\n"
279 | ]
280 | }
281 | ],
282 | "source": [
283 | "eval = Panoptica_Evaluator.load_from_config_name(\"test_config\")\n",
284 | "print(eval)"
285 | ]
286 | },
287 | {
288 | "cell_type": "code",
289 | "execution_count": null,
290 | "metadata": {},
291 | "outputs": [
292 | {
293 | "name": "stdout",
294 | "output_type": "stream",
295 | "text": [
296 | "Panoptic: Start Evaluation\n",
297 | "-- Got MatchedInstancePair, will evaluate instances\n",
298 | "\n",
299 | "+++ MATCHING +++\n",
300 | "Number of instances in reference (num_ref_instances): 22\n",
301 | "Number of instances in prediction (num_pred_instances): 22\n",
302 | "True Positives (tp): 22\n",
303 | "False Positives (fp): 0\n",
304 | "False Negatives (fn): 0\n",
305 | "Recognition Quality / F1-Score (rq): 1.0\n",
306 | "\n",
307 | "+++ GLOBAL +++\n",
308 | "Global Binary Dice (global_bin_dsc): 0.9744370224078394\n",
309 | "\n",
310 | "+++ INSTANCE +++\n",
311 | "Segmentation Quality IoU (sq): 0.8328184295330796 +- 0.15186064004517466\n",
312 | "Panoptic Quality IoU (pq): 0.8328184295330796\n",
313 | "Segmentation Quality Dsc (sq_dsc): 0.900292616009954 +- 0.10253566174957332\n",
314 | "Panoptic Quality Dsc (pq_dsc): 0.900292616009954\n",
315 | "Segmentation Quality ASSD (sq_assd): 0.250331887879225 +- 0.07696680402317076\n",
316 | "Segmentation Quality Relative Volume Difference (sq_rvd): 0.0028133049062930553 +- 0.034518928495505724\n",
317 | "\n"
318 | ]
319 | }
320 | ],
321 | "source": [
322 | "# Now use it as normal\n",
323 | "result = evaluator.evaluate(pred_masks, ref_masks)[\"ungrouped\"]\n",
324 | "print(result) # yields same results as the evaluator object manually constructed"
325 | ]
326 | }
327 | ],
328 | "metadata": {
329 | "kernelspec": {
330 | "display_name": "helm",
331 | "language": "python",
332 | "name": "python3"
333 | },
334 | "language_info": {
335 | "codemirror_mode": {
336 | "name": "ipython",
337 | "version": 3
338 | },
339 | "file_extension": ".py",
340 | "mimetype": "text/x-python",
341 | "name": "python",
342 | "nbconvert_exporter": "python",
343 | "pygments_lexer": "ipython3",
344 | "version": "3.10.14"
345 | }
346 | },
347 | "nbformat": 4,
348 | "nbformat_minor": 2
349 | }
350 |
--------------------------------------------------------------------------------
/panoptica/example_spine_matched_instance.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Use Case: Matched Instances Input\n"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Install Dependencies"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 10,
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "!pip install panoptica auxiliary rich numpy > /dev/null"
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "If you installed the packages and requirements on your own machine, you can skip this section and start from the import section.\n",
31 | "\n",
32 | "### Setup Colab environment (optional) \n",
33 | "Otherwise you can follow and execute the tutorial on your browser.\n",
34 | "In order to start working on the notebook, click on the following button, this will open this page in the Colab environment and you will be able to execute the code on your own (*Google account required*).\n",
35 | "\n",
36 | "\n",
37 | "  \n",
38 | "\n",
39 | "\n",
40 | "Now that you are visualizing the notebook in Colab, run the next cell to install the packages we will use. There are few things you should follow in order to properly set the notebook up:\n",
41 | "1. Warning: This notebook was not authored by Google. Click on 'Run anyway'.\n",
42 | "1. When the installation commands are done, there might be \"Restart runtime\" button at the end of the output. Please, click it.\n",
43 | "If you run the next cell in a Google Colab environment, it will **clone the 'tutorials' repository** in your google drive. This will create a **new folder** called \"tutorials\" in **your Google Drive**.\n",
44 | "All generated file will be created/uploaded to your Google Drive respectively.\n",
45 | "\n",
46 | "After the first execution of the next cell, you might receive some warnings and notifications, please follow these instructions:\n",
47 | " - 'Permit this notebook to access your Google Drive files?' Click on 'Yes', and select your account.\n",
48 | " - Google Drive for desktop wants to access your Google Account. Click on 'Allow'.\n",
49 | "\n",
50 | "Afterwards the \"tutorials\" folder has been created. You can navigate it through the lefthand panel in Colab. You might also have received an email that informs you about the access on your Google Drive."
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 11,
56 | "metadata": {},
57 | "outputs": [],
58 | "source": [
59 | "import sys\n",
60 | "\n",
61 | "# Check if we are in google colab currently\n",
62 | "try:\n",
63 | " import google.colab\n",
64 | "\n",
65 | " colabFlag = True\n",
66 | "except ImportError as r:\n",
67 | " colabFlag = False\n",
68 | "\n",
69 | "# Execute certain steps only if we are in a colab environment\n",
70 | "if colabFlag:\n",
71 | " # Create a folder in your Google Drive\n",
72 | " from google.colab import drive\n",
73 | "\n",
74 | " drive.mount(\"/content/drive\")\n",
75 | " # clone repository and set path\n",
76 | " !git clone https://github.com/BrainLesion/tutorials.git /content/drive/MyDrive/tutorials\n",
77 | " BASE_PATH = \"/content/drive/MyDrive/tutorials/panoptica\"\n",
78 | " sys.path.insert(0, BASE_PATH)\n",
79 | "\n",
80 | "else: # normal jupyter notebook environment\n",
81 | " BASE_PATH = \".\" # current working directory would be BraTs-Toolkit anyways if you are not in colab"
82 | ]
83 | },
84 | {
85 | "cell_type": "markdown",
86 | "metadata": {},
87 | "source": [
88 | "## Setup Imports"
89 | ]
90 | },
91 | {
92 | "cell_type": "code",
93 | "execution_count": 12,
94 | "metadata": {},
95 | "outputs": [],
96 | "source": [
97 | "import numpy as np\n",
98 | "from auxiliary.nifti.io import read_nifti\n",
99 | "from rich import print as pprint\n",
100 | "from panoptica import InputType, Panoptica_Evaluator\n",
101 | "from panoptica.metrics import Metric"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "## Load Data"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | "To demonstrate we use a reference and predicition of spine a segmentation with matched instances.\n",
116 | "\n",
117 | "\n",
118 | ""
119 | ]
120 | },
121 | {
122 | "cell_type": "code",
123 | "execution_count": 13,
124 | "metadata": {},
125 | "outputs": [
126 | {
127 | "data": {
128 | "text/plain": [
129 | "(array([ 0, 2, 3, 4, 5, 6, 7, 8, 26, 102, 103, 104, 105,\n",
130 | " 106, 107, 108, 202, 203, 204, 205, 206, 207, 208], dtype=uint8),\n",
131 | " array([ 0, 2, 3, 4, 5, 6, 7, 8, 26, 102, 103, 104, 105,\n",
132 | " 106, 107, 108, 202, 203, 204, 205, 206, 207, 208], dtype=uint8))"
133 | ]
134 | },
135 | "execution_count": 13,
136 | "metadata": {},
137 | "output_type": "execute_result"
138 | }
139 | ],
140 | "source": [
141 | "ref_masks = read_nifti(f\"{BASE_PATH}/spine_seg/matched_instance/ref.nii.gz\")\n",
142 | "pred_masks = read_nifti(f\"{BASE_PATH}/spine_seg/matched_instance/pred.nii.gz\")\n",
143 | "\n",
144 | "# labels are matching\n",
145 | "np.unique(ref_masks), np.unique(pred_masks)"
146 | ]
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "## Run Evaluation"
153 | ]
154 | },
155 | {
156 | "cell_type": "code",
157 | "execution_count": null,
158 | "metadata": {},
159 | "outputs": [
160 | {
161 | "name": "stdout",
162 | "output_type": "stream",
163 | "text": [
164 | "Panoptic: Start Evaluation\n",
165 | "-- Got MatchedInstancePair, will evaluate instances\n"
166 | ]
167 | }
168 | ],
169 | "source": [
170 | "evaluator = Panoptica_Evaluator(\n",
171 | " expected_input=InputType.MATCHED_INSTANCE,\n",
172 | " decision_metric=Metric.IOU,\n",
173 | " decision_threshold=0.5,\n",
174 | ")\n",
175 | "\n",
176 | "result = evaluator.evaluate(pred_masks, ref_masks)[\"ungrouped\"]"
177 | ]
178 | },
179 | {
180 | "cell_type": "markdown",
181 | "metadata": {},
182 | "source": [
183 | "## Inspect Results\n",
184 | "The results object allows access to individual metrics and provides helper methods for further processing"
185 | ]
186 | },
187 | {
188 | "cell_type": "code",
189 | "execution_count": 15,
190 | "metadata": {},
191 | "outputs": [
192 | {
193 | "name": "stdout",
194 | "output_type": "stream",
195 | "text": [
196 | "\n",
197 | "+++ MATCHING +++\n",
198 | "Number of instances in reference (num_ref_instances): 22\n",
199 | "Number of instances in prediction (num_pred_instances): 22\n",
200 | "True Positives (tp): 22\n",
201 | "False Positives (fp): 0\n",
202 | "False Negatives (fn): 0\n",
203 | "Recognition Quality / F1-Score (rq): 1.0\n",
204 | "\n",
205 | "+++ GLOBAL +++\n",
206 | "Global Binary Dice (global_bin_dsc): 0.9744370224078394\n",
207 | "\n",
208 | "+++ INSTANCE +++\n",
209 | "Segmentation Quality IoU (sq): 0.8328184295330796 +- 0.15186064004517466\n",
210 | "Panoptic Quality IoU (pq): 0.8328184295330796\n",
211 | "Segmentation Quality Dsc (sq_dsc): 0.900292616009954 +- 0.10253566174957332\n",
212 | "Panoptic Quality Dsc (pq_dsc): 0.900292616009954\n",
213 | "Segmentation Quality ASSD (sq_assd): 0.250331887879225 +- 0.07696680402317076\n",
214 | "Segmentation Quality Relative Volume Difference (sq_rvd): 0.0028133049062930553 +- 0.034518928495505724\n",
215 | "\n"
216 | ]
217 | }
218 | ],
219 | "source": [
220 | "# print all results\n",
221 | "print(result)"
222 | ]
223 | },
224 | {
225 | "cell_type": "code",
226 | "execution_count": 16,
227 | "metadata": {},
228 | "outputs": [
229 | {
230 | "data": {
231 | "text/html": [
232 | "
\n",
38 | "\n",
39 | "\n",
40 | "Now that you are visualizing the notebook in Colab, run the next cell to install the packages we will use. There are few things you should follow in order to properly set the notebook up:\n",
41 | "1. Warning: This notebook was not authored by Google. Click on 'Run anyway'.\n",
42 | "1. When the installation commands are done, there might be \"Restart runtime\" button at the end of the output. Please, click it.\n",
43 | "If you run the next cell in a Google Colab environment, it will **clone the 'tutorials' repository** in your google drive. This will create a **new folder** called \"tutorials\" in **your Google Drive**.\n",
44 | "All generated file will be created/uploaded to your Google Drive respectively.\n",
45 | "\n",
46 | "After the first execution of the next cell, you might receive some warnings and notifications, please follow these instructions:\n",
47 | " - 'Permit this notebook to access your Google Drive files?' Click on 'Yes', and select your account.\n",
48 | " - Google Drive for desktop wants to access your Google Account. Click on 'Allow'.\n",
49 | "\n",
50 | "Afterwards the \"tutorials\" folder has been created. You can navigate it through the lefthand panel in Colab. You might also have received an email that informs you about the access on your Google Drive."
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 11,
56 | "metadata": {},
57 | "outputs": [],
58 | "source": [
59 | "import sys\n",
60 | "\n",
61 | "# Check if we are in google colab currently\n",
62 | "try:\n",
63 | " import google.colab\n",
64 | "\n",
65 | " colabFlag = True\n",
66 | "except ImportError as r:\n",
67 | " colabFlag = False\n",
68 | "\n",
69 | "# Execute certain steps only if we are in a colab environment\n",
70 | "if colabFlag:\n",
71 | " # Create a folder in your Google Drive\n",
72 | " from google.colab import drive\n",
73 | "\n",
74 | " drive.mount(\"/content/drive\")\n",
75 | " # clone repository and set path\n",
76 | " !git clone https://github.com/BrainLesion/tutorials.git /content/drive/MyDrive/tutorials\n",
77 | " BASE_PATH = \"/content/drive/MyDrive/tutorials/panoptica\"\n",
78 | " sys.path.insert(0, BASE_PATH)\n",
79 | "\n",
80 | "else: # normal jupyter notebook environment\n",
81 | " BASE_PATH = \".\" # current working directory would be BraTs-Toolkit anyways if you are not in colab"
82 | ]
83 | },
84 | {
85 | "cell_type": "markdown",
86 | "metadata": {},
87 | "source": [
88 | "## Setup Imports"
89 | ]
90 | },
91 | {
92 | "cell_type": "code",
93 | "execution_count": 12,
94 | "metadata": {},
95 | "outputs": [],
96 | "source": [
97 | "import numpy as np\n",
98 | "from auxiliary.nifti.io import read_nifti\n",
99 | "from rich import print as pprint\n",
100 | "from panoptica import InputType, Panoptica_Evaluator\n",
101 | "from panoptica.metrics import Metric"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "## Load Data"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | "To demonstrate we use a reference and predicition of spine a segmentation with matched instances.\n",
116 | "\n",
117 | "\n",
118 | ""
119 | ]
120 | },
121 | {
122 | "cell_type": "code",
123 | "execution_count": 13,
124 | "metadata": {},
125 | "outputs": [
126 | {
127 | "data": {
128 | "text/plain": [
129 | "(array([ 0, 2, 3, 4, 5, 6, 7, 8, 26, 102, 103, 104, 105,\n",
130 | " 106, 107, 108, 202, 203, 204, 205, 206, 207, 208], dtype=uint8),\n",
131 | " array([ 0, 2, 3, 4, 5, 6, 7, 8, 26, 102, 103, 104, 105,\n",
132 | " 106, 107, 108, 202, 203, 204, 205, 206, 207, 208], dtype=uint8))"
133 | ]
134 | },
135 | "execution_count": 13,
136 | "metadata": {},
137 | "output_type": "execute_result"
138 | }
139 | ],
140 | "source": [
141 | "ref_masks = read_nifti(f\"{BASE_PATH}/spine_seg/matched_instance/ref.nii.gz\")\n",
142 | "pred_masks = read_nifti(f\"{BASE_PATH}/spine_seg/matched_instance/pred.nii.gz\")\n",
143 | "\n",
144 | "# labels are matching\n",
145 | "np.unique(ref_masks), np.unique(pred_masks)"
146 | ]
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "## Run Evaluation"
153 | ]
154 | },
155 | {
156 | "cell_type": "code",
157 | "execution_count": null,
158 | "metadata": {},
159 | "outputs": [
160 | {
161 | "name": "stdout",
162 | "output_type": "stream",
163 | "text": [
164 | "Panoptic: Start Evaluation\n",
165 | "-- Got MatchedInstancePair, will evaluate instances\n"
166 | ]
167 | }
168 | ],
169 | "source": [
170 | "evaluator = Panoptica_Evaluator(\n",
171 | " expected_input=InputType.MATCHED_INSTANCE,\n",
172 | " decision_metric=Metric.IOU,\n",
173 | " decision_threshold=0.5,\n",
174 | ")\n",
175 | "\n",
176 | "result = evaluator.evaluate(pred_masks, ref_masks)[\"ungrouped\"]"
177 | ]
178 | },
179 | {
180 | "cell_type": "markdown",
181 | "metadata": {},
182 | "source": [
183 | "## Inspect Results\n",
184 | "The results object allows access to individual metrics and provides helper methods for further processing"
185 | ]
186 | },
187 | {
188 | "cell_type": "code",
189 | "execution_count": 15,
190 | "metadata": {},
191 | "outputs": [
192 | {
193 | "name": "stdout",
194 | "output_type": "stream",
195 | "text": [
196 | "\n",
197 | "+++ MATCHING +++\n",
198 | "Number of instances in reference (num_ref_instances): 22\n",
199 | "Number of instances in prediction (num_pred_instances): 22\n",
200 | "True Positives (tp): 22\n",
201 | "False Positives (fp): 0\n",
202 | "False Negatives (fn): 0\n",
203 | "Recognition Quality / F1-Score (rq): 1.0\n",
204 | "\n",
205 | "+++ GLOBAL +++\n",
206 | "Global Binary Dice (global_bin_dsc): 0.9744370224078394\n",
207 | "\n",
208 | "+++ INSTANCE +++\n",
209 | "Segmentation Quality IoU (sq): 0.8328184295330796 +- 0.15186064004517466\n",
210 | "Panoptic Quality IoU (pq): 0.8328184295330796\n",
211 | "Segmentation Quality Dsc (sq_dsc): 0.900292616009954 +- 0.10253566174957332\n",
212 | "Panoptic Quality Dsc (pq_dsc): 0.900292616009954\n",
213 | "Segmentation Quality ASSD (sq_assd): 0.250331887879225 +- 0.07696680402317076\n",
214 | "Segmentation Quality Relative Volume Difference (sq_rvd): 0.0028133049062930553 +- 0.034518928495505724\n",
215 | "\n"
216 | ]
217 | }
218 | ],
219 | "source": [
220 | "# print all results\n",
221 | "print(result)"
222 | ]
223 | },
224 | {
225 | "cell_type": "code",
226 | "execution_count": 16,
227 | "metadata": {},
228 | "outputs": [
229 | {
230 | "data": {
231 | "text/html": [
232 | "result.pq=0.8328184295330796\n",
233 | "
\n"
234 | ],
235 | "text/plain": [
236 | "result.\u001b[33mpq\u001b[0m=\u001b[1;36m0\u001b[0m\u001b[1;36m.8328184295330796\u001b[0m\n"
237 | ]
238 | },
239 | "metadata": {},
240 | "output_type": "display_data"
241 | }
242 | ],
243 | "source": [
244 | "# get specific metric, e.g. pq\n",
245 | "pprint(f\"{result.pq=}\")"
246 | ]
247 | },
248 | {
249 | "cell_type": "code",
250 | "execution_count": 17,
251 | "metadata": {},
252 | "outputs": [
253 | {
254 | "data": {
255 | "text/html": [
256 | "results dict: \n",
257 | "{\n",
258 | " 'num_ref_instances': 22,\n",
259 | " 'num_pred_instances': 22,\n",
260 | " 'tp': 22,\n",
261 | " 'fp': 0,\n",
262 | " 'fn': 0,\n",
263 | " 'prec': 1.0,\n",
264 | " 'rec': 1.0,\n",
265 | " 'rq': 1.0,\n",
266 | " 'sq': 0.8328184295330796,\n",
267 | " 'sq_std': 0.15186064004517466,\n",
268 | " 'pq': 0.8328184295330796,\n",
269 | " 'sq_dsc': 0.900292616009954,\n",
270 | " 'sq_dsc_std': 0.10253566174957332,\n",
271 | " 'pq_dsc': 0.900292616009954,\n",
272 | " 'sq_assd': 0.250331887879225,\n",
273 | " 'sq_assd_std': 0.07696680402317076,\n",
274 | " 'sq_rvd': 0.0028133049062930553,\n",
275 | " 'sq_rvd_std': 0.034518928495505724,\n",
276 | " 'global_bin_dsc': 0.9744370224078394\n",
277 | "}\n",
278 | "\n"
279 | ],
280 | "text/plain": [
281 | "results dict: \n",
282 | "\u001b[1m{\u001b[0m\n",
283 | " \u001b[32m'num_ref_instances'\u001b[0m: \u001b[1;36m22\u001b[0m,\n",
284 | " \u001b[32m'num_pred_instances'\u001b[0m: \u001b[1;36m22\u001b[0m,\n",
285 | " \u001b[32m'tp'\u001b[0m: \u001b[1;36m22\u001b[0m,\n",
286 | " \u001b[32m'fp'\u001b[0m: \u001b[1;36m0\u001b[0m,\n",
287 | " \u001b[32m'fn'\u001b[0m: \u001b[1;36m0\u001b[0m,\n",
288 | " \u001b[32m'prec'\u001b[0m: \u001b[1;36m1.0\u001b[0m,\n",
289 | " \u001b[32m'rec'\u001b[0m: \u001b[1;36m1.0\u001b[0m,\n",
290 | " \u001b[32m'rq'\u001b[0m: \u001b[1;36m1.0\u001b[0m,\n",
291 | " \u001b[32m'sq'\u001b[0m: \u001b[1;36m0.8328184295330796\u001b[0m,\n",
292 | " \u001b[32m'sq_std'\u001b[0m: \u001b[1;36m0.15186064004517466\u001b[0m,\n",
293 | " \u001b[32m'pq'\u001b[0m: \u001b[1;36m0.8328184295330796\u001b[0m,\n",
294 | " \u001b[32m'sq_dsc'\u001b[0m: \u001b[1;36m0.900292616009954\u001b[0m,\n",
295 | " \u001b[32m'sq_dsc_std'\u001b[0m: \u001b[1;36m0.10253566174957332\u001b[0m,\n",
296 | " \u001b[32m'pq_dsc'\u001b[0m: \u001b[1;36m0.900292616009954\u001b[0m,\n",
297 | " \u001b[32m'sq_assd'\u001b[0m: \u001b[1;36m0.250331887879225\u001b[0m,\n",
298 | " \u001b[32m'sq_assd_std'\u001b[0m: \u001b[1;36m0.07696680402317076\u001b[0m,\n",
299 | " \u001b[32m'sq_rvd'\u001b[0m: \u001b[1;36m0.0028133049062930553\u001b[0m,\n",
300 | " \u001b[32m'sq_rvd_std'\u001b[0m: \u001b[1;36m0.034518928495505724\u001b[0m,\n",
301 | " \u001b[32m'global_bin_dsc'\u001b[0m: \u001b[1;36m0.9744370224078394\u001b[0m\n",
302 | "\u001b[1m}\u001b[0m\n"
303 | ]
304 | },
305 | "metadata": {},
306 | "output_type": "display_data"
307 | }
308 | ],
309 | "source": [
310 | "# get dict for further processing, e.g. for pandas\n",
311 | "pprint(\"results dict: \", result.to_dict())"
312 | ]
313 | },
314 | {
315 | "cell_type": "code",
316 | "execution_count": null,
317 | "metadata": {},
318 | "outputs": [
319 | {
320 | "name": "stdout",
321 | "output_type": "stream",
322 | "text": [
323 | "key SEMANTIC not in intermediate steps, maybe the step was skipped?\n"
324 | ]
325 | }
326 | ],
327 | "source": [
328 | "# To inspect different phases, just use the returned intermediate_steps_data object\n",
329 | "intermediate_steps_data = result.intermediate_steps_data\n",
330 | "intermediate_steps_data.original_prediction_arr # yields input prediction array\n",
331 | "intermediate_steps_data.original_reference_arr # yields input reference array\n",
332 | "\n",
333 | "intermediate_steps_data.prediction_arr(\n",
334 | " InputType.MATCHED_INSTANCE\n",
335 | ") # yields prediction array after instances have been matched\n",
336 | "intermediate_steps_data.reference_arr(\n",
337 | " InputType.MATCHED_INSTANCE\n",
338 | ") # yields reference array after instances have been matched\n",
339 | "\n",
340 | "# The other InputType do not work here, as the input was already a matched instance map, therefore the steps from instance approximation and matching have been skipped\n",
341 | "try:\n",
342 | " intermediate_steps_data.reference_arr(InputType.SEMANTIC)\n",
343 | "except AssertionError as e:\n",
344 | " print(e)\n",
345 | " # Error will indicate the problem"
346 | ]
347 | }
348 | ],
349 | "metadata": {
350 | "kernelspec": {
351 | "display_name": "helm",
352 | "language": "python",
353 | "name": "python3"
354 | },
355 | "language_info": {
356 | "codemirror_mode": {
357 | "name": "ipython",
358 | "version": 3
359 | },
360 | "file_extension": ".py",
361 | "mimetype": "text/x-python",
362 | "name": "python",
363 | "nbconvert_exporter": "python",
364 | "pygments_lexer": "ipython3",
365 | "version": "3.10.14"
366 | }
367 | },
368 | "nbformat": 4,
369 | "nbformat_minor": 2
370 | }
371 |
--------------------------------------------------------------------------------
/panoptica/example_spine_matching_algorithm.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Use Case: Unmatched Instances Input"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Install Dependencies"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "!pip install panoptica auxiliary rich numpy > /dev/null"
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "If you installed the packages and requirements on your own machine, you can skip this section and start from the import section.\n",
31 | "\n",
32 | "### Setup Colab environment (optional) \n",
33 | "Otherwise you can follow and execute the tutorial on your browser.\n",
34 | "In order to start working on the notebook, click on the following button, this will open this page in the Colab environment and you will be able to execute the code on your own (*Google account required*).\n",
35 | "\n",
36 | "\n",
37 | " \n",
38 | "\n",
39 | "\n",
40 | "Now that you are visualizing the notebook in Colab, run the next cell to install the packages we will use. There are few things you should follow in order to properly set the notebook up:\n",
41 | "1. Warning: This notebook was not authored by Google. Click on 'Run anyway'.\n",
42 | "1. When the installation commands are done, there might be \"Restart runtime\" button at the end of the output. Please, click it.\n",
43 | "If you run the next cell in a Google Colab environment, it will **clone the 'tutorials' repository** in your google drive. This will create a **new folder** called \"tutorials\" in **your Google Drive**.\n",
44 | "All generated file will be created/uploaded to your Google Drive respectively.\n",
45 | "\n",
46 | "After the first execution of the next cell, you might receive some warnings and notifications, please follow these instructions:\n",
47 | " - 'Permit this notebook to access your Google Drive files?' Click on 'Yes', and select your account.\n",
48 | " - Google Drive for desktop wants to access your Google Account. Click on 'Allow'.\n",
49 | "\n",
50 | "Afterwards the \"tutorials\" folder has been created. You can navigate it through the lefthand panel in Colab. You might also have received an email that informs you about the access on your Google Drive."
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 2,
56 | "metadata": {},
57 | "outputs": [],
58 | "source": [
59 | "import sys\n",
60 | "\n",
61 | "# Check if we are in google colab currently\n",
62 | "try:\n",
63 | " import google.colab\n",
64 | "\n",
65 | " colabFlag = True\n",
66 | "except ImportError as r:\n",
67 | " colabFlag = False\n",
68 | "\n",
69 | "# Execute certain steps only if we are in a colab environment\n",
70 | "if colabFlag:\n",
71 | " # Create a folder in your Google Drive\n",
72 | " from google.colab import drive\n",
73 | "\n",
74 | " drive.mount(\"/content/drive\")\n",
75 | " # clone repository and set path\n",
76 | " !git clone https://github.com/BrainLesion/tutorials.git /content/drive/MyDrive/tutorials\n",
77 | " BASE_PATH = \"/content/drive/MyDrive/tutorials/panoptica\"\n",
78 | " sys.path.insert(0, BASE_PATH)\n",
79 | "\n",
80 | "else: # normal jupyter notebook environment\n",
81 | " BASE_PATH = \".\" # current working directory would be BraTs-Toolkit anyways if you are not in colab"
82 | ]
83 | },
84 | {
85 | "cell_type": "markdown",
86 | "metadata": {},
87 | "source": [
88 | "## Setup Imports"
89 | ]
90 | },
91 | {
92 | "cell_type": "code",
93 | "execution_count": 3,
94 | "metadata": {},
95 | "outputs": [
96 | {
97 | "name": "stdout",
98 | "output_type": "stream",
99 | "text": [
100 | "No module named 'pandas'\n",
101 | "OPTIONAL PACKAGE MISSING\n"
102 | ]
103 | }
104 | ],
105 | "source": [
106 | "import numpy as np\n",
107 | "from auxiliary.nifti.io import read_nifti\n",
108 | "from rich import print as pprint\n",
109 | "from panoptica import NaiveThresholdMatching, Panoptica_Evaluator, InputType\n",
110 | "from panoptica.utils.segmentation_class import LabelGroup, SegmentationClassGroups"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {},
116 | "source": [
117 | "## Load Example Data"
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "metadata": {},
123 | "source": [
124 | "To demonstrate we use a reference and predicition of spine a segmentation with unmatched instances.\n",
125 | "\n",
126 | "\n",
127 | ""
128 | ]
129 | },
130 | {
131 | "cell_type": "code",
132 | "execution_count": 4,
133 | "metadata": {},
134 | "outputs": [
135 | {
136 | "data": {
137 | "text/plain": [
138 | "(array([ 0, 2, 3, 4, 5, 6, 7, 8, 26, 102, 103, 104, 105,\n",
139 | " 106, 107, 108, 202, 203, 204, 205, 206, 207, 208], dtype=uint8),\n",
140 | " array([ 0, 3, 4, 5, 6, 7, 8, 9, 26, 103, 104, 105, 106,\n",
141 | " 107, 108, 109, 203, 204, 205, 206, 207, 208, 209], dtype=uint8))"
142 | ]
143 | },
144 | "execution_count": 4,
145 | "metadata": {},
146 | "output_type": "execute_result"
147 | }
148 | ],
149 | "source": [
150 | "ref_masks = read_nifti(f\"{BASE_PATH}/spine_seg/unmatched_instance/ref.nii.gz\")\n",
151 | "pred_masks = read_nifti(f\"{BASE_PATH}/spine_seg/unmatched_instance/pred.nii.gz\")\n",
152 | "\n",
153 | "# labels are unmatched instances\n",
154 | "pred_masks[pred_masks == 27] = 26 # For later\n",
155 | "np.unique(ref_masks), np.unique(pred_masks)"
156 | ]
157 | },
158 | {
159 | "cell_type": "markdown",
160 | "metadata": {},
161 | "source": [
162 | "## Define Class Groups"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": 5,
168 | "metadata": {},
169 | "outputs": [],
170 | "source": [
171 | "# Define (optionally) semantic groups\n",
172 | "# This means that only instance within one group can be matched to each other\n",
173 | "segmentation_class_groups = SegmentationClassGroups(\n",
174 | " {\n",
175 | " \"vertebra\": LabelGroup(list(range(1, 11))),\n",
176 | " \"ivd\": LabelGroup(list(range(101, 111))),\n",
177 | " \"sacrum\": ([26], True),\n",
178 | " \"endplate\": LabelGroup(list(range(201, 211))),\n",
179 | " }\n",
180 | ")\n",
181 | "# In this case, the label 26 can only be matched with label 26 (thats why have to ensure above that 26 exists in both masks, otherwise they wouldn't be matched)"
182 | ]
183 | },
184 | {
185 | "cell_type": "markdown",
186 | "metadata": {},
187 | "source": [
188 | "## Let's do it ourselves!\n",
189 | "Panoptica allows you to call everything yourself if you really want to"
190 | ]
191 | },
192 | {
193 | "cell_type": "code",
194 | "execution_count": 6,
195 | "metadata": {},
196 | "outputs": [
197 | {
198 | "name": "stdout",
199 | "output_type": "stream",
200 | "text": [
201 | "prediction_arr= [ 0 2 3 4 5 6 7 8 26 102 103 104 105 106 107 108 202 204\n",
202 | " 206 207 209 210 211]\n",
203 | "reference_arr= [ 0 2 3 4 5 6 7 8 26 102 103 104 105 106 107 108 202 203\n",
204 | " 204 205 206 207 208]\n"
205 | ]
206 | }
207 | ],
208 | "source": [
209 | "# Input are unmatched instances, so lets match em!\n",
210 | "from panoptica import Metric\n",
211 | "\n",
212 | "# This will match based on IoU metric, will only match if instance have a IoU of 0.5 or higher and will not allow multiple predictions to be matched to the same reference\n",
213 | "matcher = NaiveThresholdMatching(\n",
214 | " matching_metric=Metric.IOU, matching_threshold=0.5, allow_many_to_one=False\n",
215 | ")\n",
216 | "\n",
217 | "# Now we have to do our processing object ourselves\n",
218 | "from panoptica import UnmatchedInstancePair\n",
219 | "\n",
220 | "unmatched_instance_input = UnmatchedInstancePair(pred_masks, ref_masks)\n",
221 | "\n",
222 | "matched_instance_output = matcher.match_instances(unmatched_instance_input)\n",
223 | "print(\"prediction_arr=\", np.unique(matched_instance_output.prediction_arr))\n",
224 | "print(\"reference_arr=\", np.unique(matched_instance_output.reference_arr))\n",
225 | "\n",
226 | "# Based of this, we see that some references are not sucessfully hit (203, 205, 208)\n",
227 | "# We can also see that we indeed have the same number of prediction instances that got no match, they will be appended afterwards (209, 210, 211)"
228 | ]
229 | },
230 | {
231 | "cell_type": "markdown",
232 | "metadata": {},
233 | "source": [
234 | "## Let's match 'em all!"
235 | ]
236 | },
237 | {
238 | "cell_type": "code",
239 | "execution_count": 7,
240 | "metadata": {},
241 | "outputs": [
242 | {
243 | "name": "stdout",
244 | "output_type": "stream",
245 | "text": [
246 | "prediction_arr= [ 0 2 3 4 5 6 7 8 26 102 103 104 105 106 107 108 202 203\n",
247 | " 204 205 206 207 208]\n",
248 | "reference_arr= [ 0 2 3 4 5 6 7 8 26 102 103 104 105 106 107 108 202 203\n",
249 | " 204 205 206 207 208]\n"
250 | ]
251 | }
252 | ],
253 | "source": [
254 | "# This will match based on IoU metric, will only match if instance have a IoU of 0.0 or higher and will not allow multiple predictions to be matched to the same reference\n",
255 | "matcher = NaiveThresholdMatching(\n",
256 | " matching_metric=Metric.IOU, matching_threshold=0.0, allow_many_to_one=False\n",
257 | ")\n",
258 | "\n",
259 | "matched_instance_output = matcher.match_instances(unmatched_instance_input)\n",
260 | "print(\"prediction_arr=\", np.unique(matched_instance_output.prediction_arr))\n",
261 | "print(\"reference_arr=\", np.unique(matched_instance_output.reference_arr))\n",
262 | "\n",
263 | "# With a threshold of 0.0, we ensure that we match as much as possible.\n",
264 | "# We see, that contrary to before, instances 203, 205, and 208 are now matched"
265 | ]
266 | },
267 | {
268 | "cell_type": "markdown",
269 | "metadata": {},
270 | "source": [
271 | "## Do it yourself\n",
272 | "\n",
273 | "Now it is up to you to explore the different matching algorithms and the best setup for your project\n",
274 | "\n",
275 | "Just remember, this setup can have drastic differences in the resulting metrics as well as interpretation of those results. For example, if you always match everything, of course your F1-Score will be 1.0. This becomes meaningless then. Also the choice of metric does matter!"
276 | ]
277 | }
278 | ],
279 | "metadata": {
280 | "kernelspec": {
281 | "display_name": "brainles",
282 | "language": "python",
283 | "name": "python3"
284 | },
285 | "language_info": {
286 | "codemirror_mode": {
287 | "name": "ipython",
288 | "version": 3
289 | },
290 | "file_extension": ".py",
291 | "mimetype": "text/x-python",
292 | "name": "python",
293 | "nbconvert_exporter": "python",
294 | "pygments_lexer": "ipython3",
295 | "version": "3.10.14"
296 | }
297 | },
298 | "nbformat": 4,
299 | "nbformat_minor": 2
300 | }
301 |
--------------------------------------------------------------------------------
/panoptica/example_spine_semantic.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Semantic Segmentation Input"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Install Dependencies"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 10,
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "!pip install panoptica auxiliary rich numpy > /dev/null"
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "If you installed the packages and requirements on your own machine, you can skip this section and start from the import section.\n",
31 | "\n",
32 | "### Setup Colab environment (optional) \n",
33 | "Otherwise you can follow and execute the tutorial on your browser.\n",
34 | "In order to start working on the notebook, click on the following button, this will open this page in the Colab environment and you will be able to execute the code on your own (*Google account required*).\n",
35 | "\n",
36 | "\n",
37 | " \n",
38 | "\n",
39 | "\n",
40 | "Now that you are visualizing the notebook in Colab, run the next cell to install the packages we will use. There are few things you should follow in order to properly set the notebook up:\n",
41 | "1. Warning: This notebook was not authored by Google. Click on 'Run anyway'.\n",
42 | "1. When the installation commands are done, there might be \"Restart runtime\" button at the end of the output. Please, click it.\n",
43 | "If you run the next cell in a Google Colab environment, it will **clone the 'tutorials' repository** in your google drive. This will create a **new folder** called \"tutorials\" in **your Google Drive**.\n",
44 | "All generated file will be created/uploaded to your Google Drive respectively.\n",
45 | "\n",
46 | "After the first execution of the next cell, you might receive some warnings and notifications, please follow these instructions:\n",
47 | " - 'Permit this notebook to access your Google Drive files?' Click on 'Yes', and select your account.\n",
48 | " - Google Drive for desktop wants to access your Google Account. Click on 'Allow'.\n",
49 | "\n",
50 | "Afterwards the \"tutorials\" folder has been created. You can navigate it through the lefthand panel in Colab. You might also have received an email that informs you about the access on your Google Drive."
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 2,
56 | "metadata": {},
57 | "outputs": [],
58 | "source": [
59 | "import sys\n",
60 | "\n",
61 | "# Check if we are in google colab currently\n",
62 | "try:\n",
63 | " import google.colab\n",
64 | "\n",
65 | " colabFlag = True\n",
66 | "except ImportError as r:\n",
67 | " colabFlag = False\n",
68 | "\n",
69 | "# Execute certain steps only if we are in a colab environment\n",
70 | "if colabFlag:\n",
71 | " # Create a folder in your Google Drive\n",
72 | " from google.colab import drive\n",
73 | "\n",
74 | " drive.mount(\"/content/drive\")\n",
75 | " # clone repository and set path\n",
76 | " !git clone https://github.com/BrainLesion/tutorials.git /content/drive/MyDrive/tutorials\n",
77 | " BASE_PATH = \"/content/drive/MyDrive/tutorials/panoptica\"\n",
78 | " sys.path.insert(0, BASE_PATH)\n",
79 | "\n",
80 | "else: # normal jupyter notebook environment\n",
81 | " BASE_PATH = \".\" # current working directory would be BraTs-Toolkit anyways if you are not in colab"
82 | ]
83 | },
84 | {
85 | "cell_type": "markdown",
86 | "metadata": {},
87 | "source": [
88 | "## Setup Imports"
89 | ]
90 | },
91 | {
92 | "cell_type": "code",
93 | "execution_count": 3,
94 | "metadata": {},
95 | "outputs": [
96 | {
97 | "name": "stdout",
98 | "output_type": "stream",
99 | "text": [
100 | "No module named 'pandas'\n",
101 | "OPTIONAL PACKAGE MISSING\n"
102 | ]
103 | }
104 | ],
105 | "source": [
106 | "from auxiliary.nifti.io import read_nifti\n",
107 | "from rich import print as pprint\n",
108 | "from panoptica import (\n",
109 | " InputType,\n",
110 | " Panoptica_Evaluator,\n",
111 | " ConnectedComponentsInstanceApproximator,\n",
112 | " NaiveThresholdMatching,\n",
113 | ")"
114 | ]
115 | },
116 | {
117 | "cell_type": "markdown",
118 | "metadata": {},
119 | "source": [
120 | "## Load Data"
121 | ]
122 | },
123 | {
124 | "cell_type": "markdown",
125 | "metadata": {},
126 | "source": [
127 | "To demonstrate we use a reference and predicition of spine a segmentation without instances.\n",
128 | "\n",
129 | ""
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 4,
135 | "metadata": {},
136 | "outputs": [],
137 | "source": [
138 | "ref_masks = read_nifti(f\"{BASE_PATH}/spine_seg/semantic/ref.nii.gz\")\n",
139 | "pred_masks = read_nifti(f\"{BASE_PATH}/spine_seg/semantic/pred.nii.gz\")"
140 | ]
141 | },
142 | {
143 | "cell_type": "markdown",
144 | "metadata": {},
145 | "source": [
146 | "To use your own data please replace the example data with your own data.\n",
147 | "\n",
148 | "In ordner to successfully load your data please use NIFTI files and the following file designation within the \"semantic\" folder: \n",
149 | "\n",
150 | "```panoptica/spine_seg/semantic/```\n",
151 | "\n",
152 | "- Reference data (\"ref.nii.gz\")\n",
153 | "- Prediction data (\"pred.nii.gz\")\n"
154 | ]
155 | },
156 | {
157 | "cell_type": "markdown",
158 | "metadata": {},
159 | "source": [
160 | "## Run Evaluation"
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": 5,
166 | "metadata": {},
167 | "outputs": [],
168 | "source": [
169 | "evaluator = Panoptica_Evaluator(\n",
170 | " expected_input=InputType.SEMANTIC,\n",
171 | " instance_approximator=ConnectedComponentsInstanceApproximator(),\n",
172 | " instance_matcher=NaiveThresholdMatching(),\n",
173 | ")"
174 | ]
175 | },
176 | {
177 | "cell_type": "markdown",
178 | "metadata": {},
179 | "source": [
180 | "## Inspect Results\n",
181 | "The results object allows access to individual metrics and provides helper methods for further processing\n"
182 | ]
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": null,
187 | "metadata": {},
188 | "outputs": [
189 | {
190 | "data": {
191 | "text/html": [
192 | "────────────────────────────────────────── Thank you for using panoptica ──────────────────────────────────────────\n",
193 | "
\n"
194 | ],
195 | "text/plain": [
196 | "\u001b[92m────────────────────────────────────────── \u001b[0mThank you for using \u001b[1mpanoptica\u001b[0m\u001b[92m ──────────────────────────────────────────\u001b[0m\n"
197 | ]
198 | },
199 | "metadata": {},
200 | "output_type": "display_data"
201 | },
202 | {
203 | "data": {
204 | "text/html": [
205 | " Please support our development by citing \n",
206 | "
\n"
207 | ],
208 | "text/plain": [
209 | " Please support our development by citing \n"
210 | ]
211 | },
212 | "metadata": {},
213 | "output_type": "display_data"
214 | },
215 | {
216 | "data": {
217 | "text/html": [
218 | " https://github.com/BrainLesion/panoptica#citation -- Thank you! \n",
219 | "
\n"
220 | ],
221 | "text/plain": [
222 | " \u001b[4;94mhttps://github.com/BrainLesion/panoptica#citation\u001b[0m -- Thank you! \n"
223 | ]
224 | },
225 | "metadata": {},
226 | "output_type": "display_data"
227 | },
228 | {
229 | "data": {
230 | "text/html": [
231 | "───────────────────────────────────────────────────────────────────────────────────────────────────────────────────\n",
232 | "
\n"
233 | ],
234 | "text/plain": [
235 | "\u001b[92m───────────────────────────────────────────────────────────────────────────────────────────────────────────────────\u001b[0m\n"
236 | ]
237 | },
238 | "metadata": {},
239 | "output_type": "display_data"
240 | },
241 | {
242 | "data": {
243 | "text/html": [
244 | "\n",
245 | "
\n"
246 | ],
247 | "text/plain": [
248 | "\n"
249 | ]
250 | },
251 | "metadata": {},
252 | "output_type": "display_data"
253 | },
254 | {
255 | "name": "stdout",
256 | "output_type": "stream",
257 | "text": [
258 | "\n",
259 | "+++ MATCHING +++\n",
260 | "Number of instances in reference (num_ref_instances): 87\n",
261 | "Number of instances in prediction (num_pred_instances): 89\n",
262 | "True Positives (tp): 73\n",
263 | "False Positives (fp): 16\n",
264 | "False Negatives (fn): 14\n",
265 | "Recognition Quality / F1-Score (rq): 0.8295454545454546\n",
266 | "\n",
267 | "+++ GLOBAL +++\n",
268 | "Global Binary Dice (global_bin_dsc): 0.9731641527805414\n",
269 | "\n",
270 | "+++ INSTANCE +++\n",
271 | "Segmentation Quality IoU (sq): 0.7940127477906024 +- 0.11547745015679488\n",
272 | "Panoptic Quality IoU (pq): 0.6586696657808406\n",
273 | "Segmentation Quality Dsc (sq_dsc): 0.8802182546605446 +- 0.07728416427007166\n",
274 | "Panoptic Quality Dsc (pq_dsc): 0.7301810521615881\n",
275 | "Segmentation Quality ASSD (sq_assd): 0.20573710924944655 +- 0.13983482367660682\n",
276 | "Segmentation Quality Relative Volume Difference (sq_rvd): 0.01134021986061723 +- 0.1217805112447998\n",
277 | "\n"
278 | ]
279 | }
280 | ],
281 | "source": [
282 | "# print all results\n",
283 | "result = evaluator.evaluate(pred_masks, ref_masks, verbose=False)[\"ungrouped\"]\n",
284 | "print(result)"
285 | ]
286 | },
287 | {
288 | "cell_type": "code",
289 | "execution_count": 7,
290 | "metadata": {},
291 | "outputs": [
292 | {
293 | "data": {
294 | "text/html": [
295 | "result.pq=0.6586696657808406\n",
296 | "
\n"
297 | ],
298 | "text/plain": [
299 | "result.\u001b[33mpq\u001b[0m=\u001b[1;36m0\u001b[0m\u001b[1;36m.6586696657808406\u001b[0m\n"
300 | ]
301 | },
302 | "metadata": {},
303 | "output_type": "display_data"
304 | }
305 | ],
306 | "source": [
307 | "# get specific metric, e.g. pq\n",
308 | "pprint(f\"{result.pq=}\")"
309 | ]
310 | },
311 | {
312 | "cell_type": "code",
313 | "execution_count": 8,
314 | "metadata": {},
315 | "outputs": [
316 | {
317 | "data": {
318 | "text/html": [
319 | "results dict: \n",
320 | "{\n",
321 | " 'num_ref_instances': 87,\n",
322 | " 'num_pred_instances': 89,\n",
323 | " 'tp': 73,\n",
324 | " 'fp': 16,\n",
325 | " 'fn': 14,\n",
326 | " 'prec': 0.8202247191011236,\n",
327 | " 'rec': 0.8390804597701149,\n",
328 | " 'rq': 0.8295454545454546,\n",
329 | " 'sq': 0.7940127477906024,\n",
330 | " 'sq_std': 0.11547745015679488,\n",
331 | " 'pq': 0.6586696657808406,\n",
332 | " 'sq_dsc': 0.8802182546605446,\n",
333 | " 'sq_dsc_std': 0.07728416427007166,\n",
334 | " 'pq_dsc': 0.7301810521615881,\n",
335 | " 'sq_assd': 0.20573710924944655,\n",
336 | " 'sq_assd_std': 0.13983482367660682,\n",
337 | " 'sq_rvd': 0.01134021986061723,\n",
338 | " 'sq_rvd_std': 0.1217805112447998,\n",
339 | " 'global_bin_dsc': 0.9731641527805414\n",
340 | "}\n",
341 | "\n"
342 | ],
343 | "text/plain": [
344 | "results dict: \n",
345 | "\u001b[1m{\u001b[0m\n",
346 | " \u001b[32m'num_ref_instances'\u001b[0m: \u001b[1;36m87\u001b[0m,\n",
347 | " \u001b[32m'num_pred_instances'\u001b[0m: \u001b[1;36m89\u001b[0m,\n",
348 | " \u001b[32m'tp'\u001b[0m: \u001b[1;36m73\u001b[0m,\n",
349 | " \u001b[32m'fp'\u001b[0m: \u001b[1;36m16\u001b[0m,\n",
350 | " \u001b[32m'fn'\u001b[0m: \u001b[1;36m14\u001b[0m,\n",
351 | " \u001b[32m'prec'\u001b[0m: \u001b[1;36m0.8202247191011236\u001b[0m,\n",
352 | " \u001b[32m'rec'\u001b[0m: \u001b[1;36m0.8390804597701149\u001b[0m,\n",
353 | " \u001b[32m'rq'\u001b[0m: \u001b[1;36m0.8295454545454546\u001b[0m,\n",
354 | " \u001b[32m'sq'\u001b[0m: \u001b[1;36m0.7940127477906024\u001b[0m,\n",
355 | " \u001b[32m'sq_std'\u001b[0m: \u001b[1;36m0.11547745015679488\u001b[0m,\n",
356 | " \u001b[32m'pq'\u001b[0m: \u001b[1;36m0.6586696657808406\u001b[0m,\n",
357 | " \u001b[32m'sq_dsc'\u001b[0m: \u001b[1;36m0.8802182546605446\u001b[0m,\n",
358 | " \u001b[32m'sq_dsc_std'\u001b[0m: \u001b[1;36m0.07728416427007166\u001b[0m,\n",
359 | " \u001b[32m'pq_dsc'\u001b[0m: \u001b[1;36m0.7301810521615881\u001b[0m,\n",
360 | " \u001b[32m'sq_assd'\u001b[0m: \u001b[1;36m0.20573710924944655\u001b[0m,\n",
361 | " \u001b[32m'sq_assd_std'\u001b[0m: \u001b[1;36m0.13983482367660682\u001b[0m,\n",
362 | " \u001b[32m'sq_rvd'\u001b[0m: \u001b[1;36m0.01134021986061723\u001b[0m,\n",
363 | " \u001b[32m'sq_rvd_std'\u001b[0m: \u001b[1;36m0.1217805112447998\u001b[0m,\n",
364 | " \u001b[32m'global_bin_dsc'\u001b[0m: \u001b[1;36m0.9731641527805414\u001b[0m\n",
365 | "\u001b[1m}\u001b[0m\n"
366 | ]
367 | },
368 | "metadata": {},
369 | "output_type": "display_data"
370 | }
371 | ],
372 | "source": [
373 | "# get dict for further processing, e.g. for pandas\n",
374 | "pprint(\"results dict: \", result.to_dict())"
375 | ]
376 | },
377 | {
378 | "cell_type": "code",
379 | "execution_count": null,
380 | "metadata": {},
381 | "outputs": [
382 | {
383 | "name": "stdout",
384 | "output_type": "stream",
385 | "text": [
386 | "InputType.SEMANTIC\n",
387 | "Prediction array shape = (170, 512, 17) unique_values= [ 0 26 41 42 43 44 45 46 47 48 49 60 61 62 100]\n",
388 | "Reference array shape = (170, 512, 17) unique_values= [ 0 26 41 42 43 44 45 46 47 48 49 60 61 62 100]\n",
389 | "\n",
390 | "InputType.UNMATCHED_INSTANCE\n",
391 | "Prediction array shape = (170, 512, 17) unique_values= [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23\n",
392 | " 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47\n",
393 | " 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71\n",
394 | " 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89]\n",
395 | "Reference array shape = (170, 512, 17) unique_values= [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23\n",
396 | " 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47\n",
397 | " 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71\n",
398 | " 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87]\n",
399 | "\n",
400 | "InputType.MATCHED_INSTANCE\n",
401 | "Prediction array shape = (170, 512, 17) unique_values= [ 0 1 2 3 4 6 7 8 9 10 12 13 14 15 16 17 18 19\n",
402 | " 20 22 23 25 26 31 33 34 35 38 40 41 42 44 45 46 47 48\n",
403 | " 49 50 51 52 53 54 55 56 57 58 59 60 61 63 64 65 66 67\n",
404 | " 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85\n",
405 | " 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103]\n",
406 | "Reference array shape = (170, 512, 17) unique_values= [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23\n",
407 | " 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47\n",
408 | " 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71\n",
409 | " 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87]\n",
410 | "\n"
411 | ]
412 | }
413 | ],
414 | "source": [
415 | "# To inspect different phases, just use the returned intermediate_steps_data object\n",
416 | "\n",
417 | "import numpy as np\n",
418 | "\n",
419 | "intermediate_steps_data = result.intermediate_steps_data\n",
420 | "intermediate_steps_data.original_prediction_arr # yields input prediction array\n",
421 | "intermediate_steps_data.original_reference_arr # yields input reference array\n",
422 | "\n",
423 | "intermediate_steps_data.prediction_arr(\n",
424 | " InputType.MATCHED_INSTANCE\n",
425 | ") # yields prediction array after instances have been matched\n",
426 | "intermediate_steps_data.reference_arr(\n",
427 | " InputType.MATCHED_INSTANCE\n",
428 | ") # yields reference array after instances have been matched\n",
429 | "\n",
430 | "# This works with all InputType\n",
431 | "for i in InputType:\n",
432 | " print(i)\n",
433 | " pred = intermediate_steps_data.prediction_arr(i)\n",
434 | " ref = intermediate_steps_data.reference_arr(i)\n",
435 | " print(\"Prediction array shape =\", pred.shape, \"unique_values=\", np.unique(pred))\n",
436 | " print(\"Reference array shape =\", ref.shape, \"unique_values=\", np.unique(ref))\n",
437 | " print()"
438 | ]
439 | }
440 | ],
441 | "metadata": {
442 | "kernelspec": {
443 | "display_name": "Python 3 (ipykernel)",
444 | "language": "python",
445 | "name": "python3"
446 | },
447 | "language_info": {
448 | "codemirror_mode": {
449 | "name": "ipython",
450 | "version": 3
451 | },
452 | "file_extension": ".py",
453 | "mimetype": "text/x-python",
454 | "name": "python",
455 | "nbconvert_exporter": "python",
456 | "pygments_lexer": "ipython3",
457 | "version": "3.10.14"
458 | }
459 | },
460 | "nbformat": 4,
461 | "nbformat_minor": 2
462 | }
463 |
--------------------------------------------------------------------------------
/panoptica/example_spine_unmatched_instance.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Use Case: Unmatched Instances Input"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## Install Dependencies"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 10,
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "!pip install panoptica auxiliary rich numpy > /dev/null"
24 | ]
25 | },
26 | {
27 | "cell_type": "markdown",
28 | "metadata": {},
29 | "source": [
30 | "If you installed the packages and requirements on your own machine, you can skip this section and start from the import section.\n",
31 | "\n",
32 | "### Setup Colab environment (optional) \n",
33 | "Otherwise you can follow and execute the tutorial on your browser.\n",
34 | "In order to start working on the notebook, click on the following button, this will open this page in the Colab environment and you will be able to execute the code on your own (*Google account required*).\n",
35 | "\n",
36 | "\n",
37 | " \n",
38 | "\n",
39 | "\n",
40 | "Now that you are visualizing the notebook in Colab, run the next cell to install the packages we will use. There are few things you should follow in order to properly set the notebook up:\n",
41 | "1. Warning: This notebook was not authored by Google. Click on 'Run anyway'.\n",
42 | "1. When the installation commands are done, there might be \"Restart runtime\" button at the end of the output. Please, click it.\n",
43 | "If you run the next cell in a Google Colab environment, it will **clone the 'tutorials' repository** in your google drive. This will create a **new folder** called \"tutorials\" in **your Google Drive**.\n",
44 | "All generated file will be created/uploaded to your Google Drive respectively.\n",
45 | "\n",
46 | "After the first execution of the next cell, you might receive some warnings and notifications, please follow these instructions:\n",
47 | " - 'Permit this notebook to access your Google Drive files?' Click on 'Yes', and select your account.\n",
48 | " - Google Drive for desktop wants to access your Google Account. Click on 'Allow'.\n",
49 | "\n",
50 | "Afterwards the \"tutorials\" folder has been created. You can navigate it through the lefthand panel in Colab. You might also have received an email that informs you about the access on your Google Drive."
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 11,
56 | "metadata": {},
57 | "outputs": [],
58 | "source": [
59 | "import sys\n",
60 | "\n",
61 | "# Check if we are in google colab currently\n",
62 | "try:\n",
63 | " import google.colab\n",
64 | "\n",
65 | " colabFlag = True\n",
66 | "except ImportError as r:\n",
67 | " colabFlag = False\n",
68 | "\n",
69 | "# Execute certain steps only if we are in a colab environment\n",
70 | "if colabFlag:\n",
71 | " # Create a folder in your Google Drive\n",
72 | " from google.colab import drive\n",
73 | "\n",
74 | " drive.mount(\"/content/drive\")\n",
75 | " # clone repository and set path\n",
76 | " !git clone https://github.com/BrainLesion/tutorials.git /content/drive/MyDrive/tutorials\n",
77 | " BASE_PATH = \"/content/drive/MyDrive/tutorials/panoptica\"\n",
78 | " sys.path.insert(0, BASE_PATH)\n",
79 | "\n",
80 | "else: # normal jupyter notebook environment\n",
81 | " BASE_PATH = \".\" # current working directory would be BraTs-Toolkit anyways if you are not in colab"
82 | ]
83 | },
84 | {
85 | "cell_type": "markdown",
86 | "metadata": {},
87 | "source": [
88 | "## Setup Imports"
89 | ]
90 | },
91 | {
92 | "cell_type": "code",
93 | "execution_count": 12,
94 | "metadata": {},
95 | "outputs": [],
96 | "source": [
97 | "import numpy as np\n",
98 | "from auxiliary.nifti.io import read_nifti\n",
99 | "from rich import print as pprint\n",
100 | "from panoptica import NaiveThresholdMatching, Panoptica_Evaluator, InputType\n",
101 | "from panoptica.utils.segmentation_class import LabelGroup, SegmentationClassGroups"
102 | ]
103 | },
104 | {
105 | "cell_type": "markdown",
106 | "metadata": {},
107 | "source": [
108 | "## Load Example Data"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | "To demonstrate we use a reference and predicition of spine a segmentation with unmatched instances.\n",
116 | "\n",
117 | "\n",
118 | ""
119 | ]
120 | },
121 | {
122 | "cell_type": "code",
123 | "execution_count": 13,
124 | "metadata": {},
125 | "outputs": [
126 | {
127 | "data": {
128 | "text/plain": [
129 | "(array([ 0, 2, 3, 4, 5, 6, 7, 8, 26, 102, 103, 104, 105,\n",
130 | " 106, 107, 108, 202, 203, 204, 205, 206, 207, 208], dtype=uint8),\n",
131 | " array([ 0, 3, 4, 5, 6, 7, 8, 9, 26, 103, 104, 105, 106,\n",
132 | " 107, 108, 109, 203, 204, 205, 206, 207, 208, 209], dtype=uint8))"
133 | ]
134 | },
135 | "execution_count": 13,
136 | "metadata": {},
137 | "output_type": "execute_result"
138 | }
139 | ],
140 | "source": [
141 | "ref_masks = read_nifti(f\"{BASE_PATH}/spine_seg/unmatched_instance/ref.nii.gz\")\n",
142 | "pred_masks = read_nifti(f\"{BASE_PATH}/spine_seg/unmatched_instance/pred.nii.gz\")\n",
143 | "\n",
144 | "# labels are unmatching\n",
145 | "pred_masks[pred_masks == 27] = 26 # For later\n",
146 | "np.unique(ref_masks), np.unique(pred_masks)"
147 | ]
148 | },
149 | {
150 | "cell_type": "markdown",
151 | "metadata": {},
152 | "source": [
153 | "## Run Evaluation"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": 14,
159 | "metadata": {},
160 | "outputs": [],
161 | "source": [
162 | "# Define (optionally) semantic groups\n",
163 | "# This means that only instance within one group can be matched to each other\n",
164 | "segmentation_class_groups = SegmentationClassGroups(\n",
165 | " {\n",
166 | " \"vertebra\": LabelGroup(list(range(1, 11))),\n",
167 | " \"ivd\": LabelGroup(list(range(101, 111))),\n",
168 | " \"sacrum\": ([26], True),\n",
169 | " \"endplate\": LabelGroup(list(range(201, 211))),\n",
170 | " }\n",
171 | ")\n",
172 | "# In this case, the label 26 can only be matched with label 26 (thats why have to ensure above that 26 exists in both masks, otherwise they wouldn't be matched)\n",
173 | "\n",
174 | "evaluator = Panoptica_Evaluator(\n",
175 | " expected_input=InputType.UNMATCHED_INSTANCE,\n",
176 | " instance_matcher=NaiveThresholdMatching(),\n",
177 | " # If you want to use segmentation class groups, give it here as argument\n",
178 | " segmentation_class_groups=segmentation_class_groups,\n",
179 | ")"
180 | ]
181 | },
182 | {
183 | "cell_type": "markdown",
184 | "metadata": {},
185 | "source": [
186 | "## Inspect Results\n",
187 | "The results object allows access to individual metrics and provides helper methods for further processing"
188 | ]
189 | },
190 | {
191 | "cell_type": "code",
192 | "execution_count": null,
193 | "metadata": {},
194 | "outputs": [
195 | {
196 | "name": "stdout",
197 | "output_type": "stream",
198 | "text": [
199 | "\n",
200 | "### Group vertebra\n",
201 | "\n",
202 | "+++ MATCHING +++\n",
203 | "Number of instances in reference (num_ref_instances): 7\n",
204 | "Number of instances in prediction (num_pred_instances): 7\n",
205 | "True Positives (tp): 7\n",
206 | "False Positives (fp): 0\n",
207 | "False Negatives (fn): 0\n",
208 | "Recognition Quality / F1-Score (rq): 1.0\n",
209 | "\n",
210 | "+++ GLOBAL +++\n",
211 | "Global Binary Dice (global_bin_dsc): 0.9631786034883428\n",
212 | "\n",
213 | "+++ INSTANCE +++\n",
214 | "Segmentation Quality IoU (sq): 0.9259373047661901 +- 0.009654749671578153\n",
215 | "Panoptic Quality IoU (pq): 0.9259373047661901\n",
216 | "Segmentation Quality Dsc (sq_dsc): 0.9615183012231253 +- 0.005245540988039026\n",
217 | "Panoptic Quality Dsc (pq_dsc): 0.9615183012231253\n",
218 | "Segmentation Quality ASSD (sq_assd): 0.16832296646947947 +- 0.01828381629759957\n",
219 | "Segmentation Quality Relative Volume Difference (sq_rvd): -0.005930868093584259 +- 0.010871203881221219\n",
220 | "\n",
221 | "\n",
222 | "### Group ivd\n",
223 | "\n",
224 | "+++ MATCHING +++\n",
225 | "Number of instances in reference (num_ref_instances): 7\n",
226 | "Number of instances in prediction (num_pred_instances): 7\n",
227 | "True Positives (tp): 7\n",
228 | "False Positives (fp): 0\n",
229 | "False Negatives (fn): 0\n",
230 | "Recognition Quality / F1-Score (rq): 1.0\n",
231 | "\n",
232 | "+++ GLOBAL +++\n",
233 | "Global Binary Dice (global_bin_dsc): 0.9423566613429801\n",
234 | "\n",
235 | "+++ INSTANCE +++\n",
236 | "Segmentation Quality IoU (sq): 0.8897861147389462 +- 0.029181150423413706\n",
237 | "Panoptic Quality IoU (pq): 0.8897861147389462\n",
238 | "Segmentation Quality Dsc (sq_dsc): 0.9414254100052913 +- 0.016436031942319355\n",
239 | "Panoptic Quality Dsc (pq_dsc): 0.9414254100052913\n",
240 | "Segmentation Quality ASSD (sq_assd): 0.29013503272997326 +- 0.05544330133482135\n",
241 | "Segmentation Quality Relative Volume Difference (sq_rvd): 0.020603174193257762 +- 0.03071580120223084\n",
242 | "\n",
243 | "\n",
244 | "### Group sacrum\n",
245 | "\n",
246 | "+++ MATCHING +++\n",
247 | "Number of instances in reference (num_ref_instances): 1\n",
248 | "Number of instances in prediction (num_pred_instances): 1\n",
249 | "True Positives (tp): 1\n",
250 | "False Positives (fp): 0\n",
251 | "False Negatives (fn): 0\n",
252 | "Recognition Quality / F1-Score (rq): 1.0\n",
253 | "\n",
254 | "+++ GLOBAL +++\n",
255 | "Global Binary Dice (global_bin_dsc): 0.9698239455931553\n",
256 | "\n",
257 | "+++ INSTANCE +++\n",
258 | "Segmentation Quality IoU (sq): 0.941415733208399 +- 0.0\n",
259 | "Panoptic Quality IoU (pq): 0.941415733208399\n",
260 | "Segmentation Quality Dsc (sq_dsc): 0.9698239455931553 +- 0.0\n",
261 | "Panoptic Quality Dsc (pq_dsc): 0.9698239455931553\n",
262 | "Segmentation Quality ASSD (sq_assd): 0.20907172118556794 +- 0.0\n",
263 | "Segmentation Quality Relative Volume Difference (sq_rvd): -0.011061174622567414 +- 0.0\n",
264 | "\n",
265 | "\n",
266 | "### Group endplate\n",
267 | "\n",
268 | "+++ MATCHING +++\n",
269 | "Number of instances in reference (num_ref_instances): 7\n",
270 | "Number of instances in prediction (num_pred_instances): 7\n",
271 | "True Positives (tp): 4\n",
272 | "False Positives (fp): 3\n",
273 | "False Negatives (fn): 3\n",
274 | "Recognition Quality / F1-Score (rq): 0.5714285714285714\n",
275 | "\n",
276 | "+++ GLOBAL +++\n",
277 | "Global Binary Dice (global_bin_dsc): 0.6793787581594264\n",
278 | "\n",
279 | "+++ INSTANCE +++\n",
280 | "Segmentation Quality IoU (sq): 0.54301762284604 +- 0.01014458743300687\n",
281 | "Panoptic Quality IoU (pq): 0.31029578448345146\n",
282 | "Segmentation Quality Dsc (sq_dsc): 0.7037824449992637 +- 0.008529812661560601\n",
283 | "Panoptic Quality Dsc (pq_dsc): 0.40216139714243637\n",
284 | "Segmentation Quality ASSD (sq_assd): 0.33450703853088465 +- 0.010995297631511717\n",
285 | "Segmentation Quality Relative Volume Difference (sq_rvd): -0.009548043713894769 +- 0.05397632450411714\n",
286 | "\n"
287 | ]
288 | }
289 | ],
290 | "source": [
291 | "# print all results\n",
292 | "results = evaluator.evaluate(pred_masks, ref_masks, verbose=False)\n",
293 | "# The groups will have the names specified above\n",
294 | "for groupname, result in results.items():\n",
295 | " print()\n",
296 | " print(\"### Group\", groupname)\n",
297 | " print(result)"
298 | ]
299 | },
300 | {
301 | "cell_type": "code",
302 | "execution_count": null,
303 | "metadata": {},
304 | "outputs": [
305 | {
306 | "data": {
307 | "text/html": [
308 | "results['vertebra'][0].pq=0.9259373047661901\n",
309 | "
\n"
310 | ],
311 | "text/plain": [
312 | "results\u001b[1m[\u001b[0m\u001b[32m'vertebra'\u001b[0m\u001b[1m]\u001b[0m\u001b[1m[\u001b[0m\u001b[1;36m0\u001b[0m\u001b[1m]\u001b[0m.\u001b[33mpq\u001b[0m=\u001b[1;36m0\u001b[0m\u001b[1;36m.9259373047661901\u001b[0m\n"
313 | ]
314 | },
315 | "metadata": {},
316 | "output_type": "display_data"
317 | }
318 | ],
319 | "source": [
320 | "# get specific metric, e.g. pq\n",
321 | "# Now we need to specify group first\n",
322 | "pprint(f\"{results['vertebra'].pq=}\")"
323 | ]
324 | },
325 | {
326 | "cell_type": "code",
327 | "execution_count": null,
328 | "metadata": {},
329 | "outputs": [
330 | {
331 | "data": {
332 | "text/html": [
333 | "results dict: \n",
334 | "{\n",
335 | " 'num_ref_instances': 7,\n",
336 | " 'num_pred_instances': 7,\n",
337 | " 'tp': 7,\n",
338 | " 'fp': 0,\n",
339 | " 'fn': 0,\n",
340 | " 'prec': 1.0,\n",
341 | " 'rec': 1.0,\n",
342 | " 'rq': 1.0,\n",
343 | " 'sq': 0.9259373047661901,\n",
344 | " 'sq_std': 0.009654749671578153,\n",
345 | " 'pq': 0.9259373047661901,\n",
346 | " 'sq_dsc': 0.9615183012231253,\n",
347 | " 'sq_dsc_std': 0.005245540988039026,\n",
348 | " 'pq_dsc': 0.9615183012231253,\n",
349 | " 'sq_assd': 0.16832296646947947,\n",
350 | " 'sq_assd_std': 0.01828381629759957,\n",
351 | " 'sq_rvd': -0.005930868093584259,\n",
352 | " 'sq_rvd_std': 0.010871203881221219,\n",
353 | " 'global_bin_dsc': 0.9631786034883428\n",
354 | "}\n",
355 | "\n"
356 | ],
357 | "text/plain": [
358 | "results dict: \n",
359 | "\u001b[1m{\u001b[0m\n",
360 | " \u001b[32m'num_ref_instances'\u001b[0m: \u001b[1;36m7\u001b[0m,\n",
361 | " \u001b[32m'num_pred_instances'\u001b[0m: \u001b[1;36m7\u001b[0m,\n",
362 | " \u001b[32m'tp'\u001b[0m: \u001b[1;36m7\u001b[0m,\n",
363 | " \u001b[32m'fp'\u001b[0m: \u001b[1;36m0\u001b[0m,\n",
364 | " \u001b[32m'fn'\u001b[0m: \u001b[1;36m0\u001b[0m,\n",
365 | " \u001b[32m'prec'\u001b[0m: \u001b[1;36m1.0\u001b[0m,\n",
366 | " \u001b[32m'rec'\u001b[0m: \u001b[1;36m1.0\u001b[0m,\n",
367 | " \u001b[32m'rq'\u001b[0m: \u001b[1;36m1.0\u001b[0m,\n",
368 | " \u001b[32m'sq'\u001b[0m: \u001b[1;36m0.9259373047661901\u001b[0m,\n",
369 | " \u001b[32m'sq_std'\u001b[0m: \u001b[1;36m0.009654749671578153\u001b[0m,\n",
370 | " \u001b[32m'pq'\u001b[0m: \u001b[1;36m0.9259373047661901\u001b[0m,\n",
371 | " \u001b[32m'sq_dsc'\u001b[0m: \u001b[1;36m0.9615183012231253\u001b[0m,\n",
372 | " \u001b[32m'sq_dsc_std'\u001b[0m: \u001b[1;36m0.005245540988039026\u001b[0m,\n",
373 | " \u001b[32m'pq_dsc'\u001b[0m: \u001b[1;36m0.9615183012231253\u001b[0m,\n",
374 | " \u001b[32m'sq_assd'\u001b[0m: \u001b[1;36m0.16832296646947947\u001b[0m,\n",
375 | " \u001b[32m'sq_assd_std'\u001b[0m: \u001b[1;36m0.01828381629759957\u001b[0m,\n",
376 | " \u001b[32m'sq_rvd'\u001b[0m: \u001b[1;36m-0.005930868093584259\u001b[0m,\n",
377 | " \u001b[32m'sq_rvd_std'\u001b[0m: \u001b[1;36m0.010871203881221219\u001b[0m,\n",
378 | " \u001b[32m'global_bin_dsc'\u001b[0m: \u001b[1;36m0.9631786034883428\u001b[0m\n",
379 | "\u001b[1m}\u001b[0m\n"
380 | ]
381 | },
382 | "metadata": {},
383 | "output_type": "display_data"
384 | }
385 | ],
386 | "source": [
387 | "# get dict for further processing, e.g. for pandas\n",
388 | "pprint(\"results dict: \", results[\"vertebra\"].to_dict())"
389 | ]
390 | },
391 | {
392 | "cell_type": "code",
393 | "execution_count": null,
394 | "metadata": {},
395 | "outputs": [
396 | {
397 | "name": "stdout",
398 | "output_type": "stream",
399 | "text": [
400 | "\n",
401 | "### Group vertebra\n",
402 | "InputType.UNMATCHED_INSTANCE\n",
403 | "Prediction array shape = (164, 399, 17) unique_values= [0 3 4 5 6 7 8 9]\n",
404 | "Reference array shape = (164, 399, 17) unique_values= [0 2 3 4 5 6 7 8]\n",
405 | "\n",
406 | "InputType.MATCHED_INSTANCE\n",
407 | "Prediction array shape = (164, 399, 17) unique_values= [0 2 3 4 5 6 7 8]\n",
408 | "Reference array shape = (164, 399, 17) unique_values= [0 2 3 4 5 6 7 8]\n",
409 | "\n",
410 | "\n",
411 | "### Group ivd\n",
412 | "InputType.UNMATCHED_INSTANCE\n",
413 | "Prediction array shape = (96, 406, 17) unique_values= [ 0 103 104 105 106 107 108 109]\n",
414 | "Reference array shape = (96, 406, 17) unique_values= [ 0 102 103 104 105 106 107 108]\n",
415 | "\n",
416 | "InputType.MATCHED_INSTANCE\n",
417 | "Prediction array shape = (96, 406, 17) unique_values= [ 0 102 103 104 105 106 107 108]\n",
418 | "Reference array shape = (96, 406, 17) unique_values= [ 0 102 103 104 105 106 107 108]\n",
419 | "\n",
420 | "\n",
421 | "### Group sacrum\n",
422 | "InputType.UNMATCHED_INSTANCE\n",
423 | "key UNMATCHED_INSTANCE not in intermediate steps, maybe the step was skipped?\n",
424 | "InputType.MATCHED_INSTANCE\n",
425 | "Prediction array shape = (140, 128, 17) unique_values= [ 0 26]\n",
426 | "Reference array shape = (140, 128, 17) unique_values= [ 0 26]\n",
427 | "\n",
428 | "\n",
429 | "### Group endplate\n",
430 | "InputType.UNMATCHED_INSTANCE\n",
431 | "Prediction array shape = (85, 385, 17) unique_values= [ 0 203 204 205 206 207 208 209]\n",
432 | "Reference array shape = (85, 385, 17) unique_values= [ 0 202 203 204 205 206 207 208]\n",
433 | "\n",
434 | "InputType.MATCHED_INSTANCE\n",
435 | "Prediction array shape = (85, 385, 17) unique_values= [ 0 202 204 206 207 209 210 211]\n",
436 | "Reference array shape = (85, 385, 17) unique_values= [ 0 202 203 204 205 206 207 208]\n",
437 | "\n"
438 | ]
439 | }
440 | ],
441 | "source": [
442 | "# To inspect different phases, just use the returned intermediate_steps_data object\n",
443 | "\n",
444 | "import numpy as np\n",
445 | "\n",
446 | "for groupname, result in results.items():\n",
447 | " print()\n",
448 | " print(\"### Group\", groupname)\n",
449 | " intermediate_steps_data = result.intermediate_steps_data\n",
450 | " intermediate_steps_data.original_prediction_arr # yields input prediction array\n",
451 | " intermediate_steps_data.original_reference_arr # yields input reference array\n",
452 | "\n",
453 | " # This works with all phases\n",
454 | " for i in [InputType.UNMATCHED_INSTANCE, InputType.MATCHED_INSTANCE]:\n",
455 | " try:\n",
456 | " print(i)\n",
457 | " pred = intermediate_steps_data.prediction_arr(i)\n",
458 | " ref = intermediate_steps_data.reference_arr(i)\n",
459 | " print(\n",
460 | " \"Prediction array shape =\",\n",
461 | " pred.shape,\n",
462 | " \"unique_values=\",\n",
463 | " np.unique(pred),\n",
464 | " )\n",
465 | " print(\n",
466 | " \"Reference array shape =\", ref.shape, \"unique_values=\", np.unique(ref)\n",
467 | " )\n",
468 | " print()\n",
469 | " except AssertionError as e:\n",
470 | " print(e)\n",
471 | " # This happens because Sacrum class group was set to single_instance, hence the Matching phase is skipped and there is no intermediate result for UNMATCHED_INSTANCE"
472 | ]
473 | }
474 | ],
475 | "metadata": {
476 | "kernelspec": {
477 | "display_name": "seg11panoptdev",
478 | "language": "python",
479 | "name": "python3"
480 | },
481 | "language_info": {
482 | "codemirror_mode": {
483 | "name": "ipython",
484 | "version": 3
485 | },
486 | "file_extension": ".py",
487 | "mimetype": "text/x-python",
488 | "name": "python",
489 | "nbconvert_exporter": "python",
490 | "pygments_lexer": "ipython3",
491 | "version": "3.11.6"
492 | }
493 | },
494 | "nbformat": 4,
495 | "nbformat_minor": 2
496 | }
497 |
--------------------------------------------------------------------------------
/panoptica/figures/matched_instance.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/panoptica/figures/matched_instance.png
--------------------------------------------------------------------------------
/panoptica/figures/semantic.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/panoptica/figures/semantic.png
--------------------------------------------------------------------------------
/panoptica/figures/unmatched_instance.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/panoptica/figures/unmatched_instance.png
--------------------------------------------------------------------------------
/panoptica/spine_seg/matched_instance/pred.nii.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/panoptica/spine_seg/matched_instance/pred.nii.gz
--------------------------------------------------------------------------------
/panoptica/spine_seg/matched_instance/ref.nii.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/panoptica/spine_seg/matched_instance/ref.nii.gz
--------------------------------------------------------------------------------
/panoptica/spine_seg/semantic/pred.nii.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/panoptica/spine_seg/semantic/pred.nii.gz
--------------------------------------------------------------------------------
/panoptica/spine_seg/semantic/ref.nii.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/panoptica/spine_seg/semantic/ref.nii.gz
--------------------------------------------------------------------------------
/panoptica/spine_seg/unmatched_instance/pred.nii.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/panoptica/spine_seg/unmatched_instance/pred.nii.gz
--------------------------------------------------------------------------------
/panoptica/spine_seg/unmatched_instance/ref.nii.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/panoptica/spine_seg/unmatched_instance/ref.nii.gz
--------------------------------------------------------------------------------
/preprocessing/.gitignore:
--------------------------------------------------------------------------------
1 | output
2 | outputs
--------------------------------------------------------------------------------
/preprocessing/README.md:
--------------------------------------------------------------------------------
1 | # Preprocessing tutorials
2 | This folder contains tutorials for the [BrainLes preprocessing package](https://github.com/BrainLesion/preprocessing). Please have a look at the Jupyter notebooks.
3 |
--------------------------------------------------------------------------------
/preprocessing/data/TCGA-DU-7294/fla.nii.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/preprocessing/data/TCGA-DU-7294/fla.nii.gz
--------------------------------------------------------------------------------
/preprocessing/data/TCGA-DU-7294/t1.nii.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/preprocessing/data/TCGA-DU-7294/t1.nii.gz
--------------------------------------------------------------------------------
/preprocessing/data/TCGA-DU-7294/t1c.nii.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/preprocessing/data/TCGA-DU-7294/t1c.nii.gz
--------------------------------------------------------------------------------
/preprocessing/data/TCGA-DU-7294/t2.nii.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/BrainLesion/tutorials/a2d3fffe821e0dfd3bb62520985239324eaeda9a/preprocessing/data/TCGA-DU-7294/t2.nii.gz
--------------------------------------------------------------------------------
/preprocessing/utils.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 | from typing import List, Optional
3 | import matplotlib.pyplot as plt
4 | import nibabel as nib
5 |
6 |
7 | def visualize_data(files: List[Path], label: str, titles: Optional[List[str]] = None):
8 | """Visualize the MRI modalities
9 |
10 | Args:
11 | files (List[Path]): List of paths to the MRI modalities
12 | label (str): Label for the y-axis on the far left left, i.e. category of the passed images (e.g. input, output)
13 | titles (Optional[List[str]], optional): Title of images. Defaults to None.
14 | """
15 | _, axes = plt.subplots(1, len(files), figsize=(len(files) * 4, 10))
16 |
17 | for i, file in enumerate(files):
18 | modality_np = nib.load(file).get_fdata().transpose(2, 1, 0)
19 | axes[i].set_title(titles[i] if titles else file.name)
20 | axes[i].imshow(modality_np[modality_np.shape[0] // 2, :, :], cmap="gray")
21 | axes[0].set_ylabel(label)
22 |
23 |
24 | def visualize_defacing(
25 | file: Path,
26 | ):
27 | """Visualize the defacing of the MRI modality
28 |
29 | Args:
30 | file (Path): Path to the MRI modality
31 | """
32 |
33 | modality_np = nib.load(file).get_fdata().transpose(2, 1, 0)
34 | plt.figure(figsize=(4, 5))
35 | plt.title(file.name)
36 | plt.imshow(modality_np[:, ::-1, 75], cmap="gray", origin="lower")
37 |
--------------------------------------------------------------------------------
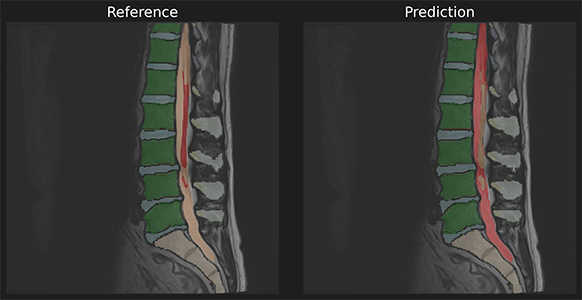 10 |
11 | `example_spine_semantic.ipynb`
12 |
13 | [](https://nbviewer.jupyter.org/github/BrainLesion/tutorials/blob/main/panoptica/example_spine_semantic.ipynb)
14 |
15 |
10 |
11 | `example_spine_semantic.ipynb`
12 |
13 | [](https://nbviewer.jupyter.org/github/BrainLesion/tutorials/blob/main/panoptica/example_spine_semantic.ipynb)
14 |
15 | 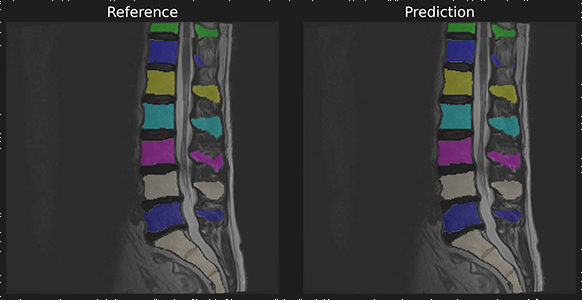 21 |
22 |
23 | `example_spine_matched_instance.ipynb`
24 |
25 | [](https://nbviewer.jupyter.org/github/BrainLesion/tutorials/blob/main/panoptica/example_spine_matched_instance.ipynb)
26 |
27 |
21 |
22 |
23 | `example_spine_matched_instance.ipynb`
24 |
25 | [](https://nbviewer.jupyter.org/github/BrainLesion/tutorials/blob/main/panoptica/example_spine_matched_instance.ipynb)
26 |
27 | 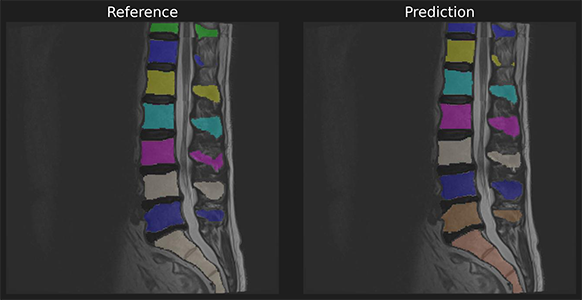 33 |
34 | `example_spine_unmatched_instance.ipynb`
35 |
36 | [](https://nbviewer.jupyter.org/github/BrainLesion/tutorials/blob/main/panoptica/example_spine_unmatched_instance.ipynb)
37 |
38 |
33 |
34 | `example_spine_unmatched_instance.ipynb`
35 |
36 | [](https://nbviewer.jupyter.org/github/BrainLesion/tutorials/blob/main/panoptica/example_spine_unmatched_instance.ipynb)
37 |
38 |