├── docs
├── .nojekyll
├── study
│ ├── 分布式策略
│ │ ├── SkyWalking学习笔记.md
│ │ ├── 分布式策略-杂记.md
│ │ ├── README.md
│ │ └── _sidebar.md
│ ├── Spring
│ │ ├── Spring回顾复习.md
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ ├── SpringMVC杂记.md
│ │ └── Spring杂记.md
│ ├── Scala
│ │ ├── 《Scala语言规范》-学习笔记.md
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── Scala杂记.md
│ ├── CICD
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── jenkins杂记.md
│ ├── React
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── 官方入门教程学习.md
│ ├── Docker
│ │ ├── README.md
│ │ └── _sidebar.md
│ ├── Python
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ ├── res
│ │ │ └── img
│ │ │ │ ├── Python5.2.3-1.png
│ │ │ │ ├── Python5.2.3-2.png
│ │ │ │ └── Python5.3.1-1.png
│ │ ├── Intro to Machine Learning--Kaggle.md
│ │ └── Machine-learning.md
│ ├── 推荐系统
│ │ ├── 《机器学习实战》-粗略读书笔记.md
│ │ ├── 协同过滤算法实战之电影推荐-学习笔记.md
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ ├── 推荐系统学习-杂记.md
│ │ └── 推荐系统项目实战.md
│ ├── 通用架构知识
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── IT老齐-视频学习笔记.md
│ ├── BigData
│ │ ├── Spark
│ │ │ └── 《(林子雨)Spark编程基础(Scala版)》-学习笔记.md
│ │ ├── Hive
│ │ │ ├── README.md
│ │ │ └── _sidebar.md
│ │ ├── HBase
│ │ │ ├── README.md
│ │ │ └── _sidebar.md
│ │ ├── Hadoop
│ │ │ ├── README.md
│ │ │ ├── _sidebar.md
│ │ │ └── Hadoop官方教程笔记.md
│ │ ├── Flink
│ │ │ ├── README.md
│ │ │ └── _sidebar.md
│ │ ├── ClickHouse
│ │ │ ├── README.md
│ │ │ └── _sidebar.md
│ │ ├── 理论
│ │ │ ├── README.md
│ │ │ └── _sidebar.md
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── 杂
│ │ │ └── tmp.md
│ ├── 编程思想
│ │ ├── README.md
│ │ └── _sidebar.md
│ ├── 计算广告
│ │ ├── README.md
│ │ └── _sidebar.md
│ ├── 负载均衡-代理
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── 负载均衡-代理-杂记.md
│ ├── 文件管理
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── FastDFS
│ │ │ └── FastDFS杂记.md
│ ├── 设计模式
│ │ ├── Head_First设计模式-读书笔记.md
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── 设计模式-学习杂记.md
│ ├── Vue
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ ├── Vue源码学习.md
│ │ ├── Vue笔记.md
│ │ └── Vue随记.md
│ ├── 领域特定语言DSL
│ │ ├── README.md
│ │ └── _sidebar.md
│ ├── 计算机网络
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── 计算机网络杂记.md
│ ├── Game-dev
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ ├── GDScript基础-学习笔记.md
│ │ └── Godot(官方教程)-学习笔记.md
│ ├── DataBase
│ │ ├── MongoDB
│ │ │ ├── README.md
│ │ │ ├── _sidebar.md
│ │ │ └── MongoDB夯实基础视频-学习笔记.md
│ │ ├── Redis
│ │ │ ├── README.md
│ │ │ ├── _sidebar.md
│ │ │ ├── 《Redis设计与实现(第二版)》-读书笔记.md
│ │ │ └── 2020最新Redis完整教程[千锋南京]-学习笔记.md
│ │ ├── DB-Connection-Pool
│ │ │ ├── README.md
│ │ │ └── _sidebar.md
│ │ ├── DatabaseSystem-Design
│ │ │ ├── README.md
│ │ │ └── _sidebar.md
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── MySQL
│ │ │ ├── README.md
│ │ │ ├── _sidebar.md
│ │ │ ├── 尚硅谷_Mycat视频教程-学习笔记.md
│ │ │ └── mysql杂笔记.md
│ ├── APM
│ │ ├── _sidebar.md
│ │ ├── README.md
│ │ └── SkyWalking
│ │ │ ├── README.md
│ │ │ ├── _sidebar.md
│ │ │ └── SkyWalking8.7.0源码分析-学习笔记.md
│ ├── kubernetes
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── [kubernetes入门]快速了解和上手容器编排工具k8s-学习记录.md
│ ├── Elastic-Stack
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ ├── LogStash-杂记.md
│ │ └── Elastic Stack(ELK)从入门到实践-学习笔记.md
│ ├── SpringCloud
│ │ ├── SpringCloud视频教程-蚂蚁课堂-学习笔记.md
│ │ ├── SpringCloud杂记.md
│ │ ├── README.md
│ │ └── _sidebar.md
│ ├── 网络安全
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ ├── 加密解密
│ │ │ └── 加密解密杂谈.md
│ │ ├── XSS
│ │ │ └── Web安全-XSS教程.md
│ │ └── SSO
│ │ │ └── CAS学习杂记.md
│ ├── Linux
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ ├── Linux知识-学习笔记.md
│ │ └── Shell学习.md
│ ├── Android
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── Android开发基础教程(2019)学习笔记.md
│ ├── Rust
│ │ ├── README.md
│ │ └── _sidebar.md
│ ├── 编程范式(ProgrammingParadigm)
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── POP(PluginOrientedProgramming)
│ │ │ ├── README.md
│ │ │ ├── _sidebar.md
│ │ │ └── POP杂记.md
│ ├── GoLang
│ │ ├── README.md
│ │ └── _sidebar.md
│ ├── MQ
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── SpringBoot_Docker_RabbitMQ消息队列场景架构实战-学习笔记.md
│ ├── 操作系统和硬件
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ ├── 计算机体系结构-量化研究方法(第六版)-学习笔记.md
│ │ └── 操作系统和硬件-杂记.md
│ ├── SpringBoot
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ ├── SpringBoot单元测试demo项目.md
│ │ ├── SpringBoot蚂蚁课堂-学习笔记.md
│ │ └── SpringBoot学习杂记.md
│ ├── LeetCode_Study
│ │ ├── README.md
│ │ ├── 数据结构与算法
│ │ │ ├── README.md
│ │ │ ├── _sidebar.md
│ │ │ ├── 递归.md
│ │ │ ├── 二叉搜索树.md
│ │ │ └── 二叉树.md
│ │ ├── _sidebar.md
│ │ ├── 初级算法
│ │ │ ├── README.md
│ │ │ ├── _sidebar.md
│ │ │ ├── 初级算法-排序和搜索.md
│ │ │ ├── 初级算法-设计问题.md
│ │ │ └── 初级算法-数学.md
│ │ ├── 中级算法
│ │ │ ├── _sidebar.md
│ │ │ ├── README.md
│ │ │ ├── 中级算法-设计问题.md
│ │ │ └── 中级算法-链表.md
│ │ ├── 高级算法
│ │ │ ├── _sidebar.md
│ │ │ ├── README.md
│ │ │ └── 高级算法-数学.md
│ │ └── 程序员面试金典
│ │ │ └── 程序员面试金典.md
│ ├── C
│ │ └── C语言杂记.md
│ ├── Netty
│ │ ├── README.md
│ │ ├── _sidebar.md
│ │ └── 个人Netty实战笔记.md
│ └── Java
│ │ ├── README.md
│ │ └── _sidebar.md
├── _navbar.md
├── _coverpage.md
├── style.css
├── _sidebar.md
├── index.html
└── README.md
└── .gitignore
/docs/.nojekyll:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | *.DS_Store
2 |
--------------------------------------------------------------------------------
/docs/study/分布式策略/SkyWalking学习笔记.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/docs/study/Spring/Spring回顾复习.md:
--------------------------------------------------------------------------------
1 | # Spring回顾复习
2 |
3 |
--------------------------------------------------------------------------------
/docs/_navbar.md:
--------------------------------------------------------------------------------
1 | * [导读](/README.md)
2 | * [首页](/)
3 |
4 |
--------------------------------------------------------------------------------
/docs/study/Scala/《Scala语言规范》-学习笔记.md:
--------------------------------------------------------------------------------
1 | # 《Scala语言规范》-学习笔记
2 |
3 |
--------------------------------------------------------------------------------
/docs/study/CICD/README.md:
--------------------------------------------------------------------------------
1 | # CICD
2 |
3 | ## 目录
4 |
5 | * [jenkins杂记](/study/CICD/jenkins杂记)
--------------------------------------------------------------------------------
/docs/study/React/README.md:
--------------------------------------------------------------------------------
1 | # React
2 |
3 | ## 目录
4 |
5 | * [官方入门教程学习](/study/React/官方入门教程学习)
--------------------------------------------------------------------------------
/docs/study/Docker/README.md:
--------------------------------------------------------------------------------
1 | # Docker
2 |
3 | ## 目录
4 |
5 | * [Docker杂学记录](/study/Docker/Docker杂学记录)
--------------------------------------------------------------------------------
/docs/study/Python/README.md:
--------------------------------------------------------------------------------
1 | # Python
2 |
3 | ## 目录
4 |
5 | * [Python数据处理](/study/Python/python数据处理)
--------------------------------------------------------------------------------
/docs/study/推荐系统/《机器学习实战》-粗略读书笔记.md:
--------------------------------------------------------------------------------
1 | # 《机器学习实战》-粗略读书笔记
2 |
3 | > 为推荐系统的搭建做准备,时间比较紧迫,暂时不细读了。
4 |
5 |
--------------------------------------------------------------------------------
/docs/study/通用架构知识/README.md:
--------------------------------------------------------------------------------
1 | # 通用架构知识
2 |
3 | ## 目录
4 |
5 | * [IT老齐-视频学习笔记](/study/通用架构知识/IT老齐-视频学习笔记)
--------------------------------------------------------------------------------
/docs/study/BigData/Spark/《(林子雨)Spark编程基础(Scala版)》-学习笔记.md:
--------------------------------------------------------------------------------
1 | # 《(林子雨)Spark编程基础(Scala版)》-学习笔记
2 |
3 |
4 |
5 |
--------------------------------------------------------------------------------
/docs/study/编程思想/README.md:
--------------------------------------------------------------------------------
1 | # 操作系统和硬件
2 |
3 | ## 目录
4 |
5 | * [《代码大全2》-读书笔记](/study/编程思想/《代码大全2》-读书笔记)
6 |
--------------------------------------------------------------------------------
/docs/study/计算广告/README.md:
--------------------------------------------------------------------------------
1 | # 计算广告
2 |
3 | ## 目录
4 |
5 | * [计算广告(网易云课堂)-学习笔记](/study/计算广告/计算广告(网易云课堂)-学习笔记)
--------------------------------------------------------------------------------
/docs/study/负载均衡-代理/README.md:
--------------------------------------------------------------------------------
1 | # 负载均衡-代理
2 |
3 | ## 目录
4 |
5 | * [负载均衡-代理-杂记](/study/负载均衡-代理/负载均衡-代理-杂记)
--------------------------------------------------------------------------------
/docs/study/Scala/README.md:
--------------------------------------------------------------------------------
1 | # Scala
2 |
3 | ## 目录
4 |
5 | * [Scala菜鸟教程学习](/study/Scala/Scala菜鸟教程学习)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/文件管理/README.md:
--------------------------------------------------------------------------------
1 | # 文件管理
2 |
3 | ## 目录
4 |
5 | * [FastDFS](/study/文件管理/FastDFS/FastDFS杂记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/设计模式/Head_First设计模式-读书笔记.md:
--------------------------------------------------------------------------------
1 | # Head_First设计模式-读书笔记
2 |
3 | > 趁着稍微有点时间,系统过一遍这个关于设计模式的经典书籍。
4 |
5 |
--------------------------------------------------------------------------------
/docs/study/BigData/Hive/README.md:
--------------------------------------------------------------------------------
1 | # Hive
2 |
3 | ## 目录
4 |
5 | * [Hive-学习笔记](/study/BigData/Hive/Hive学习笔记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/Vue/README.md:
--------------------------------------------------------------------------------
1 | # Vue
2 |
3 | ## 目录
4 |
5 | * [Vue源码学习](/study/Vue/Vue源码学习)
6 | * [Vue随记](/study/Vue/Vue随记)
--------------------------------------------------------------------------------
/docs/study/BigData/HBase/README.md:
--------------------------------------------------------------------------------
1 | # HBase
2 |
3 | ## 目录
4 |
5 | * [HBase-学习笔记](/study/BigData/HBase/HBase学习笔记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/领域特定语言DSL/README.md:
--------------------------------------------------------------------------------
1 | # 领域特定语言DSL
2 |
3 | ## 目录
4 |
5 | * [《领域特定语言》-读书笔记](/study/领域特定语言DSL/《领域特定语言》-读书笔记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/推荐系统/协同过滤算法实战之电影推荐-学习笔记.md:
--------------------------------------------------------------------------------
1 | # 协同过滤算法实战之电影推荐-学习笔记
2 |
3 | > [协同过滤算法实战之电影推荐](https://www.ipieuvre.com/course/326)
4 |
5 |
--------------------------------------------------------------------------------
/docs/study/计算机网络/README.md:
--------------------------------------------------------------------------------
1 | # 计算机网络
2 |
3 | ## 目录
4 |
5 | * [计算机网络复习](/study/计算机网络/计算机网络复习)
6 | * [计算机网络杂记](/study/计算机网络/计算机网络杂记)
--------------------------------------------------------------------------------
/docs/study/CICD/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [jenkins杂记](/study/CICD/jenkins杂记)
--------------------------------------------------------------------------------
/docs/study/Game-dev/README.md:
--------------------------------------------------------------------------------
1 | # Game-dev(游戏开发)
2 |
3 | ## 目录
4 |
5 | * [Godot(官方教程)-学习笔记](/study/Game-devk/Godot(官方教程)-学习笔记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/React/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [官方入门教程学习](/study/React/官方入门教程学习)
--------------------------------------------------------------------------------
/docs/study/Docker/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Docker杂学记录](/study/Docker/Docker杂学记录)
--------------------------------------------------------------------------------
/docs/study/Python/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Python数据处理](/study/Python/python数据处理)
--------------------------------------------------------------------------------
/docs/study/Python/res/img/Python5.2.3-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Ashiamd/docsify-notes/HEAD/docs/study/Python/res/img/Python5.2.3-1.png
--------------------------------------------------------------------------------
/docs/study/Python/res/img/Python5.2.3-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Ashiamd/docsify-notes/HEAD/docs/study/Python/res/img/Python5.2.3-2.png
--------------------------------------------------------------------------------
/docs/study/Python/res/img/Python5.3.1-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Ashiamd/docsify-notes/HEAD/docs/study/Python/res/img/Python5.3.1-1.png
--------------------------------------------------------------------------------
/docs/study/Spring/README.md:
--------------------------------------------------------------------------------
1 | # Spring
2 |
3 | ## 目录
4 |
5 | * [Spring回顾复习](/study/Spring/Spring回顾复习)
6 | * [Spring杂记](/study/Spring/Spring杂记)
--------------------------------------------------------------------------------
/docs/study/文件管理/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [FastDFS](/study/文件管理/FastDFS/FastDFS杂记)
--------------------------------------------------------------------------------
/docs/study/负载均衡-代理/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [负载均衡-代理-杂记](/study/负载均衡-代理/负载均衡-代理-杂记)
--------------------------------------------------------------------------------
/docs/study/BigData/Hadoop/README.md:
--------------------------------------------------------------------------------
1 | # Hadoop
2 |
3 | ## 目录
4 |
5 | * [分布式大数据框架Hadoop-学习笔记](/study/BigData/Hadoop/分布式大数据框架Hadoop-学习笔记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/DataBase/MongoDB/README.md:
--------------------------------------------------------------------------------
1 | # MongoDB
2 |
3 | ## 目录
4 |
5 | * [MongoDB夯实基础视频-学习笔记](/study/DataBase/MongoDB/MongoDB夯实基础视频-学习笔记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/APM/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [SkyWalking](/study/APM/SkyWalking/README)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/Scala/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Scala菜鸟教程学习](/study/Scala/Scala菜鸟教程学习)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/编程思想/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [《代码大全2》-读书笔记](/study/编程思想/《代码大全2》-读书笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/通用架构知识/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [IT老齐-视频学习笔记](/study/通用架构知识/IT老齐-视频学习笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/DataBase/Redis/README.md:
--------------------------------------------------------------------------------
1 | # Redis
2 |
3 | ## 目录
4 |
5 | * [2020最新Redis完整教程[千锋南京]-学习笔记](/study/DataBase/Redis/2020最新Redis完整教程[千锋南京]-学习笔记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/推荐系统/README.md:
--------------------------------------------------------------------------------
1 | # 推荐系统
2 |
3 | ## 目录
4 |
5 | * [《推荐系统实践》-粗略读书笔记](/study/推荐系统/《推荐系统实践》-粗略读书笔记)
6 | * [推荐系统项目实战](/study/推荐系统/推荐系统项目实战)
7 |
8 |
--------------------------------------------------------------------------------
/docs/study/计算广告/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [计算广告(网易云课堂)-学习笔记](/study/计算广告/计算广告(网易云课堂)-学习笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/Vue/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Vue源码学习](/study/Vue/Vue源码学习)
5 | * [Vue随记](/study/Vue/Vue随记)
--------------------------------------------------------------------------------
/docs/study/kubernetes/README.md:
--------------------------------------------------------------------------------
1 | # kubernetes
2 |
3 | ## 目录
4 |
5 | * [【kubernetes入门】快速了解和上手容器编排工具k8s-学习记录](/study/kubernetes/[kubernetes入门]快速了解和上手容器编排工具k8s-学习记录)
--------------------------------------------------------------------------------
/docs/study/领域特定语言DSL/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [《领域特定语言》-读书笔记](/study/领域特定语言DSL/《领域特定语言》-读书笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/DataBase/DB-Connection-Pool/README.md:
--------------------------------------------------------------------------------
1 | # DB-Connection-Pool
2 |
3 | ## 目录
4 |
5 | * [HikariCP学习笔记](/study/DataBase/DB-Connection-Pool/HikariCP学习笔记)
6 |
--------------------------------------------------------------------------------
/docs/study/Elastic-Stack/README.md:
--------------------------------------------------------------------------------
1 | # Elastic-Stack
2 |
3 | ## 目录
4 |
5 | * [Elastic-Stack(7.9官方文档)-学习笔记](/study/Elastic-Stack/Elastic-Stack(7.9官方文档)-学习笔记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/Game-dev/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Godot(官方教程)-学习笔记](/study/Game-devk/Godot(官方教程)-学习笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/APM/README.md:
--------------------------------------------------------------------------------
1 | # APM
2 |
3 | application performance monitor
4 |
5 | ## 目录
6 |
7 | * [SkyWalking](/study/APM/SkyWalking/README)
8 |
9 |
10 |
11 |
--------------------------------------------------------------------------------
/docs/study/APM/SkyWalking/README.md:
--------------------------------------------------------------------------------
1 | # SkyWalking
2 |
3 | ## 目录
4 |
5 | * [SkyWalking8.7.0源码分析-学习笔记](/study/APM/SkyWalking/SkyWalking8.7.0源码分析-学习笔记)
6 |
7 |
8 |
9 |
--------------------------------------------------------------------------------
/docs/study/BigData/Hive/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/BigData/README)
4 | * [Hive-学习笔记](/study/BigData/Hive/Hive学习笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/计算机网络/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [计算机网络复习](/study/计算机网络/计算机网络复习)
5 | * [计算机网络杂记](/study/计算机网络/计算机网络杂记)
--------------------------------------------------------------------------------
/docs/study/BigData/HBase/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/DataBase/README)
4 | * [HBase-学习笔记](/study/BigData/HBase/HBase学习笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/SpringCloud/SpringCloud视频教程-蚂蚁课堂-学习笔记.md:
--------------------------------------------------------------------------------
1 | # SpringCloud视频教程-蚂蚁课堂
2 |
3 | > 教程视频链接http://www.mayikt.com/course/video/2349
4 |
5 | ## 第一章 互联网网站架构演变过程
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/网络安全/README.md:
--------------------------------------------------------------------------------
1 | # 网络安全
2 |
3 | ## 目录
4 |
5 | * [OAuth](/study/网络安全/OAuth/OAuth学习杂记)
6 | * [XSS](/study/网络安全/XSS/Web安全-XSS教程)
7 | * [加密解密](/study/网络安全/加密解密/加密解密杂谈)
--------------------------------------------------------------------------------
/docs/study/Linux/README.md:
--------------------------------------------------------------------------------
1 | # Linux
2 |
3 | ## 目录
4 |
5 | * [Shell](/study/Linux/Shell学习)
6 | * [Shell编程复习](/study/Linux/Shell编程复习)
7 | * [Linux知识-学习笔记](/study/Linux/Linux知识-学习笔记)
--------------------------------------------------------------------------------
/docs/study/Spring/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Spring回顾复习](/study/Spring/Spring回顾复习)
5 | * [Spring杂记](/study/Spring/Spring杂记)
--------------------------------------------------------------------------------
/docs/study/推荐系统/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [《推荐系统实践》-粗略读书笔记](/study/推荐系统/《推荐系统实践》-粗略读书笔记)
5 | * [推荐系统项目实战](/study/推荐系统/推荐系统项目实战)
--------------------------------------------------------------------------------
/docs/study/Android/README.md:
--------------------------------------------------------------------------------
1 | # Android
2 |
3 | ## 目录
4 |
5 | * [Android开发基础教程(2019)学习笔记](/study/Android/Android开发基础教程(2019)学习笔记)
6 | * [W3c_Android基础入门教程](/study/Android/W3c_Android基础入门教程)
--------------------------------------------------------------------------------
/docs/study/BigData/Flink/README.md:
--------------------------------------------------------------------------------
1 | # Flink
2 |
3 | ## 目录
4 |
5 | * [Flink-学习笔记](/study/BigData/Flink/Flink学习笔记)
6 | * [尚硅谷Flink入门到实战-学习笔记](/study/BigData/Flink/尚硅谷Flink入门到实战-学习笔记)
7 |
8 |
--------------------------------------------------------------------------------
/docs/study/BigData/Hadoop/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/BigData/README)
4 | * [分布式大数据框架Hadoop-学习笔记](/study/BigData/Hadoop/分布式大数据框架Hadoop-学习笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/kubernetes/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [【kubernetes入门】快速了解和上手容器编排工具k8s-学习记录](/study/kubernetes/[kubernetes入门]快速了解和上手容器编排工具k8s-学习记录)
--------------------------------------------------------------------------------
/docs/study/分布式策略/分布式策略-杂记.md:
--------------------------------------------------------------------------------
1 | # 分布式策略杂记
2 |
3 | ## 1. 数据库
4 |
5 | ### 1. 唯一键
6 |
7 | #### 1. 雪花算法
8 |
9 | > [雪花算法和几个工具类](https://blog.csdn.net/weixin_43934607/article/details/102301364)
--------------------------------------------------------------------------------
/docs/study/DataBase/MongoDB/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/DataBase/README)
4 | * [MongoDB夯实基础视频-学习笔记](/study/DataBase/MongoDB/MongoDB夯实基础视频-学习笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/Rust/README.md:
--------------------------------------------------------------------------------
1 | # Rust
2 |
3 | ## 目录
4 |
5 | * [Rust-菜鸟教程-学习笔记](/study/Rust/Rust-菜鸟教程-学习笔记)
6 | * [The Rust Programming Language - 学习笔记](/study/Rust/TheRustProgrammingLanguage-学习笔记)
7 |
8 |
--------------------------------------------------------------------------------
/docs/study/APM/SkyWalking/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/APM/README)
4 | * [SkyWalking8.7.0源码分析-学习笔记](/study/APM/SkyWalking/SkyWalking8.7.0源码分析-学习笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/Elastic-Stack/_sidebar.md:
--------------------------------------------------------------------------------
1 | *
2 | * **目录**
3 | * [根目录(/)](/README)
4 | * [回到上一级(../)](/README)
5 | * [Elastic-Stack(7.9官方文档)-学习笔记](/study/Elastic-Stack/Elastic-Stack(7.9官方文档)-学习笔记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/设计模式/README.md:
--------------------------------------------------------------------------------
1 | # 设计模式
2 |
3 | ## 目录
4 |
5 | * [设计模式-学习杂记](/study/设计模式/设计模式-学习杂记)
6 | * [2019尚硅谷Java设计模式-学习笔记](/study/设计模式/2019尚硅谷Java设计模式-学习笔记)
7 | * [设计模式_菜鸟教程-学习笔记](/study/设计模式/设计模式_菜鸟教程-学习笔记)
--------------------------------------------------------------------------------
/docs/study/DataBase/DB-Connection-Pool/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/DataBase/README)
4 | * [HikariCP学习笔记](/study/DataBase/DB-Connection-Pool/HikariCP学习笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/DataBase/Redis/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/DataBase/README)
4 | * [2020最新Redis完整教程[千锋南京]-学习笔记](/study/DataBase/Redis/2020最新Redis完整教程[千锋南京]-学习笔记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/SpringCloud/SpringCloud杂记.md:
--------------------------------------------------------------------------------
1 | # SpringCloud杂记
2 |
3 | # 1. 学习的网课
4 |
5 | > [2023最新Spring Cloud Alibaba零基础入门教程(一套轻松搞定微服务架构)](https://www.bilibili.com/video/BV1v8411K7Y7?p=1) => 适合大致了解一遍相关的组件,之前抽空简单过了一遍
--------------------------------------------------------------------------------
/docs/study/编程范式(ProgrammingParadigm)/README.md:
--------------------------------------------------------------------------------
1 | # 编程范式(ProgrammingParadigm)
2 |
3 | ## 目录
4 |
5 | * [POP(PluginOrientedProgramming)](/study/编程范式(ProgrammingParadigm)/POP(PluginOrientedProgramming)/README)
6 |
--------------------------------------------------------------------------------
/docs/study/编程范式(ProgrammingParadigm)/_sidebar.md:
--------------------------------------------------------------------------------
1 | **目录**
2 |
3 | * [根目录(/)](/README)
4 | * [回到上一级(../)](/README)
5 | * [POP(PluginOrientedProgramming)](/study/编程范式(ProgrammingParadigm)/POP(PluginOrientedProgramming)/README)
--------------------------------------------------------------------------------
/docs/study/网络安全/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [OAuth](/study/网络安全/OAuth/OAuth学习杂记)
5 | * [XSS](/study/网络安全/XSS/Web安全-XSS教程)
6 | * [加密解密](/study/网络安全/加密解密/加密解密杂谈)
--------------------------------------------------------------------------------
/docs/study/通用架构知识/IT老齐-视频学习笔记.md:
--------------------------------------------------------------------------------
1 | # IT老齐-视频学习笔记
2 |
3 | > [【IT老齐001】聊一聊被培训机构神话的架构师](https://www.bilibili.com/video/BV1WM4y1N79G)
4 | >
5 | > 通过学习B站up主[IT老齐](https://space.bilibili.com/359351574)的视频,做一些学习笔记(可能额外补充一些自己查询的资料等)
--------------------------------------------------------------------------------
/docs/study/Linux/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Shell](/study/Linux/Shell学习)
5 | * [Shell编程复习](/study/Linux/Shell编程复习)
6 | * [Linux知识-学习笔记](/study/Linux/Linux知识-学习笔记)
--------------------------------------------------------------------------------
/docs/study/编程范式(ProgrammingParadigm)/POP(PluginOrientedProgramming)/README.md:
--------------------------------------------------------------------------------
1 | # POP(PluginOrientedProgramming)
2 |
3 | ## 目录
4 |
5 | * [POP杂记](/study/编程范式(ProgrammingParadigm)/POP(PluginOrientedProgramming)/POP杂记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/Android/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Android开发基础教程(2019)学习笔记](/study/Android/Android开发基础教程(2019)学习笔记)
5 | * [W3c_Android基础入门教程](/study/Android/W3c_Android基础入门教程)
--------------------------------------------------------------------------------
/docs/study/BigData/Flink/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/BigData/README)
4 | * [Flink-学习笔记](/study/BigData/Flink/Flink学习笔记)
5 | * [尚硅谷Flink入门到实战-学习笔记](/study/BigData/Flink/尚硅谷Flink入门到实战-学习笔记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/Rust/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Rust-菜鸟教程-学习笔记](/study/Rust/Rust-菜鸟教程-学习笔记)
5 | * [The Rust Programming Language - 学习笔记](/study/Rust/TheRustProgrammingLanguage-学习笔记)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/Spring/SpringMVC杂记.md:
--------------------------------------------------------------------------------
1 | # SpringMVC杂记
2 |
3 | > [SpringMVC常见面试题总结(超详细回答)](https://blog.csdn.net/a745233700/article/details/80963758)
4 | >
5 | > [Struts2与MVC的区别](https://blog.csdn.net/weixin_34208283/article/details/93516392)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/DataBase/DatabaseSystem-Design/README.md:
--------------------------------------------------------------------------------
1 | # DatabaseSystem-Design
2 |
3 | ## 目录
4 |
5 | * [数据库系统内幕-学习笔记-01](/study/DataBase/DatabaseSystem-Design/数据库系统内幕-学习笔记-01)
6 | * [数据库系统内幕-学习笔记-02](/study/DataBase/DatabaseSystem-Design/数据库系统内幕-学习笔记-02)
7 |
--------------------------------------------------------------------------------
/docs/study/Elastic-Stack/LogStash-杂记.md:
--------------------------------------------------------------------------------
1 | # LogStash-杂记
2 |
3 | # 1. LogStash能干啥
4 |
5 | > [Logstash](https://www.cnblogs.com/cjsblog/p/9459781.html)
6 |
7 | 充当管道pipeline,我们设定输入input、输入output以及过滤器filter后,LogStash就能完成从输入端获取数据并过滤,再将处理后的数据交给输出端。
8 |
9 |
--------------------------------------------------------------------------------
/docs/study/分布式策略/README.md:
--------------------------------------------------------------------------------
1 | # 分布式策略
2 |
3 | ## 目录
4 |
5 | * [分布式策略-杂记](/study/分布式策略/分布式策略-杂记)
6 | * [gRPC-官方文档学习](/study/分布式策略/gRPC-官方文档学习)
7 | * [MIT6.824网课学习笔记-01](/study/分布式策略/MIT6.824网课学习笔记-01)
8 | * [MIT6.824网课学习笔记-02](/study/分布式策略/MIT6.824网课学习笔记-02)
--------------------------------------------------------------------------------
/docs/study/设计模式/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [设计模式-学习杂记](/study/设计模式/设计模式-学习杂记)
5 | * [2019尚硅谷Java设计模式-学习笔记](/study/设计模式/2019尚硅谷Java设计模式-学习笔记)
6 | * [设计模式_菜鸟教程-学习笔记](/study/设计模式/设计模式_菜鸟教程-学习笔记)
7 |
8 |
--------------------------------------------------------------------------------
/docs/study/BigData/ClickHouse/README.md:
--------------------------------------------------------------------------------
1 | # ClickHouse
2 |
3 | ## 目录
4 |
5 | * [clickhouse原理解析与应用实践-学习笔记-01](/study/BigData/ClickHouse/clickhouse原理解析与应用实践-学习笔记-01)
6 | * [clickhouse原理解析与应用实践-学习笔记-02](/study/BigData/ClickHouse/clickhouse原理解析与应用实践-学习笔记-02)
7 |
8 |
--------------------------------------------------------------------------------
/docs/study/BigData/理论/README.md:
--------------------------------------------------------------------------------
1 | # 理论
2 |
3 | ## 目录
4 |
5 | * [数据密集型应用系统设计-学习笔记-01](/study/BigData/理论/数据密集型应用系统设计-学习笔记-01)
6 | * [数据密集型应用系统设计-学习笔记-02](/study/BigData/理论/数据密集型应用系统设计-学习笔记-02)
7 | * [数据密集型应用系统设计-学习笔记-03](/study/BigData/理论/数据密集型应用系统设计-学习笔记-03)
8 |
9 |
--------------------------------------------------------------------------------
/docs/study/推荐系统/推荐系统学习-杂记.md:
--------------------------------------------------------------------------------
1 | # 推荐系统学习-杂记
2 |
3 | # 1. 推荐博客
4 |
5 | > [推荐系统入门-wenjiangs](https://www.wenjiangs.com/doc/5wwt33p7g) <= 偶然发现的一个博客网站,挺不错的
6 | >
7 | > [Introduction · 面向程序员的数据挖掘指南 (yourtion.com)](https://dataminingguide.books.yourtion.com/) => 和上面一样
8 |
9 |
--------------------------------------------------------------------------------
/docs/study/编程范式(ProgrammingParadigm)/POP(PluginOrientedProgramming)/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/编程范式(ProgrammingParadigm)/README)
4 | * [POP杂记](/study/编程范式(ProgrammingParadigm)/POP(PluginOrientedProgramming)/POP杂记)
5 |
6 |
--------------------------------------------------------------------------------
/docs/study/GoLang/README.md:
--------------------------------------------------------------------------------
1 | # GoLang
2 |
3 | ## 目录
4 |
5 | * [go菜鸟教程-学习笔记](/study/GoLang/go菜鸟教程-学习笔记)
6 | * [《Go语言圣经》学习笔记-1](/study/GoLang/《Go语言圣经》学习笔记-1)
7 | * [《Go语言圣经》学习笔记-2](/study/GoLang/《Go语言圣经》学习笔记-2)
8 | * [《Go语言圣经》学习笔记-3](/study/GoLang/《Go语言圣经》学习笔记-3)
9 |
10 |
--------------------------------------------------------------------------------
/docs/study/分布式策略/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [分布式策略-杂记](/study/分布式策略/分布式策略-杂记)
5 | * [gRPC-官方文档学习](/study/分布式策略/gRPC-官方文档学习)
6 | * [MIT6.824网课学习笔记-01](/study/分布式策略/MIT6.824网课学习笔记-01)
7 | * [MIT6.824网课学习笔记-02](/study/分布式策略/MIT6.824网课学习笔记-02)
--------------------------------------------------------------------------------
/docs/study/DataBase/DatabaseSystem-Design/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/DataBase/README)
4 | * [数据库系统内幕-学习笔记-01](/study/DataBase/DatabaseSystem-Design/数据库系统内幕-学习笔记-01)
5 | * [数据库系统内幕-学习笔记-02](/study/DataBase/DatabaseSystem-Design/数据库系统内幕-学习笔记-02)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/SpringCloud/README.md:
--------------------------------------------------------------------------------
1 | # SpringCloud
2 |
3 | ## 目录
4 |
5 | * [SpringCloud最新教程IDEA版【狂神说Java系列】学习笔记](/study/SpringCloud/SpringCloud最新教程IDEA版[狂神说Java系列]-学习笔记)
6 | * [SpringCloud视频教程-蚂蚁课堂-学习笔记](/study/SpringCloud/SpringCloud视频教程-蚂蚁课堂-学习笔记)
7 | * [Sentinel官方文档-学习笔记](/study/SpringCloud/Sentinel官方文档-学习笔记)
--------------------------------------------------------------------------------
/docs/_coverpage.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | # Ashiamd的个人MD笔记
4 |
5 | > 希望自己能够越学越好,哈哈
6 |
7 | * 😀💻🕐🕑🕒🕓🕔🕕🕖🕗🕘🕙🕚🕛😶
8 | * 😶💻🕜🕝🕞🕟🕠🕡🕢🕣🕤🕥🕦🕧😪
9 | * 😪👀😎😟😤💪💪💪💻🌕🌗🌑🌞😪😴
10 |
11 | [开始阅读](README.md)
12 | [我的GitHub](https://github.com/Ashiamd/docsify-notes)
--------------------------------------------------------------------------------
/docs/study/BigData/ClickHouse/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/BigData/README)
4 | * [clickhouse原理解析与应用实践-学习笔记-01](/study/BigData/ClickHouse/clickhouse原理解析与应用实践-学习笔记-01)
5 | * [clickhouse原理解析与应用实践-学习笔记-02](/study/BigData/ClickHouse/clickhouse原理解析与应用实践-学习笔记-02)
6 |
7 |
--------------------------------------------------------------------------------
/docs/study/DataBase/README.md:
--------------------------------------------------------------------------------
1 | # DataBase
2 |
3 | ## 目录
4 |
5 | * [MySQL](/study/DataBase/MySQL/README)
6 | * [Redis](/study/DataBase/Redis/README)
7 | * [DatabaseSystem-Design](/study/DataBase/DatabaseSystem-Design/README)
8 | * [DB-Connection-Pool](/study/DataBase/DB-Connection-Pool/README)
9 |
10 |
--------------------------------------------------------------------------------
/docs/study/GoLang/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [go菜鸟教程-学习笔记](/study/GoLang/go菜鸟教程-学习笔记)
5 | * [《Go语言圣经》学习笔记-1](/study/GoLang/《Go语言圣经》学习笔记-1)
6 | * [《Go语言圣经》学习笔记-2](/study/GoLang/《Go语言圣经》学习笔记-2)
7 | * [《Go语言圣经》学习笔记-3](/study/GoLang/《Go语言圣经》学习笔记-3)
8 |
9 |
--------------------------------------------------------------------------------
/docs/study/MQ/README.md:
--------------------------------------------------------------------------------
1 | # MQ
2 |
3 | ## 目录
4 |
5 | * [Kafka权威指南-学习笔记01](/study/MQ/Kafka权威指南-学习笔记01)
6 | * [Kafka权威指南-学习笔记02](/study/MQ/Kafka权威指南-学习笔记02)
7 | * [SpringBoot+Docker+RabbitMQ消息队列场景架构实战-学习笔记](/study/MQ/SpringBoot_Docker_RabbitMQ消息队列场景架构实战-学习笔记)
8 | * [Kafka学习笔记](/study/MQ/Kafka学习笔记)
9 |
10 |
--------------------------------------------------------------------------------
/docs/study/设计模式/设计模式-学习杂记.md:
--------------------------------------------------------------------------------
1 | # 设计模式-学习杂记
2 |
3 | > 之前根据网络上的文章,琐碎地算是把常用的几种设计模式都学习过了。但是没时间整理。
4 | >
5 | > 这里先挖个坑。之后再根据一些热门书籍系统复习下吧。
6 |
7 | ## 1. 委托模式
8 |
9 | > [委托模式](https://www.jianshu.com/p/e7a5f0e45862)
10 |
11 | ## ex 1. 面向对象设计之魂的六大原则
12 |
13 | > [面向对象设计之魂的六大原则](https://zhuanlan.zhihu.com/p/58092071)
--------------------------------------------------------------------------------
/docs/study/BigData/理论/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/BigData/README)
4 | * [数据密集型应用系统设计-学习笔记-01](/study/BigData/理论/数据密集型应用系统设计-学习笔记-01)
5 | * [数据密集型应用系统设计-学习笔记-02](/study/BigData/理论/数据密集型应用系统设计-学习笔记-02)
6 | * [数据密集型应用系统设计-学习笔记-03](/study/BigData/理论/数据密集型应用系统设计-学习笔记-03)
7 |
8 |
--------------------------------------------------------------------------------
/docs/study/操作系统和硬件/README.md:
--------------------------------------------------------------------------------
1 | # 操作系统和硬件
2 |
3 | ## 目录
4 |
5 | * [操作系统和硬件-杂记](/study/操作系统和硬件/操作系统和硬件-杂记)
6 | * [操作系统系统回顾](/study/操作系统和硬件/操作系统系统回顾)
7 | * [MIT6.S081网课学习笔记-01](/study/操作系统和硬件/MIT6.S081网课学习笔记-01)
8 | * [MIT6.S081网课学习笔记-02](/study/操作系统和硬件/MIT6.S081网课学习笔记-02)
9 | * [MIT6.S081网课学习笔记-03](/study/操作系统和硬件/MIT6.S081网课学习笔记-03)
--------------------------------------------------------------------------------
/docs/study/BigData/README.md:
--------------------------------------------------------------------------------
1 | # BigData
2 |
3 | ## 目录
4 |
5 | * [理论](/study/BigData/理论/README)
6 | * [Hadoop](/study/BigData/Hadoop/README)
7 | * [HBase](/study/BigData/HBase/README)
8 | * [Hive](/study/BigData/Hive/README)
9 | * [Flink](/study/BigData/Flink/README)
10 | * [ClickHouse](/study/BigData/ClickHouse/README)
11 |
12 |
--------------------------------------------------------------------------------
/docs/study/Vue/Vue源码学习.md:
--------------------------------------------------------------------------------
1 | # Vue源码学习
2 |
3 | > 之前暑假就看过了Vue官方文档,但是看归看,并不熟悉。
4 | >
5 | > 后面又找了B站的Vue教学视频。(https://www.bilibili.com/video/av59594689)
6 | >
7 | > 我与之对应的Vue学习笔记,比较杂乱,因为当时还没接触Typora,主要是截图+自己的一些记录、思考等https://github.com/Ashiamd/VueStudyNote
8 | >
9 | > 最近刚学习完,最后几个视频章节对Vue源码有一定的分析,打算自己实践一下,看看Vue的源码,学习下。(暂时未开工)
10 |
11 |
--------------------------------------------------------------------------------
/docs/study/DataBase/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [MySQL](/study/DataBase/MySQL/README)
5 | * [Redis](/study/DataBase/Redis/README)
6 | * [DatabaseSystem-Design](/study/DataBase/DatabaseSystem-Design/README)
7 | * [DB-Connection-Pool](/study/DataBase/DB-Connection-Pool/README)
8 |
9 |
--------------------------------------------------------------------------------
/docs/study/MQ/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Kafka权威指南-学习笔记01](/study/MQ/Kafka权威指南-学习笔记01)
5 | * [Kafka权威指南-学习笔记02](/study/MQ/Kafka权威指南-学习笔记02)
6 | * [SpringBoot+Docker+RabbitMQ消息队列场景架构实战-学习笔记](/study/MQ/SpringBoot_Docker_RabbitMQ消息队列场景架构实战-学习笔记)
7 | * [Kafka学习笔记](/study/MQ/Kafka学习笔记)
--------------------------------------------------------------------------------
/docs/study/SpringCloud/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [SpringCloud最新教程IDEA版【狂神说Java系列】学习笔记](/study/SpringCloud/SpringCloud最新教程IDEA版[狂神说Java系列]-学习笔记)
5 | * [SpringCloud视频教程-蚂蚁课堂-学习笔记](/study/SpringCloud/SpringCloud视频教程-蚂蚁课堂-学习笔记)
6 | * [Sentinel官方文档-学习笔记](/study/SpringCloud/Sentinel官方文档-学习笔记)
--------------------------------------------------------------------------------
/docs/study/SpringBoot/README.md:
--------------------------------------------------------------------------------
1 | # SpringBoot
2 |
3 | ## 目录
4 |
5 | * [SpringBoot单元测试demo项目](/study/SpringBoot/SpringBoot单元测试demo项目)
6 | * [SpringBoot蚂蚁课堂-学习笔记](/study/SpringBoot/SpringBoot蚂蚁课堂-学习笔记)
7 | * [SpringBoot最新教程IDEA版【狂神说Java系列】学习笔记](/study/SpringBoot/SpringBoot最新教程IDEA版_狂神说Java系列_-学习笔记)
8 | * [SpringBoot学习杂记](/study/SpringBoot/SpringBoot学习杂记)
--------------------------------------------------------------------------------
/docs/study/操作系统和硬件/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [操作系统和硬件-杂记](/study/操作系统和硬件/操作系统和硬件-杂记)
5 | * [操作系统系统回顾](/study/操作系统和硬件/操作系统系统回顾)
6 | * [MIT6.S081网课学习笔记-01](/study/操作系统和硬件/MIT6.S081网课学习笔记-01)
7 | * [MIT6.S081网课学习笔记-02](/study/操作系统和硬件/MIT6.S081网课学习笔记-02)
8 | * [MIT6.S081网课学习笔记-03](/study/操作系统和硬件/MIT6.S081网课学习笔记-03)
--------------------------------------------------------------------------------
/docs/study/BigData/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [理论](/study/BigData/理论/README)
5 | * [Hadoop](/study/BigData/Hadoop/README)
6 | * [HBase](/study/BigData/HBase/README)
7 | * [Hive](/study/BigData/Hive/README)
8 | * [Flink](/study/BigData/Flink/README)
9 | * [ClickHouse](/study/BigData/ClickHouse/README)
10 |
11 |
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/README.md:
--------------------------------------------------------------------------------
1 | # LeetCode
2 |
3 | ## 目录
4 |
5 | * [探索-初级算法](/study/LeetCode_Study/初级算法/README)
6 | * [探索-中级算法](/study/LeetCode_Study/中级算法/README)
7 | * [探索-高级算法](/study/LeetCode_Study/高级算法/README)
8 | * [剑指Offer](/study/LeetCode_Study/剑指Offer/剑指Offer)
9 | * [程序员面试金典](/study/LeetCode_Study/程序员面试金典/程序员面试金典)
10 | * [数据结构与算法](/study/LeetCode_Study/数据结构与算法/README)
--------------------------------------------------------------------------------
/docs/study/SpringBoot/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [SpringBoot单元测试demo项目](/study/SpringBoot/SpringBoot单元测试demo项目)
5 | * [SpringBoot蚂蚁课堂-学习笔记](/study/SpringBoot/SpringBoot蚂蚁课堂-学习笔记)
6 | * [SpringBoot最新教程IDEA版【狂神说Java系列】学习笔记](/study/SpringBoot/SpringBoot最新教程IDEA版_狂神说Java系列_-学习笔记)
7 | * [SpringBoot学习杂记](/study/SpringBoot/SpringBoot学习杂记)
--------------------------------------------------------------------------------
/docs/study/DataBase/MySQL/README.md:
--------------------------------------------------------------------------------
1 | # MySQL
2 |
3 | ## 目录
4 |
5 | * [mysql入门很简单系列视频-学习笔记](/study/DataBase/MySQL/mysql入门很简单系列视频-学习笔记)
6 | * [尚硅谷_Mycat视频教程-学习笔记](/study/DataBase/MySQL/尚硅谷_Mycat视频教程-学习笔记)
7 | * [MySQL技术内幕-InnoDB存储引擎第2版-学习笔记-01](/study/DataBase/MySQL/MySQL技术内幕-InnoDB存储引擎第2版-学习笔记-01)
8 | * [MySQL技术内幕-InnoDB存储引擎第2版-学习笔记-02](/study/DataBase/MySQL/MySQL技术内幕-InnoDB存储引擎第2版-学习笔记-02)
9 |
10 |
--------------------------------------------------------------------------------
/docs/study/Game-dev/GDScript基础-学习笔记.md:
--------------------------------------------------------------------------------
1 | # GDScript基础-学习笔记
2 |
3 | > [GDScript - GDScript 基础 - 《Godot 游戏引擎 v3.5 中文文档》 - 书栈网 · BookStack](https://www.bookstack.cn/read/godot-3.5-zh/f9c328f5c1cf8c98.md)
4 | >
5 | > 以前学过JavaScript和Python,所以这里就不特地写全面的笔记了。
6 |
7 | 1. GDScript支持鸭子类型
8 |
9 | 2. GDScript继承Refrence的引用类型在计数为0时会自动释放,继承Object则需要手动管理内存
10 |
11 | 3. 一般开发时最基础的类只用到`RefCounted`,再往下的类需要手动内存管理,比较繁琐
12 | 4.
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/数据结构与算法/README.md:
--------------------------------------------------------------------------------
1 | # LeetCode-数据结构
2 |
3 | > https://leetcode-cn.com/leetbook/
4 |
5 | ## 目录
6 |
7 | * [队列&栈](/study/LeetCode_Study/数据结构/队列&栈)
8 | * [链表](/study/LeetCode_Study/数据结构/链表)
9 | * [递归](/study/LeetCode_Study/数据结构/递归)
10 | * [二叉树](/study/LeetCode_Study/数据结构/二叉树)
11 | * [二叉搜索树](https://leetcode-cn.com/leetbook/detail/introduction-to-data-structure-binary-search-tree/)
--------------------------------------------------------------------------------
/docs/study/C/C语言杂记.md:
--------------------------------------------------------------------------------
1 | # C语言杂记
2 |
3 | > 记录一些网上看到的不错的关于C语言的文章。
4 |
5 | # 1. 可见域和作用域
6 |
7 | > [**编译器的工作流程**](https://fishc.com.cn/forum.php?mod=viewthread&tid=78063&extra=page%3D1%26filter%3Dtypeid%26typeid%3D571)
8 | >
9 | > [C 生存期,作用域和可见域](https://blog.csdn.net/weixin_41049188/article/details/103091365)
10 | >
11 | > [c语言中external,static关键字用法](https://www.cnblogs.com/fah936861121/p/6679915.html)
12 |
13 |
--------------------------------------------------------------------------------
/docs/study/SpringBoot/SpringBoot单元测试demo项目.md:
--------------------------------------------------------------------------------
1 | # SpringBoot单元测试demo项目
2 |
3 | # 1. 项目介绍
4 |
5 | ## 1.1 git项目
6 |
7 | > [Ashiamd/ash_springboot_unit_test: SpringBoot JUnit unit test demo code using Mockito and PowerMock (github.com)](https://github.com/Ashiamd/ash_springboot_unit_test)
8 |
9 | ## 1.2 依赖介绍
10 |
11 | 编程语言:java (jdk17)
12 |
13 | 项目主要依赖项
14 |
15 |
16 |
17 |
18 |
19 | ## 1.3 maven依赖清单
20 |
21 |
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [探索-初级算法](/study/LeetCode_Study/初级算法/README)
5 | * [探索-中级算法](/study/LeetCode_Study/中级算法/README)
6 | * [探索-高级算法](/study/LeetCode_Study/高级算法/README)
7 | * [剑指Offer](/study/LeetCode_Study/剑指Offer/剑指Offer)
8 | * [程序员面试金典](/study/LeetCode_Study/程序员面试金典/程序员面试金典)
9 | * [数据结构与算法](/study/LeetCode_Study/数据结构与算法/README)
--------------------------------------------------------------------------------
/docs/study/Netty/README.md:
--------------------------------------------------------------------------------
1 | # Netty
2 |
3 | ## 目录
4 |
5 | * [Netty学习](/study/Netty/Netty学习)
6 | * [个人Netty实战笔记](/study/Netty/个人Netty实战笔记)
7 | * [《Netty-Redis-ZooKeeper高并发实战》学习笔记1-6章](/study/Netty/《Netty-Redis-ZooKeeper高并发实战》学习笔记1-6章)
8 | * [《Netty-Redis-ZooKeeper高并发实战》学习笔记7-9章](/study/Netty/《Netty-Redis-ZooKeeper高并发实战》学习笔记7-9章)
9 | * [《Netty-Redis-ZooKeeper高并发实战》学习笔记10-12章](/study/Netty/《Netty-Redis-ZooKeeper高并发实战》学习笔记10-12章)
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/数据结构与算法/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/LeetCode_Study/README)
4 | * [队列&栈](/study/LeetCode_Study/数据结构/队列&栈)
5 | * [链表](/study/LeetCode_Study/数据结构/链表)
6 | * [递归](/study/LeetCode_Study/数据结构/递归)
7 | * [二叉树](/study/LeetCode_Study/数据结构/二叉树)
8 | * [二叉搜索树](https://leetcode-cn.com/leetbook/detail/introduction-to-data-structure-binary-search-tree/)
9 |
10 |
--------------------------------------------------------------------------------
/docs/study/DataBase/MySQL/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/DataBase/README)
4 | * [mysql入门很简单系列视频-学习笔记](/study/DataBase/MySQL/mysql入门很简单系列视频-学习笔记)
5 | * [尚硅谷_Mycat视频教程-学习笔记](/study/DataBase/MySQL/尚硅谷_Mycat视频教程-学习笔记)
6 | * [MySQL技术内幕-InnoDB存储引擎第2版-学习笔记-01](/study/DataBase/MySQL/MySQL技术内幕-InnoDB存储引擎第2版-学习笔记-01)
7 | * [MySQL技术内幕-InnoDB存储引擎第2版-学习笔记-02](/study/DataBase/MySQL/MySQL技术内幕-InnoDB存储引擎第2版-学习笔记-02)
8 |
9 |
--------------------------------------------------------------------------------
/docs/study/Netty/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Netty学习](/study/Netty/Netty学习)
5 | * [个人Netty实战笔记](/study/Netty/个人Netty实战笔记)
6 | * [《Netty-Redis-ZooKeeper高并发实战》学习笔记1-6章](/study/Netty/《Netty-Redis-ZooKeeper高并发实战》学习笔记1-6章)
7 | * [《Netty-Redis-ZooKeeper高并发实战》学习笔记7-9章](/study/Netty/《Netty-Redis-ZooKeeper高并发实战》学习笔记7-9章)
8 | * [《Netty-Redis-ZooKeeper高并发实战》学习笔记10-12章](/study/Netty/《Netty-Redis-ZooKeeper高并发实战》学习笔记10-12章)
9 |
10 |
--------------------------------------------------------------------------------
/docs/study/操作系统和硬件/计算机体系结构-量化研究方法(第六版)-学习笔记.md:
--------------------------------------------------------------------------------
1 | # 计算机体系结构-量化研究方法(第六版)-学习笔记
2 |
3 | > [关于翻译 - 计算机体系结构-量化研究方法(第六版)-汉化 (gitbook.io)](https://mxlol233.gitbook.io/ji-suan-ji-ti-xi-jie-gou-liang-hua-yan-jiu-fang-fa-di-liu-ban-han-hua/)
4 | >
5 | > [英文版附录链接](https://www.elsevier.com/books-and-journals/book-companion/9780128119051)
6 | >
7 | > [杂文:愿他长寿:计算机体系结构:量化研究方法(第6版)中文版的故事 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/415921386)
8 | >
9 | > 网友学习笔记:[计算机体系结构-cache高速缓存 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/482651908)
--------------------------------------------------------------------------------
/docs/study/负载均衡-代理/负载均衡-代理-杂记.md:
--------------------------------------------------------------------------------
1 | # 负载均衡-代理
2 |
3 | ## 1. Nginx
4 |
5 | ### 1. 概述
6 |
7 | > [Nginx基本使用](https://www.cnblogs.com/nanianqiming/p/10630899.html)
8 |
9 | ### 2. 使用
10 |
11 | #### 0. 常见指令介绍
12 |
13 | > [nginx location指令详解](https://www.cnblogs.com/xiaoliangup/p/9175932.html)
14 |
15 | #### 1. 反向代理
16 |
17 | > [Nginx(三)------nginx 反向代理](https://www.cnblogs.com/ysocean/p/9392908.html)
18 |
19 | #### 2. 负载均衡
20 |
21 | > [浅谈Nginx负载均衡和F5的区别](https://www.cnblogs.com/Lonelydancer/p/6219567.html)
22 |
23 | ## 2. Ribbon
24 |
25 | ### 1. 概述
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/初级算法/README.md:
--------------------------------------------------------------------------------
1 | # LeetCode-探索-初级算法
2 |
3 | > https://leetcode-cn.com/explore/featured/card/top-interview-questions-easy/
4 |
5 | ## 目录
6 |
7 | * [数组](/study/LeetCode_Study/初级算法/初级算法-数组)
8 | * [字符串](/study/LeetCode_Study/初级算法/初级算法-字符串)
9 | * [树](/study/LeetCode_Study/初级算法/初级算法-树)
10 | * [排序和搜索](/study/LeetCode_Study/初级算法/初级算法-排序和搜索)
11 | * [动态规划](/study/LeetCode_Study/初级算法/初级算法-动态规划)
12 | * [设计问题](/study/LeetCode_Study/初级算法/初级算法-设计问题)
13 | * [数学](/study/LeetCode_Study/初级算法/初级算法-数学)
14 | * [其他](/study/LeetCode_Study/初级算法/初级算法-其他)
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/初级算法/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/LeetCode_Study/README)
4 | * [数组](/study/LeetCode_Study/初级算法/初级算法-数组)
5 | * [字符串](/study/LeetCode_Study/初级算法/初级算法-字符串)
6 | * [链表](/study/LeetCode_Study/初级算法/初级算法-链表)
7 | * [树](/study/LeetCode_Study/初级算法/初级算法-树)
8 | * [排序和搜索](/study/LeetCode_Study/初级算法/初级算法-排序和搜索)
9 | * [动态规划](/study/LeetCode_Study/初级算法/初级算法-动态规划)
10 | * [设计问题](/study/LeetCode_Study/初级算法/初级算法-设计问题)
11 | * [数学](/study/LeetCode_Study/初级算法/初级算法-数学)
12 | * [其他](/study/LeetCode_Study/初级算法/初级算法-其他)
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/中级算法/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/LeetCode_Study/README)
4 | * [数组和字符串](/study/LeetCode_Study/中级算法/中级算法-数组和字符串)
5 | * [链表](/study/LeetCode_Study/中级算法/中级算法-链表)
6 | * [树和图](/study/LeetCode_Study/中级算法/中级算法-树和图)
7 | * [回溯算法](/study/LeetCode_Study/中级算法/中级算法-回溯算法)
8 | * [排序和搜索](/study/LeetCode_Study/中级算法/中级算法-排序和搜索)
9 | * [动态规划](/study/LeetCode_Study/中级算法/中级算法-动态规划)
10 | * [设计问题](/study/LeetCode_Study/中级算法/中级算法-设计问题)
11 | * [数学](/study/LeetCode_Study/中级算法/中级算法-数学)
12 | * [其他](/study/LeetCode_Study/中级算法/中级算法-其他)
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/高级算法/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/study/LeetCode_Study/README)
4 | * [数组和字符串](/study/LeetCode_Study/高级算法/高级算法-数组和字符串)
5 | * [链表](/study/LeetCode_Study/高级算法/高级算法-链表)
6 | * [树和图](/study/LeetCode_Study/高级算法/高级算法-树和图)
7 | * [回溯算法](/study/LeetCode_Study/高级算法/高级算法-回溯算法)
8 | * [排序和搜索](/study/LeetCode_Study/高级算法/高级算法-排序和搜索)
9 | * [动态规划](/study/LeetCode_Study/高级算法/高级算法-动态规划)
10 | * [设计问题](/study/LeetCode_Study/高级算法/高级算法-设计问题)
11 | * [数学](/study/LeetCode_Study/高级算法/高级算法-数学)
12 | * [其他](/study/LeetCode_Study/高级算法/高级算法-其他)
--------------------------------------------------------------------------------
/docs/study/DataBase/MySQL/尚硅谷_Mycat视频教程-学习笔记.md:
--------------------------------------------------------------------------------
1 | # 尚硅谷_Mycat视频教程-学习笔记
2 |
3 | > 视频链接:[尚硅谷_Mycat视频教程](https://www.bilibili.com/video/av80469766) https://www.bilibili.com/video/av80469766
4 |
5 | ## 01-MyCat简介
6 |
7 | > [数据库分区、分表、分库、分片](https://blog.csdn.net/qq_28289405/article/details/80576614)
8 | >
9 | > [MySql从一窍不通到入门(五)Sharding:分表、分库、分片和分区](https://blog.csdn.net/kingcat666/article/details/78324678)
10 | >
11 | > [mycat的介绍及应用场景](https://blog.csdn.net/xiaozhenzi66/article/details/81286665)
12 | >
13 | > [彻底搞清分库分表(垂直分库,垂直分表,水平分库,水平分表)](https://blog.csdn.net/weixin_44062339/article/details/100491744)
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/高级算法/README.md:
--------------------------------------------------------------------------------
1 | # LeetCode-探索-高级算法
2 |
3 | > https://leetcode-cn.com/explore/interview/card/top-interview-questions-hard/
4 |
5 | ## 目录
6 |
7 | * [数组和字符串](/study/LeetCode_Study/高级算法/高级算法-数组和字符串)
8 | * [链表](/study/LeetCode_Study/高级算法/高级算法-链表)
9 | * [树和图](/study/LeetCode_Study/高级算法/高级算法-树和图)
10 | * [回溯算法](/study/LeetCode_Study/高级算法/高级算法-回溯算法)
11 | * [排序和搜索](/study/LeetCode_Study/高级算法/高级算法-排序和搜索)
12 | * [动态规划](/study/LeetCode_Study/高级算法/高级算法-动态规划)
13 | * [设计问题](/study/LeetCode_Study/高级算法/高级算法-设计问题)
14 | * [数学](/study/LeetCode_Study/高级算法/高级算法-数学)
15 | * [其他](/study/LeetCode_Study/高级算法/高级算法-其他)
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/中级算法/README.md:
--------------------------------------------------------------------------------
1 | # LeetCode-探索-中级算法
2 |
3 | > https://leetcode-cn.com/explore/interview/card/top-interview-questions-medium/
4 |
5 | ## 目录
6 |
7 | * [数组和字符串](/study/LeetCode_Study/中级算法/中级算法-数组和字符串)
8 | * [链表](/study/LeetCode_Study/中级算法/中级算法-链表)
9 | * [树和图](/study/LeetCode_Study/中级算法/中级算法-树和图)
10 | * [回溯算法](/study/LeetCode_Study/中级算法/中级算法-回溯算法)
11 | * [排序和搜索](/study/LeetCode_Study/中级算法/中级算法-排序和搜索)
12 | * [动态规划](/study/LeetCode_Study/中级算法/中级算法-动态规划)
13 | * [设计问题](/study/LeetCode_Study/中级算法/中级算法-设计问题)
14 | * [数学](/study/LeetCode_Study/中级算法/中级算法-数学)
15 | * [其他](/study/LeetCode_Study/中级算法/中级算法-其他)
--------------------------------------------------------------------------------
/docs/style.css:
--------------------------------------------------------------------------------
1 | section.cover .cover-main>p:last-child a:last-child {
2 | border: 1px solid var(--theme-color,#42b983);
3 | border-radius: 2rem;
4 | box-sizing: border-box;
5 | color: var(--theme-color,#42b983);
6 | display: inline-block;
7 | font-size: 1.05rem;
8 | letter-spacing: .1rem;
9 | margin: .5rem 1rem;
10 | padding: .75em 2rem;
11 | text-decoration: none;
12 | transition: all .15s ease;
13 | background-color: transparent;
14 | }
15 | section.cover .cover-main>p:last-child a:first-child {
16 | background-color: var(--theme-color,#42b983);
17 | color: #fff;
18 | }
--------------------------------------------------------------------------------
/docs/study/Linux/Linux知识-学习笔记.md:
--------------------------------------------------------------------------------
1 | ## Linux知识-学习笔记
2 |
3 | > 下面的知识点比较凌乱。额。
4 |
5 | ### 1. 用户空间、内核空间、内存
6 |
7 | > [什么是内核缓冲区,用户缓冲区](http://blog.chinaunix.net/uid-22906954-id-4161625.html)
8 | >
9 | > [Linux用户空间与内核空间(理解高端内存)](https://blog.csdn.net/u013377887/article/details/82724628)
10 | >
11 | > [(整理)用户空间_内核空间以及内存映射](https://blog.csdn.net/omnispace/article/details/80077769)
12 |
13 | ### 999. 杂乱知识点
14 |
15 | > [Why do linux packages expect root permissions to install?](https://superuser.com/questions/634856/why-do-linux-packages-expect-root-permissions-to-install)
16 | >
17 | > + 需要安装到共享目录下,所以需要root
18 | > + 二进制安装,路径相关的变量硬编码到程序中,所以固定路径,而固定到共享目录(需root)是最省事的
19 |
20 |
--------------------------------------------------------------------------------
/docs/study/DataBase/Redis/《Redis设计与实现(第二版)》-读书笔记.md:
--------------------------------------------------------------------------------
1 | # 《Redis设计与实现(第二版)》-读书笔记
2 |
3 | # 1. 引言
4 |
5 | ## 1.1 Redis版本说明
6 |
7 | ## 1.2 章节编排
8 |
9 | ## 1.3 推荐的阅读方法
10 |
11 | ## 1.4 行文规则
12 |
13 | ## 1.5 配套网站
14 |
15 | redisbook.com
16 |
17 | # 第一部分 数据结构与对象
18 |
19 | # 2. 简单动态字符串
20 |
21 | + C语言传统字符串,即以空字符结尾的字符数组。
22 | + Redis自己构建名为简单动态字符串(simple dynamic string,SDS)的抽象类型,用作默认字符串表示。
23 |
24 | 当需要可修改的字符串(非字符串字面量)时,Redis使用SDS表示字符串值。比如,在Redis数据库中,包含字符串的键值对在底层都是由SDS实现的。
25 |
26 | SDS在Redis中的使用场景:
27 |
28 | + 保存数据库中的字符串值(key或value的字符串值)
29 | + 用作缓冲区(buffer):AOF模块中的AOF缓冲区,以及客户端状态中的输入缓冲区。
30 |
31 | ## 2.1 SDS的定义
32 |
33 | > src/sds.h 源代码中有很多内存优化版本,这里取其共同结构。(这本书的描述较老,建议结合新版源码查阅相关文章学习)
34 |
35 | ```c
36 | struct sdshdr {
37 | int len;
38 | int alloc;
39 | char flags;
40 | char buf[];
41 | }
42 | ```
43 |
44 |
--------------------------------------------------------------------------------
/docs/study/文件管理/FastDFS/FastDFS杂记.md:
--------------------------------------------------------------------------------
1 | # FastDFS杂记
2 |
3 | ## 1. 介绍和部署
4 |
5 | > 介绍:
6 | >
7 | > [fastDFS](https://www.jianshu.com/p/b7c330a87855)
8 | >
9 | > 部署:
10 | >
11 | > [如何用docker部署FastDFS(分布式文件系统)](https://blog.csdn.net/qq_43455410/article/details/84797814?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task)
12 | >
13 | > [阿里云使用docker-compose 部署fastdfs+nginx分布式文件存储系统](https://blog.csdn.net/bondsui/article/details/90115486)
14 | >
15 | > [基于 Docker 安装 FastDFS](https://www.jianshu.com/p/1038b4d95912)
16 | >
17 | > [如何用docker部署FastDFS(分布式文件系统)](https://blog.csdn.net/qq_43455410/article/details/84797814)
18 | >
19 | > [关于FastDFS文件名命名规则,以及是否会重复的问题](https://blog.csdn.net/cihuan0804/article/details/100693738)
20 |
21 | ## 2. 分布式文件系统对比
22 |
23 | > [分布式文件系统的比较,115网盘用了fastdfs](https://www.cnblogs.com/findumars/p/6943159.html)
--------------------------------------------------------------------------------
/docs/study/网络安全/加密解密/加密解密杂谈.md:
--------------------------------------------------------------------------------
1 | # 加密解密杂谈
2 |
3 | ## 1. 对称加密
4 |
5 | ### 1. DES/AES
6 |
7 | > [java中以DES的方式实现对称加密并提供密钥的实例](https://www.jb51.net/article/120499.htm)
8 | >
9 | > [JAVA实现AES 解密报错Input length must be multiple of 16 when decrypting with padded cipher](https://www.cnblogs.com/catalina-/p/6001831.html)
10 |
11 | ## 2. 非对称加密
12 |
13 | > [常见非对称加密算法](https://blog.csdn.net/tomatoxman/article/details/89183876)
14 | >
15 | > [JAVA RSA非对称加密详解[转载]](https://www.cnblogs.com/frank-quan/p/7073457.html)
16 | >
17 | > [RSA密钥长度、明文长度和密文长度](https://blog.csdn.net/luoluo_onion/article/details/78354799)
18 |
19 | ## 3. 数字签名、数字证书
20 |
21 | > [数字签名和数字证书详解](http://www.360doc.cn/article/41390840_783477292.html)
22 | >
23 | > [数字签名和数字证书究竟是什么?](https://www.jianshu.com/p/80aa37311151)
24 | >
25 | > [PKI/CA与数字证书](https://blog.csdn.net/u013066292/article/details/79538069)
26 | >
27 | > [5分钟让你知道什么是PKI](http://www.mamicode.com/info-detail-2222963.html)
28 |
29 |
--------------------------------------------------------------------------------
/docs/study/React/官方入门教程学习.md:
--------------------------------------------------------------------------------
1 | ### 入门教程:认识React - React
2 |
3 | #### 游戏完善
4 |
5 | + 状态提升
6 |
7 | 1. 在React中,有一个命名规范,通常会将代表时间的监听prop命名为on[Event],将处理事件的监听方法命名为handle[Event]这样的格式
8 |
9 | + 为什么不可变性在React中非常重要
10 | 1. **函数组件**:如果你想写的组件只包含一个 `render` 方法,并且不包含 state,那么使用**函数组件**就会更简单。我们不需要定义一个继承于 `React.Component` 的类,我们可以定义一个函数,这个函数接收 `props` 作为参数,然后返回需要渲染的元素。函数组件写起来并不像 class 组件那么繁琐,很多组件都可以使用函数组件来写。
11 | 2. 当我们把 Square 修改成函数组件时,我们同时也把 `onClick={() => this.props.onClick()}` 改成了更短的 `onClick={props.onClick}`(注意两侧*都*没有括号)
12 |
13 | #### 时间旅行
14 |
15 | + 选择一个key
16 | 1. `key` 是 React 中一个特殊的保留属性(还有一个是 `ref`,拥有更高级的特性)。当 React 元素被创建出来的时候,React 会提取出 `key` 属性,然后把 key 直接存储在返回的元素上。虽然 `key` 看起来好像是 `props` 中的一个,但是你不能通过 `this.props.key` 来获取 `key`。React 会通过 `key` 来自动判断哪些组件需要更新。组件是不能访问到它的 `key` 的。
17 | 2. **我们强烈推荐,每次只要你构建动态列表的时候,都要指定一个合适的 key。**如果你没有找到一个合适的 key,那么你就需要考虑重新整理你的数据结构了,这样才能有合适的 key。
18 | 3. 组件的 key 值并不需要在全局都保证唯一,只需要在当前的同一级元素之前保证唯一即可。
19 |
20 | + 实现时间旅行
21 | 1.
22 |
23 |
--------------------------------------------------------------------------------
/docs/study/Game-dev/Godot(官方教程)-学习笔记.md:
--------------------------------------------------------------------------------
1 | # Godot(官方教程)-学习笔记
2 |
3 | > [Introduction — Godot Engine (stable) documentation in English](https://docs.godotengine.org/en/stable/about/introduction.html)
4 | >
5 | > [Learn Godot's GDScript From Zero by GDQuest, Xananax (itch.io)](https://gdquest.itch.io/learn-godot-gdscript)
6 | >
7 | > [Godot文件- 主 分支 — Godot Engine latest 文档 (osgeo.cn)](https://www.osgeo.cn/godot/index.html)
8 | >
9 | > [Vignette - Godot Shaders](https://godotshaders.com/shader/vignette/)
10 |
11 | 1. Godot默认子节点ready之后,才会ready父节点。如果需要在子节点中直接或间接调用到父节点的onready变量,就会报错。可以通过`await owner.ready ` 先等待父节点ready
12 | 2. `@export`变量在`__init__`之后,`_ready()`方法之前初始化,在`_ready()`可以安全访问
13 | 3. `@onready`变量在`_ready()`方法中由Godot自动初始化
14 | 4. 普通变量的初始化在`@export`变量之前
15 | 5. 初始化顺序:`普通var` > `@export` > `@onready`
16 | 6. Godot制作2D像素游戏,纹理大小Rect宽高最好设置为偶数,避免图片在相机移动时发生抖动
17 | 7. input输入事件传播的调用链(注意,输入事件的传播和输入状态查询`Input.get_axis("move_left")`是两套系统):`_input()`>`_gui_input()`>`_shortcut_input()`>`unhandled_key_input()`>`_unhandled_input()`>其他逻辑。按照上述顺序,前面的函数没有处理逻辑则继续向后检测处理逻辑。
18 |
19 | 8.
--------------------------------------------------------------------------------
/docs/study/Android/Android开发基础教程(2019)学习笔记.md:
--------------------------------------------------------------------------------
1 | # Android开发基础教程(2019)学习笔记
2 |
3 | > 二话不说,贴其中一个视频的链接,其他的也是同一个up主投递
4 | >
5 | > https://www.bilibili.com/video/av52405925/?spm_id_from=333.788.videocard.0
6 |
7 | #### 2. "Hello World"
8 |
9 | #### 3.界面布置ConstraintLayout(1)
10 |
11 | + ConstraintLayout使用魔法棒,自动部署布局
12 |
13 | #### 4. 界面布置ConstraintLayout(2)
14 |
15 | + Guideline、Barrier和Group的使用
16 | + Guideline:实际界面不显示,但是可以把元素位置锁定到其上,方便设计(主要掌握百分比辅助线使用)
17 | + Barrier:实际不显示,遇到放入其中的元素会停下,变成以另一个作为拖动边界的条件
18 | + Group:可以统一对所属的元素进行属性设置
19 |
20 | #### 5. Activity LifeCycle
21 |
22 | + onCreate()-> onStart()-> onResume() -> onPause() -> onStop() -> onDestroy()
23 | + 调用finish()会触发onDestroy(),切换为横屏也会触发onDestroy,重新创建Activity
24 | + 需要在onDestroy()之前释放资源,避免内存泄漏
25 | + 自己尝试了下,回到桌面会执行onPause(),onStop().
26 | + 关闭程序Log没显示执行onDestroy()
27 | + 从桌面回去程序执行onRestart(),onStart(),onResume()
28 |
29 | + 官方Activity生命周期图
30 |
31 | 
32 |
33 | #### 6. XXX
34 |
35 |
--------------------------------------------------------------------------------
/docs/study/Vue/Vue笔记.md:
--------------------------------------------------------------------------------
1 | # Vue笔记
2 |
3 | > 最近由于作业的原因,又重新接触了许久没碰过的Vue。
4 | >
5 | > 有时候看到不错的文章或者技巧就摘录、分享。
6 |
7 | ## 1. JavaScript模块化
8 |
9 | > [JavaScript 模块化:CommonJS、AMD、CMD、UMD 和 ES6 Module](https://www.jianshu.com/p/6e688c482b38)
10 |
11 | ### 1. CommonJS
12 |
13 | 按照声明的导入次序顺序加载模块。通常用于node.js这类服务端JS代码中。客户端则往往需要异步加载多个模块,不适合使用CommonJS。
14 |
15 | ### 2. ES6 Module
16 |
17 | 异步导入,编译期加载。通常浏览器使用。
18 |
19 | ### 3. 常用的CommonJS和ES6 Module的差异*(摘至上方引用文章)*
20 |
21 | **1. CommonJS 支持动态导入,也就是 `require(${path}/xx.js)` ,ES6 目前还不支持,但是已有提案。**
22 |
23 | **2. CommonJS 是同步导入,ES6是异步导入。**
24 |
25 | + CommonJS 因为用于服务端,文件都在本地,同步导入即使卡住主线程影响也不大。
26 |
27 | + ES6 因为用于浏览器,需要下载文件,如果也采用同步导入会对渲染有很大影响。
28 |
29 | **3. CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。**
30 |
31 | - CommonJS 模块输出的是值的拷贝,也就是说,一旦输出一个值,模块内部的变化就影响不到这个值;另一方面,如果导出的值变了,导入的值也不会变,所以如果想更新值,必须重新导入一次。
32 | - ES6 采用实时绑定的方式,导入和导出的值都指向同一个内存地址,所以导入的值会跟随导出的值变化。
33 |
34 | **4. CommonJS 模块是运行时加载,ES6 模块是编译时加载。**
35 |
36 | + CommonJS 模块就是一个对象,在导入时先加载整个模块,生成一个对象( 这个对象只有在脚本运行完才会生成 ),然后再从这个对象上读取方法,这种加载称为“运行时加载”。
37 | + ES6 模块不是对象,它的对外接口只是一种静态定义,在代码运行之前( 即编译时 )的静态解析阶段就完成了模块加载,比 CommonJS 模块的加载方式更高效。
--------------------------------------------------------------------------------
/docs/study/Java/README.md:
--------------------------------------------------------------------------------
1 | # Java
2 |
3 | ## 目录
4 |
5 | * [Java复习回顾](/study/Java/Java复习回顾)
6 | * [《Effective-Java第三版》-读书笔记-01](/study/Java/《Effective-Java第三版》-读书笔记-01)
7 | * [《Effective-Java第三版》-读书笔记-02](/study/Java/《Effective-Java第三版》-读书笔记-02)
8 | * [《Effective-Java第三版》-读书笔记-03](/study/Java/《Effective-Java第三版》-读书笔记-03)
9 | * [《Effective-Java第三版》-读书笔记-04](/study/Java/《Effective-Java第三版》-读书笔记-04)
10 | * [《Java并发编程的艺术》-读书笔记-上](/study/Java/《Java并发编程的艺术》-读书笔记-上)
11 | * [《Java并发编程的艺术》-读书笔记-下](/study/Java/《Java并发编程的艺术》-读书笔记-下)
12 | * [《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(1)](/study/Java/《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(1))
13 | * [《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(2)](/study/Java/《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(2))
14 | * [《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(3)](/study/Java/《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(3))
15 | * [Java-ASM-学习笔记01](/study/Java/Java-ASM-学习笔记01)
16 | * [Java-ASM-学习笔记02](/study/Java/Java-ASM-学习笔记02)
17 | * [Java-ASM-学习笔记03](/study/Java/Java-ASM-学习笔记03)
18 | * [Java-Agent-学习笔记](/study/Java/Java-Agent-学习笔记)
19 | * [《bytebuddy核心教程》-学习笔记](/study/Java/《bytebuddy核心教程》-学习笔记)
20 | * [《bytebuddy进阶实战》-学习笔记](/study/Java/《bytebuddy进阶实战》-学习笔记)
21 |
22 |
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/数据结构与算法/递归.md:
--------------------------------------------------------------------------------
1 | # 递归
2 |
3 | > [探索--递归](https://leetcode-cn.com/leetbook/detail/recursion/)
4 |
5 | ## 01 概述
6 |
7 | ## 02 递归原理
8 |
9 | ### 反转字符串
10 |
11 | 语言:java
12 |
13 | 思路:DFS
14 |
15 | 代码(2ms,14.57%):
16 |
17 | ```java
18 | class Solution {
19 | public void reverseString(char[] s) {
20 | if(s.length>1){
21 | dfs(s,0);
22 | }
23 | }
24 |
25 | public void dfs(char[] arrs, int index){
26 | char tmp = arrs[index];
27 | int another = arrs.length-1-index;
28 | arrs[index] = arrs[another];
29 | arrs[another] = tmp;
30 | if(index==arrs.length/2-1){
31 | return;
32 | }else{
33 | dfs(arrs, index+1);
34 | }
35 | }
36 | }
37 | ```
38 |
39 | ### 两两交换链表中的节点
40 |
41 | 语言:java
42 |
43 | 思路:DFS,这里需要注意的是,对掉后,原本head的next应该是“假设已经递归对掉完了的链表”,而不是单纯的下标2的第三个节点。
44 |
45 | 代码(0ms):
46 |
47 | ```java
48 | class Solution {
49 | public ListNode swapPairs(ListNode head) {
50 | if(head==null||head.next==null){
51 | return head;
52 | }
53 | ListNode next = head.next;
54 | head.next = swapPairs(next.next);
55 | next.next = head;
56 | return next;
57 | }
58 | }
59 | ```
60 |
61 |
--------------------------------------------------------------------------------
/docs/study/Java/_sidebar.md:
--------------------------------------------------------------------------------
1 | * **目录**
2 | * [根目录(/)](/README)
3 | * [回到上一级(../)](/README)
4 | * [Java复习回顾](/study/Java/Java复习回顾)
5 | * [《Effective-Java第三版》-读书笔记-01](/study/Java/《Effective-Java第三版》-读书笔记-01)
6 | * [《Effective-Java第三版》-读书笔记-02](/study/Java/《Effective-Java第三版》-读书笔记-02)
7 | * [《Effective-Java第三版》-读书笔记-03](/study/Java/《Effective-Java第三版》-读书笔记-03)
8 | * [《Java并发编程的艺术》-读书笔记-上](/study/Java/《Java并发编程的艺术》-读书笔记-上)
9 | * [《Java并发编程的艺术》-读书笔记-下](/study/Java/《Java并发编程的艺术》-读书笔记-下)
10 | * [《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(1)](/study/Java/《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(1))
11 | * [《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(2)](/study/Java/《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(2))
12 | * [《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(3)](/study/Java/《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(3))
13 | * [《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(4)](/study/Java/《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》-读书笔记(4))
14 | * [Java-ASM-学习笔记01](/study/Java/Java-ASM-学习笔记01)
15 | * [Java-ASM-学习笔记02](/study/Java/Java-ASM-学习笔记02)
16 | * [Java-ASM-学习笔记03](/study/Java/Java-ASM-学习笔记03)
17 | * [Java-Agent-学习笔记](/study/Java/Java-Agent-学习笔记)
18 | * [《bytebuddy核心教程》-学习笔记](/study/Java/《bytebuddy核心教程》-学习笔记)
19 | * [《bytebuddy进阶实战》-学习笔记](/study/Java/《bytebuddy进阶实战》-学习笔记)
20 |
21 |
--------------------------------------------------------------------------------
/docs/study/网络安全/XSS/Web安全-XSS教程.md:
--------------------------------------------------------------------------------
1 | # Web安全-XSS教程
2 |
3 | > 慕课网视频链接
4 | >
5 | > https://www.imooc.com/video/14367
6 |
7 | ## 理解XSS攻击方式
8 |
9 | ### 反射型
10 |
11 | #### 1. 定义
12 |
13 | 发送请求时,**XSS代码出现在URL**中,作为输入提交到服务器端,服务器端解析后响应,XSS代码随响应内容一起传回给浏览器,最后浏览器解析执行XSS代码。这个过程像一次反射,故叫反射性XSS。
14 |
15 | ### 存储型
16 |
17 | #### 1. 定义
18 |
19 | 存储型XSS和反射型XSS的差别仅在于,提交的代码会存储在服务器端(数据库,内存,文件系统等),下次请求目标页面时不用再提交XSS代码
20 |
21 |
22 |
23 | ## 掌握XSS的方法措施
24 |
25 | ### 编码
26 |
27 | #### 1. 概要
28 |
29 | 对用户输入的数据进行HTML Entity编码
30 |
31 | #### 2. 举例
32 |
33 | | 字符 | 十进制 | 转义字符 |
34 | | ------------------------------ | ------- | -------- |
35 | | " | \" | \" |
36 | | ' | \' | \' |
37 | | & | \& | \& |
38 | | < | \< | \< |
39 | | > | \> | \> |
40 | | 不断开空格(non-breaking space) | \ | \ |
41 |
42 | ### 过滤
43 |
44 | #### 1. 概要
45 |
46 | 移除用户上传的DOM属性,如onerror等
47 |
48 | 移除用户上传的Style节点、Script节点、Iframe节点等
49 |
50 | ### 校正
51 |
52 | #### 1. 概要
53 |
54 | 避免之直接对HTEML Enity解码
55 |
56 | 使用DOM Parse转换,校正不配都的DOM标签
57 |
58 |
59 |
60 |
--------------------------------------------------------------------------------
/docs/study/BigData/杂/tmp.md:
--------------------------------------------------------------------------------
1 | # 杂
2 |
3 | # 1. MPP
4 |
5 | > [MPP概述_trocp的专栏-CSDN博客_mpp数据库](https://blog.csdn.net/trocp/article/details/86687206)
6 | >
7 | > [MPP架构_迷路剑客个人博客-CSDN博客_mpp架构](https://blog.csdn.net/baichoufei90/article/details/84328666)
8 | > [MPP 与 Hadoop是什么关系? - 知乎 (zhihu.com)](https://www.zhihu.com/question/22037987)
9 |
10 | # 2. Data Lake
11 |
12 | 感觉就是弱化存储介质的差异性,统一管理,需要有完善的管理形式,方便集中读写数据、管理数据等。
13 |
14 | 一般需要对外抽象数据访问形式,使得能够简易地接入各种数据处理组件,而不过多地关心底层数据存储的差异性。
15 |
16 | > [Hello from Apache Hudi | Apache Hudi](https://hudi.apache.org/)
17 | >
18 | > [Data lake - Wikipedia](https://en.wikipedia.org/wiki/Data_lake)
19 | >
20 | > [数据湖 | 一文读懂Data Lake的概念、特征、架构与案例_Focus on Bigdata-CSDN博客_datalake](https://blog.csdn.net/u011598442/article/details/106610486)
21 | >
22 | > [数据湖(Data Lake) 总结 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/91165577)
23 | >
24 | > [DataLake 基本概念_test_fy的博客-CSDN博客_datalake](https://blog.csdn.net/test_fy/article/details/80881958)
25 |
26 | # 3. Data Fabric
27 |
28 | 感觉就是解决数据数据分布散乱的问题,类似K8s管理多个容器,Data Fabric概念管理多个复杂数据源(不是指存储介质or存储引擎,是对数据更高维度的抽象)。
29 |
30 | 比如某些服务器可能过去承载了PB级别的某种类型数据(可以是某类业务数据,多种形式的存储介质整合的产物),现在需要扩展,但是不方便迁移这些大量数据,就索性不迁移,但是通过一些服务注册、发现机制,使得这部分数据更易被读写、管理。
31 |
32 | > [IBM Cloud Pak for Data - 中国 | IBM](https://www.ibm.com/cn-zh/products/cloud-pak-for-data)
33 | >
34 | > [Data Fabric (数据经纬): 下一个IT的风口? - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/400354162)
--------------------------------------------------------------------------------
/docs/_sidebar.md:
--------------------------------------------------------------------------------
1 | * 导读
2 | * [**Android**](/study/Android/README)
3 | * [**LeetCode**](/study/LeetCode_Study/README)
4 | * [**React**](/study/React/README)
5 | * [**Vue**](/study/Vue/README)
6 | * [**GoLang**](/study/GoLang/README)
7 | * [**Java**](/study/Java/README)
8 | * [**Python**](/study/Python/README)
9 | * [**Scala**](/study/Scala/README.md)
10 | * [**Rust**](/study/Rust/README.md)
11 | * [**BigData**](/study/BigData/README.md)
12 | * [**SpringBoot**](/study/SpringBoot/README)
13 | * [**SpringCloud**](/study/SpringCloud/README)
14 | * [**MQ**](/study/MQ/README)
15 | * [**Netty**](/study/Netty/README)
16 | * [**Linux**](/study/Linux/README)
17 | * [**操作系统和硬件**](/study/操作系统和硬件/README)
18 | * [**分布式策略**](/study/分布式策略/README)
19 | * [**负载均衡-代理**](/study/负载均衡-代理/README)
20 | * [**领域特定语言DSL**](/study/领域特定语言DSL/README)
21 | * [**计算机网络**](/study/计算机网络/README)
22 | * [**网络安全**](/study/网络安全/README)
23 | * [**推荐系统**](/study/推荐系统/README)
24 | * [**设计模式**](/study/设计模式/README)
25 | * [**计算广告**](/study/计算广告/README)
26 | * [**文件管理**](/study/文件管理/README)
27 | * [**编程范式(ProgrammingParadigm)**](/study/编程范式(ProgrammingParadigm)/README.md)
28 | * [**通用架构知识**](/study/通用架构知识/README.md)
29 | * [**DataBase**](/study/DataBase/README)
30 | * [**Elastic-Stack**](/study/Elastic-Stack/README)
31 | * [**Docker**](/study/Docker/README)
32 | * [**kubernetes**](/study/kubernetes/README)
33 | * [**CICD**](/study/CICD/README)
34 | * 暂无更多...
35 |
36 |
--------------------------------------------------------------------------------
/docs/study/操作系统和硬件/操作系统和硬件-杂记.md:
--------------------------------------------------------------------------------
1 | # 操作系统和硬件-杂记
2 |
3 | ## 1. CPU
4 |
5 | ### 1.1 寄存器和缓存
6 |
7 | > [cpu寄存器和缓存](https://blog.csdn.net/weixin_41490593/article/details/91447141)
8 | >
9 | > [cpu中的四级缓存有什么作用呢?](http://ask.zol.com.cn/q/2865556.html)
10 |
11 | ## 2. Linux
12 |
13 | ### 2.1 用户态和内核态
14 |
15 | > [linux之用户态和内核态](https://www.cnblogs.com/cyyz-le/p/10962818.html)
16 |
17 | ### 2.2 系统调用
18 |
19 | > [你真的知道什么是系统调用吗?](https://www.jianshu.com/p/9c62a65b6162)
20 | >
21 | > 辅助知识
22 | >
23 | > [问下 电脑所说的什么32位 64位是什么意思啊?](https://zhidao.baidu.com/question/744264837762178692.html?qbl=relate_question_2&word=32%CE%BB%BA%CD64%CE%BB%CA%C7%B8%F9%BE%DD%CA%B2%C3%B4%C0%B4%CB%E3%B5%C4)
24 | >
25 | > [Linux用户空间与内核空间(理解高端内存)](https://www.cnblogs.com/wuchanming/p/4360277.html)
26 | >
27 | > [Linux 中的各种栈:进程栈 线程栈 内核栈 中断栈](https://blog.csdn.net/yangkuanqaz85988/article/details/52403726)
28 | >
29 | >
30 |
31 | 现代CPU通常有多种特权级别,一般总共4总,Ring0(最高特权)到Ring3(最低特权),Linux只用Ring0(内核态)和Ring3(用户态)。
32 |
33 | 操作系统通过"**中断**"来切换"用户态"和"内核态"。
34 |
35 | *(==个人感觉内核态和用户态类似内存划分的”用户进程空间“和“内核空间”==,只不过前者针对CPU,后者针对内存资源的使用。32位操作系统,CPU理论一次性能处理32bit数据,而逻辑上寻址即2^32byte也就是4G。而其中0-3G即用户空间,3-4G即内核空间,而3-4G的内核空间虽然就1G,但这个是逻辑地址,经过段页式地址映射后才是真正的物理地址。内核空间通过段页式映射,能访问到所有真正的物理内存,而用户进程只访问对应3G内存,前面这些都是指x86 CPU--32位操作系统。64位不一样,不过思想上一致)*
36 |
37 | 中断一般包含两个属性:"**中断号**"和"**中断处理程序**"。内核通过"中断向量表"查找中断号和中断处理程序对应关系。遇到中断时,CPU暂停当前执行的指令,根据中断号查找对应的中断处理程序并调用,中断处理程序调用完成后,再继续执行之前暂停执行的指令。
38 |
39 | 中断分两种:"**硬件中断**"和"**软件中断**"。软件中断就是我们的应用程序所使用的中断,往往是一条指令,比如在i386 CPU处理器,对应指令即int,int 0x80表示调用第0x80号中断处理程序。
40 |
41 |
--------------------------------------------------------------------------------
/docs/study/Spring/Spring杂记.md:
--------------------------------------------------------------------------------
1 | # Spring杂记
2 |
3 | > [Spring常见面试题总结(超详细回答)](https://blog.csdn.net/a745233700/article/details/80959716)
4 | >
5 | > [Spring IOC介绍与4种注入方式](https://zhuanlan.zhihu.com/p/34405799)
6 | >
7 | > [深入解析spring中用到的九种设计模式](https://kaiwu.lagou.com/java_architect.html)
8 | >
9 | > [Spring系列之beanFactory与ApplicationContext](https://www.cnblogs.com/xiaoxi/p/5846416.html)
10 | >
11 | > [Spring-bean的循环依赖以及解决方式](https://blog.csdn.net/u010853261/article/details/77940767)
12 | >
13 | > Spring的循环依赖的理论依据其实是基于Java的引用传递,当我们获取到对象的引用时,对象的field或则属性是可以延后设置的(但是构造器必须是在获取引用之前)。
14 | >
15 | > [为什么使用Spring的@autowired注解后就不用写setter了?](https://blog.csdn.net/qq_19782019/article/details/85038081)
16 | >
17 | > Spring偷偷的把我们用@autowired标记过的属性的【访问控制检查】给关闭了,即对每个属性进行了【setAccessible(true)】的设置,导致这些属性即使被我们标记了【private】,Spring却任然能够不通过getter和setter方法来访问这些属性,达到一定的目的。
18 | >
19 | > [Spring Bean 的scope什么时候设置为prototype,什么时候设置为singleton](https://blog.csdn.net/q276513307/article/details/78393599)
20 | >
21 | > 1.对于有实例变量的类,要设置成prototype;没有实例变量的类,就用默认的singleton
22 | > 2.Action一般我们都会设置成prototype,而Service只用singleton就可以。
23 | >
24 | > [spring boot 使用ThreadLocal实例](https://blog.csdn.net/qq_27127145/article/details/83894400)
25 | >
26 | > [关于PROPAGATION_NESTED的理解](https://blog.csdn.net/yanxin1213/article/details/100582643) <== 还有对易混淆的几个事务传播行为举例。
27 | >
28 | > PROPAGATION_REQUIRES_NEW 启动一个新的, 不依赖于环境的 "内部" 事务. 这个事务将被完全 commited 或 rolled back 而不依赖于外部事务, 它拥有自己的隔离范围, 自己的锁, 等等. 当内部事务开始执行时, 外部事务将被挂起, 内务事务结束时, 外部事务将继续执行.
29 | > 另一方面, PROPAGATION_NESTED 开始一个 "嵌套的" 事务, 它是已经存在事务的一个真正的子事务. 潜套事务开始执行时, 它将取得一个 savepoint. 如果这个嵌套事务失败, 我们将回滚到此 savepoint. 潜套事务是外部事务的一部分, 只有外部事务结束后它才会被提交.
30 |
31 |
--------------------------------------------------------------------------------
/docs/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | Document
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 | Loading...
14 |
15 |
16 |
17 |
33 |
34 |
35 |
36 |
37 |
38 |
--------------------------------------------------------------------------------
/docs/study/DataBase/MongoDB/MongoDB夯实基础视频-学习笔记.md:
--------------------------------------------------------------------------------
1 | # 【尚硅谷】前端视频_MongoDB夯实基础视频
2 |
3 | > 废话不多说,先贴上视频链接
4 | >
5 | > https://www.bilibili.com/video/av21989676?p=8
6 |
7 | ## p6-尚硅谷_MongoDB入门-插入文档
8 |
9 | 1. db.\.insert()
10 |
11 | 如果插入多条,[{},{},{}];
12 |
13 | 插入单条{},使用insertOne({})更清晰
14 |
15 | 插入多条,使用insertMany([{},{},{}])更清晰。
16 |
17 | 实际上都可以用insert(),只不过~One和~Many直观清晰
18 |
19 | ## p7-尚硅谷_MongoDB入门-查询文档
20 |
21 | 1. db.\.find()
22 |
23 | 默认查询所有;
24 |
25 | 查询条件{}
26 |
27 | ## p8-尚硅谷_MongoDB入门-修改文档
28 |
29 | 1. db.\.update({条件},{修改的值})
30 |
31 | + 默认直接用{修改的值}替换一整个原本的文档
32 | + 如果需要只对其中几个属性修改(没有该属性则添加),需要**{$set:{修改的值}}**
33 |
34 | + $unset:{属性名:任意值},删除该属性,所以值随意
35 | + **update默认只改符合条件的第一个**
36 | + 修改多个需要指定{muti:true}
37 |
38 | 2. db.\.updateMany()
39 |
40 | + 默认修改多个
41 |
42 | 3. db.\.updateOne()
43 |
44 | + 只修改一个
45 |
46 | 4. db.\.replaceOne()
47 | + 替换一个
48 |
49 | ## p9-尚硅谷_MongoDB入门-删除文档
50 |
51 | 1. db.\.remove({条件}) 和find一样
52 | + 默认和deleteMany(),删除所有符合条件的
53 | + 第二个参数\,只删除一个true/false, true即deleteOne
54 | + **如果remove({})直接全清空**,传递空对象,删除集合中所有文档,性能差,一条一条删的
55 | + 如果需要清空集合(直接**db.collection.drop()删除整个集合**,如果是最后一个集合,数据库也会没掉)
56 | 2. db.\.deleteOne()
57 | 3. db.\.deleteMany()
58 | 4. db.dropDatabase() 删除数据库
59 |
60 | ## p10-尚硅谷_MongoDB入门-练习1
61 |
62 | 1. 文档的属性如果还是文档,就把这个被包含的文档叫做内嵌文档
63 |
64 | 2. MongoDB**支持通过内嵌文档的属性作为条件进行查询**
65 | + "内嵌文档.内嵌文档的属性",**必须加上单引号or双引号**
66 | + 对内嵌文档的属性查询,对内嵌文档的内部字段匹配,**含有就行了**(比如模糊查询)
67 | + db.collection.find({'innerDoc.attr1':'wahaha'})查询collection集合中所有包含内嵌文档innerDoc及其属性attr1内含有‘wahaha’的文档。即这里只要attr1 == ‘wahaha’,或者attr1是个数组且含有'wahaha'也可以
68 | + $push和$addToSet,数组内添加
69 | + 如果数组中已经存在该元素,则$addToSet则不能添加($push可以重复)
70 |
71 | ## p11-尚硅谷_MongoDB入门-练习2
72 |
73 | 1.
--------------------------------------------------------------------------------
/docs/study/编程范式(ProgrammingParadigm)/POP(PluginOrientedProgramming)/POP杂记.md:
--------------------------------------------------------------------------------
1 | # POP杂记
2 |
3 | # 1、文章
4 |
5 | > [Plug-in (computing) - Wikipedia](https://en.wikipedia.org/wiki/Plug-in_(computing))
6 | >
7 | > [Introduction to Plugin Programming (reston.va.us)](https://www.cnri.reston.va.us/home/koe/docs/manuals/plugintut/index.html)
8 | >
9 | > [Plugin Oriented Programming — pop documentation](https://pop.readthedocs.io/en/latest/topics/pop.html) <= 强烈推荐(前提:懂Python)
10 | >
11 | > [Plugin Oriented Programming - Google Search](https://www.google.com/search?q=Plugin+Oriented+Programming&sxsrf=AOaemvLf2DFssGuyOk6kYyvtrG6hsF3XEA%3A1638636328219&ei=KJurYa_UDOis0PEPnJ6J0Ak&ved=0ahUKEwiviImCzMr0AhVoFjQIHRxPApoQ4dUDCA4&uact=5&oq=Plugin+Oriented+Programming&gs_lcp=Cgdnd3Mtd2l6EAMyBQgAEIAEMgYIABAWEB46BwgAEEcQsANKBAhBGABQvP0sWLz9LGC4gC1oAnACeACAAfICiAHyApIBAzMtMZgBAKABAqABAcgBCMABAQ&sclient=gws-wiz)
12 | >
13 | > [plugins - How to create a pluginable Java program? - Stack Overflow](https://stackoverflow.com/questions/25449/how-to-create-a-pluginable-java-program)
14 | >
15 | > [OSGi Working Group | The Eclipse Foundation](https://www.osgi.org/) <= 强烈推荐(前提:懂Java),然而好像说大部分场景被淘汰。
16 | >
17 | > [Java9模块化(Jigsaw)初识 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/29563164) <= 某种意义上,模块化就是轻量版OSGI
18 | >
19 | > [Java9模块化(Jigsaw)初识 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/29563164)
20 | >
21 | > [Java 9 正式发布,终落地 Jigsaw 项目 - 太原中软 - 博客园 (cnblogs.com)](https://www.cnblogs.com/taiyuanzhongruan/p/7591899.html)
22 | >
23 | > [Java 9中的模块系统的优缺点是什么? - 经验笔记 (nhooo.com)](https://www.nhooo.com/note/qa03fv.html)
24 | >
25 | > [JDK9的新特性:JPMS模块化 - flydean - 博客园 (cnblogs.com)](https://www.cnblogs.com/flydean/p/jdk9-java-module-jpms.html) <= 较具体的语法和使用介绍
26 | >
27 | > [JAVA代码热部署,在线不停服动态更新 - CM4J - 博客园 (cnblogs.com)](https://www.cnblogs.com/cm4j/p/hot_deploy.html) <= 推荐
28 | >
29 | > [JAVA热部署,通过agent进行代码增量热替换!!! - 张玉龙 - 博客园 (cnblogs.com) ](https://www.cnblogs.com/zyl2016/p/13666945.html)<= 强烈推荐
30 |
31 |
--------------------------------------------------------------------------------
/docs/study/Vue/Vue随记.md:
--------------------------------------------------------------------------------
1 | # Vue随记
2 |
3 | > 最近做毕设,后端Springboot+Flink已经将SlopeOne推荐算法整合完毕了,需要先做一下前端,决定用比较熟的Vue。=> 之后毕设要是结束,有时间整理的话,会把项目开源到github上。
4 | >
5 | > 这里再开个随记markdown笔记文件。
6 |
7 | ## 1.Vue模版
8 |
9 | > 同学做作业的时候,偶然发现了一个Vue模版,我觉得挺不错的,分享一下。
10 |
11 | 1. [VSCode一键生成.vue模版](https://zhuanlan.zhihu.com/p/136906175)
12 |
13 | ```vue
14 |
15 |
20 |
21 |
22 |
72 |
73 |
76 | ```
77 |
78 |
79 |
80 |
--------------------------------------------------------------------------------
/docs/study/CICD/jenkins杂记.md:
--------------------------------------------------------------------------------
1 | # Jenkins杂记
2 |
3 | # 1. 安装和使用
4 |
5 | > 零基础搭建
6 | >
7 | > [手把手教你利用Docker+jenkins部署你的网站](https://zhuanlan.zhihu.com/p/145604644)
8 | >
9 | > [Jenkins+Maven+Github+Springboot实现可持续自动部署(非常详细)](https://www.cnblogs.com/rmxd/p/11609983.html)
10 | >
11 | >
12 | >
13 | > 配置轮询git服务器,拉取更新并重新部署
14 | >
15 | > [Jenkins定时构建和轮询SCM设置说明](https://blog.csdn.net/MenofGod/article/details/81288987)
16 | >
17 | > [Jenkins定时构建与轮询SCM](https://www.cnblogs.com/panda-sweets/p/12554200.html)
18 |
19 | 上述文章贼详细。
20 |
21 | 需要注意的就是参考[Jenkins+Maven+Github+Springboot实现可持续自动部署(非常详细)](https://www.cnblogs.com/rmxd/p/11609983.html)时,需要修改最后文章下面的`.sh`可执行脚本文件,把里面的jdk、项目配置修改成自己实际的。
22 |
23 | 我自己gitee出现403问题,没法发送push的信号给jenkins,暂时没处理好,就用了折中的轮训SCM方案,每过一段时间到git服务器检查是否有新更新,有则部署jenkins项目的服务器自动拉取git项目并重新部署。
24 |
25 | # 2. 常见异常/报错/问题
26 |
27 | ## 2.1 SSH key添加问题
28 |
29 | > [jenkins:配置密钥时报错的解决:Failed to add SSH key. Message invalid privatekey(Jenkins 2.257)](https://www.cnblogs.com/architectforest/p/13707244.html)
30 |
31 | 1. 错误信息
32 |
33 | ```none
34 | jenkins.plugins.publish_over.BapPublisherException: Failed to add SSH key. Message [invalid privatekey: [B@60373f7]
35 | ```
36 |
37 | 2. 产生问题的原因
38 |
39 | 生成密钥的openssh的版本过高,jenkins不支持
40 |
41 | ```shell
42 | [root@localhost ~]# ssh-keygen -t rsa
43 | ```
44 |
45 | 查看所生成私钥的格式:
46 |
47 | ```shell
48 | [root@localhost ~]$ more .ssh/id_rsa
49 | -----BEGIN OPENSSH PRIVATE KEY-----
50 | b3BlbnNzaC1rZXktdjEAAAAABG5vbmUAAAAEbm9uZQAAAAAAAAABAAABlwAAAAdzc2gtcn
51 | …
52 | ```
53 |
54 | 密钥文件首行(jenkins 2.2.57 版本在检验密钥时还不支持这种格式)
55 |
56 | ```shell
57 | -----BEGIN OPENSSH PRIVATE KEY——
58 | ```
59 |
60 | 3. 解决方案
61 |
62 | 指定格式生成密钥文件
63 |
64 | ```shell
65 | [root@localhost ~]# ssh-keygen -m PEM -t rsa -b 4096
66 |
67 | # -m 参数指定密钥的格式,PEM是rsa之前使用的旧格式
68 | # -b 指定密钥长度。对于RSA密钥,最小要求768位,默认是2048位。
69 | ```
70 |
71 | 重新生成密钥文件
72 |
73 | ```shell
74 | [root@localhost ~]# more /root/.ssh/id_rsa
75 | -----BEGIN RSA PRIVATE KEY-----
76 | MIIJKAIBAAKCAgEA44rzAenw3N7Tpjy5KXJpVia5oSTV/HrRg7d8PdCeJ3N1AiZU
77 | ...
78 | ```
79 |
80 | 密钥首行(这样改动后可以通过jenkins对密钥格式的验证)
81 |
82 | ```
83 | -----BEGIN RSA PRIVATE KEY-----
84 | ```
85 |
86 |
87 |
88 |
--------------------------------------------------------------------------------
/docs/study/Python/Intro to Machine Learning--Kaggle.md:
--------------------------------------------------------------------------------
1 | # Intro to Machine Learning
2 |
3 | > 之前google的machine-learning课程到了中间有点懵了,就干脆先换一个看看,这个如果比较基础就先着手这个了。
4 | >
5 | > https://www.kaggle.com/learn/intro-to-machine-learning
6 |
7 | ## How Models Work
8 |
9 | ### Introduction
10 |
11 | 决策树是机器学习底层部件之一。数据科学中,我们通过划分数据集为**training set**训练集和**test set**测试集,用训练集训练模型,再用测试集测试模型,直到筛选出准确率在我们预期之内的模型。然后使用模型就可以进行诸如有监督学习的分类、回归分析,无监督学习的数据降维、聚类等操作。我自己扯得有点偏了。这里介绍决策树最底部的叶子节点**leaf**即我们预测的结果。
12 |
13 | ## Basic Data Exploration
14 |
15 | ### Using Pandas to Get Familiar With Your Data
16 |
17 | 使用pandas的DataFrame导入数据。这个比较基础,网上大概查查就懂了
18 |
19 | ### Interpreting Data Description
20 |
21 | 进行数据分析前,先自己了解下自己数据集的特点、特征等。
22 |
23 | + dataframe.describe()输出基本统计量
24 |
25 | >count 数量
26 | >
27 | >mean 均值
28 | >
29 | >std 标准差
30 | >
31 | >min 最小值
32 | >
33 | >25% 下四分位
34 | >
35 | >50% 中位数
36 | >
37 | >75% 上四分位
38 | >
39 | >max 最大值
40 |
41 | ### Exercise:Explore Your Data
42 |
43 | 就很基础地使用pandas.read_csv()读取文件,然后调用dataframe.describe()输出基本统计量,再从要求中找出(计算)指定值。
44 |
45 | ## Your First Machine Learning Model
46 |
47 | ### Select Data for Modeling
48 |
49 | 获取dataFrame的一列**Series**,其中作为预测目标**prediction target**的一列,俗称**y**
50 |
51 | ### Choose "Features"
52 |
53 | 输入模型中且后来用于预测数据的列,叫做“features”。有时候,我们需要使用除了target的所有列作为features。但是,有时更少的features会更好。
54 |
55 | 通常,features所包含的所有列数据被称为**X**
56 |
57 | 我们可以使用dataframe.describe()方法来查看数据集的基础统计量;使用dataframe.head()方法获取数据集前几行的数据。
58 |
59 | 使用这些简单的指令检查数据也是数据科学家工作的重要一环,没准就能从数据集中找到惊喜(比如某些数据和某些数据线性相关之类的吧)。
60 |
61 | ### Building Your Model
62 |
63 | 使用**scikit-learn**包创建模型models,代码中,其被写做**sklearn**。
64 |
65 | 创建模型model的步骤如下:
66 |
67 | + **Define**:选择使用的模型类别。
68 | + **Fit**:从提供的数据中捕获特征(训练模型),这是创建模型的核心步骤。
69 | + **Predict**:用模型(对新数据)进行预测
70 | + **Evaluate**:评估模型的预测准确度。
71 |
72 | 使用sklearn包内的类创建模型时,指定random_state可以设置一个随机数,让模型随机从训练集中取值(当我们手动指定值时,模型每次运行会得到相同的值。我感觉意思就是模型默认每次训练使用一个随机数算法之类的选取features中某些数据进行训练,如果我们指定这个random_state,那么每次训练都用相同的features值训练。)。不过,random_state值的设定,并不会影响模型质量。
73 |
74 | ```python
75 | from sklearn.tree import DecisionTreeRegressor
76 |
77 | # Define model. Specify a number for random_state to ensure same results each run
78 | melbourne_model = DecisionTreeRegressor(random_state=1)
79 |
80 | # Fit model
81 | melbourne_model.fit(X, y)
82 | ```
83 |
84 | 获取训练后的模型fitted model后,我们就可以用它来进行数据的预测了。
85 |
86 | ```python
87 | print("Making predictions for the following 5 houses:")
88 | print(X.head())
89 | print("The predictions are")
90 | print(melbourne_model.predict(X.head()))
91 | ```
92 |
93 | ### Exercise:Your First Machine Learning Model
94 |
95 | 1. 读取数据,选定y(需要预测的数据列)
96 | 2. 创建X(features,特征集),在创建model之前,最好再检查一下X,确保其可靠性
97 | 3. 选定需要的模型并创建,之后对模型进行训练(拟合)**Fit**,可根据需要选择给model指定一个random_state,使模型具有再生性。
98 | 4. 使用模型对指定的数据进行预测
--------------------------------------------------------------------------------
/docs/README.md:
--------------------------------------------------------------------------------
1 | # 导读
2 |
3 | > [Ashiamd的个人MD笔记](https://ashiamd.github.io/docsify-notes/) ==> https://ashiamd.github.io/docsify-notes/
4 |
5 | 该项目用于记录个人学习笔记,有部分内容来自图书、博客、论坛等。
6 |
7 | 如有**侵权**等问题,请联系ashiamd@foxmail.com,本人会第一时间删除相关内容。
8 |
9 | *笔记中的图片都来自网络(减小项目文件体积),如果加载不出来,建议下载该项目到本地阅读*
10 |
11 | ## 目录
12 |
13 | * [Android](https://ashiamd.github.io/docsify-notes/#/study/Android/README.md)
14 | * [LeetCode](https://ashiamd.github.io/docsify-notes/#/study/LeetCode_Study/README.md)
15 | * [React](https://ashiamd.github.io/docsify-notes/#/study/React/README.md)
16 | * [Vue](https://ashiamd.github.io/docsify-notes/#/study/Vue/README.md)
17 | * [GoLang](https://ashiamd.github.io/docsify-notes/#/study/GoLang/README.md)
18 | * [Java](https://ashiamd.github.io/docsify-notes/#/study/Java/README.md)
19 | * [Python](https://ashiamd.github.io/docsify-notes/#/study/Python/README.md)
20 | * [Scala](https://ashiamd.github.io/docsify-notes/#/study/Scala/README.md)
21 | * [Rust](https://ashiamd.github.io/docsify-notes/#/study/Rust/README.md)
22 | * [BigData](https://ashiamd.github.io/docsify-notes/#/study/BigData/README.md)
23 | * [SpringBoot](https://ashiamd.github.io/docsify-notes/#/study/SpringBoot/README.md)
24 | * [SpringCloud](https://ashiamd.github.io/docsify-notes/#/study/SpringCloud/README.md)
25 | * [MQ](https://ashiamd.github.io/docsify-notes/#/study/MQ/README.md)
26 | * [Netty](https://ashiamd.github.io/docsify-notes/#/study/Netty/README.md)
27 | * [Linux](https://ashiamd.github.io/docsify-notes/#/study/Linux/README.md)
28 | * [操作系统和硬件](https://ashiamd.github.io/docsify-notes/#/study/操作系统和硬件/README)
29 | * [分布式策略](https://ashiamd.github.io/docsify-notes/#/study/分布式策略/README)
30 | * [领域特定语言DSL](https://ashiamd.github.io/docsify-notes/#/study/领域特定语言DSL/README)
31 | * [负载均衡-代理](https://ashiamd.github.io/docsify-notes/#/study/负载均衡-代理/README)
32 | * [计算机网络](https://ashiamd.github.io/docsify-notes/#/study/计算机网络/README.md)
33 | * [网络安全](https://ashiamd.github.io/docsify-notes/#/study/网络安全/README.md)
34 | * [推荐系统](https://ashiamd.github.io/docsify-notes/#/study/推荐系统/README.md)
35 | * [设计模式](https://ashiamd.github.io/docsify-notes/#/study/设计模式/README.md)
36 | * [计算广告](https://ashiamd.github.io/docsify-notes/#/study/计算广告/README.md)
37 | * [文件管理](https://ashiamd.github.io/docsify-notes/#/study/文件管理/README.md)
38 | * [编程范式(ProgrammingParadigm)](https://ashiamd.github.io/docsify-notes/#/study/编程范式(ProgrammingParadigm)/README.md)
39 | * [通用架构知识](https://ashiamd.github.io/docsify-notes/#/study/通用架构知识/README.md)
40 | * [DataBase](https://ashiamd.github.io/docsify-notes/#/study/DataBase/README.md)
41 | * [Elastic-Stack](https://ashiamd.github.io/docsify-notes/#/study/Elastic-Stack/README.md)
42 |
43 | + [Docker](https://ashiamd.github.io/docsify-notes/#/study/Docker/README.md)
44 | + [kubernetes](https://ashiamd.github.io/docsify-notes/#/study/kubernetes/README.md)
45 | + [CICD](https://ashiamd.github.io/docsify-notes/#/study/CICD/README.md)
--------------------------------------------------------------------------------
/docs/study/Elastic-Stack/Elastic Stack(ELK)从入门到实践-学习笔记.md:
--------------------------------------------------------------------------------
1 | # Elastic Stack(ELK)从入门到实践 - 学习笔记
2 |
3 | > [Elastic Stack(ELK)从入门到实践](https://www.bilibili.com/video/BV1iJ411c7Az) <== 视频链接
4 | >
5 | > [Elasticsearch 的使用Demo](https://blog.csdn.net/u011580290/article/details/88226164) <= 推荐文章
6 | >
7 | > [gavin5033的博客--ELK专栏](https://blog.csdn.net/gavin5033/category_8070372.html) <= 推荐ELK学习文章
8 | >
9 | > [Elasticsearch 索引的映射配置详解 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/41929500) <= 很清晰的概述文章
10 |
11 | # 1. Elastic Stack简介
12 |
13 | ## 1.1 ELK
14 |
15 | + Elastic
16 | + Logstash
17 | + Kibana
18 |
19 | 整体的作用就是日志分析
20 |
21 | ## 1.2 Elastic Stack
22 |
23 | + **Elasticsearch**
24 |
25 | Elasticsearch **基于java**,是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
26 |
27 | + **Logstash**
28 |
29 | Logstash **基于java**,是一个开源的用于收集,**分析**和存储日志的工具。
30 |
31 | + **Kibana**
32 |
33 | Kibana **基于nodejs**,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的Web 界面,可以汇总、分析和搜索重要数据日志。
34 |
35 | + **Beats**
36 |
37 | Beats是elastic公司开源的一款**采集系统监控数据**的代理agent,是在被监控服务器上以客户端形式运行的数据收集器的统称,可以直接把数据发送给Elasticsearch或者通过Logstash发送给Elasticsearch,然后进行后续的数据分析活动。
38 |
39 | Beats由如下组成:
40 |
41 | + Packetbeat:是一个网络数据包分析器,用于监控、收集网络流量信息,Packetbeat嗅探服务器之间的流量,解析应用层协议,并关联到消息的处理,其支持ICMP (v4 and v6)、DNS、HTTP、Mysql、PostgreSQL、Redis、MongoDB、Memcache等协议;
42 | + **Filebeat:用于监控、收集服务器日志文件,其已取代 logstash forwarder;**
43 | + Metricbeat:可定期获取外部系统的监控指标信息,其可以监控、收集 Apache、HAProxy、MongoDB、MySQL、Nginx、PostgreSQL、Redis、System、Zookeeper等服务;
44 | + Winlogbeat:用于监控、收集Windows系统的日志信息;
45 |
46 | + X-Pack
47 |
48 | + Elastic Cloud
49 |
50 | # 2. Elasticsearch
51 |
52 | ## 2.1 简介
53 |
54 | ElasticSearch是一个基于[Lucene](https://baike.baidu.com/item/Lucene/6753302?fr=aladdin)的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTFUL web接口。ElasticSearch用Java开发,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
55 |
56 | 零配置、多用户、云方案、JSON数据 => ElasticSearch
57 |
58 | ## 2.2 基本概念
59 |
60 | ### 2.2.1 索引
61 |
62 | + 索引(index)是Elasticsearch对逻辑数据的逻辑存储,所以它可以分为更小的部分。
63 |
64 | + 可以把索引看成关系型数据库的表,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值。
65 |
66 | + Elasticsearch可以把索引存放在一台机器或者分散在多台服务器上,每个索引有一或多个分片(shard),每个分片可以有多个副本(replica)。
67 |
68 | ### 2.2.2 文档
69 |
70 | + 存储在Elasticsearch中的主要实体叫文档(document)。用关系型数据库来类比的话,一个文档相当于数据库表中的一行记录。
71 |
72 | + **Elasticsearch和MongoDB中的文档类似,都可以有不同的结构,但Elasticsearch的文档中,相同字段必须有相同类型。**
73 | + 文档由多个字段组成,每个字段可能多次出现在一个文档里,这样的字段叫多值字段(multivalued)。
74 | + 每个字段的类型,可以是文本、数值、日期等。字段类型也可以是复杂类型,一个字段包含其他子文档或者数组。
75 |
76 | ### 2.2.3 映射
77 |
78 | + 所有文档写进索引之前都会先进行分析,如何将输入的文本分割为词条、哪些词条又会被过滤,这种行为叫做映射(mapping)。一般由用户自己定义规则。
79 |
80 | ### 2.2.4 文档类型
81 |
82 | + 在Elasticsearch中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评论。
83 | + 每个文档可以有不同的结构。
84 | + **不同的文档类型不能为相同的属性设置不同的类型**。例如,在同一索引中的所有文档类型中,一个叫title的字段必须具有相同的类型。
85 |
86 | ## 2.3 RESTful API
87 |
88 | 在Elasticsearch中,提供了功能丰富的RESTful API的操作,包括基本的CRUD、创建索引、删除索引等操作。
89 |
90 | ### 2.3.1创建非结构化索引
91 |
92 | 在Lucene中,创建索引是需要定义字段名称以及字段的类型的,在Elasticsearch中提供了非结构化的索引,就是不需要创建索引结构,即可写入数据到索引中,实际上在Elasticsearch底层会进行结构化操作,此操作对用户是透明的。
93 |
94 | 创建空索引:
95 |
96 |
--------------------------------------------------------------------------------
/docs/study/APM/SkyWalking/SkyWalking8.7.0源码分析-学习笔记.md:
--------------------------------------------------------------------------------
1 | # SkyWalking8.7.0源码分析-学习笔记
2 |
3 | > B站视频教程:[SkyWalking8.7.0源码分析_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1dy4y1V7ck/?spm_id_from=333.788.recommend_more_video.3&vd_source=ba4d176271299cb334816d3c4cbc885f)
4 | >
5 | > 教程发布者UP主分享的思维导图:[SkyWalking 源码分析-ProcessOn](https://www.processon.com/view/link/611fc4c85653bb6788db4039)
6 |
7 | # 1. SkyWalking premain入口
8 |
9 | > 我这里下载 [**https://dlcdn.apache.org/skywalking/java-agent/8.16.0/apache-skywalking-java-agent-8.16.0-src.tgz**](https://dlcdn.apache.org/skywalking/java-agent/8.16.0/apache-skywalking-java-agent-8.16.0-src.tgz
10 | >
11 | > 对应apache skywalking官网的Java Agent部分
12 |
13 | SkyWalking premain方法(java agent)主要逻辑分5个步骤:
14 |
15 | 1. 初始化配置
16 | 2. 加载插件
17 | 3. 定制Agent(ByteBuddy字节码操作,类似的有ASM)
18 | 4. 加载服务
19 | 5. 注册关闭钩子
20 |
21 | ```java
22 | /**
23 | * Main entrance. Use byte-buddy transform to enhance all classes, which define in plugins.
24 | */
25 | // 下面这边为方便理解,只保留部分代码逻辑, 顺带删除一些 try-catch-finally块,方便整体阅读
26 | public static void premain(String agentArgs, Instrumentation instrumentation) throws PluginException {
27 | final PluginFinder pluginFinder;
28 | // 1. 初始化配置
29 | SnifferConfigInitializer.initializeCoreConfig(agentArgs);
30 |
31 | // 2. 加载插件
32 | pluginFinder = new PluginFinder(new PluginBootstrap().loadPlugins());
33 |
34 | // 3. 定制Agent(ByteBuddy字节码操作,类似的有ASM)
35 | final ByteBuddy byteBuddy = new ByteBuddy().with(TypeValidation.of(Config.Agent.IS_OPEN_DEBUGGING_CLASS));
36 | AgentBuilder agentBuilder = new AgentBuilder.Default(byteBuddy).ignore(
37 | nameStartsWith("net.bytebuddy.")
38 | .or(nameStartsWith("org.slf4j."))
39 | .or(nameStartsWith("org.groovy."))
40 | .or(nameContains("javassist"))
41 | .or(nameContains(".asm."))
42 | .or(nameContains(".reflectasm."))
43 | .or(nameStartsWith("sun.reflect"))
44 | .or(allSkyWalkingAgentExcludeToolkit())
45 | .or(ElementMatchers.isSynthetic()));
46 | // ...
47 | JDK9ModuleExporter.EdgeClasses edgeClasses = new JDK9ModuleExporter.EdgeClasses();
48 | agentBuilder = BootstrapInstrumentBoost.inject(pluginFinder, instrumentation, agentBuilder, edgeClasses);
49 | agentBuilder = JDK9ModuleExporter.openReadEdge(instrumentation, agentBuilder, edgeClasses);
50 | if (Config.Agent.IS_CACHE_ENHANCED_CLASS) {
51 | try {
52 | agentBuilder = agentBuilder.with(new CacheableTransformerDecorator(Config.Agent.CLASS_CACHE_MODE));
53 | LOGGER.info("SkyWalking agent class cache [{}] activated.", Config.Agent.CLASS_CACHE_MODE);
54 | } catch (Exception e) {
55 | LOGGER.error(e, "SkyWalking agent can't active class cache.");
56 | }
57 | }
58 | agentBuilder.type(pluginFinder.buildMatch())
59 | .transform(new Transformer(pluginFinder))
60 | .with(AgentBuilder.RedefinitionStrategy.RETRANSFORMATION)
61 | .with(new RedefinitionListener())
62 | .with(new Listener())
63 | .installOn(instrumentation);
64 | PluginFinder.pluginInitCompleted();
65 |
66 | // 4. 加载服务
67 | ServiceManager.INSTANCE.boot();
68 |
69 | // 5. 注册关闭钩子
70 | Runtime.getRuntime()
71 | .addShutdownHook(new Thread(ServiceManager.INSTANCE::shutdown, "skywalking service shutdown thread"));
72 | }
73 | ```
74 |
75 |
76 |
77 |
--------------------------------------------------------------------------------
/docs/study/SpringBoot/SpringBoot蚂蚁课堂-学习笔记.md:
--------------------------------------------------------------------------------
1 | # SpringBoot视频教程-蚂蚁课堂
2 |
3 | > 惯例视频链接: http://www.mayikt.com/course/video/3708
4 |
5 | ## 第一章 SpringBoot课程体系介绍
6 |
7 | ### 第四节 SpringBoot与SpringMVC关系
8 |
9 | spring-boot-starter-web整合SpringMVC、Spring
10 |
11 | ### 第五节 SpringCloud与SpringBoot区别
12 |
13 | 1. SpringCloud是一套比较流行的微服务解决方案框架(非RPC远程调用框架),
14 |
15 | 常用组件:
16 |
17 | Euerka 服务注册
18 |
19 | Feign 客户端实现rpc远程调用
20 |
21 | Zuul网关
22 |
23 | Ribbon 本地负载均衡器
24 |
25 | SpringCloud Config
26 |
27 | Hystrix 服务保护框架
28 |
29 | 2. SpringCloud依赖SpringBoot组件,使用SpringMVC编写Http协议接口,同时SpringCloud是一套完整的微服务解决框架
30 |
31 | > RPC介绍文章
32 | >
33 | > [浅谈RPC调用](https://www.cnblogs.com/linlinismine/p/9205676.html)
34 | >
35 | > [如何给老婆解释什么是RPC]( https://www.jianshu.com/p/2accc2840a1b)
36 |
37 | ## 第二章 SpringBoot启动方式
38 |
39 | ### 第七节 使用@EnableAutoConfiguration启动
40 |
41 | 1. @RestController注解(Spring的)
42 |
43 | 包装了@Controller和@ResponseBody,即返回json格式的方法
44 |
45 | 2. @EnableAutoConfiguration注解
46 |
47 | `@EnableAutoConfiguration`可以帮助SpringBoot应用将所有符合条件的`@Configuration`配置都加载到当前SpringBoot创建并使用的IoC容器。
48 |
49 | > [SpringBoot之@EnableAutoConfiguration注解]( https://blog.csdn.net/zxc123e/article/details/80222967 )
50 | >
51 | > 顺便复习一下IOD、DI相关知识
52 | >
53 | > [Spring bean中的properties元素内的name 和 ref都代表什么意思啊?](https://www.cnblogs.com/lemon-flm/p/7217353.html)
54 | >
55 | > [面试被问烂的 Spring IOC(求求你别再问了]( https://www.jianshu.com/p/17b66e6390fd )
56 |
57 | ### 第八节 使用@ComponentScan指定扫描包启动
58 |
59 | 1. @EnableAutoConfiguration只扫描当前类范围的包
60 |
61 | 可以用@ComponentScan指定扫描指定包范围(Spring的)
62 |
63 | ### 第九节 @SpringBootApplication启动方式
64 |
65 | 1. @SpringBootApplication实际就是(主要)@Configuraion+@EnableAutoConfiguration+@ComponentScan
66 |
67 | 其中@Configuration作用可以等同于编写类.xml配置文件,即通过java类编写对应的.xml配置文件;
68 |
69 | @EnableAutoConfiguration就是前面提到的加载配置文件的(且扫描当前类及以下的包)
70 |
71 | @ComponentScan指定扫描包(默认该类**所在的包**下所有配置类)
72 |
73 | ## 第三章 SpringBoot整合Web视图层
74 |
75 | ### 第十节 SpringBoot静态资源访问控制
76 |
77 | 1. 静态资源访问,放在resources目录的static子目录下自动识别,可以直接url访问,如果static里面再创建子目录,需要在url中加上目录名,比如:
78 |
79 | resources/static/a.js -> localhost:8080/a.js
80 |
81 | resources/static/imgs/a.png -> localhost:8080/imgs/a.png
82 |
83 | ### 第十一节 SpringBoot整合Freemarker
84 |
85 | 1. freemarker网页静态化的一种手段,SEO优化的手段之一
86 |
87 | ### 第十二节 SpringBoot整合JSP注意事项
88 |
89 | 1. 创建SpringBoot整合JSP,一定要为war类型,否则会找不到页面
90 |
91 | 2. 创建maven工程project配置离线加载,不然过慢:
92 |
93 | 创建时添加参数:archetypeCatalog=internal
94 |
95 | ### 第十三节 SpringBoot整合JSP项目实现
96 |
97 | 1. yml配置文件需要放在resources目录下,否则不生效
98 |
99 | ## 第四章 SpringBoot整合多数据源
100 |
101 | ### 第十四节 SpringBoot整合JdbcTemplate
102 |
103 | 1. pom引入相应依赖jdbc和mysql驱动包
104 |
105 | 2. yml和properties的选择,SpringBoot通常使用yml
106 |
107 | properties优先级比yml高;
108 |
109 | yml结构清晰、简化配置
110 |
111 | 3. SpringBoot2如果yml中配置多数据源,多个datasource下的url必须改为jdbc-url
112 |
113 | 4. @Autowired 自动依赖注入,复习一下;@Component注册到spring容器bean
114 |
115 | ### 第十五节 SpringBoot整合Mybatis框架
116 |
117 | 1. @SpringBootApplication 扫包不包含Mybatis,需要自己用@MapperScan
118 |
119 | ### 第十六节 SpringBoot多数据源使用分包拆数据源思路
120 |
121 | 1. 多数据源如何定位自己的数据源:
122 | 1. 分包名;
123 | 2. 注解形式;@dataSource(不推荐使用)
124 |
125 | ### 第十七节 SpringBoot整合多数据源代码实现
126 |
127 | 1. 创建一个Config.java类,使用@Configuration和@MapperScan分别把该类实现为xml配置和扫描指定位置的包
128 | 2. 多数据源配置有BUG,yml配置文件的数据源原本**“url”需改成“jdbc-url”**(亲测,确实如此)
129 | 3. 可能会在Config类中用到@Primary或@Qualifier,不然可能会报错(至少我是报错了)
130 |
131 |
--------------------------------------------------------------------------------
/docs/study/Netty/个人Netty实战笔记.md:
--------------------------------------------------------------------------------
1 | # 个人Netty实战笔记
2 |
3 | > 这个是自己使用Netty开发的时候,踩坑等的笔记。
4 | >
5 | > 有些东西暂时不方便公开,所以不会太详细地介绍
6 |
7 | ## 1. 后端的protobuf的java类转换JSON传输到前端Dart后转protobuf的dart类读取
8 |
9 | > 这个是我自己踩过的坑之一。因为某些场景中需要直接把.proto生成的java类包装成JSON通过HTTP请求返回给Dart。但是我试了很多种方式,发现都会出现奇怪的错误,但是网上没找到比较好的解决方法。
10 | >
11 | > 最后还是自己各种尝试后,试出来了一种可以在Dart识别出JSON中的proto类的数据的方式。
12 | >
13 | > 不过,这种场景终究是少数情况。我这里protobuf除这个情况以外都是用UDP数据报传输的,然后再字节数组转proto类。
14 |
15 | 我自己试过用protobuf转JSON的`protobuf-java-format`和`protobuf-java-util`来将protobuf转成JSON然后传输到Dart。而且其实protobuf生成的Java类的toString(),我自己打印到控制台,看着也是JSON格式的。这几种JSON的方式我都试过了,但是直接这么JSON后传到Dart都会出现一些奇怪的错误。再者也试过一些其他的操作,这里不一一列举,最后还是转成UTF-8编码的String传输得以成功。
16 |
17 | 出现的错误比如有:`Protocol message end-group tag did not match expected tag`、`Protocol message tag had invalid wire type.`等。
18 |
19 |
20 |
21 | 1. Java后端(这里不方便公开代码,只大致描述)
22 |
23 | 1. testController.java
24 |
25 | 这里假设你有一个Java类叫作ProtobufJavaPo,里面存了protobuf序列化数据的String形式数据的List
26 |
27 | ```java
28 | // Controller
29 | @RestController
30 | public class testController{
31 |
32 | @GetMapping("/getTest")
33 | public ProtobufJavaPo getTest() {
34 | ProtobufJavaPo protobufJavaPo = new ProtobufJavaPo();
35 | //... 省略给protobufJavaPo装填数据的过程
36 | return protobufJavaPo; // 这些都是我自己捏造的,就大概这个意思
37 | }
38 |
39 | }
40 | ```
41 |
42 | 2. ProtobufJavaPo.java
43 |
44 | 这里假设你的.proto生成的java类为TestProto.java,然后你用其Builder生成了对应的对象叫作testProto
45 |
46 | ```java
47 | // 这里用到了IDEA的Lombok插件
48 | @Data
49 | @EqualsAndHashCode(callSuper = false)
50 | @Accessors(chain = true)
51 | @JsonInclude(JsonInclude.Include.NON_NULL)
52 | public class ProtobufJavaPo implements Serializable {
53 | private static final long serialVersionUID = 1L;
54 |
55 | // protobuf序列化数据的 byte数组 使用UTF-8编码 转String
56 | // 这里假设testProto就是.proto文件生成的java类的对象
57 | // udpProtoList.add(new String(testProto.toByteArray(), StandardCharsets.UTF_8));
58 | List udpProtoList;
59 | }
60 | ```
61 |
62 | 2. Dart前端/移动端(同样都是模拟的,讲个大概)
63 | 1. HttpDart.dart
64 |
65 | 这里假设dart中,dart的.proto文件生成dart类为TestProtoDart.dart。Dart识别HTTP中JSON数据的String形式的proto数据,并重新转化成dart生成的TestProtoDart.dart。
66 |
67 | ```dart
68 | import 'package:dio/dio.dart';// 社区的http请求包。可以去(dev.pub)这个网站查找
69 | // 其余依赖我就不说了
70 | // 这里DartMess是假装有这么一个dart类作为返回值,其含有List protoList;
71 | class HttpDart {
72 |
73 | // HTTP获取JSON数据,解析里面的String字符串形式的protobuf数据
74 | // 然后转成dart中.proto生成的TestProtoDart.dart类。(这些名称什么的全都假设的)
75 | Future getProtoFromJSON() async {
76 |
77 | var response = await dio.get('XXXXXXXX(host:port)/getTest');
78 | List dynamicList = response.data['udpProtoList'];
79 | if(dynamicList!=null){
80 | var dartMess = DartMess();
81 | List protoDartList = List();
82 | dynamicList.forEach((f)=>{protoDartList.add(TestProtoDart.fromBuffer(utf8.encode(f)))});
83 | dartMess.protoList = protoDartList;
84 | return dartMess;
85 | }
86 | return null;
87 | }
88 | }
89 | ```
90 |
91 | 2. DartMess.dart
92 |
93 | ```dart
94 | class DartMess {
95 | List protoList; // TestProtoDart假设是.proto文件生成的dart类
96 | }
97 | ```
98 |
99 |
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/程序员面试金典/程序员面试金典.md:
--------------------------------------------------------------------------------
1 | # 程序员面试金典
2 |
3 | > [程序员面试金典](https://leetcode-cn.com/problemset/lcci/)
4 |
5 | ### 面试题 02.03. 删除中间节点
6 |
7 | > [面试题 02.03. 删除中间节点](https://leetcode-cn.com/problems/delete-middle-node-lcci/)
8 |
9 | 语言:java
10 |
11 | 思路:脑筋急转弯。从业务的角度理解删除中间节点。我们删除某个节点,只要"删除"后,链表的数据正好是少了我们"删除"的那个就好了。没有要求"删除"的节点的地址一定不能被使用。
12 |
13 | 这里实际删除的是当前节点的下一个节点,但是从数值排列上看,由于当前值改成下一个节点存储的值,所以看上去就是当前节点被"删除"了。
14 |
15 | 代码(0ms,100.00%):
16 |
17 | ```java
18 | class Solution {
19 | public void deleteNode(ListNode node) {
20 | node.val = node.next.val;
21 | node.next = node.next.next;
22 | }
23 | }
24 | ```
25 |
26 | ### 面试题 04.02. 最小高度树
27 |
28 | > [面试题 04.02. 最小高度树](https://leetcode-cn.com/problems/minimum-height-tree-lcci/)
29 |
30 | 语言:java
31 |
32 | 思路:DFS,每次递归时找到数组中间位置的数值当作当前根节点,然后从数组左半边DFS构造左子树,右子树同理。因为操作类似二分查找过程,所以构造出来的树正好就是二叉排序树。
33 |
34 | 代码(0ms):
35 |
36 | ```java
37 | class Solution {
38 | public TreeNode sortedArrayToBST(int[] nums) {
39 | return dfs(nums, 0, nums.length - 1);
40 | }
41 |
42 | /**
43 | * 构造 最小高度树
44 | *
45 | * @param nums
46 | * @param left
47 | * @param right
48 | * @return
49 | */
50 | public TreeNode dfs(int[] nums, int left, int right) {
51 | if (left > right) {
52 | return null;
53 | }
54 | int mid = left + (right - left) / 2;
55 | TreeNode cur = new TreeNode(nums[mid]);
56 | cur.left = dfs(nums, left, mid - 1); // 左子树
57 | cur.right = dfs(nums, mid + 1, right); // 右子树
58 | return cur;
59 | }
60 | }
61 | ```
62 |
63 | ### 面试题 02.02. 返回倒数第 k 个节点
64 |
65 | > [面试题 02.02. 返回倒数第 k 个节点](https://leetcode-cn.com/problems/kth-node-from-end-of-list-lcci/)
66 |
67 | 语言:java
68 |
69 | 思路:先用一个快指针`fast`,往后走n个位置,之后`fast`和当前位置指针`cur`同时前进,当`fast`为null时,`cur`指针指向的节点正好是倒数第K个节点。
70 |
71 | 代码(0ms,100.00%):
72 |
73 | ```java
74 | class Solution {
75 | public int kthToLast(ListNode head, int k) {
76 | ListNode preHead = new ListNode();
77 | preHead.next = head;
78 |
79 | ListNode cur = preHead,fast = preHead;
80 | while(k-->0){
81 | fast = fast.next;
82 | }
83 | while(fast!=null){
84 | cur = cur.next;
85 | fast = fast.next;
86 | }
87 | return cur.val;
88 | }
89 | }
90 | ```
91 |
92 | ### 面试题 16.07. 最大数值
93 |
94 | > [面试题 16.07. 最大数值](https://leetcode-cn.com/problems/maximum-lcci/)
95 |
96 | 语言:java
97 |
98 | 思路:一眼看上去就是位运算。(基本条件苛刻不让用条件判断的,多半就是位运算了),没怎么想好,看了别人的参考代码后尝试写的。
99 |
100 | 代码(0ms,100.00%):
101 |
102 | ```java
103 | class Solution {
104 | public int maximum(int a, int b) {
105 |
106 | // (1) 获取a和b的符号位
107 | int symbol_a = a >>> 31, symbol_b = b >>> 31;
108 |
109 | // (2) 判断a和b是否同号, 同号则sign = 0
110 | int sign = symbol_a ^ symbol_b;
111 |
112 | // (3) 判断 a-b是否为负数
113 | int resSign = (a-b)>>>31;
114 |
115 | // (4) 同号,a-b正数:a>b; 同号,a-b负数:ab; 异号,a-b负数:a [纯位运算,不用long转换,不用内置方法](https://leetcode-cn.com/problems/maximum-lcci/solution/chun-wei-yun-suan-bu-yong-longzhuan-huan-bu-yong-n/)
126 |
127 | ```java
128 | class Solution {
129 | public int maximum(int a, int b) {
130 | // 先考虑没有溢出时的情况,计算 b - a 的最高位,依照题目所给提示 k = 1 时 a > b,即 b - a 为负
131 | int k = b - a >>> 31;
132 | // 再考虑 a b 异号的情况,此时无脑选是正号的数字
133 | int aSign = a >>> 31, bSign = b >>> 31;
134 | // diff = 0 时同号,diff = 1 时异号
135 | int diff = aSign ^ bSign;
136 | // 在异号,即 diff = 1 时,使之前算出的 k 无效,只考虑两个数字的正负关系
137 | k = k & (diff ^ 1) | bSign & diff;
138 | return a * k + b * (k ^ 1);
139 | }
140 | }
141 | ```
142 |
143 |
--------------------------------------------------------------------------------
/docs/study/DataBase/MySQL/mysql杂笔记.md:
--------------------------------------------------------------------------------
1 | # 1. MySQL杂笔记
2 |
3 | > [ACID--wiki](https://en.wikipedia.org/wiki/ACID)
4 |
5 | ## 1. ACID概述
6 |
7 | ### Consistency
8 |
9 | [Consistency](https://en.wikipedia.org/wiki/Consistency_(database_systems)) ensures that a transaction can only bring the database from one valid state to another, maintaining database [invariants](https://en.wikipedia.org/wiki/Invariant_(computer_science)): any data written to the database must be valid according to all defined rules, including [constraints](https://en.wikipedia.org/wiki/Integrity_constraints), [cascades](https://en.wikipedia.org/wiki/Cascading_rollback), [triggers](https://en.wikipedia.org/wiki/Database_trigger), and any combination thereof. This prevents database corruption by an illegal transaction, but does not guarantee that a transaction is *correct*. [Referential integrity](https://en.wikipedia.org/wiki/Referential_integrity) guarantees the [primary key](https://en.wikipedia.org/wiki/Unique_key) – [foreign key](https://en.wikipedia.org/wiki/Foreign_key) relationship. [[6\]](https://en.wikipedia.org/wiki/ACID#cite_note-Date2012-6)
10 |
11 | ## 2. MySQL优化
12 |
13 | > [【MySQL优化】——看懂explain](https://blog.csdn.net/jiadajing267/article/details/81269067)
14 | >
15 | > [MySQL 中的 information_schema 数据库](https://blog.csdn.net/kikajack/article/details/80065753)
16 |
17 | ## 3. MySQL日志系统
18 |
19 | > [MySQL日志系统:redo log、binlog、undo log 区别与作用](https://blog.csdn.net/u010002184/article/details/88526708)
20 |
21 | ## 999. 杂项
22 |
23 | > [MySQL 到底能不能放到 Docker 里跑?](https://zhuanlan.zhihu.com/p/47172593)
24 | >
25 | >
26 | >
27 | > [SQL之in和exit区别篇](https://blog.csdn.net/qq_36561697/article/details/80713824) <= 回顾一下
28 | >
29 | > [in与exists的取舍](https://blog.csdn.net/dreamwbt/article/details/53363497) <= 回顾一下
30 | >
31 | > 一般而言,外循环的数量级小的,速度更快,因为外层复杂度N,但是内层走索引的话就能缩小到logM
32 | >
33 | > A join B也是笛卡尔积,最后保留指定字段相同的结果而已(A内循环,B外循环)
34 | >
35 | > A in B,先计算B,然后笛卡尔积,(A内循环,B外循环)
36 | >
37 | > A exist B,先计算A,然后笛卡尔积(B内循环,A外循环)
38 | >
39 | > not in内外表都不会用到索引,而not exists能用到索引,所以后者任何情况都比前者好
40 | >
41 | >
42 | >
43 | > 分布式事务
44 | >
45 | > [终于有人把“TCC分布式事务”实现原理讲明白了! - 阿里-马云的学习笔记 - 博客园 (cnblogs.com)](https://www.cnblogs.com/alimayun/p/12057142.html)
46 | >
47 | >
48 | >
49 | > 锁
50 | >
51 | > [MySQL死锁日志的查看和分析 - ianCloud - 博客园 (cnblogs.com)](https://www.cnblogs.com/iancloud/p/18021606)
52 | >
53 | > [MySQL锁--03---意向锁(Intention Locks)、间隙锁(Gap Locks)、临键锁(Next-Key Locks)_mysql 意向锁-CSDN博客](https://blog.csdn.net/weixin_48052161/article/details/121985667)
54 | >
55 | > [【原创】惊!史上最全的select加锁分析(Mysql) - 孤独烟 - 博客园 (cnblogs.com)](https://www.cnblogs.com/rjzheng/p/9950951.html) 超高质量
56 | >
57 | > [【原创】互联网项目中mysql应该选什么事务隔离级别 - 孤独烟 - 博客园 (cnblogs.com)](https://www.cnblogs.com/rjzheng/p/10510174.html) 超高质量
58 | >
59 | > [MySQL介于普通读和加锁读之间的读取方式:semi-consistent read - 掘金 (juejin.cn)](https://juejin.cn/post/6844904022499917838) RC下的半一致性读 说明,高质量
60 | >
61 | > [MySQL中 LBCC 和 MVCC 的理解,常见问题及示例:-CSDN博客](https://blog.csdn.net/qq_37102984/article/details/126764644) 质量不错
62 | >
63 | > [你了解MySQL的加锁规则吗? - 进击的李同学 - 博客园 (cnblogs.com)](https://www.cnblogs.com/nedulee/p/11838682.html) limit对锁的影响
64 | >
65 | > 加锁规则可以概括为:两个原则、两个优化和一个bug:
66 | >
67 | > 原则1:加锁的基本单位是next-key lock,前开后闭
68 | >
69 | > 原则2:查找过程中访问到的对象才会加锁
70 | >
71 | > 优化1:索引上的等值查询,给唯一索引加锁的时候,next-key lock退化成行锁
72 | >
73 | > 优化2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock退化为间隙锁
74 | >
75 | > 1个bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
76 | >
77 | > [锁--07_1----插入意向锁-Insert加锁过程-CSDN博客](https://blog.csdn.net/weixin_48052161/article/details/135024886) 插入意向锁
78 | >
79 | > [全面深入理解MySQL自增锁-CSDN博客](https://blog.csdn.net/Bb15070047748/article/details/131815884) 自增锁
80 | >
81 | >
82 | >
83 | > 分库分表
84 | >
85 | > [MySQL数据库之分库分表方案 - 智慧园区-老朱 - 博客园 (cnblogs.com)](https://www.cnblogs.com/IT-Evan/p/15902904.html) 高质量文章
86 | >
87 | >
88 | >
89 | > MVCC
90 | >
91 | > [看一遍就理解:MVCC原理详解 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/421769708)
92 |
93 |
--------------------------------------------------------------------------------
/docs/study/推荐系统/推荐系统项目实战.md:
--------------------------------------------------------------------------------
1 | # 推荐系统项目实战
2 |
3 | ## 1. 基于Flink技术的商品实时推荐系统(初版)
4 |
5 | > 之前趁着寒假有时间,学了一下大数据的基础知识,Hadoop、Hbase、Flink、Kafka等。做了一个简单的推荐系统。
6 | ### 1.0 演示视频
7 |
8 | > [基于Flink的实时推荐系统-初版(ps录制的时候卡卡的)](https://www.bilibili.com/video/BV1k64y1U7VC/)
9 |
10 | 录制视频的时候,开的软件有点多,加上为了方便演示,把一些时间间隔参数调小了,所以CPU一直在运作,比较卡顿。
11 | 
12 |
13 | ### 1.1 关于推荐算法
14 |
15 | 推荐算法,用到的是SlopeOne。原本打算把TF-IDF也整合进去(另一个demo工程里已经实现),但是目前需要忙的其他事情较多,只好暂时作罢(等之后各事安定下来,会抽时间完善TF-IDF部分)。
16 |
17 | 关于SlopeOne算法,这里不多做介绍,这里推荐一本书,《写给程序员的数据挖掘实践指南》。我当时找各种学习材料,也看完了《推荐系统实践》这本书,最后还是觉得《写给程序员的数据挖掘实践指南》更适合小白入门推荐算法的学习。
18 | ### 1.2 使用的技术栈
19 |
20 | 这里主要是学习为主,所以技术选型,大多是出于模拟实际场景。(即其实我并没有那么大的数量级,但是假装自己就是处在那个数量级环境下)。
21 |
22 | 这里选用的技术主要如下:
23 | + SpringBoot (传统的后端搭建,主要负责用户信息、标签、商品信息的展示)
24 | + Flink(负责热门商品、热门标签统计、SlopeOne推荐计算)
25 | + Redis(存储热门商品ID集合、热门标签ID集合、SlopeOne推荐ID集合)
26 | + MySQL(传统的用户、标签、商品等关系型数据存储)
27 | + Nginx(反向代理,产生日志,Flink的数据来源)
28 | + Flume(日志收集,将Nginx日志收集到Kafka中)
29 | + Kafka(消息队列,同时也是Flink的数据源source)
30 | + HBase(存储统计数据、SlopeOne推荐结果,需要依赖Hadoop环境)
31 | + Hadoop环境
32 | + Vue(前端页面搭建,主要繁琐的点即组件的封装)
33 | ### 1.3 大致流程
34 |
35 | 1. 前端Vue发起请求,Nginx产生日志
36 | 2. Flume监听Nginx日志文件的变动,将新数据传输到Kafka
37 | 3. Flink监听Kafka变动,过滤筛选用户行为数据
38 | 4. Flink统计热门商品、热门标签;周期计算SlopeOne推荐列表
39 |
40 | 项目中的SpringBoot模块和两个Flink模块(热门统计、SlopeOne计算)解耦合,Vue前端只从SpringBoot后端获取到数据,而关于热门商品推荐、热门标签、SlopeOne推荐列表等数据,SpringBoot从Redis中读取,无需感知Flink的存在。
41 | Flink模块会监听用户的行为数据,把被“交互”过的商品从用户的Redis推荐列表中剔除,避免重复推荐。
42 |
43 | 
44 | ### 1.4 商品数据来源
45 |
46 | 商品的数据,主要采集于京东商城。采取各种类别的商品,共1000条商品数据。
47 | 
48 | 
49 |
50 | ### 1.5 用户行为数据
51 |
52 | 这部分,我本地通过ApiFox编写自动HTTP请求的脚本,预先产生了一部分用户行为,Nginx也就对应的有日志记录了。
53 | 
54 | ### 1.6 SlopeOne推荐数据
55 |
56 | 因为预先通过脚本,进行了用户行为模拟,所以SlopeOne也已经计算出一定量的推荐数据来了。就HBase而言,有488W行的推荐数据。
57 | (这里,SlopeOne模块生成的推荐列表,只推荐用户没有交互过的商品,交互过的不会重复推荐。)
58 | 
59 |
60 | ### 1.7 代码实现
61 |
62 | 后端项目大致代码结构层级如下:
63 | 
64 | 
65 | 前端Vue项目结构大致如下
66 | 
67 | ### 1.8 结语
68 |
69 | 该项目是本人的毕业设计项目,等到毕业论文等相关事项结束后,会整理代码、数据库设计等相关材料,然后开源到我个人的[github](https://github.com/Ashiamd)上。
70 |
71 |
--------------------------------------------------------------------------------
/docs/study/Scala/Scala杂记.md:
--------------------------------------------------------------------------------
1 | # Scala杂记
2 |
3 | > [2021版 Scala大数据 完整版-通俗易懂(半天掌握)](https://www.bilibili.com/video/BV1JX4y1u7HK?p=11) <= 主要根据这个视频,先大致了解一下scala语法,后面打算再快速过一遍[Scala语言规范.pdf](https://static.runoob.com/download/Scala语言规范.pdf)
4 |
5 | # 1. 六大特性
6 |
7 | ## 1. 混编
8 |
9 | ## 2. 类型自动推断
10 |
11 | ## 3. 适合高并发和分布式
12 |
13 | ## 4. 特征特质trait
14 |
15 | ## 5. 模式匹配
16 |
17 | ## 6. 高阶函数
18 |
19 | # 2. 基本操作
20 |
21 | ## 1. 数据类型
22 |
23 | | 数据类型 | 描述 |
24 | | :------- | :----------------------------------------------------------- |
25 | | Byte | 8位有符号补码整数。数值区间为 -128 到 127 |
26 | | Short | 16位有符号补码整数。数值区间为 -32768 到 32767 |
27 | | Int | 32位有符号补码整数。数值区间为 -2147483648 到 2147483647 |
28 | | Long | 64位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807 |
29 | | Float | 32 位, IEEE 754 标准的单精度浮点数 |
30 | | Double | 64 位 IEEE 754 标准的双精度浮点数 |
31 | | Char | 16位无符号Unicode字符, 区间值为 U+0000 到 U+FFFF |
32 | | String | 字符序列 |
33 | | Boolean | true或false |
34 | | Unit | 表示无值,和其他语言中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。 |
35 | | Null | null 或空引用 |
36 | | Nothing | Nothing类型在Scala的类层级的最底端;它是任何其他类型的子类型。 |
37 | | Any | Any是所有其他类的超类 |
38 | | AnyRef | AnyRef类是Scala里所有引用类(reference class)的基类 |
39 | | Nil | 空List(长度为0) |
40 |
41 | ## 2. 操作
42 |
43 | ### 1. if控制语句
44 |
45 | ### 2. 循环语句
46 |
47 | + for循环
48 | + while循环
49 |
50 | # 3. 函数
51 |
52 | ## 1. 函数的定义
53 |
54 | + def方法名(参数列表):返回类型={方法体}
55 | + {}只有一行逻辑代码时可以省略
56 | + return可以省略,自动将最后一行的内容作为返回值,如果return没有省略,那么必须显式声明返回类型
57 | + =可以省略,表示丢弃返回值
58 | + 函数中的参数为val常量,值只能使用不可修改
59 |
60 | ## 2. 递归函数
61 |
62 | + 必须声明返回类型
63 |
64 | ## 3. 有默认值参数的函数
65 |
66 | ## 4. 可变参数函数
67 |
68 | + 类型后加星号,比如`int*`
69 |
70 | ## 5. 嵌套函数
71 |
72 | + 记得调用嵌套的函数
73 |
74 | ## 6. 偏应用函数
75 |
76 | + 绑定不变的参数
77 |
78 | ## 7. 柯里化函数
79 |
80 | > [Scala函数的柯里化](https://zhuanlan.zhihu.com/p/98096436)
81 |
82 | 实际就是利用返回值为函数的匿名函数来实现的
83 |
84 | ```scala
85 | def add(x:Int)(y:Int)=x+y
86 | def add(x:Int) = (y:Int) => x + y
87 | ```
88 |
89 | ## 8. 匿名函数
90 |
91 | ## 9. 高阶函数
92 |
93 | + 函数的参数是函数
94 | + 函数的返回类型是函数
95 | + 函数的参数、返回类型都是函数
96 |
97 | ## 10. 偏函数
98 |
99 | + 首先从观感上来看,没有match的模式匹配。所以说match的参数隐藏在了偏函数的参数中
100 | + isdefinedat
101 | + apply
102 | + 偏函数是一个只关注自己感兴趣的东西的函数
103 |
104 | # 4. 集合操作
105 |
106 | ## 1. Array
107 |
108 | ### 创建
109 |
110 | ```scala
111 | Array(1,2,3)
112 | new Array[Int](3)
113 | ```
114 |
115 | ## 2. List
116 |
117 | ### map和flatmap
118 |
119 | > [scala中的flatMap详解?](https://www.zhihu.com/question/34548588)
120 |
121 | + 一对一
122 | + 一对多
123 |
124 | ## 3. Set
125 |
126 | ### 交并差
127 |
128 | + intersect
129 | + diff
130 | + union
131 | + subsetof
132 |
133 | ## 4. Map
134 |
135 | ## 5. Tuple
136 |
137 | ### 遍历
138 |
139 | productIterator
140 |
141 | ### 二元组翻转
142 |
143 | swap
144 |
145 | # 5. trait
146 |
147 | + trait = 接口+抽象类
148 |
149 | + 多继承 extends with
150 | + 在继承多个trait的过程中,有相同的属性时,要override
151 |
152 | # 6. 默认匹配
153 |
154 | + ```scala
155 | x match{
156 | case 1 => ...
157 | case x:String => ...
158 | case _ => ...
159 | }
160 | ```
161 |
162 | + 相比java的switch case不光可以匹配值,还可以匹配类型
163 |
164 | # 7. 样例类
165 |
166 | + case class 类名
167 |
168 | + 可以不用new
169 | + 具体属性值完全相同的对象equals返回true
170 |
171 | # 8. Actor
172 |
173 | + 写法类似于线程
174 | + actor之间的相互通信
175 | + 异步非阻塞
176 | + 消息发出后不可更改
177 | + actor内部有一个类似消息队列,会定期检查队列中的消息进行处理
178 | + 使用
179 | + !:`actor ! msg`,表示给actor发msg
180 | + 先actor.start => 调用act方法 => `receive(case)`
181 |
182 | # 9. 隐式转换
183 |
184 | ## implicit
185 |
186 | ## 隐式值和隐式参数
187 |
188 | ## 隐式转换函数
189 |
190 | ## 隐式类
191 |
192 |
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/数据结构与算法/二叉搜索树.md:
--------------------------------------------------------------------------------
1 | # 二叉搜索树
2 |
3 | > [探索--二叉搜索树](https://leetcode-cn.com/leetbook/detail/introduction-to-data-structure-binary-search-tree/)
4 |
5 | ## 01 概述
6 |
7 | ## 02 二叉搜索树简介
8 |
9 | ### 验证二叉搜索树
10 |
11 | 语言:java
12 |
13 | 思路:递归左右子树,如果出现非 左<根<右的情况,则返回false。这里需要注意的是左右字数的递归调用,递归右子树时,主要考虑原节点是否大于等于右子树的值;递归左子树时主要判断原节点是小于等于原节点。
14 |
15 | 代码(0ms):
16 |
17 | ```java
18 | class Solution {
19 | public boolean isValidBST(TreeNode root) {
20 | return dfs(root, null, null);
21 | }
22 |
23 | public boolean dfs(TreeNode cur, Integer low, Integer high) {
24 | if (cur == null) {
25 | return true;
26 | }
27 | if (low != null && cur.val <= low) {
28 | return false;
29 | }
30 | if (high != null && cur.val >= high) {
31 | return false;
32 | }
33 | if (!dfs(cur.right, cur.val, high)) {
34 | return false;
35 | }
36 | if (!dfs(cur.left, low, cur.val)) {
37 | return false;
38 | }
39 | return true;
40 | }
41 | }
42 | ```
43 |
44 | 参考代码1(0ms):
45 |
46 | > [中序遍历轻松拿下,🤷♀️必须秒懂](https://leetcode-cn.com/problems/validate-binary-search-tree/solution/zhong-xu-bian-li-qing-song-na-xia-bi-xu-miao-dong-/)
47 |
48 | 使用一个`long`字段保存上一个节点值,用于判断是否符合左<根<右
49 |
50 | ```java
51 | class Solution {
52 | long pre = Long.MIN_VALUE;
53 | public boolean isValidBST(TreeNode root) {
54 | if (root == null) {
55 | return true;
56 | }
57 | // 访问左子树
58 | if (!isValidBST(root.left)) {
59 | return false;
60 | }
61 | // 访问当前节点:如果当前节点小于等于中序遍历的前一个节点,说明不满足BST,返回 false;否则继续遍历。
62 | if (root.val <= pre) {
63 | return false;
64 | }
65 | pre = root.val;
66 | // 访问右子树
67 | return isValidBST(root.right);
68 | }
69 | }
70 | ```
71 |
72 | ### 二叉搜索树迭代器
73 |
74 | 语言:java
75 |
76 | 思路:就中序遍历,用`List`存储遍历到的值。但是这个不符合要求的空间复杂度`O(h)`
77 |
78 | 代码(23ms,92.96%):
79 |
80 | ```java
81 | class BSTIterator {
82 | List res;
83 | int index = 0;
84 | public BSTIterator(TreeNode root) {
85 | res = new ArrayList<>();
86 | dfs(root);
87 | }
88 |
89 | public void dfs(TreeNode root){
90 | if(root==null){
91 | return;
92 | }
93 | dfs(root.left);
94 | res.add(root.val);
95 | dfs(root.right);
96 | }
97 |
98 | /** @return the next smallest number */
99 | public int next() {
100 | return res.get(index++);
101 | }
102 |
103 | /** @return whether we have a next smallest number */
104 | public boolean hasNext() {
105 | return index [二叉搜索树迭代器--官方题解](https://leetcode-cn.com/problems/binary-search-tree-iterator/solution/er-cha-sou-suo-shu-die-dai-qi-by-leetcode/)
113 |
114 | 受控递归。使用栈。
115 |
116 | ```java
117 | /**
118 | * Definition for a binary tree node.
119 | * public class TreeNode {
120 | * int val;
121 | * TreeNode left;
122 | * TreeNode right;
123 | * TreeNode(int x) { val = x; }
124 | * }
125 | */
126 | class BSTIterator {
127 |
128 | Stack stack;
129 |
130 | public BSTIterator(TreeNode root) {
131 |
132 | // Stack for the recursion simulation
133 | this.stack = new Stack();
134 |
135 | // Remember that the algorithm starts with a call to the helper function
136 | // with the root node as the input
137 | this._leftmostInorder(root);
138 | }
139 |
140 | private void _leftmostInorder(TreeNode root) {
141 |
142 | // For a given node, add all the elements in the leftmost branch of the tree
143 | // under it to the stack.
144 | while (root != null) {
145 | this.stack.push(root);
146 | root = root.left;
147 | }
148 | }
149 |
150 | /**
151 | * @return the next smallest number
152 | */
153 | public int next() {
154 | // Node at the top of the stack is the next smallest element
155 | TreeNode topmostNode = this.stack.pop();
156 |
157 | // Need to maintain the invariant. If the node has a right child, call the
158 | // helper function for the right child
159 | if (topmostNode.right != null) {
160 | this._leftmostInorder(topmostNode.right);
161 | }
162 |
163 | return topmostNode.val;
164 | }
165 |
166 | /**
167 | * @return whether we have a next smallest number
168 | */
169 | public boolean hasNext() {
170 | return this.stack.size() > 0;
171 | }
172 | }
173 | ```
174 |
175 |
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/初级算法/初级算法-排序和搜索.md:
--------------------------------------------------------------------------------
1 | # 初级算法
2 |
3 | > 题库链接:https://leetcode-cn.com/explore/interview/card/top-interview-questions-easy/7/trees/47/
4 |
5 | * 排序和搜索
6 |
7 | 1. 合并两个有序数组
8 |
9 | + 语言:java
10 |
11 | + 思路:判断nums1和nums2的数字大小,然后插入;如果还有剩余,再统统放到nums1的尾部
12 |
13 | + 代码(1ms):
14 |
15 | ```java
16 | class Solution {
17 | public void merge(int[] nums1, int m, int[] nums2, int n) {
18 | int i,j;
19 | for(j = 0,i = 0; j < n && i < m+n; ++i){
20 | if(nums1[i]>nums2[j]){
21 | insert(nums1,nums2[j],i);
22 | ++j;
23 | }
24 | }
25 | while(j pos; --i){
33 | nums[i] = nums[i-1];
34 | }
35 | nums[pos] = num;
36 | }
37 | }
38 | ```
39 |
40 | + 参考代码(0ms):巧妙利用双尾指针,不用插入,直接重新赋值数组的每个位置。
41 |
42 | ```java
43 | class Solution {
44 | public void merge(int[] nums1, int m, int[] nums2, int n) {
45 | int c = n+m-1;
46 | n--;m--;
47 | while(m>=0 && n>=0){
48 | nums1[c--] = nums2[n]>nums1[m] ? nums2[n--] : nums1[m--];
49 | }
50 | while(n>=0){
51 | nums1[c--] = nums2[n--];
52 | }
53 | }
54 | }
55 | ```
56 |
57 | + 参考后重写:
58 |
59 | ```java
60 | class Solution {
61 | public void merge(int[] nums1, int m, int[] nums2, int n) {
62 | int cur = m+n-1;
63 | --m;
64 | --n;
65 | while(m>=0&&n>=0){
66 | nums1[cur--] = nums2[n] > nums1[m] ? nums2[n--] : nums1[m--];
67 | }
68 | while(n>=0){
69 | nums1[cur--] = nums2[n--];
70 | }
71 | }
72 | }
73 | ```
74 |
75 | 2. 第一个错误的版本
76 |
77 | + 语言:java
78 |
79 | + 思路:二分查找,每次取中间和中间的右边那个进行判断。
80 |
81 | + 代码(19ms,击败23.74%,丢人,哈哈):
82 |
83 | ```java
84 | /* The isBadVersion API is defined in the parent class VersionControl.
85 | boolean isBadVersion(int version); */
86 |
87 | public class Solution extends VersionControl {
88 | public int firstBadVersion(int n) {
89 | if(n>1){
90 | int start = 1;
91 | int end = n;
92 | int middle;
93 | boolean left = false;
94 | boolean right = false;
95 | while(start<=end){
96 | middle = start + (end-start)/2;
97 | left = isBadVersion(middle);
98 | if(!left){
99 | right = isBadVersion(middle+1);
100 | if(right)
101 | return middle+1;
102 | else{
103 | start = middle+1;
104 | }
105 | }
106 | else{
107 | end = middle - 1;
108 | }
109 | }
110 | }
111 | return 1;
112 | }
113 | }
114 | ```
115 |
116 | + 参考代码(11ms):其实思想都是二分查找,就是我的实现代码太low了。
117 |
118 | ```java
119 | public class Solution extends VersionControl {
120 | public int firstBadVersion(int n) {
121 |
122 | int l = 1, r = n;
123 | while (l < r) {
124 | int mid = (l + r) >>> 1;
125 | if (isBadVersion(mid)) {
126 | r = mid;
127 | // System.out.println("badVersion: " + mid);
128 | } else {
129 | // System.out.println("goodVersion: " + mid);
130 | l = mid + 1;
131 | }
132 |
133 | // System.out.println("l :" + l + " r:" + r);
134 | }
135 | return r;
136 | }
137 | }
138 | ```
139 |
140 | + 参考后重写(12ms):主要是要清楚最后返回的是end,因为end就是符合条件的那个
141 |
142 | ```java
143 | /* The isBadVersion API is defined in the parent class VersionControl.
144 | boolean isBadVersion(int version); */
145 |
146 | public class Solution extends VersionControl {
147 | public int firstBadVersion(int n) {
148 | int start = 1;
149 | int end = n;
150 | int middle;
151 | while(start>>1;
153 | if(isBadVersion(middle)){
154 | end = middle;
155 | }else{
156 | start = middle + 1;
157 | }
158 | }
159 | return end;
160 | }
161 | }
162 | ```
163 |
164 |
--------------------------------------------------------------------------------
/docs/study/MQ/SpringBoot_Docker_RabbitMQ消息队列场景架构实战-学习笔记.md:
--------------------------------------------------------------------------------
1 | # SpringBoot+Docker+RabbitMQ消息队列场景架构实战-学习笔记
2 |
3 | > [视频链接](https://www.bilibili.com/video/av86571508) https://www.bilibili.com/video/av86571508
4 |
5 | ## 0. 课程大纲
6 |
7 | 1. SpringBoot整合RabbitMQ
8 | 2. RabbitMQ的常见开发模式 Direct Fanout Topic Headers
9 | 3. 如何保证消息的可靠生产和可靠投递 CAP
10 | 4. 什么是死信队列和延迟队列
11 |
12 | 5. RabbitMQ高可用
13 |
14 | ## 1. 为什么要使用RabbitMQ
15 |
16 | ### 目标
17 |
18 | 掌握和了解什么是RabbitMQ
19 |
20 | ### 分析
21 |
22 | RabbitMQ是一个开源的消息队列服务器,用来通过普通协议在完全不同的应用之间共享数据,RabbitMQ是使用Erlang语言(==数据传递==)来编写的,并且RabbitMQ是==基于AMQP协议==(协议是一种规范和约束)的。开源做到跨平台机制。
23 |
24 | 消息队列中间件是分布式系统中重要的组件,主要解决应用==解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。目前使用较多的消息队列有:ActiveMQ, RabbitMQ, ZeroMQ, Kafka,MetaMQ, RocketMQ==。
25 |
26 | ### 在什么情况下使用RabbitMQ
27 |
28 | + **读多写少用缓存(Redis);写多读少用队列(RabbitMQ, ActiveMQ)**
29 | + 解耦,系统A在代码中直接调用系统B和系统C的代码,如果将来D系统接入,系统A还需要修改代码,过于麻烦
30 | + **异步**,将消息写入消息队列,非必要的业务逻辑以异步的方式运行,加快响应速度(并行和串行)
31 | + **削峰**,并发量大的时候,所有的请求直接怼到数据库,造成数据库连接异常
32 | + 达到数据的"最终一致"
33 |
34 | ### 使用的企业
35 |
36 | + 滴滴,美团,头条,去哪儿等
37 | + 开源,性能优秀,稳定性好
38 | + 提供可靠的消息投递模式(confirm)返回模式(return)
39 | + 与SpringAMQP完美的整合,API丰富
40 | + 集群模式丰富(mirror rabbitmq),表达式配置,HA模式,镜像队列模型
41 | + 保证数据不丢失的前提做到高可用性,可用性
42 |
43 | 过去的单峰架构开发,相同的war包复制到数个服务器tomcat运行,再通过服务器的Nginx进行请求的负载均衡。由于数据库常常是影响服务响应时长的一个焦点,优化使用数据库,首先是索引化,进一步是数据库横向(集群-主从库)、竖向(业务逻辑分块)扩展、读写分离;由于数据库操作往往读多于写,所以又引入缓存;而写多于读的场景,则考虑使用消息队列。
44 |
45 | > [深入理解AMQP协议](https://blog.csdn.net/weixin_37641832/article/details/83270778)
46 | >
47 | > [XMPP详解](https://www.jianshu.com/p/84d15683b61e)
48 | >
49 | > [Mybatis的一级缓存和二级缓存的理解和区别](https://blog.csdn.net/llziseweiqiu/article/details/79413130)
50 | >
51 | > [看完这篇文章,我奶奶都懂了https的原理](https://www.jianshu.com/p/b0303de5f638)
52 |
53 | ## 2-1. 什么是AMQP高级消息队列协议
54 |
55 | ## 目标
56 |
57 | 掌握和了解什么是AMQP协议
58 |
59 | ### 概述
60 |
61 | AMQP全称:Advanced Message Queuing Protocol(高级消息队列协议)
62 |
63 | 是具有现代特性的二进制协议,是一个提供统一消息服务的应用层标准髙级消息队列协议,是应用协议的一个开发标准,为面向消息的中间件设计。
64 |
65 | ### 核心概念
66 |
67 | + **Server**:又称Broker,接受客户端的连接,实现AMQP实体服务。安装rabbitmq-server
68 | + **Connection**:连接,应用程序与Broker的网络连接TCP/IP(安全性 操作系统会对tcp有限制65535)Rabbitmq长连接的技术,我只开一次
69 | + **Channel**:网络信道,几乎所有的操作都在Channel中进行,Channel是进行消息读写的通道,客户端可以建立对各Channel,每个Channel代表一个会话任务。
70 | + **Message**:消息,服务与应用程序之间传送的数据,由Properties和body组成,Properties可是对消息进行修饰,比如消息的优先级,延迟等高级特性,Body则就是消息体的内容。
71 | + **Virtual Host**:虚拟地址,用于进行逻辑隔离,最上层的消息路由,一个虚拟主机可以有若干个 Exchange和Queue,同一个虚拟主机里面不能有相同名字的Exchange或Queue
72 | + **Exchange**:交换机,接受消息,根据路由键发送消息到绑定的队列。direct activemq kafka
73 | + **Bindings**:Exchange和Queue之间的虚拟连接,binding中可以保护多个routing key
74 | + **Routing key**:是一个路由规则,虚拟机可以用它来确定如何路由一个特定消息
75 | + **Queue**:队列,也称为Message Queue消息队列,保存消息并将它们转发给消费者。
76 |
77 | ## 2-2. 为什么要使用RabbitMQ
78 |
79 | > [还不理解“分布式事务”?这篇给你讲清楚!](https://www.cnblogs.com/zjfjava/p/10425335.html)
80 | >
81 | > [HTTP请求方法及幂等性探究](https://blog.csdn.net/qq_15037231/article/details/78051806)
82 | >
83 | > [http 请求包含哪几个部分(请求行、请求头、请求体)](https://www.cnblogs.com/qiang07/p/9304771.html)
84 |
85 | ## 3-1. 虚拟化容器技术-使用Docker-集成安装RabbitMQ
86 |
87 | ## 3-2. Rabbitmq的服务介绍
88 |
89 | ## 4. 使用RabbitMQ场景
90 |
91 | ## 5-1. SpringBoot-整合RabbitMQ发布订阅机制-Fanout-01
92 |
93 | > [RabbitMQ官网](https://www.rabbitmq.com/)
94 |
95 | ## 5-2. RabbitMQ发布订阅机制-Fanout-02
96 |
97 | ## 6. SpringBoot-整合RabbitMQ发布订阅机制-Direct
98 |
99 | ## 7. SpringBoot-整合RabbitMQ主题匹配Topic-副本
100 |
101 | ## 8. SpringBoot-RabbitMQ消息处理-持久化问题-副本
102 |
103 | > [RabbitMQ 使用QOS(服务质量)+Ack机制解决内存崩溃的情况](https://www.cnblogs.com/yxlblogs/p/10253609.html)
104 | >
105 | > [RabbitMQ基础概念详细介绍](https://www.cnblogs.com/williamjie/p/9481774.html)
106 | >
107 | > [RabbitMQ教程](https://blog.csdn.net/hellozpc/article/details/81436980)
108 | >
109 | > [基于Netty与RabbitMQ的消息服务](https://www.cnblogs.com/luxiaoxun/p/4257105.html)
110 |
111 | 了解一些点:
112 |
113 | 1. 可靠生产
114 | 2. 可靠消费
115 | 3. 消息转移
116 | 4. 什么是消息冗余
117 | 5. 什么是死信队列,重定向队列(场景是什么)
118 | 6. 什么是延迟队列(场景是什么)
119 | 7. rabbitmq高可用,集群模式有哪些:mirror queue + keepalive
120 |
121 | ## 9. 个人补充
122 |
123 | > [docker安装与使用](https://www.cnblogs.com/glh-ty/articles/9968252.html)
124 | >
125 | > [docker快速安装rabbitmq](https://www.cnblogs.com/angelyan/p/11218260.html)
126 | >
127 | > [docker 安装rabbitMQ](https://www.cnblogs.com/yufeng218/p/9452621.html)
128 | >
129 | > [阿里云-docker安装rabbitmq及无法访问主页](https://www.cnblogs.com/hellohero55/p/11953882.html)
130 | >
131 | > [Windows 下安装RabbitMQ服务器及基本配置](https://www.cnblogs.com/vaiyanzi/p/9531607.html)
132 | >
133 | > [Springboot 整合RabbitMq ,用心看完这一篇就够了](https://blog.csdn.net/qq_35387940/article/details/100514134)
134 | >
135 | > [SPRINGBOOT + JAVAMAIL + RABBITMQ实现异步邮件发送功能](http://www.freesion.com/article/4814171772/)
136 | >
137 | > [springboot2.x集成RabbitMQ实现消息发送确认 与 消息接收确认(ACK)](https://blog.csdn.net/qq_36850813/article/details/103296210)
138 | >
139 | > [RabbitMQ的死信队列详解](https://www.jianshu.com/p/986ee5eb78bc)
140 | >
141 | > [RabbitMQ基本概念(三):后台管理界面](https://baijiahao.baidu.com/s?id=1608453370506467252&wfr=spider&for=pc)
142 | >
143 | > [利用Docker-compose一键搭建rabbitmq服务器](https://www.jianshu.com/p/1127ad6ee546)
144 | >
145 | > [使用docker-compose安装RabbitMQ](https://blog.csdn.net/chuishuwu3807/article/details/100893787)
--------------------------------------------------------------------------------
/docs/study/DataBase/Redis/2020最新Redis完整教程[千锋南京]-学习笔记.md:
--------------------------------------------------------------------------------
1 | # 2020最新Redis完整教程[千锋南京]-学习笔记
2 |
3 | > 视频链接:[2020最新Redis完整教程[千锋南京]](https://www.bilibili.com/video/av82325430) https://www.bilibili.com/video/av82325430
4 |
5 | ## 1. 一些网文搜集
6 |
7 | > [docker-compose一键部署redis一主二从三哨兵模式(含密码,数据持久化)](https://www.cnblogs.com/hckblogs/p/11186311.html)
8 | >
9 | > [Redis计算地理位置距离-GeoHash](https://www.cnblogs.com/wt645631686/p/8454497.html)
10 | >
11 | > [阿里云Redis开发规范](https://yq.aliyun.com/articles/531067)
12 | >
13 | > [redis中hash和string的使用场景](https://www.jianshu.com/p/4537467bb593)
14 | >
15 | > 存储对象的方式选择:数据量大追求速度->序列化;不是极致速度追求且要求可视化->json
16 | >
17 | > [redis缓存对象,该选择json还是序列化?](https://developer.aliyun.com/ask/61601?spm=a2c6h.13159736)
18 | >
19 | > [在redis队列中将对象序列化存进去队列好还是用json好?哪个性能比较快?](https://www.zhihu.com/question/265671476/answer/297005726)
20 | >
21 | > [Redis几种对象序列化的比较](https://www.jianshu.com/p/e72ec3681fea)
22 | >
23 | > 分布式锁
24 | >
25 | > [Springboot分别使用乐观锁和分布式锁(基于redisson)完成高并发防超卖](https://blog.csdn.net/tianyaleixiaowu/article/details/90036180)
26 | >
27 | > [redis乐观锁(适用于秒杀系统)](https://www.cnblogs.com/crazylqy/p/7742097.html)
28 | >
29 | > Redis基本操作:
30 | >
31 | > [redis 获取key 过期时间](https://blog.csdn.net/zhaoyangjian724/article/details/51790977)
32 | >
33 | > [请问,redis为什么是单线程?](https://www.nowcoder.com/questionTerminal/9e7c2b4fff1d4507814346cf370fa8f6)
34 | >
35 | > SpringBoot-Redis连接超时-坑
36 | >
37 | > [springboot项目中redis连接超时问题](https://blog.csdn.net/distinySmile/article/details/105192539)
38 | >
39 | > [redis报错远程主机强迫关闭了一个现有的连接以及超时问题](http://www.classinstance.cn/detail/77.html)
40 | >
41 | > [springboot整合redis时使用Jedis代替Lettuce](https://blog.csdn.net/xianyirenx/article/details/84207393)
42 | >
43 | > 缓存
44 | >
45 | > [redis缓存在项目中的使用](https://www.cnblogs.com/fengli9998/p/6755591.html)
46 | >
47 | > 持久化机制
48 | >
49 | > [redis的 rdb 和 aof 持久化的区别](https://www.cnblogs.com/shizhengwen/p/9283973.html)
50 | >
51 | > [Redis持久化介绍 ](https://www.sohu.com/a/359201984_100233510)
52 | >
53 | > Redis 有两种持久化方案,RDB (Redis DataBase)和 AOF (Append Only File)
54 | >
55 | > - appendonly 配置redis 默认关闭,开启需要手动把no改为yes(这个我dockerhub中的官方redis6的docker-compose默认是开启的`redis-server /etc/redis/redis.conf --appendonly yes`)
56 | > - appendfilename指定本地数据库文件名,默认值为 appendonly.aof
57 | > - appendfsync everysec指定更新日志条件为每秒更新,共三种策略(aways,everyse,no)
58 | > - auto-aof-rewrite-min-size配置重写触发机制,当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。
59 | >
60 | > **AOF触发与恢复**
61 | >
62 | > AOF主要根据配置文件策略触发,可以是每次执行触发,可以是每秒触发,可以不同步。
63 | >
64 | > AOF的恢复主要是将appendonly.aof 文件拷贝到redis的安装目录的bin目录下,重启redis服务即可。但在实际开发中,可能因为某些原因导致appendonly.aof 文件异常,从而导致数据还原失败,可以通过命令redis-check-aof --fix appendonly.aof 进行修复
65 | >
66 | > AOF的工作原理是将写操作追加到文件中,文件的冗余内容会越来越多。所以Redis 新增了重写机制,通过auto-aof-rewrite-min-size控制。当AOF文件的大小超过所设定的阈值时,Redis就会对AOF文件的内容压缩。
67 | >
68 | >
69 | >
70 | > pipeline
71 | >
72 | > [Redis精通系列——Pipeline(管道)_redis管道技术pipeline_李子捌的博客-CSDN博客](https://blog.csdn.net/qq_41125219/article/details/120298689)
73 | >
74 | > [(15)redis Pipeline详解 - 简书 (jianshu.com)](https://www.jianshu.com/p/f66e9584154f)
75 | >
76 | > [Jedispipeline:Redis管道技术的利器_笔记大全_设计学院 (python100.com)](https://www.python100.com/html/109344.html)
77 | >
78 | > [Redis 管道技术——Pipeline - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/462965659?utm_id=0)
79 | >
80 | >
81 | >
82 | > 消息队列/发布订阅模式
83 | >
84 | > [redis实现消息队列&发布/订阅模式使用](https://www.cnblogs.com/qlqwjy/p/9763754.html)
85 | >
86 | >
87 | >
88 | > 事务
89 | >
90 | > [Redis事务,你真的了解吗](https://zhuanlan.zhihu.com/p/101902825?utm_source=wechat_session)
91 | >
92 | > [Redis事务详解,Redis事务不支持回滚吗?](https://baijiahao.baidu.com/s?id=1613631210471699441&wfr=spider&for=pc)
93 | >
94 | > Redis自身的事务不能够回滚,只不过事务异常or失败会清空原本将要继续往下执行的事务队列里的操作。
95 | >
96 | > 只有类型错误、参数错误等执行前语法就能检测出来的会终止Redis的事务(前面执行过的也不会回滚)。
97 | >
98 | > 然后如果EXEC了,这时候如果MULTI里面的操作正好数据不存在了什么的异常,也不会回滚。EXEC后,不管如何,都会把原本MULTI的执行完。
99 | >
100 | > **Redis的事务执行时,其他client的操作会被阻塞**。
101 | >
102 | > 非事务状态下的命令以单个命令为单位执行,前一个命令和后一个命令的客户端不一定是同一个;
103 | > 而事务状态则是以一个事务为单位,执行事务队列中的所有命令:除非当前事务执行完毕,否则服务器不会中断事务,也不会执行其他客户端的其他命令。(把Redis事务中的所有操作一次性发给Redis,减少网络带来的时间损耗)
104 | >
105 | > **通过事务+watch实现 CAS**
106 | >
107 | > Redis 提供了 WATCH 命令与事务搭配使用,实现 CAS 乐观锁的机制。
108 | > WATCH 的机制是:在事务 EXEC 命令执行时,Redis 会检查被 WATCH 的 Key,只有被 WATCH 的 Key 从 WATCH 起始时至今没有发生过变更,EXEC 才会被执行。
109 | > 如果 WATCH 的 Key 在 WATCH 命令到 EXEC 命令之间发生过变化,则 EXEC 命令会返回失败。
110 |
111 |
112 |
113 | ## 2. 地理位置处理---Redis的GeoHash和MySQL的geography类型(之后有空再详细介绍)
114 |
115 | > 最近比较忙,不细讲两者的什么特点啥的了。
116 |
117 | ### 1. MySQL的geography
118 |
119 | + 适合查找某个**指定范围内**的物体(比如一个多边形内的)
120 | + 适合需**较高精确**位置关系的场景。比如传来一个用户坐标,如果需要较精确的定位,来确定用户是否在A区域还是B区域,可以用这个。
121 | + geography往往伴随着函数计算传入的点Point位置是否在某个区域Polygon内,这个据需要数据库函数。因为走函数等于每一行都需要计算,所以是不走索引的,需要全表查找,效率就很低。设置空间索引Spatial index,可以加速这一过程(具体原理没细究,有兴趣可以自己去查一查)。
122 |
123 | 前面提到函数操作,不走索引。可以了解下virtual column,虚拟列。
124 |
125 | 过去把函数操作的值另外存一列,比如插入时间,需要另外存个时间戳版本,可以数据库写个触发器,插入时制动转化然后存到新列里面。但是这样麻烦又低效。可以新建一列,设置为虚拟列,其值是函数计算结果,这样插入数据时虚拟列的值会自动计算,而且由于虚拟列直接存在数据字典而不是持久化到磁盘,效率很高(类似于函数索引了)。
126 |
127 | ### 2. Redis的GeoHash
128 |
129 | + 适合只简单获取**某二维点周围范围情况**。比如当前位置周围有多少用户在线。
130 | + 适合**精度低**的场景。这个和GeoHash的算法有关,其本身是把地图二维化,把地图一直切两刀分成4块。具体的块状大小,和传入的经度、维度的有效位数有关。详细算法那些这里不讲,有兴趣可以到我github的DB笔记看看一些网络文章的讲解。
131 |
132 | ### 3. 两者对比
133 |
134 | 下面对比,指的是实现的方式不复杂的情况。
135 |
136 | 1. 位置关系**精度**:MySQL的geography > Redis的GeoHash
137 | 2. 实现**难易度**: MySQL的geography > Redis的GeoHash
138 |
139 | 3. 如果只是获取某点周围**大致**情况,**效率**:MySQL的geography < Redis的GeoHash
140 |
141 |
142 |
143 | 最好根据自己实际场景使用对应的技术,不是什么难用什么就对。
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/中级算法/中级算法-设计问题.md:
--------------------------------------------------------------------------------
1 | # 中级算法
2 |
3 | > 题库链接:https://leetcode-cn.com/explore/interview/card/top-interview-questions-medium/
4 |
5 | * 设计问题
6 |
7 | 1. 二叉树的序列化与反序列化
8 |
9 | + 语言:java
10 |
11 | + 思路:可以层次遍历,也可以递归前序遍历。反序列化和序列化是配套的。
12 |
13 | + 代码1(26ms,44.37%):利用层次遍历
14 |
15 | ```java
16 | public class Codec {
17 | public String serialize(TreeNode root) {
18 | if(root == null) return "[]";
19 | StringBuilder res = new StringBuilder("[");
20 | Queue queue = new LinkedList<>() {{ add(root); }};
21 | while(!queue.isEmpty()) {
22 | TreeNode node = queue.poll();
23 | if(node != null) {
24 | res.append(node.val + ",");
25 | queue.add(node.left);
26 | queue.add(node.right);
27 | }
28 | else res.append("null,");
29 | }
30 | res.deleteCharAt(res.length() - 1);
31 | res.append("]");
32 | return res.toString();
33 | }
34 |
35 | public TreeNode deserialize(String data) {
36 | if(data.equals("[]")) return null;
37 | String[] vals = data.substring(1, data.length() - 1).split(",");
38 | TreeNode root = new TreeNode(Integer.parseInt(vals[0]));
39 | Queue queue = new LinkedList<>() {{ add(root); }};
40 | int i = 1;
41 | while(!queue.isEmpty()) {
42 | TreeNode node = queue.poll();
43 | if(!vals[i].equals("null")) {
44 | node.left = new TreeNode(Integer.parseInt(vals[i]));
45 | queue.add(node.left);
46 | }
47 | i++;
48 | if(!vals[i].equals("null")) {
49 | node.right = new TreeNode(Integer.parseInt(vals[i]));
50 | queue.add(node.right);
51 | }
52 | i++;
53 | }
54 | return root;
55 | }
56 | }
57 | ```
58 |
59 | + 代码2(2ms,98.99%):递归,题目的测试样例的数字其实都是1位数。
60 |
61 | ```java
62 | public class Codec {
63 |
64 | StringBuilder sb;
65 | int i;
66 |
67 | // Encodes a tree to a single string.
68 | public String serialize(TreeNode root) {
69 | sb = new StringBuilder();
70 | serializeDFS(root);
71 | return sb.toString();
72 | }
73 |
74 | public void serializeDFS(TreeNode root) {
75 | if(root==null){
76 | sb.append("#");
77 | return;
78 | }
79 | sb.append((char)(root.val+'0'));
80 | serializeDFS(root.left);
81 | serializeDFS(root.right);
82 | }
83 |
84 | // Decodes your encoded data to tree.
85 | public TreeNode deserialize(String data) {
86 | i = 0;
87 | return deserializeDFS(data.toCharArray());
88 | }
89 |
90 | public TreeNode deserializeDFS(char[] data) {
91 | if(data[i]=='#'){
92 | ++i;
93 | return null;
94 | }
95 | TreeNode node = new TreeNode(data[i++]-'0');
96 | node.left = deserializeDFS(data);
97 | node.right = deserializeDFS(data);
98 | return node;
99 | }
100 | }
101 | ```
102 |
103 | 2. Insert Delete GetRandom O(1)
104 |
105 | + 语言:java
106 |
107 | + 思路:增加、删除、随机获取需要平均O(1),那么仅靠List是不可能同时增加和删除都是O(1)复杂度。这里可以多维护一个HashMap,保证删除的元素能理想情况O(1)找到需删除的元素,然后从List中删除。由于List本质是数组or链表,为了避免删除位置时移动位置的时间损耗or查找预删除位置遍历的时间损耗,可以先把预备删除的值和最后一个元素调换,然后删除最后一个元素,即O(1)操作。
108 |
109 | + 代码(11ms,98.88%):这里需要注意的是remove的时候,map最后先add再remove,因为可能需要删除的元素正好是数组的最后一个元素。这时候如果先remove就报错了
110 |
111 | ```java
112 | class RandomizedSet {
113 |
114 | ArrayList list;
115 | HashMap map;
116 | Random rand = new Random();
117 |
118 | /** Initialize your data structure here. */
119 | public RandomizedSet() {
120 | list = new ArrayList<>();
121 | map = new HashMap<>();
122 | }
123 |
124 | /** Inserts a value to the collection. Returns true if the collection did not already contain the specified element. */
125 | public boolean insert(int val) {
126 | if(map.containsKey(val)) return false;
127 | map.put(val,list.size());
128 | list.add(val);
129 | return true;
130 | }
131 |
132 | /** Removes a value from the collection. Returns true if the collection contained the specified element. */
133 | public boolean remove(int val) {
134 | if(!map.containsKey(val))
135 | return false;
136 | int index = map.get(val);
137 | int lastVal = list.get(list.size()-1);
138 | map.put(lastVal,index);
139 | map.remove(val);
140 | list.set(index,lastVal);
141 | list.remove(list.size()-1);
142 | return true;
143 | }
144 |
145 | /** Get a random element from the collection. */
146 | public int getRandom() {
147 | return list.get(rand.nextInt(list.size()));
148 | }
149 | }
150 | ```
151 |
152 |
153 |
154 |
--------------------------------------------------------------------------------
/docs/study/计算机网络/计算机网络杂记.md:
--------------------------------------------------------------------------------
1 | # 计算机网络杂记
2 |
3 | > 有时候回忆起一些计算机网络的知识、问题,就在这里记录下。
4 |
5 | + 物理层
6 |
7 | 线路里的电信号、无线网络里的无线信号。传输bit流
8 |
9 | * 链路层
10 |
11 | 媒体访问控制地址MAC(功能上其实类似网络层)、碰撞检测(同一交换机局域网环境下线路占用问题,一方必须等另一方释放对线路的占用才能使用线路传输数据)、指数退避(线路阻塞后指数型等待时间,一开始假如1.X秒,后面就是2,4,8...)。将网络层的分组封装成帧,传输。
12 |
13 | + 网络层
14 |
15 | 报文交换、路由。将传输成的报文,分装成分组,传输。
16 |
17 | * 传输层
18 |
19 | TCP,UDP
20 |
21 | * 应用层
22 |
23 | HTTP(GET获取,POST添加操作,PUT修改操作,DELETE删除操作)。
24 |
25 |
26 |
27 | 网络中立性,如果没有网络中立性(公平对待所有数据包),网络服务提供商就可以理所当然地提出提速的“高级套餐”(虽然现在其实某些应用之类的也有类似操作)
28 |
29 | > [DNS基础知识,记录类型,解析过程 ,配置文件优先级](https://blog.csdn.net/fanren224/article/details/79693807)
30 | >
31 | > [根域名的知识](https://www.ruanyifeng.com/blog/2018/05/root-domain.html)
32 | >
33 | > [网卡的全双工和半双工都是什么意思?有什么区别?](https://zhidao.baidu.com/question/240698053.html)
34 | >
35 | > [更改网卡的工作方式](http://blog.chinaunix.net/uid-11636352-id-1755403.html)
36 | >
37 | > [Linux 查看网卡全双工 还是半双工 以及设置网卡为半双工](https://blog.csdn.net/zhaozhanyong/article/details/5704706)
38 | >
39 | > [问 netstat -i flg 参数含义](http://suiavbxll.blog.sohu.com/183102684.html)
40 | >
41 | > [单播,多播和广播各有什么特点?](https://zhidao.baidu.com/question/512822115.html)
42 | >
43 | > [虚拟局域网]([https://baike.baidu.com/item/%E8%99%9A%E6%8B%9F%E5%B1%80%E5%9F%9F%E7%BD%91/419962?fromtitle=VLAN&fromid=320429&fr=aladdin](https://baike.baidu.com/item/虚拟局域网/419962?fromtitle=VLAN&fromid=320429&fr=aladdin))
44 | >
45 | > [计算机网络_组帧(4种通用方法)](https://blog.csdn.net/weixin_34345560/article/details/91382086)
46 | >
47 | > [如何理解cpu中断](https://www.jianshu.com/p/f09ebc197bac)
48 | >
49 | > [Linux虚拟网络设备之veth](https://segmentfault.com/a/1190000009251098)
50 | >
51 | > [Linux网络 - 数据包的接收过程](https://segmentfault.com/a/1190000008836467)
52 | >
53 | > [Linux网络 - 数据包的发送过程](https://segmentfault.com/a/1190000008926093)
54 | >
55 | > [Linux虚拟网络设备之tun/tap](https://segmentfault.com/a/1190000009249039)
56 | >
57 | > [Linux虚拟网络设备之bridge(桥)](https://segmentfault.com/a/1190000009491002)
58 | >
59 | > [Linux session和进程组概述](https://segmentfault.com/a/1190000009152815)
60 | >
61 | > [host文件 添加带有公网IP端口的地址为什么无法访问](https://www.imooc.com/qadetail/260912?t=425497)
62 | >
63 | > [Docker容器跨主机通讯的几种方式](https://blog.csdn.net/xialingming/article/details/83093031)
64 | >
65 | > [CENTOS 7 下配置默认网关](https://www.cnblogs.com/yizhipanghu/p/9963779.html)
66 | >
67 | > [无类别域间路由CIDR]([https://baike.baidu.com/item/%E6%97%A0%E7%B1%BB%E5%88%AB%E5%9F%9F%E9%97%B4%E8%B7%AF%E7%94%B1/15758573?fromtitle=CIDR&fromid=3695195&fr=aladdin](https://baike.baidu.com/item/无类别域间路由/15758573?fromtitle=CIDR&fromid=3695195&fr=aladdin))
68 | >
69 | > [vlsm](https://baike.baidu.com/item/VLSM)
70 | >
71 | > [网桥、桥接器]([https://baike.baidu.com/item/%E7%BD%91%E6%A1%A5/99310?fromtitle=%E6%A1%A5%E6%8E%A5%E5%99%A8&fromid=4161119](https://baike.baidu.com/item/网桥/99310?fromtitle=桥接器&fromid=4161119))
72 | >
73 | > [高级配置 HOSTS 设置后不管用啊。 网桥模式部署。](https://bbs.sangfor.com.cn/forum.php?mod=viewthread&tid=56325)
74 | >
75 | > [HTTPS中CA证书的签发及使用过程](https://www.cnblogs.com/xdyixia/p/11610102.html)
76 | >
77 | > [基于 Token 的身份验证:JSON Web Token(JWT)](https://www.jianshu.com/p/2036987a22fb)
78 | >
79 | > [SpringBoot集成JWT实现token验证](https://www.jianshu.com/p/e88d3f8151db)
80 | >
81 | > [Token 安全登陆防止窃取](https://www.cnblogs.com/rinack/p/11295364.html)
82 | >
83 | > [教你如何使用免费的CDN服务](https://zhuanlan.zhihu.com/p/95014452)
84 | >
85 | > [CDN是什么?使用CDN有什么优势?](https://www.zhihu.com/question/36514327)
86 | >
87 | > [路由器RIP协议]([https://baike.baidu.com/item/RIP%E5%8D%8F%E8%AE%AE/5994476?fr=aladdin](https://baike.baidu.com/item/RIP协议/5994476?fr=aladdin))
88 |
89 | 
90 |
91 | 
92 |
93 | 下面写一些自己的总结啥的,想到一些比较值得注意的点就自己总结一下。
94 |
95 | + 网卡接收数据:
96 |
97 | 网卡网络服务中,网卡NIC通过硬件中断IRQ通知CPU有数据要处理时,CPU在查询已注册的中断函数,请求调用网卡驱动NIC Driver的相对应函数,这个过程所有其他硬件不能请求硬中断,也就是没法和CPU交互;然后网卡驱动NIC Driver收到请求后,先禁用网卡的中断IQR,这样CPU就能再响应其他硬件的中断了。此时NIC Driver启用软中断,经过内核读取网卡写到内存的数据包,调用相应软中断处理函数,然后网卡把数据交给CPU让其软中断上下文中处理网络数据,接着调用协议栈响应的函数将数据给协议栈处理,待内存中所有数据包处理完后(即poll函数执行完后),才启用网卡的硬中断,这样网卡下次就能再收到数据通知CPU。
98 |
99 | 大致就是:网卡NIC-- 请求硬中断--> CPU --- 请求网卡驱动调用函数 --> NIC Driver -- 禁用网卡硬中断,此时别的硬件能够对CPU请求硬中断操作 --> NIC Driver -- 启用软中断 --> 和内核、内存、CPU在软中断过程交互处理网卡写到内存的数据 -- > 交给协议栈处理 --内存所有数据包处理完后--> 启用网卡硬中断,能够再收到数据并通知CPU
100 |
101 |
102 |
103 | ### 一些杂项记录
104 |
105 | 1. ipv4的字符串和int32互转
106 |
107 | ```java
108 | public class Test{
109 | @Test
110 | public void testIPv4AndInt32() {
111 | int ipv4Int32 = ipv4ToInt32("192.168.0.1");
112 | String ipv4 = int32ToIpv4(ipv4Int32);
113 | System.out.println("ipv4Int32 : " + ipv4Int32);
114 | System.out.println("ipv4 : " + ipv4);
115 | }
116 |
117 | /**
118 | * ipv4的字符串转int32 数字
119 | * @param ipv4 IP地址字符串
120 | * @return int32
121 | */
122 | public int ipv4ToInt32(String ipv4) {
123 | String[] ipv4Parts = ipv4.split("\\.");
124 | return Integer.parseInt(ipv4Parts[0]) << 24 | Integer.parseInt(ipv4Parts[1]) << 16 | Integer.parseInt(ipv4Parts[2]) << 8 | Integer.parseInt(ipv4Parts[3]);
125 | }
126 |
127 | /**
128 | * int32数字转String形式的ip字符串
129 | * @param ipv4Int32 IP地址存储在32位int数值中
130 | * @return String
131 | */
132 | public String int32ToIpv4(int ipv4Int32) {
133 | StringBuilder sb = new StringBuilder();
134 | sb.append(ipv4Int32 >>> 24).append('.')
135 | .append(ipv4Int32 >>> 16 & ((1<<8)-1) ).append('.')
136 | .append(ipv4Int32 >>> 8 & ((1<<8)-1) ).append('.')
137 | .append(ipv4Int32 & ((1<<8)-1));
138 | return sb.toString();
139 | }
140 | }
141 | ```
142 |
143 | 上述的输出结果如下(建议亲自尝试)
144 |
145 | ```none
146 | ipv4Int32 : -1062731775
147 | ipv4 : 192.168.0.1
148 | ```
149 |
150 |
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/高级算法/高级算法-数学.md:
--------------------------------------------------------------------------------
1 | # 高级算法
2 |
3 | > 题库链接:https://leetcode-cn.com/explore/interview/card/top-interview-questions-hard/
4 |
5 | * 数学
6 |
7 | 1. 最大数
8 |
9 | + 语言:java
10 |
11 | + 思路:做过类似的题,就能想到要改比较器,关键是如何比较两个字符串a和b,哪个放前面。而草稿纸上涂涂画画,可以得到,如果a+b>b+a,那么a后面拼接b的结果更好,也就是a放前面。
12 |
13 | 记得对0特殊处理,如果整个字符串都是0,那么返回单个0就好了。
14 |
15 | + 代码(6ms,96.16%):
16 |
17 | ```java
18 | class Solution {
19 | public String largestNumber(int[] nums) {
20 | int length = nums.length;
21 | String[] numStr = new String[length];
22 | for(int i = 0;i (b+a).compareTo(a+b));
26 |
27 | boolean notZero = false;
28 | StringBuilder sb = new StringBuilder();
29 | for(String str:numStr){
30 | sb.append(str);
31 | if(!str.equals("0"))
32 | notZero = true;
33 | }
34 | return notZero?sb.toString():"0";
35 | }
36 | }
37 | ```
38 |
39 | + 参考代码1(6ms,96.16%):思路一样,不过判断是否全零比我好。
40 |
41 | ```java
42 | class Solution {
43 | public String largestNumber(int[] nums) {
44 | String[] str=new String[nums.length];
45 | for(int i=0;i(){
49 | @Override
50 | public int compare(String o1,String o2){
51 | String order1=o1+o2;
52 | String order2=o2+o1;
53 | return order2.compareTo(order1);
54 | }
55 | });
56 | if(str[0].equals("0")) return "0";
57 | StringBuilder sb=new StringBuilder();
58 | for(int i=0;i [详细通俗的思路分析,多解法](https://leetcode-cn.com/problems/max-points-on-a-line/solution/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by--35/)
73 |
74 | + 代码(35ms,41.57%):
75 |
76 | ```java
77 | class Solution {
78 | public int maxPoints(int[][] points) {
79 | int length = points.length;
80 | if(length<3)
81 | return length;
82 | int maxCount = 0;
83 | for(int i = 0;i map = new HashMap<>();
87 | for(int j = i+1;j [详细通俗的思路分析,多解法](https://leetcode-cn.com/problems/max-points-on-a-line/solution/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by--35/)
127 |
128 | ```java
129 | class Solution {
130 | public int maxPoints(int[][] points) {
131 | if (points.length < 3) {
132 | return points.length;
133 | }
134 | int res = 0;
135 | //遍历每个点
136 | for (int i = 0; i < points.length; i++) {
137 | int duplicate = 0;
138 | int max = 0;//保存经过当前点的直线中,最多的点
139 | HashMap map = new HashMap<>();
140 | for (int j = i + 1; j < points.length; j++) {
141 | //求出分子分母
142 | int x = points[j][0] - points[i][0];
143 | int y = points[j][1] - points[i][1];
144 | if (x == 0 && y == 0) {
145 | duplicate++;
146 | continue;
147 |
148 | }
149 | //进行约分
150 | int gcd = gcd(x, y);
151 | x = x / gcd;
152 | y = y / gcd;
153 | String key = x + "@" + y;
154 | map.put(key, map.getOrDefault(key, 0) + 1);
155 | max = Math.max(max, map.get(key));
156 | }
157 | //1 代表当前考虑的点,duplicate 代表和当前的点重复的点
158 | res = Math.max(res, max + duplicate + 1);
159 | }
160 | return res;
161 | }
162 |
163 | private int gcd(int a, int b) {
164 | while (b != 0) {
165 | int temp = a % b;
166 | a = b;
167 | b = temp;
168 | }
169 | return a;
170 | }
171 | }
172 | ```
173 |
174 |
--------------------------------------------------------------------------------
/docs/study/Python/Machine-learning.md:
--------------------------------------------------------------------------------
1 | # 机器学习google教程学习
2 |
3 | >建议学习时,打开两个页面,一个切换English,一个切换中文-简体,实在不懂再切到中文页面查看相对应的描述
4 | >
5 | >google的机器学习>速成课:
6 | >
7 | >https://developers.google.cn/machine-learning/crash-course/ml-intro
8 |
9 | ## ML Concepts
10 |
11 | ### Introduction to ML
12 |
13 | 1. 为什么使用机器学习:
14 |
15 | 比如遇到像是拼写检查检查、软件多语言化、复杂图像处理等,可以使用机器学习。
16 |
17 | 拼写检查,多输入样例,给其判断就好了;
18 |
19 | 软件多语言化,做出一种语言,然后其他的语言靠样例输入,有充足样例即可;
20 |
21 | 复杂图像处理也是靠样例多次输入,让其自行生成模型处理事件就好了
22 |
23 |
24 |
25 | 学习机器学习,还有一个好处,就是改变我们过去处理问题的思维方式,过去处理方法就是完全从已知的逻辑、方式出发;而机器学习更多的是靠统计学等方式处理无法完全确定或事先不知道的事件。
26 |
27 | ### Framing
28 |
29 | 1. 了解几个基本的概念:
30 | + Labels标签:需要预测的目标(y)
31 |
32 | + Features特征:影响y的线性回归方程自变量(x)
33 |
34 | + Examples样本:特定的数据实例,分为有标签样本 labeled examples 和无标签样本 unlabeled examples 。
35 |
36 | ```python
37 | labeled examples: {features, label}: (x,y)
38 | ```
39 |
40 | 使用样本训练模型。在垃圾邮件检测系统中,有标签的样例就是那些被用户明确标记了是"垃圾邮件"or"非垃圾邮件"的分类邮件集合。
41 |
42 | 无标签的样本只包含features特征,而没有label标签。
43 |
44 | ```python
45 | unlabeled examples: {features, ?}: (x, ?)
46 | ```
47 |
48 | 一旦我们用有标签的样本label examples训练了模型,我们就可以用这个模型去预测无标签样本unlabeled examples的标签label。在前面提到的垃圾邮件检测系统中,无标签样本unlabeled examples就是人们还没有标记过的邮件(标记是"垃圾邮件",还是"非垃圾邮件")。
49 |
50 | + Models模型:模型定义了特征features和标签labels之间的关系。比如,一个垃圾邮件检测模型可能把某些特征值数据和“垃圾邮件”紧密联系到一起。下面学习一下模型model生命周期中的2个阶段:
51 | + **Training** 训练,意味着创造或者**learning**学习模型model。也就是你向模型model展示有标签的样本labeled examples使其能够逐渐学习到给定特征值features和标签labels的关系(联系)。
52 | + **Inference**推断,把训练过的模型trained model应用到没有标签的样本unlabeled examples。即使用训练过的模型trained model去做有意义的预测(y')。打比方,推断中,你可以预测新的没标签样本的平均房屋价格。
53 |
54 | + Regression vs. classification
55 |
56 | 一个回归模型**regression** model预测的是连续的值。比如,回归模型做出的预测可以回答如下问题:
57 |
58 | + XX地区的房屋价格
59 | + 用户可能点击广告的概率
60 |
61 | + 一个分类模型**classification** model预测离散值(离散的值)。比如,分类模型做出的预测可以回答如下问题:
62 |
63 | + 给定的邮件是否“垃圾邮件”
64 | + 图片描述的是狗、猫还是仓鼠
65 |
66 | ### Descending into ML
67 |
68 | 1. 学习其他模型前,先学习最简单的线性回归模型。
69 | 2. Linear Regression
70 |
71 | 3. Training and Loss
72 |
73 | **Training**训练一个模型意味着学习有标签样本的所有权重和偏差。有监督的学习,机器学习算法会通过检验大量样本构建一个模型,且试图找到一个损失最小的模型。这一过程称为**empirical risk minization**经验风险最小化
74 |
75 | 损失是对一个差劲的预测的惩罚。即,**loss**是一个表示模型对简单样本的预测的糟糕程度的数值。如果模型预测没问题,那么损失loss为0;反之,损失loss会很大。 训练模型的目标是从所有样本中找到一组平均损失“较小”的权重和偏差。
76 |
77 | + **Suqared loss**(平方损失、方差):a popular loss function
78 |
79 | ```python
80 | = the square of the difference between the label and the prediction
81 | = (observation - prediction(x))2
82 | = (y - y')2
83 | ```
84 |
85 | + **Mean square error** (**MSE**) : 指的是每个样本的平均平方损失。要计算 MSE,请求出各个样本的所有平方损失之和,然后除以样本数量。
86 |
87 | ### Reducing Loss
88 |
89 | 1. Video Lecture
90 |
91 | 了解梯度下降法;了解随机梯度下降法;小批量梯度下降法;
92 |
93 | 可以在每步上计算整个数据集的梯度,但事实证明没有必要这么做。
94 |
95 | 计算小型数据样本的梯度很好。
96 |
97 | 随机梯度下降法:一次抽取一个样本
98 |
99 | 小批量梯度下降法:每批包括10-1000个样本,损失和梯度在整批范围内达到平衡
100 |
101 | 2. An Iterative Approach
102 |
103 | 机器学习系统根据输入的标签评估所有特征, 为损失函数生成一个新值,而该值又产生新的参数值。这种学习过程会持续迭代,直到该算法发现损失可能最低的模型参数。通常,您可以不断迭代,直到总体损失不再变化或至少变化极其缓慢为止。这时候,我们可以说该模型已**收敛** **converged** 。
104 |
105 | 3. Gradient Descent
106 |
107 | Key Terms:
108 |
109 | + gradient descent 梯度下降法
110 | + step 步
111 |
112 | 4. Learning Rate
113 |
114 | Key Terms:
115 |
116 | + hyperparameter 超参数
117 | + learning rate 学习速率
118 | + step size 步长
119 |
120 | 5. Optimizing Learning Rate
121 |
122 | 6. Stochastic Gradient Descent
123 |
124 | Key Terms:
125 |
126 | + batch 批量
127 | + batch size 批量大小
128 | + mini-batch 小批量
129 | + stochastic gradient descent(SGD) 随机梯度下降法
130 |
131 | ### First Steps with TensorFlow
132 |
133 | 1. Toolkit
134 |
135 | Key Terms:
136 |
137 | + Estimators
138 | + graph 图
139 | + tensor 张量
140 |
141 | 2. Programming Exercises
142 | + Common hyperparameters in Machine Learning Crash Course exercises
143 | + steps
144 | + batch size
145 |
146 | ### Generalization
147 |
148 | 1. Video Lecture
149 |
150 | 2. Peril of Overfitting
151 |
152 | 过拟合 **overfits** 在训练的过程产生的损失较低,但是在预测新数据的表现差。
153 |
154 | + **training set** -- 用于训练模型的子集
155 | + **test set** -- 用于测试模型的子集
156 |
157 | 一般来说,在测试集上表现是否良好是衡量能否在新数据上表现良好的有用指标,前提是 :
158 |
159 | + The test set is large enough.
160 | + You don't cheat by using the same test set over and over.
161 |
162 | 3. The ML fine print
163 |
164 | 以下三项基本假设阐明了泛化:
165 |
166 | + 我们从分布中随机抽取独立且同分布**independently and identically(i.i.d)**的样本。换言之,样本间互不影响
167 | + 分布是平稳**stationary**的,即在数据集中的分布不会变化
168 | + 我们从同一分布**same distribution**中的数据划分中抽取样本
169 |
170 | 然而,事件中,我们偶尔会违背这些假设,例如:
171 |
172 | + 想象有一个选择要展示的广告的模型。如果该模型在某种程度上根据用户以前看过的广告选择广告,则会违背 i.i.d. 假设。
173 | + 想象有一个包含一年零售信息的数据集。用户的购买行为会出现季节性变化,这会违反平稳性。
174 |
175 | 如果违背了上述三项基本假设中的任何一项,那么我们就必须密切注意指标
176 |
177 | ### Training and Test Sets
178 |
179 | 1. Video Lecture
180 |
181 | 将数据集划分成训练集和测试集,训练集用于训练模型,而测试集就是用来测试模型的。
182 |
183 | 典型陷阱:请勿对测试数据进行训练
184 |
185 | 2. Splitting Lecture
186 |
187 | + **training set** -- a subset to train a model
188 | + **test set** -- a subset to test the trained model
189 |
190 | 保证划分后的测试集满足以下条件:
191 |
192 | + 规模足够大,能够产生有统计学意义的结果
193 | + 能够代表整个数据集。换言之,具有和训练集一样的特征。
194 |
195 | **切记不要对测试数据进行训练**。如果评估取得意外的好结果,有可能是不小心对测试集进行了训练。高准确率可能表明测试数据泄露到了训练集。
196 |
197 | ### Validation Set
198 |
199 | 1. Check Your Intuition
200 |
201 | 2. Video Lecture
202 |
203 | 传统地使用训练集训练模型后直接就使用测试集评估模型(之后根据测试集的效果调整模型,在测试集上选择最佳的模型),可能导致对测试集过拟合。
204 |
205 | 为了避免上述问题,中间添加一个验证集(替代原本测试集的位置),然后选出在验证集上最佳效果的模型再使用测试集测试效果,要是效果不好,那可能前面是对验证集进行了过拟合。
206 |
207 | 3. Another Partition
208 |
209 | 大意就是在训练集和测试集之间插入一个验证集,避免测试集过拟合,导致模型在新数据的预测中泛用性(效果)差。
210 |
211 | 此时数据集划分为3部分:training set、validation set、tes tset;
212 |
213 | 训练集训练模型后,验证集验证模型的准确度,最后才挑选通过验证最好的模型进行测试,要是测试效果差,说明可能对验证集过拟合。这种双重检验能够保证获取更准确的模型。
214 |
215 | 4. Programming Exercise
216 |
217 | 这里开始蒙蔽了,先歇一歇。换个更基础一点的教程
218 |
219 |
--------------------------------------------------------------------------------
/docs/study/kubernetes/[kubernetes入门]快速了解和上手容器编排工具k8s-学习记录.md:
--------------------------------------------------------------------------------
1 | # [kubernetes入门]快速了解和上手容器编排工具k8s-学习笔记
2 |
3 | > 视频链接 [【kubernetes入门】快速了解和上手容器编排工具k8s](https://www.bilibili.com/video/av61990770) https://www.bilibili.com/video/av61990770
4 |
5 | ## 概述
6 |
7 | ### 服务端
8 |
9 | 编排的容器不限于docker,只不过实际一般编排docker。master管理多个node节点,其中master主要有4个进程。
10 |
11 | 1. kube-apiserver管理node节点,同时也监听用户的指令(1-kubectl指令;2-RestAPI接口;3-WebUI)进行操作。
12 | 2. ETCD,它是一个数据库,用来存储一些元数据信息,比如各个节点的状态
13 | 3. controller manager,各种资源自动化的控制中心
14 | 4. scheduler,调度接口的主要实施者
15 |
16 | 整个流程大致就是,用户通过3种形式的指令下发到kube-apiserver,然后kube-apiserver起到传达的作用,需要controller manager和scheduler进行协调调度,同时ETCD提供元数据信息的支持,最后生成一个调度的指令传给apiserver,apiserver最终再把指令下发给管理的node节点,node再进行具体的容器的创建、销毁、扩张等操作,node操作完成后会把状态实时更新到apiserver,apiserver再把状态信息存储到ETCD中。
17 |
18 | ### 客户端
19 |
20 | 客户端node主要有3个重要的进程:
21 |
22 | 1. kubelet:和apiserver直接进行通信,并且可以直接调度容器。
23 | 2. kube-proxy:用来创建虚拟网卡
24 | 3. docker:实际的程序啥的在docker容器中运行
25 |
26 | ## 整合概述
27 |
28 | 前面提到k8s整合的容器不限于docker,所以定义了调度的最小单位是pod,一般是由一个docker和一个叫pause的东西(pause其实也是一个docker容器)组成。也就是不直接调度docker容器,而是通过更轻量的pause容器来管理调度docker容器,两者一起创建共同形成最小调度单位pod。
29 |
30 | *ps:pod其实可以有多个docker容器,但是大多数时候都是一个应用容器+一个pause*
31 |
32 | 通过google搜索kubernetes online,进入第一个[Katacoda](https://www.katacoda.com/courses/kubernetes/playground)进行在线模板操作。
33 |
34 | ```shell
35 | ## 通过kubectl进行查询,查看集群运行的位置和版本
36 | kubectl cluster-info
37 |
38 | ## 获取节点资源信息
39 | kubectl get pod # 显示No resources found. 因为没有可用的节点资源
40 |
41 | ```
42 |
43 | ## deployment
44 |
45 | ### 概述
46 |
47 | 维持pod数量。比如过去原本10个机器挂了2台,需要即时打开挂的2台避免承受不了高并发访问。(过去可以通过写脚本实时监听机器数量,要是挂了就自动通知运维人员去打开,但是效率低,不够智能)
48 |
49 | ```shell
50 | ## 创建deployment
51 | kubectl run d1 --image httpd:alpine --port 80 # kubectl run 指定名称 --image 镜像 --port 端口
52 |
53 | ## 查看启动的资源
54 | kubectl get deployments
55 |
56 | ## 在node节点中验证httpd是否运行
57 | docker ps |grep httpd
58 |
59 | ## 修改副本的数量
60 | kubectl edit deployments d1 #编辑该yaml文件里面spec: replicas: 1为2,修改副本数量为2,保存后立即生效
61 |
62 | ## 查看副本数量是否改变
63 | kubectl get deployments # 发现READY由1/1变成2/2
64 |
65 | ## 回到下方node节点,验证是否有2个docker容器运行
66 | docker ps |grep httpd # 发现有两个容器在运行
67 |
68 | ## 强行停止第一个容器的运行
69 | docker stop 第一个容器的ID
70 |
71 | ## 回到master查看运行的deployments,发现还是2个
72 | kubectl get deployments
73 |
74 | ## 到node节点再次查看运行的容器数量,发现还是2个,但是第一个容器的ID和上次的不一样,明显是新建的
75 | docker ps |grep httpd
76 |
77 | ## 也就是说我们结束掉一个pod时,deployment监听到pod数量不为设置的2,会马上再启动一个pod
78 | ```
79 |
80 | ## service
81 |
82 | ### 概述
83 |
84 | 由于deployment只做到维持pod的数量,但是实际生产需要提供一个对外暴露的接口,做到负载均衡,所以引申出来service。
85 |
86 | 一个deployment一般会创建多个pod,而service将多个pod抽象成一个服务。
87 |
88 | 下面举个例子,有2个node节点,一个deployment分配2个pod到node1、1个pod到node2;另一个deployment分配1个pod到node1、2个pod到node2。这时候前面提到的node中的kube-proxy会在这些node上面抽象出一层虚拟交换机,给第一个deployment分配的3个pod共用IP1,而第二个deployment分配的3个pod共用IP2。外界的请求到了这个虚拟交换机的指定IP和端口后会通过负载均衡的算法均匀分配到这3个deployment管理的pod服务实例,另一个deployment同理。
89 |
90 | ```shell
91 | ## 指定deployment的d1服务向外暴露80端口,并且指定运行为NodePort
92 | kubectl expose deployment d1 --target-port 80 --type NodePort
93 |
94 | ## 查看暴露给外界的service,可以把service简写成svc
95 | kubectl get svc # 可以看到下面还有一个默认启动的服务,不用管,而我们启动的服务被分配了一个虚拟的IP,CLUSTER-IP
96 |
97 | ## 可以通过这个分配的虚拟IP直接访问到内部的资源
98 | curl 10.100.126.201 # 每个人启动服务后分配的虚拟IP可能不同
99 | ```
100 |
101 | 这样service就帮我们解决了多容器之间做负载均衡和对外统一的接口映射的过程。
102 |
103 | 接下去讨论的就是不同服务之间访问的问题,就像前面docker-compose那样,不可能自己记住IP去配置。k8s也可通过deployment的名字去互相访问,而不直接手动配置IP。
104 |
105 | ```shell
106 | ## 创建第二个deployment
107 | kubectl run d2 --image nginx:alpine --port 80
108 |
109 | ## 暴露第二个服务
110 | kubectl expose deployment d2 --target-port=80 --type=NodePort
111 |
112 | ## 服务1:d1 httpd镜像;服务2:d2 nginx镜像
113 | ## 查看是否开启了两个服务,查看两者被分配的虚拟IP
114 | kubectl get svc
115 |
116 | ## 在master节点中通过sh进入进入d2的容器(参数是node查找启动的nginx对应的名称中间部分)
117 | kubectl exec -it d2-58759f8c6-gsmlm sh
118 | #这里查询nginx容器的名称对应为k8s_d2_d2-58759f8c6-gsmlm_default_d43d63a8-4ce3-11ea-8095-0242ac110008_0
119 |
120 | ## 首先进入容器后,安装curl工具
121 | apk add curl
122 |
123 | ## 因为当前在d2容器中,这里直接curl d1
124 | curl d1 # 发现能获取到httpd服务的默认信息,查看/etc/hosts发现有自动配置了一项IP路由
125 | # 10.40.0.2 d2-58759f8c6-gsmlm
126 | # 因为自动配置好了dns,所以curl d1 相当于curl 服务d1的虚拟ip
127 | ```
128 |
129 | DNS解决了服务之间的调度问题,但是面临全新的问题,服务内部抽象出来的虚拟IP,外界用户无法知道该虚拟IP,只能知道master机器的公网IP。这里需要将虚拟IP映射到外面,让用户通过代理最终访问到内部的虚拟IP,这就是我们要提到的ingress。
130 |
131 | ## ingress
132 |
133 | ### 概述
134 |
135 | ingress其实是http访问的,根据域名解析到svc,而svc本身又对应到自己的虚拟IP,这个虚拟IP再往下又集成负载均衡。
136 |
137 | ```shell
138 | ## 退出刚才的docker容器,尝试直接curl d1和d2发现无法访问到
139 | exit
140 | curl d1 # curl: (6) Could not resolve host: d1
141 | curl d2 # curl: (6) Could not resolve host: d2
142 |
143 | ## 之前d1和d2之前能互相访问是通过了虚拟出来的DNS,但是外部crul不能直接访问该虚拟出来的DNS
144 | ## https://github.com/sunwu51/notebook/blob/master/19.07/ingress-deployment.yml
145 |
146 | ## ifconfig,查看本机IP
147 | ifconfig # 172.17.0.8
148 |
149 | ## 新建一个文本文件,粘贴上面网址复制的内容,修改最后一行IP为本机IP,重新复制
150 | vim ing-dep.yml # 粘贴并保存
151 |
152 | ##
153 | kubectl apply -f ing-dep.yml
154 |
155 | ## 创建另一个配置文件
156 | ## https://github.com/sunwu51/notebook/tree/master/19.07
157 | ## 修改serviceName为d1,host随便改,比如改成a.b.c
158 | vim ing-conf.yml
159 |
160 | ##
161 | kubectl apply -f inf-conf.yml
162 |
163 | ## 以XX host访问本地ip curl -H "Host: xxx" ip
164 | curl -H "Host: a.b.c" 172.17.0.8 # 获取到httpd默认的服务信息
165 |
166 | ## 在原本的host配置多加一条
167 | vim ing-conf.yml # 复制下面的内容,修改host为a.b.d,serviceName改为h2
168 |
169 | ## 使应用生效
170 | kubectl apply -f inf-conf.yml
171 |
172 | ## 访问到httpd服务
173 | curl -H "Host: a.b.c" 172.17.0.8
174 |
175 | ## 访问到nginx服务
176 | curl -H "Host: a.b.d" 172.17.0.8
177 | ```
178 |
179 | 通过配置本地的域名,用户可以通过不同的域名访问到不同的service,解决了master无法访问到service的问题,这样用户也可以调用到内部service的服务了
180 |
181 | ## k8s网络
182 |
183 | > [K8S 容器之间通讯方式](https://www.jianshu.com/p/b4eabf55533d)
184 | >
185 | > [k8s通过service访问pod(五)](https://www.cnblogs.com/it-peng/p/11393779.html)
186 | >
187 | > [[k8s重要概念及部署k8s集群(一)](https://www.cnblogs.com/it-peng/p/11393762.html)]
188 | >
189 | > [在Play with Kubernetes平台上以测试驱动的方式部署Istio](https://www.jianshu.com/p/7f7919f598ca)
190 | >
191 | > [[k8s\]kubeadm k8s免费实验平台labs.play-with-k8s.com,k8s在线测试](https://www.cnblogs.com/iiiiher/p/8203529.html)
192 |
193 | ## k8s安装
194 |
195 | > [在 MacOS 中使用 multipass 安装 microk8s 环境](https://www.cnblogs.com/gaochundong/p/install-microk8s-on-macos-using-multipass.html)
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/中级算法/中级算法-链表.md:
--------------------------------------------------------------------------------
1 | # 中级算法
2 |
3 | > 题库链接:https://leetcode-cn.com/explore/interview/card/top-interview-questions-medium/
4 |
5 | * 链表
6 |
7 | 1. 两数相加
8 |
9 | + 语言:java
10 |
11 | + 思路:没啥好说的,就链表两两相加。该注意的是最后如果两个链表都遍历到null了,要看看进位参数是否为1,是的话,最后要补上一个节点1
12 |
13 | + 代码(3ms,41.3MB):
14 |
15 | ```java
16 | class Solution {
17 | public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
18 | ListNode res = new ListNode(0);
19 | ListNode tmpNode = res;
20 | ListNode tmpCac = null;
21 | int c = 0; // 进位
22 | int tmp = 0; // 中间计算值
23 | while(l1!=null&&l2!=null){
24 | tmp = (l1.val + l2.val + c) % 10;
25 | c = (l1.val + l2.val + c) / 10;
26 | tmpCac = new ListNode(tmp);
27 | tmpNode.next = tmpCac;
28 | tmpNode = tmpNode.next;
29 | l1 = l1.next;
30 | l2 = l2.next;
31 | }
32 | while(l1!=null){
33 | tmp = (l1.val + c) % 10;
34 | c = (l1.val + c) / 10;
35 | tmpCac = new ListNode(tmp);
36 | tmpNode.next = tmpCac;
37 | tmpNode = tmpNode.next;
38 | l1 = l1.next;
39 | }
40 | while(l2!=null){
41 | tmp = (l2.val + c) % 10;
42 | c = (l2.val + c) / 10;
43 | tmpCac = new ListNode(tmp);
44 | tmpNode.next = tmpCac;
45 | tmpNode = tmpNode.next;
46 | l2 = l2.next;
47 | }
48 | if(c!=0){
49 | tmpCac = new ListNode(1);
50 | tmpNode.next = tmpCac;
51 | tmpNode = tmpNode.next;
52 | }
53 | return res.next;
54 | }
55 | }
56 | ```
57 |
58 | + 参考代码(2ms):就不过是把l1或l2其中一条为null时候的情况给合并到整体情况+代码优化结构了,解题思路上没有本质改变。
59 |
60 | ```java
61 | class Solution {
62 |
63 | public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
64 |
65 | ListNode preNode = null;
66 | ListNode headListNode = null;
67 |
68 | int step = 0;
69 | while(!(l1 == null && l2 == null))
70 | {
71 | int l1Value = getNodeValue(l1);
72 | int l2Value = getNodeValue(l2);
73 | int val = l1Value + l2Value + step;
74 |
75 | step = (val)/10;
76 | if(step ==1){
77 | val = val - 10;
78 | }
79 |
80 | ListNode newNode = new ListNode(val);
81 | if(headListNode == null){
82 | headListNode = newNode;
83 | preNode = headListNode;
84 | }else{
85 | preNode.next = newNode;
86 | preNode = newNode;
87 | }
88 |
89 | l1 = l1 == null?null:l1.next;
90 | l2 = l2 == null?null:l2.next;
91 |
92 | if(l1 == null && l1 == null && step ==1)
93 | {
94 | newNode = new ListNode(1);
95 | preNode.next = newNode;
96 | }
97 | }
98 |
99 | return headListNode;
100 | }
101 |
102 | private int getNodeValue(ListNode node) {
103 | return node == null? 0:node.val;
104 | }
105 | }
106 | ```
107 |
108 | 2. 奇偶链表
109 |
110 | + 语言:java
111 |
112 | + 思路:一路奇数,一路偶数
113 |
114 | + 代码(0ms,41.3MB):
115 |
116 | ```java
117 | class Solution {
118 | public ListNode oddEvenList(ListNode head) {
119 | if(head==null)
120 | return null;
121 | else{// tmp1走单,tmp2走双,res2是双的暂存头
122 | ListNode tmp1 = head,tmp2 = head.next,res2 = tmp2;
123 | while(tmp1.next!=null && tmp2.next!=null){
124 | tmp1.next = tmp1.next.next;
125 | tmp2.next = tmp2.next.next;
126 | tmp1 = tmp1.next;
127 | tmp2 = tmp2.next;
128 | }
129 | tmp1.next = res2;
130 | return head;
131 | }
132 | }
133 | }
134 | ```
135 |
136 | 3. 相交链表
137 |
138 | + 语言:java
139 |
140 | + 思路:相交后,走的长度肯定一样,那么如果从尾向头看,就是只有长度相同的地方才是可能相交的地方。反正时间要求是O(n),可以先获取上下长度,然后到长度相同的位置开始判断。
141 |
142 | + 代码(1ms,43.1MB,100%):
143 |
144 | ```java
145 | public class Solution {
146 | public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
147 | if(headA==null||headB==null)
148 | return null;
149 | int len1=0,len2=0;
150 | ListNode hA=headA,hB=headB;
151 | while(!(hA==null&&hB==null)){
152 | if(hA!=null){
153 | ++len1;
154 | hA=hA.next;
155 | }
156 | if(hB!=null){
157 | ++len2;
158 | hB=hB.next;
159 | }
160 | }
161 | hA = headA;
162 | hB = headB;
163 | while(len1>len2){
164 | hA = hA.next;
165 | --len1;
166 | }
167 | while(len2>len1){
168 | hB = hB.next;
169 | --len2;
170 | }
171 | while(hA!=hB){
172 | hA = hA.next;
173 | hB = hB.next;
174 | }
175 | return hA;
176 | }
177 | }
178 | ```
179 |
180 | + 参考代码(1ms,超精简写法):他这个很巧妙,如果1和2相交,那么迟早会碰头(因为走的步数是一样的,碰头的只可能是相交点)。如果1和2不相交,那么走对方的路线,也迟早因为走的步数都是A+B而走向null。
181 |
182 | ```java
183 | public class Solution {
184 | public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
185 | ListNode l1=headA,l2=headB;
186 | while(l1!=l2){
187 | l1=(l1==null)?headB:l1.next;
188 | l2=(l2==null)?headA:l2.next;
189 | }
190 | return l1;
191 | }
192 | }
193 | ```
194 |
195 |
196 |
197 |
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/初级算法/初级算法-设计问题.md:
--------------------------------------------------------------------------------
1 | # 初级算法
2 |
3 | > 题库链接:https://leetcode-cn.com/explore/interview/card/top-interview-questions-easy/7/trees/47/
4 |
5 | * 设计问题
6 |
7 | 1. Shuffle an Array
8 |
9 | + 语言:java
10 |
11 | + 思路:看了网上说打乱的方法就是从尾部到头部遍历的时候生成随机数,然后进行位置调换。还原就没什么好说的了。
12 |
13 | > https://blog.csdn.net/m0_38082783/article/details/79579116
14 |
15 | + 代码(218ms,84.32%,还行吧):
16 |
17 | ```java
18 | class Solution {
19 |
20 | public int[] raw;
21 | public int[] backpack;
22 | public int len;
23 |
24 | public Solution(int[] nums) {
25 | raw = nums;
26 | len = nums.length;
27 | backpack = new int[len];
28 | System.arraycopy(nums,0,backpack,0,len);
29 | }
30 |
31 | /** Resets the array to its original configuration and return it. */
32 | public int[] reset() {
33 | return raw;
34 | }
35 |
36 | /** Returns a random shuffling of the array. */
37 | public int[] shuffle() {
38 | for(int i = len - 1; i >= 0; --i){
39 | int j = (int)(Math.random() * len);
40 | int tmp = backpack[i];
41 | backpack[i] = backpack[j];
42 | backpack[j] = tmp;
43 | }
44 | return backpack;
45 | }
46 | }
47 |
48 | /**
49 | * Your Solution object will be instantiated and called as such:
50 | * Solution obj = new Solution(nums);
51 | * int[] param_1 = obj.reset();
52 | * int[] param_2 = obj.shuffle();
53 | */
54 | ```
55 |
56 | + 参考代码(120ms):整体思路时一样的,都是从尾到头,生成随机数来表示替换的下标,然后进行"随机“替换
57 |
58 | ```java
59 | class Solution {
60 | private int[] original;
61 | private int[] arr;
62 | private Random r;
63 |
64 | public Solution(int[] nums) {
65 | original = nums;
66 | arr = Arrays.copyOf(nums, nums.length);
67 | r = new Random();
68 | }
69 |
70 | /** Resets the array to its original configuration and return it. */
71 | public int[] reset() {
72 | System.arraycopy(original, 0, arr, 0, original.length);
73 | return arr;
74 | }
75 |
76 | /** Returns a random shuffling of the array. */
77 | public int[] shuffle() {
78 | for(int n = arr.length; n > 1; n--) {
79 | swap(arr, n - 1, r.nextInt(n));
80 | }
81 | return arr;
82 | }
83 |
84 | private void swap(int[] nums, int i, int j) {
85 | int temp = nums[i];
86 | nums[i] = nums[j];
87 | nums[j] = temp;
88 | }
89 | }
90 |
91 | /**
92 | * Your Solution object will be instantiated and called as such:
93 | * Solution obj = new Solution(nums);
94 | * int[] param_1 = obj.reset();
95 | * int[] param_2 = obj.shuffle();
96 | */
97 | ```
98 |
99 | 2. 最小栈
100 |
101 | + 语言:java
102 |
103 | + 思路:本来打算用1个ArrayList再存储排序后的堆栈之类的来实现快速获取最小值,但是后面想想好像很麻烦。看到网上有不错的文章,里面解法1感觉思路上比较好理解
104 |
105 | > https://www.cnblogs.com/lightwindy/p/8512214.html
106 |
107 | + 代码(66ms):利用另外一个栈来存储最小值,存储条件即小于或等于当前值。一开始push的函数的if条件后半部分写成mins.peek()>x,导致如果出现入栈[0], [1], [0]后出栈[0]会使得mins为空,所以改成了>=.
108 |
109 | ```java
110 | class MinStack {
111 |
112 | Stack vals;
113 | Stack mins;
114 |
115 | /** initialize your data structure here. */
116 | public MinStack() {
117 | vals = new Stack();
118 | mins = new Stack();
119 | }
120 |
121 | public void push(int x) {
122 | vals.push(x);
123 | if(mins.empty() || mins.peek() >= x)
124 | mins.push(x);
125 | }
126 |
127 | public void pop() {
128 | int min_peek = mins.peek();
129 | int vals_peek = vals.peek();
130 | if(vals_peek == min_peek)
131 | mins.pop();
132 | vals.pop();
133 | }
134 |
135 | public int top() {
136 | return vals.peek();
137 | }
138 |
139 | public int getMin() {
140 | return mins.peek();
141 | }
142 | }
143 |
144 | /**
145 | * Your MinStack object will be instantiated and called as such:
146 | * MinStack obj = new MinStack();
147 | * obj.push(x);
148 | * obj.pop();
149 | * int param_3 = obj.top();
150 | * int param_4 = obj.getMin();
151 | */
152 | ```
153 |
154 | + 参考代码(45ms):用数组代替stack,并且有在容量不足时扩容;其用另一个数组min来保存最小值,每个下标即在当前状态下(栈顶为top时)的栈中最小值(算是动态规划的方式吧,每个下标都存储从开头至今为止的当前状态最小值);
155 |
156 | ```java
157 | class MinStack {
158 |
159 | /** initialize your data structure here. */
160 | private int[] s;
161 | private int[] min;
162 | private int top;
163 | public MinStack() {
164 | s = new int[10];
165 | min = new int[10];
166 | top = -1;
167 | }
168 | public void push(int x) {
169 | if (top == s.length - 1) {
170 | int[] temps = new int [s.length*2];
171 | int[] tempm = new int [s.length*2];
172 | for (int i = 0; i < s.length; i++){
173 | temps[i] = s[i];
174 | tempm[i] = min[i];
175 | }
176 | s = temps;
177 | min = tempm;
178 | }
179 | s[top+1] = x;
180 | if (top < 0) {
181 | min[top+1] = x;
182 | }
183 | else {
184 | min[top+1] = x < min[top] ? x : min[top];
185 | }
186 | top ++;
187 | }
188 |
189 | public void pop() {
190 | if (top >= 0){
191 | top--;
192 | }
193 | }
194 |
195 | public int top() {
196 | if (top >= 0){
197 | return s[top];
198 | }
199 | else {
200 | return -1;
201 | }
202 | }
203 |
204 | public int getMin() {
205 | return min[top];
206 | }
207 | }
208 |
209 | /**
210 | * Your MinStack object will be instantiated and called as such:
211 | * MinStack obj = new MinStack();
212 | * obj.push(x);
213 | * obj.pop();
214 | * int param_3 = obj.top();
215 | * int param_4 = obj.getMin();
216 | */
217 | ```
218 |
219 |
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/初级算法/初级算法-数学.md:
--------------------------------------------------------------------------------
1 | # 初级算法
2 |
3 | > 题库链接:https://leetcode-cn.com/explore/interview/card/top-interview-questions-easy/7/trees/47/
4 |
5 | * 数学
6 |
7 | 1. Fizz Buzz
8 |
9 | + 语言:java
10 |
11 | + 思路:就很简单地判断%3和%5就好了
12 |
13 | + 代码(3ms,81.53%):
14 |
15 | ```java
16 | class Solution {
17 | public List fizzBuzz(int n) {
18 | List res = new ArrayList();
19 | for(int i = 1; i <= n; ++i){
20 | boolean Fizz = i % 3 == 0;
21 | boolean Buzz = i % 5 == 0;
22 | boolean FizzBuzz = Fizz&&Buzz;
23 | if(FizzBuzz)
24 | res.add("FizzBuzz");
25 | else if(Fizz)
26 | res.add("Fizz");
27 | else if(Buzz)
28 | res.add("Buzz");
29 | else
30 | res.add(""+i);
31 | }
32 | return res;
33 | }
34 | }
35 | ```
36 |
37 | + 参考代码(2ms):没什么太大区别
38 |
39 | ```java
40 | class Solution {
41 | public List fizzBuzz(int n) {
42 | List list=new ArrayList();
43 | for(int i=1;i<=n;i++){
44 | if(i%3==0 && i%5==0){
45 | list.add("FizzBuzz");
46 |
47 | }
48 | else if(i%5==0){
49 | list.add("Buzz");
50 | }
51 | else if(i%3==0){
52 | list.add("Fizz");
53 | }
54 | else{
55 | list.add(i+"");
56 | }
57 | }
58 | return list;
59 | }
60 | }
61 | ```
62 |
63 | 2. 计数质数
64 |
65 | + 语言:java
66 |
67 | + 思路:我用了双层for循环,然后就果断超时了。后面看网上的文章得知用动态规划的思想,在前面几次for循环就顺便求解了后面的情况,更加省时间。
68 |
69 | > https://blog.csdn.net/qq_38595487/article/details/80032510
70 |
71 | + 代码(15ms):
72 |
73 | ```java
74 | class Solution {
75 | public int countPrimes(int n) {
76 | int count = 0;
77 | boolean disPrimses[] = new boolean[n];
78 | for(int i = 2; i < n; ++i){
79 | if(!disPrimses[i]){
80 | ++count;
81 | for(int j =1; j * i < n; ++j){
82 | disPrimses[j*i] = true;
83 | }
84 | }
85 | }
86 | return count;
87 | }
88 | }
89 | ```
90 |
91 | + 参考代码(11ms):思想都差不多,都是动态规划,在之前的循环中就先计算后面的数字是否质数,这样后面for循环可以避免重复计算,浪费时间。比较亮点的地方应该就是**这个内层循环的j是从i*i开始的**,可以进一步减少重复计算。
92 |
93 | ```java
94 | class Solution {
95 | public static int countPrimes(int n) {
96 | boolean[] notPrimes = new boolean[n+1];
97 | int count = 0;
98 | for(int i = 2; i < n; i++){
99 | if(notPrimes[i]){
100 | continue;
101 | }
102 | count++;
103 | for(long j = (long)i*i;j 1){
146 | if(n % 3 != 0)
147 | return false;
148 | n /= 3;
149 | }
150 | return true;
151 | }
152 | }
153 | ```
154 |
155 | + 参考代码(10ms):这个真的绝了,题目说考虑不用循环和递归。参考答案利用int范围的限制,获取int范围内3的最大幂,这样只要是3的幂(int),就绝对会被3整除。回想起软件测试课说要考虑边界情况(边界值测试)。
156 |
157 | ```java
158 | class Solution {
159 | public boolean isPowerOfThree(int n) {
160 | //3的阶乘的int最大值与n取模,为0代表是3的阶乘
161 | return (n>0 && 1162261467 % n == 0);
162 | }
163 | }
164 | ```
165 |
166 | 4. 罗马数字转整数
167 |
168 | + 语言:java
169 |
170 | + 思路:从前往后判断诸如LIV的比较麻烦,从尾向前则只要当前小于上一个,就用减法,其他用加法,得出最后值
171 |
172 | + 代码(4ms,99.88%):有点意外,没想到自己写的代码运行的速度还挺快的
173 |
174 | ```java
175 | class Solution {
176 |
177 | public int romanToInt(String s) {
178 | int pre = 0;
179 | int cur = 0;
180 | int res = 0;
181 | char[] arr = s.toCharArray();
182 | for(int i = arr.length-1; i >=0; --i){
183 | pre = cur;
184 | cur = getNum(arr[i]);
185 | if(cur= 0; i--) {
215 | char c = s.charAt(i);
216 | switch (c) {
217 | case 'I':
218 | res += (res >= 5 ? -1 : 1);
219 | break;
220 | case 'V':
221 | res += 5;
222 | break;
223 | case 'X':
224 | res += 10 * (res >= 50 ? -1 : 1);
225 | break;
226 | case 'L':
227 | res += 50;
228 | break;
229 | case 'C':
230 | res += 100 * (res >= 500 ? -1 : 1);
231 | break;
232 | case 'D':
233 | res += 500;
234 | break;
235 | case 'M':
236 | res += 1000;
237 | break;
238 | }
239 | }
240 | return res;
241 | }
242 | }
243 | ```
244 |
245 |
246 |
247 |
--------------------------------------------------------------------------------
/docs/study/SpringBoot/SpringBoot学习杂记.md:
--------------------------------------------------------------------------------
1 | # SpringBoot学习杂记
2 |
3 | ## 1. 依赖注入
4 |
5 | > [Spring学习(十八)Bean 的三种依赖注入方式介绍](https://www.cnblogs.com/lirunzhou/p/9843176.html)
6 | >
7 | > [@Autowired的使用:推荐对构造函数进行注释](https://blog.csdn.net/qq_22873427/article/details/73718952)
8 |
9 | # 2. AOP
10 |
11 | > [Aspectj与Spring AOP比较 - 简书 (jianshu.com)](https://www.jianshu.com/p/872d3dbdc2ca) => 图文并茂,推荐阅读
12 |
13 | # 3. Spring事务
14 |
15 | > + [Spring中同一类@Transactional修饰方法相互调用的坑_前路无畏的博客-CSDN博客](https://blog.csdn.net/fsjwin/article/details/109211355) <= 避坑推荐
16 | > + [Spring事务-随笔-Ashiamd - 博客园 (cnblogs.com)](https://www.cnblogs.com/Ashiamd/p/15085827.html)
17 | > + [Spring事务测试github项目](https://github.com/Ashiamd/SpringTransactionTest)
18 |
19 | 1. @Transactional 由于serviceImp实现的service,所以AOP默认用的Spring AOP中的jdk动态代理。因此private、protected、包级、static的不能生效,但是不报错。另外由于AOP,同类下的其他方法上的@Transactional不生效,因为是类内部方法调用,动态代理不生效。
20 |
21 | 解决方法:
22 |
23 | 1. 写在不同的类里;
24 |
25 | ```java
26 | // eg:
27 | @Service("studentService")
28 | public class StudentServiceImpl implements StudentService {
29 |
30 | @Resource
31 | private TeacherService teacherService;
32 |
33 | @Transactional(rollbackFor = Throwable.class, propagation = Propagation.REQUIRES_NEW)
34 | @Override
35 | public void A(Integer id) throws Exception {
36 | this.insert(id);
37 | teacherService.insert(id);
38 | }
39 | }
40 | ```
41 |
42 | 2. 同类,但是用AspectJ获取代理对象,用代理对象再调用同类的B方法;
43 |
44 | ```java
45 | // eg:
46 | @Service("studentService")
47 | public class StudentServiceImpl implements StudentService {
48 |
49 | @Transactional(rollbackFor = Throwable.class, propagation = Propagation.REQUIRES_NEW)
50 | @Override
51 | public void A(Integer id) throws Exception {
52 | this.insert(id);
53 | ((StudentServiceImpl)AopContext.currentProxy()).B(id);
54 | }
55 | }
56 | ```
57 |
58 | 3. 同类,依赖注入自己,再调用注入的对象的方法
59 |
60 | ```java
61 | // eg:
62 | @Service("studentService")
63 | public class StudentServiceImpl implements StudentService {
64 |
65 | @Resource
66 | private StudentService studentService;
67 |
68 | @Transactional(rollbackFor = Throwable.class, propagation = Propagation.REQUIRES_NEW)
69 | @Override
70 | public void A(Integer id) throws Exception {
71 | this.insert(id);
72 | studentService.insert(id);
73 | }
74 | }
75 | ```
76 |
77 | (ps: 可以在 `org.springframework.transaction.interceptor.TransactionAspectSupport#invokeWithinTransaction` 中打断点查看一些事务调用情况)
78 |
79 | 2. @Transactional指定的spring事务传播对 TransactionTemplate transactionTemplate 同样有效。
80 |
81 | + TransactionTemplate transactionTemplate可以通过`transactionTemplate.setPropagationBehavior(TransactionDefinition.PROPAGATION_NEVER);`设置事务传播级别。
82 | + 注意,如果在@Transactional方法内又使用transactionTemplate,那可能导致最后开了两个事务(具体看transactionTemplate设置的事务传播级别是什么,如果@Transactional和transactionTemplate都是用REQUIRES_NEW,那就是两个不相干的事务了)
83 |
84 | 3. REQUIRES_NEW 和 NESTED的区别,前者开启和原事务完全无关的新事务,回滚是独立的新事务被回滚;后者如果已经存在事务,则仅设置savepoint,和原事务是同一个事务,不过就是后者回滚只回滚到自己的检查点。如果原本没有事务,那么NESTED就和REQUIRES一样都是新建事务。
85 |
86 | 4. 由于@Transactional这边Spring传播级别通过AOP实现,所以调用方法的时候就确认是否有父事务环境了,不会等运行到中间调用B之后又重新判断(所以如果外层是Propagation.NEVER,即时方法内临时调用另一个事务方法,也不会抛出异常,外部方法始终无事务,内部被调用方法是独立的一个事务)。
87 |
88 | 5. 同一个类中方法调用会可能导致@Transactional失效,重新使得@Transcational生效的方法:
89 | 1. pom.xml 中添加AspectJ:
90 | ```xml
91 |
92 | org.springframework.boot
93 | spring-boot-starter-aop
94 |
95 | ```
96 | 2. 启动类上添加 @EnableAspectJAutoProxy(exposeProxy = true)
97 | 3. AopContext.currentProxy()操作当前的代理类
98 | ```java
99 | AopContext.currentProxy().A; // 调用代理类的.A方法。
100 | ```
101 |
102 | 6. TransactionTemplate相关
103 |
104 | - transactionTemplate.execute本身就是开一个事务,也可以手动设定事务传播级别等。和@Transactional注解的区别就是注解的形式在方法执行前设置事务传播级别和开启事务,而transactionTemplate只在execute的时候才开启事务。
105 |
106 | + TransactionTemplate transactionTemplate可以通过`transactionTemplate.setPropagationBehavior(TransactionDefinition.PROPAGATION_NEVER);`设置事务传播级别
107 |
108 | 7. Spring AOP知识回顾
109 |
110 | 1. 对于基于接口动态代理的AOP事务增强来说,由于接口的方法是public的,这就要求实现类的实现方法必须是public的, 不能是protected,private等,同时不能使用static的修饰符。
111 |
112 | 所以,可以实施接口动态代理的方法只能是使用“public” 或 “public final”修饰符的方法,其它方法不可能被动态代理,相应的也就不能实施AOP增强,也即不能进行Spring事务增强。
113 |
114 | 2. 基于CGLib字节码动态代理的方案是通过扩展被增强类,动态创建子类的方式进行AOP增强植入的。由于使用final、static、private修饰符的方法都不能被子类覆盖,相应的,这些方法将不能被实施的AOP增强。
115 |
116 | *ps:如果我们自己用jdk动态代理的原始写法,其实可以setAccessible(true)访问private修饰的东西*
117 |
118 | > [spring事务传播级别](https://blog.csdn.net/qq_36094023/article/details/90544286)
119 | >
120 | > [Spring五个事务隔离级别和七个事务传播行为](https://www.cnblogs.com/wj0816/p/8474743.html)
121 | >
122 | > [transactionTemplate用法](https://blog.csdn.net/qq_20009015/article/details/84863295)
123 | >
124 | > [Spring中Transactional放在类级别和方法级别上有什么不同?](https://zhidao.baidu.com/question/1500582510886123139.html)
125 | >
126 | > [Spring @Transactional属性可以在私有方法上工作吗?](http://www.mianshigee.com/question/172320jjt/)
127 | >
128 | > [Aspectj与Spring AOP比较](https://www.jianshu.com/p/872d3dbdc2ca)
129 | >
130 | > [JDK动态代理](https://www.cnblogs.com/zuidongfeng/p/8735241.html)
131 | >
132 | > [Spring : REQUIRED和NESTED的区别](https://blog.csdn.net/qq_31967241/article/details/107764496)
133 | >
134 | > [不同类的方法 事务问题_Spring 事务原理和使用,看完这一篇就足够了](https://blog.csdn.net/weixin_42367472/article/details/112636467)
135 | >
136 | > [Spring中同一类@Transactional修饰方法相互调用的坑](https://blog.csdn.net/fsjwin/article/details/109211355)
137 | >
138 | > [@Transactional同类方法调用不生效及解决方法](https://blog.csdn.net/weixin_38898423/article/details/113835501)
139 | >
140 | > [Spring中事务的Propagation(传播性)的取值](https://blog.csdn.net/zhang_shufeng/article/details/38706725)
141 | >
142 | > [spring+mybatis 手动开启和提交事务](https://www.cnblogs.com/xujishou/p/6210012.html)
143 | >
144 | > [AopContext.currentProxy()](https://blog.csdn.net/qq_29860591/article/details/108728150)
145 |
146 | # 4. 异常处理
147 |
148 | > [Spring的@ExceptionHandler和@RestControllerAdvice使用-随笔 - Ashiamd - 博客园 (cnblogs.com)](https://www.cnblogs.com/Ashiamd/p/15045197.html)
149 |
150 | - 如果项目中Controller继承某个带有@ExceptionHandler注解方法的类,那么Controller抛出异常时,会优先走该@ExceptionHandler注解的方法。
151 | - 此时如果有另外带有@RestControllerAdvice注解的全局异常处理器,其只处理Controller继承的@ExceptionHandler范围外的异常。
152 | - 如果@ExceptionHandler范围很大,比如是Throwable.class,那么所有异常只走Controller继承的异常处理方法,不会经过全局异常处理器。
153 |
154 | (ps:@ExceptionHandler存在多个时,最具体的一个生效,比如Throwable.class和RuntimeException.class,如果抛出后者,则拦截后者的方法生效)
155 |
156 | ```java
157 | // 举例子(下面共1. 2. 3. 三个类):
158 | /*
159 |
160 | 情况一:TestController抛出 ArrayStoreException,那么被ExceptionHandlers处理(如果ExceptinonHandlers再上抛,就直接服务停止了,而不是被ExceptionHandlers处理)
161 |
162 | 情况二:TestController抛出 ArrayStoreException以外的异常(超出AbstractController拦截的范围),那么被ExceptionHandlers处理(同样如果再上抛,直接服务停止)
163 |
164 | 情况三:假设AbstractController中的handleThrowable上的@ExceptionHandler(ArrayStoreException.class)改成@ExceptionHandler(Throwable.class),那么所有异常只被AbstractController处理,全局异常处理器无作为(当然如果其他Controller没有继承AbstractController的话,就会抛异常被全局异常处理器ExceptionHandlers处理)。
165 |
166 | */
167 |
168 | // 1. 带有@ExceptionHandler注解方法的 AbstractController
169 | public abstract class AbstractController {
170 | @ExceptionHandler(ArrayStoreException.class)
171 | public Object handleThrowable(HttpServletRequest request, Throwable e) {}
172 | }
173 |
174 | // 2. 全局异常处理器
175 | @RestControllerAdvice
176 | public class ExceptionHandlers {
177 | @ExceptionHandler(Throwable.class)
178 | public String handleThrowable(HttpServletRequest request, Throwable e) {}
179 | }
180 |
181 | // 3. 普通Controller
182 | @RestController
183 | @RequestMapping("/test")
184 | public class TestController extends AbstractController {
185 | @GetMapping("/test001")
186 | public String test001() throws Throwable {}
187 | }
188 | ```
189 |
190 |
--------------------------------------------------------------------------------
/docs/study/BigData/Hadoop/Hadoop官方教程笔记.md:
--------------------------------------------------------------------------------
1 | # Hadoop官方教程笔记
2 |
3 | # 1. Hadoop: 部署单节点集群
4 |
5 | ## 1. 目的
6 |
7 | 部署单节点Hadoop,以便之后使用Hadoop MapReduce和分布式文件系统HDFS
8 |
9 | ## 2. 准备工作
10 |
11 | ### 2.1 平台
12 |
13 | 一般建议用Linux
14 |
15 | ### 2.2 需要的软件
16 |
17 | 1. Java
18 | 2. ssh(顺带建议安装pdsh管理ssh资源)
19 |
20 | ### 2.3 安装软件
21 |
22 | 在Ubuntu发行版本上
23 |
24 | ```shell
25 | $ sudo apt-get install ssh
26 | $ sudo apt-get install pdsh
27 | ```
28 |
29 | ## 3. 下载
30 |
31 | > [下载地址](https://www.apache.org/dyn/closer.cgi/hadoop/common/)
32 | >
33 | > [文件签名校验教程](https://www.apache.org/info/verification.html)
34 |
35 | 这里我选择[最新的稳定版本3.3.0](https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/hadoop-3.3.0.tar.gz)进行下载。(mac Big Sur 11.0.1)
36 |
37 | ## 4. 部署Hadoop集群
38 |
39 | 1. 解压压缩包
40 | 2. 确保有配置java的环境变量"JAVA_HOME"
41 | 3. 尝试运行hadoop。`bin/hadoop`。正常应该有输出关于hadoop如何使用的一些文字介绍
42 |
43 | Hadoop支持3种集群部署模式:
44 |
45 | - [Local (Standalone) Mode](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Standalone_Operation) (单机模式)
46 | - [Pseudo-Distributed Mode](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Pseudo-Distributed_Operation) (伪分布式模式)
47 | - [Fully-Distributed Mode](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Fully-Distributed_Operation) (完全分布式模式)
48 |
49 | ### 4.1 单机操作
50 |
51 | 默认情况下,hadoop就是作为单个java程序,以非分布式的模式运行。单节点模式适合debug调试。
52 |
53 | 下面以解压后的conf目录作为输入,查找匹配指定正则表达式规则的匹配项,将结果输出到我们自定义的目录。
54 |
55 | ```shell
56 | $ mkdir input
57 | $ cp etc/hadoop/*.xml input
58 | $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
59 | $ cat output/*
60 | ```
61 |
62 | 最后我获取到的内容是`1 dfsadmin`
63 |
64 | ### 4.2 伪分布式操作
65 |
66 | Hadoop可以在一个节点上以伪分布式模式运行,每个Hadoop守护进程都在单独的Java进程中运行。
67 |
68 | #### 4.2.1 配置
69 |
70 | Use the following:
71 |
72 | etc/hadoop/core-site.xml:
73 |
74 | ```xml
75 |
76 |
77 | fs.defaultFS
78 | hdfs://localhost:9000
79 |
80 |
81 | ```
82 |
83 | etc/hadoop/hdfs-site.xml:
84 |
85 | ```xml
86 |
87 |
88 | dfs.replication
89 | 1
90 |
91 |
92 | ```
93 |
94 | > 这两个文件的\\ 本来都是空的。
95 |
96 | #### 4.2.2 设置免密ssh
97 |
98 | > mac需要在系统设置的"共享"里设置"允许远程登录"
99 | >
100 | > [关于Mac中ssh: connect to host localhost port 22: Connection refused](https://blog.csdn.net/u011068475/article/details/52883677)
101 |
102 | Now check that you can ssh to the localhost without a passphrase:
103 |
104 | ```ssh
105 | $ ssh localhost
106 | ```
107 |
108 | If you cannot ssh to localhost without a passphrase, execute the following commands:
109 |
110 | ```ssh
111 | $ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
112 | $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
113 | $ chmod 0600 ~/.ssh/authorized_keys
114 | ```
115 |
116 | #### 4.2.3 执行
117 |
118 | > [MapReduce和YARN区别](https://blog.csdn.net/hahachenchen789/article/details/80527706)
119 |
120 | The following instructions are to run a MapReduce job locally. If you want to execute a job on YARN, see [YARN on Single Node](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#YARN_on_Single_Node).
121 |
122 | 1. Format the filesystem:
123 |
124 | ```
125 | $ bin/hdfs namenode -format
126 | ```
127 |
128 | 2. Start NameNode daemon and DataNode daemon:
129 |
130 | ```
131 | $ sbin/start-dfs.sh
132 | ```
133 |
134 | The hadoop daemon log output is written to the `$HADOOP_LOG_DIR` directory (defaults to `$HADOOP_HOME/logs`).
135 |
136 | 3. Browse the web interface for the NameNode; by default it is available at:
137 |
138 | - NameNode - `http://localhost:9870/`
139 |
140 | 4. Make the HDFS directories required to execute MapReduce jobs:
141 |
142 | ```
143 | $ bin/hdfs dfs -mkdir /user
144 | $ bin/hdfs dfs -mkdir /user/
145 | ```
146 |
147 | 5. Copy the input files into the distributed filesystem:
148 |
149 | ```
150 | $ bin/hdfs dfs -mkdir input
151 | $ bin/hdfs dfs -put etc/hadoop/*.xml input
152 | ```
153 |
154 | 6. Run some of the examples provided:
155 |
156 | ```
157 | $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
158 | ```
159 |
160 | 7. Examine the output files: Copy the output files from the distributed filesystem to the local filesystem and examine them:
161 |
162 | ```
163 | $ bin/hdfs dfs -get output output
164 | $ cat output/*
165 | ```
166 |
167 | or
168 |
169 | View the output files on the distributed filesystem:
170 |
171 | ```
172 | $ bin/hdfs dfs -cat output/*
173 | ```
174 |
175 | 8. When you’re done, stop the daemons with:
176 |
177 | ```
178 | $ sbin/stop-dfs.sh
179 | ```
180 |
181 | #### 4.2.4 YARN on a Single Node
182 |
183 | You can run a MapReduce job on YARN in a pseudo-distributed mode by setting a few parameters and running ResourceManager daemon and NodeManager daemon in addition.
184 |
185 | The following instructions assume that 1. ~ 4. steps of [the above instructions](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Execution) are already executed.
186 |
187 | 1. Configure parameters as follows:
188 |
189 | `etc/hadoop/mapred-site.xml`:(这个文件的``原本是空的)
190 |
191 | ```
192 |
193 |
194 | mapreduce.framework.name
195 | yarn
196 |
197 |
198 | mapreduce.application.classpath
199 | $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
200 |
201 |
202 | ```
203 |
204 | `etc/hadoop/yarn-site.xml`:(这个文件的``原本是空的)
205 |
206 | ```
207 |
208 |
209 | yarn.nodemanager.aux-services
210 | mapreduce_shuffle
211 |
212 |
213 | yarn.nodemanager.env-whitelist
214 | JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
215 |
216 |
217 | ```
218 |
219 | 2. Start ResourceManager daemon and NodeManager daemon:
220 |
221 | ```
222 | $ sbin/start-yarn.sh
223 | ```
224 |
225 | 3. Browse the web interface for the ResourceManager; by default it is available at:
226 |
227 | - ResourceManager - `http://localhost:8088/`
228 |
229 | 4. Run a MapReduce job.
230 |
231 | 5. When you’re done, stop the daemons with:
232 |
233 | ```
234 | $ sbin/stop-yarn.sh
235 | ```
236 |
237 | ### 4.3 完全分布式操作
238 |
239 | For information on setting up fully-distributed, non-trivial clusters see [Cluster Setup](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html).
240 |
241 | # 5. mac安装hadoop
242 |
243 | >[mac安装hadoop及配置伪分布式](https://blog.csdn.net/weixin_44570264/article/details/106872445) <= 跟着这个确实可以
244 | >
245 | >```shell
246 | >vim ~/.bash_profile
247 | >
248 | ># hadoop-3.3.0 第一条是hadoop的解压目录
249 | >export HADOOP_HOME=/Users/ashiamd/mydocs/dev-tools/hadoop/hadoop-3.3.0
250 | >export HADOOP_INSTALL=$HADOOP_HOME
251 | >export HADOOP_MAPRED_HOME=$HADOOP_HOME
252 | >export HADOOP_COMMON_HOME=$HADOOP_HOME
253 | >export HADOOP_HDFS_HOME=$HADOOP_HOME
254 | >export YARN_HOME=$HADOOP_HOME
255 | >export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
256 | >export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
257 | >export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
258 | >```
259 |
260 |
--------------------------------------------------------------------------------
/docs/study/LeetCode_Study/数据结构与算法/二叉树.md:
--------------------------------------------------------------------------------
1 | # 二叉树
2 |
3 | > [探索--二叉树](https://leetcode-cn.com/leetbook/detail/data-structure-binary-tree/)
4 |
5 | ## 01 概述
6 |
7 | ## 02 树的遍历
8 |
9 | ### 二叉树的前序遍历
10 |
11 | 语言:java
12 |
13 | 思路:题目要求递归和迭代
14 |
15 | 代码1(0ms,100%):递归
16 |
17 | ```java
18 | /**
19 | * Definition for a binary tree node.
20 | * public class TreeNode {
21 | * int val;
22 | * TreeNode left;
23 | * TreeNode right;
24 | * TreeNode() {}
25 | * TreeNode(int val) { this.val = val; }
26 | * TreeNode(int val, TreeNode left, TreeNode right) {
27 | * this.val = val;
28 | * this.left = left;
29 | * this.right = right;
30 | * }
31 | * }
32 | */
33 | class Solution {
34 | List res = new LinkedList<>();
35 |
36 | public List preorderTraversal(TreeNode root) {
37 | dfs(root);
38 | return res;
39 | }
40 |
41 | public void dfs(TreeNode root){
42 | if(root==null){
43 | return;
44 | }
45 | res.add(root.val);
46 | dfs(root.left);
47 | dfs(root.right);
48 | }
49 | }
50 | ```
51 |
52 | 代码2(0ms,100%):迭代。借用数据结构栈,暂存右节点。
53 |
54 | 前序:中左右,则暂存每次要遍历的节点(第一个root以及之后每次的右、左节点)。由于右子树最后遍历,所以压栈底的是右子树(如果有的话)。
55 |
56 | ```java
57 | class Solution {
58 | public List preorderTraversal(TreeNode root) {
59 |
60 | List res = new LinkedList<>();
61 | LinkedList stack = new LinkedList<>();
62 | if(root!=null){
63 | stack.addFirst(root);
64 | }
65 | while(!stack.isEmpty()){
66 | TreeNode node = stack.pollFirst();
67 | res.add(node.val);
68 | if(node.right!=null){
69 | stack.addFirst(node.right);
70 | }
71 | if(node.left!=null){
72 | stack.addFirst(node.left);
73 | }
74 | }
75 | return res;
76 | }
77 | }
78 | ```
79 |
80 | ### 二叉树的中序遍历
81 |
82 | 语言:java
83 |
84 | 思路:题目要求递归和迭代
85 |
86 | 代码1(0ms,100%):递归
87 |
88 | ```java
89 | class Solution {
90 | List res = new LinkedList<>();
91 |
92 | public List inorderTraversal(TreeNode root) {
93 | dfs(root);
94 | return res;
95 | }
96 |
97 | public void dfs(TreeNode root){
98 | if(root==null){
99 | return;
100 | }
101 | dfs(root.left);
102 | res.add(root.val);
103 | dfs(root.right);
104 | }
105 | }
106 | ```
107 |
108 | 代码2(0ms):迭代
109 |
110 | ```java
111 | class Solution {
112 | public List inorderTraversal(TreeNode root) {
113 | List res = new LinkedList<>();
114 |
115 | LinkedList stack = new LinkedList<>();
116 |
117 | while (root != null || !stack.isEmpty()) {
118 |
119 | // 先一路往左
120 | while(root!=null){
121 | stack.addFirst(root);
122 | root = root.left;
123 | }
124 |
125 | root = stack.pollFirst();
126 | res.add(root.val);
127 | root = root.right;
128 | }
129 |
130 | return res;
131 | }
132 | }
133 | ```
134 |
135 | ### 二叉树的后序遍历
136 |
137 | 语言:java
138 |
139 | 思路:要求递归和迭代
140 |
141 | 代码1(0ms):递归
142 |
143 | ```java
144 | class Solution {
145 | List res = new LinkedList<>();
146 |
147 | public List postorderTraversal(TreeNode root) {
148 | dfs(root);
149 | return res;
150 | }
151 |
152 | public void dfs(TreeNode root){
153 | if(root==null){
154 | return;
155 | }
156 | dfs(root.left);
157 | dfs(root.right);
158 | res.add(root.val);
159 | }
160 | }
161 | ```
162 |
163 | 代码2(1ms,51.49%):迭代。
164 |
165 | 这个需要注意的是后续遍历的右节点判断时,可能出现反复在当前节点和右节点之间访问的死循环,所以多用个临时节点判断上一个节点是否为右节点。
166 |
167 | ```java
168 | class Solution {
169 | public List postorderTraversal(TreeNode root) {
170 | List res = new LinkedList<>();
171 | LinkedList stack = new LinkedList<>();
172 | TreeNode pre =null;
173 | while (root != null || !stack.isEmpty()) {
174 |
175 | // 先一直往左
176 | while(root!=null){
177 | stack.addFirst(root);
178 | root = root.left;
179 | }
180 |
181 | root = stack.pollFirst();
182 | if (root.right == null || root.right == pre) {
183 | res.add(root.val);
184 | pre = root;
185 | root = null;
186 | } else {
187 | stack.addFirst(root);
188 | root = root.right;
189 | }
190 | // 左右中
191 | }
192 | return res;
193 | }
194 | }
195 | ```
196 |
197 | 参考代码1(0ms):
198 |
199 | > [迭代解法,时间复杂度 O(n),空间复杂度 O(n)](https://leetcode-cn.com/problems/binary-tree-postorder-traversal/solution/die-dai-jie-fa-shi-jian-fu-za-du-onkong-jian-fu-za/)
200 |
201 | 这个模版可以套用(用于前序、中序、后序)
202 |
203 | 这个思路很有意思:
204 |
205 | 原本前序遍历使用Stack暂存中间节点,List存遍历的结果值,这时候遍历顺序为“根左右”;那么我们要的后续遍历是“左右根”。
206 |
207 | 如果把Stack暂存节点变成暂存右节点,那么就"根左右"->"根右左";
208 |
209 | 这时候再把List的添加顺序变成类似栈的加入到头部,那么最后输出的遍历顺序就完全颠倒,于是有"根左右"->"根右左"->"左右根"。
210 |
211 | ``` java
212 | class Solution {
213 | public List postorderTraversal(TreeNode root) {
214 | LinkedList result = new LinkedList<>();
215 | LinkedList stack = new LinkedList<>();
216 | while (root != null || !stack.isEmpty()) {
217 | if (root != null) {
218 | stack.push(root);
219 | result.addFirst(root.val);
220 | root = root.right;
221 | } else {
222 | root = stack.pop();
223 | root = root.left;
224 | }
225 | }
226 | return result;
227 | }
228 | }
229 | ```
230 |
231 | 参考后重写(0ms):
232 |
233 | ```java
234 | class Solution {
235 | public List postorderTraversal(TreeNode root) {
236 | LinkedList res = new LinkedList<>();
237 | Deque deque = new LinkedList<>();
238 | while(root!=null||!deque.isEmpty()){
239 | if(root!=null){
240 | res.addFirst(root.val);
241 | deque.addFirst(root);
242 | root = root.right;
243 | }else{
244 | root = deque.pollFirst();
245 | root = root.left;
246 | }
247 | }
248 | return res;
249 | }
250 | }
251 | ```
252 |
253 | ### 二叉树的层序遍历
254 |
255 | 语言:java
256 |
257 | 思路:BFS。这类经典的BFS诀窍就是使用Queue队列
258 |
259 | 代码(1ms,92.96%):
260 |
261 | ```java
262 | class Solution {
263 | public List> levelOrder(TreeNode root) {
264 | List> res = new LinkedList<>();
265 | Queue queue = new LinkedList<>();
266 |
267 | if(root!=null){
268 | queue.add(root);
269 | }
270 | while(!queue.isEmpty()){
271 | int size = queue.size();
272 | TreeNode cur;
273 | List tmp = new LinkedList<>();
274 | for(int i = 0 ;i> ans=new ArrayList<>();
297 | public List> levelOrder(TreeNode root) {
298 |
299 | //Dueue dueue=new Dueue<>();
300 | //dueue.push(root);
301 | getLeverOrder(root,1);
302 | return ans;
303 | }
304 | public void getLeverOrder(TreeNode root,int level){
305 | if(root==null)return;
306 | if(level>ans.size()){
307 | ArrayList res=new ArrayList<>();
308 | res.add(root.val);
309 | ans.add(res);
310 |
311 | }else{
312 | ans.get(level-1).add(root.val);
313 | }
314 | getLeverOrder(root.left,level+1);
315 | getLeverOrder(root.right,level+1);
316 | return;
317 | }
318 | }
319 | ```
320 |
321 | 参考后重写(1ms,92.96%):
322 |
323 | ```java
324 | class Solution {
325 | List> res = new LinkedList<>();
326 |
327 | /**
328 | * DFS层次遍历
329 | * @param root
330 | * @return
331 | */
332 | public List> levelOrder(TreeNode root) {
333 | dfs(root,1);
334 | return res;
335 | }
336 |
337 | public void dfs(TreeNode root,int level){
338 | if(root==null){
339 | return;
340 | }
341 | if(level>res.size()){
342 | List tmp = new LinkedList<>();
343 | res.add(tmp);
344 | }
345 | res.get(level-1).add(root.val);
346 | dfs(root.left,level+1);
347 | dfs(root.right,level+1);
348 | }
349 | }
350 | ```
351 |
352 |
--------------------------------------------------------------------------------
/docs/study/网络安全/SSO/CAS学习杂记.md:
--------------------------------------------------------------------------------
1 | # CAS学习杂记
2 |
3 | > 理论文章
4 | >
5 | > - [单点登录(SSO)看这一篇就够了 - 简书 (jianshu.com)](https://www.jianshu.com/p/75edcc05acfd)
6 | >- [cas 单点登录 登出流程说明_这是一个懒人的博客-CSDN博客_cas单点退出流程](https://blog.csdn.net/qq_30062125/article/details/84983764)
7 | > - [单点登录CAS实现中,感觉只要TGC就足够了,干嘛还要ST的_百度知道 (baidu.com)](https://zhidao.baidu.com/question/427773428303757572.html)
8 | >
9 | > 1. 单点登录的过程中,第一步应用服务器将请求重定向到认证服务器,用户输入账号密码认证成功后,只是在浏览器和认证服务器之间建立了信任(TGC),但是浏览器和应用服务器之间并没有建立信任。
10 | >
11 | > 2. ST是CAS认证中心认证成功后返回给浏览器,浏览器带着它去访问应用服务器,应用服务器再凭它去认证中心验证你这个用户是否合法。只有这样,浏览器和应用服务器才能建立信任的会话。
12 | > 3. 而TGC的作用主要是用于实现单点登录,就是当浏览器要访问应用服务器2时,应用服务器2也会重定向到认证服务器,但是此时由于TGC的存在,认证服务器信任了该浏览器,就不需要用户再输入账号密码了,直接返回给浏览器ST,重复2中的步骤。
13 | > - [CAS票据之ST与TGT过期策略详细说明_Java精选-CSDN博客](https://blog.csdn.net/afreon/article/details/53183157) <= 结合下面的大流程图,很清晰了。
14 | > - [CAS实现单点登录SSO执行原理探究(终于明白了)_javaloveiphone的专栏-CSDN博客_cas sso原理](https://blog.csdn.net/javaloveiphone/article/details/52439613) <= 极力推荐,超高赞文章!(多图流、完整登录退出流程)
15 | >
16 | > 实战文章
17 | >
18 | > - [基于CAS实现单点登录(SSO):工作原理_时光在路上-CSDN博客](https://blog.csdn.net/tch918/article/details/19930037)
19 | >
20 | > - [基于CAS的SSO搭建详细图文_胡云台的博客-CSDN博客](https://blog.csdn.net/qq_36879870/article/details/88544468)
21 | >
22 | > - [基于CAS的SSO(单点登录)实例 - 梦玄庭 - 博客园 (cnblogs.com)](https://www.cnblogs.com/java-meng/p/7269990.html)
23 | >
24 | > - [单点登录_HealerJean梦想博客-CSDN博客](https://blog.csdn.net/u012954706/category_7482523.html)
25 | >
26 | > - [实战springboot+CAS单点登录系统-B站视频](https://www.bilibili.com/video/BV1xy4y1r7BU)
27 | >
28 | > 下面1.CAS流程 ~ 3. 运行CAS-server根据该视频学习,后面看client的教程一般,就看个大概没往下了。
29 | >
30 | > - [SpringBoot 简单实现仿CAS单点登录系统_ljk126wy的博客-CSDN博客](https://blog.csdn.net/ljk126wy/article/details/90640608) <=. 可参考的文章
31 |
32 | # 1. CAS流程
33 |
34 | > - [单点登录(SSO)看这一篇就够了 - 简书 (jianshu.com)](https://www.jianshu.com/p/75edcc05acfd)
35 | > - [cas 单点登录 登出流程说明_这是一个懒人的博客-CSDN博客_cas单点退出流程](https://blog.csdn.net/qq_30062125/article/details/84983764)
36 |
37 | 
38 |
39 | ---
40 |
41 | - TGT:Ticket Granted Ticket(票根,可以签发ST)
42 | - TGC:Ticket Granted Cookie(cookie中CASTGC的value),存在Cookie中,可以通过他找到TGT。
43 | - ST:Service Ticket,是TGT生成的,是每个应用的票据,就是流程中的ticket
44 |
45 | 单点登录:
46 |
47 | 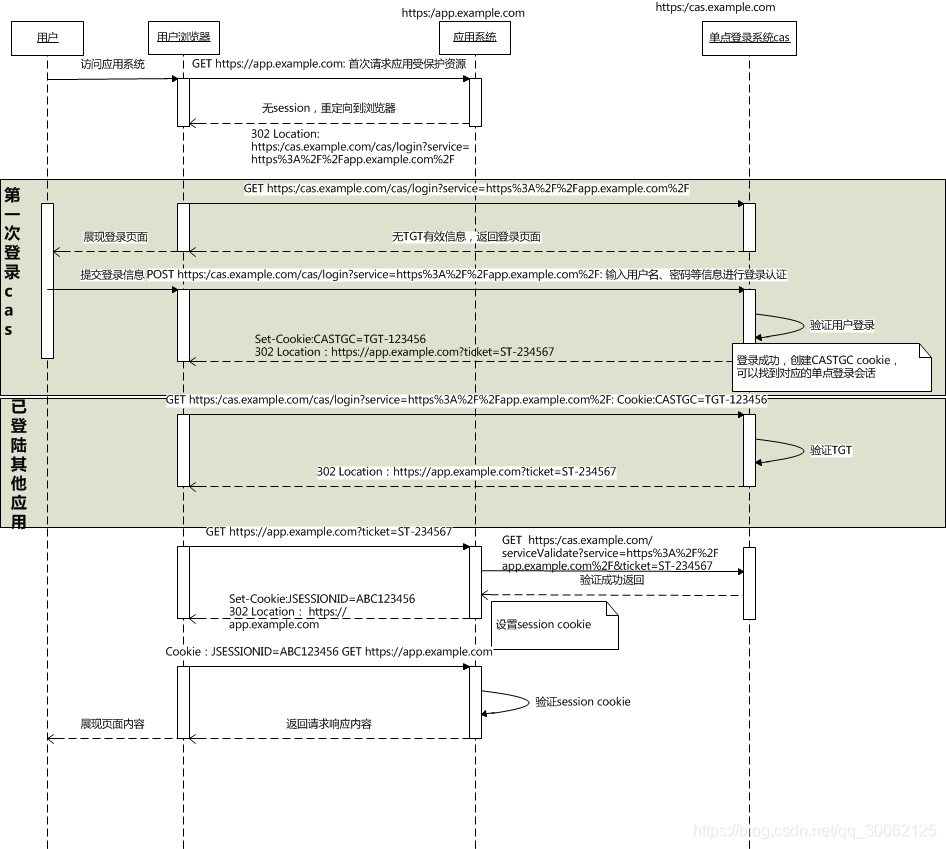
48 |
49 | 单点退出(也可以是先访问应用系统,看具体怎么实现):
50 |
51 | 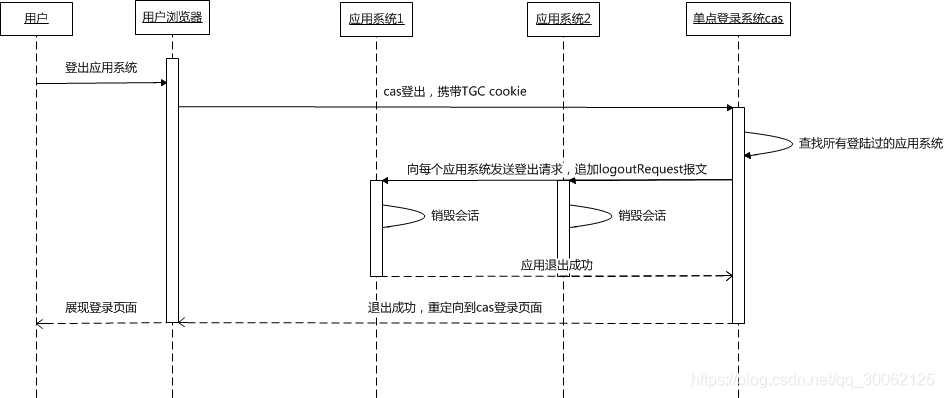
52 |
53 |
54 |
55 | # 2. 搭建Tomcat启用HTTPS
56 |
57 | CAS实现的SSO,需要HTTPS保证数据安全。
58 |
59 | > + **jdk1.8.0_261**
60 | > + **apache-tomcat-9.0.52**
61 | > + **cas-server-webapp-tomcat-5.3.14.war**
62 |
63 | ## 2.1 生成密钥和证书
64 |
65 | > [Keytool命令详解_老猿说说专栏-CSDN博客_keytool](https://blog.csdn.net/zlfing/article/details/77648430)
66 | >
67 | > [Windows下如何把安全证书导入到JDK的cacerts证书库_liruiqing的专栏-CSDN博客](https://blog.csdn.net/liruiqing/article/details/80416740)
68 | >
69 | > Keytool 是一个Java 数据证书的管理工具,Keytool 将密钥(key)和证书(certificates)存在一个称为keystore的文件中。
70 | >
71 | > 在keystore里,包含两种数据:
72 | >
73 | > + 密钥实体(Key entity)——密钥(secret key)又或者是私钥和配对公钥(采用非对称加密)
74 | > + 可信任的证书实体(trusted certificate entries)——只包含公钥
75 | >
76 | > ailas(别名)每个keystore都关联一个独一无二的alias,这个alias通常不区分大小写
77 | >
78 | > -keystore 指定密钥库的名称(产生的各类信息将不在.keystore文件中)
79 | >
80 | > -keyalg 指定密钥的[算法](http://lib.csdn.net/base/datastructure) (如 RSA DSA(如果不指定默认采用DSA))
81 | >
82 | > -v 显示密钥库中的证书详细信息
83 | >
84 | > -list 显示密钥库中的证书信息 keytool -list -v -keystore 指定keystore -storepass 密码
85 | >
86 | > -storepass 指定密钥库的密码(获取keystore信息所需的密码)
87 | >
88 | > -export 将别名指定的证书导出到文件 keytool -export -alias 需要导出的别名 -keystore 指定keystore -file 指定导出的证书位置及证书名称 -storepass 密码
89 | >
90 | > -file 参数指定导出到文件的文件名
91 | >
92 | > + 查看JDK的cacerts 中的证书列表:
93 | >
94 | > `keytool -list -v -keystore "/Library/Java/JavaVirtualMachines/jdk1.8.0_261.jdk/Contents/Home/lib/security/cacerts" -storepass changeit`
95 | >
96 | > + 删除的cacerts 中指定名称的证书:
97 | >
98 | > `keytool -delete -alias 证书别名 -keystore "/Library/Java/JavaVirtualMachines/jdk1.8.0_261.jdk/Contents/Home/lib/security/cacerts" -storepass changeit`
99 |
100 | 1. keystore生成
101 |
102 | `keytool -genkey -v -alias 别名 -keyalg RSA -keystore ./密钥库名.keystore`
103 |
104 | 2. keystore查看
105 |
106 | `keytool -list -v -keystore ./密钥库名.keystore`
107 |
108 | 3. 从密钥库导出证书
109 |
110 | `keytool -export -alias 别名 -file ./证书名.crt -keystore ./密钥库名.keystore`
111 |
112 | 4. 查看证书
113 |
114 | `keytool -printcert -file 证书名.crt`
115 |
116 | 5. 证书导入到JDK证书库
117 |
118 | `keytool -import -trustcacerts -alias 指定导入证书的别名 -file ./证书名.crt -keystore "/Library/Java/JavaVirtualMachines/jdk1.8.0_261.jdk/Contents/Home/lib/security/cacerts" -storepass changeit`
119 |
120 | > **之后实验完之后,记得把这个我们自己新建的cert证书从JDK证书库中删除!!**
121 | >
122 | > `keytool -delete -alias 证书别名 -keystore "/Library/Java/JavaVirtualMachines/jdk1.8.0_261.jdk/Contents/Home/lib/security/cacerts" -storepass changeit`
123 |
124 | ## 2.2 配置Tomcat支持HTTPS
125 |
126 | > [启动tomcat: Permission denied错误_Pompeii的专栏-CSDN博客](https://blog.csdn.net/Pompeii/article/details/40262785)
127 | >
128 | > [tomcat9.0配置https_程序员修炼之路的博客-CSDN博客](https://blog.csdn.net/qq_34756221/article/details/103957671)
129 |
130 | 1. 修改tomcat9安装目录下`conf/server.xml`
131 |
132 | ```xml
133 |
134 |
139 | ```
140 |
141 | 2. 启动tomcat
142 |
143 | ```shell
144 | $ bin/startup.sh
145 |
146 | Using CATALINA_BASE: /Users/ashiamd/mydocs/dev-tools/tomcat/apache-tomcat-10.0.10
147 | Using CATALINA_HOME: /Users/ashiamd/mydocs/dev-tools/tomcat/apache-tomcat-10.0.10
148 | Using CATALINA_TMPDIR: /Users/ashiamd/mydocs/dev-tools/tomcat/apache-tomcat-10.0.10/temp
149 | Using JRE_HOME: /Library/Java/JavaVirtualMachines/adoptopenjdk-11-openj9.jdk/Contents/Home
150 | Using CLASSPATH: /Users/ashiamd/mydocs/dev-tools/tomcat/apache-tomcat-10.0.10/bin/bootstrap.jar:/Users/ashiamd/mydocs/dev-tools/tomcat/apache-tomcat-10.0.10/bin/tomcat-juli.jar
151 | Using CATALINA_OPTS:
152 | Tomcat started.
153 | ```
154 |
155 | > 如果Permission denied
156 | >
157 | > 则执行`chmod u+x *.sh`
158 |
159 | 3. 访问本地tomcat
160 |
161 | *(google内核的浏览器可能没有继续浏览本地签证的页面的选项,换safari浏览器就好了)*
162 |
163 | ```shell
164 | $ curl http://localhost:8080/
165 |
166 | $ curl https://localhost:8443/
167 | curl: (60) SSL certificate problem: self signed certificate
168 | More details here: https://curl.haxx.se/docs/sslcerts.html
169 |
170 | curl failed to verify the legitimacy of the server and therefore could not
171 | establish a secure connection to it. To learn more about this situation and
172 | how to fix it, please visit the web page mentioned above.
173 |
174 | $ curl --insecure https://localhost:8443
175 | ```
176 |
177 | # 3. 运行CAS-server
178 |
179 | 1. 下载CAS-server的war包
180 |
181 | > [Central Repository: org/apereo/cas/cas-server-webapp-tomcat (maven.org)](https://repo1.maven.org/maven2/org/apereo/cas/cas-server-webapp-tomcat/) <= 从视频教程里找到的war包下载地址,藏得好深。。。
182 |
183 | 2. 将war包移动到tomcat的webapps目录下
184 | 3. 解压war包,将解压后的文件夹重命名为cas
185 | 4. 启动tomcat
186 | 5. 访问`https://localhost:8443/cas`
187 |
188 | 6. war包下的`WEB-INF/classes/application.properties`查看账号密码
189 |
190 | ```properties
191 | ##
192 | # CAS Authentication Credentials
193 | #
194 | cas.authn.accept.users=casuser::Mellon
195 | ```
196 |
197 | 7. 修改`WEB-INF/classes/log4j2.xml`的日志路径
198 |
199 | ```xml
200 |
201 |
202 |
203 |
204 | 自定义日志路径(文件夹)
205 |
206 | ...
207 | ```
208 |
209 | 8. 配置数据库、MD5加密等
210 |
211 | > 我主要就为了体验部署一下,所以这些就不弄了。
212 |
213 |
214 |
215 |
--------------------------------------------------------------------------------
/docs/study/Linux/Shell学习.md:
--------------------------------------------------------------------------------
1 | # Shell学习
2 |
3 | > 结合网课、课内教材、网文学习
4 | >
5 | > [【IT】Shell编程从入门到放弃(2016)【全20集】]( https://www.bilibili.com/video/av8104450?p=12 )
6 |
7 | ## 常用指令
8 |
9 | | 指令/参数 | 使用/作用 |
10 | | ---- | ------------------------------------------------------------ |
11 | | $? | 保存前一个命令的返回码 |
12 | | $* | 传给脚本或函数的参数组成的单个字符串,即除脚本名称后从第一个参数开始的字符串,每个参数以$IFS分割(一般内部域分隔符$IFS为一个空格) |
13 | | $# | 传给脚本/函数的参数的个数 |
14 |
15 |
16 |
17 | 颜色字体
18 |
19 | -e "\033[3*m内容\033[0m" 也可以是 4*m;后面如果是1m就后面的颜色都变化
20 |
21 |
22 |
23 | | 指令/参数 | 使用/作用 |
24 | | --------- | ------------------------------------ |
25 | | -d file | 返回真的条件,file存在并且是一个目录 |
26 | | -e file | File 存在 |
27 | | -f file | file存在并且是一个普通文件 |
28 |
29 |
30 |
31 | select语句,配合case语句使用
32 |
33 |
34 |
35 | sed ‘/^/&123’在每行行首插入123
36 |
37 |
38 |
39 | grep -E “正则表达式”文件 (不加-E不会有输出)
40 |
41 |
42 |
43 | awk '{print $1}' 打印第一列
44 |
45 | awk -F: 'print$1' 以“:”冒号为分隔符,打印第一列
46 |
47 |
48 |
49 | find 目录 -maxdepth 最深遍历层数 -name "文件名" 或者 -type 类型(比如f,就是普通文件)-mtime +30(三十天以前的,要是要今天的,可以是 -1)
50 |
51 |
52 |
53 | -exec 指令 {} \ ; 大括号就是等于前面执行的指令获取的结果
54 |
55 | |xargs rm -f {} \; 看情况2个都可以不用 \;
56 |
57 |
58 |
59 | 下面是运维的增量备份、全备份使用
60 |
61 | tar -g 文件,全备份
62 |
63 | echo \`date +%d\` 日; \`date +%u\` 周几;
64 |
65 |
66 |
67 | 运维根据恶意访问(22端口多次输入密码错误,强封IP)
68 |
69 |
70 |
71 | 运维根据脚本同步不同服务器的文件rsync
72 |
73 |
74 |
75 | Shell批量监控服务发送邮件报警
76 |
77 | ---
78 |
79 | # web开发自己用到的常用Linux指令
80 |
81 | ## 1. Linux远程服务器文件的上传、下载
82 |
83 | > [linux系统下的rz、sz详解](https://blog.csdn.net/mynamepg/article/details/81118580)
84 |
85 | 1. sz:将选定的文件发送(send)到本地机器
86 | 2. rz:运行该命令会弹出一个文件选择窗口,从本地选择文件上传到服务器(receive)
87 |
88 | ## 2. linux下的文本去重方法
89 |
90 | > [linux下的几种文本去重方法](https://blog.csdn.net/qq_40809549/article/details/82591302)
91 |
92 | 1. 基础使用
93 |
94 | awk命令去重输出:awk '!x[$0]++' filename
95 |
96 | 应用扩展1:cat Afile Bfile|awk '!x[$0]++' >Cfile
97 |
98 | 依次输出A、B两个文件内容,去掉B中与A重复的行,输出到C;多应用于日志拼接。
99 |
100 | 灵活扩展2:cat Afile|awk '!x[$0]++'
101 |
102 | 也可以写作:awk '!x[$0]++' Afile
103 |
104 | 去掉重复的行,输出A文件
105 |
106 | 2. 复制.bash_history到本地(配合sz指令)
107 |
108 | 先到当前用户根目录,使用ls -a确保有.bash_history文件
109 |
110 | + 使用去重指令把去重后的文件复制出来。
111 |
112 | cat .bash_history|awk '!x[$0]++' > historyXXXX.txt
113 |
114 | + 使用sz指令把文件传到本地
115 |
116 | sz historyXXXX.txt
117 |
118 | ## 3. MongoDB的启动和停止
119 |
120 | > [Centos环境下安装mongoDB](https://www.cnblogs.com/layezi/p/7290082.html)
121 |
122 | 1. MongoDB启动
123 |
124 | sudo systemctl start mongod.service
125 |
126 | 2. MongoDB停止
127 |
128 | sudo systemctl stop mongod.service
129 |
130 | 3. MongoDB重启
131 |
132 | sudo systemctl restart mongod.service
133 |
134 | ## 4. 查看进程指令
135 |
136 | > [Linux ps命令](https://www.runoob.com/linux/linux-comm-ps.html)
137 |
138 | 1. 查看指定的程序是否运行
139 |
140 | ps -ef|grep '程序名'
141 |
142 | + 查看mongod是否启动
143 |
144 | ps -ef|grep 'mongod'
145 |
146 | + 查看是否有java程序运行中(比如springboot项目)
147 |
148 | ps -ef|grep java
149 |
150 | ## 5. 查看系统信息
151 |
152 | > [Linux top命令](https://www.runoob.com/linux/linux-comm-top.html)
153 | >
154 | > [linux 下 取进程占用内存(MEM)最高的前10个进程](https://www.cnblogs.com/liuzhengliang/p/5343988.html)
155 | >
156 | > [linux系统查看系统内存和硬盘大小](https://www.cnblogs.com/yangzailu/p/10939126.html)
157 |
158 | 1. top指令(类似windows的任务管理器)
159 |
160 | 2. 查看总的内存使用情况
161 |
162 | ```shell
163 | free -m | sed -n '2p' | awk '{print""($3/$2)*100"%"}'
164 | ```
165 |
166 | 3. linux 下 取进程占用 cpu 最高的前10个进程
167 |
168 | ```shell
169 | ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head
170 | ```
171 |
172 | 4. linux 下 取进程占用内存(MEM)最高的前10个进程
173 |
174 | ```shell
175 | ps aux|head -1;ps aux|grep -v PID|sort -rn -k +4|head
176 | ```
177 |
178 | 5. 查看系统运行内存
179 |
180 | ```shell
181 | free -m
182 | # (Gb查看)
183 | free -g
184 | ```
185 |
186 | 6. 查看硬盘大小
187 |
188 | ```shell
189 | df -hl
190 | ```
191 |
192 | ## 6. ICMP检测服务器是否可连通
193 |
194 | > [Linux ping命令](https://www.runoob.com/linux/linux-comm-ping.html)
195 |
196 | 1. ping指令
197 |
198 | ## 7. 简单文件操作
199 |
200 | 1. 简单写一句话到文件中
201 |
202 | echo '我是一句废话' > test.txt
203 |
204 | 2. 删除文件(-r 递归,通常用于删除文件夹及子目录;-f强制删除,不询问)
205 |
206 | rm -rf xxxx
207 |
208 | 3. 查看文件
209 |
210 | less 文件名 (空格下一页,B上一页)
211 |
212 | 4. 监听文件(比如查看实时变化的日志文件)
213 |
214 | tail -f 文件名
215 |
216 | 5. 修改文件权限(4r读+2w写+1x执行=7)
217 |
218 | + rwx 读写执行,777三个分别表示文件拥有者用户权限、用户组权限、其他人权限
219 |
220 | + 数字设定法
221 |
222 | chmod 777 文件名or目录名
223 |
224 | + 字符设定法
225 |
226 | chmod [who] [+|-|=] [mode] 文件名
227 |
228 | > + who表示操作对象
229 | >
230 | > u表示用户;g表示用户组;o表示其他用户;a表示所有用户
231 | >
232 | > + 操作符号含义
233 | >
234 | > +表示添加权限 ;-表示取消权限;=表示删除其他所有权限后重新赋予权限
235 | >
236 | > + mode表示执行的权限
237 | >
238 | > r只读;w只写;x可执行
239 |
240 | 6. 查看当前目录文件
241 |
242 | + 不包括隐藏文件
243 |
244 | ls -l
245 |
246 | + 包括隐藏文件
247 |
248 | ls -al
249 |
250 | 7. 创建目录
251 |
252 | mkdir 目录名
253 |
254 | 8. 打印当前目录
255 |
256 | pwd
257 |
258 | 9. 查找文件
259 |
260 | 1. find <指定目录> <指定条件> <指定动作>
261 |
262 | + 从根目录起最大深度查找7层,查找名字带有‘.txt’的文件
263 |
264 | find / -maxdepth 7 -name '*.txt'
265 |
266 | + 从根目录起最大 深度查找2层,查找类型为‘f’(普通文件类型)的文件
267 |
268 | find / -maxdepth 2 -type f
269 |
270 | + 在logs目录中查找更改时间在5日以前的文件并删除它们
271 |
272 | find logs -type f -mtime +5 -exec rm { } \
273 |
274 | + 在/etc目录中查找文件名以host开头的文件,并将查找到的文件输出到标准输出
275 |
276 | find / etc -name "host*" -print
277 |
278 | ## 8. 查看端口占用
279 |
280 | > [Linux中netstat和ps命令的使用](https://blog.csdn.net/u014303647/article/details/82530495)
281 | >
282 | > [Linux 查看服务器开放的端口号](https://www.cnblogs.com/wanghuaijun/p/8971152.html)
283 |
284 | 1. Linux查看端口号占用命令
285 |
286 | netstat -pan | grep 12345
287 |
288 | `lsof -i :8080`
289 |
290 | 2. 通过进程ID查找程序
291 |
292 | ps -aux | grep 12345
293 |
294 | 3. 通过关键字查找进程
295 |
296 | ps -ef | grep java
297 |
298 | netstat -unltp|grep fdfs
299 |
300 | 4. 使用nmap工具
301 |
302 | + 查看本机开放的端口
303 |
304 | ```shell
305 | nmap 127.0.0.1
306 | ```
307 |
308 |
309 |
310 | ## 9. 强制结束某进程
311 |
312 | 1. kill -9 进程号
313 |
314 | ## 10. 后台运行程序
315 |
316 | > [nohup和&后台运行,进程查看及终止](https://blog.csdn.net/themanofcoding/article/details/81948094)
317 |
318 | 1. nohup
319 |
320 | + 这里举例后台运行springboot程序(后台运行,并指定日志输出位置)
321 |
322 | nohup java -jar SpringBoot的jar包文件.jar > /xxxx/yyy/logs.txt &
323 |
324 | nohup java -jar 自己的springboot项目.jar >日志文件名.log 2>&1 &
325 |
326 | nohup java -jar 自己的springboot项目.jar >/dev/null 2>&1 &
327 |
328 | ## 11. 查看、修改网络接口配置
329 |
330 | > [ifconfig 命令详解](https://blog.csdn.net/u011857683/article/details/83758503)
331 | >
332 | > [linux服务器查看公网IP信息的方法](https://www.cnblogs.com/ksguai/p/6090115.html)
333 | >
334 | > [linux命令之ifconfig详细解释](https://www.cnblogs.com/jxhd1/p/6281427.html)
335 | >
336 | > [ifconfig 命令详解](https://blog.csdn.net/u011857683/article/details/83758503)
337 | >
338 | > [ifconfig 中的 eth0 eth0:1 eth0.1 与 lo](https://www.cnblogs.com/jokerjason/p/10695189.html)]
339 | >
340 | > [Linux 查看网卡全双工 还是半双工 以及设置网卡为半双工](https://www.osgeo.cn/post/30ggg)
341 |
342 | 1. ifconfig
343 |
344 | + 查看自己的公网IP即信息
345 |
346 | ```shell
347 | curl ifconfig.me
348 | #不起效可以用下面这条
349 | curl cip.cc
350 | ```
351 |
352 |
353 |
354 | ## 12. 网络通讯TCP/UDP等
355 |
356 | > [Linux nc命令](https://www.runoob.com/linux/linux-comm-nc.html)
357 | >
358 | > [linux系统下tcpdump和nc工具的使用](https://blog.51cto.com/jachy/1753951)
359 | >
360 | > [Linux基础:用tcpdump抓包](https://www.cnblogs.com/chyingp/p/linux-command-tcpdump.html)
361 |
362 | 1. nc
363 |
364 | + 检测UDP端口是否连通(发UDP包)
365 |
366 | nc -vuz IPv4地址 端口号
367 |
368 | 例如 nc -vuz 123.123.123.123 12345
369 |
370 | 2. tcpdump
371 |
372 | + Linux抓包(比如监听UDP包接收发送等)
373 |
374 | tcpdump -vvv -X -n udp port 端口号
375 |
376 | 例如tcpdump -vvv -X -n udp port 12345
377 |
378 | ## 13. Docker操作RabbitMQ
379 |
380 | > [docker安装与使用](https://www.cnblogs.com/glh-ty/articles/9968252.html)
381 | >
382 | > [docker快速安装rabbitmq](https://www.cnblogs.com/angelyan/p/11218260.html)
383 | >
384 | > [docker 安装rabbitMQ](https://www.cnblogs.com/yufeng218/p/9452621.html)
385 | >
386 | > [阿里云-docker安装rabbitmq及无法访问主页](https://www.cnblogs.com/hellohero55/p/11953882.html)
387 | >
388 | > [docker运行jar文件](https://www.cnblogs.com/zhangwufei/p/9034997.html)
389 |
390 | 1. docker安装RabbitMQ后,启动
391 |
392 | ```shell
393 | docker run -d --name rabbitmq3.8.2 -p 5672:5672 -p 15672:15672 -v `pwd`/data:/var/lib/rabbitmq --hostname XX-xxx-Docker-RabbitMQ-主机名 -e RABBITMQ_DEFAULT_VHOST=XX-xxx-Docker-RabbitMQ-vhost -e RABBITMQ_DEFAULT_USER=用户名 -e RABBITMQ_DEFAULT_PASS=密码 docker中RabbitMQ的imageID
394 | ```
395 |
396 |
397 | 2. docker使用国内的加速源
398 |
399 | ```shell
400 | vim /etc/docker/daemon.json
401 | ```
402 |
403 | 修改上述json文件为以下内容
404 |
405 | ```json
406 | {"registry-mirrors": ["http://95822026.m.daocloud.io","https://registry.docker-cn.com","http://hub-mirror.c.163.com","https://almtd3fa.mirror.aliyuncs.com"]}
407 | ```
408 |
409 | ## 14. 用户操作
410 |
411 | 1. 切换用户
412 |
413 | ```she
414 | su 用户名
415 | ```
416 |
417 | ## 15. 网络检测
418 |
419 | 1. 查看是否被木马开后门(查看建立连接的程序)
420 |
421 | ```shell
422 | netstat -nb
423 | ```
424 |
425 |
--------------------------------------------------------------------------------