├── .gitattributes
├── .gitignore
├── .nojekyll
├── README.md
├── _sidebar.md
├── docs
├── distributed
│ ├── 13张图彻底搞懂分布式系统服务注册与发现原理.md
│ ├── 原来10张图就可以搞懂分布式链路追踪系统原理.md
│ └── 用大白话给你解释Zookeeper的选举机制.md
├── it-hot
│ └── 鸿蒙OS尖刀武器之分布式软总线技术.md
├── java
│ ├── annotation
│ │ └── 想自己写框架不会写Java注解可不行.md
│ ├── base
│ │ └── Java基础入门80问.md
│ ├── java8
│ │ ├── Java8函数式接口和Lambda表达式你真的会了吗.md
│ │ ├── 使用Java8 Optional类优雅解决空指针问题.md
│ │ ├── 包学会,教你用Java函数式编程重构烂代码.md
│ │ └── 请避开Stream流式编程常见的坑.md
│ ├── juc
│ │ ├── 倒计时计数CountDownLatch.md
│ │ ├── 内存泄露的原因找到了,罪魁祸首居然是Java TheadLocal.md
│ │ ├── 十张图告诉你多线程那些破事.md
│ │ ├── 图解Java中那18 把锁.md
│ │ ├── 面试官:说说Atomic原子类的实现原理.md
│ │ ├── 面试官:说说什么是Java内存模型?.md
│ │ └── 面试必问的CAS原理你会了吗.md
│ └── roadmap
│ │ └── 2021 版最新Java 学习路线图(持续刷新).md
├── mq
│ ├── Kafka支持百万级TPS的秘密都藏在这里.md
│ └── 刨根问底,kafka到底会不会丢消息.md
├── redis
│ ├── Redis 数据结构和常用命令速记.md
│ ├── Redis核心技术知识点全集.md
│ ├── 一张图搞懂Redis缓存雪崩、缓存穿透、缓存击穿.md
│ ├── 一次性将Redis RDB持久化和AOF持久化讲透.md
│ ├── 看完这20道Redis面试题,阿里面试可以约起来了.md
│ ├── 经理让我复盘上次Redis缓存雪崩事故.md
│ ├── 记一次由Redis分布式锁造成的重大事故,避免以后踩坑!.md
│ ├── 还在用单机版?教你用Docker+Redis搭建主从复制多实例.md
│ ├── 面试官再问Redis事务把这篇文章扔给他.md
│ └── 高并发场景下,到底先更新缓存还是先更新数据库?.md
└── tools
│ ├── git
│ └── 保姆级Git教程,10000字详解.md
│ ├── 推荐十款精选IntelliJIdea插件.md
│ └── 高效学习资源网站汇总.md
└── index.html
/.gitattributes:
--------------------------------------------------------------------------------
1 | *.js linguist-language=java
2 | *.css linguist-language=java
3 | *.html linguist-language=java
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .DS_Store
2 |
--------------------------------------------------------------------------------
/.nojekyll:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/CoderLeixiaoshuai/java-eight-part/77620444e663d2bd54fc2286678162f473478d35/.nojekyll
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | :star: 点右上角给一个 `Star`,鼓励技术人输出更多干货,爱了 !
2 |
3 | :gift::gift::gift: 号外号外,学习资料免费下载!
4 | - [进BAT大厂前必读的经典编程书籍,吐血整理共6G一次打包带走](http://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=502841590&idx=1&sn=938f0a4c45d2843aa7545c1f78fcffc6&chksm=0f09beec387e37faede87b50c31e37ee384093f1bd3363304054b7919f9b6266368954b4cbd8#rd)
5 | - [阿里师兄总结的JAVA核心知识点整理(283页,超级详细,高清带目录)](http://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=502841004&idx=1&sn=059dab6b76cbbc50eabd39566ee5ce28&chksm=0f09c0b6387e49a099b9c55d37e112f2049309f2a895a314f0a362e9ce5fb248ad4caafd50e8#rd)
6 |
7 | - [Github 疯传!阿里大佬「LeetCode刷题手册」开放下载了!史上最强悍!](http://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=502841057&idx=1&sn=97576b1a66502b75a6770265515b4a57&chksm=0f09c0fb387e49ed543d3fec9b3ff6ae9da6efbcf8ff52e07c15a05de9d2b90dcee1152a1b28#rd)
8 |
9 |  10 |
11 |
10 |
11 |
12 |

13 |

14 |

15 |

16 |

17 |

18 |
21 |
22 | > 什么是 Java 八股文?Java 面试中经常会问的一些知识点或者套路被大家戏称为『八股文』。希望读完本开源项目可以帮助你熟悉面试套路、拿大厂 offer。
23 | >
24 | > 勘误:如果文章内容有误欢迎[联系我](#iphone-联系我)修改,或者提交 [`PR`](https://github.com/CoderLeixiaoshuai/java-eight-part/pulls) or [`Issue`](https://github.com/CoderLeixiaoshuai/java-eight-part/issues),开源靠大家共同的努力!
25 | >
26 | > 版权说明:所有文章都已首发我的微信公众号,如果需要转载可以[联系我](#iphone-联系我)授权,恶意抄袭我会不惜一切代价维护权益,希望同行一起维护良好的创作环境。
27 |
28 | # :coffee: Java
29 |
30 | [『必看』2021 版最新Java 学习路线图(持续刷新):+1::+1::+1:](docs/java/roadmap/2021%20版最新Java%20学习路线图(持续刷新).md)
31 |
32 | ## Java入门面试题
33 | [Java基础入门80问,适合新手,老鸟直接跳过](docs/java/base/Java基础入门80问.md)
34 |
35 | ## Java并发编程(J.U.C) :+1:
36 | - [『死磕Java并发编程系列』 01 十张图告诉你多线程那些破事](docs/java/juc/十张图告诉你多线程那些破事.md)
37 | - [『死磕Java并发编程系列』 02 面试官:说说什么是Java内存模型?](docs/java/juc/面试官:说说什么是Java内存模型?.md)
38 | - [『死磕Java并发编程系列』 03 面试必问的CAS原理你会了吗?](docs/java/juc/面试必问的CAS原理你会了吗.md)
39 | - [『死磕Java并发编程系列』 04 面试官:说说Atomic原子类的实现原理?](docs/java/juc/面试官:说说Atomic原子类的实现原理.md)
40 | - [『死磕Java并发编程系列』 05 图解Java中那18 把锁.md](docs/java/juc/图解Java中那18%20把锁.md)
41 | - [『死磕Java并发编程系列』06 倒计时计数CountDownLatch](docs/java/juc/倒计时计数CountDownLatch.md)
42 | - 『死磕Java并发编程系列』07 人齐了一起干CyclicBarrier
43 | - 『死磕Java并发编程系列』08 限量供应Semaphore
44 | - 『死磕Java并发编程系列』09 一手交钱一手交货Exchange
45 | - [内存泄露的原因找到了,罪魁祸首居然是Java TheadLocal](docs/java/juc/内存泄露的原因找到了,罪魁祸首居然是Java%20TheadLocal.md)
46 |
47 | *疯狂更新中……*
48 |
49 | ## Java8实战
50 | - [『Java8实战系列』01 Java8函数式接口和Lambda表达式你真的会了吗?](docs/java/java8/Java8函数式接口和Lambda表达式你真的会了吗.md)
51 | - [『Java8实战系列』02 包学会,教你用Java函数式编程重构烂代码](docs/java/java8/包学会,教你用Java函数式编程重构烂代码.md)
52 | - [『Java8实战系列』03 请避开Stream流式编程常见的坑](docs/java/java8/请避开Stream流式编程常见的坑.md)
53 | - [『Java8实战系列』04 详解Lambda表达式中Predicate Function Consumer Supplier函数式接口](docs/java/java8/%E8%AF%A6%E8%A7%A3Lambda%E8%A1%A8%E8%BE%BE%E5%BC%8F%E4%B8%ADPredicate%20Function%20Consumer%20Supplier%E5%87%BD%E6%95%B0%E5%BC%8F%E6%8E%A5%E5%8F%A3.md)
54 | - [『Java8实战系列』05 使用Java8 Optional类优雅解决空指针问题](docs/java/java8/使用Java8%20Optional类优雅解决空指针问题.md)
55 |
56 | ## Java注解
57 | - [想自己写框架?不会写Java注解可不行!](docs/advanced/java-annotation/想自己写框架不会写Java注解可不行.md)
58 |
59 | # :baby_chick: Redis
60 |
61 | **面试八股文**
62 | - [『玩转Redis面试篇』看完这20道Redis面试题,阿里面试可以约起来了](docs/redis/看完这20道Redis面试题,阿里面试可以约起来了.md)
63 |
64 | **知识点详解**
65 | - [『玩转Redis基础篇』Redis数据结构和常用命令速记](docs/redis/Redis%20数据结构和常用命令速记.md)
66 |
67 | - [『玩转Redis基础篇』面试官再问Redis事务把这篇文章扔给他](docs/redis/面试官再问Redis事务把这篇文章扔给他.md)
68 |
69 | - [『玩转Redis基础篇』一次性将Redis RDB持久化和AOF持久化讲透](docs/redis/一次性将Redis%20RDB持久化和AOF持久化讲透.md)
70 |
71 | - [『玩转Redis基础篇』一张图搞懂Redis缓存雪崩、缓存穿透、缓存击穿](docs/redis/一张图搞懂Redis缓存雪崩、缓存穿透、缓存击穿.md)
72 |
73 | - [『玩转Redis实战篇』高并发场景下,到底先更新缓存还是先更新数据库?:+1::+1:](docs/redis/高并发场景下,到底先更新缓存还是先更新数据库?.md)
74 |
75 | - [『玩转Redis实战篇』经理让我复盘上次Redis缓存雪崩事故](docs/redis/经理让我复盘上次Redis缓存雪崩事故.md)
76 |
77 | - [『玩转Redis实战篇』还在用单机版?教你用Docker+Redis搭建主从复制多实例](docs/redis/还在用单机版?教你用Docker%2BRedis搭建主从复制多实例.md)
78 |
79 | - [『玩转Redis实战篇』记一次由Redis分布式锁造成的重大事故,避免以后踩坑!](docs/redis/记一次由Redis分布式锁造成的重大事故,避免以后踩坑!.md)
80 |
81 |
82 |
83 | # :tiger: 消息队列(kafka)
84 | - [Kafka支持百万级TPS的秘密都藏在这里:+1::+1::+1:](docs/mq/Kafka支持百万级TPS的秘密都藏在这里.md)
85 | - [刨根问底,kafka到底会不会丢消息:+1::+1::+1:](docs/mq/刨根问底,kafka到底会不会丢消息.md)
86 |
87 | # :cow: 分布式
88 |
89 | - [13张图彻底搞懂分布式系统服务注册与发现原理:+1::+1::+1:](docs/distributed/13张图彻底搞懂分布式系统服务注册与发现原理.md)
90 | - [原来10张图就可以搞懂分布式链路追踪系统原理:+1::+1::+1:](docs/distributed/原来10张图就可以搞懂分布式链路追踪系统原理.md)
91 | - [用大白话给你解释Zookeeper的选举机制:+1::+1:](docs/distributed/用大白话给你解释Zookeeper的选举机制.md)
92 |
93 | # :sheep: 关系数据库
94 |
95 | [我们为什么要分库分表?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322981&idx=1&sn=644537003c300db69934aa7acee80c8c&chksm=8f09c63fb87e4f29b5bebeca1c03e102898fcbd663b6f189a78dba8cec646f875cc01832a221&token=1553501157&lang=zh_CN#rd)
96 |
97 | # :frog: 五分钟入门系列
98 |
99 | - [5分钟带你快速了解ServiceMesh的前世今生](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322518&idx=1&sn=c6e23e98a838e7960e72623326c99360&chksm=8f09c84cb87e415a91f3a898918f45aa32ab17ed784cd68ce07945ecbb3a78b54429a38c9941&token=1553501157&lang=zh_CN#rd)
100 | - [Docker不香吗?为什么还要用k8s](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322467&idx=1&sn=30ab39d4f59135ecf6eb322fb0712189&chksm=8f09c839b87e412fdae1c39072ebdbbdcc3420b46fb66a324f5f81d8ebe621fe0ac3ef003a7d&token=1553501157&lang=zh_CN#rd)
101 |
102 | # :horse: 设计模式
103 | [说完观察者和发布订阅模式的区别,面试官不留我吃饭了](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322141&idx=1&sn=ccece65719b5693ecdc6893642caefc3&chksm=8f09cac7b87e43d1efb3fcd2ba4b59159c7fa833b777fbdffaf0e739d3530c6834f80eaffbdd&token=1553501157&lang=zh_CN#rd)
104 |
105 |
106 | # :bulb: 工具&效率提升
107 |
108 | ## Git
109 |
110 | 基础教程:
111 |
112 | - [保姆级Git教程,10000字详解,必看:+1:](docs/tools/git/保姆级Git教程,10000字详解.md)
113 |
114 | 进阶实战:
115 |
116 | - [牛逼!简单的代码提交能玩出这么多花样](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322730&idx=1&sn=6b7593e2cd29747ba424b9ca987ac86c&chksm=8f09c930b87e40269c52f2156d1ed08ce87509f4eca25aeb49f4977e97164622f614d3b93dd0&token=1553501157&lang=zh_CN#rd)
117 | - [吵疯了,Pull Request到底是个啥?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650323040&idx=1&sn=12b5f1342661c7964f8908eb1e14f590&chksm=8f09c67ab87e4f6ce6aa04b9a12ab95700089455b682eea6007e90172ec2d92f705277da34f6&token=1553501157&lang=zh_CN#rd)
118 |
119 | ## IntelliJ IDEA - Java开发利器
120 |
121 | - [开发效率不高?推荐这十款精选IntelliJ Idea插件](docs/tools/推荐十款精选IntelliJIdea插件.md)
122 |
123 | ## 代码重构
124 | - [讲点码德!避免这些代码坏味道,努力做一名优秀的程序员](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322056&idx=1&sn=ab5552ffdc868d3ea004ed0782bd80d3&chksm=8f09ca92b87e4384881ec3ab1d1b20f61c0f77e1185d5f0ad60c7b96d3420cf7f101e88492c6&token=1553501157&lang=zh_CN#rd)
125 |
126 | ## 学习资源
127 | - [高效学习资源网站汇总](docs/tools/高效学习资源网站汇总.md)
128 |
129 |
130 | # :dart: 我要进大厂系列
131 |
132 | - [两年半完成逆袭,室友终于拿到字节跳动的Offer:+1:](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321727&idx=1&sn=2e530651ba6176415cacc91f065d333c&chksm=8f09cd25b87e4433f5a7a248bf91ee64f3e1b025a3096873f543a5cf8f03f31433b6d31c0ddc&token=1941065265&lang=zh_CN#rd)
133 |
134 | - [找工作前这四个坑不要重复踩了](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321540&idx=1&sn=c17e195ec6fa7d40a6327a456f9fd4b2&chksm=8f09cc9eb87e45889fed564e4c1e461cf53863930323c9a5aa86169e94b25092bdd9097c81fc&token=1553501157&lang=zh_CN#rd)
135 |
136 | - [网易面试干货之HR解密网易招聘(上篇)](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321320&idx=1&sn=d0c73f80b6ee92aebc12dbdbcb41d8ec&chksm=8f09cfb2b87e46a4afa541bb198c0bca3acdb9067c269406447587c3c8cfd135bea0ec701bd8&scene=178&cur_album_id=1531431564587417601#rd)
137 | - [网易面试干货之HR解密网易招聘(下篇)](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321320&idx=2&sn=21940f268890e43032434b628fc08819&chksm=8f09cfb2b87e46a4e6c94b8b94667f036be9e8a3e6780e7ca8b714d18b53e0f1b96c67d07781&scene=178&cur_album_id=1531431564587417601#rd)
138 |
139 |
140 |
141 | # :see_no_evil: 程序人生
142 | - [我也是从寒门走出来的:+1::+1::+1: ](https://mp.weixin.qq.com/s/pejkW9F1QsH2toEfoNPe1g)
143 | - [逃离百度](https://mp.weixin.qq.com/s/0Sobo5R4GLE3QmEK_gbksg)
144 | - [寒门难出贵子,我当程序员让爸妈在老家长脸了:+1::+1::+1: ](https://mp.weixin.qq.com/s/GOKberslgcxN7Jl5cTrmyw)
145 | - [摊牌了,这半个月我拍"电影"去了](https://mp.weixin.qq.com/s/ihTIFUqM0z7V1zmgPvT0yA)
146 | - [谈谈拼夕夕事件!为什么我们拼尽全力却还要996](https://mp.weixin.qq.com/s/3WVde2dAKfqKv0DBt5dGLw)
147 | - [IT双职工赢在起跑线,还怕未来吗?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321489&idx=1&sn=c31f56cc06fd21e889be51e189ffed23&chksm=8f09cc4bb87e455d09e5ceda718c27cbf5df113cbe0336faf947b1bce3d28d40cc454ebf872d&token=1553501157&lang=zh_CN#rd)
148 | - [程序员版《我和我的家乡》,拼搏奋斗的IT人是家乡的骄傲!](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321444&idx=1&sn=17f3ce6c05b40afc3c18bdb23ee2f6d7&chksm=8f09cc3eb87e45289fd1e51055a4acb7d9689a8e3d4ffc598fc7fd1ca1e918f1628ee67d55c6&scene=178&cur_album_id=1531431564587417601#rd)
149 | - [女程序员在互联网界到底有没有被歧视?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321297&idx=1&sn=d547a2c54e99e6a69723e39ec955d24e&chksm=8f09cf8bb87e469d560ef47c47e59d814a224a31ccfefe12efe9e62a20abbc0f870e14660648&scene=178&cur_album_id=1531431564587417601#rd)
150 | - [离开华为换种生活,它不香吗?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321143&idx=1&sn=85a794588811541a8e920a60a0edcf4e&chksm=8f09ceedb87e47fb0b9301b6d268b4c68f5a213f47f5a1286fc800a2707b6a9bf57958bd301b&scene=178&cur_album_id=1531431564587417601#rd)
151 | - [如果可以选择,我再也不想在国企当程序员了](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321085&idx=1&sn=12a7cc5c910d547cc696c325826295e1&chksm=8f09cea7b87e47b13256c15a631506fc18fd2d8a25a4546b202f268f84347723f59a9e2e86ac&scene=178&cur_album_id=1531431564587417601#rd)
152 | - [30岁的程序员出路在哪里?](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321044&idx=1&sn=30b10126e477876229f77cd604540b57&chksm=8f09ce8eb87e47981c945363f9601bf8bd524d220fe1b1397f01a18420c8e1cc8f7c76ba94cb&scene=178&cur_album_id=1531431564587417601#rd)
153 |
154 | # :cloud: 侃天侃地侃互联网
155 |
156 | - [求伯君,一个你必须知道的程序员
157 | ](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321596&idx=1&sn=c64858e4f5ed07d53feb00b1aeec2974&chksm=8f09cca6b87e45b09eb7ddc6c35be06d1be7514330e9ac9ef144cd3a5ae61b14e1a6e22bf295&token=1553501157&lang=zh_CN#rd)
158 | - [华为鸿蒙OS尖刀武器之分布式软总线技术全解析](/docs/it-hot/鸿蒙OS尖刀武器之分布式软总线技术.md)
159 | - [汇聚开发者星星之火,华为鸿蒙系统有希望成为国产之光](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321645&idx=1&sn=c263f8db73cdbffee96c2f511ff7ae74&chksm=8f09ccf7b87e45e18eb684d620073d256f95fa25217b8d5c81116600df9a137d33fa93c92961&token=1941065265&lang=zh_CN#rd)
160 |
161 | # :boy: 关于我
162 |
163 | 大家好,我是『雷小帅』,也是微信公众号『爱笑的架构师』的作者。
164 |
165 | - :coffee:读过几年书:华中科技大学硕士毕业;
166 |
167 | - :star2:浪过几个大厂:华为、网易、百度……
168 |
169 | - :kissing:一直坚信技术能改变生活,愿保持初心,加油技术人!
170 |
171 | `我有技术和故事,等你来!`
172 |
173 | **Github 上所有的文章我都会首发在微信公众号『爱笑的架构师』,大家可以关注一下。定时推送技术干货~**
174 |
175 |
176 |

177 |
187 |

188 |
 27 |
28 | # 引入服务注册与发现组件的原因
29 |
30 | 先来看一个问题,假如现在我们要做一个商城项目,作为架构师的你应该怎样设计系统的架构?你心里肯定在想:这还不容易直接照搬淘宝的架构不就行了。但在现实的创业环境中一个项目可能是九死一生,如果一开始投入巨大的人力和财力,一旦项目失败损失就很大。
31 |
32 | 作为一位有经验的架构师需要结合公司财力、人力投入预算等现状选择最适合眼下的架构才是王道。大型网站都是从小型网站发展而来,架构也是一样。
33 |
34 | 任何一个大型网站的架构都不是从一开始就一层不变的,而是随着用户量和数据量的不断增加不断迭代演进的结果。
35 |
36 | 在架构不断迭代演进的过程中我们会遇到很多问题,**技术发展的本质就是不断发现问题再解决问题,解决问题又发现问题**。
37 |
38 | ## **单体架构**
39 |
40 | 在系统建立之初可能不会有特别多的用户,将所有的业务打成一个应用包放在tomcat容器中运行,与数据库共用一台服务器,这种架构一般称之为单体架构。
41 |
42 |
27 |
28 | # 引入服务注册与发现组件的原因
29 |
30 | 先来看一个问题,假如现在我们要做一个商城项目,作为架构师的你应该怎样设计系统的架构?你心里肯定在想:这还不容易直接照搬淘宝的架构不就行了。但在现实的创业环境中一个项目可能是九死一生,如果一开始投入巨大的人力和财力,一旦项目失败损失就很大。
31 |
32 | 作为一位有经验的架构师需要结合公司财力、人力投入预算等现状选择最适合眼下的架构才是王道。大型网站都是从小型网站发展而来,架构也是一样。
33 |
34 | 任何一个大型网站的架构都不是从一开始就一层不变的,而是随着用户量和数据量的不断增加不断迭代演进的结果。
35 |
36 | 在架构不断迭代演进的过程中我们会遇到很多问题,**技术发展的本质就是不断发现问题再解决问题,解决问题又发现问题**。
37 |
38 | ## **单体架构**
39 |
40 | 在系统建立之初可能不会有特别多的用户,将所有的业务打成一个应用包放在tomcat容器中运行,与数据库共用一台服务器,这种架构一般称之为单体架构。
41 |
42 | -2021-05-04-23-18-38](https://cdn.jsdelivr.net/gh/CoderLeixiaoshuai/assets/202102/-2021-05-04-23-18-38.png) 43 |
44 | 在初期这种架构的效率非常高,根据用户的反馈可以快速迭代上线。但是随着用户量增加,一台服务的内存和CPU吃紧,很容易造成瓶颈,新的问题来了怎么解决呢?
45 |
46 | ## 应用与数据分离
47 |
48 | 随着用户请求量增加,一台服务器的内存和CPU持续飙升,用户请求响应时间变慢。这时候可以考虑将应用与数据库拆开,各自使用一台服务器,你看问题又解决了吧。
49 |
50 |
43 |
44 | 在初期这种架构的效率非常高,根据用户的反馈可以快速迭代上线。但是随着用户量增加,一台服务的内存和CPU吃紧,很容易造成瓶颈,新的问题来了怎么解决呢?
45 |
46 | ## 应用与数据分离
47 |
48 | 随着用户请求量增加,一台服务器的内存和CPU持续飙升,用户请求响应时间变慢。这时候可以考虑将应用与数据库拆开,各自使用一台服务器,你看问题又解决了吧。
49 |
50 | 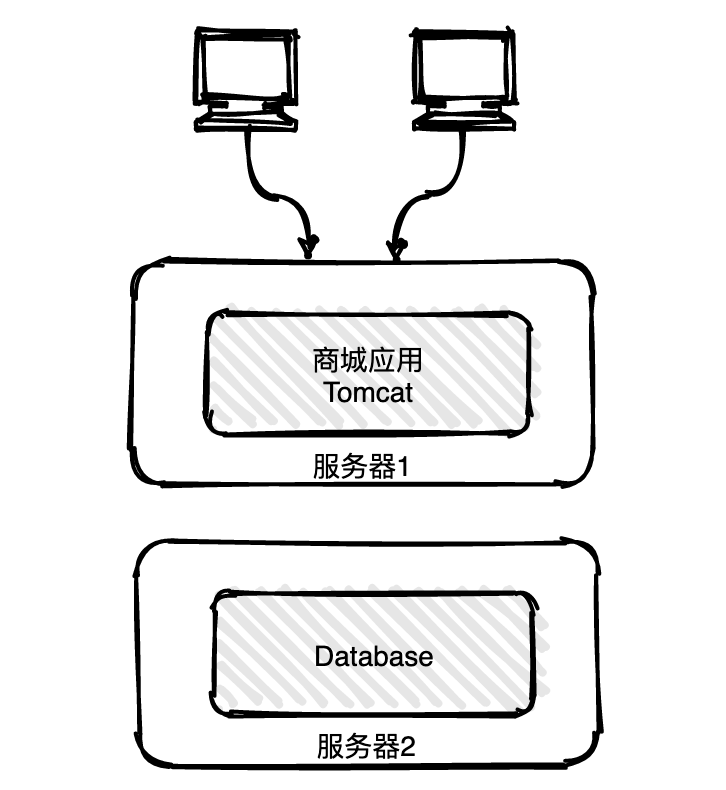 51 |
52 |
53 | 突然有一天扫地阿姨不小心碰了电线,其中一台服务器掉电了,用户所有的请求都报错,随之而来的是一系列投诉电话。
54 |
55 | ## 集群部署
56 |
57 | 单实例很容易造成单点问题,比如遇到服务器故障或者服务能力瓶颈,那怎么办?聪明的你肯定想到了,用集群呀。
58 |
59 |
51 |
52 |
53 | 突然有一天扫地阿姨不小心碰了电线,其中一台服务器掉电了,用户所有的请求都报错,随之而来的是一系列投诉电话。
54 |
55 | ## 集群部署
56 |
57 | 单实例很容易造成单点问题,比如遇到服务器故障或者服务能力瓶颈,那怎么办?聪明的你肯定想到了,用集群呀。
58 |
59 | 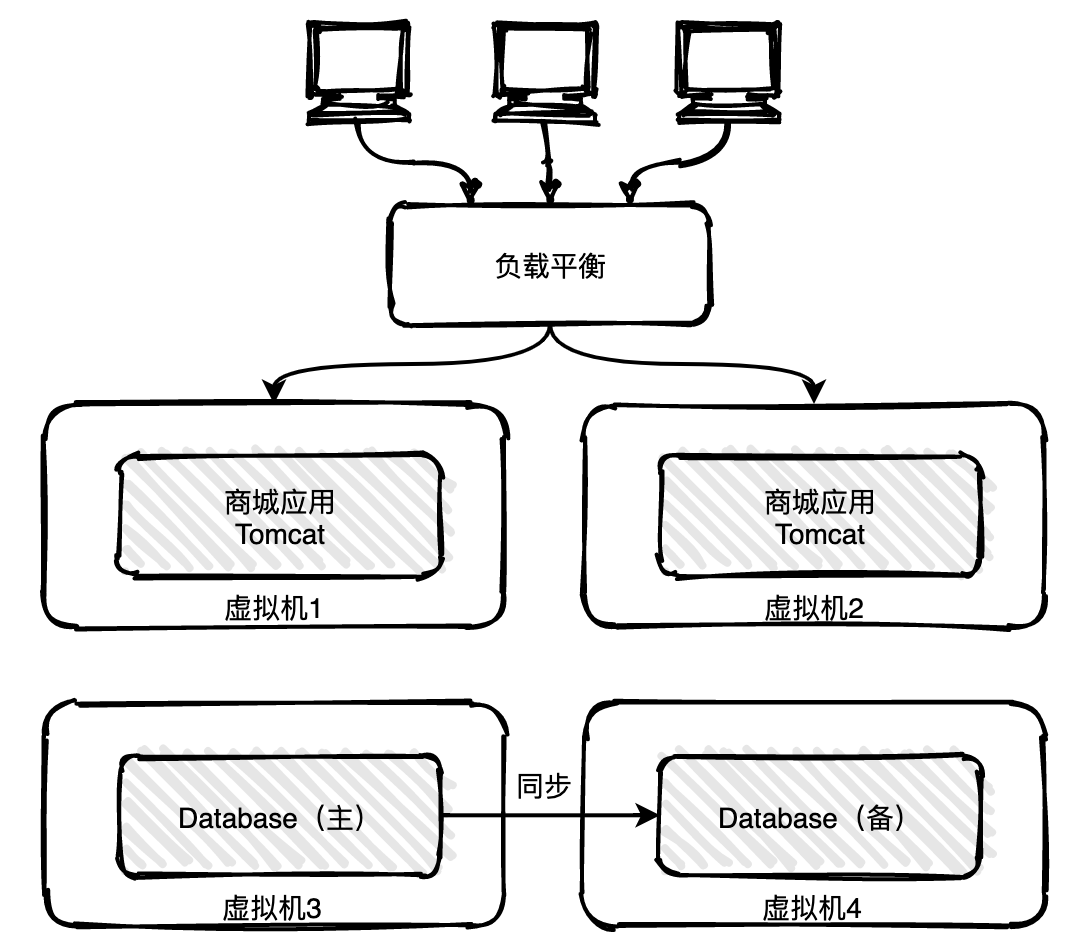 60 |
61 | 集群部署是指将应用部署在多个服务器或者虚机上,用户通过服务均衡随机访问其中的一个实例,从而使多个实例的流量均衡,如果一个实例出现故障可以将其下线,其他实例不受影响仍然可以对外提供服务。
62 |
63 | 随着用户数量快速增加,老板决定增加投入扩大团队规模。开发团队壮大后效率并没有得到显著的提高,以前小团队可以一周迭代上线一次,现在至少需要两到三周时间。
64 |
65 | 业务逻辑越来越复杂,代码间耦合很严重,修改一行代码可能引入几个线上问题。架构师意识到需要进行架构重构。
66 |
67 | ## 微服务架构
68 |
69 | 当单体架构演进到一定阶段后开发测试的复杂性都会成本增加,团队规模的扩大也会使得各自工作耦合性更严重,牵一发而动全身就是这种场景。
70 |
71 | 单体架构遇到瓶颈了,微服务架构就横空出世了。微服务就是将之前的单体服务按照业务维度进行拆分,拆分粒度可大可小,拆分时机可以分节奏进行。最佳实践是先将一些独立的功能从单体中剥离出来抽成一个或多个微服务,这样可以保障业务的连续性和稳定性。
72 |
73 |
60 |
61 | 集群部署是指将应用部署在多个服务器或者虚机上,用户通过服务均衡随机访问其中的一个实例,从而使多个实例的流量均衡,如果一个实例出现故障可以将其下线,其他实例不受影响仍然可以对外提供服务。
62 |
63 | 随着用户数量快速增加,老板决定增加投入扩大团队规模。开发团队壮大后效率并没有得到显著的提高,以前小团队可以一周迭代上线一次,现在至少需要两到三周时间。
64 |
65 | 业务逻辑越来越复杂,代码间耦合很严重,修改一行代码可能引入几个线上问题。架构师意识到需要进行架构重构。
66 |
67 | ## 微服务架构
68 |
69 | 当单体架构演进到一定阶段后开发测试的复杂性都会成本增加,团队规模的扩大也会使得各自工作耦合性更严重,牵一发而动全身就是这种场景。
70 |
71 | 单体架构遇到瓶颈了,微服务架构就横空出世了。微服务就是将之前的单体服务按照业务维度进行拆分,拆分粒度可大可小,拆分时机可以分节奏进行。最佳实践是先将一些独立的功能从单体中剥离出来抽成一个或多个微服务,这样可以保障业务的连续性和稳定性。
72 |
73 | 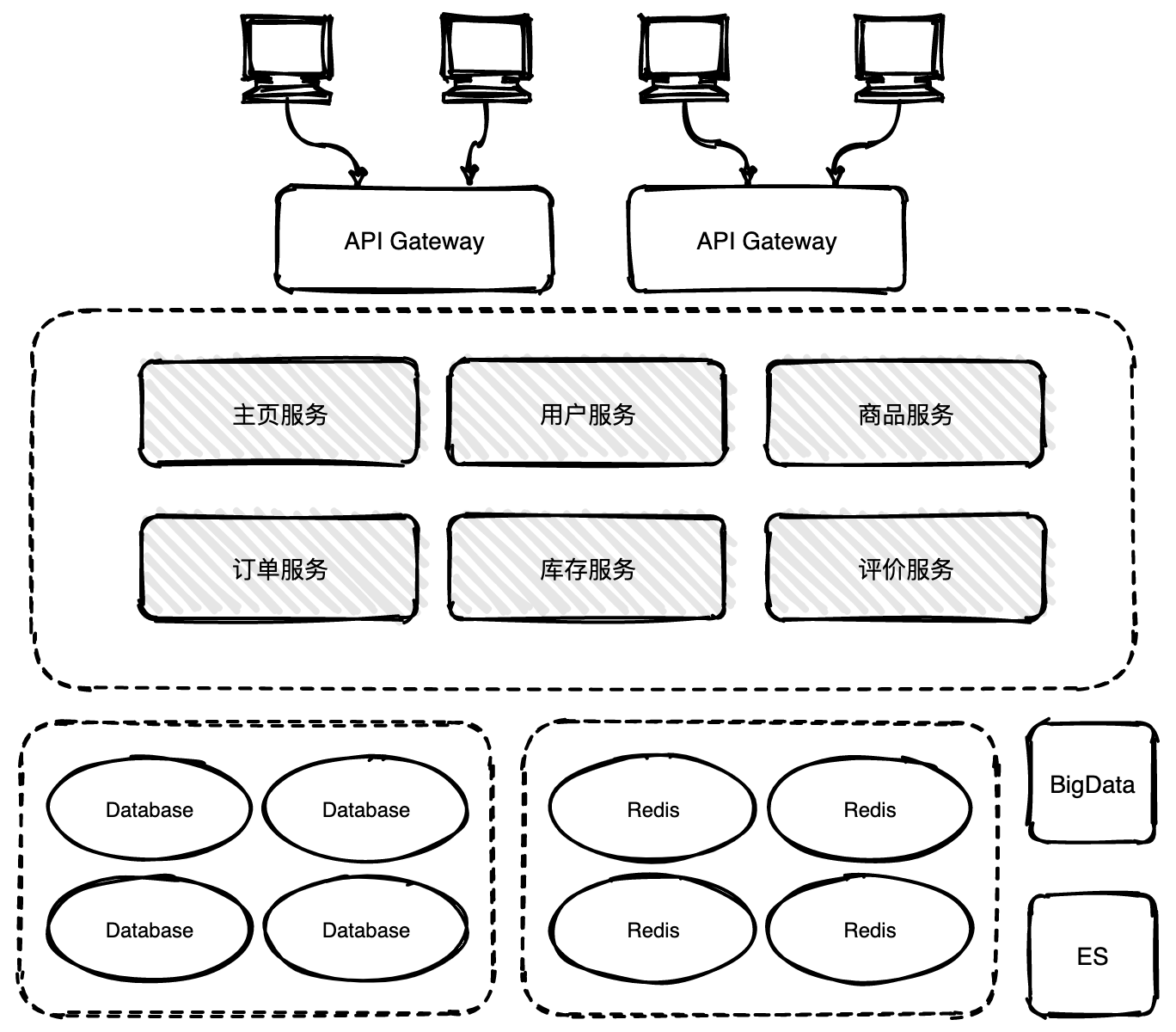 74 |
75 | 如上图将一个商用应用拆分为六个独立微服务。六个微服务可以使用Docker容器化进行多实例部署。
76 |
77 | 架构演化到这里遇到了一个难题,如果要查询用户所有的订单,用户服务可能会依赖订单服务,用户服务如何与订单服务交互呢?订单服务有多个实例该访问哪一个?
78 |
79 | 通常有几种解决办法:
80 |
81 | **(1)服务地址硬编码**
82 |
83 | 服务的地址写死在数据库或者配置文件,通过访问DNS域名进行寻址路由。
84 |
85 |
74 |
75 | 如上图将一个商用应用拆分为六个独立微服务。六个微服务可以使用Docker容器化进行多实例部署。
76 |
77 | 架构演化到这里遇到了一个难题,如果要查询用户所有的订单,用户服务可能会依赖订单服务,用户服务如何与订单服务交互呢?订单服务有多个实例该访问哪一个?
78 |
79 | 通常有几种解决办法:
80 |
81 | **(1)服务地址硬编码**
82 |
83 | 服务的地址写死在数据库或者配置文件,通过访问DNS域名进行寻址路由。
84 |
85 | 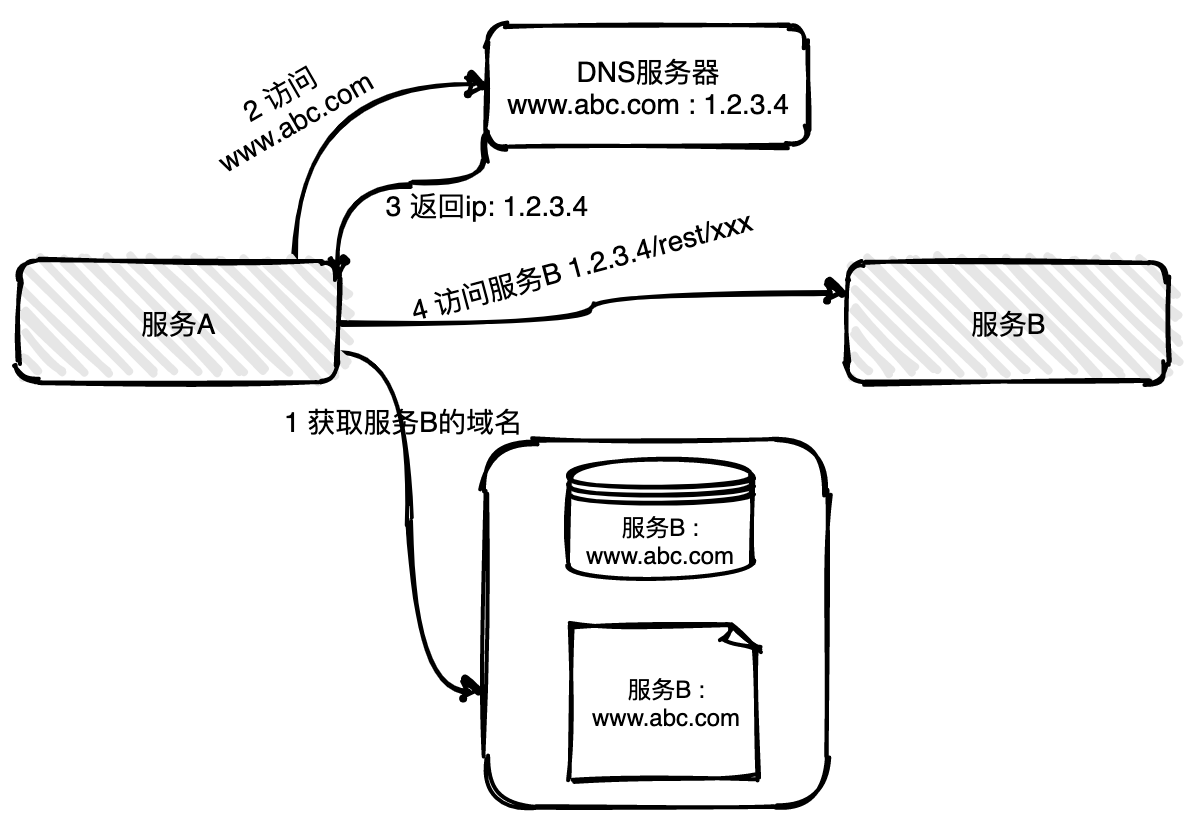 86 |
87 | 服务B的地址硬编码在数据库或者配置文件中,服务A首先需要拿到服务B的地址,然后通过DNS服务器解析获取其中一实例的真实地址,最后可以向服务B发起请求。
88 |
89 | 如果遇到大促活动需要对服务实例扩容,大促完需要对服务实例进行下线,运维人员要做大量的手工操作,非常容易误操作。
90 |
91 | **(2)服务动态注册与发现**
92 |
93 | 服务地址硬编码还有一个非常致命的问题,如果一台实例挂了,运维人员可能不能及时感知到,导致一部分用户的请求会异常。
94 |
95 | 引入服务注册与发现组件可以很好解决上面遇到的问题,避免过多的人工操作。
96 |
97 | ## 架构演进总结
98 |
99 | 在单体架构中一个应用程序就是一个服务包,包内的模块通过函数方法相互调用,模型足够简单,根本没有服务注册和发现一说。
100 |
101 | 在微服务架构中会将一个应用程序拆分为多个微服务,微服务会部署在不同的服务器、不同的容器、甚至多数据中心,微服务间要相互调用,服务注册和发现成为了一个不可或缺的组件。
102 |
103 | # 服务注册与发现基本原理
104 |
105 | 服务注册与发现是分为注册和发现两个关键的步骤。
106 |
107 | **服务注册**:服务进程在注册中心注册自己的元数据信息。通常包括主机和端口号,有时还有身份验证信息,协议,版本号,以及运行环境的信息。
108 |
109 | **服务发现**:客户端服务进程向注册中心发起查询,来获取服务的信息。服务发现的一个重要作用就是提供给客户端一个可用的服务列表。
110 |
111 | ## 服务注册
112 |
113 | 服务注册有两种形式:客户端注册和代理注册。
114 |
115 | **客户端注册**
116 |
117 | 客户端注册是服务自己要负责注册与注销的工作。当服务启动后注册线程向注册中心注册,当服务下线时注销自己。
118 |
119 |
86 |
87 | 服务B的地址硬编码在数据库或者配置文件中,服务A首先需要拿到服务B的地址,然后通过DNS服务器解析获取其中一实例的真实地址,最后可以向服务B发起请求。
88 |
89 | 如果遇到大促活动需要对服务实例扩容,大促完需要对服务实例进行下线,运维人员要做大量的手工操作,非常容易误操作。
90 |
91 | **(2)服务动态注册与发现**
92 |
93 | 服务地址硬编码还有一个非常致命的问题,如果一台实例挂了,运维人员可能不能及时感知到,导致一部分用户的请求会异常。
94 |
95 | 引入服务注册与发现组件可以很好解决上面遇到的问题,避免过多的人工操作。
96 |
97 | ## 架构演进总结
98 |
99 | 在单体架构中一个应用程序就是一个服务包,包内的模块通过函数方法相互调用,模型足够简单,根本没有服务注册和发现一说。
100 |
101 | 在微服务架构中会将一个应用程序拆分为多个微服务,微服务会部署在不同的服务器、不同的容器、甚至多数据中心,微服务间要相互调用,服务注册和发现成为了一个不可或缺的组件。
102 |
103 | # 服务注册与发现基本原理
104 |
105 | 服务注册与发现是分为注册和发现两个关键的步骤。
106 |
107 | **服务注册**:服务进程在注册中心注册自己的元数据信息。通常包括主机和端口号,有时还有身份验证信息,协议,版本号,以及运行环境的信息。
108 |
109 | **服务发现**:客户端服务进程向注册中心发起查询,来获取服务的信息。服务发现的一个重要作用就是提供给客户端一个可用的服务列表。
110 |
111 | ## 服务注册
112 |
113 | 服务注册有两种形式:客户端注册和代理注册。
114 |
115 | **客户端注册**
116 |
117 | 客户端注册是服务自己要负责注册与注销的工作。当服务启动后注册线程向注册中心注册,当服务下线时注销自己。
118 |
119 |  120 | 这种方式的缺点是注册注销逻辑与服务的业务逻辑耦合在一起,如果服务使用不同语言开发,那需要适配多套服务注册逻辑。
121 |
122 | **代理注册**
123 |
124 | 代理注册由一个单独的代理服务负责注册与注销。当服务提供者启动后以某种方式通知代理服务,然后代理服务负责向注册中心发起注册工作。
125 |
126 |
120 | 这种方式的缺点是注册注销逻辑与服务的业务逻辑耦合在一起,如果服务使用不同语言开发,那需要适配多套服务注册逻辑。
121 |
122 | **代理注册**
123 |
124 | 代理注册由一个单独的代理服务负责注册与注销。当服务提供者启动后以某种方式通知代理服务,然后代理服务负责向注册中心发起注册工作。
125 |
126 | 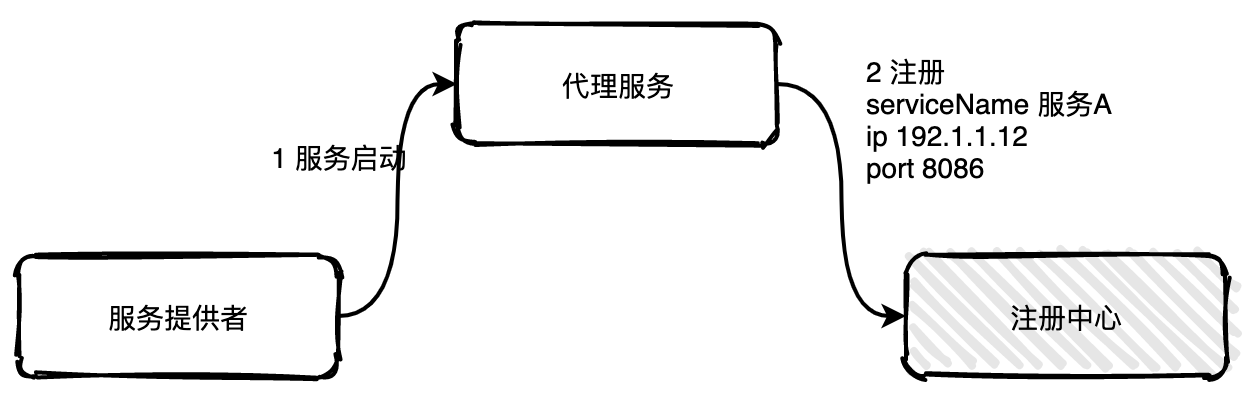 127 |
128 |
129 | 这种方式的缺点是多引用了一个代理服务,并且代理服务要保持高可用状态。
130 |
131 | ## 服务发现
132 |
133 | 服务发现也分为客户端发现和代理发现。
134 |
135 | **客户端发现**
136 |
137 | 客户端发现是指客户端负责向注册中心查询可用服务地址,获取到所有的可用实例地址列表后客户端根据负载均衡算法选择一个实例发起请求调用。
138 |
139 |
127 |
128 |
129 | 这种方式的缺点是多引用了一个代理服务,并且代理服务要保持高可用状态。
130 |
131 | ## 服务发现
132 |
133 | 服务发现也分为客户端发现和代理发现。
134 |
135 | **客户端发现**
136 |
137 | 客户端发现是指客户端负责向注册中心查询可用服务地址,获取到所有的可用实例地址列表后客户端根据负载均衡算法选择一个实例发起请求调用。
138 |
139 | 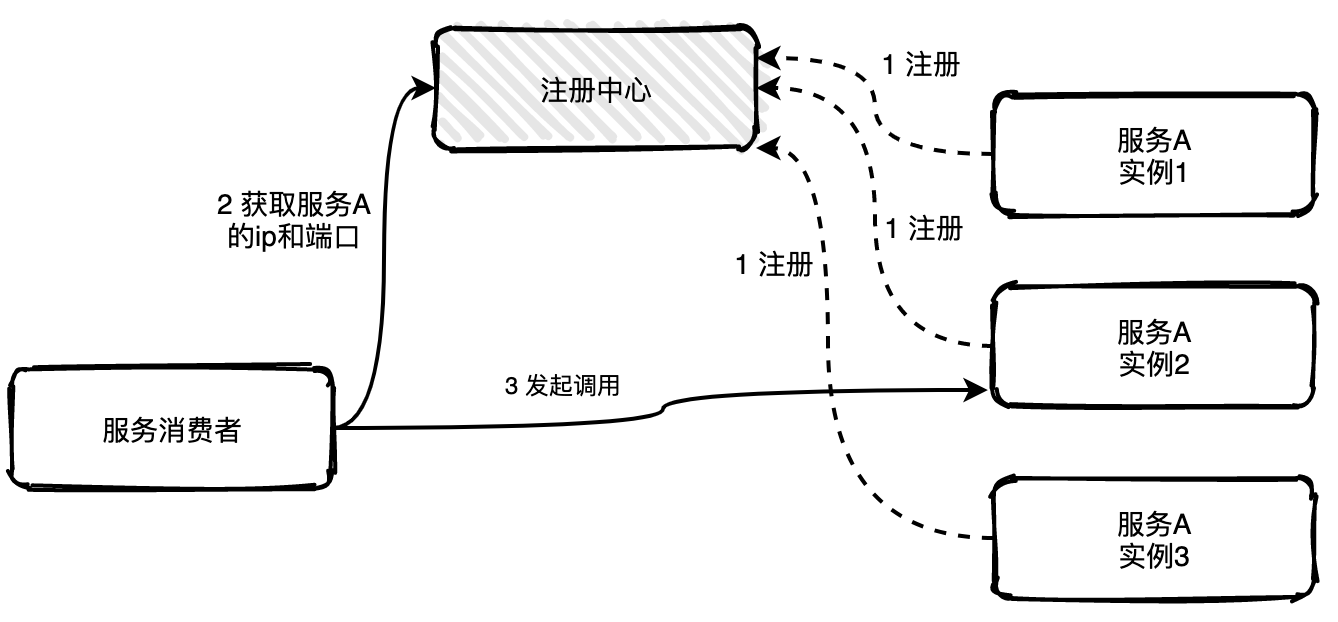 140 |
141 | 这种方式非常直接,客户端可以控制负载均衡算法。但是缺点也很明显,获取实例地址、负载均衡等逻辑与服务的业务逻辑耦合在一起,如果服务发现或者负载平衡有变化,那么所有的服务都要修改重新上线。
142 |
143 | **代理发现**
144 |
145 | 代理发现是指新增一个路由服务负责服务发现获取可用的实例列表,服务消费者如果需要调用服务A的一个实例可以直接将请求发往路由服务,路由服务根据配置好的负载均衡算法从可用的实例列表中选择一个实例将请求转发过去即可,如果发现实例不可用,路由服务还可以自行重试,服务消费者完全不用感知。
146 |
147 |
140 |
141 | 这种方式非常直接,客户端可以控制负载均衡算法。但是缺点也很明显,获取实例地址、负载均衡等逻辑与服务的业务逻辑耦合在一起,如果服务发现或者负载平衡有变化,那么所有的服务都要修改重新上线。
142 |
143 | **代理发现**
144 |
145 | 代理发现是指新增一个路由服务负责服务发现获取可用的实例列表,服务消费者如果需要调用服务A的一个实例可以直接将请求发往路由服务,路由服务根据配置好的负载均衡算法从可用的实例列表中选择一个实例将请求转发过去即可,如果发现实例不可用,路由服务还可以自行重试,服务消费者完全不用感知。
146 |
147 | 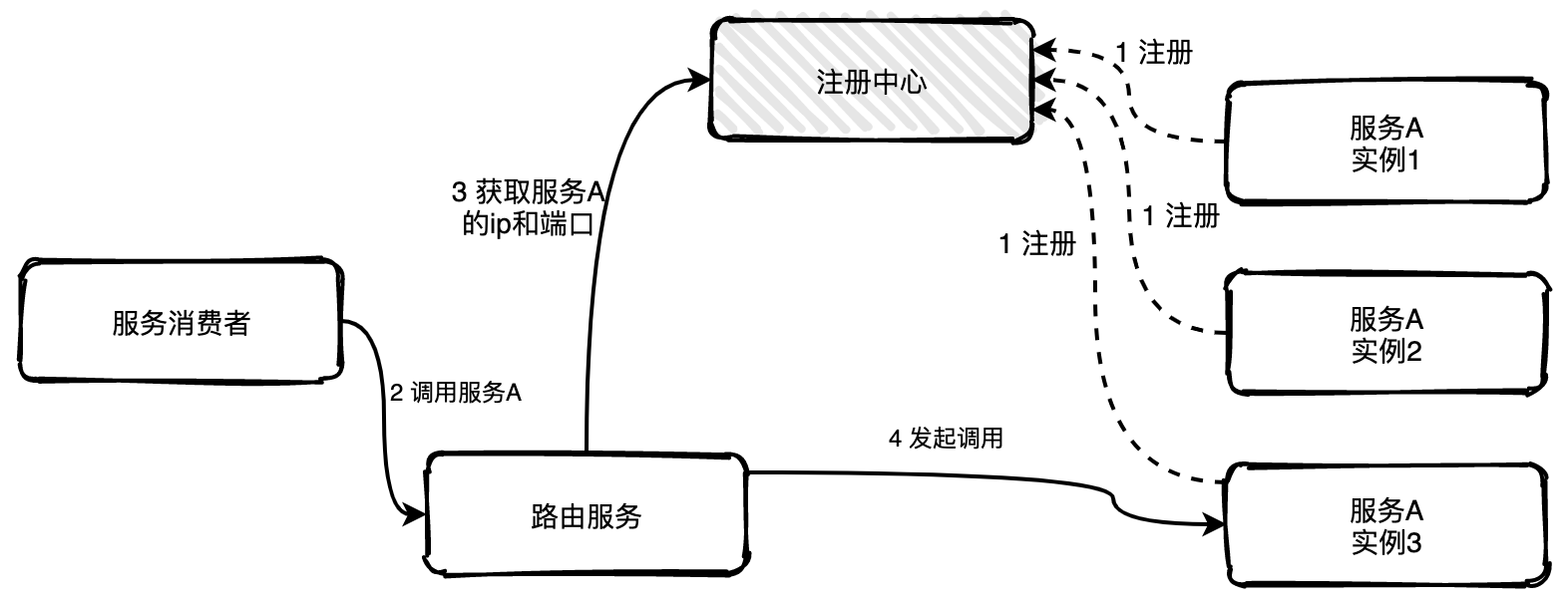 148 |
149 |
150 | ## 心跳机制
151 |
152 | 如果服务有多个实例,其中一个实例出现宕机,注册中心是可以实时感知到,并且将该实例信息从列表中移出,也称为摘机。
153 |
154 | 如何实现摘机?业界比较常用的方式是通过心跳检测的方式实现,心跳检测有**主动**和**被动**两种方式。
155 |
156 | **被动检测**是指服务主动向注册中心发送心跳消息,时间间隔可自定义,比如配置5秒发送一次,注册中心如果在三个周期内比如说15秒内没有收到实例的心跳消息,就会将该实例从列表中移除。
157 |
158 |
148 |
149 |
150 | ## 心跳机制
151 |
152 | 如果服务有多个实例,其中一个实例出现宕机,注册中心是可以实时感知到,并且将该实例信息从列表中移出,也称为摘机。
153 |
154 | 如何实现摘机?业界比较常用的方式是通过心跳检测的方式实现,心跳检测有**主动**和**被动**两种方式。
155 |
156 | **被动检测**是指服务主动向注册中心发送心跳消息,时间间隔可自定义,比如配置5秒发送一次,注册中心如果在三个周期内比如说15秒内没有收到实例的心跳消息,就会将该实例从列表中移除。
157 |
158 | 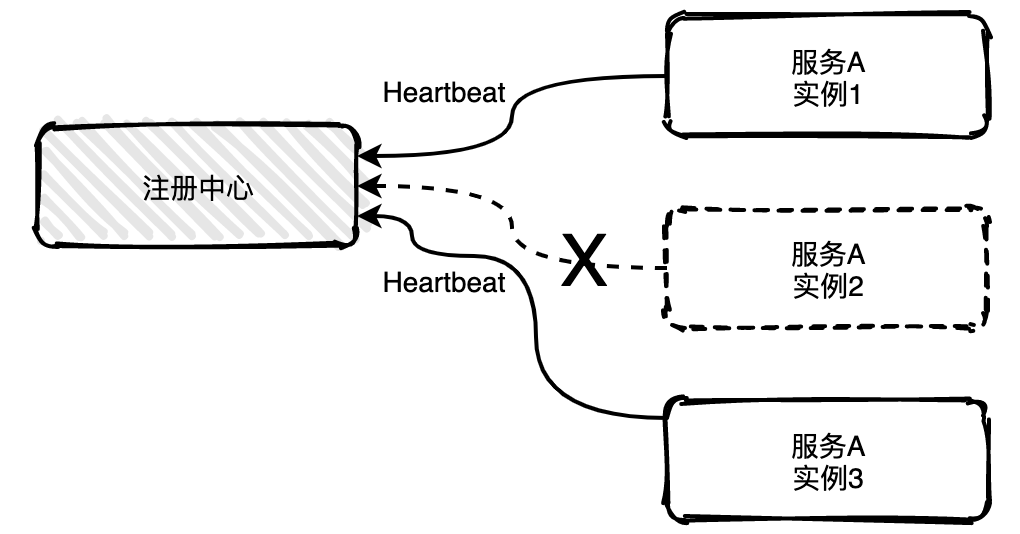 159 |
160 | 上图中服务A的实例2已经宕机不能主动给注册中心发送心跳消息,15秒之后注册就会将实例2移除掉。
161 |
162 | **主动检测**是注册中心主动发起,每隔几秒中会给所有列表中的服务实例发送心跳检测消息,如果多个周期内未发送成功或未收到回复就会主动移除该实例。
163 |
164 |
159 |
160 | 上图中服务A的实例2已经宕机不能主动给注册中心发送心跳消息,15秒之后注册就会将实例2移除掉。
161 |
162 | **主动检测**是注册中心主动发起,每隔几秒中会给所有列表中的服务实例发送心跳检测消息,如果多个周期内未发送成功或未收到回复就会主动移除该实例。
163 |
164 | 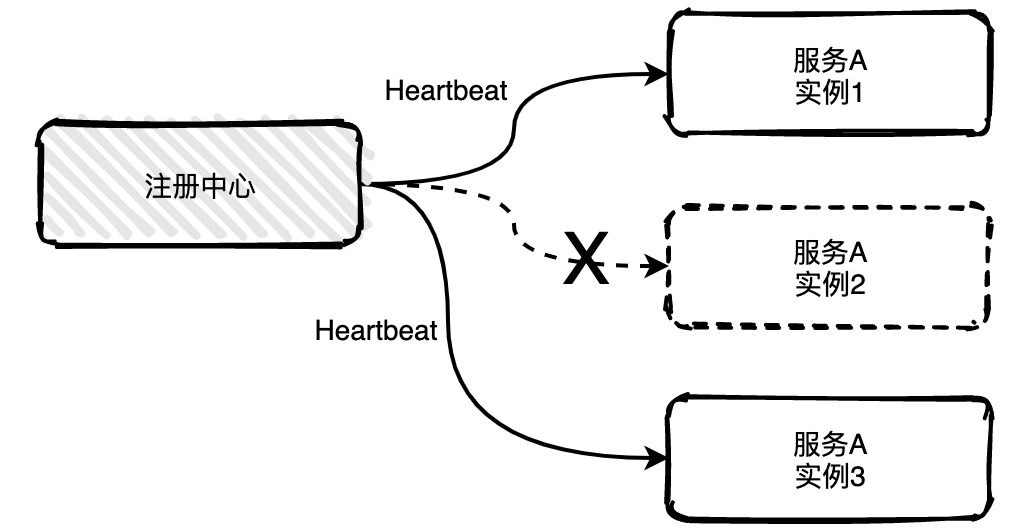 165 |
166 |
167 | # 业界常用的服务注册与发现组件对比
168 |
169 | 了解服务注册与发现的基本原理后,如果你要在项目中使用服务注册与发现组件,当面对众多的开源组件该如何进行技术选型?
170 |
171 | 在互联网公司里,有研发实力的大公司一般会选择自研或者基于开源组件进行二次开发,但是对于中小型公司来说直接选用一款开源软件会是一个不错的选择。
172 |
173 | 常用的注册与发现组件有eureka,zookeeper,consul,etcd等,由于eureka在2018年已经宣布放弃维护,这里就不再推荐使用了。
174 |
175 |
165 |
166 |
167 | # 业界常用的服务注册与发现组件对比
168 |
169 | 了解服务注册与发现的基本原理后,如果你要在项目中使用服务注册与发现组件,当面对众多的开源组件该如何进行技术选型?
170 |
171 | 在互联网公司里,有研发实力的大公司一般会选择自研或者基于开源组件进行二次开发,但是对于中小型公司来说直接选用一款开源软件会是一个不错的选择。
172 |
173 | 常用的注册与发现组件有eureka,zookeeper,consul,etcd等,由于eureka在2018年已经宣布放弃维护,这里就不再推荐使用了。
174 |
175 | 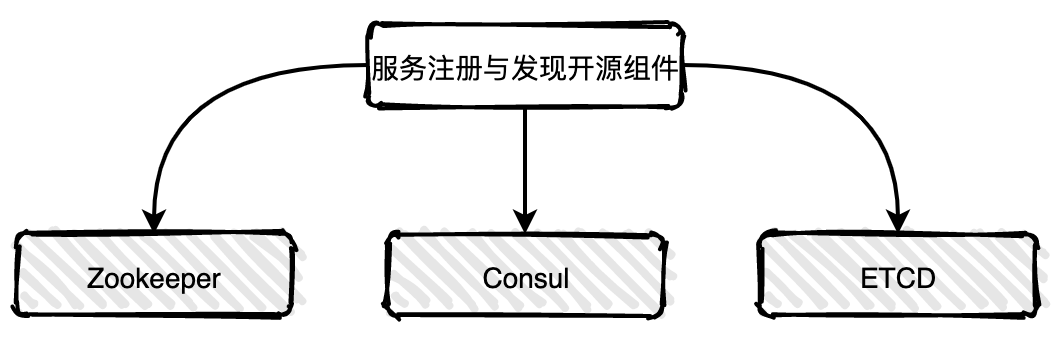 176 |
177 |
178 | 下面结合各个维度对比一下各组件。
179 |
180 | |**组件**|**优点**|**缺点**|**接口类型**|**一致性算法**|
181 | |:----|:----|:----|:----|:----|:----|:----|
182 | |zookeeper|1.功能强大,不仅仅只是服务发现;
176 |
177 |
178 | 下面结合各个维度对比一下各组件。
179 |
180 | |**组件**|**优点**|**缺点**|**接口类型**|**一致性算法**|
181 | |:----|:----|:----|:----|:----|:----|:----|
182 | |zookeeper|1.功能强大,不仅仅只是服务发现;
2.提供watcher机制可以实时获取服务提供者的状态;
3.广泛使用,dubbo等微服务框架已支持;|1.没有健康检查;
2.需要在服务中引入sdk,集成复杂度高;
3.不支持多数据中心;|sdk|Paxos|
183 | |consul|1.开箱即用,方便集成;
2.带健康检查;
3.支持多数据中心;
4.提供web管理界面;|不能实时获取服务变换通知|restful/dns|Raft|
184 | |etcd|1.开箱即用,方便集成;
2.可配置性强|1.没有健康检查;
2.需配合三方工具完成服务发现功能;
3.不支持多数据中心;|restful|Raft|
185 |
186 | 从整体上看consul的功能更加完备和均衡。接下来以consul为例详细介绍一下。
187 |
188 | # Consul——值得推荐的服务注册与发现开源组件
189 |
190 | ## 简单认识一下Consul
191 |
192 | Consul是HashiCorp公司推出的开源工,使用Go语言开发,具有开箱即可部署方便的特点。Consul是分布式的、高可用的、 可横向扩展的用于实现分布式系统的服务发现与配置。
193 |
194 | ## Consul有哪些优势?
195 |
196 | * 服务注册发现:Consul提供了通过DNS或者restful接口的方式来注册服务和发现服务。服务可根据实际情况自行选择。
197 | * 健康检查:Consul的Client可以提供任意数量的健康检查,既可以与给定的服务相关联,也可以与本地节点相关联。
198 | * 多数据中心:Consul支持多数据中心,这意味着用户不需要担心Consul自身的高可用性问题以及多数据中心带来的扩展接入等问题。
199 | ## Consul的架构图
200 |
201 | 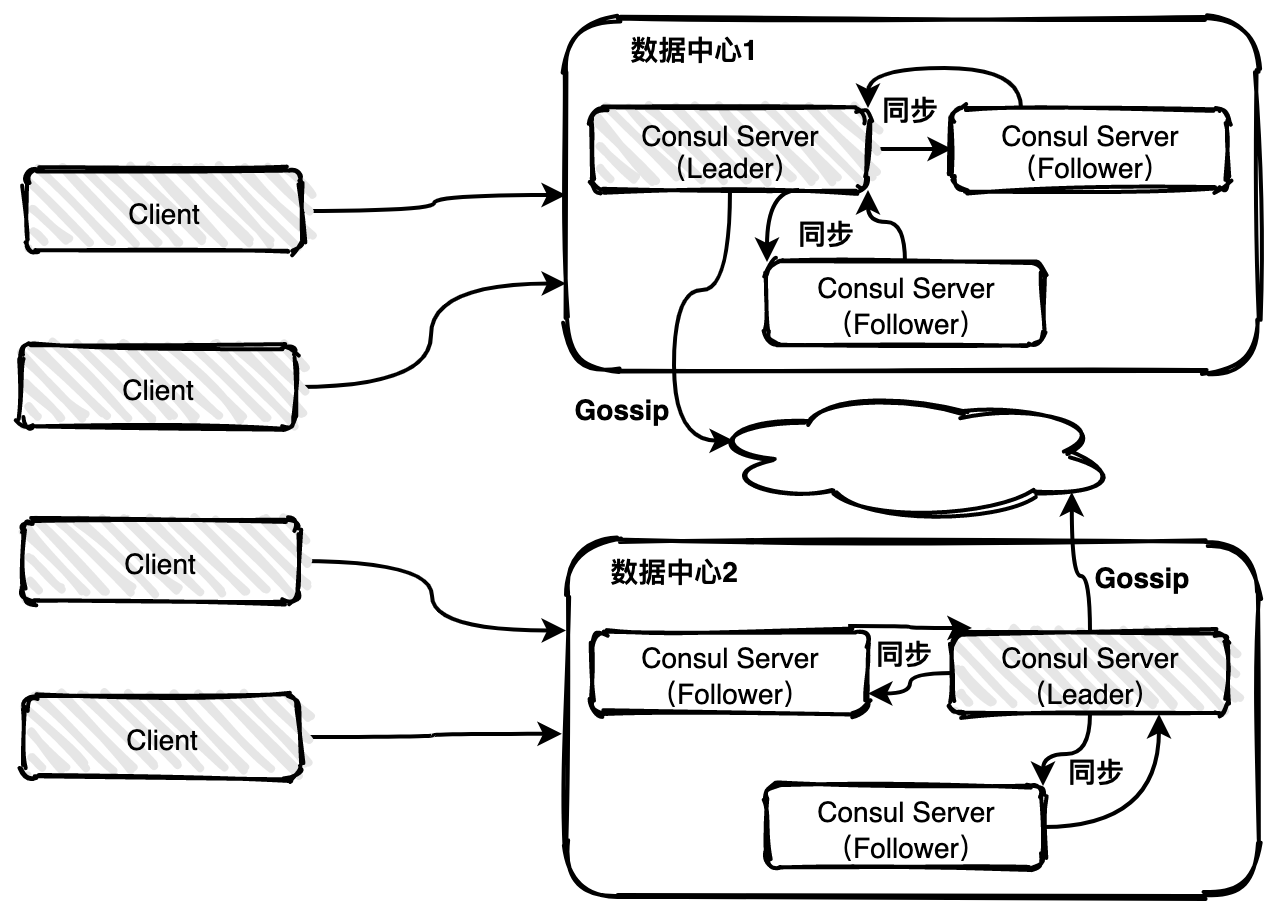 202 |
203 |
204 | Consul 实现多数据中心依赖于gossip protocol协议。这样做的目的:
205 |
206 | * 不需要使用服务器的地址来配置客户端;服务发现是自动完成的。
207 | * 健康检查故障的工作不是放在服务器上,而是分布式的。
208 | ## Consul的使用场景
209 |
210 | Consul的应用场景包括**服务注册发现**、**服务隔离**、**服务配置**等。
211 |
212 | **服务注册发现场景**中consul作为注册中心,服务地址被注册到consul中以后,可以使用consul提供的dns、http接口查询,consul支持health check。
213 |
214 | **服务隔离场景**中consul支持以服务为单位设置访问策略,能同时支持经典的平台和新兴的平台,支持tls证书分发,service-to-service加密。
215 |
216 | **服务配置场景**中consul提供key-value数据存储功能,并且能将变动迅速地通知出去,借助Consul可以实现配置共享,需要读取配置的服务可以从Consul中读取到准确的配置信息。
217 |
218 |
219 |
220 |
--------------------------------------------------------------------------------
/docs/distributed/原来10张图就可以搞懂分布式链路追踪系统原理.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321924&idx=1&sn=d8572df23b47409ab997029cb34c6c07&chksm=8f09ca1eb87e4308d81d322814fdc56acf1e3c4ff9d8655c239ad1468af512719d01b03027c8&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [分布式系统为什么需要链路追踪?](#分布式系统为什么需要链路追踪)
6 | - [什么是链路追踪?](#什么是链路追踪)
7 | - [链路追踪基本原理](#链路追踪基本原理)
8 | - [Trace](#trace)
9 | - [Span](#span)
10 | - [Annotations](#annotations)
11 | - [带内数据与带外数据](#带内数据与带外数据)
12 | - [采样](#采样)
13 | - [存储](#存储)
14 | - [业界常用链路追踪系统](#业界常用链路追踪系统)
15 | - [分布式链路追踪系统Zipkin实现](#分布式链路追踪系统zipkin实现)
16 | - [**Zipkin基本架构**](#zipkin基本架构)
17 | - [**Zipkin核心组件**](#zipkin核心组件)
18 | - [总结](#总结)
19 |
20 |
21 |
22 |
23 |
202 |
203 |
204 | Consul 实现多数据中心依赖于gossip protocol协议。这样做的目的:
205 |
206 | * 不需要使用服务器的地址来配置客户端;服务发现是自动完成的。
207 | * 健康检查故障的工作不是放在服务器上,而是分布式的。
208 | ## Consul的使用场景
209 |
210 | Consul的应用场景包括**服务注册发现**、**服务隔离**、**服务配置**等。
211 |
212 | **服务注册发现场景**中consul作为注册中心,服务地址被注册到consul中以后,可以使用consul提供的dns、http接口查询,consul支持health check。
213 |
214 | **服务隔离场景**中consul支持以服务为单位设置访问策略,能同时支持经典的平台和新兴的平台,支持tls证书分发,service-to-service加密。
215 |
216 | **服务配置场景**中consul提供key-value数据存储功能,并且能将变动迅速地通知出去,借助Consul可以实现配置共享,需要读取配置的服务可以从Consul中读取到准确的配置信息。
217 |
218 |
219 |
220 |
--------------------------------------------------------------------------------
/docs/distributed/原来10张图就可以搞懂分布式链路追踪系统原理.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321924&idx=1&sn=d8572df23b47409ab997029cb34c6c07&chksm=8f09ca1eb87e4308d81d322814fdc56acf1e3c4ff9d8655c239ad1468af512719d01b03027c8&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [分布式系统为什么需要链路追踪?](#分布式系统为什么需要链路追踪)
6 | - [什么是链路追踪?](#什么是链路追踪)
7 | - [链路追踪基本原理](#链路追踪基本原理)
8 | - [Trace](#trace)
9 | - [Span](#span)
10 | - [Annotations](#annotations)
11 | - [带内数据与带外数据](#带内数据与带外数据)
12 | - [采样](#采样)
13 | - [存储](#存储)
14 | - [业界常用链路追踪系统](#业界常用链路追踪系统)
15 | - [分布式链路追踪系统Zipkin实现](#分布式链路追踪系统zipkin实现)
16 | - [**Zipkin基本架构**](#zipkin基本架构)
17 | - [**Zipkin核心组件**](#zipkin核心组件)
18 | - [总结](#总结)
19 |
20 |
21 |
22 |
23 |  24 | # 分布式系统为什么需要链路追踪?
25 |
26 | 随着互联网业务快速扩展,软件架构也日益变得复杂,为了适应海量用户高并发请求,系统中越来越多的组件开始走向分布式化,如单体架构拆分为微服务、服务内缓存变为分布式缓存、服务组件通信变为分布式消息,这些组件共同构成了繁杂的分布式网络。
27 |
28 |
24 | # 分布式系统为什么需要链路追踪?
25 |
26 | 随着互联网业务快速扩展,软件架构也日益变得复杂,为了适应海量用户高并发请求,系统中越来越多的组件开始走向分布式化,如单体架构拆分为微服务、服务内缓存变为分布式缓存、服务组件通信变为分布式消息,这些组件共同构成了繁杂的分布式网络。
27 |
28 | 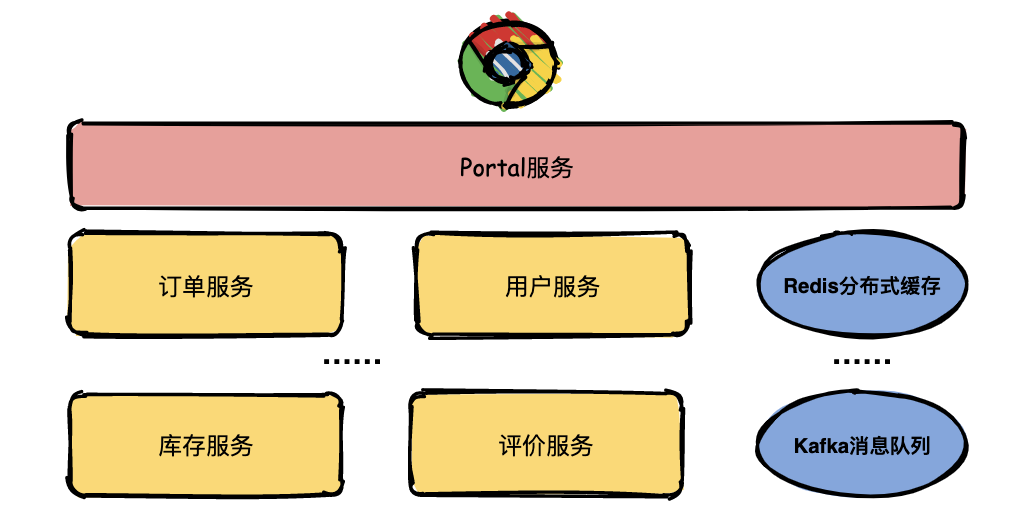 29 |
30 |
31 |
32 | 假如现在有一个系统部署了成千上万个服务,用户通过浏览器在主界面上下单一箱茅台酒,结果系统给用户提示:系统内部错误,相信用户是很崩溃的。
33 |
34 | 运营人员将问题抛给开发人员定位,开发人员只知道有异常,但是这个异常具体是由哪个微服务引起的就需要逐个服务排查了。
35 |
36 |
29 |
30 |
31 |
32 | 假如现在有一个系统部署了成千上万个服务,用户通过浏览器在主界面上下单一箱茅台酒,结果系统给用户提示:系统内部错误,相信用户是很崩溃的。
33 |
34 | 运营人员将问题抛给开发人员定位,开发人员只知道有异常,但是这个异常具体是由哪个微服务引起的就需要逐个服务排查了。
35 |
36 | 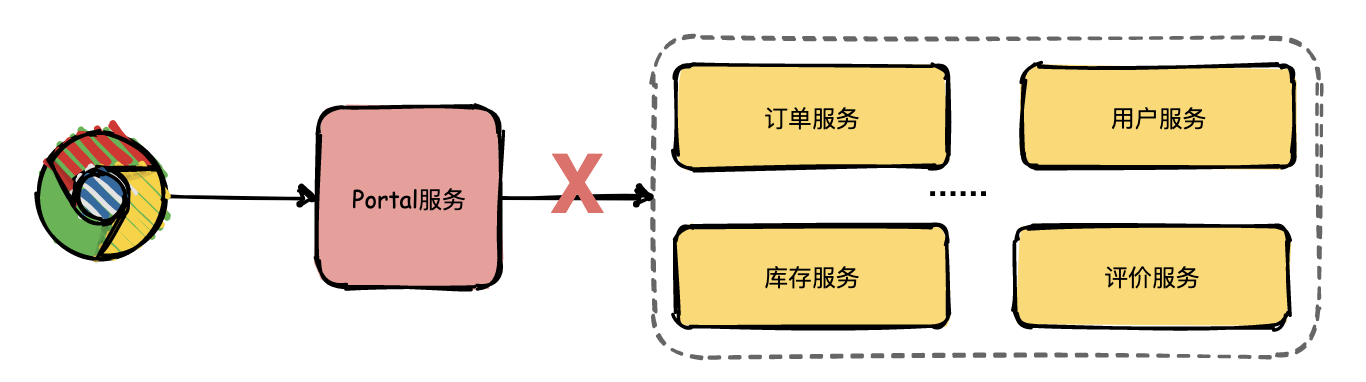 37 |
38 |
39 | 开发人员借助日志逐个排查的效率是非常低的,那有没有更好的解决方案了?**答案是引入链路追踪系统。**
40 |
41 | # 什么是链路追踪?
42 |
43 | 分布式链路追踪就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
44 |
45 | **链路跟踪主要功能:**
46 |
47 | * **故障快速定位**:可以通过调用链结合业务日志快速定位错误信息。
48 | * **链路性能可视化**:各个阶段链路耗时、服务依赖关系可以通过可视化界面展现出来。
49 | * **链路分析**:通过分析链路耗时、服务依赖关系可以得到用户的行为路径,汇总分析应用在很多业务场景。
50 | # 链路追踪基本原理
51 |
52 | 链路追踪系统(可能)最早是由Goggle公开发布的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》被大家广泛熟悉,所以各位技术大牛们如果有黑武器不要藏起来赶紧去发表论文吧。
53 |
54 | 在这篇著名的论文中主要讲述了Dapper链路追踪系统的基本原理和关键技术点。接下来挑几个重点的技术点详细给大家介绍一下。
55 |
56 | ## Trace
57 |
58 | Trace的含义比较直观,就是链路,指一个请求经过所有服务的路径,可以用下面树状的图形表示。
59 |
60 |
37 |
38 |
39 | 开发人员借助日志逐个排查的效率是非常低的,那有没有更好的解决方案了?**答案是引入链路追踪系统。**
40 |
41 | # 什么是链路追踪?
42 |
43 | 分布式链路追踪就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
44 |
45 | **链路跟踪主要功能:**
46 |
47 | * **故障快速定位**:可以通过调用链结合业务日志快速定位错误信息。
48 | * **链路性能可视化**:各个阶段链路耗时、服务依赖关系可以通过可视化界面展现出来。
49 | * **链路分析**:通过分析链路耗时、服务依赖关系可以得到用户的行为路径,汇总分析应用在很多业务场景。
50 | # 链路追踪基本原理
51 |
52 | 链路追踪系统(可能)最早是由Goggle公开发布的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》被大家广泛熟悉,所以各位技术大牛们如果有黑武器不要藏起来赶紧去发表论文吧。
53 |
54 | 在这篇著名的论文中主要讲述了Dapper链路追踪系统的基本原理和关键技术点。接下来挑几个重点的技术点详细给大家介绍一下。
55 |
56 | ## Trace
57 |
58 | Trace的含义比较直观,就是链路,指一个请求经过所有服务的路径,可以用下面树状的图形表示。
59 |
60 | 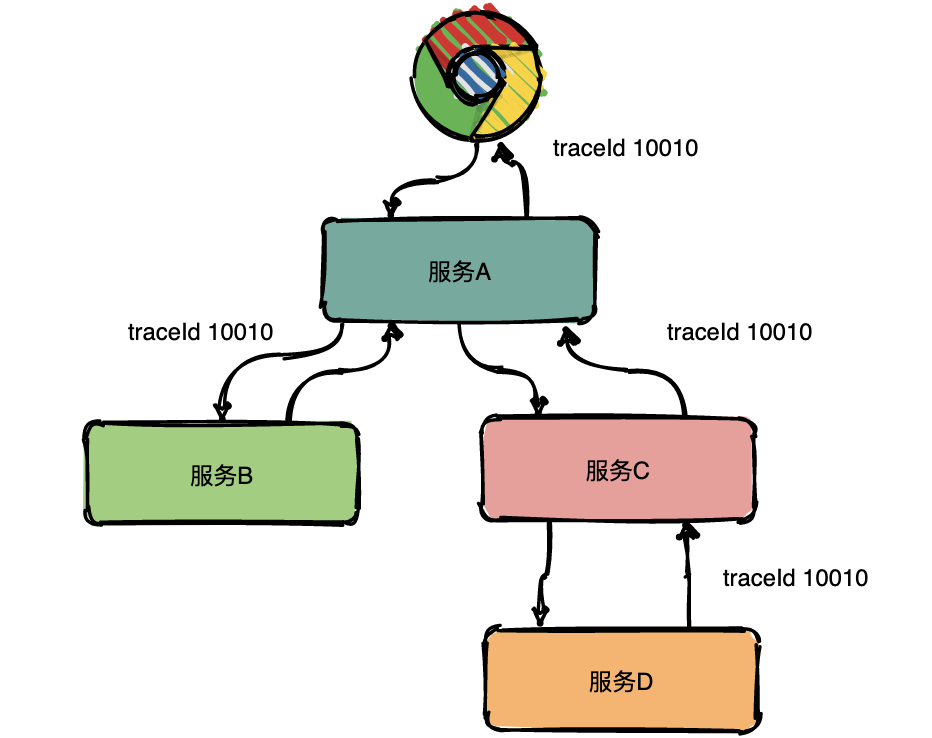 61 |
62 | 图中一条完整的链路是:chrome -> 服务A -> 服务B -> 服务C -> 服务D -> 服务E -> 服务C -> 服务A -> chrome。服务间经过的局部链路构成了一条完整的链路,其中每一条局部链路都用一个全局唯一的traceid来标识。
63 |
64 | ## Span
65 |
66 | 在上图中可以看出来请求经过了服务A,同时服务A又调用了服务B和服务C,但是先调的服务B还是服务C呢?从图中很难看出来,只有通过查看源码才知道顺序。
67 |
68 | 为了表达这种父子关系引入了Span的概念。
69 |
70 | 同一层级parent id相同,span id不同,span id从小到大表示请求的顺序,从下图中可以很明显看出服务A是先调了服务B然后再调用了C。
71 |
72 | 上下层级代表调用关系,如下图服务C的span id为2,服务D的parent id为2,这就表示服务C和服务D形成了父子关系,很明显是服务C调用了服务D。
73 |
74 |
61 |
62 | 图中一条完整的链路是:chrome -> 服务A -> 服务B -> 服务C -> 服务D -> 服务E -> 服务C -> 服务A -> chrome。服务间经过的局部链路构成了一条完整的链路,其中每一条局部链路都用一个全局唯一的traceid来标识。
63 |
64 | ## Span
65 |
66 | 在上图中可以看出来请求经过了服务A,同时服务A又调用了服务B和服务C,但是先调的服务B还是服务C呢?从图中很难看出来,只有通过查看源码才知道顺序。
67 |
68 | 为了表达这种父子关系引入了Span的概念。
69 |
70 | 同一层级parent id相同,span id不同,span id从小到大表示请求的顺序,从下图中可以很明显看出服务A是先调了服务B然后再调用了C。
71 |
72 | 上下层级代表调用关系,如下图服务C的span id为2,服务D的parent id为2,这就表示服务C和服务D形成了父子关系,很明显是服务C调用了服务D。
73 |
74 | 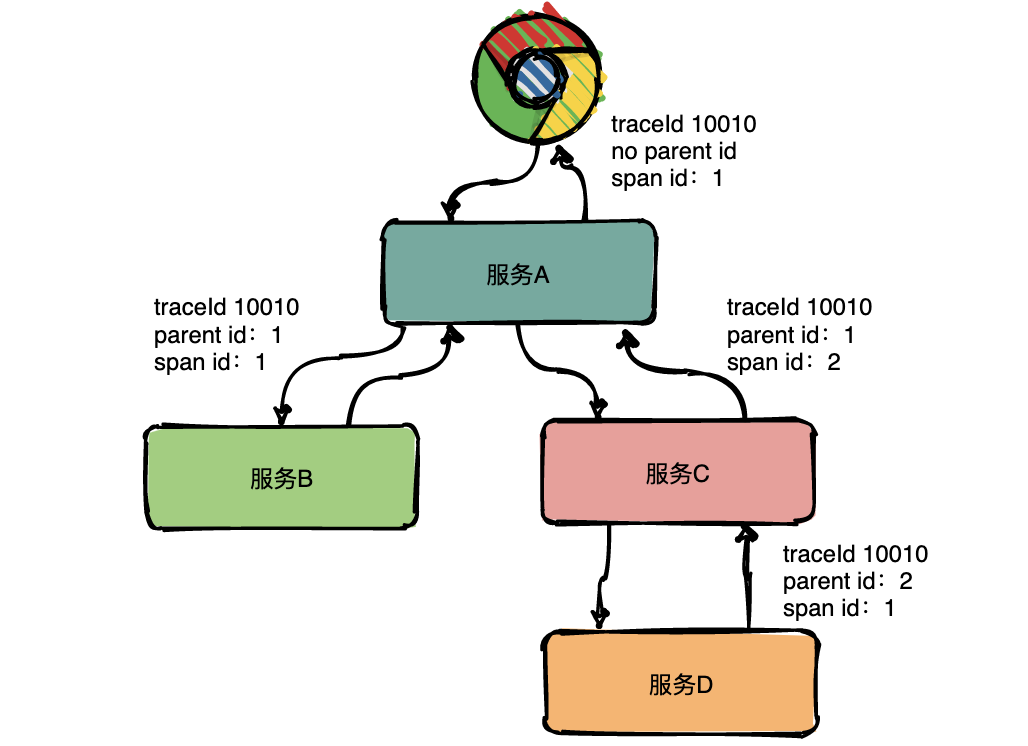 75 |
76 | **总结:通过事先在日志中埋点,找出相同traceId的日志,再加上parent id和span id就可以将一条完整的请求调用链串联起来。**
77 |
78 | ## Annotations
79 |
80 | Dapper中还定义了annotation的概念,用于用户自定义事件,用来辅助定位问题。
81 |
82 | **通****常****包含四个注解信息**:
83 | cs:Client Start,表示客户端发起请求;
84 | sr:ServerReceived,表示服务端收到请求;
85 | ss: Server Send,表示服务端完成处理,并将结果发送给客户端;
86 | cr:ClientReceived,表示客户端获取到服务端返回信息;
87 |
88 |
75 |
76 | **总结:通过事先在日志中埋点,找出相同traceId的日志,再加上parent id和span id就可以将一条完整的请求调用链串联起来。**
77 |
78 | ## Annotations
79 |
80 | Dapper中还定义了annotation的概念,用于用户自定义事件,用来辅助定位问题。
81 |
82 | **通****常****包含四个注解信息**:
83 | cs:Client Start,表示客户端发起请求;
84 | sr:ServerReceived,表示服务端收到请求;
85 | ss: Server Send,表示服务端完成处理,并将结果发送给客户端;
86 | cr:ClientReceived,表示客户端获取到服务端返回信息;
87 |
88 | 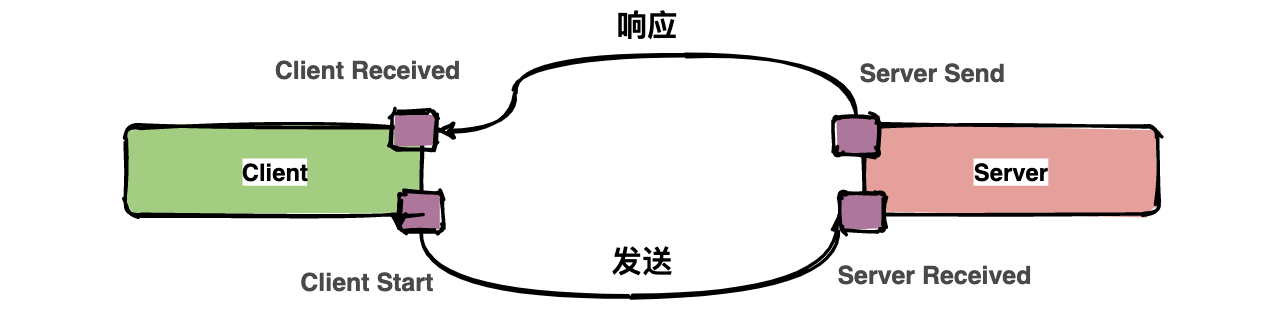 89 |
90 | 上图中描述了一次请求和响应的过程,四个点也就是对应四个Annotation事件。
91 |
92 | 如下面的图表示从客户端调用服务端的一次完整过程。如果要计算一次调用的耗时,只需要将客户端接收的时间点减去客户端开始的时间点,也就是图中时间线上的T4 - T1。如果要计算客户端发送网络耗时,也就是图中时间线上的T2 - T1,其他类似可计算。
93 |
94 |
89 |
90 | 上图中描述了一次请求和响应的过程,四个点也就是对应四个Annotation事件。
91 |
92 | 如下面的图表示从客户端调用服务端的一次完整过程。如果要计算一次调用的耗时,只需要将客户端接收的时间点减去客户端开始的时间点,也就是图中时间线上的T4 - T1。如果要计算客户端发送网络耗时,也就是图中时间线上的T2 - T1,其他类似可计算。
93 |
94 | 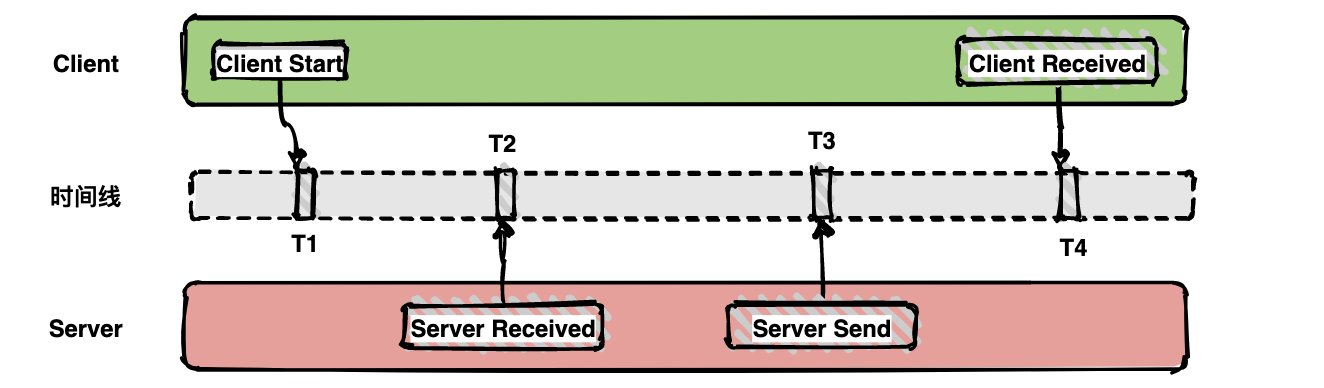 95 |
96 |
97 | ## 带内数据与带外数据
98 |
99 | 链路信息的还原依赖于**带内**和**带外**两种数据。
100 |
101 | 带外数据是各个节点产生的事件,如cs,ss,这些数据可以由节点独立生成,并且需要集中上报到存储端。通过带外数据,可以在存储端分析更多链路的细节。
102 |
103 | 带内数据如traceid,spanid,parentid,用来标识trace,span,以及span在一个trace中的位置,这些数据需要从链路的起点一直传递到终点。 通过带内数据的传递,可以将一个链路的所有过程串起来。
104 |
105 | ## 采样
106 |
107 | 由于每一个请求都会生成一个链路,为了减少性能消耗,避免存储资源的浪费,dapper并不会上报所有的span数据,而是使用采样的方式。举个例子,每秒有1000个请求访问系统,如果设置采样率为1/1000,那么只会上报一个请求到存储端。
108 |
109 |
95 |
96 |
97 | ## 带内数据与带外数据
98 |
99 | 链路信息的还原依赖于**带内**和**带外**两种数据。
100 |
101 | 带外数据是各个节点产生的事件,如cs,ss,这些数据可以由节点独立生成,并且需要集中上报到存储端。通过带外数据,可以在存储端分析更多链路的细节。
102 |
103 | 带内数据如traceid,spanid,parentid,用来标识trace,span,以及span在一个trace中的位置,这些数据需要从链路的起点一直传递到终点。 通过带内数据的传递,可以将一个链路的所有过程串起来。
104 |
105 | ## 采样
106 |
107 | 由于每一个请求都会生成一个链路,为了减少性能消耗,避免存储资源的浪费,dapper并不会上报所有的span数据,而是使用采样的方式。举个例子,每秒有1000个请求访问系统,如果设置采样率为1/1000,那么只会上报一个请求到存储端。
108 |
109 | 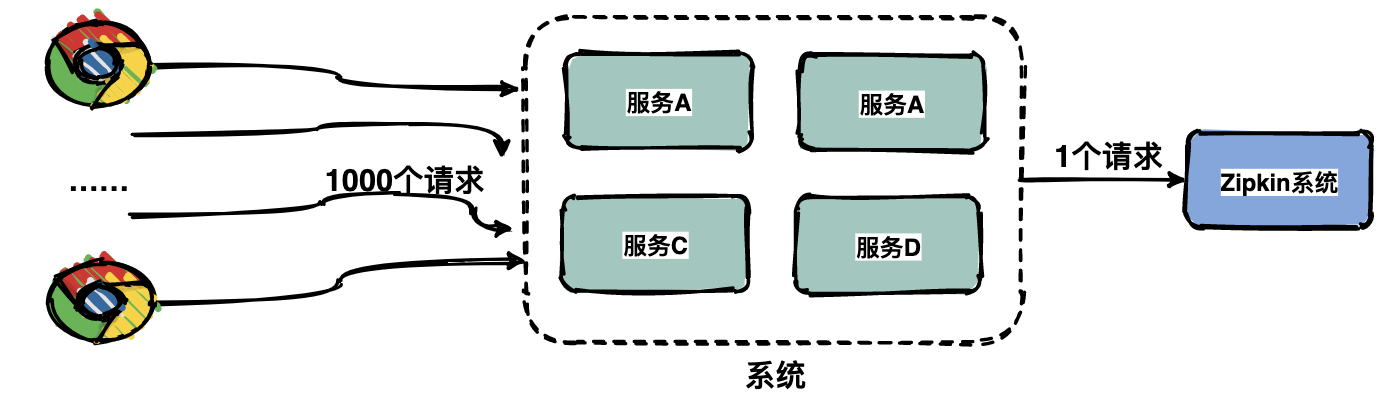 110 |
111 | 通过采集端自适应地调整采样率,控制span上报的数量,可以在发现性能瓶颈的同时,有效减少性能损耗。
112 |
113 | ## 存储
114 |
115 |
110 |
111 | 通过采集端自适应地调整采样率,控制span上报的数量,可以在发现性能瓶颈的同时,有效减少性能损耗。
112 |
113 | ## 存储
114 |
115 | 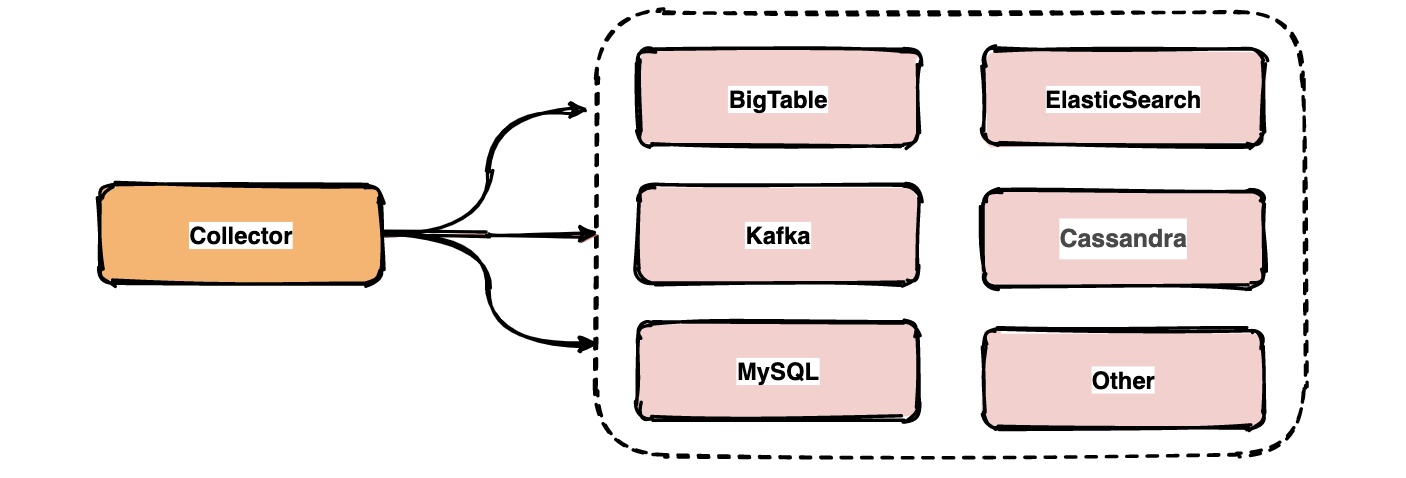 116 |
117 | 链路中的span数据经过收集和上报后会集中存储在一个地方,Dapper使用了BigTable数据仓库,常用的存储还有ElasticSearch, HBase, In-memory DB等。
118 |
119 | # 业界常用链路追踪系统
120 |
121 | Google Dapper论文发出来之后,很多公司基于链路追踪的基本原理给出了各自的解决方案,如Twitter的Zipkin,Uber的Jaeger,pinpoint,Apache开源的skywalking,还有国产如阿里的鹰眼,美团的Mtrace,滴滴Trace,新浪的Watchman,京东的Hydra,不过国内的这些基本都没有开源。
122 |
123 | 为了便于各系统间能彼此兼容互通,OpenTracing组织制定了一系列标准,旨在让各系统提供统一的接口。
124 |
125 | 下面对比一下几个开源组件,方便日后大家做技术选型。
126 |
127 |
116 |
117 | 链路中的span数据经过收集和上报后会集中存储在一个地方,Dapper使用了BigTable数据仓库,常用的存储还有ElasticSearch, HBase, In-memory DB等。
118 |
119 | # 业界常用链路追踪系统
120 |
121 | Google Dapper论文发出来之后,很多公司基于链路追踪的基本原理给出了各自的解决方案,如Twitter的Zipkin,Uber的Jaeger,pinpoint,Apache开源的skywalking,还有国产如阿里的鹰眼,美团的Mtrace,滴滴Trace,新浪的Watchman,京东的Hydra,不过国内的这些基本都没有开源。
122 |
123 | 为了便于各系统间能彼此兼容互通,OpenTracing组织制定了一系列标准,旨在让各系统提供统一的接口。
124 |
125 | 下面对比一下几个开源组件,方便日后大家做技术选型。
126 |
127 | 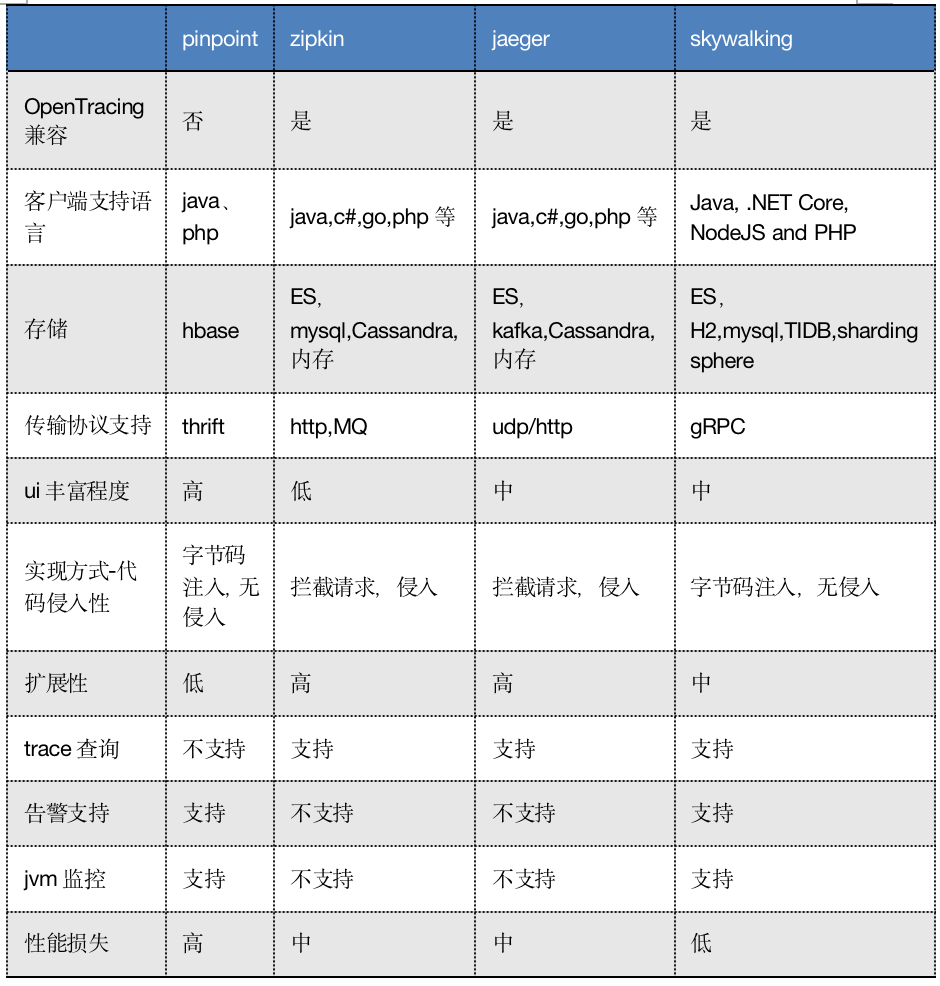 128 |
129 | 附各大开源组件的地址:
130 |
131 | * zipkin[https://zipkin.io/](https://zipkin.io/?fileGuid=Q8RQjVxpcvdvtC6q)
132 | * Jaeger[www.](http://www.baidu.com/link?url=BktsXcEs4Z1Ci_M7bV8PsKC3PZLoGVDS-omdih46FUB5HP4XXSbzSQRJW-Z0cqps&fileGuid=Q8RQjVxpcvdvtC6q)[jaeger](http://www.baidu.com/link?url=BktsXcEs4Z1Ci_M7bV8PsKC3PZLoGVDS-omdih46FUB5HP4XXSbzSQRJW-Z0cqps&fileGuid=Q8RQjVxpcvdvtC6q)[tracing.io/](http://www.baidu.com/link?url=BktsXcEs4Z1Ci_M7bV8PsKC3PZLoGVDS-omdih46FUB5HP4XXSbzSQRJW-Z0cqps&fileGuid=Q8RQjVxpcvdvtC6q)
133 | * Pinpoint[https://github.com/pinpoint-apm/pinpoint](https://github.com/pinpoint-apm/pinpoint?fileGuid=Q8RQjVxpcvdvtC6q)
134 | * SkyWalking[http://skywalking.apache.org/](http://skywalking.apache.org/?fileGuid=Q8RQjVxpcvdvtC6q)
135 |
136 | 接下来介绍一下Zipkin基本实现。
137 |
138 | # 分布式链路追踪系统Zipkin实现
139 |
140 | Zipkin 是 Twitter 的一个开源项目,它基于 Google Dapper 实现,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
141 |
142 | ## **Zipkin基本架构**
143 |
144 |
128 |
129 | 附各大开源组件的地址:
130 |
131 | * zipkin[https://zipkin.io/](https://zipkin.io/?fileGuid=Q8RQjVxpcvdvtC6q)
132 | * Jaeger[www.](http://www.baidu.com/link?url=BktsXcEs4Z1Ci_M7bV8PsKC3PZLoGVDS-omdih46FUB5HP4XXSbzSQRJW-Z0cqps&fileGuid=Q8RQjVxpcvdvtC6q)[jaeger](http://www.baidu.com/link?url=BktsXcEs4Z1Ci_M7bV8PsKC3PZLoGVDS-omdih46FUB5HP4XXSbzSQRJW-Z0cqps&fileGuid=Q8RQjVxpcvdvtC6q)[tracing.io/](http://www.baidu.com/link?url=BktsXcEs4Z1Ci_M7bV8PsKC3PZLoGVDS-omdih46FUB5HP4XXSbzSQRJW-Z0cqps&fileGuid=Q8RQjVxpcvdvtC6q)
133 | * Pinpoint[https://github.com/pinpoint-apm/pinpoint](https://github.com/pinpoint-apm/pinpoint?fileGuid=Q8RQjVxpcvdvtC6q)
134 | * SkyWalking[http://skywalking.apache.org/](http://skywalking.apache.org/?fileGuid=Q8RQjVxpcvdvtC6q)
135 |
136 | 接下来介绍一下Zipkin基本实现。
137 |
138 | # 分布式链路追踪系统Zipkin实现
139 |
140 | Zipkin 是 Twitter 的一个开源项目,它基于 Google Dapper 实现,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
141 |
142 | ## **Zipkin基本架构**
143 |
144 | 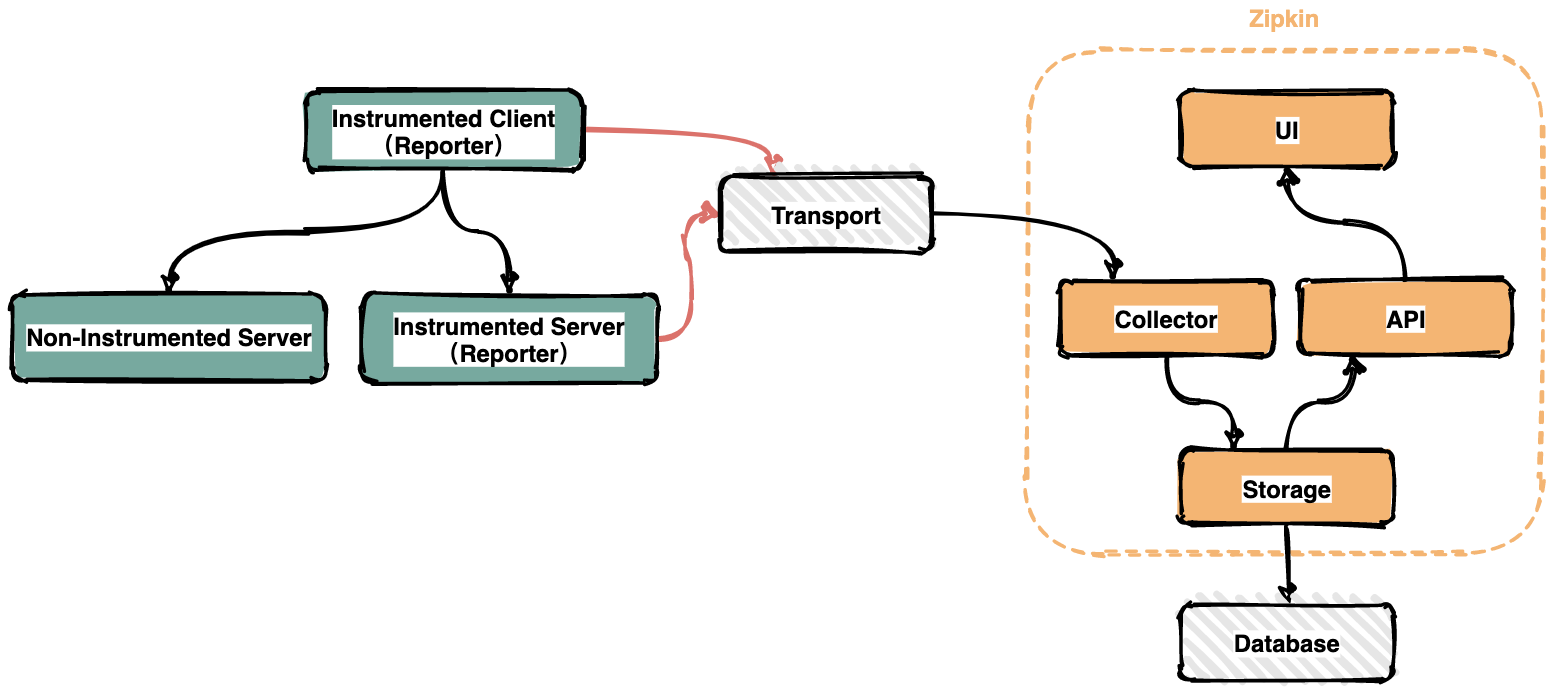 145 |
146 | 在服务运行的过程中会产生很多链路信息,产生数据的地方可以称之为Reporter。将链路信息通过多种传输方式如HTTP,RPC,kafka消息队列等发送到Zipkin的采集器,Zipkin处理后最终将链路信息保存到存储器中。运维人员通过UI界面调用接口即可查询调用链信息。
147 |
148 | ## **Zipkin核心组件**
149 |
150 | Zipkin有四大核心组件
151 |
152 |
145 |
146 | 在服务运行的过程中会产生很多链路信息,产生数据的地方可以称之为Reporter。将链路信息通过多种传输方式如HTTP,RPC,kafka消息队列等发送到Zipkin的采集器,Zipkin处理后最终将链路信息保存到存储器中。运维人员通过UI界面调用接口即可查询调用链信息。
147 |
148 | ## **Zipkin核心组件**
149 |
150 | Zipkin有四大核心组件
151 |
152 | 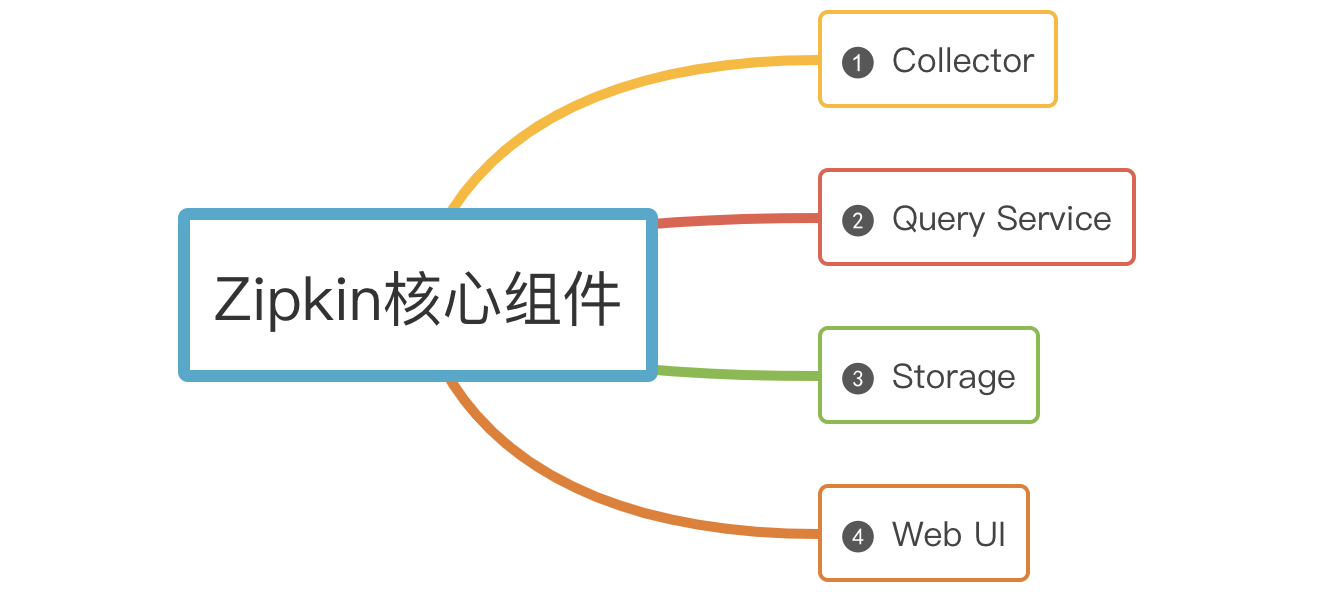 153 |
154 | **(1)Collector**
155 |
156 | 一旦Collector采集线程获取到链路追踪数据,Zipkin就会对其进行验证、存储和索引,并调用存储接口保存数据,以便进行查找。
157 |
158 | **(2)Storage**
159 |
160 | Zipkin Storage最初是为了在Cassandra上存储数据而构建的,因为Cassandra是可伸缩的,具有灵活的模式,并且在Twitter中大量使用。除了Cassandra,还支持支持ElasticSearch和MySQL存储,后续可能会提供第三方扩展。
161 |
162 | **(3)Query Service**
163 |
164 | 链路追踪数据被存储和索引之后,webui 可以调用query service查询任意数据帮助运维人员快速定位线上问题。query service提供了简单的json api来查找和检索数据。
165 |
166 | **(4)Web UI**
167 |
168 | Zipkin 提供了基本查询、搜索的web界面,运维人员可以根据具体的调用链信息快速识别线上问题。
169 |
170 | # 总结
171 |
172 | 1. 分布式链路追踪就是将每一次分布式请求还原成调用链路。
173 | 2. 链路追踪的核心概念:Trace、Span、Annotation、带内和带外数据、采样、存储。
174 | 3. 业界常用的开源组件都是基于谷歌Dapper论文演变而来;
175 | 4. Zipkin核心组件有:Collector、Storage、Query Service、Web UI。
176 |
--------------------------------------------------------------------------------
/docs/distributed/用大白话给你解释Zookeeper的选举机制.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322098&idx=1&sn=100089ec2d8c49b85f4acc5ff2af8ca5&chksm=8f09caa8b87e43be0454c4583a914779a5d78d2ae0493e2ec54fd2337d3be9ae99b391a1a35c&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [人类选举的基本原理](#人类选举的基本原理)
6 | - [Zookeeper选举的基本原理](#zookeeper选举的基本原理)
7 | - [什么场景下 Zookeeper 需要选举?](#什么场景下-zookeeper-需要选举)
8 | - [启动时期的 Leader 选举](#启动时期的-leader-选举)
9 | - [运行时期的Leader选举](#运行时期的leader选举)
10 | - [选举机制中涉及到的核心概念](#选举机制中涉及到的核心概念)
11 | - [总结](#总结)
12 |
13 |
14 |
15 | `Zookeeper` 是一个分布式服务框架,主要是用来解决分布式应用中遇到的一些数据管理问题如:`统一命名服务`、`状态同步服务`、`集群管理`、`分布式应用配置项的管理`等。
16 |
17 | 我们可以简单把 `Zookeeper` 理解为分布式家庭的大管家,那么管家团队是如何选出`Leader`的呢?好奇吗,接下来带领大家一探究竟。
18 |
19 | # 人类选举的基本原理
20 |
21 | 讲解 `Zookeeper` 选举过程前先来介绍一下人类的选举。
22 |
23 | 我们每个人或多或少都经历过几次选举,在投票的过程中可能会遇到这样几种情况:
24 |
25 | **情况1**:自己与几个候选人都比较熟,你会将票投给你认为`能力比较强的人`;
26 |
27 |
153 |
154 | **(1)Collector**
155 |
156 | 一旦Collector采集线程获取到链路追踪数据,Zipkin就会对其进行验证、存储和索引,并调用存储接口保存数据,以便进行查找。
157 |
158 | **(2)Storage**
159 |
160 | Zipkin Storage最初是为了在Cassandra上存储数据而构建的,因为Cassandra是可伸缩的,具有灵活的模式,并且在Twitter中大量使用。除了Cassandra,还支持支持ElasticSearch和MySQL存储,后续可能会提供第三方扩展。
161 |
162 | **(3)Query Service**
163 |
164 | 链路追踪数据被存储和索引之后,webui 可以调用query service查询任意数据帮助运维人员快速定位线上问题。query service提供了简单的json api来查找和检索数据。
165 |
166 | **(4)Web UI**
167 |
168 | Zipkin 提供了基本查询、搜索的web界面,运维人员可以根据具体的调用链信息快速识别线上问题。
169 |
170 | # 总结
171 |
172 | 1. 分布式链路追踪就是将每一次分布式请求还原成调用链路。
173 | 2. 链路追踪的核心概念:Trace、Span、Annotation、带内和带外数据、采样、存储。
174 | 3. 业界常用的开源组件都是基于谷歌Dapper论文演变而来;
175 | 4. Zipkin核心组件有:Collector、Storage、Query Service、Web UI。
176 |
--------------------------------------------------------------------------------
/docs/distributed/用大白话给你解释Zookeeper的选举机制.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322098&idx=1&sn=100089ec2d8c49b85f4acc5ff2af8ca5&chksm=8f09caa8b87e43be0454c4583a914779a5d78d2ae0493e2ec54fd2337d3be9ae99b391a1a35c&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [人类选举的基本原理](#人类选举的基本原理)
6 | - [Zookeeper选举的基本原理](#zookeeper选举的基本原理)
7 | - [什么场景下 Zookeeper 需要选举?](#什么场景下-zookeeper-需要选举)
8 | - [启动时期的 Leader 选举](#启动时期的-leader-选举)
9 | - [运行时期的Leader选举](#运行时期的leader选举)
10 | - [选举机制中涉及到的核心概念](#选举机制中涉及到的核心概念)
11 | - [总结](#总结)
12 |
13 |
14 |
15 | `Zookeeper` 是一个分布式服务框架,主要是用来解决分布式应用中遇到的一些数据管理问题如:`统一命名服务`、`状态同步服务`、`集群管理`、`分布式应用配置项的管理`等。
16 |
17 | 我们可以简单把 `Zookeeper` 理解为分布式家庭的大管家,那么管家团队是如何选出`Leader`的呢?好奇吗,接下来带领大家一探究竟。
18 |
19 | # 人类选举的基本原理
20 |
21 | 讲解 `Zookeeper` 选举过程前先来介绍一下人类的选举。
22 |
23 | 我们每个人或多或少都经历过几次选举,在投票的过程中可能会遇到这样几种情况:
24 |
25 | **情况1**:自己与几个候选人都比较熟,你会将票投给你认为`能力比较强的人`;
26 |
27 |  28 |
29 | **情况2**:自己也是候选人,并且与其他几个候选人都不熟,这个时候你肯定想着要去拉票,因为觉得自己才是最厉害的人呀,所有人都应该把票投给我。但是遗憾的是在拉票的过程中,你`发现别人比你强`,你开始自卑了,最终还是把票投给了自己认为最强的人。
30 |
31 |
28 |
29 | **情况2**:自己也是候选人,并且与其他几个候选人都不熟,这个时候你肯定想着要去拉票,因为觉得自己才是最厉害的人呀,所有人都应该把票投给我。但是遗憾的是在拉票的过程中,你`发现别人比你强`,你开始自卑了,最终还是把票投给了自己认为最强的人。
30 |
31 |  32 |
33 |
34 | 所有人都投完票之后,最后从投票箱中进行统计,获得票数最多的人当选。
35 |
36 |
32 |
33 |
34 | 所有人都投完票之后,最后从投票箱中进行统计,获得票数最多的人当选。
35 |
36 | 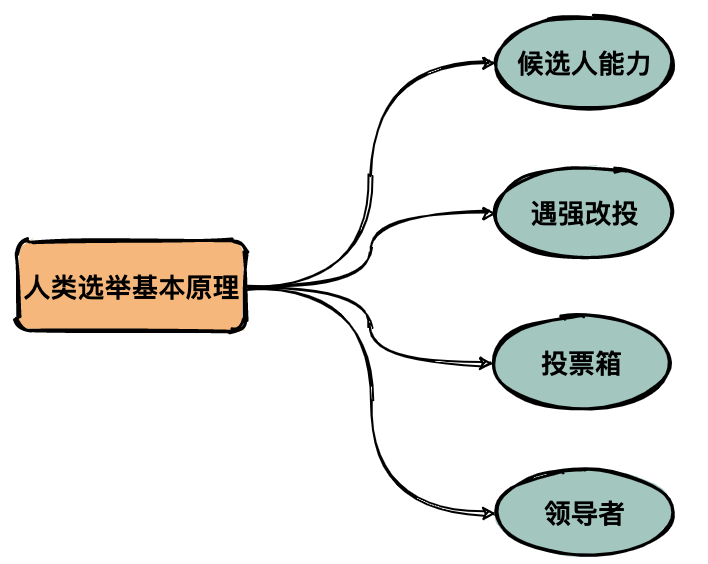 37 |
38 | 在整个投票过程中我们可以提炼出四个最核心的概念:
39 |
40 | * `候选人能力`:投票的基本原则是选最强的人。
41 | * `遇强改投`:如果后面发现更强的人可以改投票。
42 | * `投票箱`:所有人的票都会放在投票箱。
43 | * `领导者`:得票最多的人即为领导者。
44 |
45 | 从人类选举的原理我们来简单推导一下Zookeeper的选举原理。
46 |
47 |
48 |
49 | # Zookeeper选举的基本原理
50 |
51 | >注意如果 Zookeeper 是单机部署是不需要选举的,集群模式下才需要选举。
52 |
53 | Zookeeper 的选举原理和人类选举的逻辑类似,套用一下人类选举的四个基本概念详细解释一下Zookeeper。
54 |
55 | * **个人能力**
56 |
57 | 如何衡量 Zookeeper 节点个人能力?答案是靠`数据是否够新`,如果节点的数据越新就代表这个节点的个人能力越强,是不是感觉很奇怪,就是这么定的!
58 |
59 | 在 Zookeeper 中通常是以事务id(后面简称`zxid`)来标识数据的新旧程度(版本),节点最新的zxid越大代表这个节点的数据越新,也就代表这个节点能力越强。
60 |
61 | >zxid 的全称是 `ZooKeeper Transaction Id`,即 Zookeeper 事务id。
62 | * **遇强改投**
63 |
64 | 在集群选举开始时,节点首先认为自己时最强的(即数据是最新的),然后在选票上写上自己的名字(包括`zxid`和`sid`),zxid 是事务id,sid 唯一标识自己。
65 |
66 | 紧接着会将选票传递给其他节点,同时自己也会接收其他节点传过来的选票。每个节点接收到选票后会做比较,这个人是不是比我强(zxid比我大),如果比较强,那我就需要`改票`,明明别人比我强,我也不能厚着脸皮对吧。
67 |
68 | * **投票箱**
69 |
70 | 与人类选举投票箱稍微有点不一样,Zookeeper 集群会在每个节点的内存中维护一个投票箱。节点会将自己的选票以及其他节点的选票都放在这个投票箱中。由于选票时互相传阅的,所以最终每个节点投票箱中的选票会是一样的。
71 |
72 | * **领导者**
73 |
74 | 在投票的过程中会去统计是否有超过一半的选票和自己选择的是同一个节点,即都认为某个节点是最强的。一旦集群中有`超过半数`的节点都认为某个节点最强,那该节点就是领导者了,投票也宣告结束。
75 |
76 | # 什么场景下 Zookeeper 需要选举?
77 |
78 | 当 Zookeeper 集群中的一台服务器出现以下两种情况之一时,需要进入 `Leader 选举`。
79 |
80 | (1)服务器初始化启动。
81 |
82 | (2)服务器运行期间 Leader 故障。
83 |
84 | ## 启动时期的 Leader 选举
85 |
86 | 假设一个 Zookeeper 集群中有5台服务器,id从1到5编号,并且它们都是最新启动的,没有历史数据。
87 |
88 |
37 |
38 | 在整个投票过程中我们可以提炼出四个最核心的概念:
39 |
40 | * `候选人能力`:投票的基本原则是选最强的人。
41 | * `遇强改投`:如果后面发现更强的人可以改投票。
42 | * `投票箱`:所有人的票都会放在投票箱。
43 | * `领导者`:得票最多的人即为领导者。
44 |
45 | 从人类选举的原理我们来简单推导一下Zookeeper的选举原理。
46 |
47 |
48 |
49 | # Zookeeper选举的基本原理
50 |
51 | >注意如果 Zookeeper 是单机部署是不需要选举的,集群模式下才需要选举。
52 |
53 | Zookeeper 的选举原理和人类选举的逻辑类似,套用一下人类选举的四个基本概念详细解释一下Zookeeper。
54 |
55 | * **个人能力**
56 |
57 | 如何衡量 Zookeeper 节点个人能力?答案是靠`数据是否够新`,如果节点的数据越新就代表这个节点的个人能力越强,是不是感觉很奇怪,就是这么定的!
58 |
59 | 在 Zookeeper 中通常是以事务id(后面简称`zxid`)来标识数据的新旧程度(版本),节点最新的zxid越大代表这个节点的数据越新,也就代表这个节点能力越强。
60 |
61 | >zxid 的全称是 `ZooKeeper Transaction Id`,即 Zookeeper 事务id。
62 | * **遇强改投**
63 |
64 | 在集群选举开始时,节点首先认为自己时最强的(即数据是最新的),然后在选票上写上自己的名字(包括`zxid`和`sid`),zxid 是事务id,sid 唯一标识自己。
65 |
66 | 紧接着会将选票传递给其他节点,同时自己也会接收其他节点传过来的选票。每个节点接收到选票后会做比较,这个人是不是比我强(zxid比我大),如果比较强,那我就需要`改票`,明明别人比我强,我也不能厚着脸皮对吧。
67 |
68 | * **投票箱**
69 |
70 | 与人类选举投票箱稍微有点不一样,Zookeeper 集群会在每个节点的内存中维护一个投票箱。节点会将自己的选票以及其他节点的选票都放在这个投票箱中。由于选票时互相传阅的,所以最终每个节点投票箱中的选票会是一样的。
71 |
72 | * **领导者**
73 |
74 | 在投票的过程中会去统计是否有超过一半的选票和自己选择的是同一个节点,即都认为某个节点是最强的。一旦集群中有`超过半数`的节点都认为某个节点最强,那该节点就是领导者了,投票也宣告结束。
75 |
76 | # 什么场景下 Zookeeper 需要选举?
77 |
78 | 当 Zookeeper 集群中的一台服务器出现以下两种情况之一时,需要进入 `Leader 选举`。
79 |
80 | (1)服务器初始化启动。
81 |
82 | (2)服务器运行期间 Leader 故障。
83 |
84 | ## 启动时期的 Leader 选举
85 |
86 | 假设一个 Zookeeper 集群中有5台服务器,id从1到5编号,并且它们都是最新启动的,没有历史数据。
87 |
88 | 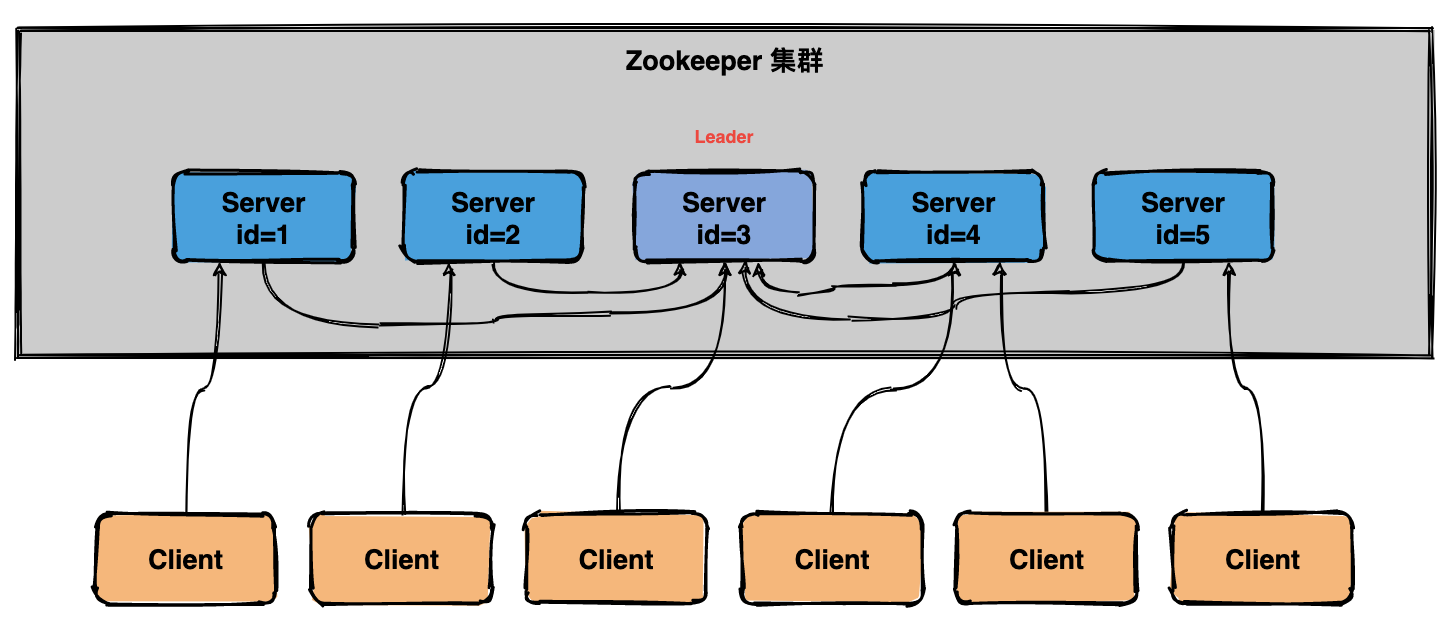 89 |
90 | 假设服务器依次启动,我们来分析一下选举过程:
91 |
92 | **(1)服务器1启动**
93 |
94 | 发起一次选举,服务器1投自己一票,此时服务器1票数一票,不够半数以上(3票),选举无法完成。
95 |
96 | 投票结果:服务器1为1票。
97 |
98 | 服务器1状态保持为`LOOKING`。
99 |
100 | **(2)服务器2启动**
101 |
102 | 发起一次选举,服务器1和2分别投自己一票,此时服务器1发现服务器2的id比自己大,更改选票投给服务器2。
103 |
104 | 投票结果:服务器1为0票,服务器2为2票。
105 |
106 | 服务器1,2状态保持`LOOKING`
107 |
108 | **(3)服务器3启动**
109 |
110 | 发起一次选举,服务器1、2、3先投自己一票,然后因为服务器3的id最大,两者更改选票投给为服务器3;
111 |
112 | 投票结果:服务器1为0票,服务器2为0票,服务器3为3票。 此时服务器3的票数已经超过半数(3票),**服务器3当选`Leader`**。
113 |
114 | 服务器1,2更改状态为`FOLLOWING`,服务器3更改状态为`LEADING`。
115 |
116 | **(4)服务器4启动**
117 |
118 | 发起一次选举,此时服务器1,2,3已经不是LOOKING 状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3。
119 |
120 | 服务器4并更改状态为`FOLLOWING`。
121 |
122 | **(5)服务器5启动**
123 |
124 | 与服务器4一样投票给3,此时服务器3一共5票,服务器5为0票。
125 |
126 | 服务器5并更改状态为`FOLLOWING`。
127 |
128 | **最终的结果**:
129 |
130 | 服务器3是 `Leader`,状态为 `LEADING`;其余服务器是 `Follower`,状态为 `FOLLOWING`。
131 |
132 | ## 运行时期的Leader选举
133 |
134 | 在 Zookeeper运行期间 `Leader` 和 `非 Leader` 各司其职,当有非 Leader 服务器宕机或加入不会影响 Leader,但是一旦 Leader 服务器挂了,那么整个 Zookeeper 集群将暂停对外服务,会触发新一轮的选举。
135 |
136 | 初始状态下服务器3当选为`Leader`,假设现在服务器3故障宕机了,此时每个服务器上zxid可能都不一样,server1为99,server2为102,server4为100,server5为101
137 |
138 |
89 |
90 | 假设服务器依次启动,我们来分析一下选举过程:
91 |
92 | **(1)服务器1启动**
93 |
94 | 发起一次选举,服务器1投自己一票,此时服务器1票数一票,不够半数以上(3票),选举无法完成。
95 |
96 | 投票结果:服务器1为1票。
97 |
98 | 服务器1状态保持为`LOOKING`。
99 |
100 | **(2)服务器2启动**
101 |
102 | 发起一次选举,服务器1和2分别投自己一票,此时服务器1发现服务器2的id比自己大,更改选票投给服务器2。
103 |
104 | 投票结果:服务器1为0票,服务器2为2票。
105 |
106 | 服务器1,2状态保持`LOOKING`
107 |
108 | **(3)服务器3启动**
109 |
110 | 发起一次选举,服务器1、2、3先投自己一票,然后因为服务器3的id最大,两者更改选票投给为服务器3;
111 |
112 | 投票结果:服务器1为0票,服务器2为0票,服务器3为3票。 此时服务器3的票数已经超过半数(3票),**服务器3当选`Leader`**。
113 |
114 | 服务器1,2更改状态为`FOLLOWING`,服务器3更改状态为`LEADING`。
115 |
116 | **(4)服务器4启动**
117 |
118 | 发起一次选举,此时服务器1,2,3已经不是LOOKING 状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3。
119 |
120 | 服务器4并更改状态为`FOLLOWING`。
121 |
122 | **(5)服务器5启动**
123 |
124 | 与服务器4一样投票给3,此时服务器3一共5票,服务器5为0票。
125 |
126 | 服务器5并更改状态为`FOLLOWING`。
127 |
128 | **最终的结果**:
129 |
130 | 服务器3是 `Leader`,状态为 `LEADING`;其余服务器是 `Follower`,状态为 `FOLLOWING`。
131 |
132 | ## 运行时期的Leader选举
133 |
134 | 在 Zookeeper运行期间 `Leader` 和 `非 Leader` 各司其职,当有非 Leader 服务器宕机或加入不会影响 Leader,但是一旦 Leader 服务器挂了,那么整个 Zookeeper 集群将暂停对外服务,会触发新一轮的选举。
135 |
136 | 初始状态下服务器3当选为`Leader`,假设现在服务器3故障宕机了,此时每个服务器上zxid可能都不一样,server1为99,server2为102,server4为100,server5为101
137 |
138 | 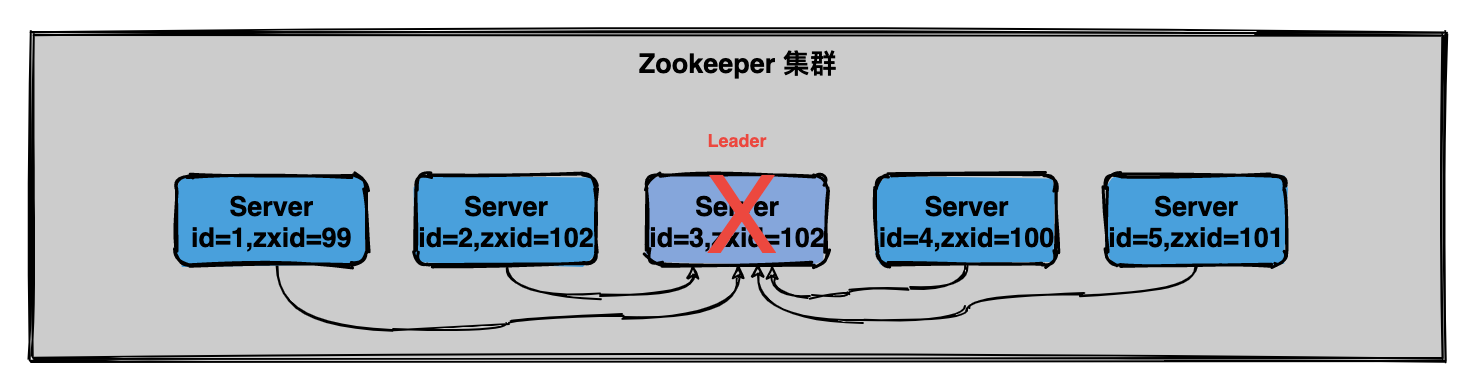 139 |
140 | 运行期选举与初始状态投票过程基本类似,大致可以分为以下几个步骤:
141 |
142 | (1)状态变更。Leader 故障后,余下的`非 Observer` 服务器都会将自己的服务器状态变更为`LOOKING`,然后开始进入`Leader选举过程`。
143 |
144 | (2)每个Server会发出投票。
145 |
146 | (3)接收来自各个服务器的投票,如果其他服务器的数据比自己的新会改投票。
147 |
148 | (4)处理和统计投票,没一轮投票结束后都会统计投票,超过半数即可当选。
149 |
150 | (5)改变服务器的状态,宣布当选。
151 |
152 | 话不多说先来一张图:
153 |
154 |
139 |
140 | 运行期选举与初始状态投票过程基本类似,大致可以分为以下几个步骤:
141 |
142 | (1)状态变更。Leader 故障后,余下的`非 Observer` 服务器都会将自己的服务器状态变更为`LOOKING`,然后开始进入`Leader选举过程`。
143 |
144 | (2)每个Server会发出投票。
145 |
146 | (3)接收来自各个服务器的投票,如果其他服务器的数据比自己的新会改投票。
147 |
148 | (4)处理和统计投票,没一轮投票结束后都会统计投票,超过半数即可当选。
149 |
150 | (5)改变服务器的状态,宣布当选。
151 |
152 | 话不多说先来一张图:
153 |
154 | 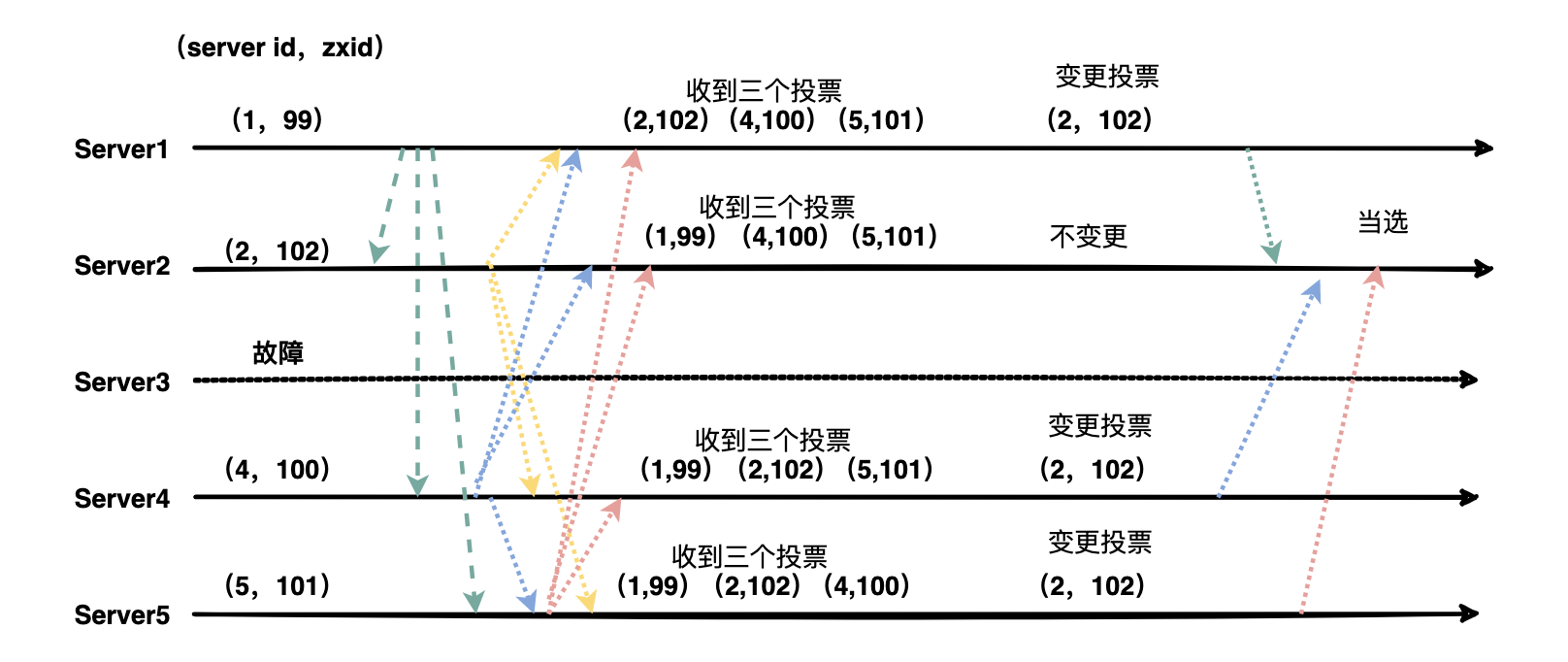 155 |
156 | (1)第一次投票,每台机器都会将票投给自己。
157 |
158 | (2)接着每台机器都会将自己的投票发给其他机器,如果发现其他机器的zxid比自己大,那么就需要改投票重新投一次。比如server1 收到了三张票,发现server2的xzid为102,pk一下发现自己输了,后面果断改投票选server2为老大。
159 |
160 | # 选举机制中涉及到的核心概念
161 |
162 | 敲黑板了,这些概念是面试必考的。
163 |
164 | **(1)Server id(或sid):服务器ID**
165 |
166 | 比如有三台服务器,编号分别是1,2,3。编号越大在选择算法中的权重越大,比如初始化启动时就是根据服务器ID进行比较。
167 |
168 | **(2)Zxid:事务ID**
169 |
170 | 服务器中存放的数据的事务ID,值越大说明数据越新,在选举算法中数据越新权重越大。
171 |
172 | **(3)Epoch:逻辑时钟**
173 |
174 | 也叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的,每投完一次票这个数据就会增加。
175 |
176 | **(4)Server状态:选举状态**
177 |
178 | `LOOKING`,竞选状态。
179 |
180 | `FOLLOWING`,随从状态,同步leader状态,参与投票。
181 |
182 | `OBSERVING`,观察状态,同步leader状态,不参与投票。
183 |
184 | `LEADING`,领导者状态。
185 |
186 | # 总结
187 |
188 | (1)Zookeeper 选举会发生在服务器初始状态和运行状态下。
189 |
190 | (2)初始状态下会根据服务器sid的编号对比,编号越大权值越大,投票过半数即可选出Leader。
191 |
192 | (3)Leader 故障会触发新一轮选举,`zxid` 代表数据越新,权值也就越大。
193 |
194 | > 没有什么比每天有成长进步更高兴的事情
195 |
--------------------------------------------------------------------------------
/docs/it-hot/鸿蒙OS尖刀武器之分布式软总线技术.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s/AM3C5z1QulG0wEKBFCyH6g)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [1 没有人能够熄灭满天星光](#1-没有人能够熄灭满天星光)
6 | - [2 必须得补的传统总线知识](#2-必须得补的传统总线知识)
7 | - [3 什么是分布式软总线?](#3-什么是分布式软总线)
8 | - [4 分布式软总线功能和原理](#4-分布式软总线功能和原理)
9 | - [4.1 分布式软总线的架构](#41-分布式软总线的架构)
10 | - [4.2 软总线之发现连接:从手动发现,进化成自发现](#42-软总线之发现连接:从手动发现进化成自发现)
11 | - [4.3 软总线组网关键技术-异构网络组网](#43-软总线组网关键技术-异构网络组网)
12 | - [4.4 软总线之传输](#44-软总线之传输)
13 | - [5 畅享未来,鸿蒙系统使能智慧生活](#5-畅享未来鸿蒙系统使能智慧生活)
14 | - [公众号](#公众号)
15 |
16 |
17 |
18 | # 1 没有人能够熄灭满天星光
19 |
20 | 华为开发者大会2020在广东东莞松山湖欧洲小镇举办,在主题演讲环节中,华为消费者业务总裁余承东宣布“鸿蒙”系统升级到2.0版本(HarmonyOS 2.0),余总表示,“鸿蒙”系统将在12月份推出手机版本,明年华为的手机将全面支持“鸿蒙”系统。
21 |
22 | “没有人能够熄灭满天星光,每一位开发者,都是华为要汇聚的星星之火”,华为消费者业务CEO余承东说,华为将全面开放核心技术、软硬件能力,与开发者们共同驱动全场景智慧生态的蓬勃发展。
23 |
24 |
155 |
156 | (1)第一次投票,每台机器都会将票投给自己。
157 |
158 | (2)接着每台机器都会将自己的投票发给其他机器,如果发现其他机器的zxid比自己大,那么就需要改投票重新投一次。比如server1 收到了三张票,发现server2的xzid为102,pk一下发现自己输了,后面果断改投票选server2为老大。
159 |
160 | # 选举机制中涉及到的核心概念
161 |
162 | 敲黑板了,这些概念是面试必考的。
163 |
164 | **(1)Server id(或sid):服务器ID**
165 |
166 | 比如有三台服务器,编号分别是1,2,3。编号越大在选择算法中的权重越大,比如初始化启动时就是根据服务器ID进行比较。
167 |
168 | **(2)Zxid:事务ID**
169 |
170 | 服务器中存放的数据的事务ID,值越大说明数据越新,在选举算法中数据越新权重越大。
171 |
172 | **(3)Epoch:逻辑时钟**
173 |
174 | 也叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的,每投完一次票这个数据就会增加。
175 |
176 | **(4)Server状态:选举状态**
177 |
178 | `LOOKING`,竞选状态。
179 |
180 | `FOLLOWING`,随从状态,同步leader状态,参与投票。
181 |
182 | `OBSERVING`,观察状态,同步leader状态,不参与投票。
183 |
184 | `LEADING`,领导者状态。
185 |
186 | # 总结
187 |
188 | (1)Zookeeper 选举会发生在服务器初始状态和运行状态下。
189 |
190 | (2)初始状态下会根据服务器sid的编号对比,编号越大权值越大,投票过半数即可选出Leader。
191 |
192 | (3)Leader 故障会触发新一轮选举,`zxid` 代表数据越新,权值也就越大。
193 |
194 | > 没有什么比每天有成长进步更高兴的事情
195 |
--------------------------------------------------------------------------------
/docs/it-hot/鸿蒙OS尖刀武器之分布式软总线技术.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s/AM3C5z1QulG0wEKBFCyH6g)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [1 没有人能够熄灭满天星光](#1-没有人能够熄灭满天星光)
6 | - [2 必须得补的传统总线知识](#2-必须得补的传统总线知识)
7 | - [3 什么是分布式软总线?](#3-什么是分布式软总线)
8 | - [4 分布式软总线功能和原理](#4-分布式软总线功能和原理)
9 | - [4.1 分布式软总线的架构](#41-分布式软总线的架构)
10 | - [4.2 软总线之发现连接:从手动发现,进化成自发现](#42-软总线之发现连接:从手动发现进化成自发现)
11 | - [4.3 软总线组网关键技术-异构网络组网](#43-软总线组网关键技术-异构网络组网)
12 | - [4.4 软总线之传输](#44-软总线之传输)
13 | - [5 畅享未来,鸿蒙系统使能智慧生活](#5-畅享未来鸿蒙系统使能智慧生活)
14 | - [公众号](#公众号)
15 |
16 |
17 |
18 | # 1 没有人能够熄灭满天星光
19 |
20 | 华为开发者大会2020在广东东莞松山湖欧洲小镇举办,在主题演讲环节中,华为消费者业务总裁余承东宣布“鸿蒙”系统升级到2.0版本(HarmonyOS 2.0),余总表示,“鸿蒙”系统将在12月份推出手机版本,明年华为的手机将全面支持“鸿蒙”系统。
21 |
22 | “没有人能够熄灭满天星光,每一位开发者,都是华为要汇聚的星星之火”,华为消费者业务CEO余承东说,华为将全面开放核心技术、软硬件能力,与开发者们共同驱动全场景智慧生态的蓬勃发展。
23 |
24 | 
25 |
26 |
27 | 在这场发布会上也详细讲解了分布式软总线的概念,下面我们来看一下分布式软总线是不是真的硬核,会给我们以后的生活带来什么影响?
28 |
29 | # 2 必须得补的传统总线知识
30 |
31 | 总线英文名叫Bus,你猜的没错也是公共汽车的意思。总线是一个非常广泛的概念,在传统计算机硬件体系中应用的非常广泛。
32 |
33 | 总线是一种内部结构,它是cpu、内存、输入、输出设备传递信息的公用通道,主机的各个部件通过总线相连接,外部设备通过相应的接口电路再与总线相连接,从而形成了计算机硬件系统。
34 |
35 | 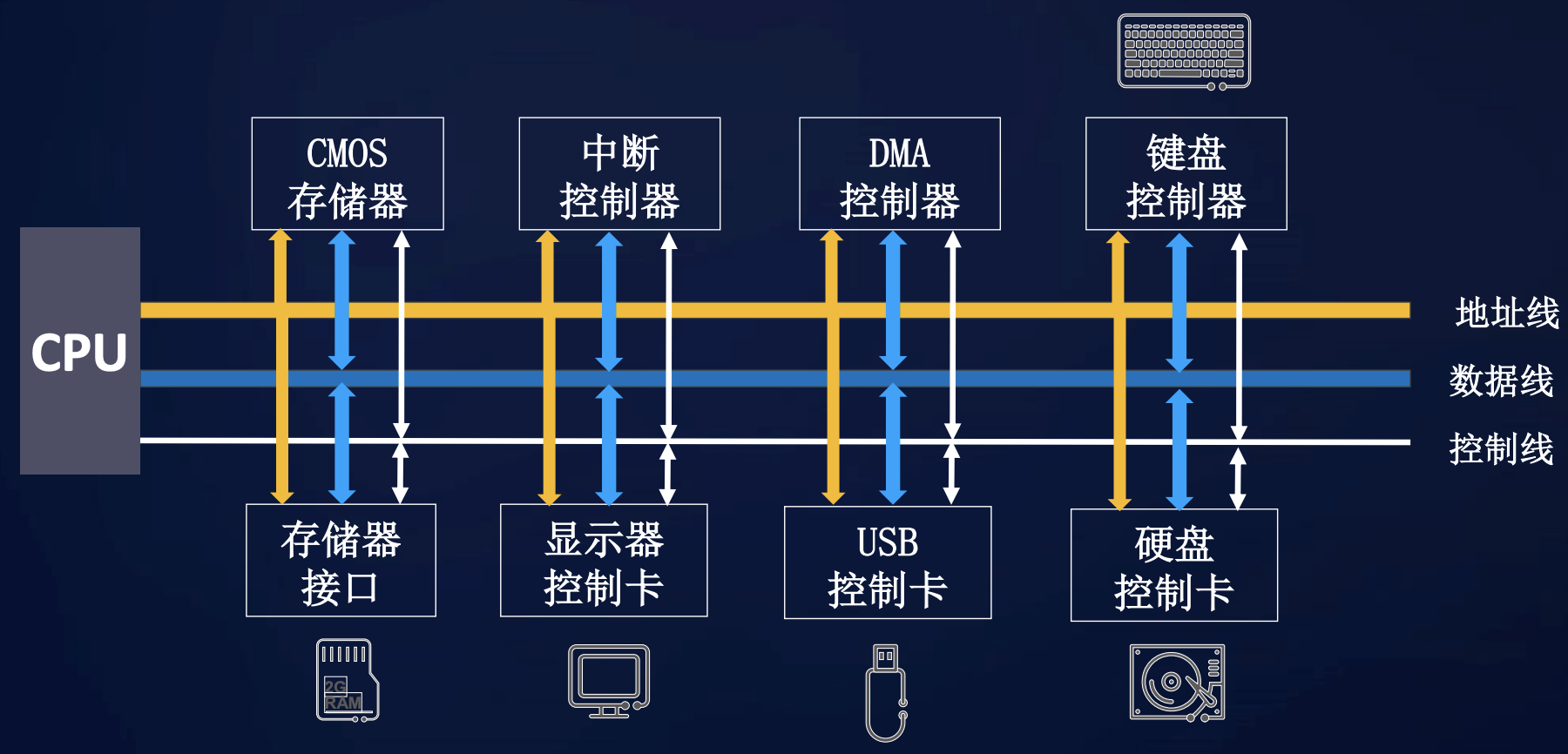
36 |
37 | 在计算机系统中,各个部件之间传送信息的公共通路叫总线,微型计算机是以总线结构来连接各个功能部件的。按照计算机所传输的信息种类,计算机的总线可以划分为数据总线、地址总线和控制总线,分别用来传输数据、数据地址和控制信号。
38 |
39 | 传统总线的典型特征:
40 |
41 | * 即插即用
42 | * 高带宽
43 | * 低时延
44 | * 高可靠
45 | * 标准
46 |
47 |
48 |
49 | # 3 什么是分布式软总线?
50 |
51 | 分布式软总线技术是基于华为多年的通信技术积累,参考计算机硬件总线,在1+8+N设备间搭建一条“无形”的总线,具备自发现、自组网、高带宽低时延的特点。
52 |
53 | >简单解释一下什么是1+8+N:
54 | >1指的是手机
55 | >8代表车机、音箱、耳机、手表/手环、平板、大屏、PC、AR/VR
56 | >N泛指其他IOT设备
57 |
58 | 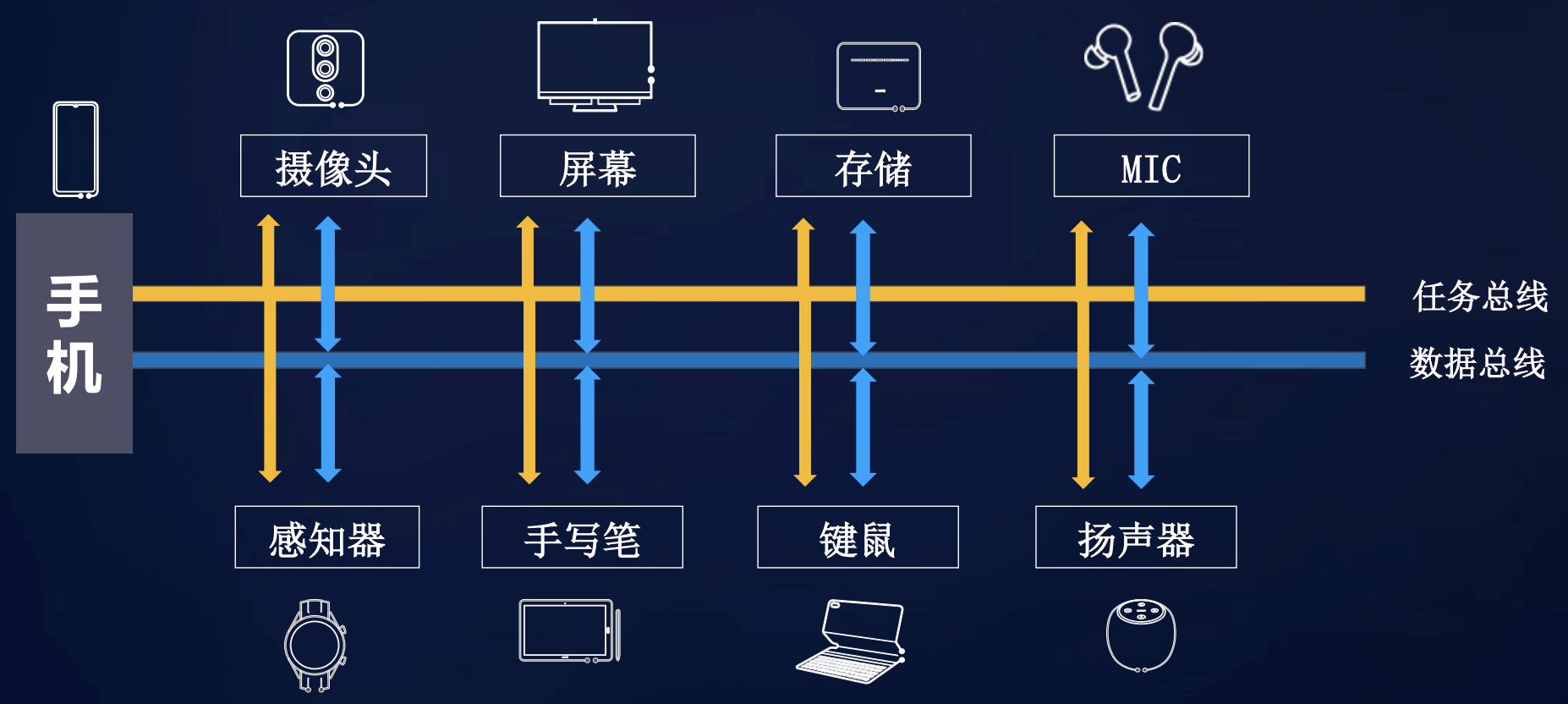
59 |
60 | HarmonyOS分布式软总线
61 |
62 | 全场景设备间可以基于软总线完成设备虚拟化、跨设备服务调用、多屏协同、文件分享等分布式业务。
63 |
64 | 分布式软总线的典型特征:
65 |
66 | * 自动发现/即连即用
67 | * 高带宽
68 | * 低时延
69 | * 高可靠
70 | * 开放/标准
71 | # 4 分布式软总线功能和原理
72 |
73 | ## 4.1 分布式软总线的架构
74 |
75 | 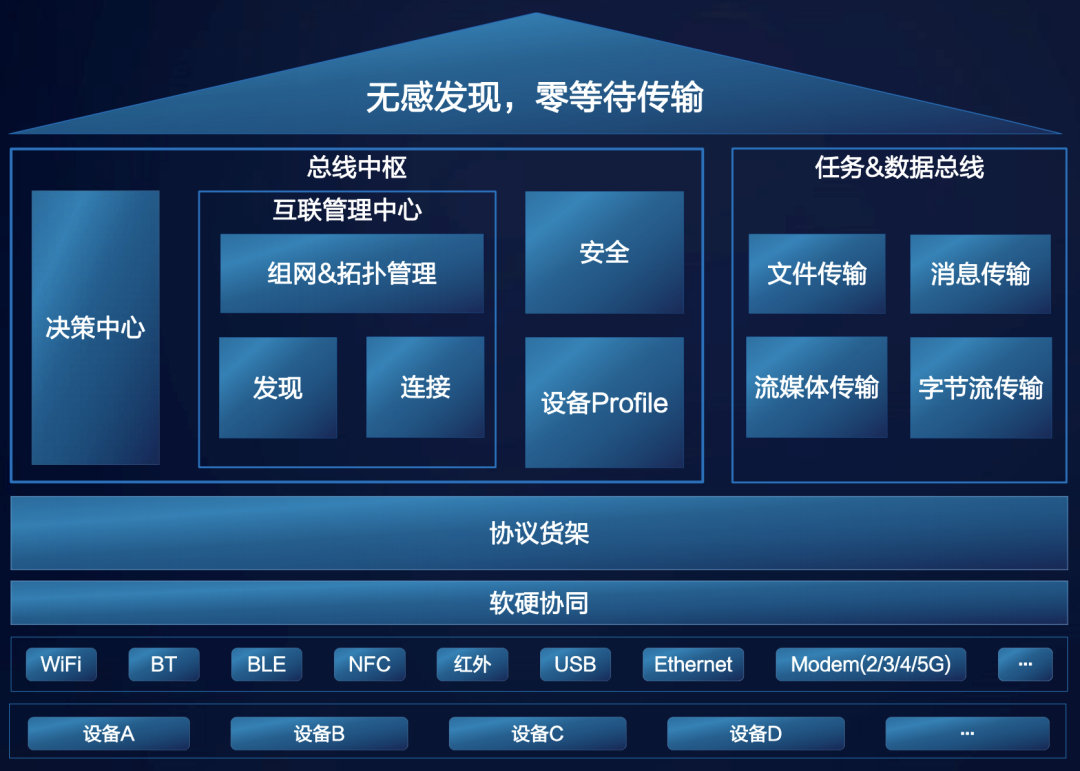
76 |
77 | 通过协议货架和软硬协同层屏蔽各种设备的协议差别,总线中枢模块负责解析命令完成设备间发现和连接,通过任务和数据两条总线实现设备间文件传输、消息传输等功能。
78 |
79 | 分布式总线的总体目标是实现设备间无感发现,零等待传输。实现这个目标需要解决三个问题:
80 |
81 | (1)设备间如何发现和连接?
82 |
83 | (2)多设备互联后如何组网?
84 |
85 | (3)多设备多协议间如何实现传输?
86 |
87 | 下面带着这三个问题我们一探究竟。
88 |
89 | ## 4.2 软总线之发现连接:从手动发现,进化成自发现
90 |
91 | 传统的设备发现是手动的,需要人干预,以生活中常见的一个例子讲解:
92 |
93 | 比如手机上有很多照片需要传到个人PC上,我们可以采用蓝牙传输,首先要打开手机和PC的蓝牙发现功能,手机或者PC点击搜索设备,然后互相配对授权即可连接上,成功连上后就可以肆无忌惮的发送照片啦。
94 |
95 | 在分享照片这个场景中有很多人为的动作:开启蓝牙发现功能、搜索设备、配对授权,这确实有点麻烦,耗费了很多时间,可能会降低分享的意愿。
96 |
97 | 
98 |
99 | 软总线提出了自动发现的概念,实现用户零等待的自发现体验,附近同账号的设备自动发现无需等待。
100 |
101 | ## 4.3 软总线组网关键技术-异构网络组网
102 |
103 | 上面的例子中手机传照片是通过蓝牙,假如PC没有蓝牙功能只有WIFI,在传统的场景中这种可能就不能实现分享传输了。
104 |
105 | 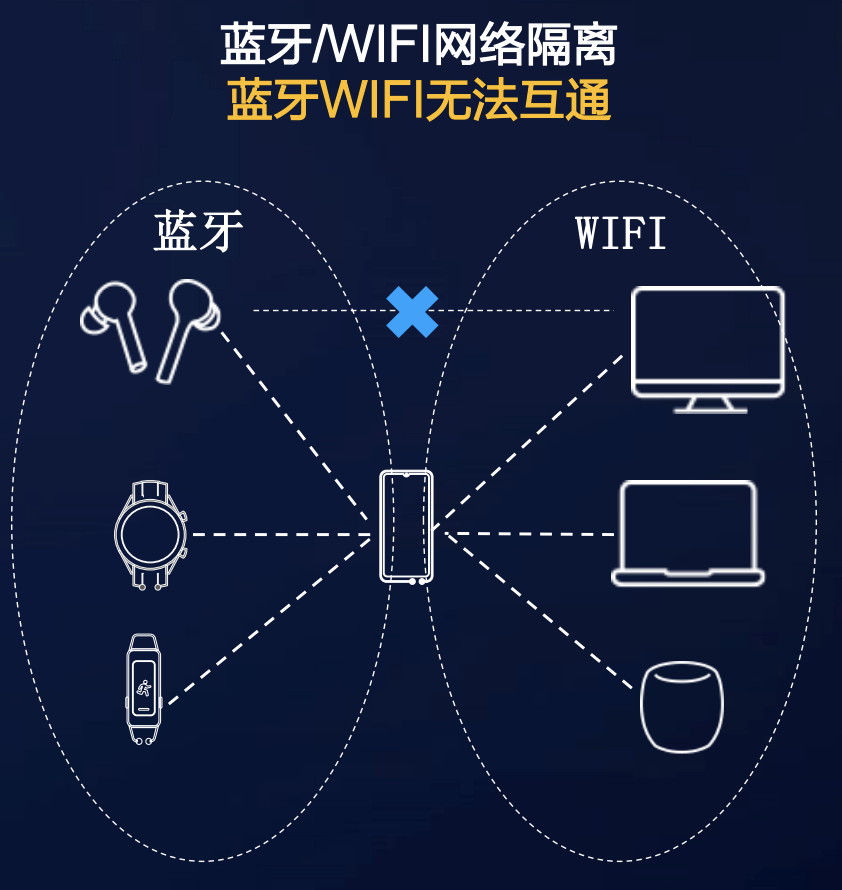
106 |
107 | 软总线能否做到手机通过蓝牙传输,PC通过WIFI接收照片呢?
108 |
109 | 答案是:当然可以。软总线提出了异构网络组网可以很好解决设备间不同协议如何交互的问题。
110 |
111 | 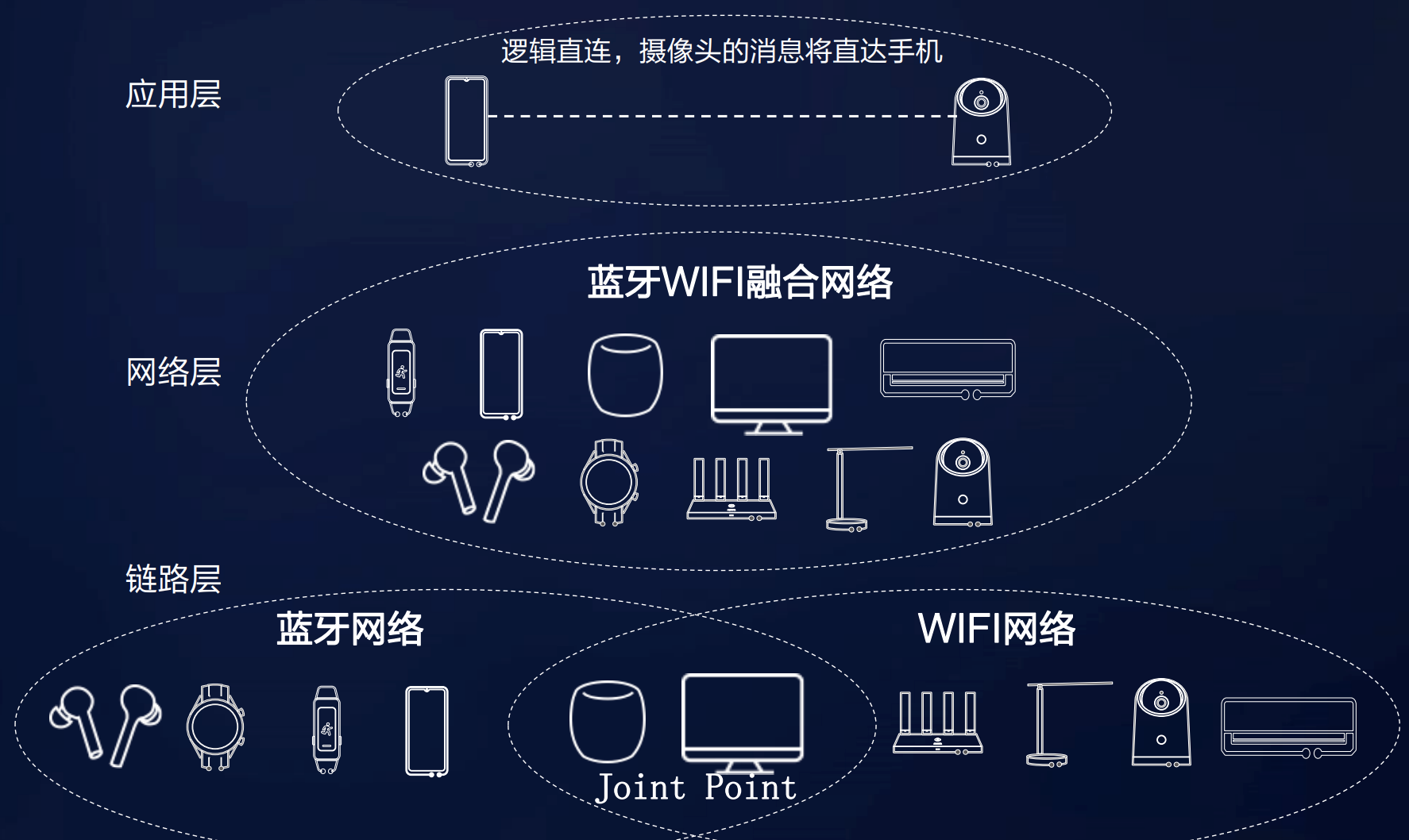
112 |
113 | 设备上线后会向网络层注册,同时网络层会与设备建立通道连接,实时检测设备的变换。网络层负责管理设备的上线下线变换,设备间可以监听自己感兴趣的设备,设备上线后可以立即与其建立连接,实现零等待体验。
114 |
115 | 软总线可以自动构建一个逻辑全连接网络,用户或者业务开发者无需关心组网方式与物理协议。
116 |
117 | 对于软件开发者来说软总线异构组网可以大大降低其开发成本。
118 |
119 | 传统开发模式:
120 |
121 | 在传统开发模式中开发者需要适配不同网络协议和标准规范。
122 |
123 | 分布式开发模式:
124 |
125 | 在HarmonyOS分布式开发模式中开发不再需要关心网络协议差异,业务开发与设备组网解耦,业务仅需监听设备上下线,开发成本大大降低。
126 |
127 | ## 4.4 软总线之传输
128 |
129 | 传统协议的传输速率差异非常大,时延也难以得到保证。
130 |
131 | 软总线传输要实现的目标:
132 |
133 | 高带宽(High Speed)
134 |
135 | 低时延(Low Latency)
136 |
137 | 高可靠(High Reliability)
138 |
139 | 软总线要实现的这三大目标的尖刀武器是:极简协议。
140 |
141 | 
142 |
143 | 将中间的四层协议栈精简为一层提升有效载荷,有效传输带宽提升20%
144 |
145 | 极简协议在传统网络协议的基础上进行增强:
146 |
147 | * 流式传输:基于UDP实现数据的保序和可靠传输;
148 | * 双轮驱动:颠覆传统TCP每包确认机制;
149 | * 不惧网损:摒弃传统滑动窗口机制,丢包快速恢复,避免阻塞;
150 | * 不惧抖动:智能感知网络变化,自适应流量控制和拥塞控制;
151 | # 5 畅享未来,鸿蒙系统使能智慧生活
152 |
153 | 鸿蒙系统的使命和目标是将不同设备的串联起来,成为设备的“万能语言”,实现万物互联的终极目标。
154 |
155 | **变化一:软件开发从业者的福音**
156 |
157 | 以前开发一款APP不仅需要为手机、手表、平板、电视等不同终端专门设计APP版本,而且还要为同类终端的不同品牌(华为、小米、OV)设计不同的APP版本。
158 |
159 | 而有了鸿蒙分布式系统架构,只需要开发一个版本,鸿蒙可以帮你“翻译”成不同终端的对应版本,真正实现一次开发就能在不同的终端上运行。
160 |
161 | 
162 |
163 | 看到这估计很多程序员们会仰天长叹:终于可以早点下班了!
164 |
165 | **变换二:可以活得更懒**
166 |
167 | 鸿蒙系统分布式架构能让你在使用某个APP软件的时候,比如看视频,可以把屏幕随意切换到电视、电脑、手机、平板、投影仪等任何一个设备的界面上。
168 |
169 | 你也不必满桌子找各种遥控器了,一个手表一个手机就可以控制家里的空调、电饭煲、汽车空调、音响、电视、电脑、门口的摄像头以及所有能联网的所有东西。
170 |
171 | 
172 |
173 | 这就是鸿蒙所构想的“万物互联”,让一个系统连接起所有上网的智能设备。大家期待吗,让我们拭目以待吧。
174 |
175 | # 公众号
176 |
177 | 公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
178 |
179 | 
--------------------------------------------------------------------------------
/docs/java/annotation/想自己写框架不会写Java注解可不行.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s/JqrJGwyU0oKdWYtHe_W31w)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [用注解一时爽,一直用一直爽](#用注解一时爽一直用一直爽)
6 | - [原来注解不神秘](#原来注解不神秘)
7 | - [造火箭啦,自己动手写一个注解](#造火箭啦自己动手写一个注解)
8 | - [第一步定义一个注解](#第一步定义一个注解)
9 | - [第二步实现注解的业务逻辑](#第二步实现注解的业务逻辑)
10 | - [第三步在业务代码中尽情的使用注解](#第三步在业务代码中尽情的使用注解)
11 | - [公众号](#公众号)
12 |
13 |
14 |
15 |
16 | 
17 |
18 | # 用注解一时爽,一直用一直爽
19 |
20 | Java后端开发进入spring全家桶时代后,开发一个微服务提供简单的增删改查接口跟玩泥巴似的非常简单,一顿操作猛如虎,回头一看代码加了一堆注解:@Controller @Autowired @Value,面向注解编程变成了大家不可缺少的操作。
21 |
22 | 想象一下如果没有注解Java程序员可以要哭瞎😭
23 |
24 | 既然注解(annotation)这么重要,用的这么爽,那注解的实现原理你知道么?我猜你只会用注解不会自己写注解(手动滑稽)。
25 |
26 | 好了,下面的内容带大家从零开始写一个注解,揭开注解神秘的面纱。
27 |
28 | # 原来注解不神秘
29 |
30 | 注解用大白话来说就是一个标记或者说是特殊的注释,如果没有解析这些标记的操作那它啥也不是。
31 |
32 | 注解的格式如同类或者方法一样有自己特殊的语法,这个语法下文会详细介绍。
33 |
34 | 那如何去解析注解呢?这就要用到Java强大的反射功能了。反射大家应该都用过,可以通过类对象获取到这个类的各种信息比如成员变量、方法等,那注解标记能不能通过反射获取呢?当然可以了。
35 |
36 | 所以注解的原理其实很简单,本质上是通过反射功能动态获取注解标记,然后按照不同的注解执行不同的操作,比如@Autowired可以注入一个对象给变量赋值。
37 |
38 | 看到这里是不是很躁动啊,来吧自己也撸一个注解。
39 |
40 | # 造火箭啦,自己动手写一个注解
41 |
42 | 便于大家理解,这里先引入一个场景:在线教育火了,经理让我写一个模块实现学生信息管理功能,考虑到分布式并发问题,经理让我务必加上分布式锁。
43 |
44 | 经理问我几天能搞定?我说至少3天。如是脑补了以下代码:
45 |
46 | ```java
47 | /**
48 | * 更新学生信息
49 | * @param student 学生对象
50 | * @return true 更新成功,false 更新失败
51 | */
52 | public boolean updateStudentInfo(Student student) {
53 | // 尝试获取分布式锁
54 | String lockKey = "student:" + student.getId();
55 | if (RedisTool.tryLock(lockKey, 10,
56 | TimeUnit.SECONDS, 5)) {
57 | try {
58 | // 这里写业务逻辑
59 | } finally {
60 | RedisTool.releaseLock(lockKey);
61 | }
62 | }
63 | // 获取锁失败
64 | return false;
65 | }
66 | ```
67 |
68 | 经理走后我在思考,我能不能只花一天时间写完,剩下两天时间用来写博客划水呢?突然灵感来了,我可以把重复的代码逻辑抽出来用注解实现不就节省代码了,哈哈,赶紧写。
69 |
70 | 使用注解之后整个方法清爽了很多,HR小姐姐都夸我写的好呢。
71 | ```java
72 | @EnableRedisLock(lockKey = "student", expireTime = 10, timeUnit = TimeUnit.SECONDS, retryTimes = 5)
73 | public boolean updateStudentInfo(Student student) {
74 | // 这里写业务逻辑
75 | // studentDao.update(student);
76 | return true;
77 | }
78 | ```
79 |
80 | 代码已经写完上库了,现在我在划水写博客呢。是不是很简洁很优雅很牛逼,怎么做到的呢,主要分为三步:1打开冰箱门,2把大象放进去,3把冰箱门关好。好了,扯远了,大家接着往下看。
81 |
82 | ## 第一步定义一个注解
83 |
84 | 
85 |
86 | 一个注解可以简单拆解为三个部分:
87 |
88 | 第一部分:注解体
89 |
90 | 注解的定义有点类似于接口(interface),只不过前面一个加了一个@符号,这个千万不能省。
91 |
92 | 第二部分:注解变量
93 |
94 | 注解变量的语法有点类似于接口里面定义的方法,变量名后面带一对括号,不同的是注解变量后面可以有默认值。另外返回值只能是Java基本类型、String类型或者枚举类,不可以是对象类型。
95 |
96 | 第三部分:元注解
97 |
98 | 元注解(meta-annotation)说白了就是给注解加注解的注解,是不是有点晕了,这种注解是JDK提前内置好的,可以直接拿来用的。不太懂也没有关系反正数量也不多,总共就4个,我们背下来吧:@Target @Retention @Documented @Inherited
99 |
100 | * Target注解
101 |
102 | 用来描述注解的使用范围,即被修饰的注解可以用在什么地方 。
103 |
104 | 注解可以用于修饰 packages、types(类、接口、枚举、注解类)、类成员(方法、构造方法、成员变量、枚举值)、方法参数和本地变量(如循环变量、catch参数),在定义注解类时使用了@Target 能够更加清晰的知道它能够被用来修饰哪些对象,具体的取值范围定义在ElementType.java 枚举类中。
105 |
106 | 比如上面我们写的Redis锁的注解就只能用于方法上了。
107 |
108 | * Retention注解
109 |
110 | 用来描述注解保留的时间范围,即注解的生命周期。在 RetentionPolicy 枚举类中定义了三个周期:
111 |
112 | ```java
113 | public enum RetentionPolicy {
114 | SOURCE, // 源文件保留
115 | CLASS, // 编译期保留,默认值
116 | RUNTIME // 运行期保留,可通过反射去获取注解信息
117 | }
118 | ```
119 | 像我们熟知的@Override注解就只能保留在源文件中,代码编译后注解就消失了。
120 | 比如上面我们写的Redis锁的注解就保留到了运行期,运行的时候可以通过反射获取信息。
121 |
122 | * Documented注解
123 |
124 | 用来描述在使用 javadoc 工具为类生成帮助文档时是否要保留其注解信息,很简单不多解释了。
125 |
126 | * Inherited注解
127 |
128 | 被Inherited注解修饰的注解具有继承性,如果父类使用了被@Inherited修饰的注解,则其子类将自动继承该注解。
129 |
130 | 好了,这一步我们已经将注解定义好了,但是这个注解如何工作呢?接着看。
131 |
132 | ## 第二步实现注解的业务逻辑
133 |
134 | 在第一步中我们发现定义的注解(@EnableRedisLock)中没有业务逻辑,只有一些变量,别忘了我们的注解是要使能Redis分布式锁的功能,那这个注解到底是怎么实现加锁和释放锁的功能呢?这个就需要我们借助反射的强大功能了。
135 | ```java
136 | @Aspect
137 | public class RedisLockAspect {
138 | @Around(value = "@annotation(com.smilelioncoder.EnableRedisLock)")
139 | public void handleRedisLock(ProceedingJoinPoint joinPoint)
140 | throws Throwable {
141 | // 通过反射获取到注解对象,可见反射非常重要的
142 | EnableRedisLock redisLock = ((MethodSignature) joinPoint.getSignature())
143 | .getMethod()
144 | .getAnnotation(EnableRedisLock.class);
145 |
146 | // 获取注解对象的变量值
147 | String lockKey = redisLock.lockKey();
148 | long expireTime = redisLock.expireTime();
149 | TimeUnit timeUnit = redisLock.timeUnit();
150 | int retryTimes = redisLock.retryTimes();
151 |
152 | // 获取锁
153 | if (tryLock(lockKey, expireTime, timeUnit, retryTimes)) {
154 | try {
155 | // 获取锁成功继续执行业务逻辑
156 | joinPoint.proceed();
157 | } finally {
158 | releseLock();
159 | }
160 | }
161 | }
162 | }
163 | ```
164 |
165 | 这里借助了切面的功能,将EnableRedisLock注解作为一个切点,只要方法上标注了这个注解就会自动执行这里的代码逻辑。
166 |
167 | 通过反射机制拿到注解对象后就可以执行加锁解锁的常用逻辑啦。Redis实现分布式锁相信大家已经很熟悉了,这里就不在啰嗦了。
168 |
169 | ## 第三步在业务代码中尽情的使用注解
170 |
171 | ```java
172 | @EnableRedisLock(lockKey = "student", expireTime = 10, timeUnit = TimeUnit.SECONDS, retryTimes = 5)
173 | public void method1(Student student) {
174 | // 这里写业务逻辑
175 | }
176 | ```
177 | 在需要加锁的方法上直接加上注解就可以啦,怎么样是不是很简单呀,赶紧在你的项目中运用起来吧。
178 | 好了,自己写一个注解的内容就介绍到这里了,学会了吗?
179 |
180 | # 公众号
181 | 公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
182 |
183 |
184 |
--------------------------------------------------------------------------------
/docs/java/java8/Java8函数式接口和Lambda表达式你真的会了吗.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321342&idx=1&sn=2d87b7fe6709a8513eb0abf58b48521d&chksm=8f09cfa4b87e46b29378661f72c832ec5bef782c362eba8cee25527a455c12239e067a80bed9&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 |
6 | - [1. Lambda表达式小试牛刀](#1-lambda表达式小试牛刀)
7 | - [2. Lambda高阶用法](#2-lambda高阶用法)
8 | - [(1)函数式接口](#1函数式接口)
9 | - [(2)函数式接口可以干什么?](#2函数式接口可以干什么)
10 | - [(3)函数描述符](#3函数描述符)
11 | - [(4)常用函数式接口](#4常用函数式接口)
12 | - [(5)将lambda表达式重构为方法引用](#5将lambda表达式重构为方法引用)
13 | - [公众号](#公众号)
14 |
15 |
16 |
17 | >Java8 由Oracle在2014年发布,是继Java5之后最具革命性的版本了。
18 | >Java8吸收其他语言的精髓带来了函数式编程,lambda表达式,Stream流等一系列新特性,学会了这些新特性,可以让你实现高效编码优雅编码。
19 | # 1. Lambda表达式小试牛刀
20 |
21 | Lambada表达式可以理解为:可传递的匿名函数的一种简洁表达方式。Lambda表达式没有名称,同普通方法一样有参数列表、函数主体、返回类型等;
22 |
23 | 下面简单看一个例子,new一个线程打印字符串,采用lambda表达式非常简洁:
24 |
25 | ```java
26 | new Thread(() -> System.out.println("hello java8 lambda")).start()
27 | ```
28 | 
29 |
30 | Thread类接受一个Runnable类型实例,查看Jdk源码发现Runnable接口是一个函数式接口,可以直接用lambda表达式替代。
31 |
32 | ```java
33 | @FunctionalInterface
34 | public interface Runnable {
35 | public abstract void run();
36 | }
37 | ```
38 | 
39 |
40 | Lambda表达式语法非常简单:
41 |
42 | ```java
43 | () -> System.out.println("hello java8 lambda")
44 | ```
45 | 
46 |
47 | * ()括号里面是参数列表,如果只有一个参数还可以写为: a -> System.out.println(a)
48 | * -> 箭头为固定写法;
49 | * System.out.println("hello java8 lambda") 为函数主体,如果有多条语句要用花括号包裹起来, 比如下面这样:
50 | ```java
51 | (a, b) -> {int sum = a + b; return sum;}
52 | ```
53 | 
54 |
55 | 综上,Lambda表达式模块可以固化为:
56 |
57 | ```java
58 | (parameter) -> {expression} 或者 (parameter) -> {statements; statements; }
59 | ```
60 | 
61 |
62 | 参数只有一个可以省略括号
63 |
64 | 如果不用Lambda表达式,使用匿名内部类的方式,写法就不是那么优雅了。
65 |
66 | ```java
67 | // before Java8
68 | new Thread(new Runnable() {
69 | @Override
70 | public void run() {
71 | System.out.println("hello java8 without lambda");
72 | }
73 | }).start();
74 | ```
75 | 
76 |
77 | # 2. Lambda高阶用法
78 |
79 | ## (1)函数式接口
80 |
81 | 函数式接口是只定义了一个抽象方法的接口。注意Java8中允许存在默认方法(default),哪怕有很多默认方法,只要有且仅有一个抽象方法,那么这个接口仍然是函数式接口。
82 |
83 | 函数式接口通常在类上有一个注解@FunctionalInterface,如:
84 |
85 | ```java
86 | @FunctionalInterface
87 | public interface Runnable {
88 | public abstract void run();
89 | }
90 | ```
91 | 
92 |
93 | ## (2)函数式接口可以干什么?
94 |
95 | 通常lambda表达式与函数式接口结合一起用,lambda表达式以内联的形式为函数式接口的抽象方法提供实现,把整个表达式作为函数式接口的实例。在没有lambda表达式之前,我们通常会使用匿名内部类的方式实现,详细对比见第一小节的实例代码。
96 |
97 | ## (3)函数描述符
98 |
99 | 函数式接口抽象方法的签名基本上就是lambda表达式的签名,我们可以将这种对应关系称为函数描述符。由一个函数式接口的抽象方法抽象为一个函数描述符,这个过程非常重要,知道了函数描述符去写lambda表达式也就非常容易了。举个例子:
100 |
101 | Runnable接口有一个抽象方法 void run(), 接受空参数返回void,那么函数描述符可以推导为: () -> void
102 |
103 | lambda表达式可以写为 () -> System.out.println("hello java8 lambda")
104 |
105 | ## (4)常用函数式接口
106 |
107 | java8 中常用函数式接口,针对基本类型java还定义了IntPredicate, LongPredicate等类型,详细可以参考jdk源码。
108 |
109 | |函数式接口|函数描述符|
110 | |:----|:----|
111 | |Predicate|T->boolean|
112 | |Consumer|T->void|
113 | |Function|T->R|
114 | |Supplier|() -> T|
115 | |UnaryOperator|T -> T|
116 | |BinaryOperator|(T,T)->T|
117 | |BiPredicate|(L,R)->boolean|
118 | |BiConsumer|(T,U)->void|
119 | |BiFunction|(T,U)->R|
120 |
121 | 至于 Predicate, Consumer, Function这些函数式接口具体作用,在后面的文章中笔者会详细介绍,这里只需有个大体印象即可。
122 |
123 | ## (5)将lambda表达式重构为方法引用
124 |
125 | 方法引用可以看作是lambda表达式的一种快捷写法,它可以调用特性的方法作为参数传递。你也可以将方法引用看作是lambda表达式的语法糖,让lambda表达式写起来更加简介。举个栗子,按学生年龄排序:
126 |
127 | ```java
128 | // before
129 | students.sort((s1, s2) -> s1.getAge.compareTo(s2.getAge()))));
130 | // after 使用方法引用
131 | students.sort(Comparator.comparing(Student::getAge()))));
132 | ```
133 | 
134 |
135 | 方法引用主要有三类:
136 |
137 | * **静态方法的方法引用**
138 |
139 | valueOf是String类的静态方法,方法引用写为 String::valueOf, 对应lambda表达式:a -> String.valueOf(a)
140 |
141 | * **任意类型实例方法的方法引用**
142 |
143 | length是String类的实例方法,方法引用写为 String::length,对应lambda表达式: (str) -> str.length()
144 |
145 | * **现有对象的实例方法的方法引用**
146 |
147 | 第三种容易与第二种混淆,现有对象指的是在lambda表达式中调用外部对象(不是入参对象)的实例方法,比如:
148 |
149 | String str = "hello java8";
150 |
151 | () -> str.length();
152 |
153 | 对应方法引用写为 str::length, 注意不是 String::length
154 |
155 | 最后我们将三类方法引用归纳如下:
156 |
157 | |lambda表达式|方法引用| |
158 | |:----|:----|:----|
159 | |(args) -> ClassName.staticMethod(args)|ClassName::staticMethod|静态方法方法引用|
160 | |(arg0, params) -> arg0.instanceMethod(params)|ClassName::instanceMethod|内部实例方法引用|
161 | |arg0
(params) -> arg0.instanceMethod(params)|arg0.instanceMethod|外部实例方法引用|
162 |
163 |
--------------------------------------------------------------------------------
/docs/java/java8/使用Java8 Optional类优雅解决空指针问题.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321295&idx=1&sn=2fdb1d4c7e44177a7b08393114e55f16&chksm=8f09cf95b87e4683e521502b33319f957a038b5ecc095171de9d287b337411f2ffb2bf1e01d5&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [1. 不受待见的空指针异常](#1-不受待见的空指针异常)
6 | - [2. 糟糕的代码](#2-糟糕的代码)
7 | - [3. 解决空指针的"银弹"](#3-解决空指针的银弹)
8 | - [4. Optional使用入门](#4-optional使用入门)
9 | - [5. 使用Optional重构代码](#5-使用optional重构代码)
10 | - [总结](#总结)
11 | - [公众号](#公众号)
12 |
13 |
14 |
15 | >Java8 由Oracle在2014年发布,是继Java5之后最具革命性的版本。
16 | >Java8吸收其他语言的精髓带来了函数式编程,lambda表达式,Stream流等一系列新特性,学会了这些新特性,可以让你实现高效编码优雅编码。
17 | # 1. 不受待见的空指针异常
18 |
19 | 有个小故事:null引用最早是由英国科学家Tony Hoare提出的,多年后Hoare为自己的这个想法感到后悔莫及,并认为这是"价值百万的重大失误"。可见空指针是多么不受待见。
20 |
21 | NullPointerException是Java开发中最常遇见的异常,遇到这种异常我们通常的解决方法是在调用的地方加一个if判空。
22 |
23 | if判空越多会造成过多的代码分支,后续代码维护也就越来越复杂。
24 |
25 | # 2. 糟糕的代码
26 |
27 | 比如看下面这个例子,使用过多的if判空。
28 |
29 | Person对象里定义了House对象,House对象里定义了Address对象:
30 |
31 | ```java
32 | public class Person {
33 | private String name;
34 | private int age;
35 | private House house;
36 | public House getHouse() {
37 | return house;
38 | }
39 | }
40 | class House {
41 | private long price;
42 | private Address address;
43 | public Address getAddress() {
44 | return address;
45 | }
46 | }
47 | class Address {
48 | private String country;
49 | private String city;
50 | public String getCity() {
51 | return city;
52 | }
53 | }
54 | ```
55 | 现在获取这个人买房的城市,那么通常会这样写:
56 | ```java
57 | public String getCity() {
58 | String city = new Person().getHouse().getAddress().getCity();
59 | return city;
60 | }
61 | ```
62 | 但是这样写容易出现空指针的问题,比如这个人没有房,House对象为null。接着你会改造这段代码,加上很多判断条件:
63 | ```java
64 | public String getCity2(Person person) {
65 | if (person != null) {
66 | House house = person.getHouse();
67 | if (house != null) {
68 | Address address = house.getAddress();
69 | if (address != null) {
70 | String city = address.getCity();
71 | return city;
72 | }
73 | }
74 | }
75 | return "unknown";
76 | }
77 | ```
78 | 为了避免空指针异常,每一层都加上判断,但是这样会造成代码嵌套太深,不易维护。
79 | 你可能想到如何改造上面的代码,比如加上提前判空退出:
80 |
81 | ```java
82 | public String getCity3(Person person) {
83 | String city = "unknown";
84 | if (person == null) {
85 | return city;
86 | }
87 | House house = person.getHouse();
88 | if (house == null) {
89 | return city;
90 | }
91 | Address address = house.getAddress();
92 | if (address == null) {
93 | return city;
94 | }
95 | return address.getCity();
96 | }
97 | ```
98 | 但是这样简单的代码已经加入了三个退出条件,非常不利于后面代码维护。那怎样才能将代码写的优雅一点呢,下面引入今天的主角"Optional"。
99 | # 3. 解决空指针的"银弹"
100 |
101 | 从Java8开始引入了一个新类 java.util.Optional,这是一个对象的容器,意味着可能包含或者没有包含一个非空的值。下面重点看一下Optional的常用方法:
102 |
103 | ```java
104 | public final class Optional {
105 | // 通过指定非空值创建Optional对象
106 | // 如果指定的值为null,会抛空指针异常
107 | public static Optional of(T value) {
108 | return new Optional<>(value);
109 | }
110 | // 通过指定可能为空的值创建Optional对象
111 | public static Optional ofNullable(T value) {
112 | return value == null ? empty() : of(value);
113 | }
114 | // 返回值,不存在抛异常
115 | public T get() {
116 | if (value == null) {
117 | throw new NoSuchElementException("No value present");
118 | }
119 | return value;
120 | }
121 | // 如果值存在,根据consumer实现类消费该值
122 | public void ifPresent(Consumer consumer) {
123 | if (value != null)
124 | consumer.accept(value);
125 | }
126 | // 如果值存在则返回,如果值为空则返回指定的默认值
127 | public T orElse(T other) {
128 | return value != null ? value : other;
129 | }
130 | // map flatmap等方法与Stream使用方法类似,这里不再赘述,读者可以参考之前的Stream系列。
131 | }
132 | ```
133 | 以上就是Optional类常用的方法,使用起来非常简单。
134 | # 4. Optional使用入门
135 |
136 | **(1)创建Optional实例**
137 |
138 | * 创建空的Optional对象。可以通过静态工厂方法Optional.Empty() 创建一个空的对象,例如:
139 | ```java
140 | Optional optionalPerson = Optional.Empty();
141 | ```
142 | * 指定非空值创建Optional对象。
143 | ```java
144 | Person person = new Person();
145 | Optional optionalPerson = Optional.of(person);
146 | ```
147 | * 指定可能为空的值创建Optional对象。
148 | ```java
149 | Person person = null; // 可能为空
150 | Optional optionalPerson = Optional.of(person);
151 | ```
152 | **(2)常用方法**
153 | **ifPresent**
154 |
155 | 如果值存在,则调用consumer实例消费该值,否则什么都不执行。举个栗子:
156 |
157 | ```java
158 | String str = "hello java8";
159 | // output: hello java8
160 | Optional.ofNullable(str).ifPresent(System.out::println);
161 | String str2 = null;
162 | // output: nothing
163 | Optional.ofNullable(str2).ifPresent(System.out::println);
164 | ```
165 | **filter, map, flatMap**
166 | 在三个方法在前面讲Stream的时候已经详细讲解过,读者可以翻看之前写的文章,这里不再赘述。
167 |
168 | **orElse**
169 |
170 | 如果value为空,则返回默认值,举个栗子:
171 |
172 | ```java
173 | public void test(String city) {
174 | String defaultCity = Optional.ofNullable(city).orElse("unknown");
175 | }
176 | ```
177 | **orElseGet**
178 | 如果value为空,则调用Supplier实例返回一个默认值。举个例子:
179 |
180 | ```java
181 | public void test2(String city) {
182 | // 如果city为空,则调用generateDefaultCity方法
183 | String defaultCity = Optional.of(city).orElseGet(this::generateDefaultCity);
184 | }
185 | private String generateDefaultCity() {
186 | return "beijing";
187 | }
188 | ```
189 | **orElseThrow**
190 | 如果value为空,则抛出自定义异常。举个栗子:
191 |
192 | ```java
193 | public void test3(String city) {
194 | // 如果city为空,则抛出空指针异常。
195 | String defaultCity = Optional.of(city).orElseThrow(NullPointerException::new);
196 | }
197 | ```
198 | # 5. 使用Optional重构代码
199 |
200 | **再看一遍重构之前的代码,使用了三个if使代码嵌套层次变得很深。**
201 |
202 | ```java
203 | // before refactor
204 | public String getCity2(Person person) {
205 | if (person != null) {
206 | House house = person.getHouse();
207 | if (house != null) {
208 | Address address = house.getAddress();
209 | if (address != null) {
210 | String city = address.getCity();
211 | return city;
212 | }
213 | }
214 | }
215 | return "unknown";
216 | }
217 | ```
218 | **使用Optional重构**
219 | ```java
220 | public String getCityUsingOptional(Person person) {
221 | String city = Optional.ofNullable(person)
222 | .map(Person::getHouse)
223 | .map(House::getAddress)
224 | .map(Address::getCity).orElse("Unknown city");
225 | return city;
226 | }
227 | ```
228 | 只使用了一行代码就获取到city值,不用再去不断的判断是否为空,这样写代码是不是很优雅呀。
229 | # 总结
230 | 使用optional类可以很优雅的解决项目中空指针的问题,但是optional也不是万能的哦,小伙伴们要适度使用。赶紧用Optional重构之前写的项目吧~**
231 |
--------------------------------------------------------------------------------
/docs/java/java8/包学会,教你用Java函数式编程重构烂代码.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321467&idx=1&sn=62376145a601f4470532ccb62deaddf3&chksm=8f09cc21b87e4537a7961f8eaf751f2b4282d02f784e10cbd6b69ef01346ca23f48ff3dc260e&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [烂代码登场](#烂代码登场)
6 | - [开始重构烂代码](#开始重构烂代码)
7 | - [**第一步:定义函数式接口**](#第一步:定义函数式接口)
8 | - [**第二步:定义模板方法**](#第二步:定义模板方法)
9 | - [**第三步:传递lambda表达式**](#第三步:传递lambda表达式)
10 | - [总结](#总结)
11 | - [公众号](#公众号)
12 |
13 |
14 |
15 |
16 |
17 | >Java8 由Oracle在2014年发布,是继Java5之后最具革命性的版本。
18 | >Java8吸收其他语言的精髓带来了函数式编程,lambda表达式,Stream流等一系列新特性,学会了这些新特性,可以让你实现高效编码优雅编码。
19 | # 烂代码登场
20 |
21 | 首先引入一个实际的例子,我们常常会写一个dao类来操作数据库,比如查询记录,插入记录等。
22 |
23 | 下面的代码中实现了查询和插入功能(引入Mybatis三方件):
24 |
25 | ```java
26 | public class StudentDao {
27 | /**
28 | * 根据学生id查询记录
29 | * @param id 学生id
30 | * @return 返回学生对象
31 | */
32 | public Student queryOne(int id) {
33 | SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
34 | SqlSession session = null;
35 | try {
36 | session = sqlSessionFactory.openSession();
37 | // 根据id查询指定的student对象
38 | return session.selectOne("com.coderspace.mapper.student.queryOne", id);
39 | } finally {
40 | if (session != null) {
41 | session.close();
42 | }
43 | }
44 | }
45 | /**
46 | * 插入一条学生记录
47 | * @param student 待插入对象
48 | * @return true if success, else return false
49 | */
50 | public boolean insert(Student student) {
51 | SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
52 | SqlSession session = null;
53 | try {
54 | session = sqlSessionFactory.openSession();
55 | // 向数据库插入student对象
56 | int rows = session.insert("com.coderspace.mapper.student.insert", student);
57 | return rows > 0;
58 | } finally {
59 | if (session != null) {
60 | session.close();
61 | }
62 | }
63 | }
64 | }
65 | ```
66 | 
67 |
68 | 睁大眼睛观察上面的代码可以发现,这两个方法有很多重复的代码。
69 |
70 | 除了下面这两行,其他的代码都是一样的,都是先获取session,然后执行核心操作,最后关闭session。
71 |
72 | ```java
73 | // 方法1中核心代码
74 | return session.selectOne("com.coderspace.mapper.student.queryOne", id);
75 | ```
76 | ```java
77 | // 方法2中核心代码
78 | int rows = session.insert("com.coderspace.mapper.student.insert", student);
79 | ```
80 | 作为一个有追求的程序员,不,应该叫代码艺术家,是不是应该考虑重构一下。
81 |
82 | 获取session和关闭session这段代码围绕着具体的核心操作代码,我们可以称这段代码为模板代码。
83 |
84 | 假如又来了一个需求,需要实现删除student方法,那么你肯定会copy上面的获取session和关闭session代码,这样做有太多重复的代码,作为一名优秀的工程师肯定不会容忍这种事情的发生。
85 |
86 | # 开始重构烂代码
87 |
88 | 怎么重构呢?现在请出我们的主角登场:**环绕执行模式使行为参数化**。
89 |
90 | 名字是不是很高大上,啥叫行为参数化?上面例子中我们已经观察到了,除了核心操作代码其他代码都是一模一样,那我们是不是可以**将核心操作代码作为入参传入模板方法中**,根据不同的行为分别执行。
91 |
92 | 变量对象很容易作为参数传入,行为可以作为参数传入吗?
93 |
94 | 答案是:当然可以,可以采用lambda表达式传入。
95 |
96 | 下面开始重构之前的例子,主要可以分为三步:
97 |
98 | (1)定义函数式接口;
99 |
100 | (2)定义模板方法;
101 |
102 | (3)传递lambda表达式
103 |
104 | 所有的环绕执行模式都可以套用上面这三步公式。
105 |
106 | ## **第一步:定义函数式接口**
107 |
108 | ```java
109 | @FunctionalInterface
110 | public interface DbOperation {
111 | /**
112 | * 通用操作数据库接口
113 | * @param session 数据库连接session
114 | * @param mapperId 关联mapper文件id操作
115 | * @param params 操作参数
116 | * @return 返回值,R泛型
117 | */
118 | R operate(SqlSession session, String mapperId, Object params);
119 | }
120 | ```
121 | 
122 |
123 | 定义了一个operate抽象方法,接收三个参数,返回泛型R。
124 |
125 | ## **第二步:定义模板方法**
126 |
127 | DbOperation是一个函数式接口,作为入参传入:
128 |
129 | ```java
130 | public class CommonDao {
131 |
132 | public R proccess(DbOperation dbOperation, String mappperId, Object params) {
133 | SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
134 | SqlSession session = null;
135 | try {
136 | session = sqlSessionFactory.openSession();
137 | // 核心操作
138 | return dbOperation.operate(session, mappperId, params);
139 | } finally {
140 | if (session != null) {
141 | session.close();
142 | }
143 | }
144 | }
145 | }
146 | ```
147 | 
148 |
149 | ## **第三步:传递lambda表达式**
150 |
151 | ```java
152 | // 根据id查询学生
153 | String mapperId = "com.coderspace.mapper.student.queryOne";
154 | int studentNo = 123;
155 | CommonDao commonDao = new CommonDao<>();
156 | // 使用lambda传递具体的行为
157 | Student studentObj = commonDao.proccess(
158 | (session, mappperId, params) -> session.selectOne(mappperId, params),
159 | mapperId, studentNo);
160 | // 插入学生记录
161 | String mapperId2 = "com.coderspace.mapper.student.insert";
162 | Student student = new Student("coderspace", 1, 100);
163 | CommonDao commonDao2 = new CommonDao<>();
164 | // 使用lambda传递具体的行为
165 | Boolean successInsert = commonDao2.proccess(
166 | (session, mappperId, params) -> session.selectOne(mappperId, params),
167 | mapperId2, student);
168 | ```
169 | 
170 |
171 | 实现了上面三步,假如要实现删除方法,CommonDao里面一行代码都不用改,只用在调用方传入不同的参数即可实现。
172 |
173 | # 总结
174 |
175 | 环绕执行模式在项目实战中大有用途,如果你发现几行易变的代码外面围绕着一堆固定的代码,这个时候你应该考虑使用lambda环绕执行模式了。
176 |
177 | 环绕执行模式固有套路请跟我一起大声读三遍:
178 |
179 | 第一步:定义函数式接口
180 |
181 | 第二步:定义模板方法
182 |
183 | 第三步:传递lambda表达式
184 |
185 | 絮叨:
186 |
187 | 是不是太太太方便了,要是被经理看到了肯定又要给涨薪,NO,拒绝!
188 |
189 |
190 | # 公众号
191 | 公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
192 |
193 |
--------------------------------------------------------------------------------
/docs/java/java8/请避开Stream流式编程常见的坑.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321100&idx=1&sn=d566cdd805d14e121dfef498d30f2b20&chksm=8f09ced6b87e47c013288565f930a83a493cad48d545024ec842c17cda3d82939c5c29307287&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [1. Stream是什么?](#1-stream是什么)
6 | - [2. Stream的特点](#2-stream的特点)
7 | - [3. 创建Stream实例的方法](#3-创建stream实例的方法)
8 | - [4. Stream常用操作](#4-stream常用操作)
9 | - [5. 实战:使用Stream重构老代码](#5-实战:使用stream重构老代码)
10 | - [6. 使用Stream常见的误区](#6-使用stream常见的误区)
11 | - [公众号](#公众号)
12 |
13 |
14 |
15 | >Java8 由Oracle在2014年发布,是继Java5之后最具革命性的版本了。
16 | >Java8吸收其他语言的精髓带来了函数式编程,lambda表达式,Stream流等一系列新特性,学会了这些新特性,可以让你实现高效编码优雅编码。
17 |
18 | # 1. Stream是什么?
19 |
20 | Stream是Java8新增的一个接口,允许以声明性方式处理数据集合。Stream不是一个集合类型不保存数据,可以把它看作是遍历数据集合的高级迭代器(Iterator)。
21 |
22 | Stream操作可以像Builder一样逐步叠加,形成一条流水线。流水线一般由数据源+零或者多个中间操作+一个终端操作所构成。中间操作可以将流转换成另外一个流,比如使用filter过滤元素,使用map映射提取值。
23 |
24 | Stream与lambda表达式密不可分,本文默认你已经掌握了lambda基础知识。
25 |
26 | # 2. Stream的特点
27 |
28 | * 只能遍历(消费)一次。Stream实例只能遍历一次,终端操作后一次遍历就结束,再次遍历需要重新生成实例,这一点类似于Iterator迭代器。
29 | * 保护数据源。对Stream中任何元素的修改都不会导致数据源被修改,比如过滤删除流中的一个元素,再次遍历该数据源依然可以获取该元素。
30 | * 懒。filter, map 操作串联起来形成一系列中间运算,如果没有一个终端操作(如collect)这些中间运算永远也不会被执行。
31 | # 3. 创建Stream实例的方法
32 |
33 | (1)使用指定值创建Stream实例
34 |
35 | ```java
36 | // of为Stream的静态方法
37 | Stream strStream = Stream.of("hello", "java8", "stream");
38 | // 或者使用基本类型流
39 | IntStream intStream = IntStream.of(1, 2, 3);
40 | ```
41 | (2)使用集合创建Stream实例(常用方式)
42 |
43 | ```java
44 | // 使用guava库,初始化一个不可变的list对象
45 | ImmutableList integers = ImmutableList.of(1, 2, 3);
46 | // List接口继承Collection接口,java8在Collection接口中添加了stream方法
47 | Stream stream = integers.stream();
48 | ```
49 | (3)使用数组创建Stream实例
50 |
51 | ```java
52 | // 初始化一个数组
53 | Integer[] array = {1, 2, 3};
54 | // 使用Arrays的静态方法stream
55 | Stream stream = Arrays.stream(array);
56 | ```
57 | (4)使用生成器创建Stream实例
58 |
59 | ```java
60 | // 随机生成100个整数
61 | Random random = new Random();
62 | // 加上limit否则就是无限流了
63 | Stream stream = Stream.generate(random::nextInt).limit(100);
64 | ```
65 | (5)使用迭代器创建Stream实例
66 |
67 | ```java
68 | // 生成100个奇数,加上limit否则就是无限流了
69 | Stream stream = Stream.iterate(1, n -> n + 2).limit(100);
70 | stream.forEach(System.out::println);
71 | ```
72 | (6)使用IO接口创建Stream实例
73 |
74 | ```java
75 | // 获取指定路径下文件信息,list方法返回Stream类型
76 | Stream pathStream = Files.list(Paths.get("/"));
77 | ```
78 | # 4. Stream常用操作
79 |
80 | Stream接口中定义了很多操作,大致可以分为两大类,一类是中间操作,另一类是终端操作;
81 |
82 | 
83 |
84 |
85 | **(1)中间操作**
86 |
87 | 中间操作会返回另外一个流,多个中间操作可以连接起来形成一个查询。
88 |
89 | 中间操作有惰性,如果流上没有一个终端操作,那么中间操作是不会做任何处理的。
90 |
91 | 下面介绍常用的中间操作:
92 |
93 | **map操作**
94 |
95 | map是将输入流中每一个元素映射为另一个元素形成输出流。
96 |
97 | ```java
98 | // 初始化一个不可变字符串
99 | List words = ImmutableList.of("hello", "java8", "stream");
100 | // 计算列表中每个单词的长度
101 | List list = words.stream()
102 | .map(String::length)
103 | .collect(Collectors.toList());
104 | // output: 5 5 6
105 | list.forEach(System.out::println);
106 | ```
107 | **flatMap操作**
108 |
109 | ```java
110 | List list1 = words.stream()
111 | .map(word -> word.split("-"))
112 | .collect(Collectors.toList());
113 |
114 | // output: [Ljava.lang.String;@59f95c5d,
115 | // [Ljava.lang.String;@5ccd43c2
116 | list1.forEach(System.out::println);
117 | ```
118 | 纳里?你预期是List, 返回却是List, 这是因为split方法返回的是String[]
119 |
120 | 这个时候你可以想到要将数组转成stream, 于是有了第二个版本
121 |
122 | ```java
123 | Stream> arrStream = words.stream()
124 | .map(word -> word.split("-"))
125 | .map(Arrays::stream);
126 |
127 | // output: java.util.stream.ReferencePipeline$Head@2c13da15,
128 | // java.util.stream.ReferencePipeline$Head@77556fd
129 | arrStream.forEach(System.out::println);
130 | ```
131 | 还是不对,这个问题使用flatMap扁平流可以解决,flatMap将流中每个元素取出来转成另外一个输出流
132 |
133 | ```java
134 | Stream strStream = words.stream()
135 | .map(word -> word.split("-"))
136 | .flatMap(Arrays::stream)
137 | .distinct();
138 | // output: hello java8 stream
139 | strStream.forEach(System.out::println);
140 | ```
141 | **filter操作**
142 |
143 | filter接收Predicate对象,按条件过滤,符合条件的元素生成另外一个流。
144 |
145 | ```java
146 | // 过滤出单词长度大于5的单词,并打印出来
147 | List words = ImmutableList.of("hello", "java8", "hello", "stream");
148 | words.stream()
149 | .filter(word -> word.length() > 5)
150 | .collect(Collectors.toList())
151 | .forEach(System.out::println);
152 | // output: stream
153 | ```
154 |
155 | **(2)终端操作**
156 |
157 | 终端操作将stream流转成具体的返回值,比如List,Integer等。常见的终端操作有:foreach, min, max, count等。
158 |
159 | foreach很常见了,下面举一个max的例子。
160 |
161 | ```java
162 | // 找出最大的值
163 | List integers = Arrays.asList(6, 20, 19);
164 | integers.stream()
165 | .max(Integer::compareTo)
166 | .ifPresent(System.out::println);
167 | // output: 20
168 | ```
169 | # 5. 实战:使用Stream重构老代码
170 |
171 | 假如有一个需求:过滤出年龄大于20岁并且分数大于95的学生。
172 |
173 | 使用for循环写法:
174 |
175 | ```java
176 | private List getStudents() {
177 | Student s1 = new Student("xiaoli", 18, 95);
178 | Student s2 = new Student("xiaoming", 21, 100);
179 | Student s3 = new Student("xiaohua", 19, 98);
180 | List studentList = Lists.newArrayList();
181 | studentList.add(s1);
182 | studentList.add(s2);
183 | studentList.add(s3);
184 | return studentList;
185 | }
186 | public void refactorBefore() {
187 | List studentList = getStudents();
188 | // 使用临时list
189 | List resultList = Lists.newArrayList();
190 | for (Student s : studentList) {
191 | if (s.getAge() > 20 && s.getScore() > 95) {
192 | resultList.add(s);
193 | }
194 | }
195 | // output: Student{name=xiaoming, age=21, score=100}
196 | resultList.forEach(System.out::println);
197 | }
198 | ```
199 | 使用for循环会初始化一个临时list用来存放最终的结果,整体看起来不够优雅和简洁。
200 |
201 | 使用lambda和stream重构后:
202 |
203 | ```java
204 | public void refactorAfter() {
205 | List studentLists = getStudents();
206 | // output: Student{name=xiaoming, age=21, score=100}
207 | studentLists.stream().filter(this::filterStudents).forEach(System.out::println);
208 | }
209 | private boolean filterStudents(Student student) {
210 | // 过滤出年龄大于20岁并且分数大于95的学生
211 | return student.getAge() > 20 && student.getScore() > 95;
212 | }
213 | ```
214 | 使用filter和方法引用使代码清晰明了,也不用声明一个临时list,非常方便。
215 |
216 | # 6. 使用Stream常见的误区
217 |
218 | (1)误区一:重复消费stream对象
219 |
220 | stream对象一旦被消费,不能再次重复消费。
221 |
222 | ```java
223 | List strings = Arrays.asList("hello", "java8", "stream");
224 | Stream stream = strings.stream();
225 | stream.forEach(System.out::println); // ok
226 | stream.forEach(System.out::println); // IllegalStateException
227 | ```
228 | 上述代码执行后报错:
229 |
230 | java.lang.IllegalStateException: stream has already been operated upon or closed
231 |
232 | (2)误区二:修改数据源
233 |
234 | 在流操作的过程中尝试添加新的string对象,结果报错:
235 |
236 | ```java
237 | List strings = Arrays.asList("hello", "java8", "stream");
238 | // expect: HELLO JAVA8 STREAM WORLD, but throw UnsupportedOperationException
239 | strings.stream()
240 | .map(s -> {
241 | strings.add("world");
242 | return s.toUpperCase();
243 | }).forEach(System.out::println);
244 | ```
245 | 注意:一定不要在操作流的过程中修改数据源。
246 |
247 | # 总结
248 | java8 流式编程在一定程度上可以使代码变得优美,不过也要避开常见的坑,如:不要重复消费对象、不要修改数据源。
249 |
--------------------------------------------------------------------------------
/docs/java/juc/倒计时计数CountDownLatch.md:
--------------------------------------------------------------------------------
1 | 在日常编码中,Java 并发编程可是少不了,试试下面这些并发编程工具类:
2 |
3 | 
4 |
5 |
6 |
7 | 今天先带领大家一起重温学习 CountDownLatch 这个牛叉的工具类。
8 |
9 | # 认识 CountDownLatch
10 |
11 | `CountDownLatch`是一个同步工具类,用来协调多个线程之间的同步,或者说起到线程之间通信的作用(非互斥)。
12 |
13 |
14 |
15 | CountDownLatch 能够使一个线程在等待另外一些线程完成各自工作之后,再继续执行。使用一个计数器进行实现。计数器初始值为线程的数量。当每一个线程完成自己任务后,计数器的值就会减一。当计数器的值为0时,表示所有的线程都已经完成一些任务,然后在CountDownLatch上等待的线程就可以恢复执行接下来的任务。
16 |
17 |
18 |
19 | 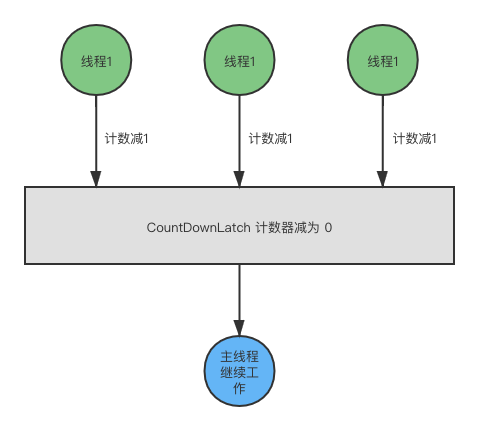
20 |
21 |
22 |
23 | # CountDownLatch 的使用
24 |
25 | CountDownLatch类使用起来非常简单。
26 |
27 | Class 位于:`java.util.concurrent.CountDownLatch`
28 |
29 |
30 |
31 | 下面简单介绍它的构造方法和常用方法。
32 |
33 | ## 构造方法
34 |
35 | CountDownLatch只提供了一个构造方法:
36 |
37 | ```java
38 | // count 为初始计数值
39 | public CountDownLatch(int count) {
40 | // ……
41 | }
42 | ```
43 |
44 | ## 常用方法
45 |
46 | ```java
47 | //常用方法1:调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行
48 | public void await() throws InterruptedException {
49 | // ……
50 | }
51 |
52 | // 常用方法2:和await()类似,只不过等待超时后count值还没变为0的话就会继续执行
53 | public boolean await(long timeout, TimeUnit unit) throws InterruptedException {
54 | // ……
55 | }
56 |
57 | // 常用方法3:将count值减1
58 | public void countDown() {
59 | // ……
60 | }
61 | ```
62 |
63 |
64 |
65 | # CountDownLatch 的应用场景
66 |
67 | 我们考虑一个场景:用户购买一个商品下单成功后,我们会给用户发送各种消息提示用户『购买成功』,比如发送邮件、微信消息、短信等。所有的消息都发送成功后,我们在后台记录一条消息表示成功。
68 |
69 |
70 |
71 | 当然我们可以使用单线程去完成,逐个完成每个操作,如下图所示:
72 |
73 | 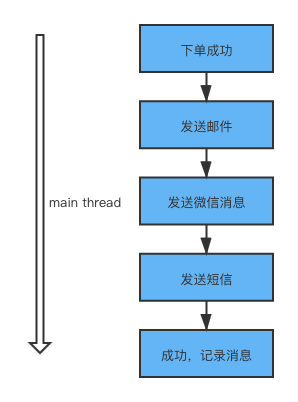
74 |
75 | 但是这样效率就会非常低。如何解决单线程效率低的问题?当然是通过多线程啦。
76 |
77 | 使用多线程也会遇到一个问题,子线程消息还没发送完,主线程可能就已经打出『所有的消息都已经发送完毕啦』,这在逻辑上肯定是不对的。我们期望所有子线程发完消息主线程才会打印消息,怎么实现呢?CountDownLatch就可以解决这一类问题。
78 |
79 | 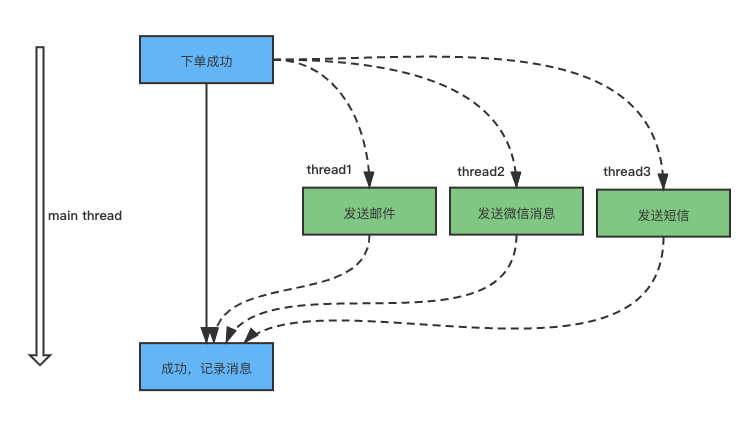
80 |
81 |
82 |
83 | 我们使用代码实现上面的需求。
84 |
85 | ```java
86 | import java.util.concurrent.*;
87 |
88 | public class OrderServiceDemo {
89 |
90 | public static void main(String[] args) throws InterruptedException {
91 | System.out.println("main thread: Success to place an order");
92 |
93 | int count = 3;
94 | CountDownLatch countDownLatch = new CountDownLatch(count);
95 |
96 | Executor executor = Executors.newFixedThreadPool(count);
97 | executor.execute(new MessageTask("email", countDownLatch));
98 | executor.execute(new MessageTask("wechat", countDownLatch));
99 | executor.execute(new MessageTask("sms", countDownLatch));
100 |
101 | // 主线程阻塞,等待所有子线程发完消息
102 | countDownLatch.await();
103 | // 所有子线程已经发完消息,计数器为0,主线程恢复
104 | System.out.println("main thread: all message has been sent");
105 | }
106 |
107 | static class MessageTask implements Runnable {
108 | private String messageName;
109 | private CountDownLatch countDownLatch;
110 |
111 | public MessageTask(String messageName, CountDownLatch countDownLatch) {
112 | this.messageName = messageName;
113 | this.countDownLatch = countDownLatch;
114 | }
115 |
116 | @Override
117 | public void run() {
118 | try {
119 | // 线程发送消息
120 | System.out.println("Send " + messageName);
121 | try {
122 | TimeUnit.SECONDS.sleep(1);
123 | } catch (InterruptedException e) {
124 | e.printStackTrace();
125 | }
126 | } finally {
127 | // 发完消息计数器减 1
128 | countDownLatch.countDown();
129 | }
130 | }
131 | }
132 | }
133 | ```
134 |
135 | 程序运行结果:
136 |
137 | ```text
138 | main thread: Success to place an order
139 | Send email
140 | Send wechat
141 | Send sms
142 | main thread: all message has been sent
143 | ```
144 |
145 | 从运行结果可以看到主线程是在所有的子线程发送完消息后才打印,这符合我们的预期。
146 |
147 | # CountDownLatch 的限制
148 |
149 | CountDownLatch是一次性的,计算器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当CountDownLatch使用完毕后,它不能再次被使用。
--------------------------------------------------------------------------------
/docs/java/juc/内存泄露的原因找到了,罪魁祸首居然是Java TheadLocal.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321684&idx=1&sn=c3f63443f7e6fb4f373a30699f51e55f&chksm=8f09cd0eb87e44185016b022fdf24e735684e91e5d1ae390b861098c18e3fb26925053b2fd50&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [ThreadLocal的value值存在哪里?](#threadlocal的value值存在哪里)
6 | - [ThreadLocal类set方法](#threadlocal类set方法)
7 | - [ThreadLocal类get方法](#threadlocal类get方法)
8 | - [ThreadLocal相关类的关系总结](#threadlocal相关类的关系总结)
9 | - [ThreadLocal内存模型原理](#threadlocal内存模型原理)
10 | - [强引用弱引用的概念](#强引用弱引用的概念)
11 | - [强引用](#强引用)
12 | - [弱引用](#弱引用)
13 | - [软引用](#软引用)
14 | - [虚引用](#虚引用)
15 | - [内存泄露是不是弱引用的锅?](#内存泄露是不是弱引用的锅)
16 | - [ThreadLocal最佳实践](#threadlocal最佳实践)
17 |
18 |
19 |
20 | 组内来了一个实习生,看这小伙子春光满面、精神抖擞、头发微少,我心头一喜:绝对是个潜力股。于是我找经理申请亲自来带他,为了帮助小伙子快速成长,我给他分了一个需求,这不需求刚上线几天就出网上问题了😭后台监控服务发现内存一直在缓慢上升,初步怀疑是内存泄露。
21 |
22 | 把实习生的PR都找出来仔细review,果然发现问题了。由于公司内部代码是保密的,这里简单写一个demo还原场景(忽略代码风格问题)。
23 |
24 | ```java
25 | public class ThreadPoolDemo {
26 | private static final ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(5, 5, 1, TimeUnit.MINUTES, new LinkedBlockingQueue<>());
27 | public static void main(String[] args) throws InterruptedException {
28 | for (int i = 0; i < 100; ++i) {
29 | poolExecutor.execute(new Runnable() {
30 | @Override
31 | public void run() {
32 | ThreadLocal threadLocal = new ThreadLocal<>();
33 | threadLocal.set(new BigObject());
34 | // 其他业务代码
35 | }
36 | });
37 | Thread.sleep(1000);
38 | }
39 | }
40 | static class BigObject {
41 | // 100M
42 | private byte[] bytes = new byte[100 * 1024 * 1024];
43 | }
44 | }
45 | ```
46 | 代码分析:
47 | * 创建一个核心线程数和最大线程数都为10的线程池,保证线程池里一直会有10个线程在运行。
48 | * 使用for循环向线程池中提交了100个任务。
49 | * 定义了一个ThreadLocal类型的变量,Value类型是大对象。
50 | * 每个任务会向threadLocal变量里塞一个大对象,然后执行其他业务逻辑。
51 | * 由于没有调用线程池的shutdown方法,线程池里的线程还是会在运行。
52 |
53 | 乍一看这代码好像没有什么问题,那为什么会导致服务GC后内存还高居不下呢?
54 |
55 | 代码中给threadLocal赋值了一个大的对象,但是执行完业务逻辑后没有调用remove方法,最后导致线程池中10个线程的threadLocals变量中包含的大对象没有被释放掉,出现了内存泄露。
56 |
57 | 大家说说这样的实习生还能留不?
58 |
59 | # ThreadLocal的value值存在哪里?
60 |
61 | 实习生说他以为线程任务结束了threadLocal赋值的对象会被JVM垃圾回收,很疑惑为什么会出现内存泄露。作为师傅我肯定要给他把原理讲透呀。
62 |
63 | ThreadLocal类提供set/get方法存储和获取value值,但实际上ThreadLocal类并不存储value值,真正存储是靠ThreadLocalMap这个类,ThreadLocalMap是ThreadLocal的一个静态内部类,它的key是ThreadLocal实例对象,value是任意Object对象。
64 |
65 | ThreadLocalMap类的定义
66 |
67 | ```java
68 | static class ThreadLocalMap {
69 | // 定义一个table数组,存储多个threadLocal对象及其value值
70 | private Entry[] table;
71 | ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
72 | table = new Entry[INITIAL_CAPACITY];
73 | int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
74 | table[i] = new Entry(firstKey, firstValue);
75 | size = 1;
76 | setThreshold(INITIAL_CAPACITY);
77 | }
78 | // 定义一个Entry类,key是一个弱引用的ThreadLocal对象
79 | // value是任意对象
80 | static class Entry extends WeakReference> {
81 | /** The value associated with this ThreadLocal. */
82 | Object value;
83 | Entry(ThreadLocal k, Object v) {
84 | super(k);
85 | value = v;
86 | }
87 | }
88 | // 省略其他
89 | }
90 | ```
91 | 进一步分析ThreadLocal类的代码,看set和get方法如何与ThreadLocalMap静态内部类关联上。
92 |
93 | ## ThreadLocal类set方法
94 |
95 | ```java
96 | public class ThreadLocal {
97 | public void set(T value) {
98 | Thread t = Thread.currentThread();
99 | ThreadLocalMap map = getMap(t);
100 | if (map != null)
101 | map.set(this, value);
102 | else
103 | createMap(t, value);
104 | }
105 |
106 | ThreadLocalMap getMap(Thread t) {
107 | return t.threadLocals;
108 | }
109 |
110 | void createMap(Thread t, T firstValue) {
111 | t.threadLocals = new ThreadLocalMap(this, firstValue);
112 | }
113 | // 省略其他方法
114 | }
115 | ```
116 | set的逻辑比较简单,就是获取当前线程的ThreadLocalMap,然后往map里添加KV,K是当前ThreadLocal实例,V是我们传入的value。
117 | 这里需要注意一下,map的获取是需要从Thread类对象里面取,看一下Thread类的定义。
118 |
119 | ```java
120 | public class Thread implements Runnable {
121 | ThreadLocal.ThreadLocalMap threadLocals = null;
122 | //省略其他
123 | }
124 | ```
125 | Thread类维护了一个ThreadLocalMap的变量引用。
126 | ## ThreadLocal类get方法
127 |
128 | get获取当前线程的对应的私有变量,是之前set或者通过initialValue的值,代码如下:
129 |
130 | ```java
131 | class ThreadLocal {
132 | public T get() {
133 | Thread t = Thread.currentThread();
134 | ThreadLocalMap map = getMap(t);
135 | if (map != null) {
136 | ThreadLocalMap.Entry e = map.getEntry(this);
137 | if (e != null)
138 | return (T)e.value;
139 | }
140 | return setInitialValue();
141 | }
142 | }
143 | ```
144 | 代码逻辑分析:
145 | * 获取当前线程的ThreadLocalMap实例;
146 | * 如果不为空,以当前ThreadLocal实例为key获取value;
147 | * 如果ThreadLocalMap为空或者根据当前ThreadLocal实例获取的value为空,则执行setInitialValue();
148 | # ThreadLocal相关类的关系总结
149 |
150 | 看了上面的分析是不是对Thread,ThreadLocal,ThreadLocalMap,Entry这几个类之间的关系有点晕了,没关系我专门画了一个UML类图来总结(忽略UML标准语法)。
151 |
152 | 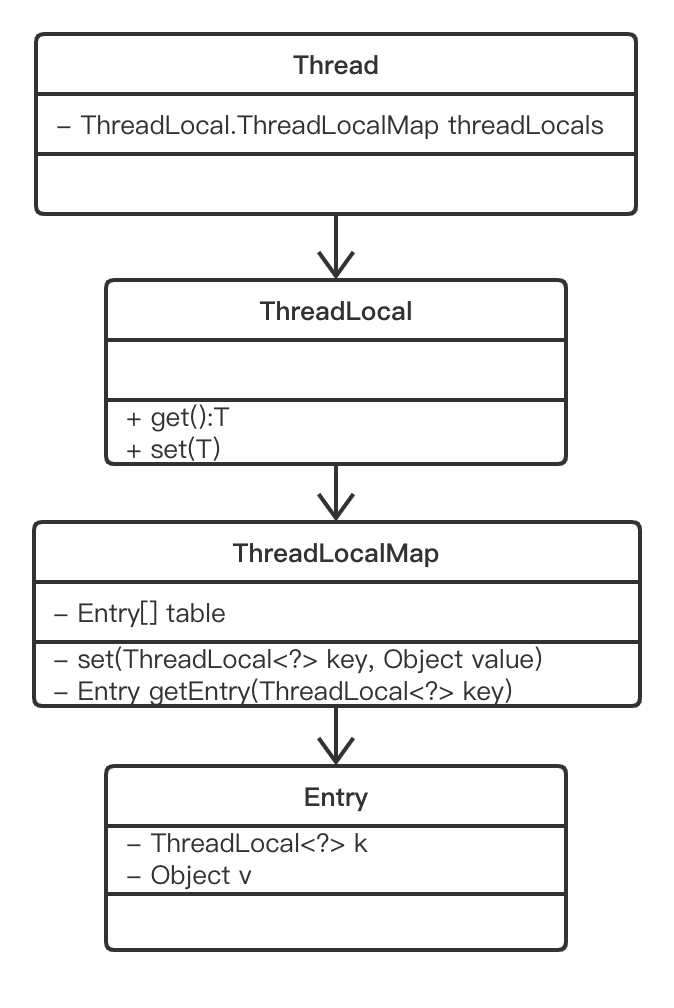 153 |
154 | * 每个线程是一个Thread实例,其内部维护一个threadLocals的实例成员,其类型是ThreadLocal.ThreadLocalMap。
155 | * 通过实例化ThreadLocal实例,我们可以对当前运行的线程设置一些线程私有的变量,通过调用ThreadLocal的set和get方法存取。
156 | * ThreadLocal本身并不是一个容器,我们存取的value实际上存储在ThreadLocalMap中,ThreadLocal只是作为TheadLocalMap的key。
157 | * 每个线程实例都对应一个TheadLocalMap实例,我们可以在同一个线程里实例化很多个ThreadLocal来存储很多种类型的值,这些ThreadLocal实例分别作为key,对应各自的value,最终存储在Entry table数组中。
158 | * 当调用ThreadLocal的set/get进行赋值/取值操作时,首先获取当前线程的ThreadLocalMap实例,然后就像操作一个普通的map一样,进行put和get。
159 | # ThreadLocal内存模型原理
160 |
161 | 经过上面的分析我们对ThreadLocal相关的类设计已经非常清楚了,下面通过一张图更加深入理解一下ThreadLocal的内存存储。
162 |
163 |
153 |
154 | * 每个线程是一个Thread实例,其内部维护一个threadLocals的实例成员,其类型是ThreadLocal.ThreadLocalMap。
155 | * 通过实例化ThreadLocal实例,我们可以对当前运行的线程设置一些线程私有的变量,通过调用ThreadLocal的set和get方法存取。
156 | * ThreadLocal本身并不是一个容器,我们存取的value实际上存储在ThreadLocalMap中,ThreadLocal只是作为TheadLocalMap的key。
157 | * 每个线程实例都对应一个TheadLocalMap实例,我们可以在同一个线程里实例化很多个ThreadLocal来存储很多种类型的值,这些ThreadLocal实例分别作为key,对应各自的value,最终存储在Entry table数组中。
158 | * 当调用ThreadLocal的set/get进行赋值/取值操作时,首先获取当前线程的ThreadLocalMap实例,然后就像操作一个普通的map一样,进行put和get。
159 | # ThreadLocal内存模型原理
160 |
161 | 经过上面的分析我们对ThreadLocal相关的类设计已经非常清楚了,下面通过一张图更加深入理解一下ThreadLocal的内存存储。
162 |
163 | 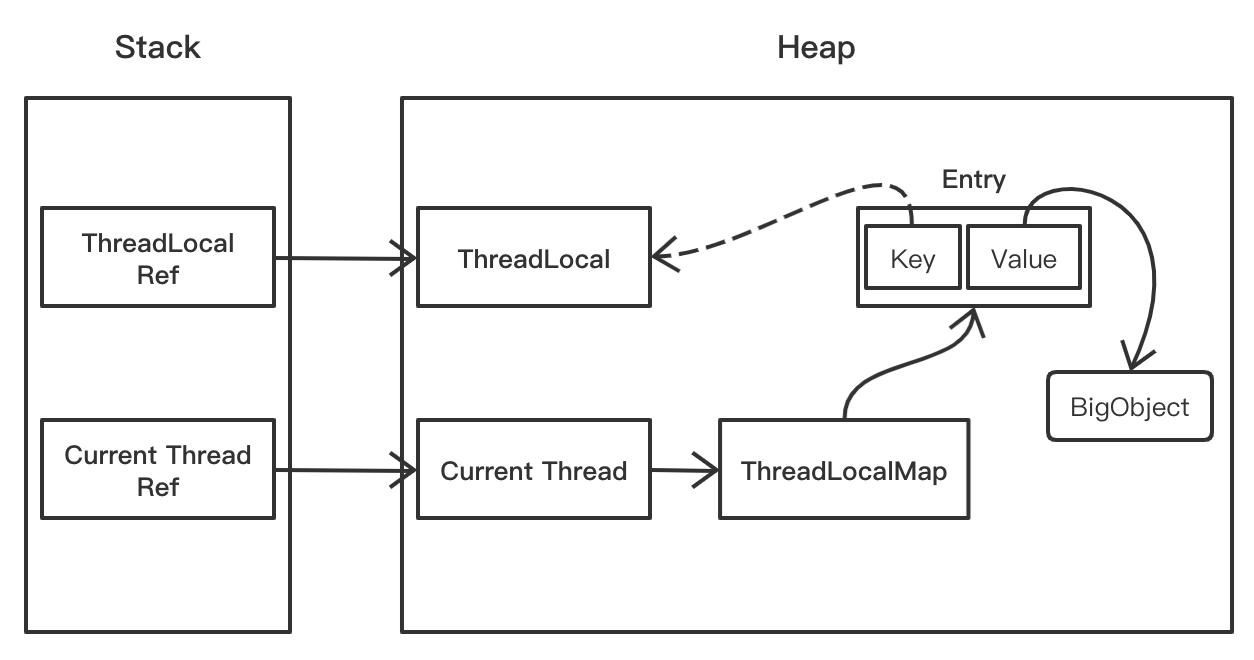 164 |
165 | 图中左边是栈,右边是堆。线程的一些局部变量和引用使用的内存属于Stack(栈)区,而普通的对象是存储在Heap(堆)区。
166 |
167 | * 线程运行时,我们定义的TheadLocal对象被初始化,存储在Heap,同时线程运行的栈区保存了指向该实例的引用,也就是图中的ThreadLocalRef。
168 | * 当ThreadLocal的set/get被调用时,虚拟机会根据当前线程的引用也就是CurrentThreadRef找到其对应在堆区的实例,然后查看其对用的TheadLocalMap实例是否被创建,如果没有,则创建并初始化。
169 | * Map实例化之后,也就拿到了该ThreadLocalMap的句柄,那么就可以将当前ThreadLocal对象作为key,进行存取操作。
170 | * 图中的虚线,表示key对应ThreadLocal实例的引用是个弱引用。
171 | # 强引用弱引用的概念
172 |
173 | ThreadLocalMap的key是一个弱引用类型,源代码如下:
174 |
175 | ```java
176 | static class ThreadLocalMap {
177 | // 定义一个Entry类,key是一个弱引用的ThreadLocal对象
178 | // value是任意对象
179 | static class Entry extends WeakReference> {
180 | /** The value associated with this ThreadLocal. */
181 | Object value;
182 | Entry(ThreadLocal k, Object v) {
183 | super(k);
184 | value = v;
185 | }
186 | }
187 | // 省略其他
188 | }
189 | ```
190 | 下面解释一下常见的几种引用概念。
191 |
192 | ## 强引用
193 |
194 | **一直活着**:类似“Object obj=new Object()”这类的引用,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象实例。
195 |
196 | ## 弱引用
197 |
198 | **回收就会死亡**:被弱引用关联的对象实例只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象实例。在JDK 1.2之后,提供了WeakReference类来实现弱引用。
199 |
200 | ## 软引用
201 |
202 | **有一次活的机会**:软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象实例列进回收范围之中进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。在JDK 1.2之后,提供了SoftReference类来实现软引用。
203 |
204 | ## 虚引用
205 |
206 | **也称为幽灵引用或者幻影引用**,它是最弱的一种引用关系。一个对象实例是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象实例被收集器回收时收到一个系统通知。在JDK 1.2之后,提供了PhantomReference类来实现虚引用。
207 |
208 | # 内存泄露是不是弱引用的锅?
209 |
210 | 从表面上看内存泄漏的根源在于使用了弱引用,但是另一个问题也同样值得思考:为什么ThreadLocalMap使用弱引用而不是强引用?
211 |
212 | 翻看官网文档的说法:
213 |
214 | >To help deal with very large and long-lived usages, the hash table entries use WeakReferences for keys.
215 | >>为了处理非常大和长期的用途,哈希表条目使用weakreference作为键。
216 |
217 | 分两种情况讨论:
218 |
219 | **(1)key 使用强引用**
220 |
221 | 引用ThreadLocal的对象被回收了,但是ThreadLocalMap还持有ThreadLocal的强引用,如果没有手动删除,ThreadLocal不会被回收,导致Entry内存泄漏。
222 |
223 | **(2)key 使用弱引**
224 |
225 | 引用ThreadLocal的对象被回收了,由于ThreadLocalMap持有ThreadLocal的弱引用,即使没有手动删除,ThreadLocal也会被回收。value在下一次ThreadLocalMap调用set、get、remove的时候会被清除。
226 |
227 | 比较两种情况,我们可以发现:由于ThreadLocalMap的生命周期跟Thread一样长,如果都没有手动删除对应key,都会导致内存泄漏,但是使用弱引用可以多一层保障:弱引用ThreadLocal被清理后key为null,对应的value在下一次ThreadLocalMap调用set、get、remove的时候可能会被清除。
228 |
229 | 因此,ThreadLocal内存泄漏的根源是:由于ThreadLocalMap的生命周期跟Thread一样长,如果没有手动删除对应key就会导致内存泄漏,而不是因为弱引用。
230 |
231 | # ThreadLocal最佳实践
232 |
233 | 通过前面几小节我们分析了ThreadLocal的类设计以及内存模型,同时也重点分析了发生内存泄露的条件和特定场景。最后结合项目中的经验给出建议使用ThreadLocal的场景:
234 |
235 | * 当需要存储线程私有变量的时候。
236 | * 当需要实现线程安全的变量时。
237 | * 当需要减少线程资源竞争的时候。
238 |
239 | 综合上面的分析,我们可以理解ThreadLocal内存泄漏的前因后果,那么怎么避免内存泄漏呢?
240 |
241 | 答案就是:每次使用完ThreadLocal,建议调用它的remove()方法,清除数据。
242 |
243 | 另外需要强调的是并不是所有使用ThreadLocal的地方,都要在最后remove(),因为他们的生命周期可能是需要和项目的生存周期一样长的,所以要进行恰当的选择,以免出现业务逻辑错误!
244 |
245 |
246 |
--------------------------------------------------------------------------------
/docs/java/juc/十张图告诉你多线程那些破事.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650324639&idx=1&sn=3079f422a81ff29549df968d67961a18&chksm=8f09c085b87e4993c30975e0e7e422865c8e92d314bc01042f139d6e57365e15e17f22451f4d&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [线程安全问题](#线程安全问题)
6 | - [活跃性问题](#活跃性问题)
7 | - [性能问题](#性能问题)
8 | - [有态度的总结](#有态度的总结)
9 |
10 |
11 |
12 | ```
13 | 头发很多的程序员:『师父,这个批量处理接口太慢了,有什么办法可以优化?』
14 |
15 | 架构师:『试试使用多线程优化』
16 |
17 | 第二天
18 |
19 | 头发很多的程序员:『师父,我已经使用了多线程,为什么接口还变慢了?』
20 |
21 | 架构师:『去给我买杯咖啡,我写篇文章告诉你』
22 |
23 | ……吭哧吭哧买咖啡去了
24 | ```
25 |
26 | 在实际工作中,错误使用多线程非但不能提高效率还可能使程序崩溃。以在路上开车为例:
27 |
28 | 在一个单向行驶的道路上,每辆汽车都遵守交通规则,这时候整体通行是正常的。『单向车道』意味着『一个线程』,『多辆车』意味着『多个job任务』。
29 |
30 | 
31 |
32 | 如果需要提升车辆的同行效率,一般的做法就是扩展车道,对应程序来说就是『加线程池』,增加线程数。这样在同一时间内,通行的车辆数远远大于单车道。
33 |
34 | 
35 |
36 | 然而成年人的世界没有那么完美,车道一旦多起来『加塞』的场景就会越来越多,出现碰撞后也会影响整条马路的通行效率。这么一对比下来『多车道』确实可能比『单车道』要慢。
37 |
38 | 
39 |
40 | 防止汽车频繁变道加塞可以采取在车道间增加『护栏』,那在程序的世界该怎么做呢?
41 |
42 | 程序世界中多线程遇到的问题归纳起来就是三类:`『线程安全问题』`、`『活跃性问题』`、`『性能问题』`,接下来会讲解这些问题,以及问题对应的解决手段。
43 |
44 | ## 线程安全问题
45 |
46 | 有时候我们会发现,明明在单线程环境中正常运行的代码,在多线程环境中可能会出现意料之外的结果,其实这就是大家常说的『线程不安全』。那到底什么是线程不安全呢?往下看。
47 |
48 | **原子性**
49 |
50 | 举一个银行转账的例子,比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元,两个操作都成功才意味着一次转账最终成功。
51 |
52 | 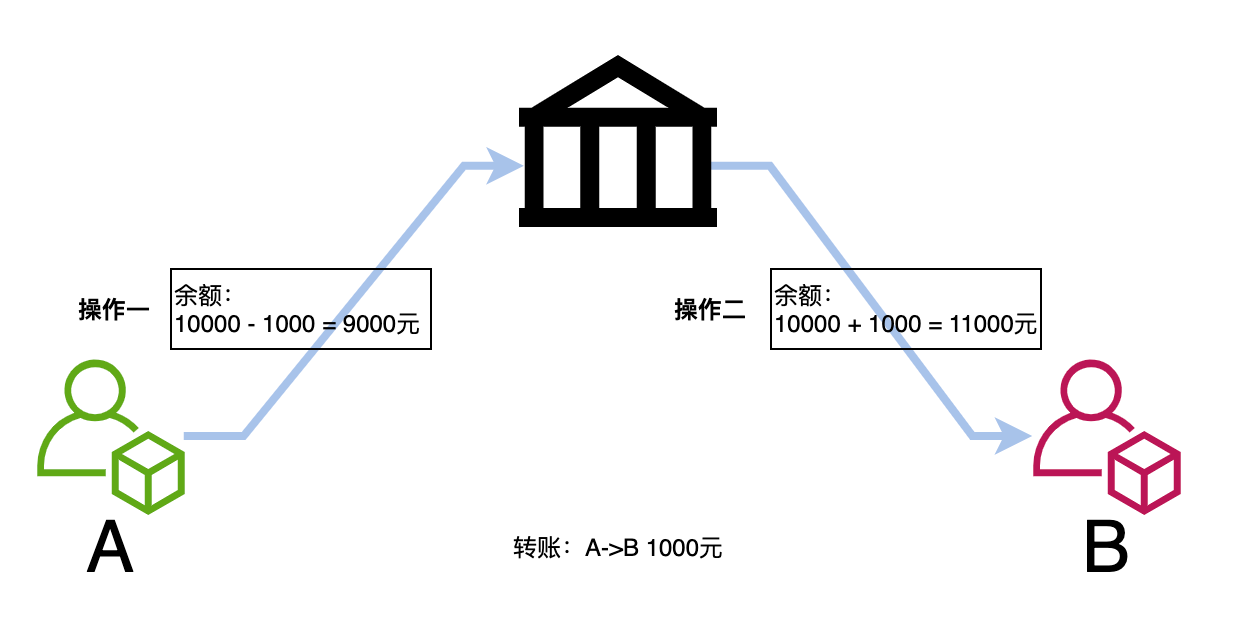
53 |
54 | 试想一下,如果这两个操作不具备原子性,从A的账户扣减了1000元之后,操作突然终止了,账户B没有增加1000元,那问题就大了。
55 |
56 | 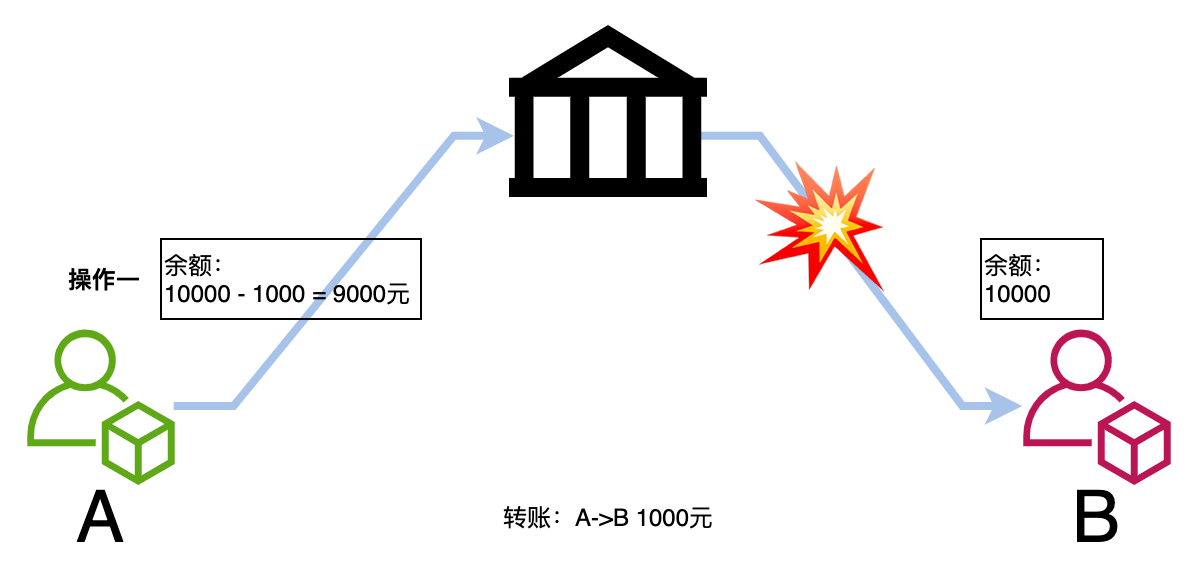
57 |
58 | 银行转账这个例子有两个步骤,出现了意外后导致转账失败,说明没有原子性。
59 |
60 | > 原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
61 | >
62 | > 原子操作:即不会被线程调度机制打断的操作,没有上下文切换。
63 |
64 | 在并发编程中很多操作都不是原子操作,出个小题目:
65 |
66 | ```java
67 | i = 0; // 操作1
68 | i++; // 操作2
69 | i = j; // 操作3
70 | i = i + 1; // 操作4
71 | ```
72 |
73 | 上面这四个操作中有哪些是原子操作,哪些不是的?不熟悉的人可能认为这些都是原子操作,其实只有操作1是原子操作。
74 |
75 | - 操作1:对基本数据类型变量的赋值是原子操作;
76 | - 操作2:包含三个操作,读取i的值,将i加1,将值赋给i;
77 | - 操作3:读取j的值,将j的值赋给i;
78 | - 操作4:包含三个操作,读取i的值,将i加1,将值赋给i;
79 |
80 | 在单线程环境下上述四个操作都不会出现问题,但是在多线程环境下,如果不通过加锁操作,往往可能得到意料之外的值。
81 |
82 | 在Java语言中通过可以使用synchronize或者lock来保证原子性。
83 |
84 | **可见性**
85 |
86 | talk is cheap,先show一段代码:
87 |
88 | ```java
89 | /**
90 | * Author: leixiaoshuai
91 | */
92 | class Test {
93 | int i = 50;
94 | int j = 0;
95 |
96 | public void update() {
97 | // 线程1执行
98 | i = 100;
99 | }
100 |
101 | public int get() {
102 | // 线程2执行
103 | j = i;
104 | return j;
105 | }
106 | }
107 | ```
108 |
109 | 线程1执行update方法将 i 赋值为100,一般情况下线程1会在自己的工作内存中完成赋值操作,却没有及时将新值刷新到主内存中。
110 |
111 | 这个时候线程2执行get方法,首先会从主内存中读取i的值,然后加载到自己的工作内存中,这个时候读取到i的值是50,再将50赋值给j,最后返回j的值就是50了。原本期望返回100,结果返回50,这就是可见性问题,线程1对变量i进行了修改,线程2没有立即看到i的新值。
112 |
113 | > 可见性:指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
114 |
115 | 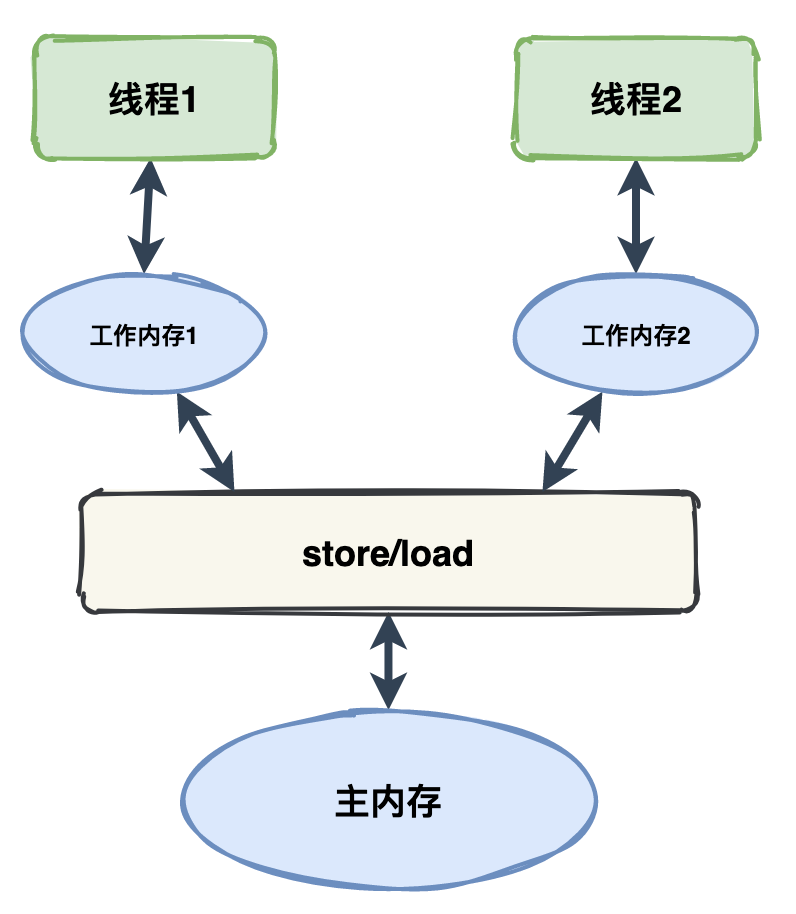
116 |
117 | 如上图每个线程都有属于自己的工作内存,工作内存和主内存间需要通过store和load等进行交互。
118 |
119 | 为了解决多线程可见性问题,Java语言提供了`volatile`这个关键字。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。而普通共享变量不能保证可见性,因为变量被修改后什么时候刷回到主存是不确定的,另外一个线程读的可能就是旧值。
120 |
121 | 当然Java的锁机制如synchronize和lock也是可以保证可见性的,加锁可以保证在同一时刻只有一个线程在执行同步代码块,释放锁之前会将变量刷回至主存,这样也就保证了可见性。
122 |
123 | 关于线程不安全的表现还有『有序性』,这个问题会在后面的文章中深入讲解。
124 |
125 | ## 活跃性问题
126 |
127 | 上面讲到为了解决`可见性`问题,我们可以采取加锁方式解决,但是如果加锁使用不当也容易引入其他问题,比如『死锁』。
128 |
129 | 在说『死锁』前我们先引入另外一个概念:`活跃性问题`。
130 |
131 | > 活跃性是指某件正确的事情最终会发生,当某个操作无法继续下去的时候,就会发生活跃性问题。
132 |
133 | 概念是不是有点拗口,如果看不懂也没关系,你可以记住活跃性问题一般有这样几类:`死锁`,`活锁`,`饥饿问题`。
134 |
135 | **(1)死锁**
136 |
137 | 死锁是指多个线程因为环形的等待锁的关系而永远的阻塞下去。一图胜千语,不多解释。
138 |
139 | 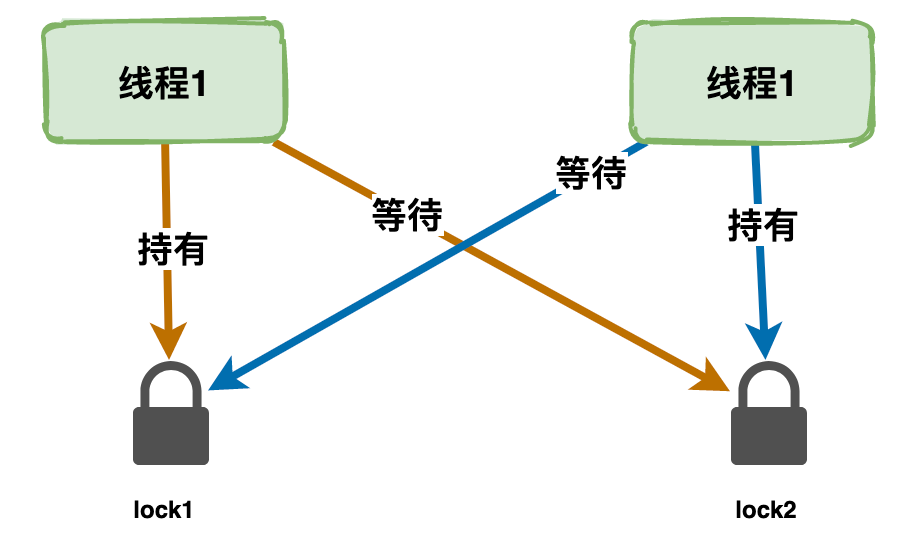
140 |
141 | **(2)活锁**
142 |
143 | 死锁是两个线程都在等待对方释放锁导致阻塞。而`活锁`的意思是线程没有阻塞,还活着呢。
144 |
145 | 当多个线程都在运行并且修改各自的状态,而其他线程彼此依赖这个状态,导致任何一个线程都无法继续执行,只能重复着自身的动作和修改自身的状态,这种场景就是发生了活锁。
146 |
147 | 
148 |
149 | 如果大家还有疑惑,那我再举一个生活中的例子,大家平时在走路的时候,迎面走来一个人,两个人互相让路,但是又同时走到了一个方向,如果一直这样重复着避让,这俩人就是发生了活锁,学到了吧,嘿嘿。
150 |
151 | **(3)饥饿**
152 |
153 | 如果一个线程无其他异常却迟迟不能继续运行,那基本是处于饥饿状态了。
154 |
155 | 常见有几种场景:
156 |
157 | - 高优先级的线程一直在运行消耗CPU,所有的低优先级线程一直处于等待;
158 | - 一些线程被永久堵塞在一个等待进入同步块的状态,而其他线程总是能在它之前持续地对该同步块进行访问;
159 |
160 | 有一个非常经典的饥饿问题就是`哲学家用餐问题`,如下图所示,有五个哲学家在用餐,每个人必须要同时拿两把叉子才可以开始就餐,如果哲学家1和哲学家3同时开始就餐,那哲学家2、4、5就得饿肚子等待了。
161 |
162 | 
163 |
164 |
165 |
166 | ## 性能问题
167 |
168 | 前面讲到了线程安全和死锁、活锁这些问题会影响多线程执行过程,如果这些都没有发生,多线程并发一定比单线程串行执行快吗,答案是不一定,因为多线程有`创建线程`和`线程上下文切换`的开销。
169 |
170 | 创建线程是直接向系统申请资源的,对操作系统来说创建一个线程的代价是十分昂贵的,需要给它分配内存、列入调度等。
171 |
172 | 线程创建完之后,还会遇到线程`上下文切换`。
173 |
174 | 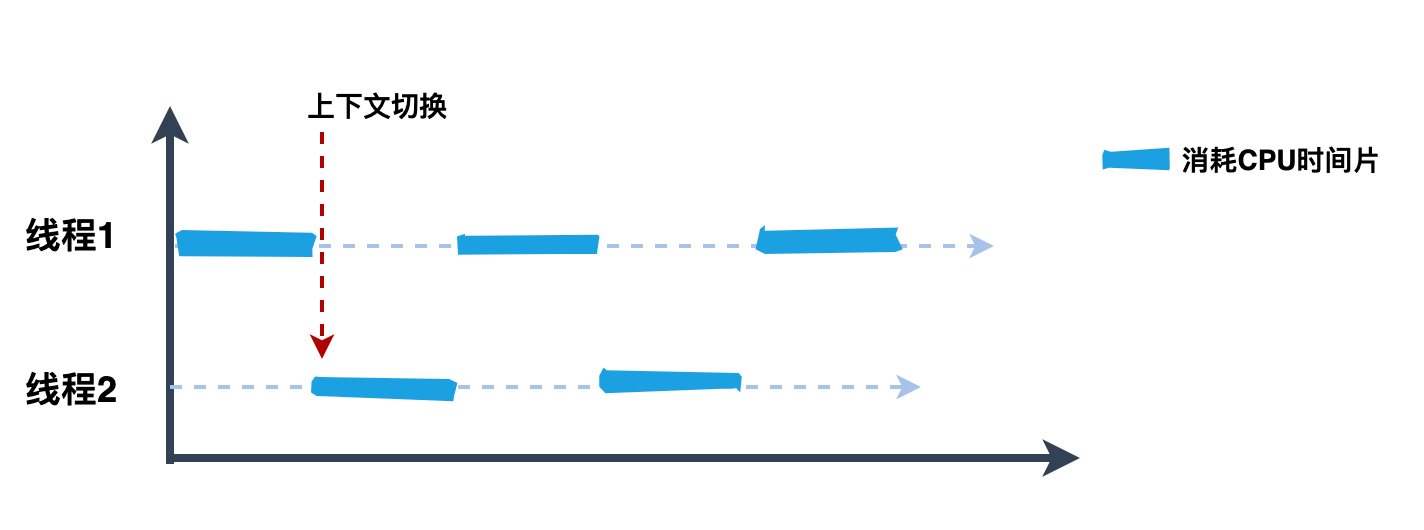
175 |
176 | CPU是很宝贵的资源速度也非常快,为了保证雨露均沾,通常为给不同的线程分配`时间片`,当CPU从执行一个线程切换到执行另一个线程时,CPU 需要保存当前线程的本地数据,程序指针等状态,并加载下一个要执行的线程的本地数据,程序指针等,这个开关被称为『上下文切换』。
177 |
178 | 一般减少上下文切换的方法有:`无锁并发编程`、`CAS 算法`、`使用协程`等。
179 |
180 | ## 有态度的总结
181 |
182 | 多线程用好了可以让程序的效率成倍提升,用不好可能比单线程还要慢。
183 |
184 | 用一张图总结一下上面讲的:
185 |
186 | 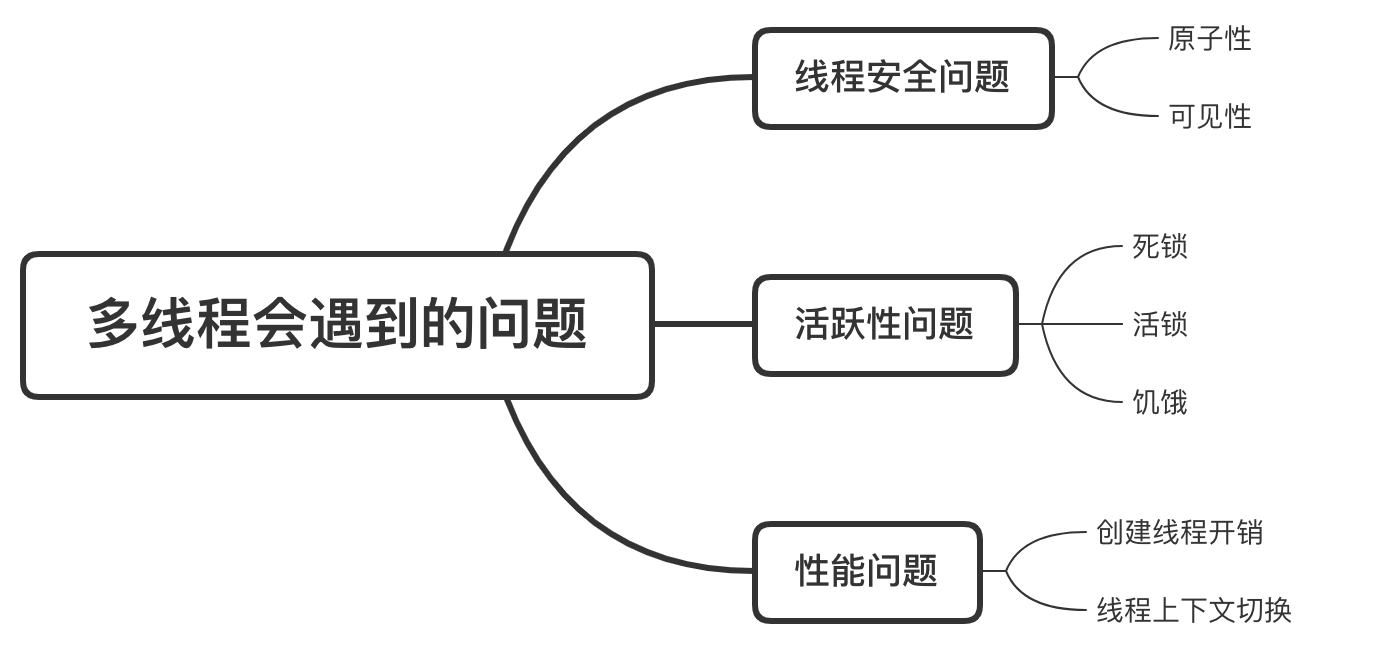
187 |
188 | -- END --
189 |
190 | 文章讲了多线程并发会遇到的问题,你可能也发现了,文章中并没有给出具体的解决方案,因为这些问题在Java语言设计过程中大神都已经为你考虑过了。
191 |
192 | Java并发编程学起来有一定难度,但这也是从`初级程序员`迈向`中高级程序员`的必经道路,接下来的文章会带领大家逐个击破!
--------------------------------------------------------------------------------
/docs/java/juc/图解Java中那18 把锁.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650325236&idx=1&sn=95a3d9aa64d5c0757bc46a46ff266832&chksm=8f09beeeb87e37f899aabc307a47488fe81b974a3e328b9f48d97cf6f03f92285398022814be&token=1565452340&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 | - [乐观锁和悲观锁](#乐观锁和悲观锁)
4 | - [独占锁和共享锁](#独占锁和共享锁)
5 | - [互斥锁和读写锁](#互斥锁和读写锁)
6 | - [公平锁和非公平锁](#公平锁和非公平锁)
7 | - [可重入锁](#可重入锁)
8 | - [自旋锁](#自旋锁)
9 | - [分段锁](#分段锁)
10 | - [锁升级(无锁|偏向锁|轻量级锁|重量级锁)](#锁升级无锁偏向锁轻量级锁重量级锁)
11 | - [锁优化技术(锁粗化、锁消除)](#锁优化技术锁粗化锁消除)
12 |
13 |
14 | # 乐观锁和悲观锁
15 |
16 | **悲观锁**
17 |
18 | `悲观锁`对应于生活中悲观的人,悲观的人总是想着事情往坏的方向发展。
19 |
20 | 举个生活中的例子,假设厕所只有一个坑位了,悲观锁上厕所会第一时间把门反锁上,这样其他人上厕所只能在门外等候,这种状态就是「阻塞」了。
21 |
22 | 回到代码世界中,一个共享数据加了悲观锁,那线程每次想操作这个数据前都会假设其他线程也可能会操作这个数据,所以每次操作前都会上锁,这样其他线程想操作这个数据拿不到锁只能阻塞了。
23 |
24 |
164 |
165 | 图中左边是栈,右边是堆。线程的一些局部变量和引用使用的内存属于Stack(栈)区,而普通的对象是存储在Heap(堆)区。
166 |
167 | * 线程运行时,我们定义的TheadLocal对象被初始化,存储在Heap,同时线程运行的栈区保存了指向该实例的引用,也就是图中的ThreadLocalRef。
168 | * 当ThreadLocal的set/get被调用时,虚拟机会根据当前线程的引用也就是CurrentThreadRef找到其对应在堆区的实例,然后查看其对用的TheadLocalMap实例是否被创建,如果没有,则创建并初始化。
169 | * Map实例化之后,也就拿到了该ThreadLocalMap的句柄,那么就可以将当前ThreadLocal对象作为key,进行存取操作。
170 | * 图中的虚线,表示key对应ThreadLocal实例的引用是个弱引用。
171 | # 强引用弱引用的概念
172 |
173 | ThreadLocalMap的key是一个弱引用类型,源代码如下:
174 |
175 | ```java
176 | static class ThreadLocalMap {
177 | // 定义一个Entry类,key是一个弱引用的ThreadLocal对象
178 | // value是任意对象
179 | static class Entry extends WeakReference> {
180 | /** The value associated with this ThreadLocal. */
181 | Object value;
182 | Entry(ThreadLocal k, Object v) {
183 | super(k);
184 | value = v;
185 | }
186 | }
187 | // 省略其他
188 | }
189 | ```
190 | 下面解释一下常见的几种引用概念。
191 |
192 | ## 强引用
193 |
194 | **一直活着**:类似“Object obj=new Object()”这类的引用,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象实例。
195 |
196 | ## 弱引用
197 |
198 | **回收就会死亡**:被弱引用关联的对象实例只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象实例。在JDK 1.2之后,提供了WeakReference类来实现弱引用。
199 |
200 | ## 软引用
201 |
202 | **有一次活的机会**:软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象实例列进回收范围之中进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。在JDK 1.2之后,提供了SoftReference类来实现软引用。
203 |
204 | ## 虚引用
205 |
206 | **也称为幽灵引用或者幻影引用**,它是最弱的一种引用关系。一个对象实例是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象实例被收集器回收时收到一个系统通知。在JDK 1.2之后,提供了PhantomReference类来实现虚引用。
207 |
208 | # 内存泄露是不是弱引用的锅?
209 |
210 | 从表面上看内存泄漏的根源在于使用了弱引用,但是另一个问题也同样值得思考:为什么ThreadLocalMap使用弱引用而不是强引用?
211 |
212 | 翻看官网文档的说法:
213 |
214 | >To help deal with very large and long-lived usages, the hash table entries use WeakReferences for keys.
215 | >>为了处理非常大和长期的用途,哈希表条目使用weakreference作为键。
216 |
217 | 分两种情况讨论:
218 |
219 | **(1)key 使用强引用**
220 |
221 | 引用ThreadLocal的对象被回收了,但是ThreadLocalMap还持有ThreadLocal的强引用,如果没有手动删除,ThreadLocal不会被回收,导致Entry内存泄漏。
222 |
223 | **(2)key 使用弱引**
224 |
225 | 引用ThreadLocal的对象被回收了,由于ThreadLocalMap持有ThreadLocal的弱引用,即使没有手动删除,ThreadLocal也会被回收。value在下一次ThreadLocalMap调用set、get、remove的时候会被清除。
226 |
227 | 比较两种情况,我们可以发现:由于ThreadLocalMap的生命周期跟Thread一样长,如果都没有手动删除对应key,都会导致内存泄漏,但是使用弱引用可以多一层保障:弱引用ThreadLocal被清理后key为null,对应的value在下一次ThreadLocalMap调用set、get、remove的时候可能会被清除。
228 |
229 | 因此,ThreadLocal内存泄漏的根源是:由于ThreadLocalMap的生命周期跟Thread一样长,如果没有手动删除对应key就会导致内存泄漏,而不是因为弱引用。
230 |
231 | # ThreadLocal最佳实践
232 |
233 | 通过前面几小节我们分析了ThreadLocal的类设计以及内存模型,同时也重点分析了发生内存泄露的条件和特定场景。最后结合项目中的经验给出建议使用ThreadLocal的场景:
234 |
235 | * 当需要存储线程私有变量的时候。
236 | * 当需要实现线程安全的变量时。
237 | * 当需要减少线程资源竞争的时候。
238 |
239 | 综合上面的分析,我们可以理解ThreadLocal内存泄漏的前因后果,那么怎么避免内存泄漏呢?
240 |
241 | 答案就是:每次使用完ThreadLocal,建议调用它的remove()方法,清除数据。
242 |
243 | 另外需要强调的是并不是所有使用ThreadLocal的地方,都要在最后remove(),因为他们的生命周期可能是需要和项目的生存周期一样长的,所以要进行恰当的选择,以免出现业务逻辑错误!
244 |
245 |
246 |
--------------------------------------------------------------------------------
/docs/java/juc/十张图告诉你多线程那些破事.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650324639&idx=1&sn=3079f422a81ff29549df968d67961a18&chksm=8f09c085b87e4993c30975e0e7e422865c8e92d314bc01042f139d6e57365e15e17f22451f4d&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [线程安全问题](#线程安全问题)
6 | - [活跃性问题](#活跃性问题)
7 | - [性能问题](#性能问题)
8 | - [有态度的总结](#有态度的总结)
9 |
10 |
11 |
12 | ```
13 | 头发很多的程序员:『师父,这个批量处理接口太慢了,有什么办法可以优化?』
14 |
15 | 架构师:『试试使用多线程优化』
16 |
17 | 第二天
18 |
19 | 头发很多的程序员:『师父,我已经使用了多线程,为什么接口还变慢了?』
20 |
21 | 架构师:『去给我买杯咖啡,我写篇文章告诉你』
22 |
23 | ……吭哧吭哧买咖啡去了
24 | ```
25 |
26 | 在实际工作中,错误使用多线程非但不能提高效率还可能使程序崩溃。以在路上开车为例:
27 |
28 | 在一个单向行驶的道路上,每辆汽车都遵守交通规则,这时候整体通行是正常的。『单向车道』意味着『一个线程』,『多辆车』意味着『多个job任务』。
29 |
30 | 
31 |
32 | 如果需要提升车辆的同行效率,一般的做法就是扩展车道,对应程序来说就是『加线程池』,增加线程数。这样在同一时间内,通行的车辆数远远大于单车道。
33 |
34 | 
35 |
36 | 然而成年人的世界没有那么完美,车道一旦多起来『加塞』的场景就会越来越多,出现碰撞后也会影响整条马路的通行效率。这么一对比下来『多车道』确实可能比『单车道』要慢。
37 |
38 | 
39 |
40 | 防止汽车频繁变道加塞可以采取在车道间增加『护栏』,那在程序的世界该怎么做呢?
41 |
42 | 程序世界中多线程遇到的问题归纳起来就是三类:`『线程安全问题』`、`『活跃性问题』`、`『性能问题』`,接下来会讲解这些问题,以及问题对应的解决手段。
43 |
44 | ## 线程安全问题
45 |
46 | 有时候我们会发现,明明在单线程环境中正常运行的代码,在多线程环境中可能会出现意料之外的结果,其实这就是大家常说的『线程不安全』。那到底什么是线程不安全呢?往下看。
47 |
48 | **原子性**
49 |
50 | 举一个银行转账的例子,比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元,两个操作都成功才意味着一次转账最终成功。
51 |
52 | 
53 |
54 | 试想一下,如果这两个操作不具备原子性,从A的账户扣减了1000元之后,操作突然终止了,账户B没有增加1000元,那问题就大了。
55 |
56 | 
57 |
58 | 银行转账这个例子有两个步骤,出现了意外后导致转账失败,说明没有原子性。
59 |
60 | > 原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
61 | >
62 | > 原子操作:即不会被线程调度机制打断的操作,没有上下文切换。
63 |
64 | 在并发编程中很多操作都不是原子操作,出个小题目:
65 |
66 | ```java
67 | i = 0; // 操作1
68 | i++; // 操作2
69 | i = j; // 操作3
70 | i = i + 1; // 操作4
71 | ```
72 |
73 | 上面这四个操作中有哪些是原子操作,哪些不是的?不熟悉的人可能认为这些都是原子操作,其实只有操作1是原子操作。
74 |
75 | - 操作1:对基本数据类型变量的赋值是原子操作;
76 | - 操作2:包含三个操作,读取i的值,将i加1,将值赋给i;
77 | - 操作3:读取j的值,将j的值赋给i;
78 | - 操作4:包含三个操作,读取i的值,将i加1,将值赋给i;
79 |
80 | 在单线程环境下上述四个操作都不会出现问题,但是在多线程环境下,如果不通过加锁操作,往往可能得到意料之外的值。
81 |
82 | 在Java语言中通过可以使用synchronize或者lock来保证原子性。
83 |
84 | **可见性**
85 |
86 | talk is cheap,先show一段代码:
87 |
88 | ```java
89 | /**
90 | * Author: leixiaoshuai
91 | */
92 | class Test {
93 | int i = 50;
94 | int j = 0;
95 |
96 | public void update() {
97 | // 线程1执行
98 | i = 100;
99 | }
100 |
101 | public int get() {
102 | // 线程2执行
103 | j = i;
104 | return j;
105 | }
106 | }
107 | ```
108 |
109 | 线程1执行update方法将 i 赋值为100,一般情况下线程1会在自己的工作内存中完成赋值操作,却没有及时将新值刷新到主内存中。
110 |
111 | 这个时候线程2执行get方法,首先会从主内存中读取i的值,然后加载到自己的工作内存中,这个时候读取到i的值是50,再将50赋值给j,最后返回j的值就是50了。原本期望返回100,结果返回50,这就是可见性问题,线程1对变量i进行了修改,线程2没有立即看到i的新值。
112 |
113 | > 可见性:指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
114 |
115 | 
116 |
117 | 如上图每个线程都有属于自己的工作内存,工作内存和主内存间需要通过store和load等进行交互。
118 |
119 | 为了解决多线程可见性问题,Java语言提供了`volatile`这个关键字。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。而普通共享变量不能保证可见性,因为变量被修改后什么时候刷回到主存是不确定的,另外一个线程读的可能就是旧值。
120 |
121 | 当然Java的锁机制如synchronize和lock也是可以保证可见性的,加锁可以保证在同一时刻只有一个线程在执行同步代码块,释放锁之前会将变量刷回至主存,这样也就保证了可见性。
122 |
123 | 关于线程不安全的表现还有『有序性』,这个问题会在后面的文章中深入讲解。
124 |
125 | ## 活跃性问题
126 |
127 | 上面讲到为了解决`可见性`问题,我们可以采取加锁方式解决,但是如果加锁使用不当也容易引入其他问题,比如『死锁』。
128 |
129 | 在说『死锁』前我们先引入另外一个概念:`活跃性问题`。
130 |
131 | > 活跃性是指某件正确的事情最终会发生,当某个操作无法继续下去的时候,就会发生活跃性问题。
132 |
133 | 概念是不是有点拗口,如果看不懂也没关系,你可以记住活跃性问题一般有这样几类:`死锁`,`活锁`,`饥饿问题`。
134 |
135 | **(1)死锁**
136 |
137 | 死锁是指多个线程因为环形的等待锁的关系而永远的阻塞下去。一图胜千语,不多解释。
138 |
139 | 
140 |
141 | **(2)活锁**
142 |
143 | 死锁是两个线程都在等待对方释放锁导致阻塞。而`活锁`的意思是线程没有阻塞,还活着呢。
144 |
145 | 当多个线程都在运行并且修改各自的状态,而其他线程彼此依赖这个状态,导致任何一个线程都无法继续执行,只能重复着自身的动作和修改自身的状态,这种场景就是发生了活锁。
146 |
147 | 
148 |
149 | 如果大家还有疑惑,那我再举一个生活中的例子,大家平时在走路的时候,迎面走来一个人,两个人互相让路,但是又同时走到了一个方向,如果一直这样重复着避让,这俩人就是发生了活锁,学到了吧,嘿嘿。
150 |
151 | **(3)饥饿**
152 |
153 | 如果一个线程无其他异常却迟迟不能继续运行,那基本是处于饥饿状态了。
154 |
155 | 常见有几种场景:
156 |
157 | - 高优先级的线程一直在运行消耗CPU,所有的低优先级线程一直处于等待;
158 | - 一些线程被永久堵塞在一个等待进入同步块的状态,而其他线程总是能在它之前持续地对该同步块进行访问;
159 |
160 | 有一个非常经典的饥饿问题就是`哲学家用餐问题`,如下图所示,有五个哲学家在用餐,每个人必须要同时拿两把叉子才可以开始就餐,如果哲学家1和哲学家3同时开始就餐,那哲学家2、4、5就得饿肚子等待了。
161 |
162 | 
163 |
164 |
165 |
166 | ## 性能问题
167 |
168 | 前面讲到了线程安全和死锁、活锁这些问题会影响多线程执行过程,如果这些都没有发生,多线程并发一定比单线程串行执行快吗,答案是不一定,因为多线程有`创建线程`和`线程上下文切换`的开销。
169 |
170 | 创建线程是直接向系统申请资源的,对操作系统来说创建一个线程的代价是十分昂贵的,需要给它分配内存、列入调度等。
171 |
172 | 线程创建完之后,还会遇到线程`上下文切换`。
173 |
174 | 
175 |
176 | CPU是很宝贵的资源速度也非常快,为了保证雨露均沾,通常为给不同的线程分配`时间片`,当CPU从执行一个线程切换到执行另一个线程时,CPU 需要保存当前线程的本地数据,程序指针等状态,并加载下一个要执行的线程的本地数据,程序指针等,这个开关被称为『上下文切换』。
177 |
178 | 一般减少上下文切换的方法有:`无锁并发编程`、`CAS 算法`、`使用协程`等。
179 |
180 | ## 有态度的总结
181 |
182 | 多线程用好了可以让程序的效率成倍提升,用不好可能比单线程还要慢。
183 |
184 | 用一张图总结一下上面讲的:
185 |
186 | 
187 |
188 | -- END --
189 |
190 | 文章讲了多线程并发会遇到的问题,你可能也发现了,文章中并没有给出具体的解决方案,因为这些问题在Java语言设计过程中大神都已经为你考虑过了。
191 |
192 | Java并发编程学起来有一定难度,但这也是从`初级程序员`迈向`中高级程序员`的必经道路,接下来的文章会带领大家逐个击破!
--------------------------------------------------------------------------------
/docs/java/juc/图解Java中那18 把锁.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650325236&idx=1&sn=95a3d9aa64d5c0757bc46a46ff266832&chksm=8f09beeeb87e37f899aabc307a47488fe81b974a3e328b9f48d97cf6f03f92285398022814be&token=1565452340&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 | - [乐观锁和悲观锁](#乐观锁和悲观锁)
4 | - [独占锁和共享锁](#独占锁和共享锁)
5 | - [互斥锁和读写锁](#互斥锁和读写锁)
6 | - [公平锁和非公平锁](#公平锁和非公平锁)
7 | - [可重入锁](#可重入锁)
8 | - [自旋锁](#自旋锁)
9 | - [分段锁](#分段锁)
10 | - [锁升级(无锁|偏向锁|轻量级锁|重量级锁)](#锁升级无锁偏向锁轻量级锁重量级锁)
11 | - [锁优化技术(锁粗化、锁消除)](#锁优化技术锁粗化锁消除)
12 |
13 |
14 | # 乐观锁和悲观锁
15 |
16 | **悲观锁**
17 |
18 | `悲观锁`对应于生活中悲观的人,悲观的人总是想着事情往坏的方向发展。
19 |
20 | 举个生活中的例子,假设厕所只有一个坑位了,悲观锁上厕所会第一时间把门反锁上,这样其他人上厕所只能在门外等候,这种状态就是「阻塞」了。
21 |
22 | 回到代码世界中,一个共享数据加了悲观锁,那线程每次想操作这个数据前都会假设其他线程也可能会操作这个数据,所以每次操作前都会上锁,这样其他线程想操作这个数据拿不到锁只能阻塞了。
23 |
24 | 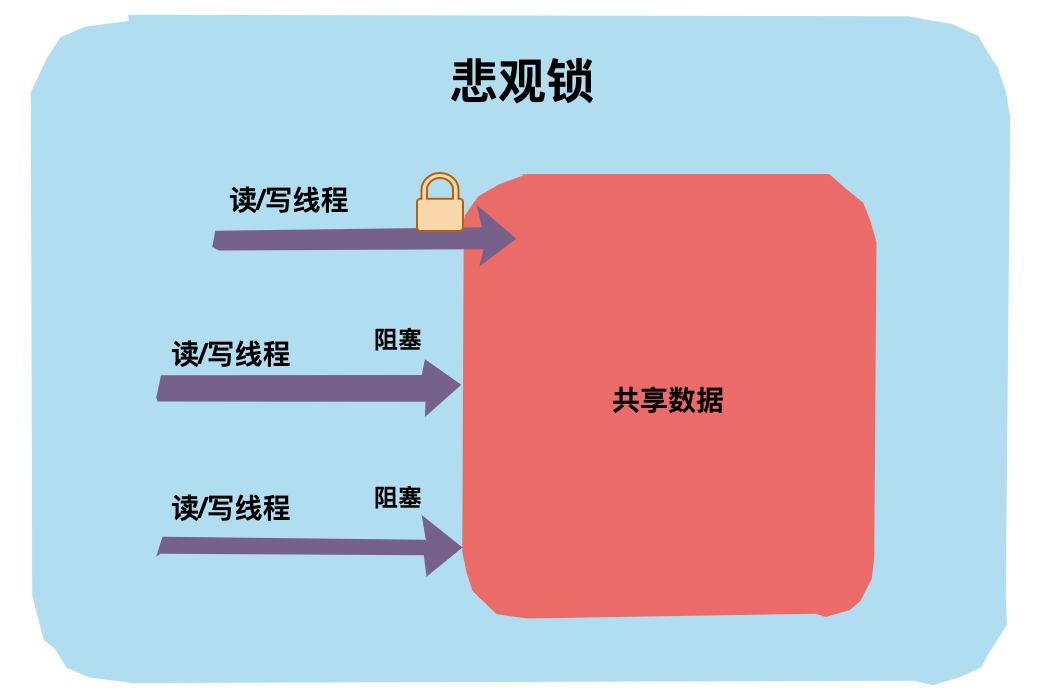 25 |
26 | 在 Java 语言中 `synchronized` 和 `ReentrantLock`等就是典型的悲观锁,还有一些使用了 synchronized 关键字的容器类如 `HashTable` 等也是悲观锁的应用。
27 |
28 | **乐观锁**
29 |
30 | `乐观锁` 对应于生活中乐观的人,乐观的人总是想着事情往好的方向发展。
31 |
32 | 举个生活中的例子,假设厕所只有一个坑位了,乐观锁认为:这荒郊野外的,又没有什么人,不会有人抢我坑位的,每次关门上锁多浪费时间,还是不加锁好了。你看乐观锁就是天生乐观!
33 |
34 | 回到代码世界中,乐观锁操作数据时不会上锁,在更新的时候会判断一下在此期间是否有其他线程去更新这个数据。
35 |
36 |
25 |
26 | 在 Java 语言中 `synchronized` 和 `ReentrantLock`等就是典型的悲观锁,还有一些使用了 synchronized 关键字的容器类如 `HashTable` 等也是悲观锁的应用。
27 |
28 | **乐观锁**
29 |
30 | `乐观锁` 对应于生活中乐观的人,乐观的人总是想着事情往好的方向发展。
31 |
32 | 举个生活中的例子,假设厕所只有一个坑位了,乐观锁认为:这荒郊野外的,又没有什么人,不会有人抢我坑位的,每次关门上锁多浪费时间,还是不加锁好了。你看乐观锁就是天生乐观!
33 |
34 | 回到代码世界中,乐观锁操作数据时不会上锁,在更新的时候会判断一下在此期间是否有其他线程去更新这个数据。
35 |
36 | 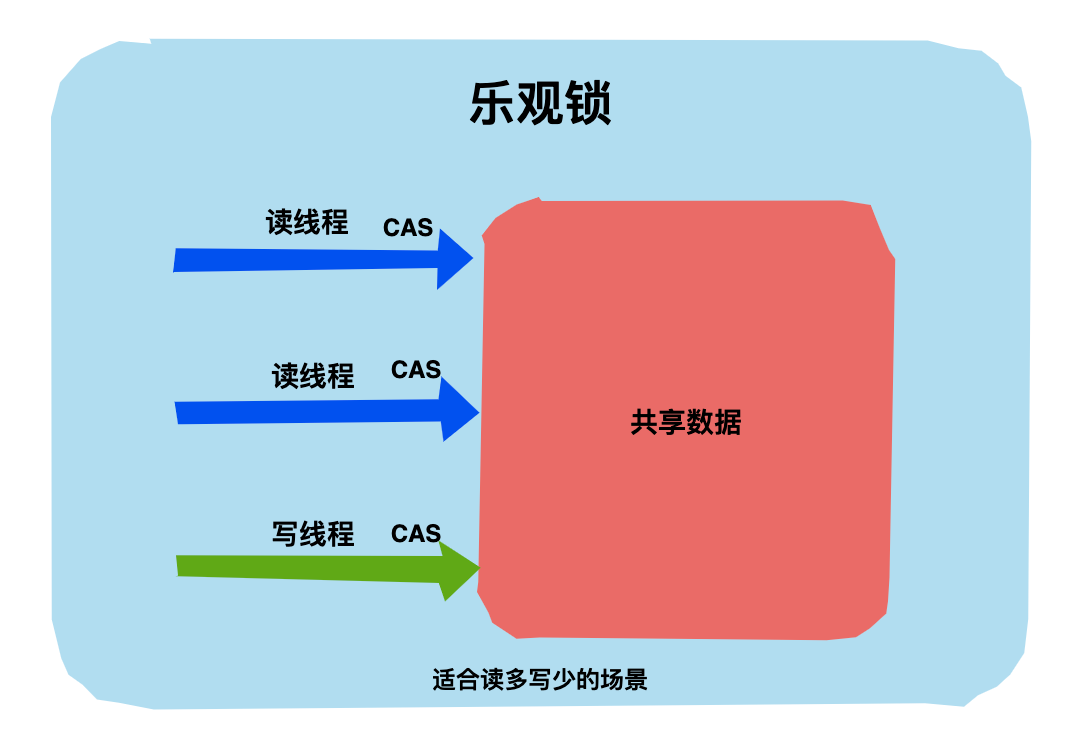 37 |
38 | 乐观锁可以使用`版本号机制`和`CAS算法`实现。在 Java 语言中 `java.util.concurrent.atomic`包下的原子类就是使用CAS 乐观锁实现的。
39 |
40 |
41 | **两种锁的使用场景**
42 |
43 | 悲观锁和乐观锁没有孰优孰劣,有其各自适应的场景。
44 |
45 | 乐观锁适用于写比较少(冲突比较小)的场景,因为不用上锁、释放锁,省去了锁的开销,从而提升了吞吐量。
46 |
47 | 如果是写多读少的场景,即冲突比较严重,线程间竞争激励,使用乐观锁就是导致线程不断进行重试,这样可能还降低了性能,这种场景下使用悲观锁就比较合适。
48 |
49 | # 独占锁和共享锁
50 |
51 | **独占锁**
52 |
53 | `独占锁`是指锁一次只能被一个线程所持有。如果一个线程对数据加上排他锁后,那么其他线程不能再对该数据加任何类型的锁。获得独占锁的线程即能读数据又能修改数据。
54 |
55 |
37 |
38 | 乐观锁可以使用`版本号机制`和`CAS算法`实现。在 Java 语言中 `java.util.concurrent.atomic`包下的原子类就是使用CAS 乐观锁实现的。
39 |
40 |
41 | **两种锁的使用场景**
42 |
43 | 悲观锁和乐观锁没有孰优孰劣,有其各自适应的场景。
44 |
45 | 乐观锁适用于写比较少(冲突比较小)的场景,因为不用上锁、释放锁,省去了锁的开销,从而提升了吞吐量。
46 |
47 | 如果是写多读少的场景,即冲突比较严重,线程间竞争激励,使用乐观锁就是导致线程不断进行重试,这样可能还降低了性能,这种场景下使用悲观锁就比较合适。
48 |
49 | # 独占锁和共享锁
50 |
51 | **独占锁**
52 |
53 | `独占锁`是指锁一次只能被一个线程所持有。如果一个线程对数据加上排他锁后,那么其他线程不能再对该数据加任何类型的锁。获得独占锁的线程即能读数据又能修改数据。
54 |
55 | 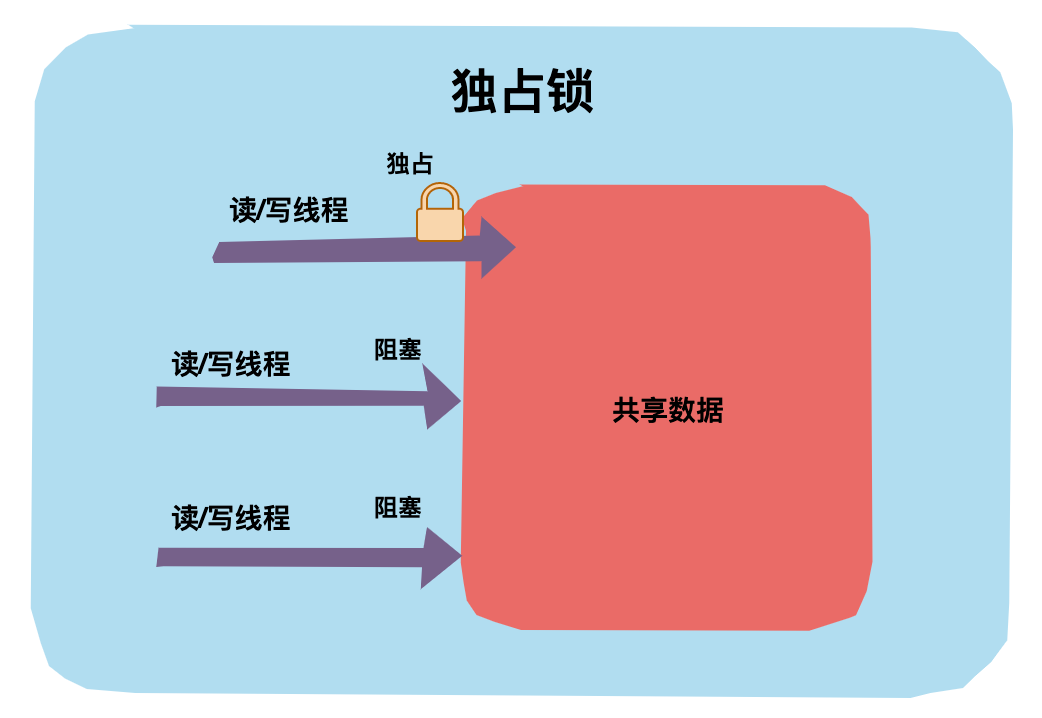 56 |
57 | JDK中的`synchronized`和`java.util.concurrent(JUC)`包中Lock的实现类就是独占锁。
58 |
59 | **共享锁**
60 |
61 | `共享锁`是指锁可被多个线程所持有。如果一个线程对数据加上共享锁后,那么其他线程只能对数据再加共享锁,不能加独占锁。获得共享锁的线程只能读数据,不能修改数据。
62 |
63 |
56 |
57 | JDK中的`synchronized`和`java.util.concurrent(JUC)`包中Lock的实现类就是独占锁。
58 |
59 | **共享锁**
60 |
61 | `共享锁`是指锁可被多个线程所持有。如果一个线程对数据加上共享锁后,那么其他线程只能对数据再加共享锁,不能加独占锁。获得共享锁的线程只能读数据,不能修改数据。
62 |
63 | 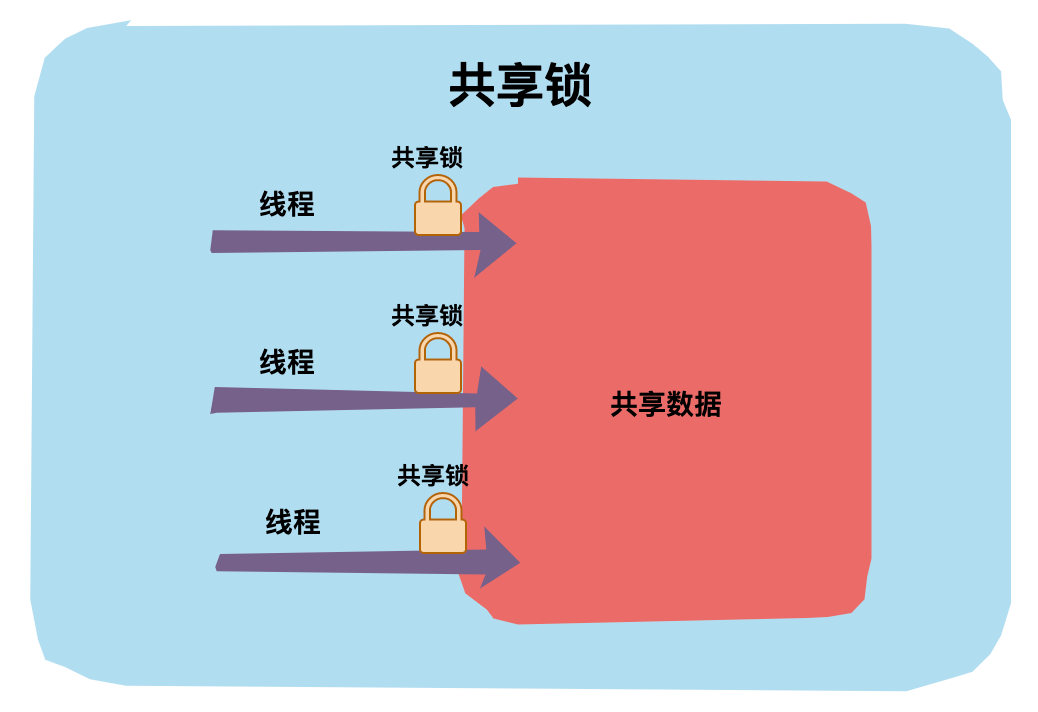 64 |
65 | 在 JDK 中 `ReentrantReadWriteLock` 就是一种共享锁。
66 |
67 |
68 | # 互斥锁和读写锁
69 |
70 | **互斥锁**
71 |
72 | `互斥锁`是独占锁的一种常规实现,是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。
73 |
74 |
64 |
65 | 在 JDK 中 `ReentrantReadWriteLock` 就是一种共享锁。
66 |
67 |
68 | # 互斥锁和读写锁
69 |
70 | **互斥锁**
71 |
72 | `互斥锁`是独占锁的一种常规实现,是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。
73 |
74 | 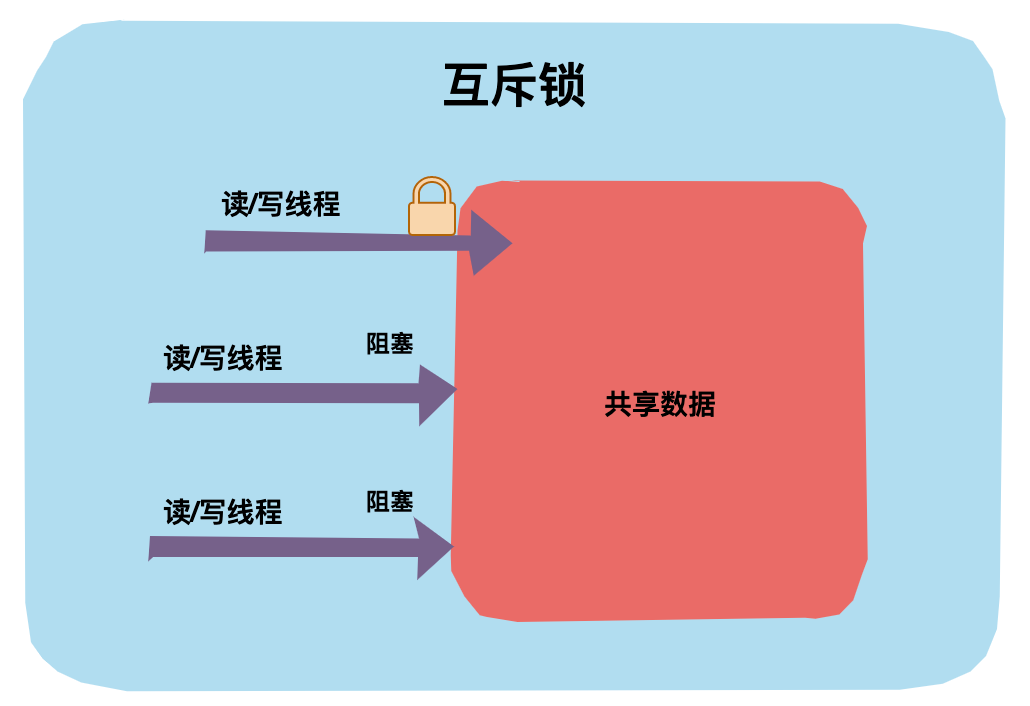 75 |
76 | 互斥锁一次只能一个线程拥有互斥锁,其他线程只有等待。
77 |
78 | **读写锁**
79 |
80 | `读写锁`是共享锁的一种具体实现。读写锁管理一组锁,一个是只读的锁,一个是写锁。
81 |
82 | 读锁可以在没有写锁的时候被多个线程同时持有,而写锁是独占的。写锁的优先级要高于读锁,一个获得了读锁的线程必须能看到前一个释放的写锁所更新的内容。
83 |
84 | 读写锁相比于互斥锁并发程度更高,每次只有一个写线程,但是同时可以有多个线程并发读。
85 |
86 |
75 |
76 | 互斥锁一次只能一个线程拥有互斥锁,其他线程只有等待。
77 |
78 | **读写锁**
79 |
80 | `读写锁`是共享锁的一种具体实现。读写锁管理一组锁,一个是只读的锁,一个是写锁。
81 |
82 | 读锁可以在没有写锁的时候被多个线程同时持有,而写锁是独占的。写锁的优先级要高于读锁,一个获得了读锁的线程必须能看到前一个释放的写锁所更新的内容。
83 |
84 | 读写锁相比于互斥锁并发程度更高,每次只有一个写线程,但是同时可以有多个线程并发读。
85 |
86 | 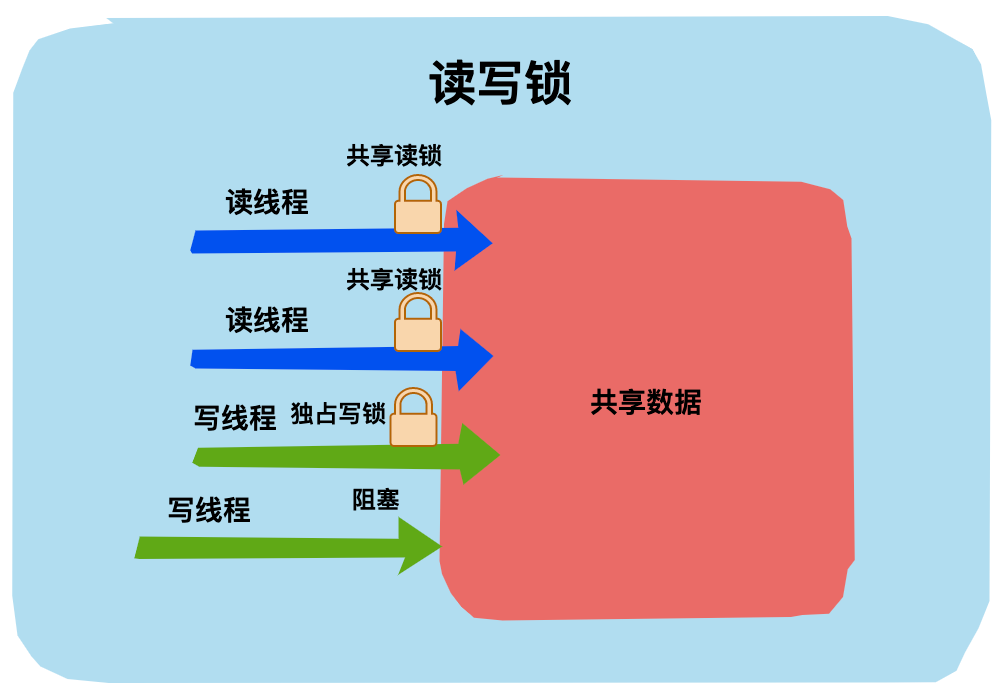 87 |
88 | 在 JDK 中定义了一个读写锁的接口:`ReadWriteLock`
89 |
90 | ```java
91 | public interface ReadWriteLock {
92 | /**
93 | * 获取读锁
94 | */
95 | Lock readLock();
96 |
97 | /**
98 | * 获取写锁
99 | */
100 | Lock writeLock();
101 | }
102 | ```
103 |
104 | `ReentrantReadWriteLock` 实现了`ReadWriteLock`接口,具体实现这里不展开,后续会深入源码解析。
105 |
106 | # 公平锁和非公平锁
107 |
108 | **公平锁**
109 |
110 | `公平锁`是指多个线程按照申请锁的顺序来获取锁,这里类似排队买票,先来的人先买,后来的人在队尾排着,这是公平的。
111 |
112 |
87 |
88 | 在 JDK 中定义了一个读写锁的接口:`ReadWriteLock`
89 |
90 | ```java
91 | public interface ReadWriteLock {
92 | /**
93 | * 获取读锁
94 | */
95 | Lock readLock();
96 |
97 | /**
98 | * 获取写锁
99 | */
100 | Lock writeLock();
101 | }
102 | ```
103 |
104 | `ReentrantReadWriteLock` 实现了`ReadWriteLock`接口,具体实现这里不展开,后续会深入源码解析。
105 |
106 | # 公平锁和非公平锁
107 |
108 | **公平锁**
109 |
110 | `公平锁`是指多个线程按照申请锁的顺序来获取锁,这里类似排队买票,先来的人先买,后来的人在队尾排着,这是公平的。
111 |
112 | 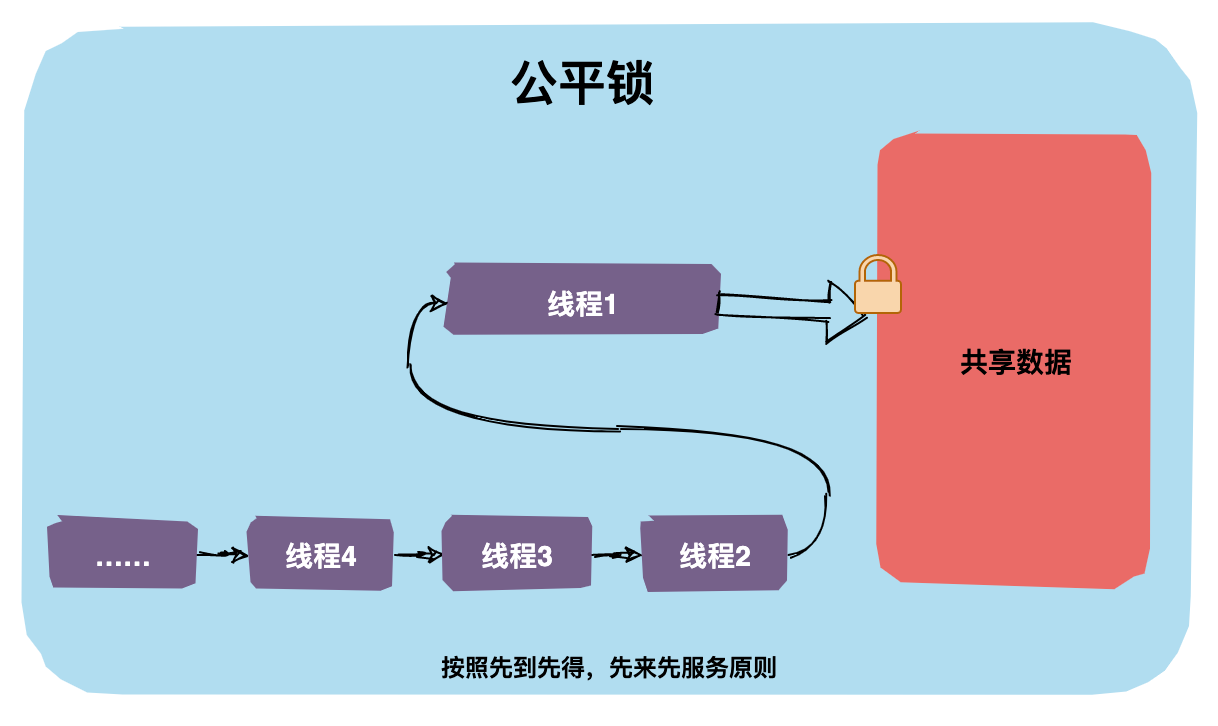 113 |
114 | 在 java 中可以通过构造函数初始化公平锁
115 |
116 | ```java
117 | /**
118 | * 创建一个可重入锁,true 表示公平锁,false 表示非公平锁。默认非公平锁
119 | */
120 | Lock lock = new ReentrantLock(true);
121 | ```
122 |
123 | **非公平锁**
124 |
125 | `非公平锁`是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁,在高并发环境下,有可能造成优先级翻转,或者饥饿的状态(某个线程一直得不到锁)。
126 |
127 |
113 |
114 | 在 java 中可以通过构造函数初始化公平锁
115 |
116 | ```java
117 | /**
118 | * 创建一个可重入锁,true 表示公平锁,false 表示非公平锁。默认非公平锁
119 | */
120 | Lock lock = new ReentrantLock(true);
121 | ```
122 |
123 | **非公平锁**
124 |
125 | `非公平锁`是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁,在高并发环境下,有可能造成优先级翻转,或者饥饿的状态(某个线程一直得不到锁)。
126 |
127 | 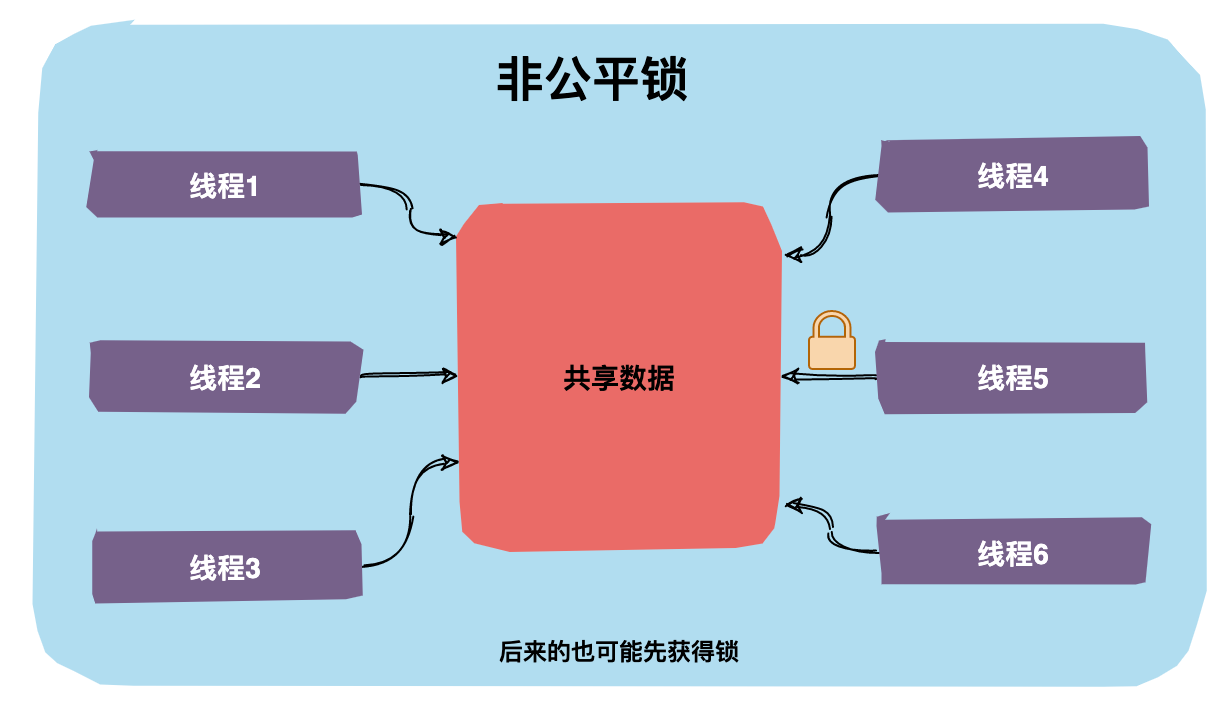 128 |
129 | 在 java 中 synchronized 关键字是非公平锁,ReentrantLock默认也是非公平锁。
130 | ```java
131 | /**
132 | * 创建一个可重入锁,true 表示公平锁,false 表示非公平锁。默认非公平锁
133 | */
134 | Lock lock = new ReentrantLock(false);
135 | ```
136 |
137 | # 可重入锁
138 |
139 | `可重入锁`又称之为`递归锁`,是指同一个线程在外层方法获取了锁,在进入内层方法会自动获取锁。
140 |
141 |
128 |
129 | 在 java 中 synchronized 关键字是非公平锁,ReentrantLock默认也是非公平锁。
130 | ```java
131 | /**
132 | * 创建一个可重入锁,true 表示公平锁,false 表示非公平锁。默认非公平锁
133 | */
134 | Lock lock = new ReentrantLock(false);
135 | ```
136 |
137 | # 可重入锁
138 |
139 | `可重入锁`又称之为`递归锁`,是指同一个线程在外层方法获取了锁,在进入内层方法会自动获取锁。
140 |
141 | 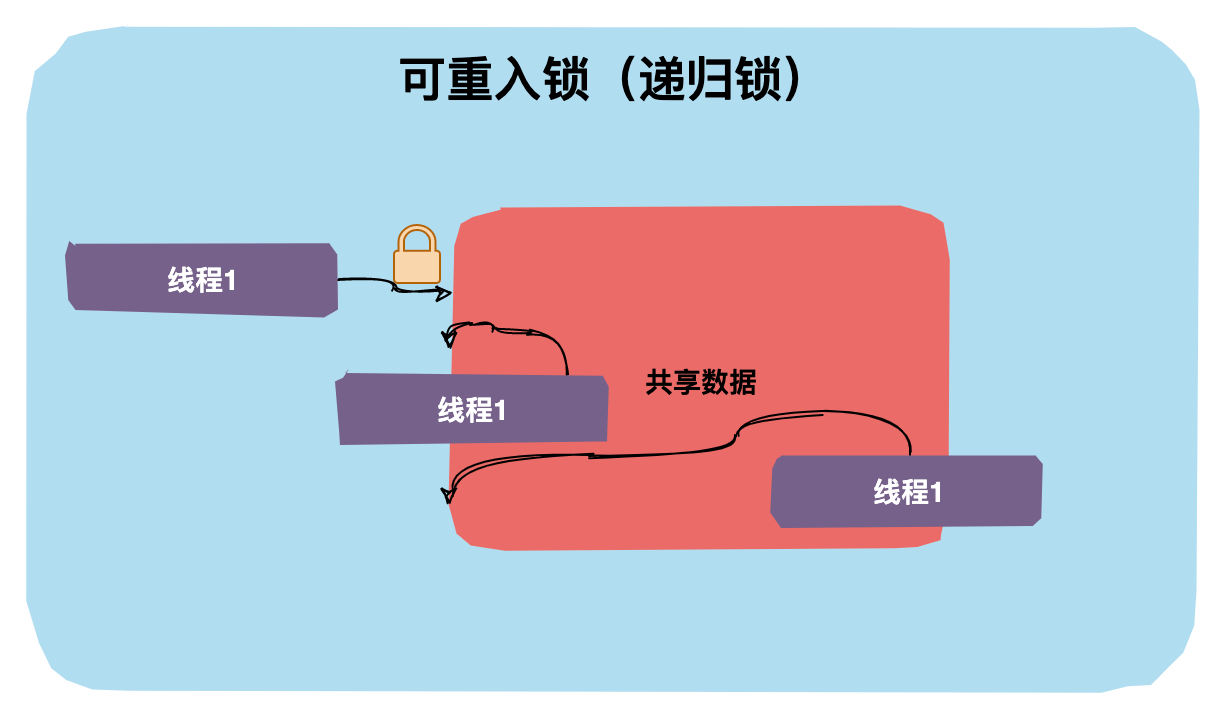 142 |
143 | 对于Java ReentrantLock而言, 他的名字就可以看出是一个可重入锁。对于Synchronized而言,也是一个可重入锁。
144 |
145 | 敲黑板:可重入锁的一个好处是可一定程度避免死锁。
146 |
147 | 以 synchronized 为例,看一下下面的代码:
148 |
149 | ```java
150 | public synchronized void mehtodA() throws Exception{
151 | // Do some magic tings
152 | mehtodB();
153 | }
154 |
155 | public synchronized void mehtodB() throws Exception{
156 | // Do some magic tings
157 | }
158 | ```
159 | 上面的代码中 methodA 调用 methodB,如果一个线程调用methodA 已经获取了锁再去调用 methodB 就不需要再次获取锁了,这就是可重入锁的特性。如果不是可重入锁的话,mehtodB 可能不会被当前线程执行,可能造成死锁。
160 |
161 | # 自旋锁
162 |
163 | `自旋锁`是指线程在没有获得锁时不是被直接挂起,而是执行一个忙循环,这个忙循环就是所谓的自旋。
164 |
165 |
142 |
143 | 对于Java ReentrantLock而言, 他的名字就可以看出是一个可重入锁。对于Synchronized而言,也是一个可重入锁。
144 |
145 | 敲黑板:可重入锁的一个好处是可一定程度避免死锁。
146 |
147 | 以 synchronized 为例,看一下下面的代码:
148 |
149 | ```java
150 | public synchronized void mehtodA() throws Exception{
151 | // Do some magic tings
152 | mehtodB();
153 | }
154 |
155 | public synchronized void mehtodB() throws Exception{
156 | // Do some magic tings
157 | }
158 | ```
159 | 上面的代码中 methodA 调用 methodB,如果一个线程调用methodA 已经获取了锁再去调用 methodB 就不需要再次获取锁了,这就是可重入锁的特性。如果不是可重入锁的话,mehtodB 可能不会被当前线程执行,可能造成死锁。
160 |
161 | # 自旋锁
162 |
163 | `自旋锁`是指线程在没有获得锁时不是被直接挂起,而是执行一个忙循环,这个忙循环就是所谓的自旋。
164 |
165 | 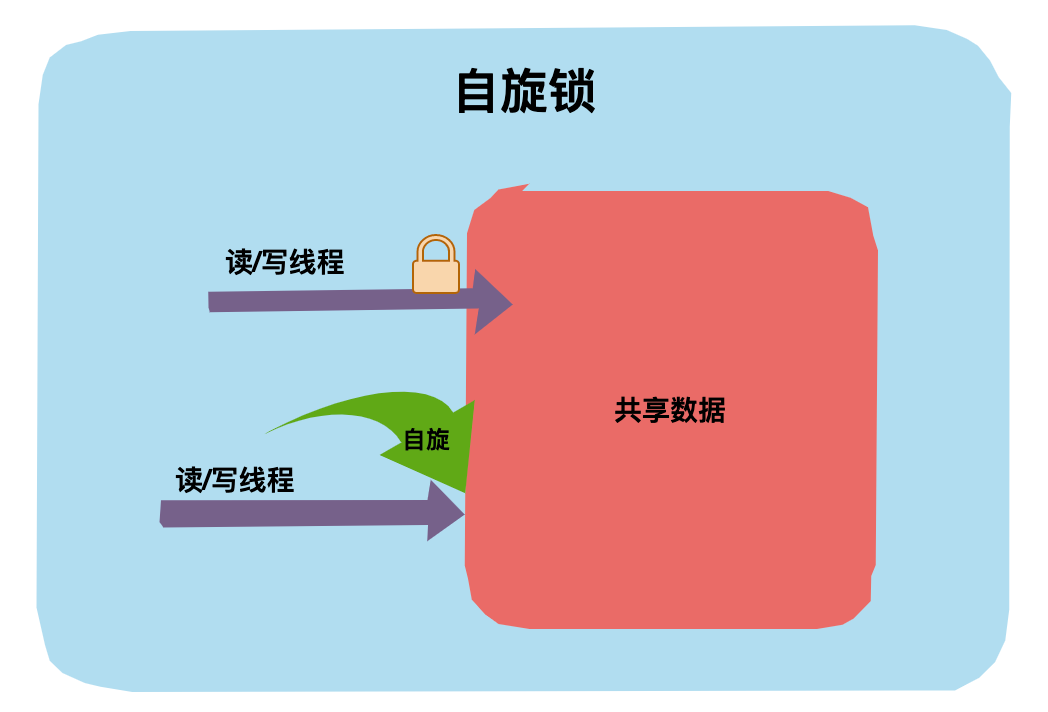 166 |
167 | 自旋锁的目的是为了减少线程被挂起的几率,因为线程的挂起和唤醒也都是耗资源的操作。
168 |
169 | 如果锁被另一个线程占用的时间比较长,即使自旋了之后当前线程还是会被挂起,忙循环就会变成浪费系统资源的操作,反而降低了整体性能。因此自旋锁是不适应锁占用时间长的并发情况的。
170 |
171 | 在 Java 中,`AtomicInteger` 类有自旋的操作,我们看一下代码:
172 | ```java
173 | public final int getAndAddInt(Object o, long offset, int delta) {
174 | int v;
175 | do {
176 | v = getIntVolatile(o, offset);
177 | } while (!compareAndSwapInt(o, offset, v, v + delta));
178 | return v;
179 | }
180 | ```
181 |
182 | CAS 操作如果失败就会一直循环获取当前 value 值然后重试。
183 |
184 | 另外自适应自旋锁也需要了解一下。
185 |
186 | 在JDK1.6又引入了自适应自旋,这个就比较智能了,自旋时间不再固定,由前一次在同一个锁上的自旋时间以及锁的拥有者的状态来决定。如果虚拟机认为这次自旋也很有可能再次成功那就会次序较多的时间,如果自旋很少成功,那以后可能就直接省略掉自旋过程,避免浪费处理器资源。
187 |
188 | # 分段锁
189 |
190 | `分段锁` 是一种锁的设计,并不是具体的一种锁。
191 |
192 | 分段锁设计目的是将锁的粒度进一步细化,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
193 |
194 |
166 |
167 | 自旋锁的目的是为了减少线程被挂起的几率,因为线程的挂起和唤醒也都是耗资源的操作。
168 |
169 | 如果锁被另一个线程占用的时间比较长,即使自旋了之后当前线程还是会被挂起,忙循环就会变成浪费系统资源的操作,反而降低了整体性能。因此自旋锁是不适应锁占用时间长的并发情况的。
170 |
171 | 在 Java 中,`AtomicInteger` 类有自旋的操作,我们看一下代码:
172 | ```java
173 | public final int getAndAddInt(Object o, long offset, int delta) {
174 | int v;
175 | do {
176 | v = getIntVolatile(o, offset);
177 | } while (!compareAndSwapInt(o, offset, v, v + delta));
178 | return v;
179 | }
180 | ```
181 |
182 | CAS 操作如果失败就会一直循环获取当前 value 值然后重试。
183 |
184 | 另外自适应自旋锁也需要了解一下。
185 |
186 | 在JDK1.6又引入了自适应自旋,这个就比较智能了,自旋时间不再固定,由前一次在同一个锁上的自旋时间以及锁的拥有者的状态来决定。如果虚拟机认为这次自旋也很有可能再次成功那就会次序较多的时间,如果自旋很少成功,那以后可能就直接省略掉自旋过程,避免浪费处理器资源。
187 |
188 | # 分段锁
189 |
190 | `分段锁` 是一种锁的设计,并不是具体的一种锁。
191 |
192 | 分段锁设计目的是将锁的粒度进一步细化,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
193 |
194 | 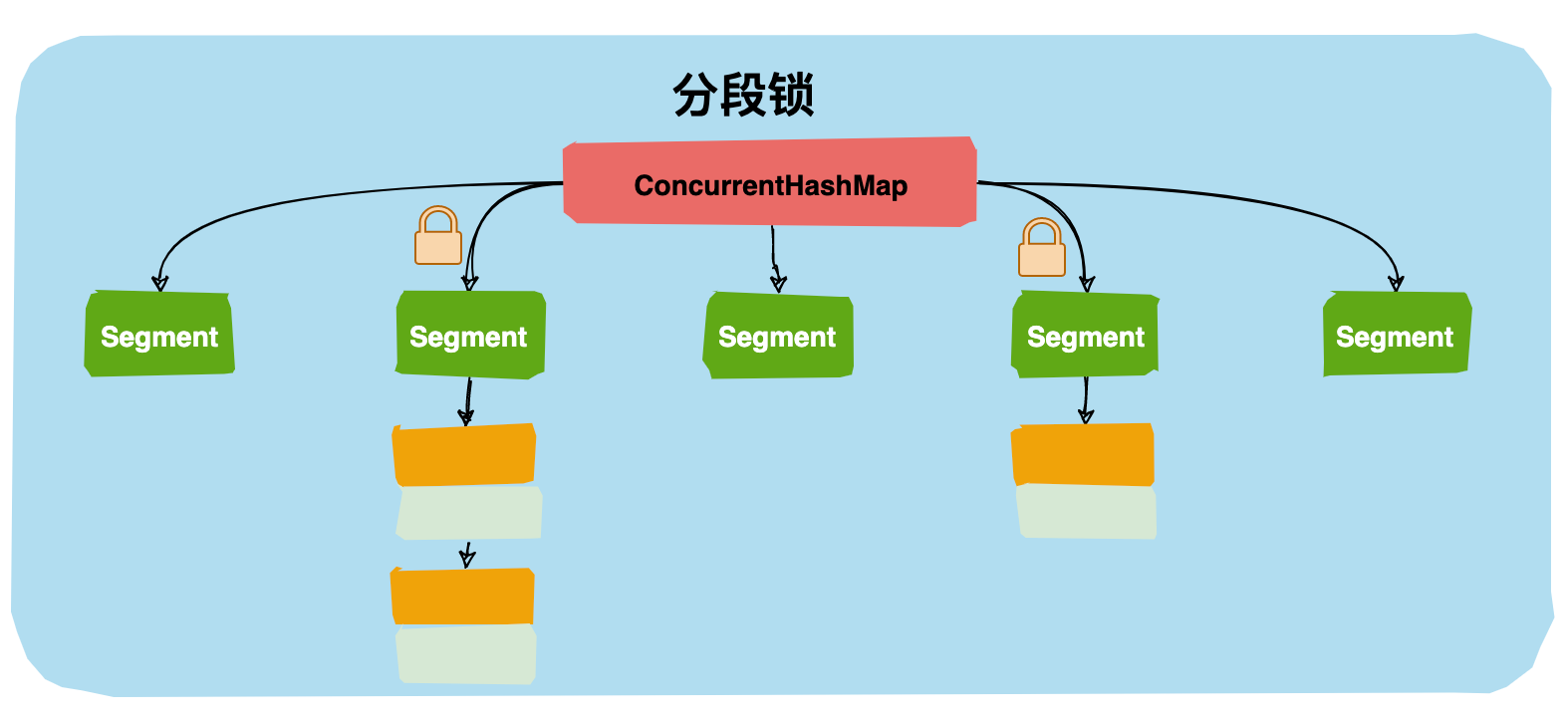 195 |
196 | 在 Java 语言中 CurrentHashMap 底层就用了分段锁,使用Segment,就可以进行并发使用了。
197 |
198 |
199 | # 锁升级(无锁|偏向锁|轻量级锁|重量级锁)
200 |
201 | JDK1.6 为了提升性能减少获得锁和释放锁所带来的消耗,引入了4种锁的状态:`无锁`、`偏向锁`、`轻量级锁`和`重量级锁`,它会随着多线程的竞争情况逐渐升级,但不能降级。
202 |
203 | **无锁**
204 |
205 | `无锁`状态其实就是上面讲的乐观锁,这里不再赘述。
206 |
207 | **偏向锁**
208 |
209 | Java偏向锁(Biased Locking)是指它会偏向于第一个访问锁的线程,如果在运行过程中,只有一个线程访问加锁的资源,不存在多线程竞争的情况,那么线程是不需要重复获取锁的,这种情况下,就会给线程加一个偏向锁。
210 |
211 | 偏向锁的实现是通过控制对象`Mark Word`的标志位来实现的,如果当前是`可偏向状态`,需要进一步判断对象头存储的线程 ID 是否与当前线程 ID 一致,如果一致直接进入。
212 |
213 | **轻量级锁**
214 |
215 | 当线程竞争变得比较激烈时,偏向锁就会升级为`轻量级锁`,轻量级锁认为虽然竞争是存在的,但是理想情况下竞争的程度很低,通过`自旋方式`等待上一个线程释放锁。
216 |
217 | **重量级锁**
218 |
219 | 如果线程并发进一步加剧,线程的自旋超过了一定次数,或者一个线程持有锁,一个线程在自旋,又来了第三个线程访问时(反正就是竞争继续加大了),轻量级锁就会膨胀为`重量级锁`,重量级锁会使除了此时拥有锁的线程以外的线程都阻塞。
220 |
221 | 升级到重量级锁其实就是互斥锁了,一个线程拿到锁,其余线程都会处于阻塞等待状态。
222 |
223 | 在 Java 中,synchronized 关键字内部实现原理就是锁升级的过程:无锁 --> 偏向锁 --> 轻量级锁 --> 重量级锁。这一过程在后续讲解 synchronized 关键字的原理时会详细介绍。
224 |
225 |
226 | # 锁优化技术(锁粗化、锁消除)
227 |
228 | **锁粗化**
229 |
230 | `锁粗化`就是将多个同步块的数量减少,并将单个同步块的作用范围扩大,本质上就是将多次上锁、解锁的请求合并为一次同步请求。
231 |
232 | 举个例子,一个循环体中有一个代码同步块,每次循环都会执行加锁解锁操作。
233 |
234 | ```java
235 | private static final Object LOCK = new Object();
236 |
237 | for(int i = 0;i < 100; i++) {
238 | synchronized(LOCK){
239 | // do some magic things
240 | }
241 | }
242 | ```
243 |
244 | 经过`锁粗化`后就变成下面这个样子了:
245 |
246 | ```java
247 | synchronized(LOCK){
248 | for(int i = 0;i < 100; i++) {
249 | // do some magic things
250 | }
251 | }
252 | ```
253 |
254 | **锁消除**
255 |
256 | `锁消除`是指虚拟机编译器在运行时检测到了共享数据没有竞争的锁,从而将这些锁进行消除。
257 |
258 | 举个例子让大家更好理解。
259 | ```java
260 | public String test(String s1, String s2){
261 | StringBuffer stringBuffer = new StringBuffer();
262 | stringBuffer.append(s1);
263 | stringBuffer.append(s2);
264 | return stringBuffer.toString();
265 | }
266 | ```
267 |
268 | 上面代码中有一个 test 方法,主要作用是将字符串 s1 和字符串 s2 串联起来。
269 |
270 | test 方法中三个变量s1, s2, stringBuffer, 它们都是局部变量,局部变量是在栈上的,栈是线程私有的,所以就算有多个线程访问 test 方法也是线程安全的。
271 |
272 | 我们都知道 StringBuffer 是线程安全的类,append 方法是同步方法,但是 test 方法本来就是线程安全的,为了提升效率,虚拟机帮我们消除了这些同步锁,这个过程就被称为`锁消除`。
273 |
274 |
275 | ```java
276 | StringBuffer.class
277 |
278 | // append 是同步方法
279 | public synchronized StringBuffer append(String str) {
280 | toStringCache = null;
281 | super.append(str);
282 | return this;
283 | }
284 | ```
285 |
286 | 一张图总结:
287 |
288 | 前面讲了 Java 语言中各种各种的锁,最后再通过六个问题统一总结一下:
289 |
290 |
195 |
196 | 在 Java 语言中 CurrentHashMap 底层就用了分段锁,使用Segment,就可以进行并发使用了。
197 |
198 |
199 | # 锁升级(无锁|偏向锁|轻量级锁|重量级锁)
200 |
201 | JDK1.6 为了提升性能减少获得锁和释放锁所带来的消耗,引入了4种锁的状态:`无锁`、`偏向锁`、`轻量级锁`和`重量级锁`,它会随着多线程的竞争情况逐渐升级,但不能降级。
202 |
203 | **无锁**
204 |
205 | `无锁`状态其实就是上面讲的乐观锁,这里不再赘述。
206 |
207 | **偏向锁**
208 |
209 | Java偏向锁(Biased Locking)是指它会偏向于第一个访问锁的线程,如果在运行过程中,只有一个线程访问加锁的资源,不存在多线程竞争的情况,那么线程是不需要重复获取锁的,这种情况下,就会给线程加一个偏向锁。
210 |
211 | 偏向锁的实现是通过控制对象`Mark Word`的标志位来实现的,如果当前是`可偏向状态`,需要进一步判断对象头存储的线程 ID 是否与当前线程 ID 一致,如果一致直接进入。
212 |
213 | **轻量级锁**
214 |
215 | 当线程竞争变得比较激烈时,偏向锁就会升级为`轻量级锁`,轻量级锁认为虽然竞争是存在的,但是理想情况下竞争的程度很低,通过`自旋方式`等待上一个线程释放锁。
216 |
217 | **重量级锁**
218 |
219 | 如果线程并发进一步加剧,线程的自旋超过了一定次数,或者一个线程持有锁,一个线程在自旋,又来了第三个线程访问时(反正就是竞争继续加大了),轻量级锁就会膨胀为`重量级锁`,重量级锁会使除了此时拥有锁的线程以外的线程都阻塞。
220 |
221 | 升级到重量级锁其实就是互斥锁了,一个线程拿到锁,其余线程都会处于阻塞等待状态。
222 |
223 | 在 Java 中,synchronized 关键字内部实现原理就是锁升级的过程:无锁 --> 偏向锁 --> 轻量级锁 --> 重量级锁。这一过程在后续讲解 synchronized 关键字的原理时会详细介绍。
224 |
225 |
226 | # 锁优化技术(锁粗化、锁消除)
227 |
228 | **锁粗化**
229 |
230 | `锁粗化`就是将多个同步块的数量减少,并将单个同步块的作用范围扩大,本质上就是将多次上锁、解锁的请求合并为一次同步请求。
231 |
232 | 举个例子,一个循环体中有一个代码同步块,每次循环都会执行加锁解锁操作。
233 |
234 | ```java
235 | private static final Object LOCK = new Object();
236 |
237 | for(int i = 0;i < 100; i++) {
238 | synchronized(LOCK){
239 | // do some magic things
240 | }
241 | }
242 | ```
243 |
244 | 经过`锁粗化`后就变成下面这个样子了:
245 |
246 | ```java
247 | synchronized(LOCK){
248 | for(int i = 0;i < 100; i++) {
249 | // do some magic things
250 | }
251 | }
252 | ```
253 |
254 | **锁消除**
255 |
256 | `锁消除`是指虚拟机编译器在运行时检测到了共享数据没有竞争的锁,从而将这些锁进行消除。
257 |
258 | 举个例子让大家更好理解。
259 | ```java
260 | public String test(String s1, String s2){
261 | StringBuffer stringBuffer = new StringBuffer();
262 | stringBuffer.append(s1);
263 | stringBuffer.append(s2);
264 | return stringBuffer.toString();
265 | }
266 | ```
267 |
268 | 上面代码中有一个 test 方法,主要作用是将字符串 s1 和字符串 s2 串联起来。
269 |
270 | test 方法中三个变量s1, s2, stringBuffer, 它们都是局部变量,局部变量是在栈上的,栈是线程私有的,所以就算有多个线程访问 test 方法也是线程安全的。
271 |
272 | 我们都知道 StringBuffer 是线程安全的类,append 方法是同步方法,但是 test 方法本来就是线程安全的,为了提升效率,虚拟机帮我们消除了这些同步锁,这个过程就被称为`锁消除`。
273 |
274 |
275 | ```java
276 | StringBuffer.class
277 |
278 | // append 是同步方法
279 | public synchronized StringBuffer append(String str) {
280 | toStringCache = null;
281 | super.append(str);
282 | return this;
283 | }
284 | ```
285 |
286 | 一张图总结:
287 |
288 | 前面讲了 Java 语言中各种各种的锁,最后再通过六个问题统一总结一下:
289 |
290 | 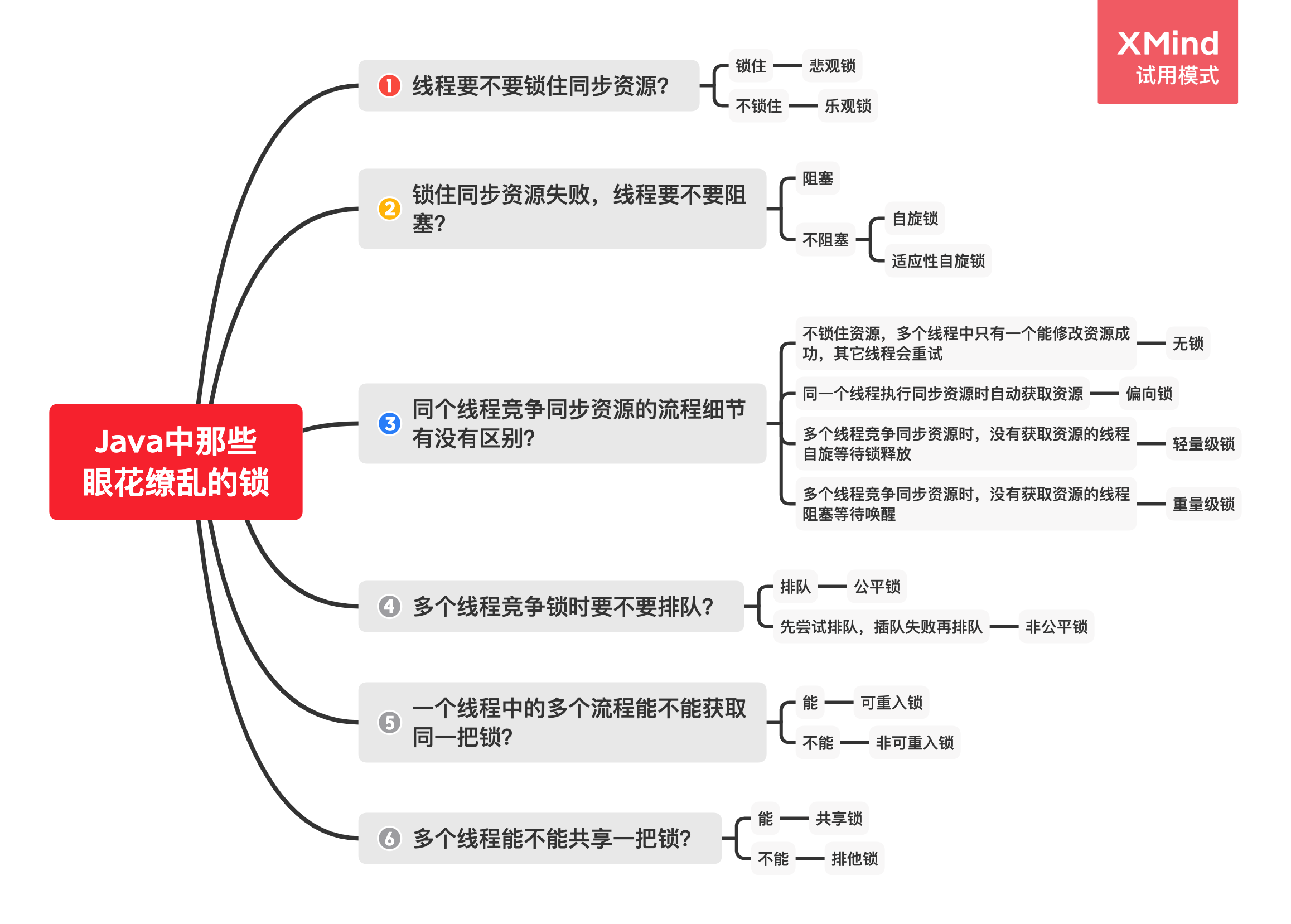 291 |
--------------------------------------------------------------------------------
/docs/java/juc/面试官:说说Atomic原子类的实现原理.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650325167&idx=1&sn=b71f86a9e25deb9a01721142fbc13902&chksm=8f09beb5b87e37a3efe9b41b2392aafdcf4ee126d4d9c4a5ecc7a39ab876f3498e2296a7e01d&token=1052638001&lang=zh_CN&scene=21#wechat_redirect)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [线程安全真的是线程的安全吗?](#线程安全真的是线程的安全吗)
6 | - [什么是 Atomic?](#什么是-atomic)
7 | - [实现一个计数器](#实现一个计数器)
8 | - [AtomicInteger 源码分析](#atomicinteger-源码分析)
9 | - [AtomicLong 和 LongAdder 谁更牛?](#atomiclong-和-longadder-谁更牛)
10 | - [总结](#总结)
11 |
12 |
13 |
14 | 当我们谈论『线程安全』的时候,肯定都会想到 Atomic 类。不错,Atomic 相关类都是线程安全的,在讲 Atomic 类之前我想再聊聊『线程安全』这个概念。
15 |
16 | # 线程安全真的是线程的安全吗?
17 |
18 | 初看『线程安全』这几个字,很容易望文生义,这不就是线程的安全吗?其实不是,线程本身没有好坏,没有『安全的线程』和『不安全的线程』之分,俗话说:人之初性本善,线程天生也是纯洁善良的,真正让线程变坏是因为访问的变量的原因,变量对于操作系统来说其实就是内存块,所以绕了这么一大圈,线程安全称为『内存的安全』可能更为贴切。
19 |
20 | 简而言之,线程访问的内存决定了这个线程是否是安全的。
21 |
22 | 变量大致可以分为**局部变量**和**共享变量**,局部变量对于 JVM 来说是栈空间,大家都背过八股文,栈是线程私有的是非共享的,那自然也是内存安全的;共享变量对于 JVM 来说一般是存在于堆上,堆上的东西是所有线程共享的,如果不加任何限制自然是不安全的。
23 |
24 | 因为线程安全这个概念已经深入人心了,所以后面我们还是用线程安全来表达内存安全的含义。
25 |
26 | 那如何解决这种`不安全`呢?方法有很多,比如:加锁、Atomic 原子类等。
27 |
28 | 好了,咱们今天先来看看`Atomic类`。
29 |
30 | # 什么是 Atomic?
31 |
32 | `Java`从`JDK1.5`开始提供`java.util.concurrent.atomic`包,这里包含了多个原子操作类。原子操作类提供了一个简单、高效、安全的方式去更新一个变量。
33 |
34 |
291 |
--------------------------------------------------------------------------------
/docs/java/juc/面试官:说说Atomic原子类的实现原理.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650325167&idx=1&sn=b71f86a9e25deb9a01721142fbc13902&chksm=8f09beb5b87e37a3efe9b41b2392aafdcf4ee126d4d9c4a5ecc7a39ab876f3498e2296a7e01d&token=1052638001&lang=zh_CN&scene=21#wechat_redirect)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [线程安全真的是线程的安全吗?](#线程安全真的是线程的安全吗)
6 | - [什么是 Atomic?](#什么是-atomic)
7 | - [实现一个计数器](#实现一个计数器)
8 | - [AtomicInteger 源码分析](#atomicinteger-源码分析)
9 | - [AtomicLong 和 LongAdder 谁更牛?](#atomiclong-和-longadder-谁更牛)
10 | - [总结](#总结)
11 |
12 |
13 |
14 | 当我们谈论『线程安全』的时候,肯定都会想到 Atomic 类。不错,Atomic 相关类都是线程安全的,在讲 Atomic 类之前我想再聊聊『线程安全』这个概念。
15 |
16 | # 线程安全真的是线程的安全吗?
17 |
18 | 初看『线程安全』这几个字,很容易望文生义,这不就是线程的安全吗?其实不是,线程本身没有好坏,没有『安全的线程』和『不安全的线程』之分,俗话说:人之初性本善,线程天生也是纯洁善良的,真正让线程变坏是因为访问的变量的原因,变量对于操作系统来说其实就是内存块,所以绕了这么一大圈,线程安全称为『内存的安全』可能更为贴切。
19 |
20 | 简而言之,线程访问的内存决定了这个线程是否是安全的。
21 |
22 | 变量大致可以分为**局部变量**和**共享变量**,局部变量对于 JVM 来说是栈空间,大家都背过八股文,栈是线程私有的是非共享的,那自然也是内存安全的;共享变量对于 JVM 来说一般是存在于堆上,堆上的东西是所有线程共享的,如果不加任何限制自然是不安全的。
23 |
24 | 因为线程安全这个概念已经深入人心了,所以后面我们还是用线程安全来表达内存安全的含义。
25 |
26 | 那如何解决这种`不安全`呢?方法有很多,比如:加锁、Atomic 原子类等。
27 |
28 | 好了,咱们今天先来看看`Atomic类`。
29 |
30 | # 什么是 Atomic?
31 |
32 | `Java`从`JDK1.5`开始提供`java.util.concurrent.atomic`包,这里包含了多个原子操作类。原子操作类提供了一个简单、高效、安全的方式去更新一个变量。
33 |
34 |  35 |
36 | Atomic 包下的原子操作类有很多,可以大致分为四种类型:
37 |
38 | - 原子操作基本类型
39 | - 原子操作数组类型
40 | - 原子操作引用类型
41 | - 原子操作更新属性
42 |
43 | Atomic原子操作类在源码中都使用了`Unsafe类`,`Unsafe类`提供了硬件级别的原子操作,可以安全地直接操作内存变量。后面讲解源码时再详细介绍。
44 |
45 | # 实现一个计数器
46 |
47 | 假如在业务代码中需要实现一个计数器的功能,啪地一下,很快我们就写出了以下的代码:
48 |
49 | ```java
50 | /**
51 | * Author: leixiaoshuai
52 | */
53 | public class Counter {
54 | private int count;
55 |
56 | public void increase() {
57 | count++;
58 | }
59 | }
60 | ```
61 |
62 | `increase`方法对 count 变量进行递增。
63 |
64 | 当代码提交上库进行`code review`时,啪地一下,很快收到了检视意见(严重级别):
65 | > 如果在多线程场景下,你的计数器可能有问题。
66 |
67 | 上大一的时候老师就讲过 `count++` 是非原子性的,它实际上包含了三个操作:读数据,加一,写回数据。
68 |
69 | 再次修改代码,多线访问`increase方法`会有问题,那就给它加个锁吧,count变量修改了其他线程可能不能即时看到,那就给变量加个 `volatile` 吧。
70 |
71 | 吭哧吭哧,代码如下:
72 |
73 | ```java
74 | /**
75 | * Author: leixiaoshuai
76 | */
77 | public class LockCounter {
78 | private volatile int count;
79 |
80 | public synchronized void increase() {
81 | count++;
82 | }
83 | }
84 | ```
85 |
86 | 一顿操作猛如虎,再次提交代码后,依然收到了检视意见(建议级别):
87 | > 加锁会影响效率,可以考虑使用原子操作类。
88 |
89 | 原子操作类?「黑人问号脸」,莫不是大佬知道我晚上有约会故意整我,不想合入代码吧。带着将信将疑的态度,打开百度谷歌,原来 AtomicInteger 可以轻松解决这个问题,手忙脚乱一顿复制粘贴代码搞定了,终于可以下班了。
90 |
91 | ```java
92 | /**
93 | * Author: leixiaoshuai
94 | */
95 | public class AtomicCounter {
96 | private AtomicInteger count = new AtomicInteger(0);
97 |
98 | public void increase() {
99 | count.incrementAndGet();
100 | }
101 | }
102 | ```
103 |
104 | # AtomicInteger 源码分析
105 |
106 | 调用`AtomicInteger类`的`incrementAndGet方法`不用加锁可以实现安全的递增,这个好神奇,下面带领大家分析一下源码是这么实现的,等不及了等不及了。
107 |
108 | 打开源码,可以看到定义的incrementAndGet方法:
109 |
110 | ```java
111 | /**
112 | * 在当前值的基础上自动加 1
113 | *
114 | * @return 更新后的值
115 | */
116 | public final int incrementAndGet() {
117 | return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
118 | }
119 | ```
120 |
121 | 通过源码可以看到实际上是调用了 unsafe 的一个方法,unsafe 是什么待会再说。
122 |
123 | 我们再看看getAndAddInt方法的参数:第一个参数 this 是当前对象的引用;第二个参数valueOffset是用来记录value值在内存中的偏移地址,第三个参数是一个常量 1;
124 |
125 | 在 AtomicInteger 中定义了一个常量`valueOffset`和一个可变的成员变量 `value`:
126 |
127 | ```java
128 | private static final Unsafe unsafe = Unsafe.getUnsafe();
129 | private static final long valueOffset;
130 |
131 | static {
132 | try {
133 | valueOffset = unsafe.objectFieldOffset
134 | (AtomicInteger.class.getDeclaredField("value"));
135 | } catch (Exception ex) { throw new Error(ex); }
136 | }
137 |
138 | private volatile int value;
139 | ```
140 |
141 | `value` 变量保存当前对象的值,`valueOffset` 是变量的内存偏移地址,也是通过调用unsafe的方法获取。
142 |
143 | ```java
144 | public final class Unsafe {
145 | // ……省略其他方法
146 |
147 | public native long objectFieldOffset(Field f);
148 | }
149 | ```
150 |
151 | 这里再说说 `Unsafe` 这个类,人如其名:不安全的类。打开 Unsafe 类会看到大部分方法都标识了 `native`,也就是说这些都是本地方法,本地方法强依赖于操作系统平台,一般都是采用`C/C++`语言编写,在调用 Unsafe 类的本地方法实际会执行这些方法,熟悉 C/C++的小伙伴可自行下载源码研究。
152 |
153 | 好了,我们再回到最开始,调用了 Unsafe 类的getAndAddInt方法:
154 |
155 | ```java
156 | public final class Unsafe {
157 | // ……省略其他方法
158 |
159 | public final int getAndAddInt(Object o, long offset, int delta) {
160 | int v;
161 | do {
162 | v = getIntVolatile(o, offset);
163 | // 循环 CAS 操作
164 | } while (!compareAndSwapInt(o, offset, v, v + delta));
165 | return v;
166 | }
167 |
168 | // 根据内存偏移地址获取当前值
169 | public native int getIntVolatile(Object o, long offset);
170 |
171 | // CAS 操作
172 | public final native boolean compareAndSwapInt(Object o, long offset,
173 | int expected,
174 | int x);
175 | }
176 | ```
177 |
178 | 通过getIntVolatile方法获取当前 AtomicInteger 对象的value值,这是一个本地方法。
179 |
180 | 然后调用compareAndSwapInt进行 CAS 原子操作,尝试在当前值的基础上加 1,如果 CAS 失败会循环进行重试。
181 |
182 | 因此compareAndSwapInt方法是最核心的,详细实现大家可以自行找源码看。这里我们看看方法的参数,一共有四个参数:o 是指当前对象;offset 是指当前对象值的内存偏移地址;expected是期望值;x是修改后的值;
183 |
184 | compareAndSwapInt方法的思路是拿到对象 o 和 offset 后会再去取对象实际的值,如果当前值与之前取的期望值是一致的就认为 value 没有被修改过,直接将 value 的值更新为 x,这样就完成了一次 CAS 操作,CAS 操作是通过操作系统保证原子性的。
185 |
186 | 如果当前值与期望值不一致,说明 value 值被修改过,那么就会重试 CAS 操作直到成功。
187 |
35 |
36 | Atomic 包下的原子操作类有很多,可以大致分为四种类型:
37 |
38 | - 原子操作基本类型
39 | - 原子操作数组类型
40 | - 原子操作引用类型
41 | - 原子操作更新属性
42 |
43 | Atomic原子操作类在源码中都使用了`Unsafe类`,`Unsafe类`提供了硬件级别的原子操作,可以安全地直接操作内存变量。后面讲解源码时再详细介绍。
44 |
45 | # 实现一个计数器
46 |
47 | 假如在业务代码中需要实现一个计数器的功能,啪地一下,很快我们就写出了以下的代码:
48 |
49 | ```java
50 | /**
51 | * Author: leixiaoshuai
52 | */
53 | public class Counter {
54 | private int count;
55 |
56 | public void increase() {
57 | count++;
58 | }
59 | }
60 | ```
61 |
62 | `increase`方法对 count 变量进行递增。
63 |
64 | 当代码提交上库进行`code review`时,啪地一下,很快收到了检视意见(严重级别):
65 | > 如果在多线程场景下,你的计数器可能有问题。
66 |
67 | 上大一的时候老师就讲过 `count++` 是非原子性的,它实际上包含了三个操作:读数据,加一,写回数据。
68 |
69 | 再次修改代码,多线访问`increase方法`会有问题,那就给它加个锁吧,count变量修改了其他线程可能不能即时看到,那就给变量加个 `volatile` 吧。
70 |
71 | 吭哧吭哧,代码如下:
72 |
73 | ```java
74 | /**
75 | * Author: leixiaoshuai
76 | */
77 | public class LockCounter {
78 | private volatile int count;
79 |
80 | public synchronized void increase() {
81 | count++;
82 | }
83 | }
84 | ```
85 |
86 | 一顿操作猛如虎,再次提交代码后,依然收到了检视意见(建议级别):
87 | > 加锁会影响效率,可以考虑使用原子操作类。
88 |
89 | 原子操作类?「黑人问号脸」,莫不是大佬知道我晚上有约会故意整我,不想合入代码吧。带着将信将疑的态度,打开百度谷歌,原来 AtomicInteger 可以轻松解决这个问题,手忙脚乱一顿复制粘贴代码搞定了,终于可以下班了。
90 |
91 | ```java
92 | /**
93 | * Author: leixiaoshuai
94 | */
95 | public class AtomicCounter {
96 | private AtomicInteger count = new AtomicInteger(0);
97 |
98 | public void increase() {
99 | count.incrementAndGet();
100 | }
101 | }
102 | ```
103 |
104 | # AtomicInteger 源码分析
105 |
106 | 调用`AtomicInteger类`的`incrementAndGet方法`不用加锁可以实现安全的递增,这个好神奇,下面带领大家分析一下源码是这么实现的,等不及了等不及了。
107 |
108 | 打开源码,可以看到定义的incrementAndGet方法:
109 |
110 | ```java
111 | /**
112 | * 在当前值的基础上自动加 1
113 | *
114 | * @return 更新后的值
115 | */
116 | public final int incrementAndGet() {
117 | return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
118 | }
119 | ```
120 |
121 | 通过源码可以看到实际上是调用了 unsafe 的一个方法,unsafe 是什么待会再说。
122 |
123 | 我们再看看getAndAddInt方法的参数:第一个参数 this 是当前对象的引用;第二个参数valueOffset是用来记录value值在内存中的偏移地址,第三个参数是一个常量 1;
124 |
125 | 在 AtomicInteger 中定义了一个常量`valueOffset`和一个可变的成员变量 `value`:
126 |
127 | ```java
128 | private static final Unsafe unsafe = Unsafe.getUnsafe();
129 | private static final long valueOffset;
130 |
131 | static {
132 | try {
133 | valueOffset = unsafe.objectFieldOffset
134 | (AtomicInteger.class.getDeclaredField("value"));
135 | } catch (Exception ex) { throw new Error(ex); }
136 | }
137 |
138 | private volatile int value;
139 | ```
140 |
141 | `value` 变量保存当前对象的值,`valueOffset` 是变量的内存偏移地址,也是通过调用unsafe的方法获取。
142 |
143 | ```java
144 | public final class Unsafe {
145 | // ……省略其他方法
146 |
147 | public native long objectFieldOffset(Field f);
148 | }
149 | ```
150 |
151 | 这里再说说 `Unsafe` 这个类,人如其名:不安全的类。打开 Unsafe 类会看到大部分方法都标识了 `native`,也就是说这些都是本地方法,本地方法强依赖于操作系统平台,一般都是采用`C/C++`语言编写,在调用 Unsafe 类的本地方法实际会执行这些方法,熟悉 C/C++的小伙伴可自行下载源码研究。
152 |
153 | 好了,我们再回到最开始,调用了 Unsafe 类的getAndAddInt方法:
154 |
155 | ```java
156 | public final class Unsafe {
157 | // ……省略其他方法
158 |
159 | public final int getAndAddInt(Object o, long offset, int delta) {
160 | int v;
161 | do {
162 | v = getIntVolatile(o, offset);
163 | // 循环 CAS 操作
164 | } while (!compareAndSwapInt(o, offset, v, v + delta));
165 | return v;
166 | }
167 |
168 | // 根据内存偏移地址获取当前值
169 | public native int getIntVolatile(Object o, long offset);
170 |
171 | // CAS 操作
172 | public final native boolean compareAndSwapInt(Object o, long offset,
173 | int expected,
174 | int x);
175 | }
176 | ```
177 |
178 | 通过getIntVolatile方法获取当前 AtomicInteger 对象的value值,这是一个本地方法。
179 |
180 | 然后调用compareAndSwapInt进行 CAS 原子操作,尝试在当前值的基础上加 1,如果 CAS 失败会循环进行重试。
181 |
182 | 因此compareAndSwapInt方法是最核心的,详细实现大家可以自行找源码看。这里我们看看方法的参数,一共有四个参数:o 是指当前对象;offset 是指当前对象值的内存偏移地址;expected是期望值;x是修改后的值;
183 |
184 | compareAndSwapInt方法的思路是拿到对象 o 和 offset 后会再去取对象实际的值,如果当前值与之前取的期望值是一致的就认为 value 没有被修改过,直接将 value 的值更新为 x,这样就完成了一次 CAS 操作,CAS 操作是通过操作系统保证原子性的。
185 |
186 | 如果当前值与期望值不一致,说明 value 值被修改过,那么就会重试 CAS 操作直到成功。
187 | 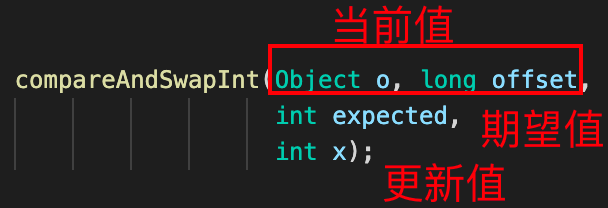 188 |
189 | AtomicInteger类中还有很多其他的方法,如:
190 |
191 | ```java
192 | decrementAndGet()
193 | getAndDecrement()
194 | getAndIncrement()
195 | accumulateAndGet()
196 | // …… 省略
197 | ```
198 |
199 | 这些方法实现原理都是大同小异,希望大家可以举一反三理解其他的方法。
200 |
201 | 另外还有一些其他的类,如:`AtomicLong`,`AtomicReference`,`AtomicIntegerArray`等,这里也不再赘述,原理都是大同小异。
202 |
203 | # AtomicLong 和 LongAdder 谁更牛?
204 |
205 | Java 在 `jdk1.8版本` 引入了 `LongAdder` 类,与 `AtomicLong` 一样可以实现加、减、递增、递减等线程安全操作,但是在高并发竞争非常激烈的场景下 `LongAdder` 的效率更胜一筹,后续单独用一篇文章进行介绍。
206 |
207 | # 总结
208 |
209 | 讲了半天,可能有的小伙伴还是比较懵,Atomic 类到底是如何实现线程安全的?
210 |
211 | 在语言层面上,Atomic 类是没有做任何同步操作的,翻看源代码方法没有任何加锁,其实最大功劳还是在 CAS 身上。CAS 利用操作系统的硬件特性实现了原子性,利用 CPU 多核能力实现了硬件层面的阻塞。
212 |
213 | 只有 CAS 的原子性保证就一定是线程安全的吗?当然不是的,通过源码发现 value 变量还用了 volatile 修饰了,保证了线程可见性。
214 |
215 | 那有些小伙伴可能要问了,那是不是加锁就没有用了,非也,虽然基于 CAS 的线程安全机制很好很高效,但是这适合一些粒度比较小的需求才有效,如果遇到非常复杂的业务逻辑还是需要加锁操作的。
216 |
217 | 大家学会了吗?
218 |
219 |
220 |
--------------------------------------------------------------------------------
/docs/java/juc/面试官:说说什么是Java内存模型?.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650324686&idx=1&sn=0f177ea0b3cbe6da00a4e8b0a46ee22c&chksm=8f09c0d4b87e49c2d98b428b3b42e70550905f36dfcf63a304743d3df88ddcd518501df60b65&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [1. 为什么要有内存模型?](#1-为什么要有内存模型)
6 | - [1.1. 硬件内存架构](#11-硬件内存架构)
7 | - [1.2. 缓存一致性问题](#12-缓存一致性问题)
8 | - [1.3. 处理器优化和指令重排序](#13-处理器优化和指令重排序)
9 | - [2. 并发编程的问题](#2-并发编程的问题)
10 | - [3. Java 内存模型](#3-java-内存模型)
11 | - [3.1. Java 运行时内存区域与硬件内存的关系](#31-java-运行时内存区域与硬件内存的关系)
12 | - [3.2. Java 线程与主内存的关系](#32-java-线程与主内存的关系)
13 | - [3.3. 线程间通信](#33-线程间通信)
14 | - [4. 有态度的总结](#4-有态度的总结)
15 |
16 |
17 |
18 | 在面试中,面试官经常喜欢问:『说说什么是Java内存模型(JMM)?』
19 |
20 | 面试者内心狂喜,这题刚背过:『Java内存主要分为五大块:堆、方法区、虚拟机栈、本地方法栈、PC寄存器,balabala……』
21 |
22 | 面试官会心一笑,露出一道光芒:『好了,今天的面试先到这里了,回去等通知吧』
23 |
24 | 一般听到等通知这句话,这场面试大概率就是凉凉了。为什么呢?因为面试者弄错了概念,面试官是想考察JMM,但是面试者一听到`Java内存`这几个关键字就开始背诵八股文了。Java内存模型(JMM)和Java运行时内存区域区别可大了呢,不要走开接着往下看,答应我要看完。
25 |
26 | # 1. 为什么要有内存模型?
27 |
28 | 要想回答这个问题,我们需要先弄懂传统计算机硬件内存架构。好了,我要开始画图了。
29 |
30 | ## 1.1. 硬件内存架构
31 |
32 | 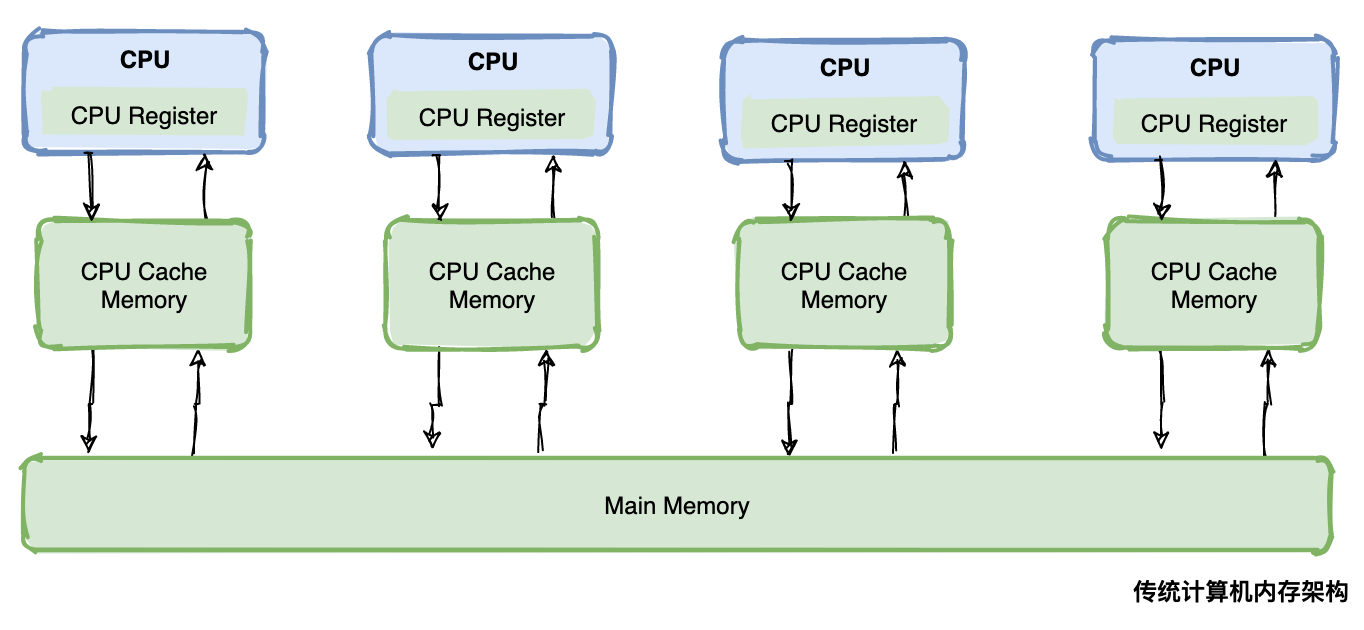
33 |
34 | (1)CPU
35 |
36 | 去过机房的同学都知道,一般在大型服务器上会配置多个CPU,每个CPU还会有多个`核`,这就意味着多个CPU或者多个核可以同时(并发)工作。如果使用Java 起了一个多线程的任务,很有可能每个 CPU 都会跑一个线程,那么你的任务在某一刻就是真正并发执行了。
37 |
38 | (2)CPU Register
39 |
40 | CPU Register也就是 CPU 寄存器。CPU 寄存器是 CPU 内部集成的,在寄存器上执行操作的效率要比在主存上高出几个数量级。
41 |
42 | (3)CPU Cache Memory
43 |
44 | CPU Cache Memory也就是 CPU 高速缓存,相对于寄存器来说,通常也可以成为 L2 二级缓存。相对于硬盘读取速度来说内存读取的效率非常高,但是与 CPU 还是相差数量级,所以在 CPU 和主存间引入了多级缓存,目的是为了做一下缓冲。
45 |
46 | (4)Main Memory
47 |
48 | Main Memory 就是主存,主存比 L1、L2 缓存要大很多。
49 |
50 | 注意:部分高端机器还有 L3 三级缓存。
51 |
52 | ## 1.2. 缓存一致性问题
53 |
54 | 由于主存与 CPU 处理器的运算能力之间有数量级的差距,所以在传统计算机内存架构中会引入高速缓存来作为主存和处理器之间的缓冲,CPU 将常用的数据放在高速缓存中,运算结束后 CPU 再讲运算结果同步到主存中。
55 |
56 | 使用高速缓存解决了 CPU 和主存速率不匹配的问题,但同时又引入另外一个新问题:缓存一致性问题。
57 |
58 | 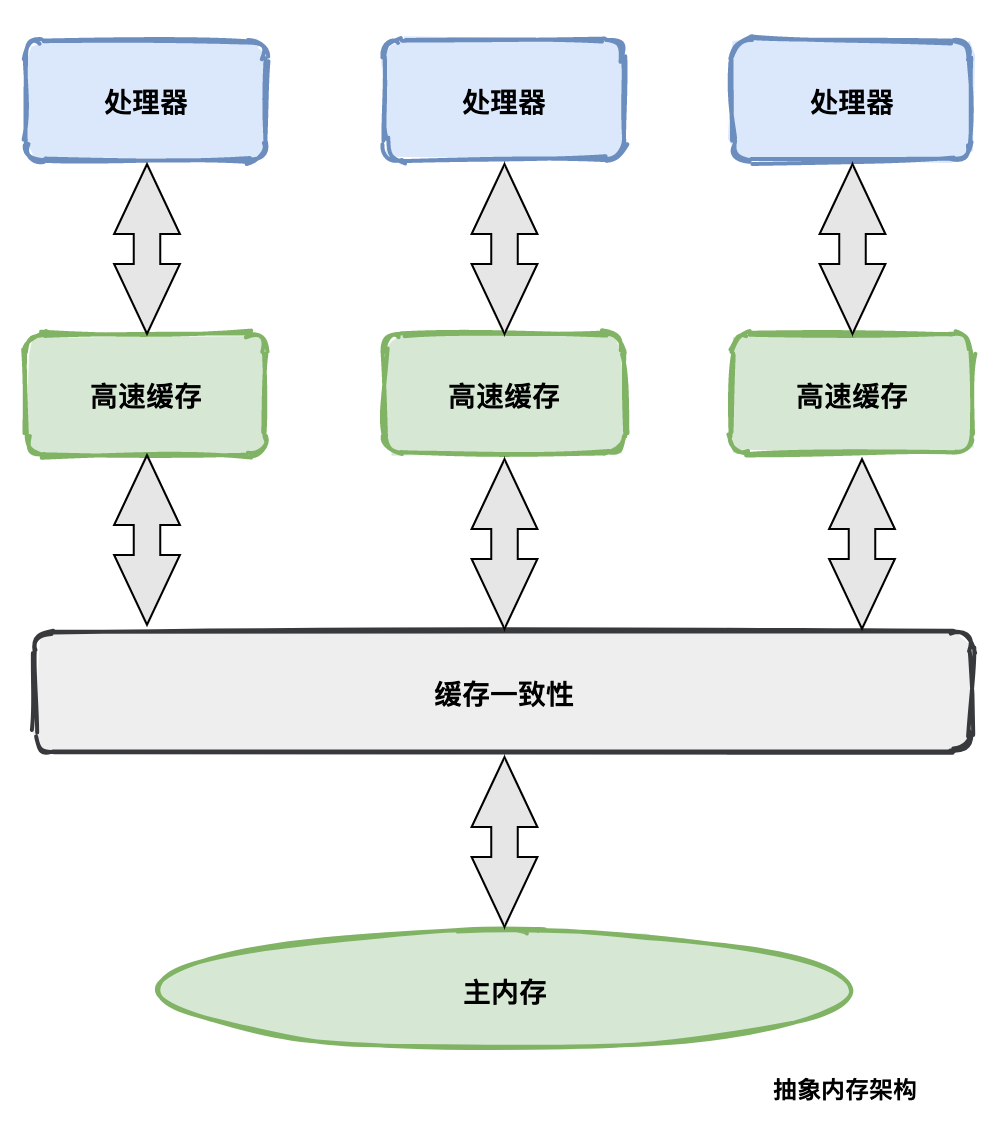
59 |
60 | 在多CPU的系统中(或者单CPU多核的系统),每个CPU内核都有自己的高速缓存,它们共享同一主内存(Main Memory)。当多个CPU的运算任务都涉及同一块主内存区域时,CPU 会将数据读取到缓存中进行运算,这可能会导致各自的缓存数据不一致。
61 |
62 | 因此需要每个 CPU 访问缓存时遵循一定的协议,在读写数据时根据协议进行操作,共同来维护缓存的一致性。这类协议有 MSI、MESI、MOSI、和 Dragon Protocol 等。
63 |
64 | ## 1.3. 处理器优化和指令重排序
65 |
66 | 为了提升性能在 CPU 和主内存之间增加了高速缓存,但在多线程并发场景可能会遇到`缓存一致性问题`。那还有没有办法进一步提升 CPU 的执行效率呢?答案是:处理器优化。
67 |
68 | > 为了使处理器内部的运算单元能够最大化被充分利用,处理器会对输入代码进行乱序执行处理,这就是处理器优化。
69 |
70 | 除了处理器会对代码进行优化处理,很多现代编程语言的编译器也会做类似的优化,比如像 Java 的即时编译器(JIT)会做指令重排序。
71 |
72 | 
73 |
74 | > 处理器优化其实也是重排序的一种类型,这里总结一下,重排序可以分为三种类型:
75 | >
76 | > - 编译器优化的重排序。编译器在不改变单线程程序语义放入前提下,可以重新安排语句的执行顺序。
77 | > - 指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
78 | > - 内存系统的重排序。由于处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
79 |
80 | # 2. 并发编程的问题
81 |
82 | 上面讲了一堆硬件相关的东西,有些同学可能会有点懵,绕了这么大圈,这些东西跟 Java 内存模型有啥关系吗?不要急咱们慢慢往下看。
83 |
84 | 熟悉 Java 并发的同学肯定对这三个问题很熟悉:『可见性问题』、『原子性问题』、『有序性问题』。如果从更深层次看这三个问题,其实就是上面讲的『缓存一致性』、『处理器优化』、『指令重排序』造成的。
85 |
86 | 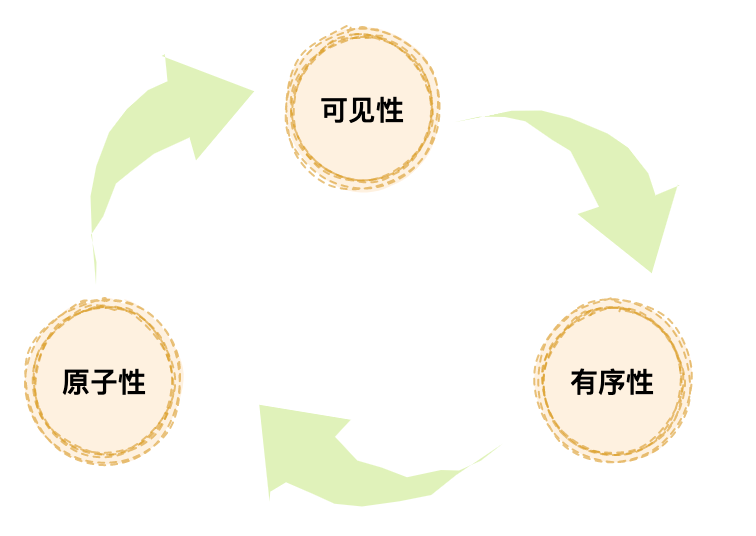
87 |
88 | 缓存一致性问题其实就是可见性问题,处理器优化可能会造成原子性问题,指令重排序会造成有序性问题,你看是不是都联系上了。
89 |
90 | 出了问题总是要解决的,那有什么办法呢?首先想到简单粗暴的办法,干掉缓存让 CPU 直接与主内存交互就解决了可见性问题,禁止处理器优化和指令重排序就解决了原子性和有序性问题,但这样一夜回到解放前了,显然不可取。
91 |
92 | 所以技术前辈们想到了在物理机器上定义出一套内存模型, 规范内存的读写操作。内存模型解决并发问题主要采用两种方式:`限制处理器优化`和`使用内存屏障`。
93 |
94 | # 3. Java 内存模型
95 |
96 | 同一套内存模型规范,不同语言在实现上可能会有些差别。接下来着重讲一下 Java 内存模型实现原理。
97 |
98 | ## 3.1. Java 运行时内存区域与硬件内存的关系
99 |
100 | 了解过 JVM 的同学都知道,JVM 运行时内存区域是分片的,分为栈、堆等,其实这些都是 JVM 定义的逻辑概念。在传统的硬件内存架构中是没有栈和堆这种概念。
101 |
102 | 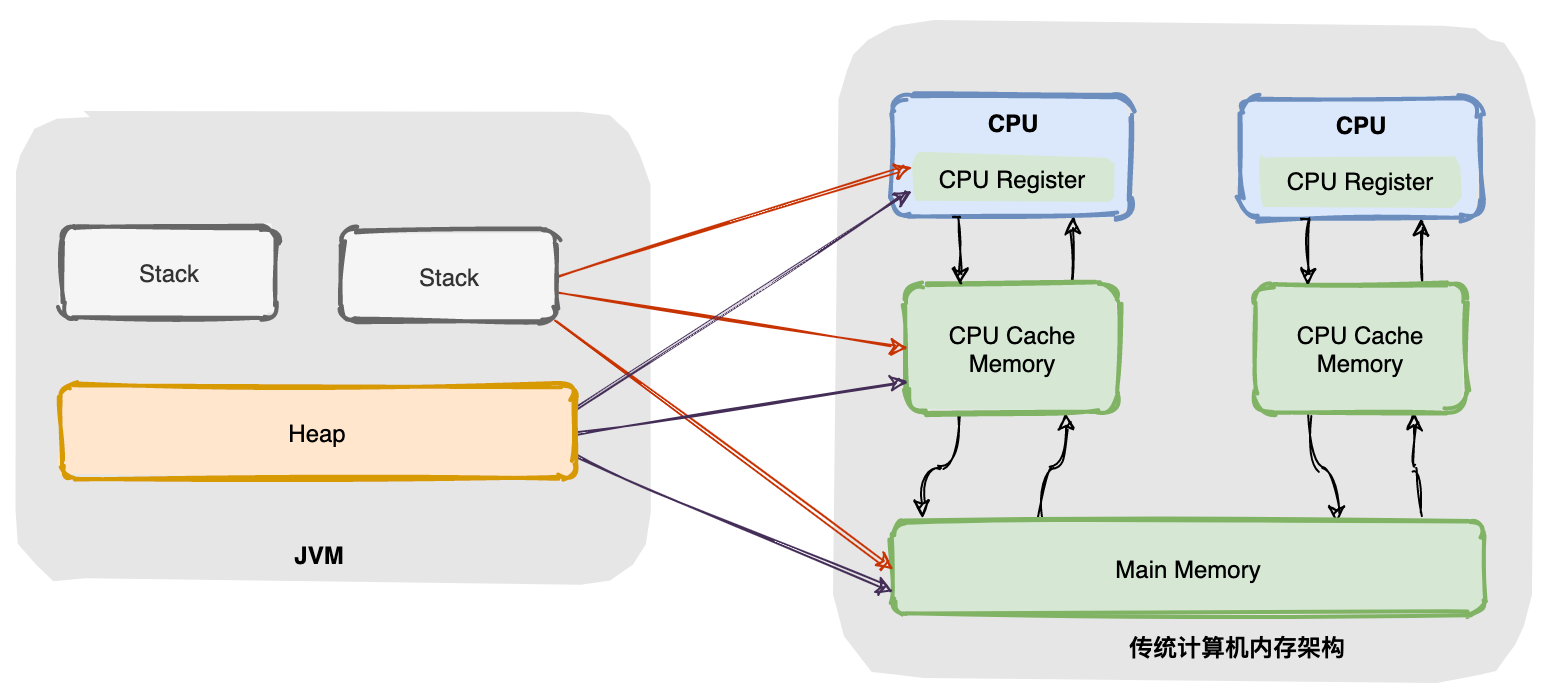
103 |
104 | 从图中可以看出栈和堆既存在于高速缓存中又存在于主内存中,所以两者并没有很直接的关系。
105 |
106 | ## 3.2. Java 线程与主内存的关系
107 |
108 | Java 内存模型是一种规范,定义了很多东西:
109 |
110 | - 所有的变量都存储在主内存(Main Memory)中。
111 | - 每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的拷贝副本。
112 | - 线程对变量的所有操作都必须在本地内存中进行,而不能直接读写主内存。
113 | - 不同的线程之间无法直接访问对方本地内存中的变量。
114 |
115 | 看文字太枯燥了,我又画了一张图:
116 |
117 | 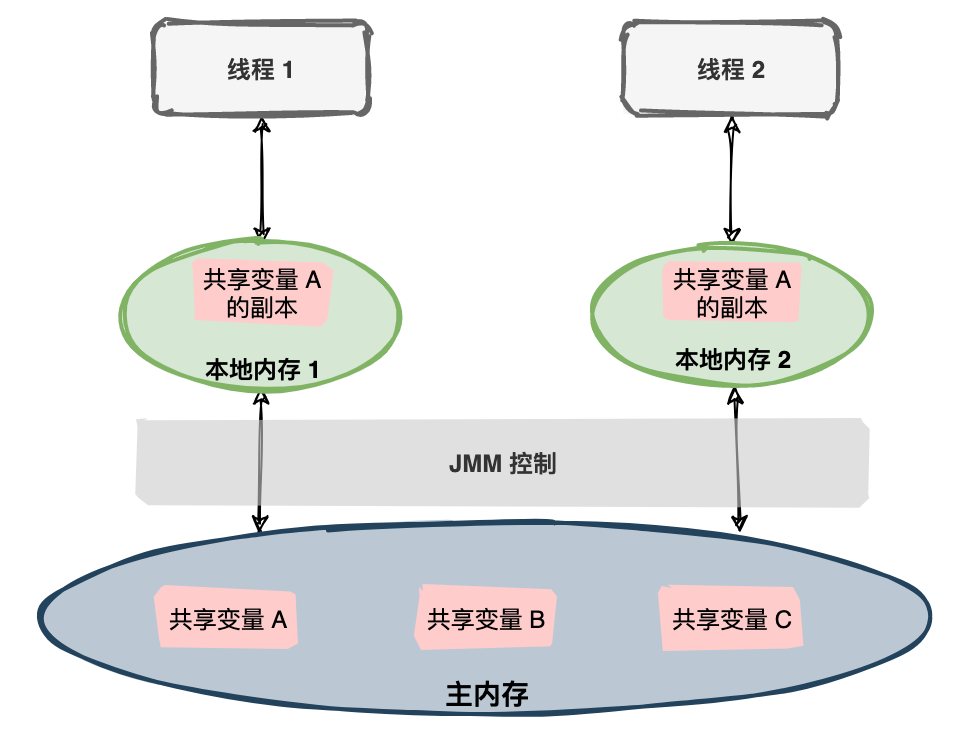
118 |
119 | ## 3.3. 线程间通信
120 |
121 | 如果两个线程都对一个共享变量进行操作,共享变量初始值为 1,每个线程都变量进行加 1,预期共享变量的值为 3。在 JMM 规范下会有一系列的操作。
122 |
123 | 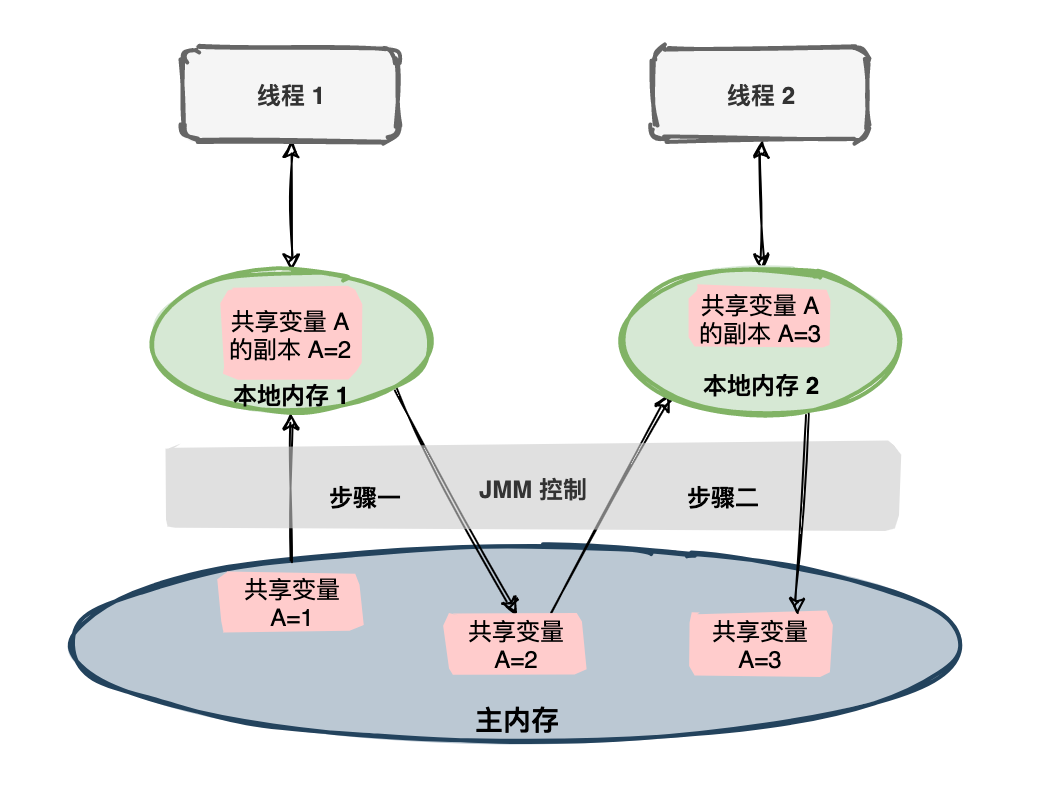
124 |
125 | 为了更好的控制主内存和本地内存的交互,Java 内存模型定义了八种操作来实现:
126 |
127 | - lock:锁定。作用于主内存的变量,把一个变量标识为一条线程独占状态。
128 | - unlock:解锁。作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
129 | - read:读取。作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
130 | - load:载入。作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
131 | - use:使用。作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
132 | - assign:赋值。作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
133 | - store:存储。作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
134 | - write:写入。作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
135 |
136 | > 注意:工作内存也就是本地内存的意思。
137 |
138 | # 4. 有态度的总结
139 |
140 | 由于CPU 和主内存间存在数量级的速率差,想到了引入了多级高速缓存的传统硬件内存架构来解决,多级高速缓存作为 CPU 和主内间的缓冲提升了整体性能。解决了速率差的问题,却又带来了缓存一致性问题。
141 |
142 | 数据同时存在于高速缓存和主内存中,如果不加以规范势必造成灾难,因此在传统机器上又抽象出了内存模型。
143 |
144 | Java 语言在遵循内存模型的基础上推出了 JMM 规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。
145 |
146 | 为了更精准控制工作内存和主内存间的交互,JMM 还定义了八种操作:`lock`, `unlock`, `read`, `load`,` use`,` assign`, `store`, `write`。
147 |
148 | -- End --
149 |
150 | 关于Java 内存模型还有很多东西没有展开讲,比如说:`内存屏障`、`happens-before`、`锁机制`、`CAS`等等。要肝一个系列了,加油!
151 |
152 | 我是雷小帅,大家有任何疑问、建议、想法欢迎在留言区套路,最后『求在看』、『求赞』、『求转发』,下期见~
--------------------------------------------------------------------------------
/docs/java/juc/面试必问的CAS原理你会了吗.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650324759&idx=1&sn=11908655d1388b44a61904a175a3a09a&chksm=8f09c10db87e481b025e620ecf86bd14ce4ab8b979264a12ac1e63de2e10eaae95eff2e3bf32&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [1. 什么是 CAS?](#1-什么是-cas)
6 | - [2. CAS 基本原理](#2-cas-基本原理)
7 | - [3. CAS 在 Java 语言中的应用](#3-cas-在-java-语言中的应用)
8 | - [4. CAS 的问题](#4-cas-的问题)
9 | - [4.1. 典型 ABA 问题](#41-典型-aba-问题)
10 | - [4.2. 自旋开销问题](#42-自旋开销问题)
11 | - [4.3. 只能保证单个变量的原子性](#43-只能保证单个变量的原子性)
12 | - [5. 有态度的总结](#5-有态度的总结)
13 |
14 |
15 |
16 | 在并发编程中我们都知道`i++`操作是非线程安全的,这是因为 `i++`操作不是原子操作。
17 |
18 | 如何保证原子性呢?常用的方法就是`加锁`。在Java语言中可以使用 `Synchronized`和`CAS`实现加锁效果。
19 |
20 | `Synchronized`是悲观锁,线程开始执行第一步就是获取锁,一旦获得锁,其他的线程进入后就会阻塞等待锁。如果不好理解,举个生活中的例子:一个人进入厕所后首先把门锁上(获取锁),然后开始上厕所,这个时候有其他人来了只能在外面等(阻塞),就算再急也没用。上完厕所完事后把门打开(解锁),其他人就可以进入了。
21 |
22 | 
23 |
24 | `CAS`是乐观锁,线程执行的时候不会加锁,假设没有冲突去完成某项操作,如果因为冲突失败了就重试,最后直到成功为止。
25 |
26 | # 1. 什么是 CAS?
27 |
28 | CAS(Compare-And-Swap)是`比较并交换`的意思,它是一条 CPU 并发原语,用于判断内存中某个值是否为预期值,如果是则更改为新的值,这个过程是`原子`的。下面用一个小示例解释一下。
29 |
30 | CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,计算后要修改后的新值B。
31 |
32 | (1)初始状态:在内存地址V中存储着变量值为 1。
33 |
34 | 
35 |
36 | (2)线程1想要把内存地址为 V 的变量值增加1。这个时候对线程1来说,旧的预期值A=1,要修改的新值B=2。
37 |
38 | 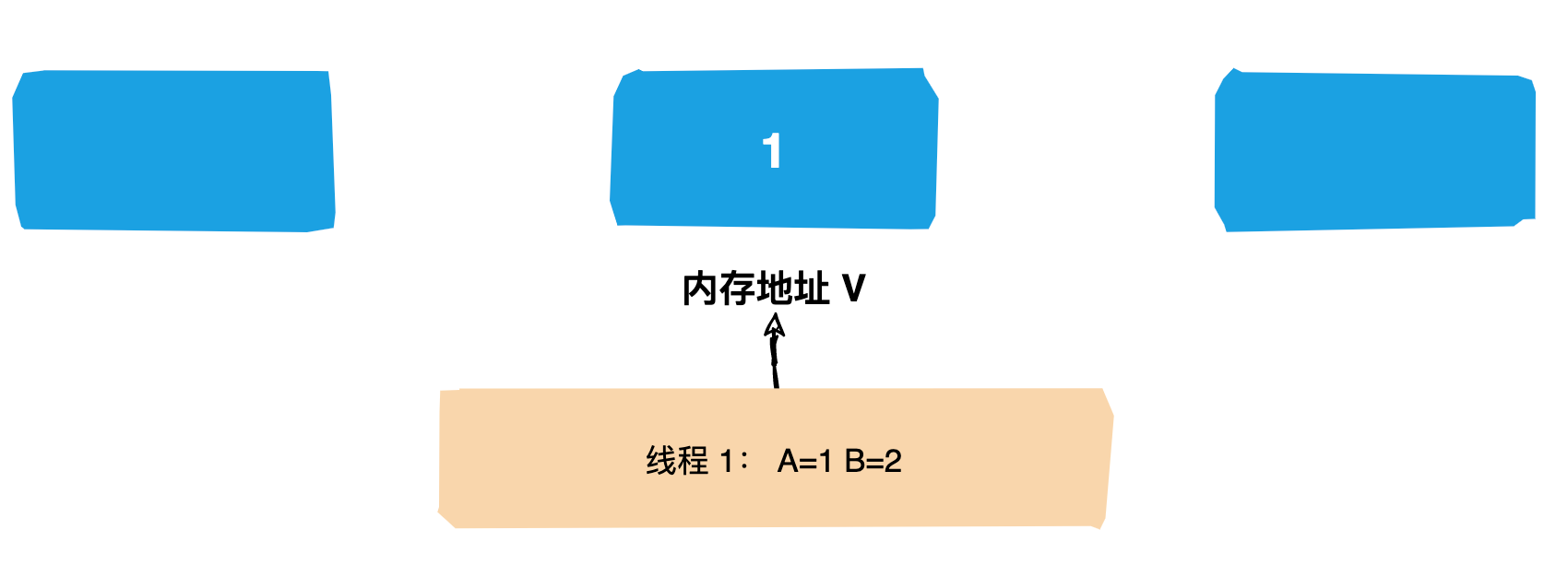
39 |
40 | (3)在线程1要提交更新之前,线程2捷足先登了,已经把内存地址V中的变量值率先更新成了2。
41 |
42 | 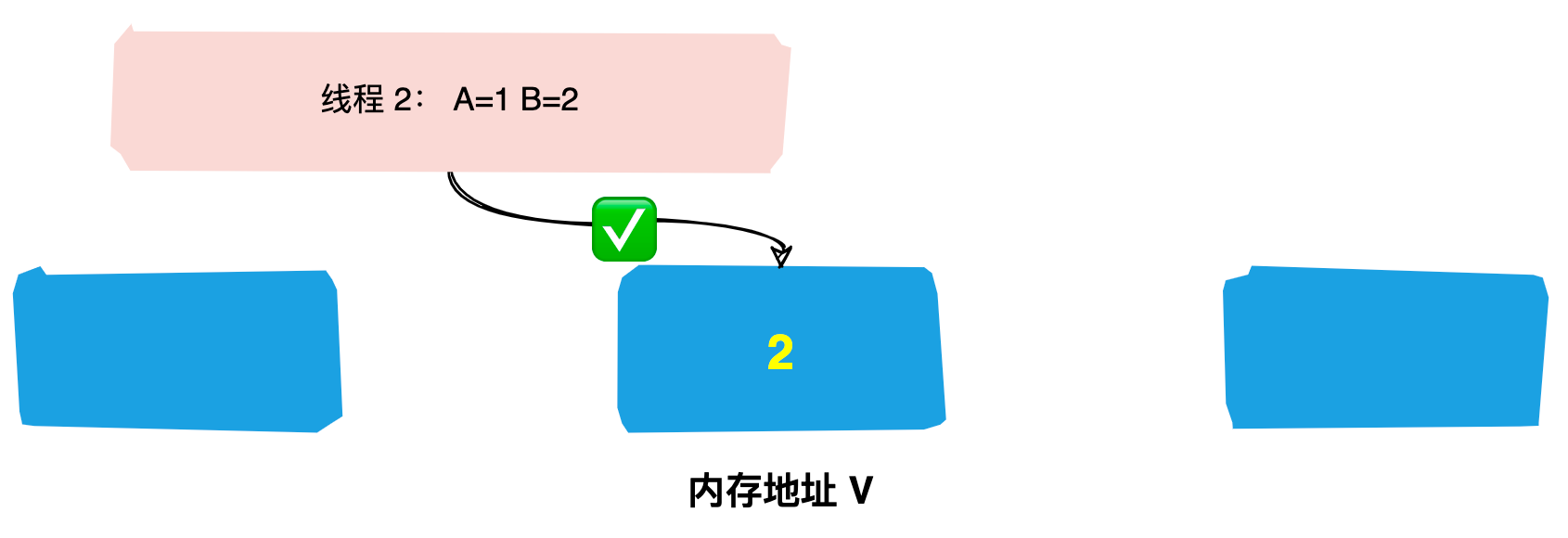
43 |
44 | (4)线程1开始提交更新,首先将预期值A和内存地址V的实际值比较(Compare),发现A不等于V的实际值,提交失败。
45 |
46 | 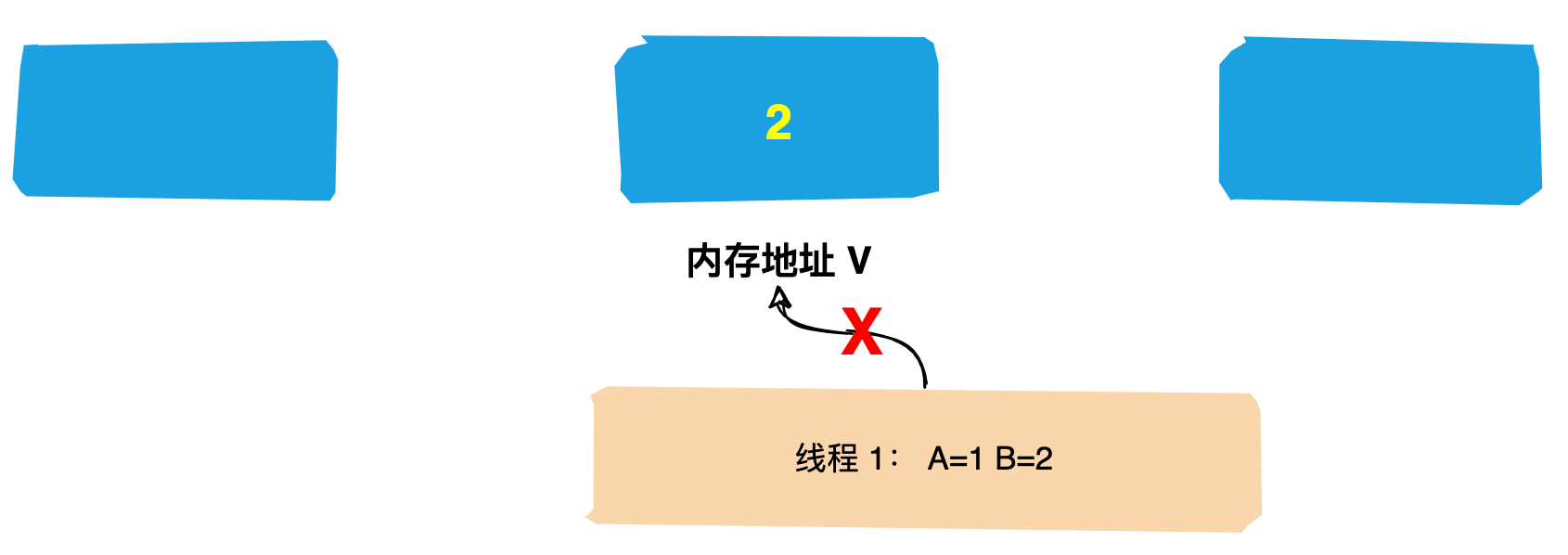
47 |
48 | (5)线程1重新获取内存地址 V 的当前值,并重新计算想要修改的新值。此时对线程1来说,A=2,B=3。这个重新尝试的过程被称为`自旋`。如果多次失败会有多次自旋。
49 |
50 | 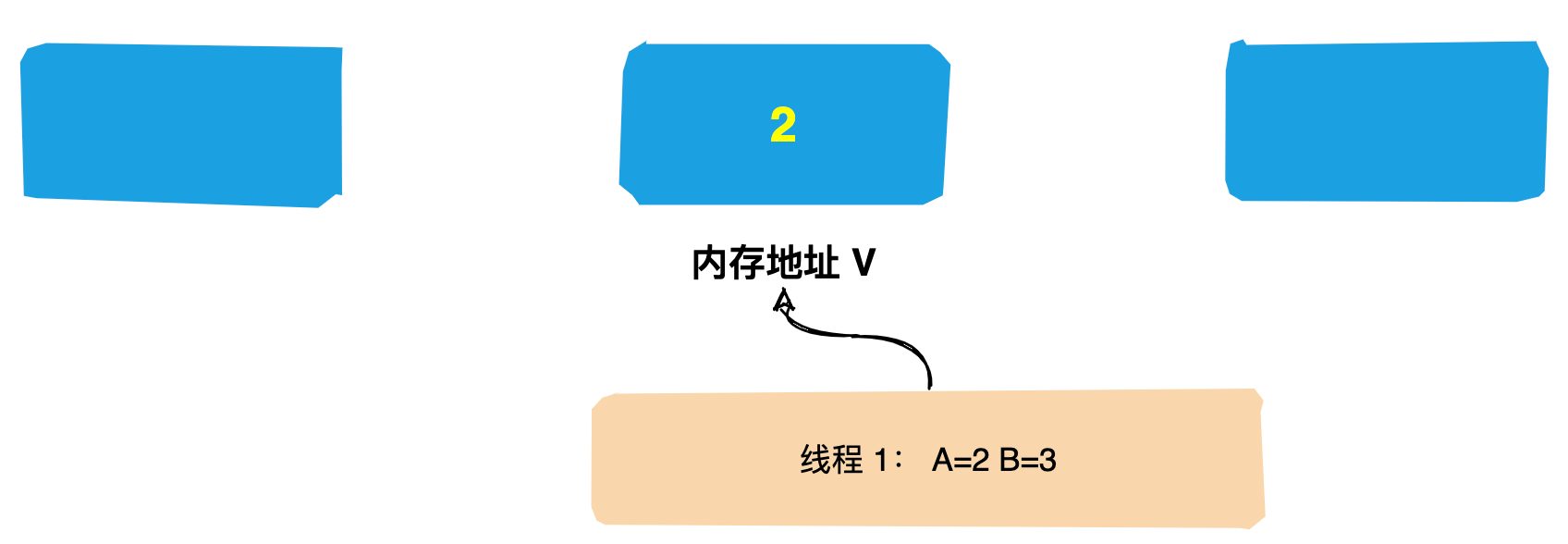
51 |
52 | (6)线程 1 再次提交更新,这一次没有其他线程改变地址 V 的值。线程1进行Compare,发现预期值 A 和内存地址 V的实际值是相等的,进行 Swap 操作,将内存地址 V 的实际值修改为 B。
53 |
54 | 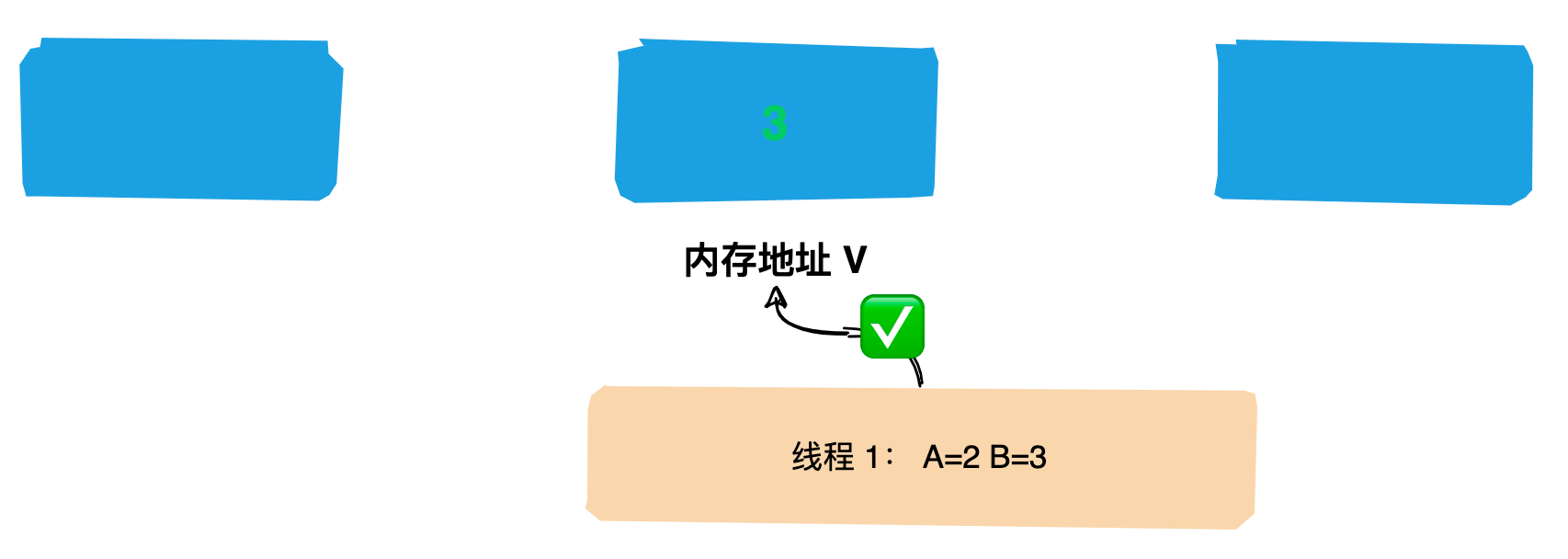
55 |
56 | 总结:更新一个变量的时候,只有当变量的预期值 A 和内存地址 V 中的实际值相同时,才会将内存地址 V 对应的值修改为 B,这整个操作就是`CAS`。
57 |
58 | # 2. CAS 基本原理
59 |
60 | CAS 主要包括两个操作:`Compare`和`Swap`,有人可能要问了:两个操作能保证是原子性吗?可以的。
61 |
62 | CAS 是一种`系统原语`,原语属于操作系统用语,原语由若干指令组成,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说 CAS 是一条 CPU 的原子指令,由操作系统硬件来保证。
63 |
64 | > 在 Intel 的 CPU 中,使用 cmpxchg 指令。
65 |
66 | 回到 Java 语言,JDK 是在 1.5 版本后才引入 CAS 操作,在`sun.misc.Unsafe`这个类中定义了 CAS 相关的方法。
67 |
68 | ```java
69 | public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object x);
70 |
71 | public final native boolean compareAndSwapInt(Object o, long offset, int expected, int x);
72 |
73 | public final native boolean compareAndSwapLong(Object o, long offset, long expected, long x);
74 | ```
75 |
76 | 可以看到方法被声明为`native`,如果对 C++ 比较熟悉可以自行下载 OpenJDK 的源码查看 unsafe.cpp,这里不再展开分析。
77 |
78 | # 3. CAS 在 Java 语言中的应用
79 |
80 | 在 Java 编程中我们通常不会直接使用到 CAS,都是通过 JDK 封装好的并发工具类来间接使用的,这些并发工具类都在`java.util.concurrent`包中。
81 |
82 | > J.U.C 是`java.util.concurrent`的简称,也就是大家常说的 Java 并发编程工具包,面试常考,非常非常重要。
83 |
84 | 目前 CAS 在 JDK 中主要应用在 J.U.C 包下的 Atomic 相关类中。
85 |
86 | 
87 |
88 | 比如说 AtomicInteger 类就可以解决 i++ 非原子性问题,通过查看源码可以发现主要是靠 volatile 关键字和 CAS 操作来实现,具体原理和源码分析后面的文章会展开分析。
89 |
90 | # 4. CAS 的问题
91 |
92 | CAS 不是万能的,也有很多问题。
93 |
94 | `敲黑板:CAS有哪些问题,这是面试高频考点,需要重点掌握`。
95 |
96 | ## 4.1. 典型 ABA 问题
97 |
98 | ABA 是 CAS 操作的一个经典问题,假设有一个变量初始值为 A,修改为 B,然后又修改为 A,这个变量实际被修改过了,但是 CAS 操作可能无法感知到。
99 |
100 | 如果是整形还好,不会影响最终结果,但如果是对象的引用类型包含了多个变量,引用没有变实际上包含的变量已经被修改,这就会造成大问题。
101 |
102 | 如何解决?思路其实很简单,在变量前加版本号,每次变量更新了就把版本号加一,结果如下:
103 |
104 | 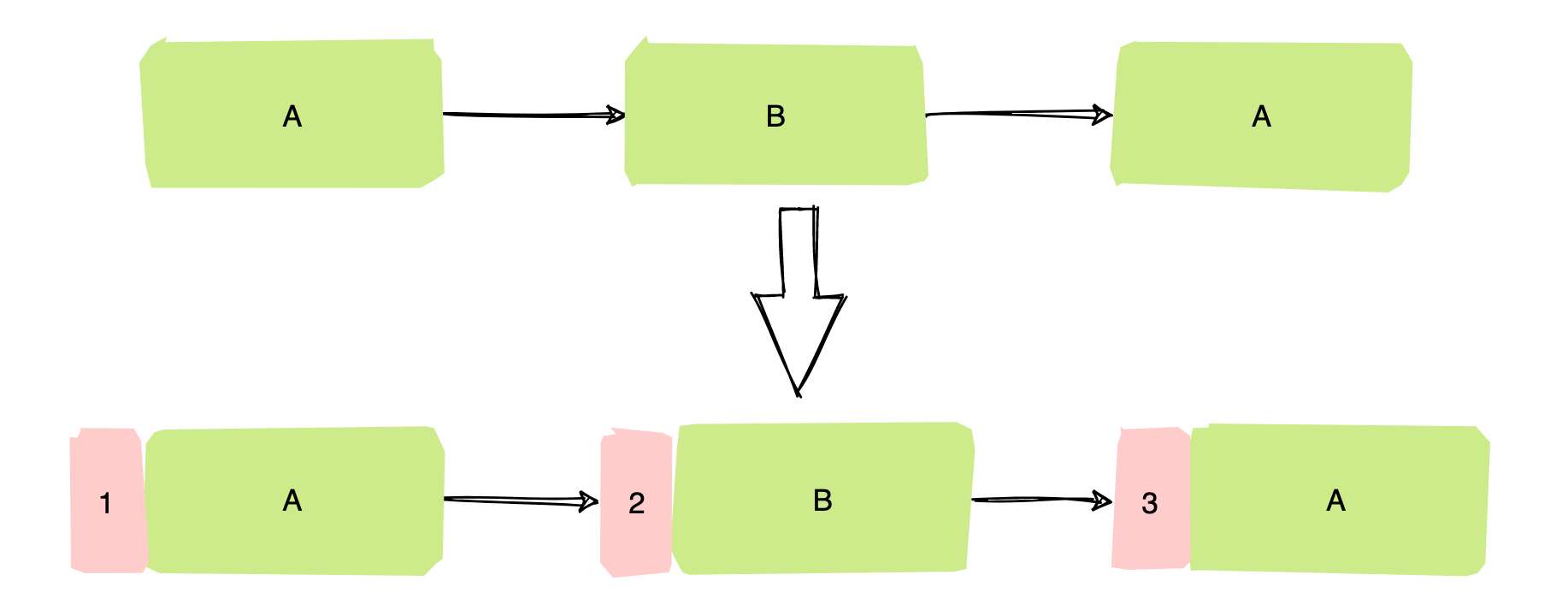
105 |
106 | 最终结果都是 A 但是版本号改变了。
107 |
108 | 从 JDK 1.5 开始提供了`AtomicStampedReference`类,这个类的 `compareAndSe `方法首先检查`当前引用`是否等于`预期引用`,并且`当前标志`是否等于`预期标志`,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
109 |
110 | ## 4.2. 自旋开销问题
111 |
112 | CAS 出现冲突后就会开始`自旋`操作,如果资源竞争非常激烈,自旋长时间不能成功就会给 CPU 带来非常大的开销。
113 |
114 | 解决方案:可以考虑限制自旋的次数,避免过度消耗 CPU;另外还可以考虑延迟执行。
115 |
116 | ## 4.3. 只能保证单个变量的原子性
117 |
118 | 当对一个共享变量执行操作时,可以使用 CAS 来保证原子性,但是如果要对多个共享变量进行操作时,CAS 是无法保证原子性的,比如需要将 i 和 j 同时加 1:
119 |
120 | i++;j++;
121 |
122 | 这个时候可以使用 synchronized 进行加锁,有没有其他办法呢?有,将多个变量操作合成一个变量操作。从 JDK1.5 开始提供了`AtomicReference` 类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
123 |
124 | # 5. 有态度的总结
125 |
126 | CAS 是 Compare And Swap,是一条 CPU 原语,由操作系统保证原子性。
127 |
128 | Java语言从 JDK1.5 版本开始引入 CAS , 并且是 Java 并发编程J.U.C 包的基石,应用非常广泛。
129 |
130 | 当然 CAS 也不是万能的,也有很多问题:典型 ABA 问题、自旋开销问题、只能保证单个变量的原子性。
131 |
--------------------------------------------------------------------------------
/docs/java/roadmap/2021 版最新Java 学习路线图(持续刷新).md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s/vc7rzYwfRC05bUR6eaUJcw)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [学Java有哪些就业方向?](#学java有哪些就业方向)
6 | - [数据结构和算法](#数据结构和算法)
7 | - [设计模式](#设计模式)
8 | - [计算机基础](#计算机基础)
9 | - [Java 入门](#java-入门)
10 | - [Java 高手进阶](#java-高手进阶)
11 | - [基础框架(SSM)](#基础框架ssm)
12 | - [微服务框架](#微服务框架)
13 | - [常用中间件](#常用中间件)
14 | - [数据库](#数据库)
15 | - [分布式架构](#分布式架构)
16 | - [必须掌握的工具软件](#必须掌握的工具软件)
17 | - [学习常见问题(FAQ)](#学习常见问题faq)
18 |
19 |
20 |
21 | **最近很多读者在问:Java 怎么学习啊?有没有什么学习路线?**
22 |
23 | 我相信这些读者或多或少都有一些 Java 基础,但由于看不到全貌,学了一段时间很容易迷失。所以我在寻思着能不能写一个学习的地图或者路线,让读者能知道下一步该学什么,自己离大厂的 offer还有多远的距离。
24 |
25 | 一个人最怕的不是路途遥远,而是看不到胜利曙光。我希望下面这篇文章能给你的学习之路带来一丝曙光,大家不妨试着读一下吧,如果有收获给我点个赞哟。
26 |
27 | > 温馨提醒:这篇文章写着写着就一万字了,建议大家关注后再收藏,以防走丢。
28 |
29 | 这篇文章主要内容包括(干货满满):
30 | - 学Java有哪些就业方向?
31 | - 数据结构和算法
32 | - 设计模式
33 | - 计算机基础
34 | - Java 入门
35 | - Java 高手进阶
36 | - 基础框架(SSM)
37 | - 微服务框架
38 | - 常用中间件
39 | - 数据库
40 | - 分布式架构
41 | - 必须掌握的工具软件
42 | - 学习资源网站列表汇总
43 | - 学习常见问题(FAQ)
44 |
45 | 买一瓶可乐,泡一杯咖啡,lets go 学习~
46 |
47 | ## 学Java有哪些就业方向?
48 | 在介绍 Java 怎么学之前我给大家介绍一下学完了能干什么,因为有目标的学习才是最高效的。
49 |
50 | 很多 Java 入门学习者对岗位或者方向的概念非常模糊,今天学安卓、后天学大数据,三心二意的学习势必造成技术不精,这就是面试官通常说的:这位面试者基础比较差。
51 |
52 | 学习技术首先要认准一个方向专注下去,有了一定积累后再将自己的知识面扩宽,找到自己感兴趣的方向再沉下去学习,周而复始你就成为这个行业的专家了。
53 |
54 | Java 这门语言,在公司里根据分工不同衍生出了众多的岗位或者技术方向。
55 |
56 | 我在 boss 直聘上搜索了 BAT 等大厂的岗位,目前有以下三类岗位非常热门:
57 |
58 | (1)安卓开发
59 | > 技能要求:
60 | > - 熟悉 Android UI 开发非常熟悉,对 UI 架构有理解,并了解基础的 UI 交互知识;
61 | > - 熟悉 Android 调试工具和方法,可以应付各种 Android 复杂问题;
62 | > - 熟悉 Android Framework 层,有通过 Android 源码阅读定位问题的经验;
63 |
64 | (2)Java 后端开发
65 | > 技能要求:
66 | > - 具备扎实的Java基础,对JVM原理有扎实的理解;对Spring、MyBatis、Dubbo等开源框架熟悉,并能了解它的原理和机制,具有大型分布式系统设计研发经验;
67 | > - 熟悉基于Mysql关系数据库设计和开发、对数据库性能优化有丰富的经验;
68 | > - 熟悉底层中间件、分布式技术(如RPC框架、缓存、消息系统等);
69 |
70 | (3)大数据/数据仓库
71 | > 技能要求:
72 | > - 熟悉Hadoop/Spark/sqoop/hive/impala/azkaban/kylin等大数据相关组件;
73 | > - 精通sql及性能调优,熟练使用java、python、scala其中一种编程语言;
74 | > - 掌握数据仓库 (DW) / OLAP /商业智能 (BI) /数据统计理论,并灵活的应用,具备大型数据仓库设计经验;
75 |
76 | 这里只列举了三类比较热门的技术岗位,希望大家结合自己的经验思考一下方向。
77 |
78 | `敲黑板:认清自己,找准方向,越早确定方向越容易成功!`
79 |
80 | ## 数据结构和算法
81 | **学什么?**
82 |
83 | 有些同学可能要问了:我学 Java 的有必要学习算法吗?答案是:`别无选择`!
84 |
85 | 国内互联网面试的流程逐渐在向国外靠拢,像字节跳动、BAT 等大厂,`手撕算法题`已经成为了必选动作。
86 |
87 | 确实, Java 相对于 C、C++有着丰富的类库和三方框架,进入工作后大部分人都是在写业务代码,俗称 API boy 或者 Crud boy,算法看起来并不是那么重要,但是考算法真的是公司面试筛选人的低成本办法,如果你写出了算法并且通过了,要么你聪明要么你勤奋(刷题了)。
88 |
89 | 所以不管你是学什么语言:C、C++、python、Java、GO,算法这一关你必须得过。数据结构和算法的面试核心知识点我已经列出来了,大家可以参考学习,逐个击破。
90 | - 栈与队列:先进先出、后进先出
91 | - 线性链表
92 | - 查找:顺序查找、二分查找
93 | - 排序:交换类、插入类、选择类
94 | - 树、二叉树、图:深度优先(DFS)、广度优先(BFS)
95 | - 递归
96 | - 分治
97 | - 滑窗
98 | - 三大牛逼算法:回溯、贪心、动态规划(DP)
99 |
100 | **怎么学?**
101 |
102 | 最好或者最笨的方法就是刷题,强烈推荐力扣:[https://leetcode-cn.com](https://leetcode-cn.com)
103 | 建议刷300题以上,要覆盖简单、中等、困难的题目。面试前要训练手感,不要生疏了,可以选保持每日或几日一题。
104 |
105 | 在刷题之前我建议你看一些书:
106 | 《漫画算法-小灰的算法之旅》
107 |
108 | > 如果你之前没有任何算法基础,这边书很适合你,可以补充数据结构和算法的基础知识,像什么是时间复杂度空间复杂度、查找、排序等。
109 | > 如果你有了一定基础了,建议你直接跳到最后面的算法实战部分。
110 |
111 | 《剑指 offer》
112 | > 非常经典的一本书,学算法的人必刷。但是要注意了,这边书里面的题目是用 C++写的,如果你是 Java 开发人员可能会有点影响。但是要记住学习算法最关键的还是解题思路和方法,用什么语言实现是其次的,如果你时间比较多我是建议你用 Java 语言再实现一遍。
113 |
114 | 《labuladong的算法小抄》
115 | > 非常推荐!这是一本很新的书,写书前作者在 Github 开源了一个项目,主要讲解 LeetCode 解题套路,Start 总数排名前40。在书的开头讲解了学习算法的基本思维和套路,建议看这边书的同时再配合 leetcode 刷题,疗效非常棒!
116 |
117 | 《算法导论》
118 | > 要是不推荐这本书是不是显得我有点 low 了,这是一本科班出身的同学必看必学的经典大部头。国外大佬写的,国内翻译的经典之作,虽然是经典但是不建议刚入门算法的同学看,因为看了这本书你可能要放弃算法了,比较难看懂。建议有了一定基础再入手这边书。
119 |
120 | 如果你觉得看书比较枯燥,可以推荐你看一些极客时间的专栏,不过是收费,但是质量非常高。
121 | 《数据结构与算法之美》
122 | > 这个专栏是文字+语音,作者是王争,前 Google 工程师。他采用最适合工程师的学习方式,不拘泥于某一特定编程语言,从实际开发场景出发,由浅入深教你学习数据结构与算法的方法,帮你搞懂基本概念和核心理论,深入理解算法精髓,帮你提升使用数据结构和算法思维解决问题的能力。
123 |
124 | 《算法面试通关40讲》
125 | > 这个专栏是视频,作者是覃超,前Facebook工程师。作者会用白板带你一步一步解题,层层深入一环扣一环,每一题还会用多种解题方法。我基本看完了,收获颇多。
126 |
127 | leetcode、书和极客专栏可以并行,学练结合,不要光看不练哦。
128 |
129 | ## 设计模式
130 | **学什么?**
131 |
132 | 金庸小说中牛叉的武功太多了,综合性最强的还是`九阳真经`,九阴真经分为上、下两卷,`上卷为内功基础,下卷为武功招式`,这些都是极负盛名的`武学秘籍`。
133 |
134 | 那大家思考一下什么是武学秘籍?其实打开来开就是一些固定的招式,牢记这些招式并运用好就是绝顶高手了。
135 |
136 | 回到编程上来,除了要写干净的代码(clean code),还要运用各种`设计模式`使代码可读性强、扩展性好、松耦合,这便是大家经常说的编码大牛。
137 |
138 | 所以不管是学武功还是学编码,都是有一些固定的招式,也就是设计模式。
139 |
140 | 说到`设计模式`很多同学可能会跳出来:这个我知道,就是单例模式、工厂模式……
141 |
142 | 巴拉巴拉说了一堆,但是真正在写代码的时候又是一脸蒙:为什么我写的代码用不到设计模式?究其原因是你的代码经验不够。
143 |
144 | 想一下设计模式是怎么来的?上个世纪四个大男人搞了一个组合叫 GoF,并出版了一本书,这本书共收录了23种设计模式,后面逐渐被人熟知。这四个人从大量的代码实践中总结了一套方法论(写代码的套路),而我们作为一个在学校的学生或者刚工作的新人,可能连代码都写的少,怎么可能轻松快速地掌握这么多设计模式。
145 |
146 | 所以说你学完了设计模式,但是还不会运用到日常的代码实践中,这个是很正常的,因为代码经验还不够。
147 |
148 | 那还学不学?当然要学,因为面试的时候有可能会问到。设计模式的理论知识我们还是要打好基础,需要掌握这些知识点:
149 | - 设计模式的六大原则:单一职责、里氏替换、依赖倒置、接口隔离、迪米特法则、开闭原则
150 | - UML 基础知识
151 | - 设计模式三大分类:创建型、结构型、行为型
152 | - 常用设计模式基本原理
153 |
154 | 经典设计模式总共有23种(现在远不止23种了,还有一些变种),全部掌握难度太大了,我们只需要掌握一些常用的就好了,必须要掌握的我用小红旗已经标出来了。
155 | 
156 |
157 | **怎么学?**
158 |
159 | 网上关于设计模式的学习资料非常多,质量也是参差不齐,大家找的时候可要擦亮眼睛。
160 |
161 | 在看书之前我还是推荐你熟悉一下 UML 的理论知识,因为你如果不懂 UML 那任何一本设计模式的书你都可能读不下去, UML 是设计模式的前提。
162 |
163 | UML 学习网站:
164 |
165 | https://www.w3cschool.cn/uml_tutorial/
166 |
167 | 不要花太多时间学习 UML,简单理解入门即可。
168 |
169 | 假设你已经入门 UML 了,那下面的这些书你可以考虑学习一下了:
170 |
171 | 《Head First 设计模式》
172 | > Head First 是一个比较经典的系列丛书,有些人非常喜欢这种风格。这本书讲枯燥的设计概念讲解的生动有趣,作为一本入手书非常值得推荐。
173 |
174 | 《大话设计模式》
175 | > 大话系列是国内非常经典的系列丛书,有众多粉丝。这本大话设计模式以对话的形式讲解知识,在当时可开创了先河。虽然书中有些例子比较牵强,但任然不失为一本入门的好书。
176 |
177 | 《图解设计模式》
178 | > 图解系列是日本的一位作者写的,有一本图解 HTTP 非常经典,这本图解设计模式也是类似的风格。由于是翻译过来的,书中有些例子可能听起来比较奇怪,貌似翻译过来的技术书都有这个问题。
179 |
180 | 《设计模式-可复用面向对象软件的基础》
181 | > 又是一本黑色大部头书,书的作者就是 GoF,大家都说经典。但是呢,经典归经典,读起来真的是晦涩难懂,对新人非常不优化,如果你想入门学习设计模式,这本书就不推荐了。不推荐为什么要说出来?经典的书如果不提,你们又要说我菜。(害)
182 |
183 | 这几本书都要看吗?当然不是,如果你是在准备面试,我个人建议是读其中一本就够了。至于说看哪一本,你可以找对应的电子书,挑一个章节试读一下,符合你的胃口就选择这一本继续读下去。
184 |
185 | 如果你已经有几年的编码经验,又想把代码写好,建议你多挑基本读读,吸收每本书的精华。
186 |
187 | ## 计算机基础
188 | 科班出身的同学对《计算机网络》和《操作系统》这两门课应该不会陌生,至于掌握了多少,你懂得,都是在考前一两周突击学习的,哈哈。
189 |
190 | 现在大公司对于应届生的要求越来越高,计网和操作系统这两门课是必考的。那些拿了 SSSP Offer 的大牛计算机基础都非常扎实。
191 |
192 | **(1)计算机网络**
193 |
194 | **学什么?**
195 |
196 | 计算网络的协议非常非常多,很多同学学完都一头雾水,或者仅仅懂一点 HTTP,但是真正要掌握的东西可不少:
197 | - OSI 七层模型、TCP/IP五层模型
198 | - 常见网络协议:HTTP、TCP/IP、UDP
199 | - 网络安全:非对称加密、数字签名、数字证书
200 | - 网络攻击:DDOS、XSS、CSRF 跨域攻击
201 |
202 | **怎么学?**
203 |
204 | 计算机网络面试有一道非常经典的面试题:说说你从URL输入到最终页面展现的过程。这一题可以覆盖大部分计网的知识点,可以从 DNS 解析到 HTTP、TCP/IP协议、物理层协议,一直到浏览器渲染页面,你技术功底有多深你就可以聊多深。希望大家学完了也能试着回答一下这个问题。
205 |
206 | 推荐几本倍受好评的书:
207 | 《网络是怎么连接的》
208 | > 这本书是一本日本作者写的。文章围绕着在浏览器中输入网址开始,一路追踪了到显示出网页内容为止的整个过程,图文并茂生动有趣,非常推荐!
209 |
210 | 《图解 HTTP》
211 | > 也是一名日本作者写的。这本书对 HTTP 协议进行了全面系统的介绍,列举了很多常见通信场景及实战案例,相信读完会有恍然大悟的感觉。书很薄,几天就可以读完,强烈推荐!
212 |
213 | 《TCP/IP详解卷1:协议》
214 | > 计算机网络的经典教材, 大部头书籍,很难啃。建议挑重点看。
215 |
216 | 最后安利一款工具,学习网络必备的抓包神奇:wireshark,如果你学网络没抓过包,那基本等于白学了(有点严重)。
217 |
218 | **(2)操作系统**
219 |
220 | **学什么?**
221 |
222 | 作为一名 Javaer 在平时的工作中可能不会直接跟操作系统打交道,因为 JVM 帮我们屏蔽了众多差异。但是要想学好 JVM,懂一点操作系统更有助于你深刻理解 JVM 工作原理。
223 |
224 | Java 学习者这部分的要求可以稍微放低,但是你如果是搞 C++的,那这部分可是你的重点。
225 | - 进程和线程的区别
226 | - 进程间的通信方式:共享内存、管道、消息
227 | - 内存管理、虚拟内存
228 | - 死锁检测和避免
229 |
230 | **怎么学?**
231 |
232 | 想要精通操作系统难度非常大,但是在面试中你要能讲出一些具体的操作系统知识,面试官会对你刮目相看。
233 |
234 | 推荐一些视频学习资料:
235 | B 站:
236 | 麻省理工 MIT 6.828(无字幕):https://www.bilibili.com/video/BV1px411E7ST
237 | 操作系统(哈工大李治军老师)32讲(全)超清:https://www.bilibili.com/video/BV1d4411v7u7
238 |
239 | 推荐书籍资料:
240 | 《深入理解计算机系统 CSAPP》
241 | > 赫赫有名的 CSAPP,全称:Computer Systems:A Programmer‘s Perspective。科班同学的圣经,哈哈,黑色大部头书籍,难啃。
242 |
243 | 《现代操作系统 (第3版)》
244 | > 操作系统领域的经典之作,因为是翻译过来的,遇到比较晦涩的先跳过,多读几遍才能消化。
245 |
246 | ## Java 入门
247 | **学什么?**
248 |
249 | Java 语言从诞生到现在已经有20多年了,从Tiobe排行榜上来看,Java 语言常年霸榜经久不衰,所以不要怕学完 Java 后突然不流行了,至少这几年Java 就业机会非常多。
250 |
251 | 如果你有其他语言的基础,比如之前学过 C、C++等,那学起 Java 应该是非常容易的,也容易上手。如果你没有语言基础,又不想了解太底层的东西,那学 Java 还是不错的。至于说 python,光从语言层面上看,python 确实非常简单,估计你一周内就可以学会并且代码写的还不错,但是 Java 不一样,一周你只能简单了解一下语法,想写好代码几乎不可能。另外 Go 语言势头很猛,大家也可以关注一下。
252 |
253 | 一般来说 Java 入门你需要掌握下面这些知识点:
254 | - 面向过程 VS 面向对象
255 | - 面向对象基本特征:封装、继承、多态
256 | - 访问控制符:private、default、protected、public
257 | - 数据类型:基本类型、引用类型
258 | - 控制流程:for、while、switch 等
259 | - 序列化
260 | - 异常处理(有点难度)
261 | - 泛型(有点难度)
262 |
263 | **怎么学?**
264 |
265 | 如果你是零基础,建议你可以找一些 Java 入门的视频看一下,网上视频鱼龙混杂,大家注意甄别。推荐一个比较好的平台:B 站(https://www.bilibili.com/)
266 | 不是让你去看二次元的,里面有很多学习资源。(嘿哈)
267 |
268 | `敲黑板啦:视频不要贪多,因为没有一个大牛是看视频看出来的。` 看视频是别人将知识点往你脑袋里灌,最大的好处是能让你快速入门,如果你想学到更多,你需要的是`自我学习`,带有思考的自我学习。
269 |
270 | 看书是一种高效的自我学习方式,推荐基本比较好的书:
271 |
272 | 《Java 核心技术卷I》
273 | > 这本书建议作为Java 之旅的第一本书,涵盖的内容非常全,比起那些30天学会 Java 之类的书,这边书更加务实。书中有些章节其实不用看,比如Swing GUI 的直接略过,因为用 Java 写桌面端应用已经过时了。
274 |
275 | 《阿里巴巴 Java 开发手册》
276 | > 大厂阿里巴巴出品的,这其实是一本 Java 编码规范,编码习惯从一开始就要养好。
277 |
278 | 《Java 编程思想(Thinking In Java)》
279 | > 这是一本非常非常经典的书,你要问搞 Java 的人如果没听过这本书那算是白学了,哈哈。其实说实话这本书我试图看过几次,最终都没有看完,一个原因是它太厚了,另外我觉得讲得太啰嗦了,所以我现在拿来垫桌子,高度合适挺好的。所以呢,建议新人不要一开始看这边书,不然你会怀疑人生还没入门就放弃了,就把它当做编程圣经,等你后面有经验了拿起来再翻翻吧。
280 |
281 | 敲黑板了:学习编程要有耐心,不要急于求成,要打好基础。也许你一个月两个月还在运行一些简单示例,这是正常的,多学习多思考。
282 |
283 | ## Java 高手进阶
284 | **学什么?**
285 |
286 | 恭喜你终于Java 入门了,大牛和菜鸟的区别在于菜鸟永远止步于入门水平,而大牛已经找到新大陆了,翻过这几座山你离高手就不远了。
287 |
288 | Java 高手进阶需要掌握的东西非常非常多,这里列举一些核心知识点,必须全部掌握的。这是 Java 面试高频考点,也是传说中 Java 八股文的一部分,面好了进入下一面,面不好回家等消息。
289 | - Java 集合类源码
290 | - 线程池
291 | - Java 代理
292 | - IO 模型
293 | - JVM
294 | - Java 并发编程(JUC)
295 |
296 | **怎么学?**
297 |
298 | Java 已经入门了,你都想进阶了,建议你不要再找视频看了,一边看书一边思考吧。
299 |
300 | 《Effective Java》
301 | > 书中列举了很多编程建议,其实就是告诉怎样去写好代码,你需要从`能写代码`(入门)过渡到`会写代码`,这本书值得一看。如果你的编码经验比较少,那这边书你可以稍微往后延,因为看完了你可能没有感同身受。
302 |
303 | 《Java8 实战》
304 | > Java15 都出来了为什么还要学 Java8 ?因为现在很多公司都还停留在 Java8, Java8是继Java5之后改动很大的一个版本,得好好学。Java8之后的版本非常不给力,换一个 JDK 版本费时费力,收益也不明显,公司肯定不愿意动了。这边书将 Java8所有的新特性都详细讲解了,非常推荐。
305 |
306 | 《深入理解 Java 虚拟机 第3版》
307 | > 周志明大神写的,非常非常经典,已经更新到第三版了。Java 虚拟机也就是 JVM,JVM 是Java 面试必考的知识,不懂这个直接回家等消息吧。这边书我看了很多遍,每次看完都有新的收获,墙裂建议大家看完。
308 |
309 | 《Java 并发编程的艺术》
310 | > 这是一本专门讲解Java并发的书,涉及到各种锁、常见安全的集合类,基本就是将 JUC(java.util.concurrent包的简称)里所有的内容覆盖了一遍,看完你一定有收获。强烈推荐!
311 |
312 | 上面推荐的几本书可能不太容易读懂,建议多读几遍。书中看不懂的地方可以在网上搜,多找一些优质的博客或者公众号看。
313 |
314 | 至此 Java 语言特性基本学习完了,就算达不到高手的水平,你也在正轨上了。
315 |
316 | ## 基础框架(SSM)
317 | **学什么?**
318 |
319 | 学习 Java 语言特性可能比较枯燥,接下来可以学习基础框架动手做一些项目,比如 Java 领域非常流行的 Spring 框架,这就是为 Java 后端量身定做的,非常好用。
320 |
321 | 在 spring 流行之前,还出现 Struts 这样流行的框架,后面由于种种原因还是被 Spring 打败了。
322 |
323 | 大家在网上应该可以经常看到 SSM 的缩写,其实就是Spring+SpringMVC+MyBatis的缩写了。
324 |
325 | 你需要掌握以下这些:
326 | - Spring 全家桶(Spring、Spring MVC、Spring Boot)使用
327 | - ORM 框架(MyBatis、Hibernate)使用
328 | - Spring 原理
329 | - ORM 框架原理
330 |
331 | **怎么学?**
332 |
333 | 学习 SSM 框架最好是动手完成一个简单的项目,建议跟着视频并且把代码敲出来,一来熟悉项目的开发流程,也可以给自己带来成就感。
334 |
335 | 敲黑板:阶段性成就感非常重要,没有这个很容易放弃学习,所以要不定时给自己定个小目标,加加鸡腿啥的。
336 |
337 | 有很多新手在做项目的时候非常纠结界面,作为一个 Java 后端程序员,你又不是全栈开发,纠结这个干什么,我的建议:要么不要界面只写接口,要么自己动手写点 html,不需要美观,实现功能即可。
338 |
339 | 跟着视频做完项目之后需要干什么?答案是:`深入理解框架原理`。会用框架并不代表你懂框架,作为一个有追求的程序员,懂原理是永远的必修课,谁让这一行太卷了呢,人无你有你最棒。
340 |
341 | 推荐几本书:
342 | 《Spring 基础内幕》
343 | > 首先声明一下这是一本讲解Spring 源码的书,不是教你做项目的书。如果需要深入理解 Spring 的技术原理,这是一本非常推荐的书。有点难啃,多读几遍。
344 |
345 | 《MyBatis 技术内幕》
346 | > MyBatis 是 ORM 框架的一种,在国内使用比较多,据说在国外喜欢用 Hibernate。这本书对 MyBatis 的使用和基本原理都介绍比较清楚了。
347 |
348 | 敲黑板:技术更新迭代很快,抓住技术的本质才能与时俱进。
349 |
350 | 关于基础框架这部分,大神们的学习方法是:使用框架 -> 懂框架 -> 造轮子。
351 |
352 | ## 微服务框架
353 | **学什么?**
354 |
355 | 近些年微服务架构非常火,究其原因是因为传统的单体架构和面向服务的架构逐渐不能满足互联网快速迭代的需求。微服务可以更容易提供持续继承和持续部署的能力,让产品更快速交付推向市场。
356 |
357 | 面向服务的架构其实在五六年前就已经提出,期间经过了一段低潮期,泡沫散去后逐渐浮现了一些好用的框架,国外以 SpringCloud 为代表,国内以 Dubbo 为代表。
358 |
359 | springCloud 和 Dubbo 有区别但是很多基本原理也是类似,大家学习的时候需要掌握技术的本质。下面列举一些核心知识点:
360 | - Dubbo框架
361 | - SpringCloud框架
362 | - 服务注册与发现
363 | - 分布式服务链路追踪
364 | - 服务隔离、熔断、降级
365 | - 服务网关
366 |
367 | **怎么学?**
368 |
369 | springCloud 和 Dubbo 在官网都有很详细的介绍文档:
370 | - Dubbo官网 http://dubbo.apache.org/ 可以切到中文版
371 | - SpringCloud 官网 https://spring.io/projects/spring-cloud
372 |
373 | 看官网技术文档大家可能会很懵,但这些确实是最权威的资料,也是一手的。
374 |
375 | SpringCloud 和 Dubbo 是这几年刚刚流行的技术,从目前看来相关书籍还是比较少,也缺少一些经典的书,我还是列几本,大家按需获取。
376 |
377 | 《深入理解Apache Dubbo与实战》
378 | > Dubbo 最开始是阿里巴巴开源的,后面捐赠给Apache 了。建议大家读这本配合源码一起看。
379 |
380 | 《Spring Cloud微服务实战》
381 | > 读这本书之前你最好先学习 spring 和 spring boot,不然会很懵。另外这本书是2017年出版的,稍微显旧,大家注意分辨新旧特性。
382 |
383 | 如果技术网站和书籍还不能满足你,建议你去搜一些视频学习,这里不做推荐以免认为是广告。推荐搜索平台:B 站、慕课网、网易云课堂。
384 |
385 | `敲黑板:微服务框架涵盖的内容非常多,也是有难点的技术,大家戒躁保持耐心。`
386 |
387 | ## 常用中间件
388 | **学什么?**
389 |
390 | 最终用户并不直接使用`中间件`,换言之`中间件`不是大众消费类软件产品。但是在大公司里中间件是不可或缺的,它是支撑大型网站架构的一些基础的组件和服务,所以非常非常有必要学。
391 |
392 | > 小百科
393 | > 中间件(Middleware)通常是指在一个大型分布式的系统中,负责各个不同组件(Component)/服务(Service)之间管理以及交互数据的。
394 |
395 | 业界开源的优秀中间件非常多,通常会根据业务的需要在系统中引入若干,下面列举了一些常见的,都是必学的,非可选哈。
396 | - 缓存:Redis、Memcached( 推荐 Redis)
397 | - 消息队列:Kafka、RocketMQ、RabbitMQ、ActiveMQ、ZeroMQ(推荐 Kafka)
398 | - 数据库中间件:ShardingSpere、Mycat
399 |
400 | **怎么学?**
401 |
402 | 每个中间件涵盖的内容都非常多,要想学精需要大量时间。
403 |
404 | Redis 中文官方网站:
405 |
406 | [http://www.redis.cn/](http://www.redis.cn/)
407 |
408 | 当做字典学习 redis 常见命令
409 |
410 | Kafka 官网:
411 |
412 | [http://kafka.apache.org/](http://kafka.apache.org/)
413 |
414 | ShardingSpere 官网:
415 |
416 | [http://shardingsphere.apache.org/index_zh.html](http://shardingsphere.apache.org/index_zh.html)
417 |
418 | Mycat 权威指南在线 PDF 版:
419 |
420 | [http://www.mycat.org.cn/document/mycat-definitive-guide.pdf](http://www.mycat.org.cn/document/mycat-definitive-guide.pdf)
421 |
422 | 推荐几本相关的书:
423 | 《Redis 设计与实现》
424 | > 这时Redis 口碑比较好的一本书,书中详细讲解了 Redis 实现原理,如果你只是想学会怎么用,可以跳过一些章节。
425 |
426 | 《深入理解Kafka:核心设计与实践原理》
427 | > 这本书既适合新手入门扫盲也适合高手进阶,想知道怎么用看前四章即可,想深入学习可以从第五章开始看,写的非常好,推荐学习!
428 |
429 | 《分布式数据库架构及企业实践——基于Mycat中间件》
430 | > Mycat 相关的书非常少,这本书是16年写的,有些陈旧了,如果对 Mycat 非常感兴趣可以简单翻一翻,但是不是特别推荐。
431 |
432 | 书看完了你还想深入学习,建议大家关注一下极客时间的两门课:
433 | 胡夕:《Kafka核心技术与实战》,老师是Apache Kafka Committer,很专业。
434 | 蒋德钧:《Redis核心技术与实战》
435 |
436 | 不过课程是付费的,手头紧的建议慎重哈。免费资源网上也有,靠大家搜索了~
437 |
438 | 中间件的学习是一个漫长的过程,不仅需要很多理论知识还需要实践经验。
439 |
440 | 比如你学 Redis 的时候,要思考五种基本数据类型各自使用场景、布隆过滤器是什么原理、用 Redis 怎么实现分布式锁,带着问题去学习效率非常高。
441 |
442 | 比如你学 Kafka 消息队列,要对比常见消息队列的优缺点、Kafka 为什么吞吐量高、Kafka 会不会丢消息以及怎么解决。
443 |
444 | 比如你学数据库中间件,要想数据库为什么要分库分表、分库分表 ID 如果处理等等。
445 |
446 | ## 数据库
447 | **学什么?**
448 |
449 | 数据库非常重要,面试也是必考的,可以考的点非常多,可以考得很浅:问一下 SQL 使用,也可以考的很深:问索引和锁的实现原理。下面列了一些常见的知识点。
450 | - 数据库基本理论:范式、索引原理、数据库引擎
451 | - SQL 基本语法
452 | - SQL 调优,explain 执行计划
453 | - 数据库事务(ACID)
454 | - 数据库锁:乐观锁、悲观锁、表锁、行锁等
455 |
456 | **怎么学?**
457 |
458 | 建议数据库零基础的同学还是要先学习一下数据库的基本理论,因为我看到很多人都是一上来就学 SQL ,最终也只是会用而已,到后面 SQL 调优的时候就很迷茫了。如果你只是想用一用数据库,这部分也可以跳过。
459 |
460 | 关于原理部分有一本非常经典的教材《数据库系统概念》以供学习,经典书籍一般都比较难啃坑也比较厚,建议大家先看目录,挑重点看。大学学过这本书的可以直接跳过了。
461 |
462 | 有了一些理论后就可以开始学习 SQL 语法了,这里推荐一本《MySQL 必知必会》,一边看书一边对着电脑敲。
463 |
464 | 当然面试大厂肯定会问一下比较难的东西,你需要搞懂索引的原理、事务 ACID、锁,问数据库这些东西必考哦!
465 |
466 | MySQL 学习书籍清单:
467 | 《数据库系统概念》
468 | > 经典数据库教材,理解一些基本原理,可略看。
469 |
470 | 《MySQL必知必会》
471 | > SQL 语法入门好书,推荐!
472 |
473 | 《MySQL技术内幕 : InnoDB存储引擎》
474 | > 数据库进阶必看,理解存储引擎以及事务、锁、索引等原理。
475 |
476 | ## 分布式架构
477 | **学什么?**
478 |
479 | 分布式这一部分就是面试的加分项了,答好了面试官会觉得你技术功底深厚,答不好,只要你前面的基础还不错也能过。所以呢,作为一个有追求的技术人,千万不要放过加分的机会。
480 |
481 | 分布式相关的内容非常多,下面列举几个在项目中或者面试中经常会遇到的知识点:
482 | - 分布式事务:两阶段提交(2PC)、补偿事务(TCC)
483 | - 分布式锁:基于关系型数据库(MySQL)、基于 Redis、基于Zookeeper
484 | - 分布式 ID:雪花算法(Snowflake)、美团 Leaf
485 |
486 | **怎么学?**
487 |
488 | 这部分内容学好非常难,在很多书中都是轻轻带过,没有深入讲解原理,所以就不推荐书了。
489 |
490 | 那怎么学呢?大家可以针对每个知识点到网上搜索优质的博客,后面我也会逐步更文讲解这些知识点,敬请期待,欢迎催更哟。
491 |
492 | ## 必须掌握的工具软件
493 | 工欲善其事,必先利其器。作为一个 Java 开发人员,你需要学习业界常用的软件,软件工具用得越熟你的编码效率越高,下班的时间可能越早(打工人太难了)。
494 | - Java 最聪明的 IDE:IntelliJ IDEA (请放弃使用 Eclipse,我有一堆理由睡服你)
495 | - 地球上最好用的版本管理工具:Git
496 | - 经久不衰的依赖管理工具:Maven
497 | - Docker
498 |
499 | 这些软件你要是用不好,那只能说明…… 你再多学学吧。
500 |
501 | ## 学习常见问题(FAQ)
502 |
503 | **1. 学了容易忘怎么办?**
504 |
505 | 这是大家学习会遇到的头号大问题,怎么解决?重复学习。
506 |
507 | 打个比方,假如你正在学习 spring 注解,突然发现了一个注解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
508 |
509 | 从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。
510 |
511 | 人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。
512 |
513 | **2. 推荐这么多书都要看完吗?**
514 |
515 | 当然不是!有一些书都是同类型的,作者写书的侧重点不一样,大家要学会挑重点看。
516 |
517 | 拿到一本书,首先要把目录多看一遍,一般而言书的前几章都是介绍型的内容,如果你已经有了基础,可以直接跳到后面原理解析或者实战部分。
518 |
519 | **3. 需要学多久才能成为技术大牛?**
520 |
521 | `学习无止境!`
522 |
523 | 业界说法,通过不断努力学习,一到两年可以达到初级水平,三到四年达到中级水平,五年可以达到高级水平。
524 |
525 | 实际上每个人的学习能力和精力不一样,时间参考意义不大。
526 |
527 | 只要你在一个方向或领域有自己的建树,就可以叫你大牛;如果你在公司是技术骨干、技术专家、架构师,也可以称之为大牛。
528 |
529 | `敲黑板:技术学习千万不要浮躁,谦卑一点多学一点,天外有天。`
530 |
531 | **4. 现在 python、Go 语言很火,要不要直接学它们?**
532 |
533 | 不要纠结语言,语言只是工具。今天 Go 很火,明天会有其他语言。
534 |
535 | 我有一个同学毕业去阿里写 Java,后面跳槽到深圳腾讯写 C++,现在又跳到字节跳动写 Go,在大佬面前这些语言只是语法不一样而已。所以建议大家打好基础,答应我一定打好基础。
536 |
537 |
538 | 『持续刷新……』
539 |
--------------------------------------------------------------------------------
/docs/mq/Kafka支持百万级TPS的秘密都藏在这里.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322018&idx=1&sn=ff1d7be13158a9d1cbc02a6d9123e503&chksm=8f09ca78b87e436e023de69301b326a9541d51b94a0d57393cc766da9dfef40c9ccaf0fdbc0c&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [Kafka 如何做到支持百万级 TPS ?](#kafka-如何做到支持百万级-tps-)
6 | - [顺序读写磁盘](#顺序读写磁盘)
7 | - [Memory Mapped Files\(MMAP\)](#memory-mapped-filesmmap)
8 | - [Zero Copy(零拷贝)](#zero-copy零拷贝)
9 | - [Batch Data(数据批量处理)](#batch-data数据批量处理)
10 | - [总结](#总结)
11 | - [公众号](#公众号)
12 |
13 |
14 |
15 |
16 | 谈到大数据传输都会想到 Kafka,Kafka 号称大数据的杀手锏,在业界有很多成熟的应用场景并且被主流公司认可。这款为大数据而生的消息中间件,以其百万级TPS的吞吐量名声大噪,迅速成为大数据领域的宠儿,在数据采集、传输、存储的过程中发挥着举足轻重的作用。
17 |
18 | 在业界已经有很多成熟的消息中间件如:RabbitMQ, RocketMQ, ActiveMQ, ZeroMQ,为什么 Kafka 在众多的敌手中依然能有一席之地,当然靠的是其强悍的吞吐量。下面带领大家来揭秘。
19 |
20 | ## Kafka 如何做到支持百万级 TPS ?
21 |
22 | 先用一张思维导图直接告诉你答案:
23 |
24 |
188 |
189 | AtomicInteger类中还有很多其他的方法,如:
190 |
191 | ```java
192 | decrementAndGet()
193 | getAndDecrement()
194 | getAndIncrement()
195 | accumulateAndGet()
196 | // …… 省略
197 | ```
198 |
199 | 这些方法实现原理都是大同小异,希望大家可以举一反三理解其他的方法。
200 |
201 | 另外还有一些其他的类,如:`AtomicLong`,`AtomicReference`,`AtomicIntegerArray`等,这里也不再赘述,原理都是大同小异。
202 |
203 | # AtomicLong 和 LongAdder 谁更牛?
204 |
205 | Java 在 `jdk1.8版本` 引入了 `LongAdder` 类,与 `AtomicLong` 一样可以实现加、减、递增、递减等线程安全操作,但是在高并发竞争非常激烈的场景下 `LongAdder` 的效率更胜一筹,后续单独用一篇文章进行介绍。
206 |
207 | # 总结
208 |
209 | 讲了半天,可能有的小伙伴还是比较懵,Atomic 类到底是如何实现线程安全的?
210 |
211 | 在语言层面上,Atomic 类是没有做任何同步操作的,翻看源代码方法没有任何加锁,其实最大功劳还是在 CAS 身上。CAS 利用操作系统的硬件特性实现了原子性,利用 CPU 多核能力实现了硬件层面的阻塞。
212 |
213 | 只有 CAS 的原子性保证就一定是线程安全的吗?当然不是的,通过源码发现 value 变量还用了 volatile 修饰了,保证了线程可见性。
214 |
215 | 那有些小伙伴可能要问了,那是不是加锁就没有用了,非也,虽然基于 CAS 的线程安全机制很好很高效,但是这适合一些粒度比较小的需求才有效,如果遇到非常复杂的业务逻辑还是需要加锁操作的。
216 |
217 | 大家学会了吗?
218 |
219 |
220 |
--------------------------------------------------------------------------------
/docs/java/juc/面试官:说说什么是Java内存模型?.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650324686&idx=1&sn=0f177ea0b3cbe6da00a4e8b0a46ee22c&chksm=8f09c0d4b87e49c2d98b428b3b42e70550905f36dfcf63a304743d3df88ddcd518501df60b65&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [1. 为什么要有内存模型?](#1-为什么要有内存模型)
6 | - [1.1. 硬件内存架构](#11-硬件内存架构)
7 | - [1.2. 缓存一致性问题](#12-缓存一致性问题)
8 | - [1.3. 处理器优化和指令重排序](#13-处理器优化和指令重排序)
9 | - [2. 并发编程的问题](#2-并发编程的问题)
10 | - [3. Java 内存模型](#3-java-内存模型)
11 | - [3.1. Java 运行时内存区域与硬件内存的关系](#31-java-运行时内存区域与硬件内存的关系)
12 | - [3.2. Java 线程与主内存的关系](#32-java-线程与主内存的关系)
13 | - [3.3. 线程间通信](#33-线程间通信)
14 | - [4. 有态度的总结](#4-有态度的总结)
15 |
16 |
17 |
18 | 在面试中,面试官经常喜欢问:『说说什么是Java内存模型(JMM)?』
19 |
20 | 面试者内心狂喜,这题刚背过:『Java内存主要分为五大块:堆、方法区、虚拟机栈、本地方法栈、PC寄存器,balabala……』
21 |
22 | 面试官会心一笑,露出一道光芒:『好了,今天的面试先到这里了,回去等通知吧』
23 |
24 | 一般听到等通知这句话,这场面试大概率就是凉凉了。为什么呢?因为面试者弄错了概念,面试官是想考察JMM,但是面试者一听到`Java内存`这几个关键字就开始背诵八股文了。Java内存模型(JMM)和Java运行时内存区域区别可大了呢,不要走开接着往下看,答应我要看完。
25 |
26 | # 1. 为什么要有内存模型?
27 |
28 | 要想回答这个问题,我们需要先弄懂传统计算机硬件内存架构。好了,我要开始画图了。
29 |
30 | ## 1.1. 硬件内存架构
31 |
32 | 
33 |
34 | (1)CPU
35 |
36 | 去过机房的同学都知道,一般在大型服务器上会配置多个CPU,每个CPU还会有多个`核`,这就意味着多个CPU或者多个核可以同时(并发)工作。如果使用Java 起了一个多线程的任务,很有可能每个 CPU 都会跑一个线程,那么你的任务在某一刻就是真正并发执行了。
37 |
38 | (2)CPU Register
39 |
40 | CPU Register也就是 CPU 寄存器。CPU 寄存器是 CPU 内部集成的,在寄存器上执行操作的效率要比在主存上高出几个数量级。
41 |
42 | (3)CPU Cache Memory
43 |
44 | CPU Cache Memory也就是 CPU 高速缓存,相对于寄存器来说,通常也可以成为 L2 二级缓存。相对于硬盘读取速度来说内存读取的效率非常高,但是与 CPU 还是相差数量级,所以在 CPU 和主存间引入了多级缓存,目的是为了做一下缓冲。
45 |
46 | (4)Main Memory
47 |
48 | Main Memory 就是主存,主存比 L1、L2 缓存要大很多。
49 |
50 | 注意:部分高端机器还有 L3 三级缓存。
51 |
52 | ## 1.2. 缓存一致性问题
53 |
54 | 由于主存与 CPU 处理器的运算能力之间有数量级的差距,所以在传统计算机内存架构中会引入高速缓存来作为主存和处理器之间的缓冲,CPU 将常用的数据放在高速缓存中,运算结束后 CPU 再讲运算结果同步到主存中。
55 |
56 | 使用高速缓存解决了 CPU 和主存速率不匹配的问题,但同时又引入另外一个新问题:缓存一致性问题。
57 |
58 | 
59 |
60 | 在多CPU的系统中(或者单CPU多核的系统),每个CPU内核都有自己的高速缓存,它们共享同一主内存(Main Memory)。当多个CPU的运算任务都涉及同一块主内存区域时,CPU 会将数据读取到缓存中进行运算,这可能会导致各自的缓存数据不一致。
61 |
62 | 因此需要每个 CPU 访问缓存时遵循一定的协议,在读写数据时根据协议进行操作,共同来维护缓存的一致性。这类协议有 MSI、MESI、MOSI、和 Dragon Protocol 等。
63 |
64 | ## 1.3. 处理器优化和指令重排序
65 |
66 | 为了提升性能在 CPU 和主内存之间增加了高速缓存,但在多线程并发场景可能会遇到`缓存一致性问题`。那还有没有办法进一步提升 CPU 的执行效率呢?答案是:处理器优化。
67 |
68 | > 为了使处理器内部的运算单元能够最大化被充分利用,处理器会对输入代码进行乱序执行处理,这就是处理器优化。
69 |
70 | 除了处理器会对代码进行优化处理,很多现代编程语言的编译器也会做类似的优化,比如像 Java 的即时编译器(JIT)会做指令重排序。
71 |
72 | 
73 |
74 | > 处理器优化其实也是重排序的一种类型,这里总结一下,重排序可以分为三种类型:
75 | >
76 | > - 编译器优化的重排序。编译器在不改变单线程程序语义放入前提下,可以重新安排语句的执行顺序。
77 | > - 指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
78 | > - 内存系统的重排序。由于处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
79 |
80 | # 2. 并发编程的问题
81 |
82 | 上面讲了一堆硬件相关的东西,有些同学可能会有点懵,绕了这么大圈,这些东西跟 Java 内存模型有啥关系吗?不要急咱们慢慢往下看。
83 |
84 | 熟悉 Java 并发的同学肯定对这三个问题很熟悉:『可见性问题』、『原子性问题』、『有序性问题』。如果从更深层次看这三个问题,其实就是上面讲的『缓存一致性』、『处理器优化』、『指令重排序』造成的。
85 |
86 | 
87 |
88 | 缓存一致性问题其实就是可见性问题,处理器优化可能会造成原子性问题,指令重排序会造成有序性问题,你看是不是都联系上了。
89 |
90 | 出了问题总是要解决的,那有什么办法呢?首先想到简单粗暴的办法,干掉缓存让 CPU 直接与主内存交互就解决了可见性问题,禁止处理器优化和指令重排序就解决了原子性和有序性问题,但这样一夜回到解放前了,显然不可取。
91 |
92 | 所以技术前辈们想到了在物理机器上定义出一套内存模型, 规范内存的读写操作。内存模型解决并发问题主要采用两种方式:`限制处理器优化`和`使用内存屏障`。
93 |
94 | # 3. Java 内存模型
95 |
96 | 同一套内存模型规范,不同语言在实现上可能会有些差别。接下来着重讲一下 Java 内存模型实现原理。
97 |
98 | ## 3.1. Java 运行时内存区域与硬件内存的关系
99 |
100 | 了解过 JVM 的同学都知道,JVM 运行时内存区域是分片的,分为栈、堆等,其实这些都是 JVM 定义的逻辑概念。在传统的硬件内存架构中是没有栈和堆这种概念。
101 |
102 | 
103 |
104 | 从图中可以看出栈和堆既存在于高速缓存中又存在于主内存中,所以两者并没有很直接的关系。
105 |
106 | ## 3.2. Java 线程与主内存的关系
107 |
108 | Java 内存模型是一种规范,定义了很多东西:
109 |
110 | - 所有的变量都存储在主内存(Main Memory)中。
111 | - 每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的拷贝副本。
112 | - 线程对变量的所有操作都必须在本地内存中进行,而不能直接读写主内存。
113 | - 不同的线程之间无法直接访问对方本地内存中的变量。
114 |
115 | 看文字太枯燥了,我又画了一张图:
116 |
117 | 
118 |
119 | ## 3.3. 线程间通信
120 |
121 | 如果两个线程都对一个共享变量进行操作,共享变量初始值为 1,每个线程都变量进行加 1,预期共享变量的值为 3。在 JMM 规范下会有一系列的操作。
122 |
123 | 
124 |
125 | 为了更好的控制主内存和本地内存的交互,Java 内存模型定义了八种操作来实现:
126 |
127 | - lock:锁定。作用于主内存的变量,把一个变量标识为一条线程独占状态。
128 | - unlock:解锁。作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
129 | - read:读取。作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
130 | - load:载入。作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
131 | - use:使用。作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
132 | - assign:赋值。作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
133 | - store:存储。作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
134 | - write:写入。作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
135 |
136 | > 注意:工作内存也就是本地内存的意思。
137 |
138 | # 4. 有态度的总结
139 |
140 | 由于CPU 和主内存间存在数量级的速率差,想到了引入了多级高速缓存的传统硬件内存架构来解决,多级高速缓存作为 CPU 和主内间的缓冲提升了整体性能。解决了速率差的问题,却又带来了缓存一致性问题。
141 |
142 | 数据同时存在于高速缓存和主内存中,如果不加以规范势必造成灾难,因此在传统机器上又抽象出了内存模型。
143 |
144 | Java 语言在遵循内存模型的基础上推出了 JMM 规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。
145 |
146 | 为了更精准控制工作内存和主内存间的交互,JMM 还定义了八种操作:`lock`, `unlock`, `read`, `load`,` use`,` assign`, `store`, `write`。
147 |
148 | -- End --
149 |
150 | 关于Java 内存模型还有很多东西没有展开讲,比如说:`内存屏障`、`happens-before`、`锁机制`、`CAS`等等。要肝一个系列了,加油!
151 |
152 | 我是雷小帅,大家有任何疑问、建议、想法欢迎在留言区套路,最后『求在看』、『求赞』、『求转发』,下期见~
--------------------------------------------------------------------------------
/docs/java/juc/面试必问的CAS原理你会了吗.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650324759&idx=1&sn=11908655d1388b44a61904a175a3a09a&chksm=8f09c10db87e481b025e620ecf86bd14ce4ab8b979264a12ac1e63de2e10eaae95eff2e3bf32&token=997683041&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [1. 什么是 CAS?](#1-什么是-cas)
6 | - [2. CAS 基本原理](#2-cas-基本原理)
7 | - [3. CAS 在 Java 语言中的应用](#3-cas-在-java-语言中的应用)
8 | - [4. CAS 的问题](#4-cas-的问题)
9 | - [4.1. 典型 ABA 问题](#41-典型-aba-问题)
10 | - [4.2. 自旋开销问题](#42-自旋开销问题)
11 | - [4.3. 只能保证单个变量的原子性](#43-只能保证单个变量的原子性)
12 | - [5. 有态度的总结](#5-有态度的总结)
13 |
14 |
15 |
16 | 在并发编程中我们都知道`i++`操作是非线程安全的,这是因为 `i++`操作不是原子操作。
17 |
18 | 如何保证原子性呢?常用的方法就是`加锁`。在Java语言中可以使用 `Synchronized`和`CAS`实现加锁效果。
19 |
20 | `Synchronized`是悲观锁,线程开始执行第一步就是获取锁,一旦获得锁,其他的线程进入后就会阻塞等待锁。如果不好理解,举个生活中的例子:一个人进入厕所后首先把门锁上(获取锁),然后开始上厕所,这个时候有其他人来了只能在外面等(阻塞),就算再急也没用。上完厕所完事后把门打开(解锁),其他人就可以进入了。
21 |
22 | 
23 |
24 | `CAS`是乐观锁,线程执行的时候不会加锁,假设没有冲突去完成某项操作,如果因为冲突失败了就重试,最后直到成功为止。
25 |
26 | # 1. 什么是 CAS?
27 |
28 | CAS(Compare-And-Swap)是`比较并交换`的意思,它是一条 CPU 并发原语,用于判断内存中某个值是否为预期值,如果是则更改为新的值,这个过程是`原子`的。下面用一个小示例解释一下。
29 |
30 | CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,计算后要修改后的新值B。
31 |
32 | (1)初始状态:在内存地址V中存储着变量值为 1。
33 |
34 | 
35 |
36 | (2)线程1想要把内存地址为 V 的变量值增加1。这个时候对线程1来说,旧的预期值A=1,要修改的新值B=2。
37 |
38 | 
39 |
40 | (3)在线程1要提交更新之前,线程2捷足先登了,已经把内存地址V中的变量值率先更新成了2。
41 |
42 | 
43 |
44 | (4)线程1开始提交更新,首先将预期值A和内存地址V的实际值比较(Compare),发现A不等于V的实际值,提交失败。
45 |
46 | 
47 |
48 | (5)线程1重新获取内存地址 V 的当前值,并重新计算想要修改的新值。此时对线程1来说,A=2,B=3。这个重新尝试的过程被称为`自旋`。如果多次失败会有多次自旋。
49 |
50 | 
51 |
52 | (6)线程 1 再次提交更新,这一次没有其他线程改变地址 V 的值。线程1进行Compare,发现预期值 A 和内存地址 V的实际值是相等的,进行 Swap 操作,将内存地址 V 的实际值修改为 B。
53 |
54 | 
55 |
56 | 总结:更新一个变量的时候,只有当变量的预期值 A 和内存地址 V 中的实际值相同时,才会将内存地址 V 对应的值修改为 B,这整个操作就是`CAS`。
57 |
58 | # 2. CAS 基本原理
59 |
60 | CAS 主要包括两个操作:`Compare`和`Swap`,有人可能要问了:两个操作能保证是原子性吗?可以的。
61 |
62 | CAS 是一种`系统原语`,原语属于操作系统用语,原语由若干指令组成,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说 CAS 是一条 CPU 的原子指令,由操作系统硬件来保证。
63 |
64 | > 在 Intel 的 CPU 中,使用 cmpxchg 指令。
65 |
66 | 回到 Java 语言,JDK 是在 1.5 版本后才引入 CAS 操作,在`sun.misc.Unsafe`这个类中定义了 CAS 相关的方法。
67 |
68 | ```java
69 | public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object x);
70 |
71 | public final native boolean compareAndSwapInt(Object o, long offset, int expected, int x);
72 |
73 | public final native boolean compareAndSwapLong(Object o, long offset, long expected, long x);
74 | ```
75 |
76 | 可以看到方法被声明为`native`,如果对 C++ 比较熟悉可以自行下载 OpenJDK 的源码查看 unsafe.cpp,这里不再展开分析。
77 |
78 | # 3. CAS 在 Java 语言中的应用
79 |
80 | 在 Java 编程中我们通常不会直接使用到 CAS,都是通过 JDK 封装好的并发工具类来间接使用的,这些并发工具类都在`java.util.concurrent`包中。
81 |
82 | > J.U.C 是`java.util.concurrent`的简称,也就是大家常说的 Java 并发编程工具包,面试常考,非常非常重要。
83 |
84 | 目前 CAS 在 JDK 中主要应用在 J.U.C 包下的 Atomic 相关类中。
85 |
86 | 
87 |
88 | 比如说 AtomicInteger 类就可以解决 i++ 非原子性问题,通过查看源码可以发现主要是靠 volatile 关键字和 CAS 操作来实现,具体原理和源码分析后面的文章会展开分析。
89 |
90 | # 4. CAS 的问题
91 |
92 | CAS 不是万能的,也有很多问题。
93 |
94 | `敲黑板:CAS有哪些问题,这是面试高频考点,需要重点掌握`。
95 |
96 | ## 4.1. 典型 ABA 问题
97 |
98 | ABA 是 CAS 操作的一个经典问题,假设有一个变量初始值为 A,修改为 B,然后又修改为 A,这个变量实际被修改过了,但是 CAS 操作可能无法感知到。
99 |
100 | 如果是整形还好,不会影响最终结果,但如果是对象的引用类型包含了多个变量,引用没有变实际上包含的变量已经被修改,这就会造成大问题。
101 |
102 | 如何解决?思路其实很简单,在变量前加版本号,每次变量更新了就把版本号加一,结果如下:
103 |
104 | 
105 |
106 | 最终结果都是 A 但是版本号改变了。
107 |
108 | 从 JDK 1.5 开始提供了`AtomicStampedReference`类,这个类的 `compareAndSe `方法首先检查`当前引用`是否等于`预期引用`,并且`当前标志`是否等于`预期标志`,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
109 |
110 | ## 4.2. 自旋开销问题
111 |
112 | CAS 出现冲突后就会开始`自旋`操作,如果资源竞争非常激烈,自旋长时间不能成功就会给 CPU 带来非常大的开销。
113 |
114 | 解决方案:可以考虑限制自旋的次数,避免过度消耗 CPU;另外还可以考虑延迟执行。
115 |
116 | ## 4.3. 只能保证单个变量的原子性
117 |
118 | 当对一个共享变量执行操作时,可以使用 CAS 来保证原子性,但是如果要对多个共享变量进行操作时,CAS 是无法保证原子性的,比如需要将 i 和 j 同时加 1:
119 |
120 | i++;j++;
121 |
122 | 这个时候可以使用 synchronized 进行加锁,有没有其他办法呢?有,将多个变量操作合成一个变量操作。从 JDK1.5 开始提供了`AtomicReference` 类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
123 |
124 | # 5. 有态度的总结
125 |
126 | CAS 是 Compare And Swap,是一条 CPU 原语,由操作系统保证原子性。
127 |
128 | Java语言从 JDK1.5 版本开始引入 CAS , 并且是 Java 并发编程J.U.C 包的基石,应用非常广泛。
129 |
130 | 当然 CAS 也不是万能的,也有很多问题:典型 ABA 问题、自旋开销问题、只能保证单个变量的原子性。
131 |
--------------------------------------------------------------------------------
/docs/java/roadmap/2021 版最新Java 学习路线图(持续刷新).md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s/vc7rzYwfRC05bUR6eaUJcw)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [学Java有哪些就业方向?](#学java有哪些就业方向)
6 | - [数据结构和算法](#数据结构和算法)
7 | - [设计模式](#设计模式)
8 | - [计算机基础](#计算机基础)
9 | - [Java 入门](#java-入门)
10 | - [Java 高手进阶](#java-高手进阶)
11 | - [基础框架(SSM)](#基础框架ssm)
12 | - [微服务框架](#微服务框架)
13 | - [常用中间件](#常用中间件)
14 | - [数据库](#数据库)
15 | - [分布式架构](#分布式架构)
16 | - [必须掌握的工具软件](#必须掌握的工具软件)
17 | - [学习常见问题(FAQ)](#学习常见问题faq)
18 |
19 |
20 |
21 | **最近很多读者在问:Java 怎么学习啊?有没有什么学习路线?**
22 |
23 | 我相信这些读者或多或少都有一些 Java 基础,但由于看不到全貌,学了一段时间很容易迷失。所以我在寻思着能不能写一个学习的地图或者路线,让读者能知道下一步该学什么,自己离大厂的 offer还有多远的距离。
24 |
25 | 一个人最怕的不是路途遥远,而是看不到胜利曙光。我希望下面这篇文章能给你的学习之路带来一丝曙光,大家不妨试着读一下吧,如果有收获给我点个赞哟。
26 |
27 | > 温馨提醒:这篇文章写着写着就一万字了,建议大家关注后再收藏,以防走丢。
28 |
29 | 这篇文章主要内容包括(干货满满):
30 | - 学Java有哪些就业方向?
31 | - 数据结构和算法
32 | - 设计模式
33 | - 计算机基础
34 | - Java 入门
35 | - Java 高手进阶
36 | - 基础框架(SSM)
37 | - 微服务框架
38 | - 常用中间件
39 | - 数据库
40 | - 分布式架构
41 | - 必须掌握的工具软件
42 | - 学习资源网站列表汇总
43 | - 学习常见问题(FAQ)
44 |
45 | 买一瓶可乐,泡一杯咖啡,lets go 学习~
46 |
47 | ## 学Java有哪些就业方向?
48 | 在介绍 Java 怎么学之前我给大家介绍一下学完了能干什么,因为有目标的学习才是最高效的。
49 |
50 | 很多 Java 入门学习者对岗位或者方向的概念非常模糊,今天学安卓、后天学大数据,三心二意的学习势必造成技术不精,这就是面试官通常说的:这位面试者基础比较差。
51 |
52 | 学习技术首先要认准一个方向专注下去,有了一定积累后再将自己的知识面扩宽,找到自己感兴趣的方向再沉下去学习,周而复始你就成为这个行业的专家了。
53 |
54 | Java 这门语言,在公司里根据分工不同衍生出了众多的岗位或者技术方向。
55 |
56 | 我在 boss 直聘上搜索了 BAT 等大厂的岗位,目前有以下三类岗位非常热门:
57 |
58 | (1)安卓开发
59 | > 技能要求:
60 | > - 熟悉 Android UI 开发非常熟悉,对 UI 架构有理解,并了解基础的 UI 交互知识;
61 | > - 熟悉 Android 调试工具和方法,可以应付各种 Android 复杂问题;
62 | > - 熟悉 Android Framework 层,有通过 Android 源码阅读定位问题的经验;
63 |
64 | (2)Java 后端开发
65 | > 技能要求:
66 | > - 具备扎实的Java基础,对JVM原理有扎实的理解;对Spring、MyBatis、Dubbo等开源框架熟悉,并能了解它的原理和机制,具有大型分布式系统设计研发经验;
67 | > - 熟悉基于Mysql关系数据库设计和开发、对数据库性能优化有丰富的经验;
68 | > - 熟悉底层中间件、分布式技术(如RPC框架、缓存、消息系统等);
69 |
70 | (3)大数据/数据仓库
71 | > 技能要求:
72 | > - 熟悉Hadoop/Spark/sqoop/hive/impala/azkaban/kylin等大数据相关组件;
73 | > - 精通sql及性能调优,熟练使用java、python、scala其中一种编程语言;
74 | > - 掌握数据仓库 (DW) / OLAP /商业智能 (BI) /数据统计理论,并灵活的应用,具备大型数据仓库设计经验;
75 |
76 | 这里只列举了三类比较热门的技术岗位,希望大家结合自己的经验思考一下方向。
77 |
78 | `敲黑板:认清自己,找准方向,越早确定方向越容易成功!`
79 |
80 | ## 数据结构和算法
81 | **学什么?**
82 |
83 | 有些同学可能要问了:我学 Java 的有必要学习算法吗?答案是:`别无选择`!
84 |
85 | 国内互联网面试的流程逐渐在向国外靠拢,像字节跳动、BAT 等大厂,`手撕算法题`已经成为了必选动作。
86 |
87 | 确实, Java 相对于 C、C++有着丰富的类库和三方框架,进入工作后大部分人都是在写业务代码,俗称 API boy 或者 Crud boy,算法看起来并不是那么重要,但是考算法真的是公司面试筛选人的低成本办法,如果你写出了算法并且通过了,要么你聪明要么你勤奋(刷题了)。
88 |
89 | 所以不管你是学什么语言:C、C++、python、Java、GO,算法这一关你必须得过。数据结构和算法的面试核心知识点我已经列出来了,大家可以参考学习,逐个击破。
90 | - 栈与队列:先进先出、后进先出
91 | - 线性链表
92 | - 查找:顺序查找、二分查找
93 | - 排序:交换类、插入类、选择类
94 | - 树、二叉树、图:深度优先(DFS)、广度优先(BFS)
95 | - 递归
96 | - 分治
97 | - 滑窗
98 | - 三大牛逼算法:回溯、贪心、动态规划(DP)
99 |
100 | **怎么学?**
101 |
102 | 最好或者最笨的方法就是刷题,强烈推荐力扣:[https://leetcode-cn.com](https://leetcode-cn.com)
103 | 建议刷300题以上,要覆盖简单、中等、困难的题目。面试前要训练手感,不要生疏了,可以选保持每日或几日一题。
104 |
105 | 在刷题之前我建议你看一些书:
106 | 《漫画算法-小灰的算法之旅》
107 |
108 | > 如果你之前没有任何算法基础,这边书很适合你,可以补充数据结构和算法的基础知识,像什么是时间复杂度空间复杂度、查找、排序等。
109 | > 如果你有了一定基础了,建议你直接跳到最后面的算法实战部分。
110 |
111 | 《剑指 offer》
112 | > 非常经典的一本书,学算法的人必刷。但是要注意了,这边书里面的题目是用 C++写的,如果你是 Java 开发人员可能会有点影响。但是要记住学习算法最关键的还是解题思路和方法,用什么语言实现是其次的,如果你时间比较多我是建议你用 Java 语言再实现一遍。
113 |
114 | 《labuladong的算法小抄》
115 | > 非常推荐!这是一本很新的书,写书前作者在 Github 开源了一个项目,主要讲解 LeetCode 解题套路,Start 总数排名前40。在书的开头讲解了学习算法的基本思维和套路,建议看这边书的同时再配合 leetcode 刷题,疗效非常棒!
116 |
117 | 《算法导论》
118 | > 要是不推荐这本书是不是显得我有点 low 了,这是一本科班出身的同学必看必学的经典大部头。国外大佬写的,国内翻译的经典之作,虽然是经典但是不建议刚入门算法的同学看,因为看了这本书你可能要放弃算法了,比较难看懂。建议有了一定基础再入手这边书。
119 |
120 | 如果你觉得看书比较枯燥,可以推荐你看一些极客时间的专栏,不过是收费,但是质量非常高。
121 | 《数据结构与算法之美》
122 | > 这个专栏是文字+语音,作者是王争,前 Google 工程师。他采用最适合工程师的学习方式,不拘泥于某一特定编程语言,从实际开发场景出发,由浅入深教你学习数据结构与算法的方法,帮你搞懂基本概念和核心理论,深入理解算法精髓,帮你提升使用数据结构和算法思维解决问题的能力。
123 |
124 | 《算法面试通关40讲》
125 | > 这个专栏是视频,作者是覃超,前Facebook工程师。作者会用白板带你一步一步解题,层层深入一环扣一环,每一题还会用多种解题方法。我基本看完了,收获颇多。
126 |
127 | leetcode、书和极客专栏可以并行,学练结合,不要光看不练哦。
128 |
129 | ## 设计模式
130 | **学什么?**
131 |
132 | 金庸小说中牛叉的武功太多了,综合性最强的还是`九阳真经`,九阴真经分为上、下两卷,`上卷为内功基础,下卷为武功招式`,这些都是极负盛名的`武学秘籍`。
133 |
134 | 那大家思考一下什么是武学秘籍?其实打开来开就是一些固定的招式,牢记这些招式并运用好就是绝顶高手了。
135 |
136 | 回到编程上来,除了要写干净的代码(clean code),还要运用各种`设计模式`使代码可读性强、扩展性好、松耦合,这便是大家经常说的编码大牛。
137 |
138 | 所以不管是学武功还是学编码,都是有一些固定的招式,也就是设计模式。
139 |
140 | 说到`设计模式`很多同学可能会跳出来:这个我知道,就是单例模式、工厂模式……
141 |
142 | 巴拉巴拉说了一堆,但是真正在写代码的时候又是一脸蒙:为什么我写的代码用不到设计模式?究其原因是你的代码经验不够。
143 |
144 | 想一下设计模式是怎么来的?上个世纪四个大男人搞了一个组合叫 GoF,并出版了一本书,这本书共收录了23种设计模式,后面逐渐被人熟知。这四个人从大量的代码实践中总结了一套方法论(写代码的套路),而我们作为一个在学校的学生或者刚工作的新人,可能连代码都写的少,怎么可能轻松快速地掌握这么多设计模式。
145 |
146 | 所以说你学完了设计模式,但是还不会运用到日常的代码实践中,这个是很正常的,因为代码经验还不够。
147 |
148 | 那还学不学?当然要学,因为面试的时候有可能会问到。设计模式的理论知识我们还是要打好基础,需要掌握这些知识点:
149 | - 设计模式的六大原则:单一职责、里氏替换、依赖倒置、接口隔离、迪米特法则、开闭原则
150 | - UML 基础知识
151 | - 设计模式三大分类:创建型、结构型、行为型
152 | - 常用设计模式基本原理
153 |
154 | 经典设计模式总共有23种(现在远不止23种了,还有一些变种),全部掌握难度太大了,我们只需要掌握一些常用的就好了,必须要掌握的我用小红旗已经标出来了。
155 | 
156 |
157 | **怎么学?**
158 |
159 | 网上关于设计模式的学习资料非常多,质量也是参差不齐,大家找的时候可要擦亮眼睛。
160 |
161 | 在看书之前我还是推荐你熟悉一下 UML 的理论知识,因为你如果不懂 UML 那任何一本设计模式的书你都可能读不下去, UML 是设计模式的前提。
162 |
163 | UML 学习网站:
164 |
165 | https://www.w3cschool.cn/uml_tutorial/
166 |
167 | 不要花太多时间学习 UML,简单理解入门即可。
168 |
169 | 假设你已经入门 UML 了,那下面的这些书你可以考虑学习一下了:
170 |
171 | 《Head First 设计模式》
172 | > Head First 是一个比较经典的系列丛书,有些人非常喜欢这种风格。这本书讲枯燥的设计概念讲解的生动有趣,作为一本入手书非常值得推荐。
173 |
174 | 《大话设计模式》
175 | > 大话系列是国内非常经典的系列丛书,有众多粉丝。这本大话设计模式以对话的形式讲解知识,在当时可开创了先河。虽然书中有些例子比较牵强,但任然不失为一本入门的好书。
176 |
177 | 《图解设计模式》
178 | > 图解系列是日本的一位作者写的,有一本图解 HTTP 非常经典,这本图解设计模式也是类似的风格。由于是翻译过来的,书中有些例子可能听起来比较奇怪,貌似翻译过来的技术书都有这个问题。
179 |
180 | 《设计模式-可复用面向对象软件的基础》
181 | > 又是一本黑色大部头书,书的作者就是 GoF,大家都说经典。但是呢,经典归经典,读起来真的是晦涩难懂,对新人非常不优化,如果你想入门学习设计模式,这本书就不推荐了。不推荐为什么要说出来?经典的书如果不提,你们又要说我菜。(害)
182 |
183 | 这几本书都要看吗?当然不是,如果你是在准备面试,我个人建议是读其中一本就够了。至于说看哪一本,你可以找对应的电子书,挑一个章节试读一下,符合你的胃口就选择这一本继续读下去。
184 |
185 | 如果你已经有几年的编码经验,又想把代码写好,建议你多挑基本读读,吸收每本书的精华。
186 |
187 | ## 计算机基础
188 | 科班出身的同学对《计算机网络》和《操作系统》这两门课应该不会陌生,至于掌握了多少,你懂得,都是在考前一两周突击学习的,哈哈。
189 |
190 | 现在大公司对于应届生的要求越来越高,计网和操作系统这两门课是必考的。那些拿了 SSSP Offer 的大牛计算机基础都非常扎实。
191 |
192 | **(1)计算机网络**
193 |
194 | **学什么?**
195 |
196 | 计算网络的协议非常非常多,很多同学学完都一头雾水,或者仅仅懂一点 HTTP,但是真正要掌握的东西可不少:
197 | - OSI 七层模型、TCP/IP五层模型
198 | - 常见网络协议:HTTP、TCP/IP、UDP
199 | - 网络安全:非对称加密、数字签名、数字证书
200 | - 网络攻击:DDOS、XSS、CSRF 跨域攻击
201 |
202 | **怎么学?**
203 |
204 | 计算机网络面试有一道非常经典的面试题:说说你从URL输入到最终页面展现的过程。这一题可以覆盖大部分计网的知识点,可以从 DNS 解析到 HTTP、TCP/IP协议、物理层协议,一直到浏览器渲染页面,你技术功底有多深你就可以聊多深。希望大家学完了也能试着回答一下这个问题。
205 |
206 | 推荐几本倍受好评的书:
207 | 《网络是怎么连接的》
208 | > 这本书是一本日本作者写的。文章围绕着在浏览器中输入网址开始,一路追踪了到显示出网页内容为止的整个过程,图文并茂生动有趣,非常推荐!
209 |
210 | 《图解 HTTP》
211 | > 也是一名日本作者写的。这本书对 HTTP 协议进行了全面系统的介绍,列举了很多常见通信场景及实战案例,相信读完会有恍然大悟的感觉。书很薄,几天就可以读完,强烈推荐!
212 |
213 | 《TCP/IP详解卷1:协议》
214 | > 计算机网络的经典教材, 大部头书籍,很难啃。建议挑重点看。
215 |
216 | 最后安利一款工具,学习网络必备的抓包神奇:wireshark,如果你学网络没抓过包,那基本等于白学了(有点严重)。
217 |
218 | **(2)操作系统**
219 |
220 | **学什么?**
221 |
222 | 作为一名 Javaer 在平时的工作中可能不会直接跟操作系统打交道,因为 JVM 帮我们屏蔽了众多差异。但是要想学好 JVM,懂一点操作系统更有助于你深刻理解 JVM 工作原理。
223 |
224 | Java 学习者这部分的要求可以稍微放低,但是你如果是搞 C++的,那这部分可是你的重点。
225 | - 进程和线程的区别
226 | - 进程间的通信方式:共享内存、管道、消息
227 | - 内存管理、虚拟内存
228 | - 死锁检测和避免
229 |
230 | **怎么学?**
231 |
232 | 想要精通操作系统难度非常大,但是在面试中你要能讲出一些具体的操作系统知识,面试官会对你刮目相看。
233 |
234 | 推荐一些视频学习资料:
235 | B 站:
236 | 麻省理工 MIT 6.828(无字幕):https://www.bilibili.com/video/BV1px411E7ST
237 | 操作系统(哈工大李治军老师)32讲(全)超清:https://www.bilibili.com/video/BV1d4411v7u7
238 |
239 | 推荐书籍资料:
240 | 《深入理解计算机系统 CSAPP》
241 | > 赫赫有名的 CSAPP,全称:Computer Systems:A Programmer‘s Perspective。科班同学的圣经,哈哈,黑色大部头书籍,难啃。
242 |
243 | 《现代操作系统 (第3版)》
244 | > 操作系统领域的经典之作,因为是翻译过来的,遇到比较晦涩的先跳过,多读几遍才能消化。
245 |
246 | ## Java 入门
247 | **学什么?**
248 |
249 | Java 语言从诞生到现在已经有20多年了,从Tiobe排行榜上来看,Java 语言常年霸榜经久不衰,所以不要怕学完 Java 后突然不流行了,至少这几年Java 就业机会非常多。
250 |
251 | 如果你有其他语言的基础,比如之前学过 C、C++等,那学起 Java 应该是非常容易的,也容易上手。如果你没有语言基础,又不想了解太底层的东西,那学 Java 还是不错的。至于说 python,光从语言层面上看,python 确实非常简单,估计你一周内就可以学会并且代码写的还不错,但是 Java 不一样,一周你只能简单了解一下语法,想写好代码几乎不可能。另外 Go 语言势头很猛,大家也可以关注一下。
252 |
253 | 一般来说 Java 入门你需要掌握下面这些知识点:
254 | - 面向过程 VS 面向对象
255 | - 面向对象基本特征:封装、继承、多态
256 | - 访问控制符:private、default、protected、public
257 | - 数据类型:基本类型、引用类型
258 | - 控制流程:for、while、switch 等
259 | - 序列化
260 | - 异常处理(有点难度)
261 | - 泛型(有点难度)
262 |
263 | **怎么学?**
264 |
265 | 如果你是零基础,建议你可以找一些 Java 入门的视频看一下,网上视频鱼龙混杂,大家注意甄别。推荐一个比较好的平台:B 站(https://www.bilibili.com/)
266 | 不是让你去看二次元的,里面有很多学习资源。(嘿哈)
267 |
268 | `敲黑板啦:视频不要贪多,因为没有一个大牛是看视频看出来的。` 看视频是别人将知识点往你脑袋里灌,最大的好处是能让你快速入门,如果你想学到更多,你需要的是`自我学习`,带有思考的自我学习。
269 |
270 | 看书是一种高效的自我学习方式,推荐基本比较好的书:
271 |
272 | 《Java 核心技术卷I》
273 | > 这本书建议作为Java 之旅的第一本书,涵盖的内容非常全,比起那些30天学会 Java 之类的书,这边书更加务实。书中有些章节其实不用看,比如Swing GUI 的直接略过,因为用 Java 写桌面端应用已经过时了。
274 |
275 | 《阿里巴巴 Java 开发手册》
276 | > 大厂阿里巴巴出品的,这其实是一本 Java 编码规范,编码习惯从一开始就要养好。
277 |
278 | 《Java 编程思想(Thinking In Java)》
279 | > 这是一本非常非常经典的书,你要问搞 Java 的人如果没听过这本书那算是白学了,哈哈。其实说实话这本书我试图看过几次,最终都没有看完,一个原因是它太厚了,另外我觉得讲得太啰嗦了,所以我现在拿来垫桌子,高度合适挺好的。所以呢,建议新人不要一开始看这边书,不然你会怀疑人生还没入门就放弃了,就把它当做编程圣经,等你后面有经验了拿起来再翻翻吧。
280 |
281 | 敲黑板了:学习编程要有耐心,不要急于求成,要打好基础。也许你一个月两个月还在运行一些简单示例,这是正常的,多学习多思考。
282 |
283 | ## Java 高手进阶
284 | **学什么?**
285 |
286 | 恭喜你终于Java 入门了,大牛和菜鸟的区别在于菜鸟永远止步于入门水平,而大牛已经找到新大陆了,翻过这几座山你离高手就不远了。
287 |
288 | Java 高手进阶需要掌握的东西非常非常多,这里列举一些核心知识点,必须全部掌握的。这是 Java 面试高频考点,也是传说中 Java 八股文的一部分,面好了进入下一面,面不好回家等消息。
289 | - Java 集合类源码
290 | - 线程池
291 | - Java 代理
292 | - IO 模型
293 | - JVM
294 | - Java 并发编程(JUC)
295 |
296 | **怎么学?**
297 |
298 | Java 已经入门了,你都想进阶了,建议你不要再找视频看了,一边看书一边思考吧。
299 |
300 | 《Effective Java》
301 | > 书中列举了很多编程建议,其实就是告诉怎样去写好代码,你需要从`能写代码`(入门)过渡到`会写代码`,这本书值得一看。如果你的编码经验比较少,那这边书你可以稍微往后延,因为看完了你可能没有感同身受。
302 |
303 | 《Java8 实战》
304 | > Java15 都出来了为什么还要学 Java8 ?因为现在很多公司都还停留在 Java8, Java8是继Java5之后改动很大的一个版本,得好好学。Java8之后的版本非常不给力,换一个 JDK 版本费时费力,收益也不明显,公司肯定不愿意动了。这边书将 Java8所有的新特性都详细讲解了,非常推荐。
305 |
306 | 《深入理解 Java 虚拟机 第3版》
307 | > 周志明大神写的,非常非常经典,已经更新到第三版了。Java 虚拟机也就是 JVM,JVM 是Java 面试必考的知识,不懂这个直接回家等消息吧。这边书我看了很多遍,每次看完都有新的收获,墙裂建议大家看完。
308 |
309 | 《Java 并发编程的艺术》
310 | > 这是一本专门讲解Java并发的书,涉及到各种锁、常见安全的集合类,基本就是将 JUC(java.util.concurrent包的简称)里所有的内容覆盖了一遍,看完你一定有收获。强烈推荐!
311 |
312 | 上面推荐的几本书可能不太容易读懂,建议多读几遍。书中看不懂的地方可以在网上搜,多找一些优质的博客或者公众号看。
313 |
314 | 至此 Java 语言特性基本学习完了,就算达不到高手的水平,你也在正轨上了。
315 |
316 | ## 基础框架(SSM)
317 | **学什么?**
318 |
319 | 学习 Java 语言特性可能比较枯燥,接下来可以学习基础框架动手做一些项目,比如 Java 领域非常流行的 Spring 框架,这就是为 Java 后端量身定做的,非常好用。
320 |
321 | 在 spring 流行之前,还出现 Struts 这样流行的框架,后面由于种种原因还是被 Spring 打败了。
322 |
323 | 大家在网上应该可以经常看到 SSM 的缩写,其实就是Spring+SpringMVC+MyBatis的缩写了。
324 |
325 | 你需要掌握以下这些:
326 | - Spring 全家桶(Spring、Spring MVC、Spring Boot)使用
327 | - ORM 框架(MyBatis、Hibernate)使用
328 | - Spring 原理
329 | - ORM 框架原理
330 |
331 | **怎么学?**
332 |
333 | 学习 SSM 框架最好是动手完成一个简单的项目,建议跟着视频并且把代码敲出来,一来熟悉项目的开发流程,也可以给自己带来成就感。
334 |
335 | 敲黑板:阶段性成就感非常重要,没有这个很容易放弃学习,所以要不定时给自己定个小目标,加加鸡腿啥的。
336 |
337 | 有很多新手在做项目的时候非常纠结界面,作为一个 Java 后端程序员,你又不是全栈开发,纠结这个干什么,我的建议:要么不要界面只写接口,要么自己动手写点 html,不需要美观,实现功能即可。
338 |
339 | 跟着视频做完项目之后需要干什么?答案是:`深入理解框架原理`。会用框架并不代表你懂框架,作为一个有追求的程序员,懂原理是永远的必修课,谁让这一行太卷了呢,人无你有你最棒。
340 |
341 | 推荐几本书:
342 | 《Spring 基础内幕》
343 | > 首先声明一下这是一本讲解Spring 源码的书,不是教你做项目的书。如果需要深入理解 Spring 的技术原理,这是一本非常推荐的书。有点难啃,多读几遍。
344 |
345 | 《MyBatis 技术内幕》
346 | > MyBatis 是 ORM 框架的一种,在国内使用比较多,据说在国外喜欢用 Hibernate。这本书对 MyBatis 的使用和基本原理都介绍比较清楚了。
347 |
348 | 敲黑板:技术更新迭代很快,抓住技术的本质才能与时俱进。
349 |
350 | 关于基础框架这部分,大神们的学习方法是:使用框架 -> 懂框架 -> 造轮子。
351 |
352 | ## 微服务框架
353 | **学什么?**
354 |
355 | 近些年微服务架构非常火,究其原因是因为传统的单体架构和面向服务的架构逐渐不能满足互联网快速迭代的需求。微服务可以更容易提供持续继承和持续部署的能力,让产品更快速交付推向市场。
356 |
357 | 面向服务的架构其实在五六年前就已经提出,期间经过了一段低潮期,泡沫散去后逐渐浮现了一些好用的框架,国外以 SpringCloud 为代表,国内以 Dubbo 为代表。
358 |
359 | springCloud 和 Dubbo 有区别但是很多基本原理也是类似,大家学习的时候需要掌握技术的本质。下面列举一些核心知识点:
360 | - Dubbo框架
361 | - SpringCloud框架
362 | - 服务注册与发现
363 | - 分布式服务链路追踪
364 | - 服务隔离、熔断、降级
365 | - 服务网关
366 |
367 | **怎么学?**
368 |
369 | springCloud 和 Dubbo 在官网都有很详细的介绍文档:
370 | - Dubbo官网 http://dubbo.apache.org/ 可以切到中文版
371 | - SpringCloud 官网 https://spring.io/projects/spring-cloud
372 |
373 | 看官网技术文档大家可能会很懵,但这些确实是最权威的资料,也是一手的。
374 |
375 | SpringCloud 和 Dubbo 是这几年刚刚流行的技术,从目前看来相关书籍还是比较少,也缺少一些经典的书,我还是列几本,大家按需获取。
376 |
377 | 《深入理解Apache Dubbo与实战》
378 | > Dubbo 最开始是阿里巴巴开源的,后面捐赠给Apache 了。建议大家读这本配合源码一起看。
379 |
380 | 《Spring Cloud微服务实战》
381 | > 读这本书之前你最好先学习 spring 和 spring boot,不然会很懵。另外这本书是2017年出版的,稍微显旧,大家注意分辨新旧特性。
382 |
383 | 如果技术网站和书籍还不能满足你,建议你去搜一些视频学习,这里不做推荐以免认为是广告。推荐搜索平台:B 站、慕课网、网易云课堂。
384 |
385 | `敲黑板:微服务框架涵盖的内容非常多,也是有难点的技术,大家戒躁保持耐心。`
386 |
387 | ## 常用中间件
388 | **学什么?**
389 |
390 | 最终用户并不直接使用`中间件`,换言之`中间件`不是大众消费类软件产品。但是在大公司里中间件是不可或缺的,它是支撑大型网站架构的一些基础的组件和服务,所以非常非常有必要学。
391 |
392 | > 小百科
393 | > 中间件(Middleware)通常是指在一个大型分布式的系统中,负责各个不同组件(Component)/服务(Service)之间管理以及交互数据的。
394 |
395 | 业界开源的优秀中间件非常多,通常会根据业务的需要在系统中引入若干,下面列举了一些常见的,都是必学的,非可选哈。
396 | - 缓存:Redis、Memcached( 推荐 Redis)
397 | - 消息队列:Kafka、RocketMQ、RabbitMQ、ActiveMQ、ZeroMQ(推荐 Kafka)
398 | - 数据库中间件:ShardingSpere、Mycat
399 |
400 | **怎么学?**
401 |
402 | 每个中间件涵盖的内容都非常多,要想学精需要大量时间。
403 |
404 | Redis 中文官方网站:
405 |
406 | [http://www.redis.cn/](http://www.redis.cn/)
407 |
408 | 当做字典学习 redis 常见命令
409 |
410 | Kafka 官网:
411 |
412 | [http://kafka.apache.org/](http://kafka.apache.org/)
413 |
414 | ShardingSpere 官网:
415 |
416 | [http://shardingsphere.apache.org/index_zh.html](http://shardingsphere.apache.org/index_zh.html)
417 |
418 | Mycat 权威指南在线 PDF 版:
419 |
420 | [http://www.mycat.org.cn/document/mycat-definitive-guide.pdf](http://www.mycat.org.cn/document/mycat-definitive-guide.pdf)
421 |
422 | 推荐几本相关的书:
423 | 《Redis 设计与实现》
424 | > 这时Redis 口碑比较好的一本书,书中详细讲解了 Redis 实现原理,如果你只是想学会怎么用,可以跳过一些章节。
425 |
426 | 《深入理解Kafka:核心设计与实践原理》
427 | > 这本书既适合新手入门扫盲也适合高手进阶,想知道怎么用看前四章即可,想深入学习可以从第五章开始看,写的非常好,推荐学习!
428 |
429 | 《分布式数据库架构及企业实践——基于Mycat中间件》
430 | > Mycat 相关的书非常少,这本书是16年写的,有些陈旧了,如果对 Mycat 非常感兴趣可以简单翻一翻,但是不是特别推荐。
431 |
432 | 书看完了你还想深入学习,建议大家关注一下极客时间的两门课:
433 | 胡夕:《Kafka核心技术与实战》,老师是Apache Kafka Committer,很专业。
434 | 蒋德钧:《Redis核心技术与实战》
435 |
436 | 不过课程是付费的,手头紧的建议慎重哈。免费资源网上也有,靠大家搜索了~
437 |
438 | 中间件的学习是一个漫长的过程,不仅需要很多理论知识还需要实践经验。
439 |
440 | 比如你学 Redis 的时候,要思考五种基本数据类型各自使用场景、布隆过滤器是什么原理、用 Redis 怎么实现分布式锁,带着问题去学习效率非常高。
441 |
442 | 比如你学 Kafka 消息队列,要对比常见消息队列的优缺点、Kafka 为什么吞吐量高、Kafka 会不会丢消息以及怎么解决。
443 |
444 | 比如你学数据库中间件,要想数据库为什么要分库分表、分库分表 ID 如果处理等等。
445 |
446 | ## 数据库
447 | **学什么?**
448 |
449 | 数据库非常重要,面试也是必考的,可以考的点非常多,可以考得很浅:问一下 SQL 使用,也可以考的很深:问索引和锁的实现原理。下面列了一些常见的知识点。
450 | - 数据库基本理论:范式、索引原理、数据库引擎
451 | - SQL 基本语法
452 | - SQL 调优,explain 执行计划
453 | - 数据库事务(ACID)
454 | - 数据库锁:乐观锁、悲观锁、表锁、行锁等
455 |
456 | **怎么学?**
457 |
458 | 建议数据库零基础的同学还是要先学习一下数据库的基本理论,因为我看到很多人都是一上来就学 SQL ,最终也只是会用而已,到后面 SQL 调优的时候就很迷茫了。如果你只是想用一用数据库,这部分也可以跳过。
459 |
460 | 关于原理部分有一本非常经典的教材《数据库系统概念》以供学习,经典书籍一般都比较难啃坑也比较厚,建议大家先看目录,挑重点看。大学学过这本书的可以直接跳过了。
461 |
462 | 有了一些理论后就可以开始学习 SQL 语法了,这里推荐一本《MySQL 必知必会》,一边看书一边对着电脑敲。
463 |
464 | 当然面试大厂肯定会问一下比较难的东西,你需要搞懂索引的原理、事务 ACID、锁,问数据库这些东西必考哦!
465 |
466 | MySQL 学习书籍清单:
467 | 《数据库系统概念》
468 | > 经典数据库教材,理解一些基本原理,可略看。
469 |
470 | 《MySQL必知必会》
471 | > SQL 语法入门好书,推荐!
472 |
473 | 《MySQL技术内幕 : InnoDB存储引擎》
474 | > 数据库进阶必看,理解存储引擎以及事务、锁、索引等原理。
475 |
476 | ## 分布式架构
477 | **学什么?**
478 |
479 | 分布式这一部分就是面试的加分项了,答好了面试官会觉得你技术功底深厚,答不好,只要你前面的基础还不错也能过。所以呢,作为一个有追求的技术人,千万不要放过加分的机会。
480 |
481 | 分布式相关的内容非常多,下面列举几个在项目中或者面试中经常会遇到的知识点:
482 | - 分布式事务:两阶段提交(2PC)、补偿事务(TCC)
483 | - 分布式锁:基于关系型数据库(MySQL)、基于 Redis、基于Zookeeper
484 | - 分布式 ID:雪花算法(Snowflake)、美团 Leaf
485 |
486 | **怎么学?**
487 |
488 | 这部分内容学好非常难,在很多书中都是轻轻带过,没有深入讲解原理,所以就不推荐书了。
489 |
490 | 那怎么学呢?大家可以针对每个知识点到网上搜索优质的博客,后面我也会逐步更文讲解这些知识点,敬请期待,欢迎催更哟。
491 |
492 | ## 必须掌握的工具软件
493 | 工欲善其事,必先利其器。作为一个 Java 开发人员,你需要学习业界常用的软件,软件工具用得越熟你的编码效率越高,下班的时间可能越早(打工人太难了)。
494 | - Java 最聪明的 IDE:IntelliJ IDEA (请放弃使用 Eclipse,我有一堆理由睡服你)
495 | - 地球上最好用的版本管理工具:Git
496 | - 经久不衰的依赖管理工具:Maven
497 | - Docker
498 |
499 | 这些软件你要是用不好,那只能说明…… 你再多学学吧。
500 |
501 | ## 学习常见问题(FAQ)
502 |
503 | **1. 学了容易忘怎么办?**
504 |
505 | 这是大家学习会遇到的头号大问题,怎么解决?重复学习。
506 |
507 | 打个比方,假如你正在学习 spring 注解,突然发现了一个注解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
508 |
509 | 从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。
510 |
511 | 人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。
512 |
513 | **2. 推荐这么多书都要看完吗?**
514 |
515 | 当然不是!有一些书都是同类型的,作者写书的侧重点不一样,大家要学会挑重点看。
516 |
517 | 拿到一本书,首先要把目录多看一遍,一般而言书的前几章都是介绍型的内容,如果你已经有了基础,可以直接跳到后面原理解析或者实战部分。
518 |
519 | **3. 需要学多久才能成为技术大牛?**
520 |
521 | `学习无止境!`
522 |
523 | 业界说法,通过不断努力学习,一到两年可以达到初级水平,三到四年达到中级水平,五年可以达到高级水平。
524 |
525 | 实际上每个人的学习能力和精力不一样,时间参考意义不大。
526 |
527 | 只要你在一个方向或领域有自己的建树,就可以叫你大牛;如果你在公司是技术骨干、技术专家、架构师,也可以称之为大牛。
528 |
529 | `敲黑板:技术学习千万不要浮躁,谦卑一点多学一点,天外有天。`
530 |
531 | **4. 现在 python、Go 语言很火,要不要直接学它们?**
532 |
533 | 不要纠结语言,语言只是工具。今天 Go 很火,明天会有其他语言。
534 |
535 | 我有一个同学毕业去阿里写 Java,后面跳槽到深圳腾讯写 C++,现在又跳到字节跳动写 Go,在大佬面前这些语言只是语法不一样而已。所以建议大家打好基础,答应我一定打好基础。
536 |
537 |
538 | 『持续刷新……』
539 |
--------------------------------------------------------------------------------
/docs/mq/Kafka支持百万级TPS的秘密都藏在这里.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322018&idx=1&sn=ff1d7be13158a9d1cbc02a6d9123e503&chksm=8f09ca78b87e436e023de69301b326a9541d51b94a0d57393cc766da9dfef40c9ccaf0fdbc0c&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [Kafka 如何做到支持百万级 TPS ?](#kafka-如何做到支持百万级-tps-)
6 | - [顺序读写磁盘](#顺序读写磁盘)
7 | - [Memory Mapped Files\(MMAP\)](#memory-mapped-filesmmap)
8 | - [Zero Copy(零拷贝)](#zero-copy零拷贝)
9 | - [Batch Data(数据批量处理)](#batch-data数据批量处理)
10 | - [总结](#总结)
11 | - [公众号](#公众号)
12 |
13 |
14 |
15 |
16 | 谈到大数据传输都会想到 Kafka,Kafka 号称大数据的杀手锏,在业界有很多成熟的应用场景并且被主流公司认可。这款为大数据而生的消息中间件,以其百万级TPS的吞吐量名声大噪,迅速成为大数据领域的宠儿,在数据采集、传输、存储的过程中发挥着举足轻重的作用。
17 |
18 | 在业界已经有很多成熟的消息中间件如:RabbitMQ, RocketMQ, ActiveMQ, ZeroMQ,为什么 Kafka 在众多的敌手中依然能有一席之地,当然靠的是其强悍的吞吐量。下面带领大家来揭秘。
19 |
20 | ## Kafka 如何做到支持百万级 TPS ?
21 |
22 | 先用一张思维导图直接告诉你答案:
23 |
24 | 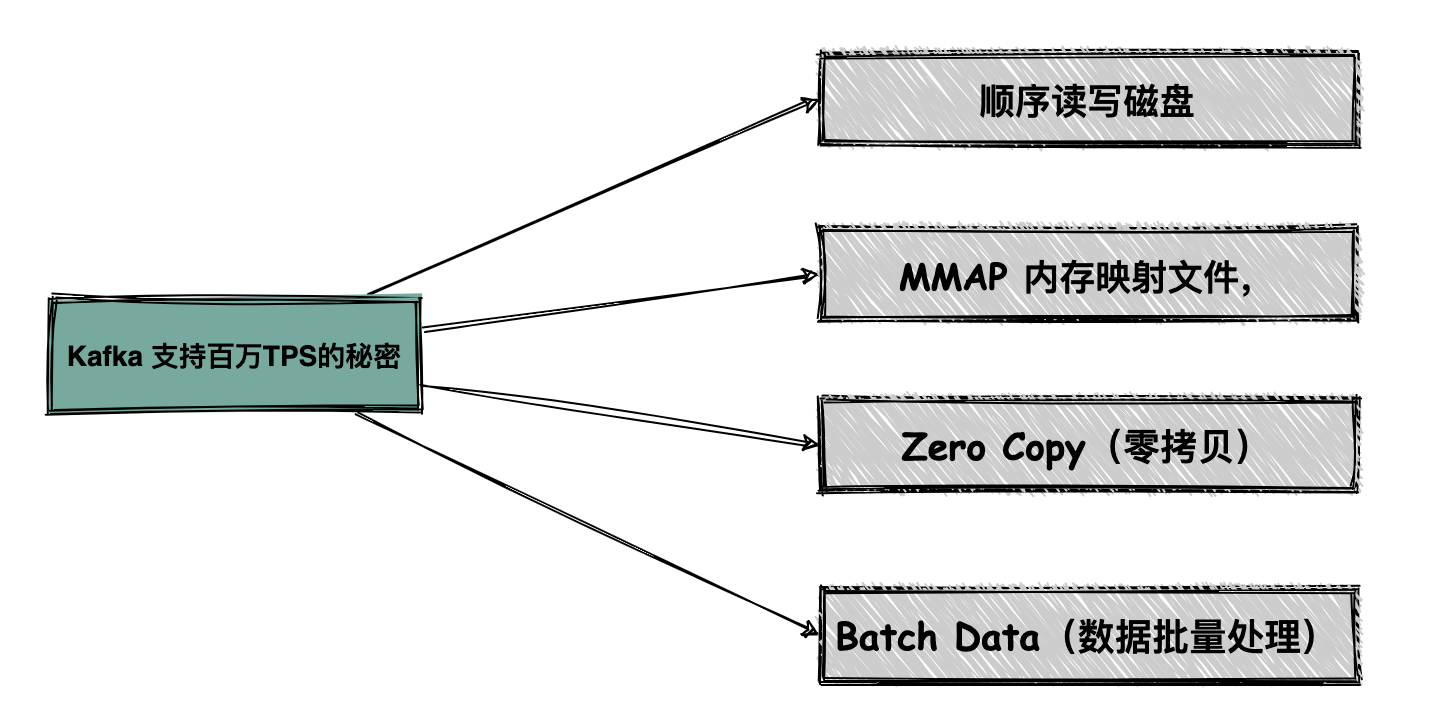 25 |
26 | ## 顺序读写磁盘
27 |
28 | 生产者写入数据和消费者读取数据都是**顺序读写**的,先来一张图直观感受一下顺序读写和随机读写的速度:
29 |
30 |
25 |
26 | ## 顺序读写磁盘
27 |
28 | 生产者写入数据和消费者读取数据都是**顺序读写**的,先来一张图直观感受一下顺序读写和随机读写的速度:
29 |
30 | 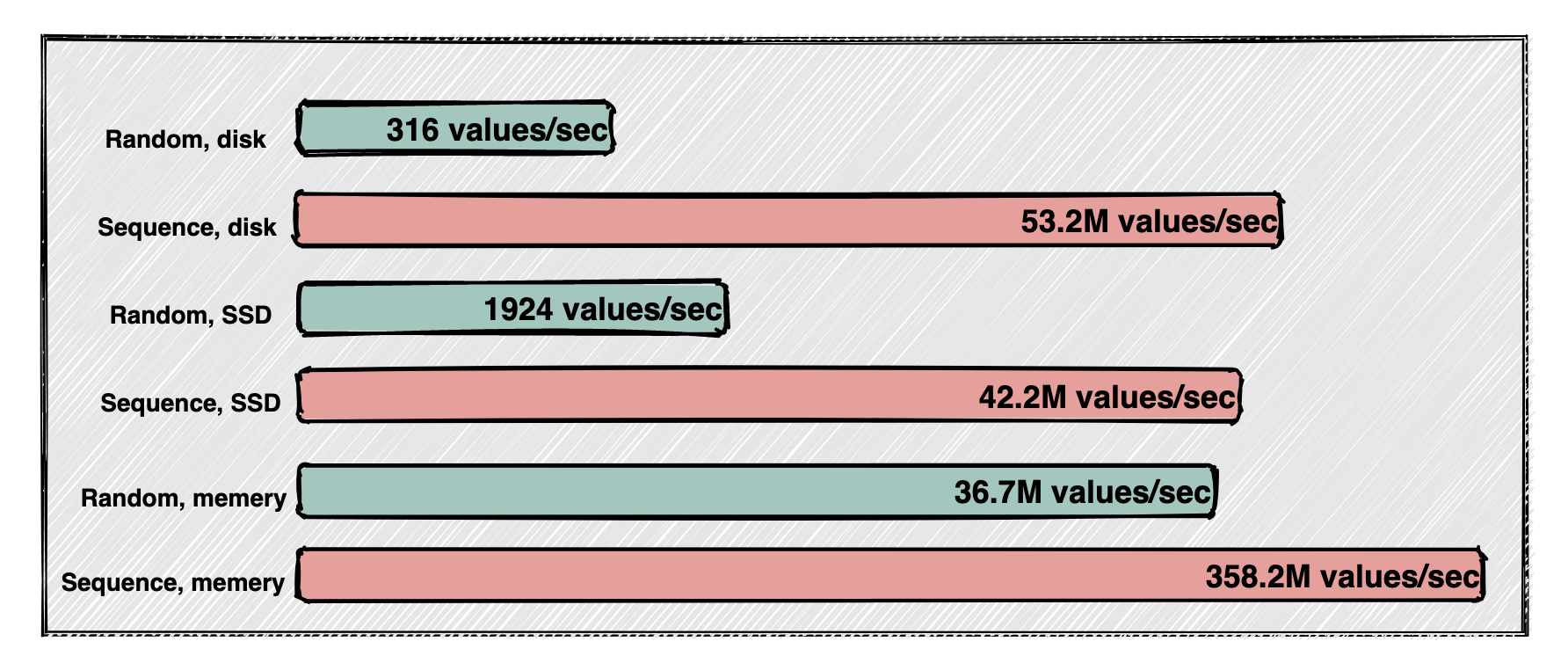 31 |
32 | 从图中可以看出传统硬盘或者SSD的顺序读写甚至超过了内存的随机读写,当然与内存的顺序读写对比差距还是很大。
33 |
34 | 所以Kafka选择顺序读写磁盘也不足为奇了。
35 |
36 | 下面以传统机械磁盘为例详细介绍一下什么是顺序读写和随机读写。
37 |
38 | **盘片**和**盘面:**一块硬盘一般有多块盘片,盘片分为上下两面,其中有效面称为盘面,一般上下都有效,也就是说:**盘面数 = 盘片数 * 2。**
39 |
40 | **磁头**:磁头切换磁道读写数据时是通过机械设备实现的,一般速度较慢;而磁头切换盘面读写数据是通过电子设备实现的,一般速度较快,因此磁头一般是先读写完柱面后才开始寻道的(不用切换磁道),这样磁盘读写效率更快。
41 |
42 |
31 |
32 | 从图中可以看出传统硬盘或者SSD的顺序读写甚至超过了内存的随机读写,当然与内存的顺序读写对比差距还是很大。
33 |
34 | 所以Kafka选择顺序读写磁盘也不足为奇了。
35 |
36 | 下面以传统机械磁盘为例详细介绍一下什么是顺序读写和随机读写。
37 |
38 | **盘片**和**盘面:**一块硬盘一般有多块盘片,盘片分为上下两面,其中有效面称为盘面,一般上下都有效,也就是说:**盘面数 = 盘片数 * 2。**
39 |
40 | **磁头**:磁头切换磁道读写数据时是通过机械设备实现的,一般速度较慢;而磁头切换盘面读写数据是通过电子设备实现的,一般速度较快,因此磁头一般是先读写完柱面后才开始寻道的(不用切换磁道),这样磁盘读写效率更快。
41 |
42 | 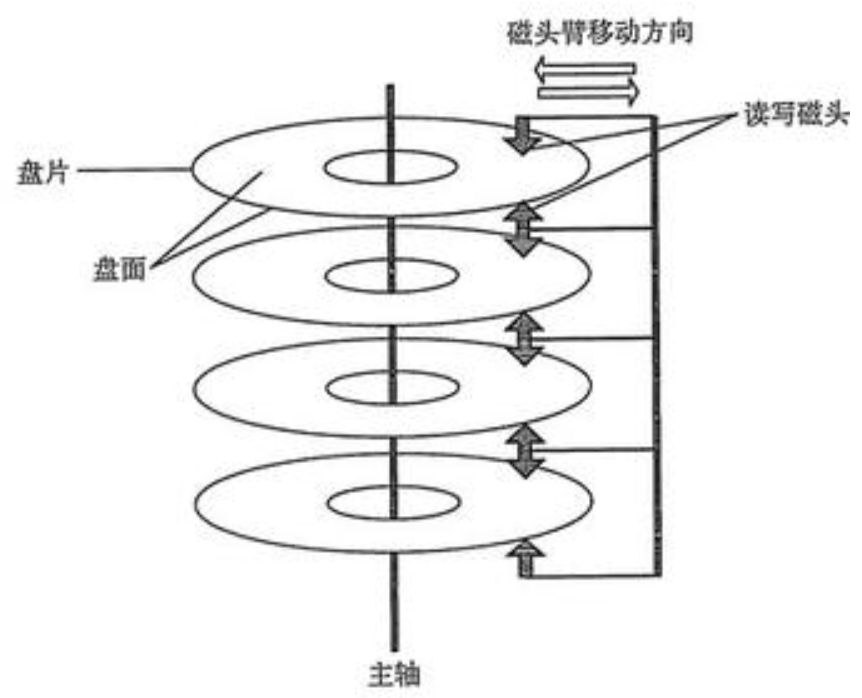 43 |
44 | **磁道**:磁道就是以中间轴为圆心的圆环,一个盘面有多个磁道,磁道之间有间隙,磁道也就是磁盘存储数据的介质。磁道上布有一层磁介质,通过磁头可以使磁介质的极性转换为数据信号,即磁盘的读,磁盘写刚好与之相反。
45 |
46 | **柱面**:磁盘中不同盘面中半径相同的磁道组成的,也就是说柱面总数 = 某个盘面的磁道数。
47 |
48 | **扇区:**单个磁道就是多个弧形扇区组成的,盘面上的每个磁道拥有的扇区数量是相等。扇区是最小存储单元,一般扇区大小为512bytes。
49 |
50 |
43 |
44 | **磁道**:磁道就是以中间轴为圆心的圆环,一个盘面有多个磁道,磁道之间有间隙,磁道也就是磁盘存储数据的介质。磁道上布有一层磁介质,通过磁头可以使磁介质的极性转换为数据信号,即磁盘的读,磁盘写刚好与之相反。
45 |
46 | **柱面**:磁盘中不同盘面中半径相同的磁道组成的,也就是说柱面总数 = 某个盘面的磁道数。
47 |
48 | **扇区:**单个磁道就是多个弧形扇区组成的,盘面上的每个磁道拥有的扇区数量是相等。扇区是最小存储单元,一般扇区大小为512bytes。
49 |
50 | 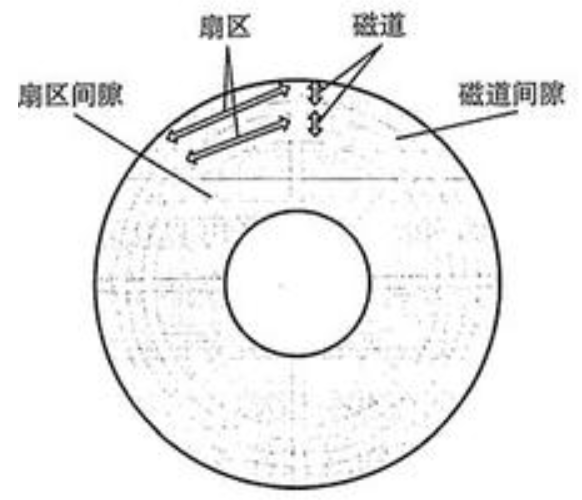 51 |
52 | 如果系统每次只读取一个扇区,那恐怕效率太低了,所以出现了block(块)的概念。文件读取的最小单位是block,根据不同操作系统一个block一般由多个扇区组成。
53 |
54 | 有了磁盘的背景知识我们就可以很容易理解顺序读写和随机读写了。
55 |
56 | >插播维基百科定义:
57 | >>顺序读写:是一种按记录的逻辑顺序进行读、写操作的存取方法 ,即按照信息在存储器中的实际位置所决定的顺序使用信息。
58 | >>随机读写:指的是当存储器中的消息被读取或写入时,所需要的时间与这段信息所在的位置无关。
59 |
60 | 当读取第一个block时,要经历寻道、旋转延迟、传输三个步骤才能读取完这个block的数据。而对于下一个block,如果它在磁盘的其他任意位置,访问它会同样经历寻道、旋转、延时、传输才能读取完这个block的数据,我们把这种方式叫做**随机读写**。但是如果这个block的起始扇区刚好在刚才访问的block的后面,磁头就能立刻遇到,不需等待直接传输,这种就叫**顺序读写**。
61 |
62 | 好,我们再回到 Kafka,详细介绍Kafka如何实现顺序读写入数据。
63 |
64 | Kafka 写入数据是顺序的,下面每一个Partition 都可以当做一个文件,每次接收到新数据后Kafka会把数据插入到文件末尾,虚框部分代表文件尾。
65 |
66 | 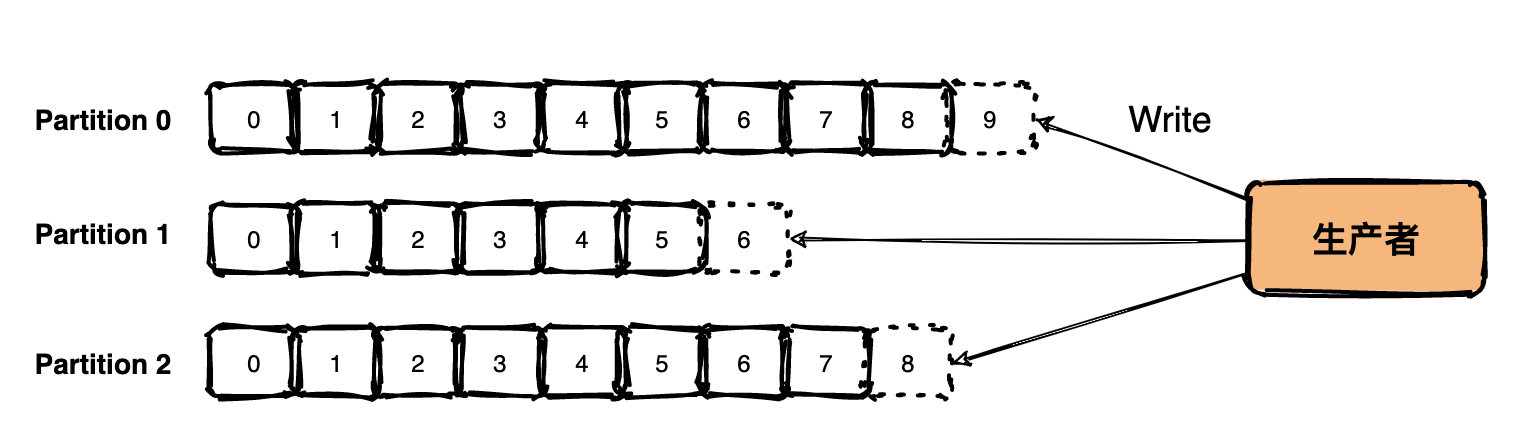
67 |
68 | 这种方法有一个问题就是删除数据不方便,所以 Kafka 一般会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个 offset 用来记录读取进度或者叫坐标。
69 |
70 | 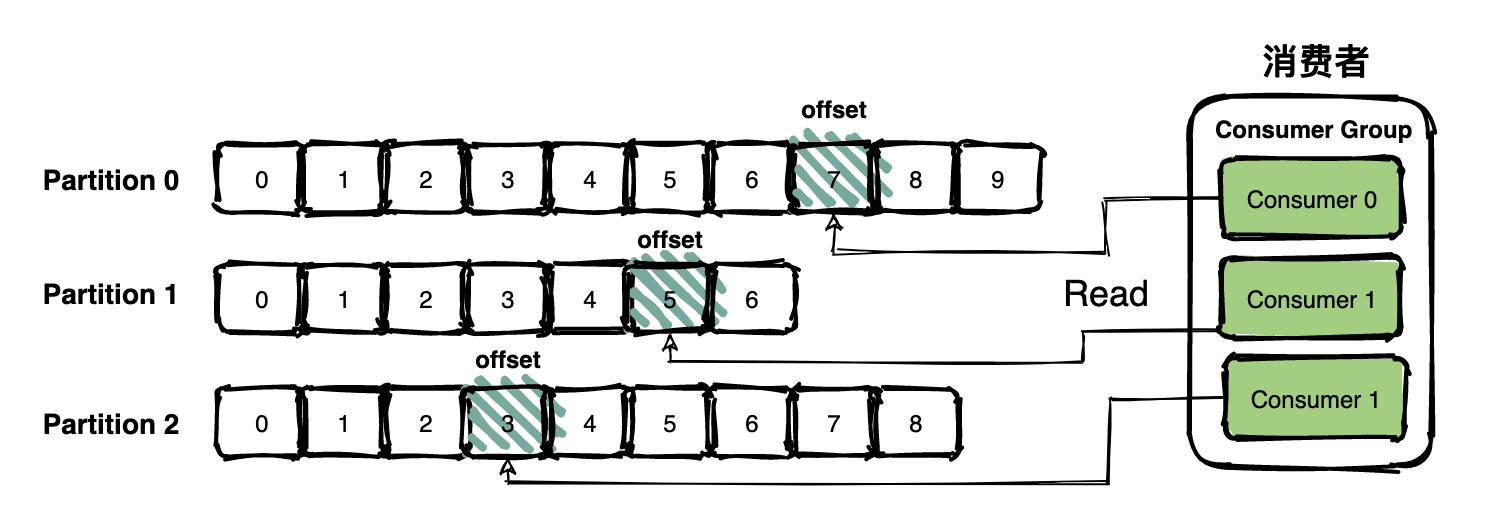
71 |
72 | ## Memory Mapped Files(MMAP)
73 |
74 | 在文章开头我们看到硬盘的顺序读写基本能与内存随机读写速度媲美,但是与内存顺序读写相比还是太慢了,那 Kafka 如果有追求想进一步提升效率怎么办?可以使用现代操作系统分页存储来充分利用内存提高I/O效率,这也是下面要介绍的 MMAP 技术。
75 |
76 | **MMAP**也就是**内存映射文件**,在64位操作系统中一般可以表示 20G 的数据文件,它的工作原理是直接利用操作系统的 Page 来实现文件到物理内存的直接映射,完成映射之后对物理内存的操作会被同步到硬盘上。
77 |
78 | 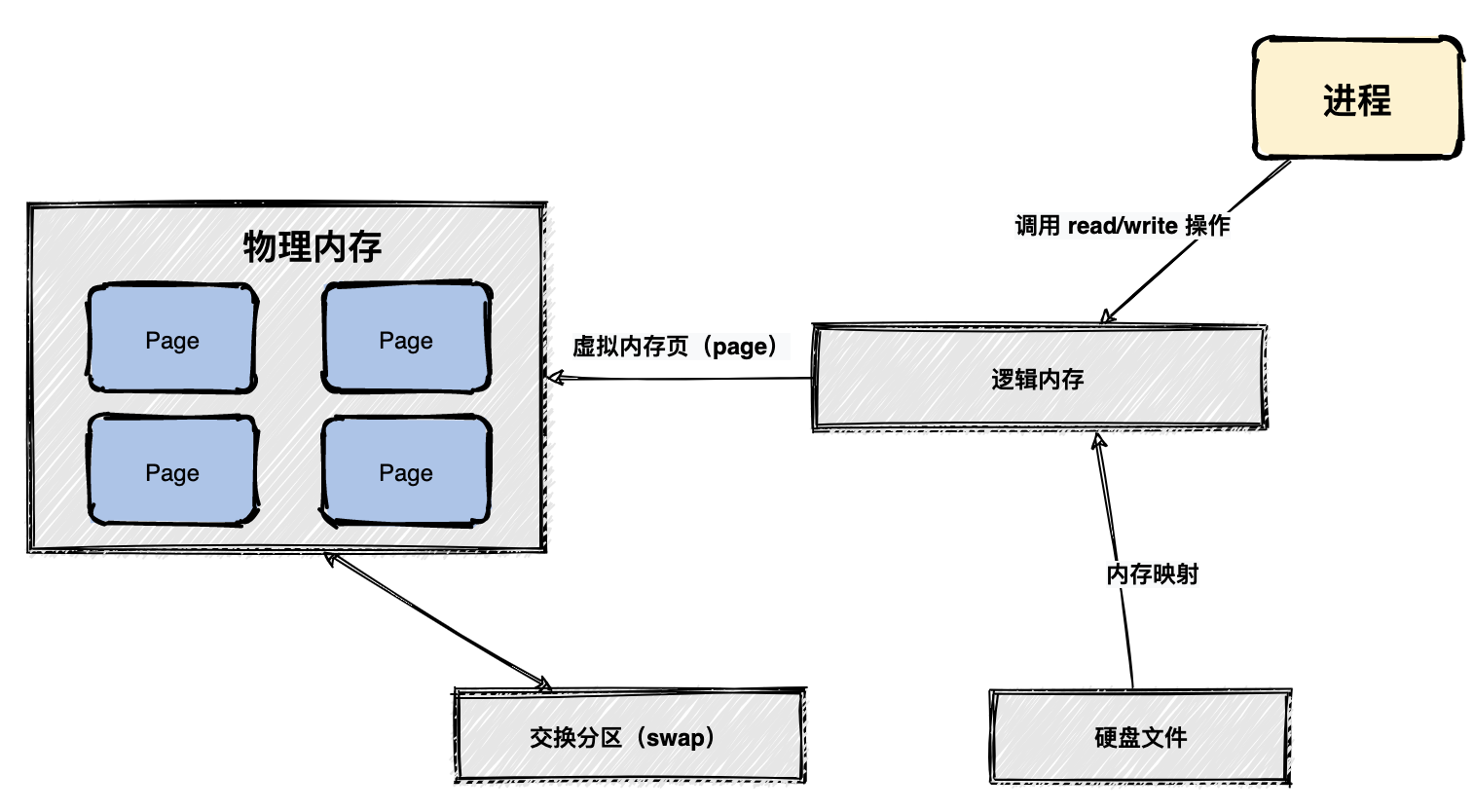
79 |
80 | 通过**MMAP**技术进程可以像读写硬盘一样读写内存(逻辑内存),不必关心内存的大小,因为有虚拟内存兜底。这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销。
81 |
82 | 也有一个很明显的缺陷,写到**MMAP**中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用 flush 的时候才把数据真正的写到硬盘。
83 |
84 | Kafka提供了一个参数:producer.type 来控制是不是主动 flush,如果Kafka写入到MMAP之后就立即flush然后再返回Producer叫同步(sync);写入MMAP之后立即返回Producer不调用flush叫异步(async)。
85 |
86 | ## Zero Copy(零拷贝)
87 |
88 | Kafka 另外一个黑技术就是使用了零拷贝,要想深刻理解零拷贝必须得知道什么是DMA。
89 |
90 | **什么是DMA?**
91 |
92 | 众所周知 CPU 的速度与磁盘 IO 的速度比起来相差几个数量级,可以用乌龟和火箭做比喻。
93 |
94 | 一般来说 IO 操作都是由 CPU 发出指令,然后等待 IO 设备完成操作后返回,那CPU会有大量的时间都在等待IO操作。
95 |
96 | 但是CPU 的等待在很多时候并没有太多的实际意义,我们对于 I/O 设备的大量操作其实都只是把内存里面的数据传输到 I/O 设备而已。比如进行大文件复制,如果所有数据都要经过 CPU,实在是有点儿太浪费时间了。
97 |
98 | 基于此就有了DMA技术,翻译过来也就是直接内存访问(Direct Memory Access),有了这个可以减少 CPU 的等待时间。
99 |
100 | **Kafka 零拷贝原理**
101 |
102 | 如果不使用零拷贝技术,消费者(consumer)从Kafka消费数据,Kafka从磁盘读数据然后发送到网络上去,数据一共发生了四次传输的过程。其中两次是 DMA 的传输,另外两次,则是通过 CPU 控制的传输。
103 |
104 |
51 |
52 | 如果系统每次只读取一个扇区,那恐怕效率太低了,所以出现了block(块)的概念。文件读取的最小单位是block,根据不同操作系统一个block一般由多个扇区组成。
53 |
54 | 有了磁盘的背景知识我们就可以很容易理解顺序读写和随机读写了。
55 |
56 | >插播维基百科定义:
57 | >>顺序读写:是一种按记录的逻辑顺序进行读、写操作的存取方法 ,即按照信息在存储器中的实际位置所决定的顺序使用信息。
58 | >>随机读写:指的是当存储器中的消息被读取或写入时,所需要的时间与这段信息所在的位置无关。
59 |
60 | 当读取第一个block时,要经历寻道、旋转延迟、传输三个步骤才能读取完这个block的数据。而对于下一个block,如果它在磁盘的其他任意位置,访问它会同样经历寻道、旋转、延时、传输才能读取完这个block的数据,我们把这种方式叫做**随机读写**。但是如果这个block的起始扇区刚好在刚才访问的block的后面,磁头就能立刻遇到,不需等待直接传输,这种就叫**顺序读写**。
61 |
62 | 好,我们再回到 Kafka,详细介绍Kafka如何实现顺序读写入数据。
63 |
64 | Kafka 写入数据是顺序的,下面每一个Partition 都可以当做一个文件,每次接收到新数据后Kafka会把数据插入到文件末尾,虚框部分代表文件尾。
65 |
66 | 
67 |
68 | 这种方法有一个问题就是删除数据不方便,所以 Kafka 一般会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个 offset 用来记录读取进度或者叫坐标。
69 |
70 | 
71 |
72 | ## Memory Mapped Files(MMAP)
73 |
74 | 在文章开头我们看到硬盘的顺序读写基本能与内存随机读写速度媲美,但是与内存顺序读写相比还是太慢了,那 Kafka 如果有追求想进一步提升效率怎么办?可以使用现代操作系统分页存储来充分利用内存提高I/O效率,这也是下面要介绍的 MMAP 技术。
75 |
76 | **MMAP**也就是**内存映射文件**,在64位操作系统中一般可以表示 20G 的数据文件,它的工作原理是直接利用操作系统的 Page 来实现文件到物理内存的直接映射,完成映射之后对物理内存的操作会被同步到硬盘上。
77 |
78 | 
79 |
80 | 通过**MMAP**技术进程可以像读写硬盘一样读写内存(逻辑内存),不必关心内存的大小,因为有虚拟内存兜底。这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销。
81 |
82 | 也有一个很明显的缺陷,写到**MMAP**中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用 flush 的时候才把数据真正的写到硬盘。
83 |
84 | Kafka提供了一个参数:producer.type 来控制是不是主动 flush,如果Kafka写入到MMAP之后就立即flush然后再返回Producer叫同步(sync);写入MMAP之后立即返回Producer不调用flush叫异步(async)。
85 |
86 | ## Zero Copy(零拷贝)
87 |
88 | Kafka 另外一个黑技术就是使用了零拷贝,要想深刻理解零拷贝必须得知道什么是DMA。
89 |
90 | **什么是DMA?**
91 |
92 | 众所周知 CPU 的速度与磁盘 IO 的速度比起来相差几个数量级,可以用乌龟和火箭做比喻。
93 |
94 | 一般来说 IO 操作都是由 CPU 发出指令,然后等待 IO 设备完成操作后返回,那CPU会有大量的时间都在等待IO操作。
95 |
96 | 但是CPU 的等待在很多时候并没有太多的实际意义,我们对于 I/O 设备的大量操作其实都只是把内存里面的数据传输到 I/O 设备而已。比如进行大文件复制,如果所有数据都要经过 CPU,实在是有点儿太浪费时间了。
97 |
98 | 基于此就有了DMA技术,翻译过来也就是直接内存访问(Direct Memory Access),有了这个可以减少 CPU 的等待时间。
99 |
100 | **Kafka 零拷贝原理**
101 |
102 | 如果不使用零拷贝技术,消费者(consumer)从Kafka消费数据,Kafka从磁盘读数据然后发送到网络上去,数据一共发生了四次传输的过程。其中两次是 DMA 的传输,另外两次,则是通过 CPU 控制的传输。
103 |
104 | 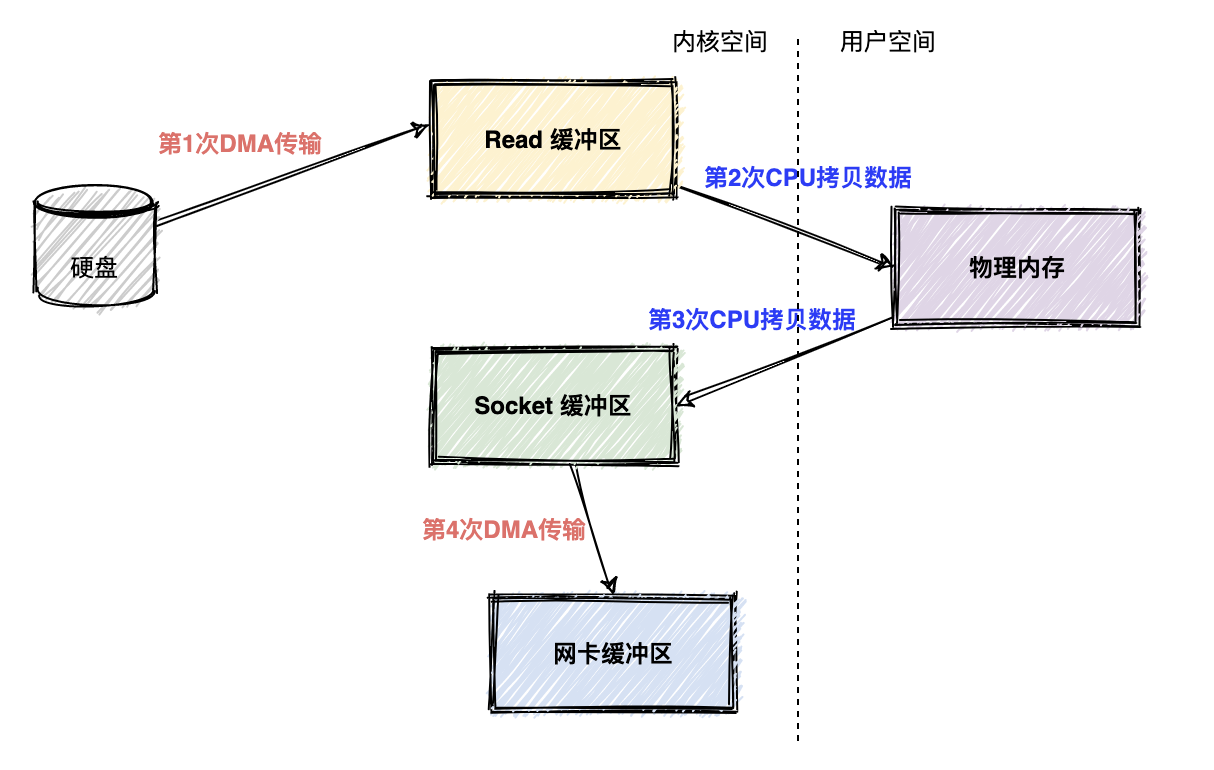 105 |
106 | **第一次传输**:从硬盘上将数据读到操作系统内核的缓冲区里,这个传输是通过 DMA 搬运的。
107 |
108 | **第二次传输**:从内核缓冲区里面的数据复制到分配的内存里面,这个传输是通过 CPU 搬运的。
109 |
110 | **第三次传输**:从分配的内存里面再写到操作系统的 Socket 的缓冲区里面去,这个传输是由 CPU 搬运的。
111 |
112 | **第四次传输**:从 Socket 的缓冲区里面写到网卡的缓冲区里面去,这个传输是通过 DMA 搬运的。
113 |
114 | 实际上在kafka中只进行了两次数据传输,如下图:
115 |
116 | 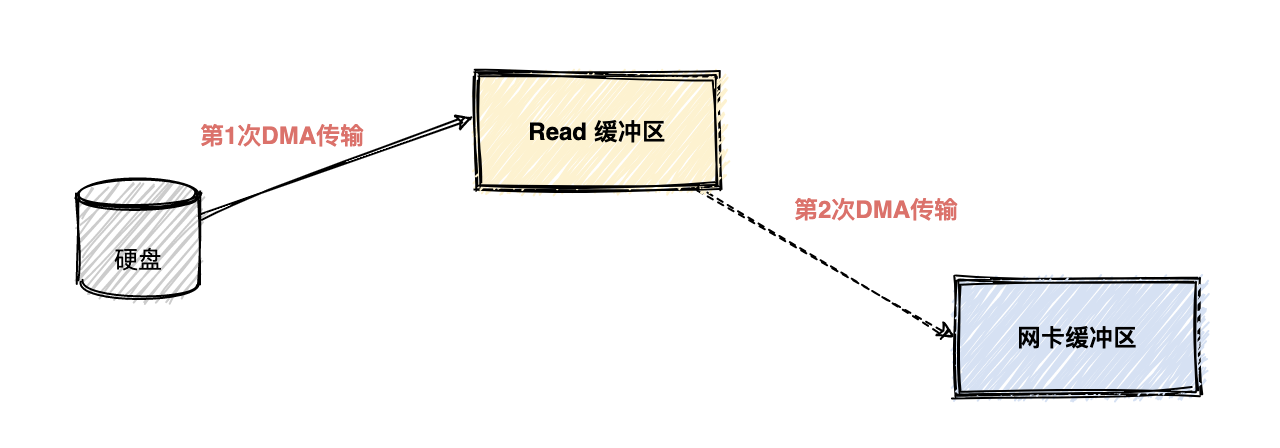
117 |
118 | **第一次传输**:通过 DMA从硬盘直接读到操作系统内核的读缓冲区里面。
119 |
120 | **第二次传输**:根据 Socket 的描述符信息直接从读缓冲区里面写入到网卡的缓冲区里面。
121 |
122 | 我们可以看到同一份数据的传输次数从四次变成了两次,并且没有通过 CPU 来进行数据搬运,所有的数据都是通过 DMA 来进行传输的。没有在内存层面去复制(Copy)数据,这个方法称之为**零拷贝(Zero-Copy)。**
123 |
124 | 无论传输数据量的大小,传输同样的数据使用了零拷贝能够缩短 65% 的时间,大幅度提升了机器传输数据的吞吐量,这也是Kafka能够支持百万TPS的一个重要原因。
125 |
126 | ## Batch Data(数据批量处理)
127 |
128 | 当消费者(consumer)需要消费数据时,首先想到的是消费者需要一条,kafka发送一条,消费者再要一条kafka再发送一条。但实际上 Kafka 不是这样做的,Kafka 耍小聪明了。
129 |
130 | Kafka 把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候 Kafka 直接把文件发送给消费者。比如说100万条消息放在一个文件中可能是10M的数据量,如果消费者和Kafka之间网络良好,10MB大概1秒就能发送完,既100万TPS,Kafka每秒处理了10万条消息。
131 |
132 | 看到这里你可以有疑问了,消费者只需要一条消息啊,kafka把整个文件都发送过来了,文件里面剩余的消息怎么办?不要忘了消费者可以通过offset记录消费进度。
133 |
134 | 发送文件还有一个好处就是可以对文件进行批量压缩,减少网络IO损耗。
135 |
136 | ## 总结
137 |
138 | 最后再总结一下 Kafka 支持百万级 TPS 的秘密:
139 |
140 | (1)顺序写入数据,在 Partition 末尾追加,所以速度最优。
141 |
142 | (2)使用 MMAP 技术将磁盘文件与内存映射,Kafka 可以像操作磁盘一样操作内存。
143 |
144 | (3)通过 DMA 技术实现零拷贝,减少数据传输次数。
145 |
146 | (4)读取数据时配合sendfile直接暴力输出,批量压缩把所有消息变成一个批量文件,合理减少网络IO损耗。
147 |
148 | # 公众号
149 | 公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
150 |
151 |
105 |
106 | **第一次传输**:从硬盘上将数据读到操作系统内核的缓冲区里,这个传输是通过 DMA 搬运的。
107 |
108 | **第二次传输**:从内核缓冲区里面的数据复制到分配的内存里面,这个传输是通过 CPU 搬运的。
109 |
110 | **第三次传输**:从分配的内存里面再写到操作系统的 Socket 的缓冲区里面去,这个传输是由 CPU 搬运的。
111 |
112 | **第四次传输**:从 Socket 的缓冲区里面写到网卡的缓冲区里面去,这个传输是通过 DMA 搬运的。
113 |
114 | 实际上在kafka中只进行了两次数据传输,如下图:
115 |
116 | 
117 |
118 | **第一次传输**:通过 DMA从硬盘直接读到操作系统内核的读缓冲区里面。
119 |
120 | **第二次传输**:根据 Socket 的描述符信息直接从读缓冲区里面写入到网卡的缓冲区里面。
121 |
122 | 我们可以看到同一份数据的传输次数从四次变成了两次,并且没有通过 CPU 来进行数据搬运,所有的数据都是通过 DMA 来进行传输的。没有在内存层面去复制(Copy)数据,这个方法称之为**零拷贝(Zero-Copy)。**
123 |
124 | 无论传输数据量的大小,传输同样的数据使用了零拷贝能够缩短 65% 的时间,大幅度提升了机器传输数据的吞吐量,这也是Kafka能够支持百万TPS的一个重要原因。
125 |
126 | ## Batch Data(数据批量处理)
127 |
128 | 当消费者(consumer)需要消费数据时,首先想到的是消费者需要一条,kafka发送一条,消费者再要一条kafka再发送一条。但实际上 Kafka 不是这样做的,Kafka 耍小聪明了。
129 |
130 | Kafka 把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候 Kafka 直接把文件发送给消费者。比如说100万条消息放在一个文件中可能是10M的数据量,如果消费者和Kafka之间网络良好,10MB大概1秒就能发送完,既100万TPS,Kafka每秒处理了10万条消息。
131 |
132 | 看到这里你可以有疑问了,消费者只需要一条消息啊,kafka把整个文件都发送过来了,文件里面剩余的消息怎么办?不要忘了消费者可以通过offset记录消费进度。
133 |
134 | 发送文件还有一个好处就是可以对文件进行批量压缩,减少网络IO损耗。
135 |
136 | ## 总结
137 |
138 | 最后再总结一下 Kafka 支持百万级 TPS 的秘密:
139 |
140 | (1)顺序写入数据,在 Partition 末尾追加,所以速度最优。
141 |
142 | (2)使用 MMAP 技术将磁盘文件与内存映射,Kafka 可以像操作磁盘一样操作内存。
143 |
144 | (3)通过 DMA 技术实现零拷贝,减少数据传输次数。
145 |
146 | (4)读取数据时配合sendfile直接暴力输出,批量压缩把所有消息变成一个批量文件,合理减少网络IO损耗。
147 |
148 | # 公众号
149 | 公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
150 |
151 |
152 |
153 |
--------------------------------------------------------------------------------
/docs/mq/刨根问底,kafka到底会不会丢消息.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321970&idx=1&sn=3a26ed6f0323c945c1eacb05c758cd62&chksm=8f09ca28b87e433e657fca2ffd9d45a74453ffeb17ee76a9bac8f2a7cfd3a0e6ac936396812c&token=1553501157&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [认识Kafka](#认识kafka)
6 | - [Kafka到底会不会丢失消息?](#kafka到底会不会丢失消息)
7 | - [生产者丢失消息](#生产者丢失消息)
8 | - [Kafka Broker丢失消息](#kafka-broker丢失消息)
9 | - [消费者丢失消息](#消费者丢失消息)
10 | - [总结](#总结)
11 | - [公众号](#公众号)
12 |
13 |
14 |
15 | 大型互联网公司一般都会要求消息传递最大限度的不丢失,比如用户服务给代金券服务发送一个消息,如果消息丢失会造成用户未收到应得的代金券,最终用户会投诉。
16 |
17 | ??为避免上面类似情况的发生,除了做好补偿措施,更应该在系设计的时候充分考虑各种异常,设计一个稳定、高可用的消息系统。
18 |
19 | # 认识Kafka
20 |
21 | 看一下维基百科的定义
22 |
23 | >Kafka是分布式发布-订阅消息系统。
24 | >它最初由LinkedIn公司开发,之后成为Apache项目的一部分。
25 | >Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。
26 |
27 | **kafka架构**
28 |
29 | Kafka的整体架构非常简单,是显式分布式架构,主要由producer、broker(kafka)和consumer组成。
30 |
31 | 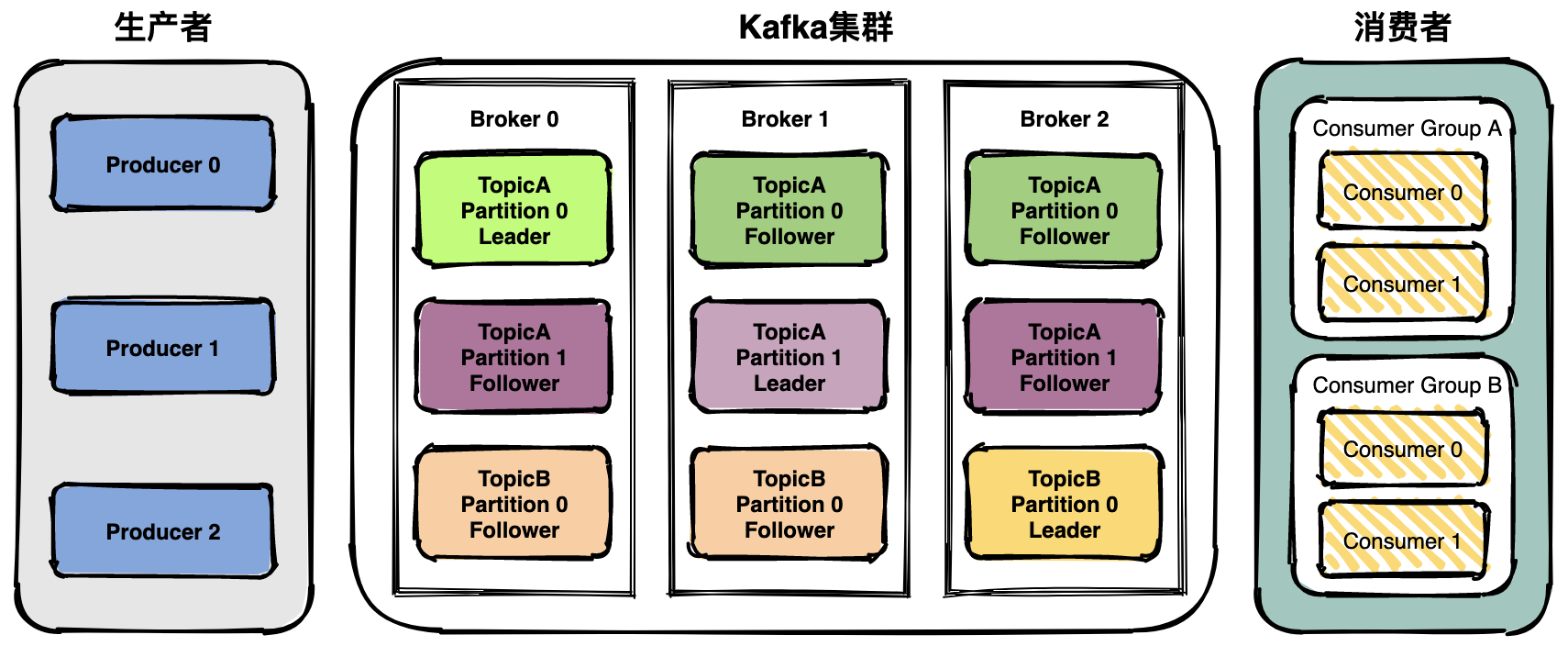 32 |
33 | **Producer**(生产者)可以将数据发布到所选择的topic(主题)中。生产者负责将记录分配到topic的哪一个 partition(分区)中。可以使用循环的方式来简单地实现负载均衡,也可以根据某些语义分区函数(如记录中的key)来完成。
34 |
35 | **Consumer**(消费者)使用一个consumer group(消费组)名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例。消费者实例可以分布在多个进程中或者多个机器上。
36 |
37 | # Kafka到底会不会丢失消息?
38 |
39 | 在讨论kafka是否丢消息前先来了解一下什么是**消息传递语义**。
40 |
41 |
32 |
33 | **Producer**(生产者)可以将数据发布到所选择的topic(主题)中。生产者负责将记录分配到topic的哪一个 partition(分区)中。可以使用循环的方式来简单地实现负载均衡,也可以根据某些语义分区函数(如记录中的key)来完成。
34 |
35 | **Consumer**(消费者)使用一个consumer group(消费组)名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例。消费者实例可以分布在多个进程中或者多个机器上。
36 |
37 | # Kafka到底会不会丢失消息?
38 |
39 | 在讨论kafka是否丢消息前先来了解一下什么是**消息传递语义**。
40 |
41 | 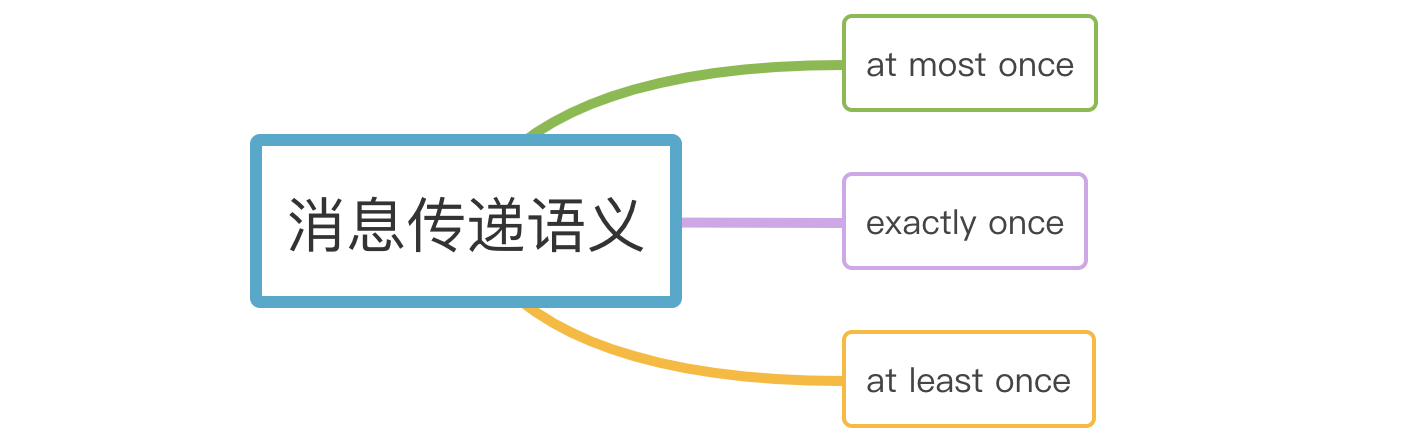 42 |
43 | message delivery semantic 也就是消息传递语义,简单说就是消息传递过程中消息传递的保证性。主要分为三种:
44 |
45 | * **at most once**:最多一次。消息可能丢失也可能被处理,但最多只会被处理一次。
46 | * **at least once**:至少一次。消息不会丢失,但可能被处理多次。可能重复,不会丢失。
47 | * **exactly once**:精确传递一次。消息被处理且只会被处理一次。不丢失不重复就一次。
48 |
49 | 理想情况下肯定是希望系统的消息传递是严格exactly once,也就是保证不丢失、只会被处理一次,但是很难做到。
50 |
51 | 回到主角Kafka,Kafka有三次消息传递的过程:
52 |
53 | 1. 生产者发消息给Kafka Broker。
54 | 2. Kafka Broker 消息同步和持久化
55 | 3. Kafka Broker 将消息传递给消费者。
56 |
57 | 在这三步中每一步都有可能会丢失消息,下面详细分析为什么会丢消息,如何最大限度避免丢失消息。
58 |
59 | # 生产者丢失消息
60 |
61 | 先介绍一下生产者发送消息的一般流程(部分流程与具体配置项强相关,这里先忽略):
62 |
63 | 1. 生产者是与leader直接交互,所以先从集群获取topic对应分区的leader元数据;
64 | 2. 获取到leader分区元数据后直接将消息发给过去;
65 | 3. Kafka Broker对应的leader分区收到消息后写入文件持久化;
66 | 4. Follower拉取Leader消息与Leader的数据保持一致;
67 | 5. Follower消息拉取完毕需要给Leader回复ACK确认消息;
68 | 6. Kafka Leader和Follower分区同步完,Leader分区会给生产者回复ACK确认消息。
69 |
70 |
42 |
43 | message delivery semantic 也就是消息传递语义,简单说就是消息传递过程中消息传递的保证性。主要分为三种:
44 |
45 | * **at most once**:最多一次。消息可能丢失也可能被处理,但最多只会被处理一次。
46 | * **at least once**:至少一次。消息不会丢失,但可能被处理多次。可能重复,不会丢失。
47 | * **exactly once**:精确传递一次。消息被处理且只会被处理一次。不丢失不重复就一次。
48 |
49 | 理想情况下肯定是希望系统的消息传递是严格exactly once,也就是保证不丢失、只会被处理一次,但是很难做到。
50 |
51 | 回到主角Kafka,Kafka有三次消息传递的过程:
52 |
53 | 1. 生产者发消息给Kafka Broker。
54 | 2. Kafka Broker 消息同步和持久化
55 | 3. Kafka Broker 将消息传递给消费者。
56 |
57 | 在这三步中每一步都有可能会丢失消息,下面详细分析为什么会丢消息,如何最大限度避免丢失消息。
58 |
59 | # 生产者丢失消息
60 |
61 | 先介绍一下生产者发送消息的一般流程(部分流程与具体配置项强相关,这里先忽略):
62 |
63 | 1. 生产者是与leader直接交互,所以先从集群获取topic对应分区的leader元数据;
64 | 2. 获取到leader分区元数据后直接将消息发给过去;
65 | 3. Kafka Broker对应的leader分区收到消息后写入文件持久化;
66 | 4. Follower拉取Leader消息与Leader的数据保持一致;
67 | 5. Follower消息拉取完毕需要给Leader回复ACK确认消息;
68 | 6. Kafka Leader和Follower分区同步完,Leader分区会给生产者回复ACK确认消息。
69 |
70 | 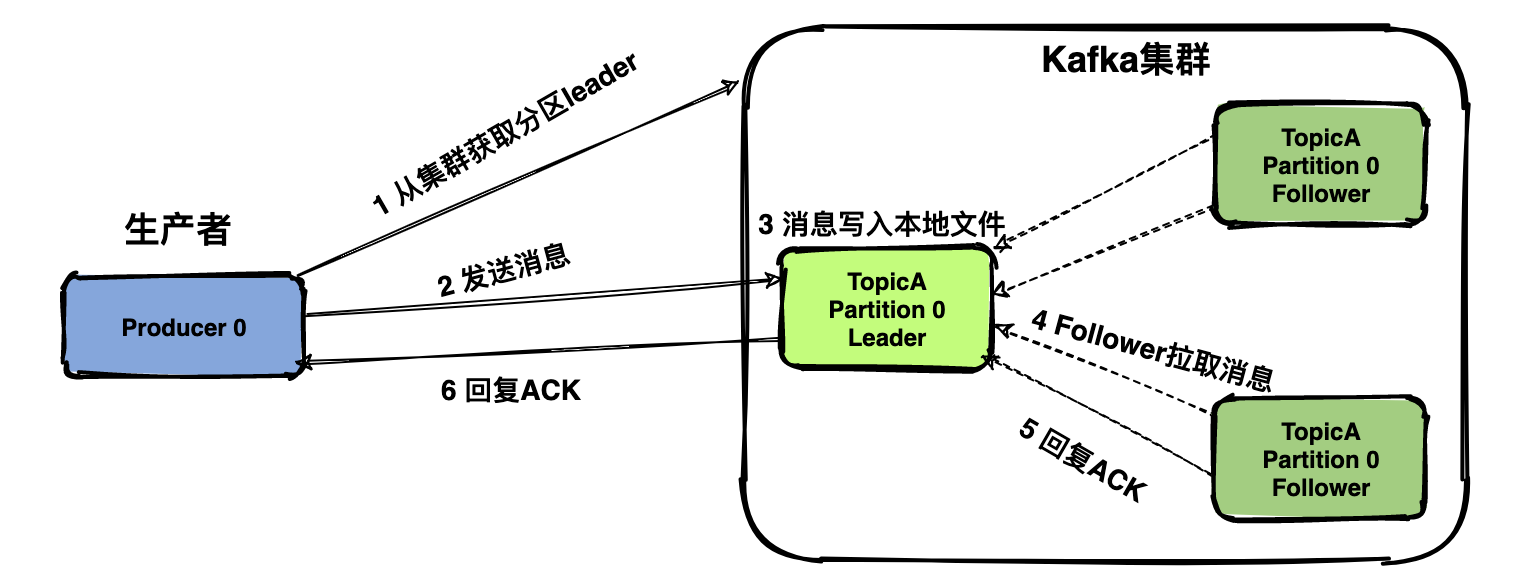 71 |
72 | 生产者采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘。消息写入Leader后,Follower是主动与Leader进行同步。
73 |
74 | Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过producer.type属性进行配置。
75 |
76 | Kafka通过配置request.required.acks属性来确认消息的生产:
77 |
78 | * 0表示不进行消息接收是否成功的确认;不能保证消息是否发送成功,生成环境基本不会用。
79 | * 1表示当Leader接收成功时确认;只要Leader存活就可以保证不丢失,保证了吞吐量。
80 | * -1或者all表示Leader和Follower都接收成功时确认;可以最大限度保证消息不丢失,但是吞吐量低。
81 |
82 | kafka producer 的参数acks 的默认值为1,所以默认的producer级别是at least once,并不能exactly once。
83 |
84 | **敲黑板了,这里可能会丢消息的!**
85 |
86 | * 如果acks配置为0,发生网络抖动消息丢了,生产者不校验ACK自然就不知道丢了。
87 | * 如果acks配置为1保证leader不丢,但是如果leader挂了,恰好选了一个没有ACK的follower,那也丢了。
88 | * all:保证leader和follower不丢,但是如果网络拥塞,没有收到ACK,会有重复发的问题。
89 | # Kafka Broker丢失消息
90 |
91 | Kafka Broker 接收到数据后会将数据进行持久化存储,你以为是下面这样的:
92 |
93 |
71 |
72 | 生产者采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘。消息写入Leader后,Follower是主动与Leader进行同步。
73 |
74 | Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过producer.type属性进行配置。
75 |
76 | Kafka通过配置request.required.acks属性来确认消息的生产:
77 |
78 | * 0表示不进行消息接收是否成功的确认;不能保证消息是否发送成功,生成环境基本不会用。
79 | * 1表示当Leader接收成功时确认;只要Leader存活就可以保证不丢失,保证了吞吐量。
80 | * -1或者all表示Leader和Follower都接收成功时确认;可以最大限度保证消息不丢失,但是吞吐量低。
81 |
82 | kafka producer 的参数acks 的默认值为1,所以默认的producer级别是at least once,并不能exactly once。
83 |
84 | **敲黑板了,这里可能会丢消息的!**
85 |
86 | * 如果acks配置为0,发生网络抖动消息丢了,生产者不校验ACK自然就不知道丢了。
87 | * 如果acks配置为1保证leader不丢,但是如果leader挂了,恰好选了一个没有ACK的follower,那也丢了。
88 | * all:保证leader和follower不丢,但是如果网络拥塞,没有收到ACK,会有重复发的问题。
89 | # Kafka Broker丢失消息
90 |
91 | Kafka Broker 接收到数据后会将数据进行持久化存储,你以为是下面这样的:
92 |
93 | 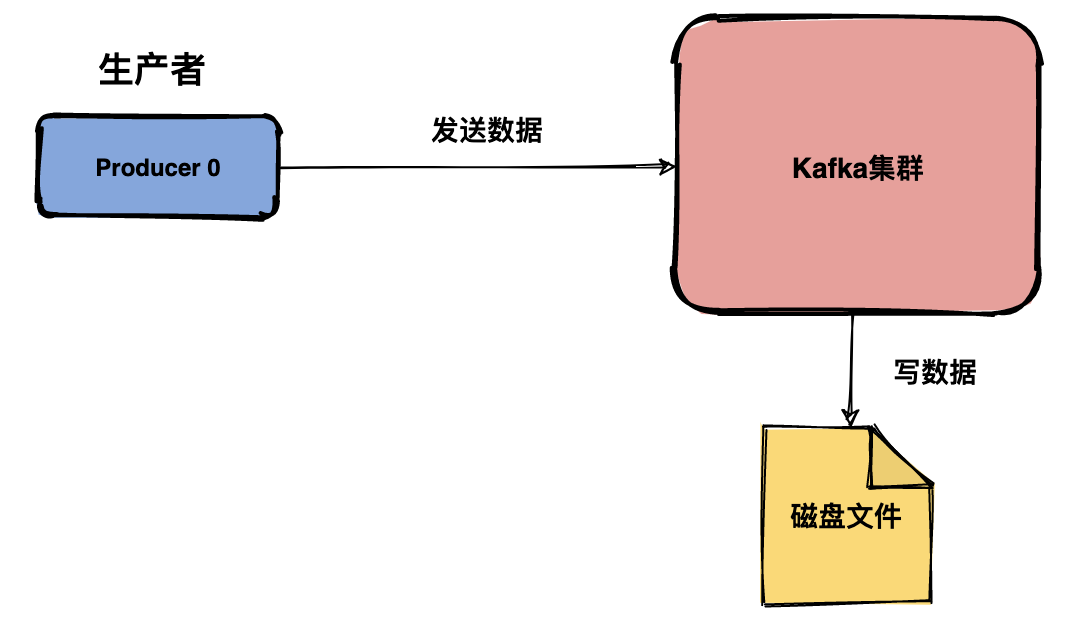 94 |
95 | 没想到是这样的:
96 |
97 |
94 |
95 | 没想到是这样的:
96 |
97 | 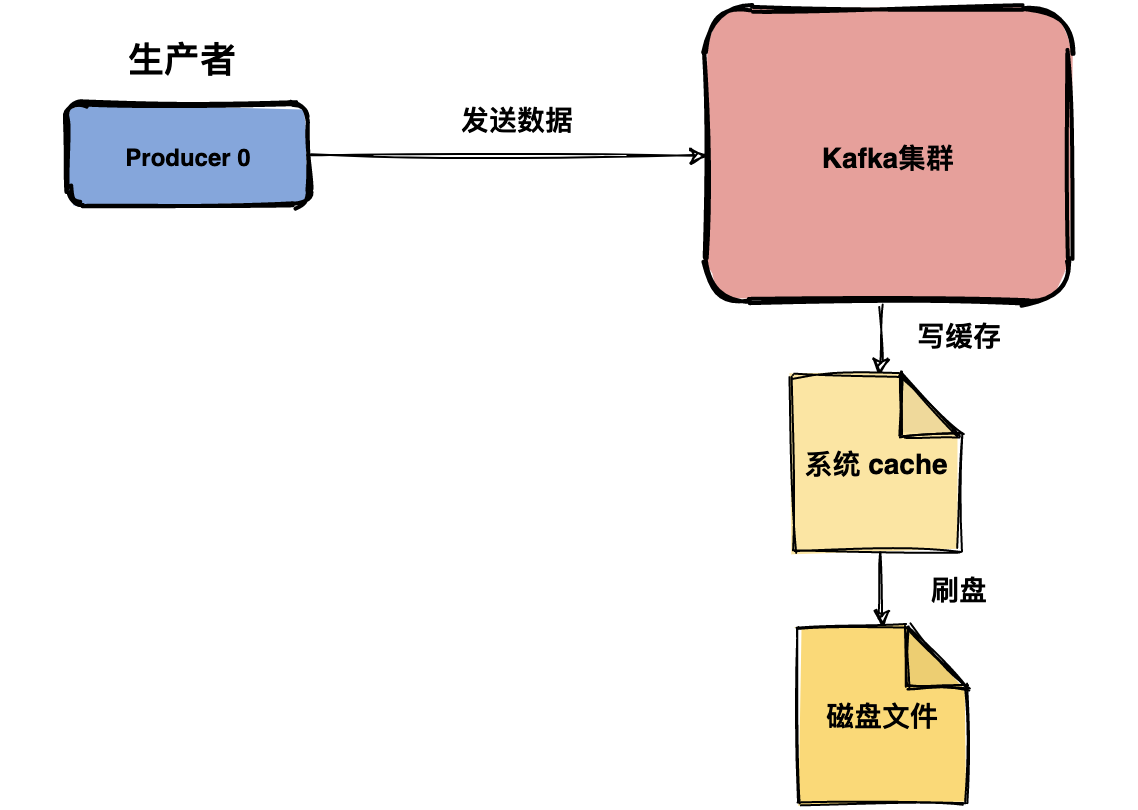 98 |
99 | 操作系统本身有一层缓存,叫做 Page Cache,当往磁盘文件写入的时候,系统会先将数据流写入缓存中,至于什么时候将缓存的数据写入文件中是由操作系统自行决定。
100 |
101 | Kafka提供了一个参数 producer.type 来控制是不是主动flush,如果Kafka写入到mmap之后就立即 flush 然后再返回 Producer 叫同步 (sync);写入mmap之后立即返回 Producer 不调用 flush 叫异步 (async)。
102 |
103 | **敲黑板了,这里可能会丢消息的!**
104 |
105 | Kafka通过多分区多副本机制中已经能最大限度保证数据不会丢失,如果数据已经写入系统 cache 中但是还没来得及刷入磁盘,此时突然机器宕机或者掉电那就丢了,当然这种情况很极端。
106 |
107 | # 消费者丢失消息
108 |
109 | 消费者通过pull模式主动的去 kafka 集群拉取消息,与producer相同的是,消费者在拉取消息的时候也是找leader分区去拉取。
110 |
111 | 多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id。同一个消费组者的消费者可以消费同一topic下不同分区的数据,但是不会出现多个消费者消费同一分区的数据。
112 |
113 |
98 |
99 | 操作系统本身有一层缓存,叫做 Page Cache,当往磁盘文件写入的时候,系统会先将数据流写入缓存中,至于什么时候将缓存的数据写入文件中是由操作系统自行决定。
100 |
101 | Kafka提供了一个参数 producer.type 来控制是不是主动flush,如果Kafka写入到mmap之后就立即 flush 然后再返回 Producer 叫同步 (sync);写入mmap之后立即返回 Producer 不调用 flush 叫异步 (async)。
102 |
103 | **敲黑板了,这里可能会丢消息的!**
104 |
105 | Kafka通过多分区多副本机制中已经能最大限度保证数据不会丢失,如果数据已经写入系统 cache 中但是还没来得及刷入磁盘,此时突然机器宕机或者掉电那就丢了,当然这种情况很极端。
106 |
107 | # 消费者丢失消息
108 |
109 | 消费者通过pull模式主动的去 kafka 集群拉取消息,与producer相同的是,消费者在拉取消息的时候也是找leader分区去拉取。
110 |
111 | 多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id。同一个消费组者的消费者可以消费同一topic下不同分区的数据,但是不会出现多个消费者消费同一分区的数据。
112 |
113 | 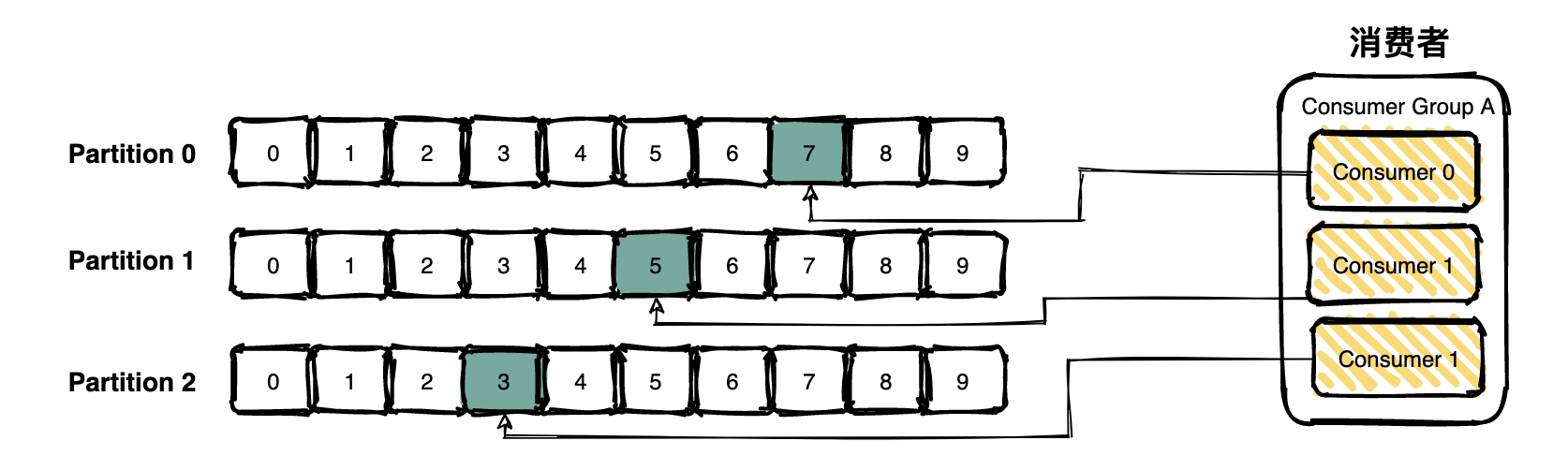 114 |
115 | 消费者消费的进度通过offset保存在kafka集群的__consumer_offsets这个topic中。
116 |
117 | 消费消息的时候主要分为两个阶段:
118 |
119 | 1、标识消息已被消费,commit offset坐标;
120 |
121 | 2、处理消息。
122 |
123 | **敲黑板了,这里可能会丢消息的!**
124 |
125 | 场景一:先commit再处理消息。如果在处理消息的时候异常了,但是offset 已经提交了,这条消息对于该消费者来说就是丢失了,再也不会消费到了。
126 |
127 | 场景二:先处理消息再commit。如果在commit之前发生异常,下次还会消费到该消息,重复消费的问题可以通过业务保证消息幂等性来解决。
128 |
129 | # 总结
130 |
131 | 那么问题来了,kafka到底会不会丢消息?答案是:会!
132 |
133 | Kafka可能会在三个阶段丢失消息:
134 |
135 | (1)生产者发送数据;
136 |
137 | (2)Kafka Broker 存储数据;
138 |
139 | (3)消费者消费数据;
140 |
141 | 在生产环境中严格做到exactly once其实是难的,同时也会牺牲效率和吞吐量,最佳实践是业务侧做好补偿机制,万一出现消息丢失可以兜底。
142 |
143 | # 公众号
144 | 公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
145 |
146 |
114 |
115 | 消费者消费的进度通过offset保存在kafka集群的__consumer_offsets这个topic中。
116 |
117 | 消费消息的时候主要分为两个阶段:
118 |
119 | 1、标识消息已被消费,commit offset坐标;
120 |
121 | 2、处理消息。
122 |
123 | **敲黑板了,这里可能会丢消息的!**
124 |
125 | 场景一:先commit再处理消息。如果在处理消息的时候异常了,但是offset 已经提交了,这条消息对于该消费者来说就是丢失了,再也不会消费到了。
126 |
127 | 场景二:先处理消息再commit。如果在commit之前发生异常,下次还会消费到该消息,重复消费的问题可以通过业务保证消息幂等性来解决。
128 |
129 | # 总结
130 |
131 | 那么问题来了,kafka到底会不会丢消息?答案是:会!
132 |
133 | Kafka可能会在三个阶段丢失消息:
134 |
135 | (1)生产者发送数据;
136 |
137 | (2)Kafka Broker 存储数据;
138 |
139 | (3)消费者消费数据;
140 |
141 | 在生产环境中严格做到exactly once其实是难的,同时也会牺牲效率和吞吐量,最佳实践是业务侧做好补偿机制,万一出现消息丢失可以兜底。
142 |
143 | # 公众号
144 | 公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
145 |
146 |
147 |
148 |
--------------------------------------------------------------------------------
/docs/redis/Redis 数据结构和常用命令速记.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650320964&idx=1&sn=c7c3435f8c9dc1b4657034dbc1f1510d&chksm=8f09ce5eb87e4748982d88402ab7d95c2770ed80813e634c42464cec671355b30a8dc53a5384&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [1. String字符串](#1--string字符串)
6 | - [2. Hash哈希](#2-hash哈希)
7 | - [3. List列表](#3-list列表)
8 | - [4. Set集合](#4-set集合)
9 | - [5. Sorted Set有序集合](#5-sorted-set有序集合)
10 | - [6. Redis常用命令参考](#6-redis常用命令参考)
11 |
12 |
13 |
14 | Redis是key-value数据库,key的类型只能是String,但是value的数据类型就比较丰富了,主要包括五种:
15 |
16 | * String
17 | * Hash
18 | * List
19 | * Set
20 | * Sorted Set
21 |
22 | 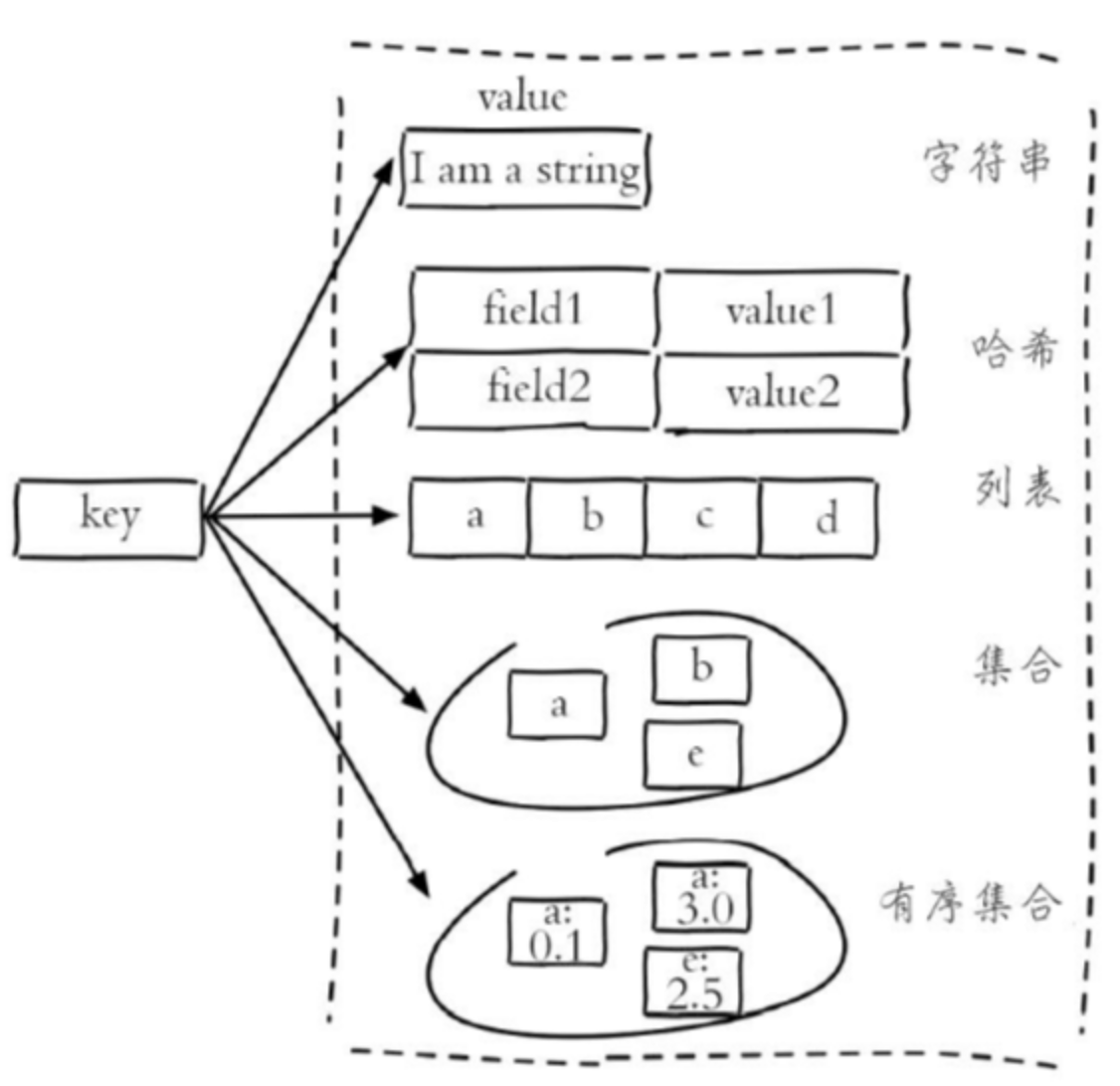
23 |
24 | ## 1. String字符串
25 |
26 | **语法**
27 |
28 | ```plain
29 | SET KEY_NAME VALUE
30 | ```
31 | string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
32 | string类型是Redis最基本的数据类型,一个键最大能存储512MB。
33 |
34 | ## 2. Hash哈希
35 |
36 | **语法**
37 |
38 | ```plain
39 | HSET KEY_NAME FIELD VALUE
40 | ```
41 | Redis hash 是一个键值(key=>value)对集合。
42 | Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
43 |
44 | ## 3. List列表
45 |
46 | **语法**
47 |
48 | ```plain
49 | //在 key 对应 list 的头部添加字符串元素
50 | LPUSH KEY_NAME VALUE1.. VALUEN
51 |
52 | //在 key 对应 list 的尾部添加字符串元素
53 | RPUSH KEY_NAME VALUE1..VALUEN
54 |
55 | //对应 list 中删除 count 个和 value 相同的元素
56 | LREM KEY_NAME COUNT VALUE
57 |
58 | //返回 key 对应 list 的长度
59 | LLEN KEY_NAME
60 | ```
61 | Redis 列表是简单的字符串列表,按照插入顺序排序。
62 | 可以添加一个元素到列表的头部(左边)或者尾部(右边)
63 |
64 | ## 4. Set集合
65 |
66 | **语法**
67 |
68 | ```plain
69 | SADD KEY_NAME VALUE1...VALUEn
70 | ```
71 | Redis的Set是string类型的无序集合。
72 | 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
73 |
74 | ## 5. Sorted Set有序集合
75 |
76 | **语法**
77 |
78 | ```plain
79 | ZADD KEY_NAME SCORE1 VALUE1.. SCOREN VALUEN
80 | ```
81 | Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
82 | 不同的是每个元素都会关联一个double类型的分数。
83 |
84 | redis正是通过分数来为集合中的成员进行从小到大的排序。
85 |
86 | zset的成员是唯一的,但分数(score)却可以重复。
87 |
88 | ## 6. Redis常用命令参考
89 |
90 | 更多命令语法可以参考官网手册:
91 |
92 | [https://www.redis.net.cn/order/](https://www.redis.net.cn/order/)
--------------------------------------------------------------------------------
/docs/redis/一张图搞懂Redis缓存雪崩、缓存穿透、缓存击穿.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321284&idx=1&sn=63f0143fd3a7ef408b9810d5208cd343&chksm=8f09cf9eb87e4688a8faef2c7dd4c70139b7a04e512a7adc266de46261477518b77e6af7d54a&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [缓存穿透](#缓存穿透)
6 | - [什么是缓存穿透?](#什么是缓存穿透)
7 | - [缓存穿透常用的解决方案](#缓存穿透常用的解决方案)
8 | - [缓存击穿](#缓存击穿)
9 | - [什么是缓存击穿?](#什么是缓存击穿)
10 | - [缓存击穿危害](#缓存击穿危害)
11 | - [如何解决](#如何解决)
12 | - [缓存雪崩](#缓存雪崩)
13 | - [什么是缓存雪崩?](#什么是缓存雪崩)
14 | - [缓存雪崩解决方案](#缓存雪崩解决方案)
15 | - [缓存预热](#缓存预热)
16 | - [什么是缓存预热?](#什么是缓存预热)
17 | - [缓存预热的操作方法](#缓存预热的操作方法)
18 | - [缓存降级](#缓存降级)
19 |
20 |
21 |
22 |  23 |
24 | 在实际生产环境中有时会遇到缓存穿透、缓存击穿、缓存雪崩等异常场景,为了避免异常带来巨大损失,我们需要了解每种异常发生的原因以及解决方案,帮助提升系统可靠性和高可用。
25 |
26 | ## 缓存穿透
27 |
28 | ### 什么是缓存穿透?
29 |
30 | 缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍,然后返回空。
31 |
32 | 如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至击垮数据库系统。
33 |
34 | ### 缓存穿透常用的解决方案
35 |
36 | **(1)布隆过滤器(推荐)**
37 |
38 | 布隆过滤器(Bloom Filter,简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率高的概率型数据结构。
39 |
40 | **布隆过滤器专门用来检测集合中是否存在特定的元素。**
41 |
42 | 如果在平时我们要判断一个元素是否在一个集合中,通常会采用查找比较的方法,下面分析不同的数据结构查找效率:
43 |
44 | * 采用线性表存储,查找时间复杂度为O(N)
45 | * 采用平衡二叉排序树(AVL、红黑树)存储,查找时间复杂度为O(logN)
46 | * 采用哈希表存储,考虑到哈希碰撞,整体时间复杂度也要O[log(n/m)]
47 |
48 | 当需要判断一个元素是否存在于海量数据集合中,不仅查找时间慢,还会占用大量存储空间。接下来看一下布隆过滤器如何解决这个问题。
49 |
50 | **布隆过滤器设计思想**
51 |
52 | 布隆过滤器由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组初始化均为0,所有的哈希函数都可以分别把输入数据尽量均匀地散列。
53 |
54 | 当要向布隆过滤器中插入一个元素时,该元素经过k个哈希函数计算产生k个哈希值,以哈希值作为位数组中的下标,将所有k个对应的比特值由0置为1。
55 |
56 | 当要查询一个元素时,同样将其经过哈希函数计算产生哈希值,然后检查对应的k个比特值:如果有任意一个比特为0,表明该元素一定不在集合中;如果所有比特均为1,表明该集合有可能性在集合中。为什么不是一定在集合中呢?因为不同的元素计算的哈希值有可能一样,会出现哈希碰撞,导致一个不存在的元素有可能对应的比特位为1,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
57 |
58 | 总结一下:布隆过滤器认为不在的,一定不会在集合中;布隆过滤器认为在的,可能在也可能不在集合中。
59 |
60 | 举个例子:下图是一个布隆过滤器,共有18个比特位,3个哈希函数。集合中三个元素x,y,z通过三个哈希函数散列到不同的比特位,并将比特位置为1。当查询元素w时,通过三个哈希函数计算,发现有一个比特位的值为0,可以肯定认为该元素不在集合中。
61 |
62 |
23 |
24 | 在实际生产环境中有时会遇到缓存穿透、缓存击穿、缓存雪崩等异常场景,为了避免异常带来巨大损失,我们需要了解每种异常发生的原因以及解决方案,帮助提升系统可靠性和高可用。
25 |
26 | ## 缓存穿透
27 |
28 | ### 什么是缓存穿透?
29 |
30 | 缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍,然后返回空。
31 |
32 | 如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至击垮数据库系统。
33 |
34 | ### 缓存穿透常用的解决方案
35 |
36 | **(1)布隆过滤器(推荐)**
37 |
38 | 布隆过滤器(Bloom Filter,简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率高的概率型数据结构。
39 |
40 | **布隆过滤器专门用来检测集合中是否存在特定的元素。**
41 |
42 | 如果在平时我们要判断一个元素是否在一个集合中,通常会采用查找比较的方法,下面分析不同的数据结构查找效率:
43 |
44 | * 采用线性表存储,查找时间复杂度为O(N)
45 | * 采用平衡二叉排序树(AVL、红黑树)存储,查找时间复杂度为O(logN)
46 | * 采用哈希表存储,考虑到哈希碰撞,整体时间复杂度也要O[log(n/m)]
47 |
48 | 当需要判断一个元素是否存在于海量数据集合中,不仅查找时间慢,还会占用大量存储空间。接下来看一下布隆过滤器如何解决这个问题。
49 |
50 | **布隆过滤器设计思想**
51 |
52 | 布隆过滤器由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组初始化均为0,所有的哈希函数都可以分别把输入数据尽量均匀地散列。
53 |
54 | 当要向布隆过滤器中插入一个元素时,该元素经过k个哈希函数计算产生k个哈希值,以哈希值作为位数组中的下标,将所有k个对应的比特值由0置为1。
55 |
56 | 当要查询一个元素时,同样将其经过哈希函数计算产生哈希值,然后检查对应的k个比特值:如果有任意一个比特为0,表明该元素一定不在集合中;如果所有比特均为1,表明该集合有可能性在集合中。为什么不是一定在集合中呢?因为不同的元素计算的哈希值有可能一样,会出现哈希碰撞,导致一个不存在的元素有可能对应的比特位为1,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
57 |
58 | 总结一下:布隆过滤器认为不在的,一定不会在集合中;布隆过滤器认为在的,可能在也可能不在集合中。
59 |
60 | 举个例子:下图是一个布隆过滤器,共有18个比特位,3个哈希函数。集合中三个元素x,y,z通过三个哈希函数散列到不同的比特位,并将比特位置为1。当查询元素w时,通过三个哈希函数计算,发现有一个比特位的值为0,可以肯定认为该元素不在集合中。
61 |
62 | 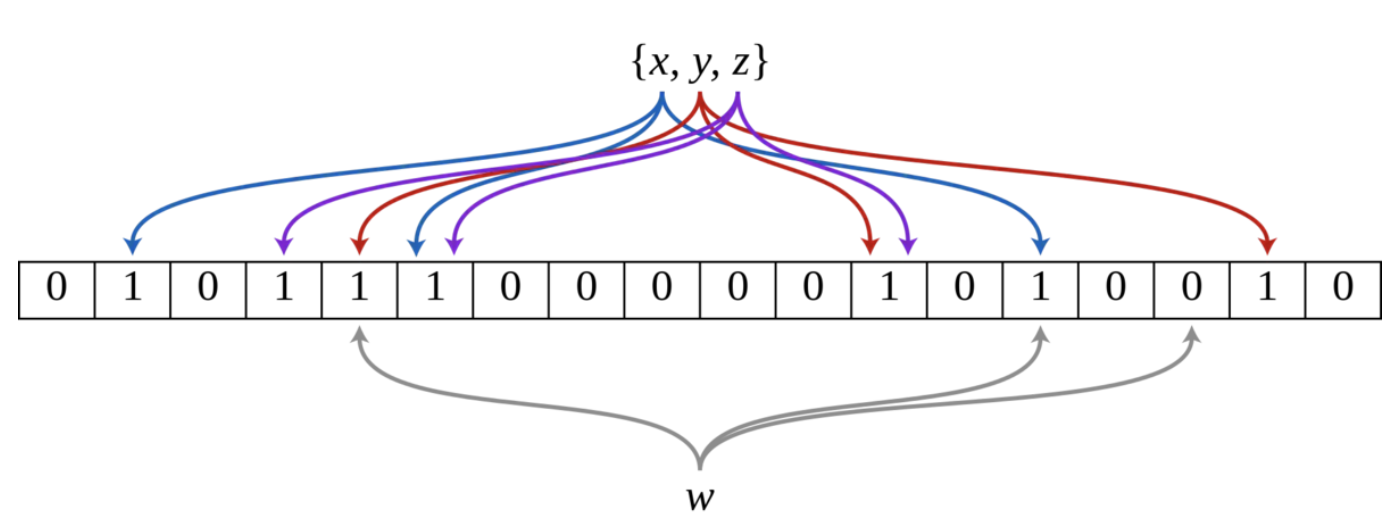
63 |
64 | **布隆过滤器优缺点**
65 |
66 | 优点:
67 |
68 | * 节省空间:不需要存储数据本身,只需要存储数据对应hash比特位
69 | * 时间复杂度低:插入和查找的时间复杂度都为O(k),k为哈希函数的个数
70 |
71 | 缺点:
72 |
73 | * 存在假阳性:布隆过滤器判断存在,可能出现元素不在集合中;判断准确率取决于哈希函数的个数
74 | * 不能删除元素:如果一个元素被删除,但是却不能从布隆过滤器中删除,这也是造成假阳性的原因了
75 |
76 | **布隆过滤器适用场景**
77 |
78 | * 爬虫系统url去重
79 | * 垃圾邮件过滤
80 | * 黑名单
81 |
82 | **(2)返回空对象**
83 |
84 | 当缓存未命中,查询持久层也为空,可以将返回的空对象写到缓存中,这样下次请求该key时直接从缓存中查询返回空对象,请求不会落到持久层数据库。为了避免存储过多空对象,通常会给空对象设置一个过期时间。
85 |
86 | 这种方法会存在两个问题:
87 |
88 | * 如果有大量的key穿透,缓存空对象会占用宝贵的内存空间。
89 | * 空对象的key设置了过期时间,在这段时间可能会存在缓存和持久层数据不一致的场景。
90 | ## 缓存击穿
91 |
92 | ### 什么是缓存击穿?
93 |
94 | 缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
95 |
96 | ### 缓存击穿危害
97 | 数据库瞬时压力骤增,造成大量请求阻塞。
98 |
99 | ### 如何解决
100 |
101 | **使用互斥锁(mutex key)**
102 |
103 | 这种思路比较简单,就是让一个线程回写缓存,其他线程等待回写缓存线程执行完,重新读缓存即可。
104 |
105 | 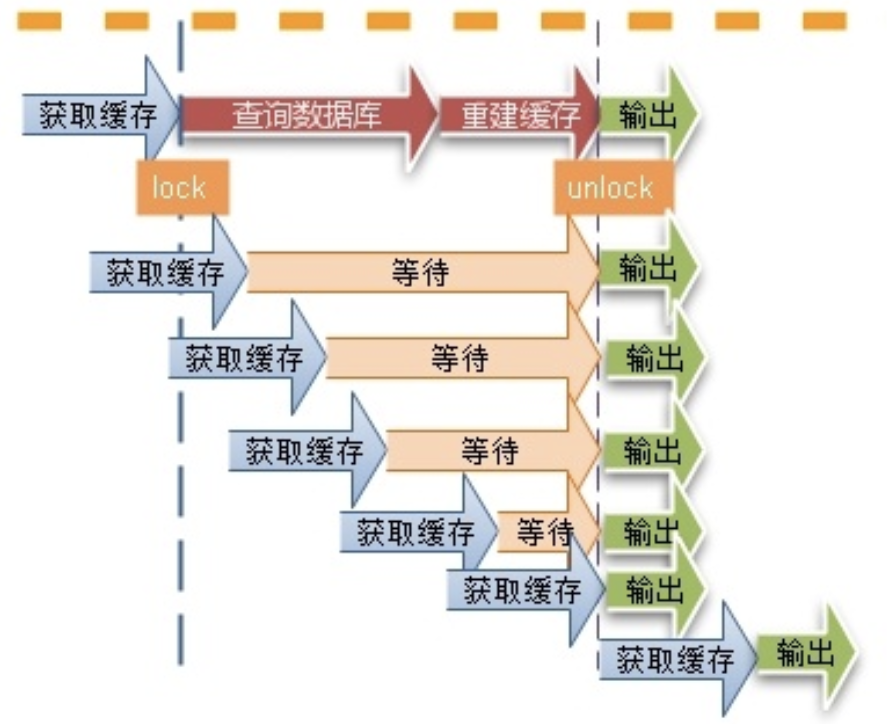
106 |
107 | 同一时间只有一个线程读数据库然后回写缓存,其他线程都处于阻塞状态。如果是高并发场景,大量线程阻塞势必会降低吞吐量。这种情况如何解决?大家可以在留言区讨论。
108 |
109 | 如果是分布式应用就需要使用分布式锁。
110 |
111 | **热点数据永不过期**
112 |
113 | 永不过期实际包含两层意思:
114 |
115 | * 物理不过期,针对热点key不设置过期时间
116 | * 逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
117 |
118 | 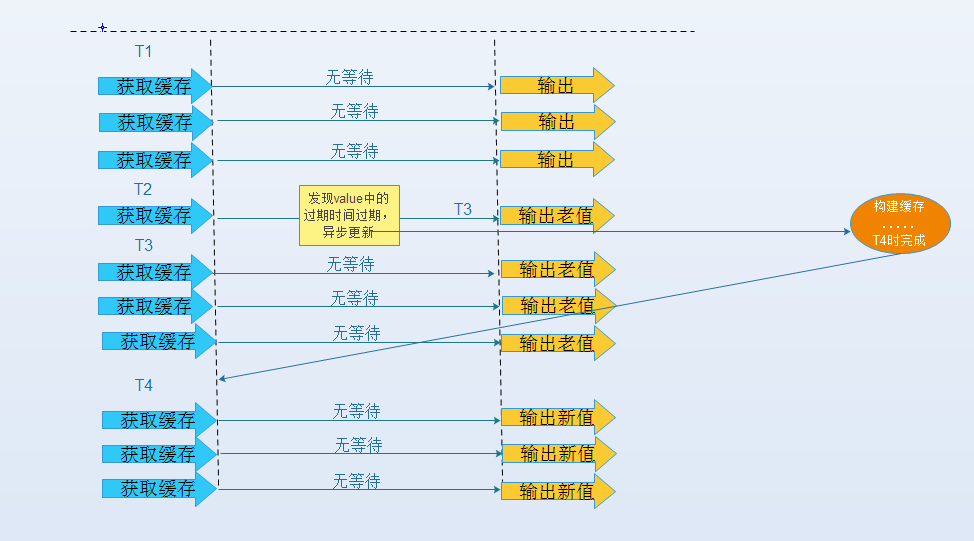
119 |
120 | 从实战看这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,对于不追求严格强一致性的系统是可以接受的。
121 |
122 | ## 缓存雪崩
123 |
124 | ### 什么是缓存雪崩?
125 |
126 | 缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,请求直接落到数据库上,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
127 |
128 | ### 缓存雪崩解决方案
129 |
130 | 常用的解决方案有:
131 |
132 | * 均匀过期
133 | * 加互斥锁
134 | * 缓存永不过期
135 | * 双层缓存策略
136 |
137 | (1)均匀过期
138 |
139 | 设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
140 |
141 | (2)加互斥锁
142 |
143 | 跟缓存击穿解决思路一致,同一时间只让一个线程构建缓存,其他线程阻塞排队。
144 |
145 | (3)缓存永不过期
146 |
147 | 跟缓存击穿解决思路一致,缓存在物理上永远不过期,用一个异步的线程更新缓存。
148 |
149 | (4)双层缓存策略
150 |
151 | 使用主备两层缓存:
152 |
153 | 主缓存:有效期按照经验值设置,设置为主读取的缓存,主缓存失效后从数据库加载最新值。
154 |
155 | 备份缓存:有效期长,获取锁失败时读取的缓存,主缓存更新时需要同步更新备份缓存。
156 |
157 | ## 缓存预热
158 |
159 | ### 什么是缓存预热?
160 |
161 | 缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统,这样就可以避免在用户请求的时候,先查询数据库,然后再将数据回写到缓存。
162 |
163 | 如果不进行预热, 那么 Redis 初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
164 |
165 | ### 缓存预热的操作方法
166 |
167 | * 数据量不大的时候,工程启动的时候进行加载缓存动作;
168 | * 数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
169 | * 数据量太大的时候,优先保证热点数据进行提前加载到缓存。
170 | ## 缓存降级
171 |
172 | 缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。
173 |
174 | 在项目实战中通常会将部分热点数据缓存到服务的内存中,这样一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大压力。
175 |
176 | 降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。
--------------------------------------------------------------------------------
/docs/redis/一次性将Redis RDB持久化和AOF持久化讲透.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321014&idx=1&sn=ad594766b3973bbf5156567849db7c48&chksm=8f09ce6cb87e477a87731ad9281d082a3b52ce3a2af705527b6a683cb341cedb71bc96419d13&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [什么是持久化?](#什么是持久化)
6 | - [Redis为什么要持久化?](#redis为什么要持久化)
7 | - [Redis如何实现持久化?](#redis如何实现持久化)
8 | - [RDB持久化](#rdb持久化)
9 | - [AOF持久化](#aof持久化)
10 | - [RDB和AOF的优缺点](#rdb和aof的优缺点)
11 |
12 |
13 |
14 | ## 什么是持久化?
15 |
16 | 持久化(Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的对象存储在数据库中,或者存储在磁盘文件中、XML数据文件中等等。
17 |
18 | 
19 |
20 | 还可以从如下两个层面简单的理解持久化 :
21 |
22 | * 应用层:如果关闭(shutdown)你的应用然后重新启动则先前的数据依然存在。
23 | * 系统层:如果关闭(shutdown)你的系统(电脑)然后重新启动则先前的数据依然存在。
24 | ## Redis为什么要持久化?
25 |
26 | Redis是内存数据库,为了保证效率所有的操作都是在内存中完成。数据都是缓存在内存中,当你重启系统或者关闭系统,之前缓存在内存中的数据都会丢失再也不能找回。因此为了避免这种情况,Redis需要实现持久化将内存中的数据存储起来。
27 |
28 | ## Redis如何实现持久化?
29 |
30 | Redis官方提供了不同级别的持久化方式:
31 |
32 | * RDB持久化:能够在指定的时间间隔能对你的数据进行快照存储。
33 | * AOF持久化:记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾。Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
34 | * 不使用持久化:如果你只希望你的数据在服务器运行的时候存在,你也可以选择不使用任何持久化方式。
35 | * 同时开启RDB和AOF:你也可以同时开启两种持久化方式,在这种情况下当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
36 |
37 | 这么多持久化方式我们应该怎么选?在选择之前我们需要搞清楚每种持久化方式的区别以及各自的优劣势。
38 |
39 | ## RDB持久化
40 |
41 | RDB(Redis Database)持久化是把当前内存数据生成快照保存到硬盘的过程,触发RDB持久化过程分为**手动触发**和**自动触发**。
42 |
43 | (1)手动触发
44 |
45 | 手动触发对应save命令,会阻塞当前Redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
46 |
47 | (2)自动触发
48 |
49 | 自动触发对应bgsave命令,Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
50 |
51 | 在redis.conf配置文件中可以配置:
52 |
53 | ```plain
54 | save
55 | ```
56 | 表示xx秒内数据修改xx次时自动触发bgsave。
57 | 如果想关闭自动触发,可以在save命令后面加一个空串,即:
58 |
59 | ```plain
60 | save ""
61 | ```
62 | 还有其他常见可以触发bgsave,如:
63 | * 如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点。
64 | * 默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则 自动执行bgsave。
65 |
66 | **bgsave工作机制**
67 |
68 | 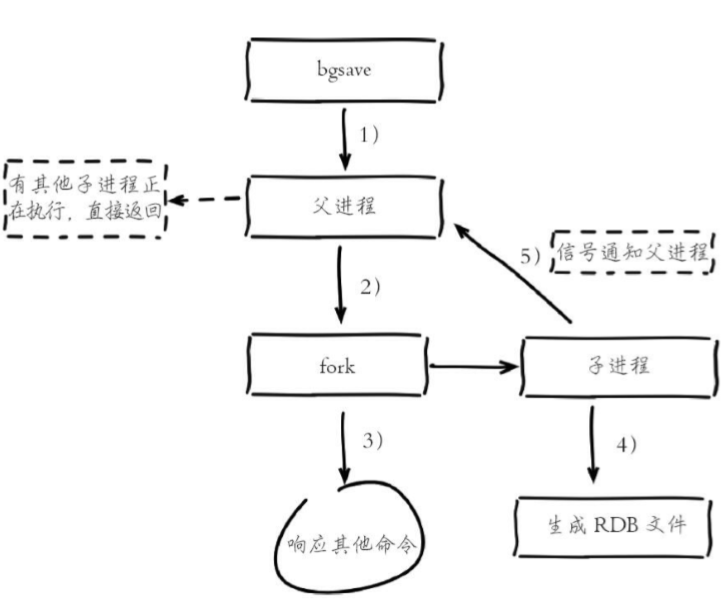
69 |
70 | (1)执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进 程,如RDB/AOF子进程,如果存在,bgsave命令直接返回。
71 |
72 | (2)父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通 过info stats命令查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒
73 |
74 | (3)父进程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令。
75 |
76 | (4)子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行lastsave命令可以获取最后一次生成RDB的 时间,对应info统计的rdb_last_save_time选项。
77 |
78 | (5)进程发送信号给父进程表示完成,父进程更新统计信息,具体见 info Persistence下的rdb_*相关选项。
79 |
80 | ## AOF持久化
81 |
82 | AOF(append only file)持久化:以独立日志的方式记录每次写命令, 重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
83 |
84 | **AOF持久化工作机制**
85 |
86 | 开启AOF功能需要配置:appendonly yes,默认不开启。
87 |
88 | AOF文件名 通过appendfilename配置设置,默认文件名是appendonly.aof。保存路径同 RDB持久化方式一致,通过dir配置指定。
89 |
90 | AOF的工作流程操作:命令写入 (append)、文件同步(sync)、文件重写(rewrite)、重启加载 (load)。
91 |
92 | 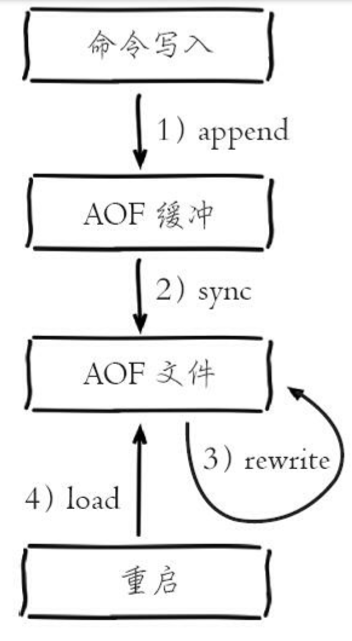
93 |
94 | (1)所有的写入命令会追加到aof_buf(缓冲区)中。
95 |
96 | (2)AOF缓冲区根据对应的策略向硬盘做同步操作。
97 |
98 | AOF为什么把命令追加到aof_buf中?Redis使用单线程响应命令,如果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负载。先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡。
99 |
100 | (3)随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
101 |
102 | (4)当Redis服务器重启时,可以加载AOF文件进行数据恢复。
103 |
104 | **AOF重写(rewrite)机制**
105 |
106 | 重写的目的:
107 |
108 | * 减小AOF文件占用空间;
109 | * 更小的AOF 文件可以更快地被Redis加载恢复。
110 |
111 | AOF重写可以分为手动触发和自动触发:
112 |
113 | * 手动触发:直接调用bgrewriteaof命令。
114 | * 自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机。
115 |
116 | auto-aof-rewrite-min-size:表示运行AOF重写时文件最小体积,默认 为64MB。
117 |
118 | auto-aof-rewrite-percentage:代表当前AOF文件空间 (aof_current_size)和上一次重写后AOF文件空间(aof_base_size)的比值。
119 |
120 | 自动触发时机
121 |
122 | 当aof_current_size>auto-aof-rewrite-minsize 并且(aof_current_size-aof_base_size)/aof_base_size>=auto-aof-rewritepercentage。
123 |
124 | 其中aof_current_size和aof_base_size可以在info Persistence统计信息中查看。
125 |
126 | 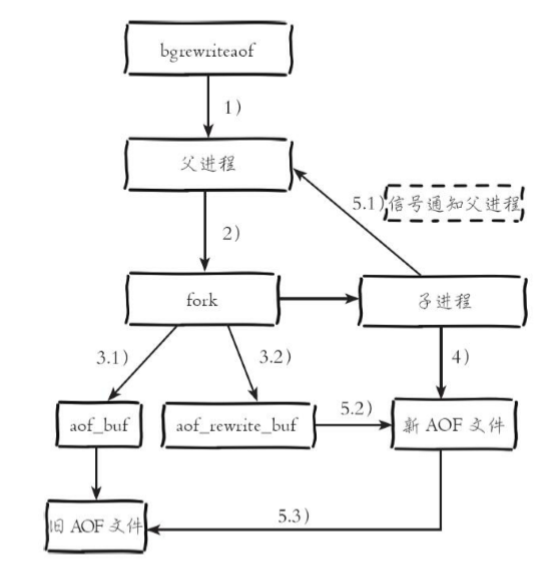
127 |
128 | AOF文件重写后为什么会变小?
129 |
130 | (1)旧的AOF文件含有无效的命令,如:del key1, hdel key2等。重写只保留最终数据的写入命令。
131 |
132 | (2)多条命令可以合并,如lpush list a,lpush list b,lpush list c可以直接转化为lpush list a b c。
133 |
134 | **AOF文件数据恢复**
135 |
136 | 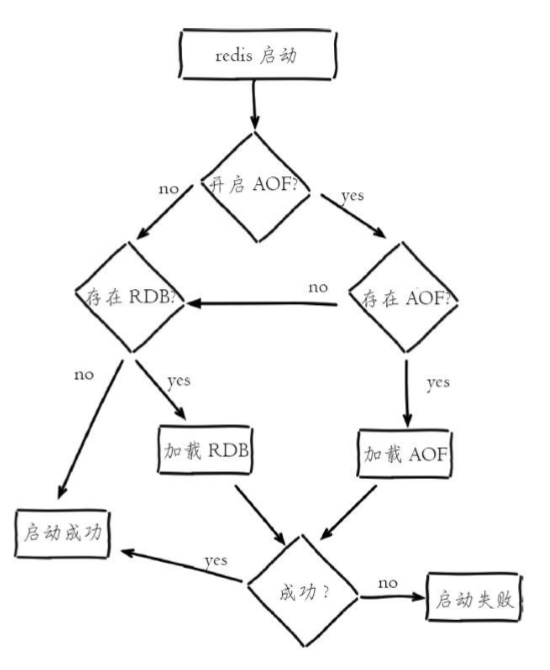
137 |
138 | 数据恢复流程说明:
139 |
140 | (1)AOF持久化开启且存在AOF文件时,优先加载AOF文件。
141 |
142 | (2)AOF关闭或者AOF文件不存在时,加载RDB文件。
143 |
144 | (3)加载AOF/RDB文件成功后,Redis启动成功。
145 |
146 | (4)AOF/RDB文件存在错误时,Redis启动失败并打印错误信息。
147 |
148 | ## RDB和AOF的优缺点
149 |
150 | **RDB优点**
151 |
152 | * RDB 是一个非常紧凑的文件,它保存了某个时间点的数据集,非常适用于数据集的备份,比如你可以在每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集。
153 | * RDB 是一个紧凑的单一文件,很方便传送到另一个远端数据中心,非常适用于灾难恢复。
154 | * RDB 在保存 RDB 文件时父进程唯一需要做的就是 fork 出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他 IO 操作,所以 RDB 持久化方式可以最大化 Redis 的性能。
155 | * 与AOF相比,在恢复大的数据集的时候,RDB 方式会更快一些。
156 |
157 | **AOF优点**
158 |
159 | * 你可以使用不同的 fsync 策略:无 fsync、每秒 fsync 、每次写的时候 fsync .使用默认的每秒 fsync 策略, Redis 的性能依然很好( fsync 是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据。
160 | * AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题。
161 | * Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
162 | * AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
163 |
164 | **RDB缺点**
165 |
166 | * Redis 要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存,万一在 Redis 意外宕机,你可能会丢失几分钟的数据。
167 | * RDB 需要经常 fork 子进程来保存数据集到硬盘上,当数据集比较大的时候, fork 的过程是非常耗时的,可能会导致 Redis 在一些毫秒级内不能响应客户端的请求。
168 |
169 | **AOF缺点**
170 |
171 | * 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
172 | * 数据恢复(load)时AOF比RDB慢,通常RDB 可以提供更有保证的最大延迟时间。
173 |
174 | **RDB和AOF简单对比总结**
175 |
176 | RDB优点:
177 |
178 | * RDB 是紧凑的二进制文件,比较适合备份,全量复制等场景
179 | * RDB 恢复数据远快于 AOF
180 |
181 | RDB缺点:
182 |
183 | * RDB 无法实现实时或者秒级持久化;
184 | * 新老版本无法兼容 RDB 格式。
185 |
186 | AOF优点:
187 |
188 | * 可以更好地保护数据不丢失;
189 | * appen-only 模式写入性能比较高;
190 | * 适合做灾难性的误删除紧急恢复。
191 |
192 | AOF缺点:
193 |
194 | * 对于同一份文件,AOF 文件要比 RDB 快照大;
195 | * AOF 开启后,会对写的 QPS 有所影响,相对于 RDB 来说 写 QPS 要下降;
196 | * 数据库恢复比较慢, 不合适做冷备。
--------------------------------------------------------------------------------
/docs/redis/经理让我复盘上次Redis缓存雪崩事故.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321968&idx=1&sn=aaa3f84046651c5b2f57b7cfa42df26f&chksm=8f09ca2ab87e433ca85d900894e96d207ee91ff1241b9d73f9da1c2639fdce1b12311326b667&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [事故背景](#事故背景)
6 | - [什么原因造成的?](#什么原因造成的)
7 | - [什么时候发现的?](#什么时候发现的)
8 | - [为什么没有早点发现?](#为什么没有早点发现)
9 | - [发现时采取了什么措施?](#发现时采取了什么措施)
10 | - [如何避免下次出现?](#如何避免下次出现)
11 | - [**复盘总结**](#复盘总结)
12 |
13 |
14 |
15 | ## 事故背景
16 |
17 | 公司最近安排了一波商品抢购活动,由于后台小哥操作失误最终导致活动效果差,被用户和代理商投诉了。经理让我带同事们一起复盘这次线上事故。
18 |
19 | ## 什么原因造成的?
20 |
21 | 抢购活动计划是零点准时开始,
22 |
23 | 22:00 运营人员通过后台将商品上线
24 |
25 | 23:00后台小哥已经将商品导入缓存中,提前预热
26 |
27 | 抢购开始的瞬间流量非常大,按计划是通过Redis承担大部分用户查询请求,避免请求全部落在数据库上。
28 |
29 |  30 |
31 |
32 | 如上图预期大部分请求会命中缓存,但是由于后台小哥预热缓存的时候将所有商品的缓存时间都设置为2小时过期,所有的商品在同一个时间点全部失效,瞬间所有的请求都落在数据库上,导致数据库扛不住压力崩溃,用户所有的请求都超时报错。
33 |
34 | 实际上所有的请求都直接落到数据库,如下图:
35 |
36 |
30 |
31 |
32 | 如上图预期大部分请求会命中缓存,但是由于后台小哥预热缓存的时候将所有商品的缓存时间都设置为2小时过期,所有的商品在同一个时间点全部失效,瞬间所有的请求都落在数据库上,导致数据库扛不住压力崩溃,用户所有的请求都超时报错。
33 |
34 | 实际上所有的请求都直接落到数据库,如下图:
35 |
36 | 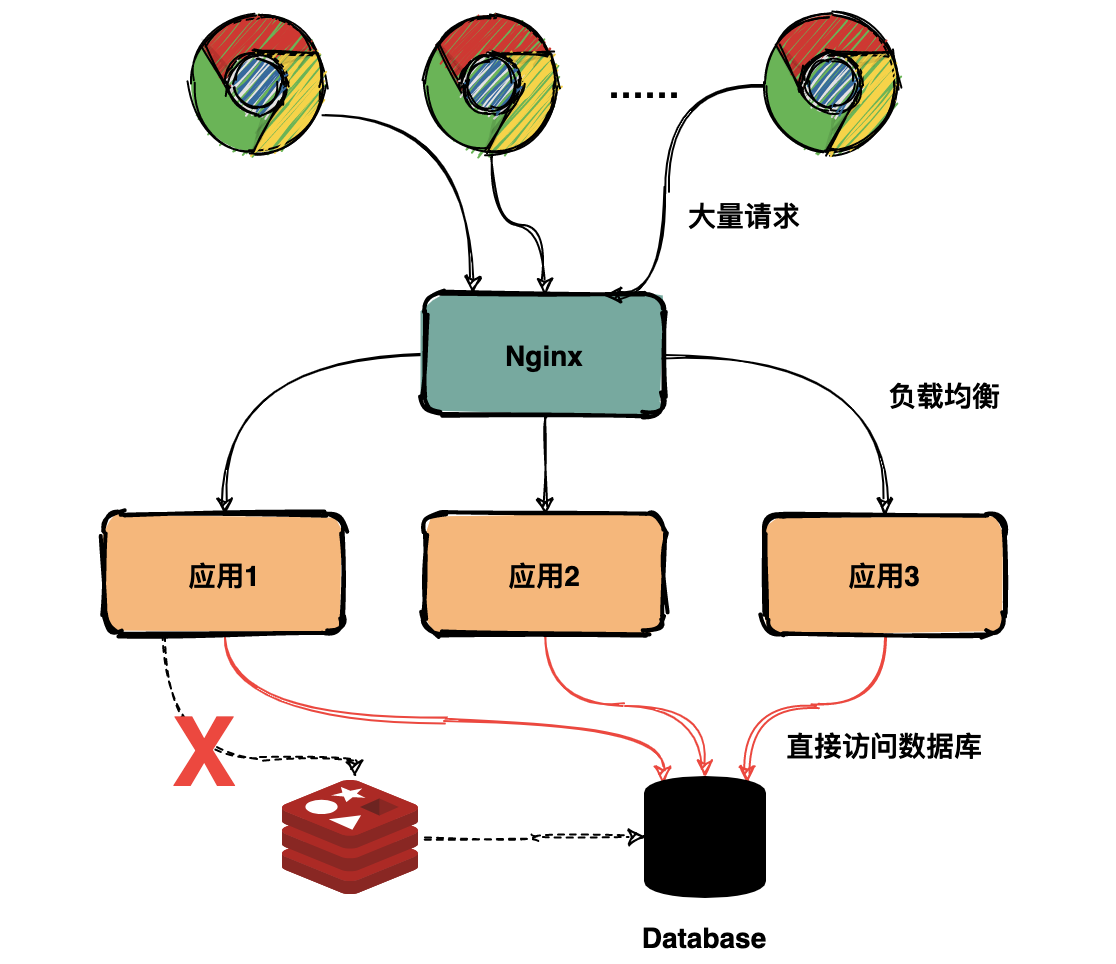 37 |
38 |
39 | ## 什么时候发现的?
40 |
41 | 凌晨01:02 SRE 收到系统告警,登录运维管理系统发现数据库节点 CPU和内存飙升超过阈值,迅速联系后台开发人员定位排查。
42 |
43 | ## 为什么没有早点发现?
44 |
45 | 由于缓存设置过期时间是2小时,凌晨1点前缓存可以命中大部分请求,数据库服务处于正常状态。
46 |
47 | ## 发现时采取了什么措施?
48 |
49 | 后台小哥通过日志定位排查发现问题后,进行了一系列操作:
50 |
51 | >首先通过API Gateway(网关)限制大部分流量进来
52 | >接着将宕机的数据库服务重启
53 | >再重新预热缓存
54 | >确认缓存和数据库服务正常后将网关流量正常放开,大约01:30 抢购活动恢复正常。
55 | ## 如何避免下次出现?
56 |
57 | 这次事故的原因其实就是出现了缓存雪崩,查询数据量巨大,请求直接落到数据库上,引起数据库压力过大宕机。
58 |
59 | 在业界解决缓存雪崩的方法其实比较成熟了,比如有:
60 |
61 | * **均匀过期**
62 | * **加互斥锁**
63 | * **缓存永不过期**
64 |
65 | **(1)均匀过期**
66 |
67 | 设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
68 |
69 |
37 |
38 |
39 | ## 什么时候发现的?
40 |
41 | 凌晨01:02 SRE 收到系统告警,登录运维管理系统发现数据库节点 CPU和内存飙升超过阈值,迅速联系后台开发人员定位排查。
42 |
43 | ## 为什么没有早点发现?
44 |
45 | 由于缓存设置过期时间是2小时,凌晨1点前缓存可以命中大部分请求,数据库服务处于正常状态。
46 |
47 | ## 发现时采取了什么措施?
48 |
49 | 后台小哥通过日志定位排查发现问题后,进行了一系列操作:
50 |
51 | >首先通过API Gateway(网关)限制大部分流量进来
52 | >接着将宕机的数据库服务重启
53 | >再重新预热缓存
54 | >确认缓存和数据库服务正常后将网关流量正常放开,大约01:30 抢购活动恢复正常。
55 | ## 如何避免下次出现?
56 |
57 | 这次事故的原因其实就是出现了缓存雪崩,查询数据量巨大,请求直接落到数据库上,引起数据库压力过大宕机。
58 |
59 | 在业界解决缓存雪崩的方法其实比较成熟了,比如有:
60 |
61 | * **均匀过期**
62 | * **加互斥锁**
63 | * **缓存永不过期**
64 |
65 | **(1)均匀过期**
66 |
67 | 设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
68 |
69 | 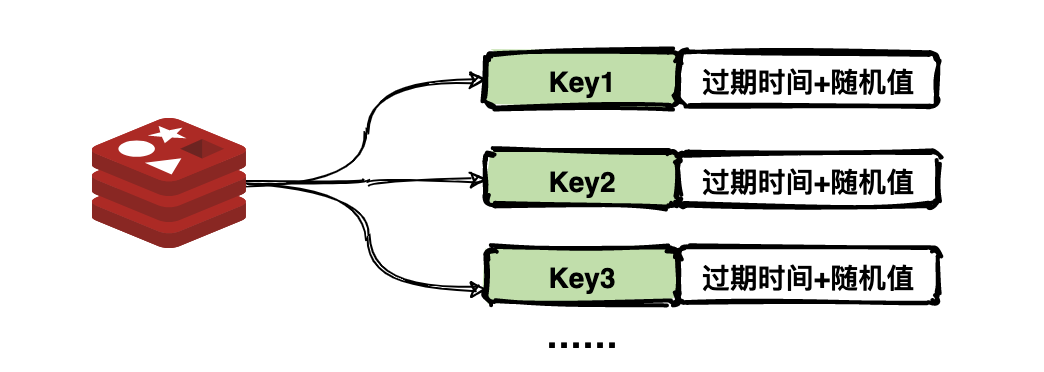 70 |
71 | **(2)加互斥锁**
72 |
73 | 跟缓存击穿解决思路一致,同一时间只让一个线程构建缓存,其他线程阻塞排队。
74 |
75 |
70 |
71 | **(2)加互斥锁**
72 |
73 | 跟缓存击穿解决思路一致,同一时间只让一个线程构建缓存,其他线程阻塞排队。
74 |
75 | 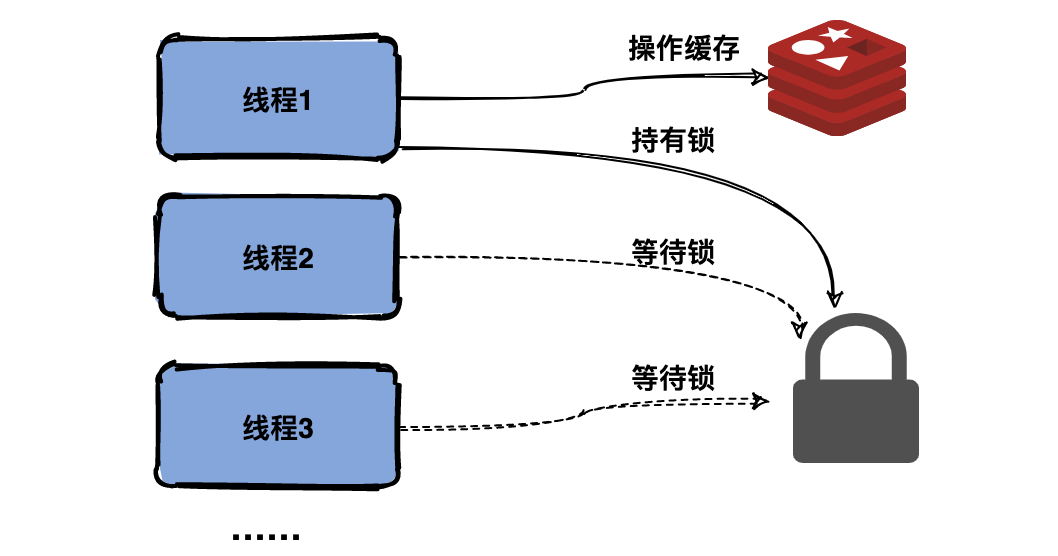 76 |
77 |
78 | **(3)缓存永不过期**
79 |
80 | 跟缓存击穿解决思路一致,缓存在物理上永远不过期,用一个异步的线程更新缓存。
81 |
82 |
76 |
77 |
78 | **(3)缓存永不过期**
79 |
80 | 跟缓存击穿解决思路一致,缓存在物理上永远不过期,用一个异步的线程更新缓存。
81 |
82 | 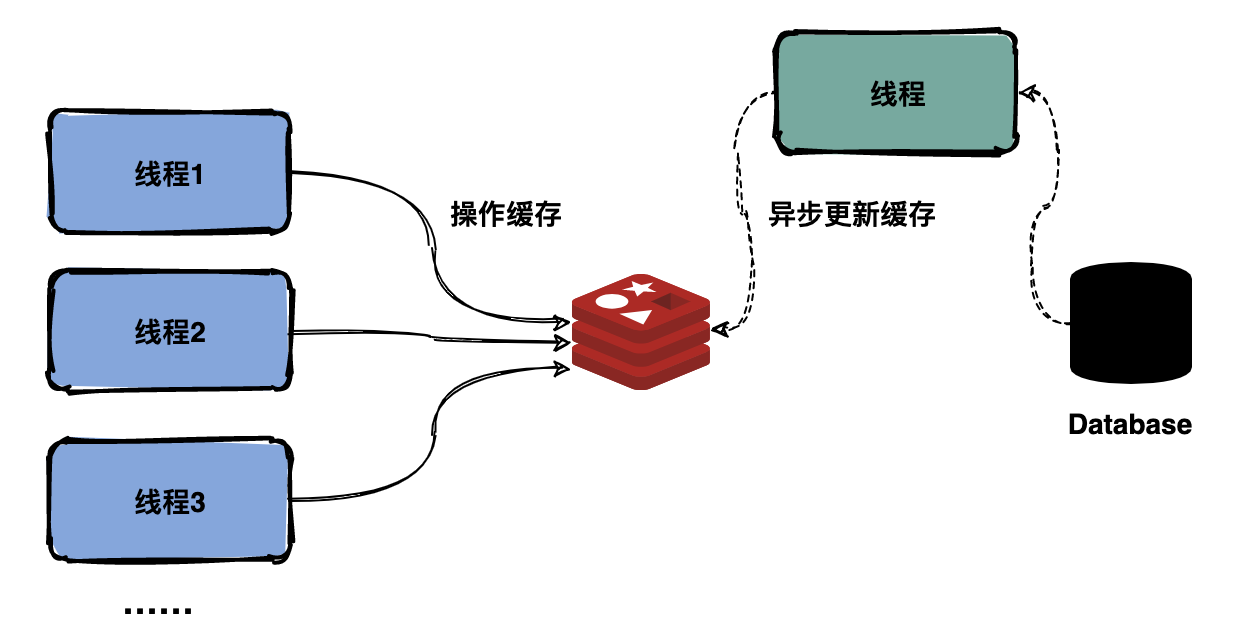 83 |
84 | ## **复盘总结**
85 |
86 | 通过与同事复盘这次线上事故,大家对于缓存雪崩有了更深刻的理解。为了避免再次出现缓存雪崩事故,大家一起讨论了多个解决方案:
87 |
88 | (1)均匀过期
89 |
90 | (2)加互斥锁
91 |
92 | (3)缓存永不过期
93 |
94 | 希望技术人能够敬畏每一行代码!
95 |
96 |
--------------------------------------------------------------------------------
/docs/redis/记一次由Redis分布式锁造成的重大事故,避免以后踩坑!.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321391&idx=2&sn=272aafc2c051e3b969efb921b5ab4e81&chksm=8f09cff5b87e46e35b7ca948e08c30a7cf7b20f1254c8609a5e910faeaae738fe035547fec95&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [前言](#前言)
6 | - [**背景**](#背景)
7 | - [事故现场](#事故现场)
8 | - [事故原因](#事故原因)
9 | - [事故分析](#事故分析)
10 | - [解决方案](#解决方案)
11 | - [实现相对安全的分布式锁](#实现相对安全的分布式锁)
12 | - [实现安全的库存校验](#实现安全的库存校验)
13 | - [改进之后的代码](#改进之后的代码)
14 | - [深度思考](#深度思考)
15 | - [分布式锁有必要么](#分布式锁有必要么)
16 | - [分布式锁的选型](#分布式锁的选型)
17 | - [再次思考分布式锁有必要么](#再次思考分布式锁有必要么)
18 | - [总结](#总结)
19 |
20 |
21 |
22 | # 前言
23 |
24 | 基于Redis使用分布式锁在当今已经不是什么新鲜事了。本篇文章主要是基于我们实际项目中因为redis分布式锁造成的事故分析及解决方案。
25 |
26 |
27 |
28 | # **背景**
29 |
30 | 我们项目中的抢购订单采用的是分布式锁来解决的。有一次,运营做了一个飞天茅台的抢购活动,库存100瓶,但是却超卖了!要知道,这个地球上飞天茅台的稀缺性啊!!!事故定为P0级重大事故...只能坦然接受。整个项目组被扣绩效了~~事故发生后,CTO指名点姓让我带头冲锋来处理,好吧,冲~
31 |
32 |
33 |
34 | # 事故现场
35 |
36 | 经过一番了解后,得知这个抢购活动接口以前从来没有出现过这种情况,但是这次为什么会超卖呢?原因在于:之前的抢购商品都不是什么稀缺性商品,而这次活动居然是**飞天茅台**,通过埋点数据分析,各项数据基本都是成倍增长,活动热烈程度可想而知!话不多说,直接上核心代码,机密部分做了伪代码处理。。。
37 |
38 | ```java
39 | public SeckillActivityRequestVO seckillHandle(SeckillActivityRequestVO request) {
40 | SeckillActivityRequestVO response;
41 | String key = "key:" + request.getSeckillId;
42 | try {
43 | Boolean lockFlag = redisTemplate.opsForValue().setIfAbsent(key, "val", 10, TimeUnit.SECONDS);
44 | if (lockFlag) {
45 | // HTTP请求用户服务进行用户相关的校验
46 | // 用户活动校验
47 |
48 | // 库存校验
49 | Object stock = redisTemplate.opsForHash().get(key+":info", "stock");
50 | assert stock != null;
51 | if (Integer.parseInt(stock.toString()) <= 0) {
52 | // 业务异常
53 | } else {
54 | redisTemplate.opsForHash().increment(key+":info", "stock", -1);
55 | // 生成订单
56 | // 发布订单创建成功事件
57 | // 构建响应VO
58 | }
59 | }
60 | } finally {
61 | // 释放锁
62 | stringRedisTemplate.delete("key");
63 | // 构建响应VO
64 | }
65 | return response;
66 | }
67 | ```
68 | 以上代码,通过分布式锁过期时间有效期10s来保障业务逻辑有足够的执行时间;采用try-finally语句块保证锁一定会及时释放。业务代码内部也对库存进行了校验。看起来很安全啊~ 别急,继续分析。。。
69 |
70 |
71 | # 事故原因
72 |
73 | 飞天茅台抢购活动吸引了大量新用户下载注册我们的APP,其中,不乏很多羊毛党,采用专业的手段来注册新用户来薅羊毛和刷单。当然我们的用户系统提前做好了防备,接入阿里云人机验证、三要素认证以及自研的风控系统等各种十八般武艺,挡住了大量的非法用户。此处不禁点个赞~
74 |
75 | **但也正因如此,让用户服务一直处于较高的运行负载中**。
76 |
77 | 抢购活动开始的一瞬间,大量的用户校验请求打到了用户服务。导致用户服务网关出现了短暂的响应延迟,有些请求的响应时长超过了10s,但由于HTTP请求的响应超时我们设置的是30s,这就导致接口一直阻塞在用户校验那里,10s后,分布式锁已经失效了,此时有新的请求进来是可以拿到锁的,也就是说锁被覆盖了。这些阻塞的接口执行完之后,又会执行释放锁的逻辑,这就把其他线程的锁释放了,导致新的请求也可以竞争到锁~这真是一个极其恶劣的循环。
78 |
79 | 这个时候只能依赖库存校验,但是偏偏库存校验不是非原子性的,采用的是**get and compare**的方式,**超卖的悲剧就这样发生了**~~~
80 |
81 |
82 |
83 | # 事故分析
84 |
85 | 仔细分析下来,可以发现,这个抢购接口在高并发场景下,是有严重的安全隐患的,主要集中在三个地方:
86 |
87 |
88 |
89 | * **没有其他系统风险容错处理**由于用户服务吃紧,网关响应延迟,但没有任何应对方式,这是超卖的**导火索**。
90 | * **看似安全的分布式锁其实一点都不安全**虽然采用了set key value [EX seconds] [PX milliseconds] [NX|XX]的方式,但是如果线程A执行的时间较长没有来得及释放,锁就过期了,此时线程B是可以获取到锁的。当线程A执行完成之后,释放锁,实际上就把线程B的锁释放掉了。这个时候,线程C又是可以获取到锁的,而此时如果线程B执行完释放锁实际上就是释放的线程C设置的锁。这是超卖的**直接原因**。
91 | * **非原子性的库存校验**非原子性的库存校验导致在并发场景下,库存校验的结果不准确。这是超卖的**根本原因**。
92 |
93 |
94 |
95 | 通过以上分析,问题的根本原因在于库存校验严重依赖了分布式锁。因为在分布式锁正常set、del的情况下,库存校验是没有问题的。但是,当分布式锁不安全可靠的时候,库存校验就没有用了。
96 |
97 |
98 |
99 | # 解决方案
100 |
101 | 知道了原因之后,我们就可以对症下药了。
102 |
103 |
104 |
105 | ## 实现相对安全的分布式锁
106 |
107 | 相对安全的定义:set、del是一一映射的,不会出现把其他现成的锁del的情况。从实际情况的角度来看,即使能做到set、del一一映射,也无法保障业务的绝对安全。因为锁的过期时间始终是有界的,除非不设置过期时间或者把过期时间设置的很长,但这样做也会带来其他问题。故没有意义。
108 |
109 | 要想实现相对安全的分布式锁,必须依赖key的value值。在释放锁的时候,通过value值的唯一性来保证不会勿删。我们基于LUA脚本实现**原子性的get and compare**,如下:
110 |
111 |
112 |
113 | ```java
114 | public void safedUnLock(String key, String val) {
115 | String luaScript = "local in = ARGV[1] local curr=redis.call('get', KEYS[1]) if in==curr then redis.call('del', KEYS[1]) end return 'OK'"";
116 | RedisScript redisScript = RedisScript.of(luaScript);
117 | redisTemplate.execute(redisScript, Collections.singletonList(key), Collections.singleton(val));
118 | }
119 | ```
120 | 我们通过LUA脚本来实现安全地解锁。
121 |
122 |
123 | ## 实现安全的库存校验
124 |
125 | 如果我们对于并发有比较深入的了解的话,会发现想 get and compare/ read and save 等操作,都是非原子性的。如果要实现原子性,我们也可以借助LUA脚本来实现。但就我们这个例子中,由于抢购活动一单只能下1瓶,因此可以不用基于LUA脚本实现而是基于redis本身的原子性。原因在于:
126 |
127 |
128 |
129 | ```java
130 | // redis会返回操作之后的结果,这个过程是原子性的
131 | Long currStock = redisTemplate.opsForHash().increment("key", "stock", -1);
132 | ```
133 | 发现没有,代码中的库存校验完全是“画蛇添足”。
134 |
135 |
136 | ## 改进之后的代码
137 |
138 | 经过以上的分析之后,我们决定新建一个DistributedLocker类专门用于处理分布式锁。
139 |
140 | ```java
141 | public SeckillActivityRequestVO seckillHandle(SeckillActivityRequestVO request) {
142 | SeckillActivityRequestVO response;
143 | String key = "key:" + request.getSeckillId();
144 | String val = UUID.randomUUID().toString();
145 | try {
146 | Boolean lockFlag = distributedLocker.lock(key, val, 10, TimeUnit.SECONDS);
147 | if (!lockFlag) {
148 | // 业务异常
149 | }
150 | // 用户活动校验
151 | // 库存校验,基于redis本身的原子性来保证
152 | Long currStock = stringRedisTemplate.opsForHash().increment(key + ":info", "stock", -1);
153 | if (currStock < 0) { // 说明库存已经扣减完了。
154 | // 业务异常。
155 | log.error("[抢购下单] 无库存");
156 | } else {
157 | // 生成订单
158 | // 发布订单创建成功事件
159 | // 构建响应
160 | }
161 | } finally {
162 | distributedLocker.safedUnLock(key, val);
163 | // 构建响应
164 | }
165 | return response;
166 | }
167 | ```
168 | ## 深度思考
169 |
170 | ### 分布式锁有必要么
171 |
172 | 改进之后,其实可以发现,我们借助于redis本身的原子性扣减库存,也是可以保证不会超卖的。对的。但是如果没有这一层锁的话,那么所有请求进来都会走一遍业务逻辑,由于依赖了其他系统,此时就会造成对其他系统的压力增大。这会增加的性能损耗和服务不稳定性,得不偿失。基于分布式锁可以在一定程度上拦截一些流量。
173 |
174 |
175 |
176 | ### 分布式锁的选型
177 |
178 | 有人提出用RedLock来实现分布式锁。RedLock的可靠性更高,但其代价是牺牲一定的性能。在本场景,这点可靠性的提升远不如性能的提升带来的性价比高。如果对于可靠性极高要求的场景,则可以采用RedLock来实现。
179 |
180 |
181 |
182 | ### 再次思考分布式锁有必要么
183 |
184 | 由于bug需要紧急修复上线,因此我们将其优化并在测试环境进行了压测之后,就立马热部署上线了。实际证明,这个优化是成功的,性能方面略微提升了一些,并在分布式锁失效的情况下,没有出现超卖的情况。
185 |
186 | 然而,还有没有优化空间呢?有的!
187 |
188 | 由于服务是集群部署,我们可以将库存均摊到集群中的每个服务器上,通过广播通知到集群的各个服务器。网关层基于用户ID做hash算法来决定请求到哪一台服务器。这样就可以基于应用缓存来实现库存的扣减和判断。性能又进一步提升了!
189 |
190 | ```java
191 | // 通过消息提前初始化好,借助ConcurrentHashMap实现高效线程安全
192 | private static ConcurrentHashMap SECKILL_FLAG_MAP = new ConcurrentHashMap<>();
193 | // 通过消息提前设置好。由于AtomicInteger本身具备原子性,因此这里可以直接使用HashMap
194 | private static Map SECKILL_STOCK_MAP = new HashMap<>();
195 | ...
196 | public SeckillActivityRequestVO seckillHandle(SeckillActivityRequestVO request) {
197 | SeckillActivityRequestVO response;
198 | Long seckillId = request.getSeckillId();
199 | if(!SECKILL_FLAG_MAP.get(requestseckillId)) {
200 | // 业务异常
201 | }
202 | // 用户活动校验
203 | // 库存校验
204 | if(SECKILL_STOCK_MAP.get(seckillId).decrementAndGet() < 0) {
205 | SECKILL_FLAG_MAP.put(seckillId, false);
206 | // 业务异常
207 | }
208 | // 生成订单
209 | // 发布订单创建成功事件
210 | // 构建响应
211 | return response;
212 | }
213 | ```
214 | 通过以上的改造,我们就完全不需要依赖redis了。性能和安全性两方面都能进一步得到提升!
215 | 当然,此方案没有考虑到机器的动态扩容、缩容等复杂场景,如果还要考虑这些话,则不如直接考虑分布式锁的解决方案。
216 |
217 |
218 |
219 | # 总结
220 |
221 | 稀缺商品超卖绝对是重大事故。如果超卖数量多的话,甚至会给平台带来非常严重的经营影响和社会影响。经过本次事故,让我意识到对于项目中的任何一行代码都不能掉以轻心,否则在某些场景下,这些正常工作的代码就会变成致命杀手!对于一个开发者而言,则设计开发方案时,一定要将方案考虑周全。怎样才能将方案考虑周全?唯有持续不断地学习!
222 |
223 | > 作者:浪漫先生
224 | > https://juejin.im/post/6854573212831842311
225 |
--------------------------------------------------------------------------------
/docs/redis/还在用单机版?教你用Docker+Redis搭建主从复制多实例.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321391&idx=1&sn=0aea8b119ccee60a1366fffb9c040695&chksm=8f09cff5b87e46e33555e89a7d4929e4b184563b11f3cbfb7b834510c68708b125f128830acf&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [0. 目标](#0-目标)
6 | - [1. 安装docker,运行docker](#1-安装docker运行docker)
7 | - [2. 拉取redis镜像文件](#2-拉取redis镜像文件)
8 | - [3. 准备好redis配置文件redis.conf](#3-准备好redis配置文件redisconf)
9 | - [4. 启动redis实例](#4-启动redis实例)
10 | - [5. 配置主从复制集群](#5-配置主从复制集群)
11 | - [6. 测试主从复制效果](#6-测试主从复制效果)
12 | - [总结](#总结)
13 |
14 |
15 |
16 |
83 |
84 | ## **复盘总结**
85 |
86 | 通过与同事复盘这次线上事故,大家对于缓存雪崩有了更深刻的理解。为了避免再次出现缓存雪崩事故,大家一起讨论了多个解决方案:
87 |
88 | (1)均匀过期
89 |
90 | (2)加互斥锁
91 |
92 | (3)缓存永不过期
93 |
94 | 希望技术人能够敬畏每一行代码!
95 |
96 |
--------------------------------------------------------------------------------
/docs/redis/记一次由Redis分布式锁造成的重大事故,避免以后踩坑!.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321391&idx=2&sn=272aafc2c051e3b969efb921b5ab4e81&chksm=8f09cff5b87e46e35b7ca948e08c30a7cf7b20f1254c8609a5e910faeaae738fe035547fec95&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [前言](#前言)
6 | - [**背景**](#背景)
7 | - [事故现场](#事故现场)
8 | - [事故原因](#事故原因)
9 | - [事故分析](#事故分析)
10 | - [解决方案](#解决方案)
11 | - [实现相对安全的分布式锁](#实现相对安全的分布式锁)
12 | - [实现安全的库存校验](#实现安全的库存校验)
13 | - [改进之后的代码](#改进之后的代码)
14 | - [深度思考](#深度思考)
15 | - [分布式锁有必要么](#分布式锁有必要么)
16 | - [分布式锁的选型](#分布式锁的选型)
17 | - [再次思考分布式锁有必要么](#再次思考分布式锁有必要么)
18 | - [总结](#总结)
19 |
20 |
21 |
22 | # 前言
23 |
24 | 基于Redis使用分布式锁在当今已经不是什么新鲜事了。本篇文章主要是基于我们实际项目中因为redis分布式锁造成的事故分析及解决方案。
25 |
26 |
27 |
28 | # **背景**
29 |
30 | 我们项目中的抢购订单采用的是分布式锁来解决的。有一次,运营做了一个飞天茅台的抢购活动,库存100瓶,但是却超卖了!要知道,这个地球上飞天茅台的稀缺性啊!!!事故定为P0级重大事故...只能坦然接受。整个项目组被扣绩效了~~事故发生后,CTO指名点姓让我带头冲锋来处理,好吧,冲~
31 |
32 |
33 |
34 | # 事故现场
35 |
36 | 经过一番了解后,得知这个抢购活动接口以前从来没有出现过这种情况,但是这次为什么会超卖呢?原因在于:之前的抢购商品都不是什么稀缺性商品,而这次活动居然是**飞天茅台**,通过埋点数据分析,各项数据基本都是成倍增长,活动热烈程度可想而知!话不多说,直接上核心代码,机密部分做了伪代码处理。。。
37 |
38 | ```java
39 | public SeckillActivityRequestVO seckillHandle(SeckillActivityRequestVO request) {
40 | SeckillActivityRequestVO response;
41 | String key = "key:" + request.getSeckillId;
42 | try {
43 | Boolean lockFlag = redisTemplate.opsForValue().setIfAbsent(key, "val", 10, TimeUnit.SECONDS);
44 | if (lockFlag) {
45 | // HTTP请求用户服务进行用户相关的校验
46 | // 用户活动校验
47 |
48 | // 库存校验
49 | Object stock = redisTemplate.opsForHash().get(key+":info", "stock");
50 | assert stock != null;
51 | if (Integer.parseInt(stock.toString()) <= 0) {
52 | // 业务异常
53 | } else {
54 | redisTemplate.opsForHash().increment(key+":info", "stock", -1);
55 | // 生成订单
56 | // 发布订单创建成功事件
57 | // 构建响应VO
58 | }
59 | }
60 | } finally {
61 | // 释放锁
62 | stringRedisTemplate.delete("key");
63 | // 构建响应VO
64 | }
65 | return response;
66 | }
67 | ```
68 | 以上代码,通过分布式锁过期时间有效期10s来保障业务逻辑有足够的执行时间;采用try-finally语句块保证锁一定会及时释放。业务代码内部也对库存进行了校验。看起来很安全啊~ 别急,继续分析。。。
69 |
70 |
71 | # 事故原因
72 |
73 | 飞天茅台抢购活动吸引了大量新用户下载注册我们的APP,其中,不乏很多羊毛党,采用专业的手段来注册新用户来薅羊毛和刷单。当然我们的用户系统提前做好了防备,接入阿里云人机验证、三要素认证以及自研的风控系统等各种十八般武艺,挡住了大量的非法用户。此处不禁点个赞~
74 |
75 | **但也正因如此,让用户服务一直处于较高的运行负载中**。
76 |
77 | 抢购活动开始的一瞬间,大量的用户校验请求打到了用户服务。导致用户服务网关出现了短暂的响应延迟,有些请求的响应时长超过了10s,但由于HTTP请求的响应超时我们设置的是30s,这就导致接口一直阻塞在用户校验那里,10s后,分布式锁已经失效了,此时有新的请求进来是可以拿到锁的,也就是说锁被覆盖了。这些阻塞的接口执行完之后,又会执行释放锁的逻辑,这就把其他线程的锁释放了,导致新的请求也可以竞争到锁~这真是一个极其恶劣的循环。
78 |
79 | 这个时候只能依赖库存校验,但是偏偏库存校验不是非原子性的,采用的是**get and compare**的方式,**超卖的悲剧就这样发生了**~~~
80 |
81 |
82 |
83 | # 事故分析
84 |
85 | 仔细分析下来,可以发现,这个抢购接口在高并发场景下,是有严重的安全隐患的,主要集中在三个地方:
86 |
87 |
88 |
89 | * **没有其他系统风险容错处理**由于用户服务吃紧,网关响应延迟,但没有任何应对方式,这是超卖的**导火索**。
90 | * **看似安全的分布式锁其实一点都不安全**虽然采用了set key value [EX seconds] [PX milliseconds] [NX|XX]的方式,但是如果线程A执行的时间较长没有来得及释放,锁就过期了,此时线程B是可以获取到锁的。当线程A执行完成之后,释放锁,实际上就把线程B的锁释放掉了。这个时候,线程C又是可以获取到锁的,而此时如果线程B执行完释放锁实际上就是释放的线程C设置的锁。这是超卖的**直接原因**。
91 | * **非原子性的库存校验**非原子性的库存校验导致在并发场景下,库存校验的结果不准确。这是超卖的**根本原因**。
92 |
93 |
94 |
95 | 通过以上分析,问题的根本原因在于库存校验严重依赖了分布式锁。因为在分布式锁正常set、del的情况下,库存校验是没有问题的。但是,当分布式锁不安全可靠的时候,库存校验就没有用了。
96 |
97 |
98 |
99 | # 解决方案
100 |
101 | 知道了原因之后,我们就可以对症下药了。
102 |
103 |
104 |
105 | ## 实现相对安全的分布式锁
106 |
107 | 相对安全的定义:set、del是一一映射的,不会出现把其他现成的锁del的情况。从实际情况的角度来看,即使能做到set、del一一映射,也无法保障业务的绝对安全。因为锁的过期时间始终是有界的,除非不设置过期时间或者把过期时间设置的很长,但这样做也会带来其他问题。故没有意义。
108 |
109 | 要想实现相对安全的分布式锁,必须依赖key的value值。在释放锁的时候,通过value值的唯一性来保证不会勿删。我们基于LUA脚本实现**原子性的get and compare**,如下:
110 |
111 |
112 |
113 | ```java
114 | public void safedUnLock(String key, String val) {
115 | String luaScript = "local in = ARGV[1] local curr=redis.call('get', KEYS[1]) if in==curr then redis.call('del', KEYS[1]) end return 'OK'"";
116 | RedisScript redisScript = RedisScript.of(luaScript);
117 | redisTemplate.execute(redisScript, Collections.singletonList(key), Collections.singleton(val));
118 | }
119 | ```
120 | 我们通过LUA脚本来实现安全地解锁。
121 |
122 |
123 | ## 实现安全的库存校验
124 |
125 | 如果我们对于并发有比较深入的了解的话,会发现想 get and compare/ read and save 等操作,都是非原子性的。如果要实现原子性,我们也可以借助LUA脚本来实现。但就我们这个例子中,由于抢购活动一单只能下1瓶,因此可以不用基于LUA脚本实现而是基于redis本身的原子性。原因在于:
126 |
127 |
128 |
129 | ```java
130 | // redis会返回操作之后的结果,这个过程是原子性的
131 | Long currStock = redisTemplate.opsForHash().increment("key", "stock", -1);
132 | ```
133 | 发现没有,代码中的库存校验完全是“画蛇添足”。
134 |
135 |
136 | ## 改进之后的代码
137 |
138 | 经过以上的分析之后,我们决定新建一个DistributedLocker类专门用于处理分布式锁。
139 |
140 | ```java
141 | public SeckillActivityRequestVO seckillHandle(SeckillActivityRequestVO request) {
142 | SeckillActivityRequestVO response;
143 | String key = "key:" + request.getSeckillId();
144 | String val = UUID.randomUUID().toString();
145 | try {
146 | Boolean lockFlag = distributedLocker.lock(key, val, 10, TimeUnit.SECONDS);
147 | if (!lockFlag) {
148 | // 业务异常
149 | }
150 | // 用户活动校验
151 | // 库存校验,基于redis本身的原子性来保证
152 | Long currStock = stringRedisTemplate.opsForHash().increment(key + ":info", "stock", -1);
153 | if (currStock < 0) { // 说明库存已经扣减完了。
154 | // 业务异常。
155 | log.error("[抢购下单] 无库存");
156 | } else {
157 | // 生成订单
158 | // 发布订单创建成功事件
159 | // 构建响应
160 | }
161 | } finally {
162 | distributedLocker.safedUnLock(key, val);
163 | // 构建响应
164 | }
165 | return response;
166 | }
167 | ```
168 | ## 深度思考
169 |
170 | ### 分布式锁有必要么
171 |
172 | 改进之后,其实可以发现,我们借助于redis本身的原子性扣减库存,也是可以保证不会超卖的。对的。但是如果没有这一层锁的话,那么所有请求进来都会走一遍业务逻辑,由于依赖了其他系统,此时就会造成对其他系统的压力增大。这会增加的性能损耗和服务不稳定性,得不偿失。基于分布式锁可以在一定程度上拦截一些流量。
173 |
174 |
175 |
176 | ### 分布式锁的选型
177 |
178 | 有人提出用RedLock来实现分布式锁。RedLock的可靠性更高,但其代价是牺牲一定的性能。在本场景,这点可靠性的提升远不如性能的提升带来的性价比高。如果对于可靠性极高要求的场景,则可以采用RedLock来实现。
179 |
180 |
181 |
182 | ### 再次思考分布式锁有必要么
183 |
184 | 由于bug需要紧急修复上线,因此我们将其优化并在测试环境进行了压测之后,就立马热部署上线了。实际证明,这个优化是成功的,性能方面略微提升了一些,并在分布式锁失效的情况下,没有出现超卖的情况。
185 |
186 | 然而,还有没有优化空间呢?有的!
187 |
188 | 由于服务是集群部署,我们可以将库存均摊到集群中的每个服务器上,通过广播通知到集群的各个服务器。网关层基于用户ID做hash算法来决定请求到哪一台服务器。这样就可以基于应用缓存来实现库存的扣减和判断。性能又进一步提升了!
189 |
190 | ```java
191 | // 通过消息提前初始化好,借助ConcurrentHashMap实现高效线程安全
192 | private static ConcurrentHashMap SECKILL_FLAG_MAP = new ConcurrentHashMap<>();
193 | // 通过消息提前设置好。由于AtomicInteger本身具备原子性,因此这里可以直接使用HashMap
194 | private static Map SECKILL_STOCK_MAP = new HashMap<>();
195 | ...
196 | public SeckillActivityRequestVO seckillHandle(SeckillActivityRequestVO request) {
197 | SeckillActivityRequestVO response;
198 | Long seckillId = request.getSeckillId();
199 | if(!SECKILL_FLAG_MAP.get(requestseckillId)) {
200 | // 业务异常
201 | }
202 | // 用户活动校验
203 | // 库存校验
204 | if(SECKILL_STOCK_MAP.get(seckillId).decrementAndGet() < 0) {
205 | SECKILL_FLAG_MAP.put(seckillId, false);
206 | // 业务异常
207 | }
208 | // 生成订单
209 | // 发布订单创建成功事件
210 | // 构建响应
211 | return response;
212 | }
213 | ```
214 | 通过以上的改造,我们就完全不需要依赖redis了。性能和安全性两方面都能进一步得到提升!
215 | 当然,此方案没有考虑到机器的动态扩容、缩容等复杂场景,如果还要考虑这些话,则不如直接考虑分布式锁的解决方案。
216 |
217 |
218 |
219 | # 总结
220 |
221 | 稀缺商品超卖绝对是重大事故。如果超卖数量多的话,甚至会给平台带来非常严重的经营影响和社会影响。经过本次事故,让我意识到对于项目中的任何一行代码都不能掉以轻心,否则在某些场景下,这些正常工作的代码就会变成致命杀手!对于一个开发者而言,则设计开发方案时,一定要将方案考虑周全。怎样才能将方案考虑周全?唯有持续不断地学习!
222 |
223 | > 作者:浪漫先生
224 | > https://juejin.im/post/6854573212831842311
225 |
--------------------------------------------------------------------------------
/docs/redis/还在用单机版?教你用Docker+Redis搭建主从复制多实例.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321391&idx=1&sn=0aea8b119ccee60a1366fffb9c040695&chksm=8f09cff5b87e46e33555e89a7d4929e4b184563b11f3cbfb7b834510c68708b125f128830acf&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [0. 目标](#0-目标)
6 | - [1. 安装docker,运行docker](#1-安装docker运行docker)
7 | - [2. 拉取redis镜像文件](#2-拉取redis镜像文件)
8 | - [3. 准备好redis配置文件redis.conf](#3-准备好redis配置文件redisconf)
9 | - [4. 启动redis实例](#4-启动redis实例)
10 | - [5. 配置主从复制集群](#5-配置主从复制集群)
11 | - [6. 测试主从复制效果](#6-测试主从复制效果)
12 | - [总结](#总结)
13 |
14 |
15 |
16 | 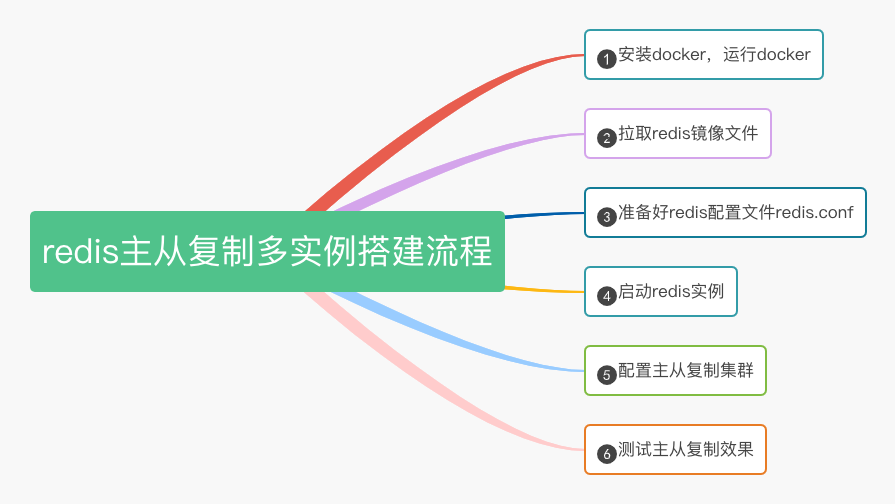 17 |
18 | # 0. 目标
19 |
20 | 本地搭建三个redis实例(一主两备),实现效果:主实例插入数据备实例可以复制同步过去。
21 |
22 | # 1. 安装docker,运行docker
23 |
24 | docker安装步骤省略,大家可以从官网下载并安装。
25 |
26 | 检查docker是否运行成功:
27 |
28 | ```plain
29 | docker info
30 | ```
31 | 出现回显表示运行成功,可以做下一步操作了。
32 |
33 | # 2. 拉取redis镜像文件
34 |
35 | 执行以下命令默认拉取tag为latest的官方redis镜像
36 |
37 | ```plain
38 | docker pull redis
39 | ```
40 |
41 | # 3. 准备好redis配置文件redis.conf
42 |
43 | 下载地址:
44 |
45 | > 链接:https://pan.baidu.com/s/14tWHtk3mch3e3VlT9TYX1A
46 | >
47 | > 提取密码:q3uk
48 |
49 | 拷贝为3三份,如:redis01.conf, redis02.conf, redis03.conf
50 |
51 | 打开所有的配置文件,修改如下配置项:
52 |
53 | * 注释只监听本地选项,可以远程连接。#bind 127.0.0.1
54 | * 关闭保护模式 protected-mode no
55 | * 打开AOF持久化开关 appendonly yes
56 | # 4. 启动redis实例
57 |
58 | ```shell
59 | # 实例1
60 | docker run -p 6381:6379 --name redis-server-01 -v /your/path/redis/conf/redis01.conf:/etc/redis/redis.conf -v /your/path/redis/data01:/data -d redis redis-server /etc/redis/redis.conf
61 |
62 | # 实例2
63 | docker run -p 6382:6379 --name redis-server-02 -v /your/path/redis/redis/conf/redis02.conf:/etc/redis/redis.conf -v /your/path/redis/data02:/data -d redis redis-server /etc/redis/redis.conf
64 |
65 | # 实例3
66 | docker run -p 6383:6379 --name redis-server-03 -v /your/path/redis/conf/redis03.conf:/etc/redis/redis.conf -v /your/path/redis/data03:/data -d redis redis-server /etc/redis/redis.conf
67 | ```
68 |
69 |
70 |
71 | 对以上命令简单解释:
72 |
73 | * 参数-p 6381:6379,6381表示宿主机端口,6379表示容器实例端口,意思是将容器实例端口映射到宿主机端口。
74 | * 参数--name redis-server-01,给容器实例命名。
75 | * 参数-v /your/path/redis/conf/redis01.conf:/etc/redis/redis.conf,冒号前是宿主机配置文件路径,冒号后是容器的配置文件路径,意思是将容器实例的配置路径映射到宿主机的路径。
76 | * 参数-v /your/path/redis/data01:/data,如上面意思相同。
77 | * 选项-d表示以后台形式运行实例。
78 | * 参数redis-server /etc/redis/redis.conf表示执行redis-server命令, /etc/redis/redis.conf表示以该配置文件启动redis实例,注意配置文件必须为redis-server命令的第一个参数。
79 |
80 | # 5. 配置主从复制集群
81 |
82 | 检查实例运行状态:
83 |
84 | ```plain
85 | docker ps
86 | ```
87 |
88 |
89 | 回显有三个redis实例即为正常。 查询实例1:redis-server-01 运行的内部ip
90 |
91 | ```plain
92 | docker inspect redis-server-01
93 | ```
94 |
95 |
96 | 通过回显可以看到:"IPAddress": "172.17.0.4" 我们将实例1规划为主,另外两个实例自然为备了,通过将主的ip和port配置在备的配置文件中即可实现主从复制的效果。
97 |
98 | 修改redis02.conf和redis03.conf配置文件,找到replicaof选项(redis5.0之前是slaveof),修改为:
99 |
100 | ```plain
101 | replicaof 172.17.0.4 6379
102 | ```
103 |
104 |
105 | 修改完毕,重启实例2和实例3:
106 |
107 | ```plain
108 | docker restart redis-server-02
109 | docker restart redis-server-03
110 | ```
111 |
112 |
113 | 检查实例1的状态是否为主,并且挂载两个备实例:
114 |
115 | ```plain
116 | docker exec -it redis-server-01 redis-cli
117 | 127.0.0.1:6379> info
118 | ```
119 |
120 |
121 | 回显如下表示主从复制配置成功:
122 |
123 | ```plain
124 | # Replication
125 | role:master
126 | connected_slaves:2
127 | slave0:ip=172.17.0.3,port=6379,state=online,offset=84,lag=1
128 | slave1:ip=172.17.0.2,port=6379,state=online,offset=84,lag=1
129 | ```
130 |
131 |
132 | # 6. 测试主从复制效果
133 |
134 | 连接redis实例1插入一条记录:
135 |
136 | ```plain
137 | docker exec -it redis-server-01 redis-cli # 连接实例1
138 | 127.0.0.1:6379> set name ray # 插入一条数据
139 | OK # 插入成功
140 | ```
141 |
142 |
143 | 连接redis实例2和实例3查看是否复制成功:
144 |
145 | ```plain
146 | docker exec -it redis-server-02 redis-cli # 连接实例2
147 | 127.0.0.1:6379> get name
148 | "ray" # 可以查到,表明从实例已经将主实例的数据同步过来了
149 | ```
150 |
151 |
152 | # 总结
153 |
154 | 搭建Redis主从复制实例需要有一点docker的基础,如果你对docker比较熟悉了,那搭建过程实在太容易了。没有docker基础,只要按照上面的命令逐个运行也可以100%成功哦。
155 |
156 | 下一篇带大家手把手搭建Redis主从复制+哨兵模式,尽请期待。
157 |
--------------------------------------------------------------------------------
/docs/redis/面试官再问Redis事务把这篇文章扔给他.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321004&idx=1&sn=a8b058868390e133cfdf77ba6d2afd9f&chksm=8f09ce76b87e476062ad446b3097e9697b1da4810fa396a65554b1dada1c195ac50e90e58b24&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 | ## 1. Redis事务生命周期
4 |
5 | * 开启事务:使用MULTI开启一个事务
6 | * 命令入队列:每次操作的命令都会加入到一个队列中,但命令此时不会真正被执行
7 | * 提交事务:使用EXEC命令提交事务,开始顺序执行队列中的命令
8 | ## 2. Redis事务到底是不是原子性的?
9 |
10 | 先看关系型数据库ACID 中关于原子性的定义:
11 |
12 | **原子性:**一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
13 |
14 | 官方文档对事务的定义:
15 |
16 | * **事务是一个单独的隔离操作**:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
17 | * **事务是一个原子操作**:事务中的命令要么全部被执行,要么全部都不执行。EXEC 命令负责触发并执行事务中的所有命令:如果客户端在使用 MULTI 开启了一个事务之后,却因为断线而没有成功执行 EXEC ,那么事务中的所有命令都不会被执行。另一方面,如果客户端成功在开启事务之后执行 EXEC ,那么事务中的所有命令都会被执行。
18 |
19 | 官方认为Redis事务是一个原子操作,这是站在执行与否的角度考虑的。但是从ACID原子性定义来看,**严格意义上讲Redis事务是非原子型的**,因为在命令顺序执行过程中,一旦发生命令执行错误Redis是不会停止执行然后回滚数据。
20 |
21 | ## 3. Redis为什么不支持回滚(roll back)?
22 |
23 | 在事务运行期间虽然Redis命令可能会执行失败,但是Redis依然会执行事务内剩余的命令而不会执行回滚操作。如果你熟悉mysql关系型数据库事务,你会对此非常疑惑,Redis官方的理由如下:
24 |
25 | >只有当被调用的Redis命令有语法错误时,这条命令才会执行失败(在将这个命令放入事务队列期间,Redis能够发现此类问题),或者对某个键执行不符合其数据类型的操作:实际上,这就意味着只有程序错误才会导致Redis命令执行失败,这种错误很有可能在程序开发期间发现,一般很少在生产环境发现。
26 | >支持事务回滚能力会导致设计复杂,这与Redis的初衷相违背,Redis的设计目标是功能简化及确保更快的运行速度。
27 | >
28 |
29 | 对于官方的这种理由有一个普遍的反对观点:程序有bug怎么办?但其实回归不能解决程序的bug,比如某位粗心的程序员计划更新键A,实际上最后更新了键B,回滚机制是没法解决这种人为错误的。正因为这种人为的错误不太可能进入生产系统,所以官方在设计Redis时选用更加简单和快速的方法,没有实现回滚的机制。
30 |
31 | ## 4. Redis事务失败场景
32 |
33 | 有三种类型的失败场景:
34 |
35 | (1)在事务提交之前,客户端执行的命令缓存(队列)失败,比如命令的语法错误(命令参数个数错误,不支持的命令等等)。如果发生这种类型的错误,Redis将向客户端返回包含错误提示信息的响应,同时Redis会清空队列中的命令并取消事务。
36 |
37 | ```plain
38 | 127.0.0.1:6379> set name xiaoming # 事务之前执行
39 | OK
40 | 127.0.0.1:6379> multi # 开启事务
41 | OK
42 | 127.0.0.1:6379> set name zhangsan # 事务中执行,命令入队列
43 | QUEUED
44 | 127.0.0.1:6379> setset name zhangsan2 # 错误的命令,模拟失败场景
45 | (error) ERR unknown command `setset`, with args beginning with: `name`, `zhangsan2`,
46 | 127.0.0.1:6379> exec # 提交事务,发现由于上条命令的错误导致事务已经自动取消了
47 | (error) EXECABORT Transaction discarded because of previous errors.
48 | 127.0.0.1:6379> get name # 查询name,发现未被修改
49 | "xiaoming"
50 | ```
51 | (2)事务提交后开始顺序执行命令,之前缓存在队列中的命令有可能执行失败。
52 | ```plain
53 | 127.0.0.1:6379> multi # 开启事务
54 | OK
55 | 127.0.0.1:6379> set name xiaoming # 设置名字
56 | QUEUED
57 | 127.0.0.1:6379> set age 18 # 设置年龄
58 | QUEUED
59 | 127.0.0.1:6379> lpush age 20 # 此处仅检查是否有语法错误,不会真正执行
60 | QUEUED
61 | 127.0.0.1:6379> exec # 提交事务后开始顺序执行命令,第三条命令执行失败
62 | 1) OK
63 | 2) OK
64 | 3) (error) WRONGTYPE Operation against a key holding the wrong kind of value
65 | 127.0.0.1:6379> get name # 第三条命令失败没有将前两条命令回滚
66 | "xiaoming"
67 | ```
68 | (3)由于乐观锁失败,事务提交时将丢弃之前缓存的所有命令序列。
69 | 通过开启两个redis客户端并结合watch命令模拟这种失败场景。
70 |
71 | ```plain
72 | # 客户端1
73 | 127.0.0.1:6379> set name xiaoming # 客户端1设置name
74 | OK
75 | 127.0.0.1:6379> watch name # 客户端1通过watch命令给name加乐观锁
76 | OK
77 | # 客户端2
78 | 127.0.0.1:6379> get name # 客户端2查询name
79 | "xiaoming"
80 | 127.0.0.1:6379> set name zhangsan # 客户端2修改name值
81 | OK
82 | # 客户端1
83 | 127.0.0.1:6379> multi # 客户端1开启事务
84 | OK
85 | 127.0.0.1:6379> set name lisi # 客户端1修改name
86 | QUEUED
87 | 127.0.0.1:6379> exec # 客户端1提交事务,返回空
88 | (nil)
89 | 127.0.0.1:6379> get name # 客户端1查询name,发现name没有被修改为lisi
90 | "zhangsan"
91 | ```
92 | 在事务过程中监控的key被其他客户端改变,则当前客户端的乐观锁失败,事务提交时将丢弃所有命令缓存队列。
93 | ## 5. Redis事务相关命令
94 |
95 | ### (1)WATCH
96 |
97 | 可以为Redis事务提供 check-and-set (CAS)行为。被WATCH的键会被监视,并会发觉这些键是否被改动过了。 如果有至少一个被监视的键在 EXEC 执行之前被修改了, 那么整个事务都会被取消, EXEC 返回nil-reply来表示事务已经失败。
98 |
99 | ### (2)MULTI
100 |
101 | 用于开启一个事务,它总是返回OK。MULTI执行之后,客户端可以继续向服务器发送任意多条命令, 这些命令不会立即被执行,而是被放到一个队列中,当 EXEC命令被调用时, 所有队列中的命令才会被执行。
102 |
103 | ### (3)UNWATCH
104 |
105 | 取消 WATCH 命令对所有 key 的监视,一般用于DISCARD和EXEC命令之前。如果在执行 WATCH 命令之后, EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了。因为 EXEC 命令会执行事务,因此 WATCH 命令的效果已经产生了;而 DISCARD 命令在取消事务的同时也会取消所有对 key 的监视,因此这两个命令执行之后,就没有必要执行 UNWATCH 了。
106 |
107 | ### (4)DISCARD
108 |
109 | 当执行 DISCARD 命令时, 事务会被放弃, 事务队列会被清空,并且客户端会从事务状态中退出。
110 |
111 | ### (5)EXEC
112 |
113 | 负责触发并执行事务中的所有命令:
114 |
115 | 如果客户端成功开启事务后执行EXEC,那么事务中的所有命令都会被执行。
116 |
117 | 如果客户端在使用MULTI开启了事务后,却因为断线而没有成功执行EXEC,那么事务中的所有命令都不会被执行。需要特别注意的是:即使事务中有某条/某些命令执行失败了,事务队列中的其他命令仍然会继续执行,Redis不会停止执行事务中的命令,而不会像我们通常使用的关系型数据库一样进行回滚。
--------------------------------------------------------------------------------
/docs/redis/高并发场景下,到底先更新缓存还是先更新数据库?.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322566&idx=1&sn=2142fe29c6a32e5a2100f4f39ee8953d&chksm=8f09c89cb87e418a3289cdfaf46c8e4593004a120ba709929b4dc97fff5be9aa3cc795ac9ceb&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [Cache aside](#cache-aside)
6 | - [Cache aside踩坑](#cache-aside踩坑)
7 | - [Read through](#read-through)
8 | - [Write through](#write-through)
9 | - [Write behind](#write-behind)
10 | - [总结一下](#总结一下)
11 |
12 |
13 |
14 | 在大型系统中,为了减少数据库压力通常会引入缓存机制,一旦引入缓存又很容易造成缓存和数据库数据不一致,导致用户看到的是旧数据。
15 |
16 | 为了减少数据不一致的情况,更新缓存和数据库的机制显得尤为重要,接下来带领大家踩踩坑。
17 |
18 | 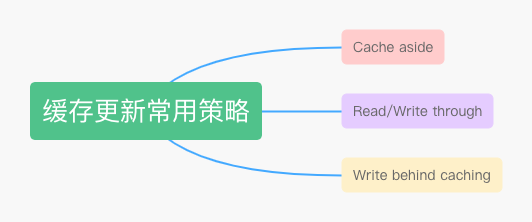
19 |
20 | ## Cache aside
21 |
22 | `Cache aside`也就是`旁路缓存`,是比较常用的缓存策略。
23 |
24 | **(1)`读请求`常见流程**
25 |
26 | 
27 |
28 | 应用首先会判断缓存是否有该数据,缓存命中直接返回数据,缓存未命中即缓存穿透到数据库,从数据库查询数据然后回写到缓存中,最后返回数据给客户端。
29 |
30 |
31 |
32 | **(2)`写请求`常见流程**
33 |
34 | 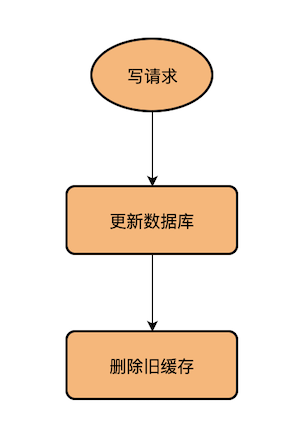
35 |
36 | 首先更新数据库,然后从缓存中删除该数据。
37 |
38 | 看了写请求的图之后,有些同学可能要问了:为什么要删除缓存,直接更新不就行了?这里涉及到几个坑,我们一步一步踩下去。
39 |
40 | ## Cache aside踩坑
41 |
42 | Cache aside策略如果用错就会遇到深坑,下面我们来逐个踩。
43 |
44 | **踩坑一:先更新数据库,再更新缓存**
45 |
46 | 如果同时有两个`写请求`需要更新数据,每个写请求都先更新数据库再更新缓存,在并发场景可能会出现数据不一致的情况。
47 |
48 | 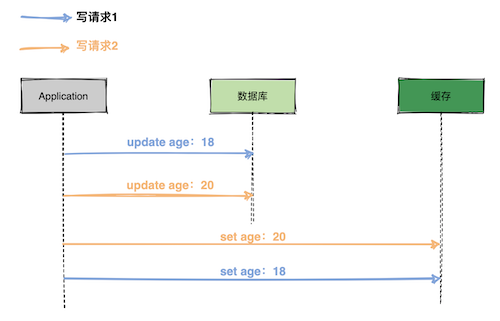
49 |
50 | 如上图的执行过程:
51 |
52 | (1)`写请求1`更新数据库,将 age 字段更新为18;
53 |
54 | (2)`写请求2`更新数据库,将 age 字段更新为20;
55 |
56 | (3)`写请求2`更新缓存,缓存 age 设置为20;
57 |
58 | (4)`写请求1`更新缓存,缓存 age 设置为18;
59 |
60 | 执行完预期结果是数据库 age 为20,缓存 age 为20,结果缓存 age为18,这就造成了缓存数据不是最新的,出现了脏数据。
61 |
62 |
63 |
64 | **踩坑二:先删缓存,再更新数据库**
65 |
66 | 如果`写请求`的处理流程是`先删缓存再更新数据库`,在一个`读请求`和一个`写请求`并发场景下可能会出现数据不一致情况。
67 |
68 | 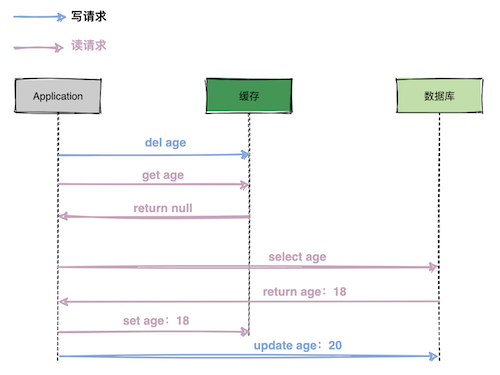
69 |
70 | 如上图的执行过程:
71 |
72 | (1)`写请求`删除缓存数据;
73 |
74 | (2)`读请求`查询缓存未击中(Hit Miss),紧接着查询数据库,将返回的数据回写到缓存中;
75 |
76 | (3)`写请求`更新数据库。
77 |
78 | 整个流程下来发现`数据库`中age为20,`缓存`中age为18,缓存和数据库数据不一致,缓存出现了脏数据。
79 |
80 |
81 |
82 | **踩坑三:先更新数据库,再删除缓存**
83 |
84 | 在实际的系统中针对`写请求`还是推荐`先更新数据库再删除缓存`,但是在理论上还是存在问题,以下面这个例子说明。
85 |
86 | 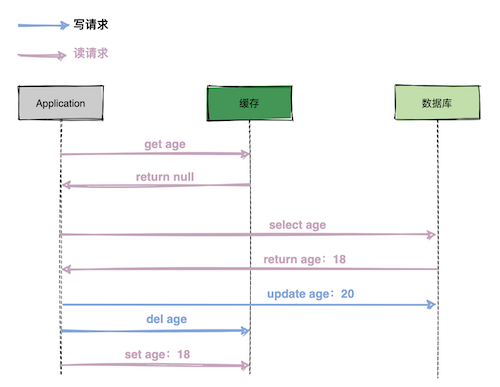
87 |
88 | 如上图的执行过程:
89 |
90 | (1)`读请求`先查询缓存,缓存未击中,查询数据库返回数据;
91 |
92 | (2)`写请求`更新数据库,删除缓存;
93 |
94 | (3)`读请求`回写缓存;
95 |
96 | 整个流程操作下来发现`数据库age为20`,`缓存age为18`,即数据库与缓存不一致,导致应用程序从缓存中读到的数据都为旧数据。
97 |
98 | 但我们仔细想一下,上述问题发生的概率其实非常低,因为通常数据库更新操作比内存操作耗时多出几个数量级,上图中最后一步回写缓存(set age 18)速度非常快,通常会在更新数据库之前完成。
99 |
100 | 如果这种极端场景出现了怎么办?我们得想一个兜底的办法:`缓存数据设置过期时间`。通常在系统中是可以允许少量的数据短时间不一致的场景出现。
101 |
102 | ## Read through
103 |
104 | 在 Cache Aside 更新模式中,应用代码需要维护两个数据源头:一个是缓存,一个是数据库。而在 `Read-Through` 策略下,应用程序无需管理缓存和数据库,只需要将数据库的同步委托给缓存提供程序 `Cache Provider` 即可。所有数据交互都是通过`抽象缓存层`完成的。
105 |
106 | 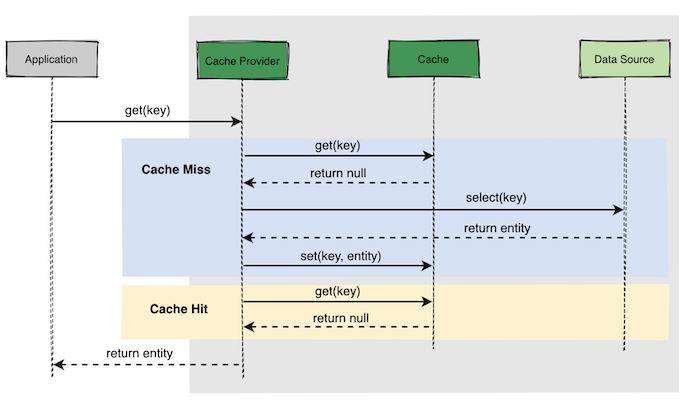
107 |
108 | 如上图,应用程序只需要与`Cache Provider`交互,不用关心是从缓存取还是数据库。
109 |
110 | 在进行大量读取时,`Read-Through` 可以减少数据源上的负载,也对缓存服务的故障具备一定的弹性。如果缓存服务挂了,则缓存提供程序仍然可以通过直接转到数据源来进行操作。
111 |
112 | `Read-Through 适用于多次请求相同数据的场景`,这与 Cache-Aside 策略非常相似,但是二者还是存在一些差别,这里再次强调一下:
113 |
114 | * 在 Cache-Aside 中,应用程序负责从数据源中获取数据并更新到缓存。
115 | * 在 Read-Through 中,此逻辑通常是由独立的缓存提供程序(Cache Provider)支持。
116 | ## Write through
117 |
118 | `Write-Through` 策略下,当发生数据更新(Write)时,缓存提供程序 `Cache Provider` 负责更新底层数据源和缓存。
119 |
120 | 缓存与数据源保持一致,并且写入时始终通过`抽象缓存层`到达数据源。
121 |
122 | `Cache Provider`类似一个代理的作用。
123 |
124 | 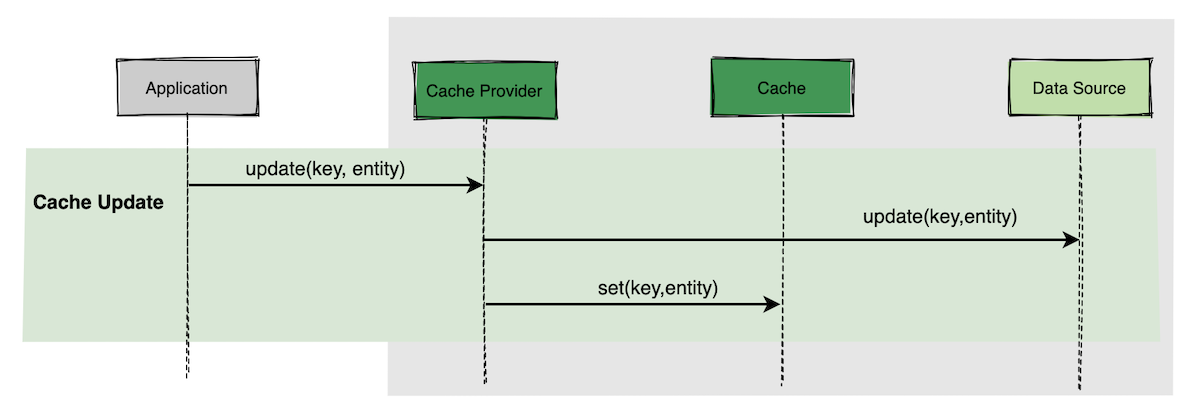
125 |
126 | ## Write behind
127 |
128 | `Write behind`在一些地方也被成为`Write back`, 简单理解就是:应用程序更新数据时只更新缓存, `Cache Provider`每隔一段时间将数据刷新到数据库中。说白了就是`延迟写入`。
129 |
130 | 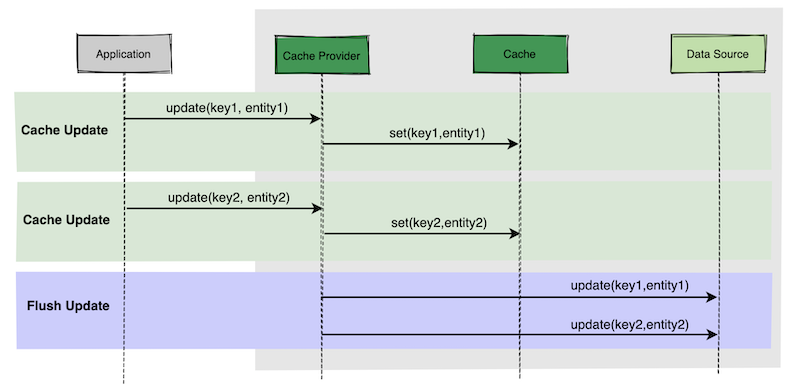
131 |
132 | 如上图,应用程序更新两个数据,Cache Provider 会立即写入缓存中,但是隔一段时间才会批量写入数据库中。
133 |
134 | 这种方式有优点也有缺点:
135 |
136 | - `优点`是数据写入速度非常快,适用于频繁写的场景。
137 |
138 | - `缺点`是缓存和数据库不是强一致性,对一致性要求高的系统慎用。
139 |
140 | ## 总结一下
141 |
142 | 学了这么多,相信大家对缓存更新的策略都已经有了清晰的认识。最后稍稍总结一下。
143 |
144 | 缓存更新的策略主要分为三种:
145 |
146 | - Cache aside
147 | - Read/Write through
148 | - Write behind
149 |
150 | Cache aside 通常会先更新数据库,然后再删除缓存,为了兜底通常还会将数据设置缓存时间。
151 |
152 | Read/Write through 一般是由一个 Cache Provider 对外提供读写操作,应用程序不用感知操作的是缓存还是数据库。
153 |
154 | Write behind简单理解就是延迟写入,Cache Provider 每隔一段时间会批量输入数据库,优点是应用程序写入速度非常快。
155 |
156 | 好了,今天先到这里了,大家学会了吗?
--------------------------------------------------------------------------------
/docs/tools/git/保姆级Git教程,10000字详解.md:
--------------------------------------------------------------------------------
1 | 大家好,我是雷小帅。
2 |
3 | 最近群里有几位老哥私我,有没有好的 git 入门资料,想学一下。
4 |
5 | 偶然看到这个很棒的教程推荐给大家,大家可以看一下,另外还有一个不错的 git 入门网站,也推荐给大家,可以搭配使用。
6 |
7 | [https://learngitbranching.js.org/?locale=zh_CN](https://learngitbranching.js.org/?locale=zh_CN)
8 |
9 |
10 |
11 | - [Git简介](#git简介)
12 | - [实用主义](#实用主义)
13 | - [准备阶段](#准备阶段)
14 | - [常用操作](#常用操作)
15 | - [git clone](#git-clone)
16 | - [git config](#git-config)
17 | - [git branch](#git-branch)
18 | - [git checkout](#git-checkout)
19 | - [git status](#git-status)
20 | - [git add](#git-add)
21 | - [git commit](#git-commit)
22 | - [git push](#git-push)
23 | - [git pull](#git-pull)
24 | - [git log](#git-log)
25 | - [git tag](#git-tag)
26 | - [.gitignore](#gitignore)
27 | - [小结](#小结)
28 | - [深入探索](#深入探索)
29 | - [基本概念](#基本概念)
30 | - [工作区(*Working Directory*)](#工作区working-directory)
31 | - [本地版本库(*Local Repository*)](#本地版本库local-repository)
32 | - [暂存区(*stage*)](#暂存区stage)
33 | - [远程版本库(*Remote Repository*)](#远程版本库remote-repository)
34 | - [以上概念之间的关系](#以上概念之间的关系)
35 | - [分支(*Branch*)](#分支branch)
36 | - [主分支(*Master*)](#主分支master)
37 | - [标签(*Tag*)](#标签tag)
38 | - [HEAD](#head)
39 | - [操作文件](#操作文件)
40 | - [git add](#git-add-1)
41 | - [git commit](#git-commit-1)
42 | - [git mv](#git-mv)
43 | - [git rm](#git-rm)
44 | - [git status](#git-status-1)
45 | - [操作分支](#操作分支)
46 | - [git branch](#git-branch-1)
47 | - [git merge](#git-merge)
48 | - [git checkout](#git-checkout-1)
49 | - [git stash](#git-stash)
50 | - [操作历史](#操作历史)
51 | - [git log](#git-log-1)
52 | - [git cherry-pick](#git-cherry-pick)
53 | - [git reset](#git-reset)
54 | - [git rebase](#git-rebase)
55 | - [git revert](#git-revert)
56 | - [git diff](#git-diff)
57 | - [git reflog](#git-reflog)
58 | - [远程版本库连接](#远程版本库连接)
59 | - [git init](#git-init)
60 | - [git remote](#git-remote)
61 | - [git fetch](#git-fetch)
62 | - [问题排查](#问题排查)
63 | - [git blame](#git-blame)
64 | - [git bisect](#git-bisect)
65 | - [更多操作](#更多操作)
66 | - [git submodule](#git-submodule)
67 | - [git gc](#git-gc)
68 | - [git archive](#git-archive)
69 |
70 |
71 |
72 |
73 | # Git简介
74 |
75 | `Git` 是一种分布式版本控制系统,它可以不受网络连接的限制,加上其它众多优点,目前已经成为程序开发人员做项目版本管理时的首选,非开发人员也可以用 `Git` 来做自己的文档版本管理工具。
76 |
77 | 大概是大二的时候开始接触和使用Git,从一开始的零接触到现在的重度依赖,真是感叹 `Git` 的强大。
78 |
79 | `Git` 的api很多,但其实平时项目中90%的需求都只需要用到几个基本的功能即可,所以本文将从 `实用主义` 和 `深入探索` 2个方面去谈谈如何在项目中使用 `Git`,一般来说,看完 `实用主义` 这一节就可以开始在项目中动手用。
80 |
81 | > 说明:本文的操作都是基于 Mac 系统
82 | >
83 |
84 | # 实用主义
85 |
86 | ## 准备阶段
87 |
88 | 进入 Git官网 下载合适你的安装包,安装好 `Git` 后,打开命令行工具,进入工作文件夹(*为了便于理解我们在系统桌面上演示*),创建一个新的demo文件夹。
89 |
90 | 
91 |
92 | 进入 Github网站 注册一个账号并登录,进入 我的博客,点击 `Clone or download`,再点击 `Use HTTPS` ,复制项目地址 `https://github.com/gafish/gafish.github.com.git` 备用。
93 |
94 | 再回到命令行工具,一切就绪,接下来进入本文的重点。
95 |
96 | ## 常用操作
97 |
98 | 所谓实用主义,就是掌握了以下知识就可以玩转 `Git`,轻松应对90%以上的需求。以下是实用主义型的Git命令列表,先大致看一下
99 |
100 | - `git clone`
101 | - `git config`
102 | - `git branch`
103 | - `git checkout`
104 | - `git status`
105 | - `git add`
106 | - `git commit`
107 | - `git push`
108 | - `git pull`
109 | - `git log`
110 | - `git tag`
111 |
112 | 接下来,将通过对 我的博客 仓库进行实例操作,讲解如何使用 `Git` 拉取代码到提交代码的整个流程。
113 |
114 | ### git clone
115 |
116 | > 从git服务器拉取代码
117 | >
118 |
119 | ```
120 | git clone https://github.com/gafish/gafish.github.com.git
121 | ```
122 |
123 | 代码下载完成后在当前文件夹中会有一个 `gafish.github.com` 的目录,通过 `cd gafish.github.com` 命令进入目录。
124 |
125 | ### git config
126 |
127 | > 配置开发者用户名和邮箱
128 | >
129 |
130 | ```
131 | git config user.name gafish
132 | git config user.email gafish@qqqq.com
133 | ```
134 |
135 | 每次代码提交的时候都会生成一条提交记录,其中会包含当前配置的用户名和邮箱。
136 |
137 | ### git branch
138 |
139 | > 创建、重命名、查看、删除项目分支,通过 `Git` 做项目开发时,一般都是在开发分支中进行,开发完成后合并分支到主干。
140 | >
141 |
142 | ```
143 | git branch daily/0.0.0
144 | ```
145 |
146 | 创建一个名为 `daily/0.0.0` 的日常开发分支,分支名只要不包括特殊字符即可。
147 |
148 | ```
149 | git branch -m daily/0.0.0 daily/0.0.1
150 | ```
151 |
152 | 如果觉得之前的分支名不合适,可以为新建的分支重命名,重命名分支名为 `daily/0.0.1`
153 |
154 | ```
155 | git branch
156 | ```
157 |
158 | 通过不带参数的branch命令可以查看当前项目分支列表
159 |
160 | ```
161 | git branch -d daily/0.0.1
162 | ```
163 |
164 | 如果分支已经完成使命则可以通过 `-d` 参数将分支删除,这里为了继续下一步操作,暂不执行删除操作
165 |
166 | ### git checkout
167 |
168 | > 切换分支
169 | >
170 |
171 | ```
172 | git checkout daily/0.0.1
173 | ```
174 |
175 | 切换到 `daily/0.0.1` 分支,后续的操作将在这个分支上进行
176 |
177 | ### git status
178 |
179 | > 查看文件变动状态
180 | >
181 |
182 | 通过任何你喜欢的编辑器对项目中的 `README.md` 文件做一些改动,保存。
183 |
184 | ```
185 | git status
186 | ```
187 |
188 | 通过 `git status` 命令可以看到文件当前状态 `Changes not staged for commit:`(*改动文件未提交到暂存区*)
189 |
190 | ```
191 | On branch daily/0.0.1
192 | Changes not staged for commit:
193 | (use "git add ..." to update what will be committed)
194 | (use "git checkout -- ..." to discard changes in working directory)
195 | modified: README.md
196 | no changes added to commit (use "git add" and/or "git commit -a")
197 | ```
198 |
199 | ### git add
200 |
201 | > 添加文件变动到暂存区
202 | >
203 |
204 | ```
205 | git add README.md
206 | ```
207 |
208 | 通过指定文件名 `README.md` 可以将该文件添加到暂存区,如果想添加所有文件可用 `git add .` 命令,这时候可通过 `git status` 看到文件当前状态 `Changes to be committed:` (*文件已提交到暂存区*)
209 |
210 | ```
211 | On branch daily/0.0.1
212 | Changes to be committed:
213 | (use "git reset HEAD ..." to unstage)
214 | modified: README.md
215 | ```
216 |
217 | ### git commit
218 |
219 | > 提交文件变动到版本库
220 | >
221 |
222 | ```
223 | git commit -m '这里写提交原因'
224 | ```
225 |
226 | 通过 `-m` 参数可直接在命令行里输入提交描述文本
227 |
228 | ### git push
229 |
230 | > 将本地的代码改动推送到服务器
231 | >
232 |
233 | ```
234 | git push origin daily/0.0.1
235 | ```
236 |
237 | `origin` 指代的是当前的git服务器地址,这行命令的意思是把 `daily/0.0.1` 分支推送到服务器,当看到命令行返回如下字符表示推送成功了。
238 |
239 | ```
240 | Counting objects: 3, done.
241 | Delta compression using up to 8 threads.
242 | Compressing objects: 100% (2/2), done.
243 | Writing objects: 100% (3/3), 267 bytes | 0 bytes/s, done.
244 | Total 3 (delta 1), reused 0 (delta 0)
245 | remote: Resolving deltas: 100% (1/1), completed with 1 local objects.
246 | To https://github.com/gafish/gafish.github.com.git
247 | * [new branch] daily/0.0.1 -> daily/0.0.1
248 | ```
249 |
250 | 现在我们回到Github网站的项目首页,点击 `Branch:master` 下拉按钮,就会看到刚才推送的 `daily/00.1` 分支了
251 |
252 | ### git pull
253 |
254 | > 将服务器上的最新代码拉取到本地
255 | >
256 |
257 | ```
258 | git pull origin daily/0.0.1
259 | ```
260 |
261 | 如果其它项目成员对项目做了改动并推送到服务器,我们需要将最新的改动更新到本地,这里我们来模拟一下这种情况。
262 |
263 | 进入Github网站的项目首页,再进入 `daily/0.0.1` 分支,在线对 `README.md` 文件做一些修改并保存,然后在命令中执行以上命令,它将把刚才在线修改的部分拉取到本地,用编辑器打开 `README.md` ,你会发现文件已经跟线上的内容同步了。
264 |
265 | *如果线上代码做了变动,而你本地的代码也有变动,拉取的代码就有可能会跟你本地的改动冲突,一般情况下 `Git` 会自动处理这种冲突合并,但如果改动的是同一行,那就需要手动来合并代码,编辑文件,保存最新的改动,再通过 `git add .`和 `git commit -m 'xxx'` 来提交合并。*
266 |
267 | ### git log
268 |
269 | > 查看版本提交记录
270 | >
271 |
272 | ```
273 | git log
274 | ```
275 |
276 | 通过以上命令,我们可以查看整个项目的版本提交记录,它里面包含了`提交人`、`日期`、`提交原因`等信息,得到的结果如下:
277 |
278 | ```
279 | commit c334730f8dba5096c54c8ac04fdc2b31ede7107a
280 | Author: gafish
281 | Date: Wed Jan 11 09:44:13 2017 +0800
282 | Update README.md
283 | commit ba6e3d21fcb1c87a718d2a73cdd11261eb672b2a
284 | Author: gafish
285 | Date: Wed Jan 11 09:31:33 2017 +0800
286 | test
287 | .....
288 | ```
289 |
290 | 提交记录可能会非常多,按 `J` 键往下翻,按 `K` 键往上翻,按 `Q` 键退出查看
291 |
292 | ### git tag
293 |
294 | > 为项目标记里程碑
295 | >
296 |
297 | ```
298 | git tag publish/0.0.1
299 | git push origin publish/0.0.1
300 | ```
301 |
302 | 当我们完成某个功能需求准备发布上线时,应该将此次完整的项目代码做个标记,并将这个标记好的版本发布到线上,这里我们以 `publish/0.0.1` 为标记名并发布,当看到命令行返回如下内容则表示发布成功了
303 |
304 | ```
305 | Total 0 (delta 0), reused 0 (delta 0)
306 | To https://github.com/gafish/gafish.github.com.git
307 | * [new tag] publish/0.0.1 -> publish/0.0.1
308 | ```
309 |
310 | ### .gitignore
311 |
312 | > 设置哪些内容不需要推送到服务器,这是一个配置文件
313 | >
314 |
315 | ```
316 | touch .gitignore
317 | ```
318 |
319 | `.gitignore` 不是 `Git` 命令,而在项目中的一个文件,通过设置 `.gitignore` 的内容告诉 `Git` 哪些文件应该被忽略不需要推送到服务器,通过以上命令可以创建一个 `.gitignore` 文件,并在编辑器中打开文件,每一行代表一个要忽略的文件或目录,如:
320 |
321 | ```
322 | demo.html
323 | build/
324 | ```
325 |
326 | 以上内容的意思是 `Git` 将忽略 `demo.html` 文件 和 `build/` 目录,这些内容不会被推送到服务器上
327 |
328 | ### 小结
329 |
330 | 通过掌握以上这些基本命令就可以在项目中开始用起来了,如果追求实用,那关于 `Git` 的学习就可以到此结束了,偶尔遇到的问题也基本上通过 `Google` 也能找到答案,如果想深入探索 `Git` 的高阶功能,那就继续往下看 `深入探索` 部分。
331 |
332 | # 深入探索
333 |
334 | ## 基本概念
335 |
336 | ### 工作区(*Working Directory*)
337 |
338 | 就是你在电脑里能看到的目录,比如上文中的 `gafish.github.com` 文件夹就是一个工作区
339 |
340 | ### 本地版本库(*Local Repository*)
341 |
342 | 工作区有一个隐藏目录 `.git`,这个不算工作区,而是 `Git` 的版本库。
343 |
344 | 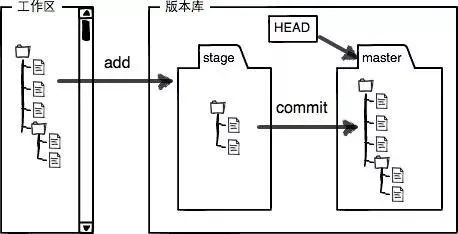
345 |
346 | ### 暂存区(*stage*)
347 |
348 | 本地版本库里存了很多东西,其中最重要的就是称为 `stage`(或者叫index)的暂存区,还有 `Git` 为我们自动创建的第一个分支 `master`,以及指向 `master` 的一个指针叫 `HEAD`。
349 |
350 | ### 远程版本库(*Remote Repository*)
351 |
352 | 一般指的是 `Git` 服务器上所对应的仓库,本文的示例所在的`github`仓库就是一个远程版本库
353 |
354 | ### 以上概念之间的关系
355 |
356 | `工作区`、`暂存区`、`本地版本库`、`远程版本库`之间几个常用的 `Git` 操作流程如下图所示:
357 |
358 | 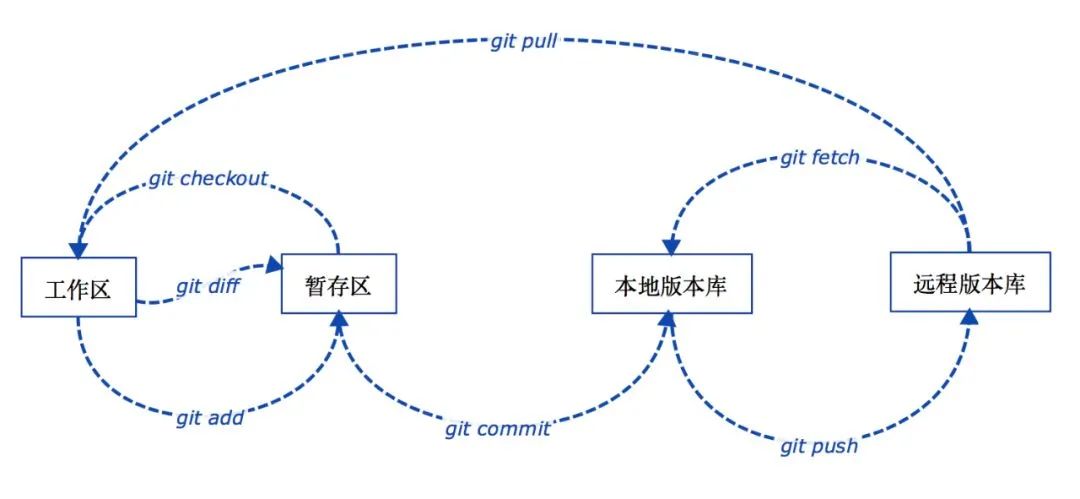
359 |
360 | ### 分支(*Branch*)
361 |
362 | 分支是为了将修改记录的整个流程分开存储,让分开的分支不受其它分支的影响,所以在同一个数据库里可以同时进行多个不同的修改
363 |
364 | 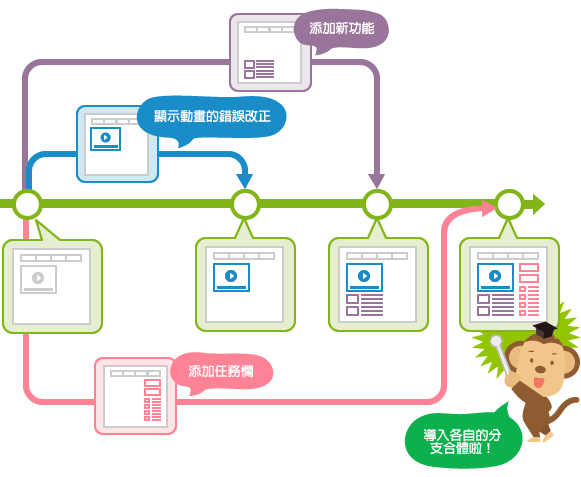
365 |
366 | ### 主分支(*Master*)
367 |
368 | 前面提到过 `master` 是 `Git` 为我们自动创建的第一个分支,也叫主分支,其它分支开发完成后都要合并到 `master`
369 |
370 | 
371 |
372 |
373 |
374 | ### 标签(*Tag*)
375 |
376 | 标签是用于标记特定的点或提交的历史,通常会用来标记发布版本的名称或版本号(如:`publish/0.0.1`),虽然标签看起来有点像分支,但打上标签的提交是固定的,不能随意的改动,参见上图中的`1.0` / `2.0` / `3.0`
377 |
378 | ### HEAD
379 |
380 | `HEAD` 指向的就是当前分支的最新提交
381 |
382 | 
383 |
384 | > 以上概念了解的差不多,那就可以继续往下看,下面将以具体的操作类型来讲解 `Git` 的高阶用法
385 | >
386 |
387 | ## 操作文件
388 |
389 | ### git add
390 |
391 | > 添加文件到暂存区
392 | >
393 |
394 | ```
395 | git add -i
396 | ```
397 |
398 | 通过此命令将打开交互式子命令系统,你将看到如下子命令
399 |
400 | ```
401 | ***Commands***
402 | 1: status 2: update 3: revert 4: add untracked
403 | 5: patch 6: diff 7: quit 8: help
404 | ```
405 |
406 | 通过输入序列号或首字母可以选择相应的功能,具体的功能解释如下:
407 |
408 | - `status`:功能上和 `git add -i` 相似,没什么鸟用
409 | - `update`:详见下方 `git add -u`
410 | - `revert`:把已经添加到暂存区的文件从暂存区剔除,其操作方式和 `update`类似
411 | - `add untracked`:可以把新增的文件添加到暂存区,其操作方式和 `update` 类似
412 | - `patch`:详见下方 `git add -p`
413 | - `diff`:比较暂存区文件和本地版本库的差异,其操作方式和 `update` 类似
414 | - `quit`:退出 `git add -i` 命令系统
415 | - `help`:查看帮助信息
416 |
417 | ```
418 | git add -p
419 | ```
420 |
421 | 直接进入交互命令中最有用的 `patch` 模式
422 |
423 | 这是交互命令中最有用的模式,其操作方式和 `update` 类似,选择后 `Git` 会显示这些文件的当前内容与本地版本库中的差异,然后您可以自己决定是否添加这些修改到暂存区,在命令行 `Stage deletion [y,n,q,a,d,/,?]?` 后输入 `y,n,q,a,d,/,?` 其中一项选择操作方式,具体功能解释如下:
424 |
425 | - y:接受修改
426 | - n:忽略修改
427 | - q:退出当前命令
428 | - a:添加修改
429 | - d:放弃修改
430 | - /:通过正则表达式匹配修改内容
431 | - ?:查看帮助信息
432 |
433 | ```
434 | git add -u
435 | ```
436 |
437 | 直接进入交互命令中的 `update` 模式
438 |
439 | 它会先列出工作区 `修改` 或 `删除` 的文件列表,`新增` 的文件不会被显示,在命令行 `Update>>` 后输入相应的列表序列号表示选中该项,回车继续选择,如果已选好,直接回车回到命令主界面
440 |
441 | ```
442 | git add --ignore-removal .
443 | ```
444 |
445 | 添加工作区 `修改` 或 `新增` 的文件列表, `删除` 的文件不会被添加
446 |
447 | ### git commit
448 |
449 | > 把暂存区的文件提交到本地版本库
450 | >
451 |
452 | ```
453 | git commit -m '第一行提交原因' -m '第二行提交原因'
454 | ```
455 |
456 | 不打开编辑器,直接在命令行中输入多行提交原因
457 |
458 | ```
459 | git commit -am '提交原因'
460 | ```
461 |
462 | 将工作区 `修改` 或 `删除` 的文件提交到本地版本库, `新增` 的文件不会被提交
463 |
464 | ```
465 | git commit --amend -m '提交原因'
466 | ```
467 |
468 | 修改最新一条提交记录的提交原因
469 |
470 | ```
471 | git commit -C HEAD
472 | ```
473 |
474 | 将当前文件改动提交到 `HEAD` 或当前分支的历史ID
475 |
476 | ### git mv
477 |
478 | > 移动或重命名文件、目录
479 | >
480 |
481 | ```
482 | git mv a.md b.md -f
483 | ```
484 |
485 | 将 `a.md` 重命名为 `b.md` ,同时添加变动到暂存区,加 `-f` 参数可以强制重命名,相比用 `mv a.md b.md` 命令省去了 `git add` 操作
486 |
487 | ### git rm
488 |
489 | > 从工作区和暂存区移除文件
490 | >
491 |
492 | ```
493 | git rm b.md
494 | ```
495 |
496 | 从工作区和暂存区移除文件 `b.md` ,同时添加变动到暂存区,相比用 `rm b.md` 命令省去了 `git add` 操作
497 |
498 | ```
499 | git rm src/ -r
500 | ```
501 |
502 | 允许从工作区和暂存区移除目录
503 |
504 | ### git status
505 |
506 | ```
507 | git status -s
508 | ```
509 |
510 | 以简短方式查看工作区和暂存区文件状态,示例如下:
511 |
512 | ```
513 | M demo.html
514 | ?? test.html
515 | git status --ignored
516 | ```
517 |
518 | 查看工作区和暂存区文件状态,包括被忽略的文件
519 |
520 | ## 操作分支
521 |
522 | ### git branch
523 |
524 | > 查看、创建、删除分支
525 | >
526 |
527 | ```
528 | git branch -a
529 | ```
530 |
531 | 查看本地版本库和远程版本库上的分支列表
532 |
533 | ```
534 | git branch -r
535 | ```
536 |
537 | 查看远程版本库上的分支列表,加上 `-d` 参数可以删除远程版本库上的分支
538 |
539 | ```
540 | git branch -D
541 | ```
542 |
543 | 分支未提交到本地版本库前强制删除分支
544 |
545 | ```
546 | git branch -vv
547 | ```
548 |
549 | 查看带有最后提交id、最近提交原因等信息的本地版本库分支列表
550 |
551 | 
552 |
553 | ### git merge
554 |
555 | > 将其它分支合并到当前分支
556 | >
557 |
558 | ```
559 | git merge --squash
560 | ```
561 |
562 | 将待合并分支上的 `commit` 合并成一个新的 `commit` 放入当前分支,适用于待合并分支的提交记录不需要保留的情况
563 |
564 | ```
565 | git merge --no-ff
566 | ```
567 |
568 | 默认情况下,`Git` 执行"`快进式合并`"(fast-farward merge),会直接将 `Master`分支指向 `Develop` 分支,使用 `--no-ff` 参数后,会执行正常合并,在 `Master`分支上生成一个新节点,保证版本演进更清晰。
569 |
570 | 
571 |
572 | ```
573 | git merge --no-edit
574 | ```
575 |
576 | 在没有冲突的情况下合并,不想手动编辑提交原因,而是用 `Git` 自动生成的类似 `Merge branch 'test'` 的文字直接提交
577 |
578 | ### git checkout
579 |
580 | > 切换分支
581 | >
582 |
583 | ```
584 | git checkout -b daily/0.0.1
585 | ```
586 |
587 | 创建 `daily/0.0.1` 分支,同时切换到这个新创建的分支
588 |
589 | ```
590 | git checkout HEAD demo.html
591 | ```
592 |
593 | 从本地版本库的 `HEAD`(也可以是提交ID、分支名、Tag名) 历史中检出 `demo.html` 覆盖当前工作区的文件,如果省略 `HEAD` 则是从暂存区检出
594 |
595 | ```
596 | git checkout --orphan new_branch
597 | ```
598 |
599 | 这个命令会创建一个全新的,完全没有历史记录的新分支,但当前源分支上所有的最新文件都还在,真是强迫症患者的福音,但这个新分支必须做一次 `git commit`操作后才会真正成为一个新分支。
600 |
601 | ```
602 | git checkout -p other_branch
603 | ```
604 |
605 | 这个命令主要用来比较两个分支间的差异内容,并提供交互式的界面来选择进一步的操作,这个命令不仅可以比较两个分支间的差异,还可以比较单个文件的差异。
606 |
607 | ### git stash
608 |
609 | > 在 `Git` 的栈中保存当前修改或删除的工作进度,当你在一个分支里做某项功能开发时,接到通知把昨天已经测试完没问题的代码发布到线上,但这时你已经在这个分支里加入了其它未提交的代码,这个时候就可以把这些未提交的代码存到栈里。
610 | >
611 |
612 | ```
613 | git stash
614 | ```
615 |
616 | 将未提交的文件保存到Git栈中
617 |
618 | ```
619 | git stash list
620 | ```
621 |
622 | 查看栈中保存的列表
623 |
624 | ```
625 | git stash show stash@{0}
626 | ```
627 |
628 | 显示栈中其中一条记录
629 |
630 | ```
631 | git stash drop stash@{0}
632 | ```
633 |
634 | 移除栈中其中一条记录
635 |
636 | ```
637 | git stash pop
638 | ```
639 |
640 | 从Git栈中检出最新保存的一条记录,并将它从栈中移除
641 |
642 | ```
643 | git stash apply stash@{0}
644 | ```
645 |
646 | 从Git栈中检出其中一条记录,但不从栈中移除
647 |
648 | ```
649 | git stash branch new_banch
650 | ```
651 |
652 | 把当前栈中最近一次记录检出并创建一个新分支
653 |
654 | ```
655 | git stash clear
656 | ```
657 |
658 | 清空栈里的所有记录
659 |
660 | ```
661 | git stash create
662 | ```
663 |
664 | 为当前修改或删除的文件创建一个自定义的栈并返回一个ID,此时并未真正存储到栈里
665 |
666 | ```
667 | git stash store xxxxxx
668 | ```
669 |
670 | 将 `create` 方法里返回的ID放到 `store` 后面,此时在栈里真正创建了一个记录,但当前修改或删除的文件并未从工作区移除
671 |
672 | ```
673 | $ git stash create
674 | 09eb9a97ad632d0825be1ece361936d1d0bdb5c7
675 | $ git stash store 09eb9a97ad632d0825be1ece361936d1d0bdb5c7
676 | $ git stash list
677 | stash@{0}: Created via "git stash store".
678 | ```
679 |
680 | ## 操作历史
681 |
682 | ### git log
683 |
684 | > 显示提交历史记录
685 | >
686 |
687 | ```
688 | git log -p
689 | ```
690 |
691 | 显示带提交差异对比的历史记录
692 |
693 | ```
694 | git log demo.html
695 | ```
696 |
697 | 显示 `demo.html` 文件的历史记录
698 |
699 | ```
700 | git log --since="2 weeks ago"
701 | ```
702 |
703 | 显示2周前开始到现在的历史记录,其它时间可以类推
704 |
705 | ```
706 | git log --before="2 weeks ago"
707 | ```
708 |
709 | 显示截止到2周前的历史记录,其它时间可以类推
710 |
711 | ```
712 | git log -10
713 | ```
714 |
715 | 显示最近10条历史记录
716 |
717 | ```
718 | git log f5f630a..HEAD
719 | ```
720 |
721 | 显示从提交ID `f5f630a` 到 `HEAD` 之间的记录,`HEAD` 可以为空或其它提交ID
722 |
723 | ```
724 | git log --pretty=oneline
725 | ```
726 |
727 | 在一行中输出简短的历史记录
728 |
729 | ```
730 | git log --pretty=format:"%h"
731 | ```
732 |
733 | 格式化输出历史记录
734 |
735 | `Git` 用各种 `placeholder` 来决定各种显示内容,我挑几个常用的显示如下:
736 |
737 | - %H: commit hash
738 | - %h: 缩短的commit hash
739 | - %T: tree hash
740 | - %t: 缩短的 tree hash
741 | - %P: parent hashes
742 | - %p: 缩短的 parent hashes
743 | - %an: 作者名字
744 | - %aN: mailmap的作者名
745 | - %ae: 作者邮箱
746 | - %ad: 日期 (--date= 制定的格式)
747 | - %ar: 日期, 相对格式(1 day ago)
748 | - %cn: 提交者名字
749 | - %ce: 提交者 email
750 | - %cd: 提交日期 (--date= 制定的格式)
751 | - %cr: 提交日期, 相对格式(1 day ago)
752 | - %d: ref名称
753 | - %s: commit信息标题
754 | - %b: commit信息内容
755 | - %n: 换行
756 |
757 | ### git cherry-pick
758 |
759 | > 合并分支的一条或几条提交记录到当前分支末梢
760 | >
761 |
762 | ```
763 | git cherry-pick 170a305
764 | ```
765 |
766 | 合并提交ID `170a305` 到当前分支末梢
767 |
768 | ### git reset
769 |
770 | > 将当前的分支重设(reset)到指定的 `` 或者 `HEAD`
771 | >
772 |
773 | ```
774 | git reset --mixed
775 | ```
776 |
777 | `--mixed` 是不带参数时的默认参数,它退回到某个版本,保留文件内容,回退提交历史
778 |
779 | ```
780 | git reset --soft
781 | ```
782 |
783 | 暂存区和工作区中的内容不作任何改变,仅仅把 `HEAD` 指向 ``
784 |
785 | ```
786 | git reset --hard
787 | ```
788 |
789 | 自从 `` 以来在工作区中的任何改变都被丢弃,并把 `HEAD` 指向 ``
790 |
791 | ### git rebase
792 |
793 | > 重新定义分支的版本库状态
794 | >
795 |
796 | ```
797 | git rebase branch_name
798 | ```
799 |
800 | 合并分支,这跟 `merge` 很像,但还是有本质区别,看下图:
801 |
802 | 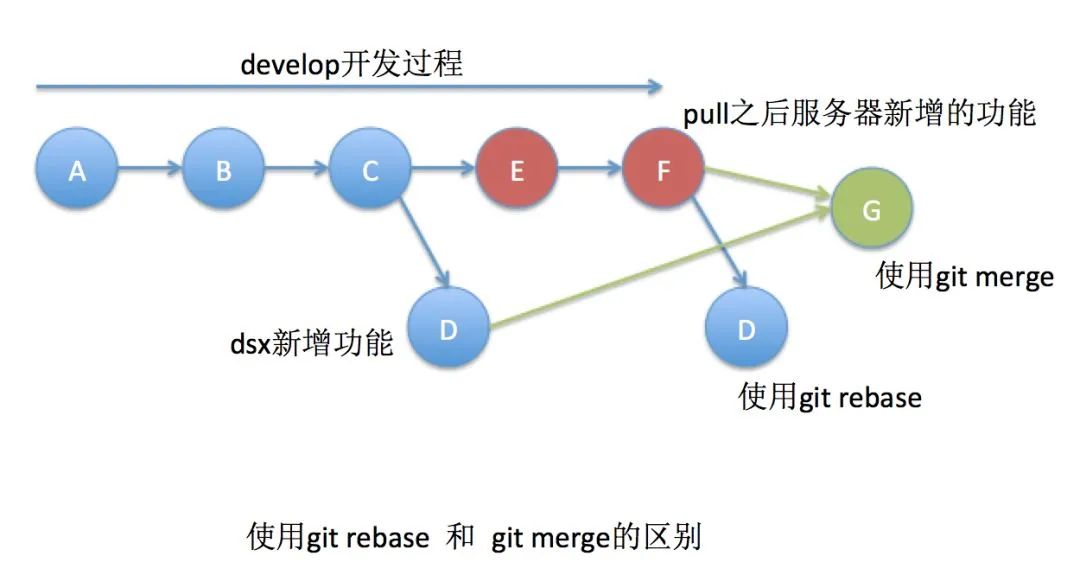
803 |
804 | 合并过程中可能需要先解决冲突,然后执行 `git rebase --continue`
805 |
806 | ```
807 | git rebase -i HEAD~~
808 | ```
809 |
810 | 打开文本编辑器,将看到从 `HEAD` 到 `HEAD~~` 的提交如下
811 |
812 | ```
813 | pick 9a54fd4 添加commit的说明
814 | pick 0d4a808 添加pull的说明
815 | # Rebase 326fc9f..0d4a808 onto d286baa
816 | #
817 | # Commands:
818 | # p, pick = use commit
819 | # r, reword = use commit, but edit the commit message
820 | # e, edit = use commit, but stop for amending
821 | # s, squash = use commit, but meld into previous commit
822 | # f, fixup = like "squash", but discard this commit's log message
823 | # x, exec = run command (the rest of the line) using shell
824 | #
825 | ```
826 |
827 | 将第一行的 `pick` 改成 `Commands` 中所列出来的命令,然后保存并退出,所对应的修改将会生效。如果移动提交记录的顺序,将改变历史记录中的排序。
828 |
829 | ### git revert
830 |
831 | > 撤销某次操作,此次操作之前和之后的 `commit` 和 `history` 都会保留,并且把这次撤销作为一次最新的提交
832 | >
833 |
834 | ```
835 | git revert HEAD
836 | ```
837 |
838 | 撤销前一次提交操作
839 |
840 | ```
841 | git revert HEAD --no-edit
842 | ```
843 |
844 | 撤销前一次提交操作,并以默认的 `Revert "xxx"` 为提交原因
845 |
846 | ```
847 | git revert -n HEAD
848 | ```
849 |
850 | 需要撤销多次操作的时候加 `-n` 参数,这样不会每次撤销操作都提交,而是等所有撤销都完成后一起提交
851 |
852 | ### git diff
853 |
854 | > 查看工作区、暂存区、本地版本库之间的文件差异,用一张图来解释
855 | >
856 |
857 | 
858 |
859 | ```
860 | git diff --stat
861 | ```
862 |
863 | 通过 `--stat` 参数可以查看变更统计数据
864 |
865 | ```
866 | test.md | 1 -
867 | 1 file changed, 1 deletion(-)
868 | ```
869 |
870 | ### git reflog
871 |
872 | `reflog` 可以查看所有分支的所有操作记录(包括commit和reset的操作、已经被删除的commit记录,跟 `git log` 的区别在于它不能查看已经删除了的commit记录
873 |
874 | ## 远程版本库连接
875 |
876 | 如果在GitHub项目初始化之前,文件已经存在于本地目录中,那可以在本地初始化本地版本库,再将本地版本库跟远程版本库连接起来
877 |
878 | ### git init
879 |
880 | > 在本地目录内部会生成.git文件夹
881 | >
882 |
883 | ### git remote
884 |
885 | ```
886 | git remote -v
887 | ```
888 |
889 | 不带参数,列出已经存在的远程分支,加上 `-v` 列出详细信息,在每一个名字后面列出其远程url
890 |
891 | ```
892 | git remote add origin https://github.com/gafish/gafish.github.com.git
893 | ```
894 |
895 | 添加一个新的远程仓库,指定一个名字,以便引用后面带的URL
896 |
897 | ### git fetch
898 |
899 | > 将远程版本库的更新取回到本地版本库
900 | >
901 |
902 | ```
903 | git fetch origin daily/0.0.1
904 | ```
905 |
906 | 默认情况下,`git fetch` 取回所有分支的更新。如果只想取回特定分支的更新,可以指定分支名。
907 |
908 | ## 问题排查
909 |
910 | ### git blame
911 |
912 | > 查看文件每行代码块的历史信息
913 | >
914 |
915 | ```
916 | git blame -L 1,10 demo.html
917 | ```
918 |
919 | 截取 `demo.html` 文件1-10行历史信息
920 |
921 | ### git bisect
922 |
923 | > 二分查找历史记录,排查BUG
924 | >
925 |
926 | ```
927 | git bisect start
928 | ```
929 |
930 | 开始二分查找
931 |
932 | ```
933 | git bisect bad
934 | ```
935 |
936 | 标记当前二分提交ID为有问题的点
937 |
938 | ```
939 | git bisect good
940 | ```
941 |
942 | 标记当前二分提交ID为没问题的点
943 |
944 | ```
945 | git bisect reset
946 | ```
947 |
948 | 查到有问题的提交ID后回到原分支
949 |
950 | ## 更多操作
951 |
952 | ### git submodule
953 |
954 | > 通过 Git 子模块可以跟踪外部版本库,它允许在某一版本库中再存储另一版本库,并且能够保持2个版本库完全独立
955 | >
956 |
957 | ```
958 | git submodule add https://github.com/gafish/demo.git demo
959 | ```
960 |
961 | 将 `demo` 仓库添加为子模块
962 |
963 | ```
964 | git submodule update demo
965 | ```
966 |
967 | 更新子模块 `demo`
968 |
969 | ### git gc
970 |
971 | > 运行Git的垃圾回收功能,清理冗余的历史快照
972 | >
973 |
974 | ### git archive
975 |
976 | > 将加了tag的某个版本打包提取
977 | >
978 |
979 | ```
980 | git archive -v --format=zip v0.1 > v0.1.zip
981 | ```
982 |
983 | `--format` 表示打包的格式,如 `zip`,`-v` 表示对应的tag名,后面跟的是tag名,如 `v0.1`。
984 |
985 | -- End --
986 |
987 |
988 |
--------------------------------------------------------------------------------
/docs/tools/推荐十款精选IntelliJIdea插件.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | - [1 Key Promoter X](#1-key-promoter-x)
4 | - [2 Alibaba Java Coding Guidelines](#2-alibaba-java-coding-guidelines)
5 | - [3 CodeGlance](#3-codeglance)
6 | - [4 Maven Helper](#4-maven-helper)
7 | - [5 Lombok](#5-lombok)
8 | - [6 JavaDoc](#6-javadoc)
9 | - [7 .ignore](#7-ignore)
10 | - [8RainbowBrackets](#8rainbowbrackets)
11 | - [9 Activate-power-mode](#9-activate-power-mode)
12 | - [10 Grep Console](#10-grep-console)
13 | - [公众号](#公众号)
14 |
15 |
16 |
17 | 俗话说:"工欲善其事必先利其器",小主从项目实战的角度在众多的idea插件中挑选了10款开发必备的神器,帮助大家在日常工作学习编码中提升开发效率。
18 |
19 | # 1 Key Promoter X
20 |
21 | 实用指数:★★★★★
22 |
23 | 装逼指数:★
24 |
25 | 你还在为记不住快捷键烦恼吗,Key Promoter X可以帮助你快速记住常用的快捷键。当你在idea中用鼠标点击菜单,它可以显示对应的快捷键以及点击次数。使用一段时间后有助于过渡到更快、无鼠标的开发。
26 |
27 |
17 |
18 | # 0. 目标
19 |
20 | 本地搭建三个redis实例(一主两备),实现效果:主实例插入数据备实例可以复制同步过去。
21 |
22 | # 1. 安装docker,运行docker
23 |
24 | docker安装步骤省略,大家可以从官网下载并安装。
25 |
26 | 检查docker是否运行成功:
27 |
28 | ```plain
29 | docker info
30 | ```
31 | 出现回显表示运行成功,可以做下一步操作了。
32 |
33 | # 2. 拉取redis镜像文件
34 |
35 | 执行以下命令默认拉取tag为latest的官方redis镜像
36 |
37 | ```plain
38 | docker pull redis
39 | ```
40 |
41 | # 3. 准备好redis配置文件redis.conf
42 |
43 | 下载地址:
44 |
45 | > 链接:https://pan.baidu.com/s/14tWHtk3mch3e3VlT9TYX1A
46 | >
47 | > 提取密码:q3uk
48 |
49 | 拷贝为3三份,如:redis01.conf, redis02.conf, redis03.conf
50 |
51 | 打开所有的配置文件,修改如下配置项:
52 |
53 | * 注释只监听本地选项,可以远程连接。#bind 127.0.0.1
54 | * 关闭保护模式 protected-mode no
55 | * 打开AOF持久化开关 appendonly yes
56 | # 4. 启动redis实例
57 |
58 | ```shell
59 | # 实例1
60 | docker run -p 6381:6379 --name redis-server-01 -v /your/path/redis/conf/redis01.conf:/etc/redis/redis.conf -v /your/path/redis/data01:/data -d redis redis-server /etc/redis/redis.conf
61 |
62 | # 实例2
63 | docker run -p 6382:6379 --name redis-server-02 -v /your/path/redis/redis/conf/redis02.conf:/etc/redis/redis.conf -v /your/path/redis/data02:/data -d redis redis-server /etc/redis/redis.conf
64 |
65 | # 实例3
66 | docker run -p 6383:6379 --name redis-server-03 -v /your/path/redis/conf/redis03.conf:/etc/redis/redis.conf -v /your/path/redis/data03:/data -d redis redis-server /etc/redis/redis.conf
67 | ```
68 |
69 |
70 |
71 | 对以上命令简单解释:
72 |
73 | * 参数-p 6381:6379,6381表示宿主机端口,6379表示容器实例端口,意思是将容器实例端口映射到宿主机端口。
74 | * 参数--name redis-server-01,给容器实例命名。
75 | * 参数-v /your/path/redis/conf/redis01.conf:/etc/redis/redis.conf,冒号前是宿主机配置文件路径,冒号后是容器的配置文件路径,意思是将容器实例的配置路径映射到宿主机的路径。
76 | * 参数-v /your/path/redis/data01:/data,如上面意思相同。
77 | * 选项-d表示以后台形式运行实例。
78 | * 参数redis-server /etc/redis/redis.conf表示执行redis-server命令, /etc/redis/redis.conf表示以该配置文件启动redis实例,注意配置文件必须为redis-server命令的第一个参数。
79 |
80 | # 5. 配置主从复制集群
81 |
82 | 检查实例运行状态:
83 |
84 | ```plain
85 | docker ps
86 | ```
87 |
88 |
89 | 回显有三个redis实例即为正常。 查询实例1:redis-server-01 运行的内部ip
90 |
91 | ```plain
92 | docker inspect redis-server-01
93 | ```
94 |
95 |
96 | 通过回显可以看到:"IPAddress": "172.17.0.4" 我们将实例1规划为主,另外两个实例自然为备了,通过将主的ip和port配置在备的配置文件中即可实现主从复制的效果。
97 |
98 | 修改redis02.conf和redis03.conf配置文件,找到replicaof选项(redis5.0之前是slaveof),修改为:
99 |
100 | ```plain
101 | replicaof 172.17.0.4 6379
102 | ```
103 |
104 |
105 | 修改完毕,重启实例2和实例3:
106 |
107 | ```plain
108 | docker restart redis-server-02
109 | docker restart redis-server-03
110 | ```
111 |
112 |
113 | 检查实例1的状态是否为主,并且挂载两个备实例:
114 |
115 | ```plain
116 | docker exec -it redis-server-01 redis-cli
117 | 127.0.0.1:6379> info
118 | ```
119 |
120 |
121 | 回显如下表示主从复制配置成功:
122 |
123 | ```plain
124 | # Replication
125 | role:master
126 | connected_slaves:2
127 | slave0:ip=172.17.0.3,port=6379,state=online,offset=84,lag=1
128 | slave1:ip=172.17.0.2,port=6379,state=online,offset=84,lag=1
129 | ```
130 |
131 |
132 | # 6. 测试主从复制效果
133 |
134 | 连接redis实例1插入一条记录:
135 |
136 | ```plain
137 | docker exec -it redis-server-01 redis-cli # 连接实例1
138 | 127.0.0.1:6379> set name ray # 插入一条数据
139 | OK # 插入成功
140 | ```
141 |
142 |
143 | 连接redis实例2和实例3查看是否复制成功:
144 |
145 | ```plain
146 | docker exec -it redis-server-02 redis-cli # 连接实例2
147 | 127.0.0.1:6379> get name
148 | "ray" # 可以查到,表明从实例已经将主实例的数据同步过来了
149 | ```
150 |
151 |
152 | # 总结
153 |
154 | 搭建Redis主从复制实例需要有一点docker的基础,如果你对docker比较熟悉了,那搭建过程实在太容易了。没有docker基础,只要按照上面的命令逐个运行也可以100%成功哦。
155 |
156 | 下一篇带大家手把手搭建Redis主从复制+哨兵模式,尽请期待。
157 |
--------------------------------------------------------------------------------
/docs/redis/面试官再问Redis事务把这篇文章扔给他.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650321004&idx=1&sn=a8b058868390e133cfdf77ba6d2afd9f&chksm=8f09ce76b87e476062ad446b3097e9697b1da4810fa396a65554b1dada1c195ac50e90e58b24&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 | ## 1. Redis事务生命周期
4 |
5 | * 开启事务:使用MULTI开启一个事务
6 | * 命令入队列:每次操作的命令都会加入到一个队列中,但命令此时不会真正被执行
7 | * 提交事务:使用EXEC命令提交事务,开始顺序执行队列中的命令
8 | ## 2. Redis事务到底是不是原子性的?
9 |
10 | 先看关系型数据库ACID 中关于原子性的定义:
11 |
12 | **原子性:**一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
13 |
14 | 官方文档对事务的定义:
15 |
16 | * **事务是一个单独的隔离操作**:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
17 | * **事务是一个原子操作**:事务中的命令要么全部被执行,要么全部都不执行。EXEC 命令负责触发并执行事务中的所有命令:如果客户端在使用 MULTI 开启了一个事务之后,却因为断线而没有成功执行 EXEC ,那么事务中的所有命令都不会被执行。另一方面,如果客户端成功在开启事务之后执行 EXEC ,那么事务中的所有命令都会被执行。
18 |
19 | 官方认为Redis事务是一个原子操作,这是站在执行与否的角度考虑的。但是从ACID原子性定义来看,**严格意义上讲Redis事务是非原子型的**,因为在命令顺序执行过程中,一旦发生命令执行错误Redis是不会停止执行然后回滚数据。
20 |
21 | ## 3. Redis为什么不支持回滚(roll back)?
22 |
23 | 在事务运行期间虽然Redis命令可能会执行失败,但是Redis依然会执行事务内剩余的命令而不会执行回滚操作。如果你熟悉mysql关系型数据库事务,你会对此非常疑惑,Redis官方的理由如下:
24 |
25 | >只有当被调用的Redis命令有语法错误时,这条命令才会执行失败(在将这个命令放入事务队列期间,Redis能够发现此类问题),或者对某个键执行不符合其数据类型的操作:实际上,这就意味着只有程序错误才会导致Redis命令执行失败,这种错误很有可能在程序开发期间发现,一般很少在生产环境发现。
26 | >支持事务回滚能力会导致设计复杂,这与Redis的初衷相违背,Redis的设计目标是功能简化及确保更快的运行速度。
27 | >
28 |
29 | 对于官方的这种理由有一个普遍的反对观点:程序有bug怎么办?但其实回归不能解决程序的bug,比如某位粗心的程序员计划更新键A,实际上最后更新了键B,回滚机制是没法解决这种人为错误的。正因为这种人为的错误不太可能进入生产系统,所以官方在设计Redis时选用更加简单和快速的方法,没有实现回滚的机制。
30 |
31 | ## 4. Redis事务失败场景
32 |
33 | 有三种类型的失败场景:
34 |
35 | (1)在事务提交之前,客户端执行的命令缓存(队列)失败,比如命令的语法错误(命令参数个数错误,不支持的命令等等)。如果发生这种类型的错误,Redis将向客户端返回包含错误提示信息的响应,同时Redis会清空队列中的命令并取消事务。
36 |
37 | ```plain
38 | 127.0.0.1:6379> set name xiaoming # 事务之前执行
39 | OK
40 | 127.0.0.1:6379> multi # 开启事务
41 | OK
42 | 127.0.0.1:6379> set name zhangsan # 事务中执行,命令入队列
43 | QUEUED
44 | 127.0.0.1:6379> setset name zhangsan2 # 错误的命令,模拟失败场景
45 | (error) ERR unknown command `setset`, with args beginning with: `name`, `zhangsan2`,
46 | 127.0.0.1:6379> exec # 提交事务,发现由于上条命令的错误导致事务已经自动取消了
47 | (error) EXECABORT Transaction discarded because of previous errors.
48 | 127.0.0.1:6379> get name # 查询name,发现未被修改
49 | "xiaoming"
50 | ```
51 | (2)事务提交后开始顺序执行命令,之前缓存在队列中的命令有可能执行失败。
52 | ```plain
53 | 127.0.0.1:6379> multi # 开启事务
54 | OK
55 | 127.0.0.1:6379> set name xiaoming # 设置名字
56 | QUEUED
57 | 127.0.0.1:6379> set age 18 # 设置年龄
58 | QUEUED
59 | 127.0.0.1:6379> lpush age 20 # 此处仅检查是否有语法错误,不会真正执行
60 | QUEUED
61 | 127.0.0.1:6379> exec # 提交事务后开始顺序执行命令,第三条命令执行失败
62 | 1) OK
63 | 2) OK
64 | 3) (error) WRONGTYPE Operation against a key holding the wrong kind of value
65 | 127.0.0.1:6379> get name # 第三条命令失败没有将前两条命令回滚
66 | "xiaoming"
67 | ```
68 | (3)由于乐观锁失败,事务提交时将丢弃之前缓存的所有命令序列。
69 | 通过开启两个redis客户端并结合watch命令模拟这种失败场景。
70 |
71 | ```plain
72 | # 客户端1
73 | 127.0.0.1:6379> set name xiaoming # 客户端1设置name
74 | OK
75 | 127.0.0.1:6379> watch name # 客户端1通过watch命令给name加乐观锁
76 | OK
77 | # 客户端2
78 | 127.0.0.1:6379> get name # 客户端2查询name
79 | "xiaoming"
80 | 127.0.0.1:6379> set name zhangsan # 客户端2修改name值
81 | OK
82 | # 客户端1
83 | 127.0.0.1:6379> multi # 客户端1开启事务
84 | OK
85 | 127.0.0.1:6379> set name lisi # 客户端1修改name
86 | QUEUED
87 | 127.0.0.1:6379> exec # 客户端1提交事务,返回空
88 | (nil)
89 | 127.0.0.1:6379> get name # 客户端1查询name,发现name没有被修改为lisi
90 | "zhangsan"
91 | ```
92 | 在事务过程中监控的key被其他客户端改变,则当前客户端的乐观锁失败,事务提交时将丢弃所有命令缓存队列。
93 | ## 5. Redis事务相关命令
94 |
95 | ### (1)WATCH
96 |
97 | 可以为Redis事务提供 check-and-set (CAS)行为。被WATCH的键会被监视,并会发觉这些键是否被改动过了。 如果有至少一个被监视的键在 EXEC 执行之前被修改了, 那么整个事务都会被取消, EXEC 返回nil-reply来表示事务已经失败。
98 |
99 | ### (2)MULTI
100 |
101 | 用于开启一个事务,它总是返回OK。MULTI执行之后,客户端可以继续向服务器发送任意多条命令, 这些命令不会立即被执行,而是被放到一个队列中,当 EXEC命令被调用时, 所有队列中的命令才会被执行。
102 |
103 | ### (3)UNWATCH
104 |
105 | 取消 WATCH 命令对所有 key 的监视,一般用于DISCARD和EXEC命令之前。如果在执行 WATCH 命令之后, EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了。因为 EXEC 命令会执行事务,因此 WATCH 命令的效果已经产生了;而 DISCARD 命令在取消事务的同时也会取消所有对 key 的监视,因此这两个命令执行之后,就没有必要执行 UNWATCH 了。
106 |
107 | ### (4)DISCARD
108 |
109 | 当执行 DISCARD 命令时, 事务会被放弃, 事务队列会被清空,并且客户端会从事务状态中退出。
110 |
111 | ### (5)EXEC
112 |
113 | 负责触发并执行事务中的所有命令:
114 |
115 | 如果客户端成功开启事务后执行EXEC,那么事务中的所有命令都会被执行。
116 |
117 | 如果客户端在使用MULTI开启了事务后,却因为断线而没有成功执行EXEC,那么事务中的所有命令都不会被执行。需要特别注意的是:即使事务中有某条/某些命令执行失败了,事务队列中的其他命令仍然会继续执行,Redis不会停止执行事务中的命令,而不会像我们通常使用的关系型数据库一样进行回滚。
--------------------------------------------------------------------------------
/docs/redis/高并发场景下,到底先更新缓存还是先更新数据库?.md:
--------------------------------------------------------------------------------
1 | > 本文首发我的微信公众号『[爱笑的架构师](https://mp.weixin.qq.com/s?__biz=MzIwODI1OTk1Nw==&mid=2650322566&idx=1&sn=2142fe29c6a32e5a2100f4f39ee8953d&chksm=8f09c89cb87e418a3289cdfaf46c8e4593004a120ba709929b4dc97fff5be9aa3cc795ac9ceb&token=875646549&lang=zh_CN#rd)』,欢迎大家关注。
2 |
3 |
4 |
5 | - [Cache aside](#cache-aside)
6 | - [Cache aside踩坑](#cache-aside踩坑)
7 | - [Read through](#read-through)
8 | - [Write through](#write-through)
9 | - [Write behind](#write-behind)
10 | - [总结一下](#总结一下)
11 |
12 |
13 |
14 | 在大型系统中,为了减少数据库压力通常会引入缓存机制,一旦引入缓存又很容易造成缓存和数据库数据不一致,导致用户看到的是旧数据。
15 |
16 | 为了减少数据不一致的情况,更新缓存和数据库的机制显得尤为重要,接下来带领大家踩踩坑。
17 |
18 | 
19 |
20 | ## Cache aside
21 |
22 | `Cache aside`也就是`旁路缓存`,是比较常用的缓存策略。
23 |
24 | **(1)`读请求`常见流程**
25 |
26 | 
27 |
28 | 应用首先会判断缓存是否有该数据,缓存命中直接返回数据,缓存未命中即缓存穿透到数据库,从数据库查询数据然后回写到缓存中,最后返回数据给客户端。
29 |
30 |
31 |
32 | **(2)`写请求`常见流程**
33 |
34 | 
35 |
36 | 首先更新数据库,然后从缓存中删除该数据。
37 |
38 | 看了写请求的图之后,有些同学可能要问了:为什么要删除缓存,直接更新不就行了?这里涉及到几个坑,我们一步一步踩下去。
39 |
40 | ## Cache aside踩坑
41 |
42 | Cache aside策略如果用错就会遇到深坑,下面我们来逐个踩。
43 |
44 | **踩坑一:先更新数据库,再更新缓存**
45 |
46 | 如果同时有两个`写请求`需要更新数据,每个写请求都先更新数据库再更新缓存,在并发场景可能会出现数据不一致的情况。
47 |
48 | 
49 |
50 | 如上图的执行过程:
51 |
52 | (1)`写请求1`更新数据库,将 age 字段更新为18;
53 |
54 | (2)`写请求2`更新数据库,将 age 字段更新为20;
55 |
56 | (3)`写请求2`更新缓存,缓存 age 设置为20;
57 |
58 | (4)`写请求1`更新缓存,缓存 age 设置为18;
59 |
60 | 执行完预期结果是数据库 age 为20,缓存 age 为20,结果缓存 age为18,这就造成了缓存数据不是最新的,出现了脏数据。
61 |
62 |
63 |
64 | **踩坑二:先删缓存,再更新数据库**
65 |
66 | 如果`写请求`的处理流程是`先删缓存再更新数据库`,在一个`读请求`和一个`写请求`并发场景下可能会出现数据不一致情况。
67 |
68 | 
69 |
70 | 如上图的执行过程:
71 |
72 | (1)`写请求`删除缓存数据;
73 |
74 | (2)`读请求`查询缓存未击中(Hit Miss),紧接着查询数据库,将返回的数据回写到缓存中;
75 |
76 | (3)`写请求`更新数据库。
77 |
78 | 整个流程下来发现`数据库`中age为20,`缓存`中age为18,缓存和数据库数据不一致,缓存出现了脏数据。
79 |
80 |
81 |
82 | **踩坑三:先更新数据库,再删除缓存**
83 |
84 | 在实际的系统中针对`写请求`还是推荐`先更新数据库再删除缓存`,但是在理论上还是存在问题,以下面这个例子说明。
85 |
86 | 
87 |
88 | 如上图的执行过程:
89 |
90 | (1)`读请求`先查询缓存,缓存未击中,查询数据库返回数据;
91 |
92 | (2)`写请求`更新数据库,删除缓存;
93 |
94 | (3)`读请求`回写缓存;
95 |
96 | 整个流程操作下来发现`数据库age为20`,`缓存age为18`,即数据库与缓存不一致,导致应用程序从缓存中读到的数据都为旧数据。
97 |
98 | 但我们仔细想一下,上述问题发生的概率其实非常低,因为通常数据库更新操作比内存操作耗时多出几个数量级,上图中最后一步回写缓存(set age 18)速度非常快,通常会在更新数据库之前完成。
99 |
100 | 如果这种极端场景出现了怎么办?我们得想一个兜底的办法:`缓存数据设置过期时间`。通常在系统中是可以允许少量的数据短时间不一致的场景出现。
101 |
102 | ## Read through
103 |
104 | 在 Cache Aside 更新模式中,应用代码需要维护两个数据源头:一个是缓存,一个是数据库。而在 `Read-Through` 策略下,应用程序无需管理缓存和数据库,只需要将数据库的同步委托给缓存提供程序 `Cache Provider` 即可。所有数据交互都是通过`抽象缓存层`完成的。
105 |
106 | 
107 |
108 | 如上图,应用程序只需要与`Cache Provider`交互,不用关心是从缓存取还是数据库。
109 |
110 | 在进行大量读取时,`Read-Through` 可以减少数据源上的负载,也对缓存服务的故障具备一定的弹性。如果缓存服务挂了,则缓存提供程序仍然可以通过直接转到数据源来进行操作。
111 |
112 | `Read-Through 适用于多次请求相同数据的场景`,这与 Cache-Aside 策略非常相似,但是二者还是存在一些差别,这里再次强调一下:
113 |
114 | * 在 Cache-Aside 中,应用程序负责从数据源中获取数据并更新到缓存。
115 | * 在 Read-Through 中,此逻辑通常是由独立的缓存提供程序(Cache Provider)支持。
116 | ## Write through
117 |
118 | `Write-Through` 策略下,当发生数据更新(Write)时,缓存提供程序 `Cache Provider` 负责更新底层数据源和缓存。
119 |
120 | 缓存与数据源保持一致,并且写入时始终通过`抽象缓存层`到达数据源。
121 |
122 | `Cache Provider`类似一个代理的作用。
123 |
124 | 
125 |
126 | ## Write behind
127 |
128 | `Write behind`在一些地方也被成为`Write back`, 简单理解就是:应用程序更新数据时只更新缓存, `Cache Provider`每隔一段时间将数据刷新到数据库中。说白了就是`延迟写入`。
129 |
130 | 
131 |
132 | 如上图,应用程序更新两个数据,Cache Provider 会立即写入缓存中,但是隔一段时间才会批量写入数据库中。
133 |
134 | 这种方式有优点也有缺点:
135 |
136 | - `优点`是数据写入速度非常快,适用于频繁写的场景。
137 |
138 | - `缺点`是缓存和数据库不是强一致性,对一致性要求高的系统慎用。
139 |
140 | ## 总结一下
141 |
142 | 学了这么多,相信大家对缓存更新的策略都已经有了清晰的认识。最后稍稍总结一下。
143 |
144 | 缓存更新的策略主要分为三种:
145 |
146 | - Cache aside
147 | - Read/Write through
148 | - Write behind
149 |
150 | Cache aside 通常会先更新数据库,然后再删除缓存,为了兜底通常还会将数据设置缓存时间。
151 |
152 | Read/Write through 一般是由一个 Cache Provider 对外提供读写操作,应用程序不用感知操作的是缓存还是数据库。
153 |
154 | Write behind简单理解就是延迟写入,Cache Provider 每隔一段时间会批量输入数据库,优点是应用程序写入速度非常快。
155 |
156 | 好了,今天先到这里了,大家学会了吗?
--------------------------------------------------------------------------------
/docs/tools/git/保姆级Git教程,10000字详解.md:
--------------------------------------------------------------------------------
1 | 大家好,我是雷小帅。
2 |
3 | 最近群里有几位老哥私我,有没有好的 git 入门资料,想学一下。
4 |
5 | 偶然看到这个很棒的教程推荐给大家,大家可以看一下,另外还有一个不错的 git 入门网站,也推荐给大家,可以搭配使用。
6 |
7 | [https://learngitbranching.js.org/?locale=zh_CN](https://learngitbranching.js.org/?locale=zh_CN)
8 |
9 |
10 |
11 | - [Git简介](#git简介)
12 | - [实用主义](#实用主义)
13 | - [准备阶段](#准备阶段)
14 | - [常用操作](#常用操作)
15 | - [git clone](#git-clone)
16 | - [git config](#git-config)
17 | - [git branch](#git-branch)
18 | - [git checkout](#git-checkout)
19 | - [git status](#git-status)
20 | - [git add](#git-add)
21 | - [git commit](#git-commit)
22 | - [git push](#git-push)
23 | - [git pull](#git-pull)
24 | - [git log](#git-log)
25 | - [git tag](#git-tag)
26 | - [.gitignore](#gitignore)
27 | - [小结](#小结)
28 | - [深入探索](#深入探索)
29 | - [基本概念](#基本概念)
30 | - [工作区(*Working Directory*)](#工作区working-directory)
31 | - [本地版本库(*Local Repository*)](#本地版本库local-repository)
32 | - [暂存区(*stage*)](#暂存区stage)
33 | - [远程版本库(*Remote Repository*)](#远程版本库remote-repository)
34 | - [以上概念之间的关系](#以上概念之间的关系)
35 | - [分支(*Branch*)](#分支branch)
36 | - [主分支(*Master*)](#主分支master)
37 | - [标签(*Tag*)](#标签tag)
38 | - [HEAD](#head)
39 | - [操作文件](#操作文件)
40 | - [git add](#git-add-1)
41 | - [git commit](#git-commit-1)
42 | - [git mv](#git-mv)
43 | - [git rm](#git-rm)
44 | - [git status](#git-status-1)
45 | - [操作分支](#操作分支)
46 | - [git branch](#git-branch-1)
47 | - [git merge](#git-merge)
48 | - [git checkout](#git-checkout-1)
49 | - [git stash](#git-stash)
50 | - [操作历史](#操作历史)
51 | - [git log](#git-log-1)
52 | - [git cherry-pick](#git-cherry-pick)
53 | - [git reset](#git-reset)
54 | - [git rebase](#git-rebase)
55 | - [git revert](#git-revert)
56 | - [git diff](#git-diff)
57 | - [git reflog](#git-reflog)
58 | - [远程版本库连接](#远程版本库连接)
59 | - [git init](#git-init)
60 | - [git remote](#git-remote)
61 | - [git fetch](#git-fetch)
62 | - [问题排查](#问题排查)
63 | - [git blame](#git-blame)
64 | - [git bisect](#git-bisect)
65 | - [更多操作](#更多操作)
66 | - [git submodule](#git-submodule)
67 | - [git gc](#git-gc)
68 | - [git archive](#git-archive)
69 |
70 |
71 |
72 |
73 | # Git简介
74 |
75 | `Git` 是一种分布式版本控制系统,它可以不受网络连接的限制,加上其它众多优点,目前已经成为程序开发人员做项目版本管理时的首选,非开发人员也可以用 `Git` 来做自己的文档版本管理工具。
76 |
77 | 大概是大二的时候开始接触和使用Git,从一开始的零接触到现在的重度依赖,真是感叹 `Git` 的强大。
78 |
79 | `Git` 的api很多,但其实平时项目中90%的需求都只需要用到几个基本的功能即可,所以本文将从 `实用主义` 和 `深入探索` 2个方面去谈谈如何在项目中使用 `Git`,一般来说,看完 `实用主义` 这一节就可以开始在项目中动手用。
80 |
81 | > 说明:本文的操作都是基于 Mac 系统
82 | >
83 |
84 | # 实用主义
85 |
86 | ## 准备阶段
87 |
88 | 进入 Git官网 下载合适你的安装包,安装好 `Git` 后,打开命令行工具,进入工作文件夹(*为了便于理解我们在系统桌面上演示*),创建一个新的demo文件夹。
89 |
90 | 
91 |
92 | 进入 Github网站 注册一个账号并登录,进入 我的博客,点击 `Clone or download`,再点击 `Use HTTPS` ,复制项目地址 `https://github.com/gafish/gafish.github.com.git` 备用。
93 |
94 | 再回到命令行工具,一切就绪,接下来进入本文的重点。
95 |
96 | ## 常用操作
97 |
98 | 所谓实用主义,就是掌握了以下知识就可以玩转 `Git`,轻松应对90%以上的需求。以下是实用主义型的Git命令列表,先大致看一下
99 |
100 | - `git clone`
101 | - `git config`
102 | - `git branch`
103 | - `git checkout`
104 | - `git status`
105 | - `git add`
106 | - `git commit`
107 | - `git push`
108 | - `git pull`
109 | - `git log`
110 | - `git tag`
111 |
112 | 接下来,将通过对 我的博客 仓库进行实例操作,讲解如何使用 `Git` 拉取代码到提交代码的整个流程。
113 |
114 | ### git clone
115 |
116 | > 从git服务器拉取代码
117 | >
118 |
119 | ```
120 | git clone https://github.com/gafish/gafish.github.com.git
121 | ```
122 |
123 | 代码下载完成后在当前文件夹中会有一个 `gafish.github.com` 的目录,通过 `cd gafish.github.com` 命令进入目录。
124 |
125 | ### git config
126 |
127 | > 配置开发者用户名和邮箱
128 | >
129 |
130 | ```
131 | git config user.name gafish
132 | git config user.email gafish@qqqq.com
133 | ```
134 |
135 | 每次代码提交的时候都会生成一条提交记录,其中会包含当前配置的用户名和邮箱。
136 |
137 | ### git branch
138 |
139 | > 创建、重命名、查看、删除项目分支,通过 `Git` 做项目开发时,一般都是在开发分支中进行,开发完成后合并分支到主干。
140 | >
141 |
142 | ```
143 | git branch daily/0.0.0
144 | ```
145 |
146 | 创建一个名为 `daily/0.0.0` 的日常开发分支,分支名只要不包括特殊字符即可。
147 |
148 | ```
149 | git branch -m daily/0.0.0 daily/0.0.1
150 | ```
151 |
152 | 如果觉得之前的分支名不合适,可以为新建的分支重命名,重命名分支名为 `daily/0.0.1`
153 |
154 | ```
155 | git branch
156 | ```
157 |
158 | 通过不带参数的branch命令可以查看当前项目分支列表
159 |
160 | ```
161 | git branch -d daily/0.0.1
162 | ```
163 |
164 | 如果分支已经完成使命则可以通过 `-d` 参数将分支删除,这里为了继续下一步操作,暂不执行删除操作
165 |
166 | ### git checkout
167 |
168 | > 切换分支
169 | >
170 |
171 | ```
172 | git checkout daily/0.0.1
173 | ```
174 |
175 | 切换到 `daily/0.0.1` 分支,后续的操作将在这个分支上进行
176 |
177 | ### git status
178 |
179 | > 查看文件变动状态
180 | >
181 |
182 | 通过任何你喜欢的编辑器对项目中的 `README.md` 文件做一些改动,保存。
183 |
184 | ```
185 | git status
186 | ```
187 |
188 | 通过 `git status` 命令可以看到文件当前状态 `Changes not staged for commit:`(*改动文件未提交到暂存区*)
189 |
190 | ```
191 | On branch daily/0.0.1
192 | Changes not staged for commit:
193 | (use "git add ..." to update what will be committed)
194 | (use "git checkout -- ..." to discard changes in working directory)
195 | modified: README.md
196 | no changes added to commit (use "git add" and/or "git commit -a")
197 | ```
198 |
199 | ### git add
200 |
201 | > 添加文件变动到暂存区
202 | >
203 |
204 | ```
205 | git add README.md
206 | ```
207 |
208 | 通过指定文件名 `README.md` 可以将该文件添加到暂存区,如果想添加所有文件可用 `git add .` 命令,这时候可通过 `git status` 看到文件当前状态 `Changes to be committed:` (*文件已提交到暂存区*)
209 |
210 | ```
211 | On branch daily/0.0.1
212 | Changes to be committed:
213 | (use "git reset HEAD ..." to unstage)
214 | modified: README.md
215 | ```
216 |
217 | ### git commit
218 |
219 | > 提交文件变动到版本库
220 | >
221 |
222 | ```
223 | git commit -m '这里写提交原因'
224 | ```
225 |
226 | 通过 `-m` 参数可直接在命令行里输入提交描述文本
227 |
228 | ### git push
229 |
230 | > 将本地的代码改动推送到服务器
231 | >
232 |
233 | ```
234 | git push origin daily/0.0.1
235 | ```
236 |
237 | `origin` 指代的是当前的git服务器地址,这行命令的意思是把 `daily/0.0.1` 分支推送到服务器,当看到命令行返回如下字符表示推送成功了。
238 |
239 | ```
240 | Counting objects: 3, done.
241 | Delta compression using up to 8 threads.
242 | Compressing objects: 100% (2/2), done.
243 | Writing objects: 100% (3/3), 267 bytes | 0 bytes/s, done.
244 | Total 3 (delta 1), reused 0 (delta 0)
245 | remote: Resolving deltas: 100% (1/1), completed with 1 local objects.
246 | To https://github.com/gafish/gafish.github.com.git
247 | * [new branch] daily/0.0.1 -> daily/0.0.1
248 | ```
249 |
250 | 现在我们回到Github网站的项目首页,点击 `Branch:master` 下拉按钮,就会看到刚才推送的 `daily/00.1` 分支了
251 |
252 | ### git pull
253 |
254 | > 将服务器上的最新代码拉取到本地
255 | >
256 |
257 | ```
258 | git pull origin daily/0.0.1
259 | ```
260 |
261 | 如果其它项目成员对项目做了改动并推送到服务器,我们需要将最新的改动更新到本地,这里我们来模拟一下这种情况。
262 |
263 | 进入Github网站的项目首页,再进入 `daily/0.0.1` 分支,在线对 `README.md` 文件做一些修改并保存,然后在命令中执行以上命令,它将把刚才在线修改的部分拉取到本地,用编辑器打开 `README.md` ,你会发现文件已经跟线上的内容同步了。
264 |
265 | *如果线上代码做了变动,而你本地的代码也有变动,拉取的代码就有可能会跟你本地的改动冲突,一般情况下 `Git` 会自动处理这种冲突合并,但如果改动的是同一行,那就需要手动来合并代码,编辑文件,保存最新的改动,再通过 `git add .`和 `git commit -m 'xxx'` 来提交合并。*
266 |
267 | ### git log
268 |
269 | > 查看版本提交记录
270 | >
271 |
272 | ```
273 | git log
274 | ```
275 |
276 | 通过以上命令,我们可以查看整个项目的版本提交记录,它里面包含了`提交人`、`日期`、`提交原因`等信息,得到的结果如下:
277 |
278 | ```
279 | commit c334730f8dba5096c54c8ac04fdc2b31ede7107a
280 | Author: gafish
281 | Date: Wed Jan 11 09:44:13 2017 +0800
282 | Update README.md
283 | commit ba6e3d21fcb1c87a718d2a73cdd11261eb672b2a
284 | Author: gafish
285 | Date: Wed Jan 11 09:31:33 2017 +0800
286 | test
287 | .....
288 | ```
289 |
290 | 提交记录可能会非常多,按 `J` 键往下翻,按 `K` 键往上翻,按 `Q` 键退出查看
291 |
292 | ### git tag
293 |
294 | > 为项目标记里程碑
295 | >
296 |
297 | ```
298 | git tag publish/0.0.1
299 | git push origin publish/0.0.1
300 | ```
301 |
302 | 当我们完成某个功能需求准备发布上线时,应该将此次完整的项目代码做个标记,并将这个标记好的版本发布到线上,这里我们以 `publish/0.0.1` 为标记名并发布,当看到命令行返回如下内容则表示发布成功了
303 |
304 | ```
305 | Total 0 (delta 0), reused 0 (delta 0)
306 | To https://github.com/gafish/gafish.github.com.git
307 | * [new tag] publish/0.0.1 -> publish/0.0.1
308 | ```
309 |
310 | ### .gitignore
311 |
312 | > 设置哪些内容不需要推送到服务器,这是一个配置文件
313 | >
314 |
315 | ```
316 | touch .gitignore
317 | ```
318 |
319 | `.gitignore` 不是 `Git` 命令,而在项目中的一个文件,通过设置 `.gitignore` 的内容告诉 `Git` 哪些文件应该被忽略不需要推送到服务器,通过以上命令可以创建一个 `.gitignore` 文件,并在编辑器中打开文件,每一行代表一个要忽略的文件或目录,如:
320 |
321 | ```
322 | demo.html
323 | build/
324 | ```
325 |
326 | 以上内容的意思是 `Git` 将忽略 `demo.html` 文件 和 `build/` 目录,这些内容不会被推送到服务器上
327 |
328 | ### 小结
329 |
330 | 通过掌握以上这些基本命令就可以在项目中开始用起来了,如果追求实用,那关于 `Git` 的学习就可以到此结束了,偶尔遇到的问题也基本上通过 `Google` 也能找到答案,如果想深入探索 `Git` 的高阶功能,那就继续往下看 `深入探索` 部分。
331 |
332 | # 深入探索
333 |
334 | ## 基本概念
335 |
336 | ### 工作区(*Working Directory*)
337 |
338 | 就是你在电脑里能看到的目录,比如上文中的 `gafish.github.com` 文件夹就是一个工作区
339 |
340 | ### 本地版本库(*Local Repository*)
341 |
342 | 工作区有一个隐藏目录 `.git`,这个不算工作区,而是 `Git` 的版本库。
343 |
344 | 
345 |
346 | ### 暂存区(*stage*)
347 |
348 | 本地版本库里存了很多东西,其中最重要的就是称为 `stage`(或者叫index)的暂存区,还有 `Git` 为我们自动创建的第一个分支 `master`,以及指向 `master` 的一个指针叫 `HEAD`。
349 |
350 | ### 远程版本库(*Remote Repository*)
351 |
352 | 一般指的是 `Git` 服务器上所对应的仓库,本文的示例所在的`github`仓库就是一个远程版本库
353 |
354 | ### 以上概念之间的关系
355 |
356 | `工作区`、`暂存区`、`本地版本库`、`远程版本库`之间几个常用的 `Git` 操作流程如下图所示:
357 |
358 | 
359 |
360 | ### 分支(*Branch*)
361 |
362 | 分支是为了将修改记录的整个流程分开存储,让分开的分支不受其它分支的影响,所以在同一个数据库里可以同时进行多个不同的修改
363 |
364 | 
365 |
366 | ### 主分支(*Master*)
367 |
368 | 前面提到过 `master` 是 `Git` 为我们自动创建的第一个分支,也叫主分支,其它分支开发完成后都要合并到 `master`
369 |
370 | 
371 |
372 |
373 |
374 | ### 标签(*Tag*)
375 |
376 | 标签是用于标记特定的点或提交的历史,通常会用来标记发布版本的名称或版本号(如:`publish/0.0.1`),虽然标签看起来有点像分支,但打上标签的提交是固定的,不能随意的改动,参见上图中的`1.0` / `2.0` / `3.0`
377 |
378 | ### HEAD
379 |
380 | `HEAD` 指向的就是当前分支的最新提交
381 |
382 | 
383 |
384 | > 以上概念了解的差不多,那就可以继续往下看,下面将以具体的操作类型来讲解 `Git` 的高阶用法
385 | >
386 |
387 | ## 操作文件
388 |
389 | ### git add
390 |
391 | > 添加文件到暂存区
392 | >
393 |
394 | ```
395 | git add -i
396 | ```
397 |
398 | 通过此命令将打开交互式子命令系统,你将看到如下子命令
399 |
400 | ```
401 | ***Commands***
402 | 1: status 2: update 3: revert 4: add untracked
403 | 5: patch 6: diff 7: quit 8: help
404 | ```
405 |
406 | 通过输入序列号或首字母可以选择相应的功能,具体的功能解释如下:
407 |
408 | - `status`:功能上和 `git add -i` 相似,没什么鸟用
409 | - `update`:详见下方 `git add -u`
410 | - `revert`:把已经添加到暂存区的文件从暂存区剔除,其操作方式和 `update`类似
411 | - `add untracked`:可以把新增的文件添加到暂存区,其操作方式和 `update` 类似
412 | - `patch`:详见下方 `git add -p`
413 | - `diff`:比较暂存区文件和本地版本库的差异,其操作方式和 `update` 类似
414 | - `quit`:退出 `git add -i` 命令系统
415 | - `help`:查看帮助信息
416 |
417 | ```
418 | git add -p
419 | ```
420 |
421 | 直接进入交互命令中最有用的 `patch` 模式
422 |
423 | 这是交互命令中最有用的模式,其操作方式和 `update` 类似,选择后 `Git` 会显示这些文件的当前内容与本地版本库中的差异,然后您可以自己决定是否添加这些修改到暂存区,在命令行 `Stage deletion [y,n,q,a,d,/,?]?` 后输入 `y,n,q,a,d,/,?` 其中一项选择操作方式,具体功能解释如下:
424 |
425 | - y:接受修改
426 | - n:忽略修改
427 | - q:退出当前命令
428 | - a:添加修改
429 | - d:放弃修改
430 | - /:通过正则表达式匹配修改内容
431 | - ?:查看帮助信息
432 |
433 | ```
434 | git add -u
435 | ```
436 |
437 | 直接进入交互命令中的 `update` 模式
438 |
439 | 它会先列出工作区 `修改` 或 `删除` 的文件列表,`新增` 的文件不会被显示,在命令行 `Update>>` 后输入相应的列表序列号表示选中该项,回车继续选择,如果已选好,直接回车回到命令主界面
440 |
441 | ```
442 | git add --ignore-removal .
443 | ```
444 |
445 | 添加工作区 `修改` 或 `新增` 的文件列表, `删除` 的文件不会被添加
446 |
447 | ### git commit
448 |
449 | > 把暂存区的文件提交到本地版本库
450 | >
451 |
452 | ```
453 | git commit -m '第一行提交原因' -m '第二行提交原因'
454 | ```
455 |
456 | 不打开编辑器,直接在命令行中输入多行提交原因
457 |
458 | ```
459 | git commit -am '提交原因'
460 | ```
461 |
462 | 将工作区 `修改` 或 `删除` 的文件提交到本地版本库, `新增` 的文件不会被提交
463 |
464 | ```
465 | git commit --amend -m '提交原因'
466 | ```
467 |
468 | 修改最新一条提交记录的提交原因
469 |
470 | ```
471 | git commit -C HEAD
472 | ```
473 |
474 | 将当前文件改动提交到 `HEAD` 或当前分支的历史ID
475 |
476 | ### git mv
477 |
478 | > 移动或重命名文件、目录
479 | >
480 |
481 | ```
482 | git mv a.md b.md -f
483 | ```
484 |
485 | 将 `a.md` 重命名为 `b.md` ,同时添加变动到暂存区,加 `-f` 参数可以强制重命名,相比用 `mv a.md b.md` 命令省去了 `git add` 操作
486 |
487 | ### git rm
488 |
489 | > 从工作区和暂存区移除文件
490 | >
491 |
492 | ```
493 | git rm b.md
494 | ```
495 |
496 | 从工作区和暂存区移除文件 `b.md` ,同时添加变动到暂存区,相比用 `rm b.md` 命令省去了 `git add` 操作
497 |
498 | ```
499 | git rm src/ -r
500 | ```
501 |
502 | 允许从工作区和暂存区移除目录
503 |
504 | ### git status
505 |
506 | ```
507 | git status -s
508 | ```
509 |
510 | 以简短方式查看工作区和暂存区文件状态,示例如下:
511 |
512 | ```
513 | M demo.html
514 | ?? test.html
515 | git status --ignored
516 | ```
517 |
518 | 查看工作区和暂存区文件状态,包括被忽略的文件
519 |
520 | ## 操作分支
521 |
522 | ### git branch
523 |
524 | > 查看、创建、删除分支
525 | >
526 |
527 | ```
528 | git branch -a
529 | ```
530 |
531 | 查看本地版本库和远程版本库上的分支列表
532 |
533 | ```
534 | git branch -r
535 | ```
536 |
537 | 查看远程版本库上的分支列表,加上 `-d` 参数可以删除远程版本库上的分支
538 |
539 | ```
540 | git branch -D
541 | ```
542 |
543 | 分支未提交到本地版本库前强制删除分支
544 |
545 | ```
546 | git branch -vv
547 | ```
548 |
549 | 查看带有最后提交id、最近提交原因等信息的本地版本库分支列表
550 |
551 | 
552 |
553 | ### git merge
554 |
555 | > 将其它分支合并到当前分支
556 | >
557 |
558 | ```
559 | git merge --squash
560 | ```
561 |
562 | 将待合并分支上的 `commit` 合并成一个新的 `commit` 放入当前分支,适用于待合并分支的提交记录不需要保留的情况
563 |
564 | ```
565 | git merge --no-ff
566 | ```
567 |
568 | 默认情况下,`Git` 执行"`快进式合并`"(fast-farward merge),会直接将 `Master`分支指向 `Develop` 分支,使用 `--no-ff` 参数后,会执行正常合并,在 `Master`分支上生成一个新节点,保证版本演进更清晰。
569 |
570 | 
571 |
572 | ```
573 | git merge --no-edit
574 | ```
575 |
576 | 在没有冲突的情况下合并,不想手动编辑提交原因,而是用 `Git` 自动生成的类似 `Merge branch 'test'` 的文字直接提交
577 |
578 | ### git checkout
579 |
580 | > 切换分支
581 | >
582 |
583 | ```
584 | git checkout -b daily/0.0.1
585 | ```
586 |
587 | 创建 `daily/0.0.1` 分支,同时切换到这个新创建的分支
588 |
589 | ```
590 | git checkout HEAD demo.html
591 | ```
592 |
593 | 从本地版本库的 `HEAD`(也可以是提交ID、分支名、Tag名) 历史中检出 `demo.html` 覆盖当前工作区的文件,如果省略 `HEAD` 则是从暂存区检出
594 |
595 | ```
596 | git checkout --orphan new_branch
597 | ```
598 |
599 | 这个命令会创建一个全新的,完全没有历史记录的新分支,但当前源分支上所有的最新文件都还在,真是强迫症患者的福音,但这个新分支必须做一次 `git commit`操作后才会真正成为一个新分支。
600 |
601 | ```
602 | git checkout -p other_branch
603 | ```
604 |
605 | 这个命令主要用来比较两个分支间的差异内容,并提供交互式的界面来选择进一步的操作,这个命令不仅可以比较两个分支间的差异,还可以比较单个文件的差异。
606 |
607 | ### git stash
608 |
609 | > 在 `Git` 的栈中保存当前修改或删除的工作进度,当你在一个分支里做某项功能开发时,接到通知把昨天已经测试完没问题的代码发布到线上,但这时你已经在这个分支里加入了其它未提交的代码,这个时候就可以把这些未提交的代码存到栈里。
610 | >
611 |
612 | ```
613 | git stash
614 | ```
615 |
616 | 将未提交的文件保存到Git栈中
617 |
618 | ```
619 | git stash list
620 | ```
621 |
622 | 查看栈中保存的列表
623 |
624 | ```
625 | git stash show stash@{0}
626 | ```
627 |
628 | 显示栈中其中一条记录
629 |
630 | ```
631 | git stash drop stash@{0}
632 | ```
633 |
634 | 移除栈中其中一条记录
635 |
636 | ```
637 | git stash pop
638 | ```
639 |
640 | 从Git栈中检出最新保存的一条记录,并将它从栈中移除
641 |
642 | ```
643 | git stash apply stash@{0}
644 | ```
645 |
646 | 从Git栈中检出其中一条记录,但不从栈中移除
647 |
648 | ```
649 | git stash branch new_banch
650 | ```
651 |
652 | 把当前栈中最近一次记录检出并创建一个新分支
653 |
654 | ```
655 | git stash clear
656 | ```
657 |
658 | 清空栈里的所有记录
659 |
660 | ```
661 | git stash create
662 | ```
663 |
664 | 为当前修改或删除的文件创建一个自定义的栈并返回一个ID,此时并未真正存储到栈里
665 |
666 | ```
667 | git stash store xxxxxx
668 | ```
669 |
670 | 将 `create` 方法里返回的ID放到 `store` 后面,此时在栈里真正创建了一个记录,但当前修改或删除的文件并未从工作区移除
671 |
672 | ```
673 | $ git stash create
674 | 09eb9a97ad632d0825be1ece361936d1d0bdb5c7
675 | $ git stash store 09eb9a97ad632d0825be1ece361936d1d0bdb5c7
676 | $ git stash list
677 | stash@{0}: Created via "git stash store".
678 | ```
679 |
680 | ## 操作历史
681 |
682 | ### git log
683 |
684 | > 显示提交历史记录
685 | >
686 |
687 | ```
688 | git log -p
689 | ```
690 |
691 | 显示带提交差异对比的历史记录
692 |
693 | ```
694 | git log demo.html
695 | ```
696 |
697 | 显示 `demo.html` 文件的历史记录
698 |
699 | ```
700 | git log --since="2 weeks ago"
701 | ```
702 |
703 | 显示2周前开始到现在的历史记录,其它时间可以类推
704 |
705 | ```
706 | git log --before="2 weeks ago"
707 | ```
708 |
709 | 显示截止到2周前的历史记录,其它时间可以类推
710 |
711 | ```
712 | git log -10
713 | ```
714 |
715 | 显示最近10条历史记录
716 |
717 | ```
718 | git log f5f630a..HEAD
719 | ```
720 |
721 | 显示从提交ID `f5f630a` 到 `HEAD` 之间的记录,`HEAD` 可以为空或其它提交ID
722 |
723 | ```
724 | git log --pretty=oneline
725 | ```
726 |
727 | 在一行中输出简短的历史记录
728 |
729 | ```
730 | git log --pretty=format:"%h"
731 | ```
732 |
733 | 格式化输出历史记录
734 |
735 | `Git` 用各种 `placeholder` 来决定各种显示内容,我挑几个常用的显示如下:
736 |
737 | - %H: commit hash
738 | - %h: 缩短的commit hash
739 | - %T: tree hash
740 | - %t: 缩短的 tree hash
741 | - %P: parent hashes
742 | - %p: 缩短的 parent hashes
743 | - %an: 作者名字
744 | - %aN: mailmap的作者名
745 | - %ae: 作者邮箱
746 | - %ad: 日期 (--date= 制定的格式)
747 | - %ar: 日期, 相对格式(1 day ago)
748 | - %cn: 提交者名字
749 | - %ce: 提交者 email
750 | - %cd: 提交日期 (--date= 制定的格式)
751 | - %cr: 提交日期, 相对格式(1 day ago)
752 | - %d: ref名称
753 | - %s: commit信息标题
754 | - %b: commit信息内容
755 | - %n: 换行
756 |
757 | ### git cherry-pick
758 |
759 | > 合并分支的一条或几条提交记录到当前分支末梢
760 | >
761 |
762 | ```
763 | git cherry-pick 170a305
764 | ```
765 |
766 | 合并提交ID `170a305` 到当前分支末梢
767 |
768 | ### git reset
769 |
770 | > 将当前的分支重设(reset)到指定的 `` 或者 `HEAD`
771 | >
772 |
773 | ```
774 | git reset --mixed
775 | ```
776 |
777 | `--mixed` 是不带参数时的默认参数,它退回到某个版本,保留文件内容,回退提交历史
778 |
779 | ```
780 | git reset --soft
781 | ```
782 |
783 | 暂存区和工作区中的内容不作任何改变,仅仅把 `HEAD` 指向 ``
784 |
785 | ```
786 | git reset --hard
787 | ```
788 |
789 | 自从 `` 以来在工作区中的任何改变都被丢弃,并把 `HEAD` 指向 ``
790 |
791 | ### git rebase
792 |
793 | > 重新定义分支的版本库状态
794 | >
795 |
796 | ```
797 | git rebase branch_name
798 | ```
799 |
800 | 合并分支,这跟 `merge` 很像,但还是有本质区别,看下图:
801 |
802 | 
803 |
804 | 合并过程中可能需要先解决冲突,然后执行 `git rebase --continue`
805 |
806 | ```
807 | git rebase -i HEAD~~
808 | ```
809 |
810 | 打开文本编辑器,将看到从 `HEAD` 到 `HEAD~~` 的提交如下
811 |
812 | ```
813 | pick 9a54fd4 添加commit的说明
814 | pick 0d4a808 添加pull的说明
815 | # Rebase 326fc9f..0d4a808 onto d286baa
816 | #
817 | # Commands:
818 | # p, pick = use commit
819 | # r, reword = use commit, but edit the commit message
820 | # e, edit = use commit, but stop for amending
821 | # s, squash = use commit, but meld into previous commit
822 | # f, fixup = like "squash", but discard this commit's log message
823 | # x, exec = run command (the rest of the line) using shell
824 | #
825 | ```
826 |
827 | 将第一行的 `pick` 改成 `Commands` 中所列出来的命令,然后保存并退出,所对应的修改将会生效。如果移动提交记录的顺序,将改变历史记录中的排序。
828 |
829 | ### git revert
830 |
831 | > 撤销某次操作,此次操作之前和之后的 `commit` 和 `history` 都会保留,并且把这次撤销作为一次最新的提交
832 | >
833 |
834 | ```
835 | git revert HEAD
836 | ```
837 |
838 | 撤销前一次提交操作
839 |
840 | ```
841 | git revert HEAD --no-edit
842 | ```
843 |
844 | 撤销前一次提交操作,并以默认的 `Revert "xxx"` 为提交原因
845 |
846 | ```
847 | git revert -n HEAD
848 | ```
849 |
850 | 需要撤销多次操作的时候加 `-n` 参数,这样不会每次撤销操作都提交,而是等所有撤销都完成后一起提交
851 |
852 | ### git diff
853 |
854 | > 查看工作区、暂存区、本地版本库之间的文件差异,用一张图来解释
855 | >
856 |
857 | 
858 |
859 | ```
860 | git diff --stat
861 | ```
862 |
863 | 通过 `--stat` 参数可以查看变更统计数据
864 |
865 | ```
866 | test.md | 1 -
867 | 1 file changed, 1 deletion(-)
868 | ```
869 |
870 | ### git reflog
871 |
872 | `reflog` 可以查看所有分支的所有操作记录(包括commit和reset的操作、已经被删除的commit记录,跟 `git log` 的区别在于它不能查看已经删除了的commit记录
873 |
874 | ## 远程版本库连接
875 |
876 | 如果在GitHub项目初始化之前,文件已经存在于本地目录中,那可以在本地初始化本地版本库,再将本地版本库跟远程版本库连接起来
877 |
878 | ### git init
879 |
880 | > 在本地目录内部会生成.git文件夹
881 | >
882 |
883 | ### git remote
884 |
885 | ```
886 | git remote -v
887 | ```
888 |
889 | 不带参数,列出已经存在的远程分支,加上 `-v` 列出详细信息,在每一个名字后面列出其远程url
890 |
891 | ```
892 | git remote add origin https://github.com/gafish/gafish.github.com.git
893 | ```
894 |
895 | 添加一个新的远程仓库,指定一个名字,以便引用后面带的URL
896 |
897 | ### git fetch
898 |
899 | > 将远程版本库的更新取回到本地版本库
900 | >
901 |
902 | ```
903 | git fetch origin daily/0.0.1
904 | ```
905 |
906 | 默认情况下,`git fetch` 取回所有分支的更新。如果只想取回特定分支的更新,可以指定分支名。
907 |
908 | ## 问题排查
909 |
910 | ### git blame
911 |
912 | > 查看文件每行代码块的历史信息
913 | >
914 |
915 | ```
916 | git blame -L 1,10 demo.html
917 | ```
918 |
919 | 截取 `demo.html` 文件1-10行历史信息
920 |
921 | ### git bisect
922 |
923 | > 二分查找历史记录,排查BUG
924 | >
925 |
926 | ```
927 | git bisect start
928 | ```
929 |
930 | 开始二分查找
931 |
932 | ```
933 | git bisect bad
934 | ```
935 |
936 | 标记当前二分提交ID为有问题的点
937 |
938 | ```
939 | git bisect good
940 | ```
941 |
942 | 标记当前二分提交ID为没问题的点
943 |
944 | ```
945 | git bisect reset
946 | ```
947 |
948 | 查到有问题的提交ID后回到原分支
949 |
950 | ## 更多操作
951 |
952 | ### git submodule
953 |
954 | > 通过 Git 子模块可以跟踪外部版本库,它允许在某一版本库中再存储另一版本库,并且能够保持2个版本库完全独立
955 | >
956 |
957 | ```
958 | git submodule add https://github.com/gafish/demo.git demo
959 | ```
960 |
961 | 将 `demo` 仓库添加为子模块
962 |
963 | ```
964 | git submodule update demo
965 | ```
966 |
967 | 更新子模块 `demo`
968 |
969 | ### git gc
970 |
971 | > 运行Git的垃圾回收功能,清理冗余的历史快照
972 | >
973 |
974 | ### git archive
975 |
976 | > 将加了tag的某个版本打包提取
977 | >
978 |
979 | ```
980 | git archive -v --format=zip v0.1 > v0.1.zip
981 | ```
982 |
983 | `--format` 表示打包的格式,如 `zip`,`-v` 表示对应的tag名,后面跟的是tag名,如 `v0.1`。
984 |
985 | -- End --
986 |
987 |
988 |
--------------------------------------------------------------------------------
/docs/tools/推荐十款精选IntelliJIdea插件.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | - [1 Key Promoter X](#1-key-promoter-x)
4 | - [2 Alibaba Java Coding Guidelines](#2-alibaba-java-coding-guidelines)
5 | - [3 CodeGlance](#3-codeglance)
6 | - [4 Maven Helper](#4-maven-helper)
7 | - [5 Lombok](#5-lombok)
8 | - [6 JavaDoc](#6-javadoc)
9 | - [7 .ignore](#7-ignore)
10 | - [8RainbowBrackets](#8rainbowbrackets)
11 | - [9 Activate-power-mode](#9-activate-power-mode)
12 | - [10 Grep Console](#10-grep-console)
13 | - [公众号](#公众号)
14 |
15 |
16 |
17 | 俗话说:"工欲善其事必先利其器",小主从项目实战的角度在众多的idea插件中挑选了10款开发必备的神器,帮助大家在日常工作学习编码中提升开发效率。
18 |
19 | # 1 Key Promoter X
20 |
21 | 实用指数:★★★★★
22 |
23 | 装逼指数:★
24 |
25 | 你还在为记不住快捷键烦恼吗,Key Promoter X可以帮助你快速记住常用的快捷键。当你在idea中用鼠标点击菜单,它可以显示对应的快捷键以及点击次数。使用一段时间后有助于过渡到更快、无鼠标的开发。
26 |
27 |
28 |
29 | # 2 Alibaba Java Coding Guidelines
30 |
31 | 实用指数:★★★★★
32 |
33 | 装逼指数:★★
34 |
35 | 这是阿里巴巴官方出品的一款代码静态检查插件,它可以针对整个项目或者单个文件进行检查,扫描完成后会生成一份检查报告,根据报告修改代码。
36 |
37 |
38 |
39 |
40 |
41 | # 3 CodeGlance
42 |
43 | 实用指数:★★★
44 |
45 | 装逼指数:★★
46 |
47 | 安装完之后会在代码编辑区的右上角显示一个缩小预览区,类似于王者荣耀或者LOL的地图功能。如果一个文件有上千行代码,可以直接在预览区里拖动快速定位到对应的代码行。
48 |
49 |
50 |
51 |
52 | # 4 Maven Helper
53 |
54 | 实用指数:★★★★★
55 |
56 | 装逼指数:★★
57 |
58 | 这是一款使用Maven管理项目的必装插件,主要用于分析项目jar依赖关系,可以快速找出冲突的jar包。
59 |
60 |
61 |
62 | # 5 Lombok
63 |
64 | 实用指数:★★★
65 |
66 | 装逼指数:★★★
67 |
68 | Lombok是一个充满争议的工具,大家可以结合它的优缺点谨慎选择。在项目有很多POJO类,每个POJO类有大量的getter/setter/toString代码,这些样板代码既没有技术含量,又影响着代码的美观,Lombok应运而生。
69 |
70 | 如果一个项目中依赖了lombok,那么需要在idea中安装lombok插件,否则项目会报错。
71 |
72 | 关于Lombok的常用注解如@Data@Setter@Getter等的使用方法大家可以上网搜索。
73 |
74 | # 6 JavaDoc
75 |
76 | 实用指数:★★★★
77 |
78 | 装逼指数:★★
79 |
80 | 在项目中经常要求写代码注释,否则不能通过代码门禁,JavaDoc工具可以一键生成注释。
81 |
82 | 插件安装成功后在菜单栏 code -> JavaDocs可以找到
83 |
84 |
85 |
86 | 自动生成注释效果如下:
87 |
88 |
89 |
90 | # 7 .ignore
91 |
92 | 实用指数:★★★★★
93 |
94 | 装逼指数:★
95 |
96 | 项目开发中通常会使用到git进行版本管理,在提交代码时经常有人将本地的不必要的文件提交到代码仓库中,使用.ignore插件可以很好解决这个问题。插件安装完成后会在项目中生成一个.ignore文件,编辑该文件忽略一些动态生成的文件,如class文件,maven的target目录等。
97 |
98 |
99 |
100 | # 8RainbowBrackets
101 |
102 | 实用指数:★
103 |
104 | 装逼指数:★★★★★
105 |
106 | 彩虹括号,代码中有多个括号会显示不同的颜色。
107 |
108 |
109 |
110 | # 9 Activate-power-mode
111 |
112 | 实用指数:★
113 |
114 | 装逼指数:★★★★★
115 |
116 | 在敲代码时有抖动酷炫的特效,非常适合给前端小姐姐表演特技。(坏笑)
117 |
118 | # 10 Grep Console
119 |
120 | 实用指数:★★★★
121 |
122 | 装逼指数:★★
123 |
124 | 运行项目后在console(控制台)输出日志,通过配置不同日志级别的颜色,可以很明显的识别错误信息,便于项目调试。
125 |
126 |
127 |
128 | 如果在线安装插件失败可以尝试离线安装,100%成功哦。微信搜索公众号:爱笑的架构师,关注后回复关键字:插件,即可获得所有的插件安装包。
129 |
130 | 附:离线安装插件步骤
131 |
132 | 第一步:
133 |
134 |
135 |
136 | 第二步:选择下载好的插件包;
137 |
138 | 第三步:重启idea即可生效。
139 |
140 | # 公众号
141 |
142 | 公众号比Github早一到两天更新,如果大家想要实时关注我更新的文章以及分享的干货,可以关注我的公众号。
143 |
144 |
--------------------------------------------------------------------------------
/docs/tools/高效学习资源网站汇总.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | - [(1)视频网站](#1视频网站)
5 | - [(2)专栏](#2专栏)
6 | - [(3)Github](#3github)
7 | - [(4)技术博客:](#4技术博客)
8 | - [(5)搜索引擎:](#5搜索引擎)
9 | - [(6)知识问答:](#6知识问答)
10 | - [(7)刷题:](#7刷题)
11 | - [(8)云笔记:](#8云笔记)
12 | - [(9)在线画图:](#9在线画图)
13 |
14 |
15 |
16 | ## (1)视频网站
17 |
18 | - B站(推荐):[https://www.bilibili.com/](https://www.bilibili.com/)
19 | - 网易云课堂:[https://study.163.com/](https://study.163.com/)
20 | - 极客学院:[https://www.jikexueyuan.com/](https://www.jikexueyuan.com/)
21 | - 慕课网:[https://www.imooc.com/](https://www.imooc.com/)
22 |
23 | ## (2)专栏
24 | - 极客时间(推荐):[https://time.geekbang.org/](https://time.geekbang.org/)
25 | - Gitchat [https://gitbook.cn/](https://gitbook.cn/)
26 |
27 | ## (3)Github
28 |
29 | - Java八股文(推荐):[https://github.com/CoderLeixiaoshuai/java-eight-part](https://github.com/CoderLeixiaoshuai/java-eight-part)
30 |
31 | ## (4)技术博客:
32 | - CSDN 博客:[https://blog.csdn.net/](https://blog.csdn.net/)
33 | - 博客园:[https://www.cnblogs.com/](https://www.cnblogs.com/)
34 | - 掘金社区(推荐):[https://juejin.cn/](https://juejin.cn/)
35 | - InfoQ:[https://xie.infoq.cn/](https://xie.infoq.cn/)
36 | - 思否:[https://segmentfault.com/](https://segmentfault.com/)
37 | - 开源中国:[https://www.oschina.net/blog](https://www.oschina.net/blog)
38 |
39 | ## (5)搜索引擎:
40 | - 百度:[https://www.baidu.com/](https://www.baidu.com/)
41 | - 谷歌:[https://www.google.com/](https://www.google.com/)
42 |
43 | ## (6)知识问答:
44 | - 知乎(推荐):[https://www.zhihu.com/](https://www.zhihu.com/)
45 | - stackoverflow(推荐): [https://stackoverflow.com/](https://stackoverflow.com/)
46 |
47 | ## (7)刷题:
48 | - 力扣(推荐):[https://leetcode-cn.com/](https://leetcode-cn.com/)
49 | - 牛客:[https://www.nowcoder.com/](https://www.nowcoder.com/)
50 |
51 | ## (8)云笔记:
52 | - 石墨:[https://shimo.im/](https://shimo.im/)
53 | - 语雀:[https://www.yuque.com/](https://www.yuque.com/)
54 | - 有道云笔记:[http://note.youdao.com/](http://note.youdao.com/)
55 | - 印象笔记:[https://www.yinxiang.com/](https://www.yinxiang.com/)
56 |
57 | 看个人习惯去选择,不推荐了。
58 |
59 | ## (9)在线画图:
60 | - processOn:[https://www.processon.com/](https://www.processon.com/)
61 | - drawio:[https://app.diagrams.net/](https://app.diagrams.net/)
62 |
63 | 各有特色,都推荐。
64 |
65 | -- End --
66 |
67 | 欢迎大家补充
--------------------------------------------------------------------------------
/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 | Java八股文
7 |
8 |
9 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
27 |
28 |
29 |
30 |
31 |
36 |
37 |
38 |
39 |
40 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
--------------------------------------------------------------------------------