├── .clang-format
├── .github
└── workflows
│ ├── build.yml
│ └── wheels.yml
├── .gitignore
├── LICENSE
├── MANIFEST.in
├── README.md
├── benchmarking
├── benchmarks.png
├── benchmarks_pyquad.png
├── jit.py
├── pyquad_benchmark.py
└── run_benchmarks.py
├── examples
├── .ipynb_checkpoints
│ └── jupyter_example-checkpoint.ipynb
├── jit.py
├── jupyter_example.ipynb
└── readme_example.py
├── pyquad
├── generate_integrands.py
├── integrands.h
├── integration
│ ├── cquad.c
│ ├── cquad_const.c
│ ├── err.c
│ ├── error.c
│ ├── fdiv.c
│ ├── gsl_errno.h
│ ├── gsl_inline.h
│ ├── gsl_integration.h
│ ├── gsl_machine.h
│ ├── gsl_math.h
│ ├── gsl_message.h
│ ├── gsl_minmax.h
│ ├── gsl_nan.h
│ ├── gsl_sys.h
│ ├── gsl_types.h
│ ├── infnan.c
│ ├── initialise.c
│ ├── positivity.c
│ ├── qags.c
│ ├── qelg.c
│ ├── qk.c
│ ├── qk15.c
│ ├── qk21.c
│ ├── qpsrt.c
│ ├── qpsrt2.c
│ ├── reset.c
│ ├── set_initial.c
│ ├── stream.c
│ ├── util.c
│ └── workspace.c
├── pyquad.pyx
└── quad.c
├── requirements.txt
├── setup.py
└── tests
├── TODO
├── test_old.py
└── test_refactor.py
/.clang-format:
--------------------------------------------------------------------------------
1 | ---
2 | BasedOnStyle: Google
3 | TabWidth: 4
4 | IndentWidth: 4
5 | UseTab: Never
6 | ---
7 |
--------------------------------------------------------------------------------
/.github/workflows/build.yml:
--------------------------------------------------------------------------------
1 | name: Build
2 |
3 | on: [push]
4 |
5 | jobs:
6 | build:
7 |
8 | runs-on: ${{ matrix.os }}
9 | strategy:
10 | matrix:
11 | python-version: [3.5, 3.6, 3.7, 3.8]
12 | os: [ubuntu-latest, macOS-latest, windows-latest]
13 |
14 | steps:
15 | - uses: actions/checkout@v2
16 | - name: Set up Python ${{ matrix.python-version }}
17 | uses: actions/setup-python@v2
18 | with:
19 | python-version: ${{ matrix.python-version }}
20 | - name: Install dependencies
21 | run: |
22 | python -m pip install --upgrade pip
23 | pip install --upgrade setuptools
24 | pip install llvmlite --prefer-binary
25 | pip install numpy cython scipy pytest
26 | pip install -e .
27 | - name: Test with pytest
28 | run: |
29 | pytest tests/
30 |
--------------------------------------------------------------------------------
/.github/workflows/wheels.yml:
--------------------------------------------------------------------------------
1 | name: Wheels
2 |
3 | on:
4 | push:
5 | # Sequence of patterns matched against refs/tags
6 | tags:
7 | - 'v*' # Push events to matching v*, i.e. v1.0, v20.15.10
8 |
9 | jobs:
10 | build_wheels:
11 | name: Build wheels on ${{ matrix.os }}
12 | runs-on: ${{ matrix.os }}
13 | strategy:
14 | matrix:
15 | os: [ubuntu-latest, macOS-latest, windows-latest]
16 |
17 | steps:
18 | - uses: actions/checkout@v2
19 | - uses: actions/setup-python@v2
20 |
21 | - name: Install cibuildwheel
22 | run: |
23 | python -m pip install --upgrade pip
24 | python -m pip install cibuildwheel
25 |
26 | - name: Build wheels
27 | run: python -m cibuildwheel --output-dir wheelhouse
28 | env:
29 | CIBW_BUILD: "cp36-* cp37-* cp38-*"
30 | CIBW_BEFORE_BUILD: "pip install --upgrade pip; pip install --upgrade setuptools; pip install cython numpy --only-binary=all; pip install llvmlite --only-binary=all; pip install numba --only-binary=all"
31 |
32 | - uses: actions/upload-artifact@v2
33 | with:
34 | path: wheelhouse/*.whl
35 |
36 | build_sdist:
37 | name: Build source distribution
38 | runs-on: ubuntu-latest
39 | steps:
40 | - uses: actions/checkout@v2
41 |
42 | - uses: actions/setup-python@v2
43 | with:
44 | python-version: '3.8'
45 |
46 | - name: Build sdist
47 | run: |
48 | python -m pip install --upgrade pip
49 | pip install --upgrade setuptools
50 | pip install llvmlite --prefer-binary
51 | pip install numpy cython scipy pytest
52 | pip install -e .
53 | python setup.py sdist
54 |
55 | - uses: actions/upload-artifact@v2
56 | with:
57 | path: dist/*.tar.gz
58 |
59 | # Upload to TestPyPI
60 | upload_wheels:
61 | name: Upload to PyPI
62 | env:
63 | TWINE_USERNAME: __token__
64 | TWINE_PASSWORD: ${{ secrets.PYPI }}
65 | TWINE_REPOSITORY: pypi
66 | needs: [build_wheels, build_sdist]
67 | runs-on: ubuntu-latest
68 | steps:
69 | - uses: actions/download-artifact@v2
70 | with:
71 | path: dist/
72 |
73 | - uses: actions/setup-python@v2
74 | with:
75 | python-version: '3.8'
76 |
77 | - name: Upload files
78 | run: |
79 | python -m pip install --upgrade pip
80 | pip install twine
81 | python3 -m twine upload dist/artifact/*
82 |
83 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | *.so
2 | pyquad.egg-info
3 | env/
4 | build/
5 | pyquad/pyquad.c
6 | __pycache__
7 | dist/
8 | conda/
9 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | GNU GENERAL PUBLIC LICENSE
2 | Version 3, 29 June 2007
3 |
4 | Copyright (C) 2007 Free Software Foundation, Inc.
5 | Everyone is permitted to copy and distribute verbatim copies
6 | of this license document, but changing it is not allowed.
7 |
8 | Preamble
9 |
10 | The GNU General Public License is a free, copyleft license for
11 | software and other kinds of works.
12 |
13 | The licenses for most software and other practical works are designed
14 | to take away your freedom to share and change the works. By contrast,
15 | the GNU General Public License is intended to guarantee your freedom to
16 | share and change all versions of a program--to make sure it remains free
17 | software for all its users. We, the Free Software Foundation, use the
18 | GNU General Public License for most of our software; it applies also to
19 | any other work released this way by its authors. You can apply it to
20 | your programs, too.
21 |
22 | When we speak of free software, we are referring to freedom, not
23 | price. Our General Public Licenses are designed to make sure that you
24 | have the freedom to distribute copies of free software (and charge for
25 | them if you wish), that you receive source code or can get it if you
26 | want it, that you can change the software or use pieces of it in new
27 | free programs, and that you know you can do these things.
28 |
29 | To protect your rights, we need to prevent others from denying you
30 | these rights or asking you to surrender the rights. Therefore, you have
31 | certain responsibilities if you distribute copies of the software, or if
32 | you modify it: responsibilities to respect the freedom of others.
33 |
34 | For example, if you distribute copies of such a program, whether
35 | gratis or for a fee, you must pass on to the recipients the same
36 | freedoms that you received. You must make sure that they, too, receive
37 | or can get the source code. And you must show them these terms so they
38 | know their rights.
39 |
40 | Developers that use the GNU GPL protect your rights with two steps:
41 | (1) assert copyright on the software, and (2) offer you this License
42 | giving you legal permission to copy, distribute and/or modify it.
43 |
44 | For the developers' and authors' protection, the GPL clearly explains
45 | that there is no warranty for this free software. For both users' and
46 | authors' sake, the GPL requires that modified versions be marked as
47 | changed, so that their problems will not be attributed erroneously to
48 | authors of previous versions.
49 |
50 | Some devices are designed to deny users access to install or run
51 | modified versions of the software inside them, although the manufacturer
52 | can do so. This is fundamentally incompatible with the aim of
53 | protecting users' freedom to change the software. The systematic
54 | pattern of such abuse occurs in the area of products for individuals to
55 | use, which is precisely where it is most unacceptable. Therefore, we
56 | have designed this version of the GPL to prohibit the practice for those
57 | products. If such problems arise substantially in other domains, we
58 | stand ready to extend this provision to those domains in future versions
59 | of the GPL, as needed to protect the freedom of users.
60 |
61 | Finally, every program is threatened constantly by software patents.
62 | States should not allow patents to restrict development and use of
63 | software on general-purpose computers, but in those that do, we wish to
64 | avoid the special danger that patents applied to a free program could
65 | make it effectively proprietary. To prevent this, the GPL assures that
66 | patents cannot be used to render the program non-free.
67 |
68 | The precise terms and conditions for copying, distribution and
69 | modification follow.
70 |
71 | TERMS AND CONDITIONS
72 |
73 | 0. Definitions.
74 |
75 | "This License" refers to version 3 of the GNU General Public License.
76 |
77 | "Copyright" also means copyright-like laws that apply to other kinds of
78 | works, such as semiconductor masks.
79 |
80 | "The Program" refers to any copyrightable work licensed under this
81 | License. Each licensee is addressed as "you". "Licensees" and
82 | "recipients" may be individuals or organizations.
83 |
84 | To "modify" a work means to copy from or adapt all or part of the work
85 | in a fashion requiring copyright permission, other than the making of an
86 | exact copy. The resulting work is called a "modified version" of the
87 | earlier work or a work "based on" the earlier work.
88 |
89 | A "covered work" means either the unmodified Program or a work based
90 | on the Program.
91 |
92 | To "propagate" a work means to do anything with it that, without
93 | permission, would make you directly or secondarily liable for
94 | infringement under applicable copyright law, except executing it on a
95 | computer or modifying a private copy. Propagation includes copying,
96 | distribution (with or without modification), making available to the
97 | public, and in some countries other activities as well.
98 |
99 | To "convey" a work means any kind of propagation that enables other
100 | parties to make or receive copies. Mere interaction with a user through
101 | a computer network, with no transfer of a copy, is not conveying.
102 |
103 | An interactive user interface displays "Appropriate Legal Notices"
104 | to the extent that it includes a convenient and prominently visible
105 | feature that (1) displays an appropriate copyright notice, and (2)
106 | tells the user that there is no warranty for the work (except to the
107 | extent that warranties are provided), that licensees may convey the
108 | work under this License, and how to view a copy of this License. If
109 | the interface presents a list of user commands or options, such as a
110 | menu, a prominent item in the list meets this criterion.
111 |
112 | 1. Source Code.
113 |
114 | The "source code" for a work means the preferred form of the work
115 | for making modifications to it. "Object code" means any non-source
116 | form of a work.
117 |
118 | A "Standard Interface" means an interface that either is an official
119 | standard defined by a recognized standards body, or, in the case of
120 | interfaces specified for a particular programming language, one that
121 | is widely used among developers working in that language.
122 |
123 | The "System Libraries" of an executable work include anything, other
124 | than the work as a whole, that (a) is included in the normal form of
125 | packaging a Major Component, but which is not part of that Major
126 | Component, and (b) serves only to enable use of the work with that
127 | Major Component, or to implement a Standard Interface for which an
128 | implementation is available to the public in source code form. A
129 | "Major Component", in this context, means a major essential component
130 | (kernel, window system, and so on) of the specific operating system
131 | (if any) on which the executable work runs, or a compiler used to
132 | produce the work, or an object code interpreter used to run it.
133 |
134 | The "Corresponding Source" for a work in object code form means all
135 | the source code needed to generate, install, and (for an executable
136 | work) run the object code and to modify the work, including scripts to
137 | control those activities. However, it does not include the work's
138 | System Libraries, or general-purpose tools or generally available free
139 | programs which are used unmodified in performing those activities but
140 | which are not part of the work. For example, Corresponding Source
141 | includes interface definition files associated with source files for
142 | the work, and the source code for shared libraries and dynamically
143 | linked subprograms that the work is specifically designed to require,
144 | such as by intimate data communication or control flow between those
145 | subprograms and other parts of the work.
146 |
147 | The Corresponding Source need not include anything that users
148 | can regenerate automatically from other parts of the Corresponding
149 | Source.
150 |
151 | The Corresponding Source for a work in source code form is that
152 | same work.
153 |
154 | 2. Basic Permissions.
155 |
156 | All rights granted under this License are granted for the term of
157 | copyright on the Program, and are irrevocable provided the stated
158 | conditions are met. This License explicitly affirms your unlimited
159 | permission to run the unmodified Program. The output from running a
160 | covered work is covered by this License only if the output, given its
161 | content, constitutes a covered work. This License acknowledges your
162 | rights of fair use or other equivalent, as provided by copyright law.
163 |
164 | You may make, run and propagate covered works that you do not
165 | convey, without conditions so long as your license otherwise remains
166 | in force. You may convey covered works to others for the sole purpose
167 | of having them make modifications exclusively for you, or provide you
168 | with facilities for running those works, provided that you comply with
169 | the terms of this License in conveying all material for which you do
170 | not control copyright. Those thus making or running the covered works
171 | for you must do so exclusively on your behalf, under your direction
172 | and control, on terms that prohibit them from making any copies of
173 | your copyrighted material outside their relationship with you.
174 |
175 | Conveying under any other circumstances is permitted solely under
176 | the conditions stated below. Sublicensing is not allowed; section 10
177 | makes it unnecessary.
178 |
179 | 3. Protecting Users' Legal Rights From Anti-Circumvention Law.
180 |
181 | No covered work shall be deemed part of an effective technological
182 | measure under any applicable law fulfilling obligations under article
183 | 11 of the WIPO copyright treaty adopted on 20 December 1996, or
184 | similar laws prohibiting or restricting circumvention of such
185 | measures.
186 |
187 | When you convey a covered work, you waive any legal power to forbid
188 | circumvention of technological measures to the extent such circumvention
189 | is effected by exercising rights under this License with respect to
190 | the covered work, and you disclaim any intention to limit operation or
191 | modification of the work as a means of enforcing, against the work's
192 | users, your or third parties' legal rights to forbid circumvention of
193 | technological measures.
194 |
195 | 4. Conveying Verbatim Copies.
196 |
197 | You may convey verbatim copies of the Program's source code as you
198 | receive it, in any medium, provided that you conspicuously and
199 | appropriately publish on each copy an appropriate copyright notice;
200 | keep intact all notices stating that this License and any
201 | non-permissive terms added in accord with section 7 apply to the code;
202 | keep intact all notices of the absence of any warranty; and give all
203 | recipients a copy of this License along with the Program.
204 |
205 | You may charge any price or no price for each copy that you convey,
206 | and you may offer support or warranty protection for a fee.
207 |
208 | 5. Conveying Modified Source Versions.
209 |
210 | You may convey a work based on the Program, or the modifications to
211 | produce it from the Program, in the form of source code under the
212 | terms of section 4, provided that you also meet all of these conditions:
213 |
214 | a) The work must carry prominent notices stating that you modified
215 | it, and giving a relevant date.
216 |
217 | b) The work must carry prominent notices stating that it is
218 | released under this License and any conditions added under section
219 | 7. This requirement modifies the requirement in section 4 to
220 | "keep intact all notices".
221 |
222 | c) You must license the entire work, as a whole, under this
223 | License to anyone who comes into possession of a copy. This
224 | License will therefore apply, along with any applicable section 7
225 | additional terms, to the whole of the work, and all its parts,
226 | regardless of how they are packaged. This License gives no
227 | permission to license the work in any other way, but it does not
228 | invalidate such permission if you have separately received it.
229 |
230 | d) If the work has interactive user interfaces, each must display
231 | Appropriate Legal Notices; however, if the Program has interactive
232 | interfaces that do not display Appropriate Legal Notices, your
233 | work need not make them do so.
234 |
235 | A compilation of a covered work with other separate and independent
236 | works, which are not by their nature extensions of the covered work,
237 | and which are not combined with it such as to form a larger program,
238 | in or on a volume of a storage or distribution medium, is called an
239 | "aggregate" if the compilation and its resulting copyright are not
240 | used to limit the access or legal rights of the compilation's users
241 | beyond what the individual works permit. Inclusion of a covered work
242 | in an aggregate does not cause this License to apply to the other
243 | parts of the aggregate.
244 |
245 | 6. Conveying Non-Source Forms.
246 |
247 | You may convey a covered work in object code form under the terms
248 | of sections 4 and 5, provided that you also convey the
249 | machine-readable Corresponding Source under the terms of this License,
250 | in one of these ways:
251 |
252 | a) Convey the object code in, or embodied in, a physical product
253 | (including a physical distribution medium), accompanied by the
254 | Corresponding Source fixed on a durable physical medium
255 | customarily used for software interchange.
256 |
257 | b) Convey the object code in, or embodied in, a physical product
258 | (including a physical distribution medium), accompanied by a
259 | written offer, valid for at least three years and valid for as
260 | long as you offer spare parts or customer support for that product
261 | model, to give anyone who possesses the object code either (1) a
262 | copy of the Corresponding Source for all the software in the
263 | product that is covered by this License, on a durable physical
264 | medium customarily used for software interchange, for a price no
265 | more than your reasonable cost of physically performing this
266 | conveying of source, or (2) access to copy the
267 | Corresponding Source from a network server at no charge.
268 |
269 | c) Convey individual copies of the object code with a copy of the
270 | written offer to provide the Corresponding Source. This
271 | alternative is allowed only occasionally and noncommercially, and
272 | only if you received the object code with such an offer, in accord
273 | with subsection 6b.
274 |
275 | d) Convey the object code by offering access from a designated
276 | place (gratis or for a charge), and offer equivalent access to the
277 | Corresponding Source in the same way through the same place at no
278 | further charge. You need not require recipients to copy the
279 | Corresponding Source along with the object code. If the place to
280 | copy the object code is a network server, the Corresponding Source
281 | may be on a different server (operated by you or a third party)
282 | that supports equivalent copying facilities, provided you maintain
283 | clear directions next to the object code saying where to find the
284 | Corresponding Source. Regardless of what server hosts the
285 | Corresponding Source, you remain obligated to ensure that it is
286 | available for as long as needed to satisfy these requirements.
287 |
288 | e) Convey the object code using peer-to-peer transmission, provided
289 | you inform other peers where the object code and Corresponding
290 | Source of the work are being offered to the general public at no
291 | charge under subsection 6d.
292 |
293 | A separable portion of the object code, whose source code is excluded
294 | from the Corresponding Source as a System Library, need not be
295 | included in conveying the object code work.
296 |
297 | A "User Product" is either (1) a "consumer product", which means any
298 | tangible personal property which is normally used for personal, family,
299 | or household purposes, or (2) anything designed or sold for incorporation
300 | into a dwelling. In determining whether a product is a consumer product,
301 | doubtful cases shall be resolved in favor of coverage. For a particular
302 | product received by a particular user, "normally used" refers to a
303 | typical or common use of that class of product, regardless of the status
304 | of the particular user or of the way in which the particular user
305 | actually uses, or expects or is expected to use, the product. A product
306 | is a consumer product regardless of whether the product has substantial
307 | commercial, industrial or non-consumer uses, unless such uses represent
308 | the only significant mode of use of the product.
309 |
310 | "Installation Information" for a User Product means any methods,
311 | procedures, authorization keys, or other information required to install
312 | and execute modified versions of a covered work in that User Product from
313 | a modified version of its Corresponding Source. The information must
314 | suffice to ensure that the continued functioning of the modified object
315 | code is in no case prevented or interfered with solely because
316 | modification has been made.
317 |
318 | If you convey an object code work under this section in, or with, or
319 | specifically for use in, a User Product, and the conveying occurs as
320 | part of a transaction in which the right of possession and use of the
321 | User Product is transferred to the recipient in perpetuity or for a
322 | fixed term (regardless of how the transaction is characterized), the
323 | Corresponding Source conveyed under this section must be accompanied
324 | by the Installation Information. But this requirement does not apply
325 | if neither you nor any third party retains the ability to install
326 | modified object code on the User Product (for example, the work has
327 | been installed in ROM).
328 |
329 | The requirement to provide Installation Information does not include a
330 | requirement to continue to provide support service, warranty, or updates
331 | for a work that has been modified or installed by the recipient, or for
332 | the User Product in which it has been modified or installed. Access to a
333 | network may be denied when the modification itself materially and
334 | adversely affects the operation of the network or violates the rules and
335 | protocols for communication across the network.
336 |
337 | Corresponding Source conveyed, and Installation Information provided,
338 | in accord with this section must be in a format that is publicly
339 | documented (and with an implementation available to the public in
340 | source code form), and must require no special password or key for
341 | unpacking, reading or copying.
342 |
343 | 7. Additional Terms.
344 |
345 | "Additional permissions" are terms that supplement the terms of this
346 | License by making exceptions from one or more of its conditions.
347 | Additional permissions that are applicable to the entire Program shall
348 | be treated as though they were included in this License, to the extent
349 | that they are valid under applicable law. If additional permissions
350 | apply only to part of the Program, that part may be used separately
351 | under those permissions, but the entire Program remains governed by
352 | this License without regard to the additional permissions.
353 |
354 | When you convey a copy of a covered work, you may at your option
355 | remove any additional permissions from that copy, or from any part of
356 | it. (Additional permissions may be written to require their own
357 | removal in certain cases when you modify the work.) You may place
358 | additional permissions on material, added by you to a covered work,
359 | for which you have or can give appropriate copyright permission.
360 |
361 | Notwithstanding any other provision of this License, for material you
362 | add to a covered work, you may (if authorized by the copyright holders of
363 | that material) supplement the terms of this License with terms:
364 |
365 | a) Disclaiming warranty or limiting liability differently from the
366 | terms of sections 15 and 16 of this License; or
367 |
368 | b) Requiring preservation of specified reasonable legal notices or
369 | author attributions in that material or in the Appropriate Legal
370 | Notices displayed by works containing it; or
371 |
372 | c) Prohibiting misrepresentation of the origin of that material, or
373 | requiring that modified versions of such material be marked in
374 | reasonable ways as different from the original version; or
375 |
376 | d) Limiting the use for publicity purposes of names of licensors or
377 | authors of the material; or
378 |
379 | e) Declining to grant rights under trademark law for use of some
380 | trade names, trademarks, or service marks; or
381 |
382 | f) Requiring indemnification of licensors and authors of that
383 | material by anyone who conveys the material (or modified versions of
384 | it) with contractual assumptions of liability to the recipient, for
385 | any liability that these contractual assumptions directly impose on
386 | those licensors and authors.
387 |
388 | All other non-permissive additional terms are considered "further
389 | restrictions" within the meaning of section 10. If the Program as you
390 | received it, or any part of it, contains a notice stating that it is
391 | governed by this License along with a term that is a further
392 | restriction, you may remove that term. If a license document contains
393 | a further restriction but permits relicensing or conveying under this
394 | License, you may add to a covered work material governed by the terms
395 | of that license document, provided that the further restriction does
396 | not survive such relicensing or conveying.
397 |
398 | If you add terms to a covered work in accord with this section, you
399 | must place, in the relevant source files, a statement of the
400 | additional terms that apply to those files, or a notice indicating
401 | where to find the applicable terms.
402 |
403 | Additional terms, permissive or non-permissive, may be stated in the
404 | form of a separately written license, or stated as exceptions;
405 | the above requirements apply either way.
406 |
407 | 8. Termination.
408 |
409 | You may not propagate or modify a covered work except as expressly
410 | provided under this License. Any attempt otherwise to propagate or
411 | modify it is void, and will automatically terminate your rights under
412 | this License (including any patent licenses granted under the third
413 | paragraph of section 11).
414 |
415 | However, if you cease all violation of this License, then your
416 | license from a particular copyright holder is reinstated (a)
417 | provisionally, unless and until the copyright holder explicitly and
418 | finally terminates your license, and (b) permanently, if the copyright
419 | holder fails to notify you of the violation by some reasonable means
420 | prior to 60 days after the cessation.
421 |
422 | Moreover, your license from a particular copyright holder is
423 | reinstated permanently if the copyright holder notifies you of the
424 | violation by some reasonable means, this is the first time you have
425 | received notice of violation of this License (for any work) from that
426 | copyright holder, and you cure the violation prior to 30 days after
427 | your receipt of the notice.
428 |
429 | Termination of your rights under this section does not terminate the
430 | licenses of parties who have received copies or rights from you under
431 | this License. If your rights have been terminated and not permanently
432 | reinstated, you do not qualify to receive new licenses for the same
433 | material under section 10.
434 |
435 | 9. Acceptance Not Required for Having Copies.
436 |
437 | You are not required to accept this License in order to receive or
438 | run a copy of the Program. Ancillary propagation of a covered work
439 | occurring solely as a consequence of using peer-to-peer transmission
440 | to receive a copy likewise does not require acceptance. However,
441 | nothing other than this License grants you permission to propagate or
442 | modify any covered work. These actions infringe copyright if you do
443 | not accept this License. Therefore, by modifying or propagating a
444 | covered work, you indicate your acceptance of this License to do so.
445 |
446 | 10. Automatic Licensing of Downstream Recipients.
447 |
448 | Each time you convey a covered work, the recipient automatically
449 | receives a license from the original licensors, to run, modify and
450 | propagate that work, subject to this License. You are not responsible
451 | for enforcing compliance by third parties with this License.
452 |
453 | An "entity transaction" is a transaction transferring control of an
454 | organization, or substantially all assets of one, or subdividing an
455 | organization, or merging organizations. If propagation of a covered
456 | work results from an entity transaction, each party to that
457 | transaction who receives a copy of the work also receives whatever
458 | licenses to the work the party's predecessor in interest had or could
459 | give under the previous paragraph, plus a right to possession of the
460 | Corresponding Source of the work from the predecessor in interest, if
461 | the predecessor has it or can get it with reasonable efforts.
462 |
463 | You may not impose any further restrictions on the exercise of the
464 | rights granted or affirmed under this License. For example, you may
465 | not impose a license fee, royalty, or other charge for exercise of
466 | rights granted under this License, and you may not initiate litigation
467 | (including a cross-claim or counterclaim in a lawsuit) alleging that
468 | any patent claim is infringed by making, using, selling, offering for
469 | sale, or importing the Program or any portion of it.
470 |
471 | 11. Patents.
472 |
473 | A "contributor" is a copyright holder who authorizes use under this
474 | License of the Program or a work on which the Program is based. The
475 | work thus licensed is called the contributor's "contributor version".
476 |
477 | A contributor's "essential patent claims" are all patent claims
478 | owned or controlled by the contributor, whether already acquired or
479 | hereafter acquired, that would be infringed by some manner, permitted
480 | by this License, of making, using, or selling its contributor version,
481 | but do not include claims that would be infringed only as a
482 | consequence of further modification of the contributor version. For
483 | purposes of this definition, "control" includes the right to grant
484 | patent sublicenses in a manner consistent with the requirements of
485 | this License.
486 |
487 | Each contributor grants you a non-exclusive, worldwide, royalty-free
488 | patent license under the contributor's essential patent claims, to
489 | make, use, sell, offer for sale, import and otherwise run, modify and
490 | propagate the contents of its contributor version.
491 |
492 | In the following three paragraphs, a "patent license" is any express
493 | agreement or commitment, however denominated, not to enforce a patent
494 | (such as an express permission to practice a patent or covenant not to
495 | sue for patent infringement). To "grant" such a patent license to a
496 | party means to make such an agreement or commitment not to enforce a
497 | patent against the party.
498 |
499 | If you convey a covered work, knowingly relying on a patent license,
500 | and the Corresponding Source of the work is not available for anyone
501 | to copy, free of charge and under the terms of this License, through a
502 | publicly available network server or other readily accessible means,
503 | then you must either (1) cause the Corresponding Source to be so
504 | available, or (2) arrange to deprive yourself of the benefit of the
505 | patent license for this particular work, or (3) arrange, in a manner
506 | consistent with the requirements of this License, to extend the patent
507 | license to downstream recipients. "Knowingly relying" means you have
508 | actual knowledge that, but for the patent license, your conveying the
509 | covered work in a country, or your recipient's use of the covered work
510 | in a country, would infringe one or more identifiable patents in that
511 | country that you have reason to believe are valid.
512 |
513 | If, pursuant to or in connection with a single transaction or
514 | arrangement, you convey, or propagate by procuring conveyance of, a
515 | covered work, and grant a patent license to some of the parties
516 | receiving the covered work authorizing them to use, propagate, modify
517 | or convey a specific copy of the covered work, then the patent license
518 | you grant is automatically extended to all recipients of the covered
519 | work and works based on it.
520 |
521 | A patent license is "discriminatory" if it does not include within
522 | the scope of its coverage, prohibits the exercise of, or is
523 | conditioned on the non-exercise of one or more of the rights that are
524 | specifically granted under this License. You may not convey a covered
525 | work if you are a party to an arrangement with a third party that is
526 | in the business of distributing software, under which you make payment
527 | to the third party based on the extent of your activity of conveying
528 | the work, and under which the third party grants, to any of the
529 | parties who would receive the covered work from you, a discriminatory
530 | patent license (a) in connection with copies of the covered work
531 | conveyed by you (or copies made from those copies), or (b) primarily
532 | for and in connection with specific products or compilations that
533 | contain the covered work, unless you entered into that arrangement,
534 | or that patent license was granted, prior to 28 March 2007.
535 |
536 | Nothing in this License shall be construed as excluding or limiting
537 | any implied license or other defenses to infringement that may
538 | otherwise be available to you under applicable patent law.
539 |
540 | 12. No Surrender of Others' Freedom.
541 |
542 | If conditions are imposed on you (whether by court order, agreement or
543 | otherwise) that contradict the conditions of this License, they do not
544 | excuse you from the conditions of this License. If you cannot convey a
545 | covered work so as to satisfy simultaneously your obligations under this
546 | License and any other pertinent obligations, then as a consequence you may
547 | not convey it at all. For example, if you agree to terms that obligate you
548 | to collect a royalty for further conveying from those to whom you convey
549 | the Program, the only way you could satisfy both those terms and this
550 | License would be to refrain entirely from conveying the Program.
551 |
552 | 13. Use with the GNU Affero General Public License.
553 |
554 | Notwithstanding any other provision of this License, you have
555 | permission to link or combine any covered work with a work licensed
556 | under version 3 of the GNU Affero General Public License into a single
557 | combined work, and to convey the resulting work. The terms of this
558 | License will continue to apply to the part which is the covered work,
559 | but the special requirements of the GNU Affero General Public License,
560 | section 13, concerning interaction through a network will apply to the
561 | combination as such.
562 |
563 | 14. Revised Versions of this License.
564 |
565 | The Free Software Foundation may publish revised and/or new versions of
566 | the GNU General Public License from time to time. Such new versions will
567 | be similar in spirit to the present version, but may differ in detail to
568 | address new problems or concerns.
569 |
570 | Each version is given a distinguishing version number. If the
571 | Program specifies that a certain numbered version of the GNU General
572 | Public License "or any later version" applies to it, you have the
573 | option of following the terms and conditions either of that numbered
574 | version or of any later version published by the Free Software
575 | Foundation. If the Program does not specify a version number of the
576 | GNU General Public License, you may choose any version ever published
577 | by the Free Software Foundation.
578 |
579 | If the Program specifies that a proxy can decide which future
580 | versions of the GNU General Public License can be used, that proxy's
581 | public statement of acceptance of a version permanently authorizes you
582 | to choose that version for the Program.
583 |
584 | Later license versions may give you additional or different
585 | permissions. However, no additional obligations are imposed on any
586 | author or copyright holder as a result of your choosing to follow a
587 | later version.
588 |
589 | 15. Disclaimer of Warranty.
590 |
591 | THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
592 | APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
593 | HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
594 | OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
595 | THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
596 | PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
597 | IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
598 | ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
599 |
600 | 16. Limitation of Liability.
601 |
602 | IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
603 | WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
604 | THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
605 | GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
606 | USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
607 | DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
608 | PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
609 | EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
610 | SUCH DAMAGES.
611 |
612 | 17. Interpretation of Sections 15 and 16.
613 |
614 | If the disclaimer of warranty and limitation of liability provided
615 | above cannot be given local legal effect according to their terms,
616 | reviewing courts shall apply local law that most closely approximates
617 | an absolute waiver of all civil liability in connection with the
618 | Program, unless a warranty or assumption of liability accompanies a
619 | copy of the Program in return for a fee.
620 |
621 | END OF TERMS AND CONDITIONS
622 |
623 | How to Apply These Terms to Your New Programs
624 |
625 | If you develop a new program, and you want it to be of the greatest
626 | possible use to the public, the best way to achieve this is to make it
627 | free software which everyone can redistribute and change under these terms.
628 |
629 | To do so, attach the following notices to the program. It is safest
630 | to attach them to the start of each source file to most effectively
631 | state the exclusion of warranty; and each file should have at least
632 | the "copyright" line and a pointer to where the full notice is found.
633 |
634 |
635 | Copyright (C)
636 |
637 | This program is free software: you can redistribute it and/or modify
638 | it under the terms of the GNU General Public License as published by
639 | the Free Software Foundation, either version 3 of the License, or
640 | (at your option) any later version.
641 |
642 | This program is distributed in the hope that it will be useful,
643 | but WITHOUT ANY WARRANTY; without even the implied warranty of
644 | MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
645 | GNU General Public License for more details.
646 |
647 | You should have received a copy of the GNU General Public License
648 | along with this program. If not, see .
649 |
650 | Also add information on how to contact you by electronic and paper mail.
651 |
652 | If the program does terminal interaction, make it output a short
653 | notice like this when it starts in an interactive mode:
654 |
655 | Copyright (C)
656 | This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
657 | This is free software, and you are welcome to redistribute it
658 | under certain conditions; type `show c' for details.
659 |
660 | The hypothetical commands `show w' and `show c' should show the appropriate
661 | parts of the General Public License. Of course, your program's commands
662 | might be different; for a GUI interface, you would use an "about box".
663 |
664 | You should also get your employer (if you work as a programmer) or school,
665 | if any, to sign a "copyright disclaimer" for the program, if necessary.
666 | For more information on this, and how to apply and follow the GNU GPL, see
667 | .
668 |
669 | The GNU General Public License does not permit incorporating your program
670 | into proprietary programs. If your program is a subroutine library, you
671 | may consider it more useful to permit linking proprietary applications with
672 | the library. If this is what you want to do, use the GNU Lesser General
673 | Public License instead of this License. But first, please read
674 | .
675 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include pyquad/quad.c
2 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 
2 | [](https://doi.org/10.5281/zenodo.3936959)
3 |
4 | # pyquad
5 |
6 | A drop-in replacment for `scipy.integrate.quad` which is much faster for repeat
7 | integrals over a parameter space.
8 |
9 | The library provides a thin, parallel wrapper for the [GNU Scientific Library (GSL)
10 | integration routines](https://www.gnu.org/software/gsl/).
11 |
12 | ## Examples
13 |
14 | The code below is a python example of integrating over a grid of parameters
15 | using `scipy.integrate.quad`,
16 |
17 | ```python
18 | import numpy as np
19 | import scipy.integrate
20 |
21 |
22 | def test_integrand_func(x, alpha, beta, i, j, k, l):
23 | return x * alpha * beta + i * j * k
24 |
25 |
26 | grid = np.random.random((10000000, 2))
27 |
28 | res = np.zeros(grid.shape[0])
29 | for i in range(res.shape[0]):
30 | res[i] = scipy.integrate.quad(
31 | test_integrand_func, 0, 1, (grid[i, 0], grid[i, 1], 1.0, 1.0, 1.0, 1.0)
32 | )[0]
33 | ```
34 |
35 | this can be replaced with,
36 |
37 | ```python
38 | import numpy as np
39 | import pyquad
40 |
41 |
42 | def test_integrand_func(x, alpha, beta, i, j, k, l):
43 | return x * alpha * beta + i * j * k
44 |
45 |
46 | grid = np.random.random((10000000, 2))
47 |
48 | res, err = pyquad.quad_grid(test_integrand_func, 0, 1, grid, (1.0, 1.0, 1.0, 1.0))
49 | ```
50 |
51 | which reduces the runtime significantly. For an example of the performance see
52 | the benchmarks below.
53 |
54 | ## Benchmarks
55 |
56 | We first compare a test integral in both pyquad and scipy,
57 |
58 | 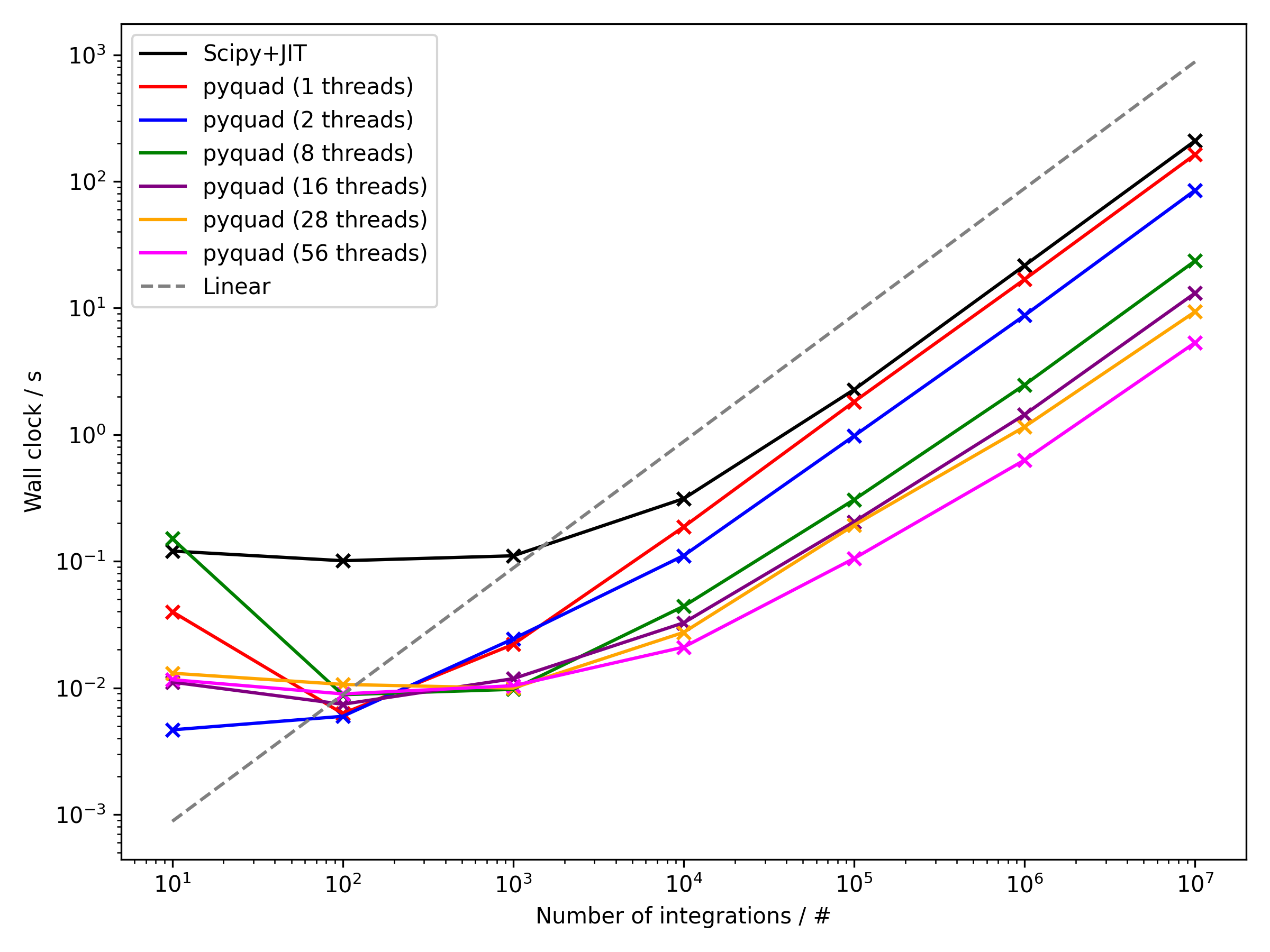
59 |
60 | and then we look in more detail at the scaling of pyquad with an increased
61 | thread count,
62 |
63 | 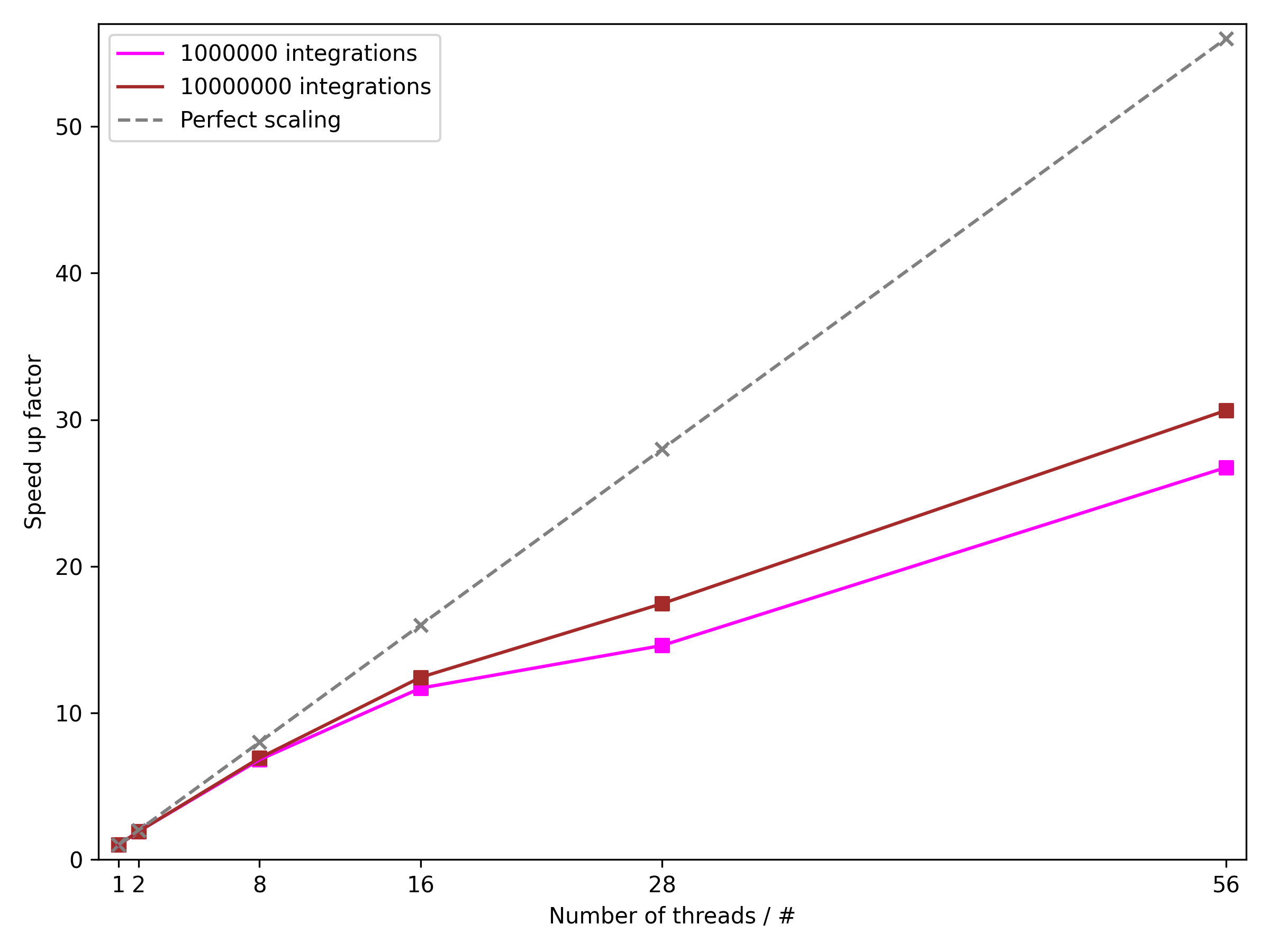
64 |
65 | These benchmarks were carried out on cosma7 which has 28 cores (2x Intel Xeon
66 | Gold 5120 CPU @ 2.20GHz). Perfect scaling was never to be expected, given the problem
67 | becomes completely memorybound with a high core count.
68 |
69 | ## Installing
70 |
71 | To get started using the package you can use pip
72 | to download wheels for linux or osx,
73 |
74 |
75 | ```
76 | pip install pyquad --user
77 | ```
78 |
79 | or you can clone the repository,
80 |
81 | ```
82 | git clone https://github.com/AshKelly/pyquad.git
83 | ```
84 |
85 | and then go into the repository and run the setup file,
86 |
87 | ```
88 | cd pyquad
89 | python setup.py install
90 | ```
91 |
92 | ### Requirements
93 |
94 | The package requires that numpy is already installed and we require a C
95 | compiler to build from source.
96 |
97 | ## Running the tests
98 |
99 | The tests are currently incredibly primitive and just do a variety of answer
100 | testing by comparing to `scipy.integrate.quad`. These can be run with,
101 |
102 | ```
103 | pytest tests
104 | ```
105 |
106 | inside the pyquad folder. You will need to install pytest and scipy for this
107 | (`pip install pytest scipy --user`)
108 | i
109 |
110 | ## History
111 |
112 | I started to write components of this to help speed up some integrals for
113 | [PyAutoLens](https://github.com/Jammy2211/PyAutoLens/). As it happened, a few
114 | other people in my department were also interested. I attempted to neaten up
115 | the API and roll it out for easy use.
116 |
117 | If you want to contribute or want any extra feature implementing please just
118 | get in touch via email or a pull request.
119 |
120 | ## Authors
121 |
122 | * **Ashley Kelly** (a.j.kelly@durham.ac.uk)
123 | * **Arnau Quera** (arnau.quera-bofarull@durham.ac.uk)
124 |
125 | ## Citations
126 |
127 | Please use the following citation:
128 |
129 | ```
130 | @software{kelly:2020,
131 | author = {Ashley J. Kelly},
132 | title = {pyquad},
133 | month = jul,
134 | year = 2020,
135 | publisher = {Zenodo},
136 | version = {0.6.4},
137 | doi = {10.5281/zenodo.3936959},
138 | url = {https://doi.org/10.5281/zenodo.3936959}
139 | }
140 | ```
141 |
142 | ## License
143 |
144 | This project is licensed under the GPL v3.0 License - see the
145 | [LICENSE.md](LICENSE.md) file for details
146 |
--------------------------------------------------------------------------------
/benchmarking/benchmarks.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AshKelly/pyquad/60a4ddd9107d49b4d74cfa928091f0182926c386/benchmarking/benchmarks.png
--------------------------------------------------------------------------------
/benchmarking/benchmarks_pyquad.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AshKelly/pyquad/60a4ddd9107d49b4d74cfa928091f0182926c386/benchmarking/benchmarks_pyquad.png
--------------------------------------------------------------------------------
/benchmarking/jit.py:
--------------------------------------------------------------------------------
1 | import numba
2 | from numba import cfunc
3 | from numba.types import intc, CPointer, float64
4 | from scipy import LowLevelCallable
5 | import inspect
6 |
7 |
8 | def jit_integrand(integrand_function):
9 | jitted_function = numba.jit(integrand_function, nopython=True)
10 | no_args = len(inspect.getfullargspec(integrand_function).args)
11 |
12 | wrapped = None
13 |
14 | if no_args == 4:
15 | def wrapped(n, xx):
16 | return jitted_function(xx[0], xx[1], xx[2], xx[3])
17 | elif no_args == 5:
18 | def wrapped(n, xx):
19 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4])
20 | elif no_args == 6:
21 | def wrapped(n, xx):
22 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5])
23 | elif no_args == 7:
24 | def wrapped(n, xx):
25 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5], xx[6])
26 | elif no_args == 8:
27 | def wrapped(n, xx):
28 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5], xx[6], xx[7])
29 | elif no_args == 9:
30 | def wrapped(n, xx):
31 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5], xx[6], xx[7], xx[8])
32 | elif no_args == 10:
33 | def wrapped(n, xx):
34 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5], xx[6], xx[7], xx[8], xx[9])
35 | elif no_args == 11:
36 | def wrapped(n, xx):
37 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5], xx[6], xx[7], xx[8], xx[9], xx[10])
38 |
39 | cf = cfunc(float64(intc, CPointer(float64)))
40 |
41 | return LowLevelCallable(cf(wrapped).ctypes)
42 |
--------------------------------------------------------------------------------
/benchmarking/pyquad_benchmark.py:
--------------------------------------------------------------------------------
1 | import matplotlib.pyplot as plt
2 | import pyquad
3 | import numpy as np
4 |
5 |
6 | INTEGRAL_METHOD = "qags"
7 | REPEATS = 20
8 |
9 |
10 | def test_func(x, a, b, c):
11 | return a*a / (x + 1.0) + b * np.sin(np.sqrt(x)) + c * np.log(x + 1) + np.tanh(x*a)
12 |
13 |
14 | def benchmark_pyquad():
15 | np.random.seed(101)
16 | grid = np.random.random((10000, 3))
17 |
18 | for repeat in range(REPEATS):
19 | res = pyquad.quad_grid(test_func, 0.0, 2.0, grid, method=INTEGRAL_METHOD,
20 | num_threads=8)[0]
21 |
22 |
23 |
24 | benchmark_pyquad()
25 |
--------------------------------------------------------------------------------
/benchmarking/run_benchmarks.py:
--------------------------------------------------------------------------------
1 | import matplotlib.pyplot as plt
2 | import scipy.integrate
3 | import pyquad
4 | import numpy as np
5 | import time
6 |
7 | from jit import jit_integrand
8 |
9 |
10 | PROBLEM_SIZES = [10,100,1000,10000,100000,1000000,10000000]
11 | REPEATS = 2
12 | NUM_THREADS = [1, 2, 8, 16, 26]
13 | COLORS = ["red", "blue", "green", "purple", "orange", "magenta", "brown",
14 | "skyblue"]
15 |
16 | INTEGRAL_METHOD = "qags"
17 |
18 | SCIPY_TTS = []
19 | PYQUAD_TTS = {}
20 |
21 |
22 | def test_func(x, a, b, c):
23 | return a*a / (x + 1.0) + b * np.sin(np.sqrt(x)) + c * np.log(x + 1) + np.tanh(x*a)
24 |
25 |
26 | def benchmark_pyquad():
27 | for threads in NUM_THREADS:
28 | PYQUAD_TTS[threads] = []
29 |
30 | for problem in PROBLEM_SIZES:
31 | np.random.seed(101)
32 | grid = np.random.random((problem, 3))
33 |
34 | for threads in NUM_THREADS:
35 | t0 = time.time()
36 | for repeat in range(REPEATS):
37 | res, _ = pyquad.quad_grid(test_func, 0.0, 2.0, grid, method=INTEGRAL_METHOD,
38 | num_threads=threads)
39 | t1 = time.time()
40 |
41 | PYQUAD_TTS[threads].append((t1 - t0)/REPEATS)
42 |
43 |
44 | def benchmark_scipy_jit():
45 | for problem in PROBLEM_SIZES:
46 | np.random.seed(101)
47 | grid = np.random.random((problem, 3))
48 |
49 | t0 = time.time()
50 | for repeat in range(REPEATS):
51 | res = np.zeros(grid.shape[0])
52 | # jit the integrand here for fair comparison
53 | jitted_integrand = jit_integrand(test_func)
54 | for i in range(res.shape[0]):
55 | res[i], _ = scipy.integrate.quad(
56 | jitted_integrand, 0, 2.0, (grid[i, 0], grid[i, 1], grid[i, 2])
57 | )
58 | t1 = time.time()
59 |
60 | SCIPY_TTS.append((t1 - t0)/REPEATS)
61 |
62 |
63 | if __name__ == "__main__":
64 | benchmark_pyquad()
65 | benchmark_scipy_jit()
66 |
67 |
68 | fig, ax = plt.subplots(1, 1, figsize=(8, 6), dpi=300)
69 |
70 | ax.plot(PROBLEM_SIZES, SCIPY_TTS, color="black", label="Scipy+JIT")
71 | ax.scatter(PROBLEM_SIZES, SCIPY_TTS, color="black", marker="x")
72 |
73 | for color, threads in zip(COLORS, NUM_THREADS):
74 | ax.plot(PROBLEM_SIZES, PYQUAD_TTS[threads], color=color,
75 | label="pyquad ({0} threads)".format(threads))
76 | ax.scatter(PROBLEM_SIZES, PYQUAD_TTS[threads], color=color, marker="x")
77 |
78 | ax.plot(PROBLEM_SIZES, (np.asarray(PROBLEM_SIZES)/PROBLEM_SIZES[1])*PYQUAD_TTS[8][1],
79 | color="grey", linestyle="--", label="Linear")
80 |
81 | ax.legend(loc="best")
82 |
83 | ax.set_xscale("log")
84 | ax.set_yscale("log")
85 |
86 | ax.set_xlabel("Number of integrations / #")
87 | ax.set_ylabel("Wall clock / s")
88 |
89 | fig.tight_layout()
90 | fig.savefig("benchmarks.png", dpi=300)
91 |
92 |
93 | fig, ax = plt.subplots(1, 1, figsize=(8, 6), dpi=300)
94 |
95 | for i, color, problem in zip(range(len(PROBLEM_SIZES)), COLORS, PROBLEM_SIZES):
96 | if problem == 1000000:
97 | TTS = []
98 | for threads in NUM_THREADS:
99 | TTS.append(PYQUAD_TTS[threads][i])
100 | ax.plot(NUM_THREADS, TTS[0]/np.asarray(TTS), color=color,
101 | label="{0} integrations".format(problem))
102 | ax.scatter(NUM_THREADS, TTS[0]/np.asarray(TTS), color=color,
103 | marker="s")
104 |
105 | if problem == 10000000:
106 | TTS = []
107 | for threads in NUM_THREADS:
108 | TTS.append(PYQUAD_TTS[threads][i])
109 | ax.plot(NUM_THREADS, TTS[0]/np.asarray(TTS), color=color,
110 | label="{0} integrations".format(problem))
111 | ax.scatter(NUM_THREADS, TTS[0]/np.asarray(TTS), color=color,
112 | marker="s")
113 |
114 | ax.plot(NUM_THREADS, NUM_THREADS, color="grey", linestyle="--",
115 | label="Perfect scaling")
116 | ax.scatter(NUM_THREADS, NUM_THREADS, color="grey", marker="x")
117 |
118 | ax.legend(loc="best")
119 |
120 | ax.set_xlabel("Number of threads / #")
121 | ax.set_ylabel("Speed up factor")
122 |
123 | ax.set_xticks(NUM_THREADS)
124 | ax.set_xticklabels(NUM_THREADS)
125 |
126 | ax.set_xlim(0, max(NUM_THREADS)+1)
127 | ax.set_ylim(0, max(NUM_THREADS)+1)
128 |
129 | fig.tight_layout()
130 | fig.savefig("benchmarks_pyquad.png", dpi=300)
131 |
--------------------------------------------------------------------------------
/examples/.ipynb_checkpoints/jupyter_example-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "import numpy as np\n",
10 | "import scipy.integrate\n",
11 | "\n",
12 | "from pyquad import quad, quad_grid\n",
13 | "from jit import jit_integrand"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 2,
19 | "metadata": {},
20 | "outputs": [],
21 | "source": [
22 | "def test_integrand_func(x, alpha, beta, i, j, k, l): \n",
23 | " return x * alpha * beta + i * j * k "
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "# pyquad.quad <-> scipy.integrate.quad"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "In a basic sense, it is possible to just drop-in the `pyquad.quad` in place of `scipy.integrate.quad`. Though for a single integral there isn't really any benefit of this,"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": 3,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "res, error = quad(test_integrand_func, 0, 1, (1., 1., 1., 1., 1., 1.))"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": 4,
52 | "metadata": {},
53 | "outputs": [
54 | {
55 | "data": {
56 | "text/plain": [
57 | "(1.5, 1.6653345369377348e-14)"
58 | ]
59 | },
60 | "execution_count": 4,
61 | "metadata": {},
62 | "output_type": "execute_result"
63 | }
64 | ],
65 | "source": [
66 | "res, error"
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": 5,
72 | "metadata": {},
73 | "outputs": [],
74 | "source": [
75 | "res, error = scipy.integrate.quad(test_integrand_func, 0, 1, (1., 1., 1., 1., 1., 1.))"
76 | ]
77 | },
78 | {
79 | "cell_type": "code",
80 | "execution_count": 6,
81 | "metadata": {},
82 | "outputs": [
83 | {
84 | "data": {
85 | "text/plain": [
86 | "(1.5, 1.6653345369377348e-14)"
87 | ]
88 | },
89 | "execution_count": 6,
90 | "metadata": {},
91 | "output_type": "execute_result"
92 | }
93 | ],
94 | "source": [
95 | "res, error"
96 | ]
97 | },
98 | {
99 | "cell_type": "markdown",
100 | "metadata": {},
101 | "source": [
102 | "# pyquad.quad_grid"
103 | ]
104 | },
105 | {
106 | "cell_type": "markdown",
107 | "metadata": {},
108 | "source": [
109 | "This is the regime where pyquad is worth the investment. If you have 6 parameters in your integrand, and you want to integrate over a range of 2 of them then in scipy it may look something like this,"
110 | ]
111 | },
112 | {
113 | "cell_type": "code",
114 | "execution_count": 7,
115 | "metadata": {},
116 | "outputs": [],
117 | "source": [
118 | "grid = np.random.random((10000000, 2))"
119 | ]
120 | },
121 | {
122 | "cell_type": "code",
123 | "execution_count": 8,
124 | "metadata": {},
125 | "outputs": [
126 | {
127 | "name": "stdout",
128 | "output_type": "stream",
129 | "text": [
130 | "CPU times: user 1min 40s, sys: 62.2 ms, total: 1min 40s\n",
131 | "Wall time: 1min 40s\n"
132 | ]
133 | }
134 | ],
135 | "source": [
136 | "%%time\n",
137 | "res = np.zeros(grid.shape[0])\n",
138 | "err = np.zeros(grid.shape[0]) \n",
139 | " \n",
140 | "for i in range(res.shape[0]): \n",
141 | " res[i], err[i] = scipy.integrate.quad(test_integrand_func, 0, 1, \n",
142 | " (grid[i, 0], grid[i, 1], 1.0, 1.0, 1.0, 1.0))"
143 | ]
144 | },
145 | {
146 | "cell_type": "code",
147 | "execution_count": 9,
148 | "metadata": {},
149 | "outputs": [
150 | {
151 | "data": {
152 | "text/plain": [
153 | "(array([1.11591324, 1.03565151, 1.29417096, ..., 1.0791415 , 1.08966962,\n",
154 | " 1.00045506]),\n",
155 | " array([1.23891258e-14, 1.14980415e-14, 1.43681840e-14, ...,\n",
156 | " 1.19808774e-14, 1.20977630e-14, 1.11072825e-14]))"
157 | ]
158 | },
159 | "execution_count": 9,
160 | "metadata": {},
161 | "output_type": "execute_result"
162 | }
163 | ],
164 | "source": [
165 | "res, err"
166 | ]
167 | },
168 | {
169 | "cell_type": "markdown",
170 | "metadata": {},
171 | "source": [
172 | "but with `pyquad.quad_grid` we are able to make the code more elegant and significantly faster by reducing calls to the python function and also compiling the integrand. All of this is done behind the API."
173 | ]
174 | },
175 | {
176 | "cell_type": "code",
177 | "execution_count": 10,
178 | "metadata": {},
179 | "outputs": [
180 | {
181 | "name": "stdout",
182 | "output_type": "stream",
183 | "text": [
184 | "CPU times: user 1.43 s, sys: 104 ms, total: 1.53 s\n",
185 | "Wall time: 1.53 s\n"
186 | ]
187 | }
188 | ],
189 | "source": [
190 | "%%time\n",
191 | "res, err = quad_grid(test_integrand_func, 0, 1, grid, (1.0, 1.0, 1.0, 1.0))"
192 | ]
193 | },
194 | {
195 | "cell_type": "code",
196 | "execution_count": 11,
197 | "metadata": {},
198 | "outputs": [
199 | {
200 | "data": {
201 | "text/plain": [
202 | "(array([1.11591324, 1.03565151, 1.29417096, ..., 1.0791415 , 1.08966962,\n",
203 | " 1.00045506]),\n",
204 | " array([1.23891258e-14, 1.14980415e-14, 1.43681840e-14, ...,\n",
205 | " 1.19808774e-14, 1.20977630e-14, 1.11072825e-14]))"
206 | ]
207 | },
208 | "execution_count": 11,
209 | "metadata": {},
210 | "output_type": "execute_result"
211 | }
212 | ],
213 | "source": [
214 | "res, err"
215 | ]
216 | },
217 | {
218 | "cell_type": "markdown",
219 | "metadata": {},
220 | "source": [
221 | "These both yield the same results, but in a slightly different time frame!"
222 | ]
223 | },
224 | {
225 | "cell_type": "markdown",
226 | "metadata": {},
227 | "source": [
228 | "It should also be noted the number of parameters in the grid can be varied, i.e, if you have a integrand which takes 6 parameters (`test_integrand_func`) then it is possible to pass all the paramters via the grid, or just one. See the exmaples below,"
229 | ]
230 | },
231 | {
232 | "cell_type": "code",
233 | "execution_count": 12,
234 | "metadata": {},
235 | "outputs": [],
236 | "source": [
237 | "grid1 = np.random.random((10000000, 6))\n",
238 | "res, err = quad_grid(test_integrand_func, 0, 1, grid1)"
239 | ]
240 | },
241 | {
242 | "cell_type": "code",
243 | "execution_count": 13,
244 | "metadata": {},
245 | "outputs": [],
246 | "source": [
247 | "grid2 = np.random.random((10000000, 1))\n",
248 | "res, err = quad_grid(test_integrand_func, 0, 1, grid2, (1., 1., 1., 1., 1.))"
249 | ]
250 | },
251 | {
252 | "cell_type": "markdown",
253 | "metadata": {},
254 | "source": [
255 | "# Parallel pyquad.quad_grid"
256 | ]
257 | },
258 | {
259 | "cell_type": "markdown",
260 | "metadata": {},
261 | "source": [
262 | "If you have a lot of integrals or a nice computer then you may benefit from using openMP. Just make sure that the OMP library is available to the compiler,"
263 | ]
264 | },
265 | {
266 | "cell_type": "code",
267 | "execution_count": 14,
268 | "metadata": {},
269 | "outputs": [
270 | {
271 | "name": "stdout",
272 | "output_type": "stream",
273 | "text": [
274 | "CPU times: user 2.96 s, sys: 128 ms, total: 3.09 s\n",
275 | "Wall time: 452 ms\n"
276 | ]
277 | }
278 | ],
279 | "source": [
280 | "%%time\n",
281 | "res, err = quad_grid(test_integrand_func, 0, 1, grid, (1.0, 1.0, 1.0, 1.0), parallel=True)"
282 | ]
283 | },
284 | {
285 | "cell_type": "code",
286 | "execution_count": 15,
287 | "metadata": {},
288 | "outputs": [
289 | {
290 | "data": {
291 | "text/plain": [
292 | "(array([1.11591324, 1.03565151, 1.29417096, ..., 1.0791415 , 1.08966962,\n",
293 | " 1.00045506]),\n",
294 | " array([1.23891258e-14, 1.14980415e-14, 1.43681840e-14, ...,\n",
295 | " 1.19808774e-14, 1.20977630e-14, 1.11072825e-14]))"
296 | ]
297 | },
298 | "execution_count": 15,
299 | "metadata": {},
300 | "output_type": "execute_result"
301 | }
302 | ],
303 | "source": [
304 | "res, err"
305 | ]
306 | },
307 | {
308 | "cell_type": "markdown",
309 | "metadata": {},
310 | "source": [
311 | "# What about vs. a jitted function?"
312 | ]
313 | },
314 | {
315 | "cell_type": "markdown",
316 | "metadata": {},
317 | "source": [
318 | "It is possible to make a function faster by using numba jit to compile the function. I'm using a jit wrapper from PyAutoLens to compare to."
319 | ]
320 | },
321 | {
322 | "cell_type": "code",
323 | "execution_count": 16,
324 | "metadata": {},
325 | "outputs": [],
326 | "source": [
327 | "@jit_integrand\n",
328 | "def test_integrand_func_jit(x, alpha, beta, i, j, k, l): \n",
329 | " return x * alpha * beta + i * j * k "
330 | ]
331 | },
332 | {
333 | "cell_type": "markdown",
334 | "metadata": {},
335 | "source": [
336 | "then we use the naive python loop again,"
337 | ]
338 | },
339 | {
340 | "cell_type": "code",
341 | "execution_count": 17,
342 | "metadata": {},
343 | "outputs": [
344 | {
345 | "name": "stdout",
346 | "output_type": "stream",
347 | "text": [
348 | "CPU times: user 29.9 s, sys: 56 ms, total: 29.9 s\n",
349 | "Wall time: 29.9 s\n"
350 | ]
351 | }
352 | ],
353 | "source": [
354 | "%%time\n",
355 | "res = np.zeros(grid.shape[0])\n",
356 | "err = np.zeros(grid.shape[0]) \n",
357 | " \n",
358 | "for i in range(res.shape[0]): \n",
359 | " res[i], err[i] = scipy.integrate.quad(test_integrand_func_jit, 0, 1, \n",
360 | " (grid[i, 0], grid[i, 1], 1.0, 1.0, 1.0, 1.0))"
361 | ]
362 | },
363 | {
364 | "cell_type": "markdown",
365 | "metadata": {},
366 | "source": [
367 | "Which is actually pretty fast! But, if speed is critical then just using numba jit is still no where near as fast a (parallel) `grid_quad`."
368 | ]
369 | },
370 | {
371 | "cell_type": "markdown",
372 | "metadata": {},
373 | "source": [
374 | "If you have any questions or issues, please get in touch! (a.j.kelly@durham.ac.uk)"
375 | ]
376 | }
377 | ],
378 | "metadata": {
379 | "kernelspec": {
380 | "display_name": "Python 3",
381 | "language": "python",
382 | "name": "python3"
383 | },
384 | "language_info": {
385 | "codemirror_mode": {
386 | "name": "ipython",
387 | "version": 3
388 | },
389 | "file_extension": ".py",
390 | "mimetype": "text/x-python",
391 | "name": "python",
392 | "nbconvert_exporter": "python",
393 | "pygments_lexer": "ipython3",
394 | "version": "3.6.7"
395 | }
396 | },
397 | "nbformat": 4,
398 | "nbformat_minor": 2
399 | }
400 |
--------------------------------------------------------------------------------
/examples/jit.py:
--------------------------------------------------------------------------------
1 | import numba
2 | from numba import cfunc
3 | from numba.types import intc, CPointer, float64
4 | from scipy import LowLevelCallable
5 | import inspect
6 |
7 | def jit_integrand(integrand_function):
8 | jitted_function = numba.jit(integrand_function, nopython=True)
9 | no_args = len(inspect.getfullargspec(integrand_function).args)
10 |
11 | wrapped = None
12 |
13 | if no_args == 4:
14 | def wrapped(n, xx):
15 | return jitted_function(xx[0], xx[1], xx[2], xx[3])
16 | elif no_args == 5:
17 | def wrapped(n, xx):
18 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4])
19 | elif no_args == 6:
20 | def wrapped(n, xx):
21 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5])
22 | elif no_args == 7:
23 | def wrapped(n, xx):
24 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5], xx[6])
25 | elif no_args == 8:
26 | def wrapped(n, xx):
27 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5], xx[6], xx[7])
28 | elif no_args == 9:
29 | def wrapped(n, xx):
30 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5], xx[6], xx[7], xx[8])
31 | elif no_args == 10:
32 | def wrapped(n, xx):
33 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5], xx[6], xx[7], xx[8], xx[9])
34 | elif no_args == 11:
35 | def wrapped(n, xx):
36 | return jitted_function(xx[0], xx[1], xx[2], xx[3], xx[4], xx[5], xx[6], xx[7], xx[8], xx[9], xx[10])
37 |
38 | cf = cfunc(float64(intc, CPointer(float64)))
39 |
40 | return LowLevelCallable(cf(wrapped).ctypes)
41 |
42 |
--------------------------------------------------------------------------------
/examples/jupyter_example.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "import numpy as np\n",
10 | "import scipy.integrate\n",
11 | "\n",
12 | "from pyquad import quad, quad_grid\n",
13 | "from jit import jit_integrand"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 2,
19 | "metadata": {},
20 | "outputs": [],
21 | "source": [
22 | "def test_integrand_func(x, alpha, beta, i, j, k, l): \n",
23 | " return x * alpha * beta + i * j * k "
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "# pyquad.quad <-> scipy.integrate.quad"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "metadata": {},
36 | "source": [
37 | "In a basic sense, it is possible to just drop-in the `pyquad.quad` in place of `scipy.integrate.quad`. Though for a single integral there isn't really any benefit of this,"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": 3,
43 | "metadata": {},
44 | "outputs": [],
45 | "source": [
46 | "res, error = quad(test_integrand_func, 0, 1, (1., 1., 1., 1., 1., 1.))"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": 4,
52 | "metadata": {},
53 | "outputs": [
54 | {
55 | "data": {
56 | "text/plain": [
57 | "(1.5, 1.6653345369377348e-14)"
58 | ]
59 | },
60 | "execution_count": 4,
61 | "metadata": {},
62 | "output_type": "execute_result"
63 | }
64 | ],
65 | "source": [
66 | "res, error"
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": 5,
72 | "metadata": {},
73 | "outputs": [],
74 | "source": [
75 | "res, error = scipy.integrate.quad(test_integrand_func, 0, 1, (1., 1., 1., 1., 1., 1.))"
76 | ]
77 | },
78 | {
79 | "cell_type": "code",
80 | "execution_count": 6,
81 | "metadata": {},
82 | "outputs": [
83 | {
84 | "data": {
85 | "text/plain": [
86 | "(1.5, 1.6653345369377348e-14)"
87 | ]
88 | },
89 | "execution_count": 6,
90 | "metadata": {},
91 | "output_type": "execute_result"
92 | }
93 | ],
94 | "source": [
95 | "res, error"
96 | ]
97 | },
98 | {
99 | "cell_type": "markdown",
100 | "metadata": {},
101 | "source": [
102 | "# pyquad.quad_grid"
103 | ]
104 | },
105 | {
106 | "cell_type": "markdown",
107 | "metadata": {},
108 | "source": [
109 | "This is the regime where pyquad is worth the investment. If you have 6 parameters in your integrand, and you want to integrate over a range of 2 of them then in scipy it may look something like this,"
110 | ]
111 | },
112 | {
113 | "cell_type": "code",
114 | "execution_count": 7,
115 | "metadata": {},
116 | "outputs": [],
117 | "source": [
118 | "grid = np.random.random((10000000, 2))"
119 | ]
120 | },
121 | {
122 | "cell_type": "code",
123 | "execution_count": 8,
124 | "metadata": {},
125 | "outputs": [
126 | {
127 | "name": "stdout",
128 | "output_type": "stream",
129 | "text": [
130 | "CPU times: user 1min 40s, sys: 62.2 ms, total: 1min 40s\n",
131 | "Wall time: 1min 40s\n"
132 | ]
133 | }
134 | ],
135 | "source": [
136 | "%%time\n",
137 | "res = np.zeros(grid.shape[0])\n",
138 | "err = np.zeros(grid.shape[0]) \n",
139 | " \n",
140 | "for i in range(res.shape[0]): \n",
141 | " res[i], err[i] = scipy.integrate.quad(test_integrand_func, 0, 1, \n",
142 | " (grid[i, 0], grid[i, 1], 1.0, 1.0, 1.0, 1.0))"
143 | ]
144 | },
145 | {
146 | "cell_type": "code",
147 | "execution_count": 9,
148 | "metadata": {},
149 | "outputs": [
150 | {
151 | "data": {
152 | "text/plain": [
153 | "(array([1.11591324, 1.03565151, 1.29417096, ..., 1.0791415 , 1.08966962,\n",
154 | " 1.00045506]),\n",
155 | " array([1.23891258e-14, 1.14980415e-14, 1.43681840e-14, ...,\n",
156 | " 1.19808774e-14, 1.20977630e-14, 1.11072825e-14]))"
157 | ]
158 | },
159 | "execution_count": 9,
160 | "metadata": {},
161 | "output_type": "execute_result"
162 | }
163 | ],
164 | "source": [
165 | "res, err"
166 | ]
167 | },
168 | {
169 | "cell_type": "markdown",
170 | "metadata": {},
171 | "source": [
172 | "but with `pyquad.quad_grid` we are able to make the code more elegant and significantly faster by reducing calls to the python function and also compiling the integrand. All of this is done behind the API."
173 | ]
174 | },
175 | {
176 | "cell_type": "code",
177 | "execution_count": 10,
178 | "metadata": {},
179 | "outputs": [
180 | {
181 | "name": "stdout",
182 | "output_type": "stream",
183 | "text": [
184 | "CPU times: user 1.43 s, sys: 104 ms, total: 1.53 s\n",
185 | "Wall time: 1.53 s\n"
186 | ]
187 | }
188 | ],
189 | "source": [
190 | "%%time\n",
191 | "res, err = quad_grid(test_integrand_func, 0, 1, grid, (1.0, 1.0, 1.0, 1.0))"
192 | ]
193 | },
194 | {
195 | "cell_type": "code",
196 | "execution_count": 11,
197 | "metadata": {},
198 | "outputs": [
199 | {
200 | "data": {
201 | "text/plain": [
202 | "(array([1.11591324, 1.03565151, 1.29417096, ..., 1.0791415 , 1.08966962,\n",
203 | " 1.00045506]),\n",
204 | " array([1.23891258e-14, 1.14980415e-14, 1.43681840e-14, ...,\n",
205 | " 1.19808774e-14, 1.20977630e-14, 1.11072825e-14]))"
206 | ]
207 | },
208 | "execution_count": 11,
209 | "metadata": {},
210 | "output_type": "execute_result"
211 | }
212 | ],
213 | "source": [
214 | "res, err"
215 | ]
216 | },
217 | {
218 | "cell_type": "markdown",
219 | "metadata": {},
220 | "source": [
221 | "These both yield the same results, but in a slightly different time frame!"
222 | ]
223 | },
224 | {
225 | "cell_type": "markdown",
226 | "metadata": {},
227 | "source": [
228 | "It should also be noted the number of parameters in the grid can be varied, i.e, if you have a integrand which takes 6 parameters (`test_integrand_func`) then it is possible to pass all the paramters via the grid, or just one. See the exmaples below,"
229 | ]
230 | },
231 | {
232 | "cell_type": "code",
233 | "execution_count": 12,
234 | "metadata": {},
235 | "outputs": [],
236 | "source": [
237 | "grid1 = np.random.random((10000000, 6))\n",
238 | "res, err = quad_grid(test_integrand_func, 0, 1, grid1)"
239 | ]
240 | },
241 | {
242 | "cell_type": "code",
243 | "execution_count": 13,
244 | "metadata": {},
245 | "outputs": [],
246 | "source": [
247 | "grid2 = np.random.random((10000000, 1))\n",
248 | "res, err = quad_grid(test_integrand_func, 0, 1, grid2, (1., 1., 1., 1., 1.))"
249 | ]
250 | },
251 | {
252 | "cell_type": "markdown",
253 | "metadata": {},
254 | "source": [
255 | "# Parallel pyquad.quad_grid"
256 | ]
257 | },
258 | {
259 | "cell_type": "markdown",
260 | "metadata": {},
261 | "source": [
262 | "If you have a lot of integrals or a nice computer then you may benefit from using openMP. Just make sure that the OMP library is available to the compiler,"
263 | ]
264 | },
265 | {
266 | "cell_type": "code",
267 | "execution_count": 14,
268 | "metadata": {},
269 | "outputs": [
270 | {
271 | "name": "stdout",
272 | "output_type": "stream",
273 | "text": [
274 | "CPU times: user 2.96 s, sys: 128 ms, total: 3.09 s\n",
275 | "Wall time: 452 ms\n"
276 | ]
277 | }
278 | ],
279 | "source": [
280 | "%%time\n",
281 | "res, err = quad_grid(test_integrand_func, 0, 1, grid, (1.0, 1.0, 1.0, 1.0), parallel=True)"
282 | ]
283 | },
284 | {
285 | "cell_type": "code",
286 | "execution_count": 15,
287 | "metadata": {},
288 | "outputs": [
289 | {
290 | "data": {
291 | "text/plain": [
292 | "(array([1.11591324, 1.03565151, 1.29417096, ..., 1.0791415 , 1.08966962,\n",
293 | " 1.00045506]),\n",
294 | " array([1.23891258e-14, 1.14980415e-14, 1.43681840e-14, ...,\n",
295 | " 1.19808774e-14, 1.20977630e-14, 1.11072825e-14]))"
296 | ]
297 | },
298 | "execution_count": 15,
299 | "metadata": {},
300 | "output_type": "execute_result"
301 | }
302 | ],
303 | "source": [
304 | "res, err"
305 | ]
306 | },
307 | {
308 | "cell_type": "markdown",
309 | "metadata": {},
310 | "source": [
311 | "# What about vs. a jitted function?"
312 | ]
313 | },
314 | {
315 | "cell_type": "markdown",
316 | "metadata": {},
317 | "source": [
318 | "It is possible to make a function faster by using numba jit to compile the function. I'm using a jit wrapper from PyAutoLens to compare to."
319 | ]
320 | },
321 | {
322 | "cell_type": "code",
323 | "execution_count": 16,
324 | "metadata": {},
325 | "outputs": [],
326 | "source": [
327 | "@jit_integrand\n",
328 | "def test_integrand_func_jit(x, alpha, beta, i, j, k, l): \n",
329 | " return x * alpha * beta + i * j * k "
330 | ]
331 | },
332 | {
333 | "cell_type": "markdown",
334 | "metadata": {},
335 | "source": [
336 | "then we use the naive python loop again,"
337 | ]
338 | },
339 | {
340 | "cell_type": "code",
341 | "execution_count": 17,
342 | "metadata": {},
343 | "outputs": [
344 | {
345 | "name": "stdout",
346 | "output_type": "stream",
347 | "text": [
348 | "CPU times: user 29.9 s, sys: 56 ms, total: 29.9 s\n",
349 | "Wall time: 29.9 s\n"
350 | ]
351 | }
352 | ],
353 | "source": [
354 | "%%time\n",
355 | "res = np.zeros(grid.shape[0])\n",
356 | "err = np.zeros(grid.shape[0]) \n",
357 | " \n",
358 | "for i in range(res.shape[0]): \n",
359 | " res[i], err[i] = scipy.integrate.quad(test_integrand_func_jit, 0, 1, \n",
360 | " (grid[i, 0], grid[i, 1], 1.0, 1.0, 1.0, 1.0))"
361 | ]
362 | },
363 | {
364 | "cell_type": "markdown",
365 | "metadata": {},
366 | "source": [
367 | "Which is actually pretty fast! But, if speed is critical then just using numba jit is still no where near as fast a (parallel) `grid_quad`."
368 | ]
369 | },
370 | {
371 | "cell_type": "markdown",
372 | "metadata": {},
373 | "source": [
374 | "If you have any questions or issues, please get in touch! (a.j.kelly@durham.ac.uk)"
375 | ]
376 | }
377 | ],
378 | "metadata": {
379 | "kernelspec": {
380 | "display_name": "Python 3",
381 | "language": "python",
382 | "name": "python3"
383 | },
384 | "language_info": {
385 | "codemirror_mode": {
386 | "name": "ipython",
387 | "version": 3
388 | },
389 | "file_extension": ".py",
390 | "mimetype": "text/x-python",
391 | "name": "python",
392 | "nbconvert_exporter": "python",
393 | "pygments_lexer": "ipython3",
394 | "version": "3.6.7"
395 | }
396 | },
397 | "nbformat": 4,
398 | "nbformat_minor": 2
399 | }
400 |
--------------------------------------------------------------------------------
/examples/readme_example.py:
--------------------------------------------------------------------------------
1 | import time
2 | import numpy as np
3 | import scipy.integrate
4 | import pyquad
5 |
6 |
7 | def test_integrand_func(x, alpha, beta, i, j, k, l):
8 | return x * alpha * beta + i * j * k
9 |
10 |
11 | grid = np.random.random((10000000, 2))
12 |
13 | res = np.zeros(grid.shape[0])
14 | t0 = time.time()
15 | for i in range(res.shape[0]):
16 | res[i] = scipy.integrate.quad(
17 | test_integrand_func, 0, 1, (grid[i, 0], grid[i, 1], 1.0, 1.0, 1.0, 1.0)
18 | )[0]
19 | print(time.time() - t0)
20 |
21 | t0 = time.time()
22 | res = pyquad.quad_grid(test_integrand_func, 0, 1, grid, (1.0, 1.0, 1.0, 1.0))
23 | print(time.time() - t0)
24 |
25 |
26 | t0 = time.time()
27 | res = pyquad.quad_grid(
28 | test_integrand_func, 0, 1, grid, (1.0, 1.0, 1.0, 1.0), parallel=True
29 | )
30 | print(time.time() - t0)
31 |
--------------------------------------------------------------------------------
/pyquad/generate_integrands.py:
--------------------------------------------------------------------------------
1 | def generate_function(num_args, num_grid_args):
2 | start_function = """
3 | static double integrand_%i_%i(double x, void * vp){
4 | params * p = (params *)vp;
5 | return p->func(
6 | x"""
7 |
8 | end_function = """
9 | );
10 | }
11 | """
12 | base_args = ",\n\t\tp->args[{}]"
13 | grid_args = ",\n\t\tp->grid_args[{}]"
14 |
15 | func = start_function%(num_args, num_grid_args)
16 | for i in range(num_grid_args):
17 | func += grid_args.format(i)
18 |
19 | for i in range(num_args):
20 | func += base_args.format(i)
21 |
22 | func += end_function
23 |
24 | return func
25 |
26 |
27 | def generate_integrands_header():
28 | header = """#ifndef INTEGRANDS
29 | #define INTEGRANDS
30 |
31 | typedef double (*integrand)(double, ...);
32 | typedef double (*integrand_wrapper)(double, void *);
33 |
34 | typedef struct{
35 | double * args;
36 | double * grid_args;
37 | integrand func;
38 | } params;
39 | """
40 |
41 | num_args = 15
42 | num_grid_args = 15
43 | for i in range(num_args):
44 | for j in range(num_grid_args):
45 | header += generate_function(i, j)
46 |
47 | header += "\nintegrand_wrapper integrand_functions[%i][%i] = {\n"%(num_args, num_grid_args)
48 | for i in range(num_args):
49 | header += "\t{ integrand_%i_%i, "%(i, 0)
50 |
51 | for j in range(1, num_grid_args - 1):
52 | header += "integrand_%i_%i, "%(i, j)
53 |
54 | header += "integrand_%i_%i },\n"%(i, num_grid_args - 1)
55 |
56 | header += "};"
57 |
58 |
59 | header += "\n\n#endif"
60 |
61 | with open("integrands.h", "w") as f:
62 | f.write(header)
63 |
64 | generate_integrands_header()
65 |
--------------------------------------------------------------------------------
/pyquad/integration/cquad.c:
--------------------------------------------------------------------------------
1 | /* integration/cquad.c
2 | *
3 | * Copyright (C) 2010 Pedro Gonnet
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #include
22 | #include
23 |
24 | #include "cquad_const.c"
25 | #include "gsl_errno.h"
26 | #include "gsl_integration.h"
27 | #include "gsl_math.h"
28 | #include "gsl_nan.h"
29 | #include "gsl_sys.h"
30 |
31 | /* Allocates a workspace for the given maximum number of intervals.
32 | Note that if the workspace gets filled, the intervals with the
33 | lowest error estimates are dropped. The maximum number of
34 | intervals is therefore not the maximum number of intervals
35 | that will be computed, but merely the size of the buffer.
36 | */
37 | gsl_integration_cquad_workspace *gsl_integration_cquad_workspace_alloc(
38 | const size_t n) {
39 | gsl_integration_cquad_workspace *w;
40 |
41 | /* Allocate first the workspace struct */
42 | w = (gsl_integration_cquad_workspace *)malloc(
43 | sizeof(gsl_integration_cquad_workspace));
44 |
45 | /* Allocate the intervals */
46 | if ((w->ivals = (gsl_integration_cquad_ival *)malloc(
47 | sizeof(gsl_integration_cquad_ival) * n)) == NULL) {
48 | free(w);
49 | }
50 |
51 | /* Allocate the max-heap indices */
52 | if ((w->heap = (size_t *)malloc(sizeof(size_t) * n)) == NULL) {
53 | free(w->ivals);
54 | free(w);
55 | }
56 |
57 | /* Remember the size of the workspace */
58 | w->size = n;
59 |
60 | /* Return the result */
61 | return w;
62 | }
63 |
64 | /* Liberates the workspace memory.
65 | */
66 |
67 | void gsl_integration_cquad_workspace_free(gsl_integration_cquad_workspace *w) {
68 | /* Nothing to be done? */
69 | if (w == NULL) return;
70 |
71 | /* Free the intervals first */
72 | if (w->ivals != NULL) free(w->ivals);
73 |
74 | /* Free the heap */
75 | if (w->heap != NULL) free(w->heap);
76 |
77 | /* Free the structure */
78 | free(w);
79 | }
80 |
81 | /* Compute the product of the fx with one of the inverse
82 | Vandermonde-like matrices. */
83 |
84 | static void Vinvfx(const double *fx, double *c, const int d) {
85 | int i, j;
86 |
87 | switch (d) {
88 | case 0:
89 | for (i = 0; i <= 4; i++) {
90 | c[i] = 0.0;
91 | for (j = 0; j <= 4; j++) c[i] += V1inv[i * 5 + j] * fx[j * 8];
92 | }
93 | break;
94 | case 1:
95 | for (i = 0; i <= 8; i++) {
96 | c[i] = 0.0;
97 | for (j = 0; j <= 8; j++) c[i] += V2inv[i * 9 + j] * fx[j * 4];
98 | }
99 | break;
100 | case 2:
101 | for (i = 0; i <= 16; i++) {
102 | c[i] = 0.0;
103 | for (j = 0; j <= 16; j++) c[i] += V3inv[i * 17 + j] * fx[j * 2];
104 | }
105 | break;
106 | case 3:
107 | for (i = 0; i <= 32; i++) {
108 | c[i] = 0.0;
109 | for (j = 0; j <= 32; j++) c[i] += V4inv[i * 33 + j] * fx[j];
110 | }
111 | break;
112 | }
113 | }
114 |
115 | /* Downdate the interpolation given by the n coefficients c
116 | by removing the nodes with indices in nans. */
117 |
118 | static void downdate(double *c, int n, int d, int *nans, int nnans) {
119 | static const int bidx[4] = {0, 6, 16, 34};
120 | double b_new[34], alpha;
121 | int i, j;
122 |
123 | for (i = 0; i <= n + 1; i++) b_new[i] = bee[bidx[d] + i];
124 | for (i = 0; i < nnans; i++) {
125 | b_new[n + 1] = b_new[n + 1] / Lalpha[n];
126 | b_new[n] = (b_new[n] + xi[nans[i]] * b_new[n + 1]) / Lalpha[n - 1];
127 | for (j = n - 1; j > 0; j--)
128 | b_new[j] = (b_new[j] + xi[nans[i]] * b_new[j + 1] -
129 | Lgamma[j + 1] * b_new[j + 2]) /
130 | Lalpha[j - 1];
131 | for (j = 0; j <= n; j++) b_new[j] = b_new[j + 1];
132 | alpha = c[n] / b_new[n];
133 | for (j = 0; j < n; j++) c[j] -= alpha * b_new[j];
134 | c[n] = 0;
135 | n--;
136 | }
137 | }
138 |
139 | /* The actual integration routine.
140 | */
141 |
142 | int gsl_integration_cquad(const gsl_function *f, double a, double b,
143 | double epsabs, double epsrel, size_t limit,
144 | void *void_ws, double *result, double *abserr) {
145 | /* Some constants that we will need. */
146 | static const int n[4] = {4, 8, 16, 32};
147 | static const int skip[4] = {8, 4, 2, 1};
148 | static const int idx[4] = {0, 5, 14, 31};
149 | static const double w = M_SQRT2 / 2;
150 | static const int ndiv_max = 20;
151 |
152 | /* recast the workspace back from the generic void */
153 | gsl_integration_cquad_workspace *ws =
154 | (gsl_integration_cquad_workspace *)void_ws;
155 |
156 | /* Actual variables (as opposed to constants above). */
157 | double m, h, temp;
158 | double igral, err, igral_final, err_final, err_excess;
159 | int nivals, neval = 0;
160 | int i, j, d, split, t;
161 | int nnans, nans[32];
162 | gsl_integration_cquad_ival *iv, *ivl, *ivr;
163 | double nc, ncdiff;
164 |
165 | /* Check for unreasonable accuracy demands */
166 | if (epsabs < 0.0 || epsrel < 0.0) return GSL_EBADTOL;
167 | if (epsabs <= 0 && epsrel < GSL_DBL_EPSILON) return GSL_EBADTOL;
168 |
169 | /* Create the first interval. */
170 | iv = &(ws->ivals[0]);
171 | m = (a + b) / 2;
172 | h = (b - a) / 2;
173 | nnans = 0;
174 | for (i = 0; i <= n[3]; i++) {
175 | iv->fx[i] = GSL_FN_EVAL(f, m + xi[i] * h);
176 | neval++;
177 | if (!gsl_finite(iv->fx[i])) {
178 | nans[nnans++] = i;
179 | iv->fx[i] = 0.0;
180 | }
181 | }
182 | Vinvfx(iv->fx, &(iv->c[idx[0]]), 0);
183 | Vinvfx(iv->fx, &(iv->c[idx[3]]), 3);
184 | Vinvfx(iv->fx, &(iv->c[idx[2]]), 2);
185 | for (i = 0; i < nnans; i++) iv->fx[nans[i]] = GSL_NAN;
186 | iv->a = a;
187 | iv->b = b;
188 | iv->depth = 3;
189 | iv->rdepth = 1;
190 | iv->ndiv = 0;
191 | iv->igral = 2 * h * iv->c[idx[3]] * w;
192 | nc = 0.0;
193 | for (i = n[2] + 1; i <= n[3]; i++) {
194 | temp = iv->c[idx[3] + i];
195 | nc += temp * temp;
196 | }
197 | ncdiff = nc;
198 | for (i = 0; i <= n[2]; i++) {
199 | temp = iv->c[idx[2] + i] - iv->c[idx[3] + i];
200 | ncdiff += temp * temp;
201 | nc += iv->c[idx[3] + i] * iv->c[idx[3] + i];
202 | }
203 | ncdiff = sqrt(ncdiff);
204 | nc = sqrt(nc);
205 | iv->err = ncdiff * 2 * h;
206 | if (ncdiff / nc > 0.1 && iv->err < 2 * h * nc) iv->err = 2 * h * nc;
207 |
208 | /* Initialize the heaps. */
209 | for (i = 0; i < ws->size; i++) ws->heap[i] = i;
210 |
211 | /* Initialize some global values. */
212 | igral = iv->igral;
213 | err = iv->err;
214 | nivals = 1;
215 | igral_final = 0.0;
216 | err_final = 0.0;
217 | err_excess = 0.0;
218 |
219 | /* Main loop. */
220 | while (nivals > 0 && err > 0.0 &&
221 | !(err <= fabs(igral) * epsrel || err <= epsabs) &&
222 | !(err_final > fabs(igral) * epsrel &&
223 | err - err_final < fabs(igral) * epsrel) &&
224 | !(err_final > epsabs && err - err_final < epsabs)) {
225 | /* Put our finger on the interval with the largest error. */
226 | iv = &(ws->ivals[ws->heap[0]]);
227 | m = (iv->a + iv->b) / 2;
228 | h = (iv->b - iv->a) / 2;
229 |
230 | /* printf
231 | ("cquad: processing ival %i (of %i) with [%e,%e] int=%e, err=%e,
232 | depth=%i\n", ws->heap[0], nivals, iv->a, iv->b, iv->igral, iv->err,
233 | iv->depth);
234 | */
235 | /* Should we try to increase the degree? */
236 | if (iv->depth < 3) {
237 | /* Keep tabs on some variables. */
238 | d = ++iv->depth;
239 |
240 | /* Get the new (missing) function values */
241 | for (i = skip[d]; i <= 32; i += 2 * skip[d]) {
242 | iv->fx[i] = GSL_FN_EVAL(f, m + xi[i] * h);
243 | neval++;
244 | }
245 | nnans = 0;
246 | for (i = 0; i <= 32; i += skip[d]) {
247 | if (!gsl_finite(iv->fx[i])) {
248 | nans[nnans++] = i;
249 | iv->fx[i] = 0.0;
250 | }
251 | }
252 |
253 | /* Compute the new coefficients. */
254 | Vinvfx(iv->fx, &(iv->c[idx[d]]), d);
255 |
256 | /* Downdate any NaNs. */
257 | if (nnans > 0) {
258 | downdate(&(iv->c[idx[d]]), n[d], d, nans, nnans);
259 | for (i = 0; i < nnans; i++) iv->fx[nans[i]] = GSL_NAN;
260 | }
261 |
262 | /* Compute the error estimate. */
263 | nc = 0.0;
264 | for (i = n[d - 1] + 1; i <= n[d]; i++) {
265 | temp = iv->c[idx[d] + i];
266 | nc += temp * temp;
267 | }
268 | ncdiff = nc;
269 | for (i = 0; i <= n[d - 1]; i++) {
270 | temp = iv->c[idx[d - 1] + i] - iv->c[idx[d] + i];
271 | ncdiff += temp * temp;
272 | nc += iv->c[idx[d] + i] * iv->c[idx[d] + i];
273 | }
274 | ncdiff = sqrt(ncdiff);
275 | nc = sqrt(nc);
276 | iv->err = ncdiff * 2 * h;
277 |
278 | /* Compute the local integral. */
279 | iv->igral = 2 * h * w * iv->c[idx[d]];
280 |
281 | /* Split the interval prematurely? */
282 | split = (nc > 0 && ncdiff / nc > 0.1);
283 |
284 | }
285 |
286 | /* Maximum degree reached, just split. */
287 | else {
288 | split = 1;
289 | }
290 |
291 | /* Should we drop this interval? */
292 | if ((m + h * xi[0]) >= (m + h * xi[1]) ||
293 | (m + h * xi[31]) >= (m + h * xi[32]) ||
294 | iv->err < fabs(iv->igral) * GSL_DBL_EPSILON * 10) {
295 | /* printf
296 | ("cquad: dumping ival %i (of %i) with [%e,%e] int=%e,
297 | err=%e, depth=%i\n", ws->heap[0], nivals, iv->a, iv->b,
298 | iv->igral, iv->err, iv->depth);
299 | */
300 | /* Keep this interval's contribution */
301 | err_final += iv->err;
302 | igral_final += iv->igral;
303 |
304 | /* Swap with the last element on the heap */
305 | t = ws->heap[nivals - 1];
306 | ws->heap[nivals - 1] = ws->heap[0];
307 | ws->heap[0] = t;
308 | nivals--;
309 |
310 | /* Fix up the heap */
311 | i = 0;
312 | while (2 * i + 1 < nivals) {
313 | /* Get the kids */
314 | j = 2 * i + 1;
315 |
316 | /* If the j+1st entry exists and is larger than the jth,
317 | use it instead. */
318 | if (j + 1 < nivals && ws->ivals[ws->heap[j + 1]].err >=
319 | ws->ivals[ws->heap[j]].err)
320 | j++;
321 |
322 | /* Do we need to move the ith entry up? */
323 | if (ws->ivals[ws->heap[j]].err <= ws->ivals[ws->heap[i]].err)
324 | break;
325 | else {
326 | t = ws->heap[j];
327 | ws->heap[j] = ws->heap[i];
328 | ws->heap[i] = t;
329 | i = j;
330 | }
331 | }
332 |
333 | }
334 |
335 | /* Do we need to split this interval? */
336 | else if (split) {
337 | /* Some values we will need often... */
338 | d = iv->depth;
339 |
340 | /* Generate the interval on the left */
341 | ivl = &(ws->ivals[ws->heap[nivals++]]);
342 | ivl->a = iv->a;
343 | ivl->b = m;
344 | ivl->depth = 0;
345 | ivl->rdepth = iv->rdepth + 1;
346 | ivl->fx[0] = iv->fx[0];
347 | ivl->fx[32] = iv->fx[16];
348 | for (i = skip[0]; i < 32; i += skip[0]) {
349 | ivl->fx[i] =
350 | GSL_FN_EVAL(f, (ivl->a + ivl->b) / 2 + xi[i] * h / 2);
351 | neval++;
352 | }
353 | nnans = 0;
354 | for (i = 0; i <= 32; i += skip[0]) {
355 | if (!gsl_finite(ivl->fx[i])) {
356 | nans[nnans++] = i;
357 | ivl->fx[i] = 0.0;
358 | }
359 | }
360 | Vinvfx(ivl->fx, ivl->c, 0);
361 | if (nnans > 0) {
362 | downdate(ivl->c, n[0], 0, nans, nnans);
363 | for (i = 0; i < nnans; i++) ivl->fx[nans[i]] = GSL_NAN;
364 | }
365 | for (i = 0; i <= n[d]; i++) {
366 | ivl->c[idx[d] + i] = 0.0;
367 | for (j = i; j <= n[d]; j++)
368 | ivl->c[idx[d] + i] += Tleft[i * 33 + j] * iv->c[idx[d] + j];
369 | }
370 | ncdiff = 0.0;
371 | for (i = 0; i <= n[0]; i++) {
372 | temp = ivl->c[i] - ivl->c[idx[d] + i];
373 | ncdiff += temp * temp;
374 | }
375 | for (i = n[0] + 1; i <= n[d]; i++) {
376 | temp = ivl->c[idx[d] + i];
377 | ncdiff += temp * temp;
378 | }
379 | ncdiff = sqrt(ncdiff);
380 | ivl->err = ncdiff * h;
381 |
382 | /* Check for divergence. */
383 | ivl->ndiv =
384 | iv->ndiv + (fabs(iv->c[0]) > 0 && ivl->c[0] / iv->c[0] > 2);
385 | if (ivl->ndiv > ndiv_max && 2 * ivl->ndiv > ivl->rdepth) {
386 | /* need copysign(INFINITY, igral) */
387 | *result = (igral >= 0) ? GSL_POSINF : GSL_NEGINF;
388 | return GSL_EDIVERGE;
389 | }
390 |
391 | /* Compute the local integral. */
392 | ivl->igral = h * w * ivl->c[0];
393 |
394 | /* Generate the interval on the right */
395 | ivr = &(ws->ivals[ws->heap[nivals++]]);
396 | ivr->a = m;
397 | ivr->b = iv->b;
398 | ivr->depth = 0;
399 | ivr->rdepth = iv->rdepth + 1;
400 | ivr->fx[0] = iv->fx[16];
401 | ivr->fx[32] = iv->fx[32];
402 | for (i = skip[0]; i < 32; i += skip[0]) {
403 | ivr->fx[i] =
404 | GSL_FN_EVAL(f, (ivr->a + ivr->b) / 2 + xi[i] * h / 2);
405 | neval++;
406 | }
407 | nnans = 0;
408 | for (i = 0; i <= 32; i += skip[0]) {
409 | if (!gsl_finite(ivr->fx[i])) {
410 | nans[nnans++] = i;
411 | ivr->fx[i] = 0.0;
412 | }
413 | }
414 | Vinvfx(ivr->fx, ivr->c, 0);
415 | if (nnans > 0) {
416 | downdate(ivr->c, n[0], 0, nans, nnans);
417 | for (i = 0; i < nnans; i++) ivr->fx[nans[i]] = GSL_NAN;
418 | }
419 | for (i = 0; i <= n[d]; i++) {
420 | ivr->c[idx[d] + i] = 0.0;
421 | for (j = i; j <= n[d]; j++)
422 | ivr->c[idx[d] + i] +=
423 | Tright[i * 33 + j] * iv->c[idx[d] + j];
424 | }
425 | ncdiff = 0.0;
426 | for (i = 0; i <= n[0]; i++) {
427 | temp = ivr->c[i] - ivr->c[idx[d] + i];
428 | ncdiff += temp * temp;
429 | }
430 | for (i = n[0] + 1; i <= n[d]; i++) {
431 | temp = ivr->c[idx[d] + i];
432 | ncdiff += temp * temp;
433 | }
434 | ncdiff = sqrt(ncdiff);
435 | ivr->err = ncdiff * h;
436 |
437 | /* Check for divergence. */
438 | ivr->ndiv =
439 | iv->ndiv + (fabs(iv->c[0]) > 0 && ivr->c[0] / iv->c[0] > 2);
440 | if (ivr->ndiv > ndiv_max && 2 * ivr->ndiv > ivr->rdepth) {
441 | /* need copysign(INFINITY, igral) */
442 | *result = (igral >= 0) ? GSL_POSINF : GSL_NEGINF;
443 | return GSL_EDIVERGE;
444 | }
445 |
446 | /* Compute the local integral. */
447 | ivr->igral = h * w * ivr->c[0];
448 |
449 | /* Fix-up the heap: we now have one interval on top
450 | that we don't need any more and two new, unsorted
451 | ones at the bottom. */
452 |
453 | /* Flip the last interval to the top of the heap and
454 | sift down. */
455 | t = ws->heap[nivals - 1];
456 | ws->heap[nivals - 1] = ws->heap[0];
457 | ws->heap[0] = t;
458 | nivals--;
459 |
460 | /* Sift this interval back down the heap. */
461 | i = 0;
462 | while (2 * i + 1 < nivals - 1) {
463 | j = 2 * i + 1;
464 | if (j + 1 < nivals - 1 && ws->ivals[ws->heap[j + 1]].err >=
465 | ws->ivals[ws->heap[j]].err)
466 | j++;
467 | if (ws->ivals[ws->heap[j]].err <= ws->ivals[ws->heap[i]].err)
468 | break;
469 | else {
470 | t = ws->heap[j];
471 | ws->heap[j] = ws->heap[i];
472 | ws->heap[i] = t;
473 | i = j;
474 | }
475 | }
476 |
477 | /* Now grab the last interval and sift it up the heap. */
478 | i = nivals - 1;
479 | while (i > 0) {
480 | j = (i - 1) / 2;
481 | if (ws->ivals[ws->heap[j]].err < ws->ivals[ws->heap[i]].err) {
482 | t = ws->heap[j];
483 | ws->heap[j] = ws->heap[i];
484 | ws->heap[i] = t;
485 | i = j;
486 | } else
487 | break;
488 | }
489 |
490 | }
491 |
492 | /* Otherwise, just fix-up the heap. */
493 | else {
494 | i = 0;
495 | while (2 * i + 1 < nivals) {
496 | j = 2 * i + 1;
497 | if (j + 1 < nivals && ws->ivals[ws->heap[j + 1]].err >=
498 | ws->ivals[ws->heap[j]].err)
499 | j++;
500 | if (ws->ivals[ws->heap[j]].err <= ws->ivals[ws->heap[i]].err)
501 | break;
502 | else {
503 | t = ws->heap[j];
504 | ws->heap[j] = ws->heap[i];
505 | ws->heap[i] = t;
506 | i = j;
507 | }
508 | }
509 | }
510 |
511 | /* If the heap is about to overflow, remove the last two
512 | intervals. */
513 | while (nivals > ws->size - 2) {
514 | iv = &(ws->ivals[ws->heap[nivals - 1]]);
515 |
516 | /* printf
517 | ("cquad: dumping ival %i (of %i) with [%e,%e] int=%e,
518 | err=%e, depth=%i\n", ws->heap[0], nivals, iv->a, iv->b,
519 | iv->igral, iv->err, iv->depth);
520 | */
521 | err_final += iv->err;
522 | igral_final += iv->igral;
523 | nivals--;
524 | }
525 |
526 | /* Collect the value of the integral and error. */
527 | igral = igral_final;
528 | err = err_final;
529 | for (i = 0; i < nivals; i++) {
530 | igral += ws->ivals[ws->heap[i]].igral;
531 | err += ws->ivals[ws->heap[i]].err;
532 | }
533 | }
534 |
535 | /* Dump the contents of the heap. */
536 | /* for (i = 0; i < nivals; i++)
537 | {
538 | iv = &(ws->ivals[ws->heap[i]]);
539 | printf
540 | ("cquad: ival %i (%i) with [%e,%e], int=%e, err=%e, depth=%i,
541 | rdepth=%i\n", i, ws->heap[i], iv->a, iv->b, iv->igral, iv->err,
542 | iv->depth, iv->rdepth);
543 | }
544 | */
545 | /* Clean up and present the results. */
546 | *result = igral;
547 | if (abserr != NULL) *abserr = err;
548 |
549 | /* All is well that ends well. */
550 | return 0;
551 | }
552 |
--------------------------------------------------------------------------------
/pyquad/integration/err.c:
--------------------------------------------------------------------------------
1 | /* integration/err.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #include
22 | #include
23 | #include "gsl_integration.h"
24 | #include "gsl_math.h"
25 |
26 | double pow_fast_ankerl(double a, double b) {
27 | union {
28 | double d;
29 | int x[2];
30 | } u = {a};
31 | u.x[1] = (int)(b * (u.x[1] - 1072632447) + 1072632447);
32 | u.x[0] = 0;
33 | return u.d;
34 | }
35 |
36 | static double rescale_error(double err, const double result_abs,
37 | const double result_asc);
38 |
39 | static double rescale_error(double err, const double result_abs,
40 | const double result_asc) {
41 | err = fabs(err);
42 |
43 | if (result_asc != 0 && err != 0) {
44 | double scale = pow_fast_ankerl((200 * err / result_asc), 1.5);
45 |
46 | if (scale < 1) {
47 | err = result_asc * scale;
48 | } else {
49 | err = result_asc;
50 | }
51 | }
52 | if (result_abs > GSL_DBL_MIN / (50 * GSL_DBL_EPSILON)) {
53 | double min_err = 50 * GSL_DBL_EPSILON * result_abs;
54 |
55 | if (min_err > err) {
56 | err = min_err;
57 | }
58 | }
59 |
60 | return err;
61 | }
62 |
--------------------------------------------------------------------------------
/pyquad/integration/error.c:
--------------------------------------------------------------------------------
1 | /* err/error.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Gerard Jungman, Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #include
22 | #include
23 | #include
24 |
25 | #include "gsl_errno.h"
26 | #include "gsl_message.h"
27 |
28 | #include "stream.c"
29 |
30 | gsl_error_handler_t *gsl_error_handler = NULL;
31 |
32 | static void no_error_handler(const char *reason, const char *file, int line,
33 | int gsl_errno);
34 |
35 | void gsl_error(const char *reason, const char *file, int line, int gsl_errno) {
36 | if (gsl_error_handler) {
37 | (*gsl_error_handler)(reason, file, line, gsl_errno);
38 | return;
39 | }
40 |
41 | gsl_stream_printf("ERROR", file, line, reason);
42 |
43 | fflush(stdout);
44 | fprintf(stderr, "Default GSL error handler invoked.\n");
45 | fflush(stderr);
46 |
47 | abort();
48 | }
49 |
50 | gsl_error_handler_t *gsl_set_error_handler(gsl_error_handler_t *new_handler) {
51 | gsl_error_handler_t *previous_handler = gsl_error_handler;
52 | gsl_error_handler = new_handler;
53 | return previous_handler;
54 | }
55 |
56 | gsl_error_handler_t *gsl_set_error_handler_off(void) {
57 | gsl_error_handler_t *previous_handler = gsl_error_handler;
58 | gsl_error_handler = no_error_handler;
59 | return previous_handler;
60 | }
61 |
62 | static void no_error_handler(const char *reason, const char *file, int line,
63 | int gsl_errno) {
64 | /* do nothing */
65 | reason = 0;
66 | file = 0;
67 | line = 0;
68 | gsl_errno = 0;
69 | return;
70 | }
71 |
--------------------------------------------------------------------------------
/pyquad/integration/fdiv.c:
--------------------------------------------------------------------------------
1 | /* sys/fdiv.c
2 | *
3 | * Copyright (C) 2001, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | //#include
22 | #include
23 | #include "gsl_sys.h"
24 |
25 | double gsl_fdiv(const double x, const double y) { return x / y; }
26 |
--------------------------------------------------------------------------------
/pyquad/integration/gsl_errno.h:
--------------------------------------------------------------------------------
1 | /* err/gsl_errno.h
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Gerard Jungman, Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #ifndef __GSL_ERRNO_H__
22 | #define __GSL_ERRNO_H__
23 |
24 | #include
25 | #include
26 | #include "gsl_types.h"
27 |
28 | #undef __BEGIN_DECLS
29 | #undef __END_DECLS
30 | #ifdef __cplusplus
31 | #define __BEGIN_DECLS extern "C" {
32 | #define __END_DECLS }
33 | #else
34 | #define __BEGIN_DECLS /* empty */
35 | #define __END_DECLS /* empty */
36 | #endif
37 |
38 | __BEGIN_DECLS
39 |
40 | enum {
41 | GSL_SUCCESS = 0,
42 | GSL_FAILURE = -1,
43 | GSL_CONTINUE = -2, /* iteration has not converged */
44 | GSL_EDOM = 1, /* input domain error, e.g sqrt(-1) */
45 | GSL_ERANGE = 2, /* output range error, e.g. exp(1e100) */
46 | GSL_EFAULT = 3, /* invalid pointer */
47 | GSL_EINVAL = 4, /* invalid argument supplied by user */
48 | GSL_EFAILED = 5, /* generic failure */
49 | GSL_EFACTOR = 6, /* factorization failed */
50 | GSL_ESANITY = 7, /* sanity check failed - shouldn't happen */
51 | GSL_ENOMEM = 8, /* malloc failed */
52 | GSL_EBADFUNC = 9, /* problem with user-supplied function */
53 | GSL_ERUNAWAY = 10, /* iterative process is out of control */
54 | GSL_EMAXITER = 11, /* exceeded max number of iterations */
55 | GSL_EZERODIV = 12, /* tried to divide by zero */
56 | GSL_EBADTOL = 13, /* user specified an invalid tolerance */
57 | GSL_ETOL = 14, /* failed to reach the specified tolerance */
58 | GSL_EUNDRFLW = 15, /* underflow */
59 | GSL_EOVRFLW = 16, /* overflow */
60 | GSL_ELOSS = 17, /* loss of accuracy */
61 | GSL_EROUND = 18, /* failed because of roundoff error */
62 | GSL_EBADLEN = 19, /* matrix, vector lengths are not conformant */
63 | GSL_ENOTSQR = 20, /* matrix not square */
64 | GSL_ESING = 21, /* apparent singularity detected */
65 | GSL_EDIVERGE = 22, /* integral or series is divergent */
66 | GSL_EUNSUP = 23, /* requested feature is not supported by the hardware */
67 | GSL_EUNIMPL = 24, /* requested feature not (yet) implemented */
68 | GSL_ECACHE = 25, /* cache limit exceeded */
69 | GSL_ETABLE = 26, /* table limit exceeded */
70 | GSL_ENOPROG = 27, /* iteration is not making progress towards solution */
71 | GSL_ENOPROGJ = 28, /* jacobian evaluations are not improving the solution */
72 | GSL_ETOLF = 29, /* cannot reach the specified tolerance in F */
73 | GSL_ETOLX = 30, /* cannot reach the specified tolerance in X */
74 | GSL_ETOLG = 31, /* cannot reach the specified tolerance in gradient */
75 | GSL_EOF = 32 /* end of file */
76 | };
77 |
78 | void gsl_error(const char *reason, const char *file, int line, int gsl_errno);
79 |
80 | void gsl_stream_printf(const char *label, const char *file, int line,
81 | const char *reason);
82 |
83 | const char *gsl_strerror(const int gsl_errno);
84 |
85 | typedef void gsl_error_handler_t(const char *reason, const char *file, int line,
86 | int gsl_errno);
87 |
88 | typedef void gsl_stream_handler_t(const char *label, const char *file, int line,
89 | const char *reason);
90 |
91 | gsl_error_handler_t *gsl_set_error_handler(gsl_error_handler_t *new_handler);
92 |
93 | gsl_error_handler_t *gsl_set_error_handler_off(void);
94 |
95 | gsl_stream_handler_t *gsl_set_stream_handler(gsl_stream_handler_t *new_handler);
96 |
97 | FILE *gsl_set_stream(FILE *new_stream);
98 |
99 | /* GSL_ERROR: call the error handler, and return the error code */
100 |
101 | #define GSL_ERROR(reason, gsl_errno) \
102 | do { \
103 | gsl_error(reason, __FILE__, __LINE__, gsl_errno); \
104 | return gsl_errno; \
105 | } while (0)
106 |
107 | /* GSL_ERROR_VAL: call the error handler, and return the given value */
108 |
109 | #define GSL_ERROR_VAL(reason, gsl_errno, value) \
110 | do { \
111 | gsl_error(reason, __FILE__, __LINE__, gsl_errno); \
112 | return value; \
113 | } while (0)
114 |
115 | /* GSL_ERROR_VOID: call the error handler, and then return
116 | (for void functions which still need to generate an error) */
117 |
118 | #define GSL_ERROR_VOID(reason, gsl_errno) \
119 | do { \
120 | gsl_error(reason, __FILE__, __LINE__, gsl_errno); \
121 | return; \
122 | } while (0)
123 |
124 | /* GSL_ERROR_NULL suitable for out-of-memory conditions */
125 |
126 | #define GSL_ERROR_NULL(reason, gsl_errno) GSL_ERROR_VAL(reason, gsl_errno, 0)
127 |
128 | /* Sometimes you have several status results returned from
129 | * function calls and you want to combine them in some sensible
130 | * way. You cannot produce a "total" status condition, but you can
131 | * pick one from a set of conditions based on an implied hierarchy.
132 | *
133 | * In other words:
134 | * you have: status_a, status_b, ...
135 | * you want: status = (status_a if it is bad, or status_b if it is bad,...)
136 | *
137 | * In this example you consider status_a to be more important and
138 | * it is checked first, followed by the others in the order specified.
139 | *
140 | * Here are some dumb macros to do this.
141 | */
142 | #define GSL_ERROR_SELECT_2(a, b) \
143 | ((a) != GSL_SUCCESS ? (a) : ((b) != GSL_SUCCESS ? (b) : GSL_SUCCESS))
144 | #define GSL_ERROR_SELECT_3(a, b, c) \
145 | ((a) != GSL_SUCCESS ? (a) : GSL_ERROR_SELECT_2(b, c))
146 | #define GSL_ERROR_SELECT_4(a, b, c, d) \
147 | ((a) != GSL_SUCCESS ? (a) : GSL_ERROR_SELECT_3(b, c, d))
148 | #define GSL_ERROR_SELECT_5(a, b, c, d, e) \
149 | ((a) != GSL_SUCCESS ? (a) : GSL_ERROR_SELECT_4(b, c, d, e))
150 |
151 | #define GSL_STATUS_UPDATE(sp, s) \
152 | do { \
153 | if ((s) != GSL_SUCCESS) *(sp) = (s); \
154 | } while (0)
155 |
156 | __END_DECLS
157 |
158 | #endif /* __GSL_ERRNO_H__ */
159 |
--------------------------------------------------------------------------------
/pyquad/integration/gsl_inline.h:
--------------------------------------------------------------------------------
1 | /* gsl_inline.h
2 | *
3 | * Copyright (C) 2008, 2009 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #ifndef __GSL_INLINE_H__
22 | #define __GSL_INLINE_H__
23 |
24 | /* In recent versiions of GCC, the inline keyword has two different
25 | forms: GNU and C99.
26 |
27 | In GNU mode we can use 'extern inline' to make inline functions
28 | work like macros. The function is only inlined--it is never output
29 | as a definition in an object file.
30 |
31 | In the new C99 mode 'extern inline' has a different meaning--it
32 | causes the definition of the function to be output in each object
33 | file where it is used. This will result in multiple-definition
34 | errors on linking. The 'inline' keyword on its own (without
35 | extern) has the same behavior as the original GNU 'extern inline'.
36 |
37 | The C99 style is the default with -std=c99 in GCC 4.3.
38 |
39 | This header file allows either form of inline to be used by
40 | redefining the macros INLINE_DECL and INLINE_FUN. These are used
41 | in the public header files as
42 |
43 | INLINE_DECL double gsl_foo (double x);
44 | #ifdef HAVE_INLINE
45 | INLINE_FUN double gsl_foo (double x) { return x+1.0; } ;
46 | #endif
47 |
48 | */
49 |
50 | #ifdef HAVE_INLINE
51 | #if defined(__GNUC_STDC_INLINE__) || defined(GSL_C99_INLINE) || \
52 | defined(HAVE_C99_INLINE)
53 | #define INLINE_DECL static inline /* use C99 inline */
54 | #define INLINE_FUN static inline
55 | #else
56 | #define INLINE_DECL /* use GNU extern inline */
57 | #define INLINE_FUN extern inline
58 | #endif
59 | #else
60 | #define INLINE_DECL /* */
61 | #endif
62 |
63 | /* Range checking conditions in headers do not require any run-time
64 | tests of the global variable gsl_check_range. They are enabled or
65 | disabled in user code at compile time with GSL_RANGE_CHECK macro.
66 | See also build.h. */
67 | #define GSL_RANGE_COND(x) (x)
68 |
69 | #endif /* __GSL_INLINE_H__ */
70 |
--------------------------------------------------------------------------------
/pyquad/integration/gsl_integration.h:
--------------------------------------------------------------------------------
1 | /* integration/gsl_integration.h
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #ifndef __GSL_INTEGRATION_H__
22 | #define __GSL_INTEGRATION_H__
23 | #include
24 | #include "gsl_machine.h"
25 | #include "gsl_math.h"
26 | #include "gsl_minmax.h"
27 |
28 | #undef __BEGIN_DECLS
29 | #undef __END_DECLS
30 | #ifdef __cplusplus
31 | #define __BEGIN_DECLS extern "C" {
32 | #define __END_DECLS }
33 | #else
34 | #define __BEGIN_DECLS /* empty */
35 | #define __END_DECLS /* empty */
36 | #endif
37 |
38 | __BEGIN_DECLS
39 |
40 | /* Workspace for adaptive integrators */
41 |
42 | typedef struct {
43 | size_t limit;
44 | size_t size;
45 | size_t nrmax;
46 | size_t i;
47 | size_t maximum_level;
48 | double *alist;
49 | double *blist;
50 | double *rlist;
51 | double *elist;
52 | size_t *order;
53 | size_t *level;
54 | } gsl_integration_workspace;
55 |
56 | gsl_integration_workspace *gsl_integration_workspace_alloc(const size_t n);
57 |
58 | void gsl_integration_workspace_free(gsl_integration_workspace *w);
59 |
60 | /* Workspace for QAWS integrator */
61 |
62 | typedef struct {
63 | double alpha;
64 | double beta;
65 | int mu;
66 | int nu;
67 | double ri[25];
68 | double rj[25];
69 | double rg[25];
70 | double rh[25];
71 | } gsl_integration_qaws_table;
72 |
73 | gsl_integration_qaws_table *gsl_integration_qaws_table_alloc(double alpha,
74 | double beta,
75 | int mu, int nu);
76 |
77 | int gsl_integration_qaws_table_set(gsl_integration_qaws_table *t, double alpha,
78 | double beta, int mu, int nu);
79 |
80 | void gsl_integration_qaws_table_free(gsl_integration_qaws_table *t);
81 |
82 | /* Workspace for QAWO integrator */
83 |
84 | enum gsl_integration_qawo_enum { GSL_INTEG_COSINE, GSL_INTEG_SINE };
85 |
86 | typedef struct {
87 | size_t n;
88 | double omega;
89 | double L;
90 | double par;
91 | enum gsl_integration_qawo_enum sine;
92 | double *chebmo;
93 | } gsl_integration_qawo_table;
94 |
95 | gsl_integration_qawo_table *gsl_integration_qawo_table_alloc(
96 | double omega, double L, enum gsl_integration_qawo_enum sine, size_t n);
97 |
98 | int gsl_integration_qawo_table_set(gsl_integration_qawo_table *t, double omega,
99 | double L,
100 | enum gsl_integration_qawo_enum sine);
101 |
102 | int gsl_integration_qawo_table_set_length(gsl_integration_qawo_table *t,
103 | double L);
104 |
105 | void gsl_integration_qawo_table_free(gsl_integration_qawo_table *t);
106 |
107 | /* Definition of an integration rule */
108 |
109 | typedef void gsl_integration_rule(const gsl_function *f, double a, double b,
110 | double *result, double *abserr,
111 | double *defabs, double *resabs);
112 |
113 | void gsl_integration_qk15(const gsl_function *f, double a, double b,
114 | double *result, double *abserr, double *resabs,
115 | double *resasc);
116 |
117 | void gsl_integration_qk21(const gsl_function *f, double a, double b,
118 | double *result, double *abserr, double *resabs,
119 | double *resasc);
120 |
121 | void gsl_integration_qk31(const gsl_function *f, double a, double b,
122 | double *result, double *abserr, double *resabs,
123 | double *resasc);
124 |
125 | void gsl_integration_qk41(const gsl_function *f, double a, double b,
126 | double *result, double *abserr, double *resabs,
127 | double *resasc);
128 |
129 | void gsl_integration_qk51(const gsl_function *f, double a, double b,
130 | double *result, double *abserr, double *resabs,
131 | double *resasc);
132 |
133 | void gsl_integration_qk61(const gsl_function *f, double a, double b,
134 | double *result, double *abserr, double *resabs,
135 | double *resasc);
136 |
137 | void gsl_integration_qcheb(gsl_function *f, double a, double b, double *cheb12,
138 | double *cheb24);
139 |
140 | /* The low-level integration rules in QUADPACK are identified by small
141 | integers (1-6). We'll use symbolic constants to refer to them. */
142 |
143 | enum {
144 | GSL_INTEG_GAUSS15 = 1, /* 15 point Gauss-Kronrod rule */
145 | GSL_INTEG_GAUSS21 = 2, /* 21 point Gauss-Kronrod rule */
146 | GSL_INTEG_GAUSS31 = 3, /* 31 point Gauss-Kronrod rule */
147 | GSL_INTEG_GAUSS41 = 4, /* 41 point Gauss-Kronrod rule */
148 | GSL_INTEG_GAUSS51 = 5, /* 51 point Gauss-Kronrod rule */
149 | GSL_INTEG_GAUSS61 = 6 /* 61 point Gauss-Kronrod rule */
150 | };
151 |
152 | void gsl_integration_qk(const int n, const double xgk[], const double wg[],
153 | const double wgk[], double fv1[], double fv2[],
154 | const gsl_function *f, double a, double b,
155 | double *result, double *abserr, double *resabs,
156 | double *resasc);
157 |
158 | int gsl_integration_qng(const gsl_function *f, double a, double b,
159 | double epsabs, double epsrel, double *result,
160 | double *abserr, size_t *neval);
161 |
162 | int gsl_integration_qag(const gsl_function *f, double a, double b,
163 | double epsabs, double epsrel, size_t limit, int key,
164 | gsl_integration_workspace *workspace, double *result,
165 | double *abserr);
166 |
167 | int gsl_integration_qagi(gsl_function *f, double epsabs, double epsrel,
168 | size_t limit, gsl_integration_workspace *workspace,
169 | double *result, double *abserr);
170 |
171 | int gsl_integration_qagiu(gsl_function *f, double a, double epsabs,
172 | double epsrel, size_t limit,
173 | gsl_integration_workspace *workspace, double *result,
174 | double *abserr);
175 |
176 | int gsl_integration_qagil(gsl_function *f, double b, double epsabs,
177 | double epsrel, size_t limit,
178 | gsl_integration_workspace *workspace, double *result,
179 | double *abserr);
180 |
181 | int gsl_integration_qags(const gsl_function *f, double a, double b,
182 | double epsabs, double epsrel, size_t limit,
183 | void *workspace, double *result, double *abserr);
184 |
185 | int gsl_integration_qagp(const gsl_function *f, double *pts, size_t npts,
186 | double epsabs, double epsrel, size_t limit,
187 | gsl_integration_workspace *workspace, double *result,
188 | double *abserr);
189 |
190 | int gsl_integration_qawc(gsl_function *f, const double a, const double b,
191 | const double c, const double epsabs,
192 | const double epsrel, const size_t limit,
193 | gsl_integration_workspace *workspace, double *result,
194 | double *abserr);
195 |
196 | int gsl_integration_qaws(gsl_function *f, const double a, const double b,
197 | gsl_integration_qaws_table *t, const double epsabs,
198 | const double epsrel, const size_t limit,
199 | gsl_integration_workspace *workspace, double *result,
200 | double *abserr);
201 |
202 | int gsl_integration_qawo(gsl_function *f, const double a, const double epsabs,
203 | const double epsrel, const size_t limit,
204 | gsl_integration_workspace *workspace,
205 | gsl_integration_qawo_table *wf, double *result,
206 | double *abserr);
207 |
208 | int gsl_integration_qawf(gsl_function *f, const double a, const double epsabs,
209 | const size_t limit,
210 | gsl_integration_workspace *workspace,
211 | gsl_integration_workspace *cycle_workspace,
212 | gsl_integration_qawo_table *wf, double *result,
213 | double *abserr);
214 |
215 | /* Workspace for fixed-order Gauss-Legendre integration */
216 |
217 | typedef struct {
218 | size_t n; /* number of points */
219 | double *x; /* Gauss abscissae/points */
220 | double *w; /* Gauss weights for each abscissae */
221 | int precomputed; /* high precision abscissae/weights precomputed? */
222 | } gsl_integration_glfixed_table;
223 |
224 | gsl_integration_glfixed_table *gsl_integration_glfixed_table_alloc(size_t n);
225 |
226 | void gsl_integration_glfixed_table_free(gsl_integration_glfixed_table *t);
227 |
228 | /* Routine for fixed-order Gauss-Legendre integration */
229 |
230 | double gsl_integration_glfixed(const gsl_function *f, double a, double b,
231 | const gsl_integration_glfixed_table *t);
232 |
233 | /* Routine to retrieve the i-th Gauss-Legendre point and weight from t */
234 |
235 | int gsl_integration_glfixed_point(double a, double b, size_t i, double *xi,
236 | double *wi,
237 | const gsl_integration_glfixed_table *t);
238 |
239 | /* Cquad integration - Pedro Gonnet */
240 |
241 | /* Data of a single interval */
242 | typedef struct {
243 | double a, b;
244 | double c[64];
245 | double fx[33];
246 | double igral, err;
247 | int depth, rdepth, ndiv;
248 | } gsl_integration_cquad_ival;
249 |
250 | /* The workspace is just a collection of intervals */
251 | typedef struct {
252 | size_t size;
253 | gsl_integration_cquad_ival *ivals;
254 | size_t *heap;
255 | } gsl_integration_cquad_workspace;
256 |
257 | gsl_integration_cquad_workspace *gsl_integration_cquad_workspace_alloc(
258 | const size_t n);
259 |
260 | void gsl_integration_cquad_workspace_free(gsl_integration_cquad_workspace *w);
261 |
262 | int gsl_integration_cquad(const gsl_function *f, double a, double b,
263 | double epsabs, double epsrel, size_t limit, void *ws,
264 | double *result, double *abserr);
265 |
266 | /* Romberg integration workspace and routines */
267 |
268 | typedef struct {
269 | size_t n; /* maximum number of steps */
270 | double *work1; /* workspace for a row of R matrix, size n */
271 | double *work2; /* workspace for a row of R matrix, size n */
272 | } gsl_integration_romberg_workspace;
273 |
274 | gsl_integration_romberg_workspace *gsl_integration_romberg_alloc(
275 | const size_t n);
276 | void gsl_integration_romberg_free(gsl_integration_romberg_workspace *w);
277 | int gsl_integration_romberg(const gsl_function *f, const double a,
278 | const double b, const double epsabs,
279 | const double epsrel, double *result, size_t *neval,
280 | gsl_integration_romberg_workspace *w);
281 |
282 | /* IQPACK related structures and routines */
283 |
284 | typedef struct {
285 | double alpha;
286 | double beta;
287 | double a;
288 | double b;
289 | double zemu;
290 | double shft;
291 | double slp;
292 | double al;
293 | double be;
294 | } gsl_integration_fixed_params;
295 |
296 | typedef struct {
297 | int (*check)(const size_t n, const gsl_integration_fixed_params *params);
298 | int (*init)(const size_t n, double *diag, double *subdiag,
299 | gsl_integration_fixed_params *params);
300 | } gsl_integration_fixed_type;
301 |
302 | typedef struct {
303 | size_t n; /* number of nodes/weights */
304 | double *weights; /* quadrature weights */
305 | double *x; /* quadrature nodes */
306 | double *diag; /* diagonal of Jacobi matrix */
307 | double *subdiag; /* subdiagonal of Jacobi matrix */
308 | const gsl_integration_fixed_type *type;
309 | } gsl_integration_fixed_workspace;
310 |
311 | /* IQPACK integral types */
312 | // GSL_VAR const gsl_integration_fixed_type * gsl_integration_fixed_legendre;
313 | // GSL_VAR const gsl_integration_fixed_type * gsl_integration_fixed_chebyshev;
314 | // GSL_VAR const gsl_integration_fixed_type * gsl_integration_fixed_gegenbauer;
315 | // GSL_VAR const gsl_integration_fixed_type * gsl_integration_fixed_jacobi;
316 | // GSL_VAR const gsl_integration_fixed_type * gsl_integration_fixed_laguerre;
317 | // GSL_VAR const gsl_integration_fixed_type * gsl_integration_fixed_hermite;
318 | // GSL_VAR const gsl_integration_fixed_type * gsl_integration_fixed_exponential;
319 | // GSL_VAR const gsl_integration_fixed_type * gsl_integration_fixed_rational;
320 | // GSL_VAR const gsl_integration_fixed_type * gsl_integration_fixed_chebyshev2;
321 |
322 | gsl_integration_fixed_workspace *gsl_integration_fixed_alloc(
323 | const gsl_integration_fixed_type *type, const size_t n, const double a,
324 | const double b, const double alpha, const double beta);
325 |
326 | void gsl_integration_fixed_free(gsl_integration_fixed_workspace *w);
327 |
328 | size_t gsl_integration_fixed_n(const gsl_integration_fixed_workspace *w);
329 |
330 | double *gsl_integration_fixed_nodes(const gsl_integration_fixed_workspace *w);
331 |
332 | double *gsl_integration_fixed_weights(const gsl_integration_fixed_workspace *w);
333 |
334 | int gsl_integration_fixed(const gsl_function *func, double *result,
335 | const gsl_integration_fixed_workspace *w);
336 |
337 | __END_DECLS
338 |
339 | #endif /* __GSL_INTEGRATION_H__ */
340 |
--------------------------------------------------------------------------------
/pyquad/integration/gsl_machine.h:
--------------------------------------------------------------------------------
1 | /* Author: B. Gough and G. Jungman */
2 | #ifndef __GSL_MACHINE_H__
3 | #define __GSL_MACHINE_H__
4 |
5 | #include
6 | #include
7 |
8 | /* magic constants; mostly for the benefit of the implementation */
9 |
10 | /* -*-MACHINE CONSTANTS-*-
11 | *
12 | * PLATFORM: Whiz-O-Matic 9000
13 | * FP_PLATFORM: IEEE-Virtual
14 | * HOSTNAME: nnn.lanl.gov
15 | * DATE: Fri Nov 20 17:53:26 MST 1998
16 | */
17 | #define GSL_DBL_EPSILON 2.2204460492503131e-16
18 | #define GSL_SQRT_DBL_EPSILON 1.4901161193847656e-08
19 | #define GSL_ROOT3_DBL_EPSILON 6.0554544523933429e-06
20 | #define GSL_ROOT4_DBL_EPSILON 1.2207031250000000e-04
21 | #define GSL_ROOT5_DBL_EPSILON 7.4009597974140505e-04
22 | #define GSL_ROOT6_DBL_EPSILON 2.4607833005759251e-03
23 | #define GSL_LOG_DBL_EPSILON (-3.6043653389117154e+01)
24 |
25 | #define GSL_DBL_MIN 2.2250738585072014e-308
26 | #define GSL_SQRT_DBL_MIN 1.4916681462400413e-154
27 | #define GSL_ROOT3_DBL_MIN 2.8126442852362996e-103
28 | #define GSL_ROOT4_DBL_MIN 1.2213386697554620e-77
29 | #define GSL_ROOT5_DBL_MIN 2.9476022969691763e-62
30 | #define GSL_ROOT6_DBL_MIN 5.3034368905798218e-52
31 | #define GSL_LOG_DBL_MIN (-7.0839641853226408e+02)
32 |
33 | #define GSL_DBL_MAX 1.7976931348623157e+308
34 | #define GSL_SQRT_DBL_MAX 1.3407807929942596e+154
35 | #define GSL_ROOT3_DBL_MAX 5.6438030941222897e+102
36 | #define GSL_ROOT4_DBL_MAX 1.1579208923731620e+77
37 | #define GSL_ROOT5_DBL_MAX 4.4765466227572707e+61
38 | #define GSL_ROOT6_DBL_MAX 2.3756689782295612e+51
39 | #define GSL_LOG_DBL_MAX 7.0978271289338397e+02
40 |
41 | #define GSL_FLT_EPSILON 1.1920928955078125e-07
42 | #define GSL_SQRT_FLT_EPSILON 3.4526698300124393e-04
43 | #define GSL_ROOT3_FLT_EPSILON 4.9215666011518501e-03
44 | #define GSL_ROOT4_FLT_EPSILON 1.8581361171917516e-02
45 | #define GSL_ROOT5_FLT_EPSILON 4.1234622211652937e-02
46 | #define GSL_ROOT6_FLT_EPSILON 7.0153878019335827e-02
47 | #define GSL_LOG_FLT_EPSILON (-1.5942385152878742e+01)
48 |
49 | #define GSL_FLT_MIN 1.1754943508222875e-38
50 | #define GSL_SQRT_FLT_MIN 1.0842021724855044e-19
51 | #define GSL_ROOT3_FLT_MIN 2.2737367544323241e-13
52 | #define GSL_ROOT4_FLT_MIN 3.2927225399135965e-10
53 | #define GSL_ROOT5_FLT_MIN 2.5944428542140822e-08
54 | #define GSL_ROOT6_FLT_MIN 4.7683715820312542e-07
55 | #define GSL_LOG_FLT_MIN (-8.7336544750553102e+01)
56 |
57 | #define GSL_FLT_MAX 3.4028234663852886e+38
58 | #define GSL_SQRT_FLT_MAX 1.8446743523953730e+19
59 | #define GSL_ROOT3_FLT_MAX 6.9814635196223242e+12
60 | #define GSL_ROOT4_FLT_MAX 4.2949672319999986e+09
61 | #define GSL_ROOT5_FLT_MAX 5.0859007855960041e+07
62 | #define GSL_ROOT6_FLT_MAX 2.6422459233807749e+06
63 | #define GSL_LOG_FLT_MAX 8.8722839052068352e+01
64 |
65 | #define GSL_SFLT_EPSILON 4.8828125000000000e-04
66 | #define GSL_SQRT_SFLT_EPSILON 2.2097086912079612e-02
67 | #define GSL_ROOT3_SFLT_EPSILON 7.8745065618429588e-02
68 | #define GSL_ROOT4_SFLT_EPSILON 1.4865088937534013e-01
69 | #define GSL_ROOT5_SFLT_EPSILON 2.1763764082403100e-01
70 | #define GSL_ROOT6_SFLT_EPSILON 2.8061551207734325e-01
71 | #define GSL_LOG_SFLT_EPSILON (-7.6246189861593985e+00)
72 |
73 | /* !MACHINE CONSTANTS! */
74 |
75 | /* a little internal backwards compatibility */
76 | #define GSL_MACH_EPS GSL_DBL_EPSILON
77 |
78 | /* Here are the constants related to or derived from
79 | * machine constants. These are not to be confused with
80 | * the constants that define various precision levels
81 | * for the precision/error system.
82 | *
83 | * This information is determined at configure time
84 | * and is platform dependent. Edit at your own risk.
85 | *
86 | * PLATFORM: WHIZ-O-MATIC
87 | * CONFIG-DATE: Thu Nov 19 19:27:18 MST 1998
88 | * CONFIG-HOST: nnn.lanl.gov
89 | */
90 |
91 | /* machine precision constants */
92 | /* #define GSL_MACH_EPS 1.0e-15 */
93 | #define GSL_SQRT_MACH_EPS 3.2e-08
94 | #define GSL_ROOT3_MACH_EPS 1.0e-05
95 | #define GSL_ROOT4_MACH_EPS 0.000178
96 | #define GSL_ROOT5_MACH_EPS 0.00100
97 | #define GSL_ROOT6_MACH_EPS 0.00316
98 | #define GSL_LOG_MACH_EPS (-34.54)
99 |
100 | #endif /* __GSL_MACHINE_H__ */
101 |
--------------------------------------------------------------------------------
/pyquad/integration/gsl_math.h:
--------------------------------------------------------------------------------
1 | /* gsl_math.h
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2004, 2007 Gerard Jungman, Brian
4 | * Gough
5 | *
6 | * This program is free software; you can redistribute it and/or modify
7 | * it under the terms of the GNU General Public License as published by
8 | * the Free Software Foundation; either version 3 of the License, or (at
9 | * your option) any later version.
10 | *
11 | * This program is distributed in the hope that it will be useful, but
12 | * WITHOUT ANY WARRANTY; without even the implied warranty of
13 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
14 | * General Public License for more details.
15 | *
16 | * You should have received a copy of the GNU General Public License
17 | * along with this program; if not, write to the Free Software
18 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
19 | * USA.
20 | */
21 |
22 | #ifndef __GSL_MATH_H__
23 | #define __GSL_MATH_H__
24 | #include
25 |
26 | #ifndef M_E
27 | #define M_E 2.71828182845904523536028747135 /* e */
28 | #endif
29 |
30 | #ifndef M_LOG2E
31 | #define M_LOG2E 1.44269504088896340735992468100 /* log_2 (e) */
32 | #endif
33 |
34 | #ifndef M_LOG10E
35 | #define M_LOG10E 0.43429448190325182765112891892 /* log_10 (e) */
36 | #endif
37 |
38 | #ifndef M_SQRT2
39 | #define M_SQRT2 1.41421356237309504880168872421 /* sqrt(2) */
40 | #endif
41 |
42 | #ifndef M_SQRT1_2
43 | #define M_SQRT1_2 0.70710678118654752440084436210 /* sqrt(1/2) */
44 | #endif
45 |
46 | #ifndef M_SQRT3
47 | #define M_SQRT3 1.73205080756887729352744634151 /* sqrt(3) */
48 | #endif
49 |
50 | #ifndef M_PI
51 | #define M_PI 3.14159265358979323846264338328 /* pi */
52 | #endif
53 |
54 | #ifndef M_PI_2
55 | #define M_PI_2 1.57079632679489661923132169164 /* pi/2 */
56 | #endif
57 |
58 | #ifndef M_PI_4
59 | #define M_PI_4 0.78539816339744830961566084582 /* pi/4 */
60 | #endif
61 |
62 | #ifndef M_SQRTPI
63 | #define M_SQRTPI 1.77245385090551602729816748334 /* sqrt(pi) */
64 | #endif
65 |
66 | #ifndef M_2_SQRTPI
67 | #define M_2_SQRTPI 1.12837916709551257389615890312 /* 2/sqrt(pi) */
68 | #endif
69 |
70 | #ifndef M_1_PI
71 | #define M_1_PI 0.31830988618379067153776752675 /* 1/pi */
72 | #endif
73 |
74 | #ifndef M_2_PI
75 | #define M_2_PI 0.63661977236758134307553505349 /* 2/pi */
76 | #endif
77 |
78 | #ifndef M_LN10
79 | #define M_LN10 2.30258509299404568401799145468 /* ln(10) */
80 | #endif
81 |
82 | #ifndef M_LN2
83 | #define M_LN2 0.69314718055994530941723212146 /* ln(2) */
84 | #endif
85 |
86 | #ifndef M_LNPI
87 | #define M_LNPI 1.14472988584940017414342735135 /* ln(pi) */
88 | #endif
89 |
90 | #ifndef M_EULER
91 | #define M_EULER 0.57721566490153286060651209008 /* Euler constant */
92 | #endif
93 |
94 | #undef __BEGIN_DECLS
95 | #undef __END_DECLS
96 | #ifdef __cplusplus
97 | #define __BEGIN_DECLS extern "C" {
98 | #define __END_DECLS }
99 | #else
100 | #define __BEGIN_DECLS /* empty */
101 | #define __END_DECLS /* empty */
102 | #endif
103 |
104 | __BEGIN_DECLS
105 |
106 | /* other needlessly compulsive abstractions */
107 |
108 | #define GSL_IS_ODD(n) ((n)&1)
109 | #define GSL_IS_EVEN(n) (!(GSL_IS_ODD(n)))
110 | #define GSL_SIGN(x) ((x) >= 0.0 ? 1 : -1)
111 |
112 | /* Return nonzero if x is a real number, i.e. non NaN or infinite. */
113 | #define GSL_IS_REAL(x) (gsl_finite(x))
114 |
115 | /* Definition of an arbitrary function with parameters */
116 |
117 | struct gsl_function_struct {
118 | double (*function)(double x, void *params);
119 | void *params;
120 | };
121 |
122 | typedef struct gsl_function_struct gsl_function;
123 |
124 | #define GSL_FN_EVAL(F, x) (*((F)->function))(x, (F)->params)
125 |
126 | /* Definition of an arbitrary function returning two values, r1, r2 */
127 |
128 | struct gsl_function_fdf_struct {
129 | double (*f)(double x, void *params);
130 | double (*df)(double x, void *params);
131 | void (*fdf)(double x, void *params, double *f, double *df);
132 | void *params;
133 | };
134 |
135 | typedef struct gsl_function_fdf_struct gsl_function_fdf;
136 |
137 | #define GSL_FN_FDF_EVAL_F(FDF, x) (*((FDF)->f))(x, (FDF)->params)
138 | #define GSL_FN_FDF_EVAL_DF(FDF, x) (*((FDF)->df))(x, (FDF)->params)
139 | #define GSL_FN_FDF_EVAL_F_DF(FDF, x, y, dy) \
140 | (*((FDF)->fdf))(x, (FDF)->params, (y), (dy))
141 |
142 | /* Definition of an arbitrary vector-valued function with parameters */
143 |
144 | struct gsl_function_vec_struct {
145 | int (*function)(double x, double y[], void *params);
146 | void *params;
147 | };
148 |
149 | typedef struct gsl_function_vec_struct gsl_function_vec;
150 |
151 | #define GSL_FN_VEC_EVAL(F, x, y) (*((F)->function))(x, y, (F)->params)
152 |
153 | __END_DECLS
154 |
155 | #endif /* __GSL_MATH_H__ */
156 |
--------------------------------------------------------------------------------
/pyquad/integration/gsl_message.h:
--------------------------------------------------------------------------------
1 | /* err/gsl_message.h
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Gerard Jungman, Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #ifndef __GSL_MESSAGE_H__
22 | #define __GSL_MESSAGE_H__
23 | #include "gsl_types.h"
24 |
25 | #undef __BEGIN_DECLS
26 | #undef __END_DECLS
27 | #ifdef __cplusplus
28 | #define __BEGIN_DECLS extern "C" {
29 | #define __END_DECLS }
30 | #else
31 | #define __BEGIN_DECLS /* empty */
32 | #define __END_DECLS /* empty */
33 | #endif
34 |
35 | __BEGIN_DECLS
36 |
37 | /* Provide a general messaging service for client use. Messages can
38 | * be selectively turned off at compile time by defining an
39 | * appropriate message mask. Client code which uses the GSL_MESSAGE()
40 | * macro must provide a mask which is or'ed with the GSL_MESSAGE_MASK.
41 | *
42 | * The messaging service can be completely turned off
43 | * by defining GSL_MESSAGING_OFF. */
44 |
45 | void gsl_message(const char *message, const char *file, int line,
46 | unsigned int mask);
47 |
48 | #ifndef GSL_MESSAGE_MASK
49 | #define GSL_MESSAGE_MASK 0xffffffffu /* default all messages allowed */
50 | #endif
51 |
52 | GSL_VAR unsigned int gsl_message_mask;
53 |
54 | /* Provide some symolic masks for client ease of use. */
55 |
56 | enum {
57 | GSL_MESSAGE_MASK_A = 1,
58 | GSL_MESSAGE_MASK_B = 2,
59 | GSL_MESSAGE_MASK_C = 4,
60 | GSL_MESSAGE_MASK_D = 8,
61 | GSL_MESSAGE_MASK_E = 16,
62 | GSL_MESSAGE_MASK_F = 32,
63 | GSL_MESSAGE_MASK_G = 64,
64 | GSL_MESSAGE_MASK_H = 128
65 | };
66 |
67 | #ifdef GSL_MESSAGING_OFF /* throw away messages */
68 | #define GSL_MESSAGE(message, mask) \
69 | do { \
70 | } while (0)
71 | #else /* output all messages */
72 | #define GSL_MESSAGE(message, mask) \
73 | do { \
74 | if (mask & GSL_MESSAGE_MASK) \
75 | gsl_message(message, __FILE__, __LINE__, mask); \
76 | } while (0)
77 | #endif
78 |
79 | __END_DECLS
80 |
81 | #endif /* __GSL_MESSAGE_H__ */
82 |
--------------------------------------------------------------------------------
/pyquad/integration/gsl_minmax.h:
--------------------------------------------------------------------------------
1 | /* gsl_minmax.h
2 | *
3 | * Copyright (C) 2008 Gerard Jungman, Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #ifndef __GSL_MINMAX_H__
22 | #define __GSL_MINMAX_H__
23 | #include "gsl_inline.h"
24 |
25 | #undef __BEGIN_DECLS
26 | #undef __END_DECLS
27 | #ifdef __cplusplus
28 | #define __BEGIN_DECLS extern "C" {
29 | #define __END_DECLS }
30 | #else
31 | #define __BEGIN_DECLS /* empty */
32 | #define __END_DECLS /* empty */
33 | #endif
34 |
35 | __BEGIN_DECLS
36 |
37 | /* Define MAX and MIN macros/functions if they don't exist. */
38 |
39 | /* plain old macros for general use */
40 | #define GSL_MAX(a, b) ((a) > (b) ? (a) : (b))
41 | #define GSL_MIN(a, b) ((a) < (b) ? (a) : (b))
42 |
43 | /* function versions of the above, in case they are needed */
44 | double gsl_max(double a, double b);
45 | double gsl_min(double a, double b);
46 |
47 | /* inline-friendly strongly typed versions */
48 | #ifdef HAVE_INLINE
49 |
50 | INLINE_FUN int GSL_MAX_INT(int a, int b);
51 | INLINE_FUN int GSL_MIN_INT(int a, int b);
52 | INLINE_FUN double GSL_MAX_DBL(double a, double b);
53 | INLINE_FUN double GSL_MIN_DBL(double a, double b);
54 | INLINE_FUN long double GSL_MAX_LDBL(long double a, long double b);
55 | INLINE_FUN long double GSL_MIN_LDBL(long double a, long double b);
56 |
57 | INLINE_FUN int GSL_MAX_INT(int a, int b) { return GSL_MAX(a, b); }
58 |
59 | INLINE_FUN int GSL_MIN_INT(int a, int b) { return GSL_MIN(a, b); }
60 |
61 | INLINE_FUN double GSL_MAX_DBL(double a, double b) { return GSL_MAX(a, b); }
62 |
63 | INLINE_FUN double GSL_MIN_DBL(double a, double b) { return GSL_MIN(a, b); }
64 |
65 | INLINE_FUN long double GSL_MAX_LDBL(long double a, long double b) {
66 | return GSL_MAX(a, b);
67 | }
68 |
69 | INLINE_FUN long double GSL_MIN_LDBL(long double a, long double b) {
70 | return GSL_MIN(a, b);
71 | }
72 | #else
73 | #define GSL_MAX_INT(a, b) GSL_MAX(a, b)
74 | #define GSL_MIN_INT(a, b) GSL_MIN(a, b)
75 | #define GSL_MAX_DBL(a, b) GSL_MAX(a, b)
76 | #define GSL_MIN_DBL(a, b) GSL_MIN(a, b)
77 | #define GSL_MAX_LDBL(a, b) GSL_MAX(a, b)
78 | #define GSL_MIN_LDBL(a, b) GSL_MIN(a, b)
79 | #endif /* HAVE_INLINE */
80 |
81 | __END_DECLS
82 |
83 | #endif /* __GSL_POW_INT_H__ */
84 |
--------------------------------------------------------------------------------
/pyquad/integration/gsl_nan.h:
--------------------------------------------------------------------------------
1 | /* gsl_nan.h
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Gerard Jungman, Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #ifndef __GSL_NAN_H__
22 | #define __GSL_NAN_H__
23 |
24 | #ifdef INFINITY
25 | #define GSL_POSINF INFINITY
26 | #define GSL_NEGINF (-INFINITY)
27 | #elif defined(HUGE_VAL)
28 | #define GSL_POSINF HUGE_VAL
29 | #define GSL_NEGINF (-HUGE_VAL)
30 | #else
31 | #define GSL_POSINF (gsl_posinf())
32 | #define GSL_NEGINF (gsl_neginf())
33 | #endif
34 |
35 | #ifdef NAN
36 | #define GSL_NAN NAN
37 | #elif defined(INFINITY)
38 | #define GSL_NAN (INFINITY / INFINITY)
39 | #else
40 | #define GSL_NAN (gsl_nan())
41 | #endif
42 |
43 | #define GSL_POSZERO (+0.0)
44 | #define GSL_NEGZERO (-0.0)
45 |
46 | #endif /* __GSL_NAN_H__ */
47 |
--------------------------------------------------------------------------------
/pyquad/integration/gsl_sys.h:
--------------------------------------------------------------------------------
1 | /* sys/gsl_sys.h
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Gerard Jungman, Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #ifndef __GSL_SYS_H__
22 | #define __GSL_SYS_H__
23 |
24 | #undef __BEGIN_DECLS
25 | #undef __END_DECLS
26 | #ifdef __cplusplus
27 | #define __BEGIN_DECLS extern "C" {
28 | #define __END_DECLS }
29 | #else
30 | #define __BEGIN_DECLS /* empty */
31 | #define __END_DECLS /* empty */
32 | #endif
33 |
34 | __BEGIN_DECLS
35 |
36 | double gsl_log1p(const double x);
37 | double gsl_expm1(const double x);
38 | double gsl_hypot(const double x, const double y);
39 | double gsl_hypot3(const double x, const double y, const double z);
40 | double gsl_acosh(const double x);
41 | double gsl_asinh(const double x);
42 | double gsl_atanh(const double x);
43 |
44 | int gsl_isnan(const double x);
45 | int gsl_isinf(const double x);
46 | int gsl_finite(const double x);
47 |
48 | double gsl_nan(void);
49 | double gsl_posinf(void);
50 | double gsl_neginf(void);
51 | double gsl_fdiv(const double x, const double y);
52 |
53 | double gsl_coerce_double(const double x);
54 | float gsl_coerce_float(const float x);
55 | long double gsl_coerce_long_double(const long double x);
56 |
57 | double gsl_ldexp(const double x, const int e);
58 | double gsl_frexp(const double x, int *e);
59 |
60 | int gsl_fcmp(const double x1, const double x2, const double epsilon);
61 |
62 | __END_DECLS
63 |
64 | #endif /* __GSL_SYS_H__ */
65 |
--------------------------------------------------------------------------------
/pyquad/integration/gsl_types.h:
--------------------------------------------------------------------------------
1 | /* gsl_types.h
2 | *
3 | * Copyright (C) 2001, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #ifndef __GSL_TYPES_H__
22 | #define __GSL_TYPES_H__
23 |
24 | #ifndef GSL_VAR
25 |
26 | #ifdef WIN32
27 | #ifdef GSL_DLL
28 | #ifdef DLL_EXPORT
29 | #define GSL_VAR extern __declspec(dllexport)
30 | #else
31 | #define GSL_VAR extern __declspec(dllimport)
32 | #endif
33 | #else
34 | #define GSL_VAR extern
35 | #endif
36 | #else
37 | #define GSL_VAR extern
38 | #endif
39 |
40 | #endif
41 |
42 | #endif /* __GSL_TYPES_H__ */
43 |
--------------------------------------------------------------------------------
/pyquad/integration/infnan.c:
--------------------------------------------------------------------------------
1 | /* sys/infnan.c
2 | *
3 | * Copyright (C) 2001, 2004, 2007, 2010 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 | #ifndef __GSL_INFNNA__
21 | #define __GSL_INFNAN__
22 |
23 | #include
24 | #define HAVE_DECL_FINITE 1
25 | #define HAVE_DECL_ISNAN 1
26 | #include
27 | //#include "ieeefp.h"
28 | //#include "fdiv.c"
29 |
30 | #include "gsl_sys.h"
31 |
32 | double gsl_nan(void) { return gsl_fdiv(0.0, 0.0); }
33 |
34 | double gsl_posinf(void) { return gsl_fdiv(+1.0, 0.0); }
35 |
36 | double gsl_neginf(void) { return gsl_fdiv(-1.0, 0.0); }
37 |
38 | // int gsl_isnan (const double x);
39 | // int gsl_isinf (const double x);
40 | // int gsl_finite (const double x);
41 |
42 | int gsl_finite(const double x) {
43 | const double y = x - x;
44 | int status = (y == y);
45 | return status;
46 | }
47 |
48 | int gsl_isnan(const double x) {
49 | int status = (x != x);
50 | return status;
51 | }
52 |
53 | int gsl_isinf(const double x) {
54 | /* isinf(3): In glibc 2.01 and earlier, isinf() returns a
55 | non-zero value (actually: 1) if x is an infinity (positive or
56 | negative). (This is all that C99 requires.) */
57 |
58 | if (isinf(x)) {
59 | return (x > 0) ? 1 : -1;
60 | } else {
61 | return 0;
62 | }
63 | }
64 |
65 | #endif
66 |
--------------------------------------------------------------------------------
/pyquad/integration/initialise.c:
--------------------------------------------------------------------------------
1 | /* integration/initialise.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2001, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | static inline void initialise(gsl_integration_workspace *workspace, double a,
22 | double b);
23 |
24 | static inline void initialise(gsl_integration_workspace *workspace, double a,
25 | double b) {
26 | workspace->size = 0;
27 | workspace->nrmax = 0;
28 | workspace->i = 0;
29 | workspace->alist[0] = a;
30 | workspace->blist[0] = b;
31 | workspace->rlist[0] = 0.0;
32 | workspace->elist[0] = 0.0;
33 | workspace->order[0] = 0;
34 | workspace->level[0] = 0;
35 |
36 | workspace->maximum_level = 0;
37 | }
38 |
--------------------------------------------------------------------------------
/pyquad/integration/positivity.c:
--------------------------------------------------------------------------------
1 | /* Compare the integral of f(x) with the integral of |f(x)|
2 | to determine if f(x) covers both positive and negative values */
3 |
4 | static inline int test_positivity(double result, double resabs);
5 |
6 | static inline int test_positivity(double result, double resabs) {
7 | int status = (fabs(result) >= (1 - 50 * GSL_DBL_EPSILON) * resabs);
8 |
9 | return status;
10 | }
11 |
--------------------------------------------------------------------------------
/pyquad/integration/qags.c:
--------------------------------------------------------------------------------
1 | /* integration/qags.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #include
22 | #include "gsl_errno.h"
23 | #include "gsl_integration.h"
24 |
25 | #include "initialise.c"
26 | #include "positivity.c"
27 | #include "qelg.c"
28 | #include "qpsrt.c"
29 | #include "qpsrt2.c"
30 | #include "reset.c"
31 | #include "set_initial.c"
32 | #include "util.c"
33 |
34 | static int qags(const gsl_function *f, const double a, const double b,
35 | const double epsabs, const double epsrel, const size_t limit,
36 | void *workspace, double *result, double *abserr,
37 | gsl_integration_rule *q);
38 |
39 | int gsl_integration_qags(const gsl_function *f, double a, double b,
40 | double epsabs, double epsrel, size_t limit,
41 | void *workspace, double *result, double *abserr) {
42 | int status = qags(f, a, b, epsabs, epsrel, limit, workspace, result, abserr,
43 | &gsl_integration_qk21);
44 | return status;
45 | }
46 |
47 | /* QAGI: evaluate an integral over an infinite range using the
48 | transformation
49 |
50 | integrate(f(x),-Inf,Inf) = integrate((f((1-t)/t) + f(-(1-t)/t))/t^2,0,1)
51 |
52 | */
53 |
54 | static double i_transform(double t, void *params);
55 |
56 | int gsl_integration_qagi(gsl_function *f, double epsabs, double epsrel,
57 | size_t limit, gsl_integration_workspace *workspace,
58 | double *result, double *abserr) {
59 | int status;
60 |
61 | gsl_function f_transform;
62 |
63 | f_transform.function = &i_transform;
64 | f_transform.params = f;
65 |
66 | status = qags(&f_transform, 0.0, 1.0, epsabs, epsrel, limit, workspace,
67 | result, abserr, &gsl_integration_qk15);
68 |
69 | return status;
70 | }
71 |
72 | static double i_transform(double t, void *params) {
73 | gsl_function *f = (gsl_function *)params;
74 | double x = (1 - t) / t;
75 | double y = GSL_FN_EVAL(f, x) + GSL_FN_EVAL(f, -x);
76 | return (y / t) / t;
77 | }
78 |
79 | /* QAGIL: Evaluate an integral over an infinite range using the
80 | transformation,
81 |
82 | integrate(f(x),-Inf,b) = integrate(f(b-(1-t)/t)/t^2,0,1)
83 |
84 | */
85 |
86 | struct il_params {
87 | double b;
88 | gsl_function *f;
89 | };
90 |
91 | static double il_transform(double t, void *params);
92 |
93 | int gsl_integration_qagil(gsl_function *f, double b, double epsabs,
94 | double epsrel, size_t limit,
95 | gsl_integration_workspace *workspace, double *result,
96 | double *abserr) {
97 | int status;
98 |
99 | gsl_function f_transform;
100 | struct il_params transform_params;
101 |
102 | transform_params.b = b;
103 | transform_params.f = f;
104 |
105 | f_transform.function = &il_transform;
106 | f_transform.params = &transform_params;
107 |
108 | status = qags(&f_transform, 0.0, 1.0, epsabs, epsrel, limit, workspace,
109 | result, abserr, &gsl_integration_qk15);
110 |
111 | return status;
112 | }
113 |
114 | static double il_transform(double t, void *params) {
115 | struct il_params *p = (struct il_params *)params;
116 | double b = p->b;
117 | gsl_function *f = p->f;
118 | double x = b - (1 - t) / t;
119 | double y = GSL_FN_EVAL(f, x);
120 | return (y / t) / t;
121 | }
122 |
123 | /* QAGIU: Evaluate an integral over an infinite range using the
124 | transformation
125 |
126 | integrate(f(x),a,Inf) = integrate(f(a+(1-t)/t)/t^2,0,1)
127 |
128 | */
129 |
130 | struct iu_params {
131 | double a;
132 | gsl_function *f;
133 | };
134 |
135 | static double iu_transform(double t, void *params);
136 |
137 | int gsl_integration_qagiu(gsl_function *f, double a, double epsabs,
138 | double epsrel, size_t limit,
139 | gsl_integration_workspace *workspace, double *result,
140 | double *abserr) {
141 | int status;
142 |
143 | gsl_function f_transform;
144 | struct iu_params transform_params;
145 |
146 | transform_params.a = a;
147 | transform_params.f = f;
148 |
149 | f_transform.function = &iu_transform;
150 | f_transform.params = &transform_params;
151 |
152 | status = qags(&f_transform, 0.0, 1.0, epsabs, epsrel, limit, workspace,
153 | result, abserr, &gsl_integration_qk15);
154 |
155 | return status;
156 | }
157 |
158 | static double iu_transform(double t, void *params) {
159 | struct iu_params *p = (struct iu_params *)params;
160 | double a = p->a;
161 | gsl_function *f = p->f;
162 | double x = a + (1 - t) / t;
163 | double y = GSL_FN_EVAL(f, x);
164 | return (y / t) / t;
165 | }
166 |
167 | /* Main integration function */
168 |
169 | static int qags(const gsl_function *f, const double a, const double b,
170 | const double epsabs, const double epsrel, const size_t limit,
171 | void *void_workspace, double *result, double *abserr,
172 | gsl_integration_rule *q) {
173 | /* recast the workspace back from the generic void */
174 | gsl_integration_workspace *workspace =
175 | (gsl_integration_workspace *)void_workspace;
176 |
177 | double area, errsum;
178 | double res_ext, err_ext;
179 | double result0, abserr0, resabs0, resasc0;
180 | double tolerance;
181 |
182 | double ertest = 0;
183 | double error_over_large_intervals = 0;
184 | double reseps = 0, abseps = 0, correc = 0;
185 | size_t ktmin = 0;
186 | int roundoff_type1 = 0, roundoff_type2 = 0, roundoff_type3 = 0;
187 | int error_type = 0, error_type2 = 0;
188 |
189 | size_t iteration = 0;
190 |
191 | int positive_integrand = 0;
192 | int extrapolate = 0;
193 | int disallow_extrapolation = 0;
194 |
195 | struct extrapolation_table table;
196 |
197 | /* Initialize results */
198 |
199 | initialise(workspace, a, b);
200 |
201 | *result = 0;
202 | *abserr = 0;
203 |
204 | if (limit > workspace->limit) {
205 | return GSL_EINVAL;
206 | }
207 |
208 | /* Test on accuracy */
209 |
210 | if (epsabs <= 0 && (epsrel < 50 * GSL_DBL_EPSILON || epsrel < 0.5e-28)) {
211 | return GSL_EBADTOL;
212 | }
213 |
214 | /* Perform the first integration */
215 |
216 | q(f, a, b, &result0, &abserr0, &resabs0, &resasc0);
217 |
218 | set_initial_result(workspace, result0, abserr0);
219 |
220 | tolerance = GSL_MAX_DBL(epsabs, epsrel * fabs(result0));
221 |
222 | if (abserr0 <= 100 * GSL_DBL_EPSILON * resabs0 && abserr0 > tolerance) {
223 | *result = result0;
224 | *abserr = abserr0;
225 |
226 | return GSL_EROUND;
227 | } else if ((abserr0 <= tolerance && abserr0 != resasc0) || abserr0 == 0.0) {
228 | *result = result0;
229 | *abserr = abserr0;
230 |
231 | return 0;
232 | } else if (limit == 1) {
233 | *result = result0;
234 | *abserr = abserr0;
235 |
236 | return GSL_EMAXITER;
237 | }
238 |
239 | /* Initialization */
240 |
241 | initialise_table(&table);
242 | append_table(&table, result0);
243 |
244 | area = result0;
245 | errsum = abserr0;
246 |
247 | res_ext = result0;
248 | err_ext = GSL_DBL_MAX;
249 |
250 | positive_integrand = test_positivity(result0, resabs0);
251 |
252 | iteration = 1;
253 |
254 | do {
255 | size_t current_level;
256 | double a1, b1, a2, b2;
257 | double a_i, b_i, r_i, e_i;
258 | double area1 = 0, area2 = 0, area12 = 0;
259 | double error1 = 0, error2 = 0, error12 = 0;
260 | double resasc1, resasc2;
261 | double resabs1, resabs2;
262 | double last_e_i;
263 |
264 | /* Bisect the subinterval with the largest error estimate */
265 |
266 | retrieve(workspace, &a_i, &b_i, &r_i, &e_i);
267 |
268 | current_level = workspace->level[workspace->i] + 1;
269 |
270 | a1 = a_i;
271 | b1 = 0.5 * (a_i + b_i);
272 | a2 = b1;
273 | b2 = b_i;
274 |
275 | iteration++;
276 |
277 | q(f, a1, b1, &area1, &error1, &resabs1, &resasc1);
278 | q(f, a2, b2, &area2, &error2, &resabs2, &resasc2);
279 |
280 | area12 = area1 + area2;
281 | error12 = error1 + error2;
282 | last_e_i = e_i;
283 |
284 | /* Improve previous approximations to the integral and test for
285 | accuracy.
286 |
287 | We write these expressions in the same way as the original
288 | QUADPACK code so that the rounding errors are the same, which
289 | makes testing easier. */
290 |
291 | errsum = errsum + error12 - e_i;
292 | area = area + area12 - r_i;
293 |
294 | tolerance = GSL_MAX_DBL(epsabs, epsrel * fabs(area));
295 |
296 | if (resasc1 != error1 && resasc2 != error2) {
297 | double delta = r_i - area12;
298 |
299 | if (fabs(delta) <= 1.0e-5 * fabs(area12) && error12 >= 0.99 * e_i) {
300 | if (!extrapolate) {
301 | roundoff_type1++;
302 | } else {
303 | roundoff_type2++;
304 | }
305 | }
306 | if (iteration > 10 && error12 > e_i) {
307 | roundoff_type3++;
308 | }
309 | }
310 |
311 | /* Test for roundoff and eventually set error flag */
312 |
313 | if (roundoff_type1 + roundoff_type2 >= 10 || roundoff_type3 >= 20) {
314 | error_type = 2; /* round off error */
315 | }
316 |
317 | if (roundoff_type2 >= 5) {
318 | error_type2 = 1;
319 | }
320 |
321 | /* set error flag in the case of bad integrand behaviour at
322 | a point of the integration range */
323 |
324 | if (subinterval_too_small(a1, a2, b2)) {
325 | error_type = 4;
326 | }
327 |
328 | /* append the newly-created intervals to the list */
329 |
330 | update(workspace, a1, b1, area1, error1, a2, b2, area2, error2);
331 |
332 | if (errsum <= tolerance) {
333 | goto compute_result;
334 | }
335 |
336 | if (error_type) {
337 | break;
338 | }
339 |
340 | if (iteration >= limit - 1) {
341 | error_type = 1;
342 | break;
343 | }
344 |
345 | if (iteration == 2) /* set up variables on first iteration */
346 | {
347 | error_over_large_intervals = errsum;
348 | ertest = tolerance;
349 | append_table(&table, area);
350 | continue;
351 | }
352 |
353 | if (disallow_extrapolation) {
354 | continue;
355 | }
356 |
357 | error_over_large_intervals += -last_e_i;
358 |
359 | if (current_level < workspace->maximum_level) {
360 | error_over_large_intervals += error12;
361 | }
362 |
363 | if (!extrapolate) {
364 | /* test whether the interval to be bisected next is the
365 | smallest interval. */
366 |
367 | if (large_interval(workspace)) continue;
368 |
369 | extrapolate = 1;
370 | workspace->nrmax = 1;
371 | }
372 |
373 | if (!error_type2 && error_over_large_intervals > ertest) {
374 | if (increase_nrmax(workspace)) continue;
375 | }
376 |
377 | /* Perform extrapolation */
378 |
379 | append_table(&table, area);
380 |
381 | qelg(&table, &reseps, &abseps);
382 |
383 | ktmin++;
384 |
385 | if (ktmin > 5 && err_ext < 0.001 * errsum) {
386 | error_type = 5;
387 | }
388 |
389 | if (abseps < err_ext) {
390 | ktmin = 0;
391 | err_ext = abseps;
392 | res_ext = reseps;
393 | correc = error_over_large_intervals;
394 | ertest = GSL_MAX_DBL(epsabs, epsrel * fabs(reseps));
395 | if (err_ext <= ertest) break;
396 | }
397 |
398 | /* Prepare bisection of the smallest interval. */
399 |
400 | if (table.n == 1) {
401 | disallow_extrapolation = 1;
402 | }
403 |
404 | if (error_type == 5) {
405 | break;
406 | }
407 |
408 | /* work on interval with largest error */
409 |
410 | reset_nrmax(workspace);
411 | extrapolate = 0;
412 | error_over_large_intervals = errsum;
413 |
414 | } while (iteration < limit);
415 |
416 | *result = res_ext;
417 | *abserr = err_ext;
418 |
419 | if (err_ext == GSL_DBL_MAX) goto compute_result;
420 |
421 | if (error_type || error_type2) {
422 | if (error_type2) {
423 | err_ext += correc;
424 | }
425 |
426 | if (error_type == 0) error_type = 3;
427 |
428 | if (res_ext != 0.0 && area != 0.0) {
429 | if (err_ext / fabs(res_ext) > errsum / fabs(area))
430 | goto compute_result;
431 | } else if (err_ext > errsum) {
432 | goto compute_result;
433 | } else if (area == 0.0) {
434 | goto return_error;
435 | }
436 | }
437 |
438 | /* Test on divergence. */
439 |
440 | {
441 | double max_area = GSL_MAX_DBL(fabs(res_ext), fabs(area));
442 |
443 | if (!positive_integrand && max_area < 0.01 * resabs0) goto return_error;
444 | }
445 |
446 | {
447 | double ratio = res_ext / area;
448 |
449 | if (ratio < 0.01 || ratio > 100.0 || errsum > fabs(area))
450 | error_type = 6;
451 | }
452 |
453 | goto return_error;
454 |
455 | compute_result:
456 |
457 | *result = sum_results(workspace);
458 | *abserr = errsum;
459 |
460 | return_error:
461 |
462 | if (error_type > 2) error_type--;
463 |
464 | if (error_type == 0) {
465 | return 0;
466 | } else if (error_type == 1) {
467 | return GSL_EMAXITER;
468 | } else if (error_type == 2) {
469 | return GSL_EROUND;
470 | } else if (error_type == 3) {
471 | return GSL_ESING;
472 | } else if (error_type == 4) {
473 | return GSL_EROUND;
474 | } else if (error_type == 5) {
475 | return GSL_EDIVERGE;
476 | } else {
477 | return GSL_EFAILED;
478 | }
479 | }
480 |
--------------------------------------------------------------------------------
/pyquad/integration/qelg.c:
--------------------------------------------------------------------------------
1 | /* integration/qelg.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | struct extrapolation_table {
22 | size_t n;
23 | double rlist2[52];
24 | size_t nres;
25 | double res3la[3];
26 | };
27 |
28 | static void initialise_table(struct extrapolation_table *table);
29 |
30 | static void append_table(struct extrapolation_table *table, double y);
31 |
32 | static void initialise_table(struct extrapolation_table *table) {
33 | table->n = 0;
34 | table->nres = 0;
35 | }
36 | #ifdef JUNK
37 | static void initialise_table(struct extrapolation_table *table, double y) {
38 | table->n = 0;
39 | table->rlist2[0] = y;
40 | table->nres = 0;
41 | }
42 | #endif
43 | static void append_table(struct extrapolation_table *table, double y) {
44 | size_t n;
45 | n = table->n;
46 | table->rlist2[n] = y;
47 | table->n++;
48 | }
49 |
50 | /* static inline void
51 | qelg (size_t * n, double epstab[],
52 | double * result, double * abserr,
53 | double res3la[], size_t * nres); */
54 |
55 | static inline void qelg(struct extrapolation_table *table, double *result,
56 | double *abserr);
57 |
58 | static inline void qelg(struct extrapolation_table *table, double *result,
59 | double *abserr) {
60 | double *epstab = table->rlist2;
61 | double *res3la = table->res3la;
62 | const size_t n = table->n - 1;
63 |
64 | const double current = epstab[n];
65 |
66 | double absolute = GSL_DBL_MAX;
67 | double relative = 5 * GSL_DBL_EPSILON * fabs(current);
68 |
69 | const size_t newelm = n / 2;
70 | const size_t n_orig = n;
71 | size_t n_final = n;
72 | size_t i;
73 |
74 | const size_t nres_orig = table->nres;
75 |
76 | *result = current;
77 | *abserr = GSL_DBL_MAX;
78 |
79 | if (n < 2) {
80 | *result = current;
81 | *abserr = GSL_MAX_DBL(absolute, relative);
82 | return;
83 | }
84 |
85 | epstab[n + 2] = epstab[n];
86 | epstab[n] = GSL_DBL_MAX;
87 |
88 | for (i = 0; i < newelm; i++) {
89 | double res = epstab[n - 2 * i + 2];
90 | double e0 = epstab[n - 2 * i - 2];
91 | double e1 = epstab[n - 2 * i - 1];
92 | double e2 = res;
93 |
94 | double e1abs = fabs(e1);
95 | double delta2 = e2 - e1;
96 | double err2 = fabs(delta2);
97 | double tol2 = GSL_MAX_DBL(fabs(e2), e1abs) * GSL_DBL_EPSILON;
98 | double delta3 = e1 - e0;
99 | double err3 = fabs(delta3);
100 | double tol3 = GSL_MAX_DBL(e1abs, fabs(e0)) * GSL_DBL_EPSILON;
101 |
102 | double e3, delta1, err1, tol1, ss;
103 |
104 | if (err2 <= tol2 && err3 <= tol3) {
105 | /* If e0, e1 and e2 are equal to within machine accuracy,
106 | convergence is assumed. */
107 |
108 | *result = res;
109 | absolute = err2 + err3;
110 | relative = 5 * GSL_DBL_EPSILON * fabs(res);
111 | *abserr = GSL_MAX_DBL(absolute, relative);
112 | return;
113 | }
114 |
115 | e3 = epstab[n - 2 * i];
116 | epstab[n - 2 * i] = e1;
117 | delta1 = e1 - e3;
118 | err1 = fabs(delta1);
119 | tol1 = GSL_MAX_DBL(e1abs, fabs(e3)) * GSL_DBL_EPSILON;
120 |
121 | /* If two elements are very close to each other, omit a part of
122 | the table by adjusting the value of n */
123 |
124 | if (err1 <= tol1 || err2 <= tol2 || err3 <= tol3) {
125 | n_final = 2 * i;
126 | break;
127 | }
128 |
129 | ss = (1 / delta1 + 1 / delta2) - 1 / delta3;
130 |
131 | /* Test to detect irregular behaviour in the table, and
132 | eventually omit a part of the table by adjusting the value of
133 | n. */
134 |
135 | if (fabs(ss * e1) <= 0.0001) {
136 | n_final = 2 * i;
137 | break;
138 | }
139 |
140 | /* Compute a new element and eventually adjust the value of
141 | result. */
142 |
143 | res = e1 + 1 / ss;
144 | epstab[n - 2 * i] = res;
145 |
146 | {
147 | const double error = err2 + fabs(res - e2) + err3;
148 |
149 | if (error <= *abserr) {
150 | *abserr = error;
151 | *result = res;
152 | }
153 | }
154 | }
155 |
156 | /* Shift the table */
157 |
158 | {
159 | const size_t limexp = 50 - 1;
160 |
161 | if (n_final == limexp) {
162 | n_final = 2 * (limexp / 2);
163 | }
164 | }
165 |
166 | if (n_orig % 2 == 1) {
167 | for (i = 0; i <= newelm; i++) {
168 | epstab[1 + i * 2] = epstab[i * 2 + 3];
169 | }
170 | } else {
171 | for (i = 0; i <= newelm; i++) {
172 | epstab[i * 2] = epstab[i * 2 + 2];
173 | }
174 | }
175 |
176 | if (n_orig != n_final) {
177 | for (i = 0; i <= n_final; i++) {
178 | epstab[i] = epstab[n_orig - n_final + i];
179 | }
180 | }
181 |
182 | table->n = n_final + 1;
183 |
184 | if (nres_orig < 3) {
185 | res3la[nres_orig] = *result;
186 | *abserr = GSL_DBL_MAX;
187 | } else { /* Compute error estimate */
188 | *abserr = (fabs(*result - res3la[2]) + fabs(*result - res3la[1]) +
189 | fabs(*result - res3la[0]));
190 |
191 | res3la[0] = res3la[1];
192 | res3la[1] = res3la[2];
193 | res3la[2] = *result;
194 | }
195 |
196 | /* In QUADPACK the variable table->nres is incremented at the top of
197 | qelg, so it increases on every call. This leads to the array
198 | res3la being accessed when its elements are still undefined, so I
199 | have moved the update to this point so that its value more
200 | useful. */
201 |
202 | table->nres = nres_orig + 1;
203 |
204 | *abserr = GSL_MAX_DBL(*abserr, 5 * GSL_DBL_EPSILON * fabs(*result));
205 |
206 | return;
207 | }
208 |
--------------------------------------------------------------------------------
/pyquad/integration/qk.c:
--------------------------------------------------------------------------------
1 | /* integration/qk.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #include
22 | #include
23 | #include "err.c"
24 | #include "gsl_integration.h"
25 |
26 | void gsl_integration_qk(const int n, const double xgk[], const double wg[],
27 | const double wgk[], double fv1[], double fv2[],
28 | const gsl_function *f, double a, double b,
29 | double *result, double *abserr, double *resabs,
30 | double *resasc) {
31 | const double center = 0.5 * (a + b);
32 | const double half_length = 0.5 * (b - a);
33 | const double abs_half_length = fabs(half_length);
34 | const double f_center = GSL_FN_EVAL(f, center);
35 |
36 | double result_gauss = 0;
37 | double result_kronrod = f_center * wgk[n - 1];
38 |
39 | double result_abs = fabs(result_kronrod);
40 | double result_asc = 0;
41 | double mean = 0, err = 0;
42 |
43 | int j;
44 |
45 | if (n % 2 == 0) {
46 | result_gauss = f_center * wg[n / 2 - 1];
47 | }
48 |
49 | for (j = 0; j < (n - 1) / 2; j++) {
50 | const int jtw = j * 2 + 1; /* in original fortran j=1,2,3 jtw=2,4,6 */
51 | const double abscissa = half_length * xgk[jtw];
52 | const double fval1 = GSL_FN_EVAL(f, center - abscissa);
53 | const double fval2 = GSL_FN_EVAL(f, center + abscissa);
54 | const double fsum = fval1 + fval2;
55 | fv1[jtw] = fval1;
56 | fv2[jtw] = fval2;
57 | result_gauss += wg[j] * fsum;
58 | result_kronrod += wgk[jtw] * fsum;
59 | result_abs += wgk[jtw] * (fabs(fval1) + fabs(fval2));
60 | }
61 |
62 | for (j = 0; j < n / 2; j++) {
63 | int jtwm1 = j * 2;
64 | const double abscissa = half_length * xgk[jtwm1];
65 | const double fval1 = GSL_FN_EVAL(f, center - abscissa);
66 | const double fval2 = GSL_FN_EVAL(f, center + abscissa);
67 | fv1[jtwm1] = fval1;
68 | fv2[jtwm1] = fval2;
69 | result_kronrod += wgk[jtwm1] * (fval1 + fval2);
70 | result_abs += wgk[jtwm1] * (fabs(fval1) + fabs(fval2));
71 | };
72 |
73 | mean = result_kronrod * 0.5;
74 |
75 | result_asc = wgk[n - 1] * fabs(f_center - mean);
76 |
77 | for (j = 0; j < n - 1; j++) {
78 | result_asc += wgk[j] * (fabs(fv1[j] - mean) + fabs(fv2[j] - mean));
79 | }
80 |
81 | /* scale by the width of the integration region */
82 |
83 | err = (result_kronrod - result_gauss) * half_length;
84 |
85 | result_kronrod *= half_length;
86 | result_abs *= abs_half_length;
87 | result_asc *= abs_half_length;
88 |
89 | *result = result_kronrod;
90 | *resabs = result_abs;
91 | *resasc = result_asc;
92 | *abserr = rescale_error(err, result_abs, result_asc);
93 | }
94 |
--------------------------------------------------------------------------------
/pyquad/integration/qk15.c:
--------------------------------------------------------------------------------
1 | /* integration/qk15.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #include "gsl_integration.h"
22 |
23 | /* Gauss quadrature weights and kronrod quadrature abscissae and
24 | weights as evaluated with 80 decimal digit arithmetic by
25 | L. W. Fullerton, Bell Labs, Nov. 1981. */
26 |
27 | static const double xgk15[8] = /* abscissae of the 15-point kronrod rule */
28 | {0.991455371120812639206854697526329, 0.949107912342758524526189684047851,
29 | 0.864864423359769072789712788640926, 0.741531185599394439863864773280788,
30 | 0.586087235467691130294144838258730, 0.405845151377397166906606412076961,
31 | 0.207784955007898467600689403773245, 0.000000000000000000000000000000000};
32 |
33 | /* xgk[1], xgk[3], ... abscissae of the 7-point gauss rule.
34 | xgk[0], xgk[2], ... abscissae to optimally extend the 7-point gauss rule */
35 |
36 | static const double wg15[4] = /* weights of the 7-point gauss rule */
37 | {0.129484966168869693270611432679082, 0.279705391489276667901467771423780,
38 | 0.381830050505118944950369775488975, 0.417959183673469387755102040816327};
39 |
40 | static const double wgk15[8] = /* weights of the 15-point kronrod rule */
41 | {0.022935322010529224963732008058970, 0.063092092629978553290700663189204,
42 | 0.104790010322250183839876322541518, 0.140653259715525918745189590510238,
43 | 0.169004726639267902826583426598550, 0.190350578064785409913256402421014,
44 | 0.204432940075298892414161999234649, 0.209482141084727828012999174891714};
45 |
46 | void gsl_integration_qk15(const gsl_function *f, double a, double b,
47 | double *result, double *abserr, double *resabs,
48 | double *resasc) {
49 | double fv1[8], fv2[8];
50 | gsl_integration_qk(8, xgk15, wg15, wgk15, fv1, fv2, f, a, b, result, abserr,
51 | resabs, resasc);
52 | }
53 |
--------------------------------------------------------------------------------
/pyquad/integration/qk21.c:
--------------------------------------------------------------------------------
1 | /* integration/qk21.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #include "gsl_integration.h"
22 |
23 | /* Gauss quadrature weights and kronrod quadrature abscissae and
24 | weights as evaluated with 80 decimal digit arithmetic by
25 | L. W. Fullerton, Bell Labs, Nov. 1981. */
26 |
27 | static const double xgk21[11] = /* abscissae of the 21-point kronrod rule */
28 | {0.995657163025808080735527280689003, 0.973906528517171720077964012084452,
29 | 0.930157491355708226001207180059508, 0.865063366688984510732096688423493,
30 | 0.780817726586416897063717578345042, 0.679409568299024406234327365114874,
31 | 0.562757134668604683339000099272694, 0.433395394129247190799265943165784,
32 | 0.294392862701460198131126603103866, 0.148874338981631210884826001129720,
33 | 0.000000000000000000000000000000000};
34 |
35 | /* xgk[1], xgk[3], ... abscissae of the 10-point gauss rule.
36 | xgk[0], xgk[2], ... abscissae to optimally extend the 10-point gauss rule */
37 |
38 | static const double wg21[5] = /* weights of the 10-point gauss rule */
39 | {0.066671344308688137593568809893332, 0.149451349150580593145776339657697,
40 | 0.219086362515982043995534934228163, 0.269266719309996355091226921569469,
41 | 0.295524224714752870173892994651338};
42 |
43 | static const double wgk21[11] = /* weights of the 21-point kronrod rule */
44 | {0.011694638867371874278064396062192, 0.032558162307964727478818972459390,
45 | 0.054755896574351996031381300244580, 0.075039674810919952767043140916190,
46 | 0.093125454583697605535065465083366, 0.109387158802297641899210590325805,
47 | 0.123491976262065851077958109831074, 0.134709217311473325928054001771707,
48 | 0.142775938577060080797094273138717, 0.147739104901338491374841515972068,
49 | 0.149445554002916905664936468389821};
50 |
51 | void gsl_integration_qk21(const gsl_function *f, double a, double b,
52 | double *result, double *abserr, double *resabs,
53 | double *resasc) {
54 | double fv1[11], fv2[11];
55 | gsl_integration_qk(11, xgk21, wg21, wgk21, fv1, fv2, f, a, b, result,
56 | abserr, resabs, resasc);
57 | }
58 |
--------------------------------------------------------------------------------
/pyquad/integration/qpsrt.c:
--------------------------------------------------------------------------------
1 | /* integration/qpsrt.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | static inline void qpsrt(gsl_integration_workspace *workspace);
22 |
23 | static inline void qpsrt(gsl_integration_workspace *workspace) {
24 | const size_t last = workspace->size - 1;
25 | const size_t limit = workspace->limit;
26 |
27 | double *elist = workspace->elist;
28 | size_t *order = workspace->order;
29 |
30 | double errmax;
31 | double errmin;
32 | int i, k, top;
33 |
34 | size_t i_nrmax = workspace->nrmax;
35 | size_t i_maxerr = order[i_nrmax];
36 |
37 | /* Check whether the list contains more than two error estimates */
38 |
39 | if (last < 2) {
40 | order[0] = 0;
41 | order[1] = 1;
42 | workspace->i = i_maxerr;
43 | return;
44 | }
45 |
46 | errmax = elist[i_maxerr];
47 |
48 | /* This part of the routine is only executed if, due to a difficult
49 | integrand, subdivision increased the error estimate. In the normal
50 | case the insert procedure should start after the nrmax-th largest
51 | error estimate. */
52 |
53 | while (i_nrmax > 0 && errmax > elist[order[i_nrmax - 1]]) {
54 | order[i_nrmax] = order[i_nrmax - 1];
55 | i_nrmax--;
56 | }
57 |
58 | /* Compute the number of elements in the list to be maintained in
59 | descending order. This number depends on the number of
60 | subdivisions still allowed. */
61 |
62 | if (last < (limit / 2 + 2)) {
63 | top = last;
64 | } else {
65 | top = limit - last + 1;
66 | }
67 |
68 | /* Insert errmax by traversing the list top-down, starting
69 | comparison from the element elist(order(i_nrmax+1)). */
70 |
71 | i = i_nrmax + 1;
72 |
73 | /* The order of the tests in the following line is important to
74 | prevent a segmentation fault */
75 |
76 | while (i < top && errmax < elist[order[i]]) {
77 | order[i - 1] = order[i];
78 | i++;
79 | }
80 |
81 | order[i - 1] = i_maxerr;
82 |
83 | /* Insert errmin by traversing the list bottom-up */
84 |
85 | errmin = elist[last];
86 |
87 | k = top - 1;
88 |
89 | while (k > i - 2 && errmin >= elist[order[k]]) {
90 | order[k + 1] = order[k];
91 | k--;
92 | }
93 |
94 | order[k + 1] = last;
95 |
96 | /* Set i_max and e_max */
97 |
98 | i_maxerr = order[i_nrmax];
99 |
100 | workspace->i = i_maxerr;
101 | workspace->nrmax = i_nrmax;
102 | }
103 |
--------------------------------------------------------------------------------
/pyquad/integration/qpsrt2.c:
--------------------------------------------------------------------------------
1 | /* integration/qpsrt2.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | /* The smallest interval has the largest error. Before bisecting
22 | decrease the sum of the errors over the larger intervals
23 | (error_over_large_intervals) and perform extrapolation. */
24 |
25 | static int increase_nrmax(gsl_integration_workspace *workspace);
26 |
27 | static int increase_nrmax(gsl_integration_workspace *workspace) {
28 | int k;
29 | int id = workspace->nrmax;
30 | int jupbnd;
31 |
32 | const size_t *level = workspace->level;
33 | const size_t *order = workspace->order;
34 |
35 | size_t limit = workspace->limit;
36 | size_t last = workspace->size - 1;
37 |
38 | if (last > (1 + limit / 2)) {
39 | jupbnd = limit + 1 - last;
40 | } else {
41 | jupbnd = last;
42 | }
43 |
44 | for (k = id; k <= jupbnd; k++) {
45 | size_t i_max = order[workspace->nrmax];
46 |
47 | workspace->i = i_max;
48 |
49 | if (level[i_max] < workspace->maximum_level) {
50 | return 1;
51 | }
52 |
53 | workspace->nrmax++;
54 | }
55 | return 0;
56 | }
57 |
58 | static int large_interval(gsl_integration_workspace *workspace) {
59 | size_t i = workspace->i;
60 | const size_t *level = workspace->level;
61 |
62 | if (level[i] < workspace->maximum_level) {
63 | return 1;
64 | } else {
65 | return 0;
66 | }
67 | }
68 |
--------------------------------------------------------------------------------
/pyquad/integration/reset.c:
--------------------------------------------------------------------------------
1 | static inline void reset_nrmax(gsl_integration_workspace *workspace);
2 |
3 | static inline void reset_nrmax(gsl_integration_workspace *workspace) {
4 | workspace->nrmax = 0;
5 | workspace->i = workspace->order[0];
6 | }
7 |
--------------------------------------------------------------------------------
/pyquad/integration/set_initial.c:
--------------------------------------------------------------------------------
1 | static inline void set_initial_result(gsl_integration_workspace *workspace,
2 | double result, double error);
3 |
4 | static inline void set_initial_result(gsl_integration_workspace *workspace,
5 | double result, double error) {
6 | workspace->size = 1;
7 | workspace->rlist[0] = result;
8 | workspace->elist[0] = error;
9 | }
10 |
--------------------------------------------------------------------------------
/pyquad/integration/stream.c:
--------------------------------------------------------------------------------
1 | /* err/stream.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Gerard Jungman, Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #include
22 | #include
23 | #include
24 |
25 | #include "gsl_errno.h"
26 | #include "gsl_message.h"
27 |
28 | FILE *gsl_stream = NULL;
29 | gsl_stream_handler_t *gsl_stream_handler = NULL;
30 |
31 | void gsl_stream_printf(const char *label, const char *file, int line,
32 | const char *reason) {
33 | if (gsl_stream == NULL) {
34 | gsl_stream = stderr;
35 | }
36 | if (gsl_stream_handler) {
37 | (*gsl_stream_handler)(label, file, line, reason);
38 | return;
39 | }
40 | fprintf(gsl_stream, "gsl: %s:%d: %s: %s\n", file, line, label, reason);
41 | }
42 |
43 | gsl_stream_handler_t *gsl_set_stream_handler(
44 | gsl_stream_handler_t *new_handler) {
45 | gsl_stream_handler_t *previous_handler = gsl_stream_handler;
46 | gsl_stream_handler = new_handler;
47 | return previous_handler;
48 | }
49 |
50 | FILE *gsl_set_stream(FILE *new_stream) {
51 | FILE *previous_stream;
52 | if (gsl_stream == NULL) {
53 | gsl_stream = stderr;
54 | }
55 | previous_stream = gsl_stream;
56 | gsl_stream = new_stream;
57 | return previous_stream;
58 | }
59 |
--------------------------------------------------------------------------------
/pyquad/integration/util.c:
--------------------------------------------------------------------------------
1 | /* integration/util.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | static inline void update(gsl_integration_workspace *workspace, double a1,
22 | double b1, double area1, double error1, double a2,
23 | double b2, double area2, double error2);
24 |
25 | static inline void retrieve(const gsl_integration_workspace *workspace,
26 | double *a, double *b, double *r, double *e);
27 |
28 | static inline void update(gsl_integration_workspace *workspace, double a1,
29 | double b1, double area1, double error1, double a2,
30 | double b2, double area2, double error2) {
31 | double *alist = workspace->alist;
32 | double *blist = workspace->blist;
33 | double *rlist = workspace->rlist;
34 | double *elist = workspace->elist;
35 | size_t *level = workspace->level;
36 |
37 | const size_t i_max = workspace->i;
38 | const size_t i_new = workspace->size;
39 |
40 | const size_t new_level = workspace->level[i_max] + 1;
41 |
42 | /* append the newly-created intervals to the list */
43 |
44 | if (error2 > error1) {
45 | alist[i_max] = a2; /* blist[maxerr] is already == b2 */
46 | rlist[i_max] = area2;
47 | elist[i_max] = error2;
48 | level[i_max] = new_level;
49 |
50 | alist[i_new] = a1;
51 | blist[i_new] = b1;
52 | rlist[i_new] = area1;
53 | elist[i_new] = error1;
54 | level[i_new] = new_level;
55 | } else {
56 | blist[i_max] = b1; /* alist[maxerr] is already == a1 */
57 | rlist[i_max] = area1;
58 | elist[i_max] = error1;
59 | level[i_max] = new_level;
60 |
61 | alist[i_new] = a2;
62 | blist[i_new] = b2;
63 | rlist[i_new] = area2;
64 | elist[i_new] = error2;
65 | level[i_new] = new_level;
66 | }
67 |
68 | workspace->size++;
69 |
70 | if (new_level > workspace->maximum_level) {
71 | workspace->maximum_level = new_level;
72 | }
73 |
74 | qpsrt(workspace);
75 | }
76 |
77 | static inline void retrieve(const gsl_integration_workspace *workspace,
78 | double *a, double *b, double *r, double *e) {
79 | const size_t i = workspace->i;
80 | double *alist = workspace->alist;
81 | double *blist = workspace->blist;
82 | double *rlist = workspace->rlist;
83 | double *elist = workspace->elist;
84 |
85 | *a = alist[i];
86 | *b = blist[i];
87 | *r = rlist[i];
88 | *e = elist[i];
89 | }
90 |
91 | static inline double sum_results(const gsl_integration_workspace *workspace);
92 |
93 | static inline double sum_results(const gsl_integration_workspace *workspace) {
94 | const double *const rlist = workspace->rlist;
95 | const size_t n = workspace->size;
96 |
97 | size_t k;
98 | double result_sum = 0;
99 |
100 | for (k = 0; k < n; k++) {
101 | result_sum += rlist[k];
102 | }
103 |
104 | return result_sum;
105 | }
106 |
107 | static inline int subinterval_too_small(double a1, double a2, double b2);
108 |
109 | static inline int subinterval_too_small(double a1, double a2, double b2) {
110 | const double e = GSL_DBL_EPSILON;
111 | const double u = GSL_DBL_MIN;
112 |
113 | double tmp = (1 + 100 * e) * (fabs(a2) + 1000 * u);
114 |
115 | int status = fabs(a1) <= tmp && fabs(b2) <= tmp;
116 |
117 | return status;
118 | }
119 |
--------------------------------------------------------------------------------
/pyquad/integration/workspace.c:
--------------------------------------------------------------------------------
1 | /* integration/workspace.c
2 | *
3 | * Copyright (C) 1996, 1997, 1998, 1999, 2000, 2007, 2009 Brian Gough
4 | *
5 | * This program is free software; you can redistribute it and/or modify
6 | * it under the terms of the GNU General Public License as published by
7 | * the Free Software Foundation; either version 3 of the License, or (at
8 | * your option) any later version.
9 | *
10 | * This program is distributed in the hope that it will be useful, but
11 | * WITHOUT ANY WARRANTY; without even the implied warranty of
12 | * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
13 | * General Public License for more details.
14 | *
15 | * You should have received a copy of the GNU General Public License
16 | * along with this program; if not, write to the Free Software
17 | * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301,
18 | * USA.
19 | */
20 |
21 | #include
22 | #include "gsl_errno.h"
23 | #include "gsl_integration.h"
24 |
25 | gsl_integration_workspace *gsl_integration_workspace_alloc(const size_t n) {
26 | gsl_integration_workspace *w;
27 |
28 | if (n == 0) {
29 | GSL_ERROR_VAL("workspace length n must be positive integer", GSL_EDOM,
30 | 0);
31 | }
32 |
33 | w = (gsl_integration_workspace *)malloc(sizeof(gsl_integration_workspace));
34 |
35 | if (w == 0) {
36 | GSL_ERROR_VAL("failed to allocate space for workspace struct",
37 | GSL_ENOMEM, 0);
38 | }
39 |
40 | w->alist = (double *)malloc(n * sizeof(double));
41 |
42 | if (w->alist == 0) {
43 | free(w); /* exception in constructor, avoid memory leak */
44 |
45 | GSL_ERROR_VAL("failed to allocate space for alist ranges", GSL_ENOMEM,
46 | 0);
47 | }
48 |
49 | w->blist = (double *)malloc(n * sizeof(double));
50 |
51 | if (w->blist == 0) {
52 | free(w->alist);
53 | free(w); /* exception in constructor, avoid memory leak */
54 |
55 | GSL_ERROR_VAL("failed to allocate space for blist ranges", GSL_ENOMEM,
56 | 0);
57 | }
58 |
59 | w->rlist = (double *)malloc(n * sizeof(double));
60 |
61 | if (w->rlist == 0) {
62 | free(w->blist);
63 | free(w->alist);
64 | free(w); /* exception in constructor, avoid memory leak */
65 |
66 | GSL_ERROR_VAL("failed to allocate space for rlist ranges", GSL_ENOMEM,
67 | 0);
68 | }
69 |
70 | w->elist = (double *)malloc(n * sizeof(double));
71 |
72 | if (w->elist == 0) {
73 | free(w->rlist);
74 | free(w->blist);
75 | free(w->alist);
76 | free(w); /* exception in constructor, avoid memory leak */
77 |
78 | GSL_ERROR_VAL("failed to allocate space for elist ranges", GSL_ENOMEM,
79 | 0);
80 | }
81 |
82 | w->order = (size_t *)malloc(n * sizeof(size_t));
83 |
84 | if (w->order == 0) {
85 | free(w->elist);
86 | free(w->rlist);
87 | free(w->blist);
88 | free(w->alist);
89 | free(w); /* exception in constructor, avoid memory leak */
90 |
91 | GSL_ERROR_VAL("failed to allocate space for order ranges", GSL_ENOMEM,
92 | 0);
93 | }
94 |
95 | w->level = (size_t *)malloc(n * sizeof(size_t));
96 |
97 | if (w->level == 0) {
98 | free(w->order);
99 | free(w->elist);
100 | free(w->rlist);
101 | free(w->blist);
102 | free(w->alist);
103 | free(w); /* exception in constructor, avoid memory leak */
104 |
105 | GSL_ERROR_VAL("failed to allocate space for order ranges", GSL_ENOMEM,
106 | 0);
107 | }
108 |
109 | w->size = 0;
110 | w->limit = n;
111 | w->maximum_level = 0;
112 |
113 | return w;
114 | }
115 |
116 | void gsl_integration_workspace_free(gsl_integration_workspace *w) {
117 | free(w->level);
118 | free(w->order);
119 | free(w->elist);
120 | free(w->rlist);
121 | free(w->blist);
122 | free(w->alist);
123 | free(w);
124 | }
125 |
126 | /*
127 | size_t
128 | gsl_integration_workspace_limit (gsl_integration_workspace * w)
129 | {
130 | return w->limit ;
131 | }
132 |
133 |
134 | size_t
135 | gsl_integration_workspace_size (gsl_integration_workspace * w)
136 | {
137 | return w->size ;
138 | }
139 | */
140 |
--------------------------------------------------------------------------------
/pyquad/pyquad.pyx:
--------------------------------------------------------------------------------
1 | cimport cython
2 | cimport numpy as np
3 |
4 | import inspect
5 | import numba
6 | import numpy as np
7 | import warnings
8 |
9 | from numba import cfunc
10 | from libc.stdlib cimport malloc, free
11 |
12 | __version__ = '0.7.0'
13 |
14 | INTEGRATION_MAP = {
15 | "qags": 0,
16 | "cquad": 1,
17 | }
18 |
19 | GSL_ERROR_DICT = {
20 | 22 : "Integral is divergent, or slowly convergent.",
21 | 21 : "Bad integrand behavior found in the integration interval.",
22 | 18 : "Cannot reach tolerance because of roundoff error.",
23 | 14 : "Failed to reach the specified tolerance.",
24 | 13 : "Tolerance cannot be achieved with given epsabs and epsrel.",
25 | 12 : "Tried to divide by zero.",
26 | 11 : "Exceeded max number of iterations.",
27 | 4 : "Iteration limit exceeds available workspace.",
28 | 2 : "Output range error, e.g. exp(1e100).",
29 | 1 : "Input domain error, e.g sqrt(-1).",
30 | -1 : "Integration failed!",
31 | }
32 |
33 |
34 | cdef extern from "quad.c":
35 | ctypedef double (*integrand)(double, ...)
36 |
37 | ctypedef struct params:
38 | double * args
39 | double * grid_args
40 | integrand func
41 |
42 | cdef void _quad(int num_args, double a, double b, void * args,
43 | double epsabs, double epsrel, size_t limit,
44 | double * result, double * error, int * status,
45 | int integration_method)
46 | cdef void _quad_grid(int num_args, int num_grid_args, double a, double b,
47 | params args, int num, double epsabs, double epsrel,
48 | size_t limit, double *, double * result, double * error,
49 | int * status, int integration_method)
50 | cdef void _quad_grid_parallel_wrapper(int num_args, int num_grid_args,
51 | double a, double b, params args, int num, double epsabs,
52 | double epsrel, size_t limit, double *, double * result,
53 | double * error, int num_threads, int pin_threads,
54 | int * status, int integration_method) nogil
55 |
56 |
57 | def cfunc_sig_generator(int num_args):
58 | sig = "float64("
59 | for i in range(num_args):
60 | sig += "float64,"
61 | sig += ")"
62 | return sig
63 |
64 |
65 | def quad(py_integrand, double a, double b, args=(), epsabs=1e-7, epsrel=1e-7,
66 | limit=50, method="qags"):
67 | num_args = len(args)
68 |
69 | # Attempt to jit the integrand
70 | try:
71 | numba_integrand = cfunc(cfunc_sig_generator(num_args+1), nopython=True,
72 | cache=True, fastmath=True)(py_integrand)
73 | except:
74 | msg = ("Failed to jit the integrand. Your integrand may use functions"+
75 | "which are unknown to numba and so nopython should be disabled!")
76 | raise NotImplementedError(msg)
77 |
78 |
79 | cdef integrand f = numba_integrand.address
80 | cdef int integration_method = INTEGRATION_MAP[method]
81 |
82 | cdef double result = 0.0
83 | cdef double error = 0.0
84 | cdef int status = 0
85 |
86 | # Parameter stucture
87 | cdef params p
88 | p.args = malloc(sizeof(double) * num_args)
89 | for i in range(num_args):
90 | p.args[i] = args[i]
91 | p.func = f
92 |
93 | # Perform integral
94 | _quad(num_args, a, b, &p, epsabs, epsrel, limit, &result, &error,
95 | &status, integration_method);
96 |
97 | free(p.args)
98 |
99 | if status:
100 | if status in GSL_ERROR_DICT:
101 | wrng_msg = GSL_ERROR_DICT[status]
102 | else:
103 | wrng_msg = "Integration failed."
104 |
105 | warnings.warn("[pyquad] " + wrng_msg)
106 |
107 | return result, error
108 |
109 |
110 | @cython.boundscheck(False)
111 | def quad_grid(py_integrand, double a, double b,
112 | np.ndarray[np.float64_t, ndim=2] grid,
113 | args=(), double epsabs=1e-7, double epsrel=1e-7, int limit=50,
114 | parallel=True, nopython=True, cache=True, int num_threads=8,
115 | int pin_threads=0, method="qags"):
116 |
117 | cdef int integration_method = INTEGRATION_MAP[method]
118 |
119 | # Ensure we have a tuple for the arguments
120 | if not isinstance(args, tuple):
121 | args = (args,)
122 |
123 | cdef int num_args = len(args)
124 | cdef int num_values = grid.shape[0]
125 | cdef int num_grid_args = grid.shape[1]
126 |
127 | # Flattened grid
128 | cdef np.float64_t[::1] flat_grid = grid.flatten()
129 |
130 | # Attempt to jit the integrand
131 | try:
132 | numba_integrand = cfunc(cfunc_sig_generator(num_args+num_grid_args+1),
133 | nopython=nopython, cache=cache)(py_integrand)
134 | except:
135 | msg = ("Failed to jit the integrand. Your integrand may use functions"+
136 | "which are unknown to numba and so nopython should be disabled!")
137 | raise NotImplementedError(msg)
138 |
139 | cdef integrand f = numba_integrand.address
140 |
141 | # Prepare arrays to store the integration results
142 | cdef np.float64_t[:] result = np.zeros(num_values, dtype="float64")
143 | cdef np.float64_t[:] error = np.zeros(num_values, dtype="float64")
144 | cdef int[:] status = np.zeros(num_values, dtype=np.dtype("i"))
145 |
146 | # Store the arguments which are fixed for each integral
147 | cdef params p
148 | p.args = malloc(sizeof(double) * num_args)
149 | for i in range(num_args):
150 | p.args[i] = args[i]
151 | p.func = f
152 |
153 | if parallel and nopython:
154 | if pin_threads == 1:
155 | warnings.warn("[pyquad] Pinned threads can cause strange behaviour"+
156 | "in some environments - use this feature with care!")
157 | with nogil:
158 | _quad_grid_parallel_wrapper(num_args, num_grid_args, a, b, p,
159 | num_values, epsabs, epsrel, limit, &flat_grid[0],
160 | &result[0], &error[0], num_threads, pin_threads, &status[0],
161 | integration_method)
162 | else:
163 | _quad_grid(num_args, num_grid_args, a, b, p, num_values, epsabs, epsrel,
164 | limit, &flat_grid[0], &result[0], &error[0], &status[0],
165 | integration_method)
166 |
167 | free(p.args)
168 |
169 | # check errors and print warnings
170 | for status_i in set(np.asarray(status)):
171 | if status_i:
172 | if status_i in GSL_ERROR_DICT:
173 | wrng_msg = GSL_ERROR_DICT[status_i]
174 | else:
175 | wrng_msg = "Integration failed."
176 | warnings.warn("[pyquad] " + wrng_msg)
177 |
178 | return np.asarray(result), np.asarray(error)
179 |
--------------------------------------------------------------------------------
/pyquad/quad.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 |
4 | #include
5 | #include
6 |
7 | #include "integration/gsl_integration.h"
8 | #include "integration/gsl_errno.h"
9 | #include "integrands.h"
10 |
11 | #if defined(WIN32) || defined(_WIN32)
12 | #define WINDOWS 1
13 | #else
14 | #define UNIX 1
15 | #endif
16 |
17 | #ifdef WINDOWS
18 | #include
19 | #endif
20 |
21 | #ifdef UNIX
22 | #include
23 | #endif
24 |
25 | typedef struct{
26 | size_t limit;
27 | params ps;
28 |
29 | int num_grid_args;
30 | int num_args;
31 |
32 | double * grid;
33 | double * result;
34 | double * error;
35 | int * status;
36 | double epsabs;
37 | double epsrel;
38 | double a;
39 | double b;
40 |
41 | int upper;
42 | int lower;
43 | int integration_method;
44 | } pthread_args;
45 |
46 |
47 | typedef int (integrator)(const gsl_function *, double, double, double, double, size_t, void *,
48 | double *, double *);
49 |
50 |
51 | void * allocate_workspace(int integration_type, size_t limit){
52 | if (integration_type == 0){
53 | return gsl_integration_workspace_alloc(limit);
54 | }
55 | else if (integration_type == 1){
56 | return gsl_integration_cquad_workspace_alloc(limit);
57 | }
58 | else{
59 | exit(1);
60 | }
61 | }
62 |
63 |
64 | void deallocate_workspace(int integration_type, void * w){
65 | if (integration_type == 0){
66 | gsl_integration_workspace_free(w);
67 | }
68 | else if (integration_type == 1){
69 | gsl_integration_cquad_workspace_free(w);
70 | }
71 | else{
72 | exit(1);
73 | }
74 | }
75 |
76 |
77 | integrator * select_integration_func(int integration_type){
78 | if (integration_type == 0){
79 | return &gsl_integration_qags;
80 | }
81 | else if (integration_type == 1){
82 | return &gsl_integration_cquad;
83 | }
84 | else{
85 | exit(1);
86 | }
87 | }
88 |
89 |
90 | void _quad(int num_args, double a, double b, void * p, double epsabs,
91 | double epsrel, size_t limit, double * result, double * error, int * status,
92 | int integration_method){
93 |
94 | void * w = allocate_workspace(integration_method, limit);
95 | integrator * func = select_integration_func(integration_method);
96 |
97 | gsl_function gfunc;
98 | gfunc.function = integrand_functions[num_args][0];
99 | gfunc.params = p;
100 |
101 | (*status) = (*func)(
102 | &gfunc, a, b, epsabs, epsrel, limit, w, result, error
103 | );
104 |
105 | deallocate_workspace(integration_method, w);
106 | }
107 |
108 |
109 | void _quad_grid(int num_args, int num_grid_args, double a, double b, params ps,
110 | int num, double epsabs, double epsrel, size_t limit, double * grid,
111 | double * result, double * error, int * status, int integration_method){
112 |
113 | // Set up the integration workspace
114 | void * w = allocate_workspace(integration_method, limit);
115 | integrator * func = select_integration_func(integration_method);
116 |
117 | gsl_function gfunc;
118 | gfunc.function = integrand_functions[num_args][num_grid_args];
119 | gfunc.params = (void *)&ps;
120 |
121 | for(int i=0; iintegration_method, pargs->limit);
135 | integrator * func = select_integration_func(pargs->integration_method);
136 |
137 | // deactivate default gsl error handler
138 | gsl_function gfunc;
139 | gfunc.function = integrand_functions[pargs->num_args][pargs->num_grid_args];
140 | gfunc.params = (void *)&pargs->ps;
141 | for(int i=pargs->lower; iupper; i++){
142 | pargs->ps.grid_args = &pargs->grid[i * pargs->num_grid_args];
143 |
144 | pargs->status[i] = (*func)(&gfunc, pargs->a, pargs->b, pargs->epsabs,
145 | pargs->epsrel, pargs->limit, w, &pargs->result[i],
146 | &pargs->error[i]);
147 | }
148 | deallocate_workspace(pargs->integration_method, w);
149 |
150 | return NULL;
151 | }
152 |
153 | void _quad_grid_parallel_wrapper(int num_args, int num_grid_args, double a,
154 | double b, params ps, int num, double epsabs, double epsrel, size_t limit,
155 | double * grid, double * result, double * error, int num_threads,
156 | int pin_threads, int * status, int integration_method){
157 |
158 | int num_per_thread = num / num_threads;
159 | pthread_args pargs[num_threads];
160 | pthread_t thread[num_threads];
161 |
162 | pthread_attr_t attr;
163 | pthread_attr_init(&attr);
164 |
165 | #ifdef LINUX_MACH
166 | cpu_set_t cpus;
167 | #endif
168 |
169 | for(int i=0; i < num_threads; i++){
170 | // Pass the relevant work
171 | pargs[i].num_args = num_args;
172 | pargs[i].num_grid_args = num_grid_args;
173 | pargs[i].grid = grid;
174 | pargs[i].limit = limit;
175 | pargs[i].ps = ps;
176 | pargs[i].result = result;
177 | pargs[i].error = error;
178 | pargs[i].a = a;
179 | pargs[i].b = b;
180 | pargs[i].epsabs = epsabs;
181 | pargs[i].epsrel = epsrel;
182 | pargs[i].status = status;
183 | pargs[i].integration_method = integration_method;
184 |
185 | // Get the range of integrals for this thread
186 | pargs[i].lower = num_per_thread * i;
187 | pargs[i].upper = num_per_thread * (i + 1);
188 |
189 | // Just ensure there are no uncalculated integrals
190 | if(i == (num_threads - 1)){
191 | pargs[i].upper = num;
192 | }
193 |
194 | // Pin each thread to an individual core
195 | #ifdef LINUX_MACH
196 | if (pin_threads == 1){
197 | CPU_ZERO(&cpus);
198 | CPU_SET(i, &cpus);
199 | pthread_attr_setaffinity_np(&attr, sizeof(cpu_set_t), &cpus);
200 | }
201 | #endif
202 |
203 | pthread_create(&thread[i], &attr, _quad_grid_parallel, (void *) &pargs[i]);
204 | }
205 |
206 | for(int i=0; i < num_threads; i++){
207 | pthread_join(thread[i], NULL);
208 | }
209 | }
210 | #else
211 | void _quad_grid_parallel_wrapper(int num_args, int num_grid_args, double a,
212 | double b, params ps, int num, double epsabs, double epsrel, size_t limit,
213 | double * grid, double * result, double * error, int num_threads,
214 | int pin_threads, int * status, int integration_method){
215 |
216 | _quad_grid(
217 | num_args, num_grid_args, a, b, ps, num, epsabs, epsrel, limit,
218 | grid, result, error, status, integration_method);
219 | }
220 | #endif
221 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | Cython>=0.28.0
2 | llvmlite>=0.27.0
3 | numba>=0.40.0
4 | numpy>=1.16.0
5 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup
2 | from setuptools.extension import Extension
3 | from sys import platform
4 |
5 | try:
6 | import numpy as np
7 | from Cython.Build import cythonize
8 | except ImportError:
9 | raise ImportError("Please install numpy and cython before building pyquad!")
10 |
11 | link_args = ["-std=c99"]
12 |
13 | if platform == "linux" or platform == "linux2":
14 | link_args.append("-D LINUX_MACH=1")
15 |
16 | src_files = ["pyquad/pyquad.pyx", "pyquad/integration/error.c",
17 | "pyquad/integration/qk.c", "pyquad/integration/qk21.c",
18 | "pyquad/integration/qk15.c", "pyquad/integration/qags.c",
19 | "pyquad/integration/workspace.c", "pyquad/integration/cquad.c",
20 | "pyquad/integration/cquad_const.c", "pyquad/integration/infnan.c",
21 | "pyquad/integration/fdiv.c"
22 | ]
23 |
24 | ext_modules=[Extension("pyquad",
25 | src_files,
26 | extra_compile_args=link_args,
27 | extra_link_args=link_args,
28 | include_dirs=[np.get_include()],
29 | language='c')]
30 |
31 | # Cythonize our modules
32 | ext_modules = cythonize(ext_modules, compiler_directives={'language_level': 3})
33 | setup(
34 | name='pyquad',
35 | version='0.7.0',
36 | author="Ashley J Kelly",
37 | license="LGPL-3.0",
38 | author_email="a.j.kelly@durham.ac.uk",
39 | description="A python wrapper for the GSL integration routines",
40 | url="https://github.com/AshKelly/pyquad",
41 | classifiers=[
42 | "Programming Language :: Python :: 3",
43 | "Operating System :: OS Independent",
44 | "Intended Audience :: Science/Research",
45 | "License :: OSI Approved :: GNU General Public License (GPL)"
46 | ],
47 | install_requires=['cython', 'numpy', 'numba'],
48 | extras_require={
49 | 'test': ['pytest', 'scipy'],
50 | },
51 | ext_modules=ext_modules,
52 | )
53 |
--------------------------------------------------------------------------------
/tests/TODO:
--------------------------------------------------------------------------------
1 | ## Refactor all tests from test.py into the new testing file and format
2 |
--------------------------------------------------------------------------------
/tests/test_old.py:
--------------------------------------------------------------------------------
1 | import scipy.integrate
2 | import pyquad
3 | import numpy as np
4 | import pytest
5 |
6 |
7 | np.random.seed(101)
8 | INTEGRAL_METHODS = ["qags", "cquad"]
9 |
10 |
11 | def function1(x, a, b, c):
12 | return x*a*a + c*b - c*b / (x + 1e-5)
13 |
14 |
15 | def function2(x, a, b, c):
16 | return a*a / (x + 1.0) + b * (1 - x) + c
17 |
18 |
19 | def function3(x, a, b, c):
20 | return a*a / (x + 1.0) + b * np.sin(x) + c * np.log(x + 1)
21 |
22 |
23 | def function4(x, a, b, c):
24 | return x*a*a + c*b - c*b / (x)
25 |
26 |
27 | def function5(x):
28 | return np.exp(x*100.0)
29 |
30 |
31 | def test_function1():
32 | for method in INTEGRAL_METHODS:
33 | res1, err1 = pyquad.quad(function1, 0., 1., (0.3, 0.1, 0.7), method=method)
34 | res2, err2 = scipy.integrate.quad(function1, 0., 1., (0.3, 0.1, 0.7),
35 | limit=200)
36 | assert np.abs(res1 - res2) < err1
37 |
38 |
39 | def test_function2():
40 | for method in INTEGRAL_METHODS:
41 | res1, err1 = pyquad.quad(function2, 0., 1., (0.99, 2.1, 1.3), method=method)
42 | res2, err2 = scipy.integrate.quad(function2, 0., 1., (0.99, 2.1, 1.3),
43 | limit=200)
44 | assert np.abs(res1 - res2) < err1
45 |
46 |
47 | def test_function3():
48 | for method in INTEGRAL_METHODS:
49 | res1, err1 = pyquad.quad(function3, 0., 4., (0.23, 0.7, 0.13), method=method)
50 | res2, err2 = scipy.integrate.quad(function3, 0., 4., (0.23, 0.7, 0.13),
51 | limit=200)
52 | assert np.abs(res1 - res2) < err1
53 |
54 |
55 | def test_warning1():
56 | args = (function4, 0., 1., (0.3, 0.1, 0.7))
57 | pytest.warns(UserWarning, pyquad.quad, *args)
58 |
59 |
60 | def test_warning2():
61 | args = (function5, 0., 1000.)
62 | pytest.warns(UserWarning, pyquad.quad, *args)
63 |
64 |
65 | def test_warning3():
66 | args = (function3, -100., 1000., (0.23, 0.7, 0.13))
67 | pytest.warns(UserWarning, pyquad.quad, *args)
68 |
69 |
70 | def test_grid_single_column():
71 | grid = np.random.random((100, 1))
72 | for method in INTEGRAL_METHODS:
73 | res = np.zeros(grid.shape[0])
74 | for i in range(res.shape[0]):
75 | res[i] = scipy.integrate.quad(
76 | function1, 0, 1, (grid[i, 0], 1.0, 1.0)
77 | )[0]
78 |
79 | res2 = pyquad.quad_grid(function1, 0, 1, grid, (1.0, 1.0), method=method)[0]
80 |
81 | assert np.abs(np.sum(res) - np.sum(res2)) < 1e-5
82 |
83 |
84 | def test_grid_one_column_with_args():
85 | grid = np.random.random((100, 1))
86 | for method in INTEGRAL_METHODS:
87 | res = np.zeros(grid.shape[0])
88 | for i in range(res.shape[0]):
89 | res[i] = scipy.integrate.quad(
90 | function2, 0, 1, (grid[i, 0], 1.0, 2.0),
91 | )[0]
92 |
93 | res2 = pyquad.quad_grid(function2, 0, 1, grid, args=(1.0, 2.0), method=method)[0]
94 |
95 | assert np.abs(np.sum(res) - np.sum(res2)) < 1e-5
96 |
97 |
98 | def test_grid_two_column_with_args():
99 | grid = np.random.random((100, 2))
100 | for method in INTEGRAL_METHODS:
101 | res = np.zeros(grid.shape[0])
102 | for i in range(res.shape[0]):
103 | res[i] = scipy.integrate.quad(
104 | function2, 0, 1, (grid[i, 0], grid[i, 1], 1.0),
105 | )[0]
106 |
107 | res2 = pyquad.quad_grid(function2, 0, 1, grid, args=(1.0), method=method)[0]
108 |
109 | assert np.abs(np.sum(res) - np.sum(res2)) < 1e-5
110 |
111 |
112 | def test_grid_full_column():
113 | grid = np.random.random((100, 3))
114 | for method in INTEGRAL_METHODS:
115 | res = np.zeros(grid.shape[0])
116 | for i in range(res.shape[0]):
117 | res[i] = scipy.integrate.quad(
118 | function1, 0, 1, (grid[i, 0], grid[i, 1], grid[i, 2])
119 | )[0]
120 |
121 | res2 = pyquad.quad_grid(function1, 0, 1, grid, method=method)[0]
122 |
123 | assert np.abs(np.sum(res) - np.sum(res2)) < 1e-5
124 |
125 |
--------------------------------------------------------------------------------
/tests/test_refactor.py:
--------------------------------------------------------------------------------
1 | import scipy.integrate
2 | import pyquad
3 | import numpy as np
4 | import pytest
5 | import warnings
6 |
7 | np.random.seed(101)
8 |
9 | INTEGRAL_METHODS = ["qags", "cquad"]
10 | LIMIT = 200
11 | N = 100
12 |
13 |
14 | def test_integrand1():
15 | """
16 | A simple polynomial with terms x to x^-1
17 |
18 | f(x) = a^2 * x + c*b - c*b / (x + 1e-5)
19 | integral: F(x) = a^2 * x^2 / 2 + c*b*x - c*b*ln(x + 1e-5) + C
20 |
21 | We repeat the integral N times with random numbers for a, b and c within
22 | the range [0.0, 10.0]
23 |
24 | There is a singularity at x = -1e-5, however the integral range that we
25 | consider here is only [0.0, 1.0]
26 | """
27 |
28 | integrand = lambda x, a, b, c: x*a*a + c*b - c*b / (x + 1e-5)
29 |
30 | analytical_sol = lambda x0, x1, a, b, c: (
31 | (a*a*x1*x1 / 2 + c*b*x1 - c*b*np.log(x1 + 1e-5)) -
32 | (a*a*x0*x0 / 2 + c*b*x0 - c*b*np.log(x0 + 1e-5))
33 | )
34 |
35 | x0 = 0.0
36 | x1 = 1.0
37 | for repeat in range(100):
38 | args = (np.random.uniform(0, 10.0),
39 | np.random.uniform(0, 10.0),
40 | np.random.uniform(0, 10.0))
41 |
42 | for method in INTEGRAL_METHODS:
43 | ana_res = analytical_sol(x0, x1, *args)
44 | res1, err1 = pyquad.quad(integrand, x0, x1, args, method=method, limit=LIMIT)
45 | res2, err2 = scipy.integrate.quad(integrand, x0, x1, args, limit=LIMIT)
46 |
47 | # Ensure abs error is less than 1 part in a million of the result
48 | assert err1 < np.abs(ana_res)*1e-6
49 | # Ensure that scipy and pyquad agree within error
50 | assert np.abs(res1 - res2) < max(err2, err1)
51 | # Ensure pyquad agrees with the analytical solution
52 | assert np.abs(res1 - ana_res) < err1
53 |
54 |
55 | def test_integrand2():
56 | """
57 | A difficult, oscillating, integrand taken from the SIAM 100-Digit Challenge
58 |
59 | f(x) = 1/(x+1e-5) * cos(1/(x+1e-5) * ln(x + 1e-5))
60 | integral: UNKNOWN
61 |
62 | This is a very challenging, slowly convering integrand. In "qags" mode
63 | scipy and pyquad agree very well and pyquad "cquad" mode also agrees within
64 | a very large error.
65 |
66 | As these integrals are VERY slowly convering, they should raise a
67 | `UserWarning` within both pyquad and scipy to alert the user the answer is
68 | not converged!
69 | """
70 |
71 | integrand = lambda x: 1/(x + 1e-5) * np.cos(1/(x + 1e-5) * np.log(x + 1e-5))
72 |
73 | x0 = 0.0
74 | x1 = 1.0
75 | for method in INTEGRAL_METHODS:
76 | # Ignore any warnings at this stage, "just shut up and calculate"
77 | with warnings.catch_warnings():
78 | warnings.simplefilter('ignore')
79 | res1, err1 = pyquad.quad(integrand, x0, x1, method=method, limit=LIMIT)
80 | res2, err2 = scipy.integrate.quad(integrand, x0, x1, limit=LIMIT)
81 |
82 | # Ensure that scipy and pyquad agree within error
83 | assert np.abs(res1 - res2) < max(err1, err2)
84 |
85 | # Re-do the integral and ensure that it raises the correct `UserWarning`
86 | args = (integrand, x0, x1)
87 | pytest.warns(UserWarning, pyquad.quad, *args)
88 | pytest.warns(UserWarning, scipy.integrate.quad, *args)
89 |
--------------------------------------------------------------------------------