├── .github
└── ISSUE_TEMPLATE
│ ├── bug_report.md
│ ├── custom.md
│ └── feature_request.md
├── EVMOverview.md
├── Internal-ethapi
├── README.md
├── accounts源码分析.md
├── a黄皮书里面出现的所有的符号索引.md
├── blockvalidator&blockprocessor.md
├── cmd-geth.md
├── cmd.md
├── consensus.md
├── core-blockchain源码分析.md
├── core-bloombits源码分析.md
├── core-chain_indexer源码解析.md
├── core-genesis创世区块源码分析.md
├── core-state-process源码分析.md
├── core-state源码分析.md
├── core-txlist交易池的一些数据结构源码分析.md
├── core-txpool交易池源码分析.md
├── core-vm-jumptable-instruction.md
├── core-vm-stack-memory源码分析.md
├── core-vm源码分析.md
├── eth-bloombits和filter源码分析.md
├── eth-downloader-peer源码分析.md
├── eth-downloader-queue.go源码分析.md
├── eth-downloader-statesync.md
├── eth-downloader源码分析.md
├── eth-fetcher源码分析.md
├── ethdb源码分析.md
├── eth以太坊协议分析.md
├── eth源码分析.md
├── event源码分析.md
├── geth启动流程分析.md
├── go-ethereum源码阅读环境搭建.md
├── hashimoto.md
├── miner-module.md
├── node源码分析.md
├── p2p-database.go源码分析.md
├── p2p-dial.go源码分析.md
├── p2p-nat源码分析.md
├── p2p-peer.go源码分析.md
├── p2p-rlpx节点之间的加密链路.md
├── p2p-server.go源码分析.md
├── p2p-table.go源码分析.md
├── p2p-udp.go源码分析.md
├── p2p源码分析.md
├── picture
├── Consensus-architecture.png
├── EVM-1.jpg
├── EVM-2.png
├── README.md
├── accounts.png
├── arch.jpg
├── block-seal-process.png
├── block-verification-process.png
├── bloom_1.png
├── bloom_2.png
├── bloom_3.png
├── bloom_4.png
├── bloom_5.png
├── bloom_6.png
├── chainindexer_1.png
├── chainindexer_2.png
├── geth_1.png
├── go_env_1.png
├── go_env_2.png
├── hashimoto-flow.png
├── hp_1.png
├── matcher_1.png
├── nat_1.png
├── nat_2.png
├── nat_3.png
├── patricia_tire.png
├── pow_hashimoto.png
├── rlp_1.png
├── rlp_2.png
├── rlp_3.png
├── rlp_4.png
├── rlp_5.png
├── rlp_6.png
├── rlpx_1.png
├── rlpx_2.png
├── rlpx_3.png
├── rpc_1.png
├── rpc_2.png
├── sign_ether.png
├── sign_ether_value.png
├── sign_exec_func.png
├── sign_exec_model.png
├── sign_func_1.png
├── sign_func_2.png
├── sign_gas_log.png
├── sign_gas_total.png
├── sign_h_b.png
├── sign_h_c.png
├── sign_h_d.png
├── sign_h_e.png
├── sign_h_g.png
├── sign_h_i.png
├── sign_h_l.png
├── sign_h_m.png
├── sign_h_n.png
├── sign_h_o.png
├── sign_h_p.png
├── sign_h_r.png
├── sign_h_s.png
├── sign_h_t.png
├── sign_h_x.png
├── sign_homestead.png
├── sign_i_a.png
├── sign_i_b.png
├── sign_i_d.png
├── sign_i_e.png
├── sign_i_h.png
├── sign_i_o.png
├── sign_i_p.png
├── sign_i_s.png
├── sign_i_v.png
├── sign_l1.png
├── sign_last_item.png
├── sign_last_item_1.png
├── sign_ls.png
├── sign_m_g.png
├── sign_m_w.png
├── sign_machine_state.png
├── sign_math_and.png
├── sign_math_any.png
├── sign_math_or.png
├── sign_memory.png
├── sign_pa.png
├── sign_placeholder_1.png
├── sign_placeholder_2.png
├── sign_placeholder_3.png
├── sign_placeholder_4.png
├── sign_r_bloom.png
├── sign_r_gasused.png
├── sign_r_i.png
├── sign_r_log.png
├── sign_r_logentry.png
├── sign_r_state.png
├── sign_receipt.png
├── sign_seq_item.png
├── sign_set_b.png
├── sign_set_b32.png
├── sign_set_p.png
├── sign_set_p256.png
├── sign_stack.png
├── sign_stack_added.png
├── sign_stack_removed.png
├── sign_state_1.png
├── sign_state_10.png
├── sign_state_2.png
├── sign_state_3.png
├── sign_state_4.png
├── sign_state_5.png
├── sign_state_6.png
├── sign_state_7.png
├── sign_state_8.png
├── sign_state_9.png
├── sign_state_balance.png
├── sign_state_code.png
├── sign_state_nonce.png
├── sign_state_root.png
├── sign_substate_a.png
├── sign_substate_al.png
├── sign_substate_ar.png
├── sign_substate_as.png
├── sign_t_data.png
├── sign_t_gaslimit.png
├── sign_t_gasprice.png
├── sign_t_lt.png
├── sign_t_nonce.png
├── sign_t_ti.png
├── sign_t_to.png
├── sign_t_tr.png
├── sign_t_ts.png
├── sign_t_value.png
├── sign_t_w.png
├── sign_u_i.png
├── sign_u_m.png
├── sign_u_pc.png
├── sign_u_s.png
├── state_1.png
├── trie_1.jpg
├── trie_1.png
├── trie_10.png
├── trie_2.png
├── trie_3.png
├── trie_4.png
├── trie_5.png
├── trie_6.png
├── trie_7.png
├── trie_8.png
├── trie_9.png
└── worldstatetrie.png
├── pos介绍proofofstake.md
├── pow一致性算法.md
├── readinguide4rlp.md
├── references
├── Kademlia协议原理简介.pdf
└── readme.md
├── rlp文件解析.md
├── rpc源码分析.md
├── todo-p2p加密算法.md
├── todo-用户账户-密钥-签名的关系.md
├── trie源码分析.md
├── types.md
├── 以太坊fast sync算法.md
├── 以太坊测试网络Clique_PoA介绍.md
├── 以太坊随机数生成方式.md
└── 封装的一些基础工具.md
/.github/ISSUE_TEMPLATE/bug_report.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Bug report
3 | about: Create a report to help us improve
4 | title: ''
5 | labels: ''
6 | assignees: ''
7 |
8 | ---
9 |
10 | **Describe the bug**
11 | A clear and concise description of what the bug is.
12 |
13 | **To Reproduce**
14 | Steps to reproduce the behavior:
15 | 1. Go to '...'
16 | 2. Click on '....'
17 | 3. Scroll down to '....'
18 | 4. See error
19 |
20 | **Expected behavior**
21 | A clear and concise description of what you expected to happen.
22 |
23 | **Screenshots**
24 | If applicable, add screenshots to help explain your problem.
25 |
26 | **Desktop (please complete the following information):**
27 | - OS: [e.g. iOS]
28 | - Browser [e.g. chrome, safari]
29 | - Version [e.g. 22]
30 |
31 | **Smartphone (please complete the following information):**
32 | - Device: [e.g. iPhone6]
33 | - OS: [e.g. iOS8.1]
34 | - Browser [e.g. stock browser, safari]
35 | - Version [e.g. 22]
36 |
37 | **Additional context**
38 | Add any other context about the problem here.
39 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/custom.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Custom issue template
3 | about: Describe this issue template's purpose here.
4 | title: ''
5 | labels: ''
6 | assignees: ''
7 |
8 | ---
9 |
10 |
11 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/feature_request.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Feature request
3 | about: Suggest an idea for this project
4 | title: ''
5 | labels: ''
6 | assignees: ''
7 |
8 | ---
9 |
10 | **Is your feature request related to a problem? Please describe.**
11 | A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
12 |
13 | **Describe the solution you'd like**
14 | A clear and concise description of what you want to happen.
15 |
16 | **Describe alternatives you've considered**
17 | A clear and concise description of any alternative solutions or features you've considered.
18 |
19 | **Additional context**
20 | Add any other context or screenshots about the feature request here.
21 |
--------------------------------------------------------------------------------
/EVMOverview.md:
--------------------------------------------------------------------------------
1 | # EVM Overview
2 | ## 1. 设计目标
3 |
4 | 在以太坊的设计原理中描述了 EVM 的设计目标:
5 |
6 | - 简单:操作码尽可能的简单,低级,数据类型尽可能少,虚拟机结构尽可能少。
7 | - 结果明确:在 VM 规范里,没有任何可能产生歧义的空间,结果应该是完全确定的,此外,计算步骤应该是精确的,以便可以计量 gas 消耗量。
8 | - 节约空间:EVM 汇编码应该尽可能紧凑。
9 | - 预期应用应具备专业化能力:在 VM 上构建的应用能够处理20字节的地址,以及32位的自定义加密值,拥有用于自定义加密的模数运算、读取区块和交易数据和状态交互等能力。
10 | - 简单安全:能够容易地建立一套操作的 gas 消耗成本模型,让 VM 不被利用。
11 | - 优化友好:应该易于优化,以便即时编译(JIT)和 VM 的加速版本能够构建出来。
12 |
13 | ## 2. 特点:
14 |
15 | - 区分临时存储(Memory,存在于每个 VM 实例中,并在 VM 执行结束后消失)和永久存储(Storage,存在于区块链的状态层)。
16 | - 采用基于栈(stack)的架构。
17 | - 机器码长度为32字节。
18 | - 没有重用 Java,或其他一些 Lisp 方言,Lua 的虚拟机,自定义虚拟机。
19 | - 使用可变的可扩展内存大小。
20 | - 限制调用深度为 1024。
21 | - 没有类型。
22 |
23 | ## 3. 原理
24 | 通常智能合约的开发流程是使用 solidity 编写逻辑代码,通过编译器编译成 bytecode,然后发布到以太坊上,以太坊底层通过 EVM 模块支持合约的执行和调用,调用时根据合约地址获取到代码,即合约的字节码,生成环境后载入到 EVM 执行。
25 |
26 | 大致流程如下图1,指令的执行过程如下图2,从 EVM code 中不断取出指令执行,利用 Gas 来实现限制循环,利用栈来进行操作,内存存储临时变量,账户状态中的 storage 用来存储数据。
27 | 
28 | 
29 |
30 | ## 4. 代码结构
31 | EVM 模块的文件比较多,这里先给出每个文件的简述,先对每个文件提供的功能有个简单的了解。
32 |
33 | ├── analysis.go // 跳转目标判定
34 | ├── common.go
35 | ├── contract.go // 合约的数据结构
36 | ├── contracts.go // 预编译好的合约
37 | ├── errors.go
38 | ├── evm.go // 对外提供的接口
39 | ├── gas.go // 用来计算指令耗费的 gas
40 | ├── gas_table.go // 指令耗费计算函数表
41 | ├── gen_structlog.go
42 | ├── instructions.go // 指令操作
43 | ├── interface.go // 定义 StateDB 的接口
44 | ├── interpreter.go // 解释器
45 | ├── intpool.go // 存放大整数
46 | ├── int_pool_verifier_empty.go
47 | ├── int_pool_verifier.go
48 | ├── jump_table.go // 指令和指令操作(操作,花费,验证)对应表
49 | ├── logger.go // 状态日志
50 | ├── memory.go // EVM 内存
51 | ├── memory_table.go // EVM 内存操作表,用来衡量操作所需内存大小
52 | ├── noop.go
53 | ├── opcodes.go // 指令以及一些对应关系
54 | ├── runtime
55 | │ ├── env.go // 执行环境
56 | │ ├── fuzz.go
57 | │ └── runtime.go // 运行接口,测试使用
58 | ├── stack.go // 栈
59 | └── stack_table.go // 栈验证
60 |
61 |
--------------------------------------------------------------------------------
/Internal-ethapi:
--------------------------------------------------------------------------------
1 | 在 internal/ethapi/api.go 中,可以通过 NewAccount 获取新账户,这个 api 可以通过交互式命令行或 rpc 接口调用。
2 |
3 | func (s *PrivateAccountAPI) NewAccount(password string) (common.Address, error) {
4 | acc, err := fetchKeystore(s.am).NewAccount(password)
5 | if err == nil {
6 | return acc.Address, nil
7 | }
8 | return common.Address{}, err
9 | }
10 |
11 | 首先调用 fetchKeystore,通过 backends 获得 KeyStore 对象,最后通过调用 keystore.go 中的 NewAccount 获得新账户。
12 | func (ks *KeyStore) NewAccount(passphrase string) (accounts.Account, error) {
13 | _, account, err := storeNewKey(ks.storage, crand.Reader, passphrase)
14 | if err != nil {
15 | return accounts.Account{}, err
16 | }
17 | ks.cache.add(account)
18 | ks.refreshWallets()
19 | return account, nil
20 | }
21 | NewAccount 会调用 storeNewKey。
22 |
23 | func storeNewKey(ks keyStore, rand io.Reader, auth string) (*Key, accounts.Account, error) {
24 | key, err := newKey(rand)
25 | if err != nil {
26 | return nil, accounts.Account{}, err
27 | }
28 | a := accounts.Account{Address: key.Address, URL: accounts.URL{Scheme: KeyStoreScheme, Path: ks.JoinPath(keyFileName(key.Address))}}
29 | if err := ks.StoreKey(a.URL.Path, key, auth); err != nil {
30 | zeroKey(key.PrivateKey)
31 | return nil, a, err
32 | }
33 | return key, a, err
34 | }
35 | 注意第一个参数是 keyStore,这是一个接口类型。
36 |
37 | type keyStore interface {
38 | GetKey(addr common.Address, filename string, auth string) (*Key, error)
39 | StoreKey(filename string, k *Key, auth string) error
40 | JoinPath(filename string) string
41 | }
42 | storeNewKey 首先调用 newKey,通过椭圆曲线加密算法获取公私钥对。
43 |
44 | func newKey(rand io.Reader) (*Key, error) {
45 | privateKeyECDSA, err := ecdsa.GenerateKey(crypto.S256(), rand)
46 | if err != nil {
47 | return nil, err
48 | }
49 | return newKeyFromECDSA(privateKeyECDSA), nil
50 | }
51 | 然后会根据参数 ks 的类型调用对应的实现,通过 geth account new 命令创建新账户,调用的就是 accounts/keystore/keystore_passphrase.go 中的实现。即
52 |
53 | func (ks keyStorePassphrase) StoreKey(filename string, key *Key, auth string) error {
54 | keyjson, err := EncryptKey(key, auth, ks.scryptN, ks.scryptP)
55 | if err != nil {
56 | return err
57 | }
58 | return writeKeyFile(filename, keyjson)
59 | }
60 |
61 | 我们可以深入到 EncryptKey 中
62 | func EncryptKey(key *Key, auth string, scryptN, scryptP int) ([]byte, error) {
63 | authArray := []byte(auth)
64 | salt := randentropy.GetEntropyCSPRNG(32)
65 | derivedKey, err := scrypt.Key(authArray, salt, scryptN, scryptR, scryptP, scryptDKLen)
66 | if err != nil {
67 | return nil, err
68 | }
69 | encryptKey := derivedKey[:16]
70 | keyBytes := math.PaddedBigBytes(key.PrivateKey.D, 32)
71 | iv := randentropy.GetEntropyCSPRNG(aes.BlockSize) // 16
72 | cipherText, err := aesCTRXOR(encryptKey, keyBytes, iv)
73 | if err != nil {
74 | return nil, err
75 | }
76 | mac := crypto.Keccak256(derivedKey[16:32], cipherText)
77 | scryptParamsJSON := make(map[string]interface{}, 5)
78 | scryptParamsJSON["n"] = scryptN
79 | scryptParamsJSON["r"] = scryptR
80 | scryptParamsJSON["p"] = scryptP
81 | scryptParamsJSON["dklen"] = scryptDKLen
82 | scryptParamsJSON["salt"] = hex.EncodeToString(salt)
83 | cipherParamsJSON := cipherparamsJSON{
84 | IV: hex.EncodeToString(iv),
85 | }
86 | cryptoStruct := cryptoJSON{
87 | Cipher: "aes-128-ctr",
88 | CipherText: hex.EncodeToString(cipherText),
89 | CipherParams: cipherParamsJSON,
90 | KDF: keyHeaderKDF,
91 | KDFParams: scryptParamsJSON,
92 | MAC: hex.EncodeToString(mac),
93 | }
94 | encryptedKeyJSONV3 := encryptedKeyJSONV3{
95 | hex.EncodeToString(key.Address[:]),
96 | cryptoStruct,
97 | key.Id.String(),
98 | version,
99 | }
100 | return json.Marshal(encryptedKeyJSONV3)
101 | }
102 | EncryptKey 的 key 参数是加密的账户,包括 ID,公私钥,地址,auth 参数是用户输入的密码,scryptN 参数是 scrypt 算法中的 N,scryptP 参数是 scrypt 算法中的 P。整个过程,首先对密码使用 scrypt 算法加密,得到加密后的密码 derivedKey,然后用 derivedKey 对私钥使用 AES-CTR 算法加密,得到密文 cipherText,再对 derivedKey 和 cipherText 进行哈希运算得到 mac,mac 起到签名的作用,在解密的时候可以验证合法性,防止别人篡改。EncryptKey 最终返回 json 字符串,Storekey 方法接下来会将其保存在文件中。
103 |
104 | 列出所有账户
105 | 列出所有账户的入口也在 internal/ethapi/api.go 里。
106 | func (s *PrivateAccountAPI) ListAccounts() []common.Address {
107 | addresses := make([]common.Address, 0) // return [] instead of nil if empty
108 | for _, wallet := range s.am.Wallets() {
109 | for _, account := range wallet.Accounts() {
110 | addresses = append(addresses, account.Address)
111 | }
112 | }
113 | return addresses
114 | }
115 | 该方法会从 Account Manager 中读取所有钱包信息,获取其对应的所有地址信息。
116 |
117 | 如果读者对 geth account 命令还有印象的话,geth account 命令还有 update,import 等方法,这里就不再讨论了。
118 |
119 | 发起转账
120 | 发起一笔转账的函数入口在 internal/ethapi/api.go 中。
121 | func (s *PublicTransactionPoolAPI) SendTransaction(ctx context.Context, args SendTxArgs) (common.Hash, error) {
122 | account := accounts.Account{Address: args.From}
123 | wallet, err := s.b.AccountManager().Find(account)
124 | if err != nil {
125 | return common.Hash{}, err
126 | }
127 | if args.Nonce == nil {
128 | s.nonceLock.LockAddr(args.From)
129 | defer s.nonceLock.UnlockAddr(args.From)
130 | }
131 | if err := args.setDefaults(ctx, s.b); err != nil {
132 | return common.Hash{}, err
133 | }
134 | tx := args.toTransaction()
135 | var chainID *big.Int
136 | if config := s.b.ChainConfig(); config.IsEIP155(s.b.CurrentBlock().Number()) {
137 | chainID = config.ChainId
138 | }
139 | signed, err := wallet.SignTx(account, tx, chainID)
140 | if err != nil {
141 | return common.Hash{}, err
142 | }
143 | return submitTransaction(ctx, s.b, signed)
144 | }
145 | 转账时,首先利用传入的参数 from 构造一个 account,表示转出方。然后通过 accountMananger 的 Find 方法获得这个账户的钱包(Find 方法在上面有介绍),接下来有一个稍特别的地方。我们知道以太坊采用的是账户余额的体系,对于 UTXO 的方式来说,防止双花的方式很直观,一个输出不能同时被两个输入而引用,这种方式自然而然地就防止了发起转账时可能出现的双花,采用账户系统的以太坊没有这种便利,以太坊的做法是,每个账户有一个 nonce 值,它等于账户累计发起的交易数量,账户发起交易时,交易数据里必须包含 nonce,而且该值必须大于账户的 nonce 值,否则为非法,如果交易的 nonce 值减去账户的 nonce 值大于1,这个交易也不能打包到区块中,这确保了交易是按照一定的顺序执行的。如果有两笔交易有相同 nonce,那么其中只有一笔交易能够成功,通过给 nonce 加锁就是用来防止双花的问题。接着调用 args.setDefaults(ctx, s.b) 方法设置一些交易默认值。最后调用 toTransaction 方法创建交易:
146 |
147 | func (args *SendTxArgs) toTransaction() *types.Transaction {
148 | var input []byte
149 | if args.Data != nil {
150 | input = *args.Data
151 | } else if args.Input != nil {
152 | input = *args.Input
153 | }
154 | if args.To == nil {
155 | return types.NewContractCreation(uint64(*args.Nonce), (*big.Int)(args.Value), uint64(*args.Gas), (*big.Int)(args.GasPrice), input)
156 | }
157 | return types.NewTransaction(uint64(*args.Nonce), *args.To, (*big.Int)(args.Value), uint64(*args.Gas), (*big.Int)(args.GasPrice), input)
158 | }
159 | 这里有两个分支,如果传入的交易的 to 参数不存在,那就表明这是一笔合约转账;如果有 to 参数,就是一笔普通的转账,深入后你会发现这两种转账最终调用的都是 newTransaction
160 |
161 | func NewTransaction(nonce uint64, to common.Address, amount *big.Int, gasLimit uint64, gasPrice *big.Int, data []byte) *Transaction {
162 | return newTransaction(nonce, &to, amount, gasLimit, gasPrice, data)
163 | }
164 | func NewContractCreation(nonce uint64, amount *big.Int, gasLimit uint64, gasPrice *big.Int, data []byte) *Transaction {
165 | return newTransaction(nonce, nil, amount, gasLimit, gasPrice, data)
166 | }
167 | newTransaction 的功能很简单,实际上就是返回一个 Transaction 实例。我们接着看 SendTransaction 方法接下来的部分。创建好一笔交易,接着我们通过 ChainConfig 方法获得区块链的配置信息,如果是 EIP155 里描述的配置,需要做特殊处理(待深入),然后调用 SignTx 对交易签名来确保这笔交易是真实有效的。SignTx 的接口定义在 accounts/accounts.go 中,这里我们看 keystore 的实现。
168 |
169 | func (ks *KeyStore) SignTx(a accounts.Account, tx *types.Transaction, chainID *big.Int) (*types.Transaction, error) {
170 | ks.mu.RLock()
171 | defer ks.mu.RUnlock()
172 | unlockedKey, found := ks.unlocked[a.Address]
173 | if !found {
174 | return nil, ErrLocked
175 | }
176 | if chainID != nil {
177 | return types.SignTx(tx, types.NewEIP155Signer(chainID), unlockedKey.PrivateKey)
178 | }
179 | return types.SignTx(tx, types.HomesteadSigner{}, unlockedKey.PrivateKey)
180 | }
181 | 首先验证账户是否已解锁,若没有解锁,直接报异常退出。接着根据 chainID 判断使用哪一种签名方式,调用相应 SignTx 方法进行签名。
182 |
183 | func SignTx(tx *Transaction, s Signer, prv *ecdsa.PrivateKey) (*Transaction, error) {
184 | h := s.Hash(tx)
185 | sig, err := crypto.Sign(h[:], prv)
186 | if err != nil {
187 | return nil, err
188 | }
189 | return tx.WithSignature(s, sig)
190 | }
191 | SignTx 的功能是调用椭圆加密函数获得签名,得到带签名的交易后,通过 SubmitTrasaction 提交交易。
192 |
193 |
194 | func submitTransaction(ctx context.Context, b Backend, tx *types.Transaction) (common.Hash, error) {
195 | if err := b.SendTx(ctx, tx); err != nil {
196 | return common.Hash{}, err
197 | }
198 | if tx.To() == nil {
199 | signer := types.MakeSigner(b.ChainConfig(), b.CurrentBlock().Number())
200 | from, err := types.Sender(signer, tx)
201 | if err != nil {
202 | return common.Hash{}, err
203 | }
204 | addr := crypto.CreateAddress(from, tx.Nonce())
205 | log.Info("Submitted contract creation", "fullhash", tx.Hash().Hex(), "contract", addr.Hex())
206 | } else {
207 | log.Info("Submitted transaction", "fullhash", tx.Hash().Hex(), "recipient", tx.To())
208 | }
209 | return tx.Hash(), nil
210 | }
211 | submitTransaction 首先调用 SendTx,这个接口在 internal/ethapi/backend.go 中定义,而实现在 eth/api_backend.go 中,这部分代码涉及到交易池,我们在单独的交易池章节进行探讨,这里就此打住。
212 |
213 | 将交易写入交易池后,如果没有因错误退出,submitTransaction 会完成提交交易,返回交易哈希值。发起交易的这个过程就结束了,剩下的就交给矿工将交易上链。
214 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Ethereum Tutorial
2 | 本文结合了一些网上资料,加上个人的原创结合而成。若有疑问,还请及时批评指出。
3 |
4 | **For the one who is not familliar with Chinese, the English version is published. [link](https://github.com/Billy1900/Ethereum-tutorial-EN)**
5 |
6 | ## 目录
7 |
8 | - [go-ethereum代码阅读环境搭建](/go-ethereum源码阅读环境搭建.md)
9 | - [以太坊黄皮书 符号索引](a黄皮书里面出现的所有的符号索引.md)
10 | - [account文件解析](/accounts源码分析.md)
11 | - build文件解析: 此文件主要用于编译安装使用
12 | - [cmd文件解析](/cmd.md)
13 | - [geth](/cmd-geth.md)
14 | - common文件: 此文件是提供系统的一些通用的工具集 (utils)
15 | - [consensus文件解析](/consensus.md)
16 | - console文件解析: Console is a JavaScript interpreted runtime environment.
17 | - contract文件: Package checkpointoracle is a an on-chain light client checkpoint oracle about contract.
18 | - core文件源码分析
19 | - [types文件解析](/types.md)
20 | - [state文件分析](/core-state源码分析.md)
21 | - [core/genesis.go](/core-genesis创世区块源码分析.md)
22 | - [core/blockchain.go](/core-blockchain源码分析.md)
23 | - [core/tx_list.go & tx_journal.go](/core-txlist交易池的一些数据结构源码分析.md)
24 | - [core/tx_pool.go](/core-txpool交易池源码分析.md)
25 | - [core/block_processor.go & block_validator.go](/blockvalidator&blockprocessor.md)
26 | - [chain_indexer.go](/core-chain_indexer源码解析.md)
27 | - [bloombits源码分析](/core-bloombits源码分析.md)
28 | - [statetransition.go & stateprocess.go](/core-state-process源码分析.md)
29 | - vm 虚拟机源码分析
30 | - [EVM Overview](/EVMOverview.md)
31 | - [虚拟机堆栈和内存数据结构分析](/core-vm-stack-memory源码分析.md)
32 | - [虚拟机指令,跳转表,解释器源码分析](/core-vm-jumptable-instruction.md)
33 | - [虚拟机源码分析](/core-vm源码分析.md)
34 | - crypto文件: 整个system涉及的有关密码学的configuration
35 | - Dashboard: The dashboard is a data visualizer integrated into geth, intended to collect and visualize useful information of an Ethereum node. It consists of two parts: 1) The client visualizes the collected data. 2) The server collects the data, and updates the clients.
36 | - [eth源码分析](/eth源码分析.md)
37 | - [ethdb源码分析](/ethdb源码分析.md)
38 | - [miner文件解析](/miner-module.md)
39 | - [p2p源码分析](/p2p源码分析.md)
40 | - [rlp源码解析](/rlp文件解析.md)
41 | - [rpc源码分析](/rpc源码分析.md)
42 | - [trie源码分析](/trie源码分析.md)
43 | - [pow一致性算法](/pow一致性算法.md)
44 | - [以太坊测试网络Clique_PoA介绍](/以太坊测试网络Clique_PoA介绍.md)
45 |
46 |
47 |
--------------------------------------------------------------------------------
/a黄皮书里面出现的所有的符号索引.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | 
4 |
5 | 是t+1时刻的状态(account trie)。
6 |
7 | 是状态转换函数,也可以理解为执行引擎。
8 |
9 |  是transaction,一次交易。
10 |
11 | 
12 |
13 |  是区块级别的状态转换函数。
14 |
15 |  是区块,由很多交易组成。
16 |
17 |  0号位置的交易。
18 |
19 |  是块终结状态转换函数(一个奖励挖矿者的函数)。
20 |
21 |  Ether的标识。
22 |
23 |  Ethereum中所用到的各种单位与Wei的换算关系(例如:一个Finney对应10^15个Wei)。
24 |
25 |  machine-state
26 |
27 | ## 一些基本的规则
28 |
29 | - 对于大多数的函数来说,都用大写字母来标识。
30 | - 元组一般用大写字母来标识
31 | - 标量或者固定大小的字节数组都用小写字母标识。 比如 n 代表交易的nonce, 有一些可能有例外,比如δ代表 一个给定指令需要的堆栈数据的多少。
32 | - 变长的字节数组一般用加粗的小写字母。 比如 **o** 代表一个message call的输出数据。对于某些重要的也可能使用加粗的大写字母
33 |
34 |
35 |  字节序列
36 |  正整数
37 |  32字节长度的字节序列
38 |  小于 2^256 的正整数
39 | **[ ]** 用于索引数组里面的对应元素
40 |  代表机器堆栈(machine's stack)的第一个对象
41 |  代表了机器内存(machine's memory)里面的前32个元素
42 |  一个占位符号,可以是任意字符代表任意对象
43 |
44 |  代表这个对象被修改后的值
45 |  中间状态
46 |  中间状态2
47 |   如果前面的f代表了一个函数, 那么后面的f*代表了一个相似的函数,不过是对内部的元素依次执行f的一个函数。
48 |
49 |  代表了列表里面的最后一个元素
50 |  代表了列表里面的最后一个元素
51 |  求x的长度
52 |
53 |
54 |  a代表某个地址,代表某个账号的nonce
55 |  banlance 余额
56 |  storage trie 的 root hash
57 |  Code的hash。 如果code是b 那么KEC(b)===这个hash
58 |
59 |
60 | 
61 |
62 |  world state collapse function
63 | 
64 |
65 |
66 |  任意的 any
67 |  并集 or
68 |  交集 and
69 |
70 |  Homestead
71 | ## 交易
72 |
73 |  交易的nonce
74 |  gasPrice
75 |  gasLimit
76 |  to
77 |  value
78 |
79 | 通过者三个值可以得到sender的地址
80 |
81 |  合约的初始化代码
82 |  方法调用的入参
83 | 
84 |
85 | ## 区块头
86 |
87 | ParentHash
88 | OmmersHash
89 | beneficiary矿工地址
90 | stateRoot
91 | transactionRoot
92 | receiptRoot
93 | logsBloom
94 | 难度
95 | number高度
96 | gasLimit
97 | gasUsed
98 | timestamp
99 | extraData
100 | mixHash
101 | nonce
102 | ## 回执
103 |
104 |  第i个交易的receipt
105 |
106 | 
107 |  交易执行后的world-state
108 | 交易执行后区块总的gas使用量
109 | 本交易执行产生的所有log的布隆过滤数据
110 | 交易产生的日志集合
111 |
112 |  Log entry Oa日志产生的地址, Ot topic Od 时间
113 |
114 | ## 交易执行
115 |  substate
116 |  suicide set
117 |  log series
118 |  refund balance
119 |
120 |  交易过程中使用的总gas数量。
121 |  交易产生的日志。
122 |
123 |  执行代码的拥有者
124 |  交易的发起者
125 |  gasPrice
126 |  inputdata
127 |  引起代码执行的地址,如果是交易那么是交易的发起人
128 |  value
129 |  需要执行的代码
130 |  当前的区块头
131 |  当前的调用深度
132 |
133 |
134 |  执行模型 s suicide set; l 日志集合 **o** 输出 ; r refund
135 |
136 |  执行函数
137 |
138 |  当前可用的gas
139 |  程序计数器
140 |  内存内容
141 |  内存中有效的word数量
142 |  堆栈内容
143 |
144 |  w代表当前需要执行的指令
145 |
146 |  指令需要移除的堆栈对象个数
147 |  指令需要增加的堆栈对象个数
148 |
--------------------------------------------------------------------------------
/blockvalidator&blockprocessor.md:
--------------------------------------------------------------------------------
1 | # block_validatore.go
2 |
3 | ## core/ Block_Validator.go/ValidateBody()
4 | func (v *BlockValidator) ValidateBody(block *types.Block) error {
5 | // Check whether the block's known, and if not, that it's linkable
6 | if v.bc.HasBlockAndState(block.Hash(), block.NumberU64()) {
7 | return ErrKnownBlock
8 | }
9 | if !v.bc.HasBlockAndState(block.ParentHash(), block.NumberU64()-1) {
10 | if !v.bc.HasBlock(block.ParentHash(), block.NumberU64()-1) {
11 | return consensus.ErrUnknownAncestor
12 | }
13 | return consensus.ErrPrunedAncestor
14 | }
15 | // Header validity is known at this point, check the uncles and transactions
16 | header := block.Header()
17 | if err := v.engine.VerifyUncles(v.bc, block); err != nil {
18 | return err
19 | }
20 | if hash := types.CalcUncleHash(block.Uncles()); hash != header.UncleHash {
21 | return fmt.Errorf("uncle root hash mismatch: have %x, want %x", hash, header.UncleHash)
22 | }
23 | if hash := types.DeriveSha(block.Transactions()); hash != header.TxHash {
24 | return fmt.Errorf("transaction root hash mismatch: have %x, want %x", hash, header.TxHash)
25 | }
26 | return nil
27 | }
28 | 这段代码主要是用来验证区块内容的。
29 | - 首先判断当前数据库中是否已经包含了该区块,如果已经有了的话返回错误。
30 | - 接着判断当前数据库中是否包含该区块的父块,如果没有的话返回错误。
31 | - 然后验证叔块的有效性及其hash值,最后计算块中交易的hash值并验证是否和区块头中的hash值一致。
32 |
33 | ## core/BlockValidator.ValidateState()
34 | func (v *BlockValidator) ValidateState(block, parent *types.Block, statedb *state.StateDB, receipts types.Receipts, usedGas uint64) error {
35 | header := block.Header()
36 | if block.GasUsed() != usedGas {
37 | return fmt.Errorf("invalid gas used (remote: %d local: %d)", block.GasUsed(), usedGas)
38 | }
39 | // Validate the received block's bloom with the one derived from the generated receipts.
40 | // For valid blocks this should always validate to true.
41 | rbloom := types.CreateBloom(receipts)
42 | if rbloom != header.Bloom {
43 | return fmt.Errorf("invalid bloom (remote: %x local: %x)", header.Bloom, rbloom)
44 | }
45 | // Tre receipt Trie's root (R = (Tr [[H1, R1], ... [Hn, R1]]))
46 | receiptSha := types.DeriveSha(receipts)
47 | if receiptSha != header.ReceiptHash {
48 | return fmt.Errorf("invalid receipt root hash (remote: %x local: %x)", header.ReceiptHash, receiptSha)
49 | }
50 | // Validate the state root against the received state root and throw
51 | // an error if they don't match.
52 | if root := statedb.IntermediateRoot(v.config.IsEIP158(header.Number)); header.Root != root {
53 | return fmt.Errorf("invalid merkle root (remote: %x local: %x)", header.Root, root)
54 | }
55 | return nil
56 | }
57 |
58 | 这部分代码主要是用来验证区块中和状态转换相关的字段是否正确,包含以下几个部分:
59 |
60 | - 判断刚刚执行交易消耗的gas值是否和区块头中的值相同
61 | - 根据刚刚执行交易获得的交易回执创建Bloom过滤器,判断是否和区块头中的Bloom过滤器相同(Bloom过滤器是一个2048位的字节数组)
62 | - 判断交易回执的hash值是否和区块头中的值相同
63 | - 计算StateDB中的MPT的Merkle Root,判断是否和区块头中的值相同
64 |
65 | 至此,区块验证流程就走完了,新区块将被写入数据库,同时更新世界状态。
66 |
67 |
68 | # block_processor.go
69 |
70 | ## core/BlockProcessor.Process()
71 | func (p *StateProcessor) Process(block *types.Block, statedb *state.StateDB, cfg vm.Config) (types.Receipts, []*types.Log, uint64, error) {
72 | var (
73 | receipts types.Receipts
74 | usedGas = new(uint64)
75 | header = block.Header()
76 | allLogs []*types.Log
77 | gp = new(GasPool).AddGas(block.GasLimit())
78 | )
79 | // Mutate the the block and state according to any hard-fork specs
80 | if p.config.DAOForkSupport && p.config.DAOForkBlock != nil && p.config.DAOForkBlock.Cmp(block.Number()) == 0 {
81 | misc.ApplyDAOHardFork(statedb)
82 | }
83 | // Iterate over and process the individual transactions
84 | for i, tx := range block.Transactions() {
85 | statedb.Prepare(tx.Hash(), block.Hash(), i)
86 | receipt, _, err := ApplyTransaction(p.config, p.bc, nil, gp, statedb, header, tx, usedGas, cfg)
87 | if err != nil {
88 | return nil, nil, 0, err
89 | }
90 | receipts = append(receipts, receipt)
91 | allLogs = append(allLogs, receipt.Logs...)
92 | }
93 | // Finalize the block, applying any consensus engine specific extras (e.g. block rewards)
94 | p.engine.Finalize(p.bc, header, statedb, block.Transactions(), block.Uncles(), receipts)
95 |
96 | return receipts, allLogs, *usedGas, nil
97 | }
98 | 这段代码其实跟挖矿代码中执行交易是一模一样的,首先调用Prepare()计算难度值,然后调用ApplyTransaction()执行交易并获取交易回执和消耗的gas值,最后通过Finalize()生成区块。
99 |
100 | 值得注意的是,传进来的StateDB是父块的世界状态,执行交易会改变这些状态,为下一步验证状态转移相关的字段做准备。
101 |
--------------------------------------------------------------------------------
/cmd.md:
--------------------------------------------------------------------------------
1 | # cmd
2 |
3 | |文件|package|说明|
4 | |-----|----------|-----------------------------------------------------------------------------------|
5 | |cmd | |命令行工具,下面又分了很多的命令行工具|
6 | |cmd |abigen |将智能合约源代码转换成容易使用的,编译时类型安全的Go语言包|
7 | |cmd |bootnode |启动一个仅仅实现网络发现的节点|
8 | |cmd | checkpoint-admin| checkpoint-admin is a utility that can be used to query checkpoint information and register stable checkpoints into an oracle contract.|
9 | |cmd | clef | Clef is an account management tool|
10 | |cmd | devp2p | ethereum p2p tool|
11 | |cmd | ethkey | an Ethereum key manager|
12 | |cmd | evm |以太坊虚拟机的开发工具, 用来提供一个可配置的,受隔离的代码调试环境|
13 | |cmd | faucet |faucet is a Ether faucet backend by a light client.|
14 | |cmd |geth |以太坊命令行客户端,最重要的一个工具|
15 | |cmd |p2psim |提供了一个工具来模拟http的API|
16 | |cmd |puppeth |创建一个新的以太坊网络的向导,一个命令组装和维护私人网路|
17 | |cmd |rlpdump |提供了一个RLP数据的格式化输出|
18 | |cmd |swarm |swarm网络的接入点|
19 | |cmd |util |提供了一些公共的工具,为Go-Ethereum命令提供说明|
20 | |cmd |wnode |这是一个简单的Whisper节点。 它可以用作独立的引导节点。此外,可以用于不同的测试和诊断目的。|
21 |
--------------------------------------------------------------------------------
/core-genesis创世区块源码分析.md:
--------------------------------------------------------------------------------
1 | # core/genesis.go
2 |
3 | genesis 是创世区块的意思. 一个区块链就是从同一个创世区块开始,通过规则形成的.不同的网络有不同的创世区块, 主网络和测试网路的创世区块是不同的.
4 |
5 | 这个模块根据传入的genesis的初始值和database,来设置genesis的状态,如果不存在创世区块,那么在database里面创建它。
6 |
7 | 数据结构
8 |
9 | // Genesis specifies the header fields, state of a genesis block. It also defines hard
10 | // fork switch-over blocks through the chain configuration.
11 | // Genesis指定header的字段,起始块的状态。 它还通过配置来定义硬叉切换块。
12 | type Genesis struct {
13 | Config *params.ChainConfig `json:"config"`
14 | Nonce uint64 `json:"nonce"`
15 | Timestamp uint64 `json:"timestamp"`
16 | ExtraData []byte `json:"extraData"`
17 | GasLimit uint64 `json:"gasLimit" gencodec:"required"`
18 | Difficulty *big.Int `json:"difficulty" gencodec:"required"`
19 | Mixhash common.Hash `json:"mixHash"`
20 | Coinbase common.Address `json:"coinbase"`
21 | Alloc GenesisAlloc `json:"alloc" gencodec:"required"`
22 |
23 | // These fields are used for consensus tests. Please don't use them
24 | // in actual genesis blocks.
25 | Number uint64 `json:"number"`
26 | GasUsed uint64 `json:"gasUsed"`
27 | ParentHash common.Hash `json:"parentHash"`
28 | }
29 |
30 | // GenesisAlloc specifies the initial state that is part of the genesis block.
31 | // GenesisAlloc 指定了最开始的区块的初始状态.
32 | type GenesisAlloc map[common.Address]GenesisAccount
33 |
34 | genesisaccount,
35 | type GenesisAlloc map[common.Address]GenesisAccount
36 | type GenesisAccount struct {
37 | Code []byte `json:"code,omitempty"`
38 | Storage map[common.Hash]common.Hash `json:"storage,omitempty"`
39 | Balance *big.Int `json:"balance" gencodec:"required"`
40 | Nonce uint64 `json:"nonce,omitempty"`
41 | PrivateKey []byte `json:"secretKey,omitempty"`
42 | }
43 |
44 |
45 | SetupGenesisBlock,
46 |
47 | // SetupGenesisBlock writes or updates the genesis block in db.
48 | //
49 | // The block that will be used is:
50 | //
51 | // genesis == nil genesis != nil
52 | // +------------------------------------------
53 | // db has no genesis | main-net default | genesis
54 | // db has genesis | from DB | genesis (if compatible)
55 | //
56 | // The stored chain configuration will be updated if it is compatible (i.e. does not
57 | // specify a fork block below the local head block). In case of a conflict, the
58 | // error is a *params.ConfigCompatError and the new, unwritten config is returned.
59 | // 如果存储的区块链配置不兼容那么会被更新(). 为了避免发生冲突,会返回一个错误,并且新的配置和原来的配置会返回.
60 | // The returned chain configuration is never nil.
61 |
62 | // genesis 如果是 testnet dev 或者是 rinkeby 模式, 那么不为nil。如果是mainnet或者是私有链接。那么为空
63 | func SetupGenesisBlock(db ethdb.Database, genesis *Genesis) (*params.ChainConfig, common.Hash, error) {
64 | if genesis != nil && genesis.Config == nil {
65 | return params.AllProtocolChanges, common.Hash{}, errGenesisNoConfig
66 | }
67 |
68 | // Just commit the new block if there is no stored genesis block.
69 | stored := GetCanonicalHash(db, 0) //获取genesis对应的区块
70 | if (stored == common.Hash{}) { //如果没有区块 最开始启动geth会进入这里。
71 | if genesis == nil {
72 | //如果genesis是nil 而且stored也是nil 那么使用主网络
73 | // 如果是test dev rinkeby 那么genesis不为空 会设置为各自的genesis
74 | log.Info("Writing default main-net genesis block")
75 | genesis = DefaultGenesisBlock()
76 | } else { // 否则使用配置的区块
77 | log.Info("Writing custom genesis block")
78 | }
79 | // 写入数据库
80 | block, err := genesis.Commit(db)
81 | return genesis.Config, block.Hash(), err
82 | }
83 |
84 | // Check whether the genesis block is already written.
85 | if genesis != nil { //如果genesis存在而且区块也存在 那么对比这两个区块是否相同
86 | block, _ := genesis.ToBlock()
87 | hash := block.Hash()
88 | if hash != stored {
89 | return genesis.Config, block.Hash(), &GenesisMismatchError{stored, hash}
90 | }
91 | }
92 |
93 | // Get the existing chain configuration.
94 | // 获取当前存在的区块链的genesis配置
95 | newcfg := genesis.configOrDefault(stored)
96 | // 获取当前的区块链的配置
97 | storedcfg, err := GetChainConfig(db, stored)
98 | if err != nil {
99 | if err == ErrChainConfigNotFound {
100 | // This case happens if a genesis write was interrupted.
101 | log.Warn("Found genesis block without chain config")
102 | err = WriteChainConfig(db, stored, newcfg)
103 | }
104 | return newcfg, stored, err
105 | }
106 | // Special case: don't change the existing config of a non-mainnet chain if no new
107 | // config is supplied. These chains would get AllProtocolChanges (and a compat error)
108 | // if we just continued here.
109 | // 特殊情况:如果没有提供新的配置,请不要更改非主网链的现有配置。
110 | // 如果我们继续这里,这些链会得到AllProtocolChanges(和compat错误)。
111 | if genesis == nil && stored != params.MainnetGenesisHash {
112 | return storedcfg, stored, nil // 如果是私有链接会从这里退出。
113 | }
114 |
115 | // Check config compatibility and write the config. Compatibility errors
116 | // are returned to the caller unless we're already at block zero.
117 | // 检查配置的兼容性,除非我们在区块0,否则返回兼容性错误.
118 | height := GetBlockNumber(db, GetHeadHeaderHash(db))
119 | if height == missingNumber {
120 | return newcfg, stored, fmt.Errorf("missing block number for head header hash")
121 | }
122 | compatErr := storedcfg.CheckCompatible(newcfg, height)
123 | // 如果区块已经写入数据了,那么就不能更改genesis配置了
124 | if compatErr != nil && height != 0 && compatErr.RewindTo != 0 {
125 | return newcfg, stored, compatErr
126 | }
127 | // 如果是主网络会从这里退出。
128 | return newcfg, stored, WriteChainConfig(db, stored, newcfg)
129 | }
130 | SetupGenesisBlock 会根据创世区块返回一个区块链的配置。从 db 参数中拿到的区块里如果没有创世区块的话,首先提交一个新区块。接着通过调用 genesis.configOrDefault(stored) 拿到当前链的配置,测试兼容性后将配置写回 DB 中。最后返回区块链的配置信息。
131 |
132 | ToBlock, 这个方法使用genesis的数据,使用基于内存的数据库,然后创建了一个block并返回(通过 types.NewBlock)
133 |
134 |
135 | // ToBlock creates the block and state of a genesis specification.
136 | func (g *Genesis) ToBlock() (*types.Block, *state.StateDB) {
137 | db, _ := ethdb.NewMemDatabase()
138 | statedb, _ := state.New(common.Hash{}, state.NewDatabase(db))
139 | for addr, account := range g.Alloc {
140 | statedb.AddBalance(addr, account.Balance)
141 | statedb.SetCode(addr, account.Code)
142 | statedb.SetNonce(addr, account.Nonce)
143 | for key, value := range account.Storage {
144 | statedb.SetState(addr, key, value)
145 | }
146 | }
147 | root := statedb.IntermediateRoot(false)
148 | head := &types.Header{
149 | Number: new(big.Int).SetUint64(g.Number),
150 | Nonce: types.EncodeNonce(g.Nonce),
151 | Time: new(big.Int).SetUint64(g.Timestamp),
152 | ParentHash: g.ParentHash,
153 | Extra: g.ExtraData,
154 | GasLimit: new(big.Int).SetUint64(g.GasLimit),
155 | GasUsed: new(big.Int).SetUint64(g.GasUsed),
156 | Difficulty: g.Difficulty,
157 | MixDigest: g.Mixhash,
158 | Coinbase: g.Coinbase,
159 | Root: root,
160 | }
161 | if g.GasLimit == 0 {
162 | head.GasLimit = params.GenesisGasLimit
163 | }
164 | if g.Difficulty == nil {
165 | head.Difficulty = params.GenesisDifficulty
166 | }
167 | return types.NewBlock(head, nil, nil, nil), statedb
168 | }
169 |
170 | Commit方法和MustCommit方法, Commit方法把给定的genesis的block和state写入数据库, 这个block被认为是规范的区块链头。
171 |
172 | // Commit writes the block and state of a genesis specification to the database.
173 | // The block is committed as the canonical head block.
174 | func (g *Genesis) Commit(db ethdb.Database) (*types.Block, error) {
175 | block, statedb := g.ToBlock()
176 | if block.Number().Sign() != 0 {
177 | return nil, fmt.Errorf("can't commit genesis block with number > 0")
178 | }
179 | if _, err := statedb.CommitTo(db, false); err != nil {
180 | return nil, fmt.Errorf("cannot write state: %v", err)
181 | }
182 | // 写入总难度
183 | if err := WriteTd(db, block.Hash(), block.NumberU64(), g.Difficulty); err != nil {
184 | return nil, err
185 | }
186 | // 写入区块
187 | if err := WriteBlock(db, block); err != nil {
188 | return nil, err
189 | }
190 | // 写入区块收据
191 | if err := WriteBlockReceipts(db, block.Hash(), block.NumberU64(), nil); err != nil {
192 | return nil, err
193 | }
194 | // 写入 headerPrefix + num (uint64 big endian) + numSuffix -> hash
195 | if err := WriteCanonicalHash(db, block.Hash(), block.NumberU64()); err != nil {
196 | return nil, err
197 | }
198 | // 写入 "LastBlock" -> hash
199 | if err := WriteHeadBlockHash(db, block.Hash()); err != nil {
200 | return nil, err
201 | }
202 | // 写入 "LastHeader" -> hash
203 | if err := WriteHeadHeaderHash(db, block.Hash()); err != nil {
204 | return nil, err
205 | }
206 | config := g.Config
207 | if config == nil {
208 | config = params.AllProtocolChanges
209 | }
210 | // 写入 ethereum-config-hash -> config
211 | return block, WriteChainConfig(db, block.Hash(), config)
212 | }
213 |
214 | // MustCommit writes the genesis block and state to db, panicking on error.
215 | // The block is committed as the canonical head block.
216 | func (g *Genesis) MustCommit(db ethdb.Database) *types.Block {
217 | block, err := g.Commit(db)
218 | if err != nil {
219 | panic(err)
220 | }
221 | return block
222 | }
223 |
224 | 返回各种模式的默认Genesis
225 |
226 | // DefaultGenesisBlock returns the Ethereum main net genesis block.
227 | func DefaultGenesisBlock() *Genesis {
228 | return &Genesis{
229 | Config: params.MainnetChainConfig,
230 | Nonce: 66,
231 | ExtraData: hexutil.MustDecode("0x11bbe8db4e347b4e8c937c1c8370e4b5ed33adb3db69cbdb7a38e1e50b1b82fa"),
232 | GasLimit: 5000,
233 | Difficulty: big.NewInt(17179869184),
234 | Alloc: decodePrealloc(mainnetAllocData),
235 | }
236 | }
237 |
238 | // DefaultTestnetGenesisBlock returns the Ropsten network genesis block.
239 | func DefaultTestnetGenesisBlock() *Genesis {
240 | return &Genesis{
241 | Config: params.TestnetChainConfig,
242 | Nonce: 66,
243 | ExtraData: hexutil.MustDecode("0x3535353535353535353535353535353535353535353535353535353535353535"),
244 | GasLimit: 16777216,
245 | Difficulty: big.NewInt(1048576),
246 | Alloc: decodePrealloc(testnetAllocData),
247 | }
248 | }
249 |
250 | // DefaultRinkebyGenesisBlock returns the Rinkeby network genesis block.
251 | func DefaultRinkebyGenesisBlock() *Genesis {
252 | return &Genesis{
253 | Config: params.RinkebyChainConfig,
254 | Timestamp: 1492009146,
255 | ExtraData: hexutil.MustDecode("0x52657370656374206d7920617574686f7269746168207e452e436172746d616e42eb768f2244c8811c63729a21a3569731535f067ffc57839b00206d1ad20c69a1981b489f772031b279182d99e65703f0076e4812653aab85fca0f00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000"),
256 | GasLimit: 4700000,
257 | Difficulty: big.NewInt(1),
258 | Alloc: decodePrealloc(rinkebyAllocData),
259 | }
260 | }
261 |
262 | // DevGenesisBlock returns the 'geth --dev' genesis block.
263 | func DevGenesisBlock() *Genesis {
264 | return &Genesis{
265 | Config: params.AllProtocolChanges,
266 | Nonce: 42,
267 | GasLimit: 4712388,
268 | Difficulty: big.NewInt(131072),
269 | Alloc: decodePrealloc(devAllocData),
270 | }
271 | }
272 |
--------------------------------------------------------------------------------
/core-vm-stack-memory源码分析.md:
--------------------------------------------------------------------------------
1 | vm使用了stack.go里面的对象Stack来作为虚拟机的堆栈。memory代表了虚拟机里面使用的内存对象。
2 |
3 | ## stack.go
4 | 比较简单,就是用1024个big.Int的定长数组来作为堆栈的存储。
5 |
6 | 构造
7 |
8 | // stack is an object for basic stack operations. Items popped to the stack are
9 | // expected to be changed and modified. stack does not take care of adding newly
10 | // initialised objects.
11 | type Stack struct {
12 | data []*big.Int
13 | }
14 |
15 | func newstack() *Stack {
16 | return &Stack{data: make([]*big.Int, 0, 1024)}
17 | }
18 |
19 | push操作
20 |
21 | func (st *Stack) push(d *big.Int) { //追加到最末尾
22 | // NOTE push limit (1024) is checked in baseCheck
23 | //stackItem := new(big.Int).Set(d)
24 | //st.data = append(st.data, stackItem)
25 | st.data = append(st.data, d)
26 | }
27 | func (st *Stack) pushN(ds ...*big.Int) {
28 | st.data = append(st.data, ds...)
29 | }
30 |
31 | pop操作
32 |
33 |
34 | func (st *Stack) pop() (ret *big.Int) { //从最末尾取出。
35 | ret = st.data[len(st.data)-1]
36 | st.data = st.data[:len(st.data)-1]
37 | return
38 | }
39 | 交换元素的值操作,还有这种操作?
40 |
41 | func (st *Stack) swap(n int) { 交换堆栈顶的元素和离栈顶n距离的元素的值。
42 | st.data[st.len()-n], st.data[st.len()-1] = st.data[st.len()-1], st.data[st.len()-n]
43 | }
44 |
45 | dup操作 像复制指定位置的值到堆顶
46 |
47 | func (st *Stack) dup(pool *intPool, n int) {
48 | st.push(pool.get().Set(st.data[st.len()-n]))
49 | }
50 |
51 | peek 操作. 偷看栈顶元素
52 |
53 | func (st *Stack) peek() *big.Int {
54 | return st.data[st.len()-1]
55 | }
56 | Back 偷看指定位置的元素
57 |
58 | // Back returns the n'th item in stack
59 | func (st *Stack) Back(n int) *big.Int {
60 | return st.data[st.len()-n-1]
61 | }
62 |
63 | require 保证堆栈元素的数量要大于等于n.
64 |
65 | func (st *Stack) require(n int) error {
66 | if st.len() < n {
67 | return fmt.Errorf("stack underflow (%d <=> %d)", len(st.data), n)
68 | }
69 | return nil
70 | }
71 |
72 | ## intpool.go
73 | 非常简单. 就是256大小的 big.int的池,用来加速bit.Int的分配
74 |
75 | var checkVal = big.NewInt(-42)
76 |
77 | const poolLimit = 256
78 |
79 | // intPool is a pool of big integers that
80 | // can be reused for all big.Int operations.
81 | type intPool struct {
82 | pool *Stack
83 | }
84 |
85 | func newIntPool() *intPool {
86 | return &intPool{pool: newstack()}
87 | }
88 |
89 | func (p *intPool) get() *big.Int {
90 | if p.pool.len() > 0 {
91 | return p.pool.pop()
92 | }
93 | return new(big.Int)
94 | }
95 | func (p *intPool) put(is ...*big.Int) {
96 | if len(p.pool.data) > poolLimit {
97 | return
98 | }
99 |
100 | for _, i := range is {
101 | // verifyPool is a build flag. Pool verification makes sure the integrity
102 | // of the integer pool by comparing values to a default value.
103 | if verifyPool {
104 | i.Set(checkVal)
105 | }
106 |
107 | p.pool.push(i)
108 | }
109 | }
110 |
111 | ## memory.go
112 |
113 | 构造, memory的存储就是byte[]. 还有一个lastGasCost的记录.
114 |
115 | type Memory struct {
116 | store []byte
117 | lastGasCost uint64
118 | }
119 |
120 | func NewMemory() *Memory {
121 | return &Memory{}
122 | }
123 |
124 | 使用首先需要使用Resize分配空间
125 |
126 | // Resize resizes the memory to size
127 | func (m *Memory) Resize(size uint64) {
128 | if uint64(m.Len()) < size {
129 | m.store = append(m.store, make([]byte, size-uint64(m.Len()))...)
130 | }
131 | }
132 |
133 | 然后使用Set来设置值
134 |
135 | // Set sets offset + size to value
136 | func (m *Memory) Set(offset, size uint64, value []byte) {
137 | // length of store may never be less than offset + size.
138 | // The store should be resized PRIOR to setting the memory
139 | if size > uint64(len(m.store)) {
140 | panic("INVALID memory: store empty")
141 | }
142 |
143 | // It's possible the offset is greater than 0 and size equals 0. This is because
144 | // the calcMemSize (common.go) could potentially return 0 when size is zero (NO-OP)
145 | if size > 0 {
146 | copy(m.store[offset:offset+size], value)
147 | }
148 | }
149 | Get来取值, 一个是获取拷贝, 一个是获取指针.
150 |
151 | // Get returns offset + size as a new slice
152 | func (self *Memory) Get(offset, size int64) (cpy []byte) {
153 | if size == 0 {
154 | return nil
155 | }
156 |
157 | if len(self.store) > int(offset) {
158 | cpy = make([]byte, size)
159 | copy(cpy, self.store[offset:offset+size])
160 |
161 | return
162 | }
163 |
164 | return
165 | }
166 |
167 | // GetPtr returns the offset + size
168 | func (self *Memory) GetPtr(offset, size int64) []byte {
169 | if size == 0 {
170 | return nil
171 | }
172 |
173 | if len(self.store) > int(offset) {
174 | return self.store[offset : offset+size]
175 | }
176 |
177 | return nil
178 | }
179 |
180 |
181 | ## 一些额外的帮助函数--stack_table.go
182 |
183 |
184 | func makeStackFunc(pop, push int) stackValidationFunc {
185 | return func(stack *Stack) error {
186 | if err := stack.require(pop); err != nil {
187 | return err
188 | }
189 |
190 | if stack.len()+push-pop > int(params.StackLimit) {
191 | return fmt.Errorf("stack limit reached %d (%d)", stack.len(), params.StackLimit)
192 | }
193 | return nil
194 | }
195 | }
196 |
197 | func makeDupStackFunc(n int) stackValidationFunc {
198 | return makeStackFunc(n, n+1)
199 | }
200 |
201 | func makeSwapStackFunc(n int) stackValidationFunc {
202 | return makeStackFunc(n, n)
203 | }
204 |
205 |
206 |
--------------------------------------------------------------------------------
/eth-downloader-peer源码分析.md:
--------------------------------------------------------------------------------
1 | peer模块包含了downloader使用的peer节点,封装了吞吐量,是否空闲,并记录了之前失败的信息。
2 |
3 |
4 | ## peer
5 |
6 | // peerConnection represents an active peer from which hashes and blocks are retrieved.
7 | type peerConnection struct {
8 | id string // Unique identifier of the peer
9 |
10 | headerIdle int32 // Current header activity state of the peer (idle = 0, active = 1) 当前的header获取的工作状态。
11 | blockIdle int32 // Current block activity state of the peer (idle = 0, active = 1) 当前的区块获取的工作状态
12 | receiptIdle int32 // Current receipt activity state of the peer (idle = 0, active = 1) 当前的收据获取的工作状态
13 | stateIdle int32 // Current node data activity state of the peer (idle = 0, active = 1) 当前节点状态的工作状态
14 |
15 | headerThroughput float64 // Number of headers measured to be retrievable per second //记录每秒能够接收多少个区块头的度量值
16 | blockThroughput float64 // Number of blocks (bodies) measured to be retrievable per second //记录每秒能够接收多少个区块的度量值
17 | receiptThroughput float64 // Number of receipts measured to be retrievable per second 记录每秒能够接收多少个收据的度量值
18 | stateThroughput float64 // Number of node data pieces measured to be retrievable per second 记录每秒能够接收多少个账户状态的度量值
19 |
20 | rtt time.Duration // Request round trip time to track responsiveness (QoS) 请求回应时间
21 |
22 | headerStarted time.Time // Time instance when the last header fetch was started 记录最后一个header fetch的请求时间
23 | blockStarted time.Time // Time instance when the last block (body) fetch was started
24 | receiptStarted time.Time // Time instance when the last receipt fetch was started
25 | stateStarted time.Time // Time instance when the last node data fetch was started
26 |
27 | lacking map[common.Hash]struct{} // Set of hashes not to request (didn't have previously) 记录的Hash值不会去请求,一般是因为之前的请求失败
28 |
29 | peer Peer // eth的peer
30 |
31 | version int // Eth protocol version number to switch strategies
32 | log log.Logger // Contextual logger to add extra infos to peer logs
33 | lock sync.RWMutex
34 | }
35 |
36 |
37 |
38 | FetchXXX
39 | FetchHeaders FetchBodies等函数 主要调用了eth.peer的功能来进行发送数据请求。
40 |
41 | // FetchHeaders sends a header retrieval request to the remote peer.
42 | func (p *peerConnection) FetchHeaders(from uint64, count int) error {
43 | // Sanity check the protocol version
44 | if p.version < 62 {
45 | panic(fmt.Sprintf("header fetch [eth/62+] requested on eth/%d", p.version))
46 | }
47 | // Short circuit if the peer is already fetching
48 | if !atomic.CompareAndSwapInt32(&p.headerIdle, 0, 1) {
49 | return errAlreadyFetching
50 | }
51 | p.headerStarted = time.Now()
52 |
53 | // Issue the header retrieval request (absolut upwards without gaps)
54 | go p.peer.RequestHeadersByNumber(from, count, 0, false)
55 |
56 | return nil
57 | }
58 |
59 | SetXXXIdle函数
60 | SetHeadersIdle, SetBlocksIdle 等函数 设置peer的状态为空闲状态,允许它执行新的请求。 同时还会通过本次传输的数据的多少来重新评估链路的吞吐量。
61 |
62 | // SetHeadersIdle sets the peer to idle, allowing it to execute new header retrieval
63 | // requests. Its estimated header retrieval throughput is updated with that measured
64 | // just now.
65 | func (p *peerConnection) SetHeadersIdle(delivered int) {
66 | p.setIdle(p.headerStarted, delivered, &p.headerThroughput, &p.headerIdle)
67 | }
68 |
69 | setIdle
70 |
71 | // setIdle sets the peer to idle, allowing it to execute new retrieval requests.
72 | // Its estimated retrieval throughput is updated with that measured just now.
73 | func (p *peerConnection) setIdle(started time.Time, delivered int, throughput *float64, idle *int32) {
74 | // Irrelevant of the scaling, make sure the peer ends up idle
75 | defer atomic.StoreInt32(idle, 0)
76 |
77 | p.lock.Lock()
78 | defer p.lock.Unlock()
79 |
80 | // If nothing was delivered (hard timeout / unavailable data), reduce throughput to minimum
81 | if delivered == 0 {
82 | *throughput = 0
83 | return
84 | }
85 | // Otherwise update the throughput with a new measurement
86 | elapsed := time.Since(started) + 1 // +1 (ns) to ensure non-zero divisor
87 | measured := float64(delivered) / (float64(elapsed) / float64(time.Second))
88 |
89 | // measurementImpact = 0.1 , 新的吞吐量=老的吞吐量*0.9 + 这次的吞吐量*0.1
90 | *throughput = (1-measurementImpact)*(*throughput) + measurementImpact*measured
91 | // 更新RTT
92 | p.rtt = time.Duration((1-measurementImpact)*float64(p.rtt) + measurementImpact*float64(elapsed))
93 |
94 | p.log.Trace("Peer throughput measurements updated",
95 | "hps", p.headerThroughput, "bps", p.blockThroughput,
96 | "rps", p.receiptThroughput, "sps", p.stateThroughput,
97 | "miss", len(p.lacking), "rtt", p.rtt)
98 | }
99 |
100 |
101 | XXXCapacity函数,用来返回当前的链接允许的吞吐量。
102 |
103 | // HeaderCapacity retrieves the peers header download allowance based on its
104 | // previously discovered throughput.
105 | func (p *peerConnection) HeaderCapacity(targetRTT time.Duration) int {
106 | p.lock.RLock()
107 | defer p.lock.RUnlock()
108 | // 这里有点奇怪,targetRTT越大,请求的数量就越多。
109 | return int(math.Min(1+math.Max(1, p.headerThroughput*float64(targetRTT)/float64(time.Second)), float64(MaxHeaderFetch)))
110 | }
111 |
112 |
113 | Lacks 用来标记上次是否失败,以便下次同样的请求不通过这个peer
114 |
115 | // MarkLacking appends a new entity to the set of items (blocks, receipts, states)
116 | // that a peer is known not to have (i.e. have been requested before). If the
117 | // set reaches its maximum allowed capacity, items are randomly dropped off.
118 | func (p *peerConnection) MarkLacking(hash common.Hash) {
119 | p.lock.Lock()
120 | defer p.lock.Unlock()
121 |
122 | for len(p.lacking) >= maxLackingHashes {
123 | for drop := range p.lacking {
124 | delete(p.lacking, drop)
125 | break
126 | }
127 | }
128 | p.lacking[hash] = struct{}{}
129 | }
130 |
131 | // Lacks retrieves whether the hash of a blockchain item is on the peers lacking
132 | // list (i.e. whether we know that the peer does not have it).
133 | func (p *peerConnection) Lacks(hash common.Hash) bool {
134 | p.lock.RLock()
135 | defer p.lock.RUnlock()
136 |
137 | _, ok := p.lacking[hash]
138 | return ok
139 | }
140 |
141 |
142 | ## peerSet
143 |
144 | // peerSet represents the collection of active peer participating in the chain
145 | // download procedure.
146 | type peerSet struct {
147 | peers map[string]*peerConnection
148 | newPeerFeed event.Feed
149 | peerDropFeed event.Feed
150 | lock sync.RWMutex
151 | }
152 |
153 |
154 | Register 和 UnRegister
155 |
156 | // Register injects a new peer into the working set, or returns an error if the
157 | // peer is already known.
158 | //
159 | // The method also sets the starting throughput values of the new peer to the
160 | // average of all existing peers, to give it a realistic chance of being used
161 | // for data retrievals.
162 | func (ps *peerSet) Register(p *peerConnection) error {
163 | // Retrieve the current median RTT as a sane default
164 | p.rtt = ps.medianRTT()
165 |
166 | // Register the new peer with some meaningful defaults
167 | ps.lock.Lock()
168 | if _, ok := ps.peers[p.id]; ok {
169 | ps.lock.Unlock()
170 | return errAlreadyRegistered
171 | }
172 | if len(ps.peers) > 0 {
173 | p.headerThroughput, p.blockThroughput, p.receiptThroughput, p.stateThroughput = 0, 0, 0, 0
174 |
175 | for _, peer := range ps.peers {
176 | peer.lock.RLock()
177 | p.headerThroughput += peer.headerThroughput
178 | p.blockThroughput += peer.blockThroughput
179 | p.receiptThroughput += peer.receiptThroughput
180 | p.stateThroughput += peer.stateThroughput
181 | peer.lock.RUnlock()
182 | }
183 | p.headerThroughput /= float64(len(ps.peers))
184 | p.blockThroughput /= float64(len(ps.peers))
185 | p.receiptThroughput /= float64(len(ps.peers))
186 | p.stateThroughput /= float64(len(ps.peers))
187 | }
188 | ps.peers[p.id] = p
189 | ps.lock.Unlock()
190 |
191 | ps.newPeerFeed.Send(p)
192 | return nil
193 | }
194 |
195 | // Unregister removes a remote peer from the active set, disabling any further
196 | // actions to/from that particular entity.
197 | func (ps *peerSet) Unregister(id string) error {
198 | ps.lock.Lock()
199 | p, ok := ps.peers[id]
200 | if !ok {
201 | defer ps.lock.Unlock()
202 | return errNotRegistered
203 | }
204 | delete(ps.peers, id)
205 | ps.lock.Unlock()
206 |
207 | ps.peerDropFeed.Send(p)
208 | return nil
209 | }
210 |
211 | XXXIdlePeers
212 |
213 | // HeaderIdlePeers retrieves a flat list of all the currently header-idle peers
214 | // within the active peer set, ordered by their reputation.
215 | func (ps *peerSet) HeaderIdlePeers() ([]*peerConnection, int) {
216 | idle := func(p *peerConnection) bool {
217 | return atomic.LoadInt32(&p.headerIdle) == 0
218 | }
219 | throughput := func(p *peerConnection) float64 {
220 | p.lock.RLock()
221 | defer p.lock.RUnlock()
222 | return p.headerThroughput
223 | }
224 | return ps.idlePeers(62, 64, idle, throughput)
225 | }
226 |
227 | // idlePeers retrieves a flat list of all currently idle peers satisfying the
228 | // protocol version constraints, using the provided function to check idleness.
229 | // The resulting set of peers are sorted by their measure throughput.
230 | func (ps *peerSet) idlePeers(minProtocol, maxProtocol int, idleCheck func(*peerConnection) bool, throughput func(*peerConnection) float64) ([]*peerConnection, int) {
231 | ps.lock.RLock()
232 | defer ps.lock.RUnlock()
233 |
234 | idle, total := make([]*peerConnection, 0, len(ps.peers)), 0
235 | for _, p := range ps.peers { //首先抽取idle的peer
236 | if p.version >= minProtocol && p.version <= maxProtocol {
237 | if idleCheck(p) {
238 | idle = append(idle, p)
239 | }
240 | total++
241 | }
242 | }
243 | for i := 0; i < len(idle); i++ { // 冒泡排序, 从吞吐量大到吞吐量小。
244 | for j := i + 1; j < len(idle); j++ {
245 | if throughput(idle[i]) < throughput(idle[j]) {
246 | idle[i], idle[j] = idle[j], idle[i]
247 | }
248 | }
249 | }
250 | return idle, total
251 | }
252 |
253 | medianRTT,求得peerset的RTT的中位数,
254 |
255 | // medianRTT returns the median RTT of te peerset, considering only the tuning
256 | // peers if there are more peers available.
257 | func (ps *peerSet) medianRTT() time.Duration {
258 | // Gather all the currnetly measured round trip times
259 | ps.lock.RLock()
260 | defer ps.lock.RUnlock()
261 |
262 | rtts := make([]float64, 0, len(ps.peers))
263 | for _, p := range ps.peers {
264 | p.lock.RLock()
265 | rtts = append(rtts, float64(p.rtt))
266 | p.lock.RUnlock()
267 | }
268 | sort.Float64s(rtts)
269 |
270 | median := rttMaxEstimate
271 | if qosTuningPeers <= len(rtts) {
272 | median = time.Duration(rtts[qosTuningPeers/2]) // Median of our tuning peers
273 | } else if len(rtts) > 0 {
274 | median = time.Duration(rtts[len(rtts)/2]) // Median of our connected peers (maintain even like this some baseline qos)
275 | }
276 | // Restrict the RTT into some QoS defaults, irrelevant of true RTT
277 | if median < rttMinEstimate {
278 | median = rttMinEstimate
279 | }
280 | if median > rttMaxEstimate {
281 | median = rttMaxEstimate
282 | }
283 | return median
284 | }
285 |
--------------------------------------------------------------------------------
/eth-downloader-statesync.md:
--------------------------------------------------------------------------------
1 | statesync 用来获取pivot point所指定的区块的所有的state 的trie树,也就是所有的账号的信息,包括普通账号和合约账户。
2 |
3 | ## 数据结构
4 | stateSync调度下载由给定state root所定义的特定state trie的请求。
5 |
6 | // stateSync schedules requests for downloading a particular state trie defined
7 | // by a given state root.
8 | type stateSync struct {
9 | d *Downloader // Downloader instance to access and manage current peerset
10 |
11 | sched *trie.TrieSync // State trie sync scheduler defining the tasks
12 | keccak hash.Hash // Keccak256 hasher to verify deliveries with
13 | tasks map[common.Hash]*stateTask // Set of tasks currently queued for retrieval
14 |
15 | numUncommitted int
16 | bytesUncommitted int
17 |
18 | deliver chan *stateReq // Delivery channel multiplexing peer responses
19 | cancel chan struct{} // Channel to signal a termination request
20 | cancelOnce sync.Once // Ensures cancel only ever gets called once
21 | done chan struct{} // Channel to signal termination completion
22 | err error // Any error hit during sync (set before completion)
23 | }
24 |
25 | 构造函数
26 |
27 | func newStateSync(d *Downloader, root common.Hash) *stateSync {
28 | return &stateSync{
29 | d: d,
30 | sched: state.NewStateSync(root, d.stateDB),
31 | keccak: sha3.NewKeccak256(),
32 | tasks: make(map[common.Hash]*stateTask),
33 | deliver: make(chan *stateReq),
34 | cancel: make(chan struct{}),
35 | done: make(chan struct{}),
36 | }
37 | }
38 |
39 | NewStateSync
40 |
41 | // NewStateSync create a new state trie download scheduler.
42 | func NewStateSync(root common.Hash, database trie.DatabaseReader) *trie.TrieSync {
43 | var syncer *trie.TrieSync
44 | callback := func(leaf []byte, parent common.Hash) error {
45 | var obj Account
46 | if err := rlp.Decode(bytes.NewReader(leaf), &obj); err != nil {
47 | return err
48 | }
49 | syncer.AddSubTrie(obj.Root, 64, parent, nil)
50 | syncer.AddRawEntry(common.BytesToHash(obj.CodeHash), 64, parent)
51 | return nil
52 | }
53 | syncer = trie.NewTrieSync(root, database, callback)
54 | return syncer
55 | }
56 |
57 | syncState, 这个函数是downloader调用的。
58 |
59 | // syncState starts downloading state with the given root hash.
60 | func (d *Downloader) syncState(root common.Hash) *stateSync {
61 | s := newStateSync(d, root)
62 | select {
63 | case d.stateSyncStart <- s:
64 | case <-d.quitCh:
65 | s.err = errCancelStateFetch
66 | close(s.done)
67 | }
68 | return s
69 | }
70 |
71 | ## 启动
72 | 在downloader中启动了一个新的goroutine 来运行stateFetcher函数。 这个函数首先试图往stateSyncStart通道来以获取信息。 而syncState这个函数会给stateSyncStart通道发送数据。
73 |
74 | // stateFetcher manages the active state sync and accepts requests
75 | // on its behalf.
76 | func (d *Downloader) stateFetcher() {
77 | for {
78 | select {
79 | case s := <-d.stateSyncStart:
80 | for next := s; next != nil; { // 这个for循环代表了downloader可以通过发送信号来随时改变需要同步的对象。
81 | next = d.runStateSync(next)
82 | }
83 | case <-d.stateCh:
84 | // Ignore state responses while no sync is running.
85 | case <-d.quitCh:
86 | return
87 | }
88 | }
89 | }
90 |
91 | 我们下面看看哪里会调用syncState()函数。processFastSyncContent这个函数会在最开始发现peer的时候启动。
92 |
93 | // processFastSyncContent takes fetch results from the queue and writes them to the
94 | // database. It also controls the synchronisation of state nodes of the pivot block.
95 | func (d *Downloader) processFastSyncContent(latest *types.Header) error {
96 | // Start syncing state of the reported head block.
97 | // This should get us most of the state of the pivot block.
98 | stateSync := d.syncState(latest.Root)
99 |
100 |
101 |
102 | runStateSync,这个方法从stateCh获取已经下载好的状态,然后把他投递到deliver通道上等待别人处理。
103 |
104 | // runStateSync runs a state synchronisation until it completes or another root
105 | // hash is requested to be switched over to.
106 | func (d *Downloader) runStateSync(s *stateSync) *stateSync {
107 | var (
108 | active = make(map[string]*stateReq) // Currently in-flight requests
109 | finished []*stateReq // Completed or failed requests
110 | timeout = make(chan *stateReq) // Timed out active requests
111 | )
112 | defer func() {
113 | // Cancel active request timers on exit. Also set peers to idle so they're
114 | // available for the next sync.
115 | for _, req := range active {
116 | req.timer.Stop()
117 | req.peer.SetNodeDataIdle(len(req.items))
118 | }
119 | }()
120 | // Run the state sync.
121 | // 运行状态同步
122 | go s.run()
123 | defer s.Cancel()
124 |
125 | // Listen for peer departure events to cancel assigned tasks
126 | peerDrop := make(chan *peerConnection, 1024)
127 | peerSub := s.d.peers.SubscribePeerDrops(peerDrop)
128 | defer peerSub.Unsubscribe()
129 |
130 | for {
131 | // Enable sending of the first buffered element if there is one.
132 | var (
133 | deliverReq *stateReq
134 | deliverReqCh chan *stateReq
135 | )
136 | if len(finished) > 0 {
137 | deliverReq = finished[0]
138 | deliverReqCh = s.deliver
139 | }
140 |
141 | select {
142 | // The stateSync lifecycle:
143 | // 另外一个stateSync申请运行。 我们退出。
144 | case next := <-d.stateSyncStart:
145 | return next
146 |
147 | case <-s.done:
148 | return nil
149 |
150 | // Send the next finished request to the current sync:
151 | // 发送已经下载好的数据给sync
152 | case deliverReqCh <- deliverReq:
153 | finished = append(finished[:0], finished[1:]...)
154 |
155 | // Handle incoming state packs:
156 | // 处理进入的数据包。 downloader接收到state的数据会发送到这个通道上面。
157 | case pack := <-d.stateCh:
158 | // Discard any data not requested (or previsouly timed out)
159 | req := active[pack.PeerId()]
160 | if req == nil {
161 | log.Debug("Unrequested node data", "peer", pack.PeerId(), "len", pack.Items())
162 | continue
163 | }
164 | // Finalize the request and queue up for processing
165 | req.timer.Stop()
166 | req.response = pack.(*statePack).states
167 |
168 | finished = append(finished, req)
169 | delete(active, pack.PeerId())
170 |
171 | // Handle dropped peer connections:
172 | case p := <-peerDrop:
173 | // Skip if no request is currently pending
174 | req := active[p.id]
175 | if req == nil {
176 | continue
177 | }
178 | // Finalize the request and queue up for processing
179 | req.timer.Stop()
180 | req.dropped = true
181 |
182 | finished = append(finished, req)
183 | delete(active, p.id)
184 |
185 | // Handle timed-out requests:
186 | case req := <-timeout:
187 | // If the peer is already requesting something else, ignore the stale timeout.
188 | // This can happen when the timeout and the delivery happens simultaneously,
189 | // causing both pathways to trigger.
190 | if active[req.peer.id] != req {
191 | continue
192 | }
193 | // Move the timed out data back into the download queue
194 | finished = append(finished, req)
195 | delete(active, req.peer.id)
196 |
197 | // Track outgoing state requests:
198 | case req := <-d.trackStateReq:
199 | // If an active request already exists for this peer, we have a problem. In
200 | // theory the trie node schedule must never assign two requests to the same
201 | // peer. In practive however, a peer might receive a request, disconnect and
202 | // immediately reconnect before the previous times out. In this case the first
203 | // request is never honored, alas we must not silently overwrite it, as that
204 | // causes valid requests to go missing and sync to get stuck.
205 | if old := active[req.peer.id]; old != nil {
206 | log.Warn("Busy peer assigned new state fetch", "peer", old.peer.id)
207 |
208 | // Make sure the previous one doesn't get siletly lost
209 | old.timer.Stop()
210 | old.dropped = true
211 |
212 | finished = append(finished, old)
213 | }
214 | // Start a timer to notify the sync loop if the peer stalled.
215 | req.timer = time.AfterFunc(req.timeout, func() {
216 | select {
217 | case timeout <- req:
218 | case <-s.done:
219 | // Prevent leaking of timer goroutines in the unlikely case where a
220 | // timer is fired just before exiting runStateSync.
221 | }
222 | })
223 | active[req.peer.id] = req
224 | }
225 | }
226 | }
227 |
228 |
229 | run和loop方法,获取任务,分配任务,获取结果。
230 |
231 | func (s *stateSync) run() {
232 | s.err = s.loop()
233 | close(s.done)
234 | }
235 |
236 | // loop is the main event loop of a state trie sync. It it responsible for the
237 | // assignment of new tasks to peers (including sending it to them) as well as
238 | // for the processing of inbound data. Note, that the loop does not directly
239 | // receive data from peers, rather those are buffered up in the downloader and
240 | // pushed here async. The reason is to decouple processing from data receipt
241 | // and timeouts.
242 | func (s *stateSync) loop() error {
243 | // Listen for new peer events to assign tasks to them
244 | newPeer := make(chan *peerConnection, 1024)
245 | peerSub := s.d.peers.SubscribeNewPeers(newPeer)
246 | defer peerSub.Unsubscribe()
247 |
248 | // Keep assigning new tasks until the sync completes or aborts
249 | // 一直等到 sync完成或者被被终止
250 | for s.sched.Pending() > 0 {
251 | // 把数据从缓存里面刷新到持久化存储里面。 这也就是命令行 --cache指定的大小。
252 | if err := s.commit(false); err != nil {
253 | return err
254 | }
255 | // 指派任务,
256 | s.assignTasks()
257 | // Tasks assigned, wait for something to happen
258 | select {
259 | case <-newPeer:
260 | // New peer arrived, try to assign it download tasks
261 |
262 | case <-s.cancel:
263 | return errCancelStateFetch
264 |
265 | case req := <-s.deliver:
266 | // 接收到runStateSync方法投递过来的返回信息,注意 返回信息里面包含了成功请求的也包含了未成功请求的。
267 | // Response, disconnect or timeout triggered, drop the peer if stalling
268 | log.Trace("Received node data response", "peer", req.peer.id, "count", len(req.response), "dropped", req.dropped, "timeout", !req.dropped && req.timedOut())
269 | if len(req.items) <= 2 && !req.dropped && req.timedOut() {
270 | // 2 items are the minimum requested, if even that times out, we've no use of
271 | // this peer at the moment.
272 | log.Warn("Stalling state sync, dropping peer", "peer", req.peer.id)
273 | s.d.dropPeer(req.peer.id)
274 | }
275 | // Process all the received blobs and check for stale delivery
276 | stale, err := s.process(req)
277 | if err != nil {
278 | log.Warn("Node data write error", "err", err)
279 | return err
280 | }
281 | // The the delivery contains requested data, mark the node idle (otherwise it's a timed out delivery)
282 | if !stale {
283 | req.peer.SetNodeDataIdle(len(req.response))
284 | }
285 | }
286 | }
287 | return s.commit(true)
288 | }
--------------------------------------------------------------------------------
/ethdb源码分析.md:
--------------------------------------------------------------------------------
1 | go-ethereum所有的数据存储在levelDB这个Google开源的KeyValue文件数据库中,整个区块链的所有数据都存储在一个levelDB的数据库中,levelDB支持按照文件大小切分文件的功能,所以我们看到的区块链的数据都是一个一个小文件,其实这些小文件都是同一个levelDB实例。这里简单的看下levelDB的go封装代码。
2 |
3 | levelDB官方网站介绍的特点
4 |
5 | **特点**:
6 |
7 | - key和value都是任意长度的字节数组;
8 | - entry(即一条K-V记录)默认是按照key的字典顺序存储的,当然开发者也可以重载这个排序函数;
9 | - 提供的基本操作接口:Put()、Delete()、Get()、Batch();
10 | - 支持批量操作以原子操作进行;
11 | - 可以创建数据全景的snapshot(快照),并允许在快照中查找数据;
12 | - 可以通过前向(或后向)迭代器遍历数据(迭代器会隐含的创建一个snapshot);
13 | - 自动使用Snappy压缩数据;
14 | - 可移植性;
15 |
16 | **限制**:
17 |
18 | - 非关系型数据模型(NoSQL),不支持sql语句,也不支持索引;
19 | - 一次只允许一个进程访问一个特定的数据库;
20 | - 没有内置的C/S架构,但开发者可以使用LevelDB库自己封装一个server;
21 |
22 |
23 | 源码所在的目录在ethereum/ethdb目录。代码比较简单, 分为下面三个文件
24 |
25 | - database.go levelDB的封装代码
26 | - memory_database.go 供测试用的基于内存的数据库,不会持久化为文件,仅供测试
27 | - interface.go 定义了数据库的接口
28 | - database_test.go 测试案例
29 |
30 | ## interface.go
31 | 看下面的代码,基本上定义了KeyValue数据库的基本操作, Put, Get, Has, Delete等基本操作,levelDB是不支持SQL的,基本可以理解为数据结构里面的Map。
32 |
33 | package ethdb
34 | const IdealBatchSize = 100 * 1024
35 |
36 | // Putter wraps the database write operation supported by both batches and regular databases.
37 | //Putter接口定义了批量操作和普通操作的写入接口
38 | type Putter interface {
39 | Put(key []byte, value []byte) error
40 | }
41 |
42 | // Database wraps all database operations. All methods are safe for concurrent use.
43 | //数据库接口定义了所有的数据库操作, 所有的方法都是多线程安全的。
44 | type Database interface {
45 | Putter
46 | Get(key []byte) ([]byte, error)
47 | Has(key []byte) (bool, error)
48 | Delete(key []byte) error
49 | Close()
50 | NewBatch() Batch
51 | }
52 |
53 | // Batch is a write-only database that commits changes to its host database
54 | // when Write is called. Batch cannot be used concurrently.
55 | //批量操作接口,不能多线程同时使用,当Write方法被调用的时候,数据库会提交写入的更改。
56 | type Batch interface {
57 | Putter
58 | ValueSize() int // amount of data in the batch
59 | Write() error
60 | }
61 |
62 | ## memory_database.go
63 | 这个基本上就是封装了一个内存的Map结构。然后使用了一把锁来对多线程进行资源的保护。
64 |
65 | type MemDatabase struct {
66 | db map[string][]byte
67 | lock sync.RWMutex
68 | }
69 |
70 | func NewMemDatabase() (*MemDatabase, error) {
71 | return &MemDatabase{
72 | db: make(map[string][]byte),
73 | }, nil
74 | }
75 |
76 | func (db *MemDatabase) Put(key []byte, value []byte) error {
77 | db.lock.Lock()
78 | defer db.lock.Unlock()
79 | db.db[string(key)] = common.CopyBytes(value)
80 | return nil
81 | }
82 | func (db *MemDatabase) Has(key []byte) (bool, error) {
83 | db.lock.RLock()
84 | defer db.lock.RUnlock()
85 |
86 | _, ok := db.db[string(key)]
87 | return ok, nil
88 | }
89 |
90 | 然后是Batch的操作。也比较简单,一看便明白。
91 |
92 |
93 | type kv struct{ k, v []byte }
94 | type memBatch struct {
95 | db *MemDatabase
96 | writes []kv
97 | size int
98 | }
99 | func (b *memBatch) Put(key, value []byte) error {
100 | b.writes = append(b.writes, kv{common.CopyBytes(key), common.CopyBytes(value)})
101 | b.size += len(value)
102 | return nil
103 | }
104 | func (b *memBatch) Write() error {
105 | b.db.lock.Lock()
106 | defer b.db.lock.Unlock()
107 |
108 | for _, kv := range b.writes {
109 | b.db.db[string(kv.k)] = kv.v
110 | }
111 | return nil
112 | }
113 |
114 |
115 | ## database.go
116 | 这个就是实际ethereum客户端使用的代码, 封装了levelDB的接口。
117 |
118 |
119 | import (
120 | "strconv"
121 | "strings"
122 | "sync"
123 | "time"
124 |
125 | "github.com/ethereum/go-ethereum/log"
126 | "github.com/ethereum/go-ethereum/metrics"
127 | "github.com/syndtr/goleveldb/leveldb"
128 | "github.com/syndtr/goleveldb/leveldb/errors"
129 | "github.com/syndtr/goleveldb/leveldb/filter"
130 | "github.com/syndtr/goleveldb/leveldb/iterator"
131 | "github.com/syndtr/goleveldb/leveldb/opt"
132 | gometrics "github.com/rcrowley/go-metrics"
133 | )
134 |
135 | 使用了github.com/syndtr/goleveldb/leveldb的leveldb的封装,所以一些使用的文档可以在那里找到。可以看到,数据结构主要增加了很多的Mertrics用来记录数据库的使用情况,增加了quitChan用来处理停止时候的一些情况,这个后面会分析。如果下面代码可能有疑问的地方应该再Filter: filter.NewBloomFilter(10)这个可以暂时不用关注,这个是levelDB里面用来进行性能优化的一个选项,可以不用理会。
136 |
137 |
138 | type LDBDatabase struct {
139 | fn string // filename for reporting
140 | db *leveldb.DB // LevelDB instance
141 |
142 | getTimer gometrics.Timer // Timer for measuring the database get request counts and latencies
143 | putTimer gometrics.Timer // Timer for measuring the database put request counts and latencies
144 | ...metrics
145 |
146 | quitLock sync.Mutex // Mutex protecting the quit channel access
147 | quitChan chan chan error // Quit channel to stop the metrics collection before closing the database
148 |
149 | log log.Logger // Contextual logger tracking the database path
150 | }
151 |
152 | // NewLDBDatabase returns a LevelDB wrapped object.
153 | func NewLDBDatabase(file string, cache int, handles int) (*LDBDatabase, error) {
154 | logger := log.New("database", file)
155 | // Ensure we have some minimal caching and file guarantees
156 | if cache < 16 {
157 | cache = 16
158 | }
159 | if handles < 16 {
160 | handles = 16
161 | }
162 | logger.Info("Allocated cache and file handles", "cache", cache, "handles", handles)
163 | // Open the db and recover any potential corruptions
164 | db, err := leveldb.OpenFile(file, &opt.Options{
165 | OpenFilesCacheCapacity: handles,
166 | BlockCacheCapacity: cache / 2 * opt.MiB,
167 | WriteBuffer: cache / 4 * opt.MiB, // Two of these are used internally
168 | Filter: filter.NewBloomFilter(10),
169 | })
170 | if _, corrupted := err.(*errors.ErrCorrupted); corrupted {
171 | db, err = leveldb.RecoverFile(file, nil)
172 | }
173 | // (Re)check for errors and abort if opening of the db failed
174 | if err != nil {
175 | return nil, err
176 | }
177 | return &LDBDatabase{
178 | fn: file,
179 | db: db,
180 | log: logger,
181 | }, nil
182 | }
183 |
184 |
185 | 再看看下面的Put和Has的代码,因为github.com/syndtr/goleveldb/leveldb封装之后的代码是支持多线程同时访问的,所以下面这些代码是不用使用锁来保护的,这个可以注意一下。这里面大部分的代码都是直接调用leveldb的封装,所以不详细介绍了。 有一个比较有意思的地方是Metrics代码。
186 |
187 | // Put puts the given key / value to the queue
188 | func (db *LDBDatabase) Put(key []byte, value []byte) error {
189 | // Measure the database put latency, if requested
190 | if db.putTimer != nil {
191 | defer db.putTimer.UpdateSince(time.Now())
192 | }
193 | // Generate the data to write to disk, update the meter and write
194 | //value = rle.Compress(value)
195 |
196 | if db.writeMeter != nil {
197 | db.writeMeter.Mark(int64(len(value)))
198 | }
199 | return db.db.Put(key, value, nil)
200 | }
201 |
202 | func (db *LDBDatabase) Has(key []byte) (bool, error) {
203 | return db.db.Has(key, nil)
204 | }
205 |
206 | ### Metrics的处理
207 | 之前在创建NewLDBDatabase的时候,并没有初始化内部的很多Mertrics,这个时候Mertrics是为nil的。初始化Mertrics是在Meter方法中。外部传入了一个prefix参数,然后创建了各种Mertrics(具体如何创建Merter,会后续在Meter专题进行分析),然后创建了quitChan。 最后启动了一个线程调用了db.meter方法。
208 |
209 | // Meter configures the database metrics collectors and
210 | func (db *LDBDatabase) Meter(prefix string) {
211 | // Short circuit metering if the metrics system is disabled
212 | if !metrics.Enabled {
213 | return
214 | }
215 | // Initialize all the metrics collector at the requested prefix
216 | db.getTimer = metrics.NewTimer(prefix + "user/gets")
217 | db.putTimer = metrics.NewTimer(prefix + "user/puts")
218 | db.delTimer = metrics.NewTimer(prefix + "user/dels")
219 | db.missMeter = metrics.NewMeter(prefix + "user/misses")
220 | db.readMeter = metrics.NewMeter(prefix + "user/reads")
221 | db.writeMeter = metrics.NewMeter(prefix + "user/writes")
222 | db.compTimeMeter = metrics.NewMeter(prefix + "compact/time")
223 | db.compReadMeter = metrics.NewMeter(prefix + "compact/input")
224 | db.compWriteMeter = metrics.NewMeter(prefix + "compact/output")
225 |
226 | // Create a quit channel for the periodic collector and run it
227 | db.quitLock.Lock()
228 | db.quitChan = make(chan chan error)
229 | db.quitLock.Unlock()
230 |
231 | go db.meter(3 * time.Second)
232 | }
233 |
234 | 这个方法每3秒钟获取一次leveldb内部的计数器,然后把他们公布到metrics子系统。 这是一个无限循环的方法, 直到quitChan收到了一个退出信号。
235 |
236 | // meter periodically retrieves internal leveldb counters and reports them to
237 | // the metrics subsystem.
238 | // This is how a stats table look like (currently):
239 | //下面的注释就是我们调用 db.db.GetProperty("leveldb.stats")返回的字符串,后续的代码需要解析这个字符串并把信息写入到Meter中。
240 |
241 | // Compactions
242 | // Level | Tables | Size(MB) | Time(sec) | Read(MB) | Write(MB)
243 | // -------+------------+---------------+---------------+---------------+---------------
244 | // 0 | 0 | 0.00000 | 1.27969 | 0.00000 | 12.31098
245 | // 1 | 85 | 109.27913 | 28.09293 | 213.92493 | 214.26294
246 | // 2 | 523 | 1000.37159 | 7.26059 | 66.86342 | 66.77884
247 | // 3 | 570 | 1113.18458 | 0.00000 | 0.00000 | 0.00000
248 |
249 | func (db *LDBDatabase) meter(refresh time.Duration) {
250 | // Create the counters to store current and previous values
251 | counters := make([][]float64, 2)
252 | for i := 0; i < 2; i++ {
253 | counters[i] = make([]float64, 3)
254 | }
255 | // Iterate ad infinitum and collect the stats
256 | for i := 1; ; i++ {
257 | // Retrieve the database stats
258 | stats, err := db.db.GetProperty("leveldb.stats")
259 | if err != nil {
260 | db.log.Error("Failed to read database stats", "err", err)
261 | return
262 | }
263 | // Find the compaction table, skip the header
264 | lines := strings.Split(stats, "\n")
265 | for len(lines) > 0 && strings.TrimSpace(lines[0]) != "Compactions" {
266 | lines = lines[1:]
267 | }
268 | if len(lines) <= 3 {
269 | db.log.Error("Compaction table not found")
270 | return
271 | }
272 | lines = lines[3:]
273 |
274 | // Iterate over all the table rows, and accumulate the entries
275 | for j := 0; j < len(counters[i%2]); j++ {
276 | counters[i%2][j] = 0
277 | }
278 | for _, line := range lines {
279 | parts := strings.Split(line, "|")
280 | if len(parts) != 6 {
281 | break
282 | }
283 | for idx, counter := range parts[3:] {
284 | value, err := strconv.ParseFloat(strings.TrimSpace(counter), 64)
285 | if err != nil {
286 | db.log.Error("Compaction entry parsing failed", "err", err)
287 | return
288 | }
289 | counters[i%2][idx] += value
290 | }
291 | }
292 | // Update all the requested meters
293 | if db.compTimeMeter != nil {
294 | db.compTimeMeter.Mark(int64((counters[i%2][0] - counters[(i-1)%2][0]) * 1000 * 1000 * 1000))
295 | }
296 | if db.compReadMeter != nil {
297 | db.compReadMeter.Mark(int64((counters[i%2][1] - counters[(i-1)%2][1]) * 1024 * 1024))
298 | }
299 | if db.compWriteMeter != nil {
300 | db.compWriteMeter.Mark(int64((counters[i%2][2] - counters[(i-1)%2][2]) * 1024 * 1024))
301 | }
302 | // Sleep a bit, then repeat the stats collection
303 | select {
304 | case errc := <-db.quitChan:
305 | // Quit requesting, stop hammering the database
306 | errc <- nil
307 | return
308 |
309 | case <-time.After(refresh):
310 | // Timeout, gather a new set of stats
311 | }
312 | }
313 | }
314 |
315 |
--------------------------------------------------------------------------------
/eth源码分析.md:
--------------------------------------------------------------------------------
1 | eth的源码又下面几个包
2 |
3 | - downloader 主要用于和网络同步,包含了传统同步方式和快速同步方式
4 | - fetcher 主要用于基于块通知的同步,接收到当我们接收到NewBlockHashesMsg消息得时候,我们只收到了很多Block的hash值。 需要通过hash值来同步区块。
5 | - filter 提供基于RPC的过滤功能,包括实时数据的同步(PendingTx),和历史的日志查询(Log filter)
6 | - gasprice 提供gas的价格建议, 根据过去几个区块的gasprice,来得到当前的gasprice的建议价格
7 |
8 |
9 | eth 协议部分源码分析
10 |
11 | - [以太坊的网络协议大概流程](eth以太坊协议分析.md)
12 |
13 | fetcher部分的源码分析
14 |
15 | - [fetch部分源码分析](eth-fetcher源码分析.md)
16 |
17 | downloader 部分源码分析
18 |
19 | - [节点快速同步算法](以太坊fast%20sync算法.md)
20 | - [用来提供下载任务的调度和结果组装 queue.go](eth-downloader-queue.go源码分析.md)
21 | - [用来代表对端,提供QoS等功能 peer.go](eth-downloader-peer源码分析.md)
22 | - [快速同步算法 用来提供Pivot point的 state-root的同步 statesync.go](eth-downloader-statesync.md)
23 | - [同步的大致流程的分析 ](eth-downloader源码分析.md)
24 |
25 | filter 部分源码分析
26 |
27 | - [提供布隆过滤器的查询和RPC过滤功能](eth-bloombits和filter源码分析.md)
28 |
--------------------------------------------------------------------------------
/event源码分析.md:
--------------------------------------------------------------------------------
1 | event包实现了同一个进程内部的事件发布和订阅模式。
2 |
3 | ## event.go
4 |
5 | 目前这部分代码被标记为Deprecated,告知用户使用Feed这个对象。 不过在代码中任然有使用。 而且这部分的代码也不多。 就简单介绍一下。
6 |
7 | 数据结构
8 | TypeMux是主要的使用。 subm记录了所有的订阅者。 可以看到每中类型都可以有很多的订阅者。
9 |
10 | // TypeMuxEvent is a time-tagged notification pushed to subscribers.
11 | type TypeMuxEvent struct {
12 | Time time.Time
13 | Data interface{}
14 | }
15 |
16 | // A TypeMux dispatches events to registered receivers. Receivers can be
17 | // registered to handle events of certain type. Any operation
18 | // called after mux is stopped will return ErrMuxClosed.
19 | //
20 | // The zero value is ready to use.
21 | //
22 | // Deprecated: use Feed
23 | type TypeMux struct {
24 | mutex sync.RWMutex
25 | subm map[reflect.Type][]*TypeMuxSubscription
26 | stopped bool
27 | }
28 |
29 |
30 | 创建一个订阅,可以同时订阅多种类型。
31 |
32 | // Subscribe creates a subscription for events of the given types. The
33 | // subscription's channel is closed when it is unsubscribed
34 | // or the mux is closed.
35 | func (mux *TypeMux) Subscribe(types ...interface{}) *TypeMuxSubscription {
36 | sub := newsub(mux)
37 | mux.mutex.Lock()
38 | defer mux.mutex.Unlock()
39 | if mux.stopped {
40 | // set the status to closed so that calling Unsubscribe after this
41 | // call will short circuit.
42 | sub.closed = true
43 | close(sub.postC)
44 | } else {
45 | if mux.subm == nil {
46 | mux.subm = make(map[reflect.Type][]*TypeMuxSubscription)
47 | }
48 | for _, t := range types {
49 | rtyp := reflect.TypeOf(t)
50 | oldsubs := mux.subm[rtyp]
51 | if find(oldsubs, sub) != -1 {
52 | panic(fmt.Sprintf("event: duplicate type %s in Subscribe", rtyp))
53 | }
54 | subs := make([]*TypeMuxSubscription, len(oldsubs)+1)
55 | copy(subs, oldsubs)
56 | subs[len(oldsubs)] = sub
57 | mux.subm[rtyp] = subs
58 | }
59 | }
60 | return sub
61 | }
62 |
63 | // TypeMuxSubscription is a subscription established through TypeMux.
64 | type TypeMuxSubscription struct {
65 | mux *TypeMux
66 | created time.Time
67 | closeMu sync.Mutex
68 | closing chan struct{}
69 | closed bool
70 |
71 | // these two are the same channel. they are stored separately so
72 | // postC can be set to nil without affecting the return value of
73 | // Chan.
74 | postMu sync.RWMutex
75 | // readC 和 postC 其实是同一个channel。 不过一个是从channel读 一个只从channel写
76 | // 单方向的channel
77 | readC <-chan *TypeMuxEvent
78 | postC chan<- *TypeMuxEvent
79 | }
80 |
81 | func newsub(mux *TypeMux) *TypeMuxSubscription {
82 | c := make(chan *TypeMuxEvent)
83 | return &TypeMuxSubscription{
84 | mux: mux,
85 | created: time.Now(),
86 | readC: c,
87 | postC: c,
88 | closing: make(chan struct{}),
89 | }
90 | }
91 |
92 | 发布一个event到TypeMux上面,这个时候所有订阅了这个类型的都会收到这个消息。
93 |
94 | // Post sends an event to all receivers registered for the given type.
95 | // It returns ErrMuxClosed if the mux has been stopped.
96 | func (mux *TypeMux) Post(ev interface{}) error {
97 | event := &TypeMuxEvent{
98 | Time: time.Now(),
99 | Data: ev,
100 | }
101 | rtyp := reflect.TypeOf(ev)
102 | mux.mutex.RLock()
103 | if mux.stopped {
104 | mux.mutex.RUnlock()
105 | return ErrMuxClosed
106 | }
107 | subs := mux.subm[rtyp]
108 | mux.mutex.RUnlock()
109 | for _, sub := range subs {
110 | // 阻塞式的投递。
111 | sub.deliver(event)
112 | }
113 | return nil
114 | }
115 |
116 |
117 | func (s *TypeMuxSubscription) deliver(event *TypeMuxEvent) {
118 | // Short circuit delivery if stale event
119 | if s.created.After(event.Time) {
120 | return
121 | }
122 | // Otherwise deliver the event
123 | s.postMu.RLock()
124 | defer s.postMu.RUnlock()
125 |
126 | select { //阻塞方式的方法
127 | case s.postC <- event:
128 | case <-s.closing:
129 | }
130 | }
131 |
132 |
133 | ## feed.go
134 | 目前主要使用的对象。取代了前面说的event.go内部的TypeMux
135 |
136 | feed数据结构
137 |
138 | // Feed implements one-to-many subscriptions where the carrier of events is a channel.
139 | // Values sent to a Feed are delivered to all subscribed channels simultaneously.
140 | // Feed 实现了 1对多的订阅模式,使用了channel来传递事件。 发送给Feed的值会同时被传递给所有订阅的channel。
141 | // Feeds can only be used with a single type. The type is determined by the first Send or
142 | // Subscribe operation. Subsequent calls to these methods panic if the type does not
143 | // match.
144 | // Feed只能被单个类型使用。这个和之前的event不同,event可以使用多个类型。 类型被第一个Send调用或者是Subscribe调用决定。 后续的调用如果类型和其不一致会panic
145 | // The zero value is ready to use.
146 | type Feed struct {
147 | once sync.Once // ensures that init only runs once
148 | sendLock chan struct{} // sendLock has a one-element buffer and is empty when held.It protects sendCases.
149 | removeSub chan interface{} // interrupts Send
150 | sendCases caseList // the active set of select cases used by Send
151 |
152 | // The inbox holds newly subscribed channels until they are added to sendCases.
153 | mu sync.Mutex
154 | inbox caseList
155 | etype reflect.Type
156 | closed bool
157 | }
158 |
159 | 初始化 初始化会被once来保护保证只会被执行一次。
160 |
161 | func (f *Feed) init() {
162 | f.removeSub = make(chan interface{})
163 | f.sendLock = make(chan struct{}, 1)
164 | f.sendLock <- struct{}{}
165 | f.sendCases = caseList{{Chan: reflect.ValueOf(f.removeSub), Dir: reflect.SelectRecv}}
166 | }
167 |
168 | 订阅,订阅投递了一个channel。 相对与event的不同。event的订阅是传入了需要订阅的类型,然后channel是在event的订阅代码里面构建然后返回的。 这种直接投递channel的模式可能会更加灵活。
169 | 然后根据传入的channel生成了SelectCase。放入inbox。
170 |
171 | // Subscribe adds a channel to the feed. Future sends will be delivered on the channel
172 | // until the subscription is canceled. All channels added must have the same element type.
173 | //
174 | // The channel should have ample buffer space to avoid blocking other subscribers.
175 | // Slow subscribers are not dropped.
176 | func (f *Feed) Subscribe(channel interface{}) Subscription {
177 | f.once.Do(f.init)
178 |
179 | chanval := reflect.ValueOf(channel)
180 | chantyp := chanval.Type()
181 | if chantyp.Kind() != reflect.Chan || chantyp.ChanDir()&reflect.SendDir == 0 { // 如果类型不是channel。 或者是channel的方向不能发送数据。那么错误退出。
182 | panic(errBadChannel)
183 | }
184 | sub := &feedSub{feed: f, channel: chanval, err: make(chan error, 1)}
185 |
186 | f.mu.Lock()
187 | defer f.mu.Unlock()
188 | if !f.typecheck(chantyp.Elem()) {
189 | panic(feedTypeError{op: "Subscribe", got: chantyp, want: reflect.ChanOf(reflect.SendDir, f.etype)})
190 | }
191 | // Add the select case to the inbox.
192 | // The next Send will add it to f.sendCases.
193 | cas := reflect.SelectCase{Dir: reflect.SelectSend, Chan: chanval}
194 | f.inbox = append(f.inbox, cas)
195 | return sub
196 | }
197 |
198 |
199 | Send方法,feed的Send方法不是遍历所有的channel然后阻塞方式的发送。这样可能导致慢的客户端影响快的客户端。 而是使用反射的方式使用SelectCase。 首先调用非阻塞方式的TrySend来尝试发送。这样如果没有慢的客户端。数据会直接全部发送完成。 如果TrySend部分客户端失败。 那么后续在循环Select的方式发送。 我猜测这也是feed会取代event的原因。
200 |
201 |
202 | // Send delivers to all subscribed channels simultaneously.
203 | // It returns the number of subscribers that the value was sent to.
204 | func (f *Feed) Send(value interface{}) (nsent int) {
205 | f.once.Do(f.init)
206 | <-f.sendLock
207 |
208 | // Add new cases from the inbox after taking the send lock.
209 | f.mu.Lock()
210 | f.sendCases = append(f.sendCases, f.inbox...)
211 | f.inbox = nil
212 | f.mu.Unlock()
213 |
214 | // Set the sent value on all channels.
215 | rvalue := reflect.ValueOf(value)
216 | if !f.typecheck(rvalue.Type()) {
217 | f.sendLock <- struct{}{}
218 | panic(feedTypeError{op: "Send", got: rvalue.Type(), want: f.etype})
219 | }
220 | for i := firstSubSendCase; i < len(f.sendCases); i++ {
221 | f.sendCases[i].Send = rvalue
222 | }
223 |
224 | // Send until all channels except removeSub have been chosen.
225 | cases := f.sendCases
226 | for {
227 | // Fast path: try sending without blocking before adding to the select set.
228 | // This should usually succeed if subscribers are fast enough and have free
229 | // buffer space.
230 | for i := firstSubSendCase; i < len(cases); i++ {
231 | if cases[i].Chan.TrySend(rvalue) {
232 | nsent++
233 | cases = cases.deactivate(i)
234 | i--
235 | }
236 | }
237 | if len(cases) == firstSubSendCase {
238 | break
239 | }
240 | // Select on all the receivers, waiting for them to unblock.
241 | chosen, recv, _ := reflect.Select(cases)
242 | if chosen == 0 /* <-f.removeSub */ {
243 | index := f.sendCases.find(recv.Interface())
244 | f.sendCases = f.sendCases.delete(index)
245 | if index >= 0 && index < len(cases) {
246 | cases = f.sendCases[:len(cases)-1]
247 | }
248 | } else {
249 | cases = cases.deactivate(chosen)
250 | nsent++
251 | }
252 | }
253 |
254 | // Forget about the sent value and hand off the send lock.
255 | for i := firstSubSendCase; i < len(f.sendCases); i++ {
256 | f.sendCases[i].Send = reflect.Value{}
257 | }
258 | f.sendLock <- struct{}{}
259 | return nsent
260 | }
261 |
262 |
--------------------------------------------------------------------------------
/geth启动流程分析.md:
--------------------------------------------------------------------------------
1 | geth是我们的go-ethereum最主要的一个命令行工具。 也是我们的各种网络的接入点(主网络main-net 测试网络test-net 和私有网络)。支持运行在全节点模式或者轻量级节点模式。 其他程序可以通过它暴露的JSON RPC调用来访问以太坊网络的功能。
2 |
3 | 如果什么命令都不输入直接运行geth。 就会默认启动一个全节点模式的节点。 连接到主网络。 我们看看启动的主要流程是什么,涉及到了那些组件。
4 |
5 |
6 | ## 启动的main函数 cmd/geth/main.go
7 | 看到main函数一上来就直接运行了。 最开始看的时候是有点懵逼的。 后面发现go语言里面有两个默认的函数,一个是main()函数。一个是init()函数。 go语言会自动按照一定的顺序先调用所有包的init()函数。然后才会调用main()函数。
8 |
9 | func main() {
10 | if err := app.Run(os.Args); err != nil {
11 | fmt.Fprintln(os.Stderr, err)
12 | os.Exit(1)
13 | }
14 | }
15 |
16 |
17 | main.go的init函数
18 | app是一个三方包gopkg.in/urfave/cli.v1的实例。 这个三方包的用法大致就是首先构造这个app对象。 通过代码配置app对象的行为,提供一些回调函数。然后运行的时候直接在main函数里面运行 app.Run(os.Args)就行了。
19 |
20 | import (
21 | ...
22 | "gopkg.in/urfave/cli.v1"
23 | )
24 |
25 | var (
26 |
27 | app = utils.NewApp(gitCommit, "the go-ethereum command line interface")
28 | // flags that configure the node
29 | nodeFlags = []cli.Flag{
30 | utils.IdentityFlag,
31 | utils.UnlockedAccountFlag,
32 | utils.PasswordFileFlag,
33 | utils.BootnodesFlag,
34 | ...
35 | }
36 |
37 | rpcFlags = []cli.Flag{
38 | utils.RPCEnabledFlag,
39 | utils.RPCListenAddrFlag,
40 | ...
41 | }
42 |
43 | whisperFlags = []cli.Flag{
44 | utils.WhisperEnabledFlag,
45 | ...
46 | }
47 | )
48 | func init() {
49 | // Initialize the CLI app and start Geth
50 | // Action字段表示如果用户没有输入其他的子命令的情况下,会调用这个字段指向的函数。
51 | app.Action = geth
52 | app.HideVersion = true // we have a command to print the version
53 | app.Copyright = "Copyright 2013-2017 The go-ethereum Authors"
54 | // Commands 是所有支持的子命令
55 | app.Commands = []cli.Command{
56 | // See chaincmd.go:
57 | initCommand,
58 | importCommand,
59 | exportCommand,
60 | removedbCommand,
61 | dumpCommand,
62 | // See monitorcmd.go:
63 | monitorCommand,
64 | // See accountcmd.go:
65 | accountCommand,
66 | walletCommand,
67 | // See consolecmd.go:
68 | consoleCommand,
69 | attachCommand,
70 | javascriptCommand,
71 | // See misccmd.go:
72 | makecacheCommand,
73 | makedagCommand,
74 | versionCommand,
75 | bugCommand,
76 | licenseCommand,
77 | // See config.go
78 | dumpConfigCommand,
79 | }
80 | sort.Sort(cli.CommandsByName(app.Commands))
81 | // 所有能够解析的Options
82 | app.Flags = append(app.Flags, nodeFlags...)
83 | app.Flags = append(app.Flags, rpcFlags...)
84 | app.Flags = append(app.Flags, consoleFlags...)
85 | app.Flags = append(app.Flags, debug.Flags...)
86 | app.Flags = append(app.Flags, whisperFlags...)
87 |
88 | app.Before = func(ctx *cli.Context) error {
89 | runtime.GOMAXPROCS(runtime.NumCPU())
90 | if err := debug.Setup(ctx); err != nil {
91 | return err
92 | }
93 | // Start system runtime metrics collection
94 | go metrics.CollectProcessMetrics(3 * time.Second)
95 |
96 | utils.SetupNetwork(ctx)
97 | return nil
98 | }
99 |
100 | app.After = func(ctx *cli.Context) error {
101 | debug.Exit()
102 | console.Stdin.Close() // Resets terminal mode.
103 | return nil
104 | }
105 | }
106 |
107 | 如果我们没有输入任何的参数,那么会自动调用geth方法。
108 |
109 | // geth is the main entry point into the system if no special subcommand is ran.
110 | // It creates a default node based on the command line arguments and runs it in
111 | // blocking mode, waiting for it to be shut down.
112 | // 如果没有指定特殊的子命令,那么geth是系统主要的入口。
113 | // 它会根据提供的参数创建一个默认的节点。并且以阻塞的模式运行这个节点,等待着节点被终止。
114 | func geth(ctx *cli.Context) error {
115 | node := makeFullNode(ctx)
116 | startNode(ctx, node)
117 | node.Wait()
118 | return nil
119 | }
120 |
121 | makeFullNode函数,
122 |
123 | func makeFullNode(ctx *cli.Context) *node.Node {
124 | // 根据命令行参数和一些特殊的配置来创建一个node
125 | stack, cfg := makeConfigNode(ctx)
126 | // 把eth的服务注册到这个节点上面。 eth服务是以太坊的主要的服务。 是以太坊功能的提供者。
127 | utils.RegisterEthService(stack, &cfg.Eth)
128 |
129 | // Whisper must be explicitly enabled by specifying at least 1 whisper flag or in dev mode
130 | // Whisper是一个新的模块,用来进行加密通讯的功能。 需要显式的提供参数来启用,或者是处于开发模式。
131 | shhEnabled := enableWhisper(ctx)
132 | shhAutoEnabled := !ctx.GlobalIsSet(utils.WhisperEnabledFlag.Name) && ctx.GlobalIsSet(utils.DevModeFlag.Name)
133 | if shhEnabled || shhAutoEnabled {
134 | if ctx.GlobalIsSet(utils.WhisperMaxMessageSizeFlag.Name) {
135 | cfg.Shh.MaxMessageSize = uint32(ctx.Int(utils.WhisperMaxMessageSizeFlag.Name))
136 | }
137 | if ctx.GlobalIsSet(utils.WhisperMinPOWFlag.Name) {
138 | cfg.Shh.MinimumAcceptedPOW = ctx.Float64(utils.WhisperMinPOWFlag.Name)
139 | }
140 | // 注册Shh服务
141 | utils.RegisterShhService(stack, &cfg.Shh)
142 | }
143 |
144 | // Add the Ethereum Stats daemon if requested.
145 | if cfg.Ethstats.URL != "" {
146 | // 注册 以太坊的状态服务。 默认情况下是没有启动的。
147 | utils.RegisterEthStatsService(stack, cfg.Ethstats.URL)
148 | }
149 |
150 | // Add the release oracle service so it boots along with node.
151 | // release oracle服务是用来查看客户端版本是否是最新版本的服务。
152 | // 如果需要更新。 那么会通过打印日志来提示版本更新。
153 | // release 是通过智能合约的形式来运行的。 后续会详细讨论这个服务。
154 | if err := stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
155 | config := release.Config{
156 | Oracle: relOracle,
157 | Major: uint32(params.VersionMajor),
158 | Minor: uint32(params.VersionMinor),
159 | Patch: uint32(params.VersionPatch),
160 | }
161 | commit, _ := hex.DecodeString(gitCommit)
162 | copy(config.Commit[:], commit)
163 | return release.NewReleaseService(ctx, config)
164 | }); err != nil {
165 | utils.Fatalf("Failed to register the Geth release oracle service: %v", err)
166 | }
167 | return stack
168 | }
169 |
170 | makeConfigNode。 这个函数主要是通过配置文件和flag来生成整个系统的运行配置。
171 |
172 | func makeConfigNode(ctx *cli.Context) (*node.Node, gethConfig) {
173 | // Load defaults.
174 | cfg := gethConfig{
175 | Eth: eth.DefaultConfig,
176 | Shh: whisper.DefaultConfig,
177 | Node: defaultNodeConfig(),
178 | }
179 |
180 | // Load config file.
181 | if file := ctx.GlobalString(configFileFlag.Name); file != "" {
182 | if err := loadConfig(file, &cfg); err != nil {
183 | utils.Fatalf("%v", err)
184 | }
185 | }
186 |
187 | // Apply flags.
188 | utils.SetNodeConfig(ctx, &cfg.Node)
189 | stack, err := node.New(&cfg.Node)
190 | if err != nil {
191 | utils.Fatalf("Failed to create the protocol stack: %v", err)
192 | }
193 | utils.SetEthConfig(ctx, stack, &cfg.Eth)
194 | if ctx.GlobalIsSet(utils.EthStatsURLFlag.Name) {
195 | cfg.Ethstats.URL = ctx.GlobalString(utils.EthStatsURLFlag.Name)
196 | }
197 |
198 | utils.SetShhConfig(ctx, stack, &cfg.Shh)
199 |
200 | return stack, cfg
201 | }
202 |
203 | RegisterEthService
204 |
205 | // RegisterEthService adds an Ethereum client to the stack.
206 | func RegisterEthService(stack *node.Node, cfg *eth.Config) {
207 | var err error
208 | // 如果同步模式是轻量级的同步模式。 那么启动轻量级的客户端。
209 | if cfg.SyncMode == downloader.LightSync {
210 | err = stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
211 | return les.New(ctx, cfg)
212 | })
213 | } else {
214 | // 否则会启动全节点
215 | err = stack.Register(func(ctx *node.ServiceContext) (node.Service, error) {
216 | fullNode, err := eth.New(ctx, cfg)
217 | if fullNode != nil && cfg.LightServ > 0 {
218 | // 默认LightServ的大小是0 也就是不会启动LesServer
219 | // LesServer是给轻量级节点提供服务的。
220 | ls, _ := les.NewLesServer(fullNode, cfg)
221 | fullNode.AddLesServer(ls)
222 | }
223 | return fullNode, err
224 | })
225 | }
226 | if err != nil {
227 | Fatalf("Failed to register the Ethereum service: %v", err)
228 | }
229 | }
230 |
231 |
232 | startNode
233 |
234 | // startNode boots up the system node and all registered protocols, after which
235 | // it unlocks any requested accounts, and starts the RPC/IPC interfaces and the
236 | // miner.
237 | func startNode(ctx *cli.Context, stack *node.Node) {
238 | // Start up the node itself
239 | utils.StartNode(stack)
240 |
241 | // Unlock any account specifically requested
242 | ks := stack.AccountManager().Backends(keystore.KeyStoreType)[0].(*keystore.KeyStore)
243 |
244 | passwords := utils.MakePasswordList(ctx)
245 | unlocks := strings.Split(ctx.GlobalString(utils.UnlockedAccountFlag.Name), ",")
246 | for i, account := range unlocks {
247 | if trimmed := strings.TrimSpace(account); trimmed != "" {
248 | unlockAccount(ctx, ks, trimmed, i, passwords)
249 | }
250 | }
251 | // Register wallet event handlers to open and auto-derive wallets
252 | events := make(chan accounts.WalletEvent, 16)
253 | stack.AccountManager().Subscribe(events)
254 |
255 | go func() {
256 | // Create an chain state reader for self-derivation
257 | rpcClient, err := stack.Attach()
258 | if err != nil {
259 | utils.Fatalf("Failed to attach to self: %v", err)
260 | }
261 | stateReader := ethclient.NewClient(rpcClient)
262 |
263 | // Open any wallets already attached
264 | for _, wallet := range stack.AccountManager().Wallets() {
265 | if err := wallet.Open(""); err != nil {
266 | log.Warn("Failed to open wallet", "url", wallet.URL(), "err", err)
267 | }
268 | }
269 | // Listen for wallet event till termination
270 | for event := range events {
271 | switch event.Kind {
272 | case accounts.WalletArrived:
273 | if err := event.Wallet.Open(""); err != nil {
274 | log.Warn("New wallet appeared, failed to open", "url", event.Wallet.URL(), "err", err)
275 | }
276 | case accounts.WalletOpened:
277 | status, _ := event.Wallet.Status()
278 | log.Info("New wallet appeared", "url", event.Wallet.URL(), "status", status)
279 |
280 | if event.Wallet.URL().Scheme == "ledger" {
281 | event.Wallet.SelfDerive(accounts.DefaultLedgerBaseDerivationPath, stateReader)
282 | } else {
283 | event.Wallet.SelfDerive(accounts.DefaultBaseDerivationPath, stateReader)
284 | }
285 |
286 | case accounts.WalletDropped:
287 | log.Info("Old wallet dropped", "url", event.Wallet.URL())
288 | event.Wallet.Close()
289 | }
290 | }
291 | }()
292 | // Start auxiliary services if enabled
293 | if ctx.GlobalBool(utils.MiningEnabledFlag.Name) {
294 | // Mining only makes sense if a full Ethereum node is running
295 | var ethereum *eth.Ethereum
296 | if err := stack.Service(ðereum); err != nil {
297 | utils.Fatalf("ethereum service not running: %v", err)
298 | }
299 | // Use a reduced number of threads if requested
300 | if threads := ctx.GlobalInt(utils.MinerThreadsFlag.Name); threads > 0 {
301 | type threaded interface {
302 | SetThreads(threads int)
303 | }
304 | if th, ok := ethereum.Engine().(threaded); ok {
305 | th.SetThreads(threads)
306 | }
307 | }
308 | // Set the gas price to the limits from the CLI and start mining
309 | ethereum.TxPool().SetGasPrice(utils.GlobalBig(ctx, utils.GasPriceFlag.Name))
310 | if err := ethereum.StartMining(true); err != nil {
311 | utils.Fatalf("Failed to start mining: %v", err)
312 | }
313 | }
314 | }
315 |
316 | 总结:
317 |
318 | 整个启动过程其实就是解析参数。然后创建和启动节点。 然后把服务注入到节点中。 所有跟以太坊相关的功能都是以服务的形式实现的。
319 |
320 |
321 | 如果除开所有注册进去的服务。 这个时候系统开启的goroutine有哪些。 这里做一个总结。
322 |
323 |
324 | 目前所有的常驻的goroutine有下面一些。 主要是p2p相关的服务。 以及RPC相关的服务。
325 |
326 | 
327 |
328 |
--------------------------------------------------------------------------------
/go-ethereum源码阅读环境搭建.md:
--------------------------------------------------------------------------------
1 | # go-ethereum环境搭载
2 |
3 | ## windows 10 64bit
4 | 首先下载go安装包进行安装,因为GO的网站被墙,所以从下面地址下载。
5 |
6 | https://studygolang.com/dl/golang/go1.9.1.windows-amd64.msi
7 |
8 | 安装好之后,设置环境变量,把C:\Go\bin目录添加到你的PATH环境变量, 然后增加一个GOPATH的环境变量,GOPATH的值设置为你的GO语言下载的代码路径(我设置的是C:\GOPATH)
9 |
10 | 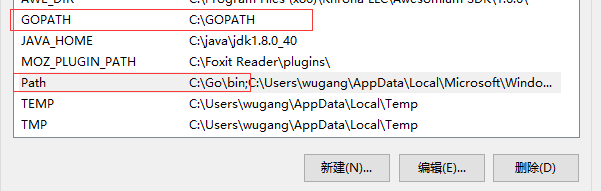
11 |
12 | 安装git工具,请参考网络上的教程安装git工具, go语言从github自动下载代码需要git工具的支持
13 |
14 | 打开命令行工具下载 go-ethereum的代码
15 |
16 | go get github.com/ethereum/go-ethereum
17 |
18 | 命令执行成功之后,代码就会下载到下面这个目录,%GOPATH%\src\github.com\ethereum\go-ethereum
19 | 如果执行过程中出现
20 |
21 | # github.com/ethereum/go-ethereum/crypto/secp256k1
22 | exec: "gcc": executable file not found in %PATH%
23 |
24 | 则需要安装gcc工具,我们从下面地址下载并安装
25 |
26 | http://tdm-gcc.tdragon.net/download
27 |
28 | 接下来安装IDE工具。 我是用的IDE是JetBrains的Gogland。 可以在下面地址下载
29 |
30 | https://download.jetbrains.com/go/gogland-173.2696.28.exe
31 |
32 | 安装完成后打开IDE. 选择File -> Open -> 选择GOPATH\src\github.com\ethereum\go-ethereum目录打开。
33 |
34 | 然后打开go-ethereum/rlp/decode_test.go. 在编辑框右键选择运行, 如果运行成功,代表环境搭建完成。
35 |
36 | 
37 |
38 | ## Ubuntu 16.04 64bit
39 |
40 | go安装包进行安装
41 |
42 | apt install golang-go git -y
43 |
44 | golang环境配置:
45 |
46 | 编辑/etc/profile文件,在该文件中加入以下内容:
47 | export GOROOT=/usr/bin/go
48 | export GOPATH=/root/home/goproject
49 | export GOBIN=/root/home/goproject/bin
50 | export GOLIB=/root/home/goproject/
51 | export PATH=$PATH:$GOBIN:$GOPATH/bin:$GOROOT/bin
52 | 执行以下命令,使得环境变量生效:
53 |
54 | # source /etc/profile
55 |
56 | 下载源码:
57 |
58 | #cd /root/home/goproject; mkdir src; cd src #进入go项目目录,并创建src目录, 并进入src目录
59 | #git clone https://github.com/ethereum/go-ethereum
60 |
61 | 使用vim或其他IDE打开即可
62 |
63 | ## go ethereum 目录大概介绍
64 | go-ethereum项目的组织结构基本上是按照功能模块划分的目录
65 |
66 |
67 | accounts 实现了一个高等级的以太坊账户管理
68 | bmt 二进制的默克尔树的实现
69 | build 主要是编译和构建的一些脚本和配置
70 | cmd 命令行工具,又分了很多的命令行工具,下面一个一个介绍
71 | /abigen Source code generator to convert Ethereum contract definitions into easy to use, compile-time type-safe Go packages
72 | /bootnode 启动一个仅仅实现网络发现的节点
73 | /evm 以太坊虚拟机的开发工具, 用来提供一个可配置的,受隔离的代码调试环境
74 | /faucet
75 | /geth 以太坊命令行客户端,最重要的一个工具
76 | /p2psim 提供了一个工具来模拟http的API
77 | /puppeth 创建一个新的以太坊网络的向导
78 | /rlpdump 提供了一个RLP数据的格式化输出
79 | /swarm swarm网络的接入点
80 | /util 提供了一些公共的工具
81 | /wnode 这是一个简单的Whisper节点。 它可以用作独立的引导节点。此外,可以用于不同的测试和诊断目的。
82 | common 提供了一些公共的工具类
83 | compression Package rle implements the run-length encoding used for Ethereum data.
84 | consensus 提供了以太坊的一些共识算法,比如ethhash, clique(proof-of-authority)
85 | console console类
86 | contracts
87 | core 以太坊的核心数据结构和算法(虚拟机,状态,区块链,布隆过滤器)
88 | crypto 加密和hash算法,
89 | eth 实现了以太坊的协议
90 | ethclient 提供了以太坊的RPC客户端
91 | ethdb eth的数据库(包括实际使用的leveldb和供测试使用的内存数据库)
92 | ethstats 提供网络状态的报告
93 | event 处理实时的事件
94 | les 实现了以太坊的轻量级协议子集
95 | light 实现为以太坊轻量级客户端提供按需检索的功能
96 | log 提供对人机都友好的日志信息
97 | metrics 提供磁盘计数器
98 | miner 提供以太坊的区块创建和挖矿
99 | mobile 移动端使用的一些warpper
100 | node 以太坊的多种类型的节点
101 | p2p 以太坊p2p网络协议
102 | rlp 以太坊序列化处理
103 | rpc 远程方法调用
104 | swarm swarm网络处理
105 | tests 测试
106 | trie 以太坊重要的数据结构Package trie implements Merkle Patricia Tries.
107 | whisper 提供了whisper节点的协议。
108 |
109 |
--------------------------------------------------------------------------------
/hashimoto.md:
--------------------------------------------------------------------------------
1 | Hashimoto :I/O bound proof of work
2 |
3 |
4 | Abstract: Using a cryptographic hash function not as a proofofwork by itself, but
5 | rather as a generator of pointers to a shared data set, allows for an I/O bound
6 | proof of work. This method of proof of work is difficult to optimize via ASIC
7 | design, and difficult to outsource to nodes without the full data set. The name is
8 | based on the three operations which comprise the algorithm: hash, shift, and
9 | modulo.
10 |
11 | 摘要:使用密码散列函数本身并不作为工作的证明,
12 | 而是作为指向共享数据集的指针生成器,允许I / O绑定
13 | 工作证明。 这种工作证明方法很难通过ASIC设计来优化,并且在没有完整数据集的情况下很难外包给节点。 这个名字是基于构成算法的三个操作:散列,移位和
14 | 模。
15 |
16 |
17 | The need for proofs which are difficult to outsource and optimize
18 |
19 | 工作量证明难以外包和优化的需求
20 |
21 | A common challenge in cryptocurrency development is maintaining decentralization ofthe
22 | network. The use ofproofofwork to achieve decentralized consensus has been most notably
23 | demonstrated by Bitcoin, which uses partial collisions with zero ofsha256, similar to hashcash. As
24 | Bitcoin’s popularity has grown, dedicated hardware (currently application specific integrated circuits, or
25 | ASICs) has been produced to rapidly iterate the hashbased proofofwork function. Newer projects
26 | similar to Bitcoin often use different algorithms for proofofwork, and often with the goal ofASIC
27 | resistance. For algorithms such as Bitcoin’s, the improvement factor ofASICs means that commodity
28 | computer hardware can no longer be effectively used, potentially limiting adoption.
29 |
30 | 加密货币发展的一项挑战就是如何维持去中心化的网络结构。 正如比特币采用sha256哈希谜题的工作量证明方式来达到去中心化的一致性。 随着比特币的流行,专用硬件(目前的专用集成电路,或者是ASICs)已经被用来快速的执行基于hash方式的工作量证明函数。类似比特币的新项目通常使用不同的工作量证明算法,而且通常都有抵抗ASICs的目标。对于诸如比特币之类的算法,ASIC的对于性能的提升意味着普通的商业计算机硬件不再有效使用,可能会被限制采用。
31 |
32 | Proofofwork can also be “outsourced”, or performed by a dedicated machine (a “miner”)
33 | without knowledge ofwhat is being verified. This is often the case in Bitcoin’s “mining pools”. It is also
34 | beneficial for a proofofwork algorithm to be difficult to outsource, in order to promote decentralization
35 | and encourage all nodes participating in the proofofwork process to also verify transactions. With these
36 | goals in mind, we present Hashimoto, an I/O bound proofofwork algorithm we believe to be resistant to
37 | both ASIC design and outsourcing.
38 |
39 | 工作量证明同样能够被外包出去,或者使用专用的机器(矿机)来执行工作量证明,而这些机器对于验证的内容并不清楚。比特币的“矿池”通常就是这种情况。如果工作量证明算法很难外包,以促进去中心化
40 | 并鼓励参与证明过程的所有节点也验证交易。为了达到这个目标,我们设计了hashimoti, 一个基于I/O 带宽的工作量证明算法,我们认为这个算法可以抵抗ASICs,同时也难以外包。
41 |
42 | Initial attempts at "ASIC resistance" involved changing Bitcoin's sha256 algorithm for a different,
43 | more memory intensive algorithm, Percival's "scrypt" password based key derivation function1. Many
44 | implementations set the scrypt arguments to low memory requirements, defeating much ofthe purpose of
45 | the key derivation algorithm. While changing to a new algorithm, coupled with the relative obscurity of the
46 | various scryptbased cryptocurrencies allowed for a delay, scrypt optimized ASICs are now available.
47 | Similar attempts at variations or multiple heterogeneous hash functions can at best only delay ASIC
48 | implementations.
49 |
50 | “ASIC抗性”的初始尝试包括改变比特币的sha256算法,用不同的,更多的内存密集型算法,Percival's "scrypt" password based key derivation function。许多实现都将脚本参数设置为低内存要求,这大大破坏了密钥派生算法的目的。在改用新算法的同时,再加上各种以scrypt为基础的加密货币的相对朦胧可能导致延迟,而且scrypt优化的ASIC现在已经上市。类似的变化尝试或多个异构散列函数最多只能延迟ASIC实现。
51 |
52 | Leveraging shared data sets to create I/O bound proofs
53 |
54 | 利用共享数据集创建I / O限制证明
55 |
56 | "A supercomputer is a device for turning compute-bound problems into I/O-bound problems."
57 | -Ken Batcher
58 |
59 |
60 | “超级计算机是将计算受限问题转化为I / O约束问题的一种设备。”
61 | Ken Batcher
62 |
63 | Instead, an algorithm will have little room to be sped up by new hardware if it acts in a way that commodity computer systems are already optimized for.
64 |
65 | 相反,如果一种算法以商品计算机系统已经优化的方式运行,那么算法将没有多少空间可以被新硬件加速。
66 |
67 | Since I/O bounds are what decades ofcomputing research has gone towards solving, it's unlikely that the relatively small motivation ofmining a few coins would be able to advance the state ofthe art in cache hierarchies. In the case that advances are made, they will be likely to impact the entire industry of computer hardware.
68 |
69 | 由于I / O界限是几十年来计算研究已经解决的问题,挖掘一些加密货币的相对较小的动机将不可能提高缓存层次结构的艺术水平。 在取得进展的情况下,可能会影响整个计算机硬件产业。
70 |
71 | Fortuitously, all nodes participating in current implementations ofcryptocurrency have a large set of mutually agreed upon data; indeed this “blockchain” is the foundation ofthe currency. Using this large data set can both limit the advantage ofspecialized hardware, and require working nodes to have the entire data set.
72 |
73 | 幸运的是,参与当前加密货币实施的所有节点都有大量相互同意的数据;实际上,“区块链”是货币的基础。 使用这个大数据集既可以限制专用硬件的优点,又可以让工作节点拥有整个数据集。
74 |
75 | Hashimoto is based offBitcoin’s proofofwork2. In Bitcoin’s case, as in Hashimoto, a successful
76 | proofsatisfies the following inequality:
77 |
78 | Hashimoto是基于比特币的工作量证明。 在比特币的情况下,和Hashimoto一样,一个成功的证明满足以下不等式:
79 |
80 | hash_output < target
81 |
82 | For bitcoin, the hash_output is determined by
83 |
84 | 在比特币中, hash_output是由下面决定的。
85 |
86 | hash_output = sha256(prev_hash, merkle_root, nonce)
87 |
88 | where prev_hash is the previous block’s hash and cannot be changed. The merkle_root is based on the transactions included in the block, and will be different for each individual node. The nonce is rapidly incremented as hash_outputs are calculated and do not satisfy the inequality. Thus the bottleneck of the proofis the sha256 function, and increasing the speed ofsha256 or parallelizing it is something ASICs can do very effectively.
89 |
90 | prev_hash是前一个区块的hash值,而且不能更改。merkle_root是基于区块中的交易生成的,并且对于每个单独的节点将是不同的。我们通过修改nonce的值来让上面的不等式成立。这样整个工作量证明的瓶颈在于sha256方法,而且通过ASIC可以极大增加sha256的计算速度,或者并行的运行它。
91 |
92 | Hashimoto uses this hash output as a starting point, which is used to generated inputs for a second hash function. We call the original hash hash_output_A, and the final result of the prooffinal_output.
93 |
94 | Hashimoto使用这个hash_output作为一个起点,用来生成第二个hash函数的输入。我们称原始的hash为hash_output_A, 最终的结果为 prooffinal_output.
95 |
96 | Hash_output_A can be used to select many transactions from the shared blockchain, which are then used as inputs to the second hash. Instead of organizing transactions into blocks, for this purpose it is simpler to organize all transactions sequentially. For example, the 47th transaction of the 815th block might be termed transaction 141,918. We will use 64 transactions, though higher and lower numbers could work, with different access properties. We define the following functions:
97 |
98 | hash_output_a可用于从共享区块链中选择多个事务,然后将其用作第二个散列的输入。 而不是组织交易成块,为此目的是顺序组织所有交易更简单。 例如,第815个区块的第47个交易可能被称为交易141,918。 我们将使用64个交易,尽管更高和更低的数字可以工作,具有不同的访问属性。 我们定义以下功能:
99 |
100 | - nonce 64bits. A new nonce is created for each attempt.
101 | - get_txid(T) return the txid (a hash ofa transaction) of transaction number T from block B.
102 | - block_height the current height ofthe block chain, which increases at each new block
103 |
104 | - nonce 64bits. 每次尝试会生成一个新的nonce值.
105 | - get_txid(T) 从block B中通过交易序号来获取交易id
106 | - block_height 当前的区块高度
107 |
108 | Hashimoto chooses transactions by doing the following:
109 |
110 | Hashimoto 通过下面的算法来挑选交易:
111 |
112 | hash_output_A = sha256(prev_hash, merkle_root, nonce)
113 | for i = 0 to 63 do
114 | shifted_A = hash_output_A >> i
115 | transaction = shifted_A mod total_transactions
116 | txid[i] = get_txid(transaction) << i
117 | end for
118 | txid_mix = txid[0] ⊕ txid[1] … ⊕ txid[63]
119 | final_output = txid_mix ⊕ (nonce << 192)
120 |
121 | The target is then compared with final_output, and smaller values are accepted as proofs.
122 |
123 | 如果 final_output 比 target小,那么就会被接受。
124 |
125 |
126 |
--------------------------------------------------------------------------------
/node源码分析.md:
--------------------------------------------------------------------------------
1 | node在go ethereum中代表了一个节点。 可能是全节点,可能是轻量级节点。 node可以理解为一个进程,以太坊由运行在世界各地的很多中类型的node组成。
2 |
3 | 一个典型的node就是一个p2p的节点。 运行了p2p网络协议,同时根据节点类型不同,运行了不同的业务层协议(以区别网络层协议。 参考p2p peer中的Protocol接口)。
4 |
5 | node的结构。
6 |
7 | // Node is a container on which services can be registered.
8 | type Node struct {
9 | eventmux *event.TypeMux // Event multiplexer used between the services of a stack
10 | config *Config
11 | accman *accounts.Manager
12 |
13 | ephemeralKeystore string // if non-empty, the key directory that will be removed by Stop
14 | instanceDirLock flock.Releaser // prevents concurrent use of instance directory
15 |
16 | serverConfig p2p.Config
17 | server *p2p.Server // Currently running P2P networking layer
18 |
19 | serviceFuncs []ServiceConstructor // Service constructors (in dependency order)
20 | services map[reflect.Type]Service // Currently running services
21 |
22 | rpcAPIs []rpc.API // List of APIs currently provided by the node
23 | inprocHandler *rpc.Server // In-process RPC request handler to process the API requests
24 |
25 | ipcEndpoint string // IPC endpoint to listen at (empty = IPC disabled)
26 | ipcListener net.Listener // IPC RPC listener socket to serve API requests
27 | ipcHandler *rpc.Server // IPC RPC request handler to process the API requests
28 |
29 | httpEndpoint string // HTTP endpoint (interface + port) to listen at (empty = HTTP disabled)
30 | httpWhitelist []string // HTTP RPC modules to allow through this endpoint
31 | httpListener net.Listener // HTTP RPC listener socket to server API requests
32 | httpHandler *rpc.Server // HTTP RPC request handler to process the API requests
33 |
34 | wsEndpoint string // Websocket endpoint (interface + port) to listen at (empty = websocket disabled)
35 | wsListener net.Listener // Websocket RPC listener socket to server API requests
36 | wsHandler *rpc.Server // Websocket RPC request handler to process the API requests
37 |
38 | stop chan struct{} // Channel to wait for termination notifications
39 | lock sync.RWMutex
40 | }
41 |
42 |
43 | 节点的初始化, 节点的初始化并不依赖其他的外部组件, 只依赖一个Config对象。
44 |
45 | // New creates a new P2P node, ready for protocol registration.
46 | func New(conf *Config) (*Node, error) {
47 | // Copy config and resolve the datadir so future changes to the current
48 | // working directory don't affect the node.
49 | confCopy := *conf
50 | conf = &confCopy
51 | if conf.DataDir != "" { //转化为绝对路径。
52 | absdatadir, err := filepath.Abs(conf.DataDir)
53 | if err != nil {
54 | return nil, err
55 | }
56 | conf.DataDir = absdatadir
57 | }
58 | // Ensure that the instance name doesn't cause weird conflicts with
59 | // other files in the data directory.
60 | if strings.ContainsAny(conf.Name, `/\`) {
61 | return nil, errors.New(`Config.Name must not contain '/' or '\'`)
62 | }
63 | if conf.Name == datadirDefaultKeyStore {
64 | return nil, errors.New(`Config.Name cannot be "` + datadirDefaultKeyStore + `"`)
65 | }
66 | if strings.HasSuffix(conf.Name, ".ipc") {
67 | return nil, errors.New(`Config.Name cannot end in ".ipc"`)
68 | }
69 | // Ensure that the AccountManager method works before the node has started.
70 | // We rely on this in cmd/geth.
71 | am, ephemeralKeystore, err := makeAccountManager(conf)
72 | if err != nil {
73 | return nil, err
74 | }
75 | // Note: any interaction with Config that would create/touch files
76 | // in the data directory or instance directory is delayed until Start.
77 | return &Node{
78 | accman: am,
79 | ephemeralKeystore: ephemeralKeystore,
80 | config: conf,
81 | serviceFuncs: []ServiceConstructor{},
82 | ipcEndpoint: conf.IPCEndpoint(),
83 | httpEndpoint: conf.HTTPEndpoint(),
84 | wsEndpoint: conf.WSEndpoint(),
85 | eventmux: new(event.TypeMux),
86 | }, nil
87 | }
88 |
89 |
90 | ### node 服务和协议的注册
91 | 因为node并没有负责具体的业务逻辑。所以具体的业务逻辑是通过注册的方式来注册到node里面来的。
92 | 其他模块通过Register方法来注册了一个 服务构造函数。 使用这个服务构造函数可以生成服务。
93 |
94 |
95 | // Register injects a new service into the node's stack. The service created by
96 | // the passed constructor must be unique in its type with regard to sibling ones.
97 | func (n *Node) Register(constructor ServiceConstructor) error {
98 | n.lock.Lock()
99 | defer n.lock.Unlock()
100 |
101 | if n.server != nil {
102 | return ErrNodeRunning
103 | }
104 | n.serviceFuncs = append(n.serviceFuncs, constructor)
105 | return nil
106 | }
107 |
108 | 服务是什么
109 |
110 | type ServiceConstructor func(ctx *ServiceContext) (Service, error)
111 | // Service is an individual protocol that can be registered into a node.
112 | //
113 | // Notes:
114 | //
115 | // • Service life-cycle management is delegated to the node. The service is allowed to
116 | // initialize itself upon creation, but no goroutines should be spun up outside of the
117 | // Start method.
118 | //
119 | // • Restart logic is not required as the node will create a fresh instance
120 | // every time a service is started.
121 |
122 | // 服务的生命周期管理已经代理给node管理。该服务允许在创建时自动初始化,但是在Start方法之外不应该启动goroutines。
123 | // 重新启动逻辑不是必需的,因为节点将在每次启动服务时创建一个新的实例。
124 | type Service interface {
125 | // Protocols retrieves the P2P protocols the service wishes to start.
126 | // 服务希望提供的p2p协议
127 | Protocols() []p2p.Protocol
128 |
129 | // APIs retrieves the list of RPC descriptors the service provides
130 | // 服务希望提供的RPC方法的描述
131 | APIs() []rpc.API
132 |
133 | // Start is called after all services have been constructed and the networking
134 | // layer was also initialized to spawn any goroutines required by the service.
135 | // 所有服务已经构建完成后,调用开始,并且网络层也被初始化以产生服务所需的任何goroutine。
136 | Start(server *p2p.Server) error
137 |
138 | // Stop terminates all goroutines belonging to the service, blocking until they
139 | // are all terminated.
140 |
141 | // Stop方法会停止这个服务拥有的所有goroutine。 需要阻塞到所有的goroutine都已经终止
142 | Stop() error
143 | }
144 |
145 |
146 | ### node的启动
147 | node的启动过程会创建和运行一个p2p的节点。
148 |
149 | // Start create a live P2P node and starts running it.
150 | func (n *Node) Start() error {
151 | n.lock.Lock()
152 | defer n.lock.Unlock()
153 |
154 | // Short circuit if the node's already running
155 | if n.server != nil {
156 | return ErrNodeRunning
157 | }
158 | if err := n.openDataDir(); err != nil {
159 | return err
160 | }
161 |
162 | // Initialize the p2p server. This creates the node key and
163 | // discovery databases.
164 | n.serverConfig = n.config.P2P
165 | n.serverConfig.PrivateKey = n.config.NodeKey()
166 | n.serverConfig.Name = n.config.NodeName()
167 | if n.serverConfig.StaticNodes == nil {
168 | // 处理配置文件static-nodes.json
169 | n.serverConfig.StaticNodes = n.config.StaticNodes()
170 | }
171 | if n.serverConfig.TrustedNodes == nil {
172 | // 处理配置文件trusted-nodes.json
173 | n.serverConfig.TrustedNodes = n.config.TrustedNodes()
174 | }
175 | if n.serverConfig.NodeDatabase == "" {
176 | n.serverConfig.NodeDatabase = n.config.NodeDB()
177 | }
178 | //创建了p2p服务器
179 | running := &p2p.Server{Config: n.serverConfig}
180 | log.Info("Starting peer-to-peer node", "instance", n.serverConfig.Name)
181 |
182 | // Otherwise copy and specialize the P2P configuration
183 | services := make(map[reflect.Type]Service)
184 | for _, constructor := range n.serviceFuncs {
185 | // Create a new context for the particular service
186 | ctx := &ServiceContext{
187 | config: n.config,
188 | services: make(map[reflect.Type]Service),
189 | EventMux: n.eventmux,
190 | AccountManager: n.accman,
191 | }
192 | for kind, s := range services { // copy needed for threaded access
193 | ctx.services[kind] = s
194 | }
195 | // Construct and save the service
196 | // 创建所有注册的服务。
197 | service, err := constructor(ctx)
198 | if err != nil {
199 | return err
200 | }
201 | kind := reflect.TypeOf(service)
202 | if _, exists := services[kind]; exists {
203 | return &DuplicateServiceError{Kind: kind}
204 | }
205 | services[kind] = service
206 | }
207 | // Gather the protocols and start the freshly assembled P2P server
208 | // 收集所有的p2p的protocols并插入p2p.Rrotocols
209 | for _, service := range services {
210 | running.Protocols = append(running.Protocols, service.Protocols()...)
211 | }
212 | // 启动了p2p服务器
213 | if err := running.Start(); err != nil {
214 | return convertFileLockError(err)
215 | }
216 | // Start each of the services
217 | // 启动每一个服务
218 | started := []reflect.Type{}
219 | for kind, service := range services {
220 | // Start the next service, stopping all previous upon failure
221 | if err := service.Start(running); err != nil {
222 | for _, kind := range started {
223 | services[kind].Stop()
224 | }
225 | running.Stop()
226 |
227 | return err
228 | }
229 | // Mark the service started for potential cleanup
230 | started = append(started, kind)
231 | }
232 | // Lastly start the configured RPC interfaces
233 | // 最后启动RPC服务
234 | if err := n.startRPC(services); err != nil {
235 | for _, service := range services {
236 | service.Stop()
237 | }
238 | running.Stop()
239 | return err
240 | }
241 | // Finish initializing the startup
242 | n.services = services
243 | n.server = running
244 | n.stop = make(chan struct{})
245 |
246 | return nil
247 | }
248 |
249 |
250 | startRPC,这个方法收集所有的apis。 并依次调用启动各个RPC服务器, 默认是启动InProc和IPC。 如果指定也可以配置是否启动HTTP和websocket。
251 |
252 | // startRPC is a helper method to start all the various RPC endpoint during node
253 | // startup. It's not meant to be called at any time afterwards as it makes certain
254 | // assumptions about the state of the node.
255 | func (n *Node) startRPC(services map[reflect.Type]Service) error {
256 | // Gather all the possible APIs to surface
257 | apis := n.apis()
258 | for _, service := range services {
259 | apis = append(apis, service.APIs()...)
260 | }
261 | // Start the various API endpoints, terminating all in case of errors
262 | if err := n.startInProc(apis); err != nil {
263 | return err
264 | }
265 | if err := n.startIPC(apis); err != nil {
266 | n.stopInProc()
267 | return err
268 | }
269 | if err := n.startHTTP(n.httpEndpoint, apis, n.config.HTTPModules, n.config.HTTPCors); err != nil {
270 | n.stopIPC()
271 | n.stopInProc()
272 | return err
273 | }
274 | if err := n.startWS(n.wsEndpoint, apis, n.config.WSModules, n.config.WSOrigins, n.config.WSExposeAll); err != nil {
275 | n.stopHTTP()
276 | n.stopIPC()
277 | n.stopInProc()
278 | return err
279 | }
280 | // All API endpoints started successfully
281 | n.rpcAPIs = apis
282 | return nil
283 | }
284 |
285 |
286 | startXXX 是具体的RPC的启动,流程都是大同小异。在v1.8.12 版本中 node\node.go 文件中startIPC()、startHTTP()、startWS()三个方法的具体启动方式封装到 rpc\endpoints.go 文件对应函数中
287 |
288 | // StartWSEndpoint starts a websocket endpoint
289 | func StartWSEndpoint(endpoint string, apis []API, modules []string, wsOrigins []string, exposeAll bool) (net.Listener, *Server, error) {
290 |
291 | // Generate the whitelist based on the allowed modules
292 | // 生成白名单
293 | whitelist := make(map[string]bool)
294 | for _, module := range modules {
295 | whitelist[module] = true
296 | }
297 | // Register all the APIs exposed by the services
298 | handler := NewServer()
299 | for _, api := range apis {
300 | if exposeAll || whitelist[api.Namespace] || (len(whitelist) == 0 && api.Public) { // 只有这几种情况下才会把这个api进行注册。
301 | if err := handler.RegisterName(api.Namespace, api.Service); err != nil {
302 | return nil, nil, err
303 | }
304 | log.Debug("WebSocket registered", "service", api.Service, "namespace", api.Namespace)
305 | }
306 | }
307 | // All APIs registered, start the HTTP listener
308 | // 所有 APIs 都已经注册,启动 HTTP 监听器
309 | var (
310 | listener net.Listener
311 | err error
312 | )
313 | if listener, err = net.Listen("tcp", endpoint); err != nil {
314 | return nil, nil, err
315 | }
316 | go NewWSServer(wsOrigins, handler).Serve(listener)
317 | return listener, handler, err
318 |
319 | }
320 |
321 |
--------------------------------------------------------------------------------
/p2p-database.go源码分析.md:
--------------------------------------------------------------------------------
1 | p2p包实现了通用的p2p网络协议。包括节点的查找,节点状态的维护,节点连接的建立等p2p的功能。p2p 包实现的是通用的p2p协议。 某一种具体的协议(比如eth协议。 whisper协议。 swarm协议)被封装成特定的接口注入p2p包。所以p2p内部不包含具体协议的实现。 只完成了p2p网络应该做的事情。
2 |
3 |
4 | ## discover / discv5 节点发现
5 | 目前使用的包是discover。 discv5是最近才开发的功能,还是属于实验性质,基本上是discover包的一些优化。 这里我们暂时只分析discover的代码。 对其完成的功能做一个基本的介绍。
6 |
7 |
8 | ### database.go
9 | 顾名思义,这个文件内部主要实现了节点的持久化,因为p2p网络节点的节点发现和维护都是比较花时间的,为了反复启动的时候,能够把之前的工作继承下来,避免每次都重新发现。 所以持久化的工作是必须的。
10 |
11 | 之前我们分析了ethdb的代码和trie的代码,trie的持久化工作使用了leveldb。 这里同样也使用了leveldb。 不过p2p的leveldb实例和主要的区块链的leveldb实例不是同一个。
12 |
13 | newNodeDB,根据参数path来看打开基于内存的数据库,还是基于文件的数据库。
14 |
15 | // newNodeDB creates a new node database for storing and retrieving infos about
16 | // known peers in the network. If no path is given, an in-memory, temporary
17 | // database is constructed.
18 | func newNodeDB(path string, version int, self NodeID) (*nodeDB, error) {
19 | if path == "" {
20 | return newMemoryNodeDB(self)
21 | }
22 | return newPersistentNodeDB(path, version, self)
23 | }
24 | // newMemoryNodeDB creates a new in-memory node database without a persistent
25 | // backend.
26 | func newMemoryNodeDB(self NodeID) (*nodeDB, error) {
27 | db, err := leveldb.Open(storage.NewMemStorage(), nil)
28 | if err != nil {
29 | return nil, err
30 | }
31 | return &nodeDB{
32 | lvl: db,
33 | self: self,
34 | quit: make(chan struct{}),
35 | }, nil
36 | }
37 |
38 | // newPersistentNodeDB creates/opens a leveldb backed persistent node database,
39 | // also flushing its contents in case of a version mismatch.
40 | func newPersistentNodeDB(path string, version int, self NodeID) (*nodeDB, error) {
41 | opts := &opt.Options{OpenFilesCacheCapacity: 5}
42 | db, err := leveldb.OpenFile(path, opts)
43 | if _, iscorrupted := err.(*errors.ErrCorrupted); iscorrupted {
44 | db, err = leveldb.RecoverFile(path, nil)
45 | }
46 | if err != nil {
47 | return nil, err
48 | }
49 | // The nodes contained in the cache correspond to a certain protocol version.
50 | // Flush all nodes if the version doesn't match.
51 | currentVer := make([]byte, binary.MaxVarintLen64)
52 | currentVer = currentVer[:binary.PutVarint(currentVer, int64(version))]
53 | blob, err := db.Get(nodeDBVersionKey, nil)
54 | switch err {
55 | case leveldb.ErrNotFound:
56 | // Version not found (i.e. empty cache), insert it
57 | if err := db.Put(nodeDBVersionKey, currentVer, nil); err != nil {
58 | db.Close()
59 | return nil, err
60 | }
61 | case nil:
62 | // Version present, flush if different
63 | //版本不同,先删除所有的数据库文件,重新创建一个。
64 | if !bytes.Equal(blob, currentVer) {
65 | db.Close()
66 | if err = os.RemoveAll(path); err != nil {
67 | return nil, err
68 | }
69 | return newPersistentNodeDB(path, version, self)
70 | }
71 | }
72 | return &nodeDB{
73 | lvl: db,
74 | self: self,
75 | quit: make(chan struct{}),
76 | }, nil
77 | }
78 |
79 |
80 | Node的存储,查询和删除
81 |
82 | // node retrieves a node with a given id from the database.
83 | func (db *nodeDB) node(id NodeID) *Node {
84 | blob, err := db.lvl.Get(makeKey(id, nodeDBDiscoverRoot), nil)
85 | if err != nil {
86 | return nil
87 | }
88 | node := new(Node)
89 | if err := rlp.DecodeBytes(blob, node); err != nil {
90 | log.Error("Failed to decode node RLP", "err", err)
91 | return nil
92 | }
93 | node.sha = crypto.Keccak256Hash(node.ID[:])
94 | return node
95 | }
96 |
97 | // updateNode inserts - potentially overwriting - a node into the peer database.
98 | func (db *nodeDB) updateNode(node *Node) error {
99 | blob, err := rlp.EncodeToBytes(node)
100 | if err != nil {
101 | return err
102 | }
103 | return db.lvl.Put(makeKey(node.ID, nodeDBDiscoverRoot), blob, nil)
104 | }
105 |
106 | // deleteNode deletes all information/keys associated with a node.
107 | func (db *nodeDB) deleteNode(id NodeID) error {
108 | deleter := db.lvl.NewIterator(util.BytesPrefix(makeKey(id, "")), nil)
109 | for deleter.Next() {
110 | if err := db.lvl.Delete(deleter.Key(), nil); err != nil {
111 | return err
112 | }
113 | }
114 | return nil
115 | }
116 |
117 | Node的结构
118 |
119 | type Node struct {
120 | IP net.IP // len 4 for IPv4 or 16 for IPv6
121 | UDP, TCP uint16 // port numbers
122 | ID NodeID // the node's public key
123 | // This is a cached copy of sha3(ID) which is used for node
124 | // distance calculations. This is part of Node in order to make it
125 | // possible to write tests that need a node at a certain distance.
126 | // In those tests, the content of sha will not actually correspond
127 | // with ID.
128 | sha common.Hash
129 | // whether this node is currently being pinged in order to replace
130 | // it in a bucket
131 | contested bool
132 | }
133 |
134 | 节点超时处理
135 |
136 |
137 | // ensureExpirer is a small helper method ensuring that the data expiration
138 | // mechanism is running. If the expiration goroutine is already running, this
139 | // method simply returns.
140 | // ensureExpirer方法用来确保expirer方法在运行。 如果expirer已经运行,那么这个方法就直接返回。
141 | // 这个方法设置的目的是为了在网络成功启动后在开始进行数据超时丢弃的工作(以防一些潜在的有用的种子节点被丢弃)。
142 | // The goal is to start the data evacuation only after the network successfully
143 | // bootstrapped itself (to prevent dumping potentially useful seed nodes). Since
144 | // it would require significant overhead to exactly trace the first successful
145 | // convergence, it's simpler to "ensure" the correct state when an appropriate
146 | // condition occurs (i.e. a successful bonding), and discard further events.
147 | func (db *nodeDB) ensureExpirer() {
148 | db.runner.Do(func() { go db.expirer() })
149 | }
150 |
151 | // expirer should be started in a go routine, and is responsible for looping ad
152 | // infinitum and dropping stale data from the database.
153 | func (db *nodeDB) expirer() {
154 | tick := time.Tick(nodeDBCleanupCycle)
155 | for {
156 | select {
157 | case <-tick:
158 | if err := db.expireNodes(); err != nil {
159 | log.Error("Failed to expire nodedb items", "err", err)
160 | }
161 |
162 | case <-db.quit:
163 | return
164 | }
165 | }
166 | }
167 |
168 | // expireNodes iterates over the database and deletes all nodes that have not
169 | // been seen (i.e. received a pong from) for some allotted time.
170 | //这个方法遍历所有的节点,如果某个节点最后接收消息超过指定值,那么就删除这个节点。
171 | func (db *nodeDB) expireNodes() error {
172 | threshold := time.Now().Add(-nodeDBNodeExpiration)
173 |
174 | // Find discovered nodes that are older than the allowance
175 | it := db.lvl.NewIterator(nil, nil)
176 | defer it.Release()
177 |
178 | for it.Next() {
179 | // Skip the item if not a discovery node
180 | id, field := splitKey(it.Key())
181 | if field != nodeDBDiscoverRoot {
182 | continue
183 | }
184 | // Skip the node if not expired yet (and not self)
185 | if !bytes.Equal(id[:], db.self[:]) {
186 | if seen := db.lastPong(id); seen.After(threshold) {
187 | continue
188 | }
189 | }
190 | // Otherwise delete all associated information
191 | db.deleteNode(id)
192 | }
193 | return nil
194 | }
195 |
196 |
197 | 一些状态更新函数
198 |
199 | // lastPing retrieves the time of the last ping packet send to a remote node,
200 | // requesting binding.
201 | func (db *nodeDB) lastPing(id NodeID) time.Time {
202 | return time.Unix(db.fetchInt64(makeKey(id, nodeDBDiscoverPing)), 0)
203 | }
204 |
205 | // updateLastPing updates the last time we tried contacting a remote node.
206 | func (db *nodeDB) updateLastPing(id NodeID, instance time.Time) error {
207 | return db.storeInt64(makeKey(id, nodeDBDiscoverPing), instance.Unix())
208 | }
209 |
210 | // lastPong retrieves the time of the last successful contact from remote node.
211 | func (db *nodeDB) lastPong(id NodeID) time.Time {
212 | return time.Unix(db.fetchInt64(makeKey(id, nodeDBDiscoverPong)), 0)
213 | }
214 |
215 | // updateLastPong updates the last time a remote node successfully contacted.
216 | func (db *nodeDB) updateLastPong(id NodeID, instance time.Time) error {
217 | return db.storeInt64(makeKey(id, nodeDBDiscoverPong), instance.Unix())
218 | }
219 |
220 | // findFails retrieves the number of findnode failures since bonding.
221 | func (db *nodeDB) findFails(id NodeID) int {
222 | return int(db.fetchInt64(makeKey(id, nodeDBDiscoverFindFails)))
223 | }
224 |
225 | // updateFindFails updates the number of findnode failures since bonding.
226 | func (db *nodeDB) updateFindFails(id NodeID, fails int) error {
227 | return db.storeInt64(makeKey(id, nodeDBDiscoverFindFails), int64(fails))
228 | }
229 |
230 |
231 | 从数据库里面随机挑选合适种子节点
232 |
233 |
234 | // querySeeds retrieves random nodes to be used as potential seed nodes
235 | // for bootstrapping.
236 | func (db *nodeDB) querySeeds(n int, maxAge time.Duration) []*Node {
237 | var (
238 | now = time.Now()
239 | nodes = make([]*Node, 0, n)
240 | it = db.lvl.NewIterator(nil, nil)
241 | id NodeID
242 | )
243 | defer it.Release()
244 |
245 | seek:
246 | for seeks := 0; len(nodes) < n && seeks < n*5; seeks++ {
247 | // Seek to a random entry. The first byte is incremented by a
248 | // random amount each time in order to increase the likelihood
249 | // of hitting all existing nodes in very small databases.
250 | ctr := id[0]
251 | rand.Read(id[:])
252 | id[0] = ctr + id[0]%16
253 | it.Seek(makeKey(id, nodeDBDiscoverRoot))
254 |
255 | n := nextNode(it)
256 | if n == nil {
257 | id[0] = 0
258 | continue seek // iterator exhausted
259 | }
260 | if n.ID == db.self {
261 | continue seek
262 | }
263 | if now.Sub(db.lastPong(n.ID)) > maxAge {
264 | continue seek
265 | }
266 | for i := range nodes {
267 | if nodes[i].ID == n.ID {
268 | continue seek // duplicate
269 | }
270 | }
271 | nodes = append(nodes, n)
272 | }
273 | return nodes
274 | }
275 |
276 | // reads the next node record from the iterator, skipping over other
277 | // database entries.
278 | func nextNode(it iterator.Iterator) *Node {
279 | for end := false; !end; end = !it.Next() {
280 | id, field := splitKey(it.Key())
281 | if field != nodeDBDiscoverRoot {
282 | continue
283 | }
284 | var n Node
285 | if err := rlp.DecodeBytes(it.Value(), &n); err != nil {
286 | log.Warn("Failed to decode node RLP", "id", id, "err", err)
287 | continue
288 | }
289 | return &n
290 | }
291 | return nil
292 | }
293 |
294 |
295 |
296 |
--------------------------------------------------------------------------------
/p2p-dial.go源码分析.md:
--------------------------------------------------------------------------------
1 | dial.go在p2p里面主要负责建立链接的部分工作。 比如发现建立链接的节点。 与节点建立链接。 通过discover来查找指定节点的地址。等功能。
2 |
3 |
4 | dial.go里面利用一个dailstate的数据结构来存储中间状态,是dial功能里面的核心数据结构。
5 |
6 | // dialstate schedules dials and discovery lookups.
7 | // it get's a chance to compute new tasks on every iteration
8 | // of the main loop in Server.run.
9 | type dialstate struct {
10 | maxDynDials int //最大的动态节点链接数量
11 | ntab discoverTable //discoverTable 用来做节点查询的
12 | netrestrict *netutil.Netlist
13 |
14 | lookupRunning bool
15 | dialing map[discover.NodeID]connFlag //正在链接的节点
16 | lookupBuf []*discover.Node // current discovery lookup results //当前的discovery查询结果
17 | randomNodes []*discover.Node // filled from Table //从discoverTable随机查询的节点
18 | static map[discover.NodeID]*dialTask //静态的节点。
19 | hist *dialHistory
20 |
21 | start time.Time // time when the dialer was first used
22 | bootnodes []*discover.Node // default dials when there are no peers //这个是内置的节点。 如果没有找到其他节点。那么使用链接这些节点。
23 | }
24 |
25 | dailstate的创建过程。
26 |
27 | func newDialState(static []*discover.Node, bootnodes []*discover.Node, ntab discoverTable, maxdyn int, netrestrict *netutil.Netlist) *dialstate {
28 | s := &dialstate{
29 | maxDynDials: maxdyn,
30 | ntab: ntab,
31 | netrestrict: netrestrict,
32 | static: make(map[discover.NodeID]*dialTask),
33 | dialing: make(map[discover.NodeID]connFlag),
34 | bootnodes: make([]*discover.Node, len(bootnodes)),
35 | randomNodes: make([]*discover.Node, maxdyn/2),
36 | hist: new(dialHistory),
37 | }
38 | copy(s.bootnodes, bootnodes)
39 | for _, n := range static {
40 | s.addStatic(n)
41 | }
42 | return s
43 | }
44 |
45 | dail最重要的方法是newTasks方法。这个方法用来生成task。 task是一个接口。有一个Do的方法。
46 |
47 | type task interface {
48 | Do(*Server)
49 | }
50 |
51 | func (s *dialstate) newTasks(nRunning int, peers map[discover.NodeID]*Peer, now time.Time) []task {
52 | if s.start == (time.Time{}) {
53 | s.start = now
54 | }
55 |
56 | var newtasks []task
57 | //addDial是一个内部方法, 首先通过checkDial检查节点。然后设置状态,最后把节点增加到newtasks队列里面。
58 | addDial := func(flag connFlag, n *discover.Node) bool {
59 | if err := s.checkDial(n, peers); err != nil {
60 | log.Trace("Skipping dial candidate", "id", n.ID, "addr", &net.TCPAddr{IP: n.IP, Port: int(n.TCP)}, "err", err)
61 | return false
62 | }
63 | s.dialing[n.ID] = flag
64 | newtasks = append(newtasks, &dialTask{flags: flag, dest: n})
65 | return true
66 | }
67 |
68 | // Compute number of dynamic dials necessary at this point.
69 | needDynDials := s.maxDynDials
70 | //首先判断已经建立的连接的类型。如果是动态类型。那么需要建立动态链接数量减少。
71 | for _, p := range peers {
72 | if p.rw.is(dynDialedConn) {
73 | needDynDials--
74 | }
75 | }
76 | //然后再判断正在建立的链接。如果是动态类型。那么需要建立动态链接数量减少。
77 | for _, flag := range s.dialing {
78 | if flag&dynDialedConn != 0 {
79 | needDynDials--
80 | }
81 | }
82 |
83 | // Expire the dial history on every invocation.
84 | s.hist.expire(now)
85 |
86 | // Create dials for static nodes if they are not connected.
87 | //查看所有的静态类型。如果可以那么也创建链接。
88 | for id, t := range s.static {
89 | err := s.checkDial(t.dest, peers)
90 | switch err {
91 | case errNotWhitelisted, errSelf:
92 | log.Warn("Removing static dial candidate", "id", t.dest.ID, "addr", &net.TCPAddr{IP: t.dest.IP, Port: int(t.dest.TCP)}, "err", err)
93 | delete(s.static, t.dest.ID)
94 | case nil:
95 | s.dialing[id] = t.flags
96 | newtasks = append(newtasks, t)
97 | }
98 | }
99 | // If we don't have any peers whatsoever, try to dial a random bootnode. This
100 | // scenario is useful for the testnet (and private networks) where the discovery
101 | // table might be full of mostly bad peers, making it hard to find good ones.
102 | //如果当前还没有任何链接。 而且20秒(fallbackInterval)内没有创建任何链接。 那么就使用bootnode创建链接。
103 | if len(peers) == 0 && len(s.bootnodes) > 0 && needDynDials > 0 && now.Sub(s.start) > fallbackInterval {
104 | bootnode := s.bootnodes[0]
105 | s.bootnodes = append(s.bootnodes[:0], s.bootnodes[1:]...)
106 | s.bootnodes = append(s.bootnodes, bootnode)
107 |
108 | if addDial(dynDialedConn, bootnode) {
109 | needDynDials--
110 | }
111 | }
112 | // Use random nodes from the table for half of the necessary
113 | // dynamic dials.
114 | //否则使用1/2的随机节点创建链接。
115 | randomCandidates := needDynDials / 2
116 | if randomCandidates > 0 {
117 | n := s.ntab.ReadRandomNodes(s.randomNodes)
118 | for i := 0; i < randomCandidates && i < n; i++ {
119 | if addDial(dynDialedConn, s.randomNodes[i]) {
120 | needDynDials--
121 | }
122 | }
123 | }
124 | // Create dynamic dials from random lookup results, removing tried
125 | // items from the result buffer.
126 | i := 0
127 | for ; i < len(s.lookupBuf) && needDynDials > 0; i++ {
128 | if addDial(dynDialedConn, s.lookupBuf[i]) {
129 | needDynDials--
130 | }
131 | }
132 | s.lookupBuf = s.lookupBuf[:copy(s.lookupBuf, s.lookupBuf[i:])]
133 | // Launch a discovery lookup if more candidates are needed.
134 | // 如果就算这样也不能创建足够动态链接。 那么创建一个discoverTask用来再网络上查找其他的节点。放入lookupBuf
135 | if len(s.lookupBuf) < needDynDials && !s.lookupRunning {
136 | s.lookupRunning = true
137 | newtasks = append(newtasks, &discoverTask{})
138 | }
139 |
140 | // Launch a timer to wait for the next node to expire if all
141 | // candidates have been tried and no task is currently active.
142 | // This should prevent cases where the dialer logic is not ticked
143 | // because there are no pending events.
144 | // 如果当前没有任何任务需要做,那么创建一个睡眠的任务返回。
145 | if nRunning == 0 && len(newtasks) == 0 && s.hist.Len() > 0 {
146 | t := &waitExpireTask{s.hist.min().exp.Sub(now)}
147 | newtasks = append(newtasks, t)
148 | }
149 | return newtasks
150 | }
151 |
152 |
153 | checkDial方法, 用来检查任务是否需要创建链接。
154 |
155 | func (s *dialstate) checkDial(n *discover.Node, peers map[discover.NodeID]*Peer) error {
156 | _, dialing := s.dialing[n.ID]
157 | switch {
158 | case dialing: //正在创建
159 | return errAlreadyDialing
160 | case peers[n.ID] != nil: //已经链接了
161 | return errAlreadyConnected
162 | case s.ntab != nil && n.ID == s.ntab.Self().ID: //建立的对象不是自己
163 | return errSelf
164 | case s.netrestrict != nil && !s.netrestrict.Contains(n.IP): //网络限制。 对方的IP地址不在白名单里面。
165 | return errNotWhitelisted
166 | case s.hist.contains(n.ID): // 这个ID曾经链接过。
167 | return errRecentlyDialed
168 | }
169 | return nil
170 | }
171 |
172 | taskDone方法。 这个方法再task完成之后会被调用。 查看task的类型。如果是链接任务,那么增加到hist里面。 并从正在链接的队列删除。 如果是查询任务。 把查询的记过放在lookupBuf里面。
173 |
174 | func (s *dialstate) taskDone(t task, now time.Time) {
175 | switch t := t.(type) {
176 | case *dialTask:
177 | s.hist.add(t.dest.ID, now.Add(dialHistoryExpiration))
178 | delete(s.dialing, t.dest.ID)
179 | case *discoverTask:
180 | s.lookupRunning = false
181 | s.lookupBuf = append(s.lookupBuf, t.results...)
182 | }
183 | }
184 |
185 |
186 |
187 | dialTask.Do方法,不同的task有不同的Do方法。 dailTask主要负责建立链接。 如果t.dest是没有ip地址的。 那么尝试通过resolve查询ip地址。 然后调用dial方法创建链接。 对于静态的节点。如果第一次失败,那么会尝试再次resolve静态节点。然后再尝试dial(因为静态节点的ip是配置的。 如果静态节点的ip地址变动。那么我们尝试resolve静态节点的新地址,然后调用链接。)
188 |
189 | func (t *dialTask) Do(srv *Server) {
190 | if t.dest.Incomplete() {
191 | if !t.resolve(srv) {
192 | return
193 | }
194 | }
195 | success := t.dial(srv, t.dest)
196 | // Try resolving the ID of static nodes if dialing failed.
197 | if !success && t.flags&staticDialedConn != 0 {
198 | if t.resolve(srv) {
199 | t.dial(srv, t.dest)
200 | }
201 | }
202 | }
203 |
204 | resolve方法。这个方法主要调用了discover网络的Resolve方法。如果失败,那么超时再试
205 |
206 | // resolve attempts to find the current endpoint for the destination
207 | // using discovery.
208 | //
209 | // Resolve operations are throttled with backoff to avoid flooding the
210 | // discovery network with useless queries for nodes that don't exist.
211 | // The backoff delay resets when the node is found.
212 | func (t *dialTask) resolve(srv *Server) bool {
213 | if srv.ntab == nil {
214 | log.Debug("Can't resolve node", "id", t.dest.ID, "err", "discovery is disabled")
215 | return false
216 | }
217 | if t.resolveDelay == 0 {
218 | t.resolveDelay = initialResolveDelay
219 | }
220 | if time.Since(t.lastResolved) < t.resolveDelay {
221 | return false
222 | }
223 | resolved := srv.ntab.Resolve(t.dest.ID)
224 | t.lastResolved = time.Now()
225 | if resolved == nil {
226 | t.resolveDelay *= 2
227 | if t.resolveDelay > maxResolveDelay {
228 | t.resolveDelay = maxResolveDelay
229 | }
230 | log.Debug("Resolving node failed", "id", t.dest.ID, "newdelay", t.resolveDelay)
231 | return false
232 | }
233 | // The node was found.
234 | t.resolveDelay = initialResolveDelay
235 | t.dest = resolved
236 | log.Debug("Resolved node", "id", t.dest.ID, "addr", &net.TCPAddr{IP: t.dest.IP, Port: int(t.dest.TCP)})
237 | return true
238 | }
239 |
240 |
241 | dial方法,这个方法进行了实际的网络连接操作。 主要通过srv.SetupConn方法来完成, 后续再分析Server.go的时候再分析这个方法。
242 |
243 | // dial performs the actual connection attempt.
244 | func (t *dialTask) dial(srv *Server, dest *discover.Node) bool {
245 | fd, err := srv.Dialer.Dial(dest)
246 | if err != nil {
247 | log.Trace("Dial error", "task", t, "err", err)
248 | return false
249 | }
250 | mfd := newMeteredConn(fd, false)
251 | srv.SetupConn(mfd, t.flags, dest)
252 | return true
253 | }
254 |
255 | discoverTask和waitExpireTask的Do方法,
256 |
257 | func (t *discoverTask) Do(srv *Server) {
258 | // newTasks generates a lookup task whenever dynamic dials are
259 | // necessary. Lookups need to take some time, otherwise the
260 | // event loop spins too fast.
261 | next := srv.lastLookup.Add(lookupInterval)
262 | if now := time.Now(); now.Before(next) {
263 | time.Sleep(next.Sub(now))
264 | }
265 | srv.lastLookup = time.Now()
266 | var target discover.NodeID
267 | rand.Read(target[:])
268 | t.results = srv.ntab.Lookup(target)
269 | }
270 |
271 |
272 | func (t waitExpireTask) Do(*Server) {
273 | time.Sleep(t.Duration)
274 | }
--------------------------------------------------------------------------------
/p2p-nat源码分析.md:
--------------------------------------------------------------------------------
1 | nat是网络地址转换的意思。 这部分的源码比较独立而且单一,这里就暂时不分析了。 大家了解基本的功能就行了。
2 |
3 | nat下面有upnp和pmp两种网络协议。
4 |
5 | ### upnp的应用场景(pmp是和upnp类似的协议)
6 |
7 | 如果用户是通过NAT接入Internet的,同时需要使用BC、电骡eMule等P2P这样的软件,这时UPnP功能就会带来很大的便利。利用UPnP能自动的把BC、电骡eMule等侦听的端口号映射到公网上,以便公网上的用户也能对NAT私网侧发起连接。
8 |
9 |
10 | 主要功能就是提供接口可以把内网的IP+端口 映射为 路由器的IP+端口。 这样就等于内网的程序有了外网的IP地址, 这样公网的用户就可以直接对你进行访问了。 不然就需要通过UDP打洞这种方式来进行访问。
11 |
12 |
13 |
14 | ### p2p中的UDP协议
15 |
16 | 现在大部分用户运行的环境都是内网环境。 内网环境下监听的端口,其他公网的程序是无法直接访问的。需要经过一个打洞的过程。 双方才能联通。这就是所谓的UDP打洞。
17 |
18 | 
19 | 外网希望直接访问内网上的程序是无法实现的。 因为路由器并不知道如何路由数据给内网的这个程序。
20 |
21 | 那么我们首先通过内网的程序联系外网的程序,这样路由器就会自动给内网的这个程序分配一个端口。并在路由器里面记录一条映射 192.168.1.1:3003 -> 111.21.12.12:3003 。这个映射关系随着时间会老化最终消失。
22 |
23 | 
24 |
25 | 等路由器建立这样的映射关系后。 互联网上的其他程序就可以快乐的访问111.21.12.12:3003这个端口了。因为所有送到这个端口的数据最终会被路由到192.168.1.1:3003这个端口。这就是所谓的打洞的过程。
26 |
27 | 
28 |
29 |
30 |
31 |
32 |
--------------------------------------------------------------------------------
/p2p-peer.go源码分析.md:
--------------------------------------------------------------------------------
1 | 在p2p代码里面。 peer代表了一条创建好的网络链路。在一条链路上可能运行着多个协议。比如以太坊的协议(eth)。 Swarm的协议。 或者是Whisper的协议。
2 |
3 | peer的结构
4 |
5 | type protoRW struct {
6 | Protocol
7 | in chan Msg // receices read messages
8 | closed <-chan struct{} // receives when peer is shutting down
9 | wstart <-chan struct{} // receives when write may start
10 | werr chan<- error // for write results
11 | offset uint64
12 | w MsgWriter
13 | }
14 |
15 | // Protocol represents a P2P subprotocol implementation.
16 | type Protocol struct {
17 | // Name should contain the official protocol name,
18 | // often a three-letter word.
19 | Name string
20 |
21 | // Version should contain the version number of the protocol.
22 | Version uint
23 |
24 | // Length should contain the number of message codes used
25 | // by the protocol.
26 | Length uint64
27 |
28 | // Run is called in a new groutine when the protocol has been
29 | // negotiated with a peer. It should read and write messages from
30 | // rw. The Payload for each message must be fully consumed.
31 | //
32 | // The peer connection is closed when Start returns. It should return
33 | // any protocol-level error (such as an I/O error) that is
34 | // encountered.
35 | Run func(peer *Peer, rw MsgReadWriter) error
36 |
37 | // NodeInfo is an optional helper method to retrieve protocol specific metadata
38 | // about the host node.
39 | NodeInfo func() interface{}
40 |
41 | // PeerInfo is an optional helper method to retrieve protocol specific metadata
42 | // about a certain peer in the network. If an info retrieval function is set,
43 | // but returns nil, it is assumed that the protocol handshake is still running.
44 | PeerInfo func(id discover.NodeID) interface{}
45 | }
46 |
47 | // Peer represents a connected remote node.
48 | type Peer struct {
49 | rw *conn
50 | running map[string]*protoRW //运行的协议
51 | log log.Logger
52 | created mclock.AbsTime
53 |
54 | wg sync.WaitGroup
55 | protoErr chan error
56 | closed chan struct{}
57 | disc chan DiscReason
58 |
59 | // events receives message send / receive events if set
60 | events *event.Feed
61 | }
62 |
63 | peer的创建,根据匹配找到当前Peer支持的protomap
64 |
65 | func newPeer(conn *conn, protocols []Protocol) *Peer {
66 | protomap := matchProtocols(protocols, conn.caps, conn)
67 | p := &Peer{
68 | rw: conn,
69 | running: protomap,
70 | created: mclock.Now(),
71 | disc: make(chan DiscReason),
72 | protoErr: make(chan error, len(protomap)+1), // protocols + pingLoop
73 | closed: make(chan struct{}),
74 | log: log.New("id", conn.id, "conn", conn.flags),
75 | }
76 | return p
77 | }
78 |
79 | peer的启动, 启动了两个goroutine线程。 一个是读取。一个是执行ping操作。
80 |
81 | func (p *Peer) run() (remoteRequested bool, err error) {
82 | var (
83 | writeStart = make(chan struct{}, 1) //用来控制什么时候可以写入的管道。
84 | writeErr = make(chan error, 1)
85 | readErr = make(chan error, 1)
86 | reason DiscReason // sent to the peer
87 | )
88 | p.wg.Add(2)
89 | go p.readLoop(readErr)
90 | go p.pingLoop()
91 |
92 | // Start all protocol handlers.
93 | writeStart <- struct{}{}
94 | //启动所有的协议。
95 | p.startProtocols(writeStart, writeErr)
96 |
97 | // Wait for an error or disconnect.
98 | loop:
99 | for {
100 | select {
101 | case err = <-writeErr:
102 | // A write finished. Allow the next write to start if
103 | // there was no error.
104 | if err != nil {
105 | reason = DiscNetworkError
106 | break loop
107 | }
108 | writeStart <- struct{}{}
109 | case err = <-readErr:
110 | if r, ok := err.(DiscReason); ok {
111 | remoteRequested = true
112 | reason = r
113 | } else {
114 | reason = DiscNetworkError
115 | }
116 | break loop
117 | case err = <-p.protoErr:
118 | reason = discReasonForError(err)
119 | break loop
120 | case err = <-p.disc:
121 | break loop
122 | }
123 | }
124 |
125 | close(p.closed)
126 | p.rw.close(reason)
127 | p.wg.Wait()
128 | return remoteRequested, err
129 | }
130 |
131 | startProtocols方法,这个方法遍历所有的协议。
132 |
133 | func (p *Peer) startProtocols(writeStart <-chan struct{}, writeErr chan<- error) {
134 | p.wg.Add(len(p.running))
135 | for _, proto := range p.running {
136 | proto := proto
137 | proto.closed = p.closed
138 | proto.wstart = writeStart
139 | proto.werr = writeErr
140 | var rw MsgReadWriter = proto
141 | if p.events != nil {
142 | rw = newMsgEventer(rw, p.events, p.ID(), proto.Name)
143 | }
144 | p.log.Trace(fmt.Sprintf("Starting protocol %s/%d", proto.Name, proto.Version))
145 | // 等于这里为每一个协议都开启了一个goroutine。 调用其Run方法。
146 | go func() {
147 | // proto.Run(p, rw)这个方法应该是一个死循环。 如果返回就说明遇到了错误。
148 | err := proto.Run(p, rw)
149 | if err == nil {
150 | p.log.Trace(fmt.Sprintf("Protocol %s/%d returned", proto.Name, proto.Version))
151 | err = errProtocolReturned
152 | } else if err != io.EOF {
153 | p.log.Trace(fmt.Sprintf("Protocol %s/%d failed", proto.Name, proto.Version), "err", err)
154 | }
155 | p.protoErr <- err
156 | p.wg.Done()
157 | }()
158 | }
159 | }
160 |
161 |
162 | 回过头来再看看readLoop方法。 这个方法也是一个死循环。 调用p.rw来读取一个Msg(这个rw实际是之前提到的frameRLPx的对象,也就是分帧之后的对象。然后根据Msg的类型进行对应的处理,如果Msg的类型是内部运行的协议的类型。那么发送到对应协议的proto.in队列上面。
163 |
164 |
165 | func (p *Peer) readLoop(errc chan<- error) {
166 | defer p.wg.Done()
167 | for {
168 | msg, err := p.rw.ReadMsg()
169 | if err != nil {
170 | errc <- err
171 | return
172 | }
173 | msg.ReceivedAt = time.Now()
174 | if err = p.handle(msg); err != nil {
175 | errc <- err
176 | return
177 | }
178 | }
179 | }
180 | func (p *Peer) handle(msg Msg) error {
181 | switch {
182 | case msg.Code == pingMsg:
183 | msg.Discard()
184 | go SendItems(p.rw, pongMsg)
185 | case msg.Code == discMsg:
186 | var reason [1]DiscReason
187 | // This is the last message. We don't need to discard or
188 | // check errors because, the connection will be closed after it.
189 | rlp.Decode(msg.Payload, &reason)
190 | return reason[0]
191 | case msg.Code < baseProtocolLength:
192 | // ignore other base protocol messages
193 | return msg.Discard()
194 | default:
195 | // it's a subprotocol message
196 | proto, err := p.getProto(msg.Code)
197 | if err != nil {
198 | return fmt.Errorf("msg code out of range: %v", msg.Code)
199 | }
200 | select {
201 | case proto.in <- msg:
202 | return nil
203 | case <-p.closed:
204 | return io.EOF
205 | }
206 | }
207 | return nil
208 | }
209 |
210 | 在看看pingLoop。这个方法很简单。就是定时的发送pingMsg消息到对端。
211 |
212 | func (p *Peer) pingLoop() {
213 | ping := time.NewTimer(pingInterval)
214 | defer p.wg.Done()
215 | defer ping.Stop()
216 | for {
217 | select {
218 | case <-ping.C:
219 | if err := SendItems(p.rw, pingMsg); err != nil {
220 | p.protoErr <- err
221 | return
222 | }
223 | ping.Reset(pingInterval)
224 | case <-p.closed:
225 | return
226 | }
227 | }
228 | }
229 |
230 | 最后再看看protoRW的read和write方法。 可以看到读取和写入都是阻塞式的。
231 |
232 | func (rw *protoRW) WriteMsg(msg Msg) (err error) {
233 | if msg.Code >= rw.Length {
234 | return newPeerError(errInvalidMsgCode, "not handled")
235 | }
236 | msg.Code += rw.offset
237 | select {
238 | case <-rw.wstart: //等到可以写入的受在执行写入。 这难道是为了多线程控制么。
239 | err = rw.w.WriteMsg(msg)
240 | // Report write status back to Peer.run. It will initiate
241 | // shutdown if the error is non-nil and unblock the next write
242 | // otherwise. The calling protocol code should exit for errors
243 | // as well but we don't want to rely on that.
244 | rw.werr <- err
245 | case <-rw.closed:
246 | err = fmt.Errorf("shutting down")
247 | }
248 | return err
249 | }
250 |
251 | func (rw *protoRW) ReadMsg() (Msg, error) {
252 | select {
253 | case msg := <-rw.in:
254 | msg.Code -= rw.offset
255 | return msg, nil
256 | case <-rw.closed:
257 | return Msg{}, io.EOF
258 | }
259 | }
260 |
--------------------------------------------------------------------------------
/p2p源码分析.md:
--------------------------------------------------------------------------------
1 | p2p的源码又下面几个包
2 |
3 | - discover 包含了[Kademlia协议](references/Kademlia协议原理简介.pdf)。是基于UDP的p2p节点发现协议。
4 | - discv5 新的节点发现协议。 还是试验属性。本次分析没有涉及。
5 | - nat 网络地址转换的部分代码
6 | - netutil 一些工具
7 | - simulations p2p网络的模拟。 本次分析没有涉及。
8 |
9 | discover部分的源码分析
10 |
11 | - [发现的节点的持久化存储 database.go](p2p-database.go源码分析.md)
12 | - [Kademlia协议的核心逻辑 tabel.go](p2p-table.go源码分析.md)
13 | - [UDP协议的处理逻辑udp.go](p2p-udp.go源码分析.md)
14 | - [网络地址转换 nat.go](p2p-nat源码分析.md)
15 |
16 | p2p/ 部分源码分析
17 |
18 | - [节点之间的加密链路处理协议 rlpx.go](p2p-rlpx节点之间的加密链路.md)
19 | - [挑选节点然后进行连接的处理逻辑 dail.go](p2p-dial.go源码分析.md)
20 | - [节点和节点连接的处理以及协议的处理 peer.go](p2p-peer.go源码分析.md)
21 | - [p2p服务器的逻辑 server.go](p2p-server.go源码分析.md)
22 |
--------------------------------------------------------------------------------
/picture/Consensus-architecture.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/Consensus-architecture.png
--------------------------------------------------------------------------------
/picture/EVM-1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/EVM-1.jpg
--------------------------------------------------------------------------------
/picture/EVM-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/EVM-2.png
--------------------------------------------------------------------------------
/picture/README.md:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/picture/accounts.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/accounts.png
--------------------------------------------------------------------------------
/picture/arch.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/arch.jpg
--------------------------------------------------------------------------------
/picture/block-seal-process.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/block-seal-process.png
--------------------------------------------------------------------------------
/picture/block-verification-process.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/block-verification-process.png
--------------------------------------------------------------------------------
/picture/bloom_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/bloom_1.png
--------------------------------------------------------------------------------
/picture/bloom_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/bloom_2.png
--------------------------------------------------------------------------------
/picture/bloom_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/bloom_3.png
--------------------------------------------------------------------------------
/picture/bloom_4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/bloom_4.png
--------------------------------------------------------------------------------
/picture/bloom_5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/bloom_5.png
--------------------------------------------------------------------------------
/picture/bloom_6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/bloom_6.png
--------------------------------------------------------------------------------
/picture/chainindexer_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/chainindexer_1.png
--------------------------------------------------------------------------------
/picture/chainindexer_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/chainindexer_2.png
--------------------------------------------------------------------------------
/picture/geth_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/geth_1.png
--------------------------------------------------------------------------------
/picture/go_env_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/go_env_1.png
--------------------------------------------------------------------------------
/picture/go_env_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/go_env_2.png
--------------------------------------------------------------------------------
/picture/hashimoto-flow.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/hashimoto-flow.png
--------------------------------------------------------------------------------
/picture/hp_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/hp_1.png
--------------------------------------------------------------------------------
/picture/matcher_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/matcher_1.png
--------------------------------------------------------------------------------
/picture/nat_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/nat_1.png
--------------------------------------------------------------------------------
/picture/nat_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/nat_2.png
--------------------------------------------------------------------------------
/picture/nat_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/nat_3.png
--------------------------------------------------------------------------------
/picture/patricia_tire.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/patricia_tire.png
--------------------------------------------------------------------------------
/picture/pow_hashimoto.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/pow_hashimoto.png
--------------------------------------------------------------------------------
/picture/rlp_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/rlp_1.png
--------------------------------------------------------------------------------
/picture/rlp_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/rlp_2.png
--------------------------------------------------------------------------------
/picture/rlp_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/rlp_3.png
--------------------------------------------------------------------------------
/picture/rlp_4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/rlp_4.png
--------------------------------------------------------------------------------
/picture/rlp_5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/rlp_5.png
--------------------------------------------------------------------------------
/picture/rlp_6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/rlp_6.png
--------------------------------------------------------------------------------
/picture/rlpx_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/rlpx_1.png
--------------------------------------------------------------------------------
/picture/rlpx_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/rlpx_2.png
--------------------------------------------------------------------------------
/picture/rlpx_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/rlpx_3.png
--------------------------------------------------------------------------------
/picture/rpc_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/rpc_1.png
--------------------------------------------------------------------------------
/picture/rpc_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/rpc_2.png
--------------------------------------------------------------------------------
/picture/sign_ether.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_ether.png
--------------------------------------------------------------------------------
/picture/sign_ether_value.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_ether_value.png
--------------------------------------------------------------------------------
/picture/sign_exec_func.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_exec_func.png
--------------------------------------------------------------------------------
/picture/sign_exec_model.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_exec_model.png
--------------------------------------------------------------------------------
/picture/sign_func_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_func_1.png
--------------------------------------------------------------------------------
/picture/sign_func_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_func_2.png
--------------------------------------------------------------------------------
/picture/sign_gas_log.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_gas_log.png
--------------------------------------------------------------------------------
/picture/sign_gas_total.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_gas_total.png
--------------------------------------------------------------------------------
/picture/sign_h_b.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_b.png
--------------------------------------------------------------------------------
/picture/sign_h_c.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_c.png
--------------------------------------------------------------------------------
/picture/sign_h_d.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_d.png
--------------------------------------------------------------------------------
/picture/sign_h_e.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_e.png
--------------------------------------------------------------------------------
/picture/sign_h_g.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_g.png
--------------------------------------------------------------------------------
/picture/sign_h_i.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_i.png
--------------------------------------------------------------------------------
/picture/sign_h_l.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_l.png
--------------------------------------------------------------------------------
/picture/sign_h_m.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_m.png
--------------------------------------------------------------------------------
/picture/sign_h_n.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_n.png
--------------------------------------------------------------------------------
/picture/sign_h_o.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_o.png
--------------------------------------------------------------------------------
/picture/sign_h_p.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_p.png
--------------------------------------------------------------------------------
/picture/sign_h_r.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_r.png
--------------------------------------------------------------------------------
/picture/sign_h_s.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_s.png
--------------------------------------------------------------------------------
/picture/sign_h_t.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_t.png
--------------------------------------------------------------------------------
/picture/sign_h_x.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_h_x.png
--------------------------------------------------------------------------------
/picture/sign_homestead.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_homestead.png
--------------------------------------------------------------------------------
/picture/sign_i_a.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_i_a.png
--------------------------------------------------------------------------------
/picture/sign_i_b.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_i_b.png
--------------------------------------------------------------------------------
/picture/sign_i_d.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_i_d.png
--------------------------------------------------------------------------------
/picture/sign_i_e.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_i_e.png
--------------------------------------------------------------------------------
/picture/sign_i_h.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_i_h.png
--------------------------------------------------------------------------------
/picture/sign_i_o.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_i_o.png
--------------------------------------------------------------------------------
/picture/sign_i_p.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_i_p.png
--------------------------------------------------------------------------------
/picture/sign_i_s.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_i_s.png
--------------------------------------------------------------------------------
/picture/sign_i_v.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_i_v.png
--------------------------------------------------------------------------------
/picture/sign_l1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_l1.png
--------------------------------------------------------------------------------
/picture/sign_last_item.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_last_item.png
--------------------------------------------------------------------------------
/picture/sign_last_item_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_last_item_1.png
--------------------------------------------------------------------------------
/picture/sign_ls.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_ls.png
--------------------------------------------------------------------------------
/picture/sign_m_g.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_m_g.png
--------------------------------------------------------------------------------
/picture/sign_m_w.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_m_w.png
--------------------------------------------------------------------------------
/picture/sign_machine_state.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_machine_state.png
--------------------------------------------------------------------------------
/picture/sign_math_and.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_math_and.png
--------------------------------------------------------------------------------
/picture/sign_math_any.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_math_any.png
--------------------------------------------------------------------------------
/picture/sign_math_or.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_math_or.png
--------------------------------------------------------------------------------
/picture/sign_memory.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_memory.png
--------------------------------------------------------------------------------
/picture/sign_pa.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_pa.png
--------------------------------------------------------------------------------
/picture/sign_placeholder_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_placeholder_1.png
--------------------------------------------------------------------------------
/picture/sign_placeholder_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_placeholder_2.png
--------------------------------------------------------------------------------
/picture/sign_placeholder_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_placeholder_3.png
--------------------------------------------------------------------------------
/picture/sign_placeholder_4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_placeholder_4.png
--------------------------------------------------------------------------------
/picture/sign_r_bloom.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_r_bloom.png
--------------------------------------------------------------------------------
/picture/sign_r_gasused.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_r_gasused.png
--------------------------------------------------------------------------------
/picture/sign_r_i.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_r_i.png
--------------------------------------------------------------------------------
/picture/sign_r_log.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_r_log.png
--------------------------------------------------------------------------------
/picture/sign_r_logentry.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_r_logentry.png
--------------------------------------------------------------------------------
/picture/sign_r_state.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_r_state.png
--------------------------------------------------------------------------------
/picture/sign_receipt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_receipt.png
--------------------------------------------------------------------------------
/picture/sign_seq_item.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_seq_item.png
--------------------------------------------------------------------------------
/picture/sign_set_b.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_set_b.png
--------------------------------------------------------------------------------
/picture/sign_set_b32.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_set_b32.png
--------------------------------------------------------------------------------
/picture/sign_set_p.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_set_p.png
--------------------------------------------------------------------------------
/picture/sign_set_p256.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_set_p256.png
--------------------------------------------------------------------------------
/picture/sign_stack.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_stack.png
--------------------------------------------------------------------------------
/picture/sign_stack_added.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_stack_added.png
--------------------------------------------------------------------------------
/picture/sign_stack_removed.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_stack_removed.png
--------------------------------------------------------------------------------
/picture/sign_state_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_1.png
--------------------------------------------------------------------------------
/picture/sign_state_10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_10.png
--------------------------------------------------------------------------------
/picture/sign_state_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_2.png
--------------------------------------------------------------------------------
/picture/sign_state_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_3.png
--------------------------------------------------------------------------------
/picture/sign_state_4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_4.png
--------------------------------------------------------------------------------
/picture/sign_state_5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_5.png
--------------------------------------------------------------------------------
/picture/sign_state_6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_6.png
--------------------------------------------------------------------------------
/picture/sign_state_7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_7.png
--------------------------------------------------------------------------------
/picture/sign_state_8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_8.png
--------------------------------------------------------------------------------
/picture/sign_state_9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_9.png
--------------------------------------------------------------------------------
/picture/sign_state_balance.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_balance.png
--------------------------------------------------------------------------------
/picture/sign_state_code.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_code.png
--------------------------------------------------------------------------------
/picture/sign_state_nonce.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_nonce.png
--------------------------------------------------------------------------------
/picture/sign_state_root.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_state_root.png
--------------------------------------------------------------------------------
/picture/sign_substate_a.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_substate_a.png
--------------------------------------------------------------------------------
/picture/sign_substate_al.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_substate_al.png
--------------------------------------------------------------------------------
/picture/sign_substate_ar.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_substate_ar.png
--------------------------------------------------------------------------------
/picture/sign_substate_as.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_substate_as.png
--------------------------------------------------------------------------------
/picture/sign_t_data.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_t_data.png
--------------------------------------------------------------------------------
/picture/sign_t_gaslimit.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_t_gaslimit.png
--------------------------------------------------------------------------------
/picture/sign_t_gasprice.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_t_gasprice.png
--------------------------------------------------------------------------------
/picture/sign_t_lt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_t_lt.png
--------------------------------------------------------------------------------
/picture/sign_t_nonce.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_t_nonce.png
--------------------------------------------------------------------------------
/picture/sign_t_ti.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_t_ti.png
--------------------------------------------------------------------------------
/picture/sign_t_to.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_t_to.png
--------------------------------------------------------------------------------
/picture/sign_t_tr.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_t_tr.png
--------------------------------------------------------------------------------
/picture/sign_t_ts.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_t_ts.png
--------------------------------------------------------------------------------
/picture/sign_t_value.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_t_value.png
--------------------------------------------------------------------------------
/picture/sign_t_w.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_t_w.png
--------------------------------------------------------------------------------
/picture/sign_u_i.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_u_i.png
--------------------------------------------------------------------------------
/picture/sign_u_m.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_u_m.png
--------------------------------------------------------------------------------
/picture/sign_u_pc.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_u_pc.png
--------------------------------------------------------------------------------
/picture/sign_u_s.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/sign_u_s.png
--------------------------------------------------------------------------------
/picture/state_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/state_1.png
--------------------------------------------------------------------------------
/picture/trie_1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/trie_1.jpg
--------------------------------------------------------------------------------
/picture/trie_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/trie_1.png
--------------------------------------------------------------------------------
/picture/trie_10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/trie_10.png
--------------------------------------------------------------------------------
/picture/trie_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/trie_2.png
--------------------------------------------------------------------------------
/picture/trie_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/trie_3.png
--------------------------------------------------------------------------------
/picture/trie_4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/trie_4.png
--------------------------------------------------------------------------------
/picture/trie_5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/trie_5.png
--------------------------------------------------------------------------------
/picture/trie_6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/trie_6.png
--------------------------------------------------------------------------------
/picture/trie_7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/trie_7.png
--------------------------------------------------------------------------------
/picture/trie_8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/trie_8.png
--------------------------------------------------------------------------------
/picture/trie_9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/trie_9.png
--------------------------------------------------------------------------------
/picture/worldstatetrie.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/picture/worldstatetrie.png
--------------------------------------------------------------------------------
/pos介绍proofofstake.md:
--------------------------------------------------------------------------------
1 | **Proof-of-stake(POS)**是加密货币的区块链网络达到分布式共识的一种算法。在基于Pos的加密货币中,下一个区块的创建者是通过组合随机选择,财富值,或者是年龄等条件选择出来的。相反的是,基于Pow的加密货币(比如比特币)是通过破解hash谜题来决定区块的创建者。
2 |
3 | ## 多种区块选择机制
4 |
5 | Proof-of-stake 必须有一种方法来定义区块链中的下一个有效的区块。如果仅仅基于账户余额会导致中心化的结果,因为如果单个最富有的成员会拥有永久的优势。相反,有几种不同的选择方法被设计出来。
6 |
7 | ### 随机区块选择
8 |
9 | Nxt 和 BlackCoin 使用了随机的方式来预测下一个区块产生者,通过使用一个公式,这个公式选择用户股份hash值的最小值。argmin hash(stake)。 因为股份是公开的,所有的节点都可以计算出相同的值。
10 |
11 | ### 基于币龄选择
12 |
13 | Peercoin 的 proof-of-stake 系统组合了随机选择和币龄的概念。币龄就是 币的数量乘以币的持有时间。 持有时间超过30天的币将有机会成为下一个区块的锻造者。 币龄更大的用户会有更大的机会来签署下一个区块。然而,一旦用来签署了一个区块,那么他的币龄会被清0。必须再等待30天才有可能签署下一个区块。同样,币龄最多只会累计到90天的上限就不会增加了,这是为了避免币龄非常大的用户对区块链具有绝对的作用。这个处理过程使得网络安全,而且逐渐的创造新的货币,而不会消耗非常大的计算资源。Peercoin的开发者申明在这样的网络上进行攻击会比Pow更加困难,因为没有中心化的矿池,而且获取51%的货币会比获取51%的算力更加困难。
14 |
15 | ## 优势
16 |
17 | Proof of Work 依赖能源的消耗。 根据bitcoin矿场操作员声称,2014年没产生一个bitcoin的能源消耗达到了240kWh(相当于燃烧16加仑汽油,就碳的生产而言。)。而且能源的消费是非加密货币支付的。Proof of Stake的效率是Pow的几千倍。
18 |
19 | 区块生产者的激励方式同样不同。 在Pow模式下,区块的生产者可能并没有拥有任何的加密货币。矿工的意图是最大化的他们自己的收益,这样的不一致是否会降低货币的安全性或者提高系统的安全风险也是不清楚的。在Pos系统中,这些守护系统安全的人总是有用货币比较多的人
20 |
21 | ## 批评
22 |
23 | 一些作者认为pos不是分布式一致性协议的理想选项。其中的一个问题就是通常讲的"nothing at stake"问题,这个问题是说对于区块链的生产者来说,在两个分叉的点同时投票不会产生任何问题,而这样的可能会导致一致性难以解决。因为同时工作在多条链上面只会消耗很少的资源(根Pow不同),任何人都可以滥用这个特性,从而使得任何人都在不同的链上可以双花。
24 |
25 | 同样有很多尝试解决这个问题的办法:
26 |
27 | - 以太坊建议使用Slasher协议允许用户惩罚作弊的人。如果有人尝试在多个不同的区块分支上创建区块,那么会被认为是作弊者。这个提案假设如果你想创建一个分叉你必须双重签名,如果你创建了一个分叉而又没有stake,那么你会被惩罚。然而Slasher从来没有被采用。以太坊开发者认为Pow是一个值得正视的问题。计划用一个不同的Pos协议CASPER来替代。
28 | - Peercoin 采用了中心化的广播检查点的方法(使用开发者私钥签署). 区块链的重建的深度不能超过最新的检查点。折衷在于开发者是中心化的权利机构而且控制着区块链。
29 | - Nxt 的协议仅仅允许最新的720个块重建。然而,这仅仅调整了问题。一个客户端可以跟随一个有721个区块的分叉,而不管这个分叉是不是最高的区块链,从而阻止了一致性。
30 | - Proof of burn 和 proof of stake的混合协议。Proof of burn作为checkpoint节点存在,拥有最高的奖励,不包含交易,是最安全的。。。TODO
31 | - pow和pos的混合。pos作为依赖pow的一个扩展,基于Proof of Activity提案,这个提案希望解决nothing-at-stake问题,使用pow矿工挖矿,而pos作为第二认证机制
32 | -
--------------------------------------------------------------------------------
/references/Kademlia协议原理简介.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/references/Kademlia协议原理简介.pdf
--------------------------------------------------------------------------------
/references/readme.md:
--------------------------------------------------------------------------------
1 | # Kad网络介绍
2 | 虚线包含的部分就是各子树,由上到下各层的前缀分别为 0,01,000,0010。
3 | > 按照上文的理解:对于任意一个节点,都可以把这颗二叉树分解为一系列连续的,不包含自己的子树。最高层的子树,由整颗树不包含自己的树的另一半组成; 下一层子树由剩下部分不包含自己的一半组成;依此类推,直到分割完整颗树。
4 |
5 | 虚线包含的部分就是各子树,由上到下各层的前缀分别为 1,01,000,0010。
6 |
7 | 每一个这样的列表都称之为一个 K 桶,并且每个 K 桶内部信息存放位置是根据上次看到的时间顺序排列,最近(least-recently)看到的放在头部,最后(most-recently)看到的放在尾部。每个桶都有不超过 k 个的数据项。
8 | > 最近(least-recently)与最后(most-recently)的翻译,会产生歧义
9 |
10 | 最近最少(least-recently)访问的节点放在队列头,最近最多(most-recently)访问的节点放在队列尾部。以模拟gnutella用户行为分析的结果,最近最多访问的活跃节点,也是将来最有可能需要访问的节点
11 |
--------------------------------------------------------------------------------
/todo-p2p加密算法.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/todo-p2p加密算法.md
--------------------------------------------------------------------------------
/todo-用户账户-密钥-签名的关系.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Billy1900/Ethereum-tutorial/31f18eb7fb2b312bda8c40986b90b92e68dbfcd7/todo-用户账户-密钥-签名的关系.md
--------------------------------------------------------------------------------
/types.md:
--------------------------------------------------------------------------------
1 | # core/types
2 | ### core/types/block.go
3 | block data stucture:
4 | type Block struct {
5 | header *Header
6 | uncles []*Header
7 | transactions Transactions
8 | hash atomic.Value
9 | size atomic.Value
10 | td *big.Int
11 | ReceivedAt time.Time
12 | ReceivedFrom interface{}
13 | }
14 | |字段 |描述|
15 | |--------|------------------------------|
16 | |header |指向 Header 结构(之后会详细说明),header 存储一个区块的基本信息。|
17 | |uncles |指向 Header 结构|
18 | |transactions| 一组 transaction 结构|
19 | |hash |当前区块的哈希值|
20 | |size |当前区块的大小|
21 | |td |当前区块高度|
22 | |ReceivedAt| 接收时间|
23 | |ReceivedFrom| 来源|
24 |
25 | 交易组成区块,一个一个区块以单向链表的形式连在一起组成区块链
26 | Header data structure:
27 | type Header struct {
28 | ParentHash common.Hash `json:"parentHash" gencodec:"required"`
29 | UncleHash common.Hash `json:"sha3Uncles" gencodec:"required"`
30 | Coinbase common.Address `json:"miner" gencodec:"required"`
31 | Root common.Hash `json:"stateRoot" gencodec:"required"`
32 | TxHash common.Hash `json:"transactionsRoot" gencodec:"required"`
33 | ReceiptHash common.Hash `json:"receiptsRoot" gencodec:"required"`
34 | Bloom Bloom `json:"logsBloom" gencodec:"required"`
35 | Difficulty *big.Int `json:"difficulty" gencodec:"required"`
36 | Number *big.Int `json:"number" gencodec:"required"`
37 | GasLimit uint64 `json:"gasLimit" gencodec:"required"`
38 | GasUsed uint64 `json:"gasUsed" gencodec:"required"`
39 | Time *big.Int `json:"timestamp" gencodec:"required"`
40 | Extra []byte `json:"extraData" gencodec:"required"`
41 | MixDigest common.Hash `json:"mixHash" gencodec:"required"`
42 | Nonce BlockNonce `json:"nonce" gencodec:"required"`
43 | }
44 | |字段| 描述|
45 | |--------|-------|
46 | |ParentHash| 父区块的哈希值|
47 | |UncleHash |叔区块的哈希值|
48 | |Coinbase |矿工得到奖励的账户,一般是矿工本地第一个账户|
49 | |Root |表示当前所有用户状态|
50 | |TxHash |本区块所有交易 Hash,即摘要|
51 | |ReceiptHash |本区块所有收据 Hash,即摘要|
52 | |Bloom |布隆过滤器,用来搜索收据|
53 | |Difficulty |该区块难度,动态调整,与父区块和本区块挖矿时间有关。
54 | |Number |该区块高度|
55 | |GasLimit gas |用量上限,该数值根据父区块 gas 用量调节,如果 parentGasUsed > parentGasLimit * (2/3) ,则增大该数值,反之则减小该数值。|
56 | |GasUsed |实际花费的 gas|
57 | |Time |新区块的出块时间,严格来说是开始挖矿的时间|
58 | |Extra |额外数据|
59 | |MixDigest| 混合哈希,与nonce 结合使用|
60 | |Nonce |加密学中的概念|
61 | |ParentHash |表示该区块的父区块哈希,我们通过 ParentHash 这个字段将一个一个区块连接起来组成区块链,但实际上我们并不会直接将链整个的存起来,它是以一定的数据结构一块一块存放的,geth 的底层数据库用的是 LevelDB,这是一个 key-value 数据库,要得到父区块时,我们通过 ParentHash 以及其他字符串组成 key,在 LevelDB 中查询该 key 对应的值,就能拿到父区块。|
62 |
63 | ### core/types/transaction.go
64 | type Transaction struct {
65 | data txdata
66 | // caches
67 | hash atomic.Value
68 | size atomic.Value
69 | from atomic.Value
70 | }
71 |
72 | type txdata struct {
73 | AccountNonce uint64 `json:"nonce" gencodec:"required"`
74 | Price *big.Int `json:"gasPrice" gencodec:"required"`
75 | GasLimit uint64 `json:"gas" gencodec:"required"`
76 | Recipient *common.Address `json:"to" rlp:"nil"` // nil means contract creation
77 | Amount *big.Int `json:"value" gencodec:"required"`
78 | Payload []byte `json:"input" gencodec:"required"`
79 |
80 | // Signature values
81 | V *big.Int `json:"v" gencodec:"required"`
82 | R *big.Int `json:"r" gencodec:"required"`
83 | S *big.Int `json:"s" gencodec:"required"`
84 |
85 | // This is only used when marshaling to JSON.
86 | Hash *common.Hash `json:"hash" rlp:"-"`
87 | }
88 | 转账的定义中只有转入方,转出方的地址没有直接暴露,这是 Ethereum 的安全保护策略
89 |
90 | 每一笔转账都有独立的 Price 和 GasLimit
91 |
--------------------------------------------------------------------------------
/以太坊fast sync算法.md:
--------------------------------------------------------------------------------
1 | # Sync算法
2 |
3 | 翻译内容来自 ( [https://github.com/ethereum/go-ethereum/pull/1889](https://github.com/ethereum/go-ethereum/pull/1889) )
4 |
5 | This PR aggregates a lot of small modifications to core, trie, eth and other packages to collectively implement the eth/63 fast synchronization algorithm. In short, geth --fast.
6 |
7 | 这个提交请求包含了对core,trie,eth和其他一些package的微小的修改,来共同实现eth/63的快速同步算法。 简单来说, geth --fast.
8 |
9 | ## Algorithm 算法
10 |
11 | The goal of the the fast sync algorithm is to exchange processing power for bandwidth usage. Instead of processing the entire block-chain one link at a time, and replay all transactions that ever happened in history, fast syncing downloads the transaction receipts along the blocks, and pulls an entire recent state database. This allows a fast synced node to still retain its status an an archive node containing all historical data for user queries (and thus not influence the network's health in general), but at the same time to reassemble a recent network state at a fraction of the time it would take full block processing.
12 |
13 | 快速同步算法的目标是用带宽换计算。 快速同步不是通过一个链接处理整个区块链,而是重放历史上发生的所有事务,快速同步会沿着这些块下载事务处理单据,然后拉取整个最近的状态数据库。 这允许快速同步的节点仍然保持其包含用于用户查询的所有历史数据的存档节点的状态(并且因此不会一般地影响网络的健康状况),对于最新的区块状态更改,会使用全量的区块处理方式。
14 |
15 | An outline of the fast sync algorithm would be:
16 |
17 | - Similarly to classical sync, download the block headers and bodies that make up the blockchain
18 | - Similarly to classical sync, verify the header chain's consistency (POW, total difficulty, etc)
19 | - Instead of processing the blocks, download the transaction receipts as defined by the header
20 | - Store the downloaded blockchain, along with the receipt chain, enabling all historical queries
21 | - When the chain reaches a recent enough state (head - 1024 blocks), pause for state sync:
22 | - Retrieve the entire Merkel Patricia state trie defined by the root hash of the pivot point
23 | - For every account found in the trie, retrieve it's contract code and internal storage state trie
24 | - Upon successful trie download, mark the pivot point (head - 1024 blocks) as the current head
25 | - Import all remaining blocks (1024) by fully processing them as in the classical sync
26 |
27 | 快速同步算法的概要:
28 |
29 | - 与原有的同步类似,下载组成区块链的区块头和区块body
30 | - 类似于原有的同步,验证区块头的一致性(POW,总难度等)
31 | - 下载由区块头定义的交易收据,而不是处理区块。
32 | - 存储下载的区块链和收据链,启用所有历史查询
33 | - 当链条达到最近的状态(头部 - 1024个块)时,暂停状态同步:
34 | - 获取由 pivot point定义的区块的完整的Merkel Patricia Trie状态
35 | - 对于Merkel Patricia Trie里面的每个账户,获取他的合约代码和中间存储的Trie
36 | - 当Merkel Patricia Trie下载成功后,将pivot point定义的区块作为当前的区块头
37 | - 通过像原有的同步一样对其进行完全处理,导入所有剩余的块(1024)
38 |
39 | ## 分析 Analysis
40 | By downloading and verifying the entire header chain, we can guarantee with all the security of the classical sync, that the hashes (receipts, state tries, etc) contained within the headers are valid. Based on those hashes, we can confidently download transaction receipts and the entire state trie afterwards. Additionally, by placing the pivoting point (where fast sync switches to block processing) a bit below the current head (1024 blocks), we can ensure that even larger chain reorganizations can be handled without the need of a new sync (as we have all the state going that many blocks back).
41 |
42 | 通过下载和验证整个头部链,我们可以保证传统同步的所有安全性,头部中包含的哈希(收据,状态尝试等)是有效的。 基于这些哈希,我们可以自信地下载交易收据和整个状态树。 另外,通过将pivoting point(快速同步切换到区块处理)放置在当前区块头(1024块)的下方一点,我们可以确保甚至可以处理更大的区块链重组,而不需要新的同步(因为我们有所有的状态 TODO)。
43 |
44 | ## 注意事项 Caveats
45 | The historical block-processing based synchronization mechanism has two (approximately similarly costing) bottlenecks: transaction processing and PoW verification. The baseline fast sync algorithm successfully circumvents the transaction processing, skipping the need to iterate over every single state the system ever was in. However, verifying the proof of work associated with each header is still a notably CPU intensive operation.
46 |
47 | 基于历史块处理的同步机制具有两个(近似相似成本)瓶颈:交易处理和PoW验证。 基线快速同步算法成功地绕开了事务处理,跳过了对系统曾经处于的每一个状态进行迭代的需要。但是,验证与每个头相关联的工作证明仍然是CPU密集型操作。
48 |
49 | However, we can notice an interesting phenomenon during header verification. With a negligible probability of error, we can still guarantee the validity of the chain, only by verifying every K-th header, instead of each and every one. By selecting a single header at random out of every K headers to verify, we guarantee the validity of an N-length chain with the probability of (1/K)^(N/K) (i.e. we have 1/K chance to spot a forgery in K blocks, a verification that's repeated N/K times).
50 |
51 | 但是,我们可以在区块头验证期间注意到一个有趣的现象 由于错误概率可以忽略不计,我们仍然可以保证链的有效性,只需要验证每个第K个头,而不是每个头。 通过从每个K头中随机选择一个头来验证,我们保证N长度链的可能会被伪造的概率为(1 / K)^(N / K)(在K块中我们有1 / K的机会发现一个伪造,而验证经行了N/K次。)。
52 |
53 | Let's define the negligible probability Pn as the probability of obtaining a 256 bit SHA3 collision (i.e. the hash Ethereum is built upon): 1/2^128. To honor the Ethereum security requirements, we need to choose the minimum chain length N (below which we veriy every header) and maximum K verification batch size such as (1/K)^(N/K) <= Pn holds. Calculating this for various {N, K} pairs is pretty straighforward, a simple and lenient solution being http://play.golang.org/p/B-8sX_6Dq0.
54 |
55 | 我们将可忽略概率Pn定义为获得256位SHA3冲突(以太坊的Hash算法)的概率:1/2 ^ 128。 为了遵守以太坊的安全要求,我们需要选择最小链长N(在我们每个块都验证之前),最大K验证批量大小如(1 / K)^(N / K)<= Pn。 对各种{N,K}对进行计算是非常直接的,一个简单和宽松的解决方案是http://play.golang.org/p/B-8sX_6Dq0。
56 |
57 | |N |K |N |K |N |K |N |K |
58 | | ------|-------|-------|-----------|-------|-----------|-------|---|
59 | |1024 |43 |1792 |91 |2560 |143 |3328 |198|
60 | |1152 |51 |1920 |99 |2688 |152 |3456 |207|
61 | |1280 |58 |2048 |108 |2816 |161 |3584 |217|
62 | |1408 |66 |2176 |116 |2944 |170 |3712 |226|
63 | |1536 |74 |2304 |128 |3072 |179 |3840 |236|
64 | |1664 |82 |2432 |134 |3200 |189 |3968 |246|
65 |
66 |
67 | The above table should be interpreted in such a way, that if we verify every K-th header, after N headers the probability of a forgery is smaller than the probability of an attacker producing a SHA3 collision. It also means, that if a forgery is indeed detected, the last N headers should be discarded as not safe enough. Any {N, K} pair may be chosen from the above table, and to keep the numbers reasonably looking, we chose N=2048, K=100. This will be fine tuned later after being able to observe network bandwidth/latency effects and possibly behavior on more CPU limited devices.
68 |
69 | 上面的表格应该这样解释:如果我们每隔K个区块头验证一次区块头,在N个区块头之后,伪造的概率小于攻击者产生SHA3冲突的概率。 这也意味着,如果确实发现了伪造,那么最后的N个头部应该被丢弃,因为不够安全。 可以从上表中选择任何{N,K}对,为了选择一个看起来好看点的数字,我们选择N = 2048,K = 100。 后续可能会根据网络带宽/延迟影响以及可能在一些CPU性能比较受限的设备上运行的情况来进行调整。
70 |
71 | Using this caveat however would mean, that the pivot point can be considered secure only after N headers have been imported after the pivot itself. To prove the pivot safe faster, we stop the "gapped verificatios" X headers before the pivot point, and verify every single header onward, including an additioanl X headers post-pivot before accepting the pivot's state. Given the above N and K numbers, we chose X=24 as a safe number.
72 |
73 | 然而,使用这个特性意味着,只有导入N个区块之后再导入pivot节点才被认为是安全的。 为了更快地证明pivot的安全性,我们在距离pivot节点X距离的地方停止隔块验证的行为,对随后出现的每一个块进行验证直到pivot。 鉴于上述N和K数字,我们选择X = 24作为安全数字。
74 |
75 | With this caveat calculated, the fast sync should be modified so that up to the pivoting point - X, only every K=100-th header should be verified (at random), after which all headers up to pivot point + X should be fully verified before starting state database downloading. Note: if a sync fails due to header verification the last N headers must be discarded as they cannot be trusted enough.
76 |
77 | 通过计算caveat,快速同步需要修改为pivoting point - X,每隔100个区块头随机挑选其中的一个来进行验证,之后的每一个块都需要在状态数据库下载完成之后完全验证,如果因为区块头验证失败导致的同步失败,那么最后的N个区块头都需要被丢弃,应为他们达不到信任标准。
78 |
79 |
80 | ## 缺点 Weakness
81 | Blockchain protocols in general (i.e. Bitcoin, Ethereum, and the others) are susceptible to Sybil attacks, where an attacker tries to completely isolate a node from the rest of the network, making it believe a false truth as to what the state of the real network is. This permits the attacker to spend certain funds in both the real network and this "fake bubble". However, the attacker can only maintain this state as long as it's feeding new valid blocks it itself is forging; and to successfully shadow the real network, it needs to do this with a chain height and difficulty close to the real network. In short, to pull off a successful Sybil attack, the attacker needs to match the network's hash rate, so it's a very expensive attack.
82 |
83 | 常见的区块链(比如比特币,以太坊以及其他)是比较容易受女巫攻击的影响,攻击者试图把被攻击者从主网络上完全隔离开,让被攻击者接收一个虚假的状态。这就允许攻击者在真实的网络同时这个虚假的网络上花费同一笔资金。然而这个需要攻击者提供真实的自己锻造的区块,而且需要成功的影响真实的网络,就需要在区块高度和难度上接近真实的网络。简单来说,为了成功的实施女巫攻击,攻击者需要接近主网络的hash rate,所以是一个非常昂贵的攻击。
84 |
85 | Compared to the classical Sybil attack, fast sync provides such an attacker with an extra ability, that of feeding a node a view of the network that's not only different from the real network, but also that might go around the EVM mechanics. The Ethereum protocol only validates state root hashes by processing all the transactions against the previous state root. But by skipping the transaction processing, we cannot prove that the state root contained within the fast sync pivot point is valid or not, so as long as an attacker can maintain a fake blockchain that's on par with the real network, it could create an invalid view of the network's state.
86 |
87 | 与传统的女巫攻击相比,快速同步为攻击者提供了一种额外的能力,即为节点提供一个不仅与真实网络不同的网络视图,而且还可能绕过EVM机制。 以太坊协议只通过处理所有事务与以前的状态根来验证状态根散列。 但是通过跳过事务处理,我们无法证明快速同步pivot point中包含的state root是否有效,所以只要攻击者能够保持与真实网络相同的假区块链,就可以创造一个无效的网络状态视图。
88 |
89 | To avoid opening up nodes to this extra attacker ability, fast sync (beside being solely opt-in) will only ever run during an initial sync (i.e. when the node's own blockchain is empty). After a node managed to successfully sync with the network, fast sync is forever disabled. This way anybody can quickly catch up with the network, but after the node caught up, the extra attack vector is plugged in. This feature permits users to safely use the fast sync flag (--fast), without having to worry about potential state root attacks happening to them in the future. As an additional safety feature, if a fast sync fails close to or after the random pivot point, fast sync is disabled as a safety precaution and the node reverts to full, block-processing based synchronization.
90 |
91 | 为了避免将节点开放给这个额外的攻击者能力,快速同步(特别指定)将只在初始同步期间运行(节点的本地区块链是空的)。 在一个节点成功与网络同步后,快速同步永远被禁用。 这样任何人都可以快速地赶上网络,但是在节点追上之后,额外的攻击矢量就被插入了。这个特性允许用户安全地使用快速同步标志(--fast),而不用担心潜在的状态 在未来发生的根攻击。 作为附加的安全功能,如果快速同步在随机 pivot point附近或之后失败,则作为安全预防措施禁用快速同步,并且节点恢复到基于块处理的完全同步。
92 |
93 | ## 性能 Performance
94 | To benchmark the performance of the new algorithm, four separate tests were run: full syncing from scrath on Frontier and Olympic, using both the classical sync as well as the new sync mechanism. In all scenarios there were two nodes running on a single machine: a seed node featuring a fully synced database, and a leech node with only the genesis block pulling the data. In all test scenarios the seed node had a fast-synced database (smaller, less disk contention) and both nodes were given 1GB database cache (--cache=1024).
95 |
96 | 为了对新算法的性能进行基准测试,运行了四个单独的测试:使用经典同步以及新的同步机制,从Frontier和Olympic上的scrath完全同步。 在所有情况下,在一台机器上运行两个节点:具有完全同步的数据库的种子节点,以及只有起始块拉动数据的水蛭节点。 在所有测试场景中,种子节点都有一个快速同步的数据库(更小,更少的磁盘争用),两个节点都有1GB的数据库缓存(--cache = 1024)。
97 |
98 | The machine running the tests was a Zenbook Pro, Core i7 4720HQ, 12GB RAM, 256GB m.2 SSD, Ubuntu 15.04.
99 |
100 | 运行测试的机器是Zenbook Pro,Core i7 4720HQ,12GB RAM,256GB m.2 SSD,Ubuntu 15.04。
101 |
102 | | Dataset (blocks, states) | Normal sync (time, db) | Fast sync (time, db) |
103 | | ------------------------- |:-------------------------:| ---------------------------:|
104 | |Frontier, 357677 blocks, 42.4K states | 12:21 mins, 1.6 GB | 2:49 mins, 235.2 MB |
105 | |Olympic, 837869 blocks, 10.2M states | 4:07:55 hours, 21 GB | 31:32 mins, 3.8 GB |
106 |
107 |
108 | The resulting databases contain the entire blockchain (all blocks, all uncles, all transactions), every transaction receipt and generated logs, and the entire state trie of the head 1024 blocks. This allows a fast synced node to act as a full archive node from all intents and purposes.
109 |
110 | 结果数据库包含整个区块链(所有区块,所有的区块,所有的交易),每个交易收据和生成的日志,以及头1024块的整个状态树。 这使得一个快速的同步节点可以充当所有意图和目的的完整归档节点。
111 |
112 |
113 | ## 结束语 Closing remarks
114 | The fast sync algorithm requires the functionality defined by eth/63. Because of this, testing in the live network requires for at least a handful of discoverable peers to update their nodes to eth/63. On the same note, verifying that the implementation is truly correct will also entail waiting for the wider deployment of eth/63.
115 |
116 | 快速同步算法需要由eth / 63定义的功能。 正因为如此,现网中的测试至少需要少数几个可发现的对等节点将其节点更新到eth / 63。 同样的说明,验证这个实施是否真正正确还需要等待eth / 63的更广泛部署。
117 |
--------------------------------------------------------------------------------
/以太坊测试网络Clique_PoA介绍.md:
--------------------------------------------------------------------------------
1 | https://github.com/ethereum/EIPs/issues/225
2 |
3 | Clique的模式下,用户是无法获取以太币的,因为无法挖矿,所以如果需要以太币, 需要通过特殊的途径来获取。
4 |
5 | 可以通过这个网站获取ether
6 |
7 | https://faucet.rinkeby.io/
8 |
9 | 需要有google+账号,facebook或者twitter账号才能获取, 详细的获取办法参考上面的网站。
10 |
11 |
12 |
13 | Clique 是以太坊的一个Power of authority 的实现, 现在主要在Rinkeby 测试网络使用。
14 |
15 | ## 1. 背景
16 |
17 | 以太坊的第一个官方测试网是Morden。它从2015年7月到2016年11月,由于Geth和Parity之间累积的垃圾和一些testnet的共识问题,最终决定停止重新启动testnet。
18 |
19 | Ropsten就这样诞生了,清理掉了所有的垃圾,从一个干净的石板开始。这一运行状况一直持续到2017年2月底,当时恶意行为者决定滥用Pow,并逐步将GasLimit从正常的470万提高到90亿,此时发送巨大的交易损害整个网络。甚至在此之前,攻击者尝试了多次非常长的区块链重组,导致不同客户端之间的网络分裂,甚至是不同的版本。
20 |
21 | 这些攻击的根本原因在于PoW网络的安全性与它背后的计算能力一样安全。从零开始重新启动一个新的测试网络并不能解决任何问题,因为攻击者可以反复安装相同的攻击。Parity 团队决定采取一个紧急的解决办法,回滚大量的区块,制定一个不允许GasLimit超过一定门槛的软交叉。
22 |
23 | 虽然这个解决方案可能在短期内工作:
24 |
25 | 这并不高雅:以太坊应该有动态的限制
26 | 这不是可移植的:其他客户需要自己实现新的fork逻辑
27 | 它与同步模式不兼容:fast sync和轻客户端都运气不佳
28 | 这只是延长了攻击的时间:垃圾依然可以在无尽的情况下稳步推进
29 | Parity的解决方案虽然不完美,但仍然可行。我想提出一个更长期的替代解决方案,涉及更多,但应该足够简单,以便能够在合理的时间内推出。
30 |
31 |
32 | ## 2. 标准化的PoA
33 |
34 | 如上所述,在没有价值的网络中,Pow不能安全地工作。 以太坊有以Casper为基础的长期PoS目标,但是这是一个繁琐的研究,所以我们不能很快依靠这个来解决今天的问题。 然而,一种解决方案很容易实施,而且足够有效地正确地修复测试网络,即权威证明方案(proof-of-authority scheme)。
35 |
36 | 注意,Parity确实有PoA的实现,虽然看起来比需要的更复杂,没有太多的协议文档,但是很难看到它可以和其他客户一起玩。 我欢迎他们基于他们的经验来给我的这个提案更多的反馈。
37 |
38 | 这里描述的PoA协议的主要设计目标是实现和嵌入任何现有的以太坊客户端应该是非常简单的,同时允许使用现有的同步技术(快速,轻松,扭曲),而不需要客户端开发者添加 定制逻辑到关键软件。
39 |
40 | ## 3. PoA101
41 |
42 | 对于那些没有意识到PoA如何运作的人来说,这是一个非常简单的协议,而不是矿工们为了解决一个困难的问题而竞相争夺,授权签署者可以随时自行决定是否创建新的块。
43 |
44 | 挑战围绕着如何控制挖矿频率,如何在不同的签名者之间分配负载(和机会)以及如何动态调整签名者列表。 下一节定义一个处理所有这些场景的建议协议。
45 |
46 | ## 4. Rinkeby: proof-of-authority
47 |
48 | 总体来说,有两种同步区块链的方法:
49 |
50 | - 传统的方法是把所有的事务一个接一个地进行起始块和紧缩。这种方式尝试过而且已经被证明在以太坊这种复杂的网络中非常耗费计算资源。
51 | 另一种是只下载区块链头并验证它们的有效性,此后可以从网络上下载一个任意的最近的状态并检查最近的header。
52 | - PoA方案基于这样的想法,即块可能只能由可信签署人完成。 因此,客户端看到的每个块(或header)都可以与可信任的签名者列表进行匹配。 这里面临的挑战是如何维护一个可以及时更改的授权签名者列表? 明显的答案(将其存储在以太坊合同中)也是错误的答案:在快速同步期间是无法访问状态的。
53 |
54 | **1) 维护授权签名者列表的协议必须完全包含在块头中。**
55 |
56 | 下一个显而易见的想法是改变块标题的结构,这样就可以放弃PoW的概念,并引入新的字段来迎合投票机制。 这也是错误的答案:在多个实现中更改这样一个核心数据结构将是一个开发,维护和安全的噩梦。
57 |
58 | **2) 维护授权签名者列表的协议必须完全适合当前的数据模型。**
59 |
60 | 所以,根据以上所述,我们不能使用EVM进行投票,而是不得不求助于区块头。 而且我们不能改变区块头字段,而不得不求助于当前可用的字段。 没有太多的选择。
61 |
62 | **3) 把区块头的一些其他字段用来实现投票和签名**
63 |
64 | 当前仅用作有趣元数据的最明显的字段是块头中的32字节的ExtraData部分。 矿工们通常把他们的客户端和版本放在那里,但是有些人用另外的“信息”填充它们。 该协议将扩展此字段以增加65字节用来存放矿工的KEC签名。 这将允许任何获得一个区块的人员根据授权签名者的名单对其进行验证。 同时它也使得区块头中的矿工地址的字段作废。
65 |
66 | 请注意,更改区块头的长度是非侵入性操作,因为所有代码(例如RLP编码,哈希)都不可知,所以客户端不需要定制逻辑。
67 |
68 | 以上就足以验证一个链,但我们如何更新一个动态的签名者列表。 答案是,我们可以重新使用新近过时的矿工字段beneficiary和PoA废弃的nonce字段来创建投票协议:
69 |
70 | - 在常规块中,这两个字段都将被设置为零。
71 | - 如果签名者希望对授权签名人列表进行更改,则会:
72 | - 将矿工字段**beneficiary**设置为希望投票的签署者
73 | - 将**nonce**设置为0或0xff ... f来投票赞成添加或踢出
74 |
75 | 任何同步链的客户端都可以在数据块处理过程中“统计”选票,并通过普通投票保持授权签名者的动态变化列表。 初始的一组签名者通过创世区块的参数提供(以避免在起始状态中部署“最初选民名单”合同的复杂性)。
76 |
77 | 为了避免有一个无限的窗口来统计票数,并且允许定期清除陈旧的提议,我们可以重新使用ethash的概念 epoch,每个epoch 转换都会刷新所有未决的投票。 此外,这些epoch 转换还可以作为包含头部额外数据内的当前授权签名者列表的无状态检查点。 这允许客户端仅基于检查点散列进行同步,而不必重播在链上进行的所有投票。 它同样允许用包含了初始签名者的创世区块来完全定义区块链
78 |
79 | ### (1) 攻击媒介:恶意签名者
80 |
81 | 可能发生恶意用户被添加到签名者列表中,或者签名者密钥/机器受到威胁。 在这种情况下,协议需要能够抵御重组和垃圾邮件。 所提出的解决方案是,给定N个授权签名者的列表,任何签名者可能只在每个K中填充1个块。这确保损害是有限的,其余的矿工可以投出恶意用户。
82 |
83 | ### (2) 攻击媒介:审查签名者
84 |
85 | 另一个有趣的攻击媒介是如果一个签名者(或者一组签名者)试图检查出从授权列表中删除它们的块。 为了解决这个问题,我们限制了签名者允许的最小频率为N / 2。 这确保了恶意签名者需要控制至少51%的签名帐户,在这种情况下,游戏就是无论如何也无法进行下去了。
86 |
87 | ### (3) 攻击媒介:垃圾邮件签名者
88 |
89 | 最后的小型攻击媒介就是恶意签署者在每一个块内注入新的投票建议。 由于节点需要统计所有投票来创建授权签名者的实际列表,所以他们需要通过时间跟踪所有投票。 没有限制投票窗口,这可能会慢慢增长,但却是无限的。 解决方法是放置一个W块的移动窗口,之后投票被认为是陈旧的。 一个理智的窗户可能是1-2个时代。 我们将这称为一个时代。
90 |
91 | ### (4) 攻击媒介:并发块
92 |
93 | 如果授权签名者的数量是N,并且我们允许每个签名者在K中填充1个块,那么在任何时间N-K个矿工都被允许为Mint。 为了避免这些争夺块,每个签名者将添加一个小的随机“抵消”,以释放一个新的块。 这确保了小叉子是罕见的,但偶尔还会发生(如在主网上)。 如果一个签名者被滥用权威而引起混乱,那么这个签名就可以被投票出去。
94 |
95 | ## 5. 注意
96 |
97 | ### 这是否表明建议我们使用一个被审查testnet?
98 |
99 | 该提议表明,考虑到某些行为者的恶意性质,并且鉴于“垄断资金”网络中PoW计划的弱点,最好是建立一个网络,使其具有一定的垃圾过滤功能,开发人员可以依靠它来测试其程序。
100 |
101 | 为什么规范PoA?
102 |
103 | 不同的客户在不同的情况下会更好。 Go可能在服务器端环境中很棒,但CPP可能更适合在RPI Zero上运行。
104 |
105 | 手动投票是不是很麻烦?
106 |
107 | 这是一个实现细节,但是签名者可以利用基于合同的投票策略,利用EVM的全部功能,只将结果推送到平均节点的头部进行验证。
108 |
109 | ## 6. 澄清和反馈
110 |
111 | - 这个建议并不排除客户端运行基于PoW的测试网络,无论是Ropsten还是基于它的新的测试网络。理想的情况是客户提供一种连接PoW以及基于PoA的测试网络的方法(#225(评论))。
112 |
113 | - 协议参数尽管可以在客户端实施者的破坏中进行配置,但Rinkeby网络应该尽可能地靠近主网络。这包括动态GasLimit,15秒左右的可变区块时间,GasPrice等(#225(评论))。
114 |
115 | - 该方案要求至少有K个签名者随时上网,因为这是确保“最小化”多样性所需的最少人数。这意味着如果超过K,则网络停止。这应该通过确保签名者是高运行时间的机器来解决,并且在发生太多故障之前及时地将失败的机器投票出去(#225(评论))。
116 |
117 | - 该提案并没有解决“合法的”垃圾邮件问题,就像在攻击者有效地使用testnet以创建垃圾一样,但是如果没有PoW挖掘,攻击者可能无法获得无限的ether来攻击。一种可能性是以有限的方式(例如每天10次)(#225(评论)),以GitHub(或其他任何方式)帐户为基础提供一个获取ether的途径。
118 |
119 | - 有人建议为当时包含授权签名者列表的每个epoch创建checkpoint block。这将允许稍后的轻客户说“从这里同步”,而不需要从起源开始。这可以在签名之前作为前缀添加到extradata字段(#225(comment))。
120 |
121 |
122 | ## 7. Clique PoA 一致性协议 (Clique proof-of-authority consensus protocol )
123 | 我们定义下面的常量:
124 |
125 | - EPOCH_LENGTH:检查点并重置未决投票的块数。
126 | - 建议30000,以便和主网络的ethhash epoch类似
127 | - BLOCK_PERIOD:两个连续块的时间戳之间的最小差异。
128 | - 建议15,以便和主网络的ethhash epoch类似
129 | - EXTRA_VANITY:固定数量的ExtraData前缀字节为签名者vanity保留。
130 | - 建议的32个字节以便和当前的ExtraData的长度相同。
131 | - EXTRA_SEAL:为签名者印章保留的固定数量的额外数据后缀字节。
132 | - 保存签名的65个字节,基于标准secp256k1曲线。
133 | - NONCE_AUTH:魔术随机数字0xffffffffffffffff投票添加一个新的签名者。
134 | - NONCE_DROP:魔术随机数字0x0000000000000000对移除签名者进行投票。
135 | - UNCLE_HASH:始终Keccak256(RLP([]))作为Uncles在PoW之外没有任何意义。
136 | - DIFF_NOTURN:如果当前没有轮到你签名,那么你签名的区块的难度就是这个难度。
137 | - 建议1,因为它只需要是一个任意的基线常数。
138 | - DIFF_INTURN:如果当前轮到你签名,那么你签名的难度。
139 | - 建议2, 这样就比没有轮到的签名者难度要高。
140 |
141 | 我们还定义了以下每块的常量:
142 |
143 | - BLOCK_NUMBER:链中的块高度,创世区块的高度是0。
144 | - SIGNER_COUNT:在区块链中中特定实例上有效的授权签名者的数量。
145 | - SIGNER_INDEX:当前授权签名者的排序列表中的索引。
146 | - SIGNER_LIMIT:每隔这么多块,签名者只能签署一块。
147 | - 必须有floor(SIGNER_COUNT / 2)+1 这么多签名者同意才能达成某项决议。
148 |
149 | 我们重新调整区块头字段的用途,如下所示:
150 |
151 | - beneficiary:建议修改授权签名人名单的地址。
152 | - 应该正常填写零,只有投票时修改。
153 | - 尽管如此,仍然允许任意值(甚至是无意义的值,例如投出非签名者),以避免增加围绕投票机制的额外复杂性。
154 | - 必须在检查点(即epoch转换)块填充零。
155 | - nonce:Signer关于受益人字段中定义的账户的建议。
156 | - NONCE_DROP 提议取消授权受益人作为现有签名者。
157 | - NONCE_AUTH 提出授权受益人作为新的签名者。
158 | - 必须在检查点块填充零。
159 | - 除了上述两者(现在)之外,不得采用任何其他值。
160 | - extraData: vanity, checkpointing and signer signatures的组合字段。
161 | - 第一个EXTRA_VANITY字节(固定长度)可以包含任意签名者vanity data。
162 | - 最后一个EXTRA_SEAL字节(固定长度)是密封标题的签名者签名。
163 | - 检查点块必须包含一个签名者列表(N * 20字节),否则省略。
164 | - 检查点块附加数据部分中的签署者列表必须按升序排序。
165 | - mixHash:为了分叉保留。类似于Dao的额外数据
166 | - 在正常操作期间必须填入零。
167 | - ommersHash:必须是UNCLE_HASH,因为在PoW之外,Uncles叔没有任何意义。
168 | - timestamp:必须至少为父区块的时间戳 + BLOCK_PERIOD。
169 | - difficulty:包含块的独立得分 来推导链的质量。
170 | - 如果BLOCK_NUMBER%SIGNER_COUNT!= SIGNER_INDEX,则必须为DIFF_NOTURN
171 | - 如果BLOCK_NUMBER%SIGNER_COUNT == SIGNER_INDEX,则必须为DIFF_INTURN
172 |
173 |
174 | ### 1) Authorizing a block
175 | 为了给网络授权一个块,签名者需要签署包含除签名本身以外的所有内容。 这意味着哈希包含区块头的每个字段(包括nonce和mixDigest),还有除了65字节签名后缀外的extraData。 这些字段按照其在黄皮书中定义的顺序进行hash。
176 |
177 | 该散列使用标准的secp256k1曲线进行签名,得到的65字节签名(R,S,V,其中V为0或1)作为尾随的65字节后缀嵌入到extraData中。
178 |
179 | 为了确保恶意签名者(签名密钥丢失)不能在网络上受到破坏,每位签名者都可以在SIGNER_LIMIT连续块中签最多一个。 顺序不是固定的,不过(DIFF_INTURN)的签名者签出的区块难度要比(DIFF_NOTURN)高
180 |
181 | #### 授权策略
182 |
183 | 只要签名者符合上述规范,他们可以授权和分配他们认为合适的块, 下面的建议策略会减少网络流量和分叉,所以这是一个建议的功能:
184 |
185 | - 如果签署者被允许签署一个区块(在授权清单上并且最近没有签署)。
186 | - 计算下一个块的最佳签名时间(父+ BLOCK_PERIOD)。
187 | - 如果轮到了,等待准确的时间到达,立即签字和播放。
188 | - 如果没有轮到,则延迟 rand(SIGNER_COUNT * 500ms)这么久的时间签名。
189 | 这个小小的策略将确保当前轮到的签名者(谁的块更重)对签名和传播与外转签名者有稍微的优势。 此外,该方案允许随着签名者数目的增加而具有一定规模。
190 |
191 | ### 2) 投票签署者
192 |
193 | 每个epoch转换(包括创世区块)作为一个无状态的检查点,有能力的客户端应该能够同步而不需要任何以前的状态。 这意味着新epoch header不得包含投票,所有未落实的投票都将被丢弃,并从头开始计数。
194 |
195 | 对于所有非epoch 转换块:
196 |
197 | - 签名者可以使用自己签署的区块投一票,以提出对授权列表的更改。
198 | - 对每一个提案只保留最新的一个投票。
199 | - 随着链条的进展,投票也会生效(允许同时提交提案)。
200 | - 达成多数人意见的提案SIGNER_LIMIT立即生效。
201 | - 对于客户端实现的简单性,无效的提议不会受到惩罚。
202 |
203 |
204 | **生效的提案意味着放弃对该提案的所有未决投票(无论是赞成还是反对),并从一个清晰的名单开始。**
205 |
206 | ### 3) 级联投票
207 |
208 | 签名者取消授权期间可能会出现复杂的案例。如果先前授权的签署者被撤销,则批准提案所需的签名者数量可能会减少一个。这可能会导致一个或多个未决的提案达成共识,执行这些提案可能会进一步影响新的提案。
209 |
210 | 当多个相冲突的提议同时通过时(例如,添加新的签名者vs删除现有的提案者),处理这种情况并不明显,评估顺序可能会彻底改变最终授权列表的结果。由于签名者可能会在他们自己的每一个区块中反转他们自己的投票,所以哪一个提案将是“第一”并不那么明显。
211 |
212 | 为了避免级联执行所带来的缺陷,解决的办法是明确禁止级联效应。换句话说:只有当前标题/投票的受益人可以被添加到授权列表或从授权列表中删除。如果这导致其他建议达成共识,那么当他们各自的受益者再次“触发”时,这些建议将被执行(因为大多数人的共识仍然在这一点上)。
213 |
214 | ### 4) 投票策略
215 |
216 | 由于区块链可以有很小的reorgs,所以“cast-and-forget”的天真投票机制可能不是最优的,因为包含singleton投票的区块可能不会在最终的链中结束。
217 |
218 | 一个简单但工作的策略是允许用户在签名者上配置“提案”(例如“add 0x ...”,“drop 0x ...”)。 签署的代码,然后可以选择一个随机的建议,每块它签署和注入。 这确保了多个并发提案以及reorgs最终在链上被注意到。
219 |
220 | 这个列表可能在一定数量的块/epoch后过期,但重要的是要认识到“看”一个提案通过并不意味着它不会被重新组合,所以当提案通过时不应该立即放弃。
221 |
222 |
223 |
--------------------------------------------------------------------------------
/封装的一些基础工具.md:
--------------------------------------------------------------------------------
1 | # 封装的一些基础工具
2 | 在[以太坊](https://github.com/ethereum/go-ethereum)项目中,存在对golang生态体系中一些优秀工具进行封装的小模块,由于功能较为单一,单独成篇显得过于单薄。但是由于以太坊对这些小工具的封装非常优雅,具有很强的独立性和实用性。我们在此作一些分析,至少对于熟悉以太坊源码的编码方式是有帮助的。
3 | ## metrics(探针)
4 | 在[ethdb源码分析](/ethdb源码分析.md)中,我们看到了对[goleveldb](https://github.com/syndtr/goleveldb)项目的封装。ethdb除了对goleveldb抽象了一层:
5 |
6 | [type Database interface](https://github.com/ethereum/go-ethereum/blob/master/ethdb/interface.go#L29)
7 |
8 | 以支持与MemDatabase的同接口使用互换外,还在LDBDatabase中使用很多[gometrics](https://github.com/rcrowley/go-metrics)包下面的探针工具,以及能启动一个goroutine执行
9 |
10 | [go db.meter(3 * time.Second)](https://github.com/ethereum/go-ethereum/blob/master/ethdb/database.go#L198)
11 |
12 | 以3秒为周期,收集使用goleveldb过程中的延时和I/O数据量等指标。看起来很方便,但问题是我们如何使用这些收集来的信息呢?
13 |
14 | ## log(日志)
15 | golang的内置log包一直被作为槽点,而以太坊项目也不例外。故引入了[log15](https://github.com/inconshreveable/log15)以解决日志使用不便的问题。
16 |
17 |
18 |
--------------------------------------------------------------------------------