├── LICENSE
├── README.md
├── images
├── databricks.png
├── experts.png
├── gating.png
├── makemoehf2.png
├── makemoehf3.png
├── makemoelogo.png
├── mlflow_dash.png
├── moe.png
├── noisytopkgating.png
├── readme.txt
├── routing_result.png
├── self_attention.png
├── sparseMoEfinal.png
└── topk.png
├── input.txt
├── makeMoE.py
├── makeMoE_Concise.ipynb
├── makeMoE_from_Scratch.ipynb
└── makeMoE_from_Scratch_with_Expert_Capacity.ipynb
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2024 Avinash Sooriyarachchi
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # makeMoE
2 |
3 |
4 |

5 |
 "
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "metadata": {
16 | "application/vnd.databricks.v1+cell": {
17 | "cellMetadata": {},
18 | "inputWidgets": {},
19 | "nuid": "8e9b80fc-12cf-41a9-a0de-354f678b412b",
20 | "showTitle": false,
21 | "title": ""
22 | },
23 | "id": "90vgVgmDkRJQ"
24 | },
25 | "source": [
26 | "#### Sparse mixture of experts language model from scratch inspired by (and largely based on) Andrej Karpathy's makemore (https://github.com/karpathy/makemore) :)\n",
27 | "\n",
28 | "This is a from scratch implementation of a sparse mixture of experts language model. This is inspired by and largely based on Andrej Karpathy's project 'makemore' and borrows most of the re-usable components from that implementation. Just like makemore, makeMoE is also an autoregressive character-level language model but uses the aforementioned sparse mixture of experts architecture.\n",
29 | "\n",
30 | "Just like makemore, pytorch is the only requirement (so I hope the from scratch claim is justified).\n",
31 | "\n",
32 | "Significant Changes from the makemore architecture\n",
33 | "\n",
34 | "- Sparse mixture of experts instead of the solitary feed forward neural net.\n",
35 | "- Top-k gating and noisy top-k gating implementations.\n",
36 | "- initialization - Kaiming He initialization is used here but the point of this notebook is to be hackable so you can swap in Xavier Glorot etc. and take it for a spin.\n",
37 | "\n",
38 | "Unchanged from makemore\n",
39 | "- The dataset, preprocessing (tokenization), and the language modeling task Andrej chose originally - generate Shakespeare-like text\n",
40 | "- Casusal self attention implementation\n",
41 | "- Training loop\n",
42 | "- Inference logic\n",
43 | "\n",
44 | "Publications heavily referenced for this implementation:\n",
45 | "- Mixtral of experts: https://arxiv.org/pdf/2401.04088.pdf\n",
46 | "- Outrageosly Large Neural Networks: The Sparsely-Gated Mixture-Of-Experts layer: https://arxiv.org/pdf/1701.06538.pdf\n",
47 | "\n",
48 | "\n",
49 | "This notebook walks through the intuition for the entire model architecture and how everything comes together\n",
50 | "\n",
51 | "The code was entirely developed on Databricks using a single A100 for compute. If you're running this on Databricks, you can scale this on an arbitrarily large GPU cluster with no issues in the cloud provider of your choice\n",
52 | "\n",
53 | "I chose to use mlflow (which comes pre-installed in Databricks. You can pip install easily elsewhere) as I find it helpful to track and log all the metrics necessary. This is entirely optional.\n",
54 | "\n",
55 | "Please note that the implementation emphasizes readability and hackability vs performance, so there are many ways in which you could improve this. Please try and let me know\n"
56 | ]
57 | },
58 | {
59 | "cell_type": "markdown",
60 | "metadata": {
61 | "application/vnd.databricks.v1+cell": {
62 | "cellMetadata": {
63 | "byteLimit": 2048000,
64 | "rowLimit": 10000
65 | },
66 | "inputWidgets": {},
67 | "nuid": "2f4a58a8-bd4c-40de-a4a9-95457842db0b",
68 | "showTitle": false,
69 | "title": ""
70 | },
71 | "id": "hywLNfb0kRJT"
72 | },
73 | "source": [
74 | "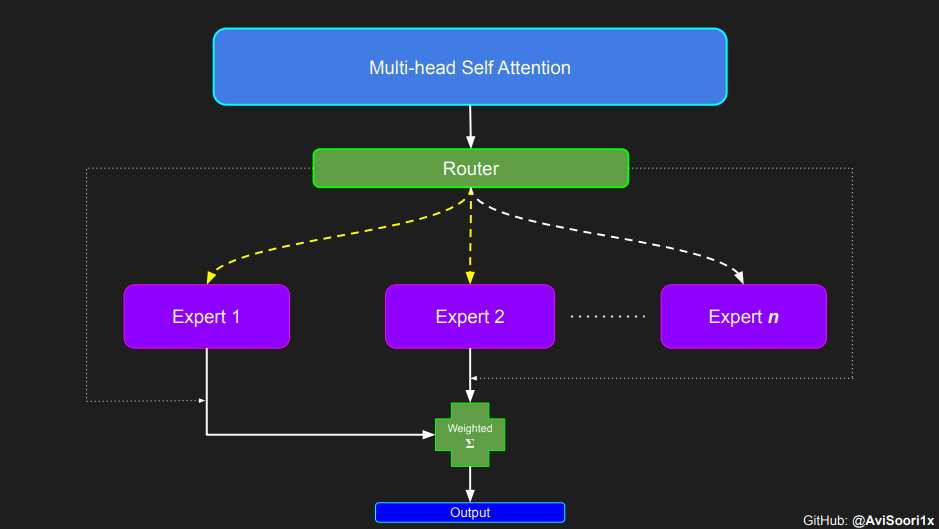"
75 | ]
76 | },
77 | {
78 | "cell_type": "code",
79 | "execution_count": null,
80 | "metadata": {
81 | "application/vnd.databricks.v1+cell": {
82 | "cellMetadata": {
83 | "byteLimit": 2048000,
84 | "rowLimit": 10000
85 | },
86 | "inputWidgets": {},
87 | "nuid": "35b3daa3-3b3b-47af-b3e7-be95878f9e06",
88 | "showTitle": false,
89 | "title": ""
90 | },
91 | "id": "RQAnP6_RkRJU"
92 | },
93 | "outputs": [],
94 | "source": [
95 | "#Using mlflow is entirely optional. I personally like to use MLFlow to track and log everything. If you're using Databricks, it comes pre-installed.\n",
96 | "%pip install mlflow"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": null,
102 | "metadata": {
103 | "application/vnd.databricks.v1+cell": {
104 | "cellMetadata": {
105 | "byteLimit": 2048000,
106 | "rowLimit": 10000
107 | },
108 | "inputWidgets": {},
109 | "nuid": "5e1a3e38-8717-42ec-9bbc-71d3712c1c68",
110 | "showTitle": false,
111 | "title": ""
112 | },
113 | "id": "V521QQ_qkRJV"
114 | },
115 | "outputs": [],
116 | "source": [
117 | "#Import the necessary packages and set seed for reproducibility. For this notebook, pytorch is all you need\n",
118 | "import torch\n",
119 | "import torch.nn as nn\n",
120 | "from torch.nn import functional as F\n",
121 | "torch.manual_seed(42)\n",
122 | "#Optional\n",
123 | "import mlflow"
124 | ]
125 | },
126 | {
127 | "cell_type": "markdown",
128 | "metadata": {
129 | "application/vnd.databricks.v1+cell": {
130 | "cellMetadata": {},
131 | "inputWidgets": {},
132 | "nuid": "faf99ef2-39bb-46fc-b772-05d6d0482bbc",
133 | "showTitle": false,
134 | "title": ""
135 | },
136 | "id": "-4r_QNRRkRJV"
137 | },
138 | "source": [
139 | "Next few sections, downloading the data, preprocessing it and self attention are directly from makemore. I have elaborated a little on self attention and added visual aids to understand the process a bit better."
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": null,
145 | "metadata": {
146 | "application/vnd.databricks.v1+cell": {
147 | "cellMetadata": {
148 | "byteLimit": 2048000,
149 | "rowLimit": 10000
150 | },
151 | "inputWidgets": {},
152 | "nuid": "45143d84-28c7-463d-9fb5-e21122842600",
153 | "showTitle": false,
154 | "title": ""
155 | },
156 | "id": "2GhDw0yWkRJV",
157 | "outputId": "22b79649-9819-4c65-a46a-d0796d6c9085"
158 | },
159 | "outputs": [
160 | {
161 | "name": "stdout",
162 | "output_type": "stream",
163 | "text": [
164 | "--2024-01-25 06:11:57-- https://raw.githubusercontent.com/AviSoori1x/makeMoE/main/input.txt\r\n",
165 | "Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.110.133, 185.199.109.133, ...\r\n",
166 | "Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.\r\n",
167 | "HTTP request sent, awaiting response... 200 OK\r\n",
168 | "Length: 1115394 (1.1M) [text/plain]\r\n",
169 | "Saving to: ‘input.txt.2’\r\n",
170 | "\r\n",
171 | "\rinput.txt.2 0%[ ] 0 --.-KB/s \rinput.txt.2 100%[===================>] 1.06M --.-KB/s in 0.04s \r\n",
172 | "\r\n",
173 | "2024-01-25 06:11:57 (30.2 MB/s) - ‘input.txt.2’ saved [1115394/1115394]\r\n",
174 | "\r\n"
175 | ]
176 | }
177 | ],
178 | "source": [
179 | "# Downloading the tiny shakespeare dataset\n",
180 | "!wget https://raw.githubusercontent.com/AviSoori1x/makeMoE/main/input.txt"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": null,
186 | "metadata": {
187 | "application/vnd.databricks.v1+cell": {
188 | "cellMetadata": {
189 | "byteLimit": 2048000,
190 | "rowLimit": 10000
191 | },
192 | "inputWidgets": {},
193 | "nuid": "192e830a-762d-4573-9484-70a58deb1fec",
194 | "showTitle": false,
195 | "title": ""
196 | },
197 | "id": "3sPAL1AKkRJW"
198 | },
199 | "outputs": [],
200 | "source": [
201 | "# read it in to inspect it\n",
202 | "with open('input.txt', 'r', encoding='utf-8') as f:\n",
203 | " text = f.read()"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": null,
209 | "metadata": {
210 | "application/vnd.databricks.v1+cell": {
211 | "cellMetadata": {
212 | "byteLimit": 2048000,
213 | "rowLimit": 10000
214 | },
215 | "inputWidgets": {},
216 | "nuid": "2d7181b7-f5e5-4ab5-bdd8-74c507c798ad",
217 | "showTitle": false,
218 | "title": ""
219 | },
220 | "id": "wNkF3RYLkRJX",
221 | "outputId": "671be677-be3d-49e0-d391-569559a99ae2"
222 | },
223 | "outputs": [
224 | {
225 | "name": "stdout",
226 | "output_type": "stream",
227 | "text": [
228 | "length of dataset in characters: 1115394\n"
229 | ]
230 | }
231 | ],
232 | "source": [
233 | "print(\"length of dataset in characters: \", len(text))"
234 | ]
235 | },
236 | {
237 | "cell_type": "code",
238 | "execution_count": null,
239 | "metadata": {
240 | "application/vnd.databricks.v1+cell": {
241 | "cellMetadata": {
242 | "byteLimit": 2048000,
243 | "rowLimit": 10000
244 | },
245 | "inputWidgets": {},
246 | "nuid": "68032e07-8625-4750-a340-bc8f4eed2458",
247 | "showTitle": false,
248 | "title": ""
249 | },
250 | "id": "AHIwr-yxkRJX",
251 | "outputId": "fa10ee0f-c8cb-4ba1-9fb1-79f9fbf336fe"
252 | },
253 | "outputs": [
254 | {
255 | "name": "stdout",
256 | "output_type": "stream",
257 | "text": [
258 | "First Citizen:\n",
259 | "Before we proceed any further, hear me speak.\n",
260 | "\n",
261 | "All:\n",
262 | "Speak, speak.\n",
263 | "\n",
264 | "First Citizen:\n",
265 | "You are all resolved rather to die than to famish?\n",
266 | "\n",
267 | "All:\n",
268 | "Resolved. resolved.\n",
269 | "\n",
270 | "First Citizen:\n",
271 | "First, you know Caius Marcius is chief enemy to the people.\n",
272 | "\n",
273 | "All:\n",
274 | "We know't, we know't.\n",
275 | "\n",
276 | "First Citizen:\n",
277 | "Let us kill him, and we'll have corn at our own price.\n",
278 | "Is't a verdict?\n",
279 | "\n",
280 | "All:\n",
281 | "No more talking on't; let it be done: away, away!\n",
282 | "\n",
283 | "Second Citizen:\n",
284 | "One word, good citizens.\n",
285 | "\n",
286 | "First Citizen:\n",
287 | "We are accounted poor citizens, the patricians good.\n",
288 | "What authority surfeits on would relieve us: if they\n",
289 | "would yield us but the superfluity, while it were\n",
290 | "wholesome, we might guess they relieved us humanely;\n",
291 | "but they think we are too dear: the leanness that\n",
292 | "afflicts us, the object of our misery, is as an\n",
293 | "inventory to particularise their abundance; our\n",
294 | "sufferance is a gain to them Let us revenge this with\n",
295 | "our pikes, ere we become rakes: for the gods know I\n",
296 | "speak this in hunger for bread, not in thirst for revenge.\n",
297 | "\n",
298 | "\n"
299 | ]
300 | }
301 | ],
302 | "source": [
303 | "# let's look at the first 1000 characters\n",
304 | "print(text[:1000])"
305 | ]
306 | },
307 | {
308 | "cell_type": "code",
309 | "execution_count": null,
310 | "metadata": {
311 | "application/vnd.databricks.v1+cell": {
312 | "cellMetadata": {
313 | "byteLimit": 2048000,
314 | "rowLimit": 10000
315 | },
316 | "inputWidgets": {},
317 | "nuid": "b6995ad6-c9ac-4a21-9da0-ebbd3273c991",
318 | "showTitle": false,
319 | "title": ""
320 | },
321 | "id": "DHGayz7mkRJY",
322 | "outputId": "54b52e55-b6b9-4bdc-974a-5c48a43e1497"
323 | },
324 | "outputs": [
325 | {
326 | "name": "stdout",
327 | "output_type": "stream",
328 | "text": [
329 | "\n",
330 | " !$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz\n",
331 | "65\n"
332 | ]
333 | }
334 | ],
335 | "source": [
336 | "# here are all the unique characters that occur in this text\n",
337 | "chars = sorted(list(set(text)))\n",
338 | "vocab_size = len(chars)\n",
339 | "print(''.join(chars))\n",
340 | "print(vocab_size)"
341 | ]
342 | },
343 | {
344 | "cell_type": "code",
345 | "execution_count": null,
346 | "metadata": {
347 | "application/vnd.databricks.v1+cell": {
348 | "cellMetadata": {
349 | "byteLimit": 2048000,
350 | "rowLimit": 10000
351 | },
352 | "inputWidgets": {},
353 | "nuid": "43002fa3-ffd3-416c-9aaf-0a03b19c7bc1",
354 | "showTitle": false,
355 | "title": ""
356 | },
357 | "id": "pzn11WJckRJY",
358 | "outputId": "cd7b3ff1-680b-4036-b3c8-b597a361aeb3"
359 | },
360 | "outputs": [
361 | {
362 | "name": "stdout",
363 | "output_type": "stream",
364 | "text": [
365 | "[46, 47, 47, 1, 58, 46, 43, 56, 43]\n",
366 | "hii there\n"
367 | ]
368 | }
369 | ],
370 | "source": [
371 | "# create a mapping from characters to integers\n",
372 | "stoi = { ch:i for i,ch in enumerate(chars) }\n",
373 | "itos = { i:ch for i,ch in enumerate(chars) }\n",
374 | "encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers\n",
375 | "decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string\n",
376 | "\n",
377 | "print(encode(\"hii there\"))\n",
378 | "print(decode(encode(\"hii there\")))"
379 | ]
380 | },
381 | {
382 | "cell_type": "code",
383 | "execution_count": null,
384 | "metadata": {
385 | "application/vnd.databricks.v1+cell": {
386 | "cellMetadata": {
387 | "byteLimit": 2048000,
388 | "rowLimit": 10000
389 | },
390 | "inputWidgets": {},
391 | "nuid": "b4609fc4-09c7-4a39-8367-e9ee39d440ed",
392 | "showTitle": false,
393 | "title": ""
394 | },
395 | "id": "YbBGz0O2kRJY",
396 | "outputId": "49e94dde-6e1f-4a9e-a18b-9b8f1c51de86"
397 | },
398 | "outputs": [
399 | {
400 | "name": "stdout",
401 | "output_type": "stream",
402 | "text": [
403 | "torch.Size([1115394]) torch.int64\n",
404 | "tensor([18, 47, 56, 57, 58, 1, 15, 47, 58, 47, 64, 43, 52, 10, 0, 14, 43, 44,\n",
405 | " 53, 56, 43, 1, 61, 43, 1, 54, 56, 53, 41, 43, 43, 42, 1, 39, 52, 63,\n",
406 | " 1, 44, 59, 56, 58, 46, 43, 56, 6, 1, 46, 43, 39, 56, 1, 51, 43, 1,\n",
407 | " 57, 54, 43, 39, 49, 8, 0, 0, 13, 50, 50, 10, 0, 31, 54, 43, 39, 49,\n",
408 | " 6, 1, 57, 54, 43, 39, 49, 8, 0, 0, 18, 47, 56, 57, 58, 1, 15, 47,\n",
409 | " 58, 47, 64, 43, 52, 10, 0, 37, 53, 59, 1, 39, 56, 43, 1, 39, 50, 50,\n",
410 | " 1, 56, 43, 57, 53, 50, 60, 43, 42, 1, 56, 39, 58, 46, 43, 56, 1, 58,\n",
411 | " 53, 1, 42, 47, 43, 1, 58, 46, 39, 52, 1, 58, 53, 1, 44, 39, 51, 47,\n",
412 | " 57, 46, 12, 0, 0, 13, 50, 50, 10, 0, 30, 43, 57, 53, 50, 60, 43, 42,\n",
413 | " 8, 1, 56, 43, 57, 53, 50, 60, 43, 42, 8, 0, 0, 18, 47, 56, 57, 58,\n",
414 | " 1, 15, 47, 58, 47, 64, 43, 52, 10, 0, 18, 47, 56, 57, 58, 6, 1, 63,\n",
415 | " 53, 59, 1, 49, 52, 53, 61, 1, 15, 39, 47, 59, 57, 1, 25, 39, 56, 41,\n",
416 | " 47, 59, 57, 1, 47, 57, 1, 41, 46, 47, 43, 44, 1, 43, 52, 43, 51, 63,\n",
417 | " 1, 58, 53, 1, 58, 46, 43, 1, 54, 43, 53, 54, 50, 43, 8, 0, 0, 13,\n",
418 | " 50, 50, 10, 0, 35, 43, 1, 49, 52, 53, 61, 5, 58, 6, 1, 61, 43, 1,\n",
419 | " 49, 52, 53, 61, 5, 58, 8, 0, 0, 18, 47, 56, 57, 58, 1, 15, 47, 58,\n",
420 | " 47, 64, 43, 52, 10, 0, 24, 43, 58, 1, 59, 57, 1, 49, 47, 50, 50, 1,\n",
421 | " 46, 47, 51, 6, 1, 39, 52, 42, 1, 61, 43, 5, 50, 50, 1, 46, 39, 60,\n",
422 | " 43, 1, 41, 53, 56, 52, 1, 39, 58, 1, 53, 59, 56, 1, 53, 61, 52, 1,\n",
423 | " 54, 56, 47, 41, 43, 8, 0, 21, 57, 5, 58, 1, 39, 1, 60, 43, 56, 42,\n",
424 | " 47, 41, 58, 12, 0, 0, 13, 50, 50, 10, 0, 26, 53, 1, 51, 53, 56, 43,\n",
425 | " 1, 58, 39, 50, 49, 47, 52, 45, 1, 53, 52, 5, 58, 11, 1, 50, 43, 58,\n",
426 | " 1, 47, 58, 1, 40, 43, 1, 42, 53, 52, 43, 10, 1, 39, 61, 39, 63, 6,\n",
427 | " 1, 39, 61, 39, 63, 2, 0, 0, 31, 43, 41, 53, 52, 42, 1, 15, 47, 58,\n",
428 | " 47, 64, 43, 52, 10, 0, 27, 52, 43, 1, 61, 53, 56, 42, 6, 1, 45, 53,\n",
429 | " 53, 42, 1, 41, 47, 58, 47, 64, 43, 52, 57, 8, 0, 0, 18, 47, 56, 57,\n",
430 | " 58, 1, 15, 47, 58, 47, 64, 43, 52, 10, 0, 35, 43, 1, 39, 56, 43, 1,\n",
431 | " 39, 41, 41, 53, 59, 52, 58, 43, 42, 1, 54, 53, 53, 56, 1, 41, 47, 58,\n",
432 | " 47, 64, 43, 52, 57, 6, 1, 58, 46, 43, 1, 54, 39, 58, 56, 47, 41, 47,\n",
433 | " 39, 52, 57, 1, 45, 53, 53, 42, 8, 0, 35, 46, 39, 58, 1, 39, 59, 58,\n",
434 | " 46, 53, 56, 47, 58, 63, 1, 57, 59, 56, 44, 43, 47, 58, 57, 1, 53, 52,\n",
435 | " 1, 61, 53, 59, 50, 42, 1, 56, 43, 50, 47, 43, 60, 43, 1, 59, 57, 10,\n",
436 | " 1, 47, 44, 1, 58, 46, 43, 63, 0, 61, 53, 59, 50, 42, 1, 63, 47, 43,\n",
437 | " 50, 42, 1, 59, 57, 1, 40, 59, 58, 1, 58, 46, 43, 1, 57, 59, 54, 43,\n",
438 | " 56, 44, 50, 59, 47, 58, 63, 6, 1, 61, 46, 47, 50, 43, 1, 47, 58, 1,\n",
439 | " 61, 43, 56, 43, 0, 61, 46, 53, 50, 43, 57, 53, 51, 43, 6, 1, 61, 43,\n",
440 | " 1, 51, 47, 45, 46, 58, 1, 45, 59, 43, 57, 57, 1, 58, 46, 43, 63, 1,\n",
441 | " 56, 43, 50, 47, 43, 60, 43, 42, 1, 59, 57, 1, 46, 59, 51, 39, 52, 43,\n",
442 | " 50, 63, 11, 0, 40, 59, 58, 1, 58, 46, 43, 63, 1, 58, 46, 47, 52, 49,\n",
443 | " 1, 61, 43, 1, 39, 56, 43, 1, 58, 53, 53, 1, 42, 43, 39, 56, 10, 1,\n",
444 | " 58, 46, 43, 1, 50, 43, 39, 52, 52, 43, 57, 57, 1, 58, 46, 39, 58, 0,\n",
445 | " 39, 44, 44, 50, 47, 41, 58, 57, 1, 59, 57, 6, 1, 58, 46, 43, 1, 53,\n",
446 | " 40, 48, 43, 41, 58, 1, 53, 44, 1, 53, 59, 56, 1, 51, 47, 57, 43, 56,\n",
447 | " 63, 6, 1, 47, 57, 1, 39, 57, 1, 39, 52, 0, 47, 52, 60, 43, 52, 58,\n",
448 | " 53, 56, 63, 1, 58, 53, 1, 54, 39, 56, 58, 47, 41, 59, 50, 39, 56, 47,\n",
449 | " 57, 43, 1, 58, 46, 43, 47, 56, 1, 39, 40, 59, 52, 42, 39, 52, 41, 43,\n",
450 | " 11, 1, 53, 59, 56, 0, 57, 59, 44, 44, 43, 56, 39, 52, 41, 43, 1, 47,\n",
451 | " 57, 1, 39, 1, 45, 39, 47, 52, 1, 58, 53, 1, 58, 46, 43, 51, 1, 24,\n",
452 | " 43, 58, 1, 59, 57, 1, 56, 43, 60, 43, 52, 45, 43, 1, 58, 46, 47, 57,\n",
453 | " 1, 61, 47, 58, 46, 0, 53, 59, 56, 1, 54, 47, 49, 43, 57, 6, 1, 43,\n",
454 | " 56, 43, 1, 61, 43, 1, 40, 43, 41, 53, 51, 43, 1, 56, 39, 49, 43, 57,\n",
455 | " 10, 1, 44, 53, 56, 1, 58, 46, 43, 1, 45, 53, 42, 57, 1, 49, 52, 53,\n",
456 | " 61, 1, 21, 0, 57, 54, 43, 39, 49, 1, 58, 46, 47, 57, 1, 47, 52, 1,\n",
457 | " 46, 59, 52, 45, 43, 56, 1, 44, 53, 56, 1, 40, 56, 43, 39, 42, 6, 1,\n",
458 | " 52, 53, 58, 1, 47, 52, 1, 58, 46, 47, 56, 57, 58, 1, 44, 53, 56, 1,\n",
459 | " 56, 43, 60, 43, 52, 45, 43, 8, 0, 0])\n"
460 | ]
461 | }
462 | ],
463 | "source": [
464 | "# let's now encode the entire text dataset and store it into a torch.Tensor\n",
465 | "data = torch.tensor(encode(text), dtype=torch.long)\n",
466 | "print(data.shape, data.dtype)\n",
467 | "print(data[:1000]) # the 1000 characters we looked at earier will to the GPT look like this"
468 | ]
469 | },
470 | {
471 | "cell_type": "code",
472 | "execution_count": null,
473 | "metadata": {
474 | "application/vnd.databricks.v1+cell": {
475 | "cellMetadata": {
476 | "byteLimit": 2048000,
477 | "rowLimit": 10000
478 | },
479 | "inputWidgets": {},
480 | "nuid": "88f7cb0d-02ff-42b0-92a5-a505dc3f8f25",
481 | "showTitle": false,
482 | "title": ""
483 | },
484 | "id": "hoLIeA7YkRJZ"
485 | },
486 | "outputs": [],
487 | "source": [
488 | "# Let's now split up the data into train and validation sets\n",
489 | "n = int(0.9*len(data)) # first 90% will be train, rest val\n",
490 | "train_data = data[:n]\n",
491 | "val_data = data[n:]"
492 | ]
493 | },
494 | {
495 | "cell_type": "code",
496 | "execution_count": null,
497 | "metadata": {
498 | "application/vnd.databricks.v1+cell": {
499 | "cellMetadata": {
500 | "byteLimit": 2048000,
501 | "rowLimit": 10000
502 | },
503 | "inputWidgets": {},
504 | "nuid": "6b554ddf-50f4-441b-8acf-10b81a508b7e",
505 | "showTitle": false,
506 | "title": ""
507 | },
508 | "id": "VY55nr6EkRJZ",
509 | "outputId": "1a5685e9-66bb-40ed-f19a-f0cb09e8e51c"
510 | },
511 | "outputs": [
512 | {
513 | "data": {
514 | "text/plain": [
515 | "tensor([18, 47, 56, 57, 58, 1, 15, 47, 58])"
516 | ]
517 | },
518 | "execution_count": 26,
519 | "metadata": {},
520 | "output_type": "execute_result"
521 | }
522 | ],
523 | "source": [
524 | "block_size = 8\n",
525 | "train_data[:block_size+1]"
526 | ]
527 | },
528 | {
529 | "cell_type": "code",
530 | "execution_count": null,
531 | "metadata": {
532 | "application/vnd.databricks.v1+cell": {
533 | "cellMetadata": {
534 | "byteLimit": 2048000,
535 | "rowLimit": 10000
536 | },
537 | "inputWidgets": {},
538 | "nuid": "22ba4512-309d-4895-a908-2ef3efa317bc",
539 | "showTitle": false,
540 | "title": ""
541 | },
542 | "id": "5YbgrB9HkRJZ",
543 | "outputId": "05577a5f-10d5-495b-82e8-c3278b4fdea0"
544 | },
545 | "outputs": [
546 | {
547 | "name": "stdout",
548 | "output_type": "stream",
549 | "text": [
550 | "when input is tensor([18]) the target: 47\n",
551 | "when input is tensor([18, 47]) the target: 56\n",
552 | "when input is tensor([18, 47, 56]) the target: 57\n",
553 | "when input is tensor([18, 47, 56, 57]) the target: 58\n",
554 | "when input is tensor([18, 47, 56, 57, 58]) the target: 1\n",
555 | "when input is tensor([18, 47, 56, 57, 58, 1]) the target: 15\n",
556 | "when input is tensor([18, 47, 56, 57, 58, 1, 15]) the target: 47\n",
557 | "when input is tensor([18, 47, 56, 57, 58, 1, 15, 47]) the target: 58\n"
558 | ]
559 | }
560 | ],
561 | "source": [
562 | "x = train_data[:block_size]\n",
563 | "y = train_data[1:block_size+1]\n",
564 | "for t in range(block_size):\n",
565 | " context = x[:t+1]\n",
566 | " target = y[t]\n",
567 | " print(f\"when input is {context} the target: {target}\")"
568 | ]
569 | },
570 | {
571 | "cell_type": "code",
572 | "execution_count": null,
573 | "metadata": {
574 | "application/vnd.databricks.v1+cell": {
575 | "cellMetadata": {
576 | "byteLimit": 2048000,
577 | "rowLimit": 10000
578 | },
579 | "inputWidgets": {},
580 | "nuid": "bf386bff-0f63-4358-82fc-6c7d02c37321",
581 | "showTitle": false,
582 | "title": ""
583 | },
584 | "id": "Oaxhage8kRJZ"
585 | },
586 | "outputs": [],
587 | "source": [
588 | "batch_size = 4 # how many independent sequences will we process in parallel?\n",
589 | "block_size = 8 # what is the maximum context length for predictions?"
590 | ]
591 | },
592 | {
593 | "cell_type": "code",
594 | "execution_count": null,
595 | "metadata": {
596 | "application/vnd.databricks.v1+cell": {
597 | "cellMetadata": {
598 | "byteLimit": 2048000,
599 | "rowLimit": 10000
600 | },
601 | "inputWidgets": {},
602 | "nuid": "99acd85c-233f-4f2d-a062-028dbcde9960",
603 | "showTitle": false,
604 | "title": ""
605 | },
606 | "id": "HfpkIUNdkRJZ",
607 | "outputId": "1ad2bc10-2b4a-458b-a6ee-a169728ec90d"
608 | },
609 | "outputs": [
610 | {
611 | "data": {
612 | "text/plain": [
613 | "tensor([250930, 237205, 974116, 383898])"
614 | ]
615 | },
616 | "execution_count": 29,
617 | "metadata": {},
618 | "output_type": "execute_result"
619 | }
620 | ],
621 | "source": [
622 | "ix = torch.randint(len(data) - block_size, (batch_size,))\n",
623 | "ix"
624 | ]
625 | },
626 | {
627 | "cell_type": "code",
628 | "execution_count": null,
629 | "metadata": {
630 | "application/vnd.databricks.v1+cell": {
631 | "cellMetadata": {
632 | "byteLimit": 2048000,
633 | "rowLimit": 10000
634 | },
635 | "inputWidgets": {},
636 | "nuid": "e46dc826-9f39-4aed-b2d2-f9ea401136de",
637 | "showTitle": false,
638 | "title": ""
639 | },
640 | "id": "faoGVPG3kRJa",
641 | "outputId": "dcf8b139-d8f8-4565-a962-62d094c5da9f"
642 | },
643 | "outputs": [
644 | {
645 | "data": {
646 | "text/plain": [
647 | "tensor([[42, 1, 58, 46, 59, 57, 1, 21],\n",
648 | " [54, 56, 47, 43, 57, 58, 11, 0],\n",
649 | " [49, 47, 52, 45, 12, 1, 58, 46],\n",
650 | " [58, 46, 53, 59, 58, 1, 56, 43]])"
651 | ]
652 | },
653 | "execution_count": 30,
654 | "metadata": {},
655 | "output_type": "execute_result"
656 | }
657 | ],
658 | "source": [
659 | "x = torch.stack([data[i:i+block_size] for i in ix])\n",
660 | "y = torch.stack([data[i+1:i+block_size+1] for i in ix])\n",
661 | "x"
662 | ]
663 | },
664 | {
665 | "cell_type": "code",
666 | "execution_count": null,
667 | "metadata": {
668 | "application/vnd.databricks.v1+cell": {
669 | "cellMetadata": {
670 | "byteLimit": 2048000,
671 | "rowLimit": 10000
672 | },
673 | "inputWidgets": {},
674 | "nuid": "2886aedf-200e-40bd-9a9d-4658cf6c509b",
675 | "showTitle": false,
676 | "title": ""
677 | },
678 | "id": "hkllYFCPkRJa",
679 | "outputId": "9350713c-be0f-492a-c873-bd279226668d"
680 | },
681 | "outputs": [
682 | {
683 | "data": {
684 | "text/plain": [
685 | "tensor([[ 1, 58, 46, 59, 57, 1, 21, 1],\n",
686 | " [56, 47, 43, 57, 58, 11, 0, 37],\n",
687 | " [47, 52, 45, 12, 1, 58, 46, 53],\n",
688 | " [46, 53, 59, 58, 1, 56, 43, 42]])"
689 | ]
690 | },
691 | "execution_count": 31,
692 | "metadata": {},
693 | "output_type": "execute_result"
694 | }
695 | ],
696 | "source": [
697 | "y"
698 | ]
699 | },
700 | {
701 | "cell_type": "markdown",
702 | "metadata": {
703 | "application/vnd.databricks.v1+cell": {
704 | "cellMetadata": {},
705 | "inputWidgets": {},
706 | "nuid": "a486fc04-ed29-456f-918b-5f8395e455cb",
707 | "showTitle": false,
708 | "title": ""
709 | },
710 | "id": "tWrajECBkRJa"
711 | },
712 | "source": [
713 | "The following code block clearly shows the autoregressive nature of the prediction and how the context is a rolling windows over a 1 dimentional arrangement of tokens (characters in this case)"
714 | ]
715 | },
716 | {
717 | "cell_type": "code",
718 | "execution_count": null,
719 | "metadata": {
720 | "application/vnd.databricks.v1+cell": {
721 | "cellMetadata": {
722 | "byteLimit": 2048000,
723 | "rowLimit": 10000
724 | },
725 | "inputWidgets": {},
726 | "nuid": "49a86e10-ac37-4b92-8f18-775cd4853fdc",
727 | "showTitle": false,
728 | "title": ""
729 | },
730 | "id": "xjgtxxztkRJa",
731 | "outputId": "1be0ebc2-b22d-4136-e77d-ecdafded66d2"
732 | },
733 | "outputs": [
734 | {
735 | "name": "stdout",
736 | "output_type": "stream",
737 | "text": [
738 | "inputs:\n",
739 | "torch.Size([4, 8])\n",
740 | "tensor([[ 6, 0, 14, 43, 44, 53, 56, 43],\n",
741 | " [39, 1, 42, 59, 43, 1, 39, 52],\n",
742 | " [47, 41, 43, 1, 39, 52, 42, 1],\n",
743 | " [53, 44, 1, 50, 43, 58, 1, 58]])\n",
744 | "targets:\n",
745 | "torch.Size([4, 8])\n",
746 | "tensor([[ 0, 14, 43, 44, 53, 56, 43, 1],\n",
747 | " [ 1, 42, 59, 43, 1, 39, 52, 42],\n",
748 | " [41, 43, 1, 39, 52, 42, 1, 42],\n",
749 | " [44, 1, 50, 43, 58, 1, 58, 46]])\n",
750 | "----\n",
751 | "when input is [6] the target: 0\n",
752 | "when input is [6, 0] the target: 14\n",
753 | "when input is [6, 0, 14] the target: 43\n",
754 | "when input is [6, 0, 14, 43] the target: 44\n",
755 | "when input is [6, 0, 14, 43, 44] the target: 53\n",
756 | "when input is [6, 0, 14, 43, 44, 53] the target: 56\n",
757 | "when input is [6, 0, 14, 43, 44, 53, 56] the target: 43\n",
758 | "when input is [6, 0, 14, 43, 44, 53, 56, 43] the target: 1\n",
759 | "when input is [39] the target: 1\n",
760 | "when input is [39, 1] the target: 42\n",
761 | "when input is [39, 1, 42] the target: 59\n",
762 | "when input is [39, 1, 42, 59] the target: 43\n",
763 | "when input is [39, 1, 42, 59, 43] the target: 1\n",
764 | "when input is [39, 1, 42, 59, 43, 1] the target: 39\n",
765 | "when input is [39, 1, 42, 59, 43, 1, 39] the target: 52\n",
766 | "when input is [39, 1, 42, 59, 43, 1, 39, 52] the target: 42\n",
767 | "when input is [47] the target: 41\n",
768 | "when input is [47, 41] the target: 43\n",
769 | "when input is [47, 41, 43] the target: 1\n",
770 | "when input is [47, 41, 43, 1] the target: 39\n",
771 | "when input is [47, 41, 43, 1, 39] the target: 52\n",
772 | "when input is [47, 41, 43, 1, 39, 52] the target: 42\n",
773 | "when input is [47, 41, 43, 1, 39, 52, 42] the target: 1\n",
774 | "when input is [47, 41, 43, 1, 39, 52, 42, 1] the target: 42\n",
775 | "when input is [53] the target: 44\n",
776 | "when input is [53, 44] the target: 1\n",
777 | "when input is [53, 44, 1] the target: 50\n",
778 | "when input is [53, 44, 1, 50] the target: 43\n",
779 | "when input is [53, 44, 1, 50, 43] the target: 58\n",
780 | "when input is [53, 44, 1, 50, 43, 58] the target: 1\n",
781 | "when input is [53, 44, 1, 50, 43, 58, 1] the target: 58\n",
782 | "when input is [53, 44, 1, 50, 43, 58, 1, 58] the target: 46\n"
783 | ]
784 | }
785 | ],
786 | "source": [
787 | "def get_batch(split):\n",
788 | " # generate a small batch of data of inputs x and targets y\n",
789 | " data = train_data if split == 'train' else val_data\n",
790 | " ix = torch.randint(len(data) - block_size, (batch_size,))\n",
791 | " x = torch.stack([data[i:i+block_size] for i in ix])\n",
792 | " y = torch.stack([data[i+1:i+block_size+1] for i in ix])\n",
793 | " return x, y\n",
794 | "\n",
795 | "xb, yb = get_batch('train')\n",
796 | "print('inputs:')\n",
797 | "print(xb.shape)\n",
798 | "print(xb)\n",
799 | "print('targets:')\n",
800 | "print(yb.shape)\n",
801 | "print(yb)\n",
802 | "\n",
803 | "print('----')\n",
804 | "\n",
805 | "for b in range(batch_size): # batch dimension\n",
806 | " for t in range(block_size): # time dimension\n",
807 | " context = xb[b, :t+1]\n",
808 | " target = yb[b,t]\n",
809 | " print(f\"when input is {context.tolist()} the target: {target}\")"
810 | ]
811 | },
812 | {
813 | "cell_type": "markdown",
814 | "metadata": {
815 | "application/vnd.databricks.v1+cell": {
816 | "cellMetadata": {},
817 | "inputWidgets": {},
818 | "nuid": "dde3273f-0519-4108-ba84-dfd99e020722",
819 | "showTitle": false,
820 | "title": ""
821 | },
822 | "id": "RlON_gNikRJa"
823 | },
824 | "source": [
825 | "### Understanding the intuition of Causal Scaled Dot Product Self Attention\n",
826 | "\n",
827 | "This code is borrowed from Andrej Karpathy's excellent makemore repository linked in the repo"
828 | ]
829 | },
830 | {
831 | "cell_type": "markdown",
832 | "metadata": {
833 | "application/vnd.databricks.v1+cell": {
834 | "cellMetadata": {
835 | "byteLimit": 2048000,
836 | "rowLimit": 10000
837 | },
838 | "inputWidgets": {},
839 | "nuid": "e435d0cf-1383-446a-9026-cd80b4266019",
840 | "showTitle": false,
841 | "title": ""
842 | },
843 | "id": "uBVWP40SkRJa"
844 | },
845 | "source": [
846 | "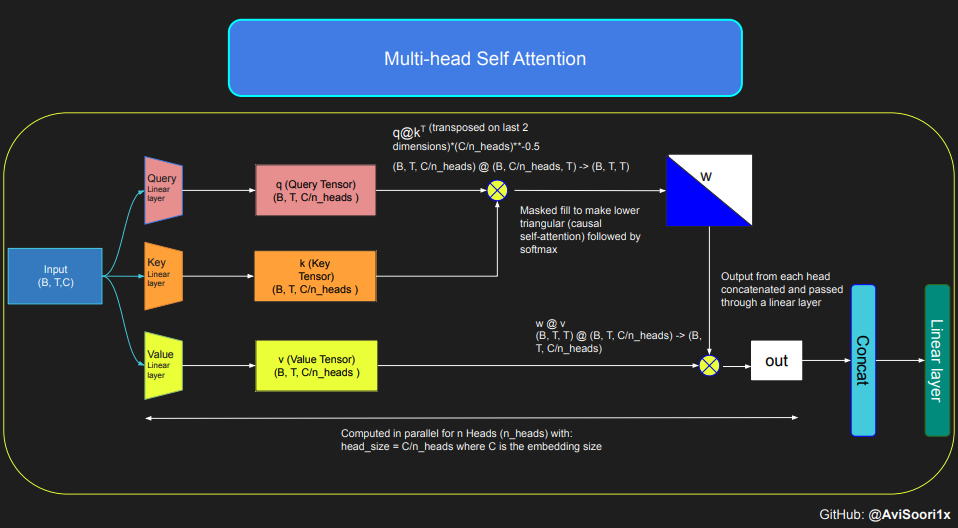"
847 | ]
848 | },
849 | {
850 | "cell_type": "markdown",
851 | "metadata": {
852 | "application/vnd.databricks.v1+cell": {
853 | "cellMetadata": {},
854 | "inputWidgets": {},
855 | "nuid": "97660589-1719-48c0-ad6f-4f7c2888348a",
856 | "showTitle": false,
857 | "title": ""
858 | },
859 | "id": "i-jFgMntkRJa"
860 | },
861 | "source": [
862 | "The provided code demonstrates self-attention's mechanics and fundamental concepts, specifically focusing on the classic scaled dot product self-attention. In this variant, the query, key, and value matrices all originate from the same input sequence. To ensure the integrity of the autoregressive language generation process, particularly in a decoder-only model, the code implements masking. This masking technique is crucial as it obscures any information following the current token's position, thereby directing the model's attention to only the preceding parts of the sequence. Such an attention mechanism is known as causal self-attention. It's important to note that the Sparse Mixture of Experts model isn't restricted to decoder-only Transformer architectures. In fact, much of the significant work in this field, particularly that by Shazeer et al, revolves around the T5 architecture, which encompasses both encoder and decoder components in the Transformer model."
863 | ]
864 | },
865 | {
866 | "cell_type": "code",
867 | "execution_count": null,
868 | "metadata": {
869 | "application/vnd.databricks.v1+cell": {
870 | "cellMetadata": {
871 | "byteLimit": 2048000,
872 | "rowLimit": 10000
873 | },
874 | "inputWidgets": {},
875 | "nuid": "6f82ca41-a301-4a92-aed9-ba7ac3a2bf88",
876 | "showTitle": false,
877 | "title": ""
878 | },
879 | "id": "lxMSgZWGkRJb",
880 | "outputId": "8d968403-a14f-4f3c-f2ce-9099a2b34f1e"
881 | },
882 | "outputs": [
883 | {
884 | "data": {
885 | "text/plain": [
886 | "torch.Size([4, 8, 16])"
887 | ]
888 | },
889 | "execution_count": 33,
890 | "metadata": {},
891 | "output_type": "execute_result"
892 | }
893 | ],
894 | "source": [
895 | "torch.manual_seed(1337)\n",
896 | "B,T,C = 4,8,32 # batch, time, channels\n",
897 | "x = torch.randn(B,T,C)\n",
898 | "\n",
899 | "# let's see a single Head perform self-attention\n",
900 | "head_size = 16\n",
901 | "key = nn.Linear(C, head_size, bias=False)\n",
902 | "query = nn.Linear(C, head_size, bias=False)\n",
903 | "value = nn.Linear(C, head_size, bias=False)\n",
904 | "k = key(x) # (B, T, 16)\n",
905 | "q = query(x) # (B, T, 16)\n",
906 | "wei = q @ k.transpose(-2, -1) # (B, T, 16) @ (B, 16, T) ---> (B, T, T)\n",
907 | "\n",
908 | "tril = torch.tril(torch.ones(T, T))\n",
909 | "#wei = torch.zeros((T,T))\n",
910 | "wei = wei.masked_fill(tril == 0, float('-inf'))\n",
911 | "wei = F.softmax(wei, dim=-1) #B,T,T\n",
912 | "\n",
913 | "v = value(x) #B,T,H\n",
914 | "out = wei @ v # (B,T,T) @ (B,T,H) -> (B,T,H)\n",
915 | "#The output from this final matrix product is subsequently passsed through a linear layer as shown in the diagram above\n",
916 | "\n",
917 | "out.shape"
918 | ]
919 | },
920 | {
921 | "cell_type": "markdown",
922 | "metadata": {
923 | "application/vnd.databricks.v1+cell": {
924 | "cellMetadata": {},
925 | "inputWidgets": {},
926 | "nuid": "49c278ec-19db-4c5d-b4a3-3bdc45c5a443",
927 | "showTitle": false,
928 | "title": ""
929 | },
930 | "id": "cA3iXggEkRJb"
931 | },
932 | "source": [
933 | "Generalizing and Modularizing code for causal self attention and multi-head causal self attention. Multi-head self attention applied multiple attention heads in parallel, each focusing on a separate section of the channel (the embedding dimension)"
934 | ]
935 | },
936 | {
937 | "cell_type": "code",
938 | "execution_count": null,
939 | "metadata": {
940 | "application/vnd.databricks.v1+cell": {
941 | "cellMetadata": {
942 | "byteLimit": 2048000,
943 | "rowLimit": 10000
944 | },
945 | "inputWidgets": {},
946 | "nuid": "608c6c9f-fb93-43ed-9580-5e782fd90d61",
947 | "showTitle": false,
948 | "title": ""
949 | },
950 | "id": "909nX3PHkRJb"
951 | },
952 | "outputs": [],
953 | "source": [
954 | "#Causal scaled dot product self-Attention Head\n",
955 | "\n",
956 | "n_embd = 64\n",
957 | "n_head = 4\n",
958 | "n_layer = 4\n",
959 | "head_size = 16\n",
960 | "dropout = 0.1\n",
961 | "\n",
962 | "class Head(nn.Module):\n",
963 | " \"\"\" one head of self-attention \"\"\"\n",
964 | "\n",
965 | " def __init__(self, head_size):\n",
966 | " super().__init__()\n",
967 | " self.key = nn.Linear(n_embd, head_size, bias=False)\n",
968 | " self.query = nn.Linear(n_embd, head_size, bias=False)\n",
969 | " self.value = nn.Linear(n_embd, head_size, bias=False)\n",
970 | " self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))\n",
971 | "\n",
972 | " self.dropout = nn.Dropout(dropout)\n",
973 | "\n",
974 | " def forward(self, x):\n",
975 | " B,T,C = x.shape\n",
976 | " k = self.key(x) # (B,T,C)\n",
977 | " q = self.query(x) # (B,T,C)\n",
978 | " # compute attention scores (\"affinities\")\n",
979 | " wei = q @ k.transpose(-2,-1) * C**-0.5 # (B, T, C) @ (B, C, T) -> (B, T, T)\n",
980 | " wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)\n",
981 | " wei = F.softmax(wei, dim=-1) # (B, T, T)\n",
982 | " wei = self.dropout(wei)\n",
983 | " # perform the weighted aggregation of the values\n",
984 | " v = self.value(x) # (B,T,C)\n",
985 | " out = wei @ v # (B, T, T) @ (B, T, C) -> (B, T, C)\n",
986 | " return out"
987 | ]
988 | },
989 | {
990 | "cell_type": "code",
991 | "execution_count": null,
992 | "metadata": {
993 | "application/vnd.databricks.v1+cell": {
994 | "cellMetadata": {
995 | "byteLimit": 2048000,
996 | "rowLimit": 10000
997 | },
998 | "inputWidgets": {},
999 | "nuid": "6e8b31af-f45a-4066-8288-fb0d9c8e2aff",
1000 | "showTitle": false,
1001 | "title": ""
1002 | },
1003 | "id": "T3MoVK_WkRJb"
1004 | },
1005 | "outputs": [],
1006 | "source": [
1007 | "#Multi-Headed Self Attention\n",
1008 | "class MultiHeadAttention(nn.Module):\n",
1009 | " \"\"\" multiple heads of self-attention in parallel \"\"\"\n",
1010 | "\n",
1011 | " def __init__(self, num_heads, head_size):\n",
1012 | " super().__init__()\n",
1013 | " self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])\n",
1014 | " self.proj = nn.Linear(n_embd, n_embd)\n",
1015 | " self.dropout = nn.Dropout(dropout)\n",
1016 | "\n",
1017 | " def forward(self, x):\n",
1018 | " out = torch.cat([h(x) for h in self.heads], dim=-1)\n",
1019 | " out = self.dropout(self.proj(out))\n",
1020 | " return out\n"
1021 | ]
1022 | },
1023 | {
1024 | "cell_type": "code",
1025 | "execution_count": null,
1026 | "metadata": {
1027 | "application/vnd.databricks.v1+cell": {
1028 | "cellMetadata": {
1029 | "byteLimit": 2048000,
1030 | "rowLimit": 10000
1031 | },
1032 | "inputWidgets": {},
1033 | "nuid": "16267e9a-008b-46e3-82ce-2ae41396a1a1",
1034 | "showTitle": false,
1035 | "title": ""
1036 | },
1037 | "id": "T-w53_mSkRJb",
1038 | "outputId": "052e4478-b284-43c7-924c-fcf13deea320"
1039 | },
1040 | "outputs": [
1041 | {
1042 | "data": {
1043 | "text/plain": [
1044 | "torch.Size([4, 8, 64])"
1045 | ]
1046 | },
1047 | "execution_count": 68,
1048 | "metadata": {},
1049 | "output_type": "execute_result"
1050 | }
1051 | ],
1052 | "source": [
1053 | "#Confirming that what's output from multi head attention is the original embedding size\n",
1054 | "B,T,C = 4,8,64 # batch, time, channels\n",
1055 | "x = torch.randn(B,T,C)\n",
1056 | "mha = MultiHeadAttention(4,16)\n",
1057 | "mha(x).shape"
1058 | ]
1059 | },
1060 | {
1061 | "cell_type": "markdown",
1062 | "metadata": {
1063 | "application/vnd.databricks.v1+cell": {
1064 | "cellMetadata": {},
1065 | "inputWidgets": {},
1066 | "nuid": "5f7ff128-7fe5-4a91-b9f2-208e2132e505",
1067 | "showTitle": false,
1068 | "title": ""
1069 | },
1070 | "id": "wNlJTtfhkRJb"
1071 | },
1072 | "source": [
1073 | "### Creating an Expert module i.e. a simple Multi Layer Perceptron"
1074 | ]
1075 | },
1076 | {
1077 | "cell_type": "markdown",
1078 | "metadata": {
1079 | "application/vnd.databricks.v1+cell": {
1080 | "cellMetadata": {},
1081 | "inputWidgets": {},
1082 | "nuid": "f6e422a5-57c1-4b2f-b7b9-2757e109848a",
1083 | "showTitle": false,
1084 | "title": ""
1085 | },
1086 | "id": "zv3fGRpbkRJb"
1087 | },
1088 | "source": [
1089 | "In the Sparse Mixture of Experts (MoE) architecture, the self-attention mechanism within each transformer block remains unchanged. However, a notable alteration occurs in the structure of each block: the standard feed-forward neural network is replaced with several sparsely activated feed-forward networks, known as experts. \"Sparse activation\" refers to the process where each token in the sequence is routed to only a limited number of these experts – typically one or two – out of the total pool available. This modification allows for specialized processing of different parts of the input data, enabling the model to handle a wider range of complexities efficiently."
1090 | ]
1091 | },
1092 | {
1093 | "cell_type": "markdown",
1094 | "metadata": {
1095 | "application/vnd.databricks.v1+cell": {
1096 | "cellMetadata": {},
1097 | "inputWidgets": {},
1098 | "nuid": "efe9fdcc-82eb-4047-9233-ad3cfe8759b1",
1099 | "showTitle": false,
1100 | "title": ""
1101 | },
1102 | "id": "7Kz0Y_P0kRJc"
1103 | },
1104 | "source": [
1105 | "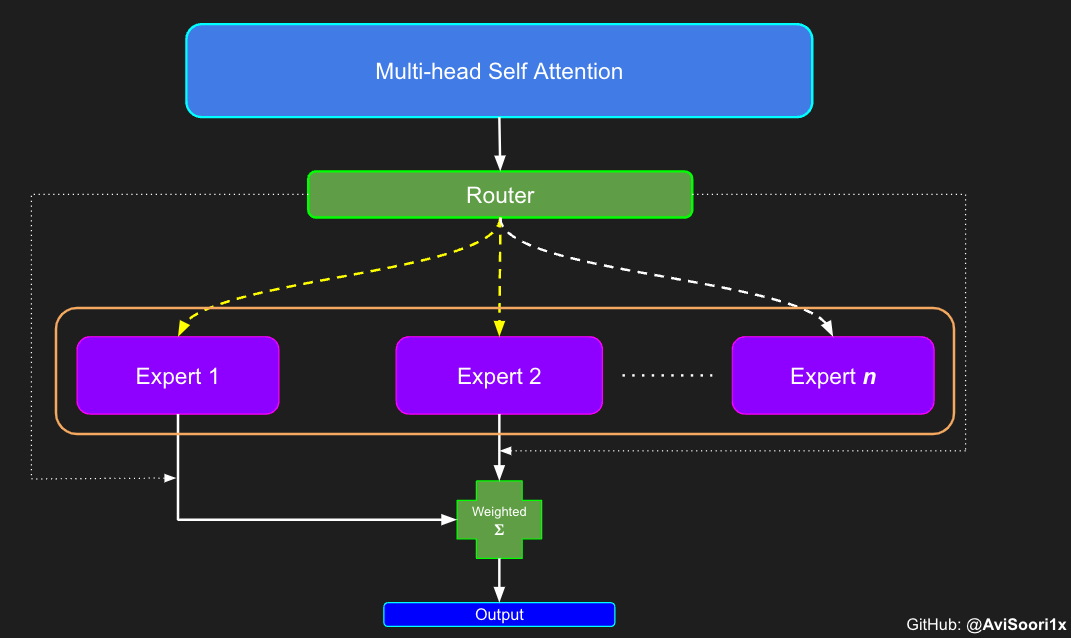"
1106 | ]
1107 | },
1108 | {
1109 | "cell_type": "code",
1110 | "execution_count": null,
1111 | "metadata": {
1112 | "application/vnd.databricks.v1+cell": {
1113 | "cellMetadata": {
1114 | "byteLimit": 2048000,
1115 | "rowLimit": 10000
1116 | },
1117 | "inputWidgets": {},
1118 | "nuid": "a2f0f382-ab4a-45e1-9dce-27ae0d3da641",
1119 | "showTitle": false,
1120 | "title": ""
1121 | },
1122 | "id": "a-9CYWXgkRJc"
1123 | },
1124 | "outputs": [],
1125 | "source": [
1126 | "#Expert module\n",
1127 | "class Expert(nn.Module):\n",
1128 | " \"\"\" An MLP is a simple linear layer followed by a non-linearity i.e. each Expert \"\"\"\n",
1129 | "\n",
1130 | " def __init__(self, n_embd):\n",
1131 | " super().__init__()\n",
1132 | " self.net = nn.Sequential(\n",
1133 | " nn.Linear(n_embd, 4 * n_embd),\n",
1134 | " nn.ReLU(),\n",
1135 | " nn.Linear(4 * n_embd, n_embd),\n",
1136 | " nn.Dropout(dropout),\n",
1137 | " )\n",
1138 | "\n",
1139 | " def forward(self, x):\n",
1140 | " return self.net(x)"
1141 | ]
1142 | },
1143 | {
1144 | "cell_type": "markdown",
1145 | "metadata": {
1146 | "application/vnd.databricks.v1+cell": {
1147 | "cellMetadata": {},
1148 | "inputWidgets": {},
1149 | "nuid": "a7764385-26e9-4d75-9aa7-ce011023e24e",
1150 | "showTitle": false,
1151 | "title": ""
1152 | },
1153 | "id": "qderdEuykRJc"
1154 | },
1155 | "source": [
1156 | "### Top-k Gating Intuition through an Example"
1157 | ]
1158 | },
1159 | {
1160 | "cell_type": "markdown",
1161 | "metadata": {
1162 | "application/vnd.databricks.v1+cell": {
1163 | "cellMetadata": {},
1164 | "inputWidgets": {},
1165 | "nuid": "d3fca4df-4c47-4e9a-98cd-08cf8ccf7726",
1166 | "showTitle": false,
1167 | "title": ""
1168 | },
1169 | "id": "VxJv5y44kRJc"
1170 | },
1171 | "source": [
1172 | "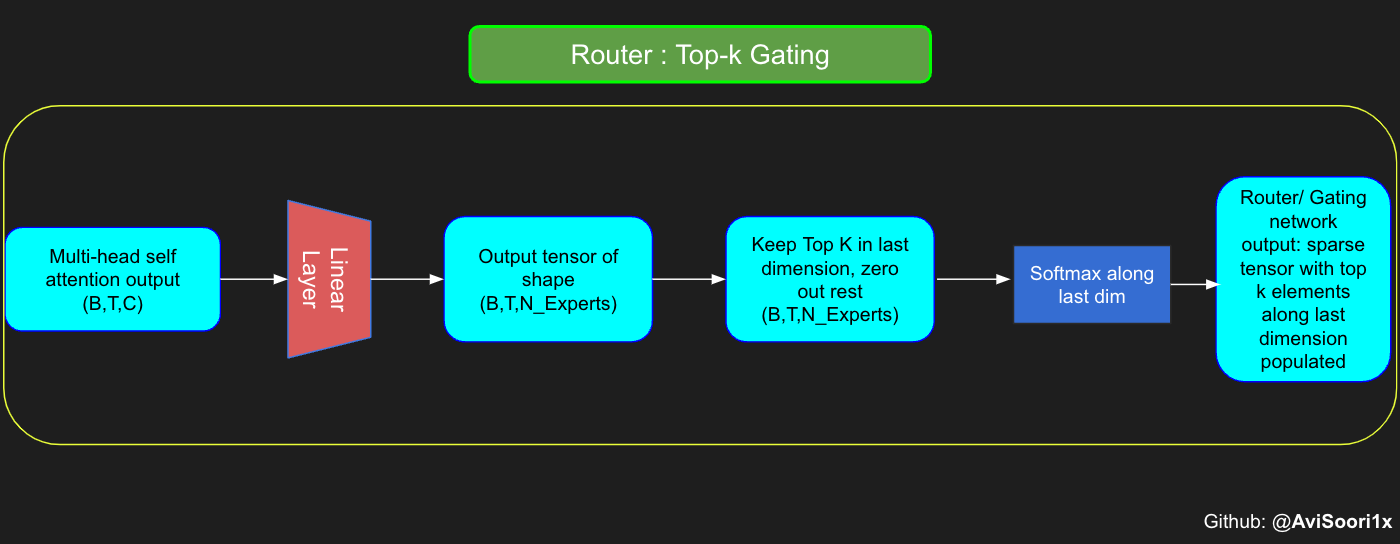"
1173 | ]
1174 | },
1175 | {
1176 | "cell_type": "markdown",
1177 | "metadata": {
1178 | "application/vnd.databricks.v1+cell": {
1179 | "cellMetadata": {},
1180 | "inputWidgets": {},
1181 | "nuid": "8e494b86-cdb2-4f2a-8824-5fa2ef4b2606",
1182 | "showTitle": false,
1183 | "title": ""
1184 | },
1185 | "id": "n6DuhY0DkRJc"
1186 | },
1187 | "source": [
1188 | "The gating network, also known as the router, determines which expert network receives the output for each token from the multi-head attention. Let's consider a simple example: suppose there are 4 experts, and the token is to be routed to the top 2 experts. Initially, we input the token into the gating network through a linear layer. This layer projects the input tensor from a shape of (2, 4, 32) — representing (Batch size, Tokens, n_embed, where n_embed is the channel dimension of the input) — to a new shape of (2, 4, 4), which corresponds to (Batch size, Tokens, num_experts), where num_experts is the count of expert networks. Following this, we determine the top k=2 highest values and their respective indices along the last dimension."
1189 | ]
1190 | },
1191 | {
1192 | "cell_type": "code",
1193 | "execution_count": null,
1194 | "metadata": {
1195 | "application/vnd.databricks.v1+cell": {
1196 | "cellMetadata": {
1197 | "byteLimit": 2048000,
1198 | "rowLimit": 10000
1199 | },
1200 | "inputWidgets": {},
1201 | "nuid": "621916ff-2290-4e2f-9fd7-5181ed98d540",
1202 | "showTitle": false,
1203 | "title": ""
1204 | },
1205 | "id": "pNAuFDDvkRJc",
1206 | "outputId": "a9d313d5-1dd1-4df8-9c9a-dc6d0b90d4ed"
1207 | },
1208 | "outputs": [
1209 | {
1210 | "data": {
1211 | "text/plain": [
1212 | "(tensor([[[ 0.0246, -0.0190],\n",
1213 | " [ 0.1991, 0.1513],\n",
1214 | " [ 0.9749, 0.7185],\n",
1215 | " [ 0.4406, -0.8357]],\n",
1216 | " \n",
1217 | " [[ 0.6206, -0.0503],\n",
1218 | " [ 0.8635, 0.3784],\n",
1219 | " [ 0.6828, 0.5972],\n",
1220 | " [ 0.4743, 0.3420]]], grad_fn=),\n",
1221 | " tensor([[[2, 3],\n",
1222 | " [2, 1],\n",
1223 | " [3, 1],\n",
1224 | " [2, 1]],\n",
1225 | " \n",
1226 | " [[0, 2],\n",
1227 | " [0, 3],\n",
1228 | " [3, 2],\n",
1229 | " [3, 0]]]))"
1230 | ]
1231 | },
1232 | "execution_count": 69,
1233 | "metadata": {},
1234 | "output_type": "execute_result"
1235 | }
1236 | ],
1237 | "source": [
1238 | "#Understanding how gating works\n",
1239 | "num_experts = 4\n",
1240 | "top_k=2\n",
1241 | "n_embed=32\n",
1242 | "\n",
1243 | "\n",
1244 | "#Example multi-head attention output for a simple illustrative example, consider n_embed=32, context_length=4 and batch_size=2\n",
1245 | "mh_output = torch.randn(2, 4, n_embed)\n",
1246 | "\n",
1247 | "topkgate_linear = nn.Linear(n_embed, num_experts) # nn.Linear(32, 4)\n",
1248 | "\n",
1249 | "logits = topkgate_linear(mh_output)\n",
1250 | "top_k_logits, top_k_indices = logits.topk(top_k, dim=-1) # Get top-k experts\n",
1251 | "top_k_logits, top_k_indices"
1252 | ]
1253 | },
1254 | {
1255 | "cell_type": "markdown",
1256 | "metadata": {
1257 | "application/vnd.databricks.v1+cell": {
1258 | "cellMetadata": {},
1259 | "inputWidgets": {},
1260 | "nuid": "0f135ff7-0aa3-4b6d-ab5e-42399c48427b",
1261 | "showTitle": false,
1262 | "title": ""
1263 | },
1264 | "id": "EKwAyJxrkRJd"
1265 | },
1266 | "source": [
1267 | "Obtain the sparse gating output by only keeping the top k values in their respective index along the last dimension. Fill the rest with '-inf' and pass through a softmax activation. This pushes '-inf' values to zero, makes the top two values more accentuated and sum to 1. This summation to 1 helps with the weighting of expert outputs"
1268 | ]
1269 | },
1270 | {
1271 | "cell_type": "code",
1272 | "execution_count": null,
1273 | "metadata": {
1274 | "application/vnd.databricks.v1+cell": {
1275 | "cellMetadata": {
1276 | "byteLimit": 2048000,
1277 | "rowLimit": 10000
1278 | },
1279 | "inputWidgets": {},
1280 | "nuid": "735e160a-ef1e-424d-b6d9-09f63ea99ec1",
1281 | "showTitle": false,
1282 | "title": ""
1283 | },
1284 | "id": "IiVejzOpkRJd",
1285 | "outputId": "2ff61217-56f8-4835-d310-2169240fb4a1"
1286 | },
1287 | "outputs": [
1288 | {
1289 | "data": {
1290 | "text/plain": [
1291 | "tensor([[[ -inf, -inf, 0.0246, -0.0190],\n",
1292 | " [ -inf, 0.1513, 0.1991, -inf],\n",
1293 | " [ -inf, 0.7185, -inf, 0.9749],\n",
1294 | " [ -inf, -0.8357, 0.4406, -inf]],\n",
1295 | "\n",
1296 | " [[ 0.6206, -inf, -0.0503, -inf],\n",
1297 | " [ 0.8635, -inf, -inf, 0.3784],\n",
1298 | " [ -inf, -inf, 0.5972, 0.6828],\n",
1299 | " [ 0.3420, -inf, -inf, 0.4743]]], grad_fn=)"
1300 | ]
1301 | },
1302 | "execution_count": 70,
1303 | "metadata": {},
1304 | "output_type": "execute_result"
1305 | }
1306 | ],
1307 | "source": [
1308 | "zeros = torch.full_like(logits, float('-inf')) #full_like clones a tensor and fills it with a specified value (like infinity) for masking or calculations.\n",
1309 | "sparse_logits = zeros.scatter(-1, top_k_indices, top_k_logits)\n",
1310 | "sparse_logits"
1311 | ]
1312 | },
1313 | {
1314 | "cell_type": "code",
1315 | "execution_count": null,
1316 | "metadata": {
1317 | "application/vnd.databricks.v1+cell": {
1318 | "cellMetadata": {
1319 | "byteLimit": 2048000,
1320 | "rowLimit": 10000
1321 | },
1322 | "inputWidgets": {},
1323 | "nuid": "9146e6f9-4eee-4a8b-8338-55072719ed59",
1324 | "showTitle": false,
1325 | "title": ""
1326 | },
1327 | "id": "HFgRxDF4kRJh",
1328 | "outputId": "cde71bbf-ba67-4972-eef1-2fba48a106d5"
1329 | },
1330 | "outputs": [
1331 | {
1332 | "data": {
1333 | "text/plain": [
1334 | "tensor([[[0.0000, 0.0000, 0.5109, 0.4891],\n",
1335 | " [0.0000, 0.4881, 0.5119, 0.0000],\n",
1336 | " [0.0000, 0.4362, 0.0000, 0.5638],\n",
1337 | " [0.0000, 0.2182, 0.7818, 0.0000]],\n",
1338 | "\n",
1339 | " [[0.6617, 0.0000, 0.3383, 0.0000],\n",
1340 | " [0.6190, 0.0000, 0.0000, 0.3810],\n",
1341 | " [0.0000, 0.0000, 0.4786, 0.5214],\n",
1342 | " [0.4670, 0.0000, 0.0000, 0.5330]]], grad_fn=)"
1343 | ]
1344 | },
1345 | "execution_count": 71,
1346 | "metadata": {},
1347 | "output_type": "execute_result"
1348 | }
1349 | ],
1350 | "source": [
1351 | "gating_output= F.softmax(sparse_logits, dim=-1)\n",
1352 | "gating_output"
1353 | ]
1354 | },
1355 | {
1356 | "cell_type": "markdown",
1357 | "metadata": {
1358 | "application/vnd.databricks.v1+cell": {
1359 | "cellMetadata": {},
1360 | "inputWidgets": {},
1361 | "nuid": "fe558b12-e443-4b62-9a85-c59120456352",
1362 | "showTitle": false,
1363 | "title": ""
1364 | },
1365 | "id": "dGJrq2uqkRJh"
1366 | },
1367 | "source": [
1368 | "### Generalizing and Modularizing above code and adding noisy top-k Gating for load balancing"
1369 | ]
1370 | },
1371 | {
1372 | "cell_type": "code",
1373 | "execution_count": null,
1374 | "metadata": {
1375 | "application/vnd.databricks.v1+cell": {
1376 | "cellMetadata": {
1377 | "byteLimit": 2048000,
1378 | "rowLimit": 10000
1379 | },
1380 | "inputWidgets": {},
1381 | "nuid": "45516b59-d814-4853-a34e-d36aae9f04eb",
1382 | "showTitle": false,
1383 | "title": ""
1384 | },
1385 | "id": "TKp4DqwYkRJh"
1386 | },
1387 | "outputs": [],
1388 | "source": [
1389 | "# First define the top k router module\n",
1390 | "class TopkRouter(nn.Module):\n",
1391 | " def __init__(self, n_embed, num_experts, top_k):\n",
1392 | " super(TopkRouter, self).__init__()\n",
1393 | " self.top_k = top_k\n",
1394 | " self.linear =nn.Linear(n_embed, num_experts)\n",
1395 | "\n",
1396 | " def forward(self, mh_ouput):\n",
1397 | " # mh_ouput is the output tensor from multihead self attention block\n",
1398 | " logits = self.linear(mh_output)\n",
1399 | " top_k_logits, indices = logits.topk(self.top_k, dim=-1)\n",
1400 | " zeros = torch.full_like(logits, float('-inf'))\n",
1401 | " sparse_logits = zeros.scatter(-1, indices, top_k_logits)\n",
1402 | " router_output = F.softmax(sparse_logits, dim=-1)\n",
1403 | " return router_output, indices\n",
1404 | "\n"
1405 | ]
1406 | },
1407 | {
1408 | "cell_type": "code",
1409 | "execution_count": null,
1410 | "metadata": {
1411 | "application/vnd.databricks.v1+cell": {
1412 | "cellMetadata": {
1413 | "byteLimit": 2048000,
1414 | "rowLimit": 10000
1415 | },
1416 | "inputWidgets": {},
1417 | "nuid": "c500844f-0866-4bbf-acef-c0c1d4979721",
1418 | "showTitle": false,
1419 | "title": ""
1420 | },
1421 | "id": "KjkouzwkkRJh",
1422 | "outputId": "4e5cd861-4f75-4e98-c3cf-5697fb5f7451"
1423 | },
1424 | "outputs": [
1425 | {
1426 | "data": {
1427 | "text/plain": [
1428 | "(torch.Size([2, 4, 4]),\n",
1429 | " tensor([[[0.4359, 0.0000, 0.5641, 0.0000],\n",
1430 | " [0.6075, 0.0000, 0.3925, 0.0000],\n",
1431 | " [0.6916, 0.3084, 0.0000, 0.0000],\n",
1432 | " [0.0000, 0.0000, 0.4342, 0.5658]],\n",
1433 | " \n",
1434 | " [[0.0000, 0.4527, 0.5473, 0.0000],\n",
1435 | " [0.5313, 0.4687, 0.0000, 0.0000],\n",
1436 | " [0.0000, 0.5572, 0.4428, 0.0000],\n",
1437 | " [0.0000, 0.6293, 0.3707, 0.0000]]], grad_fn=),\n",
1438 | " tensor([[[2, 0],\n",
1439 | " [0, 2],\n",
1440 | " [0, 1],\n",
1441 | " [3, 2]],\n",
1442 | " \n",
1443 | " [[2, 1],\n",
1444 | " [0, 1],\n",
1445 | " [1, 2],\n",
1446 | " [1, 2]]]))"
1447 | ]
1448 | },
1449 | "execution_count": 72,
1450 | "metadata": {},
1451 | "output_type": "execute_result"
1452 | }
1453 | ],
1454 | "source": [
1455 | "#Testing this out:\n",
1456 | "num_experts = 4\n",
1457 | "top_k = 2\n",
1458 | "n_embd = 32\n",
1459 | "\n",
1460 | "mh_output = torch.randn(2, 4, n_embd) # Example input\n",
1461 | "top_k_gate = TopkRouter(n_embd, num_experts, top_k)\n",
1462 | "gating_output, indices = top_k_gate(mh_output)\n",
1463 | "gating_output.shape, gating_output, indices\n",
1464 | "#And it works!!"
1465 | ]
1466 | },
1467 | {
1468 | "cell_type": "markdown",
1469 | "metadata": {
1470 | "application/vnd.databricks.v1+cell": {
1471 | "cellMetadata": {},
1472 | "inputWidgets": {},
1473 | "nuid": "9fa02d0c-3688-4d01-811d-d0b2b851ab33",
1474 | "showTitle": false,
1475 | "title": ""
1476 | },
1477 | "id": "tAouN-GwkRJi"
1478 | },
1479 | "source": [
1480 | "Althought the mixtral paper released recently does not make any mention of it, I believe Noisy top-k Gating is an important tool in training MoE models. Essentially, you don't want all the tokens to be sent to the same set of 'favored' experts. You want a fine balance of exploitation and exploration. For this purpose, to load balance, it is helpful to add standard normal noise to the logits from the gating linear layer. This makes training more efficient"
1481 | ]
1482 | },
1483 | {
1484 | "cell_type": "markdown",
1485 | "metadata": {
1486 | "application/vnd.databricks.v1+cell": {
1487 | "cellMetadata": {},
1488 | "inputWidgets": {},
1489 | "nuid": "e05b3306-b89f-4ebc-901b-f16398a925c2",
1490 | "showTitle": false,
1491 | "title": ""
1492 | },
1493 | "id": "aWeueE83kRJi"
1494 | },
1495 | "source": [
1496 | "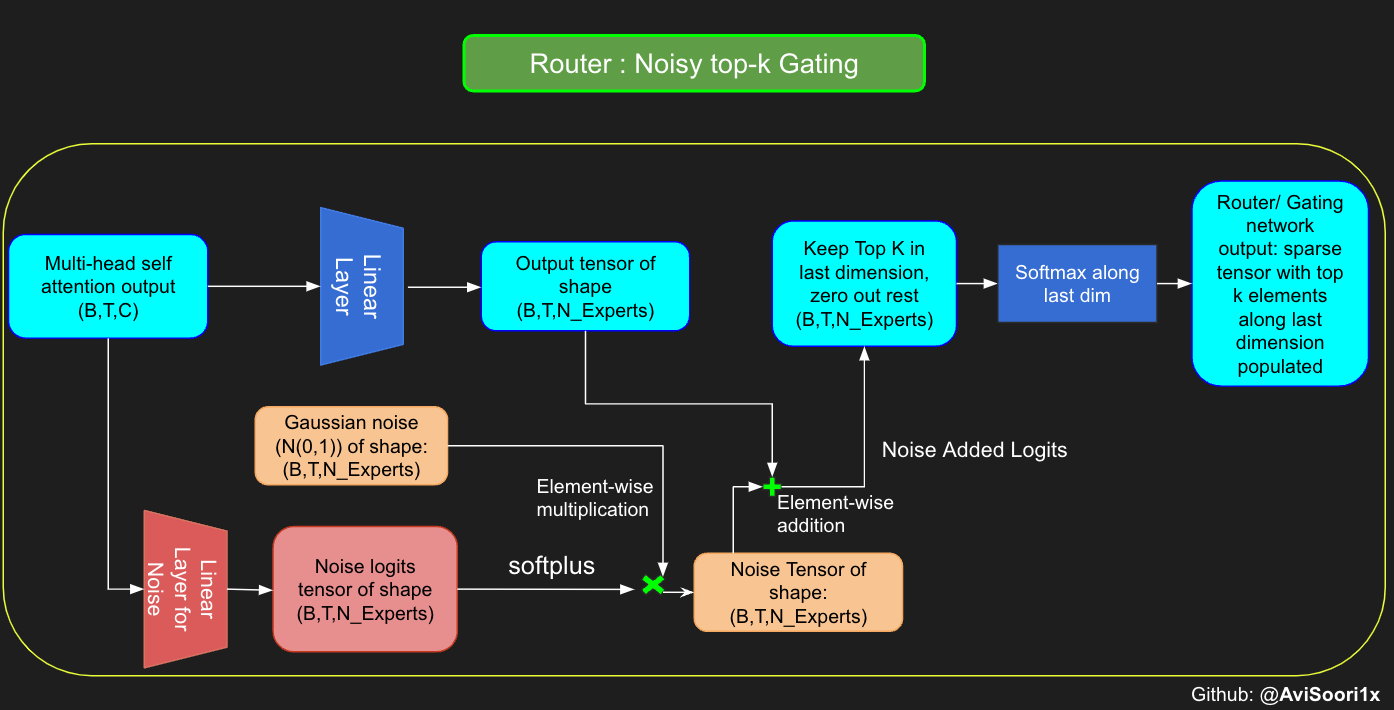"
1497 | ]
1498 | },
1499 | {
1500 | "cell_type": "code",
1501 | "execution_count": null,
1502 | "metadata": {
1503 | "application/vnd.databricks.v1+cell": {
1504 | "cellMetadata": {
1505 | "byteLimit": 2048000,
1506 | "rowLimit": 10000
1507 | },
1508 | "inputWidgets": {},
1509 | "nuid": "dda4d805-373c-48f7-9037-da08fbc06e64",
1510 | "showTitle": false,
1511 | "title": ""
1512 | },
1513 | "id": "ZBrN-w3JkRJi"
1514 | },
1515 | "outputs": [],
1516 | "source": [
1517 | "#Changing the above to accomodate noisy top-k gating\n",
1518 | "class NoisyTopkRouter(nn.Module):\n",
1519 | " def __init__(self, n_embed, num_experts, top_k):\n",
1520 | " super(NoisyTopkRouter, self).__init__()\n",
1521 | " self.top_k = top_k\n",
1522 | " #layer for router logits\n",
1523 | " self.topkroute_linear = nn.Linear(n_embed, num_experts)\n",
1524 | " self.noise_linear =nn.Linear(n_embed, num_experts)\n",
1525 | "\n",
1526 | "\n",
1527 | " def forward(self, mh_output):\n",
1528 | " # mh_ouput is the output tensor from multihead self attention block\n",
1529 | " logits = self.topkroute_linear(mh_output)\n",
1530 | "\n",
1531 | " #Noise logits\n",
1532 | " noise_logits = self.noise_linear(mh_output)\n",
1533 | "\n",
1534 | " #Adding scaled unit gaussian noise to the logits\n",
1535 | " noise = torch.randn_like(logits)*F.softplus(noise_logits)\n",
1536 | " noisy_logits = logits + noise\n",
1537 | "\n",
1538 | " top_k_logits, indices = noisy_logits.topk(self.top_k, dim=-1)\n",
1539 | " zeros = torch.full_like(noisy_logits, float('-inf'))\n",
1540 | " sparse_logits = zeros.scatter(-1, indices, top_k_logits)\n",
1541 | " router_output = F.softmax(sparse_logits, dim=-1)\n",
1542 | " return router_output, indices"
1543 | ]
1544 | },
1545 | {
1546 | "cell_type": "code",
1547 | "execution_count": null,
1548 | "metadata": {
1549 | "application/vnd.databricks.v1+cell": {
1550 | "cellMetadata": {
1551 | "byteLimit": 2048000,
1552 | "rowLimit": 10000
1553 | },
1554 | "inputWidgets": {},
1555 | "nuid": "a01a9d6b-fedb-427d-b0da-c3b2a75a8643",
1556 | "showTitle": false,
1557 | "title": ""
1558 | },
1559 | "id": "7Q6KcH9AkRJi",
1560 | "outputId": "7aea5328-ba96-4c98-b550-042ecf440700"
1561 | },
1562 | "outputs": [
1563 | {
1564 | "data": {
1565 | "text/plain": [
1566 | "(torch.Size([2, 4, 8]),\n",
1567 | " tensor([[[0.0000, 0.0000, 0.0000, 0.5903, 0.0000, 0.0000, 0.0000, 0.4097],\n",
1568 | " [0.6794, 0.0000, 0.0000, 0.0000, 0.0000, 0.3206, 0.0000, 0.0000],\n",
1569 | " [0.0000, 0.0000, 0.0000, 0.0000, 0.2743, 0.7257, 0.0000, 0.0000],\n",
1570 | " [0.0000, 0.0000, 0.1950, 0.0000, 0.8050, 0.0000, 0.0000, 0.0000]],\n",
1571 | " \n",
1572 | " [[0.0000, 0.0000, 0.3905, 0.0000, 0.0000, 0.6095, 0.0000, 0.0000],\n",
1573 | " [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.3606, 0.6394],\n",
1574 | " [0.5243, 0.0000, 0.4757, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],\n",
1575 | " [0.0000, 0.0000, 0.0000, 0.5627, 0.0000, 0.0000, 0.4373, 0.0000]]],\n",
1576 | " grad_fn=),\n",
1577 | " tensor([[[3, 7],\n",
1578 | " [0, 5],\n",
1579 | " [5, 4],\n",
1580 | " [4, 2]],\n",
1581 | " \n",
1582 | " [[5, 2],\n",
1583 | " [7, 6],\n",
1584 | " [0, 2],\n",
1585 | " [3, 6]]]))"
1586 | ]
1587 | },
1588 | "execution_count": 53,
1589 | "metadata": {},
1590 | "output_type": "execute_result"
1591 | }
1592 | ],
1593 | "source": [
1594 | "#Testing this out, again:\n",
1595 | "num_experts = 8\n",
1596 | "top_k = 2\n",
1597 | "n_embd = 16\n",
1598 | "\n",
1599 | "mh_output = torch.randn(2, 4, n_embd) # Example input\n",
1600 | "noisy_top_k_gate = NoisyTopkRouter(n_embd, num_experts, top_k)\n",
1601 | "gating_output, indices = noisy_top_k_gate(mh_output)\n",
1602 | "gating_output.shape, gating_output, indices\n",
1603 | "#It works!!"
1604 | ]
1605 | },
1606 | {
1607 | "cell_type": "markdown",
1608 | "metadata": {
1609 | "application/vnd.databricks.v1+cell": {
1610 | "cellMetadata": {},
1611 | "inputWidgets": {},
1612 | "nuid": "076fa004-a165-42a7-b729-0bca8ad39418",
1613 | "showTitle": false,
1614 | "title": ""
1615 | },
1616 | "id": "XyKjpR-dkRJi"
1617 | },
1618 | "source": [
1619 | "\n",
1620 | "### Creating a sparse Mixture of Experts module\n"
1621 | ]
1622 | },
1623 | {
1624 | "cell_type": "markdown",
1625 | "metadata": {
1626 | "application/vnd.databricks.v1+cell": {
1627 | "cellMetadata": {},
1628 | "inputWidgets": {},
1629 | "nuid": "6747b8de-0086-4cb0-8fbd-46ee95457eb9",
1630 | "showTitle": false,
1631 | "title": ""
1632 | },
1633 | "id": "UsRCy7i3kRJi"
1634 | },
1635 | "source": [
1636 | "The primary aspect of this process involves the gating network's output. After acquiring these results, the top k values are selectively multiplied with the outputs from the corresponding top-k experts for a given token. This selective multiplication forms a weighted sum, which constitutes the SparseMoe block's output. The critical and challenging part of this process is to avoid unnecessary multiplications. It's essential to conduct forward passes only for the top_k experts and then compute this weighted sum. Performing forward passes for each expert would defeat the purpose of employing a sparse MoE, as it would no longer be sparse."
1637 | ]
1638 | },
1639 | {
1640 | "cell_type": "code",
1641 | "execution_count": null,
1642 | "metadata": {
1643 | "application/vnd.databricks.v1+cell": {
1644 | "cellMetadata": {
1645 | "byteLimit": 2048000,
1646 | "rowLimit": 10000
1647 | },
1648 | "inputWidgets": {},
1649 | "nuid": "d6809b3f-4be9-4859-b39e-24fcdd6c8d86",
1650 | "showTitle": false,
1651 | "title": ""
1652 | },
1653 | "id": "7dDUHU_IkRJi"
1654 | },
1655 | "outputs": [],
1656 | "source": [
1657 | "class SparseMoE(nn.Module):\n",
1658 | " def __init__(self, n_embed, num_experts, top_k):\n",
1659 | " super(SparseMoE, self).__init__()\n",
1660 | " self.router = NoisyTopkRouter(n_embed, num_experts, top_k)\n",
1661 | " self.experts = nn.ModuleList([Expert(n_embed) for _ in range(num_experts)])\n",
1662 | " self.top_k = top_k\n",
1663 | "\n",
1664 | " def forward(self, x):\n",
1665 | " gating_output, indices = self.router(x)\n",
1666 | " final_output = torch.zeros_like(x)\n",
1667 | "\n",
1668 | " # Reshape inputs for batch processing\n",
1669 | " flat_x = x.view(-1, x.size(-1))\n",
1670 | " flat_gating_output = gating_output.view(-1, gating_output.size(-1))\n",
1671 | "\n",
1672 | " # Process each expert in parallel\n",
1673 | " for i, expert in enumerate(self.experts):\n",
1674 | " # Create a mask for the inputs where the current expert is in top-k\n",
1675 | " expert_mask = (indices == i).any(dim=-1)\n",
1676 | " flat_mask = expert_mask.view(-1)\n",
1677 | "\n",
1678 | " if flat_mask.any():\n",
1679 | " expert_input = flat_x[flat_mask]\n",
1680 | " expert_output = expert(expert_input)\n",
1681 | "\n",
1682 | " # Extract and apply gating scores\n",
1683 | " gating_scores = flat_gating_output[flat_mask, i].unsqueeze(1)\n",
1684 | " weighted_output = expert_output * gating_scores\n",
1685 | "\n",
1686 | " # Update final output additively by indexing and adding\n",
1687 | " final_output[expert_mask] += weighted_output.squeeze(1)\n",
1688 | "\n",
1689 | " return final_output\n",
1690 | "\n",
1691 | "\n"
1692 | ]
1693 | },
1694 | {
1695 | "cell_type": "code",
1696 | "execution_count": null,
1697 | "metadata": {
1698 | "application/vnd.databricks.v1+cell": {
1699 | "cellMetadata": {
1700 | "byteLimit": 2048000,
1701 | "rowLimit": 10000
1702 | },
1703 | "inputWidgets": {},
1704 | "nuid": "06239630-0a1c-47c9-976c-7770f3d82e18",
1705 | "showTitle": false,
1706 | "title": ""
1707 | },
1708 | "id": "q8kDLI1ukRJj",
1709 | "outputId": "69e7b330-cd47-4094-99c2-7928f8b60d0d"
1710 | },
1711 | "outputs": [
1712 | {
1713 | "name": "stdout",
1714 | "output_type": "stream",
1715 | "text": [
1716 | "Shape of the final output: torch.Size([4, 8, 16])\n",
1717 | "tensor([[[-0.0124, -0.0000, -0.0108, -0.0143, -0.0194, 0.0898, -0.0572,\n",
1718 | " -0.0453, 0.0351, -0.0658, 0.0853, -0.1535, 0.1538, 0.0340,\n",
1719 | " -0.0605, -0.0227],\n",
1720 | " [-0.1214, 0.0766, -0.0763, -0.0457, 0.0166, -0.0268, -0.0185,\n",
1721 | " 0.1372, -0.1202, -0.1757, 0.1136, 0.0000, -0.2136, -0.2425,\n",
1722 | " 0.0288, 0.0558],\n",
1723 | " [-0.0000, 0.2654, 0.0843, 0.0458, 0.2352, 0.2606, -0.1340,\n",
1724 | " -0.0359, 0.0971, -0.0165, -0.0690, 0.0838, -0.2352, -0.0203,\n",
1725 | " 0.3269, -0.1147],\n",
1726 | " [-0.0240, -0.0332, 0.1032, 0.0554, 0.0276, -0.0000, 0.0204,\n",
1727 | " -0.0719, 0.1320, -0.1036, 0.0562, 0.0419, 0.0832, -0.2330,\n",
1728 | " -0.0000, -0.0260],\n",
1729 | " [-0.1457, 0.2298, 0.2523, 0.3260, 0.0813, -0.1724, 0.2074,\n",
1730 | " -0.0335, 0.1967, -0.0120, -0.0000, 0.0296, -0.0000, 0.2665,\n",
1731 | " 0.0430, 0.1385],\n",
1732 | " [-0.0000, -0.0434, 0.1454, -0.0459, 0.0238, -0.0000, -0.0702,\n",
1733 | " -0.0082, -0.0920, -0.0000, -0.0085, 0.0000, -0.2530, -0.4184,\n",
1734 | " -0.1274, 0.0950],\n",
1735 | " [-0.0546, 0.0944, 0.2003, 0.1041, 0.0753, -0.0000, 0.0733,\n",
1736 | " -0.0000, 0.0678, 0.0014, -0.0723, -0.0742, 0.0435, -0.0637,\n",
1737 | " 0.0122, 0.0000],\n",
1738 | " [ 0.0446, 0.0268, -0.0366, 0.1081, -0.0579, -0.1137, 0.0549,\n",
1739 | " 0.0162, 0.0200, -0.0445, -0.0532, 0.1075, -0.0230, 0.1296,\n",
1740 | " -0.1638, 0.0537]],\n",
1741 | "\n",
1742 | " [[-0.0390, -0.0269, 0.1131, -0.0722, 0.1846, -0.0380, -0.1055,\n",
1743 | " -0.0782, 0.1396, 0.0696, -0.0958, 0.0161, -0.0769, -0.1703,\n",
1744 | " -0.0732, -0.0180],\n",
1745 | " [-0.1349, 0.2449, -0.1247, -0.0149, 0.0774, -0.0732, 0.0755,\n",
1746 | " -0.0000, 0.0900, -0.1598, -0.1198, -0.0007, -0.0159, -0.2708,\n",
1747 | " -0.0636, -0.0289],\n",
1748 | " [ 0.0368, 0.0000, -0.1293, -0.0336, 0.0515, -0.0790, 0.0472,\n",
1749 | " -0.0830, 0.0000, -0.0521, -0.1743, -0.0205, 0.0320, -0.1011,\n",
1750 | " 0.0055, -0.0228],\n",
1751 | " [ 0.0993, -0.0521, 0.2786, -0.0304, -0.0000, 0.1973, -0.0000,\n",
1752 | " 0.0400, 0.0748, -0.1042, -0.3078, 0.0385, -0.2545, 0.3172,\n",
1753 | " -0.3621, -0.0708],\n",
1754 | " [ 0.0000, 0.1344, 0.0696, -0.2714, -0.1912, 0.0044, -0.1503,\n",
1755 | " -0.0262, 0.0000, -0.0136, -0.0329, -0.4539, 0.0990, 0.2285,\n",
1756 | " -0.3197, 0.0112],\n",
1757 | " [-0.1248, 0.1747, -0.1317, -0.1361, -0.0093, -0.0505, 0.0239,\n",
1758 | " -0.0009, -0.1792, 0.0079, 0.1453, -0.1140, -0.2461, -0.0000,\n",
1759 | " 0.1578, 0.1527],\n",
1760 | " [-0.2012, 0.2509, -0.0933, -0.0000, 0.1976, -0.1527, -0.0379,\n",
1761 | " 0.3109, -0.2121, 0.0012, 0.3155, 0.1832, -0.0000, -0.4221,\n",
1762 | " 0.2019, 0.1104],\n",
1763 | " [-0.1177, -0.1666, -0.0471, -0.0000, 0.0864, 0.1395, -0.1160,\n",
1764 | " 0.0994, -0.0007, 0.0159, 0.1186, 0.0068, -0.1566, -0.1419,\n",
1765 | " -0.0000, -0.1168]],\n",
1766 | "\n",
1767 | " [[-0.1889, -0.1712, -0.0252, 0.0000, 0.1354, 0.0078, -0.3176,\n",
1768 | " -0.0588, 0.0764, 0.1522, -0.1602, 0.2140, -0.1569, -0.0161,\n",
1769 | " 0.0060, -0.2089],\n",
1770 | " [-0.0592, -0.1243, -0.0000, -0.1623, 0.0841, -0.0263, -0.0239,\n",
1771 | " 0.2556, 0.2700, 0.0405, 0.0842, -0.0692, -0.0505, 0.0000,\n",
1772 | " -0.4926, 0.1858],\n",
1773 | " [ 0.0551, -0.0318, 0.0195, -0.0098, -0.0351, -0.0271, 0.0646,\n",
1774 | " 0.0014, 0.0169, -0.0162, -0.0135, 0.0070, 0.0116, -0.0627,\n",
1775 | " -0.0154, 0.0733],\n",
1776 | " [-0.1270, 0.3063, -0.1849, 0.0446, -0.0512, 0.0783, -0.0440,\n",
1777 | " 0.1640, 0.1924, -0.1780, 0.0000, -0.0520, -0.0187, -0.0196,\n",
1778 | " 0.3640, -0.0000],\n",
1779 | " [ 0.0000, 0.0442, 0.1172, 0.0441, -0.0102, 0.0660, 0.0529,\n",
1780 | " -0.1618, 0.1265, 0.0812, -0.1357, -0.0991, -0.0341, 0.1885,\n",
1781 | " -0.0000, -0.0753],\n",
1782 | " [ 0.0524, 0.2439, -0.1062, -0.1822, 0.1625, -0.0000, 0.2078,\n",
1783 | " 0.1900, 0.1585, -0.1435, 0.1644, 0.0843, 0.0162, 0.0000,\n",
1784 | " 0.0924, 0.1394],\n",
1785 | " [-0.0000, -0.0693, 0.0000, -0.1409, -0.0603, 0.0282, 0.1201,\n",
1786 | " -0.2591, -0.1273, -0.1428, 0.0000, -0.0790, 0.0134, -0.1038,\n",
1787 | " 0.0461, 0.1344],\n",
1788 | " [-0.1980, -0.0087, 0.0991, -0.0000, -0.2497, -0.1385, -0.0985,\n",
1789 | " 0.0974, -0.4163, -0.1940, -0.1078, 0.0458, -0.2890, -0.2785,\n",
1790 | " -0.1109, 0.1543]],\n",
1791 | "\n",
1792 | " [[-0.0324, 0.0557, -0.0000, -0.1034, 0.1203, 0.0427, -0.0242,\n",
1793 | " 0.0000, -0.1433, -0.0120, 0.1024, -0.0855, -0.0474, -0.0702,\n",
1794 | " 0.0556, 0.0727],\n",
1795 | " [ 0.1194, -0.0000, 0.0720, -0.0555, -0.1901, -0.4236, 0.0438,\n",
1796 | " 0.1632, 0.1087, 0.0192, -0.0385, 0.0332, -0.0000, 0.0847,\n",
1797 | " 0.1672, 0.1100],\n",
1798 | " [-0.0620, -0.0724, 0.0220, -0.0000, -0.0757, -0.0936, 0.0000,\n",
1799 | " 0.0757, -0.0122, -0.1435, -0.0289, 0.0000, -0.0816, -0.0648,\n",
1800 | " -0.0638, 0.0208],\n",
1801 | " [-0.1030, 0.1554, 0.1701, 0.2989, 0.0000, -0.0722, 0.1687,\n",
1802 | " -0.1795, -0.0000, -0.0000, -0.0096, -0.2642, -0.2379, 0.1062,\n",
1803 | " -0.1318, 0.3303],\n",
1804 | " [-0.0768, 0.1000, 0.0917, -0.0479, -0.0475, 0.0435, 0.1054,\n",
1805 | " 0.0197, 0.1609, -0.0499, -0.2033, 0.0000, 0.0201, 0.1276,\n",
1806 | " -0.0000, -0.0724],\n",
1807 | " [ 0.0046, 0.0318, 0.0000, -0.2774, -0.0000, -0.1755, -0.0641,\n",
1808 | " -0.0596, 0.0422, 0.0099, 0.0066, -0.1313, -0.0019, 0.1601,\n",
1809 | " -0.1242, 0.0000],\n",
1810 | " [-0.0234, 0.3237, 0.0500, 0.0302, -0.1091, -0.0000, 0.0154,\n",
1811 | " -0.0177, -0.0602, -0.4930, -0.1593, -0.1109, -0.0000, 0.1590,\n",
1812 | " 0.0000, -0.1682],\n",
1813 | " [-0.1681, -0.1363, 0.0161, -0.0556, 0.0000, -0.1762, -0.0621,\n",
1814 | " 0.0830, -0.0099, -0.0000, 0.0494, -0.0318, -0.0597, 0.0600,\n",
1815 | " 0.0852, 0.0050]]], grad_fn=)\n"
1816 | ]
1817 | }
1818 | ],
1819 | "source": [
1820 | "import torch\n",
1821 | "import torch.nn as nn\n",
1822 | "\n",
1823 | "#Let's test this out\n",
1824 | "num_experts = 8\n",
1825 | "top_k = 2\n",
1826 | "n_embd = 16\n",
1827 | "dropout=0.1\n",
1828 | "\n",
1829 | "mh_output = torch.randn(4, 8, n_embd) # Example multi-head attention output\n",
1830 | "sparse_moe = SparseMoE(n_embd, num_experts, top_k)\n",
1831 | "final_output = sparse_moe(mh_output)\n",
1832 | "print(\"Shape of the final output:\", final_output.shape)\n",
1833 | "print(final_output)"
1834 | ]
1835 | },
1836 | {
1837 | "cell_type": "markdown",
1838 | "metadata": {
1839 | "application/vnd.databricks.v1+cell": {
1840 | "cellMetadata": {},
1841 | "inputWidgets": {},
1842 | "nuid": "7476ca07-a315-4108-aa77-46173a703ca2",
1843 | "showTitle": false,
1844 | "title": ""
1845 | },
1846 | "id": "l7GoxCi2kRJj"
1847 | },
1848 | "source": [
1849 | "To emphasize, it's important to recognize that the magnitudes of the top_k experts output from the Router/ gating network, as illustrated in the code above, are also significant. These top_k indices identify the experts that are activated, and the magnitude of the values in those top_k dimensions determines their respective weighting. This concept of weighted summation is further highlighted in the diagram below."
1850 | ]
1851 | },
1852 | {
1853 | "cell_type": "markdown",
1854 | "metadata": {
1855 | "application/vnd.databricks.v1+cell": {
1856 | "cellMetadata": {},
1857 | "inputWidgets": {},
1858 | "nuid": "d99b5dce-301e-4380-8263-b5cfb4136ab2",
1859 | "showTitle": false,
1860 | "title": ""
1861 | },
1862 | "id": "e9a_oQ2akRJj"
1863 | },
1864 | "source": [
1865 | "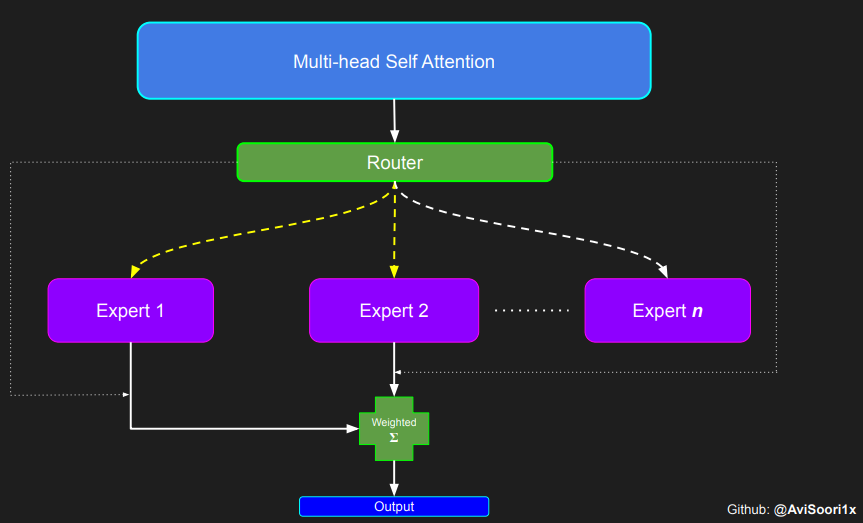"
1866 | ]
1867 | },
1868 | {
1869 | "cell_type": "markdown",
1870 | "metadata": {
1871 | "application/vnd.databricks.v1+cell": {
1872 | "cellMetadata": {},
1873 | "inputWidgets": {},
1874 | "nuid": "da5f3be4-f155-4d6c-bcbd-2f88a088261f",
1875 | "showTitle": false,
1876 | "title": ""
1877 | },
1878 | "id": "vMZCda7dkRJj"
1879 | },
1880 | "source": [
1881 | "### Putting it all together"
1882 | ]
1883 | },
1884 | {
1885 | "cell_type": "code",
1886 | "execution_count": null,
1887 | "metadata": {
1888 | "application/vnd.databricks.v1+cell": {
1889 | "cellMetadata": {
1890 | "byteLimit": 2048000,
1891 | "rowLimit": 10000
1892 | },
1893 | "inputWidgets": {},
1894 | "nuid": "0eaf71cd-c77e-40c7-b5be-e364e91685cf",
1895 | "showTitle": false,
1896 | "title": ""
1897 | },
1898 | "id": "f8yczkFHkRJj"
1899 | },
1900 | "outputs": [],
1901 | "source": [
1902 | "#First defining hyperparameters and boiler plate code. Imports and data preparation code is repeated for convenience\n",
1903 | "import torch\n",
1904 | "import torch.nn as nn\n",
1905 | "from torch.nn import functional as F\n",
1906 | "from torch.nn import init\n",
1907 | "\n",
1908 | "# hyperparameters\n",
1909 | "batch_size = 16 # how many independent sequences will we process in parallel?\n",
1910 | "block_size = 32 # what is the maximum context length for predictions?\n",
1911 | "max_iters = 5000\n",
1912 | "eval_interval = 100\n",
1913 | "learning_rate = 1e-3\n",
1914 | "device = 'cuda' if torch.cuda.is_available() else 'cpu'\n",
1915 | "eval_iters = 400\n",
1916 | "head_size = 16\n",
1917 | "n_embed = 128\n",
1918 | "n_head = 8\n",
1919 | "n_layer = 8\n",
1920 | "dropout = 0.1\n",
1921 | "num_experts = 8\n",
1922 | "top_k = 2\n",
1923 | "# ------------\n",
1924 | "\n",
1925 | "torch.manual_seed(1337)\n",
1926 | "\n",
1927 | "with open('input.txt', 'r', encoding='utf-8') as f:\n",
1928 | " text = f.read()\n",
1929 | "\n",
1930 | "# here are all the unique characters that occur in this text\n",
1931 | "chars = sorted(list(set(text)))\n",
1932 | "vocab_size = len(chars)\n",
1933 | "# create a mapping from characters to integers\n",
1934 | "stoi = { ch:i for i,ch in enumerate(chars) }\n",
1935 | "itos = { i:ch for i,ch in enumerate(chars) }\n",
1936 | "encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers\n",
1937 | "decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string\n",
1938 | "\n",
1939 | "# Train and test splits\n",
1940 | "data = torch.tensor(encode(text), dtype=torch.long)\n",
1941 | "n = int(0.9*len(data)) # first 90% will be train, rest val\n",
1942 | "train_data = data[:n]\n",
1943 | "val_data = data[n:]\n",
1944 | "\n",
1945 | "# data loading\n",
1946 | "def get_batch(split):\n",
1947 | " # generate a small batch of data of inputs x and targets y\n",
1948 | " data = train_data if split == 'train' else val_data\n",
1949 | " ix = torch.randint(len(data) - block_size, (batch_size,))\n",
1950 | " x = torch.stack([data[i:i+block_size] for i in ix])\n",
1951 | " y = torch.stack([data[i+1:i+block_size+1] for i in ix])\n",
1952 | " x, y = x.to(device), y.to(device)\n",
1953 | " return x, y\n",
1954 | "\n",
1955 | "@torch.no_grad()\n",
1956 | "def estimate_loss():\n",
1957 | " out = {}\n",
1958 | " model.eval()\n",
1959 | " for split in ['train', 'val']:\n",
1960 | " losses = torch.zeros(eval_iters)\n",
1961 | " for k in range(eval_iters):\n",
1962 | " X, Y = get_batch(split)\n",
1963 | " logits, loss = model(X, Y)\n",
1964 | " losses[k] = loss.item()\n",
1965 | " out[split] = losses.mean()\n",
1966 | " model.train()\n",
1967 | " return out"
1968 | ]
1969 | },
1970 | {
1971 | "cell_type": "code",
1972 | "execution_count": null,
1973 | "metadata": {
1974 | "application/vnd.databricks.v1+cell": {
1975 | "cellMetadata": {
1976 | "byteLimit": 2048000,
1977 | "rowLimit": 10000
1978 | },
1979 | "inputWidgets": {},
1980 | "nuid": "ee1180f7-5004-4425-87fe-9a81a17b9024",
1981 | "showTitle": false,
1982 | "title": ""
1983 | },
1984 | "id": "QfxJ6B2fkRJj"
1985 | },
1986 | "outputs": [],
1987 | "source": [
1988 | "class Head(nn.Module):\n",
1989 | " \"\"\" one head of self-attention \"\"\"\n",
1990 | "\n",
1991 | " def __init__(self, head_size):\n",
1992 | " super().__init__()\n",
1993 | " self.key = nn.Linear(n_embed, head_size, bias=False)\n",
1994 | " self.query = nn.Linear(n_embed, head_size, bias=False)\n",
1995 | " self.value = nn.Linear(n_embed, head_size, bias=False)\n",
1996 | " self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))\n",
1997 | "\n",
1998 | " self.dropout = nn.Dropout(dropout)\n",
1999 | "\n",
2000 | " def forward(self, x):\n",
2001 | " B,T,C = x.shape\n",
2002 | " k = self.key(x) # (B,T,C)\n",
2003 | " q = self.query(x) # (B,T,C)\n",
2004 | " # compute attention scores (\"affinities\")\n",
2005 | " wei = q @ k.transpose(-2,-1) * C**-0.5 # (B, T, C) @ (B, C, T) -> (B, T, T)\n",
2006 | " wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)\n",
2007 | " wei = F.softmax(wei, dim=-1) # (B, T, T)\n",
2008 | " wei = self.dropout(wei)\n",
2009 | " # perform the weighted aggregation of the values\n",
2010 | " v = self.value(x) # (B,T,C)\n",
2011 | " out = wei @ v # (B, T, T) @ (B, T, C) -> (B, T, C)\n",
2012 | " return out\n",
2013 | "\n",
2014 | "#Multi-Headed Self Attention\n",
2015 | "class MultiHeadAttention(nn.Module):\n",
2016 | " \"\"\" multiple heads of self-attention in parallel \"\"\"\n",
2017 | "\n",
2018 | " def __init__(self, num_heads, head_size):\n",
2019 | " super().__init__()\n",
2020 | " self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])\n",
2021 | " self.proj = nn.Linear(n_embed, n_embed)\n",
2022 | " self.dropout = nn.Dropout(dropout)\n",
2023 | "\n",
2024 | " def forward(self, x):\n",
2025 | " out = torch.cat([h(x) for h in self.heads], dim=-1)\n",
2026 | " out = self.dropout(self.proj(out))\n",
2027 | " return out\n"
2028 | ]
2029 | },
2030 | {
2031 | "cell_type": "code",
2032 | "execution_count": null,
2033 | "metadata": {
2034 | "application/vnd.databricks.v1+cell": {
2035 | "cellMetadata": {
2036 | "byteLimit": 2048000,
2037 | "rowLimit": 10000
2038 | },
2039 | "inputWidgets": {},
2040 | "nuid": "03611a92-aaa2-4e0d-9755-cba56f96c794",
2041 | "showTitle": false,
2042 | "title": ""
2043 | },
2044 | "id": "y35jVCZYkRJk"
2045 | },
2046 | "outputs": [],
2047 | "source": [
2048 | "#Expert module\n",
2049 | "class Expert(nn.Module):\n",
2050 | " \"\"\" An MLP is a simple linear layer followed by a non-linearity i.e. each Expert \"\"\"\n",
2051 | "\n",
2052 | " def __init__(self, n_embed):\n",
2053 | " super().__init__()\n",
2054 | " self.net = nn.Sequential(\n",
2055 | " nn.Linear(n_embed, 4 * n_embed),\n",
2056 | " nn.ReLU(),\n",
2057 | " nn.Linear(4 * n_embed, n_embed),\n",
2058 | " nn.Dropout(dropout),\n",
2059 | " )\n",
2060 | "\n",
2061 | " def forward(self, x):\n",
2062 | " return self.net(x)\n",
2063 | "\n",
2064 | "#noisy top-k gating\n",
2065 | "class NoisyTopkRouter(nn.Module):\n",
2066 | " def __init__(self, n_embed, num_experts, top_k):\n",
2067 | " super(NoisyTopkRouter, self).__init__()\n",
2068 | " self.top_k = top_k\n",
2069 | " #layer for router logits\n",
2070 | " self.topkroute_linear = nn.Linear(n_embed, num_experts)\n",
2071 | " self.noise_linear =nn.Linear(n_embed, num_experts)\n",
2072 | "\n",
2073 | "\n",
2074 | " def forward(self, mh_output):\n",
2075 | " # mh_ouput is the output tensor from multihead self attention block\n",
2076 | " logits = self.topkroute_linear(mh_output)\n",
2077 | "\n",
2078 | " #Noise logits\n",
2079 | " noise_logits = self.noise_linear(mh_output)\n",
2080 | "\n",
2081 | " #Adding scaled unit gaussian noise to the logits\n",
2082 | " noise = torch.randn_like(logits)*F.softplus(noise_logits)\n",
2083 | " noisy_logits = logits + noise\n",
2084 | "\n",
2085 | " top_k_logits, indices = noisy_logits.topk(self.top_k, dim=-1)\n",
2086 | " zeros = torch.full_like(noisy_logits, float('-inf'))\n",
2087 | " sparse_logits = zeros.scatter(-1, indices, top_k_logits)\n",
2088 | " router_output = F.softmax(sparse_logits, dim=-1)\n",
2089 | " return router_output, indices\n",
2090 | "\n",
2091 | "#Now create the sparse mixture of experts module\n",
2092 | "class SparseMoE(nn.Module):\n",
2093 | " def __init__(self, n_embed, num_experts, top_k):\n",
2094 | " super(SparseMoE, self).__init__()\n",
2095 | " self.router = NoisyTopkRouter(n_embed, num_experts, top_k)\n",
2096 | " self.experts = nn.ModuleList([Expert(n_embed) for _ in range(num_experts)])\n",
2097 | " self.top_k = top_k\n",
2098 | "\n",
2099 | " def forward(self, x):\n",
2100 | " gating_output, indices = self.router(x)\n",
2101 | " final_output = torch.zeros_like(x)\n",
2102 | "\n",
2103 | " # Reshape inputs for batch processing\n",
2104 | " flat_x = x.view(-1, x.size(-1))\n",
2105 | " flat_gating_output = gating_output.view(-1, gating_output.size(-1))\n",
2106 | "\n",
2107 | " # Process each expert in parallel\n",
2108 | " for i, expert in enumerate(self.experts):\n",
2109 | " # Create a mask for the inputs where the current expert is in top-k\n",
2110 | " expert_mask = (indices == i).any(dim=-1)\n",
2111 | " flat_mask = expert_mask.view(-1)\n",
2112 | "\n",
2113 | " if flat_mask.any():\n",
2114 | " expert_input = flat_x[flat_mask]\n",
2115 | " expert_output = expert(expert_input)\n",
2116 | "\n",
2117 | " # Extract and apply gating scores\n",
2118 | " gating_scores = flat_gating_output[flat_mask, i].unsqueeze(1)\n",
2119 | " weighted_output = expert_output * gating_scores\n",
2120 | "\n",
2121 | " # Update final output additively by indexing and adding\n",
2122 | " final_output[expert_mask] += weighted_output.squeeze(1)\n",
2123 | "\n",
2124 | " return final_output"
2125 | ]
2126 | },
2127 | {
2128 | "cell_type": "code",
2129 | "execution_count": null,
2130 | "metadata": {
2131 | "application/vnd.databricks.v1+cell": {
2132 | "cellMetadata": {
2133 | "byteLimit": 2048000,
2134 | "rowLimit": 10000
2135 | },
2136 | "inputWidgets": {},
2137 | "nuid": "bfdff2bb-092f-41c8-9a33-c84e6f8d6633",
2138 | "showTitle": false,
2139 | "title": ""
2140 | },
2141 | "id": "jGiuRsSgkRJk"
2142 | },
2143 | "outputs": [],
2144 | "source": [
2145 | "#First create a self attention + mixture of experts block, that may be repeated several number of times\n",
2146 | "#Copy pasting key architecture variables for clarity\n",
2147 | "\n",
2148 | "class Block(nn.Module):\n",
2149 | " \"\"\" Mixture of Experts Transformer block: communication followed by computation (multi-head self attention + SparseMoE) \"\"\"\n",
2150 | "\n",
2151 | " def __init__(self, n_embed, n_head, num_experts, top_k):\n",
2152 | " # n_embed: embedding dimension, n_head: the number of heads we'd like\n",
2153 | " super().__init__()\n",
2154 | " head_size = n_embed // n_head\n",
2155 | " self.sa = MultiHeadAttention(n_head, head_size)\n",
2156 | " self.smoe = SparseMoE(n_embed, num_experts, top_k)\n",
2157 | " self.ln1 = nn.LayerNorm(n_embed)\n",
2158 | " self.ln2 = nn.LayerNorm(n_embed)\n",
2159 | "\n",
2160 | " def forward(self, x):\n",
2161 | " x = x + self.sa(self.ln1(x))\n",
2162 | " x = x + self.smoe(self.ln2(x))\n",
2163 | " return x"
2164 | ]
2165 | },
2166 | {
2167 | "cell_type": "code",
2168 | "execution_count": null,
2169 | "metadata": {
2170 | "application/vnd.databricks.v1+cell": {
2171 | "cellMetadata": {
2172 | "byteLimit": 2048000,
2173 | "rowLimit": 10000
2174 | },
2175 | "inputWidgets": {},
2176 | "nuid": "2d32a276-d0cc-4808-90d7-62441771af44",
2177 | "showTitle": false,
2178 | "title": ""
2179 | },
2180 | "id": "RpyZBA71kRJk"
2181 | },
2182 | "outputs": [],
2183 | "source": [
2184 | "#Finally putting it all together to crease a sparse mixture of experts language model\n",
2185 | "class SparseMoELanguageModel(nn.Module):\n",
2186 | "\n",
2187 | " def __init__(self):\n",
2188 | " super().__init__()\n",
2189 | " # each token directly reads off the logits for the next token from a lookup table\n",
2190 | " self.token_embedding_table = nn.Embedding(vocab_size, n_embed)\n",
2191 | " self.position_embedding_table = nn.Embedding(block_size, n_embed)\n",
2192 | " self.blocks = nn.Sequential(*[Block(n_embed, n_head=n_head, num_experts=num_experts,top_k=top_k) for _ in range(n_layer)])\n",
2193 | " self.ln_f = nn.LayerNorm(n_embed) # final layer norm\n",
2194 | " self.lm_head = nn.Linear(n_embed, vocab_size)\n",
2195 | "\n",
2196 | " def forward(self, idx, targets=None):\n",
2197 | " B, T = idx.shape\n",
2198 | "\n",
2199 | " # idx and targets are both (B,T) tensor of integers\n",
2200 | " tok_emb = self.token_embedding_table(idx) # (B,T,C)\n",
2201 | " pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)\n",
2202 | " x = tok_emb + pos_emb # (B,T,C)\n",
2203 | " x = self.blocks(x) # (B,T,C)\n",
2204 | " x = self.ln_f(x) # (B,T,C)\n",
2205 | " logits = self.lm_head(x) # (B,T,vocab_size)\n",
2206 | "\n",
2207 | " if targets is None:\n",
2208 | " loss = None\n",
2209 | " else:\n",
2210 | " B, T, C = logits.shape\n",
2211 | " logits = logits.view(B*T, C)\n",
2212 | " targets = targets.view(B*T)\n",
2213 | " loss = F.cross_entropy(logits, targets)\n",
2214 | "\n",
2215 | " return logits, loss\n",
2216 | "\n",
2217 | " def generate(self, idx, max_new_tokens):\n",
2218 | " # idx is (B, T) array of indices in the current context\n",
2219 | " for _ in range(max_new_tokens):\n",
2220 | " # crop idx to the last block_size tokens\n",
2221 | " idx_cond = idx[:, -block_size:]\n",
2222 | " # get the predictions\n",
2223 | " logits, loss = self(idx_cond)\n",
2224 | " # focus only on the last time step\n",
2225 | " logits = logits[:, -1, :] # becomes (B, C)\n",
2226 | " # apply softmax to get probabilities\n",
2227 | " probs = F.softmax(logits, dim=-1) # (B, C)\n",
2228 | " # sample from the distribution\n",
2229 | " idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)\n",
2230 | " # append sampled index to the running sequence\n",
2231 | " idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)\n",
2232 | " return idx"
2233 | ]
2234 | },
2235 | {
2236 | "cell_type": "markdown",
2237 | "metadata": {
2238 | "application/vnd.databricks.v1+cell": {
2239 | "cellMetadata": {},
2240 | "inputWidgets": {},
2241 | "nuid": "622ba7ce-3f20-4820-8982-93f3d3b7be09",
2242 | "showTitle": false,
2243 | "title": ""
2244 | },
2245 | "id": "bBzQXmfykRJk"
2246 | },
2247 | "source": [
2248 | "Kaiming He initialization is used here because of presence of ReLU activations in the experts. Feel free to experiment with Glorot initialization which is more commonly used in transformers. Jeremy Howard's Fastai Part 2 has an excellent lecture that implements these from scratch: https://course.fast.ai/Lessons/lesson17.html"
2249 | ]
2250 | },
2251 | {
2252 | "cell_type": "code",
2253 | "execution_count": null,
2254 | "metadata": {
2255 | "application/vnd.databricks.v1+cell": {
2256 | "cellMetadata": {
2257 | "byteLimit": 2048000,
2258 | "rowLimit": 10000
2259 | },
2260 | "inputWidgets": {},
2261 | "nuid": "a6d3c057-08ee-4c1b-8013-6a88b2eadac5",
2262 | "showTitle": false,
2263 | "title": ""
2264 | },
2265 | "id": "guGaJqHbkRJk"
2266 | },
2267 | "outputs": [],
2268 | "source": [
2269 | "\n",
2270 | "def kaiming_init_weights(m):\n",
2271 | " if isinstance (m, (nn.Linear)):\n",
2272 | " init.kaiming_normal_(m.weight)"
2273 | ]
2274 | },
2275 | {
2276 | "cell_type": "code",
2277 | "execution_count": null,
2278 | "metadata": {
2279 | "application/vnd.databricks.v1+cell": {
2280 | "cellMetadata": {
2281 | "byteLimit": 2048000,
2282 | "rowLimit": 10000
2283 | },
2284 | "inputWidgets": {},
2285 | "nuid": "5b4d9525-8405-4a51-adda-661aba004e57",
2286 | "showTitle": false,
2287 | "title": ""
2288 | },
2289 | "id": "nJGGkXz4kRJl",
2290 | "outputId": "8518ec23-caa0-4167-88c6-65a7c905743a"
2291 | },
2292 | "outputs": [
2293 | {
2294 | "data": {
2295 | "text/plain": [
2296 | "SparseMoELanguageModel(\n",
2297 | " (token_embedding_table): Embedding(65, 128)\n",
2298 | " (position_embedding_table): Embedding(32, 128)\n",
2299 | " (blocks): Sequential(\n",
2300 | " (0): Block(\n",
2301 | " (sa): MultiHeadAttention(\n",
2302 | " (heads): ModuleList(\n",
2303 | " (0-7): 8 x Head(\n",
2304 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2305 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2306 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2307 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2308 | " )\n",
2309 | " )\n",
2310 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2311 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2312 | " )\n",
2313 | " (smoe): SparseMoE(\n",
2314 | " (router): NoisyTopkRouter(\n",
2315 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2316 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2317 | " )\n",
2318 | " (experts): ModuleList(\n",
2319 | " (0-7): 8 x Expert(\n",
2320 | " (net): Sequential(\n",
2321 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2322 | " (1): ReLU()\n",
2323 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2324 | " (3): Dropout(p=0.1, inplace=False)\n",
2325 | " )\n",
2326 | " )\n",
2327 | " )\n",
2328 | " )\n",
2329 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2330 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2331 | " )\n",
2332 | " (1): Block(\n",
2333 | " (sa): MultiHeadAttention(\n",
2334 | " (heads): ModuleList(\n",
2335 | " (0-7): 8 x Head(\n",
2336 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2337 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2338 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2339 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2340 | " )\n",
2341 | " )\n",
2342 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2343 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2344 | " )\n",
2345 | " (smoe): SparseMoE(\n",
2346 | " (router): NoisyTopkRouter(\n",
2347 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2348 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2349 | " )\n",
2350 | " (experts): ModuleList(\n",
2351 | " (0-7): 8 x Expert(\n",
2352 | " (net): Sequential(\n",
2353 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2354 | " (1): ReLU()\n",
2355 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2356 | " (3): Dropout(p=0.1, inplace=False)\n",
2357 | " )\n",
2358 | " )\n",
2359 | " )\n",
2360 | " )\n",
2361 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2362 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2363 | " )\n",
2364 | " (2): Block(\n",
2365 | " (sa): MultiHeadAttention(\n",
2366 | " (heads): ModuleList(\n",
2367 | " (0-7): 8 x Head(\n",
2368 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2369 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2370 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2371 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2372 | " )\n",
2373 | " )\n",
2374 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2375 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2376 | " )\n",
2377 | " (smoe): SparseMoE(\n",
2378 | " (router): NoisyTopkRouter(\n",
2379 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2380 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2381 | " )\n",
2382 | " (experts): ModuleList(\n",
2383 | " (0-7): 8 x Expert(\n",
2384 | " (net): Sequential(\n",
2385 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2386 | " (1): ReLU()\n",
2387 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2388 | " (3): Dropout(p=0.1, inplace=False)\n",
2389 | " )\n",
2390 | " )\n",
2391 | " )\n",
2392 | " )\n",
2393 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2394 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2395 | " )\n",
2396 | " (3): Block(\n",
2397 | " (sa): MultiHeadAttention(\n",
2398 | " (heads): ModuleList(\n",
2399 | " (0-7): 8 x Head(\n",
2400 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2401 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2402 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2403 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2404 | " )\n",
2405 | " )\n",
2406 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2407 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2408 | " )\n",
2409 | " (smoe): SparseMoE(\n",
2410 | " (router): NoisyTopkRouter(\n",
2411 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2412 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2413 | " )\n",
2414 | " (experts): ModuleList(\n",
2415 | " (0-7): 8 x Expert(\n",
2416 | " (net): Sequential(\n",
2417 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2418 | " (1): ReLU()\n",
2419 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2420 | " (3): Dropout(p=0.1, inplace=False)\n",
2421 | " )\n",
2422 | " )\n",
2423 | " )\n",
2424 | " )\n",
2425 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2426 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2427 | " )\n",
2428 | " (4): Block(\n",
2429 | " (sa): MultiHeadAttention(\n",
2430 | " (heads): ModuleList(\n",
2431 | " (0-7): 8 x Head(\n",
2432 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2433 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2434 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2435 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2436 | " )\n",
2437 | " )\n",
2438 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2439 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2440 | " )\n",
2441 | " (smoe): SparseMoE(\n",
2442 | " (router): NoisyTopkRouter(\n",
2443 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2444 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2445 | " )\n",
2446 | " (experts): ModuleList(\n",
2447 | " (0-7): 8 x Expert(\n",
2448 | " (net): Sequential(\n",
2449 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2450 | " (1): ReLU()\n",
2451 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2452 | " (3): Dropout(p=0.1, inplace=False)\n",
2453 | " )\n",
2454 | " )\n",
2455 | " )\n",
2456 | " )\n",
2457 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2458 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2459 | " )\n",
2460 | " (5): Block(\n",
2461 | " (sa): MultiHeadAttention(\n",
2462 | " (heads): ModuleList(\n",
2463 | " (0-7): 8 x Head(\n",
2464 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2465 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2466 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2467 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2468 | " )\n",
2469 | " )\n",
2470 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2471 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2472 | " )\n",
2473 | " (smoe): SparseMoE(\n",
2474 | " (router): NoisyTopkRouter(\n",
2475 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2476 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2477 | " )\n",
2478 | " (experts): ModuleList(\n",
2479 | " (0-7): 8 x Expert(\n",
2480 | " (net): Sequential(\n",
2481 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2482 | " (1): ReLU()\n",
2483 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2484 | " (3): Dropout(p=0.1, inplace=False)\n",
2485 | " )\n",
2486 | " )\n",
2487 | " )\n",
2488 | " )\n",
2489 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2490 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2491 | " )\n",
2492 | " (6): Block(\n",
2493 | " (sa): MultiHeadAttention(\n",
2494 | " (heads): ModuleList(\n",
2495 | " (0-7): 8 x Head(\n",
2496 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2497 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2498 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2499 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2500 | " )\n",
2501 | " )\n",
2502 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2503 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2504 | " )\n",
2505 | " (smoe): SparseMoE(\n",
2506 | " (router): NoisyTopkRouter(\n",
2507 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2508 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2509 | " )\n",
2510 | " (experts): ModuleList(\n",
2511 | " (0-7): 8 x Expert(\n",
2512 | " (net): Sequential(\n",
2513 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2514 | " (1): ReLU()\n",
2515 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2516 | " (3): Dropout(p=0.1, inplace=False)\n",
2517 | " )\n",
2518 | " )\n",
2519 | " )\n",
2520 | " )\n",
2521 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2522 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2523 | " )\n",
2524 | " (7): Block(\n",
2525 | " (sa): MultiHeadAttention(\n",
2526 | " (heads): ModuleList(\n",
2527 | " (0-7): 8 x Head(\n",
2528 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2529 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2530 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2531 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2532 | " )\n",
2533 | " )\n",
2534 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2535 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2536 | " )\n",
2537 | " (smoe): SparseMoE(\n",
2538 | " (router): NoisyTopkRouter(\n",
2539 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2540 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2541 | " )\n",
2542 | " (experts): ModuleList(\n",
2543 | " (0-7): 8 x Expert(\n",
2544 | " (net): Sequential(\n",
2545 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2546 | " (1): ReLU()\n",
2547 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2548 | " (3): Dropout(p=0.1, inplace=False)\n",
2549 | " )\n",
2550 | " )\n",
2551 | " )\n",
2552 | " )\n",
2553 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2554 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2555 | " )\n",
2556 | " )\n",
2557 | " (ln_f): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2558 | " (lm_head): Linear(in_features=128, out_features=65, bias=True)\n",
2559 | ")"
2560 | ]
2561 | },
2562 | "execution_count": 38,
2563 | "metadata": {},
2564 | "output_type": "execute_result"
2565 | }
2566 | ],
2567 | "source": [
2568 | "model = SparseMoELanguageModel()\n",
2569 | "model.apply(kaiming_init_weights)"
2570 | ]
2571 | },
2572 | {
2573 | "cell_type": "markdown",
2574 | "metadata": {
2575 | "application/vnd.databricks.v1+cell": {
2576 | "cellMetadata": {},
2577 | "inputWidgets": {},
2578 | "nuid": "6adf1d04-e668-4d14-b691-161ea4e4dccf",
2579 | "showTitle": false,
2580 | "title": ""
2581 | },
2582 | "id": "_cb1-L8ckRJl"
2583 | },
2584 | "source": [
2585 | "I have used mlflow to track and log the metrics I care about and the training hyperparameters. The training loop in the next cell includes this mlflow code. If you prefer to just train without using mlflow, the subsequent cell has code without the mlflow code. However, I find it very convenient to track parameters and metrics, particularly when experimenting."
2586 | ]
2587 | },
2588 | {
2589 | "cell_type": "code",
2590 | "execution_count": null,
2591 | "metadata": {
2592 | "application/vnd.databricks.v1+cell": {
2593 | "cellMetadata": {
2594 | "byteLimit": 2048000,
2595 | "rowLimit": 10000
2596 | },
2597 | "inputWidgets": {},
2598 | "nuid": "b8968247-0d7b-4460-b96b-06743b31c55d",
2599 | "showTitle": false,
2600 | "title": ""
2601 | },
2602 | "id": "WTG1Fv4SkRJl",
2603 | "outputId": "38318015-63a9-4959-cfe0-cab305625f49"
2604 | },
2605 | "outputs": [
2606 | {
2607 | "name": "stdout",
2608 | "output_type": "stream",
2609 | "text": [
2610 | "8.996545 M parameters\n",
2611 | "step 0: train loss 5.3223, val loss 5.3166\n",
2612 | "step 100: train loss 2.7351, val loss 2.7429\n",
2613 | "step 200: train loss 2.5125, val loss 2.5233\n",
2614 | "step 300: train loss 2.4239, val loss 2.4384\n",
2615 | "step 400: train loss 2.3477, val loss 2.3656\n",
2616 | "step 500: train loss 2.2743, val loss 2.3040\n",
2617 | "step 600: train loss 2.2087, val loss 2.2199\n",
2618 | "step 700: train loss 2.1461, val loss 2.1853\n",
2619 | "step 800: train loss 2.1018, val loss 2.1418\n",
2620 | "step 900: train loss 2.0592, val loss 2.1055\n",
2621 | "step 1000: train loss 2.0138, val loss 2.0822\n",
2622 | "step 1100: train loss 1.9820, val loss 2.0486\n",
2623 | "step 1200: train loss 1.9536, val loss 2.0383\n",
2624 | "step 1300: train loss 1.9218, val loss 2.0070\n",
2625 | "step 1400: train loss 1.9077, val loss 2.0059\n",
2626 | "step 1500: train loss 1.8831, val loss 1.9784\n",
2627 | "step 1600: train loss 1.8527, val loss 1.9740\n",
2628 | "step 1700: train loss 1.8309, val loss 1.9468\n",
2629 | "step 1800: train loss 1.8157, val loss 1.9401\n",
2630 | "step 1900: train loss 1.7953, val loss 1.9243\n",
2631 | "step 2000: train loss 1.7853, val loss 1.9158\n",
2632 | "step 2100: train loss 1.7746, val loss 1.8969\n",
2633 | "step 2200: train loss 1.7527, val loss 1.8901\n",
2634 | "step 2300: train loss 1.7433, val loss 1.8770\n",
2635 | "step 2400: train loss 1.7327, val loss 1.8827\n",
2636 | "step 2500: train loss 1.7183, val loss 1.8713\n",
2637 | "step 2600: train loss 1.7155, val loss 1.8592\n",
2638 | "step 2700: train loss 1.7089, val loss 1.8564\n",
2639 | "step 2800: train loss 1.6978, val loss 1.8500\n",
2640 | "step 2900: train loss 1.6902, val loss 1.8340\n",
2641 | "step 3000: train loss 1.6854, val loss 1.8398\n",
2642 | "step 3100: train loss 1.6680, val loss 1.8313\n",
2643 | "step 3200: train loss 1.6666, val loss 1.8225\n",
2644 | "step 3300: train loss 1.6508, val loss 1.8268\n",
2645 | "step 3400: train loss 1.6499, val loss 1.8148\n",
2646 | "step 3500: train loss 1.6438, val loss 1.8068\n",
2647 | "step 3600: train loss 1.6317, val loss 1.7923\n",
2648 | "step 3700: train loss 1.6314, val loss 1.7856\n",
2649 | "step 3800: train loss 1.6260, val loss 1.7862\n",
2650 | "step 3900: train loss 1.6092, val loss 1.7757\n",
2651 | "step 4000: train loss 1.6116, val loss 1.7753\n",
2652 | "step 4100: train loss 1.6024, val loss 1.7823\n",
2653 | "step 4200: train loss 1.6067, val loss 1.7650\n",
2654 | "step 4300: train loss 1.5895, val loss 1.7629\n",
2655 | "step 4400: train loss 1.5940, val loss 1.7623\n",
2656 | "step 4500: train loss 1.5937, val loss 1.7506\n",
2657 | "step 4600: train loss 1.5941, val loss 1.7743\n",
2658 | "step 4700: train loss 1.5787, val loss 1.7646\n",
2659 | "step 4800: train loss 1.5786, val loss 1.7585\n",
2660 | "step 4900: train loss 1.5719, val loss 1.7439\n",
2661 | "step 4999: train loss 1.5712, val loss 1.7508\n"
2662 | ]
2663 | }
2664 | ],
2665 | "source": [
2666 | "#Using MLFlow\n",
2667 | "m = model.to(device)\n",
2668 | "# print the number of parameters in the model\n",
2669 | "print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')\n",
2670 | "\n",
2671 | "# create a PyTorch optimizer\n",
2672 | "optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)\n",
2673 | "#mlflow.set_experiment(\"makeMoE\")\n",
2674 | "with mlflow.start_run():\n",
2675 | " #If you use mlflow.autolog() this will be automatically logged. I chose to explicitly log here for completeness\n",
2676 | " params = {\"batch_size\": batch_size , \"block_size\" : block_size, \"max_iters\": max_iters, \"eval_interval\": eval_interval,\n",
2677 | " \"learning_rate\": learning_rate, \"device\": device, \"eval_iters\": eval_iters, \"dropout\" : dropout, \"num_experts\": num_experts, \"top_k\": top_k }\n",
2678 | " mlflow.log_params(params)\n",
2679 | " for iter in range(max_iters):\n",
2680 | "\n",
2681 | " # every once in a while evaluate the loss on train and val sets\n",
2682 | " if iter % eval_interval == 0 or iter == max_iters - 1:\n",
2683 | " losses = estimate_loss()\n",
2684 | " print(f\"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}\")\n",
2685 | " metrics = {\"train_loss\": float(losses['train']), \"val_loss\": float(losses['val'])}\n",
2686 | " mlflow.log_metrics(metrics, step=iter)\n",
2687 | "\n",
2688 | "\n",
2689 | " # sample a batch of data\n",
2690 | " xb, yb = get_batch('train')\n",
2691 | "\n",
2692 | " # evaluate the loss\n",
2693 | " logits, loss = model(xb, yb)\n",
2694 | " optimizer.zero_grad(set_to_none=True)\n",
2695 | " loss.backward()\n",
2696 | " optimizer.step()"
2697 | ]
2698 | },
2699 | {
2700 | "cell_type": "markdown",
2701 | "metadata": {
2702 | "application/vnd.databricks.v1+cell": {
2703 | "cellMetadata": {},
2704 | "inputWidgets": {},
2705 | "nuid": "1ed96085-c292-4624-a2cc-be8aad38df79",
2706 | "showTitle": false,
2707 | "title": ""
2708 | },
2709 | "id": "jFBVfgfekRJl"
2710 | },
2711 | "source": [
2712 | "Logging train and validation losses gives you a good indication of how the training is going. The plot shows that I probably should have stopped around 4500 steps (when the validation loss jumps up a bit)\n",
2713 | "\n",
2714 | ""
2715 | ]
2716 | },
2717 | {
2718 | "cell_type": "code",
2719 | "execution_count": null,
2720 | "metadata": {
2721 | "application/vnd.databricks.v1+cell": {
2722 | "cellMetadata": {},
2723 | "inputWidgets": {},
2724 | "nuid": "6360e1b7-94c4-4ef1-a850-9bc93f49a083",
2725 | "showTitle": false,
2726 | "title": ""
2727 | },
2728 | "id": "WP_2lcRUkRJl"
2729 | },
2730 | "outputs": [],
2731 | "source": [
2732 | "#Not using MLflow\n",
2733 | "m = model.to(device)\n",
2734 | "# print the number of parameters in the model\n",
2735 | "print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')\n",
2736 | "\n",
2737 | "# create a PyTorch optimizer\n",
2738 | "optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)\n",
2739 | "\n",
2740 | "for iter in range(max_iters):\n",
2741 | "\n",
2742 | " # every once in a while evaluate the loss on train and val sets\n",
2743 | " if iter % eval_interval == 0 or iter == max_iters - 1:\n",
2744 | " losses = estimate_loss()\n",
2745 | " print(f\"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}\")\n",
2746 | "\n",
2747 | " # sample a batch of data\n",
2748 | " xb, yb = get_batch('train')\n",
2749 | "\n",
2750 | " # evaluate the loss\n",
2751 | " logits, loss = model(xb, yb)\n",
2752 | " optimizer.zero_grad(set_to_none=True)\n",
2753 | " loss.backward()\n",
2754 | " optimizer.step()"
2755 | ]
2756 | },
2757 | {
2758 | "cell_type": "code",
2759 | "execution_count": null,
2760 | "metadata": {
2761 | "application/vnd.databricks.v1+cell": {
2762 | "cellMetadata": {
2763 | "byteLimit": 2048000,
2764 | "rowLimit": 10000
2765 | },
2766 | "inputWidgets": {},
2767 | "nuid": "8aa6e4c4-c688-4985-a3b8-e2af1f771e54",
2768 | "showTitle": false,
2769 | "title": ""
2770 | },
2771 | "id": "W4yshpXMkRJl",
2772 | "outputId": "e69af1c7-2e2f-475c-eeba-b20dec8532c2"
2773 | },
2774 | "outputs": [
2775 | {
2776 | "name": "stdout",
2777 | "output_type": "stream",
2778 | "text": [
2779 | "\n",
2780 | "And, rem?\n",
2781 | "He say, the soul froom, from Merver:\n",
2782 | "And cirture muck on this part son Turn the will:\n",
2783 | "The fulist somet on glace: O they were\n",
2784 | "Le I scide, on thouch scaribe hoptant would\n",
2785 | "And chnot did the croblarious too contle your life,,\n",
2786 | "Some lo you her, alas forfour-porth, it, see!\n",
2787 | "What, when is a strong of though first.\n",
2788 | "\n",
2789 | "DUKE VINCENVENTIO:\n",
2790 | "If it ever fecond he town sue kigh now,\n",
2791 | "That thou wold'st is steen 't.\n",
2792 | "\n",
2793 | "SIMNA:\n",
2794 | "Angent her; no, my a born Yorthort,\n",
2795 | "Romeoos soun and lawf to your sawe with ch a woft ttastly defy,\n",
2796 | "To declay the soul art; and meart smad.\n",
2797 | "\n",
2798 | "CORPIOLLANUS:\n",
2799 | "Which I cannot shall do from by born und ot cold warrike,\n",
2800 | "What king we best anone wrave's going of heard and good\n",
2801 | "Thus playvage; you have wold the grace.\n",
2802 | "\n",
2803 | "KING EDWARD:\n",
2804 | "Daughtia I they honour of your king thissand yish, there Marcius has found Romeo\n",
2805 | "And Havaulint cound is the and such shall diake her forture\n",
2806 | "The rights:' chy Villona, in I thenruns!\n",
2807 | "\n",
2808 | "What you, in posinn the dayms bore,\n",
2809 | "As recompe sontts stand, where thronough is thy gracieful misic?\n",
2810 | "\n",
2811 | "DUKE VINCENCENTIO:\n",
2812 | "When I fangly wilt dovines ear ach surch to mearts treck impost not,\n",
2813 | "Lord, go my abeging thus, igainst onlove's incruent!\n",
2814 | "\n",
2815 | "Pum, God GlouNT:\n",
2816 | "Why, to this unclomer bed: who we priol,\n",
2817 | "Farewell eye! first me, thosto I are the affair yea, to not, when\n",
2818 | "on you his give magetine.\n",
2819 | "\n",
2820 | "DUKE VINCENTIO:\n",
2821 | "I have madast true; he hope ever thrubt a got to crave.\n",
2822 | "\n",
2823 | "ClONTISTINGNUS:\n",
2824 | "TYet ago, cumbot to down withat these was the connoure.\n",
2825 | "This, when your elses: deaths, Henry, thrink and of mennine effirm'd, 'tis littly Beardings agay\n",
2826 | "Teld, are is steek make rough, in\n",
2827 | "having givant and of thy that jucing an,\n",
2828 | "But, over no some.\n",
2829 | "\n",
2830 | "WARWICK:\n",
2831 | "I am last, cromend, Cablarlius;\n",
2832 | "That everceigal whils ghaves nobled him ineace?\n",
2833 | "\n",
2834 | "LEONTES:\n",
2835 | "May, It it say; was thou suit hast\n",
2836 | "on yough. I am follow to the balk it;\n",
2837 | "Sixcted Harce petchol by his doubard'd,\n",
2838 | "I am chouncealos! a my life, and see me jeblearry, be with fliful so son!\n",
2839 | "\n",
2840 | "LEONTES:\n",
2841 | "How wus have up frompriton!\n",
2842 | "\n",
2843 | "BRUTUS:\n",
2844 | "To and than \n"
2845 | ]
2846 | }
2847 | ],
2848 | "source": [
2849 | "# generate from the model. Not great. Not too bad either\n",
2850 | "context = torch.zeros((1, 1), dtype=torch.long, device=device)\n",
2851 | "print(decode(m.generate(context, max_new_tokens=2000)[0].tolist()))"
2852 | ]
2853 | }
2854 | ],
2855 | "metadata": {
2856 | "application/vnd.databricks.v1+notebook": {
2857 | "dashboards": [],
2858 | "language": "python",
2859 | "notebookMetadata": {
2860 | "pythonIndentUnit": 4
2861 | },
2862 | "notebookName": "makeMoE_from_Scratch",
2863 | "widgets": {}
2864 | },
2865 | "colab": {
2866 | "include_colab_link": true,
2867 | "provenance": []
2868 | },
2869 | "language_info": {
2870 | "name": "python"
2871 | }
2872 | },
2873 | "nbformat": 4,
2874 | "nbformat_minor": 0
2875 | }
2876 |
--------------------------------------------------------------------------------
"
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "metadata": {
16 | "application/vnd.databricks.v1+cell": {
17 | "cellMetadata": {},
18 | "inputWidgets": {},
19 | "nuid": "8e9b80fc-12cf-41a9-a0de-354f678b412b",
20 | "showTitle": false,
21 | "title": ""
22 | },
23 | "id": "90vgVgmDkRJQ"
24 | },
25 | "source": [
26 | "#### Sparse mixture of experts language model from scratch inspired by (and largely based on) Andrej Karpathy's makemore (https://github.com/karpathy/makemore) :)\n",
27 | "\n",
28 | "This is a from scratch implementation of a sparse mixture of experts language model. This is inspired by and largely based on Andrej Karpathy's project 'makemore' and borrows most of the re-usable components from that implementation. Just like makemore, makeMoE is also an autoregressive character-level language model but uses the aforementioned sparse mixture of experts architecture.\n",
29 | "\n",
30 | "Just like makemore, pytorch is the only requirement (so I hope the from scratch claim is justified).\n",
31 | "\n",
32 | "Significant Changes from the makemore architecture\n",
33 | "\n",
34 | "- Sparse mixture of experts instead of the solitary feed forward neural net.\n",
35 | "- Top-k gating and noisy top-k gating implementations.\n",
36 | "- initialization - Kaiming He initialization is used here but the point of this notebook is to be hackable so you can swap in Xavier Glorot etc. and take it for a spin.\n",
37 | "\n",
38 | "Unchanged from makemore\n",
39 | "- The dataset, preprocessing (tokenization), and the language modeling task Andrej chose originally - generate Shakespeare-like text\n",
40 | "- Casusal self attention implementation\n",
41 | "- Training loop\n",
42 | "- Inference logic\n",
43 | "\n",
44 | "Publications heavily referenced for this implementation:\n",
45 | "- Mixtral of experts: https://arxiv.org/pdf/2401.04088.pdf\n",
46 | "- Outrageosly Large Neural Networks: The Sparsely-Gated Mixture-Of-Experts layer: https://arxiv.org/pdf/1701.06538.pdf\n",
47 | "\n",
48 | "\n",
49 | "This notebook walks through the intuition for the entire model architecture and how everything comes together\n",
50 | "\n",
51 | "The code was entirely developed on Databricks using a single A100 for compute. If you're running this on Databricks, you can scale this on an arbitrarily large GPU cluster with no issues in the cloud provider of your choice\n",
52 | "\n",
53 | "I chose to use mlflow (which comes pre-installed in Databricks. You can pip install easily elsewhere) as I find it helpful to track and log all the metrics necessary. This is entirely optional.\n",
54 | "\n",
55 | "Please note that the implementation emphasizes readability and hackability vs performance, so there are many ways in which you could improve this. Please try and let me know\n"
56 | ]
57 | },
58 | {
59 | "cell_type": "markdown",
60 | "metadata": {
61 | "application/vnd.databricks.v1+cell": {
62 | "cellMetadata": {
63 | "byteLimit": 2048000,
64 | "rowLimit": 10000
65 | },
66 | "inputWidgets": {},
67 | "nuid": "2f4a58a8-bd4c-40de-a4a9-95457842db0b",
68 | "showTitle": false,
69 | "title": ""
70 | },
71 | "id": "hywLNfb0kRJT"
72 | },
73 | "source": [
74 | ""
75 | ]
76 | },
77 | {
78 | "cell_type": "code",
79 | "execution_count": null,
80 | "metadata": {
81 | "application/vnd.databricks.v1+cell": {
82 | "cellMetadata": {
83 | "byteLimit": 2048000,
84 | "rowLimit": 10000
85 | },
86 | "inputWidgets": {},
87 | "nuid": "35b3daa3-3b3b-47af-b3e7-be95878f9e06",
88 | "showTitle": false,
89 | "title": ""
90 | },
91 | "id": "RQAnP6_RkRJU"
92 | },
93 | "outputs": [],
94 | "source": [
95 | "#Using mlflow is entirely optional. I personally like to use MLFlow to track and log everything. If you're using Databricks, it comes pre-installed.\n",
96 | "%pip install mlflow"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": null,
102 | "metadata": {
103 | "application/vnd.databricks.v1+cell": {
104 | "cellMetadata": {
105 | "byteLimit": 2048000,
106 | "rowLimit": 10000
107 | },
108 | "inputWidgets": {},
109 | "nuid": "5e1a3e38-8717-42ec-9bbc-71d3712c1c68",
110 | "showTitle": false,
111 | "title": ""
112 | },
113 | "id": "V521QQ_qkRJV"
114 | },
115 | "outputs": [],
116 | "source": [
117 | "#Import the necessary packages and set seed for reproducibility. For this notebook, pytorch is all you need\n",
118 | "import torch\n",
119 | "import torch.nn as nn\n",
120 | "from torch.nn import functional as F\n",
121 | "torch.manual_seed(42)\n",
122 | "#Optional\n",
123 | "import mlflow"
124 | ]
125 | },
126 | {
127 | "cell_type": "markdown",
128 | "metadata": {
129 | "application/vnd.databricks.v1+cell": {
130 | "cellMetadata": {},
131 | "inputWidgets": {},
132 | "nuid": "faf99ef2-39bb-46fc-b772-05d6d0482bbc",
133 | "showTitle": false,
134 | "title": ""
135 | },
136 | "id": "-4r_QNRRkRJV"
137 | },
138 | "source": [
139 | "Next few sections, downloading the data, preprocessing it and self attention are directly from makemore. I have elaborated a little on self attention and added visual aids to understand the process a bit better."
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": null,
145 | "metadata": {
146 | "application/vnd.databricks.v1+cell": {
147 | "cellMetadata": {
148 | "byteLimit": 2048000,
149 | "rowLimit": 10000
150 | },
151 | "inputWidgets": {},
152 | "nuid": "45143d84-28c7-463d-9fb5-e21122842600",
153 | "showTitle": false,
154 | "title": ""
155 | },
156 | "id": "2GhDw0yWkRJV",
157 | "outputId": "22b79649-9819-4c65-a46a-d0796d6c9085"
158 | },
159 | "outputs": [
160 | {
161 | "name": "stdout",
162 | "output_type": "stream",
163 | "text": [
164 | "--2024-01-25 06:11:57-- https://raw.githubusercontent.com/AviSoori1x/makeMoE/main/input.txt\r\n",
165 | "Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.110.133, 185.199.109.133, ...\r\n",
166 | "Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.\r\n",
167 | "HTTP request sent, awaiting response... 200 OK\r\n",
168 | "Length: 1115394 (1.1M) [text/plain]\r\n",
169 | "Saving to: ‘input.txt.2’\r\n",
170 | "\r\n",
171 | "\rinput.txt.2 0%[ ] 0 --.-KB/s \rinput.txt.2 100%[===================>] 1.06M --.-KB/s in 0.04s \r\n",
172 | "\r\n",
173 | "2024-01-25 06:11:57 (30.2 MB/s) - ‘input.txt.2’ saved [1115394/1115394]\r\n",
174 | "\r\n"
175 | ]
176 | }
177 | ],
178 | "source": [
179 | "# Downloading the tiny shakespeare dataset\n",
180 | "!wget https://raw.githubusercontent.com/AviSoori1x/makeMoE/main/input.txt"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": null,
186 | "metadata": {
187 | "application/vnd.databricks.v1+cell": {
188 | "cellMetadata": {
189 | "byteLimit": 2048000,
190 | "rowLimit": 10000
191 | },
192 | "inputWidgets": {},
193 | "nuid": "192e830a-762d-4573-9484-70a58deb1fec",
194 | "showTitle": false,
195 | "title": ""
196 | },
197 | "id": "3sPAL1AKkRJW"
198 | },
199 | "outputs": [],
200 | "source": [
201 | "# read it in to inspect it\n",
202 | "with open('input.txt', 'r', encoding='utf-8') as f:\n",
203 | " text = f.read()"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": null,
209 | "metadata": {
210 | "application/vnd.databricks.v1+cell": {
211 | "cellMetadata": {
212 | "byteLimit": 2048000,
213 | "rowLimit": 10000
214 | },
215 | "inputWidgets": {},
216 | "nuid": "2d7181b7-f5e5-4ab5-bdd8-74c507c798ad",
217 | "showTitle": false,
218 | "title": ""
219 | },
220 | "id": "wNkF3RYLkRJX",
221 | "outputId": "671be677-be3d-49e0-d391-569559a99ae2"
222 | },
223 | "outputs": [
224 | {
225 | "name": "stdout",
226 | "output_type": "stream",
227 | "text": [
228 | "length of dataset in characters: 1115394\n"
229 | ]
230 | }
231 | ],
232 | "source": [
233 | "print(\"length of dataset in characters: \", len(text))"
234 | ]
235 | },
236 | {
237 | "cell_type": "code",
238 | "execution_count": null,
239 | "metadata": {
240 | "application/vnd.databricks.v1+cell": {
241 | "cellMetadata": {
242 | "byteLimit": 2048000,
243 | "rowLimit": 10000
244 | },
245 | "inputWidgets": {},
246 | "nuid": "68032e07-8625-4750-a340-bc8f4eed2458",
247 | "showTitle": false,
248 | "title": ""
249 | },
250 | "id": "AHIwr-yxkRJX",
251 | "outputId": "fa10ee0f-c8cb-4ba1-9fb1-79f9fbf336fe"
252 | },
253 | "outputs": [
254 | {
255 | "name": "stdout",
256 | "output_type": "stream",
257 | "text": [
258 | "First Citizen:\n",
259 | "Before we proceed any further, hear me speak.\n",
260 | "\n",
261 | "All:\n",
262 | "Speak, speak.\n",
263 | "\n",
264 | "First Citizen:\n",
265 | "You are all resolved rather to die than to famish?\n",
266 | "\n",
267 | "All:\n",
268 | "Resolved. resolved.\n",
269 | "\n",
270 | "First Citizen:\n",
271 | "First, you know Caius Marcius is chief enemy to the people.\n",
272 | "\n",
273 | "All:\n",
274 | "We know't, we know't.\n",
275 | "\n",
276 | "First Citizen:\n",
277 | "Let us kill him, and we'll have corn at our own price.\n",
278 | "Is't a verdict?\n",
279 | "\n",
280 | "All:\n",
281 | "No more talking on't; let it be done: away, away!\n",
282 | "\n",
283 | "Second Citizen:\n",
284 | "One word, good citizens.\n",
285 | "\n",
286 | "First Citizen:\n",
287 | "We are accounted poor citizens, the patricians good.\n",
288 | "What authority surfeits on would relieve us: if they\n",
289 | "would yield us but the superfluity, while it were\n",
290 | "wholesome, we might guess they relieved us humanely;\n",
291 | "but they think we are too dear: the leanness that\n",
292 | "afflicts us, the object of our misery, is as an\n",
293 | "inventory to particularise their abundance; our\n",
294 | "sufferance is a gain to them Let us revenge this with\n",
295 | "our pikes, ere we become rakes: for the gods know I\n",
296 | "speak this in hunger for bread, not in thirst for revenge.\n",
297 | "\n",
298 | "\n"
299 | ]
300 | }
301 | ],
302 | "source": [
303 | "# let's look at the first 1000 characters\n",
304 | "print(text[:1000])"
305 | ]
306 | },
307 | {
308 | "cell_type": "code",
309 | "execution_count": null,
310 | "metadata": {
311 | "application/vnd.databricks.v1+cell": {
312 | "cellMetadata": {
313 | "byteLimit": 2048000,
314 | "rowLimit": 10000
315 | },
316 | "inputWidgets": {},
317 | "nuid": "b6995ad6-c9ac-4a21-9da0-ebbd3273c991",
318 | "showTitle": false,
319 | "title": ""
320 | },
321 | "id": "DHGayz7mkRJY",
322 | "outputId": "54b52e55-b6b9-4bdc-974a-5c48a43e1497"
323 | },
324 | "outputs": [
325 | {
326 | "name": "stdout",
327 | "output_type": "stream",
328 | "text": [
329 | "\n",
330 | " !$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz\n",
331 | "65\n"
332 | ]
333 | }
334 | ],
335 | "source": [
336 | "# here are all the unique characters that occur in this text\n",
337 | "chars = sorted(list(set(text)))\n",
338 | "vocab_size = len(chars)\n",
339 | "print(''.join(chars))\n",
340 | "print(vocab_size)"
341 | ]
342 | },
343 | {
344 | "cell_type": "code",
345 | "execution_count": null,
346 | "metadata": {
347 | "application/vnd.databricks.v1+cell": {
348 | "cellMetadata": {
349 | "byteLimit": 2048000,
350 | "rowLimit": 10000
351 | },
352 | "inputWidgets": {},
353 | "nuid": "43002fa3-ffd3-416c-9aaf-0a03b19c7bc1",
354 | "showTitle": false,
355 | "title": ""
356 | },
357 | "id": "pzn11WJckRJY",
358 | "outputId": "cd7b3ff1-680b-4036-b3c8-b597a361aeb3"
359 | },
360 | "outputs": [
361 | {
362 | "name": "stdout",
363 | "output_type": "stream",
364 | "text": [
365 | "[46, 47, 47, 1, 58, 46, 43, 56, 43]\n",
366 | "hii there\n"
367 | ]
368 | }
369 | ],
370 | "source": [
371 | "# create a mapping from characters to integers\n",
372 | "stoi = { ch:i for i,ch in enumerate(chars) }\n",
373 | "itos = { i:ch for i,ch in enumerate(chars) }\n",
374 | "encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers\n",
375 | "decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string\n",
376 | "\n",
377 | "print(encode(\"hii there\"))\n",
378 | "print(decode(encode(\"hii there\")))"
379 | ]
380 | },
381 | {
382 | "cell_type": "code",
383 | "execution_count": null,
384 | "metadata": {
385 | "application/vnd.databricks.v1+cell": {
386 | "cellMetadata": {
387 | "byteLimit": 2048000,
388 | "rowLimit": 10000
389 | },
390 | "inputWidgets": {},
391 | "nuid": "b4609fc4-09c7-4a39-8367-e9ee39d440ed",
392 | "showTitle": false,
393 | "title": ""
394 | },
395 | "id": "YbBGz0O2kRJY",
396 | "outputId": "49e94dde-6e1f-4a9e-a18b-9b8f1c51de86"
397 | },
398 | "outputs": [
399 | {
400 | "name": "stdout",
401 | "output_type": "stream",
402 | "text": [
403 | "torch.Size([1115394]) torch.int64\n",
404 | "tensor([18, 47, 56, 57, 58, 1, 15, 47, 58, 47, 64, 43, 52, 10, 0, 14, 43, 44,\n",
405 | " 53, 56, 43, 1, 61, 43, 1, 54, 56, 53, 41, 43, 43, 42, 1, 39, 52, 63,\n",
406 | " 1, 44, 59, 56, 58, 46, 43, 56, 6, 1, 46, 43, 39, 56, 1, 51, 43, 1,\n",
407 | " 57, 54, 43, 39, 49, 8, 0, 0, 13, 50, 50, 10, 0, 31, 54, 43, 39, 49,\n",
408 | " 6, 1, 57, 54, 43, 39, 49, 8, 0, 0, 18, 47, 56, 57, 58, 1, 15, 47,\n",
409 | " 58, 47, 64, 43, 52, 10, 0, 37, 53, 59, 1, 39, 56, 43, 1, 39, 50, 50,\n",
410 | " 1, 56, 43, 57, 53, 50, 60, 43, 42, 1, 56, 39, 58, 46, 43, 56, 1, 58,\n",
411 | " 53, 1, 42, 47, 43, 1, 58, 46, 39, 52, 1, 58, 53, 1, 44, 39, 51, 47,\n",
412 | " 57, 46, 12, 0, 0, 13, 50, 50, 10, 0, 30, 43, 57, 53, 50, 60, 43, 42,\n",
413 | " 8, 1, 56, 43, 57, 53, 50, 60, 43, 42, 8, 0, 0, 18, 47, 56, 57, 58,\n",
414 | " 1, 15, 47, 58, 47, 64, 43, 52, 10, 0, 18, 47, 56, 57, 58, 6, 1, 63,\n",
415 | " 53, 59, 1, 49, 52, 53, 61, 1, 15, 39, 47, 59, 57, 1, 25, 39, 56, 41,\n",
416 | " 47, 59, 57, 1, 47, 57, 1, 41, 46, 47, 43, 44, 1, 43, 52, 43, 51, 63,\n",
417 | " 1, 58, 53, 1, 58, 46, 43, 1, 54, 43, 53, 54, 50, 43, 8, 0, 0, 13,\n",
418 | " 50, 50, 10, 0, 35, 43, 1, 49, 52, 53, 61, 5, 58, 6, 1, 61, 43, 1,\n",
419 | " 49, 52, 53, 61, 5, 58, 8, 0, 0, 18, 47, 56, 57, 58, 1, 15, 47, 58,\n",
420 | " 47, 64, 43, 52, 10, 0, 24, 43, 58, 1, 59, 57, 1, 49, 47, 50, 50, 1,\n",
421 | " 46, 47, 51, 6, 1, 39, 52, 42, 1, 61, 43, 5, 50, 50, 1, 46, 39, 60,\n",
422 | " 43, 1, 41, 53, 56, 52, 1, 39, 58, 1, 53, 59, 56, 1, 53, 61, 52, 1,\n",
423 | " 54, 56, 47, 41, 43, 8, 0, 21, 57, 5, 58, 1, 39, 1, 60, 43, 56, 42,\n",
424 | " 47, 41, 58, 12, 0, 0, 13, 50, 50, 10, 0, 26, 53, 1, 51, 53, 56, 43,\n",
425 | " 1, 58, 39, 50, 49, 47, 52, 45, 1, 53, 52, 5, 58, 11, 1, 50, 43, 58,\n",
426 | " 1, 47, 58, 1, 40, 43, 1, 42, 53, 52, 43, 10, 1, 39, 61, 39, 63, 6,\n",
427 | " 1, 39, 61, 39, 63, 2, 0, 0, 31, 43, 41, 53, 52, 42, 1, 15, 47, 58,\n",
428 | " 47, 64, 43, 52, 10, 0, 27, 52, 43, 1, 61, 53, 56, 42, 6, 1, 45, 53,\n",
429 | " 53, 42, 1, 41, 47, 58, 47, 64, 43, 52, 57, 8, 0, 0, 18, 47, 56, 57,\n",
430 | " 58, 1, 15, 47, 58, 47, 64, 43, 52, 10, 0, 35, 43, 1, 39, 56, 43, 1,\n",
431 | " 39, 41, 41, 53, 59, 52, 58, 43, 42, 1, 54, 53, 53, 56, 1, 41, 47, 58,\n",
432 | " 47, 64, 43, 52, 57, 6, 1, 58, 46, 43, 1, 54, 39, 58, 56, 47, 41, 47,\n",
433 | " 39, 52, 57, 1, 45, 53, 53, 42, 8, 0, 35, 46, 39, 58, 1, 39, 59, 58,\n",
434 | " 46, 53, 56, 47, 58, 63, 1, 57, 59, 56, 44, 43, 47, 58, 57, 1, 53, 52,\n",
435 | " 1, 61, 53, 59, 50, 42, 1, 56, 43, 50, 47, 43, 60, 43, 1, 59, 57, 10,\n",
436 | " 1, 47, 44, 1, 58, 46, 43, 63, 0, 61, 53, 59, 50, 42, 1, 63, 47, 43,\n",
437 | " 50, 42, 1, 59, 57, 1, 40, 59, 58, 1, 58, 46, 43, 1, 57, 59, 54, 43,\n",
438 | " 56, 44, 50, 59, 47, 58, 63, 6, 1, 61, 46, 47, 50, 43, 1, 47, 58, 1,\n",
439 | " 61, 43, 56, 43, 0, 61, 46, 53, 50, 43, 57, 53, 51, 43, 6, 1, 61, 43,\n",
440 | " 1, 51, 47, 45, 46, 58, 1, 45, 59, 43, 57, 57, 1, 58, 46, 43, 63, 1,\n",
441 | " 56, 43, 50, 47, 43, 60, 43, 42, 1, 59, 57, 1, 46, 59, 51, 39, 52, 43,\n",
442 | " 50, 63, 11, 0, 40, 59, 58, 1, 58, 46, 43, 63, 1, 58, 46, 47, 52, 49,\n",
443 | " 1, 61, 43, 1, 39, 56, 43, 1, 58, 53, 53, 1, 42, 43, 39, 56, 10, 1,\n",
444 | " 58, 46, 43, 1, 50, 43, 39, 52, 52, 43, 57, 57, 1, 58, 46, 39, 58, 0,\n",
445 | " 39, 44, 44, 50, 47, 41, 58, 57, 1, 59, 57, 6, 1, 58, 46, 43, 1, 53,\n",
446 | " 40, 48, 43, 41, 58, 1, 53, 44, 1, 53, 59, 56, 1, 51, 47, 57, 43, 56,\n",
447 | " 63, 6, 1, 47, 57, 1, 39, 57, 1, 39, 52, 0, 47, 52, 60, 43, 52, 58,\n",
448 | " 53, 56, 63, 1, 58, 53, 1, 54, 39, 56, 58, 47, 41, 59, 50, 39, 56, 47,\n",
449 | " 57, 43, 1, 58, 46, 43, 47, 56, 1, 39, 40, 59, 52, 42, 39, 52, 41, 43,\n",
450 | " 11, 1, 53, 59, 56, 0, 57, 59, 44, 44, 43, 56, 39, 52, 41, 43, 1, 47,\n",
451 | " 57, 1, 39, 1, 45, 39, 47, 52, 1, 58, 53, 1, 58, 46, 43, 51, 1, 24,\n",
452 | " 43, 58, 1, 59, 57, 1, 56, 43, 60, 43, 52, 45, 43, 1, 58, 46, 47, 57,\n",
453 | " 1, 61, 47, 58, 46, 0, 53, 59, 56, 1, 54, 47, 49, 43, 57, 6, 1, 43,\n",
454 | " 56, 43, 1, 61, 43, 1, 40, 43, 41, 53, 51, 43, 1, 56, 39, 49, 43, 57,\n",
455 | " 10, 1, 44, 53, 56, 1, 58, 46, 43, 1, 45, 53, 42, 57, 1, 49, 52, 53,\n",
456 | " 61, 1, 21, 0, 57, 54, 43, 39, 49, 1, 58, 46, 47, 57, 1, 47, 52, 1,\n",
457 | " 46, 59, 52, 45, 43, 56, 1, 44, 53, 56, 1, 40, 56, 43, 39, 42, 6, 1,\n",
458 | " 52, 53, 58, 1, 47, 52, 1, 58, 46, 47, 56, 57, 58, 1, 44, 53, 56, 1,\n",
459 | " 56, 43, 60, 43, 52, 45, 43, 8, 0, 0])\n"
460 | ]
461 | }
462 | ],
463 | "source": [
464 | "# let's now encode the entire text dataset and store it into a torch.Tensor\n",
465 | "data = torch.tensor(encode(text), dtype=torch.long)\n",
466 | "print(data.shape, data.dtype)\n",
467 | "print(data[:1000]) # the 1000 characters we looked at earier will to the GPT look like this"
468 | ]
469 | },
470 | {
471 | "cell_type": "code",
472 | "execution_count": null,
473 | "metadata": {
474 | "application/vnd.databricks.v1+cell": {
475 | "cellMetadata": {
476 | "byteLimit": 2048000,
477 | "rowLimit": 10000
478 | },
479 | "inputWidgets": {},
480 | "nuid": "88f7cb0d-02ff-42b0-92a5-a505dc3f8f25",
481 | "showTitle": false,
482 | "title": ""
483 | },
484 | "id": "hoLIeA7YkRJZ"
485 | },
486 | "outputs": [],
487 | "source": [
488 | "# Let's now split up the data into train and validation sets\n",
489 | "n = int(0.9*len(data)) # first 90% will be train, rest val\n",
490 | "train_data = data[:n]\n",
491 | "val_data = data[n:]"
492 | ]
493 | },
494 | {
495 | "cell_type": "code",
496 | "execution_count": null,
497 | "metadata": {
498 | "application/vnd.databricks.v1+cell": {
499 | "cellMetadata": {
500 | "byteLimit": 2048000,
501 | "rowLimit": 10000
502 | },
503 | "inputWidgets": {},
504 | "nuid": "6b554ddf-50f4-441b-8acf-10b81a508b7e",
505 | "showTitle": false,
506 | "title": ""
507 | },
508 | "id": "VY55nr6EkRJZ",
509 | "outputId": "1a5685e9-66bb-40ed-f19a-f0cb09e8e51c"
510 | },
511 | "outputs": [
512 | {
513 | "data": {
514 | "text/plain": [
515 | "tensor([18, 47, 56, 57, 58, 1, 15, 47, 58])"
516 | ]
517 | },
518 | "execution_count": 26,
519 | "metadata": {},
520 | "output_type": "execute_result"
521 | }
522 | ],
523 | "source": [
524 | "block_size = 8\n",
525 | "train_data[:block_size+1]"
526 | ]
527 | },
528 | {
529 | "cell_type": "code",
530 | "execution_count": null,
531 | "metadata": {
532 | "application/vnd.databricks.v1+cell": {
533 | "cellMetadata": {
534 | "byteLimit": 2048000,
535 | "rowLimit": 10000
536 | },
537 | "inputWidgets": {},
538 | "nuid": "22ba4512-309d-4895-a908-2ef3efa317bc",
539 | "showTitle": false,
540 | "title": ""
541 | },
542 | "id": "5YbgrB9HkRJZ",
543 | "outputId": "05577a5f-10d5-495b-82e8-c3278b4fdea0"
544 | },
545 | "outputs": [
546 | {
547 | "name": "stdout",
548 | "output_type": "stream",
549 | "text": [
550 | "when input is tensor([18]) the target: 47\n",
551 | "when input is tensor([18, 47]) the target: 56\n",
552 | "when input is tensor([18, 47, 56]) the target: 57\n",
553 | "when input is tensor([18, 47, 56, 57]) the target: 58\n",
554 | "when input is tensor([18, 47, 56, 57, 58]) the target: 1\n",
555 | "when input is tensor([18, 47, 56, 57, 58, 1]) the target: 15\n",
556 | "when input is tensor([18, 47, 56, 57, 58, 1, 15]) the target: 47\n",
557 | "when input is tensor([18, 47, 56, 57, 58, 1, 15, 47]) the target: 58\n"
558 | ]
559 | }
560 | ],
561 | "source": [
562 | "x = train_data[:block_size]\n",
563 | "y = train_data[1:block_size+1]\n",
564 | "for t in range(block_size):\n",
565 | " context = x[:t+1]\n",
566 | " target = y[t]\n",
567 | " print(f\"when input is {context} the target: {target}\")"
568 | ]
569 | },
570 | {
571 | "cell_type": "code",
572 | "execution_count": null,
573 | "metadata": {
574 | "application/vnd.databricks.v1+cell": {
575 | "cellMetadata": {
576 | "byteLimit": 2048000,
577 | "rowLimit": 10000
578 | },
579 | "inputWidgets": {},
580 | "nuid": "bf386bff-0f63-4358-82fc-6c7d02c37321",
581 | "showTitle": false,
582 | "title": ""
583 | },
584 | "id": "Oaxhage8kRJZ"
585 | },
586 | "outputs": [],
587 | "source": [
588 | "batch_size = 4 # how many independent sequences will we process in parallel?\n",
589 | "block_size = 8 # what is the maximum context length for predictions?"
590 | ]
591 | },
592 | {
593 | "cell_type": "code",
594 | "execution_count": null,
595 | "metadata": {
596 | "application/vnd.databricks.v1+cell": {
597 | "cellMetadata": {
598 | "byteLimit": 2048000,
599 | "rowLimit": 10000
600 | },
601 | "inputWidgets": {},
602 | "nuid": "99acd85c-233f-4f2d-a062-028dbcde9960",
603 | "showTitle": false,
604 | "title": ""
605 | },
606 | "id": "HfpkIUNdkRJZ",
607 | "outputId": "1ad2bc10-2b4a-458b-a6ee-a169728ec90d"
608 | },
609 | "outputs": [
610 | {
611 | "data": {
612 | "text/plain": [
613 | "tensor([250930, 237205, 974116, 383898])"
614 | ]
615 | },
616 | "execution_count": 29,
617 | "metadata": {},
618 | "output_type": "execute_result"
619 | }
620 | ],
621 | "source": [
622 | "ix = torch.randint(len(data) - block_size, (batch_size,))\n",
623 | "ix"
624 | ]
625 | },
626 | {
627 | "cell_type": "code",
628 | "execution_count": null,
629 | "metadata": {
630 | "application/vnd.databricks.v1+cell": {
631 | "cellMetadata": {
632 | "byteLimit": 2048000,
633 | "rowLimit": 10000
634 | },
635 | "inputWidgets": {},
636 | "nuid": "e46dc826-9f39-4aed-b2d2-f9ea401136de",
637 | "showTitle": false,
638 | "title": ""
639 | },
640 | "id": "faoGVPG3kRJa",
641 | "outputId": "dcf8b139-d8f8-4565-a962-62d094c5da9f"
642 | },
643 | "outputs": [
644 | {
645 | "data": {
646 | "text/plain": [
647 | "tensor([[42, 1, 58, 46, 59, 57, 1, 21],\n",
648 | " [54, 56, 47, 43, 57, 58, 11, 0],\n",
649 | " [49, 47, 52, 45, 12, 1, 58, 46],\n",
650 | " [58, 46, 53, 59, 58, 1, 56, 43]])"
651 | ]
652 | },
653 | "execution_count": 30,
654 | "metadata": {},
655 | "output_type": "execute_result"
656 | }
657 | ],
658 | "source": [
659 | "x = torch.stack([data[i:i+block_size] for i in ix])\n",
660 | "y = torch.stack([data[i+1:i+block_size+1] for i in ix])\n",
661 | "x"
662 | ]
663 | },
664 | {
665 | "cell_type": "code",
666 | "execution_count": null,
667 | "metadata": {
668 | "application/vnd.databricks.v1+cell": {
669 | "cellMetadata": {
670 | "byteLimit": 2048000,
671 | "rowLimit": 10000
672 | },
673 | "inputWidgets": {},
674 | "nuid": "2886aedf-200e-40bd-9a9d-4658cf6c509b",
675 | "showTitle": false,
676 | "title": ""
677 | },
678 | "id": "hkllYFCPkRJa",
679 | "outputId": "9350713c-be0f-492a-c873-bd279226668d"
680 | },
681 | "outputs": [
682 | {
683 | "data": {
684 | "text/plain": [
685 | "tensor([[ 1, 58, 46, 59, 57, 1, 21, 1],\n",
686 | " [56, 47, 43, 57, 58, 11, 0, 37],\n",
687 | " [47, 52, 45, 12, 1, 58, 46, 53],\n",
688 | " [46, 53, 59, 58, 1, 56, 43, 42]])"
689 | ]
690 | },
691 | "execution_count": 31,
692 | "metadata": {},
693 | "output_type": "execute_result"
694 | }
695 | ],
696 | "source": [
697 | "y"
698 | ]
699 | },
700 | {
701 | "cell_type": "markdown",
702 | "metadata": {
703 | "application/vnd.databricks.v1+cell": {
704 | "cellMetadata": {},
705 | "inputWidgets": {},
706 | "nuid": "a486fc04-ed29-456f-918b-5f8395e455cb",
707 | "showTitle": false,
708 | "title": ""
709 | },
710 | "id": "tWrajECBkRJa"
711 | },
712 | "source": [
713 | "The following code block clearly shows the autoregressive nature of the prediction and how the context is a rolling windows over a 1 dimentional arrangement of tokens (characters in this case)"
714 | ]
715 | },
716 | {
717 | "cell_type": "code",
718 | "execution_count": null,
719 | "metadata": {
720 | "application/vnd.databricks.v1+cell": {
721 | "cellMetadata": {
722 | "byteLimit": 2048000,
723 | "rowLimit": 10000
724 | },
725 | "inputWidgets": {},
726 | "nuid": "49a86e10-ac37-4b92-8f18-775cd4853fdc",
727 | "showTitle": false,
728 | "title": ""
729 | },
730 | "id": "xjgtxxztkRJa",
731 | "outputId": "1be0ebc2-b22d-4136-e77d-ecdafded66d2"
732 | },
733 | "outputs": [
734 | {
735 | "name": "stdout",
736 | "output_type": "stream",
737 | "text": [
738 | "inputs:\n",
739 | "torch.Size([4, 8])\n",
740 | "tensor([[ 6, 0, 14, 43, 44, 53, 56, 43],\n",
741 | " [39, 1, 42, 59, 43, 1, 39, 52],\n",
742 | " [47, 41, 43, 1, 39, 52, 42, 1],\n",
743 | " [53, 44, 1, 50, 43, 58, 1, 58]])\n",
744 | "targets:\n",
745 | "torch.Size([4, 8])\n",
746 | "tensor([[ 0, 14, 43, 44, 53, 56, 43, 1],\n",
747 | " [ 1, 42, 59, 43, 1, 39, 52, 42],\n",
748 | " [41, 43, 1, 39, 52, 42, 1, 42],\n",
749 | " [44, 1, 50, 43, 58, 1, 58, 46]])\n",
750 | "----\n",
751 | "when input is [6] the target: 0\n",
752 | "when input is [6, 0] the target: 14\n",
753 | "when input is [6, 0, 14] the target: 43\n",
754 | "when input is [6, 0, 14, 43] the target: 44\n",
755 | "when input is [6, 0, 14, 43, 44] the target: 53\n",
756 | "when input is [6, 0, 14, 43, 44, 53] the target: 56\n",
757 | "when input is [6, 0, 14, 43, 44, 53, 56] the target: 43\n",
758 | "when input is [6, 0, 14, 43, 44, 53, 56, 43] the target: 1\n",
759 | "when input is [39] the target: 1\n",
760 | "when input is [39, 1] the target: 42\n",
761 | "when input is [39, 1, 42] the target: 59\n",
762 | "when input is [39, 1, 42, 59] the target: 43\n",
763 | "when input is [39, 1, 42, 59, 43] the target: 1\n",
764 | "when input is [39, 1, 42, 59, 43, 1] the target: 39\n",
765 | "when input is [39, 1, 42, 59, 43, 1, 39] the target: 52\n",
766 | "when input is [39, 1, 42, 59, 43, 1, 39, 52] the target: 42\n",
767 | "when input is [47] the target: 41\n",
768 | "when input is [47, 41] the target: 43\n",
769 | "when input is [47, 41, 43] the target: 1\n",
770 | "when input is [47, 41, 43, 1] the target: 39\n",
771 | "when input is [47, 41, 43, 1, 39] the target: 52\n",
772 | "when input is [47, 41, 43, 1, 39, 52] the target: 42\n",
773 | "when input is [47, 41, 43, 1, 39, 52, 42] the target: 1\n",
774 | "when input is [47, 41, 43, 1, 39, 52, 42, 1] the target: 42\n",
775 | "when input is [53] the target: 44\n",
776 | "when input is [53, 44] the target: 1\n",
777 | "when input is [53, 44, 1] the target: 50\n",
778 | "when input is [53, 44, 1, 50] the target: 43\n",
779 | "when input is [53, 44, 1, 50, 43] the target: 58\n",
780 | "when input is [53, 44, 1, 50, 43, 58] the target: 1\n",
781 | "when input is [53, 44, 1, 50, 43, 58, 1] the target: 58\n",
782 | "when input is [53, 44, 1, 50, 43, 58, 1, 58] the target: 46\n"
783 | ]
784 | }
785 | ],
786 | "source": [
787 | "def get_batch(split):\n",
788 | " # generate a small batch of data of inputs x and targets y\n",
789 | " data = train_data if split == 'train' else val_data\n",
790 | " ix = torch.randint(len(data) - block_size, (batch_size,))\n",
791 | " x = torch.stack([data[i:i+block_size] for i in ix])\n",
792 | " y = torch.stack([data[i+1:i+block_size+1] for i in ix])\n",
793 | " return x, y\n",
794 | "\n",
795 | "xb, yb = get_batch('train')\n",
796 | "print('inputs:')\n",
797 | "print(xb.shape)\n",
798 | "print(xb)\n",
799 | "print('targets:')\n",
800 | "print(yb.shape)\n",
801 | "print(yb)\n",
802 | "\n",
803 | "print('----')\n",
804 | "\n",
805 | "for b in range(batch_size): # batch dimension\n",
806 | " for t in range(block_size): # time dimension\n",
807 | " context = xb[b, :t+1]\n",
808 | " target = yb[b,t]\n",
809 | " print(f\"when input is {context.tolist()} the target: {target}\")"
810 | ]
811 | },
812 | {
813 | "cell_type": "markdown",
814 | "metadata": {
815 | "application/vnd.databricks.v1+cell": {
816 | "cellMetadata": {},
817 | "inputWidgets": {},
818 | "nuid": "dde3273f-0519-4108-ba84-dfd99e020722",
819 | "showTitle": false,
820 | "title": ""
821 | },
822 | "id": "RlON_gNikRJa"
823 | },
824 | "source": [
825 | "### Understanding the intuition of Causal Scaled Dot Product Self Attention\n",
826 | "\n",
827 | "This code is borrowed from Andrej Karpathy's excellent makemore repository linked in the repo"
828 | ]
829 | },
830 | {
831 | "cell_type": "markdown",
832 | "metadata": {
833 | "application/vnd.databricks.v1+cell": {
834 | "cellMetadata": {
835 | "byteLimit": 2048000,
836 | "rowLimit": 10000
837 | },
838 | "inputWidgets": {},
839 | "nuid": "e435d0cf-1383-446a-9026-cd80b4266019",
840 | "showTitle": false,
841 | "title": ""
842 | },
843 | "id": "uBVWP40SkRJa"
844 | },
845 | "source": [
846 | ""
847 | ]
848 | },
849 | {
850 | "cell_type": "markdown",
851 | "metadata": {
852 | "application/vnd.databricks.v1+cell": {
853 | "cellMetadata": {},
854 | "inputWidgets": {},
855 | "nuid": "97660589-1719-48c0-ad6f-4f7c2888348a",
856 | "showTitle": false,
857 | "title": ""
858 | },
859 | "id": "i-jFgMntkRJa"
860 | },
861 | "source": [
862 | "The provided code demonstrates self-attention's mechanics and fundamental concepts, specifically focusing on the classic scaled dot product self-attention. In this variant, the query, key, and value matrices all originate from the same input sequence. To ensure the integrity of the autoregressive language generation process, particularly in a decoder-only model, the code implements masking. This masking technique is crucial as it obscures any information following the current token's position, thereby directing the model's attention to only the preceding parts of the sequence. Such an attention mechanism is known as causal self-attention. It's important to note that the Sparse Mixture of Experts model isn't restricted to decoder-only Transformer architectures. In fact, much of the significant work in this field, particularly that by Shazeer et al, revolves around the T5 architecture, which encompasses both encoder and decoder components in the Transformer model."
863 | ]
864 | },
865 | {
866 | "cell_type": "code",
867 | "execution_count": null,
868 | "metadata": {
869 | "application/vnd.databricks.v1+cell": {
870 | "cellMetadata": {
871 | "byteLimit": 2048000,
872 | "rowLimit": 10000
873 | },
874 | "inputWidgets": {},
875 | "nuid": "6f82ca41-a301-4a92-aed9-ba7ac3a2bf88",
876 | "showTitle": false,
877 | "title": ""
878 | },
879 | "id": "lxMSgZWGkRJb",
880 | "outputId": "8d968403-a14f-4f3c-f2ce-9099a2b34f1e"
881 | },
882 | "outputs": [
883 | {
884 | "data": {
885 | "text/plain": [
886 | "torch.Size([4, 8, 16])"
887 | ]
888 | },
889 | "execution_count": 33,
890 | "metadata": {},
891 | "output_type": "execute_result"
892 | }
893 | ],
894 | "source": [
895 | "torch.manual_seed(1337)\n",
896 | "B,T,C = 4,8,32 # batch, time, channels\n",
897 | "x = torch.randn(B,T,C)\n",
898 | "\n",
899 | "# let's see a single Head perform self-attention\n",
900 | "head_size = 16\n",
901 | "key = nn.Linear(C, head_size, bias=False)\n",
902 | "query = nn.Linear(C, head_size, bias=False)\n",
903 | "value = nn.Linear(C, head_size, bias=False)\n",
904 | "k = key(x) # (B, T, 16)\n",
905 | "q = query(x) # (B, T, 16)\n",
906 | "wei = q @ k.transpose(-2, -1) # (B, T, 16) @ (B, 16, T) ---> (B, T, T)\n",
907 | "\n",
908 | "tril = torch.tril(torch.ones(T, T))\n",
909 | "#wei = torch.zeros((T,T))\n",
910 | "wei = wei.masked_fill(tril == 0, float('-inf'))\n",
911 | "wei = F.softmax(wei, dim=-1) #B,T,T\n",
912 | "\n",
913 | "v = value(x) #B,T,H\n",
914 | "out = wei @ v # (B,T,T) @ (B,T,H) -> (B,T,H)\n",
915 | "#The output from this final matrix product is subsequently passsed through a linear layer as shown in the diagram above\n",
916 | "\n",
917 | "out.shape"
918 | ]
919 | },
920 | {
921 | "cell_type": "markdown",
922 | "metadata": {
923 | "application/vnd.databricks.v1+cell": {
924 | "cellMetadata": {},
925 | "inputWidgets": {},
926 | "nuid": "49c278ec-19db-4c5d-b4a3-3bdc45c5a443",
927 | "showTitle": false,
928 | "title": ""
929 | },
930 | "id": "cA3iXggEkRJb"
931 | },
932 | "source": [
933 | "Generalizing and Modularizing code for causal self attention and multi-head causal self attention. Multi-head self attention applied multiple attention heads in parallel, each focusing on a separate section of the channel (the embedding dimension)"
934 | ]
935 | },
936 | {
937 | "cell_type": "code",
938 | "execution_count": null,
939 | "metadata": {
940 | "application/vnd.databricks.v1+cell": {
941 | "cellMetadata": {
942 | "byteLimit": 2048000,
943 | "rowLimit": 10000
944 | },
945 | "inputWidgets": {},
946 | "nuid": "608c6c9f-fb93-43ed-9580-5e782fd90d61",
947 | "showTitle": false,
948 | "title": ""
949 | },
950 | "id": "909nX3PHkRJb"
951 | },
952 | "outputs": [],
953 | "source": [
954 | "#Causal scaled dot product self-Attention Head\n",
955 | "\n",
956 | "n_embd = 64\n",
957 | "n_head = 4\n",
958 | "n_layer = 4\n",
959 | "head_size = 16\n",
960 | "dropout = 0.1\n",
961 | "\n",
962 | "class Head(nn.Module):\n",
963 | " \"\"\" one head of self-attention \"\"\"\n",
964 | "\n",
965 | " def __init__(self, head_size):\n",
966 | " super().__init__()\n",
967 | " self.key = nn.Linear(n_embd, head_size, bias=False)\n",
968 | " self.query = nn.Linear(n_embd, head_size, bias=False)\n",
969 | " self.value = nn.Linear(n_embd, head_size, bias=False)\n",
970 | " self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))\n",
971 | "\n",
972 | " self.dropout = nn.Dropout(dropout)\n",
973 | "\n",
974 | " def forward(self, x):\n",
975 | " B,T,C = x.shape\n",
976 | " k = self.key(x) # (B,T,C)\n",
977 | " q = self.query(x) # (B,T,C)\n",
978 | " # compute attention scores (\"affinities\")\n",
979 | " wei = q @ k.transpose(-2,-1) * C**-0.5 # (B, T, C) @ (B, C, T) -> (B, T, T)\n",
980 | " wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)\n",
981 | " wei = F.softmax(wei, dim=-1) # (B, T, T)\n",
982 | " wei = self.dropout(wei)\n",
983 | " # perform the weighted aggregation of the values\n",
984 | " v = self.value(x) # (B,T,C)\n",
985 | " out = wei @ v # (B, T, T) @ (B, T, C) -> (B, T, C)\n",
986 | " return out"
987 | ]
988 | },
989 | {
990 | "cell_type": "code",
991 | "execution_count": null,
992 | "metadata": {
993 | "application/vnd.databricks.v1+cell": {
994 | "cellMetadata": {
995 | "byteLimit": 2048000,
996 | "rowLimit": 10000
997 | },
998 | "inputWidgets": {},
999 | "nuid": "6e8b31af-f45a-4066-8288-fb0d9c8e2aff",
1000 | "showTitle": false,
1001 | "title": ""
1002 | },
1003 | "id": "T3MoVK_WkRJb"
1004 | },
1005 | "outputs": [],
1006 | "source": [
1007 | "#Multi-Headed Self Attention\n",
1008 | "class MultiHeadAttention(nn.Module):\n",
1009 | " \"\"\" multiple heads of self-attention in parallel \"\"\"\n",
1010 | "\n",
1011 | " def __init__(self, num_heads, head_size):\n",
1012 | " super().__init__()\n",
1013 | " self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])\n",
1014 | " self.proj = nn.Linear(n_embd, n_embd)\n",
1015 | " self.dropout = nn.Dropout(dropout)\n",
1016 | "\n",
1017 | " def forward(self, x):\n",
1018 | " out = torch.cat([h(x) for h in self.heads], dim=-1)\n",
1019 | " out = self.dropout(self.proj(out))\n",
1020 | " return out\n"
1021 | ]
1022 | },
1023 | {
1024 | "cell_type": "code",
1025 | "execution_count": null,
1026 | "metadata": {
1027 | "application/vnd.databricks.v1+cell": {
1028 | "cellMetadata": {
1029 | "byteLimit": 2048000,
1030 | "rowLimit": 10000
1031 | },
1032 | "inputWidgets": {},
1033 | "nuid": "16267e9a-008b-46e3-82ce-2ae41396a1a1",
1034 | "showTitle": false,
1035 | "title": ""
1036 | },
1037 | "id": "T-w53_mSkRJb",
1038 | "outputId": "052e4478-b284-43c7-924c-fcf13deea320"
1039 | },
1040 | "outputs": [
1041 | {
1042 | "data": {
1043 | "text/plain": [
1044 | "torch.Size([4, 8, 64])"
1045 | ]
1046 | },
1047 | "execution_count": 68,
1048 | "metadata": {},
1049 | "output_type": "execute_result"
1050 | }
1051 | ],
1052 | "source": [
1053 | "#Confirming that what's output from multi head attention is the original embedding size\n",
1054 | "B,T,C = 4,8,64 # batch, time, channels\n",
1055 | "x = torch.randn(B,T,C)\n",
1056 | "mha = MultiHeadAttention(4,16)\n",
1057 | "mha(x).shape"
1058 | ]
1059 | },
1060 | {
1061 | "cell_type": "markdown",
1062 | "metadata": {
1063 | "application/vnd.databricks.v1+cell": {
1064 | "cellMetadata": {},
1065 | "inputWidgets": {},
1066 | "nuid": "5f7ff128-7fe5-4a91-b9f2-208e2132e505",
1067 | "showTitle": false,
1068 | "title": ""
1069 | },
1070 | "id": "wNlJTtfhkRJb"
1071 | },
1072 | "source": [
1073 | "### Creating an Expert module i.e. a simple Multi Layer Perceptron"
1074 | ]
1075 | },
1076 | {
1077 | "cell_type": "markdown",
1078 | "metadata": {
1079 | "application/vnd.databricks.v1+cell": {
1080 | "cellMetadata": {},
1081 | "inputWidgets": {},
1082 | "nuid": "f6e422a5-57c1-4b2f-b7b9-2757e109848a",
1083 | "showTitle": false,
1084 | "title": ""
1085 | },
1086 | "id": "zv3fGRpbkRJb"
1087 | },
1088 | "source": [
1089 | "In the Sparse Mixture of Experts (MoE) architecture, the self-attention mechanism within each transformer block remains unchanged. However, a notable alteration occurs in the structure of each block: the standard feed-forward neural network is replaced with several sparsely activated feed-forward networks, known as experts. \"Sparse activation\" refers to the process where each token in the sequence is routed to only a limited number of these experts – typically one or two – out of the total pool available. This modification allows for specialized processing of different parts of the input data, enabling the model to handle a wider range of complexities efficiently."
1090 | ]
1091 | },
1092 | {
1093 | "cell_type": "markdown",
1094 | "metadata": {
1095 | "application/vnd.databricks.v1+cell": {
1096 | "cellMetadata": {},
1097 | "inputWidgets": {},
1098 | "nuid": "efe9fdcc-82eb-4047-9233-ad3cfe8759b1",
1099 | "showTitle": false,
1100 | "title": ""
1101 | },
1102 | "id": "7Kz0Y_P0kRJc"
1103 | },
1104 | "source": [
1105 | ""
1106 | ]
1107 | },
1108 | {
1109 | "cell_type": "code",
1110 | "execution_count": null,
1111 | "metadata": {
1112 | "application/vnd.databricks.v1+cell": {
1113 | "cellMetadata": {
1114 | "byteLimit": 2048000,
1115 | "rowLimit": 10000
1116 | },
1117 | "inputWidgets": {},
1118 | "nuid": "a2f0f382-ab4a-45e1-9dce-27ae0d3da641",
1119 | "showTitle": false,
1120 | "title": ""
1121 | },
1122 | "id": "a-9CYWXgkRJc"
1123 | },
1124 | "outputs": [],
1125 | "source": [
1126 | "#Expert module\n",
1127 | "class Expert(nn.Module):\n",
1128 | " \"\"\" An MLP is a simple linear layer followed by a non-linearity i.e. each Expert \"\"\"\n",
1129 | "\n",
1130 | " def __init__(self, n_embd):\n",
1131 | " super().__init__()\n",
1132 | " self.net = nn.Sequential(\n",
1133 | " nn.Linear(n_embd, 4 * n_embd),\n",
1134 | " nn.ReLU(),\n",
1135 | " nn.Linear(4 * n_embd, n_embd),\n",
1136 | " nn.Dropout(dropout),\n",
1137 | " )\n",
1138 | "\n",
1139 | " def forward(self, x):\n",
1140 | " return self.net(x)"
1141 | ]
1142 | },
1143 | {
1144 | "cell_type": "markdown",
1145 | "metadata": {
1146 | "application/vnd.databricks.v1+cell": {
1147 | "cellMetadata": {},
1148 | "inputWidgets": {},
1149 | "nuid": "a7764385-26e9-4d75-9aa7-ce011023e24e",
1150 | "showTitle": false,
1151 | "title": ""
1152 | },
1153 | "id": "qderdEuykRJc"
1154 | },
1155 | "source": [
1156 | "### Top-k Gating Intuition through an Example"
1157 | ]
1158 | },
1159 | {
1160 | "cell_type": "markdown",
1161 | "metadata": {
1162 | "application/vnd.databricks.v1+cell": {
1163 | "cellMetadata": {},
1164 | "inputWidgets": {},
1165 | "nuid": "d3fca4df-4c47-4e9a-98cd-08cf8ccf7726",
1166 | "showTitle": false,
1167 | "title": ""
1168 | },
1169 | "id": "VxJv5y44kRJc"
1170 | },
1171 | "source": [
1172 | ""
1173 | ]
1174 | },
1175 | {
1176 | "cell_type": "markdown",
1177 | "metadata": {
1178 | "application/vnd.databricks.v1+cell": {
1179 | "cellMetadata": {},
1180 | "inputWidgets": {},
1181 | "nuid": "8e494b86-cdb2-4f2a-8824-5fa2ef4b2606",
1182 | "showTitle": false,
1183 | "title": ""
1184 | },
1185 | "id": "n6DuhY0DkRJc"
1186 | },
1187 | "source": [
1188 | "The gating network, also known as the router, determines which expert network receives the output for each token from the multi-head attention. Let's consider a simple example: suppose there are 4 experts, and the token is to be routed to the top 2 experts. Initially, we input the token into the gating network through a linear layer. This layer projects the input tensor from a shape of (2, 4, 32) — representing (Batch size, Tokens, n_embed, where n_embed is the channel dimension of the input) — to a new shape of (2, 4, 4), which corresponds to (Batch size, Tokens, num_experts), where num_experts is the count of expert networks. Following this, we determine the top k=2 highest values and their respective indices along the last dimension."
1189 | ]
1190 | },
1191 | {
1192 | "cell_type": "code",
1193 | "execution_count": null,
1194 | "metadata": {
1195 | "application/vnd.databricks.v1+cell": {
1196 | "cellMetadata": {
1197 | "byteLimit": 2048000,
1198 | "rowLimit": 10000
1199 | },
1200 | "inputWidgets": {},
1201 | "nuid": "621916ff-2290-4e2f-9fd7-5181ed98d540",
1202 | "showTitle": false,
1203 | "title": ""
1204 | },
1205 | "id": "pNAuFDDvkRJc",
1206 | "outputId": "a9d313d5-1dd1-4df8-9c9a-dc6d0b90d4ed"
1207 | },
1208 | "outputs": [
1209 | {
1210 | "data": {
1211 | "text/plain": [
1212 | "(tensor([[[ 0.0246, -0.0190],\n",
1213 | " [ 0.1991, 0.1513],\n",
1214 | " [ 0.9749, 0.7185],\n",
1215 | " [ 0.4406, -0.8357]],\n",
1216 | " \n",
1217 | " [[ 0.6206, -0.0503],\n",
1218 | " [ 0.8635, 0.3784],\n",
1219 | " [ 0.6828, 0.5972],\n",
1220 | " [ 0.4743, 0.3420]]], grad_fn=),\n",
1221 | " tensor([[[2, 3],\n",
1222 | " [2, 1],\n",
1223 | " [3, 1],\n",
1224 | " [2, 1]],\n",
1225 | " \n",
1226 | " [[0, 2],\n",
1227 | " [0, 3],\n",
1228 | " [3, 2],\n",
1229 | " [3, 0]]]))"
1230 | ]
1231 | },
1232 | "execution_count": 69,
1233 | "metadata": {},
1234 | "output_type": "execute_result"
1235 | }
1236 | ],
1237 | "source": [
1238 | "#Understanding how gating works\n",
1239 | "num_experts = 4\n",
1240 | "top_k=2\n",
1241 | "n_embed=32\n",
1242 | "\n",
1243 | "\n",
1244 | "#Example multi-head attention output for a simple illustrative example, consider n_embed=32, context_length=4 and batch_size=2\n",
1245 | "mh_output = torch.randn(2, 4, n_embed)\n",
1246 | "\n",
1247 | "topkgate_linear = nn.Linear(n_embed, num_experts) # nn.Linear(32, 4)\n",
1248 | "\n",
1249 | "logits = topkgate_linear(mh_output)\n",
1250 | "top_k_logits, top_k_indices = logits.topk(top_k, dim=-1) # Get top-k experts\n",
1251 | "top_k_logits, top_k_indices"
1252 | ]
1253 | },
1254 | {
1255 | "cell_type": "markdown",
1256 | "metadata": {
1257 | "application/vnd.databricks.v1+cell": {
1258 | "cellMetadata": {},
1259 | "inputWidgets": {},
1260 | "nuid": "0f135ff7-0aa3-4b6d-ab5e-42399c48427b",
1261 | "showTitle": false,
1262 | "title": ""
1263 | },
1264 | "id": "EKwAyJxrkRJd"
1265 | },
1266 | "source": [
1267 | "Obtain the sparse gating output by only keeping the top k values in their respective index along the last dimension. Fill the rest with '-inf' and pass through a softmax activation. This pushes '-inf' values to zero, makes the top two values more accentuated and sum to 1. This summation to 1 helps with the weighting of expert outputs"
1268 | ]
1269 | },
1270 | {
1271 | "cell_type": "code",
1272 | "execution_count": null,
1273 | "metadata": {
1274 | "application/vnd.databricks.v1+cell": {
1275 | "cellMetadata": {
1276 | "byteLimit": 2048000,
1277 | "rowLimit": 10000
1278 | },
1279 | "inputWidgets": {},
1280 | "nuid": "735e160a-ef1e-424d-b6d9-09f63ea99ec1",
1281 | "showTitle": false,
1282 | "title": ""
1283 | },
1284 | "id": "IiVejzOpkRJd",
1285 | "outputId": "2ff61217-56f8-4835-d310-2169240fb4a1"
1286 | },
1287 | "outputs": [
1288 | {
1289 | "data": {
1290 | "text/plain": [
1291 | "tensor([[[ -inf, -inf, 0.0246, -0.0190],\n",
1292 | " [ -inf, 0.1513, 0.1991, -inf],\n",
1293 | " [ -inf, 0.7185, -inf, 0.9749],\n",
1294 | " [ -inf, -0.8357, 0.4406, -inf]],\n",
1295 | "\n",
1296 | " [[ 0.6206, -inf, -0.0503, -inf],\n",
1297 | " [ 0.8635, -inf, -inf, 0.3784],\n",
1298 | " [ -inf, -inf, 0.5972, 0.6828],\n",
1299 | " [ 0.3420, -inf, -inf, 0.4743]]], grad_fn=)"
1300 | ]
1301 | },
1302 | "execution_count": 70,
1303 | "metadata": {},
1304 | "output_type": "execute_result"
1305 | }
1306 | ],
1307 | "source": [
1308 | "zeros = torch.full_like(logits, float('-inf')) #full_like clones a tensor and fills it with a specified value (like infinity) for masking or calculations.\n",
1309 | "sparse_logits = zeros.scatter(-1, top_k_indices, top_k_logits)\n",
1310 | "sparse_logits"
1311 | ]
1312 | },
1313 | {
1314 | "cell_type": "code",
1315 | "execution_count": null,
1316 | "metadata": {
1317 | "application/vnd.databricks.v1+cell": {
1318 | "cellMetadata": {
1319 | "byteLimit": 2048000,
1320 | "rowLimit": 10000
1321 | },
1322 | "inputWidgets": {},
1323 | "nuid": "9146e6f9-4eee-4a8b-8338-55072719ed59",
1324 | "showTitle": false,
1325 | "title": ""
1326 | },
1327 | "id": "HFgRxDF4kRJh",
1328 | "outputId": "cde71bbf-ba67-4972-eef1-2fba48a106d5"
1329 | },
1330 | "outputs": [
1331 | {
1332 | "data": {
1333 | "text/plain": [
1334 | "tensor([[[0.0000, 0.0000, 0.5109, 0.4891],\n",
1335 | " [0.0000, 0.4881, 0.5119, 0.0000],\n",
1336 | " [0.0000, 0.4362, 0.0000, 0.5638],\n",
1337 | " [0.0000, 0.2182, 0.7818, 0.0000]],\n",
1338 | "\n",
1339 | " [[0.6617, 0.0000, 0.3383, 0.0000],\n",
1340 | " [0.6190, 0.0000, 0.0000, 0.3810],\n",
1341 | " [0.0000, 0.0000, 0.4786, 0.5214],\n",
1342 | " [0.4670, 0.0000, 0.0000, 0.5330]]], grad_fn=)"
1343 | ]
1344 | },
1345 | "execution_count": 71,
1346 | "metadata": {},
1347 | "output_type": "execute_result"
1348 | }
1349 | ],
1350 | "source": [
1351 | "gating_output= F.softmax(sparse_logits, dim=-1)\n",
1352 | "gating_output"
1353 | ]
1354 | },
1355 | {
1356 | "cell_type": "markdown",
1357 | "metadata": {
1358 | "application/vnd.databricks.v1+cell": {
1359 | "cellMetadata": {},
1360 | "inputWidgets": {},
1361 | "nuid": "fe558b12-e443-4b62-9a85-c59120456352",
1362 | "showTitle": false,
1363 | "title": ""
1364 | },
1365 | "id": "dGJrq2uqkRJh"
1366 | },
1367 | "source": [
1368 | "### Generalizing and Modularizing above code and adding noisy top-k Gating for load balancing"
1369 | ]
1370 | },
1371 | {
1372 | "cell_type": "code",
1373 | "execution_count": null,
1374 | "metadata": {
1375 | "application/vnd.databricks.v1+cell": {
1376 | "cellMetadata": {
1377 | "byteLimit": 2048000,
1378 | "rowLimit": 10000
1379 | },
1380 | "inputWidgets": {},
1381 | "nuid": "45516b59-d814-4853-a34e-d36aae9f04eb",
1382 | "showTitle": false,
1383 | "title": ""
1384 | },
1385 | "id": "TKp4DqwYkRJh"
1386 | },
1387 | "outputs": [],
1388 | "source": [
1389 | "# First define the top k router module\n",
1390 | "class TopkRouter(nn.Module):\n",
1391 | " def __init__(self, n_embed, num_experts, top_k):\n",
1392 | " super(TopkRouter, self).__init__()\n",
1393 | " self.top_k = top_k\n",
1394 | " self.linear =nn.Linear(n_embed, num_experts)\n",
1395 | "\n",
1396 | " def forward(self, mh_ouput):\n",
1397 | " # mh_ouput is the output tensor from multihead self attention block\n",
1398 | " logits = self.linear(mh_output)\n",
1399 | " top_k_logits, indices = logits.topk(self.top_k, dim=-1)\n",
1400 | " zeros = torch.full_like(logits, float('-inf'))\n",
1401 | " sparse_logits = zeros.scatter(-1, indices, top_k_logits)\n",
1402 | " router_output = F.softmax(sparse_logits, dim=-1)\n",
1403 | " return router_output, indices\n",
1404 | "\n"
1405 | ]
1406 | },
1407 | {
1408 | "cell_type": "code",
1409 | "execution_count": null,
1410 | "metadata": {
1411 | "application/vnd.databricks.v1+cell": {
1412 | "cellMetadata": {
1413 | "byteLimit": 2048000,
1414 | "rowLimit": 10000
1415 | },
1416 | "inputWidgets": {},
1417 | "nuid": "c500844f-0866-4bbf-acef-c0c1d4979721",
1418 | "showTitle": false,
1419 | "title": ""
1420 | },
1421 | "id": "KjkouzwkkRJh",
1422 | "outputId": "4e5cd861-4f75-4e98-c3cf-5697fb5f7451"
1423 | },
1424 | "outputs": [
1425 | {
1426 | "data": {
1427 | "text/plain": [
1428 | "(torch.Size([2, 4, 4]),\n",
1429 | " tensor([[[0.4359, 0.0000, 0.5641, 0.0000],\n",
1430 | " [0.6075, 0.0000, 0.3925, 0.0000],\n",
1431 | " [0.6916, 0.3084, 0.0000, 0.0000],\n",
1432 | " [0.0000, 0.0000, 0.4342, 0.5658]],\n",
1433 | " \n",
1434 | " [[0.0000, 0.4527, 0.5473, 0.0000],\n",
1435 | " [0.5313, 0.4687, 0.0000, 0.0000],\n",
1436 | " [0.0000, 0.5572, 0.4428, 0.0000],\n",
1437 | " [0.0000, 0.6293, 0.3707, 0.0000]]], grad_fn=),\n",
1438 | " tensor([[[2, 0],\n",
1439 | " [0, 2],\n",
1440 | " [0, 1],\n",
1441 | " [3, 2]],\n",
1442 | " \n",
1443 | " [[2, 1],\n",
1444 | " [0, 1],\n",
1445 | " [1, 2],\n",
1446 | " [1, 2]]]))"
1447 | ]
1448 | },
1449 | "execution_count": 72,
1450 | "metadata": {},
1451 | "output_type": "execute_result"
1452 | }
1453 | ],
1454 | "source": [
1455 | "#Testing this out:\n",
1456 | "num_experts = 4\n",
1457 | "top_k = 2\n",
1458 | "n_embd = 32\n",
1459 | "\n",
1460 | "mh_output = torch.randn(2, 4, n_embd) # Example input\n",
1461 | "top_k_gate = TopkRouter(n_embd, num_experts, top_k)\n",
1462 | "gating_output, indices = top_k_gate(mh_output)\n",
1463 | "gating_output.shape, gating_output, indices\n",
1464 | "#And it works!!"
1465 | ]
1466 | },
1467 | {
1468 | "cell_type": "markdown",
1469 | "metadata": {
1470 | "application/vnd.databricks.v1+cell": {
1471 | "cellMetadata": {},
1472 | "inputWidgets": {},
1473 | "nuid": "9fa02d0c-3688-4d01-811d-d0b2b851ab33",
1474 | "showTitle": false,
1475 | "title": ""
1476 | },
1477 | "id": "tAouN-GwkRJi"
1478 | },
1479 | "source": [
1480 | "Althought the mixtral paper released recently does not make any mention of it, I believe Noisy top-k Gating is an important tool in training MoE models. Essentially, you don't want all the tokens to be sent to the same set of 'favored' experts. You want a fine balance of exploitation and exploration. For this purpose, to load balance, it is helpful to add standard normal noise to the logits from the gating linear layer. This makes training more efficient"
1481 | ]
1482 | },
1483 | {
1484 | "cell_type": "markdown",
1485 | "metadata": {
1486 | "application/vnd.databricks.v1+cell": {
1487 | "cellMetadata": {},
1488 | "inputWidgets": {},
1489 | "nuid": "e05b3306-b89f-4ebc-901b-f16398a925c2",
1490 | "showTitle": false,
1491 | "title": ""
1492 | },
1493 | "id": "aWeueE83kRJi"
1494 | },
1495 | "source": [
1496 | ""
1497 | ]
1498 | },
1499 | {
1500 | "cell_type": "code",
1501 | "execution_count": null,
1502 | "metadata": {
1503 | "application/vnd.databricks.v1+cell": {
1504 | "cellMetadata": {
1505 | "byteLimit": 2048000,
1506 | "rowLimit": 10000
1507 | },
1508 | "inputWidgets": {},
1509 | "nuid": "dda4d805-373c-48f7-9037-da08fbc06e64",
1510 | "showTitle": false,
1511 | "title": ""
1512 | },
1513 | "id": "ZBrN-w3JkRJi"
1514 | },
1515 | "outputs": [],
1516 | "source": [
1517 | "#Changing the above to accomodate noisy top-k gating\n",
1518 | "class NoisyTopkRouter(nn.Module):\n",
1519 | " def __init__(self, n_embed, num_experts, top_k):\n",
1520 | " super(NoisyTopkRouter, self).__init__()\n",
1521 | " self.top_k = top_k\n",
1522 | " #layer for router logits\n",
1523 | " self.topkroute_linear = nn.Linear(n_embed, num_experts)\n",
1524 | " self.noise_linear =nn.Linear(n_embed, num_experts)\n",
1525 | "\n",
1526 | "\n",
1527 | " def forward(self, mh_output):\n",
1528 | " # mh_ouput is the output tensor from multihead self attention block\n",
1529 | " logits = self.topkroute_linear(mh_output)\n",
1530 | "\n",
1531 | " #Noise logits\n",
1532 | " noise_logits = self.noise_linear(mh_output)\n",
1533 | "\n",
1534 | " #Adding scaled unit gaussian noise to the logits\n",
1535 | " noise = torch.randn_like(logits)*F.softplus(noise_logits)\n",
1536 | " noisy_logits = logits + noise\n",
1537 | "\n",
1538 | " top_k_logits, indices = noisy_logits.topk(self.top_k, dim=-1)\n",
1539 | " zeros = torch.full_like(noisy_logits, float('-inf'))\n",
1540 | " sparse_logits = zeros.scatter(-1, indices, top_k_logits)\n",
1541 | " router_output = F.softmax(sparse_logits, dim=-1)\n",
1542 | " return router_output, indices"
1543 | ]
1544 | },
1545 | {
1546 | "cell_type": "code",
1547 | "execution_count": null,
1548 | "metadata": {
1549 | "application/vnd.databricks.v1+cell": {
1550 | "cellMetadata": {
1551 | "byteLimit": 2048000,
1552 | "rowLimit": 10000
1553 | },
1554 | "inputWidgets": {},
1555 | "nuid": "a01a9d6b-fedb-427d-b0da-c3b2a75a8643",
1556 | "showTitle": false,
1557 | "title": ""
1558 | },
1559 | "id": "7Q6KcH9AkRJi",
1560 | "outputId": "7aea5328-ba96-4c98-b550-042ecf440700"
1561 | },
1562 | "outputs": [
1563 | {
1564 | "data": {
1565 | "text/plain": [
1566 | "(torch.Size([2, 4, 8]),\n",
1567 | " tensor([[[0.0000, 0.0000, 0.0000, 0.5903, 0.0000, 0.0000, 0.0000, 0.4097],\n",
1568 | " [0.6794, 0.0000, 0.0000, 0.0000, 0.0000, 0.3206, 0.0000, 0.0000],\n",
1569 | " [0.0000, 0.0000, 0.0000, 0.0000, 0.2743, 0.7257, 0.0000, 0.0000],\n",
1570 | " [0.0000, 0.0000, 0.1950, 0.0000, 0.8050, 0.0000, 0.0000, 0.0000]],\n",
1571 | " \n",
1572 | " [[0.0000, 0.0000, 0.3905, 0.0000, 0.0000, 0.6095, 0.0000, 0.0000],\n",
1573 | " [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.3606, 0.6394],\n",
1574 | " [0.5243, 0.0000, 0.4757, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],\n",
1575 | " [0.0000, 0.0000, 0.0000, 0.5627, 0.0000, 0.0000, 0.4373, 0.0000]]],\n",
1576 | " grad_fn=),\n",
1577 | " tensor([[[3, 7],\n",
1578 | " [0, 5],\n",
1579 | " [5, 4],\n",
1580 | " [4, 2]],\n",
1581 | " \n",
1582 | " [[5, 2],\n",
1583 | " [7, 6],\n",
1584 | " [0, 2],\n",
1585 | " [3, 6]]]))"
1586 | ]
1587 | },
1588 | "execution_count": 53,
1589 | "metadata": {},
1590 | "output_type": "execute_result"
1591 | }
1592 | ],
1593 | "source": [
1594 | "#Testing this out, again:\n",
1595 | "num_experts = 8\n",
1596 | "top_k = 2\n",
1597 | "n_embd = 16\n",
1598 | "\n",
1599 | "mh_output = torch.randn(2, 4, n_embd) # Example input\n",
1600 | "noisy_top_k_gate = NoisyTopkRouter(n_embd, num_experts, top_k)\n",
1601 | "gating_output, indices = noisy_top_k_gate(mh_output)\n",
1602 | "gating_output.shape, gating_output, indices\n",
1603 | "#It works!!"
1604 | ]
1605 | },
1606 | {
1607 | "cell_type": "markdown",
1608 | "metadata": {
1609 | "application/vnd.databricks.v1+cell": {
1610 | "cellMetadata": {},
1611 | "inputWidgets": {},
1612 | "nuid": "076fa004-a165-42a7-b729-0bca8ad39418",
1613 | "showTitle": false,
1614 | "title": ""
1615 | },
1616 | "id": "XyKjpR-dkRJi"
1617 | },
1618 | "source": [
1619 | "\n",
1620 | "### Creating a sparse Mixture of Experts module\n"
1621 | ]
1622 | },
1623 | {
1624 | "cell_type": "markdown",
1625 | "metadata": {
1626 | "application/vnd.databricks.v1+cell": {
1627 | "cellMetadata": {},
1628 | "inputWidgets": {},
1629 | "nuid": "6747b8de-0086-4cb0-8fbd-46ee95457eb9",
1630 | "showTitle": false,
1631 | "title": ""
1632 | },
1633 | "id": "UsRCy7i3kRJi"
1634 | },
1635 | "source": [
1636 | "The primary aspect of this process involves the gating network's output. After acquiring these results, the top k values are selectively multiplied with the outputs from the corresponding top-k experts for a given token. This selective multiplication forms a weighted sum, which constitutes the SparseMoe block's output. The critical and challenging part of this process is to avoid unnecessary multiplications. It's essential to conduct forward passes only for the top_k experts and then compute this weighted sum. Performing forward passes for each expert would defeat the purpose of employing a sparse MoE, as it would no longer be sparse."
1637 | ]
1638 | },
1639 | {
1640 | "cell_type": "code",
1641 | "execution_count": null,
1642 | "metadata": {
1643 | "application/vnd.databricks.v1+cell": {
1644 | "cellMetadata": {
1645 | "byteLimit": 2048000,
1646 | "rowLimit": 10000
1647 | },
1648 | "inputWidgets": {},
1649 | "nuid": "d6809b3f-4be9-4859-b39e-24fcdd6c8d86",
1650 | "showTitle": false,
1651 | "title": ""
1652 | },
1653 | "id": "7dDUHU_IkRJi"
1654 | },
1655 | "outputs": [],
1656 | "source": [
1657 | "class SparseMoE(nn.Module):\n",
1658 | " def __init__(self, n_embed, num_experts, top_k):\n",
1659 | " super(SparseMoE, self).__init__()\n",
1660 | " self.router = NoisyTopkRouter(n_embed, num_experts, top_k)\n",
1661 | " self.experts = nn.ModuleList([Expert(n_embed) for _ in range(num_experts)])\n",
1662 | " self.top_k = top_k\n",
1663 | "\n",
1664 | " def forward(self, x):\n",
1665 | " gating_output, indices = self.router(x)\n",
1666 | " final_output = torch.zeros_like(x)\n",
1667 | "\n",
1668 | " # Reshape inputs for batch processing\n",
1669 | " flat_x = x.view(-1, x.size(-1))\n",
1670 | " flat_gating_output = gating_output.view(-1, gating_output.size(-1))\n",
1671 | "\n",
1672 | " # Process each expert in parallel\n",
1673 | " for i, expert in enumerate(self.experts):\n",
1674 | " # Create a mask for the inputs where the current expert is in top-k\n",
1675 | " expert_mask = (indices == i).any(dim=-1)\n",
1676 | " flat_mask = expert_mask.view(-1)\n",
1677 | "\n",
1678 | " if flat_mask.any():\n",
1679 | " expert_input = flat_x[flat_mask]\n",
1680 | " expert_output = expert(expert_input)\n",
1681 | "\n",
1682 | " # Extract and apply gating scores\n",
1683 | " gating_scores = flat_gating_output[flat_mask, i].unsqueeze(1)\n",
1684 | " weighted_output = expert_output * gating_scores\n",
1685 | "\n",
1686 | " # Update final output additively by indexing and adding\n",
1687 | " final_output[expert_mask] += weighted_output.squeeze(1)\n",
1688 | "\n",
1689 | " return final_output\n",
1690 | "\n",
1691 | "\n"
1692 | ]
1693 | },
1694 | {
1695 | "cell_type": "code",
1696 | "execution_count": null,
1697 | "metadata": {
1698 | "application/vnd.databricks.v1+cell": {
1699 | "cellMetadata": {
1700 | "byteLimit": 2048000,
1701 | "rowLimit": 10000
1702 | },
1703 | "inputWidgets": {},
1704 | "nuid": "06239630-0a1c-47c9-976c-7770f3d82e18",
1705 | "showTitle": false,
1706 | "title": ""
1707 | },
1708 | "id": "q8kDLI1ukRJj",
1709 | "outputId": "69e7b330-cd47-4094-99c2-7928f8b60d0d"
1710 | },
1711 | "outputs": [
1712 | {
1713 | "name": "stdout",
1714 | "output_type": "stream",
1715 | "text": [
1716 | "Shape of the final output: torch.Size([4, 8, 16])\n",
1717 | "tensor([[[-0.0124, -0.0000, -0.0108, -0.0143, -0.0194, 0.0898, -0.0572,\n",
1718 | " -0.0453, 0.0351, -0.0658, 0.0853, -0.1535, 0.1538, 0.0340,\n",
1719 | " -0.0605, -0.0227],\n",
1720 | " [-0.1214, 0.0766, -0.0763, -0.0457, 0.0166, -0.0268, -0.0185,\n",
1721 | " 0.1372, -0.1202, -0.1757, 0.1136, 0.0000, -0.2136, -0.2425,\n",
1722 | " 0.0288, 0.0558],\n",
1723 | " [-0.0000, 0.2654, 0.0843, 0.0458, 0.2352, 0.2606, -0.1340,\n",
1724 | " -0.0359, 0.0971, -0.0165, -0.0690, 0.0838, -0.2352, -0.0203,\n",
1725 | " 0.3269, -0.1147],\n",
1726 | " [-0.0240, -0.0332, 0.1032, 0.0554, 0.0276, -0.0000, 0.0204,\n",
1727 | " -0.0719, 0.1320, -0.1036, 0.0562, 0.0419, 0.0832, -0.2330,\n",
1728 | " -0.0000, -0.0260],\n",
1729 | " [-0.1457, 0.2298, 0.2523, 0.3260, 0.0813, -0.1724, 0.2074,\n",
1730 | " -0.0335, 0.1967, -0.0120, -0.0000, 0.0296, -0.0000, 0.2665,\n",
1731 | " 0.0430, 0.1385],\n",
1732 | " [-0.0000, -0.0434, 0.1454, -0.0459, 0.0238, -0.0000, -0.0702,\n",
1733 | " -0.0082, -0.0920, -0.0000, -0.0085, 0.0000, -0.2530, -0.4184,\n",
1734 | " -0.1274, 0.0950],\n",
1735 | " [-0.0546, 0.0944, 0.2003, 0.1041, 0.0753, -0.0000, 0.0733,\n",
1736 | " -0.0000, 0.0678, 0.0014, -0.0723, -0.0742, 0.0435, -0.0637,\n",
1737 | " 0.0122, 0.0000],\n",
1738 | " [ 0.0446, 0.0268, -0.0366, 0.1081, -0.0579, -0.1137, 0.0549,\n",
1739 | " 0.0162, 0.0200, -0.0445, -0.0532, 0.1075, -0.0230, 0.1296,\n",
1740 | " -0.1638, 0.0537]],\n",
1741 | "\n",
1742 | " [[-0.0390, -0.0269, 0.1131, -0.0722, 0.1846, -0.0380, -0.1055,\n",
1743 | " -0.0782, 0.1396, 0.0696, -0.0958, 0.0161, -0.0769, -0.1703,\n",
1744 | " -0.0732, -0.0180],\n",
1745 | " [-0.1349, 0.2449, -0.1247, -0.0149, 0.0774, -0.0732, 0.0755,\n",
1746 | " -0.0000, 0.0900, -0.1598, -0.1198, -0.0007, -0.0159, -0.2708,\n",
1747 | " -0.0636, -0.0289],\n",
1748 | " [ 0.0368, 0.0000, -0.1293, -0.0336, 0.0515, -0.0790, 0.0472,\n",
1749 | " -0.0830, 0.0000, -0.0521, -0.1743, -0.0205, 0.0320, -0.1011,\n",
1750 | " 0.0055, -0.0228],\n",
1751 | " [ 0.0993, -0.0521, 0.2786, -0.0304, -0.0000, 0.1973, -0.0000,\n",
1752 | " 0.0400, 0.0748, -0.1042, -0.3078, 0.0385, -0.2545, 0.3172,\n",
1753 | " -0.3621, -0.0708],\n",
1754 | " [ 0.0000, 0.1344, 0.0696, -0.2714, -0.1912, 0.0044, -0.1503,\n",
1755 | " -0.0262, 0.0000, -0.0136, -0.0329, -0.4539, 0.0990, 0.2285,\n",
1756 | " -0.3197, 0.0112],\n",
1757 | " [-0.1248, 0.1747, -0.1317, -0.1361, -0.0093, -0.0505, 0.0239,\n",
1758 | " -0.0009, -0.1792, 0.0079, 0.1453, -0.1140, -0.2461, -0.0000,\n",
1759 | " 0.1578, 0.1527],\n",
1760 | " [-0.2012, 0.2509, -0.0933, -0.0000, 0.1976, -0.1527, -0.0379,\n",
1761 | " 0.3109, -0.2121, 0.0012, 0.3155, 0.1832, -0.0000, -0.4221,\n",
1762 | " 0.2019, 0.1104],\n",
1763 | " [-0.1177, -0.1666, -0.0471, -0.0000, 0.0864, 0.1395, -0.1160,\n",
1764 | " 0.0994, -0.0007, 0.0159, 0.1186, 0.0068, -0.1566, -0.1419,\n",
1765 | " -0.0000, -0.1168]],\n",
1766 | "\n",
1767 | " [[-0.1889, -0.1712, -0.0252, 0.0000, 0.1354, 0.0078, -0.3176,\n",
1768 | " -0.0588, 0.0764, 0.1522, -0.1602, 0.2140, -0.1569, -0.0161,\n",
1769 | " 0.0060, -0.2089],\n",
1770 | " [-0.0592, -0.1243, -0.0000, -0.1623, 0.0841, -0.0263, -0.0239,\n",
1771 | " 0.2556, 0.2700, 0.0405, 0.0842, -0.0692, -0.0505, 0.0000,\n",
1772 | " -0.4926, 0.1858],\n",
1773 | " [ 0.0551, -0.0318, 0.0195, -0.0098, -0.0351, -0.0271, 0.0646,\n",
1774 | " 0.0014, 0.0169, -0.0162, -0.0135, 0.0070, 0.0116, -0.0627,\n",
1775 | " -0.0154, 0.0733],\n",
1776 | " [-0.1270, 0.3063, -0.1849, 0.0446, -0.0512, 0.0783, -0.0440,\n",
1777 | " 0.1640, 0.1924, -0.1780, 0.0000, -0.0520, -0.0187, -0.0196,\n",
1778 | " 0.3640, -0.0000],\n",
1779 | " [ 0.0000, 0.0442, 0.1172, 0.0441, -0.0102, 0.0660, 0.0529,\n",
1780 | " -0.1618, 0.1265, 0.0812, -0.1357, -0.0991, -0.0341, 0.1885,\n",
1781 | " -0.0000, -0.0753],\n",
1782 | " [ 0.0524, 0.2439, -0.1062, -0.1822, 0.1625, -0.0000, 0.2078,\n",
1783 | " 0.1900, 0.1585, -0.1435, 0.1644, 0.0843, 0.0162, 0.0000,\n",
1784 | " 0.0924, 0.1394],\n",
1785 | " [-0.0000, -0.0693, 0.0000, -0.1409, -0.0603, 0.0282, 0.1201,\n",
1786 | " -0.2591, -0.1273, -0.1428, 0.0000, -0.0790, 0.0134, -0.1038,\n",
1787 | " 0.0461, 0.1344],\n",
1788 | " [-0.1980, -0.0087, 0.0991, -0.0000, -0.2497, -0.1385, -0.0985,\n",
1789 | " 0.0974, -0.4163, -0.1940, -0.1078, 0.0458, -0.2890, -0.2785,\n",
1790 | " -0.1109, 0.1543]],\n",
1791 | "\n",
1792 | " [[-0.0324, 0.0557, -0.0000, -0.1034, 0.1203, 0.0427, -0.0242,\n",
1793 | " 0.0000, -0.1433, -0.0120, 0.1024, -0.0855, -0.0474, -0.0702,\n",
1794 | " 0.0556, 0.0727],\n",
1795 | " [ 0.1194, -0.0000, 0.0720, -0.0555, -0.1901, -0.4236, 0.0438,\n",
1796 | " 0.1632, 0.1087, 0.0192, -0.0385, 0.0332, -0.0000, 0.0847,\n",
1797 | " 0.1672, 0.1100],\n",
1798 | " [-0.0620, -0.0724, 0.0220, -0.0000, -0.0757, -0.0936, 0.0000,\n",
1799 | " 0.0757, -0.0122, -0.1435, -0.0289, 0.0000, -0.0816, -0.0648,\n",
1800 | " -0.0638, 0.0208],\n",
1801 | " [-0.1030, 0.1554, 0.1701, 0.2989, 0.0000, -0.0722, 0.1687,\n",
1802 | " -0.1795, -0.0000, -0.0000, -0.0096, -0.2642, -0.2379, 0.1062,\n",
1803 | " -0.1318, 0.3303],\n",
1804 | " [-0.0768, 0.1000, 0.0917, -0.0479, -0.0475, 0.0435, 0.1054,\n",
1805 | " 0.0197, 0.1609, -0.0499, -0.2033, 0.0000, 0.0201, 0.1276,\n",
1806 | " -0.0000, -0.0724],\n",
1807 | " [ 0.0046, 0.0318, 0.0000, -0.2774, -0.0000, -0.1755, -0.0641,\n",
1808 | " -0.0596, 0.0422, 0.0099, 0.0066, -0.1313, -0.0019, 0.1601,\n",
1809 | " -0.1242, 0.0000],\n",
1810 | " [-0.0234, 0.3237, 0.0500, 0.0302, -0.1091, -0.0000, 0.0154,\n",
1811 | " -0.0177, -0.0602, -0.4930, -0.1593, -0.1109, -0.0000, 0.1590,\n",
1812 | " 0.0000, -0.1682],\n",
1813 | " [-0.1681, -0.1363, 0.0161, -0.0556, 0.0000, -0.1762, -0.0621,\n",
1814 | " 0.0830, -0.0099, -0.0000, 0.0494, -0.0318, -0.0597, 0.0600,\n",
1815 | " 0.0852, 0.0050]]], grad_fn=)\n"
1816 | ]
1817 | }
1818 | ],
1819 | "source": [
1820 | "import torch\n",
1821 | "import torch.nn as nn\n",
1822 | "\n",
1823 | "#Let's test this out\n",
1824 | "num_experts = 8\n",
1825 | "top_k = 2\n",
1826 | "n_embd = 16\n",
1827 | "dropout=0.1\n",
1828 | "\n",
1829 | "mh_output = torch.randn(4, 8, n_embd) # Example multi-head attention output\n",
1830 | "sparse_moe = SparseMoE(n_embd, num_experts, top_k)\n",
1831 | "final_output = sparse_moe(mh_output)\n",
1832 | "print(\"Shape of the final output:\", final_output.shape)\n",
1833 | "print(final_output)"
1834 | ]
1835 | },
1836 | {
1837 | "cell_type": "markdown",
1838 | "metadata": {
1839 | "application/vnd.databricks.v1+cell": {
1840 | "cellMetadata": {},
1841 | "inputWidgets": {},
1842 | "nuid": "7476ca07-a315-4108-aa77-46173a703ca2",
1843 | "showTitle": false,
1844 | "title": ""
1845 | },
1846 | "id": "l7GoxCi2kRJj"
1847 | },
1848 | "source": [
1849 | "To emphasize, it's important to recognize that the magnitudes of the top_k experts output from the Router/ gating network, as illustrated in the code above, are also significant. These top_k indices identify the experts that are activated, and the magnitude of the values in those top_k dimensions determines their respective weighting. This concept of weighted summation is further highlighted in the diagram below."
1850 | ]
1851 | },
1852 | {
1853 | "cell_type": "markdown",
1854 | "metadata": {
1855 | "application/vnd.databricks.v1+cell": {
1856 | "cellMetadata": {},
1857 | "inputWidgets": {},
1858 | "nuid": "d99b5dce-301e-4380-8263-b5cfb4136ab2",
1859 | "showTitle": false,
1860 | "title": ""
1861 | },
1862 | "id": "e9a_oQ2akRJj"
1863 | },
1864 | "source": [
1865 | ""
1866 | ]
1867 | },
1868 | {
1869 | "cell_type": "markdown",
1870 | "metadata": {
1871 | "application/vnd.databricks.v1+cell": {
1872 | "cellMetadata": {},
1873 | "inputWidgets": {},
1874 | "nuid": "da5f3be4-f155-4d6c-bcbd-2f88a088261f",
1875 | "showTitle": false,
1876 | "title": ""
1877 | },
1878 | "id": "vMZCda7dkRJj"
1879 | },
1880 | "source": [
1881 | "### Putting it all together"
1882 | ]
1883 | },
1884 | {
1885 | "cell_type": "code",
1886 | "execution_count": null,
1887 | "metadata": {
1888 | "application/vnd.databricks.v1+cell": {
1889 | "cellMetadata": {
1890 | "byteLimit": 2048000,
1891 | "rowLimit": 10000
1892 | },
1893 | "inputWidgets": {},
1894 | "nuid": "0eaf71cd-c77e-40c7-b5be-e364e91685cf",
1895 | "showTitle": false,
1896 | "title": ""
1897 | },
1898 | "id": "f8yczkFHkRJj"
1899 | },
1900 | "outputs": [],
1901 | "source": [
1902 | "#First defining hyperparameters and boiler plate code. Imports and data preparation code is repeated for convenience\n",
1903 | "import torch\n",
1904 | "import torch.nn as nn\n",
1905 | "from torch.nn import functional as F\n",
1906 | "from torch.nn import init\n",
1907 | "\n",
1908 | "# hyperparameters\n",
1909 | "batch_size = 16 # how many independent sequences will we process in parallel?\n",
1910 | "block_size = 32 # what is the maximum context length for predictions?\n",
1911 | "max_iters = 5000\n",
1912 | "eval_interval = 100\n",
1913 | "learning_rate = 1e-3\n",
1914 | "device = 'cuda' if torch.cuda.is_available() else 'cpu'\n",
1915 | "eval_iters = 400\n",
1916 | "head_size = 16\n",
1917 | "n_embed = 128\n",
1918 | "n_head = 8\n",
1919 | "n_layer = 8\n",
1920 | "dropout = 0.1\n",
1921 | "num_experts = 8\n",
1922 | "top_k = 2\n",
1923 | "# ------------\n",
1924 | "\n",
1925 | "torch.manual_seed(1337)\n",
1926 | "\n",
1927 | "with open('input.txt', 'r', encoding='utf-8') as f:\n",
1928 | " text = f.read()\n",
1929 | "\n",
1930 | "# here are all the unique characters that occur in this text\n",
1931 | "chars = sorted(list(set(text)))\n",
1932 | "vocab_size = len(chars)\n",
1933 | "# create a mapping from characters to integers\n",
1934 | "stoi = { ch:i for i,ch in enumerate(chars) }\n",
1935 | "itos = { i:ch for i,ch in enumerate(chars) }\n",
1936 | "encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers\n",
1937 | "decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string\n",
1938 | "\n",
1939 | "# Train and test splits\n",
1940 | "data = torch.tensor(encode(text), dtype=torch.long)\n",
1941 | "n = int(0.9*len(data)) # first 90% will be train, rest val\n",
1942 | "train_data = data[:n]\n",
1943 | "val_data = data[n:]\n",
1944 | "\n",
1945 | "# data loading\n",
1946 | "def get_batch(split):\n",
1947 | " # generate a small batch of data of inputs x and targets y\n",
1948 | " data = train_data if split == 'train' else val_data\n",
1949 | " ix = torch.randint(len(data) - block_size, (batch_size,))\n",
1950 | " x = torch.stack([data[i:i+block_size] for i in ix])\n",
1951 | " y = torch.stack([data[i+1:i+block_size+1] for i in ix])\n",
1952 | " x, y = x.to(device), y.to(device)\n",
1953 | " return x, y\n",
1954 | "\n",
1955 | "@torch.no_grad()\n",
1956 | "def estimate_loss():\n",
1957 | " out = {}\n",
1958 | " model.eval()\n",
1959 | " for split in ['train', 'val']:\n",
1960 | " losses = torch.zeros(eval_iters)\n",
1961 | " for k in range(eval_iters):\n",
1962 | " X, Y = get_batch(split)\n",
1963 | " logits, loss = model(X, Y)\n",
1964 | " losses[k] = loss.item()\n",
1965 | " out[split] = losses.mean()\n",
1966 | " model.train()\n",
1967 | " return out"
1968 | ]
1969 | },
1970 | {
1971 | "cell_type": "code",
1972 | "execution_count": null,
1973 | "metadata": {
1974 | "application/vnd.databricks.v1+cell": {
1975 | "cellMetadata": {
1976 | "byteLimit": 2048000,
1977 | "rowLimit": 10000
1978 | },
1979 | "inputWidgets": {},
1980 | "nuid": "ee1180f7-5004-4425-87fe-9a81a17b9024",
1981 | "showTitle": false,
1982 | "title": ""
1983 | },
1984 | "id": "QfxJ6B2fkRJj"
1985 | },
1986 | "outputs": [],
1987 | "source": [
1988 | "class Head(nn.Module):\n",
1989 | " \"\"\" one head of self-attention \"\"\"\n",
1990 | "\n",
1991 | " def __init__(self, head_size):\n",
1992 | " super().__init__()\n",
1993 | " self.key = nn.Linear(n_embed, head_size, bias=False)\n",
1994 | " self.query = nn.Linear(n_embed, head_size, bias=False)\n",
1995 | " self.value = nn.Linear(n_embed, head_size, bias=False)\n",
1996 | " self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))\n",
1997 | "\n",
1998 | " self.dropout = nn.Dropout(dropout)\n",
1999 | "\n",
2000 | " def forward(self, x):\n",
2001 | " B,T,C = x.shape\n",
2002 | " k = self.key(x) # (B,T,C)\n",
2003 | " q = self.query(x) # (B,T,C)\n",
2004 | " # compute attention scores (\"affinities\")\n",
2005 | " wei = q @ k.transpose(-2,-1) * C**-0.5 # (B, T, C) @ (B, C, T) -> (B, T, T)\n",
2006 | " wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)\n",
2007 | " wei = F.softmax(wei, dim=-1) # (B, T, T)\n",
2008 | " wei = self.dropout(wei)\n",
2009 | " # perform the weighted aggregation of the values\n",
2010 | " v = self.value(x) # (B,T,C)\n",
2011 | " out = wei @ v # (B, T, T) @ (B, T, C) -> (B, T, C)\n",
2012 | " return out\n",
2013 | "\n",
2014 | "#Multi-Headed Self Attention\n",
2015 | "class MultiHeadAttention(nn.Module):\n",
2016 | " \"\"\" multiple heads of self-attention in parallel \"\"\"\n",
2017 | "\n",
2018 | " def __init__(self, num_heads, head_size):\n",
2019 | " super().__init__()\n",
2020 | " self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])\n",
2021 | " self.proj = nn.Linear(n_embed, n_embed)\n",
2022 | " self.dropout = nn.Dropout(dropout)\n",
2023 | "\n",
2024 | " def forward(self, x):\n",
2025 | " out = torch.cat([h(x) for h in self.heads], dim=-1)\n",
2026 | " out = self.dropout(self.proj(out))\n",
2027 | " return out\n"
2028 | ]
2029 | },
2030 | {
2031 | "cell_type": "code",
2032 | "execution_count": null,
2033 | "metadata": {
2034 | "application/vnd.databricks.v1+cell": {
2035 | "cellMetadata": {
2036 | "byteLimit": 2048000,
2037 | "rowLimit": 10000
2038 | },
2039 | "inputWidgets": {},
2040 | "nuid": "03611a92-aaa2-4e0d-9755-cba56f96c794",
2041 | "showTitle": false,
2042 | "title": ""
2043 | },
2044 | "id": "y35jVCZYkRJk"
2045 | },
2046 | "outputs": [],
2047 | "source": [
2048 | "#Expert module\n",
2049 | "class Expert(nn.Module):\n",
2050 | " \"\"\" An MLP is a simple linear layer followed by a non-linearity i.e. each Expert \"\"\"\n",
2051 | "\n",
2052 | " def __init__(self, n_embed):\n",
2053 | " super().__init__()\n",
2054 | " self.net = nn.Sequential(\n",
2055 | " nn.Linear(n_embed, 4 * n_embed),\n",
2056 | " nn.ReLU(),\n",
2057 | " nn.Linear(4 * n_embed, n_embed),\n",
2058 | " nn.Dropout(dropout),\n",
2059 | " )\n",
2060 | "\n",
2061 | " def forward(self, x):\n",
2062 | " return self.net(x)\n",
2063 | "\n",
2064 | "#noisy top-k gating\n",
2065 | "class NoisyTopkRouter(nn.Module):\n",
2066 | " def __init__(self, n_embed, num_experts, top_k):\n",
2067 | " super(NoisyTopkRouter, self).__init__()\n",
2068 | " self.top_k = top_k\n",
2069 | " #layer for router logits\n",
2070 | " self.topkroute_linear = nn.Linear(n_embed, num_experts)\n",
2071 | " self.noise_linear =nn.Linear(n_embed, num_experts)\n",
2072 | "\n",
2073 | "\n",
2074 | " def forward(self, mh_output):\n",
2075 | " # mh_ouput is the output tensor from multihead self attention block\n",
2076 | " logits = self.topkroute_linear(mh_output)\n",
2077 | "\n",
2078 | " #Noise logits\n",
2079 | " noise_logits = self.noise_linear(mh_output)\n",
2080 | "\n",
2081 | " #Adding scaled unit gaussian noise to the logits\n",
2082 | " noise = torch.randn_like(logits)*F.softplus(noise_logits)\n",
2083 | " noisy_logits = logits + noise\n",
2084 | "\n",
2085 | " top_k_logits, indices = noisy_logits.topk(self.top_k, dim=-1)\n",
2086 | " zeros = torch.full_like(noisy_logits, float('-inf'))\n",
2087 | " sparse_logits = zeros.scatter(-1, indices, top_k_logits)\n",
2088 | " router_output = F.softmax(sparse_logits, dim=-1)\n",
2089 | " return router_output, indices\n",
2090 | "\n",
2091 | "#Now create the sparse mixture of experts module\n",
2092 | "class SparseMoE(nn.Module):\n",
2093 | " def __init__(self, n_embed, num_experts, top_k):\n",
2094 | " super(SparseMoE, self).__init__()\n",
2095 | " self.router = NoisyTopkRouter(n_embed, num_experts, top_k)\n",
2096 | " self.experts = nn.ModuleList([Expert(n_embed) for _ in range(num_experts)])\n",
2097 | " self.top_k = top_k\n",
2098 | "\n",
2099 | " def forward(self, x):\n",
2100 | " gating_output, indices = self.router(x)\n",
2101 | " final_output = torch.zeros_like(x)\n",
2102 | "\n",
2103 | " # Reshape inputs for batch processing\n",
2104 | " flat_x = x.view(-1, x.size(-1))\n",
2105 | " flat_gating_output = gating_output.view(-1, gating_output.size(-1))\n",
2106 | "\n",
2107 | " # Process each expert in parallel\n",
2108 | " for i, expert in enumerate(self.experts):\n",
2109 | " # Create a mask for the inputs where the current expert is in top-k\n",
2110 | " expert_mask = (indices == i).any(dim=-1)\n",
2111 | " flat_mask = expert_mask.view(-1)\n",
2112 | "\n",
2113 | " if flat_mask.any():\n",
2114 | " expert_input = flat_x[flat_mask]\n",
2115 | " expert_output = expert(expert_input)\n",
2116 | "\n",
2117 | " # Extract and apply gating scores\n",
2118 | " gating_scores = flat_gating_output[flat_mask, i].unsqueeze(1)\n",
2119 | " weighted_output = expert_output * gating_scores\n",
2120 | "\n",
2121 | " # Update final output additively by indexing and adding\n",
2122 | " final_output[expert_mask] += weighted_output.squeeze(1)\n",
2123 | "\n",
2124 | " return final_output"
2125 | ]
2126 | },
2127 | {
2128 | "cell_type": "code",
2129 | "execution_count": null,
2130 | "metadata": {
2131 | "application/vnd.databricks.v1+cell": {
2132 | "cellMetadata": {
2133 | "byteLimit": 2048000,
2134 | "rowLimit": 10000
2135 | },
2136 | "inputWidgets": {},
2137 | "nuid": "bfdff2bb-092f-41c8-9a33-c84e6f8d6633",
2138 | "showTitle": false,
2139 | "title": ""
2140 | },
2141 | "id": "jGiuRsSgkRJk"
2142 | },
2143 | "outputs": [],
2144 | "source": [
2145 | "#First create a self attention + mixture of experts block, that may be repeated several number of times\n",
2146 | "#Copy pasting key architecture variables for clarity\n",
2147 | "\n",
2148 | "class Block(nn.Module):\n",
2149 | " \"\"\" Mixture of Experts Transformer block: communication followed by computation (multi-head self attention + SparseMoE) \"\"\"\n",
2150 | "\n",
2151 | " def __init__(self, n_embed, n_head, num_experts, top_k):\n",
2152 | " # n_embed: embedding dimension, n_head: the number of heads we'd like\n",
2153 | " super().__init__()\n",
2154 | " head_size = n_embed // n_head\n",
2155 | " self.sa = MultiHeadAttention(n_head, head_size)\n",
2156 | " self.smoe = SparseMoE(n_embed, num_experts, top_k)\n",
2157 | " self.ln1 = nn.LayerNorm(n_embed)\n",
2158 | " self.ln2 = nn.LayerNorm(n_embed)\n",
2159 | "\n",
2160 | " def forward(self, x):\n",
2161 | " x = x + self.sa(self.ln1(x))\n",
2162 | " x = x + self.smoe(self.ln2(x))\n",
2163 | " return x"
2164 | ]
2165 | },
2166 | {
2167 | "cell_type": "code",
2168 | "execution_count": null,
2169 | "metadata": {
2170 | "application/vnd.databricks.v1+cell": {
2171 | "cellMetadata": {
2172 | "byteLimit": 2048000,
2173 | "rowLimit": 10000
2174 | },
2175 | "inputWidgets": {},
2176 | "nuid": "2d32a276-d0cc-4808-90d7-62441771af44",
2177 | "showTitle": false,
2178 | "title": ""
2179 | },
2180 | "id": "RpyZBA71kRJk"
2181 | },
2182 | "outputs": [],
2183 | "source": [
2184 | "#Finally putting it all together to crease a sparse mixture of experts language model\n",
2185 | "class SparseMoELanguageModel(nn.Module):\n",
2186 | "\n",
2187 | " def __init__(self):\n",
2188 | " super().__init__()\n",
2189 | " # each token directly reads off the logits for the next token from a lookup table\n",
2190 | " self.token_embedding_table = nn.Embedding(vocab_size, n_embed)\n",
2191 | " self.position_embedding_table = nn.Embedding(block_size, n_embed)\n",
2192 | " self.blocks = nn.Sequential(*[Block(n_embed, n_head=n_head, num_experts=num_experts,top_k=top_k) for _ in range(n_layer)])\n",
2193 | " self.ln_f = nn.LayerNorm(n_embed) # final layer norm\n",
2194 | " self.lm_head = nn.Linear(n_embed, vocab_size)\n",
2195 | "\n",
2196 | " def forward(self, idx, targets=None):\n",
2197 | " B, T = idx.shape\n",
2198 | "\n",
2199 | " # idx and targets are both (B,T) tensor of integers\n",
2200 | " tok_emb = self.token_embedding_table(idx) # (B,T,C)\n",
2201 | " pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)\n",
2202 | " x = tok_emb + pos_emb # (B,T,C)\n",
2203 | " x = self.blocks(x) # (B,T,C)\n",
2204 | " x = self.ln_f(x) # (B,T,C)\n",
2205 | " logits = self.lm_head(x) # (B,T,vocab_size)\n",
2206 | "\n",
2207 | " if targets is None:\n",
2208 | " loss = None\n",
2209 | " else:\n",
2210 | " B, T, C = logits.shape\n",
2211 | " logits = logits.view(B*T, C)\n",
2212 | " targets = targets.view(B*T)\n",
2213 | " loss = F.cross_entropy(logits, targets)\n",
2214 | "\n",
2215 | " return logits, loss\n",
2216 | "\n",
2217 | " def generate(self, idx, max_new_tokens):\n",
2218 | " # idx is (B, T) array of indices in the current context\n",
2219 | " for _ in range(max_new_tokens):\n",
2220 | " # crop idx to the last block_size tokens\n",
2221 | " idx_cond = idx[:, -block_size:]\n",
2222 | " # get the predictions\n",
2223 | " logits, loss = self(idx_cond)\n",
2224 | " # focus only on the last time step\n",
2225 | " logits = logits[:, -1, :] # becomes (B, C)\n",
2226 | " # apply softmax to get probabilities\n",
2227 | " probs = F.softmax(logits, dim=-1) # (B, C)\n",
2228 | " # sample from the distribution\n",
2229 | " idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)\n",
2230 | " # append sampled index to the running sequence\n",
2231 | " idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)\n",
2232 | " return idx"
2233 | ]
2234 | },
2235 | {
2236 | "cell_type": "markdown",
2237 | "metadata": {
2238 | "application/vnd.databricks.v1+cell": {
2239 | "cellMetadata": {},
2240 | "inputWidgets": {},
2241 | "nuid": "622ba7ce-3f20-4820-8982-93f3d3b7be09",
2242 | "showTitle": false,
2243 | "title": ""
2244 | },
2245 | "id": "bBzQXmfykRJk"
2246 | },
2247 | "source": [
2248 | "Kaiming He initialization is used here because of presence of ReLU activations in the experts. Feel free to experiment with Glorot initialization which is more commonly used in transformers. Jeremy Howard's Fastai Part 2 has an excellent lecture that implements these from scratch: https://course.fast.ai/Lessons/lesson17.html"
2249 | ]
2250 | },
2251 | {
2252 | "cell_type": "code",
2253 | "execution_count": null,
2254 | "metadata": {
2255 | "application/vnd.databricks.v1+cell": {
2256 | "cellMetadata": {
2257 | "byteLimit": 2048000,
2258 | "rowLimit": 10000
2259 | },
2260 | "inputWidgets": {},
2261 | "nuid": "a6d3c057-08ee-4c1b-8013-6a88b2eadac5",
2262 | "showTitle": false,
2263 | "title": ""
2264 | },
2265 | "id": "guGaJqHbkRJk"
2266 | },
2267 | "outputs": [],
2268 | "source": [
2269 | "\n",
2270 | "def kaiming_init_weights(m):\n",
2271 | " if isinstance (m, (nn.Linear)):\n",
2272 | " init.kaiming_normal_(m.weight)"
2273 | ]
2274 | },
2275 | {
2276 | "cell_type": "code",
2277 | "execution_count": null,
2278 | "metadata": {
2279 | "application/vnd.databricks.v1+cell": {
2280 | "cellMetadata": {
2281 | "byteLimit": 2048000,
2282 | "rowLimit": 10000
2283 | },
2284 | "inputWidgets": {},
2285 | "nuid": "5b4d9525-8405-4a51-adda-661aba004e57",
2286 | "showTitle": false,
2287 | "title": ""
2288 | },
2289 | "id": "nJGGkXz4kRJl",
2290 | "outputId": "8518ec23-caa0-4167-88c6-65a7c905743a"
2291 | },
2292 | "outputs": [
2293 | {
2294 | "data": {
2295 | "text/plain": [
2296 | "SparseMoELanguageModel(\n",
2297 | " (token_embedding_table): Embedding(65, 128)\n",
2298 | " (position_embedding_table): Embedding(32, 128)\n",
2299 | " (blocks): Sequential(\n",
2300 | " (0): Block(\n",
2301 | " (sa): MultiHeadAttention(\n",
2302 | " (heads): ModuleList(\n",
2303 | " (0-7): 8 x Head(\n",
2304 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2305 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2306 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2307 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2308 | " )\n",
2309 | " )\n",
2310 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2311 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2312 | " )\n",
2313 | " (smoe): SparseMoE(\n",
2314 | " (router): NoisyTopkRouter(\n",
2315 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2316 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2317 | " )\n",
2318 | " (experts): ModuleList(\n",
2319 | " (0-7): 8 x Expert(\n",
2320 | " (net): Sequential(\n",
2321 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2322 | " (1): ReLU()\n",
2323 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2324 | " (3): Dropout(p=0.1, inplace=False)\n",
2325 | " )\n",
2326 | " )\n",
2327 | " )\n",
2328 | " )\n",
2329 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2330 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2331 | " )\n",
2332 | " (1): Block(\n",
2333 | " (sa): MultiHeadAttention(\n",
2334 | " (heads): ModuleList(\n",
2335 | " (0-7): 8 x Head(\n",
2336 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2337 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2338 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2339 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2340 | " )\n",
2341 | " )\n",
2342 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2343 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2344 | " )\n",
2345 | " (smoe): SparseMoE(\n",
2346 | " (router): NoisyTopkRouter(\n",
2347 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2348 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2349 | " )\n",
2350 | " (experts): ModuleList(\n",
2351 | " (0-7): 8 x Expert(\n",
2352 | " (net): Sequential(\n",
2353 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2354 | " (1): ReLU()\n",
2355 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2356 | " (3): Dropout(p=0.1, inplace=False)\n",
2357 | " )\n",
2358 | " )\n",
2359 | " )\n",
2360 | " )\n",
2361 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2362 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2363 | " )\n",
2364 | " (2): Block(\n",
2365 | " (sa): MultiHeadAttention(\n",
2366 | " (heads): ModuleList(\n",
2367 | " (0-7): 8 x Head(\n",
2368 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2369 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2370 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2371 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2372 | " )\n",
2373 | " )\n",
2374 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2375 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2376 | " )\n",
2377 | " (smoe): SparseMoE(\n",
2378 | " (router): NoisyTopkRouter(\n",
2379 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2380 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2381 | " )\n",
2382 | " (experts): ModuleList(\n",
2383 | " (0-7): 8 x Expert(\n",
2384 | " (net): Sequential(\n",
2385 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2386 | " (1): ReLU()\n",
2387 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2388 | " (3): Dropout(p=0.1, inplace=False)\n",
2389 | " )\n",
2390 | " )\n",
2391 | " )\n",
2392 | " )\n",
2393 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2394 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2395 | " )\n",
2396 | " (3): Block(\n",
2397 | " (sa): MultiHeadAttention(\n",
2398 | " (heads): ModuleList(\n",
2399 | " (0-7): 8 x Head(\n",
2400 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2401 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2402 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2403 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2404 | " )\n",
2405 | " )\n",
2406 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2407 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2408 | " )\n",
2409 | " (smoe): SparseMoE(\n",
2410 | " (router): NoisyTopkRouter(\n",
2411 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2412 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2413 | " )\n",
2414 | " (experts): ModuleList(\n",
2415 | " (0-7): 8 x Expert(\n",
2416 | " (net): Sequential(\n",
2417 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2418 | " (1): ReLU()\n",
2419 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2420 | " (3): Dropout(p=0.1, inplace=False)\n",
2421 | " )\n",
2422 | " )\n",
2423 | " )\n",
2424 | " )\n",
2425 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2426 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2427 | " )\n",
2428 | " (4): Block(\n",
2429 | " (sa): MultiHeadAttention(\n",
2430 | " (heads): ModuleList(\n",
2431 | " (0-7): 8 x Head(\n",
2432 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2433 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2434 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2435 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2436 | " )\n",
2437 | " )\n",
2438 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2439 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2440 | " )\n",
2441 | " (smoe): SparseMoE(\n",
2442 | " (router): NoisyTopkRouter(\n",
2443 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2444 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2445 | " )\n",
2446 | " (experts): ModuleList(\n",
2447 | " (0-7): 8 x Expert(\n",
2448 | " (net): Sequential(\n",
2449 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2450 | " (1): ReLU()\n",
2451 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2452 | " (3): Dropout(p=0.1, inplace=False)\n",
2453 | " )\n",
2454 | " )\n",
2455 | " )\n",
2456 | " )\n",
2457 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2458 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2459 | " )\n",
2460 | " (5): Block(\n",
2461 | " (sa): MultiHeadAttention(\n",
2462 | " (heads): ModuleList(\n",
2463 | " (0-7): 8 x Head(\n",
2464 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2465 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2466 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2467 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2468 | " )\n",
2469 | " )\n",
2470 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2471 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2472 | " )\n",
2473 | " (smoe): SparseMoE(\n",
2474 | " (router): NoisyTopkRouter(\n",
2475 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2476 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2477 | " )\n",
2478 | " (experts): ModuleList(\n",
2479 | " (0-7): 8 x Expert(\n",
2480 | " (net): Sequential(\n",
2481 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2482 | " (1): ReLU()\n",
2483 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2484 | " (3): Dropout(p=0.1, inplace=False)\n",
2485 | " )\n",
2486 | " )\n",
2487 | " )\n",
2488 | " )\n",
2489 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2490 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2491 | " )\n",
2492 | " (6): Block(\n",
2493 | " (sa): MultiHeadAttention(\n",
2494 | " (heads): ModuleList(\n",
2495 | " (0-7): 8 x Head(\n",
2496 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2497 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2498 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2499 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2500 | " )\n",
2501 | " )\n",
2502 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2503 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2504 | " )\n",
2505 | " (smoe): SparseMoE(\n",
2506 | " (router): NoisyTopkRouter(\n",
2507 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2508 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2509 | " )\n",
2510 | " (experts): ModuleList(\n",
2511 | " (0-7): 8 x Expert(\n",
2512 | " (net): Sequential(\n",
2513 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2514 | " (1): ReLU()\n",
2515 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2516 | " (3): Dropout(p=0.1, inplace=False)\n",
2517 | " )\n",
2518 | " )\n",
2519 | " )\n",
2520 | " )\n",
2521 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2522 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2523 | " )\n",
2524 | " (7): Block(\n",
2525 | " (sa): MultiHeadAttention(\n",
2526 | " (heads): ModuleList(\n",
2527 | " (0-7): 8 x Head(\n",
2528 | " (key): Linear(in_features=128, out_features=16, bias=False)\n",
2529 | " (query): Linear(in_features=128, out_features=16, bias=False)\n",
2530 | " (value): Linear(in_features=128, out_features=16, bias=False)\n",
2531 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2532 | " )\n",
2533 | " )\n",
2534 | " (proj): Linear(in_features=128, out_features=128, bias=True)\n",
2535 | " (dropout): Dropout(p=0.1, inplace=False)\n",
2536 | " )\n",
2537 | " (smoe): SparseMoE(\n",
2538 | " (router): NoisyTopkRouter(\n",
2539 | " (topkroute_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2540 | " (noise_linear): Linear(in_features=128, out_features=8, bias=True)\n",
2541 | " )\n",
2542 | " (experts): ModuleList(\n",
2543 | " (0-7): 8 x Expert(\n",
2544 | " (net): Sequential(\n",
2545 | " (0): Linear(in_features=128, out_features=512, bias=True)\n",
2546 | " (1): ReLU()\n",
2547 | " (2): Linear(in_features=512, out_features=128, bias=True)\n",
2548 | " (3): Dropout(p=0.1, inplace=False)\n",
2549 | " )\n",
2550 | " )\n",
2551 | " )\n",
2552 | " )\n",
2553 | " (ln1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2554 | " (ln2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2555 | " )\n",
2556 | " )\n",
2557 | " (ln_f): LayerNorm((128,), eps=1e-05, elementwise_affine=True)\n",
2558 | " (lm_head): Linear(in_features=128, out_features=65, bias=True)\n",
2559 | ")"
2560 | ]
2561 | },
2562 | "execution_count": 38,
2563 | "metadata": {},
2564 | "output_type": "execute_result"
2565 | }
2566 | ],
2567 | "source": [
2568 | "model = SparseMoELanguageModel()\n",
2569 | "model.apply(kaiming_init_weights)"
2570 | ]
2571 | },
2572 | {
2573 | "cell_type": "markdown",
2574 | "metadata": {
2575 | "application/vnd.databricks.v1+cell": {
2576 | "cellMetadata": {},
2577 | "inputWidgets": {},
2578 | "nuid": "6adf1d04-e668-4d14-b691-161ea4e4dccf",
2579 | "showTitle": false,
2580 | "title": ""
2581 | },
2582 | "id": "_cb1-L8ckRJl"
2583 | },
2584 | "source": [
2585 | "I have used mlflow to track and log the metrics I care about and the training hyperparameters. The training loop in the next cell includes this mlflow code. If you prefer to just train without using mlflow, the subsequent cell has code without the mlflow code. However, I find it very convenient to track parameters and metrics, particularly when experimenting."
2586 | ]
2587 | },
2588 | {
2589 | "cell_type": "code",
2590 | "execution_count": null,
2591 | "metadata": {
2592 | "application/vnd.databricks.v1+cell": {
2593 | "cellMetadata": {
2594 | "byteLimit": 2048000,
2595 | "rowLimit": 10000
2596 | },
2597 | "inputWidgets": {},
2598 | "nuid": "b8968247-0d7b-4460-b96b-06743b31c55d",
2599 | "showTitle": false,
2600 | "title": ""
2601 | },
2602 | "id": "WTG1Fv4SkRJl",
2603 | "outputId": "38318015-63a9-4959-cfe0-cab305625f49"
2604 | },
2605 | "outputs": [
2606 | {
2607 | "name": "stdout",
2608 | "output_type": "stream",
2609 | "text": [
2610 | "8.996545 M parameters\n",
2611 | "step 0: train loss 5.3223, val loss 5.3166\n",
2612 | "step 100: train loss 2.7351, val loss 2.7429\n",
2613 | "step 200: train loss 2.5125, val loss 2.5233\n",
2614 | "step 300: train loss 2.4239, val loss 2.4384\n",
2615 | "step 400: train loss 2.3477, val loss 2.3656\n",
2616 | "step 500: train loss 2.2743, val loss 2.3040\n",
2617 | "step 600: train loss 2.2087, val loss 2.2199\n",
2618 | "step 700: train loss 2.1461, val loss 2.1853\n",
2619 | "step 800: train loss 2.1018, val loss 2.1418\n",
2620 | "step 900: train loss 2.0592, val loss 2.1055\n",
2621 | "step 1000: train loss 2.0138, val loss 2.0822\n",
2622 | "step 1100: train loss 1.9820, val loss 2.0486\n",
2623 | "step 1200: train loss 1.9536, val loss 2.0383\n",
2624 | "step 1300: train loss 1.9218, val loss 2.0070\n",
2625 | "step 1400: train loss 1.9077, val loss 2.0059\n",
2626 | "step 1500: train loss 1.8831, val loss 1.9784\n",
2627 | "step 1600: train loss 1.8527, val loss 1.9740\n",
2628 | "step 1700: train loss 1.8309, val loss 1.9468\n",
2629 | "step 1800: train loss 1.8157, val loss 1.9401\n",
2630 | "step 1900: train loss 1.7953, val loss 1.9243\n",
2631 | "step 2000: train loss 1.7853, val loss 1.9158\n",
2632 | "step 2100: train loss 1.7746, val loss 1.8969\n",
2633 | "step 2200: train loss 1.7527, val loss 1.8901\n",
2634 | "step 2300: train loss 1.7433, val loss 1.8770\n",
2635 | "step 2400: train loss 1.7327, val loss 1.8827\n",
2636 | "step 2500: train loss 1.7183, val loss 1.8713\n",
2637 | "step 2600: train loss 1.7155, val loss 1.8592\n",
2638 | "step 2700: train loss 1.7089, val loss 1.8564\n",
2639 | "step 2800: train loss 1.6978, val loss 1.8500\n",
2640 | "step 2900: train loss 1.6902, val loss 1.8340\n",
2641 | "step 3000: train loss 1.6854, val loss 1.8398\n",
2642 | "step 3100: train loss 1.6680, val loss 1.8313\n",
2643 | "step 3200: train loss 1.6666, val loss 1.8225\n",
2644 | "step 3300: train loss 1.6508, val loss 1.8268\n",
2645 | "step 3400: train loss 1.6499, val loss 1.8148\n",
2646 | "step 3500: train loss 1.6438, val loss 1.8068\n",
2647 | "step 3600: train loss 1.6317, val loss 1.7923\n",
2648 | "step 3700: train loss 1.6314, val loss 1.7856\n",
2649 | "step 3800: train loss 1.6260, val loss 1.7862\n",
2650 | "step 3900: train loss 1.6092, val loss 1.7757\n",
2651 | "step 4000: train loss 1.6116, val loss 1.7753\n",
2652 | "step 4100: train loss 1.6024, val loss 1.7823\n",
2653 | "step 4200: train loss 1.6067, val loss 1.7650\n",
2654 | "step 4300: train loss 1.5895, val loss 1.7629\n",
2655 | "step 4400: train loss 1.5940, val loss 1.7623\n",
2656 | "step 4500: train loss 1.5937, val loss 1.7506\n",
2657 | "step 4600: train loss 1.5941, val loss 1.7743\n",
2658 | "step 4700: train loss 1.5787, val loss 1.7646\n",
2659 | "step 4800: train loss 1.5786, val loss 1.7585\n",
2660 | "step 4900: train loss 1.5719, val loss 1.7439\n",
2661 | "step 4999: train loss 1.5712, val loss 1.7508\n"
2662 | ]
2663 | }
2664 | ],
2665 | "source": [
2666 | "#Using MLFlow\n",
2667 | "m = model.to(device)\n",
2668 | "# print the number of parameters in the model\n",
2669 | "print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')\n",
2670 | "\n",
2671 | "# create a PyTorch optimizer\n",
2672 | "optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)\n",
2673 | "#mlflow.set_experiment(\"makeMoE\")\n",
2674 | "with mlflow.start_run():\n",
2675 | " #If you use mlflow.autolog() this will be automatically logged. I chose to explicitly log here for completeness\n",
2676 | " params = {\"batch_size\": batch_size , \"block_size\" : block_size, \"max_iters\": max_iters, \"eval_interval\": eval_interval,\n",
2677 | " \"learning_rate\": learning_rate, \"device\": device, \"eval_iters\": eval_iters, \"dropout\" : dropout, \"num_experts\": num_experts, \"top_k\": top_k }\n",
2678 | " mlflow.log_params(params)\n",
2679 | " for iter in range(max_iters):\n",
2680 | "\n",
2681 | " # every once in a while evaluate the loss on train and val sets\n",
2682 | " if iter % eval_interval == 0 or iter == max_iters - 1:\n",
2683 | " losses = estimate_loss()\n",
2684 | " print(f\"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}\")\n",
2685 | " metrics = {\"train_loss\": float(losses['train']), \"val_loss\": float(losses['val'])}\n",
2686 | " mlflow.log_metrics(metrics, step=iter)\n",
2687 | "\n",
2688 | "\n",
2689 | " # sample a batch of data\n",
2690 | " xb, yb = get_batch('train')\n",
2691 | "\n",
2692 | " # evaluate the loss\n",
2693 | " logits, loss = model(xb, yb)\n",
2694 | " optimizer.zero_grad(set_to_none=True)\n",
2695 | " loss.backward()\n",
2696 | " optimizer.step()"
2697 | ]
2698 | },
2699 | {
2700 | "cell_type": "markdown",
2701 | "metadata": {
2702 | "application/vnd.databricks.v1+cell": {
2703 | "cellMetadata": {},
2704 | "inputWidgets": {},
2705 | "nuid": "1ed96085-c292-4624-a2cc-be8aad38df79",
2706 | "showTitle": false,
2707 | "title": ""
2708 | },
2709 | "id": "jFBVfgfekRJl"
2710 | },
2711 | "source": [
2712 | "Logging train and validation losses gives you a good indication of how the training is going. The plot shows that I probably should have stopped around 4500 steps (when the validation loss jumps up a bit)\n",
2713 | "\n",
2714 | ""
2715 | ]
2716 | },
2717 | {
2718 | "cell_type": "code",
2719 | "execution_count": null,
2720 | "metadata": {
2721 | "application/vnd.databricks.v1+cell": {
2722 | "cellMetadata": {},
2723 | "inputWidgets": {},
2724 | "nuid": "6360e1b7-94c4-4ef1-a850-9bc93f49a083",
2725 | "showTitle": false,
2726 | "title": ""
2727 | },
2728 | "id": "WP_2lcRUkRJl"
2729 | },
2730 | "outputs": [],
2731 | "source": [
2732 | "#Not using MLflow\n",
2733 | "m = model.to(device)\n",
2734 | "# print the number of parameters in the model\n",
2735 | "print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')\n",
2736 | "\n",
2737 | "# create a PyTorch optimizer\n",
2738 | "optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)\n",
2739 | "\n",
2740 | "for iter in range(max_iters):\n",
2741 | "\n",
2742 | " # every once in a while evaluate the loss on train and val sets\n",
2743 | " if iter % eval_interval == 0 or iter == max_iters - 1:\n",
2744 | " losses = estimate_loss()\n",
2745 | " print(f\"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}\")\n",
2746 | "\n",
2747 | " # sample a batch of data\n",
2748 | " xb, yb = get_batch('train')\n",
2749 | "\n",
2750 | " # evaluate the loss\n",
2751 | " logits, loss = model(xb, yb)\n",
2752 | " optimizer.zero_grad(set_to_none=True)\n",
2753 | " loss.backward()\n",
2754 | " optimizer.step()"
2755 | ]
2756 | },
2757 | {
2758 | "cell_type": "code",
2759 | "execution_count": null,
2760 | "metadata": {
2761 | "application/vnd.databricks.v1+cell": {
2762 | "cellMetadata": {
2763 | "byteLimit": 2048000,
2764 | "rowLimit": 10000
2765 | },
2766 | "inputWidgets": {},
2767 | "nuid": "8aa6e4c4-c688-4985-a3b8-e2af1f771e54",
2768 | "showTitle": false,
2769 | "title": ""
2770 | },
2771 | "id": "W4yshpXMkRJl",
2772 | "outputId": "e69af1c7-2e2f-475c-eeba-b20dec8532c2"
2773 | },
2774 | "outputs": [
2775 | {
2776 | "name": "stdout",
2777 | "output_type": "stream",
2778 | "text": [
2779 | "\n",
2780 | "And, rem?\n",
2781 | "He say, the soul froom, from Merver:\n",
2782 | "And cirture muck on this part son Turn the will:\n",
2783 | "The fulist somet on glace: O they were\n",
2784 | "Le I scide, on thouch scaribe hoptant would\n",
2785 | "And chnot did the croblarious too contle your life,,\n",
2786 | "Some lo you her, alas forfour-porth, it, see!\n",
2787 | "What, when is a strong of though first.\n",
2788 | "\n",
2789 | "DUKE VINCENVENTIO:\n",
2790 | "If it ever fecond he town sue kigh now,\n",
2791 | "That thou wold'st is steen 't.\n",
2792 | "\n",
2793 | "SIMNA:\n",
2794 | "Angent her; no, my a born Yorthort,\n",
2795 | "Romeoos soun and lawf to your sawe with ch a woft ttastly defy,\n",
2796 | "To declay the soul art; and meart smad.\n",
2797 | "\n",
2798 | "CORPIOLLANUS:\n",
2799 | "Which I cannot shall do from by born und ot cold warrike,\n",
2800 | "What king we best anone wrave's going of heard and good\n",
2801 | "Thus playvage; you have wold the grace.\n",
2802 | "\n",
2803 | "KING EDWARD:\n",
2804 | "Daughtia I they honour of your king thissand yish, there Marcius has found Romeo\n",
2805 | "And Havaulint cound is the and such shall diake her forture\n",
2806 | "The rights:' chy Villona, in I thenruns!\n",
2807 | "\n",
2808 | "What you, in posinn the dayms bore,\n",
2809 | "As recompe sontts stand, where thronough is thy gracieful misic?\n",
2810 | "\n",
2811 | "DUKE VINCENCENTIO:\n",
2812 | "When I fangly wilt dovines ear ach surch to mearts treck impost not,\n",
2813 | "Lord, go my abeging thus, igainst onlove's incruent!\n",
2814 | "\n",
2815 | "Pum, God GlouNT:\n",
2816 | "Why, to this unclomer bed: who we priol,\n",
2817 | "Farewell eye! first me, thosto I are the affair yea, to not, when\n",
2818 | "on you his give magetine.\n",
2819 | "\n",
2820 | "DUKE VINCENTIO:\n",
2821 | "I have madast true; he hope ever thrubt a got to crave.\n",
2822 | "\n",
2823 | "ClONTISTINGNUS:\n",
2824 | "TYet ago, cumbot to down withat these was the connoure.\n",
2825 | "This, when your elses: deaths, Henry, thrink and of mennine effirm'd, 'tis littly Beardings agay\n",
2826 | "Teld, are is steek make rough, in\n",
2827 | "having givant and of thy that jucing an,\n",
2828 | "But, over no some.\n",
2829 | "\n",
2830 | "WARWICK:\n",
2831 | "I am last, cromend, Cablarlius;\n",
2832 | "That everceigal whils ghaves nobled him ineace?\n",
2833 | "\n",
2834 | "LEONTES:\n",
2835 | "May, It it say; was thou suit hast\n",
2836 | "on yough. I am follow to the balk it;\n",
2837 | "Sixcted Harce petchol by his doubard'd,\n",
2838 | "I am chouncealos! a my life, and see me jeblearry, be with fliful so son!\n",
2839 | "\n",
2840 | "LEONTES:\n",
2841 | "How wus have up frompriton!\n",
2842 | "\n",
2843 | "BRUTUS:\n",
2844 | "To and than \n"
2845 | ]
2846 | }
2847 | ],
2848 | "source": [
2849 | "# generate from the model. Not great. Not too bad either\n",
2850 | "context = torch.zeros((1, 1), dtype=torch.long, device=device)\n",
2851 | "print(decode(m.generate(context, max_new_tokens=2000)[0].tolist()))"
2852 | ]
2853 | }
2854 | ],
2855 | "metadata": {
2856 | "application/vnd.databricks.v1+notebook": {
2857 | "dashboards": [],
2858 | "language": "python",
2859 | "notebookMetadata": {
2860 | "pythonIndentUnit": 4
2861 | },
2862 | "notebookName": "makeMoE_from_Scratch",
2863 | "widgets": {}
2864 | },
2865 | "colab": {
2866 | "include_colab_link": true,
2867 | "provenance": []
2868 | },
2869 | "language_info": {
2870 | "name": "python"
2871 | }
2872 | },
2873 | "nbformat": 4,
2874 | "nbformat_minor": 0
2875 | }
2876 |
--------------------------------------------------------------------------------