├── tests
├── __init__.py
├── data
│ ├── test_interval.py
│ └── test_helpers_data.py
├── optimization
│ └── test_gaussian.py
└── models
│ ├── test_helpers_models.py
│ └── test_models_builder.py
├── eventdetector_ts
├── data
│ ├── __init__.py
│ ├── interval.py
│ └── helpers_data.py
├── optimization
│ ├── __init__.py
│ ├── algorithms.py
│ └── event_extraction_pipeline.py
├── prediction
│ ├── __init__.py
│ ├── utils.py
│ └── prediction.py
├── metamodel
│ ├── __init__.py
│ ├── utils.py
│ └── meta_model.py
├── models
│ ├── __init__.py
│ ├── helpers_models.py
│ └── models_trainer.py
├── plotter
│ ├── __init__.py
│ ├── helpers.py
│ └── plotter.py
└── __init__.py
├── images
├── op_bs.png
├── op_ccf.png
├── delta_t_bs.png
├── losses_bs.png
├── losses_ccf.png
├── op_mex_ccf.png
├── delta_t_ccf.png
├── losses_mex_ccf.png
├── inputs_event_detector.png
└── logo_eventdetector.svg
├── requirements.txt
├── requirements_dev.txt
├── .gitignore
├── LICENSE
├── pyproject.toml
├── .github
└── workflows
│ └── unit_tests.yml
└── README.md
/tests/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
4 |
--------------------------------------------------------------------------------
/eventdetector_ts/data/__init__.py:
--------------------------------------------------------------------------------
1 | VALUE_ERROR = ValueError("Invalid TimeUnit value.")
2 |
--------------------------------------------------------------------------------
/images/op_bs.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/CodeSignal/hire_eventdetector/main/images/op_bs.png
--------------------------------------------------------------------------------
/images/op_ccf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/CodeSignal/hire_eventdetector/main/images/op_ccf.png
--------------------------------------------------------------------------------
/eventdetector_ts/optimization/__init__.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 | logger = logging.getLogger(__name__)
4 |
--------------------------------------------------------------------------------
/eventdetector_ts/prediction/__init__.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 | logger = logging.getLogger(__name__)
4 |
--------------------------------------------------------------------------------
/images/delta_t_bs.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/CodeSignal/hire_eventdetector/main/images/delta_t_bs.png
--------------------------------------------------------------------------------
/images/losses_bs.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/CodeSignal/hire_eventdetector/main/images/losses_bs.png
--------------------------------------------------------------------------------
/images/losses_ccf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/CodeSignal/hire_eventdetector/main/images/losses_ccf.png
--------------------------------------------------------------------------------
/images/op_mex_ccf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/CodeSignal/hire_eventdetector/main/images/op_mex_ccf.png
--------------------------------------------------------------------------------
/images/delta_t_ccf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/CodeSignal/hire_eventdetector/main/images/delta_t_ccf.png
--------------------------------------------------------------------------------
/eventdetector_ts/metamodel/__init__.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 | logger_meta_model = logging.getLogger(__name__)
4 |
--------------------------------------------------------------------------------
/images/losses_mex_ccf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/CodeSignal/hire_eventdetector/main/images/losses_mex_ccf.png
--------------------------------------------------------------------------------
/images/inputs_event_detector.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/CodeSignal/hire_eventdetector/main/images/inputs_event_detector.png
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | joblib
2 | matplotlib
3 | numpy
4 | pandas
5 | python_dateutil
6 | scikit_learn
7 | scipy
8 | seaborn
9 | sympy
10 | colorlog
11 | pydot
12 | pyqt5
13 | tqdm
--------------------------------------------------------------------------------
/requirements_dev.txt:
--------------------------------------------------------------------------------
1 | joblib
2 | matplotlib
3 | numpy
4 | pandas
5 | python_dateutil
6 | scikit_learn
7 | scipy
8 | seaborn
9 | sympy
10 | tensorflow
11 | colorlog
12 | pydot
13 | pyqt5
14 | tqdm
15 |
--------------------------------------------------------------------------------
/eventdetector_ts/models/__init__.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 | logger_models = logging.getLogger(__name__)
4 |
5 | ACTIVATION_FUNCTIONS = ["relu", "sigmoid", "tanh", "softmax", "leaky_relu", "elu", "selu", "swish"]
6 |
--------------------------------------------------------------------------------
/eventdetector_ts/plotter/__init__.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 | logger = logging.getLogger(__name__)
4 | COLOR_TRUE = "k" # black
5 | COLOR_PREDICTED = "r" # red
6 | STYLE_TRUE = "-" # solid line
7 | STYLE_PREDICTED = "--" # dashed line
8 | FIG_SIZE = (6, 4.5) # width, height in inches
9 | PALETTE = "tab10" # categorical color map
10 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized files
2 | *.py[cod]
3 | __pycache__/
4 | *.py[cod]?
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | dist/
11 | build/
12 | eggs/
13 | *.egg-info/
14 | .svn/
15 | *.swp
16 | *.tar.gz
17 | *.tgz
18 | *.zip
19 | *.rar
20 |
21 | # Development
22 | *.bak
23 | *.tmp
24 |
25 | # IDE specific files
26 | .vscode/
27 | .idea/
28 |
29 | # Jupyter Notebook
30 | .ipynb_checkpoints/
31 |
32 | # Environment
33 | .env
34 | env/
35 | venv/
36 | ENV/
37 | env.bak/
38 | venv.bak/
39 |
40 | # Compiled Python modules
41 | *.pyd
42 |
43 | # Coverage
44 | .coverage
45 | .coverage.*
46 | htmlcov/
47 |
48 | # Type checking
49 | .mypy_cache/
50 | .dmypy.json
51 |
52 | # Sphinx documentation
53 | docs/_build/
54 |
55 | # Ignore .pkl file
56 | *.pkl
57 |
58 |
59 |
--------------------------------------------------------------------------------
/eventdetector_ts/optimization/algorithms.py:
--------------------------------------------------------------------------------
1 | from typing import Union
2 |
3 | import numpy as np
4 |
5 |
6 | def convolve_with_gaussian_kernel(signal: np.ndarray, sigma: Union[int, float], m: int) -> np.ndarray:
7 | """
8 | Convolve a signal with a Gaussian kernel.
9 |
10 | Args:
11 | signal (np.ndarray): The input signal to convolve.
12 | sigma (Union[int, float]): The standard deviation of the Gaussian kernel.
13 | m (int): The radius of the kernel.
14 |
15 | Returns:
16 | np.ndarray: The convolved signal.
17 |
18 | """
19 |
20 | # Create the Gaussian kernel
21 | kernel = (1 / (np.sqrt(2 * np.pi) * sigma)) * np.exp(-(np.arange(-m, m + 1) ** 2) / (2 * sigma ** 2))
22 | kernel /= np.sum(kernel) # Normalize the kernel
23 |
24 | # Perform the convolution
25 | convolved_signal = np.convolve(signal, kernel, mode='same')
26 |
27 | return convolved_signal
28 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) [year] [fullname]
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
--------------------------------------------------------------------------------
/tests/data/test_interval.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from datetime import datetime, timedelta
3 |
4 | from eventdetector_ts.data.interval import Interval
5 |
6 |
7 | class TestInterval(unittest.TestCase):
8 | def setUp(self):
9 | self.interval1 = Interval(datetime(2010, 7, 21, 18, 25), datetime(2010, 7, 21, 18, 28))
10 | self.interval2 = Interval(datetime(2010, 7, 21, 18, 24, 30), datetime(2010, 7, 21, 18, 27, 30))
11 | self.interval3 = Interval(datetime(2010, 7, 21, 18, 26, 30), datetime(2010, 7, 21, 18, 29, 30))
12 |
13 | def test_overlap(self):
14 | self.assertEqual(self.interval1.overlap(self.interval2), timedelta(seconds=150))
15 | self.assertEqual(self.interval1.overlap(self.interval3), timedelta(seconds=90))
16 | self.assertEqual(self.interval2.overlap(self.interval3), timedelta(seconds=60))
17 |
18 | def test_overlapping_parameter(self):
19 | self.assertEqual(round(self.interval1.overlapping_parameter(self.interval2), 3), 0.714)
20 | self.assertEqual(round(self.interval1.overlapping_parameter(self.interval3), 3), 0.333)
21 | self.assertEqual(round(self.interval2.overlapping_parameter(self.interval3), 3), 0.200)
22 |
23 |
24 | if __name__ == '__main__':
25 | unittest.main()
26 |
--------------------------------------------------------------------------------
/tests/optimization/test_gaussian.py:
--------------------------------------------------------------------------------
1 | import unittest
2 |
3 | import numpy as np
4 |
5 | from eventdetector_ts.optimization.algorithms import convolve_with_gaussian_kernel
6 |
7 |
8 | def convolution_with_gaussian(signal, sigma, m):
9 | signal_size = len(signal)
10 |
11 | output = []
12 | for n in range(signal_size):
13 | temp = 0
14 | sum_kernel = 0
15 | for i in range(-m, m + 1):
16 | g_i = (1 / (np.sqrt(2 * np.pi) * sigma)) * np.exp(-(i ** 2) / (2. * sigma ** 2))
17 | if 0 <= (n - i) < signal_size:
18 | temp += g_i * signal[n - i]
19 | sum_kernel += g_i
20 |
21 | output.append(temp / sum_kernel)
22 | return output
23 |
24 |
25 | class TestGaussianFilter(unittest.TestCase):
26 | def test_gaussian_filter(self):
27 | signal = np.array([1.0, 2, 3, 4.0, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16])
28 | sigma = 1
29 | m = 2
30 |
31 | convolved_signal = convolve_with_gaussian_kernel(signal=signal, sigma=sigma, m=m)
32 | convolved_signal_expected = convolution_with_gaussian(signal=signal, sigma=sigma, m=m)
33 |
34 | # Check if the outputs are equal
35 | np.testing.assert_allclose(convolved_signal_expected, convolved_signal, atol=1e-8)
36 |
37 |
38 | if __name__ == '__main__':
39 | unittest.main()
40 |
--------------------------------------------------------------------------------
/tests/models/test_helpers_models.py:
--------------------------------------------------------------------------------
1 | import unittest
2 |
3 | import numpy as np
4 | import tensorflow as tf
5 |
6 | from eventdetector_ts.models.helpers_models import CustomEarlyStopping
7 |
8 |
9 | class TestHelpers(unittest.TestCase):
10 | def setUp(self):
11 | pass
12 |
13 | class TestCustomEarlyStopping(tf.test.TestCase):
14 | def test_on_epoch_end(self):
15 | # Create a custom early stopping callback
16 | early_stopping = CustomEarlyStopping(ratio=2.0, patience=3, verbose=0)
17 |
18 | # Set up test data
19 | x_train = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
20 | y_train = np.array([0, 1, 1, 0])
21 | x_val = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
22 | y_val = np.array([0, 1, 1, 0])
23 |
24 | # Define a simple model
25 | model = tf.keras.models.Sequential([
26 | tf.keras.layers.Dense(2, activation='sigmoid', input_shape=(2,)),
27 | tf.keras.layers.Dense(1, activation='sigmoid')
28 | ])
29 | model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
30 |
31 | # Train the model with the custom early stopping callback
32 | model.fit(x_train, y_train, epochs=10, validation_data=(x_val, y_val), callbacks=[early_stopping])
33 |
34 | # Check that training was stopped early
35 | self.assertLess(early_stopping.stopped_epoch, 10)
36 |
37 |
38 | if __name__ == '__main__':
39 | unittest.main()
40 |
--------------------------------------------------------------------------------
/eventdetector_ts/prediction/utils.py:
--------------------------------------------------------------------------------
1 | import csv
2 | import os
3 | from typing import List
4 |
5 | import numpy as np
6 | import seaborn as sns
7 | from matplotlib import pyplot as plt
8 |
9 | from eventdetector_ts.plotter import COLOR_PREDICTED, COLOR_TRUE
10 |
11 |
12 | def plot_prediction(predicted_op: np.ndarray, filtered_predicted_op: np.ndarray) -> None:
13 | """
14 | Plot the original and filtered predicted Op
15 | Args:
16 | predicted_op (np.ndarray): Predicted Op
17 | filtered_predicted_op (np.ndarray): Filtered predicted Op
18 |
19 | Returns:
20 | None
21 | """
22 | sns.set(style="ticks", palette="Set2")
23 | plt.figure(figsize=(8, 6)) # Set the figure size
24 |
25 | # Plot the true and predicted values using Seaborn
26 | n = len(predicted_op)
27 | sns.lineplot(x=np.arange(n), y=predicted_op, color=COLOR_TRUE, label='Predicted Op')
28 | sns.lineplot(x=np.arange(n), y=filtered_predicted_op, color=COLOR_PREDICTED, label='Filtered Predicted Op')
29 |
30 | # Add labels and title to the plot
31 | plt.xlabel('Partitions')
32 | plt.ylabel('Op')
33 | plt.title('Predicted Op')
34 | # Add legend
35 | plt.legend()
36 | # Show
37 | plt.show()
38 |
39 |
40 | def write_events_to_csv(events: List, name: str) -> None:
41 | path = os.path.join(f"{name}.csv")
42 | with open(path, 'w', encoding='UTF8', newline='') as f:
43 | writer = csv.writer(f, delimiter=' ')
44 | for (start_time, end_time) in events:
45 | writer.writerow([start_time, end_time])
46 |
--------------------------------------------------------------------------------
/eventdetector_ts/plotter/helpers.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime
2 |
3 | import matplotlib.dates as mdates
4 | from matplotlib.patches import Rectangle
5 |
6 | from eventdetector_ts import TimeUnit
7 | from eventdetector_ts.data.helpers_data import convert_time_to_datetime, get_timedelta
8 |
9 |
10 | def event_to_rectangle(event, width_events_s: float, time_unit: TimeUnit, color, height=1, style="solid"):
11 | """
12 | Function to convert an event to a rectangle object for visualization.
13 |
14 | Args:
15 | event (datetime or other): The event timestamp or object.
16 | width_events_s (float): The width of events in the unit of time for the dataset.
17 | time_unit (TimeUnit): The time unit of the partition size.
18 | color (str): The color of the rectangle.
19 | height (int): The height of the rectangle.
20 | style (str): The line style of the rectangle.
21 |
22 | Returns:
23 | Rectangle: The rectangle object representing the event.
24 |
25 | """
26 | time = event
27 | if not isinstance(event, datetime):
28 | time = convert_time_to_datetime(event, to_timestamp=False)
29 | w_s_timedelta = get_timedelta(float(width_events_s) / 2, time_unit)
30 | start_time = time - w_s_timedelta
31 | end_time = time + w_s_timedelta
32 |
33 | start_rect = mdates.date2num(start_time)
34 | end_rect = mdates.date2num(end_time)
35 |
36 | width_rect = end_rect - start_rect
37 | rect = Rectangle((start_rect, 0), width_rect, height, edgecolor=color, linestyle=style,
38 | facecolor='none', linewidth=1)
39 |
40 | return rect
41 |
--------------------------------------------------------------------------------
/tests/models/test_models_builder.py:
--------------------------------------------------------------------------------
1 | import unittest
2 |
3 | import tensorflow as tf
4 | from sympy.testing import pytest
5 |
6 | from eventdetector_ts import RNN_ENCODER_DECODER, FFN, CNN, RNN_BIDIRECTIONAL, CONV_LSTM1D, LSTM, SELF_ATTENTION
7 | from eventdetector_ts.models.models_builder import ModelBuilder, ModelCreator
8 |
9 |
10 | class TestModelsBuilder(unittest.TestCase):
11 | def setUp(self):
12 | # create a model builder with an input layer
13 | self.inputs = tf.keras.layers.Input(shape=(10,))
14 | self.model_builder = ModelBuilder(self.inputs)
15 | self.inputs_rnn = tf.keras.Input(shape=(45, 5), name="Input")
16 |
17 | def test_check_input_shape(self):
18 | # create a layer with compatible input shape and call __check_input_shape
19 | layer1 = tf.keras.layers.Dense(5)
20 | output1 = self.model_builder._ModelBuilder__check_input_shape(layer1)
21 | self.assertEqual(output1.shape, tf.TensorShape([None, 10]))
22 |
23 | def test_add_layer(self):
24 | layer1 = tf.keras.layers.Dense(5)
25 | self.model_builder._ModelBuilder__add_layer(layer1)
26 | self.assertEqual(self.model_builder.outputs.shape, tf.TensorShape([None, 5]))
27 |
28 | layer2 = tf.keras.layers.Conv2D(32, kernel_size=3)
29 | with pytest.raises(ValueError):
30 | self.model_builder._ModelBuilder__add_layer(layer2)
31 |
32 | def test_create_models(self):
33 | model_creator = ModelCreator(
34 | [(RNN_ENCODER_DECODER, 1), (FFN, 2), (CNN, 2), (RNN_BIDIRECTIONAL, 1), (CONV_LSTM1D, 1), (LSTM, 3),
35 | (SELF_ATTENTION, 3)],
36 | hyperparams_rnn=(1, 2, 45, 46, "tanh"),
37 | hyperparams_cnn=(64, 65, 3, 4, 1, 1, "relu"),
38 | hyperparams_ffn=(1, 2, 64, 128, "sigmoid"), save_models_as_dot_format=False, root_dir=None, dropout=0.3,
39 | last_act_func="sigmoid", hyperparams_transformer=(256, 4, 1, True, "relu"))
40 |
41 | model_creator.create_models(inputs=self.inputs_rnn)
42 |
43 | for key, value in model_creator.created_models.items():
44 | keras_model: tf.keras.Model = value
45 | self.assertEqual(keras_model.layers[-1].output_shape, (None, 1))
46 |
47 |
48 | if __name__ == '__main__':
49 | unittest.main()
50 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.ruff]
2 | line-length = 120
3 |
4 | [tool.coverage.run]
5 | omit = [
6 | "eventdetector_ts/plotter/*",
7 | "eventdetector_ts/prediction/*",
8 | "eventdetector_ts/metamodel/*",
9 | "eventdetector_ts/optimization/event_extraction_pipeline.py",
10 | "eventdetector_ts/models/models_trainer.py"
11 | ]
12 | source = ["eventdetector_ts"]
13 |
14 | [build-system]
15 | requires = ["flit_core>=3.4"]
16 | build-backend = "flit_core.buildapi"
17 |
18 | [project]
19 | name = "eventdetector_ts"
20 | version = "1.1.0"
21 | description = "EventDetector introduces a universal event detection method for multivariate time series. Unlike traditional deep-learning methods, it's regression-based, requiring only reference events. The robust stacked ensemble, from Feed-Forward Neural Networks to Transformers, ensures accuracy by mitigating biases. The package supports practical implementation, excelling in detecting events with precision, validated across diverse domains."
22 | keywords = [
23 | "Universal Event Detection",
24 | "Multivariate Time Series",
25 | "Regression-based",
26 | "Stacked Ensemble Learning",
27 | "Deep Learning Models",
28 | "Feed-Forward Neural Networks",
29 | "Transformers",
30 | "Event Detection Package",
31 | "Rare Events",
32 | "Imbalanced Datasets",
33 | "Anomaly Detection",
34 | "Change Point Detection",
35 | "Fraud Detection",
36 | "Empirical Validations"
37 | ]
38 | authors = [
39 | { name = "Menouar Azib", email = "menouar.azib@akkodis.com" }
40 | ]
41 |
42 | maintainers = [
43 | { name = "Menouar Azib", email = "menouar.azib@akkodis.com" }
44 | ]
45 | requires-python = ">=3.9"
46 | readme = "README.md"
47 | license = { file = "LICENSE" }
48 | classifiers = ["License :: OSI Approved :: MIT License", "Programming Language :: Python :: 3", "Operating System :: OS Independent"]
49 |
50 | dependencies = [
51 | "joblib",
52 | "matplotlib",
53 | "numpy",
54 | "pandas",
55 | "python_dateutil",
56 | "scikit_learn",
57 | "scipy",
58 | "seaborn",
59 | "sympy",
60 | "colorlog",
61 | "pydot",
62 | "pyqt5",
63 | "tqdm"
64 | ]
65 |
66 | [project.urls]
67 | "Homepage" = "https://github.com/menouarazib/eventdetector"
68 | "Bug Tracker" = "https://github.com/menouarazib/eventdetector/issues"
--------------------------------------------------------------------------------
/.github/workflows/unit_tests.yml:
--------------------------------------------------------------------------------
1 | name: Tests and Lint
2 |
3 | on:
4 | push:
5 | branches:
6 | - master
7 | - dev
8 | paths-ignore:
9 | - 'README.md'
10 | - 'pyproject.toml'
11 |
12 | jobs:
13 | build:
14 | runs-on: ${{ matrix.os }}
15 | strategy:
16 | matrix:
17 | os: [ ubuntu-latest, windows-latest, macos-latest ]
18 | python-version: [ "3.9", "3.10", "3.11" ]
19 |
20 | steps:
21 | - uses: actions/checkout@v3
22 | - name: Set up Python ${{ matrix.python-version }}
23 | uses: actions/setup-python@v4
24 | with:
25 | python-version: ${{ matrix.python-version }}
26 | - name: Update pip and setuptools
27 | run: |
28 | python -m pip install --upgrade pip
29 | python -m pip install --upgrade setuptools
30 |
31 | - name: Install dependencies
32 | run: |
33 | pip install --no-cache-dir ruff pytest coverage
34 | pip install --no-cache-dir -r requirements_dev.txt
35 | - name: Lint with ruff
36 | run: |
37 | # stop the build if there are Python syntax errors or undefined names
38 | ruff --output-format=github --select=E9,F63,F7,F82 --target-version=py37 .
39 | # default set of ruff rules with GitHub Annotations
40 | ruff --output-format=github --target-version=py37 .
41 | continue-on-error: true
42 | - name: List files in workspace
43 | run: |
44 | ls "${{ github.workspace }}"
45 | - name: Run unit tests with coverage
46 | env: # Add the env section with GITHUB_TOKEN
47 | GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
48 | run: |
49 | coverage run -m pytest tests/
50 | coverage xml -o coverage.xml
51 | - name: Upload coverage report (only for ubuntu-latest and python 3.10)
52 | if: ${{ matrix.os == 'ubuntu-latest' && matrix.python-version == '3.10' }}
53 | uses: actions/upload-artifact@v3
54 | with:
55 | name: coverage-report
56 | path: coverage.xml
57 | - name: Run Coveralls (only for ubuntu-latest and python 3.10)
58 | if: ${{ matrix.os == 'ubuntu-latest' && matrix.python-version == '3.10' }}
59 | env:
60 | GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
61 | uses: coverallsapp/github-action@v2
62 |
--------------------------------------------------------------------------------
/eventdetector_ts/data/interval.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime, timedelta
2 |
3 |
4 | class Interval:
5 | """
6 | Represents a time interval between two datetime objects. This class is used to model an event or partition in
7 | time-series.
8 | """
9 |
10 | def __init__(self, start_time: datetime, end_time: datetime):
11 | """
12 | Constructs an interval for a given start and end time.
13 |
14 | Args:
15 | start_time (datetime): The starting time of the interval.
16 | end_time (datetime): The ending time of the interval.
17 | """
18 | self.start_time = start_time
19 | self.end_time = end_time
20 | self.duration = self.end_time - self.start_time
21 |
22 | def __str__(self) -> str:
23 | """
24 | Returns a string representation of the interval in the format "start_time ---> end_time".
25 |
26 | Returns:
27 | str: A string representation of the interval.
28 | """
29 | return "{} ---> {}".format(self.start_time, self.end_time)
30 |
31 | def __repr__(self) -> str:
32 | """
33 | Returns a string representation of the interval in the format "start_time ---> end_time".
34 |
35 | Returns:
36 | str: A string representation of the interval.
37 | """
38 | return "{} ---> {}".format(self.start_time, self.end_time)
39 |
40 | def overlap(self, other: 'Interval') -> timedelta:
41 | """
42 | Computes the overlapping time (ot) between this interval and another interval.
43 |
44 | Args:
45 | other (Interval): Another interval to compare with.
46 |
47 | Returns:
48 | timedelta: The overlapping time between this interval and the other interval as a timedelta object.
49 | """
50 | overlap_start_time = max(self.start_time, other.start_time)
51 | overlap_end_time = min(self.end_time, other.end_time)
52 | overlap_duration = max(timedelta(0), overlap_end_time - overlap_start_time)
53 | return overlap_duration
54 |
55 | def overlapping_parameter(self, other: 'Interval') -> float:
56 | """
57 | Computes the overlapping parameter between this interval and another interval.
58 |
59 | Args:
60 | other (Interval): Another interval to compare with.
61 |
62 | Returns:
63 | float: A floating number between 0.0 and 1.0 representing the degree of overlap between the two intervals.
64 | """
65 | if other is None:
66 | return 0.0
67 | overlap_duration = self.overlap(other)
68 | total_duration = self.duration + other.duration - overlap_duration
69 | return overlap_duration / total_duration
70 |
--------------------------------------------------------------------------------
/eventdetector_ts/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | from enum import Enum
3 | from logging import config
4 | from typing import Dict, Optional
5 | from urllib.request import urlretrieve
6 |
7 | import pandas as pd
8 | from tqdm import tqdm
9 |
10 | TIME_LABEL = "time"
11 | MIDDLE_EVENT_LABEL = "event"
12 |
13 | LSTM = "LSTM"
14 | GRU = "GRU"
15 | CNN = "CNN"
16 | RNN_BIDIRECTIONAL = "RNN_BIDIRECTIONAL"
17 | CONV_LSTM1D = "CONV_LSTM_1D"
18 | RNN_ENCODER_DECODER = "RNN_ENCODER_DECODER"
19 | CNN_RNN = "CNN_RNN"
20 | SELF_ATTENTION = "SELF_ATTENTION"
21 | TRANSFORMER = "TRANSFORMER"
22 | FFN = "FFN"
23 |
24 | FILL_NAN_ZEROS = 'zeros'
25 | FILL_NAN_FFILL = 'ffill'
26 | FILL_NAN_BFILL = 'bfill'
27 | FILL_NAN_MEDIAN = 'median'
28 |
29 | TYPE_TRAINING_AVERAGE = 'average'
30 | TYPE_TRAINING_FFN = 'ffn'
31 | META_MODEL_NETWORK = "meta_model_ffn"
32 | META_MODEL_SCALER = "meta_model_scaler"
33 |
34 | # Define constants for scaler types
35 | MIN_MAX_SCALER = "MinMaxScaler"
36 | STANDARD_SCALER = "StandardScaler"
37 | ROBUST_SCALER = "RobustScaler"
38 |
39 | SCALERS_DIR = "scalers"
40 | MODELS_DIR = "models"
41 | OUTPUT_DIR = "output"
42 | CONFIG_FILE = ".config.json"
43 | # Store some important values for prediction
44 | config_dict: Dict = {}
45 |
46 |
47 | class TimeUnit(Enum):
48 | """
49 | An enumeration of different time units.
50 |
51 | Attributes:
52 | SECOND: The time unit is in seconds.
53 | MILLISECOND: The time unit is in milliseconds.
54 | MICROSECOND: The time unit is in microseconds.
55 | MINUTE: The time unit is in minutes.
56 | HOUR: The time unit is in hours.
57 | DAY: The time unit is in days.
58 | YEAR: The time unit is in years.
59 | """
60 | SECOND = "second"
61 | MILLISECOND = "millisecond"
62 | MICROSECOND = "microsecond"
63 | MINUTE = "minute"
64 | HOUR = "hour"
65 | DAY = "day"
66 | YEAR = "year"
67 |
68 | @classmethod
69 | def _missing_(cls, value):
70 | return cls.SECOND
71 |
72 | def __str__(self):
73 | return self.value
74 |
75 |
76 | LOGGING_CONFIG = {
77 | "version": 1,
78 | "disable_existing_loggers": False,
79 | "formatters": {
80 | "colored": {
81 | "()": "colorlog.ColoredFormatter",
82 | "format": "%(asctime)s %(log_color)s[%(levelname)s] %(name)s: %(message)s",
83 | "datefmt": "%Y-%m-%d %H:%M:%S",
84 | "log_colors": {
85 | "DEBUG": "cyan",
86 | "INFO": "white",
87 | "WARNING": "yellow",
88 | "ERROR": "red",
89 | "CRITICAL": "red,bg_white",
90 | },
91 | },
92 | },
93 | "handlers": {
94 | "console": {
95 | "class": "logging.StreamHandler",
96 | "level": "DEBUG",
97 | "formatter": "colored",
98 | "stream": "ext://sys.stdout",
99 | },
100 | },
101 | "loggers": {
102 | "": {
103 | "handlers": ["console"],
104 | "level": "INFO",
105 | "propagate": False,
106 | },
107 | },
108 | }
109 |
110 | config.dictConfig(LOGGING_CONFIG)
111 |
112 |
113 | def my_hook(t):
114 | """
115 | Wraps tqdm instance. Don't forget to close() or __exit__()
116 | the tqdm instance once you're done with it (easiest using `with` syntax).
117 |
118 | Example
119 | -------
120 |
121 |
122 |
123 | """
124 | last_b = [0]
125 |
126 | def inner(b=1, bsize=1, t_size=None):
127 | """
128 | b : int, optional
129 | Number of blocks just transferred [default: 1].
130 | bsize : int, optional
131 | Size of each block (in tqdm units) [default: 1].
132 | t_size : int, optional
133 | Total size (in tqdm units). If [default: None] remains unchanged.
134 | """
135 | if t_size is not None:
136 | t.total = t_size
137 | t.update((b - last_b[0]) * bsize)
138 | last_b[0] = b
139 |
140 | return inner
141 |
142 |
143 | def load_dataset(file_path: str, name: str, url=None, index_col: Optional[int] = 0) -> pd.DataFrame:
144 | """
145 | Load a dataset from a file. If the file is not found, it will be downloaded from the given URL.
146 |
147 | Args:
148 | name: Name of the file to load
149 | index_col: the same value as pandas index_col
150 | file_path (str): The path to the dataset file.
151 | url (str): The URL from which to download the dataset (optional).
152 |
153 | Returns:
154 | pandas.DataFrame: The loaded dataset.
155 | """
156 |
157 | file_extension = os.path.splitext(file_path)[1].lower()
158 |
159 | if not os.path.isfile(file_path) and url:
160 | # Dataset file isn't found, download it
161 | with tqdm(unit='B', unit_scale=True, leave=True, miniters=1,
162 | desc=f"Downloading {name}") as t: # all optional kwargs
163 | urlretrieve(url, filename=file_path,
164 | reporthook=my_hook(t), data=None)
165 |
166 | if file_extension == ".csv":
167 | # Read CSV file
168 | dataset = pd.read_csv(file_path, index_col=index_col)
169 | elif file_extension == ".pkl":
170 | # Read Pickle file
171 | dataset = pd.read_pickle(file_path)
172 | else:
173 | raise ValueError(f"Unsupported file format: {file_extension}")
174 |
175 | # Return the loaded dataset
176 | return dataset
177 |
178 |
179 | def load_martian_bow_shock():
180 | """
181 | Load the Martian bow shock dataset and events, for more information check this link: http://amda.cdpp.eu/
182 |
183 | Returns:
184 | A dataset and events as pd.DataFrame
185 |
186 | """
187 | url_dataset = "https://archive.org/download/martian_bow_shock_dataset/martian_bow_shock_dataset.pkl"
188 | url_events = "https://archive.org/download/martian_bow_shock_events/martian_bow_shock_events.csv"
189 | data_set = load_dataset(file_path="martian_bow_shock_dataset.pkl", name="Martian Bow Shock data set",
190 | url=url_dataset)
191 | events = load_dataset(file_path="martian_bow_shock_events.csv", name="Martian Bow Shock events", index_col=None,
192 | url=url_events)
193 |
194 | return data_set, events
195 |
196 |
197 | def load_credit_card_fraud():
198 | """
199 | Load the credit card fraud dataset and events, for more information check this link: https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
200 |
201 | Returns:
202 | A dataset and events as pd.DataFrame
203 |
204 | """
205 | url_dataset = "https://archive.org/download/credit_card_fraud_dataset/credit_card_fraud_dataset.csv"
206 | url_events = "https://archive.org/download/credit_card_fraud_events/credit_card_fraud_events.csv"
207 |
208 | data_set = load_dataset(file_path="credit_card_fraud_dataset.csv", name="Credit Card Fraud data set",
209 | url=url_dataset)
210 | events = load_dataset(file_path="credit_card_fraud_events.csv", name="Credit Card Fraud events", index_col=None,
211 | url=url_events)
212 |
213 | return data_set, events
214 |
--------------------------------------------------------------------------------
/eventdetector_ts/models/helpers_models.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 | import numpy as np
4 | import tensorflow as tf
5 | from sklearn.model_selection import KFold
6 |
7 |
8 | class CustomEarlyStopping(tf.keras.callbacks.Callback):
9 | """
10 | Create a custom early stopping callback that stops training when the ratio of current training loss to current
11 | validation loss is less than a specified ratio for a number of consecutive epochs.
12 |
13 | Args:
14 | ratio (float): Ratio to compare current train loss and current val loss against.
15 | patience (int): Number of epochs to wait before stopping training.
16 | verbose (int, optional): Verbosity level.
17 |
18 | Attributes:
19 | stopped_epoch (int or None): Last epoch index where training was stopped.
20 | best (float or None): Best validation loss observed so far.
21 | best_epoch (int or None): Index of the epoch where the best validation loss was observed.
22 | ratio (float): Ratio to compare current train loss and current val loss against.
23 | patience (int): Number of epochs to wait before stopping training.
24 | verbose (int): Verbosity level.
25 | wait (int): Number of epochs since the last time the ratio was greater than self.ratio.
26 | monitor_op (function): Comparison operator for the ratio.
27 | best_weights (np.ndarray or None): Model weights at the epoch with the best validation loss.
28 | """
29 |
30 | def __init__(self, ratio: float, patience: int, verbose: int = 1):
31 | super().__init__()
32 | self.stopped_epoch = None
33 | self.best = None
34 | self.best_epoch = None
35 | self.ratio = ratio
36 | self.patience = patience
37 | self.verbose = verbose
38 | self.wait = 0
39 | self.monitor_op = np.greater
40 | self.best_weights = None
41 |
42 | def on_train_begin(self, logs=None):
43 | """
44 | Initialize instance attributes.
45 | """
46 | self.wait = 0
47 | self.best_weights = None
48 | self.stopped_epoch = 0
49 | self.best_epoch = 0
50 | self.best = np.inf
51 |
52 | def on_epoch_end(self, epoch, logs=None):
53 | """
54 | Update the best validation loss and check whether to stop training.
55 | """
56 | if logs is not None:
57 | if self.best_weights is None:
58 | self.best_weights = self.model.get_weights()
59 |
60 | current_val = logs.get('val_loss') # Current validation loss
61 | current_train = logs.get('loss') # Current training loss
62 | if current_val is None:
63 | logging.warning(
64 | "Early stopping conditioned on metric `%s` "
65 | "which is not available. Available metrics are: %s",
66 | 'val_loss',
67 | ",".join(list(logs.keys())),
68 | )
69 |
70 | # Update the best validation loss and weights
71 | if self.monitor_op(self.best, current_val):
72 | self.best = current_val
73 | self.best_weights = self.model.get_weights()
74 | self.best_epoch = epoch
75 |
76 | # If the ratio of current training loss to current validation loss is greater than the specified ratio.
77 | if self.monitor_op(np.divide(current_train, current_val), self.ratio):
78 | self.wait = 0
79 | else:
80 | # Only check after the first epoch.
81 | if self.wait >= self.patience and epoch > 0:
82 | self.stopped_epoch = epoch
83 | self.model.stop_training = True
84 | if self.verbose > 0:
85 | tf.print(
86 | "Restoring model weights from "
87 | "the end of the best epoch: "
88 | f"{self.best_epoch + 1}."
89 | )
90 | self.model.set_weights(self.best_weights)
91 | self.wait += 1
92 |
93 | def on_train_end(self, logs=None):
94 | """
95 | Print a message indicating that training was stopped early.
96 | """
97 | if logs is not None:
98 | if self.stopped_epoch > 0 and self.verbose > 0:
99 | tf.print(
100 | f"Epoch {self.stopped_epoch + 1}: early stopping. "
101 | "Restoring model weights from "
102 | "the end of the best epoch: "
103 | f"{self.best_epoch + 1}. "
104 | "Best validation loss: "
105 | f"{self.best}."
106 | )
107 |
108 |
109 | class SelfAttention(tf.keras.layers.Layer):
110 | """
111 | Self-Attention layer for Neural Networks
112 | """
113 |
114 | def __init__(self, units: int, **kwargs) -> None:
115 | super().__init__()
116 | self.last_attention_weights = None
117 | # Instantiate a multi-head attention layer with key dimensionality of units
118 | # and a single head
119 | self.mha = tf.keras.layers.MultiHeadAttention(key_dim=units, num_heads=1, **kwargs)
120 | # Instantiate a normalization layer
121 | self.layer_norm = tf.keras.layers.LayerNormalization()
122 | # Instantiate an addition layer
123 | self.add = tf.keras.layers.Add()
124 |
125 | def call(self, query: tf.Tensor) -> tf.Tensor:
126 | """
127 | Apply a self-attention mechanism on the input query and return the output.
128 |
129 | Args:
130 | query: input tensor to the layer.
131 |
132 | Return:
133 | output tensor of the layer.
134 | """
135 | # Apply multi-head attention on a query
136 | attn_output, attn_scores = self.mha(
137 | query=query,
138 | key=query,
139 | value=query,
140 | return_attention_scores=True)
141 |
142 | # Store the attention scores in last_attention_weights for inspection
143 | self.last_attention_weights = attn_scores
144 |
145 | # Add the attention output to the query and normalize it
146 | x = self.add([query, attn_output])
147 | x = self.layer_norm(x)
148 |
149 | return x
150 |
151 |
152 | def custom_cross_val_score(model: tf.keras.Model, x: np.ndarray, y: np.ndarray, cv: KFold, epochs: int, batch_size: int,
153 | callbacks: list) -> np.ndarray:
154 | """
155 | A function to perform custom cross-validation for a Keras model.
156 |
157 | Args:
158 | model: A Keras model.
159 | x: The input data.
160 | y: The target data.
161 | cv: A KFold cross-validation object.
162 | epochs: The number of epochs for training.
163 | batch_size: The batch size for training.
164 | callbacks: A list of Keras callbacks.
165 |
166 | Returns:
167 | The mean of the validation loss across all folds.
168 | """
169 | scores = []
170 | for train_index, val_index in cv.split(x):
171 | train_x, train_y = x[train_index], y[train_index]
172 | val_x, val_y = x[val_index], y[val_index]
173 | history = model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, callbacks=callbacks,
174 | validation_data=(val_x, val_y), verbose=0)
175 | scores.append(np.min(history.history['val_loss']))
176 | return np.mean(scores)
177 |
--------------------------------------------------------------------------------
/eventdetector_ts/prediction/prediction.py:
--------------------------------------------------------------------------------
1 | import json
2 | import os
3 | from typing import Dict, List, Tuple, Any
4 |
5 | import joblib
6 | import numpy as np
7 | import pandas as pd
8 | import tensorflow as tf
9 |
10 | from eventdetector_ts import CONFIG_FILE, SCALERS_DIR, TYPE_TRAINING_FFN, TimeUnit, MODELS_DIR, META_MODEL_NETWORK, \
11 | META_MODEL_SCALER
12 | from eventdetector_ts.data.helpers_data import convert_dataframe_to_overlapping_partitions, get_timedelta
13 | from eventdetector_ts.optimization.algorithms import convolve_with_gaussian_kernel
14 | from eventdetector_ts.optimization.event_extraction_pipeline import get_peaks, compute_op_as_mid_times
15 | from eventdetector_ts.prediction import logger
16 |
17 |
18 | def load_model_with_fallback(model_path: str) -> tf.keras.Model:
19 | """
20 | Load a Keras model with fallback mechanisms for different formats.
21 |
22 | Args:
23 | model_path (str): Path to the model file
24 |
25 | Returns:
26 | tf.keras.Model: Loaded model
27 | """
28 | try:
29 | # Try loading with Keras 3 format first
30 | return tf.keras.models.load_model(model_path)
31 | except ValueError as e:
32 | if "File format not supported" in str(e):
33 | # Try loading as SavedModel format
34 | try:
35 | saved_model = tf.saved_model.load(model_path)
36 | # Convert SavedModel to Keras model
37 | class SavedModelWrapper(tf.keras.Model):
38 | def __init__(self, saved_model):
39 | super().__init__()
40 | self.saved_model = saved_model
41 |
42 | def call(self, inputs):
43 | return self.saved_model(inputs)
44 |
45 | return SavedModelWrapper(saved_model)
46 | except Exception:
47 | # If all else fails, try H5 format
48 | h5_path = model_path.replace('.keras', '.h5')
49 | if os.path.exists(h5_path):
50 | return tf.keras.models.load_model(h5_path)
51 | else:
52 | raise e
53 | else:
54 | raise e
55 |
56 |
57 | def load_config_file(path: str) -> Dict:
58 | """
59 | Load config file of the meta-model.
60 |
61 | Args:
62 | path (str): Where the config file is stored
63 |
64 | Returns:
65 | Data as a Dict which contains all configuration information
66 | """
67 | config_file_path = os.path.join(path, CONFIG_FILE)
68 | if not os.path.exists(config_file_path):
69 | msg: str = f"The config file {CONFIG_FILE} does not exist in this path: {config_file_path}"
70 | logger.critical(msg)
71 | raise ValueError(msg)
72 |
73 | with open(config_file_path, 'r') as f:
74 | config_: Dict = json.load(f)
75 | return config_
76 |
77 |
78 | def load_models(model_keys: List[str], output_dir: str) -> List[tf.keras.Model]:
79 | """
80 | Loads the trained models.
81 | Args:
82 | model_keys (List[str]): List of model's name
83 | output_dir (str): The parent directory where the trained models are stored
84 |
85 | Returns:
86 | List of keras models
87 | """
88 | models: List[tf.keras.Model] = []
89 | for key in model_keys:
90 | path = os.path.join(output_dir, MODELS_DIR)
91 | # Add .keras extension if not already present
92 | if not key.endswith('.keras'):
93 | key = f"{key}.keras"
94 | path = os.path.join(path, key)
95 | models.append(load_model_with_fallback(path))
96 | return models
97 |
98 |
99 | def apply_scaling(x: np.ndarray, config_data: Dict) -> np.ndarray:
100 | """
101 | Scaling input data according to the stored scalers.
102 | Args:
103 | x (np.ndarray): Input data to be scaled
104 | config_data (Dict): Configuration Data
105 |
106 | Returns:
107 | Scaled data.
108 | """
109 | n_time_steps = x.shape[1]
110 | output_dir: str = config_data.get("output_dir")
111 | scalers_dir = os.path.join(output_dir, SCALERS_DIR)
112 | try:
113 | for i in range(n_time_steps):
114 | scaler_i_path = os.path.join(scalers_dir, f'scaler_{i}.joblib')
115 | # Print progress
116 | print("\rLoading and applying scalers...{}/{}".format(i + 1, n_time_steps), end="")
117 | # Load the scaler from disk
118 | print(scaler_i_path)
119 | scaler = joblib.load(scaler_i_path)
120 | x[:, i, :] = scaler.transform(x[:, i, :])
121 | except ValueError as e:
122 | logger.critical(e)
123 | raise e
124 |
125 | logger.info("Convert data to float32 for consistency...")
126 | x = np.asarray(x).astype('float32')
127 | return x
128 |
129 |
130 | def load_meta_model(output_dir: str) -> Tuple[tf.keras.Model, Any]:
131 | """
132 | Load the metamodel network and the scaler.
133 | Args:
134 | output_dir (str): The parent directory where the trained models are stored
135 |
136 | Returns:
137 | tf.keras.Model, StanderScaler
138 | """
139 | path = os.path.join(output_dir, MODELS_DIR)
140 | # Add .keras extension if not already present
141 | meta_model_name = META_MODEL_NETWORK
142 | if not meta_model_name.endswith('.keras'):
143 | meta_model_name = f"{meta_model_name}.keras"
144 | path = os.path.join(path, meta_model_name)
145 | model = load_model_with_fallback(path)
146 |
147 | scalers_dir = os.path.join(output_dir, SCALERS_DIR)
148 | scaler_path = os.path.join(scalers_dir, f'{META_MODEL_SCALER}.joblib')
149 | scaler = joblib.load(scaler_path)
150 |
151 | return model, scaler
152 |
153 |
154 | def predict(dataset: pd.DataFrame, path: str) -> Tuple[List, np.ndarray, np.ndarray]:
155 | """
156 | Generates output predictions for the input dataset
157 | Args:
158 | dataset (pd.DataFrame): The input dataset.
159 | path (str): The path to the created folder by the MetaModel.
160 |
161 | Returns:
162 | Tuple[List, np.ndarray, np.ndarray]: Predicted events, predicted Op and filtered predicted Op
163 | """
164 |
165 | if path is None or not isinstance(path, str) or len(path) == 0:
166 | msg: str = f"The provided path {path} is not valid."
167 | logger.critical(msg)
168 | raise ValueError(msg)
169 |
170 | config_data: Dict = load_config_file(path=path)
171 | config_data['output_dir'] = path
172 | logger.info(f"Config dict: {config_data}")
173 | logger.info("Converting the dataset to overlapping partitions.")
174 | dataset_as_overlapping_partitions: np.ndarray = convert_dataframe_to_overlapping_partitions(dataset,
175 | width=config_data.get(
176 | "width"),
177 | step=config_data.get(
178 | "step"),
179 | fill_method=config_data.get(
180 | 'fill_nan'))
181 | # Remove the column containing the timestamps from the overlapping partitions
182 | x: np.ndarray = np.delete(dataset_as_overlapping_partitions, -1, axis=2)
183 | logger.info(f"The shape of the input data: {x.shape}")
184 | x = apply_scaling(x=x, config_data=config_data)
185 | model_keys: List[str] = config_data.get('models')
186 | logger.info(f"Loading models: {model_keys}")
187 | models: List[tf.keras.Model] = load_models(model_keys=model_keys, output_dir=config_data.get('output_dir'))
188 | batch_size: int = config_data.get("batch_size")
189 | predictions = []
190 | logger.info("Making prediction from the trained models")
191 | for model in models:
192 | # Make predictions using each model
193 | predicted_y: np.ndarray = model.predict(x, batch_size=batch_size)
194 | predicted_y = predicted_y.flatten()
195 | predictions.append(predicted_y)
196 |
197 | type_training: str = config_data.get('type_training')
198 | # Convert a list of 1D NumPy arrays to 2D NumPy array
199 | predictions = np.stack(predictions, axis=1)
200 | if type_training == TYPE_TRAINING_FFN:
201 | logger.info("Loading the MetaModel and its Scaler")
202 | model, scaler = load_meta_model(output_dir=config_data.get('output_dir'))
203 | predictions = scaler.transform(predictions)
204 | logger.info("Make a final prediction using the network of the MetaModel")
205 | predicted_op = model.predict(predictions, batch_size=batch_size)
206 | predicted_op = predicted_op.flatten()
207 | else:
208 | logger.info("Make a final prediction by averaging")
209 | predicted_op = np.mean(predictions, axis=1)
210 |
211 | sigma, m, h = config_data.get('best_combination')
212 | logger.info(f"Applying Gaussian Filter with sigma = {sigma} and m = {m}")
213 | filtered_predicted_op = convolve_with_gaussian_kernel(predicted_op, sigma=sigma, m=m)
214 | logger.info("Computing filtered predictions as a function of the mid-times of the overlapping partitions")
215 | t, filtered_predicted_op = compute_op_as_mid_times(overlapping_partitions=dataset_as_overlapping_partitions,
216 | op_g=filtered_predicted_op)
217 | logger.info(f"Computing peaks with h = {h:.2f}")
218 | s_peaks = get_peaks(h=h, t=t, op_g=filtered_predicted_op)
219 | predicted_events = []
220 | time_unit: TimeUnit = TimeUnit.__call__(config_data.get('time_unit'))
221 | radius = get_timedelta(config_data.get("width_events_s") / 2.0, time_unit)
222 | logger.info(f"Generating a predicted events with radius = {radius}, predicted op and a filtered predicted op")
223 | for i in range(len(s_peaks)):
224 | predicted_event = s_peaks[i]
225 | start_time = predicted_event - radius
226 | end_time = predicted_event + radius
227 | predicted_events.append((start_time.isoformat(), end_time.isoformat()))
228 | return predicted_events, predicted_op, filtered_predicted_op
229 |
--------------------------------------------------------------------------------
/tests/data/test_helpers_data.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from datetime import datetime, timedelta
3 |
4 | import numpy as np
5 | import pandas as pd
6 | from pandas.core.dtypes.common import is_datetime64_any_dtype
7 | from sympy.testing import pytest
8 |
9 | from eventdetector_ts import TimeUnit
10 | from eventdetector_ts.data.helpers_data import overlapping_partitions, compute_middle_event, \
11 | num_columns, convert_dataframe_to_overlapping_partitions, get_timedelta, get_total_units, check_time_unit, \
12 | convert_dataset_index_to_datetime, convert_seconds_to_time_unit
13 |
14 |
15 | def test_overlapping_partitions():
16 | data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
17 | expected_output = np.array([[[1, 2, 3], [4, 5, 6]], [[4, 5, 6], [7, 8, 9]], [[7, 8, 9], [10, 11, 12]]])
18 | assert np.array_equal(overlapping_partitions(data, width=2, step=1), expected_output)
19 |
20 |
21 | class TestHelpers(unittest.TestCase):
22 |
23 | def setUp(self):
24 | self.n: int = 100
25 |
26 | def test_overlapping_partitions(self):
27 | # Test case 1: 1D input
28 | data1 = np.array([1, 2, 3, 4, 5])
29 | result1 = overlapping_partitions(data1, width=3, step=1)
30 | expected1 = np.array([[1, 2, 3], [2, 3, 4], [3, 4, 5]])
31 | self.assertTrue(np.array_equal(result1, expected1))
32 |
33 | # Test case 2: partition width greater than the size of the input data
34 | data2 = np.array([1, 2, 3, 4, 5])
35 | with pytest.raises(ValueError):
36 | overlapping_partitions(data2, width=6, step=1)
37 |
38 | # Test case 3: 2D input
39 | data3 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
40 | result3 = overlapping_partitions(data3, width=2, step=1)
41 | expected3 = np.array([[[1, 2, 3], [4, 5, 6]], [[4, 5, 6], [7, 8, 9]]])
42 | assert np.array_equal(result3, expected3)
43 |
44 | # Test case 4: 2D input
45 | data4 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
46 | result4 = overlapping_partitions(data4, width=2, step=2)
47 | expected4 = np.array([[[1, 2, 3], [4, 5, 6]]])
48 | assert np.array_equal(result4, expected4)
49 |
50 | def test_convert_dataframe_to_overlapping_partitions(self):
51 | # Create a sample DataFrame with datetime index and real-valued features
52 |
53 | data = np.random.rand(self.n, 3)
54 | index = pd.date_range(start='2022-01-01', periods=self.n, freq='D')
55 | df = pd.DataFrame(data=data, columns=['feat1', 'feat2', 'feat3'], index=index)
56 |
57 | # Test overlapping partition generation with default settings
58 | sw = convert_dataframe_to_overlapping_partitions(df, width=2, step=1)
59 | expected_shape = (self.n - 1, 2, 4) # Number of partitions, partition width, number of features+time
60 | self.assertEqual(sw.shape, expected_shape)
61 |
62 | # Test overlapping partition generation with custom settings
63 | sw = convert_dataframe_to_overlapping_partitions(df, width=14, step=7, fill_method='ffill')
64 | expected_shape = (13, 14, 4) # Number of partitions, partition width, number of features+time
65 | self.assertEqual(sw.shape, expected_shape)
66 |
67 | def test_compute_middle_event(self):
68 | # Test case 1: List of events with 2 columns
69 | events_list = [['2022-01-01', '2022-01-02'], ['2022-01-03', '2022-01-05']]
70 | expected_output = pd.DataFrame({'event': [datetime(2022, 1, 1, 12, 0), datetime(2022, 1, 4)]})
71 | # call function to get actual output
72 | actual_output = compute_middle_event(events_list)
73 |
74 | # compare expected and actual outputs
75 | pd.testing.assert_frame_equal(expected_output, actual_output)
76 |
77 | # Test case 2: List of events with 1 column
78 | events_list = [['2022-01-01'], ['2022-01-03']]
79 | expected_output = pd.DataFrame({"event": [datetime(2022, 1, 1), datetime(2022, 1, 3)]})
80 | # call function to get actual output
81 | actual_output = compute_middle_event(events_list)
82 |
83 | # compare expected and actual outputs
84 | pd.testing.assert_frame_equal(expected_output, actual_output)
85 | # Test case 3: Pandas DataFrame with 2 columns
86 | events_df = pd.DataFrame({'Starting Date': ['2022-01-01', '2022-01-03'],
87 | 'Ending Date': ['2022-01-02', '2022-01-05']})
88 | expected_output = pd.DataFrame({"event": [datetime(2022, 1, 1, 12, 0), datetime(2022, 1, 4)]})
89 | # call function to get actual output
90 | actual_output = compute_middle_event(events_df)
91 |
92 | # compare expected and actual outputs
93 | pd.testing.assert_frame_equal(expected_output, actual_output)
94 |
95 | # Test case 4: Pandas DataFrame with 1 column
96 | expected_output = pd.DataFrame({"event": [datetime(2022, 1, 1), datetime(2022, 1, 3)]})
97 | # call function to get actual output
98 | actual_output = compute_middle_event(events_list)
99 |
100 | # compare expected and actual outputs
101 | pd.testing.assert_frame_equal(expected_output, actual_output)
102 |
103 | # Test case 5: Empty list of events
104 | events_list = []
105 | with pytest.raises(ValueError):
106 | compute_middle_event(events_list)
107 |
108 | # Test case 6: Empty DataFrame of events
109 | events_df = pd.DataFrame()
110 | with pytest.raises(ValueError):
111 | compute_middle_event(events_df)
112 |
113 | # Test case 7: Invalid input format for events
114 | events_list = [[1, 2], [3, 4, 5]]
115 | with pytest.raises(ValueError):
116 | compute_middle_event(events_list)
117 |
118 | def test_empty_list(self):
119 | self.assertEqual(num_columns([]), 0)
120 |
121 | def test_single_column_list(self):
122 | self.assertEqual(num_columns([1, 2, 3]), 1)
123 |
124 | def test_multi_column_list(self):
125 | self.assertEqual(num_columns([[1, 2], [3, 4], [5, 6]]), 2)
126 |
127 | def test_mixed_list(self):
128 | self.assertEqual(num_columns([[1, 2], 3, 4]), 2)
129 |
130 | def test_microsecond(self):
131 | result = get_timedelta(100, TimeUnit.MICROSECOND)
132 | self.assertEqual(result, timedelta(microseconds=100))
133 |
134 | def test_millisecond(self):
135 | result = get_timedelta(500, TimeUnit.MILLISECOND)
136 | self.assertEqual(result, timedelta(milliseconds=500))
137 |
138 | def test_second(self):
139 | result = get_timedelta(60, TimeUnit.SECOND)
140 | self.assertEqual(result, timedelta(seconds=60))
141 |
142 | def test_minute(self):
143 | result = get_timedelta(30, TimeUnit.MINUTE)
144 | self.assertEqual(result, timedelta(minutes=30))
145 |
146 | def test_hour(self):
147 | result = get_timedelta(2, TimeUnit.HOUR)
148 | self.assertEqual(result, timedelta(hours=2))
149 |
150 | def test_day(self):
151 | result = get_timedelta(5, TimeUnit.DAY)
152 | self.assertEqual(result, timedelta(days=5))
153 |
154 | def test_year(self):
155 | result = get_timedelta(2, TimeUnit.YEAR)
156 | self.assertEqual(result, timedelta(days=2 * 365))
157 |
158 | def test_invalid_unit(self):
159 | with self.assertRaises(ValueError):
160 | get_timedelta(10, "null")
161 |
162 | def test_microsecond_(self):
163 | td = timedelta(microseconds=123456789)
164 | self.assertEqual(get_total_units(td, TimeUnit.MICROSECOND), 123456789)
165 |
166 | def test_millisecond_(self):
167 | td = timedelta(milliseconds=123456)
168 | self.assertEqual(get_total_units(td, TimeUnit.MILLISECOND), 123456)
169 |
170 | def test_second_(self):
171 | td = timedelta(seconds=123)
172 | self.assertEqual(get_total_units(td, TimeUnit.SECOND), 123)
173 |
174 | def test_minute_(self):
175 | td = timedelta(minutes=2)
176 | self.assertEqual(get_total_units(td, TimeUnit.MINUTE), 2)
177 |
178 | def test_hour_(self):
179 | td = timedelta(hours=1)
180 | self.assertEqual(get_total_units(td, TimeUnit.HOUR), 1)
181 |
182 | def test_day_(self):
183 | td = timedelta(days=3)
184 | self.assertEqual(get_total_units(td, TimeUnit.DAY), 3)
185 |
186 | def test_year_(self):
187 | td = timedelta(days=365.25)
188 | self.assertAlmostEqual(get_total_units(td, TimeUnit.YEAR), 1.0, places=2)
189 |
190 | def test_invalid_unit_(self):
191 | td = timedelta(seconds=123)
192 | with self.assertRaises(ValueError):
193 | get_total_units(td, "invalid_unit")
194 |
195 | def test_year__(self):
196 | diff = timedelta(days=365)
197 | expected_result = (1, TimeUnit.YEAR)
198 | self.assertEqual(check_time_unit(diff), expected_result)
199 |
200 | def test_day__(self):
201 | diff = timedelta(days=2)
202 | expected_result = (2, TimeUnit.DAY)
203 | self.assertEqual(check_time_unit(diff), expected_result)
204 |
205 | def test_hour__(self):
206 | diff = timedelta(hours=1)
207 | expected_result = (1, TimeUnit.HOUR)
208 | self.assertEqual(check_time_unit(diff), expected_result)
209 |
210 | def test_minute__(self):
211 | diff = timedelta(minutes=2)
212 | expected_result = (2, TimeUnit.MINUTE)
213 | self.assertEqual(check_time_unit(diff), expected_result)
214 |
215 | def test_second__(self):
216 | diff = timedelta(seconds=30)
217 | expected_result = (30, TimeUnit.SECOND)
218 | self.assertEqual(check_time_unit(diff), expected_result)
219 |
220 | def test_millisecond__(self):
221 | diff = timedelta(milliseconds=500)
222 | expected_result = (500, TimeUnit.MILLISECOND)
223 | self.assertEqual(check_time_unit(diff), expected_result)
224 |
225 | def test_microsecond__(self):
226 | diff = timedelta(microseconds=200)
227 | expected_result = (200, TimeUnit.MICROSECOND)
228 | self.assertEqual(check_time_unit(diff), expected_result)
229 |
230 | def test_invalid_time(self):
231 | diff = timedelta(microseconds=0)
232 | with self.assertRaises(ValueError):
233 | check_time_unit(diff)
234 |
235 | def test_convert_datetime_index(self):
236 | # Create a DataFrame with a datetime index
237 | data = {'value': [1, 2, 3, 4, 5]}
238 | index = pd.date_range(start='2023-01-01', periods=5)
239 | dataset = pd.DataFrame(data, index=index)
240 |
241 | # Call the function to convert the index to datetime
242 | convert_dataset_index_to_datetime(dataset)
243 |
244 | # Check if the index is in datetime format
245 | self.assertTrue(is_datetime64_any_dtype(dataset.index))
246 |
247 | def test_non_datetime_index(self):
248 | # Create a DataFrame with a non-datetime index
249 | data = {'value': [1, 2, 3, 4, 5]}
250 | index = ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05']
251 | dataset = pd.DataFrame(data, index=index)
252 |
253 | # Call the function to convert the index to datetime
254 | convert_dataset_index_to_datetime(dataset)
255 |
256 | # Check if the index is converted to datetime format
257 | self.assertTrue(is_datetime64_any_dtype(dataset.index))
258 |
259 | def test_conversion(self):
260 | self.assertEqual(convert_seconds_to_time_unit(1, TimeUnit.SECOND), 1)
261 | self.assertEqual(convert_seconds_to_time_unit(60, TimeUnit.MINUTE), 1)
262 | self.assertEqual(convert_seconds_to_time_unit(3600, TimeUnit.HOUR), 1)
263 |
264 |
265 | if __name__ == '__main__':
266 | unittest.main()
267 |
--------------------------------------------------------------------------------
/eventdetector_ts/optimization/event_extraction_pipeline.py:
--------------------------------------------------------------------------------
1 | from datetime import timedelta
2 | from math import ceil
3 | from typing import Tuple, Union
4 |
5 | import numpy as np
6 | import pandas as pd
7 | from scipy.signal import find_peaks
8 |
9 | from eventdetector_ts import MIDDLE_EVENT_LABEL, TimeUnit, config_dict
10 | from eventdetector_ts.data.helpers_data import get_timedelta, get_total_units
11 | from eventdetector_ts.optimization import logger
12 | from eventdetector_ts.optimization.algorithms import convolve_with_gaussian_kernel
13 |
14 |
15 | class OptimizationData:
16 | """
17 | OptimizationData class represents the data used for the event extraction pipeline.
18 |
19 | Attributes:
20 | - time_unit (TimeUnit): Unit of time used in the dataset.
21 | - true_events (pd.DataFrame): DataFrame to store true events.
22 | - predicted_op (np.ndarray): Array to store predicted outcomes.
23 | - delta Union[int, float]: The maximum time tolerance used to determine the correspondence between a predicted
24 | event and its actual counterpart in the true events.
25 | - s_h (float): A step parameter for the peak height threshold h.
26 | - s_s (int): Step size in time unit for overlapping the partition.
27 | - w_s (int): Size in time unit of the overlapping partition.
28 | - t_max (float): The maximum total time related to sigma.
29 | - output_dir (str): The parent directory.
30 | - big_sigma (int): Value calculated based on t_max, w_s, and s_s.
31 | - overlapping_partitions (np.ndarray): Array to store overalapping partitions.
32 |
33 | """
34 |
35 | def __init__(self, t_max: float, w_s: int, s_s: int,
36 | s_h: float,
37 | delta: Union[int, float],
38 | output_dir: str, time_unit: TimeUnit):
39 | """
40 | Initializes the OptimizationData object.
41 |
42 | Args:
43 | t_max (float): The maximum total time related to sigma.
44 | w_s (int): Size in time unit of the overalapping partition.
45 | s_s (int): Step size in time unit for overalapping the partition.
46 | s_h (float): A step parameter for the peak height threshold h.
47 | delta Union[int, float]: The maximum time tolerance used to determine the correspondence between a predicted
48 | event and its actual counterpart in the true events.
49 | output_dir (str): The parent directory.
50 | time_unit (TimeUnit): Unit of time used in the dataset.
51 | """
52 | self.time_unit = time_unit
53 | self.true_events: pd.DataFrame = pd.DataFrame()
54 | self.predicted_op: np.ndarray = np.empty(shape=(0,))
55 | self.delta = delta
56 | self.s_h = s_h
57 | self.s_s = s_s
58 | self.w_s = w_s
59 | self.t_max = t_max
60 | self.output_dir = output_dir
61 | self.big_sigma = 1 + ceil((self.t_max - self.w_s) / self.s_s)
62 | self.overlapping_partitions: np.ndarray = np.empty(shape=(0,))
63 |
64 | def set_true_events(self, true_events: pd.DataFrame) -> None:
65 | self.true_events = true_events
66 |
67 | def set_overlapping_partitions(self, overlapping_partitions: np.ndarray):
68 | self.overlapping_partitions = overlapping_partitions
69 |
70 | def set_predicted_op(self, predicted_op: np.ndarray):
71 | self.predicted_op = predicted_op
72 | overlapping_partitions_test = self.overlapping_partitions[-len(predicted_op):]
73 | self.overlapping_partitions = overlapping_partitions_test
74 | first_partition_test_data = self.overlapping_partitions[0]
75 | last_partition_test_data = self.overlapping_partitions[-1]
76 | start_date_test_data = first_partition_test_data[0][-1].to_pydatetime()
77 | end_date_test_data = last_partition_test_data[0][-1].to_pydatetime()
78 | logger.info(
79 | f"Starting and ending dates of test data are respectively {start_date_test_data} --> {end_date_test_data}")
80 |
81 | true_events_test = self.true_events[(self.true_events[MIDDLE_EVENT_LABEL] >= start_date_test_data) & (
82 | self.true_events[MIDDLE_EVENT_LABEL] <= end_date_test_data)]
83 | self.true_events = true_events_test
84 |
85 |
86 | def get_peaks(h: float, t: np.ndarray, op_g: np.ndarray) -> np.ndarray:
87 | """
88 | Compute peaks for given mid_times of partitions, op values, and threshold h.
89 | Args:
90 | h (float): Threshold for peaks.
91 | t (np.ndarray): mid_times of partitions
92 | op_g (np.ndarray): op values
93 |
94 | Returns:
95 | np.ndarray: Peaks.
96 | """
97 | peaks, _ = find_peaks(op_g, height=np.array([h, 1.0]))
98 | return t[peaks]
99 |
100 |
101 | def compute_op_as_mid_times(overlapping_partitions: np.ndarray, op_g: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
102 | """
103 | Compute op as a function of mid-times of partitions instead of partition's index.
104 | Args:
105 | overlapping_partitions (np.ndarray): overalapping partitions
106 | op_g (np.ndarray): Op array
107 |
108 | Returns:
109 | Tuple[np.ndarray, np.ndarray]: mid-times of partitions, op as a function of mid-times of partitions
110 | """
111 | t = []
112 | op_g_ = []
113 | for n in range(len(op_g)):
114 | w_n = overlapping_partitions[n]
115 | b_n = w_n[0][-1].to_pydatetime()
116 | e_n = w_n[-1][-1].to_pydatetime()
117 | c_n = b_n + (e_n - b_n) / 2
118 | t.append(c_n)
119 | op_g_.append(op_g[n])
120 | t, op_g_ = np.array(t), np.array(op_g_)
121 | return t, op_g_
122 |
123 |
124 | class OptimizationCalculator:
125 | def __init__(self, optimization_data: OptimizationData):
126 | self.optimization_data = optimization_data
127 |
128 | def apply_gaussian_filter(self, sigma: int, m: int) -> np.ndarray:
129 | return convolve_with_gaussian_kernel(self.optimization_data.predicted_op, sigma, m=m)
130 |
131 | def __compute_op_as_mid_times(self, op_g: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
132 | return compute_op_as_mid_times(self.optimization_data.overlapping_partitions, op_g)
133 |
134 | def __util_method(self, s_peaks: np.ndarray, delta_with_time_unit: timedelta) -> Tuple[int, int, int, list]:
135 | """
136 | Useful method for compute_f1score method.
137 | Args:
138 | s_peaks (np.ndarray): peaks of op.
139 | delta_with_time_unit (timedelta): delta as number in unit time.
140 |
141 | Returns:
142 | tp, fp, fn, delta_t
143 | """
144 | e_t = self.optimization_data.true_events.copy()
145 |
146 | fp: int = 0
147 | tp: int = 0
148 | delta_t: list = []
149 | for m_p in s_peaks:
150 | signed_delta = delta_with_time_unit
151 | t_t = None
152 | for i, t_e in enumerate(e_t[MIDDLE_EVENT_LABEL]):
153 | m_t = t_e
154 | diff = m_p - m_t
155 |
156 | if abs(diff) <= delta_with_time_unit:
157 | if t_t is None or abs(m_p - t_t) > abs(diff):
158 | t_t = m_t
159 | signed_delta = diff
160 |
161 | if t_t is not None:
162 | tp += 1
163 | e_t = e_t.drop(e_t[e_t[MIDDLE_EVENT_LABEL] == t_t].index)
164 | diff = get_total_units(timedelta_=signed_delta, unit=self.optimization_data.time_unit)
165 |
166 | delta_t.append(diff)
167 | else:
168 | fp += 1
169 | fn: int = len(e_t)
170 | return tp, fp, fn, delta_t
171 |
172 | def compute_f1score(self, sigma: int, m: int, h: float):
173 | delta_with_time_unit = get_timedelta(self.optimization_data.delta, self.optimization_data.time_unit)
174 | op_g: np.ndarray = self.apply_gaussian_filter(sigma=sigma, m=m)
175 | t, op_g = self.__compute_op_as_mid_times(op_g=op_g)
176 | s_peaks = get_peaks(h=h, t=t, op_g=op_g)
177 | tp, fp, fn, delta_t = self.__util_method(s_peaks=s_peaks, delta_with_time_unit=delta_with_time_unit)
178 |
179 | if tp + fp == 0 or tp + fn == 0:
180 | return 0.0, 0.0, 0.0, [], []
181 |
182 | precision = tp / (tp + fp)
183 | recall = tp / (tp + fn)
184 | if precision + recall == 0:
185 | return 0.0, 0.0, 0.0, [], []
186 | return (2.0 * precision * recall) / (precision + recall), precision, recall, s_peaks.tolist(), delta_t
187 |
188 | def evaluate_combination(self, combination):
189 | sigma, m, h = combination
190 | f1_score, precision, recall, peaks, delta_t = self.compute_f1score(sigma, m, h)
191 | formatted_combination = ', '.join(f'{item:.4f}' for item in combination)
192 | if f1_score > 0:
193 | logger.info(
194 | f"Evaluated Combination [sigma, m, h] : [{formatted_combination}] => [F1 Score: {f1_score:.4f}, "
195 | f"Precision: {precision:.4f}, Recall: {recall:.4f}]")
196 | return f1_score, precision, recall, peaks, delta_t
197 |
198 |
199 | class EventOptimization:
200 | """
201 | After obtaining the predicted op values from the metamodel, they are then processed
202 | through an optimization algorithm to extract the predicted events. This involves applying
203 | a Gaussian filter to smooth out the predictions and identifying peaks in the resulting signal
204 | that correspond to the mid-times of the predicted events, which are then compared to the
205 | actual events in the test set. The performance of the algorithm is evaluated by computing
206 | metrics such as F1-Score, which combines precision and recall using their harmonic means.
207 | Maximizing the F1-Score is the preferred metric for evaluating models since it requires
208 | simultaneously maximizing precision and recall.
209 | """
210 |
211 | def __init__(self, optimization_data: OptimizationData):
212 | self.optimization_data = optimization_data
213 | self.optimization_calculator: OptimizationCalculator = OptimizationCalculator(self.optimization_data)
214 | self.results = ()
215 |
216 | def max_f1score(self) -> tuple[list, list]:
217 | """
218 | The optimization process aims to maximize the F1-Score metric by fine-tuning several parameters,
219 | including the filter size (2m + 1) and standard deviation (σ) of the Gaussian filter,
220 | and the peak height threshold h.
221 |
222 | Returns:
223 | list of peaks, delta_t
224 | """
225 | sigma_range = range(1, self.optimization_data.big_sigma + 1)
226 | h_values = np.arange(0, 1, self.optimization_data.s_h)
227 | # Create a list of all combinations to evaluate
228 | combinations = [(sigma, m, h) for sigma in sigma_range for m in [sigma, 2 * sigma, 3 * sigma] for
229 | h in h_values]
230 |
231 | try:
232 | # Evaluate combinations sequentially
233 | results = [self.optimization_calculator.evaluate_combination(combination) for combination in
234 | combinations]
235 | except ValueError as e:
236 | logger.error(e)
237 | exit(0)
238 |
239 | # Find the combination with the maximum F1 score
240 | best_combination_index = np.argmax(list(map(lambda metrics: metrics[0], results)))
241 | best_combination = combinations[best_combination_index]
242 | config_dict["best_combination"] = best_combination
243 | self.results = results[best_combination_index]
244 | max_f1_score, precision, recall, peaks, delta_t = self.results
245 |
246 | formatted_combination = ', '.join(f'{item:.4f}' for item in best_combination)
247 | logger.warning(
248 | f"Best Combination [sigma, m, h] : [{formatted_combination}] => "
249 | f"[Max F1 Score: {max_f1_score:.4f} => Precision:{precision:.4f}, Recall:{recall:.4f}]")
250 | return peaks, delta_t
251 |
--------------------------------------------------------------------------------
/eventdetector_ts/plotter/plotter.py:
--------------------------------------------------------------------------------
1 | import csv
2 | import os
3 | from typing import Dict
4 |
5 | import matplotlib.dates as mdates
6 | import matplotlib.pyplot as plt
7 | import numpy as np
8 | import pandas as pd
9 | import seaborn as sns
10 | from matplotlib.patches import Patch
11 |
12 | from eventdetector_ts import OUTPUT_DIR, TimeUnit, MIDDLE_EVENT_LABEL
13 | from eventdetector_ts.data.helpers_data import get_timedelta
14 | from eventdetector_ts.plotter import logger, COLOR_TRUE, COLOR_PREDICTED, STYLE_PREDICTED, STYLE_TRUE, FIG_SIZE, PALETTE
15 | from eventdetector_ts.plotter.helpers import event_to_rectangle
16 |
17 |
18 | class Plotter:
19 | """
20 | The Plotter class is responsible for generating and saving plots of the predicted and true op, events, delta_t,...
21 | It provides a convenient way to visualize and compare the performance of a
22 | predictive model against the actual observed values.
23 | """
24 |
25 | def __init__(self, root_dir: str, time_unit: TimeUnit, width_events_s: float) -> None:
26 | """
27 | Initialize the Plotter object.
28 |
29 | Args:
30 | root_dir (str): The root directory for saving the plots.
31 | time_unit (TimeUnit): The unit time of the dataset.
32 | width_events_s (float): The width of events in the unit of time for the dataset.
33 | """
34 |
35 | self.val_losses = {}
36 | self.train_losses = {}
37 | self.val_loss_meta_model: list = []
38 | self.train_loss_meta_model: list = []
39 | self.width_events_s = width_events_s
40 | self.time_unit = time_unit
41 | # Whether to display the plots or not. Defaults to False.
42 | self.show = True
43 | self.root_dir = root_dir
44 | self.predicted_y: np.ndarray = np.empty(shape=(0,))
45 | self.test_y: np.ndarray = np.empty(shape=(0,))
46 | self.predicted_events: list = []
47 | self.true_events: pd.DataFrame = pd.DataFrame()
48 | self.delta_t: list = []
49 | self.working_dir = os.path.join(root_dir, OUTPUT_DIR)
50 | os.makedirs(self.working_dir)
51 |
52 | def set_show(self, show: bool) -> None:
53 | """
54 | Set show value
55 | Args:
56 | show (bool): Value to set for 'self.show'
57 |
58 | Returns:
59 | None
60 | """
61 | self.show = show
62 |
63 | def set_data_op(self, test_y: np.ndarray, predicted_y: np.ndarray) -> None:
64 | """
65 | Set test_y and predicted_y
66 | Args:
67 | test_y: The true op values
68 | predicted_y: The predicted op values
69 |
70 | Returns:
71 | None
72 | """
73 | self.test_y = test_y
74 | self.predicted_y = predicted_y
75 |
76 | def set_data_events(self, predicted_events: list, true_events: pd.DataFrame) -> None:
77 | """
78 | Set true and predicted events
79 | Args:
80 | predicted_events (list): List of predicted events computed by the optimization process
81 | true_events (pd.DataFrame): DataFrame of true events
82 |
83 | Returns:
84 | None
85 | """
86 | self.predicted_events = predicted_events
87 | self.true_events = true_events
88 |
89 | def set_delta_t(self, delta_t: list) -> None:
90 | """
91 | Set delta_t
92 | Args:
93 | delta_t (list): Each item of this list contains the accepted delta in time unit between
94 | true event its correspondent in the list of predicted events
95 |
96 | Returns:
97 | None
98 | """
99 | self.delta_t = delta_t
100 |
101 | def set_losses(self, train_losses: Dict[str, list], val_losses: Dict[str, list],
102 | train_loss_meta_model: list, val_loss_meta_model: list) -> None:
103 | """
104 | Set losses of all trained models.
105 | Args:
106 | train_losses (Dict[str, list]): train losses.
107 | val_losses (Dict[str, list]): val losses.
108 | train_loss_meta_model (list): train loss for the metamodel.
109 | val_loss_meta_model (list): val loss for the metamodel.
110 | Returns:
111 | None
112 | """
113 | self.train_losses = train_losses
114 | self.val_losses = val_losses
115 | self.train_loss_meta_model = train_loss_meta_model
116 | self.val_loss_meta_model = val_loss_meta_model
117 |
118 | def plot_prediction(self) -> None:
119 | """
120 | Plot the true and the predicted op and save it.
121 |
122 | Returns:
123 | None
124 | """
125 |
126 | logger.info("Plotting and saving the figure displaying the true and the predicted op")
127 | # Create the plot using Seaborn
128 | # Set the ggplot style
129 | sns.set(style="ticks", palette=PALETTE)
130 | plt.figure(figsize=FIG_SIZE) # Set the figure size
131 | # Plot the true and predicted values using Seaborn
132 | n = len(self.test_y)
133 | sns.lineplot(x=np.arange(n), y=self.test_y, color=COLOR_TRUE, label='True Op')
134 | sns.lineplot(x=np.arange(n), y=self.predicted_y, color=COLOR_PREDICTED, label='Predicted Op')
135 | # Add labels and title to the plot
136 | plt.xlabel('Windows')
137 | plt.ylabel('Op')
138 | plt.title('True Op vs Predicted Op')
139 | # Add legend
140 | plt.legend()
141 | # Save the plot to a file
142 | path = os.path.join(self.working_dir, "op.png")
143 | plt.savefig(path, dpi=300)
144 | # Show the plot
145 | if self.show:
146 | plt.show()
147 | self.__save_op()
148 |
149 | def plot_predicted_events(self) -> None:
150 | """
151 | Plot the true and the predicted events and save it.
152 |
153 | Returns:
154 | None
155 | """
156 |
157 | logger.info("Plotting and saving the figure displaying the true events and the predicted events")
158 | fig, ax = plt.subplots(figsize=FIG_SIZE)
159 | sns.set(style="ticks", palette=PALETTE)
160 |
161 | for i, predicted_event in enumerate(self.predicted_events):
162 | rect1 = event_to_rectangle(event=predicted_event, width_events_s=self.width_events_s,
163 | time_unit=self.time_unit,
164 | color=COLOR_PREDICTED,
165 | style=STYLE_PREDICTED)
166 | ax.add_patch(rect1)
167 |
168 | for _, test_date in self.true_events[MIDDLE_EVENT_LABEL].items():
169 | rect1 = event_to_rectangle(event=test_date, width_events_s=self.width_events_s, time_unit=self.time_unit,
170 | color=COLOR_TRUE,
171 | style=STYLE_TRUE)
172 | ax.add_patch(rect1)
173 |
174 | locator = mdates.AutoDateLocator(minticks=3)
175 | formatter = mdates.AutoDateFormatter(locator)
176 | ax.xaxis.set_major_locator(locator)
177 | ax.xaxis.set_major_formatter(formatter)
178 |
179 | start_time = self.true_events[MIDDLE_EVENT_LABEL].iloc[0]
180 | end_time = self.true_events[MIDDLE_EVENT_LABEL].iloc[-1]
181 | ax.set_xlim([start_time, end_time])
182 | ax.set_ylim([0.0, 1.01])
183 |
184 | predicted_patch = Patch(color=COLOR_PREDICTED, label='Predicted Events')
185 | true_patch = Patch(color=COLOR_TRUE, label='True Events')
186 | ax.legend(handles=[predicted_patch, true_patch], edgecolor="black")
187 |
188 | # Save the plot to a file
189 | path = os.path.join(self.working_dir, "events.png")
190 | plt.savefig(path, dpi=300)
191 | # Show the plot
192 | if self.show:
193 | plt.show()
194 | self.__save_events()
195 |
196 | def plot_delta_t(self, bins=30) -> None:
197 | """
198 | Plots a histogram for delta t.
199 |
200 | Args:
201 | bins (int): The number of bins in the histogram. Default is 10.
202 |
203 | Returns:
204 | None
205 | """
206 | sns.set(style="ticks", palette=PALETTE)
207 | plt.figure(figsize=FIG_SIZE)
208 |
209 | sns.histplot(self.delta_t, bins=bins, binrange=(-self.width_events_s, self.width_events_s))
210 |
211 | plt.xlabel(f'delta ({self.time_unit})')
212 | plt.ylabel('Number of events')
213 |
214 | std = np.std(self.delta_t)
215 | mu = np.mean(self.delta_t)
216 |
217 | plt.title(f'Histogram std = {std:.2f}, mu = {mu:.2f}')
218 | # Save the plot to a file
219 | path = os.path.join(self.working_dir, "delta_t.png")
220 | plt.savefig(path, dpi=300)
221 | # Show the plot
222 | if self.show:
223 | plt.show()
224 |
225 | def plot_losses(self):
226 | """
227 | Plot losses for all trained models.
228 | Returns:
229 | None
230 | """
231 | meta_model_was_used: bool = len(self.val_loss_meta_model) > 0
232 |
233 | sns.set(style="ticks", palette=PALETTE)
234 | if meta_model_was_used:
235 | fig, (ax1, ax2) = plt.subplots(1, 2)
236 | fig.set_size_inches((11, 8.5), forward=False)
237 | else:
238 | fig, ax1 = plt.subplots(figsize=FIG_SIZE)
239 | y_label = 'Loss'
240 | x_label = 'Epochs'
241 | colors = sns.color_palette(PALETTE, len(self.val_losses))
242 | lifestyle_val = '--'
243 | lifestyle_train = '-'
244 | for i, (model_name, val_loss) in enumerate(self.val_losses.items()):
245 | epochs = range(1, len(val_loss) + 1)
246 | train_loss = self.train_losses[model_name]
247 | ax1.plot(epochs, train_loss, linestyle=lifestyle_train, color=colors[i],
248 | label='Training Loss - {}'.format(model_name))
249 | ax1.plot(epochs, val_loss, linestyle=lifestyle_val, color=colors[i],
250 | label='Validation Loss - {}'.format(model_name))
251 | ax1.set_ylabel(y_label)
252 | ax1.set_xlabel(x_label)
253 | ax1.legend()
254 |
255 | if len(self.val_loss_meta_model) > 0:
256 | epochs_meta = range(1, len(self.val_loss_meta_model) + 1)
257 | ax2.plot(epochs_meta, self.train_loss_meta_model, linestyle=lifestyle_train, color='b',
258 | label='Training Loss - Meta Model')
259 | ax2.plot(epochs_meta, self.val_loss_meta_model, linestyle=lifestyle_val, color='g',
260 | label='Validation Loss - Meta Model')
261 | ax2.set_ylabel(y_label)
262 | ax2.set_xlabel(x_label)
263 | ax2.legend()
264 |
265 | fig.suptitle('Training and Validation Losses')
266 | plt.tight_layout()
267 | # Save the plot to a file
268 | path = os.path.join(self.working_dir, "losses.png")
269 | plt.savefig(path, dpi=300)
270 | # Show the plot
271 | if self.show:
272 | plt.show()
273 |
274 | def __save_events(self) -> None:
275 | """
276 | Save predicted events/true events to csv files.
277 |
278 | Returns:
279 | None
280 | """
281 | path = os.path.join(self.working_dir, "predicted_events.csv")
282 | radius = get_timedelta(float(self.width_events_s) / 2.0, self.time_unit)
283 | with open(path, 'w', encoding='UTF8', newline='') as f:
284 | writer = csv.writer(f, delimiter=' ')
285 | for i in range(len(self.predicted_events)):
286 | predicted_event = self.predicted_events[i]
287 | start_time = predicted_event - radius
288 | end_time = predicted_event + radius
289 |
290 | start_time = start_time.replace(microsecond=0)
291 | end_time = end_time.replace(microsecond=0)
292 |
293 | writer.writerow([start_time.isoformat(), end_time.isoformat()])
294 |
295 | path = os.path.join(self.working_dir, "true_events.csv")
296 | with open(path, 'w', encoding='UTF8', newline='') as f:
297 | writer = csv.writer(f, delimiter=' ')
298 | for _, test_date in enumerate(self.true_events[MIDDLE_EVENT_LABEL]):
299 | start_time = test_date - radius
300 | end_time = test_date + radius
301 |
302 | start_time = start_time.replace(microsecond=0)
303 | end_time = end_time.replace(microsecond=0)
304 |
305 | writer.writerow([start_time.isoformat(), end_time.isoformat()])
306 |
307 | def __save_op(self) -> None:
308 | """
309 | Save predicted/true Op into csv file.
310 |
311 | Returns:
312 | None
313 | """
314 | df = pd.DataFrame({'True-Op': self.test_y, 'Predicted-Op': self.predicted_y})
315 | path = os.path.join(self.working_dir, "op.csv")
316 | df.to_csv(path, index=True, sep=" ")
317 |
--------------------------------------------------------------------------------
/eventdetector_ts/models/models_trainer.py:
--------------------------------------------------------------------------------
1 | import os
2 | from typing import Dict, Tuple
3 |
4 | import joblib
5 | import numpy as np
6 | import tensorflow as tf
7 | from numpy import ndarray
8 | from sklearn.model_selection import KFold, train_test_split
9 | from sklearn.preprocessing import StandardScaler
10 |
11 | from eventdetector_ts import MODELS_DIR, META_MODEL_NETWORK, config_dict, TYPE_TRAINING_FFN, SCALERS_DIR, \
12 | META_MODEL_SCALER
13 | from eventdetector_ts.metamodel.utils import DataSplitter
14 | from eventdetector_ts.models import logger_models
15 | from eventdetector_ts.models.helpers_models import CustomEarlyStopping, custom_cross_val_score
16 | from eventdetector_ts.models.models_builder import ModelBuilder
17 |
18 |
19 | class ModelTrainer:
20 | """
21 | A class used to train and evaluate machine learning models.
22 |
23 | Attributes:
24 | data_splitter (DataSplitter): An object of the DataSplitter class, which is used to split the data
25 | into train and test sets.
26 | epochs (int): The number of epochs to train the models.
27 | batch_size (int): The batch size to use during training.
28 | pa (int): The patience value to use for the EarlyStopping callback.
29 | t_r (float): The ratio value to use for the CustomEarlyStopping callback.
30 | use_kfold (bool): Whether to use K-Fold cross-validation or not.
31 | val_size (float): The size of the validation set to use during training.
32 | epsilon (float): A small constant used to control the size of set which contains the top models
33 | with the lowest MSE values.
34 | save_models_as_dot_format (bool): Whether to save the models as a dot format file.
35 | The default value is False. If set to True, then you should have graphviz software
36 | to be installed on your machine.
37 | train_losses (Dict[str, np.ndarray]): A dictionary containing the training losses for each model.
38 | val_losses (Dict[str, np.ndarray]): A dictionary containing the validation losses for each model.
39 | val_loss_meta_model (np.ndarray): val loss for the meta_model.
40 | train_loss_meta_model (np.ndarray): train loss for the meta_model
41 | """
42 |
43 | def __init__(self, data_splitter: DataSplitter, epochs: int,
44 | batch_size: int, pa: int, t_r: float,
45 | use_kfold: bool, val_size: float, epsilon: float, save_models_as_dot_format: bool) -> None:
46 | """
47 | Initialize the ModelTrainer object.
48 |
49 | Args:
50 | data_splitter (DataSplitter): An object of the DataSplitter class, which is used to split the data
51 | into train and test sets.
52 | epochs (int): The number of epochs to train the models.
53 | batch_size (int): The batch size to use during training.
54 | pa (int): The patience value to use for the EarlyStopping callback.
55 | t_r (float): The ratio value to use for the CustomEarlyStopping callback.
56 | use_kfold (bool): Whether to use K-Fold cross-validation or not.
57 | val_size (float): The size of the validation set to use during training.
58 | epsilon (float): A small constant used to control the size of set which contains the top models
59 | with the lowest MSE values.
60 | save_models_as_dot_format (bool): Whether to save the models as a dot format file.
61 | The default value is False. If set to True, then you should have graphviz software
62 | to be installed on your machine.
63 | """
64 |
65 | self.val_loss_meta_model: list = []
66 | self.train_loss_meta_model: list = []
67 | self.save_models_as_dot_format = save_models_as_dot_format
68 | self.best_models: Dict[str, tf.keras.Model] = {}
69 | self.train_losses: Dict[str, list] = {}
70 | self.val_losses: Dict[str, list] = {}
71 | self.data_splitter: DataSplitter = data_splitter
72 | self.epochs: int = epochs
73 | self.batch_size: int = batch_size
74 | self.pa = pa
75 | self.t_r = t_r
76 | self.use_kfold = use_kfold
77 | self.val_size = val_size
78 | self.epsilon = epsilon
79 |
80 | def fitting_models(self, created_models: Dict[str, tf.keras.Model]) -> None:
81 | """
82 | Fits the created models to the training data and saves the training and validation losses.
83 |
84 | Args:
85 | created_models: A dictionary containing the created models with their names as keys
86 | and the models as values.
87 |
88 | Returns:
89 | None
90 | """
91 | # Define early stopping based on validation loss
92 | early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=self.pa * 2)
93 | # Define custom early stopping based on a ratio and patience
94 | custom_early_stopping = CustomEarlyStopping(ratio=self.t_r, patience=self.pa, verbose=1)
95 | # Loop through each model in the created models dictionary
96 | for model_name, model in created_models.items():
97 | # If using k-fold cross-validation
98 | if self.use_kfold:
99 | logger_models.info("Performing a KFold cross-validation")
100 | # Calculate cross validation score using custom function
101 | score: np.ndarray = custom_cross_val_score(model=model, x=self.data_splitter.train_x,
102 | y=self.data_splitter.train_y,
103 | cv=KFold(n_splits=5, shuffle=False), epochs=self.epochs,
104 | batch_size=self.batch_size,
105 | callbacks=[early_stopping, custom_early_stopping])
106 | # Print cross validation score for the current model
107 | logger_models.info(f"The cross validation score for {model_name} is {score}")
108 | # Split training data into training and validation sets
109 | train_x, val_x, train_y, val_y = train_test_split(self.data_splitter.train_x, self.data_splitter.train_y,
110 | test_size=self.val_size,
111 | shuffle=False)
112 | # Print message indicating fitting of a current model
113 | logger_models.info(f"Summary of {model_name}...")
114 | logger_models.info(model.summary())
115 | logger_models.info(f"Fitting of {model_name}...")
116 | # Fit the model using training data and validate using validation data
117 | history = model.fit(train_x, train_y, epochs=self.epochs,
118 | batch_size=self.batch_size, verbose=1,
119 | validation_data=(val_x, val_y),
120 | callbacks=[early_stopping, custom_early_stopping])
121 | # Save training and validation errors for the current model
122 | self.train_losses[model_name] = history.history['loss']
123 | self.val_losses[model_name] = history.history['val_loss']
124 |
125 | losses_test_data: Dict[str, tf.keras.Model] = {}
126 | min_loss = np.inf
127 | for model_name, model in created_models.items():
128 | logger_models.info(f"Evaluating model {model_name} on test data")
129 | loss = model.evaluate(self.data_splitter.test_x, self.data_splitter.test_y, batch_size=self.batch_size)
130 | logger_models.info(f"The loss value of model {model_name} on test data is {loss:.4f}")
131 | losses_test_data[model_name] = loss
132 | if min_loss > loss:
133 | min_loss = loss
134 |
135 | logger_models.info(f"Selecting best models based on the min MSE {min_loss:.4f} and epsilon {self.epsilon}:")
136 | for model_name, loss_ in losses_test_data.items():
137 | if loss_ <= (min_loss + self.epsilon):
138 | self.best_models[model_name] = created_models[model_name]
139 | logger_models.info(f"Best models selected: {self.best_models.keys()}")
140 |
141 | config_dict["models"] = list(self.best_models.keys())
142 |
143 | def save_best_models(self, output_dir: str) -> None:
144 | """
145 | Save the best models to the specified output directory.
146 |
147 | Args:
148 | output_dir (str): The directory to save the best models.
149 |
150 | Returns:
151 | None
152 | """
153 |
154 | for model_name, model in self.best_models.items():
155 | # Print the name of the current model being saved
156 | logger_models.info(f"Current model to be saved on the disk is {model_name}")
157 | model_name_with_ext = f"{model_name}.keras"
158 | model_path = os.path.join(output_dir, MODELS_DIR, model_name_with_ext)
159 |
160 | # Save in Keras 3 compatible format
161 | model.save(model_path, save_format='keras')
162 |
163 | logger_models.info("Models saved successfully.")
164 |
165 | def train_meta_model(self, type_training: str, hyperparams_mm_network: Tuple[int, int], output_dir: str) \
166 | -> tuple[ndarray, float, ndarray]:
167 | """
168 | Trains the metamodel using the best models predictions as features.
169 |
170 | Args:
171 | type_training: The type of training to use, either "ffn" or "mean".
172 | hyperparams_mm_network: A tuple containing the hyperparameters the MetaModel network.
173 | output_dir: The directory to save the trained models to.
174 |
175 | Returns:
176 | A tuple containing the final prediction and the loss.
177 | """
178 | predictions = []
179 | for model_name, model in self.best_models.items():
180 | # Make predictions for the test set using each model
181 | predicted_y: np.ndarray = model.predict(self.data_splitter.test_x, batch_size=self.batch_size)
182 | predicted_y = predicted_y.flatten()
183 | predictions.append(predicted_y)
184 |
185 | # Convert a list of 1D NumPy arrays to 2D NumPy array
186 | x = np.stack(predictions, axis=1)
187 |
188 | if type_training == TYPE_TRAINING_FFN:
189 | logger_models.info("Train the MetaModel using a FFN to produce a final prediction")
190 | # Split the data into training and test sets
191 | train_x, test_x, train_y, test_y = train_test_split(x, self.data_splitter.test_y,
192 | test_size=self.data_splitter.test_size,
193 | shuffle=False)
194 | scaler = StandardScaler()
195 | train_x = scaler.fit_transform(train_x)
196 | test_x = scaler.transform(test_x)
197 | scalers_dir = os.path.join(output_dir, SCALERS_DIR)
198 | scaler_path = os.path.join(scalers_dir, f"{META_MODEL_SCALER}.joblib")
199 | joblib.dump(scaler, scaler_path)
200 | # Build the FFN model
201 | inputs = tf.keras.Input(shape=(train_x.shape[1],), name="input")
202 | layers, units = hyperparams_mm_network
203 | model_builder: ModelBuilder = ModelBuilder(inputs=inputs)
204 |
205 | for _ in range(layers):
206 | units_j = units
207 | model_builder.add_dense_layer(units=units_j)
208 | model_builder.add_dense_layer(units=1, dropout=None)
209 | keras_model = model_builder.build(name=META_MODEL_NETWORK, root_dir=output_dir,
210 | save_models_as_dot_format=self.save_models_as_dot_format)
211 | # Train the model
212 | logger_models.info("Fitting the MetaModel network...")
213 | history = keras_model.fit(train_x, train_y, epochs=self.epochs, batch_size=self.batch_size, verbose=1,
214 | validation_data=(test_x, test_y))
215 |
216 | path = os.path.join(output_dir, MODELS_DIR)
217 | model_path = os.path.join(path, META_MODEL_NETWORK)
218 | keras_model.save(model_path, save_format='keras')
219 | logger_models.info("MetaModel network saved successfully.")
220 | self.train_loss_meta_model = history.history['loss']
221 | self.val_loss_meta_model = history.history['val_loss']
222 |
223 | # final_prediction: np.ndarray = keras_model.predict(self.data_splitter.test_x, batch_size=self.batch_size)
224 | final_prediction: np.ndarray = keras_model.predict(test_x, batch_size=self.batch_size)
225 | final_prediction = final_prediction.flatten()
226 | return final_prediction, tf.keras.losses.mse(final_prediction, test_y), test_y
227 | else:
228 | # Compute the average prediction
229 | logger_models.info("Compute the average of predictions to produce a final prediction")
230 | final_prediction = np.mean(x, axis=1)
231 | return final_prediction, tf.keras.losses.mse(final_prediction,
232 | self.data_splitter.test_y), self.data_splitter.test_y
233 |
--------------------------------------------------------------------------------
/images/logo_eventdetector.svg:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/eventdetector_ts/metamodel/utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import re
3 | from typing import Dict, Tuple
4 |
5 | import joblib
6 | import numpy as np
7 | import pandas as pd
8 | from sklearn.model_selection import train_test_split
9 | from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
10 |
11 | from eventdetector_ts import MIN_MAX_SCALER, ROBUST_SCALER, SCALERS_DIR, FILL_NAN_ZEROS, FILL_NAN_FFILL, \
12 | FILL_NAN_BFILL, FILL_NAN_MEDIAN, RNN_BIDIRECTIONAL, CONV_LSTM1D, RNN_ENCODER_DECODER, FFN, CNN_RNN, \
13 | GRU, CNN, SELF_ATTENTION, LSTM, TYPE_TRAINING_AVERAGE, TYPE_TRAINING_FFN, STANDARD_SCALER, TRANSFORMER
14 | from eventdetector_ts.data.helpers_data import InvalidArgumentError
15 |
16 |
17 | class DataSplitter:
18 | """
19 | A class for splitting and scaling data into training, test sets and applying scalers to each
20 | time step in the data.
21 | """
22 |
23 | def __init__(self, test_size: float, scaler_type: str):
24 | """
25 | Initialize the DataSplitter object.
26 |
27 | Args:
28 | test_size: The fraction of data to use for testing.
29 | scaler_type: The type of scaler to use.
30 | """
31 |
32 | self.train_x: np.ndarray = np.empty(shape=(0,))
33 | self.test_x: np.ndarray = np.empty(shape=(0,))
34 | self.train_y: np.ndarray = np.empty(shape=(0,))
35 | self.test_y: np.ndarray = np.empty(shape=(0,))
36 | self.scalers: Dict[int, StandardScaler | MinMaxScaler | ROBUST_SCALER] = {}
37 | self.test_size: float = test_size
38 | self.scaler_type: str = scaler_type
39 |
40 | def split_data_and_apply_scaler(self, x: np.ndarray, y: np.ndarray) -> None:
41 | """
42 | Split the data into training, validation, and test sets and apply the specified scaler to each time step.
43 |
44 | Args:
45 | x: The input data with shape (n_samples, n_time_steps, n_features).
46 | y: The target data with shape (n_samples,).
47 |
48 | Returns:
49 | A tuple containing the training, validation, and test sets as numpy arrays and a dictionary of scalers.
50 | """
51 | assert x.ndim == 3, "x must be a 3D array."
52 | assert y.ndim == 1, "y must be a 1D array."
53 | assert x.shape[0] == y.shape[0], "x and y must have the same number of samples."
54 |
55 | # Split the data into training and test sets
56 | self.train_x, self.test_x, self.train_y, self.test_y = train_test_split(x, y, test_size=self.test_size,
57 | shuffle=False)
58 |
59 | n_time_steps = x.shape[1]
60 |
61 | self.scalers = {}
62 | # Apply scaler to each time step
63 | for i in range(n_time_steps):
64 | scaler = StandardScaler()
65 | if self.scaler_type == MIN_MAX_SCALER:
66 | scaler = MinMaxScaler()
67 | elif self.scaler_type == ROBUST_SCALER:
68 | scaler = RobustScaler()
69 | self.scalers[i] = scaler
70 | self.train_x[:, i, :] = self.scalers[i].fit_transform(self.train_x[:, i, :])
71 | self.test_x[:, i, :] = self.scalers[i].transform(self.test_x[:, i, :])
72 |
73 | def save_scalers(self, output_dir: str) -> None:
74 | """
75 | Saves the scalers to disk.
76 |
77 | Args:
78 | output_dir: the directory where the scalers should be saved
79 |
80 | Returns:
81 | None
82 | """
83 | # Create the directory if it doesn't exist
84 | scalers_dir = os.path.join(output_dir, SCALERS_DIR)
85 | if not os.path.exists(scalers_dir):
86 | os.makedirs(scalers_dir)
87 |
88 | # Save each scaler to disk
89 | n_time_steps: int = self.test_x.shape[1]
90 | for i in range(n_time_steps):
91 | # Generate the path to save the scaler to
92 | scaler_i_path = os.path.join(scalers_dir, f'scaler_{i}.joblib')
93 | # Print progress
94 | print("\rSaving scaling...{}/{}".format(i + 1, n_time_steps), end="")
95 | # Save the scaler to disk
96 | joblib.dump(self.scalers[i], scaler_i_path)
97 | print()
98 |
99 |
100 | def validate_required_args(meta_model) -> None:
101 | """
102 | Validate the required arguments of the MetaModel.
103 |
104 | Args:
105 | meta_model (MetaModel): A MetaModel instance.
106 |
107 | Returns:
108 | None
109 |
110 | Raises:
111 | ValueError: If any of the arguments are invalid.
112 | """
113 |
114 | __validate_required_args(meta_model=meta_model)
115 |
116 | if meta_model.dataset is None or meta_model.dataset.empty:
117 | raise InvalidArgumentError("dataset cannot be None or empty.")
118 | elif not isinstance(meta_model.dataset, pd.DataFrame):
119 | raise InvalidArgumentError("dataset should be a Pandas DataFrame.")
120 |
121 | if len(meta_model.dataset) < meta_model.width:
122 | raise InvalidArgumentError("Dataset length is smaller than the given partition width.")
123 |
124 | if meta_model.events is None or (isinstance(meta_model.events, pd.DataFrame) and meta_model.events.empty) or \
125 | (isinstance(meta_model.events, list) and len(meta_model.events) == 0):
126 | raise InvalidArgumentError("Events is empty or None.")
127 | elif not isinstance(meta_model.events, (list, pd.DataFrame)):
128 | raise InvalidArgumentError("Events should be a list or a Pandas DataFrame.")
129 |
130 | if not re.match(r"^\w+$", meta_model.output_dir):
131 | raise InvalidArgumentError(
132 | "Output directory name can only contain alphanumeric characters and underscores.")
133 |
134 |
135 | def __validate_required_args(meta_model) -> None:
136 | if not isinstance(meta_model.step, int) or meta_model.step <= 0:
137 | raise InvalidArgumentError("step should be a positive integer.")
138 |
139 | if not isinstance(meta_model.width, int) or meta_model.width <= meta_model.step:
140 | raise InvalidArgumentError(f"width should be greater than step = {meta_model.step}.")
141 |
142 | if meta_model.width_events is not None and not isinstance(meta_model.width_events,
143 | (int, float)) and meta_model.width_events <= 0:
144 | raise InvalidArgumentError("width_events should be either a positive integer or positive float.")
145 |
146 |
147 | def validate_args(meta_model) -> None:
148 | """
149 | Validate the arguments of the MetaModel.
150 |
151 | Args:
152 | meta_model (MetaModel): A MetaModel instance.
153 |
154 | Returns:
155 | None
156 |
157 | Raises:
158 | ValueError: If any of the arguments are invalid.
159 | """
160 |
161 | validate_args_1(meta_model)
162 | validate_args_2(meta_model)
163 | validate_args_3(meta_model)
164 | validate_args_4(meta_model)
165 | validate_args_5(meta_model)
166 |
167 | if len(meta_model.hyperparams_mm_network) != 3:
168 | raise ValueError("hyperparams_mm_network must be a tuple of length 3")
169 |
170 | if not all(isinstance(val, int) for val in meta_model.hyperparams_mm_network[:-1]):
171 | raise ValueError("hyperparams_mm_network values must be integers except the last which is"
172 | " the activation function (str)")
173 |
174 | if not isinstance(meta_model.save_models_as_dot_format, bool):
175 | raise InvalidArgumentError("Invalid save_models_as_dot_format parameter: must be a boolean.")
176 |
177 | if meta_model.dropout is None or not 0 <= meta_model.dropout < 1 or not isinstance(meta_model.dropout, float):
178 | raise InvalidArgumentError("Invalid dropout parameter: must be a float between 0 and 1.0.")
179 |
180 |
181 | def validate_args_1(meta_model) -> None:
182 | """
183 | Validate the arguments of the MetaModel.
184 |
185 | Args:
186 | meta_model (MetaModel): A MetaModel instance.
187 |
188 | Returns:
189 | None
190 |
191 | Raises:
192 | ValueError: If any of the arguments are invalid.
193 | """
194 |
195 | if meta_model.fill_nan not in [FILL_NAN_ZEROS, FILL_NAN_FFILL, FILL_NAN_BFILL, FILL_NAN_MEDIAN]:
196 | raise InvalidArgumentError(
197 | f"Invalid method for filling NaN values. Supported methods are"
198 | f" {FILL_NAN_ZEROS}, {FILL_NAN_FFILL}, {FILL_NAN_BFILL}, and {FILL_NAN_MEDIAN}.")
199 |
200 | if not isinstance(meta_model.epochs, int) or meta_model.epochs <= 0:
201 | raise InvalidArgumentError("epochs should be a positive integer.")
202 |
203 | if not isinstance(meta_model.batch_size, int) or meta_model.batch_size <= 0:
204 | raise InvalidArgumentError("batch_size should be a positive integer.")
205 |
206 | if not isinstance(meta_model.t_max, float) and not isinstance(meta_model.t_max, int):
207 | raise InvalidArgumentError("t_max should be float/int.")
208 |
209 | if meta_model.t_max <= meta_model.w_s:
210 | raise InvalidArgumentError(f"t_max should be greater than w_s {meta_model.w_s}.")
211 |
212 | if not isinstance(meta_model.delta, (int, float)) or meta_model.delta <= 0:
213 | raise InvalidArgumentError("delta should be either a positive integer or positive float.")
214 |
215 | if not (0 < meta_model.s_h < 1):
216 | raise InvalidArgumentError("s_h should be a float between 0 and 1 exclusive.")
217 |
218 | if not isinstance(meta_model.epsilon, float) or not (0 < meta_model.epsilon <= 1):
219 | raise InvalidArgumentError("epsilon should be a positive number between 0 and 1.")
220 |
221 | if not isinstance(meta_model.pa, int) or meta_model.pa <= 0:
222 | raise InvalidArgumentError("pa should be a positive integer.")
223 |
224 |
225 | def validate_args_2(meta_model) -> None:
226 | """
227 | Validate the arguments of the MetaModel.
228 |
229 | Args:
230 | meta_model (MetaModel): A MetaModel instance.
231 |
232 | Returns:
233 | None
234 |
235 | Raises:
236 | ValueError: If any of the arguments are invalid.
237 | """
238 |
239 | if not isinstance(meta_model.t_r, float) or not (0 < meta_model.t_r <= 1):
240 | raise InvalidArgumentError("t_r should be a positive number between 0 and 1.")
241 |
242 | if meta_model.time_window is not None and (
243 | not isinstance(meta_model.time_window, (int, float)) or meta_model.time_window <= 0):
244 | raise InvalidArgumentError("time_window should be either a positive integer or positive float.")
245 |
246 | if not all(isinstance(model, (str, tuple)) and
247 | (isinstance(model, str) or (isinstance(model, tuple) and len(model) == 2 and isinstance(model[0],
248 | str) and
249 | isinstance(model[1], int)))
250 | for model in meta_model.models):
251 | raise InvalidArgumentError(
252 | "Invalid format for models. It should be a list of strings or tuples of (string, integer).")
253 |
254 |
255 | def validate_model_type(model):
256 | if model not in [LSTM, GRU, CNN, RNN_BIDIRECTIONAL, CONV_LSTM1D, RNN_ENCODER_DECODER, CNN_RNN,
257 | SELF_ATTENTION, FFN, TRANSFORMER]:
258 | raise InvalidArgumentError(
259 | f"Invalid model type {model}. Supported models are {LSTM}, {GRU}, {CNN}, {RNN_BIDIRECTIONAL},"
260 | f" {CONV_LSTM1D}, {RNN_ENCODER_DECODER}, {CNN_RNN}, {SELF_ATTENTION}, {TRANSFORMER}, and {FFN}.")
261 |
262 |
263 | def validate_model_instances(model_instances):
264 | if not isinstance(model_instances, int) or model_instances <= 0:
265 | raise InvalidArgumentError("Number of model instances should be a positive integer.")
266 |
267 |
268 | def validate_args_3(meta_model) -> None:
269 | """
270 | Validate the arguments of the MetaModel.
271 |
272 | Args:
273 | meta_model (MetaModel): A MetaModel instance.
274 |
275 | Returns:
276 | None
277 |
278 | Raises:
279 | ValueError: If any of the arguments are invalid.
280 | """
281 |
282 | for model in meta_model.models:
283 | if isinstance(model, str):
284 | validate_model_type(model)
285 | elif isinstance(model, tuple) and len(model) == 2:
286 | model_type, model_instances = model
287 | validate_model_type(model_type)
288 | validate_model_instances(model_instances)
289 | else:
290 | raise InvalidArgumentError(f"Invalid model specification {model}.")
291 |
292 |
293 | def validate_args_4(meta_model) -> None:
294 | """
295 | Validate the arguments of the MetaModel.
296 |
297 | Args:
298 | meta_model (MetaModel): A MetaModel instance.
299 |
300 | Returns:
301 | None
302 |
303 | Raises:
304 | ValueError: If any of the arguments are invalid.
305 | """
306 |
307 | if meta_model.type_training not in [TYPE_TRAINING_AVERAGE, TYPE_TRAINING_FFN]:
308 | raise InvalidArgumentError(
309 | f"Invalid type of training technique. Supported techniques are "
310 | f"{TYPE_TRAINING_AVERAGE} and {TYPE_TRAINING_FFN}.")
311 |
312 | if meta_model.scaler not in [MIN_MAX_SCALER, STANDARD_SCALER, ROBUST_SCALER]:
313 | raise InvalidArgumentError(
314 | f"Invalid type of scaler technique. Supported techniques are {MIN_MAX_SCALER},"
315 | f" {STANDARD_SCALER} and {ROBUST_SCALER}.")
316 |
317 | if not isinstance(meta_model.use_kfold, bool):
318 | raise InvalidArgumentError("Invalid use_kfold parameter: must be a boolean.")
319 |
320 | if not 0 < meta_model.test_size < 1 or not isinstance(meta_model.test_size, float):
321 | raise InvalidArgumentError("Invalid test_size parameter: must be a float between 0 and 1.")
322 |
323 | if not 0 < meta_model.val_size < 1 or not isinstance(meta_model.val_size, float):
324 | raise InvalidArgumentError("Invalid val_size parameter: must be a float between 0 and 1.")
325 |
326 | if len(meta_model.hyperparams_transformer) != 5:
327 | raise ValueError("hyperparams_transformer must be a tuple of length 5")
328 |
329 |
330 | def validate_args_5(meta_model) -> None:
331 | """
332 | Validate the arguments of the MetaModel.
333 |
334 | Args:
335 | meta_model (MetaModel): A MetaModel instance.
336 |
337 | Returns:
338 | None
339 |
340 | Raises:
341 | ValueError: If any of the arguments are invalid.
342 | """
343 |
344 | param1, param2, param3, param4, param5 = meta_model.hyperparams_transformer
345 | if not (all(isinstance(p, int) for p in [param1, param2, param3]) and isinstance(param4, bool) and isinstance(
346 | param5,
347 | str)):
348 | raise ValueError("hyperparams_transformer values must be Tuple[int, int, int, bool, str]")
349 |
350 |
351 | def validate_ffn(meta_model) -> Tuple:
352 | hyperparams_ffn = meta_model.hyperparams_ffn
353 | l_ffn = len(hyperparams_ffn)
354 | print(l_ffn)
355 |
356 | if not 2 < l_ffn < 6:
357 | raise ValueError("hyperparams_ffn must be a tuple of length 3, 4 or 5")
358 |
359 | if l_ffn == 3:
360 | max_layers, min_neurons, max_neurons = hyperparams_ffn
361 | return 1, max_layers, min_neurons, max_neurons, "sigmoid"
362 |
363 | if l_ffn == 4:
364 | if isinstance(hyperparams_ffn[-1], str):
365 | max_layers, min_neurons, max_neurons, activation = hyperparams_ffn
366 | return 1, max_layers, min_neurons, max_neurons, activation
367 | else:
368 | min_layers, max_layers, min_neurons, max_neurons = hyperparams_ffn
369 | return min_layers, max_layers, min_neurons, max_neurons, "sigmoid"
370 |
371 | return hyperparams_ffn
372 |
373 |
374 | def validate_cnn(meta_model) -> Tuple:
375 | hyperparams_cnn = meta_model.hyperparams_cnn
376 | l_cnn = len(hyperparams_cnn)
377 |
378 | if not 4 < l_cnn < 8:
379 | raise ValueError("hyperparams_cnn must be a tuple of length between 5 and 7.")
380 |
381 | if l_cnn == 5:
382 | min_f, max_f, min_k, max_k, max_layers = hyperparams_cnn
383 | return min_f, max_f, min_k, max_k, 1, max_layers, "relu"
384 |
385 | if l_cnn == 6:
386 | if isinstance(hyperparams_cnn[-1], str):
387 | min_f, max_f, min_k, max_k, max_layers, activation = hyperparams_cnn
388 | return min_f, max_f, min_k, max_k, 1, max_layers, activation
389 | else:
390 | min_f, max_f, min_k, max_k, min_layers, max_layers = hyperparams_cnn
391 | return min_f, max_f, min_k, max_k, min_layers, max_layers, "relu"
392 |
393 | return hyperparams_cnn
394 |
395 |
396 | def validate_rnn(meta_model) -> Tuple:
397 | hyperparams_rnn = meta_model.hyperparams_rnn
398 | l_rnn = len(hyperparams_rnn)
399 |
400 | if not 2 < l_rnn < 6:
401 | raise ValueError("hyperparams_rnn must be a tuple of length 3, 4 or 5")
402 |
403 | if l_rnn == 3:
404 | max_layers, min_neurons, max_neurons = hyperparams_rnn
405 | return 1, max_layers, min_neurons, max_neurons, "tanh"
406 |
407 | if l_rnn == 4:
408 | if isinstance(hyperparams_rnn[-1], str):
409 | max_layers, min_neurons, max_neurons, activation = hyperparams_rnn
410 | return 1, max_layers, min_neurons, max_neurons, activation
411 | else:
412 | min_layers, max_layers, min_neurons, max_neurons = hyperparams_rnn
413 | return min_layers, max_layers, min_neurons, max_neurons, "tanh"
414 |
415 | return hyperparams_rnn
416 |
--------------------------------------------------------------------------------
/eventdetector_ts/data/helpers_data.py:
--------------------------------------------------------------------------------
1 | import json
2 | from datetime import datetime, timedelta
3 | from functools import reduce
4 | from typing import Optional, Union, Tuple, Dict
5 |
6 | import numpy as np
7 | import pandas as pd
8 | from dateutil.parser import parser
9 | # noinspection PyUnresolvedReferences
10 | from numpy.lib.stride_tricks import as_strided
11 | from pandas.core.dtypes.common import is_datetime64_any_dtype
12 |
13 | from eventdetector_ts import TIME_LABEL, FILL_NAN_ZEROS, FILL_NAN_FFILL, FILL_NAN_BFILL, FILL_NAN_MEDIAN, \
14 | MIDDLE_EVENT_LABEL, TimeUnit
15 | from eventdetector_ts.data import VALUE_ERROR
16 | from eventdetector_ts.data.interval import Interval
17 |
18 |
19 | def overlapping_partitions(data: np.ndarray, width: int, step: int = 1):
20 | """
21 | Splits an input numpy array into a set of overlapping partitions.
22 |
23 | Args:
24 | data: Input numpy array to be split into overlapping partitions
25 | width: Width of each overlapping partition
26 | step: The step size between successive partitions (default=1)
27 |
28 | Returns:
29 | Numpy array of shape (nb_partitions, width, data.ndim), containing the created overlapping partitions.
30 | """
31 | if width > data.shape[0]:
32 | raise ValueError("Partition size cannot be greater than the size of the input data")
33 | if step > width:
34 | raise ValueError("Step size cannot be greater than partition size")
35 |
36 | # Compute the parameters for creating the overlapping partitions
37 | np_partitions = (data.shape[0] - width) // step + 1
38 | shape = (np_partitions, width) + data.shape[1:]
39 | strides = (step * data.strides[0],) + data.strides
40 |
41 | # Use as_strided to create the overlapping partitions
42 | partitioned_array = as_strided(data, shape=shape, strides=strides)
43 |
44 | return partitioned_array
45 |
46 |
47 | def convert_dataframe_to_overlapping_partitions(
48 | dataframe: pd.DataFrame,
49 | width: int,
50 | step: int,
51 | fill_method: Optional[str] = None
52 | ) -> np.ndarray:
53 | """
54 | Converts a given DataFrame to overlapping partitions.
55 |
56 | Args:
57 | dataframe: Input DataFrame of features
58 | width: Width of each overlapping partition
59 | step: The step size between successive partitions
60 | fill_method: The method to use for filling NaNs. Supported methods are 'zeros', 'ffill', 'bfill', and 'median'.
61 | If None, NaNs are left as-is. (default=None)
62 |
63 | Returns:
64 | Numpy array of shape (np_partitions, width, nb_features), containing the created overlapping partitions.
65 | """
66 |
67 | dataframe = dataframe.copy()
68 | dataframe.index = pd.to_datetime(dataframe.index)
69 | dataframe.loc[:, TIME_LABEL] = dataframe.index.to_pydatetime()
70 |
71 | if fill_method == FILL_NAN_ZEROS:
72 | dataframe = dataframe.fillna(0)
73 | elif fill_method == FILL_NAN_FFILL:
74 | dataframe = dataframe.ffill()
75 | elif fill_method == FILL_NAN_BFILL:
76 | dataframe = dataframe.bfill()
77 | elif fill_method == FILL_NAN_MEDIAN:
78 | dataframe = dataframe.fillna(dataframe.median())
79 | elif fill_method is not None:
80 | raise ValueError(f"Unsupported fill method: {fill_method}")
81 |
82 | sw = overlapping_partitions(dataframe.to_numpy(), width=width, step=step)
83 | return sw
84 |
85 |
86 | class InvalidArgumentError(ValueError):
87 | """Raised when an invalid argument is passed to a function or method."""
88 |
89 | def __init__(self, message):
90 | """
91 | Initialize a new InvalidArgumentError with the specified error message.
92 |
93 | Args:
94 | message (str): The error message to display.
95 | """
96 | super().__init__(message)
97 |
98 |
99 | def convert_time_to_datetime(date: Union[str, pd.Timestamp, float, int], to_timestamp: bool = True) -> \
100 | Union[float, datetime]:
101 | """
102 | Converts a date string, pandas Timestamp, or numeric timestamp to a Python datetime or Unix timestamp.
103 |
104 | Args:
105 | date: The input date as a string, pandas Timestamp, or numeric timestamp.
106 | to_timestamp: If True (default), return the date as a Unix timestamp (float), otherwise as a Python datetime.
107 |
108 | Returns:
109 | The input date as a Unix timestamp or Python datetime object.
110 | """
111 |
112 | if isinstance(date, pd.Timestamp):
113 | dt = date.to_pydatetime()
114 | elif isinstance(date, (float, int)):
115 | dt = datetime.fromtimestamp(date)
116 | elif isinstance(date, str):
117 | dt = parser.parse(date, ignoretz=True)
118 | else:
119 | raise ValueError(f"Invalid date format {date}. Supported formats are str, pd.Timestamp, float, and int.")
120 |
121 | if to_timestamp:
122 | return (dt - datetime(1970, 1, 1)).total_seconds()
123 | return dt
124 |
125 |
126 | def num_columns(lst: list) -> int:
127 | """
128 | Returns the number of columns in a list.
129 |
130 | Args:
131 | lst (list): The list to check.
132 |
133 | Returns:
134 | int: The number of columns in the list.
135 | """
136 |
137 | if not lst:
138 | # if the list is empty return 0
139 | return 0
140 | elif isinstance(lst[0], list):
141 | # if the first element of the list is a list, return the length of the first list
142 | return len(lst[0])
143 | else:
144 | # otherwise return 1, because the list has only one column
145 | return 1
146 |
147 |
148 | def compute_middle_event(events: Union[list, pd.DataFrame]) -> pd.DataFrame:
149 | """
150 | Computes the middle date of events and returns it as a DataFrame.
151 |
152 | Args:
153 | events (Union[list, pd.DataFrame]): A list or pandas DataFrame containing the starting and ending
154 | dates of events.
155 |
156 | Returns:
157 | pd.DataFrame: A pandas DataFrame with a single column containing the middle dates of events.
158 | """
159 | column1 = "Starting Date"
160 | column2 = "Ending Date"
161 | is2d = True
162 |
163 | if isinstance(events, list):
164 | nb_columns = num_columns(events)
165 | if nb_columns == 2:
166 | df = pd.DataFrame(events, columns=[column1, column2])
167 | elif nb_columns == 1:
168 | df = pd.DataFrame(events, columns=[column1])
169 |
170 | is2d = False
171 | else:
172 | raise ValueError(
173 | f"The list of events is not compatible. The number of columns {nb_columns} should not exceed 2.")
174 | elif isinstance(events, pd.DataFrame):
175 | df = events
176 | columns = events.columns
177 | if len(columns) == 2:
178 | df = df.rename(columns={columns[0]: column1, columns[1]: column2})
179 | elif len(columns) == 1:
180 | is2d = False
181 | df = df.rename(columns={columns[0]: column1})
182 | else:
183 | raise ValueError("The dataframe of events in not compatible, columns should not exceed 2")
184 | else:
185 | raise ValueError("The events argument must be a list or pandas DataFrame.")
186 |
187 | df[column1] = pd.to_datetime(df[column1])
188 | if is2d:
189 | df[column2] = pd.to_datetime(df[column2])
190 |
191 | if is2d:
192 | df[column1] = df[column1].apply(lambda x: convert_time_to_datetime(x) / 2)
193 | df[column2] = df[column2].apply(lambda x: convert_time_to_datetime(x) / 2)
194 | df[MIDDLE_EVENT_LABEL] = df[column1] + df[column2]
195 | else:
196 | df[MIDDLE_EVENT_LABEL] = df[column1].apply(lambda x: convert_time_to_datetime(x))
197 |
198 | df[MIDDLE_EVENT_LABEL] = df[MIDDLE_EVENT_LABEL].apply(lambda x: datetime.utcfromtimestamp(x))
199 | df = df[[MIDDLE_EVENT_LABEL]]
200 | df = df.sort_values(by=MIDDLE_EVENT_LABEL)
201 | return df
202 |
203 |
204 | def remove_close_events(events_df: pd.DataFrame, delta_unit_time: int, unit: TimeUnit,
205 | remove_overlapping_events: bool) -> pd.DataFrame:
206 | """
207 | Removes events from a DataFrame that occur too close together.
208 |
209 | Args:
210 | unit: The time unit
211 | events_df: A pandas DataFrame containing events with a column named 'middle_event'.
212 | delta_unit_time: A integer representing the minimum time in unit time between events.
213 | remove_overlapping_events: A flag to indicate if we remove the overlapping events or not.
214 |
215 | Returns:
216 | A pandas DataFrame with close events removed.
217 | """
218 |
219 | # Convert delta to timedelta
220 | delta = get_timedelta(delta_unit_time, unit)
221 |
222 | # List to hold indices of events to delete
223 | events_to_delete = []
224 |
225 | # Loop through all events
226 | for i in range(len(events_df)):
227 | # Get middle time of the current event
228 | mid_time = events_df.iloc[i][MIDDLE_EVENT_LABEL]
229 |
230 | # Skip current event if it's already marked for deletion
231 | if i in events_to_delete:
232 | continue
233 |
234 | # Loop through all remaining events
235 | for j in range(i + 1, len(events_df)):
236 | # Get middle time of the next event
237 | mid_time1 = events_df.iloc[j][MIDDLE_EVENT_LABEL]
238 |
239 | # If the next event is too close to the current event, mark it for deletion
240 | if (mid_time1 - mid_time) <= delta:
241 | events_to_delete.append(j)
242 | else:
243 | break
244 |
245 | # Drop events that were marked for deletion
246 | if remove_overlapping_events:
247 | return events_df.drop(events_df.index[events_to_delete])
248 | return events_df
249 |
250 |
251 | def convert_events_to_intervals(events_df: pd.DataFrame, width_events_s: float, unit: TimeUnit) \
252 | -> list[Interval]:
253 | """
254 | Convert events from a pandas DataFrame to intervals.
255 |
256 | Args:
257 | events_df (pd.DataFrame): DataFrame containing the events' data.
258 | width_events_s (float): The width of events in the unit of time for the dataset.
259 | unit: The unit time
260 |
261 | Returns:
262 | list[Interval]: A list of intervals.
263 |
264 | """
265 | # Create an empty list to store the intervals
266 | events_intervals = []
267 |
268 | # Loop over the events in the DataFrame
269 | for i in range(len(events_df)):
270 | # Get the middle event time
271 | mid_time = events_df.iloc[i][MIDDLE_EVENT_LABEL]
272 |
273 | width_events_s_float = float(width_events_s)
274 | # Compute the radius of the interval based on the event size
275 | radius = get_timedelta(delta_unit_time=width_events_s_float / 2, unit=unit)
276 |
277 | # Create an interval with the middle event time at the center
278 | interval = Interval(mid_time - radius, mid_time + radius)
279 |
280 | # Add the interval to the list of intervals
281 | events_intervals.append(interval)
282 |
283 | # Return the list of intervals
284 | return events_intervals
285 |
286 |
287 | def get_union_times_events(events_df: pd.DataFrame, time_window: int, unit_time: TimeUnit) -> pd.DatetimeIndex:
288 | """
289 | Given a DataFrame of events and a time partition size in unit time, computes a DatetimeIndex of all times during
290 | which at least one event was taking place.
291 |
292 | Args:
293 | events_df (pd.DataFrame): A DataFrame containing at least a MIDDLE_EVENT_LABEL column with the datetime
294 | of each event.
295 | time_window (int): The size of the time window to consider before and after each event.
296 | unit_time (TimeUnit): The unit time
297 |
298 | Returns:
299 | pd.DatetimeIndex: A DatetimeIndex of all times during which at least one event was taking place.
300 | """
301 |
302 | times_during_events = []
303 | previous_range = None
304 | for i, event_time in enumerate(events_df[MIDDLE_EVENT_LABEL]):
305 | start_time = event_time - get_timedelta(time_window, unit=unit_time)
306 | end_time = event_time + get_timedelta(time_window, unit=unit_time)
307 | # Generate a list of dates between start_time and end_time with a frequency of exactly (end_time - start_time).
308 | # This ensures that the last date is exactly equal to end_time (useful when we generate overlapping ranges).
309 | dates_between = pd.date_range(start=start_time, end=end_time, freq=end_time - start_time)
310 |
311 | if previous_range is None:
312 | times_during_events.append(dates_between)
313 | previous_range = dates_between
314 | else:
315 | # Check if the current range overlaps with the previous one.
316 | ranges_overlap = max(previous_range[0], previous_range[-1]) < min(dates_between[0], dates_between[-1])
317 | if not ranges_overlap:
318 | # If the ranges don't overlap, then we need to merge the previous and current ranges.
319 | merged_range = pd.date_range(start=previous_range[0], end=dates_between[-1],
320 | freq=dates_between[-1] - previous_range[0])
321 | # Replace the last range we added to the list with the merged range.
322 | times_during_events[-1] = merged_range
323 | previous_range = merged_range
324 | else:
325 | previous_range = dates_between
326 | times_during_events.append(dates_between)
327 |
328 | # Use the reduce function to combine all the overlapping ranges we generated.
329 | union_ranges = reduce(lambda x, y: x.union(y), times_during_events)
330 | # Remove any timezone information from the resulting DatetimeIndex, if present.
331 | union_ranges = union_ranges.tz_localize(None)
332 | return union_ranges
333 |
334 |
335 | def get_dataset_within_events_times(data_set: pd.DataFrame, events_times: pd.DatetimeIndex) -> pd.DataFrame:
336 | """
337 | Extracts the data from the given dataset that falls within the specified event times.
338 |
339 | Args:
340 | data_set: A pandas DataFrame containing the data to extract.
341 | events_times: A pandas DatetimeIndex containing the times of events.
342 |
343 | Returns:
344 | A pandas DataFrame containing the data within the specified event times.
345 | """
346 |
347 | dataset_within_events_times = []
348 |
349 | # Iterate through the event times by pairs
350 | for i in range(0, len(events_times) - 1, 2):
351 | partition_start_time = events_times[i]
352 | partition_end_time = events_times[i + 1]
353 |
354 | # Extract the data within the event time
355 | data_within_event_time = data_set.loc[partition_start_time: partition_end_time]
356 |
357 | dataset_within_events_times.append(data_within_event_time)
358 |
359 | # Concatenate all the data extracted from events times
360 | return pd.concat(dataset_within_events_times)
361 |
362 |
363 | def op(dataset_as_overlapping_partitions: np.ndarray, events_as_intervals: list[Interval]) -> \
364 | tuple[np.ndarray, np.ndarray]:
365 | """
366 | Calculates the "op" value for each overlapping partition in the dataset, based on the overlapping parameter
367 | between the partition and a set of events.
368 |
369 | Args: dataset_as_overlapping_partitions: A numpy ndarray containing the overlapping partitions for the dataset,
370 | where each overlapping partition is a 2D numpy ndarray containing the data points for the partition and their
371 | timestamps. events_as_intervals: A list of Interval objects representing the events in the dataset.
372 |
373 | Returns:
374 | A tuple containing two values:
375 | - A numpy ndarray containing the overlapping partitions for the dataset, with the timestamp column removed.
376 | - A numpy ndarray of floating-point values representing the "op" value
377 | for each overlapping partition in the dataset.
378 | """
379 |
380 | # The index of the first event that hasn't been checked yet
381 | starting_event_index = 0
382 |
383 | # List to store the calculated op values for each overlapping partition
384 | op_values = []
385 |
386 | # Iterate through each overlapping partition in the dataset
387 | for partition in dataset_as_overlapping_partitions:
388 | # Get the start and end times of the current overlapping partition
389 | partition_start_time = partition[0][-1].to_pydatetime()
390 | partition_end_time = partition[-1][-1].to_pydatetime()
391 |
392 | # Create an Interval object to represent the current overlapping partition
393 | partition_interval = Interval(partition_start_time, partition_end_time)
394 |
395 | # Initialize the op value for the current overlapping partition to 0
396 | current_op_value = 0
397 |
398 | # Iterate through each event that hasn't been checked yet
399 | for event_index in range(starting_event_index, len(events_as_intervals)):
400 | # Get the Interval object for the current event
401 | current_event_interval = events_as_intervals[event_index]
402 |
403 | # If the start time of the current partition is greater than or equal to the end time of the current event,
404 | # we can skip this event since it doesn't overlap with the current partition
405 | if partition_interval.start_time >= current_event_interval.end_time:
406 | starting_event_index = event_index + 1
407 | continue
408 |
409 | # Calculate the overlapping parameter between the current partition and the current event
410 | overlapping_parameter = partition_interval.overlapping_parameter(current_event_interval)
411 |
412 | # If the overlapping parameter is 0, there is no overlap between the current partition and the current event
413 | if overlapping_parameter == 0:
414 | break
415 |
416 | # Update the op value for the current partition if the overlapping parameter is greater than the current op
417 | # value
418 | if overlapping_parameter > current_op_value:
419 | current_op_value = overlapping_parameter
420 |
421 | # Add the op value for the current partition to the list of op values
422 | op_values.append(current_op_value)
423 |
424 | # Remove the column containing the timestamps from the overlapping partitions
425 | dataset_as_overlapping_partitions = np.delete(dataset_as_overlapping_partitions, -1, axis=2)
426 |
427 | # Return the updated overlapping partitions and the op values
428 | return dataset_as_overlapping_partitions, np.array(op_values)
429 |
430 |
431 | def get_timedelta(delta_unit_time: Union[int, float], unit: TimeUnit) -> timedelta:
432 | """
433 | Returns a timedelta object with the specified delta_unit_time in the specified TimeUnit.
434 |
435 | Args:
436 | delta_unit_time: The delta unit time value.
437 | unit: The TimeUnit enum value representing the unit of time.
438 |
439 | Returns:
440 | A timedelta object with the specified delta_unit_time in the specified TimeUnit.
441 | """
442 | if unit == TimeUnit.MICROSECOND:
443 | return timedelta(microseconds=delta_unit_time)
444 | elif unit == TimeUnit.MILLISECOND:
445 | return timedelta(milliseconds=delta_unit_time)
446 | elif unit == TimeUnit.SECOND:
447 | return timedelta(seconds=delta_unit_time)
448 | elif unit == TimeUnit.MINUTE:
449 | return timedelta(minutes=delta_unit_time)
450 | elif unit == TimeUnit.HOUR:
451 | return timedelta(hours=delta_unit_time)
452 | elif unit == TimeUnit.DAY:
453 | return timedelta(days=delta_unit_time)
454 | elif unit == TimeUnit.YEAR:
455 | return timedelta(days=delta_unit_time * 365)
456 | else:
457 | raise VALUE_ERROR
458 |
459 |
460 | def get_total_units(timedelta_: timedelta, unit: Union[TimeUnit, object]) -> float:
461 | if unit == TimeUnit.MICROSECOND:
462 | return timedelta_.total_seconds() * 1e6
463 | elif unit == TimeUnit.MILLISECOND:
464 | return timedelta_.total_seconds() * 1e3
465 | elif unit == TimeUnit.SECOND:
466 | return timedelta_.total_seconds()
467 | elif unit == TimeUnit.MINUTE:
468 | return timedelta_.total_seconds() / 60
469 | elif unit == TimeUnit.HOUR:
470 | return timedelta_.total_seconds() / 3600
471 | elif unit == TimeUnit.DAY:
472 | return timedelta_.total_seconds() / (3600 * 24)
473 | elif unit == TimeUnit.YEAR:
474 | return timedelta_.total_seconds() / (3600 * 24 * 365.25)
475 | else:
476 | raise VALUE_ERROR
477 |
478 |
479 | def check_time_unit(diff: timedelta) -> Tuple[int, TimeUnit]:
480 | """
481 | Method to determine the unit of time of the dataset.
482 |
483 | Args:
484 | diff (timedelta): The time difference to be checked.
485 |
486 | Returns:
487 | Tuple[int, TimeUnit]: A tuple with the time value and its unit.
488 | """
489 |
490 | if diff.total_seconds() >= 31536000: # 1 year in seconds
491 | years = int(diff.total_seconds() / 31536000)
492 | t_s = years
493 | time_unit = TimeUnit.YEAR
494 | elif diff.total_seconds() >= 86400: # 1 day in seconds
495 | days = int(diff.total_seconds() / 86400)
496 | t_s = days
497 | time_unit = TimeUnit.DAY
498 | elif diff.total_seconds() >= 3600: # 1 hour in seconds
499 | hours = int(diff.total_seconds() / 3600)
500 | t_s = hours
501 | time_unit = TimeUnit.HOUR
502 | elif diff.total_seconds() >= 60: # 1 minute in seconds
503 | minutes = int(diff.total_seconds() / 60)
504 | t_s = minutes
505 | time_unit = TimeUnit.MINUTE
506 | elif diff.total_seconds() >= 1:
507 | t_s = int(diff.total_seconds())
508 | time_unit = TimeUnit.SECOND
509 | elif diff.total_seconds() * 1000 >= 1:
510 | t_s = int(diff.total_seconds() * 1000)
511 | time_unit = TimeUnit.MILLISECOND
512 | elif diff.total_seconds() * 1000000 >= 1:
513 | t_s = int(diff.total_seconds() * 1000000)
514 | time_unit = TimeUnit.MICROSECOND
515 | else:
516 | raise ValueError("Could not determine the unit of time of the dataset")
517 |
518 | return t_s, time_unit
519 |
520 |
521 | def convert_seconds_to_time_unit(value: Union[float, int], unit: TimeUnit) -> Union[float, int]:
522 | """
523 | Converts a given value from seconds to a specified time unit.
524 |
525 | Args:
526 | value (Union[float, int]): The value in seconds that needs to be converted.
527 | unit (TimeUnit): The target time unit for the conversion.
528 |
529 | Returns:
530 | Union[float, int]: The converted value in the target time unit.
531 |
532 | Raises:
533 | ValueError: If an invalid TimeUnit is provided.
534 | """
535 | conversion_factors = {
536 | TimeUnit.MICROSECOND: 1e6,
537 | TimeUnit.MILLISECOND: 1e3,
538 | TimeUnit.SECOND: 1,
539 | TimeUnit.MINUTE: 1 / 60,
540 | TimeUnit.HOUR: 1 / 3600,
541 | TimeUnit.DAY: 1 / (3600 * 24),
542 | TimeUnit.YEAR: 1 / (3600 * 24 * 365.25)
543 | }
544 |
545 | if unit in conversion_factors:
546 | return value * conversion_factors[unit]
547 |
548 | raise VALUE_ERROR
549 |
550 |
551 | def save_dict_to_json(path: str, data: Dict):
552 | """
553 | Save a dictionary into a json file
554 | Args:
555 | path (str): the path where to store the json file
556 | data (Dict): the dictionary
557 |
558 | Returns:
559 |
560 | """
561 | with open(path, 'w') as f:
562 | json.dump(data, f)
563 |
564 |
565 | def convert_dataset_index_to_datetime(dataset: pd.DataFrame) -> None:
566 | """
567 | Check if the index of the DataFrame dataset is already in the datetime format. If the index is not in datetime
568 | format, dataset.index = pd.to_datetime(dataset.index) statement is executed to convert it.
569 |
570 | Args:
571 | dataset (pd.DataFrame): A dataset as pandas DataFrame
572 |
573 | Returns:
574 | None
575 | """
576 | if not is_datetime64_any_dtype(dataset.index):
577 | dataset.index = pd.to_datetime(dataset.index)
578 |
--------------------------------------------------------------------------------
/eventdetector_ts/metamodel/meta_model.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pprint
3 | import shutil
4 | from typing import Union, Dict, Optional
5 |
6 | import numpy as np
7 | import pandas as pd
8 | import tensorflow as tf
9 |
10 | from eventdetector_ts import FFN, FILL_NAN_ZEROS, TYPE_TRAINING_AVERAGE, STANDARD_SCALER, \
11 | config_dict, CONFIG_FILE
12 | from eventdetector_ts.data.helpers_data import compute_middle_event, remove_close_events, \
13 | convert_events_to_intervals, get_union_times_events, get_dataset_within_events_times, \
14 | convert_dataframe_to_overlapping_partitions, op, check_time_unit, save_dict_to_json, \
15 | convert_dataset_index_to_datetime, convert_seconds_to_time_unit
16 | from eventdetector_ts.metamodel import logger_meta_model
17 | from eventdetector_ts.metamodel.utils import DataSplitter, validate_args, validate_required_args, validate_ffn, \
18 | validate_cnn, validate_rnn
19 | from eventdetector_ts.models.models_builder import ModelCreator
20 | from eventdetector_ts.models.models_trainer import ModelTrainer
21 | from eventdetector_ts.optimization.event_extraction_pipeline import OptimizationData, EventOptimization
22 | from eventdetector_ts.plotter.plotter import Plotter
23 |
24 |
25 | class MetaModel:
26 | def __init__(
27 | self,
28 | output_dir: str,
29 | dataset: pd.DataFrame,
30 | events: Union[list, pd.DataFrame],
31 | width: int,
32 | step: int = 1,
33 | width_events: Optional[Union[int, float]] = None,
34 | **kwargs
35 | ):
36 | """
37 | Initializes a new instance of the MetaModel class.
38 |
39 | Args:
40 | output_dir (str): The name or path of the directory where all outputs will be saved.
41 | If output_dir is a folder name, the full path in the current directory will be created.
42 | dataset (pd.DataFrame): The input dataset as a Pandas DataFrame.
43 | events (Union[list, pd.DataFrame]): The input events as either a list or a Pandas DataFrame.
44 | width (int): Number of consecutive time steps in each partition (window) when creating overlapping
45 | partitions (sliding windows).
46 | step (int = 1): Number of time steps to advance the sliding window. Default to 1.
47 | width_events (Union[int, float] = None): The width of each event.
48 | If it's an integer, it represents the number of time steps that constitute an event.
49 | If it's a float, it represents the duration in seconds of each event.
50 | If not provided (None), it defaults to the value of (width -1).
51 | kwargs (Dict): Optional keyword arguments for additional parameters.
52 | - t_max (float): The maximum total time is linked to the `sigma variable of the Gaussian filter.
53 | This time should be expressed in the same unit of time (seconds, minutes, etc.) as used in the
54 | dataset. The unit of time for the dataset is determined by its time sampling. In other words,
55 | the `sigma` variable should align with the timescale used in your time series data.
56 | The default value is calculated as (3 x (width-1) x time_sampling) / 2.
57 | - delta (Union[int, float]): The maximum time tolerance used to determine the correspondence
58 | between a predicted event and its actual counterpart in the true events. If it's an integer, it
59 | represents the number of time steps. If it's a float, it represents the duration in seconds
60 | The default value is width_events x time_sampling.
61 | - s_h (float): A step parameter for adjusting the peak height threshold `h` during the peak detection
62 | process. The default value is 0.05.
63 | - epsilon (float): A small constant used to control the size of set which contains the top models
64 | with the lowest MSE values. The default value is 0.0002.
65 | - pa (int): The patience for the early stopping algorithm. The default value is 5.
66 | - t_r (float): The ratio threshold for the early stopping algorithm.
67 | The default value is 0.97.
68 | - time_window (Union[int, float] = None): This parameter controls the amount of data within the dataset
69 | is used for the training process. If it's an integer, it represents a specific number time steps.
70 | If it's a float, it represents a duration in seconds. By default, it is set to None, which means all
71 | available data will be used. However, if a value is provided, the dataset will include a specific
72 | interval of data surrounding each reference event. This interval includes data from both sides of
73 | each event, with a duration equal to the specified `time_window`. Setting a `time_window` in some
74 | situations can offer several advantages, such as accelerating the training process and enhancing
75 | the neural networks' understanding of rare events.
76 | - models (List[Union[str, Tuple[str, int]]]): Determines the type of deep learning models to use.
77 | If a tuple is passed, it specifies both the model type and the number of instances to run.
78 | The default value is [(FFN, 2)].
79 | - hyperparams_ffn (Tuple[int, int, int, int, str]): Specify for the FFN the minimum and the maximum
80 | number of layers, the minimum and the maximum number of neurons per layer, and the activation
81 | function. The default value is (1, 3, 64, 256, "sigmoid"). The List of available activation
82 | functions are ["relu","sigmoid","tanh","softmax","leaky_relu","elu","selu","swish"].
83 | If you pass `None`, no activation is applied (i.e. "linear" activation: `a(x) = x`).
84 | - hyperparams_cnn (Tuple[int, int, int, int, int, str]): Specify for the CNN the minimum, maximum number
85 | of filters, the minimum, the maximum kernel size, the minimum and the maximum number of pooling
86 | layers, and the activation function. The default value is (16, 64, 3, 8, 1, 2, "relu").
87 | - hyperparams_transformer (Tuple[int, int, int, bool, str]): Specify for Transformer the Key dimension,
88 | number of heads, the number of the encoder blocks, a flag to indicate the use of the original
89 | architecture, and the activation function. The default value is (256, 8, 10, True, "relu").
90 | - hyperparams_rnn (Tuple[int, int, int, str]): Specify for the RNN the minimum and the maximum number
91 | of RNN layers, the minimum and the maximum number of hidden units, and the activation function.
92 | The default value is (1, 2, 16, 128, "tanh").
93 | - hyperparams_mm_network (Tuple[int, int, str]): Specify for the MetaModel network the number
94 | of layers, the number of neurons per layer, and the activation function.
95 | The default value is (1, 32, "sigmoid").
96 | - epochs (int): The number of epochs to train different models. The default value is False 256.
97 | - batch_size (int): The number of samples per gradient update.
98 | The default value is 32.
99 | - fill_nan (str): Specifies the method to use for filling NaN values in the dataset.
100 | Supported methods are 'zeros', 'ffill', 'bfill', and 'median'.
101 | The default is 'zeros'.
102 | - type_training (str):Specifies the type of training technique to use for the MetaModel.
103 | Supported techniques are 'average' and 'ffn'.
104 | The default is 'average'.
105 | - scaler (str): The type of scaler to use for preprocessing the data.
106 | Possible values are "MinMaxScaler", "StandardScaler", and "RobustScaler".
107 | Default is "StandardScaler"
108 | - use_kfold (bool): Whether to use k-fold cross-validation technique or not.
109 | The default value is False.
110 | - test_size (float): The proportion of the dataset to include in the test split.
111 | Should be a value between 0 and 1. Default is 0.2.
112 | - val_size (float): The proportion of the training set to use for validation.
113 | Should be a value between 0 and 1. Default is 0.2.
114 | - save_models_as_dot_format (bool = False): Whether to save the models as a dot format file.
115 | The default value is False. If set to True, then you should have graphviz software
116 | to be installed on your machine.
117 | - remove_overlapping_events (bool = True): Whether to remove the overlapping events or not.
118 | The default value is True.
119 | - dropout (float = 0.3): The dropout rate, which determines the fraction of input units to drop during
120 | training.
121 | - last_act_func (str = "sigmoid"): Activation function for the final layer of each model. Defaults to
122 | "sigmoid". If set to `None`, no activation will be applied (i.e., "linear" activation: `a(x) = x`).
123 |
124 | """
125 | self.step = step
126 | self.width = width
127 | self.events = events
128 | self.dataset = dataset
129 | self.output_dir = output_dir
130 | self.width_events = width_events
131 | validate_required_args(self)
132 | self.kwargs: Dict = kwargs
133 | self.y = np.empty(shape=(0,))
134 | self.x = np.empty(shape=(0,))
135 | self.__compute_and_set_time_sampling()
136 | self.__set_defaults()
137 | validate_args(self)
138 |
139 | if self.save_models_as_dot_format:
140 | logger_meta_model.warning("save_models_as_dot_format is set to true, "
141 | "you should have graphviz software to be installed on your machine.")
142 | self.__create_output_dir()
143 | # Create a `ModelCreator` object with the provided models and hyperparameters
144 | self.model_creator: ModelCreator = ModelCreator(models=self.models, hyperparams_ffn=self.hyperparams_ffn,
145 | hyperparams_cnn=self.hyperparams_cnn,
146 | hyperparams_rnn=self.hyperparams_rnn,
147 | hyperparams_transformer=self.hyperparams_transformer,
148 | last_act_func=self.last_act_func, dropout=self.dropout,
149 | save_models_as_dot_format=self.save_models_as_dot_format,
150 | root_dir=self.output_dir)
151 | # Create a `DataSplitter` object with the provided test_size and scaler_type
152 | self.data_splitter: DataSplitter = DataSplitter(test_size=self.test_size, scaler_type=self.scaler)
153 | # Create a `ModelTrainer` object with the provided data_splitter, epochs,
154 | # batch_size, pa, t_r, use_kfold, val_size, epsilon and save_models_as_dot_format.
155 | self.model_trainer: ModelTrainer = ModelTrainer(data_splitter=self.data_splitter, epochs=self.epochs,
156 | batch_size=self.batch_size, pa=self.pa, t_r=self.t_r,
157 | use_kfold=self.use_kfold,
158 | val_size=self.val_size, epsilon=self.epsilon,
159 | save_models_as_dot_format=self.save_models_as_dot_format)
160 | # class represents the data used for the event extraction pipeline.
161 | self.optimization_data: OptimizationData = OptimizationData(t_max=self.t_max, w_s=self.w_s, s_s=self.s_s,
162 | s_h=self.s_h, delta=self.delta,
163 | output_dir=self.output_dir,
164 | time_unit=self.time_unit)
165 |
166 | self.event_optimization: EventOptimization = EventOptimization(optimization_data=self.optimization_data)
167 | # The Plotter class is responsible for generating and saving plots.
168 | self.plotter: Plotter = Plotter(root_dir=self.output_dir, time_unit=self.time_unit,
169 | width_events_s=self.width_events_s)
170 |
171 | def __create_output_dir(self) -> None:
172 | """
173 | Check if output_dir is already a complete path, if output_dir is a folder name,
174 | create the full path in the current directory.
175 |
176 | Returns:
177 | None
178 | """
179 |
180 | # Check if output_dir is already a complete path
181 | if os.path.isabs(self.output_dir):
182 | if not os.path.exists(self.output_dir):
183 | logger_meta_model.critical(f"{self.output_dir} does not exists")
184 | raise ValueError(f"{self.output_dir} does not exists")
185 |
186 | # If output_dir is a folder name, create the full path in the current directory
187 | else:
188 | # Get the absolute path of the current directory
189 | current_directory = os.path.abspath(".")
190 | self.output_dir = os.path.join(current_directory, self.output_dir)
191 | if os.path.exists(self.output_dir):
192 | logger_meta_model.warning(f"The working directory '{self.output_dir}' exists and it will be deleted")
193 | shutil.rmtree(self.output_dir)
194 | logger_meta_model.info(f"Creating the working directory at: '{self.output_dir}'")
195 | os.makedirs(self.output_dir)
196 |
197 | config_dict['output_dir'] = self.output_dir
198 |
199 | def __set_defaults_bis(self) -> None:
200 | """
201 | Sets default values for any missing keyword arguments in self.kwargs.
202 |
203 | Returns:
204 | None
205 | """
206 | if self.width_events is None:
207 | self.width_events = self.width
208 | self.t_max = self.kwargs.get('t_max', (3.0 * self.w_s) / 2) # the minimum should be equal to w_s
209 |
210 | if self.kwargs.get('delta') is None:
211 | self.delta = self.width_events_s
212 | else:
213 | if isinstance(self.kwargs.get('delta'), float):
214 | self.delta = convert_seconds_to_time_unit(value=self.kwargs.get('delta'), unit=self.time_unit)
215 | else:
216 | self.delta = self.kwargs.get('delta') * self.t_s
217 |
218 | self.s_h = self.kwargs.get('s_h', 0.05)
219 | self.epsilon = self.kwargs.get('epsilon', 0.0002)
220 | self.pa = self.kwargs.get('pa', 5)
221 | self.t_r = self.kwargs.get('t_r', 0.97)
222 |
223 | def __set_defaults(self) -> None:
224 | """
225 | Sets default values for any missing keyword arguments in self.kwargs.
226 |
227 | Returns:
228 | None
229 | """
230 | self.__set_defaults_bis()
231 |
232 | if self.kwargs.get('time_window') is None:
233 | self.time_window = None
234 | else:
235 | if isinstance(self.kwargs.get('time_window'), float):
236 | self.time_window = convert_seconds_to_time_unit(value=self.kwargs.get('time_window'),
237 | unit=self.time_unit)
238 | else:
239 | self.time_window = self.kwargs.get('time_window') * self.t_s
240 |
241 | self.models = self.kwargs.get('models', [(FFN, 2)])
242 | for i, model in enumerate(self.models):
243 | if isinstance(model, str):
244 | self.models[i] = (model, 1)
245 | elif isinstance(model, tuple) and len(model) == 1:
246 | self.models[i] = (model[0], 1)
247 |
248 | self.hyperparams_ffn = self.kwargs.get('hyperparams_ffn', (1, 3, 64, 256, "sigmoid"))
249 | self.hyperparams_ffn = validate_ffn(self)
250 | self.hyperparams_cnn = self.kwargs.get('hyperparams_cnn', (16, 64, 3, 8, 1, 2, "relu"))
251 | self.hyperparams_cnn = validate_cnn(self)
252 | self.hyperparams_rnn = self.kwargs.get('hyperparams_rnn', (1, 2, 16, 128, "tanh"))
253 | self.hyperparams_rnn = validate_rnn(self)
254 | self.hyperparams_transformer = self.kwargs.get("hyperparams_transformer", (256, 4, 1, True, "relu"))
255 | self.hyperparams_mm_network = self.kwargs.get('hyperparams_mm_network', (1, 32, "sigmoid"))
256 | self.epochs = self.kwargs.get('epochs', 256)
257 | self.batch_size = self.kwargs.get('batch_size', 32)
258 | self.fill_nan = self.kwargs.get('fill_nan', FILL_NAN_ZEROS)
259 | self.type_training = self.kwargs.get('type_training', TYPE_TRAINING_AVERAGE)
260 | self.scaler = self.kwargs.get('scaler', STANDARD_SCALER)
261 | self.use_kfold = self.kwargs.get('use_kfold', False)
262 | self.test_size = self.kwargs.get('test_size', 0.2)
263 | self.val_size = self.kwargs.get('val_size', 0.2)
264 |
265 | self.save_models_as_dot_format = self.kwargs.get('save_models_as_dot_format', False)
266 | self.remove_overlapping_events = self.kwargs.get("remove_overlapping_events", True)
267 | self.last_act_func = self.kwargs.get("last_act_func", "sigmoid")
268 | self.dropout = self.kwargs.get("dropout", 0.3)
269 |
270 | log_dict = {
271 | 'width_events_s': self.width_events_s,
272 | 't_max': self.t_max,
273 | 'delta': self.delta,
274 | 's_h': self.s_h,
275 | 'epsilon': self.epsilon,
276 | 'pa': self.pa,
277 | 't_r': self.t_r,
278 | 'time_window': self.time_window,
279 | 'models': self.models,
280 | 'hyperparams_ffn': self.hyperparams_ffn,
281 | 'hyperparams_cnn': self.hyperparams_cnn,
282 | 'hyperparams_rnn': self.hyperparams_rnn,
283 | 'hyperparams_transformer': self.hyperparams_transformer,
284 | 'hyperparams_mm_network': self.hyperparams_mm_network,
285 | 'epochs': self.epochs,
286 | 'batch_size': self.batch_size,
287 | 'fill_nan': self.fill_nan,
288 | 'type_training': self.type_training,
289 | 'scaler': self.scaler,
290 | 'use_kfold': self.use_kfold,
291 | 'test_size': self.test_size,
292 | 'val_size': self.val_size,
293 | 'save_models_as_dot_format': self.save_models_as_dot_format,
294 | "remove_overlapping_events": self.remove_overlapping_events,
295 | "last_act_func": self.last_act_func,
296 | "dropout": self.dropout
297 | }
298 |
299 | log_message = pprint.pformat(log_dict, indent=4)
300 | logger_meta_model.info(log_message)
301 |
302 | config_dict.update({'width': self.width, 'step': self.step, 'batch_size': self.batch_size,
303 | 'type_training': self.type_training, 'fill_nan': self.fill_nan})
304 |
305 | def __compute_and_set_time_sampling(self) -> None:
306 | """
307 | Compute the time sampling of the dataset by calculating the time difference between the first two index values.
308 | Then set the corresponding parameters: t_s, w_s, and s_s.
309 |
310 | Returns:
311 | None
312 |
313 | Raises:
314 | TypeError: If the index of the dataset is not in datetime format.
315 | """
316 | try:
317 | logger_meta_model.info("checks if the index of the dataset is already in the datetime format.")
318 | convert_dataset_index_to_datetime(self.dataset)
319 | # Get the first two index values of the dataset
320 | a = self.dataset.index[0]
321 | b = self.dataset.index[1]
322 | # Calculate the time difference between the first two index values
323 | diff = b - a
324 | # Check the units of the time difference
325 | logger_meta_model.info("Computing the time sampling and time unit of the dataset")
326 | self.t_s, self.time_unit = check_time_unit(diff=diff)
327 | logger_meta_model.warning(f"The time sampling t_s is {self.t_s} {self.time_unit}s")
328 | self.w_s = self.t_s * (self.width - 1)
329 | self.s_s = self.t_s * self.step
330 |
331 | if self.width_events is None:
332 | self.width_events_s = self.w_s
333 | else:
334 | self.width_events_s = self.t_s * self.width_events
335 |
336 | if isinstance(self.width_events, float):
337 | self.width_events_s = convert_seconds_to_time_unit(value=self.width_events, unit=self.time_unit)
338 |
339 | config_dict['w_s'] = self.w_s
340 | config_dict['width_events_s'] = self.width_events_s
341 | config_dict['time_unit'] = self.time_unit.value
342 | except AttributeError:
343 | logger_meta_model.critical("The dataset is not compatible with the datetime format")
344 | raise TypeError("The index should be in datetime format.")
345 |
346 | def prepare_data_and_computing_op(self) -> None:
347 | """
348 | Prepare the events and dataset for computing op.
349 | This method will compute the middle event of the given events, remove any close events based on the self.w_s,
350 | and convert the remaining events to intervals. If a time partition is specified, it will get the union of
351 | event times and extract the corresponding portion of the dataset.
352 |
353 | The dataset will then be converted to overlapping partitions using the specified width and step size,
354 | and the $op$ (overlapping parameter) values will be computed for each partition based on the given intervals.
355 |
356 | Finally, the learning data (overlapping partitions and corresponding $op$ values) will be stored in
357 | the instance variables x and y.
358 |
359 | Returns:
360 | None
361 | """
362 |
363 | logger_meta_model.info("Computes the middle date of events...")
364 |
365 | self.events = compute_middle_event(self.events)
366 |
367 | logger_meta_model.info("Removes events that occur too close together...")
368 | temp: int = len(self.events)
369 | self.events = remove_close_events(self.events, self.width_events_s, self.time_unit,
370 | self.remove_overlapping_events)
371 |
372 | logger_meta_model.warning(f"A total of {temp - len(self.events)}/{temp} events were removed due to overlapping")
373 | logger_meta_model.info("Convert events to intervals...")
374 | intervals = convert_events_to_intervals(self.events, self.width_events_s, self.time_unit)
375 |
376 | if self.time_window is not None:
377 | logger_meta_model.warning(f"time_window is provided = {self.time_window} {self.time_unit}s")
378 | events_times = get_union_times_events(self.events, self.time_window, self.time_unit)
379 | self.dataset = get_dataset_within_events_times(self.dataset, events_times)
380 |
381 | logger_meta_model.info("Computing overlapping partitions...")
382 | overlapping_partitions = convert_dataframe_to_overlapping_partitions(self.dataset, width=self.width,
383 | step=self.step,
384 | fill_method=self.fill_nan)
385 |
386 | logger_meta_model.info("Computing op...")
387 | self.x, self.y = op(dataset_as_overlapping_partitions=overlapping_partitions, events_as_intervals=intervals)
388 |
389 | # Convert x and y arrays to float32 for consistency
390 | self.x = np.asarray(self.x).astype('float32')
391 | self.y = np.asarray(self.y).astype('float32')
392 |
393 | self.optimization_data.set_overlapping_partitions(overlapping_partitions)
394 | self.optimization_data.set_true_events(self.events)
395 |
396 | def build_stacking_learning(self) -> None:
397 | """
398 | Builds a stacking learning pipeline using the provided models and hyperparameters.
399 |
400 | Returns:
401 | None
402 | """
403 |
404 | # Get the number of time steps and features from the x data
405 | n_time_steps, n_features = self.x.shape[1], self.x.shape[2]
406 | config_dict['n_time_steps'] = n_time_steps
407 | inputs = tf.keras.Input(shape=(n_time_steps, n_features), name="input")
408 | # Call the `create_models` method to create the models
409 | logger_meta_model.info(f"Create the following models: {list(map(lambda x: x[0], self.models))}")
410 | self.model_creator.create_models(inputs=inputs)
411 | logger_meta_model.info("Split the data into training, validation, and test sets and apply "
412 | "the specified scaler to each time step...")
413 | self.data_splitter.split_data_and_apply_scaler(x=self.x, y=self.y)
414 | logger_meta_model.info("Saves the scalers to disk...")
415 | self.data_splitter.save_scalers(output_dir=self.output_dir)
416 | logger_meta_model.info("Fits the created models to the training data...")
417 | self.model_trainer.fitting_models(self.model_creator.created_models)
418 | logger_meta_model.info("Saving the best models...")
419 | self.model_trainer.save_best_models(output_dir=self.output_dir)
420 | predicted_y, loss, test_y = self.model_trainer.train_meta_model(type_training=self.type_training,
421 | hyperparams_mm_network
422 | =self.hyperparams_mm_network,
423 | output_dir=self.output_dir)
424 | self.optimization_data.set_predicted_op(predicted_op=predicted_y)
425 | logger_meta_model.info(f"The loss of the MetaModel is {loss:.4f}")
426 | self.plotter.set_data_op(test_y=test_y, predicted_y=predicted_y)
427 | self.plotter.set_losses(train_losses=self.model_trainer.train_losses,
428 | val_losses=self.model_trainer.val_losses, train_loss_meta_model=
429 | self.model_trainer.train_loss_meta_model,
430 | val_loss_meta_model=self.model_trainer.val_loss_meta_model)
431 |
432 | def event_extraction_optimization(self) -> None:
433 | """
434 | Run the Event Extraction Optimization process.
435 |
436 | Returns:
437 | None
438 | """
439 |
440 | predicted_events, delta_t = self.event_optimization.max_f1score()
441 | path = os.path.join(self.output_dir, CONFIG_FILE)
442 | logger_meta_model.info(f"Saving config file into {path}")
443 | save_dict_to_json(path=path, data=config_dict)
444 | self.plotter.set_data_events(predicted_events=predicted_events, true_events=self.optimization_data.true_events)
445 | self.plotter.set_delta_t(delta_t=delta_t)
446 |
447 | def plot_save(self, show_plots: bool = True) -> None:
448 | """
449 | Plot the results: losses, true/predicted op, true/predicted events, deltat_t.
450 |
451 | Args:
452 | show_plots (bool): whether to show the plots or not.
453 |
454 | Returns:
455 | None
456 | """
457 | self.plotter.set_show(show=show_plots)
458 | self.plotter.plot_losses()
459 | self.plotter.plot_prediction()
460 | self.plotter.plot_predicted_events()
461 | self.plotter.plot_delta_t(bins=10)
462 |
463 | def fit(self) -> None:
464 | """
465 | Run prepare_data_and_computing_op, build_stacking_learning, event_extraction_optimization, and plot_save
466 |
467 | Returns:
468 | None
469 | """
470 | self.prepare_data_and_computing_op()
471 | self.build_stacking_learning()
472 | self.event_extraction_optimization()
473 | self.plot_save()
474 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | [](https://www.python.org/downloads/)
6 | [](https://pypi.org/project/eventdetector-ts/)
7 | 
8 | [](https://coveralls.io/github/menouarazib/eventdetector?branch=master)
9 | [](https://github.com/menouarazib/eventdetector/blob/master/LICENSE)
10 | [](https://doi.org/10.48550/arXiv.2310.16485)
11 |
12 | A Comprehensive Python Library for Deep Learning-Based Event Detection in Multivariate Time Series Data
13 | ==========================================================
14 | ## Table of Contents
15 |
16 | - [Introduction](#introduction)
17 | - [Installation](#installation)
18 | - [Quickstart](#quickstart-examples)
19 | - [Make Prediction](#make-prediction)
20 | - [Documentation](#documentation)
21 | - [How to credit our package](#how-to-credit-our-package)
22 | - [Futures Works](#future-works)
23 | - [References](#references)
24 |
25 |
26 | ## Introduction
27 | Event detection in time series data is crucial in various domains, including finance, healthcare, cybersecurity, and science. Accurately identifying events in time series data is vital for making informed decisions, detecting anomalies, and predicting future trends. Despite extensive research exploring diverse methods for event detection in time series, with deep learning approaches being among the most advanced, there is still room for improvement and innovation in this field. In this paper, we present a new deep learning supervised method for detecting events in multivariate time series data. Our method combines four distinct novelties compared to existing deep-learning supervised methods. Firstly, it is based on regression instead of binary classification. Secondly, it does not require labeled datasets where each point is labeled; instead, it only requires reference events defined as time points or intervals of time. Thirdly, it is designed to be robust by using a stacked ensemble learning meta-model that combines deep learning models, ranging from classic feed-forward neural networks (FFNs) to state-of-the-art architectures like transformers. This ensemble approach can mitigate individual model weaknesses and biases, resulting in more robust predictions. Finally, to facilitate practical implementation, we have developed a Python package to accompany our proposed method. The package, called eventdetector-ts, can be installed through the Python Package Index (PyPI). In this paper, we present our method and provide a comprehensive guide on the usage of the package. We showcase its versatility and effectiveness through different real-world use cases from natural language processing (NLP) to financial security domains.
28 |
29 |
30 |
31 |
32 |
33 | ## Installation
34 |
35 | **Before installing this package, please ensure that you have `TensorFlow` installed in your environment.** This package relies on `TensorFlow` for its functionality, but does not include it as a dependency to allow users to manage their own TensorFlow installations. You can install TensorFlow via pip with `pip install tensorflow`.
36 |
37 | Once TensorFlow is installed, you can proceed with the installation of this package.
38 | Please follow the instructions below:
39 | ### PyPi installation
40 |
41 | pip install eventdetector-ts
42 |
43 | ### Manual installation
44 | To get started using **Event Detector**, simply follow the instructions below to install the required packages and
45 | dependencies.
46 | #### Clone the repository:
47 |
48 |
git clone https://github.com/menouarazib/eventdetector.git
49 | cd eventdetector
50 |
148 |
149 | #### Comparison of Predicted `op` and True `op`
150 | The Figure below illustrates the comparison between the predicted $op$ values and the true $op$ values on the Bow Shock Crossings and Credit Card Frauds.
151 |
152 |
153 |
154 |
155 |
156 | #### Distribution of time differences δ(t) between predicted events and ground truth events for Bow Shock Crossings and Credit Card Frauds
157 |
158 |
159 |
160 |
161 |
162 |
163 | ## Make Prediction
164 | ```python
165 | from eventdetector_ts.prediction.prediction import predict
166 | from eventdetector_ts.prediction.utils import plot_prediction
167 |
168 | dataset_for_prediction = ...
169 |
170 | # Call the 'predict' method
171 | predicted_events, predicted_op, filtered_predicted_op = predict(dataset=dataset_for_prediction,
172 | path='path to output_dir')
173 | # Plot the predictions
174 | plot_prediction(predicted_op=predicted_op, filtered_predicted_op=filtered_predicted_op)
175 | ```
176 |
177 | ## Documentation
178 | For a deeper understanding of the parameters presented below,
179 | please refer to our paper available at this [link](https://osf.io/uabjg).
180 |
181 | ### Meta Model
182 | The first step is to instantiate the `MetaModel` object with the required arguments:
183 | ```python
184 | from eventdetector_ts.metamodel.meta_model import MetaModel
185 |
186 | meta_model = MetaModel(output_dir=..., dataset=..., events=..., width=..., step=...)
187 | ```
188 | For a complete description of the required and optional arguments, please refer to the following tables:
189 |
190 | #### Required Arguments
191 | | Argument | Type | Description | Default Value |
192 | |----------------|---------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------|
193 | | `output_dir` | str | The name or path of the directory where all outputs will be saved. If `output_dir` is a folder name, the full path in the current directory will be created. | - |
194 | | `dataset` | pd.DataFrame | The input dataset as a Pandas DataFrame. | - |
195 | | `events` | Union[list, pd.DataFrame] | The input events as either a list or a Pandas DataFrame. | - |
196 | | `width` | int | Number of consecutive time steps in each partition (window) when creating overlapping partitions (sliding windows). | - |
197 | | `step` | int | Number of time steps to advance the sliding window. | 1 |
198 | | `width_events` | Union[int, float] | The width of each event. If it's an `ìnt`, it represents the number of time steps that constitute an event. If it's a `float`, it represents the duration in seconds of each event. If not provided (None), it defaults to the value of `width -1`. | `width -1` |
199 |
200 | #### Optional Arguments: Kwargs
201 | | Argument | Type | Description | Default Value |
202 | |-----------------------------|------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------|
203 | | `t_max` | float | The maximum total time is linked to the `sigma` variable of the Gaussian filter. This time should be expressed in the same unit of time (seconds, minutes, etc.) as used in the dataset. The unit of time for the dataset is determined by its time sampling. In other words, the `sigma` variable should align with the timescale used in your time series data. | (3 x `(width -1)` x time_sampling) / 2 |
204 | | `delta` | Union[int, float] | The maximum time tolerance used to determine the correspondence between a predicted event and its actual counterpart in the true events. If it's an integer, it represents the number of time steps. If it's a float, it represents the duration in seconds. | `width_events` x time_sampling |
205 | | `s_h` | float | A step parameter for adjusting the peak height threshold `h` during the peak detection process. | 0.05 |
206 | | `epsilon` | float | A small constant used to control the size of set which contains the top models with the lowest MSE values. | 0.0002 |
207 | | `pa` | int | The patience for the early stopping algorithm. | 5 |
208 | | `t_r` | float | The ratio threshold for the early stopping algorithm. | 0.97 |
209 | | `time_window` | Union[int, float] | This parameter controls the amount of data within the dataset is used for the training process. If it's an integer, it represents a specific number time steps. If it's a float, it represents a duration in seconds. By default, it is set to None, which means all available data will be used. However, if a value is provided, the dataset will include a specific interval of data surrounding each reference event. This interval includes data from both sides of each event, with a duration equal to the specified `time_window`. Setting a `time_window` in some situations can offer several advantages, such as accelerating the training process and enhancing the neural networks' understanding of rare events. | None |
210 | | `models` | List[Union[str, Tuple[str, int]]] | Determines the type of deep learning models and the number of instances to use. Available models: `LSTM`, `GRU`, `CNN`, `RNN_BIDIRECTIONAL`, `RNN_ENCODER_DECODER`, `CNN_RNN`, `FFN`, `CONV_LSTM1D`, `SELF_ATTENTION`, `TRANSFORMER`. | `[(FFN, 2)]` |
211 | | `hyperparams_ffn` | Tuple[int, int, int, int, str] | Specify for the FFN the minimum and the maximum number of layers, the minimum and the maximum number of neurons per layer, and the activation function. The List of available activation functions are ["relu","sigmoid","tanh","softmax","leaky_relu","elu","selu","swish"]. If you pass `None`, no activation is applied (i.e. "linear" activation: `a(x) = x`). | (1, 3, 64, 256, "sigmoid") |
212 | | `hyperparams_cnn` | Tuple[int, int, int, int, int, int, str] | Specify for the CNN the minimum and maximum number of filters, the minimum and the maximum kernel size, the minimum and maximum number of pooling layers, and the activation function. | (16, 64, 3, 8 , 1, 2, "relu") |
213 | | `hyperparams_transformer` | Tuple[int, int, int, bool, str] | Specify for Transformer the Key dimension, number of heads, the number of the encoder blocks, a flag to indicate the use of the original architecture, and the activation function. | (256, 8, 10, True, "relu") |
214 | | `hyperparams_rnn` | Tuple[int, int, int, int, str] | Specify for the RNN the minimum and maximum number of recurrent layers,the minimum and the maximum number of hidden units, and the activation function. | (1,2, 16, 128,"tanh") |
215 | | `hyperparams_mm_network` | Tuple[int,int,str] | Specify for the MetaModel network the number of layers,the number of neurons per layer, and the activation function. | (1 ,32,"sigmoid") |
216 | | `epochs` | int | The number of epochs to train different models. | 256 |
217 | | `batch_size` | int | The number of samples per gradient update. | 32 |
218 | | `fill_nan` | str | Specifies the method to use for filling `NaN` values in the dataset. Supported methods are 'zeros', 'ffill', 'bfill', and 'median'. | "zeros" |
219 | | `type_training` | str | Specifies the type of training technique to use for the MetaModel. Supported techniques are 'average' and 'ffn'. | "average" |
220 | | `scaler` | str | The type of scaler to use for preprocessing the data. Possible values are "MinMaxScaler", "StandardScaler", and "RobustScaler". | "StandardScaler" |
221 | | `use_kfold` | bool | Whether to use k-fold cross-validation technique or not. | False |
222 | | `test_size` | float | The proportion of the dataset to include in the test split. Should be a value between 0 and 1. | 0.2 |
223 | | `val_size` | float | The proportion of the training set to use for validation. Should be a value between 0 and 1. | 0.2 |
224 | | `save_models_as_dot_format` | bool | Whether to save the models as a dot format file. If set to True, then you should have graphviz software installed on your machine. | False |
225 | | `remove_overlapping_events` | bool | Whether to remove the overlapping events or not. | True |
226 | | `dropout` | float | The dropout rate, which determines the fraction of input units to drop during training. | 0.3 |
227 | | `last_act_func` | str | Activation function for the final layer of each model. If set to `None`, no activation will be applied (i.e., "linear" activation: `a(x) = x`). | "sigmoid" |
228 |
229 | #### The method `fit`
230 | The method `fit` calls automatically the following methods:
231 | ##### Prepare data for computing the overlapping parameter `op`
232 | The second thing to do is to prepare the events and the dataset for computing `op`:
233 | ```python
234 | meta_model.prepare_data_and_computing_op()
235 | ```
236 |
237 | ##### Stacking Ensemble Learning Pipeline
238 | The third thing to do is to build a stacking learning pipeline using the provided models and hyperparameters:
239 |
240 | ```python
241 | meta_model.build_stacking_learning()
242 | ```
243 |
244 | ##### Event Extraction Optimization
245 | The fourth thing to do is to run the Event Extraction Optimization process:
246 |
247 | ```python
248 | meta_model.event_extraction_optimization()
249 | ```
250 |
251 | ##### Get The Results and Plots
252 | Finally, you can plot the results, which are saved automatically: losses, true/predicted ops, true/predicted events, and delta_t.
253 |
254 | ```python
255 | meta_model.plot_save(show_plots=True)
256 | ```
257 | ## How to credit our package
258 |
259 | If you use our package, please cite the following papers:
260 |
261 | ```bash
262 | @INPROCEEDINGS{10459857,
263 | author={Azib, Menouar and Renard, Benjamin and Garnier, Philippe and Génot, Vincent and André, Nicolas},
264 | booktitle={2023 International Conference on Machine Learning and Applications (ICMLA)},
265 | title={A Comprehensive Python Library for Deep Learning-Based Event Detection in Multivariate Time Series Data},
266 | year={2023},
267 | volume={},
268 | number={},
269 | pages={1399-1404},
270 | keywords={Deep learning;Technological innovation;Event detection;Time series analysis;Predictive models;Tagging;Transformers;Event Detection in Time Series;Regression;Python Package;Information Retrieval;Natural Language Pro-cessing (NLP)},
271 | doi={10.1109/ICMLA58977.2023.00211}
272 | }
273 | ```
274 |
275 | # Future Works
276 | In our future works, we aim to enhance our model’s capabilities by predicting events of varying durations. This would be a significant improvement over our current approach, which only predicts the midpoint of events with a fixed duration.
277 |
278 | # References
279 |
280 | [1] F. K. Alarfaj, I. Malik, H. U. Khan, N. Almusallam, M. Ramzan and M. Ahmed, “Credit Card Fraud Detection Using State-of-the-Art Machine Learning and Deep Learning Algorithms,” in IEEE Access, vol. 10, pp. 39700-39715, 2022, doi: 10.1109/ACCESS.2022.3166891.
281 |
282 |
283 | [2] D. Varmedja, M. Karanovic, S. Sladojevic, M. Arsenovic and A. Anderla, “Credit Card Fraud Detection - Machine Learning methods,” 2019 18th International Symposium INFOTEH-JAHORINA (INFOTEH), East Sarajevo, Bosnia and Herzegovina, 2019, pp. 1-5, doi: 10.1109/INFOTEH.2019.8717766.
284 |
285 |
286 | [3] E. Ileberi, Y. Sun and Z. Wang, “A machine learning based credit card fraud detection using the GA algorithm for feature selection,” in J Big Data, vol. 9, no. 24, 2022. [Online]. Available: https://doi.org/10.1186/s40537-022-00573-8.
287 |
288 |
289 | [4] I. K. Cheng, N. Achilleos and A. Smith, “Automated bow shock and magnetopause boundary detection with Cassini using threshold and deep learning methods,” Front. Astron. Space Sci., vol. 9, 2022, doi: 10.3389/fspas.2022.1016453.
290 |
291 |
--------------------------------------------------------------------------------
 31 |
31 | 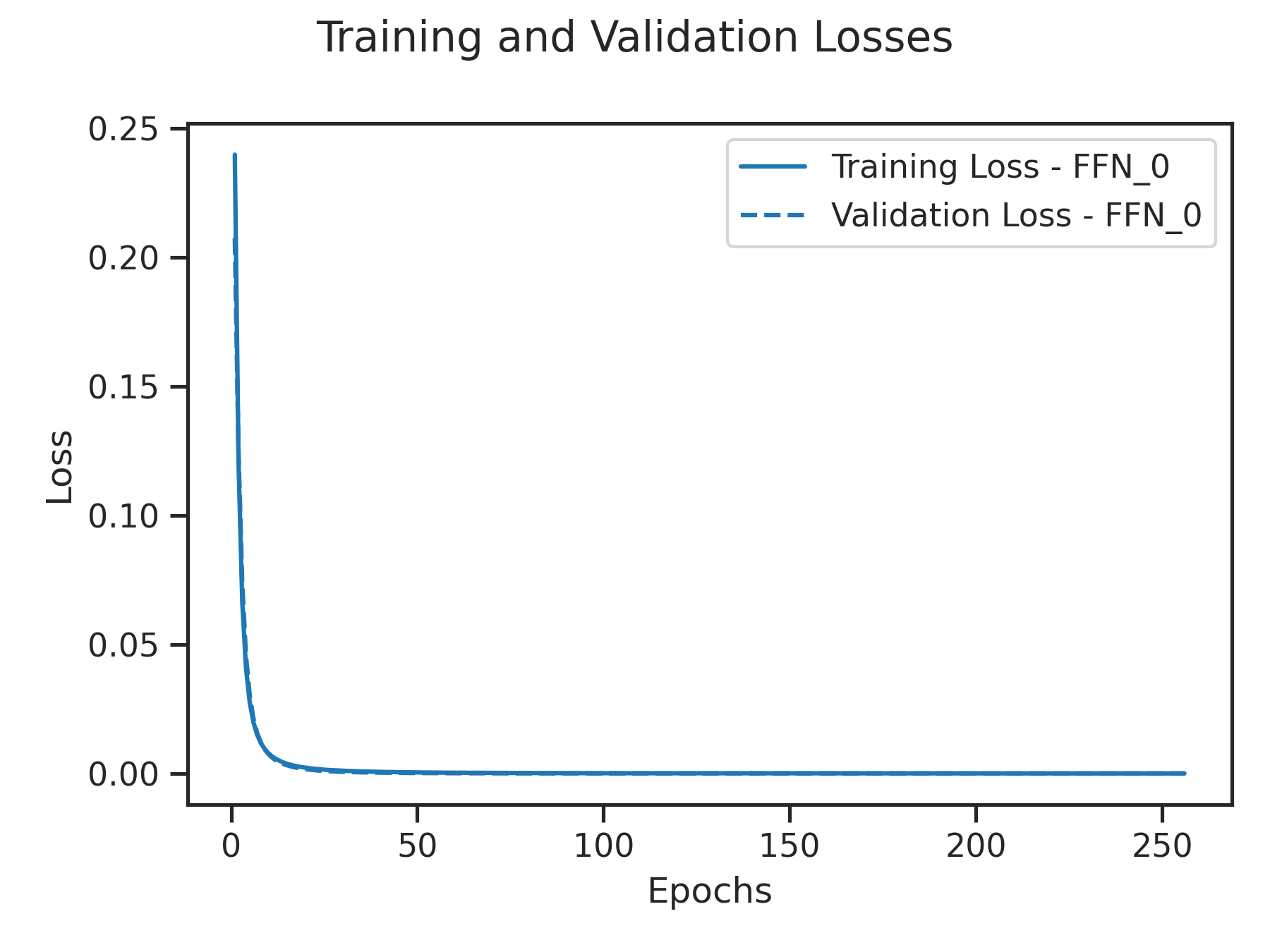 146 |
146 | 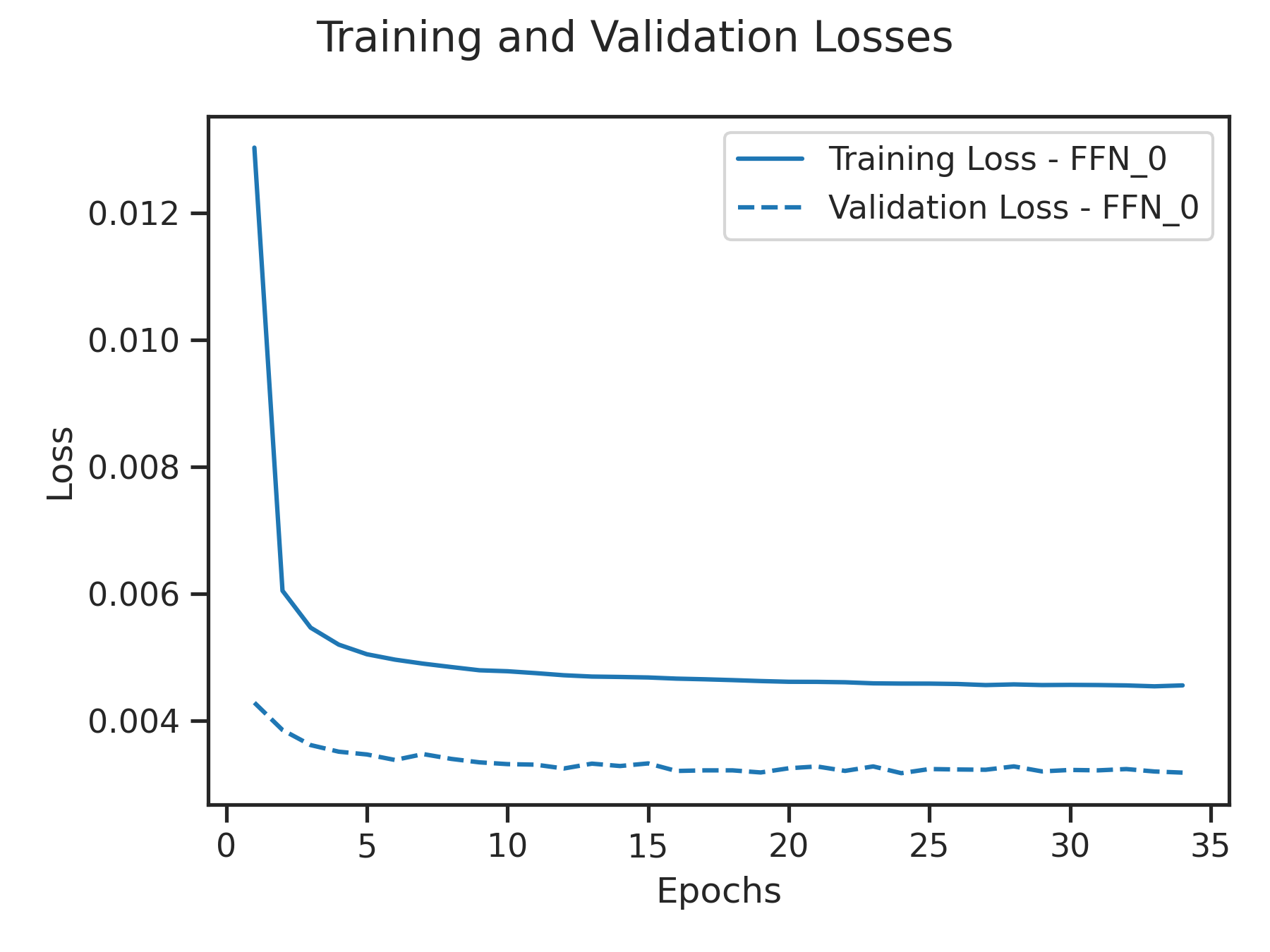 147 |
147 | 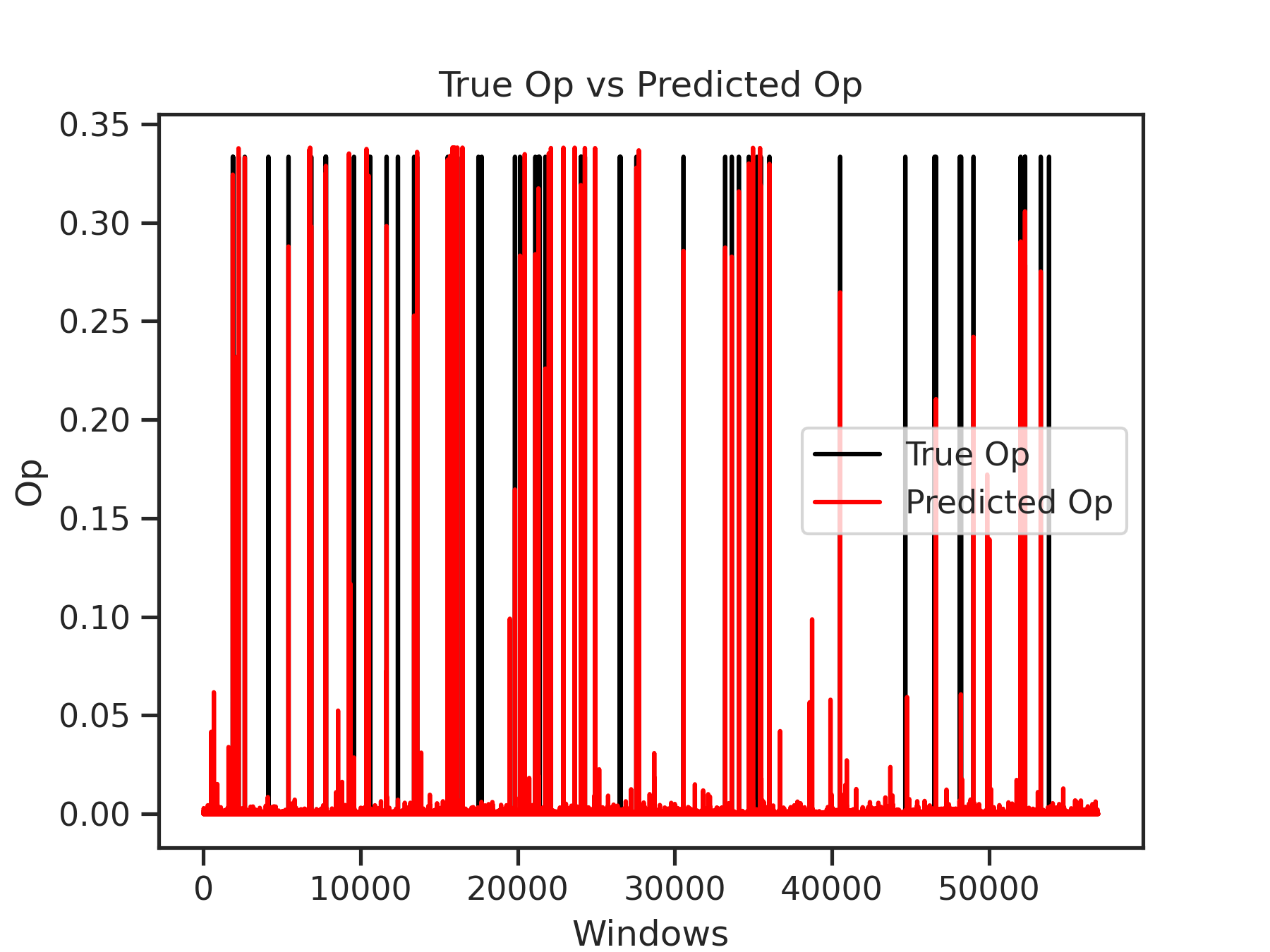 153 |
153 | 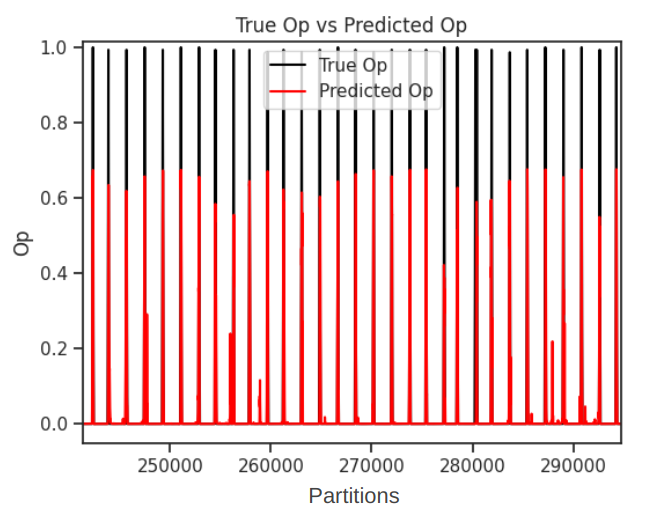 154 |
154 |  159 |
159 |  160 |
160 |