├── .gitattributes
├── .github
├── README.md
└── workflows
│ └── sync-to-hf.yaml
├── .gitignore
├── LICENSE
├── README-main.md
├── README.md
├── autoagents
├── __init__.py
├── agents
│ ├── __init__.py
│ ├── agents
│ │ ├── __init__.py
│ │ ├── search.py
│ │ ├── search_v3.py
│ │ └── wiki_agent.py
│ ├── models
│ │ └── custom.py
│ ├── spaces
│ │ └── app.py
│ ├── tools
│ │ ├── __init__.py
│ │ └── tools.py
│ └── utils
│ │ ├── __init__.py
│ │ ├── constants.py
│ │ └── logger.py
├── data
│ ├── action_name_transformation.py
│ ├── create_sft_dataset.py
│ ├── dataset.py
│ ├── generate_action_data.py
│ └── generate_action_tasks
│ │ ├── REACT.ipynb
│ │ ├── README.md
│ │ ├── generate_data.py
│ │ ├── generate_data_chat_api.py
│ │ ├── goals_test.json
│ │ ├── goals_train.json
│ │ ├── goals_valid.json
│ │ ├── previous_goals.json
│ │ ├── prompt.txt
│ │ ├── requirements.txt
│ │ ├── run_genenerate_data.sh
│ │ ├── seed_tasks_test.jsonl
│ │ ├── seed_tasks_train.jsonl
│ │ ├── seed_tasks_valid.jsonl
│ │ └── utils.py
├── eval
│ ├── README.md
│ ├── __init__.py
│ ├── bamboogle.py
│ ├── hotpotqa
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── constants.py
│ │ ├── eval_async.py
│ │ ├── hotpotqa_eval.py
│ │ └── run_eval.py
│ ├── metrics.py
│ ├── reward
│ │ ├── eval.py
│ │ └── get_scores.py
│ └── test.py
├── serve
│ ├── README.md
│ ├── action_api_server.py
│ ├── action_model_worker.py
│ ├── controller.sh
│ ├── model_worker.sh
│ ├── openai_api.sh
│ └── serve_rescale.py
└── train
│ ├── README.md
│ ├── scripts
│ ├── action_finetuning.sh
│ ├── action_finetuning_v3.sh
│ ├── conv_finetuning.sh
│ ├── longchat_action_finetuning.sh
│ └── longchat_conv_finetuning.sh
│ ├── test_v3_preprocess.py
│ ├── train.py
│ └── train_v3.py
├── requirements.txt
└── setup.py
/.gitattributes:
--------------------------------------------------------------------------------
1 | *.7z filter=lfs diff=lfs merge=lfs -text
2 | *.arrow filter=lfs diff=lfs merge=lfs -text
3 | *.bin filter=lfs diff=lfs merge=lfs -text
4 | *.bz2 filter=lfs diff=lfs merge=lfs -text
5 | *.ckpt filter=lfs diff=lfs merge=lfs -text
6 | *.ftz filter=lfs diff=lfs merge=lfs -text
7 | *.gz filter=lfs diff=lfs merge=lfs -text
8 | *.h5 filter=lfs diff=lfs merge=lfs -text
9 | *.joblib filter=lfs diff=lfs merge=lfs -text
10 | *.lfs.* filter=lfs diff=lfs merge=lfs -text
11 | *.mlmodel filter=lfs diff=lfs merge=lfs -text
12 | *.model filter=lfs diff=lfs merge=lfs -text
13 | *.msgpack filter=lfs diff=lfs merge=lfs -text
14 | *.npy filter=lfs diff=lfs merge=lfs -text
15 | *.npz filter=lfs diff=lfs merge=lfs -text
16 | *.onnx filter=lfs diff=lfs merge=lfs -text
17 | *.ot filter=lfs diff=lfs merge=lfs -text
18 | *.parquet filter=lfs diff=lfs merge=lfs -text
19 | *.pb filter=lfs diff=lfs merge=lfs -text
20 | *.pickle filter=lfs diff=lfs merge=lfs -text
21 | *.pkl filter=lfs diff=lfs merge=lfs -text
22 | *.pt filter=lfs diff=lfs merge=lfs -text
23 | *.pth filter=lfs diff=lfs merge=lfs -text
24 | *.rar filter=lfs diff=lfs merge=lfs -text
25 | *.safetensors filter=lfs diff=lfs merge=lfs -text
26 | saved_model/**/* filter=lfs diff=lfs merge=lfs -text
27 | *.tar.* filter=lfs diff=lfs merge=lfs -text
28 | *.tflite filter=lfs diff=lfs merge=lfs -text
29 | *.tgz filter=lfs diff=lfs merge=lfs -text
30 | *.wasm filter=lfs diff=lfs merge=lfs -text
31 | *.xz filter=lfs diff=lfs merge=lfs -text
32 | *.zip filter=lfs diff=lfs merge=lfs -text
33 | *.zst filter=lfs diff=lfs merge=lfs -text
34 | *tfevents* filter=lfs diff=lfs merge=lfs -text
35 |
--------------------------------------------------------------------------------
/.github/README.md:
--------------------------------------------------------------------------------
1 | ../README-main.md
--------------------------------------------------------------------------------
/.github/workflows/sync-to-hf.yaml:
--------------------------------------------------------------------------------
1 | name: Sync to Hugging Face hub
2 | on:
3 | push:
4 | branches: [main]
5 |
6 | # to run this workflow manually from the Actions tab
7 | workflow_dispatch:
8 |
9 | jobs:
10 | sync-to-hub:
11 | runs-on: ubuntu-latest
12 | steps:
13 | - uses: actions/checkout@v3
14 | with:
15 | fetch-depth: 0
16 | lfs: true
17 | ref: hf-active
18 | - name: Push to hub
19 | env:
20 | HF_TOKEN: ${{ secrets.HF_TOKEN }}
21 | run: git push https://omkarenator:$HF_TOKEN@huggingface.co/spaces/AutoLLM/AutoAgents hf-active:main
22 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | share/python-wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 | MANIFEST
28 | .DS_Store
29 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 AutoLLM
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README-main.md:
--------------------------------------------------------------------------------
1 | # AutoAgents
2 |
3 | 
4 |
5 | Unlock complex question answering in LLMs with enhanced chain-of-thought reasoning and information-seeking capabilities.
6 |
7 | ## 👉 Overview
8 |
9 | The purpose of this project is to extend LLMs ability to answer more complex questions through chain-of-thought reasoning and information-seeking actions.
10 |
11 | We are excited to release the initial version of AutoAgents, a proof-of-concept on what can be achieved with only well-written prompts. This is the initial step towards our first big milestone, releasing and open-sourcing the AutoAgents 7B model!
12 |
13 | Come try out our [Huggingface Space](https://huggingface.co/spaces/AutoLLM/AutoAgents)!
14 |
15 |
16 |
17 | ## 🤖 The AutoAgents Project
18 |
19 | This project demonstrates LLMs capability to execute a complex user goal: understand a user's goal, generate a plan, use proper tools, and deliver a final result.
20 |
21 | For simplicity, our first attempt starts with a Web Search Agent.
22 |
23 |
24 |
25 | ## 💫 How it works:
26 |
27 | 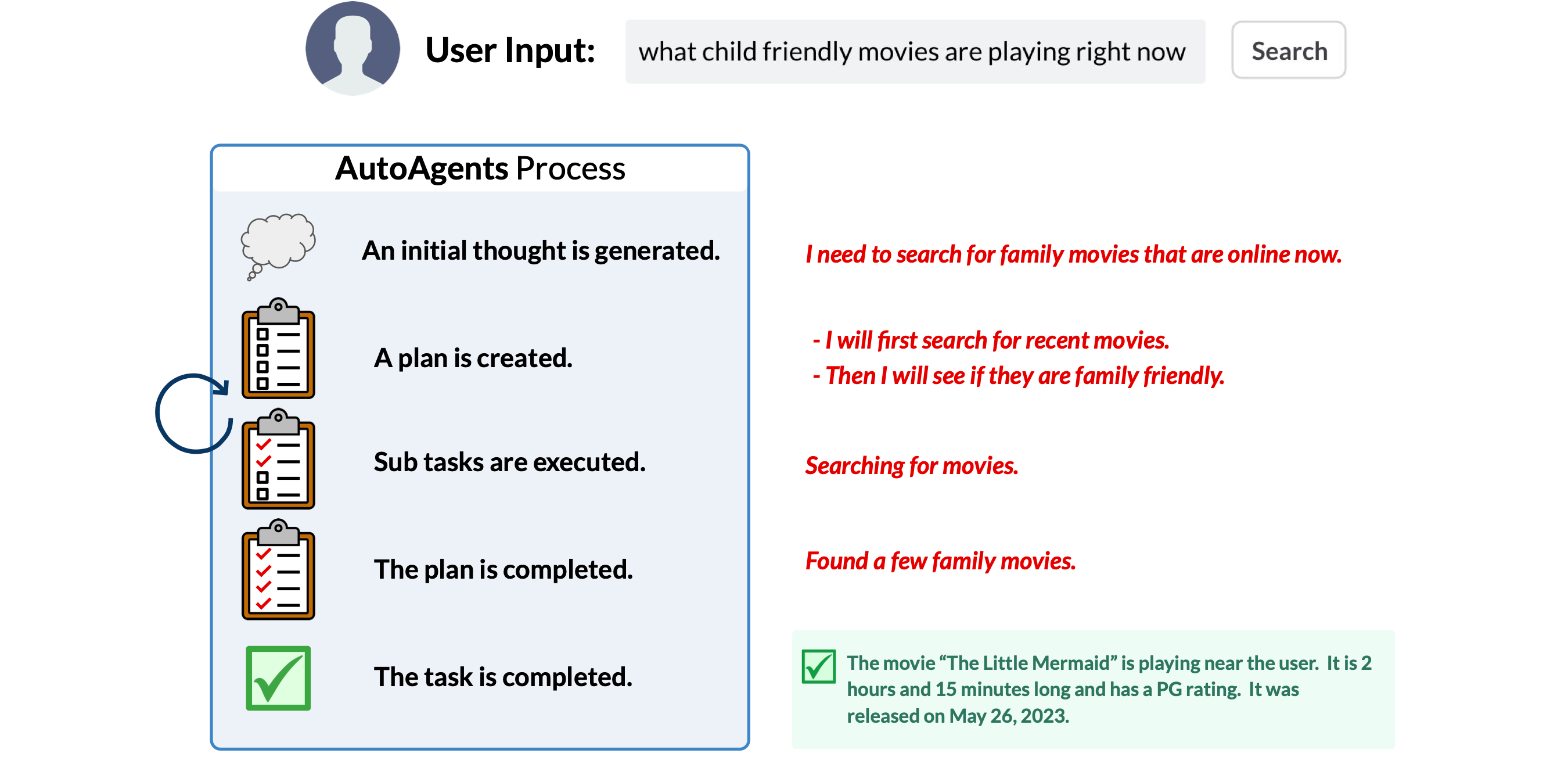
28 |
29 |
30 |
31 | ## 📔 Examples
32 |
33 | Ask your AutoAgent to do what a real person would do using the internet:
34 |
35 | For example:
36 |
37 | *1. Recommend a kid friendly movie that is playing at a theater near Sunnyvale. Give me the showtimes and a link to purchase the tickets*
38 |
39 | *2. What is the average age of the past three president when they took office*
40 |
41 | *3. What is the mortgage rate right now and how does that compare to the past two years*
42 |
43 |
44 |
45 | ## 💁 Roadmap
46 |
47 | * ~~HuggingFace Space demo using OpenAI models~~ [LINK](https://huggingface.co/spaces/AutoLLM/AutoAgents)
48 | * AutoAgents [7B] Model
49 | * Initial Release:
50 | * Finetune and release a 7B parameter fine-tuned search model
51 | * AutoAgents Dataset
52 | * A high-quality dataset for a diverse set of search scenarios (why quality and diversity?[1](https://arxiv.org/abs/2305.11206))
53 | * Reduce Model Inference Overhead
54 | * Affordance Modeling [2](https://en.wikipedia.org/wiki/Affordance)
55 | * Extend Support to Additional Tools
56 | * Customizable Document Search set (e.g. personal documents)
57 | * Support Multi-turn Dialogue
58 | * Advanced Flow Control in Plan Execution
59 |
60 | We are actively developing a few interesting things, check back here or follow us on [Twitter](https://twitter.com/AutoLLM) for any new development.
61 |
62 | If you are interested in any other problems, feel free to shoot us an issue.
63 |
64 |
65 |
66 | ## 🧭 How to use this repo?
67 |
68 | This repo contains the entire code to run the search agent from your local browser. All you need is an OpenAI API key to begin.
69 |
70 | To run the search agent locally:
71 |
72 | 1. Clone the repo and change the directory
73 |
74 | ```bash
75 | git clone https://github.com/AutoLLM/AutoAgents.git
76 | cd AutoAgents
77 | ```
78 |
79 | 2. Install the dependencies
80 |
81 | ```bash
82 | pip install -r requirements.txt
83 | ```
84 |
85 | 3. Install the `autoagents` package
86 |
87 | ```bash
88 | pip install -e .
89 | ```
90 |
91 | 4. Make sure you have your OpenAI API key set as an environment variable. Alternatively, you can also feed it through the input text-box on the sidebar.
92 |
93 | ```bash
94 | export OPENAI_API_KEY=sk-xxxxxx
95 | ```
96 |
97 | 5. Run the Streamlit app
98 |
99 | ```bash
100 | streamlit run autoagents/agents/spaces/app.py
101 | ```
102 |
103 | This should open a browser window where you can type your search query.
104 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: AutoAgents
3 | emoji: 🐢
4 | colorFrom: green
5 | colorTo: purple
6 | sdk: streamlit
7 | sdk_version: 1.21.0
8 | python_version: 3.10.11
9 | app_file: autoagents/spaces/app.py
10 | pinned: true
11 | ---
12 |
13 | Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
14 |
--------------------------------------------------------------------------------
/autoagents/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AutoLLM/AutoAgents/e1210c7884f951f1b90254e40c162e81fc1442f3/autoagents/__init__.py
--------------------------------------------------------------------------------
/autoagents/agents/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AutoLLM/AutoAgents/e1210c7884f951f1b90254e40c162e81fc1442f3/autoagents/agents/__init__.py
--------------------------------------------------------------------------------
/autoagents/agents/agents/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AutoLLM/AutoAgents/e1210c7884f951f1b90254e40c162e81fc1442f3/autoagents/agents/agents/__init__.py
--------------------------------------------------------------------------------
/autoagents/agents/agents/search.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import uuid
4 | import re
5 | from datetime import date
6 | import asyncio
7 | from collections import defaultdict
8 | from pprint import pprint
9 | from typing import List, Union, Any, Optional, Dict
10 |
11 | from langchain.agents import Tool, AgentExecutor, LLMSingleActionAgent, AgentOutputParser
12 | from langchain.prompts import StringPromptTemplate
13 | from langchain import LLMChain
14 | from langchain.chat_models import ChatOpenAI
15 | from langchain.schema import AgentAction, AgentFinish
16 | from langchain.callbacks import get_openai_callback
17 | from langchain.callbacks.base import AsyncCallbackHandler
18 | from langchain.callbacks.manager import AsyncCallbackManager
19 | from langchain.base_language import BaseLanguageModel
20 |
21 | from autoagents.agents.tools.tools import search_tool, note_tool, rewrite_search_query, finish_tool
22 | from autoagents.agents.utils.logger import InteractionsLogger
23 | from autoagents.agents.utils.constants import LOG_SAVE_DIR
24 |
25 | from pydantic import BaseModel, ValidationError, Extra # pydantic==1.10.11
26 |
27 |
28 | class InterOutputSchema(BaseModel):
29 | thought: str
30 | reasoning: str
31 | plan: List[str]
32 | action: str
33 | action_input: str
34 | class Config:
35 | extra = Extra.forbid
36 |
37 |
38 | class FinalOutputSchema(BaseModel):
39 | thought: str
40 | reasoning: str
41 | plan: List[str]
42 | action: str
43 | action_input: str
44 | citations: List[str]
45 | class Config:
46 | extra = Extra.forbid
47 |
48 |
49 | def check_valid(o):
50 | try:
51 | if o.get("action") == "Tool_Finish":
52 | FinalOutputSchema(**o)
53 | else:
54 | InterOutputSchema(**o)
55 | except ValidationError:
56 | return False
57 | return True
58 |
59 |
60 | # Set up the base template
61 | template = """We are working together to satisfy the user's original goal
62 | step-by-step. Play to your strengths as an LLM. Make sure the plan is
63 | achievable using the available tools. The final answer should be descriptive,
64 | and should include all relevant details.
65 |
66 | Today is {today}.
67 |
68 | ## Goal:
69 | {input}
70 |
71 | If you require assistance or additional information, you should use *only* one
72 | of the following tools: {tools}.
73 |
74 | ## History
75 | {agent_scratchpad}
76 |
77 | Do not repeat any past actions in History, because you will not get additional
78 | information. If the last action is Tool_Search, then you should use Tool_Notepad to keep
79 | critical information. If you have gathered all information in your plannings
80 | to satisfy the user's original goal, then respond immediately with the Finish
81 | Action.
82 |
83 | ## Output format
84 | You MUST produce JSON output with below keys:
85 | "thought": "current train of thought",
86 | "reasoning": "reasoning",
87 | "plan": [
88 | "short bulleted",
89 | "list that conveys",
90 | "next-step plan",
91 | ],
92 | "action": "the action to take",
93 | "action_input": "the input to the Action",
94 | """
95 |
96 |
97 | # Set up a prompt template
98 | class CustomPromptTemplate(StringPromptTemplate):
99 | # The template to use
100 | template: str
101 | # The list of tools available
102 | tools: List[Tool]
103 | ialogger: InteractionsLogger
104 |
105 | def format(self, **kwargs) -> str:
106 | # Get the intermediate steps [(AgentAction, Observation)]
107 | # Format them in a particular way
108 | intermediate_steps = kwargs.pop("intermediate_steps")
109 | history = []
110 | # Set the agent_scratchpad variable to that value
111 | for i, (action, observation) in enumerate(intermediate_steps):
112 | if action.tool not in [tool.name for tool in self.tools]:
113 | raise Exception("Invalid tool requested by the model.")
114 | parsed = json.loads(action.log)
115 | if i == len(intermediate_steps) - 1:
116 | # Add observation only for the last action
117 | parsed["observation"] = observation
118 | history.append(parsed)
119 | self.ialogger.add_history(history)
120 | kwargs["agent_scratchpad"] = json.dumps(history)
121 | # Create a tools variable from the list of tools provided
122 | kwargs["tools"] = "\n".join([f"{tool.name}: {tool.description}" for tool in self.tools])
123 | # Create a list of tool names for the tools provided
124 | kwargs["tool_names"] = ", ".join([tool.name for tool in self.tools])
125 | kwargs["today"] = date.today()
126 | final_prompt = self.template.format(**kwargs)
127 | self.ialogger.add_system(final_prompt)
128 | return final_prompt
129 |
130 |
131 | class CustomOutputParser(AgentOutputParser):
132 | class Config:
133 | arbitrary_types_allowed = True
134 | ialogger: InteractionsLogger
135 | llm: BaseLanguageModel
136 | new_action_input: Optional[str]
137 | action_history = defaultdict(set)
138 |
139 | def parse(self, llm_output: str) -> Union[AgentAction, AgentFinish]:
140 | self.ialogger.add_ai(llm_output)
141 | parsed = json.loads(llm_output)
142 | if not check_valid(parsed):
143 | raise ValueError(f"Could not parse LLM output: `{llm_output}`")
144 |
145 | # Parse out the action and action input
146 | action = parsed["action"]
147 | action_input = parsed["action_input"]
148 |
149 | if action == "Tool_Finish":
150 | return AgentFinish(return_values={"output": action_input}, log=llm_output)
151 |
152 | if action_input in self.action_history[action]:
153 | new_action_input = rewrite_search_query(action_input,
154 | self.action_history[action],
155 | self.llm)
156 | self.ialogger.add_message({"query_rewrite": True})
157 | self.new_action_input = new_action_input
158 | self.action_history[action].add(new_action_input)
159 | return AgentAction(tool=action, tool_input=new_action_input, log=llm_output)
160 | else:
161 | # Return the action and action input
162 | self.action_history[action].add(action_input)
163 | return AgentAction(tool=action, tool_input=action_input, log=llm_output)
164 |
165 |
166 | class ActionRunner:
167 | def __init__(self,
168 | outputq,
169 | llm: BaseLanguageModel,
170 | persist_logs: bool = False,
171 | prompt_template: str = template,
172 | tools: List[Tool] = [search_tool, note_tool, finish_tool]):
173 | self.ialogger = InteractionsLogger(name=f"{uuid.uuid4().hex[:6]}", persist=persist_logs)
174 | prompt = CustomPromptTemplate(template=prompt_template,
175 | tools=tools,
176 | input_variables=["input", "intermediate_steps"],
177 | ialogger=self.ialogger)
178 |
179 | output_parser = CustomOutputParser(ialogger=self.ialogger, llm=llm)
180 | self.model_name = llm.model_name
181 |
182 | class MyCustomHandler(AsyncCallbackHandler):
183 | def __init__(self):
184 | pass
185 |
186 | async def on_chain_end(self, outputs, **kwargs) -> None:
187 | if "text" in outputs:
188 | await outputq.put(outputs["text"])
189 |
190 | async def on_agent_action(
191 | self,
192 | action: AgentAction,
193 | *,
194 | run_id: uuid.UUID,
195 | parent_run_id: Optional[uuid.UUID] = None,
196 | **kwargs: Any,
197 | ) -> None:
198 | if (new_action_input := output_parser.new_action_input):
199 | await outputq.put(RuntimeWarning(f"Action Input Rewritten: {new_action_input}"))
200 | # Notify users
201 | output_parser.new_action_input = None
202 |
203 | async def on_tool_start(
204 | self,
205 | serialized: Dict[str, Any],
206 | input_str: str,
207 | *,
208 | run_id: uuid.UUID,
209 | parent_run_id: Optional[uuid.UUID] = None,
210 | **kwargs: Any,
211 | ) -> None:
212 | pass
213 |
214 | async def on_tool_end(
215 | self,
216 | output: str,
217 | *,
218 | run_id: uuid.UUID,
219 | parent_run_id: Optional[uuid.UUID] = None,
220 | **kwargs: Any,
221 | ) -> None:
222 | await outputq.put(output)
223 |
224 | handler = MyCustomHandler()
225 |
226 | llm_chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler])
227 | tool_names = [tool.name for tool in tools]
228 | for tool in tools:
229 | tool.callbacks = [handler]
230 |
231 | agent = LLMSingleActionAgent(
232 | llm_chain=llm_chain,
233 | output_parser=output_parser,
234 | stop=["0xdeadbeef"], # required
235 | allowed_tools=tool_names
236 | )
237 | callback_manager = AsyncCallbackManager([handler])
238 |
239 | # Finally create the Executor
240 | self.agent_executor = AgentExecutor.from_agent_and_tools(agent=agent,
241 | tools=tools,
242 | verbose=False,
243 | callback_manager=callback_manager)
244 |
245 | async def run(self, goal: str, outputq, save_dir=LOG_SAVE_DIR):
246 | self.ialogger.set_goal(goal)
247 | try:
248 | with get_openai_callback() as cb:
249 | output = await self.agent_executor.arun(goal)
250 | self.ialogger.add_cost({"total_tokens": cb.total_tokens,
251 | "prompt_tokens": cb.prompt_tokens,
252 | "completion_tokens": cb.completion_tokens,
253 | "total_cost": cb.total_cost,
254 | "successful_requests": cb.successful_requests})
255 | self.ialogger.save(save_dir)
256 | except Exception as e:
257 | self.ialogger.add_message({"error": str(e)})
258 | self.ialogger.save(save_dir)
259 | await outputq.put(e)
260 | return
261 | return output
262 |
--------------------------------------------------------------------------------
/autoagents/agents/agents/search_v3.py:
--------------------------------------------------------------------------------
1 | from datetime import date
2 | import json
3 | import uuid
4 | from collections import defaultdict
5 | from typing import List, Union, Any, Optional, Dict
6 |
7 | from langchain.agents import Tool, AgentExecutor, LLMSingleActionAgent, AgentOutputParser
8 | from langchain.prompts import StringPromptTemplate
9 | from langchain import LLMChain
10 | from langchain.schema import AgentAction, AgentFinish
11 | from langchain.callbacks import get_openai_callback
12 | from langchain.callbacks.base import AsyncCallbackHandler
13 | from langchain.callbacks.manager import AsyncCallbackManager
14 | from langchain.base_language import BaseLanguageModel
15 |
16 | from autoagents.agents.tools.tools import search_tool_v3, note_tool_v3, finish_tool_v3
17 | from autoagents.agents.utils.logger import InteractionsLogger
18 | from autoagents.agents.utils.constants import LOG_SAVE_DIR
19 | from autoagents.agents.agents.search import check_valid
20 |
21 |
22 | # Set up a prompt template
23 | class CustomPromptTemplate(StringPromptTemplate):
24 | # The list of tools available
25 | tools: List[Tool]
26 | ialogger: InteractionsLogger
27 |
28 | def format(self, **kwargs) -> str:
29 | # Get the intermediate steps [(AgentAction, Observation)]
30 | # Format them in a particular way
31 | intermediate_steps = kwargs.pop("intermediate_steps")
32 | history = []
33 | # Set the agent_scratchpad variable to that value
34 | for i, (action, observation) in enumerate(intermediate_steps):
35 | if action.tool not in [tool.name for tool in self.tools]:
36 | raise Exception("Invalid tool requested by the model.")
37 | parsed = json.loads(action.log)
38 | if i == len(intermediate_steps) - 1:
39 | # Add observation only for the last action
40 | parsed["observation"] = observation
41 | history.append(parsed)
42 | self.ialogger.add_history(history)
43 | goal = kwargs["input"]
44 | goal = f"Today is {date.today()}. {goal}"
45 | list_prompt =[]
46 | list_prompt.append({"role": "goal", "content": goal})
47 | list_prompt.append({"role": "tools", "content": [{tool.name: tool.description} for tool in self.tools]})
48 | list_prompt.append({"role": "history", "content": history})
49 | return json.dumps(list_prompt)
50 |
51 |
52 | class CustomOutputParser(AgentOutputParser):
53 | class Config:
54 | arbitrary_types_allowed = True
55 | ialogger: InteractionsLogger
56 | llm: BaseLanguageModel
57 | new_action_input: Optional[str]
58 | action_history = defaultdict(set)
59 |
60 | def parse(self, llm_output: str) -> Union[AgentAction, AgentFinish]:
61 | try:
62 | parsed = json.loads(llm_output)
63 | except json.decoder.JSONDecodeError:
64 | raise ValueError(f"Could not parse LLM output: `{llm_output}`")
65 | if not check_valid(parsed):
66 | raise ValueError(f"Could not parse LLM output: `{llm_output}`")
67 | self.ialogger.add_ai(llm_output)
68 | # Parse out the action and action input
69 | action = parsed["action"]
70 | action_input = parsed["action_input"]
71 |
72 | if action == "Tool_Finish":
73 | return AgentFinish(return_values={"output": action_input}, log=llm_output)
74 | return AgentAction(tool=action, tool_input=action_input, log=llm_output)
75 |
76 |
77 | class ActionRunnerV3:
78 | def __init__(self,
79 | outputq,
80 | llm: BaseLanguageModel,
81 | persist_logs: bool = False,
82 | tools = [search_tool_v3, note_tool_v3, finish_tool_v3]):
83 | self.ialogger = InteractionsLogger(name=f"{uuid.uuid4().hex[:6]}", persist=persist_logs)
84 | self.ialogger.set_tools([{tool.name: tool.description} for tool in tools])
85 | prompt = CustomPromptTemplate(tools=tools,
86 | input_variables=["input", "intermediate_steps"],
87 | ialogger=self.ialogger)
88 | output_parser = CustomOutputParser(ialogger=self.ialogger, llm=llm)
89 |
90 | class MyCustomHandler(AsyncCallbackHandler):
91 | def __init__(self):
92 | pass
93 |
94 | async def on_chain_end(self, outputs, **kwargs) -> None:
95 | if "text" in outputs:
96 | await outputq.put(outputs["text"])
97 |
98 | async def on_agent_action(
99 | self,
100 | action: AgentAction,
101 | *,
102 | run_id: uuid.UUID,
103 | parent_run_id: Optional[uuid.UUID] = None,
104 | **kwargs: Any,
105 | ) -> None:
106 | pass
107 |
108 | async def on_tool_start(
109 | self,
110 | serialized: Dict[str, Any],
111 | input_str: str,
112 | *,
113 | run_id: uuid.UUID,
114 | parent_run_id: Optional[uuid.UUID] = None,
115 | **kwargs: Any,
116 | ) -> None:
117 | pass
118 |
119 | async def on_tool_end(
120 | self,
121 | output: str,
122 | *,
123 | run_id: uuid.UUID,
124 | parent_run_id: Optional[uuid.UUID] = None,
125 | **kwargs: Any,
126 | ) -> None:
127 | await outputq.put(output)
128 |
129 | handler = MyCustomHandler()
130 | llm_chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler])
131 | tool_names = [tool.name for tool in tools]
132 | for tool in tools:
133 | tool.callbacks = [handler]
134 |
135 | agent = LLMSingleActionAgent(
136 | llm_chain=llm_chain,
137 | output_parser=output_parser,
138 | stop=["0xdeadbeef"], # required
139 | allowed_tools=tool_names
140 | )
141 | callback_manager = AsyncCallbackManager([handler])
142 | # Finally create the Executor
143 | self.agent_executor = AgentExecutor.from_agent_and_tools(agent=agent,
144 | tools=tools,
145 | verbose=False,
146 | callback_manager=callback_manager)
147 |
148 | async def run(self, goal: str, outputq, save_dir=LOG_SAVE_DIR):
149 | goal = f"Today is {date.today()}. {goal}"
150 | self.ialogger.set_goal(goal)
151 | try:
152 | with get_openai_callback() as cb:
153 | output = await self.agent_executor.arun(goal)
154 | self.ialogger.add_cost({"total_tokens": cb.total_tokens,
155 | "prompt_tokens": cb.prompt_tokens,
156 | "completion_tokens": cb.completion_tokens,
157 | "total_cost": cb.total_cost,
158 | "successful_requests": cb.successful_requests})
159 | self.ialogger.save(save_dir)
160 | except Exception as e:
161 | self.ialogger.add_message({"error": str(e)})
162 | self.ialogger.save(save_dir)
163 | await outputq.put(e)
164 | return
165 | return output
166 |
--------------------------------------------------------------------------------
/autoagents/agents/agents/wiki_agent.py:
--------------------------------------------------------------------------------
1 | from langchain.base_language import BaseLanguageModel
2 | from autoagents.agents.agents.search import ActionRunner
3 | from autoagents.agents.agents.search_v3 import ActionRunnerV3
4 | from autoagents.agents.tools.tools import wiki_dump_search_tool, wiki_note_tool, finish_tool
5 |
6 |
7 | # Set up the base template
8 | template = """We are working together to satisfy the user's original goal
9 | step-by-step. Play to your strengths as an LLM. Make sure the plan is
10 | achievable using the available tools. The final answer should be descriptive,
11 | and should include all relevant details.
12 |
13 | Today is {today}.
14 |
15 | ## Goal:
16 | {input}
17 |
18 | If you require assistance or additional information, you should use *only* one
19 | of the following tools: {tools}.
20 |
21 | ## History
22 | {agent_scratchpad}
23 |
24 | Do not repeat any past actions in History, because you will not get additional
25 | information. If the last action is Tool_Wikipedia, then you should use Tool_Notepad to keep
26 | critical information. If you have gathered all information in your plannings
27 | to satisfy the user's original goal, then respond immediately with the Finish
28 | Action.
29 |
30 | ## Output format
31 | You MUST produce JSON output with below keys:
32 | "thought": "current train of thought",
33 | "reasoning": "reasoning",
34 | "plan": [
35 | "short bulleted",
36 | "list that conveys",
37 | "next-step plan",
38 | ],
39 | "action": "the action to take",
40 | "action_input": "the input to the Action",
41 | """
42 |
43 |
44 | class WikiActionRunner(ActionRunner):
45 |
46 | def __init__(self, outputq, llm: BaseLanguageModel, persist_logs: bool = False):
47 |
48 | super().__init__(
49 | outputq, llm, persist_logs,
50 | prompt_template=template,
51 | tools=[wiki_dump_search_tool, wiki_note_tool, finish_tool]
52 | )
53 |
54 | class WikiActionRunnerV3(ActionRunnerV3):
55 | def __init__(self, outputq, llm: BaseLanguageModel, persist_logs: bool = False):
56 |
57 | super().__init__(
58 | outputq, llm, persist_logs,
59 | tools=[wiki_dump_search_tool, wiki_note_tool, finish_tool]
60 | )
61 |
--------------------------------------------------------------------------------
/autoagents/agents/models/custom.py:
--------------------------------------------------------------------------------
1 | import requests
2 | import json
3 |
4 | from langchain.llms.base import LLM
5 |
6 |
7 | class CustomLLM(LLM):
8 | model_name: str
9 | completions_url: str = "http://localhost:8000/v1/chat/completions"
10 | temperature: float = 0.
11 | max_tokens: int = 1024
12 |
13 | @property
14 | def _llm_type(self) -> str:
15 | return "custom"
16 |
17 | def _call(self, prompt: str, stop=None) -> str:
18 | r = requests.post(
19 | self.completions_url,
20 | json={
21 | "model": self.model_name,
22 | "messages": [{"role": "user", "content": prompt}],
23 | "stop": stop,
24 | "temperature": self.temperature,
25 | "max_tokens": self.max_tokens
26 | },
27 | )
28 | result = r.json()
29 | try:
30 | return result["choices"][0]["message"]["content"]
31 | except:
32 | raise RuntimeError(result)
33 |
34 | async def _acall(self, prompt: str, stop=None) -> str:
35 | return self._call(prompt, stop)
36 |
37 |
38 | class CustomLLMV3(LLM):
39 | model_name: str
40 | completions_url: str = "http://localhost:8004/v1/completions"
41 | temperature: float = 0.
42 | max_tokens: int = 1024
43 |
44 | @property
45 | def _llm_type(self) -> str:
46 | return "custom"
47 |
48 | def _call(self, prompt: str, stop=None) -> str:
49 | r = requests.post(
50 | self.completions_url,
51 | json={
52 | "model": self.model_name,
53 | "prompt": json.loads(prompt),
54 | "stop": "\n\n",
55 | "temperature": self.temperature,
56 | "max_tokens": self.max_tokens
57 | },
58 | )
59 | result = r.json()
60 | if result.get("object") == "error":
61 | raise RuntimeError(result.get("message"))
62 | else:
63 | return result["choices"][0]["text"]
64 |
65 | async def _acall(self, prompt: str, stop=None) -> str:
66 | return self._call(prompt, stop)
67 |
--------------------------------------------------------------------------------
/autoagents/agents/spaces/app.py:
--------------------------------------------------------------------------------
1 | import os
2 | import asyncio
3 | import json
4 | import random
5 | from datetime import date, datetime, timezone, timedelta
6 | from ast import literal_eval
7 |
8 | import streamlit as st
9 | import openai
10 |
11 | from autoagents.agents.utils.constants import MAIN_HEADER, MAIN_CAPTION, SAMPLE_QUESTIONS
12 | from autoagents.agents.agents.search import ActionRunner
13 |
14 | from langchain.chat_models import ChatOpenAI
15 |
16 |
17 | async def run():
18 | output_acc = ""
19 | st.session_state["random"] = random.randint(0, 99)
20 | if "task" not in st.session_state:
21 | st.session_state.task = None
22 | if "model_name" not in st.session_state:
23 | st.session_state.model_name = "gpt-3.5-turbo"
24 |
25 | st.set_page_config(
26 | page_title="Search Agent",
27 | page_icon="🤖",
28 | layout="wide",
29 | initial_sidebar_state="expanded",
30 | )
31 |
32 | st.title(MAIN_HEADER)
33 | st.caption(MAIN_CAPTION)
34 |
35 | with st.form("my_form", clear_on_submit=False):
36 | st.markdown("", unsafe_allow_html=True)
37 | user_input = st.text_input(
38 | "You: ",
39 | key="input",
40 | placeholder="Ask me anything ...",
41 | label_visibility="hidden",
42 | )
43 |
44 | submitted = st.form_submit_button(
45 | "Search", help="Hit to submit the search query."
46 | )
47 |
48 | # Ask the user to enter their OpenAI API key
49 | if (api_key := st.sidebar.text_input("OpenAI api-key", type="password")):
50 | api_org = None
51 | else:
52 | api_key, api_org = os.getenv("OPENAI_API_KEY"), os.getenv("OPENAI_API_ORG")
53 | with st.sidebar:
54 | model_dict = {
55 | "gpt-3.5-turbo": "GPT-3.5-turbo",
56 | "gpt-4": "GPT-4 (Better but slower)",
57 | }
58 | st.radio(
59 | "OpenAI model",
60 | model_dict.keys(),
61 | key="model_name",
62 | format_func=lambda x: model_dict[x],
63 | )
64 |
65 | time_zone = str(datetime.now(timezone(timedelta(0))).astimezone().tzinfo)
66 | st.markdown(f"**The system time zone is {time_zone} and the date is {date.today()}**")
67 |
68 | st.markdown("**Example Queries:**")
69 | for q in SAMPLE_QUESTIONS:
70 | st.markdown(f"*{q}*")
71 |
72 | if not api_key:
73 | st.warning(
74 | "API key required to try this app. The API key is not stored in any form. [This](https://help.openai.com/en/articles/4936850-where-do-i-find-my-secret-api-key) might help."
75 | )
76 | elif api_org and st.session_state.model_name == "gpt-4":
77 | st.warning(
78 | "The free API key does not support GPT-4. Please switch to GPT-3.5-turbo or input your own API key."
79 | )
80 | else:
81 | outputq = asyncio.Queue()
82 | runner = ActionRunner(outputq,
83 | ChatOpenAI(openai_api_key=api_key,
84 | openai_organization=api_org,
85 | temperature=0,
86 | model_name=st.session_state.model_name),
87 | persist_logs=True) # log to HF-dataset
88 |
89 | async def cleanup(e):
90 | st.error(e)
91 | await st.session_state.task
92 | st.session_state.task = None
93 | st.stop()
94 |
95 | placeholder = st.empty()
96 |
97 | if user_input and submitted:
98 | if st.session_state.task is not None:
99 | with placeholder.container():
100 | st.session_state.task.cancel()
101 | st.warning("Previous search aborted", icon="⚠️")
102 |
103 | st.session_state.task = asyncio.create_task(
104 | runner.run(user_input, outputq)
105 | )
106 | iterations = 0
107 | with st.expander("Search Results", expanded=True):
108 | while True:
109 | with st.spinner("Wait for it..."):
110 | output = await outputq.get()
111 | placeholder.empty()
112 | if isinstance(output, Exception):
113 | if isinstance(output, openai.error.AuthenticationError):
114 | await cleanup(f"AuthenticationError: Invalid OpenAI API key.")
115 | elif isinstance(output, openai.error.InvalidRequestError) \
116 | and output._message == "The model: `gpt-4` does not exist":
117 | await cleanup(f"The free API key does not support GPT-4. Please switch to GPT-3.5-turbo or input your own API key.")
118 | elif isinstance(output, openai.error.OpenAIError):
119 | await cleanup(output)
120 | elif isinstance(output, RuntimeWarning):
121 | st.warning(output)
122 | continue
123 | else:
124 | await cleanup("Something went wrong. Please try searching again.")
125 | return
126 | try:
127 | parsed = json.loads(output)
128 | st.json(output, expanded=True)
129 | st.write("---")
130 | iterations += 1
131 | if parsed.get("action") == "Finish":
132 | break
133 | except:
134 | output_fmt = literal_eval(output)
135 | st.json(output_fmt, expanded=False)
136 | if iterations >= runner.agent_executor.max_iterations:
137 | await cleanup(
138 | f"Maximum iterations ({iterations}) exceeded. You can try running the search again or try a variation of the query."
139 | )
140 | return
141 | # Found the answer
142 | final_answer = await st.session_state.task
143 | final_answer = final_answer.replace("$", "\$")
144 | # st.success accepts md
145 | st.success(final_answer, icon="✅")
146 | st.balloons()
147 | st.session_state.task = None
148 | st.stop()
149 |
150 | if __name__ == "__main__":
151 | loop = asyncio.new_event_loop()
152 | loop.set_debug(enabled=False)
153 | loop.run_until_complete(run())
154 |
--------------------------------------------------------------------------------
/autoagents/agents/tools/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AutoLLM/AutoAgents/e1210c7884f951f1b90254e40c162e81fc1442f3/autoagents/agents/tools/__init__.py
--------------------------------------------------------------------------------
/autoagents/agents/tools/tools.py:
--------------------------------------------------------------------------------
1 | import wikipedia
2 | import requests
3 | from elasticsearch import Elasticsearch
4 |
5 | from duckpy import Client
6 | from langchain import PromptTemplate, LLMChain, Wikipedia
7 | from langchain.agents import Tool
8 | from langchain.agents.react.base import DocstoreExplorer
9 |
10 | from langchain.base_language import BaseLanguageModel
11 |
12 |
13 | MAX_SEARCH_RESULTS = 5 # Number of search results to observe at a time
14 |
15 | INDEX_NAME = "wiki-dump-2017"
16 |
17 | # Create the client instance
18 | es_client = None
19 |
20 | search_description = """ Useful for when you need to ask with search. Use direct language and be
21 | EXPLICIT in what you want to search. Do NOT use filler words.
22 |
23 | ## Examples of incorrect use
24 | {
25 | "action": "Tool_Search",
26 | "action_input": "[name of bagel shop] menu"
27 | }
28 |
29 | The action_input cannot be None or empty.
30 | """
31 |
32 | notepad_description = """ Useful for when you need to note-down specific
33 | information for later reference. Please provide the website and full
34 | information you want to note-down in the action_input and all future prompts
35 | will remember it. This is the mandatory tool after using the Tool_Search.
36 | Using Tool_Notepad does not always lead to a final answer.
37 |
38 | ## Examples of using Notepad tool
39 | {
40 | "action": "Tool_Notepad",
41 | "action_input": "(www.website.com) the information you want to note-down"
42 | }
43 | """
44 |
45 | wiki_notepad_description = """ Useful for when you need to note-down specific
46 | information for later reference. Please provide the website and full
47 | information you want to note-down in the action_input and all future prompts
48 | will remember it. This is the mandatory tool after using the Tool_Wikipedia.
49 | Using Tool_Notepad does not always lead to a final answer.
50 |
51 | ## Examples of using Notepad tool
52 | {
53 | "action": "Tool_Notepad",
54 | "action_input": "(www.website.com) the information you want to note-down"
55 | }
56 | """
57 |
58 | wiki_search_description = """ Useful for when you need to get some information about a certain entity. Use direct language and be
59 | concise about what you want to retrieve. Note: the action input MUST be a wikipedia entity instead of a long sentence.
60 |
61 | ## Examples of correct use
62 | 1. Action: Tool_Wikipedia
63 | Action Input: Colorado orogeny
64 |
65 | The Action Input cannot be None or empty.
66 | """
67 |
68 | wiki_lookup_description = """ This tool is helpful when you want to retrieve sentences containing a specific text snippet after checking a Wikipedia entity.
69 | It should be utilized when a successful Wikipedia search does not provide sufficient information.
70 | Keep your lookup concise, using no more than three words.
71 |
72 | ## Examples of correct use
73 | 1. Action: Tool_Lookup
74 | Action Input: eastern sector
75 |
76 | The Action Input cannot be None or empty.
77 | """
78 |
79 |
80 | async def ddg(query: str):
81 | if query is None or query.lower().strip().strip('"') == "none" or query.lower().strip().strip('"') == "null":
82 | x = "The action_input field is empty. Please provide a search query."
83 | return [x]
84 | else:
85 | client = Client()
86 | return client.search(query)[:MAX_SEARCH_RESULTS]
87 |
88 | docstore=DocstoreExplorer(Wikipedia())
89 |
90 | async def notepad(x: str) -> str:
91 | return f"{[x]}"
92 |
93 | async def wikisearch(x: str) -> str:
94 | title_list = wikipedia.search(x)
95 | if not title_list:
96 | return docstore.search(x)
97 | title = title_list[0]
98 | return f"Wikipedia Page Title: {title}\nWikipedia Page Content: {docstore.search(title)}"
99 |
100 | async def wikilookup(x: str) -> str:
101 | return docstore.lookup(x)
102 |
103 | async def wikidumpsearch_es(x: str) -> str:
104 | global es_client
105 | if es_client is None:
106 | es_client = Elasticsearch("http://localhost:9200")
107 | resp = es_client.search(
108 | index=INDEX_NAME, query={"match": {"text": x}}, size=MAX_SEARCH_RESULTS
109 | )
110 | res = []
111 | for hit in resp['hits']['hits']:
112 | doc = hit["_source"]
113 | res.append({
114 | "title": doc["title"],
115 | "text": ''.join(sent for sent in doc["text"][1]),
116 | "url": doc["url"]
117 | })
118 | if doc["title"] == x:
119 | return [{
120 | "title": doc["title"],
121 | "text": '\n'.join(''.join(paras) for paras in doc["text"][1:3])
122 | if len(doc["text"]) > 2
123 | else '\n'.join(''.join(paras) for paras in doc["text"]),
124 | "url": doc["url"]
125 | }]
126 | return res
127 |
128 | async def wikidumpsearch_embed(x: str) -> str:
129 | res = []
130 | for obj in vector_search(x):
131 | paras = obj["text"].split('\n')
132 | cur = {
133 | "title": obj["sources"][0]["title"],
134 | "text": paras[min(1, len(paras) - 1)],
135 | "url": obj["sources"][0]["url"]
136 | }
137 | res.append(cur)
138 | if cur["title"] == x:
139 | return [{
140 | "title": obj["sources"][0]["title"],
141 | "text": '\n'.join(paras[1:3] if len(paras) > 2 else paras),
142 | "url": obj["sources"][0]["url"]
143 | }]
144 | return res
145 |
146 | def vector_search(
147 | query: str,
148 | url: str = "http://0.0.0.0:8080/query",
149 | max_candidates: int = MAX_SEARCH_RESULTS
150 | ):
151 | response = requests.post(
152 | url=url, json={"query_list": [query]}
153 | ).json()["result"][0]["top_answers"]
154 | return response[:min(max_candidates, len(response))]
155 |
156 |
157 | search_tool = Tool(name="Tool_Search",
158 | func=lambda x: x,
159 | coroutine=ddg,
160 | description=search_description)
161 |
162 | note_tool = Tool(name="Tool_Notepad",
163 | func=lambda x: x,
164 | coroutine=notepad,
165 | description=notepad_description)
166 |
167 | wiki_note_tool = Tool(name="Tool_Notepad",
168 | func=lambda x: x,
169 | coroutine=notepad,
170 | description=wiki_notepad_description)
171 |
172 | wiki_search_tool = Tool(
173 | name="Tool_Wikipedia",
174 | func=lambda x: x,
175 | coroutine=wikisearch,
176 | description=wiki_search_description
177 | )
178 |
179 | wiki_lookup_tool = Tool(
180 | name="Tool_Lookup",
181 | func=lambda x: x,
182 | coroutine=wikilookup,
183 | description=wiki_lookup_description
184 | )
185 |
186 | wiki_dump_search_tool = Tool(
187 | name="Tool_Wikipedia",
188 | func=lambda x: x,
189 | coroutine=wikidumpsearch_embed,
190 | description=wiki_search_description
191 | )
192 |
193 | async def final(x: str):
194 | pass
195 |
196 | finish_description = """ Useful when you have enough information to produce a
197 | final answer that achieves the original Goal.
198 |
199 | You must also include this key in the output for the Tool_Finish action
200 | "citations": ["www.example.com/a/list/of/websites: what facts you got from the website",
201 | "www.example.com/used/to/produce/the/action/and/action/input: "what facts you got from the website",
202 | "www.webiste.com/include/the/citations/from/the/previous/steps/as/well: "what facts you got from the website",
203 | "www.website.com": "this section is only needed for the final answer"]
204 |
205 | ## Examples of using Finish tool
206 | {
207 | "action": "Tool_Finish",
208 | "action_input": "final answer",
209 | "citations": ["www.example.com: what facts you got from the website"]
210 | }
211 | """
212 |
213 | finish_tool = Tool(name="Tool_Finish",
214 | func=lambda x: x,
215 | coroutine=final,
216 | description=finish_description)
217 |
218 | def rewrite_search_query(q: str, search_history, llm: BaseLanguageModel) -> str:
219 | history_string = '\n'.join(search_history)
220 | template ="""We are using the Search tool.
221 | # Previous queries:
222 | {history_string}. \n\n Rewrite query {action_input} to be
223 | different from the previous queries."""
224 | prompt = PromptTemplate(template=template,
225 | input_variables=["action_input", "history_string"])
226 | llm_chain = LLMChain(prompt=prompt, llm=llm)
227 | result = llm_chain.predict(action_input=q, history_string=history_string)
228 | return result
229 |
230 |
231 | ### Prompt V3 tools
232 |
233 | search_description_v3 = """Useful for when you need to ask with search."""
234 | notepad_description_v3 = """ Useful for when you need to note-down specific information for later reference."""
235 | finish_description_v3 = """Useful when you have enough information to produce a final answer that achieves the original Goal."""
236 |
237 | search_tool_v3 = Tool(name="Tool_Search",
238 | func=lambda x: x,
239 | coroutine=ddg,
240 | description=search_description_v3)
241 |
242 | note_tool_v3 = Tool(name="Tool_Notepad",
243 | func=lambda x: x,
244 | coroutine=notepad,
245 | description=notepad_description_v3)
246 |
247 | finish_tool_v3 = Tool(name="Tool_Finish",
248 | func=lambda x: x,
249 | coroutine=final,
250 | description=finish_description_v3)
251 |
--------------------------------------------------------------------------------
/autoagents/agents/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AutoLLM/AutoAgents/e1210c7884f951f1b90254e40c162e81fc1442f3/autoagents/agents/utils/__init__.py
--------------------------------------------------------------------------------
/autoagents/agents/utils/constants.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 |
4 | MAIN_HEADER = "Web Search Agent"
5 |
6 | MAIN_CAPTION = """This is a proof-of-concept search agent that reasons, plans,
7 | and executes web searches to collect information on your behalf. It aims to
8 | resolve your question by breaking it down into step-by-step subtasks. All the
9 | intermediate results will be presented.
10 |
11 | *DISCLAIMER*: We are collecting search queries, so please refrain from
12 | providing any personal information. If you wish to avoid this, you can run the
13 | app locally by following the instructions on our
14 | [Github](https://github.com/AutoLLM/AutoAgents)."""
15 |
16 | SAMPLE_QUESTIONS = [
17 | "Recommend me a movie in theater now to watch with kids.",
18 | "Who is the most recent NBA MVP? Which team does he play for? What are his career stats?",
19 | "Who is the head coach of AC Milan now? How long has he been coaching the team?",
20 | "What is the mortgage rate right now and how does that compare to the past two years?",
21 | "What is the weather like in San Francisco today? What about tomorrow?",
22 | "When and where is the upcoming concert for Taylor Swift? Share a link to purchase tickets.",
23 | "Find me recent studies focusing on hallucination in large language models. Provide the link to each study found.",
24 | ]
25 |
26 | LOG_SAVE_DIR: str = os.path.join(os.getcwd(), "data")
27 |
--------------------------------------------------------------------------------
/autoagents/agents/utils/logger.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | from typing import Dict, Any, List
4 | import uuid
5 | from datetime import datetime
6 | import pytz
7 |
8 | import huggingface_hub
9 | from huggingface_hub import Repository
10 |
11 | from autoagents.agents.utils.constants import LOG_SAVE_DIR
12 |
13 |
14 | class InteractionsLogger:
15 | def __init__(self, name: str, persist=False):
16 | self.persist = persist
17 | self.messages = []
18 | self.counter = 0
19 | self.name = name # unique id
20 | HF_TOKEN = os.environ.get("HF_TOKEN")
21 | HF_DATASET_REPO_URL = os.environ.get("HF_DATASET_REPO_URL")
22 | if (HF_TOKEN is not None) and (HF_DATASET_REPO_URL is not None):
23 | self.repo = Repository(
24 | local_dir="data", clone_from=HF_DATASET_REPO_URL, use_auth_token=HF_TOKEN
25 | )
26 | else:
27 | self.repo = None
28 |
29 | def set_goal(self, goal: str):
30 | self.messages.append({"goal": goal})
31 |
32 | def set_tools(self, tools: List):
33 | self.messages.append({"tools": tools})
34 |
35 | def add_history(self, hist: Dict):
36 | self.convos = [{"from": "history", "value": hist}]
37 |
38 | def add_ai(self, msg: Dict):
39 | self.convos.append({"from": "ai", "value": msg})
40 | self.messages.append({"id": f"{self.name}_{self.counter}", "conversations": self.convos})
41 | self.counter += 1
42 |
43 | def add_system(self, more: Dict):
44 | self.convos.append({"from": "system", "value": more})
45 |
46 | def add_message(self, data: Dict[str, Any]):
47 | self.messages.append(data)
48 |
49 | def save(self, save_dir=LOG_SAVE_DIR):
50 | self.add_message({"datetime": datetime.now(pytz.utc).strftime("%m/%d/%Y %H:%M:%S %Z%z")})
51 | if self.persist:
52 | if not os.path.isdir(save_dir):
53 | os.mkdir(save_dir)
54 | # TODO: want to add retry in a loop?
55 | if self.repo is not None:
56 | self.repo.git_pull()
57 | fname = uuid.uuid4().hex[:16]
58 | with open(os.path.join(save_dir, f"{fname}.json"), "w") as f:
59 | json.dump(self.messages, f, indent=2)
60 | if self.repo is not None:
61 | commit_url = self.repo.push_to_hub()
62 |
63 | def add_cost(self, cost):
64 | self.messages.append({"metrics": cost})
65 |
--------------------------------------------------------------------------------
/autoagents/data/action_name_transformation.py:
--------------------------------------------------------------------------------
1 | import json
2 | import uuid
3 | import argparse
4 |
5 |
6 | parser = argparse.ArgumentParser()
7 | parser.add_argument('input')
8 | parser.add_argument('output')
9 |
10 | args = parser.parse_args()
11 |
12 |
13 | def transform(conversation, search_word, notepad_word):
14 | for i, message in enumerate(conversation):
15 | conversation[i]["value"] = \
16 | message["value"].replace(
17 | "Tool_Search", search_word).replace(
18 | "Tool_Notepad", notepad_word)
19 | return conversation
20 |
21 |
22 | input_file = args.input
23 | output_file = args.output
24 |
25 | with open(input_file, "r") as f:
26 | body = json.load(f)
27 |
28 | result = []
29 | for elem in body:
30 | search_word = str(uuid.uuid4())[:6]
31 | notepad_word = str(uuid.uuid4())[:6]
32 | elem = {
33 | "id": elem["id"],
34 | "conversations": transform(elem["conversations"], search_word, notepad_word)}
35 | result.append(elem)
36 | with open(output_file, "w") as f:
37 | json.dump(result, f, indent=2)
38 |
--------------------------------------------------------------------------------
/autoagents/data/create_sft_dataset.py:
--------------------------------------------------------------------------------
1 | import json
2 | import glob
3 | from collections import Counter
4 | import argparse
5 |
6 | counts = Counter()
7 |
8 | Goals = set()
9 |
10 | def process_file(data, name):
11 | if name.startswith("train_data") or name.startswith("final") or name.startswith("ab_"):
12 | return
13 | for d in data:
14 | if "error" in d:
15 | counts["error"] += 1
16 | return
17 | elif "query_rewrite" in d:
18 | counts["query_rewrite"] += 1
19 | return
20 | output = json.loads(data[-3]["conversations"][2]["value"])
21 | if output["action"] != "Tool_Finish":
22 | counts["no_final_answer"] += 1
23 | return
24 | # remove dups in case
25 | goal = data[0]["goal"]
26 | if goal not in Goals:
27 | Goals.add(goal)
28 | else:
29 | return
30 | costs = data[-2]
31 | data = data[1:-2]
32 |
33 | counts["conv_len"] += len(data)
34 | counts["total"] += 1
35 |
36 | counts["totals_cost"] += costs["metrics"]["total_cost"]
37 | data_new = []
38 | for d in data:
39 | convs = []
40 | for conv in d["conversations"]:
41 | k, v = conv.values()
42 | if k == "system":
43 | convs.append({"from": "human", "value": v})
44 | elif k == "ai":
45 | convs.append({"from": "gpt", "value": v})
46 | assert len(convs) == 2
47 | data_new.append({"id": d["id"], "conversations": convs})
48 | return data_new
49 |
50 | def main(dir_path, save=False):
51 | assert dir_path is not None
52 | train_data = []
53 | for name in glob.glob(f"{dir_path}/*.json"):
54 | dname = name.split("/")[-1].split(".")[0]
55 | with open(f"{dir_path}/{dname}.json", "r") as file:
56 | data = json.load(file)
57 | if (filtered_data := process_file(data, dname)):
58 | train_data += filtered_data
59 | if save:
60 | with open(f"{dir_path}/sft_data.json", "w") as f:
61 | json.dump(train_data, f, indent=2)
62 | print(counts)
63 |
64 | if __name__ == "__main__":
65 | parser = argparse.ArgumentParser()
66 | parser.add_argument('data_dir_path', type=str)
67 | parser.add_argument("--save", action="store_true")
68 | args = parser.parse_args()
69 | main(args.data_dir_path, args.save)
70 |
71 |
--------------------------------------------------------------------------------
/autoagents/data/dataset.py:
--------------------------------------------------------------------------------
1 | import datetime
2 |
3 | BAMBOOGLE = {
4 | "questions": ['Who was president of the United States in the year that Citibank was founded?', 'What rocket was the first spacecraft that ever approached Uranus launched on?', 'In what year was the company that was founded as Sound of Music added to the S&P 500?', 'Who was the first African American mayor of the most populous city in the United States?', "When did the last king from Britain's House of Hanover die?", 'When did the president who set the precedent of a two term limit enter office?', 'When did the president who set the precedent of a two term limit leave office?', 'How many people died in the second most powerful earthquake ever recorded?', 'Can people who have celiac eat camel meat?', 'What was the final book written by the author of On the Origin of Species?', 'When was the company that built the first steam locomotive to carry passengers on a public rail line founded?', 'Which Theranos whistleblower is not related to a senior American government official?', 'What is the fastest air-breathing manned aircraft mostly made out of?', 'Who built the fastest air-breathing manned aircraft?', 'When was the author of The Population Bomb born?', 'When did the author of Annabel Lee enlist in the army?', 'What was the religion of the inventor of the Polio vaccine?', 'Who was the second wife of the founder of CNN?', 'When did the first prime minister of the Russian Empire come into office?', 'What is the primary male hormone derived from?', 'The Filipino statesman who established the government-in-exile during the outbreak of World War II was also the mayor of what city?', 'Where was the person who shared the Nobel Prize in Physics in 1954 with Max Born born?', 'When was the person who shared the Nobel Prize in Physics in 1954 with Max Born born?', 'What was the founding date of the university in which Plotonium was discovered?', 'The material out of which the Great Sphinx of Giza is made of is mainly composed of what mineral?', 'The husband of Lady Godiva was Earl of which Anglic kingdom?', 'The machine used to extract honey from honeycombs uses which physical force?', 'What is the third letter of the top level domain of the military?', 'In what year was the government department where the internet originated at founded?', 'The main actor of Indiana Jones is a licensed what?', 'When was the person after which the Hubble Space Telescope is named after born?', 'When did the person who gave the Checkers speech die?', 'When was the philosopher that formulated the hard problem of consciousness born?', 'What is the capital of the second largest state in the US by area?', 'What is the maximum airspeed (in km/h) of the third fastest bird?', 'Who founded the city where the founder of geometry lived?', 'What is the capital of the country where yoga originated?', 'The fourth largest city in Germany was originally called what?', "When did Nirvana's second most selling studio album come out?", 'What was the job of the father of the founder of psychoanalysis?', 'How much protein in four boiled egg yolks?', 'What is the political party of the American president who entered into the Paris agreement?', 'The most populous city in Punjab is how large (area wise)?', 'What was the death toll of the second largest volcanic eruption in the 20th century?', 'What was the death toll of the most intense Atlantic hurricane?', 'Who was the head of NASA during Apollo 11?', 'Who is the father of the father of George Washington?', 'Who is the mother of the father of George Washington?', 'Who is the father of the father of Barack Obama?', 'Who is the mother of the father of Barack Obama?', 'Who was mayor of New York City when Fiorello H. La Guardia was born?', 'Who was president of the U.S. when superconductivity was discovered?', 'When was the person Russ Hanneman is based on born?', "When was the first location of the world's largest coffeehouse chain opened?", 'Who directed the highest grossing film?', 'When was the longest bridge in the world opened?', 'Which company was responsible for the largest pharmaceutical settlement?', 'In what year was the tallest self-supporting tower completed?', 'In what year was the tallest fixed steel structure completed?', 'In what year was the tallest lattice tower completed?', 'In what year was the current tallest wooden lattice tower completed?', 'In what country is the second tallest statue in the world?', 'When was the tallest ferris wheel in the world completed?', 'In what year was the tallest lighthouse completed?', 'In what country is the world largest desalination plant?', 'The most populous national capital city was established in what year?', 'The third largest river (by discharge) in the world is in what countries?', 'What is the highest elevation (in meters) of the second largest island in the world?', 'What is the length of the second deepest river in the world?', 'In what country is the third largest stadium in the world?', 'Who is the largest aircraft carrier in the world is named after?', 'In what year did the oldest cat ever recorded with the Cat of the Year award?', 'In what year was the country that is the third largest exporter of coffee founded?', 'Who was the commander for the space mission that had the first spacewalk?', 'Who is the predecessor of the longest-reigning British monarch?', 'In 2016, who was the host of the longest running talk show?', 'In 2016, who was the host of the longest running American game show?', 'Who wrote the novel on which the longest running show in Broadway history is based on?', 'In what country was the only cruise line that flies the American flag incorporated in?', 'In what year did work begin on the second longest road tunnel in the world?', 'What is the official color of the third oldest surviving university?', 'Who succeeded the longest reigning Roman emperor?', 'Who preceded the Roman emperor that declared war on the sea?', 'Who produced the longest running video game franchise?', 'Who was the father of the father of psychoanalysis?', 'Who was the father of the father of empiricism?', 'Who is the father of the father of observational astronomy?', 'Who is the father of the father of modern Hebrew?', 'Who is the father of the father of modern experimental psychology?', 'Who is the father of the originator of cybernetics?', 'Who is the father of the father of the hydrogen bomb?', 'Who was the father of the father of computer science?', 'Who was the father of the father of behaviorism?', 'Who was the father of the founder of modern human anatomy?', 'What was the father of the last surviving Canadian father of Confederation?', 'When was the person who said “Now, I am become Death, the destroyer of worlds.” born?', 'Who was the father of the father of information theory?', 'When was the person who delivered the "Quit India" speech born?', 'When did the president who warned about the military industrial complex die?', 'When did the president who said Tear Down This Wall die?', 'What is the lowest elevation of the longest railway tunnel?', 'When did the person who said "Cogito, ergo sum." die?', 'When did the person who delivered the Gettysburg Address die?', 'Who was governor of Florida during Hurricane Irma?', "For which club did the winner of the 2007 Ballon d'Or play for in 2012?", "What's the capital city of the country that was the champion of the 2010 World Cup?", 'When was the anime studio that made Sword Art Online founded?', 'Who was the first king of the longest Chinese dynasty?', 'Who was the last emperor of the dynasty that succeeded the Song dynasty?', "What's the motto of the oldest California State university?", "What's the capital of the state that the College of William & Mary is in?", "What's the capital of the state that Washington University in St. Louis is in?", "What's the capital of the state that Harvard University is in?", "What's the capital of the state that the Space Needle is at?", "Which team won in women's volleyball in the most recent Summer Olympics that was held in London?", 'What is the nickname of the easternmost U.S. state?', 'What is the nickname for the state that is the home to the “Avocado Capital of the World"?', 'What rocket was used for the mission that landed the first humans on the moon?', 'When did the war that Neil Armstrong served in end?', 'What is the nickname for the state that Mount Rainier is located in?', 'When was the composer of Carol of the Bells born?', 'Who is the father of the scientist at MIT that won the Queen Elizabeth Prize for Engineering in 2013?', 'Who was the mother of the emperor of Japan during World War I?', 'Which element has an atomic number that is double that of hydrogen?', 'What was the motto of the Olympics that had Fuwa as the mascots?'],
5 | "answers": ['james madison', 'Titan IIIE', 1999, 'David Dinkins', '20 June 1837', 'April 30, 1789', 'March 4, 1797', 131, 'Yes', 'The Formation of Vegetable Mould Through the Action of Worms', 1823, 'Erika Cheung', 'Titanium', 'Lockheed Corporation', datetime.datetime(1932, 5, 29, 0, 0), 1827, 'Jewish', 'Jane Shirley Smith', datetime.datetime(1905, 11, 6, 0, 0), 'cholesterol', 'Quezon City', 'Oranienburg, Germany', 'January 8, 1891', 'March 23, 1868', 'calcite', 'Mercia', 'Centrifugal Force', 'l', 1947, 'pilot', 'November 20, 1889', datetime.datetime(1994, 4, 22, 0, 0), datetime.datetime(1966, 4, 20, 0, 0), 'Austin', '320 km/h', 'Alexander the Great', 'New Delhi', 'Colonia Claudia Ara Agrippinensium', datetime.datetime(1993, 9, 13, 0, 0), 'wool merchant', 10.8, 'Democratic Party', '310 square kilometers', 847, 52, 'Thomas O. Paine', 'Lawrence Washington', 'Mildred Warner', 'Hussein Onyango Obama', 'Habiba Akumu Nyanjango', 'William Russell Grace', 'William Howard Taft', datetime.datetime(1958, 7, 31, 0, 0), datetime.datetime(1971, 3, 30, 0, 0), 'James Cameroon', datetime.datetime(2011, 6, 30, 0, 0), 'GlaxoSmithKline', 2012, 1988, 2012, 1935, 'China', 2021, 1902, 'Saudi Arabia', '1045 BC', 'India and Bangladesh', '4,884 m', '6,300 km', 'United States', 'Gerald R. Ford', 1999, 1810, 'Pavel Belyayev', 'George VI\n', 'Jimmy Fallon', 'Drew Carey', 'Gaston Leroux', 'Bermuda', 1992, 'Cambridge Blue', 'Tiberius', 'Tiberius', 'MECC', 'Jacob Freud', 'Sir Nicholas Bacon', 'Vincenzo Galilei', 'Yehuda Leib', 'Maximilian Wundt', 'Leo Wiener', 'Max Teller', 'Julius Mathison Turing', 'Pickens Butler Watson', 'Anders van Wesel', 'Charles Tupper Sr.', datetime.datetime(1904, 4, 22, 0, 0), 'Claude Sr.', 'October 2, 1869', datetime.datetime(1969, 3, 28, 0, 0), datetime.datetime(2004, 6, 5, 0, 0), '312 m', 'February 11, 1650', 'April 15, 1865', 'Rick Scott', 'Real Madrid', 'Madrid', datetime.datetime(2005, 5, 9, 0, 0), 'King Wu of Zhou', 'Toghon Temür', 'Powering Silicon Valley', 'Richmond', 'Jefferson City', 'Boston', 'Olympia', 'Brazil', 'Pine Tree State', 'Golden State', 'Saturn V', datetime.datetime(1953, 7, 27, 0, 0), 'Evergreen State', 'December 13, 1877', 'Conway Berners-Lee', 'Yanagiwara Naruko', 'Helium', 'One World, One Dream']
6 | }
7 |
8 | DEFAULT_Q = [
9 | (0, "list 3 cities and their current populations where Paramore is playing this year."),
10 | (1, "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?"),
11 | (2, "How many watermelons can fit in a Tesla Model S?"),
12 | (3, "Recommend me some laptops suitable for UI designers under $2000. Please include brand and price."),
13 | (4, "Build me a vacation plan for Rome and Milan this summer for seven days. Include place to visit and hotels to stay. "),
14 | (5, "What is the sum of ages of the wives of Barack Obama and Donald Trump?"),
15 | (6, "Who is the most recent NBA MVP? Which team does he play for? What is his season stats?"),
16 | (7, "What were the scores for the last three games for the Los Angeles Lakers? Provide the dates and opposing teams."),
17 | (8, "Which team won in women's volleyball in the Summer Olympics that was held in London?"),
18 | (9, "Provide a summary of the latest COVID-19 research paper published. Include the title, authors and abstract."),
19 | (10, "What is the top grossing movie in theatres this week? Provide the movie title, director, and a brief synopsis of the movie's plot. Attach a review for this movie."),
20 | (11, "Recommend a bagel shop near the Strip district in Pittsburgh that offer vegan food"),
21 | (12, "Who are some top researchers in the field of machine learning systems nowadays?"),
22 | ]
23 |
24 | FT = [
25 | (0, "Briefly explain the current global climate change adaptation strategy and its effectiveness."),
26 | (1, "What steps should be taken to prepare a backyard garden for spring planting?"),
27 | (2, "Report the critical reception of the latest superhero movie."),
28 | (3, "When is the next NBA or NFL finals game scheduled?"),
29 | (4, "Which national parks or nature reserves are currently open for visitors near Denver, Colorado?"),
30 | (5, "Who are the most recent Nobel Prize winners in physics, chemistry, and medicine, and what are their respective contributions?"),
31 | ]
32 |
33 | HF = [
34 | (0, "Recommend me a movie in theater now to watch with kids."),
35 | (1, "Who is the most recent NBA MVP? Which team does he play for? What are his career stats?"),
36 | (2, "Who is the head coach of AC Milan now? How long has he been coaching the team?"),
37 | (3, "What is the mortgage rate right now and how does that compare to the past two years?"),
38 | (4, "What is the weather like in San Francisco today? What about tomorrow?"),
39 | (5, "When and where is the upcoming concert for Taylor Swift? Share a link to purchase tickets."),
40 | (6, "Find me recent studies focusing on hallucination in large language models. Provide the link to each study found."),
41 | ]
42 |
--------------------------------------------------------------------------------
/autoagents/data/generate_action_data.py:
--------------------------------------------------------------------------------
1 | # Script generates action data from goals calling GPT-4
2 | import os
3 | import asyncio
4 | import argparse
5 | from tqdm import tqdm
6 |
7 | from multiprocessing import Pool
8 |
9 | from autoagents.agents.agents.search import ActionRunner
10 | from autoagents.eval.test import AWAIT_TIMEOUT
11 | from langchain.chat_models import ChatOpenAI
12 | import json
13 |
14 |
15 | async def work(user_input):
16 | outputq = asyncio.Queue()
17 | llm = ChatOpenAI(openai_api_key=os.getenv("OPENAI_API_KEY"),
18 | openai_organization=os.getenv("OPENAI_API_ORG"),
19 | temperature=0.,
20 | model_name="gpt-4")
21 | runner = ActionRunner(outputq, llm=llm, persist_logs=True)
22 | task = asyncio.create_task(runner.run(user_input, outputq))
23 |
24 | while True:
25 | try:
26 | output = await asyncio.wait_for(outputq.get(), AWAIT_TIMEOUT)
27 | except asyncio.TimeoutError:
28 | return
29 | if isinstance(output, RuntimeWarning):
30 | print(output)
31 | continue
32 | elif isinstance(output, Exception):
33 | print(output)
34 | return
35 | try:
36 | parsed = json.loads(output)
37 | if parsed["action"] in ("Tool_Finish", "Tool_Abort"):
38 | break
39 | except:
40 | pass
41 | await task
42 |
43 | def main(q):
44 | asyncio.run(work(q))
45 |
46 | if __name__ == "__main__":
47 | parser = argparse.ArgumentParser()
48 | parser.add_argument('--goals', type=str, help="file containing JSON array of goals", required=True)
49 | parser.add_argument("--num_data", type=int, default=-1, help="number of goals for generation")
50 | args = parser.parse_args()
51 | with open(args.goals, "r") as file:
52 | data = json.load(file)
53 | if args.num_data > -1 and len(data) > args.num_data:
54 | data = data[:args.num_data]
55 | with Pool(processes=4) as pool:
56 | for _ in tqdm(pool.imap_unordered(main, data), total=len(data)):
57 | pass
58 |
--------------------------------------------------------------------------------
/autoagents/data/generate_action_tasks/README.md:
--------------------------------------------------------------------------------
1 | # Generate_action_tasks
2 | Generate action tasks for AutoGPT following self-instruct.
3 |
4 |
5 | ## What does this repo do
6 |
7 | This repo only generates the tasks that needs the agent to complete, not the full action data that includes reasoning, planning and execution of tools. That part of codes is implemented together with the AutoAgent repo.
8 |
9 |
10 | ## Repo Structure
11 |
12 | * `REACT.ipynb` is the exploration of creating action data.
13 | * `generate_data_chat_api.py` is the main file that adopts openAI's API to generate more tasks based on in-context learning.
14 | * `prompt.txt` is the prompt used by `generate_data_chat_api.py`
15 | * `seed_tasks.jsonl`: the manually labeled tasks for in-context learning
16 | * `generate_data_chat_api.py`: uses the completion API, not the chat API.
17 |
18 |
19 | ## Usage
20 | Simply run
21 | `sh run_genenerate_data.sh`. Parameters could be modified.
22 |
23 |
--------------------------------------------------------------------------------
/autoagents/data/generate_action_tasks/generate_data.py:
--------------------------------------------------------------------------------
1 | """
2 | run:
3 | python -m generate_data generate_agents_data \
4 | --output_dir ./ \
5 | --num_agents_to_generate 10 \
6 | --model_name="text-davinci-003" \
7 | """
8 | import time
9 | import json
10 | import os
11 | import random
12 | import re
13 | import string
14 | from functools import partial
15 | from multiprocessing import Pool
16 |
17 | import numpy as np
18 | import tqdm
19 | from rouge_score import rouge_scorer
20 | import utils
21 |
22 | import fire
23 | import pdb
24 |
25 | '''
26 | The tools used by Auto-GPT are available at:
27 | https://github.com/Significant-Gravitas/Auto-GPT/tree/master/autogpt/commands
28 | '''
29 |
30 | def encode_prompt(prompt_agents):
31 | """Encode multiple prompt instructions into a single string."""
32 | prompt = open("./prompt.txt").read() + "\n"
33 |
34 | for idx, task_dict in enumerate(prompt_agents):
35 | (name, goal) = task_dict["name"], task_dict["goal"]
36 | if not goal:
37 | raise
38 | prompt += f"###\n"
39 | prompt += f"{idx + 1}. Name: {name}\n"
40 | prompt += f"{idx + 1}. Goal:\n{goal}\n"
41 | prompt += f"###\n"
42 | prompt += f"{idx + 2}. Name:"
43 | return prompt
44 |
45 |
46 | def post_process_gpt_response(num_prompt_agents, response):
47 | print ("post_process_gpt_response")
48 | if response is None:
49 | return []
50 | raw_instructions = f"{num_prompt_agents+1}. Name:" + response["text"]
51 | raw_instructions = re.split("###", raw_instructions)
52 | agents = []
53 | for idx, inst in enumerate(raw_instructions):
54 | # if the decoding stops due to length, the last example is likely truncated so we discard it
55 | if idx == len(raw_instructions) - 1 and response["finish_reason"] == "length":
56 | continue
57 | idx += num_prompt_agents + 1
58 | splitted_data = re.split(f"{idx}\.\s+(Name|Goal):", inst)
59 | if len(splitted_data) != 5:
60 | continue
61 | else:
62 | name = splitted_data[2].strip()
63 | role = splitted_data[4].strip()
64 | # goals = splitted_data[6].strip()
65 | # goals = "" if goals.lower() == "" else goals
66 | # filter out too short or too long role
67 | if len(role.split()) <= 3 or len(role.split()) > 150:
68 | continue
69 | # filter based on keywords that are not suitable for language models.
70 | blacklist = [
71 | "kill",
72 | "harm",
73 | "discriminate",
74 | ]
75 | blacklist += []
76 | if any(find_word_in_string(word, role) for word in blacklist):
77 | continue
78 | # filter those starting with punctuation
79 | if role[0] in string.punctuation:
80 | continue
81 | # filter those starting with non-english character
82 | if not role[0].isascii():
83 | continue
84 | agents.append({"name": name, "goal": role})
85 | return agents
86 |
87 |
88 | def find_word_in_string(w, s):
89 | return re.compile(r"\b({0})\b".format(w), flags=re.IGNORECASE).search(s)
90 |
91 |
92 | def generate_agents_data(
93 | output_dir="./",
94 | seed_tasks_path="./seed_tasks.jsonl",
95 | num_agents_to_generate=20,
96 | model_name="text-davinci-003",
97 | num_prompt_agents=5,
98 | request_batch_size=1,
99 | temperature=1.0,
100 | top_p=1.0,
101 | num_cpus=16,
102 | ):
103 | print ("generate_instruction_following_data")
104 | seed_tasks = [json.loads(l) for l in open(seed_tasks_path, "r")]
105 | seed_agent_data = [
106 | {"name": t["name"], "goal": t["goal"]}
107 | for t in seed_tasks
108 | ]
109 | print(f"Loaded {len(seed_agent_data)} human-written seed agents")
110 |
111 | os.makedirs(output_dir, exist_ok=True)
112 | request_idx = 0
113 | # load the LM-generated instructions
114 | machine_agent_data = []
115 | if os.path.exists(os.path.join(output_dir, "regen.json")):
116 | machine_agent_data = utils.jload(os.path.join(output_dir, "regen.json"))
117 | print(f"Loaded {len(machine_agent_data)} machine-generated agents")
118 |
119 | # similarities = {}
120 | scorer = rouge_scorer.RougeScorer(["rougeL"], use_stemmer=False)
121 |
122 | # now let's generate new instructions!
123 | progress_bar = tqdm.tqdm(total=num_agents_to_generate)
124 | if machine_agent_data:
125 | progress_bar.update(len(machine_agent_data))
126 |
127 | # first we tokenize all the seed instructions and generated machine instructions
128 | all_roles = [d["goal"] for d in seed_agent_data] + [
129 | d["goal"] for d in machine_agent_data
130 | ]
131 | all_instruction_tokens = [scorer._tokenizer.tokenize(role) for role in all_roles]
132 |
133 | while len(machine_agent_data) < num_agents_to_generate:
134 | request_idx += 1
135 |
136 | batch_inputs = []
137 | for _ in range(request_batch_size):
138 | # only sampling from the seed tasks
139 | prompt_agents = random.sample(seed_agent_data, num_prompt_agents)
140 | prompt = encode_prompt(prompt_agents)
141 | batch_inputs.append(prompt)
142 | decoding_args = utils.OpenAIDecodingArguments(
143 | temperature=temperature,
144 | n=1,
145 | max_tokens=3072, # hard-code to maximize the length. the requests will be automatically adjusted
146 | top_p=top_p,
147 | stop=["\n20", "20.", "20."],
148 | )
149 | request_start = time.time()
150 | results = utils.openai_completion(
151 | prompts=batch_inputs,
152 | model_name=model_name,
153 | batch_size=request_batch_size,
154 | decoding_args=decoding_args,
155 | logit_bias={"50256": -100}, # prevent the <|endoftext|> token from being generated
156 | )
157 | request_duration = time.time() - request_start
158 |
159 | process_start = time.time()
160 | agent_data = []
161 | for result in results:
162 | new_agents = post_process_gpt_response(num_prompt_agents, result)
163 | agent_data += new_agents
164 |
165 | total = len(agent_data)
166 | keep = 0
167 | for agent_data_entry in agent_data:
168 | # computing similarity with the pre-tokenzied instructions
169 | new_agent_tokens = scorer._tokenizer.tokenize(agent_data_entry["goal"])
170 | with Pool(num_cpus) as p:
171 | rouge_scores = p.map(
172 | partial(rouge_scorer._score_lcs, new_agent_tokens),
173 | all_instruction_tokens,
174 | )
175 | rouge_scores = [score.fmeasure for score in rouge_scores]
176 | most_similar_instructions = {
177 | all_roles[i]: rouge_scores[i] for i in np.argsort(rouge_scores)[-10:][::-1]
178 | }
179 | if max(rouge_scores) > 0.7:
180 | continue
181 | else:
182 | keep += 1
183 | agent_data_entry["most_similar_instructions"] = most_similar_instructions
184 | agent_data_entry["avg_similarity_score"] = float(np.mean(rouge_scores))
185 | machine_agent_data.append(agent_data_entry)
186 | all_roles.append(agent_data_entry["goal"])
187 | all_instruction_tokens.append(new_agent_tokens)
188 | progress_bar.update(1)
189 | process_duration = time.time() - process_start
190 | print(f"Request {request_idx} took {request_duration:.2f}s, processing took {process_duration:.2f}s")
191 | print(f"Generated {total} agents, kept {keep} agents")
192 | utils.jdump(machine_agent_data, os.path.join(output_dir, "self-gen.json"))
193 |
194 |
195 | def main(task, **kwargs):
196 | globals()[task](**kwargs)
197 |
198 |
199 | if __name__ == "__main__":
200 | fire.Fire(main)
--------------------------------------------------------------------------------
/autoagents/data/generate_action_tasks/generate_data_chat_api.py:
--------------------------------------------------------------------------------
1 | """
2 | run:
3 | python -m generate_data_chat_api generate_agents_data \
4 | --output_dir ./new_data \
5 | --seed_tasks_path ./seed_tasks.jsonl \
6 | --num_agents_to_generate 1000 \
7 | --model_name="gpt-4" \
8 | """
9 | import time
10 | import json
11 | import os
12 | import random
13 | import re
14 | import string
15 | from functools import partial
16 | from multiprocessing import Pool
17 |
18 | import numpy as np
19 | import tqdm
20 | from rouge_score import rouge_scorer
21 | import utils
22 |
23 | import fire
24 | import pdb
25 |
26 | '''
27 | The tools used by Auto-GPT are available at:
28 | https://github.com/Significant-Gravitas/Auto-GPT/tree/master/autogpt/commands
29 | '''
30 |
31 | def encode_prompt(prompt_agents):
32 | """Encode multiple prompt instructions into a single string."""
33 | prompt = open("./prompt.txt").read() + "\n"
34 |
35 | for idx, task_dict in enumerate(prompt_agents):
36 | (name, goal) = task_dict["name"], task_dict["goal"]
37 | if not goal:
38 | raise
39 | prompt += f"###\n"
40 | prompt += f"{idx + 1}. Name: {name}\n"
41 | prompt += f"{idx + 1}. Goal:\n{goal}\n"
42 | prompt += f"###\n"
43 | prompt += f"{idx + 2}. Name:"
44 | return prompt
45 |
46 |
47 | def post_process_chat_gpt_response(num_prompt_agents, response):
48 | print ("post_process_gpt_response")
49 | if response is None:
50 | return []
51 | raw_instructions = f"{num_prompt_agents+1}. Name:" + response['message']['content']
52 | raw_instructions = re.split("###", raw_instructions)
53 | agents = []
54 | for idx, inst in enumerate(raw_instructions):
55 | # if the decoding stops due to length, the last example is likely truncated so we discard it
56 | if idx == len(raw_instructions) - 1 and response["finish_reason"] == "length":
57 | continue
58 | idx += num_prompt_agents + 1
59 | splitted_data = re.split(f"{idx}\.\s+(Name|Goal):", inst)
60 | if len(splitted_data) != 5:
61 | continue
62 | else:
63 | name = splitted_data[2].strip()
64 | goal = splitted_data[4].strip()
65 | # filter out too short or too long role
66 | if len(goal.split()) <= 3 or len(goal.split()) > 150:
67 | continue
68 | # filter based on keywords that are not suitable for language models.
69 | blacklist = [
70 | "kill",
71 | "harm",
72 | "discriminate",
73 | "racist",
74 | "figure",
75 | "plot",
76 | "chart",
77 | "image",
78 | "images",
79 | "graph",
80 | "graphs",
81 | "picture",
82 | "pictures",
83 | "file",
84 | "files",
85 | "draw",
86 | "plot",
87 | "go to",
88 | "video",
89 | "audio",
90 | "flowchart",
91 | "diagram",
92 | ]
93 | blacklist += []
94 | if any(find_word_in_string(word, goal) for word in blacklist):
95 | continue
96 | # filter those starting with punctuation
97 | if goal[0] in string.punctuation:
98 | continue
99 | # filter those starting with non-english character
100 | if not goal[0].isascii():
101 | continue
102 | agents.append({"name": name, "goal": goal})
103 | return agents
104 |
105 |
106 | def find_word_in_string(w, s):
107 | return re.compile(r"\b({0})\b".format(w), flags=re.IGNORECASE).search(s)
108 |
109 |
110 | def generate_agents_data(
111 | output_dir="./",
112 | seed_tasks_path="./new_seed_tasks.jsonl",
113 | num_agents_to_generate=50,
114 | model_name="gpt-3.5-turbo",
115 | num_prompt_agents=8,
116 | temperature=1.0,
117 | top_p=1.0,
118 | num_cpus=8,
119 | ):
120 | print ("generate_instruction_following_data")
121 | seed_tasks = [json.loads(l) for l in open(seed_tasks_path, "r")]
122 | seed_agent_data = [
123 | {"name": t["name"], "goal": t["goal"], "task_id": t["task_id"]}
124 | for t in seed_tasks
125 | ]
126 | print(f"Loaded {len(seed_agent_data)} human-written seed agents")
127 |
128 | os.makedirs(output_dir, exist_ok=True)
129 | request_idx = 0
130 | # load the LM-generated instructions
131 | machine_agent_data = []
132 | machine_data_path = os.path.join(output_dir, "self-gen-batch1.json")
133 | if os.path.exists(machine_data_path):
134 | # machine_agent_data = utils.jload(machine_data_path)
135 | machine_agent_data = [json.loads(l) for l in open(machine_data_path, "r")]
136 | print(f"Loaded {len(machine_agent_data)} machine-generated agents")
137 |
138 | # similarities = {}
139 | scorer = rouge_scorer.RougeScorer(["rougeL"], use_stemmer=False)
140 |
141 | # now let's generate new instructions!
142 | progress_bar = tqdm.tqdm(total=num_agents_to_generate)
143 | if machine_agent_data:
144 | progress_bar.update(len(machine_agent_data))
145 |
146 | previous_goals = []
147 | if os.path.isfile("previous_goals.json"):
148 | with open("previous_goals.json", 'r') as f:
149 | previous_goals = json.load(f)
150 |
151 | # first we tokenize all the seed instructions and generated machine instructions
152 | all_goals = [d["goal"] for d in seed_agent_data] + [
153 | d["goal"] for d in machine_agent_data
154 | ] + previous_goals
155 | all_goals = list(set(all_goals))
156 | all_instruction_tokens = [scorer._tokenizer.tokenize(role) for role in all_goals]
157 |
158 | while len(machine_agent_data) < num_agents_to_generate:
159 | request_idx += 1
160 |
161 | # only sampling from the seed tasks
162 | prompt_agents = random.sample(seed_agent_data, num_prompt_agents)
163 | prompt = encode_prompt(prompt_agents)
164 |
165 | decoding_args = utils.OpenAIDecodingArguments(
166 | temperature=temperature,
167 | n=1,
168 | max_tokens=3072, # hard-code to maximize the length. the requests will be automatically adjusted
169 | top_p=top_p,
170 | stop=["\n60", "60."],
171 | )
172 | request_start = time.time()
173 | results = utils.openai_completion(
174 | prompts=prompt,
175 | model_name=model_name,
176 | batch_size=1,
177 | decoding_args=decoding_args,
178 | logit_bias={"100257": -100}, # prevent the <|endoftext|> from being generated
179 | # "100265":-100, "100276":-100 for <|im_end|> and token
180 | )
181 | request_duration = time.time() - request_start
182 |
183 | process_start = time.time()
184 | agent_data = post_process_chat_gpt_response(num_prompt_agents, results)
185 |
186 | total = len(agent_data)
187 | keep = 0
188 | for agent_data_entry in agent_data:
189 | # computing similarity with the pre-tokenzied instructions
190 | new_agent_tokens = scorer._tokenizer.tokenize(agent_data_entry["goal"])
191 | with Pool(num_cpus) as p:
192 | rouge_scores = p.map(
193 | partial(rouge_scorer._score_lcs, new_agent_tokens),
194 | all_instruction_tokens,
195 | )
196 | rouge_scores = [score.fmeasure for score in rouge_scores]
197 | # most_similar_instructions = {
198 | # all_goals[i]: rouge_scores[i] for i in np.argsort(rouge_scores)[-10:][::-1]
199 | # }
200 | max_score = max(rouge_scores)
201 | if max_score > 0.40:
202 | continue
203 | else:
204 | keep += 1
205 | # agent_data_entry["most_similar_instructions"] = most_similar_instructions
206 | # agent_data_entry["avg_similarity_score"] = float(np.mean(rouge_scores))
207 | agent_data_entry["max_similarity_score"] = max_score
208 | agent_data_entry["seed_tasks"] = [task["task_id"] for task in prompt_agents]
209 | machine_agent_data.append(agent_data_entry)
210 | all_goals.append(agent_data_entry["goal"])
211 | all_instruction_tokens.append(new_agent_tokens)
212 | progress_bar.update(1)
213 | process_duration = time.time() - process_start
214 | print(f"Request {request_idx} took {request_duration:.2f}s, processing took {process_duration:.2f}s")
215 | print(f"Generated {total} agents, kept {keep} agents")
216 | utils.jdump(machine_agent_data, os.path.join(output_dir, "self-gen.json"))
217 |
218 |
219 | def main(task, **kwargs):
220 | globals()[task](**kwargs)
221 |
222 |
223 | if __name__ == "__main__":
224 | fire.Fire(main)
--------------------------------------------------------------------------------
/autoagents/data/generate_action_tasks/prompt.txt:
--------------------------------------------------------------------------------
1 | You have been asked to generate a set of 60 diverse tasks, each with defined goals and descriptions.
2 | These tasks will be given to a GPT model to carry out multi-step reasoning, planning, and execution of tools, without requiring user assistance.
3 | Today is Apr 30, 2023.
4 |
5 | Here are the requirements:
6 | 1. To maximize diversity, try not to repeat verbs and use diverse language for the goals.
7 | 2. The goals should be in English.
8 | 3. The goals should be 1 to 3 sentences long. Either an imperative sentence or a question is permitted.
9 | 4. Refrain from requesting the accomplishment of highly abstract or open-ended tasks, such as generating wealth or solving global issues.
10 | 5. The goal should be entirely autonomous, utilizing the given tools and eliminating the need for real-time user interaction.
11 | 6. Bear in mind that completing each goal may involve multiple steps instead of just a single step executed by the language model and tools.
12 | 7. The goal cannot be directly answerable and solvable using the language model. For example, "What is the capital of France?" and "Translate a paragraph of text from English to Spanish" are not acceptable.
13 | 8. The goal should include time-sensitive elements that may require up-to-date knowledge beyond what the current language model possesses, such as identifying upcoming event or reporting the latest news.
14 |
15 | The following tools will be provided and system will return observations:
16 | 1. {search: useful for when you need to answer questions about current events. You should ask targeted questions, args: "query"}
17 | 2. {finish: use this to signal that you have finished all your objectives, args: "response": "Final Answer: get the final answer to achieve the original goal. "}
18 |
19 | List of 60 goals:
20 |
--------------------------------------------------------------------------------
/autoagents/data/generate_action_tasks/requirements.txt:
--------------------------------------------------------------------------------
1 | numpy
2 | rouge_score
3 | fire
4 | openai
5 | transformers>=4.26.1
6 | torch
7 | sentencepiece
8 | tokenizers==0.12.1
9 | wandb
10 |
--------------------------------------------------------------------------------
/autoagents/data/generate_action_tasks/run_genenerate_data.sh:
--------------------------------------------------------------------------------
1 | # Use this for chat API:
2 | python -m generate_data_chat_api generate_agents_data \
3 | --output_dir ./new_data \
4 | --seed_tasks_path ./seed_tasks.jsonl \
5 | --num_agents_to_generate 1000 \
6 | --model_name="gpt-4"
--------------------------------------------------------------------------------
/autoagents/data/generate_action_tasks/seed_tasks_test.jsonl:
--------------------------------------------------------------------------------
1 | {"name": "urgent_car", "goal": "Find me the top 5 urgent care centers near the 750 7th Avenue. List the distances for each of them.", "task_id": "39f5f08e76fe4a66"}
2 | {"name": "pitchcer_filter", "goal": "I just got a Denali Water Pitcher (standard filter). When should I change the filter?", "task_id": "6b34a2619ead4216"}
3 | {"name": "a16z_investments", "goal": "List 3 most significant investments of a16z and their current combined valuation.", "task_id": "b475e11d5fd94049"}
4 | {"name": "musci_band", "goal": "What are the names of the current members of American heavy metal band who wrote the music for Hurt Locker The Musical?", "task_id": "faeadb6d51bc4c1a"}
5 | {"name": "international_traveler", "goal": "Recommend the top 5 national parks in the United States for international travelers. Provide a list of estimated cost for each destination.", "task_id": "6441ee70888e48f0"}
6 | {"name": "mars_explorer", "goal": "Come up with a reasonable, actionable plan to get me to Mars.", "task_id": "63d60d723b0e468b"}
7 | {"name": "calculus_mathematicians", "goal": "Name a few mathematicians who contributed to the development of Calculus and also provide their contributions.", "task_id": "aa80dbf861bc437b"}
8 | {"name": "car_purchaser", "goal": "I am deciding between purchasing a 2023 Ioniq 5 and a 2023 Solterra. I repeatedly have to drive from SF to LA so I need a car with good battery life and charges quickly. Which option should I choose?", "task_id": "174497295ebd4e32"}
--------------------------------------------------------------------------------
/autoagents/data/generate_action_tasks/seed_tasks_train.jsonl:
--------------------------------------------------------------------------------
1 | {"name": "holiday_chef", "goal": "Find the upcoming holiday and generate a home recipe to celebrate.", "task_id": "5c28888898184a75"}
2 | {"name": "pitt_weather_reporter", "goal": "Get weather forcast for San Francisco tomorrow.", "task_id": "479ce326b693458e"}
3 | {"name": "current_weather", "goal": "What is the current temperature and weather condition in Paris?", "task_id": "10825a7b70f24cdc"}
4 | {"name": "ucl_reporter", "goal": "Who is the most recent NBA MVP? Which team does he play for? What are his career stats?", "task_id": "67e21d88864040b6"}
5 | {"name": "nba_reporter", "goal": "Who is the leading goalscorer in the current season of the UEFA Champions League?", "task_id": "201cbef897f04aa8"}
6 | {"name": "sports_score", "goal": "What was the final score of the latest NBA game between the Los Angeles Lakers and Memphis Grizzlies?", "task_id": "27d3ff8da66b4638"}
7 | {"name": "sports_odds_maker", "goal": "What are the betting odds for the next UFC fight between Conor McGregor?", "task_id": "a4857bf2bd504c68"}
8 | {"name": "usopen_champion_bio", "goal": "What is the hometown of the reigning champion for U.S. Open, men's single?", "task_id": "19d05341e4cb4acd"}
9 | {"name": "stock_invester", "goal": "Can you find the stock that paid out highest dividend recently?. Should have source to support the reasons. Recommend at most three stocks", "task_id": "31e07ce5dc6f4413"}
10 | {"name": "active_stocks", "goal": "Recommend me three most actively traded stocks recently.", "task_id": "21651d01eb4a4a3e"}
11 | {"name": "stock_prices", "goal": "Get the current stock price for Apple Inc. (AAPL). How large is its volume today?", "task_id": "6ce1eb431d434730"}
12 | {"name": "best_movie", "goal": "What is the highest grossing movie of all time. Find one movie, including the movie name, director and description.", "task_id": "eb4d5283fd4b4250"}
13 | {"name": "family_movie", "goal": "Recommend a kid-friendly movie that is playing at a theater near Sunnyvale. Give me the showtimes and a link to purchase the tickets", "task_id": "1d8aae1cafb648b8"}
14 | {"name": "book_recommendation", "goal": "Recommend the 10 best-selling books on Amazon. Include books name and author.", "task_id": "9b33cf57d4194577"}
15 | {"name": "crime_reporter", "goal": "Give me the most recent crime alert in New York City. Include the crime time, location and description", "task_id": "405d201e150c4ea2"}
16 | {"name": "concert_location", "goal": "Give me information about the next concert performed in Las Vegas.", "task_id": "98e0661782424bdc"}
17 | {"name": "check_flights_nonstop", "goal": "What is the earlist non-stop flight from Seattle to San Francisco?", "task_id": "da2b7a5e52084210"}
18 | {"name": "flight_status", "goal": "What is the status of flight AA101 from New York to London scheduled today? Is there a delay or cancellation?", "task_id": "fb719d0ca75647c6"}
19 | {"name": "laptop_recommend", "goal": "Recommend me some laptops suitable for UI designers under $2000. Please include brand and price.", "task_id": "7cfbd8e07d764745"}
20 | {"name": "podcast_planner", "goal": "Write a podcast outline on a recent political event", "task_id": "1aaf9a6a8d0c494e"}
21 | {"name": "langchain", "goal": "What is the LangChain framework? Give me an example in Python.", "task_id": "f9f9f399a96f4b9b"}
22 | {"name": "Ilya_paper", "goal": "Can you give me the title of the paper the Ilya Sutskever wrote when he was about 30?", "task_id": "dee6e17fc9054a63"}
23 | {"name": "tom_cruise_pay", "goal": "How much did Tom Cruise make on his latest movie? Can you include both the movie names and the amount of money?", "task_id": "3749fd7592e846de"}
24 | {"name": "matt_damon_director", "goal": "Who is the director of the next movie with Matt Damon?", "task_id": "ace796ed525d4ec2"}
25 | {"name": "holiday_planner", "goal": "What are the top three places to visit in Europe during the summer of 2022? Provide a brief description of each location, including their popular attractions and must-see landmarks.", "task_id": "8d58b4facee24ed2"}
26 | {"name": "holiday_destination", "goal": "What is the best holiday destination for budget travelers in United States during summer of 2023? Provide an estimated cost for a week's stay.", "task_id": "bf1663cc8c844843"}
27 | {"name": "find_restaurant", "goal": "Suggest a fancy Italian restaurant in New York City suitable for a romantic dinner. Provide the address, phone number, and website for the restaurant.", "task_id": "4ae39cbeff834050"}
28 | {"name": "book_reader", "goal": "What is the most popular science-fiction book on the New York Times Best Sellers list? Provide the author's name, book title, and a brief description of the plot.", "task_id": "8f1f5ada0058409b"}
29 | {"name": "text_summarizer", "goal": "Can you find some latest articles on the COVID-19 vaccine?", "task_id": "97563fc2f3e04351"}
30 | {"name": "job_searcher", "goal": "Find a job opening for a software engineer in San Francisco with competitive salary, at a company with at least 100 employees.", "task_id": "ee8539e503ae4854"}
31 | {"name": "music_listener", "goal": "What is currently the #1 song on the Billboard Hot 100 chart? Provide the song title, artist, and genre.", "task_id": "62461e3a44dc43b2"}
32 | {"name": "university_finder", "goal": "Rank the top three universities in the United States for computer science programs in year 2023, including their location, tuition fees, and notable alumni. Provide a brief description of each university's computer science program.", "task_id": "d1bb40f375e645a6"}
33 | {"name": "video_game_reviews", "goal": "What are the top three video games released in the last six months, according to their user ratings on Metacritic? Provide a brief summary of each game's strengths and weaknesses.", "task_id": "bb44d84662824824"}
34 | {"name": "news_headline", "goal": "What is the headline of the most viewed news articles today?", "task_id": "8b2f4c86fb45452a"}
35 | {"name": "upcoming_concerts", "goal": "When and where is the upcoming concert for Taylor Swift? Share a link to purchase tickets.", "task_id": "07f3c15f494340a3"}
36 | {"name": "stock_analyst", "goal": "What's the stock price for Tesla as of yesterday's closing bell? Provide the stock symbol, closing price, and a brief analysis of the stock's performance.", "task_id": "3ee477d14f3944ea"}
37 | {"name": "book_store_locator", "goal": "Find the nearest Barnes & Noble bookstore to zip code 15213.", "task_id": "4b5f52a47d8c487e"}
38 | {"name": "covid_statistics", "goal": "Provide the current COVID-19 statistics for the United States.", "task_id": "7b86aba330614722"}
39 | {"name": "pet_adoption_finder", "goal": "What is the best animal shelter that is currently allowing adoptions of cats or dogs in Seattle?", "task_id": "ab57b69aeee84e05"}
40 | {"name": "car_buyer", "goal": "Find a high-rated sedan car model that has been released within the last year. Provide information about the car's fuel efficiency and safety features.", "task_id": "f1dfe422c7924439"}
41 | {"name": "latest_tech_gadgets", "goal": "What are the newest tech gadgets on the market?", "task_id": "b92921736a8b4b23"}
42 | {"name": "popular_streamer", "goal": "Who is the streamer that has the most subscribers currently one of the most popular and what games do they stream? How many?", "task_id": "8bde59a428a943bc"}
43 | {"name": "TV_show_recommendation", "goal": "Recommend a drama TV show that is currently streaming on Netflix. Provide a brief plot summary and the rating.", "task_id": "7f012ca4be67485c"}
44 | {"name": "age_calculator", "goal": "What is the sum of ages of the wives of Barack Obama and Donald Trump?", "task_id": "e30679fc81a641a2"}
45 | {"name": "volleyball_winnder", "goal": "Which team won in women's volleyball in the Summer Olympics that was held in London?", "task_id": "7a6dd09052194d1c"}
46 | {"name": "olympic_medal", "goal": "Which country won the most gold medals in the last Winter Olympics?", "task_id": "50ae10f10dad46b8"}
47 | {"name": "vegan_bagel", "goal": "Recommend a bagel shop near the Strip district in Pittsburgh that offer vegan food", "task_id": "d25eccefd8af462b"}
--------------------------------------------------------------------------------
/autoagents/data/generate_action_tasks/seed_tasks_valid.jsonl:
--------------------------------------------------------------------------------
1 | {"name": "autogpt_adoption", "goal": "What are the main reasons AutoGPT hasn't been adopted by the general public?", "task_id": "7bc03fce036e4302"}
2 | {"name": "tax_rate", "goal": "Find the latest local income tax rate for an individual working in the City of Pittsburgh. What is the deadline for tax return filing this year?", "task_id": "61b6dd397931404a"}
3 | {"name": "female_gymnast", "goal": "I love the Olympics and Women's Gymnastics is my favorite event. Which female gymnast alive today has the most medals?", "task_id": "ff3a57e32a324060"}
4 | {"name": "columbus_physicians", "goal": "Who are the top 5 primary care physicians in Columbus, OH? Include a detailed list for each physician and their expertise.", "task_id": "a42c239a3b8a44df"}
5 | {"name": "sangiovese_wine", "goal": "Suggest a couple of good, budget-friendly wines for someone who likes Sangiovese.", "task_id": "9fc48092050e4fef"}
6 | {"name": "khaleesi_dragons", "goal": "Name Khaleesi's three dragons and their character development throughout the seasons of Game of Thrones.", "task_id": "38a57d996ffc4d01"}
7 | {"name": "remote_worker", "goal": "If I am making \u00a3100000 working remotely in London, how much more spare money would I have if I had the same remote job in Bath?", "task_id": "ba5a3e97724f44fc"}
8 | {"name": "llama2_service", "goal": "I would like to deploy an inference service of LLAMA 2 for a week. Which cloud platforms should I choose and what are the price plans for different options?", "task_id": "e9db9ae025f84c8b"}
9 | {"name": "netflix_movie", "goal": "Provide a list of top-rated movies released this year from Netflix. Summarize their plots and reviews.", "task_id": "71cd3750f6854f61"}
10 | {"name": "civic_driver", "goal": "Suppose that I get my 2023 Honda Civic serviced, and then drive from Maine to San Diego. How many more miles should I drive before getting my car serviced again?", "task_id": "e41ab586a6294cc0"}
11 | {"name": "tbill_yield", "goal": "What is the current estimated yield for the treasury bills issued recently? Compare it with the yields of the treasury bills issued last month.", "task_id": "66898415ed24453a"}
12 | {"name": "book_reader", "goal": "Find me a book that explores similar themes to Spain's highest grossing movie in 2022. Why should I read it?", "task_id": "c1a7411b35544256"}
13 | {"name": "car_renter", "goal": "I plan to rent a car to drive from San Jose, CA to Los Angeles, CA with two friends. Recommend three economical options from different car rental companies and provide the estimated budget for each of the options.", "task_id": "2404514031784c7c"}
14 | {"name": "pittsburgh_events", "goal": "List 3 popular events happening in the city of Pittsburgh over the labor day weekend. Also provide entry fee, accessibility, bag policy, parking information etc about each of the events. Please try to include events involving food.", "task_id": "ff9f418eb3424e7a"}
15 | {"name": "nfl_team", "goal": "Which NFL team has the youngest opening day roster in history? What was that teams record at the end of the year?", "task_id": "bdd0b5aafac6442c"}
--------------------------------------------------------------------------------
/autoagents/data/generate_action_tasks/utils.py:
--------------------------------------------------------------------------------
1 | import dataclasses
2 | import logging
3 | import math
4 | import os
5 | import io
6 | import sys
7 | import time
8 | import json
9 | from typing import Optional, Sequence, Union
10 |
11 | import openai
12 | import tqdm
13 | from openai import openai_object
14 | import copy
15 | import pdb
16 |
17 | StrOrOpenAIObject = Union[str, openai_object.OpenAIObject]
18 |
19 | openai_org = os.getenv("OPENAI_ORG")
20 | if openai_org is not None:
21 | openai.organization = openai_org
22 | logging.warning(f"Switching to organization: {openai_org} for OAI API key.")
23 |
24 |
25 | @dataclasses.dataclass
26 | class OpenAIDecodingArguments(object):
27 | max_tokens: int = 1800
28 | temperature: float = 0.2
29 | top_p: float = 1.0
30 | n: int = 1
31 | stream: bool = False
32 | stop: Optional[Sequence[str]] = None
33 | presence_penalty: float = 0.0
34 | frequency_penalty: float = 0.0
35 | # logprobs: Optional[int] = None
36 |
37 |
38 | def openai_completion(
39 | prompts: Union[str, Sequence[str], Sequence[dict], dict],
40 | decoding_args: OpenAIDecodingArguments,
41 | model_name="text-davinci-003",
42 | sleep_time=2,
43 | batch_size=1,
44 | max_instances=sys.maxsize,
45 | max_batches=sys.maxsize,
46 | return_text=False,
47 | **decoding_kwargs,
48 | ):
49 | """Decode with OpenAI API.
50 |
51 | Args:
52 | prompts: A string or a list of strings to complete. If it is a chat model the strings should be formatted
53 | as explained here: https://github.com/openai/openai-python/blob/main/chatml.md. If it is a chat model
54 | it can also be a dictionary (or list thereof) as explained here:
55 | https://github.com/openai/openai-cookbook/blob/main/examples/How_to_format_inputs_to_ChatGPT_models.ipynb
56 | decoding_args: Decoding arguments.
57 | model_name: Model name. Can be either in the format of "org/model" or just "model".
58 | sleep_time: Time to sleep once the rate-limit is hit.
59 | batch_size: Number of prompts to send in a single request. Only for non chat model.
60 | max_instances: Maximum number of prompts to decode.
61 | max_batches: Maximum number of batches to decode. This argument will be deprecated in the future.
62 | return_text: If True, return text instead of full completion object (which contains things like logprob).
63 | decoding_kwargs: Additional decoding arguments. Pass in `best_of` and `logit_bias` if you need them.
64 |
65 | Returns:
66 | A completion or a list of completions.
67 | Depending on return_text, return_openai_object, and decoding_args.n, the completion type can be one of
68 | - a string (if return_text is True)
69 | - an openai_object.OpenAIObject object (if return_text is False)
70 | - a list of objects of the above types (if decoding_args.n > 1)
71 | """
72 | is_chat_model = "gpt-3.5" in model_name or "gpt-4" in model_name
73 | is_single_prompt = isinstance(prompts, (str, dict))
74 | if is_single_prompt:
75 | prompts = [prompts]
76 |
77 | if max_batches < sys.maxsize:
78 | logging.warning(
79 | "`max_batches` will be deprecated in the future, please use `max_instances` instead."
80 | "Setting `max_instances` to `max_batches * batch_size` for now."
81 | )
82 | max_instances = max_batches * batch_size
83 |
84 | prompts = prompts[:max_instances]
85 | num_prompts = len(prompts)
86 | prompt_batches = [
87 | prompts[batch_id * batch_size : (batch_id + 1) * batch_size]
88 | for batch_id in range(int(math.ceil(num_prompts / batch_size)))
89 | ]
90 |
91 | completions = []
92 | for batch_id, prompt_batch in tqdm.tqdm(
93 | enumerate(prompt_batches),
94 | desc="prompt_batches",
95 | total=len(prompt_batches),
96 | ):
97 | batch_decoding_args = copy.deepcopy(decoding_args) # cloning the decoding_args
98 |
99 | while True:
100 | try:
101 | shared_kwargs = dict(
102 | model=model_name,
103 | **batch_decoding_args.__dict__,
104 | **decoding_kwargs,
105 | )
106 | if is_chat_model:
107 | completion_batch = openai.ChatCompletion.create(
108 | messages=[
109 | {"role": "system", "content": "You are a helpful assistant."},
110 | {"role": "user", "content": prompt_batch[0]}
111 | ],
112 | **shared_kwargs
113 | )
114 | else:
115 | completion_batch = openai.Completion.create(prompt=prompt_batch, **shared_kwargs)
116 |
117 | choices = completion_batch.choices
118 |
119 | for choice in choices:
120 | choice["total_tokens"] = completion_batch.usage.total_tokens
121 | completions.extend(choices)
122 | break
123 | except openai.error.OpenAIError as e:
124 | logging.warning(f"OpenAIError: {e}.")
125 | if "Please reduce your prompt" in str(e):
126 | batch_decoding_args.max_tokens = int(batch_decoding_args.max_tokens * 0.8)
127 | logging.warning(f"Reducing target length to {batch_decoding_args.max_tokens}, Retrying...")
128 | else:
129 | logging.warning("Hit request rate limit; retrying...")
130 | time.sleep(sleep_time) # Annoying rate limit on requests.
131 |
132 | if return_text:
133 | completions = [completion.text for completion in completions]
134 | if decoding_args.n > 1:
135 | # make completions a nested list, where each entry is a consecutive decoding_args.n of original entries.
136 | completions = [completions[i : i + decoding_args.n] for i in range(0, len(completions), decoding_args.n)]
137 | if is_single_prompt:
138 | # Return non-tuple if only 1 input and 1 generation.
139 | (completions,) = completions
140 | return completions
141 |
142 |
143 | def _make_w_io_base(f, mode: str):
144 | if not isinstance(f, io.IOBase):
145 | f_dirname = os.path.dirname(f)
146 | if f_dirname != "":
147 | os.makedirs(f_dirname, exist_ok=True)
148 | f = open(f, mode=mode)
149 | return f
150 |
151 |
152 | def _make_r_io_base(f, mode: str):
153 | if not isinstance(f, io.IOBase):
154 | f = open(f, mode=mode)
155 | return f
156 |
157 |
158 | def jdump(obj, f, mode="w", indent=4, default=str):
159 | """Dump a str or dictionary to a file in json format.
160 |
161 | Args:
162 | obj: An object to be written.
163 | f: A string path to the location on disk.
164 | mode: Mode for opening the file.
165 | indent: Indent for storing json dictionaries.
166 | default: A function to handle non-serializable entries; defaults to `str`.
167 | """
168 | f = _make_w_io_base(f, mode)
169 | if isinstance(obj, (dict, list)):
170 | json.dump(obj, f, indent=indent, default=default)
171 | elif isinstance(obj, str):
172 | f.write(obj)
173 | else:
174 | raise ValueError(f"Unexpected type: {type(obj)}")
175 | f.close()
176 |
177 |
178 | def jload(f, mode="r"):
179 | """Load a .json file into a dictionary."""
180 | f = _make_r_io_base(f, mode)
181 | jdict = json.load(f)
182 | f.close()
183 | return jdict
184 |
--------------------------------------------------------------------------------
/autoagents/eval/README.md:
--------------------------------------------------------------------------------
1 | Use test.py to evaluate models:
2 |
3 | ```
4 | PYTHONPATH=`pwd` python autoagents/eval/test.py --help
5 | ```
6 | ```
7 | usage: test.py [-h] [--model MODEL] [--temperature TEMPERATURE] [--agent [{ddg,wiki}]] [--persist-logs]
8 | [--dataset [{default,hotpotqa,ft,hf,bamboogle}]] [--eval] [--prompt-version [{v2,v3}]] [--slice SLICE]
9 |
10 | optional arguments:
11 | -h, --help show this help message and exit
12 | --model MODEL model to be tested
13 | --temperature TEMPERATURE
14 | model temperature
15 | --agent [{ddg,wiki}] which action agent we want to interact with(default: ddg)
16 | --persist-logs persist logs on disk, enable this feature for later eval purpose
17 | --log-save-dir LOG_SAVE_DIR
18 | dir to save logs
19 | --dataset [{default,hotpotqa,ft,hf,bamboogle}]
20 | which dataset we want to interact with(default: default)
21 | --eval enable automatic eval
22 | --prompt-version [{v2,v3}]
23 | which version of prompt to use(default: v2)
24 | --slice SLICE slice the dataset from left, question list will start from index 0 to slice - 1
25 | ```
26 | Sample command to eval on Hotpotqa dataset:
27 | ```
28 | PYTHONPATH=`pwd` python autoagents/eval/test.py --model gpt-4 --temperature 0 --agent wiki --persist-logs --dataset hotpotqa --prompt-version v2 --eval
29 | ```
30 |
31 | Sample command to eval on Bamboogle dataset:
32 | ```
33 | PYTHONPATH=`pwd` python autoagents/eval/test.py --model gpt-4 --temperature 0 --agent ddg --persist-logs --dataset bamboogle --prompt-version v2 --eval
34 | ```
35 | These commands will generate model logs under `data` folders automatically and run evaluation scripts on those logs.
36 |
37 |
38 | ## Common Metrics
39 |
40 | ### general counts
41 |
42 | - total_logs
43 |
44 | Total number of log json files evaluated
45 |
46 | - total_steps
47 |
48 | Total number of steps in all log files evaluated
49 |
50 | - total_rewrites
51 |
52 | Total number of rewrites triggered
53 |
54 | - total_valid
55 |
56 | Number of valid log files. In most cases, a log is valid when it does not contain any errors.
57 |
58 | - valid_steps
59 |
60 | Aggregated number of steps in valid log files.
61 |
62 | - search_invoked
63 |
64 | Number of times `Tool_Search` or `Tool_Wikipedia` is invoked.
65 |
66 | - notepad_invoked
67 |
68 | Number of times `Tool_Notepad` is invoked.
69 |
70 | - Endwith_{action/tool}
71 |
72 | Number of times a conversation ends with a specific tool.
73 |
74 | - visit_in_plan
75 |
76 | Number of plans that start with `Visit`
77 |
78 | - len_hist
79 |
80 | Aggregated length of history trace
81 |
82 | - duplicate_actions
83 |
84 | Number of duplicate {action}+{action_inputs} pairs
85 |
86 | - Finish_with_dups
87 |
88 | Number of duplicate `Tool_Finish`+{action_inputs} pairs
89 |
90 | - average_answer_missing
91 |
92 | The ratio of times when the agent fails to produce a final answer for an input sample.
93 |
94 | - average_steps
95 |
96 | Average number of steps in a conversation to reach the final answer.
97 |
98 | - total_samples
99 |
100 | The total number of samples/goals evaluated.
101 |
102 | - finished_samples
103 |
104 | The number of samples where the agent is able to call `Tool_Finish` for it.
105 |
106 | ### error counts
107 |
108 | Count the number of times a specific pattern of error occurs in the error log.
109 |
110 | - invalid_tools_error
111 |
112 | Check whether error log contains "Invalid tool requested by the model.".
113 |
114 | - context_len_error
115 |
116 | Check whether error log contains "This model's maximum context length".
117 |
118 | - dns_error
119 |
120 | Check whether error log contains "[Errno -3] Temporary failure in name resolution".
121 |
122 | - parse_error
123 |
124 | Check whether error log contains "Could not parse LLM output:".
125 |
126 | - rate_limit_error
127 |
128 | Check whether error log contains "Rate limit reached for ".
129 |
130 | - connection_error
131 |
132 | Check whether error log contains "[Errno 111] Connection refused".
133 |
134 | - other_error
135 |
136 | Any other kinds of uncaught exceptions will be marked as other_error.
137 |
138 | ### plan patterns
139 |
140 | Occurrence of action sequences
141 |
142 | - Tool_Search->Tool_Notepad
143 |
144 | - Tool_Search->Tool_Search->Tool_Notepad
145 |
146 | - Tool_Search->Tool_Search->Tool_Search->Tool_Notepad
147 |
148 | - …
149 |
150 | ### histograms
151 |
152 | - len_history_trace
153 |
154 | histogram of the lengths of history trace
155 |
156 | - len_initial_plan
157 |
158 | histogram of the lengths of initial plans
159 |
--------------------------------------------------------------------------------
/autoagents/eval/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AutoLLM/AutoAgents/e1210c7884f951f1b90254e40c162e81fc1442f3/autoagents/eval/__init__.py
--------------------------------------------------------------------------------
/autoagents/eval/bamboogle.py:
--------------------------------------------------------------------------------
1 | import glob
2 | import json
3 | import os
4 | import pprint
5 | import shutil
6 |
7 | from autoagents.data.dataset import BAMBOOGLE
8 | from autoagents.eval.metrics import get_common_stats
9 | from autoagents.eval.hotpotqa.eval_async import check_answer_equivalency
10 | from autoagents.agents.utils.constants import LOG_SAVE_DIR
11 | from tqdm import tqdm
12 | from langchain.chat_models import ChatOpenAI
13 |
14 |
15 | async def eval(eval_results_path: str=LOG_SAVE_DIR):
16 | files = glob.glob(f"{eval_results_path}/*.json")
17 | evalllm = ChatOpenAI(
18 | openai_api_key=os.getenv("OPENAI_API_KEY"),
19 | openai_organization=os.getenv("OPENAI_API_ORG"),
20 | temperature=0,
21 | model="gpt-3.5-turbo",
22 | request_timeout=120
23 | )
24 | print(f"Found {len(files)} log files! Starts to analyze......")
25 | common_stats = get_common_stats(files)
26 | print(common_stats)
27 | accuracy = 0
28 | correct_res_dir, wrong_res_dir, err_res_dir = f"{eval_results_path}-eval/correct", f"{eval_results_path}-eval/wrong", f"{eval_results_path}-eval/error"
29 | os.makedirs(correct_res_dir, exist_ok=True)
30 | os.makedirs(wrong_res_dir, exist_ok=True)
31 | os.makedirs(err_res_dir, exist_ok=True)
32 | for file in tqdm(files):
33 | finish = False
34 | with open(file, "r") as f:
35 | log_data = json.load(f)
36 | has_error = any([True if "error" in entry else False for entry in log_data])
37 | for entry in log_data:
38 | if not has_error:
39 | if "goal" in entry:
40 | question = entry["goal"]
41 | if "conversations" in entry:
42 | output = json.loads(entry["conversations"][-1]["value"])
43 | if output["action"] == "Tool_Finish":
44 | finish = True
45 | action_input = output["action_input"]
46 | for i in range(len(BAMBOOGLE["questions"])):
47 | if question == BAMBOOGLE["questions"][i]:
48 | answer = BAMBOOGLE["answers"][i]
49 | resp_obj = await check_answer_equivalency(question, answer, action_input, evalllm)
50 | is_correct = int(resp_obj.get("is_inferable", 0))
51 | if is_correct:
52 | shutil.copy2(file, correct_res_dir)
53 | else:
54 | shutil.copy2(file, wrong_res_dir)
55 | accuracy += is_correct
56 | else:
57 | shutil.copy2(file, err_res_dir)
58 | if not finish:
59 | shutil.copy2(file, wrong_res_dir)
60 | counts = common_stats["counts"]
61 | total_samples = counts["total_samples"]
62 | finished_samples = counts["finished_samples"]
63 | print(f'accuracy overall is {accuracy}/{total_samples}={accuracy/total_samples}')
64 | print(f'accuracy on finished samples is {accuracy}/{finished_samples}={accuracy/finished_samples}')
65 | counts["accuracy on finished samples"] = accuracy/finished_samples
66 | counts["accuracy"] = accuracy/total_samples
67 | counts["average_answer_missing"] = (total_samples - finished_samples) / total_samples
68 | pprint.pprint(common_stats)
69 | with open(f"{eval_results_path}-eval/stats.json", "w") as f:
70 | json.dump(common_stats, f)
71 |
--------------------------------------------------------------------------------
/autoagents/eval/hotpotqa/README.md:
--------------------------------------------------------------------------------
1 | # Search LLM Evaluation
2 |
3 | ## Overview
4 |
5 | ### Dataset
6 | - [HotpotQA](https://hotpotqa.github.io/)
7 | - [Fullwiki Dev Set](http://curtis.ml.cmu.edu/datasets/hotpot/hotpot_dev_fullwiki_v1.json)
8 |
9 | ### Metrics
10 | - Recall/Precision/F1
11 | - Mean Reciprocal Rank (MRR)
12 | - Accuracy
13 | - Missing Rate
14 |
15 | ## Results
16 |
17 | - Overall
18 | | Metric | LLM | 30 Samples | 100 Samples | 500 Samples |
19 | | --- | --- | --- | --- | --- |
20 | | LLM Accuracy | GPT-3.5-turbo | 0.4 | 0.35 | 0.328|
21 | | LLM Accuracy | GPT-4 | **0.7** | **0.55** | **0.414** |
22 | | Supporting facts recall | GPT-3.5-turbo | 0.3833 | 0.355 | 0.313 |
23 | | Supporting facts recall | GPT-4 | **0.5333** | **0.44** | **0.353** |
24 | | Max MRR | GPT-3.5-turbo | 0.2606 | 0.2862 | 0.2412 |
25 | | Max MRR | GPT-4 | **0.3531** | **0.3229** | **0.2740** |
26 | | First MRR | GPT-3.5-turbo | 0.2522 | 0.2799 | 0.2355 |
27 | | First MRR | GPT-4 | **0.3531** | **0.3204** | **0.2704** |
28 | | Last MRR | GPT-3.5-turbo | 0.2592 | 0.2743 | 0.2288 |
29 | | Last MRR | GPT-4 | **0.3481** | **0.3127** | **0.2663** |
30 |
31 | - Only on output with final answers
32 | | Metric | LLM | 30 Samples | 100 Samples | 500 Samples |
33 | | --- | --- | --- | --- | --- |
34 | | LLM Accuracy | GPT-3.5-turbo | 0.48 | 0.4667 | 0.5031 |
35 | | LLM Accuracy | GPT-4 | **0.8077** | **0.7534** | **0.6635** |
36 | | Supporting facts recall | GPT-3.5-turbo | 0.46 | 0.4733 | 0.4801 |
37 | | Supporting facts recall | GPT-4 | **0.6154** | **0.6027** | **0.5657** |
38 | | Max MRR | GPT-3.5-turbo | 0.3127 | 0.3816 | 0.3700 |
39 | | Max MRR | GPT-4 | **0.4074** | **0.4424** | **0.4390** |
40 | | First MRR | GPT-3.5-turbo | 0.3027 | 0.3732 | 0.3611 |
41 | | First MRR | GPT-4 | **0.4074** | **0.4389** | **0.4333** |
42 | | Last MRR | GPT-3.5-turbo | 0.311 | 0.3657 | 0.3510 |
43 | | Last MRR | GPT-4 | **0.4016** | **0.4283** | **0.4267** |
44 |
45 | - Error rate
46 | | Metric | LLM | 30 Samples | 100 Samples | 500 Samples |
47 | | --- | --- | --- | --- | --- |
48 | | Parsing error rate | GPT-3.5-turbo | 0.0667 | 0.01 | 0.06 |
49 | | Parsing error rate | GPT-4 | 0.0667 | **0** | **0.008** |
50 | | Missiong rate | GPT-3.5-turbo | 0.1667 | **0.25** | **0.348** |
51 | | Missiong rate | GPT-4 | **0.1333** | 0.27 | 0.376 |
52 |
53 |
--------------------------------------------------------------------------------
/autoagents/eval/hotpotqa/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AutoLLM/AutoAgents/e1210c7884f951f1b90254e40c162e81fc1442f3/autoagents/eval/hotpotqa/__init__.py
--------------------------------------------------------------------------------
/autoagents/eval/hotpotqa/constants.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 |
4 | MODEL_NAME: str = "gpt-3.5-turbo"
5 |
6 | PERSIST_LOGS: bool = True
7 |
8 | EVAL_MODEL_NAME: str = "gpt-3.5-turbo"
9 |
10 | TEMPERATURE: float = 0
11 |
12 | NUM_SAMPLES_TOTAL: int = 200
13 |
14 | AWAIT_TIMEOUT: int = 360
15 |
16 | ROUND_WAITTIME: int = 10
17 |
18 | MAX_RETRY_ROUND: int = 1
19 |
20 | MAX_ROUND_STEPS: int = 30
21 |
22 | OPENAI_MODEL_NAMES = {"gpt-3.5-turbo", "gpt-4"}
23 |
24 | PARENT_DIRECTORY: str = os.path.dirname(os.path.abspath(__file__))
25 |
26 | GT_FILE: str = os.path.join(PARENT_DIRECTORY, "hotpot_dev_fullwiki_v1.json")
27 |
28 | GT_URL: str = "http://curtis.ml.cmu.edu/datasets/hotpot/hotpot_dev_fullwiki_v1.json"
29 |
30 | RESULTS_DIR: str = os.path.join(PARENT_DIRECTORY, f"results_{MODEL_NAME}")
31 |
32 | OUTPUT_FILE: str = os.path.join(RESULTS_DIR, f"prediction.json")
33 |
34 | RUN_EVAL_LOG_FILE: str = os.path.join(RESULTS_DIR, "run_eval.log")
35 |
36 | WRONG_ANS_OUTPUT_FILE: str = os.path.join(RESULTS_DIR, f"wrong_answers.json")
37 |
38 | NEW_LOG_DIR: str = os.path.join(RESULTS_DIR, "data")
39 |
--------------------------------------------------------------------------------
/autoagents/eval/hotpotqa/eval_async.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import asyncio
4 | import requests
5 | from argparse import ArgumentParser
6 | from typing import Optional, Union
7 | from tqdm.asyncio import tqdm_asyncio
8 | from langchain.schema import HumanMessage
9 | from langchain.chat_models import ChatOpenAI
10 |
11 | from autoagents.eval.hotpotqa.constants import *
12 | from autoagents.agents.utils.constants import LOG_SAVE_DIR
13 | from autoagents.eval.metrics import get_summary_from_log_data
14 | from autoagents.eval.hotpotqa.hotpotqa_eval import eval
15 |
16 |
17 | class HotpotqaAsyncEval:
18 |
19 | def __init__(
20 | self,
21 | model: str,
22 | ckpt_dir: Optional[str] = None,
23 | pred_file: Optional[str] = None
24 | ):
25 |
26 | if ckpt_dir is None:
27 | ckpt_dir = os.path.join(PARENT_DIRECTORY, f"results_{model}")
28 |
29 | if not os.path.isdir(ckpt_dir):
30 | os.mkdir(ckpt_dir)
31 |
32 | self.pred_file = pred_file or os.path.join(ckpt_dir, "prediction.json")
33 | self.new_log_dir = os.path.join(ckpt_dir, "data")
34 | self.wrong_ans_file = os.path.join(ckpt_dir, "wrong_ans.json")
35 |
36 | def get_questions(self, total: Optional[int] = None):
37 | dataset = prepare_dataset(total=total, pred_ckpt=self.pred_file)
38 | return [data["question"] for data in dataset]
39 |
40 | def run(self, log_dir: Optional[str] = None):
41 |
42 | if log_dir is None:
43 | if not os.path.isdir(self.new_log_dir):
44 | os.mkdir(self.new_log_dir)
45 | if os.path.isdir(LOG_SAVE_DIR):
46 | for log_file in os.listdir(LOG_SAVE_DIR):
47 | os.rename(
48 | src=os.path.join(LOG_SAVE_DIR, log_file),
49 | dst=os.path.join(self.new_log_dir, log_file)
50 | )
51 | os.rmdir(LOG_SAVE_DIR)
52 | log_dir = self.new_log_dir
53 |
54 | pred_dict = predict_log_dir(log_dir=log_dir, pred_ckpt=self.pred_file)
55 |
56 | self.save_output(pred_dict=pred_dict)
57 |
58 | eval(self.pred_file, GT_FILE)
59 |
60 | def save_output(self, pred_dict: dict):
61 |
62 | with open(self.pred_file, 'w') as f:
63 | json.dump(pred_dict, f, indent=2)
64 |
65 | wrong_ans = []
66 | for qid, stat in pred_dict["statistics"].items():
67 | if stat["summary"]["counts"].get("equivalency", 0) == 0:
68 | wrong_ans.append({
69 | "question": stat["question"],
70 | "gt_answer": stat["gt_answer"],
71 | "prediction": pred_dict["answer"].get(qid, ''),
72 | "reasoning": stat["reasoning"]
73 | })
74 | with open(self.wrong_ans_file, 'w') as f:
75 | json.dump(wrong_ans, f, indent=2)
76 |
77 |
78 | def get_pred_dict(pred_ckpt: Optional[str] = None):
79 |
80 | if pred_ckpt is not None and os.path.isfile(pred_ckpt):
81 | with open(pred_ckpt, 'r') as f:
82 | return json.load(f)
83 |
84 | return {"answer": {}, "statistics": {}, "sp": {}, "error": {}}
85 |
86 |
87 | def prepare_dataset(
88 | total: Optional[int] = None,
89 | pred_ckpt: Optional[Union[str, dict]] = None,
90 | log_dir: Optional[str] = None
91 | ):
92 |
93 | full_dataset = get_hotpotqa_fullwiki_devset()
94 | filtered_dataset = []
95 |
96 | if total is None:
97 | total = len(full_dataset)
98 |
99 | if log_dir is not None and os.path.isdir(log_dir):
100 | goal_set: set = set()
101 | for log_file in os.listdir(log_dir):
102 | with open(os.path.join(log_dir, log_file), 'r') as f:
103 | try:
104 | log_data = json.load(f)
105 | except json.decoder.JSONDecodeError:
106 | continue
107 | if log_data and isinstance(log_data, list):
108 | goal = None
109 | for entry in log_data:
110 | if "goal" in entry:
111 | goal = entry["goal"]
112 | break
113 | if goal:
114 | goal_set.add(goal)
115 | for data in full_dataset:
116 | for goal in goal_set:
117 | if data["question"] in goal:
118 | filtered_dataset.append(data)
119 | return filtered_dataset
120 |
121 | if isinstance(pred_ckpt, dict):
122 | pred_dict = pred_ckpt
123 | else:
124 | pred_dict = get_pred_dict(pred_ckpt=pred_ckpt)
125 |
126 | dataset = []
127 | num_new_ids = 0
128 | for data in full_dataset:
129 | if data["_id"] not in pred_dict["statistics"]:
130 | if len(pred_dict["statistics"]) + num_new_ids >= total:
131 | break
132 | dataset.append(data)
133 | num_new_ids += 1
134 | elif data["_id"] in pred_dict.get("error", []):
135 | dataset.append(data)
136 |
137 | return dataset
138 |
139 |
140 | def get_hotpotqa_fullwiki_devset(file: str = GT_FILE, url: str = GT_URL):
141 |
142 | if not os.path.isfile(file):
143 | response = requests.get(url)
144 | with open(file, 'wb') as f:
145 | f.write(response.content)
146 |
147 | with open(file, 'r') as f:
148 | return json.load(f)
149 |
150 |
151 | def evaluate_log_dir(
152 | log_dir: str = LOG_SAVE_DIR,
153 | pred_ckpt: Optional[str] = None
154 | ):
155 | pred_ckpt = pred_ckpt or os.path.join(PARENT_DIRECTORY, "prediction.json")
156 | pred_dict = predict_log_dir(log_dir=log_dir, pred_ckpt=pred_ckpt)
157 | with open(pred_ckpt, 'w') as f:
158 | json.dump(pred_dict, f, indent=2)
159 | eval(pred_ckpt, GT_FILE)
160 |
161 |
162 | def predict_log_dir(
163 | log_dir: str = LOG_SAVE_DIR,
164 | pred_ckpt: Optional[str] = None
165 | ):
166 | dataset = {
167 | data["question"]: data for data in prepare_dataset(log_dir=log_dir)
168 | }
169 |
170 | pred_dict = get_pred_dict(pred_ckpt=pred_ckpt)
171 |
172 | asyncio.run(collect_metrics(
173 | pred_dict=pred_dict, dataset=dataset, log_files=[
174 | os.path.join(log_dir, file) for file in os.listdir(log_dir)
175 | ]
176 | ))
177 |
178 | return pred_dict
179 |
180 |
181 | async def collect_metrics(pred_dict: dict, dataset: dict, log_files: list):
182 |
183 | semaphore = asyncio.Semaphore(10)
184 |
185 | async def process_log_file(log_file: str):
186 | async with semaphore:
187 | with open(log_file, "r") as f:
188 | try:
189 | log_data = json.load(f)
190 | except json.decoder.JSONDecodeError:
191 | return
192 | await evaluate_log_data(log_data, pred_dict, dataset)
193 |
194 | await tqdm_asyncio.gather(*[
195 | process_log_file(log_file) for log_file in log_files
196 | ])
197 |
198 |
199 | async def evaluate_log_data(
200 | log_data: dict, pred_dict: dict, dataset: dict
201 | ):
202 |
203 | if not log_data or not isinstance(log_data, list):
204 | return
205 | summary = get_summary_from_log_data(log_data=log_data)
206 | question = summary["question"]
207 | if question is None:
208 | return
209 | gt = None
210 | for q in dataset:
211 | if q in question:
212 | gt = dataset[q]
213 | break
214 | if gt is None:
215 | return
216 | qid = gt["_id"]
217 | if qid in pred_dict["answer"]:
218 | return
219 | for key in list(pred_dict.keys()):
220 | if qid in pred_dict[key]:
221 | del pred_dict[key][qid]
222 |
223 | titles = []
224 | statistics = {
225 | "reasoning": '',
226 | "question": question,
227 | "gt_answer": gt["answer"],
228 | "gt_citations": [fact[0] for fact in gt["supporting_facts"]],
229 | "raw_citation_urls": [],
230 | "citations": {},
231 | "summary": summary
232 | }
233 |
234 | if summary["answer"] is not None:
235 | pred_dict["answer"][gt["_id"]] = summary["answer"]
236 | if gt["_id"] in pred_dict["error"]:
237 | del pred_dict["error"][gt["_id"]]
238 | await evaluate_final_answer(summary["answer"], gt, pred_dict, statistics)
239 |
240 | for entry in log_data:
241 |
242 | if "error" in entry:
243 | pred_dict["error"][qid] = entry["error"]
244 |
245 | if "conversations" in entry:
246 | await process_conversation_log(
247 | entry["conversations"], statistics, titles
248 | )
249 |
250 | if titles:
251 | pred_dict["sp"][qid] = titles
252 | if isinstance(statistics["citations"], dict):
253 | statistics["citations"] = []
254 | pred_dict["statistics"][qid] = statistics
255 | if qid not in pred_dict["answer"] and qid not in pred_dict["error"]:
256 | pred_dict["error"][qid] = json.dumps(statistics, indent=2)
257 |
258 |
259 | async def process_conversation_log(
260 | conversations: list, statistics: dict, titles: list
261 | ):
262 | try:
263 | observation = conversations[0]["value"][-1]["observation"]
264 | titles.append([doc["title"] for doc in observation])
265 | for doc in observation:
266 | statistics["citations"][doc["url"]] = doc["title"]
267 | except:
268 | pass
269 |
270 | try:
271 | prediction = json.loads(conversations[-1]["value"])
272 | except json.decoder.JSONDecodeError:
273 | statistics["summary"]["error_counts"]["parse_error"] += 1
274 | return
275 | if prediction["action"] == "Tool_Finish":
276 | # Get list of citations
277 | citations = []
278 | for citation in prediction.get("citations", []):
279 | if ": " not in citation:
280 | continue
281 | url = citation.split(": ")[0]
282 | statistics["raw_citation_urls"].append(url)
283 | if url in statistics["citations"]:
284 | citations.append(statistics["citations"].get(url))
285 | statistics["citations"] = citations
286 |
287 |
288 | async def evaluate_final_answer(
289 | final_answer: str, data: dict, pred_dict, statistics, llm=None
290 | ):
291 |
292 | question: str = data["question"]
293 | gt_answer: str = data["answer"]
294 |
295 | try:
296 | # Use GPT to determine if the final output is equivalent with the ground truth
297 | resp_obj = await check_answer_equivalency(question, gt_answer, final_answer, llm)
298 | statistics["summary"]["counts"]["equivalency"] = int(resp_obj.get("is_inferable", 0))
299 | statistics["reasoning"] = resp_obj.get("reasoning", '')
300 |
301 | except Exception as e:
302 | pred_dict["error"][data["_id"]] = f"Error during evalutaion: {e}"
303 |
304 |
305 | async def check_answer_equivalency(question: str, answer1: str, answer2: str, llm=None):
306 |
307 | if llm is None:
308 | llm = ChatOpenAI(
309 | openai_api_key=os.getenv("OPENAI_API_KEY"),
310 | openai_organization=os.getenv("OPENAI_API_ORG"),
311 | temperature=0,
312 | model=EVAL_MODEL_NAME,
313 | request_timeout=AWAIT_TIMEOUT
314 | )
315 |
316 | # Use GPT to determine if the answer1 is equivalent with answer2
317 | resp = await llm.agenerate([[HumanMessage(
318 | content=f"Given a question and a pair of answers. Determine if Answer1 can be strictly infered from Answer2. Return False if given the information in Answer2, we cannot determine whether Answer1 is right. Add detailed explaination and reasioning. Format your answer in JSON with a boolean field called 'is_inferable' and a string field 'reasoning' that can be loaded in python.\n\nQuestion: '{question}'\n\nAnswer1: '{answer1}'\n\nAnswer2: '{answer2}'"
319 | )]])
320 | return json.loads(resp.generations[0][0].text.strip())
321 |
322 |
323 | def main():
324 |
325 | parser = ArgumentParser()
326 | parser.add_argument("log_dir", type=str, help="path of the log directory")
327 | parser.add_argument("--pred_ckpt", type=str, help="path of the log directory")
328 | args = parser.parse_args()
329 | evaluate_log_dir(args.log_dir, args.pred_ckpt)
330 |
331 | if __name__ == "__main__":
332 | main()
333 |
--------------------------------------------------------------------------------
/autoagents/eval/hotpotqa/hotpotqa_eval.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import numpy as np
3 | import ujson as json
4 | import re
5 | import string
6 | from collections import Counter
7 | from pprint import pprint
8 |
9 |
10 | def normalize_answer(s):
11 |
12 | def remove_articles(text):
13 | return re.sub(r'\b(a|an|the)\b', ' ', text)
14 |
15 | def white_space_fix(text):
16 | return ' '.join(text.split())
17 |
18 | def remove_punc(text):
19 | exclude = set(string.punctuation)
20 | return ''.join(ch for ch in text if ch not in exclude)
21 |
22 | def lower(text):
23 | return text.lower()
24 |
25 | return white_space_fix(remove_articles(remove_punc(lower(s))))
26 |
27 |
28 | def f1_score(prediction, ground_truth):
29 | normalized_prediction = normalize_answer(prediction)
30 | normalized_ground_truth = normalize_answer(ground_truth)
31 |
32 | ZERO_METRIC = (0, 0, 0)
33 |
34 | # if normalized_prediction in ['yes', 'no', 'noanswer'] and normalized_prediction != normalized_ground_truth:
35 | # return ZERO_METRIC
36 | # if normalized_ground_truth in ['yes', 'no', 'noanswer'] and normalized_prediction != normalized_ground_truth:
37 | # return ZERO_METRIC
38 |
39 | prediction_tokens = normalized_prediction.split()
40 | ground_truth_tokens = normalized_ground_truth.split()
41 | common = Counter(prediction_tokens) & Counter(ground_truth_tokens)
42 | num_same = sum(common.values())
43 | if num_same == 0:
44 | return ZERO_METRIC
45 | precision = 1.0 * num_same / len(prediction_tokens)
46 | recall = 1.0 * num_same / len(ground_truth_tokens)
47 | f1 = (2 * precision * recall) / (precision + recall)
48 | return f1, precision, recall
49 |
50 |
51 | def exact_match_score(prediction, ground_truth):
52 | return (normalize_answer(prediction) == normalize_answer(ground_truth))
53 |
54 | def update_answer(metrics, prediction, gold):
55 | em = exact_match_score(prediction, gold)
56 | f1, prec, recall = f1_score(prediction, gold)
57 | metrics['em'] += float(em)
58 | metrics['f1'] += f1
59 | metrics['prec'] += prec
60 | metrics['recall'] += recall
61 | return em, prec, recall
62 |
63 | def update_sp(metrics, prediction, gold, statistics):
64 |
65 | # Only match titles
66 | cur_sp_pred = set(title for rank in prediction for title in rank)
67 | gold_sp_pred = set(x[0] for x in gold)
68 |
69 | tp, fp, fn = 0, 0, 0
70 | for e in cur_sp_pred:
71 | if e in gold_sp_pred:
72 | tp += 1
73 | else:
74 | fp += 1
75 | for e in gold_sp_pred:
76 | if e not in cur_sp_pred:
77 | fn += 1
78 | prec = 1.0 * tp / (tp + fp) if tp + fp > 0 else 0.0
79 | recall = 1.0 * tp / (tp + fn) if tp + fn > 0 else 0.0
80 | f1 = 2 * prec * recall / (prec + recall) if prec + recall > 0 else 0.0
81 | em = 1.0 if fp + fn == 0 else 0.0
82 | metrics['sp_em'] += em
83 | metrics['sp_f1'] += f1
84 | metrics['sp_prec'] += prec
85 | metrics['sp_recall'] += recall
86 |
87 | if all(e in cur_sp_pred for e in gold_sp_pred) and \
88 | statistics["summary"]["counts"].get("equivalency", 0) == 0:
89 | metrics["wrong_infer"] += 1
90 |
91 | title_to_ranks = {}
92 | for title_list in prediction:
93 | for i, title in enumerate(title_list):
94 | if title not in gold_sp_pred:
95 | continue
96 | if title not in title_to_ranks:
97 | title_to_ranks[title] = [i + 1] * 3
98 | title_to_ranks[title][0] = min(i + 1, title_to_ranks[title][0])
99 | title_to_ranks[title][2] = i + 1
100 | n_gt_titles = len(gold_sp_pred)
101 | cur_ranks = title_to_ranks.values()
102 | metrics["max_mrr"] += sum(1 / ranks[0] for ranks in cur_ranks) / n_gt_titles
103 | metrics["first_mrr"] += sum(1 / ranks[1] for ranks in cur_ranks) / n_gt_titles
104 | metrics["last_mrr"] += sum(1 / ranks[2] for ranks in cur_ranks) / n_gt_titles
105 |
106 | return em, prec, recall
107 |
108 | def update_last_sp(metrics, statistics, gold):
109 |
110 | # Only match titles
111 | cur_sp_pred = set(title for title in statistics.get("citations", []))
112 | gold_sp_pred = set(x[0] for x in gold)
113 |
114 | tp, fp, fn = 0, 0, 0
115 | for e in cur_sp_pred:
116 | if e in gold_sp_pred:
117 | tp += 1
118 | else:
119 | fp += 1
120 | for e in gold_sp_pred:
121 | if e not in cur_sp_pred:
122 | fn += 1
123 | prec = 1.0 * tp / (tp + fp) if tp + fp > 0 else 0.0
124 | recall = 1.0 * tp / (tp + fn) if tp + fn > 0 else 0.0
125 | f1 = 2 * prec * recall / (prec + recall) if prec + recall > 0 else 0.0
126 | em = 1.0 if fp + fn == 0 else 0.0
127 | metrics['last_sp_em'] += em
128 | metrics['last_sp_f1'] += f1
129 | metrics['last_sp_prec'] += prec
130 | metrics['last_sp_recall'] += recall
131 |
132 | return em, prec, recall
133 |
134 | def eval(prediction_file, gold_file):
135 | with open(prediction_file) as f:
136 | prediction = json.load(f)
137 | print(f"len answer = {len(prediction['answer'])}, len error = {len(prediction['error'])}, len sp = {len(prediction['sp'])}, len statistics = {len(prediction['statistics'])}")
138 |
139 | with open(gold_file) as f:
140 | gold = []
141 | for data in json.load(f):
142 | if data["_id"] in prediction["statistics"]:
143 | gold.append(data)
144 |
145 | metrics = {'em': 0, 'f1': 0, 'prec': 0, 'recall': 0,
146 | 'sp_em': 0, 'sp_f1': 0, 'sp_prec': 0, 'sp_recall': 0,
147 | 'last_sp_em': 0, 'last_sp_f1': 0, 'last_sp_prec': 0, 'last_sp_recall': 0,
148 | 'joint_em': 0, 'joint_f1': 0, 'joint_prec': 0, 'joint_recall': 0,
149 | "max_mrr": 0, "first_mrr": 0, "last_mrr": 0, "wrong_infer": 0}
150 | stats = {
151 | "counts": Counter(), # general counters
152 | "error_counts": Counter(), # error counters
153 | "plan_counts": Counter(), # plan patterns
154 | "len_history_trace": [],
155 | "len_initial_plan": []
156 | }
157 | for dp in gold:
158 | cur_id = dp['_id']
159 | can_eval_joint = True
160 | if cur_id not in prediction['answer']:
161 | print('missing answer {}'.format(cur_id))
162 | can_eval_joint = False
163 | else:
164 | em, prec, recall = update_answer(
165 | metrics, prediction['answer'][cur_id], dp['answer'])
166 | summary = prediction['statistics'][cur_id]["summary"]
167 | stats["counts"] += summary["counts"]
168 | stats["error_counts"] += summary["error_counts"]
169 | stats["plan_counts"] += summary["plan_counts"]
170 | stats["len_history_trace"].extend(summary["len_history_trace"])
171 | stats["len_initial_plan"].extend(summary["len_initial_plan"])
172 |
173 | if cur_id not in prediction['sp']:
174 | print('missing sp fact {}'.format(cur_id))
175 | can_eval_joint = False
176 | else:
177 | sp_em, sp_prec, sp_recall = update_sp(
178 | metrics, prediction['sp'][cur_id], dp['supporting_facts'], prediction['statistics'][cur_id])
179 | update_last_sp(
180 | metrics, prediction['statistics'].get(cur_id, {}), dp['supporting_facts']
181 | )
182 |
183 | if can_eval_joint:
184 | joint_prec = prec * sp_prec
185 | joint_recall = recall * sp_recall
186 | if joint_prec + joint_recall > 0:
187 | joint_f1 = 2 * joint_prec * joint_recall / (joint_prec + joint_recall)
188 | else:
189 | joint_f1 = 0.
190 | joint_em = em * sp_em
191 |
192 | metrics['joint_em'] += joint_em
193 | metrics['joint_f1'] += joint_f1
194 | metrics['joint_prec'] += joint_prec
195 | metrics['joint_recall'] += joint_recall
196 |
197 | N = len(gold)
198 | for k in metrics.keys():
199 | metrics[k] /= N
200 |
201 | hist, rng = np.histogram(stats["len_history_trace"], bins=range(0, 16))
202 | stats["len_history_trace"] = hist.tolist()
203 | hist, rng = np.histogram(stats["len_initial_plan"], bins=range(0, 16))
204 | stats["len_initial_plan"] = hist.tolist()
205 |
206 | stats["error_rate"] = {
207 | error: cnt / N
208 | for error, cnt in stats["error_counts"].items()
209 | }
210 | stats["avg_metrics"] = {
211 | metric: cnt / N
212 | for metric, cnt in stats["counts"].items()
213 | }
214 | metrics.update(stats)
215 |
216 | metrics["ans_missing_rate"] = 1 - len(prediction["answer"]) / N
217 | metrics["sp_missing_rate"] = 1 - len(prediction["sp"]) / N
218 | metrics["num_evaluated"] = N
219 | metrics["llm_accuracy_on_finished_samples"] = stats["avg_metrics"]["equivalency"] / (1 - metrics["ans_missing_rate"])
220 |
221 | pprint(metrics)
222 |
223 | if __name__ == '__main__':
224 | eval(sys.argv[1], sys.argv[2])
225 |
--------------------------------------------------------------------------------
/autoagents/eval/hotpotqa/run_eval.py:
--------------------------------------------------------------------------------
1 | import os
2 | import time
3 | import asyncio
4 | import json
5 | import logging
6 | from langchain.chat_models import ChatOpenAI
7 | from pprint import pformat
8 | from ast import literal_eval
9 | from multiprocessing import Pool, Manager
10 | from functools import partial
11 | from tqdm import tqdm
12 |
13 | from autoagents.agents.agents.wiki_agent import WikiActionRunner
14 | from autoagents.agents.models.custom import CustomLLM
15 | from autoagents.eval.hotpotqa.eval_async import (
16 | evaluate_final_answer, prepare_dataset
17 | )
18 | from autoagents.eval.hotpotqa.hotpotqa_eval import eval
19 | from autoagents.eval.hotpotqa.constants import *
20 | from autoagents.agents.utils.constants import LOG_SAVE_DIR
21 |
22 |
23 | if not os.path.isdir(RESULTS_DIR):
24 | os.mkdir(RESULTS_DIR)
25 |
26 | logger = logging.getLogger(__name__)
27 | logger.setLevel(level=logging.DEBUG)
28 | log_filehandler = logging.FileHandler(RUN_EVAL_LOG_FILE)
29 | log_filehandler.setLevel(logging.DEBUG)
30 | log_filehandler.setFormatter(
31 | logging.Formatter('%(asctime)s - %(name)s - %(levelname)s \n%(message)s')
32 | )
33 | logger.addHandler(log_filehandler)
34 |
35 |
36 | def get_llms():
37 | if MODEL_NAME not in OPENAI_MODEL_NAMES:
38 | llm = CustomLLM(
39 | model_name=MODEL_NAME,
40 | temperature=TEMPERATURE,
41 | request_timeout=AWAIT_TIMEOUT
42 | )
43 | else:
44 | llm = ChatOpenAI(
45 | openai_api_key=os.getenv("OPENAI_API_KEY"),
46 | openai_organization=os.getenv("OPENAI_API_ORG"),
47 | temperature=TEMPERATURE,
48 | model_name=MODEL_NAME,
49 | request_timeout=AWAIT_TIMEOUT
50 | )
51 |
52 | evalllm = ChatOpenAI(
53 | openai_api_key=os.getenv("OPENAI_API_KEY"),
54 | openai_organization=os.getenv("OPENAI_API_ORG"),
55 | temperature=0,
56 | model=EVAL_MODEL_NAME,
57 | request_timeout=AWAIT_TIMEOUT
58 | )
59 | return llm, evalllm
60 |
61 |
62 | async def work(data, pred_dict):
63 | outputq = asyncio.Queue()
64 | user_input = data["question"]
65 |
66 | llm, evalllm = get_llms()
67 | runner = WikiActionRunner(outputq, llm=llm, persist_logs=PERSIST_LOGS)
68 | task = asyncio.create_task(runner.run(user_input, outputq))
69 |
70 | titles = []
71 | statistics = {
72 | "steps": 0, "equivalency": 0, "reasoning": '', "question": user_input, "gt_answer": data["answer"], "raw_citation_urls": [], "citations": {}, "rewritten": 0, "search_invoked": 0, "notepad_invoked": 0, "multi_tools": 0, "parse_error": 0, "invalid_tool": 0, "context_len_err": 0
73 | }
74 | for _ in range(runner.agent_executor.max_iterations or MAX_ROUND_STEPS):
75 |
76 | try:
77 | output = await asyncio.wait_for(outputq.get(), AWAIT_TIMEOUT)
78 | except asyncio.TimeoutError:
79 | logger.error(f"Question: {user_input}\nError: Timed out waiting for output from queue\n")
80 | pred_dict["error"][data["_id"]] = "Timed out waiting for output from queue."
81 | break
82 | statistics["steps"] += 1
83 |
84 | if isinstance(output, Exception):
85 | logger.error(f"Question: {user_input}\nError: {output}\n")
86 | if isinstance(output, RuntimeWarning) and "Action Input Rewritten: " in str(output):
87 | statistics["rewritten"] += 1
88 | continue
89 | else:
90 | if "Could not parse LLM output: " in str(output):
91 | statistics["parse_error"] += 1
92 | elif "Invalid tool requested by the model." in str(output):
93 | statistics["invalid_tool"] += 1
94 | elif "This model's maximum context length is" in str(output):
95 | statistics["context_len_err"] += 1
96 | pred_dict["error"][data["_id"]] = str(output)
97 | break
98 |
99 | parsed = get_parsed_output(user_input, output, statistics, titles)
100 |
101 | if isinstance(parsed, dict) and parsed.get("action") == "Tool_Finish":
102 | final_answer: str = parsed["action_input"]
103 | logger.info(f"Question: {user_input}\nFinal Output: {final_answer}\n")
104 |
105 | # Get list of citations
106 | citations = []
107 | for citation in parsed.get("citations", []):
108 | if ": " not in citation:
109 | continue
110 | url = citation.split(": ")[0]
111 | statistics["raw_citation_urls"].append(url)
112 | if url in statistics["citations"]:
113 | citations.append(statistics["citations"].get(url))
114 | statistics["citations"] = citations
115 |
116 | await evaluate_final_answer(final_answer, data, pred_dict, statistics, evalllm)
117 |
118 | break
119 | if titles:
120 | pred_dict["sp"][data["_id"]] = json.dumps(titles)
121 | if isinstance(statistics["citations"], dict):
122 | statistics["citations"] = []
123 | pred_dict["statistics"][data["_id"]] = json.dumps(statistics)
124 | if data["_id"] not in pred_dict["answer"] and data["_id"] not in pred_dict["error"]:
125 | pred_dict["error"][data["_id"]] = json.dumps(statistics, indent=2)
126 |
127 | # await task
128 | try:
129 | return await asyncio.wait_for(task, AWAIT_TIMEOUT)
130 | except asyncio.TimeoutError:
131 | logger.error(f"Question: {user_input}\nError: Timed out waiting for task to complete\n")
132 | pred_dict["error"][data["_id"]] = "Timed out waiting for task to complete."
133 |
134 |
135 | def get_parsed_output(user_input, output, statistics, titles):
136 | parsed = None
137 | try:
138 | parsed = json.loads(output)
139 | logger.debug(f"Question: {user_input}\n{json.dumps(parsed, indent=2)}")
140 | if parsed["action"] == "Tool_Wikipedia":
141 | statistics["search_invoked"] += 1
142 | elif parsed["action"] == "Tool_Notepad":
143 | statistics["notepad_invoked"] += 1
144 | except:
145 | try:
146 | parsed = literal_eval(output)
147 | logger.debug(f"Question: {user_input}\n{json.dumps(parsed, indent=2)}")
148 | if isinstance(parsed, list) and isinstance(parsed[0], dict) and "title" in parsed[0]:
149 | titles.append([doc["title"] for doc in parsed])
150 | for doc in parsed:
151 | statistics["citations"][doc["url"]] = doc["title"]
152 | except:
153 | logger.debug(f"Question: {user_input}\n{output}")
154 | return parsed
155 |
156 |
157 | def save_output():
158 |
159 | if PERSIST_LOGS:
160 | for log_file in os.listdir(LOG_SAVE_DIR):
161 | os.rename(
162 | src=os.path.join(LOG_SAVE_DIR, log_file),
163 | dst=os.path.join(NEW_LOG_DIR, log_file)
164 | )
165 | os.rmdir(LOG_SAVE_DIR)
166 |
167 | output_dict = dict(pred_dict)
168 | for k in list(output_dict.keys()):
169 | output_dict[k] = dict(output_dict[k])
170 | if k in ("sp", "statistics"):
171 | for qid in output_dict[k]:
172 | output_dict[k][qid] = json.loads(output_dict[k][qid])
173 | if isinstance(output_dict[k][qid], str):
174 | output_dict[k][qid] = json.loads(output_dict[k][qid])
175 |
176 | logger.info(pformat(output_dict, indent=2))
177 | with open(OUTPUT_FILE, 'w') as f:
178 | json.dump(output_dict, f, indent=2)
179 |
180 | wrong_ans = []
181 | for qid, stat in output_dict["statistics"].items():
182 | if stat["equivalency"] == 0:
183 | wrong_ans.append({
184 | "question": stat["question"],
185 | "gt_answer": stat["gt_answer"],
186 | "prediction": output_dict["answer"].get(qid, ''),
187 | "reasoning": stat["reasoning"]
188 | })
189 | with open(WRONG_ANS_OUTPUT_FILE, 'w') as f:
190 | json.dump(wrong_ans, f, indent=2)
191 |
192 |
193 | def initialize_pred_dict():
194 |
195 | pred_dict["answer"] = manager.dict()
196 | pred_dict["statistics"] = manager.dict()
197 | pred_dict["sp"] = manager.dict()
198 | pred_dict["error"] = manager.dict()
199 |
200 | cur_dict = {}
201 | if os.path.isfile(OUTPUT_FILE):
202 | with open(OUTPUT_FILE, 'r') as f:
203 | cur_dict = json.load(f)
204 | pred_dict["answer"].update(cur_dict["answer"])
205 | for _id, sp in cur_dict["sp"].items():
206 | pred_dict["sp"][_id] = json.dumps(sp)
207 | for _id, stat in cur_dict["statistics"].items():
208 | pred_dict["statistics"][_id] = json.dumps(stat)
209 |
210 |
211 | def retry(dataset):
212 |
213 | # Retry until we get all the final answers
214 | round = 0
215 | while pred_dict["error"] and round < MAX_RETRY_ROUND:
216 |
217 | logger.info(
218 | f"Round {round}. Start retrying failed samples: "
219 | f"{json.dumps(dict(pred_dict['error']), indent=2)}"
220 | )
221 |
222 | retry_data = []
223 | for i in range(len(dataset)):
224 | if dataset[i]["_id"] in pred_dict["error"]:
225 | retry_data.append(dataset[i])
226 | del pred_dict["error"][dataset[i]["_id"]]
227 |
228 | time.sleep(ROUND_WAITTIME)
229 |
230 | with Pool(processes=10) as pool:
231 | for _ in tqdm(pool.imap_unordered(
232 | partial(main, pred_dict=pred_dict), retry_data
233 | ), total=len(retry_data)):
234 | pass
235 |
236 | round += 1
237 |
238 |
239 | def main(data, pred_dict):
240 | asyncio.run(work(data, pred_dict))
241 |
242 |
243 | if __name__ == "__main__":
244 |
245 | manager = Manager()
246 |
247 | pred_dict = manager.dict()
248 |
249 | initialize_pred_dict()
250 |
251 | dataset = prepare_dataset(total=NUM_SAMPLES_TOTAL, pred_ckpt=pred_dict)
252 |
253 | if PERSIST_LOGS:
254 | if not os.path.isdir(LOG_SAVE_DIR):
255 | os.mkdir(LOG_SAVE_DIR)
256 | if not os.path.isdir(NEW_LOG_DIR):
257 | os.mkdir(NEW_LOG_DIR)
258 |
259 | with Pool(processes=10) as pool:
260 | for _ in tqdm(pool.imap_unordered(
261 | partial(main, pred_dict=pred_dict), dataset
262 | ), total=len(dataset)):
263 | pass
264 |
265 | retry(dataset=dataset)
266 |
267 | save_output()
268 |
269 | eval(OUTPUT_FILE, GT_FILE)
270 |
--------------------------------------------------------------------------------
/autoagents/eval/metrics.py:
--------------------------------------------------------------------------------
1 | import json
2 | import glob
3 | from argparse import ArgumentParser
4 | from collections import Counter, defaultdict
5 | import numpy as np
6 | from pprint import pprint
7 |
8 |
9 | def get_common_stats(log_files):
10 | stats = {
11 | "counts": Counter(), # general counters
12 | "error_counts": Counter(), # error counters
13 | "plan_counts": Counter(), # plan patterns
14 | "len_history_trace": [],
15 | "len_initial_plan": []
16 | }
17 | samples = set()
18 | finished_samples = set()
19 | for file in log_files:
20 | with open(file, "r") as f:
21 | try:
22 | log_data = json.load(f)
23 | except json.decoder.JSONDecodeError:
24 | continue
25 | summary = get_summary_from_log_data(log_data=log_data)
26 | stats["counts"] += summary["counts"]
27 | stats["error_counts"] += summary["error_counts"]
28 | stats["plan_counts"] += summary["plan_counts"]
29 | stats["len_history_trace"].extend(summary["len_history_trace"])
30 | stats["len_initial_plan"].extend(summary["len_initial_plan"])
31 | if summary["question"] is not None:
32 | samples.add(summary["question"])
33 | if summary["answer"] is not None:
34 | finished_samples.add(summary["question"])
35 | stats["counts"]["total_samples"] = len(samples)
36 | stats["counts"]["finished_samples"] = len(finished_samples)
37 |
38 | hist, rng = np.histogram(stats["len_history_trace"], bins=range(0, 16))
39 | stats["len_history_trace"] = hist.tolist()
40 |
41 | hist, rng = np.histogram(stats["len_initial_plan"], bins=range(0, 16))
42 | stats["len_initial_plan"] = hist.tolist()
43 |
44 | return stats
45 |
46 |
47 | def get_summary_from_log_data(log_data: list):
48 |
49 | counts = Counter() # general counters
50 | error_counts = Counter() # error counters
51 | plan_counts = Counter() # plan patterns
52 | len_initial_plan = []
53 | len_history_trace = []
54 |
55 | summary = dict(
56 | counts=counts,
57 | error_counts=error_counts,
58 | plan_counts=plan_counts,
59 | len_history_trace=len_history_trace,
60 | len_initial_plan=len_initial_plan,
61 | question=None,
62 | answer=None
63 | )
64 |
65 | # Handle errors and rewrites
66 | is_valid: bool = True
67 | counts["total_logs"] += 1
68 | for entry in log_data:
69 | if "id" in entry:
70 | counts["total_steps"] += 1
71 | if "goal" in entry:
72 | summary["question"] = entry["goal"]
73 | if "error" in entry:
74 | if "Expecting value" in entry["error"]:
75 | # This is the old rewrite error
76 | pass
77 | elif "Invalid tool requested by the model." in entry["error"]:
78 | error_counts["invalid_tools_error"] += 1
79 | is_valid = False
80 | elif "This model's maximum context length" in entry["error"]:
81 | error_counts["context_len_error"] += 1
82 | if len(log_data) < 4:
83 | is_valid = False
84 | elif "[Errno -3] Temporary failure in name resolution" in entry["error"]:
85 | error_counts["dns_error"] += 1
86 | elif "Could not parse LLM output:" in entry["error"]:
87 | error_counts["parse_error"] += 1
88 | is_valid = False
89 | elif "Rate limit reached for " in entry["error"]:
90 | error_counts["rate_limit_error"] += 1
91 | is_valid = False
92 | elif "[Errno 111] Connection refused" in entry["error"]:
93 | error_counts["connection_error"] += 1
94 | is_valid = False
95 | else:
96 | error_counts["other_error"] += 1
97 | is_valid = False
98 | elif "query_rewrite" in entry:
99 | counts["total_rewrites"] += 1
100 |
101 | if not is_valid:
102 | return summary
103 | counts["total_valid"] += 1
104 |
105 | for entry in log_data:
106 | if "conversations" in entry:
107 | counts["valid_steps"] += 1
108 | prediction = json.loads(entry["conversations"][-1]["value"])
109 | action = prediction["action"]
110 | if action == "Tool_Search" or action == "Tool_Wikipedia":
111 | counts["search_invoked"] += 1
112 | elif action == "Tool_Notepad":
113 | counts["notepad_invoked"] += 1
114 | elif action == "Tool_Finish":
115 | summary["answer"] = prediction["action_input"]
116 |
117 | # do last-step history analysis, log_data[-3]
118 | try:
119 | last_convo = log_data[-3]["conversations"]
120 | if last_convo[1]["from"] in ("gpt", "ai"):
121 | # we don't have the system key in prompt_v3
122 | output = json.loads(last_convo[1]["value"])
123 | else:
124 | output = json.loads(last_convo[2]["value"])
125 | except:
126 | return summary
127 |
128 | counts[f"EndWith_{output['action']}"] += 1
129 |
130 | if last_convo[0]["from"] == "history":
131 | hist = last_convo[0]["value"]
132 | actions = [h["action"] for h in hist]
133 | if len(actions) < 5 and len(actions) > 0:
134 | actions_str = "->".join(actions)
135 | plan_counts[actions_str] += 1
136 | if actions_str == "Tool_Notepad":
137 | pass
138 | if actions_str == "Tool_Search->Tool_Search->Tool_Notepad":
139 | pass
140 | if actions_str == "Tool_Search->Tool_Search->Tool_Search->Tool_Notepad":
141 | pass
142 | plans = []
143 | for plan in [h["plan"] for h in hist]:
144 | plans.extend(plan)
145 | for plan in plans:
146 | if plan.startswith("Visit"):
147 | counts["visit_in_plan"] += 1
148 | break
149 |
150 | len_hist = len(hist)
151 | if len_hist > 0:
152 | len_plan0 = len(hist[0]["plan"])
153 | len_initial_plan.append(len_plan0)
154 | if len_plan0 == 1:
155 | pass
156 | counts["len_hist"] += len_hist
157 | len_history_trace.append(len_hist)
158 |
159 | # find out if there are duplicate action+action_inputs
160 | inputs = defaultdict(set)
161 | plans = set()
162 | for h in hist + [output]:
163 | if h["action"] in inputs:
164 | if h["action_input"] in inputs[h["action"]]:
165 | if output["action"] == "Tool_Finish":
166 | counts["Finish_with_dups"] += 1
167 | break
168 | else: # only count duplicates that didn't finish
169 | counts["duplicate_actions"] += 1
170 | break
171 | inputs[h["action"]].add(h["action_input"])
172 |
173 | return summary
174 |
175 |
176 | def main():
177 |
178 | parser = ArgumentParser()
179 | parser.add_argument("log_dir", type=str, help="path of the log directory")
180 | args = parser.parse_args()
181 |
182 | stats = get_common_stats(log_files=glob.glob(f"{args.log_dir}/*.json"))
183 | pprint(stats)
184 |
185 |
186 | if __name__ == "__main__":
187 | main()
188 |
--------------------------------------------------------------------------------
/autoagents/eval/reward/eval.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import asyncio
4 | import argparse
5 | from tqdm.asyncio import tqdm_asyncio
6 | from langchain.schema import HumanMessage
7 | from langchain.chat_models import ChatOpenAI
8 |
9 |
10 | PARENT_DIR: str = os.path.dirname(os.path.abspath(__file__))
11 | DATASET_FILE: str = os.path.join(PARENT_DIR, "transformed.json")
12 | NUM_DATA: int = 100
13 | EVAL_MODEL_NAME: str = "gpt-4"
14 | AWAIT_TIMEOUT: int = 360
15 | RETRY_COUNT = 2
16 |
17 |
18 | def get_dataset(dataset_file: str = DATASET_FILE):
19 | with open(dataset_file, 'r') as f:
20 | dataset = json.load(f)
21 | return dataset
22 |
23 |
24 | async def evaluate(data, model, results):
25 |
26 | conversations = data["conversations"]
27 | history = conversations[0]["value"]
28 | model_output = conversations[1]["value"]
29 |
30 | prompt = f"""Given an input with a final goal, a set of detailed instructions and a history of the query/thoughts/plan/action/observation, the search agent need to generate a next step plan to fulfill user's input query. Evalluate a set of plans generated by a search agent. The input and the generated plans are both delimited by triple backticks.
31 |
32 | Input:
33 | ```
34 | {history}
35 | ```
36 |
37 | Next step plan of Agent:
38 | ```
39 | {model_output}
40 | ```
41 |
42 | Consider evaluate the next step plan based on the following aspects/metrics:
43 | - Clarity: The plan should be clear and understandable.
44 | - Effectiveness: The plan should be correct and move towards the final goal to answer the input query.
45 |
46 | Your answer should include a score on a scale of 0 to 5, where 0 means terrible, 1 means bad, 2 means acceptable, 3 means okay, 4 means good, and 5 means wonderful. Format your output in a json consisting of overall_score, overall_judgement, clarity_score, clarity_reasoning, effectiveness_score, and effectiveness_reasoning.
47 | """
48 |
49 | llm = ChatOpenAI(
50 | openai_api_key=os.getenv("OPENAI_API_KEY"),
51 | openai_organization=os.getenv("OPENAI_API_ORG"),
52 | temperature=0,
53 | model=model,
54 | request_timeout=AWAIT_TIMEOUT
55 | )
56 |
57 | retry_cnt = 0
58 | while retry_cnt <= RETRY_COUNT:
59 | try:
60 | resp = await llm.agenerate([[HumanMessage(content=prompt)]])
61 | resp_obj = json.loads(resp.generations[0][0].text.strip())
62 | resp_obj["data_id"] = data["id"]
63 |
64 | results.append(resp_obj)
65 | break
66 |
67 | except Exception as e:
68 | print(e)
69 | retry_cnt += 1
70 |
71 |
72 | async def main(dataset, model, num_data):
73 |
74 | results = []
75 |
76 | semaphore = asyncio.Semaphore(10)
77 |
78 | async def process_data(data):
79 | async with semaphore:
80 | await evaluate(data, model, results)
81 |
82 | await tqdm_asyncio.gather(*[process_data(data) for data in dataset])
83 |
84 | with open(f"response_eval_{model}_{num_data}.json", 'w') as f:
85 | json.dump(results, f, indent=2)
86 |
87 |
88 | if __name__ == "__main__":
89 | parser = argparse.ArgumentParser()
90 | parser.add_argument(
91 | "--dataset_file", type=str, default=DATASET_FILE,
92 | help="file containing the dataset"
93 | )
94 | parser.add_argument("--eval_model", type=str, default=EVAL_MODEL_NAME)
95 | parser.add_argument("--num_data", type=int, default=NUM_DATA)
96 | args = parser.parse_args()
97 |
98 | dataset = get_dataset(dataset_file=args.dataset_file)[:args.num_data]
99 | asyncio.run(main(dataset, args.eval_model, args.num_data))
100 |
--------------------------------------------------------------------------------
/autoagents/eval/reward/get_scores.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import argparse
4 |
5 |
6 | if __name__ == "__main__":
7 | parser = argparse.ArgumentParser()
8 | parser.add_argument(
9 | "input_file", type=str,
10 | help="file containing the evaluation results"
11 | )
12 | args = parser.parse_args()
13 |
14 | if os.path.isfile(args.input_file):
15 | with open(args.input_file, 'r') as f:
16 | results = json.load(f)
17 | num = len(results)
18 |
19 | stats = {"avg_overall": 0, "avg_clarity": 0, "avg_effectiveness": 0}
20 | for obj in results:
21 | stats["avg_overall"] += obj.get("overall_score", 0)
22 | stats["avg_clarity"] += obj.get("clarity_score", 0)
23 | stats["avg_effectiveness"] += obj.get("effectiveness_score", 0)
24 |
25 | for key in stats:
26 | stats[key] /= num
27 | stats["num"] = num
28 | print(stats)
29 |
--------------------------------------------------------------------------------
/autoagents/eval/test.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import asyncio
3 | import json
4 | import os
5 | from tqdm.asyncio import tqdm_asyncio
6 |
7 | from autoagents.agents.agents.search import ActionRunner
8 | from autoagents.agents.agents.wiki_agent import WikiActionRunner, WikiActionRunnerV3
9 | from autoagents.agents.agents.search_v3 import ActionRunnerV3
10 | from autoagents.agents.models.custom import CustomLLM, CustomLLMV3
11 | from autoagents.agents.utils.constants import LOG_SAVE_DIR
12 | from autoagents.data.dataset import BAMBOOGLE, DEFAULT_Q, FT, HF
13 | from autoagents.eval.bamboogle import eval as eval_bamboogle
14 | from autoagents.eval.hotpotqa.eval_async import HotpotqaAsyncEval, NUM_SAMPLES_TOTAL
15 | from langchain.chat_models import ChatOpenAI
16 |
17 |
18 | OPENAI_MODEL_NAMES = {"gpt-3.5-turbo", "gpt-4"}
19 | AWAIT_TIMEOUT: int = 120
20 | MAX_RETRIES: int = 2
21 |
22 |
23 | async def work(user_input: str, model: str, temperature: int, agent: str, prompt_version: str, persist_logs: bool, log_save_dir: str):
24 | if model not in OPENAI_MODEL_NAMES:
25 | if prompt_version == "v2":
26 | llm = CustomLLM(
27 | model_name=model,
28 | temperature=temperature,
29 | request_timeout=AWAIT_TIMEOUT
30 | )
31 | elif prompt_version == "v3":
32 | llm = CustomLLMV3(
33 | model_name=model,
34 | temperature=temperature,
35 | request_timeout=AWAIT_TIMEOUT
36 | )
37 | else:
38 | llm = ChatOpenAI(
39 | openai_api_key=os.getenv("OPENAI_API_KEY"),
40 | openai_organization=os.getenv("OPENAI_API_ORG"),
41 | temperature=temperature,
42 | model_name=model,
43 | request_timeout=AWAIT_TIMEOUT
44 | )
45 |
46 | retry_count = 0
47 | while retry_count < MAX_RETRIES:
48 | outputq = asyncio.Queue()
49 | if agent == "ddg":
50 | if prompt_version == "v2":
51 | runner = ActionRunner(outputq, llm=llm, persist_logs=persist_logs)
52 | elif prompt_version == "v3":
53 | runner = ActionRunnerV3(outputq, llm=llm, persist_logs=persist_logs)
54 | elif agent == "wiki":
55 | if prompt_version == "v2":
56 | runner = WikiActionRunner(outputq, llm=llm, persist_logs=persist_logs)
57 | elif prompt_version == "v3":
58 | runner = WikiActionRunnerV3(outputq, llm=llm, persist_logs=persist_logs)
59 | task = asyncio.create_task(runner.run(user_input, outputq, log_save_dir))
60 | while True:
61 | try:
62 | output = await asyncio.wait_for(outputq.get(), AWAIT_TIMEOUT)
63 | except asyncio.TimeoutError:
64 | task.cancel()
65 | retry_count += 1
66 | break
67 | if isinstance(output, RuntimeWarning):
68 | print(f"Question: {user_input}")
69 | print(output)
70 | continue
71 | elif isinstance(output, Exception):
72 | task.cancel()
73 | print(f"Question: {user_input}")
74 | print(output)
75 | retry_count += 1
76 | break
77 | try:
78 | parsed = json.loads(output)
79 | print(json.dumps(parsed, indent=2))
80 | print("-----------------------------------------------------------")
81 | if parsed["action"] == "Tool_Finish":
82 | return await task
83 | except:
84 | print(f"Question: {user_input}")
85 | print(output)
86 | print("-----------------------------------------------------------")
87 |
88 |
89 | async def main(questions, args):
90 | sem = asyncio.Semaphore(10)
91 |
92 | async def safe_work(user_input: str, model: str, temperature: int, agent: str, prompt_version: str, persist_logs: bool, log_save_dir: str):
93 | async with sem:
94 | return await work(user_input, model, temperature, agent, prompt_version, persist_logs, log_save_dir)
95 |
96 | persist_logs = True if args.persist_logs else False
97 | await tqdm_asyncio.gather(*[safe_work(q, args.model, args.temperature, args.agent, args.prompt_version, persist_logs, args.log_save_dir) for q in questions])
98 |
99 |
100 | if __name__ == "__main__":
101 | parser = argparse.ArgumentParser()
102 | parser.add_argument("--model", type=str, default="gpt-3.5-turbo", help="model to be tested")
103 | parser.add_argument("--temperature", type=float, default=0, help="model temperature")
104 | parser.add_argument("--agent",
105 | default="ddg",
106 | const="ddg",
107 | nargs="?",
108 | choices=("ddg", "wiki"),
109 | help='which action agent we want to interact with(default: ddg)'
110 | )
111 | parser.add_argument("--persist-logs", action="store_true", help="persist logs on disk, enable this feature for later eval purpose")
112 | parser.add_argument("--log-save-dir", type=str, default=LOG_SAVE_DIR, help="dir to save logs")
113 | parser.add_argument("--dataset",
114 | default="default",
115 | const="default",
116 | nargs="?",
117 | choices=("default", "hotpotqa", "ft", "hf", "bamboogle"),
118 | help='which dataset we want to interact with(default: default)'
119 | )
120 | parser.add_argument("--eval", action="store_true", help="enable automatic eval")
121 | parser.add_argument("--prompt-version",
122 | default="v2",
123 | const="v3",
124 | nargs="?",
125 | choices=("v2", "v3"),
126 | help='which version of prompt to use(default: v2)'
127 | )
128 | parser.add_argument("--slice", type=int, help="slice the dataset from left, question list will start from index 0 to slice - 1")
129 | args = parser.parse_args()
130 | print(args)
131 | if args.prompt_version == "v3" and args.model in OPENAI_MODEL_NAMES:
132 | raise ValueError("Prompt v3 is not compatiable with OPENAI models, please adjust your settings!")
133 | if not args.persist_logs and args.eval:
134 | raise ValueError("Please enable persist_logs feature to allow eval code to run!")
135 | if not args.log_save_dir and args.persist_logs:
136 | raise ValueError("Please endbale persist_logs feature to configure log dir location!")
137 | questions = []
138 | if args.dataset == "ft":
139 | questions = [q for _, q in FT]
140 | elif args.dataset == "hf":
141 | questions = [q for _, q in HF]
142 | elif args.dataset == "hotpotqa":
143 | hotpotqa_eval = HotpotqaAsyncEval(model=args.model)
144 | questions = hotpotqa_eval.get_questions(args.slice or NUM_SAMPLES_TOTAL)
145 | elif args.dataset == "bamboogle":
146 | questions = BAMBOOGLE["questions"]
147 | else:
148 | questions = [q for _, q in DEFAULT_Q]
149 | if args.slice and args.dataset != "hotpotqa":
150 | questions = questions[:args.slice]
151 | asyncio.run(main(questions, args))
152 | if args.eval:
153 | if args.dataset == "bamboogle":
154 | if args.log_save_dir:
155 | asyncio.run(eval_bamboogle(args.log_save_dir))
156 | else:
157 | asyncio.run(eval_bamboogle())
158 | elif args.dataset == "hotpotqa":
159 | if args.log_save_dir:
160 | hotpotqa_eval.run(args.log_save_dir)
161 | else:
162 | hotpotqa_eval.run()
163 |
--------------------------------------------------------------------------------
/autoagents/serve/README.md:
--------------------------------------------------------------------------------
1 | ## SERVING
2 |
3 | To serve the models, run the following simultaniously (in multiple terminals or using background tasks)
4 |
5 |
6 | ```
7 | bash autoagents/serve/controller.sh
8 | ```
9 |
10 | ```
11 | bash autoagents/serve/openai_api.sh
12 | ```
13 |
14 | ```
15 | MODEL_PATH=/some/path/to/your/model CONDENSE_RESCALE=1 bash autoagents/serve/model_worker.sh
16 | ```
17 |
18 | You may have multiple `model_worker.sh` instances. If you are using LongChat, set `CONDENSE_RESCALE` to be whatever scaling you are using (e.g. 4 or 8)
19 |
20 | ### Prompt V3 serving
21 |
22 | 1. Start the model server
23 | ```
24 | python3 autoagents/serve/action_model_worker.py --model-path /path/to/model/checkpoint --controller http://localhost:21001 --port 31008 --worker http://localhost:31008
25 | ```
26 |
27 | 2. Start the completion API server, default address http://localhost:8004
28 | ```
29 | python3 autoagents/serve/action_api_server.py
30 | ```
31 |
--------------------------------------------------------------------------------
/autoagents/serve/action_api_server.py:
--------------------------------------------------------------------------------
1 | """A server that provides OpenAI-compatible RESTful APIs. It supports:
2 |
3 | - Completions
4 |
5 | Usage:
6 | python3 -m autoagents.serve.action_api_server
7 | """
8 | import asyncio
9 | import argparse
10 | import json
11 | import logging
12 | from typing import Optional, Union, Dict, List, Any
13 |
14 | import fastapi
15 | from fastapi.middleware.cors import CORSMiddleware
16 | from fastapi.responses import StreamingResponse, JSONResponse
17 | import httpx
18 | from pydantic import BaseSettings
19 | import shortuuid
20 | import tiktoken
21 | import uvicorn
22 |
23 | from fastchat.constants import (
24 | WORKER_API_TIMEOUT,
25 | ErrorCode,
26 | )
27 | from fastchat.conversation import Conversation, SeparatorStyle
28 | from fastapi.exceptions import RequestValidationError
29 | from fastchat.protocol.openai_api_protocol import (
30 | CompletionRequest,
31 | CompletionResponse,
32 | CompletionResponseChoice,
33 | CompletionResponseStreamChoice,
34 | CompletionStreamResponse,
35 | ErrorResponse,
36 | ModelCard,
37 | ModelList,
38 | ModelPermission,
39 | UsageInfo,
40 | )
41 |
42 | logger = logging.getLogger(__name__)
43 |
44 | conv_template_map = {}
45 |
46 |
47 | class AppSettings(BaseSettings):
48 | # The address of the model controller.
49 | controller_address: str = "http://localhost:21001"
50 | api_keys: List[str] = None
51 |
52 |
53 | app_settings = AppSettings()
54 | app = fastapi.FastAPI()
55 | headers = {"User-Agent": "FastChat API Server"}
56 |
57 |
58 | def create_error_response(code: int, message: str) -> JSONResponse:
59 | return JSONResponse(
60 | ErrorResponse(message=message, code=code).dict(), status_code=400
61 | )
62 |
63 |
64 | @app.exception_handler(RequestValidationError)
65 | async def validation_exception_handler(request, exc):
66 | return create_error_response(ErrorCode.VALIDATION_TYPE_ERROR, str(exc))
67 |
68 |
69 | async def check_model(request) -> Optional[JSONResponse]:
70 | controller_address = app_settings.controller_address
71 | ret = None
72 | async with httpx.AsyncClient() as client:
73 | try:
74 | _worker_addr = await get_worker_address(request.model, client)
75 | except:
76 | models_ret = await client.post(controller_address + "/list_models")
77 | models = models_ret.json()["models"]
78 | ret = create_error_response(
79 | ErrorCode.INVALID_MODEL,
80 | f"Only {'&&'.join(models)} allowed now, your model {request.model}",
81 | )
82 | return ret
83 |
84 |
85 | async def check_length(request, prompt, max_tokens):
86 | async with httpx.AsyncClient() as client:
87 | worker_addr = await get_worker_address(request.model, client)
88 |
89 | response = await client.post(
90 | worker_addr + "/model_details",
91 | headers=headers,
92 | json={"model": request.model},
93 | timeout=WORKER_API_TIMEOUT,
94 | )
95 | context_len = response.json()["context_length"]
96 |
97 | response = await client.post(
98 | worker_addr + "/count_token",
99 | headers=headers,
100 | json={"model": request.model, "prompt": json.dumps(prompt)},
101 | timeout=WORKER_API_TIMEOUT,
102 | )
103 | token_num = response.json()["count"]
104 |
105 | if token_num + max_tokens > context_len:
106 | return create_error_response(
107 | ErrorCode.CONTEXT_OVERFLOW,
108 | f"This model's maximum context length is {context_len} tokens. "
109 | f"However, you requested {max_tokens + token_num} tokens "
110 | f"({token_num} in the messages, "
111 | f"{max_tokens} in the completion). "
112 | f"Please reduce the length of the messages or completion.",
113 | )
114 | else:
115 | return None
116 |
117 |
118 | def check_requests(request) -> Optional[JSONResponse]:
119 | # Check all params
120 | if request.max_tokens is not None and request.max_tokens <= 0:
121 | return create_error_response(
122 | ErrorCode.PARAM_OUT_OF_RANGE,
123 | f"{request.max_tokens} is less than the minimum of 1 - 'max_tokens'",
124 | )
125 | if request.n is not None and request.n <= 0:
126 | return create_error_response(
127 | ErrorCode.PARAM_OUT_OF_RANGE,
128 | f"{request.n} is less than the minimum of 1 - 'n'",
129 | )
130 | if request.temperature is not None and request.temperature < 0:
131 | return create_error_response(
132 | ErrorCode.PARAM_OUT_OF_RANGE,
133 | f"{request.temperature} is less than the minimum of 0 - 'temperature'",
134 | )
135 | if request.temperature is not None and request.temperature > 2:
136 | return create_error_response(
137 | ErrorCode.PARAM_OUT_OF_RANGE,
138 | f"{request.temperature} is greater than the maximum of 2 - 'temperature'",
139 | )
140 | if request.top_p is not None and request.top_p < 0:
141 | return create_error_response(
142 | ErrorCode.PARAM_OUT_OF_RANGE,
143 | f"{request.top_p} is less than the minimum of 0 - 'top_p'",
144 | )
145 | if request.top_p is not None and request.top_p > 1:
146 | return create_error_response(
147 | ErrorCode.PARAM_OUT_OF_RANGE,
148 | f"{request.top_p} is greater than the maximum of 1 - 'temperature'",
149 | )
150 | if request.stop is not None and (
151 | not isinstance(request.stop, str) and not isinstance(request.stop, list)
152 | ):
153 | return create_error_response(
154 | ErrorCode.PARAM_OUT_OF_RANGE,
155 | f"{request.stop} is not valid under any of the given schemas - 'stop'",
156 | )
157 |
158 | return None
159 |
160 |
161 | def process_input(model_name, inp):
162 | if isinstance(inp, str):
163 | inp = [inp]
164 | elif isinstance(inp, list):
165 | if isinstance(inp[0], int):
166 | decoding = tiktoken.model.encoding_for_model(model_name)
167 | inp = [decoding.decode(inp)]
168 | elif isinstance(inp[0], list):
169 | decoding = tiktoken.model.encoding_for_model(model_name)
170 | inp = [decoding.decode(text) for text in inp]
171 |
172 | return inp
173 |
174 |
175 | async def get_gen_params(
176 | model_name: str,
177 | messages: Union[str, List[Dict[str, str]]],
178 | *,
179 | temperature: float,
180 | top_p: float,
181 | max_tokens: Optional[int],
182 | echo: Optional[bool],
183 | stream: Optional[bool],
184 | stop: Optional[Union[str, List[str]]],
185 | ) -> Dict[str, Any]:
186 | conv = await get_conv(model_name)
187 | conv = Conversation(
188 | name=conv["name"],
189 | system_message=conv["system_message"],
190 | roles=conv["roles"],
191 | messages=list(conv["messages"]), # prevent in-place modification
192 | offset=conv["offset"],
193 | sep_style=SeparatorStyle(conv["sep_style"]),
194 | sep=conv["sep"],
195 | sep2=conv["sep2"],
196 | stop_str=conv["stop_str"],
197 | stop_token_ids=conv["stop_token_ids"],
198 | )
199 |
200 | if isinstance(messages, str):
201 | prompt = messages
202 | else:
203 | for message in messages:
204 | msg_role = message["role"]
205 | if msg_role == "goal":
206 | conv.append_message(conv.roles[0], json.dumps(message["content"]))
207 | elif msg_role == "tools":
208 | conv.append_message(conv.roles[1], json.dumps(message["content"]))
209 | elif msg_role == "history":
210 | conv.append_message(conv.roles[2], json.dumps(message["content"]))
211 | else:
212 | raise ValueError(f"Unknown role: {msg_role}")
213 |
214 | # Add a blank message for the assistant.
215 | conv.append_message(conv.roles[3], None)
216 | prompt = conv.get_prompt()
217 |
218 | if max_tokens is None:
219 | max_tokens = 512
220 | gen_params = {
221 | "model": model_name,
222 | "prompt": prompt,
223 | "temperature": temperature,
224 | "top_p": top_p,
225 | "max_new_tokens": max_tokens,
226 | "echo": echo,
227 | "stream": stream,
228 | }
229 |
230 | if not stop:
231 | gen_params.update(
232 | {"stop": conv.stop_str, "stop_token_ids": conv.stop_token_ids}
233 | )
234 | else:
235 | gen_params.update({"stop": stop})
236 |
237 | logger.info(f"==== request ====\n{gen_params}")
238 | return gen_params
239 |
240 |
241 | async def get_worker_address(model_name: str, client: httpx.AsyncClient) -> str:
242 | """
243 | Get worker address based on the requested model
244 |
245 | :param model_name: The worker's model name
246 | :param client: The httpx client to use
247 | :return: Worker address from the controller
248 | :raises: :class:`ValueError`: No available worker for requested model
249 | """
250 | controller_address = app_settings.controller_address
251 |
252 | ret = await client.post(
253 | controller_address + "/get_worker_address", json={"model": model_name}
254 | )
255 | worker_addr = ret.json()["address"]
256 | # No available worker
257 | if worker_addr == "":
258 | raise ValueError(f"No available worker for {model_name}")
259 |
260 | logger.info(f"model_name: {model_name}, worker_addr: {worker_addr}")
261 | return worker_addr
262 |
263 |
264 | async def get_conv(model_name: str):
265 | async with httpx.AsyncClient() as client:
266 | worker_addr = await get_worker_address(model_name, client)
267 | conv_template = conv_template_map.get((worker_addr, model_name))
268 | if conv_template is None:
269 | response = await client.post(
270 | worker_addr + "/worker_get_conv_template",
271 | headers=headers,
272 | json={"model": model_name},
273 | timeout=WORKER_API_TIMEOUT,
274 | )
275 | conv_template = response.json()["conv"]
276 | conv_template_map[(worker_addr, model_name)] = conv_template
277 | return conv_template
278 |
279 |
280 | @app.get("/v1/models")
281 | async def show_available_models():
282 | controller_address = app_settings.controller_address
283 | async with httpx.AsyncClient() as client:
284 | ret = await client.post(controller_address + "/refresh_all_workers")
285 | ret = await client.post(controller_address + "/list_models")
286 | models = ret.json()["models"]
287 | models.sort()
288 | # TODO: return real model permission details
289 | model_cards = []
290 | for m in models:
291 | model_cards.append(ModelCard(id=m, root=m, permission=[ModelPermission()]))
292 | return ModelList(data=model_cards)
293 |
294 |
295 |
296 | @app.post("/v1/completions")
297 | async def create_completion(request: CompletionRequest):
298 | if (error_check_ret := await check_model(request)):
299 | return error_check_ret
300 | if (error_check_ret := check_requests(request)):
301 | return error_check_ret
302 |
303 | if (error_check_ret := await check_length(request, request.prompt, request.max_tokens)):
304 | return error_check_ret
305 |
306 | if request.stream:
307 | generator = generate_completion_stream_generator(request, request.n)
308 | return StreamingResponse(generator, media_type="text/event-stream")
309 | else:
310 | text_completions = []
311 | gen_params = await get_gen_params(
312 | request.model,
313 | request.prompt,
314 | temperature=request.temperature,
315 | top_p=request.top_p,
316 | max_tokens=request.max_tokens,
317 | echo=request.echo,
318 | stream=request.stream,
319 | stop=request.stop,
320 | )
321 | logger.info(f"{gen_params}")
322 | for i in range(request.n):
323 | content = asyncio.create_task(generate_completion(gen_params))
324 | text_completions.append(content)
325 |
326 | try:
327 | all_tasks = await asyncio.wait_for(asyncio.gather(*text_completions), timeout=500)
328 | except Exception as e:
329 | return create_error_response(ErrorCode.INTERNAL_ERROR, str(e))
330 |
331 | choices = []
332 | usage = UsageInfo()
333 | for i, content in enumerate(all_tasks):
334 | if content["error_code"] != 0:
335 | return create_error_response(content["error_code"], content["text"])
336 | choices.append(
337 | CompletionResponseChoice(
338 | index=i,
339 | text=content["text"],
340 | logprobs=content.get("logprobs", None),
341 | finish_reason=content.get("finish_reason", "stop"),
342 | )
343 | )
344 | task_usage = UsageInfo.parse_obj(content["usage"])
345 | for usage_key, usage_value in task_usage.dict().items():
346 | setattr(usage, usage_key, getattr(usage, usage_key) + usage_value)
347 |
348 | return CompletionResponse(
349 | model=request.model, choices=choices, usage=UsageInfo.parse_obj(usage)
350 | )
351 |
352 |
353 | async def generate_completion_stream_generator(request: CompletionRequest, n: int):
354 | model_name = request.model
355 | id = f"cmpl-{shortuuid.random()}"
356 | finish_stream_events = []
357 | for text in request.prompt:
358 | for i in range(n):
359 | previous_text = ""
360 | gen_params = await get_gen_params(
361 | request.model,
362 | text,
363 | temperature=request.temperature,
364 | top_p=request.top_p,
365 | max_tokens=request.max_tokens,
366 | echo=request.echo,
367 | stream=request.stream,
368 | stop=request.stop,
369 | )
370 | async for content in generate_completion_stream(gen_params):
371 | if content["error_code"] != 0:
372 | yield f"data: {json.dumps(content, ensure_ascii=False)}\n\n"
373 | yield "data: [DONE]\n\n"
374 | return
375 | decoded_unicode = content["text"].replace("\ufffd", "")
376 | delta_text = decoded_unicode[len(previous_text) :]
377 | previous_text = decoded_unicode
378 | # todo: index is not apparent
379 | choice_data = CompletionResponseStreamChoice(
380 | index=i,
381 | text=delta_text,
382 | logprobs=content.get("logprobs", None),
383 | finish_reason=content.get("finish_reason", None),
384 | )
385 | chunk = CompletionStreamResponse(
386 | id=id,
387 | object="text_completion",
388 | choices=[choice_data],
389 | model=model_name,
390 | )
391 | if len(delta_text) == 0:
392 | if content.get("finish_reason", None) is not None:
393 | finish_stream_events.append(chunk)
394 | continue
395 | yield f"data: {chunk.json(exclude_unset=True, ensure_ascii=False)}\n\n"
396 | # There is not "content" field in the last delta message, so exclude_none to exclude field "content".
397 | for finish_chunk in finish_stream_events:
398 | yield f"data: {finish_chunk.json(exclude_unset=True, ensure_ascii=False)}\n\n"
399 | yield "data: [DONE]\n\n"
400 |
401 |
402 | async def generate_completion_stream(payload: Dict[str, Any]):
403 | async with httpx.AsyncClient() as client:
404 | worker_addr = await get_worker_address(payload["model"], client)
405 | delimiter = b"\0"
406 | async with client.stream(
407 | "POST",
408 | worker_addr + "/worker_generate_stream",
409 | headers=headers,
410 | json=payload,
411 | timeout=WORKER_API_TIMEOUT,
412 | ) as response:
413 | # content = await response.aread()
414 | async for raw_chunk in response.aiter_raw():
415 | for chunk in raw_chunk.split(delimiter):
416 | if not chunk:
417 | continue
418 | data = json.loads(chunk.decode())
419 | yield data
420 |
421 |
422 | async def generate_completion(payload: Dict[str, Any]):
423 | async with httpx.AsyncClient() as client:
424 | worker_addr = await get_worker_address(payload["model"], client)
425 |
426 | response = await client.post(
427 | worker_addr + "/worker_generate",
428 | headers=headers,
429 | json=payload,
430 | timeout=WORKER_API_TIMEOUT,
431 | )
432 | completion = response.json()
433 | return completion
434 |
435 |
436 | if __name__ == "__main__":
437 | parser = argparse.ArgumentParser(
438 | description="FastChat ChatGPT-Compatible RESTful API server."
439 | )
440 | parser.add_argument("--host", type=str, default="localhost", help="host name")
441 | parser.add_argument("--port", type=int, default=8004, help="port number")
442 | parser.add_argument(
443 | "--controller-address", type=str, default="http://localhost:21001"
444 | )
445 | parser.add_argument(
446 | "--allow-credentials", action="store_true", help="allow credentials"
447 | )
448 | parser.add_argument(
449 | "--allowed-origins", type=json.loads, default=["*"], help="allowed origins"
450 | )
451 | parser.add_argument(
452 | "--allowed-methods", type=json.loads, default=["*"], help="allowed methods"
453 | )
454 | parser.add_argument(
455 | "--allowed-headers", type=json.loads, default=["*"], help="allowed headers"
456 | )
457 | args = parser.parse_args()
458 |
459 | app.add_middleware(
460 | CORSMiddleware,
461 | allow_origins=args.allowed_origins,
462 | allow_credentials=args.allow_credentials,
463 | allow_methods=args.allowed_methods,
464 | allow_headers=args.allowed_headers,
465 | )
466 | app_settings.controller_address = args.controller_address
467 |
468 | logger.info(f"args: {args}")
469 |
470 | uvicorn.run(app, host=args.host, port=args.port, log_level="info")
471 |
--------------------------------------------------------------------------------
/autoagents/serve/action_model_worker.py:
--------------------------------------------------------------------------------
1 | import uvicorn
2 | import fastchat.serve.model_worker as model_worker
3 | from fastchat.conversation import (
4 | SeparatorStyle,
5 | Conversation,
6 | register_conv_template,
7 | get_conv_template
8 | )
9 | from fastchat.model.model_adapter import (
10 | register_model_adapter,
11 | BaseModelAdapter
12 | )
13 | from transformers import (
14 | AutoConfig,
15 | AutoModelForCausalLM,
16 | AutoTokenizer
17 | )
18 |
19 | class ActionAdapter(BaseModelAdapter):
20 | """The model adapter for Action Vicuna"""
21 |
22 | def match(self, model_path: str):
23 | return "action" in model_path
24 |
25 | def load_model(self, model_path: str, from_pretrained_kwargs: dict):
26 | config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
27 | tokenizer = AutoTokenizer.from_pretrained(
28 | model_path, config=config, trust_remote_code=True
29 | )
30 | model = AutoModelForCausalLM.from_pretrained(
31 | model_path,
32 | config=config,
33 | trust_remote_code=True,
34 | low_cpu_mem_usage=True,
35 | **from_pretrained_kwargs,
36 | )
37 | return model, tokenizer
38 |
39 | def get_default_conv_template(self, model_path: str) -> Conversation:
40 | return get_conv_template("action")
41 |
42 |
43 | if __name__ == "__main__":
44 | # Action LLM default template
45 | register_conv_template(
46 | Conversation(
47 | name="action",
48 | system_message="Below is a goal you need to achieve. Given the available tools and history of past actions provide the next action to perform.",
49 | roles=("### Goal", "### Tools", "### History", "### Next action"),
50 | messages=(),
51 | offset=0,
52 | sep_style=SeparatorStyle.ADD_COLON_SINGLE,
53 | sep="\n\n", # separator between roles
54 | )
55 | )
56 | register_model_adapter(ActionAdapter)
57 | args, model_worker.worker = model_worker.create_model_worker()
58 | # hardcode the conv template
59 | args.conv_template = "action"
60 | uvicorn.run(model_worker.app, host=args.host, port=args.port, log_level="info")
61 |
--------------------------------------------------------------------------------
/autoagents/serve/controller.sh:
--------------------------------------------------------------------------------
1 | python3 -m fastchat.serve.controller
2 |
--------------------------------------------------------------------------------
/autoagents/serve/model_worker.sh:
--------------------------------------------------------------------------------
1 | CONDENSE_RESCALE=1 python3 serve/serve_rescale.py --model-path $MODEL_PATH
2 |
--------------------------------------------------------------------------------
/autoagents/serve/openai_api.sh:
--------------------------------------------------------------------------------
1 | python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
2 |
--------------------------------------------------------------------------------
/autoagents/serve/serve_rescale.py:
--------------------------------------------------------------------------------
1 | import uvicorn
2 |
3 | from fastchat.train.llama_flash_attn_monkey_patch import (
4 | replace_llama_attn_with_flash_attn,
5 | )
6 |
7 | import os
8 |
9 | # TODO: change from env var to proper args (passing the rest of the args to create_model_worker)
10 | rescale = int(os.environ.get("CONDENSE_RESCALE", 1))
11 | if rescale > 1:
12 | from longchat.train.monkey_patch.llama_condense_monkey_patch import replace_llama_with_condense
13 | replace_llama_with_condense(rescale)
14 |
15 |
16 |
17 | from fastchat.serve.model_worker import create_model_worker
18 |
19 | if __name__ == "__main__":
20 | args, worker = create_model_worker()
21 | uvicorn.run(app, host=args.host, port=args.port, log_level="info")
22 |
--------------------------------------------------------------------------------
/autoagents/train/README.md:
--------------------------------------------------------------------------------
1 | ## Fine Tuning
2 |
3 | To train an action finetuned model from Llama 2, do the following:
4 |
5 | 1. Ensure that your cluster has enough GPU RAM for your model. Modify the `--nproc_per_node` and `--nnodes` values in each of the `train/scripts/` files to match your topology. If you are using only a single machine, you may hardcode `$RANK` to 0. Otherwise, ensure that `--master_addr` is set to the address of the rank 0 worker.
6 | 2. Modify `--data_path`, `--output_dir`, and `--model_name_or_path` to match the data and models you are using. Note that the output of `conv_finetuning.sh` and `longchat_conv_finetuning.sh` will be used as the model input for `action_finetuning.sh` and `longchat_action_finetuning.sh`. If using LongChat, make sure that `CONDENSE_RESCALE` is set to the right value.
7 | 3. Run either `conv_finetuning.sh` or `longchat_conv_finetuning.sh` with the appropriate environment variables set (see step 1). You will need to run it from the root directory of this repository.
8 | 4. Run either `action_finetuning.sh` or `longchat_action_finetuning.sh` with the appropriate environment variables set (see step 1). Make sure that if you use LongChat for the first finetuning, you use LongChat for the second. You will need to run it from the root directory of this repository.
9 |
10 | ### For the action V3 prompt
11 |
12 | Follow steps 1 and 2 above, and run `action_finetuning_v3.sh`.
13 |
--------------------------------------------------------------------------------
/autoagents/train/scripts/action_finetuning.sh:
--------------------------------------------------------------------------------
1 | python3 -m torch.distributed.run --nproc_per_node=8 \
2 | --master_port=20005 --nnodes=1 --node_rank=$RANK --master_addr=127.0.0.1 \
3 | autoagents/train/train.py \
4 | --model_name_or_path input-model \
5 | --data_path json-data.json \
6 | --bf16 True \
7 | --output_dir output-path \
8 | --num_train_epochs 2 \
9 | --per_device_train_batch_size 1 \
10 | --per_device_eval_batch_size 1 \
11 | --gradient_accumulation_steps 16 \
12 | --evaluation_strategy "no" \
13 | --save_strategy "steps" \
14 | --save_steps 40 \
15 | --save_total_limit 20 \
16 | --learning_rate 2e-5 \
17 | --weight_decay 0. \
18 | --warmup_ratio 0.03 \
19 | --lr_scheduler_type "cosine" \
20 | --logging_steps 1 \
21 | --fsdp "full_shard auto_wrap" \
22 | --fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
23 | --tf32 True \
24 | --model_max_length 4096 \
25 | --gradient_checkpointing True \
26 | --lazy_preprocess True
27 |
--------------------------------------------------------------------------------
/autoagents/train/scripts/action_finetuning_v3.sh:
--------------------------------------------------------------------------------
1 | python3 -m torch.distributed.run --nproc_per_node=8 \
2 | --master_port=20005 --nnodes=1 --node_rank=$RANK --master_addr=127.0.0.1 \
3 | autoagents/train/train_v3.py \
4 | --model_name_or_path input-model \
5 | --data_path json-data.json \
6 | --bf16 True \
7 | --output_dir output-path \
8 | --num_train_epochs 2 \
9 | --per_device_train_batch_size 1 \
10 | --per_device_eval_batch_size 1 \
11 | --gradient_accumulation_steps 16 \
12 | --evaluation_strategy "no" \
13 | --save_strategy "steps" \
14 | --save_steps 40 \
15 | --save_total_limit 20 \
16 | --learning_rate 2e-5 \
17 | --weight_decay 0. \
18 | --warmup_ratio 0.03 \
19 | --lr_scheduler_type "cosine" \
20 | --logging_steps 1 \
21 | --fsdp "full_shard auto_wrap" \
22 | --fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
23 | --tf32 True \
24 | --model_max_length 4096 \
25 | --gradient_checkpointing True \
26 | --lazy_preprocess True
27 |
--------------------------------------------------------------------------------
/autoagents/train/scripts/conv_finetuning.sh:
--------------------------------------------------------------------------------
1 | python3 -m torch.distributed.run --nproc_per_node=8 \
2 | --master_port=20005 --nnodes=1 --node_rank=$RANK --master_addr=127.0.0.1 \
3 | autoagents/train/train.py \
4 | --model_name_or_path meta-llama/Llama-2-13b-hf \
5 | --data_path path-to-sharegpt-data.json \
6 | --bf16 True \
7 | --output_dir output-directory-path \
8 | --num_train_epochs 1 \
9 | --per_device_train_batch_size 1 \
10 | --per_device_eval_batch_size 1 \
11 | --gradient_accumulation_steps 16 \
12 | --evaluation_strategy "no" \
13 | --save_strategy "steps" \
14 | --save_steps 40 \
15 | --save_total_limit 20 \
16 | --learning_rate 2e-5 \
17 | --weight_decay 0. \
18 | --warmup_ratio 0.03 \
19 | --lr_scheduler_type "cosine" \
20 | --logging_steps 1 \
21 | --tf32 True \
22 | --fsdp "full_shard auto_wrap" \
23 | --fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
24 | --model_max_length 4096 \
25 | --gradient_checkpointing True \
26 | --lazy_preprocess True \
27 |
--------------------------------------------------------------------------------
/autoagents/train/scripts/longchat_action_finetuning.sh:
--------------------------------------------------------------------------------
1 | CONDENSE_RESCALE=4 python3 -m torch.distributed.run --nproc_per_node=8 \
2 | --master_port=20005 --nnodes=1 --node_rank=$RANK --master_addr=127.0.0.1 \
3 | autoagents/train/train.py \
4 | --model_name_or_path input-model \
5 | --data_path json-data.json \
6 | --bf16 True \
7 | --output_dir output-path \
8 | --num_train_epochs 2 \
9 | --per_device_train_batch_size 1 \
10 | --per_device_eval_batch_size 1 \
11 | --gradient_accumulation_steps 16 \
12 | --evaluation_strategy "no" \
13 | --save_strategy "steps" \
14 | --save_steps 40 \
15 | --save_total_limit 20 \
16 | --learning_rate 2e-5 \
17 | --weight_decay 0. \
18 | --warmup_ratio 0.03 \
19 | --lr_scheduler_type "cosine" \
20 | --logging_steps 1 \
21 | --fsdp "full_shard auto_wrap" \
22 | --fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
23 | --tf32 True \
24 | --model_max_length 4096 \
25 | --gradient_checkpointing True \
26 | --lazy_preprocess True \
27 |
--------------------------------------------------------------------------------
/autoagents/train/scripts/longchat_conv_finetuning.sh:
--------------------------------------------------------------------------------
1 | CONDENSE_RESCALE=4 python3 -m torch.distributed.run --nproc_per_node=8 \
2 | --master_port=20005 --nnodes=1 --node_rank=$RANK --master_addr=127.0.0.1 \
3 | autoagents/train/train.py \
4 | --model_name_or_path meta-llama/Llama-2-13b-hf \
5 | --data_path path-to-sharegpt-data.json \
6 | --bf16 True \
7 | --output_dir output-directory-path \
8 | --num_train_epochs 1 \
9 | --per_device_train_batch_size 1 \
10 | --per_device_eval_batch_size 1 \
11 | --gradient_accumulation_steps 16 \
12 | --evaluation_strategy "no" \
13 | --save_strategy "steps" \
14 | --save_steps 40 \
15 | --save_total_limit 20 \
16 | --learning_rate 2e-5 \
17 | --weight_decay 0. \
18 | --warmup_ratio 0.03 \
19 | --lr_scheduler_type "cosine" \
20 | --logging_steps 1 \
21 | --tf32 True \
22 | --fsdp "full_shard auto_wrap" \
23 | --fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
24 | --model_max_length 4096 \
25 | --gradient_checkpointing True \
26 | --lazy_preprocess True \
27 |
--------------------------------------------------------------------------------
/autoagents/train/test_v3_preprocess.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import json
3 | import torch
4 | import click
5 | import tempfile
6 | import transformers
7 | from transformers.trainer_pt_utils import LabelSmoother
8 | from torch.utils.data import Dataset
9 | from typing import Dict
10 |
11 | from fastchat.conversation import (
12 | SeparatorStyle,
13 | Conversation,
14 | register_conv_template
15 | )
16 | from fastchat.model.model_adapter import (
17 | get_conversation_template,
18 | register_model_adapter
19 | )
20 |
21 | from train_v3 import ActionAdapter
22 |
23 | IGNORE_TOKEN_ID = LabelSmoother.ignore_index
24 |
25 | def rank0_print(*x):
26 | print(*x)
27 |
28 |
29 | def preprocess(
30 | sources,
31 | tokenizer: transformers.PreTrainedTokenizer,
32 | ) -> Dict:
33 | conv = get_conversation_template("action")
34 | roles = {"goal": conv.roles[0],
35 | "tools": conv.roles[1],
36 | "history": conv.roles[2],
37 | "next_action": conv.roles[3]}
38 |
39 | # Apply prompt templates
40 | conversations = []
41 | for i, source in enumerate(sources):
42 | if roles[source[0]["from"]] != conv.roles[0]:
43 | # Skip the first one if it is not from human
44 | source = source[1:]
45 |
46 | conv.messages = []
47 | for j, sentence in enumerate(source):
48 | role = roles[sentence["from"]]
49 | conv.append_message(role, sentence["value"])
50 | conversations.append(conv.get_prompt())
51 |
52 | # Tokenize conversations
53 | input_ids = tokenizer(
54 | conversations,
55 | return_tensors="pt",
56 | padding="max_length",
57 | max_length=tokenizer.model_max_length,
58 | truncation=True,
59 | ).input_ids
60 | targets = input_ids.clone()
61 |
62 | assert conv.sep_style == SeparatorStyle.ADD_COLON_SINGLE
63 |
64 | show_index = 3
65 | # Mask targets
66 | sep = conv.sep + conv.roles[-1] + ": "
67 | for i, (conversation, target) in enumerate(zip(conversations, targets)):
68 | if i == show_index:
69 | z = target.clone()
70 | z = torch.where(z == IGNORE_TOKEN_ID, tokenizer.unk_token_id, z)
71 | rank0_print(tokenizer.decode(z))
72 |
73 | total_len = int(target.ne(tokenizer.pad_token_id).sum()) # = len(tokenizer(conversation).input_ids)
74 | inputs, outputs = conversation.split(sep) # [.., goal, history | next_action]
75 | cur_len = 0
76 | instruction_len = len(tokenizer(inputs + sep).input_ids) - 1
77 | target[cur_len:cur_len+instruction_len] = IGNORE_TOKEN_ID
78 | cur_len += instruction_len - 1
79 | outputs_len = len(tokenizer(outputs).input_ids)
80 | target[cur_len+outputs_len:] = IGNORE_TOKEN_ID
81 | cur_len += outputs_len
82 |
83 | if i == show_index:
84 | z = target.clone()
85 | z = torch.where(z == IGNORE_TOKEN_ID, tokenizer.unk_token_id, z)
86 | rank0_print(tokenizer.decode(z))
87 |
88 | if cur_len < tokenizer.model_max_length:
89 | if cur_len != total_len:
90 | target[:] = IGNORE_TOKEN_ID
91 | rank0_print(
92 | f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
93 | f" (ignored)"
94 | )
95 |
96 | return dict(
97 | input_ids=input_ids,
98 | labels=targets,
99 | attention_mask=input_ids.ne(tokenizer.pad_token_id),
100 | )
101 |
102 | class SupervisedDataset(Dataset):
103 | """Dataset for supervised fine-tuning."""
104 |
105 | def __init__(self, raw_data, tokenizer: transformers.PreTrainedTokenizer):
106 | super(SupervisedDataset, self).__init__()
107 |
108 | rank0_print("Formatting inputs...")
109 | sources = [example["conversations"] for example in raw_data]
110 | data_dict = preprocess(sources, tokenizer)
111 |
112 | self.input_ids = data_dict["input_ids"]
113 | self.labels = data_dict["labels"]
114 | self.attention_mask = data_dict["attention_mask"]
115 |
116 | def __len__(self):
117 | return len(self.input_ids)
118 |
119 | def __getitem__(self, i) -> Dict[str, torch.Tensor]:
120 | return dict(
121 | input_ids=self.input_ids[i],
122 | labels=self.labels[i],
123 | attention_mask=self.attention_mask[i],
124 | )
125 |
126 |
127 | def make_supervised_data_module(
128 | tokenizer: transformers.PreTrainedTokenizer, data_path
129 | ) -> Dict:
130 | """Make dataset and collator for supervised fine-tuning."""
131 | dataset_cls = (
132 | SupervisedDataset
133 | )
134 | rank0_print("Loading data...")
135 | raw_data = json.load(open(data_path, "r"))
136 |
137 | # Split train/test
138 | np.random.seed(0)
139 | perm = np.random.permutation(len(raw_data))
140 | split = int(len(perm) * 0.98)
141 | train_indices = perm[:split]
142 | eval_indices = perm[split:]
143 | train_raw_data = [raw_data[i] for i in train_indices]
144 | eval_raw_data = [raw_data[i] for i in eval_indices]
145 | rank0_print(f"#train {len(train_raw_data)}, #eval {len(eval_raw_data)}")
146 |
147 | train_dataset = dataset_cls(train_raw_data, tokenizer=tokenizer)
148 | eval_dataset = dataset_cls(eval_raw_data, tokenizer=tokenizer)
149 | return dict(train_dataset=train_dataset, eval_dataset=eval_dataset)
150 |
151 |
152 | @click.command()
153 | @click.option('--model_name_or_path', required=True)
154 | @click.option('--data_path', required=True)
155 | @click.option('--model_max_length', default=4096)
156 | def main(model_name_or_path, data_path, model_max_length):
157 | tokenizer = transformers.AutoTokenizer.from_pretrained(
158 | model_name_or_path,
159 | cache_dir=tempfile.TemporaryDirectory().name,
160 | model_max_length=model_max_length,
161 | padding_side="right",
162 | use_fast=False,
163 | legacy=False,
164 | )
165 |
166 | tokenizer.pad_token = tokenizer.unk_token
167 | make_supervised_data_module(tokenizer=tokenizer, data_path=data_path)
168 |
169 | if __name__ == "__main__":
170 | # Action LLM default template
171 | register_conv_template(
172 | Conversation(
173 | name="action",
174 | system_message="Below is a goal you need to achieve. Given the available tools and history of past actions provide the next action to perform.",
175 | roles=("### Goal", "### Tools", "### History", "### Next action"),
176 | messages=(),
177 | offset=0,
178 | sep_style=SeparatorStyle.ADD_COLON_SINGLE,
179 | sep="\n\n", # separator between roles
180 | )
181 | )
182 | register_model_adapter(ActionAdapter)
183 | main()
184 |
--------------------------------------------------------------------------------
/autoagents/train/train.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | rescale = int(os.environ.get("CONDENSE_RESCALE", 1))
4 | if rescale > 1:
5 | from longchat.train.monkey_patch.llama_condense_monkey_patch import replace_llama_with_condense
6 | replace_llama_with_condense(rescale)
7 |
8 | from longchat.train.monkey_patch.llama_flash_attn_monkey_patch import replace_llama_attn_with_flash_attn
9 |
10 | replace_llama_attn_with_flash_attn()
11 |
12 | from fastchat.train.train import train
13 |
14 | if __name__ == "__main__":
15 | train()
16 |
--------------------------------------------------------------------------------
/autoagents/train/train_v3.py:
--------------------------------------------------------------------------------
1 | # Make it more memory efficient by monkey patching the LLaMA model with FlashAttn.
2 | # Need to call this before importing transformers.
3 | try:
4 | from fastchat.train.llama_flash_attn_monkey_patch import (
5 | replace_llama_attn_with_flash_attn,
6 | )
7 |
8 | replace_llama_attn_with_flash_attn()
9 | except ImportError:
10 | pass # ignore if flash-attn not installed
11 |
12 | from typing import Dict
13 | import torch
14 | from fastchat.conversation import (
15 | SeparatorStyle,
16 | Conversation,
17 | register_conv_template,
18 | get_conv_template
19 | )
20 | from fastchat.model.model_adapter import (
21 | get_conversation_template,
22 | BaseModelAdapter,
23 | register_model_adapter
24 | )
25 | from transformers import (
26 | AutoConfig,
27 | AutoModelForCausalLM,
28 | AutoTokenizer,
29 | PreTrainedTokenizer
30 | )
31 |
32 | import fastchat.train.train as train
33 | from fastchat.train.train import rank0_print
34 | from fastchat.train.train import IGNORE_TOKEN_ID
35 |
36 | class ActionAdapter(BaseModelAdapter):
37 | """The model adapter for Action Vicuna"""
38 |
39 | def match(self, model_path: str):
40 | return "action" in model_path
41 |
42 | def load_model(self, model_path: str, from_pretrained_kwargs: dict):
43 | config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
44 | tokenizer = AutoTokenizer.from_pretrained(
45 | model_path, config=config, trust_remote_code=True
46 | )
47 | model = AutoModelForCausalLM.from_pretrained(
48 | model_path,
49 | config=config,
50 | trust_remote_code=True,
51 | low_cpu_mem_usage=True,
52 | **from_pretrained_kwargs,
53 | )
54 | return model, tokenizer
55 |
56 | def get_default_conv_template(self, model_path: str) -> Conversation:
57 | return get_conv_template("action")
58 |
59 |
60 | def preprocess(
61 | sources,
62 | tokenizer: PreTrainedTokenizer,
63 | ) -> Dict:
64 | conv = get_conversation_template("action")
65 | roles = {"goal": conv.roles[0],
66 | "tools": conv.roles[1],
67 | "history": conv.roles[2],
68 | "next_action": conv.roles[3]}
69 |
70 | # Apply prompt templates
71 | conversations = []
72 | for i, source in enumerate(sources):
73 | if roles[source[0]["from"]] != conv.roles[0]:
74 | # Skip the first one if it is not from human
75 | source = source[1:]
76 |
77 | conv.messages = []
78 | for j, sentence in enumerate(source):
79 | role = roles[sentence["from"]]
80 | conv.append_message(role, sentence["value"])
81 | conversations.append(conv.get_prompt())
82 |
83 | # Tokenize conversations
84 | input_ids = tokenizer(
85 | conversations,
86 | return_tensors="pt",
87 | padding="max_length",
88 | max_length=tokenizer.model_max_length,
89 | truncation=True,
90 | ).input_ids
91 | targets = input_ids.clone()
92 |
93 | assert conv.sep_style == SeparatorStyle.ADD_COLON_SINGLE
94 |
95 | # Mask targets
96 | sep = conv.sep + conv.roles[-1] + ": "
97 | for conversation, target in zip(conversations, targets):
98 | if False:
99 | z = target.clone()
100 | z = torch.where(z == IGNORE_TOKEN_ID, tokenizer.unk_token_id, z)
101 | rank0_print(tokenizer.decode(z))
102 |
103 | total_len = int(target.ne(tokenizer.pad_token_id).sum())
104 | inputs, outputs = conversation.split(sep) # [.., goal, history | next_action]
105 | cur_len = 0
106 | instruction_len = len(tokenizer(inputs + sep).input_ids) - 1
107 | target[cur_len:cur_len+instruction_len] = IGNORE_TOKEN_ID
108 | cur_len += instruction_len - 1
109 | outputs_len = len(tokenizer(outputs).input_ids)
110 | target[cur_len+outputs_len:] = IGNORE_TOKEN_ID
111 | cur_len += outputs_len
112 |
113 | if False:
114 | z = target.clone()
115 | z = torch.where(z == IGNORE_TOKEN_ID, tokenizer.unk_token_id, z)
116 | rank0_print(tokenizer.decode(z))
117 |
118 | if cur_len < tokenizer.model_max_length:
119 | if cur_len != total_len:
120 | target[:] = IGNORE_TOKEN_ID
121 | rank0_print(
122 | f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
123 | f" (ignored)"
124 | )
125 |
126 | return dict(
127 | input_ids=input_ids,
128 | labels=targets,
129 | attention_mask=input_ids.ne(tokenizer.pad_token_id),
130 | )
131 |
132 |
133 |
134 | if __name__ == "__main__":
135 | # Action LLM default template
136 | register_conv_template(
137 | Conversation(
138 | name="action",
139 | system_message="Below is a goal you need to achieve. Given the available tools and history of past actions provide the next action to perform.",
140 | roles=("### Goal", "### Tools", "### History", "### Next action"),
141 | messages=(),
142 | offset=0,
143 | sep_style=SeparatorStyle.ADD_COLON_SINGLE,
144 | sep="\n\n", # separator between roles
145 | )
146 | )
147 | register_model_adapter(ActionAdapter)
148 |
149 | # Monkeypatch preprocessing which handles the action roles
150 | train.preprocess = preprocess
151 | train.train()
152 |
153 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | openai>=0.27.7
2 | langchain>=0.0.193
3 | duckpy
4 | huggingface_hub
5 | pytz
6 | click
7 | pydantic==1.10.11
8 | git+https://github.com/lm-sys/FastChat@v0.2.25
9 | git+https://github.com/DachengLi1/LongChat@0a4d022
10 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 |
3 | setup(
4 | name='autoagents',
5 | version='0.1.0',
6 | packages=find_packages(include=['agents', 'agents.*'])
7 | )
8 |
--------------------------------------------------------------------------------