├── requirements.txt
├── code
├── augment.py
└── eda.py
└── README.md
/requirements.txt:
--------------------------------------------------------------------------------
1 | jieba
2 | synonyms
3 |
--------------------------------------------------------------------------------
/code/augment.py:
--------------------------------------------------------------------------------
1 | # @Author : zhany
2 | # @Time : 2019/03/20
3 |
4 | #!/usr/bin/env python
5 | # -*- coding: utf-8 -*-
6 |
7 | from eda import *
8 |
9 | import argparse
10 | ap = argparse.ArgumentParser()
11 | ap.add_argument("--input", required=True, type=str, help="原始数据的输入文件目录")
12 | ap.add_argument("--output", required=False, type=str, help="增强数据后的输出文件目录")
13 | ap.add_argument("--num_aug", required=False, type=int, help="每条原始语句增强的语句数")
14 | ap.add_argument("--alpha", required=False, type=float, help="每条语句中将会被改变的单词数占比")
15 | args = ap.parse_args()
16 |
17 | #输出文件
18 | output = None
19 | if args.output:
20 | output = args.output
21 | else:
22 | from os.path import dirname, basename, join
23 | output = join(dirname(args.input), 'eda_' + basename(args.input))
24 |
25 | #每条原始语句增强的语句数
26 | num_aug = 9 #default
27 | if args.num_aug:
28 | num_aug = args.num_aug
29 |
30 | #每条语句中将会被改变的单词数占比
31 | alpha = 0.1 #default
32 | if args.alpha:
33 | alpha = args.alpha
34 |
35 | def gen_eda(train_orig, output_file, alpha, num_aug=9):
36 |
37 | writer = open(output_file, 'w')
38 | lines = open(train_orig, 'r').readlines()
39 |
40 | print("正在使用EDA生成增强语句...")
41 | for i, line in enumerate(lines):
42 | parts = line[:-1].split('\t') #使用[:-1]是把\n去掉了
43 | label = parts[0]
44 | sentence = parts[1]
45 | aug_sentences = eda(sentence, alpha_sr=alpha, alpha_ri=alpha, alpha_rs=alpha, p_rd=alpha, num_aug=num_aug)
46 | for aug_sentence in aug_sentences:
47 | writer.write(label + "\t" + aug_sentence + '\n')
48 |
49 | writer.close()
50 | print("已生成增强语句!")
51 | print(output_file)
52 |
53 | if __name__ == "__main__":
54 | gen_eda(args.input, output, alpha=alpha, num_aug=num_aug)
55 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # NLP中数据增强的实现
2 |
3 | 本工具是论文[《EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks》](https://arxiv.org/abs/1901.11196)的代码实现。
4 | 原作者虽给出了针对英文语料数据增强的代码实现,但不适合中文语料。我经过对原论文附上的代码的修改,现在推出这个适合中文语料的数据增强EDA的实现。
5 |
6 | # TODO:尝试替换不同的中文同义词库,测试它们的效果
7 |
8 | # 使用方法
9 |
10 | 1. 先将需要处理的语料按照下面的例子处理好成固定的格式:
11 | ```
12 | 0 今天天气不错哦。
13 |
14 | 1 今天天气不行啊!不能出去玩了。
15 |
16 | 0 又是阳光明媚的一天!
17 | ```
18 |
19 |
20 | 即,标签+一个制表符\t+内容
21 |
22 |
23 |
24 | 2. 命令使用例子:
25 |
26 | `$python code/augment.py --input=train.txt --output=train_augmented.txt --num_aug=16 --alpha=0.05`
27 |
28 | 这里:
29 |
30 | input参数:需要进行增强的语料文件
31 |
32 | output参数:输出文件
33 |
34 | num_aug参数:每一条语料将增强的个数
35 |
36 | alpha参数:每一条语料中改动的词所占的比例
37 |
38 |
39 |
40 | 具体使用方法同英文语料情况。请参考[eda_nlp](https://github.com/jasonwei20/eda_nlp)。
41 |
42 |
43 |
44 | # 参考/感谢
45 |
46 | - 原仓库:[eda_nlp](https://github.com/jasonwei20/eda_nlp)。感谢原作者的付出。Thanks to the author of the paper.
47 |
48 | - [jieba分词](https://github.com/fxsjy/jieba)
49 | - [Synonyms](https://github.com/huyingxi/Synonyms)
50 |
51 |
52 | # 原论文阅读笔记
53 | [《EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks》](https://arxiv.org/abs/1901.11196)
54 |
55 |
56 | # 简介
57 |
58 |
59 | 在这篇论文中,作者提出所谓的EDA,即简单数据增强(easy data augmentation),包括了四种方法:**同义词替换、随机插入、随机交换、随机删除**。作者使用了CNN和RNN分别在五种不同的文本分类任务中做了实验,实验表明,EDA提升了分类效果。作者也表示,平均情况下,仅使用50%的原始数据,再使用EDA进行数据增强,能取得和使用所有数据情况下训练得到的准确率。
60 |
61 |
62 |
63 | # 已有方法及其问题所在
64 |
65 | - 英法互译
66 | - 同义词替换
67 | - 数据噪声
68 |
69 | 由于没有一般的语言转换的通用规则,因此NLP中的通用数据增强技术人们探索甚少。上述若干方法,相对于其能提升的性能,实现开销更大。
70 |
71 | 作者还列举出了其他一些增强方法,而EDA的优点在于能以更简单的方法获得差不多的性能。
72 |
73 |
74 |
75 | # 创新思路
76 |
77 | 在本文,作者提出**通用的**NLP数据增强技术,命名为EDA。同时作者表示,他们是第一个给数据增强引入文本编辑技术的人。EDA的提出,也是一定程度上受计算机视觉上增强技术的启发而得到。下面详细介绍EDA的四个方法:
78 |
79 | 对于训练集中的每个句子,执行下列操作:
80 |
81 | - 同义词替换(Synonym Replacement, SR):从句子中随机选取n个不属于停用词集的单词,并随机选择其同义词替换它们;
82 | - 随机插入(Random Insertion, RI):随机的找出句中某个不属于停用词集的词,并求出其随机的同义词,将该同义词插入句子的一个随机位置。重复n次;
83 | - 随机交换(Random Swap, RS):随机的选择句中两个单词并交换它们的位置。重复n次;
84 | - 随机删除(Random Deletion, RD):以 $p$ 的概率,随机的移除句中的每个单词;
85 |
86 | 这些方法里,只有SR曾经被人研究过,其他三种方法都是本文作者首次提出。
87 |
88 | 值得一提的是,长句子相对于短句子,存在一个特性:长句比短句有更多的单词,因此长句在保持原有的类别标签的情况下,能吸收更多的噪声。为了充分利用这个特性,作者提出一个方法:基于句子长度来变化改变的单词数,换句话说,就是不同的句长,因增强而改变的单词数可能不同。具体实现:对于SR、RI、RS,遵循公式:$n$ = $\alpha$ * $l$,$l$ 表示句长,$\alpha$ 表示一个句子中需要改变的单词数的比例。在RD中,让 $p$ 和 $\alpha$ 相等。另外,每个原始句子,生成个增强的句子。
89 |
90 |
91 |
92 | # 实验环节
93 |
94 | ## 实验设置
95 |
96 | 作者使用了5个不同的Benchmark数据集(这里不再介绍每个数据集是什么,如果你想了解可以去查原论文,但没太大必要),这样就有5种文本分类任务,使用了两个state-of-the-art文本分类的模型:[LSTM-RNN](https://arxiv.org/abs/1605.05101)和[CNNs](https://arxiv.org/abs/1408.5882)。并将有无EDA作为对比,同时因为欲得到EDA在小数据集上的实验效果,将训练数据集大小分为500、2000、5000、完整这4个量级。每个训练效果是在5个文本分类任务上的效果均值。
97 |
98 | ## 实验结果
99 |
100 | - 实验结果是:在完整的数据集上,平均性能提升0.8%;在大小为500的训练集上,提升3.0%。具体见如下表1:
101 |
102 |
103 | 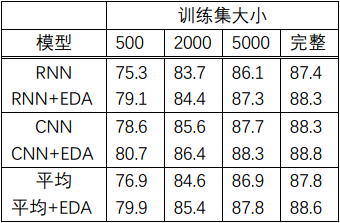
104 | 表1
105 |
106 | - 作者指出,EDA在小训练集上有更好的性能效果。若使用完整的训练集数据,不使用EDA的情况下,最佳的平均准确率达到88.3%。若使用50%的训练集数据并且使用EDA的情况下,最佳的平均准确率达到88.6%,超过前述情况。
107 |
108 | - 若句子中有多个单词被改变了,那么句子的原始标签类别是否还会有效?作者做了实验:首先,使用RNN在一未使用EDA过的数据集上进行训练;然后,对测试集进行EDA扩增,每个原始句子扩增出9个增强的句子,将这些句子作为测试集输入到RNN中;最后,从最后一个全连接层取出输出向量。应用t-SNE技术,将这些向量以二维的形式表示出来。实验结果就是,增强句子的隐藏空间表征紧紧环绕在这些原始句子的周围。作者的结论是,句子中有多个单词被改变了,那么句子的原始标签类别就可能无效了。
109 |
110 | - 对于EDA中的每个方法,单独提升的效果如何?作者做实验得出的结论是,对于每个方法在小数据集上取得的效果更明显。$\alpha$ 如果太大的话,甚至会降低模型表现效果,$\alpha$=0.1似乎是最佳值。
111 |
112 | - 如何选取合适的增强语句个数?在较小的数据集上,模型容易过拟合,因此生成多一点的语料能取得较好的效果。对于较大的数据集,每句话生成超过4个句子对于模型的效果提升就没有太大帮助。因此,作者推荐实际使用中的一些参数选取如表2所示:
113 |
114 | 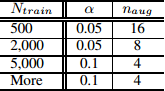
115 | 表2
116 |
117 | 其中,$n_{aug}$ :每个原始语句的增强语句个数;$N_{train}$:训练集大小
118 |
119 |
120 |
121 | # 其它
122 |
123 | ## 1. EDA提高文本分类的效果的原理是什么?
124 |
125 | - 生成类似于原始数据的增强数据会引入一定程度的噪声,有助于防止过拟合;
126 |
127 | - 使用EDA可以通过同义词替换和随机插入操作引入新的词汇,允许模型泛化到那些在测试集中但不在训练集中的单词;
128 |
129 | ## 2. 为什么使用EDA而不使用语境增强、噪声、GAN和反向翻译?
130 |
131 | 上述的其它增强技术作者都希望你使用,它们确实在一些情况下取得比EDA较好的性能,但是,由于需要一个深度学习模型,这些技术往往在其取得的效果面前,付出的实现代价更高。而EDA的目标在于,使用简单方便的技术就能取得相接近的结果。
132 |
133 | ## 3. EDA是否有可能会降低模型的性能?
134 |
135 | 确实有可能。原因在于,EDA有可能在增强的过程中,改变了句子的意思,但其仍保留原始的类别标签,从而产生了标签错误的句子。
136 |
--------------------------------------------------------------------------------
/code/eda.py:
--------------------------------------------------------------------------------
1 | # @Author : zhany
2 | # @Time : 2019/03/20
3 |
4 | #!/usr/bin/env python
5 | # -*- coding: utf-8 -*-
6 |
7 | import jieba
8 | import synonyms
9 | import random
10 | from random import shuffle
11 |
12 | random.seed(2019)
13 |
14 | #停用词列表,默认使用哈工大停用词表
15 | f = open('stopwords/HIT_stop_words.txt')
16 | stop_words = list()
17 | for stop_word in f.readlines():
18 | stop_words.append(stop_word[:-1])
19 |
20 |
21 | #考虑到与英文的不同,暂时搁置
22 | #文本清理
23 | '''
24 | import re
25 | def get_only_chars(line):
26 | #1.清除所有的数字
27 | '''
28 |
29 |
30 | ########################################################################
31 | # 同义词替换
32 | # 替换一个语句中的n个单词为其同义词
33 | ########################################################################
34 | def synonym_replacement(words, n):
35 | new_words = words.copy()
36 | random_word_list = list(set([word for word in words if word not in stop_words]))
37 | random.shuffle(random_word_list)
38 | num_replaced = 0
39 | for random_word in random_word_list:
40 | synonyms = get_synonyms(random_word)
41 | if len(synonyms) >= 1:
42 | synonym = random.choice(synonyms)
43 | new_words = [synonym if word == random_word else word for word in new_words]
44 | num_replaced += 1
45 | if num_replaced >= n:
46 | break
47 |
48 | sentence = ' '.join(new_words)
49 | new_words = sentence.split(' ')
50 |
51 | return new_words
52 |
53 | def get_synonyms(word):
54 | return synonyms.nearby(word)[0]
55 |
56 |
57 | ########################################################################
58 | # 随机插入
59 | # 随机在语句中插入n个词
60 | ########################################################################
61 | def random_insertion(words, n):
62 | new_words = words.copy()
63 | for _ in range(n):
64 | add_word(new_words)
65 | return new_words
66 |
67 | def add_word(new_words):
68 | synonyms = []
69 | counter = 0
70 | while len(synonyms) < 1:
71 | random_word = new_words[random.randint(0, len(new_words)-1)]
72 | synonyms = get_synonyms(random_word)
73 | counter += 1
74 | if counter >= 10:
75 | return
76 | random_synonym = random.choice(synonyms)
77 | random_idx = random.randint(0, len(new_words)-1)
78 | new_words.insert(random_idx, random_synonym)
79 |
80 |
81 | ########################################################################
82 | # Random swap
83 | # Randomly swap two words in the sentence n times
84 | ########################################################################
85 |
86 | def random_swap(words, n):
87 | new_words = words.copy()
88 | for _ in range(n):
89 | new_words = swap_word(new_words)
90 | return new_words
91 |
92 | def swap_word(new_words):
93 | random_idx_1 = random.randint(0, len(new_words)-1)
94 | random_idx_2 = random_idx_1
95 | counter = 0
96 | while random_idx_2 == random_idx_1:
97 | random_idx_2 = random.randint(0, len(new_words)-1)
98 | counter += 1
99 | if counter > 3:
100 | return new_words
101 | new_words[random_idx_1], new_words[random_idx_2] = new_words[random_idx_2], new_words[random_idx_1]
102 | return new_words
103 |
104 | ########################################################################
105 | # 随机删除
106 | # 以概率p删除语句中的词
107 | ########################################################################
108 | def random_deletion(words, p):
109 |
110 | if len(words) == 1:
111 | return words
112 |
113 | new_words = []
114 | for word in words:
115 | r = random.uniform(0, 1)
116 | if r > p:
117 | new_words.append(word)
118 |
119 | if len(new_words) == 0:
120 | rand_int = random.randint(0, len(words)-1)
121 | return [words[rand_int]]
122 |
123 | return new_words
124 |
125 |
126 | ########################################################################
127 | #EDA函数
128 | def eda(sentence, alpha_sr=0.1, alpha_ri=0.1, alpha_rs=0.1, p_rd=0.1, num_aug=9):
129 | seg_list = jieba.cut(sentence)
130 | seg_list = " ".join(seg_list)
131 | words = list(seg_list.split())
132 | num_words = len(words)
133 |
134 | augmented_sentences = []
135 | num_new_per_technique = int(num_aug/4)+1
136 | n_sr = max(1, int(alpha_sr * num_words))
137 | n_ri = max(1, int(alpha_ri * num_words))
138 | n_rs = max(1, int(alpha_rs * num_words))
139 |
140 | #print(words, "\n")
141 |
142 |
143 | #同义词替换sr
144 | for _ in range(num_new_per_technique):
145 | a_words = synonym_replacement(words, n_sr)
146 | augmented_sentences.append(' '.join(a_words))
147 |
148 | #随机插入ri
149 | for _ in range(num_new_per_technique):
150 | a_words = random_insertion(words, n_ri)
151 | augmented_sentences.append(' '.join(a_words))
152 |
153 | #随机交换rs
154 | for _ in range(num_new_per_technique):
155 | a_words = random_swap(words, n_rs)
156 | augmented_sentences.append(' '.join(a_words))
157 |
158 |
159 | #随机删除rd
160 | for _ in range(num_new_per_technique):
161 | a_words = random_deletion(words, p_rd)
162 | augmented_sentences.append(' '.join(a_words))
163 |
164 | #print(augmented_sentences)
165 | shuffle(augmented_sentences)
166 |
167 | if num_aug >= 1:
168 | augmented_sentences = augmented_sentences[:num_aug]
169 | else:
170 | keep_prob = num_aug / len(augmented_sentences)
171 | augmented_sentences = [s for s in augmented_sentences if random.uniform(0, 1) < keep_prob]
172 |
173 | augmented_sentences.append(seg_list)
174 |
175 | return augmented_sentences
176 |
177 | ##
178 | #测试用例
179 | #eda(sentence="我们就像蒲公英,我也祈祷着能和你飞去同一片土地")
180 |
--------------------------------------------------------------------------------