├── covidmx
├── tests
│ ├── __init__.py
│ ├── test_serendipia.py
│ ├── test_dge.py
│ └── test_plots.py
├── __init__.py
├── covidmx.py
├── utils.py
├── dge_plot.py
├── serendipia.py
└── dge.py
├── .github
├── images
│ ├── confirmados-nacional.png
│ ├── sospechosos-nacional.png
│ ├── confirmados-MÉXICO-muns.png
│ ├── confirmados-JALISCO-muns.png
│ ├── confirmados-MORELOS-muns.png
│ ├── confirmados-nacional-muns.png
│ └── confirmados-CIUDAD DE MÉXICO-muns.png
└── workflows
│ ├── pythonpublish.yml
│ ├── dev_test.yml
│ └── pythonpackage.yml
├── requirements.txt
├── Dockerfile
├── Makefile
├── setup.py
├── LICENSE
├── .gitignore
└── README.md
/covidmx/tests/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/covidmx/__init__.py:
--------------------------------------------------------------------------------
1 | from covidmx.covidmx import CovidMX
2 |
--------------------------------------------------------------------------------
/.github/images/confirmados-nacional.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AzulGarza/covidmx/HEAD/.github/images/confirmados-nacional.png
--------------------------------------------------------------------------------
/.github/images/sospechosos-nacional.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AzulGarza/covidmx/HEAD/.github/images/sospechosos-nacional.png
--------------------------------------------------------------------------------
/.github/images/confirmados-MÉXICO-muns.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AzulGarza/covidmx/HEAD/.github/images/confirmados-MÉXICO-muns.png
--------------------------------------------------------------------------------
/.github/images/confirmados-JALISCO-muns.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AzulGarza/covidmx/HEAD/.github/images/confirmados-JALISCO-muns.png
--------------------------------------------------------------------------------
/.github/images/confirmados-MORELOS-muns.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AzulGarza/covidmx/HEAD/.github/images/confirmados-MORELOS-muns.png
--------------------------------------------------------------------------------
/.github/images/confirmados-nacional-muns.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AzulGarza/covidmx/HEAD/.github/images/confirmados-nacional-muns.png
--------------------------------------------------------------------------------
/.github/images/confirmados-CIUDAD DE MÉXICO-muns.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/AzulGarza/covidmx/HEAD/.github/images/confirmados-CIUDAD DE MÉXICO-muns.png
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | more-itertools>=6.0.0
2 | pandas>=0.25.2
3 | Unidecode>=1.1.1
4 | requests==2.21.0
5 | xlrd==1.2.0
6 | mapsmx==0.0.3
7 | matplotlib==3.0.3
8 | mapclassify==2.2.0
9 | descartes==1.1.0
10 | wget>=1.0
11 | tqdm
12 |
--------------------------------------------------------------------------------
/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM python:3.7.2
2 |
3 | # Install requirements
4 | COPY requirements.txt /tmp/requirements.txt
5 | RUN pip install -r /tmp/requirements.txt
6 |
7 | RUN pip install jupyterlab
8 |
9 | RUN apt-get -qq update && apt-get install -y build-essential \
10 | libssl-dev groff \
11 | && rm -rf /var/lib/apt/lists/*
12 |
--------------------------------------------------------------------------------
/Makefile:
--------------------------------------------------------------------------------
1 | IMAGE := covidmx
2 | ROOT := $(shell dirname $(realpath $(firstword ${MAKEFILE_LIST})))
3 | PORT := 8888
4 | JUPYTER_KIND := lab
5 | STORAGE_DIR := storage
6 |
7 | DOCKER_PARAMETERS := \
8 | --user $(shell id -u) \
9 | -v ${ROOT}:/covidmx \
10 | -w /covidmx
11 |
12 | init:
13 | docker build . -t ${IMAGE} && mkdir -p ${STORAGE_DIR}
14 |
15 | jupyter:
16 | docker run -d --rm ${DOCKER_PARAMETERS} -e HOME=/tmp -p ${PORT}:8888 ${IMAGE} \
17 | bash -c "jupyter ${JUPYTER_KIND} --ip=0.0.0.0 --no-browser --NotebookApp.token=''"
18 |
--------------------------------------------------------------------------------
/covidmx/tests/test_serendipia.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from covidmx import CovidMX
3 |
4 |
5 | def test_returns_data():
6 | try:
7 | covid_data = CovidMX(source='Serendipia').get_data()
8 | covid_data = CovidMX(source='Serendipia', date='18-04-2020').get_data()
9 | raw_data = CovidMX(source='Serendipia', clean=False).get_data()
10 | confirmed = CovidMX(source='Serendipia', kind="confirmed").get_data()
11 | suspects = CovidMX(source='Serendipia', kind="suspects").get_data()
12 | except BaseException:
13 | assert False, "Test Serendipia failed"
14 |
--------------------------------------------------------------------------------
/.github/workflows/pythonpublish.yml:
--------------------------------------------------------------------------------
1 | # This workflows will upload a Python Package using Twine when a release is created
2 | # For more information see: https://help.github.com/en/actions/language-and-framework-guides/using-python-with-github-actions#publishing-to-package-registries
3 |
4 | name: Upload Python Package
5 |
6 | on:
7 | release:
8 | types: [created]
9 |
10 | jobs:
11 | deploy:
12 |
13 | runs-on: ubuntu-latest
14 |
15 | steps:
16 | - uses: actions/checkout@v2
17 | - name: Set up Python
18 | uses: actions/setup-python@v1
19 | with:
20 | python-version: '3.x'
21 | - name: Install dependencies
22 | run: |
23 | python -m pip install --upgrade pip
24 | pip install setuptools wheel twine
25 | - name: Build and publish
26 | env:
27 | TWINE_USERNAME: ${{ secrets.PYPI_USERNAME }}
28 | TWINE_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
29 | run: |
30 | python setup.py sdist bdist_wheel
31 | twine upload dist/*
32 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | import setuptools
2 |
3 | with open("README.md", "r") as fh:
4 | long_description = fh.read()
5 |
6 | setuptools.setup(
7 | name="covidmx",
8 | version="0.3.1",
9 | author="Federico Garza",
10 | author_email="fede.garza.ramirez@gmail.com",
11 | description="Python API to get information about COVID-19 in México.",
12 | long_description=long_description,
13 | long_description_content_type="text/markdown",
14 | url="https://github.com/FedericoGarza/covidmx",
15 | packages=setuptools.find_packages(),
16 | classifiers=[
17 | "Programming Language :: Python :: 3",
18 | "License :: OSI Approved :: MIT License",
19 | "Operating System :: OS Independent",
20 | ],
21 | python_requires='>=3.5',
22 | install_requires = [
23 | "more-itertools>=6.0.0",
24 | "pandas>=0.25.2",
25 | "Unidecode>=1.1.1",
26 | "requests>=2.21.0",
27 | "xlrd>=1.2.0",
28 | "mapsmx>=0.0.3",
29 | "matplotlib>=3.0.3",
30 | "mapclassify>=2.2.0",
31 | "descartes>=1.1.0",
32 | "wget>=1.0"
33 | ]
34 | )
35 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2020 Federico Garza
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/covidmx/tests/test_dge.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from covidmx import CovidMX
3 | import shutil
4 |
5 | def test_returns_data():
6 | try:
7 | covid_dge_data_saved = CovidMX(data_path="./database").get_data() #date='07-06-2020',
8 | shutil.rmtree("./database")
9 | covid_dge_data = CovidMX().get_data()
10 | raw_dge_data = CovidMX(clean=False).get_data()
11 | covid_dge_data, catalogo_data = CovidMX(return_catalogo=True).get_data()
12 | covid_dge_data, descripcion_data = CovidMX(return_descripcion=True).get_data()
13 | covid_dge_data, catalogo_data, descripcion_data = CovidMX(return_catalogo=True, return_descripcion=True).get_data()
14 |
15 | historical_date = CovidMX(clean=False, date='04-12-2020', date_format='%m-%d-%Y').get_data()
16 | historical_date_1 = CovidMX(date='2020-04-12', date_format='%Y-%m-%d').get_data()
17 | historical_date_2 = CovidMX(clean=False, date='12-04-2020').get_data()
18 |
19 | except BaseException:
20 | assert False, "Test DGE failed"
21 |
22 |
23 | def main():
24 | test_returns_data()
25 |
26 | if __name__ == "__main__":
27 | main()
28 |
--------------------------------------------------------------------------------
/.github/workflows/dev_test.yml:
--------------------------------------------------------------------------------
1 | # This workflow will install Python dependencies, run tests and lint with a variety of Python versions
2 | # For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
3 |
4 | name: Python package
5 |
6 | on:
7 | push:
8 | branches: [ dev ]
9 |
10 | jobs:
11 | build:
12 |
13 | runs-on: ubuntu-latest
14 | strategy:
15 | matrix:
16 | python-version: [3.5, 3.6, 3.7, 3.8]
17 |
18 | steps:
19 | - uses: actions/checkout@v2
20 | - name: Set up Python ${{ matrix.python-version }}
21 | uses: actions/setup-python@v1
22 | with:
23 | python-version: ${{ matrix.python-version }}
24 | - name: Install dependencies
25 | run: |
26 | python -m pip install --upgrade pip
27 | pip install -r requirements.txt
28 | - name: Lint with flake8
29 | run: |
30 | pip install flake8
31 | # stop the build if there are Python syntax errors or undefined names
32 | flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
33 | # exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
34 | flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
35 | - name: Test with pytest
36 | run: |
37 | pip install pytest
38 | pytest
39 |
--------------------------------------------------------------------------------
/covidmx/tests/test_plots.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from covidmx import CovidMX
3 |
4 |
5 | def test_makes_plot():
6 | try:
7 | dge_plot = CovidMX().get_plot()
8 | for st in dge_plot.available_status:
9 | file_name = '{}.png'.format(st)
10 | mx_map = dge_plot.plot_map(status=st, save_file_name=file_name)
11 | mx_map_with_muns = dge_plot.plot_map(status=st, add_municipalities=True, save_file_name=file_name)
12 | cdmx_map = dge_plot.plot_map(status=st, state='CIUDAD DE MÉXICO', save_file_name=file_name)
13 | cdmx_map_with_muns = dge_plot.plot_map(status=st, state='CIUDAD DE MÉXICO', add_municipalities=True, save_file_name=file_name)
14 |
15 | dge_plot_historical = CovidMX(date='04-12-2020', date_format='%m-%d-%Y').get_plot()
16 | for st in dge_plot_historical.available_status:
17 | mx_map_h = dge_plot_historical.plot_map(status=st, save_file_name=file_name)
18 | mx_map_with_muns_h = dge_plot_historical.plot_map(status=st, add_municipalities=True, save_file_name=file_name)
19 | cdmx_map_h = dge_plot_historical.plot_map(status=st, state='CIUDAD DE MÉXICO', save_file_name=file_name)
20 | cdmx_map_with_muns_h = dge_plot_historical.plot_map(status=st, state='CIUDAD DE MÉXICO', add_municipalities=True, save_file_name=file_name)
21 | except BaseException:
22 | assert False, "Test DGEPlot failed"
23 |
--------------------------------------------------------------------------------
/.github/workflows/pythonpackage.yml:
--------------------------------------------------------------------------------
1 | # This workflow will install Python dependencies, run tests and lint with a variety of Python versions
2 | # For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
3 |
4 | name: Python package
5 |
6 | on:
7 | push:
8 | branches: [ master ]
9 | pull_request:
10 | branches: [ master ]
11 |
12 | jobs:
13 | build:
14 |
15 | runs-on: ubuntu-latest
16 | strategy:
17 | matrix:
18 | python-version: [3.5, 3.6, 3.7, 3.8]
19 |
20 | steps:
21 | - uses: actions/checkout@v2
22 | - name: Set up Python ${{ matrix.python-version }}
23 | uses: actions/setup-python@v1
24 | with:
25 | python-version: ${{ matrix.python-version }}
26 | - name: Install dependencies
27 | run: |
28 | python -m pip install --upgrade pip
29 | pip install -r requirements.txt
30 | - name: Lint with flake8
31 | run: |
32 | pip install flake8
33 | # stop the build if there are Python syntax errors or undefined names
34 | flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
35 | # exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
36 | flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
37 | - name: Test with pytest
38 | run: |
39 | pip install pytest
40 | pytest
41 |
--------------------------------------------------------------------------------
/covidmx/covidmx.py:
--------------------------------------------------------------------------------
1 | from covidmx.serendipia import Serendipia
2 | from covidmx.dge import DGE
3 |
4 |
5 | def CovidMX(source="DGE", **kwargs):
6 | """
7 | Returns COVID19 data from source.
8 |
9 | Parameters
10 | ----------
11 | Args:
12 | source (str): Source of data. Allowed: DGE, Serendipia.
13 | Kwargs (source="DGE"):
14 | clean (bool): Whether data cleaning will be performed. Default True (recommended).
15 | Return decoded variables.
16 | return_catalogo (bool): Whether catalogue of encoding will be returned.
17 | return_descripcion (bool): Whether a full description of variables will be returned.
18 | date (str): To get historical data published that date.
19 | date_format (str): Format of supplied date.
20 | Kwargs (source="Serendipia"):
21 | date (str): Date to consider. If not present returns last found data.
22 | kind (str): Kind of data. Allowed: 'confirmed', 'suspects'. If not present returns both.
23 | clean (bool): Whether data cleaning will be performed. Default True (recommended).
24 | add_search_date (bool): Wheter add date to the DFs.
25 | date_format (str): date format if needed
26 | """
27 | allowed_sources = ["DGE", "Serendipia"]
28 |
29 | assert source in allowed_sources, \
30 | "CovidMX only supports {} as sources".format(', '.join(allowed_sources))
31 |
32 | if source == "DGE":
33 | return DGE(**kwargs)
34 |
35 | if source == "Serendipia":
36 | return Serendipia(**kwargs)
37 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | pip-wheel-metadata/
24 | share/python-wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 | MANIFEST
29 |
30 | # PyInstaller
31 | # Usually these files are written by a python script from a template
32 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
33 | *.manifest
34 | *.spec
35 |
36 | # Installer logs
37 | pip-log.txt
38 | pip-delete-this-directory.txt
39 |
40 | # Unit test / coverage reports
41 | htmlcov/
42 | .tox/
43 | .nox/
44 | .coverage
45 | .coverage.*
46 | .cache
47 | nosetests.xml
48 | coverage.xml
49 | *.cover
50 | *.py,cover
51 | .hypothesis/
52 | .pytest_cache/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | target/
76 |
77 | # Jupyter Notebook
78 | .ipynb_checkpoints
79 |
80 | # IPython
81 | profile_default/
82 | ipython_config.py
83 |
84 | # pyenv
85 | .python-version
86 |
87 | # pipenv
88 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
89 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
90 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
91 | # install all needed dependencies.
92 | #Pipfile.lock
93 |
94 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
95 | __pypackages__/
96 |
97 | # Celery stuff
98 | celerybeat-schedule
99 | celerybeat.pid
100 |
101 | # SageMath parsed files
102 | *.sage.py
103 |
104 | # Environments
105 | .env
106 | .venv
107 | env/
108 | venv/
109 | ENV/
110 | env.bak/
111 | venv.bak/
112 |
113 | # Spyder project settings
114 | .spyderproject
115 | .spyproject
116 |
117 | # Rope project settings
118 | .ropeproject
119 |
120 | # mkdocs documentation
121 | /site
122 |
123 | # mypy
124 | .mypy_cache/
125 | .dmypy.json
126 | dmypy.json
127 |
128 | # Pyre type checker
129 | .pyre/
130 | *.png
131 | Untitle*.ipynb
132 |
133 | .idea/
--------------------------------------------------------------------------------
/covidmx/utils.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | from pathlib import Path
5 | from typing import Tuple, Union
6 | import logging
7 |
8 | import requests
9 | import zipfile
10 | import subprocess
11 | from tqdm import tqdm
12 |
13 | logging.basicConfig(level=logging.INFO)
14 | logger = logging.getLogger(__name__)
15 |
16 |
17 | def download_file(directory: Union[str, Path], source_url: str, decompress: bool = False) -> None:
18 | """Download data from source_ulr inside directory.
19 |
20 | Parameters
21 | ----------
22 | directory: str, Path
23 | Custom directory where data will be downloaded.
24 | source_url: str
25 | URL where data is hosted.
26 | decompress: bool
27 | Wheter decompress downloaded file. Default False.
28 | """
29 | if isinstance(directory, str):
30 | directory = Path(directory)
31 | directory.mkdir(parents=True, exist_ok=True)
32 |
33 | filename = source_url.split('/')[-1]
34 | filepath = directory / filename
35 |
36 | # Streaming, so we can iterate over the response.
37 | r = requests.get(source_url, stream=True)
38 | # Total size in bytes.
39 | total_size = int(r.headers.get('content-length', 0))
40 | block_size = 1024 #1 Kibibyte
41 |
42 | t = tqdm(total=total_size, unit='iB', unit_scale=True)
43 | with open(filepath, 'wb') as f:
44 | for data in r.iter_content(block_size):
45 | t.update(len(data))
46 | f.write(data)
47 | t.close()
48 |
49 | if total_size != 0 and t.n != total_size:
50 | logger.error('ERROR, something went wrong downloading data')
51 |
52 | size = filepath.stat().st_size
53 | logger.info(f'Successfully downloaded {filename}, {size}, bytes.')
54 |
55 | if decompress:
56 | with zipfile.ZipFile(filepath, 'r') as zip_ref:
57 | extracted = zip_ref.namelist()
58 | zip_ref.extractall(directory)
59 |
60 | extracted = [directory / file for file in extracted]
61 |
62 | logger.info(f'Successfully decompressed {filepath}')
63 |
64 | return extracted
65 |
66 |
67 | translate_serendipia = {
68 | 'confirmed': 'positivos',
69 | 'suspects': 'sospechosos'
70 | }
71 |
72 | translate_romero = {
73 | 'confirmed': 'confirmed',
74 | 'deaths': 'deaths',
75 | 'negatives': 'negatives',
76 | 'suspects': 'suspects'
77 | }
78 |
79 | translate_flores = {
80 | 'confirmed': 'confirmed',
81 | 'deaths': 'deaths',
82 | 'negatives': 'negatives',
83 | 'suspects': 'probables'
84 | }
85 |
--------------------------------------------------------------------------------
/covidmx/dge_plot.py:
--------------------------------------------------------------------------------
1 | from mapsmx import MapsMX
2 | import pandas as pd
3 | import matplotlib.pyplot as plt
4 |
5 | class DGEPlot:
6 | """
7 | Class to plot dge information
8 | """
9 |
10 | def __init__(self, dge_data, catalogue, description):
11 |
12 | self.dge_data = self.prepare_data(dge_data)
13 | self.dge_data['cve_ent'] = self.dge_data['cve_ent'].astype(int).astype(str)
14 | self.catalogue = catalogue
15 | self.description = description
16 |
17 | #Downloading geo information
18 | state_geo = MapsMX().get_geo('state')
19 | state_geo['cve_ent'] = state_geo['cve_ent'].astype(int).astype(str)
20 |
21 | mun_geo = MapsMX().get_geo('municipality')
22 | mun_geo[['cve_ent', 'cve_mun']] = mun_geo[['cve_ent', 'cve_mun']].astype(int).astype(str)
23 | mun_geo['cve_mun'] = mun_geo['cve_ent'] + '_' + mun_geo['cve_mun']
24 |
25 |
26 | self.state_geo = state_geo
27 | self.mun_geo = mun_geo
28 | self.available_states = self.dge_data['entidad_res'].unique()
29 | self.available_status = ['confirmados', 'negativos', 'sospechosos', 'muertos']
30 |
31 | def prepare_data(self, df):
32 |
33 | df = df.rename(columns={
34 | 'entidad_res_original': 'cve_ent',
35 | 'municipio_res_original': 'cve_mun'
36 | })
37 |
38 | df['muertos'] = df['fecha_def'].notna().astype(int)
39 |
40 | replace_resultado = {'Positivo SARS-CoV-2': 'confirmados',
41 | 'No positivo SARS-CoV-2': 'negativos',
42 | 'Resultado pendiente':'sospechosos'}
43 |
44 | df['resultado'] = df['resultado'].replace(replace_resultado)
45 | df = pd.concat([df, pd.get_dummies(df['resultado'])], axis=1)
46 |
47 | int_vars = list(replace_resultado.values()) + ['muertos']
48 | df[int_vars] = df[int_vars].astype(int)
49 |
50 | return df
51 |
52 | def plot_map(self, status='confirmados', state=None,
53 | add_municipalities=False, save_file_name = None,
54 | cmap='Reds',
55 | scheme='quantiles', k=4, legend=True, zorder=1,
56 | missing_kwds={'color': 'lightgray', 'label': 'Sin info'}, **kwargs):
57 | """
58 | Plot geography information
59 |
60 | Parameters
61 | ----------
62 | status: str
63 | One of confirmados, sospechosos, negativos, muertos
64 | state: str
65 | Plot particular state.
66 | add_municipalities: bool
67 | Wheter add municipalities to plot
68 | """
69 |
70 | assert status in self.available_status, 'Please provide some of the following status: {}'.format(', '.join(self.available_status))
71 | if state is not None:
72 | assert state in self.available_states, 'Please provide some of the following states: {}'.format(', '.join(self.available_states))
73 |
74 | # if last_date_to_consider is not None:
75 | # last_date = pd.to_datetime(last_date_to_consider, format=format_date)
76 | # plot_data = self.dge_data[self.dge_data['fecha_sintomas']<=last_date]
77 | # else:
78 | # plot_data = self.dge_data
79 |
80 | group_cols = ['entidad_res', 'cve_ent']
81 |
82 | if add_municipalities:
83 | group_cols += ['municipio_res', 'cve_mun']
84 |
85 | needed_cols = [status] + group_cols
86 |
87 | plot_data = self.dge_data[needed_cols]
88 | state_geo_plot = self.state_geo
89 | mun_geo_plot = self.mun_geo
90 |
91 | if state is not None:
92 | plot_data = plot_data[plot_data['entidad_res'].str.lower() == state.lower()]
93 | cve_ent = str(plot_data['cve_ent'].unique()[0])
94 | state_geo_plot = self.state_geo[self.state_geo['cve_ent']==cve_ent]
95 | mun_geo_plot = self.mun_geo[self.mun_geo['cve_ent']==cve_ent]
96 |
97 | plot_data = plot_data.groupby(group_cols).agg(sum).reset_index()
98 |
99 | if add_municipalities:
100 | plot_data = plot_data.drop(columns='cve_ent')
101 | plot_data = mun_geo_plot.merge(plot_data, how='left', on='cve_mun')
102 |
103 | geometry = 'geometry_mun'
104 | else:
105 | plot_data = state_geo_plot.merge(plot_data, how='left', on='cve_ent')
106 | geometry = 'geometry_ent'
107 |
108 | base = state_geo_plot.boundary.plot(color=None,
109 | edgecolor='black',
110 | linewidth=0.6,
111 | figsize=(10,9))
112 |
113 | if add_municipalities and state is not None:
114 | mun_geo_plot.boundary.plot(ax=base, color=None,
115 | edgecolor='black',
116 | linewidth=0.2)
117 |
118 | plot_obj = plot_data.set_geometry(geometry).plot(ax=base,
119 | column=status,
120 | cmap=cmap,
121 | scheme=scheme,
122 | k=k,
123 | legend=legend,
124 | zorder=zorder,
125 | missing_kwds=missing_kwds,
126 | **kwargs)
127 | base.set_axis_off()
128 | plt.axis('equal')
129 |
130 | title = 'Casos ' + status + ' por COVID-19'
131 |
132 | if state is not None:
133 | title += '\n'
134 | title += state.title()
135 |
136 | act_date = self.date
137 | if self.date is None:
138 | act_date = self.dge_data['fecha_actualizacion'][0]
139 | act_date = act_date.date()
140 | act_date = str(act_date)
141 |
142 | title += '\n'
143 | title += 'Fecha de actualizacion de los datos: {}'.format(act_date)
144 |
145 |
146 | plt.title(title, fontsize=20)
147 |
148 |
149 | if save_file_name is not None:
150 | plt.savefig(save_file_name, bbox_inches='tight', pad_inches=0)
151 | plt.close()
152 | else:
153 | plt.show()
154 |
155 |
156 | return plot_obj
157 |
--------------------------------------------------------------------------------
/covidmx/serendipia.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | from itertools import product
3 | from unidecode import unidecode
4 | from covidmx.utils import translate_serendipia
5 | pd.options.mode.chained_assignment = None
6 |
7 |
8 | class Serendipia:
9 |
10 | def __init__(
11 | self,
12 | date=None,
13 | kind=None,
14 | clean=True,
15 | add_search_date=True,
16 | date_format='%d-%m-%Y'):
17 | """
18 | Returns COVID19 data from serendipia.
19 |
20 | Parameters
21 | ----------
22 | date: str or list
23 | Date to consider. If not present returns last found data.
24 | kind: str
25 | Kind of data. Allowed: 'confirmados', 'sospechosos'. If not present returns both.
26 | clean: boolean
27 | If data cleaning will be performed. Default True (recommended).
28 | add_search_date: boolean
29 | If add date to the DFs.
30 | date_format: str
31 | date format if needed
32 | """
33 |
34 | self.allowed_kinds = translate_serendipia
35 |
36 | if not (isinstance(date, str) or date is None):
37 | raise ValueError('date must be string')
38 |
39 | if not (isinstance(kind, str) or kind is None):
40 | raise ValueError('kind must be string')
41 |
42 | self.date = date
43 |
44 | if not self.date:
45 | self.search_date = True
46 | else:
47 | self.search_date = False
48 |
49 | if not kind:
50 | self.kind = self.allowed_kinds
51 | else:
52 | assert kind in self.allowed_kinds.keys(), 'Serendipia source only considers {}. Please use one of them.'.format(
53 | ', '.join(self.allowed_kinds.keys()))
54 |
55 | self.kind = [kind]
56 |
57 | self.clean = clean
58 | self.add_search_date = add_search_date
59 | self.date_format = date_format
60 |
61 | def get_data(self):
62 |
63 | print('Reading data')
64 | dfs = [
65 | self.read_data(
66 | dt, ki) for dt, ki in product(
67 | [self.date], self.kind)]
68 |
69 | if self.clean:
70 | print('Cleaning data')
71 | dfs = [self.clean_data(df) for df in dfs]
72 |
73 | dfs = pd.concat(dfs, sort=True).reset_index(drop=True)
74 |
75 | return dfs
76 |
77 | def read_data(self, date, kind):
78 |
79 | if self.search_date:
80 | df, found_date = self.search_data(5, kind)
81 |
82 | if self.add_search_date:
83 | df.loc[:, 'fecha_busqueda'] = found_date
84 |
85 | return df
86 |
87 | url = self.get_url(date, kind)
88 |
89 | try:
90 | df = pd.read_csv(url)
91 |
92 | if self.add_search_date:
93 | df.loc[:, 'fecha_busqueda'] = date
94 |
95 | return df
96 | except BaseException:
97 | raise RuntimeError(
98 | 'Cannot read the data. Maybe theres no information for {} and {}'.format(
99 | kind, date))
100 |
101 | def search_data(self, max_times, kind):
102 | print('Searching last date available for {}...'.format(kind))
103 |
104 | search_dates = pd.date_range(
105 | end=pd.to_datetime('today'),
106 | periods=max_times)[::-1]
107 |
108 | for date in search_dates:
109 | date_formatted = date.strftime(self.date_format)
110 | url = self.get_url(date_formatted, kind)
111 | try:
112 | df = pd.read_csv(url)
113 | print('Last date available: {}'.format(date_formatted))
114 | return df, date_formatted
115 | except BaseException:
116 | continue
117 |
118 | raise RuntimeError('No date found for {}'.format(kind))
119 |
120 | def clean_data(self, df):
121 |
122 | df.columns = df.columns.str.lower().str.replace(
123 | ' |-|\n', '_').str.replace('°', '').map(unidecode)
124 |
125 | if [i for i in list(df.columns) if i.startswith('identificac')]:
126 | df.columns = df.columns.str.replace(r'(?<=identificacion)(\w+)', '')
127 |
128 | # Removing Fuente row
129 | if [i for i in list(df.columns) if i.startswith('n_caso')]:
130 | df = df[~df['n_caso'].str.contains('Fuente|Corte')]
131 |
132 | # converting to datetime format
133 | df.loc[:, 'fecha_busqueda'] = pd.to_datetime(
134 | df['fecha_busqueda'], format=self.date_format)
135 |
136 | if [i for i in list(df.columns) if i.startswith('fecha_de_inicio')]:
137 | df.loc[:, 'fecha_de_inicio_de_sintomas'] = pd.to_datetime(
138 | df['fecha_de_inicio_de_sintomas'], format='%d/%m/%Y')
139 |
140 | return df
141 |
142 | def get_url(self, date, kind):
143 | """
144 | Returns the url of serendipia.
145 |
146 | Parameters
147 | ----------
148 | date: str
149 | String date.
150 | kind: str
151 | String with kind of data. Allowed: 'positivos', 'sospechosos'
152 | """
153 | date_ts = pd.to_datetime(date, format=self.date_format)
154 | year = date_ts.strftime('%Y')
155 | month = date_ts.strftime('%m')
156 | date_f = date_ts.strftime('%Y.%m.%d')
157 |
158 | serendipia_change = pd.to_datetime('19-04-2020', format=self.date_format)
159 |
160 | spec_kind = self.allowed_kinds[kind]
161 |
162 | if spec_kind == 'positivos':
163 | if date_ts >= serendipia_change:
164 | date_f = date_ts.strftime('%d%m%Y')
165 | url = 'https://serendipia.digital/wp-content/uploads/{}/{}/covid-19-mexico-{}.csv'.format(year, month, date_f)
166 | else:
167 | url = 'https://serendipia.digital/wp-content/uploads/{}/{}/Tabla_casos_{}_COVID-19_resultado_InDRE_{}-Table-1.csv'.format(year, month, spec_kind, date_f)
168 | else:
169 | if date_ts >= serendipia_change:
170 | date_f = date_ts.strftime('%d%m%Y')
171 | url = 'https://serendipia.digital/wp-content/uploads/{}/{}/covid-19-mexico-{}-{}.csv'.format(year, month, spec_kind, date_f)
172 | else:
173 | url = 'https://serendipia.digital/wp-content/uploads/{}/{}/Tabla_casos_{}_COVID-19_{}-Table-1.csv'.format(year, month, spec_kind, date_f)
174 |
175 | return url
176 |
--------------------------------------------------------------------------------
/covidmx/dge.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import wget
3 | import os
4 | import zipfile
5 | import shutil
6 | from io import BytesIO
7 | import requests
8 | from zipfile import ZipFile
9 | import pandas as pd
10 | from itertools import product
11 | from unidecode import unidecode
12 | from covidmx.utils import download_file, translate_serendipia
13 | from covidmx.dge_plot import DGEPlot
14 |
15 | pd.options.mode.chained_assignment = None
16 |
17 | URL_DATA = 'http://datosabiertos.salud.gob.mx/gobmx/salud/datos_abiertos/datos_abiertos_covid19.zip'
18 | URL_DESCRIPTION = 'http://datosabiertos.salud.gob.mx/gobmx/salud/datos_abiertos/diccionario_datos_covid19.zip'
19 | URL_HISTORICAL = 'http://187.191.75.115/gobmx/salud/datos_abiertos/historicos/datos_abiertos_covid19_{}.zip'
20 |
21 | logging.basicConfig(level=logging.INFO)
22 | logger = logging.getLogger(__name__)
23 |
24 |
25 | class DGE:
26 |
27 | def __init__(
28 | self,
29 | data_path='data',
30 | clean=True,
31 | return_catalogo=False,
32 | return_descripcion=False,
33 | date=None,
34 | date_format='%d-%m-%Y'):
35 | """
36 | Returns COVID19 data from the Direccion General de Epidemiología
37 |
38 | """
39 | self.data_path = data_path
40 | self.clean = clean
41 | self.return_catalogo = return_catalogo
42 | self.return_descripcion = return_descripcion
43 |
44 | self.date = date
45 | if date is not None:
46 | self.date = pd.to_datetime(date, format=date_format)
47 | if self.date >= pd.to_datetime('2020-04-12'):
48 | raise Exception('Historical data only available as of 2020-04-12')
49 |
50 | def get_data(self, preserve_original=None):
51 |
52 | if not os.path.exists(self.data_path):
53 | os.mkdir(self.data_path)
54 | clean_data_file= os.path.join(self.data_path, os.path.split(URL_DATA)[1]).replace("zip", "csv")
55 |
56 | logger.info('Reading data from Direccion General de Epidemiologia...')
57 | df, catalogo, descripcion = self.read_data()
58 | logger.info('Data readed')
59 |
60 | if self.clean and not os.path.exists(clean_data_file):
61 | logger.info('Cleaning data')
62 | df = self.clean_data(df, catalogo, descripcion, preserve_original)
63 | if self.data_path is not None:
64 | logger.info("Save cleaned database " + clean_data_file)
65 | df.to_csv(clean_data_file, index=False)
66 | elif self.clean and os.path.exists(clean_data_file):
67 | logger.info("Open cleaned " + clean_data_file)
68 | df = pd.read_csv(clean_data_file)
69 |
70 | logger.info('Ready!')
71 |
72 | if self.return_catalogo and not self.return_descripcion:
73 | return df, catalogo
74 |
75 | if self.return_descripcion and not self.return_catalogo:
76 | return df, descripcion
77 |
78 | if self.return_catalogo and self.return_descripcion:
79 | return df, catalogo, descripcion
80 |
81 |
82 | return df
83 |
84 | def get_encoded_data(self, path, encoding='UTF-8'):
85 | try:
86 | data = pd.read_csv(path, encoding=encoding)
87 | except BaseException as e:
88 | if isinstance(e, UnicodeDecodeError):
89 | encoding = 'ISO-8859-1'
90 | data = self.get_encoded_data(path, encoding)
91 | else:
92 | raise RuntimeError('Cannot read the data.')
93 |
94 | return data
95 |
96 | def parse_catalogo_data(self, sheet, df):
97 |
98 | if sheet in ['Catálogo RESULTADO_LAB', 'Catálogo CLASIFICACION_FINAL']:
99 | df = df.dropna()
100 | df.columns = df.iloc[0]
101 | df = df.iloc[1:].reset_index(drop=True)
102 |
103 | return df
104 |
105 | def read_data(self, encoding='UTF-8'):
106 | if self.date is None:
107 | data_path, = download_file(self.data_path, URL_DATA, decompress=True)
108 | else:
109 | date_f = self.date.strftime('%d.%m.%Y')
110 | data_path = URL_HISTORICAL.format(date_f)
111 |
112 | data = self.get_encoded_data(data_path)
113 |
114 | _, catalogo_path, desc_path = download_file(self.data_path, URL_DESCRIPTION, decompress=True)
115 |
116 | catalogo = pd.read_excel(catalogo_path, sheet_name=None)
117 | catalogo_original = {
118 | sheet: self.parse_catalogo_data(sheet, df) \
119 | for sheet, df in catalogo.items()
120 | }
121 |
122 | desc = pd.read_excel(desc_path)
123 |
124 | return data, catalogo_original, desc
125 |
126 | def get_dict_replace(self, key, df):
127 | if key == 'ENTIDADES':
128 | return dict(zip(df['CLAVE_ENTIDAD'], df['ENTIDAD_FEDERATIVA']))
129 |
130 | elif key == 'MUNICIPIOS':
131 | id_mun = df['CLAVE_ENTIDAD'].astype(int).astype(str) + \
132 | '_' + \
133 | df['CLAVE_MUNICIPIO'].astype(int).astype(str)
134 |
135 | return dict(zip(id_mun, df['MUNICIPIO']))
136 |
137 | else:
138 | return dict(zip(df['CLAVE'], df['DESCRIPCIÓN']))
139 |
140 | def clean_formato_fuente(self, formato):
141 | if 'CATÁLOGO' in formato or 'CATALÓGO' in formato:
142 | return formato.replace(
143 | 'CATÁLOGO: ',
144 | '').replace(
145 | 'CATALÓGO: ',
146 | '').replace(
147 | ' ',
148 | '')
149 | elif 'TEXT' in formato:
150 | return None
151 | elif 'TEXTO' in formato and '99' in formato:
152 | return {'99': 'SE IGNORA'}
153 | elif 'TEXTO' in formato and '97' in formato:
154 | return {'97': 'NO APLICA'}
155 | elif 'NUMÉRICA' in formato or 'NÚMERICA' in formato:
156 | return None
157 | elif 'AAAA' in formato:
158 | return formato.replace(
159 | 'AAAA',
160 | '%Y').replace(
161 | 'MM',
162 | '%m').replace(
163 | 'DD',
164 | '%d')
165 |
166 | return formato
167 |
168 | def clean_nombre_variable(self, nombre_variable):
169 | if 'OTRAS_COM' in nombre_variable:
170 | return 'OTRA_COM'
171 |
172 | return nombre_variable
173 |
174 | def replace_values(self, data, col_name, desc_dict, catalogo_dict):
175 | formato = desc_dict[col_name]
176 | if 'FECHA' in col_name:
177 | df = pd.to_datetime(data[col_name], format=formato,
178 | errors='coerce')
179 |
180 | return df
181 |
182 | if formato is None:
183 | return data[col_name]
184 |
185 | if isinstance(formato, dict):
186 | return data[col_name].replace(formato)
187 |
188 | replacement = catalogo_dict[formato]
189 |
190 | return data[col_name].replace(replacement)
191 |
192 | def clean_data(self, df, catalogo, descripcion, preserve_original=None):
193 | #Using catlogo
194 | catalogo_dict = {
195 | key.replace('Catálogo ', '') \
196 | .replace('de ', ''): df \
197 | for key, df in catalogo.items()
198 | }
199 |
200 | catalogo_dict = {
201 | key: self.get_dict_replace(key, df) \
202 | for key, df in catalogo_dict.items()
203 | }
204 |
205 | #Cleaning description
206 | nombre_variable = descripcion['NOMBRE DE VARIABLE'].apply(self.clean_nombre_variable)
207 | formato_o_fuente = descripcion['FORMATO O FUENTE'].apply(self.clean_formato_fuente)
208 | desc_dict = dict(zip(nombre_variable, formato_o_fuente))
209 |
210 | df['MUNICIPIO_RES'] = df['ENTIDAD_RES'].astype(str) + \
211 | '_' + \
212 | df['MUNICIPIO_RES'].astype('Int64').astype(str)
213 |
214 | #Updating cols
215 | if preserve_original is None:
216 | preserve_original = []
217 |
218 | for col in df.columns:
219 | if col in preserve_original:
220 | new_col = col + '_original'
221 | df[new_col] = df[col]
222 |
223 | df[col] = self.replace_values(df, col, desc_dict, catalogo_dict)
224 |
225 | df.columns = df.columns.str.lower()
226 |
227 | return df
228 |
229 | def get_plot(self):
230 | self.return_catalogo = True
231 | self.return_descripcion = True
232 | self.clean = True
233 |
234 | dge_data, catalogue, description = self.get_data(preserve_original=['MUNICIPIO_RES', 'ENTIDAD_RES'])
235 |
236 | dge_plot = DGEPlot(dge_data, catalogue, description)
237 | dge_plot.date = self.date
238 |
239 | return dge_plot
240 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [](https://github.com/FedericoGarza/covidmx/tree/master)
2 | [](https://pypi.python.org/pypi/covidmx/)
3 | [](https://doi.org/10.5281/zenodo.3758590)
4 | [](https://pepy.tech/project/covidmx)
5 | [](https://www.python.org/downloads/release/python-350+/)
6 | [](https://github.com/FedericoGarza/covidmx/blob/master/LICENSE)
7 |
8 | # covidmx
9 | Python API to get information about COVID-19 in México.
10 |
11 | # Requirements
12 |
13 | ```
14 | more-itertools>=6.0.0
15 | pandas>=0.25.2
16 | Unidecode>=1.1.1
17 | requests==2.21.0
18 | xlrd==1.2.0
19 | mapsmx==0.0.3
20 | matplotlib==3.0.3
21 | mapclassify==2.2.0
22 | descartes==1.1.0
23 | ```
24 |
25 | # How to install
26 |
27 | ```
28 | pip install covidmx
29 | ```
30 |
31 | # How to use
32 |
33 | ## Dirección General de Epidemiología
34 |
35 | The mexican *Dirección General de Epidemiología* [has released open data](https://www.gob.mx/salud/documentos/datos-abiertos-152127) about COVID-19 in México. This source contains information at the individual level such as gender, municipality and health status (smoker, obesity, etc). The package `covidmx` now can handle this source as default. Some variables are encoded as integers and the source also includes a data dictionary with all relevant information. When you pass `clean=True` (default option) returns the decoded data. You can also have access to the catalogue using `return_catalogo=True` and to the description of each one of the variables with `return_descripcion=True`. When you use some of this parameters, the API returns a tuple.
36 |
37 | ```python
38 | from covidmx import CovidMX
39 |
40 | covid_dge_data = CovidMX().get_data()
41 | raw_dge_data = CovidMX(clean=False).get_data()
42 | covid_dge_data, catalogo_data = CovidMX(return_catalogo=True).get_data()
43 | covid_dge_data, descripcion_data = CovidMX(return_descripcion=True).get_data()
44 | covid_dge_data, catalogo_data, descripcion_data = CovidMX(return_catalogo=True, return_descripcion=True).get_data()
45 | ```
46 |
47 | To get historical data use:
48 |
49 | ```python
50 | covid_dge_data = CovidMX(date='12-04-2020').get_data()
51 | ```
52 |
53 | Default date format is `%d-%m-%Y`, but you can also use a particular format with:
54 |
55 |
56 | ```python
57 | covid_dge_data = CovidMX(date='2020-04-12', date_format='%Y-%m-%d').get_data()
58 | ```
59 |
60 | ### Plot module
61 |
62 | As of version 0.3.0, `covidmx` includes a module to create maps of different COVID-19 status at the national and state levels, with the possibility of including municipalities (using information of the *Dirección General de Epidemiologia*).
63 |
64 | ```python
65 | from covidmx import CovidMX
66 |
67 | dge_plot = CovidMX().get_plot()
68 | ```
69 |
70 | You can check available status and available states using:
71 |
72 | ```python
73 | dge_plot.available_states
74 |
75 | array(['MÉXICO', 'CIUDAD DE MÉXICO', 'TAMAULIPAS', 'BAJA CALIFORNIA',
76 | 'YUCATÁN', 'GUERRERO', 'BAJA CALIFORNIA SUR', 'JALISCO',
77 | 'NUEVO LEÓN', 'SONORA', 'VERACRUZ DE IGNACIO DE LA LLAVE',
78 | 'PUEBLA', 'CAMPECHE', 'GUANAJUATO', 'SAN LUIS POTOSÍ',
79 | 'MICHOACÁN DE OCAMPO', 'COAHUILA DE ZARAGOZA', 'QUERÉTARO',
80 | 'AGUASCALIENTES', 'TABASCO', 'HIDALGO', 'ZACATECAS', 'DURANGO',
81 | 'CHIHUAHUA', 'CHIAPAS', 'SINALOA', 'QUINTANA ROO', 'MORELOS',
82 | 'TLAXCALA', 'NAYARIT', 'OAXACA', 'COLIMA'], dtype=object)
83 | ```
84 |
85 | ```python
86 | dge_plot.available_status
87 |
88 | ['confirmados', 'negativos', 'sospechosos', 'muertos']
89 | ```
90 |
91 | To plot a national map just use:
92 |
93 | ```python
94 | dge_plot.plot_map(status='confirmados')
95 | ```
96 |
97 | 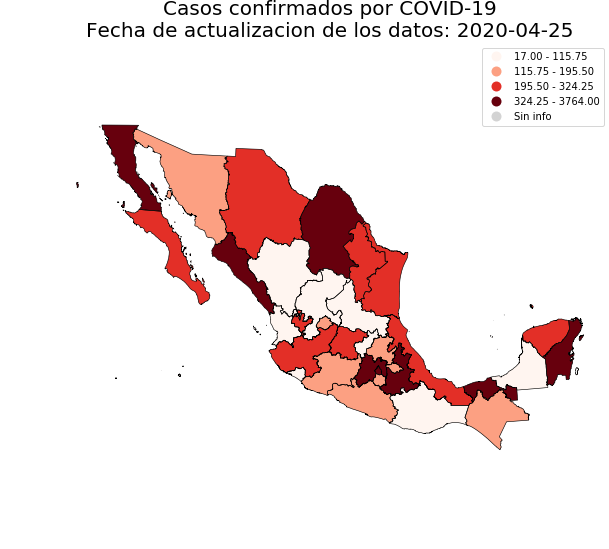 98 |
99 |
100 | If you want to include municipalities use:
101 |
102 | ```python
103 | dge_plot.plot_map(status='confirmados', add_municipalities=True)
104 | ```
105 |
98 |
99 |
100 | If you want to include municipalities use:
101 |
102 | ```python
103 | dge_plot.plot_map(status='confirmados', add_municipalities=True)
104 | ```
105 | 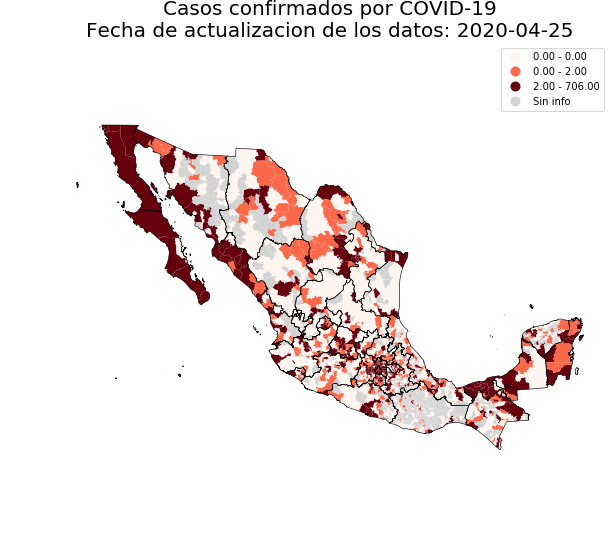 106 |
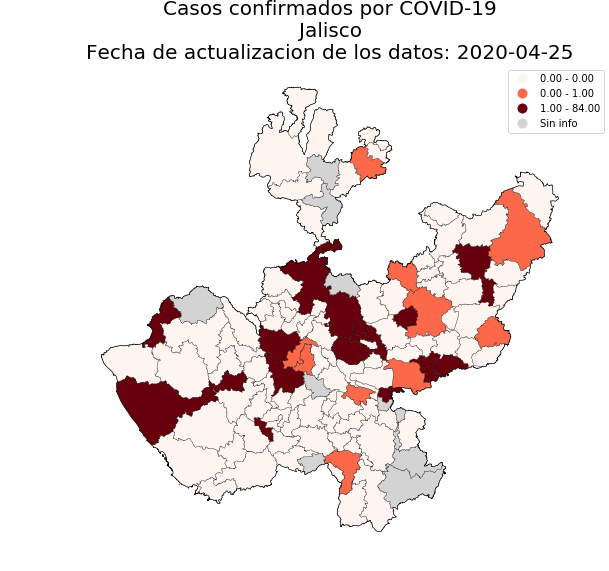
107 |
108 | You can pass a particular state filling the `state` argument with a valid name included in the `available_states` attribute:
109 |
110 | ```python
111 | dge_plot.plot_map(status='confirmados', state='CIUDAD DE MÉXICO', add_municipalities=True)
112 | ```
113 |
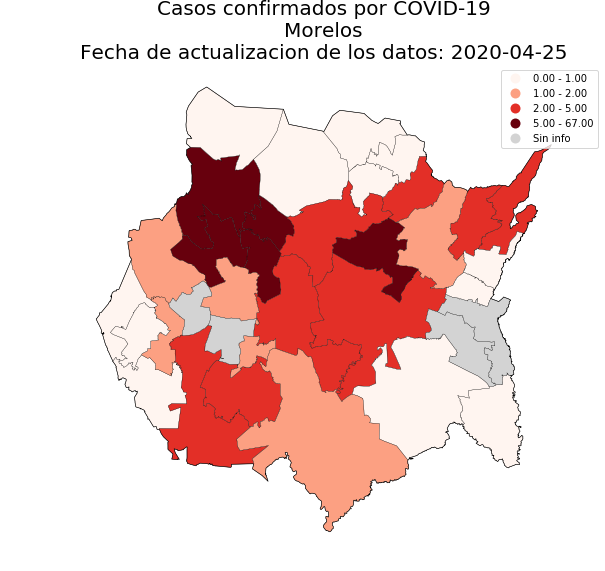
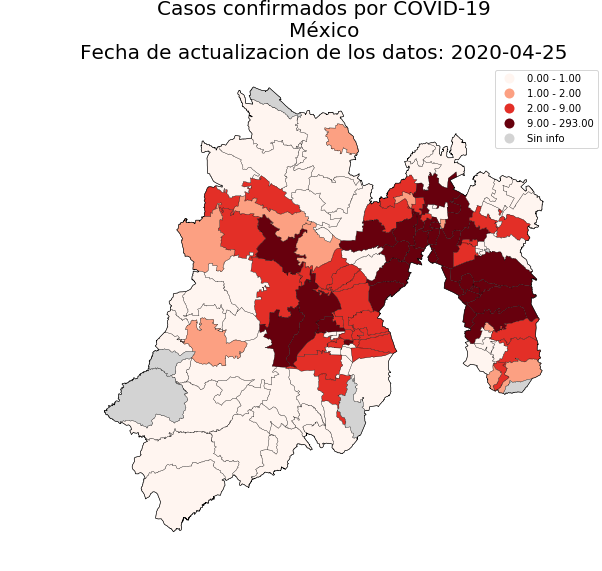
114 | |`state='CIUDAD DE MÉXICO'`| `state='JALISCO'`| `state='MORELOS'`| `state='MÉXICO'`|
115 | |:------------------------:|:----------------:|:----------------:|:---------------:|
116 | |
106 |
107 |
108 | You can pass a particular state filling the `state` argument with a valid name included in the `available_states` attribute:
109 |
110 | ```python
111 | dge_plot.plot_map(status='confirmados', state='CIUDAD DE MÉXICO', add_municipalities=True)
112 | ```
113 |
114 | |`state='CIUDAD DE MÉXICO'`| `state='JALISCO'`| `state='MORELOS'`| `state='MÉXICO'`|
115 | |:------------------------:|:----------------:|:----------------:|:---------------:|
116 | |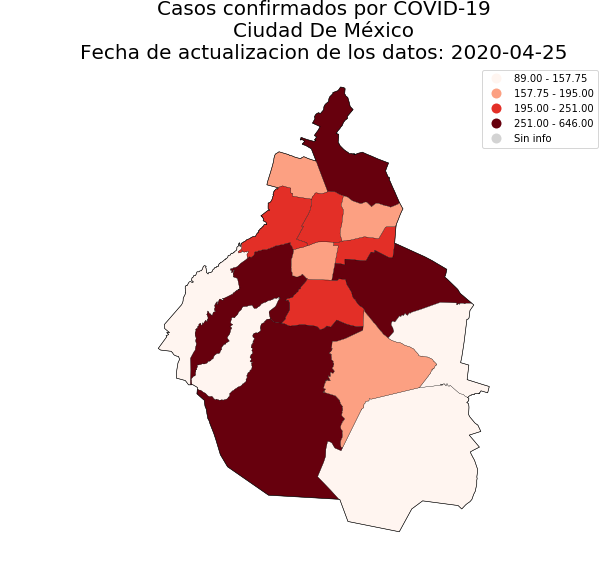 |
|  |
|  |
|  |
117 |
118 |
119 | Finally you can plot another interest variable (according to `available_status` attribute):
120 |
121 | ```python
122 | dge_plot.plot_map(status='sospechosos', add_municipalities=True)
123 | ```
124 |
|
117 |
118 |
119 | Finally you can plot another interest variable (according to `available_status` attribute):
120 |
121 | ```python
122 | dge_plot.plot_map(status='sospechosos', add_municipalities=True)
123 | ```
124 | 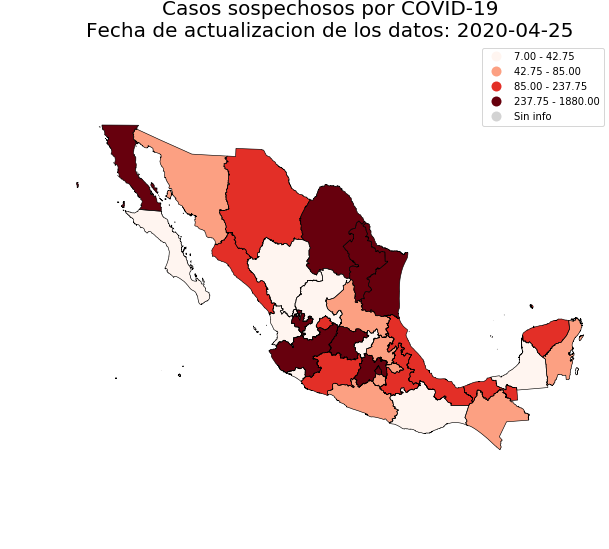 125 |
126 | You can save your maps using `save_file_name`:
127 |
128 | ```python
129 | dge_plot.plot_map(status='sospechosos', add_municipalities=True, save_file_name='sospechosos-nacional.png')
130 | ```
131 |
132 | ## Serendipia
133 |
134 | Serendipia [publishes daily information](https://serendipia.digital/2020/03/datos-abiertos-sobre-casos-de-coronavirus-covid-19-en-mexico/) of the mexican *Secretaría de Salud* about covid in open format (.csv). This api downloads this data easily, making it useful for task automation.
135 |
136 | ```python
137 | from covidmx import CovidMX
138 |
139 | latest_published_data = CovidMX(source='Serendipia').get_data()
140 | ```
141 |
142 | Then `CovidMX` instances a `Serendipia` class, searches the latest published data for both confirmed and suspects individuals and finally clean the data. Nevertheless, a more specific search can be conducted (see docs for details).
143 |
144 | ```python
145 | raw_data = CovidMX(source='Serendipia', clean=False).get_data()
146 | confirmed = CovidMX(source='Serendipia', kind="confirmed").get_data()
147 | suspects = CovidMX(source='Serendipia',kind="suspects").get_data()
148 | particular_published_date = CovidMX(source='Serendipia', date='2020-04-10', date_format='%Y-%m-%d').get_data()
149 | ```
150 |
151 | # Cite as
152 |
153 | - Federico Garza Ramírez (2020). *covidmx: Python API to get information about COVID-19 in México*. Python package version 0.3.1. https://github.com/FedericoGarza/covidmx.
154 |
155 | # Acknowledgments
156 |
157 | - [Max Mergenthaler](https://github.com/mergenthaler)
158 | - [Mario Jimenez](https://github.com/isccarrasco)
159 |
160 | # Release information
161 |
162 | ## 0.3.1 (Current version)
163 |
164 | - 2020-06-01
165 | - Updated new urls from serendipia source. (Thanks to [Mario Jimenez](https://github.com/isccarrasco).)
166 |
167 | ## 0.3.0
168 |
169 | - 2020-04-26.
170 | - Includes a plot module at state and municipality leveles.
171 | - Includes a better handling of encodings. (Thanks to [Mario Jimenez](https://github.com/isccarrasco).)
172 |
173 |
174 | ## 0.2.5
175 |
176 | - 2020-04-20. The [*Dirección General de Epidemiología*](https://www.gob.mx/salud/documentos/datos-abiertos-152127):
177 | - Added an id column.
178 | - Released historical information.
179 | - Now the API can handle this changes.
180 |
181 | ## 0.2.4
182 |
183 | - 2020-04-16. The [*Dirección General de Epidemiología*](https://www.gob.mx/salud/documentos/datos-abiertos-152127) source renamed two columns:
184 | - `HABLA_LENGUA_INDI` -> `HABLA_LENGUA_INDIG` (column name and description are now homologated)
185 | - `OTRA_CON` -> `OTRA_COM`
186 | - Now the API can handle this change.
187 |
188 | ## 0.2.3
189 |
190 | - Now works with `python3.5+`.
191 | - Using `clean=True` returns encoded data instead of decoded data without cleaning columns (as works in `0.2.0` and `0.2.1`).
192 |
193 | ## 0.2.1
194 |
195 | - Minor changes to README.
196 |
197 | ## 0.2.0
198 |
199 | - Added new source: [*Dirección General de Epidemiología*](https://www.gob.mx/salud/documentos/datos-abiertos-152127). Default source.
200 | - Only works with `python3.7+`.
201 |
202 | ## 0.1.1
203 |
204 | - Minor changes to README.
205 |
206 | ## 0.1.0
207 |
208 | First realease.
209 |
210 | - Only one source, [Serendipia](https://serendipia.digital/2020/03/datos-abiertos-sobre-casos-de-coronavirus-covid-19-en-mexico/). Default source.
211 |
--------------------------------------------------------------------------------
125 |
126 | You can save your maps using `save_file_name`:
127 |
128 | ```python
129 | dge_plot.plot_map(status='sospechosos', add_municipalities=True, save_file_name='sospechosos-nacional.png')
130 | ```
131 |
132 | ## Serendipia
133 |
134 | Serendipia [publishes daily information](https://serendipia.digital/2020/03/datos-abiertos-sobre-casos-de-coronavirus-covid-19-en-mexico/) of the mexican *Secretaría de Salud* about covid in open format (.csv). This api downloads this data easily, making it useful for task automation.
135 |
136 | ```python
137 | from covidmx import CovidMX
138 |
139 | latest_published_data = CovidMX(source='Serendipia').get_data()
140 | ```
141 |
142 | Then `CovidMX` instances a `Serendipia` class, searches the latest published data for both confirmed and suspects individuals and finally clean the data. Nevertheless, a more specific search can be conducted (see docs for details).
143 |
144 | ```python
145 | raw_data = CovidMX(source='Serendipia', clean=False).get_data()
146 | confirmed = CovidMX(source='Serendipia', kind="confirmed").get_data()
147 | suspects = CovidMX(source='Serendipia',kind="suspects").get_data()
148 | particular_published_date = CovidMX(source='Serendipia', date='2020-04-10', date_format='%Y-%m-%d').get_data()
149 | ```
150 |
151 | # Cite as
152 |
153 | - Federico Garza Ramírez (2020). *covidmx: Python API to get information about COVID-19 in México*. Python package version 0.3.1. https://github.com/FedericoGarza/covidmx.
154 |
155 | # Acknowledgments
156 |
157 | - [Max Mergenthaler](https://github.com/mergenthaler)
158 | - [Mario Jimenez](https://github.com/isccarrasco)
159 |
160 | # Release information
161 |
162 | ## 0.3.1 (Current version)
163 |
164 | - 2020-06-01
165 | - Updated new urls from serendipia source. (Thanks to [Mario Jimenez](https://github.com/isccarrasco).)
166 |
167 | ## 0.3.0
168 |
169 | - 2020-04-26.
170 | - Includes a plot module at state and municipality leveles.
171 | - Includes a better handling of encodings. (Thanks to [Mario Jimenez](https://github.com/isccarrasco).)
172 |
173 |
174 | ## 0.2.5
175 |
176 | - 2020-04-20. The [*Dirección General de Epidemiología*](https://www.gob.mx/salud/documentos/datos-abiertos-152127):
177 | - Added an id column.
178 | - Released historical information.
179 | - Now the API can handle this changes.
180 |
181 | ## 0.2.4
182 |
183 | - 2020-04-16. The [*Dirección General de Epidemiología*](https://www.gob.mx/salud/documentos/datos-abiertos-152127) source renamed two columns:
184 | - `HABLA_LENGUA_INDI` -> `HABLA_LENGUA_INDIG` (column name and description are now homologated)
185 | - `OTRA_CON` -> `OTRA_COM`
186 | - Now the API can handle this change.
187 |
188 | ## 0.2.3
189 |
190 | - Now works with `python3.5+`.
191 | - Using `clean=True` returns encoded data instead of decoded data without cleaning columns (as works in `0.2.0` and `0.2.1`).
192 |
193 | ## 0.2.1
194 |
195 | - Minor changes to README.
196 |
197 | ## 0.2.0
198 |
199 | - Added new source: [*Dirección General de Epidemiología*](https://www.gob.mx/salud/documentos/datos-abiertos-152127). Default source.
200 | - Only works with `python3.7+`.
201 |
202 | ## 0.1.1
203 |
204 | - Minor changes to README.
205 |
206 | ## 0.1.0
207 |
208 | First realease.
209 |
210 | - Only one source, [Serendipia](https://serendipia.digital/2020/03/datos-abiertos-sobre-casos-de-coronavirus-covid-19-en-mexico/). Default source.
211 |
--------------------------------------------------------------------------------