他进程等待,等刚才那个进程输出完毕之后,另一个进程再进行输出,这样就不会出现输出没有换行的现象了。
191 |
192 | 这种解决方案实际上就是实现了**进程互斥**,避免了多个进程同时抢占临界区(输出)资源。我们可以通过 `multiprocessing` 中的` Lock` 来实现。`Lock`,即锁,**在一个进程输出时,加锁,其他进程等待。等此进程执行结束后,释放锁,其他进程可以进行输出**。
193 |
194 | 我们首先实现一个不加锁的实例,代码如下:
195 | 
196 | 运行结果如下:
197 |
198 | ```python
199 | Pid: 74030 LoopCount: 0
200 | Pid: 74031 LoopCount: 0
201 | Pid: 74032 LoopCount: 0
202 | Pid: 74033 LoopCount: 0
203 | Pid: 74034 LoopCount: 0
204 | Pid: 74030 LoopCount: 1
205 | Pid: 74031 LoopCount: 1
206 | Pid: 74032 LoopCount: 1Pid: 74033 LoopCount: 1
207 | Pid: 74034 LoopCount: 1
208 | Pid: 74030 LoopCount: 2
209 | ```
210 | 可以看到运行结果中有些输出已经出现了不换行的问题。
211 |
212 | 我们对其加锁,取消掉刚才代码中的两行注释,重新运行,运行结果如下:
213 |
214 | ```python
215 | Pid: 74061 LoopCount: 0
216 | Pid: 74062 LoopCount: 0
217 | Pid: 74063 LoopCount: 0
218 | Pid: 74064 LoopCount: 0
219 | Pid: 74065 LoopCount: 0
220 | Pid: 74061 LoopCount: 1
221 | Pid: 74062 LoopCount: 1
222 | Pid: 74063 LoopCount: 1
223 | Pid: 74064 LoopCount: 1
224 | Pid: 74065 LoopCount: 1
225 | Pid: 74061 LoopCount: 2
226 | Pid: 74062 LoopCount: 2
227 | Pid: 74064 LoopCount: 2
228 | ```
229 | 这时输出效果就正常了。
230 |
231 | 所以,在访问一些临界区资源时,使用 Lock 可以有效避免进程同时占用资源而导致的一些问题。
232 | ##### 信号量
233 |
234 | 进程互斥锁可以使同一时刻只有一个进程能访问共享资源,如上面的例子所展示的那样,在同一时刻只能有一个进程输出结果。但有时候我们需要允许多个进程来访问共享资源,同时还需要限制能访问共享资源的进程的数量。
235 |
236 | 这种需求该如何实现呢?可以用信号量,信号量是进程同步过程中一个比较重要的角色。它可以控制临界资源的数量,**实现多个进程同时访问共享资源,限制进程的并发量**。
237 |
238 | 如果你学过操作系统,那么一定对这方面非常了解,如果你还不了解信号量是什么,可以先熟悉一下这个概念。
239 |
240 | 我们可以用 `multiprocessing` 库中的 `Semaphore` 来实现信号量。
241 |
242 | 那么接下来我们就用一个实例来演示一下进程之间利用 `Semaphore` 做到多个进程共享资源,同时又限制同时可访问的进程数量,代码如下:
243 | 
244 | 如上代码实现了经典的生产者和消费者问题。它定义了两个进程类,一个是消费者,一个是生产者。
245 |
246 | 另外,这里使用 `multiprocessing` 中的 `Queue` 定义了一个共享队列,然后定义了两个信号量 `Semaphore`,一个代表缓冲区空余数,一个表示缓冲区占用数。
247 |
248 | 生产者 Producer 使用 acquire 方法来占用一个缓冲区位置,缓冲区空闲区大小减 1,接下来进行加锁,对缓冲区进行操作,然后释放锁,最后让代表占用的缓冲区位置数量加 1,消费者则相反。
249 |
250 | 运行结果如下:
251 | ```python
252 | Producer append an element
253 | Producer append an element
254 | Consumer pop an element
255 | Consumer pop an element
256 | Producer append an element
257 | Producer append an element
258 | Consumer pop an element
259 | Consumer pop an element
260 | Producer append an element
261 | Producer append an element
262 | Consumer pop an element
263 | Consumer pop an element
264 | Producer append an element
265 | Producer append an element
266 | ```
267 | 我们发现两个进程在交替运行,生产者先放入缓冲区物品,然后消费者取出,不停地进行循环。 你可以通过上面的例子来体会信号量 `Semaphore` 的用法,通过 `Semaphore` 我们很好地控制了进程对资源的并发访问数量。
268 | ##### 队列
269 |
270 | 在上面的例子中我们使用 `Queue` 作为进程通信的**共享队列**使用。
271 |
272 | 而如果我们把上面程序中的 Queue 换成普通的 list,是完全起不到效果的,因为进程和进程之间的资源是不共享的。即使在一个进程中改变了这个 list,在另一个进程也不能获取到这个 list 的状态,所以声明全局变量对多进程是没有用处的。
273 |
274 | 那进程如何共享数据呢?可以用 `Queue`,即队列。当然这里的队列指的是 `multiprocessing` 里面的 `Queue`。
275 |
276 | 依然用上面的例子,我们一个进程向队列中放入随机数据,然后另一个进程取出数据。
277 | 
278 | 运行结果如下:
279 | ```python
280 | Producer put 0.719213647437
281 | Producer put 0.44287326683
282 | Consumer get 0.719213647437
283 | Consumer get 0.44287326683
284 | Producer put 0.722859424381
285 | Producer put 0.525321338921
286 | Consumer get 0.722859424381
287 | Consumer get 0.525321338921
288 | ```
289 | 在上面的例子中我们声明了两个进程,一个进程为生产者 Producer,另一个为消费者 Consumer,生产者不断向 Queue 里面添加随机数,消费者不断从队列里面取随机数。
290 |
291 | 生产者在放数据的时候调用了 Queue 的 put 方法,消费者在取的时候使用了 get 方法,这样我们就通过 Queue 实现两个进程的数据共享了。
292 | ##### 管道
293 | 刚才我们使用 `Queue` 实现了进程间的**数据共享**,那么进程之间直接**通信**,如收发信息,用什么比较好呢?可以用 `Pipe`,管道。
294 |
295 | 管道,我们可以把它理解为两个进程之间通信的通道。管道可以是单向的,即 `half-duplex`:一个进程负责发消息,另一个进程负责收消息;也可以是双向的 `duplex`,即互相收发消息。
296 |
297 | 默认声明 `Pipe` 对象是双向管道,如果要创建单向管道,可以在初始化的时候传入 `deplex` 参数为 `False`。
298 |
299 | 我们用一个实例来感受一下:
300 | 
301 | 在这个例子里我们声明了一个默认为双向的管道,然后将管道的两端分别传给两个进程。两个进程互相收发。观察一下结果:
302 | ```python
303 | Producer Received: Consumer Words
304 | Consumer Received: Producer Words
305 | Main Process Ended
306 | ```
307 | 管道 `Pipe` 就像进程之间搭建的桥梁,利用它我们就可以很方便地实现进程间通信了。
308 | ##### 进程池
309 |
310 | 在前面,我们讲了可以使用 `Process` 来创建进程,同时也讲了如何用 `Semaphore` 来控制进程的并发执行数量。
311 |
312 | 假如现在我们遇到这么一个问题,我有 10000 个任务,每个任务需要启动一个进程来执行,并且一个进程运行完毕之后要紧接着启动下一个进程,同时我还需要控制进程的并发数量,不能并发太高,不然 CPU 处理不过来(如果同时运行的进程能维持在一个最高恒定值当然利用率是最高的)。
313 |
314 | 那么我们该如何来实现这个需求呢?
315 |
316 | 用 `Process` 和 `Semaphore` 可以实现,但是实现起来比较我们可以用 `Process` 和 `Semaphore` 解决问题,但是实现起来比较烦琐。而这种需求在平时又是非常常见的。此时,我们就可以派上进程池了,即 `multiprocessing` 中的 `Pool`。
317 |
318 | `Pool` 可以提供指定数量的进程,供用户调用,当有新的请求提交到 pool 中时,如果池还没有满,就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来执行它。
319 |
320 | 我们用一个实例来实现一下,代码如下:
321 | 
322 | 在这个例子中我们声明了一个大小为 3 的进程池,通过 `processes` 参数来指定,如果不指定,那么会自动根据处理器内核来分配进程数。接着我们使用 `apply_async` 方法将进程添加进去,`args` 可以用来传递参数。
323 |
324 | 运行结果如下:
325 |
326 | ```python
327 | Main Process started
328 | Start process: 0
329 | Start process: 1
330 | Start process: 2
331 | End process 0
332 | End process 1
333 | End process 2
334 | Start process: 3
335 | End process 3
336 | Main Process ended
337 | ```
338 | 进程池大小为 3,所以最初可以看到有 3 个进程同时执行,第进程池大小为 3,所以最初可以看到有 3 个进程同时执行,第4个进程在等待,在有进程运行完毕之后,第4个进程马上跟着运行,出现了如上的运行效果。
339 |
340 | 最后,我们要记得调用 close 方法来关闭进程池,使其不再接受新的任务,然后调用 join 方法让主进程等待子进程的退出,等子进程运行完毕之后,主进程接着运行并结束。
341 |
342 | 不过上面的写法多少有些烦琐,这里再介绍进程池一个更好用的 `map` 方法,可以将上述写法简化很多。
343 |
344 | `map` 方法是怎么用的呢?第一个参数就是要启动的进程对应的执行方法,第 2 个参数是一个可迭代对象,其中的每个元素会被传递给这个执行方法。
345 |
346 | 举个例子:现在我们有一个 list,里面包含了很多 URL,另外我们也定义了一个方法用来抓取每个 URL 内容并解析,那么我们可以直接在 map 的第一个参数传入方法名,第 2 个参数传入 URL 数组。
347 |
348 | 我们用一个实例来感受一下:
349 | 
350 | 这个例子中我们先定义了一个 scrape 方法,它接收一个参数 url,这里就是请求了一下这个链接,然后输出爬取成功的信息,如果发生错误,则会输出爬取失败的信息。
351 |
352 | 首先我们要初始化一个 Pool,指定进程数为 3。然后我们声明一个 urls 列表,接着我们调用了 map 方法,第 1 个参数就是进程对应的执行方法,第 2 个参数就是 urls 列表,map 方法会依次将 urls 的每个元素作为 scrape 的参数传递并启动一个新的进程,加到进程池中执行。
353 |
354 | 运行结果如下:
355 |
356 | ```python
357 | URL https://www.baidu.com Scraped
358 | URL http://xxxyxxx.net not Scraped
359 | URL http://blog.csdn.net/ Scraped
360 | URL http://www.meituan.com/ Scraped
361 | ```
362 | 这样,我们就可以实现 3 个进程并行运行。不同的进程相互独立地输出了对应的爬取结果。
363 |
364 |
365 | 可以看到,我们利用 Pool 的 map 方法非常方便地实现了多进程的执行。后面我们也会在实战案例中结合进程池来实现数据的爬取。
366 |
367 |
368 |
369 | 以上便是 Python 中多进程的基本用法,本节内容比较多,后面的实战案例也会用到这些内容,需要好好掌握。
370 |
--------------------------------------------------------------------------------
/第08讲:解析无所不能的正则表达式.md:
--------------------------------------------------------------------------------
1 | 在上个课时中,我们学会了如何用 Requests 来获取网页的源代码,得到 HTML 代码。但我们如何从 HTML 代码中获取真正想要的数据呢?
2 |
3 | 正则表达式就是一个有效的方法。
4 |
5 | 本课时中,我们将学习正则表达式的相关用法。正则表达式是处理字符串的强大工具,它有自己特定的语法结构。有了它,我们就能实现字符串的检索、替换、匹配验证。
6 |
7 | 当然,对于爬虫来说,有了它,要从 HTML 里提取想要的信息就非常方便了。
8 |
9 | #### 实例引入
10 |
11 | 说了这么多,可能我们对正则表达式的概念还是比较模糊,下面就用几个实例来看一下正则表达式的用法。
12 |
13 | 打开开源中国提供的正则表达式测试工具 **http://tool.oschina.net/regex/**,输入待匹配的文本,然后选择常用的正则表达式,就可以得出相应的匹配结果了。
14 |
15 | 例如,输入下面这段待匹配的文本:
16 | > Hello, my phone number is 010-86432100 and email is
17 | > cqc@cuiqingcai.com, and my website is https://cuiqingcai.com.
18 |
19 | 这段字符串中包含了一个电话号码和一个电子邮件,接下来就尝试用正则表达式提取出来,如图所示。
20 | 
21 | 在网页右侧选择 “匹配 Email 地址”,就可以看到下方出现了文本中的 E-mail。如果选择 “匹配网址 URL”,就可以看到下方出现了文本中的 URL。是不是非常神奇?
22 |
23 | 其实,这里使用了正则表达式的匹配功能,也就是用一定规则将特定的文本提取出来。
24 |
25 | 比方说,电子邮件是有其特定的组成格式的:一段字符串 + @ 符号 + 某个域名。而 URL的组成格式则是协议类型 + 冒号加双斜线 + 域名和路径。
26 |
27 | 可以用下面的正则表达式匹配 URL:
28 | 
29 | 用这个正则表达式去匹配一个字符串,如果这个字符串中包含类似 URL 的文本,那就会被提取出来。
30 |
31 | 这个看上去乱糟糟的正则表达式其实有特定的语法规则。比如,a-z 匹配任意的小写字母,**\s 匹配任意的空白字符**,*** 匹配前面任意多个字符**。这一长串的正则表达式就是这么多匹配规则的组合。
32 |
33 | 写好正则表达式后,就可以拿它去一个长字符串里匹配查找了。不论这个字符串里面有什么,只要符合我们写的规则,统统可以找出来。对于网页来说,如果想找出网页源代码里有多少 URL,用 URL 的正则表达式去匹配即可。
34 |
35 | 下表中列出了常用的匹配规则:
36 | 
37 | 
38 | 看完之后,你可能有点晕晕的吧,不用担心,后面我们会详细讲解一些常见规则的用法。
39 |
40 | 其实正则表达式不是 Python 独有的,它也可以用在其他编程语言中。但是 Python 的 `re `库提供了整个正则表达式的实现,利用这个库,可以在 Python 中使用正则表达式。
41 |
42 | 在 Python 中写正则表达式几乎都用这个库,下面就来了解它的一些常用方法。
43 | #### match
44 | 首先介绍一个常用的匹配方法 —— `match`,向它传入要匹配的字符串,以及正则表达式,就可以检测这个正则表达式是否匹配字符串。
45 |
46 | **match 方法会尝试从字符串的起始位置匹配正则表达式**,如果匹配,就返回匹配成功的结果;如果不匹配,就返回 None。
47 |
48 |
49 |
50 | 示例如下:
51 |
52 | ```python
53 | import re
54 |
55 | content='Hello 123 4567 World_This is a Regex Demo'
56 | print(len(content))
57 |
58 | result=re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}\s\w{2}',content)
59 | print(result)
60 | print(result.group())
61 | print(result.span())
62 | ```
63 | 运行结果如下:
64 | ```python
65 | 41
66 |
67 | Hello 123 4567 World_This is
68 | (0, 28)
69 | ```
70 | 这里首先声明了一个字符串,其中包含英文字母、空白字符、数字等。接下来,我们写一个正则表达式:
71 | 
72 | 用它来匹配这个长字符串。开头的 **^ 匹配字符串的开头**,也就是以 Hello 开头; \s 匹配空白字符,用来匹配目标字符串的空格;\d 匹配数字,3 个 \d 匹配 123;再写 1 个 \s 匹配空格;后面的 4567,其实依然能用 4 个 \d 来匹配,但是这么写比较烦琐,所以后面可以跟 {4} 代表匹配前面的规则 4 次,也就是匹配 4 个数字;后面再紧接 1 个空白字符,最后\w{10} 匹配 10 个字母及下划线。
73 |
74 | 我们注意到,这里并没有把目标字符串匹配完,不过依然可以进行匹配,只不过匹配结果短一点而已。
75 |
76 | 而在 **match 方法中,第一个参数传入正则表达式,第二个参数传入要匹配的字符串**。
77 |
78 | 打印输出结果,可以看到结果是 `SRE_Match` 对象,这证明成功匹配。该对象有两个方法:`group` 方法可以**输出匹配的内容**,结果是 `Hello 123 4567 World_This`,这恰好是正则表达式规则所匹配的内容;`span` 方法可以**输出匹配的范围**,结果是 (0, 25),这就是匹配到的结果字符串在原字符串中的位置范围。
79 |
80 | 通过上面的例子,我们基本了解了如何在 Python 中使用正则表达式来匹配一段文字。
81 |
82 | #### 匹配目标
83 | 刚才我们用 `match` 方法得到了匹配到的字符串内容,但当我们想从字符串中提取一部分内容,该怎么办呢?
84 |
85 | 就像最前面的实例一样,要从一段文本中提取出邮件或电话号码等内容。**我们可以使用 () 括号将想提取的子字符串括起来**。() 实际上标记了一个子表达式的开始和结束位置,被标记的每个子表达式会依次对应每一个分组,调用 group 方法传入分组的索引即可获取提取的结果。
86 |
87 | 示例如下:
88 |
89 | ```python
90 | import re
91 |
92 | content='Hello 1234567 World_This is a Regex Demo'
93 | print(len(content))
94 |
95 | result=re.match('^Hello\s(\d+)\sWorld',content)
96 | print(result)
97 | print(result.group())
98 | print(result.group(1))
99 | print(result.span())
100 | ```
101 | 这里我们想把字符串中的 1234567 提取出来,此时可以将数字部分的正则表达式用 () 括起来,然后调用了 group(1) 获取匹配结果。
102 |
103 | 运行结果如下
104 |
105 | ```python
106 | 40
107 |
108 | Hello 1234567 World
109 | 1234567
110 | (0, 19)
111 | ```
112 | 可以看到,我们成功得到了 1234567。这里用的是 group(1),它与 group() 有所不同,后者会输出完整的匹配结果,**而前者会输出第一个被 () 包围的匹配结果**。假如正则表达式后面还有 () 包括的内容,那么可以依次用 group(2)、group(3) 等来获取。
113 | #### 通用匹配
114 |
115 | 刚才我们写的正则表达比较复杂,出现空白字符我们就写 \s 匹配,出现数字我们就用 \d 匹配,这样的工作量非常大。
116 |
117 | 我们还可以用一个万能匹配来减少这些工作,那就是 **.***。
118 |
119 | 其中 . 可以匹配任意字符(除换行符),* 代表匹配前面的字符无限次,它们组合在一起就可以匹配任意字符了。有了它,我们就不用挨个字符的匹配了。
120 |
121 | 接着上面的例子,我们可以改写一下正则表达式:
122 |
123 | ```python
124 | import re
125 |
126 | content='Hello 123 4567 World_This is a Regex Demo'
127 | print(len(content))
128 |
129 | result=re.match('^Hello.*Demo$',content)
130 | #result=re.match('^Hello(.*)Regex',content)
131 | print(result)
132 | print(result.group())
133 | print(result.span())
134 | ```
135 | 这里我们将中间部分直接省略,全部用 .* 来代替,最后加一个结尾字符就好了。
136 |
137 |
138 |
139 | 运行结果如下:
140 | ```python
141 | 41
142 |
143 | Hello 123 4567 World_This is a Regex Demo
144 | (0, 41)
145 | ```
146 | 可以看到,group 方法输出了匹配的全部字符串,也就是说我们写的正则表达式匹配到了目标字符串的全部内容;span 方法输出 (0, 41),这是整个字符串的长度。
147 |
148 | 因此,我们可以使用 .* 简化正则表达式的书写。
149 | #### 贪婪与非贪婪
150 | 使用上面的通用匹配 .* 时,有时候匹配到的并不是我们想要的结果。
151 |
152 | 看下面的例子:
153 |
154 | ```python
155 | import re
156 |
157 | content='Hello 1234567 World_This is a Regex Demo'
158 | print(len(content))
159 |
160 | result=re.match('^He.*(\d+).*Demo$',content)
161 | print(result)
162 | print(result.group(1))
163 | ```
164 | 这里我们依然想获取中间的数字,所以中间依然写的是 (\d+)。由于数字两侧的内容比较杂乱,所以略写成 .*。最后,组成 ^He.*(\d+).*Demo$,看样子并没有什么问题。
165 |
166 | 我们看下运行结果:
167 |
168 | ```python
169 | 40
170 |
171 | 7
172 | ```
173 | 奇怪的事情发生了,我们只得到了 7 这个数字,这是怎么回事呢?
174 |
175 | 这里就涉及一个贪婪匹配与非贪婪匹配的问题了。在贪婪匹配下,.* 会匹配尽可能多的字符。正则表达式中 .* 后面是 \d+,也就是至少一个数字,并没有指定具体多少个数字,因此,.* 就尽可能匹配多的字符,这里就把 123456 匹配了,给 \d+ 留下一个可满足条件的数字 7,最后得到的内容就只有数字 7 了。
176 |
177 | 这显然会给我们带来很大的不便。有时候,匹配结果会莫名其妙少了一部分内容。其实,这里只需要使用**非贪婪匹配**就好了。非贪婪匹配的写法是 .*?,多了一个 ?,那么它可以达到怎样的效果?
178 |
179 | 我们再用实例看一下:
180 | ```python
181 | import re
182 |
183 | content='Hello 1234567 World_This is a Regex Demo'
184 | print(len(content))
185 |
186 | result=re.match('^He.*?(\d+).*Demo$',content)
187 | print(result)
188 | print(result.group(1))
189 | ```
190 | 这里我们只是将第一个.* 改成了 .*?,转变为非贪婪匹配。
191 |
192 | 结果如下:
193 | ```python
194 | 40
195 |
196 | 1234567
197 | ```
198 | 此时就可以成功获取 1234567 了。原因可想而知,**贪婪匹配是尽可能匹配多的字符,非贪婪匹配就是尽可能匹配少的字符**。当 .*? 匹配到 Hello 后面的空白字符时,再往后的字符就是数字了,而 \d+ 恰好可以匹配,那么 .*? 就不再进行匹配,交给 \d+ 去匹配后面的数字。这样 .*? 匹配了尽可能少的字符,\d+ 的结果就是 1234567 了。
199 |
200 | 所以,在做匹配的时候,字符串中间尽量使用非贪婪匹配,也就是用 .*? 来代替 .*,以免出现匹配结果缺失的情况。
201 |
202 | 但需要注意的是,如果匹配的结果在字符串结尾,.*? 就有可能匹配不到任何内容了,因为它会匹配尽可能少的字符。例如:
203 | ```python
204 | content='http://weibo.com/comment/KEraCN'
205 | result1=re.match('http.*?comment/(.*?)',content)
206 | result2=re.match('http.*?comment/(.*)',content)
207 | print('result1',result1.group(1))
208 | print('result2',result2.group(1))
209 | ```
210 | 运行结果如下:
211 | ```python
212 | result1
213 | result2 KEraCN
214 | ```
215 | 可以观察到,.*? 没有匹配到任何结果,而 .* 则尽量匹配多的内容,成功得到了匹配结果。
216 | #### 修饰符
217 | 正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。
218 |
219 | 我们用实例来看一下:
220 |
221 | ```python
222 | import re
223 |
224 | content='''Hello 1234567 World_This
225 | is a Regex Demo'''
226 |
227 | result=re.match('^He.*?(\d+).*?Demo$',content)
228 | print(result.group(1))
229 | ```
230 | 和上面的例子相仿,我们在字符串中加了**换行符**,正则表达式还是一样的,用来匹配其中的数字。看一下运行结果:
231 | ```python
232 | Traceback (most recent call last):
233 | File "D:/pycharm/Test/test/test2.py", line 7, in
234 | print(result.group(1))
235 | AttributeError: 'NoneType' object has no attribute 'group'
236 | ```
237 | 运行直接报错,也就是说正则表达式没有匹配到这个字符串,返回结果为 None,而我们又调用了 group 方法导致 AttributeError。
238 |
239 | 为什么加了一个换行符,就匹配不到了呢?这是
240 |
241 | **因为我们匹配的是除换行符之外的任意字符**,当遇到换行符时,.*? 就不能匹配了,导致匹配失败。
242 |
243 | 这里只需加一个修饰符 re.S,即可修正这个错误:
244 | ```python
245 | result=re.match('^He.*?(\d+).*?Demo$',content,re.S)
246 | ```
247 | 这个修饰符的作用是匹配包括换行符在内的所有字符。
248 |
249 | 此时运行结果如下:
250 |
251 | ```python
252 | 1234567
253 | ```
254 | 这个 `re.S` 在网页匹配中经常用到。因为 HTML 节点经常会有换行,**加上它,就可以匹配节点与节点之间的换行了**。
255 |
256 |
257 | 另外,还有一些修饰符,在必要的情况下也可以使用,如表所示:
258 | 
259 |
260 | #### 转义匹配
261 | 我们知道正则表达式定义了许多匹配模式,如匹配除换行符以外的任意字符,但如果目标字符串里面就包含 .,那该怎么办呢?
262 |
263 | 这里就需要用到转义匹配了,示例如下:
264 | ```python
265 | content='( 百度 )www.baidu.com'
266 | result=re.match('\( 百度 \)www\.baidu\.com',content)
267 | print(result)
268 | ```
269 | 当遇到用于正则匹配模式的特殊字符时,在前面加反斜线转义一下即可。例 . 就可以用 \. 来匹配。
270 |
271 | 运行结果如下:
272 | ```python
273 |
274 | ```
275 | 可以看到,这里成功匹配到了原字符串。
276 |
277 | 这些是写正则表达式常用的几个知识点,熟练掌握它们对后面写正则表达式匹配非常有帮助。
278 |
279 | #### search
280 | 前面提到过,**match 方法是从字符串的开头开始匹配的,一旦开头不匹配,那么整个匹配就失败了**。
281 |
282 | 我们看下面的例子:
283 | ```python
284 | content='Extra stings Hello 1234567 World_This is a Regex Demo Extra string'
285 | result=re.match('Hello.*?(\d+).*?Demo',content)
286 | print(result)
287 | ```
288 | 这里的字符串以 Extra 开头,但是正则表达式以 Hello 开头,整个正则表达式是字符串的一部分,但是这样匹配是失败的。
289 |
290 | 运行结果如下:
291 | ```python
292 | None
293 | ```
294 | 因为 match 方法在使用时需要考虑到开头的内容,这在做匹配时并不方便。它**更适合用来检测某个字符串是否符合某个正则表达式的规则**。
295 |
296 | 这里有另外一个方法 `search`,它在匹配时会扫描整个字符串,然后返回第一个成功匹配的结果。也就是说,正则表达式可以是字符串的一部分,在匹配时,search 方法会依次扫描字符串,直到找到第一个符合规则的字符串,然后返回匹配内容,如果搜索完了还没有找到,就返回 None。
297 |
298 | 我们把上面代码中的 match 方法修改成 search,再看下运行结果:
299 | ```python
300 | content='Extra stings Hello 1234567 World_This is a Regex Demo Extra string'
301 | result=re.search('Hello.*?(\d+).*?Demo',content)
302 | print(result)
303 | print(result.group(1))
304 |
305 |
306 | 1234567
307 | ```
308 | 这时就得到了匹配结果。
309 |
310 | 因此,为了匹配方便,我们可以尽量使用 search 方法。
311 |
312 | 下面再用几个实例来看看 search 方法的用法。
313 |
314 | 这里有一段待匹配的 HTML 文本,接下来我们写几个正则表达式实例来实现相应信息的提取:
315 | ```python
316 | html='''
317 |
经典老歌
318 |
经典老歌列表
319 |
320 | - 一路上有你
321 | -
322 | 沧海一声笑
323 |
324 | -
325 | 往事随风
326 |
327 | - 光辉岁月
328 |
461 |
经典老歌
462 |
经典老歌列表
463 |
464 | - 一路上有你
465 | -
466 | 沧海一声笑
467 |
468 | -
469 | 往事随风
470 |
471 | - 光辉岁月
472 | - 记事本
473 | - 但愿人长久
474 |
475 |