├── .gitignore
├── Dataset SQLite3 Example.ipynb
├── LICENSE
├── README.md
├── model_coverage.py
├── model_generator.py
├── model_guardrails.py
├── pretrain_bert.py
├── pretrain_coverage.py
├── requirements.txt
├── train_generator.py
├── train_summary_loop.py
├── utils_dataset.py
├── utils_logplot.py
├── utils_misc.py
└── utils_tokenizer.py
/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
--------------------------------------------------------------------------------
/Dataset SQLite3 Example.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# SQLite Creation"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "Example of creating a dataset that will be compatible with [Summary Loop](https://github.com/CannyLab/summary_loop) training scripts.\n",
15 | "\n",
16 | "Another option is to modify the [collate_fn](https://pytorch.org/docs/stable/data.html) of the scripts, to interface with another data format.\n"
17 | ]
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": null,
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "import sqlite3, os # This is a built in, no need to install\n",
26 | "\n",
27 | "example_dataset = [\n",
28 | " {\"title\": \"Example document1\", \"body\": \"The body of the very first document in the collection\"},\n",
29 | " {\"title\": \"Example document2\", \"body\": \"The body of the second document in the collection. You could put any data in here.\"},\n",
30 | "]"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": null,
36 | "metadata": {},
37 | "outputs": [],
38 | "source": [
39 | "db_file = \"/home/phillab/dataset/example_dataset.db\"\n",
40 | "\n",
41 | "if os.path.isfile(db_file):\n",
42 | " os.remove(db_file)\n",
43 | "\n",
44 | "conn = sqlite3.connect(db_file,detect_types=sqlite3.PARSE_DECLTYPES)\n",
45 | "conn.row_factory = sqlite3.Row\n",
46 | "c = conn.cursor()"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": null,
52 | "metadata": {},
53 | "outputs": [],
54 | "source": [
55 | "# CREATE TABLE\n",
56 | "\n",
57 | "sql_create = \"CREATE TABLE articles (id INTEGER PRIMARY KEY AUTOINCREMENT, title TEXT NOT NULL, body TEXT);\"\n",
58 | "c.execute(sql_create)\n",
59 | "conn.commit()"
60 | ]
61 | },
62 | {
63 | "cell_type": "code",
64 | "execution_count": null,
65 | "metadata": {},
66 | "outputs": [],
67 | "source": [
68 | "sql_insert = \"INSERT INTO articles (title, body) VALUES (?, ?)\"\n",
69 | "\n",
70 | "for a in example_dataset:\n",
71 | " c.execute(sql_insert, (a['title'], a['body']))\n",
72 | "conn.commit()"
73 | ]
74 | }
75 | ],
76 | "metadata": {
77 | "kernelspec": {
78 | "display_name": "Python 3",
79 | "language": "python",
80 | "name": "python3"
81 | },
82 | "language_info": {
83 | "codemirror_mode": {
84 | "name": "ipython",
85 | "version": 3
86 | },
87 | "file_extension": ".py",
88 | "mimetype": "text/x-python",
89 | "name": "python",
90 | "nbconvert_exporter": "python",
91 | "pygments_lexer": "ipython3",
92 | "version": "3.6.10"
93 | }
94 | },
95 | "nbformat": 4,
96 | "nbformat_minor": 2
97 | }
98 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Summary Loop
2 |
3 | This repository contains the code for ACL2020 paper: [The Summary Loop: Learning to Write Abstractive Summaries Without Examples](http://people.ischool.berkeley.edu/~hearst/papers/Laban_ACL2020_Abstractive_Summarization.pdf).
4 |
5 |
6 | 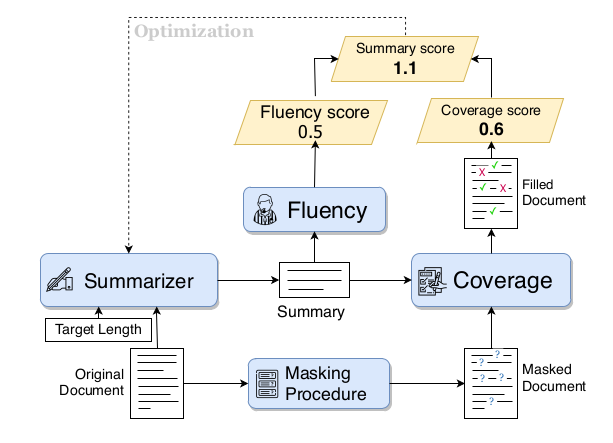 7 |
7 |
8 |
9 | ## Training Procedure
10 |
11 | We provide pre-trained models for each component needed in the [Summary Loop Release](https://github.com/CannyLab/summary_loop/releases/tag/v0.1):
12 |
13 | - `keyword_extractor.joblib`: An sklearn pipeline that will extract can be used to compute tf-idf scores of words according to the BERT vocabulary, which is used by the Masking Procedure,
14 | - `bert_coverage.bin`: A bert-base-uncased finetuned model on the task of Coverage for the news domain,
15 | - `fluency_news_bs32.bin`: A GPT2 (base) model finetuned on a large corpus of news articles, used as the Fluency model,
16 | - `gpt2_copier23.bin`: A GPT2 (base) model that can be used as an initial point for the Summarizer model.
17 |
18 | [In the release](https://github.com/CannyLab/summary_loop/releases/tag/v0.1), we also provide:
19 | - `pretrain_coverage.py` script to train a coverage model from scratch,
20 | - `train_generator.py` to train a fluency model from scratch (we recommend Fluency model on domain of summaries, such as news, legal, etc.)
21 |
22 | Once all the pretraining models are ready, training a summarizer can be done using the `train_summary_loop.py`:
23 | ```
24 | python train_summary_loop.py --experiment wikinews_test --dataset_file data/wikinews.db
25 | ```
26 |
27 | ## CNN/DM Test Set Model Generation
28 |
29 | We provide the 11,490 summaries produces by the Summary Loop models on the test portion of the CNN/Daily Mail dataset.
30 | The release is [available here](https://github.com/CannyLab/summary_loop/releases/tag/0.3). This is intended to facilitate comparison to future work, and analysis work, such as analysis of abstractiveness and factuality.
31 |
32 | ## Generator Model
33 |
34 | *[New January 2022]* The model card for Summary Loop 46 has been added to the HuggingFace model hub, working with the latest version of the HuggingFace library. See the model card here for usage: https://huggingface.co/philippelaban/summary_loop46
35 |
36 | The model can be loaded in the following way:
37 | ```
38 | from transformers import GPT2LMHeadModel, GPT2TokenizerFast
39 |
40 | model = GPT2LMHeadModel.from_pretrained("philippelaban/summary_loop46")
41 | tokenizer = GPT2TokenizerFast.from_pretrained("philippelaban/summary_loop46")
42 | ```
43 | Usage examples in the [model card](https://huggingface.co/philippelaban/summary_loop46).
44 |
45 | ## Scorer Models
46 |
47 | The Coverage and Fluency model and Guardrails scores can be used separately for analysis, evaluation, etc.
48 | They are respectively in `model_coverage.py` and `model_guardrails.py`, each model is implemented as a class with a `score(document, summary)` function.
49 | The Fluency model is a Language model, which is also the generator (in `model_generator.py`).
50 | Examples of how to run each model are included in the class files, at the bottom of the files.
51 |
52 | ## Bringing in your own data
53 |
54 | Want to test out the Summary Loop on a different language/type of text?
55 | A [Jupyter Notebook](https://github.com/CannyLab/summary_loop/blob/master/Dataset%20SQLite3%20Example.ipynb) can help you bring your own data into the SQLite format we use in the pre-training scripts. Otherwise you can modify the scripts' data loading (`DataLoader`) and collate function (`collate_fn`).
56 |
57 | ## Cite the work
58 |
59 | If you make use of the code, models, or algorithm, please cite our paper:
60 | ```
61 | @inproceedings{laban2020summary,
62 | title={The Summary Loop: Learning to Write Abstractive Summaries Without Examples},
63 | author={Laban, Philippe and Hsi, Andrew and Canny, John and Hearst, Marti A},
64 | booktitle={Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
65 | volume={1},
66 | year={2020}
67 | }
68 | ```
69 |
70 | ## Contributing
71 |
72 | If you'd like to contribute, or have questions or suggestions, you can contact us at phillab@berkeley.edu.
73 | All contributions welcome! For example, if you have a type of text data on which you want to apply the Summary Loop.
74 |
--------------------------------------------------------------------------------
/model_coverage.py:
--------------------------------------------------------------------------------
1 | from transformers.tokenization_bert import BertTokenizer
2 | from transformers.modeling_bert import BertForMaskedLM
3 | from torch.nn.modules.loss import CrossEntropyLoss
4 | import torch, os, time, tqdm, numpy as np, h5py
5 |
6 | from sklearn.feature_extraction.text import TfidfTransformer, CountVectorizer
7 | from sklearn.feature_extraction import DictVectorizer
8 | from sklearn.pipeline import Pipeline
9 | from collections import Counter
10 | import joblib
11 |
12 | class KeywordExtractor():
13 | def __init__(self, n_kws=15):
14 | self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
15 | self.n_kws = n_kws
16 |
17 | self.bert_w2i = {w: i for i, w in enumerate(self.tokenizer.vocab)}
18 | self.bert_vocab = self.tokenizer.vocab
19 | # self.dataset = h5py.File("/home/phillab/data/headliner_6M.hdf5")
20 | # self.dset = self.dataset['name']
21 | self.keyworder = None
22 | self.i2w = None
23 | # self.cache = {}
24 | # self.cache_keys = []
25 |
26 | def train(self):
27 | stop_words = ["'", ".", "!", "?", ",", '"', '-', 'i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
28 | stop_indices = set([bert_w2i[w] for w in stop_words if w in bert_w2i])
29 | dv = DictVectorizer()
30 | tt = TfidfTransformer()
31 | self.keyworder = Pipeline([('counter', dv), ('tfidf', tt)])
32 |
33 | def remove_stop_words(tokenized):
34 | return [w for w in tokenized if w not in stop_indices]
35 |
36 | N = 100000
37 | text_inputs = [self.tokenizer.encode(dset[i][0].decode()) for i in tqdm.tqdm_notebook(range(N))] # Tokenize
38 | text_inputs = [remove_stop_words(text) for text in text_inputs] # Remove stop words
39 |
40 | text_inputs = [Counter(text) for text in text_inputs] # Make a Count dictionary
41 | training_output = self.keyworder.fit_transform(text_inputs)
42 |
43 | def save(self, outfile):
44 | joblib.dump(self.keyworder, outfile)
45 |
46 | def reload(self, infile):
47 | self.keyworder = joblib.load(infile)
48 | self.counter = self.keyworder.named_steps['counter']
49 | self.i2w = {i:w for w,i in self.counter.vocabulary_.items()}
50 |
51 | def extract_keywords(self, unmasked):
52 | # if text in self.cache:
53 | # return self.cache[text]
54 |
55 | # unmasked = self.tokenizer.encode(text)
56 | tfidf = self.keyworder.transform([Counter(unmasked)])
57 | kws = np.argsort(tfidf.toarray()[0])[::-1][:self.n_kws]
58 | kws_is = [self.i2w[kw] for kw in kws]
59 | kws_texts = [self.tokenizer.ids_to_tokens[kwi] for kwi in kws_is]
60 | # print(kws_is, kws_texts)
61 | outputs = (kws_is, kws_texts)
62 |
63 | # if len(self.cache) > 1000:
64 | # del self.cache[self.cache_keys.pop(0)]
65 | # self.cache[text] = outputs
66 | # self.cache_keys.append(text)
67 | return outputs
68 |
69 | class KeywordCoverage():
70 | def __init__(self, device, keyword_model_file, model_file=None, n_kws=15):
71 | self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
72 | self.vocab_size = self.tokenizer.vocab_size
73 | self.n_kws = n_kws
74 |
75 | self.mask_id = 103
76 | self.sep_id = 102
77 |
78 | self.kw_ex = KeywordExtractor(n_kws=self.n_kws)
79 | self.kw_ex.reload(keyword_model_file)
80 | self.model = BertForMaskedLM.from_pretrained("bert-base-uncased")
81 | self.device = device
82 | self.model.to(self.device)
83 | if model_file is not None:
84 | self.reload_model(model_file)
85 |
86 | def mask_text(self, text_tokenized):
87 | kws_is, kws_texts = self.kw_ex.extract_keywords(text_tokenized)
88 | kws_is = set(kws_is)
89 | # unmasked = self.tokenizer.encode(text)
90 | masked = [self.mask_id if wi in kws_is else wi for wi in text_tokenized]
91 | return masked
92 |
93 | def reload_model(self, model_file):
94 | print(self.model.load_state_dict(torch.load(model_file), strict=False))
95 |
96 | def save_model(self, model_file):
97 | torch.save(self.model.state_dict(), model_file)
98 |
99 | def build_io(self, contents_tokenized, summaries):
100 | N = len(contents_tokenized)
101 | maskeds, unmaskeds = [], []
102 | summ_toks = []
103 | T1 = time.time()
104 | for content_tokenized, summary in zip(contents_tokenized, summaries):
105 | masked = self.mask_text(content_tokenized) # .decode()
106 | maskeds.append(torch.LongTensor(masked))
107 | unmaskeds.append(torch.LongTensor(content_tokenized))
108 | summ_toks.append(torch.LongTensor(self.tokenizer.encode(summary))) # .decode()
109 | T2 = time.time()
110 | input_ids = torch.nn.utils.rnn.pad_sequence(maskeds, batch_first=True, padding_value=0)
111 | labels = torch.nn.utils.rnn.pad_sequence(unmaskeds, batch_first=True, padding_value=0)
112 | input_ids = input_ids[:, :300]
113 | labels = labels[:, :300]
114 |
115 | summ_toks = torch.nn.utils.rnn.pad_sequence(summ_toks, batch_first=True, padding_value=0)
116 | summ_toks = summ_toks[:, :100]
117 | T3 = time.time()
118 | seps = torch.LongTensor([self.sep_id] * N).unsqueeze(1)
119 | input_ids = torch.cat((summ_toks, seps, input_ids), dim=1)
120 | labels = torch.cat((summ_toks, seps, labels), dim=1)
121 | is_masked = input_ids.eq(torch.LongTensor([self.mask_id])).long()
122 |
123 | # Make the labels classifier friendly
124 | labels = labels * is_masked + (1-is_masked) * torch.LongTensor([-1])
125 |
126 | T4 = time.time()
127 | # print(T2-T1, T3-T2, T4-T3)
128 | labels = labels.to(self.device)
129 | input_ids = input_ids.to(self.device)
130 | is_masked = is_masked.to(self.device)
131 |
132 | return input_ids, is_masked, labels
133 | def train_batch(self, contents, summaries):
134 | contents_tokenized = [self.tokenizer.encode(cont) for cont in contents]
135 |
136 | input_ids, is_masked, labels = self.build_io(contents_tokenized, summaries)
137 |
138 | outputs, = self.model(input_ids)
139 | cross_ent = CrossEntropyLoss(ignore_index=-1)
140 | loss = cross_ent(outputs.view(-1, self.vocab_size), labels.view(-1))
141 |
142 | num_masks = torch.sum(is_masked, dim=1).float() + 0.1
143 | with torch.no_grad():
144 | preds = torch.argmax(outputs, dim=2)
145 | accs = torch.sum(preds.eq(labels).long() * is_masked, dim=1).float() / num_masks
146 | return loss, accs.mean().item()
147 |
148 | def score(self, summaries, contents, bodies_tokenized, lengths=None, extra=None):
149 | contents_tokenized = bodies_tokenized
150 | # self.model.eval()
151 | with torch.no_grad():
152 | input_ids_w, is_masked_w, labels_w = self.build_io(contents_tokenized, summaries)
153 | outputs_w, = self.model(input_ids_w)
154 | preds_w = torch.argmax(outputs_w, dim=2)
155 | num_masks_w = torch.sum(is_masked_w, dim=1).float() + 0.1
156 | accs_w = torch.sum(preds_w.eq(labels_w).long() * is_masked_w, dim=1).float() / num_masks_w
157 |
158 | if extra is not None:
159 | accs_wo = extra # We're in the argmax, and this has already been computed in the sampled
160 | else:
161 | input_ids_wo, is_masked_wo, labels_wo = self.build_io(contents_tokenized, [""] * len(contents_tokenized))
162 | outputs_wo, = self.model(input_ids_wo)
163 | preds_wo = torch.argmax(outputs_wo, dim=2)
164 | num_masks_wo = torch.sum(is_masked_wo, dim=1).float() + 0.1
165 | accs_wo = torch.sum(preds_wo.eq(labels_wo).long() * is_masked_wo, dim=1).float() / num_masks_wo
166 | score = accs_w - accs_wo
167 | return score.tolist(), accs_wo
168 |
169 | if __name__ == "__main__":
170 | import utils_tokenizer
171 |
172 | # contents = ["Rowan Williams and Simon Russell Beale: Shakespeare - Spiritual, Secular or Both? [17] Was Shakespeare a secret Catholic in an age of recusansy laws? Or a steadfast Anglican? And what cryptic clues do his plays provide? The Archbishop of Canterbury examines the Bard's relationship with religion. Oxfam Stage, PS5 Gareth Malone: Music for the People [18] Having made choral music cool with kids - sort of - as the beaming maestro in BAFTA-winning BBC series The Choir, Malone now directs his seemingly limitless enthusiasm to the broader classical genre. 5.15pm Ofxam Stage, PS5 Sir Colin Humphreys: Cambridge Series 1: The Mystery of The Last Supper [21] The distinguished physicist turned biblical historian explains the primary revelation of his latest book: that the Last Supper took place on Holy Wednesday, not Maundy Thursday. All down to calendaring, apparently. 5.15pm Llwyfan Cymru - Wales Stage, PS5 Rachel Campbell-Johnston: Mysterious Wisdom [22] From fertile Kent gardens to the pastoral elegance of the Campania countryside, Samuel Palmer was a master of lanscape painting. Rachel Campbell-Johnston discusses her new book on the lynchpin of British Romanticism. 6.30pm Elmley Foundation Theatre, PS5 Anthony Sattin: Lifting the Veil [27] While the UK population's mini-break plans to Egypt may be shelved for the forseeale future, this hasn't dettered Anthony Sattin's infatuation. He traces two centuries of kindred spirits drawn to the beguiling mores of the Land of the Pharoahs. 7.45pm Llwyfan Cymru - Wales Stage, PS5 Simon Mitton - Cambridge Series 3: From Alexandria to Cambridge [29] The secrets of life, the universe and everything have been written in the stars since time began. Astrophysicist and academic Simon Mitton believes they are now more readily available - in books. Here he explores five key works, from Copernicus to Newton. 9.30pm Oxfam Stage, PS8 Jason Byrne: Cirque du Byrne"]
173 | contents = ["To the chagrin of New York antiques dealers, lawmakers in Albany have voted to outlaw the sale of virtually all items containing more than small amounts of elephant ivory, mammoth ivory or rhinoceros horn. The legislation, which is backed by Gov. Andrew M. Cuomo, will essentially eliminate New York's central role in a well-established, nationwide trade with an estimated annual value of $500 million. Lawmakers say the prohibitions are needed to curtail the slaughter of endangered African elephants and rhinos, which they say is fueled by a global black market in poached ivory, some of which has turned up in New York. The illegal ivory trade has no place in New York State, and we will not stand for individuals who violate the law by supporting it,\" Mr. Cuomo said in a statement on Tuesday, during the debate on the bill. The bill was approved by the Assembly on Thursday, 97 to 2, and passed the Senate, 43 to 17, on Friday morning. Mr. Cuomo is expected to sign it within a week. Assemblyman Robert K. Sweeney, Democrat of Lindenhurst, a sponsor, said that the law \"recognizes the significant impact our state can have on clamping down on illegal ivory sales\" and that it would help rescue elephants from \"ruthless poaching operations run by terrorists and organized crime.\" Dealers and collectors who trade in ivory antiques owned long before the era of mass poaching say the restrictions, which are stiffer than similar federal rules announced in May, will hurt legitimate sellers but do little to protect endangered animals. The real threat to elephants and rhinos, they say, comes from the enormous illicit market in tusks and horns based in China and other Asian nations. \"It is masterful self-deception to think the elephant can be saved by banning ivory in New"]
174 | summaries = [""]
175 |
176 | models_folder = "/home/phillab/models/"
177 | model_file = os.path.join(models_folder, "bert_coverage_cnndm_lr4e5_0.bin")
178 | # model_file = os.path.join(models_folder, "bert_coverage_cnndm_bs64_0.bin")
179 | kw_cov = KeywordCoverage("cuda", model_file=model_file, keyword_model_file=os.path.join(models_folder, "keyword_extractor.joblib"))
180 | bert_tokenizer = utils_tokenizer.BERTCacheTokenizer()
181 |
182 | contents_tokenized = [bert_tokenizer.encode(body) for body in contents]
183 | scores, no_summ_acc = kw_cov.score(summaries, contents, contents_tokenized)
184 |
185 | for body, score, ns_score in zip(contents, scores, no_summ_acc):
186 | print("----------------")
187 | print("----------------")
188 | print("----------------")
189 | print(body)
190 | print("---")
191 | print(score)
192 | print("---")
193 | print(ns_score)
194 |
--------------------------------------------------------------------------------
/model_generator.py:
--------------------------------------------------------------------------------
1 | from transformers import GPT2LMHeadModel, GPT2Config
2 |
3 | import torch.utils.data.dataset
4 | import utils_tokenizer
5 | import torch, tqdm
6 |
7 | def pad(data, padval=0):
8 | return torch.nn.utils.rnn.pad_sequence(data, batch_first=True, padding_value=padval)
9 |
10 | class GeneTransformer:
11 | def __init__(self, max_output_length=25, max_input_length=300, device='cpu', tokenizer_type='gpt2', bpe_model="", starter_model=None):
12 | if tokenizer_type == "gpt2":
13 | self.tokenizer = utils_tokenizer.GPT2Tokenizer()
14 | config = GPT2Config.from_pretrained("gpt2")
15 |
16 | elif tokenizer_type == "bpecap":
17 | self.tokenizer = utils_tokenizer.BPETokenizer(bpe_model)
18 | config = GPT2Config.from_dict({"finetuning_task": None, "initializer_range": 0.02,
19 | "layer_norm_epsilon": 1e-05, "n_ctx": 1024, "n_embd": 768, "n_head": 12, "n_layer": 12, "n_positions": 1024, "num_labels": 1,
20 | "resid_pdrop": 0.1, "use_bfloat16": False, "vocab_size": self.tokenizer.vocab_size})
21 | else:
22 | print("Tokenizer unrecognized. Should be gpt2 or bpecap.")
23 | exit()
24 |
25 | self.model = GPT2LMHeadModel(config)
26 |
27 | self.model.to(device)
28 | self.device = device
29 | if starter_model is not None:
30 | self.reload(starter_model)
31 |
32 | self.max_output_length = max_output_length
33 | self.max_input_length = max_input_length
34 |
35 | self.model.train()
36 | self.mode = "train"
37 |
38 | def reload(self, from_file):
39 | print(self.model.load_state_dict(torch.load(from_file), strict=False))
40 |
41 | def save(self, to_file):
42 | torch.save(self.model.state_dict(), to_file)
43 |
44 | def preprocess_input(self, bodies, special_append=None):
45 | if special_append is None:
46 | special_append = [[] for i in range(len(bodies))]
47 | inputs = [torch.LongTensor(spe+self.tokenizer.encode(body)) for body, spe in zip(bodies, special_append)]
48 | inputs = pad(inputs, padval=0)
49 | inputs = inputs[:, :self.max_input_length].to(self.device)
50 | return inputs
51 |
52 | def preprocess_batch(self, bodies, summaries, special_append=None):
53 | inputs = self.preprocess_input(bodies, special_append)
54 |
55 | # Big hack
56 | if special_append is None:
57 | special_append = [[] for i in range(len(bodies))]
58 |
59 | summaries = [spe+self.tokenizer.encode(summ) for summ, spe in zip(summaries, special_append)]
60 |
61 | summaries = [summ[:(self.max_output_length-1)] for summ in summaries] # We cut short, but we want the end token at the end
62 |
63 | summ_inp = pad([torch.LongTensor([self.tokenizer.start_id]+summ) for summ in summaries], padval=0).to(self.device)
64 | summ_out = pad([torch.LongTensor(summ+[self.tokenizer.end_id]) for summ in summaries], padval=-1).to(self.device)
65 | # summ_inp = summ_inp[:, :self.max_output_length].to(self.device)
66 | # summ_out = summ_out[:, :self.max_output_length].to(self.device)
67 | return inputs, summ_inp, summ_out
68 |
69 | def train_batch(self, bodies, summaries, special_append=None, no_preinput=False):
70 | # if self.mode != 'train':
71 | # print("BEWARE. Model is not in train mode.")
72 |
73 | inputs, summ_inp, summ_out = self.preprocess_batch(bodies, summaries, special_append)
74 | past = None
75 | if not no_preinput:
76 | _, past = self.model(input_ids=inputs, past_key_values=None)
77 | logits, _ = self.model(input_ids=summ_inp, past_key_values=past)
78 | crit = torch.nn.CrossEntropyLoss(ignore_index=-1)
79 | loss = crit(logits.view(-1, self.tokenizer.vocab_size), summ_out.contiguous().view(-1))
80 | return loss
81 |
82 | def train(self):
83 | self.model.train()
84 | self.mode = 'train'
85 |
86 | def eval(self):
87 | self.model.eval()
88 | self.mode = 'eval'
89 |
90 | def decode_batch(self, bodies, special_append=None, max_output_length=100, sample=False, return_scores=False, return_logprobs=False, input_past=None):
91 | N = len(bodies)
92 | current = torch.LongTensor([self.tokenizer.start_id] * N).to(self.device).unsqueeze(1)
93 | build_up = None
94 | scores = torch.zeros((N)).to(self.device)
95 | total_logprobs = []
96 |
97 | # Sometimes, we process the same input, as we run it once as a sampled, and once as an argmax, in which case we should reuse the computation
98 | if input_past is None:
99 | inputs = self.preprocess_input(bodies, special_append)
100 | _, input_past = self.model(input_ids=inputs, past_key_values=None)
101 |
102 | past = input_past
103 | while build_up is None or (build_up.shape[1] < max_output_length and not all([self.tokenizer.end_id in build for build in build_up])):
104 | logits, past = self.model(input_ids=current, past_key_values=past)
105 | probs = torch.nn.functional.softmax(logits, dim=2).squeeze(1)
106 | logprobs = torch.nn.functional.log_softmax(logits, dim=2)
107 | if sample:
108 | current = torch.multinomial(probs, 1)
109 | else:
110 | current = torch.argmax(logprobs, dim=2)
111 |
112 | if build_up is None:
113 | build_up = current
114 | else:
115 | build_up = torch.cat((build_up, current), dim=1)
116 |
117 | if return_logprobs:
118 | selected_logprobs = logprobs[torch.arange(N), 0, current.squeeze()].unsqueeze(1)
119 | total_logprobs.append(selected_logprobs)
120 |
121 | not_finished = (1-torch.any(build_up ==self.tokenizer.end_id, dim=1).float()).to(self.device)
122 | scores += not_finished * logprobs[torch.arange(N), :, current.squeeze(1)].squeeze()
123 |
124 | end_id = self.tokenizer.end_id
125 | build_up = [build.tolist() for build in build_up]
126 | end_indices = [max_output_length+1 if end_id not in build else build.index(end_id) for build in build_up]
127 | outputs = [self.tokenizer.decode(build)+"END" for build in build_up]
128 | outputs = [S[:S.index("END")] for S in outputs]
129 |
130 | if return_logprobs:
131 | return outputs, torch.cat(total_logprobs, dim=1), build_up, input_past, end_indices
132 | elif return_scores:
133 | return outputs, scores.tolist()
134 | else:
135 | return outputs
136 |
137 | def decode_beam_batch(self, bodies, beam_size=3, max_output_length=100, sample=False):
138 | if self.mode != 'eval':
139 | print("BEWARE. Model is not in eval mode.")
140 | self.eval() # << Surely you are not training with beam decode?
141 |
142 | batch_size = len(bodies)
143 | N = batch_size * beam_size
144 | inputs = self.preprocess_input(bodies)
145 | next_words = torch.LongTensor([self.tokenizer.start_id] * N).to(self.device).unsqueeze(1)
146 | build_up = None
147 | scores = torch.zeros((N)).to(self.device)
148 |
149 | one_every_k = torch.FloatTensor([1] + [0] * (beam_size-1)).repeat(batch_size*beam_size).to(self.device)
150 |
151 | # Sometimes, we process the same input, as we run it once as a sampled, and once as an argmax, in which case we should reuse the computation
152 | _, input_past = self.model(input_ids=inputs, past_key_values=None)
153 | input_past = [torch.repeat_interleave(p, repeats=beam_size, dim=1) for p in input_past]
154 |
155 | past = input_past
156 | while build_up is None or (build_up.shape[1] < max_output_length and not all([self.tokenizer.end_id in build for build in build_up])):
157 | logits, past = self.model(input_ids=next_words, past_key_values=past)
158 | probs = torch.nn.functional.softmax(logits, dim=2).squeeze(1)
159 | logprobs = torch.nn.functional.log_softmax(logits, dim=2)
160 |
161 | if sample:
162 | all_selects = torch.multinomial(probs, beam_size).unsqueeze(1)
163 | else:
164 | _, all_selects = torch.topk(logprobs, k=beam_size, dim=2)
165 |
166 | if build_up is not None:
167 | not_finished = (1-torch.any(build_up==self.tokenizer.end_id, dim=1).float()).to(self.device)
168 | else:
169 | not_finished = torch.ones_like(scores, dtype=torch.float, device=self.device)
170 |
171 | expanded_not_finished = torch.repeat_interleave(not_finished, repeats=beam_size)
172 |
173 | expanded_score = torch.repeat_interleave(scores, repeats=beam_size) # This should be batch_size * beam_size²
174 | added_score = logprobs[torch.repeat_interleave(torch.arange(N), repeats=beam_size), 0, all_selects.view(-1)]
175 | expanded_score += (expanded_not_finished*added_score)
176 |
177 | # We don't want you to select from finished beams
178 | expanded_score -= (1-expanded_not_finished)*(1-one_every_k)*1000.0
179 |
180 | batched_scores = expanded_score.view(batch_size, -1)
181 |
182 | if build_up is None:
183 | choices = torch.arange(beam_size, device=self.device).repeat(batch_size)
184 | batched_choices = choices.view(batch_size, beam_size)
185 |
186 | else:
187 | _, batched_choices = torch.topk(batched_scores, k=beam_size, dim=1) # Going from k² choices per element to k choices.
188 |
189 | batched_tracks = (batched_choices / beam_size).long()
190 | tracks = beam_size*torch.repeat_interleave(torch.arange(batch_size), repeats=beam_size).to(self.device) + batched_tracks.view(-1)
191 |
192 | selected_scores = batched_scores[torch.repeat_interleave(torch.arange(batch_size), repeats=beam_size), batched_choices.view(-1)]
193 |
194 | # Figure out the kept words to be added to the build-up
195 | per_batch_selects = all_selects.view(batch_size, -1)
196 | next_words = per_batch_selects[torch.repeat_interleave(torch.arange(batch_size), repeats=beam_size), batched_choices.view(-1)]
197 | next_words = next_words.unsqueeze(1)
198 |
199 | # [BOOKKEEPING] Going from k² to k options at each time means we have to swap all the caches around: past, build-up
200 | if build_up is not None:
201 | build_up = build_up[tracks, :]
202 | past = [p[:, tracks, :] for p in past]
203 |
204 | # Update the latest scores, and the current_build
205 | if build_up is None:
206 | build_up = next_words
207 | else:
208 | build_up = torch.cat((build_up, next_words), dim=1)
209 | scores = selected_scores.view(-1)
210 |
211 | batched_build_up = build_up.view(batch_size, beam_size, -1)
212 | batched_scores = scores.view(batch_size, -1)
213 | # torch.cuda.empty_cache()
214 |
215 | outputs = []
216 | for beams in batched_build_up:
217 | out_beams = [self.tokenizer.decode(beam.tolist())+"END" for beam in beams]
218 | out_beams = [S[:S.index("END")] for S in out_beams]
219 | outputs.append(out_beams)
220 |
221 | return outputs, batched_scores.tolist()
222 |
223 | def decode(self, bodies, max_output_length=100, max_batch_size=8, beam_size=1, return_scores=False, sample=False, progress=False):
224 | N = len(bodies)
225 | outputs = []
226 | scores = []
227 | iterator = range(0, N, max_batch_size)
228 | if progress:
229 | iterator = tqdm.tqdm(iterator)
230 | for i in iterator:
231 | batch_bodies = bodies[i:min(N, i+max_batch_size)]
232 | with torch.no_grad():
233 | if beam_size > 1:
234 | batch_outputs = self.decode_beam_batch(batch_bodies, beam_size=beam_size, max_output_length=max_output_length, sample=sample)
235 | else:
236 | batch_outputs = self.decode_batch(batch_bodies, max_output_length=max_output_length, sample=sample, return_scores=return_scores)
237 | if return_scores:
238 | batch_outputs, batch_scores = batch_outputs
239 | scores.extend(batch_scores)
240 | outputs.extend(batch_outputs)
241 |
242 | if return_scores:
243 | return outputs, scores
244 | else:
245 | return outputs
246 |
247 | def score(self, summaries, bodies, bodies_tokenized=None, lengths=None, extra=None):
248 | # Unconditional rating of the summaries
249 | self.model.eval()
250 | # if self.mode != 'eval':
251 | # print("BEWARE. Model is not in eval mode.")
252 |
253 | inputs, summ_inp, summ_out = self.preprocess_batch(bodies, summaries)
254 | summ_out = summ_out.contiguous()
255 |
256 | with torch.no_grad():
257 | logits, _ = self.model(input_ids=summ_inp, past_key_values=None)
258 |
259 | crit = torch.nn.CrossEntropyLoss(ignore_index=-1, reduction='none')
260 | loss = crit(logits.view(-1, self.tokenizer.vocab_size), summ_out.view(-1)).view(summ_out.shape)
261 | mask = (summ_inp != torch.LongTensor([0]).to(self.device)).float()
262 | non_pad_count = torch.sum(mask, dim=1)
263 | loss_per = torch.sum(loss, dim=1) / non_pad_count
264 |
265 | score = (10.0 - loss_per) / 10.0
266 | return score.tolist(), None
267 |
268 | def score_pairs(self, bodies, summaries):
269 | if self.mode != 'eval':
270 | print("BEWARE. Model is not in eval mode.")
271 |
272 | inputs, summ_inp, summ_out = self.preprocess_batch(bodies, summaries)
273 |
274 | with torch.no_grad():
275 | _, past = self.model(input_ids=inputs, past_key_values=None)
276 | logits, _ = self.model(input_ids=summ_inp, past_key_values=past)
277 |
278 | crit = torch.nn.CrossEntropyLoss(ignore_index=-1, reduction='none')
279 | loss = crit(logits.view(-1, self.tokenizer.vocab_size), summ_out.view(-1)).view(summ_out.shape)
280 | mask = (summ_inp != torch.LongTensor([0]).to(self.device)).float()
281 | non_pad_count = torch.sum(mask, dim=1)
282 | loss_per = torch.sum(loss, dim=1) / non_pad_count
283 |
284 | return loss_per.tolist()
285 |
--------------------------------------------------------------------------------
/model_guardrails.py:
--------------------------------------------------------------------------------
1 | from transformers.modeling_bert import BertForNextSentencePrediction
2 | from transformers.tokenization_bert import BertTokenizer
3 | from torch.utils.data import DataLoader, RandomSampler, TensorDataset
4 | from torch.nn.modules.loss import CrossEntropyLoss
5 | import torch, os, sys, nltk, tqdm, time, math
6 | from transformers.optimization import AdamW
7 | from utils_logplot import LogPlot
8 | from collections import Counter
9 |
10 | STOP_WORDS = set(["'", ".", "!", "?", ",", '"', '-', 'we', 'our', 'you', 'he', 'him', 'she', 'her', 'it', "it's", 'its', 'they', 'their', 'this', 'that', 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'have', 'has', 'had', 'do', 'does', 'did', 'a', 'an', 'the', 'and', 'or', 'as', 'of', 'at', 'by', 'to', 'not', 'so', "'s", "in", "for", "with", "on"])
11 |
12 | class PatternPenalty:
13 | # Depending on how many words are used a large fraction of the last X summaries
14 | def __init__(self, history_length=30):
15 | self.stop_words = STOP_WORDS
16 | self.history_words = []
17 | self.ngram_history = []
18 | self.history_length = history_length
19 |
20 | def score(self, summaries, bodies, bodies_tokenized=None, lengths=None, extra=None):
21 | batch_words = []
22 | batch_ngrams = []
23 | for summary in summaries:
24 | words = nltk.tokenize.word_tokenize(summary.lower())
25 | gram = 2
26 | n_grams = [tuple(words[i:(i+gram)]) for i in range(len(words)-gram+1)]
27 |
28 | word_set = set(words)-self.stop_words
29 | word_set = [w for w in word_set if len(w) > 1]
30 | self.history_words.append(word_set)
31 | self.ngram_history.append(n_grams)
32 | batch_words.append(word_set)
33 | batch_ngrams.append(n_grams)
34 |
35 | self.history_words = self.history_words[-self.history_length:] # Trim
36 | self.ngram_history = self.ngram_history[-self.history_length:] # Trim
37 |
38 | word_counter = Counter([w for words in self.history_words for w in words])
39 | ngram_counter = Counter([ng for ngrams in self.ngram_history for ng in ngrams])
40 |
41 | scores = []
42 | for words, ngrams in zip(batch_words, batch_ngrams):
43 | score = 0.0
44 |
45 | if any(word_counter[w] > 0.5*self.history_length for w in words):
46 | score = 1.0
47 | if any(ngram_counter[ng] > 0.5*self.history_length for ng in ngrams):
48 | score = 1.0
49 | # print(">>>",ngram_counter.most_common(8))
50 | scores.append(score)
51 | return scores, None
52 |
53 | class LengthPenalty:
54 | # Depending on how many words are used a large fraction of the last X summaries
55 | def __init__(self, target_length):
56 | self.target_length = float(target_length)
57 |
58 | def score(self, summaries, bodies, bodies_tokenized=None, lengths=None, extra=None):
59 | # In lengths, the number of tokens. Is -1 if the summary did not produce an END token, which will be maximum penalty, by design.
60 | # scores = [1.0-L/self.target_length for L in lengths]
61 | scores = [1.0 if L > self.target_length else 1.0-L/self.target_length for L in lengths] # This lets it go beyond for free
62 |
63 | return scores, None
64 |
65 | class RepeatPenalty:
66 | # Shouldn't use non-stop words several times in a summary. Fairly constraining.
67 | def __init__(self):
68 | self.stop_words = STOP_WORDS
69 |
70 | def score(self, summaries, bodies, bodies_tokenized=None, lengths=None, extra=None):
71 | scores = []
72 | for summary in summaries:
73 | words = nltk.tokenize.word_tokenize(summary.lower())
74 | L = len(words)
75 | N_1 = max(2, math.ceil(L / 10.0)) # You shouldn't use the same non-stop word more than 3 times.
76 | N_2 = math.ceil(L / 8.0)
77 | word_counts = Counter([w for w in words if w not in self.stop_words])
78 | all_word_counts = Counter([w for w in words if len(w) > 1])
79 | if len(word_counts) > 0 and len(all_word_counts) > 0 and (word_counts.most_common(1)[0][1] > N_1 or all_word_counts.most_common(1)[0][1] > N_2):
80 | # print(L, N_1, N_2)
81 | # print("Repeat penalty:", word_counts.most_common(3), all_word_counts.most_common(3))
82 | scores.append(1.0)
83 | else:
84 | scores.append(0.0)
85 | return scores, None
86 |
87 | # if __name__ == "__main__":
88 | # import argparse
89 |
90 | # parser = argparse.ArgumentParser()
91 | # parser.add_argument("--gpu_nb", type=int, default=3, help="Which GPU to use. For now single GPU.")
92 | # parser.add_argument("--train_batch_size", type=int, default=8, help="Training batch size.")
93 | # parser.add_argument("--device", type=str, default="cuda", help="cuda or cpu")
94 | # parser.add_argument("--do_train", action='store_true', help="Whether to do some training.")
95 |
96 | # args = parser.parse_args()
97 | # os.environ["CUDA_VISIBLE_DEVICES"] = ""+str(args.gpu_nb)
98 |
99 | # print("Loading model")
100 | # fluency = FluencyCoLA(args.device, model_file="/home/phillab/models/news_gpt2_bs32.bin")
101 |
102 | # if args.do_train:
103 | # dataloader = fluency.get_training_dataset(args.train_batch_size)
104 | # param_optimizer = list(fluency.model.named_parameters())
105 | # no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
106 | # optimizer_grouped_parameters = [
107 | # {'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
108 | # {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
109 | # ]
110 |
111 | # optimizer = AdamW(optimizer_grouped_parameters, lr=2e-5)
112 | # scheduler = WarmupLinearSchedule(optimizer, warmup_steps=0, t_total=len(dataloader))
113 | # logplot = LogPlot("/home/phillab/logs/fluency/bert_cola_gpu.log")
114 |
115 | # time_save = time.time()
116 | # optim_every = 4
117 |
118 | # for epi in range(1):
119 | # print("Epoch", epi)
120 | # for ib, batch in tqdm.tqdm(enumerate(dataloader), total=len(dataloader)):
121 | # batch = tuple(t.to(args.device) for t in batch)
122 | # input_ids, masks, token_types, labels = batch
123 | # outputs, = fluency.get_output(input_ids, masks, token_types)
124 |
125 | # cross_ent = CrossEntropyLoss()
126 | # loss = cross_ent(outputs, labels)
127 | # acc = torch.argmax(outputs,dim=1).eq(labels).float().mean().item()
128 |
129 | # loss.backward()
130 |
131 | # if ib%optim_every == 0:
132 | # scheduler.step() # Update learning rate schedule
133 | # optimizer.step()
134 | # optimizer.zero_grad()
135 |
136 | # logplot.cache({"loss": loss.item(), "accuracy": acc}, prefix="T_")
137 | # if time.time()-time_save > 60.0:
138 | # logplot.save(printing=True)
139 | # time_save = time.time()
140 | # fluency.save_model("/home/phillab/models/bert_fluency_cola_b.bin")
141 |
142 | if __name__ == "__main__":
143 |
144 | summary = "India's Telecom Commission is seeking clarity on 2G spectrum auction issues including the auction"
145 | summary = "The 39-year-old French star of the silent comedy The Artist scooped the Best Actor statue at the Academy Awards in"
146 | summary = "The two available units cost $574,000 and $649,900."
147 |
148 | reppen = RepeatPenalty()
149 | print(reppen.score([summary], [""]))
150 |
--------------------------------------------------------------------------------
/pretrain_bert.py:
--------------------------------------------------------------------------------
1 | from pytorch_transformers.optimization import AdamW, WarmupLinearSchedule
2 | from pytorch_transformers.tokenization_bert import BertTokenizer
3 | from pytorch_transformers.modeling_bert import BertForPreTraining
4 | from torch.utils.data import DataLoader, RandomSampler
5 | import torch, os, time, utils_misc, argparse
6 | from utils_dataset import SQLDataset
7 | from utils_logplot import LogPlot
8 | import random
9 |
10 | parser = argparse.ArgumentParser()
11 | parser.add_argument("--gpu_nb", type=int, default=3, help="Which GPU to use. For now single GPU.")
12 | parser.add_argument("--train_batch_size", type=int, default=8, help="Training batch size.")
13 | parser.add_argument("--optim_every", type=int, default=8, help="Optimize every x backprops. A multiplier to the true batch size.")
14 | parser.add_argument("--device", type=str, default="cuda", help="cuda or cpu")
15 | parser.add_argument("--dataset_file", type=str, default="/home/phillab/data/headliner_6M.hdf5", help="Which dataset file to use.")
16 |
17 | args = parser.parse_args()
18 |
19 | os.environ["CUDA_VISIBLE_DEVICES"] = ""+str(args.gpu_nb)
20 |
21 | learning_rate = 2e-5
22 | n_epochs = 3
23 |
24 | tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
25 | tokenizer.max_len = 10000
26 | model = BertForPreTraining.from_pretrained("bert-base-uncased")
27 | model.to(args.device)
28 | print("Model loaded")
29 |
30 | vocab_size = tokenizer.vocab_size
31 |
32 | summ = LogPlot("/home/phillab/logs/bert-base-uncased/bert_news.log")
33 |
34 | def random_word(tokens, tokenizer):
35 | output_label = []
36 |
37 | for i, token in enumerate(tokens):
38 | prob = random.random()
39 | # mask token with 15% probability
40 | if prob < 0.15:
41 | prob /= 0.15
42 |
43 | # 80% randomly change token to mask token
44 | if prob < 0.8:
45 | tokens[i] = "[MASK]"
46 |
47 | # 10% randomly change token to random token
48 | elif prob < 0.9:
49 | tokens[i] = random.choice(list(tokenizer.vocab.items()))[0]
50 | # -> rest 10% randomly keep current token
51 | output_label.append(tokenizer.vocab[token])
52 | else:
53 | # no masking token (will be ignored by loss function later)
54 | output_label.append(-1)
55 |
56 | return tokens, output_label
57 |
58 | def _truncate_seq_pair(tokens_a, tokens_b, max_length):
59 | """Truncates a sequence pair in place to the maximum length."""
60 | while True:
61 | total_length = len(tokens_a) + len(tokens_b)
62 | if total_length <= max_length:
63 | break
64 | if len(tokens_a) > len(tokens_b):
65 | tokens_a.pop()
66 | else:
67 | tokens_b.pop()
68 |
69 | def convert_example_to_features(tokens_a, tokens_b, max_seq_length, tokenizer):
70 | _truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
71 |
72 | tokens_a, t1_label = random_word(tokens_a, tokenizer)
73 | tokens_b, t2_label = random_word(tokens_b, tokenizer)
74 | # concatenate lm labels and account for CLS, SEP, SEP
75 |
76 | # The convention in BERT is:
77 | # (a) For sequence pairs:
78 | # tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
79 | # type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1
80 | # (b) For single sequences:
81 | # tokens: [CLS] the dog is hairy . [SEP]
82 | # type_ids: 0 0 0 0 0 0 0
83 | #
84 |
85 | tokens = ["[CLS]"] + tokens_a + ["[SEP]"] + tokens_b + ["[SEP]"]
86 | segment_ids = [0] + (len(tokens_a) * [0]) + [0] + (len(tokens_b) * [1]) + [1]
87 | lm_label_ids = [-1] + t1_label + [-1] + t2_label + [-1]
88 |
89 | input_ids = tokenizer.convert_tokens_to_ids(tokens)
90 |
91 | pad_amount = max_seq_length - len(input_ids)
92 | input_mask = [1] * len(input_ids) + [0] * pad_amount
93 | input_ids += [0] * pad_amount
94 | segment_ids += [0] * pad_amount
95 | lm_label_ids += [-1] * pad_amount
96 |
97 | return input_ids, input_mask, segment_ids, lm_label_ids
98 |
99 | def collate_func(inps):
100 | bodies = [inp['body'] for inp in inps]
101 | bodies_tokenized = [tokenizer.tokenize(body) for body in bodies]
102 |
103 | max_length = 400
104 | half_length = int(max_length/2)
105 |
106 | is_next_labels = []
107 | mid_point = int(len(inps)/2)
108 | batch_ids, batch_mask, batch_segments, batch_lm_label_ids, batch_is_next = [], [], [], [], []
109 | for i in range(mid_point):
110 | is_next = 1 if random.random() < 0.5 else 0
111 |
112 | tokens_a = bodies_tokenized[i]
113 | if is_next == 0:
114 | tokens_b = bodies_tokenized[i]
115 | else:
116 | tokens_b = bodies_tokenized[i+mid_point]
117 | tokens_a = tokens_a[:half_length]
118 | tokens_b = tokens_b[half_length:max_length]
119 | input_ids, input_mask, segment_ids, lm_label_ids = convert_example_to_features(tokens_a, tokens_b, max_length, tokenizer)
120 |
121 | batch_ids.append(input_ids)
122 | batch_mask.append(input_mask)
123 | batch_segments.append(segment_ids)
124 | batch_lm_label_ids.append(lm_label_ids)
125 | batch_is_next.append(is_next)
126 |
127 | batch_ids = torch.LongTensor(batch_ids)
128 | batch_mask = torch.LongTensor(batch_mask)
129 | batch_segments = torch.LongTensor(batch_segments)
130 | batch_lm_label_ids = torch.LongTensor(batch_lm_label_ids)
131 | batch_is_next = torch.LongTensor(batch_is_next)
132 |
133 | return batch_ids, batch_mask, batch_segments, batch_lm_label_ids, batch_is_next
134 |
135 | dataset = SQLDataset(args.dataset_file)
136 | dataloader = DataLoader(dataset=dataset, batch_size=2*args.train_batch_size, sampler=RandomSampler(dataset), drop_last=True, collate_fn=collate_func)
137 |
138 | param_optimizer = list(model.named_parameters())
139 | no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
140 | optimizer_grouped_parameters = [
141 | {'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
142 | {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
143 | ]
144 |
145 | model.train()
146 |
147 | optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate)
148 | scheduler = WarmupLinearSchedule(optimizer, warmup_steps=0, t_total=n_epochs*len(dataloader))
149 |
150 | time_save = time.time()
151 |
152 | for _ in range(n_epochs):
153 | for ib, batch in enumerate(dataloader):
154 | batch = tuple(t.to(args.device) for t in batch)
155 | input_ids, input_mask, segment_ids, lm_label_ids, is_next = batch
156 |
157 | loss, mlm_logits, is_next_logits = model(input_ids, segment_ids, input_mask, lm_label_ids, is_next)
158 |
159 | loss.backward()
160 | is_next_acc = is_next.eq(torch.argmax(is_next_logits, dim=1)).float().mean().item()
161 |
162 |
163 | num_predicts = (1.0 - lm_label_ids.eq(-1)).sum().item()
164 | mlm_acc = (lm_label_ids.view(-1).eq(torch.argmax(mlm_logits,dim=2).view(-1)).float().sum()/num_predicts).item()
165 |
166 | if ib%args.optim_every == 0:
167 | scheduler.step() # Update learning rate schedule
168 | optimizer.step()
169 | optimizer.zero_grad()
170 | torch.cuda.empty_cache()
171 |
172 | summ.cache({"loss": loss.item(), "mlm_acc": mlm_acc, "is_next_acc": is_next_acc}, prefix="T_")
173 | if time.time()-time_save > 60.0:
174 | summ.save(printing=True)
175 | time_save = time.time()
176 | torch.save(model.state_dict(), "/home/phillab/models/news_bert_bs"+str(args.optim_every*args.train_batch_size)+".bin")
177 |
--------------------------------------------------------------------------------
/pretrain_coverage.py:
--------------------------------------------------------------------------------
1 | from transformers.optimization import AdamW
2 | from torch.utils.data import DataLoader, RandomSampler
3 |
4 | import tqdm, nltk, torch, time, numpy as np, argparse, os
5 | from utils_logplot import LogPlot
6 | from model_coverage import KeywordCoverage
7 | from utils_dataset import SQLDataset
8 | import utils_misc
9 |
10 | parser = argparse.ArgumentParser()
11 | parser.add_argument("--experiment", type=str, required=True, help="Experiment name. Will be used to save a model file and a log file.")
12 | parser.add_argument("--dataset_file", type=str, required=True, help="Which dataset file to use. Can be full path or the root folder will be attached.")
13 |
14 | parser.add_argument("--train_batch_size", type=int, default=8, help="Training batch size.")
15 | parser.add_argument("--n_kws", type=int, default=15, help="Top n words (tf-idf wise) will be masked in the coverage model.")
16 | parser.add_argument("--device", type=str, default="cuda", help="cuda or cpu")
17 | parser.add_argument('--fp16', action='store_true', help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit")
18 |
19 | models_folder = "/home/ubuntu/models/"
20 | logs_folder = "/home/ubuntu/logs/"
21 |
22 |
23 | args = parser.parse_args()
24 |
25 | if args.device == "cuda":
26 | freer_gpu = str(utils_misc.get_freer_gpu())
27 | os.environ["CUDA_VISIBLE_DEVICES"] = ""+str(freer_gpu)
28 | args.experiment += "_"+freer_gpu
29 |
30 | def collate_func(documents):
31 | # When pretraining the coverage model, can feed real summaries, or the first K words of the document as summaries (for full unsupervised).
32 | return [utils_misc.cut300(doc['body']) for doc in documents], [" ".join(doc['body'].split()[:50]) for doc in documents]
33 |
34 | dataset = SQLDataset(args.dataset_file)
35 | dataloader = DataLoader(dataset=dataset, batch_size=args.train_batch_size, sampler=RandomSampler(dataset), drop_last=True, collate_fn=collate_func)
36 |
37 | kw_cov = KeywordCoverage(args.device, keyword_model_file=os.path.join(models_folder, "keyword_extractor.joblib"), n_kws=args.n_kws) # , model_file=os.path.join(models_folder, "news_bert_bs64.bin")
38 | kw_cov.model.train()
39 | print("Loaded model")
40 |
41 | param_optimizer = list(kw_cov.model.named_parameters())
42 | no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
43 | optimizer_grouped_parameters = [
44 | {'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
45 | {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
46 | ]
47 |
48 | optimizer = AdamW(optimizer_grouped_parameters, lr=2e-5)
49 | logplot = LogPlot(os.path.join(logs_folder, "coverage/bert_coverage_%s.log" % (args.experiment)))
50 |
51 | if args.fp16:
52 | try:
53 | from apex import amp
54 | except ImportError:
55 | raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
56 | kw_cov.model, optimizer = amp.initialize(kw_cov.model, optimizer, opt_level="O1") # For now O1. See details at https://nvidia.github.io/apex/amp.html
57 |
58 | time_save = time.time()
59 | optim_every = 4
60 |
61 | for ib, batch in enumerate(dataloader):
62 | contents, summaries = batch
63 | loss, acc = kw_cov.train_batch(contents, summaries)
64 | if args.fp16:
65 | with amp.scale_loss(loss, optimizer) as scaled_loss:
66 | scaled_loss.backward()
67 | else:
68 | loss.backward()
69 |
70 | if ib%optim_every == 0:
71 | optimizer.step()
72 | optimizer.zero_grad()
73 |
74 | logplot.cache({"loss": loss.item(), "accuracy": acc, "count": len(batch)}, prefix="T_")
75 | if time.time()-time_save > 60.0:
76 | logplot.save(printing=True)
77 | time_save = time.time()
78 | kw_cov.save_model(os.path.join(models_folder, "bert_coverage_%s.bin" % (args.experiment)))
79 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | transformers==3.1.0
2 | sklearn==0.22.1
3 | nltk==3.5
4 | h5py
5 | tqdm
6 | matplotlib
7 |
--------------------------------------------------------------------------------
/train_generator.py:
--------------------------------------------------------------------------------
1 | from transformers.optimization import AdamW
2 | from model_generator import GeneTransformer
3 | from torch.utils.data import DataLoader, RandomSampler
4 | import torch, os, time, argparse, tqdm
5 | from utils_dataset import SQLDataset
6 | from utils_logplot import LogPlot
7 | from datetime import datetime
8 | import utils_misc
9 |
10 | parser = argparse.ArgumentParser()
11 | parser.add_argument("--experiment", type=str, required=True, help="Experiment name. Will be used to save a model file and a log file.")
12 | parser.add_argument("--dataset_file", type=str, required=True, help="Which dataset file to use.")
13 | parser.add_argument("--task", type=str, required=True, help="Which generation task to perform. Can be: `cgen` (conditionally generate), lm` (language modeling) or `copy`. `cgen` is useful to train a supervised model, when data is available (for example a headline generator, summarizer, etc). `lm` is an unconditional language model, such as the GPT2 model, can be used to train a Fluency model. `copy` can be used to pretrain the generator for the summary_loop, this speeds up training of the summary_loop as the generator already starts with the strong baseline of copying the first K words of the input.")
14 | parser.add_argument("--max_output_length", required=True, type=int, help="Maximum output length. Saves time if the sequences are short.")
15 |
16 | parser.add_argument("--train_batch_size", type=int, default=8, help="Training batch size.")
17 | parser.add_argument("--n_epochs", type=int, default=3, help="Number of epochs to run over the data.")
18 | parser.add_argument("--optim_every", type=int, default=4, help="Optimize every x backprops. A multiplier to the true batch size.")
19 | parser.add_argument("--device", type=str, default="cuda", help="cuda or cpu")
20 | parser.add_argument('--fp16', action='store_true', help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit")
21 | parser.add_argument('--starter_model', default="", help="which model to start with. Leave empty string for random inizialitation")
22 |
23 | args = parser.parse_args()
24 |
25 | models_folder = "/home/ubuntu/models/"
26 | logs_folder = "/home/ubuntu/logs/"
27 |
28 | if args.device == "cuda":
29 | freer_gpu = str(utils_misc.get_freer_gpu())
30 | os.environ["CUDA_VISIBLE_DEVICES"] = ""+str(freer_gpu)
31 | args.experiment += "_"+freer_gpu
32 |
33 | learning_rate = 2e-5
34 | n_epochs = args.n_epochs
35 |
36 | model = GeneTransformer(tokenizer_type="gpt2", max_output_length=args.max_output_length, device=args.device, bpe_model="")
37 | if len(args.starter_model) > 0:
38 | model.reload(os.path.join(models_folder, args.starter_model))
39 |
40 | print("Model loaded")
41 |
42 | def collate_func(documents):
43 | return [utils_misc.cut300(doc['body']) for doc in documents], [doc['title'] for doc in documents]
44 |
45 | dataset = SQLDataset(args.dataset_file)
46 |
47 | N = len(dataset)
48 | N_dev = 500
49 | N_train = N-N_dev
50 | d_train, d_dev = torch.utils.data.dataset.random_split(dataset, [N_train, N_dev])
51 |
52 | dl_train = DataLoader(dataset=d_train, batch_size=args.train_batch_size, sampler=RandomSampler(d_train), collate_fn=collate_func)
53 | dl_dev = DataLoader(dataset=d_dev, batch_size=20, sampler=RandomSampler(d_dev), collate_fn=collate_func)
54 |
55 | param_optimizer = list(model.model.named_parameters())
56 | no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
57 | optimizer_grouped_parameters = [
58 | {'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
59 | {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
60 | ]
61 |
62 | logplot_file = os.path.join(logs_folder, "generator_%s.log" % (args.experiment))
63 | summ = LogPlot(logplot_file)
64 |
65 | optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate)
66 |
67 | if args.fp16:
68 | try:
69 | from apex import amp
70 | except ImportError:
71 | raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
72 | model.model, optimizer = amp.initialize(model.model, optimizer, opt_level="O2") # For now O1. See details at https://nvidia.github.io/apex/amp.html
73 |
74 | print("Started training")
75 | time_save = time.time()
76 |
77 | def map_batch(batch, task):
78 | sources, targets = batch
79 |
80 | if task == "cgen":
81 | pass # already in shape
82 | elif task == "copy":
83 | targets = sources
84 | elif task == "lm":
85 | targets = sources
86 | sources = [""] * len(sources)
87 | return sources, targets
88 |
89 | no_preinput = (args.task == "lm")
90 | for _ in range(n_epochs):
91 | for ib, batch in enumerate(dl_train):
92 | model.train()
93 | sources, targets = map_batch(batch, args.task)
94 |
95 | loss = model.train_batch(sources, targets, no_preinput=no_preinput)
96 | if args.fp16:
97 | with amp.scale_loss(loss, optimizer) as scaled_loss:
98 | scaled_loss.backward()
99 | else:
100 | loss.backward()
101 |
102 | if ib%args.optim_every == 0:
103 | optimizer.step()
104 | optimizer.zero_grad()
105 |
106 | summ.cache({"loss": loss.item(), "count": len(batch)}, prefix="T_")
107 | if time.time()-time_save > 60.0:
108 |
109 | print("Starting the eval")
110 | model.eval()
111 |
112 | with torch.no_grad():
113 | for batch in tqdm.tqdm(dl_dev):
114 | sources, targets = map_batch(batch, args.task)
115 | loss = model.train_batch(sources, targets, no_preinput=no_preinput)
116 | summ.cache({"loss": loss.item(), "count": len(batch)}, prefix="E_")
117 |
118 | summ.save(printing=True)
119 | time_save = time.time()
120 | model_output_file = os.path.join(models_folder, "gpt2_"+args.experiment+".bin")
121 | model.save(model_output_file)
122 |
--------------------------------------------------------------------------------
/train_summary_loop.py:
--------------------------------------------------------------------------------
1 | from torch.utils.data import DataLoader, RandomSampler
2 | from utils_dataset import SQLDataset, HDF5Dataset
3 | import torch, os, time, argparse, numpy as np
4 | from transformers.optimization import AdamW
5 | from model_generator import GeneTransformer
6 | import utils_misc, utils_tokenizer
7 | from utils_logplot import LogPlot
8 | from datetime import datetime
9 |
10 | from model_coverage import KeywordCoverage
11 | from model_guardrails import PatternPenalty, LengthPenalty, RepeatPenalty
12 | import threading, queue
13 |
14 | user = os.getlogin()
15 |
16 | parser = argparse.ArgumentParser()
17 | parser.add_argument("--experiment", type=str, required=True, help="Experiment name. Will be used to save a model file and a log file.")
18 | parser.add_argument("--dataset_file", type=str, required=True, help="Which dataset file to use. Can be full path or the root folder will be attached.")
19 |
20 | parser.add_argument("--train_batch_size", type=int, default=5, help="Training batch size.")
21 | parser.add_argument("--n_epochs", type=int, default=3, help="Number of epochs to run over the data.")
22 | parser.add_argument("--optim_every", type=int, default=4, help="Optimize every x backprops. A multiplier to the true batch size.")
23 | parser.add_argument("--max_output_length", type=int, default=25, help="Maximum output length. Saves time if the sequences are short.")
24 | parser.add_argument("--save_every", type=int, default=60, help="Number of seconds between any two saves.")
25 | parser.add_argument("--device", type=str, default="cuda", help="cuda or cpu")
26 | parser.add_argument('--fp16', action='store_true', help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit")
27 | parser.add_argument("--ckpt_every", type=int, default=600, help="If 0, checkpointing is not used. Otherwise, checkpointing is done very x seconds.")
28 | parser.add_argument("--ckpt_lookback", type=int, default=300, help="When checkpointing, will consider the avg total score of the last x samples.")
29 |
30 | args = parser.parse_args()
31 | if args.device == "cuda":
32 | freer_gpu = str(utils_misc.get_freer_gpu())
33 | os.environ["CUDA_VISIBLE_DEVICES"] = ""+str(freer_gpu)
34 | args.experiment += "_"+freer_gpu
35 |
36 | models_folder = "/home/phillab/models/"
37 | log_folder = "/home/phillab/logs/"
38 |
39 | summarizer_model_start = os.path.join(models_folder, "gpt2_copier23.bin")
40 |
41 | ckpt_every = args.ckpt_every
42 | ckpt_lookback = int((args.ckpt_lookback+args.train_batch_size-1)/args.train_batch_size)
43 | total_score_history = []
44 | best_ckpt_score = None
45 |
46 | ckpt_file = os.path.join(models_folder, "summarizer_"+args.experiment+"_ckpt.bin")
47 | ckpt_optimizer_file = os.path.join(models_folder, "summarizer_optimizer_"+args.experiment+"_ckpt.bin")
48 |
49 | learning_rate = 2e-5
50 | n_epochs = args.n_epochs
51 |
52 | if args.device == "cuda":
53 | print("Training on GPU "+str(freer_gpu))
54 |
55 | bert_tokenizer = utils_tokenizer.BERTCacheTokenizer()
56 | print("---------------")
57 |
58 | summarizer = GeneTransformer(max_output_length=args.max_output_length, device=args.device, tokenizer_type='gpt2', starter_model=summarizer_model_start)
59 | print("Summarizer loaded")
60 |
61 | def collate_func(inps):
62 | if ".db" in args.dataset_file:
63 | return [a['body'] for a in inps]
64 | else:
65 | return [inp[0].decode() for inp in inps]
66 |
67 |
68 | param_optimizer = list(summarizer.model.named_parameters())
69 | no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
70 | optimizer_grouped_parameters = [
71 | {'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
72 | {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
73 | ]
74 |
75 | logplot_file = os.path.join(log_folder, "summary_loop_%s.log" % (args.experiment))
76 | logplot = LogPlot(logplot_file)
77 |
78 | optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate)
79 | time_save = time.time()
80 | time_ckpt = time.time()
81 |
82 | if args.fp16:
83 | try:
84 | from apex import amp
85 | except ImportError:
86 | raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
87 | summarizer.model, optimizer = amp.initialize(summarizer.model, optimizer, opt_level="O1") # For now O1. See details at https://nvidia.github.io/apex/amp.html
88 |
89 | print("Loading scorers")
90 |
91 | coverage_model_file = os.path.join(models_folder, "bert_coverage_google_cnndm_length15_1.bin")
92 | coverage_keyword_model_file = os.path.join(models_folder, "keyword_extractor.joblib")
93 | fluency_news_model_file = os.path.join(models_folder, "news_gpt2_bs32.bin")
94 |
95 | scorers = [{"name": "coverage", "importance": 10.0, "sign": 1.0, "model": KeywordCoverage(args.device, keyword_model_file=coverage_keyword_model_file, model_file=coverage_model_file)},
96 | {"name": "fluency", "importance": 2.0, "sign": 1.0, "model": GeneTransformer(max_output_length=args.max_output_length, device=args.device, starter_model=fluency_news_model_file)},
97 | {"name": "patpen", "importance": 5.0, "sign": -1.0, "model": PatternPenalty()},
98 | {"name": "lengthpen", "importance": 2.0, "sign": -1.0, "model": LengthPenalty(args.max_output_length)},
99 | {"name": "reppen", "importance": 2.0, "sign": -1.0, "model": RepeatPenalty()}
100 | ]
101 |
102 | def background_tokenizer(bodies, out_queue):
103 | out_queue.put([bert_tokenizer.encode(body) for body in bodies])
104 |
105 |
106 | my_queue = queue.Queue()
107 | print("Started training")
108 |
109 | if ".db" in args.dataset_file:
110 | all_dataset = SQLDataset(args.dataset_file)
111 | else:
112 | all_dataset = HDF5Dataset(args.dataset_file, collection_name="name")
113 |
114 | dataset = all_dataset
115 |
116 | print("Dataset size:", len(dataset))
117 | dataloader = DataLoader(dataset=dataset, batch_size=args.train_batch_size, sampler=RandomSampler(dataset), drop_last=True, collate_fn=collate_func)
118 |
119 | for epi in range(n_epochs):
120 | print("=================== EPOCH", epi, "===================")
121 | for ib, documents in enumerate(dataloader):
122 | Timer = {}
123 |
124 | T1 = time.time()
125 | log_obj = {}
126 |
127 | bodies = [" ".join(doc.split(" ")[:300]) for doc in documents]
128 |
129 | # We run tokenization in the background, as it is BERT tokenization only used after the summarizer has run. Saves about 5% of time.
130 | thread1 = threading.Thread(target=background_tokenizer, args=(bodies, my_queue))
131 | # bodies_bert_tokenized = [bert_tokenizer.enncode(body) for body in bodies] # This is the not background version
132 | thread1.start()
133 |
134 | T2 = time.time()
135 | Timer["preprocessing_starting"] = T2-T1
136 |
137 | # T1b = time.time()
138 | sampled_summaries, sampled_logprobs, sampled_tokens, input_past, sampled_end_idxs = summarizer.decode_batch(bodies, max_output_length=args.max_output_length, return_logprobs=True, sample=True)
139 |
140 | T3 = time.time()
141 | Timer["generator_sampled"] = T3-T2
142 | with torch.no_grad():
143 | argmax_summaries, argmax_end_idxs = summarizer.decode_batch(bodies, max_output_length=args.max_output_length, input_past=input_past)
144 | T4 = time.time()
145 | Timer["generator_argmax"] = T4-T3
146 |
147 | selected_logprobs = torch.sum(sampled_logprobs, dim=1)
148 | batch_size, seq_length = sampled_logprobs.shape
149 |
150 | # We join it here, saying the tokenization that's been running in the background should be done by now.
151 | thread1.join()
152 | bodies_bert_tokenized = my_queue.get()
153 |
154 | scores_track = {}
155 | total_sampled_scores = torch.FloatTensor([0.0] * batch_size).to(args.device)
156 | total_argmax_scores = torch.FloatTensor([0.0] * batch_size).to(args.device)
157 | for scorer in scorers:
158 | T = time.time()
159 | sampled_scores, extra = scorer['model'].score(sampled_summaries, bodies, bodies_tokenized=bodies_bert_tokenized, extra=None, lengths=sampled_end_idxs)
160 | sampled_scores = torch.FloatTensor(sampled_scores).to(args.device)
161 |
162 | argmax_scores, _ = scorer['model'].score(argmax_summaries, bodies, bodies_tokenized=bodies_bert_tokenized, extra=extra, lengths=argmax_end_idxs)
163 | argmax_scores = torch.FloatTensor(argmax_scores).to(args.device)
164 |
165 | Timer["scores_"+scorer['name']] = time.time()-T
166 | total_sampled_scores += (scorer['sign'])*(scorer['importance'])*sampled_scores
167 | total_argmax_scores += (scorer['sign'])*(scorer['importance'])*argmax_scores
168 | log_obj[scorer['name']+"_score"] = sampled_scores.mean().item()
169 | scores_track[scorer['name']+"_scores"] = sampled_scores
170 |
171 | T5 = time.time()
172 | Timer['all_scores'] = T5-T4
173 | Loss = torch.mean((total_argmax_scores - total_sampled_scores) * selected_logprobs)
174 |
175 | if args.fp16:
176 | with amp.scale_loss(Loss, optimizer) as scaled_loss:
177 | scaled_loss.backward()
178 | else:
179 | Loss.backward()
180 |
181 | T6 = time.time()
182 | Timer['backward'] = T6-T5
183 |
184 | if ib % args.optim_every == 0:
185 | optimizer.step()
186 | optimizer.zero_grad()
187 |
188 | T7 = time.time()
189 | Timer['optim'] = T7-T6
190 |
191 | # log_obj['summary_nwords'] = int(np.mean([summ.count(" ")+1 for summ in sampled_summaries]))
192 | avg_total = total_sampled_scores.mean().item()
193 |
194 | total_score_history.append(avg_total)
195 | log_obj['summary_nwords'] = int(np.mean(sampled_end_idxs))
196 | log_obj['loss'] = Loss.item()
197 | log_obj['total_score'] = avg_total
198 | log_obj['count'] = batch_size
199 | logplot.cache(log_obj, prefix="T_")
200 |
201 | Tfinal = time.time()
202 | Timer['total'] = Tfinal - T1
203 | # print(Timer)
204 |
205 | if (time.time()-time_save > args.save_every):
206 | print("==========================================")
207 | print(bodies[0])
208 | print("-----------")
209 | print(sampled_summaries[0])
210 | print("-----------")
211 | print("Total score:", total_sampled_scores[0].item())
212 | for scorer in scorers:
213 | print(scorer['name']+" score:", scores_track[scorer['name']+"_scores"][0].item())
214 | print("-----------")
215 |
216 | logplot.save(printing=True)
217 | # print(Timer)
218 |
219 | time_save = time.time()
220 | print("==========================================")
221 |
222 | if ckpt_every > 0 and len(total_score_history) > ckpt_lookback:
223 | current_score = np.mean(total_score_history[-ckpt_lookback:])
224 |
225 | if time.time()-time_ckpt > ckpt_every:
226 | revert_ckpt = best_ckpt_score is not None and current_score < min(1.2*best_ckpt_score, 0.8*best_ckpt_score) # Could be negative or positive
227 | print("================================== CKPT TIME, "+str(datetime.now())+" =================================")
228 | print("Previous best:", best_ckpt_score)
229 | print("Current Score:", current_score)
230 | print("[CKPT] Am I reverting?", ("yes" if revert_ckpt else "no! BEST CKPT"))
231 | if revert_ckpt:
232 | summarizer.model.load_state_dict(torch.load(ckpt_file))
233 | optimizer.load_state_dict(torch.load(ckpt_optimizer_file))
234 | time_ckpt = time.time()
235 | print("==============================================================================")
236 |
237 | if best_ckpt_score is None or current_score > best_ckpt_score:
238 | print("[CKPT] Saved new best at: %.3f %s" % (current_score, "["+str(datetime.now())+"]"))
239 | best_ckpt_score = current_score
240 | torch.save(summarizer.model.state_dict(), ckpt_file)
241 | torch.save(optimizer.state_dict(), ckpt_optimizer_file)
242 |
--------------------------------------------------------------------------------
/utils_dataset.py:
--------------------------------------------------------------------------------
1 | import h5py, torch, sys, os, sqlite3
2 | import torch.utils.data.dataset
3 |
4 | class HDF5Dataset(torch.utils.data.dataset.Dataset):
5 | def __init__(self, filename, collection_name='name'):
6 | self.f = h5py.File(filename,'r')
7 | self.dset = self.f[collection_name]
8 |
9 | def __getitem__(self, index):
10 | return self.dset[index]
11 |
12 | def __len__(self):
13 | return len(self.dset)
14 |
15 | class SQLDataset(torch.utils.data.dataset.Dataset):
16 | def __init__(self, filename, table_name='articles', cut=None):
17 | self.table_name = table_name
18 | self.conn = sqlite3.connect(filename, detect_types=sqlite3.PARSE_DECLTYPES)
19 | self.conn.row_factory = sqlite3.Row
20 | self.cut = cut
21 | self.curr = self.conn.cursor()
22 |
23 | def __getitem__(self, index):
24 | if self.cut is not None:
25 | res = self.curr.execute("SELECT * FROM "+self.table_name+" WHERE cut_id=? and cut=?", (index, self.cut))
26 | else:
27 | res = self.curr.execute("SELECT * FROM "+self.table_name+" WHERE id= ?", (index,))
28 | return [dict(r) for r in res][0]
29 |
30 | def __len__(self):
31 | if self.cut is not None:
32 | N = self.curr.execute("SELECT COUNT(*) as count FROM "+self.table_name+" WHERE cut = ?", (self.cut,)).fetchone()[0]
33 | else:
34 | N = self.curr.execute("SELECT COUNT(*) as count FROM "+self.table_name).fetchone()[0]
35 | return N
36 |
--------------------------------------------------------------------------------
/utils_logplot.py:
--------------------------------------------------------------------------------
1 | from matplotlib import pyplot as plt
2 | from datetime import datetime
3 | import numpy as np
4 | import json, os
5 |
6 | def geom(data, alpha=0.995):
7 | gdata = [data[0]]
8 | for d in data[1:]:
9 | gdata.append(gdata[-1]*alpha + (1-alpha)*d)
10 | return gdata
11 |
12 | def plot(files=[], folder=None, filt='', geo=0, xaxis='steps', maxy={}):
13 | # filt: a filter substring. Only keys with this substring will be plotted. For example 'V' to plot only validation values
14 | # geo: a float between (0,1.0) that is used for smoothing the series. Values closer to 1.0 lead to more smoothing. 0.99 is a lot of smoothing
15 | # xaxis: what to base the x-axis on. `steps` will just be a range(len(values)). `datetime` will show absolute times.
16 |
17 | if folder is not None:
18 | files = [os.path.join(folder, fn) for fn in os.listdir(folder) if os.path.isfile(os.path.join(folder, fn))]
19 |
20 | bad_keys = ['datetime']
21 | full_summary = {}
22 | for file in files:
23 | full_summ = []
24 | with open(file, "r") as f:
25 | for line in f:
26 | if len(line) == 0: continue
27 | try: obj = json.loads(line)
28 | except:
29 | obj = {}
30 | if 'datetime' in obj:
31 | obj['datetime'] = datetime.strptime(obj['datetime'][:19], "%Y-%m-%d %H:%M:%S")
32 | full_summ.append(obj)
33 | full_summary[file] = full_summ
34 |
35 | all_keys = list(set([k for file, full_summ in full_summary.items() for summ in full_summ for k in summ]))
36 | all_keys = [k for k in all_keys if filt in k and k not in bad_keys]
37 |
38 | xlabel = None
39 |
40 | for k in all_keys:
41 | plt.figure()
42 | plt.title(k)
43 | legend = []
44 | for file in files:
45 | subsumm = [summ for summ in full_summary[file] if k in summ]
46 | if xaxis in ['datetime', 'seconds']:
47 | subsumm = [summ for summ in subsumm if 'datetime' in summ]
48 | if k in maxy:
49 | subsumm = [summ for summ in subsumm if summ[k] < maxy[k]]
50 | if len(subsumm) == 0: continue
51 |
52 | xs = list(range(len(subsumm)))
53 | ys = geom([summ[k] for summ in subsumm], geo)
54 | if xaxis in ['datetime', 'seconds']:
55 | xs = [summ['datetime'] for summ in subsumm]
56 | if xaxis == 'seconds':
57 | start = min(xs)
58 | xs = np.array([(dt - start).total_seconds() for dt in xs])
59 | second_span =xs[-1]
60 | if xlabel is None:
61 | if second_span > 3*86400:
62 | xlabel = 'days'
63 | elif second_span > 5*3600:
64 | xlabel = 'hours'
65 | elif second_span > 10*60:
66 | xlabel = 'minutes'
67 |
68 | if xlabel == 'days': xs /= 86400.0
69 | if xlabel == 'hours': xs /= 3600.0
70 | if xlabel == 'minutes': xs /= 60.0
71 |
72 | if xaxis != 'seconds':
73 | xlabel = xaxis
74 | legend.append(file.split("/")[-1])
75 | plt.plot(xs, ys)
76 | plt.ylabel(k)
77 | plt.xlabel(xlabel)
78 | plt.legend(legend)
79 |
80 | class LogPlot():
81 |
82 | def __init__(self, where_to):
83 | # `where_to` the file where you want to save the summaries
84 | self.current_cache = {}
85 | self.where_to = where_to
86 |
87 | def cache(self, results, prefix=''):
88 | # Results should be a dict of keys (of things to save) and values to save {"Loss": 1.0}
89 | # Prefix: will be added to each key string (for instance a "T" for training, an "V" for validation)
90 |
91 | for k, val in results.items():
92 | nk = prefix+k
93 | if nk not in self.current_cache:
94 | self.current_cache[nk] = []
95 | self.current_cache[nk].append(float(val))
96 | return self
97 |
98 | def save(self, printing=False):
99 | def reduce_array(vals, k):
100 | if k == "T_count": return sum(vals)
101 | else: return float(np.mean(vals))
102 |
103 | save_obj = {k: reduce_array(vals, k) for k, vals in self.current_cache.items()}
104 | save_obj['datetime'] = str(datetime.now())
105 | f = open(self.where_to, "a"); f.write(json.dumps(save_obj)+"\n"); f.close()
106 | self.clear_cache()
107 | if printing: print(save_obj)
108 |
109 | def clear_cache(self):
110 | self.current_cache = {} # Reempty the cache
111 |
--------------------------------------------------------------------------------
/utils_misc.py:
--------------------------------------------------------------------------------
1 | import torch, sys, os, numpy as np
2 |
3 | def pad(data, padval=0):
4 | return torch.nn.utils.rnn.pad_sequence(data, batch_first=True, padding_value=padval)
5 |
6 | def get_freer_gpu():
7 | os.system('nvidia-smi -q -d Memory |grep -A4 GPU|grep Free >tmp_smi')
8 | memory_available = [int(x.split()[2]) for x in open('tmp_smi', 'r').readlines()]
9 | os.remove("tmp_smi")
10 | return np.argmax(memory_available)
11 |
12 | def cut300(text):
13 | return " ".join(text.split()[:300])
14 |
15 | class DoublePrint(object):
16 | def __init__(self, name, mode):
17 | self.file = open(name, mode)
18 | self.stdout = sys.stdout
19 | self.sterr = sys.stderr
20 | sys.stderr = self
21 | sys.stdout = self
22 |
23 | def __del__(self):
24 | sys.stdout = self.stdout
25 | sys.stderr = self.stderr
26 | self.file.close()
27 |
28 | def write(self, data):
29 | self.file.write(data)
30 | self.stdout.write(data)
31 | self.file.flush()
32 |
33 | def flush(self):
34 | self.file.flush()
35 |
--------------------------------------------------------------------------------
/utils_tokenizer.py:
--------------------------------------------------------------------------------
1 | from transformers import GPT2Tokenizer as GPT2Tok
2 | from transformers import BertTokenizer as BertTok
3 | import sentencepiece as spm
4 |
5 | class Capita:
6 | def forward(self, text):
7 | # words = nltk.tokenize.word_tokenize(text)
8 | words = text.split(" ")
9 | final_words = []
10 | for word in words:
11 | if not word.isalpha():
12 | final_words.append(word.lower())
13 | else:
14 | if word.islower():
15 | pass
16 | elif word.isupper():
17 | final_words.append("⇧")
18 | elif word[0].isupper() and word[1:].islower():
19 | final_words.append("↑")
20 | else:
21 | final_words.append("↑")
22 | final_words.append(word.lower())
23 | return " ".join(final_words)
24 |
25 | def backward(self, text):
26 | words = text.split(" ")
27 | final_words = []
28 | all_caps = False
29 | capitalized = False
30 | for w in words:
31 | if w == "⇧":
32 | all_caps = True
33 | elif w == "↑":
34 | capitalized = True
35 | else:
36 | final_word = w
37 | if all_caps:
38 | final_word = final_word.upper()
39 | elif capitalized:
40 | if len(final_word) <= 1:
41 | final_word = final_word.upper()
42 | else:
43 | final_word = final_word[0].upper()+final_word[1:]
44 | final_words.append(final_word)
45 | all_caps = False
46 | capitalized = False
47 | return " ".join(final_words)
48 |
49 | class BPETokenizer:
50 | def __init__(self, bpe_model, use_capita=True):
51 | self.sp = spm.SentencePieceProcessor()
52 | self.sp.Load(bpe_model)
53 | self.use_capita = use_capita
54 |
55 | self.pad_tok, self.start_tok, self.end_tok = "", "", ""
56 | self.pad_id, self.start_id, self.end_id = tuple(self.sp.piece_to_id(p) for p in [self.pad_tok, self.start_tok, self.end_tok])
57 |
58 | self.vocab_size = self.sp.get_piece_size()
59 |
60 | if self.use_capita:
61 | self.cpt = Capita()
62 |
63 | def tokenize(self, text):
64 | if len(text) == 0:
65 | return []
66 | if text[:len(self.start_tok)] == self.start_tok and text[len(self.start_tok)] != " ":
67 | text = text.replace(self.start_tok, self.start_tok+" ")
68 |
69 | if self.use_capita:
70 | text = self.cpt.forward(text)
71 | tokens = self.sp.encode_as_pieces(text)
72 | tokens = [w for i, w in enumerate(tokens) if (i < (len(tokens)-1) and tokens[i+1] not in ["⇧", "↑"]) or i==(len(tokens)-1)]
73 | if tokens[0] == "▁":
74 | tokens = tokens[1:]
75 | return tokens
76 |
77 | def encode(self, text):
78 | tokens = self.tokenize(text)
79 | token_ids = [self.sp.piece_to_id(w) for w in tokens]
80 | return token_ids
81 |
82 | def decode(self, token_ids):
83 | text = self.sp.decode_ids(token_ids).replace("⇧", " ⇧").replace("↑", " ↑")
84 | if self.use_capita:
85 | text = self.cpt.backward(text)
86 | text = text.replace(self.start_tok+" ", self.start_tok)
87 | return text
88 |
89 | class BERTCacheTokenizer:
90 | def __init__(self):
91 | self.cache = {}
92 | self.cache_keys = []
93 | self.tokenizer = BertTok.from_pretrained("bert-base-uncased")
94 | # self.tokenizer.max_len = 10000 # This was removed in later transformer tokenizers
95 |
96 | def encode(self, text):
97 | if text in self.cache:
98 | return self.cache[text]
99 |
100 | output = self.tokenizer.encode(text)
101 |
102 | if len(self.cache) > 1000:
103 | del self.cache[self.cache_keys.pop(0)]
104 | self.cache[text] = output
105 | self.cache_keys.append(text)
106 | return output
107 |
108 | class GPT2Tokenizer:
109 | def __init__(self):
110 | self.tokenizer = GPT2Tok.from_pretrained("gpt2")
111 | # self.tokenizer.max_len = 10000
112 |
113 | self.pad_tok, self.start_tok, self.end_tok = "", " ST", " END"
114 |
115 | self.pad_id = 0
116 | self.start_id = self.tokenizer.encode(self.start_tok)[0]
117 | self.end_id = self.tokenizer.encode(self.end_tok)[0]
118 | self.vocab_size = self.tokenizer.vocab_size
119 |
120 | def tokenize(self, text):
121 | return self.tokenizer.tokenize(text)
122 |
123 | def encode(self, text):
124 | return self.tokenizer.encode(text)
125 |
126 | def decode(self, token_ids):
127 | return self.tokenizer.decode(token_ids)
128 |
--------------------------------------------------------------------------------