├── .gitignore
├── Algorithm
├── .keep
├── 배열,리스트,스택,큐.md
└── 정렬 알고리즘.md
├── DataStructure
└── 해시테이블.md
├── Database
├── B-Tree와 B+Tree.md
├── Join.md
├── SQL_VS_NOSQL.md
├── 데이터베이스 클러스터링 VS 레플리카 6768dd1874c74763a3033dac6002f6ec.md
├── 데이터베이스인덱스.md
├── 정규화
│ ├── BCNF1.png
│ ├── BCNF2.png
│ ├── 이상현상과 결정자1.png
│ ├── 이상현상과 결정자2.png
│ ├── 이상현상과 결정자3.png
│ ├── 정규화.md
│ ├── 제1정규형.png
│ ├── 제2정규형1.png
│ ├── 제2정규형2.png
│ ├── 제3정규형1.png
│ └── 제3정규형2.png
└── 트랜잭션.md
├── DesignPattern
└── MVC,MVVM,MVP
│ ├── MVC, MVVM, MVP.md
│ ├── mvc1.png
│ ├── mvp1.png
│ └── mvvm1.png
├── Development
├── CORS
│ ├── CORS 0e3c01bc007c4adf83e4842c6db23bf6.md
│ └── CORS 0e3c01bc007c4adf83e4842c6db23bf6
│ │ ├── Untitled 1.png
│ │ └── Untitled.png
├── IoC, DI, AOP.md
├── Web Server & WAS.md
├── block&nonblock-sync&async
│ ├── Blocking & Non-Blocking - Synchronous & Asynchrono 9f3213ff70fc47edaf8749c28974a713.md
│ └── Blocking & Non-Blocking - Synchronous & Asynchrono 9f3213ff70fc47edaf8749c28974a713
│ │ ├── Untitled 1.png
│ │ ├── Untitled 2.png
│ │ ├── Untitled 3.png
│ │ ├── Untitled 4.png
│ │ ├── Untitled 5.png
│ │ ├── Untitled 6.png
│ │ ├── Untitled 7.png
│ │ ├── Untitled 8.png
│ │ ├── Untitled 9.png
│ │ └── Untitled.png
├── observer&pub-sub
│ ├── Observer & Pub-Sub Pattern 823bd016417c4e228cf53e98c52be269.md
│ └── Observer & Pub-Sub Pattern 823bd016417c4e228cf53e98c52be269
│ │ ├── Untitled 1.png
│ │ ├── Untitled 2.png
│ │ ├── Untitled 3.png
│ │ └── Untitled.png
├── 객체지향 프로그래밍.md
├── 웹_보안.md
└── 함수형 프로그래밍.md
├── Network
├── CDN.md
├── DNS.md
├── HTTP,HTTPS.md
├── OSI 7 계층.md
├── TCP_UDP
│ ├── TCP UDP 5780e78099a8404393d51e88a365562a.md
│ └── TCP UDP 5780e78099a8404393d51e88a365562a
│ │ ├── Untitled 1.png
│ │ ├── Untitled 10.png
│ │ ├── Untitled 11.png
│ │ ├── Untitled 12.png
│ │ ├── Untitled 13.png
│ │ ├── Untitled 14.png
│ │ ├── Untitled 15.png
│ │ ├── Untitled 16.png
│ │ ├── Untitled 2.png
│ │ ├── Untitled 3.png
│ │ ├── Untitled 4.png
│ │ ├── Untitled 5.png
│ │ ├── Untitled 6.png
│ │ ├── Untitled 7.png
│ │ ├── Untitled 8.png
│ │ ├── Untitled 9.png
│ │ └── Untitled.png
└── 로드밸런싱.md
├── OperatingSystem
├── CPU 스케줄러.md
├── IPC.md
├── 가상 메모리.md
├── 병행성.md
├── 인터럽트와 시스템콜.md
└── 프로세스와 스레드.md
└── README.md
/.gitignore:
--------------------------------------------------------------------------------
1 |
2 | # Created by https://www.toptal.com/developers/gitignore/api/macos,windows
3 | # Edit at https://www.toptal.com/developers/gitignore?templates=macos,windows
4 |
5 | ### macOS ###
6 | # General
7 | .DS_Store
8 | .AppleDouble
9 | .LSOverride
10 | .idea
11 |
12 | # Icon must end with two \r
13 | Icon
14 |
15 |
16 | # Thumbnails
17 | ._*
18 |
19 | # Files that might appear in the root of a volume
20 | .DocumentRevisions-V100
21 | .fseventsd
22 | .Spotlight-V100
23 | .TemporaryItems
24 | .Trashes
25 | .VolumeIcon.icns
26 | .com.apple.timemachine.donotpresent
27 |
28 | # Directories potentially created on remote AFP share
29 | .AppleDB
30 | .AppleDesktop
31 | Network Trash Folder
32 | Temporary Items
33 | .apdisk
34 |
35 | ### Windows ###
36 | # Windows thumbnail cache files
37 | Thumbs.db
38 | Thumbs.db:encryptable
39 | ehthumbs.db
40 | ehthumbs_vista.db
41 |
42 | # Dump file
43 | *.stackdump
44 |
45 | # Folder config file
46 | [Dd]esktop.ini
47 |
48 | # Recycle Bin used on file shares
49 | $RECYCLE.BIN/
50 |
51 | # Windows Installer files
52 | *.cab
53 | *.msi
54 | *.msix
55 | *.msm
56 | *.msp
57 |
58 | # Windows shortcuts
59 | *.lnk
60 |
61 | # End of https://www.toptal.com/developers/gitignore/api/macos,windows
--------------------------------------------------------------------------------
/Algorithm/.keep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Algorithm/.keep
--------------------------------------------------------------------------------
/Algorithm/배열,리스트,스택,큐.md:
--------------------------------------------------------------------------------
1 | # 배열,리스트,스택,큐
2 |
3 | ### 선형 자료 구조
4 |
5 | 
6 |
7 | 선형 자료 구조란 데이터 구조를 구성하는 요소들이 서로 인접하여 순차적인 방식으로 정렬 (이어져 있다는 뜻)되어 있음을 뜻한다. 가장 일반적인 선형 자료구조인 배열, 리스트에 대해 알아보자
8 |
9 | ### 배열
10 |
11 | 
12 |
13 | 이미지 출처: [TCP SCHOOL](http://www.tcpschool.com/)
14 |
15 | 연관된 데이터들을 그룹으로 관리하기 위한 자료구조로 자료형들이 메모리 공간상에서 연속적으로 저장되어 있는 구조이다. 때문에 물리적 저장공간과 논리적 저장공간이 같고, 각각의 `요소` 들에 `인덱스` 가 붙어있다.
16 |
17 | - 인덱스를 통해서 데이터에 바로 접근 가능하다. (랜덤 엑세스)
18 |
19 | > **Random access(임의 접근):** 메모리 주소만 있어도 즉시 데이터를 읽을 수 있는 호출 방식
20 | **Sequential access (순차 접근):** 데이터의 위치까지 맨앞부터 차례로 탐색하는 방식
21 | >
22 | - 데이터를 추가하거나 삭제 할 때 배열 내 다른 데이터의 순서를 다시 매겨야 한다.
23 | - 크기가 고정되어있다.
24 | - 1차원 배열부터 다차원 배열까지 구성이 가능하다.
25 | - **`Cache hit`** 가능성이 커져 성능에 큰 도움이 된다
26 |
27 | > CPU가 참조하고자 하는 메모리가 캐시에 존재하고 있을 경우 Cache Hit라고 한다.
28 | >
29 | - 각 기능별 복잡도
30 |
31 | 
32 |
33 |
34 |
35 | ### 리스트
36 |
37 | 배열이 가지고 있는 인덱스라는 장점을 버리고 빈틈없는 적재라는 장점을 취한 자료구조이다. 노드(node)라고 불리는 리스트의 요소들은 데이터 요소와 포인터의 쌍으로 구성된다. 각 노드들은 흩어진 상태로 저장이 되고, 각 노드에 접근시 이전 요소의 포인터를 사용하여 접근한다.
38 |
39 | 
40 |
41 | 
42 |
43 | 이미지 출처: [TCP SCHOOL](http://www.tcpschool.com/java/java_collectionFramework_list)
44 | - 해당 리스트에 진입하는 첫 노드 지점을 헤드라고 한다
45 | - 노드 하나가 다음노드의 포인터 하나만 갖는 유형이 `단반향 연결 리스트`
46 | - 마지막 노드는 보통 `null` 값을 가지게 된다.
47 | - 노드 하나가 이전노드, 다음노드의 포인터 모두 갖는 유형이 `양방향 연결 리스트`
48 | - 단방향에 비해 삭제할 때나 양방향 순회시 더 효율적
49 | - 순차성을 보장하지 못하기 때문에 **Spatical locality** 보장이 되지 않아 **`cache hit`** 가 어렵다.
50 |
51 | > **Spatical locality:** 최근 접근했던 주소 근처의 주소들을 접근하는 경향을 말함
52 | >
53 | - 순환 연결 리스트(circular linked list)
54 | - 모든 노드들이 원형으로 연결됨, 마지막 노드가 첫 번째 노드와 연결됨
55 | - 단방향 또는 양방향 모두 가능
56 | - 각 기능별 복잡도
57 |
58 | 
59 |
60 |
61 | ### 스택
62 | 
63 |
64 | 이미지 출처: [programiz](https://www.programiz.com/dsa/stack)
65 |
66 | 추가된 요소를 메모리의 가장 앞 주소에 배치하는 자료구조 요소를 스택의 최상단에서만 삭제 및 추가할 수 있다. 마지막에 넣은 요소가 제일 먼저 나오기 때문에 LIFO(Last In First Out) 후입선출이라 한다.
67 |
68 | - 스택에 요소를 추가하는 동작을 `push` 라 한다
69 | - 스택에 요소를 삭제할 때 가장 마지막으로 추가된 요소를 삭제는 동작을 `pop` 이라 한다.
70 | - 크기를 늘릴 수 있는지 여부에 따라 정적 스택(배열이용)과 동적 스택(리스트이용)으로 구분
71 | - 함수 호출, 스케줄링 등 다양한 부분에서 사용됨
72 | - 각 기능별 복잡도
73 |
74 | 
75 |
76 |
77 | ### 큐
78 | 
79 |
80 | 이미지 출처: [programiz](https://www.programiz.com/dsa/stack)
81 |
82 | 각 요소에 우선순위를 부여하는 자료 구조, 먼저 추가된 요소가 우선적으로 삭제된다는 점에서 FIFO(First in First out ) 선입선출이라 한다.
83 |
84 | - 큐 맨 뒤쪽에 요소를 추가하는 동작을 `enqueue` 라 한다.
85 | - 큐에서 가장 오랫동안 있던 요소가 먼저 삭제되고, 그 동작을 `dequeue` 라고 한다.
86 | - **우선순위큐**
87 | - 큐에 모든 요소에는 우선순위가 있으며 우선순위가 높은 요소는 우선순위가 낮은 요소보다 먼저 삭제된다.
88 | - 각 기능별 복잡도
89 |
90 | 
91 |
92 |
93 |
94 |
95 | ## 참고자료
96 |
97 | - 생활코딩 배열
98 |
99 | [배열 - Data Structure (자료구조)](https://opentutorials.org/module/1335/8677)
100 |
101 | - 생활코딩 리스트
102 |
103 | [리스트 (List) - Data Structure (자료구조)](https://opentutorials.org/module/1335/8636)
104 |
105 | - 위키 스택
106 |
107 | [스택 - 위키백과, 우리 모두의 백과사전](https://ko.wikipedia.org/wiki/%EC%8A%A4%ED%83%9D)
108 |
109 |
110 | - 자료구조 시간복잡도
111 |
112 | [[알고리즘]자료구조에 따른 시간복잡도 O(n) 정리](https://blog.naver.com/PostView.nhn?blogId=jhc9639&logNo=221339684077&redirect=Dlog&widgetTypeCall=true&directAccess=false)
113 |
114 | - 그외
115 |
116 | [[ 자료구조 ] 배열(Array) vs 리스트(List) - 특징, 차이](https://jy-tblog.tistory.com/38)
117 |
118 | - 서적 참고
119 |
120 | 코드 없는 알고리즘과 데이터 구조 - 암스트롱수베로 / 류태호 역
--------------------------------------------------------------------------------
/Algorithm/정렬 알고리즘.md:
--------------------------------------------------------------------------------
1 | # 정렬 알고리즘
2 |
3 | # 설명
4 |
5 | 정렬이란 원소들을 번호순이나 사전 순서와 같이 일정한 순서태로 열거하는 작업
6 |
7 | # 종류
8 |
9 | ## 버블 정렬
10 |
11 | ### 설명
12 |
13 | 매번 연속된 두 인덱스를 비교하여 오름차순의 경우 더 큰값이 뒤로 오도록 두 수를 교환하는 방법
14 |
15 | 회차마다 정렬된 수는 맨 뒤에 존재하게 되므로 비교는 n-(회차 수) 만큼 하면 된다.
16 |
17 | 
18 |
19 | ```python
20 | def bubbleSort(arr):
21 | n = len(arr)
22 | for i in range(n):
23 | for j in range(1, n-i):
24 | if arr[j] < arr[j-1]:
25 | arr[j], arr[j-1] = arr[j-1], arr[j]
26 | ```
27 |
28 | - 시간복잡도
29 | - 최선 시간복잡도 : O(n^2)
30 | - 최악 시간복잡도 : O(n^2)
31 | - 공간복잡도 : O(n), 예비 O(1)
32 | - 안정 정렬
33 |
34 |
35 |
36 | ## 선택 정렬
37 |
38 |
39 |
40 | ### 설명
41 |
42 | 1. 주어진 리스트 중에 최소값을 찾아 맨 앞의 값과 교환
43 | 2. 정렬된 값을 제외한 나머지 값들에 대해 반복한다.
44 |
45 | 
46 |
47 | ### 코드
48 |
49 | ```python
50 | def selectSort(arr):
51 | n = len(arr)
52 | for i in range(n-1):
53 | minIdx = i
54 | for j in range(i+1, n):
55 | if arr[j] < arr[minIdx]:
56 | minIdx = j
57 | arr[i], arr[minIdx] = arr[minIdx], arr[i]
58 | ```
59 |
60 | - 시간복잡도
61 | - 최선 시간복잡도, 최악 시간복잡도 : O(n^2)
62 | - 공간복잡도 : O(n), 예비 O(1)
63 | - 불안정 정렬
64 |
65 | 
66 |
67 |
68 | ## 삽입 정렬
69 |
70 |
71 |
72 | ### 설명
73 |
74 | 현재 위치에서, 그 앞의 미리 정렬된 부분에서의 자신의 위치를 찾아 삽입하는 방법
75 |
76 | 
77 |
78 | ### 코드
79 |
80 | ```python
81 | def insert_sort(arr):
82 | n = len(arr)
83 | for i in range(1, n):
84 | j = i - 1
85 | key = arr[i]
86 | while arr[j] > key and j >= 0:
87 | arr[j+1] = arr[j]
88 | j -= 1
89 | arr[j+1] = key
90 | ```
91 |
92 | - 시간복잡도
93 | - 최선 시간복잡도 : O(n)
94 | - 최악 시간복잡도 : O(n^2)
95 | - 공간복잡도 : O(n), 예비 O(1)
96 | - 안정 정렬
97 |
98 |
99 |
100 | ## 힙 정렬
101 |
102 |
103 |
104 | ### 설명
105 |
106 | 힙을 사용한 정렬
107 |
108 |
109 |
110 | ### 힙
111 |
112 | - 최솟값이나 최댓값을 빠르게 찾아내기 위한 이진 트리
113 |
114 | - 힙순서 : 모든 부모노드는 자식노드보다 우선순위가 높다.
115 | - 최대힙 : 모든 부모노드가 자식노드보다 값이 크다.
116 |
117 | 
118 |
119 | - 최소힙 : 모든 부모노드가 자식노드보다 값이 작다.
120 |
121 | 
122 |
123 | - 완전이진트리 : 마지막 레벨을 제외한 모든 레벨이 채워져있으며, 마지막 레벨의 모든 노드는 가능한 한 가장 왼쪽에 있다.
124 |
125 | - 높이 : O(log n)
126 |
127 |
128 |
129 | ### 최대힙을 사용한 정렬(상향식)
130 |
131 | - 상향식이란?
132 | - 낮은 레벨의 부트리 2개를 하나로 합치면서 루트노드까지 반복한다.
133 | - 하나로 합치면서 위해 downHeap을 통해 힙의 균형을 맞춘다.
134 | - 말단노드부터 루트노드 위쪽으로 진행되어 상향식이라고 한다.
135 |
136 | 
137 |
138 | - 배열을 최대힙으로 만들기
139 |
140 | 
141 |
142 | - 최대힙에서 하나씩 빼내어 정렬하기
143 |
144 | 
145 |
146 |
147 |
148 |
149 | ### 코드
150 |
151 | ```python
152 | def heapSort(A):
153 | n = len(A)
154 | buildHeap(A, n)
155 | for i in range(n, 1, -1):
156 | A[1], A[i] = A[i], A[1]
157 | downHeap(1, i-1)
158 |
159 | def buildHeap(A, n):
160 | for i in range(n//2, 0, -1):
161 | downHeap(i, n)
162 |
163 | def downHeap(i, last):
164 | left = 2*i
165 | right = 2*i+1
166 |
167 | if left > last:
168 | return
169 |
170 | greater = left
171 |
172 | if right <= last:
173 | if A[right] > A[greater]:
174 | greater = right
175 |
176 | if A[i] >= A[greater]:
177 | return
178 |
179 | A[i], A[greater] = A[greater], A[i]
180 | downHeap(greater, last)
181 | ```
182 |
183 | - 시간복잡도
184 | - 최선 시간복잡도: O(n log n)
185 | - 최악 시간복잡도: O(n log n)
186 | - 공간복잡도: O(n), 예비 O(1)
187 |
188 |
189 |
190 | ## 병합 정렬
191 |
192 |
193 |
194 | ### 설명
195 |
196 | 분할통치(분할정복)법에 기초한 정렬 알고리즘이다.
197 |
198 | 1. 분할(divide) : 정렬되지 않은 리스트를 분리된 부분리스트로 나눈다.
199 | 2. 재귀(recur) : 각 부분리스트를 각각 재귀적으로 정렬한다.
200 | 3. 통치(conquer) : 각 부분리스트를 단일 순서리스트로 합친다.
201 |
202 | 베이스 케이스 : 원소가 1개인 리스트
203 |
204 |
205 |
206 | ### 분할 과정
207 |
208 | 
209 |
210 |
211 |
212 | ### 통치 과정
213 |
214 | 
215 |
216 | 
217 |
218 |
219 |
220 | ### 코드
221 |
222 | ```python
223 | def mergeSort(A, l, r):
224 | if(l <= r):
225 | m = (l+r)//2
226 | mergeSort(A, l, m)
227 | mergeSort(A, m + 1, r)
228 | merge(A, l, m, r)
229 |
230 | def merge(A, l, m, r):
231 | i, j = l, m + 1
232 | B = []
233 | while i <= m and j <= r:
234 | if(A[i] <= A[j]):
235 | B.append(A[i])
236 | i += 1
237 | else:
238 | B.append(A[j])
239 | while i <= m:
240 | B.append(A[i])
241 | while j <= r:
242 | B.append(A[j])
243 | for k in range(l, r+1):
244 | A[k] = B[k]
245 | ```
246 |
247 | - 시간복잡도
248 | - 최선 시간복잡도 : O(n log n)
249 | - 최악 시간복잡도 : O(n log n)
250 |
251 | 
252 |
253 | - 공간복잡도 : O(n), 예비 O(n)
254 |
255 | - 안정 정렬
256 |
257 |
258 |
259 | ## 퀵 정렬
260 |
261 |
262 |
263 | ### 설명
264 |
265 | 분할통치법에 기초한 정렬 알고리즘
266 |
267 | 1. 분할(divide): 기준원소 p(pivot)를 택하여 리스트 L을 다음 세 부분으로 분할
268 | - LT : p보다 작은 원소들
269 | - EQ : p와 같은 원소들
270 | - GT : p보다 큰 원소들
271 | 2. 재귀(recur): LT와 GT를 정렬
272 | 3. 통치(conquer): LT, EQ, GT를 결합
273 |
274 |
275 |
276 | ### 기준 원소 선택
277 |
278 | - 쉬운 방법
279 | - 맨 앞, 맨 뒤, 중간 원소
280 | - 조금 복잡한 방법
281 | - **맨 앞, 중간, 맨 뒤 위치 원소들의 중앙값(가장 많이 사용, 중앙에서 분할될 가능성이 높아 정렬의 성능이 좋아짐)**
282 | - 0/4, 1/4, 2/4, 3/4, 4/4 위치 원소들의 중앙값
283 | - 전체 원소의 중앙값
284 | - 무작위 방법
285 | - 무작위 방식으로 원소 선택 (안정성이 떨어짐)
286 | - 기준 원소 선택의 영향
287 | - 분할 결과
288 | - 수행 성능
289 |
290 |
291 |
292 | ### 퀵 정렬 과정
293 |
294 | - 초기 상태
295 |
296 | 
297 |
298 | - 분할, 재귀
299 |
300 | 
301 |
302 | - 통치
303 |
304 | 
305 |
306 | - 재귀, 분할, 통치
307 |
308 | 
309 |
310 | - 통치
311 |
312 | 
313 |
314 | - 재귀, 통치
315 |
316 | 
317 |
318 |
319 |
320 | ### 코드
321 |
322 | ```python
323 | def quickSort(L):
324 | if len(L) > 1:
325 | k = len(L)//2 # 편의상, 기준 원소 선택 방법
326 | LT, EQ, GT = partition(L, K)
327 | quickSort(LT)
328 | quickSort(GT)
329 | L = LT + EQ + GT
330 |
331 | def partition(L, K):
332 | L = deque(L)
333 | p = L[k]
334 | LT, EQ, GT = [], [], []
335 | while L:
336 | e = L.popleft()
337 | if e < p:
338 | LT.append(e)
339 | elif e == p:
340 | EQ.append(e)
341 | else:
342 | GT.append(e)
343 | return LT, EQ, GT
344 | ```
345 |
346 |
347 |
348 | ### 코드(제자리 정렬)
349 |
350 | ```python
351 | def quickSort(L, l, r):
352 | if l < r:
353 | k = l+(r-l)//2 # 편의상, l 과 r 사이의 수
354 | p = partition(L, l, r, k)
355 | quickSort(L, l, p-1)
356 | quickSort(L, p+1, r)
357 |
358 | def partition(A, l, r, k):
359 | p = A[k]
360 | A[k], A[r] = A[r], A[k]
361 | i, j = l, r-1
362 | while i <= j:
363 | while i <= j and A[i] <= p:
364 | i += 1
365 | while j >= i and A[j] >= p:
366 | j -= 1
367 | if i < j:
368 | A[i], A[j] = A[j], A[i]
369 | A[i], A[r] = A[r], A[i]
370 | return i
371 | ```
372 |
373 | - 시간복잡도
374 | - 최선 시간복잡도, 평균 시간복잡도 : O(n log n)
375 | - 최악 시간복잡도 : O(n^2)
376 |
377 | 
378 |
379 | - n + (n-1) + (n-2) + ... + 2 + 1
380 |
381 | - 공간복잡도 : 일반 O(n), 제자리 O(n)
382 |
383 | - 불안정 정렬
384 |
385 |
386 |
387 | 
388 |
389 |
390 |
391 | ---
392 |
393 | - 참고 자료
394 |
395 | [https://ko.wikipedia.org/wiki/정렬_알고리즘](https://ko.wikipedia.org/wiki/%EC%A0%95%EB%A0%AC_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)
396 |
397 | [https://hsp1116.tistory.com/33](https://hsp1116.tistory.com/33)
398 |
399 | 학교 자료
--------------------------------------------------------------------------------
/DataStructure/해시테이블.md:
--------------------------------------------------------------------------------
1 | ## 해시 테이블
2 |
3 | 효율적으로 데이터를 빠르게 저장하고 엑세스하는 자료구조입니다.
4 | 해시함수를 통해 키를 해시값으로 매핑하며 해당 해시값을 index, 주소 삼아 데이터의 값을 저장하는 자료구조입니다. 여기서 데이터가 저장되는 곳을 버킷이라고 부릅니다.
5 |
6 |
7 |
8 | ### 충돌
9 |
10 | 해시 함수가 서로 다른 키를 같은 해시 값로 반환하는 경우 충돌이라고 부릅니다.
11 |
12 | 키 k1, k2 의 경우 h(k1) = h(k2) 인 상황입니다. 이러한 충돌은 해시 함수의 알고리즘이 정교하게 작동해도 피할 수가 없습니다.
13 |
14 | 이러한 충돌이 발생하지 않는다면 O(1) 의 시간 복잡도로 삽입, 수정, 삭제 연산이 이루어지지만 충돌이 발생한다면 최악에 O(Key 의 개수) 의 시간이 발생합니다.
15 |
16 | 이러한 충돌을 최대한 줄이는 것이 해시 테이블의 핵심입니다.
17 |
18 | ### 충돌 해결
19 |
20 | 해시 테이블의 충돌을 완화하는 방법으로 **해시 테이블 구조 개선**, **해시 함수 개선** 이 존재합니다.
21 |
22 | ### 해시 테이블 구조 개선
23 |
24 | - Separate Chaining
25 |
26 | 충돌 발생시 해시 테이블 동일한 버킷에 연결리스트 형태로 저장하는 방식입니다. 즉, 테이블이 차지한 메모리에서 추가적인 메모리 공간을 활용하는 방식입니다.
27 |
28 | 
29 |
30 |
31 | 데이터의 삽입의 경우 연결 리스트 추가시간인 O(1) 시간복잡도가 걸립니다.
32 |
33 | 수정 및 삭제, 탐색의 경우 최악의 경우 O(key 의 갯수) 의 시간복잡도가 걸립니다.
34 |
35 |
40 |
41 | - Open Addressing
42 |
43 | Chaining 과 달리 테이블의 비어있는 주소를 활용하는 방식입니다. 해당 방식의 테이블에서 비어있는 버킷을 탐사하는 시간이 중요합니다. 탐사의 방식은 대표적으로 3가지가 존재합니다.
44 |
45 | - 선형탐사(Linear probing)
46 |
47 | 해시 값에 대한 버킷이 이미 데치터가 존재하는 경우 바로 다음 버킷을 탐사하는 방식입니다.
48 | 가장 간단한 방식으로 단점도 명확합니다. 특정 해시값 주변 버킷들이 이미 다 채워져있는 primary clustering 의 경우 선형의 시간복잡도가 필요합니다.
49 |
50 | - 제곱탐사(Quadratic probing)
51 |
52 | 충돌이 발생시마다 충돌 횟수의 제곱수만큼 버킷을 이동하는 방식입니다.
53 | 예를들어 처음 충돌이 발생하면 1^2 만큼 이동하여 버킷을 확인합니다. 해당 버킷도 또 충돌이 발생한다면 2^2 만큼 이동한 버킷을 확인합니다. 마찬가지로 또 충돌이 발생한다면 3^2 만큼 이동하는 방식을 통해 충돌이 발생하지 않는 버킷을 탐사합니다.
54 |
55 | 이 경우도 단점이 존재합니다. 초기 해시값 즉 다양한 key 에 대해서 해시 함수의 결과값이 동일한 경우가 많은 secondary clustering 의 경우 마찬가지로 선형의 시간복잡도가 필요합니다.
56 |
57 | - 이중해싱(double hashing)
58 |
59 | 2개의 해시 함수를 준비하여 하나는 초기 해시값, 다른 하나는 충돌 발생시 이동폭을 얻기위해 사용합니다. 이런 경우 초기 해시값이 동일한 키라고 하더라도 다른 이동폭을 가지므로 앞선 primary clustering, secondary clustering 에서의 취약점이 해소됩니다.
60 |
61 |
62 | load factor 비율로 bucket size
63 |
64 |
65 | ### 해시 함수?
66 |
67 | 임의의 길이의 데이터 Key 를 고정된 길이의 해시(해시 값, 해시 코드, Hash 체크섬)로 매핑하는 해싱과정을 수행하는 함수입니다.
68 |
69 | 여기서 특정 값으로 치우치지 않고 해시값이 고르게 분포되는 것을 좋은 해시함수의 기준입니다.
70 |
71 | ### 해시 함수 종류
72 |
73 | - Division Method
74 |
75 | Key 값 k를 해시 테이블의 크기 n 으로 나눈 나머지를 해시값으로 사용하는 방식입니다.
76 | n 은 소수를 사용하는 것이 좋습니다
77 | 테이블의 크기가 정해진다는 단점이 있습니다.
78 | h(k) = k mod n
79 |
80 | - Multiplication Method
81 |
82 | Key 값 k, 0 과 1사이의 실수 A 임의의 m(보통 2의 제곱수)가 있을 때 다음의 수식을 통해 해시값을 구하는 방식입니다.
83 | 2진수 연산에 최적화된 컴퓨터 구조를 고려한 해시함수라고 합니다.
84 | h(k) = (kA mod 1) x m
85 |
86 | - Mid Square Method
87 |
88 | Key 값 k 를 제곱한 후 특정 자릿수 r 의 값을 해시값으로 사용하는 방식입니다.
89 |
90 |
91 | ## 참고자료
92 |
93 | [위키](https://namu.wiki/w/%ED%95%B4%EC%8B%9C)
94 |
95 | [wikipedia](https://en.wikipedia.org/wiki/Hash_table)
96 |
97 | [Hash 위키](http://wiki.pchero21.com/wiki/Hash#Hash_function)
98 |
99 | [해시 테이블](https://dbehdrhs.tistory.com/70)
100 |
101 | [해시 테이블 충돌](https://baeharam.github.io/posts/data-structure/hash-table/)
102 |
103 | [충돌 개선](https://en.wikipedia.org/wiki/Hash_table#Separate_chaining)
104 |
105 | [Java 8 Hash Table](https://d2.naver.com/helloworld/831311)
--------------------------------------------------------------------------------
/Database/B-Tree와 B+Tree.md:
--------------------------------------------------------------------------------
1 | # B-Tree와 B+Tree
2 |
3 |
4 |
5 | # B-Tree
6 |
7 | 트리 자료구조의 일종으로, 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 수가 2이상인 트리 구조이다.
8 |
9 | **최상위 노드**를 `root`노드라고 하며, **최하위 노드**들을 `leaf`노드라고 한다. **그 사이 계층의 노드**들은 `internal`노드라고 부른다.
10 |
11 | 
12 |
13 | 하나의 노드에 여러 개의 데이터가 있을 수 있다.
14 |
15 | 데이터의 순서는 이진 탐색 트리와 유사하다.
16 |
17 | 노드 내 데이터를 최대 M-1개, 최소 [M/2]-1개를 가지는 B-Tree를 **M차 B-Tree**라고 부른다.
18 |
19 | 자식 노드의 최소 및 최대 수는 특별한 구현에 대해서 결정되어 있다.
20 |
21 | 노드의 단위는 **page**로, **하드디스크의 저장 단위**에 맞추어져 있어 데이터베이스와 파일시스템에서 잘 쓰인다.
22 |
23 |
24 |
25 | ## 규칙
26 |
27 | - root 노드는 **2개 이상**의 자식을 가져야 한다.
28 | - M차 B-Tree는 루트 노드를 제외한 나머지 노드는 **최소 M/2개, 최대 M개의 자식 노드**가 있어야 한다.
29 | - **N개의 데이터**가 있는 하나의 노드는 **N+1개의 자식노드**를 갖고 있다.
30 |
31 | ⇒ **N개의 데이터**가 있다면 **자식 노드의 포인터는 N+1개**이다.
32 |
33 | 
34 |
35 |
36 | ## 탐색
37 |
38 | 1. 노드 안에서: 순차검색
39 |
40 | 2. 트리 안에서: 하향식 트리 검색
41 |
42 |
43 |
44 | ## 삽입
45 |
46 | 1. 삽입될 위치 검색
47 | 2. 삽입
48 | 1. 노드의 공간이 남아있을 때
49 |
50 | 노드 안에서 오름차순으로 삽입
51 |
52 | 2. 노드의 공간이 없을 때
53 | 1. 오름차순으로 삽입
54 | 2. 노드안에서 중앙값으로 분할하여 중앙값의 데이터를 부모 노드로 오름차순으로 삽입
55 | 3. i~ii 과정을 `root`노드까지 반복
56 |
57 | ex) 최대 2개의 데이터를 가지는 2차 B-Tree
58 |
59 | 
60 |
61 | 1. 4 삽입
62 |
63 | 
64 |
65 | 2. 노드 중앙값 분할
66 |
67 | 
68 |
69 | 3. root노드 중앙값 분할
70 |
71 | 
72 |
73 |
74 | ## 삭제
75 |
76 | 1. 삭제할 데이터가 위치한 노드 검색
77 |
78 | 1. 삭제할 데이터가 leaf노드에 있는 경우
79 | 1. 현재 노드의 데이터 개수가 최소 개수보다 클 때
80 |
81 | 삭제
82 |
83 | 2. 현재 노드의 데이터 개수가 최소 개수일 때
84 |
85 | 1) 왼쪽 또는 오른쪽 형제노드의 데이터 개수가 최소 개수 이상일때
86 |
87 | a) 현재노드를 현재노드와 형제노드 사이의 부모노드 데이터로 교체
88 |
89 | b) 형제노드가 왼쪽이라면 최대값을, 오른쪽이라면 최소값을 부모노드 데이터와 교체
90 |
91 | 2) 부모노드의 데이터는 최소 개수보다 많고, 형제노드 모두 데이터 개수가 최소 개수일 때
92 |
93 | a) 현재노드 삭제
94 |
95 | b) 부모노드의 데이터 최대값 또는 최소값을 형제노드와 합친다.
96 |
97 | 3) 부모노드, 형제노드 모두 데이터 개수가 최소 개수일 때
98 |
99 | a) 현재노드 삭제
100 |
101 | b) 부모노드를 인접한 형제노드와 병합 후 조상노드의 자식으로 위치시킨다.
102 |
103 | i) B-Tree의 조건이 맞춰줄 때까지 반복
104 |
105 | 2. 삭제할 데이터가 leaf노드에 없는 경우
106 | 1. 현재노드와 자식노드의 데이터 개수가 최소 개수보다 클 때
107 |
108 | 1) 왼쪽 서브트리의 최댓값과 위치를 변경한다.
109 |
110 | 2) 왼쪽 서브트리의 최댓값과 변경된 데이터를 삭제한다.
111 |
112 | 3) a. 과정을 한다.
113 |
114 | 2. 현재노드와 자식노드 모두 데이터 개수가 최소 개수일 경우
115 |
116 | 1. 데이터를 삭제하고 양쪽 자식노드를 합친다.
117 |
118 | 2. 부모의 데이터를 인접한 형제노드에 붙이고, 1)에서 합쳤던 노드를 자식노드로 위치시킨다.
119 |
120 |
121 |
122 |
123 | ## 특징
124 |
125 | 모든 노드에 key와 data가 들어있다.
126 |
127 | 데이터를 정렬된 상태로 보관
128 |
129 | 상향식 구성
130 |
131 | 삽입과 삭제시 균형을 유지하기 위한 작업
132 |
133 | 동일한 높이의 leaf노드 (Balanced)
134 |
135 | O(logN) 검색시간 보장
136 |
137 |
138 |
139 | # B+Tree
140 |
141 | B-Tree에서 확장된 개념의 트리구조이다.
142 |
143 | leaf노드에만 key와 data를 저장하고, 나머지 노드에는 key만 담겨있다. leaf노드끼리는 linked list로 연결되어 있다.
144 |
145 | 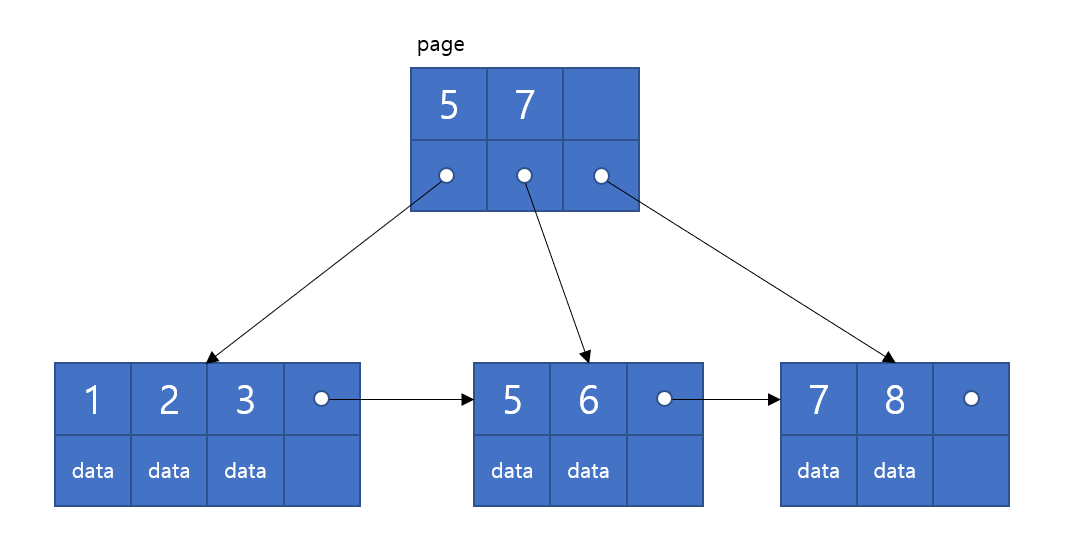
146 |
147 |
148 |
149 | ## 삽입
150 |
151 | - 삽입할 노드의 데이터 개수가 최대값보다 작을 때
152 |
153 | 데이터 삽입
154 |
155 | - 삽입할 노드의 데이터 개수가 최대값일 때
156 |
157 | 2개로 분할하여 중간값을 부모노드에 추가
158 |
159 | - 부모노드의 데이터 개수가 최대값일 때
160 |
161 | B-Tree 삽입 과정과 동일
162 |
163 |
164 |
165 |
166 | ## 삭제
167 |
168 | - 삭제할 키가 노드의 첫번째 데이터가 아닐 때
169 |
170 | 데이터 삭제
171 |
172 | - 삭제할 키가 노드의 첫번째 데이터일 때
173 | - 노드의 데이터 개수가 최소값이 아닐 때
174 |
175 | 삭제 후 삭제된 key가 있던 노드의 key값을 오른쪽 key로 변경한다.
176 |
177 | - 노드의 데이터 개수가 최소값일 때
178 | - 형제노드의 데이터 개수가 최소값이 아닐 때
179 |
180 | 삭제 후 인접한 형제노드의 key와 자리를 바꾼 후 부모노드의 key를 알맞게 수정한다.
181 |
182 | - 형제노드의 데이터 개수가 최소값일 때
183 | - 부모노드의 데이터 개수가 최소값이 아닐 때
184 |
185 | 삭제 후 삭제된 key가 있던 노드의 key 삭제
186 |
187 | - 부모노드의 데이터 개수가 최소값일 때
188 |
189 | 현재노드와 부모노드 삭제 후 조상노드에 형제노드를 연결하고 조상노드에 대해서는 B-Tree와 동일
190 |
191 |
192 |
193 | ## 장점
194 |
195 | 오직 leaf노드에만 데이터를 담기 때문에 저장공간을 더 확보하고 더 많은 key들을 수용할 수 있다. 하나의 노드에 더 많은 key를 담을 수 있기 때문에 트리의 높이가 더 낮아진다.
196 |
197 | leaf노드끼리 서로 연결되어 있기 때문에 범위 검색에 유리하다.
198 |
199 | 풀 스캔 시, B+Tree는 leaf노드로 한 번의 선형탐색만 하면 되기 때문에 B-Tree보다 빠르다.
200 |
201 | →데이터베이스 시스템 인덱스 구성에 매우 효율적이다.
202 |
203 |
204 |
205 | ## 단점
206 |
207 | B-Tree의 경우 최상의 경우 특정 key의 데이터를 찾기 위해 leaf노드까지 가지 않아도 되지만, B+Tree의 경우 반드시 특정 key에 접근하기 위해서 leaf node까지 가야 한다.
208 |
209 |
210 |
211 | ---
212 |
213 | - 참고자료
214 |
215 | [https://ko.wikipedia.org/wiki/B_트리](https://ko.wikipedia.org/wiki/B_%ED%8A%B8%EB%A6%AC)
216 |
217 | [https://velog.io/@emplam27/자료구조-그림으로-알아보는-B-Tree](https://velog.io/@emplam27/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C-%EC%95%8C%EC%95%84%EB%B3%B4%EB%8A%94-B-Tree)
218 |
219 | [https://velog.io/@emplam27/자료구조-그림으로-알아보는-B-Plus-Tree](https://velog.io/@emplam27/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C-%EC%95%8C%EC%95%84%EB%B3%B4%EB%8A%94-B-Plus-Tree)
220 |
221 | [https://slenderankle.tistory.com/159](https://slenderankle.tistory.com/159)
222 |
223 | [https://rebro.kr/167](https://rebro.kr/167)
--------------------------------------------------------------------------------
/Database/Join.md:
--------------------------------------------------------------------------------
1 | # JOIN
2 |
3 | > JOIN은 데이터베이스 내의 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현해 줍니다. 이러한 JOIN은 보통 SELECT 문과 함께 자주 사용됩니다. → [TCP School JOIN](http://tcpschool.com/mysql/mysql_multipleTable_join)
4 | >
5 |
6 | 
7 |
8 | SQL을 접하면서 DB를 설계하고 사용할 때 JOIN은 가장 자주 사용하게 되는 개념이라고 할 수 있을 정도로 많이 쓰인다. 항상 성능에 대해서 고민하게 되는 친구지만, 나름 RDBS(관계형데이터베이스)의 꽃이라고 생각되는 JOIN에 대해서 정리해 보려고 한다.
9 |
10 | ## 1. 조인과 관계대수
11 |
12 | 관계대수란 릴레이션(테이블)에서 데이터를 추출하는데 사용되는 언어라고 할 수 있다. 관계형 데이터베이스 이론의 코드 박사(codd)는 이렇게 정의했다.
13 |
14 | - 관계 대수: 원하는 정보를 어떻게(How) 찾는지를 명시하는 절차적 언어
15 | - 관계 해석: 어떤(what) 데이터를 찾는지 만 명시하는 선언적 언어
16 |
17 | SQL 언어는 관계해석을 기반으로 하며 관계 대수 개념이 혼합되어 있고, DBMS 내부에서는 관계 대수에 기반을 둔 연산을 수행한다. 관계 대수를 정리해보면 다음 과 같다.
18 |
19 | 
20 |
21 | 여기서 Join은 유도된 연산자로 Cartesian Product 와 Selection을 함께 실행하여 얻은 결과와 동일하다.
22 |
23 | > 다른건 다 감이 오는데 `카티전 프로덕트`..? 이게 뭘까 싶을 수 있다. `카티전 프로덕트`는 집합에서 곱의 개념으로 A= {a, b, c} , B = {1, 2} 일 때 (a,1), (a, 2), (b,1), (b,2), (c, 1), (c,2) 처럼 나타 낼 수 있다. 엄청나게 많은 결과를 생성하기 때문에 많이 사용되지는 않는다.
24 | >
25 |
26 | ## 2. 다양한 조인들...
27 |
28 | 관계 대수에서 언급된 조인들을 하나씩 살펴 보자
29 |
30 | ### Theta Join(세타 조인), Equal Join(동등 조인), Natural Join(자연 조인)
31 |
32 | 
33 |
34 | 그림처럼 비교 조건 (<, =, >)을 만족하는 Join이 Theta Join이고 그중 비교 조건이 (=)일 때 Equal Join이 된다.
35 |
36 | > 간혹 Inner Join이 곧 Equal Join이라고 생각 하는 경우가 있는데, 엄밀히 따지자면 틀린 이야기다. Outer Join에서도 Equal Join처럼 동등 비교 조건문이 들어갈 수 있기도 하고, Inner Join사용시에 Equal Join도 사용 가능한 것으로 생각하면 된다.
37 | >
38 |
39 | Equal Join에서 중복 속성을 제거하게 되면 Natural Join이 됩니다. Natural Join은 다음과 같이 두 테이블에 같은 이름의 열이 있을 때 생략하여 사용 가능하다.
40 |
41 | ```sql
42 | SELECT * FROM A NATURAL JOIN B;
43 | ```
44 |
45 | ### Inner Join
46 | 그림에서 보이는 것처럼 교집합을 나타낸다.
47 |
48 | 
49 |
50 | 출처: [TCPschool](http://tcpschool.com/mysql/mysql_multipleTable_join)
51 |
52 | 아래 처럼 작성할 수 있다.
53 |
54 | ```sql
55 | SELECT * FROM A JOIN B ON A.id = B.id;
56 | ```
57 |
58 | ### Outer Join
59 |
60 | Inner Join의 결과로 나오지 않는 행도 NULL값으로 포함해서 결과를 나타내는 Join이다.
61 |
62 | 어느 쪽을 기준으로 합치냐에 따라서 Left Join , Right Join으로 나뉜다.
63 |
64 | **Left Join**
65 |
66 | 
67 |
68 | 출처: [TCPschool](http://tcpschool.com/mysql/mysql_multipleTable_join)
69 |
70 | 첫 번째 테이블을 기준으로 두 번째 테이블을 조합하는 Join이다. ON절의 조건을 만족하지 않더라도 첫 번째 테이블을 표시하고, 두 번째 테이블의 필드를 NULL로 표시한다.
71 |
72 | ```sql
73 | SELECT * FROM A LEFT JOIN B ON A.id = B.id;
74 | ```
75 |
76 | **Right Join**
77 |
78 | 
79 |
80 | 출처: [TCPschool](http://tcpschool.com/mysql/mysql_multipleTable_join)
81 |
82 | Left Join과는 반대로 두 번째 테이블을 기준으로 첫 번째 테이블을 조합하는 Join이다. ON절의 조건을 만족하지 않더라도 두 번째 테이블을 표시하고, 첫 번째 테이블의 필드를 NULL로 표시한다.
83 |
84 | ```sql
85 | SELECT * FROM A RIGHT JOIN B ON A.id = B.id;
86 | ```
87 |
88 | ### Cross Join
89 |
90 | `Cross Join` 은 관계 대수에서 잠깐 언급했던 `Cartesian Product` 와 같다. 카티전 조인이라고도 한다.
91 |
92 | ```sql
93 | SELECT * FROM A CROSS JOIN B ON A.id = B.id;
94 | ```
95 |
96 | ### Self Join
97 |
98 | 말그대로 자기 자신을 Join하는 방법이다. A 테이블을 각각 Child, Parent로 지정해서 사용한다.
99 |
100 | ```sql
101 | SELECT * FROM A AS parent JOIN A AS child
102 | ```
103 |
104 | ### Semi Join
105 |
106 | 솔직히 처음 들어보는 조인이었다. 조사해보니 세미 조인은 서브 쿼리와 메인 쿼리와의 연결을 위한 유사 조인 이었다...(~~가짜야가짜~~)
107 |
108 | 1:n 관계에서 1의 컬럼만을 사용할 경우 사용할 수 있는데, 집계함수 없이 group by나 distinct를 사용해서 중복제거를 하고 있다면 성능 향상의 효과를 얻을 수 있다.
109 |
110 | In 과 Exists를 통해 사용할 수 있다고 한다.
111 |
112 | ```sql
113 | SELECT * FROM A WHERE A.name IN (SELECT B.name FROM B );
114 | ```
115 |
116 | ```sql
117 | SELECT * FROM A WHERE EXISTS (SELECT 1 FROM B WHERE A.name = B.name)
118 | ```
119 |
120 | 자세한건 아래 블로그와 참고자료에 첨부한 유튜브 영상을 참고하자
121 |
122 | [블로그](https://songii00.github.io/2019/08/10/2019-08-10-%EC%84%B8%EB%AF%B8%EC%A1%B0%EC%9D%B8/)
123 |
124 | ## 3. 조인 동작 방식
125 |
126 | Mysql 에서는 **NESTED LOOP JOIN(NL Join)**을 사용하고 있으며, 이외에 **SORT-MERGE JOIN, HASH JOIN**이 있다. Hash Join의 경우 Mysql 8.0부터 지원하고 있다고 한다.
127 |
128 | ### **NESTED LOOP JOIN(NL Join)**
129 |
130 | 우리가 프로그래밍에서 사용하는 반복문과 유사한 방식으로 조인을 수행하는데, 반복문 외부에서 먼저 읽어지는 테이블을 `Driving Table` 이라고 하고, 반복문 내부에서 나중에 읽어지는 테이블을 `Driven Table`이라고 한다.
131 |
132 | Inner Join의 경우에는 옵티마이저가 순서를 조절해 최적화 하기 때문에 쿼리에서의 테이블 순서가 보장 되지 않고, Outer Join의 경우에는 Outer 테이블을 먼저 읽기 때문에 옵티마이저가 선택할 수 없다.
133 |
134 | 어찌 되었건 옵티마이저의 실행계획을 통해서 `Driving Table` 과 `Driven Table` 이 정해졌다면 다음 프로세스를 따른다.
135 |
136 | 
137 |
138 | 출처: [https://coding-factory.tistory.com/756](https://coding-factory.tistory.com/756)
139 |
140 | 1. `Driving Table` 에서 주어진 WHERE 조건문을 만족하는 행을 찾는다. (인덱스 OR 풀스캔등)
141 | 2. `Driving Table` 의 조인 KEY 값을 가지고 `Driven Table` 에서 조인을 수행 (랜덤 Access)
142 | 3. 반복
143 |
144 | Driving Table의 조건을 만족하는 결과가 많을 수록 반복문의 n의 크기가 커지고, Driven Table에 더 많이 접근해야 하므로 성능은 나빠지게 된다.
145 |
146 | 그러므로 `힌트` 나 `뷰` 를 통해서 선택된 `Driving Table` 의 크기가 작아지도록 해야 한다.
147 |
148 | ### 마무리
149 |
150 | 관계 대수 부터 각 Join과 Join의 동작 방식까지 간단하게 살펴 보았다. Join 때문에 성능 이슈가 많이 생겨서 반정규화를 하거나 아예 NoSQL을 이용하는 경우도 많지만 근-본인 관계형 DB에서 Join에 대해 조금 더 잘 이해하는 계기가 되었다. 조인 동작 방식에 대해서는 추후에 더 자세히 공부해볼 예정이다.
151 |
152 | ## 참고자료
153 |
154 | - 코드박사 와 데이터베이스 만화
155 |
156 | [내 계좌 비밀번호는 어떻게 저장되어 있을까? RDBMS](https://brunch.co.kr/@hvnpoet/133)
157 |
158 | - 관계 대수
159 |
160 | [](https://jehwanyoo.net/2020/09/25/%EA%B4%80%EA%B3%84%EB%8C%80%EC%88%98-Relational-Algebra-%EC%9A%94%EC%95%BD-%EC%A0%95%EB%A6%AC/)
161 |
162 | [[Database] 관계대수](https://m.blog.naver.com/aservmz/221960633361)
163 |
164 | “Mysql로 배우는 데이터베이스 개론과 실습” 책 참고
165 |
166 | - TCP School
167 |
168 | [코딩교육 티씨피스쿨](http://tcpschool.com/mysql/mysql_multipleTable_join)
169 |
170 | - 세미 조인
171 |
172 | [세미조인](https://songii00.github.io/2019/08/10/2019-08-10-%EC%84%B8%EB%AF%B8%EC%A1%B0%EC%9D%B8/)
173 |
174 | [조인보다 빠른 세미 조인, Semi Join, exists, in](https://www.youtube.com/watch?v=YxauObfs4HQ)
175 |
176 | [2.3.5. 세미(Semi) 조인](http://wiki.gurubee.net/pages/viewpage.action?pageId=1966761)
177 |
178 | - 조인
179 |
180 | [[MySQL] 7장 조인 : JOIN (INNER, LEFT, RIGHT)](https://futurists.tistory.com/17)
181 |
182 | [[MYSQL] JOIN(조인)](https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=islove8587&logNo=221049861998)
183 |
184 | - Equal Join == Inner join ???
185 |
186 | [Is inner join the same as equi-join?](https://stackoverflow.com/questions/5471063/is-inner-join-the-same-as-equi-join)
187 |
188 | - join 동작 방식
189 |
190 | [[DB] 데이터베이스 NESTED LOOPS JOIN (중첩 루프 조인)에 대하여](https://coding-factory.tistory.com/756)
191 |
192 | [* JOIN 원리](https://kshmc.tistory.com/entry/JOIN-%EC%9B%90%EB%A6%AC)
193 |
194 | [SQL 최적화 기본원리 (조인 수행 원리)](https://cornswrold.tistory.com/84)
--------------------------------------------------------------------------------
/Database/SQL_VS_NOSQL.md:
--------------------------------------------------------------------------------
1 | # SQL VS NOSQL
2 |
3 | ## ✨ SQL? NOSQL?
4 |
5 | > SQL이란 SQL(Structured Query Language)로 원래의 의미는 RDB의 Query Language이지만, RDB에서만 쓰이므로 RDB를 SQL이라고 말하기도한다. 여기서도 SQL == RDB로 쓰겠다. 그리고, MySQL(SQL), MongoDB(NoSQL)기준으로 설명한다.
6 | >
7 |
8 | ### SQL
9 |
10 |
14 |
15 | > 여기서 일관성이란 RDB는 데이터의 중복 저장을 피하기 위해서 여러 데이터를 여러 테이블에 분산하여 저장하고 관계를 정해줌으로써 지켜준다.
16 | >
17 | - 모델링의 순서가 [ 테이블 → 쿼리 ]로, 테이블의 형태를 먼저 정하고 그에 맞는 쿼리를 작성하게 된다.
18 |
19 | > 이런 점은 데이터의 일관성을 중요시하는 RDB의 컨셉때문이다.
20 | >
21 |
22 | ### NOSQL
23 |
24 |
28 |
29 | > NoSQL은 데이터를 중복 저장하지만, 내가 원하는 정보를 한개의 document에 모두 담을 수 있다. 따라서, 대용량 데이터에 대해서 빠른 처리가 가능하다.(Join이 없으므로)
30 | >
31 | - 모델링의 순서가 [ 쿼리 → 도큐멘트 ]로, 필요한 쿼리에 따라서 도큐멘트를 만들게 된다.
32 |
33 | ## 📝 용어
34 |
35 | ### 공통
36 |
37 | - Schema: Table(Collection)의 구조를 정의한다.
38 |
39 |
43 |
44 | - Join: RDB에서 관계를 가지는 테이블의 데이터도 함께 가져오고 싶을 때 사용하는 쿼리 기법
45 |
46 |
50 |
51 | - Join 동작방식의 차이
52 |
53 | SQL
54 |
55 | - Join시 외래키를 통해서 추가적인 Table에 접근하고, 외래키는 해당 Record를 직접 참조하므로 매우 빠른 속도로 가져올 수 있다.
56 |
57 | NOSQL
58 |
59 | - Lookup시 추가로 찾는 Collection을 Full Scan해서 맞는 Document를 찾게된다.
60 | - 여기서, 적절한 Indexing을 통해서 Lookup의 성능을 높일 수 있다.
61 | - 또한, NOSQL은 스키마가 유연하고 모든 데이터가 들어갈 수 있으므로, Document의 Field에 Document자체가 들어갈 수 있다. 이러한 기법을 Embedding기법이라고 한다.
62 |
63 |
67 |
68 | - 또한, Link기법으로 특정 Document를 직접 참조할 수도 있다.
69 |
70 | ### SQL
71 |
72 | - Table: 데이터를 저장하는 표(Table)
73 | - Row(Record): Table에서 한개의 데이터를 나타낸다.
74 | - Column(Field): Table에서 데이터가 가질 수 있는 각 속성이다.
75 | - Relationship: Table과 Table의 관계이다.
76 |
77 | ### NoSQL
78 |
79 | - Collection: == RDB의 Table
80 | - Document: == RDB의 Row(Record)
81 | - Field: == RDB의 Column(Field)
82 |
83 | ## ⚡️ Transaction
84 |
85 |
89 |
90 | ### ACID
91 |
92 | > Transaction을 보장하기 위해서는 아래 4가지 조건을 만족해야 한다.
93 | >
94 | - Atomicity(원자성): 모든 연산에 대해서 모두 처리/실패 → all-or-nothing
95 | - Consistency(일관성): 데이터는 미리 정의된 규칙(제약조건, 도메인, ...)에 부합
96 | - Isolation(): 트랜잭션동안 다른 트랜잭션 간섭 불가
97 | - Durability(지속성): 트랜잭션 이후 데이터들의 영구 보존
98 |
99 | ### SQL
100 |
101 |
105 |
106 | ### NOSQL
107 |
108 |
112 |
113 | - MongoDB Manual의 내용
114 |
115 | > In version 4.0, MongoDB supports multi-document transactions on replica sets.
116 | In version 4.2, MongoDB introduces distributed transactions, which adds support for multi-document transactions on sharded clusters and incorporates the existing support for multi-document transactions on replica sets.
117 |
118 | To use transactions on MongoDB 4.2 deployments (replica sets and sharded clusters), clients must use MongoDB drivers updated for MongoDB 4.2.
119 | >
120 |
121 | 4.0부터 Multi-Document의 Transaction을 지원하기 시작했으며, 이 때부터 DB로써 사용할 수 있는 역량을 갖췄다고 평가된다. 그 아래는 4.2부터는 샤딩을 통해 확장된 상태에서 지원한다고 써있다.
122 |
123 | - NOSQL도 ACID를 만족한다고?
124 |
125 | 아래 MongoDB의 Manual을 읽어보면 그러한거 같다. 이제 ACID Transactions 된다고 자랑하는 글
126 |
127 | [ACID Transactions Basics](https://www.mongodb.com/basics/acid-transactions)
128 |
129 |
130 | ## 🌝 특성
131 |
132 | ### ACID of SQL
133 |
134 | ### BASE of NOSQL
135 |
136 |
140 |
141 | > ACID와 대조되는 가용성과 성능을 중시하는 특징
142 | >
143 | - Basically Available(가용성): 데이터는 항상 접근이 가능, 데이터는 중복 저장
144 | - Soft-state(독립성): 노드의 상태는 외부의 정보를 통해 결정
145 | - Eventually Consistent(일관성): 일정 시간 경과시 데이터의 일관성을 유지
146 |
147 | ### BASE VS ACID
148 |
149 | | 항목 | BASE | ACID |
150 | | --- | --- | --- |
151 | | 적용대상 | NoSQL | RDBMS |
152 | | 범위 | 시스템 전체 대상 | 개별 트랜잭션 적용 |
153 | | 일관성 | 약한 일관성 | 강한 일관성 |
154 | | 중점사항 | 성능과 가용성 | 무결성, 일관성 |
155 | | 관리주체 | 주로 개발자 | DBMS 트랜잭션 |
156 | | 데이터처리 | 유사 응답 허용 | 처리 순서 보장 |
157 | | 변경성 | 변경 어려움 | 변경 용이 |
158 | | 디자인 | 쿼리 디자인 중요 | 테이블 디자인 중요 |
159 | | CAP이론 | C+P, A+P 만족 | C+A 만족 |
160 | | 적용사례 | Big Table | Oracle RAC |
161 |
162 | ## 👾 CAP 이론
163 |
164 |
168 |
169 | - Consistency(일관성): 모든 노드들은 같은 시간에 동일한 항목에 대하여 같은 내용의 데이터를 제공한다.
170 | - Availability(가용성): 모든 사용자들이 읽기및 쓰기가 가능하며, 몇몇 노드의 장애시 다른 노드에 영향을 끼치지 않는다.
171 | - Partition-tolerance(분할 내성): 메시지 전달이 실패하거나 일부 시스템이 망가져도 시스템은 정상 동작해야 한다.
172 |
173 | > 현재 DB들은 이중에 2가지를 만족하도록 만들어진다.
174 | >
175 |
176 | > SQL(CA), NoSQL(CA, AP)
177 | >
178 |
179 | ## 👐 확장
180 |
181 | > 확장이란 성능 또는 용량 초과로 인한 DB의 확장이다.
182 | >
183 |
184 | ### 수평 확장 of NOSQL
185 |
186 |
190 |
191 | > NOSQL은 비교적 쉬운 수평 확장을 샤딩을 통해서 지원한다. 샤딩이란 같은 Collection내의 Document를 분산하여 저장하는 방식이다.
192 | >
193 | - 샤딩을 통한 비교적 쉬운 수평 확장
194 | - 유연한 스키마 변경을 통한 확장
195 |
196 | ### 수직 확장 of SQL
197 |
198 |
202 |
203 | > SQL은 Schema변경이 거의 불가능하므로 수직 확장만이 가능하다. 수평 확장도 가능하지만, 매우 매우 어렵다고 볼 수 있다.
204 | >
205 |
206 | > NOSQL은 수직 확장이 안되는가? 수평 확장이 인력과 서버 비용 모두 통틀어서 더 좋은 선택이므로 수직 확장할 필요는 없다.
207 | >
208 |
209 | ## 👀 정규화와 비정규화
210 |
211 | ### 정규화(Normalization)
212 |
213 |
217 |
218 | > 정규화를 통해서 이상(Anomaly)현상을 방지할 수 있다. 이상 현상이란 개발자가 원하지 않는 데이터의 삭제 / 삽입 / 갱신되는것을 말한다.
219 | >
220 |
221 | ### 비정규화(Denormalization)
222 |
223 |
227 |
228 | > 정규화는 1 ~ 5단계가 있으며, 숫자가 높아질수록 데이터의 중복이 없다. 현업에서는 보통 3단계 정도까지를 사용한다.
229 | >
230 |
231 | ### SQL & NOSQL
232 |
233 | - SQL: 정규화를 통해서 데이터의 중복을 없애는것을 지향한다.
234 | - NOSQL: 비정규화를 통해서 빠른 성능과 가용성을 지향한다.
235 |
236 | ## 👍 장점과 단점
237 |
238 |
242 |
243 | - SQL
244 | - 장점: 관계를 통해서 데이터의 일관성을 강제하므로 설계만 잘 해놓으면 사용시 편리하다.
245 | - 단점: 일관성, 트랜잭션을 위해서 잘못된 설계시 많은 성능 저하가 일어날 수 있다, 설계/수정이 어렵다.
246 | - NoSQL
247 | - 장점: 대용량 데이터에 좋은 성능을 기대할 수 있다, 설계 / 수정 / 확장이 쉽다
248 |
249 | > 대용량 데이터일 경우,
250 | 1. 데이터가 많아짐으로써 DB를 확장할 때 샤딩을 통해 쉽게 할 수 있다.
251 | 2. 형태가 다른 데이터를 모두 받아서 사용할 수 있다.
252 | >
253 | - 단점: 데이터의 일관성을 개발자가 신경써주어야 한다.
254 |
255 | ## 😭 예상 질문
256 |
257 | - SQL과 NOSQL의 차이는 무엇인가요?
258 | - 가장 큰 차이점은 데이터의 일관성을 중요시할 것이냐, 가용성과 확장성을 중요시할 것이냐 입니다. SQL은 일관성을 잘 지킬 수 있으며, NOSQL은 쉬운 수정과 수평 확장을 할 수 있습니다.
259 | - SQL의 장점과 단점은 무엇인가요?
260 | - SQL의 장점은 설계된 Table과 Schema를 통해서 데이터의 일관성을 보장받을 수 있습니다. 단점은 잘 못 설계된 Table과 Schema는 성능을 저하시킬 수 있고, Schema의 수정이 힘드며 확장시 수직 확장을 해야함이 있습니다.
261 | - NOSQL의 장점과 단점은 무엇인가요?
262 | - NOSQL의 장점은 가용성과 유연성입니다. 유연한 Schema를 통해서 Agile한 DB 설계를 할 수 있으며 확장시에도 상대적으로 쉬운 샤딩을 통한 수평확장입니다. 단점은 중복 저장으로 데이터의 일관성이 보장되지 않을 수 있고, DB 스토리지를 낭비할 수 있으며 업데이트 쿼리시 Document크기에 따라서 성능이 저하될 수 있습니다.
263 | - 언제 SQL을 사용하고, 언제 NOSQL을 사용해야 할까요?
264 | - 데이터의 형태가 정해져 있고, 일관성이 중요하고 DB 스토리지가 넉넉하지 않다면 SQL을, 유연한 수정과 확장성을 고려한다면 NOSQL 사용을 고려해볼 수 있습니다.
265 | - 대용량 데이터 처리가 NoSQL 이 더 유리한가?
266 | - 유연한 데이터 유형
267 | - 서버의 수평확장에 유리한 구조
268 | - SQL과 NOSQL의 사용 경험에 대해서 말해주세요
269 | - 개발시 어떤 sql를 사용할 것인가?
270 | - 관계에 따라
271 | - 보안이 중요하다면 SQL을 사용하는 것이 유리하다.
272 |
273 | > 트랜잭션의 안정성, 유연한 Schema로 SQL Injection에 취약하다.
274 | >
275 | - 둘 다 적절히 사용
276 |
277 | ## 👨💻 참고
278 |
279 | - 그룹 프로젝트 정리 노션
280 |
281 | [SQL VS NoSQL](https://www.notion.so/SQL-VS-NoSQL-13a24463cac04934adbee88b8bd96fd2)
282 |
283 | - 정규화
284 |
285 | [#02. 이상(Anomaly)현상과 정규화(Normalization)](https://movenpick.tistory.com/29)
286 |
287 | [데이터베이스 정규화 1NF, 2NF, 3NF, BCNF](https://3months.tistory.com/193)
288 |
289 | - 비교
290 |
291 | [SQL과 NOSQL의 차이 | 👨🏻💻 Tech Interview](https://gyoogle.dev/blog/computer-science/data-base/SQL%20&%20NOSQL.html)
292 |
293 | [SQL vs NoSQL](https://velog.io/@thms200/SQL-vs-NoSQL)
294 |
295 | - 모델링
296 |
297 | [NoSQL 데이터 모델링](https://more-learn.tistory.com/5)
298 |
299 | [MongoDB 데이터 관계 모델링](https://devhaks.github.io/2019/11/30/mongodb-model-relationships/)
300 |
301 | - 트랜잭션
302 |
303 | [[DB기초] 트랜잭션이란 무엇인가?](https://coding-factory.tistory.com/226)
304 |
305 | [What is NoSQL? NoSQL Databases Explained](https://www.mongodb.com/nosql-explained)
306 |
307 | - BASE
308 |
309 | [NoSQL 데이터베이스 접속 시 보안 고려사항](http://channy.creation.net/project/dev.kthcorp.com/2012/01/26/security-considerations-in-accessing-nosql-databases/index.html)
310 |
311 | - 보안
312 |
313 | [NoSQL BASE 속성 > 도리의 디지털라이프](http://blog.skby.net/nosql-base-%EC%86%8D%EC%84%B1/)
314 |
--------------------------------------------------------------------------------
/Database/데이터베이스 클러스터링 VS 레플리카 6768dd1874c74763a3033dac6002f6ec.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Replication
4 |
5 | ### 기본구성
6 |
7 | - 데이터를 실질적으로 저장하는 소스서버 (Master)
8 | - 소스서버(Master)의 데이터를 복제해서 저장하는 레플리카서버(Slave)
9 |
10 | ### Replication시 장점
11 |
12 | - 스케일 아웃 → 레플리카서버를 늘려서 트래픽을 감당 가능하게 동적으로 규모를 늘릴 수 있음
13 | - 데이터 백업시 소스 서버에서 하면 실제 서버에 부담을 줄 수 있기 때문에 레플리카 서버에서 백업을 진행하여 부담을 줄인다.
14 | - 데이터 분석용 서버를 구성해서 특정용도를 위한 서버를 따로 구축할 수 있다.
15 | - 데이터의 지리적 분산: 특정 지역에 레플리카 서버를 구축해 응답속도를 개선 가능
16 |
17 | ### 바이너리 로그
18 |
19 | MySQL에서 모든 변경 사항을 순서대로 저장하고 있음 다음 명령어로 볼 수 있다.
20 |
21 | ```sql
22 | show binary logs
23 | show mater status;
24 | ```
25 |
26 | 소스 서버의 바이너리 로그가 레플리카 서버로 저장되고 그것을 통해 데이터의 동기화가 진행됨
27 |
28 | ### 바이너리 로그 저장방식
29 |
30 | - Statement 방식: SQL문을 바이너리 로그에 그대로 기록함
31 | - 트랜잭션 격리 수준이 REPEATABLE-READ 이상이어야 데이터가 일치함
32 | - 비 확정적으로 실행되는 쿼리(order by limit delete같은 매번 다르게 평가되는)가 있으면 데이터가 달라질 수 도 있음
33 | - Row 방식: 변경된 데이터 자체를 기록하는 Row 방식
34 | - 가장 일관적인 데이터 저장 방식 → 안전함
35 | - 단시간에 로그파일이 커짐
36 | - Mixed: statement와 row방식을 혼합함
37 | - statement로 기록했을때 안전하지 않을것같으면 row방식으로 기록함
38 |
39 | ### 복제과정
40 | 
41 |
42 | 이러한 복제 과정은 3개의 스레드를 통해 복제되는데
43 |
44 | 1. 소스서버의 Binary Log Dump Thread가 바이너리 로그를 레플리카서버에 전송함
45 | 2. 레플리카서버의 Replication I/O Thread 바이너리 로그 이벤트를 레플리카 서버에 Relay Log파일로 저장
46 |
47 | (연결시 사용정보는connection metadata에 있고, slave_master_info에 저장됨)
48 |
49 | 3. 레플리카서버의 Replication SQL Thread는 Replication I/O Thread에 의해 작성된 Relay Log파일을 읽고 실행함
50 |
51 | (릴레이 로그 이벤트를 서버에 적용하는 컴포넌트를 applier라고 하는데 이벤트가 저장된 릴레이로그 파일명,위치와 소스서버에 연결할 때 사용하는 정보가 저장되어있다. slave_relay_log_info테이블에 저장됨)
52 |
53 |
54 | ### 변경 내용식별
55 |
56 | - 바이너리 로그 파일 위치 기반
57 | - 레플리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일내에서 위치로 바이너리 로그 이벤트를 식별해서 복제함
58 | - server-id={n}으로 서버를 식별함 각 서버마다 넘버링을 해줘야함 → 이벤트가 처음 발생한 위치를 식별하기 위해 서버 아이디를 지정해야함
59 | - 글로벌 트랜잭션 ID 기반(GTID)
60 | - MySQL 버전 5.5까지는 바이너리 로그 파일 위치 기반으로만 가능했음 → 식별과정이 소스서버에서만 유효함 , 레플리카서버에 동일한 위치에 저장된다고 보장할 수 없음
61 |
62 | [MySQL GTID 를 사용한 Replication(복제) 설정](https://hoing.io/archives/18445)
63 |
64 |
65 | ### 복제 동기화 방식
66 |
67 | - 비동기 복제
68 | - 제대로 적용됬는지 확인하지 않음 ,데이터가 100% 일치하지 않음
69 | - 반동기 복제
70 | - 소스 서버는 레플리카 서버가 소스 서버로부터 전달 받은 변경 이벤트를 릴레이 로그에 기록 후 응답을 보내면 그때 트렌잭션을 커밋함
71 | - 비동기 방식보다 트랜젝션 처리가 느려짐, 응답이안오면 무제한으로 기다릴수있으니 일정시간지나면 비동기 복제로 젼환
72 |
73 | ### Replication 종류
74 |
75 | **싱글 레플리카 복제**
76 | 
77 |
78 | - 하나의 소스 서버에 하나의 레플리카서버
79 | - 소스 서버에 문제가 생길 경우 예비서버 역할, 데이터 백업 수행을 위한 용도
80 |
81 | **멀티 레플리카 복제**
82 |
83 | 
84 |
85 | - 하나의 소스 서버에 두 개의 레플리카 서버
86 | - 하나는 백업용, 하나는 읽기 요청 분산
87 |
88 | **체인 복제**
89 |
90 | 
91 | - 하나의 소스 서버에 레플리카가 여러개 달리면 바이너리 로그 복사작업이 부담이 될 수 있음
92 | - 소스 서버가 해야할 로그 배포역할을 다른서버로 넘길수있음
93 |
94 | **듀얼 소스 복제**
95 | 
96 |
97 | - 두개의 서버가 소스이자 레플리카
98 | - 각 서버에서 변경한 데이터는 각 서버에 전달되어서 동일한 데이터를 갖게됨
99 | - Active -Active(항상가동) 형태, Activae - Standby(일부는 대기)형태로 가능
100 | - 그냥 레플리케이션 방식과 달리 한서버에서 문제가 생기면 바로 전환가능
101 |
102 | **멀티 소스 복제**
103 | 
104 | - 하나의 레플리카 서버가 여러개의 소스서버를 가짐
105 | - 여러 서버에 존재하는 다른 데이터를 통합하거나 샤딩 되어있는 테이블을 하나의 테이블로 통합할 때 사용함
106 |
107 | # Clustering
108 |
109 | - 레플리케이션은 저장소 + 서버가 개별로 생성되지만 클러스터링은 db스토리지 하나와 다수의 서버로 구성됨
110 |
111 | ## 연결방식
112 |
113 | ## Active-Active 방식
114 |
115 | - 클러스터를 구성하는 컴포넌트들이 동시에 가동되는 방식, 하나의 저장소를 공유함
116 |
117 | ### 장점
118 |
119 | - 시스템이 다운되어 있는 시간이 짧기 때문에 시스템 전체가 정지하는 것을 방지할 수 있음
120 | - 동시에 가동하기 때문에 전체 cpu,메모리등이 증가해 성능 향상도 기대할 수 있음
121 |
122 | ### 단점
123 |
124 | - 저장소에서 병목이 일어날 수 있어서 높은 성능향상을 기대하기 어려울 수도 있다.
125 | - Active-Active 방식을 지원 하는 데이터 DBMS가 한정적이다.
126 | - ( Oracle = RAC(Real Application Cluster, DB2 = pureScale 라는 이름의 Active-Active 클러스터링이 가능하고, 다른 DBMS에서는 Active-Standby 클러스터링만 대응하고 있다.
127 | - MySQL에서는 지원해주지 않는 걸로 보임 → MySQL Cluster를 사용하는 것 같은데 InnoDB가 아니라고 함 , 아래에 작성한 **Galera cluster**를 솔루션으로 사용한다고함
128 | - 서버를 여러대 한꺼번에 운영하므로 비용이 증가함
129 |
130 | ## Active-Standby 방식
131 |
132 | - 클러스터를 구성하는 컴포넌트중 Active만 사용하다가 장애가 생기면 standby가 작동하는 구성
133 | - Cold-Standby:평소에 DB가 작동하지 않다가 Active DB에 장애 작동하는 구성
134 | - Hot-Standby: 평소에 Standby DB가 작동되는 구성이다.
135 | - Hot-standby는 라이선스료를 많이 지급 한다는점에서 단점이 있음
136 | - Standby DB 서버는 일정 간격으로 Active DB에 이상이 없는지를 조사하기 위한 통신을 하고 있다. 이 통신을 '**Heartbeat**'라고 한다. Active DB에 장애가 발생하면 이 신호가 끊기기 때문에Standby 측은 Active가 '죽었다'는 것을 알 수 있다.
137 |
138 | ### **Galera cluster**
139 |
140 | - 동기방식의 clustering을 지원해주는 오픈소스로 보임
141 |
142 | [Galera Cluster for MySQL](https://galeracluster.com/)
143 |
144 | [[MariaDB] Galera Cluster - 소개](https://myinfrabox.tistory.com/214)
145 |
146 |
147 | ### 참고 자료
148 |
149 | - 레플리케이션 참고
150 |
151 | [[MySQL] Replication (3) - Replication을 사용하는 이유](https://blog.seulgi.kim/2015/05/why-use-mysql-replication.html)
152 |
153 | - 데이터베이스의 다중화
154 |
155 | [[Database] DB 서버의 다중화 클러스터링(Multiplexing Clustering)과 리플리케이션(Replication)](https://kgh940525.tistory.com/entry/Database-DB-%EC%84%9C%EB%B2%84%EC%9D%98-%EB%8B%A4%EC%A4%91%ED%99%94Multiplexing-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0%EB%A7%81-%EB%A6%AC%ED%94%8C%EB%A6%AC%EC%BC%80%EC%9D%B4%EC%85%98Replication)
156 |
157 | - 레플리케이션 소개 영상: 작동원리, 장단점, 종류 -> 정말좋은 영상!
158 |
159 | [[10분 테코톡] ✌️ 영이의 Replication](https://www.youtube.com/watch?v=95bnLnIxyWI&t=1s)
160 |
161 | - 레플리케이션 설정
162 |
163 | [MySQL Replication(복제) - 단방향 이중화](https://server-talk.tistory.com/240)
164 |
165 | - DB 아키텍쳐 종류 및 설명 (데이터베이스 첫걸음 책)
166 |
167 | [https://hololo-kumo.tistory.com/220](https://hololo-kumo.tistory.com/220)
168 |
169 | [https://milhouse93.tistory.com/38?category=750797](https://milhouse93.tistory.com/38?category=750797)
--------------------------------------------------------------------------------
/Database/데이터베이스인덱스.md:
--------------------------------------------------------------------------------
1 | # 데이터베이스 인덱스
2 |
3 | ### 인덱스?
4 |
5 | DB 테이블에서 필요한 데이터를 빠르게 찾기 위해서 인덱스를 사용할 수 있다. 인덱스를 생성하면, 특정 컬럼의 데이터들을 정렬하여 별도의 메모리 공간에 주소와 함께 저장된다. 쉽게 비유하자면 책에 있는 목차(색인)이라고 할 수 있다. SQL 튜닝에서 중요한 Index에 대해서 알아보자
6 |
7 | 
8 |
9 | ### 인덱스를 사용하는 이유
10 |
11 | 인덱스의 가장 큰 특징은 데이터들이 정렬되어있다는 점이다. 덕분에 다양한 장점이 있는데, 다음과 같다.
12 |
13 | - Where
14 | - 인덱스가 없다면 Where절 사용시 레코드를 처음부터 끝까지 다 읽는 Full Table Scan이 일어나게된다. 하지만 인덱스 테이블은 데이터들이 정렬되어 저장되어 있기 때문에 해당 조건 (Where)에 맞는 데이터들을 빠르게 찾아낼 수 있다.
15 | - Order by
16 | - 인덱스가 없다면 정렬과 동시에 1차적으로 메모리에서 정렬이 이루어지고 메모리보다 큰 작업이 필요하다면 디스크 I/O도 추가적으로 발생됩니다. 하지만 인덱스 이용시 바로 가져오면 된다.
17 | - Min, Max
18 | - MIN값과 MAX값을 레코드의 시작값과 끝 값 한건씩만 가져오면 되기에 FULL TABE SCAN으로 테이블을 다 뒤져서 작업하는 것보다 훨씬 효율적으로 찾을 수 있습니다.
19 |
20 | ### 인덱스의 자료구조
21 |
22 | **Hash Table**
23 |
24 | 대부분의 Index는 B+Tree 자료구조를 이용하고 있다. 하지만 탐색능력만 따지면 O(1)시간의 Hash Table구조를 사용할 수 있을텐데 이유가 무엇일까? **해쉬테이블을** DB 인덱스로 사용할 수 없는 이유는 다음과 같다.
25 |
26 | 가장 큰 문제로 “***우리는 DB에서 등호(=) 뿐 아니라 부등호(<, >)도 사용할 수 있다”*** 모든 값이 정렬되어 있지 않으므로, 해시 테이블에서는 특정 기준보다 크거나 작은 값을 찾을 수 없다.
27 |
28 | > MySQL InnoDB에서는 메모리 버퍼 풀에서 레코드 검색을 위한 [어댑티브 해시 인덱스](https://tech.kakao.com/2016/04/07/innodb-adaptive-hash-index/)로 사용
29 | >
30 |
31 | **Array**
32 |
33 | 배열의 문제는 간단하다. 탐색이 O(1)이라 해도 삽입 삭제시 O(N)시간이 걸리기 때문이다. 또
34 |
35 | **데이터 수정이 일어날때도 퀵 정렬, 병합 정렬 등 배열 자료구조에서 O(N*logN) 시간으로 재정렬을 이루어야 한다는 점도 있다.**
36 |
37 | > 참고로 B-tree의 삽입, 삭제는 트리의 높이(h)에 따른 O(h)의 시간 복잡도를 가지는데, 이는 logN보다 훨씬 작은 값이다.
38 | >
39 |
40 | **결론적으로 DB 인덱스로 B-Tree가 가장 적합한 이유들을 정리하면 아래와 같다.**
41 |
42 | 1. **항상 정렬된 상태로 특정 값보다 크고 작은 부등호 연산에 문제가 없다.**
43 | 2. **참조 포인터가 적어 방대한 데이터 양에도 빠른 메모리 접근이 가능하다.**
44 | 3. **데이터 탐색뿐 아니라, 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도를 가진다.**
45 |
46 | ### 인덱스의 종류
47 |
48 | 인덱스에는 **클러스터드 인덱스 (Clustered Index)** 와 **논-클러스터드 인덱스 (Non-Clustered Index)** 2가지 종류가 존재한다.
49 |
50 | 
51 |
52 | ### 클러스터드 인덱스
53 |
54 | - 인덱스 키의 순서에 따라 데이터가 정렬되어 저장되는 방식
55 | - 실제 데이터가 순서대로 저장되어 있어 인덱스를 검색하지 않아도 원하는 데이터를 빠르게 찾을 수 있다.
56 | - 데이터 삽입, 삭제 발생 시 **순서를 유지**하기 위해 **데이터를 재정렬**해야한다.
57 | - 한 개의 릴레이션에 **하나의 인덱스만 생성 가능**
58 |
59 | ### 넌클러스터드 인덱스
60 |
61 | - 인덱스의 키 값만 정렬되어 있을 뿐 실제 데이터는 정렬되지 않는 방식
62 | - 데이터를 검색하기 위해서는 먼저 인덱스를 검색하여 실제 데이터 위치를 확인해야 하므로 **클러스터드 인덱스에 비해 검색 속도가 떨어진다.**
63 | - 한 개의 릴레이션에 여러 인덱스를 만들 수 있다.
64 |
65 | ### 인덱스의 장점
66 |
67 | - 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
68 | - 전반적인 시스템의 부하를 줄일 수 있다.
69 |
70 | ### 인덱스의 단점
71 |
72 | - 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다.
73 | - 인덱스를 관리하기 위해 추가 작업이 필요하다.
74 | - 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다.
75 |
76 | ### 인덱스의 관리
77 |
78 | DBMS는 index를 항상 최신의 **정렬된 상태로 유지**해야 원하는 값을 빠르게 탐색할 수 있다.
79 |
80 | 그렇기 때문에 인덱스가 적용된 컬럼에 INSERT, UPDATE, DELETE가 수행된다면 각각 다음과 같은 연산을 추가적으로 해줘야하며, 그에 따른 오버헤드가 발생한다.
81 |
82 | - INSERT : 새로운 데이터에 대한 인덱스를 추가함
83 | - DELETE : 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행
84 | - UPDATE : 기존의 인덱스를 사용하지 않음 처리하고, 갱신된 데이터에 대해 인덱스를 추가함
85 |
86 | 만약 CREATE, DELETE, UPDATE가 빈번한 속성에 인덱스를 걸게 되면 인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과가 발생할 수 있다.
87 |
88 | 만약 어떤 테이블에 UPDATE와 DELETE가 빈번하게 발생된다면 실제 데이터는 10만건이지만 인덱스는 100만 건이 넘어가게 되어, SQL문 처리 시 비대해진 인덱스에 의해 **오히려 성능이 떨어지게** 될 것이다.
89 |
90 | ### 인덱스는 언제 써야 하는가?
91 |
92 | 보통 인덱스는 한 테이블당 3~5개가 적당하다. 큰 결정 조건으로는 아래 4가지 기준이 있다.
93 |
94 | - **카디널리티 (Cardinality)**
95 | - **카디널리티가 높으면(↑) 인덱스 설정에 좋은 컬럼이다. (인덱스를 통해 불필요한 데이터의 대부분을 걸러낼 수 있음.)**카디널리티가 높다 = 한 컬럼이 갖고 있는 값의 중복도가 낮음. (= 값들이 대부분 다른 값을 가짐.)카디널리티가 낮다 = 한 컬럼이 갖고 있는 값의 중복도가 높음. (= 값들이 거의 같은 값을 가짐 )
96 | - **선택도 (Selectivity)**
97 |
98 | **선택도가 낮으면(↓) 인덱스 설정에 좋은 컬럼이다. (일반적으로 5~10%가 적당함.)**선택도가 높다 = 한 컬럼이 갖고 있는 값 하나로 여러 row가 찾아진다.선택도가 낮다 = 한 컬럼이 갖고 있는 값 하나로 적은 row가 찾아진다.
99 |
100 | > 선택도 계산법 (= 컬럼의 특정 값의 row 수 / 테이블의 총 row 수 * 100)
101 | ex) 10개의 데이터에서 고유한 학번(grade) 컬럼,
102 | 2명씩 같은 이름(name) 컬럼,
103 | 5명씩 같은 나이(age) 컬럼인 경우
104 | ① 학번(grade) 컬럼 선택도: 1 / 10 = 10%
105 | ② 이름(name) 컬럼 선택도: 2 / 10 = 20%
106 | ③ 나이(age) 컬럼 선택도: 5 / 10 = 50%
107 | >
108 | - **조회 활용도**
109 | - **조회 활용도가 높으면(↑) 인덱스 설정에 좋은 컬럼이다.**해당 컬럼이 실제 작업에서 얼마나 활용되는지에 대한 값.(`WHERE`의 대상 컬럼으로 많이 활용되는지로 판단하면 된다.)
110 | - **수정 빈도**
111 | - **수정 빈도가 낮으면(↓) 인덱스 설정에 좋은 컬럼이다.**인덱스도 테이블이기 때문에, 인덱스로 지정된 컬럼의 값이 바뀌게 되면 인덱스 테이블도 새롭게 갱신되어야 하기 때문.
112 |
113 |
114 |
115 | ## 참고자료
116 |
117 | - hash table index, b-tree index
118 |
119 | [데이터베이스 인덱스는 왜 'B-Tree'를 선택하였는가](https://helloinyong.tistory.com/296)
120 |
121 | - 인덱스란?
122 |
123 | [](https://mangkyu.tistory.com/96)
124 |
125 | - DB 인덱스
126 |
127 | [[DB] 데이터베이스 인덱스(Index) 란 무엇인가?](https://coding-factory.tistory.com/746)
128 |
129 | [[면접 대비] 데이터베이스 - 인덱스](https://velog.io/@syleemk/%EB%A9%B4%EC%A0%91-%EB%8C%80%EB%B9%84-%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%EC%9D%B8%EB%8D%B1%EC%8A%A4)
130 |
131 | - 인덱스 종류, 인덱스 사용이유
132 |
133 | [효과적인 DB index 설정하기](https://velog.io/@jwpark06/%ED%9A%A8%EA%B3%BC%EC%A0%81%EC%9D%B8-DB-index-%EC%84%A4%EC%A0%95%ED%95%98%EA%B8%B0)
134 |
135 | [](https://yurimkoo.github.io/db/2020/03/14/db-index.html)
--------------------------------------------------------------------------------
/Database/정규화/BCNF1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/BCNF1.png
--------------------------------------------------------------------------------
/Database/정규화/BCNF2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/BCNF2.png
--------------------------------------------------------------------------------
/Database/정규화/이상현상과 결정자1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/이상현상과 결정자1.png
--------------------------------------------------------------------------------
/Database/정규화/이상현상과 결정자2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/이상현상과 결정자2.png
--------------------------------------------------------------------------------
/Database/정규화/이상현상과 결정자3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/이상현상과 결정자3.png
--------------------------------------------------------------------------------
/Database/정규화/정규화.md:
--------------------------------------------------------------------------------
1 | # 📌 정규화(normalization)
2 |
3 | 이상 현상이 발생하는 테이블을 수정하여 정상으로 만드는 과정을 정규화(normalization)라고 한다.
4 | 정규화를 하기 위해서는 우선 테이블을 분석하여 기본키와 함수 종속성을 파악해야 한다.
5 | 그 후 릴레이션을 분해하여 제거한다.
6 | 분해된 릴레이션에 이상현상이 남아 있다면 없어질 때까지 분해 한다.
7 |
8 | > `TIP`
9 | 릴레이션과 테이블은 같은 의미로 쓰인다.
10 | 보통 테이블은 실무와 같은 구조보다 데이터를 강조하는 측면이 있고
11 | 릴레이션은 구조에 관한 이론을 강조하는 텍스트측면이 있다.
12 | >
13 |
14 |
15 |
16 | ## ❓ 이상현상(anomaly)?
17 |
18 | 이상이란 잘못 설계된 테이블로 삽입, 수정, 삭제와 같은 데이터 조작시 일어나는 일이다.
19 | ex) 튜플 삽입시 NULL 삽입, 하나의 튜플 삭제시 연쇄 삭제, 수정시 불일치 문제 발생 등
20 |
21 |
22 |
23 | ## ❓ 함수 종속성(FD, Functional Dependency)?
24 |
25 | > 수강 신청 릴레이션
26 | >
27 | >
28 | > 
29 | >
30 |
31 | 수강 신청 릴레이션은 각 속성 사이에 의존성이 존재한다.
32 | '알고리즘' 강좌는 '계란관 101' 한 곳 뿐이다.
33 | 반면 이름이 '유정란'인 경우에는 '알고리즘', '데이터베이스' 두 강좌가 있다.
34 |
35 | 이처럼 강좌이름을 알면 강의실을 알 수 있는데
36 | 어떤 속성 A를 알면 B의 값이 유일해지는 의존 관계를 `'속성B는 속성A에 종속한다'` or `'속성A는 속성B를 결정한다'`라고 한다.
37 | 그리고 `A → B`와 같이 표기 한다.
38 |
39 | `A → B`와 같이 왼쪽 속성(A)의 모든 값에 의하여 오른쪽 속성(B)의 값이 유일하게 결정될때 `'함수적으로 종속한다'`라고 한다. 그리고 이렇게 종속하는 성질을 `함수 종속성`이라고 한다.
40 |
41 | > **함수 종속성 규칙**
42 | >
43 | 부분집합 규칙: if Y ⊆ X, then X → Y
44 | 증가 규칙: if X → Y, then XZ → YZ
45 | 이행 규칙: if X → Y and Y → Z, then X → Z
46 | >
47 | >
48 | > **위의 세 가지 규칙으로 얻을 수 있는 규칙**
49 | > 결합 규칙: if X → Y and X → Z, then X → YZ
50 | > 분해 규칙: if X → YZ, then X → Y and X → Z
51 | > 유사 이행 규칙: if X → Y and WY → Z, then WX → Z
52 | >
53 | > 이 함수 종속성의 규칙은 릴레이션에 적용된다.
54 | >
55 |
56 |
57 |
58 | ## 🔍 이상현상과 결정자
59 |
60 | 
61 |
62 | 이상현상은 한개의 릴레이션에 두개 이상의 정보가 포함되어 있을때 나타난다.
63 | 학생수강성적 릴레이션의 경우 학생정보와 강좌정보가 한 릴레이션에 포함되어 있기 때문에 이상현상이 나타난다.
64 |
65 | 
66 |
67 | 모든 결정자를 살펴보면 (학생번호, 강좌이름), 학생번호, 강좌이름, 학과 이다.
68 | 이 중 (학생번호, 강좌이름)은 키본키이면서 결정자이고 학생번호, 강좌이름, 학과는 키본키가 아니면서 결정자이다.
69 | 이상현상은 기본키가 아니면서 결정자인 속성이 있을때 발생함으로 릴레이션을 분해해야한다.
70 |
71 | 
72 |
73 | 위의 사진과 분해할 경우 더 이상 이상현상이 발생하지 않는다.
74 |
75 |
76 |
77 | ## 🔍 정규화 과정
78 |
79 | > 이상현상이 발생하는 릴레이션을 분해하여 이상현상을 없애는 과정을 정규화라고 한다.
80 | 릴레이션은 정규형이라는 개념으로 구분하며 정규형이 높을수록 이상현상은 줄어든다.
81 | >
82 |
83 | ### 제 1정규형
84 |
85 | ***정의: 릴레이션 R의 모든 속성 값이 원자값을 가지면 제 1정규형이다.***
86 |
87 | > **예시**
88 | >
89 | >
90 | > 
91 | >
92 |
93 |
94 |
95 | ### 제 2정규형
96 |
97 | 제 2정규형은 릴레이션의 기본키가 복합키일 때, 복합키의 일부분이 다른 속성의 결정자인지 여부를 판단하는 것이다.
98 | ***정의: 릴레이션 R이 제 1정규형이고 기본키가 아닌 속성이 기본키에 완전 함수 종속일때 제 2정규형이라고 한다.***
99 |
100 | > 완전 함수 종속성
101 | >
102 | >
103 | > 제 2정규형을 이해하기 위해서는 완전 함수 종속성을 알아야 한다. 정의는 다음과 같다
104 | > **정의: A와 B가 릴레이션R의 속성이고 A → B 종속성이 성립할때, B가 A의 속성 전체에 함수 종속하고 부분 집합 속성에 함수 종속하지 않을 경우 완전 함수 종속(full functional dependency)이라고 한다.**
105 | >
106 | > ex) (A1, A2) → B인데 A1 → B 이면 불완전 함수 종속이다.
107 | >
108 |
109 | > **예시**
110 | >
111 | >
112 | > 
113 | >
114 | > **이상현상**
115 | >
116 | > - 삭제이상
117 | > 101 학번의 학생이 수강을 취소하게 되면 알고리즘 과목의 강의실에 대한 정보가 사라진다.
118 | > - 삽입이상
119 | > '세계사'라는 과목이 '정란관102'로 새로 개설되어도 신청한 학생이 없어 학번과 성적에 `NULL`값을 넣어야 한다.
120 | >
121 | > **2정규형으로 변환**
122 | >
123 | > 
124 | >
125 |
126 |
127 |
128 | ### 제 3정규형
129 |
130 | 제 3정규형은 속성들이 이행적으로 종속되어 있는지 여부를 판단하는 것이다.
131 | ***정의: 릴레이션R이 제 2정규형이고 기본키가 아닌 속성이 기본키에 비이행적으로 종속할 때 제 3정규형이라고 한다.***
132 | `TIP` 이행적 종속이란 A → B, B → C가 성립할 때 A → C가 성립되는 함수 종속성이다.
133 |
134 | > **예시**
135 | >
136 | >
137 | > 
138 | >
139 | > **이상현상**
140 | >
141 | > - 삭제이상
142 | > 402 학번의 학생이 수강을 취소하게 되면 스포츠경영학 과목의 수강료에 대한 정보가 사라진다.
143 | > - 삽입이상
144 | > 운영체제 과목이 개설되어 15,000원을 삽입 해야 하는데, 아직 신청한 학생이 없어 학번을 `NULL`값으로 삽입해야하는 문제 발생
145 | > - 수정이상
146 | > 데이터베이스 수강료를 15,000원으로 변경할 경우 데이터 불일치가 발생할 가능성이 있다.
147 | >
148 | > **제 3정규형으로 변환**
149 | >
150 | > 
151 | >
152 |
153 |
154 |
155 | ### BCNF
156 |
157 | 릴레이션에 존재하는 함수 종속성에서 모든 결정자가 후보키이면 BCNF(Boyce Codd Normal Form) 정규형이다.
158 | ***정의: 릴레이션 R에서 함수 종속성 X → Y가 성립할 때 모든 결정자 X가 후보키이면 BCNF 정규형이라고 한다.***
159 |
160 | > `TIP` 후보키는 기본키로 사용할 수 있는 속성들을 뜻한다.
161 | 즉 유일성과 최소성을 만족해야 한다.
162 | >
163 |
164 | > **예시**
165 | >
166 | >
167 | > 
168 | >
169 | > **이상현상**
170 | >
171 | > - 삭제이상
172 | > 1601번의 학생이 수강을 취소하면 김교수의 정보가 사라진다.
173 | > - 삽입이상
174 | > 최교스기 특강을 새로 열면 아직 신청한 학생이 없어 학생번호를 NULL 값으로 삽입해야 한다.
175 | > - 수정이상
176 | > 박교수가 특강이름을 데이터베이스 개론으로 변경할 경우 불일치가 발생할 수 있다.
177 | >
178 | > **이상현상의 원인**
179 | >
180 | > 교수는 특강이름을 결정하는 결정자이면서 후보키가 아니다.
181 | > 이와 같이 결정자이면서 후보키가 아닌 속성이 존재하면 이상현상이 발생한다.
182 | >
183 | > **BCNF정규형으로 변환**
184 | >
185 | > 
186 | >
187 |
188 |
189 |
190 | ### 🎉 정리
191 |
192 | 제 4정규형은 다치종속성을 가진 릴레이션에 관한 내용, 제 5정규형은 프로젝트-조인 정규형이라고 부르며 조인종석성을 가진 릴레이션이다. 대부분의 릴레이션은 BCNF까지 정규화하면 실제적인 이상현상은 없어진다. 그래서 이 글에서도 따로 다루지는 않는다.
193 |
194 |
195 |
196 | ## ✨ References
197 | - 박우창, 남송휘, 이현룡, 『mysql로 배우는 데이터베이스 개론과 실습』, 한빛아카데미
--------------------------------------------------------------------------------
/Database/정규화/제1정규형.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/제1정규형.png
--------------------------------------------------------------------------------
/Database/정규화/제2정규형1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/제2정규형1.png
--------------------------------------------------------------------------------
/Database/정규화/제2정규형2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/제2정규형2.png
--------------------------------------------------------------------------------
/Database/정규화/제3정규형1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/제3정규형1.png
--------------------------------------------------------------------------------
/Database/정규화/제3정규형2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/제3정규형2.png
--------------------------------------------------------------------------------
/Database/트랜잭션.md:
--------------------------------------------------------------------------------
1 | # 트랜잭션
2 |
3 | DBMS에서 데이터를 다루는 논리적인 작업의 단위로, 작업의 단위는 사람이 정하는 기준에 따라 다르다.
4 |
5 | 데이터베이스는 정확한 데이터를 유지 및 오류 발생 시 빠르게 복구하고, 데이터베이스가 항상 정확하고 일관된 상태를 유지할 수 있도록 하는 것이 트랜잭션이다.
6 |
7 |
8 |
9 | # 성질(ACID)
10 |
11 | - **원자성 (Atomicity)** : 트랜잭션이 데이터베이스에 모두 반영되거나 모두 반영되지 않아야 한다.
12 |
13 | - **일관성 (Consistency)** : 데이터베이스는 항상 일관된 상태를 유지해야한다.
14 | - 트랜잭션 전후에도 항상 데이터베이스의 **무결성 제약조건**와 **일관성 조건**을 만족해야 한다.
15 |
16 | > **무결성 제약조건** : 테이블에 부적절한 자료가 입력되는 것을 방지하기 위해 테이블 생성할 때 각 컬럼에 대해 정의하는 여러가지 규칙
17 | ex) not null, unique, primary key, foreign key, check ...
18 | [참고](https://yongstudy.tistory.com/52)
19 |
20 | **일관성 조건** : 올바른 시스템을 정의하기 위한 비명시적인 설계
21 | ex) 자금 이체 후 두 계좌 잔고의 합은 이전과 같아야한다. 계좌의 잔고는 음수가 아니다.
22 |
23 | >
24 | - 트랜잭션 실행 중간에는 만족하지 않아도 된다.
25 |
26 | - **고립성 (Isolation)** : 트랜잭션이 다른 트랜잭션의 연산에 영향을 끼치면 안 된다.
27 |
28 | - **지속성 (Durability)** : 트랜잭션이 성공적으로 완료됐을 경우, 결과는 영구적으로 반영되어야 한다.
29 |
30 |
31 |
32 | - **원자성**과 **지속성**을 유지하기 위해 **[회복](https://www.notion.so/125c44f658124e3ea214c057d1f2c3d3)** 기능을 지원한다.
33 | - **일관성**과 **고립성**을 유지하기 위해 **[동시성 제어](https://www.notion.so/125c44f658124e3ea214c057d1f2c3d3)**를 한다.
34 | - **일관성**을 유지하기 위해 **무결성 제약조건**을 이용한다.
35 |
36 |
37 |
38 | # 트랜잭션 연산
39 |
40 | 데이터베이스는 트랜잭션 연산을 통해 트랜잭션 후에도 데이터베이스를 일관된 상태로 만든다.
41 |
42 | - Commit
43 | - 트랜잭션의 수행이 완료됐고 데이터베이스가 일관성있는 상태에 있을 때, 트랜잭션의 결과를 데이터베이스에 반영한다.
44 | - Rollback
45 | - 트랜잭션이 비정상적으로 종료되어 트랜잭션의 원자성이 깨진 경우, 트랜잭션을 처음부터 다시 시작하거나, 트랜잭션의 부분적으로만 연산된 결과를 취소시킨다.
46 |
47 |
48 |
49 | # 트랜잭션 상태
50 |
51 | 
52 |
53 | - **활동(Active)**
54 | - 모든 트랜잭션의 첫 상태로, 트랜잭션이 시작되어 실행되고 있는 상태
55 | - **부분 완료(Partially Committed)**
56 | - 트랜잭션의 마지막 연산까지 수행했고 commit 연산을 수행하기 직전의 상태
57 | - 데이터는 여전히 데이터베이스에 저장되지 않는다.
58 | - **완료(Committed)**
59 | - 트랜잭션을 성공적으로 완료한 상태
60 | - 트랜잭션의 모든 작업이 데이터베이스에 반영되어 변경 사항이 데이터베이스에 영구적으로 저장된다.
61 | - **실패(Failed)**
62 | - 트랜잭션 수행 중, 오류가 발생하여 트랜잭션이 중단된 상태
63 | - **철회(Aborted)**
64 | - 트랜잭션이 중단되어 rollback된 상태
65 | - rollback된 이후 데이터베이스 복구 모듈은 다음 두 가지 작업 중 하나를 선택한다.
66 | - 트랜잭션 다시 시작
67 | - 트랜잭션 종료
68 |
69 |
70 |
71 | # 동시성 제어(Concurrency Control)
72 |
73 | 다중 사용자 환경에서 둘 이상의 트랜잭션이 동시에 수행될 때, 일관성을 해치지 않도록 트랜잭션의 데이터 접근을 제어하는 것
74 |
75 |
76 |
77 | # 트랜잭션 스케줄
78 |
79 | 여러 트랜잭션들을 어떤 순서에 따라 실행시킬 건지 관리하는 것
80 |
81 | - **직렬 스케줄(Serial Schedule)** : 트랜잭션 별로 연산들을 순차적으로 실행시키는 것
82 |
83 | - **비직렬 스케줄(Non-Serial Schedule)** : 인터리빙 방식을 이용하여 트랜잭션들을 병행하여 실행시키는 것
84 |
85 | - **직렬 가능 스케줄(Serializable Schedule)** : 직렬 스케줄에 따라 수행한 것과 같이 정확한 결과를 생성하는 비직렬 스케줄
86 |
87 |
88 |
89 | # 트랜잭션 격리 수준(Isolation Level)
90 |
91 | 트랜잭션이 동시에 진행 중인 다른 트랜잭션에 의해 간섭받는 정도
92 |
93 | - 0단계 : read-uncommitted
94 | - 1단계 : read-committed
95 | - 2단계 : repeatable-read
96 | - 3단계 : serializable
97 |
98 | 단계가 높아질 수록 트랜잭션 간 간섭이 적으며 직렬적이고, 낮을 수록 트랜잭션 간 간섭은 많지만 동시성을 보장한다.
99 |
100 | 격리 수준을 적절히 조절함으로써 데이터베이스의 **일관성(consistency)**과 **동시성(concurrency)**을 조정할 수 있다.
101 |
102 | → [lock 알아보기](https://mangkyu.tistory.com/30?category=761304)
103 |
104 |
105 |
106 | ## READ-UNCOMMITTED
107 |
108 | 처리중이거나 커밋되지 않은 트랜잭션의 데이터 변경 내용을 다른 트랜잭션이 읽는 것을 허용한다.
109 |
110 | 
111 |
112 | ### 발생될 수 있는 현상
113 |
114 | - [Dirty Read](#트랜잭션-격리-수준-정리)
115 | - Non-Repeatable Read
116 | - Phantom Read
117 |
118 |
119 |
120 | ## READ-COMMITTED
121 |
122 | 커밋이 완료된 트랜잭션의 변경사항만 다른 트랜잭션에서 조회할 수 있다.
123 |
124 | 
125 |
126 | ### 발생될 수 있는 현상
127 |
128 | - [Non-Repeatable Read](#트랜잭션-격리-수준-정리)
129 | - Phantom Read
130 |
131 |
132 |
133 | ## REPEATABLE-READ
134 |
135 | 커밋이 완료된 트랜잭션의 변경사항만 다른 트랜잭션에서 조회할 수 있다.
136 |
137 | 트랜잭션 범위 내에서 조회한 내용이 항상 동일함을 보장한다.
138 |
139 | 
140 |
141 | ### 발생될 수 있는 현상
142 |
143 | - [Phantom Read](#트랜잭션-격리-수준-정리)
144 |
145 |
146 |
147 | ## SERIALIZABLE
148 |
149 | 한 트랜잭션에서 사용하는 데이터를 다른 트랜잭션에서 접근할 수 없다.
150 |
151 | 가장 안전하지만 성능이 매우 떨어진다.
152 |
153 |
154 |
155 | ### 트랜잭션 격리 수준 정리
156 |
157 | 
158 |
159 | - Dirty Read: 무효화된 데이터 값을 읽는 현상
160 |
161 | 
162 |
163 | - Non-Repeatable Read : 하나의 트랜잭션 안에서 다른 트랜잭션으로 인해 read 연산 시 서로 다른 값을 읽는 데이터 불일치 현상
164 |
165 | 
166 |
167 | - Phantom Read : 한 트랜잭션 내에서 여러 번 조회시 나타나는 현상으로, 해당 쿼리로 읽히는 데이터에 레코드가 새로 생기거나 없어져 있는 현상
168 |
169 | 
170 |
171 |
172 |
173 |
174 | # 트랜잭션 교착상태(Dead Lock)
175 |
176 | 트랜잭션 서로가 작업 수행을 차단하기 때문에 발생하는 현상.
177 |
178 |
179 |
180 | ### 해결 방법
181 |
182 | - 격리 수준을 낮춘다.
183 | - 잠금 타임아웃을 건다. → 일정 시간이 지나면 트랜잭션을 롤백시킨다.
184 |
185 |
186 |
187 | # 회복
188 |
189 | 데이터베이스에 장애가 발생했을 때 데이터베이스를 일관성 있는 상태로 되돌리는 기능
190 |
191 | → check point 알아보기
192 |
193 |
194 |
195 | ## 장애 유형
196 |
197 | - 트랜잭션 장애 : 트랜잭션의 실행 시 논리적인 오류로 발생할 수 있는 에러 상황
198 | - 시스템 장애 : 하드웨어 시스템 자체에서 발생할 수 있는 에러 상황
199 | - 미디어 장애 : 디스크 자체의 손상으로 발생할 수 있는 에러 상황
200 |
201 |
202 |
203 | ## 로그 파일
204 |
205 | 데이터페이스는 데이터의 손실을 방지하기 위해 트랜잭션의 기록을 추적하는 로그 파일을 사용한다.
206 |
207 | 로그 파일은 트랜잭션이 반영한 모든 데이터의 변경사항을 데이터베이스에 기록하기 전에 미리 기록해두는 별도의 데이터베이스이며, 하드디스크에 저장된다.
208 |
209 | 로그 구조 : 트랜잭션 번호, 로그 타입, 데이터 항목 이름, 수정 전 값, 수정 후 값
210 |
211 | 로그 타입 : START, INSERT, UPDATE, DELETE, ABORT, COMMIT 등 트랜잭션의 연산 타입
212 |
213 |
214 |
215 | ## 로그 파일을 이용한 회복
216 |
217 | - REDO : 로그 파일에 트랜잭션의 START 기록과 COMMIT 기록이 모두 있을 때, 변경한 내용을 다시 기록하여 일관성을 보장하는 방법
218 | - UNDO : 로그 파일에 트랜잭션의 START 기록이 있지만 COMMIT 기록이 없을 때, 로그를 역순으로 참조하여 롤백시키는 방법
219 |
220 |
221 |
222 | ## 체크포인트를 이용한 회복
223 |
224 | 로그파일에 트랜잭션을 기록할 때 특정 지점에 체크포인트를 표시하고,
225 |
226 | 장애 발생 시 체크포인트 이전에 처리된 트랜잭션은 회복에서 제외하고 체크포인트 이후에 처리된 내용에 대해서만 회복 작업을 수행한다.
227 |
228 | - checkpoint 이후, 장애 발생 이전에 commit이 완료된 경우 redo 수행
229 | - 장애 발생 시점까지 commit되지 못한 경우 undo 수행
230 |
231 | 
232 |
233 |
234 |
235 | ## 덤프를 이용한 회복
236 |
237 | 일정 주기로 원본 데이터베이스의 내용을 백업용 데이터베이스에 저장하여 원본 데이터베이스에 문제가 발생했을 때 백업용 데이터베이스의 내용을 다시 원본 데이터베이스로 옮기는 방법
238 |
239 |
240 |
241 |
242 |
243 | ---
244 |
245 | ### 참고자료
246 |
247 | [https://mangkyu.tistory.com/30?category=761304](https://mangkyu.tistory.com/30?category=761304)
248 |
249 | [https://mommoo.tistory.com/62](https://mommoo.tistory.com/62)
250 |
251 | [https://velog.io/@wldus9503/데이터베이스-트랜잭션Transaction란](https://velog.io/@wldus9503/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98Transaction%EB%9E%80)
252 |
253 | [https://ehpub.co.kr/tag/트랜잭션의-상태/](https://ehpub.co.kr/tag/%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98%EC%9D%98-%EC%83%81%ED%83%9C/)
254 |
255 | [https://brunch.co.kr/@skeks463/28](https://brunch.co.kr/@skeks463/28)
256 |
257 | [https://www.cubrid.org/manual/ko/9.3.0/sql/transaction.html](https://www.cubrid.org/manual/ko/9.3.0/sql/transaction.html)
--------------------------------------------------------------------------------
/DesignPattern/MVC,MVVM,MVP/MVC, MVVM, MVP.md:
--------------------------------------------------------------------------------
1 | # 📌 디자인 패턴이란?
2 |
3 | - 디자인 패턴은 건축으로치면 공법에 해당하는 것으로 소프트웨어의 개발 방법을 공식화 한 것이다. 소수의 뛰어난 엔지니어가 해결한 문제를 다수의 엔지니어들이 처리 할 수 있도록 한 규칙이면서, 구현자들 간의 커뮤니케이션의 효율성을 높이는 기법이다.
4 | - 명확하게 정답이 있는 형태는 아니며, 프로젝트의 상황에 맞추어 적용 가능
5 |
6 | ## 🔍 사용 목적 및 이유
7 |
8 | 1. 우리 주변에서 자주 반복해서 발생하는 문제와 그 문제를 해결하는 핵심을 기술해 동일한 일을 두번 다시 하지 않고 해결할 수 있도록 한다.
9 | 2. 구체적인 설명 없이 구조화된 패턴에 대한 사전 지식으로 개발자 간에 커뮤니케이션이 수월하다.
10 | 3. 설계 과정의 속도를 높일 수 있다. 이미 검증된 구조이기 때문이다.
11 |
12 | # 📌 MVC**(Model-View-Controller)** 패턴
13 |
14 | - MVC 패턴은 Model + View + Controller를 합친 용어
15 |
16 | ## 🔍 구조
17 |
18 | 
19 |
20 | - Controller : 사용자의 입력을 받고 처리하고 뿌리는거 모두하는 부분 (Model과 View 사이에서 컨트롤)
21 | - Model : 어플리케이션에서 사용되는 데이터와 그 데이터를 처리하는 부분
22 | - View : 사용자에게 보여지는 UI 부분 (클라이언트 측 기술인 html/css/javascript들을 모아둔 컨테이너 / View는 Controller의 존재를 모른다 / View 는 Model 의 변화에 대해 직접적으로 알지 못한다 → 옵저버 패턴과 같은 방식으로 간접적으로 인지)
23 |
24 | ## 🔍 동작
25 |
26 | 1. 사용자의 입력들은 Controller에 들어오게 됩니다.
27 | 2. Controller는 사용자의 입력을 확인하고, Model을 업데이트합니다.
28 | 3. Controller는 Model을 나타내줄 View를 선택합니다.
29 | 4. View는 Model을 이용하여 화면을 나타냅니다.
30 |
31 | ## 🔍 특징
32 |
33 | Controller는 여러개의 View를 선택할 수 있는 1:n 구조입니다.(m:n 다대다 관계일 수도 있다)
34 | Controller는 View를 선택할 뿐 직접 업데이트 하지 않습니다. (View는 Controller를 알지 못합니다.)
35 |
36 | ## 🔍 장점
37 |
38 | MVC 패턴의 장점은 널리 사용되고 있는 패턴이라는 점에 걸맞게 가장 단순합니다.
39 | 단순하다 보니 보편적으로 많이 사용되는 디자인패턴입니다.
40 | 그리고 각 구성요소를 독립시킴으로써 각 팀으로 하여금 맡은 부분의 개발에만 따로 집중 할 수 있게 하여 개발의 효율성을 높일 뿐만 아니라. 개발 완료 후에도 유지보수성과 확장성을 보장한다.
41 |
42 | ## 🔍 단점
43 |
44 | MVC 패턴의 단점은 View와 Model 사이의 의존성이 높다는 것입니다.
45 | View와 Model의 높은 의존성은 어플리케이션이 커질 수록 복잡하지고 유지보수가 어렵게 만들 수 있습니다.
46 | MVC 패턴의 경우에는 규모가 커질수록 Controller가 비대해져 복잡도가 증가한다.
47 |
48 | # 📌 MVP**(Model-View-Presenter)** 패턴
49 |
50 | - MVP 패턴은 Model + View + Presenter를 합친 용어
51 | - MVC 패턴에서 Controller 대신 Presenter가 존재
52 |
53 | ## 🔍 구조
54 |
55 | 
56 |
57 | - Presenter : View에서 요청한 정보로 Model을 가공하여 View에 전달해 주는 부분 (ui 없이 로직이 존재 / Model 을 업데이트하고, 원하는 데이터를 가져온다)
58 | - Model : 어플리케이션에서 사용되는 데이터와 그 데이터를 처리하는 부분
59 | - View : 사용자에게 보여지는 UI 부분 (입력을 받는 부분 / Model의 존재를 모른다)
60 |
61 | ## 🔍 동작
62 |
63 | 1. 사용자의 입력들은 View를 통해 들어오게 됩니다.
64 | 2. View는 데이터를 Presenter에 요청합니다.
65 | 3. Presenter는 Model에게 데이터를 요청합니다.
66 | 4. Model은 Presenter에서 요청받은 데이터를 응답합니다.
67 | 5. Presenter는 View에게 데이터를 응답합니다.
68 | 6. View는 Presenter가 응답한 데이터를 이용하여 화면을 나타냅니다.
69 |
70 | ## 🔍 특징
71 |
72 | Presenter는 View와 Model의 인스턴스를 가지고 있어 둘을 연결하는 접착제 역할을 합니다.
73 | Presenter와 View는 1:1 관계입니다.
74 |
75 | ## 🔍 장점
76 |
77 | MVP 패턴은 MVC 패턴의 단점이었던 View와 Model의 의존성을 해결하였습니다
78 |
79 | ## 🔍 단점
80 |
81 | MVC 패턴의 단점인 View와 Model 사이의 의존성은 해결되었지만, View와 Presenter 사이의 의존성이 커지는 단점이 있습니다.
82 | 어플리케이션이 복잡해 질 수록 View와 Presenter 사이의 의존성이 강해지는 단점이 있습니다.
83 |
84 | # 📌 MVVM 패턴
85 |
86 | - MVVM 패턴은 Model + View + View Model를 합친 용어입니다.
87 | Model과 View은 다른 패턴과 동일합니다.
88 | - MVP 패턴에서 Presenter가 ViewModel가 된 패턴
89 |
90 | ## 🔍 구조
91 |
92 | 
93 |
94 | - Model : 어플리케이션에서 사용되는 데이터와 그 데이터를 처리하는 부분입니다.
95 | - View : 사용자에서 보여지는 UI 부분입니다. (입력을 ViewModel에 알림 / View는 ViewModel을 구독하고 있음)
96 | - ViewModel : View를 표현하기 위해 만든 View를 위한 Model입니다. View를 나타내 주기 위한 Model이자 View를 나타내기 위한 데이터 처리를 하는 부분입니다. (ViewModel은 데이터를 바꾸기만함 / 어떤 화면을 그리라고 안알려줌)
97 |
98 | ## 🔍 동작
99 |
100 | 1. 사용자의 입력들은 View를 통해 들어오게 됩니다.
101 | 2. View에 입력이 들어오면, Command 패턴으로 View Model에 입력을 전달합니다.
102 | 3. View Model은 Model에게 데이터를 요청합니다.
103 | 4. Model은 View Model에게 요청받은 데이터를 응답합니다.
104 | 5. View Model은 응답 받은 데이터를 가공하여 저장합니다.
105 | 6. View는 View Model과 Data Binding하여 화면을 나타냅니다.
106 |
107 | ## 🔍 특징
108 |
109 | MVVM 패턴은 [Command 패턴](https://ko.wikipedia.org/wiki/%EC%BB%A4%EB%A7%A8%EB%93%9C_%ED%8C%A8%ED%84%B4)과 [Data Binding](https://en.wikipedia.org/wiki/Data_binding) 두 가지 패턴을 사용하여 구현되었습니다.
110 | Command 패턴과 Data Binding을 이용하여 View와 View Model 사이의 의존성을 없앴습니다.
111 | View Model과 View는 1:n 관계입니다.
112 |
113 | [[WEB] 양방향 단방향 데이터 바인딩](https://velog.io/@sunaaank/data-binding)
114 |
115 | 데이터 바인딩이란?
116 |
117 | ## 🔍 장점
118 |
119 | MVVM 패턴은 View와 Model 사이의 의존성이 없습니다. 또한 Command 패턴과 Data Binding을 사용하여 View와 View Model 사이의 의존성 또한 없앤 디자인패턴입니다. 각각의 부분은 독립적이기 때문에 모듈화 하여 개발할 수 있습니다.
120 |
121 | ## 🔍 단점
122 |
123 | MVVM 패턴의 단점은 View Model의 설계가 쉽지 않다는 점입니다.
124 |
125 | # 👋 예상 질문
126 |
127 | - MVC 패턴이 뭘까요?
128 |
129 | 데이터를 처리하는 Model, 사용자에게 보여지는 화면 부분의 View, 입력을 받아 View에 전달하여 화면을 갱신하고 동시에 Model에 전달하여 데이터 처리까지하는 Controller를 사용하는 패턴입니다.
130 | 각 구성요소를 나눔으로써 개발의 효율성을 높이면서 유지보수에도 유리한 패턴입니다.
131 |
132 | - MVC, MVP, MVVM 패턴의 차이점이 뭘까요?
133 |
134 | MVC 패턴은 위에서 말한바와 동일하고 여기서 Controller 대신 Presenter를 통해서 Model과 View의 의존성을 없애면 MVP 패턴이 되고
135 | MVVM 패턴은 MVP 패턴에서 View와 Presenter의 강한 의존성을 ViewModel로 대체하여 데이터 바인딩을 통해 결합도를 낮춘 패턴입니다.
136 |
137 | - 그렇다면 MVVM 패턴이 가장 좋은 패턴인가요?
138 |
139 | 정답은 없다고 생각합니다.
140 | 가장 단순한 MVC 패턴이 유리할수도 있고 View가 가장 가벼운 MVP 패턴이 디자인 재사용에 유리하여 좋을수도 디자인과 동작까지 재사용에 유리한 MVVM도 설계 자체가 어려울 수 있어 상황에 맞게 적절히 사용하는것이 좋다고 생각합니다.
141 |
142 |
143 | # ✨ References
144 |
145 | - MVC, MVP, MVVM 패턴 특징
146 |
147 | [[디자인패턴] MVC, MVP, MVVM 비교](https://beomy.tistory.com/43)
148 |
149 | - 디자인 패턴이란
150 |
151 | [[Design Pattern] 디자인 패턴 이해 목적 및 사용 이유](https://developercc.tistory.com/17)
152 |
153 | [MVC 디자인 패턴 - 생활코딩](https://opentutorials.org/course/697/3828)
154 |
155 | - 데이터 바인딩이란
156 |
157 | [[WEB] 양방향 단방향 데이터 바인딩](https://velog.io/@sunaaank/data-binding)
--------------------------------------------------------------------------------
/DesignPattern/MVC,MVVM,MVP/mvc1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/DesignPattern/MVC,MVVM,MVP/mvc1.png
--------------------------------------------------------------------------------
/DesignPattern/MVC,MVVM,MVP/mvp1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/DesignPattern/MVC,MVVM,MVP/mvp1.png
--------------------------------------------------------------------------------
/DesignPattern/MVC,MVVM,MVP/mvvm1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/DesignPattern/MVC,MVVM,MVP/mvvm1.png
--------------------------------------------------------------------------------
/Development/CORS/CORS 0e3c01bc007c4adf83e4842c6db23bf6.md:
--------------------------------------------------------------------------------
1 | # CORS
2 |
3 | ## 👾 CORS(Cross Origin Resource Sharing)
4 |
5 |
9 |
10 | > 😯 다른 출처의 자원을 왜 사용 못하게 하나요?
11 | SOP(Same Origin Policy)때문입니다. 이는 다른 출처에서 불러온 자원과 상호작용(Javascript 에서 사용됨)을 방지하기 위해 나온 정책입니다. 이 정책을 우회하는 표준 방법입니다.
12 | >
13 | > - SOP(Same Origin Policy)
14 | >
15 | >
19 | >
20 | > > 출처(Origin): URL의 Protocol(Scheme) + Host + Port
21 | > >
22 | > 1. 출처 상속
23 | >
24 | > about:blank, javascript:와 같은 URL은 출처를 가지고 있지 않아서, 이런 경우에는 해당 창을 만든 URL을 상속받는다.
25 | >
26 | > 2. 출처 변경
27 | >
28 | > 상위 도메인으로의 출처의 변경도 가능하다. 예를 들어, ‘[http://sotre.company.com/dir/index.html](http://sotre.company.com/dir/index.html)’ 에서
29 | >
30 | > ```
31 | > document.domain = 'company.com';
32 | > ```
33 | >
34 | > 와 같이 domain을 바꿀 수 있습니다. 단. document.domain의 값을 바꾸면 port가 null로 설정 되기 때문에 나(요청 Origin)와 상대(요청될 Origin)의 port를 모두 맞춰줘야 합니다.(
124 | ```
125 |
126 | ### DOM Based XSS
127 |
128 | 위에서 설명한 두 XSS공격은 서버 측 결함으로 인해 공격이 실행된다. 하지만 DOM Based XSS공격은 서버와 관계없이 클라이언트측 코드가 원래 의도와 다르게 실행되면서 나타난다.
129 |
130 | 
131 |
132 |
133 | ### 대응 방법
134 |
135 | 최신 프레임워크, 라이브러리를 이용하면 대부분 XSS에 대한 방어가 자동으로 된다.
136 |
137 | - **XSS 공격에 대한 문자열 필터링**
138 | - **XSS 방어 라이브러리 사용**
139 | - **웹 방화벽 사용**
140 |
141 | ## CSRF(Cross-Site Request Forgery)
142 |
143 | 사이트 간 요청 위조, 해커가 사용자의 의지와는 무관하게 권한을 얻어 공격을 의미한다.
144 |
145 | 사용자가 해커의 피싱 사이트에 접속을 해 로그인을 하거나, XSS공격으로 악성 스크립트가 실행되어 의도하지 않은 api가 실행되는 경우 해당한다.
146 |
147 | 실제로 1800 만명의 개인정보가 해킹당한 2008년 옥션의 경우 관리자가 작업중 메일을 조회하면서 해당 태그가 담긴 이메일을 열었다.
148 |
149 | ```html
150 |
151 | ```
152 |
153 | 열자마자 해당 이미지 파일을 받아오기 위해 URL이 실행되고 해커가 원하는 대로 id,pw가 모두 변경되었다.
154 |
155 | ### 대응 방법
156 |
157 | 일반적으로는 쓰기/변경이 가능한 post,updated,delete API에 방어를 적용하고, 중요한 정보를 가진 Get 조회에 적용할 수 있다. 방법은 다음과 같다.
158 |
159 | - **Referrer 검증:** 서버에서 reqeust header에 있는 referrer 속성을 검증하여 차단하는 방법
160 |
161 | > **HTTP 리퍼러**(HTTP referer)는 [웹 브라우저](https://ko.wikipedia.org/wiki/%EC%9B%B9_%EB%B8%8C%EB%9D%BC%EC%9A%B0%EC%A0%80)로 [월드 와이드 웹](https://ko.wikipedia.org/wiki/%EC%9B%94%EB%93%9C_%EC%99%80%EC%9D%B4%EB%93%9C_%EC%9B%B9)을 서핑할 때, [하이퍼링크](https://ko.wikipedia.org/wiki/%ED%95%98%EC%9D%B4%ED%8D%BC%EB%A7%81%ED%81%AC)를 통해서 각각의 [사이트](https://ko.wikipedia.org/wiki/%EC%82%AC%EC%9D%B4%ED%8A%B8)로 방문시 남는 흔적을 말한다. →([위키](https://ko.wikipedia.org/wiki/HTTP_%EB%A6%AC%ED%8D%BC%EB%9F%AC))
162 | >
163 |
164 | 리퍼러는 조작 또한 가능하기 때문에 리퍼러 정보를 사용할 때에는 보안에 항상 주의해야 한다. 그리고 같은 도메인 내에서 XSS 취약점이 있는 경우 위험해 질 수 있다.(도메인 단위 검증에서도 세밀하게 하면 가능하긴 하다.)
165 |
166 | - **CSRF Token (Security Token):** 모든 요청에 토큰을 발급, 서버에서 검증하는 방법
167 |
168 | 로그인시 토큰을 생성하여 세션에 저장하고, 모든 요청시 검증함, 세션을 사용할 수 있는 환경이어야 함.
169 |
170 | - **Double Submit Cookie 검증:** 웹 브라우저의 same origin 정책으로 타 도메인의 쿠키값을 확인,수정하지 못한다는 것을 이용한 방어기법, 세션을 사용한 검증보다 가벼움
171 | 1. 클라이언트에서 요청시 토큰 생성하여 쿠키에 저장
172 | 2. 동일한 토큰 값을 요청 파라미터에 저장하여 서버에 전송
173 | 3. 서버에서 쿠키의 토큰 값과 파라미터의 토큰값이 일치하는지 검사
174 | - **CAPTCHA: 사람이 요청 한 것이 맞는지 검증하는 방식,**
175 |
176 | > 우리가 자주보던 이런걸 캡차라고함 → [위키](https://namu.wiki/w/CAPTCHA)
177 | >
178 | >
179 | > 
180 | >
181 |
182 |
183 |
184 | ## 참고자료
185 |
186 | - 정말 좋은 글 / 위에 언급된 공격에 이외에도 다양한 공격소개
187 |
188 | [웹 개발을 위해 꼭 알아야하는 보안 공격](https://kciter.so/posts/basic-web-hacking)
189 |
190 | - OWASP
191 |
192 | [한발 앞서 살펴보는 OWASP Top 10 2021 (Draft)](http://www.igloosec.co.kr/BLOG_%ED%95%9C%EB%B0%9C%20%EC%95%9E%EC%84%9C%20%EC%82%B4%ED%8E%B4%EB%B3%B4%EB%8A%94%20OWASP%20Top%2010%202021%20(Draft)?searchItem=&searchWord=&bbsCateId=1&gotoPage=1)
193 |
194 | - SQL Injection
195 |
196 | [SQL Injection 이란? (SQL 삽입 공격)](https://noirstar.tistory.com/264)
197 |
198 | [](https://namu.wiki/w/SQL%20injection)
199 |
200 | - XSS
201 |
202 | [](https://www.koreascience.or.kr/article/JAKO201306464554241.pdf)
203 |
204 | [Cross-site Scripting (XSS 개념과 원리)](https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=lstarrlodyl&logNo=221941738753)
205 |
206 | [XSS(Cross-Site Scripting) 공격](https://velog.io/@gs0351/XSSCross-Site-Scripting-%EA%B3%B5%EA%B2%A9)
207 |
208 | - CSRF
209 |
210 | [[Attack] CSRF(사이트 간 요청 위조, Cross-site request forgery)](https://t-okk.tistory.com/80)
211 |
212 | [](https://itstory.tk/entry/CSRF-%EA%B3%B5%EA%B2%A9%EC%9D%B4%EB%9E%80-%EA%B7%B8%EB%A6%AC%EA%B3%A0-CSRF-%EB%B0%A9%EC%96%B4-%EB%B0%A9%EB%B2%95)
213 |
214 | [웹 사이트 보안 공격 (XSS, CSRF)](https://velog.io/@minjae-mj/%EC%9B%B9%EC%82%AC%EC%9D%B4%ED%8A%B8-%EB%B3%B4%EC%95%88-%EA%B3%B5%EA%B2%A9-XSS-CSRF)
215 |
216 | - doubole submit cookie
217 |
218 | [CSRF 공격](https://velog.io/@jeong3320/CSRF-%EA%B3%B5%EA%B2%A9)
--------------------------------------------------------------------------------
/Development/함수형 프로그래밍.md:
--------------------------------------------------------------------------------
1 | # 함수형 프로그래밍
2 |
3 | ### 프로그래밍 패러다임
4 |
5 | > 프로그래머에게 프로그래밍의 관점을 갖게 하고 코드를 어떻게 작성할 지 결정하는 역할을 한다.
6 |
7 | ### 명령형 프로그래밍
8 |
9 | > 무엇을 할 것인지 나타내기 보다 **어떻게** 할 것인지를 설명하는 방식
10 |
11 | - **절차지향 프로그래밍**
12 |
13 | 수행되어야 할 순차적인 처리 과정을 포함하는 방식 (C, C++)
14 |
15 | - **객체지향 프로그래밍**
16 |
17 | 객체들의 집합으로 프로그램의 상호작용을 표현 (C++, Java, C#)
18 |
19 | ### 선언형 프로그래밍
20 |
21 | > 어떻게 할 건지를 나타내기 보다 **무엇**을 할 건지를 설명하는 방식
22 |
23 | - 함수형 프로그래밍
24 |
25 | 순수함수를 조합하고 소프트웨어를 만드는 방식
26 |
27 |
28 |
29 | # 함수형 프로그래밍
30 |
31 | ### 정의
32 |
33 | > 거의 모든 것을 순수함수로 나누어 문제를 해결하는 기법으로, 작은 문제를 해결하기 위한 함수를 작성하여 가독성을 높이고 유지보수를 용이하게 해준다.
34 |
35 | **부수 효과가 없는 순수 함수를 1급 객체로 간주하여 파라미터로 넘기거나 반환값으로 사용할 수 잇으며, 참조 투명성을 지킬 수 있다.**
36 |
37 |
38 |
39 | ### **부수효과 (side-effect)**
40 |
41 | - 변수의 값이 변경
42 | - 자료 구조를 제자리에서 수정
43 | - 객체의 필드값을 설정
44 | - 예외나 오류가 발생하며 실행이 중단됨
45 | - 콘솔 또는 파일 I/O가 발생함
46 |
47 |
48 |
49 | ### **순수함수**
50 |
51 | > 어떤 함수에 동일한 인자를 주었을 때 항상 같은 값을 리턴하는 함수 + 외부의 상태를 변경하지 않는 함수
52 |
53 | **부수효과들을 제거한 함수를 순수함수라고 부르며 함수형 프로그래밍에서 사용하는 함수는 순수함수 이다.**
54 |
55 | **효과**
56 |
57 | - 함수 자체가 독립적이며 부수효과가 없기 때문에 Thread에 안정성을 보장받을 수 있다.
58 | - 병렬처리를 동기화 없이 진행할 수 있다.
59 |
60 |
61 |
62 | ### **1급 객체**
63 |
64 | 다음과 같은 것들이 가능한 객체를 의미한다.
65 |
66 | - 변수나 데이터 구조 안에 담을 수 있다.
67 | - 파라미터로 전달할 수 있다.
68 | - 반호나값으로 사용할 수 있다.
69 | - 할당에 사용된 이름과 무관핫게 고유한 구별이 가능하다.
70 |
71 | **함수형 프로그래밍에서는 함수는 1급 객체로 취급받기 때문에 함수를 파라미터로 넘기는 등의 작업이 가능하다.**
72 |
73 |
74 |
75 | ### **참조 투명성**
76 |
77 | **함수형 프로그래밍에서는 동일한 인자에 대해 항상 동일한 결과를 반환해야 한다. ⇒ 외부의 영향을 받지 않는다.**
78 |
79 | 참조 투명성을 통해 기존의 값은 병경되지 않고 유지된다. (Immutable Data)
80 |
81 |
82 |
83 | ### **고차 함수**
84 |
85 | - 함수에 함수를 파라미터로 전달하는 함수
86 | - 반환값으로 함수를 반환하는 함수
87 |
88 |
89 |
90 | ### 장점
91 |
92 | - 높은 수준의 추상화를 제공한다.
93 | - 함수 단위의 코드 재사용이 수월하다.
94 | - 불변성을 지향하기 때문에 동작을 예측하기 쉬워진다.
95 |
96 | ### 단점
97 |
98 | - 순수함수를 구현하기 위해 코드의 가독성이 떨어질 수 있다.
99 | - 함수형 프로그래밍에서는 반복을 for문이 아닌 재귀를 통해 이뤄지는데 재귀적 코드 스타일은 무한루프에 빠질 수 있다.
100 | - 순수함수를 쓰는건 쉽지만 조합하는 것은 어려울 수 있다.
101 |
102 |
103 |
104 | ## 클로저
105 |
106 | ### 정의
107 |
108 | > 생성될 당시의 환경을 기억하는 함수를 말한다. 환경이라고 하면 스코프체인 자체를 말하는데 스코프체인을 통해 접근 할 수 있는 변수나 함수가 스코프가 해제되어야 할 시점에도 사라지지 않는다.
109 |
110 |
111 |
112 | **내부함수**
113 |
114 | 자바스크립트는 함수 안에서 또 다른 함수를 선언할 수 있다. 함수 안에 선언된 함수를 내부함수 라고 한다.
115 |
116 | 내부함수는 내부함수를 포함하고 있는 외부함수의 문맥(context)에 접근할 수 있을 뿐만 아니라 **외부함수가 종료된 이후에도 내부 함수를 통해 접근할 수 있다**.
117 |
118 |
119 |
120 |
121 |
122 | **스코프**
123 |
124 | > 변수에 접근할 수 있는 **범위**
125 |
126 | - 전역 스코프
127 |
128 | - 전역에 선언되어 있어 어느 곳에서든지 해당 변수에 접근할 수 있다
129 |
130 | - 지역 스코프
131 |
132 | - 해당 지역에서만 접근할 수 있어 지역을 벗어난 곳에서 접근할 수 없다
133 | - 함수 스코프 : 함수가 생성될 때마다 새로운 스코프가 형성됨
134 | - 블록 스코프 : 블록 `{}` 이 생성될 때마다 새로운 스코프가 형성됨
135 | - 자바스크립트는 원래 함수 스코프를 따랐는데 `let`, `const`의 등장으로 블록 스코프를 형성하는 것도 가능해졌다.
136 | - [함수 스코프 vs 블록 스코프](https://velog.io/@fromzoo/%ED%95%A8%EC%88%98%EC%8A%A4%EC%BD%94%ED%94%84-vs-%EB%B8%94%EB%A1%9D%EC%8A%A4%EC%BD%94%ED%94%84)
137 |
138 |
139 |
140 | **문맥(context)**
141 |
142 | > this 키워드 값이 무엇인지를 나타낸다.⇒ **함수가 속해있는 객체**가 무엇인지 의미한다.
143 |
144 | - 만약 함수가 전역 스코프에서 선언되었다면, 이때의 문맥(context)는 global이다.
145 |
146 | 클로저를 이용해 카운터를 구현해보며 이해해보자.
147 |
148 | ```jsx
149 | function createCounter = () => {
150 | let count = 0;
151 |
152 | return function() {
153 | return (count += 1);
154 | }
155 | }
156 |
157 | const counter1 = createCounter();
158 | const counter2 = createCounter();
159 |
160 | console.log(counter1()); // 1
161 | console.log(counter1()); // 2
162 | console.log(counter2()); // 1
163 | ```
164 |
165 | `createCounter` 함수는 안에서 `count + 1` 를 반환하는 함수를 선언하고 리턴해준다. 이 때 내부에 선언된 함수는 외부의 지역변수 `count`에 접근할 수 있다.
166 |
167 | `createCounter` 함수를 호출하고 난 뒤 스코프가 해제되어야 하는 시점인데 외부함수의 지역변수를 사용하는 내부함수가 `counter1, 2` 에 각각 할당되어있기 때문에 해제되지 않고 외부함수 스코프에 접근할 수 있다.
168 |
169 | counter1과 counter2가 생성되었을 때의 환경을 각각 가지고 있기 때문에 실행했을 때 결과가 다르게 독립적으로 동작하는 것을 볼 수 있다.
170 |
171 | **객체보다 클로저의 활용에서 은닉화가 더 극대화 된다.** 함수 내부의 변수는 외부에서 접근할 방법이 전혀 없기 때문이다.
172 |
173 |
174 |
175 | ## 커링
176 |
177 | 여러개의 파라미터를 가진 함수를 호출 할 경우, 파라미터의 수보다 적은 파라미터를 인자로 받으면 누락된 파라미터를 다음 파라미터로 받는 기법
178 |
179 | ```jsx
180 | function sum(a, b) {
181 | return a + b;
182 | }
183 | ```
184 |
185 | `sum` 함수가 동작하려면 a, b를 모두 전달 받아야 한다. 이를 커링함수로 수정하면 다음과 같다.
186 |
187 | ```jsx
188 | function adder(a) {
189 | return function(b) {
190 | return a + b;
191 | }
192 | }
193 |
194 | console.log(adder(5)(1)); // 6
195 |
196 | const add5 = adder(5);
197 | console.log(add5(1)); // 6
198 | ```
199 |
200 | 어떤 함수를 호출할 때 매개 변수가 항상 비슷할 때 유용하게 사용할 수 있는 기법이다. 매번 새로운 인자를 전달하지 않아도 바깥에 있는 함수가 인자를 전달하고, 새로운 인자는 내부 함수가 받게 된다.
201 |
202 | `add5` 는 클로저를 이용한 것이고 `adder` 함수에 5를 인자로 넣었을 때의 환경을 기억하는 내부함수이다.
203 |
204 | 굳이 `add5` 함수를 선언하지 않고 `adder(5)(1)` 이런식으로 바로 호출할 수 있다.
205 |
206 | **함수의 재사용성과 코드의 가독성을 향상시킬 수 있다.**
207 |
208 |
209 |
210 | # 객체지향 vs 함수형
211 |
212 | - 객체지향은 함수의 동작부를 캡슐화하여 코드를 이해할 수 있게 한다.
213 |
214 | **클래스 디자인과 객체들의 관계를 중심으로 코드 작성이 이루어진다**. 따라서 상태, 멤버변수, 메서드 등이 긴밀한 관계를 가지고 있다. 특히 멤버변수가 어떤 상태를 가지고 있는가에 따라 결과가 달라진다.
215 |
216 | 객체가 일급객체
217 |
218 |
219 |
220 | - 함수형은 동작부를 최소화해서 코드의 이해를 돕는다.
221 |
222 | **값의 연산 및 결과 도출 중심으로 코드 작성이 이루어진다**. 함수 내부에서 인자로 받은 값을 별도로 저장하거나 하지 않고, 간결한 과정으로 처리하고 매핑하는데에 주 목적을 둔다.
223 |
224 | 함수가 일급객체
225 |
226 |
227 |
228 | 다형성은 강하게 비결합된 시스템을 만들어주기 때문에 바람직하다. 설계된 구조의 경계 사이에서 종속성이 역전될 수 있게끔 해준다. 다른 모듈들에 영향을 주지 않으면서도 수정이 가능하게 된다.
229 |
230 | ⇒ 유지 보수와 개발이 편한 시스템
231 |
232 |
233 |
234 | 참조 투명성은 시스템을 예상 가능하게 만들어주기 때문에 바람직하다. 스레드 경쟁상태같은 동시성 관련 문제도 현저리 줄여준다.
235 |
236 | ⇒ 내부 상태를 바꿀수 없다는 성질은 시스템을 이해하기 쉽고 개발하기 쉽게 만든다.
237 |
238 |
239 |
240 | 결국 두가지 패러다임 모두 개발을 편하고 쉽게 하기 위한 패러다임.
241 |
242 | **두 가지 패러다임은 서로 대비되는 개념이 아니고 구현하려는 기능에 맞도록 적절한 방법을 골라서 사용하면 된다.** 한가지 패러다임을 선택했다고 해서 다른 쪽을 배제하려는 자세는 오히려 시스템의 구조를 약하게 만든다.
243 |
244 |
245 |
246 | ### ⇒ 적절히 상황에 맞게 잘 쓰자!
247 |
248 |
249 |
250 |
251 |
252 | ### 참고
253 |
254 | [함수형 프로그래밍이란](https://mangkyu.tistory.com/111)
255 |
256 | [함수형프로그래밍 - 클로저](https://velog.io/@rnjsrntkd95/%ED%81%B4%EB%A1%9C%EC%A0%80Closure-%ED%95%A8%EC%88%98%ED%98%95-%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D)
257 |
258 | [스코프란](https://medium.com/@su_bak/javascript-%EC%8A%A4%EC%BD%94%ED%94%84-scope-%EB%9E%80-bc761cba1023)
259 |
260 | [클로저 - 생활코딩](https://opentutorials.org/course/743/6544)
261 |
262 | [클로저와 객체](https://ui.toast.com/weekly-pick/ko_20160701)
263 |
264 | [기존의 사고 방식을 깨부수는 함수형 사고](https://evan-moon.github.io/2019/12/15/about-functional-thinking/)
265 |
--------------------------------------------------------------------------------
/Network/CDN.md:
--------------------------------------------------------------------------------
1 | ## CDN(Content Delivery Network) 이란?
2 |
3 | 콘텐츠 전송 네트워크는 지리적으로 분산된 서버 집단으로 웹 콘텐츠 고속 전송을 위한 기술입니다. 일반적으로 오리진 서버와 각 지역에 PoP(Cache Server)로 구성하여 사용됩니다.
4 |
5 | HTML, JS, CSS, Image, 동영상부터 웹에 필요한 콘텐츠들을 신속하게 전송하며 Netflix, Amazon, Youtube 과 같은 웹사이트들도 CDN 을 사용하고 있습니다. CDN 의 주요 목적은 웹 서버의 대역폭을 사용자에게 가장 가까운 서버로 분산하는 것을 목적으로 DDoS 공격을 완화가 가능합니다.
6 |
7 | ## 이점은?
8 |
9 | CDN 을 구성한다면 성능, 가용성, 보안에 이점을 기대할 수 있습니다.
10 |
11 | ### 성능
12 |
13 | CDN 서버는 자원을 캐싱합니다. 사용자가 웹 콘텐츠를 요청하는 경우 오리진 서버와 물리적으로 거리가 있을 수 있습니다. 하지만 CDN 을 활용한다면 물리적으로 거리가 있는 오리진 서버가 아닌 사용자 근처에 존재하는 CDN 서버에게 콘텐츠를 응답받을 수 있습니다.
14 |
15 | **정적 콘텐츠**
16 |
17 | 일반적으로 CDN 서버에서 자원을 일정시간 동안 캐싱하여 사용자에게 제공합니다.
18 |
19 | **동적 콘텐츠**
20 |
21 | 동적 콘텐츠는 스크립트로 인해 생성되는 자원으로 매번 다른 결과가 발생될 수 있습니다. 그렇기 때문에 캐싱이 제기능을 하기 힘듭니다.
22 |
23 | 하지만 최신 CDN 은 동적 콘텐츠를 보다 빠르게 전달하기 위해 짧은 캐싱 시간 혹은 오리진 서버와 데이터 압축 혹은 HTTP 2.0, WS 등의 방식으로 최적화를 시도할 수 있습니다.
24 |
25 | ### 가용성
26 |
27 | MSA 의 핵심 개념으로 서버는 장애 혹은 과도한 트래픽이 발생해도 사용자에게 콘텐츠가 제공되어야 하는 개념입니다.
28 |
29 | CDN 을 구성하지 않으면 전세계의 사용자들이 자원에 접속하기 위해 전부 오리진 서버로 요청이 도달하게 됩니다.
30 |
31 | CDN 을 구성한다면 각 사용자들은 각 지역에 구성된 CDN 서버로 트래픽이 분산되며 해당 CDN 서버들 역시 이중화를 통해 가용성을 보장합니다.
32 |
33 | ### 보안
34 |
35 | CDN 을 사용하면 DDoS 공격을 어느정도 보완할 수 있습니다.
36 |
37 | - DDoS 공격?
38 |
39 | ```jsx
40 | DDOS 란?
41 | 네트워크 계층, 어플리케이션 계층에 대한 사이버 공격입니다.
42 | - 네트워크 계층
43 | 대역폭 얍축 공격
44 | 서버가 제공할 수 없는 대량의 트랙픽을 발생시킴으로 서비스 중단을
45 | 초래합니다. 예로는 "Reflection attack" 등이
46 | 존재합니다.
47 | 세션 하이재킹
48 | 공격자는 서버로 데이터 요청 패킷을 보내고 서버의 응답을 무시하여
49 | 서버의 리소스를 낭비시킵니다. 예로는 "TCP SYN flood attack"
50 | 등이 존재합니다.
51 |
52 | - 어플리케이션 계층
53 | 간단하게 HTTP 요청을 많이 보내여 서버의 성능 저하를 유발합니다.
54 | "HTTP GET flood attack", "HTTP POST flood attack"
55 | 등이 존재합니다.
56 | ```
57 |
58 | ```jsx
59 | Reflection attack?
60 | UDP 프로토콜 서비스를 제공하는 반사 서버를 구성하여 공격하는
61 | 방식입니다.
62 | 송신자의 IP 주소를 피해받는 서버의 IP 주소로 스푸핑하여 UDP
63 | 프로토콜을 구성한 반사 서버로 요청을 보냅니다. 해당 반사 서버
64 | 들은 모두 피해자의 IP 주소로 응답을 전송합니다. 이런 행위를
65 | 비 연결적 UDP 프로토콜로 빠르게 반복하여 서버의 장애를
66 | 발생시키는 공격방식입니다.
67 | ```
68 |
69 | ```jsx
70 | TCP SYN flooding attack?
71 | 기본적으로 TCP 3 way handshake 를 이용하는 공격입니다.
72 | 지속적으로 다른 IP 를 사용하여 연결의 시작인 SYN 을 보내며
73 | 공격자는 서버의 SYN-ACK 를 받지 않거나 승인을 하지 않습니다.
74 | 이 경우 서버는 클라이언트의 SYN-ACK 의 승인을 기다리는 상태인
75 | "half-open" 상태가 유지되며 서버의 연결 오버플로 테이블 초과시
76 | 서비스의 장애가 발생합니다.
77 | ```
78 |
79 |
80 | 기본 CDN 역할로 어느정도 DDoS 공격은 완화됩니다.
81 |
82 | 예를 들어 CDN 구성으로 인해 전세계 사용자들은 지리적으로 근처에 존재하는 서버로 요청을 합니다. DDoS 공격으로 인한 트래픽 부하는 특정 지역에 국한될 것입니다. 하지만 DDoS 공격이 완전히 해결된 것은 아닙니다. DDoS 공격이 걸린 해당 지역은 서비스의 장애를 겪을 것 입니다. 또한 캐싱되지 않은 자원이나 캐시가 이루어지지 않는 동적 콘텐츠의 경우는 그대로 오리진 서버에 트래픽이 전달됩니다.
83 |
84 | CDN 의 역할만으로 DDoS 공격에 완전히 대비되는 것은 아니므로 오늘날 CDN 제공 업체는 WAF(웹 어플리케이션 방화벽), DDoS 완화 서비스 등 클라우드 기반 보안 솔루션을 제공합니다.
85 |
86 | ## 참고자료
87 |
88 | [CDN 이점](https://www.akamai.com/ko/our-thinking/cdn/what-is-a-cdn)
89 |
90 | [DDoS, CDN](https://www.cdnetworks.com/ko/cloud-security-blog/employing-cdn-as-a-ddos-mitigation-can-be-useful/)
91 |
92 | [Reflection attack](https://namu.wiki/w/%EB%B6%84%EC%82%B0%20%EB%B0%98%EC%82%AC%20%EC%84%9C%EB%B9%84%EC%8A%A4%20%EA%B1%B0%EB%B6%80%20%EA%B3%B5%EA%B2%A9?from=DRDos)
93 |
94 | [SYN flood attack](https://www.imperva.com/learn/ddos/syn-flood/)
95 |
96 | [CDN 캐싱](https://www.cloudflare.com/ko-kr/learning/cdn/caching-static-and-dynamic-content/)
97 |
98 | [CDN Dynamic Content Optimization](https://gcorelabs.com/blog/how-to-speed-up-dynamic-content-delivery-using-cdn/)
99 |
100 | [Cloud vs CDN](https://www.inap.com/blog/cdn-versus-cloud-computing-whats-difference-do-i-need-both/)
--------------------------------------------------------------------------------
/Network/DNS.md:
--------------------------------------------------------------------------------
1 | ## DNS(Domain Name System)
2 |
3 | 호스트의 도메인 이름과 호스트의 네트워크 주소(ip address) 변경해주는 System 입니다.
4 |
5 | 해당 DNS 기능이 없다면 [naver.com](http://naver.com) 과 같은 도메인 이름으로 웹 사이트에 접근할 수 없으며 해당 호스트의 네트워크 주소를 통해서만 접근이 가능합니다.
6 |
7 | > 응용계층에서 http 프로토콜과 병렬로 이루어지는 작업입니다.
8 | >
9 |
10 | ### Domain
11 |
12 | IP 를 사용하는 서버의 주소를 사용자가 기억하기 쉽게 만들어진 주소로 `.` 으로 구분됩니다.
13 |
14 | > 💡 URL 이 도메인?
15 | URL Web Site 자원의 주소입니다.
16 | 도메인을 포함하여 프로토콜, 자원의 경로, 자원의 Parameter, Fragment 까지 구성된 주소로 도메인의 상위 개념입니다.
17 |
18 |
19 | **루트 도메인 체계**
20 |
21 | 
22 |
23 |
24 | - **Root Domain**
25 |
26 | 인터넷 체계에서와 웹사이트 수준에서 다른 의미를 가집니다.
27 |
28 | 인터넷 체계 수준에서는 TLD 보다 높은 인터넷 계층 수준입니다. TLD 뒤 이름없는 `.` 만으로 구분되지만 묵시적으로 사용됩니다.
29 |
30 | 웹 사이트 수준에서는 TLD 부터 도메인 이름까지를 루트 도메인으로 부릅니다.
31 |
32 | > ex. dongmin.dev
33 | >
34 | - **TLD(Top Level Domain)**
35 |
36 | 인터넷 DNS 시스템에서 루트 도메인 이후에 명시되는 것을 TLD 라고 부릅니다. ccTLD, gTLD, New gTLD 가 존재합니다.
37 |
38 | - ccTLD
39 |
40 | 국가 코드 최상위 도메인으로 국가, 종속 지역을 나타내는 도메인 이름입니다.
41 |
42 | 특정 국가를 타겟팅하는 웹사이트의 경우 Google SEO 에 보다 효과적입니다.
43 |
44 | > ex. kr, jp ...
45 | >
46 | - gTLD
47 |
48 | 일반 최상위 도메인으로 국가 코드 최상위 도메인을 제외한 일반적으로 사용되는 최상위 도메인입니다.
49 |
50 | > ex. com, net
51 | >
52 | - New gTLD
53 |
54 | 특정 기업이나 기관의 신청으로 기존의 gTLD 이외의 생성되는 도메인입니다.
55 |
56 | - **SLD(Second Level Domain)**
57 |
58 | 최상위 도메인 바로 아래 영역에 존재하는 도메인입니다.
59 |
60 | - ccSLD
61 |
62 | 최상위 도메인이 국가 코드 도메인인 경우 도메인 등록 조직을 나타냅니다.
63 |
64 | > ex. co.kr, [ac.kr](http://ac.kr) ...
65 | >
66 | - SLD
67 |
68 | 최상위 도메인이 일반 최상위 도메인인 경우 일반적으로 등록 조직이 지정한 도메인 이름이 됩니다.
69 |
70 | > ex. [naver.com](http://naver.com), dongmin.dev
71 | >
72 | - **3LD(Third Level Domain)**
73 |
74 | 국가 코드 도메인을 사용하는 경우 등록 조직이 지정한 도메인 이름입니다.
75 |
76 | > ex. konkuk.ac.kr
77 | >
78 |
79 |
80 | ### DNS Server 종류
81 |
82 | > 💡 DNS Server ?
83 | 관리하는 도메인 이름과 ip 주소를 매핑하여 관리하며 클라이언트의 요청이 들어오면 ip 주소나 도메인 이름을 반환해주는 Server 입니다.
84 |
85 |
86 | - **Recursive Name Server**
87 |
88 | Local DNS Server, 기지국 DNS Server 라고도 불립니다. 말그대로 재귀적으로 Domain 에 대해서 IP 작업을 찾습니다.
89 |
90 | 우선 DNS 쿼리를 받으면 캐시 목록을 통해 결과를 찾습니다. 결과값이 없다면 Root Name Server, TLD Name Server, Authoritative Name Server 순으로 요청과 응답을 하며 결과값을 Client 로 전달합니다.
91 |
92 | - **Root Name Server**
93 |
94 | 전역적인 최상위 도메인 TLD 목록 정보가 구성되어 있습니다. 12 개의 조직에서 구성되어 운영됩니다.
95 |
96 | Recursive Name Server 의 DNS 쿼리에 대해서 TLD Name Server 주소를 반환하는 역을 맡습니다.
97 |
98 | - **TLD Name Server**
99 |
100 | Top Level Domain 을 관리하는 Name Server 입니다.
101 |
102 | com 과 같은 특정 TLD 에 대한 웹사이트 정보들로 구성되어 있어 요청받은 도메인의 Authoritative Name Server 의 주소를 반환합니다.
103 |
104 | - **Authoritative Name Server**
105 |
106 | IP 주소를 얻는 마지막 단계입니다. 도메인 이름에 대한 고유 정보와 각 레코드 정보들이 존재합니다. 일반적으로 도메인/호스팅 업체들의 DNS 서버이며 개인 DNS 서버 역시 Authoritative Name Server 로 분류됩니다.
107 |
108 | A 레코드에서 도메인을 찾았다면 해당 IP 를 반환하며 CNAME 레코드에서 도메인을 찾은경우 해당 도메인을 Recursive Name Server 로 반환하여 Recursive Name Server 는 처음부터 IP 를 찾아가는 과정을 수행합니다.
109 |
110 |
111 | ### Process
112 |
113 |
114 |
115 |
116 | 1. 사용자가 브라우저를 통해 [www.dongmin.dev](http://www.dongmin.dev) 에 접근합니다.
117 | 2. Recursive DNS Server 로 [www.dongmin.dev](http://www.dongmin.dev) 의 IP 주소를 요청합니다.
118 | 3. Recursive DNS Server 레코드에 정보가 없는 경우 Root DNS Server 로 [www.dongmin.dev](http://www.dongmin.dev) IP 주소를 요청합니다.
119 | 4. Root DNS Server 는 요청 받은 도메인의 Top Level Domain(.dev) Name Server 의 IP 주소를 반환합니다.
120 | 5. Recursive DNS Server 는 응답받은 TLD Name Server IP 로 [www.dongmin.dev](http://www.dongmin.dev) IP 주소를 요청합니다.
121 | 6. TLD Name Server 는 [www.dongmin.dev](http://www.dongmin.dev) 에서 dongmin.dev 를 관리하는 Authoritative Name Server 주소를 반환합니다.
122 | 7. 마지막으로 Recursive DNS Server 는 Authoritative Name Server 로 [www.dongmin.dev](http://www.dongmin.dev) IP 주소를 요청합니다.
123 | 8. Authoritative Name Server 는 명시된 레코드에서 도메인을 찾으며 A 레코드에서 찾았다면 해당 IP 주소를 Recursive DNS Server 로 반환합니다.
124 | 9. Authoritative Name Server 로 부터 받은 IP 주소를 Recursive DNS Server 는 TTL 만큼 캐싱하며 브라우저에게 IP 주소를 응답합니다.
125 | 10. 브라우저는 응답받은 IP 주소를 통해 Web Server 에 접근합니다.
126 |
127 | > 💡 DNS 에서 사용하는 전송 프로토콜은 뭘까?
128 | 기본적으로 DNS message 가 512 byte 이하일 경우 UDP 프로토콜을 사용하여 통신하며 zone-transfer, 512 byte 초과시 TCP 프로토콜을 사용하여 통신합니다.
129 |
130 |
131 | > 💡 zone-transfer ?
132 | Master DNS 와 Slave DNS 서버로 이중화가 구성된 경우 발생하는 작업입니다.
133 | 한마디로 Master 서버의 Zone(도메인과 IP 매핑 정보) 파일을 Slave 서버로 최신화하는 작업입니다.
134 |
135 |
136 | ## 참고자료
137 |
138 | [DNS Process](https://www.cloudflare.com/ko-kr/learning/dns/dns-server-types/)
139 |
140 | [Root Domain](https://raventools.com/marketing-glossary/root-domain/)
141 |
142 | [Name Server 종류](https://www.dynu.com/en-US/Blog/Article?Article=DNS-Servers-Authoritative-Recursive-Root-TLD)
143 |
144 | [Domain 체계](https://better-together.tistory.com/128)
145 |
146 | [Second-level domain](https://en.wikipedia.org/wiki/Second-level_domain)
147 |
148 | [ccTLD](https://www.affde.com/ko/what-is-a-cctld.html)
149 |
150 | [DNS 512 byte UDP](https://serverfault.com/questions/587625/why-dns-through-udp-has-a-512-bytes-limit)
--------------------------------------------------------------------------------
/Network/HTTP,HTTPS.md:
--------------------------------------------------------------------------------
1 | # HTTP, HTTPS
2 |
3 | ](https://mdn.mozillademos.org/files/13677/Fetching_a_page.png)
4 |
5 | 출처 : [MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
6 |
7 | ## HTTP(HyperTextTransferProtocol)
8 |
9 | HTML과 같은 하이퍼미디어 문서를 전송하기 위한 어플리케이션 레이어 프로토콜입니다.
10 |
11 | HTTP는 비연결성의 무상태 프로토콜이며 서버/클라이언트 모델을 따라 데이터를 주고 받고, 기본 포트로 80번 포트를 사용합니다.
12 |
13 | ### HTTP 버전별 기능
14 |
15 | - HTTP/0.9
16 | - HTTP의 가장 초기 버전으로 원래는 버전 번호가 없는데 구분을 위해 향후 붙였다고 합니다
17 | - 헤더 없이 단순히 HTML 파일만 전송하며, GET 메소드만 사용 가능
18 | - HTTP/1.0 – 확장성 만들기
19 | - 헤더를 통해 HTTP 버전 코드를 송신하고, 상태 코드를 회신 받을 수 있게 되었습니다.
20 | - 헤더의 Content-Type을 통해 HTML이 아닌 형태도 전송 가능해졌습니다. (문자열 전송)
21 | - 사용가능한 메서드: GET, POST, PUT
22 | - HTTP/1.1 (표준 프로토콜)
23 | - Keep Alive로 커넥션이 재사용 될 수 있도록 개선되었습니다.
24 | - Host 헤더가 추가되어 동일 IP 주소에 다른 도메인을 호스트하는 기능이 서버 코로케이션을 가능하게 했습니다.
25 | - 사용가능한 메서드: OPTIONS, GET, HEAD, POST, PUT, DELETE, TRACE
26 | - HTTP/2 – 더 나은 성능을 위한 프로토콜
27 | - 2015년에 발표됨, 구글의 SPDY를 기반으로 표준화 되었습니다.
28 | - 문자열 전송 기반이 아닌 이진 데이터 전송 기반으로, 스트림, 메시지 및 프레임으로 데이터 교환 방식이 변경됨
29 | - 스트림: 구성된 연결 내에서 전달되는 바이트의 양방향 흐름이며, 하나 이상의 메세지가 전달 가능함(request or response는 하나의 메시지)
30 | - 메시지: 논리적 요청 또는 응답 메시지에 매핑되는 프레임의 전체 시퀀스
31 | - 프레임: http/2.0에서 통신의 최소 단위, 각 최소 단위에는 하나의 프라임 헤더가 포함된다. 이 프라임 헤더는 최소한으로 프레임이 속하는 스트림을 식별한다. Headers Type Frame, Data Type Frame이 존재한다.
32 | - 주요 스팩
33 | - HTTP Header Data Compression (HTTP 헤더 데이터 압축)
34 |
35 | 이전 Header의 중복되는 필드를 재전송하지 않아서 데이터를 절약하고, HPACK이라는 Header 압축방식을 이용하여 데이터 전송 효율을 높였다.
36 |
37 | - Server Push
38 |
39 | 클라이언트가 요청 하지 않은 JavaScript, CSS, Font, 이미지 파일 등과 같이 필요하게 될 특정 파일들을 서버에서 단일 HTTP 요청 응답으로 전송 가능하게 한다.
40 |
41 | - HOL(Head-of-Line) 문제 해결
42 |
43 | HTTP/1.1 까지는 한번에 하나의 파일만 전송이 가능했었지만, 여러 파일을 한번에 병렬 전송할 수 있께 개선되었다.
44 |
45 | - Stream 우선순위
46 |
47 | HTTP 메시지가 많은 개별 프레임으로 분할될 수 있고 여러 스트림의 프레임을 다중화(Multiplexing)할 수 있게 되면서, 스트림들의 우선순위를 지정할 필요가 생겼다. 클라이언트는 우선순위 지정을 위해 ‘우선순위 지정 트리'를 사용하여 서버의 스트림처리 우선순위를 지정할 수 있다. 서버는 우선순위가 높은 응답이 클라이언트에 우선적으로 전달될 수 있도록 대역폭을 설정한다.
48 |
49 |
50 | - HTTP/3
51 | - QUIC(Quick UDP Internet Connections) 프로토콜 사용, UDP를 사용한다.
52 | - 클라이언트의 IP가 바뀌어도 연결이 유지됨, (ex)와이파이에서 LTE로 전환할때)
53 |
54 | ### HTTP 구성요소
55 |
56 | - HTTP는 요청(Request)와 응답(Response)로 구성되어 있다.
57 | - 시작줄, 헤더, 바디로 이루어져있다.
58 | - **요청**
59 |
60 | ](https://mdn.mozillademos.org/files/13687/HTTP_Request.png)
61 | 출처: [MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
62 |
63 | 시작줄에 수행하고자 하는 메서드, HTTP 버전과 같은 프로토콜이 표시된다.
64 |
65 | 헤더에는 가져오려는 리소스의 경로; 예를 들면 [프로토콜](https://developer.mozilla.org/ko/docs/Glossary/Protocol) (`http://`), [도메인 (en-US)](https://developer.mozilla.org/en-US/docs/Glossary/Domain) (여기서는 `developer.mozilla.org`), 또는 TCP [포트 (en-US)](https://developer.mozilla.org/en-US/docs/Glossary/Port) (여기서는 `80`)인 요소들을 제거한 리소스의 URL입니다.
66 |
67 | > 그 이외에 추가하고자 하는 헤더, POST의 경우 body가 들어감
68 | >
69 | - **응답**
70 | ](https://mdn.mozillademos.org/files/13691/HTTP_Response.png)
71 | 출처: [MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
72 | - 시작줄에 HTTP 프로토콜 버전, 상태코드와 메시지가 표시된다.
73 | - 그 이외에 각종 헤더들이 들어가고, 요청에 맞는 리소스가 body에 포함되기도 한다.
74 |
75 | ## HTTPS (Hyper Text Transfer Protocol Secure)
76 |
77 | 말 그대로 HTTP에 Secure, 보안이 추가된 프로토콜이며 443번을 기본 포트로 사용한다. 클라이언트와 서버간의 모든 커뮤니케이션을 암호화 하기 위해 SSL / TLS 를 사용한다.
78 |
79 | ### 대칭키와 비대칭키(공개키)
80 |
81 | **대칭키**의 경우에는 암호화, 복호화에 사용하는 키가 동일하고 속도가 빠른 대신 키를 교환 해야 하기 때문에 탈취 관리를 해야하고, 기밀성을 제공하지만 무결성/인증을 보장하지 않는다.
82 |
83 | **비대칭키(공개키)**는 암복호화에 사용하는 키가 서로 다르며 속도가 느린 대신 , 기밀성, 무결성,인증 기능이 모두 제공된다. 대표적으로 RSA가 있다.
84 |
85 | ### 공개키와 비밀키 (Public Key Private Key )
86 |
87 | 비대칭키로 공개키와 비밀키를 사용하는데 다음과 같다.
88 |
89 | 1) 공개키로 암호화 하면 개인키로만 복호화 가능하다
90 |
91 | 2) 개인키로 암호화 하면 공개키로만 복호화가 가능하다.
92 |
93 | 따라서 1)의 경우 개인키를 가지고 있어야만 볼 수 있고, 2)의 경우 공개키로 복호화가 된다면 해당 정보에 대한 신뢰성이 보장된다.
94 |
95 | ### TSL / SSL
96 |
97 | 암호화를 담당하는 프로토콜, HTTPS에서 사용됨
98 |
99 | **SSL (Secure Scoket Layer)**
100 |
101 | - HTTP와 독립된 프로토콜로 HTTP 외에도 다방면으로 사용되고 있습니다.
102 | - 두 통신 사이에 핸드셰이크를 통해 인증 프로세스가 진행됨
103 |
104 | **TLS (Transport Layer Security)**
105 |
106 | - TLS는 SSL 3.0을 기초로 해서 IETF가 만든 프로토콜이다. (TLS 1.0 == SSL3.1)
107 | - SSL과 거의 동일하다고 생각하면 됨
108 |
109 | ### HTTPS 동작과정(SSL)
110 |
111 | 서버는 클라이언트가 요청을 보낼 때 암호화를 하기 위한 공개키를 생성해야 하는데, 일반적으로는 인증된 기관(Certificate Authority) 에 공개키를 전송하여 인증서를 발급받고 있다. 자세한 과정은 다음과 같다.
112 |
113 | - 공개키 암호화 방식과 대칭키 암호화 방식의 장점을 활용해 하이브리드 사용
114 | - 데이터를 대칭키 방식으로 암복호화하고, 공개키 방식으로 대칭키 전달
115 | 1. **클라이언트가 서버 접속하여 Handshaking 과정에서 서로 탐색**
116 |
117 | 1.1. **Client Hello**
118 |
119 | - 클라이언트가 서버에게 전송할 데이터
120 | - 클라이언트 측에서 생성한 **랜덤 데이터**
121 | - 클-서 암호화 방식 통일을 위해 **클라이언트가 사용할 수 있는 암호화 방식**
122 | - 이전에 이미 Handshaking 기록이 있다면 자원 절약을 위해 기존 세션을 재활용하기 위한 **세션 아이디**
123 |
124 | 1.2. **Server Hello**
125 |
126 | - Client Hello에 대한 응답으로 전송할 데이터
127 | - 서버 측에서 생성한 **랜덤 데이터**
128 | - **서버가 선택한 클라이언트의 암호화 방식**
129 | - **SSL 인증서**
130 |
131 | 1.3. **Client 인증 확인**
132 |
133 | - 서버로부터 받은 인증서가 CA에 의해 발급되었는지 본인이 가지고 있는 목록에서 확인하고, 목록에 있다면 CA 공개키로 인증서 복호화
134 | - 클-서 각각의 랜덤 데이터를 조합하여 pre master secret 값 생성(데이터 송수신 시 대칭키 암호화에 사용할 키)
135 | - pre master secret 값을 공개키 방식으로 서버 전달(공개키는 서버로부터 받은 인증서에 포함)
136 | - 일련의 과정을 거쳐 session key 생성
137 |
138 | 1.4. **Server 인증 확인**
139 |
140 | - 서버는 비공개키로 복호화하여 pre master secret 값 취득(대칭키 공유 완료)
141 | - 일련의 과정을 거쳐 session key 생성
142 |
143 | 1.5. **Handshaking 종료**
144 |
145 | 2. **데이터 전송**
146 | - 서버와 클라이언트는 session key를 활용해 데이터를 암복호화하여 데이터 송수신
147 | 3. **연결 종료 및 session key 폐기**
148 |
149 |
150 |
151 | ## 참고자료
152 |
153 | - HTTP 버전
154 |
155 | [HTTP의 진화 - HTTP | MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP)
156 |
157 | [HTTP](https://itwiki.kr/w/HTTP)
158 |
159 | [HTTP/1.1, /2, /3 의 차이점](https://velog.io/@zzzz465/HTTP1.1-2-3-%EC%9D%98-%EC%B0%A8%EC%9D%B4%EC%A0%90)
160 |
161 | [[CS/Network] HTTP 버전 별 특징](https://koonii.tistory.com/m/21)
162 |
163 | - HTTP 구성요소
164 |
165 | [HTTP 개요 - HTTP | MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
166 |
167 | - HTTPS와 TSL/SSL
168 |
169 | [](https://velog.io/@moonyoung/HTTPS%EC%9D%98-%EC%9B%90%EB%A6%AC)
170 |
171 | [HTTPS 와 SSL(TLS)](https://futurecreator.github.io/2018/07/12/https-and-ssl-tls/)
172 |
173 | [✔ SSL/TLS 보안](https://velog.io/@saseungmin/SSLTLS-%EB%B3%B4%EC%95%88)
174 |
175 | [대칭키 vs 공개키(비대칭키)](https://velog.io/@gs0351/%EB%8C%80%EC%B9%AD%ED%82%A4-vs-%EA%B3%B5%EA%B0%9C%ED%82%A4%EB%B9%84%EB%8C%80%EC%B9%AD%ED%82%A4)
176 |
177 | [✔ SSL/TLS 보안](https://velog.io/@saseungmin/SSLTLS-%EB%B3%B4%EC%95%88)
178 |
179 | [tech-interview/network.md at master · WeareSoft/tech-interview](https://github.com/WeareSoft/tech-interview/blob/master/contents/network.md)
180 |
181 | - HTTP 2.0
182 |
183 | [HTTP/2(HTTP 2.0) 정리](https://velog.io/@taesunny/HTTP2HTTP-2.0-%EC%A0%95%EB%A6%AC)
184 |
185 | [HTTP/2 소개 | Web Fundamentals | Google Developers](https://developers.google.com/web/fundamentals/performance/http2?hl=ko)
--------------------------------------------------------------------------------
/Network/OSI 7 계층.md:
--------------------------------------------------------------------------------
1 | ## OSI(Open Systems Interconnection) 모델이란?
2 |
3 | 컴퓨터 시스템이 네트워크를 통해 통신하며 사용하는 7개의 계층으로 국제 통신 표준 규약
4 |
5 | 
6 |
7 | OSI 7계층 데이터 전송 흐름
8 |
9 | ## 기능
10 |
11 | ### [**Layer 7] 응용 계층 (Application Layer)**
12 |
13 | OSI 모델의 최상위 계층으로 통신의 최종 목적지로 다양한 프로토콜
14 |
15 | **기능**
16 |
17 | - Network Virtual Terminal
18 | 어플리케이션은 원격 호스트의 에뮬레이션을 생성하여 사용자가 원격 호스트에 log on 하는 기능
19 | 사용자의 컴퓨터 ↔ 소프트웨어 터미널 ↔ 호스트 형식의 통신
20 | - Directory Service
21 | 다양한 전역 정보에 대한 엑세스 기능
22 | - File Transfer Access and Management(FTAM)
23 | 파일에 엑세스하고 파일을 관리하는 표준 메커니즘
24 | 원격 컴퓨터의 파일에 엑세스 및 관리, 검색 기능
25 | - Mail Service
26 |
27 | **단위 - Data**
28 |
29 | **키워드**
30 |
31 | > HTTP, FTP, SMTP, Telnet 등
32 | >
33 |
34 | ### [Layer 6] 표현 계층 (Presentation Layer)
35 |
36 | 응용 계층으로부터 전송 받거나 전송해야되는 데이터를 인코딩, 디코딩 하는 계층
37 | 암호화 복호화 작업도 해당 계층에서 이루어짐
38 |
39 | **기능**
40 |
41 | - 번역
42 | 네트워크에 필요한 형식과 어플리케이션의 데이터의 형식 변환 기능
43 | 송신 데이터 → 비트 스트림 (인코딩)
44 | 수신 데이터 → 문자 및 숫자 (디코딩)
45 | - 암호화
46 | 송신기에서 암호화, 수신기에서 복호화 작업을 수행하는 기능
47 | - 압축
48 | 대역폭을 줄이기 위해 데이터를 압축하는 기능
49 | 오디오, 비디오, 텍스트 등 멀티미디어 전송에 중요하며 0으로 전송되는 비트의 수를 줄이는 역할
50 |
51 | **단위 - Data**
52 |
53 | **키워드**
54 |
55 | > ASCII, JPEG, MPEG 등
56 | >
57 |
58 | ### [Layer 5] 세션 계층 (Session Layer)
59 |
60 | 통신하는 호스트 사이 세션 설정 및 유지 및 동기화를 처리하는 계층
61 | **기능**
62 |
63 | - 동기화
64 | 통신하는 메세지 스트림에 대해 동기화 지점으로 체크포인트를 추가하며 세션이 중단되면 체크포인트를 통해 데이터 전송을 재개할 수 있는 기능
65 | - 토큰 관리
66 | 각 사용자가 중요한 작업을 동시에 엑세스하는 것을 방지하기 위한 기능
67 | - Dialog Control
68 | 두 시스템이 반이중, 전이중으로 서로 통신을 시작할 수 있도록 설정하는 기능
69 |
70 | **단위 - Data**
71 |
72 | ### [Layer 4] 전송 계층 (Transport Layer)
73 |
74 | 송신 과정은 상위 계층에서 전달받은 데이터를 더 작은 조각(Segment, Databram)으로 분할하여 네트워크 계층으로 전달하며 수신 과정은 분할된 조각(Segment, Databram)을 재조립하는 프로세스간 논리적 통신을 수행하는 계층
75 | 데이터가 잘못 수신되었는지 확인하며 다시 요청하는 오류 제어 기능을 수행
76 |
77 | **기능**
78 |
79 | - Service Point Addressing
80 | 해당 Layer header 에 서비스 포인트 주소인 포트번호를 포함하여 올바른 프로세스로 메세지를 전달하는 기능
81 | - 분할 및 재조립
82 | 메세지는 시퀀스 번호가 포함되어 있는 세그먼트 형태로 분할
83 | 세그먼트의 시퀀스 번호를 통해 메세지 재조립
84 | - 흐름 제어
85 | 종단간(end-to-end) 신뢰성있는 메세지 전달을 보장하는 기능
86 | - 오류 제어
87 | 수신 과정에서 메세지가 오류 없이 전달 받았는지 확인하는 기능
88 |
89 | **단위 - Segment(TCP), Datagram(UDP)**
90 |
91 | **키워드**
92 |
93 | > TCP, UDP
94 |
95 |
103 |
104 | ### [Layer 3] 네트워크 계층 (Network Layer)
105 |
106 | 네트워크에서 패킷의 소스-대상 또는 호스트-호스트 사이 논리적 통신을 담당하는 계층
107 |
108 | **기능**
109 |
110 | - 라우팅
111 | 라우터, 게이트웨이를 통해 패킷을 최종 목적지로 라우팅하기 위한 기능
112 | - ARP
113 | 송신 과정에서 수신자의 MAC Address 를 알 수 없는 경우 수신자의 IP와 ARP Address 를 담은 패킷을 네트워크에 뿌리며 수신자의 MAC Address 를 담은 응답을 받는 기능
114 | - 캡슐화
115 | 인터네트워크의 각 장치를 식별하기 위해 발신자와 수신자의 IP 를 네트워크 계층에 의해 헤더에 배치
116 | - 분할
117 |
118 | 큰 패킷을 보다 작은 패킷으로 분할하는 기능
119 |
120 |
121 | **단위 - Packet**
122 |
123 | **키워드**
124 |
125 | > 라우터, IP
126 | >
127 |
128 | ### [Layer 2] 데이터 링크 계층 (Data Link Layer)
129 |
130 | 물리 계층으로 송수신 되는 데이터를 안전하게 전달되도록 처리하는 계층
131 |
132 | **기능**
133 |
134 | - 프레이밍
135 | 관리가능한 네트워크 계층에서 수신되는 비트 스트림이 프레임으로 해당 비트 스트림 분할은 데이터 링크 계층에서 수행
136 | - 흐름제어
137 | 빠른 송신기로 인해 느린 수신기의 트래픽을 방지하기 여분의 비트를 버퍼링하여 흐름제어
138 | - 오류 제어
139 | 프레임 끝부분에 트레일러를 추가하여 프레임의 복제 방지
140 | - 엑세스 제어
141 | 두개 이상의 장치가 해당 링크에 연결된 경우 주어진 시간에 가능한 장치를 결정하는 기능
142 |
143 | **단위 - Frame**
144 |
145 | **키워드**
146 |
147 | > 브릿지, 스위치
148 | >
149 |
150 | ### [Layer 1] 물리 계층 (Physical Layer)
151 |
152 | OSI 의 가장 낮은 계층으로 다른 물리적 컴퓨터로 전기적 신호를 전송하는 계층
153 | 오직 0, 1의 데이터 전송만을 다루는 계층
154 |
155 | **기능**
156 |
157 | - 비트 표현
158 | 데이터 링크 계층의 비트 스트림을 0, 1 신호로 변경하는 기능
159 | - 동기화
160 | 수신기와 송신기의 비트 수준의 동기화를 처리하는 기능
161 |
162 | **단위 - Bit**
163 |
164 | **키워드**
165 |
166 | > 허브, 리피터
167 | >
168 |
169 | ## 질문 리스트
170 |
171 | - OSI 모델과 7 layer 대해서 서술해주세요.
172 |
173 | - 웹 브라우저는 Application Layer 에 속해있나요?
174 |
175 | - TCP 와 UDP 의 차이를 서술해주세요.
176 |
177 | - 네트워크 계층과 전송 계층의 차이를 서술해주세요.
178 |
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a.md:
--------------------------------------------------------------------------------
1 | # TCP / UDP
2 |
3 | ## 🐌 Transport Layer
4 |
5 |
9 |
10 | > **Network VS Transport Layer**
11 | Network Layer는 MAC + IP를 사용하여 구분하므로 Host간의 통신을 책임진다.
12 | Transport Layer는 MAC + IP + Port를 사용하여 구분하므로 Host내의 Process간의 통신을 책임진다.
13 | >
14 |
15 | ## 🎒 배경 지식
16 |
17 | ### Multiplexing / Demultiplexing
18 |
19 | 한개의 Host내의 Process들이 목표 Process에 맞도록 Transport Header를 작성(Multiplexing) / 해석(Demultiplexing)한다.
20 |
21 | > **Socket VS Port**
22 | Port는 OS내부의 Process들이 Networking에 사용할 수 있는 고유한 값이고, Socket은 Process가 Networking을 이용하기 위해서 반드시 사용해야하는 창구이다.
23 | → Socket을 열기 위해서는 Host의 IP, Port, Protocol이 필요하다.
24 | → ☝️ **같은 Process가 같은 Port를 이용해서 여러개의 Socket을 열 수 있다. 즉, Socket ≠ Port.**
25 | >
26 | - RDT Principle
27 |
28 | > 여기의 내용은 추가적인 내용이고, 간략하게 써놓았습니다. 키워드를 통해서 검색하시면 더 자세한 내용을 볼 수 있습니다.
29 | >
30 |
31 |
35 |
36 | - RDT 1.0: 이미 Reliable한 채널을 사용하고 있음. 즉, 이미 Reliable
37 | - RDT 2.0: bit eroor가 있을 수 있는 채널을 사용하고 있음.
38 |
39 | > bit error를 통신으로 어떻게 복구해낼 수 있을까?
40 | >
41 |
42 | → ACK와 NAK를 사용하여 복구
43 |
44 | > 하지만, ACK와 NAK가 손실 / 변형되면 무용지물...
45 | >
46 | - RDT 2.1: ACK와 NAK가 손실될 경우도 처리해보자!
47 |
48 | → sequence number + ACK / NAK
49 |
50 | - RDT 2.2: NAK를 없애고 ACK만 사용해보자
51 | - RDT 3.0: Packet 손실이 있는 경우도 고려해보자!
52 |
53 | → Timer 추가
54 |
55 |
56 | ### Pipelined Protocol
57 |
58 |
62 |
63 | 1. Go Back N
64 | - ACK는 수신자가 그 전의 데이터는 모두 받음을 나타냄
65 | - Timer를 가장 오래된 Packet에 대해서 1개만 작동시킴
66 | - Timer가 만료되면 윈도우의 모든 데이터 재전송
67 |
68 | → n의 크기를 가지는 윈도우를 모두 보내므로 Go Back N이라고 부른다.
69 |
70 | 2. Selective Repeat
71 | - ACK는 개별적인 Packet의 받음을 나타냄
72 | - TImer를 모든 Packet에 대하여 작동시킴
73 | - Timer가 만료되면 해당 Packet만 재전송
74 |
75 | → 선택적으로 재전송 하므로 Selective Repeat라고 부른다.
76 |
77 |
78 | ## ⚡️ UDP(User Datagram Protocol)
79 |
80 |
84 |
85 | ### 특징
86 |
87 | - Lost: 손실이 발생할 수 있음
88 | - Out of Order: 데이터의 순서를 보장하지 않음
89 | - Connectionless: 통신을 따로 맺지않고 데이터를 바로 보냄(No Handshake)
90 | - only Optional Cehcksum: Datagram의 유효성만 Checksum(1이 보수의 합)을 통해서 검증함
91 |
92 | > 검증이 실패하더라도 UDP자체의 Cover X
93 | >
94 | - 1의 보수의 합 with Checksum?
95 |
96 | > 1의 보수는 모든 bit를 not연산 즉, 뒤집어 준 형태이다.
97 | >
98 |
99 | 체크섬 과정
100 |
101 | 1. 모든 데이터(Header + Pseudo Header + Ddata)를 Word단위로 쪼갠후, 더한다.
102 | 2. carry bit를 더한다.
103 | 3. 1의 보수를 취한다.
104 |
105 | → 체크섬을 사용하면 송신측을 만들어 보내고, 수신측은 새로 만들어 같은 값인지 확인한다.
106 |
107 | - Throughput의 제한없이 데이터를 마구 보낼 수 있음
108 | - Overhead가 적음(속도가 빠름)
109 |
110 | → 작은 Header 크기, 쉬운 검증 과정, Connectionless
111 |
112 | - Reliable하게 할 수 없을까?
113 |
114 |
118 |
119 | ARQ(Automatic Repeat reQuest)
120 |
121 | - Sequence Number를 사용하여 순서를 보장하고, ACK를 수신측에서 보냈을 경우만 다음 Sequence를 보냄
122 | - ACK, NACK모두 받지 못하였을 경우에는 Timeout으로 다음 Sequence를 보냄
123 |
124 | → 너무 UDP Segment의 크기가 고정이므로 너무 느린 속도
125 |
126 |
127 | GBN ARQ(Go Back N ARQ)
128 |
129 | - 파이프라인 방식으로 수신측의 ACK를 이용해 윈도우를 이동함
130 |
131 | > ACK는 해당 Sequence까지는 모두 받았음을 확인해주는 역할
132 | >
133 | - 중간 Sequence가 변형 / 손실된 경우 송신측에서 ACK를 받지 못하였으므로 윈도우를 해당 Sequence부터 재시작함
134 | - NACK가 오거나 ACK / NACK가 모두 오지 않으면 손실된 중간 Sequence부터 윈도우를 다시시작, 전송함
135 |
136 | → 윈도우의 범위가 크다면 네트워크 문제 발생시 대량의 데이터를 다시 보내주어야 함
137 |
138 |
139 | SR ARQ(Selective Repeat ARQ)
140 |
141 | - ACK를 순서대로 하지 않고, 중간 Sequence가 비었다면 해당 Sequence만 재전송
142 |
143 | > ACK가 해당 Sequence까지의 확인이 아니라, 해당 Sequence의 확인으로 변경
144 | >
145 |
146 | > Sequence Number Issue
147 | Sequence Number가 무한히 커질 수 없으므로, Circular하게 돌아가면서 발생하는 Issue
148 | 송신측, 수신측의 Window가 다른 곳을 바라보고 있는데 Sequence Number가 같아지면서 Data의 순서가 바뀜
149 | → 따라서, Sequence Number의 최댓값 // 2로 윈도우의 크기를 제한해야 한다(겹치지 않게)
150 | >
151 |
152 | ### UDP Segment 구조
153 |
154 | 
155 |
156 | UDP Segment - 단순
157 |
158 | Source / Destination Port를 기준으로 Demultiplexing이 이루어진다.
159 |
160 | 선택적으로 checksum을 사용하여 데이터의 손실 여부를 파악할 수 있다.
161 |
162 | → 아주 단순한 구조
163 |
164 | > ☝️ TCP / UDP의 Header에는 IP가 담겨있지 않다. 그 이유는 Network Layer에서 IP를 통해서 Networking되어 Host를 찾아왔기 때문에(송신자의 IP도 알고 있음) Transport Layer Protocol에서는 Port정보만 사용한다.
165 | >
166 |
167 | > ☝️ UDP에서 Source Port는 통신에서 직접 사용되지 않는다. Dest Port를 보고 찾아갈 뿐, Source는 수신측에서 정보를 활용하기 위함이다.
168 | >
169 |
170 | ## 🌂 TCP
171 |
172 |
176 |
177 | ### 특징
178 |
179 | - Point to Point: 1대 1통신임
180 | - Reliable: 데이터의 손실이 없음
181 | - In Order Byte Stream: 데이터의 순서를 보장
182 | - Pipelined: 파이프라인 기법을 통해서 최적화
183 | - Full Duplex: 한개의 연결로 양방향 통신이 가능함
184 | - Connection Oriented: 연결을 만들고 통신을 진행함
185 | - Flow Controlled: 송신자의 상태에 따른 데이터 전송량 변화
186 |
187 | ### TCP Segment 구조
188 |
189 | 
191 |
192 | TCP Segment - 복잡
193 | 모두 sender가 사용하는 header이고, ack number / window size는 receiver가 사용할 정보이다.
194 |
195 | Sequence Number를 통해서 현재 Segment의 순서를 나타낸다.
196 |
197 | Acknowledgement Number를 통해서 내(송신자 or 수신자)가 받아야할 다음 Sequence Number를 나타낸다.
198 |
199 | ### 데이터 송 / 수신
200 |
201 | 
203 |
204 | 가장 일반적인 기본 통신과정
205 | seq로 데이터를 보내고, ack에 받을 데이터를 주면 상대가 그에 응답한다.
206 |
207 | ### RTT(TCP Round Trip Time), Timeout
208 |
209 | TCP에서는 RTT에 맞도록 Timeout이 설정된다(timeout을 사용해 ack가 안올 시 다시 전송).
210 |
211 | Timeout은 RTT가 매번 바뀌므로 최근 RTT의 평균값을 이용한다.
212 |
213 | ### Reliable Data Transfer
214 |
215 | > TCP는 Unreliable한 Network환경에서 Reliable한 통신을 만들어내려고 아래와 같은 방법을 사용한다.
216 | >
217 | - Pipelined Segments
218 | - Cumulative Acks(누적되는 Ack)
219 | - Single Retransmission Timer
220 | - Retransmission at: Timeout, Duplicate Ack
221 |
222 | ### Sender 동작 방식
223 |
224 |
228 |
229 | > Go-Back-N의 cummulative ack 방식처럼 중간에 패킷 하나가 빠지면 계속해서 빠진 패킷에 대한 ack을 전송하며, retransmission timer는 하나만 설정한다. 하지만, ****selective repeat 방식처럼 순서에 맞지 않게 온 패킷들도 버퍼에 다 보관해 놓는다.
230 | >
231 |
232 | Sequence를 보내고 Timer을 시작한다.
233 |
234 | - Timeout → 재전송 후 Timer 재시작
235 | - Ack 받음 → 해당 Segment의 Ack를 체크하고, 다른 Segment에 대한 Timer 재시작
236 |
237 | 재전송 시나리오
238 |
239 | 1. Ack 못 받음
240 |
241 | 
242 |
243 | Timeout으로 인한 재전송
244 |
245 | 2. Network 지연
246 |
247 | 
249 |
250 | 수신자가 Ack를 보냈지만, Network지연으로 Timeout이 먼저발생.
251 | 송신자는 나중에 받은 Ack를 통해서 앞의 데이터는 잘 받은걸로 간주하고 그 다음 Sequence부터 전송
252 |
253 | 3. 건너뛴 Ack
254 |
255 | 
257 |
258 | 수신자가 Ack를 보냈지만, 중간 Ack가 유실됨
259 | 송신자는 나중에 받은 Ack를 통해서 앞의 데이터는 잘 받은걸로 간주하고 그 다음 Sequence부터 전송
260 |
261 | 4. 중복된 Ack
262 |
263 | 
265 |
266 | Sender가 보낸 데이터에 대해서 수신자가 못받은 데이터가 있다면 중복된 Ack를 받음.
267 | 3개의 중복된 Ack가 있으면 유실된걸로 판단하고 가장 작은 Sequence(Ack)부터 다시 시작
268 |
269 |
270 | ### Flow Control
271 |
272 | > 수신자가 감당할 만큼의 데이터를 판단하여 Throughput을 조정
273 | >
274 | - Flow Control 방법들
275 |
276 | > 현재 네트워크는 모두 Sliding Window를 사용한다.
277 | >
278 | 1. Stop and Wait
279 |
280 | Sequence Segment 하나씩 보내고, ACK를 확인하는 과정을 반복한다.
281 |
282 | 
283 |
284 | 직관적이고 쉽지만 느리기 때문에 현재 사용되지 않는다.
285 |
286 | 2. Slding Window
287 |
288 | Window를 움직이면서 Pipeline을 형성한다.
289 |
290 | 
291 |
292 | 윈도우를 옮기면서 모두 전송하기 때문에 복잡하지만 효율적이다.
293 |
294 |
295 | Receiver Buffer Overflow
296 |
297 | 
298 |
299 | Receiver
300 |
301 | → Receiver의 Buffer를 Application이 비워주는 속도보다, Sender의 속도가 빠르면 Overflow 발생!
302 |
303 | 
304 |
305 | Receiver Buffer
306 |
307 | 그러므로, Free Buffer Size(rwnd)를 sender에게 보내주어서 sender가 ‘in-flight’(Unacked Segment)를 조정하게 함
308 |
309 | ### Handshake
310 |
311 | > TCP는 연결을 만들어놓고 통신하기 때문에 연결을 끊고 / 맺는 과정(Handshake)을 가진다.
312 | >
313 | - 3 Way Handshake(Opening)
314 |
315 | 
316 |
317 | SYN - SYN_ACK - SYN_ACK_ACK 순으로 이루어진다.
318 |
319 | 1. A가 B에게 SYN bit를 올리고, 랜덤한 seq(a)를 보낸다.
320 | 2. B가 A에게 SYN bit와 ACK bit를 올리고, 랜덤한 seq(b)와 ack(a + 1)를 보낸다.
321 | 3. A가 B에게 ACK bit를 올리고, ack(b + 1)를 보낸다.
322 |
323 | SYN, ACK bit는 SYN과정인지 ACK과정인지 알려주는 용도로 0(False) or 1(True)로 사용한다.
324 |
325 | Seq, Ack는 랜덤한 숫자와, ack = seq + 1을 통해서 이루어진다.
326 |
327 | > 왜 처음 seq가 0이 아니고 랜덤한 숫자죠?
328 | → 이는 seq0부터 시작되어 예측 가능한 점을 이용한 해킹 수법이 있기 때문이라도 한다.
329 | >
330 | - 2 way로 handshake하면 안되나요?
331 |
332 | 안됩니다!
333 | 왜냐하면, 2 way는 segment유실과 network상황 + timer로 인해서 이상하게 연결이 수립되는 경우가 있기 때문입니다.
334 |
335 | 
336 |
337 | 타이머와 엉켜서 반쪽짜리 연결이 수립된다.
338 |
339 | - 4 Way Handshake(Closing)
340 |
341 | 
342 |
343 | FIN - ACK - FIN - ACK로 이루어진다.
344 |
345 | 1. A가 B에게 FIN bit를 올리고, seq를 보낸다.
346 | 2. B가 A에게 ACK bit를 올리고, ack를 보낸다.
347 |
348 | > 여기서 B의 timer가 시작된다.(남은 데이터를 받기 위해서)
349 | 다음 과정 전까지는 데이터를 받으면서 ACK를 보내주면서 통신할 수 있다.
350 | >
351 | 3. B가 A에게 FIN bit를 올리고, seq를 보낸다.
352 |
353 | > 이 과정은 모든 데이터를 받았거나, 3번에서의 timer로 인해서 발생한다.
354 | >
355 | 4. A가 B에게 ACK bit를 올리고, ack를 보낸다.
356 |
357 | > A는 이제부터 원래의 timer의 2배만큼 기다리면서 B의 ack에 맞는 데이터를 보내준다.
358 | B는 더이상 ack나 데이터를 보내지 못하고 받을수만 있다.
359 | >
360 |
361 | ### Congestion Control
362 |
363 |
367 |
368 | - Congestion?
369 |
370 | 
371 |
372 | Router를 사이에둔 host들
373 |
374 | > R = Router의 허용된 네트워크 양
375 | >
376 | 1. Infinite Queue of Router
377 |
378 | 
379 |
380 | 2개의 연결이 있으므로 R/2을 넘을 경우 무한 delay가 발생한다.
381 |
382 | 2. Finite Queue of Router
383 |
384 | 
385 |
386 | Router의 Queue가 꽉차면 버려지므로 TCP가 처리하게 된다.
387 |
388 | > TCP의 관점에서 retransmit을 고려하게 되면, 버려진 packet들은 retransmit이 되는데... retransmit하는 사이에 또 timeout이 되는게 반복되어서 R/2도 못채울 수 있는게 현실이다.
389 | >
390 | - TCP Congestion Control
391 |
392 | > 윈도우 사이즈를 loss가 날때까지 천천히 늘리고, loss가 나면 줄이고를 반복하자.
393 | >
394 | - Slow Start: 윈도우 사이즈를 처음는 천천히 증가하고 나중에는 많이 늘리자.
395 |
396 | > 1 - 2 - 4 ...와 같이 2배씩 증가를 시킨다. 따라서, 나중에는 기하급수적으로 크게 늘어난다.
397 | >
398 | - ssthresh: 윈도우 사이즈 증가를 linear로 바꾸는 시점
399 |
400 | > loss 발생시 발생 지점의 1/2로 설정이됨
401 | >
402 | - RENO 방식
403 | - timeout 발생시: 윈도우를 1로 감소
404 | - 3 duplicate 발생시: 윈도우를 절반으로 감소
405 | - Tahoe 방식
406 | - timeout, 3 duplicate 발생시: 윈도우를 1로 감소
407 |
408 | ## 🙋♂️ 예상 질문
409 |
410 | - UDP와 TCP의 차이점이 무엇인가요?
411 |
412 | UDP와 TCP모두 Transport Layer에서 작동합니다. UDP는 데이터의 전송 여부와 순서를 보장하지 않는 connectionless Protocol입니다. TCP는 데이터의 전송 여부와 순서를 보장하기 위해서 1 대 1로연결을 맺고 통신을 하는 Connection Oriented Protocol입니다.
413 |
414 | - UDP와 TCP를 사용하는 예시를 말해주세요
415 |
416 | UDP는 데이터의 양이 많고 데이터의 중요성이 상대적으로 덜한 곳에서 쓰입니다. 예를 들어서 음악과 비디오의 스트리밍입니다. TCP는 데이터의 중요성이 더한 곳에서 쓰입니다. 예를 들어서 HTTP와 메일이 있습니다.
417 |
418 | - 3 way Handshake와 4 way Handshake에 대해서 설명해주세요
419 |
420 | 3 Way Handshake는 TCP가 연결을 맺기 위해서 사용되는 방법이며, SYN - SYN_ACK - SYN_ACK_ACK순서로 진행됩니다. 간단한 2 Way말고 3 Way를 사용한 이유는 2 Way Handshake시에는 타이머와 네트워크 지연으로 인한 반쪽짜리 연결이 만들어질 수 있기 때문입니다. 4 Way Handshake는 TCP가 연결을 끊을 때 사용하는 방식입니다. FIN - ACK - FIN - ACK순서로 진행됩니다. 연결 시작과 다르게 끊을 때 4 Way인 이유는 아직 전송되지 않은 데이터를 기다리기 위해서입니다.
421 |
422 | - Go Back N과 Selective Repeat는 각 언제 사용될까요?
423 |
424 | Go BAck N과 Selective Repeat는 Sliding Window를 사용할 때 에러 처리 기법입니다. Go Back N은 상대적으로 재전송 되는 데이터의 양이 많기 때문에 전송되는 데이터의 양이 작을 때 유리합니다. Selective Repeaet는 상대적으로 재전송되는 양이 적지만 재전송 되는 데이터의 송신측 에서의 정렬, 다수의 타이머를 사용하면서 부하가 상대적으로 크기 때문에 데이터의 양이 적을 때 유리합니다.
425 |
426 | - QUIC과 HTTP3에 대해서 알고있는걸 말해주세요
427 |
428 | HTTP3(QUIC)은 UDP를 사용함으로써 handshake과정을 없애서 RTT를 없애 속도를 높일 수 있었습니다. 또한, 다중 스트림을 사용하여 TCP에서 loss 발생에 대한 HOL(Head Of Line)을 해결하였습니다.
429 |
430 |
431 | ## 👀 참고
432 |
433 | - TCP / UDP 전반적인 특징
434 |
435 | [[TCP/UDP] TCP와 UDP의 특징과 차이](https://mangkyu.tistory.com/15)
436 |
437 | - Socket VS Port
438 |
439 | [이해가 쉬운 기술 블로그 : 네이버 블로그](https://blog.naver.com/myca11/221389847130)
440 |
441 | - UDP Checksum
442 |
443 | [UDP checksum 계산](https://limjunho.github.io/2021/06/05/UDP-cksum.html)
444 |
445 | - UDP with Reliable
446 |
447 | [Computer Network 7 - UDP](https://heegyukim.medium.com/computer-network-7-udp-86d45323d5c7)
448 |
449 | - TCP seq / ack 과정
450 |
451 | [TCP의 개념 (Transmission Control Protocol)](https://ddongwon.tistory.com/m/84?category=801335)
452 |
453 | - HTTP3(QUIC)
454 |
455 | [HTTP/3의 TCP/UDP 요약](https://json8.tistory.com/70)
456 |
457 | [QUIC 프로토콜](https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=renucs&logNo=220887163028)
458 |
459 | - 학교 수업 자료
460 |
461 | [](http://www.sfu.ca/~ljilja/ENSC835/News/Kurose_Ross/Chapter_3_V7.01.pdf)
462 |
463 | - GBN / SR
464 |
465 | [[네트워크] Go-Back-N, Selective Repeat](https://snoop-study.tistory.com/65)
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 1.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 10.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 11.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 12.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 13.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 13.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 14.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 15.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 15.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 16.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 16.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 2.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 3.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 4.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 5.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 6.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 7.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 8.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 9.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled.png
--------------------------------------------------------------------------------
/Network/로드밸런싱.md:
--------------------------------------------------------------------------------
1 | ## 🌞 로드밸런싱이란?
2 |
3 | 여러 서버의 작업을 분산하여 웹 사이트, 어플리케이션, 데이터베이스 등 서비스의 성능과 안정성을 향상시켜주며 고가용성 인프라의 핵심 구성요소
4 |
5 |
15 |
16 | ### 🌝 이점은?
17 |
18 | 1. **수평 확장**
19 | 고가의 서버로 수직확장하는 것이 아닌 저렴한 다수의 서버를 증설하는 수평확장 가능
20 | 2. **무중단 서비스**
21 | 서버 한대의 장애가 발생하거나 동기적인 작업을 처리하는 경우 다른 서버로 트래픽 분배하여 최종 사용자(End User)에게 영향이 없다
22 | 3. **대량의 트래픽 분배**
23 | 단일 서버에 높은 부하를 수행하지 않고 여러 서버에 작업을 분산하여 적은 양의 작업을 수행하게 하며 장애나 부하가 적은 구성을 경험한다
24 |
25 | ### 🌚 단점은?
26 |
27 | 1. **세션 데이터 관리**
28 | 특정 사용자에 대한 세션을 하나의 서버에 저장하는 경우 추후 다른 서버로 밸런싱된다면 클라이언트의 세션이 유지되지 않으며 부가적인 처리가 필요함
29 |
30 | ### 🤔 유형
31 |
32 | - **하드웨어 로드밸런서**
33 | 애플리케이션과 네트워크 트래픽을 분산하기 위해 물리적 사내 하드웨어 장치에 의존하는 방식
34 | 많은 트래픽을 처리할 수 있지만 가격이 높으며 유연성이 낮음
35 | ex. Switch
36 | - **소프트웨어 로드밸런서**
37 | 사용 또는 오픈소스 어플리케이션을 설치하여 사용하는 방식
38 | 하드웨어 로드밸런서에 비해 가격이 낮습니다.
39 | ex. Nginx, HAProxy
40 |
41 |
42 | ### 🔍 분산 알고리즘
43 |
44 | - **라운드로빈**
45 | 요청에 대하여 서버를 순차적으로 선택하는 알고리즘
46 | 각 서버의 성능과 처리시간이 짧은 어플리케이션에 권장
47 | - **가중 라운드로빈**
48 | 각 서버의 가중치를 부여해 처리 용량을 지정하는 알고리즘
49 | - **최소 연결 방식**
50 | 로드 밸런서가 연결이 가장 적은 서버를 선택하는 알고리즘
51 | 다양한 처리용량(일정하지 않은 응답 속도, 서버의 성능차이)이 발생하는 어플리케이션에 권장
52 | - **IP 해시**
53 | 클라이언트의 IP주소를 특정 서버로 매핑하여 사용자와 항상 동일한 서버의 연결을 보장하는 알고리즘
54 |
55 |
61 |
62 | ### ⭐️ 주요기능
63 |
64 | - **NAT(Network Address Translation) : 네트워크 주소 변환**
65 | 네트워크 계층에서 IP 패킷의 TCP/UDP 포트 숫자와 출발지 및 목적지의 IP 주소 등을 재기록
66 |
67 | 즉 다수의 서버의 사설 IP 를 하나의 공인 IP로 변환해주는 기능
68 |
69 |
72 |
73 | | NAT | Proxy |
74 | | --- | --- |
75 | | 네트워크 계층 | 응용계층 |
76 | | 사설 IP ↔ 공인 IP 역할 | 클라이언트와 서버 사이 중재자 역할 |
77 | | Router 나 방화벽 등 주변 장치에 의해 동작 | DMZ(내부, 외부 네트워크 사이 영역) Zone 에 배치하여 동작 |
78 | | 요청과 응답 사이 네트워크 계층에서 사설 IP 를 공인 IP 로 변경 | 요청과 응답이 Proxy Server 를 거쳐서 전송 |
79 |
80 | - **DSR(Dynamic Source Routing Protocol) : 동적 소스 라우팅 프로토콜**
81 | 서버에서 클라이언트로 요청에 대한 응답을 하는 경우 스위치의 IP가 아닌 클라이언트의 IP를 전달하여 네트워크 스위치를 거치지 않고 바로 클라이언트를 찾음
82 | - Replicated Server 들이 큰 용량의 응답을 보내게 된다면 Client 로 전달전 Load Balancer 에서 병목 현상이 발생
83 | DSR 기능을 사용하여 큰 사이즈의 응답 패킷에 대해서 로드밸런서를 거치지 않고 바로 클라이언트로 전송
84 | - **Tunneling**
85 | 서버와 클라이언트간 중간에서 터널링을 제공
86 | 연결된 상호 간에만 캡슐화된 패킷을 구별하여 캡슐화를 해제
87 |
88 | ### 🛎 종류
89 |
90 |
91 |
92 | - **L2**
93 | - Layer 2 데이터 링크 계층에서 MAC 주소를 바탕으로 로드밸런싱
94 | - L2SDR 전략을 사용하려면 MAC 주소의 변환만 가능하므로 로드밸런서와 서버는 같은 네트워크에 존재해야됨
95 | - **L3**
96 | - Layer 3 네트워크 계층에서 IP 를 기준으로 로드밸런싱
97 | - L2 에 라우팅 기능이 추가된 형태
98 | - **L4 = Network Load Balancing(NLB)**
99 | - Layer 4 전송계층(TCP/UDP)에서 IP, Port 번호를 기준으로 로드밸런싱
100 | - VIP(Virtual IP)을 통해서 Replicated Servers 그룹화하여 관리
101 | - L2, L3 의 기능도 사용가능하며 섬세한 라우팅 처리를 제공
102 | - 주로 RR 방식의 알고리즘을 사용하지만 사용자로 인해 다른 알고리즘 사용 가능
103 |
104 | 
105 |
106 |
107 | - **L7**
108 | - Layer 7 응용계층에서 TCP/UDP 는 물론 URL, FTP, 쿠키 등의 정보를 기준으로 로드밸런싱
109 | - TLS Termination 이 발생
110 |
111 |
116 |
117 | - 상위 계층에서 로드를 분산하므로 다른 로드밸런서에 비해 더욱 섬세한 라우팅이 가능
118 | - 캐싱 기능을 제공
119 | - DoS/DDoS와 같은 비정상적인 트래픽을 사전에 필터링할 수 있음
120 | - 적절한 알고리즘을 사용해 로드밸런싱
121 |
122 | 
123 |
124 | ## 📚 참고자료
125 |
126 | [로드밸런싱이란](https://www.digitalocean.com/community/tutorials/what-is-load-balancing#how-does-the-load-balancer-choose-the-backend-server)
127 |
128 | [로드밸런서의 기능, 분산 알고리즘 종류](http://wiki.hash.kr/index.php/%EB%A1%9C%EB%93%9C%EB%B0%B8%EB%9F%B0%EC%8B%B1)
129 |
130 | [로드밸런싱(Load Balancing)과 고가용성(HA)](https://prohannah.tistory.com/62)
131 |
132 | [L2, L3, L4, L7 로드밸런싱](https://tomining.tistory.com/117)
133 |
134 | [L4, L7 오해할 수 있는 내용](https://aws-hyoh.tistory.com/entry/L4L7-%EB%A1%9C%EB%93%9C%EB%B0%B8%EB%9F%B0%EC%8B%B1-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0)
135 |
136 | [NAT 의 역할](https://aws-hyoh.tistory.com/entry/L4-%EC%8A%A4%EC%9C%84%EC%B9%98-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-3)
137 |
138 | [NAVER D2 HAProxy](https://d2.naver.com/helloworld/284659)
139 |
140 | [SSL Termination이란 무엇인가?](https://sepiros.tistory.com/m/50?category=1090822)
141 |
142 | [더욱 Deep Dive](https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/19860014876.pdf)
143 |
--------------------------------------------------------------------------------
/OperatingSystem/CPU 스케줄러.md:
--------------------------------------------------------------------------------
1 | # CPU 스케줄러
2 |
3 |
4 |
5 | # 설명
6 |
7 | 멀티프로그래밍에서 CPU 이용률을 최대화 하기 위해, 특정 알고리즘으로 Main memory에 적재되어 **ready queue**에 있는 프로세스를 선택하여 CPU를 프로세스에 할당해주는 것으로, **Short-term scheduler**라고도 한다.
8 |
9 |
10 |
11 | # Dispatcher
12 |
13 | CPU 스케줄러의 일부분으로, CPU의 제어권을 프로세스에 주는 작업을 한다.
14 |
15 | - context switch
16 |
17 | - user mode로 전환
18 |
19 | - 유저 프로그램의 적절한 위치로 이동하여 프로그램을 재시작한다.
20 |
21 | - Dispatch latency : dispatcher가 한 프로세스를 멈추고 다른 프로세스를 시작하는 시간(짧을 수록 좋음)
22 |
23 |
24 |
25 | # CPU Scheduling이 발생하는 상황
26 |
27 | - 선점(preemptive) 스케줄링: 프로세스가 강제(비자발)적으로 CPU를 내주는 방식
28 |
29 | 
30 |
31 | - running → ready
32 | - waiting → ready
33 | - 비선점(nonpreemptive) 스케줄링: 프로세스가 자발적으로 CPU를 내주는 방식
34 |
35 | 
36 |
37 | - running → waiting
38 |
39 | - running → terminate
40 |
41 |
42 |
43 |
44 | # 스케줄링 기준
45 |
46 | - CPU utilization(CPU 이용률) - CPU를 얼마나 바쁘게 유지했는지
47 |
48 | - Throughput(처리량) - 시간 단위 당 실행시간을 완료한 프로세스의 수
49 |
50 | - Turnaround time(수행 시간) - 프로세스가 시작해서 끝날 때까지의 시간
51 |
52 | - Waiting time(대기 시간) - 프로세스가 **ready queue**에서 기다린 시간
53 |
54 | - Response time(응답 시간) - 프로그램을 수행해서 첫 번째 응답이 나타날 때까지의 시간
55 |
56 |
57 |
58 | # 스케줄링 알고리즘 최적화 기준
59 |
60 | - Max CPU utilization
61 |
62 | - Max throughput
63 |
64 | - Min turnaround time
65 |
66 | - Min waiting time
67 |
68 | - Min response time
69 |
70 |
71 |
72 | # 스케줄링 알고리즘
73 |
74 |
75 |
76 | ## 비선점형 스케줄링
77 |
78 |
79 |
80 | ### First Come, First Served(FCFS) Scheduling
81 |
82 | - 먼저 CPU를 요청하는 프로세스에 CPU를 할당하는 방식
83 |
84 | - Burst Time이 긴 프로세스가 먼저 요청하면 **convey effect**가 발생됨
85 |
86 | 
87 |
88 | 
89 |
90 | **대기 시간**: P1 = 0, P2 = 24, P3 = 27
91 |
92 | **평균 대기 시간**: (0+24+27)/3 = 17
93 |
94 | - Burst Time이 짧은 프로세스가 먼저 요청할수록 유리함
95 |
96 | 
97 |
98 | **대기 시간**: P1 = 6, P2 = 0, P3 = 3
99 |
100 | **평균 대기 시간**: (6+0+3)/3 = 3
101 |
102 | - convey effect: 짧은 프로세스가 긴 프로세스 뒤에 기다리게 되는 현상
103 |
104 |
105 |
106 | ### Shortest-Job-First(SJF) Scheduling
107 |
108 | - 짧은 수행 시간을 가진 프로세스를 먼저 처리하는 방식
109 |
110 | - 평균 대기 시간이 최소화 됨
111 |
112 | 
113 |
114 | 
115 |
116 | **평균 대기 시간**: (0 + 3 + 9 + 16)/4 =7
117 |
118 | - 대기 시간이 긴 프로세스는 오래 기다려야 한다.
119 |
120 |
121 |
122 | ## 선점형 알고리즘
123 |
124 | ### Shortest Remaining Time First(SRTF) Scheduling
125 |
126 | - SJF 알고리즘에서 선점 정책을 도입한 방식
127 | - 잔여시간이 가장 짧은 프로세스를 우선으로 CPU할당을 한다.
128 | - Arrival Time 개념이 추가됨
129 |
130 | 
131 |
132 | 
133 |
134 | 평균 대기 시간 : [(10-1)+(1-1)+(17-2)+(5-3)]/4 = 6.5
135 |
136 | 수행 시작된 시간 - 이미 처리한 시간 - 도착 시간
137 |
138 | - 잦은 선점에 대한 문맥 교환 오버헤드 증가
139 |
140 | ### Priority Scheduling
141 |
142 | - 프로세스에 우선순위를 메겨, 우선순위가 높은 프로세스부터 처리하는 방식
143 | - 선점형, 비선점형 모두 존재
144 | - Starvation 문제: 우선순위가 낮은 프로세스는 계속 기다려야한다.
145 | - Aging 기법: 기다리는 시간만큼 프로세스의 우선순위를 높여준다.
146 |
147 | ### Round Robin(RR) Scheduling
148 |
149 | - 각 프로세스는 작은 단위 시간(time quantum)을 가지고 있다. (보통 10-100 ms)
150 |
151 | - 단위 시간이 지나면 프로세스는 선점되어 ready queue의 끝으로 이동한다.
152 |
153 | - n개의 프로세스가 ready queue 안에 있고, 단위 시간이 q이면, 각 프로세스의 대기시간은 (n-1)q 시간보다 많이 기다리지 않는다.
154 |
155 | - 단위 시간이 클 수록 FCFS와 같아지고, 작을 수록 context switch로 인한 오버헤드가 커진다.
156 |
157 |
158 |
159 | # Multilevel Queue
160 |
161 | - ready queue는 여러 단계의 큐로 나누어져 있다.
162 |
163 | 
164 |
165 | - 사용자와 상호작용하는 프로세스는 상위 레벨에, 백그라운드로 돌아가는 프로세스는 하위 레벨에 배치한다.
166 | - 상위 레벨은 주로 RR 알고리즘을, 하위 레벨은 주로 FCFS 알고리즘을 적용한다.
167 |
168 | - 각 큐마다 스케줄링 알고리즘을 갖고 있다.
169 |
170 | - 우선순위가 고정되어 있으면 하위 레벨 queue의 프로세스들은 상위 레벨의 프로세스가 모두 수행되지 않으면 실행되지 않는 **starvation** 현상이 나타남
171 |
172 | - 하위 레벨의 프로세스가 실행되고 있어도 상위 레벨에 프로세스가 들어오면 선점된다.
173 |
174 |
175 |
176 | # Multilevel Feedback Queue
177 |
178 | - Multilevel Queue를 확장한 방식으로, 프로세스는 각 큐를 이동할 수 있다.
179 | - aging 기법을 사용하여 starvation 현상을 방지한다.
180 | - Parameter
181 | - 큐의 수
182 |
183 | - 각 큐의 스케줄링 알고리즘
184 |
185 | - 언제 프로세스 우선순위를 높이는 지 결정하는 메소드
186 |
187 | - 언제 프로세스 우선순위를 낮추는 지 결정하는 메소드
188 |
189 | - 프로세스가 서비스를 필요로 할 때 프로세스가 들어갈 큐를 결정하는 메소드
190 |
191 |
192 |
193 |
194 | # Multiple-Processor Scheduling
195 |
196 | - 여러 개의 CPU를 사용하는 시스템에서의 스케줄링 방법
197 | - 제약: 다중프로세서 내의 동질의 프로세서들
198 | - Asymmetric multiprocessing 비대칭 다중처리
199 | - Master-Slave 구조
200 | - Master 프로세서가 모든 스케줄링 결정을 하고, Slave 프로세서들은 그 결정에 따른다.
201 | - 오직 한 프로세서만 시스템 자료 구조에 접근하여 데이터 공유의 필요성을 배제한다.
202 | - Symmetric multiprocessing(SMP) 대칭 다중처리
203 | - 각 프로세서가 자기 스케줄링을 한다.
204 | - 모든 프로세서는 common ready queue에 있거나, 각자의 private queue에 있게 된다.
205 | - **common queue**는 모든 프로세서가 접근할 수 있어서 경쟁 상태를 야기하기 때문에 lock이 필요하다.
206 | - **private queue**는 큐마다 부하의 양이 다르다.
207 | - Processor affinity 프로세서 친화성
208 | - 프로세스는 현재 실행되고 있는 프로세서에 친화성을 가진다.
209 |
210 | 
211 |
212 | 특정 CPU에 할당된 프로세스를 CPU가 있는 가장 가까운 메모리에 할당하여 가능한 빠른 메모리 엑세스를 제공한다.
213 |
214 | - soft affinity 약한 친화성
215 | - hard affinity 강한 친화성
216 | - Load Balancing 부화 균등화
217 | - SMP이면, 효율성을 위해 모든 CPU를 로드해야한다.
218 |
219 | - SMP 시스템에서 부하가 고르게 분산되도록 한다.
220 |
221 | - Push migration : 특정 테스크가 각 프로세서의 로드를 감시하다가 과부하된 CPU에서 다른 CPU들로 프로세스를 옮긴다.
222 |
223 | - Pull migration : idle상태의 프로세서들은 바쁜 프로세서에서 대기중엔 프로세스들을 가져온다.
224 |
225 |
226 |
227 | ---
228 |
229 | - 참고자료
230 |
231 | [https://velog.io/@ss-won/OS-CPU-Scheduler와-Dispatcher](https://velog.io/@ss-won/OS-CPU-Scheduler%EC%99%80-Dispatcher)
232 |
233 | [https://velog.io/@jacob0122/CPU-Scheduling-Scheduler](https://velog.io/@jacob0122/CPU-Scheduling-Scheduler)
234 |
235 | [https://jhnyang.tistory.com/372](https://jhnyang.tistory.com/372)
236 |
237 | [https://imbf.github.io/computer-science(cs)/2020/10/18/CPU-Scheduling.html](https://imbf.github.io/computer-science(cs)/2020/10/18/CPU-Scheduling.html)
238 |
239 | [https://hyunah030.tistory.com/4](https://hyunah030.tistory.com/4)
240 |
241 | [https://haun25ne.tistory.com/52](https://haun25ne.tistory.com/52)
242 |
243 | 운영체제 공룡책
--------------------------------------------------------------------------------
/OperatingSystem/IPC.md:
--------------------------------------------------------------------------------
1 | # IPC
2 |
3 | 프로세스들은 유저공간에서 OS로부터 할당받은 독립된 공간에서 운행한다.
4 |
5 | 그렇기 때문에 서로 간에 통신이 어렵다.
6 |
7 | 이를 해결하기 위해서 커널 영역에서 IPC 기술을 제공하고 있다.
8 |
9 | - 프로세스간 통신이 필요할 때 사용
10 | - 동기화가 필요하고 **커널이 제공한다.**
11 |
12 | # 종류
13 |
14 | ## 1. PIPE
15 |
16 | 
17 |
18 | 익명의 파이프를 만들어서 부모-자식 간에 단방향 통신을 지원한다.
19 |
20 | 하나의 파이프로는 한쪽 방향으로만 통신 가능해서 읽기/쓰기를 모두 하기 원한다면 2개의 파이프를 사용해야한다.
21 |
22 | 기본적으로 read, write시에 block되기 때문에 read가 대기중이라면 끝나기 전에는 write할 수 없다.
23 |
24 | ### 장단점
25 |
26 | - 장점
27 | - 간단하게 구현 가능
28 | - 기본적으로 pipe(배열) 명령어로 생성 가능하고 read, write 명령어를 사용한다.
29 | - 단점
30 | - 양방향 통신으로 활용하려면 파이프를 2개 만들어야하는데 이 과정이 꽤 복잡하다.
31 | - 양방향 하고 싶으면 굳이 파이프 사용 x
32 | - buffer가 작기 때문에 overflow될 수 있다.
33 | - 부모-자식 프로세스 간에만 사용 가능하다.
34 |
35 | ## 2. Named PIPE
36 |
37 | 
38 |
39 | 위의 PIPE와 동일한 내용이지만 차이점은 파이프에 이름을 부여해 사용한다.
40 |
41 | **why???**
42 |
43 | 부모-자식 간에 통신할 때는 서로를 명확히 알고 있으므로 굳이 파이프가 어떤 파이프인지 알 필요가 없다.
44 |
45 | 하지만 **부모-자식 관계가 아닌 프로세스들 간에 통신할 때** 파이프를 사용한다면 어떤 파이프를 통해서 통신하는지 알아야하기 때문
46 |
47 | ## 3. Messaging passing ⭐️
48 |
49 | 커널이 메모리 보호를 위해서 대리 전달해주는 방식
50 |
51 | 따라서, 안전하고 동기화 문제를 신경쓰지 않아도 된다. → 커널이 알아서 동기화 해줌
52 |
53 | 그러나 번거롭고 오버헤드가 크다.
54 |
55 | ex) 프로세스 A가 커널로 메시지를 보내면 그걸 커널이 프로세스 B에게 보내준다.
56 |
57 | ### 모델
58 |
59 | 1. Direct Communication
60 | - A가 커널에 메시지를 직접 주고 커널이 B에게 메시지를 직접 전달
61 | 
62 |
63 | 2. Indirect Communication
64 | - A가 커널에 있는 메시지 박스에 넣어두면 B는 그 박스에 가서 읽어오는 방식
65 | 
66 |
67 |
68 | 둘의 차이는 커널이 직접 주냐 아니냐
69 |
70 | ### Message Queue
71 |
72 | 
73 |
74 | Message passing은 구현보다는 개념적으로 사용되는 용어이다. 프로세스 간의 통신을 하기 위해 메시지를 어떻게 전송할지에 대한 방법론이고 그 구체적인 방법 중 하나가 Message queue 구현 방법이다.(보통 Messaging Passing이라함은 Message Queue라고 해도 무방)
75 |
76 | 파이프는 데이터 흐름이라면 Message Queue는 선입선출의 자료구조를 가지고 메모리 공간을 통해 전달한다.
77 |
78 | 데이터에 번호를 붙힘으로써 다수의 프로세스가 동시에 데이터를 다룰 수 있다.
79 |
80 | ### 장단점
81 |
82 | - 장점
83 | - 비동기 방식이기 때문에 데이터가 많아도 처리가 가능하다.
84 | - 다수의 프로세스끼리 메시지를 보내고 꺼낼 수 있다.
85 | - 즉, 분산처리에 용의
86 | - 단점
87 | - 메시지가 잘 전달되었는지 알 수 없다.
88 | - 데이터가 많을 수록 추가 메모리 자원이 필요하다.
89 |
90 | ## 4. Shared memory ⭐️
91 |
92 | 
93 |
94 | 두 프로세스간의 공유된 메모리를 생성 후 이용하는 것
95 |
96 | 프로세스가 공유 메모리 할당을 커널에 요청하면 커널은 할당해주고, 어떤 프로세스건 해당 메모리 영역에 접근 할 수 있다.
97 |
98 | 단순히 공유 메모리를 point하는 방식으로 프로세스에서 사용되는 메모리가 증가되지는 않는다.
99 |
100 | ### 장단점
101 |
102 | - 장점
103 | - 따로 통신을 이용해 데이터를 주고 받지 않고 바로 메모리에 접근하기 때문에 모든 IPC 중 가장 빠르다.
104 | - 단점
105 | - 메시지 전달이 아니기 때문에 데이터를 읽어야하는 시점을 알 수 없다.
106 | - 공유 자원을 이용하므로 동기화 문제를 해결해야한다.
107 | - 커널에 종속적이기 때문에 허용하고 있는 공유메모리 사이즈를 확인해야한다.
108 |
109 | ## 5. Memory Map
110 |
111 | 
112 |
113 | 기존적으로 공유 메모리와 비슷한데 메모리 맵은 파일을 메모리에 매핑시켜서 공유한다는 점이다.
114 |
115 | 즉, 디스크에 있는 파일과 프로세스의 페이지가 연결된다. → 가상 메모리의 페이징 기법과 비슷
116 |
117 | 통신 느낌보단 파일 접근을 효율적으로 하기 위한 기법이라고 생각
118 |
119 | ex) 파일이 오픈되면 파일의 데이터가 메모리에 올라가게되는데 다른 프로세스에서 똑같은 파일을 열어서 메모리에 같은 걸 또 올리면 낭비가 심해지게 되고 데이터 일관성에도 문제가 생김.
120 |
121 | 그래서 이런 경우 기존 메모리 공간에 같이 접근해서 데이터를 읽고 쓰는 작업을 하는 듯(이 때, 동기화 문제를 스레드가 알아서 해주는 것 같다..!)
122 |
123 | ### 장단점
124 |
125 | - 장점
126 | - 대용량 데이터를 공유 할 때 사용한다.(메모리에 전부 올라가지 않아도 되니까)
127 | - File I/O가 느릴 때 사용하면 좋다.
128 | - 단점
129 | - 파일의 크기를 변경할 수 없다.(사용하기 전, 후 에만 변경 가능)
130 | - 얼마나 많은 데이터를 얼마나 오랫동안 메모리에 둘 것인지를 컨트롤할 수 없다.
131 |
132 | ## 6. Socket
133 |
134 | 
135 |
136 | 같은 도메인 내에서도 물론 연결 가능하고, 추가적으로 외부 프로세스와 통신할 때 사용한다.
137 |
138 | 서버 : bind, listen, accept
139 |
140 | 클라이언트 : connect
141 |
142 | 즉, 네트워크를 통해 프로세스 간에 통신을 진행
143 |
144 | ### 장단점
145 |
146 | - 장점
147 | - 외부 시스템과 통신이 가능하다.
148 | - 단점
149 | - 네트워크 프로그래밍이 가능해야한다.
150 |
151 | # 결론
152 |
153 | 
154 |
155 | 결국 IPC란 두 개의 프로세스간 통신을 의미하는데 굳이 하나의 컴퓨터에 있는 두 개의 프로세스만을 의미하는 것이 아니다.
156 |
157 | 서로 다른 컴퓨터의 프로세스들도 통신하는 것도 IPC = 결국 네트워킹이다.
158 |
159 | # 질문 리스트
160 |
161 | - IPC 기법에 대해 설명해주세요
162 |
163 | 프로세스들은 유저공간에서 OS로부터 할당받은 독립된 공간에서 운행하기 때문에 서로 간에 통신이 어렵습니다. 따라서 이를 해결하기 위해서 커널 영역에서 제공하는 IPC 기술을 통해 통신합니다.
164 |
165 | - IPC 기법의 종류를 아는데로 설명해주세요
166 |
167 | 대표적으로는 파이프, message queue, share memory가 있을 것 같습니다.
168 |
169 | 파이프는 익명의 파이프라면 부모-자식 프로세스간에 단방향으로 데이터를 공유하는 방법이고 named 파이프라면 부모-자식 관계가 아닌 프로세스끼리도 파이프를 이용해 통신할 수 있는 방법입니다.
170 |
171 | 파이프가 데이터 흐름이라면 Message Queue는 선입선출의 자료구조를 가지고 메모리 공간을 통해 단방향 전달 하는 방법으로 비동기 방식을 가지고 있고 여러 프로세스끼리 통신이 가능합니다.
172 |
173 | 마지막으로 share memory는 커널이 공유 메모리를 할당해주면 모든 프로세스가 해당 공유 메모리에 접근하여 사용하는 방식입니다.
174 |
175 |
176 | # 참고
177 |
178 | [https://www.byfuls.com/programming/read?id=63](https://www.byfuls.com/programming/read?id=63)
179 |
180 | 사진 자료
181 | [https://doitnow-man.tistory.com/110](https://doitnow-man.tistory.com/110)
182 |
--------------------------------------------------------------------------------
/OperatingSystem/가상 메모리.md:
--------------------------------------------------------------------------------
1 | # 가상 메모리
2 |
3 | # ⭐️ 등장 배경
4 |
5 | 기존 메모리 관리는 하나의 프로그램 전체를 실제 물리 메모리에 올리는 방식을 사용했다.
6 |
7 | 하지만 메모리에 많은 프로세스들을 올리고자 하는데 물리 메모리에 전부 올리기에는 한계가 존재한다. (메모리 용량 부족, 페이지 교체 성능 이슈)
8 |
9 | 컴퓨터는 폰 노이만 구조이기 때문에 사용할 코드는 반드시 메모리에 있어야해서 코드를 물리 메모리에 전부 올린다는 발상이었지만 프로그램을 사용하는데 그 때마다 필요한 코드들만 있어도 실행이 되기 때문에 불필요하게 전체의 프로그램이 메모리에 올라와 있지 않아도 된다는 점에서 아이디어를 얻었다고 한다.
10 |
11 | 따라서 프로그램 전체가 아닌 **필요한 일부분만 실제 메모리에 올리는 기법**인 가상 메모리를 사용하게 되었다.
12 |
13 | 이런 방법을 사용하면
14 |
15 | 1. 더 많은 프로그램들을 동시에 메모리에 올려 작업할 수 있다.
16 | 2. 한 번에 올리는 소스 양이 적기 때문에 Disk와 Memory간 I/O 작업 속도가 빨라진다.
17 |
18 | 등의 장점을 얻을 수 있다.
19 |
20 | 
21 |
22 | # ⭐️ 아이디어
23 |
24 | 프로세스는 가상 주소를 사용하고, 실제 해당 주소에서 데이터를 읽고 쓸 때만 물리 주소로 변경한다.
25 |
26 | - Virtual address : 프로세스가 참조하는 주소
27 | - 디스크의 페이지 파일에 저장된다.
28 | - 페이지 교체할 때 이 디스크 swap영역에서 페이지를 가져오는 것
29 | - Physical address : 실제 메모리 주소
30 |
31 | CPU는 가상 메모리를 다루는데, 실제 물리 주소 접근시 MMU(Memory Management Unit)를 통해 물리 메모리에 접근한다.
32 |
33 | - MMU : CPU에서 코드 실행 시 가상 메모리 주소를 물리 주소 값으로 변환해주는 하드웨어 장치
34 |
35 | # ⭐️ Paging
36 |
37 | ## 등장 배경
38 |
39 | 메모리에 프로세스를 연속 할당할 때 발생하는 **외부 단편화**를 해결하기 위해 사용한다.
40 |
41 | 
42 |
43 | ## 개념
44 |
45 | - page : 가상 메모리 공간의 최소 단위
46 | - frame : 물리 메모리 공간의 최소 단위
47 |
48 | 크기가 동일한 page로 가상 메모리 공간과 이에 매칭되는 물리 메모리 공간을 관리한다.
49 |
50 | 이 page들은 실제 들어있는 데이터 양과 관계없이 모두 고정 크기를 가진다.
51 |
52 | 이 때, 고정된 각 크기는 시스템에 따라 다르다.
53 |
54 | - 크기가 작을 수록 내부 단편화가 해결되지만, 페이지 개수 증가로 인해 페이지 단위의 I/O가 증가한다.
55 |
56 | 각 프로세스의 PCB에는 page Table 구조체를 가리키는 주소가 있는데 이 테이블에는 가상/물리 주소의 매핑 정보가 담겨있고 이를 활용한다.
57 |
58 | 
59 |
60 | ## 원리
61 |
62 | 가상 주소와 물리 주소를 동일한 크기로 자르고 어디에 배치되는지 기록하며 배치한다면?? 자투리 공간이 발생하지 않고 딱 맞게 배치된다.
63 |
64 | 
65 |
66 | 이렇게 하면 프로세스를 연속할당 할 필요가 없기 때문에 **외부단편화 문제를 해결**할 수 있다.
67 |
68 | 고정 크기라는 것 때문에 **내부단편화가 발생**하긴 하지만 외부단편화로 인해 발생하는 낭비 공간이 더 크기 때문에 이를 감수하더라도 페이징을 사용하는 것이 이득이다.
69 |
70 | 그런데 생각해보면 프로세스는 **차례대로 읽어 수행**되는 linear address가 필요한데 paging 기법처럼 프로세스가 조각으로 나뉘어져 따로 놀고 있는데 어떻게 연속적으로 실행될까??
71 |
72 | → Page Table을 이용
73 |
74 | # ⭐️ Page Table
75 |
76 | - 프로세스 생성시 PCB에 페이지 테이블 정보가 생성된다.
77 | - 프로세스 구동시, page table의 base 주소가 별도 레지스터에 저장되고, CPU가 가상 주소 접근시 MMU는 page table의 base 주소에 접근해 물리 주소를 얻는다.
78 | - 이 때, 페이지들이 연달아 실행될 수 있도록 순서에 맞는 물리 주소 위치를 찾아준다.
79 | - 즉, linear하게 수행시킬 수 있다.
80 |
81 | 
82 |
83 | 기본적으로 배열처럼 인덱스가 페이지 번호를 가리키고 그 배열에 담고 있는 숫자가 매핑할 프레임 번호를 뜻한다.
84 |
85 | ## 페이지 크기와 가상 주소 구성
86 |
87 | CPU에 의해서 생성되는 주소를 가상 주소, RAM에 실질적으로 로드되는 주소를 물리 주소라고 했는데 위 예시에서 0,1,2,3 등 말고 실제 이 주소들은 어떻게 구성되어 있는지를 알아보자.
88 |
89 | 가상 주소는 페이지 번호(p)와 페이지 오프셋(d)으로 구성된다.
90 |
91 | - p : 매핑을 위해 page와 frame은 번호를 갖는데, 페이지 순서에 해당하는 숫자를 의미한다.
92 | - but, 덩어리인 page만으로 정확한 주소를 표기할 수 없기 때문에 오프셋을 추가로 사용한다.
93 | - d : page내의 번호를 의미한다.
94 | - 하나의 페이지가 4KB라 가정하면 page 0의 주소는 0 ~ 2^12까지이다.
95 |
96 | 가상 주소 구하기
97 |
98 | os가 32bit이고, 페이지 크기가 4KB라고 가정할 때
99 |
100 | 2^32 / 2^12 = 2^20
101 |
102 | 즉, CPU는 한 번에 2^20개의 페이지 번호를 구분할 수 있다.
103 |
104 | 따라서 32bit라고 할 때 앞의 20bit는 페이지 번호를 의미하고, 뒤 12bit는 오프셋을 의미한다.
105 |
106 | ## **가상 주소 → 물리 주소 변환 FLOW**
107 |
108 | 
109 |
110 | - p : 페이지 번호
111 | - f : 프레임 번호
112 | - d : 페이지 오프셋
113 |
114 | d를 제외한 나머지 비트에 있는 page 번호를 page table에서 검색하면 frame 번호가 나온다.
115 |
116 | page와 frame 크기는 똑같기 때문에 오프셋은 동일하다.
117 |
118 | ex)
119 |
120 | PageSize = 1KB
121 |
122 | PageTable = 1 3 5 4
123 |
124 | **가상 주소 3000의 물리 주소는??**
125 |
126 | 1KB는 10bit로 표현 가능하고 3000은 101110111000(2) 이다.
127 |
128 | 따라서 d(오프셋)는 뒤의 10자리 (1110111000(2))이고 p(페이지 번호)는 남은 앞에 2개 (10(2))이다. 따라서 p는 2이기 때문에 두 번째 인덱스인 5 → 101(2)와 d를 붙인 1011110111000(2)가 물리 주소이다.
129 |
130 | 위와 같은 과정으로 물리 주소를 참조하지만 매번 페이지 테이블을 이용하는 것은 매우 비효율적이기 때문에 TLB를 이용한다.
131 |
132 | ## TLB(Translation Lookaside Buffer)
133 |
134 | - MMU에 소속된 칩으로, 자주 참조되는 가상 주소- 물리 주소 변환 정보를 저장해놓은 캐시이다.
135 | - 과정
136 | 1. 가상 주소로 접근 시, TLB에 먼저 접근하여 변환정보가 있는지 확인
137 | 2. 있으면 바로 반환
138 | 3. 없으면 Page Table에서 해당 물리 주소를 찾아 TLB에 갱신 후, TLB miss가 발생한 명령어를 재실행
139 |
140 | 
141 |
142 | 따라서 TLB의 hit rate가 속도에 많은 영향을 끼친다.
143 |
144 | # ⭐️ 참고
145 |
146 | [Interview_Question_for_Beginner/OS at master · JaeYeopHan/Interview_Question_for_Beginner](https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/OS#%EA%B0%80%EC%83%81-%EB%A9%94%EB%AA%A8%EB%A6%AC)
147 |
--------------------------------------------------------------------------------
/OperatingSystem/병행성.md:
--------------------------------------------------------------------------------
1 | # 📌 병행성**(Concurrency)**
2 |
3 | 운영체제의 설계의 핵심은 모두 프로세스와 쓰레드와 연관이 있으며 대표적으로 다음이 있다.
4 |
5 | - 멀티프로그래밍: 단일처리기(프로세서) 시스템 상에서 다수의 프로세스 관리
6 | - 멀티프로세싱: 멀티프로세서 시스템 상에서 다수의 프로세스 관리
7 | - 분산처리: 다수의 분산된 컴퓨터 시스템들 상에서 수행되는 다수의 프로세스 관리 (대표적인 예로 클러스터 시스템이 있다)
8 |
9 | 그리고 운영체제의 설계의 핵심은 병행성(concurrency)이다.
10 | 병행성이란 여러 계산을 동시에 수행하는 시스템의 특성으로 프로세스간 통신, 자원에 대한 공유와 경쟁, 프로세스 활동들의 동기화, 프로세스에 대한 처리기 시간 할당 등 다양한 이슈를 포함한다.
11 |
12 | > **병행성 관련 주요 용어**
13 |
14 | 원자적 연산(atomic operation) : 명령어들로 구성된 함수 또는 액션으로 더 이상 분할할 수 없는 단위 어떤 프로세스도 중간 상태를 볼 수 없고 연산을 중단할 수 없다 이 명령어들은 수행되거나 되지않거나 둘중 하나이다.
15 |
16 | 임계영역(critical section) : 공유 자원을 접근하는 프로세스 내부의 코드 영역, 두개의 프로세스가 임계영역에 들어가서는 안된다.
17 |
18 | 교착상태(deadlock) : 두개 이상의 프로세스들이 더 이상 진행을 할 수 없는 상태, 각 프로세스가 다른 프로세스의 진행을 기다리면서 대기할때 발생한다.
19 |
20 | 라이브락(livelock) : 두개 이상의 프로세스들이 다른 프로세스의 상태 변화에 따라 자신의 상태를 변화 시키는 작업만 하는 상태,프로세스들이 열심히 일하는 것처럼 보이지만 실제로는 유용하지 않은 작업들을 하고 있다.
21 |
22 | 상호 배제(mutual exclusion) : 한 프로세스가 공유자원을 접근하는 임계역영 코드를 수행하는 중이면 다른 프로세스들은 공유 자원에 접근하는 임계영역 코드를 수행할 수 없다는 조건이다.
23 |
24 | 경쟁상태(race condition) : 두개 이상의 프로세스가 공유 자원을 동시에 접근하려는 상태, 최종 수행 결과는 프로세스들의 상대적인 수행 순서에 따라 달라진다.
25 |
26 | 기아(starvation) : 특정 프로세스가 수행 가능한 상태임에도 매우 오랜 기간 동안 스케줄링 되지 못하는 경우
27 |
28 | **병렬처리를 위한 기법**
29 |
30 | 인터리빙(interleaving) : 멀티프로그래밍에서 여러개의 프로세스가 번갈아가면서 수행되어 마치 동시에 수행되는 것과 같게 되는것
31 |
32 | 오버래핑(overlapping) : 여러개의 처리기로 실제로 여러 작업을 처리하는 것
33 | >
34 |
35 | 병행성에는 한 가지 문제점이 있다. 각각의 프로세스의 속도를 예측할 수 없다는 것이다.
36 | 예측할 수 없는 프로세스들이 동일한 자원을 두고 경쟁하다보니 다음과 같은 문제를 야기한다.
37 |
38 | 1. 전역 자원의 공유에 어려움이 있다.
39 | ex) 두개의 프로세스가 같은 전역 변수를 사용
40 | 2. 운영체제가 자원을 최적으로 할당하기 어려워진다.
41 | ex) 자원 할당 후 일시정지
42 | 3. 프로그래밍 오류를 찾아내는 것이 어려워진다.
43 | ex) 특정 실행 순서에 따른 오류
44 |
45 | 따라서 프로세서간 충돌을 방지할 **상호배제**가 필요하다.
46 |
47 | # 📌 상호배제(Mutual exclusion)
48 |
49 | 상호 배제를 보장하기 위해서는 다음의 요구 조건들이 만족되어야 한다.
50 |
51 | 1. 상호 배제가 강제되어야 한다.
52 | 2. 임계영역 외의 코드에서 수행이 멈춘 프로세스는 다른 프로세스의 수행을 간섭해서는 안된다.
53 | 3. 임계영역에 접근하고자 하는 프로세스의 수행이 무한히 미루어져서는 안된다. 즉 기아 상태, 교착 상태가 발생해서는 안된다.
54 | 4. 임계영역이 비어있고 임계영역 진입을 원하는 프로세스는 즉시 임계영역에 들어 갈 수 있다.
55 | 5. 프로세스 개수나 상대적인 프로세스 수행 속도에 대한 가정은 없어야 한다.
56 | 6. 임계영역에 들어간 프로세스는 일정한 시간 내에 임계영역에서 나와야 한다.
57 |
58 | # 📌 상호배제: 소프트웨어적 접근 방법
59 |
60 | 운영체제나 프로그래밍 언어 차원의 지원 없이 프로세스간 협력을 통해 직접 상호 배제를 보장한다.
61 | 수행 부하가 크고, 잘 설계되지 않았을 경우 오동작 가능성이 높다.
62 |
63 | ## 🔍 데커(Dekker) 알고리즘
64 |
65 | [데커의 알고리즘 - 위키백과, 우리 모두의 백과사전](https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%BB%A4%EC%9D%98_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)
66 |
67 | ## 🔍 피터슨(**Peterson**) 알고리즘
68 |
69 | [피터슨의 알고리즘 - 위키백과, 우리 모두의 백과사전](https://ko.wikipedia.org/wiki/%ED%94%BC%ED%84%B0%EC%8A%A8%EC%9D%98_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)
70 |
71 | ### 💡 참고
72 |
73 | [[IT 기술면접 준비자료] 상호배제(Mutual Exclusion)와 상호배제 알고리즘](https://preamtree.tistory.com/26)
74 |
75 | 데커(Dekker) / 피터슨(Peterson) / 제과점(Bakery) 알고리즘
76 |
77 | # 📌 상호배제: 하드웨어적 접근 방법
78 |
79 | 상호배제를 보장하기 위한 하드웨어적인 접근 방법을 알아보자
80 |
81 | ## 🔍 인터럽트 금지
82 |
83 | 상호 배제를 보장할 수 있는 가장 간단한 방법은 프로세스가 인터럽트 되지 않도록 하는 것이다싱글 프로세서에서 병행 처리(concurrent processing)되는 프로세스들은 인터리빙되기 때문이다.
84 |
85 | 또한 프로세스는 운영체제 서비스를 호출하거나 인터럽트 될 때까지 계속 실행하기 때문에 인터럽트가 발생하지 않으면 한 프로세스의 지속적인 실행을 보장 가능하다.
86 | 이를 위해 시스템 커널에서 인터럽트를 허용하거나 비허용할 수 있는 기본 인터페이스를 제공한다.
87 |
88 | ```powershell
89 | while(true){
90 | // 인터럽트 금지
91 | // 임계 영역
92 | // 인터럽트 허용
93 | // 임계 영역 이후 코드
94 | }
95 | ```
96 |
97 | > 단, 멀티프로세서 시스템에서는 효과가 없다.
98 | 두개 이상의 프로세서를 가지는 컴퓨터 시스템에서는 인터럽트가 금지된 상황에서도 서로 다른 프로세스가 공유 자원을 동시에 접근하는 경우가 가능하기 때문이다.
99 | >
100 |
101 | ### 단점
102 |
103 | - 부하가 크다.
104 | 인터럽트 비허용 시, 그 사이 외부에서 발생하는 이벤트에 대한 처리와 다른 프로세스에 대한 스케줄링 등 모든 기능이 중지되어 시스템 수행 효율이 확연하게 감소할 가능성이 높다.
105 | - 멀티프로세서 시스템에서는 올바른 접근 방법이 아니다.
106 |
107 | ## 🔍 특별한 기계 명령어
108 |
109 | 멀티 프로세서 환경에서 여러 프로세서들은 공통의 주기억 장치를 공유하며, 이때 모든 프로세서는 동등한 관계에서 독립적으로 동작한다. (인터럽트 기법으로 상호배제 보장 불가)
110 |
111 | 하드웨어 수준에서 특정 메모리 주소가 접근되고 있을 때, 같은 위치에 대한 접근 요청은 차단된다는 것에 기반해 상호배제를 보장하기 위한 두 가지 명령어가 구현된다.
112 | 이때 기계 명령어는 두 개의 기능을 원자적으로 처리한다.
113 |
114 | ### 1. Compare & Swap 명령어
115 |
116 | `compare_and_swap()` : 테스트하려는 값과 저장된 값을 비교한다.
117 |
118 | 이 함수는 원자적으로 수행되기 때문에 중간에 중단되는 경우는 없다.대부분 모든 프로세서에서 지원하며, 대부분의 운영체제에서 병행성을 위해 이 명령어를 사용한다.
119 |
120 | ### 2. Exchange 명령어
121 |
122 | `exchange()` : 레지스터 값과 메모리에 들어있던 값을 서로 교체하는 기능 수행
123 |
124 | 
125 |
126 | > 실제로 이 함수가 아니고 하드웨어 명령어이다.
127 | 이해를 돕기위한 코드라 생각하면 된다.
128 | >
129 |
130 | ### Compare & Swap, Exchange 명령어를 이용한 상호배제 보장
131 |
132 | 
134 |
135 | 필기가 난잡하고 더럽지만 매우 디테일하게 적어놨다
136 | 정녕 자세히 알고싶다면 읽어보자
137 |
138 | ### 장점
139 |
140 | - 싱글 프로세서 시스템 뿐만 아니라 공유 메모리를 사용하는 멀티 프로세서 시스템에서도 사용가능하다.
141 | - 간단하고 검증이 쉽다.
142 | - 서로 다른 변수를 사용하면 다중 임계 영역을 지원할 수 있다.
143 |
144 | ### 단점
145 |
146 | - 바쁜 대기를 사용한다
147 | 임계영역에 진입하는 것을 대기하고 있는 프로세스는 처리기를 계속 사용하게 된다.
148 | `TIP` 바쁜 대기란 임계영역에 진입하기 위한 허가를 획득할 때까지 변수를 테스트하는 명령을 반복 실행하며 대기하는 것을 말한다.
149 | - 기아가 발생할 수 있다
150 | 한 프로세스가 임계영역에서 빠져나올 때, 대기하고 있던 다수의 프로세스 중 하나만 다시 임계영역에 진입이 가능한데, 이 때 각 프로세스의 길이나 특성, 대기시간 등을 고려하지 않기 때문에 무한정 기다리는 프로세스가 생길 수도 있다.
151 | - 교착상태에 빠질 수 있다.
152 | 싱글 프로세서 시스템에서 P1 이라는 프로세스가 임계영역에 진입한다.
153 | 그때 P2 라는 P1보다 우선순위가 높은 프로세스가 생겨 운영체제가 P2를 스케줄하여 P2에게 자원을 할당하려 할 때 P2와 P1이 같은 자원을 사용하려 하면 P2는 상호배제조건에 의해 바쁜 대기를 수행한다.
154 | 이때 P2가 계속 프로세서를 점유하고 있기 때문에 우선순위가 높은 P2로 인해 P1은 다시 스케줄링될 수 없다. -> P2가 실행상태에 있기 때문이다.
155 |
156 | 소프트웨어적 방법과 하드웨어적 방법은 모두 단점을 갖고 있기 때문에 새로운 해결책이 필요하다.
157 |
158 | # 📌 상호배제: 운영체제와 프로그래밍 언어 수준에서 접근 방법
159 |
160 | ## 🔍 세마포어(Semaphore)
161 |
162 | 멀티 프로그래밍 환경에서 공유된 자원에 대한 접근을 제한하는 방법
163 |
164 | - 임계영역에 접근하는 프로세스들을 제어하는 데 사용한다.
165 | - block(수면)과 wake up(깨움)을 지원한다.
166 | - 세마포어란 프로세스 간에 시그널을 주고받기 위해 사용되는 정수 값을 갖는 변수로 다음 3가지 인터페이스를 통해 접근할 수 있다.
167 | - **Initialize(초기화 연산)** : 최초에 세마포어 값을 음이 아닌 값으로 초기화한다.
168 | - **Decrement(semWait, 대기 연산)**
169 | - 세마포어 값을 하나 감소시킨다.
170 | - 값이 음수가 되면 semWait를 호출한 프로세스는 block 상태로 바꾼다.
171 | - 음수가 아니면 해당 프로세스는 임계영역에 접근하여 연산을 계속 수행할 수 있다.
172 | - **Increment(semSignal, 시그널 연산)**
173 | - 연산을 마친 프로세스는 이 함수를 호출해 세마포어 값을 하나 증가시킨다
174 | - 값이 양수가 아니면(<=0) semWait 연산으로 block된 프로세스를 깨운다.
175 | - 이진 세마포어는 세마포어 값을 0또는 1만 가질 수 있는 세마포어이다.
176 |
177 | 
178 |
179 | 카운팅(범용) 세마포어
180 |
181 | 
182 |
183 | 이진(바이너리) 세마포어
184 |
185 | ### 세마포어는 바쁜대기와 기아를 해결
186 |
187 | - OS는 blocked 큐를 갖고 있기 때문에 바쁜 대기 문제가 해결된다.
188 | - 큐에는 순서가 있기 때문에 기아 문제가 해결된다.
189 |
190 | ### 세마포어의 특징
191 |
192 | - 일반적으로 프로세스가 세마포어를 감소시키기 전까지는 그 프로세스가 block될지 안될지 알 수 없다.
193 | - 싱글 프로세서 시스템에서 프로세스가 세마포어를 증가시키고 block된 프로세스를 깨우면, 이 두 프로세스 모두 수행가능 상태가 되어 누가 먼저 수행될 지 알 수 없다.
194 | - 세마포어에 시그널을 보낼 때, 우리는 다른 프로세스가 대기 중인지 여부를 알 필요가 없다. block된 프로세스의 개수가 0또는 1일 수 있다.
195 |
196 | ### 세마포어 동작 예시
197 |
198 | 
199 |
200 | ### 생산자/소비자(producer/consumer) 문제
201 |
202 | 한정 버퍼(bounded-buffer) 문제라고도 한다.
203 |
204 | 유한한 개수의 물건(데이터)을 임시로 보관하는 보관함(버퍼)에 여러 명의 생산자들과 소비자들이 접근한다. **생산자는 데이터를 만들어 버퍼에 저장해나가고, 소비자는 버퍼에 있는 데이터를 꺼내 소비하는(비우는) 프로세스이다.**
205 | 이때 저장할 공간이 없는 문제가 발생할 수 있다. 소비자는 물건이 필요할 때 보관함에서 물건을 하나 가져온다. 이 때는 소비할 물건이 없는 문제가 발생할 수 있다.
206 |
207 | 이때 버퍼는 공유자원이므로 버퍼에 대한 접근 즉, 저장하고 꺼내는 일들이 상호배제 되어야한다.또한, 버퍼가 꽉 차있을 때는 생산자가 기다려야하고, 버퍼가 비었을 때는 소비자가 기다려야한다.
208 |
209 | ### 무한공유 버퍼인경우
210 |
211 | 
212 |
213 | 만약 소비자가 먼저 실행될 경우, 세마포어 n의 값이 음수가 되면서 block에 걸리고 생산자와 실행되어 버퍼를 채우며 n의 값을 올려 소비자의 block을 푼다
214 |
215 | ### 유한공유 버퍼인경우
216 |
217 | 
218 |
219 | 무한 버퍼와 같은 원리로 작동을 하며 무한 버퍼와는 달리 유한 버퍼이므로 버퍼가 꽉 찰 때를 표시해줄 수 있는 e값이 있다. e가 꽉 찬 상태 즉, e가 음수가 되면 block이 걸리게 되며 소비자만이 작동하게 된다.
220 |
221 | ## 🔍 뮤텍스(Mutex)
222 |
223 | 뮤텍스는 세마포어와 마찬가지로 병행 처리를 위한 동기화 기법 중 하나입니다.
224 | 이진 세마포어와 같이 초기값을 1과 0으로 가집니다.
225 | 임계영역에 들어갈 때 락(lock)을 걸어 다른 프로세스(혹은 쓰레드)가 접근하지 못하도록 하고,
226 | 임계영역에서 나와 해당 락을 해제(unlock) 합니다.
227 |
228 | ### **뮤텍스와 세마포어의 차이는?**
229 |
230 | 세마포어는 공유 자원에 세마포어의 변수만큼의 프로세스(또는 쓰레드)가 접근할 수 있습니다.
231 | 반면에 뮤텍스는 오직 1개만의 프로세스(또는 쓰레드)만 접근할 수 있습니다.
232 | 현재 수행중인 프로세스가 아닌 다른 프로세스가 세마포어를 해제할 수 있습니다.
233 | 하지만 뮤텍스는 락(lock)을 획득한 프로세스가 반드시 그 락을 해제해야 합니다.
234 |
235 | ## 🔍 모니터
236 |
237 | - 모니터란 프로그래밍 언어 수준에서 제공되는 구성체(라이브러리, 클래스)
238 | - 세마포어와 동일한 상호배제 기능을 제공하고 보다 사용하기 쉽다는 장점을 가지고 있다.
239 |
240 | # 📌 데드락(DeadLock)
241 |
242 | 상호 배제에 의해 나타나는 문제점으로, 둘 이상의 프로세스들이 자원을 점유한 상태에서 서로 다른 프로세스가 점유하고 있는 자원을 요구하며 무한정 기다리는 현상을 의미한다.
243 |
244 | ## 발생조건 4가지
245 |
246 | - **상호 배제 조건(Mutual Exclusion)** 입니다. **자원은 한 번에 한 프로세스만 사용 가능하다** 는 조건입니다.
247 | - **점유 대기 조건(Hold And Wait)** 입니다. **최소한 하나의 자원을 점유(Lock)**하고 있으면서 다른 프로세스에 할당되어 사용되고 있는 **자원을 추가로 점유하기 위해 대기(Wait)** 하는 프로세스가 존재해야 합니다.
248 | - **비선점 조건(No preemption)**이 있습니다. 다른 프로세스에 할당된 자원은 해당 프로세스가 사용이 끝날때까지 **강제로 빼앗을 수 없습니다.**
249 | - **순환 대기 조건(Circular Wait)**이 있습니다. 프로세스의 집합에서 **순환 형태(사이클)로 자원을 대기(Wait)** 하고 있어야 합니다.
250 |
251 | 이러한 **상호 배제, 점유 대기, 비선점, 순환 대기** 4가지 조건을 모두 성립해야 데드락이 발생할 수 있습니다.
252 |
253 | ## 데드락의 처리방법
254 |
255 | 데드락을 처리하기 위한 방법으로 예방, 회피, 탐지 및 회복, 무시 가 있습니다.
256 | **예방(Prevention)** 이란, **데드락 발생 조건 중 하나를 제거하면서 해결**하는 방법입니다. 즉, 상호 배제, 점유 대기, 비선점, 순환 대기 4가지 조건 중 하나를 제거합니다.
257 |
258 | 다음으로, **회피(Avoidance)** 는 **데드락이 발생할 시 피해가는 방법**입니다. 대표적으로, **은행원 알고리즘**을 사용하여 피해갑니다.
259 |
260 | 또, **탐지 및 회복(Detection & Recovery)** 은 **자원 할당 그래프를 통해 데드락을 감지**하며, 만약 데드락을 감지할 경우 **이전 상태로 회복**하는 방법이죠. 일부러 데드락을 발생하게 놔두고 감지해서 회복하는 경우도 있습니다.
261 |
262 | 마지막으로, **무시(Ignore)** 는 말 그대로 데드락 발생을 무시하고 지나가는 방법입니다.
263 |
264 | ## 교착상태 예방
265 |
266 | 교착상태가 발생하기 위한 4가지 필요충분 조건 중 하나를 설계 단계에서 배제하는 방법이다.
267 |
268 | - 상호 배제 : 운영체제에서 반드시 보장해주어야 함
269 | - 점유 대기 : 프로세스가 필요한 모든 자원을 한꺼번에 요청
270 | - 비선점 : 프로세스가 새로운 자원 요청에 실패하면 기존의 자원들을 반납한 후 다시 요청 or 운영체제가 강제적으로 자원을 반납시킴
271 | - 환형 대기 : 자원 할당 순서(자원 유형)를 미리 정해두면 없앨 수 있음
272 |
273 | ## 교착상태 회피
274 |
275 | **은행원 알고리즘(Banker Algorithm)**을 사용합니다.
276 | ****데드락을 처리하기 위한 방법 중 **회피에 해당**하는 알고리즘입니다. 데드락에 빠질 수 있는 상태를 불안전 상태, 데드락에 빠질 수 없는 상태를 안전 상태 라고 가정했을 때, 운영체제는 이러한 안전 상태인 경우에만 요청을 허락하여 자원을 할당해주고, 나머지 요구들은 안전 상태가 될 때 까지 계속 거절하는 알고리즘입니다.
277 |
278 | 즉, **은행원 알고리즘**은 은행은 **최소한 한 명에게 대출해줄 수 있는 돈을 가지고 있어야 한다**는 뜻에서 나왔으며, 바꿔말하면 **운영체제가 최소한 하나의 프로세스가 일을 수행할 수 있는 경우에만 요청을 허락하여 시스템의 자원을 할당해주는 것**과 같습니다.
279 |
280 | # 👋 예상 질문
281 |
282 | - 데드락이란 무엇인가요?
283 |
284 | 데드락은 프로세스가 자원을 얻지 못해서 다음 일을 처리하지 못하는 상태 입니다. 즉, 교착 상태라고도 말하는데요. 보통 시스템적으로 한정된 자원을 여러 곳에서 동시에 사용하려고 할 때 발생합니다.
285 |
286 | 예를 들어,
287 | 프로세스 1이 리소스 1을 사용하고 있고, 리소스 2를 사용하기 위해 요청했으며
288 | 프로세스 2가 리소스 1을 사용하기 위해 요청했고, 리소스 2를 사용하고 있다면
289 |
290 | 프로세스 1 -> 리소스 1(사용 - Lock) / 리소스 2(요청 - Wait)
291 | 프로세스 2 -> 리소스 1(요청 - Wait) / 리소스 2(사용 - Lock)
292 |
293 | 상태가 되서 프로세스 1, 2 모두 다음 리소스를 얻지 못해 멈추게 됩니다. 이는 사거리의 모든 자동차가 서 있는 상태와 같습니다
294 |
295 |
296 | # ✨ References
297 |
298 | - William Stallings, 『운영체제 제8판 : 내부구조 및 설계원리』, 프로텍미디어
299 | - 세종대 운영체제 수업 내용 + 내 필기
300 | - 병행성 내용 요약
301 |
302 | [나만의 백과사전 - 병행성 : 상호배제, 동기화, 교착상태, 기아](https://velog.io/@pu1etproof/%EB%82%98%EB%A7%8C%EC%9D%98-%EB%B0%B1%EA%B3%BC%EC%82%AC%EC%A0%84-%EB%B3%91%ED%96%89%EC%84%B1-%EC%83%81%ED%98%B8%EB%B0%B0%EC%A0%9C-%EB%8F%99%EA%B8%B0%ED%99%94-%EA%B5%90%EC%B0%A9%EC%83%81%ED%83%9C-%EA%B8%B0%EC%95%84#1-%EC%83%81%ED%98%B8%EB%B0%B0%EC%A0%9C%EB%A5%BC-%EB%B3%B4%EC%9E%A5%ED%95%98%EA%B8%B0-%EC%9C%84%ED%95%9C-%EC%86%8C%ED%94%84%ED%8A%B8%EC%9B%A8%EC%96%B4%EC%A0%81-%EC%A0%91%EA%B7%BC-%EB%B0%A9%EB%B2%95)
303 |
304 | - 데드락 질문 정리
305 |
306 | [[OS] 2020.11.16. 오늘의 면접 Q&A](https://maivve.tistory.com/270)
307 |
308 | - 뮤텍스 세마포어 차이점
309 |
310 | [Semaphore(뮤텍스)와 Mutex(세마포어)의 차이점은?](https://junghyun100.github.io/Semaphore&Mutex/)
--------------------------------------------------------------------------------
/OperatingSystem/인터럽트와 시스템콜.md:
--------------------------------------------------------------------------------
1 | # 운영체제 구조 및 동작원리(Mode, System call, Interrupt
2 |
3 | Created At: December 10, 2021 10:00 PM
4 | Updated At: December 23, 2021 10:23 PM
5 |
6 | # 운영체제 시작
7 |
8 | 컴퓨터가 처음 부팅되면 Bootstrap 프로그램이 실행된다.
9 |
10 | 이 프로그램은 시스템을 모두 초기화하고 OS를 메모리에 올려 실행하게끔 하고 OS가 실행되면서 다음 event를 기다리게 된다.
11 |
12 | 이 event를 interrupt라고 부른다.
13 |
14 | (Node.js의 event와 비슷)
15 |
16 | ex) 윈도우가 실행이 되면서 잠금을 걸어놨다면 비밀번호를 입력하라는 창이 뜰 텐데 OS는 이 창을 띄우고 "비밀번호의 입력(입출력장치)"이라는 interrupt를 기다리게 된다. 그동안 OS는 아무 행동도 취하지 않으며 대기 상태이다.
17 |
18 | # Interrupt
19 |
20 | 운영체제는 기본적으로 **interrupt(event)-driven** 방식이다.
21 |
22 | 하드웨어가 어떤 이벤트를 CPU에게 알리기 위해서 사용하는 방법 or 실행 중인 프로세스가 CPU 내의 인터럽트 라인을 세팅해 인터럽트를 걸기도함(소프트웨어)
23 |
24 | **전자를 비동기식 인터럽트라고 부르는데 하드웨어에 의해 걸리고, 후자를 동기식 인터럽트라고 부르는데 소프트웨어에 의해 걸린다.**
25 |
26 | 하드웨어 인터럽트 : I/O 장치, 전원 등 (키보드, 마우스 입력)
27 |
28 | - 조금 Deep한 내용
29 |
30 | ## Hardware Interrupt
31 |
32 | Hardware는 입출력장치인 I/O와 해당 장치를 제어하는 controller로 이루어져 있다.
33 |
34 | 우리가 사용하는 키보드, 디스크에도 모두 controller가 있으며 이것들이 우리가 입력하는 데이터들을 본체에 전송을 하게 된다. 그리고 각 장치에 해당하는 OS에는 해당 Hardware와 데이터를 주고받기 위해 그 기기에 대한 Device Driver(D/D)가 필요하다.
35 |
36 | 본체에서 보내는 데이터는 D/D의 buffer(데이터 전송을 위한 임시 저장 장치)에 저장되었다가 나가게 되고 I/O 장치에서 보내는 데이터 또한 controller의 buffer에 저장되었다가 전송된다. 이러한 전송 완료에 대한 메시지를 interrupt로 발생시킨다.
37 |
38 | 하지만 이 때 buffer의 용량이 상당히 작기 때문에 대용량의 데이터 전송시에 문제가 생기고 CPU에게 인터럽트를 많이 걸게 되므로 빈번한 OS의 개입이 이루어진다.
39 |
40 | 이런 문제를 해결하기 위해서 Direct Memory Access가 도입되었는데
41 |
42 | DMA는 장치에 대한 연결의 interrupt를 발생시킨 후 OS는 모든 권한을 DMA에게 위임하기 때문에 빈번한 OS의 개입이 없고 전송 단위 또한 커서 빠르게 전송할 수 있다.
43 |
44 | 즉, DMA는 CPU(OS)의 개입 없이 디바이스 컨트롤러와 메모리 사이에 데이터를 이동하도록 하는 것
45 |
46 | 
47 |
48 | 이 방식을 사용함으로써 얻을 수 있는 점은 CPU가 디바이스와 메모리 사이를 중재할 필요가 사라지기 때문에 CPU는 그동안 다른 일들을 할 수 있다는 것이다. 또한 바이트 단위가 아닌 블록 단위로 인터럽트를 걸기 때문에 오버헤드를 줄일 수 있다.
49 |
50 |
51 | 소프트웨어 인터럽트(trap or exception) : 소프트웨어가 OS 서비스를 요청하거나 에러를 일으켰을 때 발생 (파일 읽기/쓰기, 0으로 나누기, 오버플로우 등)
52 |
53 | 소프트웨어는 3가지로 나뉨
54 |
55 | 1. Trap : 의도적으로 일으킨 예외 (ISR 종료 후 실행 재개) → 시스템 콜
56 | 2. Fault : 복구가 가능할 수도 있는 예외 (ISR 종료 후 실행을 재개할 가능성 있음) → 0으로 나누기, 잘못된 메모리 접근
57 | 3. Abort : 복구 불가능한 예외 (ISR 실행 시 프로그램 강제 종료) → 하드웨어 고장
58 |
59 | ## 과정
60 |
61 | CPU에 인터럽트가 걸리면 가장 먼저 **명령어의 주소를 저장을 한다**. 그 이유는 Interrupt의 대응하는 행위를 끝내고 다시 그다음 명령어를 수행하거나 다시 대기 상태로 돌아오기 위함 (context switch를 위해서?)
62 |
63 | 이후 Interrupt Service Routine(ISR)에 제어권을 넘겨주는 과정을 거치는데 **Interrupt Vector Table이라는 곳에서 해당 Interrupt에 대한 주소를 찾고(인터럽트 핸들러 주소 = ISR 시작 주소) 그리고 그 주소로 이동해 처리를 실행한다.(ISR).**
64 |
65 | ISR이 끝나고 나면 OS는 **저장해 놓았던 주소로 되돌아가** 이후 명령어를 수행
66 |
67 | (Interrupt Vector Table은 인터럽트 종류별로 **인터럽트 핸들러**의 주소가 담긴 테이블이다.)
68 |
69 | ## Dual-Mode Execution
70 |
71 | 사용자가 인터럽트처럼 Kernel상의 작업(컴퓨터의 Core에 해당하는 작업)을 직접 건드려 명령하고 수행하게 된다면 잘못하다가는 시스템 전체에 큰 악영향을 끼칠 수 있음
72 |
73 | 일반 사용자가 컴퓨터에 치명적인 명령어를 사용할 수 없도록, 일반 사용자로부터 시스템을 보호하기 위해 **하드웨어적**으로 **이중 모드(dual mode)**라는 것을 지원한다.
74 |
75 | 이중 모드는 **사용자 모드(user mode)**와 **커널 모드(kernel mode)**로 나뉜다. 그리고 mode bit(user mode=1, kernel mode=0)를 통해 두 모드를 구분한다. 일반적으로 사용자 프로세스는 사용자 모드에서는 실행되지만 어떤 특정한 명령들은 커널 모드에서만 실행된다. 이 특정한 명령어들을 **특권 명령(privileged instruction)**이라고 하는데 잘못된 접근으로부터 OS와 사용자를 보호하기 위해 모아놓은 명령어들의 집합을 말한다. 여기에 포함된 명령어들은 OS만이 실행할 수 있다.
76 |
77 | 그래서 각 명령어에 Mode-bit를 심어서 **해당 명령어의 Mode-bit와 현재 시스템 상의 Mode-bit가 같을 시에만 해당 명령어를 수행**하게 끔 하는 것
78 |
79 | ex)
80 |
81 | ```c
82 | printf("출력");
83 | ```
84 |
85 | 위 코드는 출력하는 행위로 I/O 작업에 해당한다.
86 |
87 | 이런 I/O작업은 OS만 접근이 가능해야 한다.
88 |
89 | 위 함수를 까보면 여러 가지 명령어중에 **INT 80**이라는 명령어가 있는데 특수 명령어로 현재 Mode를 바꿔주는 역할을 한다.
90 |
91 | 즉 이전까지 수행되던 명령어들은 User-Mode였다면 화면에 출력하기 위해서는 Kernel-Mode가 필요하므로
92 |
93 | 위의 명령어를 통해 Mode를 Kernel-Mode로 변환 후 I/O 장치에 출력을 하는 명령을 OS가 내리게 된다.
94 |
95 | 그리고 함수가 끝날 때는 다시 User-Mode로 돌아간다.
96 |
97 | 이러한 **bit를 바꾸는 행위를 System Call**이라고 한다.
98 |
99 | 커널에서 수행되어야 하는 몇 가지 중요한 명령어들 : Turn off interrupts, Access I/O devices, Set value of Timer 등
100 |
101 | System call이 일어나면 Interrupt 동작원리(Interrupt Vector Table, Interrupt Vector Routine)와 같이 해당 **System Call에 대한 번호를 Table에서 찾아서 Routine을 실행**하게 된다.
102 |
103 | 
104 |
105 | # 시스템 콜
106 |
107 | 
108 |
109 | 위에서 말했던 특권 명령을 실행하고자 하면, 반드시 사용자 모드에서 커널 모드로 전환해야한다.
110 |
111 | 이 때, 특권 명령을 실행하기 위해 **커널 모드로의 전환을 요청하는 인터페이스를 시스템 콜** 이라고 한다.(trap의 한 종류)
112 |
113 | ## 시스템 콜이 필요한 이유??
114 |
115 | - 우리가 일반적으로 사용하는 프로그램은 **응용 프로그램** 이다. 유저레벨의 프로그램은 유저레벨의 함수들만으로는 많은 기능을 구현하기 힘들기 때문에, 무조건 커널의 도움을 받아야만 한다.
116 | - 반드시 커널에 관련한 것들은 커널모드로 전환하여 해당 작업을 수행해야한다.
117 |
118 | ## 시스템 콜 종류
119 |
120 | 1. 프로세스 제어용 시스템 콜
121 | - fork, wait, exec
122 | 2. 파일에 대한 입출력 시스템 콜
123 | - open, create, close, read 등
124 | 3. 소켓 기반 입출력 시스템 콜
125 | - socket, bind, listen, connect 등
126 |
127 | ## 과정
128 |
129 | 프로세스가 디스크로부터 파일을 읽어오는 명령이라고 가정
130 |
131 | 1. 프로세스가 시스템 콜을 요청하면서 CPU 내에 인터럽트 라인을 세팅한다.
132 | 2. CPU는 실행 중이던 명령어를 마치고 인터럽트 라인을 통해 인터럽트가 걸렸음을 인지한다.
133 | 3. mode bit를 0으로 바꾸고 OS에게 제어권을 넘긴다.
134 | 4. 현재 실행 중이던 프로세서의 상태 및 정보를 PCB에 저장하고 PC에는 다음에 실행할 명령어의 주소를 저장한다.
135 | 5. 시스템 콜 루틴에 해당하는 곳으로 가서 시스템 콜 테이블을 참조해 파일 읽기에 해당하는 시스템 콜을 실행한다.
136 | 6. 루틴이 끝나면 mode bit를 1로 바꾸고 PCB에 저장했던 상태들과 PC를 복원시킨다.
137 | 7. PC에 저장된 주소(=마지막으로 실행했던 명령어의 다음)로 이동해 계속 실행한다.
138 |
139 | ## TIP
140 |
141 | I/O 명령을 실행할 때 CPU 제어권이 어디로 가냐에 따라 동기식(소프트웨어에 의해 발생), 비동기식(하드웨어에 의해 발생) 두 가지로 나뉜다.
142 |
143 | - **동기식 I/O**는 I/O 명령 요청이 완료되어야지만 사용자 프로그램에 제어가 넘어간다.
144 | - **비동기식 I/O**는 I/O 명령이 끝날 때까지 기다리지 않고 사용자 프로그램으로 제어가 넘어가고 I/O가 완료되면 인터럽트로 알린다.
145 |
146 | 위 과정은 동기식 I/O를 기준으로 한 설명
147 |
148 | 만약 비동기식 이라면?? 즉, 하드웨어라면??
149 |
150 | 5번부터 다르게 실행된다.
151 |
152 | 1. 다른 프로세스의 PCB와 PC를 읽어와서 실행한다.
153 | 2. I/O 명령을 마치면 디바이스 컨트롤러(Device controller) 가 CPU에게 인터럽트를 건다.(하드웨어 인터럽트 부분의 deep 내용 참고)
154 | 3. CPU가 인터럽트를 인지하면 실행 중이던 프로세스를 다시 PCB에 저장하고 OS에게 제어권을 준다.
155 | 4. 그리고 OS는 디바이스 컨트롤러로부터 버퍼에 저장된 데이터를 받아와서 I/O를 요청했던 명령어의 메모리 영역에 데이터를 저장한다.
156 |
157 | # 참고
158 |
159 | - 인터럽트와 시스템 콜
160 | [https://baked-corn.tistory.com/3](https://baked-corn.tistory.com/3)
161 | [https://velog.io/@chowisely/Operating-Systems-Interrupt-System-Call](https://velog.io/@chowisely/Operating-Systems-Interrupt-System-Call)
162 | [https://github.com/Songwonseok/CS-Study/blob/main/OS/시스템 콜 (System Call).md](https://github.com/Songwonseok/CS-Study/blob/main/OS/%EC%8B%9C%EC%8A%A4%ED%85%9C%20%EC%BD%9C%20(System%20Call).md)
163 | - 시스템 콜 종류
164 | [https://whitesnake1004.tistory.com/2](https://whitesnake1004.tistory.com/2)
165 |
--------------------------------------------------------------------------------
/OperatingSystem/프로세스와 스레드.md:
--------------------------------------------------------------------------------
1 | # ⭐️ 프로세스
2 |
3 | 프로그램은 **메모리에 올라오지 않은 정적인 코드 덩어리** 라고하는데 이 프로그램이 실제 메모리에 올라가 실행되고 있으면 프로세스라고 부른다.
4 |
5 | 즉, OS로부터 시스템 자원을 할당받는 작업의 단위이다.
6 |
7 | 
8 |
9 | ## 프로세스 특징
10 |
11 | 프로세스는 최소 1개의 스레드를 가지고 있고 각각 독립된 메모리 영역을 할당받는다.
12 |
13 | 독립되어있기 때문에 별도의 주소 공간에서 실행되며, 일반적인 방법으로는 다른 프로세스에 접근할 수 없다.(IPC를 사용하면 접근 가능)
14 |
15 | ### 프로세스의 메모리 구조
16 |
17 | - Code 영역
18 | - 컴파일된 코드 자체가 저장된다.
19 | - 프로세스가 사용하는 기계어로 된 프로그램 명령들이 위치해 있다.
20 | - Data 영역
21 | - 전역변수, 정적변수, 배열, 구조체 등이 저장된다.
22 | - 자세하게 말하면 **초기화 된 데이터는 Data영역**에, **초기화 되지 않은 데이터는 BSS 영역**에 저장된다.
23 | - 이 둘을 구분하는 이유??
24 | - 초기화 되지 않는 변수는 프로그램이 실행될 때 영역만 잡아주면 되고 그 값을 프로그램에 저장하고 있을 필요가 없으나 초기화된 변수는 그 값도 프로그램에 저장하고 있어야하기 때문에 구분한다.
25 | - 프로그램이 실행될 때 생성되고 프로그램이 종료되면 반환된다.
26 | - Heap 영역
27 | - 필요에 의해 동적으로 메모리를 할당 하고자 할 때 사용하는 메모리 영역
28 | - 메모리 주소 값에 의해서만 참조되고 사용된다.
29 | - Stack 영역
30 | - 프로그램이 자동으로 사용하는 **임시 메모리** 영역
31 | - 지역변수, 매개변수, 리턴 값 등 잠시 사용되었다가 사라지는 데이터
32 | - 함수 호출 시 생성되고, 함수가 끝나면 반환된다.
33 | - 이 스택 사이즈는 프로세스가 메모리에 로드 될 때 고정되어 할당된다. 따라서 런타임에 사이즈를 변경할 수 없다.
34 |
35 | ## 프로세스 상태
36 |
37 | 
38 |
39 | - New : 프로세스가 생성되었을 때
40 | - Ready : 프로세스가 프로세서에게 할당 받기를 기다릴 때
41 | - Running : 프로세스가 실행 상태일 때
42 | - Waiting(Blocked) : 프로세스가 어떤 이벤트가 발생하기를 기다릴 때
43 | - Suspended : 프로세스의 실행이 중지되었을 때
44 | - 메모리를 강제로 뺏긴 상태(디스크 swap-out)
45 | - Ready에서 swap-out이면 Suspended Ready, Blocked에서 swap-out이면 Suspended Block
46 | - Terminated : 프로세스의 실행이 종료되었을 때
47 |
48 | 프로세스는 위 6단계에 따라 **프로세스 큐(Job, Ready, Device)**에 각각 올라가있고 큐에 올리는 일은 **프로세스 스케줄러가 담당**한다.
49 |
50 | ### Ready와 Waiting의 차이
51 |
52 | - I/O 작업이나 기타 이벤트로 인한 상태 변화에는 Running → Waiting → Ready → Running 의 순서로 변한다.
53 | - 즉, 준비가 다 끝나지 않은 프로세스가 준비를 끝내기위해서 대기 중인 상태
54 | - 프로세스 스케줄링에 의한 상태 변화(time out, interrupt)에는 Running → Ready → Running 의 순서로 변한다.
55 | - 즉, 준비가 다 끝난 프로세스가 실행되기를 기다리는 상태
56 |
57 | ### Context Switching → 프로세스의 상태를 바꿔주는 것
58 |
59 | ## 프로세스 Queue와 스케줄러
60 |
61 | 프로세스의 큐는 Job, Ready, Device가 존재한다.
62 |
63 | - Job Queue : 시스템 상의 모든 프로세스들을 의미
64 | - Ready Queue : 메모리에 올라가 있고 실행을 기다리는 프로세스들을 의미
65 | - Device Queue : I/O 작업을 위해 기다리고 있는 프로세스들을 의미
66 |
67 | 
68 |
69 | 이러한 큐에 어떤 것을 올릴지 결정하는 것이 스케줄러이다.
70 |
71 | - Long-Term Scheduler(장기 스케줄러)
72 | - Job Scheduler라고도 불리며 **Ready Queue에 어떤 것들을 올려야하는지 결정**하는 스케줄러이다.
73 | - 즉, **디스크**에 있는 프로그램을 **메모리**로 올려 프로세스로 만드는 작업
74 | - 속도는 빠르지 않아도 괜찮다.
75 | - 멀티 프로그래밍의 정도를 제어
76 | - 그 이유는 얘가 메모리에 프로세스를 올려주기 때문에 I/O-bound 프로세스와 CPU-bound 프로세스를 적절히 섞어서 올려줘야 한다.
77 | - 상태 변경 : New → Ready(in memory)
78 | - Short-Term Scheduler(단기 스케줄러)
79 | - 우리들이 알고 있는 CPU Scheduler 라고 불리며 **어떤 프로세스에게 CPU 자원을 할당할 것인지를 결정**하는 스케줄러이다.
80 | - 즉, **메모리**에 올라와 있는 프로세스를 **CPU에게 할당**
81 | - CPU 자원 할당은 매우 짧은 시간 단위로 반복되기 때문에 속도가 빨라야한다.
82 | - 상태 변경 : Ready → Running
83 | - Medium-Term Scheduler(중기 스케줄러)
84 | - 실행하기에 필요한 자원이 부족한 프로세스들 중 **어떤 프로세스를 Swap-out 하여 Disk에 저장할지, 어떤 프로세스를 Swap-in 해야하는지를 결정**해주는 스케줄러이다.
85 | - 즉, **메모리**에 너무 많은 프로세스가 동시에 올라가있다면 **디스크**로 내보내는 작업
86 | - 상태 변경 : Ready → Suspended
87 | - Terminated가 아니다.
88 | - 누군가 다시 재개시켜줘야(swap-in해줘야) 다시 Ready로 돌아갈 수 있다.
89 |
90 | ## PCB(Process Control Block)
91 |
92 | 특정 프로세스에 대한 중요한 정보를 저장하고 있는 OS의 자료구조이다.
93 |
94 | 프로세스 생성과 동시에 고유한 PCB가 생성되고 프로세스 전환시(인터럽트나 시스템콜)에 PCB에 기록하고 사용한다.
95 |
96 | - PCB에 저장되는 정보들 중 중요한 것들
97 | - PID : 프로세스 식별 번호
98 | - 상태
99 | - CPU 스케줄링 정보
100 | - TCB가 PCB를 참조
101 | - 레지스터
102 | - PC(Program Counter) : 프로세스가 다음에 실행할 명령어의 주소
103 |
104 | 
105 |
106 | - 추가 내용(같이 고민해볼 점)
107 |
108 | 스케줄링에는 Context Switching 시간까지 포함되어 있다.
109 |
110 | 따라서 PCB의 저장과 복원이 오래걸리면 그만큼 작업을 수행할 수 있는 시간이 짧아지는 것
111 |
112 | 따라서 **PCB의 저장과 복원은 H/W로 구현해서 작업 효율을 최대한 늘린다고 한다.**
113 |
114 | 근데 OS의 자료구조인데 하드웨어..? 잘 모르겠다.
115 |
116 |
117 | # ⭐️ 스레드
118 |
119 | 멀티 스레드와 혼용해서 설명
120 |
121 | 프로세스의 수행 경로
122 |
123 | 즉, 프로세스가 할당받은 자원을 이용하는 실행의 단위(흐름)
124 |
125 | ex) 메신저 프로그램에서 “내가 입력”, “상대방이 입력한 것을 출력” 등 하나씩이 실행 단위이다.
126 |
127 | 
128 |
129 | ## 스레드가 필요한 이유
130 |
131 | 결론은 프로세스만으로 요구 사항을 충족하기 쉽지 않아서이다.
132 |
133 | 예를 들어서 메신저 프로그램일 때, 내가 입력한 것을 출력해줌과 동시에 상대방이 입력한 것도 출력해야한다.
134 |
135 | 이 때, 싱글 프로세스를 사용한다면 키보드 입력을 기다릴 때 상대방으로부터 온 메시지를 받을 수 없다.
136 |
137 | 왜냐면 하나의 path만 가지고 있기 때문
138 |
139 | 
140 |
141 | 대충 이런 느낌이다.(프로세스는 기본적으로 하나의 스레드를 가지고 있음)
142 |
143 | 따라서 프로세스를 추가로 생성해야하는데 문제는 프로세스 자체가 독립된 자원을 할당 받기 때문에 서로 공유하지 않아서 관련되지 않은 실행 path를 가진다.
144 |
145 | 
146 |
147 | 그럼 뭐다?? 서로 통신(IPC) 해야하는데 프로그램이 커지고 시간이 지날수록 비효율적이다.(PCB 추가, 메모리 추가, Context Switching 등)
148 |
149 | - IPC는 커널을 껴서 통신해야한다.
150 |
151 | 그래서 하나의 프로세스에 여러 path를 만들고 자원을 공유하는 멀티 스레드를 사용하는 것(다수의 path가 필요한 것 뿐이기 때문에 굳이 자원 낭비를 하지 말자!)
152 |
153 | ## 스레드 특징
154 |
155 | 스레드는 프로세스와 다르게 Stack만 따로 할당 받고 Code, Data, Heap 영역은 공유한다.
156 |
157 | 정확히는 프로세스와 동일하게 실행 상태를 갖고 Register와 Stack을 독립적으로 할당받는다.
158 |
159 | ### Stack과 Register를 독립적으로 할당받는 이유??
160 |
161 | - stack
162 | - 스레드는 하나의 독립적인 실행단위이기 때문에 각각 독립적인 stack을 가진다.(독립적인 함수 호출)
163 | - 즉, 함수 호출 시 인자, 리턴 값 지역 변수 등을 독립적으로 가지기 위해서
164 | - register
165 | - 프로세스와 똑같이 CPU를 할당받고, 선점당할 수 있다.
166 | - 따라서 Context Switching이 발생하게 되므로 실행하고 있는 코드의 지점을 저장하는 PC 등을 스레드마다 독립적으로 할당해야 한다.
167 |
168 | ## 장점
169 |
170 | 1. 사용자에 대한 응답성 증가
171 | - 하나의 스레드가 waiting인 동안 다른 스레드가 실행되어 다른 작업을 빨리 처리할 수 있기 때문
172 | 2. 프로세스의 자원과 메모리 공유
173 | - 하나의 같은 주소 공간에서 여러 개의 스레드를 실행해 병렬성, 성능향상을 가질 수 있다.
174 | 3. 경제성
175 | - 한 프로세스의 자원을 공유하기 때문에 프로세스끼리 Context Switching하는 것보다 스레드끼리 하는 것이 오버헤드가 적다.
176 | - 스레드가 Context Switching 오버헤드가 작은 이유 : 스레드는 Stack, Register만 하면 되고 RAM과 CPU 사이의 캐시를 사용 가능하지만 프로세스는 캐시까지 초기화되어버린다.
177 | 4. 다중 프로세서(CPU) 구조 활용
178 | - 멀티 스레드를 통해 병렬로 수행할 수 있기 때문
179 |
180 | # ⭐️ 멀티 프로세스
181 |
182 | 하나의 응용 프로그램을 여러 개의 프로세스로 구성해 각 프로세스가 하나의 작업을 처리하도록 하는 것
183 |
184 | 
185 |
186 | ## 장단점
187 |
188 | - 장점
189 | - 여러 개의 자식 프로세스 중 하나에 문제가 발생하면 그 자식 프로세스만 죽는 것 이상으로 다른 영향이 확산되지 않는다.
190 | - 단점
191 | - Context Switching에서의 오버헤드 프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 프로세스 사이에서 공유하는 메모리가 없어, Context Switching가 발생하면 캐쉬에 있는 모든 데이터를 모두 리셋하고 다시 캐쉬 정보를 불러와야 한다.
192 | - 프로세스 사이의 어렵고 복잡한 통신 기법(IPC) 프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 하나의 프로그램에 속하는 프로세스들 사이의 변수를 공유할 수 없다.
193 |
194 | # ⭐️ 멀티 스레드
195 |
196 | 하나의 응용프로그램을 여러 개의 스레드로 구성하고 각 스레드로 하여금 하나의 작업을 처리하도록 하는 것이다.
197 |
198 | 대부분 많은 운영체제들이 멀티 스레딩을 기본으로 하고 있다.
199 |
200 | 
201 |
202 | 
203 |
204 | ex)
205 |
206 | 워드에서 키보드 입력을 기다리고, 주기적으로 저장하고, 타이핑 에러 체크하고 등을 전부 동시에 한다.
207 |
208 | 저 3개를 프로세스로 할 순 있는데 매우 비효율적
209 |
210 | 따라서
211 |
212 | 워드 → 프로세스 하나
213 |
214 | 키보드 입력 → 스레드
215 |
216 | 주기적 저장 → 스레드
217 |
218 | 타이핑 에러 체크 → 스레드
219 |
220 | ## 장단점
221 |
222 | - 장점
223 | - 시스템 자원 소모 감소 (자원의 효율성 증대)
224 | - 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다.
225 | - 시스템 처리량 증가 (처리 비용 감소)
226 | - 스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어들게 된다.
227 | - 스레드 사이의 작업량이 작아 Context Switching이 빠르다.
228 | - 간단한 통신 방법으로 인한 프로그램 응답 시간 단축
229 | - 스레드는 프로세스 내의 Stack 영역을 제외한 모든 메모리를 공유하기 때문에 통신의 부담이 적다.
230 | - 단점
231 | - 주의 깊은 설계가 필요하다.
232 | - 디버깅이 까다롭다.
233 | - 단일 프로세스 시스템의 경우 효과를 기대하기 어렵다.
234 | - 다른 프로세스에서 스레드를 제어할 수 없다. (즉, 프로세스 밖에서 스레드 각각을 제어할 수 없다.)
235 | - 멀티 스레드의 경우 자원 공유의 문제가 발생한다. (동기화 문제)
236 | - 하나의 스레드에 문제가 발생하면 전체 프로세스가 영향을 받는다
237 |
238 | ## 멀티 스레드 모델(조금 deep 한 내용)
239 |
240 | 모델을 설명하기 전에 **User Thread**와 **Kernel Thread**에 대해 알아야한다.
241 |
242 | - User Thread
243 | - 사용자가 관리하는 스레드
244 | - 스레드 전환시 커널 모드 권한이 필요없고 빠르게 만들고 관리할 수 있다.(커널 스레드보다 오버헤드가 적음 → Context Switch가 없다.(사용자 영역 스레드에서 행동하기 때문 → 메모리 상에 저장해놓나??))
245 | - 사용자 영역에서 하기 때문에 운영체제에 의존적이지 않다.(커널이 제공해주지 않고 라이브러리를 활용)
246 | - 하지만 일반적인 OS에서는 대부분의 시스템 호출이 차단되고 다중 처리를 활용할 수 없다.(I/O 작업 등에 의해 블록되면 전체 스레드가 멈춘다.)
247 | - Kernel Thread
248 | - 운영체제가 직접 커널에서 제공하고 관리하는 스레드
249 | - 하나의 프로세스는 적어도 하나의 커널 스레드를 가진다.
250 | - 프로세스의 스레드들을 한꺼번에 디스패치할 수 있기 때문에 멀티 프로세서 환경에서 좋다.
251 | - 다른 스레드가 입출력 작업이 끝날 때까지 기다릴 필요가 없다.
252 | - 안정성과 다양한 기능을 제공
253 | - 하지만 스케줄링과 동기화를 위해 커널을 호출하는데 무겁고 오래걸린다. 즉, 사용자모드에서 커널모드로 전환이 빈번하게 이루어지면 성능 저하가 발생한다. 또한 구현하기 어렵고 자원을 더 많이 소비한다.
254 |
255 | ### 1. Many-to-One Model
256 |
257 | 
258 |
259 | - 하나의 Kernel Thread가 다수의 User Thread를 처리하는 구조(=User Thread만 사용했다고 보면 됨)
260 | - User Thread를 처리하던 중 시스템 콜에 의해 blocking되면 **전체 프로세스가 막히게 된다.**
261 |
262 | ### 2. One-to-One Model
263 |
264 | 
265 |
266 | - User Thread 한 개 당 Kernel Thread를 대응시켜 작업하는 구조
267 | - 과도한 Kernel Thread 생성 문제가 있다.
268 |
269 | ### 3. Many-to-Many Model
270 |
271 | 
272 |
273 | - 1,2를 어느정도 보완한 모델로 다수의 User Thread를 다수의 Kernel Thread가 처리하는 구조
274 | - Kernel Thread의 숫자는 User Thread의 숫자보다 같거나 작아야한다.
275 |
276 | ### 4. Two-Level Model
277 |
278 | 
279 |
280 | - 최종적으로 보안된 모델로 2+3을 합친 구조이다.
281 | - 중요한 작업은 One-to-One 처럼, 나머지는 Many-to-Many 처럼 처리함으로써 혹시나 있을 중요한 작업에서의 기다림 현상을 줄일 수 있다.
282 |
283 |
284 | # ⭐️ 참고
285 |
286 | 프로세스와 스레드
287 | [https://github.com/Songwonseok/CS-Study/blob/main/OS/프로세스vs스레드.md](https://github.com/Songwonseok/CS-Study/blob/main/OS/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4vs%EC%8A%A4%EB%A0%88%EB%93%9C.md)
288 | [https://coder-in-war.tistory.com/entry/OS-00-프로세스와-스레드의-차이?category=994187](https://coder-in-war.tistory.com/entry/OS-00-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4%EC%99%80-%EC%8A%A4%EB%A0%88%EB%93%9C%EC%9D%98-%EC%B0%A8%EC%9D%B4?category=994187)
289 |
290 | 프로세스
291 | [https://baked-corn.tistory.com/5?category=718232](https://baked-corn.tistory.com/5?category=718232)
292 | 스레드
293 | [https://baked-corn.tistory.com/6?category=718232](https://baked-corn.tistory.com/6?category=718232)
294 |
295 | OS 튜토리얼
296 | [https://www.tutorialspoint.com/operating_system/index.htm](https://www.tutorialspoint.com/operating_system/index.htm)
297 |
298 | 프로세스 상태, 큐, 스케줄러
299 | [https://kosaf04pyh.tistory.com/190](https://kosaf04pyh.tistory.com/190)
300 |
301 | 멀티 스레드 모델
302 | [https://www.crocus.co.kr/1255](https://www.crocus.co.kr/1255)
303 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Backend_Interview_Study
2 |
3 | ### 참여자
4 | | | | | | | | |
5 | | :------: | :------: |:------------------------------------------------------:| :------: | :------: | :------: | :------: |
6 | | **[김영한](https://github.com/soosungp33)** | **[유정한](https://github.com/youjeonghan)** | **[김동민](https://github.com/dmin0211)** | **[방규빈](https://github.com/9b2n)** | **[이유노](https://github.com/FloralLife)** | **[이신필](https://github.com/lee-3-8)** | **[홍승용](https://github.com/isanghaessi)** |
7 |
8 |
9 | ### 그라운드 룰
10 | - 스터디 일정 : 매주 화, 금 (다수의 인원이 일정이 생긴다면 조정할 수 있습니다)
11 |
12 | - 시간 : 오전 10시
13 |
14 | - 주제
15 | - 자료구조
16 | - 네트워크
17 | - 운영체제
18 | - 데이터베이스
19 | - 알고리즘
20 | - 개발상식
21 | - 디자인패턴
22 |
23 | - 발표시간 : 질문포함 20분
24 |
25 | - 발표 주요 요소
26 | - 주제
27 | - 내용
28 | - 예상 질문 리스트
29 | - 참고자료
30 |
31 | - 커밋 양식
32 | - [분야(영어)][close #13] : 내용
--------------------------------------------------------------------------------
 7 |
8 | ### 충돌
9 |
10 | 해시 함수가 서로 다른 키를 같은 해시 값로 반환하는 경우 충돌이라고 부릅니다.
11 |
12 | 키 k1, k2 의 경우 h(k1) = h(k2) 인 상황입니다. 이러한 충돌은 해시 함수의 알고리즘이 정교하게 작동해도 피할 수가 없습니다.
13 |
14 | 이러한 충돌이 발생하지 않는다면 O(1) 의 시간 복잡도로 삽입, 수정, 삭제 연산이 이루어지지만 충돌이 발생한다면 최악에 O(Key 의 개수) 의 시간이 발생합니다.
15 |
16 | 이러한 충돌을 최대한 줄이는 것이 해시 테이블의 핵심입니다.
17 |
18 | ### 충돌 해결
19 |
20 | 해시 테이블의 충돌을 완화하는 방법으로 **해시 테이블 구조 개선**, **해시 함수 개선** 이 존재합니다.
21 |
22 | ### 해시 테이블 구조 개선
23 |
24 | - Separate Chaining
25 |
26 | 충돌 발생시 해시 테이블 동일한 버킷에 연결리스트 형태로 저장하는 방식입니다. 즉, 테이블이 차지한 메모리에서 추가적인 메모리 공간을 활용하는 방식입니다.
27 |
28 | 
29 |
30 |
31 | 데이터의 삽입의 경우 연결 리스트 추가시간인 O(1) 시간복잡도가 걸립니다.
32 |
33 | 수정 및 삭제, 탐색의 경우 최악의 경우 O(key 의 갯수) 의 시간복잡도가 걸립니다.
34 |
35 |
40 |
41 | - Open Addressing
42 |
43 | Chaining 과 달리 테이블의 비어있는 주소를 활용하는 방식입니다. 해당 방식의 테이블에서 비어있는 버킷을 탐사하는 시간이 중요합니다. 탐사의 방식은 대표적으로 3가지가 존재합니다.
44 |
45 | - 선형탐사(Linear probing)
46 |
47 | 해시 값에 대한 버킷이 이미 데치터가 존재하는 경우 바로 다음 버킷을 탐사하는 방식입니다.
48 | 가장 간단한 방식으로 단점도 명확합니다. 특정 해시값 주변 버킷들이 이미 다 채워져있는 primary clustering 의 경우 선형의 시간복잡도가 필요합니다.
49 |
50 | - 제곱탐사(Quadratic probing)
51 |
52 | 충돌이 발생시마다 충돌 횟수의 제곱수만큼 버킷을 이동하는 방식입니다.
53 | 예를들어 처음 충돌이 발생하면 1^2 만큼 이동하여 버킷을 확인합니다. 해당 버킷도 또 충돌이 발생한다면 2^2 만큼 이동한 버킷을 확인합니다. 마찬가지로 또 충돌이 발생한다면 3^2 만큼 이동하는 방식을 통해 충돌이 발생하지 않는 버킷을 탐사합니다.
54 |
55 | 이 경우도 단점이 존재합니다. 초기 해시값 즉 다양한 key 에 대해서 해시 함수의 결과값이 동일한 경우가 많은 secondary clustering 의 경우 마찬가지로 선형의 시간복잡도가 필요합니다.
56 |
57 | - 이중해싱(double hashing)
58 |
59 | 2개의 해시 함수를 준비하여 하나는 초기 해시값, 다른 하나는 충돌 발생시 이동폭을 얻기위해 사용합니다. 이런 경우 초기 해시값이 동일한 키라고 하더라도 다른 이동폭을 가지므로 앞선 primary clustering, secondary clustering 에서의 취약점이 해소됩니다.
60 |
61 |
62 | load factor 비율로 bucket size
63 |
64 |
65 | ### 해시 함수?
66 |
67 | 임의의 길이의 데이터 Key 를 고정된 길이의 해시(해시 값, 해시 코드, Hash 체크섬)로 매핑하는 해싱과정을 수행하는 함수입니다.
68 |
69 | 여기서 특정 값으로 치우치지 않고 해시값이 고르게 분포되는 것을 좋은 해시함수의 기준입니다.
70 |
71 | ### 해시 함수 종류
72 |
73 | - Division Method
74 |
75 | Key 값 k를 해시 테이블의 크기 n 으로 나눈 나머지를 해시값으로 사용하는 방식입니다.
76 | n 은 소수를 사용하는 것이 좋습니다
77 | 테이블의 크기가 정해진다는 단점이 있습니다.
78 | h(k) = k mod n
79 |
80 | - Multiplication Method
81 |
82 | Key 값 k, 0 과 1사이의 실수 A 임의의 m(보통 2의 제곱수)가 있을 때 다음의 수식을 통해 해시값을 구하는 방식입니다.
83 | 2진수 연산에 최적화된 컴퓨터 구조를 고려한 해시함수라고 합니다.
84 | h(k) = (kA mod 1) x m
85 |
86 | - Mid Square Method
87 |
88 | Key 값 k 를 제곱한 후 특정 자릿수 r 의 값을 해시값으로 사용하는 방식입니다.
89 |
90 |
91 | ## 참고자료
92 |
93 | [위키](https://namu.wiki/w/%ED%95%B4%EC%8B%9C)
94 |
95 | [wikipedia](https://en.wikipedia.org/wiki/Hash_table)
96 |
97 | [Hash 위키](http://wiki.pchero21.com/wiki/Hash#Hash_function)
98 |
99 | [해시 테이블](https://dbehdrhs.tistory.com/70)
100 |
101 | [해시 테이블 충돌](https://baeharam.github.io/posts/data-structure/hash-table/)
102 |
103 | [충돌 개선](https://en.wikipedia.org/wiki/Hash_table#Separate_chaining)
104 |
105 | [Java 8 Hash Table](https://d2.naver.com/helloworld/831311)
--------------------------------------------------------------------------------
/Database/B-Tree와 B+Tree.md:
--------------------------------------------------------------------------------
1 | # B-Tree와 B+Tree
2 |
3 |
4 |
5 | # B-Tree
6 |
7 | 트리 자료구조의 일종으로, 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 수가 2이상인 트리 구조이다.
8 |
9 | **최상위 노드**를 `root`노드라고 하며, **최하위 노드**들을 `leaf`노드라고 한다. **그 사이 계층의 노드**들은 `internal`노드라고 부른다.
10 |
11 | 
12 |
13 | 하나의 노드에 여러 개의 데이터가 있을 수 있다.
14 |
15 | 데이터의 순서는 이진 탐색 트리와 유사하다.
16 |
17 | 노드 내 데이터를 최대 M-1개, 최소 [M/2]-1개를 가지는 B-Tree를 **M차 B-Tree**라고 부른다.
18 |
19 | 자식 노드의 최소 및 최대 수는 특별한 구현에 대해서 결정되어 있다.
20 |
21 | 노드의 단위는 **page**로, **하드디스크의 저장 단위**에 맞추어져 있어 데이터베이스와 파일시스템에서 잘 쓰인다.
22 |
23 |
24 |
25 | ## 규칙
26 |
27 | - root 노드는 **2개 이상**의 자식을 가져야 한다.
28 | - M차 B-Tree는 루트 노드를 제외한 나머지 노드는 **최소 M/2개, 최대 M개의 자식 노드**가 있어야 한다.
29 | - **N개의 데이터**가 있는 하나의 노드는 **N+1개의 자식노드**를 갖고 있다.
30 |
31 | ⇒ **N개의 데이터**가 있다면 **자식 노드의 포인터는 N+1개**이다.
32 |
33 | 
34 |
35 |
36 | ## 탐색
37 |
38 | 1. 노드 안에서: 순차검색
39 |
40 | 2. 트리 안에서: 하향식 트리 검색
41 |
42 |
43 |
44 | ## 삽입
45 |
46 | 1. 삽입될 위치 검색
47 | 2. 삽입
48 | 1. 노드의 공간이 남아있을 때
49 |
50 | 노드 안에서 오름차순으로 삽입
51 |
52 | 2. 노드의 공간이 없을 때
53 | 1. 오름차순으로 삽입
54 | 2. 노드안에서 중앙값으로 분할하여 중앙값의 데이터를 부모 노드로 오름차순으로 삽입
55 | 3. i~ii 과정을 `root`노드까지 반복
56 |
57 | ex) 최대 2개의 데이터를 가지는 2차 B-Tree
58 |
59 | 
60 |
61 | 1. 4 삽입
62 |
63 | 
64 |
65 | 2. 노드 중앙값 분할
66 |
67 | 
68 |
69 | 3. root노드 중앙값 분할
70 |
71 | 
72 |
73 |
74 | ## 삭제
75 |
76 | 1. 삭제할 데이터가 위치한 노드 검색
77 |
78 | 1. 삭제할 데이터가 leaf노드에 있는 경우
79 | 1. 현재 노드의 데이터 개수가 최소 개수보다 클 때
80 |
81 | 삭제
82 |
83 | 2. 현재 노드의 데이터 개수가 최소 개수일 때
84 |
85 | 1) 왼쪽 또는 오른쪽 형제노드의 데이터 개수가 최소 개수 이상일때
86 |
87 | a) 현재노드를 현재노드와 형제노드 사이의 부모노드 데이터로 교체
88 |
89 | b) 형제노드가 왼쪽이라면 최대값을, 오른쪽이라면 최소값을 부모노드 데이터와 교체
90 |
91 | 2) 부모노드의 데이터는 최소 개수보다 많고, 형제노드 모두 데이터 개수가 최소 개수일 때
92 |
93 | a) 현재노드 삭제
94 |
95 | b) 부모노드의 데이터 최대값 또는 최소값을 형제노드와 합친다.
96 |
97 | 3) 부모노드, 형제노드 모두 데이터 개수가 최소 개수일 때
98 |
99 | a) 현재노드 삭제
100 |
101 | b) 부모노드를 인접한 형제노드와 병합 후 조상노드의 자식으로 위치시킨다.
102 |
103 | i) B-Tree의 조건이 맞춰줄 때까지 반복
104 |
105 | 2. 삭제할 데이터가 leaf노드에 없는 경우
106 | 1. 현재노드와 자식노드의 데이터 개수가 최소 개수보다 클 때
107 |
108 | 1) 왼쪽 서브트리의 최댓값과 위치를 변경한다.
109 |
110 | 2) 왼쪽 서브트리의 최댓값과 변경된 데이터를 삭제한다.
111 |
112 | 3) a. 과정을 한다.
113 |
114 | 2. 현재노드와 자식노드 모두 데이터 개수가 최소 개수일 경우
115 |
116 | 1. 데이터를 삭제하고 양쪽 자식노드를 합친다.
117 |
118 | 2. 부모의 데이터를 인접한 형제노드에 붙이고, 1)에서 합쳤던 노드를 자식노드로 위치시킨다.
119 |
120 |
121 |
122 |
123 | ## 특징
124 |
125 | 모든 노드에 key와 data가 들어있다.
126 |
127 | 데이터를 정렬된 상태로 보관
128 |
129 | 상향식 구성
130 |
131 | 삽입과 삭제시 균형을 유지하기 위한 작업
132 |
133 | 동일한 높이의 leaf노드 (Balanced)
134 |
135 | O(logN) 검색시간 보장
136 |
137 |
138 |
139 | # B+Tree
140 |
141 | B-Tree에서 확장된 개념의 트리구조이다.
142 |
143 | leaf노드에만 key와 data를 저장하고, 나머지 노드에는 key만 담겨있다. leaf노드끼리는 linked list로 연결되어 있다.
144 |
145 | 
146 |
147 |
148 |
149 | ## 삽입
150 |
151 | - 삽입할 노드의 데이터 개수가 최대값보다 작을 때
152 |
153 | 데이터 삽입
154 |
155 | - 삽입할 노드의 데이터 개수가 최대값일 때
156 |
157 | 2개로 분할하여 중간값을 부모노드에 추가
158 |
159 | - 부모노드의 데이터 개수가 최대값일 때
160 |
161 | B-Tree 삽입 과정과 동일
162 |
163 |
164 |
165 |
166 | ## 삭제
167 |
168 | - 삭제할 키가 노드의 첫번째 데이터가 아닐 때
169 |
170 | 데이터 삭제
171 |
172 | - 삭제할 키가 노드의 첫번째 데이터일 때
173 | - 노드의 데이터 개수가 최소값이 아닐 때
174 |
175 | 삭제 후 삭제된 key가 있던 노드의 key값을 오른쪽 key로 변경한다.
176 |
177 | - 노드의 데이터 개수가 최소값일 때
178 | - 형제노드의 데이터 개수가 최소값이 아닐 때
179 |
180 | 삭제 후 인접한 형제노드의 key와 자리를 바꾼 후 부모노드의 key를 알맞게 수정한다.
181 |
182 | - 형제노드의 데이터 개수가 최소값일 때
183 | - 부모노드의 데이터 개수가 최소값이 아닐 때
184 |
185 | 삭제 후 삭제된 key가 있던 노드의 key 삭제
186 |
187 | - 부모노드의 데이터 개수가 최소값일 때
188 |
189 | 현재노드와 부모노드 삭제 후 조상노드에 형제노드를 연결하고 조상노드에 대해서는 B-Tree와 동일
190 |
191 |
192 |
193 | ## 장점
194 |
195 | 오직 leaf노드에만 데이터를 담기 때문에 저장공간을 더 확보하고 더 많은 key들을 수용할 수 있다. 하나의 노드에 더 많은 key를 담을 수 있기 때문에 트리의 높이가 더 낮아진다.
196 |
197 | leaf노드끼리 서로 연결되어 있기 때문에 범위 검색에 유리하다.
198 |
199 | 풀 스캔 시, B+Tree는 leaf노드로 한 번의 선형탐색만 하면 되기 때문에 B-Tree보다 빠르다.
200 |
201 | →데이터베이스 시스템 인덱스 구성에 매우 효율적이다.
202 |
203 |
204 |
205 | ## 단점
206 |
207 | B-Tree의 경우 최상의 경우 특정 key의 데이터를 찾기 위해 leaf노드까지 가지 않아도 되지만, B+Tree의 경우 반드시 특정 key에 접근하기 위해서 leaf node까지 가야 한다.
208 |
209 |
210 |
211 | ---
212 |
213 | - 참고자료
214 |
215 | [https://ko.wikipedia.org/wiki/B_트리](https://ko.wikipedia.org/wiki/B_%ED%8A%B8%EB%A6%AC)
216 |
217 | [https://velog.io/@emplam27/자료구조-그림으로-알아보는-B-Tree](https://velog.io/@emplam27/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C-%EC%95%8C%EC%95%84%EB%B3%B4%EB%8A%94-B-Tree)
218 |
219 | [https://velog.io/@emplam27/자료구조-그림으로-알아보는-B-Plus-Tree](https://velog.io/@emplam27/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C-%EC%95%8C%EC%95%84%EB%B3%B4%EB%8A%94-B-Plus-Tree)
220 |
221 | [https://slenderankle.tistory.com/159](https://slenderankle.tistory.com/159)
222 |
223 | [https://rebro.kr/167](https://rebro.kr/167)
--------------------------------------------------------------------------------
/Database/Join.md:
--------------------------------------------------------------------------------
1 | # JOIN
2 |
3 | > JOIN은 데이터베이스 내의 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현해 줍니다. 이러한 JOIN은 보통 SELECT 문과 함께 자주 사용됩니다. → [TCP School JOIN](http://tcpschool.com/mysql/mysql_multipleTable_join)
4 | >
5 |
6 | 
7 |
8 | SQL을 접하면서 DB를 설계하고 사용할 때 JOIN은 가장 자주 사용하게 되는 개념이라고 할 수 있을 정도로 많이 쓰인다. 항상 성능에 대해서 고민하게 되는 친구지만, 나름 RDBS(관계형데이터베이스)의 꽃이라고 생각되는 JOIN에 대해서 정리해 보려고 한다.
9 |
10 | ## 1. 조인과 관계대수
11 |
12 | 관계대수란 릴레이션(테이블)에서 데이터를 추출하는데 사용되는 언어라고 할 수 있다. 관계형 데이터베이스 이론의 코드 박사(codd)는 이렇게 정의했다.
13 |
14 | - 관계 대수: 원하는 정보를 어떻게(How) 찾는지를 명시하는 절차적 언어
15 | - 관계 해석: 어떤(what) 데이터를 찾는지 만 명시하는 선언적 언어
16 |
17 | SQL 언어는 관계해석을 기반으로 하며 관계 대수 개념이 혼합되어 있고, DBMS 내부에서는 관계 대수에 기반을 둔 연산을 수행한다. 관계 대수를 정리해보면 다음 과 같다.
18 |
19 | 
20 |
21 | 여기서 Join은 유도된 연산자로 Cartesian Product 와 Selection을 함께 실행하여 얻은 결과와 동일하다.
22 |
23 | > 다른건 다 감이 오는데 `카티전 프로덕트`..? 이게 뭘까 싶을 수 있다. `카티전 프로덕트`는 집합에서 곱의 개념으로 A= {a, b, c} , B = {1, 2} 일 때 (a,1), (a, 2), (b,1), (b,2), (c, 1), (c,2) 처럼 나타 낼 수 있다. 엄청나게 많은 결과를 생성하기 때문에 많이 사용되지는 않는다.
24 | >
25 |
26 | ## 2. 다양한 조인들...
27 |
28 | 관계 대수에서 언급된 조인들을 하나씩 살펴 보자
29 |
30 | ### Theta Join(세타 조인), Equal Join(동등 조인), Natural Join(자연 조인)
31 |
32 | 
33 |
34 | 그림처럼 비교 조건 (<, =, >)을 만족하는 Join이 Theta Join이고 그중 비교 조건이 (=)일 때 Equal Join이 된다.
35 |
36 | > 간혹 Inner Join이 곧 Equal Join이라고 생각 하는 경우가 있는데, 엄밀히 따지자면 틀린 이야기다. Outer Join에서도 Equal Join처럼 동등 비교 조건문이 들어갈 수 있기도 하고, Inner Join사용시에 Equal Join도 사용 가능한 것으로 생각하면 된다.
37 | >
38 |
39 | Equal Join에서 중복 속성을 제거하게 되면 Natural Join이 됩니다. Natural Join은 다음과 같이 두 테이블에 같은 이름의 열이 있을 때 생략하여 사용 가능하다.
40 |
41 | ```sql
42 | SELECT * FROM A NATURAL JOIN B;
43 | ```
44 |
45 | ### Inner Join
46 | 그림에서 보이는 것처럼 교집합을 나타낸다.
47 |
48 | 
49 |
50 | 출처: [TCPschool](http://tcpschool.com/mysql/mysql_multipleTable_join)
51 |
52 | 아래 처럼 작성할 수 있다.
53 |
54 | ```sql
55 | SELECT * FROM A JOIN B ON A.id = B.id;
56 | ```
57 |
58 | ### Outer Join
59 |
60 | Inner Join의 결과로 나오지 않는 행도 NULL값으로 포함해서 결과를 나타내는 Join이다.
61 |
62 | 어느 쪽을 기준으로 합치냐에 따라서 Left Join , Right Join으로 나뉜다.
63 |
64 | **Left Join**
65 |
66 | 
67 |
68 | 출처: [TCPschool](http://tcpschool.com/mysql/mysql_multipleTable_join)
69 |
70 | 첫 번째 테이블을 기준으로 두 번째 테이블을 조합하는 Join이다. ON절의 조건을 만족하지 않더라도 첫 번째 테이블을 표시하고, 두 번째 테이블의 필드를 NULL로 표시한다.
71 |
72 | ```sql
73 | SELECT * FROM A LEFT JOIN B ON A.id = B.id;
74 | ```
75 |
76 | **Right Join**
77 |
78 | 
79 |
80 | 출처: [TCPschool](http://tcpschool.com/mysql/mysql_multipleTable_join)
81 |
82 | Left Join과는 반대로 두 번째 테이블을 기준으로 첫 번째 테이블을 조합하는 Join이다. ON절의 조건을 만족하지 않더라도 두 번째 테이블을 표시하고, 첫 번째 테이블의 필드를 NULL로 표시한다.
83 |
84 | ```sql
85 | SELECT * FROM A RIGHT JOIN B ON A.id = B.id;
86 | ```
87 |
88 | ### Cross Join
89 |
90 | `Cross Join` 은 관계 대수에서 잠깐 언급했던 `Cartesian Product` 와 같다. 카티전 조인이라고도 한다.
91 |
92 | ```sql
93 | SELECT * FROM A CROSS JOIN B ON A.id = B.id;
94 | ```
95 |
96 | ### Self Join
97 |
98 | 말그대로 자기 자신을 Join하는 방법이다. A 테이블을 각각 Child, Parent로 지정해서 사용한다.
99 |
100 | ```sql
101 | SELECT * FROM A AS parent JOIN A AS child
102 | ```
103 |
104 | ### Semi Join
105 |
106 | 솔직히 처음 들어보는 조인이었다. 조사해보니 세미 조인은 서브 쿼리와 메인 쿼리와의 연결을 위한 유사 조인 이었다...(~~가짜야가짜~~)
107 |
108 | 1:n 관계에서 1의 컬럼만을 사용할 경우 사용할 수 있는데, 집계함수 없이 group by나 distinct를 사용해서 중복제거를 하고 있다면 성능 향상의 효과를 얻을 수 있다.
109 |
110 | In 과 Exists를 통해 사용할 수 있다고 한다.
111 |
112 | ```sql
113 | SELECT * FROM A WHERE A.name IN (SELECT B.name FROM B );
114 | ```
115 |
116 | ```sql
117 | SELECT * FROM A WHERE EXISTS (SELECT 1 FROM B WHERE A.name = B.name)
118 | ```
119 |
120 | 자세한건 아래 블로그와 참고자료에 첨부한 유튜브 영상을 참고하자
121 |
122 | [블로그](https://songii00.github.io/2019/08/10/2019-08-10-%EC%84%B8%EB%AF%B8%EC%A1%B0%EC%9D%B8/)
123 |
124 | ## 3. 조인 동작 방식
125 |
126 | Mysql 에서는 **NESTED LOOP JOIN(NL Join)**을 사용하고 있으며, 이외에 **SORT-MERGE JOIN, HASH JOIN**이 있다. Hash Join의 경우 Mysql 8.0부터 지원하고 있다고 한다.
127 |
128 | ### **NESTED LOOP JOIN(NL Join)**
129 |
130 | 우리가 프로그래밍에서 사용하는 반복문과 유사한 방식으로 조인을 수행하는데, 반복문 외부에서 먼저 읽어지는 테이블을 `Driving Table` 이라고 하고, 반복문 내부에서 나중에 읽어지는 테이블을 `Driven Table`이라고 한다.
131 |
132 | Inner Join의 경우에는 옵티마이저가 순서를 조절해 최적화 하기 때문에 쿼리에서의 테이블 순서가 보장 되지 않고, Outer Join의 경우에는 Outer 테이블을 먼저 읽기 때문에 옵티마이저가 선택할 수 없다.
133 |
134 | 어찌 되었건 옵티마이저의 실행계획을 통해서 `Driving Table` 과 `Driven Table` 이 정해졌다면 다음 프로세스를 따른다.
135 |
136 | 
137 |
138 | 출처: [https://coding-factory.tistory.com/756](https://coding-factory.tistory.com/756)
139 |
140 | 1. `Driving Table` 에서 주어진 WHERE 조건문을 만족하는 행을 찾는다. (인덱스 OR 풀스캔등)
141 | 2. `Driving Table` 의 조인 KEY 값을 가지고 `Driven Table` 에서 조인을 수행 (랜덤 Access)
142 | 3. 반복
143 |
144 | Driving Table의 조건을 만족하는 결과가 많을 수록 반복문의 n의 크기가 커지고, Driven Table에 더 많이 접근해야 하므로 성능은 나빠지게 된다.
145 |
146 | 그러므로 `힌트` 나 `뷰` 를 통해서 선택된 `Driving Table` 의 크기가 작아지도록 해야 한다.
147 |
148 | ### 마무리
149 |
150 | 관계 대수 부터 각 Join과 Join의 동작 방식까지 간단하게 살펴 보았다. Join 때문에 성능 이슈가 많이 생겨서 반정규화를 하거나 아예 NoSQL을 이용하는 경우도 많지만 근-본인 관계형 DB에서 Join에 대해 조금 더 잘 이해하는 계기가 되었다. 조인 동작 방식에 대해서는 추후에 더 자세히 공부해볼 예정이다.
151 |
152 | ## 참고자료
153 |
154 | - 코드박사 와 데이터베이스 만화
155 |
156 | [내 계좌 비밀번호는 어떻게 저장되어 있을까? RDBMS](https://brunch.co.kr/@hvnpoet/133)
157 |
158 | - 관계 대수
159 |
160 | [](https://jehwanyoo.net/2020/09/25/%EA%B4%80%EA%B3%84%EB%8C%80%EC%88%98-Relational-Algebra-%EC%9A%94%EC%95%BD-%EC%A0%95%EB%A6%AC/)
161 |
162 | [[Database] 관계대수](https://m.blog.naver.com/aservmz/221960633361)
163 |
164 | “Mysql로 배우는 데이터베이스 개론과 실습” 책 참고
165 |
166 | - TCP School
167 |
168 | [코딩교육 티씨피스쿨](http://tcpschool.com/mysql/mysql_multipleTable_join)
169 |
170 | - 세미 조인
171 |
172 | [세미조인](https://songii00.github.io/2019/08/10/2019-08-10-%EC%84%B8%EB%AF%B8%EC%A1%B0%EC%9D%B8/)
173 |
174 | [조인보다 빠른 세미 조인, Semi Join, exists, in](https://www.youtube.com/watch?v=YxauObfs4HQ)
175 |
176 | [2.3.5. 세미(Semi) 조인](http://wiki.gurubee.net/pages/viewpage.action?pageId=1966761)
177 |
178 | - 조인
179 |
180 | [[MySQL] 7장 조인 : JOIN (INNER, LEFT, RIGHT)](https://futurists.tistory.com/17)
181 |
182 | [[MYSQL] JOIN(조인)](https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=islove8587&logNo=221049861998)
183 |
184 | - Equal Join == Inner join ???
185 |
186 | [Is inner join the same as equi-join?](https://stackoverflow.com/questions/5471063/is-inner-join-the-same-as-equi-join)
187 |
188 | - join 동작 방식
189 |
190 | [[DB] 데이터베이스 NESTED LOOPS JOIN (중첩 루프 조인)에 대하여](https://coding-factory.tistory.com/756)
191 |
192 | [* JOIN 원리](https://kshmc.tistory.com/entry/JOIN-%EC%9B%90%EB%A6%AC)
193 |
194 | [SQL 최적화 기본원리 (조인 수행 원리)](https://cornswrold.tistory.com/84)
--------------------------------------------------------------------------------
/Database/SQL_VS_NOSQL.md:
--------------------------------------------------------------------------------
1 | # SQL VS NOSQL
2 |
3 | ## ✨ SQL? NOSQL?
4 |
5 | > SQL이란 SQL(Structured Query Language)로 원래의 의미는 RDB의 Query Language이지만, RDB에서만 쓰이므로 RDB를 SQL이라고 말하기도한다. 여기서도 SQL == RDB로 쓰겠다. 그리고, MySQL(SQL), MongoDB(NoSQL)기준으로 설명한다.
6 | >
7 |
8 | ### SQL
9 |
10 |
14 |
15 | > 여기서 일관성이란 RDB는 데이터의 중복 저장을 피하기 위해서 여러 데이터를 여러 테이블에 분산하여 저장하고 관계를 정해줌으로써 지켜준다.
16 | >
17 | - 모델링의 순서가 [ 테이블 → 쿼리 ]로, 테이블의 형태를 먼저 정하고 그에 맞는 쿼리를 작성하게 된다.
18 |
19 | > 이런 점은 데이터의 일관성을 중요시하는 RDB의 컨셉때문이다.
20 | >
21 |
22 | ### NOSQL
23 |
24 |
28 |
29 | > NoSQL은 데이터를 중복 저장하지만, 내가 원하는 정보를 한개의 document에 모두 담을 수 있다. 따라서, 대용량 데이터에 대해서 빠른 처리가 가능하다.(Join이 없으므로)
30 | >
31 | - 모델링의 순서가 [ 쿼리 → 도큐멘트 ]로, 필요한 쿼리에 따라서 도큐멘트를 만들게 된다.
32 |
33 | ## 📝 용어
34 |
35 | ### 공통
36 |
37 | - Schema: Table(Collection)의 구조를 정의한다.
38 |
39 |
43 |
44 | - Join: RDB에서 관계를 가지는 테이블의 데이터도 함께 가져오고 싶을 때 사용하는 쿼리 기법
45 |
46 |
50 |
51 | - Join 동작방식의 차이
52 |
53 | SQL
54 |
55 | - Join시 외래키를 통해서 추가적인 Table에 접근하고, 외래키는 해당 Record를 직접 참조하므로 매우 빠른 속도로 가져올 수 있다.
56 |
57 | NOSQL
58 |
59 | - Lookup시 추가로 찾는 Collection을 Full Scan해서 맞는 Document를 찾게된다.
60 | - 여기서, 적절한 Indexing을 통해서 Lookup의 성능을 높일 수 있다.
61 | - 또한, NOSQL은 스키마가 유연하고 모든 데이터가 들어갈 수 있으므로, Document의 Field에 Document자체가 들어갈 수 있다. 이러한 기법을 Embedding기법이라고 한다.
62 |
63 |
67 |
68 | - 또한, Link기법으로 특정 Document를 직접 참조할 수도 있다.
69 |
70 | ### SQL
71 |
72 | - Table: 데이터를 저장하는 표(Table)
73 | - Row(Record): Table에서 한개의 데이터를 나타낸다.
74 | - Column(Field): Table에서 데이터가 가질 수 있는 각 속성이다.
75 | - Relationship: Table과 Table의 관계이다.
76 |
77 | ### NoSQL
78 |
79 | - Collection: == RDB의 Table
80 | - Document: == RDB의 Row(Record)
81 | - Field: == RDB의 Column(Field)
82 |
83 | ## ⚡️ Transaction
84 |
85 |
89 |
90 | ### ACID
91 |
92 | > Transaction을 보장하기 위해서는 아래 4가지 조건을 만족해야 한다.
93 | >
94 | - Atomicity(원자성): 모든 연산에 대해서 모두 처리/실패 → all-or-nothing
95 | - Consistency(일관성): 데이터는 미리 정의된 규칙(제약조건, 도메인, ...)에 부합
96 | - Isolation(): 트랜잭션동안 다른 트랜잭션 간섭 불가
97 | - Durability(지속성): 트랜잭션 이후 데이터들의 영구 보존
98 |
99 | ### SQL
100 |
101 |
105 |
106 | ### NOSQL
107 |
108 |
112 |
113 | - MongoDB Manual의 내용
114 |
115 | > In version 4.0, MongoDB supports multi-document transactions on replica sets.
116 | In version 4.2, MongoDB introduces distributed transactions, which adds support for multi-document transactions on sharded clusters and incorporates the existing support for multi-document transactions on replica sets.
117 |
118 | To use transactions on MongoDB 4.2 deployments (replica sets and sharded clusters), clients must use MongoDB drivers updated for MongoDB 4.2.
119 | >
120 |
121 | 4.0부터 Multi-Document의 Transaction을 지원하기 시작했으며, 이 때부터 DB로써 사용할 수 있는 역량을 갖췄다고 평가된다. 그 아래는 4.2부터는 샤딩을 통해 확장된 상태에서 지원한다고 써있다.
122 |
123 | - NOSQL도 ACID를 만족한다고?
124 |
125 | 아래 MongoDB의 Manual을 읽어보면 그러한거 같다. 이제 ACID Transactions 된다고 자랑하는 글
126 |
127 | [ACID Transactions Basics](https://www.mongodb.com/basics/acid-transactions)
128 |
129 |
130 | ## 🌝 특성
131 |
132 | ### ACID of SQL
133 |
134 | ### BASE of NOSQL
135 |
136 |
140 |
141 | > ACID와 대조되는 가용성과 성능을 중시하는 특징
142 | >
143 | - Basically Available(가용성): 데이터는 항상 접근이 가능, 데이터는 중복 저장
144 | - Soft-state(독립성): 노드의 상태는 외부의 정보를 통해 결정
145 | - Eventually Consistent(일관성): 일정 시간 경과시 데이터의 일관성을 유지
146 |
147 | ### BASE VS ACID
148 |
149 | | 항목 | BASE | ACID |
150 | | --- | --- | --- |
151 | | 적용대상 | NoSQL | RDBMS |
152 | | 범위 | 시스템 전체 대상 | 개별 트랜잭션 적용 |
153 | | 일관성 | 약한 일관성 | 강한 일관성 |
154 | | 중점사항 | 성능과 가용성 | 무결성, 일관성 |
155 | | 관리주체 | 주로 개발자 | DBMS 트랜잭션 |
156 | | 데이터처리 | 유사 응답 허용 | 처리 순서 보장 |
157 | | 변경성 | 변경 어려움 | 변경 용이 |
158 | | 디자인 | 쿼리 디자인 중요 | 테이블 디자인 중요 |
159 | | CAP이론 | C+P, A+P 만족 | C+A 만족 |
160 | | 적용사례 | Big Table | Oracle RAC |
161 |
162 | ## 👾 CAP 이론
163 |
164 |
168 |
169 | - Consistency(일관성): 모든 노드들은 같은 시간에 동일한 항목에 대하여 같은 내용의 데이터를 제공한다.
170 | - Availability(가용성): 모든 사용자들이 읽기및 쓰기가 가능하며, 몇몇 노드의 장애시 다른 노드에 영향을 끼치지 않는다.
171 | - Partition-tolerance(분할 내성): 메시지 전달이 실패하거나 일부 시스템이 망가져도 시스템은 정상 동작해야 한다.
172 |
173 | > 현재 DB들은 이중에 2가지를 만족하도록 만들어진다.
174 | >
175 |
176 | > SQL(CA), NoSQL(CA, AP)
177 | >
178 |
179 | ## 👐 확장
180 |
181 | > 확장이란 성능 또는 용량 초과로 인한 DB의 확장이다.
182 | >
183 |
184 | ### 수평 확장 of NOSQL
185 |
186 |
190 |
191 | > NOSQL은 비교적 쉬운 수평 확장을 샤딩을 통해서 지원한다. 샤딩이란 같은 Collection내의 Document를 분산하여 저장하는 방식이다.
192 | >
193 | - 샤딩을 통한 비교적 쉬운 수평 확장
194 | - 유연한 스키마 변경을 통한 확장
195 |
196 | ### 수직 확장 of SQL
197 |
198 |
202 |
203 | > SQL은 Schema변경이 거의 불가능하므로 수직 확장만이 가능하다. 수평 확장도 가능하지만, 매우 매우 어렵다고 볼 수 있다.
204 | >
205 |
206 | > NOSQL은 수직 확장이 안되는가? 수평 확장이 인력과 서버 비용 모두 통틀어서 더 좋은 선택이므로 수직 확장할 필요는 없다.
207 | >
208 |
209 | ## 👀 정규화와 비정규화
210 |
211 | ### 정규화(Normalization)
212 |
213 |
217 |
218 | > 정규화를 통해서 이상(Anomaly)현상을 방지할 수 있다. 이상 현상이란 개발자가 원하지 않는 데이터의 삭제 / 삽입 / 갱신되는것을 말한다.
219 | >
220 |
221 | ### 비정규화(Denormalization)
222 |
223 |
227 |
228 | > 정규화는 1 ~ 5단계가 있으며, 숫자가 높아질수록 데이터의 중복이 없다. 현업에서는 보통 3단계 정도까지를 사용한다.
229 | >
230 |
231 | ### SQL & NOSQL
232 |
233 | - SQL: 정규화를 통해서 데이터의 중복을 없애는것을 지향한다.
234 | - NOSQL: 비정규화를 통해서 빠른 성능과 가용성을 지향한다.
235 |
236 | ## 👍 장점과 단점
237 |
238 |
242 |
243 | - SQL
244 | - 장점: 관계를 통해서 데이터의 일관성을 강제하므로 설계만 잘 해놓으면 사용시 편리하다.
245 | - 단점: 일관성, 트랜잭션을 위해서 잘못된 설계시 많은 성능 저하가 일어날 수 있다, 설계/수정이 어렵다.
246 | - NoSQL
247 | - 장점: 대용량 데이터에 좋은 성능을 기대할 수 있다, 설계 / 수정 / 확장이 쉽다
248 |
249 | > 대용량 데이터일 경우,
250 | 1. 데이터가 많아짐으로써 DB를 확장할 때 샤딩을 통해 쉽게 할 수 있다.
251 | 2. 형태가 다른 데이터를 모두 받아서 사용할 수 있다.
252 | >
253 | - 단점: 데이터의 일관성을 개발자가 신경써주어야 한다.
254 |
255 | ## 😭 예상 질문
256 |
257 | - SQL과 NOSQL의 차이는 무엇인가요?
258 | - 가장 큰 차이점은 데이터의 일관성을 중요시할 것이냐, 가용성과 확장성을 중요시할 것이냐 입니다. SQL은 일관성을 잘 지킬 수 있으며, NOSQL은 쉬운 수정과 수평 확장을 할 수 있습니다.
259 | - SQL의 장점과 단점은 무엇인가요?
260 | - SQL의 장점은 설계된 Table과 Schema를 통해서 데이터의 일관성을 보장받을 수 있습니다. 단점은 잘 못 설계된 Table과 Schema는 성능을 저하시킬 수 있고, Schema의 수정이 힘드며 확장시 수직 확장을 해야함이 있습니다.
261 | - NOSQL의 장점과 단점은 무엇인가요?
262 | - NOSQL의 장점은 가용성과 유연성입니다. 유연한 Schema를 통해서 Agile한 DB 설계를 할 수 있으며 확장시에도 상대적으로 쉬운 샤딩을 통한 수평확장입니다. 단점은 중복 저장으로 데이터의 일관성이 보장되지 않을 수 있고, DB 스토리지를 낭비할 수 있으며 업데이트 쿼리시 Document크기에 따라서 성능이 저하될 수 있습니다.
263 | - 언제 SQL을 사용하고, 언제 NOSQL을 사용해야 할까요?
264 | - 데이터의 형태가 정해져 있고, 일관성이 중요하고 DB 스토리지가 넉넉하지 않다면 SQL을, 유연한 수정과 확장성을 고려한다면 NOSQL 사용을 고려해볼 수 있습니다.
265 | - 대용량 데이터 처리가 NoSQL 이 더 유리한가?
266 | - 유연한 데이터 유형
267 | - 서버의 수평확장에 유리한 구조
268 | - SQL과 NOSQL의 사용 경험에 대해서 말해주세요
269 | - 개발시 어떤 sql를 사용할 것인가?
270 | - 관계에 따라
271 | - 보안이 중요하다면 SQL을 사용하는 것이 유리하다.
272 |
273 | > 트랜잭션의 안정성, 유연한 Schema로 SQL Injection에 취약하다.
274 | >
275 | - 둘 다 적절히 사용
276 |
277 | ## 👨💻 참고
278 |
279 | - 그룹 프로젝트 정리 노션
280 |
281 | [SQL VS NoSQL](https://www.notion.so/SQL-VS-NoSQL-13a24463cac04934adbee88b8bd96fd2)
282 |
283 | - 정규화
284 |
285 | [#02. 이상(Anomaly)현상과 정규화(Normalization)](https://movenpick.tistory.com/29)
286 |
287 | [데이터베이스 정규화 1NF, 2NF, 3NF, BCNF](https://3months.tistory.com/193)
288 |
289 | - 비교
290 |
291 | [SQL과 NOSQL의 차이 | 👨🏻💻 Tech Interview](https://gyoogle.dev/blog/computer-science/data-base/SQL%20&%20NOSQL.html)
292 |
293 | [SQL vs NoSQL](https://velog.io/@thms200/SQL-vs-NoSQL)
294 |
295 | - 모델링
296 |
297 | [NoSQL 데이터 모델링](https://more-learn.tistory.com/5)
298 |
299 | [MongoDB 데이터 관계 모델링](https://devhaks.github.io/2019/11/30/mongodb-model-relationships/)
300 |
301 | - 트랜잭션
302 |
303 | [[DB기초] 트랜잭션이란 무엇인가?](https://coding-factory.tistory.com/226)
304 |
305 | [What is NoSQL? NoSQL Databases Explained](https://www.mongodb.com/nosql-explained)
306 |
307 | - BASE
308 |
309 | [NoSQL 데이터베이스 접속 시 보안 고려사항](http://channy.creation.net/project/dev.kthcorp.com/2012/01/26/security-considerations-in-accessing-nosql-databases/index.html)
310 |
311 | - 보안
312 |
313 | [NoSQL BASE 속성 > 도리의 디지털라이프](http://blog.skby.net/nosql-base-%EC%86%8D%EC%84%B1/)
314 |
--------------------------------------------------------------------------------
/Database/데이터베이스 클러스터링 VS 레플리카 6768dd1874c74763a3033dac6002f6ec.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Replication
4 |
5 | ### 기본구성
6 |
7 | - 데이터를 실질적으로 저장하는 소스서버 (Master)
8 | - 소스서버(Master)의 데이터를 복제해서 저장하는 레플리카서버(Slave)
9 |
10 | ### Replication시 장점
11 |
12 | - 스케일 아웃 → 레플리카서버를 늘려서 트래픽을 감당 가능하게 동적으로 규모를 늘릴 수 있음
13 | - 데이터 백업시 소스 서버에서 하면 실제 서버에 부담을 줄 수 있기 때문에 레플리카 서버에서 백업을 진행하여 부담을 줄인다.
14 | - 데이터 분석용 서버를 구성해서 특정용도를 위한 서버를 따로 구축할 수 있다.
15 | - 데이터의 지리적 분산: 특정 지역에 레플리카 서버를 구축해 응답속도를 개선 가능
16 |
17 | ### 바이너리 로그
18 |
19 | MySQL에서 모든 변경 사항을 순서대로 저장하고 있음 다음 명령어로 볼 수 있다.
20 |
21 | ```sql
22 | show binary logs
23 | show mater status;
24 | ```
25 |
26 | 소스 서버의 바이너리 로그가 레플리카 서버로 저장되고 그것을 통해 데이터의 동기화가 진행됨
27 |
28 | ### 바이너리 로그 저장방식
29 |
30 | - Statement 방식: SQL문을 바이너리 로그에 그대로 기록함
31 | - 트랜잭션 격리 수준이 REPEATABLE-READ 이상이어야 데이터가 일치함
32 | - 비 확정적으로 실행되는 쿼리(order by limit delete같은 매번 다르게 평가되는)가 있으면 데이터가 달라질 수 도 있음
33 | - Row 방식: 변경된 데이터 자체를 기록하는 Row 방식
34 | - 가장 일관적인 데이터 저장 방식 → 안전함
35 | - 단시간에 로그파일이 커짐
36 | - Mixed: statement와 row방식을 혼합함
37 | - statement로 기록했을때 안전하지 않을것같으면 row방식으로 기록함
38 |
39 | ### 복제과정
40 | 
41 |
42 | 이러한 복제 과정은 3개의 스레드를 통해 복제되는데
43 |
44 | 1. 소스서버의 Binary Log Dump Thread가 바이너리 로그를 레플리카서버에 전송함
45 | 2. 레플리카서버의 Replication I/O Thread 바이너리 로그 이벤트를 레플리카 서버에 Relay Log파일로 저장
46 |
47 | (연결시 사용정보는connection metadata에 있고, slave_master_info에 저장됨)
48 |
49 | 3. 레플리카서버의 Replication SQL Thread는 Replication I/O Thread에 의해 작성된 Relay Log파일을 읽고 실행함
50 |
51 | (릴레이 로그 이벤트를 서버에 적용하는 컴포넌트를 applier라고 하는데 이벤트가 저장된 릴레이로그 파일명,위치와 소스서버에 연결할 때 사용하는 정보가 저장되어있다. slave_relay_log_info테이블에 저장됨)
52 |
53 |
54 | ### 변경 내용식별
55 |
56 | - 바이너리 로그 파일 위치 기반
57 | - 레플리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일내에서 위치로 바이너리 로그 이벤트를 식별해서 복제함
58 | - server-id={n}으로 서버를 식별함 각 서버마다 넘버링을 해줘야함 → 이벤트가 처음 발생한 위치를 식별하기 위해 서버 아이디를 지정해야함
59 | - 글로벌 트랜잭션 ID 기반(GTID)
60 | - MySQL 버전 5.5까지는 바이너리 로그 파일 위치 기반으로만 가능했음 → 식별과정이 소스서버에서만 유효함 , 레플리카서버에 동일한 위치에 저장된다고 보장할 수 없음
61 |
62 | [MySQL GTID 를 사용한 Replication(복제) 설정](https://hoing.io/archives/18445)
63 |
64 |
65 | ### 복제 동기화 방식
66 |
67 | - 비동기 복제
68 | - 제대로 적용됬는지 확인하지 않음 ,데이터가 100% 일치하지 않음
69 | - 반동기 복제
70 | - 소스 서버는 레플리카 서버가 소스 서버로부터 전달 받은 변경 이벤트를 릴레이 로그에 기록 후 응답을 보내면 그때 트렌잭션을 커밋함
71 | - 비동기 방식보다 트랜젝션 처리가 느려짐, 응답이안오면 무제한으로 기다릴수있으니 일정시간지나면 비동기 복제로 젼환
72 |
73 | ### Replication 종류
74 |
75 | **싱글 레플리카 복제**
76 | 
77 |
78 | - 하나의 소스 서버에 하나의 레플리카서버
79 | - 소스 서버에 문제가 생길 경우 예비서버 역할, 데이터 백업 수행을 위한 용도
80 |
81 | **멀티 레플리카 복제**
82 |
83 | 
84 |
85 | - 하나의 소스 서버에 두 개의 레플리카 서버
86 | - 하나는 백업용, 하나는 읽기 요청 분산
87 |
88 | **체인 복제**
89 |
90 | 
91 | - 하나의 소스 서버에 레플리카가 여러개 달리면 바이너리 로그 복사작업이 부담이 될 수 있음
92 | - 소스 서버가 해야할 로그 배포역할을 다른서버로 넘길수있음
93 |
94 | **듀얼 소스 복제**
95 | 
96 |
97 | - 두개의 서버가 소스이자 레플리카
98 | - 각 서버에서 변경한 데이터는 각 서버에 전달되어서 동일한 데이터를 갖게됨
99 | - Active -Active(항상가동) 형태, Activae - Standby(일부는 대기)형태로 가능
100 | - 그냥 레플리케이션 방식과 달리 한서버에서 문제가 생기면 바로 전환가능
101 |
102 | **멀티 소스 복제**
103 | 
104 | - 하나의 레플리카 서버가 여러개의 소스서버를 가짐
105 | - 여러 서버에 존재하는 다른 데이터를 통합하거나 샤딩 되어있는 테이블을 하나의 테이블로 통합할 때 사용함
106 |
107 | # Clustering
108 |
109 | - 레플리케이션은 저장소 + 서버가 개별로 생성되지만 클러스터링은 db스토리지 하나와 다수의 서버로 구성됨
110 |
111 | ## 연결방식
112 |
113 | ## Active-Active 방식
114 |
115 | - 클러스터를 구성하는 컴포넌트들이 동시에 가동되는 방식, 하나의 저장소를 공유함
116 |
117 | ### 장점
118 |
119 | - 시스템이 다운되어 있는 시간이 짧기 때문에 시스템 전체가 정지하는 것을 방지할 수 있음
120 | - 동시에 가동하기 때문에 전체 cpu,메모리등이 증가해 성능 향상도 기대할 수 있음
121 |
122 | ### 단점
123 |
124 | - 저장소에서 병목이 일어날 수 있어서 높은 성능향상을 기대하기 어려울 수도 있다.
125 | - Active-Active 방식을 지원 하는 데이터 DBMS가 한정적이다.
126 | - ( Oracle = RAC(Real Application Cluster, DB2 = pureScale 라는 이름의 Active-Active 클러스터링이 가능하고, 다른 DBMS에서는 Active-Standby 클러스터링만 대응하고 있다.
127 | - MySQL에서는 지원해주지 않는 걸로 보임 → MySQL Cluster를 사용하는 것 같은데 InnoDB가 아니라고 함 , 아래에 작성한 **Galera cluster**를 솔루션으로 사용한다고함
128 | - 서버를 여러대 한꺼번에 운영하므로 비용이 증가함
129 |
130 | ## Active-Standby 방식
131 |
132 | - 클러스터를 구성하는 컴포넌트중 Active만 사용하다가 장애가 생기면 standby가 작동하는 구성
133 | - Cold-Standby:평소에 DB가 작동하지 않다가 Active DB에 장애 작동하는 구성
134 | - Hot-Standby: 평소에 Standby DB가 작동되는 구성이다.
135 | - Hot-standby는 라이선스료를 많이 지급 한다는점에서 단점이 있음
136 | - Standby DB 서버는 일정 간격으로 Active DB에 이상이 없는지를 조사하기 위한 통신을 하고 있다. 이 통신을 '**Heartbeat**'라고 한다. Active DB에 장애가 발생하면 이 신호가 끊기기 때문에Standby 측은 Active가 '죽었다'는 것을 알 수 있다.
137 |
138 | ### **Galera cluster**
139 |
140 | - 동기방식의 clustering을 지원해주는 오픈소스로 보임
141 |
142 | [Galera Cluster for MySQL](https://galeracluster.com/)
143 |
144 | [[MariaDB] Galera Cluster - 소개](https://myinfrabox.tistory.com/214)
145 |
146 |
147 | ### 참고 자료
148 |
149 | - 레플리케이션 참고
150 |
151 | [[MySQL] Replication (3) - Replication을 사용하는 이유](https://blog.seulgi.kim/2015/05/why-use-mysql-replication.html)
152 |
153 | - 데이터베이스의 다중화
154 |
155 | [[Database] DB 서버의 다중화 클러스터링(Multiplexing Clustering)과 리플리케이션(Replication)](https://kgh940525.tistory.com/entry/Database-DB-%EC%84%9C%EB%B2%84%EC%9D%98-%EB%8B%A4%EC%A4%91%ED%99%94Multiplexing-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0%EB%A7%81-%EB%A6%AC%ED%94%8C%EB%A6%AC%EC%BC%80%EC%9D%B4%EC%85%98Replication)
156 |
157 | - 레플리케이션 소개 영상: 작동원리, 장단점, 종류 -> 정말좋은 영상!
158 |
159 | [[10분 테코톡] ✌️ 영이의 Replication](https://www.youtube.com/watch?v=95bnLnIxyWI&t=1s)
160 |
161 | - 레플리케이션 설정
162 |
163 | [MySQL Replication(복제) - 단방향 이중화](https://server-talk.tistory.com/240)
164 |
165 | - DB 아키텍쳐 종류 및 설명 (데이터베이스 첫걸음 책)
166 |
167 | [https://hololo-kumo.tistory.com/220](https://hololo-kumo.tistory.com/220)
168 |
169 | [https://milhouse93.tistory.com/38?category=750797](https://milhouse93.tistory.com/38?category=750797)
--------------------------------------------------------------------------------
/Database/데이터베이스인덱스.md:
--------------------------------------------------------------------------------
1 | # 데이터베이스 인덱스
2 |
3 | ### 인덱스?
4 |
5 | DB 테이블에서 필요한 데이터를 빠르게 찾기 위해서 인덱스를 사용할 수 있다. 인덱스를 생성하면, 특정 컬럼의 데이터들을 정렬하여 별도의 메모리 공간에 주소와 함께 저장된다. 쉽게 비유하자면 책에 있는 목차(색인)이라고 할 수 있다. SQL 튜닝에서 중요한 Index에 대해서 알아보자
6 |
7 | 
8 |
9 | ### 인덱스를 사용하는 이유
10 |
11 | 인덱스의 가장 큰 특징은 데이터들이 정렬되어있다는 점이다. 덕분에 다양한 장점이 있는데, 다음과 같다.
12 |
13 | - Where
14 | - 인덱스가 없다면 Where절 사용시 레코드를 처음부터 끝까지 다 읽는 Full Table Scan이 일어나게된다. 하지만 인덱스 테이블은 데이터들이 정렬되어 저장되어 있기 때문에 해당 조건 (Where)에 맞는 데이터들을 빠르게 찾아낼 수 있다.
15 | - Order by
16 | - 인덱스가 없다면 정렬과 동시에 1차적으로 메모리에서 정렬이 이루어지고 메모리보다 큰 작업이 필요하다면 디스크 I/O도 추가적으로 발생됩니다. 하지만 인덱스 이용시 바로 가져오면 된다.
17 | - Min, Max
18 | - MIN값과 MAX값을 레코드의 시작값과 끝 값 한건씩만 가져오면 되기에 FULL TABE SCAN으로 테이블을 다 뒤져서 작업하는 것보다 훨씬 효율적으로 찾을 수 있습니다.
19 |
20 | ### 인덱스의 자료구조
21 |
22 | **Hash Table**
23 |
24 | 대부분의 Index는 B+Tree 자료구조를 이용하고 있다. 하지만 탐색능력만 따지면 O(1)시간의 Hash Table구조를 사용할 수 있을텐데 이유가 무엇일까? **해쉬테이블을** DB 인덱스로 사용할 수 없는 이유는 다음과 같다.
25 |
26 | 가장 큰 문제로 “***우리는 DB에서 등호(=) 뿐 아니라 부등호(<, >)도 사용할 수 있다”*** 모든 값이 정렬되어 있지 않으므로, 해시 테이블에서는 특정 기준보다 크거나 작은 값을 찾을 수 없다.
27 |
28 | > MySQL InnoDB에서는 메모리 버퍼 풀에서 레코드 검색을 위한 [어댑티브 해시 인덱스](https://tech.kakao.com/2016/04/07/innodb-adaptive-hash-index/)로 사용
29 | >
30 |
31 | **Array**
32 |
33 | 배열의 문제는 간단하다. 탐색이 O(1)이라 해도 삽입 삭제시 O(N)시간이 걸리기 때문이다. 또
34 |
35 | **데이터 수정이 일어날때도 퀵 정렬, 병합 정렬 등 배열 자료구조에서 O(N*logN) 시간으로 재정렬을 이루어야 한다는 점도 있다.**
36 |
37 | > 참고로 B-tree의 삽입, 삭제는 트리의 높이(h)에 따른 O(h)의 시간 복잡도를 가지는데, 이는 logN보다 훨씬 작은 값이다.
38 | >
39 |
40 | **결론적으로 DB 인덱스로 B-Tree가 가장 적합한 이유들을 정리하면 아래와 같다.**
41 |
42 | 1. **항상 정렬된 상태로 특정 값보다 크고 작은 부등호 연산에 문제가 없다.**
43 | 2. **참조 포인터가 적어 방대한 데이터 양에도 빠른 메모리 접근이 가능하다.**
44 | 3. **데이터 탐색뿐 아니라, 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도를 가진다.**
45 |
46 | ### 인덱스의 종류
47 |
48 | 인덱스에는 **클러스터드 인덱스 (Clustered Index)** 와 **논-클러스터드 인덱스 (Non-Clustered Index)** 2가지 종류가 존재한다.
49 |
50 | 
51 |
52 | ### 클러스터드 인덱스
53 |
54 | - 인덱스 키의 순서에 따라 데이터가 정렬되어 저장되는 방식
55 | - 실제 데이터가 순서대로 저장되어 있어 인덱스를 검색하지 않아도 원하는 데이터를 빠르게 찾을 수 있다.
56 | - 데이터 삽입, 삭제 발생 시 **순서를 유지**하기 위해 **데이터를 재정렬**해야한다.
57 | - 한 개의 릴레이션에 **하나의 인덱스만 생성 가능**
58 |
59 | ### 넌클러스터드 인덱스
60 |
61 | - 인덱스의 키 값만 정렬되어 있을 뿐 실제 데이터는 정렬되지 않는 방식
62 | - 데이터를 검색하기 위해서는 먼저 인덱스를 검색하여 실제 데이터 위치를 확인해야 하므로 **클러스터드 인덱스에 비해 검색 속도가 떨어진다.**
63 | - 한 개의 릴레이션에 여러 인덱스를 만들 수 있다.
64 |
65 | ### 인덱스의 장점
66 |
67 | - 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
68 | - 전반적인 시스템의 부하를 줄일 수 있다.
69 |
70 | ### 인덱스의 단점
71 |
72 | - 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다.
73 | - 인덱스를 관리하기 위해 추가 작업이 필요하다.
74 | - 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다.
75 |
76 | ### 인덱스의 관리
77 |
78 | DBMS는 index를 항상 최신의 **정렬된 상태로 유지**해야 원하는 값을 빠르게 탐색할 수 있다.
79 |
80 | 그렇기 때문에 인덱스가 적용된 컬럼에 INSERT, UPDATE, DELETE가 수행된다면 각각 다음과 같은 연산을 추가적으로 해줘야하며, 그에 따른 오버헤드가 발생한다.
81 |
82 | - INSERT : 새로운 데이터에 대한 인덱스를 추가함
83 | - DELETE : 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행
84 | - UPDATE : 기존의 인덱스를 사용하지 않음 처리하고, 갱신된 데이터에 대해 인덱스를 추가함
85 |
86 | 만약 CREATE, DELETE, UPDATE가 빈번한 속성에 인덱스를 걸게 되면 인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과가 발생할 수 있다.
87 |
88 | 만약 어떤 테이블에 UPDATE와 DELETE가 빈번하게 발생된다면 실제 데이터는 10만건이지만 인덱스는 100만 건이 넘어가게 되어, SQL문 처리 시 비대해진 인덱스에 의해 **오히려 성능이 떨어지게** 될 것이다.
89 |
90 | ### 인덱스는 언제 써야 하는가?
91 |
92 | 보통 인덱스는 한 테이블당 3~5개가 적당하다. 큰 결정 조건으로는 아래 4가지 기준이 있다.
93 |
94 | - **카디널리티 (Cardinality)**
95 | - **카디널리티가 높으면(↑) 인덱스 설정에 좋은 컬럼이다. (인덱스를 통해 불필요한 데이터의 대부분을 걸러낼 수 있음.)**카디널리티가 높다 = 한 컬럼이 갖고 있는 값의 중복도가 낮음. (= 값들이 대부분 다른 값을 가짐.)카디널리티가 낮다 = 한 컬럼이 갖고 있는 값의 중복도가 높음. (= 값들이 거의 같은 값을 가짐 )
96 | - **선택도 (Selectivity)**
97 |
98 | **선택도가 낮으면(↓) 인덱스 설정에 좋은 컬럼이다. (일반적으로 5~10%가 적당함.)**선택도가 높다 = 한 컬럼이 갖고 있는 값 하나로 여러 row가 찾아진다.선택도가 낮다 = 한 컬럼이 갖고 있는 값 하나로 적은 row가 찾아진다.
99 |
100 | > 선택도 계산법 (= 컬럼의 특정 값의 row 수 / 테이블의 총 row 수 * 100)
101 | ex) 10개의 데이터에서 고유한 학번(grade) 컬럼,
102 | 2명씩 같은 이름(name) 컬럼,
103 | 5명씩 같은 나이(age) 컬럼인 경우
104 | ① 학번(grade) 컬럼 선택도: 1 / 10 = 10%
105 | ② 이름(name) 컬럼 선택도: 2 / 10 = 20%
106 | ③ 나이(age) 컬럼 선택도: 5 / 10 = 50%
107 | >
108 | - **조회 활용도**
109 | - **조회 활용도가 높으면(↑) 인덱스 설정에 좋은 컬럼이다.**해당 컬럼이 실제 작업에서 얼마나 활용되는지에 대한 값.(`WHERE`의 대상 컬럼으로 많이 활용되는지로 판단하면 된다.)
110 | - **수정 빈도**
111 | - **수정 빈도가 낮으면(↓) 인덱스 설정에 좋은 컬럼이다.**인덱스도 테이블이기 때문에, 인덱스로 지정된 컬럼의 값이 바뀌게 되면 인덱스 테이블도 새롭게 갱신되어야 하기 때문.
112 |
113 |
114 |
115 | ## 참고자료
116 |
117 | - hash table index, b-tree index
118 |
119 | [데이터베이스 인덱스는 왜 'B-Tree'를 선택하였는가](https://helloinyong.tistory.com/296)
120 |
121 | - 인덱스란?
122 |
123 | [](https://mangkyu.tistory.com/96)
124 |
125 | - DB 인덱스
126 |
127 | [[DB] 데이터베이스 인덱스(Index) 란 무엇인가?](https://coding-factory.tistory.com/746)
128 |
129 | [[면접 대비] 데이터베이스 - 인덱스](https://velog.io/@syleemk/%EB%A9%B4%EC%A0%91-%EB%8C%80%EB%B9%84-%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%EC%9D%B8%EB%8D%B1%EC%8A%A4)
130 |
131 | - 인덱스 종류, 인덱스 사용이유
132 |
133 | [효과적인 DB index 설정하기](https://velog.io/@jwpark06/%ED%9A%A8%EA%B3%BC%EC%A0%81%EC%9D%B8-DB-index-%EC%84%A4%EC%A0%95%ED%95%98%EA%B8%B0)
134 |
135 | [](https://yurimkoo.github.io/db/2020/03/14/db-index.html)
--------------------------------------------------------------------------------
/Database/정규화/BCNF1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/BCNF1.png
--------------------------------------------------------------------------------
/Database/정규화/BCNF2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/BCNF2.png
--------------------------------------------------------------------------------
/Database/정규화/이상현상과 결정자1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/이상현상과 결정자1.png
--------------------------------------------------------------------------------
/Database/정규화/이상현상과 결정자2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/이상현상과 결정자2.png
--------------------------------------------------------------------------------
/Database/정규화/이상현상과 결정자3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/이상현상과 결정자3.png
--------------------------------------------------------------------------------
/Database/정규화/정규화.md:
--------------------------------------------------------------------------------
1 | # 📌 정규화(normalization)
2 |
3 | 이상 현상이 발생하는 테이블을 수정하여 정상으로 만드는 과정을 정규화(normalization)라고 한다.
4 | 정규화를 하기 위해서는 우선 테이블을 분석하여 기본키와 함수 종속성을 파악해야 한다.
5 | 그 후 릴레이션을 분해하여 제거한다.
6 | 분해된 릴레이션에 이상현상이 남아 있다면 없어질 때까지 분해 한다.
7 |
8 | > `TIP`
9 | 릴레이션과 테이블은 같은 의미로 쓰인다.
10 | 보통 테이블은 실무와 같은 구조보다 데이터를 강조하는 측면이 있고
11 | 릴레이션은 구조에 관한 이론을 강조하는 텍스트측면이 있다.
12 | >
13 |
14 |
7 |
8 | ### 충돌
9 |
10 | 해시 함수가 서로 다른 키를 같은 해시 값로 반환하는 경우 충돌이라고 부릅니다.
11 |
12 | 키 k1, k2 의 경우 h(k1) = h(k2) 인 상황입니다. 이러한 충돌은 해시 함수의 알고리즘이 정교하게 작동해도 피할 수가 없습니다.
13 |
14 | 이러한 충돌이 발생하지 않는다면 O(1) 의 시간 복잡도로 삽입, 수정, 삭제 연산이 이루어지지만 충돌이 발생한다면 최악에 O(Key 의 개수) 의 시간이 발생합니다.
15 |
16 | 이러한 충돌을 최대한 줄이는 것이 해시 테이블의 핵심입니다.
17 |
18 | ### 충돌 해결
19 |
20 | 해시 테이블의 충돌을 완화하는 방법으로 **해시 테이블 구조 개선**, **해시 함수 개선** 이 존재합니다.
21 |
22 | ### 해시 테이블 구조 개선
23 |
24 | - Separate Chaining
25 |
26 | 충돌 발생시 해시 테이블 동일한 버킷에 연결리스트 형태로 저장하는 방식입니다. 즉, 테이블이 차지한 메모리에서 추가적인 메모리 공간을 활용하는 방식입니다.
27 |
28 | 
29 |
30 |
31 | 데이터의 삽입의 경우 연결 리스트 추가시간인 O(1) 시간복잡도가 걸립니다.
32 |
33 | 수정 및 삭제, 탐색의 경우 최악의 경우 O(key 의 갯수) 의 시간복잡도가 걸립니다.
34 |
35 |
40 |
41 | - Open Addressing
42 |
43 | Chaining 과 달리 테이블의 비어있는 주소를 활용하는 방식입니다. 해당 방식의 테이블에서 비어있는 버킷을 탐사하는 시간이 중요합니다. 탐사의 방식은 대표적으로 3가지가 존재합니다.
44 |
45 | - 선형탐사(Linear probing)
46 |
47 | 해시 값에 대한 버킷이 이미 데치터가 존재하는 경우 바로 다음 버킷을 탐사하는 방식입니다.
48 | 가장 간단한 방식으로 단점도 명확합니다. 특정 해시값 주변 버킷들이 이미 다 채워져있는 primary clustering 의 경우 선형의 시간복잡도가 필요합니다.
49 |
50 | - 제곱탐사(Quadratic probing)
51 |
52 | 충돌이 발생시마다 충돌 횟수의 제곱수만큼 버킷을 이동하는 방식입니다.
53 | 예를들어 처음 충돌이 발생하면 1^2 만큼 이동하여 버킷을 확인합니다. 해당 버킷도 또 충돌이 발생한다면 2^2 만큼 이동한 버킷을 확인합니다. 마찬가지로 또 충돌이 발생한다면 3^2 만큼 이동하는 방식을 통해 충돌이 발생하지 않는 버킷을 탐사합니다.
54 |
55 | 이 경우도 단점이 존재합니다. 초기 해시값 즉 다양한 key 에 대해서 해시 함수의 결과값이 동일한 경우가 많은 secondary clustering 의 경우 마찬가지로 선형의 시간복잡도가 필요합니다.
56 |
57 | - 이중해싱(double hashing)
58 |
59 | 2개의 해시 함수를 준비하여 하나는 초기 해시값, 다른 하나는 충돌 발생시 이동폭을 얻기위해 사용합니다. 이런 경우 초기 해시값이 동일한 키라고 하더라도 다른 이동폭을 가지므로 앞선 primary clustering, secondary clustering 에서의 취약점이 해소됩니다.
60 |
61 |
62 | load factor 비율로 bucket size
63 |
64 |
65 | ### 해시 함수?
66 |
67 | 임의의 길이의 데이터 Key 를 고정된 길이의 해시(해시 값, 해시 코드, Hash 체크섬)로 매핑하는 해싱과정을 수행하는 함수입니다.
68 |
69 | 여기서 특정 값으로 치우치지 않고 해시값이 고르게 분포되는 것을 좋은 해시함수의 기준입니다.
70 |
71 | ### 해시 함수 종류
72 |
73 | - Division Method
74 |
75 | Key 값 k를 해시 테이블의 크기 n 으로 나눈 나머지를 해시값으로 사용하는 방식입니다.
76 | n 은 소수를 사용하는 것이 좋습니다
77 | 테이블의 크기가 정해진다는 단점이 있습니다.
78 | h(k) = k mod n
79 |
80 | - Multiplication Method
81 |
82 | Key 값 k, 0 과 1사이의 실수 A 임의의 m(보통 2의 제곱수)가 있을 때 다음의 수식을 통해 해시값을 구하는 방식입니다.
83 | 2진수 연산에 최적화된 컴퓨터 구조를 고려한 해시함수라고 합니다.
84 | h(k) = (kA mod 1) x m
85 |
86 | - Mid Square Method
87 |
88 | Key 값 k 를 제곱한 후 특정 자릿수 r 의 값을 해시값으로 사용하는 방식입니다.
89 |
90 |
91 | ## 참고자료
92 |
93 | [위키](https://namu.wiki/w/%ED%95%B4%EC%8B%9C)
94 |
95 | [wikipedia](https://en.wikipedia.org/wiki/Hash_table)
96 |
97 | [Hash 위키](http://wiki.pchero21.com/wiki/Hash#Hash_function)
98 |
99 | [해시 테이블](https://dbehdrhs.tistory.com/70)
100 |
101 | [해시 테이블 충돌](https://baeharam.github.io/posts/data-structure/hash-table/)
102 |
103 | [충돌 개선](https://en.wikipedia.org/wiki/Hash_table#Separate_chaining)
104 |
105 | [Java 8 Hash Table](https://d2.naver.com/helloworld/831311)
--------------------------------------------------------------------------------
/Database/B-Tree와 B+Tree.md:
--------------------------------------------------------------------------------
1 | # B-Tree와 B+Tree
2 |
3 |
4 |
5 | # B-Tree
6 |
7 | 트리 자료구조의 일종으로, 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 수가 2이상인 트리 구조이다.
8 |
9 | **최상위 노드**를 `root`노드라고 하며, **최하위 노드**들을 `leaf`노드라고 한다. **그 사이 계층의 노드**들은 `internal`노드라고 부른다.
10 |
11 | 
12 |
13 | 하나의 노드에 여러 개의 데이터가 있을 수 있다.
14 |
15 | 데이터의 순서는 이진 탐색 트리와 유사하다.
16 |
17 | 노드 내 데이터를 최대 M-1개, 최소 [M/2]-1개를 가지는 B-Tree를 **M차 B-Tree**라고 부른다.
18 |
19 | 자식 노드의 최소 및 최대 수는 특별한 구현에 대해서 결정되어 있다.
20 |
21 | 노드의 단위는 **page**로, **하드디스크의 저장 단위**에 맞추어져 있어 데이터베이스와 파일시스템에서 잘 쓰인다.
22 |
23 |
24 |
25 | ## 규칙
26 |
27 | - root 노드는 **2개 이상**의 자식을 가져야 한다.
28 | - M차 B-Tree는 루트 노드를 제외한 나머지 노드는 **최소 M/2개, 최대 M개의 자식 노드**가 있어야 한다.
29 | - **N개의 데이터**가 있는 하나의 노드는 **N+1개의 자식노드**를 갖고 있다.
30 |
31 | ⇒ **N개의 데이터**가 있다면 **자식 노드의 포인터는 N+1개**이다.
32 |
33 | 
34 |
35 |
36 | ## 탐색
37 |
38 | 1. 노드 안에서: 순차검색
39 |
40 | 2. 트리 안에서: 하향식 트리 검색
41 |
42 |
43 |
44 | ## 삽입
45 |
46 | 1. 삽입될 위치 검색
47 | 2. 삽입
48 | 1. 노드의 공간이 남아있을 때
49 |
50 | 노드 안에서 오름차순으로 삽입
51 |
52 | 2. 노드의 공간이 없을 때
53 | 1. 오름차순으로 삽입
54 | 2. 노드안에서 중앙값으로 분할하여 중앙값의 데이터를 부모 노드로 오름차순으로 삽입
55 | 3. i~ii 과정을 `root`노드까지 반복
56 |
57 | ex) 최대 2개의 데이터를 가지는 2차 B-Tree
58 |
59 | 
60 |
61 | 1. 4 삽입
62 |
63 | 
64 |
65 | 2. 노드 중앙값 분할
66 |
67 | 
68 |
69 | 3. root노드 중앙값 분할
70 |
71 | 
72 |
73 |
74 | ## 삭제
75 |
76 | 1. 삭제할 데이터가 위치한 노드 검색
77 |
78 | 1. 삭제할 데이터가 leaf노드에 있는 경우
79 | 1. 현재 노드의 데이터 개수가 최소 개수보다 클 때
80 |
81 | 삭제
82 |
83 | 2. 현재 노드의 데이터 개수가 최소 개수일 때
84 |
85 | 1) 왼쪽 또는 오른쪽 형제노드의 데이터 개수가 최소 개수 이상일때
86 |
87 | a) 현재노드를 현재노드와 형제노드 사이의 부모노드 데이터로 교체
88 |
89 | b) 형제노드가 왼쪽이라면 최대값을, 오른쪽이라면 최소값을 부모노드 데이터와 교체
90 |
91 | 2) 부모노드의 데이터는 최소 개수보다 많고, 형제노드 모두 데이터 개수가 최소 개수일 때
92 |
93 | a) 현재노드 삭제
94 |
95 | b) 부모노드의 데이터 최대값 또는 최소값을 형제노드와 합친다.
96 |
97 | 3) 부모노드, 형제노드 모두 데이터 개수가 최소 개수일 때
98 |
99 | a) 현재노드 삭제
100 |
101 | b) 부모노드를 인접한 형제노드와 병합 후 조상노드의 자식으로 위치시킨다.
102 |
103 | i) B-Tree의 조건이 맞춰줄 때까지 반복
104 |
105 | 2. 삭제할 데이터가 leaf노드에 없는 경우
106 | 1. 현재노드와 자식노드의 데이터 개수가 최소 개수보다 클 때
107 |
108 | 1) 왼쪽 서브트리의 최댓값과 위치를 변경한다.
109 |
110 | 2) 왼쪽 서브트리의 최댓값과 변경된 데이터를 삭제한다.
111 |
112 | 3) a. 과정을 한다.
113 |
114 | 2. 현재노드와 자식노드 모두 데이터 개수가 최소 개수일 경우
115 |
116 | 1. 데이터를 삭제하고 양쪽 자식노드를 합친다.
117 |
118 | 2. 부모의 데이터를 인접한 형제노드에 붙이고, 1)에서 합쳤던 노드를 자식노드로 위치시킨다.
119 |
120 |
121 |
122 |
123 | ## 특징
124 |
125 | 모든 노드에 key와 data가 들어있다.
126 |
127 | 데이터를 정렬된 상태로 보관
128 |
129 | 상향식 구성
130 |
131 | 삽입과 삭제시 균형을 유지하기 위한 작업
132 |
133 | 동일한 높이의 leaf노드 (Balanced)
134 |
135 | O(logN) 검색시간 보장
136 |
137 |
138 |
139 | # B+Tree
140 |
141 | B-Tree에서 확장된 개념의 트리구조이다.
142 |
143 | leaf노드에만 key와 data를 저장하고, 나머지 노드에는 key만 담겨있다. leaf노드끼리는 linked list로 연결되어 있다.
144 |
145 | 
146 |
147 |
148 |
149 | ## 삽입
150 |
151 | - 삽입할 노드의 데이터 개수가 최대값보다 작을 때
152 |
153 | 데이터 삽입
154 |
155 | - 삽입할 노드의 데이터 개수가 최대값일 때
156 |
157 | 2개로 분할하여 중간값을 부모노드에 추가
158 |
159 | - 부모노드의 데이터 개수가 최대값일 때
160 |
161 | B-Tree 삽입 과정과 동일
162 |
163 |
164 |
165 |
166 | ## 삭제
167 |
168 | - 삭제할 키가 노드의 첫번째 데이터가 아닐 때
169 |
170 | 데이터 삭제
171 |
172 | - 삭제할 키가 노드의 첫번째 데이터일 때
173 | - 노드의 데이터 개수가 최소값이 아닐 때
174 |
175 | 삭제 후 삭제된 key가 있던 노드의 key값을 오른쪽 key로 변경한다.
176 |
177 | - 노드의 데이터 개수가 최소값일 때
178 | - 형제노드의 데이터 개수가 최소값이 아닐 때
179 |
180 | 삭제 후 인접한 형제노드의 key와 자리를 바꾼 후 부모노드의 key를 알맞게 수정한다.
181 |
182 | - 형제노드의 데이터 개수가 최소값일 때
183 | - 부모노드의 데이터 개수가 최소값이 아닐 때
184 |
185 | 삭제 후 삭제된 key가 있던 노드의 key 삭제
186 |
187 | - 부모노드의 데이터 개수가 최소값일 때
188 |
189 | 현재노드와 부모노드 삭제 후 조상노드에 형제노드를 연결하고 조상노드에 대해서는 B-Tree와 동일
190 |
191 |
192 |
193 | ## 장점
194 |
195 | 오직 leaf노드에만 데이터를 담기 때문에 저장공간을 더 확보하고 더 많은 key들을 수용할 수 있다. 하나의 노드에 더 많은 key를 담을 수 있기 때문에 트리의 높이가 더 낮아진다.
196 |
197 | leaf노드끼리 서로 연결되어 있기 때문에 범위 검색에 유리하다.
198 |
199 | 풀 스캔 시, B+Tree는 leaf노드로 한 번의 선형탐색만 하면 되기 때문에 B-Tree보다 빠르다.
200 |
201 | →데이터베이스 시스템 인덱스 구성에 매우 효율적이다.
202 |
203 |
204 |
205 | ## 단점
206 |
207 | B-Tree의 경우 최상의 경우 특정 key의 데이터를 찾기 위해 leaf노드까지 가지 않아도 되지만, B+Tree의 경우 반드시 특정 key에 접근하기 위해서 leaf node까지 가야 한다.
208 |
209 |
210 |
211 | ---
212 |
213 | - 참고자료
214 |
215 | [https://ko.wikipedia.org/wiki/B_트리](https://ko.wikipedia.org/wiki/B_%ED%8A%B8%EB%A6%AC)
216 |
217 | [https://velog.io/@emplam27/자료구조-그림으로-알아보는-B-Tree](https://velog.io/@emplam27/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C-%EC%95%8C%EC%95%84%EB%B3%B4%EB%8A%94-B-Tree)
218 |
219 | [https://velog.io/@emplam27/자료구조-그림으로-알아보는-B-Plus-Tree](https://velog.io/@emplam27/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C-%EC%95%8C%EC%95%84%EB%B3%B4%EB%8A%94-B-Plus-Tree)
220 |
221 | [https://slenderankle.tistory.com/159](https://slenderankle.tistory.com/159)
222 |
223 | [https://rebro.kr/167](https://rebro.kr/167)
--------------------------------------------------------------------------------
/Database/Join.md:
--------------------------------------------------------------------------------
1 | # JOIN
2 |
3 | > JOIN은 데이터베이스 내의 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현해 줍니다. 이러한 JOIN은 보통 SELECT 문과 함께 자주 사용됩니다. → [TCP School JOIN](http://tcpschool.com/mysql/mysql_multipleTable_join)
4 | >
5 |
6 | 
7 |
8 | SQL을 접하면서 DB를 설계하고 사용할 때 JOIN은 가장 자주 사용하게 되는 개념이라고 할 수 있을 정도로 많이 쓰인다. 항상 성능에 대해서 고민하게 되는 친구지만, 나름 RDBS(관계형데이터베이스)의 꽃이라고 생각되는 JOIN에 대해서 정리해 보려고 한다.
9 |
10 | ## 1. 조인과 관계대수
11 |
12 | 관계대수란 릴레이션(테이블)에서 데이터를 추출하는데 사용되는 언어라고 할 수 있다. 관계형 데이터베이스 이론의 코드 박사(codd)는 이렇게 정의했다.
13 |
14 | - 관계 대수: 원하는 정보를 어떻게(How) 찾는지를 명시하는 절차적 언어
15 | - 관계 해석: 어떤(what) 데이터를 찾는지 만 명시하는 선언적 언어
16 |
17 | SQL 언어는 관계해석을 기반으로 하며 관계 대수 개념이 혼합되어 있고, DBMS 내부에서는 관계 대수에 기반을 둔 연산을 수행한다. 관계 대수를 정리해보면 다음 과 같다.
18 |
19 | 
20 |
21 | 여기서 Join은 유도된 연산자로 Cartesian Product 와 Selection을 함께 실행하여 얻은 결과와 동일하다.
22 |
23 | > 다른건 다 감이 오는데 `카티전 프로덕트`..? 이게 뭘까 싶을 수 있다. `카티전 프로덕트`는 집합에서 곱의 개념으로 A= {a, b, c} , B = {1, 2} 일 때 (a,1), (a, 2), (b,1), (b,2), (c, 1), (c,2) 처럼 나타 낼 수 있다. 엄청나게 많은 결과를 생성하기 때문에 많이 사용되지는 않는다.
24 | >
25 |
26 | ## 2. 다양한 조인들...
27 |
28 | 관계 대수에서 언급된 조인들을 하나씩 살펴 보자
29 |
30 | ### Theta Join(세타 조인), Equal Join(동등 조인), Natural Join(자연 조인)
31 |
32 | 
33 |
34 | 그림처럼 비교 조건 (<, =, >)을 만족하는 Join이 Theta Join이고 그중 비교 조건이 (=)일 때 Equal Join이 된다.
35 |
36 | > 간혹 Inner Join이 곧 Equal Join이라고 생각 하는 경우가 있는데, 엄밀히 따지자면 틀린 이야기다. Outer Join에서도 Equal Join처럼 동등 비교 조건문이 들어갈 수 있기도 하고, Inner Join사용시에 Equal Join도 사용 가능한 것으로 생각하면 된다.
37 | >
38 |
39 | Equal Join에서 중복 속성을 제거하게 되면 Natural Join이 됩니다. Natural Join은 다음과 같이 두 테이블에 같은 이름의 열이 있을 때 생략하여 사용 가능하다.
40 |
41 | ```sql
42 | SELECT * FROM A NATURAL JOIN B;
43 | ```
44 |
45 | ### Inner Join
46 | 그림에서 보이는 것처럼 교집합을 나타낸다.
47 |
48 | 
49 |
50 | 출처: [TCPschool](http://tcpschool.com/mysql/mysql_multipleTable_join)
51 |
52 | 아래 처럼 작성할 수 있다.
53 |
54 | ```sql
55 | SELECT * FROM A JOIN B ON A.id = B.id;
56 | ```
57 |
58 | ### Outer Join
59 |
60 | Inner Join의 결과로 나오지 않는 행도 NULL값으로 포함해서 결과를 나타내는 Join이다.
61 |
62 | 어느 쪽을 기준으로 합치냐에 따라서 Left Join , Right Join으로 나뉜다.
63 |
64 | **Left Join**
65 |
66 | 
67 |
68 | 출처: [TCPschool](http://tcpschool.com/mysql/mysql_multipleTable_join)
69 |
70 | 첫 번째 테이블을 기준으로 두 번째 테이블을 조합하는 Join이다. ON절의 조건을 만족하지 않더라도 첫 번째 테이블을 표시하고, 두 번째 테이블의 필드를 NULL로 표시한다.
71 |
72 | ```sql
73 | SELECT * FROM A LEFT JOIN B ON A.id = B.id;
74 | ```
75 |
76 | **Right Join**
77 |
78 | 
79 |
80 | 출처: [TCPschool](http://tcpschool.com/mysql/mysql_multipleTable_join)
81 |
82 | Left Join과는 반대로 두 번째 테이블을 기준으로 첫 번째 테이블을 조합하는 Join이다. ON절의 조건을 만족하지 않더라도 두 번째 테이블을 표시하고, 첫 번째 테이블의 필드를 NULL로 표시한다.
83 |
84 | ```sql
85 | SELECT * FROM A RIGHT JOIN B ON A.id = B.id;
86 | ```
87 |
88 | ### Cross Join
89 |
90 | `Cross Join` 은 관계 대수에서 잠깐 언급했던 `Cartesian Product` 와 같다. 카티전 조인이라고도 한다.
91 |
92 | ```sql
93 | SELECT * FROM A CROSS JOIN B ON A.id = B.id;
94 | ```
95 |
96 | ### Self Join
97 |
98 | 말그대로 자기 자신을 Join하는 방법이다. A 테이블을 각각 Child, Parent로 지정해서 사용한다.
99 |
100 | ```sql
101 | SELECT * FROM A AS parent JOIN A AS child
102 | ```
103 |
104 | ### Semi Join
105 |
106 | 솔직히 처음 들어보는 조인이었다. 조사해보니 세미 조인은 서브 쿼리와 메인 쿼리와의 연결을 위한 유사 조인 이었다...(~~가짜야가짜~~)
107 |
108 | 1:n 관계에서 1의 컬럼만을 사용할 경우 사용할 수 있는데, 집계함수 없이 group by나 distinct를 사용해서 중복제거를 하고 있다면 성능 향상의 효과를 얻을 수 있다.
109 |
110 | In 과 Exists를 통해 사용할 수 있다고 한다.
111 |
112 | ```sql
113 | SELECT * FROM A WHERE A.name IN (SELECT B.name FROM B );
114 | ```
115 |
116 | ```sql
117 | SELECT * FROM A WHERE EXISTS (SELECT 1 FROM B WHERE A.name = B.name)
118 | ```
119 |
120 | 자세한건 아래 블로그와 참고자료에 첨부한 유튜브 영상을 참고하자
121 |
122 | [블로그](https://songii00.github.io/2019/08/10/2019-08-10-%EC%84%B8%EB%AF%B8%EC%A1%B0%EC%9D%B8/)
123 |
124 | ## 3. 조인 동작 방식
125 |
126 | Mysql 에서는 **NESTED LOOP JOIN(NL Join)**을 사용하고 있으며, 이외에 **SORT-MERGE JOIN, HASH JOIN**이 있다. Hash Join의 경우 Mysql 8.0부터 지원하고 있다고 한다.
127 |
128 | ### **NESTED LOOP JOIN(NL Join)**
129 |
130 | 우리가 프로그래밍에서 사용하는 반복문과 유사한 방식으로 조인을 수행하는데, 반복문 외부에서 먼저 읽어지는 테이블을 `Driving Table` 이라고 하고, 반복문 내부에서 나중에 읽어지는 테이블을 `Driven Table`이라고 한다.
131 |
132 | Inner Join의 경우에는 옵티마이저가 순서를 조절해 최적화 하기 때문에 쿼리에서의 테이블 순서가 보장 되지 않고, Outer Join의 경우에는 Outer 테이블을 먼저 읽기 때문에 옵티마이저가 선택할 수 없다.
133 |
134 | 어찌 되었건 옵티마이저의 실행계획을 통해서 `Driving Table` 과 `Driven Table` 이 정해졌다면 다음 프로세스를 따른다.
135 |
136 | 
137 |
138 | 출처: [https://coding-factory.tistory.com/756](https://coding-factory.tistory.com/756)
139 |
140 | 1. `Driving Table` 에서 주어진 WHERE 조건문을 만족하는 행을 찾는다. (인덱스 OR 풀스캔등)
141 | 2. `Driving Table` 의 조인 KEY 값을 가지고 `Driven Table` 에서 조인을 수행 (랜덤 Access)
142 | 3. 반복
143 |
144 | Driving Table의 조건을 만족하는 결과가 많을 수록 반복문의 n의 크기가 커지고, Driven Table에 더 많이 접근해야 하므로 성능은 나빠지게 된다.
145 |
146 | 그러므로 `힌트` 나 `뷰` 를 통해서 선택된 `Driving Table` 의 크기가 작아지도록 해야 한다.
147 |
148 | ### 마무리
149 |
150 | 관계 대수 부터 각 Join과 Join의 동작 방식까지 간단하게 살펴 보았다. Join 때문에 성능 이슈가 많이 생겨서 반정규화를 하거나 아예 NoSQL을 이용하는 경우도 많지만 근-본인 관계형 DB에서 Join에 대해 조금 더 잘 이해하는 계기가 되었다. 조인 동작 방식에 대해서는 추후에 더 자세히 공부해볼 예정이다.
151 |
152 | ## 참고자료
153 |
154 | - 코드박사 와 데이터베이스 만화
155 |
156 | [내 계좌 비밀번호는 어떻게 저장되어 있을까? RDBMS](https://brunch.co.kr/@hvnpoet/133)
157 |
158 | - 관계 대수
159 |
160 | [](https://jehwanyoo.net/2020/09/25/%EA%B4%80%EA%B3%84%EB%8C%80%EC%88%98-Relational-Algebra-%EC%9A%94%EC%95%BD-%EC%A0%95%EB%A6%AC/)
161 |
162 | [[Database] 관계대수](https://m.blog.naver.com/aservmz/221960633361)
163 |
164 | “Mysql로 배우는 데이터베이스 개론과 실습” 책 참고
165 |
166 | - TCP School
167 |
168 | [코딩교육 티씨피스쿨](http://tcpschool.com/mysql/mysql_multipleTable_join)
169 |
170 | - 세미 조인
171 |
172 | [세미조인](https://songii00.github.io/2019/08/10/2019-08-10-%EC%84%B8%EB%AF%B8%EC%A1%B0%EC%9D%B8/)
173 |
174 | [조인보다 빠른 세미 조인, Semi Join, exists, in](https://www.youtube.com/watch?v=YxauObfs4HQ)
175 |
176 | [2.3.5. 세미(Semi) 조인](http://wiki.gurubee.net/pages/viewpage.action?pageId=1966761)
177 |
178 | - 조인
179 |
180 | [[MySQL] 7장 조인 : JOIN (INNER, LEFT, RIGHT)](https://futurists.tistory.com/17)
181 |
182 | [[MYSQL] JOIN(조인)](https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=islove8587&logNo=221049861998)
183 |
184 | - Equal Join == Inner join ???
185 |
186 | [Is inner join the same as equi-join?](https://stackoverflow.com/questions/5471063/is-inner-join-the-same-as-equi-join)
187 |
188 | - join 동작 방식
189 |
190 | [[DB] 데이터베이스 NESTED LOOPS JOIN (중첩 루프 조인)에 대하여](https://coding-factory.tistory.com/756)
191 |
192 | [* JOIN 원리](https://kshmc.tistory.com/entry/JOIN-%EC%9B%90%EB%A6%AC)
193 |
194 | [SQL 최적화 기본원리 (조인 수행 원리)](https://cornswrold.tistory.com/84)
--------------------------------------------------------------------------------
/Database/SQL_VS_NOSQL.md:
--------------------------------------------------------------------------------
1 | # SQL VS NOSQL
2 |
3 | ## ✨ SQL? NOSQL?
4 |
5 | > SQL이란 SQL(Structured Query Language)로 원래의 의미는 RDB의 Query Language이지만, RDB에서만 쓰이므로 RDB를 SQL이라고 말하기도한다. 여기서도 SQL == RDB로 쓰겠다. 그리고, MySQL(SQL), MongoDB(NoSQL)기준으로 설명한다.
6 | >
7 |
8 | ### SQL
9 |
10 |
14 |
15 | > 여기서 일관성이란 RDB는 데이터의 중복 저장을 피하기 위해서 여러 데이터를 여러 테이블에 분산하여 저장하고 관계를 정해줌으로써 지켜준다.
16 | >
17 | - 모델링의 순서가 [ 테이블 → 쿼리 ]로, 테이블의 형태를 먼저 정하고 그에 맞는 쿼리를 작성하게 된다.
18 |
19 | > 이런 점은 데이터의 일관성을 중요시하는 RDB의 컨셉때문이다.
20 | >
21 |
22 | ### NOSQL
23 |
24 |
28 |
29 | > NoSQL은 데이터를 중복 저장하지만, 내가 원하는 정보를 한개의 document에 모두 담을 수 있다. 따라서, 대용량 데이터에 대해서 빠른 처리가 가능하다.(Join이 없으므로)
30 | >
31 | - 모델링의 순서가 [ 쿼리 → 도큐멘트 ]로, 필요한 쿼리에 따라서 도큐멘트를 만들게 된다.
32 |
33 | ## 📝 용어
34 |
35 | ### 공통
36 |
37 | - Schema: Table(Collection)의 구조를 정의한다.
38 |
39 |
43 |
44 | - Join: RDB에서 관계를 가지는 테이블의 데이터도 함께 가져오고 싶을 때 사용하는 쿼리 기법
45 |
46 |
50 |
51 | - Join 동작방식의 차이
52 |
53 | SQL
54 |
55 | - Join시 외래키를 통해서 추가적인 Table에 접근하고, 외래키는 해당 Record를 직접 참조하므로 매우 빠른 속도로 가져올 수 있다.
56 |
57 | NOSQL
58 |
59 | - Lookup시 추가로 찾는 Collection을 Full Scan해서 맞는 Document를 찾게된다.
60 | - 여기서, 적절한 Indexing을 통해서 Lookup의 성능을 높일 수 있다.
61 | - 또한, NOSQL은 스키마가 유연하고 모든 데이터가 들어갈 수 있으므로, Document의 Field에 Document자체가 들어갈 수 있다. 이러한 기법을 Embedding기법이라고 한다.
62 |
63 |
67 |
68 | - 또한, Link기법으로 특정 Document를 직접 참조할 수도 있다.
69 |
70 | ### SQL
71 |
72 | - Table: 데이터를 저장하는 표(Table)
73 | - Row(Record): Table에서 한개의 데이터를 나타낸다.
74 | - Column(Field): Table에서 데이터가 가질 수 있는 각 속성이다.
75 | - Relationship: Table과 Table의 관계이다.
76 |
77 | ### NoSQL
78 |
79 | - Collection: == RDB의 Table
80 | - Document: == RDB의 Row(Record)
81 | - Field: == RDB의 Column(Field)
82 |
83 | ## ⚡️ Transaction
84 |
85 |
89 |
90 | ### ACID
91 |
92 | > Transaction을 보장하기 위해서는 아래 4가지 조건을 만족해야 한다.
93 | >
94 | - Atomicity(원자성): 모든 연산에 대해서 모두 처리/실패 → all-or-nothing
95 | - Consistency(일관성): 데이터는 미리 정의된 규칙(제약조건, 도메인, ...)에 부합
96 | - Isolation(): 트랜잭션동안 다른 트랜잭션 간섭 불가
97 | - Durability(지속성): 트랜잭션 이후 데이터들의 영구 보존
98 |
99 | ### SQL
100 |
101 |
105 |
106 | ### NOSQL
107 |
108 |
112 |
113 | - MongoDB Manual의 내용
114 |
115 | > In version 4.0, MongoDB supports multi-document transactions on replica sets.
116 | In version 4.2, MongoDB introduces distributed transactions, which adds support for multi-document transactions on sharded clusters and incorporates the existing support for multi-document transactions on replica sets.
117 |
118 | To use transactions on MongoDB 4.2 deployments (replica sets and sharded clusters), clients must use MongoDB drivers updated for MongoDB 4.2.
119 | >
120 |
121 | 4.0부터 Multi-Document의 Transaction을 지원하기 시작했으며, 이 때부터 DB로써 사용할 수 있는 역량을 갖췄다고 평가된다. 그 아래는 4.2부터는 샤딩을 통해 확장된 상태에서 지원한다고 써있다.
122 |
123 | - NOSQL도 ACID를 만족한다고?
124 |
125 | 아래 MongoDB의 Manual을 읽어보면 그러한거 같다. 이제 ACID Transactions 된다고 자랑하는 글
126 |
127 | [ACID Transactions Basics](https://www.mongodb.com/basics/acid-transactions)
128 |
129 |
130 | ## 🌝 특성
131 |
132 | ### ACID of SQL
133 |
134 | ### BASE of NOSQL
135 |
136 |
140 |
141 | > ACID와 대조되는 가용성과 성능을 중시하는 특징
142 | >
143 | - Basically Available(가용성): 데이터는 항상 접근이 가능, 데이터는 중복 저장
144 | - Soft-state(독립성): 노드의 상태는 외부의 정보를 통해 결정
145 | - Eventually Consistent(일관성): 일정 시간 경과시 데이터의 일관성을 유지
146 |
147 | ### BASE VS ACID
148 |
149 | | 항목 | BASE | ACID |
150 | | --- | --- | --- |
151 | | 적용대상 | NoSQL | RDBMS |
152 | | 범위 | 시스템 전체 대상 | 개별 트랜잭션 적용 |
153 | | 일관성 | 약한 일관성 | 강한 일관성 |
154 | | 중점사항 | 성능과 가용성 | 무결성, 일관성 |
155 | | 관리주체 | 주로 개발자 | DBMS 트랜잭션 |
156 | | 데이터처리 | 유사 응답 허용 | 처리 순서 보장 |
157 | | 변경성 | 변경 어려움 | 변경 용이 |
158 | | 디자인 | 쿼리 디자인 중요 | 테이블 디자인 중요 |
159 | | CAP이론 | C+P, A+P 만족 | C+A 만족 |
160 | | 적용사례 | Big Table | Oracle RAC |
161 |
162 | ## 👾 CAP 이론
163 |
164 |
168 |
169 | - Consistency(일관성): 모든 노드들은 같은 시간에 동일한 항목에 대하여 같은 내용의 데이터를 제공한다.
170 | - Availability(가용성): 모든 사용자들이 읽기및 쓰기가 가능하며, 몇몇 노드의 장애시 다른 노드에 영향을 끼치지 않는다.
171 | - Partition-tolerance(분할 내성): 메시지 전달이 실패하거나 일부 시스템이 망가져도 시스템은 정상 동작해야 한다.
172 |
173 | > 현재 DB들은 이중에 2가지를 만족하도록 만들어진다.
174 | >
175 |
176 | > SQL(CA), NoSQL(CA, AP)
177 | >
178 |
179 | ## 👐 확장
180 |
181 | > 확장이란 성능 또는 용량 초과로 인한 DB의 확장이다.
182 | >
183 |
184 | ### 수평 확장 of NOSQL
185 |
186 |
190 |
191 | > NOSQL은 비교적 쉬운 수평 확장을 샤딩을 통해서 지원한다. 샤딩이란 같은 Collection내의 Document를 분산하여 저장하는 방식이다.
192 | >
193 | - 샤딩을 통한 비교적 쉬운 수평 확장
194 | - 유연한 스키마 변경을 통한 확장
195 |
196 | ### 수직 확장 of SQL
197 |
198 |
202 |
203 | > SQL은 Schema변경이 거의 불가능하므로 수직 확장만이 가능하다. 수평 확장도 가능하지만, 매우 매우 어렵다고 볼 수 있다.
204 | >
205 |
206 | > NOSQL은 수직 확장이 안되는가? 수평 확장이 인력과 서버 비용 모두 통틀어서 더 좋은 선택이므로 수직 확장할 필요는 없다.
207 | >
208 |
209 | ## 👀 정규화와 비정규화
210 |
211 | ### 정규화(Normalization)
212 |
213 |
217 |
218 | > 정규화를 통해서 이상(Anomaly)현상을 방지할 수 있다. 이상 현상이란 개발자가 원하지 않는 데이터의 삭제 / 삽입 / 갱신되는것을 말한다.
219 | >
220 |
221 | ### 비정규화(Denormalization)
222 |
223 |
227 |
228 | > 정규화는 1 ~ 5단계가 있으며, 숫자가 높아질수록 데이터의 중복이 없다. 현업에서는 보통 3단계 정도까지를 사용한다.
229 | >
230 |
231 | ### SQL & NOSQL
232 |
233 | - SQL: 정규화를 통해서 데이터의 중복을 없애는것을 지향한다.
234 | - NOSQL: 비정규화를 통해서 빠른 성능과 가용성을 지향한다.
235 |
236 | ## 👍 장점과 단점
237 |
238 |
242 |
243 | - SQL
244 | - 장점: 관계를 통해서 데이터의 일관성을 강제하므로 설계만 잘 해놓으면 사용시 편리하다.
245 | - 단점: 일관성, 트랜잭션을 위해서 잘못된 설계시 많은 성능 저하가 일어날 수 있다, 설계/수정이 어렵다.
246 | - NoSQL
247 | - 장점: 대용량 데이터에 좋은 성능을 기대할 수 있다, 설계 / 수정 / 확장이 쉽다
248 |
249 | > 대용량 데이터일 경우,
250 | 1. 데이터가 많아짐으로써 DB를 확장할 때 샤딩을 통해 쉽게 할 수 있다.
251 | 2. 형태가 다른 데이터를 모두 받아서 사용할 수 있다.
252 | >
253 | - 단점: 데이터의 일관성을 개발자가 신경써주어야 한다.
254 |
255 | ## 😭 예상 질문
256 |
257 | - SQL과 NOSQL의 차이는 무엇인가요?
258 | - 가장 큰 차이점은 데이터의 일관성을 중요시할 것이냐, 가용성과 확장성을 중요시할 것이냐 입니다. SQL은 일관성을 잘 지킬 수 있으며, NOSQL은 쉬운 수정과 수평 확장을 할 수 있습니다.
259 | - SQL의 장점과 단점은 무엇인가요?
260 | - SQL의 장점은 설계된 Table과 Schema를 통해서 데이터의 일관성을 보장받을 수 있습니다. 단점은 잘 못 설계된 Table과 Schema는 성능을 저하시킬 수 있고, Schema의 수정이 힘드며 확장시 수직 확장을 해야함이 있습니다.
261 | - NOSQL의 장점과 단점은 무엇인가요?
262 | - NOSQL의 장점은 가용성과 유연성입니다. 유연한 Schema를 통해서 Agile한 DB 설계를 할 수 있으며 확장시에도 상대적으로 쉬운 샤딩을 통한 수평확장입니다. 단점은 중복 저장으로 데이터의 일관성이 보장되지 않을 수 있고, DB 스토리지를 낭비할 수 있으며 업데이트 쿼리시 Document크기에 따라서 성능이 저하될 수 있습니다.
263 | - 언제 SQL을 사용하고, 언제 NOSQL을 사용해야 할까요?
264 | - 데이터의 형태가 정해져 있고, 일관성이 중요하고 DB 스토리지가 넉넉하지 않다면 SQL을, 유연한 수정과 확장성을 고려한다면 NOSQL 사용을 고려해볼 수 있습니다.
265 | - 대용량 데이터 처리가 NoSQL 이 더 유리한가?
266 | - 유연한 데이터 유형
267 | - 서버의 수평확장에 유리한 구조
268 | - SQL과 NOSQL의 사용 경험에 대해서 말해주세요
269 | - 개발시 어떤 sql를 사용할 것인가?
270 | - 관계에 따라
271 | - 보안이 중요하다면 SQL을 사용하는 것이 유리하다.
272 |
273 | > 트랜잭션의 안정성, 유연한 Schema로 SQL Injection에 취약하다.
274 | >
275 | - 둘 다 적절히 사용
276 |
277 | ## 👨💻 참고
278 |
279 | - 그룹 프로젝트 정리 노션
280 |
281 | [SQL VS NoSQL](https://www.notion.so/SQL-VS-NoSQL-13a24463cac04934adbee88b8bd96fd2)
282 |
283 | - 정규화
284 |
285 | [#02. 이상(Anomaly)현상과 정규화(Normalization)](https://movenpick.tistory.com/29)
286 |
287 | [데이터베이스 정규화 1NF, 2NF, 3NF, BCNF](https://3months.tistory.com/193)
288 |
289 | - 비교
290 |
291 | [SQL과 NOSQL의 차이 | 👨🏻💻 Tech Interview](https://gyoogle.dev/blog/computer-science/data-base/SQL%20&%20NOSQL.html)
292 |
293 | [SQL vs NoSQL](https://velog.io/@thms200/SQL-vs-NoSQL)
294 |
295 | - 모델링
296 |
297 | [NoSQL 데이터 모델링](https://more-learn.tistory.com/5)
298 |
299 | [MongoDB 데이터 관계 모델링](https://devhaks.github.io/2019/11/30/mongodb-model-relationships/)
300 |
301 | - 트랜잭션
302 |
303 | [[DB기초] 트랜잭션이란 무엇인가?](https://coding-factory.tistory.com/226)
304 |
305 | [What is NoSQL? NoSQL Databases Explained](https://www.mongodb.com/nosql-explained)
306 |
307 | - BASE
308 |
309 | [NoSQL 데이터베이스 접속 시 보안 고려사항](http://channy.creation.net/project/dev.kthcorp.com/2012/01/26/security-considerations-in-accessing-nosql-databases/index.html)
310 |
311 | - 보안
312 |
313 | [NoSQL BASE 속성 > 도리의 디지털라이프](http://blog.skby.net/nosql-base-%EC%86%8D%EC%84%B1/)
314 |
--------------------------------------------------------------------------------
/Database/데이터베이스 클러스터링 VS 레플리카 6768dd1874c74763a3033dac6002f6ec.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Replication
4 |
5 | ### 기본구성
6 |
7 | - 데이터를 실질적으로 저장하는 소스서버 (Master)
8 | - 소스서버(Master)의 데이터를 복제해서 저장하는 레플리카서버(Slave)
9 |
10 | ### Replication시 장점
11 |
12 | - 스케일 아웃 → 레플리카서버를 늘려서 트래픽을 감당 가능하게 동적으로 규모를 늘릴 수 있음
13 | - 데이터 백업시 소스 서버에서 하면 실제 서버에 부담을 줄 수 있기 때문에 레플리카 서버에서 백업을 진행하여 부담을 줄인다.
14 | - 데이터 분석용 서버를 구성해서 특정용도를 위한 서버를 따로 구축할 수 있다.
15 | - 데이터의 지리적 분산: 특정 지역에 레플리카 서버를 구축해 응답속도를 개선 가능
16 |
17 | ### 바이너리 로그
18 |
19 | MySQL에서 모든 변경 사항을 순서대로 저장하고 있음 다음 명령어로 볼 수 있다.
20 |
21 | ```sql
22 | show binary logs
23 | show mater status;
24 | ```
25 |
26 | 소스 서버의 바이너리 로그가 레플리카 서버로 저장되고 그것을 통해 데이터의 동기화가 진행됨
27 |
28 | ### 바이너리 로그 저장방식
29 |
30 | - Statement 방식: SQL문을 바이너리 로그에 그대로 기록함
31 | - 트랜잭션 격리 수준이 REPEATABLE-READ 이상이어야 데이터가 일치함
32 | - 비 확정적으로 실행되는 쿼리(order by limit delete같은 매번 다르게 평가되는)가 있으면 데이터가 달라질 수 도 있음
33 | - Row 방식: 변경된 데이터 자체를 기록하는 Row 방식
34 | - 가장 일관적인 데이터 저장 방식 → 안전함
35 | - 단시간에 로그파일이 커짐
36 | - Mixed: statement와 row방식을 혼합함
37 | - statement로 기록했을때 안전하지 않을것같으면 row방식으로 기록함
38 |
39 | ### 복제과정
40 | 
41 |
42 | 이러한 복제 과정은 3개의 스레드를 통해 복제되는데
43 |
44 | 1. 소스서버의 Binary Log Dump Thread가 바이너리 로그를 레플리카서버에 전송함
45 | 2. 레플리카서버의 Replication I/O Thread 바이너리 로그 이벤트를 레플리카 서버에 Relay Log파일로 저장
46 |
47 | (연결시 사용정보는connection metadata에 있고, slave_master_info에 저장됨)
48 |
49 | 3. 레플리카서버의 Replication SQL Thread는 Replication I/O Thread에 의해 작성된 Relay Log파일을 읽고 실행함
50 |
51 | (릴레이 로그 이벤트를 서버에 적용하는 컴포넌트를 applier라고 하는데 이벤트가 저장된 릴레이로그 파일명,위치와 소스서버에 연결할 때 사용하는 정보가 저장되어있다. slave_relay_log_info테이블에 저장됨)
52 |
53 |
54 | ### 변경 내용식별
55 |
56 | - 바이너리 로그 파일 위치 기반
57 | - 레플리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일내에서 위치로 바이너리 로그 이벤트를 식별해서 복제함
58 | - server-id={n}으로 서버를 식별함 각 서버마다 넘버링을 해줘야함 → 이벤트가 처음 발생한 위치를 식별하기 위해 서버 아이디를 지정해야함
59 | - 글로벌 트랜잭션 ID 기반(GTID)
60 | - MySQL 버전 5.5까지는 바이너리 로그 파일 위치 기반으로만 가능했음 → 식별과정이 소스서버에서만 유효함 , 레플리카서버에 동일한 위치에 저장된다고 보장할 수 없음
61 |
62 | [MySQL GTID 를 사용한 Replication(복제) 설정](https://hoing.io/archives/18445)
63 |
64 |
65 | ### 복제 동기화 방식
66 |
67 | - 비동기 복제
68 | - 제대로 적용됬는지 확인하지 않음 ,데이터가 100% 일치하지 않음
69 | - 반동기 복제
70 | - 소스 서버는 레플리카 서버가 소스 서버로부터 전달 받은 변경 이벤트를 릴레이 로그에 기록 후 응답을 보내면 그때 트렌잭션을 커밋함
71 | - 비동기 방식보다 트랜젝션 처리가 느려짐, 응답이안오면 무제한으로 기다릴수있으니 일정시간지나면 비동기 복제로 젼환
72 |
73 | ### Replication 종류
74 |
75 | **싱글 레플리카 복제**
76 | 
77 |
78 | - 하나의 소스 서버에 하나의 레플리카서버
79 | - 소스 서버에 문제가 생길 경우 예비서버 역할, 데이터 백업 수행을 위한 용도
80 |
81 | **멀티 레플리카 복제**
82 |
83 | 
84 |
85 | - 하나의 소스 서버에 두 개의 레플리카 서버
86 | - 하나는 백업용, 하나는 읽기 요청 분산
87 |
88 | **체인 복제**
89 |
90 | 
91 | - 하나의 소스 서버에 레플리카가 여러개 달리면 바이너리 로그 복사작업이 부담이 될 수 있음
92 | - 소스 서버가 해야할 로그 배포역할을 다른서버로 넘길수있음
93 |
94 | **듀얼 소스 복제**
95 | 
96 |
97 | - 두개의 서버가 소스이자 레플리카
98 | - 각 서버에서 변경한 데이터는 각 서버에 전달되어서 동일한 데이터를 갖게됨
99 | - Active -Active(항상가동) 형태, Activae - Standby(일부는 대기)형태로 가능
100 | - 그냥 레플리케이션 방식과 달리 한서버에서 문제가 생기면 바로 전환가능
101 |
102 | **멀티 소스 복제**
103 | 
104 | - 하나의 레플리카 서버가 여러개의 소스서버를 가짐
105 | - 여러 서버에 존재하는 다른 데이터를 통합하거나 샤딩 되어있는 테이블을 하나의 테이블로 통합할 때 사용함
106 |
107 | # Clustering
108 |
109 | - 레플리케이션은 저장소 + 서버가 개별로 생성되지만 클러스터링은 db스토리지 하나와 다수의 서버로 구성됨
110 |
111 | ## 연결방식
112 |
113 | ## Active-Active 방식
114 |
115 | - 클러스터를 구성하는 컴포넌트들이 동시에 가동되는 방식, 하나의 저장소를 공유함
116 |
117 | ### 장점
118 |
119 | - 시스템이 다운되어 있는 시간이 짧기 때문에 시스템 전체가 정지하는 것을 방지할 수 있음
120 | - 동시에 가동하기 때문에 전체 cpu,메모리등이 증가해 성능 향상도 기대할 수 있음
121 |
122 | ### 단점
123 |
124 | - 저장소에서 병목이 일어날 수 있어서 높은 성능향상을 기대하기 어려울 수도 있다.
125 | - Active-Active 방식을 지원 하는 데이터 DBMS가 한정적이다.
126 | - ( Oracle = RAC(Real Application Cluster, DB2 = pureScale 라는 이름의 Active-Active 클러스터링이 가능하고, 다른 DBMS에서는 Active-Standby 클러스터링만 대응하고 있다.
127 | - MySQL에서는 지원해주지 않는 걸로 보임 → MySQL Cluster를 사용하는 것 같은데 InnoDB가 아니라고 함 , 아래에 작성한 **Galera cluster**를 솔루션으로 사용한다고함
128 | - 서버를 여러대 한꺼번에 운영하므로 비용이 증가함
129 |
130 | ## Active-Standby 방식
131 |
132 | - 클러스터를 구성하는 컴포넌트중 Active만 사용하다가 장애가 생기면 standby가 작동하는 구성
133 | - Cold-Standby:평소에 DB가 작동하지 않다가 Active DB에 장애 작동하는 구성
134 | - Hot-Standby: 평소에 Standby DB가 작동되는 구성이다.
135 | - Hot-standby는 라이선스료를 많이 지급 한다는점에서 단점이 있음
136 | - Standby DB 서버는 일정 간격으로 Active DB에 이상이 없는지를 조사하기 위한 통신을 하고 있다. 이 통신을 '**Heartbeat**'라고 한다. Active DB에 장애가 발생하면 이 신호가 끊기기 때문에Standby 측은 Active가 '죽었다'는 것을 알 수 있다.
137 |
138 | ### **Galera cluster**
139 |
140 | - 동기방식의 clustering을 지원해주는 오픈소스로 보임
141 |
142 | [Galera Cluster for MySQL](https://galeracluster.com/)
143 |
144 | [[MariaDB] Galera Cluster - 소개](https://myinfrabox.tistory.com/214)
145 |
146 |
147 | ### 참고 자료
148 |
149 | - 레플리케이션 참고
150 |
151 | [[MySQL] Replication (3) - Replication을 사용하는 이유](https://blog.seulgi.kim/2015/05/why-use-mysql-replication.html)
152 |
153 | - 데이터베이스의 다중화
154 |
155 | [[Database] DB 서버의 다중화 클러스터링(Multiplexing Clustering)과 리플리케이션(Replication)](https://kgh940525.tistory.com/entry/Database-DB-%EC%84%9C%EB%B2%84%EC%9D%98-%EB%8B%A4%EC%A4%91%ED%99%94Multiplexing-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0%EB%A7%81-%EB%A6%AC%ED%94%8C%EB%A6%AC%EC%BC%80%EC%9D%B4%EC%85%98Replication)
156 |
157 | - 레플리케이션 소개 영상: 작동원리, 장단점, 종류 -> 정말좋은 영상!
158 |
159 | [[10분 테코톡] ✌️ 영이의 Replication](https://www.youtube.com/watch?v=95bnLnIxyWI&t=1s)
160 |
161 | - 레플리케이션 설정
162 |
163 | [MySQL Replication(복제) - 단방향 이중화](https://server-talk.tistory.com/240)
164 |
165 | - DB 아키텍쳐 종류 및 설명 (데이터베이스 첫걸음 책)
166 |
167 | [https://hololo-kumo.tistory.com/220](https://hololo-kumo.tistory.com/220)
168 |
169 | [https://milhouse93.tistory.com/38?category=750797](https://milhouse93.tistory.com/38?category=750797)
--------------------------------------------------------------------------------
/Database/데이터베이스인덱스.md:
--------------------------------------------------------------------------------
1 | # 데이터베이스 인덱스
2 |
3 | ### 인덱스?
4 |
5 | DB 테이블에서 필요한 데이터를 빠르게 찾기 위해서 인덱스를 사용할 수 있다. 인덱스를 생성하면, 특정 컬럼의 데이터들을 정렬하여 별도의 메모리 공간에 주소와 함께 저장된다. 쉽게 비유하자면 책에 있는 목차(색인)이라고 할 수 있다. SQL 튜닝에서 중요한 Index에 대해서 알아보자
6 |
7 | 
8 |
9 | ### 인덱스를 사용하는 이유
10 |
11 | 인덱스의 가장 큰 특징은 데이터들이 정렬되어있다는 점이다. 덕분에 다양한 장점이 있는데, 다음과 같다.
12 |
13 | - Where
14 | - 인덱스가 없다면 Where절 사용시 레코드를 처음부터 끝까지 다 읽는 Full Table Scan이 일어나게된다. 하지만 인덱스 테이블은 데이터들이 정렬되어 저장되어 있기 때문에 해당 조건 (Where)에 맞는 데이터들을 빠르게 찾아낼 수 있다.
15 | - Order by
16 | - 인덱스가 없다면 정렬과 동시에 1차적으로 메모리에서 정렬이 이루어지고 메모리보다 큰 작업이 필요하다면 디스크 I/O도 추가적으로 발생됩니다. 하지만 인덱스 이용시 바로 가져오면 된다.
17 | - Min, Max
18 | - MIN값과 MAX값을 레코드의 시작값과 끝 값 한건씩만 가져오면 되기에 FULL TABE SCAN으로 테이블을 다 뒤져서 작업하는 것보다 훨씬 효율적으로 찾을 수 있습니다.
19 |
20 | ### 인덱스의 자료구조
21 |
22 | **Hash Table**
23 |
24 | 대부분의 Index는 B+Tree 자료구조를 이용하고 있다. 하지만 탐색능력만 따지면 O(1)시간의 Hash Table구조를 사용할 수 있을텐데 이유가 무엇일까? **해쉬테이블을** DB 인덱스로 사용할 수 없는 이유는 다음과 같다.
25 |
26 | 가장 큰 문제로 “***우리는 DB에서 등호(=) 뿐 아니라 부등호(<, >)도 사용할 수 있다”*** 모든 값이 정렬되어 있지 않으므로, 해시 테이블에서는 특정 기준보다 크거나 작은 값을 찾을 수 없다.
27 |
28 | > MySQL InnoDB에서는 메모리 버퍼 풀에서 레코드 검색을 위한 [어댑티브 해시 인덱스](https://tech.kakao.com/2016/04/07/innodb-adaptive-hash-index/)로 사용
29 | >
30 |
31 | **Array**
32 |
33 | 배열의 문제는 간단하다. 탐색이 O(1)이라 해도 삽입 삭제시 O(N)시간이 걸리기 때문이다. 또
34 |
35 | **데이터 수정이 일어날때도 퀵 정렬, 병합 정렬 등 배열 자료구조에서 O(N*logN) 시간으로 재정렬을 이루어야 한다는 점도 있다.**
36 |
37 | > 참고로 B-tree의 삽입, 삭제는 트리의 높이(h)에 따른 O(h)의 시간 복잡도를 가지는데, 이는 logN보다 훨씬 작은 값이다.
38 | >
39 |
40 | **결론적으로 DB 인덱스로 B-Tree가 가장 적합한 이유들을 정리하면 아래와 같다.**
41 |
42 | 1. **항상 정렬된 상태로 특정 값보다 크고 작은 부등호 연산에 문제가 없다.**
43 | 2. **참조 포인터가 적어 방대한 데이터 양에도 빠른 메모리 접근이 가능하다.**
44 | 3. **데이터 탐색뿐 아니라, 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도를 가진다.**
45 |
46 | ### 인덱스의 종류
47 |
48 | 인덱스에는 **클러스터드 인덱스 (Clustered Index)** 와 **논-클러스터드 인덱스 (Non-Clustered Index)** 2가지 종류가 존재한다.
49 |
50 | 
51 |
52 | ### 클러스터드 인덱스
53 |
54 | - 인덱스 키의 순서에 따라 데이터가 정렬되어 저장되는 방식
55 | - 실제 데이터가 순서대로 저장되어 있어 인덱스를 검색하지 않아도 원하는 데이터를 빠르게 찾을 수 있다.
56 | - 데이터 삽입, 삭제 발생 시 **순서를 유지**하기 위해 **데이터를 재정렬**해야한다.
57 | - 한 개의 릴레이션에 **하나의 인덱스만 생성 가능**
58 |
59 | ### 넌클러스터드 인덱스
60 |
61 | - 인덱스의 키 값만 정렬되어 있을 뿐 실제 데이터는 정렬되지 않는 방식
62 | - 데이터를 검색하기 위해서는 먼저 인덱스를 검색하여 실제 데이터 위치를 확인해야 하므로 **클러스터드 인덱스에 비해 검색 속도가 떨어진다.**
63 | - 한 개의 릴레이션에 여러 인덱스를 만들 수 있다.
64 |
65 | ### 인덱스의 장점
66 |
67 | - 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
68 | - 전반적인 시스템의 부하를 줄일 수 있다.
69 |
70 | ### 인덱스의 단점
71 |
72 | - 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다.
73 | - 인덱스를 관리하기 위해 추가 작업이 필요하다.
74 | - 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다.
75 |
76 | ### 인덱스의 관리
77 |
78 | DBMS는 index를 항상 최신의 **정렬된 상태로 유지**해야 원하는 값을 빠르게 탐색할 수 있다.
79 |
80 | 그렇기 때문에 인덱스가 적용된 컬럼에 INSERT, UPDATE, DELETE가 수행된다면 각각 다음과 같은 연산을 추가적으로 해줘야하며, 그에 따른 오버헤드가 발생한다.
81 |
82 | - INSERT : 새로운 데이터에 대한 인덱스를 추가함
83 | - DELETE : 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행
84 | - UPDATE : 기존의 인덱스를 사용하지 않음 처리하고, 갱신된 데이터에 대해 인덱스를 추가함
85 |
86 | 만약 CREATE, DELETE, UPDATE가 빈번한 속성에 인덱스를 걸게 되면 인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과가 발생할 수 있다.
87 |
88 | 만약 어떤 테이블에 UPDATE와 DELETE가 빈번하게 발생된다면 실제 데이터는 10만건이지만 인덱스는 100만 건이 넘어가게 되어, SQL문 처리 시 비대해진 인덱스에 의해 **오히려 성능이 떨어지게** 될 것이다.
89 |
90 | ### 인덱스는 언제 써야 하는가?
91 |
92 | 보통 인덱스는 한 테이블당 3~5개가 적당하다. 큰 결정 조건으로는 아래 4가지 기준이 있다.
93 |
94 | - **카디널리티 (Cardinality)**
95 | - **카디널리티가 높으면(↑) 인덱스 설정에 좋은 컬럼이다. (인덱스를 통해 불필요한 데이터의 대부분을 걸러낼 수 있음.)**카디널리티가 높다 = 한 컬럼이 갖고 있는 값의 중복도가 낮음. (= 값들이 대부분 다른 값을 가짐.)카디널리티가 낮다 = 한 컬럼이 갖고 있는 값의 중복도가 높음. (= 값들이 거의 같은 값을 가짐 )
96 | - **선택도 (Selectivity)**
97 |
98 | **선택도가 낮으면(↓) 인덱스 설정에 좋은 컬럼이다. (일반적으로 5~10%가 적당함.)**선택도가 높다 = 한 컬럼이 갖고 있는 값 하나로 여러 row가 찾아진다.선택도가 낮다 = 한 컬럼이 갖고 있는 값 하나로 적은 row가 찾아진다.
99 |
100 | > 선택도 계산법 (= 컬럼의 특정 값의 row 수 / 테이블의 총 row 수 * 100)
101 | ex) 10개의 데이터에서 고유한 학번(grade) 컬럼,
102 | 2명씩 같은 이름(name) 컬럼,
103 | 5명씩 같은 나이(age) 컬럼인 경우
104 | ① 학번(grade) 컬럼 선택도: 1 / 10 = 10%
105 | ② 이름(name) 컬럼 선택도: 2 / 10 = 20%
106 | ③ 나이(age) 컬럼 선택도: 5 / 10 = 50%
107 | >
108 | - **조회 활용도**
109 | - **조회 활용도가 높으면(↑) 인덱스 설정에 좋은 컬럼이다.**해당 컬럼이 실제 작업에서 얼마나 활용되는지에 대한 값.(`WHERE`의 대상 컬럼으로 많이 활용되는지로 판단하면 된다.)
110 | - **수정 빈도**
111 | - **수정 빈도가 낮으면(↓) 인덱스 설정에 좋은 컬럼이다.**인덱스도 테이블이기 때문에, 인덱스로 지정된 컬럼의 값이 바뀌게 되면 인덱스 테이블도 새롭게 갱신되어야 하기 때문.
112 |
113 |
114 |
115 | ## 참고자료
116 |
117 | - hash table index, b-tree index
118 |
119 | [데이터베이스 인덱스는 왜 'B-Tree'를 선택하였는가](https://helloinyong.tistory.com/296)
120 |
121 | - 인덱스란?
122 |
123 | [](https://mangkyu.tistory.com/96)
124 |
125 | - DB 인덱스
126 |
127 | [[DB] 데이터베이스 인덱스(Index) 란 무엇인가?](https://coding-factory.tistory.com/746)
128 |
129 | [[면접 대비] 데이터베이스 - 인덱스](https://velog.io/@syleemk/%EB%A9%B4%EC%A0%91-%EB%8C%80%EB%B9%84-%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%EC%9D%B8%EB%8D%B1%EC%8A%A4)
130 |
131 | - 인덱스 종류, 인덱스 사용이유
132 |
133 | [효과적인 DB index 설정하기](https://velog.io/@jwpark06/%ED%9A%A8%EA%B3%BC%EC%A0%81%EC%9D%B8-DB-index-%EC%84%A4%EC%A0%95%ED%95%98%EA%B8%B0)
134 |
135 | [](https://yurimkoo.github.io/db/2020/03/14/db-index.html)
--------------------------------------------------------------------------------
/Database/정규화/BCNF1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/BCNF1.png
--------------------------------------------------------------------------------
/Database/정규화/BCNF2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/BCNF2.png
--------------------------------------------------------------------------------
/Database/정규화/이상현상과 결정자1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/이상현상과 결정자1.png
--------------------------------------------------------------------------------
/Database/정규화/이상현상과 결정자2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/이상현상과 결정자2.png
--------------------------------------------------------------------------------
/Database/정규화/이상현상과 결정자3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Database/정규화/이상현상과 결정자3.png
--------------------------------------------------------------------------------
/Database/정규화/정규화.md:
--------------------------------------------------------------------------------
1 | # 📌 정규화(normalization)
2 |
3 | 이상 현상이 발생하는 테이블을 수정하여 정상으로 만드는 과정을 정규화(normalization)라고 한다.
4 | 정규화를 하기 위해서는 우선 테이블을 분석하여 기본키와 함수 종속성을 파악해야 한다.
5 | 그 후 릴레이션을 분해하여 제거한다.
6 | 분해된 릴레이션에 이상현상이 남아 있다면 없어질 때까지 분해 한다.
7 |
8 | > `TIP`
9 | 릴레이션과 테이블은 같은 의미로 쓰인다.
10 | 보통 테이블은 실무와 같은 구조보다 데이터를 강조하는 측면이 있고
11 | 릴레이션은 구조에 관한 이론을 강조하는 텍스트측면이 있다.
12 | >
13 |
14 |  114 |
115 |
116 | 1. 사용자가 브라우저를 통해 [www.dongmin.dev](http://www.dongmin.dev) 에 접근합니다.
117 | 2. Recursive DNS Server 로 [www.dongmin.dev](http://www.dongmin.dev) 의 IP 주소를 요청합니다.
118 | 3. Recursive DNS Server 레코드에 정보가 없는 경우 Root DNS Server 로 [www.dongmin.dev](http://www.dongmin.dev) IP 주소를 요청합니다.
119 | 4. Root DNS Server 는 요청 받은 도메인의 Top Level Domain(.dev) Name Server 의 IP 주소를 반환합니다.
120 | 5. Recursive DNS Server 는 응답받은 TLD Name Server IP 로 [www.dongmin.dev](http://www.dongmin.dev) IP 주소를 요청합니다.
121 | 6. TLD Name Server 는 [www.dongmin.dev](http://www.dongmin.dev) 에서 dongmin.dev 를 관리하는 Authoritative Name Server 주소를 반환합니다.
122 | 7. 마지막으로 Recursive DNS Server 는 Authoritative Name Server 로 [www.dongmin.dev](http://www.dongmin.dev) IP 주소를 요청합니다.
123 | 8. Authoritative Name Server 는 명시된 레코드에서 도메인을 찾으며 A 레코드에서 찾았다면 해당 IP 주소를 Recursive DNS Server 로 반환합니다.
124 | 9. Authoritative Name Server 로 부터 받은 IP 주소를 Recursive DNS Server 는 TTL 만큼 캐싱하며 브라우저에게 IP 주소를 응답합니다.
125 | 10. 브라우저는 응답받은 IP 주소를 통해 Web Server 에 접근합니다.
126 |
127 | > 💡 DNS 에서 사용하는 전송 프로토콜은 뭘까?
128 | 기본적으로 DNS message 가 512 byte 이하일 경우 UDP 프로토콜을 사용하여 통신하며 zone-transfer, 512 byte 초과시 TCP 프로토콜을 사용하여 통신합니다.
129 |
130 |
131 | > 💡 zone-transfer ?
132 | Master DNS 와 Slave DNS 서버로 이중화가 구성된 경우 발생하는 작업입니다.
133 | 한마디로 Master 서버의 Zone(도메인과 IP 매핑 정보) 파일을 Slave 서버로 최신화하는 작업입니다.
134 |
135 |
136 | ## 참고자료
137 |
138 | [DNS Process](https://www.cloudflare.com/ko-kr/learning/dns/dns-server-types/)
139 |
140 | [Root Domain](https://raventools.com/marketing-glossary/root-domain/)
141 |
142 | [Name Server 종류](https://www.dynu.com/en-US/Blog/Article?Article=DNS-Servers-Authoritative-Recursive-Root-TLD)
143 |
144 | [Domain 체계](https://better-together.tistory.com/128)
145 |
146 | [Second-level domain](https://en.wikipedia.org/wiki/Second-level_domain)
147 |
148 | [ccTLD](https://www.affde.com/ko/what-is-a-cctld.html)
149 |
150 | [DNS 512 byte UDP](https://serverfault.com/questions/587625/why-dns-through-udp-has-a-512-bytes-limit)
--------------------------------------------------------------------------------
/Network/HTTP,HTTPS.md:
--------------------------------------------------------------------------------
1 | # HTTP, HTTPS
2 |
3 | ](https://mdn.mozillademos.org/files/13677/Fetching_a_page.png)
4 |
5 | 출처 : [MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
6 |
7 | ## HTTP(HyperTextTransferProtocol)
8 |
9 | HTML과 같은 하이퍼미디어 문서를 전송하기 위한 어플리케이션 레이어 프로토콜입니다.
10 |
11 | HTTP는 비연결성의 무상태 프로토콜이며 서버/클라이언트 모델을 따라 데이터를 주고 받고, 기본 포트로 80번 포트를 사용합니다.
12 |
13 | ### HTTP 버전별 기능
14 |
15 | - HTTP/0.9
16 | - HTTP의 가장 초기 버전으로 원래는 버전 번호가 없는데 구분을 위해 향후 붙였다고 합니다
17 | - 헤더 없이 단순히 HTML 파일만 전송하며, GET 메소드만 사용 가능
18 | - HTTP/1.0 – 확장성 만들기
19 | - 헤더를 통해 HTTP 버전 코드를 송신하고, 상태 코드를 회신 받을 수 있게 되었습니다.
20 | - 헤더의 Content-Type을 통해 HTML이 아닌 형태도 전송 가능해졌습니다. (문자열 전송)
21 | - 사용가능한 메서드: GET, POST, PUT
22 | - HTTP/1.1 (표준 프로토콜)
23 | - Keep Alive로 커넥션이 재사용 될 수 있도록 개선되었습니다.
24 | - Host 헤더가 추가되어 동일 IP 주소에 다른 도메인을 호스트하는 기능이 서버 코로케이션을 가능하게 했습니다.
25 | - 사용가능한 메서드: OPTIONS, GET, HEAD, POST, PUT, DELETE, TRACE
26 | - HTTP/2 – 더 나은 성능을 위한 프로토콜
27 | - 2015년에 발표됨, 구글의 SPDY를 기반으로 표준화 되었습니다.
28 | - 문자열 전송 기반이 아닌 이진 데이터 전송 기반으로, 스트림, 메시지 및 프레임으로 데이터 교환 방식이 변경됨
29 | - 스트림: 구성된 연결 내에서 전달되는 바이트의 양방향 흐름이며, 하나 이상의 메세지가 전달 가능함(request or response는 하나의 메시지)
30 | - 메시지: 논리적 요청 또는 응답 메시지에 매핑되는 프레임의 전체 시퀀스
31 | - 프레임: http/2.0에서 통신의 최소 단위, 각 최소 단위에는 하나의 프라임 헤더가 포함된다. 이 프라임 헤더는 최소한으로 프레임이 속하는 스트림을 식별한다. Headers Type Frame, Data Type Frame이 존재한다.
32 | - 주요 스팩
33 | - HTTP Header Data Compression (HTTP 헤더 데이터 압축)
34 |
35 | 이전 Header의 중복되는 필드를 재전송하지 않아서 데이터를 절약하고, HPACK이라는 Header 압축방식을 이용하여 데이터 전송 효율을 높였다.
36 |
37 | - Server Push
38 |
39 | 클라이언트가 요청 하지 않은 JavaScript, CSS, Font, 이미지 파일 등과 같이 필요하게 될 특정 파일들을 서버에서 단일 HTTP 요청 응답으로 전송 가능하게 한다.
40 |
41 | - HOL(Head-of-Line) 문제 해결
42 |
43 | HTTP/1.1 까지는 한번에 하나의 파일만 전송이 가능했었지만, 여러 파일을 한번에 병렬 전송할 수 있께 개선되었다.
44 |
45 | - Stream 우선순위
46 |
47 | HTTP 메시지가 많은 개별 프레임으로 분할될 수 있고 여러 스트림의 프레임을 다중화(Multiplexing)할 수 있게 되면서, 스트림들의 우선순위를 지정할 필요가 생겼다. 클라이언트는 우선순위 지정을 위해 ‘우선순위 지정 트리'를 사용하여 서버의 스트림처리 우선순위를 지정할 수 있다. 서버는 우선순위가 높은 응답이 클라이언트에 우선적으로 전달될 수 있도록 대역폭을 설정한다.
48 |
49 |
50 | - HTTP/3
51 | - QUIC(Quick UDP Internet Connections) 프로토콜 사용, UDP를 사용한다.
52 | - 클라이언트의 IP가 바뀌어도 연결이 유지됨, (ex)와이파이에서 LTE로 전환할때)
53 |
54 | ### HTTP 구성요소
55 |
56 | - HTTP는 요청(Request)와 응답(Response)로 구성되어 있다.
57 | - 시작줄, 헤더, 바디로 이루어져있다.
58 | - **요청**
59 |
60 | ](https://mdn.mozillademos.org/files/13687/HTTP_Request.png)
61 | 출처: [MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
62 |
63 | 시작줄에 수행하고자 하는 메서드, HTTP 버전과 같은 프로토콜이 표시된다.
64 |
65 | 헤더에는 가져오려는 리소스의 경로; 예를 들면 [프로토콜](https://developer.mozilla.org/ko/docs/Glossary/Protocol) (`http://`), [도메인 (en-US)](https://developer.mozilla.org/en-US/docs/Glossary/Domain) (여기서는 `developer.mozilla.org`), 또는 TCP [포트 (en-US)](https://developer.mozilla.org/en-US/docs/Glossary/Port) (여기서는 `80`)인 요소들을 제거한 리소스의 URL입니다.
66 |
67 | > 그 이외에 추가하고자 하는 헤더, POST의 경우 body가 들어감
68 | >
69 | - **응답**
70 | ](https://mdn.mozillademos.org/files/13691/HTTP_Response.png)
71 | 출처: [MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
72 | - 시작줄에 HTTP 프로토콜 버전, 상태코드와 메시지가 표시된다.
73 | - 그 이외에 각종 헤더들이 들어가고, 요청에 맞는 리소스가 body에 포함되기도 한다.
74 |
75 | ## HTTPS (Hyper Text Transfer Protocol Secure)
76 |
77 | 말 그대로 HTTP에 Secure, 보안이 추가된 프로토콜이며 443번을 기본 포트로 사용한다. 클라이언트와 서버간의 모든 커뮤니케이션을 암호화 하기 위해 SSL / TLS 를 사용한다.
78 |
79 | ### 대칭키와 비대칭키(공개키)
80 |
81 | **대칭키**의 경우에는 암호화, 복호화에 사용하는 키가 동일하고 속도가 빠른 대신 키를 교환 해야 하기 때문에 탈취 관리를 해야하고, 기밀성을 제공하지만 무결성/인증을 보장하지 않는다.
82 |
83 | **비대칭키(공개키)**는 암복호화에 사용하는 키가 서로 다르며 속도가 느린 대신 , 기밀성, 무결성,인증 기능이 모두 제공된다. 대표적으로 RSA가 있다.
84 |
85 | ### 공개키와 비밀키 (Public Key Private Key )
86 |
87 | 비대칭키로 공개키와 비밀키를 사용하는데 다음과 같다.
88 |
89 | 1) 공개키로 암호화 하면 개인키로만 복호화 가능하다
90 |
91 | 2) 개인키로 암호화 하면 공개키로만 복호화가 가능하다.
92 |
93 | 따라서 1)의 경우 개인키를 가지고 있어야만 볼 수 있고, 2)의 경우 공개키로 복호화가 된다면 해당 정보에 대한 신뢰성이 보장된다.
94 |
95 | ### TSL / SSL
96 |
97 | 암호화를 담당하는 프로토콜, HTTPS에서 사용됨
98 |
99 | **SSL (Secure Scoket Layer)**
100 |
101 | - HTTP와 독립된 프로토콜로 HTTP 외에도 다방면으로 사용되고 있습니다.
102 | - 두 통신 사이에 핸드셰이크를 통해 인증 프로세스가 진행됨
103 |
104 | **TLS (Transport Layer Security)**
105 |
106 | - TLS는 SSL 3.0을 기초로 해서 IETF가 만든 프로토콜이다. (TLS 1.0 == SSL3.1)
107 | - SSL과 거의 동일하다고 생각하면 됨
108 |
109 | ### HTTPS 동작과정(SSL)
110 |
111 | 서버는 클라이언트가 요청을 보낼 때 암호화를 하기 위한 공개키를 생성해야 하는데, 일반적으로는 인증된 기관(Certificate Authority) 에 공개키를 전송하여 인증서를 발급받고 있다. 자세한 과정은 다음과 같다.
112 |
113 | - 공개키 암호화 방식과 대칭키 암호화 방식의 장점을 활용해 하이브리드 사용
114 | - 데이터를 대칭키 방식으로 암복호화하고, 공개키 방식으로 대칭키 전달
115 | 1. **클라이언트가 서버 접속하여 Handshaking 과정에서 서로 탐색**
116 |
117 | 1.1. **Client Hello**
118 |
119 | - 클라이언트가 서버에게 전송할 데이터
120 | - 클라이언트 측에서 생성한 **랜덤 데이터**
121 | - 클-서 암호화 방식 통일을 위해 **클라이언트가 사용할 수 있는 암호화 방식**
122 | - 이전에 이미 Handshaking 기록이 있다면 자원 절약을 위해 기존 세션을 재활용하기 위한 **세션 아이디**
123 |
124 | 1.2. **Server Hello**
125 |
126 | - Client Hello에 대한 응답으로 전송할 데이터
127 | - 서버 측에서 생성한 **랜덤 데이터**
128 | - **서버가 선택한 클라이언트의 암호화 방식**
129 | - **SSL 인증서**
130 |
131 | 1.3. **Client 인증 확인**
132 |
133 | - 서버로부터 받은 인증서가 CA에 의해 발급되었는지 본인이 가지고 있는 목록에서 확인하고, 목록에 있다면 CA 공개키로 인증서 복호화
134 | - 클-서 각각의 랜덤 데이터를 조합하여 pre master secret 값 생성(데이터 송수신 시 대칭키 암호화에 사용할 키)
135 | - pre master secret 값을 공개키 방식으로 서버 전달(공개키는 서버로부터 받은 인증서에 포함)
136 | - 일련의 과정을 거쳐 session key 생성
137 |
138 | 1.4. **Server 인증 확인**
139 |
140 | - 서버는 비공개키로 복호화하여 pre master secret 값 취득(대칭키 공유 완료)
141 | - 일련의 과정을 거쳐 session key 생성
142 |
143 | 1.5. **Handshaking 종료**
144 |
145 | 2. **데이터 전송**
146 | - 서버와 클라이언트는 session key를 활용해 데이터를 암복호화하여 데이터 송수신
147 | 3. **연결 종료 및 session key 폐기**
148 |
149 |
150 |
151 | ## 참고자료
152 |
153 | - HTTP 버전
154 |
155 | [HTTP의 진화 - HTTP | MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP)
156 |
157 | [HTTP](https://itwiki.kr/w/HTTP)
158 |
159 | [HTTP/1.1, /2, /3 의 차이점](https://velog.io/@zzzz465/HTTP1.1-2-3-%EC%9D%98-%EC%B0%A8%EC%9D%B4%EC%A0%90)
160 |
161 | [[CS/Network] HTTP 버전 별 특징](https://koonii.tistory.com/m/21)
162 |
163 | - HTTP 구성요소
164 |
165 | [HTTP 개요 - HTTP | MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
166 |
167 | - HTTPS와 TSL/SSL
168 |
169 | [](https://velog.io/@moonyoung/HTTPS%EC%9D%98-%EC%9B%90%EB%A6%AC)
170 |
171 | [HTTPS 와 SSL(TLS)](https://futurecreator.github.io/2018/07/12/https-and-ssl-tls/)
172 |
173 | [✔ SSL/TLS 보안](https://velog.io/@saseungmin/SSLTLS-%EB%B3%B4%EC%95%88)
174 |
175 | [대칭키 vs 공개키(비대칭키)](https://velog.io/@gs0351/%EB%8C%80%EC%B9%AD%ED%82%A4-vs-%EA%B3%B5%EA%B0%9C%ED%82%A4%EB%B9%84%EB%8C%80%EC%B9%AD%ED%82%A4)
176 |
177 | [✔ SSL/TLS 보안](https://velog.io/@saseungmin/SSLTLS-%EB%B3%B4%EC%95%88)
178 |
179 | [tech-interview/network.md at master · WeareSoft/tech-interview](https://github.com/WeareSoft/tech-interview/blob/master/contents/network.md)
180 |
181 | - HTTP 2.0
182 |
183 | [HTTP/2(HTTP 2.0) 정리](https://velog.io/@taesunny/HTTP2HTTP-2.0-%EC%A0%95%EB%A6%AC)
184 |
185 | [HTTP/2 소개 | Web Fundamentals | Google Developers](https://developers.google.com/web/fundamentals/performance/http2?hl=ko)
--------------------------------------------------------------------------------
/Network/OSI 7 계층.md:
--------------------------------------------------------------------------------
1 | ## OSI(Open Systems Interconnection) 모델이란?
2 |
3 | 컴퓨터 시스템이 네트워크를 통해 통신하며 사용하는 7개의 계층으로 국제 통신 표준 규약
4 |
5 | 
6 |
7 | OSI 7계층 데이터 전송 흐름
8 |
9 | ## 기능
10 |
11 | ### [**Layer 7] 응용 계층 (Application Layer)**
12 |
13 | OSI 모델의 최상위 계층으로 통신의 최종 목적지로 다양한 프로토콜
14 |
15 | **기능**
16 |
17 | - Network Virtual Terminal
18 | 어플리케이션은 원격 호스트의 에뮬레이션을 생성하여 사용자가 원격 호스트에 log on 하는 기능
19 | 사용자의 컴퓨터 ↔ 소프트웨어 터미널 ↔ 호스트 형식의 통신
20 | - Directory Service
21 | 다양한 전역 정보에 대한 엑세스 기능
22 | - File Transfer Access and Management(FTAM)
23 | 파일에 엑세스하고 파일을 관리하는 표준 메커니즘
24 | 원격 컴퓨터의 파일에 엑세스 및 관리, 검색 기능
25 | - Mail Service
26 |
27 | **단위 - Data**
28 |
29 | **키워드**
30 |
31 | > HTTP, FTP, SMTP, Telnet 등
32 | >
33 |
34 | ### [Layer 6] 표현 계층 (Presentation Layer)
35 |
36 | 응용 계층으로부터 전송 받거나 전송해야되는 데이터를 인코딩, 디코딩 하는 계층
37 | 암호화 복호화 작업도 해당 계층에서 이루어짐
38 |
39 | **기능**
40 |
41 | - 번역
42 | 네트워크에 필요한 형식과 어플리케이션의 데이터의 형식 변환 기능
43 | 송신 데이터 → 비트 스트림 (인코딩)
44 | 수신 데이터 → 문자 및 숫자 (디코딩)
45 | - 암호화
46 | 송신기에서 암호화, 수신기에서 복호화 작업을 수행하는 기능
47 | - 압축
48 | 대역폭을 줄이기 위해 데이터를 압축하는 기능
49 | 오디오, 비디오, 텍스트 등 멀티미디어 전송에 중요하며 0으로 전송되는 비트의 수를 줄이는 역할
50 |
51 | **단위 - Data**
52 |
53 | **키워드**
54 |
55 | > ASCII, JPEG, MPEG 등
56 | >
57 |
58 | ### [Layer 5] 세션 계층 (Session Layer)
59 |
60 | 통신하는 호스트 사이 세션 설정 및 유지 및 동기화를 처리하는 계층
61 | **기능**
62 |
63 | - 동기화
64 | 통신하는 메세지 스트림에 대해 동기화 지점으로 체크포인트를 추가하며 세션이 중단되면 체크포인트를 통해 데이터 전송을 재개할 수 있는 기능
65 | - 토큰 관리
66 | 각 사용자가 중요한 작업을 동시에 엑세스하는 것을 방지하기 위한 기능
67 | - Dialog Control
68 | 두 시스템이 반이중, 전이중으로 서로 통신을 시작할 수 있도록 설정하는 기능
69 |
70 | **단위 - Data**
71 |
72 | ### [Layer 4] 전송 계층 (Transport Layer)
73 |
74 | 송신 과정은 상위 계층에서 전달받은 데이터를 더 작은 조각(Segment, Databram)으로 분할하여 네트워크 계층으로 전달하며 수신 과정은 분할된 조각(Segment, Databram)을 재조립하는 프로세스간 논리적 통신을 수행하는 계층
75 | 데이터가 잘못 수신되었는지 확인하며 다시 요청하는 오류 제어 기능을 수행
76 |
77 | **기능**
78 |
79 | - Service Point Addressing
80 | 해당 Layer header 에 서비스 포인트 주소인 포트번호를 포함하여 올바른 프로세스로 메세지를 전달하는 기능
81 | - 분할 및 재조립
82 | 메세지는 시퀀스 번호가 포함되어 있는 세그먼트 형태로 분할
83 | 세그먼트의 시퀀스 번호를 통해 메세지 재조립
84 | - 흐름 제어
85 | 종단간(end-to-end) 신뢰성있는 메세지 전달을 보장하는 기능
86 | - 오류 제어
87 | 수신 과정에서 메세지가 오류 없이 전달 받았는지 확인하는 기능
88 |
89 | **단위 - Segment(TCP), Datagram(UDP)**
90 |
91 | **키워드**
92 |
93 | > TCP, UDP
94 |
95 |
103 |
104 | ### [Layer 3] 네트워크 계층 (Network Layer)
105 |
106 | 네트워크에서 패킷의 소스-대상 또는 호스트-호스트 사이 논리적 통신을 담당하는 계층
107 |
108 | **기능**
109 |
110 | - 라우팅
111 | 라우터, 게이트웨이를 통해 패킷을 최종 목적지로 라우팅하기 위한 기능
112 | - ARP
113 | 송신 과정에서 수신자의 MAC Address 를 알 수 없는 경우 수신자의 IP와 ARP Address 를 담은 패킷을 네트워크에 뿌리며 수신자의 MAC Address 를 담은 응답을 받는 기능
114 | - 캡슐화
115 | 인터네트워크의 각 장치를 식별하기 위해 발신자와 수신자의 IP 를 네트워크 계층에 의해 헤더에 배치
116 | - 분할
117 |
118 | 큰 패킷을 보다 작은 패킷으로 분할하는 기능
119 |
120 |
121 | **단위 - Packet**
122 |
123 | **키워드**
124 |
125 | > 라우터, IP
126 | >
127 |
128 | ### [Layer 2] 데이터 링크 계층 (Data Link Layer)
129 |
130 | 물리 계층으로 송수신 되는 데이터를 안전하게 전달되도록 처리하는 계층
131 |
132 | **기능**
133 |
134 | - 프레이밍
135 | 관리가능한 네트워크 계층에서 수신되는 비트 스트림이 프레임으로 해당 비트 스트림 분할은 데이터 링크 계층에서 수행
136 | - 흐름제어
137 | 빠른 송신기로 인해 느린 수신기의 트래픽을 방지하기 여분의 비트를 버퍼링하여 흐름제어
138 | - 오류 제어
139 | 프레임 끝부분에 트레일러를 추가하여 프레임의 복제 방지
140 | - 엑세스 제어
141 | 두개 이상의 장치가 해당 링크에 연결된 경우 주어진 시간에 가능한 장치를 결정하는 기능
142 |
143 | **단위 - Frame**
144 |
145 | **키워드**
146 |
147 | > 브릿지, 스위치
148 | >
149 |
150 | ### [Layer 1] 물리 계층 (Physical Layer)
151 |
152 | OSI 의 가장 낮은 계층으로 다른 물리적 컴퓨터로 전기적 신호를 전송하는 계층
153 | 오직 0, 1의 데이터 전송만을 다루는 계층
154 |
155 | **기능**
156 |
157 | - 비트 표현
158 | 데이터 링크 계층의 비트 스트림을 0, 1 신호로 변경하는 기능
159 | - 동기화
160 | 수신기와 송신기의 비트 수준의 동기화를 처리하는 기능
161 |
162 | **단위 - Bit**
163 |
164 | **키워드**
165 |
166 | > 허브, 리피터
167 | >
168 |
169 | ## 질문 리스트
170 |
171 | - OSI 모델과 7 layer 대해서 서술해주세요.
172 |
173 | - 웹 브라우저는 Application Layer 에 속해있나요?
174 |
175 | - TCP 와 UDP 의 차이를 서술해주세요.
176 |
177 | - 네트워크 계층과 전송 계층의 차이를 서술해주세요.
178 |
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a.md:
--------------------------------------------------------------------------------
1 | # TCP / UDP
2 |
3 | ## 🐌 Transport Layer
4 |
5 |
9 |
10 | > **Network VS Transport Layer**
11 | Network Layer는 MAC + IP를 사용하여 구분하므로 Host간의 통신을 책임진다.
12 | Transport Layer는 MAC + IP + Port를 사용하여 구분하므로 Host내의 Process간의 통신을 책임진다.
13 | >
14 |
15 | ## 🎒 배경 지식
16 |
17 | ### Multiplexing / Demultiplexing
18 |
19 | 한개의 Host내의 Process들이 목표 Process에 맞도록 Transport Header를 작성(Multiplexing) / 해석(Demultiplexing)한다.
20 |
21 | > **Socket VS Port**
22 | Port는 OS내부의 Process들이 Networking에 사용할 수 있는 고유한 값이고, Socket은 Process가 Networking을 이용하기 위해서 반드시 사용해야하는 창구이다.
23 | → Socket을 열기 위해서는 Host의 IP, Port, Protocol이 필요하다.
24 | → ☝️ **같은 Process가 같은 Port를 이용해서 여러개의 Socket을 열 수 있다. 즉, Socket ≠ Port.**
25 | >
26 | - RDT Principle
27 |
28 | > 여기의 내용은 추가적인 내용이고, 간략하게 써놓았습니다. 키워드를 통해서 검색하시면 더 자세한 내용을 볼 수 있습니다.
29 | >
30 |
31 |
35 |
36 | - RDT 1.0: 이미 Reliable한 채널을 사용하고 있음. 즉, 이미 Reliable
37 | - RDT 2.0: bit eroor가 있을 수 있는 채널을 사용하고 있음.
38 |
39 | > bit error를 통신으로 어떻게 복구해낼 수 있을까?
40 | >
41 |
42 | → ACK와 NAK를 사용하여 복구
43 |
44 | > 하지만, ACK와 NAK가 손실 / 변형되면 무용지물...
45 | >
46 | - RDT 2.1: ACK와 NAK가 손실될 경우도 처리해보자!
47 |
48 | → sequence number + ACK / NAK
49 |
50 | - RDT 2.2: NAK를 없애고 ACK만 사용해보자
51 | - RDT 3.0: Packet 손실이 있는 경우도 고려해보자!
52 |
53 | → Timer 추가
54 |
55 |
56 | ### Pipelined Protocol
57 |
58 |
62 |
63 | 1. Go Back N
64 | - ACK는 수신자가 그 전의 데이터는 모두 받음을 나타냄
65 | - Timer를 가장 오래된 Packet에 대해서 1개만 작동시킴
66 | - Timer가 만료되면 윈도우의 모든 데이터 재전송
67 |
68 | → n의 크기를 가지는 윈도우를 모두 보내므로 Go Back N이라고 부른다.
69 |
70 | 2. Selective Repeat
71 | - ACK는 개별적인 Packet의 받음을 나타냄
72 | - TImer를 모든 Packet에 대하여 작동시킴
73 | - Timer가 만료되면 해당 Packet만 재전송
74 |
75 | → 선택적으로 재전송 하므로 Selective Repeat라고 부른다.
76 |
77 |
78 | ## ⚡️ UDP(User Datagram Protocol)
79 |
80 |
84 |
85 | ### 특징
86 |
87 | - Lost: 손실이 발생할 수 있음
88 | - Out of Order: 데이터의 순서를 보장하지 않음
89 | - Connectionless: 통신을 따로 맺지않고 데이터를 바로 보냄(No Handshake)
90 | - only Optional Cehcksum: Datagram의 유효성만 Checksum(1이 보수의 합)을 통해서 검증함
91 |
92 | > 검증이 실패하더라도 UDP자체의 Cover X
93 | >
94 | - 1의 보수의 합 with Checksum?
95 |
96 | > 1의 보수는 모든 bit를 not연산 즉, 뒤집어 준 형태이다.
97 | >
98 |
99 | 체크섬 과정
100 |
101 | 1. 모든 데이터(Header + Pseudo Header + Ddata)를 Word단위로 쪼갠후, 더한다.
102 | 2. carry bit를 더한다.
103 | 3. 1의 보수를 취한다.
104 |
105 | → 체크섬을 사용하면 송신측을 만들어 보내고, 수신측은 새로 만들어 같은 값인지 확인한다.
106 |
107 | - Throughput의 제한없이 데이터를 마구 보낼 수 있음
108 | - Overhead가 적음(속도가 빠름)
109 |
110 | → 작은 Header 크기, 쉬운 검증 과정, Connectionless
111 |
112 | - Reliable하게 할 수 없을까?
113 |
114 |
118 |
119 | ARQ(Automatic Repeat reQuest)
120 |
121 | - Sequence Number를 사용하여 순서를 보장하고, ACK를 수신측에서 보냈을 경우만 다음 Sequence를 보냄
122 | - ACK, NACK모두 받지 못하였을 경우에는 Timeout으로 다음 Sequence를 보냄
123 |
124 | → 너무 UDP Segment의 크기가 고정이므로 너무 느린 속도
125 |
126 |
127 | GBN ARQ(Go Back N ARQ)
128 |
129 | - 파이프라인 방식으로 수신측의 ACK를 이용해 윈도우를 이동함
130 |
131 | > ACK는 해당 Sequence까지는 모두 받았음을 확인해주는 역할
132 | >
133 | - 중간 Sequence가 변형 / 손실된 경우 송신측에서 ACK를 받지 못하였으므로 윈도우를 해당 Sequence부터 재시작함
134 | - NACK가 오거나 ACK / NACK가 모두 오지 않으면 손실된 중간 Sequence부터 윈도우를 다시시작, 전송함
135 |
136 | → 윈도우의 범위가 크다면 네트워크 문제 발생시 대량의 데이터를 다시 보내주어야 함
137 |
138 |
139 | SR ARQ(Selective Repeat ARQ)
140 |
141 | - ACK를 순서대로 하지 않고, 중간 Sequence가 비었다면 해당 Sequence만 재전송
142 |
143 | > ACK가 해당 Sequence까지의 확인이 아니라, 해당 Sequence의 확인으로 변경
144 | >
145 |
146 | > Sequence Number Issue
147 | Sequence Number가 무한히 커질 수 없으므로, Circular하게 돌아가면서 발생하는 Issue
148 | 송신측, 수신측의 Window가 다른 곳을 바라보고 있는데 Sequence Number가 같아지면서 Data의 순서가 바뀜
149 | → 따라서, Sequence Number의 최댓값 // 2로 윈도우의 크기를 제한해야 한다(겹치지 않게)
150 | >
151 |
152 | ### UDP Segment 구조
153 |
154 | 
155 |
156 | UDP Segment - 단순
157 |
158 | Source / Destination Port를 기준으로 Demultiplexing이 이루어진다.
159 |
160 | 선택적으로 checksum을 사용하여 데이터의 손실 여부를 파악할 수 있다.
161 |
162 | → 아주 단순한 구조
163 |
164 | > ☝️ TCP / UDP의 Header에는 IP가 담겨있지 않다. 그 이유는 Network Layer에서 IP를 통해서 Networking되어 Host를 찾아왔기 때문에(송신자의 IP도 알고 있음) Transport Layer Protocol에서는 Port정보만 사용한다.
165 | >
166 |
167 | > ☝️ UDP에서 Source Port는 통신에서 직접 사용되지 않는다. Dest Port를 보고 찾아갈 뿐, Source는 수신측에서 정보를 활용하기 위함이다.
168 | >
169 |
170 | ## 🌂 TCP
171 |
172 |
176 |
177 | ### 특징
178 |
179 | - Point to Point: 1대 1통신임
180 | - Reliable: 데이터의 손실이 없음
181 | - In Order Byte Stream: 데이터의 순서를 보장
182 | - Pipelined: 파이프라인 기법을 통해서 최적화
183 | - Full Duplex: 한개의 연결로 양방향 통신이 가능함
184 | - Connection Oriented: 연결을 만들고 통신을 진행함
185 | - Flow Controlled: 송신자의 상태에 따른 데이터 전송량 변화
186 |
187 | ### TCP Segment 구조
188 |
189 | 
191 |
192 | TCP Segment - 복잡
193 | 모두 sender가 사용하는 header이고, ack number / window size는 receiver가 사용할 정보이다.
194 |
195 | Sequence Number를 통해서 현재 Segment의 순서를 나타낸다.
196 |
197 | Acknowledgement Number를 통해서 내(송신자 or 수신자)가 받아야할 다음 Sequence Number를 나타낸다.
198 |
199 | ### 데이터 송 / 수신
200 |
201 | 
203 |
204 | 가장 일반적인 기본 통신과정
205 | seq로 데이터를 보내고, ack에 받을 데이터를 주면 상대가 그에 응답한다.
206 |
207 | ### RTT(TCP Round Trip Time), Timeout
208 |
209 | TCP에서는 RTT에 맞도록 Timeout이 설정된다(timeout을 사용해 ack가 안올 시 다시 전송).
210 |
211 | Timeout은 RTT가 매번 바뀌므로 최근 RTT의 평균값을 이용한다.
212 |
213 | ### Reliable Data Transfer
214 |
215 | > TCP는 Unreliable한 Network환경에서 Reliable한 통신을 만들어내려고 아래와 같은 방법을 사용한다.
216 | >
217 | - Pipelined Segments
218 | - Cumulative Acks(누적되는 Ack)
219 | - Single Retransmission Timer
220 | - Retransmission at: Timeout, Duplicate Ack
221 |
222 | ### Sender 동작 방식
223 |
224 |
228 |
229 | > Go-Back-N의 cummulative ack 방식처럼 중간에 패킷 하나가 빠지면 계속해서 빠진 패킷에 대한 ack을 전송하며, retransmission timer는 하나만 설정한다. 하지만, ****selective repeat 방식처럼 순서에 맞지 않게 온 패킷들도 버퍼에 다 보관해 놓는다.
230 | >
231 |
232 | Sequence를 보내고 Timer을 시작한다.
233 |
234 | - Timeout → 재전송 후 Timer 재시작
235 | - Ack 받음 → 해당 Segment의 Ack를 체크하고, 다른 Segment에 대한 Timer 재시작
236 |
237 | 재전송 시나리오
238 |
239 | 1. Ack 못 받음
240 |
241 | 
242 |
243 | Timeout으로 인한 재전송
244 |
245 | 2. Network 지연
246 |
247 | 
249 |
250 | 수신자가 Ack를 보냈지만, Network지연으로 Timeout이 먼저발생.
251 | 송신자는 나중에 받은 Ack를 통해서 앞의 데이터는 잘 받은걸로 간주하고 그 다음 Sequence부터 전송
252 |
253 | 3. 건너뛴 Ack
254 |
255 | 
257 |
258 | 수신자가 Ack를 보냈지만, 중간 Ack가 유실됨
259 | 송신자는 나중에 받은 Ack를 통해서 앞의 데이터는 잘 받은걸로 간주하고 그 다음 Sequence부터 전송
260 |
261 | 4. 중복된 Ack
262 |
263 | 
265 |
266 | Sender가 보낸 데이터에 대해서 수신자가 못받은 데이터가 있다면 중복된 Ack를 받음.
267 | 3개의 중복된 Ack가 있으면 유실된걸로 판단하고 가장 작은 Sequence(Ack)부터 다시 시작
268 |
269 |
270 | ### Flow Control
271 |
272 | > 수신자가 감당할 만큼의 데이터를 판단하여 Throughput을 조정
273 | >
274 | - Flow Control 방법들
275 |
276 | > 현재 네트워크는 모두 Sliding Window를 사용한다.
277 | >
278 | 1. Stop and Wait
279 |
280 | Sequence Segment 하나씩 보내고, ACK를 확인하는 과정을 반복한다.
281 |
282 | 
283 |
284 | 직관적이고 쉽지만 느리기 때문에 현재 사용되지 않는다.
285 |
286 | 2. Slding Window
287 |
288 | Window를 움직이면서 Pipeline을 형성한다.
289 |
290 | 
291 |
292 | 윈도우를 옮기면서 모두 전송하기 때문에 복잡하지만 효율적이다.
293 |
294 |
295 | Receiver Buffer Overflow
296 |
297 | 
298 |
299 | Receiver
300 |
301 | → Receiver의 Buffer를 Application이 비워주는 속도보다, Sender의 속도가 빠르면 Overflow 발생!
302 |
303 | 
304 |
305 | Receiver Buffer
306 |
307 | 그러므로, Free Buffer Size(rwnd)를 sender에게 보내주어서 sender가 ‘in-flight’(Unacked Segment)를 조정하게 함
308 |
309 | ### Handshake
310 |
311 | > TCP는 연결을 만들어놓고 통신하기 때문에 연결을 끊고 / 맺는 과정(Handshake)을 가진다.
312 | >
313 | - 3 Way Handshake(Opening)
314 |
315 | 
316 |
317 | SYN - SYN_ACK - SYN_ACK_ACK 순으로 이루어진다.
318 |
319 | 1. A가 B에게 SYN bit를 올리고, 랜덤한 seq(a)를 보낸다.
320 | 2. B가 A에게 SYN bit와 ACK bit를 올리고, 랜덤한 seq(b)와 ack(a + 1)를 보낸다.
321 | 3. A가 B에게 ACK bit를 올리고, ack(b + 1)를 보낸다.
322 |
323 | SYN, ACK bit는 SYN과정인지 ACK과정인지 알려주는 용도로 0(False) or 1(True)로 사용한다.
324 |
325 | Seq, Ack는 랜덤한 숫자와, ack = seq + 1을 통해서 이루어진다.
326 |
327 | > 왜 처음 seq가 0이 아니고 랜덤한 숫자죠?
328 | → 이는 seq0부터 시작되어 예측 가능한 점을 이용한 해킹 수법이 있기 때문이라도 한다.
329 | >
330 | - 2 way로 handshake하면 안되나요?
331 |
332 | 안됩니다!
333 | 왜냐하면, 2 way는 segment유실과 network상황 + timer로 인해서 이상하게 연결이 수립되는 경우가 있기 때문입니다.
334 |
335 | 
336 |
337 | 타이머와 엉켜서 반쪽짜리 연결이 수립된다.
338 |
339 | - 4 Way Handshake(Closing)
340 |
341 | 
342 |
343 | FIN - ACK - FIN - ACK로 이루어진다.
344 |
345 | 1. A가 B에게 FIN bit를 올리고, seq를 보낸다.
346 | 2. B가 A에게 ACK bit를 올리고, ack를 보낸다.
347 |
348 | > 여기서 B의 timer가 시작된다.(남은 데이터를 받기 위해서)
349 | 다음 과정 전까지는 데이터를 받으면서 ACK를 보내주면서 통신할 수 있다.
350 | >
351 | 3. B가 A에게 FIN bit를 올리고, seq를 보낸다.
352 |
353 | > 이 과정은 모든 데이터를 받았거나, 3번에서의 timer로 인해서 발생한다.
354 | >
355 | 4. A가 B에게 ACK bit를 올리고, ack를 보낸다.
356 |
357 | > A는 이제부터 원래의 timer의 2배만큼 기다리면서 B의 ack에 맞는 데이터를 보내준다.
358 | B는 더이상 ack나 데이터를 보내지 못하고 받을수만 있다.
359 | >
360 |
361 | ### Congestion Control
362 |
363 |
367 |
368 | - Congestion?
369 |
370 | 
371 |
372 | Router를 사이에둔 host들
373 |
374 | > R = Router의 허용된 네트워크 양
375 | >
376 | 1. Infinite Queue of Router
377 |
378 | 
379 |
380 | 2개의 연결이 있으므로 R/2을 넘을 경우 무한 delay가 발생한다.
381 |
382 | 2. Finite Queue of Router
383 |
384 | 
385 |
386 | Router의 Queue가 꽉차면 버려지므로 TCP가 처리하게 된다.
387 |
388 | > TCP의 관점에서 retransmit을 고려하게 되면, 버려진 packet들은 retransmit이 되는데... retransmit하는 사이에 또 timeout이 되는게 반복되어서 R/2도 못채울 수 있는게 현실이다.
389 | >
390 | - TCP Congestion Control
391 |
392 | > 윈도우 사이즈를 loss가 날때까지 천천히 늘리고, loss가 나면 줄이고를 반복하자.
393 | >
394 | - Slow Start: 윈도우 사이즈를 처음는 천천히 증가하고 나중에는 많이 늘리자.
395 |
396 | > 1 - 2 - 4 ...와 같이 2배씩 증가를 시킨다. 따라서, 나중에는 기하급수적으로 크게 늘어난다.
397 | >
398 | - ssthresh: 윈도우 사이즈 증가를 linear로 바꾸는 시점
399 |
400 | > loss 발생시 발생 지점의 1/2로 설정이됨
401 | >
402 | - RENO 방식
403 | - timeout 발생시: 윈도우를 1로 감소
404 | - 3 duplicate 발생시: 윈도우를 절반으로 감소
405 | - Tahoe 방식
406 | - timeout, 3 duplicate 발생시: 윈도우를 1로 감소
407 |
408 | ## 🙋♂️ 예상 질문
409 |
410 | - UDP와 TCP의 차이점이 무엇인가요?
411 |
412 | UDP와 TCP모두 Transport Layer에서 작동합니다. UDP는 데이터의 전송 여부와 순서를 보장하지 않는 connectionless Protocol입니다. TCP는 데이터의 전송 여부와 순서를 보장하기 위해서 1 대 1로연결을 맺고 통신을 하는 Connection Oriented Protocol입니다.
413 |
414 | - UDP와 TCP를 사용하는 예시를 말해주세요
415 |
416 | UDP는 데이터의 양이 많고 데이터의 중요성이 상대적으로 덜한 곳에서 쓰입니다. 예를 들어서 음악과 비디오의 스트리밍입니다. TCP는 데이터의 중요성이 더한 곳에서 쓰입니다. 예를 들어서 HTTP와 메일이 있습니다.
417 |
418 | - 3 way Handshake와 4 way Handshake에 대해서 설명해주세요
419 |
420 | 3 Way Handshake는 TCP가 연결을 맺기 위해서 사용되는 방법이며, SYN - SYN_ACK - SYN_ACK_ACK순서로 진행됩니다. 간단한 2 Way말고 3 Way를 사용한 이유는 2 Way Handshake시에는 타이머와 네트워크 지연으로 인한 반쪽짜리 연결이 만들어질 수 있기 때문입니다. 4 Way Handshake는 TCP가 연결을 끊을 때 사용하는 방식입니다. FIN - ACK - FIN - ACK순서로 진행됩니다. 연결 시작과 다르게 끊을 때 4 Way인 이유는 아직 전송되지 않은 데이터를 기다리기 위해서입니다.
421 |
422 | - Go Back N과 Selective Repeat는 각 언제 사용될까요?
423 |
424 | Go BAck N과 Selective Repeat는 Sliding Window를 사용할 때 에러 처리 기법입니다. Go Back N은 상대적으로 재전송 되는 데이터의 양이 많기 때문에 전송되는 데이터의 양이 작을 때 유리합니다. Selective Repeaet는 상대적으로 재전송되는 양이 적지만 재전송 되는 데이터의 송신측 에서의 정렬, 다수의 타이머를 사용하면서 부하가 상대적으로 크기 때문에 데이터의 양이 적을 때 유리합니다.
425 |
426 | - QUIC과 HTTP3에 대해서 알고있는걸 말해주세요
427 |
428 | HTTP3(QUIC)은 UDP를 사용함으로써 handshake과정을 없애서 RTT를 없애 속도를 높일 수 있었습니다. 또한, 다중 스트림을 사용하여 TCP에서 loss 발생에 대한 HOL(Head Of Line)을 해결하였습니다.
429 |
430 |
431 | ## 👀 참고
432 |
433 | - TCP / UDP 전반적인 특징
434 |
435 | [[TCP/UDP] TCP와 UDP의 특징과 차이](https://mangkyu.tistory.com/15)
436 |
437 | - Socket VS Port
438 |
439 | [이해가 쉬운 기술 블로그 : 네이버 블로그](https://blog.naver.com/myca11/221389847130)
440 |
441 | - UDP Checksum
442 |
443 | [UDP checksum 계산](https://limjunho.github.io/2021/06/05/UDP-cksum.html)
444 |
445 | - UDP with Reliable
446 |
447 | [Computer Network 7 - UDP](https://heegyukim.medium.com/computer-network-7-udp-86d45323d5c7)
448 |
449 | - TCP seq / ack 과정
450 |
451 | [TCP의 개념 (Transmission Control Protocol)](https://ddongwon.tistory.com/m/84?category=801335)
452 |
453 | - HTTP3(QUIC)
454 |
455 | [HTTP/3의 TCP/UDP 요약](https://json8.tistory.com/70)
456 |
457 | [QUIC 프로토콜](https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=renucs&logNo=220887163028)
458 |
459 | - 학교 수업 자료
460 |
461 | [](http://www.sfu.ca/~ljilja/ENSC835/News/Kurose_Ross/Chapter_3_V7.01.pdf)
462 |
463 | - GBN / SR
464 |
465 | [[네트워크] Go-Back-N, Selective Repeat](https://snoop-study.tistory.com/65)
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 1.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 10.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 11.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 12.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 13.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 13.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 14.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 15.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 15.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 16.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 16.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 2.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 3.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 4.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 5.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 6.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 7.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 8.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 9.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled.png
--------------------------------------------------------------------------------
/Network/로드밸런싱.md:
--------------------------------------------------------------------------------
1 | ## 🌞 로드밸런싱이란?
2 |
3 | 여러 서버의 작업을 분산하여 웹 사이트, 어플리케이션, 데이터베이스 등 서비스의 성능과 안정성을 향상시켜주며 고가용성 인프라의 핵심 구성요소
4 |
5 |
15 |
16 | ### 🌝 이점은?
17 |
18 | 1. **수평 확장**
19 | 고가의 서버로 수직확장하는 것이 아닌 저렴한 다수의 서버를 증설하는 수평확장 가능
20 | 2. **무중단 서비스**
21 | 서버 한대의 장애가 발생하거나 동기적인 작업을 처리하는 경우 다른 서버로 트래픽 분배하여 최종 사용자(End User)에게 영향이 없다
22 | 3. **대량의 트래픽 분배**
23 | 단일 서버에 높은 부하를 수행하지 않고 여러 서버에 작업을 분산하여 적은 양의 작업을 수행하게 하며 장애나 부하가 적은 구성을 경험한다
24 |
25 | ### 🌚 단점은?
26 |
27 | 1. **세션 데이터 관리**
28 | 특정 사용자에 대한 세션을 하나의 서버에 저장하는 경우 추후 다른 서버로 밸런싱된다면 클라이언트의 세션이 유지되지 않으며 부가적인 처리가 필요함
29 |
30 | ### 🤔 유형
31 |
32 | - **하드웨어 로드밸런서**
33 | 애플리케이션과 네트워크 트래픽을 분산하기 위해 물리적 사내 하드웨어 장치에 의존하는 방식
34 | 많은 트래픽을 처리할 수 있지만 가격이 높으며 유연성이 낮음
35 | ex. Switch
36 | - **소프트웨어 로드밸런서**
37 | 사용 또는 오픈소스 어플리케이션을 설치하여 사용하는 방식
38 | 하드웨어 로드밸런서에 비해 가격이 낮습니다.
39 | ex. Nginx, HAProxy
40 |
41 |
42 | ### 🔍 분산 알고리즘
43 |
44 | - **라운드로빈**
45 | 요청에 대하여 서버를 순차적으로 선택하는 알고리즘
46 | 각 서버의 성능과 처리시간이 짧은 어플리케이션에 권장
47 | - **가중 라운드로빈**
48 | 각 서버의 가중치를 부여해 처리 용량을 지정하는 알고리즘
49 | - **최소 연결 방식**
50 | 로드 밸런서가 연결이 가장 적은 서버를 선택하는 알고리즘
51 | 다양한 처리용량(일정하지 않은 응답 속도, 서버의 성능차이)이 발생하는 어플리케이션에 권장
52 | - **IP 해시**
53 | 클라이언트의 IP주소를 특정 서버로 매핑하여 사용자와 항상 동일한 서버의 연결을 보장하는 알고리즘
54 |
55 |
61 |
62 | ### ⭐️ 주요기능
63 |
64 | - **NAT(Network Address Translation) : 네트워크 주소 변환**
65 | 네트워크 계층에서 IP 패킷의 TCP/UDP 포트 숫자와 출발지 및 목적지의 IP 주소 등을 재기록
66 |
67 | 즉 다수의 서버의 사설 IP 를 하나의 공인 IP로 변환해주는 기능
68 |
69 |
72 |
73 | | NAT | Proxy |
74 | | --- | --- |
75 | | 네트워크 계층 | 응용계층 |
76 | | 사설 IP ↔ 공인 IP 역할 | 클라이언트와 서버 사이 중재자 역할 |
77 | | Router 나 방화벽 등 주변 장치에 의해 동작 | DMZ(내부, 외부 네트워크 사이 영역) Zone 에 배치하여 동작 |
78 | | 요청과 응답 사이 네트워크 계층에서 사설 IP 를 공인 IP 로 변경 | 요청과 응답이 Proxy Server 를 거쳐서 전송 |
79 |
80 | - **DSR(Dynamic Source Routing Protocol) : 동적 소스 라우팅 프로토콜**
81 | 서버에서 클라이언트로 요청에 대한 응답을 하는 경우 스위치의 IP가 아닌 클라이언트의 IP를 전달하여 네트워크 스위치를 거치지 않고 바로 클라이언트를 찾음
82 | - Replicated Server 들이 큰 용량의 응답을 보내게 된다면 Client 로 전달전 Load Balancer 에서 병목 현상이 발생
83 | DSR 기능을 사용하여 큰 사이즈의 응답 패킷에 대해서 로드밸런서를 거치지 않고 바로 클라이언트로 전송
84 | - **Tunneling**
85 | 서버와 클라이언트간 중간에서 터널링을 제공
86 | 연결된 상호 간에만 캡슐화된 패킷을 구별하여 캡슐화를 해제
87 |
88 | ### 🛎 종류
89 |
90 |
114 |
115 |
116 | 1. 사용자가 브라우저를 통해 [www.dongmin.dev](http://www.dongmin.dev) 에 접근합니다.
117 | 2. Recursive DNS Server 로 [www.dongmin.dev](http://www.dongmin.dev) 의 IP 주소를 요청합니다.
118 | 3. Recursive DNS Server 레코드에 정보가 없는 경우 Root DNS Server 로 [www.dongmin.dev](http://www.dongmin.dev) IP 주소를 요청합니다.
119 | 4. Root DNS Server 는 요청 받은 도메인의 Top Level Domain(.dev) Name Server 의 IP 주소를 반환합니다.
120 | 5. Recursive DNS Server 는 응답받은 TLD Name Server IP 로 [www.dongmin.dev](http://www.dongmin.dev) IP 주소를 요청합니다.
121 | 6. TLD Name Server 는 [www.dongmin.dev](http://www.dongmin.dev) 에서 dongmin.dev 를 관리하는 Authoritative Name Server 주소를 반환합니다.
122 | 7. 마지막으로 Recursive DNS Server 는 Authoritative Name Server 로 [www.dongmin.dev](http://www.dongmin.dev) IP 주소를 요청합니다.
123 | 8. Authoritative Name Server 는 명시된 레코드에서 도메인을 찾으며 A 레코드에서 찾았다면 해당 IP 주소를 Recursive DNS Server 로 반환합니다.
124 | 9. Authoritative Name Server 로 부터 받은 IP 주소를 Recursive DNS Server 는 TTL 만큼 캐싱하며 브라우저에게 IP 주소를 응답합니다.
125 | 10. 브라우저는 응답받은 IP 주소를 통해 Web Server 에 접근합니다.
126 |
127 | > 💡 DNS 에서 사용하는 전송 프로토콜은 뭘까?
128 | 기본적으로 DNS message 가 512 byte 이하일 경우 UDP 프로토콜을 사용하여 통신하며 zone-transfer, 512 byte 초과시 TCP 프로토콜을 사용하여 통신합니다.
129 |
130 |
131 | > 💡 zone-transfer ?
132 | Master DNS 와 Slave DNS 서버로 이중화가 구성된 경우 발생하는 작업입니다.
133 | 한마디로 Master 서버의 Zone(도메인과 IP 매핑 정보) 파일을 Slave 서버로 최신화하는 작업입니다.
134 |
135 |
136 | ## 참고자료
137 |
138 | [DNS Process](https://www.cloudflare.com/ko-kr/learning/dns/dns-server-types/)
139 |
140 | [Root Domain](https://raventools.com/marketing-glossary/root-domain/)
141 |
142 | [Name Server 종류](https://www.dynu.com/en-US/Blog/Article?Article=DNS-Servers-Authoritative-Recursive-Root-TLD)
143 |
144 | [Domain 체계](https://better-together.tistory.com/128)
145 |
146 | [Second-level domain](https://en.wikipedia.org/wiki/Second-level_domain)
147 |
148 | [ccTLD](https://www.affde.com/ko/what-is-a-cctld.html)
149 |
150 | [DNS 512 byte UDP](https://serverfault.com/questions/587625/why-dns-through-udp-has-a-512-bytes-limit)
--------------------------------------------------------------------------------
/Network/HTTP,HTTPS.md:
--------------------------------------------------------------------------------
1 | # HTTP, HTTPS
2 |
3 | ](https://mdn.mozillademos.org/files/13677/Fetching_a_page.png)
4 |
5 | 출처 : [MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
6 |
7 | ## HTTP(HyperTextTransferProtocol)
8 |
9 | HTML과 같은 하이퍼미디어 문서를 전송하기 위한 어플리케이션 레이어 프로토콜입니다.
10 |
11 | HTTP는 비연결성의 무상태 프로토콜이며 서버/클라이언트 모델을 따라 데이터를 주고 받고, 기본 포트로 80번 포트를 사용합니다.
12 |
13 | ### HTTP 버전별 기능
14 |
15 | - HTTP/0.9
16 | - HTTP의 가장 초기 버전으로 원래는 버전 번호가 없는데 구분을 위해 향후 붙였다고 합니다
17 | - 헤더 없이 단순히 HTML 파일만 전송하며, GET 메소드만 사용 가능
18 | - HTTP/1.0 – 확장성 만들기
19 | - 헤더를 통해 HTTP 버전 코드를 송신하고, 상태 코드를 회신 받을 수 있게 되었습니다.
20 | - 헤더의 Content-Type을 통해 HTML이 아닌 형태도 전송 가능해졌습니다. (문자열 전송)
21 | - 사용가능한 메서드: GET, POST, PUT
22 | - HTTP/1.1 (표준 프로토콜)
23 | - Keep Alive로 커넥션이 재사용 될 수 있도록 개선되었습니다.
24 | - Host 헤더가 추가되어 동일 IP 주소에 다른 도메인을 호스트하는 기능이 서버 코로케이션을 가능하게 했습니다.
25 | - 사용가능한 메서드: OPTIONS, GET, HEAD, POST, PUT, DELETE, TRACE
26 | - HTTP/2 – 더 나은 성능을 위한 프로토콜
27 | - 2015년에 발표됨, 구글의 SPDY를 기반으로 표준화 되었습니다.
28 | - 문자열 전송 기반이 아닌 이진 데이터 전송 기반으로, 스트림, 메시지 및 프레임으로 데이터 교환 방식이 변경됨
29 | - 스트림: 구성된 연결 내에서 전달되는 바이트의 양방향 흐름이며, 하나 이상의 메세지가 전달 가능함(request or response는 하나의 메시지)
30 | - 메시지: 논리적 요청 또는 응답 메시지에 매핑되는 프레임의 전체 시퀀스
31 | - 프레임: http/2.0에서 통신의 최소 단위, 각 최소 단위에는 하나의 프라임 헤더가 포함된다. 이 프라임 헤더는 최소한으로 프레임이 속하는 스트림을 식별한다. Headers Type Frame, Data Type Frame이 존재한다.
32 | - 주요 스팩
33 | - HTTP Header Data Compression (HTTP 헤더 데이터 압축)
34 |
35 | 이전 Header의 중복되는 필드를 재전송하지 않아서 데이터를 절약하고, HPACK이라는 Header 압축방식을 이용하여 데이터 전송 효율을 높였다.
36 |
37 | - Server Push
38 |
39 | 클라이언트가 요청 하지 않은 JavaScript, CSS, Font, 이미지 파일 등과 같이 필요하게 될 특정 파일들을 서버에서 단일 HTTP 요청 응답으로 전송 가능하게 한다.
40 |
41 | - HOL(Head-of-Line) 문제 해결
42 |
43 | HTTP/1.1 까지는 한번에 하나의 파일만 전송이 가능했었지만, 여러 파일을 한번에 병렬 전송할 수 있께 개선되었다.
44 |
45 | - Stream 우선순위
46 |
47 | HTTP 메시지가 많은 개별 프레임으로 분할될 수 있고 여러 스트림의 프레임을 다중화(Multiplexing)할 수 있게 되면서, 스트림들의 우선순위를 지정할 필요가 생겼다. 클라이언트는 우선순위 지정을 위해 ‘우선순위 지정 트리'를 사용하여 서버의 스트림처리 우선순위를 지정할 수 있다. 서버는 우선순위가 높은 응답이 클라이언트에 우선적으로 전달될 수 있도록 대역폭을 설정한다.
48 |
49 |
50 | - HTTP/3
51 | - QUIC(Quick UDP Internet Connections) 프로토콜 사용, UDP를 사용한다.
52 | - 클라이언트의 IP가 바뀌어도 연결이 유지됨, (ex)와이파이에서 LTE로 전환할때)
53 |
54 | ### HTTP 구성요소
55 |
56 | - HTTP는 요청(Request)와 응답(Response)로 구성되어 있다.
57 | - 시작줄, 헤더, 바디로 이루어져있다.
58 | - **요청**
59 |
60 | ](https://mdn.mozillademos.org/files/13687/HTTP_Request.png)
61 | 출처: [MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
62 |
63 | 시작줄에 수행하고자 하는 메서드, HTTP 버전과 같은 프로토콜이 표시된다.
64 |
65 | 헤더에는 가져오려는 리소스의 경로; 예를 들면 [프로토콜](https://developer.mozilla.org/ko/docs/Glossary/Protocol) (`http://`), [도메인 (en-US)](https://developer.mozilla.org/en-US/docs/Glossary/Domain) (여기서는 `developer.mozilla.org`), 또는 TCP [포트 (en-US)](https://developer.mozilla.org/en-US/docs/Glossary/Port) (여기서는 `80`)인 요소들을 제거한 리소스의 URL입니다.
66 |
67 | > 그 이외에 추가하고자 하는 헤더, POST의 경우 body가 들어감
68 | >
69 | - **응답**
70 | ](https://mdn.mozillademos.org/files/13691/HTTP_Response.png)
71 | 출처: [MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
72 | - 시작줄에 HTTP 프로토콜 버전, 상태코드와 메시지가 표시된다.
73 | - 그 이외에 각종 헤더들이 들어가고, 요청에 맞는 리소스가 body에 포함되기도 한다.
74 |
75 | ## HTTPS (Hyper Text Transfer Protocol Secure)
76 |
77 | 말 그대로 HTTP에 Secure, 보안이 추가된 프로토콜이며 443번을 기본 포트로 사용한다. 클라이언트와 서버간의 모든 커뮤니케이션을 암호화 하기 위해 SSL / TLS 를 사용한다.
78 |
79 | ### 대칭키와 비대칭키(공개키)
80 |
81 | **대칭키**의 경우에는 암호화, 복호화에 사용하는 키가 동일하고 속도가 빠른 대신 키를 교환 해야 하기 때문에 탈취 관리를 해야하고, 기밀성을 제공하지만 무결성/인증을 보장하지 않는다.
82 |
83 | **비대칭키(공개키)**는 암복호화에 사용하는 키가 서로 다르며 속도가 느린 대신 , 기밀성, 무결성,인증 기능이 모두 제공된다. 대표적으로 RSA가 있다.
84 |
85 | ### 공개키와 비밀키 (Public Key Private Key )
86 |
87 | 비대칭키로 공개키와 비밀키를 사용하는데 다음과 같다.
88 |
89 | 1) 공개키로 암호화 하면 개인키로만 복호화 가능하다
90 |
91 | 2) 개인키로 암호화 하면 공개키로만 복호화가 가능하다.
92 |
93 | 따라서 1)의 경우 개인키를 가지고 있어야만 볼 수 있고, 2)의 경우 공개키로 복호화가 된다면 해당 정보에 대한 신뢰성이 보장된다.
94 |
95 | ### TSL / SSL
96 |
97 | 암호화를 담당하는 프로토콜, HTTPS에서 사용됨
98 |
99 | **SSL (Secure Scoket Layer)**
100 |
101 | - HTTP와 독립된 프로토콜로 HTTP 외에도 다방면으로 사용되고 있습니다.
102 | - 두 통신 사이에 핸드셰이크를 통해 인증 프로세스가 진행됨
103 |
104 | **TLS (Transport Layer Security)**
105 |
106 | - TLS는 SSL 3.0을 기초로 해서 IETF가 만든 프로토콜이다. (TLS 1.0 == SSL3.1)
107 | - SSL과 거의 동일하다고 생각하면 됨
108 |
109 | ### HTTPS 동작과정(SSL)
110 |
111 | 서버는 클라이언트가 요청을 보낼 때 암호화를 하기 위한 공개키를 생성해야 하는데, 일반적으로는 인증된 기관(Certificate Authority) 에 공개키를 전송하여 인증서를 발급받고 있다. 자세한 과정은 다음과 같다.
112 |
113 | - 공개키 암호화 방식과 대칭키 암호화 방식의 장점을 활용해 하이브리드 사용
114 | - 데이터를 대칭키 방식으로 암복호화하고, 공개키 방식으로 대칭키 전달
115 | 1. **클라이언트가 서버 접속하여 Handshaking 과정에서 서로 탐색**
116 |
117 | 1.1. **Client Hello**
118 |
119 | - 클라이언트가 서버에게 전송할 데이터
120 | - 클라이언트 측에서 생성한 **랜덤 데이터**
121 | - 클-서 암호화 방식 통일을 위해 **클라이언트가 사용할 수 있는 암호화 방식**
122 | - 이전에 이미 Handshaking 기록이 있다면 자원 절약을 위해 기존 세션을 재활용하기 위한 **세션 아이디**
123 |
124 | 1.2. **Server Hello**
125 |
126 | - Client Hello에 대한 응답으로 전송할 데이터
127 | - 서버 측에서 생성한 **랜덤 데이터**
128 | - **서버가 선택한 클라이언트의 암호화 방식**
129 | - **SSL 인증서**
130 |
131 | 1.3. **Client 인증 확인**
132 |
133 | - 서버로부터 받은 인증서가 CA에 의해 발급되었는지 본인이 가지고 있는 목록에서 확인하고, 목록에 있다면 CA 공개키로 인증서 복호화
134 | - 클-서 각각의 랜덤 데이터를 조합하여 pre master secret 값 생성(데이터 송수신 시 대칭키 암호화에 사용할 키)
135 | - pre master secret 값을 공개키 방식으로 서버 전달(공개키는 서버로부터 받은 인증서에 포함)
136 | - 일련의 과정을 거쳐 session key 생성
137 |
138 | 1.4. **Server 인증 확인**
139 |
140 | - 서버는 비공개키로 복호화하여 pre master secret 값 취득(대칭키 공유 완료)
141 | - 일련의 과정을 거쳐 session key 생성
142 |
143 | 1.5. **Handshaking 종료**
144 |
145 | 2. **데이터 전송**
146 | - 서버와 클라이언트는 session key를 활용해 데이터를 암복호화하여 데이터 송수신
147 | 3. **연결 종료 및 session key 폐기**
148 |
149 |
150 |
151 | ## 참고자료
152 |
153 | - HTTP 버전
154 |
155 | [HTTP의 진화 - HTTP | MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP)
156 |
157 | [HTTP](https://itwiki.kr/w/HTTP)
158 |
159 | [HTTP/1.1, /2, /3 의 차이점](https://velog.io/@zzzz465/HTTP1.1-2-3-%EC%9D%98-%EC%B0%A8%EC%9D%B4%EC%A0%90)
160 |
161 | [[CS/Network] HTTP 버전 별 특징](https://koonii.tistory.com/m/21)
162 |
163 | - HTTP 구성요소
164 |
165 | [HTTP 개요 - HTTP | MDN](https://developer.mozilla.org/ko/docs/Web/HTTP/Overview)
166 |
167 | - HTTPS와 TSL/SSL
168 |
169 | [](https://velog.io/@moonyoung/HTTPS%EC%9D%98-%EC%9B%90%EB%A6%AC)
170 |
171 | [HTTPS 와 SSL(TLS)](https://futurecreator.github.io/2018/07/12/https-and-ssl-tls/)
172 |
173 | [✔ SSL/TLS 보안](https://velog.io/@saseungmin/SSLTLS-%EB%B3%B4%EC%95%88)
174 |
175 | [대칭키 vs 공개키(비대칭키)](https://velog.io/@gs0351/%EB%8C%80%EC%B9%AD%ED%82%A4-vs-%EA%B3%B5%EA%B0%9C%ED%82%A4%EB%B9%84%EB%8C%80%EC%B9%AD%ED%82%A4)
176 |
177 | [✔ SSL/TLS 보안](https://velog.io/@saseungmin/SSLTLS-%EB%B3%B4%EC%95%88)
178 |
179 | [tech-interview/network.md at master · WeareSoft/tech-interview](https://github.com/WeareSoft/tech-interview/blob/master/contents/network.md)
180 |
181 | - HTTP 2.0
182 |
183 | [HTTP/2(HTTP 2.0) 정리](https://velog.io/@taesunny/HTTP2HTTP-2.0-%EC%A0%95%EB%A6%AC)
184 |
185 | [HTTP/2 소개 | Web Fundamentals | Google Developers](https://developers.google.com/web/fundamentals/performance/http2?hl=ko)
--------------------------------------------------------------------------------
/Network/OSI 7 계층.md:
--------------------------------------------------------------------------------
1 | ## OSI(Open Systems Interconnection) 모델이란?
2 |
3 | 컴퓨터 시스템이 네트워크를 통해 통신하며 사용하는 7개의 계층으로 국제 통신 표준 규약
4 |
5 | 
6 |
7 | OSI 7계층 데이터 전송 흐름
8 |
9 | ## 기능
10 |
11 | ### [**Layer 7] 응용 계층 (Application Layer)**
12 |
13 | OSI 모델의 최상위 계층으로 통신의 최종 목적지로 다양한 프로토콜
14 |
15 | **기능**
16 |
17 | - Network Virtual Terminal
18 | 어플리케이션은 원격 호스트의 에뮬레이션을 생성하여 사용자가 원격 호스트에 log on 하는 기능
19 | 사용자의 컴퓨터 ↔ 소프트웨어 터미널 ↔ 호스트 형식의 통신
20 | - Directory Service
21 | 다양한 전역 정보에 대한 엑세스 기능
22 | - File Transfer Access and Management(FTAM)
23 | 파일에 엑세스하고 파일을 관리하는 표준 메커니즘
24 | 원격 컴퓨터의 파일에 엑세스 및 관리, 검색 기능
25 | - Mail Service
26 |
27 | **단위 - Data**
28 |
29 | **키워드**
30 |
31 | > HTTP, FTP, SMTP, Telnet 등
32 | >
33 |
34 | ### [Layer 6] 표현 계층 (Presentation Layer)
35 |
36 | 응용 계층으로부터 전송 받거나 전송해야되는 데이터를 인코딩, 디코딩 하는 계층
37 | 암호화 복호화 작업도 해당 계층에서 이루어짐
38 |
39 | **기능**
40 |
41 | - 번역
42 | 네트워크에 필요한 형식과 어플리케이션의 데이터의 형식 변환 기능
43 | 송신 데이터 → 비트 스트림 (인코딩)
44 | 수신 데이터 → 문자 및 숫자 (디코딩)
45 | - 암호화
46 | 송신기에서 암호화, 수신기에서 복호화 작업을 수행하는 기능
47 | - 압축
48 | 대역폭을 줄이기 위해 데이터를 압축하는 기능
49 | 오디오, 비디오, 텍스트 등 멀티미디어 전송에 중요하며 0으로 전송되는 비트의 수를 줄이는 역할
50 |
51 | **단위 - Data**
52 |
53 | **키워드**
54 |
55 | > ASCII, JPEG, MPEG 등
56 | >
57 |
58 | ### [Layer 5] 세션 계층 (Session Layer)
59 |
60 | 통신하는 호스트 사이 세션 설정 및 유지 및 동기화를 처리하는 계층
61 | **기능**
62 |
63 | - 동기화
64 | 통신하는 메세지 스트림에 대해 동기화 지점으로 체크포인트를 추가하며 세션이 중단되면 체크포인트를 통해 데이터 전송을 재개할 수 있는 기능
65 | - 토큰 관리
66 | 각 사용자가 중요한 작업을 동시에 엑세스하는 것을 방지하기 위한 기능
67 | - Dialog Control
68 | 두 시스템이 반이중, 전이중으로 서로 통신을 시작할 수 있도록 설정하는 기능
69 |
70 | **단위 - Data**
71 |
72 | ### [Layer 4] 전송 계층 (Transport Layer)
73 |
74 | 송신 과정은 상위 계층에서 전달받은 데이터를 더 작은 조각(Segment, Databram)으로 분할하여 네트워크 계층으로 전달하며 수신 과정은 분할된 조각(Segment, Databram)을 재조립하는 프로세스간 논리적 통신을 수행하는 계층
75 | 데이터가 잘못 수신되었는지 확인하며 다시 요청하는 오류 제어 기능을 수행
76 |
77 | **기능**
78 |
79 | - Service Point Addressing
80 | 해당 Layer header 에 서비스 포인트 주소인 포트번호를 포함하여 올바른 프로세스로 메세지를 전달하는 기능
81 | - 분할 및 재조립
82 | 메세지는 시퀀스 번호가 포함되어 있는 세그먼트 형태로 분할
83 | 세그먼트의 시퀀스 번호를 통해 메세지 재조립
84 | - 흐름 제어
85 | 종단간(end-to-end) 신뢰성있는 메세지 전달을 보장하는 기능
86 | - 오류 제어
87 | 수신 과정에서 메세지가 오류 없이 전달 받았는지 확인하는 기능
88 |
89 | **단위 - Segment(TCP), Datagram(UDP)**
90 |
91 | **키워드**
92 |
93 | > TCP, UDP
94 |
95 |
103 |
104 | ### [Layer 3] 네트워크 계층 (Network Layer)
105 |
106 | 네트워크에서 패킷의 소스-대상 또는 호스트-호스트 사이 논리적 통신을 담당하는 계층
107 |
108 | **기능**
109 |
110 | - 라우팅
111 | 라우터, 게이트웨이를 통해 패킷을 최종 목적지로 라우팅하기 위한 기능
112 | - ARP
113 | 송신 과정에서 수신자의 MAC Address 를 알 수 없는 경우 수신자의 IP와 ARP Address 를 담은 패킷을 네트워크에 뿌리며 수신자의 MAC Address 를 담은 응답을 받는 기능
114 | - 캡슐화
115 | 인터네트워크의 각 장치를 식별하기 위해 발신자와 수신자의 IP 를 네트워크 계층에 의해 헤더에 배치
116 | - 분할
117 |
118 | 큰 패킷을 보다 작은 패킷으로 분할하는 기능
119 |
120 |
121 | **단위 - Packet**
122 |
123 | **키워드**
124 |
125 | > 라우터, IP
126 | >
127 |
128 | ### [Layer 2] 데이터 링크 계층 (Data Link Layer)
129 |
130 | 물리 계층으로 송수신 되는 데이터를 안전하게 전달되도록 처리하는 계층
131 |
132 | **기능**
133 |
134 | - 프레이밍
135 | 관리가능한 네트워크 계층에서 수신되는 비트 스트림이 프레임으로 해당 비트 스트림 분할은 데이터 링크 계층에서 수행
136 | - 흐름제어
137 | 빠른 송신기로 인해 느린 수신기의 트래픽을 방지하기 여분의 비트를 버퍼링하여 흐름제어
138 | - 오류 제어
139 | 프레임 끝부분에 트레일러를 추가하여 프레임의 복제 방지
140 | - 엑세스 제어
141 | 두개 이상의 장치가 해당 링크에 연결된 경우 주어진 시간에 가능한 장치를 결정하는 기능
142 |
143 | **단위 - Frame**
144 |
145 | **키워드**
146 |
147 | > 브릿지, 스위치
148 | >
149 |
150 | ### [Layer 1] 물리 계층 (Physical Layer)
151 |
152 | OSI 의 가장 낮은 계층으로 다른 물리적 컴퓨터로 전기적 신호를 전송하는 계층
153 | 오직 0, 1의 데이터 전송만을 다루는 계층
154 |
155 | **기능**
156 |
157 | - 비트 표현
158 | 데이터 링크 계층의 비트 스트림을 0, 1 신호로 변경하는 기능
159 | - 동기화
160 | 수신기와 송신기의 비트 수준의 동기화를 처리하는 기능
161 |
162 | **단위 - Bit**
163 |
164 | **키워드**
165 |
166 | > 허브, 리피터
167 | >
168 |
169 | ## 질문 리스트
170 |
171 | - OSI 모델과 7 layer 대해서 서술해주세요.
172 |
173 | - 웹 브라우저는 Application Layer 에 속해있나요?
174 |
175 | - TCP 와 UDP 의 차이를 서술해주세요.
176 |
177 | - 네트워크 계층과 전송 계층의 차이를 서술해주세요.
178 |
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a.md:
--------------------------------------------------------------------------------
1 | # TCP / UDP
2 |
3 | ## 🐌 Transport Layer
4 |
5 |
9 |
10 | > **Network VS Transport Layer**
11 | Network Layer는 MAC + IP를 사용하여 구분하므로 Host간의 통신을 책임진다.
12 | Transport Layer는 MAC + IP + Port를 사용하여 구분하므로 Host내의 Process간의 통신을 책임진다.
13 | >
14 |
15 | ## 🎒 배경 지식
16 |
17 | ### Multiplexing / Demultiplexing
18 |
19 | 한개의 Host내의 Process들이 목표 Process에 맞도록 Transport Header를 작성(Multiplexing) / 해석(Demultiplexing)한다.
20 |
21 | > **Socket VS Port**
22 | Port는 OS내부의 Process들이 Networking에 사용할 수 있는 고유한 값이고, Socket은 Process가 Networking을 이용하기 위해서 반드시 사용해야하는 창구이다.
23 | → Socket을 열기 위해서는 Host의 IP, Port, Protocol이 필요하다.
24 | → ☝️ **같은 Process가 같은 Port를 이용해서 여러개의 Socket을 열 수 있다. 즉, Socket ≠ Port.**
25 | >
26 | - RDT Principle
27 |
28 | > 여기의 내용은 추가적인 내용이고, 간략하게 써놓았습니다. 키워드를 통해서 검색하시면 더 자세한 내용을 볼 수 있습니다.
29 | >
30 |
31 |
35 |
36 | - RDT 1.0: 이미 Reliable한 채널을 사용하고 있음. 즉, 이미 Reliable
37 | - RDT 2.0: bit eroor가 있을 수 있는 채널을 사용하고 있음.
38 |
39 | > bit error를 통신으로 어떻게 복구해낼 수 있을까?
40 | >
41 |
42 | → ACK와 NAK를 사용하여 복구
43 |
44 | > 하지만, ACK와 NAK가 손실 / 변형되면 무용지물...
45 | >
46 | - RDT 2.1: ACK와 NAK가 손실될 경우도 처리해보자!
47 |
48 | → sequence number + ACK / NAK
49 |
50 | - RDT 2.2: NAK를 없애고 ACK만 사용해보자
51 | - RDT 3.0: Packet 손실이 있는 경우도 고려해보자!
52 |
53 | → Timer 추가
54 |
55 |
56 | ### Pipelined Protocol
57 |
58 |
62 |
63 | 1. Go Back N
64 | - ACK는 수신자가 그 전의 데이터는 모두 받음을 나타냄
65 | - Timer를 가장 오래된 Packet에 대해서 1개만 작동시킴
66 | - Timer가 만료되면 윈도우의 모든 데이터 재전송
67 |
68 | → n의 크기를 가지는 윈도우를 모두 보내므로 Go Back N이라고 부른다.
69 |
70 | 2. Selective Repeat
71 | - ACK는 개별적인 Packet의 받음을 나타냄
72 | - TImer를 모든 Packet에 대하여 작동시킴
73 | - Timer가 만료되면 해당 Packet만 재전송
74 |
75 | → 선택적으로 재전송 하므로 Selective Repeat라고 부른다.
76 |
77 |
78 | ## ⚡️ UDP(User Datagram Protocol)
79 |
80 |
84 |
85 | ### 특징
86 |
87 | - Lost: 손실이 발생할 수 있음
88 | - Out of Order: 데이터의 순서를 보장하지 않음
89 | - Connectionless: 통신을 따로 맺지않고 데이터를 바로 보냄(No Handshake)
90 | - only Optional Cehcksum: Datagram의 유효성만 Checksum(1이 보수의 합)을 통해서 검증함
91 |
92 | > 검증이 실패하더라도 UDP자체의 Cover X
93 | >
94 | - 1의 보수의 합 with Checksum?
95 |
96 | > 1의 보수는 모든 bit를 not연산 즉, 뒤집어 준 형태이다.
97 | >
98 |
99 | 체크섬 과정
100 |
101 | 1. 모든 데이터(Header + Pseudo Header + Ddata)를 Word단위로 쪼갠후, 더한다.
102 | 2. carry bit를 더한다.
103 | 3. 1의 보수를 취한다.
104 |
105 | → 체크섬을 사용하면 송신측을 만들어 보내고, 수신측은 새로 만들어 같은 값인지 확인한다.
106 |
107 | - Throughput의 제한없이 데이터를 마구 보낼 수 있음
108 | - Overhead가 적음(속도가 빠름)
109 |
110 | → 작은 Header 크기, 쉬운 검증 과정, Connectionless
111 |
112 | - Reliable하게 할 수 없을까?
113 |
114 |
118 |
119 | ARQ(Automatic Repeat reQuest)
120 |
121 | - Sequence Number를 사용하여 순서를 보장하고, ACK를 수신측에서 보냈을 경우만 다음 Sequence를 보냄
122 | - ACK, NACK모두 받지 못하였을 경우에는 Timeout으로 다음 Sequence를 보냄
123 |
124 | → 너무 UDP Segment의 크기가 고정이므로 너무 느린 속도
125 |
126 |
127 | GBN ARQ(Go Back N ARQ)
128 |
129 | - 파이프라인 방식으로 수신측의 ACK를 이용해 윈도우를 이동함
130 |
131 | > ACK는 해당 Sequence까지는 모두 받았음을 확인해주는 역할
132 | >
133 | - 중간 Sequence가 변형 / 손실된 경우 송신측에서 ACK를 받지 못하였으므로 윈도우를 해당 Sequence부터 재시작함
134 | - NACK가 오거나 ACK / NACK가 모두 오지 않으면 손실된 중간 Sequence부터 윈도우를 다시시작, 전송함
135 |
136 | → 윈도우의 범위가 크다면 네트워크 문제 발생시 대량의 데이터를 다시 보내주어야 함
137 |
138 |
139 | SR ARQ(Selective Repeat ARQ)
140 |
141 | - ACK를 순서대로 하지 않고, 중간 Sequence가 비었다면 해당 Sequence만 재전송
142 |
143 | > ACK가 해당 Sequence까지의 확인이 아니라, 해당 Sequence의 확인으로 변경
144 | >
145 |
146 | > Sequence Number Issue
147 | Sequence Number가 무한히 커질 수 없으므로, Circular하게 돌아가면서 발생하는 Issue
148 | 송신측, 수신측의 Window가 다른 곳을 바라보고 있는데 Sequence Number가 같아지면서 Data의 순서가 바뀜
149 | → 따라서, Sequence Number의 최댓값 // 2로 윈도우의 크기를 제한해야 한다(겹치지 않게)
150 | >
151 |
152 | ### UDP Segment 구조
153 |
154 | 
155 |
156 | UDP Segment - 단순
157 |
158 | Source / Destination Port를 기준으로 Demultiplexing이 이루어진다.
159 |
160 | 선택적으로 checksum을 사용하여 데이터의 손실 여부를 파악할 수 있다.
161 |
162 | → 아주 단순한 구조
163 |
164 | > ☝️ TCP / UDP의 Header에는 IP가 담겨있지 않다. 그 이유는 Network Layer에서 IP를 통해서 Networking되어 Host를 찾아왔기 때문에(송신자의 IP도 알고 있음) Transport Layer Protocol에서는 Port정보만 사용한다.
165 | >
166 |
167 | > ☝️ UDP에서 Source Port는 통신에서 직접 사용되지 않는다. Dest Port를 보고 찾아갈 뿐, Source는 수신측에서 정보를 활용하기 위함이다.
168 | >
169 |
170 | ## 🌂 TCP
171 |
172 |
176 |
177 | ### 특징
178 |
179 | - Point to Point: 1대 1통신임
180 | - Reliable: 데이터의 손실이 없음
181 | - In Order Byte Stream: 데이터의 순서를 보장
182 | - Pipelined: 파이프라인 기법을 통해서 최적화
183 | - Full Duplex: 한개의 연결로 양방향 통신이 가능함
184 | - Connection Oriented: 연결을 만들고 통신을 진행함
185 | - Flow Controlled: 송신자의 상태에 따른 데이터 전송량 변화
186 |
187 | ### TCP Segment 구조
188 |
189 | 
191 |
192 | TCP Segment - 복잡
193 | 모두 sender가 사용하는 header이고, ack number / window size는 receiver가 사용할 정보이다.
194 |
195 | Sequence Number를 통해서 현재 Segment의 순서를 나타낸다.
196 |
197 | Acknowledgement Number를 통해서 내(송신자 or 수신자)가 받아야할 다음 Sequence Number를 나타낸다.
198 |
199 | ### 데이터 송 / 수신
200 |
201 | 
203 |
204 | 가장 일반적인 기본 통신과정
205 | seq로 데이터를 보내고, ack에 받을 데이터를 주면 상대가 그에 응답한다.
206 |
207 | ### RTT(TCP Round Trip Time), Timeout
208 |
209 | TCP에서는 RTT에 맞도록 Timeout이 설정된다(timeout을 사용해 ack가 안올 시 다시 전송).
210 |
211 | Timeout은 RTT가 매번 바뀌므로 최근 RTT의 평균값을 이용한다.
212 |
213 | ### Reliable Data Transfer
214 |
215 | > TCP는 Unreliable한 Network환경에서 Reliable한 통신을 만들어내려고 아래와 같은 방법을 사용한다.
216 | >
217 | - Pipelined Segments
218 | - Cumulative Acks(누적되는 Ack)
219 | - Single Retransmission Timer
220 | - Retransmission at: Timeout, Duplicate Ack
221 |
222 | ### Sender 동작 방식
223 |
224 |
228 |
229 | > Go-Back-N의 cummulative ack 방식처럼 중간에 패킷 하나가 빠지면 계속해서 빠진 패킷에 대한 ack을 전송하며, retransmission timer는 하나만 설정한다. 하지만, ****selective repeat 방식처럼 순서에 맞지 않게 온 패킷들도 버퍼에 다 보관해 놓는다.
230 | >
231 |
232 | Sequence를 보내고 Timer을 시작한다.
233 |
234 | - Timeout → 재전송 후 Timer 재시작
235 | - Ack 받음 → 해당 Segment의 Ack를 체크하고, 다른 Segment에 대한 Timer 재시작
236 |
237 | 재전송 시나리오
238 |
239 | 1. Ack 못 받음
240 |
241 | 
242 |
243 | Timeout으로 인한 재전송
244 |
245 | 2. Network 지연
246 |
247 | 
249 |
250 | 수신자가 Ack를 보냈지만, Network지연으로 Timeout이 먼저발생.
251 | 송신자는 나중에 받은 Ack를 통해서 앞의 데이터는 잘 받은걸로 간주하고 그 다음 Sequence부터 전송
252 |
253 | 3. 건너뛴 Ack
254 |
255 | 
257 |
258 | 수신자가 Ack를 보냈지만, 중간 Ack가 유실됨
259 | 송신자는 나중에 받은 Ack를 통해서 앞의 데이터는 잘 받은걸로 간주하고 그 다음 Sequence부터 전송
260 |
261 | 4. 중복된 Ack
262 |
263 | 
265 |
266 | Sender가 보낸 데이터에 대해서 수신자가 못받은 데이터가 있다면 중복된 Ack를 받음.
267 | 3개의 중복된 Ack가 있으면 유실된걸로 판단하고 가장 작은 Sequence(Ack)부터 다시 시작
268 |
269 |
270 | ### Flow Control
271 |
272 | > 수신자가 감당할 만큼의 데이터를 판단하여 Throughput을 조정
273 | >
274 | - Flow Control 방법들
275 |
276 | > 현재 네트워크는 모두 Sliding Window를 사용한다.
277 | >
278 | 1. Stop and Wait
279 |
280 | Sequence Segment 하나씩 보내고, ACK를 확인하는 과정을 반복한다.
281 |
282 | 
283 |
284 | 직관적이고 쉽지만 느리기 때문에 현재 사용되지 않는다.
285 |
286 | 2. Slding Window
287 |
288 | Window를 움직이면서 Pipeline을 형성한다.
289 |
290 | 
291 |
292 | 윈도우를 옮기면서 모두 전송하기 때문에 복잡하지만 효율적이다.
293 |
294 |
295 | Receiver Buffer Overflow
296 |
297 | 
298 |
299 | Receiver
300 |
301 | → Receiver의 Buffer를 Application이 비워주는 속도보다, Sender의 속도가 빠르면 Overflow 발생!
302 |
303 | 
304 |
305 | Receiver Buffer
306 |
307 | 그러므로, Free Buffer Size(rwnd)를 sender에게 보내주어서 sender가 ‘in-flight’(Unacked Segment)를 조정하게 함
308 |
309 | ### Handshake
310 |
311 | > TCP는 연결을 만들어놓고 통신하기 때문에 연결을 끊고 / 맺는 과정(Handshake)을 가진다.
312 | >
313 | - 3 Way Handshake(Opening)
314 |
315 | 
316 |
317 | SYN - SYN_ACK - SYN_ACK_ACK 순으로 이루어진다.
318 |
319 | 1. A가 B에게 SYN bit를 올리고, 랜덤한 seq(a)를 보낸다.
320 | 2. B가 A에게 SYN bit와 ACK bit를 올리고, 랜덤한 seq(b)와 ack(a + 1)를 보낸다.
321 | 3. A가 B에게 ACK bit를 올리고, ack(b + 1)를 보낸다.
322 |
323 | SYN, ACK bit는 SYN과정인지 ACK과정인지 알려주는 용도로 0(False) or 1(True)로 사용한다.
324 |
325 | Seq, Ack는 랜덤한 숫자와, ack = seq + 1을 통해서 이루어진다.
326 |
327 | > 왜 처음 seq가 0이 아니고 랜덤한 숫자죠?
328 | → 이는 seq0부터 시작되어 예측 가능한 점을 이용한 해킹 수법이 있기 때문이라도 한다.
329 | >
330 | - 2 way로 handshake하면 안되나요?
331 |
332 | 안됩니다!
333 | 왜냐하면, 2 way는 segment유실과 network상황 + timer로 인해서 이상하게 연결이 수립되는 경우가 있기 때문입니다.
334 |
335 | 
336 |
337 | 타이머와 엉켜서 반쪽짜리 연결이 수립된다.
338 |
339 | - 4 Way Handshake(Closing)
340 |
341 | 
342 |
343 | FIN - ACK - FIN - ACK로 이루어진다.
344 |
345 | 1. A가 B에게 FIN bit를 올리고, seq를 보낸다.
346 | 2. B가 A에게 ACK bit를 올리고, ack를 보낸다.
347 |
348 | > 여기서 B의 timer가 시작된다.(남은 데이터를 받기 위해서)
349 | 다음 과정 전까지는 데이터를 받으면서 ACK를 보내주면서 통신할 수 있다.
350 | >
351 | 3. B가 A에게 FIN bit를 올리고, seq를 보낸다.
352 |
353 | > 이 과정은 모든 데이터를 받았거나, 3번에서의 timer로 인해서 발생한다.
354 | >
355 | 4. A가 B에게 ACK bit를 올리고, ack를 보낸다.
356 |
357 | > A는 이제부터 원래의 timer의 2배만큼 기다리면서 B의 ack에 맞는 데이터를 보내준다.
358 | B는 더이상 ack나 데이터를 보내지 못하고 받을수만 있다.
359 | >
360 |
361 | ### Congestion Control
362 |
363 |
367 |
368 | - Congestion?
369 |
370 | 
371 |
372 | Router를 사이에둔 host들
373 |
374 | > R = Router의 허용된 네트워크 양
375 | >
376 | 1. Infinite Queue of Router
377 |
378 | 
379 |
380 | 2개의 연결이 있으므로 R/2을 넘을 경우 무한 delay가 발생한다.
381 |
382 | 2. Finite Queue of Router
383 |
384 | 
385 |
386 | Router의 Queue가 꽉차면 버려지므로 TCP가 처리하게 된다.
387 |
388 | > TCP의 관점에서 retransmit을 고려하게 되면, 버려진 packet들은 retransmit이 되는데... retransmit하는 사이에 또 timeout이 되는게 반복되어서 R/2도 못채울 수 있는게 현실이다.
389 | >
390 | - TCP Congestion Control
391 |
392 | > 윈도우 사이즈를 loss가 날때까지 천천히 늘리고, loss가 나면 줄이고를 반복하자.
393 | >
394 | - Slow Start: 윈도우 사이즈를 처음는 천천히 증가하고 나중에는 많이 늘리자.
395 |
396 | > 1 - 2 - 4 ...와 같이 2배씩 증가를 시킨다. 따라서, 나중에는 기하급수적으로 크게 늘어난다.
397 | >
398 | - ssthresh: 윈도우 사이즈 증가를 linear로 바꾸는 시점
399 |
400 | > loss 발생시 발생 지점의 1/2로 설정이됨
401 | >
402 | - RENO 방식
403 | - timeout 발생시: 윈도우를 1로 감소
404 | - 3 duplicate 발생시: 윈도우를 절반으로 감소
405 | - Tahoe 방식
406 | - timeout, 3 duplicate 발생시: 윈도우를 1로 감소
407 |
408 | ## 🙋♂️ 예상 질문
409 |
410 | - UDP와 TCP의 차이점이 무엇인가요?
411 |
412 | UDP와 TCP모두 Transport Layer에서 작동합니다. UDP는 데이터의 전송 여부와 순서를 보장하지 않는 connectionless Protocol입니다. TCP는 데이터의 전송 여부와 순서를 보장하기 위해서 1 대 1로연결을 맺고 통신을 하는 Connection Oriented Protocol입니다.
413 |
414 | - UDP와 TCP를 사용하는 예시를 말해주세요
415 |
416 | UDP는 데이터의 양이 많고 데이터의 중요성이 상대적으로 덜한 곳에서 쓰입니다. 예를 들어서 음악과 비디오의 스트리밍입니다. TCP는 데이터의 중요성이 더한 곳에서 쓰입니다. 예를 들어서 HTTP와 메일이 있습니다.
417 |
418 | - 3 way Handshake와 4 way Handshake에 대해서 설명해주세요
419 |
420 | 3 Way Handshake는 TCP가 연결을 맺기 위해서 사용되는 방법이며, SYN - SYN_ACK - SYN_ACK_ACK순서로 진행됩니다. 간단한 2 Way말고 3 Way를 사용한 이유는 2 Way Handshake시에는 타이머와 네트워크 지연으로 인한 반쪽짜리 연결이 만들어질 수 있기 때문입니다. 4 Way Handshake는 TCP가 연결을 끊을 때 사용하는 방식입니다. FIN - ACK - FIN - ACK순서로 진행됩니다. 연결 시작과 다르게 끊을 때 4 Way인 이유는 아직 전송되지 않은 데이터를 기다리기 위해서입니다.
421 |
422 | - Go Back N과 Selective Repeat는 각 언제 사용될까요?
423 |
424 | Go BAck N과 Selective Repeat는 Sliding Window를 사용할 때 에러 처리 기법입니다. Go Back N은 상대적으로 재전송 되는 데이터의 양이 많기 때문에 전송되는 데이터의 양이 작을 때 유리합니다. Selective Repeaet는 상대적으로 재전송되는 양이 적지만 재전송 되는 데이터의 송신측 에서의 정렬, 다수의 타이머를 사용하면서 부하가 상대적으로 크기 때문에 데이터의 양이 적을 때 유리합니다.
425 |
426 | - QUIC과 HTTP3에 대해서 알고있는걸 말해주세요
427 |
428 | HTTP3(QUIC)은 UDP를 사용함으로써 handshake과정을 없애서 RTT를 없애 속도를 높일 수 있었습니다. 또한, 다중 스트림을 사용하여 TCP에서 loss 발생에 대한 HOL(Head Of Line)을 해결하였습니다.
429 |
430 |
431 | ## 👀 참고
432 |
433 | - TCP / UDP 전반적인 특징
434 |
435 | [[TCP/UDP] TCP와 UDP의 특징과 차이](https://mangkyu.tistory.com/15)
436 |
437 | - Socket VS Port
438 |
439 | [이해가 쉬운 기술 블로그 : 네이버 블로그](https://blog.naver.com/myca11/221389847130)
440 |
441 | - UDP Checksum
442 |
443 | [UDP checksum 계산](https://limjunho.github.io/2021/06/05/UDP-cksum.html)
444 |
445 | - UDP with Reliable
446 |
447 | [Computer Network 7 - UDP](https://heegyukim.medium.com/computer-network-7-udp-86d45323d5c7)
448 |
449 | - TCP seq / ack 과정
450 |
451 | [TCP의 개념 (Transmission Control Protocol)](https://ddongwon.tistory.com/m/84?category=801335)
452 |
453 | - HTTP3(QUIC)
454 |
455 | [HTTP/3의 TCP/UDP 요약](https://json8.tistory.com/70)
456 |
457 | [QUIC 프로토콜](https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=renucs&logNo=220887163028)
458 |
459 | - 학교 수업 자료
460 |
461 | [](http://www.sfu.ca/~ljilja/ENSC835/News/Kurose_Ross/Chapter_3_V7.01.pdf)
462 |
463 | - GBN / SR
464 |
465 | [[네트워크] Go-Back-N, Selective Repeat](https://snoop-study.tistory.com/65)
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 1.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 10.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 11.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 12.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 13.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 13.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 14.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 15.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 15.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 16.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 16.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 2.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 3.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 4.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 5.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 6.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 7.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 8.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled 9.png
--------------------------------------------------------------------------------
/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BoostUpStudy/Backend_Interview_Study/aa78027fc7f2081ab6f5eef37b0b2af1ccdfe21c/Network/TCP_UDP/TCP UDP 5780e78099a8404393d51e88a365562a/Untitled.png
--------------------------------------------------------------------------------
/Network/로드밸런싱.md:
--------------------------------------------------------------------------------
1 | ## 🌞 로드밸런싱이란?
2 |
3 | 여러 서버의 작업을 분산하여 웹 사이트, 어플리케이션, 데이터베이스 등 서비스의 성능과 안정성을 향상시켜주며 고가용성 인프라의 핵심 구성요소
4 |
5 |
15 |
16 | ### 🌝 이점은?
17 |
18 | 1. **수평 확장**
19 | 고가의 서버로 수직확장하는 것이 아닌 저렴한 다수의 서버를 증설하는 수평확장 가능
20 | 2. **무중단 서비스**
21 | 서버 한대의 장애가 발생하거나 동기적인 작업을 처리하는 경우 다른 서버로 트래픽 분배하여 최종 사용자(End User)에게 영향이 없다
22 | 3. **대량의 트래픽 분배**
23 | 단일 서버에 높은 부하를 수행하지 않고 여러 서버에 작업을 분산하여 적은 양의 작업을 수행하게 하며 장애나 부하가 적은 구성을 경험한다
24 |
25 | ### 🌚 단점은?
26 |
27 | 1. **세션 데이터 관리**
28 | 특정 사용자에 대한 세션을 하나의 서버에 저장하는 경우 추후 다른 서버로 밸런싱된다면 클라이언트의 세션이 유지되지 않으며 부가적인 처리가 필요함
29 |
30 | ### 🤔 유형
31 |
32 | - **하드웨어 로드밸런서**
33 | 애플리케이션과 네트워크 트래픽을 분산하기 위해 물리적 사내 하드웨어 장치에 의존하는 방식
34 | 많은 트래픽을 처리할 수 있지만 가격이 높으며 유연성이 낮음
35 | ex. Switch
36 | - **소프트웨어 로드밸런서**
37 | 사용 또는 오픈소스 어플리케이션을 설치하여 사용하는 방식
38 | 하드웨어 로드밸런서에 비해 가격이 낮습니다.
39 | ex. Nginx, HAProxy
40 |
41 |
42 | ### 🔍 분산 알고리즘
43 |
44 | - **라운드로빈**
45 | 요청에 대하여 서버를 순차적으로 선택하는 알고리즘
46 | 각 서버의 성능과 처리시간이 짧은 어플리케이션에 권장
47 | - **가중 라운드로빈**
48 | 각 서버의 가중치를 부여해 처리 용량을 지정하는 알고리즘
49 | - **최소 연결 방식**
50 | 로드 밸런서가 연결이 가장 적은 서버를 선택하는 알고리즘
51 | 다양한 처리용량(일정하지 않은 응답 속도, 서버의 성능차이)이 발생하는 어플리케이션에 권장
52 | - **IP 해시**
53 | 클라이언트의 IP주소를 특정 서버로 매핑하여 사용자와 항상 동일한 서버의 연결을 보장하는 알고리즘
54 |
55 |
61 |
62 | ### ⭐️ 주요기능
63 |
64 | - **NAT(Network Address Translation) : 네트워크 주소 변환**
65 | 네트워크 계층에서 IP 패킷의 TCP/UDP 포트 숫자와 출발지 및 목적지의 IP 주소 등을 재기록
66 |
67 | 즉 다수의 서버의 사설 IP 를 하나의 공인 IP로 변환해주는 기능
68 |
69 |
72 |
73 | | NAT | Proxy |
74 | | --- | --- |
75 | | 네트워크 계층 | 응용계층 |
76 | | 사설 IP ↔ 공인 IP 역할 | 클라이언트와 서버 사이 중재자 역할 |
77 | | Router 나 방화벽 등 주변 장치에 의해 동작 | DMZ(내부, 외부 네트워크 사이 영역) Zone 에 배치하여 동작 |
78 | | 요청과 응답 사이 네트워크 계층에서 사설 IP 를 공인 IP 로 변경 | 요청과 응답이 Proxy Server 를 거쳐서 전송 |
79 |
80 | - **DSR(Dynamic Source Routing Protocol) : 동적 소스 라우팅 프로토콜**
81 | 서버에서 클라이언트로 요청에 대한 응답을 하는 경우 스위치의 IP가 아닌 클라이언트의 IP를 전달하여 네트워크 스위치를 거치지 않고 바로 클라이언트를 찾음
82 | - Replicated Server 들이 큰 용량의 응답을 보내게 된다면 Client 로 전달전 Load Balancer 에서 병목 현상이 발생
83 | DSR 기능을 사용하여 큰 사이즈의 응답 패킷에 대해서 로드밸런서를 거치지 않고 바로 클라이언트로 전송
84 | - **Tunneling**
85 | 서버와 클라이언트간 중간에서 터널링을 제공
86 | 연결된 상호 간에만 캡슐화된 패킷을 구별하여 캡슐화를 해제
87 |
88 | ### 🛎 종류
89 |
90 |  91 |
92 | - **L2**
93 | - Layer 2 데이터 링크 계층에서 MAC 주소를 바탕으로 로드밸런싱
94 | - L2SDR 전략을 사용하려면 MAC 주소의 변환만 가능하므로 로드밸런서와 서버는 같은 네트워크에 존재해야됨
95 | - **L3**
96 | - Layer 3 네트워크 계층에서 IP 를 기준으로 로드밸런싱
97 | - L2 에 라우팅 기능이 추가된 형태
98 | - **L4 = Network Load Balancing(NLB)**
99 | - Layer 4 전송계층(TCP/UDP)에서 IP, Port 번호를 기준으로 로드밸런싱
100 | - VIP(Virtual IP)을 통해서 Replicated Servers 그룹화하여 관리
101 | - L2, L3 의 기능도 사용가능하며 섬세한 라우팅 처리를 제공
102 | - 주로 RR 방식의 알고리즘을 사용하지만 사용자로 인해 다른 알고리즘 사용 가능
103 |
104 | 
105 |
106 |
107 | - **L7**
108 | - Layer 7 응용계층에서 TCP/UDP 는 물론 URL, FTP, 쿠키 등의 정보를 기준으로 로드밸런싱
109 | - TLS Termination 이 발생
110 |
111 |
116 |
117 | - 상위 계층에서 로드를 분산하므로 다른 로드밸런서에 비해 더욱 섬세한 라우팅이 가능
118 | - 캐싱 기능을 제공
119 | - DoS/DDoS와 같은 비정상적인 트래픽을 사전에 필터링할 수 있음
120 | - 적절한 알고리즘을 사용해 로드밸런싱
121 |
122 | 
123 |
124 | ## 📚 참고자료
125 |
126 | [로드밸런싱이란](https://www.digitalocean.com/community/tutorials/what-is-load-balancing#how-does-the-load-balancer-choose-the-backend-server)
127 |
128 | [로드밸런서의 기능, 분산 알고리즘 종류](http://wiki.hash.kr/index.php/%EB%A1%9C%EB%93%9C%EB%B0%B8%EB%9F%B0%EC%8B%B1)
129 |
130 | [로드밸런싱(Load Balancing)과 고가용성(HA)](https://prohannah.tistory.com/62)
131 |
132 | [L2, L3, L4, L7 로드밸런싱](https://tomining.tistory.com/117)
133 |
134 | [L4, L7 오해할 수 있는 내용](https://aws-hyoh.tistory.com/entry/L4L7-%EB%A1%9C%EB%93%9C%EB%B0%B8%EB%9F%B0%EC%8B%B1-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0)
135 |
136 | [NAT 의 역할](https://aws-hyoh.tistory.com/entry/L4-%EC%8A%A4%EC%9C%84%EC%B9%98-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-3)
137 |
138 | [NAVER D2 HAProxy](https://d2.naver.com/helloworld/284659)
139 |
140 | [SSL Termination이란 무엇인가?](https://sepiros.tistory.com/m/50?category=1090822)
141 |
142 | [더욱 Deep Dive](https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/19860014876.pdf)
143 |
--------------------------------------------------------------------------------
/OperatingSystem/CPU 스케줄러.md:
--------------------------------------------------------------------------------
1 | # CPU 스케줄러
2 |
3 |
4 |
5 | # 설명
6 |
7 | 멀티프로그래밍에서 CPU 이용률을 최대화 하기 위해, 특정 알고리즘으로 Main memory에 적재되어 **ready queue**에 있는 프로세스를 선택하여 CPU를 프로세스에 할당해주는 것으로, **Short-term scheduler**라고도 한다.
8 |
9 |
10 |
11 | # Dispatcher
12 |
13 | CPU 스케줄러의 일부분으로, CPU의 제어권을 프로세스에 주는 작업을 한다.
14 |
15 | - context switch
16 |
17 | - user mode로 전환
18 |
19 | - 유저 프로그램의 적절한 위치로 이동하여 프로그램을 재시작한다.
20 |
21 | - Dispatch latency : dispatcher가 한 프로세스를 멈추고 다른 프로세스를 시작하는 시간(짧을 수록 좋음)
22 |
23 |
24 |
25 | # CPU Scheduling이 발생하는 상황
26 |
27 | - 선점(preemptive) 스케줄링: 프로세스가 강제(비자발)적으로 CPU를 내주는 방식
28 |
29 | 
30 |
31 | - running → ready
32 | - waiting → ready
33 | - 비선점(nonpreemptive) 스케줄링: 프로세스가 자발적으로 CPU를 내주는 방식
34 |
35 | 
36 |
37 | - running → waiting
38 |
39 | - running → terminate
40 |
41 |
42 |
43 |
44 | # 스케줄링 기준
45 |
46 | - CPU utilization(CPU 이용률) - CPU를 얼마나 바쁘게 유지했는지
47 |
48 | - Throughput(처리량) - 시간 단위 당 실행시간을 완료한 프로세스의 수
49 |
50 | - Turnaround time(수행 시간) - 프로세스가 시작해서 끝날 때까지의 시간
51 |
52 | - Waiting time(대기 시간) - 프로세스가 **ready queue**에서 기다린 시간
53 |
54 | - Response time(응답 시간) - 프로그램을 수행해서 첫 번째 응답이 나타날 때까지의 시간
55 |
56 |
57 |
58 | # 스케줄링 알고리즘 최적화 기준
59 |
60 | - Max CPU utilization
61 |
62 | - Max throughput
63 |
64 | - Min turnaround time
65 |
66 | - Min waiting time
67 |
68 | - Min response time
69 |
70 |
71 |
72 | # 스케줄링 알고리즘
73 |
74 |
75 |
76 | ## 비선점형 스케줄링
77 |
78 |
79 |
80 | ### First Come, First Served(FCFS) Scheduling
81 |
82 | - 먼저 CPU를 요청하는 프로세스에 CPU를 할당하는 방식
83 |
84 | - Burst Time이 긴 프로세스가 먼저 요청하면 **convey effect**가 발생됨
85 |
86 | 
87 |
88 | 
89 |
90 | **대기 시간**: P1 = 0, P2 = 24, P3 = 27
91 |
92 | **평균 대기 시간**: (0+24+27)/3 = 17
93 |
94 | - Burst Time이 짧은 프로세스가 먼저 요청할수록 유리함
95 |
96 | 
97 |
98 | **대기 시간**: P1 = 6, P2 = 0, P3 = 3
99 |
100 | **평균 대기 시간**: (6+0+3)/3 = 3
101 |
102 | - convey effect: 짧은 프로세스가 긴 프로세스 뒤에 기다리게 되는 현상
103 |
104 |
105 |
106 | ### Shortest-Job-First(SJF) Scheduling
107 |
108 | - 짧은 수행 시간을 가진 프로세스를 먼저 처리하는 방식
109 |
110 | - 평균 대기 시간이 최소화 됨
111 |
112 | 
113 |
114 | 
115 |
116 | **평균 대기 시간**: (0 + 3 + 9 + 16)/4 =7
117 |
118 | - 대기 시간이 긴 프로세스는 오래 기다려야 한다.
119 |
120 |
121 |
122 | ## 선점형 알고리즘
123 |
124 | ### Shortest Remaining Time First(SRTF) Scheduling
125 |
126 | - SJF 알고리즘에서 선점 정책을 도입한 방식
127 | - 잔여시간이 가장 짧은 프로세스를 우선으로 CPU할당을 한다.
128 | - Arrival Time 개념이 추가됨
129 |
130 | 
131 |
132 | 
133 |
134 | 평균 대기 시간 : [(10-1)+(1-1)+(17-2)+(5-3)]/4 = 6.5
135 |
136 | 수행 시작된 시간 - 이미 처리한 시간 - 도착 시간
137 |
138 | - 잦은 선점에 대한 문맥 교환 오버헤드 증가
139 |
140 | ### Priority Scheduling
141 |
142 | - 프로세스에 우선순위를 메겨, 우선순위가 높은 프로세스부터 처리하는 방식
143 | - 선점형, 비선점형 모두 존재
144 | - Starvation 문제: 우선순위가 낮은 프로세스는 계속 기다려야한다.
145 | - Aging 기법: 기다리는 시간만큼 프로세스의 우선순위를 높여준다.
146 |
147 | ### Round Robin(RR) Scheduling
148 |
149 | - 각 프로세스는 작은 단위 시간(time quantum)을 가지고 있다. (보통 10-100 ms)
150 |
151 | - 단위 시간이 지나면 프로세스는 선점되어 ready queue의 끝으로 이동한다.
152 |
153 | - n개의 프로세스가 ready queue 안에 있고, 단위 시간이 q이면, 각 프로세스의 대기시간은 (n-1)q 시간보다 많이 기다리지 않는다.
154 |
155 | - 단위 시간이 클 수록 FCFS와 같아지고, 작을 수록 context switch로 인한 오버헤드가 커진다.
156 |
157 |
158 |
159 | # Multilevel Queue
160 |
161 | - ready queue는 여러 단계의 큐로 나누어져 있다.
162 |
163 | 
164 |
165 | - 사용자와 상호작용하는 프로세스는 상위 레벨에, 백그라운드로 돌아가는 프로세스는 하위 레벨에 배치한다.
166 | - 상위 레벨은 주로 RR 알고리즘을, 하위 레벨은 주로 FCFS 알고리즘을 적용한다.
167 |
168 | - 각 큐마다 스케줄링 알고리즘을 갖고 있다.
169 |
170 | - 우선순위가 고정되어 있으면 하위 레벨 queue의 프로세스들은 상위 레벨의 프로세스가 모두 수행되지 않으면 실행되지 않는 **starvation** 현상이 나타남
171 |
172 | - 하위 레벨의 프로세스가 실행되고 있어도 상위 레벨에 프로세스가 들어오면 선점된다.
173 |
174 |
175 |
176 | # Multilevel Feedback Queue
177 |
178 | - Multilevel Queue를 확장한 방식으로, 프로세스는 각 큐를 이동할 수 있다.
179 | - aging 기법을 사용하여 starvation 현상을 방지한다.
180 | - Parameter
181 | - 큐의 수
182 |
183 | - 각 큐의 스케줄링 알고리즘
184 |
185 | - 언제 프로세스 우선순위를 높이는 지 결정하는 메소드
186 |
187 | - 언제 프로세스 우선순위를 낮추는 지 결정하는 메소드
188 |
189 | - 프로세스가 서비스를 필요로 할 때 프로세스가 들어갈 큐를 결정하는 메소드
190 |
191 |
192 |
193 |
194 | # Multiple-Processor Scheduling
195 |
196 | - 여러 개의 CPU를 사용하는 시스템에서의 스케줄링 방법
197 | - 제약: 다중프로세서 내의 동질의 프로세서들
198 | - Asymmetric multiprocessing 비대칭 다중처리
199 | - Master-Slave 구조
200 | - Master 프로세서가 모든 스케줄링 결정을 하고, Slave 프로세서들은 그 결정에 따른다.
201 | - 오직 한 프로세서만 시스템 자료 구조에 접근하여 데이터 공유의 필요성을 배제한다.
202 | - Symmetric multiprocessing(SMP) 대칭 다중처리
203 | - 각 프로세서가 자기 스케줄링을 한다.
204 | - 모든 프로세서는 common ready queue에 있거나, 각자의 private queue에 있게 된다.
205 | - **common queue**는 모든 프로세서가 접근할 수 있어서 경쟁 상태를 야기하기 때문에 lock이 필요하다.
206 | - **private queue**는 큐마다 부하의 양이 다르다.
207 | - Processor affinity 프로세서 친화성
208 | - 프로세스는 현재 실행되고 있는 프로세서에 친화성을 가진다.
209 |
210 | 
211 |
212 | 특정 CPU에 할당된 프로세스를 CPU가 있는 가장 가까운 메모리에 할당하여 가능한 빠른 메모리 엑세스를 제공한다.
213 |
214 | - soft affinity 약한 친화성
215 | - hard affinity 강한 친화성
216 | - Load Balancing 부화 균등화
217 | - SMP이면, 효율성을 위해 모든 CPU를 로드해야한다.
218 |
219 | - SMP 시스템에서 부하가 고르게 분산되도록 한다.
220 |
221 | - Push migration : 특정 테스크가 각 프로세서의 로드를 감시하다가 과부하된 CPU에서 다른 CPU들로 프로세스를 옮긴다.
222 |
223 | - Pull migration : idle상태의 프로세서들은 바쁜 프로세서에서 대기중엔 프로세스들을 가져온다.
224 |
225 |
226 |
227 | ---
228 |
229 | - 참고자료
230 |
231 | [https://velog.io/@ss-won/OS-CPU-Scheduler와-Dispatcher](https://velog.io/@ss-won/OS-CPU-Scheduler%EC%99%80-Dispatcher)
232 |
233 | [https://velog.io/@jacob0122/CPU-Scheduling-Scheduler](https://velog.io/@jacob0122/CPU-Scheduling-Scheduler)
234 |
235 | [https://jhnyang.tistory.com/372](https://jhnyang.tistory.com/372)
236 |
237 | [https://imbf.github.io/computer-science(cs)/2020/10/18/CPU-Scheduling.html](https://imbf.github.io/computer-science(cs)/2020/10/18/CPU-Scheduling.html)
238 |
239 | [https://hyunah030.tistory.com/4](https://hyunah030.tistory.com/4)
240 |
241 | [https://haun25ne.tistory.com/52](https://haun25ne.tistory.com/52)
242 |
243 | 운영체제 공룡책
--------------------------------------------------------------------------------
/OperatingSystem/IPC.md:
--------------------------------------------------------------------------------
1 | # IPC
2 |
3 | 프로세스들은 유저공간에서 OS로부터 할당받은 독립된 공간에서 운행한다.
4 |
5 | 그렇기 때문에 서로 간에 통신이 어렵다.
6 |
7 | 이를 해결하기 위해서 커널 영역에서 IPC 기술을 제공하고 있다.
8 |
9 | - 프로세스간 통신이 필요할 때 사용
10 | - 동기화가 필요하고 **커널이 제공한다.**
11 |
12 | # 종류
13 |
14 | ## 1. PIPE
15 |
16 | 
17 |
18 | 익명의 파이프를 만들어서 부모-자식 간에 단방향 통신을 지원한다.
19 |
20 | 하나의 파이프로는 한쪽 방향으로만 통신 가능해서 읽기/쓰기를 모두 하기 원한다면 2개의 파이프를 사용해야한다.
21 |
22 | 기본적으로 read, write시에 block되기 때문에 read가 대기중이라면 끝나기 전에는 write할 수 없다.
23 |
24 | ### 장단점
25 |
26 | - 장점
27 | - 간단하게 구현 가능
28 | - 기본적으로 pipe(배열) 명령어로 생성 가능하고 read, write 명령어를 사용한다.
29 | - 단점
30 | - 양방향 통신으로 활용하려면 파이프를 2개 만들어야하는데 이 과정이 꽤 복잡하다.
31 | - 양방향 하고 싶으면 굳이 파이프 사용 x
32 | - buffer가 작기 때문에 overflow될 수 있다.
33 | - 부모-자식 프로세스 간에만 사용 가능하다.
34 |
35 | ## 2. Named PIPE
36 |
37 | 
38 |
39 | 위의 PIPE와 동일한 내용이지만 차이점은 파이프에 이름을 부여해 사용한다.
40 |
41 | **why???**
42 |
43 | 부모-자식 간에 통신할 때는 서로를 명확히 알고 있으므로 굳이 파이프가 어떤 파이프인지 알 필요가 없다.
44 |
45 | 하지만 **부모-자식 관계가 아닌 프로세스들 간에 통신할 때** 파이프를 사용한다면 어떤 파이프를 통해서 통신하는지 알아야하기 때문
46 |
47 | ## 3. Messaging passing ⭐️
48 |
49 | 커널이 메모리 보호를 위해서 대리 전달해주는 방식
50 |
51 | 따라서, 안전하고 동기화 문제를 신경쓰지 않아도 된다. → 커널이 알아서 동기화 해줌
52 |
53 | 그러나 번거롭고 오버헤드가 크다.
54 |
55 | ex) 프로세스 A가 커널로 메시지를 보내면 그걸 커널이 프로세스 B에게 보내준다.
56 |
57 | ### 모델
58 |
59 | 1. Direct Communication
60 | - A가 커널에 메시지를 직접 주고 커널이 B에게 메시지를 직접 전달
61 | 
62 |
63 | 2. Indirect Communication
64 | - A가 커널에 있는 메시지 박스에 넣어두면 B는 그 박스에 가서 읽어오는 방식
65 | 
66 |
67 |
68 | 둘의 차이는 커널이 직접 주냐 아니냐
69 |
70 | ### Message Queue
71 |
72 | 
73 |
74 | Message passing은 구현보다는 개념적으로 사용되는 용어이다. 프로세스 간의 통신을 하기 위해 메시지를 어떻게 전송할지에 대한 방법론이고 그 구체적인 방법 중 하나가 Message queue 구현 방법이다.(보통 Messaging Passing이라함은 Message Queue라고 해도 무방)
75 |
76 | 파이프는 데이터 흐름이라면 Message Queue는 선입선출의 자료구조를 가지고 메모리 공간을 통해 전달한다.
77 |
78 | 데이터에 번호를 붙힘으로써 다수의 프로세스가 동시에 데이터를 다룰 수 있다.
79 |
80 | ### 장단점
81 |
82 | - 장점
83 | - 비동기 방식이기 때문에 데이터가 많아도 처리가 가능하다.
84 | - 다수의 프로세스끼리 메시지를 보내고 꺼낼 수 있다.
85 | - 즉, 분산처리에 용의
86 | - 단점
87 | - 메시지가 잘 전달되었는지 알 수 없다.
88 | - 데이터가 많을 수록 추가 메모리 자원이 필요하다.
89 |
90 | ## 4. Shared memory ⭐️
91 |
92 | 
93 |
94 | 두 프로세스간의 공유된 메모리를 생성 후 이용하는 것
95 |
96 | 프로세스가 공유 메모리 할당을 커널에 요청하면 커널은 할당해주고, 어떤 프로세스건 해당 메모리 영역에 접근 할 수 있다.
97 |
98 | 단순히 공유 메모리를 point하는 방식으로 프로세스에서 사용되는 메모리가 증가되지는 않는다.
99 |
100 | ### 장단점
101 |
102 | - 장점
103 | - 따로 통신을 이용해 데이터를 주고 받지 않고 바로 메모리에 접근하기 때문에 모든 IPC 중 가장 빠르다.
104 | - 단점
105 | - 메시지 전달이 아니기 때문에 데이터를 읽어야하는 시점을 알 수 없다.
106 | - 공유 자원을 이용하므로 동기화 문제를 해결해야한다.
107 | - 커널에 종속적이기 때문에 허용하고 있는 공유메모리 사이즈를 확인해야한다.
108 |
109 | ## 5. Memory Map
110 |
111 | 
112 |
113 | 기존적으로 공유 메모리와 비슷한데 메모리 맵은 파일을 메모리에 매핑시켜서 공유한다는 점이다.
114 |
115 | 즉, 디스크에 있는 파일과 프로세스의 페이지가 연결된다. → 가상 메모리의 페이징 기법과 비슷
116 |
117 | 통신 느낌보단 파일 접근을 효율적으로 하기 위한 기법이라고 생각
118 |
119 | ex) 파일이 오픈되면 파일의 데이터가 메모리에 올라가게되는데 다른 프로세스에서 똑같은 파일을 열어서 메모리에 같은 걸 또 올리면 낭비가 심해지게 되고 데이터 일관성에도 문제가 생김.
120 |
121 | 그래서 이런 경우 기존 메모리 공간에 같이 접근해서 데이터를 읽고 쓰는 작업을 하는 듯(이 때, 동기화 문제를 스레드가 알아서 해주는 것 같다..!)
122 |
123 | ### 장단점
124 |
125 | - 장점
126 | - 대용량 데이터를 공유 할 때 사용한다.(메모리에 전부 올라가지 않아도 되니까)
127 | - File I/O가 느릴 때 사용하면 좋다.
128 | - 단점
129 | - 파일의 크기를 변경할 수 없다.(사용하기 전, 후 에만 변경 가능)
130 | - 얼마나 많은 데이터를 얼마나 오랫동안 메모리에 둘 것인지를 컨트롤할 수 없다.
131 |
132 | ## 6. Socket
133 |
134 | 
135 |
136 | 같은 도메인 내에서도 물론 연결 가능하고, 추가적으로 외부 프로세스와 통신할 때 사용한다.
137 |
138 | 서버 : bind, listen, accept
139 |
140 | 클라이언트 : connect
141 |
142 | 즉, 네트워크를 통해 프로세스 간에 통신을 진행
143 |
144 | ### 장단점
145 |
146 | - 장점
147 | - 외부 시스템과 통신이 가능하다.
148 | - 단점
149 | - 네트워크 프로그래밍이 가능해야한다.
150 |
151 | # 결론
152 |
153 | 
154 |
155 | 결국 IPC란 두 개의 프로세스간 통신을 의미하는데 굳이 하나의 컴퓨터에 있는 두 개의 프로세스만을 의미하는 것이 아니다.
156 |
157 | 서로 다른 컴퓨터의 프로세스들도 통신하는 것도 IPC = 결국 네트워킹이다.
158 |
159 | # 질문 리스트
160 |
161 | - IPC 기법에 대해 설명해주세요
162 |
163 | 프로세스들은 유저공간에서 OS로부터 할당받은 독립된 공간에서 운행하기 때문에 서로 간에 통신이 어렵습니다. 따라서 이를 해결하기 위해서 커널 영역에서 제공하는 IPC 기술을 통해 통신합니다.
164 |
165 | - IPC 기법의 종류를 아는데로 설명해주세요
166 |
167 | 대표적으로는 파이프, message queue, share memory가 있을 것 같습니다.
168 |
169 | 파이프는 익명의 파이프라면 부모-자식 프로세스간에 단방향으로 데이터를 공유하는 방법이고 named 파이프라면 부모-자식 관계가 아닌 프로세스끼리도 파이프를 이용해 통신할 수 있는 방법입니다.
170 |
171 | 파이프가 데이터 흐름이라면 Message Queue는 선입선출의 자료구조를 가지고 메모리 공간을 통해 단방향 전달 하는 방법으로 비동기 방식을 가지고 있고 여러 프로세스끼리 통신이 가능합니다.
172 |
173 | 마지막으로 share memory는 커널이 공유 메모리를 할당해주면 모든 프로세스가 해당 공유 메모리에 접근하여 사용하는 방식입니다.
174 |
175 |
176 | # 참고
177 |
178 | [https://www.byfuls.com/programming/read?id=63](https://www.byfuls.com/programming/read?id=63)
179 |
180 | 사진 자료
181 | [https://doitnow-man.tistory.com/110](https://doitnow-man.tistory.com/110)
182 |
--------------------------------------------------------------------------------
/OperatingSystem/가상 메모리.md:
--------------------------------------------------------------------------------
1 | # 가상 메모리
2 |
3 | # ⭐️ 등장 배경
4 |
5 | 기존 메모리 관리는 하나의 프로그램 전체를 실제 물리 메모리에 올리는 방식을 사용했다.
6 |
7 | 하지만 메모리에 많은 프로세스들을 올리고자 하는데 물리 메모리에 전부 올리기에는 한계가 존재한다. (메모리 용량 부족, 페이지 교체 성능 이슈)
8 |
9 | 컴퓨터는 폰 노이만 구조이기 때문에 사용할 코드는 반드시 메모리에 있어야해서 코드를 물리 메모리에 전부 올린다는 발상이었지만 프로그램을 사용하는데 그 때마다 필요한 코드들만 있어도 실행이 되기 때문에 불필요하게 전체의 프로그램이 메모리에 올라와 있지 않아도 된다는 점에서 아이디어를 얻었다고 한다.
10 |
11 | 따라서 프로그램 전체가 아닌 **필요한 일부분만 실제 메모리에 올리는 기법**인 가상 메모리를 사용하게 되었다.
12 |
13 | 이런 방법을 사용하면
14 |
15 | 1. 더 많은 프로그램들을 동시에 메모리에 올려 작업할 수 있다.
16 | 2. 한 번에 올리는 소스 양이 적기 때문에 Disk와 Memory간 I/O 작업 속도가 빨라진다.
17 |
18 | 등의 장점을 얻을 수 있다.
19 |
20 | 
21 |
22 | # ⭐️ 아이디어
23 |
24 | 프로세스는 가상 주소를 사용하고, 실제 해당 주소에서 데이터를 읽고 쓸 때만 물리 주소로 변경한다.
25 |
26 | - Virtual address : 프로세스가 참조하는 주소
27 | - 디스크의 페이지 파일에 저장된다.
28 | - 페이지 교체할 때 이 디스크 swap영역에서 페이지를 가져오는 것
29 | - Physical address : 실제 메모리 주소
30 |
31 | CPU는 가상 메모리를 다루는데, 실제 물리 주소 접근시 MMU(Memory Management Unit)를 통해 물리 메모리에 접근한다.
32 |
33 | - MMU : CPU에서 코드 실행 시 가상 메모리 주소를 물리 주소 값으로 변환해주는 하드웨어 장치
34 |
35 | # ⭐️ Paging
36 |
37 | ## 등장 배경
38 |
39 | 메모리에 프로세스를 연속 할당할 때 발생하는 **외부 단편화**를 해결하기 위해 사용한다.
40 |
41 | 
42 |
43 | ## 개념
44 |
45 | - page : 가상 메모리 공간의 최소 단위
46 | - frame : 물리 메모리 공간의 최소 단위
47 |
48 | 크기가 동일한 page로 가상 메모리 공간과 이에 매칭되는 물리 메모리 공간을 관리한다.
49 |
50 | 이 page들은 실제 들어있는 데이터 양과 관계없이 모두 고정 크기를 가진다.
51 |
52 | 이 때, 고정된 각 크기는 시스템에 따라 다르다.
53 |
54 | - 크기가 작을 수록 내부 단편화가 해결되지만, 페이지 개수 증가로 인해 페이지 단위의 I/O가 증가한다.
55 |
56 | 각 프로세스의 PCB에는 page Table 구조체를 가리키는 주소가 있는데 이 테이블에는 가상/물리 주소의 매핑 정보가 담겨있고 이를 활용한다.
57 |
58 | 
59 |
60 | ## 원리
61 |
62 | 가상 주소와 물리 주소를 동일한 크기로 자르고 어디에 배치되는지 기록하며 배치한다면?? 자투리 공간이 발생하지 않고 딱 맞게 배치된다.
63 |
64 | 
65 |
66 | 이렇게 하면 프로세스를 연속할당 할 필요가 없기 때문에 **외부단편화 문제를 해결**할 수 있다.
67 |
68 | 고정 크기라는 것 때문에 **내부단편화가 발생**하긴 하지만 외부단편화로 인해 발생하는 낭비 공간이 더 크기 때문에 이를 감수하더라도 페이징을 사용하는 것이 이득이다.
69 |
70 | 그런데 생각해보면 프로세스는 **차례대로 읽어 수행**되는 linear address가 필요한데 paging 기법처럼 프로세스가 조각으로 나뉘어져 따로 놀고 있는데 어떻게 연속적으로 실행될까??
71 |
72 | → Page Table을 이용
73 |
74 | # ⭐️ Page Table
75 |
76 | - 프로세스 생성시 PCB에 페이지 테이블 정보가 생성된다.
77 | - 프로세스 구동시, page table의 base 주소가 별도 레지스터에 저장되고, CPU가 가상 주소 접근시 MMU는 page table의 base 주소에 접근해 물리 주소를 얻는다.
78 | - 이 때, 페이지들이 연달아 실행될 수 있도록 순서에 맞는 물리 주소 위치를 찾아준다.
79 | - 즉, linear하게 수행시킬 수 있다.
80 |
81 | 
82 |
83 | 기본적으로 배열처럼 인덱스가 페이지 번호를 가리키고 그 배열에 담고 있는 숫자가 매핑할 프레임 번호를 뜻한다.
84 |
85 | ## 페이지 크기와 가상 주소 구성
86 |
87 | CPU에 의해서 생성되는 주소를 가상 주소, RAM에 실질적으로 로드되는 주소를 물리 주소라고 했는데 위 예시에서 0,1,2,3 등 말고 실제 이 주소들은 어떻게 구성되어 있는지를 알아보자.
88 |
89 | 가상 주소는 페이지 번호(p)와 페이지 오프셋(d)으로 구성된다.
90 |
91 | - p : 매핑을 위해 page와 frame은 번호를 갖는데, 페이지 순서에 해당하는 숫자를 의미한다.
92 | - but, 덩어리인 page만으로 정확한 주소를 표기할 수 없기 때문에 오프셋을 추가로 사용한다.
93 | - d : page내의 번호를 의미한다.
94 | - 하나의 페이지가 4KB라 가정하면 page 0의 주소는 0 ~ 2^12까지이다.
95 |
96 | 가상 주소 구하기
97 |
98 | os가 32bit이고, 페이지 크기가 4KB라고 가정할 때
99 |
100 | 2^32 / 2^12 = 2^20
101 |
102 | 즉, CPU는 한 번에 2^20개의 페이지 번호를 구분할 수 있다.
103 |
104 | 따라서 32bit라고 할 때 앞의 20bit는 페이지 번호를 의미하고, 뒤 12bit는 오프셋을 의미한다.
105 |
106 | ## **가상 주소 → 물리 주소 변환 FLOW**
107 |
108 | 
109 |
110 | - p : 페이지 번호
111 | - f : 프레임 번호
112 | - d : 페이지 오프셋
113 |
114 | d를 제외한 나머지 비트에 있는 page 번호를 page table에서 검색하면 frame 번호가 나온다.
115 |
116 | page와 frame 크기는 똑같기 때문에 오프셋은 동일하다.
117 |
118 | ex)
119 |
120 | PageSize = 1KB
121 |
122 | PageTable = 1 3 5 4
123 |
124 | **가상 주소 3000의 물리 주소는??**
125 |
126 | 1KB는 10bit로 표현 가능하고 3000은 101110111000(2) 이다.
127 |
128 | 따라서 d(오프셋)는 뒤의 10자리 (1110111000(2))이고 p(페이지 번호)는 남은 앞에 2개 (10(2))이다. 따라서 p는 2이기 때문에 두 번째 인덱스인 5 → 101(2)와 d를 붙인 1011110111000(2)가 물리 주소이다.
129 |
130 | 위와 같은 과정으로 물리 주소를 참조하지만 매번 페이지 테이블을 이용하는 것은 매우 비효율적이기 때문에 TLB를 이용한다.
131 |
132 | ## TLB(Translation Lookaside Buffer)
133 |
134 | - MMU에 소속된 칩으로, 자주 참조되는 가상 주소- 물리 주소 변환 정보를 저장해놓은 캐시이다.
135 | - 과정
136 | 1. 가상 주소로 접근 시, TLB에 먼저 접근하여 변환정보가 있는지 확인
137 | 2. 있으면 바로 반환
138 | 3. 없으면 Page Table에서 해당 물리 주소를 찾아 TLB에 갱신 후, TLB miss가 발생한 명령어를 재실행
139 |
140 | 
141 |
142 | 따라서 TLB의 hit rate가 속도에 많은 영향을 끼친다.
143 |
144 | # ⭐️ 참고
145 |
146 | [Interview_Question_for_Beginner/OS at master · JaeYeopHan/Interview_Question_for_Beginner](https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/OS#%EA%B0%80%EC%83%81-%EB%A9%94%EB%AA%A8%EB%A6%AC)
147 |
--------------------------------------------------------------------------------
/OperatingSystem/병행성.md:
--------------------------------------------------------------------------------
1 | # 📌 병행성**(Concurrency)**
2 |
3 | 운영체제의 설계의 핵심은 모두 프로세스와 쓰레드와 연관이 있으며 대표적으로 다음이 있다.
4 |
5 | - 멀티프로그래밍: 단일처리기(프로세서) 시스템 상에서 다수의 프로세스 관리
6 | - 멀티프로세싱: 멀티프로세서 시스템 상에서 다수의 프로세스 관리
7 | - 분산처리: 다수의 분산된 컴퓨터 시스템들 상에서 수행되는 다수의 프로세스 관리 (대표적인 예로 클러스터 시스템이 있다)
8 |
9 | 그리고 운영체제의 설계의 핵심은 병행성(concurrency)이다.
10 | 병행성이란 여러 계산을 동시에 수행하는 시스템의 특성으로 프로세스간 통신, 자원에 대한 공유와 경쟁, 프로세스 활동들의 동기화, 프로세스에 대한 처리기 시간 할당 등 다양한 이슈를 포함한다.
11 |
12 | > **병행성 관련 주요 용어**
13 |
14 | 원자적 연산(atomic operation) : 명령어들로 구성된 함수 또는 액션으로 더 이상 분할할 수 없는 단위 어떤 프로세스도 중간 상태를 볼 수 없고 연산을 중단할 수 없다 이 명령어들은 수행되거나 되지않거나 둘중 하나이다.
15 |
16 | 임계영역(critical section) : 공유 자원을 접근하는 프로세스 내부의 코드 영역, 두개의 프로세스가 임계영역에 들어가서는 안된다.
17 |
18 | 교착상태(deadlock) : 두개 이상의 프로세스들이 더 이상 진행을 할 수 없는 상태, 각 프로세스가 다른 프로세스의 진행을 기다리면서 대기할때 발생한다.
19 |
20 | 라이브락(livelock) : 두개 이상의 프로세스들이 다른 프로세스의 상태 변화에 따라 자신의 상태를 변화 시키는 작업만 하는 상태,프로세스들이 열심히 일하는 것처럼 보이지만 실제로는 유용하지 않은 작업들을 하고 있다.
21 |
22 | 상호 배제(mutual exclusion) : 한 프로세스가 공유자원을 접근하는 임계역영 코드를 수행하는 중이면 다른 프로세스들은 공유 자원에 접근하는 임계영역 코드를 수행할 수 없다는 조건이다.
23 |
24 | 경쟁상태(race condition) : 두개 이상의 프로세스가 공유 자원을 동시에 접근하려는 상태, 최종 수행 결과는 프로세스들의 상대적인 수행 순서에 따라 달라진다.
25 |
26 | 기아(starvation) : 특정 프로세스가 수행 가능한 상태임에도 매우 오랜 기간 동안 스케줄링 되지 못하는 경우
27 |
28 | **병렬처리를 위한 기법**
29 |
30 | 인터리빙(interleaving) : 멀티프로그래밍에서 여러개의 프로세스가 번갈아가면서 수행되어 마치 동시에 수행되는 것과 같게 되는것
31 |
32 | 오버래핑(overlapping) : 여러개의 처리기로 실제로 여러 작업을 처리하는 것
33 | >
34 |
35 | 병행성에는 한 가지 문제점이 있다. 각각의 프로세스의 속도를 예측할 수 없다는 것이다.
36 | 예측할 수 없는 프로세스들이 동일한 자원을 두고 경쟁하다보니 다음과 같은 문제를 야기한다.
37 |
38 | 1. 전역 자원의 공유에 어려움이 있다.
39 | ex) 두개의 프로세스가 같은 전역 변수를 사용
40 | 2. 운영체제가 자원을 최적으로 할당하기 어려워진다.
41 | ex) 자원 할당 후 일시정지
42 | 3. 프로그래밍 오류를 찾아내는 것이 어려워진다.
43 | ex) 특정 실행 순서에 따른 오류
44 |
45 | 따라서 프로세서간 충돌을 방지할 **상호배제**가 필요하다.
46 |
47 | # 📌 상호배제(Mutual exclusion)
48 |
49 | 상호 배제를 보장하기 위해서는 다음의 요구 조건들이 만족되어야 한다.
50 |
51 | 1. 상호 배제가 강제되어야 한다.
52 | 2. 임계영역 외의 코드에서 수행이 멈춘 프로세스는 다른 프로세스의 수행을 간섭해서는 안된다.
53 | 3. 임계영역에 접근하고자 하는 프로세스의 수행이 무한히 미루어져서는 안된다. 즉 기아 상태, 교착 상태가 발생해서는 안된다.
54 | 4. 임계영역이 비어있고 임계영역 진입을 원하는 프로세스는 즉시 임계영역에 들어 갈 수 있다.
55 | 5. 프로세스 개수나 상대적인 프로세스 수행 속도에 대한 가정은 없어야 한다.
56 | 6. 임계영역에 들어간 프로세스는 일정한 시간 내에 임계영역에서 나와야 한다.
57 |
58 | # 📌 상호배제: 소프트웨어적 접근 방법
59 |
60 | 운영체제나 프로그래밍 언어 차원의 지원 없이 프로세스간 협력을 통해 직접 상호 배제를 보장한다.
61 | 수행 부하가 크고, 잘 설계되지 않았을 경우 오동작 가능성이 높다.
62 |
63 | ## 🔍 데커(Dekker) 알고리즘
64 |
65 | [데커의 알고리즘 - 위키백과, 우리 모두의 백과사전](https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%BB%A4%EC%9D%98_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)
66 |
67 | ## 🔍 피터슨(**Peterson**) 알고리즘
68 |
69 | [피터슨의 알고리즘 - 위키백과, 우리 모두의 백과사전](https://ko.wikipedia.org/wiki/%ED%94%BC%ED%84%B0%EC%8A%A8%EC%9D%98_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)
70 |
71 | ### 💡 참고
72 |
73 | [[IT 기술면접 준비자료] 상호배제(Mutual Exclusion)와 상호배제 알고리즘](https://preamtree.tistory.com/26)
74 |
75 | 데커(Dekker) / 피터슨(Peterson) / 제과점(Bakery) 알고리즘
76 |
77 | # 📌 상호배제: 하드웨어적 접근 방법
78 |
79 | 상호배제를 보장하기 위한 하드웨어적인 접근 방법을 알아보자
80 |
81 | ## 🔍 인터럽트 금지
82 |
83 | 상호 배제를 보장할 수 있는 가장 간단한 방법은 프로세스가 인터럽트 되지 않도록 하는 것이다싱글 프로세서에서 병행 처리(concurrent processing)되는 프로세스들은 인터리빙되기 때문이다.
84 |
85 | 또한 프로세스는 운영체제 서비스를 호출하거나 인터럽트 될 때까지 계속 실행하기 때문에 인터럽트가 발생하지 않으면 한 프로세스의 지속적인 실행을 보장 가능하다.
86 | 이를 위해 시스템 커널에서 인터럽트를 허용하거나 비허용할 수 있는 기본 인터페이스를 제공한다.
87 |
88 | ```powershell
89 | while(true){
90 | // 인터럽트 금지
91 | // 임계 영역
92 | // 인터럽트 허용
93 | // 임계 영역 이후 코드
94 | }
95 | ```
96 |
97 | > 단, 멀티프로세서 시스템에서는 효과가 없다.
98 | 두개 이상의 프로세서를 가지는 컴퓨터 시스템에서는 인터럽트가 금지된 상황에서도 서로 다른 프로세스가 공유 자원을 동시에 접근하는 경우가 가능하기 때문이다.
99 | >
100 |
101 | ### 단점
102 |
103 | - 부하가 크다.
104 | 인터럽트 비허용 시, 그 사이 외부에서 발생하는 이벤트에 대한 처리와 다른 프로세스에 대한 스케줄링 등 모든 기능이 중지되어 시스템 수행 효율이 확연하게 감소할 가능성이 높다.
105 | - 멀티프로세서 시스템에서는 올바른 접근 방법이 아니다.
106 |
107 | ## 🔍 특별한 기계 명령어
108 |
109 | 멀티 프로세서 환경에서 여러 프로세서들은 공통의 주기억 장치를 공유하며, 이때 모든 프로세서는 동등한 관계에서 독립적으로 동작한다. (인터럽트 기법으로 상호배제 보장 불가)
110 |
111 | 하드웨어 수준에서 특정 메모리 주소가 접근되고 있을 때, 같은 위치에 대한 접근 요청은 차단된다는 것에 기반해 상호배제를 보장하기 위한 두 가지 명령어가 구현된다.
112 | 이때 기계 명령어는 두 개의 기능을 원자적으로 처리한다.
113 |
114 | ### 1. Compare & Swap 명령어
115 |
116 | `compare_and_swap()` : 테스트하려는 값과 저장된 값을 비교한다.
117 |
118 | 이 함수는 원자적으로 수행되기 때문에 중간에 중단되는 경우는 없다.대부분 모든 프로세서에서 지원하며, 대부분의 운영체제에서 병행성을 위해 이 명령어를 사용한다.
119 |
120 | ### 2. Exchange 명령어
121 |
122 | `exchange()` : 레지스터 값과 메모리에 들어있던 값을 서로 교체하는 기능 수행
123 |
124 | 
125 |
126 | > 실제로 이 함수가 아니고 하드웨어 명령어이다.
127 | 이해를 돕기위한 코드라 생각하면 된다.
128 | >
129 |
130 | ### Compare & Swap, Exchange 명령어를 이용한 상호배제 보장
131 |
132 | 
134 |
135 | 필기가 난잡하고 더럽지만 매우 디테일하게 적어놨다
136 | 정녕 자세히 알고싶다면 읽어보자
137 |
138 | ### 장점
139 |
140 | - 싱글 프로세서 시스템 뿐만 아니라 공유 메모리를 사용하는 멀티 프로세서 시스템에서도 사용가능하다.
141 | - 간단하고 검증이 쉽다.
142 | - 서로 다른 변수를 사용하면 다중 임계 영역을 지원할 수 있다.
143 |
144 | ### 단점
145 |
146 | - 바쁜 대기를 사용한다
147 | 임계영역에 진입하는 것을 대기하고 있는 프로세스는 처리기를 계속 사용하게 된다.
148 | `TIP` 바쁜 대기란 임계영역에 진입하기 위한 허가를 획득할 때까지 변수를 테스트하는 명령을 반복 실행하며 대기하는 것을 말한다.
149 | - 기아가 발생할 수 있다
150 | 한 프로세스가 임계영역에서 빠져나올 때, 대기하고 있던 다수의 프로세스 중 하나만 다시 임계영역에 진입이 가능한데, 이 때 각 프로세스의 길이나 특성, 대기시간 등을 고려하지 않기 때문에 무한정 기다리는 프로세스가 생길 수도 있다.
151 | - 교착상태에 빠질 수 있다.
152 | 싱글 프로세서 시스템에서 P1 이라는 프로세스가 임계영역에 진입한다.
153 | 그때 P2 라는 P1보다 우선순위가 높은 프로세스가 생겨 운영체제가 P2를 스케줄하여 P2에게 자원을 할당하려 할 때 P2와 P1이 같은 자원을 사용하려 하면 P2는 상호배제조건에 의해 바쁜 대기를 수행한다.
154 | 이때 P2가 계속 프로세서를 점유하고 있기 때문에 우선순위가 높은 P2로 인해 P1은 다시 스케줄링될 수 없다. -> P2가 실행상태에 있기 때문이다.
155 |
156 | 소프트웨어적 방법과 하드웨어적 방법은 모두 단점을 갖고 있기 때문에 새로운 해결책이 필요하다.
157 |
158 | # 📌 상호배제: 운영체제와 프로그래밍 언어 수준에서 접근 방법
159 |
160 | ## 🔍 세마포어(Semaphore)
161 |
162 | 멀티 프로그래밍 환경에서 공유된 자원에 대한 접근을 제한하는 방법
163 |
164 | - 임계영역에 접근하는 프로세스들을 제어하는 데 사용한다.
165 | - block(수면)과 wake up(깨움)을 지원한다.
166 | - 세마포어란 프로세스 간에 시그널을 주고받기 위해 사용되는 정수 값을 갖는 변수로 다음 3가지 인터페이스를 통해 접근할 수 있다.
167 | - **Initialize(초기화 연산)** : 최초에 세마포어 값을 음이 아닌 값으로 초기화한다.
168 | - **Decrement(semWait, 대기 연산)**
169 | - 세마포어 값을 하나 감소시킨다.
170 | - 값이 음수가 되면 semWait를 호출한 프로세스는 block 상태로 바꾼다.
171 | - 음수가 아니면 해당 프로세스는 임계영역에 접근하여 연산을 계속 수행할 수 있다.
172 | - **Increment(semSignal, 시그널 연산)**
173 | - 연산을 마친 프로세스는 이 함수를 호출해 세마포어 값을 하나 증가시킨다
174 | - 값이 양수가 아니면(<=0) semWait 연산으로 block된 프로세스를 깨운다.
175 | - 이진 세마포어는 세마포어 값을 0또는 1만 가질 수 있는 세마포어이다.
176 |
177 | 
178 |
179 | 카운팅(범용) 세마포어
180 |
181 | 
182 |
183 | 이진(바이너리) 세마포어
184 |
185 | ### 세마포어는 바쁜대기와 기아를 해결
186 |
187 | - OS는 blocked 큐를 갖고 있기 때문에 바쁜 대기 문제가 해결된다.
188 | - 큐에는 순서가 있기 때문에 기아 문제가 해결된다.
189 |
190 | ### 세마포어의 특징
191 |
192 | - 일반적으로 프로세스가 세마포어를 감소시키기 전까지는 그 프로세스가 block될지 안될지 알 수 없다.
193 | - 싱글 프로세서 시스템에서 프로세스가 세마포어를 증가시키고 block된 프로세스를 깨우면, 이 두 프로세스 모두 수행가능 상태가 되어 누가 먼저 수행될 지 알 수 없다.
194 | - 세마포어에 시그널을 보낼 때, 우리는 다른 프로세스가 대기 중인지 여부를 알 필요가 없다. block된 프로세스의 개수가 0또는 1일 수 있다.
195 |
196 | ### 세마포어 동작 예시
197 |
198 | 
199 |
200 | ### 생산자/소비자(producer/consumer) 문제
201 |
202 | 한정 버퍼(bounded-buffer) 문제라고도 한다.
203 |
204 | 유한한 개수의 물건(데이터)을 임시로 보관하는 보관함(버퍼)에 여러 명의 생산자들과 소비자들이 접근한다. **생산자는 데이터를 만들어 버퍼에 저장해나가고, 소비자는 버퍼에 있는 데이터를 꺼내 소비하는(비우는) 프로세스이다.**
205 | 이때 저장할 공간이 없는 문제가 발생할 수 있다. 소비자는 물건이 필요할 때 보관함에서 물건을 하나 가져온다. 이 때는 소비할 물건이 없는 문제가 발생할 수 있다.
206 |
207 | 이때 버퍼는 공유자원이므로 버퍼에 대한 접근 즉, 저장하고 꺼내는 일들이 상호배제 되어야한다.또한, 버퍼가 꽉 차있을 때는 생산자가 기다려야하고, 버퍼가 비었을 때는 소비자가 기다려야한다.
208 |
209 | ### 무한공유 버퍼인경우
210 |
211 | 
212 |
213 | 만약 소비자가 먼저 실행될 경우, 세마포어 n의 값이 음수가 되면서 block에 걸리고 생산자와 실행되어 버퍼를 채우며 n의 값을 올려 소비자의 block을 푼다
214 |
215 | ### 유한공유 버퍼인경우
216 |
217 | 
218 |
219 | 무한 버퍼와 같은 원리로 작동을 하며 무한 버퍼와는 달리 유한 버퍼이므로 버퍼가 꽉 찰 때를 표시해줄 수 있는 e값이 있다. e가 꽉 찬 상태 즉, e가 음수가 되면 block이 걸리게 되며 소비자만이 작동하게 된다.
220 |
221 | ## 🔍 뮤텍스(Mutex)
222 |
223 | 뮤텍스는 세마포어와 마찬가지로 병행 처리를 위한 동기화 기법 중 하나입니다.
224 | 이진 세마포어와 같이 초기값을 1과 0으로 가집니다.
225 | 임계영역에 들어갈 때 락(lock)을 걸어 다른 프로세스(혹은 쓰레드)가 접근하지 못하도록 하고,
226 | 임계영역에서 나와 해당 락을 해제(unlock) 합니다.
227 |
228 | ### **뮤텍스와 세마포어의 차이는?**
229 |
230 | 세마포어는 공유 자원에 세마포어의 변수만큼의 프로세스(또는 쓰레드)가 접근할 수 있습니다.
231 | 반면에 뮤텍스는 오직 1개만의 프로세스(또는 쓰레드)만 접근할 수 있습니다.
232 | 현재 수행중인 프로세스가 아닌 다른 프로세스가 세마포어를 해제할 수 있습니다.
233 | 하지만 뮤텍스는 락(lock)을 획득한 프로세스가 반드시 그 락을 해제해야 합니다.
234 |
235 | ## 🔍 모니터
236 |
237 | - 모니터란 프로그래밍 언어 수준에서 제공되는 구성체(라이브러리, 클래스)
238 | - 세마포어와 동일한 상호배제 기능을 제공하고 보다 사용하기 쉽다는 장점을 가지고 있다.
239 |
240 | # 📌 데드락(DeadLock)
241 |
242 | 상호 배제에 의해 나타나는 문제점으로, 둘 이상의 프로세스들이 자원을 점유한 상태에서 서로 다른 프로세스가 점유하고 있는 자원을 요구하며 무한정 기다리는 현상을 의미한다.
243 |
244 | ## 발생조건 4가지
245 |
246 | - **상호 배제 조건(Mutual Exclusion)** 입니다. **자원은 한 번에 한 프로세스만 사용 가능하다** 는 조건입니다.
247 | - **점유 대기 조건(Hold And Wait)** 입니다. **최소한 하나의 자원을 점유(Lock)**하고 있으면서 다른 프로세스에 할당되어 사용되고 있는 **자원을 추가로 점유하기 위해 대기(Wait)** 하는 프로세스가 존재해야 합니다.
248 | - **비선점 조건(No preemption)**이 있습니다. 다른 프로세스에 할당된 자원은 해당 프로세스가 사용이 끝날때까지 **강제로 빼앗을 수 없습니다.**
249 | - **순환 대기 조건(Circular Wait)**이 있습니다. 프로세스의 집합에서 **순환 형태(사이클)로 자원을 대기(Wait)** 하고 있어야 합니다.
250 |
251 | 이러한 **상호 배제, 점유 대기, 비선점, 순환 대기** 4가지 조건을 모두 성립해야 데드락이 발생할 수 있습니다.
252 |
253 | ## 데드락의 처리방법
254 |
255 | 데드락을 처리하기 위한 방법으로 예방, 회피, 탐지 및 회복, 무시 가 있습니다.
256 | **예방(Prevention)** 이란, **데드락 발생 조건 중 하나를 제거하면서 해결**하는 방법입니다. 즉, 상호 배제, 점유 대기, 비선점, 순환 대기 4가지 조건 중 하나를 제거합니다.
257 |
258 | 다음으로, **회피(Avoidance)** 는 **데드락이 발생할 시 피해가는 방법**입니다. 대표적으로, **은행원 알고리즘**을 사용하여 피해갑니다.
259 |
260 | 또, **탐지 및 회복(Detection & Recovery)** 은 **자원 할당 그래프를 통해 데드락을 감지**하며, 만약 데드락을 감지할 경우 **이전 상태로 회복**하는 방법이죠. 일부러 데드락을 발생하게 놔두고 감지해서 회복하는 경우도 있습니다.
261 |
262 | 마지막으로, **무시(Ignore)** 는 말 그대로 데드락 발생을 무시하고 지나가는 방법입니다.
263 |
264 | ## 교착상태 예방
265 |
266 | 교착상태가 발생하기 위한 4가지 필요충분 조건 중 하나를 설계 단계에서 배제하는 방법이다.
267 |
268 | - 상호 배제 : 운영체제에서 반드시 보장해주어야 함
269 | - 점유 대기 : 프로세스가 필요한 모든 자원을 한꺼번에 요청
270 | - 비선점 : 프로세스가 새로운 자원 요청에 실패하면 기존의 자원들을 반납한 후 다시 요청 or 운영체제가 강제적으로 자원을 반납시킴
271 | - 환형 대기 : 자원 할당 순서(자원 유형)를 미리 정해두면 없앨 수 있음
272 |
273 | ## 교착상태 회피
274 |
275 | **은행원 알고리즘(Banker Algorithm)**을 사용합니다.
276 | ****데드락을 처리하기 위한 방법 중 **회피에 해당**하는 알고리즘입니다. 데드락에 빠질 수 있는 상태를 불안전 상태, 데드락에 빠질 수 없는 상태를 안전 상태 라고 가정했을 때, 운영체제는 이러한 안전 상태인 경우에만 요청을 허락하여 자원을 할당해주고, 나머지 요구들은 안전 상태가 될 때 까지 계속 거절하는 알고리즘입니다.
277 |
278 | 즉, **은행원 알고리즘**은 은행은 **최소한 한 명에게 대출해줄 수 있는 돈을 가지고 있어야 한다**는 뜻에서 나왔으며, 바꿔말하면 **운영체제가 최소한 하나의 프로세스가 일을 수행할 수 있는 경우에만 요청을 허락하여 시스템의 자원을 할당해주는 것**과 같습니다.
279 |
280 | # 👋 예상 질문
281 |
282 | - 데드락이란 무엇인가요?
283 |
284 | 데드락은 프로세스가 자원을 얻지 못해서 다음 일을 처리하지 못하는 상태 입니다. 즉, 교착 상태라고도 말하는데요. 보통 시스템적으로 한정된 자원을 여러 곳에서 동시에 사용하려고 할 때 발생합니다.
285 |
286 | 예를 들어,
287 | 프로세스 1이 리소스 1을 사용하고 있고, 리소스 2를 사용하기 위해 요청했으며
288 | 프로세스 2가 리소스 1을 사용하기 위해 요청했고, 리소스 2를 사용하고 있다면
289 |
290 | 프로세스 1 -> 리소스 1(사용 - Lock) / 리소스 2(요청 - Wait)
291 | 프로세스 2 -> 리소스 1(요청 - Wait) / 리소스 2(사용 - Lock)
292 |
293 | 상태가 되서 프로세스 1, 2 모두 다음 리소스를 얻지 못해 멈추게 됩니다. 이는 사거리의 모든 자동차가 서 있는 상태와 같습니다
294 |
295 |
296 | # ✨ References
297 |
298 | - William Stallings, 『운영체제 제8판 : 내부구조 및 설계원리』, 프로텍미디어
299 | - 세종대 운영체제 수업 내용 + 내 필기
300 | - 병행성 내용 요약
301 |
302 | [나만의 백과사전 - 병행성 : 상호배제, 동기화, 교착상태, 기아](https://velog.io/@pu1etproof/%EB%82%98%EB%A7%8C%EC%9D%98-%EB%B0%B1%EA%B3%BC%EC%82%AC%EC%A0%84-%EB%B3%91%ED%96%89%EC%84%B1-%EC%83%81%ED%98%B8%EB%B0%B0%EC%A0%9C-%EB%8F%99%EA%B8%B0%ED%99%94-%EA%B5%90%EC%B0%A9%EC%83%81%ED%83%9C-%EA%B8%B0%EC%95%84#1-%EC%83%81%ED%98%B8%EB%B0%B0%EC%A0%9C%EB%A5%BC-%EB%B3%B4%EC%9E%A5%ED%95%98%EA%B8%B0-%EC%9C%84%ED%95%9C-%EC%86%8C%ED%94%84%ED%8A%B8%EC%9B%A8%EC%96%B4%EC%A0%81-%EC%A0%91%EA%B7%BC-%EB%B0%A9%EB%B2%95)
303 |
304 | - 데드락 질문 정리
305 |
306 | [[OS] 2020.11.16. 오늘의 면접 Q&A](https://maivve.tistory.com/270)
307 |
308 | - 뮤텍스 세마포어 차이점
309 |
310 | [Semaphore(뮤텍스)와 Mutex(세마포어)의 차이점은?](https://junghyun100.github.io/Semaphore&Mutex/)
--------------------------------------------------------------------------------
/OperatingSystem/인터럽트와 시스템콜.md:
--------------------------------------------------------------------------------
1 | # 운영체제 구조 및 동작원리(Mode, System call, Interrupt
2 |
3 | Created At: December 10, 2021 10:00 PM
4 | Updated At: December 23, 2021 10:23 PM
5 |
6 | # 운영체제 시작
7 |
8 | 컴퓨터가 처음 부팅되면 Bootstrap 프로그램이 실행된다.
9 |
10 | 이 프로그램은 시스템을 모두 초기화하고 OS를 메모리에 올려 실행하게끔 하고 OS가 실행되면서 다음 event를 기다리게 된다.
11 |
12 | 이 event를 interrupt라고 부른다.
13 |
14 | (Node.js의 event와 비슷)
15 |
16 | ex) 윈도우가 실행이 되면서 잠금을 걸어놨다면 비밀번호를 입력하라는 창이 뜰 텐데 OS는 이 창을 띄우고 "비밀번호의 입력(입출력장치)"이라는 interrupt를 기다리게 된다. 그동안 OS는 아무 행동도 취하지 않으며 대기 상태이다.
17 |
18 | # Interrupt
19 |
20 | 운영체제는 기본적으로 **interrupt(event)-driven** 방식이다.
21 |
22 | 하드웨어가 어떤 이벤트를 CPU에게 알리기 위해서 사용하는 방법 or 실행 중인 프로세스가 CPU 내의 인터럽트 라인을 세팅해 인터럽트를 걸기도함(소프트웨어)
23 |
24 | **전자를 비동기식 인터럽트라고 부르는데 하드웨어에 의해 걸리고, 후자를 동기식 인터럽트라고 부르는데 소프트웨어에 의해 걸린다.**
25 |
26 | 하드웨어 인터럽트 : I/O 장치, 전원 등 (키보드, 마우스 입력)
27 |
28 | - 조금 Deep한 내용
29 |
30 | ## Hardware Interrupt
31 |
32 | Hardware는 입출력장치인 I/O와 해당 장치를 제어하는 controller로 이루어져 있다.
33 |
34 | 우리가 사용하는 키보드, 디스크에도 모두 controller가 있으며 이것들이 우리가 입력하는 데이터들을 본체에 전송을 하게 된다. 그리고 각 장치에 해당하는 OS에는 해당 Hardware와 데이터를 주고받기 위해 그 기기에 대한 Device Driver(D/D)가 필요하다.
35 |
36 | 본체에서 보내는 데이터는 D/D의 buffer(데이터 전송을 위한 임시 저장 장치)에 저장되었다가 나가게 되고 I/O 장치에서 보내는 데이터 또한 controller의 buffer에 저장되었다가 전송된다. 이러한 전송 완료에 대한 메시지를 interrupt로 발생시킨다.
37 |
38 | 하지만 이 때 buffer의 용량이 상당히 작기 때문에 대용량의 데이터 전송시에 문제가 생기고 CPU에게 인터럽트를 많이 걸게 되므로 빈번한 OS의 개입이 이루어진다.
39 |
40 | 이런 문제를 해결하기 위해서 Direct Memory Access가 도입되었는데
41 |
42 | DMA는 장치에 대한 연결의 interrupt를 발생시킨 후 OS는 모든 권한을 DMA에게 위임하기 때문에 빈번한 OS의 개입이 없고 전송 단위 또한 커서 빠르게 전송할 수 있다.
43 |
44 | 즉, DMA는 CPU(OS)의 개입 없이 디바이스 컨트롤러와 메모리 사이에 데이터를 이동하도록 하는 것
45 |
46 | 
47 |
48 | 이 방식을 사용함으로써 얻을 수 있는 점은 CPU가 디바이스와 메모리 사이를 중재할 필요가 사라지기 때문에 CPU는 그동안 다른 일들을 할 수 있다는 것이다. 또한 바이트 단위가 아닌 블록 단위로 인터럽트를 걸기 때문에 오버헤드를 줄일 수 있다.
49 |
50 |
51 | 소프트웨어 인터럽트(trap or exception) : 소프트웨어가 OS 서비스를 요청하거나 에러를 일으켰을 때 발생 (파일 읽기/쓰기, 0으로 나누기, 오버플로우 등)
52 |
53 | 소프트웨어는 3가지로 나뉨
54 |
55 | 1. Trap : 의도적으로 일으킨 예외 (ISR 종료 후 실행 재개) → 시스템 콜
56 | 2. Fault : 복구가 가능할 수도 있는 예외 (ISR 종료 후 실행을 재개할 가능성 있음) → 0으로 나누기, 잘못된 메모리 접근
57 | 3. Abort : 복구 불가능한 예외 (ISR 실행 시 프로그램 강제 종료) → 하드웨어 고장
58 |
59 | ## 과정
60 |
61 | CPU에 인터럽트가 걸리면 가장 먼저 **명령어의 주소를 저장을 한다**. 그 이유는 Interrupt의 대응하는 행위를 끝내고 다시 그다음 명령어를 수행하거나 다시 대기 상태로 돌아오기 위함 (context switch를 위해서?)
62 |
63 | 이후 Interrupt Service Routine(ISR)에 제어권을 넘겨주는 과정을 거치는데 **Interrupt Vector Table이라는 곳에서 해당 Interrupt에 대한 주소를 찾고(인터럽트 핸들러 주소 = ISR 시작 주소) 그리고 그 주소로 이동해 처리를 실행한다.(ISR).**
64 |
65 | ISR이 끝나고 나면 OS는 **저장해 놓았던 주소로 되돌아가** 이후 명령어를 수행
66 |
67 | (Interrupt Vector Table은 인터럽트 종류별로 **인터럽트 핸들러**의 주소가 담긴 테이블이다.)
68 |
69 | ## Dual-Mode Execution
70 |
71 | 사용자가 인터럽트처럼 Kernel상의 작업(컴퓨터의 Core에 해당하는 작업)을 직접 건드려 명령하고 수행하게 된다면 잘못하다가는 시스템 전체에 큰 악영향을 끼칠 수 있음
72 |
73 | 일반 사용자가 컴퓨터에 치명적인 명령어를 사용할 수 없도록, 일반 사용자로부터 시스템을 보호하기 위해 **하드웨어적**으로 **이중 모드(dual mode)**라는 것을 지원한다.
74 |
75 | 이중 모드는 **사용자 모드(user mode)**와 **커널 모드(kernel mode)**로 나뉜다. 그리고 mode bit(user mode=1, kernel mode=0)를 통해 두 모드를 구분한다. 일반적으로 사용자 프로세스는 사용자 모드에서는 실행되지만 어떤 특정한 명령들은 커널 모드에서만 실행된다. 이 특정한 명령어들을 **특권 명령(privileged instruction)**이라고 하는데 잘못된 접근으로부터 OS와 사용자를 보호하기 위해 모아놓은 명령어들의 집합을 말한다. 여기에 포함된 명령어들은 OS만이 실행할 수 있다.
76 |
77 | 그래서 각 명령어에 Mode-bit를 심어서 **해당 명령어의 Mode-bit와 현재 시스템 상의 Mode-bit가 같을 시에만 해당 명령어를 수행**하게 끔 하는 것
78 |
79 | ex)
80 |
81 | ```c
82 | printf("출력");
83 | ```
84 |
85 | 위 코드는 출력하는 행위로 I/O 작업에 해당한다.
86 |
87 | 이런 I/O작업은 OS만 접근이 가능해야 한다.
88 |
89 | 위 함수를 까보면 여러 가지 명령어중에 **INT 80**이라는 명령어가 있는데 특수 명령어로 현재 Mode를 바꿔주는 역할을 한다.
90 |
91 | 즉 이전까지 수행되던 명령어들은 User-Mode였다면 화면에 출력하기 위해서는 Kernel-Mode가 필요하므로
92 |
93 | 위의 명령어를 통해 Mode를 Kernel-Mode로 변환 후 I/O 장치에 출력을 하는 명령을 OS가 내리게 된다.
94 |
95 | 그리고 함수가 끝날 때는 다시 User-Mode로 돌아간다.
96 |
97 | 이러한 **bit를 바꾸는 행위를 System Call**이라고 한다.
98 |
99 | 커널에서 수행되어야 하는 몇 가지 중요한 명령어들 : Turn off interrupts, Access I/O devices, Set value of Timer 등
100 |
101 | System call이 일어나면 Interrupt 동작원리(Interrupt Vector Table, Interrupt Vector Routine)와 같이 해당 **System Call에 대한 번호를 Table에서 찾아서 Routine을 실행**하게 된다.
102 |
103 | 
104 |
105 | # 시스템 콜
106 |
107 | 
108 |
109 | 위에서 말했던 특권 명령을 실행하고자 하면, 반드시 사용자 모드에서 커널 모드로 전환해야한다.
110 |
111 | 이 때, 특권 명령을 실행하기 위해 **커널 모드로의 전환을 요청하는 인터페이스를 시스템 콜** 이라고 한다.(trap의 한 종류)
112 |
113 | ## 시스템 콜이 필요한 이유??
114 |
115 | - 우리가 일반적으로 사용하는 프로그램은 **응용 프로그램** 이다. 유저레벨의 프로그램은 유저레벨의 함수들만으로는 많은 기능을 구현하기 힘들기 때문에, 무조건 커널의 도움을 받아야만 한다.
116 | - 반드시 커널에 관련한 것들은 커널모드로 전환하여 해당 작업을 수행해야한다.
117 |
118 | ## 시스템 콜 종류
119 |
120 | 1. 프로세스 제어용 시스템 콜
121 | - fork, wait, exec
122 | 2. 파일에 대한 입출력 시스템 콜
123 | - open, create, close, read 등
124 | 3. 소켓 기반 입출력 시스템 콜
125 | - socket, bind, listen, connect 등
126 |
127 | ## 과정
128 |
129 | 프로세스가 디스크로부터 파일을 읽어오는 명령이라고 가정
130 |
131 | 1. 프로세스가 시스템 콜을 요청하면서 CPU 내에 인터럽트 라인을 세팅한다.
132 | 2. CPU는 실행 중이던 명령어를 마치고 인터럽트 라인을 통해 인터럽트가 걸렸음을 인지한다.
133 | 3. mode bit를 0으로 바꾸고 OS에게 제어권을 넘긴다.
134 | 4. 현재 실행 중이던 프로세서의 상태 및 정보를 PCB에 저장하고 PC에는 다음에 실행할 명령어의 주소를 저장한다.
135 | 5. 시스템 콜 루틴에 해당하는 곳으로 가서 시스템 콜 테이블을 참조해 파일 읽기에 해당하는 시스템 콜을 실행한다.
136 | 6. 루틴이 끝나면 mode bit를 1로 바꾸고 PCB에 저장했던 상태들과 PC를 복원시킨다.
137 | 7. PC에 저장된 주소(=마지막으로 실행했던 명령어의 다음)로 이동해 계속 실행한다.
138 |
139 | ## TIP
140 |
141 | I/O 명령을 실행할 때 CPU 제어권이 어디로 가냐에 따라 동기식(소프트웨어에 의해 발생), 비동기식(하드웨어에 의해 발생) 두 가지로 나뉜다.
142 |
143 | - **동기식 I/O**는 I/O 명령 요청이 완료되어야지만 사용자 프로그램에 제어가 넘어간다.
144 | - **비동기식 I/O**는 I/O 명령이 끝날 때까지 기다리지 않고 사용자 프로그램으로 제어가 넘어가고 I/O가 완료되면 인터럽트로 알린다.
145 |
146 | 위 과정은 동기식 I/O를 기준으로 한 설명
147 |
148 | 만약 비동기식 이라면?? 즉, 하드웨어라면??
149 |
150 | 5번부터 다르게 실행된다.
151 |
152 | 1. 다른 프로세스의 PCB와 PC를 읽어와서 실행한다.
153 | 2. I/O 명령을 마치면 디바이스 컨트롤러(Device controller) 가 CPU에게 인터럽트를 건다.(하드웨어 인터럽트 부분의 deep 내용 참고)
154 | 3. CPU가 인터럽트를 인지하면 실행 중이던 프로세스를 다시 PCB에 저장하고 OS에게 제어권을 준다.
155 | 4. 그리고 OS는 디바이스 컨트롤러로부터 버퍼에 저장된 데이터를 받아와서 I/O를 요청했던 명령어의 메모리 영역에 데이터를 저장한다.
156 |
157 | # 참고
158 |
159 | - 인터럽트와 시스템 콜
160 | [https://baked-corn.tistory.com/3](https://baked-corn.tistory.com/3)
161 | [https://velog.io/@chowisely/Operating-Systems-Interrupt-System-Call](https://velog.io/@chowisely/Operating-Systems-Interrupt-System-Call)
162 | [https://github.com/Songwonseok/CS-Study/blob/main/OS/시스템 콜 (System Call).md](https://github.com/Songwonseok/CS-Study/blob/main/OS/%EC%8B%9C%EC%8A%A4%ED%85%9C%20%EC%BD%9C%20(System%20Call).md)
163 | - 시스템 콜 종류
164 | [https://whitesnake1004.tistory.com/2](https://whitesnake1004.tistory.com/2)
165 |
--------------------------------------------------------------------------------
/OperatingSystem/프로세스와 스레드.md:
--------------------------------------------------------------------------------
1 | # ⭐️ 프로세스
2 |
3 | 프로그램은 **메모리에 올라오지 않은 정적인 코드 덩어리** 라고하는데 이 프로그램이 실제 메모리에 올라가 실행되고 있으면 프로세스라고 부른다.
4 |
5 | 즉, OS로부터 시스템 자원을 할당받는 작업의 단위이다.
6 |
7 | 
8 |
9 | ## 프로세스 특징
10 |
11 | 프로세스는 최소 1개의 스레드를 가지고 있고 각각 독립된 메모리 영역을 할당받는다.
12 |
13 | 독립되어있기 때문에 별도의 주소 공간에서 실행되며, 일반적인 방법으로는 다른 프로세스에 접근할 수 없다.(IPC를 사용하면 접근 가능)
14 |
15 | ### 프로세스의 메모리 구조
16 |
17 | - Code 영역
18 | - 컴파일된 코드 자체가 저장된다.
19 | - 프로세스가 사용하는 기계어로 된 프로그램 명령들이 위치해 있다.
20 | - Data 영역
21 | - 전역변수, 정적변수, 배열, 구조체 등이 저장된다.
22 | - 자세하게 말하면 **초기화 된 데이터는 Data영역**에, **초기화 되지 않은 데이터는 BSS 영역**에 저장된다.
23 | - 이 둘을 구분하는 이유??
24 | - 초기화 되지 않는 변수는 프로그램이 실행될 때 영역만 잡아주면 되고 그 값을 프로그램에 저장하고 있을 필요가 없으나 초기화된 변수는 그 값도 프로그램에 저장하고 있어야하기 때문에 구분한다.
25 | - 프로그램이 실행될 때 생성되고 프로그램이 종료되면 반환된다.
26 | - Heap 영역
27 | - 필요에 의해 동적으로 메모리를 할당 하고자 할 때 사용하는 메모리 영역
28 | - 메모리 주소 값에 의해서만 참조되고 사용된다.
29 | - Stack 영역
30 | - 프로그램이 자동으로 사용하는 **임시 메모리** 영역
31 | - 지역변수, 매개변수, 리턴 값 등 잠시 사용되었다가 사라지는 데이터
32 | - 함수 호출 시 생성되고, 함수가 끝나면 반환된다.
33 | - 이 스택 사이즈는 프로세스가 메모리에 로드 될 때 고정되어 할당된다. 따라서 런타임에 사이즈를 변경할 수 없다.
34 |
35 | ## 프로세스 상태
36 |
37 | 
38 |
39 | - New : 프로세스가 생성되었을 때
40 | - Ready : 프로세스가 프로세서에게 할당 받기를 기다릴 때
41 | - Running : 프로세스가 실행 상태일 때
42 | - Waiting(Blocked) : 프로세스가 어떤 이벤트가 발생하기를 기다릴 때
43 | - Suspended : 프로세스의 실행이 중지되었을 때
44 | - 메모리를 강제로 뺏긴 상태(디스크 swap-out)
45 | - Ready에서 swap-out이면 Suspended Ready, Blocked에서 swap-out이면 Suspended Block
46 | - Terminated : 프로세스의 실행이 종료되었을 때
47 |
48 | 프로세스는 위 6단계에 따라 **프로세스 큐(Job, Ready, Device)**에 각각 올라가있고 큐에 올리는 일은 **프로세스 스케줄러가 담당**한다.
49 |
50 | ### Ready와 Waiting의 차이
51 |
52 | - I/O 작업이나 기타 이벤트로 인한 상태 변화에는 Running → Waiting → Ready → Running 의 순서로 변한다.
53 | - 즉, 준비가 다 끝나지 않은 프로세스가 준비를 끝내기위해서 대기 중인 상태
54 | - 프로세스 스케줄링에 의한 상태 변화(time out, interrupt)에는 Running → Ready → Running 의 순서로 변한다.
55 | - 즉, 준비가 다 끝난 프로세스가 실행되기를 기다리는 상태
56 |
57 | ### Context Switching → 프로세스의 상태를 바꿔주는 것
58 |
59 | ## 프로세스 Queue와 스케줄러
60 |
61 | 프로세스의 큐는 Job, Ready, Device가 존재한다.
62 |
63 | - Job Queue : 시스템 상의 모든 프로세스들을 의미
64 | - Ready Queue : 메모리에 올라가 있고 실행을 기다리는 프로세스들을 의미
65 | - Device Queue : I/O 작업을 위해 기다리고 있는 프로세스들을 의미
66 |
67 | 
68 |
69 | 이러한 큐에 어떤 것을 올릴지 결정하는 것이 스케줄러이다.
70 |
71 | - Long-Term Scheduler(장기 스케줄러)
72 | - Job Scheduler라고도 불리며 **Ready Queue에 어떤 것들을 올려야하는지 결정**하는 스케줄러이다.
73 | - 즉, **디스크**에 있는 프로그램을 **메모리**로 올려 프로세스로 만드는 작업
74 | - 속도는 빠르지 않아도 괜찮다.
75 | - 멀티 프로그래밍의 정도를 제어
76 | - 그 이유는 얘가 메모리에 프로세스를 올려주기 때문에 I/O-bound 프로세스와 CPU-bound 프로세스를 적절히 섞어서 올려줘야 한다.
77 | - 상태 변경 : New → Ready(in memory)
78 | - Short-Term Scheduler(단기 스케줄러)
79 | - 우리들이 알고 있는 CPU Scheduler 라고 불리며 **어떤 프로세스에게 CPU 자원을 할당할 것인지를 결정**하는 스케줄러이다.
80 | - 즉, **메모리**에 올라와 있는 프로세스를 **CPU에게 할당**
81 | - CPU 자원 할당은 매우 짧은 시간 단위로 반복되기 때문에 속도가 빨라야한다.
82 | - 상태 변경 : Ready → Running
83 | - Medium-Term Scheduler(중기 스케줄러)
84 | - 실행하기에 필요한 자원이 부족한 프로세스들 중 **어떤 프로세스를 Swap-out 하여 Disk에 저장할지, 어떤 프로세스를 Swap-in 해야하는지를 결정**해주는 스케줄러이다.
85 | - 즉, **메모리**에 너무 많은 프로세스가 동시에 올라가있다면 **디스크**로 내보내는 작업
86 | - 상태 변경 : Ready → Suspended
87 | - Terminated가 아니다.
88 | - 누군가 다시 재개시켜줘야(swap-in해줘야) 다시 Ready로 돌아갈 수 있다.
89 |
90 | ## PCB(Process Control Block)
91 |
92 | 특정 프로세스에 대한 중요한 정보를 저장하고 있는 OS의 자료구조이다.
93 |
94 | 프로세스 생성과 동시에 고유한 PCB가 생성되고 프로세스 전환시(인터럽트나 시스템콜)에 PCB에 기록하고 사용한다.
95 |
96 | - PCB에 저장되는 정보들 중 중요한 것들
97 | - PID : 프로세스 식별 번호
98 | - 상태
99 | - CPU 스케줄링 정보
100 | - TCB가 PCB를 참조
101 | - 레지스터
102 | - PC(Program Counter) : 프로세스가 다음에 실행할 명령어의 주소
103 |
104 | 
105 |
106 | - 추가 내용(같이 고민해볼 점)
107 |
108 | 스케줄링에는 Context Switching 시간까지 포함되어 있다.
109 |
110 | 따라서 PCB의 저장과 복원이 오래걸리면 그만큼 작업을 수행할 수 있는 시간이 짧아지는 것
111 |
112 | 따라서 **PCB의 저장과 복원은 H/W로 구현해서 작업 효율을 최대한 늘린다고 한다.**
113 |
114 | 근데 OS의 자료구조인데 하드웨어..? 잘 모르겠다.
115 |
116 |
117 | # ⭐️ 스레드
118 |
119 | 멀티 스레드와 혼용해서 설명
120 |
121 | 프로세스의 수행 경로
122 |
123 | 즉, 프로세스가 할당받은 자원을 이용하는 실행의 단위(흐름)
124 |
125 | ex) 메신저 프로그램에서 “내가 입력”, “상대방이 입력한 것을 출력” 등 하나씩이 실행 단위이다.
126 |
127 | 
128 |
129 | ## 스레드가 필요한 이유
130 |
131 | 결론은 프로세스만으로 요구 사항을 충족하기 쉽지 않아서이다.
132 |
133 | 예를 들어서 메신저 프로그램일 때, 내가 입력한 것을 출력해줌과 동시에 상대방이 입력한 것도 출력해야한다.
134 |
135 | 이 때, 싱글 프로세스를 사용한다면 키보드 입력을 기다릴 때 상대방으로부터 온 메시지를 받을 수 없다.
136 |
137 | 왜냐면 하나의 path만 가지고 있기 때문
138 |
139 | 
140 |
141 | 대충 이런 느낌이다.(프로세스는 기본적으로 하나의 스레드를 가지고 있음)
142 |
143 | 따라서 프로세스를 추가로 생성해야하는데 문제는 프로세스 자체가 독립된 자원을 할당 받기 때문에 서로 공유하지 않아서 관련되지 않은 실행 path를 가진다.
144 |
145 | 
146 |
147 | 그럼 뭐다?? 서로 통신(IPC) 해야하는데 프로그램이 커지고 시간이 지날수록 비효율적이다.(PCB 추가, 메모리 추가, Context Switching 등)
148 |
149 | - IPC는 커널을 껴서 통신해야한다.
150 |
151 | 그래서 하나의 프로세스에 여러 path를 만들고 자원을 공유하는 멀티 스레드를 사용하는 것(다수의 path가 필요한 것 뿐이기 때문에 굳이 자원 낭비를 하지 말자!)
152 |
153 | ## 스레드 특징
154 |
155 | 스레드는 프로세스와 다르게 Stack만 따로 할당 받고 Code, Data, Heap 영역은 공유한다.
156 |
157 | 정확히는 프로세스와 동일하게 실행 상태를 갖고 Register와 Stack을 독립적으로 할당받는다.
158 |
159 | ### Stack과 Register를 독립적으로 할당받는 이유??
160 |
161 | - stack
162 | - 스레드는 하나의 독립적인 실행단위이기 때문에 각각 독립적인 stack을 가진다.(독립적인 함수 호출)
163 | - 즉, 함수 호출 시 인자, 리턴 값 지역 변수 등을 독립적으로 가지기 위해서
164 | - register
165 | - 프로세스와 똑같이 CPU를 할당받고, 선점당할 수 있다.
166 | - 따라서 Context Switching이 발생하게 되므로 실행하고 있는 코드의 지점을 저장하는 PC 등을 스레드마다 독립적으로 할당해야 한다.
167 |
168 | ## 장점
169 |
170 | 1. 사용자에 대한 응답성 증가
171 | - 하나의 스레드가 waiting인 동안 다른 스레드가 실행되어 다른 작업을 빨리 처리할 수 있기 때문
172 | 2. 프로세스의 자원과 메모리 공유
173 | - 하나의 같은 주소 공간에서 여러 개의 스레드를 실행해 병렬성, 성능향상을 가질 수 있다.
174 | 3. 경제성
175 | - 한 프로세스의 자원을 공유하기 때문에 프로세스끼리 Context Switching하는 것보다 스레드끼리 하는 것이 오버헤드가 적다.
176 | - 스레드가 Context Switching 오버헤드가 작은 이유 : 스레드는 Stack, Register만 하면 되고 RAM과 CPU 사이의 캐시를 사용 가능하지만 프로세스는 캐시까지 초기화되어버린다.
177 | 4. 다중 프로세서(CPU) 구조 활용
178 | - 멀티 스레드를 통해 병렬로 수행할 수 있기 때문
179 |
180 | # ⭐️ 멀티 프로세스
181 |
182 | 하나의 응용 프로그램을 여러 개의 프로세스로 구성해 각 프로세스가 하나의 작업을 처리하도록 하는 것
183 |
184 | 
185 |
186 | ## 장단점
187 |
188 | - 장점
189 | - 여러 개의 자식 프로세스 중 하나에 문제가 발생하면 그 자식 프로세스만 죽는 것 이상으로 다른 영향이 확산되지 않는다.
190 | - 단점
191 | - Context Switching에서의 오버헤드 프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 프로세스 사이에서 공유하는 메모리가 없어, Context Switching가 발생하면 캐쉬에 있는 모든 데이터를 모두 리셋하고 다시 캐쉬 정보를 불러와야 한다.
192 | - 프로세스 사이의 어렵고 복잡한 통신 기법(IPC) 프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 하나의 프로그램에 속하는 프로세스들 사이의 변수를 공유할 수 없다.
193 |
194 | # ⭐️ 멀티 스레드
195 |
196 | 하나의 응용프로그램을 여러 개의 스레드로 구성하고 각 스레드로 하여금 하나의 작업을 처리하도록 하는 것이다.
197 |
198 | 대부분 많은 운영체제들이 멀티 스레딩을 기본으로 하고 있다.
199 |
200 | 
201 |
202 | 
203 |
204 | ex)
205 |
206 | 워드에서 키보드 입력을 기다리고, 주기적으로 저장하고, 타이핑 에러 체크하고 등을 전부 동시에 한다.
207 |
208 | 저 3개를 프로세스로 할 순 있는데 매우 비효율적
209 |
210 | 따라서
211 |
212 | 워드 → 프로세스 하나
213 |
214 | 키보드 입력 → 스레드
215 |
216 | 주기적 저장 → 스레드
217 |
218 | 타이핑 에러 체크 → 스레드
219 |
220 | ## 장단점
221 |
222 | - 장점
223 | - 시스템 자원 소모 감소 (자원의 효율성 증대)
224 | - 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다.
225 | - 시스템 처리량 증가 (처리 비용 감소)
226 | - 스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어들게 된다.
227 | - 스레드 사이의 작업량이 작아 Context Switching이 빠르다.
228 | - 간단한 통신 방법으로 인한 프로그램 응답 시간 단축
229 | - 스레드는 프로세스 내의 Stack 영역을 제외한 모든 메모리를 공유하기 때문에 통신의 부담이 적다.
230 | - 단점
231 | - 주의 깊은 설계가 필요하다.
232 | - 디버깅이 까다롭다.
233 | - 단일 프로세스 시스템의 경우 효과를 기대하기 어렵다.
234 | - 다른 프로세스에서 스레드를 제어할 수 없다. (즉, 프로세스 밖에서 스레드 각각을 제어할 수 없다.)
235 | - 멀티 스레드의 경우 자원 공유의 문제가 발생한다. (동기화 문제)
236 | - 하나의 스레드에 문제가 발생하면 전체 프로세스가 영향을 받는다
237 |
238 | ## 멀티 스레드 모델(조금 deep 한 내용)
239 |
240 | 모델을 설명하기 전에 **User Thread**와 **Kernel Thread**에 대해 알아야한다.
241 |
242 | - User Thread
243 | - 사용자가 관리하는 스레드
244 | - 스레드 전환시 커널 모드 권한이 필요없고 빠르게 만들고 관리할 수 있다.(커널 스레드보다 오버헤드가 적음 → Context Switch가 없다.(사용자 영역 스레드에서 행동하기 때문 → 메모리 상에 저장해놓나??))
245 | - 사용자 영역에서 하기 때문에 운영체제에 의존적이지 않다.(커널이 제공해주지 않고 라이브러리를 활용)
246 | - 하지만 일반적인 OS에서는 대부분의 시스템 호출이 차단되고 다중 처리를 활용할 수 없다.(I/O 작업 등에 의해 블록되면 전체 스레드가 멈춘다.)
247 | - Kernel Thread
248 | - 운영체제가 직접 커널에서 제공하고 관리하는 스레드
249 | - 하나의 프로세스는 적어도 하나의 커널 스레드를 가진다.
250 | - 프로세스의 스레드들을 한꺼번에 디스패치할 수 있기 때문에 멀티 프로세서 환경에서 좋다.
251 | - 다른 스레드가 입출력 작업이 끝날 때까지 기다릴 필요가 없다.
252 | - 안정성과 다양한 기능을 제공
253 | - 하지만 스케줄링과 동기화를 위해 커널을 호출하는데 무겁고 오래걸린다. 즉, 사용자모드에서 커널모드로 전환이 빈번하게 이루어지면 성능 저하가 발생한다. 또한 구현하기 어렵고 자원을 더 많이 소비한다.
254 |
255 | ### 1. Many-to-One Model
256 |
257 | 
258 |
259 | - 하나의 Kernel Thread가 다수의 User Thread를 처리하는 구조(=User Thread만 사용했다고 보면 됨)
260 | - User Thread를 처리하던 중 시스템 콜에 의해 blocking되면 **전체 프로세스가 막히게 된다.**
261 |
262 | ### 2. One-to-One Model
263 |
264 | 
265 |
266 | - User Thread 한 개 당 Kernel Thread를 대응시켜 작업하는 구조
267 | - 과도한 Kernel Thread 생성 문제가 있다.
268 |
269 | ### 3. Many-to-Many Model
270 |
271 | 
272 |
273 | - 1,2를 어느정도 보완한 모델로 다수의 User Thread를 다수의 Kernel Thread가 처리하는 구조
274 | - Kernel Thread의 숫자는 User Thread의 숫자보다 같거나 작아야한다.
275 |
276 | ### 4. Two-Level Model
277 |
278 | 
279 |
280 | - 최종적으로 보안된 모델로 2+3을 합친 구조이다.
281 | - 중요한 작업은 One-to-One 처럼, 나머지는 Many-to-Many 처럼 처리함으로써 혹시나 있을 중요한 작업에서의 기다림 현상을 줄일 수 있다.
282 |
283 |
284 | # ⭐️ 참고
285 |
286 | 프로세스와 스레드
287 | [https://github.com/Songwonseok/CS-Study/blob/main/OS/프로세스vs스레드.md](https://github.com/Songwonseok/CS-Study/blob/main/OS/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4vs%EC%8A%A4%EB%A0%88%EB%93%9C.md)
288 | [https://coder-in-war.tistory.com/entry/OS-00-프로세스와-스레드의-차이?category=994187](https://coder-in-war.tistory.com/entry/OS-00-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4%EC%99%80-%EC%8A%A4%EB%A0%88%EB%93%9C%EC%9D%98-%EC%B0%A8%EC%9D%B4?category=994187)
289 |
290 | 프로세스
291 | [https://baked-corn.tistory.com/5?category=718232](https://baked-corn.tistory.com/5?category=718232)
292 | 스레드
293 | [https://baked-corn.tistory.com/6?category=718232](https://baked-corn.tistory.com/6?category=718232)
294 |
295 | OS 튜토리얼
296 | [https://www.tutorialspoint.com/operating_system/index.htm](https://www.tutorialspoint.com/operating_system/index.htm)
297 |
298 | 프로세스 상태, 큐, 스케줄러
299 | [https://kosaf04pyh.tistory.com/190](https://kosaf04pyh.tistory.com/190)
300 |
301 | 멀티 스레드 모델
302 | [https://www.crocus.co.kr/1255](https://www.crocus.co.kr/1255)
303 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Backend_Interview_Study
2 |
3 | ### 참여자
4 | |
91 |
92 | - **L2**
93 | - Layer 2 데이터 링크 계층에서 MAC 주소를 바탕으로 로드밸런싱
94 | - L2SDR 전략을 사용하려면 MAC 주소의 변환만 가능하므로 로드밸런서와 서버는 같은 네트워크에 존재해야됨
95 | - **L3**
96 | - Layer 3 네트워크 계층에서 IP 를 기준으로 로드밸런싱
97 | - L2 에 라우팅 기능이 추가된 형태
98 | - **L4 = Network Load Balancing(NLB)**
99 | - Layer 4 전송계층(TCP/UDP)에서 IP, Port 번호를 기준으로 로드밸런싱
100 | - VIP(Virtual IP)을 통해서 Replicated Servers 그룹화하여 관리
101 | - L2, L3 의 기능도 사용가능하며 섬세한 라우팅 처리를 제공
102 | - 주로 RR 방식의 알고리즘을 사용하지만 사용자로 인해 다른 알고리즘 사용 가능
103 |
104 | 
105 |
106 |
107 | - **L7**
108 | - Layer 7 응용계층에서 TCP/UDP 는 물론 URL, FTP, 쿠키 등의 정보를 기준으로 로드밸런싱
109 | - TLS Termination 이 발생
110 |
111 |
116 |
117 | - 상위 계층에서 로드를 분산하므로 다른 로드밸런서에 비해 더욱 섬세한 라우팅이 가능
118 | - 캐싱 기능을 제공
119 | - DoS/DDoS와 같은 비정상적인 트래픽을 사전에 필터링할 수 있음
120 | - 적절한 알고리즘을 사용해 로드밸런싱
121 |
122 | 
123 |
124 | ## 📚 참고자료
125 |
126 | [로드밸런싱이란](https://www.digitalocean.com/community/tutorials/what-is-load-balancing#how-does-the-load-balancer-choose-the-backend-server)
127 |
128 | [로드밸런서의 기능, 분산 알고리즘 종류](http://wiki.hash.kr/index.php/%EB%A1%9C%EB%93%9C%EB%B0%B8%EB%9F%B0%EC%8B%B1)
129 |
130 | [로드밸런싱(Load Balancing)과 고가용성(HA)](https://prohannah.tistory.com/62)
131 |
132 | [L2, L3, L4, L7 로드밸런싱](https://tomining.tistory.com/117)
133 |
134 | [L4, L7 오해할 수 있는 내용](https://aws-hyoh.tistory.com/entry/L4L7-%EB%A1%9C%EB%93%9C%EB%B0%B8%EB%9F%B0%EC%8B%B1-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0)
135 |
136 | [NAT 의 역할](https://aws-hyoh.tistory.com/entry/L4-%EC%8A%A4%EC%9C%84%EC%B9%98-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-3)
137 |
138 | [NAVER D2 HAProxy](https://d2.naver.com/helloworld/284659)
139 |
140 | [SSL Termination이란 무엇인가?](https://sepiros.tistory.com/m/50?category=1090822)
141 |
142 | [더욱 Deep Dive](https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/19860014876.pdf)
143 |
--------------------------------------------------------------------------------
/OperatingSystem/CPU 스케줄러.md:
--------------------------------------------------------------------------------
1 | # CPU 스케줄러
2 |
3 |
4 |
5 | # 설명
6 |
7 | 멀티프로그래밍에서 CPU 이용률을 최대화 하기 위해, 특정 알고리즘으로 Main memory에 적재되어 **ready queue**에 있는 프로세스를 선택하여 CPU를 프로세스에 할당해주는 것으로, **Short-term scheduler**라고도 한다.
8 |
9 |
10 |
11 | # Dispatcher
12 |
13 | CPU 스케줄러의 일부분으로, CPU의 제어권을 프로세스에 주는 작업을 한다.
14 |
15 | - context switch
16 |
17 | - user mode로 전환
18 |
19 | - 유저 프로그램의 적절한 위치로 이동하여 프로그램을 재시작한다.
20 |
21 | - Dispatch latency : dispatcher가 한 프로세스를 멈추고 다른 프로세스를 시작하는 시간(짧을 수록 좋음)
22 |
23 |
24 |
25 | # CPU Scheduling이 발생하는 상황
26 |
27 | - 선점(preemptive) 스케줄링: 프로세스가 강제(비자발)적으로 CPU를 내주는 방식
28 |
29 | 
30 |
31 | - running → ready
32 | - waiting → ready
33 | - 비선점(nonpreemptive) 스케줄링: 프로세스가 자발적으로 CPU를 내주는 방식
34 |
35 | 
36 |
37 | - running → waiting
38 |
39 | - running → terminate
40 |
41 |
42 |
43 |
44 | # 스케줄링 기준
45 |
46 | - CPU utilization(CPU 이용률) - CPU를 얼마나 바쁘게 유지했는지
47 |
48 | - Throughput(처리량) - 시간 단위 당 실행시간을 완료한 프로세스의 수
49 |
50 | - Turnaround time(수행 시간) - 프로세스가 시작해서 끝날 때까지의 시간
51 |
52 | - Waiting time(대기 시간) - 프로세스가 **ready queue**에서 기다린 시간
53 |
54 | - Response time(응답 시간) - 프로그램을 수행해서 첫 번째 응답이 나타날 때까지의 시간
55 |
56 |
57 |
58 | # 스케줄링 알고리즘 최적화 기준
59 |
60 | - Max CPU utilization
61 |
62 | - Max throughput
63 |
64 | - Min turnaround time
65 |
66 | - Min waiting time
67 |
68 | - Min response time
69 |
70 |
71 |
72 | # 스케줄링 알고리즘
73 |
74 |
75 |
76 | ## 비선점형 스케줄링
77 |
78 |
79 |
80 | ### First Come, First Served(FCFS) Scheduling
81 |
82 | - 먼저 CPU를 요청하는 프로세스에 CPU를 할당하는 방식
83 |
84 | - Burst Time이 긴 프로세스가 먼저 요청하면 **convey effect**가 발생됨
85 |
86 | 
87 |
88 | 
89 |
90 | **대기 시간**: P1 = 0, P2 = 24, P3 = 27
91 |
92 | **평균 대기 시간**: (0+24+27)/3 = 17
93 |
94 | - Burst Time이 짧은 프로세스가 먼저 요청할수록 유리함
95 |
96 | 
97 |
98 | **대기 시간**: P1 = 6, P2 = 0, P3 = 3
99 |
100 | **평균 대기 시간**: (6+0+3)/3 = 3
101 |
102 | - convey effect: 짧은 프로세스가 긴 프로세스 뒤에 기다리게 되는 현상
103 |
104 |
105 |
106 | ### Shortest-Job-First(SJF) Scheduling
107 |
108 | - 짧은 수행 시간을 가진 프로세스를 먼저 처리하는 방식
109 |
110 | - 평균 대기 시간이 최소화 됨
111 |
112 | 
113 |
114 | 
115 |
116 | **평균 대기 시간**: (0 + 3 + 9 + 16)/4 =7
117 |
118 | - 대기 시간이 긴 프로세스는 오래 기다려야 한다.
119 |
120 |
121 |
122 | ## 선점형 알고리즘
123 |
124 | ### Shortest Remaining Time First(SRTF) Scheduling
125 |
126 | - SJF 알고리즘에서 선점 정책을 도입한 방식
127 | - 잔여시간이 가장 짧은 프로세스를 우선으로 CPU할당을 한다.
128 | - Arrival Time 개념이 추가됨
129 |
130 | 
131 |
132 | 
133 |
134 | 평균 대기 시간 : [(10-1)+(1-1)+(17-2)+(5-3)]/4 = 6.5
135 |
136 | 수행 시작된 시간 - 이미 처리한 시간 - 도착 시간
137 |
138 | - 잦은 선점에 대한 문맥 교환 오버헤드 증가
139 |
140 | ### Priority Scheduling
141 |
142 | - 프로세스에 우선순위를 메겨, 우선순위가 높은 프로세스부터 처리하는 방식
143 | - 선점형, 비선점형 모두 존재
144 | - Starvation 문제: 우선순위가 낮은 프로세스는 계속 기다려야한다.
145 | - Aging 기법: 기다리는 시간만큼 프로세스의 우선순위를 높여준다.
146 |
147 | ### Round Robin(RR) Scheduling
148 |
149 | - 각 프로세스는 작은 단위 시간(time quantum)을 가지고 있다. (보통 10-100 ms)
150 |
151 | - 단위 시간이 지나면 프로세스는 선점되어 ready queue의 끝으로 이동한다.
152 |
153 | - n개의 프로세스가 ready queue 안에 있고, 단위 시간이 q이면, 각 프로세스의 대기시간은 (n-1)q 시간보다 많이 기다리지 않는다.
154 |
155 | - 단위 시간이 클 수록 FCFS와 같아지고, 작을 수록 context switch로 인한 오버헤드가 커진다.
156 |
157 |
158 |
159 | # Multilevel Queue
160 |
161 | - ready queue는 여러 단계의 큐로 나누어져 있다.
162 |
163 | 
164 |
165 | - 사용자와 상호작용하는 프로세스는 상위 레벨에, 백그라운드로 돌아가는 프로세스는 하위 레벨에 배치한다.
166 | - 상위 레벨은 주로 RR 알고리즘을, 하위 레벨은 주로 FCFS 알고리즘을 적용한다.
167 |
168 | - 각 큐마다 스케줄링 알고리즘을 갖고 있다.
169 |
170 | - 우선순위가 고정되어 있으면 하위 레벨 queue의 프로세스들은 상위 레벨의 프로세스가 모두 수행되지 않으면 실행되지 않는 **starvation** 현상이 나타남
171 |
172 | - 하위 레벨의 프로세스가 실행되고 있어도 상위 레벨에 프로세스가 들어오면 선점된다.
173 |
174 |
175 |
176 | # Multilevel Feedback Queue
177 |
178 | - Multilevel Queue를 확장한 방식으로, 프로세스는 각 큐를 이동할 수 있다.
179 | - aging 기법을 사용하여 starvation 현상을 방지한다.
180 | - Parameter
181 | - 큐의 수
182 |
183 | - 각 큐의 스케줄링 알고리즘
184 |
185 | - 언제 프로세스 우선순위를 높이는 지 결정하는 메소드
186 |
187 | - 언제 프로세스 우선순위를 낮추는 지 결정하는 메소드
188 |
189 | - 프로세스가 서비스를 필요로 할 때 프로세스가 들어갈 큐를 결정하는 메소드
190 |
191 |
192 |
193 |
194 | # Multiple-Processor Scheduling
195 |
196 | - 여러 개의 CPU를 사용하는 시스템에서의 스케줄링 방법
197 | - 제약: 다중프로세서 내의 동질의 프로세서들
198 | - Asymmetric multiprocessing 비대칭 다중처리
199 | - Master-Slave 구조
200 | - Master 프로세서가 모든 스케줄링 결정을 하고, Slave 프로세서들은 그 결정에 따른다.
201 | - 오직 한 프로세서만 시스템 자료 구조에 접근하여 데이터 공유의 필요성을 배제한다.
202 | - Symmetric multiprocessing(SMP) 대칭 다중처리
203 | - 각 프로세서가 자기 스케줄링을 한다.
204 | - 모든 프로세서는 common ready queue에 있거나, 각자의 private queue에 있게 된다.
205 | - **common queue**는 모든 프로세서가 접근할 수 있어서 경쟁 상태를 야기하기 때문에 lock이 필요하다.
206 | - **private queue**는 큐마다 부하의 양이 다르다.
207 | - Processor affinity 프로세서 친화성
208 | - 프로세스는 현재 실행되고 있는 프로세서에 친화성을 가진다.
209 |
210 | 
211 |
212 | 특정 CPU에 할당된 프로세스를 CPU가 있는 가장 가까운 메모리에 할당하여 가능한 빠른 메모리 엑세스를 제공한다.
213 |
214 | - soft affinity 약한 친화성
215 | - hard affinity 강한 친화성
216 | - Load Balancing 부화 균등화
217 | - SMP이면, 효율성을 위해 모든 CPU를 로드해야한다.
218 |
219 | - SMP 시스템에서 부하가 고르게 분산되도록 한다.
220 |
221 | - Push migration : 특정 테스크가 각 프로세서의 로드를 감시하다가 과부하된 CPU에서 다른 CPU들로 프로세스를 옮긴다.
222 |
223 | - Pull migration : idle상태의 프로세서들은 바쁜 프로세서에서 대기중엔 프로세스들을 가져온다.
224 |
225 |
226 |
227 | ---
228 |
229 | - 참고자료
230 |
231 | [https://velog.io/@ss-won/OS-CPU-Scheduler와-Dispatcher](https://velog.io/@ss-won/OS-CPU-Scheduler%EC%99%80-Dispatcher)
232 |
233 | [https://velog.io/@jacob0122/CPU-Scheduling-Scheduler](https://velog.io/@jacob0122/CPU-Scheduling-Scheduler)
234 |
235 | [https://jhnyang.tistory.com/372](https://jhnyang.tistory.com/372)
236 |
237 | [https://imbf.github.io/computer-science(cs)/2020/10/18/CPU-Scheduling.html](https://imbf.github.io/computer-science(cs)/2020/10/18/CPU-Scheduling.html)
238 |
239 | [https://hyunah030.tistory.com/4](https://hyunah030.tistory.com/4)
240 |
241 | [https://haun25ne.tistory.com/52](https://haun25ne.tistory.com/52)
242 |
243 | 운영체제 공룡책
--------------------------------------------------------------------------------
/OperatingSystem/IPC.md:
--------------------------------------------------------------------------------
1 | # IPC
2 |
3 | 프로세스들은 유저공간에서 OS로부터 할당받은 독립된 공간에서 운행한다.
4 |
5 | 그렇기 때문에 서로 간에 통신이 어렵다.
6 |
7 | 이를 해결하기 위해서 커널 영역에서 IPC 기술을 제공하고 있다.
8 |
9 | - 프로세스간 통신이 필요할 때 사용
10 | - 동기화가 필요하고 **커널이 제공한다.**
11 |
12 | # 종류
13 |
14 | ## 1. PIPE
15 |
16 | 
17 |
18 | 익명의 파이프를 만들어서 부모-자식 간에 단방향 통신을 지원한다.
19 |
20 | 하나의 파이프로는 한쪽 방향으로만 통신 가능해서 읽기/쓰기를 모두 하기 원한다면 2개의 파이프를 사용해야한다.
21 |
22 | 기본적으로 read, write시에 block되기 때문에 read가 대기중이라면 끝나기 전에는 write할 수 없다.
23 |
24 | ### 장단점
25 |
26 | - 장점
27 | - 간단하게 구현 가능
28 | - 기본적으로 pipe(배열) 명령어로 생성 가능하고 read, write 명령어를 사용한다.
29 | - 단점
30 | - 양방향 통신으로 활용하려면 파이프를 2개 만들어야하는데 이 과정이 꽤 복잡하다.
31 | - 양방향 하고 싶으면 굳이 파이프 사용 x
32 | - buffer가 작기 때문에 overflow될 수 있다.
33 | - 부모-자식 프로세스 간에만 사용 가능하다.
34 |
35 | ## 2. Named PIPE
36 |
37 | 
38 |
39 | 위의 PIPE와 동일한 내용이지만 차이점은 파이프에 이름을 부여해 사용한다.
40 |
41 | **why???**
42 |
43 | 부모-자식 간에 통신할 때는 서로를 명확히 알고 있으므로 굳이 파이프가 어떤 파이프인지 알 필요가 없다.
44 |
45 | 하지만 **부모-자식 관계가 아닌 프로세스들 간에 통신할 때** 파이프를 사용한다면 어떤 파이프를 통해서 통신하는지 알아야하기 때문
46 |
47 | ## 3. Messaging passing ⭐️
48 |
49 | 커널이 메모리 보호를 위해서 대리 전달해주는 방식
50 |
51 | 따라서, 안전하고 동기화 문제를 신경쓰지 않아도 된다. → 커널이 알아서 동기화 해줌
52 |
53 | 그러나 번거롭고 오버헤드가 크다.
54 |
55 | ex) 프로세스 A가 커널로 메시지를 보내면 그걸 커널이 프로세스 B에게 보내준다.
56 |
57 | ### 모델
58 |
59 | 1. Direct Communication
60 | - A가 커널에 메시지를 직접 주고 커널이 B에게 메시지를 직접 전달
61 | 
62 |
63 | 2. Indirect Communication
64 | - A가 커널에 있는 메시지 박스에 넣어두면 B는 그 박스에 가서 읽어오는 방식
65 | 
66 |
67 |
68 | 둘의 차이는 커널이 직접 주냐 아니냐
69 |
70 | ### Message Queue
71 |
72 | 
73 |
74 | Message passing은 구현보다는 개념적으로 사용되는 용어이다. 프로세스 간의 통신을 하기 위해 메시지를 어떻게 전송할지에 대한 방법론이고 그 구체적인 방법 중 하나가 Message queue 구현 방법이다.(보통 Messaging Passing이라함은 Message Queue라고 해도 무방)
75 |
76 | 파이프는 데이터 흐름이라면 Message Queue는 선입선출의 자료구조를 가지고 메모리 공간을 통해 전달한다.
77 |
78 | 데이터에 번호를 붙힘으로써 다수의 프로세스가 동시에 데이터를 다룰 수 있다.
79 |
80 | ### 장단점
81 |
82 | - 장점
83 | - 비동기 방식이기 때문에 데이터가 많아도 처리가 가능하다.
84 | - 다수의 프로세스끼리 메시지를 보내고 꺼낼 수 있다.
85 | - 즉, 분산처리에 용의
86 | - 단점
87 | - 메시지가 잘 전달되었는지 알 수 없다.
88 | - 데이터가 많을 수록 추가 메모리 자원이 필요하다.
89 |
90 | ## 4. Shared memory ⭐️
91 |
92 | 
93 |
94 | 두 프로세스간의 공유된 메모리를 생성 후 이용하는 것
95 |
96 | 프로세스가 공유 메모리 할당을 커널에 요청하면 커널은 할당해주고, 어떤 프로세스건 해당 메모리 영역에 접근 할 수 있다.
97 |
98 | 단순히 공유 메모리를 point하는 방식으로 프로세스에서 사용되는 메모리가 증가되지는 않는다.
99 |
100 | ### 장단점
101 |
102 | - 장점
103 | - 따로 통신을 이용해 데이터를 주고 받지 않고 바로 메모리에 접근하기 때문에 모든 IPC 중 가장 빠르다.
104 | - 단점
105 | - 메시지 전달이 아니기 때문에 데이터를 읽어야하는 시점을 알 수 없다.
106 | - 공유 자원을 이용하므로 동기화 문제를 해결해야한다.
107 | - 커널에 종속적이기 때문에 허용하고 있는 공유메모리 사이즈를 확인해야한다.
108 |
109 | ## 5. Memory Map
110 |
111 | 
112 |
113 | 기존적으로 공유 메모리와 비슷한데 메모리 맵은 파일을 메모리에 매핑시켜서 공유한다는 점이다.
114 |
115 | 즉, 디스크에 있는 파일과 프로세스의 페이지가 연결된다. → 가상 메모리의 페이징 기법과 비슷
116 |
117 | 통신 느낌보단 파일 접근을 효율적으로 하기 위한 기법이라고 생각
118 |
119 | ex) 파일이 오픈되면 파일의 데이터가 메모리에 올라가게되는데 다른 프로세스에서 똑같은 파일을 열어서 메모리에 같은 걸 또 올리면 낭비가 심해지게 되고 데이터 일관성에도 문제가 생김.
120 |
121 | 그래서 이런 경우 기존 메모리 공간에 같이 접근해서 데이터를 읽고 쓰는 작업을 하는 듯(이 때, 동기화 문제를 스레드가 알아서 해주는 것 같다..!)
122 |
123 | ### 장단점
124 |
125 | - 장점
126 | - 대용량 데이터를 공유 할 때 사용한다.(메모리에 전부 올라가지 않아도 되니까)
127 | - File I/O가 느릴 때 사용하면 좋다.
128 | - 단점
129 | - 파일의 크기를 변경할 수 없다.(사용하기 전, 후 에만 변경 가능)
130 | - 얼마나 많은 데이터를 얼마나 오랫동안 메모리에 둘 것인지를 컨트롤할 수 없다.
131 |
132 | ## 6. Socket
133 |
134 | 
135 |
136 | 같은 도메인 내에서도 물론 연결 가능하고, 추가적으로 외부 프로세스와 통신할 때 사용한다.
137 |
138 | 서버 : bind, listen, accept
139 |
140 | 클라이언트 : connect
141 |
142 | 즉, 네트워크를 통해 프로세스 간에 통신을 진행
143 |
144 | ### 장단점
145 |
146 | - 장점
147 | - 외부 시스템과 통신이 가능하다.
148 | - 단점
149 | - 네트워크 프로그래밍이 가능해야한다.
150 |
151 | # 결론
152 |
153 | 
154 |
155 | 결국 IPC란 두 개의 프로세스간 통신을 의미하는데 굳이 하나의 컴퓨터에 있는 두 개의 프로세스만을 의미하는 것이 아니다.
156 |
157 | 서로 다른 컴퓨터의 프로세스들도 통신하는 것도 IPC = 결국 네트워킹이다.
158 |
159 | # 질문 리스트
160 |
161 | - IPC 기법에 대해 설명해주세요
162 |
163 | 프로세스들은 유저공간에서 OS로부터 할당받은 독립된 공간에서 운행하기 때문에 서로 간에 통신이 어렵습니다. 따라서 이를 해결하기 위해서 커널 영역에서 제공하는 IPC 기술을 통해 통신합니다.
164 |
165 | - IPC 기법의 종류를 아는데로 설명해주세요
166 |
167 | 대표적으로는 파이프, message queue, share memory가 있을 것 같습니다.
168 |
169 | 파이프는 익명의 파이프라면 부모-자식 프로세스간에 단방향으로 데이터를 공유하는 방법이고 named 파이프라면 부모-자식 관계가 아닌 프로세스끼리도 파이프를 이용해 통신할 수 있는 방법입니다.
170 |
171 | 파이프가 데이터 흐름이라면 Message Queue는 선입선출의 자료구조를 가지고 메모리 공간을 통해 단방향 전달 하는 방법으로 비동기 방식을 가지고 있고 여러 프로세스끼리 통신이 가능합니다.
172 |
173 | 마지막으로 share memory는 커널이 공유 메모리를 할당해주면 모든 프로세스가 해당 공유 메모리에 접근하여 사용하는 방식입니다.
174 |
175 |
176 | # 참고
177 |
178 | [https://www.byfuls.com/programming/read?id=63](https://www.byfuls.com/programming/read?id=63)
179 |
180 | 사진 자료
181 | [https://doitnow-man.tistory.com/110](https://doitnow-man.tistory.com/110)
182 |
--------------------------------------------------------------------------------
/OperatingSystem/가상 메모리.md:
--------------------------------------------------------------------------------
1 | # 가상 메모리
2 |
3 | # ⭐️ 등장 배경
4 |
5 | 기존 메모리 관리는 하나의 프로그램 전체를 실제 물리 메모리에 올리는 방식을 사용했다.
6 |
7 | 하지만 메모리에 많은 프로세스들을 올리고자 하는데 물리 메모리에 전부 올리기에는 한계가 존재한다. (메모리 용량 부족, 페이지 교체 성능 이슈)
8 |
9 | 컴퓨터는 폰 노이만 구조이기 때문에 사용할 코드는 반드시 메모리에 있어야해서 코드를 물리 메모리에 전부 올린다는 발상이었지만 프로그램을 사용하는데 그 때마다 필요한 코드들만 있어도 실행이 되기 때문에 불필요하게 전체의 프로그램이 메모리에 올라와 있지 않아도 된다는 점에서 아이디어를 얻었다고 한다.
10 |
11 | 따라서 프로그램 전체가 아닌 **필요한 일부분만 실제 메모리에 올리는 기법**인 가상 메모리를 사용하게 되었다.
12 |
13 | 이런 방법을 사용하면
14 |
15 | 1. 더 많은 프로그램들을 동시에 메모리에 올려 작업할 수 있다.
16 | 2. 한 번에 올리는 소스 양이 적기 때문에 Disk와 Memory간 I/O 작업 속도가 빨라진다.
17 |
18 | 등의 장점을 얻을 수 있다.
19 |
20 | 
21 |
22 | # ⭐️ 아이디어
23 |
24 | 프로세스는 가상 주소를 사용하고, 실제 해당 주소에서 데이터를 읽고 쓸 때만 물리 주소로 변경한다.
25 |
26 | - Virtual address : 프로세스가 참조하는 주소
27 | - 디스크의 페이지 파일에 저장된다.
28 | - 페이지 교체할 때 이 디스크 swap영역에서 페이지를 가져오는 것
29 | - Physical address : 실제 메모리 주소
30 |
31 | CPU는 가상 메모리를 다루는데, 실제 물리 주소 접근시 MMU(Memory Management Unit)를 통해 물리 메모리에 접근한다.
32 |
33 | - MMU : CPU에서 코드 실행 시 가상 메모리 주소를 물리 주소 값으로 변환해주는 하드웨어 장치
34 |
35 | # ⭐️ Paging
36 |
37 | ## 등장 배경
38 |
39 | 메모리에 프로세스를 연속 할당할 때 발생하는 **외부 단편화**를 해결하기 위해 사용한다.
40 |
41 | 
42 |
43 | ## 개념
44 |
45 | - page : 가상 메모리 공간의 최소 단위
46 | - frame : 물리 메모리 공간의 최소 단위
47 |
48 | 크기가 동일한 page로 가상 메모리 공간과 이에 매칭되는 물리 메모리 공간을 관리한다.
49 |
50 | 이 page들은 실제 들어있는 데이터 양과 관계없이 모두 고정 크기를 가진다.
51 |
52 | 이 때, 고정된 각 크기는 시스템에 따라 다르다.
53 |
54 | - 크기가 작을 수록 내부 단편화가 해결되지만, 페이지 개수 증가로 인해 페이지 단위의 I/O가 증가한다.
55 |
56 | 각 프로세스의 PCB에는 page Table 구조체를 가리키는 주소가 있는데 이 테이블에는 가상/물리 주소의 매핑 정보가 담겨있고 이를 활용한다.
57 |
58 | 
59 |
60 | ## 원리
61 |
62 | 가상 주소와 물리 주소를 동일한 크기로 자르고 어디에 배치되는지 기록하며 배치한다면?? 자투리 공간이 발생하지 않고 딱 맞게 배치된다.
63 |
64 | 
65 |
66 | 이렇게 하면 프로세스를 연속할당 할 필요가 없기 때문에 **외부단편화 문제를 해결**할 수 있다.
67 |
68 | 고정 크기라는 것 때문에 **내부단편화가 발생**하긴 하지만 외부단편화로 인해 발생하는 낭비 공간이 더 크기 때문에 이를 감수하더라도 페이징을 사용하는 것이 이득이다.
69 |
70 | 그런데 생각해보면 프로세스는 **차례대로 읽어 수행**되는 linear address가 필요한데 paging 기법처럼 프로세스가 조각으로 나뉘어져 따로 놀고 있는데 어떻게 연속적으로 실행될까??
71 |
72 | → Page Table을 이용
73 |
74 | # ⭐️ Page Table
75 |
76 | - 프로세스 생성시 PCB에 페이지 테이블 정보가 생성된다.
77 | - 프로세스 구동시, page table의 base 주소가 별도 레지스터에 저장되고, CPU가 가상 주소 접근시 MMU는 page table의 base 주소에 접근해 물리 주소를 얻는다.
78 | - 이 때, 페이지들이 연달아 실행될 수 있도록 순서에 맞는 물리 주소 위치를 찾아준다.
79 | - 즉, linear하게 수행시킬 수 있다.
80 |
81 | 
82 |
83 | 기본적으로 배열처럼 인덱스가 페이지 번호를 가리키고 그 배열에 담고 있는 숫자가 매핑할 프레임 번호를 뜻한다.
84 |
85 | ## 페이지 크기와 가상 주소 구성
86 |
87 | CPU에 의해서 생성되는 주소를 가상 주소, RAM에 실질적으로 로드되는 주소를 물리 주소라고 했는데 위 예시에서 0,1,2,3 등 말고 실제 이 주소들은 어떻게 구성되어 있는지를 알아보자.
88 |
89 | 가상 주소는 페이지 번호(p)와 페이지 오프셋(d)으로 구성된다.
90 |
91 | - p : 매핑을 위해 page와 frame은 번호를 갖는데, 페이지 순서에 해당하는 숫자를 의미한다.
92 | - but, 덩어리인 page만으로 정확한 주소를 표기할 수 없기 때문에 오프셋을 추가로 사용한다.
93 | - d : page내의 번호를 의미한다.
94 | - 하나의 페이지가 4KB라 가정하면 page 0의 주소는 0 ~ 2^12까지이다.
95 |
96 | 가상 주소 구하기
97 |
98 | os가 32bit이고, 페이지 크기가 4KB라고 가정할 때
99 |
100 | 2^32 / 2^12 = 2^20
101 |
102 | 즉, CPU는 한 번에 2^20개의 페이지 번호를 구분할 수 있다.
103 |
104 | 따라서 32bit라고 할 때 앞의 20bit는 페이지 번호를 의미하고, 뒤 12bit는 오프셋을 의미한다.
105 |
106 | ## **가상 주소 → 물리 주소 변환 FLOW**
107 |
108 | 
109 |
110 | - p : 페이지 번호
111 | - f : 프레임 번호
112 | - d : 페이지 오프셋
113 |
114 | d를 제외한 나머지 비트에 있는 page 번호를 page table에서 검색하면 frame 번호가 나온다.
115 |
116 | page와 frame 크기는 똑같기 때문에 오프셋은 동일하다.
117 |
118 | ex)
119 |
120 | PageSize = 1KB
121 |
122 | PageTable = 1 3 5 4
123 |
124 | **가상 주소 3000의 물리 주소는??**
125 |
126 | 1KB는 10bit로 표현 가능하고 3000은 101110111000(2) 이다.
127 |
128 | 따라서 d(오프셋)는 뒤의 10자리 (1110111000(2))이고 p(페이지 번호)는 남은 앞에 2개 (10(2))이다. 따라서 p는 2이기 때문에 두 번째 인덱스인 5 → 101(2)와 d를 붙인 1011110111000(2)가 물리 주소이다.
129 |
130 | 위와 같은 과정으로 물리 주소를 참조하지만 매번 페이지 테이블을 이용하는 것은 매우 비효율적이기 때문에 TLB를 이용한다.
131 |
132 | ## TLB(Translation Lookaside Buffer)
133 |
134 | - MMU에 소속된 칩으로, 자주 참조되는 가상 주소- 물리 주소 변환 정보를 저장해놓은 캐시이다.
135 | - 과정
136 | 1. 가상 주소로 접근 시, TLB에 먼저 접근하여 변환정보가 있는지 확인
137 | 2. 있으면 바로 반환
138 | 3. 없으면 Page Table에서 해당 물리 주소를 찾아 TLB에 갱신 후, TLB miss가 발생한 명령어를 재실행
139 |
140 | 
141 |
142 | 따라서 TLB의 hit rate가 속도에 많은 영향을 끼친다.
143 |
144 | # ⭐️ 참고
145 |
146 | [Interview_Question_for_Beginner/OS at master · JaeYeopHan/Interview_Question_for_Beginner](https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/OS#%EA%B0%80%EC%83%81-%EB%A9%94%EB%AA%A8%EB%A6%AC)
147 |
--------------------------------------------------------------------------------
/OperatingSystem/병행성.md:
--------------------------------------------------------------------------------
1 | # 📌 병행성**(Concurrency)**
2 |
3 | 운영체제의 설계의 핵심은 모두 프로세스와 쓰레드와 연관이 있으며 대표적으로 다음이 있다.
4 |
5 | - 멀티프로그래밍: 단일처리기(프로세서) 시스템 상에서 다수의 프로세스 관리
6 | - 멀티프로세싱: 멀티프로세서 시스템 상에서 다수의 프로세스 관리
7 | - 분산처리: 다수의 분산된 컴퓨터 시스템들 상에서 수행되는 다수의 프로세스 관리 (대표적인 예로 클러스터 시스템이 있다)
8 |
9 | 그리고 운영체제의 설계의 핵심은 병행성(concurrency)이다.
10 | 병행성이란 여러 계산을 동시에 수행하는 시스템의 특성으로 프로세스간 통신, 자원에 대한 공유와 경쟁, 프로세스 활동들의 동기화, 프로세스에 대한 처리기 시간 할당 등 다양한 이슈를 포함한다.
11 |
12 | > **병행성 관련 주요 용어**
13 |
14 | 원자적 연산(atomic operation) : 명령어들로 구성된 함수 또는 액션으로 더 이상 분할할 수 없는 단위 어떤 프로세스도 중간 상태를 볼 수 없고 연산을 중단할 수 없다 이 명령어들은 수행되거나 되지않거나 둘중 하나이다.
15 |
16 | 임계영역(critical section) : 공유 자원을 접근하는 프로세스 내부의 코드 영역, 두개의 프로세스가 임계영역에 들어가서는 안된다.
17 |
18 | 교착상태(deadlock) : 두개 이상의 프로세스들이 더 이상 진행을 할 수 없는 상태, 각 프로세스가 다른 프로세스의 진행을 기다리면서 대기할때 발생한다.
19 |
20 | 라이브락(livelock) : 두개 이상의 프로세스들이 다른 프로세스의 상태 변화에 따라 자신의 상태를 변화 시키는 작업만 하는 상태,프로세스들이 열심히 일하는 것처럼 보이지만 실제로는 유용하지 않은 작업들을 하고 있다.
21 |
22 | 상호 배제(mutual exclusion) : 한 프로세스가 공유자원을 접근하는 임계역영 코드를 수행하는 중이면 다른 프로세스들은 공유 자원에 접근하는 임계영역 코드를 수행할 수 없다는 조건이다.
23 |
24 | 경쟁상태(race condition) : 두개 이상의 프로세스가 공유 자원을 동시에 접근하려는 상태, 최종 수행 결과는 프로세스들의 상대적인 수행 순서에 따라 달라진다.
25 |
26 | 기아(starvation) : 특정 프로세스가 수행 가능한 상태임에도 매우 오랜 기간 동안 스케줄링 되지 못하는 경우
27 |
28 | **병렬처리를 위한 기법**
29 |
30 | 인터리빙(interleaving) : 멀티프로그래밍에서 여러개의 프로세스가 번갈아가면서 수행되어 마치 동시에 수행되는 것과 같게 되는것
31 |
32 | 오버래핑(overlapping) : 여러개의 처리기로 실제로 여러 작업을 처리하는 것
33 | >
34 |
35 | 병행성에는 한 가지 문제점이 있다. 각각의 프로세스의 속도를 예측할 수 없다는 것이다.
36 | 예측할 수 없는 프로세스들이 동일한 자원을 두고 경쟁하다보니 다음과 같은 문제를 야기한다.
37 |
38 | 1. 전역 자원의 공유에 어려움이 있다.
39 | ex) 두개의 프로세스가 같은 전역 변수를 사용
40 | 2. 운영체제가 자원을 최적으로 할당하기 어려워진다.
41 | ex) 자원 할당 후 일시정지
42 | 3. 프로그래밍 오류를 찾아내는 것이 어려워진다.
43 | ex) 특정 실행 순서에 따른 오류
44 |
45 | 따라서 프로세서간 충돌을 방지할 **상호배제**가 필요하다.
46 |
47 | # 📌 상호배제(Mutual exclusion)
48 |
49 | 상호 배제를 보장하기 위해서는 다음의 요구 조건들이 만족되어야 한다.
50 |
51 | 1. 상호 배제가 강제되어야 한다.
52 | 2. 임계영역 외의 코드에서 수행이 멈춘 프로세스는 다른 프로세스의 수행을 간섭해서는 안된다.
53 | 3. 임계영역에 접근하고자 하는 프로세스의 수행이 무한히 미루어져서는 안된다. 즉 기아 상태, 교착 상태가 발생해서는 안된다.
54 | 4. 임계영역이 비어있고 임계영역 진입을 원하는 프로세스는 즉시 임계영역에 들어 갈 수 있다.
55 | 5. 프로세스 개수나 상대적인 프로세스 수행 속도에 대한 가정은 없어야 한다.
56 | 6. 임계영역에 들어간 프로세스는 일정한 시간 내에 임계영역에서 나와야 한다.
57 |
58 | # 📌 상호배제: 소프트웨어적 접근 방법
59 |
60 | 운영체제나 프로그래밍 언어 차원의 지원 없이 프로세스간 협력을 통해 직접 상호 배제를 보장한다.
61 | 수행 부하가 크고, 잘 설계되지 않았을 경우 오동작 가능성이 높다.
62 |
63 | ## 🔍 데커(Dekker) 알고리즘
64 |
65 | [데커의 알고리즘 - 위키백과, 우리 모두의 백과사전](https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%BB%A4%EC%9D%98_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)
66 |
67 | ## 🔍 피터슨(**Peterson**) 알고리즘
68 |
69 | [피터슨의 알고리즘 - 위키백과, 우리 모두의 백과사전](https://ko.wikipedia.org/wiki/%ED%94%BC%ED%84%B0%EC%8A%A8%EC%9D%98_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)
70 |
71 | ### 💡 참고
72 |
73 | [[IT 기술면접 준비자료] 상호배제(Mutual Exclusion)와 상호배제 알고리즘](https://preamtree.tistory.com/26)
74 |
75 | 데커(Dekker) / 피터슨(Peterson) / 제과점(Bakery) 알고리즘
76 |
77 | # 📌 상호배제: 하드웨어적 접근 방법
78 |
79 | 상호배제를 보장하기 위한 하드웨어적인 접근 방법을 알아보자
80 |
81 | ## 🔍 인터럽트 금지
82 |
83 | 상호 배제를 보장할 수 있는 가장 간단한 방법은 프로세스가 인터럽트 되지 않도록 하는 것이다싱글 프로세서에서 병행 처리(concurrent processing)되는 프로세스들은 인터리빙되기 때문이다.
84 |
85 | 또한 프로세스는 운영체제 서비스를 호출하거나 인터럽트 될 때까지 계속 실행하기 때문에 인터럽트가 발생하지 않으면 한 프로세스의 지속적인 실행을 보장 가능하다.
86 | 이를 위해 시스템 커널에서 인터럽트를 허용하거나 비허용할 수 있는 기본 인터페이스를 제공한다.
87 |
88 | ```powershell
89 | while(true){
90 | // 인터럽트 금지
91 | // 임계 영역
92 | // 인터럽트 허용
93 | // 임계 영역 이후 코드
94 | }
95 | ```
96 |
97 | > 단, 멀티프로세서 시스템에서는 효과가 없다.
98 | 두개 이상의 프로세서를 가지는 컴퓨터 시스템에서는 인터럽트가 금지된 상황에서도 서로 다른 프로세스가 공유 자원을 동시에 접근하는 경우가 가능하기 때문이다.
99 | >
100 |
101 | ### 단점
102 |
103 | - 부하가 크다.
104 | 인터럽트 비허용 시, 그 사이 외부에서 발생하는 이벤트에 대한 처리와 다른 프로세스에 대한 스케줄링 등 모든 기능이 중지되어 시스템 수행 효율이 확연하게 감소할 가능성이 높다.
105 | - 멀티프로세서 시스템에서는 올바른 접근 방법이 아니다.
106 |
107 | ## 🔍 특별한 기계 명령어
108 |
109 | 멀티 프로세서 환경에서 여러 프로세서들은 공통의 주기억 장치를 공유하며, 이때 모든 프로세서는 동등한 관계에서 독립적으로 동작한다. (인터럽트 기법으로 상호배제 보장 불가)
110 |
111 | 하드웨어 수준에서 특정 메모리 주소가 접근되고 있을 때, 같은 위치에 대한 접근 요청은 차단된다는 것에 기반해 상호배제를 보장하기 위한 두 가지 명령어가 구현된다.
112 | 이때 기계 명령어는 두 개의 기능을 원자적으로 처리한다.
113 |
114 | ### 1. Compare & Swap 명령어
115 |
116 | `compare_and_swap()` : 테스트하려는 값과 저장된 값을 비교한다.
117 |
118 | 이 함수는 원자적으로 수행되기 때문에 중간에 중단되는 경우는 없다.대부분 모든 프로세서에서 지원하며, 대부분의 운영체제에서 병행성을 위해 이 명령어를 사용한다.
119 |
120 | ### 2. Exchange 명령어
121 |
122 | `exchange()` : 레지스터 값과 메모리에 들어있던 값을 서로 교체하는 기능 수행
123 |
124 | 
125 |
126 | > 실제로 이 함수가 아니고 하드웨어 명령어이다.
127 | 이해를 돕기위한 코드라 생각하면 된다.
128 | >
129 |
130 | ### Compare & Swap, Exchange 명령어를 이용한 상호배제 보장
131 |
132 | 
134 |
135 | 필기가 난잡하고 더럽지만 매우 디테일하게 적어놨다
136 | 정녕 자세히 알고싶다면 읽어보자
137 |
138 | ### 장점
139 |
140 | - 싱글 프로세서 시스템 뿐만 아니라 공유 메모리를 사용하는 멀티 프로세서 시스템에서도 사용가능하다.
141 | - 간단하고 검증이 쉽다.
142 | - 서로 다른 변수를 사용하면 다중 임계 영역을 지원할 수 있다.
143 |
144 | ### 단점
145 |
146 | - 바쁜 대기를 사용한다
147 | 임계영역에 진입하는 것을 대기하고 있는 프로세스는 처리기를 계속 사용하게 된다.
148 | `TIP` 바쁜 대기란 임계영역에 진입하기 위한 허가를 획득할 때까지 변수를 테스트하는 명령을 반복 실행하며 대기하는 것을 말한다.
149 | - 기아가 발생할 수 있다
150 | 한 프로세스가 임계영역에서 빠져나올 때, 대기하고 있던 다수의 프로세스 중 하나만 다시 임계영역에 진입이 가능한데, 이 때 각 프로세스의 길이나 특성, 대기시간 등을 고려하지 않기 때문에 무한정 기다리는 프로세스가 생길 수도 있다.
151 | - 교착상태에 빠질 수 있다.
152 | 싱글 프로세서 시스템에서 P1 이라는 프로세스가 임계영역에 진입한다.
153 | 그때 P2 라는 P1보다 우선순위가 높은 프로세스가 생겨 운영체제가 P2를 스케줄하여 P2에게 자원을 할당하려 할 때 P2와 P1이 같은 자원을 사용하려 하면 P2는 상호배제조건에 의해 바쁜 대기를 수행한다.
154 | 이때 P2가 계속 프로세서를 점유하고 있기 때문에 우선순위가 높은 P2로 인해 P1은 다시 스케줄링될 수 없다. -> P2가 실행상태에 있기 때문이다.
155 |
156 | 소프트웨어적 방법과 하드웨어적 방법은 모두 단점을 갖고 있기 때문에 새로운 해결책이 필요하다.
157 |
158 | # 📌 상호배제: 운영체제와 프로그래밍 언어 수준에서 접근 방법
159 |
160 | ## 🔍 세마포어(Semaphore)
161 |
162 | 멀티 프로그래밍 환경에서 공유된 자원에 대한 접근을 제한하는 방법
163 |
164 | - 임계영역에 접근하는 프로세스들을 제어하는 데 사용한다.
165 | - block(수면)과 wake up(깨움)을 지원한다.
166 | - 세마포어란 프로세스 간에 시그널을 주고받기 위해 사용되는 정수 값을 갖는 변수로 다음 3가지 인터페이스를 통해 접근할 수 있다.
167 | - **Initialize(초기화 연산)** : 최초에 세마포어 값을 음이 아닌 값으로 초기화한다.
168 | - **Decrement(semWait, 대기 연산)**
169 | - 세마포어 값을 하나 감소시킨다.
170 | - 값이 음수가 되면 semWait를 호출한 프로세스는 block 상태로 바꾼다.
171 | - 음수가 아니면 해당 프로세스는 임계영역에 접근하여 연산을 계속 수행할 수 있다.
172 | - **Increment(semSignal, 시그널 연산)**
173 | - 연산을 마친 프로세스는 이 함수를 호출해 세마포어 값을 하나 증가시킨다
174 | - 값이 양수가 아니면(<=0) semWait 연산으로 block된 프로세스를 깨운다.
175 | - 이진 세마포어는 세마포어 값을 0또는 1만 가질 수 있는 세마포어이다.
176 |
177 | 
178 |
179 | 카운팅(범용) 세마포어
180 |
181 | 
182 |
183 | 이진(바이너리) 세마포어
184 |
185 | ### 세마포어는 바쁜대기와 기아를 해결
186 |
187 | - OS는 blocked 큐를 갖고 있기 때문에 바쁜 대기 문제가 해결된다.
188 | - 큐에는 순서가 있기 때문에 기아 문제가 해결된다.
189 |
190 | ### 세마포어의 특징
191 |
192 | - 일반적으로 프로세스가 세마포어를 감소시키기 전까지는 그 프로세스가 block될지 안될지 알 수 없다.
193 | - 싱글 프로세서 시스템에서 프로세스가 세마포어를 증가시키고 block된 프로세스를 깨우면, 이 두 프로세스 모두 수행가능 상태가 되어 누가 먼저 수행될 지 알 수 없다.
194 | - 세마포어에 시그널을 보낼 때, 우리는 다른 프로세스가 대기 중인지 여부를 알 필요가 없다. block된 프로세스의 개수가 0또는 1일 수 있다.
195 |
196 | ### 세마포어 동작 예시
197 |
198 | 
199 |
200 | ### 생산자/소비자(producer/consumer) 문제
201 |
202 | 한정 버퍼(bounded-buffer) 문제라고도 한다.
203 |
204 | 유한한 개수의 물건(데이터)을 임시로 보관하는 보관함(버퍼)에 여러 명의 생산자들과 소비자들이 접근한다. **생산자는 데이터를 만들어 버퍼에 저장해나가고, 소비자는 버퍼에 있는 데이터를 꺼내 소비하는(비우는) 프로세스이다.**
205 | 이때 저장할 공간이 없는 문제가 발생할 수 있다. 소비자는 물건이 필요할 때 보관함에서 물건을 하나 가져온다. 이 때는 소비할 물건이 없는 문제가 발생할 수 있다.
206 |
207 | 이때 버퍼는 공유자원이므로 버퍼에 대한 접근 즉, 저장하고 꺼내는 일들이 상호배제 되어야한다.또한, 버퍼가 꽉 차있을 때는 생산자가 기다려야하고, 버퍼가 비었을 때는 소비자가 기다려야한다.
208 |
209 | ### 무한공유 버퍼인경우
210 |
211 | 
212 |
213 | 만약 소비자가 먼저 실행될 경우, 세마포어 n의 값이 음수가 되면서 block에 걸리고 생산자와 실행되어 버퍼를 채우며 n의 값을 올려 소비자의 block을 푼다
214 |
215 | ### 유한공유 버퍼인경우
216 |
217 | 
218 |
219 | 무한 버퍼와 같은 원리로 작동을 하며 무한 버퍼와는 달리 유한 버퍼이므로 버퍼가 꽉 찰 때를 표시해줄 수 있는 e값이 있다. e가 꽉 찬 상태 즉, e가 음수가 되면 block이 걸리게 되며 소비자만이 작동하게 된다.
220 |
221 | ## 🔍 뮤텍스(Mutex)
222 |
223 | 뮤텍스는 세마포어와 마찬가지로 병행 처리를 위한 동기화 기법 중 하나입니다.
224 | 이진 세마포어와 같이 초기값을 1과 0으로 가집니다.
225 | 임계영역에 들어갈 때 락(lock)을 걸어 다른 프로세스(혹은 쓰레드)가 접근하지 못하도록 하고,
226 | 임계영역에서 나와 해당 락을 해제(unlock) 합니다.
227 |
228 | ### **뮤텍스와 세마포어의 차이는?**
229 |
230 | 세마포어는 공유 자원에 세마포어의 변수만큼의 프로세스(또는 쓰레드)가 접근할 수 있습니다.
231 | 반면에 뮤텍스는 오직 1개만의 프로세스(또는 쓰레드)만 접근할 수 있습니다.
232 | 현재 수행중인 프로세스가 아닌 다른 프로세스가 세마포어를 해제할 수 있습니다.
233 | 하지만 뮤텍스는 락(lock)을 획득한 프로세스가 반드시 그 락을 해제해야 합니다.
234 |
235 | ## 🔍 모니터
236 |
237 | - 모니터란 프로그래밍 언어 수준에서 제공되는 구성체(라이브러리, 클래스)
238 | - 세마포어와 동일한 상호배제 기능을 제공하고 보다 사용하기 쉽다는 장점을 가지고 있다.
239 |
240 | # 📌 데드락(DeadLock)
241 |
242 | 상호 배제에 의해 나타나는 문제점으로, 둘 이상의 프로세스들이 자원을 점유한 상태에서 서로 다른 프로세스가 점유하고 있는 자원을 요구하며 무한정 기다리는 현상을 의미한다.
243 |
244 | ## 발생조건 4가지
245 |
246 | - **상호 배제 조건(Mutual Exclusion)** 입니다. **자원은 한 번에 한 프로세스만 사용 가능하다** 는 조건입니다.
247 | - **점유 대기 조건(Hold And Wait)** 입니다. **최소한 하나의 자원을 점유(Lock)**하고 있으면서 다른 프로세스에 할당되어 사용되고 있는 **자원을 추가로 점유하기 위해 대기(Wait)** 하는 프로세스가 존재해야 합니다.
248 | - **비선점 조건(No preemption)**이 있습니다. 다른 프로세스에 할당된 자원은 해당 프로세스가 사용이 끝날때까지 **강제로 빼앗을 수 없습니다.**
249 | - **순환 대기 조건(Circular Wait)**이 있습니다. 프로세스의 집합에서 **순환 형태(사이클)로 자원을 대기(Wait)** 하고 있어야 합니다.
250 |
251 | 이러한 **상호 배제, 점유 대기, 비선점, 순환 대기** 4가지 조건을 모두 성립해야 데드락이 발생할 수 있습니다.
252 |
253 | ## 데드락의 처리방법
254 |
255 | 데드락을 처리하기 위한 방법으로 예방, 회피, 탐지 및 회복, 무시 가 있습니다.
256 | **예방(Prevention)** 이란, **데드락 발생 조건 중 하나를 제거하면서 해결**하는 방법입니다. 즉, 상호 배제, 점유 대기, 비선점, 순환 대기 4가지 조건 중 하나를 제거합니다.
257 |
258 | 다음으로, **회피(Avoidance)** 는 **데드락이 발생할 시 피해가는 방법**입니다. 대표적으로, **은행원 알고리즘**을 사용하여 피해갑니다.
259 |
260 | 또, **탐지 및 회복(Detection & Recovery)** 은 **자원 할당 그래프를 통해 데드락을 감지**하며, 만약 데드락을 감지할 경우 **이전 상태로 회복**하는 방법이죠. 일부러 데드락을 발생하게 놔두고 감지해서 회복하는 경우도 있습니다.
261 |
262 | 마지막으로, **무시(Ignore)** 는 말 그대로 데드락 발생을 무시하고 지나가는 방법입니다.
263 |
264 | ## 교착상태 예방
265 |
266 | 교착상태가 발생하기 위한 4가지 필요충분 조건 중 하나를 설계 단계에서 배제하는 방법이다.
267 |
268 | - 상호 배제 : 운영체제에서 반드시 보장해주어야 함
269 | - 점유 대기 : 프로세스가 필요한 모든 자원을 한꺼번에 요청
270 | - 비선점 : 프로세스가 새로운 자원 요청에 실패하면 기존의 자원들을 반납한 후 다시 요청 or 운영체제가 강제적으로 자원을 반납시킴
271 | - 환형 대기 : 자원 할당 순서(자원 유형)를 미리 정해두면 없앨 수 있음
272 |
273 | ## 교착상태 회피
274 |
275 | **은행원 알고리즘(Banker Algorithm)**을 사용합니다.
276 | ****데드락을 처리하기 위한 방법 중 **회피에 해당**하는 알고리즘입니다. 데드락에 빠질 수 있는 상태를 불안전 상태, 데드락에 빠질 수 없는 상태를 안전 상태 라고 가정했을 때, 운영체제는 이러한 안전 상태인 경우에만 요청을 허락하여 자원을 할당해주고, 나머지 요구들은 안전 상태가 될 때 까지 계속 거절하는 알고리즘입니다.
277 |
278 | 즉, **은행원 알고리즘**은 은행은 **최소한 한 명에게 대출해줄 수 있는 돈을 가지고 있어야 한다**는 뜻에서 나왔으며, 바꿔말하면 **운영체제가 최소한 하나의 프로세스가 일을 수행할 수 있는 경우에만 요청을 허락하여 시스템의 자원을 할당해주는 것**과 같습니다.
279 |
280 | # 👋 예상 질문
281 |
282 | - 데드락이란 무엇인가요?
283 |
284 | 데드락은 프로세스가 자원을 얻지 못해서 다음 일을 처리하지 못하는 상태 입니다. 즉, 교착 상태라고도 말하는데요. 보통 시스템적으로 한정된 자원을 여러 곳에서 동시에 사용하려고 할 때 발생합니다.
285 |
286 | 예를 들어,
287 | 프로세스 1이 리소스 1을 사용하고 있고, 리소스 2를 사용하기 위해 요청했으며
288 | 프로세스 2가 리소스 1을 사용하기 위해 요청했고, 리소스 2를 사용하고 있다면
289 |
290 | 프로세스 1 -> 리소스 1(사용 - Lock) / 리소스 2(요청 - Wait)
291 | 프로세스 2 -> 리소스 1(요청 - Wait) / 리소스 2(사용 - Lock)
292 |
293 | 상태가 되서 프로세스 1, 2 모두 다음 리소스를 얻지 못해 멈추게 됩니다. 이는 사거리의 모든 자동차가 서 있는 상태와 같습니다
294 |
295 |
296 | # ✨ References
297 |
298 | - William Stallings, 『운영체제 제8판 : 내부구조 및 설계원리』, 프로텍미디어
299 | - 세종대 운영체제 수업 내용 + 내 필기
300 | - 병행성 내용 요약
301 |
302 | [나만의 백과사전 - 병행성 : 상호배제, 동기화, 교착상태, 기아](https://velog.io/@pu1etproof/%EB%82%98%EB%A7%8C%EC%9D%98-%EB%B0%B1%EA%B3%BC%EC%82%AC%EC%A0%84-%EB%B3%91%ED%96%89%EC%84%B1-%EC%83%81%ED%98%B8%EB%B0%B0%EC%A0%9C-%EB%8F%99%EA%B8%B0%ED%99%94-%EA%B5%90%EC%B0%A9%EC%83%81%ED%83%9C-%EA%B8%B0%EC%95%84#1-%EC%83%81%ED%98%B8%EB%B0%B0%EC%A0%9C%EB%A5%BC-%EB%B3%B4%EC%9E%A5%ED%95%98%EA%B8%B0-%EC%9C%84%ED%95%9C-%EC%86%8C%ED%94%84%ED%8A%B8%EC%9B%A8%EC%96%B4%EC%A0%81-%EC%A0%91%EA%B7%BC-%EB%B0%A9%EB%B2%95)
303 |
304 | - 데드락 질문 정리
305 |
306 | [[OS] 2020.11.16. 오늘의 면접 Q&A](https://maivve.tistory.com/270)
307 |
308 | - 뮤텍스 세마포어 차이점
309 |
310 | [Semaphore(뮤텍스)와 Mutex(세마포어)의 차이점은?](https://junghyun100.github.io/Semaphore&Mutex/)
--------------------------------------------------------------------------------
/OperatingSystem/인터럽트와 시스템콜.md:
--------------------------------------------------------------------------------
1 | # 운영체제 구조 및 동작원리(Mode, System call, Interrupt
2 |
3 | Created At: December 10, 2021 10:00 PM
4 | Updated At: December 23, 2021 10:23 PM
5 |
6 | # 운영체제 시작
7 |
8 | 컴퓨터가 처음 부팅되면 Bootstrap 프로그램이 실행된다.
9 |
10 | 이 프로그램은 시스템을 모두 초기화하고 OS를 메모리에 올려 실행하게끔 하고 OS가 실행되면서 다음 event를 기다리게 된다.
11 |
12 | 이 event를 interrupt라고 부른다.
13 |
14 | (Node.js의 event와 비슷)
15 |
16 | ex) 윈도우가 실행이 되면서 잠금을 걸어놨다면 비밀번호를 입력하라는 창이 뜰 텐데 OS는 이 창을 띄우고 "비밀번호의 입력(입출력장치)"이라는 interrupt를 기다리게 된다. 그동안 OS는 아무 행동도 취하지 않으며 대기 상태이다.
17 |
18 | # Interrupt
19 |
20 | 운영체제는 기본적으로 **interrupt(event)-driven** 방식이다.
21 |
22 | 하드웨어가 어떤 이벤트를 CPU에게 알리기 위해서 사용하는 방법 or 실행 중인 프로세스가 CPU 내의 인터럽트 라인을 세팅해 인터럽트를 걸기도함(소프트웨어)
23 |
24 | **전자를 비동기식 인터럽트라고 부르는데 하드웨어에 의해 걸리고, 후자를 동기식 인터럽트라고 부르는데 소프트웨어에 의해 걸린다.**
25 |
26 | 하드웨어 인터럽트 : I/O 장치, 전원 등 (키보드, 마우스 입력)
27 |
28 | - 조금 Deep한 내용
29 |
30 | ## Hardware Interrupt
31 |
32 | Hardware는 입출력장치인 I/O와 해당 장치를 제어하는 controller로 이루어져 있다.
33 |
34 | 우리가 사용하는 키보드, 디스크에도 모두 controller가 있으며 이것들이 우리가 입력하는 데이터들을 본체에 전송을 하게 된다. 그리고 각 장치에 해당하는 OS에는 해당 Hardware와 데이터를 주고받기 위해 그 기기에 대한 Device Driver(D/D)가 필요하다.
35 |
36 | 본체에서 보내는 데이터는 D/D의 buffer(데이터 전송을 위한 임시 저장 장치)에 저장되었다가 나가게 되고 I/O 장치에서 보내는 데이터 또한 controller의 buffer에 저장되었다가 전송된다. 이러한 전송 완료에 대한 메시지를 interrupt로 발생시킨다.
37 |
38 | 하지만 이 때 buffer의 용량이 상당히 작기 때문에 대용량의 데이터 전송시에 문제가 생기고 CPU에게 인터럽트를 많이 걸게 되므로 빈번한 OS의 개입이 이루어진다.
39 |
40 | 이런 문제를 해결하기 위해서 Direct Memory Access가 도입되었는데
41 |
42 | DMA는 장치에 대한 연결의 interrupt를 발생시킨 후 OS는 모든 권한을 DMA에게 위임하기 때문에 빈번한 OS의 개입이 없고 전송 단위 또한 커서 빠르게 전송할 수 있다.
43 |
44 | 즉, DMA는 CPU(OS)의 개입 없이 디바이스 컨트롤러와 메모리 사이에 데이터를 이동하도록 하는 것
45 |
46 | 
47 |
48 | 이 방식을 사용함으로써 얻을 수 있는 점은 CPU가 디바이스와 메모리 사이를 중재할 필요가 사라지기 때문에 CPU는 그동안 다른 일들을 할 수 있다는 것이다. 또한 바이트 단위가 아닌 블록 단위로 인터럽트를 걸기 때문에 오버헤드를 줄일 수 있다.
49 |
50 |
51 | 소프트웨어 인터럽트(trap or exception) : 소프트웨어가 OS 서비스를 요청하거나 에러를 일으켰을 때 발생 (파일 읽기/쓰기, 0으로 나누기, 오버플로우 등)
52 |
53 | 소프트웨어는 3가지로 나뉨
54 |
55 | 1. Trap : 의도적으로 일으킨 예외 (ISR 종료 후 실행 재개) → 시스템 콜
56 | 2. Fault : 복구가 가능할 수도 있는 예외 (ISR 종료 후 실행을 재개할 가능성 있음) → 0으로 나누기, 잘못된 메모리 접근
57 | 3. Abort : 복구 불가능한 예외 (ISR 실행 시 프로그램 강제 종료) → 하드웨어 고장
58 |
59 | ## 과정
60 |
61 | CPU에 인터럽트가 걸리면 가장 먼저 **명령어의 주소를 저장을 한다**. 그 이유는 Interrupt의 대응하는 행위를 끝내고 다시 그다음 명령어를 수행하거나 다시 대기 상태로 돌아오기 위함 (context switch를 위해서?)
62 |
63 | 이후 Interrupt Service Routine(ISR)에 제어권을 넘겨주는 과정을 거치는데 **Interrupt Vector Table이라는 곳에서 해당 Interrupt에 대한 주소를 찾고(인터럽트 핸들러 주소 = ISR 시작 주소) 그리고 그 주소로 이동해 처리를 실행한다.(ISR).**
64 |
65 | ISR이 끝나고 나면 OS는 **저장해 놓았던 주소로 되돌아가** 이후 명령어를 수행
66 |
67 | (Interrupt Vector Table은 인터럽트 종류별로 **인터럽트 핸들러**의 주소가 담긴 테이블이다.)
68 |
69 | ## Dual-Mode Execution
70 |
71 | 사용자가 인터럽트처럼 Kernel상의 작업(컴퓨터의 Core에 해당하는 작업)을 직접 건드려 명령하고 수행하게 된다면 잘못하다가는 시스템 전체에 큰 악영향을 끼칠 수 있음
72 |
73 | 일반 사용자가 컴퓨터에 치명적인 명령어를 사용할 수 없도록, 일반 사용자로부터 시스템을 보호하기 위해 **하드웨어적**으로 **이중 모드(dual mode)**라는 것을 지원한다.
74 |
75 | 이중 모드는 **사용자 모드(user mode)**와 **커널 모드(kernel mode)**로 나뉜다. 그리고 mode bit(user mode=1, kernel mode=0)를 통해 두 모드를 구분한다. 일반적으로 사용자 프로세스는 사용자 모드에서는 실행되지만 어떤 특정한 명령들은 커널 모드에서만 실행된다. 이 특정한 명령어들을 **특권 명령(privileged instruction)**이라고 하는데 잘못된 접근으로부터 OS와 사용자를 보호하기 위해 모아놓은 명령어들의 집합을 말한다. 여기에 포함된 명령어들은 OS만이 실행할 수 있다.
76 |
77 | 그래서 각 명령어에 Mode-bit를 심어서 **해당 명령어의 Mode-bit와 현재 시스템 상의 Mode-bit가 같을 시에만 해당 명령어를 수행**하게 끔 하는 것
78 |
79 | ex)
80 |
81 | ```c
82 | printf("출력");
83 | ```
84 |
85 | 위 코드는 출력하는 행위로 I/O 작업에 해당한다.
86 |
87 | 이런 I/O작업은 OS만 접근이 가능해야 한다.
88 |
89 | 위 함수를 까보면 여러 가지 명령어중에 **INT 80**이라는 명령어가 있는데 특수 명령어로 현재 Mode를 바꿔주는 역할을 한다.
90 |
91 | 즉 이전까지 수행되던 명령어들은 User-Mode였다면 화면에 출력하기 위해서는 Kernel-Mode가 필요하므로
92 |
93 | 위의 명령어를 통해 Mode를 Kernel-Mode로 변환 후 I/O 장치에 출력을 하는 명령을 OS가 내리게 된다.
94 |
95 | 그리고 함수가 끝날 때는 다시 User-Mode로 돌아간다.
96 |
97 | 이러한 **bit를 바꾸는 행위를 System Call**이라고 한다.
98 |
99 | 커널에서 수행되어야 하는 몇 가지 중요한 명령어들 : Turn off interrupts, Access I/O devices, Set value of Timer 등
100 |
101 | System call이 일어나면 Interrupt 동작원리(Interrupt Vector Table, Interrupt Vector Routine)와 같이 해당 **System Call에 대한 번호를 Table에서 찾아서 Routine을 실행**하게 된다.
102 |
103 | 
104 |
105 | # 시스템 콜
106 |
107 | 
108 |
109 | 위에서 말했던 특권 명령을 실행하고자 하면, 반드시 사용자 모드에서 커널 모드로 전환해야한다.
110 |
111 | 이 때, 특권 명령을 실행하기 위해 **커널 모드로의 전환을 요청하는 인터페이스를 시스템 콜** 이라고 한다.(trap의 한 종류)
112 |
113 | ## 시스템 콜이 필요한 이유??
114 |
115 | - 우리가 일반적으로 사용하는 프로그램은 **응용 프로그램** 이다. 유저레벨의 프로그램은 유저레벨의 함수들만으로는 많은 기능을 구현하기 힘들기 때문에, 무조건 커널의 도움을 받아야만 한다.
116 | - 반드시 커널에 관련한 것들은 커널모드로 전환하여 해당 작업을 수행해야한다.
117 |
118 | ## 시스템 콜 종류
119 |
120 | 1. 프로세스 제어용 시스템 콜
121 | - fork, wait, exec
122 | 2. 파일에 대한 입출력 시스템 콜
123 | - open, create, close, read 등
124 | 3. 소켓 기반 입출력 시스템 콜
125 | - socket, bind, listen, connect 등
126 |
127 | ## 과정
128 |
129 | 프로세스가 디스크로부터 파일을 읽어오는 명령이라고 가정
130 |
131 | 1. 프로세스가 시스템 콜을 요청하면서 CPU 내에 인터럽트 라인을 세팅한다.
132 | 2. CPU는 실행 중이던 명령어를 마치고 인터럽트 라인을 통해 인터럽트가 걸렸음을 인지한다.
133 | 3. mode bit를 0으로 바꾸고 OS에게 제어권을 넘긴다.
134 | 4. 현재 실행 중이던 프로세서의 상태 및 정보를 PCB에 저장하고 PC에는 다음에 실행할 명령어의 주소를 저장한다.
135 | 5. 시스템 콜 루틴에 해당하는 곳으로 가서 시스템 콜 테이블을 참조해 파일 읽기에 해당하는 시스템 콜을 실행한다.
136 | 6. 루틴이 끝나면 mode bit를 1로 바꾸고 PCB에 저장했던 상태들과 PC를 복원시킨다.
137 | 7. PC에 저장된 주소(=마지막으로 실행했던 명령어의 다음)로 이동해 계속 실행한다.
138 |
139 | ## TIP
140 |
141 | I/O 명령을 실행할 때 CPU 제어권이 어디로 가냐에 따라 동기식(소프트웨어에 의해 발생), 비동기식(하드웨어에 의해 발생) 두 가지로 나뉜다.
142 |
143 | - **동기식 I/O**는 I/O 명령 요청이 완료되어야지만 사용자 프로그램에 제어가 넘어간다.
144 | - **비동기식 I/O**는 I/O 명령이 끝날 때까지 기다리지 않고 사용자 프로그램으로 제어가 넘어가고 I/O가 완료되면 인터럽트로 알린다.
145 |
146 | 위 과정은 동기식 I/O를 기준으로 한 설명
147 |
148 | 만약 비동기식 이라면?? 즉, 하드웨어라면??
149 |
150 | 5번부터 다르게 실행된다.
151 |
152 | 1. 다른 프로세스의 PCB와 PC를 읽어와서 실행한다.
153 | 2. I/O 명령을 마치면 디바이스 컨트롤러(Device controller) 가 CPU에게 인터럽트를 건다.(하드웨어 인터럽트 부분의 deep 내용 참고)
154 | 3. CPU가 인터럽트를 인지하면 실행 중이던 프로세스를 다시 PCB에 저장하고 OS에게 제어권을 준다.
155 | 4. 그리고 OS는 디바이스 컨트롤러로부터 버퍼에 저장된 데이터를 받아와서 I/O를 요청했던 명령어의 메모리 영역에 데이터를 저장한다.
156 |
157 | # 참고
158 |
159 | - 인터럽트와 시스템 콜
160 | [https://baked-corn.tistory.com/3](https://baked-corn.tistory.com/3)
161 | [https://velog.io/@chowisely/Operating-Systems-Interrupt-System-Call](https://velog.io/@chowisely/Operating-Systems-Interrupt-System-Call)
162 | [https://github.com/Songwonseok/CS-Study/blob/main/OS/시스템 콜 (System Call).md](https://github.com/Songwonseok/CS-Study/blob/main/OS/%EC%8B%9C%EC%8A%A4%ED%85%9C%20%EC%BD%9C%20(System%20Call).md)
163 | - 시스템 콜 종류
164 | [https://whitesnake1004.tistory.com/2](https://whitesnake1004.tistory.com/2)
165 |
--------------------------------------------------------------------------------
/OperatingSystem/프로세스와 스레드.md:
--------------------------------------------------------------------------------
1 | # ⭐️ 프로세스
2 |
3 | 프로그램은 **메모리에 올라오지 않은 정적인 코드 덩어리** 라고하는데 이 프로그램이 실제 메모리에 올라가 실행되고 있으면 프로세스라고 부른다.
4 |
5 | 즉, OS로부터 시스템 자원을 할당받는 작업의 단위이다.
6 |
7 | 
8 |
9 | ## 프로세스 특징
10 |
11 | 프로세스는 최소 1개의 스레드를 가지고 있고 각각 독립된 메모리 영역을 할당받는다.
12 |
13 | 독립되어있기 때문에 별도의 주소 공간에서 실행되며, 일반적인 방법으로는 다른 프로세스에 접근할 수 없다.(IPC를 사용하면 접근 가능)
14 |
15 | ### 프로세스의 메모리 구조
16 |
17 | - Code 영역
18 | - 컴파일된 코드 자체가 저장된다.
19 | - 프로세스가 사용하는 기계어로 된 프로그램 명령들이 위치해 있다.
20 | - Data 영역
21 | - 전역변수, 정적변수, 배열, 구조체 등이 저장된다.
22 | - 자세하게 말하면 **초기화 된 데이터는 Data영역**에, **초기화 되지 않은 데이터는 BSS 영역**에 저장된다.
23 | - 이 둘을 구분하는 이유??
24 | - 초기화 되지 않는 변수는 프로그램이 실행될 때 영역만 잡아주면 되고 그 값을 프로그램에 저장하고 있을 필요가 없으나 초기화된 변수는 그 값도 프로그램에 저장하고 있어야하기 때문에 구분한다.
25 | - 프로그램이 실행될 때 생성되고 프로그램이 종료되면 반환된다.
26 | - Heap 영역
27 | - 필요에 의해 동적으로 메모리를 할당 하고자 할 때 사용하는 메모리 영역
28 | - 메모리 주소 값에 의해서만 참조되고 사용된다.
29 | - Stack 영역
30 | - 프로그램이 자동으로 사용하는 **임시 메모리** 영역
31 | - 지역변수, 매개변수, 리턴 값 등 잠시 사용되었다가 사라지는 데이터
32 | - 함수 호출 시 생성되고, 함수가 끝나면 반환된다.
33 | - 이 스택 사이즈는 프로세스가 메모리에 로드 될 때 고정되어 할당된다. 따라서 런타임에 사이즈를 변경할 수 없다.
34 |
35 | ## 프로세스 상태
36 |
37 | 
38 |
39 | - New : 프로세스가 생성되었을 때
40 | - Ready : 프로세스가 프로세서에게 할당 받기를 기다릴 때
41 | - Running : 프로세스가 실행 상태일 때
42 | - Waiting(Blocked) : 프로세스가 어떤 이벤트가 발생하기를 기다릴 때
43 | - Suspended : 프로세스의 실행이 중지되었을 때
44 | - 메모리를 강제로 뺏긴 상태(디스크 swap-out)
45 | - Ready에서 swap-out이면 Suspended Ready, Blocked에서 swap-out이면 Suspended Block
46 | - Terminated : 프로세스의 실행이 종료되었을 때
47 |
48 | 프로세스는 위 6단계에 따라 **프로세스 큐(Job, Ready, Device)**에 각각 올라가있고 큐에 올리는 일은 **프로세스 스케줄러가 담당**한다.
49 |
50 | ### Ready와 Waiting의 차이
51 |
52 | - I/O 작업이나 기타 이벤트로 인한 상태 변화에는 Running → Waiting → Ready → Running 의 순서로 변한다.
53 | - 즉, 준비가 다 끝나지 않은 프로세스가 준비를 끝내기위해서 대기 중인 상태
54 | - 프로세스 스케줄링에 의한 상태 변화(time out, interrupt)에는 Running → Ready → Running 의 순서로 변한다.
55 | - 즉, 준비가 다 끝난 프로세스가 실행되기를 기다리는 상태
56 |
57 | ### Context Switching → 프로세스의 상태를 바꿔주는 것
58 |
59 | ## 프로세스 Queue와 스케줄러
60 |
61 | 프로세스의 큐는 Job, Ready, Device가 존재한다.
62 |
63 | - Job Queue : 시스템 상의 모든 프로세스들을 의미
64 | - Ready Queue : 메모리에 올라가 있고 실행을 기다리는 프로세스들을 의미
65 | - Device Queue : I/O 작업을 위해 기다리고 있는 프로세스들을 의미
66 |
67 | 
68 |
69 | 이러한 큐에 어떤 것을 올릴지 결정하는 것이 스케줄러이다.
70 |
71 | - Long-Term Scheduler(장기 스케줄러)
72 | - Job Scheduler라고도 불리며 **Ready Queue에 어떤 것들을 올려야하는지 결정**하는 스케줄러이다.
73 | - 즉, **디스크**에 있는 프로그램을 **메모리**로 올려 프로세스로 만드는 작업
74 | - 속도는 빠르지 않아도 괜찮다.
75 | - 멀티 프로그래밍의 정도를 제어
76 | - 그 이유는 얘가 메모리에 프로세스를 올려주기 때문에 I/O-bound 프로세스와 CPU-bound 프로세스를 적절히 섞어서 올려줘야 한다.
77 | - 상태 변경 : New → Ready(in memory)
78 | - Short-Term Scheduler(단기 스케줄러)
79 | - 우리들이 알고 있는 CPU Scheduler 라고 불리며 **어떤 프로세스에게 CPU 자원을 할당할 것인지를 결정**하는 스케줄러이다.
80 | - 즉, **메모리**에 올라와 있는 프로세스를 **CPU에게 할당**
81 | - CPU 자원 할당은 매우 짧은 시간 단위로 반복되기 때문에 속도가 빨라야한다.
82 | - 상태 변경 : Ready → Running
83 | - Medium-Term Scheduler(중기 스케줄러)
84 | - 실행하기에 필요한 자원이 부족한 프로세스들 중 **어떤 프로세스를 Swap-out 하여 Disk에 저장할지, 어떤 프로세스를 Swap-in 해야하는지를 결정**해주는 스케줄러이다.
85 | - 즉, **메모리**에 너무 많은 프로세스가 동시에 올라가있다면 **디스크**로 내보내는 작업
86 | - 상태 변경 : Ready → Suspended
87 | - Terminated가 아니다.
88 | - 누군가 다시 재개시켜줘야(swap-in해줘야) 다시 Ready로 돌아갈 수 있다.
89 |
90 | ## PCB(Process Control Block)
91 |
92 | 특정 프로세스에 대한 중요한 정보를 저장하고 있는 OS의 자료구조이다.
93 |
94 | 프로세스 생성과 동시에 고유한 PCB가 생성되고 프로세스 전환시(인터럽트나 시스템콜)에 PCB에 기록하고 사용한다.
95 |
96 | - PCB에 저장되는 정보들 중 중요한 것들
97 | - PID : 프로세스 식별 번호
98 | - 상태
99 | - CPU 스케줄링 정보
100 | - TCB가 PCB를 참조
101 | - 레지스터
102 | - PC(Program Counter) : 프로세스가 다음에 실행할 명령어의 주소
103 |
104 | 
105 |
106 | - 추가 내용(같이 고민해볼 점)
107 |
108 | 스케줄링에는 Context Switching 시간까지 포함되어 있다.
109 |
110 | 따라서 PCB의 저장과 복원이 오래걸리면 그만큼 작업을 수행할 수 있는 시간이 짧아지는 것
111 |
112 | 따라서 **PCB의 저장과 복원은 H/W로 구현해서 작업 효율을 최대한 늘린다고 한다.**
113 |
114 | 근데 OS의 자료구조인데 하드웨어..? 잘 모르겠다.
115 |
116 |
117 | # ⭐️ 스레드
118 |
119 | 멀티 스레드와 혼용해서 설명
120 |
121 | 프로세스의 수행 경로
122 |
123 | 즉, 프로세스가 할당받은 자원을 이용하는 실행의 단위(흐름)
124 |
125 | ex) 메신저 프로그램에서 “내가 입력”, “상대방이 입력한 것을 출력” 등 하나씩이 실행 단위이다.
126 |
127 | 
128 |
129 | ## 스레드가 필요한 이유
130 |
131 | 결론은 프로세스만으로 요구 사항을 충족하기 쉽지 않아서이다.
132 |
133 | 예를 들어서 메신저 프로그램일 때, 내가 입력한 것을 출력해줌과 동시에 상대방이 입력한 것도 출력해야한다.
134 |
135 | 이 때, 싱글 프로세스를 사용한다면 키보드 입력을 기다릴 때 상대방으로부터 온 메시지를 받을 수 없다.
136 |
137 | 왜냐면 하나의 path만 가지고 있기 때문
138 |
139 | 
140 |
141 | 대충 이런 느낌이다.(프로세스는 기본적으로 하나의 스레드를 가지고 있음)
142 |
143 | 따라서 프로세스를 추가로 생성해야하는데 문제는 프로세스 자체가 독립된 자원을 할당 받기 때문에 서로 공유하지 않아서 관련되지 않은 실행 path를 가진다.
144 |
145 | 
146 |
147 | 그럼 뭐다?? 서로 통신(IPC) 해야하는데 프로그램이 커지고 시간이 지날수록 비효율적이다.(PCB 추가, 메모리 추가, Context Switching 등)
148 |
149 | - IPC는 커널을 껴서 통신해야한다.
150 |
151 | 그래서 하나의 프로세스에 여러 path를 만들고 자원을 공유하는 멀티 스레드를 사용하는 것(다수의 path가 필요한 것 뿐이기 때문에 굳이 자원 낭비를 하지 말자!)
152 |
153 | ## 스레드 특징
154 |
155 | 스레드는 프로세스와 다르게 Stack만 따로 할당 받고 Code, Data, Heap 영역은 공유한다.
156 |
157 | 정확히는 프로세스와 동일하게 실행 상태를 갖고 Register와 Stack을 독립적으로 할당받는다.
158 |
159 | ### Stack과 Register를 독립적으로 할당받는 이유??
160 |
161 | - stack
162 | - 스레드는 하나의 독립적인 실행단위이기 때문에 각각 독립적인 stack을 가진다.(독립적인 함수 호출)
163 | - 즉, 함수 호출 시 인자, 리턴 값 지역 변수 등을 독립적으로 가지기 위해서
164 | - register
165 | - 프로세스와 똑같이 CPU를 할당받고, 선점당할 수 있다.
166 | - 따라서 Context Switching이 발생하게 되므로 실행하고 있는 코드의 지점을 저장하는 PC 등을 스레드마다 독립적으로 할당해야 한다.
167 |
168 | ## 장점
169 |
170 | 1. 사용자에 대한 응답성 증가
171 | - 하나의 스레드가 waiting인 동안 다른 스레드가 실행되어 다른 작업을 빨리 처리할 수 있기 때문
172 | 2. 프로세스의 자원과 메모리 공유
173 | - 하나의 같은 주소 공간에서 여러 개의 스레드를 실행해 병렬성, 성능향상을 가질 수 있다.
174 | 3. 경제성
175 | - 한 프로세스의 자원을 공유하기 때문에 프로세스끼리 Context Switching하는 것보다 스레드끼리 하는 것이 오버헤드가 적다.
176 | - 스레드가 Context Switching 오버헤드가 작은 이유 : 스레드는 Stack, Register만 하면 되고 RAM과 CPU 사이의 캐시를 사용 가능하지만 프로세스는 캐시까지 초기화되어버린다.
177 | 4. 다중 프로세서(CPU) 구조 활용
178 | - 멀티 스레드를 통해 병렬로 수행할 수 있기 때문
179 |
180 | # ⭐️ 멀티 프로세스
181 |
182 | 하나의 응용 프로그램을 여러 개의 프로세스로 구성해 각 프로세스가 하나의 작업을 처리하도록 하는 것
183 |
184 | 
185 |
186 | ## 장단점
187 |
188 | - 장점
189 | - 여러 개의 자식 프로세스 중 하나에 문제가 발생하면 그 자식 프로세스만 죽는 것 이상으로 다른 영향이 확산되지 않는다.
190 | - 단점
191 | - Context Switching에서의 오버헤드 프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 프로세스 사이에서 공유하는 메모리가 없어, Context Switching가 발생하면 캐쉬에 있는 모든 데이터를 모두 리셋하고 다시 캐쉬 정보를 불러와야 한다.
192 | - 프로세스 사이의 어렵고 복잡한 통신 기법(IPC) 프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 하나의 프로그램에 속하는 프로세스들 사이의 변수를 공유할 수 없다.
193 |
194 | # ⭐️ 멀티 스레드
195 |
196 | 하나의 응용프로그램을 여러 개의 스레드로 구성하고 각 스레드로 하여금 하나의 작업을 처리하도록 하는 것이다.
197 |
198 | 대부분 많은 운영체제들이 멀티 스레딩을 기본으로 하고 있다.
199 |
200 | 
201 |
202 | 
203 |
204 | ex)
205 |
206 | 워드에서 키보드 입력을 기다리고, 주기적으로 저장하고, 타이핑 에러 체크하고 등을 전부 동시에 한다.
207 |
208 | 저 3개를 프로세스로 할 순 있는데 매우 비효율적
209 |
210 | 따라서
211 |
212 | 워드 → 프로세스 하나
213 |
214 | 키보드 입력 → 스레드
215 |
216 | 주기적 저장 → 스레드
217 |
218 | 타이핑 에러 체크 → 스레드
219 |
220 | ## 장단점
221 |
222 | - 장점
223 | - 시스템 자원 소모 감소 (자원의 효율성 증대)
224 | - 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다.
225 | - 시스템 처리량 증가 (처리 비용 감소)
226 | - 스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어들게 된다.
227 | - 스레드 사이의 작업량이 작아 Context Switching이 빠르다.
228 | - 간단한 통신 방법으로 인한 프로그램 응답 시간 단축
229 | - 스레드는 프로세스 내의 Stack 영역을 제외한 모든 메모리를 공유하기 때문에 통신의 부담이 적다.
230 | - 단점
231 | - 주의 깊은 설계가 필요하다.
232 | - 디버깅이 까다롭다.
233 | - 단일 프로세스 시스템의 경우 효과를 기대하기 어렵다.
234 | - 다른 프로세스에서 스레드를 제어할 수 없다. (즉, 프로세스 밖에서 스레드 각각을 제어할 수 없다.)
235 | - 멀티 스레드의 경우 자원 공유의 문제가 발생한다. (동기화 문제)
236 | - 하나의 스레드에 문제가 발생하면 전체 프로세스가 영향을 받는다
237 |
238 | ## 멀티 스레드 모델(조금 deep 한 내용)
239 |
240 | 모델을 설명하기 전에 **User Thread**와 **Kernel Thread**에 대해 알아야한다.
241 |
242 | - User Thread
243 | - 사용자가 관리하는 스레드
244 | - 스레드 전환시 커널 모드 권한이 필요없고 빠르게 만들고 관리할 수 있다.(커널 스레드보다 오버헤드가 적음 → Context Switch가 없다.(사용자 영역 스레드에서 행동하기 때문 → 메모리 상에 저장해놓나??))
245 | - 사용자 영역에서 하기 때문에 운영체제에 의존적이지 않다.(커널이 제공해주지 않고 라이브러리를 활용)
246 | - 하지만 일반적인 OS에서는 대부분의 시스템 호출이 차단되고 다중 처리를 활용할 수 없다.(I/O 작업 등에 의해 블록되면 전체 스레드가 멈춘다.)
247 | - Kernel Thread
248 | - 운영체제가 직접 커널에서 제공하고 관리하는 스레드
249 | - 하나의 프로세스는 적어도 하나의 커널 스레드를 가진다.
250 | - 프로세스의 스레드들을 한꺼번에 디스패치할 수 있기 때문에 멀티 프로세서 환경에서 좋다.
251 | - 다른 스레드가 입출력 작업이 끝날 때까지 기다릴 필요가 없다.
252 | - 안정성과 다양한 기능을 제공
253 | - 하지만 스케줄링과 동기화를 위해 커널을 호출하는데 무겁고 오래걸린다. 즉, 사용자모드에서 커널모드로 전환이 빈번하게 이루어지면 성능 저하가 발생한다. 또한 구현하기 어렵고 자원을 더 많이 소비한다.
254 |
255 | ### 1. Many-to-One Model
256 |
257 | 
258 |
259 | - 하나의 Kernel Thread가 다수의 User Thread를 처리하는 구조(=User Thread만 사용했다고 보면 됨)
260 | - User Thread를 처리하던 중 시스템 콜에 의해 blocking되면 **전체 프로세스가 막히게 된다.**
261 |
262 | ### 2. One-to-One Model
263 |
264 | 
265 |
266 | - User Thread 한 개 당 Kernel Thread를 대응시켜 작업하는 구조
267 | - 과도한 Kernel Thread 생성 문제가 있다.
268 |
269 | ### 3. Many-to-Many Model
270 |
271 | 
272 |
273 | - 1,2를 어느정도 보완한 모델로 다수의 User Thread를 다수의 Kernel Thread가 처리하는 구조
274 | - Kernel Thread의 숫자는 User Thread의 숫자보다 같거나 작아야한다.
275 |
276 | ### 4. Two-Level Model
277 |
278 | 
279 |
280 | - 최종적으로 보안된 모델로 2+3을 합친 구조이다.
281 | - 중요한 작업은 One-to-One 처럼, 나머지는 Many-to-Many 처럼 처리함으로써 혹시나 있을 중요한 작업에서의 기다림 현상을 줄일 수 있다.
282 |
283 |
284 | # ⭐️ 참고
285 |
286 | 프로세스와 스레드
287 | [https://github.com/Songwonseok/CS-Study/blob/main/OS/프로세스vs스레드.md](https://github.com/Songwonseok/CS-Study/blob/main/OS/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4vs%EC%8A%A4%EB%A0%88%EB%93%9C.md)
288 | [https://coder-in-war.tistory.com/entry/OS-00-프로세스와-스레드의-차이?category=994187](https://coder-in-war.tistory.com/entry/OS-00-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4%EC%99%80-%EC%8A%A4%EB%A0%88%EB%93%9C%EC%9D%98-%EC%B0%A8%EC%9D%B4?category=994187)
289 |
290 | 프로세스
291 | [https://baked-corn.tistory.com/5?category=718232](https://baked-corn.tistory.com/5?category=718232)
292 | 스레드
293 | [https://baked-corn.tistory.com/6?category=718232](https://baked-corn.tistory.com/6?category=718232)
294 |
295 | OS 튜토리얼
296 | [https://www.tutorialspoint.com/operating_system/index.htm](https://www.tutorialspoint.com/operating_system/index.htm)
297 |
298 | 프로세스 상태, 큐, 스케줄러
299 | [https://kosaf04pyh.tistory.com/190](https://kosaf04pyh.tistory.com/190)
300 |
301 | 멀티 스레드 모델
302 | [https://www.crocus.co.kr/1255](https://www.crocus.co.kr/1255)
303 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Backend_Interview_Study
2 |
3 | ### 참여자
4 | |  |
|  |
|  |
|  |
|  |
|  |
|  |
5 | | :------: | :------: |:------------------------------------------------------:| :------: | :------: | :------: | :------: |
6 | | **[김영한](https://github.com/soosungp33)** | **[유정한](https://github.com/youjeonghan)** | **[김동민](https://github.com/dmin0211)** | **[방규빈](https://github.com/9b2n)** | **[이유노](https://github.com/FloralLife)** | **[이신필](https://github.com/lee-3-8)** | **[홍승용](https://github.com/isanghaessi)** |
7 |
8 |
9 | ### 그라운드 룰
10 | - 스터디 일정 : 매주 화, 금 (다수의 인원이 일정이 생긴다면 조정할 수 있습니다)
11 |
12 | - 시간 : 오전 10시
13 |
14 | - 주제
15 | - 자료구조
16 | - 네트워크
17 | - 운영체제
18 | - 데이터베이스
19 | - 알고리즘
20 | - 개발상식
21 | - 디자인패턴
22 |
23 | - 발표시간 : 질문포함 20분
24 |
25 | - 발표 주요 요소
26 | - 주제
27 | - 내용
28 | - 예상 질문 리스트
29 | - 참고자료
30 |
31 | - 커밋 양식
32 | - [분야(영어)][close #13] : 내용
--------------------------------------------------------------------------------
|
5 | | :------: | :------: |:------------------------------------------------------:| :------: | :------: | :------: | :------: |
6 | | **[김영한](https://github.com/soosungp33)** | **[유정한](https://github.com/youjeonghan)** | **[김동민](https://github.com/dmin0211)** | **[방규빈](https://github.com/9b2n)** | **[이유노](https://github.com/FloralLife)** | **[이신필](https://github.com/lee-3-8)** | **[홍승용](https://github.com/isanghaessi)** |
7 |
8 |
9 | ### 그라운드 룰
10 | - 스터디 일정 : 매주 화, 금 (다수의 인원이 일정이 생긴다면 조정할 수 있습니다)
11 |
12 | - 시간 : 오전 10시
13 |
14 | - 주제
15 | - 자료구조
16 | - 네트워크
17 | - 운영체제
18 | - 데이터베이스
19 | - 알고리즘
20 | - 개발상식
21 | - 디자인패턴
22 |
23 | - 발표시간 : 질문포함 20분
24 |
25 | - 발표 주요 요소
26 | - 주제
27 | - 내용
28 | - 예상 질문 리스트
29 | - 참고자료
30 |
31 | - 커밋 양식
32 | - [분야(영어)][close #13] : 내용
--------------------------------------------------------------------------------