├── .gitignore
├── 01-intro
├── README.md
├── documents-llm.json
├── documents.json
├── elastic-search.md
├── open-ai-alternatives.md
├── parse-faq.ipynb
└── rag-intro.ipynb
├── 02-vector-search
└── README.md
├── 03-evaluation
└── README.md
├── 04-monitoring
└── README.md
├── 05-best-practices
├── README.md
├── documents-with-ids.json
├── ground-truth-data.csv
├── hybrid-search-and-reranking-es.ipynb
├── hybrid-search-langchain.ipynb
└── llm-zoomcamp-best-practicies.pdf
├── 06-project-example
├── README.md
└── content-processing-summary.md
├── README.md
├── after-sign-up.md
├── asking-questions.md
├── awesome-llms.md
├── cohorts
├── 2024
│ ├── 01-intro
│ │ └── homework.md
│ ├── 02-open-source
│ │ ├── README.md
│ │ ├── docker-compose.yaml
│ │ ├── homework.md
│ │ ├── huggingface-flan-t5.ipynb
│ │ ├── huggingface-mistral-7b.ipynb
│ │ ├── huggingface-phi3.ipynb
│ │ ├── ollama.ipynb
│ │ ├── prompt.md
│ │ ├── qa_faq.py
│ │ ├── rag-intro.ipynb
│ │ ├── serving-hugging-face-models.md
│ │ └── starter.ipynb
│ ├── 03-vector-search
│ │ ├── README.md
│ │ ├── demo_es.ipynb
│ │ ├── homework.md
│ │ └── homework_solution.ipynb
│ ├── 04-monitoring
│ │ ├── README.md
│ │ ├── app
│ │ │ ├── .env
│ │ │ ├── Dockerfile
│ │ │ ├── README.MD
│ │ │ ├── app.py
│ │ │ ├── assistant.py
│ │ │ ├── db.py
│ │ │ ├── docker-compose.yaml
│ │ │ ├── generate_data.py
│ │ │ ├── prep.py
│ │ │ └── requirements.txt
│ │ ├── code.md
│ │ ├── dashboard.json
│ │ ├── data
│ │ │ ├── evaluations-aqa.csv
│ │ │ ├── evaluations-qa.csv
│ │ │ ├── results-gpt35-cosine.csv
│ │ │ ├── results-gpt35.csv
│ │ │ ├── results-gpt4o-cosine.csv
│ │ │ ├── results-gpt4o-mini-cosine.csv
│ │ │ ├── results-gpt4o-mini.csv
│ │ │ └── results-gpt4o.csv
│ │ ├── grafana.md
│ │ ├── homework.md
│ │ ├── offline-rag-evaluation.ipynb
│ │ └── solution.ipynb
│ ├── 05-orchestration
│ │ ├── README.md
│ │ ├── code
│ │ │ └── 06_retrieval.py
│ │ ├── homework.md
│ │ └── parse-faq-llm.ipynb
│ ├── README.md
│ ├── competition
│ │ ├── README.md
│ │ ├── data
│ │ │ ├── test.csv
│ │ │ └── train.csv
│ │ ├── scorer.py
│ │ ├── starter_notebook.ipynb
│ │ └── starter_notebook_submission.csv
│ ├── project.md
│ └── workshops
│ │ └── dlt.md
└── 2025
│ ├── 01-intro
│ └── homework.md
│ ├── README.md
│ ├── course-launch-stream-summary.md
│ ├── pre-course-q-a-stream-summary.md
│ └── project.md
├── etc
└── chunking.md
├── images
├── llm-zoomcamp-2025.jpg
├── llm-zoomcamp.jpg
├── qdrant.png
└── saturn-cloud.png
├── learning-in-public.md
└── project.md
/.gitignore:
--------------------------------------------------------------------------------
1 | .ipynb_checkpoints/
2 | __pycache__/
3 | .venv
4 | .envrc
5 |
--------------------------------------------------------------------------------
/01-intro/README.md:
--------------------------------------------------------------------------------
1 | # Module 1: Introduction
2 |
3 | In this module, we will learn what LLM and RAG are and
4 | implement a simple RAG pipeline to answer questions about
5 | the FAQ Documents from our Zoomcamp courses
6 |
7 | What we will do:
8 |
9 | * Index Zoomcamp FAQ documents
10 | * DE Zoomcamp: https://docs.google.com/document/d/19bnYs80DwuUimHM65UV3sylsCn2j1vziPOwzBwQrebw/edit
11 | * ML Zoomcamp: https://docs.google.com/document/d/1LpPanc33QJJ6BSsyxVg-pWNMplal84TdZtq10naIhD8/edit
12 | * MLOps Zoomcamp: https://docs.google.com/document/d/12TlBfhIiKtyBv8RnsoJR6F72bkPDGEvPOItJIxaEzE0/edit
13 | * Create a Q&A system for answering questions about these documents
14 |
15 | ## 1.1 Introduction to LLM and RAG
16 |
17 |
18 |  19 |
20 |
21 | * LLM
22 | * RAG
23 | * RAG architecture
24 | * Course outcome
25 |
26 |
27 | ## 1.2 Preparing the Environment
28 |
29 |
30 |
19 |
20 |
21 | * LLM
22 | * RAG
23 | * RAG architecture
24 | * Course outcome
25 |
26 |
27 | ## 1.2 Preparing the Environment
28 |
29 |
30 |  31 |
32 |
33 | * Installing libraries
34 | * Alternative: installing anaconda or miniconda
35 |
36 | ```bash
37 | pip install tqdm notebook==7.1.2 openai elasticsearch==8.13.0 pandas scikit-learn ipywidgets
38 | ```
39 |
40 | ## 1.3 Retrieval
41 |
42 |
43 |
31 |
32 |
33 | * Installing libraries
34 | * Alternative: installing anaconda or miniconda
35 |
36 | ```bash
37 | pip install tqdm notebook==7.1.2 openai elasticsearch==8.13.0 pandas scikit-learn ipywidgets
38 | ```
39 |
40 | ## 1.3 Retrieval
41 |
42 |
43 |  44 |
45 |
46 | Note: as of now, you can install minsearch with pip:
47 |
48 | ```bash
49 | pip install minsearch
50 | ```
51 |
52 | * We will use the search engine we build in the [build-your-own-search-engine workshop](https://github.com/alexeygrigorev/build-your-own-search-engine): [minsearch](https://github.com/alexeygrigorev/minsearch)
53 | * Indexing the documents
54 | * Peforming the search
55 |
56 |
57 | ## 1.4 Generation with OpenAI
58 |
59 |
60 |
44 |
45 |
46 | Note: as of now, you can install minsearch with pip:
47 |
48 | ```bash
49 | pip install minsearch
50 | ```
51 |
52 | * We will use the search engine we build in the [build-your-own-search-engine workshop](https://github.com/alexeygrigorev/build-your-own-search-engine): [minsearch](https://github.com/alexeygrigorev/minsearch)
53 | * Indexing the documents
54 | * Peforming the search
55 |
56 |
57 | ## 1.4 Generation with OpenAI
58 |
59 |
60 |  61 |
62 |
63 | * Invoking OpenAI API
64 | * Building the prompt
65 | * Getting the answer
66 |
67 |
68 | If you don't want to use a service, you can run an LLM locally
69 | refer to [module 2](../02-open-source/) for more details.
70 |
71 | In particular, check "2.7 Ollama - Running LLMs on a CPU" -
72 | it can work with OpenAI API, so to make the example from 1.4
73 | work locally, you only need to change a few lines of code.
74 |
75 |
76 | ## 1.4.2 OpenAI API Alternatives
77 |
78 |
79 |
61 |
62 |
63 | * Invoking OpenAI API
64 | * Building the prompt
65 | * Getting the answer
66 |
67 |
68 | If you don't want to use a service, you can run an LLM locally
69 | refer to [module 2](../02-open-source/) for more details.
70 |
71 | In particular, check "2.7 Ollama - Running LLMs on a CPU" -
72 | it can work with OpenAI API, so to make the example from 1.4
73 | work locally, you only need to change a few lines of code.
74 |
75 |
76 | ## 1.4.2 OpenAI API Alternatives
77 |
78 |
79 |  80 |
81 |
82 | [Open AI Alternatives](../awesome-llms.md#openai-api-alternatives)
83 |
84 |
85 | ## 1.5 Cleaned RAG flow
86 |
87 |
88 |
80 |
81 |
82 | [Open AI Alternatives](../awesome-llms.md#openai-api-alternatives)
83 |
84 |
85 | ## 1.5 Cleaned RAG flow
86 |
87 |
88 | 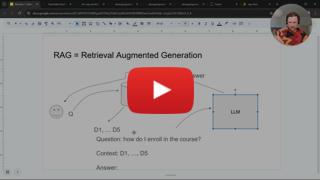 89 |
90 |
91 | * Cleaning the code we wrote so far
92 | * Making it modular
93 |
94 | ## 1.6 Searching with ElasticSearch
95 |
96 |
97 |
89 |
90 |
91 | * Cleaning the code we wrote so far
92 | * Making it modular
93 |
94 | ## 1.6 Searching with ElasticSearch
95 |
96 |
97 | 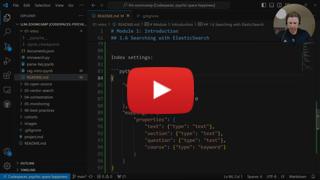 98 |
99 |
100 | * Run ElasticSearch with Docker
101 | * Index the documents
102 | * Replace MinSearch with ElasticSearch
103 |
104 | Running ElasticSearch:
105 |
106 | ```bash
107 | docker run -it \
108 | --rm \
109 | --name elasticsearch \
110 | -m 4GB \
111 | -p 9200:9200 \
112 | -p 9300:9300 \
113 | -e "discovery.type=single-node" \
114 | -e "xpack.security.enabled=false" \
115 | docker.elastic.co/elasticsearch/elasticsearch:8.4.3
116 | ```
117 |
118 | If the previous command doesn't work (i.e. you see "error pulling image configuration"), try to run ElasticSearch directly from Docker Hub:
119 |
120 | ```bash
121 | docker run -it \
122 | --rm \
123 | --name elasticsearch \
124 | -p 9200:9200 \
125 | -p 9300:9300 \
126 | -e "discovery.type=single-node" \
127 | -e "xpack.security.enabled=false" \
128 | elasticsearch:8.4.3
129 | ```
130 |
131 | Index settings:
132 |
133 | ```python
134 | {
135 | "settings": {
136 | "number_of_shards": 1,
137 | "number_of_replicas": 0
138 | },
139 | "mappings": {
140 | "properties": {
141 | "text": {"type": "text"},
142 | "section": {"type": "text"},
143 | "question": {"type": "text"},
144 | "course": {"type": "keyword"}
145 | }
146 | }
147 | }
148 | ```
149 |
150 | Query:
151 |
152 | ```python
153 | {
154 | "size": 5,
155 | "query": {
156 | "bool": {
157 | "must": {
158 | "multi_match": {
159 | "query": query,
160 | "fields": ["question^3", "text", "section"],
161 | "type": "best_fields"
162 | }
163 | },
164 | "filter": {
165 | "term": {
166 | "course": "data-engineering-zoomcamp"
167 | }
168 | }
169 | }
170 | }
171 | }
172 | ```
173 |
174 | We use `"type": "best_fields"`. You can read more about
175 | different types of `multi_match` search in [elastic-search.md](elastic-search.md).
176 |
177 | # 1.7 Homework
178 | More information [here](../cohorts/2025/01-intro/homework.md).
179 |
180 |
181 | # Extra materials
182 |
183 | * If you're curious to know how the code for parsing the FAQ works, check [this video](https://www.loom.com/share/ff54d898188b402d880dbea2a7cb8064)
184 |
185 | # Open-Source LLMs (optional)
186 |
187 | It's also possible to run LLMs locally. For that, we
188 | can use Ollama. Check these videos from LLM Zoomcamp 2024
189 | if you're interested in learning more about it:
190 |
191 | * [Ollama - Running LLMs on a CPU](https://www.youtube.com/watch?v=PVpBGs_iSjY&list=PL3MmuxUbc_hIB4fSqLy_0AfTjVLpgjV3R)
192 | * [Ollama & Phi3 + Elastic in Docker-Compose](https://www.youtube.com/watch?v=4juoo_jk96U&list=PL3MmuxUbc_hIB4fSqLy_0AfTjVLpgjV3R)
193 | * [UI for RAG](https://www.youtube.com/watch?v=R6L8PZ-7bGo&list=PL3MmuxUbc_hIB4fSqLy_0AfTjVLpgjV3R)
194 |
195 | To see the command lines used in the videos,
196 | see [2024 cohort folder](../cohorts/2024/02-open-source#27-ollama---running-llms-on-a-cpu)
197 |
198 | # Notes
199 |
200 | * [Notes by slavaheroes](https://github.com/slavaheroes/llm-zoomcamp/blob/homeworks/01-intro/notes.md)
201 | * [Notes by Pham Nguyen Hung](https://hung.bearblog.dev/llm-zoomcamp-1-rag/)
202 | * [Notes by dimzachar](https://github.com/dimzachar/llm_zoomcamp/blob/master/notes/01-intro/README.md)
203 | * [Notes by Olawale Ogundeji](https://github.com/presiZHai/LLM-Zoomcamp/blob/main/01-intro/notes.md)
204 | * [Notes by Uchechukwu](https://medium.com/@njokuuchechi/an-intro-to-large-language-models-llms-0c51c09abe10)
205 | * [Notes by Kamal](https://github.com/mk-hassan/llm-zoomcamp/blob/main/Module-1%3A%20Introduction%20to%20LLMs%20and%20RAG/README.md)
206 | * [Notes by Marat](https://machine-mind-ml.medium.com/discovering-semantic-search-and-rag-with-large-language-models-be7d9ba5bef4)
207 | * [Notes by Waleed](https://waleedayoub.com/post/llmzoomcamp_week1-intro_notes/)
208 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
209 |
--------------------------------------------------------------------------------
/01-intro/elastic-search.md:
--------------------------------------------------------------------------------
1 | # Elastic Search
2 |
3 | This document contains useful things about Elasticsearch
4 |
5 | # `multi_match` Query in Elasticsearch
6 |
7 | The `multi_match` query is used to search for a given text across multiple fields in an Elasticsearch index.
8 |
9 | It provides various types to control how the matching is executed and scored.
10 |
11 | There are multiple types of `multi_match` queries:
12 |
13 | - `best_fields`: Returns the highest score from any one field.
14 | - `most_fields`: Combines the scores from all fields.
15 | - `cross_fields`: Treats fields as one big field for scoring.
16 | - `phrase`: Searches for the query as an exact phrase.
17 | - `phrase_prefix`: Searches for the query as a prefix of a phrase.
18 |
19 |
20 | ## `best_fields`
21 |
22 | The `best_fields` type searches each field separately and returns the highest score from any one of the fields.
23 |
24 | This type is useful when you want to find documents where at least one field matches the query well.
25 |
26 |
27 | ```json
28 | {
29 | "size": 5,
30 | "query": {
31 | "bool": {
32 | "must": {
33 | "multi_match": {
34 | "query": "How do I run docker on Windows?",
35 | "fields": ["question", "text"],
36 | "type": "best_fields"
37 | }
38 | }
39 | }
40 | }
41 | }
42 | ```
43 |
44 | ## `most_fields`
45 |
46 | The `most_fields` type searches each field and combines the scores from all fields.
47 |
48 | This is useful when the relevance of a document increases with more matching fields.
49 |
50 | ```json
51 | {
52 | "multi_match": {
53 | "query": "How do I run docker on Windows?",
54 | "fields": ["question^4", "text"],
55 | "type": "most_fields"
56 | }
57 | }
58 | ```
59 |
60 | ## `cross_fields`
61 |
62 | The `cross_fields` type treats fields as though they were one big field.
63 |
64 | It is suitable for cases where you have fields representing the same text in different ways, such as synonyms.
65 |
66 | ```json
67 | {
68 | "multi_match": {
69 | "query": "How do I run docker on Windows?",
70 | "fields": ["question", "text"],
71 | "type": "cross_fields"
72 | }
73 | }
74 | ```
75 |
76 | ## `phrase`
77 |
78 | The `phrase` type looks for the query as an exact phrase within the fields.
79 |
80 | It is useful for exact match searches.
81 |
82 | ```json
83 | {
84 | "multi_match": {
85 | "query": "How do I run docker on Windows?",
86 | "fields": ["question", "text"],
87 | "type": "phrase"
88 | }
89 | }
90 | ```
91 |
92 | ## `phrase_prefix`
93 |
94 | The `phrase_prefix` type searches for documents that contain the query as a prefix of a phrase.
95 |
96 | This is useful for autocomplete or typeahead functionality.
97 |
98 |
99 | ```json
100 | {
101 | "multi_match": {
102 | "query": "How do I run docker on Windows?",
103 | "fields": ["question", "text"],
104 | "type": "phrase_prefix"
105 | }
106 | }
107 | ```
--------------------------------------------------------------------------------
/01-intro/open-ai-alternatives.md:
--------------------------------------------------------------------------------
1 | moved [here](https://github.com/DataTalksClub/llm-zoomcamp/blob/main/awesome-llms.md#openai-api-alternatives)
2 |
--------------------------------------------------------------------------------
/01-intro/parse-faq.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 8,
6 | "id": "4cd1eaa8-3424-41ad-9cf2-3e8548712865",
7 | "metadata": {},
8 | "outputs": [],
9 | "source": [
10 | "import io\n",
11 | "\n",
12 | "import requests\n",
13 | "import docx"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 24,
19 | "id": "8180e7e4-b90d-4900-a59b-d22e5d6537c4",
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "def clean_line(line):\n",
24 | " line = line.strip()\n",
25 | " line = line.strip('\\uFEFF')\n",
26 | " return line\n",
27 | "\n",
28 | "def read_faq(file_id):\n",
29 | " url = f'https://docs.google.com/document/d/{file_id}/export?format=docx'\n",
30 | " \n",
31 | " response = requests.get(url)\n",
32 | " response.raise_for_status()\n",
33 | " \n",
34 | " with io.BytesIO(response.content) as f_in:\n",
35 | " doc = docx.Document(f_in)\n",
36 | "\n",
37 | " questions = []\n",
38 | "\n",
39 | " question_heading_style = 'heading 2'\n",
40 | " section_heading_style = 'heading 1'\n",
41 | " \n",
42 | " heading_id = ''\n",
43 | " section_title = ''\n",
44 | " question_title = ''\n",
45 | " answer_text_so_far = ''\n",
46 | " \n",
47 | " for p in doc.paragraphs:\n",
48 | " style = p.style.name.lower()\n",
49 | " p_text = clean_line(p.text)\n",
50 | " \n",
51 | " if len(p_text) == 0:\n",
52 | " continue\n",
53 | " \n",
54 | " if style == section_heading_style:\n",
55 | " section_title = p_text\n",
56 | " continue\n",
57 | " \n",
58 | " if style == question_heading_style:\n",
59 | " answer_text_so_far = answer_text_so_far.strip()\n",
60 | " if answer_text_so_far != '' and section_title != '' and question_title != '':\n",
61 | " questions.append({\n",
62 | " 'text': answer_text_so_far,\n",
63 | " 'section': section_title,\n",
64 | " 'question': question_title,\n",
65 | " })\n",
66 | " answer_text_so_far = ''\n",
67 | " \n",
68 | " question_title = p_text\n",
69 | " continue\n",
70 | " \n",
71 | " answer_text_so_far += '\\n' + p_text\n",
72 | " \n",
73 | " answer_text_so_far = answer_text_so_far.strip()\n",
74 | " if answer_text_so_far != '' and section_title != '' and question_title != '':\n",
75 | " questions.append({\n",
76 | " 'text': answer_text_so_far,\n",
77 | " 'section': section_title,\n",
78 | " 'question': question_title,\n",
79 | " })\n",
80 | "\n",
81 | " return questions"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 25,
87 | "id": "7d3c2dd7-f64a-4dc7-a4e3-3e8aadfa720f",
88 | "metadata": {},
89 | "outputs": [],
90 | "source": [
91 | "faq_documents = {\n",
92 | " 'data-engineering-zoomcamp': '19bnYs80DwuUimHM65UV3sylsCn2j1vziPOwzBwQrebw',\n",
93 | " 'machine-learning-zoomcamp': '1LpPanc33QJJ6BSsyxVg-pWNMplal84TdZtq10naIhD8',\n",
94 | " 'mlops-zoomcamp': '12TlBfhIiKtyBv8RnsoJR6F72bkPDGEvPOItJIxaEzE0',\n",
95 | "}"
96 | ]
97 | },
98 | {
99 | "cell_type": "code",
100 | "execution_count": 27,
101 | "id": "f94efe26-05e8-4ae5-a0fa-0a8e16852816",
102 | "metadata": {},
103 | "outputs": [
104 | {
105 | "name": "stdout",
106 | "output_type": "stream",
107 | "text": [
108 | "data-engineering-zoomcamp\n",
109 | "machine-learning-zoomcamp\n",
110 | "mlops-zoomcamp\n"
111 | ]
112 | }
113 | ],
114 | "source": [
115 | "documents = []\n",
116 | "\n",
117 | "for course, file_id in faq_documents.items():\n",
118 | " print(course)\n",
119 | " course_documents = read_faq(file_id)\n",
120 | " documents.append({'course': course, 'documents': course_documents})"
121 | ]
122 | },
123 | {
124 | "cell_type": "code",
125 | "execution_count": 29,
126 | "id": "06b8d8be-f656-4cc3-893f-b159be8fda21",
127 | "metadata": {},
128 | "outputs": [],
129 | "source": [
130 | "import json"
131 | ]
132 | },
133 | {
134 | "cell_type": "code",
135 | "execution_count": 32,
136 | "id": "30d50bc1-8d26-44ee-8734-cafce05e0523",
137 | "metadata": {},
138 | "outputs": [],
139 | "source": [
140 | "with open('documents.json', 'wt') as f_out:\n",
141 | " json.dump(documents, f_out, indent=2)"
142 | ]
143 | },
144 | {
145 | "cell_type": "code",
146 | "execution_count": 33,
147 | "id": "0eabb1c6-5cc6-4d4d-a6da-e27d41cea546",
148 | "metadata": {},
149 | "outputs": [
150 | {
151 | "name": "stdout",
152 | "output_type": "stream",
153 | "text": [
154 | "[\n",
155 | " {\n",
156 | " \"course\": \"data-engineering-zoomcamp\",\n",
157 | " \"documents\": [\n",
158 | " {\n",
159 | " \"text\": \"The purpose of this document is to capture frequently asked technical questions\\nThe exact day and hour of the course will be 15th Jan 2024 at 17h00. The course will start with the first \\u201cOffice Hours'' live.1\\nSubscribe to course public Google Calendar (it works from Desktop only).\\nRegister before the course starts using this link.\\nJoin the course Telegram channel with announcements.\\nDon\\u2019t forget to register in DataTalks.Club's Slack and join the channel.\",\n",
160 | " \"section\": \"General course-related questions\",\n",
161 | " \"question\": \"Course - When will the course start?\"\n",
162 | " },\n",
163 | " {\n"
164 | ]
165 | }
166 | ],
167 | "source": [
168 | "!head documents.json"
169 | ]
170 | },
171 | {
172 | "cell_type": "code",
173 | "execution_count": null,
174 | "id": "1b21af5c-2f6d-49e7-92e9-ca229e2473b9",
175 | "metadata": {},
176 | "outputs": [],
177 | "source": []
178 | }
179 | ],
180 | "metadata": {
181 | "kernelspec": {
182 | "display_name": "Python 3 (ipykernel)",
183 | "language": "python",
184 | "name": "python3"
185 | },
186 | "language_info": {
187 | "codemirror_mode": {
188 | "name": "ipython",
189 | "version": 3
190 | },
191 | "file_extension": ".py",
192 | "mimetype": "text/x-python",
193 | "name": "python",
194 | "nbconvert_exporter": "python",
195 | "pygments_lexer": "ipython3",
196 | "version": "3.9.13"
197 | }
198 | },
199 | "nbformat": 4,
200 | "nbformat_minor": 5
201 | }
202 |
--------------------------------------------------------------------------------
/02-vector-search/README.md:
--------------------------------------------------------------------------------
1 | # Vector Search
2 |
3 | TBA
4 |
5 | ## Homework
6 |
7 | See [here](../cohorts/2025/02-vector-search/homework.md)
8 |
9 |
10 | # Notes
11 |
12 | * Notes from [2024 edition](../cohorts/2024/03-vector-search/)
13 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
14 |
--------------------------------------------------------------------------------
/03-evaluation/README.md:
--------------------------------------------------------------------------------
1 | # RAG and LLM Evaluation
2 |
3 | TBA
4 |
5 | ## Homework
6 |
7 | TBA
8 |
9 | # Notes
10 |
11 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
12 |
--------------------------------------------------------------------------------
/04-monitoring/README.md:
--------------------------------------------------------------------------------
1 | # Module 4: Evaluation and Monitoring
2 |
3 | In this module, we will learn how to evaluate and monitor our LLM and RAG system.
4 |
5 | In the evaluation part, we assess the quality of our entire RAG
6 | system before it goes live.
7 |
8 | In the monitoring part, we collect, store and visualize
9 | metrics to assess the answer quality of a deployed LLM. We also
10 | collect chat history and user feedback.
11 |
12 |
13 | TBA
14 |
15 | # Notes
16 |
17 | * Notes from [2024 edition](../cohorts/2024/04-monitoring/)
18 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
19 |
--------------------------------------------------------------------------------
/05-best-practices/README.md:
--------------------------------------------------------------------------------
1 | # Module 6: Best practices
2 |
3 | In this module, we'll cover the techniques that could improve your RAG pipeline.
4 |
5 | ## 6.1 Techniques to Improve RAG Pipeline
6 |
7 |
8 |
98 |
99 |
100 | * Run ElasticSearch with Docker
101 | * Index the documents
102 | * Replace MinSearch with ElasticSearch
103 |
104 | Running ElasticSearch:
105 |
106 | ```bash
107 | docker run -it \
108 | --rm \
109 | --name elasticsearch \
110 | -m 4GB \
111 | -p 9200:9200 \
112 | -p 9300:9300 \
113 | -e "discovery.type=single-node" \
114 | -e "xpack.security.enabled=false" \
115 | docker.elastic.co/elasticsearch/elasticsearch:8.4.3
116 | ```
117 |
118 | If the previous command doesn't work (i.e. you see "error pulling image configuration"), try to run ElasticSearch directly from Docker Hub:
119 |
120 | ```bash
121 | docker run -it \
122 | --rm \
123 | --name elasticsearch \
124 | -p 9200:9200 \
125 | -p 9300:9300 \
126 | -e "discovery.type=single-node" \
127 | -e "xpack.security.enabled=false" \
128 | elasticsearch:8.4.3
129 | ```
130 |
131 | Index settings:
132 |
133 | ```python
134 | {
135 | "settings": {
136 | "number_of_shards": 1,
137 | "number_of_replicas": 0
138 | },
139 | "mappings": {
140 | "properties": {
141 | "text": {"type": "text"},
142 | "section": {"type": "text"},
143 | "question": {"type": "text"},
144 | "course": {"type": "keyword"}
145 | }
146 | }
147 | }
148 | ```
149 |
150 | Query:
151 |
152 | ```python
153 | {
154 | "size": 5,
155 | "query": {
156 | "bool": {
157 | "must": {
158 | "multi_match": {
159 | "query": query,
160 | "fields": ["question^3", "text", "section"],
161 | "type": "best_fields"
162 | }
163 | },
164 | "filter": {
165 | "term": {
166 | "course": "data-engineering-zoomcamp"
167 | }
168 | }
169 | }
170 | }
171 | }
172 | ```
173 |
174 | We use `"type": "best_fields"`. You can read more about
175 | different types of `multi_match` search in [elastic-search.md](elastic-search.md).
176 |
177 | # 1.7 Homework
178 | More information [here](../cohorts/2025/01-intro/homework.md).
179 |
180 |
181 | # Extra materials
182 |
183 | * If you're curious to know how the code for parsing the FAQ works, check [this video](https://www.loom.com/share/ff54d898188b402d880dbea2a7cb8064)
184 |
185 | # Open-Source LLMs (optional)
186 |
187 | It's also possible to run LLMs locally. For that, we
188 | can use Ollama. Check these videos from LLM Zoomcamp 2024
189 | if you're interested in learning more about it:
190 |
191 | * [Ollama - Running LLMs on a CPU](https://www.youtube.com/watch?v=PVpBGs_iSjY&list=PL3MmuxUbc_hIB4fSqLy_0AfTjVLpgjV3R)
192 | * [Ollama & Phi3 + Elastic in Docker-Compose](https://www.youtube.com/watch?v=4juoo_jk96U&list=PL3MmuxUbc_hIB4fSqLy_0AfTjVLpgjV3R)
193 | * [UI for RAG](https://www.youtube.com/watch?v=R6L8PZ-7bGo&list=PL3MmuxUbc_hIB4fSqLy_0AfTjVLpgjV3R)
194 |
195 | To see the command lines used in the videos,
196 | see [2024 cohort folder](../cohorts/2024/02-open-source#27-ollama---running-llms-on-a-cpu)
197 |
198 | # Notes
199 |
200 | * [Notes by slavaheroes](https://github.com/slavaheroes/llm-zoomcamp/blob/homeworks/01-intro/notes.md)
201 | * [Notes by Pham Nguyen Hung](https://hung.bearblog.dev/llm-zoomcamp-1-rag/)
202 | * [Notes by dimzachar](https://github.com/dimzachar/llm_zoomcamp/blob/master/notes/01-intro/README.md)
203 | * [Notes by Olawale Ogundeji](https://github.com/presiZHai/LLM-Zoomcamp/blob/main/01-intro/notes.md)
204 | * [Notes by Uchechukwu](https://medium.com/@njokuuchechi/an-intro-to-large-language-models-llms-0c51c09abe10)
205 | * [Notes by Kamal](https://github.com/mk-hassan/llm-zoomcamp/blob/main/Module-1%3A%20Introduction%20to%20LLMs%20and%20RAG/README.md)
206 | * [Notes by Marat](https://machine-mind-ml.medium.com/discovering-semantic-search-and-rag-with-large-language-models-be7d9ba5bef4)
207 | * [Notes by Waleed](https://waleedayoub.com/post/llmzoomcamp_week1-intro_notes/)
208 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
209 |
--------------------------------------------------------------------------------
/01-intro/elastic-search.md:
--------------------------------------------------------------------------------
1 | # Elastic Search
2 |
3 | This document contains useful things about Elasticsearch
4 |
5 | # `multi_match` Query in Elasticsearch
6 |
7 | The `multi_match` query is used to search for a given text across multiple fields in an Elasticsearch index.
8 |
9 | It provides various types to control how the matching is executed and scored.
10 |
11 | There are multiple types of `multi_match` queries:
12 |
13 | - `best_fields`: Returns the highest score from any one field.
14 | - `most_fields`: Combines the scores from all fields.
15 | - `cross_fields`: Treats fields as one big field for scoring.
16 | - `phrase`: Searches for the query as an exact phrase.
17 | - `phrase_prefix`: Searches for the query as a prefix of a phrase.
18 |
19 |
20 | ## `best_fields`
21 |
22 | The `best_fields` type searches each field separately and returns the highest score from any one of the fields.
23 |
24 | This type is useful when you want to find documents where at least one field matches the query well.
25 |
26 |
27 | ```json
28 | {
29 | "size": 5,
30 | "query": {
31 | "bool": {
32 | "must": {
33 | "multi_match": {
34 | "query": "How do I run docker on Windows?",
35 | "fields": ["question", "text"],
36 | "type": "best_fields"
37 | }
38 | }
39 | }
40 | }
41 | }
42 | ```
43 |
44 | ## `most_fields`
45 |
46 | The `most_fields` type searches each field and combines the scores from all fields.
47 |
48 | This is useful when the relevance of a document increases with more matching fields.
49 |
50 | ```json
51 | {
52 | "multi_match": {
53 | "query": "How do I run docker on Windows?",
54 | "fields": ["question^4", "text"],
55 | "type": "most_fields"
56 | }
57 | }
58 | ```
59 |
60 | ## `cross_fields`
61 |
62 | The `cross_fields` type treats fields as though they were one big field.
63 |
64 | It is suitable for cases where you have fields representing the same text in different ways, such as synonyms.
65 |
66 | ```json
67 | {
68 | "multi_match": {
69 | "query": "How do I run docker on Windows?",
70 | "fields": ["question", "text"],
71 | "type": "cross_fields"
72 | }
73 | }
74 | ```
75 |
76 | ## `phrase`
77 |
78 | The `phrase` type looks for the query as an exact phrase within the fields.
79 |
80 | It is useful for exact match searches.
81 |
82 | ```json
83 | {
84 | "multi_match": {
85 | "query": "How do I run docker on Windows?",
86 | "fields": ["question", "text"],
87 | "type": "phrase"
88 | }
89 | }
90 | ```
91 |
92 | ## `phrase_prefix`
93 |
94 | The `phrase_prefix` type searches for documents that contain the query as a prefix of a phrase.
95 |
96 | This is useful for autocomplete or typeahead functionality.
97 |
98 |
99 | ```json
100 | {
101 | "multi_match": {
102 | "query": "How do I run docker on Windows?",
103 | "fields": ["question", "text"],
104 | "type": "phrase_prefix"
105 | }
106 | }
107 | ```
--------------------------------------------------------------------------------
/01-intro/open-ai-alternatives.md:
--------------------------------------------------------------------------------
1 | moved [here](https://github.com/DataTalksClub/llm-zoomcamp/blob/main/awesome-llms.md#openai-api-alternatives)
2 |
--------------------------------------------------------------------------------
/01-intro/parse-faq.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 8,
6 | "id": "4cd1eaa8-3424-41ad-9cf2-3e8548712865",
7 | "metadata": {},
8 | "outputs": [],
9 | "source": [
10 | "import io\n",
11 | "\n",
12 | "import requests\n",
13 | "import docx"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 24,
19 | "id": "8180e7e4-b90d-4900-a59b-d22e5d6537c4",
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "def clean_line(line):\n",
24 | " line = line.strip()\n",
25 | " line = line.strip('\\uFEFF')\n",
26 | " return line\n",
27 | "\n",
28 | "def read_faq(file_id):\n",
29 | " url = f'https://docs.google.com/document/d/{file_id}/export?format=docx'\n",
30 | " \n",
31 | " response = requests.get(url)\n",
32 | " response.raise_for_status()\n",
33 | " \n",
34 | " with io.BytesIO(response.content) as f_in:\n",
35 | " doc = docx.Document(f_in)\n",
36 | "\n",
37 | " questions = []\n",
38 | "\n",
39 | " question_heading_style = 'heading 2'\n",
40 | " section_heading_style = 'heading 1'\n",
41 | " \n",
42 | " heading_id = ''\n",
43 | " section_title = ''\n",
44 | " question_title = ''\n",
45 | " answer_text_so_far = ''\n",
46 | " \n",
47 | " for p in doc.paragraphs:\n",
48 | " style = p.style.name.lower()\n",
49 | " p_text = clean_line(p.text)\n",
50 | " \n",
51 | " if len(p_text) == 0:\n",
52 | " continue\n",
53 | " \n",
54 | " if style == section_heading_style:\n",
55 | " section_title = p_text\n",
56 | " continue\n",
57 | " \n",
58 | " if style == question_heading_style:\n",
59 | " answer_text_so_far = answer_text_so_far.strip()\n",
60 | " if answer_text_so_far != '' and section_title != '' and question_title != '':\n",
61 | " questions.append({\n",
62 | " 'text': answer_text_so_far,\n",
63 | " 'section': section_title,\n",
64 | " 'question': question_title,\n",
65 | " })\n",
66 | " answer_text_so_far = ''\n",
67 | " \n",
68 | " question_title = p_text\n",
69 | " continue\n",
70 | " \n",
71 | " answer_text_so_far += '\\n' + p_text\n",
72 | " \n",
73 | " answer_text_so_far = answer_text_so_far.strip()\n",
74 | " if answer_text_so_far != '' and section_title != '' and question_title != '':\n",
75 | " questions.append({\n",
76 | " 'text': answer_text_so_far,\n",
77 | " 'section': section_title,\n",
78 | " 'question': question_title,\n",
79 | " })\n",
80 | "\n",
81 | " return questions"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 25,
87 | "id": "7d3c2dd7-f64a-4dc7-a4e3-3e8aadfa720f",
88 | "metadata": {},
89 | "outputs": [],
90 | "source": [
91 | "faq_documents = {\n",
92 | " 'data-engineering-zoomcamp': '19bnYs80DwuUimHM65UV3sylsCn2j1vziPOwzBwQrebw',\n",
93 | " 'machine-learning-zoomcamp': '1LpPanc33QJJ6BSsyxVg-pWNMplal84TdZtq10naIhD8',\n",
94 | " 'mlops-zoomcamp': '12TlBfhIiKtyBv8RnsoJR6F72bkPDGEvPOItJIxaEzE0',\n",
95 | "}"
96 | ]
97 | },
98 | {
99 | "cell_type": "code",
100 | "execution_count": 27,
101 | "id": "f94efe26-05e8-4ae5-a0fa-0a8e16852816",
102 | "metadata": {},
103 | "outputs": [
104 | {
105 | "name": "stdout",
106 | "output_type": "stream",
107 | "text": [
108 | "data-engineering-zoomcamp\n",
109 | "machine-learning-zoomcamp\n",
110 | "mlops-zoomcamp\n"
111 | ]
112 | }
113 | ],
114 | "source": [
115 | "documents = []\n",
116 | "\n",
117 | "for course, file_id in faq_documents.items():\n",
118 | " print(course)\n",
119 | " course_documents = read_faq(file_id)\n",
120 | " documents.append({'course': course, 'documents': course_documents})"
121 | ]
122 | },
123 | {
124 | "cell_type": "code",
125 | "execution_count": 29,
126 | "id": "06b8d8be-f656-4cc3-893f-b159be8fda21",
127 | "metadata": {},
128 | "outputs": [],
129 | "source": [
130 | "import json"
131 | ]
132 | },
133 | {
134 | "cell_type": "code",
135 | "execution_count": 32,
136 | "id": "30d50bc1-8d26-44ee-8734-cafce05e0523",
137 | "metadata": {},
138 | "outputs": [],
139 | "source": [
140 | "with open('documents.json', 'wt') as f_out:\n",
141 | " json.dump(documents, f_out, indent=2)"
142 | ]
143 | },
144 | {
145 | "cell_type": "code",
146 | "execution_count": 33,
147 | "id": "0eabb1c6-5cc6-4d4d-a6da-e27d41cea546",
148 | "metadata": {},
149 | "outputs": [
150 | {
151 | "name": "stdout",
152 | "output_type": "stream",
153 | "text": [
154 | "[\n",
155 | " {\n",
156 | " \"course\": \"data-engineering-zoomcamp\",\n",
157 | " \"documents\": [\n",
158 | " {\n",
159 | " \"text\": \"The purpose of this document is to capture frequently asked technical questions\\nThe exact day and hour of the course will be 15th Jan 2024 at 17h00. The course will start with the first \\u201cOffice Hours'' live.1\\nSubscribe to course public Google Calendar (it works from Desktop only).\\nRegister before the course starts using this link.\\nJoin the course Telegram channel with announcements.\\nDon\\u2019t forget to register in DataTalks.Club's Slack and join the channel.\",\n",
160 | " \"section\": \"General course-related questions\",\n",
161 | " \"question\": \"Course - When will the course start?\"\n",
162 | " },\n",
163 | " {\n"
164 | ]
165 | }
166 | ],
167 | "source": [
168 | "!head documents.json"
169 | ]
170 | },
171 | {
172 | "cell_type": "code",
173 | "execution_count": null,
174 | "id": "1b21af5c-2f6d-49e7-92e9-ca229e2473b9",
175 | "metadata": {},
176 | "outputs": [],
177 | "source": []
178 | }
179 | ],
180 | "metadata": {
181 | "kernelspec": {
182 | "display_name": "Python 3 (ipykernel)",
183 | "language": "python",
184 | "name": "python3"
185 | },
186 | "language_info": {
187 | "codemirror_mode": {
188 | "name": "ipython",
189 | "version": 3
190 | },
191 | "file_extension": ".py",
192 | "mimetype": "text/x-python",
193 | "name": "python",
194 | "nbconvert_exporter": "python",
195 | "pygments_lexer": "ipython3",
196 | "version": "3.9.13"
197 | }
198 | },
199 | "nbformat": 4,
200 | "nbformat_minor": 5
201 | }
202 |
--------------------------------------------------------------------------------
/02-vector-search/README.md:
--------------------------------------------------------------------------------
1 | # Vector Search
2 |
3 | TBA
4 |
5 | ## Homework
6 |
7 | See [here](../cohorts/2025/02-vector-search/homework.md)
8 |
9 |
10 | # Notes
11 |
12 | * Notes from [2024 edition](../cohorts/2024/03-vector-search/)
13 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
14 |
--------------------------------------------------------------------------------
/03-evaluation/README.md:
--------------------------------------------------------------------------------
1 | # RAG and LLM Evaluation
2 |
3 | TBA
4 |
5 | ## Homework
6 |
7 | TBA
8 |
9 | # Notes
10 |
11 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
12 |
--------------------------------------------------------------------------------
/04-monitoring/README.md:
--------------------------------------------------------------------------------
1 | # Module 4: Evaluation and Monitoring
2 |
3 | In this module, we will learn how to evaluate and monitor our LLM and RAG system.
4 |
5 | In the evaluation part, we assess the quality of our entire RAG
6 | system before it goes live.
7 |
8 | In the monitoring part, we collect, store and visualize
9 | metrics to assess the answer quality of a deployed LLM. We also
10 | collect chat history and user feedback.
11 |
12 |
13 | TBA
14 |
15 | # Notes
16 |
17 | * Notes from [2024 edition](../cohorts/2024/04-monitoring/)
18 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
19 |
--------------------------------------------------------------------------------
/05-best-practices/README.md:
--------------------------------------------------------------------------------
1 | # Module 6: Best practices
2 |
3 | In this module, we'll cover the techniques that could improve your RAG pipeline.
4 |
5 | ## 6.1 Techniques to Improve RAG Pipeline
6 |
7 |
8 | 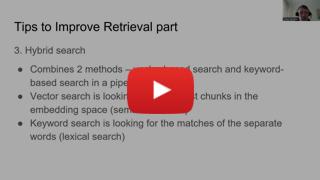 9 |
10 |
11 | * Small-to-Big chunk retrieval
12 | * Leveraging document metadata
13 | * Hybrid search
14 | * User query rewriting
15 | * Document reranking
16 |
17 | Links:
18 | * [Slides](llm-zoomcamp-best-practicies.pdf)
19 | * [Five Techniques for Improving RAG Chatbots - Nikita Kozodoi [Video]](https://www.youtube.com/watch?v=xPYmClWk5O8)
20 | * [Survey on RAG techniques [Article]](https://arxiv.org/abs/2312.10997)
21 |
22 |
23 | ## 6.2 Hybrid search
24 |
25 |
26 |
9 |
10 |
11 | * Small-to-Big chunk retrieval
12 | * Leveraging document metadata
13 | * Hybrid search
14 | * User query rewriting
15 | * Document reranking
16 |
17 | Links:
18 | * [Slides](llm-zoomcamp-best-practicies.pdf)
19 | * [Five Techniques for Improving RAG Chatbots - Nikita Kozodoi [Video]](https://www.youtube.com/watch?v=xPYmClWk5O8)
20 | * [Survey on RAG techniques [Article]](https://arxiv.org/abs/2312.10997)
21 |
22 |
23 | ## 6.2 Hybrid search
24 |
25 |
26 |  27 |
28 |
29 | * Hybrid search strategy
30 | * Hybrid search in Elasticsearch
31 |
32 | Links:
33 | * [Notebook](hybrid-search-and-reranking-es.ipynb)
34 | * [Hybrid search [Elasticsearch Guide]](https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html#_combine_approximate_knn_with_other_features)
35 | * [Hybrid search [Tutorial]](https://www.elastic.co/search-labs/tutorials/search-tutorial/vector-search/hybrid-search)
36 |
37 |
38 | ## 6.3 Document Reranking
39 |
40 |
41 |
27 |
28 |
29 | * Hybrid search strategy
30 | * Hybrid search in Elasticsearch
31 |
32 | Links:
33 | * [Notebook](hybrid-search-and-reranking-es.ipynb)
34 | * [Hybrid search [Elasticsearch Guide]](https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html#_combine_approximate_knn_with_other_features)
35 | * [Hybrid search [Tutorial]](https://www.elastic.co/search-labs/tutorials/search-tutorial/vector-search/hybrid-search)
36 |
37 |
38 | ## 6.3 Document Reranking
39 |
40 |
41 |  42 |
43 |
44 | * Reranking concept and metrics
45 | * Reciprocal Rank Fusion (RRF)
46 | * Handmade raranking implementation
47 |
48 | Links:
49 | * [Reciprocal Rank Fusion (RRF) method [Elasticsearch Guide]](https://www.elastic.co/guide/en/elasticsearch/reference/current/rrf.html)
50 | * [RRF method [Article]](https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf)
51 | * [Elasticsearch subscription plans](https://www.elastic.co/subscriptions)
52 |
53 | We should pull and run a docker container with Elasticsearch 8.9.0 or higher in order to use reranking based on RRF algorithm:
54 |
55 | ```bash
56 | docker run -it \
57 | --rm \
58 | --name elasticsearch \
59 | -m 4GB \
60 | -p 9200:9200 \
61 | -p 9300:9300 \
62 | -e "discovery.type=single-node" \
63 | -e "xpack.security.enabled=false" \
64 | docker.elastic.co/elasticsearch/elasticsearch:8.9.0
65 | ```
66 |
67 |
68 | ## 6.4 Hybrid search with LangChain
69 |
70 |
71 |
42 |
43 |
44 | * Reranking concept and metrics
45 | * Reciprocal Rank Fusion (RRF)
46 | * Handmade raranking implementation
47 |
48 | Links:
49 | * [Reciprocal Rank Fusion (RRF) method [Elasticsearch Guide]](https://www.elastic.co/guide/en/elasticsearch/reference/current/rrf.html)
50 | * [RRF method [Article]](https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf)
51 | * [Elasticsearch subscription plans](https://www.elastic.co/subscriptions)
52 |
53 | We should pull and run a docker container with Elasticsearch 8.9.0 or higher in order to use reranking based on RRF algorithm:
54 |
55 | ```bash
56 | docker run -it \
57 | --rm \
58 | --name elasticsearch \
59 | -m 4GB \
60 | -p 9200:9200 \
61 | -p 9300:9300 \
62 | -e "discovery.type=single-node" \
63 | -e "xpack.security.enabled=false" \
64 | docker.elastic.co/elasticsearch/elasticsearch:8.9.0
65 | ```
66 |
67 |
68 | ## 6.4 Hybrid search with LangChain
69 |
70 |
71 |  72 |
73 |
74 | * LangChain: Introduction
75 | * ElasticsearchRetriever
76 | * Hybrid search implementation
77 |
78 | ```bash
79 | pip install -qU langchain langchain-elasticsearch langchain-huggingface
80 | ```
81 |
82 | Links:
83 | * [Notebook](hybrid-search-langchain.ipynb)
84 | * [Chatbot Implementation [Tutorial]](https://www.elastic.co/search-labs/tutorials/chatbot-tutorial/implementation)
85 | * [ElasticsearchRetriever](https://python.langchain.com/v0.2/docs/integrations/retrievers/elasticsearch_retriever/)
86 |
87 |
88 | ## Homework
89 |
90 | TBD
91 |
92 | # Notes
93 |
94 | * First link goes here
95 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
96 |
--------------------------------------------------------------------------------
/05-best-practices/llm-zoomcamp-best-practicies.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DataTalksClub/llm-zoomcamp/b9d8bd63621736c75fa8d6d0def5ad6656c0b981/05-best-practices/llm-zoomcamp-best-practicies.pdf
--------------------------------------------------------------------------------
/06-project-example/README.md:
--------------------------------------------------------------------------------
1 | # 7. End-to-End Project Example
2 |
3 | Links:
4 |
5 | * [Project alexeygrigorev/fitness-assistant](https://github.com/alexeygrigorev/fitness-assistant)
6 | * [Project criteria](../project.md#evaluation-criteria)
7 |
8 |
9 | Note: check the final result, it's a bit different
10 | from what we showed in the videos: we further improved it
11 | by doing some small things here and there, like improved
12 | README, code readability, etc.
13 |
14 |
15 | ## 7.1. Fitness assistant project
16 |
17 |
18 |
72 |
73 |
74 | * LangChain: Introduction
75 | * ElasticsearchRetriever
76 | * Hybrid search implementation
77 |
78 | ```bash
79 | pip install -qU langchain langchain-elasticsearch langchain-huggingface
80 | ```
81 |
82 | Links:
83 | * [Notebook](hybrid-search-langchain.ipynb)
84 | * [Chatbot Implementation [Tutorial]](https://www.elastic.co/search-labs/tutorials/chatbot-tutorial/implementation)
85 | * [ElasticsearchRetriever](https://python.langchain.com/v0.2/docs/integrations/retrievers/elasticsearch_retriever/)
86 |
87 |
88 | ## Homework
89 |
90 | TBD
91 |
92 | # Notes
93 |
94 | * First link goes here
95 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
96 |
--------------------------------------------------------------------------------
/05-best-practices/llm-zoomcamp-best-practicies.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DataTalksClub/llm-zoomcamp/b9d8bd63621736c75fa8d6d0def5ad6656c0b981/05-best-practices/llm-zoomcamp-best-practicies.pdf
--------------------------------------------------------------------------------
/06-project-example/README.md:
--------------------------------------------------------------------------------
1 | # 7. End-to-End Project Example
2 |
3 | Links:
4 |
5 | * [Project alexeygrigorev/fitness-assistant](https://github.com/alexeygrigorev/fitness-assistant)
6 | * [Project criteria](../project.md#evaluation-criteria)
7 |
8 |
9 | Note: check the final result, it's a bit different
10 | from what we showed in the videos: we further improved it
11 | by doing some small things here and there, like improved
12 | README, code readability, etc.
13 |
14 |
15 | ## 7.1. Fitness assistant project
16 |
17 |
18 |  19 |
20 |
21 | * Generating data for the project
22 | * Setting up the project
23 | * Implementing the initial version of the RAG flow
24 |
25 | ## 7.2. Evaluating retrieval
26 |
27 |
28 |
19 |
20 |
21 | * Generating data for the project
22 | * Setting up the project
23 | * Implementing the initial version of the RAG flow
24 |
25 | ## 7.2. Evaluating retrieval
26 |
27 |
28 |  29 |
30 |
31 | * Preparing the README file
32 | * Generating gold standard evaluation data
33 | * Evaluting retrieval
34 | * Findning the best boosting coefficients
35 |
36 |
37 | ## 7.3 Evaluating RAG
38 |
39 |
40 |
29 |
30 |
31 | * Preparing the README file
32 | * Generating gold standard evaluation data
33 | * Evaluting retrieval
34 | * Findning the best boosting coefficients
35 |
36 |
37 | ## 7.3 Evaluating RAG
38 |
39 |
40 |  41 |
42 |
43 | * Using LLM-as-a-Judge (type 2)
44 | * Comparing gpt-4o-mini with gpt-4o
45 |
46 | ## 7.4 Interface and ingestion pipeline
47 |
48 |
49 |
41 |
42 |
43 | * Using LLM-as-a-Judge (type 2)
44 | * Comparing gpt-4o-mini with gpt-4o
45 |
46 | ## 7.4 Interface and ingestion pipeline
47 |
48 |
49 |  50 |
51 |
52 | * Turnining the jupyter notebook into a script
53 | * Creating the ingestion pipeline
54 | * Creating the API interface with Flask
55 | * Improving README
56 |
57 |
58 | ## 7.5 Monitoring and containerization
59 |
60 |
61 |
50 |
51 |
52 | * Turnining the jupyter notebook into a script
53 | * Creating the ingestion pipeline
54 | * Creating the API interface with Flask
55 | * Improving README
56 |
57 |
58 | ## 7.5 Monitoring and containerization
59 |
60 |
61 |  62 |
63 |
64 | * Creating a Docker image for our application
65 | * Putting everything in docker compose
66 | * Logging all the information for monitoring purposes
67 |
68 |
69 | ## 7.6 Summary and closing remarks
70 |
71 |
72 |
62 |
63 |
64 | * Creating a Docker image for our application
65 | * Putting everything in docker compose
66 | * Logging all the information for monitoring purposes
67 |
68 |
69 | ## 7.6 Summary and closing remarks
70 |
71 |
72 | 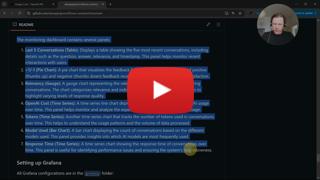 73 |
74 |
75 | * Changes between 7.5 and 7.6 (postres logging, grafara, cli.py, etc)
76 | * README file improvements
77 | * Total cost of the project (~$2) and how to lower it
78 | * Using generated data for real-life projects
79 |
80 |
81 | ## 7.7 Chunking for longer texts
82 |
83 |
84 |
73 |
74 |
75 | * Changes between 7.5 and 7.6 (postres logging, grafara, cli.py, etc)
76 | * README file improvements
77 | * Total cost of the project (~$2) and how to lower it
78 | * Using generated data for real-life projects
79 |
80 |
81 | ## 7.7 Chunking for longer texts
82 |
83 |
84 |  85 |
86 |
87 | * Different chunking strategies
88 | * [Use cases: multiple articles, one article, slide decks](content-processing-summary.md)
89 |
90 | Links:
91 |
92 | * https://chatgpt.com/share/a4616f6b-43f4-4225-9d03-bb69c723c210
93 | * https://chatgpt.com/share/74217c02-95e6-46ae-b5a5-ca79f9a07084
94 | * https://chatgpt.com/share/8cf0ebde-c53f-4c6f-82ae-c6cc52b2fd0b
95 |
96 | # Notes
97 |
98 | * First link goes here
99 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
100 |
--------------------------------------------------------------------------------
/06-project-example/content-processing-summary.md:
--------------------------------------------------------------------------------
1 | # Content Processing Cases and Steps
2 |
3 | ## Case: Multiple Articles
4 |
5 | - Assign each article a document id
6 | - Chunk the articles
7 | - Assign each chunk a unique chunk id (could be doc_id + chunk_number)
8 | - Evaluate retrieval: separate hitrate for both doc_id and chunk_id
9 | - Evaluate RAG: LLM as a Judge
10 | - Tuning chunk size: use metrics from Evaluate RAG
11 |
12 | Example JSON structure for a chunk:
13 | ```json
14 | {
15 | "doc_id": "ashdiasdh",
16 | "chunk_id": "ashdiasdh_1",
17 | "text": "actual text"
18 | }
19 | ```
20 |
21 | ## Case: Single Article / Transcript / Etc.
22 |
23 | Example: the user provides YouTubeID, you initialize the system and now you can talk to it
24 |
25 | - Chunk it
26 | - Evaluation as for multiple articles
27 |
28 |
29 | ## Case: Book or Very Long Form Content
30 |
31 | - Experiment with it
32 | - Each chapter / section can be a separate document
33 | - Use LLM as a Judge to see which approach works best
34 |
35 | ## Case: Images
36 |
37 | - Describe the images using gpt-4o-mini
38 | - [CLIP](https://openai.com/index/clip/)
39 | - Each image is a separate document
40 |
41 | ## Case: Slides
42 |
43 | - Same as with images + multiple articles
44 | - "Chunking": slide deck = document, slide = chunk
45 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
85 |
86 |
87 | * Different chunking strategies
88 | * [Use cases: multiple articles, one article, slide decks](content-processing-summary.md)
89 |
90 | Links:
91 |
92 | * https://chatgpt.com/share/a4616f6b-43f4-4225-9d03-bb69c723c210
93 | * https://chatgpt.com/share/74217c02-95e6-46ae-b5a5-ca79f9a07084
94 | * https://chatgpt.com/share/8cf0ebde-c53f-4c6f-82ae-c6cc52b2fd0b
95 |
96 | # Notes
97 |
98 | * First link goes here
99 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
100 |
--------------------------------------------------------------------------------
/06-project-example/content-processing-summary.md:
--------------------------------------------------------------------------------
1 | # Content Processing Cases and Steps
2 |
3 | ## Case: Multiple Articles
4 |
5 | - Assign each article a document id
6 | - Chunk the articles
7 | - Assign each chunk a unique chunk id (could be doc_id + chunk_number)
8 | - Evaluate retrieval: separate hitrate for both doc_id and chunk_id
9 | - Evaluate RAG: LLM as a Judge
10 | - Tuning chunk size: use metrics from Evaluate RAG
11 |
12 | Example JSON structure for a chunk:
13 | ```json
14 | {
15 | "doc_id": "ashdiasdh",
16 | "chunk_id": "ashdiasdh_1",
17 | "text": "actual text"
18 | }
19 | ```
20 |
21 | ## Case: Single Article / Transcript / Etc.
22 |
23 | Example: the user provides YouTubeID, you initialize the system and now you can talk to it
24 |
25 | - Chunk it
26 | - Evaluation as for multiple articles
27 |
28 |
29 | ## Case: Book or Very Long Form Content
30 |
31 | - Experiment with it
32 | - Each chapter / section can be a separate document
33 | - Use LLM as a Judge to see which approach works best
34 |
35 | ## Case: Images
36 |
37 | - Describe the images using gpt-4o-mini
38 | - [CLIP](https://openai.com/index/clip/)
39 | - Each image is a separate document
40 |
41 | ## Case: Slides
42 |
43 | - Same as with images + multiple articles
44 | - "Chunking": slide deck = document, slide = chunk
45 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |  3 |
3 |
4 |
5 |
6 | LLM Zoomcamp: A Free Course on Real-Life Applications of LLMs
7 |
8 |
9 |
10 | In 10 weeks, learn how to build AI systems that answer questions about your knowledge base. Gain hands-on experience with LLMs, RAG, vector search, evaluation, monitoring, and more.
11 |
12 |
13 |
14 |  15 |
15 |
16 |
17 |
18 | Join Slack •
19 | #course-llm-zoomcamp Channel •
20 | Telegram Announcements •
21 | Course Playlist •
22 | FAQ
23 |
24 |
25 | ## How to Take LLM Zoomcamp
26 |
27 | ### 2025 Cohort
28 | - **Start Date**: June 2, 2025, 17:00 CET
29 | - **Register Here**: [Sign up](https://airtable.com/appPPxkgYLH06Mvbw/shr7WtxHEPXxaui0Q)
30 |
31 | 2025 cohort checklist:
32 | - Subscribe to our [Google Calendar](https://calendar.google.com/calendar/?cid=NjkxOThkOGFhZmUyZmQwMzZjNDFkNmE2ZDIyNjE5YjdiMmQyZDVjZTYzOGMxMzQyZmNkYjE5Y2VkNDYxOTUxY0Bncm91cC5jYWxlbmRhci5nb29nbGUuY29t)
33 | - Check [2025 cohort folder](https://github.com/DataTalksClub/llm-zoomcamp/tree/main/cohorts/2025) to stay updated
34 | - Watch [live Q&A](https://youtube.com/live/8lgiOLMMKcY) about the course
35 | - Watch [live course launch](https://www.youtube.com/live/FgnelhEJFj0) stream
36 | - Save the [2025 course playlist](https://youtube.com/playlist?list=PL3MmuxUbc_hIoBpuc900htYF4uhEAbaT-&si=n7CuD0DEgPtnbtsI) on YouTube
37 | - Check course content by navigating to the right module on GitHub
38 | - Share this course with a friend!
39 |
40 | ### Self-Paced Learning
41 | You can follow the course at your own pace:
42 | 1. Watch the course videos.
43 | 2. Complete the homework assignments.
44 | 3. Work on a project and share it in Slack for feedback.
45 |
46 | ## Syllabus
47 |
48 | ### Pre-course Workshops
49 | - [Build a Search Engine](https://www.youtube.com/watch?v=nMrGK5QgPVE) ([Code](https://github.com/alexeygrigorev/build-your-own-search-engine))
50 |
51 | ### Modules
52 |
53 | #### [Module 1: Introduction to LLMs and RAG](01-intro/)
54 | - Basics of LLMs and Retrieval-Augmented Generation (RAG)
55 | - OpenAI API and text search with Elasticsearch
56 |
57 | #### [Module 2: Vector Search](02-vector-search/)
58 |
59 | - Vector search and embeddings
60 | - Indexing and retrieving data efficiently
61 | - Using Qdrant as the vestor database
62 |
63 | #### [Module 3: Evaluation](03-evaluation/)
64 |
65 | - Search evaluation
66 | - Online vs offline evaluation
67 | - LLM as a Judge
68 |
69 | #### [Module 4: Monitoring](04-monitoring/)
70 |
71 | - Online evaluation techniques
72 | - Monitoring user feedback with dashboards
73 |
74 |
75 | #### [Module 5: Best Practices](05-best-practices/)
76 | - Hybrid search
77 | - Document reranking
78 |
79 | #### [Module 6: Bonus - End-to-End Project](06-project-example/)
80 | - Build a fitness assistant using LLMs
81 |
82 | ### [Capstone Project](project.md)
83 |
84 | Put eveything you learned into practice
85 |
86 | ## Meet the Instructors
87 | - [Alexey Grigorev](https://linkedin.com/in/agrigorev/)
88 | - [Timur Kamaliev](https://www.linkedin.com/in/timurkamaliev/)
89 |
90 | ## Community & Support
91 |
92 | ### **Getting Help on Slack**
93 | Join the [`#course-llm-zoomcamp`](https://app.slack.com/client/T01ATQK62F8/C06TEGTGM3J) channel on [DataTalks.Club Slack](https://datatalks.club/slack.html) for discussions, troubleshooting, and networking.
94 |
95 | To keep discussions organized:
96 | - Follow [our guidelines](asking-questions.md) when posting questions.
97 | - Review the [community guidelines](https://datatalks.club/slack/guidelines.html).
98 |
99 | ## Sponsors & Supporters
100 | A special thanks to our course sponsors for making this initiative possible!
101 |
102 |
103 |
104 |  105 |
106 |
105 |
106 |
107 |
108 |
109 |
110 |  111 |
112 |
111 |
112 |
113 |
114 |
115 |
116 |  117 |
118 |
117 |
118 |
119 |
120 |
121 | Interested in supporting our community? Reach out to [alexey@datatalks.club](mailto:alexey@datatalks.club).
122 |
123 | ## About DataTalks.Club
124 |
125 |
126 |  127 |
127 |
128 |
129 |
130 | DataTalks.Club is a global online community of data enthusiasts. It's a place to discuss data, learn, share knowledge, ask and answer questions, and support each other.
131 |
132 |
133 |
134 | Website •
135 | Join Slack Community •
136 | Newsletter •
137 | Upcoming Events •
138 | Google Calendar •
139 | YouTube •
140 | GitHub •
141 | LinkedIn •
142 | Twitter
143 |
144 |
145 | All the activity at DataTalks.Club mainly happens on [Slack](https://datatalks.club/slack.html). We post updates there and discuss different aspects of data, career questions, and more.
146 |
147 | At DataTalksClub, we organize online events, community activities, and free courses. You can learn more about what we do at [DataTalksClub Community Navigation](https://www.notion.so/DataTalksClub-Community-Navigation-bf070ad27ba44bf6bbc9222082f0e5a8?pvs=21).
148 |
--------------------------------------------------------------------------------
/after-sign-up.md:
--------------------------------------------------------------------------------
1 | ## Thank you!
2 |
3 | Thanks for signining up for the course.
4 |
5 | Here are some things you should do before you start the course:
6 |
7 | - Register in [DataTalks.Club's Slack](https://datatalks.club/slack.html)
8 | - Join the [`#course-llm-zoomcamp`](https://app.slack.com/client/T01ATQK62F8/C06TEGTGM3J) channel
9 | - Join the [course Telegram channel with announcements](https://t.me/llm_zoomcamp)
10 | - Subscribe to [DataTalks.Club's YouTube channel](https://www.youtube.com/c/DataTalksClub) and check [the course playlist](https://www.youtube.com/playlist?list=PL3MmuxUbc_hKiIVNf7DeEt_tGjypOYtKV)
11 | - Subscribe to our [Course Calendar](https://calendar.google.com/calendar/?cid=NjkxOThkOGFhZmUyZmQwMzZjNDFkNmE2ZDIyNjE5YjdiMmQyZDVjZTYzOGMxMzQyZmNkYjE5Y2VkNDYxOTUxY0Bncm91cC5jYWxlbmRhci5nb29nbGUuY29t)
12 | - Check our [Technical FAQ](https://docs.google.com/document/d/1m2KexowAXTmexfC5rVTCSnaShvdUQ8Ag2IEiwBDHxN0/edit?usp=sharing) if you have questions
13 |
14 | See you in the course!
15 |
--------------------------------------------------------------------------------
/asking-questions.md:
--------------------------------------------------------------------------------
1 | ## Asking questions
2 |
3 | If you have any questions, ask them
4 | in the [`#course-llm-zoomcamp`](https://app.slack.com/client/T01ATQK62F8/C06TEGTGM3J) channel in [DataTalks.Club](https://datatalks.club) slack.
5 |
6 | To keep our discussion in Slack more organized, we ask you to follow these suggestions:
7 |
8 | * Before asking a question, check [FAQ](https://docs.google.com/document/d/1m2KexowAXTmexfC5rVTCSnaShvdUQ8Ag2IEiwBDHxN0/edit?usp=sharing).
9 | * Use threads. When you have a problem, first describe the problem shortly
10 | and then put the actual error in the thread - so it doesn't take the entire screen.
11 | * Instead of screenshots, it's better to copy-paste the error you're getting in text.
12 | Use ` ``` ` for formatting your code.
13 | It's very difficult to read text from screenshots.
14 | * Please don't take pictures of your code with a phone. It's even harder to read. Follow the previous suggestion,
15 | and in rare cases when you need to show what happens on your screen, take a screenshot.
16 | * You don't need to tag the instructors when you have a problem. We will see it eventually.
17 | * If somebody helped you with your problem and it's not in [FAQ](https://docs.google.com/document/d/1m2KexowAXTmexfC5rVTCSnaShvdUQ8Ag2IEiwBDHxN0/edit?usp=sharing), please add it there.
18 | It'll help other students.
19 |
--------------------------------------------------------------------------------
/awesome-llms.md:
--------------------------------------------------------------------------------
1 | # Awesome LLMs
2 |
3 | In this file, we will collect all interesting links
4 |
5 | ## OpenAI API Alternatives
6 |
7 | OpenAI and GPT are not the only hosted LLMs that we can use.
8 | There are other services that we can use
9 |
10 |
11 | * [mistral.ai](https://mistral.ai) (5€ free credit on sign up)
12 | * [Groq](https://console.groq.com) (can inference from open source LLMs with rate limits)
13 | * [TogetherAI](https://api.together.ai) (can inference from variety of open source LLMs, 25$ free credit on sign up)
14 | * [Google Gemini](https://ai.google.dev/gemini-api/docs/get-started/tutorial?lang=python) (2 months unlimited access)
15 | * [OpenRouterAI](https://openrouter.ai/) (some small open-source models, such as Gemma 7B, are free)
16 | * [HuggingFace API](https://huggingface.co/docs/api-inference/index) (over 150,000 open-source models, rate-limited and free)
17 | * [Cohere](https://cohere.com/) (provides a developer trail key which allows upto 100 reqs/min for generating, summarizing, and classifying text. Read more [here](https://cohere.com/blog/free-developer-tier-announcement))
18 | * [wit](https://wit.ai/) (Facebook AI Afiliate - free)
19 | * [Anthropic API](https://www.anthropic.com/pricing#anthropic-api) (starting from $0.25 / MTok for input and $1.25 / MTok for the output for the most affordable model)
20 | * [AI21Labs API](https://www.ai21.com/pricing#foundation-models) (Free trial including $10 credits for 3 months)
21 | * [Replicate](https://replicate.com/) (faster inference, can host any ML model. charges 0.10$ per 1M input tokens for llama/Mistral model)
22 |
23 |
24 | ## Local LLMs on CPUs
25 |
26 | These services help run LLMs locally, also without GPUs
27 |
28 | - [ollama](https://github.com/ollama/ollama)
29 | - [Jan.AI](https://jan.ai/)
30 | - [h2oGPT](https://github.com/h2oai/h2ogpt)
31 |
32 |
33 | ## Applications
34 | - **Text Generation**
35 | - [OpenAI GPT-3 Playground](https://platform.openai.com/playground)
36 | - [AI Dungeon](https://play.aidungeon.io/)
37 | - **Chatbots**
38 | - [Rasa](https://rasa.com/)
39 | - [Microsoft Bot Framework](https://dev.botframework.com/)
40 | - **Sentiment Analysis**
41 | - [VADER Sentiment Analysis](https://github.com/cjhutto/vaderSentiment)
42 | - [TextBlob](https://textblob.readthedocs.io/en/dev/)
43 | - **Summarization**
44 | - [Sumy](https://github.com/miso-belica/sumy)
45 | - [Hugging Face Transformers Summarization](https://huggingface.co/transformers/task_summary.html)
46 | - **Translation**
47 | - [MarianMT by Hugging Face](https://huggingface.co/transformers/model_doc/marian.html)
48 |
49 | ## Fine-Tuning
50 | - **Guides and Tutorials**
51 | - [Fine-Tuning GPT-3](https://platform.openai.com/docs/guides/fine-tuning)
52 | - [Hugging Face Fine-Tuning Tutorial](https://huggingface.co/transformers/training.html)
53 | - **Tools and Frameworks**
54 | - [Hugging Face Trainer](https://huggingface.co/transformers/main_classes/trainer.html)
55 | - [Fastai](https://docs.fast.ai/text.learner.html)
56 | - **Colab Notebooks**
57 | - [Fine-Tuning BERT on Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)
58 | - [Fine-Tuning GPT-2 on Colab](https://colab.research.google.com/github/fastai/course-v3/blob/master/nbs/dl2/12a_ulmfit.ipynb)
59 |
60 | ## Prompt Engineering
61 | - **Techniques and Best Practices**
62 | - [OpenAI Prompt Engineering Guide](https://platform.openai.com/docs/guides/completions/best-practices)
63 | - [Prompt Design for GPT-3](https://beta.openai.com/docs/guides/prompt-design)
64 | - **Tools**
65 | - [Prompt Designer](https://promptdesigner.com/)
66 | - [Prompt Engineering Toolkit](https://github.com/prompt-engineering/awesome-prompt-engineering)
67 | - **Examples and Case Studies**
68 | - [Awesome ChatGPT Prompts](https://github.com/f/awesome-chatgpt-prompts)
69 | - [GPT-3 Prompt Engineering Examples](https://github.com/shreyashankar/gpt-3-sandbox)
70 |
71 | ## Deployment
72 | - **Hosting Services**
73 | - [Hugging Face Inference API](https://huggingface.co/inference-api)
74 | - [AWS SageMaker](https://aws.amazon.com/sagemaker/)
75 | - **Serverless Deployments**
76 | - [Serverless GPT-3 with AWS Lambda](https://towardsdatascience.com/building-serverless-gpt-3-powered-apis-with-aws-lambda-f2d4b8a91058)
77 | - [Deploying on Vercel](https://vercel.com/guides/deploying-next-and-vercel-api-with-openai-gpt-3)
78 | - **Containerization**
79 | - [Dockerizing a GPT Model](https://medium.com/swlh/dockerize-your-gpt-3-chatbot-28dd48c19c91)
80 | - [Kubernetes for ML Deployments](https://towardsdatascience.com/kubernetes-for-machine-learning-6c7f5c5466a2)
81 |
82 | ## Monitoring and Logging
83 | - **Best Practices**
84 | - [Logging and Monitoring AI Models](https://www.dominodatalab.com/resources/whitepapers/logging-and-monitoring-for-machine-learning)
85 | - [Monitor Your NLP Models](https://towardsdatascience.com/monitor-your-nlp-models-40c2fb141a51)
86 |
87 | ## Ethics and Bias
88 | - **Frameworks and Guidelines**
89 | - [AI Ethics Guidelines Global Inventory](https://algorithmwatch.org/en/project/ai-ethics-guidelines-global-inventory/)
90 | - [Google AI Principles](https://ai.google/principles/)
91 | - **Tools**
92 | - [Fairness Indicators](https://www.tensorflow.org/tfx/guide/fairness_indicators)
93 | - [IBM AI Fairness 360](https://aif360.mybluemix.net/)
94 | - **Research Papers**
95 | - [Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification](http://gendershades.org/overview.html)
96 | - [AI Fairness and Bias](https://arxiv.org/abs/1908.09635)
97 |
98 |
99 |
100 |
--------------------------------------------------------------------------------
/cohorts/2024/01-intro/homework.md:
--------------------------------------------------------------------------------
1 | ## Homework: Introduction
2 |
3 | In this homework, we'll learn more about search and use Elastic Search for practice.
4 |
5 | > It's possible that your answers won't match exactly. If it's the case, select the closest one.
6 |
7 | ## Q1. Running Elastic
8 |
9 | Run Elastic Search 8.4.3, and get the cluster information. If you run it on localhost, this is how you do it:
10 |
11 | ```bash
12 | curl localhost:9200
13 | ```
14 |
15 | What's the `version.build_hash` value?
16 |
17 |
18 | ## Getting the data
19 |
20 | Now let's get the FAQ data. You can run this snippet:
21 |
22 | ```python
23 | import requests
24 |
25 | docs_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main/01-intro/documents.json?raw=1'
26 | docs_response = requests.get(docs_url)
27 | documents_raw = docs_response.json()
28 |
29 | documents = []
30 |
31 | for course in documents_raw:
32 | course_name = course['course']
33 |
34 | for doc in course['documents']:
35 | doc['course'] = course_name
36 | documents.append(doc)
37 | ```
38 |
39 | Note that you need to have the `requests` library:
40 |
41 | ```bash
42 | pip install requests
43 | ```
44 |
45 | ## Q2. Indexing the data
46 |
47 | Index the data in the same way as was shown in the course videos. Make the `course` field a keyword and the rest should be text.
48 |
49 | Don't forget to install the ElasticSearch client for Python:
50 |
51 | ```bash
52 | pip install elasticsearch
53 | ```
54 |
55 | Which function do you use for adding your data to elastic?
56 |
57 | * `insert`
58 | * `index`
59 | * `put`
60 | * `add`
61 |
62 | ## Q3. Searching
63 |
64 | Now let's search in our index.
65 |
66 | We will execute a query "How do I execute a command in a running docker container?".
67 |
68 | Use only `question` and `text` fields and give `question` a boost of 4, and use `"type": "best_fields"`.
69 |
70 | What's the score for the top ranking result?
71 |
72 | * 94.05
73 | * 84.05
74 | * 74.05
75 | * 64.05
76 |
77 | Look at the `_score` field.
78 |
79 | ## Q4. Filtering
80 |
81 | Now let's only limit the questions to `machine-learning-zoomcamp`.
82 |
83 | Return 3 results. What's the 3rd question returned by the search engine?
84 |
85 | * How do I debug a docker container?
86 | * How do I copy files from a different folder into docker container’s working directory?
87 | * How do Lambda container images work?
88 | * How can I annotate a graph?
89 |
90 | ## Q5. Building a prompt
91 |
92 | Now we're ready to build a prompt to send to an LLM.
93 |
94 | Take the records returned from Elasticsearch in Q4 and use this template to build the context. Separate context entries by two linebreaks (`\n\n`)
95 | ```python
96 | context_template = """
97 | Q: {question}
98 | A: {text}
99 | """.strip()
100 | ```
101 |
102 | Now use the context you just created along with the "How do I execute a command in a running docker container?" question
103 | to construct a prompt using the template below:
104 |
105 | ```
106 | prompt_template = """
107 | You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.
108 | Use only the facts from the CONTEXT when answering the QUESTION.
109 |
110 | QUESTION: {question}
111 |
112 | CONTEXT:
113 | {context}
114 | """.strip()
115 | ```
116 |
117 | What's the length of the resulting prompt? (use the `len` function)
118 |
119 | * 962
120 | * 1462
121 | * 1962
122 | * 2462
123 |
124 | ## Q6. Tokens
125 |
126 | When we use the OpenAI Platform, we're charged by the number of
127 | tokens we send in our prompt and receive in the response.
128 |
129 | The OpenAI python package uses `tiktoken` for tokenization:
130 |
131 | ```bash
132 | pip install tiktoken
133 | ```
134 |
135 | Let's calculate the number of tokens in our query:
136 |
137 | ```python
138 | encoding = tiktoken.encoding_for_model("gpt-4o")
139 | ```
140 |
141 | Use the `encode` function. How many tokens does our prompt have?
142 |
143 | * 122
144 | * 222
145 | * 322
146 | * 422
147 |
148 | Note: to decode back a token into a word, you can use the `decode_single_token_bytes` function:
149 |
150 | ```python
151 | encoding.decode_single_token_bytes(63842)
152 | ```
153 |
154 | ## Bonus: generating the answer (ungraded)
155 |
156 | Let's send the prompt to OpenAI. What's the response?
157 |
158 | Note: you can replace OpenAI with Ollama. See module 2.
159 |
160 | ## Bonus: calculating the costs (ungraded)
161 |
162 | Suppose that on average per request we send 150 tokens and receive back 250 tokens.
163 |
164 | How much will it cost to run 1000 requests?
165 |
166 | You can see the prices [here](https://openai.com/api/pricing/)
167 |
168 | On June 17, the prices for gpt4o are:
169 |
170 | * Input: $0.005 / 1K tokens
171 | * Output: $0.015 / 1K tokens
172 |
173 | You can redo the calculations with the values you got in Q6 and Q7.
174 |
175 |
176 | ## Submit the results
177 |
178 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2025/homework/hw1
179 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
180 |
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/README.md:
--------------------------------------------------------------------------------
1 | # 2. Open-Source LLMs
2 |
3 | In the previous module, we used OpenAI via OpenAI API. It's
4 | a very convenient way to use an LLM, but you have to pay
5 | for the usage, and you don't have control over the
6 | model you get to use.
7 |
8 | In this module, we'll look at using open-source LLMs instead.
9 |
10 | ## 2.1 Open-Source LLMs - Introduction
11 |
12 |
13 | 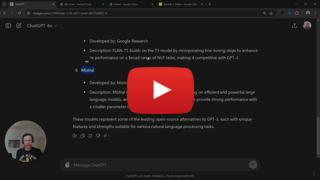 14 |
15 |
16 | * Open-Source LLMs
17 | * Replacing the LLM box in the RAG flow
18 |
19 | ## 2.2 Using a GPU in Saturn Cloud
20 |
21 |
22 |
14 |
15 |
16 | * Open-Source LLMs
17 | * Replacing the LLM box in the RAG flow
18 |
19 | ## 2.2 Using a GPU in Saturn Cloud
20 |
21 |
22 |  23 |
24 |
25 | * Registering in Saturn Cloud
26 | * Configuring secrets and git
27 | * Creating an instance with a GPU
28 |
29 | ```bash
30 | pip install -U transformers accelerate bitsandbytes sentencepiece
31 | ```
32 |
33 | Links:
34 |
35 | * https://saturncloud.io/
36 | * https://github.com/DataTalksClub/llm-zoomcamp-saturncloud
37 |
38 | Google Colab as an alternative:
39 |
40 | * [Video](https://www.loom.com/share/591f39e4e231486bbfc3fbd316ec03c5)
41 | * [Notebook](https://colab.research.google.com/drive/1XmxUZutZXoAEdQZU45EXWPseBX9s2NRd)
42 |
43 | ## 2.3 FLAN-T5
44 |
45 |
46 |
23 |
24 |
25 | * Registering in Saturn Cloud
26 | * Configuring secrets and git
27 | * Creating an instance with a GPU
28 |
29 | ```bash
30 | pip install -U transformers accelerate bitsandbytes sentencepiece
31 | ```
32 |
33 | Links:
34 |
35 | * https://saturncloud.io/
36 | * https://github.com/DataTalksClub/llm-zoomcamp-saturncloud
37 |
38 | Google Colab as an alternative:
39 |
40 | * [Video](https://www.loom.com/share/591f39e4e231486bbfc3fbd316ec03c5)
41 | * [Notebook](https://colab.research.google.com/drive/1XmxUZutZXoAEdQZU45EXWPseBX9s2NRd)
42 |
43 | ## 2.3 FLAN-T5
44 |
45 |
46 | 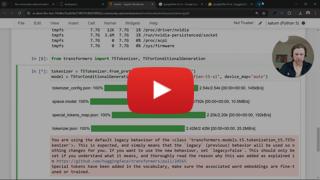 47 |
48 |
49 | * Model: `google/flan-t5-xl`
50 | * Notebook: [huggingface-flan-t5.ipynb](huggingface-flan-t5.ipynb)
51 |
52 | ```bash
53 | import os
54 | os.environ['HF_HOME'] = '/run/cache/'
55 | ```
56 |
57 | Links:
58 |
59 | * https://huggingface.co/google/flan-t5-xl
60 | * https://huggingface.co/docs/transformers/en/model_doc/flan-t5
61 |
62 | Explanation of Parameters:
63 |
64 | * `max_length`: Set this to a higher value if you want longer responses. For example, `max_length=300`.
65 | * `num_beams`: Increasing this can lead to more thorough exploration of possible sequences. Typical values are between 5 and 10.
66 | * `do_sample`: Set this to `True` to use sampling methods. This can produce more diverse responses.
67 | * `temperature`: Lowering this value makes the model more confident and deterministic, while higher values increase diversity. Typical values range from 0.7 to 1.5.
68 | * `top_k` and `top_p`: These parameters control nucleus sampling. `top_k` limits the sampling pool to the top `k` tokens, while `top_p` uses cumulative probability to cut off the sampling pool. Adjust these based on the desired level of randomness.
69 |
70 |
71 | ## 2.4 Phi 3 Mini
72 |
73 |
74 |
47 |
48 |
49 | * Model: `google/flan-t5-xl`
50 | * Notebook: [huggingface-flan-t5.ipynb](huggingface-flan-t5.ipynb)
51 |
52 | ```bash
53 | import os
54 | os.environ['HF_HOME'] = '/run/cache/'
55 | ```
56 |
57 | Links:
58 |
59 | * https://huggingface.co/google/flan-t5-xl
60 | * https://huggingface.co/docs/transformers/en/model_doc/flan-t5
61 |
62 | Explanation of Parameters:
63 |
64 | * `max_length`: Set this to a higher value if you want longer responses. For example, `max_length=300`.
65 | * `num_beams`: Increasing this can lead to more thorough exploration of possible sequences. Typical values are between 5 and 10.
66 | * `do_sample`: Set this to `True` to use sampling methods. This can produce more diverse responses.
67 | * `temperature`: Lowering this value makes the model more confident and deterministic, while higher values increase diversity. Typical values range from 0.7 to 1.5.
68 | * `top_k` and `top_p`: These parameters control nucleus sampling. `top_k` limits the sampling pool to the top `k` tokens, while `top_p` uses cumulative probability to cut off the sampling pool. Adjust these based on the desired level of randomness.
69 |
70 |
71 | ## 2.4 Phi 3 Mini
72 |
73 |
74 |  75 |
76 |
77 | * Model: `microsoft/Phi-3-mini-128k-instruct`
78 | * Notebook: [huggingface-phi3.ipynb](huggingface-phi3.ipynb)
79 |
80 |
81 | Links:
82 |
83 | * https://huggingface.co/microsoft/Phi-3-mini-128k-instruct
84 |
85 | ## 2.5 Mistral-7B and HuggingFace Hub Authentication
86 |
87 |
88 |
75 |
76 |
77 | * Model: `microsoft/Phi-3-mini-128k-instruct`
78 | * Notebook: [huggingface-phi3.ipynb](huggingface-phi3.ipynb)
79 |
80 |
81 | Links:
82 |
83 | * https://huggingface.co/microsoft/Phi-3-mini-128k-instruct
84 |
85 | ## 2.5 Mistral-7B and HuggingFace Hub Authentication
86 |
87 |
88 |  89 |
90 |
91 | * Model: `mistralai/Mistral-7B-v0.1`
92 | * Notebook: [huggingface-mistral-7b.ipynb](huggingface-mistral-7b.ipynb)
93 |
94 | [ChatGPT instructions for serving](serving-hugging-face-models.md)
95 |
96 |
97 | Links:
98 |
99 | * https://huggingface.co/docs/transformers/en/llm_tutorial
100 | * https://huggingface.co/settings/tokens
101 | * https://huggingface.co/mistralai/Mistral-7B-v0.1
102 |
103 |
104 | ## 2.6 Other models
105 |
106 |
107 |
89 |
90 |
91 | * Model: `mistralai/Mistral-7B-v0.1`
92 | * Notebook: [huggingface-mistral-7b.ipynb](huggingface-mistral-7b.ipynb)
93 |
94 | [ChatGPT instructions for serving](serving-hugging-face-models.md)
95 |
96 |
97 | Links:
98 |
99 | * https://huggingface.co/docs/transformers/en/llm_tutorial
100 | * https://huggingface.co/settings/tokens
101 | * https://huggingface.co/mistralai/Mistral-7B-v0.1
102 |
103 |
104 | ## 2.6 Other models
105 |
106 |
107 | 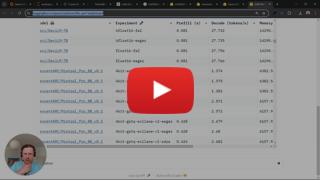 108 |
109 |
110 | * [`LLM360/Amber`](https://huggingface.co/LLM360/Amber)
111 | * [Gemma-7B](https://huggingface.co/blog/gemma)
112 | * [SaulLM-7B](https://huggingface.co/papers/2403.03883)
113 | * [Granite-7B](https://huggingface.co/ibm-granite/granite-7b-base)
114 | * [MPT-7B](https://huggingface.co/mosaicml/mpt-7b)
115 | * [OpenLLaMA-7B](https://huggingface.co/openlm-research/open_llama_7b)
116 |
117 | Where to find them:
118 |
119 | * Leaderboards
120 | * Google
121 | * ChatGPT
122 |
123 | Links:
124 |
125 | * https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
126 | * https://huggingface.co/spaces/optimum/llm-perf-leaderboard
127 |
128 |
129 | ## 2.7 Ollama - Running LLMs on a CPU
130 |
131 |
132 |
108 |
109 |
110 | * [`LLM360/Amber`](https://huggingface.co/LLM360/Amber)
111 | * [Gemma-7B](https://huggingface.co/blog/gemma)
112 | * [SaulLM-7B](https://huggingface.co/papers/2403.03883)
113 | * [Granite-7B](https://huggingface.co/ibm-granite/granite-7b-base)
114 | * [MPT-7B](https://huggingface.co/mosaicml/mpt-7b)
115 | * [OpenLLaMA-7B](https://huggingface.co/openlm-research/open_llama_7b)
116 |
117 | Where to find them:
118 |
119 | * Leaderboards
120 | * Google
121 | * ChatGPT
122 |
123 | Links:
124 |
125 | * https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
126 | * https://huggingface.co/spaces/optimum/llm-perf-leaderboard
127 |
128 |
129 | ## 2.7 Ollama - Running LLMs on a CPU
130 |
131 |
132 |  133 |
134 |
135 | * The easiest way to run an LLM without a GPU is using [Ollama](https://github.com/ollama/ollama)
136 | * Notebook [ollama.ipynb](ollama.ipynb)
137 |
138 | For Linux:
139 |
140 | ```bash
141 | curl -fsSL https://ollama.com/install.sh | sh
142 |
143 | ollama start
144 | ollama pull phi3
145 | ollama run phi3
146 | ```
147 |
148 | [Prompt example](prompt.md)
149 |
150 | Connecting to it with OpenAI API:
151 |
152 | ```python
153 | from openai import OpenAI
154 |
155 | client = OpenAI(
156 | base_url='http://localhost:11434/v1/',
157 | api_key='ollama',
158 | )
159 | ```
160 |
161 | Docker
162 |
163 | ```bash
164 | docker run -it \
165 | -v ollama:/root/.ollama \
166 | -p 11434:11434 \
167 | --name ollama \
168 | ollama/ollama
169 | ```
170 |
171 | Pulling the model
172 |
173 | ```bash
174 | docker exec -it ollama bash
175 | ollama pull phi3
176 | ```
177 |
178 |
179 | ## 2.8 Ollama & Phi3 + Elastic in Docker-Compose
180 |
181 |
182 |
133 |
134 |
135 | * The easiest way to run an LLM without a GPU is using [Ollama](https://github.com/ollama/ollama)
136 | * Notebook [ollama.ipynb](ollama.ipynb)
137 |
138 | For Linux:
139 |
140 | ```bash
141 | curl -fsSL https://ollama.com/install.sh | sh
142 |
143 | ollama start
144 | ollama pull phi3
145 | ollama run phi3
146 | ```
147 |
148 | [Prompt example](prompt.md)
149 |
150 | Connecting to it with OpenAI API:
151 |
152 | ```python
153 | from openai import OpenAI
154 |
155 | client = OpenAI(
156 | base_url='http://localhost:11434/v1/',
157 | api_key='ollama',
158 | )
159 | ```
160 |
161 | Docker
162 |
163 | ```bash
164 | docker run -it \
165 | -v ollama:/root/.ollama \
166 | -p 11434:11434 \
167 | --name ollama \
168 | ollama/ollama
169 | ```
170 |
171 | Pulling the model
172 |
173 | ```bash
174 | docker exec -it ollama bash
175 | ollama pull phi3
176 | ```
177 |
178 |
179 | ## 2.8 Ollama & Phi3 + Elastic in Docker-Compose
180 |
181 |
182 |  183 |
184 |
185 | * Creating a Docker-Compose file
186 | * Re-running the module 1 notebook
187 |
188 | * Notebook: [rag-intro.ipynb](rag-intro.ipynb)
189 |
190 | ## 2.9 UI for RAG
191 |
192 |
193 |
183 |
184 |
185 | * Creating a Docker-Compose file
186 | * Re-running the module 1 notebook
187 |
188 | * Notebook: [rag-intro.ipynb](rag-intro.ipynb)
189 |
190 | ## 2.9 UI for RAG
191 |
192 |
193 |  194 |
195 |
196 | * Putting it in Streamlit
197 | * [Code](qa_faq.py)
198 |
199 | If you want to learn more about streamlit, you can
200 | use [this material](https://github.com/DataTalksClub/project-of-the-week/blob/main/2022-08-14-frontend.md)
201 | from [our repository with projects of the week](https://github.com/DataTalksClub/project-of-the-week/tree/main).
202 |
203 | ## Homework
204 |
205 | See [here](../cohorts/2024/02-open-source/homework.md)
206 |
207 | # Notes
208 |
209 | * [Workaround by Pham Nguyen Hung to use ElasticSearch container with Saturn Cloud & Google Colab instead of minsearch](https://hung.bearblog.dev/llm-zoomcamp-zrok/)
210 | * [Notes by slavaheroes](https://github.com/slavaheroes/llm-zoomcamp/blob/homeworks/02-open-source/notes.md)
211 | * [Notes by Pham Nguyen Hung](https://hung.bearblog.dev/llm-zoomcamp-2-os/)
212 | * [Notes by Marat on Open-Sourced and Closed-Sourced Models and ways to run them](https://machine-mind-ml.medium.com/open-sourced-vs-closed-sourced-llms-2392c7db6e10)
213 | * [Notes by dimzachar](https://github.com/dimzachar/llm_zoomcamp/blob/master/notes/02-open-source/README.md)
214 | * [Notes by Waleed](https://waleedayoub.com/post/llmzoomcamp_week2-open-source_notes/)
215 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
216 |
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/docker-compose.yaml:
--------------------------------------------------------------------------------
1 | version: '3.8'
2 |
3 | services:
4 | elasticsearch:
5 | image: docker.elastic.co/elasticsearch/elasticsearch:8.4.3
6 | container_name: elasticsearch
7 | environment:
8 | - discovery.type=single-node
9 | - xpack.security.enabled=false
10 | ports:
11 | - "9200:9200"
12 | - "9300:9300"
13 |
14 | ollama:
15 | image: ollama/ollama
16 | container_name: ollama
17 | volumes:
18 | - ollama:/root/.ollama
19 | ports:
20 | - "11434:11434"
21 |
22 | volumes:
23 | ollama:
24 |
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/homework.md:
--------------------------------------------------------------------------------
1 | ## Homework: Open-Source LLMs
2 |
3 | In this homework, we'll experiment more with Ollama
4 |
5 | > It's possible that your answers won't match exactly. If it's the case, select the closest one.
6 |
7 | Solution: https://www.loom.com/share/f04a63aaf0db4bf58194ba425f1fcffa
8 |
9 | ## Q1. Running Ollama with Docker
10 |
11 | Let's run ollama with Docker. We will need to execute the
12 | same command as in the lectures:
13 |
14 | ```bash
15 | docker run -it \
16 | --rm \
17 | -v ollama:/root/.ollama \
18 | -p 11434:11434 \
19 | --name ollama \
20 | ollama/ollama
21 | ```
22 |
23 | What's the version of ollama client?
24 |
25 | To find out, enter the container and execute `ollama` with the `-v` flag.
26 |
27 |
28 | ## Q2. Downloading an LLM
29 |
30 | We will donwload a smaller LLM - gemma:2b.
31 |
32 | Again let's enter the container and pull the model:
33 |
34 | ```bash
35 | ollama pull gemma:2b
36 | ```
37 |
38 | In docker, it saved the results into `/root/.ollama`
39 |
40 | We're interested in the metadata about this model. You can find
41 | it in `models/manifests/registry.ollama.ai/library`
42 |
43 | What's the content of the file related to gemma?
44 |
45 | ## Q3. Running the LLM
46 |
47 | Test the following prompt: "10 * 10". What's the answer?
48 |
49 | ## Q4. Donwloading the weights
50 |
51 | We don't want to pull the weights every time we run
52 | a docker container. Let's do it once and have them available
53 | every time we start a container.
54 |
55 | First, we will need to change how we run the container.
56 |
57 | Instead of mapping the `/root/.ollama` folder to a named volume,
58 | let's map it to a local directory:
59 |
60 | ```bash
61 | mkdir ollama_files
62 |
63 | docker run -it \
64 | --rm \
65 | -v ./ollama_files:/root/.ollama \
66 | -p 11434:11434 \
67 | --name ollama \
68 | ollama/ollama
69 | ```
70 |
71 | Now pull the model:
72 |
73 | ```bash
74 | docker exec -it ollama ollama pull gemma:2b
75 | ```
76 |
77 | What's the size of the `ollama_files/models` folder?
78 |
79 | * 0.6G
80 | * 1.2G
81 | * 1.7G
82 | * 2.2G
83 |
84 | Hint: on linux, you can use `du -h` for that.
85 |
86 | ## Q5. Adding the weights
87 |
88 | Let's now stop the container and add the weights
89 | to a new image
90 |
91 | For that, let's create a `Dockerfile`:
92 |
93 | ```dockerfile
94 | FROM ollama/ollama
95 |
96 | COPY ...
97 | ```
98 |
99 | What do you put after `COPY`?
100 |
101 | ## Q6. Serving it
102 |
103 | Let's build it:
104 |
105 | ```bash
106 | docker build -t ollama-gemma2b .
107 | ```
108 |
109 | And run it:
110 |
111 | ```bash
112 | docker run -it --rm -p 11434:11434 ollama-gemma2b
113 | ```
114 |
115 | We can connect to it using the OpenAI client
116 |
117 | Let's test it with the following prompt:
118 |
119 | ```python
120 | prompt = "What's the formula for energy?"
121 | ```
122 |
123 | Also, to make results reproducible, set the `temperature` parameter to 0:
124 |
125 | ```bash
126 | response = client.chat.completions.create(
127 | #...
128 | temperature=0.0
129 | )
130 | ```
131 |
132 | How many completion tokens did you get in response?
133 |
134 | * 304
135 | * 604
136 | * 904
137 | * 1204
138 |
139 | ## Submit the results
140 |
141 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2024/homework/hw2
142 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
143 |
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/ollama.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 2,
6 | "id": "506fab2a-a50c-42bd-a106-c83a9d2828ea",
7 | "metadata": {},
8 | "outputs": [
9 | {
10 | "name": "stderr",
11 | "output_type": "stream",
12 | "text": [
13 | "--2024-06-13 13:53:24-- https://raw.githubusercontent.com/alexeygrigorev/minsearch/main/minsearch.py\n",
14 | "Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.111.133, 185.199.110.133, 185.199.108.133, ...\n",
15 | "Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.111.133|:443... connected.\n",
16 | "HTTP request sent, awaiting response... 200 OK\n",
17 | "Length: 3832 (3.7K) [text/plain]\n",
18 | "Saving to: 'minsearch.py'\n",
19 | "\n",
20 | " 0K ... 100% 579K=0.006s\n",
21 | "\n",
22 | "2024-06-13 13:53:24 (579 KB/s) - 'minsearch.py' saved [3832/3832]\n",
23 | "\n"
24 | ]
25 | }
26 | ],
27 | "source": [
28 | "!rm -f minsearch.py\n",
29 | "!wget https://raw.githubusercontent.com/alexeygrigorev/minsearch/main/minsearch.py"
30 | ]
31 | },
32 | {
33 | "cell_type": "code",
34 | "execution_count": 3,
35 | "id": "3ac947de-effd-4b61-8792-a6d7a133f347",
36 | "metadata": {},
37 | "outputs": [
38 | {
39 | "data": {
40 | "text/plain": [
41 | ""
42 | ]
43 | },
44 | "execution_count": 3,
45 | "metadata": {},
46 | "output_type": "execute_result"
47 | }
48 | ],
49 | "source": [
50 | "import requests \n",
51 | "import minsearch\n",
52 | "\n",
53 | "docs_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main/01-intro/documents.json?raw=1'\n",
54 | "docs_response = requests.get(docs_url)\n",
55 | "documents_raw = docs_response.json()\n",
56 | "\n",
57 | "documents = []\n",
58 | "\n",
59 | "for course in documents_raw:\n",
60 | " course_name = course['course']\n",
61 | "\n",
62 | " for doc in course['documents']:\n",
63 | " doc['course'] = course_name\n",
64 | " documents.append(doc)\n",
65 | "\n",
66 | "index = minsearch.Index(\n",
67 | " text_fields=[\"question\", \"text\", \"section\"],\n",
68 | " keyword_fields=[\"course\"]\n",
69 | ")\n",
70 | "\n",
71 | "index.fit(documents)"
72 | ]
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": 4,
77 | "id": "8f087272-b44d-4738-9ea2-175ec63a058b",
78 | "metadata": {},
79 | "outputs": [],
80 | "source": [
81 | "def search(query):\n",
82 | " boost = {'question': 3.0, 'section': 0.5}\n",
83 | "\n",
84 | " results = index.search(\n",
85 | " query=query,\n",
86 | " filter_dict={'course': 'data-engineering-zoomcamp'},\n",
87 | " boost_dict=boost,\n",
88 | " num_results=5\n",
89 | " )\n",
90 | "\n",
91 | " return results"
92 | ]
93 | },
94 | {
95 | "cell_type": "code",
96 | "execution_count": 8,
97 | "id": "742ab881-499a-4675-83c4-2013ea1377b9",
98 | "metadata": {},
99 | "outputs": [],
100 | "source": [
101 | "def build_prompt(query, search_results):\n",
102 | " prompt_template = \"\"\"\n",
103 | "You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.\n",
104 | "Use only the facts from the CONTEXT when answering the QUESTION.\n",
105 | "\n",
106 | "QUESTION: {question}\n",
107 | "\n",
108 | "CONTEXT: \n",
109 | "{context}\n",
110 | "\"\"\".strip()\n",
111 | "\n",
112 | " context = \"\"\n",
113 | " \n",
114 | " for doc in search_results:\n",
115 | " context = context + f\"section: {doc['section']}\\nquestion: {doc['question']}\\nanswer: {doc['text']}\\n\\n\"\n",
116 | " \n",
117 | " prompt = prompt_template.format(question=query, context=context).strip()\n",
118 | " return prompt\n",
119 | "\n",
120 | "def llm(prompt):\n",
121 | " response = client.chat.completions.create(\n",
122 | " model='phi3',\n",
123 | " messages=[{\"role\": \"user\", \"content\": prompt}]\n",
124 | " )\n",
125 | " \n",
126 | " return response.choices[0].message.content"
127 | ]
128 | },
129 | {
130 | "cell_type": "code",
131 | "execution_count": 6,
132 | "id": "fe8bff3e-b672-42be-866b-f2d9bb217106",
133 | "metadata": {},
134 | "outputs": [],
135 | "source": [
136 | "def rag(query):\n",
137 | " search_results = search(query)\n",
138 | " prompt = build_prompt(query, search_results)\n",
139 | " answer = llm(prompt)\n",
140 | " return answer"
141 | ]
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": 7,
146 | "id": "091a77e6-936b-448e-a04b-bad1001f5bb0",
147 | "metadata": {},
148 | "outputs": [],
149 | "source": [
150 | "from openai import OpenAI\n",
151 | "\n",
152 | "client = OpenAI(\n",
153 | " base_url='http://localhost:11434/v1/',\n",
154 | " api_key='ollama',\n",
155 | ")"
156 | ]
157 | },
158 | {
159 | "cell_type": "code",
160 | "execution_count": 12,
161 | "id": "9ee527a3-3331-4f4e-b6c8-f659ffc113f5",
162 | "metadata": {},
163 | "outputs": [
164 | {
165 | "data": {
166 | "text/plain": [
167 | "' This statement serves as an example to verify the functionality of various systems, such as text processing software or programming functions. It\\'s commonly used by developers during debugging sessions to ensure commands are working correctly without producing any unintended output.\\n\\nHere\\'s how you might include it in different contexts:\\n\\n**1. Using it as a command line test in a script:**\\nIf writing a shell script or using command-line tools, the statement can be inserted directly to demonstrate functionality. For instance, using `echo` on Unix-like systems:\\n```bash\\n#!/bin/bash\\necho \"This is a test\"\\necho \"This is also a test for confirmation.\"\\n```\\n\\n**2. Inserting it into a programming function as a placeholder or comment (in Python):**\\nAs a comment in code to remind future developers that the block can be replaced with actual implementation:\\n```python\\ndef process_text(input_string):\\n # Test input: \"This is a test\"\\n print(\"Testing...\")\\n # Replace this line with your processing logic\\n return input_string.upper() # Example operation\\n```\\n\\n**3. Using in documentation or comments within software development code:**\\nDemonstrate how the statement can be used to clarify intentions when developing software, such as in a README file or inline comment:\\n```markdown\\n# Test Command Functionality\\nThis section contains commands that serve to test system functionality.\\n`echo \"This is a test\"` - A simple command to check output behavior.\\n```\\n\\nIn each case, the statement `This is a test` fulfills its role as a straightforward demonstration or placeholder within development and testing workflows.'"
168 | ]
169 | },
170 | "execution_count": 12,
171 | "metadata": {},
172 | "output_type": "execute_result"
173 | }
174 | ],
175 | "source": [
176 | "llm('write that this is a test')"
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": 13,
182 | "id": "21aa255e-c971-44ca-9826-a721df3ad063",
183 | "metadata": {},
184 | "outputs": [
185 | {
186 | "name": "stdout",
187 | "output_type": "stream",
188 | "text": [
189 | " This statement serves as an example to verify the functionality of various systems, such as text processing software or programming functions. It's commonly used by developers during debugging sessions to ensure commands are working correctly without producing any unintended output.\n",
190 | "\n",
191 | "Here's how you might include it in different contexts:\n",
192 | "\n",
193 | "**1. Using it as a command line test in a script:**\n",
194 | "If writing a shell script or using command-line tools, the statement can be inserted directly to demonstrate functionality. For instance, using `echo` on Unix-like systems:\n",
195 | "```bash\n",
196 | "#!/bin/bash\n",
197 | "echo \"This is a test\"\n",
198 | "echo \"This is also a test for confirmation.\"\n",
199 | "```\n",
200 | "\n",
201 | "**2. Inserting it into a programming function as a placeholder or comment (in Python):**\n",
202 | "As a comment in code to remind future developers that the block can be replaced with actual implementation:\n",
203 | "```python\n",
204 | "def process_text(input_string):\n",
205 | " # Test input: \"This is a test\"\n",
206 | " print(\"Testing...\")\n",
207 | " # Replace this line with your processing logic\n",
208 | " return input_string.upper() # Example operation\n",
209 | "```\n",
210 | "\n",
211 | "**3. Using in documentation or comments within software development code:**\n",
212 | "Demonstrate how the statement can be used to clarify intentions when developing software, such as in a README file or inline comment:\n",
213 | "```markdown\n",
214 | "# Test Command Functionality\n",
215 | "This section contains commands that serve to test system functionality.\n",
216 | "`echo \"This is a test\"` - A simple command to check output behavior.\n",
217 | "```\n",
218 | "\n",
219 | "In each case, the statement `This is a test` fulfills its role as a straightforward demonstration or placeholder within development and testing workflows.\n"
220 | ]
221 | }
222 | ],
223 | "source": [
224 | "print(_)"
225 | ]
226 | },
227 | {
228 | "cell_type": "code",
229 | "execution_count": null,
230 | "id": "988ece59-951a-4b32-ba3f-cb8efb66a9bb",
231 | "metadata": {},
232 | "outputs": [],
233 | "source": []
234 | }
235 | ],
236 | "metadata": {
237 | "kernelspec": {
238 | "display_name": "Python 3 (ipykernel)",
239 | "language": "python",
240 | "name": "python3"
241 | },
242 | "language_info": {
243 | "codemirror_mode": {
244 | "name": "ipython",
245 | "version": 3
246 | },
247 | "file_extension": ".py",
248 | "mimetype": "text/x-python",
249 | "name": "python",
250 | "nbconvert_exporter": "python",
251 | "pygments_lexer": "ipython3",
252 | "version": "3.11.9"
253 | }
254 | },
255 | "nbformat": 4,
256 | "nbformat_minor": 5
257 | }
258 |
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/prompt.md:
--------------------------------------------------------------------------------
1 |
2 | Question: I just discovered the couse. can i still enrol
3 |
4 | Context:
5 |
6 | Course - Can I still join the course after the start date?
7 | Yes, even if you don't register, you're still eligible to submit the homeworks.
8 | Be aware, however, that there will be deadlines for turning in the final projects. So don't leave everything for the last minute.
9 |
10 | Environment - Is Python 3.9 still the recommended version to use in 2024?
11 | Yes, for simplicity (of troubleshooting against the recorded videos) and stability. [source]
12 | But Python 3.10 and 3.11 should work fine.
13 |
14 | How can we contribute to the course?
15 | Star the repo! Share it with friends if you find it useful ❣️
16 | Create a PR if you see you can improve the text or the structure of the repository.
17 |
18 | Are we still using the NYC Trip data for January 2021? Or are we using the 2022 data?
19 | We will use the same data, as the project will essentially remain the same as last year’s. The data is available here
20 |
21 | Docker-Compose - docker-compose still not available after changing .bashrc
22 | This is happen to me after following 1.4.1 video where we are installing docker compose in our Google Cloud VM. In my case, the docker-compose file downloaded from github named docker-compose-linux-x86_64 while it is more convenient to use docker-compose command instead. So just change the docker-compose-linux-x86_64 into docker-compose.
23 |
24 | Answer:
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/qa_faq.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import time
3 |
4 | from elasticsearch import Elasticsearch
5 | from openai import OpenAI
6 |
7 | client = OpenAI(
8 | base_url='http://localhost:11434/v1/',
9 | api_key='ollama',
10 | )
11 |
12 | es_client = Elasticsearch('http://localhost:9200')
13 |
14 |
15 | def elastic_search(query, index_name = "course-questions"):
16 | search_query = {
17 | "size": 5,
18 | "query": {
19 | "bool": {
20 | "must": {
21 | "multi_match": {
22 | "query": query,
23 | "fields": ["question^3", "text", "section"],
24 | "type": "best_fields"
25 | }
26 | },
27 | "filter": {
28 | "term": {
29 | "course": "data-engineering-zoomcamp"
30 | }
31 | }
32 | }
33 | }
34 | }
35 |
36 | response = es_client.search(index=index_name, body=search_query)
37 |
38 | result_docs = []
39 |
40 | for hit in response['hits']['hits']:
41 | result_docs.append(hit['_source'])
42 |
43 | return result_docs
44 |
45 |
46 | def build_prompt(query, search_results):
47 | prompt_template = """
48 | You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.
49 | Use only the facts from the CONTEXT when answering the QUESTION.
50 |
51 | QUESTION: {question}
52 |
53 | CONTEXT:
54 | {context}
55 | """.strip()
56 |
57 | context = ""
58 |
59 | for doc in search_results:
60 | context = context + f"section: {doc['section']}\nquestion: {doc['question']}\nanswer: {doc['text']}\n\n"
61 |
62 | prompt = prompt_template.format(question=query, context=context).strip()
63 | return prompt
64 |
65 | def llm(prompt):
66 | response = client.chat.completions.create(
67 | model='phi3',
68 | messages=[{"role": "user", "content": prompt}]
69 | )
70 |
71 | return response.choices[0].message.content
72 |
73 |
74 | def rag(query):
75 | search_results = elastic_search(query)
76 | prompt = build_prompt(query, search_results)
77 | answer = llm(prompt)
78 | return answer
79 |
80 |
81 | def main():
82 | st.title("RAG Function Invocation")
83 |
84 | user_input = st.text_input("Enter your input:")
85 |
86 | if st.button("Ask"):
87 | with st.spinner('Processing...'):
88 | output = rag(user_input)
89 | st.success("Completed!")
90 | st.write(output)
91 |
92 | if __name__ == "__main__":
93 | main()
94 |
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/rag-intro.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 3,
6 | "id": "ef8e9cdc-dfd4-4e54-a332-4b9bde4e6047",
7 | "metadata": {},
8 | "outputs": [],
9 | "source": [
10 | "from openai import OpenAI\n",
11 | "\n",
12 | "client = OpenAI(\n",
13 | " base_url='http://localhost:11434/v1/',\n",
14 | " api_key='ollama',\n",
15 | ")"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 7,
21 | "id": "2c05052f-a85a-4137-8398-0fd0be678599",
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "from elasticsearch import Elasticsearch"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": 8,
31 | "id": "a78df1cc-5a5a-40b4-b673-19c7f0319453",
32 | "metadata": {},
33 | "outputs": [],
34 | "source": [
35 | "es_client = Elasticsearch('http://localhost:9200') "
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 9,
41 | "id": "c9367c18-41ad-495e-9920-1a0c552f0d18",
42 | "metadata": {},
43 | "outputs": [
44 | {
45 | "data": {
46 | "text/plain": [
47 | "ObjectApiResponse({'acknowledged': True, 'shards_acknowledged': True, 'index': 'course-questions'})"
48 | ]
49 | },
50 | "execution_count": 9,
51 | "metadata": {},
52 | "output_type": "execute_result"
53 | }
54 | ],
55 | "source": [
56 | "index_settings = {\n",
57 | " \"settings\": {\n",
58 | " \"number_of_shards\": 1,\n",
59 | " \"number_of_replicas\": 0\n",
60 | " },\n",
61 | " \"mappings\": {\n",
62 | " \"properties\": {\n",
63 | " \"text\": {\"type\": \"text\"},\n",
64 | " \"section\": {\"type\": \"text\"},\n",
65 | " \"question\": {\"type\": \"text\"},\n",
66 | " \"course\": {\"type\": \"keyword\"} \n",
67 | " }\n",
68 | " }\n",
69 | "}\n",
70 | "\n",
71 | "index_name = \"course-questions\"\n",
72 | "\n",
73 | "es_client.indices.create(index=index_name, body=index_settings)"
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 10,
79 | "id": "e131e3a3-4051-4fd7-8e4d-d17c2af2ad75",
80 | "metadata": {},
81 | "outputs": [],
82 | "source": [
83 | "import requests \n",
84 | "\n",
85 | "docs_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main/01-intro/documents.json?raw=1'\n",
86 | "docs_response = requests.get(docs_url)\n",
87 | "documents_raw = docs_response.json()\n",
88 | "\n",
89 | "documents = []\n",
90 | "\n",
91 | "for course in documents_raw:\n",
92 | " course_name = course['course']\n",
93 | "\n",
94 | " for doc in course['documents']:\n",
95 | " doc['course'] = course_name\n",
96 | " documents.append(doc)"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": 12,
102 | "id": "5c230059-e219-4a13-a7f8-ede4cf1b028f",
103 | "metadata": {},
104 | "outputs": [],
105 | "source": [
106 | "from tqdm.auto import tqdm"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": 13,
112 | "id": "70fe3c97-916d-42c0-bd7b-4f42d9056409",
113 | "metadata": {},
114 | "outputs": [
115 | {
116 | "data": {
117 | "application/vnd.jupyter.widget-view+json": {
118 | "model_id": "d74c0925b2eb48b8b301b1f418b6938a",
119 | "version_major": 2,
120 | "version_minor": 0
121 | },
122 | "text/plain": [
123 | " 0%| | 0/948 [00:00"
42 | ]
43 | },
44 | "execution_count": 3,
45 | "metadata": {},
46 | "output_type": "execute_result"
47 | }
48 | ],
49 | "source": [
50 | "import requests \n",
51 | "import minsearch\n",
52 | "\n",
53 | "docs_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main/01-intro/documents.json?raw=1'\n",
54 | "docs_response = requests.get(docs_url)\n",
55 | "documents_raw = docs_response.json()\n",
56 | "\n",
57 | "documents = []\n",
58 | "\n",
59 | "for course in documents_raw:\n",
60 | " course_name = course['course']\n",
61 | "\n",
62 | " for doc in course['documents']:\n",
63 | " doc['course'] = course_name\n",
64 | " documents.append(doc)\n",
65 | "\n",
66 | "index = minsearch.Index(\n",
67 | " text_fields=[\"question\", \"text\", \"section\"],\n",
68 | " keyword_fields=[\"course\"]\n",
69 | ")\n",
70 | "\n",
71 | "index.fit(documents)"
72 | ]
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": 4,
77 | "id": "8f087272-b44d-4738-9ea2-175ec63a058b",
78 | "metadata": {},
79 | "outputs": [],
80 | "source": [
81 | "def search(query):\n",
82 | " boost = {'question': 3.0, 'section': 0.5}\n",
83 | "\n",
84 | " results = index.search(\n",
85 | " query=query,\n",
86 | " filter_dict={'course': 'data-engineering-zoomcamp'},\n",
87 | " boost_dict=boost,\n",
88 | " num_results=5\n",
89 | " )\n",
90 | "\n",
91 | " return results"
92 | ]
93 | },
94 | {
95 | "cell_type": "code",
96 | "execution_count": 8,
97 | "id": "742ab881-499a-4675-83c4-2013ea1377b9",
98 | "metadata": {},
99 | "outputs": [],
100 | "source": [
101 | "def build_prompt(query, search_results):\n",
102 | " prompt_template = \"\"\"\n",
103 | "You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.\n",
104 | "Use only the facts from the CONTEXT when answering the QUESTION.\n",
105 | "\n",
106 | "QUESTION: {question}\n",
107 | "\n",
108 | "CONTEXT: \n",
109 | "{context}\n",
110 | "\"\"\".strip()\n",
111 | "\n",
112 | " context = \"\"\n",
113 | " \n",
114 | " for doc in search_results:\n",
115 | " context = context + f\"section: {doc['section']}\\nquestion: {doc['question']}\\nanswer: {doc['text']}\\n\\n\"\n",
116 | " \n",
117 | " prompt = prompt_template.format(question=query, context=context).strip()\n",
118 | " return prompt\n",
119 | "\n",
120 | "def llm(prompt):\n",
121 | " response = client.chat.completions.create(\n",
122 | " model='gpt-4o',\n",
123 | " messages=[{\"role\": \"user\", \"content\": prompt}]\n",
124 | " )\n",
125 | " \n",
126 | " return response.choices[0].message.content"
127 | ]
128 | },
129 | {
130 | "cell_type": "code",
131 | "execution_count": 6,
132 | "id": "fe8bff3e-b672-42be-866b-f2d9bb217106",
133 | "metadata": {},
134 | "outputs": [],
135 | "source": [
136 | "def rag(query):\n",
137 | " search_results = search(query)\n",
138 | " prompt = build_prompt(query, search_results)\n",
139 | " answer = llm(prompt)\n",
140 | " return answer"
141 | ]
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": null,
146 | "id": "988ece59-951a-4b32-ba3f-cb8efb66a9bb",
147 | "metadata": {},
148 | "outputs": [],
149 | "source": []
150 | }
151 | ],
152 | "metadata": {
153 | "kernelspec": {
154 | "display_name": "Python 3 (ipykernel)",
155 | "language": "python",
156 | "name": "python3"
157 | },
158 | "language_info": {
159 | "codemirror_mode": {
160 | "name": "ipython",
161 | "version": 3
162 | },
163 | "file_extension": ".py",
164 | "mimetype": "text/x-python",
165 | "name": "python",
166 | "nbconvert_exporter": "python",
167 | "pygments_lexer": "ipython3",
168 | "version": "3.11.9"
169 | }
170 | },
171 | "nbformat": 4,
172 | "nbformat_minor": 5
173 | }
174 |
--------------------------------------------------------------------------------
/cohorts/2024/03-vector-search/README.md:
--------------------------------------------------------------------------------
1 | # Vector Search
2 |
3 | ## 3.1 Introduction to Vector Search
4 |
5 |
6 |
194 |
195 |
196 | * Putting it in Streamlit
197 | * [Code](qa_faq.py)
198 |
199 | If you want to learn more about streamlit, you can
200 | use [this material](https://github.com/DataTalksClub/project-of-the-week/blob/main/2022-08-14-frontend.md)
201 | from [our repository with projects of the week](https://github.com/DataTalksClub/project-of-the-week/tree/main).
202 |
203 | ## Homework
204 |
205 | See [here](../cohorts/2024/02-open-source/homework.md)
206 |
207 | # Notes
208 |
209 | * [Workaround by Pham Nguyen Hung to use ElasticSearch container with Saturn Cloud & Google Colab instead of minsearch](https://hung.bearblog.dev/llm-zoomcamp-zrok/)
210 | * [Notes by slavaheroes](https://github.com/slavaheroes/llm-zoomcamp/blob/homeworks/02-open-source/notes.md)
211 | * [Notes by Pham Nguyen Hung](https://hung.bearblog.dev/llm-zoomcamp-2-os/)
212 | * [Notes by Marat on Open-Sourced and Closed-Sourced Models and ways to run them](https://machine-mind-ml.medium.com/open-sourced-vs-closed-sourced-llms-2392c7db6e10)
213 | * [Notes by dimzachar](https://github.com/dimzachar/llm_zoomcamp/blob/master/notes/02-open-source/README.md)
214 | * [Notes by Waleed](https://waleedayoub.com/post/llmzoomcamp_week2-open-source_notes/)
215 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
216 |
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/docker-compose.yaml:
--------------------------------------------------------------------------------
1 | version: '3.8'
2 |
3 | services:
4 | elasticsearch:
5 | image: docker.elastic.co/elasticsearch/elasticsearch:8.4.3
6 | container_name: elasticsearch
7 | environment:
8 | - discovery.type=single-node
9 | - xpack.security.enabled=false
10 | ports:
11 | - "9200:9200"
12 | - "9300:9300"
13 |
14 | ollama:
15 | image: ollama/ollama
16 | container_name: ollama
17 | volumes:
18 | - ollama:/root/.ollama
19 | ports:
20 | - "11434:11434"
21 |
22 | volumes:
23 | ollama:
24 |
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/homework.md:
--------------------------------------------------------------------------------
1 | ## Homework: Open-Source LLMs
2 |
3 | In this homework, we'll experiment more with Ollama
4 |
5 | > It's possible that your answers won't match exactly. If it's the case, select the closest one.
6 |
7 | Solution: https://www.loom.com/share/f04a63aaf0db4bf58194ba425f1fcffa
8 |
9 | ## Q1. Running Ollama with Docker
10 |
11 | Let's run ollama with Docker. We will need to execute the
12 | same command as in the lectures:
13 |
14 | ```bash
15 | docker run -it \
16 | --rm \
17 | -v ollama:/root/.ollama \
18 | -p 11434:11434 \
19 | --name ollama \
20 | ollama/ollama
21 | ```
22 |
23 | What's the version of ollama client?
24 |
25 | To find out, enter the container and execute `ollama` with the `-v` flag.
26 |
27 |
28 | ## Q2. Downloading an LLM
29 |
30 | We will donwload a smaller LLM - gemma:2b.
31 |
32 | Again let's enter the container and pull the model:
33 |
34 | ```bash
35 | ollama pull gemma:2b
36 | ```
37 |
38 | In docker, it saved the results into `/root/.ollama`
39 |
40 | We're interested in the metadata about this model. You can find
41 | it in `models/manifests/registry.ollama.ai/library`
42 |
43 | What's the content of the file related to gemma?
44 |
45 | ## Q3. Running the LLM
46 |
47 | Test the following prompt: "10 * 10". What's the answer?
48 |
49 | ## Q4. Donwloading the weights
50 |
51 | We don't want to pull the weights every time we run
52 | a docker container. Let's do it once and have them available
53 | every time we start a container.
54 |
55 | First, we will need to change how we run the container.
56 |
57 | Instead of mapping the `/root/.ollama` folder to a named volume,
58 | let's map it to a local directory:
59 |
60 | ```bash
61 | mkdir ollama_files
62 |
63 | docker run -it \
64 | --rm \
65 | -v ./ollama_files:/root/.ollama \
66 | -p 11434:11434 \
67 | --name ollama \
68 | ollama/ollama
69 | ```
70 |
71 | Now pull the model:
72 |
73 | ```bash
74 | docker exec -it ollama ollama pull gemma:2b
75 | ```
76 |
77 | What's the size of the `ollama_files/models` folder?
78 |
79 | * 0.6G
80 | * 1.2G
81 | * 1.7G
82 | * 2.2G
83 |
84 | Hint: on linux, you can use `du -h` for that.
85 |
86 | ## Q5. Adding the weights
87 |
88 | Let's now stop the container and add the weights
89 | to a new image
90 |
91 | For that, let's create a `Dockerfile`:
92 |
93 | ```dockerfile
94 | FROM ollama/ollama
95 |
96 | COPY ...
97 | ```
98 |
99 | What do you put after `COPY`?
100 |
101 | ## Q6. Serving it
102 |
103 | Let's build it:
104 |
105 | ```bash
106 | docker build -t ollama-gemma2b .
107 | ```
108 |
109 | And run it:
110 |
111 | ```bash
112 | docker run -it --rm -p 11434:11434 ollama-gemma2b
113 | ```
114 |
115 | We can connect to it using the OpenAI client
116 |
117 | Let's test it with the following prompt:
118 |
119 | ```python
120 | prompt = "What's the formula for energy?"
121 | ```
122 |
123 | Also, to make results reproducible, set the `temperature` parameter to 0:
124 |
125 | ```bash
126 | response = client.chat.completions.create(
127 | #...
128 | temperature=0.0
129 | )
130 | ```
131 |
132 | How many completion tokens did you get in response?
133 |
134 | * 304
135 | * 604
136 | * 904
137 | * 1204
138 |
139 | ## Submit the results
140 |
141 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2024/homework/hw2
142 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
143 |
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/ollama.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 2,
6 | "id": "506fab2a-a50c-42bd-a106-c83a9d2828ea",
7 | "metadata": {},
8 | "outputs": [
9 | {
10 | "name": "stderr",
11 | "output_type": "stream",
12 | "text": [
13 | "--2024-06-13 13:53:24-- https://raw.githubusercontent.com/alexeygrigorev/minsearch/main/minsearch.py\n",
14 | "Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.111.133, 185.199.110.133, 185.199.108.133, ...\n",
15 | "Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.111.133|:443... connected.\n",
16 | "HTTP request sent, awaiting response... 200 OK\n",
17 | "Length: 3832 (3.7K) [text/plain]\n",
18 | "Saving to: 'minsearch.py'\n",
19 | "\n",
20 | " 0K ... 100% 579K=0.006s\n",
21 | "\n",
22 | "2024-06-13 13:53:24 (579 KB/s) - 'minsearch.py' saved [3832/3832]\n",
23 | "\n"
24 | ]
25 | }
26 | ],
27 | "source": [
28 | "!rm -f minsearch.py\n",
29 | "!wget https://raw.githubusercontent.com/alexeygrigorev/minsearch/main/minsearch.py"
30 | ]
31 | },
32 | {
33 | "cell_type": "code",
34 | "execution_count": 3,
35 | "id": "3ac947de-effd-4b61-8792-a6d7a133f347",
36 | "metadata": {},
37 | "outputs": [
38 | {
39 | "data": {
40 | "text/plain": [
41 | ""
42 | ]
43 | },
44 | "execution_count": 3,
45 | "metadata": {},
46 | "output_type": "execute_result"
47 | }
48 | ],
49 | "source": [
50 | "import requests \n",
51 | "import minsearch\n",
52 | "\n",
53 | "docs_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main/01-intro/documents.json?raw=1'\n",
54 | "docs_response = requests.get(docs_url)\n",
55 | "documents_raw = docs_response.json()\n",
56 | "\n",
57 | "documents = []\n",
58 | "\n",
59 | "for course in documents_raw:\n",
60 | " course_name = course['course']\n",
61 | "\n",
62 | " for doc in course['documents']:\n",
63 | " doc['course'] = course_name\n",
64 | " documents.append(doc)\n",
65 | "\n",
66 | "index = minsearch.Index(\n",
67 | " text_fields=[\"question\", \"text\", \"section\"],\n",
68 | " keyword_fields=[\"course\"]\n",
69 | ")\n",
70 | "\n",
71 | "index.fit(documents)"
72 | ]
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": 4,
77 | "id": "8f087272-b44d-4738-9ea2-175ec63a058b",
78 | "metadata": {},
79 | "outputs": [],
80 | "source": [
81 | "def search(query):\n",
82 | " boost = {'question': 3.0, 'section': 0.5}\n",
83 | "\n",
84 | " results = index.search(\n",
85 | " query=query,\n",
86 | " filter_dict={'course': 'data-engineering-zoomcamp'},\n",
87 | " boost_dict=boost,\n",
88 | " num_results=5\n",
89 | " )\n",
90 | "\n",
91 | " return results"
92 | ]
93 | },
94 | {
95 | "cell_type": "code",
96 | "execution_count": 8,
97 | "id": "742ab881-499a-4675-83c4-2013ea1377b9",
98 | "metadata": {},
99 | "outputs": [],
100 | "source": [
101 | "def build_prompt(query, search_results):\n",
102 | " prompt_template = \"\"\"\n",
103 | "You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.\n",
104 | "Use only the facts from the CONTEXT when answering the QUESTION.\n",
105 | "\n",
106 | "QUESTION: {question}\n",
107 | "\n",
108 | "CONTEXT: \n",
109 | "{context}\n",
110 | "\"\"\".strip()\n",
111 | "\n",
112 | " context = \"\"\n",
113 | " \n",
114 | " for doc in search_results:\n",
115 | " context = context + f\"section: {doc['section']}\\nquestion: {doc['question']}\\nanswer: {doc['text']}\\n\\n\"\n",
116 | " \n",
117 | " prompt = prompt_template.format(question=query, context=context).strip()\n",
118 | " return prompt\n",
119 | "\n",
120 | "def llm(prompt):\n",
121 | " response = client.chat.completions.create(\n",
122 | " model='phi3',\n",
123 | " messages=[{\"role\": \"user\", \"content\": prompt}]\n",
124 | " )\n",
125 | " \n",
126 | " return response.choices[0].message.content"
127 | ]
128 | },
129 | {
130 | "cell_type": "code",
131 | "execution_count": 6,
132 | "id": "fe8bff3e-b672-42be-866b-f2d9bb217106",
133 | "metadata": {},
134 | "outputs": [],
135 | "source": [
136 | "def rag(query):\n",
137 | " search_results = search(query)\n",
138 | " prompt = build_prompt(query, search_results)\n",
139 | " answer = llm(prompt)\n",
140 | " return answer"
141 | ]
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": 7,
146 | "id": "091a77e6-936b-448e-a04b-bad1001f5bb0",
147 | "metadata": {},
148 | "outputs": [],
149 | "source": [
150 | "from openai import OpenAI\n",
151 | "\n",
152 | "client = OpenAI(\n",
153 | " base_url='http://localhost:11434/v1/',\n",
154 | " api_key='ollama',\n",
155 | ")"
156 | ]
157 | },
158 | {
159 | "cell_type": "code",
160 | "execution_count": 12,
161 | "id": "9ee527a3-3331-4f4e-b6c8-f659ffc113f5",
162 | "metadata": {},
163 | "outputs": [
164 | {
165 | "data": {
166 | "text/plain": [
167 | "' This statement serves as an example to verify the functionality of various systems, such as text processing software or programming functions. It\\'s commonly used by developers during debugging sessions to ensure commands are working correctly without producing any unintended output.\\n\\nHere\\'s how you might include it in different contexts:\\n\\n**1. Using it as a command line test in a script:**\\nIf writing a shell script or using command-line tools, the statement can be inserted directly to demonstrate functionality. For instance, using `echo` on Unix-like systems:\\n```bash\\n#!/bin/bash\\necho \"This is a test\"\\necho \"This is also a test for confirmation.\"\\n```\\n\\n**2. Inserting it into a programming function as a placeholder or comment (in Python):**\\nAs a comment in code to remind future developers that the block can be replaced with actual implementation:\\n```python\\ndef process_text(input_string):\\n # Test input: \"This is a test\"\\n print(\"Testing...\")\\n # Replace this line with your processing logic\\n return input_string.upper() # Example operation\\n```\\n\\n**3. Using in documentation or comments within software development code:**\\nDemonstrate how the statement can be used to clarify intentions when developing software, such as in a README file or inline comment:\\n```markdown\\n# Test Command Functionality\\nThis section contains commands that serve to test system functionality.\\n`echo \"This is a test\"` - A simple command to check output behavior.\\n```\\n\\nIn each case, the statement `This is a test` fulfills its role as a straightforward demonstration or placeholder within development and testing workflows.'"
168 | ]
169 | },
170 | "execution_count": 12,
171 | "metadata": {},
172 | "output_type": "execute_result"
173 | }
174 | ],
175 | "source": [
176 | "llm('write that this is a test')"
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": 13,
182 | "id": "21aa255e-c971-44ca-9826-a721df3ad063",
183 | "metadata": {},
184 | "outputs": [
185 | {
186 | "name": "stdout",
187 | "output_type": "stream",
188 | "text": [
189 | " This statement serves as an example to verify the functionality of various systems, such as text processing software or programming functions. It's commonly used by developers during debugging sessions to ensure commands are working correctly without producing any unintended output.\n",
190 | "\n",
191 | "Here's how you might include it in different contexts:\n",
192 | "\n",
193 | "**1. Using it as a command line test in a script:**\n",
194 | "If writing a shell script or using command-line tools, the statement can be inserted directly to demonstrate functionality. For instance, using `echo` on Unix-like systems:\n",
195 | "```bash\n",
196 | "#!/bin/bash\n",
197 | "echo \"This is a test\"\n",
198 | "echo \"This is also a test for confirmation.\"\n",
199 | "```\n",
200 | "\n",
201 | "**2. Inserting it into a programming function as a placeholder or comment (in Python):**\n",
202 | "As a comment in code to remind future developers that the block can be replaced with actual implementation:\n",
203 | "```python\n",
204 | "def process_text(input_string):\n",
205 | " # Test input: \"This is a test\"\n",
206 | " print(\"Testing...\")\n",
207 | " # Replace this line with your processing logic\n",
208 | " return input_string.upper() # Example operation\n",
209 | "```\n",
210 | "\n",
211 | "**3. Using in documentation or comments within software development code:**\n",
212 | "Demonstrate how the statement can be used to clarify intentions when developing software, such as in a README file or inline comment:\n",
213 | "```markdown\n",
214 | "# Test Command Functionality\n",
215 | "This section contains commands that serve to test system functionality.\n",
216 | "`echo \"This is a test\"` - A simple command to check output behavior.\n",
217 | "```\n",
218 | "\n",
219 | "In each case, the statement `This is a test` fulfills its role as a straightforward demonstration or placeholder within development and testing workflows.\n"
220 | ]
221 | }
222 | ],
223 | "source": [
224 | "print(_)"
225 | ]
226 | },
227 | {
228 | "cell_type": "code",
229 | "execution_count": null,
230 | "id": "988ece59-951a-4b32-ba3f-cb8efb66a9bb",
231 | "metadata": {},
232 | "outputs": [],
233 | "source": []
234 | }
235 | ],
236 | "metadata": {
237 | "kernelspec": {
238 | "display_name": "Python 3 (ipykernel)",
239 | "language": "python",
240 | "name": "python3"
241 | },
242 | "language_info": {
243 | "codemirror_mode": {
244 | "name": "ipython",
245 | "version": 3
246 | },
247 | "file_extension": ".py",
248 | "mimetype": "text/x-python",
249 | "name": "python",
250 | "nbconvert_exporter": "python",
251 | "pygments_lexer": "ipython3",
252 | "version": "3.11.9"
253 | }
254 | },
255 | "nbformat": 4,
256 | "nbformat_minor": 5
257 | }
258 |
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/prompt.md:
--------------------------------------------------------------------------------
1 |
2 | Question: I just discovered the couse. can i still enrol
3 |
4 | Context:
5 |
6 | Course - Can I still join the course after the start date?
7 | Yes, even if you don't register, you're still eligible to submit the homeworks.
8 | Be aware, however, that there will be deadlines for turning in the final projects. So don't leave everything for the last minute.
9 |
10 | Environment - Is Python 3.9 still the recommended version to use in 2024?
11 | Yes, for simplicity (of troubleshooting against the recorded videos) and stability. [source]
12 | But Python 3.10 and 3.11 should work fine.
13 |
14 | How can we contribute to the course?
15 | Star the repo! Share it with friends if you find it useful ❣️
16 | Create a PR if you see you can improve the text or the structure of the repository.
17 |
18 | Are we still using the NYC Trip data for January 2021? Or are we using the 2022 data?
19 | We will use the same data, as the project will essentially remain the same as last year’s. The data is available here
20 |
21 | Docker-Compose - docker-compose still not available after changing .bashrc
22 | This is happen to me after following 1.4.1 video where we are installing docker compose in our Google Cloud VM. In my case, the docker-compose file downloaded from github named docker-compose-linux-x86_64 while it is more convenient to use docker-compose command instead. So just change the docker-compose-linux-x86_64 into docker-compose.
23 |
24 | Answer:
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/qa_faq.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import time
3 |
4 | from elasticsearch import Elasticsearch
5 | from openai import OpenAI
6 |
7 | client = OpenAI(
8 | base_url='http://localhost:11434/v1/',
9 | api_key='ollama',
10 | )
11 |
12 | es_client = Elasticsearch('http://localhost:9200')
13 |
14 |
15 | def elastic_search(query, index_name = "course-questions"):
16 | search_query = {
17 | "size": 5,
18 | "query": {
19 | "bool": {
20 | "must": {
21 | "multi_match": {
22 | "query": query,
23 | "fields": ["question^3", "text", "section"],
24 | "type": "best_fields"
25 | }
26 | },
27 | "filter": {
28 | "term": {
29 | "course": "data-engineering-zoomcamp"
30 | }
31 | }
32 | }
33 | }
34 | }
35 |
36 | response = es_client.search(index=index_name, body=search_query)
37 |
38 | result_docs = []
39 |
40 | for hit in response['hits']['hits']:
41 | result_docs.append(hit['_source'])
42 |
43 | return result_docs
44 |
45 |
46 | def build_prompt(query, search_results):
47 | prompt_template = """
48 | You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.
49 | Use only the facts from the CONTEXT when answering the QUESTION.
50 |
51 | QUESTION: {question}
52 |
53 | CONTEXT:
54 | {context}
55 | """.strip()
56 |
57 | context = ""
58 |
59 | for doc in search_results:
60 | context = context + f"section: {doc['section']}\nquestion: {doc['question']}\nanswer: {doc['text']}\n\n"
61 |
62 | prompt = prompt_template.format(question=query, context=context).strip()
63 | return prompt
64 |
65 | def llm(prompt):
66 | response = client.chat.completions.create(
67 | model='phi3',
68 | messages=[{"role": "user", "content": prompt}]
69 | )
70 |
71 | return response.choices[0].message.content
72 |
73 |
74 | def rag(query):
75 | search_results = elastic_search(query)
76 | prompt = build_prompt(query, search_results)
77 | answer = llm(prompt)
78 | return answer
79 |
80 |
81 | def main():
82 | st.title("RAG Function Invocation")
83 |
84 | user_input = st.text_input("Enter your input:")
85 |
86 | if st.button("Ask"):
87 | with st.spinner('Processing...'):
88 | output = rag(user_input)
89 | st.success("Completed!")
90 | st.write(output)
91 |
92 | if __name__ == "__main__":
93 | main()
94 |
--------------------------------------------------------------------------------
/cohorts/2024/02-open-source/rag-intro.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 3,
6 | "id": "ef8e9cdc-dfd4-4e54-a332-4b9bde4e6047",
7 | "metadata": {},
8 | "outputs": [],
9 | "source": [
10 | "from openai import OpenAI\n",
11 | "\n",
12 | "client = OpenAI(\n",
13 | " base_url='http://localhost:11434/v1/',\n",
14 | " api_key='ollama',\n",
15 | ")"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 7,
21 | "id": "2c05052f-a85a-4137-8398-0fd0be678599",
22 | "metadata": {},
23 | "outputs": [],
24 | "source": [
25 | "from elasticsearch import Elasticsearch"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": 8,
31 | "id": "a78df1cc-5a5a-40b4-b673-19c7f0319453",
32 | "metadata": {},
33 | "outputs": [],
34 | "source": [
35 | "es_client = Elasticsearch('http://localhost:9200') "
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 9,
41 | "id": "c9367c18-41ad-495e-9920-1a0c552f0d18",
42 | "metadata": {},
43 | "outputs": [
44 | {
45 | "data": {
46 | "text/plain": [
47 | "ObjectApiResponse({'acknowledged': True, 'shards_acknowledged': True, 'index': 'course-questions'})"
48 | ]
49 | },
50 | "execution_count": 9,
51 | "metadata": {},
52 | "output_type": "execute_result"
53 | }
54 | ],
55 | "source": [
56 | "index_settings = {\n",
57 | " \"settings\": {\n",
58 | " \"number_of_shards\": 1,\n",
59 | " \"number_of_replicas\": 0\n",
60 | " },\n",
61 | " \"mappings\": {\n",
62 | " \"properties\": {\n",
63 | " \"text\": {\"type\": \"text\"},\n",
64 | " \"section\": {\"type\": \"text\"},\n",
65 | " \"question\": {\"type\": \"text\"},\n",
66 | " \"course\": {\"type\": \"keyword\"} \n",
67 | " }\n",
68 | " }\n",
69 | "}\n",
70 | "\n",
71 | "index_name = \"course-questions\"\n",
72 | "\n",
73 | "es_client.indices.create(index=index_name, body=index_settings)"
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 10,
79 | "id": "e131e3a3-4051-4fd7-8e4d-d17c2af2ad75",
80 | "metadata": {},
81 | "outputs": [],
82 | "source": [
83 | "import requests \n",
84 | "\n",
85 | "docs_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main/01-intro/documents.json?raw=1'\n",
86 | "docs_response = requests.get(docs_url)\n",
87 | "documents_raw = docs_response.json()\n",
88 | "\n",
89 | "documents = []\n",
90 | "\n",
91 | "for course in documents_raw:\n",
92 | " course_name = course['course']\n",
93 | "\n",
94 | " for doc in course['documents']:\n",
95 | " doc['course'] = course_name\n",
96 | " documents.append(doc)"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": 12,
102 | "id": "5c230059-e219-4a13-a7f8-ede4cf1b028f",
103 | "metadata": {},
104 | "outputs": [],
105 | "source": [
106 | "from tqdm.auto import tqdm"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": 13,
112 | "id": "70fe3c97-916d-42c0-bd7b-4f42d9056409",
113 | "metadata": {},
114 | "outputs": [
115 | {
116 | "data": {
117 | "application/vnd.jupyter.widget-view+json": {
118 | "model_id": "d74c0925b2eb48b8b301b1f418b6938a",
119 | "version_major": 2,
120 | "version_minor": 0
121 | },
122 | "text/plain": [
123 | " 0%| | 0/948 [00:00"
42 | ]
43 | },
44 | "execution_count": 3,
45 | "metadata": {},
46 | "output_type": "execute_result"
47 | }
48 | ],
49 | "source": [
50 | "import requests \n",
51 | "import minsearch\n",
52 | "\n",
53 | "docs_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main/01-intro/documents.json?raw=1'\n",
54 | "docs_response = requests.get(docs_url)\n",
55 | "documents_raw = docs_response.json()\n",
56 | "\n",
57 | "documents = []\n",
58 | "\n",
59 | "for course in documents_raw:\n",
60 | " course_name = course['course']\n",
61 | "\n",
62 | " for doc in course['documents']:\n",
63 | " doc['course'] = course_name\n",
64 | " documents.append(doc)\n",
65 | "\n",
66 | "index = minsearch.Index(\n",
67 | " text_fields=[\"question\", \"text\", \"section\"],\n",
68 | " keyword_fields=[\"course\"]\n",
69 | ")\n",
70 | "\n",
71 | "index.fit(documents)"
72 | ]
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": 4,
77 | "id": "8f087272-b44d-4738-9ea2-175ec63a058b",
78 | "metadata": {},
79 | "outputs": [],
80 | "source": [
81 | "def search(query):\n",
82 | " boost = {'question': 3.0, 'section': 0.5}\n",
83 | "\n",
84 | " results = index.search(\n",
85 | " query=query,\n",
86 | " filter_dict={'course': 'data-engineering-zoomcamp'},\n",
87 | " boost_dict=boost,\n",
88 | " num_results=5\n",
89 | " )\n",
90 | "\n",
91 | " return results"
92 | ]
93 | },
94 | {
95 | "cell_type": "code",
96 | "execution_count": 8,
97 | "id": "742ab881-499a-4675-83c4-2013ea1377b9",
98 | "metadata": {},
99 | "outputs": [],
100 | "source": [
101 | "def build_prompt(query, search_results):\n",
102 | " prompt_template = \"\"\"\n",
103 | "You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.\n",
104 | "Use only the facts from the CONTEXT when answering the QUESTION.\n",
105 | "\n",
106 | "QUESTION: {question}\n",
107 | "\n",
108 | "CONTEXT: \n",
109 | "{context}\n",
110 | "\"\"\".strip()\n",
111 | "\n",
112 | " context = \"\"\n",
113 | " \n",
114 | " for doc in search_results:\n",
115 | " context = context + f\"section: {doc['section']}\\nquestion: {doc['question']}\\nanswer: {doc['text']}\\n\\n\"\n",
116 | " \n",
117 | " prompt = prompt_template.format(question=query, context=context).strip()\n",
118 | " return prompt\n",
119 | "\n",
120 | "def llm(prompt):\n",
121 | " response = client.chat.completions.create(\n",
122 | " model='gpt-4o',\n",
123 | " messages=[{\"role\": \"user\", \"content\": prompt}]\n",
124 | " )\n",
125 | " \n",
126 | " return response.choices[0].message.content"
127 | ]
128 | },
129 | {
130 | "cell_type": "code",
131 | "execution_count": 6,
132 | "id": "fe8bff3e-b672-42be-866b-f2d9bb217106",
133 | "metadata": {},
134 | "outputs": [],
135 | "source": [
136 | "def rag(query):\n",
137 | " search_results = search(query)\n",
138 | " prompt = build_prompt(query, search_results)\n",
139 | " answer = llm(prompt)\n",
140 | " return answer"
141 | ]
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": null,
146 | "id": "988ece59-951a-4b32-ba3f-cb8efb66a9bb",
147 | "metadata": {},
148 | "outputs": [],
149 | "source": []
150 | }
151 | ],
152 | "metadata": {
153 | "kernelspec": {
154 | "display_name": "Python 3 (ipykernel)",
155 | "language": "python",
156 | "name": "python3"
157 | },
158 | "language_info": {
159 | "codemirror_mode": {
160 | "name": "ipython",
161 | "version": 3
162 | },
163 | "file_extension": ".py",
164 | "mimetype": "text/x-python",
165 | "name": "python",
166 | "nbconvert_exporter": "python",
167 | "pygments_lexer": "ipython3",
168 | "version": "3.11.9"
169 | }
170 | },
171 | "nbformat": 4,
172 | "nbformat_minor": 5
173 | }
174 |
--------------------------------------------------------------------------------
/cohorts/2024/03-vector-search/README.md:
--------------------------------------------------------------------------------
1 | # Vector Search
2 |
3 | ## 3.1 Introduction to Vector Search
4 |
5 |
6 | 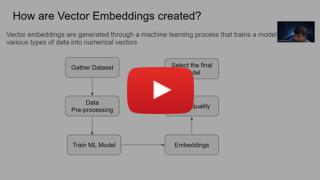 7 |
8 |
9 | * [Slides](https://github.com/dataML007/elastic_search/blob/main/Introduction%20to%20Vector%20DB.pdf)
10 |
11 |
12 | ## 3.2 Semantic Search with Elasticsearch
13 |
14 |
15 |
7 |
8 |
9 | * [Slides](https://github.com/dataML007/elastic_search/blob/main/Introduction%20to%20Vector%20DB.pdf)
10 |
11 |
12 | ## 3.2 Semantic Search with Elasticsearch
13 |
14 |
15 |  16 |
17 |
18 | * Notebook: [demo_es.ipynb](demo_es.ipynb)
19 |
20 | ### 3.2.2 Advanced Semantic Search
21 |
22 |
23 |
16 |
17 |
18 | * Notebook: [demo_es.ipynb](demo_es.ipynb)
19 |
20 | ### 3.2.2 Advanced Semantic Search
21 |
22 |
23 |  24 |
25 |
26 |
27 | ## 3.3 Evaluating Retrieval
28 |
29 | ### 3.3.1 Introduction
30 |
31 |
32 |
24 |
25 |
26 |
27 | ## 3.3 Evaluating Retrieval
28 |
29 | ### 3.3.1 Introduction
30 |
31 |
32 |  33 |
34 |
35 | Plan for the section:
36 |
37 | * Why do we need evaluation
38 | * [Evaluation metrics](eval/evaluation-metrics.md)
39 | * Ground truth / gold standard data
40 | * Generating ground truth with LLM
41 | * Evaluating the search resuls
42 |
43 |
44 | ### 3.3.2 Getting ground truth data
45 |
46 |
47 |
33 |
34 |
35 | Plan for the section:
36 |
37 | * Why do we need evaluation
38 | * [Evaluation metrics](eval/evaluation-metrics.md)
39 | * Ground truth / gold standard data
40 | * Generating ground truth with LLM
41 | * Evaluating the search resuls
42 |
43 |
44 | ### 3.3.2 Getting ground truth data
45 |
46 |
47 |  48 |
49 |
50 | * Approaches for getting evaluation data
51 | * Using OpenAI to generate evaluation data
52 |
53 | Links:
54 |
55 | * [notebook](eval/ground-truth-data.ipynb)
56 | * [documents with ids](eval/documents-with-ids.json)
57 | * [queries generated by OpenAI (pickle)](eval/results.bin)
58 | * [ground truth dataset](eval/ground-truth-data.csv)
59 |
60 |
61 | ### 3.3.3 Ranking evaluation: text search
62 |
63 |
64 |
48 |
49 |
50 | * Approaches for getting evaluation data
51 | * Using OpenAI to generate evaluation data
52 |
53 | Links:
54 |
55 | * [notebook](eval/ground-truth-data.ipynb)
56 | * [documents with ids](eval/documents-with-ids.json)
57 | * [queries generated by OpenAI (pickle)](eval/results.bin)
58 | * [ground truth dataset](eval/ground-truth-data.csv)
59 |
60 |
61 | ### 3.3.3 Ranking evaluation: text search
62 |
63 |
64 | 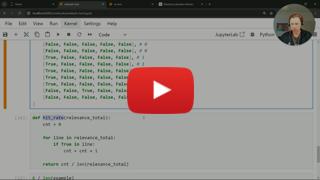 65 |
66 |
67 | * Elasticsearch with text results
68 | * minsearch
69 |
70 | Links:
71 |
72 | * [Notebook](eval/evaluate-text.ipynb)
73 |
74 | ### 3.3.4 Ranking evaluation: vector search
75 |
76 |
77 |
65 |
66 |
67 | * Elasticsearch with text results
68 | * minsearch
69 |
70 | Links:
71 |
72 | * [Notebook](eval/evaluate-text.ipynb)
73 |
74 | ### 3.3.4 Ranking evaluation: vector search
75 |
76 |
77 |  78 |
79 |
80 | * Elasticsearch with vector search
81 | * Ranking with question, answer, question+answer embeddings
82 |
83 | Links:
84 |
85 | * [Notebook](eval/evaluate-vector.ipynb)
86 |
87 | ## Homework
88 |
89 | See [here](../cohorts/2024/03-vector-search/homework.md)
90 |
91 |
92 | # Notes
93 |
94 | * [Notes by dimzachar](https://github.com/dimzachar/llm_zoomcamp/blob/master/notes/03-vector-search/README.md)
95 | * [Notes by slavaheroes](https://github.com/slavaheroes/llm-zoomcamp/blob/homeworks/03-vector-search/notes.md)
96 | * [Notes on Vector Search and Vector Databases by Marat](https://machine-mind-ml.medium.com/enhancing-llm-performance-with-vector-search-and-vector-databases-1f20eb1cc650)
97 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
98 |
--------------------------------------------------------------------------------
/cohorts/2024/03-vector-search/homework.md:
--------------------------------------------------------------------------------
1 | ## Homework: Vector Search
2 |
3 | In this homework, we'll experiemnt with vector with and without Elasticsearch
4 |
5 | > It's possible that your answers won't match exactly. If it's the case, select the closest one.
6 |
7 | Solution:
8 |
9 | * Video: https://www.loom.com/share/979b9e1f0a964fff88cd62d37e7515f9
10 | * Notebook: [homework_solution.ipynb](homework_solution.ipynb)
11 |
12 |
13 |
14 | ## Q1. Getting the embeddings model
15 |
16 | First, we will get the embeddings model `multi-qa-distilbert-cos-v1` from
17 | [the Sentence Transformer library](https://www.sbert.net/docs/sentence_transformer/pretrained_models.html#model-overview)
18 |
19 | ```bash
20 | from sentence_transformers import SentenceTransformer
21 | embedding_model = SentenceTransformer(model_name)
22 | ```
23 |
24 | Create the embedding for this user question:
25 |
26 | ```python
27 | user_question = "I just discovered the course. Can I still join it?"
28 | ```
29 |
30 | What's the first value of the resulting vector?
31 |
32 | * -0.24
33 | * -0.04
34 | * 0.07
35 | * 0.27
36 |
37 |
38 | ## Prepare the documents
39 |
40 | Now we will create the embeddings for the documents.
41 |
42 | Load the documents with ids that we prepared in the module:
43 |
44 | ```python
45 | import requests
46 |
47 | base_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main'
48 | relative_url = '03-vector-search/eval/documents-with-ids.json'
49 | docs_url = f'{base_url}/{relative_url}?raw=1'
50 | docs_response = requests.get(docs_url)
51 | documents = docs_response.json()
52 | ```
53 |
54 | We will use only a subset of the questions - the questions
55 | for `"machine-learning-zoomcamp"`. After filtering, you should
56 | have only 375 documents
57 |
58 | ## Q2. Creating the embeddings
59 |
60 | Now for each document, we will create an embedding for both question and answer fields.
61 |
62 | We want to put all of them into a single matrix `X`:
63 |
64 | - Create a list `embeddings`
65 | - Iterate over each document
66 | - `qa_text = f'{question} {text}'`
67 | - compute the embedding for `qa_text`, append to `embeddings`
68 | - At the end, let `X = np.array(embeddings)` (`import numpy as np`)
69 |
70 | What's the shape of X? (`X.shape`). Include the parantheses.
71 |
72 |
73 |
74 | ## Q3. Search
75 |
76 | We have the embeddings and the query vector. Now let's compute the
77 | cosine similarity between the vector from Q1 (let's call it `v`) and the matrix from Q2.
78 |
79 | The vectors returned from the embedding model are already
80 | normalized (you can check it by computing a dot product of a vector
81 | with itself - it should return something very close to 1.0). This means that in order
82 | to compute the coside similarity, it's sufficient to
83 | multiply the matrix `X` by the vector `v`:
84 |
85 |
86 | ```python
87 | scores = X.dot(v)
88 | ```
89 |
90 | What's the highest score in the results?
91 |
92 | - 65.0
93 | - 6.5
94 | - 0.65
95 | - 0.065
96 |
97 |
98 | ## Vector search
99 |
100 | We can now compute the similarity between a query vector and all the embeddings.
101 |
102 | Let's use this to implement our own vector search
103 |
104 | ```python
105 | class VectorSearchEngine():
106 | def __init__(self, documents, embeddings):
107 | self.documents = documents
108 | self.embeddings = embeddings
109 |
110 | def search(self, v_query, num_results=10):
111 | scores = self.embeddings.dot(v_query)
112 | idx = np.argsort(-scores)[:num_results]
113 | return [self.documents[i] for i in idx]
114 |
115 | search_engine = VectorSearchEngine(documents=documents, embeddings=X)
116 | search_engine.search(v, num_results=5)
117 | ```
118 |
119 | If you don't understand how the `search` function work:
120 |
121 | * Ask ChatGTP or any other LLM of your choice to explain the code
122 | * Check our pre-course workshop about implementing a search engine [here](https://github.com/alexeygrigorev/build-your-own-search-engine)
123 |
124 | (Note: you can replace `argsort` with `argpartition` to make it a lot faster)
125 |
126 |
127 | ## Q4. Hit-rate for our search engine
128 |
129 | Let's evaluate the performance of our own search engine. We will
130 | use the hitrate metric for evaluation.
131 |
132 | First, load the ground truth dataset:
133 |
134 | ```python
135 | import pandas as pd
136 |
137 | base_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main'
138 | relative_url = '03-vector-search/eval/ground-truth-data.csv'
139 | ground_truth_url = f'{base_url}/{relative_url}?raw=1'
140 |
141 | df_ground_truth = pd.read_csv(ground_truth_url)
142 | df_ground_truth = df_ground_truth[df_ground_truth.course == 'machine-learning-zoomcamp']
143 | ground_truth = df_ground_truth.to_dict(orient='records')
144 | ```
145 |
146 | Now use the code from the module to calculate the hitrate of
147 | `VectorSearchEngine` with `num_results=5`.
148 |
149 | What did you get?
150 |
151 | * 0.93
152 | * 0.73
153 | * 0.53
154 | * 0.33
155 |
156 | ## Q5. Indexing with Elasticsearch
157 |
158 | Now let's index these documents with elasticsearch
159 |
160 | * Create the index with the same settings as in the module (but change the dimensions)
161 | * Index the embeddings (note: you've already computed them)
162 |
163 | After indexing, let's perform the search of the same query from Q1.
164 |
165 | What's the ID of the document with the highest score?
166 |
167 | ## Q6. Hit-rate for Elasticsearch
168 |
169 | The search engine we used in Q4 computed the similarity between
170 | the query and ALL the vectors in our database. Usually this is
171 | not practical, as we may have a lot of data.
172 |
173 | Elasticsearch uses approximate techniques to make it faster.
174 |
175 | Let's evaluate how worse the results are when we switch from
176 | exact search (as in Q4) to approximate search with Elastic.
177 |
178 | What's hitrate for our dataset for Elastic?
179 |
180 | * 0.93
181 | * 0.73
182 | * 0.53
183 | * 0.33
184 |
185 |
186 | ## Submit the results
187 |
188 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2024/homework/hw3
189 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
190 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/README.md:
--------------------------------------------------------------------------------
1 | # Module 4: Evaluation and Monitoring
2 |
3 | In this module, we will learn how to evaluate and monitor our LLM and RAG system.
4 |
5 | In the evaluation part, we assess the quality of our entire RAG
6 | system before it goes live.
7 |
8 | In the monitoring part, we collect, store and visualize
9 | metrics to assess the answer quality of a deployed LLM. We also
10 | collect chat history and user feedback.
11 |
12 |
13 | ## 4.1 Introduction to monitoring answer quality
14 |
15 |
16 |
78 |
79 |
80 | * Elasticsearch with vector search
81 | * Ranking with question, answer, question+answer embeddings
82 |
83 | Links:
84 |
85 | * [Notebook](eval/evaluate-vector.ipynb)
86 |
87 | ## Homework
88 |
89 | See [here](../cohorts/2024/03-vector-search/homework.md)
90 |
91 |
92 | # Notes
93 |
94 | * [Notes by dimzachar](https://github.com/dimzachar/llm_zoomcamp/blob/master/notes/03-vector-search/README.md)
95 | * [Notes by slavaheroes](https://github.com/slavaheroes/llm-zoomcamp/blob/homeworks/03-vector-search/notes.md)
96 | * [Notes on Vector Search and Vector Databases by Marat](https://machine-mind-ml.medium.com/enhancing-llm-performance-with-vector-search-and-vector-databases-1f20eb1cc650)
97 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
98 |
--------------------------------------------------------------------------------
/cohorts/2024/03-vector-search/homework.md:
--------------------------------------------------------------------------------
1 | ## Homework: Vector Search
2 |
3 | In this homework, we'll experiemnt with vector with and without Elasticsearch
4 |
5 | > It's possible that your answers won't match exactly. If it's the case, select the closest one.
6 |
7 | Solution:
8 |
9 | * Video: https://www.loom.com/share/979b9e1f0a964fff88cd62d37e7515f9
10 | * Notebook: [homework_solution.ipynb](homework_solution.ipynb)
11 |
12 |
13 |
14 | ## Q1. Getting the embeddings model
15 |
16 | First, we will get the embeddings model `multi-qa-distilbert-cos-v1` from
17 | [the Sentence Transformer library](https://www.sbert.net/docs/sentence_transformer/pretrained_models.html#model-overview)
18 |
19 | ```bash
20 | from sentence_transformers import SentenceTransformer
21 | embedding_model = SentenceTransformer(model_name)
22 | ```
23 |
24 | Create the embedding for this user question:
25 |
26 | ```python
27 | user_question = "I just discovered the course. Can I still join it?"
28 | ```
29 |
30 | What's the first value of the resulting vector?
31 |
32 | * -0.24
33 | * -0.04
34 | * 0.07
35 | * 0.27
36 |
37 |
38 | ## Prepare the documents
39 |
40 | Now we will create the embeddings for the documents.
41 |
42 | Load the documents with ids that we prepared in the module:
43 |
44 | ```python
45 | import requests
46 |
47 | base_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main'
48 | relative_url = '03-vector-search/eval/documents-with-ids.json'
49 | docs_url = f'{base_url}/{relative_url}?raw=1'
50 | docs_response = requests.get(docs_url)
51 | documents = docs_response.json()
52 | ```
53 |
54 | We will use only a subset of the questions - the questions
55 | for `"machine-learning-zoomcamp"`. After filtering, you should
56 | have only 375 documents
57 |
58 | ## Q2. Creating the embeddings
59 |
60 | Now for each document, we will create an embedding for both question and answer fields.
61 |
62 | We want to put all of them into a single matrix `X`:
63 |
64 | - Create a list `embeddings`
65 | - Iterate over each document
66 | - `qa_text = f'{question} {text}'`
67 | - compute the embedding for `qa_text`, append to `embeddings`
68 | - At the end, let `X = np.array(embeddings)` (`import numpy as np`)
69 |
70 | What's the shape of X? (`X.shape`). Include the parantheses.
71 |
72 |
73 |
74 | ## Q3. Search
75 |
76 | We have the embeddings and the query vector. Now let's compute the
77 | cosine similarity between the vector from Q1 (let's call it `v`) and the matrix from Q2.
78 |
79 | The vectors returned from the embedding model are already
80 | normalized (you can check it by computing a dot product of a vector
81 | with itself - it should return something very close to 1.0). This means that in order
82 | to compute the coside similarity, it's sufficient to
83 | multiply the matrix `X` by the vector `v`:
84 |
85 |
86 | ```python
87 | scores = X.dot(v)
88 | ```
89 |
90 | What's the highest score in the results?
91 |
92 | - 65.0
93 | - 6.5
94 | - 0.65
95 | - 0.065
96 |
97 |
98 | ## Vector search
99 |
100 | We can now compute the similarity between a query vector and all the embeddings.
101 |
102 | Let's use this to implement our own vector search
103 |
104 | ```python
105 | class VectorSearchEngine():
106 | def __init__(self, documents, embeddings):
107 | self.documents = documents
108 | self.embeddings = embeddings
109 |
110 | def search(self, v_query, num_results=10):
111 | scores = self.embeddings.dot(v_query)
112 | idx = np.argsort(-scores)[:num_results]
113 | return [self.documents[i] for i in idx]
114 |
115 | search_engine = VectorSearchEngine(documents=documents, embeddings=X)
116 | search_engine.search(v, num_results=5)
117 | ```
118 |
119 | If you don't understand how the `search` function work:
120 |
121 | * Ask ChatGTP or any other LLM of your choice to explain the code
122 | * Check our pre-course workshop about implementing a search engine [here](https://github.com/alexeygrigorev/build-your-own-search-engine)
123 |
124 | (Note: you can replace `argsort` with `argpartition` to make it a lot faster)
125 |
126 |
127 | ## Q4. Hit-rate for our search engine
128 |
129 | Let's evaluate the performance of our own search engine. We will
130 | use the hitrate metric for evaluation.
131 |
132 | First, load the ground truth dataset:
133 |
134 | ```python
135 | import pandas as pd
136 |
137 | base_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main'
138 | relative_url = '03-vector-search/eval/ground-truth-data.csv'
139 | ground_truth_url = f'{base_url}/{relative_url}?raw=1'
140 |
141 | df_ground_truth = pd.read_csv(ground_truth_url)
142 | df_ground_truth = df_ground_truth[df_ground_truth.course == 'machine-learning-zoomcamp']
143 | ground_truth = df_ground_truth.to_dict(orient='records')
144 | ```
145 |
146 | Now use the code from the module to calculate the hitrate of
147 | `VectorSearchEngine` with `num_results=5`.
148 |
149 | What did you get?
150 |
151 | * 0.93
152 | * 0.73
153 | * 0.53
154 | * 0.33
155 |
156 | ## Q5. Indexing with Elasticsearch
157 |
158 | Now let's index these documents with elasticsearch
159 |
160 | * Create the index with the same settings as in the module (but change the dimensions)
161 | * Index the embeddings (note: you've already computed them)
162 |
163 | After indexing, let's perform the search of the same query from Q1.
164 |
165 | What's the ID of the document with the highest score?
166 |
167 | ## Q6. Hit-rate for Elasticsearch
168 |
169 | The search engine we used in Q4 computed the similarity between
170 | the query and ALL the vectors in our database. Usually this is
171 | not practical, as we may have a lot of data.
172 |
173 | Elasticsearch uses approximate techniques to make it faster.
174 |
175 | Let's evaluate how worse the results are when we switch from
176 | exact search (as in Q4) to approximate search with Elastic.
177 |
178 | What's hitrate for our dataset for Elastic?
179 |
180 | * 0.93
181 | * 0.73
182 | * 0.53
183 | * 0.33
184 |
185 |
186 | ## Submit the results
187 |
188 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2024/homework/hw3
189 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
190 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/README.md:
--------------------------------------------------------------------------------
1 | # Module 4: Evaluation and Monitoring
2 |
3 | In this module, we will learn how to evaluate and monitor our LLM and RAG system.
4 |
5 | In the evaluation part, we assess the quality of our entire RAG
6 | system before it goes live.
7 |
8 | In the monitoring part, we collect, store and visualize
9 | metrics to assess the answer quality of a deployed LLM. We also
10 | collect chat history and user feedback.
11 |
12 |
13 | ## 4.1 Introduction to monitoring answer quality
14 |
15 |
16 | 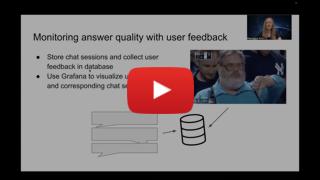 17 |
18 |
19 | * Why monitoring LLM systems?
20 | * Monitoring answer quality of LLMs
21 | * Monitoring answer quality with user feedback
22 | * What else to monitor, that is not covered by this module?
23 |
24 |
25 | ## 4.2 Offline vs Online (RAG) evaluation
26 |
27 |
28 |
17 |
18 |
19 | * Why monitoring LLM systems?
20 | * Monitoring answer quality of LLMs
21 | * Monitoring answer quality with user feedback
22 | * What else to monitor, that is not covered by this module?
23 |
24 |
25 | ## 4.2 Offline vs Online (RAG) evaluation
26 |
27 |
28 | 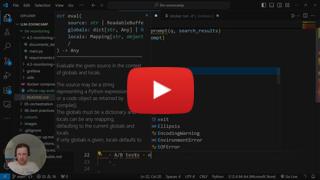 29 |
30 |
31 | * Modules recap
32 | * Online vs offline evaluation
33 | * Offline evaluation metrics
34 |
35 |
36 | ## 4.3 Generating data for offline RAG evaluation
37 |
38 |
39 |
29 |
30 |
31 | * Modules recap
32 | * Online vs offline evaluation
33 | * Offline evaluation metrics
34 |
35 |
36 | ## 4.3 Generating data for offline RAG evaluation
37 |
38 |
39 |  40 |
41 |
42 | Links:
43 |
44 | * [notebook](offline-rag-evaluation.ipynb)
45 | * [results-gpt4o.csv](data/results-gpt4o.csv) (answers from GPT-4o)
46 | * [results-gpt35.csv](data/results-gpt35.csv) (answers from GPT-3.5-Turbo)
47 |
48 |
49 | ## 4.4 Offline RAG evaluation: cosine similarity
50 |
51 |
52 |
40 |
41 |
42 | Links:
43 |
44 | * [notebook](offline-rag-evaluation.ipynb)
45 | * [results-gpt4o.csv](data/results-gpt4o.csv) (answers from GPT-4o)
46 | * [results-gpt35.csv](data/results-gpt35.csv) (answers from GPT-3.5-Turbo)
47 |
48 |
49 | ## 4.4 Offline RAG evaluation: cosine similarity
50 |
51 |
52 |  53 |
54 |
55 | Content
56 |
57 | * A->Q->A' cosine similarity
58 | * Evaluating gpt-4o
59 | * Evaluating gpt-3.5-turbo
60 | * Evaluating gpt-4o-mini
61 |
62 | Links:
63 |
64 | * [notebook](offline-rag-evaluation.ipynb)
65 | * [results-gpt4o-cosine.csv](data/results-gpt4o-cosine.csv) (answers with cosine calculated from GPT-4o)
66 | * [results-gpt35-cosine.csv](data/results-gpt35-cosine.csv) (answers with cosine calculated from GPT-3.5-Turbo)
67 | * [results-gpt4o-mini.csv](data/results-gpt4o-mini.csv) (answers from GPT-4o-mini)
68 | * [results-gpt4o-mini-cosine.csv](data/results-gpt4o-mini-cosine.csv) (answers with cosine calculated from GPT-4o-mini)
69 |
70 |
71 | ## 4.5 Offline RAG evaluation: LLM as a judge
72 |
73 |
74 |
53 |
54 |
55 | Content
56 |
57 | * A->Q->A' cosine similarity
58 | * Evaluating gpt-4o
59 | * Evaluating gpt-3.5-turbo
60 | * Evaluating gpt-4o-mini
61 |
62 | Links:
63 |
64 | * [notebook](offline-rag-evaluation.ipynb)
65 | * [results-gpt4o-cosine.csv](data/results-gpt4o-cosine.csv) (answers with cosine calculated from GPT-4o)
66 | * [results-gpt35-cosine.csv](data/results-gpt35-cosine.csv) (answers with cosine calculated from GPT-3.5-Turbo)
67 | * [results-gpt4o-mini.csv](data/results-gpt4o-mini.csv) (answers from GPT-4o-mini)
68 | * [results-gpt4o-mini-cosine.csv](data/results-gpt4o-mini-cosine.csv) (answers with cosine calculated from GPT-4o-mini)
69 |
70 |
71 | ## 4.5 Offline RAG evaluation: LLM as a judge
72 |
73 |
74 |  75 |
76 |
77 | * LLM as a judge
78 | * A->Q->A' evaluation
79 | * Q->A evaluation
80 |
81 |
82 | Links:
83 |
84 | * [notebook](offline-rag-evaluation.ipynb)
85 | * [evaluations-aqa.csv](data/evaluations-aqa.csv) (A->Q->A evaluation results)
86 | * [evaluations-qa.csv](data/evaluations-qa.csv) (Q->A evaluation results)
87 | https://youtu.be/
88 |
89 |
90 | ## 4.6 Capturing user feedback
91 |
92 |
93 |
75 |
76 |
77 | * LLM as a judge
78 | * A->Q->A' evaluation
79 | * Q->A evaluation
80 |
81 |
82 | Links:
83 |
84 | * [notebook](offline-rag-evaluation.ipynb)
85 | * [evaluations-aqa.csv](data/evaluations-aqa.csv) (A->Q->A evaluation results)
86 | * [evaluations-qa.csv](data/evaluations-qa.csv) (Q->A evaluation results)
87 | https://youtu.be/
88 |
89 |
90 | ## 4.6 Capturing user feedback
91 |
92 |
93 |  94 |
95 |
96 | > You can see the prompts and the output from claude [here](code.md)
97 |
98 | Content
99 |
100 | * Adding +1 and -1 buttons
101 | * Setting up a postgres database
102 | * Putting everything in docker compose
103 |
104 | ```bash
105 | pip install pgcli
106 | pgcli -h localhost -U your_username -d course_assistant -W
107 | ```
108 |
109 |
110 | Links:
111 |
112 | * [final code](app/)
113 | * [intermediate code from claude](code.md#46-capturing-user-feedback)
114 |
115 |
116 | ### 4.6.2 Capturing user feedback: part 2
117 |
118 |
119 |
94 |
95 |
96 | > You can see the prompts and the output from claude [here](code.md)
97 |
98 | Content
99 |
100 | * Adding +1 and -1 buttons
101 | * Setting up a postgres database
102 | * Putting everything in docker compose
103 |
104 | ```bash
105 | pip install pgcli
106 | pgcli -h localhost -U your_username -d course_assistant -W
107 | ```
108 |
109 |
110 | Links:
111 |
112 | * [final code](app/)
113 | * [intermediate code from claude](code.md#46-capturing-user-feedback)
114 |
115 |
116 | ### 4.6.2 Capturing user feedback: part 2
117 |
118 |
119 |  120 |
121 |
122 | * adding vector search
123 | * adding OpenAI
124 |
125 | Links:
126 |
127 | * [final code](app/)
128 | * [intermediate code from claude](code.md#462-capturing-user-feedback-part-2)
129 |
130 |
131 | ## 4.7 Monitoring the system
132 |
133 |
134 |
120 |
121 |
122 | * adding vector search
123 | * adding OpenAI
124 |
125 | Links:
126 |
127 | * [final code](app/)
128 | * [intermediate code from claude](code.md#462-capturing-user-feedback-part-2)
129 |
130 |
131 | ## 4.7 Monitoring the system
132 |
133 |
134 |  135 |
136 |
137 | * Setting up Grafana
138 | * Tokens and costs
139 | * QA relevance
140 | * User feedback
141 | * Other metrics
142 |
143 | Links:
144 |
145 | * [final code](app/)
146 | * [SQL queries for Grafana](grafana.md)
147 | * [intermediate code from claude](code.md#47-monitoring)
148 |
149 | ### 4.7.2 Extra Grafana video
150 |
151 |
152 |
135 |
136 |
137 | * Setting up Grafana
138 | * Tokens and costs
139 | * QA relevance
140 | * User feedback
141 | * Other metrics
142 |
143 | Links:
144 |
145 | * [final code](app/)
146 | * [SQL queries for Grafana](grafana.md)
147 | * [intermediate code from claude](code.md#47-monitoring)
148 |
149 | ### 4.7.2 Extra Grafana video
150 |
151 |
152 |  153 |
154 |
155 | * Grafana variables
156 | * Exporting and importing dashboards
157 |
158 | Links:
159 |
160 | * [SQL queries for Grafana](grafana.md)
161 | * [Grafana dashboard](dashboard.json)
162 |
163 | ## Homework
164 |
165 | See [here](../cohorts/2024/04-monitoring/homework.md)
166 |
167 |
168 | ## Extra resources
169 |
170 | ### Overview of the module
171 |
172 | 
173 |
174 | https://www.loom.com/share/1dd375ec4b0d458fabdfc2b841089031
175 |
176 | # Notes
177 |
178 | * [Notes by slavaheroes](https://github.com/slavaheroes/llm-zoomcamp/blob/homeworks/04-monitoring/notes.md)
179 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
180 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/.env:
--------------------------------------------------------------------------------
1 | # PostgreSQL Configuration
2 | POSTGRES_HOST=postgres
3 | POSTGRES_DB=course_assistant
4 | POSTGRES_USER=your_username
5 | POSTGRES_PASSWORD=your_password
6 | POSTGRES_PORT=5432
7 |
8 | # Elasticsearch Configuration
9 | ELASTIC_URL_LOCAL=http://localhost:9200
10 | ELASTIC_URL=http://elasticsearch:9200
11 | ELASTIC_PORT=9200
12 |
13 | # Ollama Configuration
14 | OLLAMA_PORT=11434
15 |
16 | # Streamlit Configuration
17 | STREAMLIT_PORT=8501
18 |
19 | # Other Configuration
20 | MODEL_NAME=multi-qa-MiniLM-L6-cos-v1
21 | INDEX_NAME=course-questions
22 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM python:3.9-slim
2 |
3 | ENV PYTHONUNBUFFERED=1
4 |
5 | WORKDIR /app
6 |
7 | COPY requirements.txt .
8 | RUN pip install --no-cache-dir -r requirements.txt
9 |
10 | COPY . .
11 |
12 | CMD ["streamlit", "run", "app.py"]
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/README.MD:
--------------------------------------------------------------------------------
1 | ## Additional notes for those trying the streamlit/grafana out
2 |
3 | 1) The following packages are required when you run some of .py scripts
4 |
5 | ```
6 | pip install psycopg2-binary python-dotenv
7 | pip install pgcli
8 | ```
9 |
10 |
11 | 2) To download the phi3 model to the container
12 | ```
13 | docker-compose up -d
14 | docker-compose exec ollama ollama pull phi3
15 | ```
16 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/app.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import time
3 | import uuid
4 |
5 | from assistant import get_answer
6 | from db import (
7 | save_conversation,
8 | save_feedback,
9 | get_recent_conversations,
10 | get_feedback_stats,
11 | )
12 |
13 |
14 | def print_log(message):
15 | print(message, flush=True)
16 |
17 |
18 | def main():
19 | print_log("Starting the Course Assistant application")
20 | st.title("Course Assistant")
21 |
22 | # Session state initialization
23 | if "conversation_id" not in st.session_state:
24 | st.session_state.conversation_id = str(uuid.uuid4())
25 | print_log(
26 | f"New conversation started with ID: {st.session_state.conversation_id}"
27 | )
28 | if "count" not in st.session_state:
29 | st.session_state.count = 0
30 | print_log("Feedback count initialized to 0")
31 |
32 | # Course selection
33 | course = st.selectbox(
34 | "Select a course:",
35 | ["machine-learning-zoomcamp", "data-engineering-zoomcamp", "mlops-zoomcamp"],
36 | )
37 | print_log(f"User selected course: {course}")
38 |
39 | # Model selection
40 | model_choice = st.selectbox(
41 | "Select a model:",
42 | ["ollama/phi3", "openai/gpt-3.5-turbo", "openai/gpt-4o", "openai/gpt-4o-mini"],
43 | )
44 | print_log(f"User selected model: {model_choice}")
45 |
46 | # Search type selection
47 | search_type = st.radio("Select search type:", ["Text", "Vector"])
48 | print_log(f"User selected search type: {search_type}")
49 |
50 | # User input
51 | user_input = st.text_input("Enter your question:")
52 |
53 | if st.button("Ask"):
54 | print_log(f"User asked: '{user_input}'")
55 | with st.spinner("Processing..."):
56 | print_log(
57 | f"Getting answer from assistant using {model_choice} model and {search_type} search"
58 | )
59 | start_time = time.time()
60 | answer_data = get_answer(user_input, course, model_choice, search_type)
61 | end_time = time.time()
62 | print_log(f"Answer received in {end_time - start_time:.2f} seconds")
63 | st.success("Completed!")
64 | st.write(answer_data["answer"])
65 |
66 | # Display monitoring information
67 | st.write(f"Response time: {answer_data['response_time']:.2f} seconds")
68 | st.write(f"Relevance: {answer_data['relevance']}")
69 | st.write(f"Model used: {answer_data['model_used']}")
70 | st.write(f"Total tokens: {answer_data['total_tokens']}")
71 | if answer_data["openai_cost"] > 0:
72 | st.write(f"OpenAI cost: ${answer_data['openai_cost']:.4f}")
73 |
74 | # Save conversation to database
75 | print_log("Saving conversation to database")
76 | save_conversation(
77 | st.session_state.conversation_id, user_input, answer_data, course
78 | )
79 | print_log("Conversation saved successfully")
80 | # Generate a new conversation ID for next question
81 | st.session_state.conversation_id = str(uuid.uuid4())
82 |
83 | # Feedback buttons
84 | col1, col2 = st.columns(2)
85 | with col1:
86 | if st.button("+1"):
87 | st.session_state.count += 1
88 | print_log(
89 | f"Positive feedback received. New count: {st.session_state.count}"
90 | )
91 | save_feedback(st.session_state.conversation_id, 1)
92 | print_log("Positive feedback saved to database")
93 | with col2:
94 | if st.button("-1"):
95 | st.session_state.count -= 1
96 | print_log(
97 | f"Negative feedback received. New count: {st.session_state.count}"
98 | )
99 | save_feedback(st.session_state.conversation_id, -1)
100 | print_log("Negative feedback saved to database")
101 |
102 | st.write(f"Current count: {st.session_state.count}")
103 |
104 | # Display recent conversations
105 | st.subheader("Recent Conversations")
106 | relevance_filter = st.selectbox(
107 | "Filter by relevance:", ["All", "RELEVANT", "PARTLY_RELEVANT", "NON_RELEVANT"]
108 | )
109 | recent_conversations = get_recent_conversations(
110 | limit=5, relevance=relevance_filter if relevance_filter != "All" else None
111 | )
112 | for conv in recent_conversations:
113 | st.write(f"Q: {conv['question']}")
114 | st.write(f"A: {conv['answer']}")
115 | st.write(f"Relevance: {conv['relevance']}")
116 | st.write(f"Model: {conv['model_used']}")
117 | st.write("---")
118 |
119 | # Display feedback stats
120 | feedback_stats = get_feedback_stats()
121 | st.subheader("Feedback Statistics")
122 | st.write(f"Thumbs up: {feedback_stats['thumbs_up']}")
123 | st.write(f"Thumbs down: {feedback_stats['thumbs_down']}")
124 |
125 |
126 | print_log("Streamlit app loop completed")
127 |
128 |
129 | if __name__ == "__main__":
130 | print_log("Course Assistant application started")
131 | main()
132 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/assistant.py:
--------------------------------------------------------------------------------
1 | import os
2 | import time
3 | import json
4 |
5 | from openai import OpenAI
6 |
7 | from elasticsearch import Elasticsearch
8 | from sentence_transformers import SentenceTransformer
9 |
10 |
11 | ELASTIC_URL = os.getenv("ELASTIC_URL", "http://elasticsearch:9200")
12 | OLLAMA_URL = os.getenv("OLLAMA_URL", "http://ollama:11434/v1/")
13 | OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "your-api-key-here")
14 |
15 |
16 | es_client = Elasticsearch(ELASTIC_URL)
17 | ollama_client = OpenAI(base_url=OLLAMA_URL, api_key="ollama")
18 | openai_client = OpenAI(api_key=OPENAI_API_KEY)
19 |
20 | model = SentenceTransformer("multi-qa-MiniLM-L6-cos-v1")
21 |
22 |
23 | def elastic_search_text(query, course, index_name="course-questions"):
24 | search_query = {
25 | "size": 5,
26 | "query": {
27 | "bool": {
28 | "must": {
29 | "multi_match": {
30 | "query": query,
31 | "fields": ["question^3", "text", "section"],
32 | "type": "best_fields",
33 | }
34 | },
35 | "filter": {"term": {"course": course}},
36 | }
37 | },
38 | }
39 |
40 | response = es_client.search(index=index_name, body=search_query)
41 | return [hit["_source"] for hit in response["hits"]["hits"]]
42 |
43 |
44 | def elastic_search_knn(field, vector, course, index_name="course-questions"):
45 | knn = {
46 | "field": field,
47 | "query_vector": vector,
48 | "k": 5,
49 | "num_candidates": 10000,
50 | "filter": {"term": {"course": course}},
51 | }
52 |
53 | search_query = {
54 | "knn": knn,
55 | "_source": ["text", "section", "question", "course", "id"],
56 | }
57 |
58 | es_results = es_client.search(index=index_name, body=search_query)
59 |
60 | return [hit["_source"] for hit in es_results["hits"]["hits"]]
61 |
62 |
63 | def build_prompt(query, search_results):
64 | prompt_template = """
65 | You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.
66 | Use only the facts from the CONTEXT when answering the QUESTION.
67 |
68 | QUESTION: {question}
69 |
70 | CONTEXT:
71 | {context}
72 | """.strip()
73 |
74 | context = "\n\n".join(
75 | [
76 | f"section: {doc['section']}\nquestion: {doc['question']}\nanswer: {doc['text']}"
77 | for doc in search_results
78 | ]
79 | )
80 | return prompt_template.format(question=query, context=context).strip()
81 |
82 |
83 | def llm(prompt, model_choice):
84 | start_time = time.time()
85 | if model_choice.startswith('ollama/'):
86 | response = ollama_client.chat.completions.create(
87 | model=model_choice.split('/')[-1],
88 | messages=[{"role": "user", "content": prompt}]
89 | )
90 | answer = response.choices[0].message.content
91 | tokens = {
92 | 'prompt_tokens': response.usage.prompt_tokens,
93 | 'completion_tokens': response.usage.completion_tokens,
94 | 'total_tokens': response.usage.total_tokens
95 | }
96 | elif model_choice.startswith('openai/'):
97 | response = openai_client.chat.completions.create(
98 | model=model_choice.split('/')[-1],
99 | messages=[{"role": "user", "content": prompt}]
100 | )
101 | answer = response.choices[0].message.content
102 | tokens = {
103 | 'prompt_tokens': response.usage.prompt_tokens,
104 | 'completion_tokens': response.usage.completion_tokens,
105 | 'total_tokens': response.usage.total_tokens
106 | }
107 | else:
108 | raise ValueError(f"Unknown model choice: {model_choice}")
109 |
110 | end_time = time.time()
111 | response_time = end_time - start_time
112 |
113 | return answer, tokens, response_time
114 |
115 |
116 | def evaluate_relevance(question, answer):
117 | prompt_template = """
118 | You are an expert evaluator for a Retrieval-Augmented Generation (RAG) system.
119 | Your task is to analyze the relevance of the generated answer to the given question.
120 | Based on the relevance of the generated answer, you will classify it
121 | as "NON_RELEVANT", "PARTLY_RELEVANT", or "RELEVANT".
122 |
123 | Here is the data for evaluation:
124 |
125 | Question: {question}
126 | Generated Answer: {answer}
127 |
128 | Please analyze the content and context of the generated answer in relation to the question
129 | and provide your evaluation in parsable JSON without using code blocks:
130 |
131 | {{
132 | "Relevance": "NON_RELEVANT" | "PARTLY_RELEVANT" | "RELEVANT",
133 | "Explanation": "[Provide a brief explanation for your evaluation]"
134 | }}
135 | """.strip()
136 |
137 | prompt = prompt_template.format(question=question, answer=answer)
138 | evaluation, tokens, _ = llm(prompt, 'openai/gpt-4o-mini')
139 |
140 | try:
141 | json_eval = json.loads(evaluation)
142 | return json_eval['Relevance'], json_eval['Explanation'], tokens
143 | except json.JSONDecodeError:
144 | return "UNKNOWN", "Failed to parse evaluation", tokens
145 |
146 |
147 | def calculate_openai_cost(model_choice, tokens):
148 | openai_cost = 0
149 |
150 | if model_choice == 'openai/gpt-3.5-turbo':
151 | openai_cost = (tokens['prompt_tokens'] * 0.0015 + tokens['completion_tokens'] * 0.002) / 1000
152 | elif model_choice in ['openai/gpt-4o', 'openai/gpt-4o-mini']:
153 | openai_cost = (tokens['prompt_tokens'] * 0.03 + tokens['completion_tokens'] * 0.06) / 1000
154 |
155 | return openai_cost
156 |
157 |
158 | def get_answer(query, course, model_choice, search_type):
159 | if search_type == 'Vector':
160 | vector = model.encode(query)
161 | search_results = elastic_search_knn('question_text_vector', vector, course)
162 | else:
163 | search_results = elastic_search_text(query, course)
164 |
165 | prompt = build_prompt(query, search_results)
166 | answer, tokens, response_time = llm(prompt, model_choice)
167 |
168 | relevance, explanation, eval_tokens = evaluate_relevance(query, answer)
169 |
170 | openai_cost = calculate_openai_cost(model_choice, tokens)
171 |
172 | return {
173 | 'answer': answer,
174 | 'response_time': response_time,
175 | 'relevance': relevance,
176 | 'relevance_explanation': explanation,
177 | 'model_used': model_choice,
178 | 'prompt_tokens': tokens['prompt_tokens'],
179 | 'completion_tokens': tokens['completion_tokens'],
180 | 'total_tokens': tokens['total_tokens'],
181 | 'eval_prompt_tokens': eval_tokens['prompt_tokens'],
182 | 'eval_completion_tokens': eval_tokens['completion_tokens'],
183 | 'eval_total_tokens': eval_tokens['total_tokens'],
184 | 'openai_cost': openai_cost
185 | }
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/db.py:
--------------------------------------------------------------------------------
1 | import os
2 | import psycopg2
3 | from psycopg2.extras import DictCursor
4 | from datetime import datetime
5 | from zoneinfo import ZoneInfo
6 |
7 | tz = ZoneInfo("Europe/Berlin")
8 |
9 |
10 | def get_db_connection():
11 | return psycopg2.connect(
12 | host=os.getenv("POSTGRES_HOST", "postgres"),
13 | database=os.getenv("POSTGRES_DB", "course_assistant"),
14 | user=os.getenv("POSTGRES_USER", "your_username"),
15 | password=os.getenv("POSTGRES_PASSWORD", "your_password"),
16 | )
17 |
18 |
19 | def init_db():
20 | conn = get_db_connection()
21 | try:
22 | with conn.cursor() as cur:
23 | cur.execute("DROP TABLE IF EXISTS feedback")
24 | cur.execute("DROP TABLE IF EXISTS conversations")
25 |
26 | cur.execute("""
27 | CREATE TABLE conversations (
28 | id TEXT PRIMARY KEY,
29 | question TEXT NOT NULL,
30 | answer TEXT NOT NULL,
31 | course TEXT NOT NULL,
32 | model_used TEXT NOT NULL,
33 | response_time FLOAT NOT NULL,
34 | relevance TEXT NOT NULL,
35 | relevance_explanation TEXT NOT NULL,
36 | prompt_tokens INTEGER NOT NULL,
37 | completion_tokens INTEGER NOT NULL,
38 | total_tokens INTEGER NOT NULL,
39 | eval_prompt_tokens INTEGER NOT NULL,
40 | eval_completion_tokens INTEGER NOT NULL,
41 | eval_total_tokens INTEGER NOT NULL,
42 | openai_cost FLOAT NOT NULL,
43 | timestamp TIMESTAMP WITH TIME ZONE NOT NULL
44 | )
45 | """)
46 | cur.execute("""
47 | CREATE TABLE feedback (
48 | id SERIAL PRIMARY KEY,
49 | conversation_id TEXT REFERENCES conversations(id),
50 | feedback INTEGER NOT NULL,
51 | timestamp TIMESTAMP WITH TIME ZONE NOT NULL
52 | )
53 | """)
54 | conn.commit()
55 | finally:
56 | conn.close()
57 |
58 |
59 | def save_conversation(conversation_id, question, answer_data, course, timestamp=None):
60 | if timestamp is None:
61 | timestamp = datetime.now(tz)
62 |
63 | conn = get_db_connection()
64 | try:
65 | with conn.cursor() as cur:
66 | cur.execute(
67 | """
68 | INSERT INTO conversations
69 | (id, question, answer, course, model_used, response_time, relevance,
70 | relevance_explanation, prompt_tokens, completion_tokens, total_tokens,
71 | eval_prompt_tokens, eval_completion_tokens, eval_total_tokens, openai_cost, timestamp)
72 | VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, COALESCE(%s, CURRENT_TIMESTAMP))
73 | """,
74 | (
75 | conversation_id,
76 | question,
77 | answer_data["answer"],
78 | course,
79 | answer_data["model_used"],
80 | answer_data["response_time"],
81 | answer_data["relevance"],
82 | answer_data["relevance_explanation"],
83 | answer_data["prompt_tokens"],
84 | answer_data["completion_tokens"],
85 | answer_data["total_tokens"],
86 | answer_data["eval_prompt_tokens"],
87 | answer_data["eval_completion_tokens"],
88 | answer_data["eval_total_tokens"],
89 | answer_data["openai_cost"],
90 | timestamp,
91 | ),
92 | )
93 | conn.commit()
94 | finally:
95 | conn.close()
96 |
97 |
98 | def save_feedback(conversation_id, feedback, timestamp=None):
99 | if timestamp is None:
100 | timestamp = datetime.now(tz)
101 |
102 | conn = get_db_connection()
103 | try:
104 | with conn.cursor() as cur:
105 | cur.execute(
106 | "INSERT INTO feedback (conversation_id, feedback, timestamp) VALUES (%s, %s, COALESCE(%s, CURRENT_TIMESTAMP))",
107 | (conversation_id, feedback, timestamp),
108 | )
109 | conn.commit()
110 | finally:
111 | conn.close()
112 |
113 |
114 | def get_recent_conversations(limit=5, relevance=None):
115 | conn = get_db_connection()
116 | try:
117 | with conn.cursor(cursor_factory=DictCursor) as cur:
118 | query = """
119 | SELECT c.*, f.feedback
120 | FROM conversations c
121 | LEFT JOIN feedback f ON c.id = f.conversation_id
122 | """
123 | if relevance:
124 | query += f" WHERE c.relevance = '{relevance}'"
125 | query += " ORDER BY c.timestamp DESC LIMIT %s"
126 |
127 | cur.execute(query, (limit,))
128 | return cur.fetchall()
129 | finally:
130 | conn.close()
131 |
132 |
133 | def get_feedback_stats():
134 | conn = get_db_connection()
135 | try:
136 | with conn.cursor(cursor_factory=DictCursor) as cur:
137 | cur.execute("""
138 | SELECT
139 | SUM(CASE WHEN feedback > 0 THEN 1 ELSE 0 END) as thumbs_up,
140 | SUM(CASE WHEN feedback < 0 THEN 1 ELSE 0 END) as thumbs_down
141 | FROM feedback
142 | """)
143 | return cur.fetchone()
144 | finally:
145 | conn.close()
146 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/docker-compose.yaml:
--------------------------------------------------------------------------------
1 | version: '3.8'
2 |
3 | services:
4 | elasticsearch:
5 | image: docker.elastic.co/elasticsearch/elasticsearch:8.4.3
6 | container_name: elasticsearch
7 | environment:
8 | - discovery.type=single-node
9 | - xpack.security.enabled=false
10 | ports:
11 | - "${ELASTIC_PORT:-9200}:9200"
12 | - "9300:9300"
13 | volumes:
14 | - elasticsearch_data:/usr/share/elasticsearch/data
15 |
16 | ollama:
17 | image: ollama/ollama
18 | container_name: ollama
19 | volumes:
20 | - ollama_data:/root/.ollama
21 | ports:
22 | - "${OLLAMA_PORT:-11434}:11434"
23 |
24 | postgres:
25 | image: postgres:13
26 | container_name: postgres
27 | environment:
28 | POSTGRES_DB: ${POSTGRES_DB}
29 | POSTGRES_USER: ${POSTGRES_USER}
30 | POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
31 | ports:
32 | - "${POSTGRES_PORT:-5432}:5432"
33 | volumes:
34 | - postgres_data:/var/lib/postgresql/data
35 |
36 | streamlit:
37 | build:
38 | context: .
39 | dockerfile: Dockerfile
40 | container_name: streamlit
41 | environment:
42 | - ELASTIC_URL=http://elasticsearch:${ELASTIC_PORT:-9200}
43 | - OLLAMA_URL=http://ollama:${OLLAMA_PORT:-11434}/v1/
44 | - POSTGRES_HOST=postgres
45 | - POSTGRES_DB=${POSTGRES_DB}
46 | - POSTGRES_USER=${POSTGRES_USER}
47 | - POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
48 | - MODEL_NAME=${MODEL_NAME}
49 | - INDEX_NAME=${INDEX_NAME}
50 | - OPENAI_API_KEY=${OPENAI_API_KEY}
51 | ports:
52 | - "${STREAMLIT_PORT:-8501}:8501"
53 | depends_on:
54 | - elasticsearch
55 | - ollama
56 | - postgres
57 |
58 | grafana:
59 | image: grafana/grafana:latest
60 | container_name: grafana
61 | ports:
62 | - "3000:3000"
63 | volumes:
64 | - grafana_data:/var/lib/grafana
65 | environment:
66 | - GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_ADMIN_PASSWORD:-admin}
67 | depends_on:
68 | - postgres
69 |
70 | volumes:
71 | elasticsearch_data:
72 | ollama_data:
73 | postgres_data:
74 | grafana_data:
75 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/generate_data.py:
--------------------------------------------------------------------------------
1 | import time
2 | import random
3 | import uuid
4 | from datetime import datetime, timedelta
5 | from zoneinfo import ZoneInfo
6 | from db import save_conversation, save_feedback, get_db_connection
7 |
8 | # Set the timezone to CET (Europe/Berlin)
9 | tz = ZoneInfo("Europe/Berlin")
10 |
11 | # List of sample questions and answers
12 | SAMPLE_QUESTIONS = [
13 | "What is machine learning?",
14 | "How does linear regression work?",
15 | "Explain the concept of overfitting.",
16 | "What is the difference between supervised and unsupervised learning?",
17 | "How does cross-validation help in model evaluation?",
18 | ]
19 |
20 | SAMPLE_ANSWERS = [
21 | "Machine learning is a subset of artificial intelligence that focuses on the development of algorithms and statistical models that enable computer systems to improve their performance on a specific task through experience.",
22 | "Linear regression is a statistical method used to model the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data.",
23 | "Overfitting occurs when a machine learning model learns the training data too well, including its noise and fluctuations, resulting in poor generalization to new, unseen data.",
24 | "Supervised learning involves training models on labeled data, while unsupervised learning deals with finding patterns in unlabeled data without predefined outputs.",
25 | "Cross-validation is a technique used to assess how well a model will generalize to an independent dataset. It involves partitioning the data into subsets, training the model on a subset, and validating it on the remaining data.",
26 | ]
27 |
28 | COURSES = ["machine-learning-zoomcamp", "data-engineering-zoomcamp", "mlops-zoomcamp"]
29 | MODELS = ["ollama/phi3", "openai/gpt-3.5-turbo", "openai/gpt-4o", "openai/gpt-4o-mini"]
30 | RELEVANCE = ["RELEVANT", "PARTLY_RELEVANT", "NON_RELEVANT"]
31 |
32 |
33 | def generate_synthetic_data(start_time, end_time):
34 | current_time = start_time
35 | conversation_count = 0
36 | print(f"Starting historical data generation from {start_time} to {end_time}")
37 | while current_time < end_time:
38 | conversation_id = str(uuid.uuid4())
39 | question = random.choice(SAMPLE_QUESTIONS)
40 | answer = random.choice(SAMPLE_ANSWERS)
41 | course = random.choice(COURSES)
42 | model = random.choice(MODELS)
43 | relevance = random.choice(RELEVANCE)
44 |
45 | openai_cost = 0
46 |
47 | if model.startswith("openai/"):
48 | openai_cost = random.uniform(0.001, 0.1)
49 |
50 | answer_data = {
51 | "answer": answer,
52 | "response_time": random.uniform(0.5, 5.0),
53 | "relevance": relevance,
54 | "relevance_explanation": f"This answer is {relevance.lower()} to the question.",
55 | "model_used": model,
56 | "prompt_tokens": random.randint(50, 200),
57 | "completion_tokens": random.randint(50, 300),
58 | "total_tokens": random.randint(100, 500),
59 | "eval_prompt_tokens": random.randint(50, 150),
60 | "eval_completion_tokens": random.randint(20, 100),
61 | "eval_total_tokens": random.randint(70, 250),
62 | "openai_cost": openai_cost,
63 | }
64 |
65 | save_conversation(conversation_id, question, answer_data, course, current_time)
66 | print(
67 | f"Saved conversation: ID={conversation_id}, Time={current_time}, Course={course}, Model={model}"
68 | )
69 |
70 | if random.random() < 0.7:
71 | feedback = 1 if random.random() < 0.8 else -1
72 | save_feedback(conversation_id, feedback, current_time)
73 | print(
74 | f"Saved feedback for conversation {conversation_id}: {'Positive' if feedback > 0 else 'Negative'}"
75 | )
76 |
77 | current_time += timedelta(minutes=random.randint(1, 15))
78 | conversation_count += 1
79 | if conversation_count % 10 == 0:
80 | print(f"Generated {conversation_count} conversations so far...")
81 |
82 | print(
83 | f"Historical data generation complete. Total conversations: {conversation_count}"
84 | )
85 |
86 |
87 | def generate_live_data():
88 | conversation_count = 0
89 | print("Starting live data generation...")
90 | while True:
91 | current_time = datetime.now(tz)
92 | # current_time = None
93 | conversation_id = str(uuid.uuid4())
94 | question = random.choice(SAMPLE_QUESTIONS)
95 | answer = random.choice(SAMPLE_ANSWERS)
96 | course = random.choice(COURSES)
97 | model = random.choice(MODELS)
98 | relevance = random.choice(RELEVANCE)
99 |
100 | openai_cost = 0
101 |
102 | if model.startswith("openai/"):
103 | openai_cost = random.uniform(0.001, 0.1)
104 |
105 | answer_data = {
106 | "answer": answer,
107 | "response_time": random.uniform(0.5, 5.0),
108 | "relevance": relevance,
109 | "relevance_explanation": f"This answer is {relevance.lower()} to the question.",
110 | "model_used": model,
111 | "prompt_tokens": random.randint(50, 200),
112 | "completion_tokens": random.randint(50, 300),
113 | "total_tokens": random.randint(100, 500),
114 | "eval_prompt_tokens": random.randint(50, 150),
115 | "eval_completion_tokens": random.randint(20, 100),
116 | "eval_total_tokens": random.randint(70, 250),
117 | "openai_cost": openai_cost,
118 | }
119 |
120 | save_conversation(conversation_id, question, answer_data, course, current_time)
121 | print(
122 | f"Saved live conversation: ID={conversation_id}, Time={current_time}, Course={course}, Model={model}"
123 | )
124 |
125 | if random.random() < 0.7:
126 | feedback = 1 if random.random() < 0.8 else -1
127 | save_feedback(conversation_id, feedback, current_time)
128 | print(
129 | f"Saved feedback for live conversation {conversation_id}: {'Positive' if feedback > 0 else 'Negative'}"
130 | )
131 |
132 | conversation_count += 1
133 | if conversation_count % 10 == 0:
134 | print(f"Generated {conversation_count} live conversations so far...")
135 |
136 | time.sleep(1)
137 |
138 |
139 | if __name__ == "__main__":
140 | print(f"Script started at {datetime.now(tz)}")
141 | end_time = datetime.now(tz)
142 | start_time = end_time - timedelta(hours=6)
143 | print(f"Generating historical data from {start_time} to {end_time}")
144 | generate_synthetic_data(start_time, end_time)
145 | print("Historical data generation complete.")
146 |
147 | print("Starting live data generation... Press Ctrl+C to stop.")
148 | try:
149 | generate_live_data()
150 | except KeyboardInterrupt:
151 | print(f"Live data generation stopped at {datetime.now(tz)}.")
152 | finally:
153 | print(f"Script ended at {datetime.now(tz)}")
154 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/prep.py:
--------------------------------------------------------------------------------
1 | import os
2 | import requests
3 | import pandas as pd
4 | from sentence_transformers import SentenceTransformer
5 | from elasticsearch import Elasticsearch
6 | from tqdm.auto import tqdm
7 | from dotenv import load_dotenv
8 |
9 | from db import init_db
10 |
11 | load_dotenv()
12 |
13 | ELASTIC_URL = os.getenv("ELASTIC_URL_LOCAL")
14 | MODEL_NAME = os.getenv("MODEL_NAME")
15 | INDEX_NAME = os.getenv("INDEX_NAME")
16 |
17 | BASE_URL = "https://github.com/DataTalksClub/llm-zoomcamp/blob/main"
18 |
19 |
20 | def fetch_documents():
21 | print("Fetching documents...")
22 | relative_url = "03-vector-search/eval/documents-with-ids.json"
23 | docs_url = f"{BASE_URL}/{relative_url}?raw=1"
24 | docs_response = requests.get(docs_url)
25 | documents = docs_response.json()
26 | print(f"Fetched {len(documents)} documents")
27 | return documents
28 |
29 |
30 | def fetch_ground_truth():
31 | print("Fetching ground truth data...")
32 | relative_url = "03-vector-search/eval/ground-truth-data.csv"
33 | ground_truth_url = f"{BASE_URL}/{relative_url}?raw=1"
34 | df_ground_truth = pd.read_csv(ground_truth_url)
35 | df_ground_truth = df_ground_truth[
36 | df_ground_truth.course == "machine-learning-zoomcamp"
37 | ]
38 | ground_truth = df_ground_truth.to_dict(orient="records")
39 | print(f"Fetched {len(ground_truth)} ground truth records")
40 | return ground_truth
41 |
42 |
43 | def load_model():
44 | print(f"Loading model: {MODEL_NAME}")
45 | return SentenceTransformer(MODEL_NAME)
46 |
47 |
48 | def setup_elasticsearch():
49 | print("Setting up Elasticsearch...")
50 | es_client = Elasticsearch(ELASTIC_URL)
51 |
52 | index_settings = {
53 | "settings": {"number_of_shards": 1, "number_of_replicas": 0},
54 | "mappings": {
55 | "properties": {
56 | "text": {"type": "text"},
57 | "section": {"type": "text"},
58 | "question": {"type": "text"},
59 | "course": {"type": "keyword"},
60 | "id": {"type": "keyword"},
61 | "question_text_vector": {
62 | "type": "dense_vector",
63 | "dims": 384,
64 | "index": True,
65 | "similarity": "cosine",
66 | },
67 | }
68 | },
69 | }
70 |
71 | es_client.indices.delete(index=INDEX_NAME, ignore_unavailable=True)
72 | es_client.indices.create(index=INDEX_NAME, body=index_settings)
73 | print(f"Elasticsearch index '{INDEX_NAME}' created")
74 | return es_client
75 |
76 |
77 | def index_documents(es_client, documents, model):
78 | print("Indexing documents...")
79 | for doc in tqdm(documents):
80 | question = doc["question"]
81 | text = doc["text"]
82 | doc["question_text_vector"] = model.encode(question + " " + text).tolist()
83 | es_client.index(index=INDEX_NAME, document=doc)
84 | print(f"Indexed {len(documents)} documents")
85 |
86 |
87 | def main():
88 | # you may consider to comment
89 | # if you just want to init the db or didn't want to re-index
90 | print("Starting the indexing process...")
91 |
92 | documents = fetch_documents()
93 | ground_truth = fetch_ground_truth()
94 | model = load_model()
95 | es_client = setup_elasticsearch()
96 | index_documents(es_client, documents, model)
97 | # you may consider to comment
98 |
99 | print("Initializing database...")
100 | init_db()
101 |
102 | print("Indexing process completed successfully!")
103 |
104 |
105 | if __name__ == "__main__":
106 | main()
107 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/requirements.txt:
--------------------------------------------------------------------------------
1 | streamlit
2 | elasticsearch==8.14.0
3 | psycopg2-binary==2.9.9
4 | python-dotenv
5 | openai==1.35.7
6 | sentence-transformers==2.7.0
7 | numpy==1.26.4
8 |
9 | --find-links https://download.pytorch.org/whl/cpu/torch_stable.html
10 | torch==2.3.1+cpu
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/grafana.md:
--------------------------------------------------------------------------------
1 | ## Original queries
2 |
3 | Response Time Panel:
4 |
5 | ```sql
6 | SELECT
7 | timestamp AS time,
8 | response_time
9 | FROM conversations
10 | ORDER BY timestamp
11 | ```
12 |
13 | Relevance Distribution Panel:
14 |
15 | ```sql
16 | SELECT
17 | relevance,
18 | COUNT(*) as count
19 | FROM conversations
20 | GROUP BY relevance
21 | ```
22 |
23 | Model Usage Panel:
24 |
25 | ```sql
26 | SELECT
27 | model_used,
28 | COUNT(*) as count
29 | FROM conversations
30 | GROUP BY model_used
31 | ```
32 |
33 |
34 | Token Usage Panel:
35 |
36 | ```sql
37 | SELECT
38 | timestamp AS time,
39 | total_tokens
40 | FROM conversations
41 | ORDER BY timestamp
42 | ```
43 |
44 | OpenAI Cost Panel:
45 |
46 | ```sql
47 | SELECT
48 | timestamp AS time,
49 | openai_cost
50 | FROM conversations
51 | WHERE openai_cost > 0
52 | ORDER BY timestamp
53 | ```
54 |
55 | Recent Conversations Panel:
56 |
57 | ```sql
58 | SELECT
59 | timestamp AS time,
60 | question,
61 | answer,
62 | relevance
63 | FROM conversations
64 | ORDER BY timestamp DESC
65 | LIMIT 5
66 | ```
67 |
68 | Feedback Statistics Panel:
69 |
70 | ```sql
71 | SELECT
72 | SUM(CASE WHEN feedback > 0 THEN 1 ELSE 0 END) as thumbs_up,
73 | SUM(CASE WHEN feedback < 0 THEN 1 ELSE 0 END) as thumbs_down
74 | FROM feedback
75 | ```
76 |
77 | ## Revised queries
78 |
79 | We can (and should) also use special grafana variables
80 |
81 | - `$__timeFrom()` and `$__timeTo()`: Start and end of the selected time range
82 | - `$__timeGroup(timestamp, $__interval)`: Groups results by time intervals automatically calculated by Grafana
83 |
84 | ### 1. Response Time Panel
85 |
86 | This query shows the response time for each conversation within the selected time range:
87 |
88 | ```sql
89 | SELECT
90 | timestamp AS time,
91 | response_time
92 | FROM conversations
93 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
94 | ORDER BY timestamp
95 | ```
96 |
97 | ### 2. Relevance Distribution Panel
98 |
99 | This query counts the number of conversations for each relevance category within the selected time range:
100 |
101 | ```sql
102 | SELECT
103 | relevance,
104 | COUNT(*) as count
105 | FROM conversations
106 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
107 | GROUP BY relevance
108 | ```
109 |
110 | ### 3. Model Usage Panel
111 |
112 | This query counts the number of times each model was used within the selected time range:
113 |
114 | ```sql
115 | SELECT
116 | model_used,
117 | COUNT(*) as count
118 | FROM conversations
119 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
120 | GROUP BY model_used
121 | ```
122 |
123 | ### 4. Token Usage Panel
124 |
125 | This query shows the average token usage over time, grouped by Grafana's automatically calculated interval:
126 |
127 | ```sql
128 | SELECT
129 | $__timeGroup(timestamp, $__interval) AS time,
130 | AVG(total_tokens) AS avg_tokens
131 | FROM conversations
132 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
133 | GROUP BY 1
134 | ORDER BY 1
135 | ```
136 |
137 | ### 5. OpenAI Cost Panel
138 |
139 | This query shows the total OpenAI cost over time, grouped by Grafana's automatically calculated interval:
140 |
141 | ```sql
142 | SELECT
143 | $__timeGroup(timestamp, $__interval) AS time,
144 | SUM(openai_cost) AS total_cost
145 | FROM conversations
146 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
147 | AND openai_cost > 0
148 | GROUP BY 1
149 | ORDER BY 1
150 | ```
151 |
152 | ### 6. Recent Conversations Panel
153 |
154 | This query retrieves the 5 most recent conversations within the selected time range:
155 |
156 | ```sql
157 | SELECT
158 | timestamp AS time,
159 | question,
160 | answer,
161 | relevance
162 | FROM conversations
163 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
164 | ORDER BY timestamp DESC
165 | LIMIT 5
166 | ```
167 |
168 | ### 7. Feedback Statistics Panel
169 |
170 | This query calculates the total number of positive and negative feedback within the selected time range:
171 |
172 | ```sql
173 | SELECT
174 | SUM(CASE WHEN feedback > 0 THEN 1 ELSE 0 END) as thumbs_up,
175 | SUM(CASE WHEN feedback < 0 THEN 1 ELSE 0 END) as thumbs_down
176 | FROM feedback
177 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
178 | ```
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/homework.md:
--------------------------------------------------------------------------------
1 | ## Homework: Evaluation and Monitoring
2 |
3 | Solution: [solution.ipynb](solution.ipynb)
4 |
5 | In this homework, we'll evaluate the quality of our RAG system.
6 |
7 | > It's possible that your answers won't match exactly. If it's the case, select the closest one.
8 |
9 | Solution:
10 |
11 | * Video: TBA
12 | * Notebook: TBA
13 |
14 | ## Getting the data
15 |
16 | Let's start by getting the dataset. We will use the data we generated in the module.
17 |
18 | In particular, we'll evaluate the quality of our RAG system
19 | with [gpt-4o-mini](https://github.com/DataTalksClub/llm-zoomcamp/blob/main/04-monitoring/data/results-gpt4o-mini.csv)
20 |
21 |
22 | Read it:
23 |
24 | ```python
25 | url = f'{github_url}?raw=1'
26 | df = pd.read_csv(url)
27 | ```
28 |
29 | We will use only the first 300 documents:
30 |
31 |
32 | ```python
33 | df = df.iloc[:300]
34 | ```
35 |
36 | ## Q1. Getting the embeddings model
37 |
38 | Now, get the embeddings model `multi-qa-mpnet-base-dot-v1` from
39 | [the Sentence Transformer library](https://www.sbert.net/docs/sentence_transformer/pretrained_models.html#model-overview)
40 |
41 | > Note: this is not the same model as in HW3
42 |
43 | ```bash
44 | from sentence_transformers import SentenceTransformer
45 | embedding_model = SentenceTransformer(model_name)
46 | ```
47 |
48 | Create the embeddings for the first LLM answer:
49 |
50 | ```python
51 | answer_llm = df.iloc[0].answer_llm
52 | ```
53 |
54 | What's the first value of the resulting vector?
55 |
56 | * -0.42
57 | * -0.22
58 | * -0.02
59 | * 0.21
60 |
61 |
62 | ## Q2. Computing the dot product
63 |
64 |
65 | Now for each answer pair, let's create embeddings and compute dot product between them
66 |
67 | We will put the results (scores) into the `evaluations` list
68 |
69 | What's the 75% percentile of the score?
70 |
71 | * 21.67
72 | * 31.67
73 | * 41.67
74 | * 51.67
75 |
76 | ## Q3. Computing the cosine
77 |
78 | From Q2, we can see that the results are not within the [0, 1] range. It's because the vectors coming from this model are not normalized.
79 |
80 | So we need to normalize them.
81 |
82 | To do it, we
83 |
84 | * Compute the norm of a vector
85 | * Divide each element by this norm
86 |
87 | So, for vector `v`, it'll be `v / ||v||`
88 |
89 | In numpy, this is how you do it:
90 |
91 | ```python
92 | norm = np.sqrt((v * v).sum())
93 | v_norm = v / norm
94 | ```
95 |
96 | Let's put it into a function and then compute dot product
97 | between normalized vectors. This will give us cosine similarity
98 |
99 | What's the 75% cosine in the scores?
100 |
101 | * 0.63
102 | * 0.73
103 | * 0.83
104 | * 0.93
105 |
106 | ## Q4. Rouge
107 |
108 | Now we will explore an alternative metric - the ROUGE score.
109 |
110 | This is a set of metrics that compares two answers based on the overlap of n-grams, word sequences, and word pairs.
111 |
112 | It can give a more nuanced view of text similarity than just cosine similarity alone.
113 |
114 | We don't need to implement it ourselves, there's a python package for it:
115 |
116 | ```bash
117 | pip install rouge
118 | ```
119 |
120 | (The latest version at the moment of writing is `1.0.1`)
121 |
122 | Let's compute the ROUGE score between the answers at the index 10 of our dataframe (`doc_id=5170565b`)
123 |
124 | ```
125 | from rouge import Rouge
126 | rouge_scorer = Rouge()
127 |
128 | scores = rouge_scorer.get_scores(r['answer_llm'], r['answer_orig'])[0]
129 | ```
130 |
131 | There are three scores: `rouge-1`, `rouge-2` and `rouge-l`, and precision, recall and F1 score for each.
132 |
133 | * `rouge-1` - the overlap of unigrams,
134 | * `rouge-2` - bigrams,
135 | * `rouge-l` - the longest common subsequence
136 |
137 | What's the F score for `rouge-1`?
138 |
139 | - 0.35
140 | - 0.45
141 | - 0.55
142 | - 0.65
143 |
144 | ## Q5. Average rouge score
145 |
146 | Let's compute the average F-score between `rouge-1`, `rouge-2` and `rouge-l` for the same record from Q4
147 |
148 | - 0.35
149 | - 0.45
150 | - 0.55
151 | - 0.65
152 |
153 | ## Q6. Average rouge score for all the data points
154 |
155 | Now let's compute the F-score for all the records and create a dataframe from them.
156 |
157 | What's the average F-score in `rouge_2` across all the records?
158 |
159 | - 0.10
160 | - 0.20
161 | - 0.30
162 | - 0.40
163 |
164 |
165 |
166 | ## Submit the results
167 |
168 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2024/homework/hw4
169 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
170 |
--------------------------------------------------------------------------------
/cohorts/2024/05-orchestration/README.md:
--------------------------------------------------------------------------------
1 | # Data Preparation in RAG
2 |
3 | ## Getting started
4 |
5 | 1. Clone [repository](https://github.com/mage-ai/rag-project)
6 | ```bash
7 | git clone https://github.com/mage-ai/rag-project
8 | cd rag-project
9 | ```
10 | 3. navigate to the `rag-project/llm` directory, add `spacy` to the requirements.txt.
11 | 4. Then update the `Dockerfile` found in the `rag-project` directory with the following:
12 | ```YAML
13 | RUN python -m spacy download en_core_web_sm
14 | ```
15 | 4. Run
16 |
17 | ```bash
18 | `./scripts/start.sh`
19 | ```
20 |
21 | Once started, go to [http://localhost:6789/](http://localhost:6789/)
22 |
23 | For more setup information, refer to these [instructions](https://docs.mage.ai/getting-started/setup#docker-compose-template)
24 |
25 |
26 | ## 0. Module overview
27 |
28 |
29 |
153 |
154 |
155 | * Grafana variables
156 | * Exporting and importing dashboards
157 |
158 | Links:
159 |
160 | * [SQL queries for Grafana](grafana.md)
161 | * [Grafana dashboard](dashboard.json)
162 |
163 | ## Homework
164 |
165 | See [here](../cohorts/2024/04-monitoring/homework.md)
166 |
167 |
168 | ## Extra resources
169 |
170 | ### Overview of the module
171 |
172 | 
173 |
174 | https://www.loom.com/share/1dd375ec4b0d458fabdfc2b841089031
175 |
176 | # Notes
177 |
178 | * [Notes by slavaheroes](https://github.com/slavaheroes/llm-zoomcamp/blob/homeworks/04-monitoring/notes.md)
179 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
180 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/.env:
--------------------------------------------------------------------------------
1 | # PostgreSQL Configuration
2 | POSTGRES_HOST=postgres
3 | POSTGRES_DB=course_assistant
4 | POSTGRES_USER=your_username
5 | POSTGRES_PASSWORD=your_password
6 | POSTGRES_PORT=5432
7 |
8 | # Elasticsearch Configuration
9 | ELASTIC_URL_LOCAL=http://localhost:9200
10 | ELASTIC_URL=http://elasticsearch:9200
11 | ELASTIC_PORT=9200
12 |
13 | # Ollama Configuration
14 | OLLAMA_PORT=11434
15 |
16 | # Streamlit Configuration
17 | STREAMLIT_PORT=8501
18 |
19 | # Other Configuration
20 | MODEL_NAME=multi-qa-MiniLM-L6-cos-v1
21 | INDEX_NAME=course-questions
22 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM python:3.9-slim
2 |
3 | ENV PYTHONUNBUFFERED=1
4 |
5 | WORKDIR /app
6 |
7 | COPY requirements.txt .
8 | RUN pip install --no-cache-dir -r requirements.txt
9 |
10 | COPY . .
11 |
12 | CMD ["streamlit", "run", "app.py"]
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/README.MD:
--------------------------------------------------------------------------------
1 | ## Additional notes for those trying the streamlit/grafana out
2 |
3 | 1) The following packages are required when you run some of .py scripts
4 |
5 | ```
6 | pip install psycopg2-binary python-dotenv
7 | pip install pgcli
8 | ```
9 |
10 |
11 | 2) To download the phi3 model to the container
12 | ```
13 | docker-compose up -d
14 | docker-compose exec ollama ollama pull phi3
15 | ```
16 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/app.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import time
3 | import uuid
4 |
5 | from assistant import get_answer
6 | from db import (
7 | save_conversation,
8 | save_feedback,
9 | get_recent_conversations,
10 | get_feedback_stats,
11 | )
12 |
13 |
14 | def print_log(message):
15 | print(message, flush=True)
16 |
17 |
18 | def main():
19 | print_log("Starting the Course Assistant application")
20 | st.title("Course Assistant")
21 |
22 | # Session state initialization
23 | if "conversation_id" not in st.session_state:
24 | st.session_state.conversation_id = str(uuid.uuid4())
25 | print_log(
26 | f"New conversation started with ID: {st.session_state.conversation_id}"
27 | )
28 | if "count" not in st.session_state:
29 | st.session_state.count = 0
30 | print_log("Feedback count initialized to 0")
31 |
32 | # Course selection
33 | course = st.selectbox(
34 | "Select a course:",
35 | ["machine-learning-zoomcamp", "data-engineering-zoomcamp", "mlops-zoomcamp"],
36 | )
37 | print_log(f"User selected course: {course}")
38 |
39 | # Model selection
40 | model_choice = st.selectbox(
41 | "Select a model:",
42 | ["ollama/phi3", "openai/gpt-3.5-turbo", "openai/gpt-4o", "openai/gpt-4o-mini"],
43 | )
44 | print_log(f"User selected model: {model_choice}")
45 |
46 | # Search type selection
47 | search_type = st.radio("Select search type:", ["Text", "Vector"])
48 | print_log(f"User selected search type: {search_type}")
49 |
50 | # User input
51 | user_input = st.text_input("Enter your question:")
52 |
53 | if st.button("Ask"):
54 | print_log(f"User asked: '{user_input}'")
55 | with st.spinner("Processing..."):
56 | print_log(
57 | f"Getting answer from assistant using {model_choice} model and {search_type} search"
58 | )
59 | start_time = time.time()
60 | answer_data = get_answer(user_input, course, model_choice, search_type)
61 | end_time = time.time()
62 | print_log(f"Answer received in {end_time - start_time:.2f} seconds")
63 | st.success("Completed!")
64 | st.write(answer_data["answer"])
65 |
66 | # Display monitoring information
67 | st.write(f"Response time: {answer_data['response_time']:.2f} seconds")
68 | st.write(f"Relevance: {answer_data['relevance']}")
69 | st.write(f"Model used: {answer_data['model_used']}")
70 | st.write(f"Total tokens: {answer_data['total_tokens']}")
71 | if answer_data["openai_cost"] > 0:
72 | st.write(f"OpenAI cost: ${answer_data['openai_cost']:.4f}")
73 |
74 | # Save conversation to database
75 | print_log("Saving conversation to database")
76 | save_conversation(
77 | st.session_state.conversation_id, user_input, answer_data, course
78 | )
79 | print_log("Conversation saved successfully")
80 | # Generate a new conversation ID for next question
81 | st.session_state.conversation_id = str(uuid.uuid4())
82 |
83 | # Feedback buttons
84 | col1, col2 = st.columns(2)
85 | with col1:
86 | if st.button("+1"):
87 | st.session_state.count += 1
88 | print_log(
89 | f"Positive feedback received. New count: {st.session_state.count}"
90 | )
91 | save_feedback(st.session_state.conversation_id, 1)
92 | print_log("Positive feedback saved to database")
93 | with col2:
94 | if st.button("-1"):
95 | st.session_state.count -= 1
96 | print_log(
97 | f"Negative feedback received. New count: {st.session_state.count}"
98 | )
99 | save_feedback(st.session_state.conversation_id, -1)
100 | print_log("Negative feedback saved to database")
101 |
102 | st.write(f"Current count: {st.session_state.count}")
103 |
104 | # Display recent conversations
105 | st.subheader("Recent Conversations")
106 | relevance_filter = st.selectbox(
107 | "Filter by relevance:", ["All", "RELEVANT", "PARTLY_RELEVANT", "NON_RELEVANT"]
108 | )
109 | recent_conversations = get_recent_conversations(
110 | limit=5, relevance=relevance_filter if relevance_filter != "All" else None
111 | )
112 | for conv in recent_conversations:
113 | st.write(f"Q: {conv['question']}")
114 | st.write(f"A: {conv['answer']}")
115 | st.write(f"Relevance: {conv['relevance']}")
116 | st.write(f"Model: {conv['model_used']}")
117 | st.write("---")
118 |
119 | # Display feedback stats
120 | feedback_stats = get_feedback_stats()
121 | st.subheader("Feedback Statistics")
122 | st.write(f"Thumbs up: {feedback_stats['thumbs_up']}")
123 | st.write(f"Thumbs down: {feedback_stats['thumbs_down']}")
124 |
125 |
126 | print_log("Streamlit app loop completed")
127 |
128 |
129 | if __name__ == "__main__":
130 | print_log("Course Assistant application started")
131 | main()
132 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/assistant.py:
--------------------------------------------------------------------------------
1 | import os
2 | import time
3 | import json
4 |
5 | from openai import OpenAI
6 |
7 | from elasticsearch import Elasticsearch
8 | from sentence_transformers import SentenceTransformer
9 |
10 |
11 | ELASTIC_URL = os.getenv("ELASTIC_URL", "http://elasticsearch:9200")
12 | OLLAMA_URL = os.getenv("OLLAMA_URL", "http://ollama:11434/v1/")
13 | OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "your-api-key-here")
14 |
15 |
16 | es_client = Elasticsearch(ELASTIC_URL)
17 | ollama_client = OpenAI(base_url=OLLAMA_URL, api_key="ollama")
18 | openai_client = OpenAI(api_key=OPENAI_API_KEY)
19 |
20 | model = SentenceTransformer("multi-qa-MiniLM-L6-cos-v1")
21 |
22 |
23 | def elastic_search_text(query, course, index_name="course-questions"):
24 | search_query = {
25 | "size": 5,
26 | "query": {
27 | "bool": {
28 | "must": {
29 | "multi_match": {
30 | "query": query,
31 | "fields": ["question^3", "text", "section"],
32 | "type": "best_fields",
33 | }
34 | },
35 | "filter": {"term": {"course": course}},
36 | }
37 | },
38 | }
39 |
40 | response = es_client.search(index=index_name, body=search_query)
41 | return [hit["_source"] for hit in response["hits"]["hits"]]
42 |
43 |
44 | def elastic_search_knn(field, vector, course, index_name="course-questions"):
45 | knn = {
46 | "field": field,
47 | "query_vector": vector,
48 | "k": 5,
49 | "num_candidates": 10000,
50 | "filter": {"term": {"course": course}},
51 | }
52 |
53 | search_query = {
54 | "knn": knn,
55 | "_source": ["text", "section", "question", "course", "id"],
56 | }
57 |
58 | es_results = es_client.search(index=index_name, body=search_query)
59 |
60 | return [hit["_source"] for hit in es_results["hits"]["hits"]]
61 |
62 |
63 | def build_prompt(query, search_results):
64 | prompt_template = """
65 | You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.
66 | Use only the facts from the CONTEXT when answering the QUESTION.
67 |
68 | QUESTION: {question}
69 |
70 | CONTEXT:
71 | {context}
72 | """.strip()
73 |
74 | context = "\n\n".join(
75 | [
76 | f"section: {doc['section']}\nquestion: {doc['question']}\nanswer: {doc['text']}"
77 | for doc in search_results
78 | ]
79 | )
80 | return prompt_template.format(question=query, context=context).strip()
81 |
82 |
83 | def llm(prompt, model_choice):
84 | start_time = time.time()
85 | if model_choice.startswith('ollama/'):
86 | response = ollama_client.chat.completions.create(
87 | model=model_choice.split('/')[-1],
88 | messages=[{"role": "user", "content": prompt}]
89 | )
90 | answer = response.choices[0].message.content
91 | tokens = {
92 | 'prompt_tokens': response.usage.prompt_tokens,
93 | 'completion_tokens': response.usage.completion_tokens,
94 | 'total_tokens': response.usage.total_tokens
95 | }
96 | elif model_choice.startswith('openai/'):
97 | response = openai_client.chat.completions.create(
98 | model=model_choice.split('/')[-1],
99 | messages=[{"role": "user", "content": prompt}]
100 | )
101 | answer = response.choices[0].message.content
102 | tokens = {
103 | 'prompt_tokens': response.usage.prompt_tokens,
104 | 'completion_tokens': response.usage.completion_tokens,
105 | 'total_tokens': response.usage.total_tokens
106 | }
107 | else:
108 | raise ValueError(f"Unknown model choice: {model_choice}")
109 |
110 | end_time = time.time()
111 | response_time = end_time - start_time
112 |
113 | return answer, tokens, response_time
114 |
115 |
116 | def evaluate_relevance(question, answer):
117 | prompt_template = """
118 | You are an expert evaluator for a Retrieval-Augmented Generation (RAG) system.
119 | Your task is to analyze the relevance of the generated answer to the given question.
120 | Based on the relevance of the generated answer, you will classify it
121 | as "NON_RELEVANT", "PARTLY_RELEVANT", or "RELEVANT".
122 |
123 | Here is the data for evaluation:
124 |
125 | Question: {question}
126 | Generated Answer: {answer}
127 |
128 | Please analyze the content and context of the generated answer in relation to the question
129 | and provide your evaluation in parsable JSON without using code blocks:
130 |
131 | {{
132 | "Relevance": "NON_RELEVANT" | "PARTLY_RELEVANT" | "RELEVANT",
133 | "Explanation": "[Provide a brief explanation for your evaluation]"
134 | }}
135 | """.strip()
136 |
137 | prompt = prompt_template.format(question=question, answer=answer)
138 | evaluation, tokens, _ = llm(prompt, 'openai/gpt-4o-mini')
139 |
140 | try:
141 | json_eval = json.loads(evaluation)
142 | return json_eval['Relevance'], json_eval['Explanation'], tokens
143 | except json.JSONDecodeError:
144 | return "UNKNOWN", "Failed to parse evaluation", tokens
145 |
146 |
147 | def calculate_openai_cost(model_choice, tokens):
148 | openai_cost = 0
149 |
150 | if model_choice == 'openai/gpt-3.5-turbo':
151 | openai_cost = (tokens['prompt_tokens'] * 0.0015 + tokens['completion_tokens'] * 0.002) / 1000
152 | elif model_choice in ['openai/gpt-4o', 'openai/gpt-4o-mini']:
153 | openai_cost = (tokens['prompt_tokens'] * 0.03 + tokens['completion_tokens'] * 0.06) / 1000
154 |
155 | return openai_cost
156 |
157 |
158 | def get_answer(query, course, model_choice, search_type):
159 | if search_type == 'Vector':
160 | vector = model.encode(query)
161 | search_results = elastic_search_knn('question_text_vector', vector, course)
162 | else:
163 | search_results = elastic_search_text(query, course)
164 |
165 | prompt = build_prompt(query, search_results)
166 | answer, tokens, response_time = llm(prompt, model_choice)
167 |
168 | relevance, explanation, eval_tokens = evaluate_relevance(query, answer)
169 |
170 | openai_cost = calculate_openai_cost(model_choice, tokens)
171 |
172 | return {
173 | 'answer': answer,
174 | 'response_time': response_time,
175 | 'relevance': relevance,
176 | 'relevance_explanation': explanation,
177 | 'model_used': model_choice,
178 | 'prompt_tokens': tokens['prompt_tokens'],
179 | 'completion_tokens': tokens['completion_tokens'],
180 | 'total_tokens': tokens['total_tokens'],
181 | 'eval_prompt_tokens': eval_tokens['prompt_tokens'],
182 | 'eval_completion_tokens': eval_tokens['completion_tokens'],
183 | 'eval_total_tokens': eval_tokens['total_tokens'],
184 | 'openai_cost': openai_cost
185 | }
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/db.py:
--------------------------------------------------------------------------------
1 | import os
2 | import psycopg2
3 | from psycopg2.extras import DictCursor
4 | from datetime import datetime
5 | from zoneinfo import ZoneInfo
6 |
7 | tz = ZoneInfo("Europe/Berlin")
8 |
9 |
10 | def get_db_connection():
11 | return psycopg2.connect(
12 | host=os.getenv("POSTGRES_HOST", "postgres"),
13 | database=os.getenv("POSTGRES_DB", "course_assistant"),
14 | user=os.getenv("POSTGRES_USER", "your_username"),
15 | password=os.getenv("POSTGRES_PASSWORD", "your_password"),
16 | )
17 |
18 |
19 | def init_db():
20 | conn = get_db_connection()
21 | try:
22 | with conn.cursor() as cur:
23 | cur.execute("DROP TABLE IF EXISTS feedback")
24 | cur.execute("DROP TABLE IF EXISTS conversations")
25 |
26 | cur.execute("""
27 | CREATE TABLE conversations (
28 | id TEXT PRIMARY KEY,
29 | question TEXT NOT NULL,
30 | answer TEXT NOT NULL,
31 | course TEXT NOT NULL,
32 | model_used TEXT NOT NULL,
33 | response_time FLOAT NOT NULL,
34 | relevance TEXT NOT NULL,
35 | relevance_explanation TEXT NOT NULL,
36 | prompt_tokens INTEGER NOT NULL,
37 | completion_tokens INTEGER NOT NULL,
38 | total_tokens INTEGER NOT NULL,
39 | eval_prompt_tokens INTEGER NOT NULL,
40 | eval_completion_tokens INTEGER NOT NULL,
41 | eval_total_tokens INTEGER NOT NULL,
42 | openai_cost FLOAT NOT NULL,
43 | timestamp TIMESTAMP WITH TIME ZONE NOT NULL
44 | )
45 | """)
46 | cur.execute("""
47 | CREATE TABLE feedback (
48 | id SERIAL PRIMARY KEY,
49 | conversation_id TEXT REFERENCES conversations(id),
50 | feedback INTEGER NOT NULL,
51 | timestamp TIMESTAMP WITH TIME ZONE NOT NULL
52 | )
53 | """)
54 | conn.commit()
55 | finally:
56 | conn.close()
57 |
58 |
59 | def save_conversation(conversation_id, question, answer_data, course, timestamp=None):
60 | if timestamp is None:
61 | timestamp = datetime.now(tz)
62 |
63 | conn = get_db_connection()
64 | try:
65 | with conn.cursor() as cur:
66 | cur.execute(
67 | """
68 | INSERT INTO conversations
69 | (id, question, answer, course, model_used, response_time, relevance,
70 | relevance_explanation, prompt_tokens, completion_tokens, total_tokens,
71 | eval_prompt_tokens, eval_completion_tokens, eval_total_tokens, openai_cost, timestamp)
72 | VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, COALESCE(%s, CURRENT_TIMESTAMP))
73 | """,
74 | (
75 | conversation_id,
76 | question,
77 | answer_data["answer"],
78 | course,
79 | answer_data["model_used"],
80 | answer_data["response_time"],
81 | answer_data["relevance"],
82 | answer_data["relevance_explanation"],
83 | answer_data["prompt_tokens"],
84 | answer_data["completion_tokens"],
85 | answer_data["total_tokens"],
86 | answer_data["eval_prompt_tokens"],
87 | answer_data["eval_completion_tokens"],
88 | answer_data["eval_total_tokens"],
89 | answer_data["openai_cost"],
90 | timestamp,
91 | ),
92 | )
93 | conn.commit()
94 | finally:
95 | conn.close()
96 |
97 |
98 | def save_feedback(conversation_id, feedback, timestamp=None):
99 | if timestamp is None:
100 | timestamp = datetime.now(tz)
101 |
102 | conn = get_db_connection()
103 | try:
104 | with conn.cursor() as cur:
105 | cur.execute(
106 | "INSERT INTO feedback (conversation_id, feedback, timestamp) VALUES (%s, %s, COALESCE(%s, CURRENT_TIMESTAMP))",
107 | (conversation_id, feedback, timestamp),
108 | )
109 | conn.commit()
110 | finally:
111 | conn.close()
112 |
113 |
114 | def get_recent_conversations(limit=5, relevance=None):
115 | conn = get_db_connection()
116 | try:
117 | with conn.cursor(cursor_factory=DictCursor) as cur:
118 | query = """
119 | SELECT c.*, f.feedback
120 | FROM conversations c
121 | LEFT JOIN feedback f ON c.id = f.conversation_id
122 | """
123 | if relevance:
124 | query += f" WHERE c.relevance = '{relevance}'"
125 | query += " ORDER BY c.timestamp DESC LIMIT %s"
126 |
127 | cur.execute(query, (limit,))
128 | return cur.fetchall()
129 | finally:
130 | conn.close()
131 |
132 |
133 | def get_feedback_stats():
134 | conn = get_db_connection()
135 | try:
136 | with conn.cursor(cursor_factory=DictCursor) as cur:
137 | cur.execute("""
138 | SELECT
139 | SUM(CASE WHEN feedback > 0 THEN 1 ELSE 0 END) as thumbs_up,
140 | SUM(CASE WHEN feedback < 0 THEN 1 ELSE 0 END) as thumbs_down
141 | FROM feedback
142 | """)
143 | return cur.fetchone()
144 | finally:
145 | conn.close()
146 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/docker-compose.yaml:
--------------------------------------------------------------------------------
1 | version: '3.8'
2 |
3 | services:
4 | elasticsearch:
5 | image: docker.elastic.co/elasticsearch/elasticsearch:8.4.3
6 | container_name: elasticsearch
7 | environment:
8 | - discovery.type=single-node
9 | - xpack.security.enabled=false
10 | ports:
11 | - "${ELASTIC_PORT:-9200}:9200"
12 | - "9300:9300"
13 | volumes:
14 | - elasticsearch_data:/usr/share/elasticsearch/data
15 |
16 | ollama:
17 | image: ollama/ollama
18 | container_name: ollama
19 | volumes:
20 | - ollama_data:/root/.ollama
21 | ports:
22 | - "${OLLAMA_PORT:-11434}:11434"
23 |
24 | postgres:
25 | image: postgres:13
26 | container_name: postgres
27 | environment:
28 | POSTGRES_DB: ${POSTGRES_DB}
29 | POSTGRES_USER: ${POSTGRES_USER}
30 | POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
31 | ports:
32 | - "${POSTGRES_PORT:-5432}:5432"
33 | volumes:
34 | - postgres_data:/var/lib/postgresql/data
35 |
36 | streamlit:
37 | build:
38 | context: .
39 | dockerfile: Dockerfile
40 | container_name: streamlit
41 | environment:
42 | - ELASTIC_URL=http://elasticsearch:${ELASTIC_PORT:-9200}
43 | - OLLAMA_URL=http://ollama:${OLLAMA_PORT:-11434}/v1/
44 | - POSTGRES_HOST=postgres
45 | - POSTGRES_DB=${POSTGRES_DB}
46 | - POSTGRES_USER=${POSTGRES_USER}
47 | - POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
48 | - MODEL_NAME=${MODEL_NAME}
49 | - INDEX_NAME=${INDEX_NAME}
50 | - OPENAI_API_KEY=${OPENAI_API_KEY}
51 | ports:
52 | - "${STREAMLIT_PORT:-8501}:8501"
53 | depends_on:
54 | - elasticsearch
55 | - ollama
56 | - postgres
57 |
58 | grafana:
59 | image: grafana/grafana:latest
60 | container_name: grafana
61 | ports:
62 | - "3000:3000"
63 | volumes:
64 | - grafana_data:/var/lib/grafana
65 | environment:
66 | - GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_ADMIN_PASSWORD:-admin}
67 | depends_on:
68 | - postgres
69 |
70 | volumes:
71 | elasticsearch_data:
72 | ollama_data:
73 | postgres_data:
74 | grafana_data:
75 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/generate_data.py:
--------------------------------------------------------------------------------
1 | import time
2 | import random
3 | import uuid
4 | from datetime import datetime, timedelta
5 | from zoneinfo import ZoneInfo
6 | from db import save_conversation, save_feedback, get_db_connection
7 |
8 | # Set the timezone to CET (Europe/Berlin)
9 | tz = ZoneInfo("Europe/Berlin")
10 |
11 | # List of sample questions and answers
12 | SAMPLE_QUESTIONS = [
13 | "What is machine learning?",
14 | "How does linear regression work?",
15 | "Explain the concept of overfitting.",
16 | "What is the difference between supervised and unsupervised learning?",
17 | "How does cross-validation help in model evaluation?",
18 | ]
19 |
20 | SAMPLE_ANSWERS = [
21 | "Machine learning is a subset of artificial intelligence that focuses on the development of algorithms and statistical models that enable computer systems to improve their performance on a specific task through experience.",
22 | "Linear regression is a statistical method used to model the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data.",
23 | "Overfitting occurs when a machine learning model learns the training data too well, including its noise and fluctuations, resulting in poor generalization to new, unseen data.",
24 | "Supervised learning involves training models on labeled data, while unsupervised learning deals with finding patterns in unlabeled data without predefined outputs.",
25 | "Cross-validation is a technique used to assess how well a model will generalize to an independent dataset. It involves partitioning the data into subsets, training the model on a subset, and validating it on the remaining data.",
26 | ]
27 |
28 | COURSES = ["machine-learning-zoomcamp", "data-engineering-zoomcamp", "mlops-zoomcamp"]
29 | MODELS = ["ollama/phi3", "openai/gpt-3.5-turbo", "openai/gpt-4o", "openai/gpt-4o-mini"]
30 | RELEVANCE = ["RELEVANT", "PARTLY_RELEVANT", "NON_RELEVANT"]
31 |
32 |
33 | def generate_synthetic_data(start_time, end_time):
34 | current_time = start_time
35 | conversation_count = 0
36 | print(f"Starting historical data generation from {start_time} to {end_time}")
37 | while current_time < end_time:
38 | conversation_id = str(uuid.uuid4())
39 | question = random.choice(SAMPLE_QUESTIONS)
40 | answer = random.choice(SAMPLE_ANSWERS)
41 | course = random.choice(COURSES)
42 | model = random.choice(MODELS)
43 | relevance = random.choice(RELEVANCE)
44 |
45 | openai_cost = 0
46 |
47 | if model.startswith("openai/"):
48 | openai_cost = random.uniform(0.001, 0.1)
49 |
50 | answer_data = {
51 | "answer": answer,
52 | "response_time": random.uniform(0.5, 5.0),
53 | "relevance": relevance,
54 | "relevance_explanation": f"This answer is {relevance.lower()} to the question.",
55 | "model_used": model,
56 | "prompt_tokens": random.randint(50, 200),
57 | "completion_tokens": random.randint(50, 300),
58 | "total_tokens": random.randint(100, 500),
59 | "eval_prompt_tokens": random.randint(50, 150),
60 | "eval_completion_tokens": random.randint(20, 100),
61 | "eval_total_tokens": random.randint(70, 250),
62 | "openai_cost": openai_cost,
63 | }
64 |
65 | save_conversation(conversation_id, question, answer_data, course, current_time)
66 | print(
67 | f"Saved conversation: ID={conversation_id}, Time={current_time}, Course={course}, Model={model}"
68 | )
69 |
70 | if random.random() < 0.7:
71 | feedback = 1 if random.random() < 0.8 else -1
72 | save_feedback(conversation_id, feedback, current_time)
73 | print(
74 | f"Saved feedback for conversation {conversation_id}: {'Positive' if feedback > 0 else 'Negative'}"
75 | )
76 |
77 | current_time += timedelta(minutes=random.randint(1, 15))
78 | conversation_count += 1
79 | if conversation_count % 10 == 0:
80 | print(f"Generated {conversation_count} conversations so far...")
81 |
82 | print(
83 | f"Historical data generation complete. Total conversations: {conversation_count}"
84 | )
85 |
86 |
87 | def generate_live_data():
88 | conversation_count = 0
89 | print("Starting live data generation...")
90 | while True:
91 | current_time = datetime.now(tz)
92 | # current_time = None
93 | conversation_id = str(uuid.uuid4())
94 | question = random.choice(SAMPLE_QUESTIONS)
95 | answer = random.choice(SAMPLE_ANSWERS)
96 | course = random.choice(COURSES)
97 | model = random.choice(MODELS)
98 | relevance = random.choice(RELEVANCE)
99 |
100 | openai_cost = 0
101 |
102 | if model.startswith("openai/"):
103 | openai_cost = random.uniform(0.001, 0.1)
104 |
105 | answer_data = {
106 | "answer": answer,
107 | "response_time": random.uniform(0.5, 5.0),
108 | "relevance": relevance,
109 | "relevance_explanation": f"This answer is {relevance.lower()} to the question.",
110 | "model_used": model,
111 | "prompt_tokens": random.randint(50, 200),
112 | "completion_tokens": random.randint(50, 300),
113 | "total_tokens": random.randint(100, 500),
114 | "eval_prompt_tokens": random.randint(50, 150),
115 | "eval_completion_tokens": random.randint(20, 100),
116 | "eval_total_tokens": random.randint(70, 250),
117 | "openai_cost": openai_cost,
118 | }
119 |
120 | save_conversation(conversation_id, question, answer_data, course, current_time)
121 | print(
122 | f"Saved live conversation: ID={conversation_id}, Time={current_time}, Course={course}, Model={model}"
123 | )
124 |
125 | if random.random() < 0.7:
126 | feedback = 1 if random.random() < 0.8 else -1
127 | save_feedback(conversation_id, feedback, current_time)
128 | print(
129 | f"Saved feedback for live conversation {conversation_id}: {'Positive' if feedback > 0 else 'Negative'}"
130 | )
131 |
132 | conversation_count += 1
133 | if conversation_count % 10 == 0:
134 | print(f"Generated {conversation_count} live conversations so far...")
135 |
136 | time.sleep(1)
137 |
138 |
139 | if __name__ == "__main__":
140 | print(f"Script started at {datetime.now(tz)}")
141 | end_time = datetime.now(tz)
142 | start_time = end_time - timedelta(hours=6)
143 | print(f"Generating historical data from {start_time} to {end_time}")
144 | generate_synthetic_data(start_time, end_time)
145 | print("Historical data generation complete.")
146 |
147 | print("Starting live data generation... Press Ctrl+C to stop.")
148 | try:
149 | generate_live_data()
150 | except KeyboardInterrupt:
151 | print(f"Live data generation stopped at {datetime.now(tz)}.")
152 | finally:
153 | print(f"Script ended at {datetime.now(tz)}")
154 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/prep.py:
--------------------------------------------------------------------------------
1 | import os
2 | import requests
3 | import pandas as pd
4 | from sentence_transformers import SentenceTransformer
5 | from elasticsearch import Elasticsearch
6 | from tqdm.auto import tqdm
7 | from dotenv import load_dotenv
8 |
9 | from db import init_db
10 |
11 | load_dotenv()
12 |
13 | ELASTIC_URL = os.getenv("ELASTIC_URL_LOCAL")
14 | MODEL_NAME = os.getenv("MODEL_NAME")
15 | INDEX_NAME = os.getenv("INDEX_NAME")
16 |
17 | BASE_URL = "https://github.com/DataTalksClub/llm-zoomcamp/blob/main"
18 |
19 |
20 | def fetch_documents():
21 | print("Fetching documents...")
22 | relative_url = "03-vector-search/eval/documents-with-ids.json"
23 | docs_url = f"{BASE_URL}/{relative_url}?raw=1"
24 | docs_response = requests.get(docs_url)
25 | documents = docs_response.json()
26 | print(f"Fetched {len(documents)} documents")
27 | return documents
28 |
29 |
30 | def fetch_ground_truth():
31 | print("Fetching ground truth data...")
32 | relative_url = "03-vector-search/eval/ground-truth-data.csv"
33 | ground_truth_url = f"{BASE_URL}/{relative_url}?raw=1"
34 | df_ground_truth = pd.read_csv(ground_truth_url)
35 | df_ground_truth = df_ground_truth[
36 | df_ground_truth.course == "machine-learning-zoomcamp"
37 | ]
38 | ground_truth = df_ground_truth.to_dict(orient="records")
39 | print(f"Fetched {len(ground_truth)} ground truth records")
40 | return ground_truth
41 |
42 |
43 | def load_model():
44 | print(f"Loading model: {MODEL_NAME}")
45 | return SentenceTransformer(MODEL_NAME)
46 |
47 |
48 | def setup_elasticsearch():
49 | print("Setting up Elasticsearch...")
50 | es_client = Elasticsearch(ELASTIC_URL)
51 |
52 | index_settings = {
53 | "settings": {"number_of_shards": 1, "number_of_replicas": 0},
54 | "mappings": {
55 | "properties": {
56 | "text": {"type": "text"},
57 | "section": {"type": "text"},
58 | "question": {"type": "text"},
59 | "course": {"type": "keyword"},
60 | "id": {"type": "keyword"},
61 | "question_text_vector": {
62 | "type": "dense_vector",
63 | "dims": 384,
64 | "index": True,
65 | "similarity": "cosine",
66 | },
67 | }
68 | },
69 | }
70 |
71 | es_client.indices.delete(index=INDEX_NAME, ignore_unavailable=True)
72 | es_client.indices.create(index=INDEX_NAME, body=index_settings)
73 | print(f"Elasticsearch index '{INDEX_NAME}' created")
74 | return es_client
75 |
76 |
77 | def index_documents(es_client, documents, model):
78 | print("Indexing documents...")
79 | for doc in tqdm(documents):
80 | question = doc["question"]
81 | text = doc["text"]
82 | doc["question_text_vector"] = model.encode(question + " " + text).tolist()
83 | es_client.index(index=INDEX_NAME, document=doc)
84 | print(f"Indexed {len(documents)} documents")
85 |
86 |
87 | def main():
88 | # you may consider to comment
89 | # if you just want to init the db or didn't want to re-index
90 | print("Starting the indexing process...")
91 |
92 | documents = fetch_documents()
93 | ground_truth = fetch_ground_truth()
94 | model = load_model()
95 | es_client = setup_elasticsearch()
96 | index_documents(es_client, documents, model)
97 | # you may consider to comment
98 |
99 | print("Initializing database...")
100 | init_db()
101 |
102 | print("Indexing process completed successfully!")
103 |
104 |
105 | if __name__ == "__main__":
106 | main()
107 |
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/app/requirements.txt:
--------------------------------------------------------------------------------
1 | streamlit
2 | elasticsearch==8.14.0
3 | psycopg2-binary==2.9.9
4 | python-dotenv
5 | openai==1.35.7
6 | sentence-transformers==2.7.0
7 | numpy==1.26.4
8 |
9 | --find-links https://download.pytorch.org/whl/cpu/torch_stable.html
10 | torch==2.3.1+cpu
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/grafana.md:
--------------------------------------------------------------------------------
1 | ## Original queries
2 |
3 | Response Time Panel:
4 |
5 | ```sql
6 | SELECT
7 | timestamp AS time,
8 | response_time
9 | FROM conversations
10 | ORDER BY timestamp
11 | ```
12 |
13 | Relevance Distribution Panel:
14 |
15 | ```sql
16 | SELECT
17 | relevance,
18 | COUNT(*) as count
19 | FROM conversations
20 | GROUP BY relevance
21 | ```
22 |
23 | Model Usage Panel:
24 |
25 | ```sql
26 | SELECT
27 | model_used,
28 | COUNT(*) as count
29 | FROM conversations
30 | GROUP BY model_used
31 | ```
32 |
33 |
34 | Token Usage Panel:
35 |
36 | ```sql
37 | SELECT
38 | timestamp AS time,
39 | total_tokens
40 | FROM conversations
41 | ORDER BY timestamp
42 | ```
43 |
44 | OpenAI Cost Panel:
45 |
46 | ```sql
47 | SELECT
48 | timestamp AS time,
49 | openai_cost
50 | FROM conversations
51 | WHERE openai_cost > 0
52 | ORDER BY timestamp
53 | ```
54 |
55 | Recent Conversations Panel:
56 |
57 | ```sql
58 | SELECT
59 | timestamp AS time,
60 | question,
61 | answer,
62 | relevance
63 | FROM conversations
64 | ORDER BY timestamp DESC
65 | LIMIT 5
66 | ```
67 |
68 | Feedback Statistics Panel:
69 |
70 | ```sql
71 | SELECT
72 | SUM(CASE WHEN feedback > 0 THEN 1 ELSE 0 END) as thumbs_up,
73 | SUM(CASE WHEN feedback < 0 THEN 1 ELSE 0 END) as thumbs_down
74 | FROM feedback
75 | ```
76 |
77 | ## Revised queries
78 |
79 | We can (and should) also use special grafana variables
80 |
81 | - `$__timeFrom()` and `$__timeTo()`: Start and end of the selected time range
82 | - `$__timeGroup(timestamp, $__interval)`: Groups results by time intervals automatically calculated by Grafana
83 |
84 | ### 1. Response Time Panel
85 |
86 | This query shows the response time for each conversation within the selected time range:
87 |
88 | ```sql
89 | SELECT
90 | timestamp AS time,
91 | response_time
92 | FROM conversations
93 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
94 | ORDER BY timestamp
95 | ```
96 |
97 | ### 2. Relevance Distribution Panel
98 |
99 | This query counts the number of conversations for each relevance category within the selected time range:
100 |
101 | ```sql
102 | SELECT
103 | relevance,
104 | COUNT(*) as count
105 | FROM conversations
106 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
107 | GROUP BY relevance
108 | ```
109 |
110 | ### 3. Model Usage Panel
111 |
112 | This query counts the number of times each model was used within the selected time range:
113 |
114 | ```sql
115 | SELECT
116 | model_used,
117 | COUNT(*) as count
118 | FROM conversations
119 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
120 | GROUP BY model_used
121 | ```
122 |
123 | ### 4. Token Usage Panel
124 |
125 | This query shows the average token usage over time, grouped by Grafana's automatically calculated interval:
126 |
127 | ```sql
128 | SELECT
129 | $__timeGroup(timestamp, $__interval) AS time,
130 | AVG(total_tokens) AS avg_tokens
131 | FROM conversations
132 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
133 | GROUP BY 1
134 | ORDER BY 1
135 | ```
136 |
137 | ### 5. OpenAI Cost Panel
138 |
139 | This query shows the total OpenAI cost over time, grouped by Grafana's automatically calculated interval:
140 |
141 | ```sql
142 | SELECT
143 | $__timeGroup(timestamp, $__interval) AS time,
144 | SUM(openai_cost) AS total_cost
145 | FROM conversations
146 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
147 | AND openai_cost > 0
148 | GROUP BY 1
149 | ORDER BY 1
150 | ```
151 |
152 | ### 6. Recent Conversations Panel
153 |
154 | This query retrieves the 5 most recent conversations within the selected time range:
155 |
156 | ```sql
157 | SELECT
158 | timestamp AS time,
159 | question,
160 | answer,
161 | relevance
162 | FROM conversations
163 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
164 | ORDER BY timestamp DESC
165 | LIMIT 5
166 | ```
167 |
168 | ### 7. Feedback Statistics Panel
169 |
170 | This query calculates the total number of positive and negative feedback within the selected time range:
171 |
172 | ```sql
173 | SELECT
174 | SUM(CASE WHEN feedback > 0 THEN 1 ELSE 0 END) as thumbs_up,
175 | SUM(CASE WHEN feedback < 0 THEN 1 ELSE 0 END) as thumbs_down
176 | FROM feedback
177 | WHERE timestamp BETWEEN $__timeFrom() AND $__timeTo()
178 | ```
--------------------------------------------------------------------------------
/cohorts/2024/04-monitoring/homework.md:
--------------------------------------------------------------------------------
1 | ## Homework: Evaluation and Monitoring
2 |
3 | Solution: [solution.ipynb](solution.ipynb)
4 |
5 | In this homework, we'll evaluate the quality of our RAG system.
6 |
7 | > It's possible that your answers won't match exactly. If it's the case, select the closest one.
8 |
9 | Solution:
10 |
11 | * Video: TBA
12 | * Notebook: TBA
13 |
14 | ## Getting the data
15 |
16 | Let's start by getting the dataset. We will use the data we generated in the module.
17 |
18 | In particular, we'll evaluate the quality of our RAG system
19 | with [gpt-4o-mini](https://github.com/DataTalksClub/llm-zoomcamp/blob/main/04-monitoring/data/results-gpt4o-mini.csv)
20 |
21 |
22 | Read it:
23 |
24 | ```python
25 | url = f'{github_url}?raw=1'
26 | df = pd.read_csv(url)
27 | ```
28 |
29 | We will use only the first 300 documents:
30 |
31 |
32 | ```python
33 | df = df.iloc[:300]
34 | ```
35 |
36 | ## Q1. Getting the embeddings model
37 |
38 | Now, get the embeddings model `multi-qa-mpnet-base-dot-v1` from
39 | [the Sentence Transformer library](https://www.sbert.net/docs/sentence_transformer/pretrained_models.html#model-overview)
40 |
41 | > Note: this is not the same model as in HW3
42 |
43 | ```bash
44 | from sentence_transformers import SentenceTransformer
45 | embedding_model = SentenceTransformer(model_name)
46 | ```
47 |
48 | Create the embeddings for the first LLM answer:
49 |
50 | ```python
51 | answer_llm = df.iloc[0].answer_llm
52 | ```
53 |
54 | What's the first value of the resulting vector?
55 |
56 | * -0.42
57 | * -0.22
58 | * -0.02
59 | * 0.21
60 |
61 |
62 | ## Q2. Computing the dot product
63 |
64 |
65 | Now for each answer pair, let's create embeddings and compute dot product between them
66 |
67 | We will put the results (scores) into the `evaluations` list
68 |
69 | What's the 75% percentile of the score?
70 |
71 | * 21.67
72 | * 31.67
73 | * 41.67
74 | * 51.67
75 |
76 | ## Q3. Computing the cosine
77 |
78 | From Q2, we can see that the results are not within the [0, 1] range. It's because the vectors coming from this model are not normalized.
79 |
80 | So we need to normalize them.
81 |
82 | To do it, we
83 |
84 | * Compute the norm of a vector
85 | * Divide each element by this norm
86 |
87 | So, for vector `v`, it'll be `v / ||v||`
88 |
89 | In numpy, this is how you do it:
90 |
91 | ```python
92 | norm = np.sqrt((v * v).sum())
93 | v_norm = v / norm
94 | ```
95 |
96 | Let's put it into a function and then compute dot product
97 | between normalized vectors. This will give us cosine similarity
98 |
99 | What's the 75% cosine in the scores?
100 |
101 | * 0.63
102 | * 0.73
103 | * 0.83
104 | * 0.93
105 |
106 | ## Q4. Rouge
107 |
108 | Now we will explore an alternative metric - the ROUGE score.
109 |
110 | This is a set of metrics that compares two answers based on the overlap of n-grams, word sequences, and word pairs.
111 |
112 | It can give a more nuanced view of text similarity than just cosine similarity alone.
113 |
114 | We don't need to implement it ourselves, there's a python package for it:
115 |
116 | ```bash
117 | pip install rouge
118 | ```
119 |
120 | (The latest version at the moment of writing is `1.0.1`)
121 |
122 | Let's compute the ROUGE score between the answers at the index 10 of our dataframe (`doc_id=5170565b`)
123 |
124 | ```
125 | from rouge import Rouge
126 | rouge_scorer = Rouge()
127 |
128 | scores = rouge_scorer.get_scores(r['answer_llm'], r['answer_orig'])[0]
129 | ```
130 |
131 | There are three scores: `rouge-1`, `rouge-2` and `rouge-l`, and precision, recall and F1 score for each.
132 |
133 | * `rouge-1` - the overlap of unigrams,
134 | * `rouge-2` - bigrams,
135 | * `rouge-l` - the longest common subsequence
136 |
137 | What's the F score for `rouge-1`?
138 |
139 | - 0.35
140 | - 0.45
141 | - 0.55
142 | - 0.65
143 |
144 | ## Q5. Average rouge score
145 |
146 | Let's compute the average F-score between `rouge-1`, `rouge-2` and `rouge-l` for the same record from Q4
147 |
148 | - 0.35
149 | - 0.45
150 | - 0.55
151 | - 0.65
152 |
153 | ## Q6. Average rouge score for all the data points
154 |
155 | Now let's compute the F-score for all the records and create a dataframe from them.
156 |
157 | What's the average F-score in `rouge_2` across all the records?
158 |
159 | - 0.10
160 | - 0.20
161 | - 0.30
162 | - 0.40
163 |
164 |
165 |
166 | ## Submit the results
167 |
168 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2024/homework/hw4
169 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
170 |
--------------------------------------------------------------------------------
/cohorts/2024/05-orchestration/README.md:
--------------------------------------------------------------------------------
1 | # Data Preparation in RAG
2 |
3 | ## Getting started
4 |
5 | 1. Clone [repository](https://github.com/mage-ai/rag-project)
6 | ```bash
7 | git clone https://github.com/mage-ai/rag-project
8 | cd rag-project
9 | ```
10 | 3. navigate to the `rag-project/llm` directory, add `spacy` to the requirements.txt.
11 | 4. Then update the `Dockerfile` found in the `rag-project` directory with the following:
12 | ```YAML
13 | RUN python -m spacy download en_core_web_sm
14 | ```
15 | 4. Run
16 |
17 | ```bash
18 | `./scripts/start.sh`
19 | ```
20 |
21 | Once started, go to [http://localhost:6789/](http://localhost:6789/)
22 |
23 | For more setup information, refer to these [instructions](https://docs.mage.ai/getting-started/setup#docker-compose-template)
24 |
25 |
26 | ## 0. Module overview
27 |
28 |
29 |  30 |
31 |
32 | ## 1. Ingest
33 |
34 | In this section, we cover the ingestion of documents from a single data source.
35 |
36 |
37 |
30 |
31 |
32 | ## 1. Ingest
33 |
34 | In this section, we cover the ingestion of documents from a single data source.
35 |
36 |
37 |  38 |
39 |
40 | * [Code](https://github.com/mage-ai/rag-project/blob/master/llm/rager/data_loaders/runic_oblivion.py)
41 | * [Document link for API Data Loader](https://raw.githubusercontent.com/DataTalksClub/llm-zoomcamp/main/01-intro/documents.json)
42 |
43 | ## 2. Chunk
44 |
45 | Once data is ingested, we break it into manageable chunks.
46 |
47 | The Q&A data is already chunked - the texts are small
48 | and easy to process and index. But other datasets might
49 | not be (book texts, transcripts, etc).
50 |
51 | In this video, we will talk about turning large texts
52 | into smaller documents - i.e. chunking.
53 |
54 |
55 |
38 |
39 |
40 | * [Code](https://github.com/mage-ai/rag-project/blob/master/llm/rager/data_loaders/runic_oblivion.py)
41 | * [Document link for API Data Loader](https://raw.githubusercontent.com/DataTalksClub/llm-zoomcamp/main/01-intro/documents.json)
42 |
43 | ## 2. Chunk
44 |
45 | Once data is ingested, we break it into manageable chunks.
46 |
47 | The Q&A data is already chunked - the texts are small
48 | and easy to process and index. But other datasets might
49 | not be (book texts, transcripts, etc).
50 |
51 | In this video, we will talk about turning large texts
52 | into smaller documents - i.e. chunking.
53 |
54 |
55 |  56 |
57 |
58 |
59 | [Code](https://github.com/mage-ai/rag-project/blob/master/llm/rager/transformers/radiant_photon.py)
60 |
61 | ## 3. Tokenization
62 |
63 | Tokenization is a crucial step in text processing and preparing the data for effective retrieval.
64 |
65 |
66 |
56 |
57 |
58 |
59 | [Code](https://github.com/mage-ai/rag-project/blob/master/llm/rager/transformers/radiant_photon.py)
60 |
61 | ## 3. Tokenization
62 |
63 | Tokenization is a crucial step in text processing and preparing the data for effective retrieval.
64 |
65 |
66 |  67 |
68 |
69 | [Code](https://github.com/mage-ai/rag-project/blob/master/llm/rager/transformers/vivid_nexus.py)
70 |
71 | ## 4. Embed
72 |
73 | Embedding data translates text into numerical vectors that can be processed by models.
74 |
75 | Previously we used sentence transformers for that. In this video we show a different strategy for it.
76 |
77 |
78 |
79 |
67 |
68 |
69 | [Code](https://github.com/mage-ai/rag-project/blob/master/llm/rager/transformers/vivid_nexus.py)
70 |
71 | ## 4. Embed
72 |
73 | Embedding data translates text into numerical vectors that can be processed by models.
74 |
75 | Previously we used sentence transformers for that. In this video we show a different strategy for it.
76 |
77 |
78 |
79 |  80 |
81 |
82 |
83 | [Code](https://github.com/mage-ai/rag-project/blob/master/llm/rager/transformers/prismatic_axiom.py)
84 |
85 |
86 | ## 5. Export
87 |
88 | After processing, data needs to be exported for storage so that it can be retrieved for better contextualization of user queries.
89 |
90 | Here we will save the embeddings to elasticsearch
91 |
92 | please make sure to use the name given to your elasticsearch service in your docker compose file followed by the port as the connection string, e.g below
93 |
94 | `` http://elasticsearch:9200
95 |
96 |
97 |
98 |
80 |
81 |
82 |
83 | [Code](https://github.com/mage-ai/rag-project/blob/master/llm/rager/transformers/prismatic_axiom.py)
84 |
85 |
86 | ## 5. Export
87 |
88 | After processing, data needs to be exported for storage so that it can be retrieved for better contextualization of user queries.
89 |
90 | Here we will save the embeddings to elasticsearch
91 |
92 | please make sure to use the name given to your elasticsearch service in your docker compose file followed by the port as the connection string, e.g below
93 |
94 | `` http://elasticsearch:9200
95 |
96 |
97 |
98 |  99 |
100 |
101 | [Code](https://github.com/mage-ai/rag-project/blob/master/llm/rager/data_exporters/numinous_fission.py)
102 |
103 | ## 6. Retrieval: Test Vector Search Query
104 |
105 | After exporting the chunks and embeddings, we can test the search query to retrieve relevant documents on sample queries.
106 |
107 |
108 |
99 |
100 |
101 | [Code](https://github.com/mage-ai/rag-project/blob/master/llm/rager/data_exporters/numinous_fission.py)
102 |
103 | ## 6. Retrieval: Test Vector Search Query
104 |
105 | After exporting the chunks and embeddings, we can test the search query to retrieve relevant documents on sample queries.
106 |
107 |
108 |  109 |
110 |
111 | [Code](code/06_retrieval.py)
112 |
113 | ## 7. Trigger Daily Runs
114 |
115 | Automation is key to maintaining and updating your system.
116 | This section demonstrates how to schedule and trigger daily runs for your data pipelines, ensuring up-to-date and consistent data processing.
117 |
118 |
119 |
109 |
110 |
111 | [Code](code/06_retrieval.py)
112 |
113 | ## 7. Trigger Daily Runs
114 |
115 | Automation is key to maintaining and updating your system.
116 | This section demonstrates how to schedule and trigger daily runs for your data pipelines, ensuring up-to-date and consistent data processing.
117 |
118 |
119 |  120 |
121 |
122 | ## Homework
123 |
124 | See [here](../cohorts/2024/05-orchestration/homework.md).
125 |
126 | # Notes
127 |
128 | * First link goes here
129 | * [Notes by Abiodun Mage RAG error fixes](https://github.com/AOGbadamosi2018/llm-zoomcamp/blob/main/06%20-%20orchestration/mage_rag_notes.md).
130 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
131 |
--------------------------------------------------------------------------------
/cohorts/2024/05-orchestration/code/06_retrieval.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List, Union
2 |
3 | import numpy as np
4 | from elasticsearch import Elasticsearch, exceptions
5 |
6 |
7 | SAMPLE__EMBEDDINGS = [
8 | [-0.1465761959552765, -0.4822517931461334, 0.07130702584981918, -0.25872930884361267, -0.1563894897699356, 0.16641047596931458, 0.24484659731388092, 0.2410498708486557, 0.008032954297959805, 0.17045290768146515, -0.009397129528224468, 0.09619587659835815, -0.22729521989822388, 0.10254761576652527, 0.016890447586774826, -0.13290464878082275, 0.11240798979997635, -0.11204371601343155, -0.057132963091135025, -0.011206787079572678, -0.007982085458934307, 0.279083788394928, 0.20115645229816437, -0.1427406221628189, -0.19398854672908783, -0.035979654639959335, 0.20723149180412292, 0.29891034960746765, 0.21407313644886017, 0.09746530652046204, 0.1671638935804367, 0.08161208778619766, 0.3090828061103821, -0.20648667216300964, 0.48498260974884033, -0.12691514194011688, 0.518856406211853, -0.26291757822036743, -0.0949832871556282, 0.09556109458208084, -0.20844918489456177, 0.2685297429561615, 0.053442806005477905, 0.05103180184960365, 0.1029752567410469, 0.04935301095247269, -0.11679927259683609, -0.012528933584690094, -0.08489680290222168, 0.013589601963758469, -0.32059246301651, 0.10357264429330826, -0.09533575177192688, 0.02984568662941456, 0.2793693542480469, -0.2653750777244568, -0.24152781069278717, -0.3563413619995117, 0.09674381464719772, -0.26155123114585876, -0.1397126317024231, -0.009133181534707546, 0.05972130224108696, -0.10438819974660873, 0.21889159083366394, 0.0694752112030983, -0.1312003880739212, -0.31072548031806946, -0.002836169209331274, 0.2468366175889969, 0.09420009702444077, 0.1284026801586151, -0.03227006644010544, -0.012532072141766548, 0.6650756597518921, -0.14863784611225128, 0.005239118821918964, -0.3317912817001343, 0.16372767090797424, -0.20166568458080292, 0.029721004888415337, -0.18536655604839325, -0.3608534038066864, -0.18234892189502716, 0.019248824566602707, 0.25257956981658936, 0.09671413153409958, 0.15569280087947845, -0.38228726387023926, 0.37017977237701416, 0.03356296569108963, -0.21182948350906372, 0.48848846554756165, 0.18350018560886383, -0.23519110679626465, -0.17464864253997803], [-0.18246106803417206, -0.36036479473114014, 0.3282334506511688, -0.230922132730484, 0.09600532799959183, 0.6859422326087952, 0.0581890344619751, 0.4913463294506073, 0.1536773443222046, -0.2965141832828522, 0.08466599136590958, 0.319297194480896, -0.15651769936084747, -0.043428342789411545, 0.014402368105947971, 0.16681505739688873, 0.22521673142910004, -0.2715776264667511, -0.11033261567354202, -0.04398636147379875, 0.3480629622936249, 0.11897992342710495, 0.8724615573883057, 0.10258488357067108, -0.5719427466392517, -0.03029855526983738, 0.23351268470287323, 0.20660561323165894, 0.575685441493988, -0.12116186320781708, 0.18459142744541168, -0.12865227460861206, 0.3948173522949219, -0.34464019536972046, 0.6699116230010986, -0.45167359709739685, 1.1505522727966309, -0.4498964548110962, -0.3248189687728882, -0.29674994945526123, -0.3570491075515747, 0.5436431765556335, 0.49576905369758606, -0.11180296540260315, -0.02045607566833496, -0.22768598794937134, -0.37912657856941223, -0.30414703488349915, -0.48289090394973755, -0.04158346354961395, -0.3547952473163605, 0.0687602087855339, 0.041512664407491684, 0.33524179458618164, 0.21826978027820587, -0.443082332611084, -0.5049593448638916, -0.5298929810523987, -0.02618088759481907, -0.2748631536960602, -0.1986193209886551, 0.35475826263427734, 0.22456413507461548, -0.29532068967819214, 0.25150877237319946, 0.243370920419693, -0.29938358068466187, -0.2128247618675232, -0.15292000770568848, -0.14813245832920074, -0.06183856353163719, -0.1251668632030487, 0.14256533980369568, -0.22781267762184143, 0.8101184964179993, 0.19796361029148102, 0.09104947745800018, -0.4860817790031433, 0.3078012764453888, -0.27373194694519043, 0.11800770461559296, -0.45869407057762146, 0.09508189558982849, -0.23971715569496155, -0.27427223324775696, 0.5139415264129639, 0.1871502846479416, 0.06647063046693802, -0.4054469168186188, 0.4751380681991577, 0.17067894339561462, 0.12443914264440536, 0.3577817678451538, 0.10574143379926682, -0.3181760311126709, -0.23804502189159393]
9 | ]
10 |
11 |
12 | @data_loader
13 | def search(*args, **kwargs) -> List[Dict]:
14 | """
15 | query_embedding: Union[List[int], np.ndarray]
16 | """
17 |
18 | connection_string = kwargs.get('connection_string', 'http://localhost:9200')
19 | index_name = kwargs.get('index_name', 'documents')
20 | source = kwargs.get('source', "cosineSimilarity(params.query_vector, 'embedding') + 1.0")
21 | top_k = kwargs.get('top_k', 5)
22 | chunk_column = kwargs.get('chunk_column', 'content')
23 |
24 | query_embedding = None
25 | if len(args):
26 | query_embedding = args[0]
27 | if not query_embedding:
28 | query_embedding = SAMPLE__EMBEDDINGS[0]
29 |
30 | if isinstance(query_embedding, np.ndarray):
31 | query_embedding = query_embedding.tolist()
32 |
33 | script_query = {
34 | "script_score": {
35 | "query": {"match_all": {}},
36 | "script": {
37 | "source": source,
38 | "params": {"query_vector": query_embedding},
39 | }
40 | }
41 | }
42 |
43 | print("Sending script query:", script_query)
44 |
45 | es_client = Elasticsearch(connection_string)
46 |
47 | try:
48 | response = es_client.search(
49 | index=index_name,
50 | body={
51 | "size": top_k,
52 | "query": script_query,
53 | "_source": [chunk_column],
54 | },
55 | )
56 |
57 | print("Raw response from Elasticsearch:", response)
58 |
59 | return [hit['_source'][chunk_column] for hit in response['hits']['hits']]
60 |
61 | except exceptions.BadRequestError as e:
62 | print(f"BadRequestError: {e.info}")
63 | return []
64 | except Exception as e:
65 | print(f"Unexpected error: {e}")
66 | return []
67 |
--------------------------------------------------------------------------------
/cohorts/2024/05-orchestration/homework.md:
--------------------------------------------------------------------------------
1 | ## Homework: LLM Orchestration and Ingestion
2 |
3 | > It's possible that your answers won't match exactly. If it's the case, select the closest one.
4 |
5 | Our FAQ documents change with time: students add more records
6 | and edit existing ones. We need to keep our index in sync.
7 |
8 | There are two ways of doing it:
9 |
10 | 1. Incremental: you only update records that got changed, created or deleted
11 | 2. Full update: you recreate the entire index from scratch
12 |
13 | In this homework, we'll look at full update. We will run our
14 | indexing pipeline daily and re-create the index from scracth
15 | each time we run.
16 |
17 |
18 | For that, we created two FAQ documents for LLM Zoomcamp
19 |
20 | * [version 1](https://docs.google.com/document/d/1qZjwHkvP0lXHiE4zdbWyUXSVfmVGzougDD6N37bat3E/edit)
21 | * [version 2](https://docs.google.com/document/d/1T3MdwUvqCL3jrh3d3VCXQ8xE0UqRzI3bfgpfBq3ZWG0/edit)
22 |
23 | First, we will run our ingestion pipeline with version 1
24 | and then with version 2.
25 |
26 | ## Q1. Running Mage
27 |
28 | Clone the same repo we used in the module and run mage:
29 |
30 |
31 | ```bash
32 | git clone https://github.com/mage-ai/rag-project
33 | ```
34 |
35 | Add the following libraries to the requirements document:
36 |
37 | ```
38 | python-docx
39 | elasticsearch
40 | ```
41 |
42 | Make sure you use the latest version of mage:
43 |
44 | ```bash
45 | docker pull mageai/mageai:llm
46 | ```
47 |
48 | Start it:
49 |
50 | ```bash
51 | ./scripts/start.sh
52 | ```
53 |
54 | Now mage is running on [http://localhost:6789/](http://localhost:6789/)
55 |
56 | What's the version of mage?
57 |
58 | ## Creating a RAG pipeline
59 |
60 | Create a RAG pipeline
61 |
62 |
63 | ## Q2. Reading the documents
64 |
65 | Now we can ingest the documents. Create a custom code ingestion
66 | block
67 |
68 | Let's read the documents. We will use the same code we used
69 | for parsing FAQ: [parse-faq-llm.ipynb](parse-faq-llm.ipynb)
70 |
71 |
72 | Use the following document_id: 1qZjwHkvP0lXHiE4zdbWyUXSVfmVGzougDD6N37bat3E
73 |
74 | Which is the document ID of
75 | [LLM FAQ version 1](https://docs.google.com/document/d/1qZjwHkvP0lXHiE4zdbWyUXSVfmVGzougDD6N37bat3E/edit)
76 |
77 | Copy the code to the editor
78 | How many FAQ documents we processed?
79 |
80 | * 1
81 | * 2
82 | * 3
83 | * 4
84 |
85 | ## Q3. Chunking
86 |
87 | We don't really need to do any chuncking because our documents
88 | already have well-specified boundaries. So we just need
89 | to return the documents without any changes.
90 |
91 | So let's go to the transformation part and add a custom code
92 | chunking block:
93 |
94 | ```python
95 | documents = []
96 |
97 | for doc in data['documents']:
98 | doc['course'] = data['course']
99 | # previously we used just "id" for document ID
100 | doc['document_id'] = generate_document_id(doc)
101 | documents.append(doc)
102 |
103 | print(len(documents))
104 |
105 | return documents
106 | ```
107 |
108 |
109 | Where `data` is the input parameter to the transformer.
110 |
111 | And the `generate_document_id` is defined in the same way
112 | as in module 4:
113 |
114 | ```python
115 | import hashlib
116 |
117 | def generate_document_id(doc):
118 | combined = f"{doc['course']}-{doc['question']}-{doc['text'][:10]}"
119 | hash_object = hashlib.md5(combined.encode())
120 | hash_hex = hash_object.hexdigest()
121 | document_id = hash_hex[:8]
122 | return document_id
123 | ```
124 |
125 | Note: if instead of a single dictionary you get a list,
126 | add a for loop:
127 |
128 | ```python
129 | for course_dict in data:
130 | ...
131 | ```
132 |
133 | You can check the type of `data` with this code:
134 |
135 | ```python
136 | print(type(data))
137 | ```
138 |
139 | How many documents (chunks) do we have in the output?
140 |
141 | * 66
142 | * 76
143 | * 86
144 | * 96
145 |
146 |
147 |
148 | ## Tokenization and embeddings
149 |
150 | We don't need any tokenization, so we skip it.
151 |
152 | Because currently it's required in mage, we can create
153 | a dummy code block:
154 |
155 | * Create a custom code block
156 | * Don't change it
157 |
158 | Because we will use text search, we also don't need embeddings,
159 | so skip it too.
160 |
161 | If you want to use sentence transformers - the ones from module
162 | 3 - you don't need tokenization, but need embeddings
163 | (you don't need it for this homework)
164 |
165 |
166 | ## Q4. Export
167 |
168 | Now we're ready to index the data with elasticsearch. For that,
169 | we use the Export part of the pipeline
170 |
171 | * Go to the Export part
172 | * Select vector databases -> Elasticsearch
173 | * Open the code for editing
174 |
175 | Because we won't use vector search, but usual text search, we
176 | will need to adjust the code.
177 |
178 | First, let's change the line where we read the index name:
179 |
180 | ```python
181 | index_name = kwargs.get('index_name', 'documents')
182 | ```
183 |
184 | To `index_name_prefix` - we will parametrize it with the day
185 | and time we run the pipeline
186 |
187 | ```python
188 | from datetime import datetime
189 |
190 | index_name_prefix = kwargs.get('index_name', 'documents')
191 | current_time = datetime.now().strftime("%Y%m%d_%M%S")
192 | index_name = f"{index_name_prefix}_{current_time}"
193 | print("index name:", index_name)
194 | ```
195 |
196 |
197 | We will need to save the name in a global variable, so it can be accessible in other code blocks
198 |
199 | ```python
200 | from mage_ai.data_preparation.variable_manager import set_global_variable
201 |
202 | set_global_variable('YOUR_PIPELINE_NAME', 'index_name', index_name)
203 | ```
204 |
205 | Where your pipeline name is the name of the pipeline, e.g.
206 | `transcendent_nexus` (replace the space with underscore `_`)
207 |
208 |
209 |
210 | Replace index settings with the settings we used previously:
211 |
212 | ```python
213 | index_settings = {
214 | "settings": {
215 | "number_of_shards": number_of_shards,
216 | "number_of_replicas": number_of_replicas
217 | },
218 | "mappings": {
219 | "properties": {
220 | "text": {"type": "text"},
221 | "section": {"type": "text"},
222 | "question": {"type": "text"},
223 | "course": {"type": "keyword"},
224 | "document_id": {"type": "keyword"}
225 | }
226 | }
227 | }
228 | ```
229 |
230 | Remove the embeddings line:
231 |
232 | ```python
233 | if isinstance(document[vector_column_name], np.ndarray):
234 | document[vector_column_name] = document[vector_column_name].tolist()
235 | ```
236 |
237 | At the end (outside of the indexing for loop), print the last document:
238 |
239 | ```python
240 | print(document)
241 | ```
242 |
243 | Now execute the block.
244 |
245 | What's the last document id?
246 |
247 | Also note the index name.
248 |
249 |
250 | ## Q5. Testing the retrieval
251 |
252 | Now let's test the retrieval. Use mage or jupyter notebook to
253 | test it.
254 |
255 | Let's use the following query: "When is the next cohort?"
256 |
257 | What's the ID of the top matching result?
258 |
259 |
260 | ## Q6. Reindexing
261 |
262 | Our FAQ document changes: every day course participants add
263 | new records or improve existing ones.
264 |
265 | Imagine some time passed and the document changed. For that we have another version of the FAQ document: [version 2](https://docs.google.com/document/d/1T3MdwUvqCL3jrh3d3VCXQ8xE0UqRzI3bfgpfBq3ZWG0/edit).
266 |
267 | The ID of this document is `1T3MdwUvqCL3jrh3d3VCXQ8xE0UqRzI3bfgpfBq3ZWG0`.
268 |
269 | Let's re-execute the entire pipeline with the updated data.
270 |
271 | For the same query "When is the next cohort?". What's the ID of the top matching result?
272 |
273 |
274 |
275 | ## Submit the results
276 |
277 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2024/homework/hw5
278 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
279 |
--------------------------------------------------------------------------------
/cohorts/2024/05-orchestration/parse-faq-llm.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "id": "4cd1eaa8-3424-41ad-9cf2-3e8548712865",
7 | "metadata": {},
8 | "outputs": [],
9 | "source": [
10 | "import io\n",
11 | "\n",
12 | "import requests\n",
13 | "import docx"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 2,
19 | "id": "8180e7e4-b90d-4900-a59b-d22e5d6537c4",
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "def clean_line(line):\n",
24 | " line = line.strip()\n",
25 | " line = line.strip('\\uFEFF')\n",
26 | " return line\n",
27 | "\n",
28 | "def read_faq(file_id):\n",
29 | " url = f'https://docs.google.com/document/d/{file_id}/export?format=docx'\n",
30 | " \n",
31 | " response = requests.get(url)\n",
32 | " response.raise_for_status()\n",
33 | " \n",
34 | " with io.BytesIO(response.content) as f_in:\n",
35 | " doc = docx.Document(f_in)\n",
36 | "\n",
37 | " questions = []\n",
38 | "\n",
39 | " question_heading_style = 'heading 2'\n",
40 | " section_heading_style = 'heading 1'\n",
41 | " \n",
42 | " heading_id = ''\n",
43 | " section_title = ''\n",
44 | " question_title = ''\n",
45 | " answer_text_so_far = ''\n",
46 | " \n",
47 | " for p in doc.paragraphs:\n",
48 | " style = p.style.name.lower()\n",
49 | " p_text = clean_line(p.text)\n",
50 | " \n",
51 | " if len(p_text) == 0:\n",
52 | " continue\n",
53 | " \n",
54 | " if style == section_heading_style:\n",
55 | " section_title = p_text\n",
56 | " continue\n",
57 | " \n",
58 | " if style == question_heading_style:\n",
59 | " answer_text_so_far = answer_text_so_far.strip()\n",
60 | " if answer_text_so_far != '' and section_title != '' and question_title != '':\n",
61 | " questions.append({\n",
62 | " 'text': answer_text_so_far,\n",
63 | " 'section': section_title,\n",
64 | " 'question': question_title,\n",
65 | " })\n",
66 | " answer_text_so_far = ''\n",
67 | " \n",
68 | " question_title = p_text\n",
69 | " continue\n",
70 | " \n",
71 | " answer_text_so_far += '\\n' + p_text\n",
72 | " \n",
73 | " answer_text_so_far = answer_text_so_far.strip()\n",
74 | " if answer_text_so_far != '' and section_title != '' and question_title != '':\n",
75 | " questions.append({\n",
76 | " 'text': answer_text_so_far,\n",
77 | " 'section': section_title,\n",
78 | " 'question': question_title,\n",
79 | " })\n",
80 | "\n",
81 | " return questions"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 3,
87 | "id": "7d3c2dd7-f64a-4dc7-a4e3-3e8aadfa720f",
88 | "metadata": {},
89 | "outputs": [],
90 | "source": [
91 | "faq_documents = {\n",
92 | " 'llm-zoomcamp': '1m2KexowAXTmexfC5rVTCSnaShvdUQ8Ag2IEiwBDHxN0',\n",
93 | "}"
94 | ]
95 | },
96 | {
97 | "cell_type": "code",
98 | "execution_count": 4,
99 | "id": "f94efe26-05e8-4ae5-a0fa-0a8e16852816",
100 | "metadata": {},
101 | "outputs": [
102 | {
103 | "name": "stdout",
104 | "output_type": "stream",
105 | "text": [
106 | "llm-zoomcamp\n"
107 | ]
108 | }
109 | ],
110 | "source": [
111 | "documents = []\n",
112 | "\n",
113 | "for course, file_id in faq_documents.items():\n",
114 | " print(course)\n",
115 | " course_documents = read_faq(file_id)\n",
116 | " documents.append({'course': course, 'documents': course_documents})"
117 | ]
118 | },
119 | {
120 | "cell_type": "code",
121 | "execution_count": null,
122 | "id": "1b21af5c-2f6d-49e7-92e9-ca229e2473b9",
123 | "metadata": {},
124 | "outputs": [],
125 | "source": []
126 | }
127 | ],
128 | "metadata": {
129 | "kernelspec": {
130 | "display_name": "Python 3 (ipykernel)",
131 | "language": "python",
132 | "name": "python3"
133 | },
134 | "language_info": {
135 | "codemirror_mode": {
136 | "name": "ipython",
137 | "version": 3
138 | },
139 | "file_extension": ".py",
140 | "mimetype": "text/x-python",
141 | "name": "python",
142 | "nbconvert_exporter": "python",
143 | "pygments_lexer": "ipython3",
144 | "version": "3.12.3"
145 | }
146 | },
147 | "nbformat": 4,
148 | "nbformat_minor": 5
149 | }
150 |
--------------------------------------------------------------------------------
/cohorts/2024/README.md:
--------------------------------------------------------------------------------
1 | # LLM Zoomcamp 2024 Edition
2 |
3 |
4 | Important links:
5 |
6 | - [Pre-Course Q&A Stream](https://www.youtube.com/watch?v=YuxVHZ88hfg&list=PL3MmuxUbc_hKiIVNf7DeEt_tGjypOYtKV)
7 | - [Course Launch Stream](https://www.youtube.com/watch?v=ifpqpB1ksGc)
8 | - [2024 Edition Youtube Playlist](https://www.youtube.com/playlist?list=PL3MmuxUbc_hKiIVNf7DeEt_tGjypOYtKV)
9 | - [Course management platform](https://courses.datatalks.club/llm-zoomcamp-2024/)
10 |
11 | [**LLM Zoomcamp 2024 Competition**](https://github.com/DataTalksClub/llm-zoomcamp/tree/main/cohorts/2024/competition#llm-zoomcamp-2024-competition)
12 |
13 | * Deadline: September 30, 2024
14 | * Practice and receive additional points for the course!
15 |
16 | [**Module 1: Introduction to LLMs and RAG**](01-intro)
17 |
18 | * [Homework](01-intro/homework.md)
19 | * [Solution](01-intro/homework_solution.ipynb)
20 |
21 | [**Module 2: Open-source LLMs and self-hosting LLMs**](02-open-source)
22 |
23 | * [Homework and solution](02-open-source/homework.md)
24 |
25 | [**Module 3: Vector databases**](03-vector-search)
26 |
27 | * [Homework and solution](03-vector-search/homework.md)
28 |
29 | [**Module 4: Evaluation and monitoring**](04-monitoring)
30 |
31 | * [Module explainer](https://www.loom.com/share/1dd375ec4b0d458fabdfc2b841089031)
32 | * [Homework](04-monitoring/homework.md)
33 |
34 | **Office hours**
35 |
36 | * [Office hours 1](https://www.youtube.com/watch?v=q4Mb4SN-doo)
37 | * [Office hours 2](https://www.youtube.com/watch?v=lre6h7vqz7A)
38 | * [Office hours 3 and 4](https://www.loom.com/share/b57b995f79364da68da1d1826a766794)
39 |
--------------------------------------------------------------------------------
/cohorts/2024/competition/README.md:
--------------------------------------------------------------------------------
1 | # LLM Zoomcamp 2024 Competition
2 |
3 | In the competition, you need to use LLMs to solve high school mathematics problems.
4 | Your task is to develop models that can accurately solve these problems and submit your predictions.
5 |
6 | For more details, visit the [competition page](https://www.kaggle.com/competitions/llm-zoomcamp-2024-competition/overview).
7 |
8 |
9 | ## Getting started
10 |
11 | Getting started code: [starter_notebook.ipynb](starter_notebook.ipynb)
12 |
13 | You will need to install langchain for this code:
14 |
15 | ```bash
16 | pip install -qU langchain-openai langchain
17 | ```
18 |
19 | Thanks [Blaq](https://www.linkedin.com/in/chinonsoodiaka/) for contibuting the notebook!
20 |
21 | Note that the solution is not deterministic: when you run
22 | it again on the same record, sometimes the solution is different
23 | from the initial run.
24 |
25 | Which might be more a feature than a bug:
26 | what if you run it multuple times and get the majority vote?
27 |
28 | ## Community solutions
29 |
30 | - Pastor Solo - getting started notebook on Kaggle - https://www.kaggle.com/code/pastorsoto/starter-notebook
31 | - Slava Shen - chain of thoughts - https://www.kaggle.com/code/vyacheslavshen/double-check-with-llms
32 |
33 | ## Evaluation
34 |
35 | We use accuracy as the evaluation metric. Sometimes multiple
36 | answers are correct. In this case, a solution is correct if
37 | it matches at least one of the possible answers.
38 |
39 | You can find the code for evaluation in [scorer.py](scorer.py) - it's taken [from kaggle](https://www.kaggle.com/code/dremovd/accuracy-multiple-correct?scriptVersionId=158029538)
40 | and this is exactly the code we use in the competition.
41 |
--------------------------------------------------------------------------------
/cohorts/2024/competition/scorer.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import numpy as np
3 |
4 |
5 | class ParticipantVisibleError(Exception):
6 | # If you want an error message to be shown to participants, you must raise the error as a ParticipantVisibleError
7 | # All other errors will only be shown to the competition host. This helps prevent unintentional leakage of solution data.
8 | pass
9 |
10 |
11 | def score(solution: pd.DataFrame, submission: pd.DataFrame, row_id_column_name: str) -> float:
12 | '''
13 | Accuracy that works with multiple correct answers.
14 | '''
15 | solution = solution.set_index(row_id_column_name, drop=True)
16 | submission = submission.set_index(row_id_column_name, drop=True)
17 | submission = submission.loc[solution.index]
18 |
19 | target_column = 'answer'
20 | assert target_column in solution.columns
21 | assert target_column in submission.columns
22 |
23 | # This fix is needed because submission is loaded with default parameters
24 | # Pandas magically converts string column into float
25 | def fix_suffix(value):
26 | if value.endswith('.0'):
27 | return value[:-2]
28 | else:
29 | return value
30 |
31 | submission[target_column] = submission[target_column].astype(str)
32 | submission[target_column] = submission[target_column].apply(fix_suffix)
33 |
34 |
35 | def convert_to_list(value):
36 | values = [v.strip() for v in value.strip().lstrip('[').rstrip(']').split(',')]
37 | return values
38 |
39 | solution[target_column] = solution[target_column].astype(str).apply(convert_to_list)
40 |
41 | correct = [
42 | submit_answer in correct_answer
43 | for correct_answer, submit_answer in zip(
44 | solution[target_column].values,
45 | submission[target_column].values
46 | )
47 | ]
48 |
49 | return np.mean(correct)
--------------------------------------------------------------------------------
/cohorts/2024/competition/starter_notebook_submission.csv:
--------------------------------------------------------------------------------
1 | problem_id,answer
2 | 11919,12.0
3 | 8513,285.0
4 | 7887,4.0
5 | 5272,6.0
6 | 8295,13.0
7 | 3219,15.0
8 | 7235,55.0
9 | 3688,21.0
10 | 6116,2412.0
11 | 4720,34.0
12 | 12122,40.8
13 | 4311,4.0
14 | 8283,7.0
15 | 8347,2.0
16 | 4170,220.0
17 | 4,21.0
18 | 8307,150.0
19 | 7108,544.0
20 | 7775,800.0
21 | 7680,216.0
22 | 8780,1680.0
23 | 8707,2.25
24 | 7863,5.0
25 | 12036,66.0
26 | 4569,3.0
27 | 8134,21.0
28 | 160,3.0
29 | 2869,70.0
30 | 3309,10.0
31 | 6941,0.462
32 | 4880,6.0
33 | 5126,0.5
34 | 7059,0.0
35 | 10649,45.0
36 | 10357,1.0
37 | 2445,10.0
38 | 5755,27.9
39 | 4849,0.0
40 | 1216,46.0
41 | 7787,77.0
42 | 2405,3.0
43 | 3041,6.0
44 | 10411,222240.0
45 | 7081,328.0
46 | 6018,4.0
47 | 8948,80.0
48 | 4658,54.0
49 | 11679,64.0
50 | 5390,99.2
51 | 5319,-4.0
52 | 6907,2.5
53 | 9695,5.0
54 | 12092,100.0
55 | 8458,20.0
56 | 7136,31.0
57 | 11922,8.4
58 | 6101,1350.0
59 | 245,63.0
60 | 7880,10.0
61 | 12166,4.0
62 | 8116,12.0
63 | 13554,520.0
64 | 4249,66.0
65 | 12184,3.0
66 | 5232,-4.0
67 | 9499,40980.0
68 | 4908,24.0
69 | 7452,5.0
70 | 13512,10.75
71 | 9253,6000.0
72 | 12338,4.0
73 | 4478,3.0
74 | 5170,-5.0
75 | 3122,515.0
76 | 10457,15.0
77 | 2370,10.0
78 | 8670,6.25
79 | 9446,40.0
80 | 8083,1.0
81 | 5321,-6.0
82 | 9388,0.0
83 | 8443,8.0
84 | 8138,600.0
85 | 12084,23.0
86 | 3305,11.0
87 | 4810,23.0
88 | 25,0.361
89 | 217,10.0
90 | 1421,14563.0
91 | 6914,1.0
92 | 4724,23.0
93 | 10460,26.0
94 | 1324,40.0
95 | 5268,3.0
96 | 5164,6.0
97 | 3519,650.0
98 | 7934,12.0
99 | 9390,0.0
100 | 7137,22.0
101 | 5914,300.0
102 |
--------------------------------------------------------------------------------
/cohorts/2024/project.md:
--------------------------------------------------------------------------------
1 | ## Course Project
2 |
3 | The goal of this project is to apply everything we learned
4 | in this course and build an end-to-end RAG project.
5 |
6 | Remember that to pass the project, you must evaluate 3 peers. If you don't do that, your project can't be considered compelete.
7 |
8 |
9 | ## Submitting
10 |
11 | ### Project Attempt #1
12 |
13 | * Project: https://courses.datatalks.club/llm-zoomcamp-2024/project/project1
14 | * Review: https://courses.datatalks.club/llm-zoomcamp-2024/project/project1/eval
15 |
16 |
17 | ### Project Attempt #2
18 |
19 | * Project: https://courses.datatalks.club/llm-zoomcamp-2024/project/project2
20 | * Review: https://courses.datatalks.club/llm-zoomcamp-2024/project/project2/eval
21 |
22 |
23 | > **Important**: update your "Certificate name" here: https://courses.datatalks.club/llm-zoomcamp-2024/enrollment -
24 | this is what we will use when generating certificates for you.
25 |
26 |
27 | ## Evaluation criteria
28 |
29 | See [here](../../project.md#evaluation-criteria)
--------------------------------------------------------------------------------
/cohorts/2024/workshops/dlt.md:
--------------------------------------------------------------------------------
1 | # Open source data ingestion for RAGs with dlt
2 |
3 | Video: https://www.youtube.com/watch?v=qUNyfR_X2Mo
4 |
5 | Homework solution: https://drive.google.com/file/d/1M1dKtAO-v3oYIztqMS8fXlLsBnqcmA-O/view?usp=sharing
6 |
7 | In this hands-on workshop, we’ll learn how to build a data ingestion pipeline using dlt to load data from a REST API into LanceDB so you can have an always up to date RAG.
8 |
9 | We’ll cover the following steps:
10 |
11 | * Extract data from REST APIs
12 | * Loading and vectorizing into LanceDB, which unlike other vector DBs stores the data _and_ the embeddings
13 | * Incremental loading
14 |
15 | By the end of this workshop, you’ll be able to write a portable, OSS data pipeline for your RAG that you can deploy anywhere, such as python notebooks, virtual machines, or orchestrators like Airflow, Dagster or Mage.
16 |
17 |
18 | # Resources
19 |
20 | * Slides: [dlt-LLM-Zoomcamp.pdf](https://github.com/user-attachments/files/16131729/dlt.LLM.Zoomcamp.pdf)
21 | * [Google Colab notebook](https://colab.research.google.com/drive/1nNOybHdWQiwUUuJFZu__xvJxL_ADU3xl?usp=sharing) - make a copy to follow along!
22 |
23 | ---
24 |
25 | # Homework
26 |
27 | In the workshop, we extracted contents from two pages in notion titled "Workshop: Benefits and Perks" and "Workshop: Working hours, PTO, and Vacation".
28 |
29 | Repeat the same process for a third page titled "Homework: Employee handbook" (hidden from public view, but accessible via API key):
30 |
31 | 1. Modify the REST API source to extract only this page.
32 | 2. Write the output into a separate table called "homework".
33 | 3. Remember to update the table name in all cells where you connect to a lancedb table.
34 |
35 | To do this you can use the [workshop Colab](https://colab.research.google.com/drive/1nNOybHdWQiwUUuJFZu__xvJxL_ADU3xl?usp=sharing) as a basis.
36 |
37 | Now, answer the following questions:
38 |
39 | ## Q1. Rows in LanceDB
40 |
41 | How many rows does the lancedb table "notion_pages__homework" have?
42 |
43 | * 14
44 | * 15
45 | * 16
46 | * 17
47 |
48 | ## Q2. Running the Pipeline: Last edited time
49 |
50 | In the demo, we created an incremental dlt resource `rest_api_notion_incremental` that keeps track of `last_edited_time`. What value does it store after you've run your pipeline once? (Hint: you will be able to get this value by performing some aggregation function on the column `last_edited_time` of the table)
51 |
52 | * `Timestamp('2024-07-05 22:34:00+0000', tz='UTC') (OR "2024-07-05T22:34:00.000Z")`
53 | * `Timestamp('2024-07-05 23:33:00+0000', tz='UTC') (OR "2024-07-05T23:33:00.000Z")`
54 | * `Timestamp('2024-07-05 23:52:00+0000', tz='UTC') (OR "2024-07-05T23:52:00.000Z")`
55 | * `Timestamp('2024-07-05 22:56:00+0000', tz='UTC') (OR "2024-07-05T22:56:00.000Z")`
56 |
57 |
58 | ## Q3. Ask the Assistant
59 |
60 | Find out with the help of the AI assistant: how many PTO days are the employees entitled to in a year?
61 |
62 | * 20
63 | * 25
64 | * 30
65 | * 35
66 |
67 | ## Submit the results
68 |
69 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2024/homework/workshop1
70 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
71 |
--------------------------------------------------------------------------------
/cohorts/2025/01-intro/homework.md:
--------------------------------------------------------------------------------
1 | ## Homework: Introduction
2 |
3 | In this homework, we'll learn more about search and use Elastic Search for practice.
4 |
5 | > It's possible that your answers won't match exactly. If it's the case, select the closest one.
6 |
7 |
8 | ## Q1. Running Elastic
9 |
10 | Run Elastic Search 8.17.6, and get the cluster information. If you run it on localhost, this is how you do it:
11 |
12 | ```bash
13 | curl localhost:9200
14 | ```
15 |
16 | What's the `version.build_hash` value?
17 |
18 |
19 | ## Getting the data
20 |
21 | Now let's get the FAQ data. You can run this snippet:
22 |
23 | ```python
24 | import requests
25 |
26 | docs_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main/01-intro/documents.json?raw=1'
27 | docs_response = requests.get(docs_url)
28 | documents_raw = docs_response.json()
29 |
30 | documents = []
31 |
32 | for course in documents_raw:
33 | course_name = course['course']
34 |
35 | for doc in course['documents']:
36 | doc['course'] = course_name
37 | documents.append(doc)
38 | ```
39 |
40 | Note that you need to have the `requests` library:
41 |
42 | ```bash
43 | pip install requests
44 | ```
45 |
46 | ## Q2. Indexing the data
47 |
48 | Index the data in the same way as was shown in the course videos. Make the `course` field a keyword and the rest should be text.
49 |
50 | Don't forget to install the ElasticSearch client for Python:
51 |
52 | ```bash
53 | pip install elasticsearch
54 | ```
55 |
56 | Which function do you use for adding your data to elastic?
57 |
58 | * `insert`
59 | * `index`
60 | * `put`
61 | * `add`
62 |
63 | ## Q3. Searching
64 |
65 | Now let's search in our index.
66 |
67 | We will execute a query "How do execute a command on a Kubernetes pod?".
68 |
69 | Use only `question` and `text` fields and give `question` a boost of 4, and use `"type": "best_fields"`.
70 |
71 | What's the score for the top ranking result?
72 |
73 | * 84.50
74 | * 64.50
75 | * 44.50
76 | * 24.50
77 |
78 | Look at the `_score` field.
79 |
80 | ## Q4. Filtering
81 |
82 | Now ask a different question: "How do copy a file to a Docker container?".
83 |
84 | This time we are only interested in questions from `machine-learning-zoomcamp`.
85 |
86 | Return 3 results. What's the 3rd question returned by the search engine?
87 |
88 | * How do I debug a docker container?
89 | * How do I copy files from a different folder into docker container’s working directory?
90 | * How do Lambda container images work?
91 | * How can I annotate a graph?
92 |
93 | ## Q5. Building a prompt
94 |
95 | Now we're ready to build a prompt to send to an LLM.
96 |
97 | Take the records returned from Elasticsearch in Q4 and use this template to build the context. Separate context entries by two linebreaks (`\n\n`)
98 | ```python
99 | context_template = """
100 | Q: {question}
101 | A: {text}
102 | """.strip()
103 | ```
104 |
105 | Now use the context you just created along with the "How do I execute a command in a running docker container?" question
106 | to construct a prompt using the template below:
107 |
108 | ```
109 | prompt_template = """
110 | You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.
111 | Use only the facts from the CONTEXT when answering the QUESTION.
112 |
113 | QUESTION: {question}
114 |
115 | CONTEXT:
116 | {context}
117 | """.strip()
118 | ```
119 |
120 | What's the length of the resulting prompt? (use the `len` function)
121 |
122 | * 946
123 | * 1446
124 | * 1946
125 | * 2446
126 |
127 | ## Q6. Tokens
128 |
129 | When we use the OpenAI Platform, we're charged by the number of
130 | tokens we send in our prompt and receive in the response.
131 |
132 | The OpenAI python package uses `tiktoken` for tokenization:
133 |
134 | ```bash
135 | pip install tiktoken
136 | ```
137 |
138 | Let's calculate the number of tokens in our query:
139 |
140 | ```python
141 | encoding = tiktoken.encoding_for_model("gpt-4o")
142 | ```
143 |
144 | Use the `encode` function. How many tokens does our prompt have?
145 |
146 | * 120
147 | * 220
148 | * 320
149 | * 420
150 |
151 | Note: to decode back a token into a word, you can use the `decode_single_token_bytes` function:
152 |
153 | ```python
154 | encoding.decode_single_token_bytes(63842)
155 | ```
156 |
157 | ## Bonus: generating the answer (ungraded)
158 |
159 | Let's send the prompt to OpenAI. What's the response?
160 |
161 | Note: you can replace OpenAI with Ollama. See module 2.
162 |
163 | ## Bonus: calculating the costs (ungraded)
164 |
165 | Suppose that on average per request we send 150 tokens and receive back 250 tokens.
166 |
167 | How much will it cost to run 1000 requests?
168 |
169 | You can see the prices [here](https://openai.com/api/pricing/)
170 |
171 | On June 17, the prices for gpt4o are:
172 |
173 | * Input: $0.005 / 1K tokens
174 | * Output: $0.015 / 1K tokens
175 |
176 | You can redo the calculations with the values you got in Q6 and Q7.
177 |
178 |
179 | ## Submit the results
180 |
181 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2025/homework/hw1
182 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
183 |
--------------------------------------------------------------------------------
/cohorts/2025/README.md:
--------------------------------------------------------------------------------
1 | # LLM Zoomcamp 2025 Edition
2 |
3 | Important links:
4 |
5 | - Pre-Course Q&A Stream: [video](https://www.youtube.com/live/8lgiOLMMKcY), [summary](/cohorts/2025/pre-course-q-a-stream-summary.md)
6 | - Course Launch Stream: [video](https://www.youtube.com/live/FgnelhEJFj0), [summary](/cohorts/2025/course-launch-stream-summary.md)
7 | - [2025 Edition Youtube Playlist](https://www.youtube.com/playlist?list=PL3MmuxUbc_hIoBpuc900htYF4uhEAbaT-)
8 | - [Course management platform](https://courses.datatalks.club/llm-zoomcamp-2025/)
9 |
10 |
11 | [**Module 1: Introduction to LLMs and RAG**](01-intro)
12 |
13 | * [Homework](01-intro/homework.md)
14 |
15 |
16 |
--------------------------------------------------------------------------------
/cohorts/2025/course-launch-stream-summary.md:
--------------------------------------------------------------------------------
1 | # Key Takeaways from the LLM Zoomcamp 2025 Launch Stream
2 |
3 | [](https://youtu.be/FgnelhEJFj0)
4 |
5 | > **[Watch the LLM Zoomcamp 2025 Launch Stream](https://youtu.be/FgnelhEJFj0)**
6 |
7 | ---
8 |
9 | ## Table of Contents
10 |
11 | - [Quick Summary](#quick-summary)
12 | - [Meet the Team](#meet-the-2025-team)
13 | - [Prerequisites](#prerequisites)
14 | - [Course Architecture](#course-architecture)
15 | - [Module Breakdown](#module-breakdown)
16 | - [Timeline & Deadlines](#timeline--deadlines)
17 | - [Getting Help](#getting-help)
18 | - [Earning Points](#earning-points)
19 | - [Communication Channels](#communication-channels)
20 | - [Sponsors & Support](#sponsors--support)
21 | - [FAQ Highlights](#faq-highlights)
22 | - [Next Steps](#next-steps)
23 |
24 | ---
25 |
26 | ## Quick Summary
27 |
28 |
120 |
121 |
122 | ## Homework
123 |
124 | See [here](../cohorts/2024/05-orchestration/homework.md).
125 |
126 | # Notes
127 |
128 | * First link goes here
129 | * [Notes by Abiodun Mage RAG error fixes](https://github.com/AOGbadamosi2018/llm-zoomcamp/blob/main/06%20-%20orchestration/mage_rag_notes.md).
130 | * Did you take notes? Add them above this line (Send a PR with *links* to your notes)
131 |
--------------------------------------------------------------------------------
/cohorts/2024/05-orchestration/code/06_retrieval.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List, Union
2 |
3 | import numpy as np
4 | from elasticsearch import Elasticsearch, exceptions
5 |
6 |
7 | SAMPLE__EMBEDDINGS = [
8 | [-0.1465761959552765, -0.4822517931461334, 0.07130702584981918, -0.25872930884361267, -0.1563894897699356, 0.16641047596931458, 0.24484659731388092, 0.2410498708486557, 0.008032954297959805, 0.17045290768146515, -0.009397129528224468, 0.09619587659835815, -0.22729521989822388, 0.10254761576652527, 0.016890447586774826, -0.13290464878082275, 0.11240798979997635, -0.11204371601343155, -0.057132963091135025, -0.011206787079572678, -0.007982085458934307, 0.279083788394928, 0.20115645229816437, -0.1427406221628189, -0.19398854672908783, -0.035979654639959335, 0.20723149180412292, 0.29891034960746765, 0.21407313644886017, 0.09746530652046204, 0.1671638935804367, 0.08161208778619766, 0.3090828061103821, -0.20648667216300964, 0.48498260974884033, -0.12691514194011688, 0.518856406211853, -0.26291757822036743, -0.0949832871556282, 0.09556109458208084, -0.20844918489456177, 0.2685297429561615, 0.053442806005477905, 0.05103180184960365, 0.1029752567410469, 0.04935301095247269, -0.11679927259683609, -0.012528933584690094, -0.08489680290222168, 0.013589601963758469, -0.32059246301651, 0.10357264429330826, -0.09533575177192688, 0.02984568662941456, 0.2793693542480469, -0.2653750777244568, -0.24152781069278717, -0.3563413619995117, 0.09674381464719772, -0.26155123114585876, -0.1397126317024231, -0.009133181534707546, 0.05972130224108696, -0.10438819974660873, 0.21889159083366394, 0.0694752112030983, -0.1312003880739212, -0.31072548031806946, -0.002836169209331274, 0.2468366175889969, 0.09420009702444077, 0.1284026801586151, -0.03227006644010544, -0.012532072141766548, 0.6650756597518921, -0.14863784611225128, 0.005239118821918964, -0.3317912817001343, 0.16372767090797424, -0.20166568458080292, 0.029721004888415337, -0.18536655604839325, -0.3608534038066864, -0.18234892189502716, 0.019248824566602707, 0.25257956981658936, 0.09671413153409958, 0.15569280087947845, -0.38228726387023926, 0.37017977237701416, 0.03356296569108963, -0.21182948350906372, 0.48848846554756165, 0.18350018560886383, -0.23519110679626465, -0.17464864253997803], [-0.18246106803417206, -0.36036479473114014, 0.3282334506511688, -0.230922132730484, 0.09600532799959183, 0.6859422326087952, 0.0581890344619751, 0.4913463294506073, 0.1536773443222046, -0.2965141832828522, 0.08466599136590958, 0.319297194480896, -0.15651769936084747, -0.043428342789411545, 0.014402368105947971, 0.16681505739688873, 0.22521673142910004, -0.2715776264667511, -0.11033261567354202, -0.04398636147379875, 0.3480629622936249, 0.11897992342710495, 0.8724615573883057, 0.10258488357067108, -0.5719427466392517, -0.03029855526983738, 0.23351268470287323, 0.20660561323165894, 0.575685441493988, -0.12116186320781708, 0.18459142744541168, -0.12865227460861206, 0.3948173522949219, -0.34464019536972046, 0.6699116230010986, -0.45167359709739685, 1.1505522727966309, -0.4498964548110962, -0.3248189687728882, -0.29674994945526123, -0.3570491075515747, 0.5436431765556335, 0.49576905369758606, -0.11180296540260315, -0.02045607566833496, -0.22768598794937134, -0.37912657856941223, -0.30414703488349915, -0.48289090394973755, -0.04158346354961395, -0.3547952473163605, 0.0687602087855339, 0.041512664407491684, 0.33524179458618164, 0.21826978027820587, -0.443082332611084, -0.5049593448638916, -0.5298929810523987, -0.02618088759481907, -0.2748631536960602, -0.1986193209886551, 0.35475826263427734, 0.22456413507461548, -0.29532068967819214, 0.25150877237319946, 0.243370920419693, -0.29938358068466187, -0.2128247618675232, -0.15292000770568848, -0.14813245832920074, -0.06183856353163719, -0.1251668632030487, 0.14256533980369568, -0.22781267762184143, 0.8101184964179993, 0.19796361029148102, 0.09104947745800018, -0.4860817790031433, 0.3078012764453888, -0.27373194694519043, 0.11800770461559296, -0.45869407057762146, 0.09508189558982849, -0.23971715569496155, -0.27427223324775696, 0.5139415264129639, 0.1871502846479416, 0.06647063046693802, -0.4054469168186188, 0.4751380681991577, 0.17067894339561462, 0.12443914264440536, 0.3577817678451538, 0.10574143379926682, -0.3181760311126709, -0.23804502189159393]
9 | ]
10 |
11 |
12 | @data_loader
13 | def search(*args, **kwargs) -> List[Dict]:
14 | """
15 | query_embedding: Union[List[int], np.ndarray]
16 | """
17 |
18 | connection_string = kwargs.get('connection_string', 'http://localhost:9200')
19 | index_name = kwargs.get('index_name', 'documents')
20 | source = kwargs.get('source', "cosineSimilarity(params.query_vector, 'embedding') + 1.0")
21 | top_k = kwargs.get('top_k', 5)
22 | chunk_column = kwargs.get('chunk_column', 'content')
23 |
24 | query_embedding = None
25 | if len(args):
26 | query_embedding = args[0]
27 | if not query_embedding:
28 | query_embedding = SAMPLE__EMBEDDINGS[0]
29 |
30 | if isinstance(query_embedding, np.ndarray):
31 | query_embedding = query_embedding.tolist()
32 |
33 | script_query = {
34 | "script_score": {
35 | "query": {"match_all": {}},
36 | "script": {
37 | "source": source,
38 | "params": {"query_vector": query_embedding},
39 | }
40 | }
41 | }
42 |
43 | print("Sending script query:", script_query)
44 |
45 | es_client = Elasticsearch(connection_string)
46 |
47 | try:
48 | response = es_client.search(
49 | index=index_name,
50 | body={
51 | "size": top_k,
52 | "query": script_query,
53 | "_source": [chunk_column],
54 | },
55 | )
56 |
57 | print("Raw response from Elasticsearch:", response)
58 |
59 | return [hit['_source'][chunk_column] for hit in response['hits']['hits']]
60 |
61 | except exceptions.BadRequestError as e:
62 | print(f"BadRequestError: {e.info}")
63 | return []
64 | except Exception as e:
65 | print(f"Unexpected error: {e}")
66 | return []
67 |
--------------------------------------------------------------------------------
/cohorts/2024/05-orchestration/homework.md:
--------------------------------------------------------------------------------
1 | ## Homework: LLM Orchestration and Ingestion
2 |
3 | > It's possible that your answers won't match exactly. If it's the case, select the closest one.
4 |
5 | Our FAQ documents change with time: students add more records
6 | and edit existing ones. We need to keep our index in sync.
7 |
8 | There are two ways of doing it:
9 |
10 | 1. Incremental: you only update records that got changed, created or deleted
11 | 2. Full update: you recreate the entire index from scratch
12 |
13 | In this homework, we'll look at full update. We will run our
14 | indexing pipeline daily and re-create the index from scracth
15 | each time we run.
16 |
17 |
18 | For that, we created two FAQ documents for LLM Zoomcamp
19 |
20 | * [version 1](https://docs.google.com/document/d/1qZjwHkvP0lXHiE4zdbWyUXSVfmVGzougDD6N37bat3E/edit)
21 | * [version 2](https://docs.google.com/document/d/1T3MdwUvqCL3jrh3d3VCXQ8xE0UqRzI3bfgpfBq3ZWG0/edit)
22 |
23 | First, we will run our ingestion pipeline with version 1
24 | and then with version 2.
25 |
26 | ## Q1. Running Mage
27 |
28 | Clone the same repo we used in the module and run mage:
29 |
30 |
31 | ```bash
32 | git clone https://github.com/mage-ai/rag-project
33 | ```
34 |
35 | Add the following libraries to the requirements document:
36 |
37 | ```
38 | python-docx
39 | elasticsearch
40 | ```
41 |
42 | Make sure you use the latest version of mage:
43 |
44 | ```bash
45 | docker pull mageai/mageai:llm
46 | ```
47 |
48 | Start it:
49 |
50 | ```bash
51 | ./scripts/start.sh
52 | ```
53 |
54 | Now mage is running on [http://localhost:6789/](http://localhost:6789/)
55 |
56 | What's the version of mage?
57 |
58 | ## Creating a RAG pipeline
59 |
60 | Create a RAG pipeline
61 |
62 |
63 | ## Q2. Reading the documents
64 |
65 | Now we can ingest the documents. Create a custom code ingestion
66 | block
67 |
68 | Let's read the documents. We will use the same code we used
69 | for parsing FAQ: [parse-faq-llm.ipynb](parse-faq-llm.ipynb)
70 |
71 |
72 | Use the following document_id: 1qZjwHkvP0lXHiE4zdbWyUXSVfmVGzougDD6N37bat3E
73 |
74 | Which is the document ID of
75 | [LLM FAQ version 1](https://docs.google.com/document/d/1qZjwHkvP0lXHiE4zdbWyUXSVfmVGzougDD6N37bat3E/edit)
76 |
77 | Copy the code to the editor
78 | How many FAQ documents we processed?
79 |
80 | * 1
81 | * 2
82 | * 3
83 | * 4
84 |
85 | ## Q3. Chunking
86 |
87 | We don't really need to do any chuncking because our documents
88 | already have well-specified boundaries. So we just need
89 | to return the documents without any changes.
90 |
91 | So let's go to the transformation part and add a custom code
92 | chunking block:
93 |
94 | ```python
95 | documents = []
96 |
97 | for doc in data['documents']:
98 | doc['course'] = data['course']
99 | # previously we used just "id" for document ID
100 | doc['document_id'] = generate_document_id(doc)
101 | documents.append(doc)
102 |
103 | print(len(documents))
104 |
105 | return documents
106 | ```
107 |
108 |
109 | Where `data` is the input parameter to the transformer.
110 |
111 | And the `generate_document_id` is defined in the same way
112 | as in module 4:
113 |
114 | ```python
115 | import hashlib
116 |
117 | def generate_document_id(doc):
118 | combined = f"{doc['course']}-{doc['question']}-{doc['text'][:10]}"
119 | hash_object = hashlib.md5(combined.encode())
120 | hash_hex = hash_object.hexdigest()
121 | document_id = hash_hex[:8]
122 | return document_id
123 | ```
124 |
125 | Note: if instead of a single dictionary you get a list,
126 | add a for loop:
127 |
128 | ```python
129 | for course_dict in data:
130 | ...
131 | ```
132 |
133 | You can check the type of `data` with this code:
134 |
135 | ```python
136 | print(type(data))
137 | ```
138 |
139 | How many documents (chunks) do we have in the output?
140 |
141 | * 66
142 | * 76
143 | * 86
144 | * 96
145 |
146 |
147 |
148 | ## Tokenization and embeddings
149 |
150 | We don't need any tokenization, so we skip it.
151 |
152 | Because currently it's required in mage, we can create
153 | a dummy code block:
154 |
155 | * Create a custom code block
156 | * Don't change it
157 |
158 | Because we will use text search, we also don't need embeddings,
159 | so skip it too.
160 |
161 | If you want to use sentence transformers - the ones from module
162 | 3 - you don't need tokenization, but need embeddings
163 | (you don't need it for this homework)
164 |
165 |
166 | ## Q4. Export
167 |
168 | Now we're ready to index the data with elasticsearch. For that,
169 | we use the Export part of the pipeline
170 |
171 | * Go to the Export part
172 | * Select vector databases -> Elasticsearch
173 | * Open the code for editing
174 |
175 | Because we won't use vector search, but usual text search, we
176 | will need to adjust the code.
177 |
178 | First, let's change the line where we read the index name:
179 |
180 | ```python
181 | index_name = kwargs.get('index_name', 'documents')
182 | ```
183 |
184 | To `index_name_prefix` - we will parametrize it with the day
185 | and time we run the pipeline
186 |
187 | ```python
188 | from datetime import datetime
189 |
190 | index_name_prefix = kwargs.get('index_name', 'documents')
191 | current_time = datetime.now().strftime("%Y%m%d_%M%S")
192 | index_name = f"{index_name_prefix}_{current_time}"
193 | print("index name:", index_name)
194 | ```
195 |
196 |
197 | We will need to save the name in a global variable, so it can be accessible in other code blocks
198 |
199 | ```python
200 | from mage_ai.data_preparation.variable_manager import set_global_variable
201 |
202 | set_global_variable('YOUR_PIPELINE_NAME', 'index_name', index_name)
203 | ```
204 |
205 | Where your pipeline name is the name of the pipeline, e.g.
206 | `transcendent_nexus` (replace the space with underscore `_`)
207 |
208 |
209 |
210 | Replace index settings with the settings we used previously:
211 |
212 | ```python
213 | index_settings = {
214 | "settings": {
215 | "number_of_shards": number_of_shards,
216 | "number_of_replicas": number_of_replicas
217 | },
218 | "mappings": {
219 | "properties": {
220 | "text": {"type": "text"},
221 | "section": {"type": "text"},
222 | "question": {"type": "text"},
223 | "course": {"type": "keyword"},
224 | "document_id": {"type": "keyword"}
225 | }
226 | }
227 | }
228 | ```
229 |
230 | Remove the embeddings line:
231 |
232 | ```python
233 | if isinstance(document[vector_column_name], np.ndarray):
234 | document[vector_column_name] = document[vector_column_name].tolist()
235 | ```
236 |
237 | At the end (outside of the indexing for loop), print the last document:
238 |
239 | ```python
240 | print(document)
241 | ```
242 |
243 | Now execute the block.
244 |
245 | What's the last document id?
246 |
247 | Also note the index name.
248 |
249 |
250 | ## Q5. Testing the retrieval
251 |
252 | Now let's test the retrieval. Use mage or jupyter notebook to
253 | test it.
254 |
255 | Let's use the following query: "When is the next cohort?"
256 |
257 | What's the ID of the top matching result?
258 |
259 |
260 | ## Q6. Reindexing
261 |
262 | Our FAQ document changes: every day course participants add
263 | new records or improve existing ones.
264 |
265 | Imagine some time passed and the document changed. For that we have another version of the FAQ document: [version 2](https://docs.google.com/document/d/1T3MdwUvqCL3jrh3d3VCXQ8xE0UqRzI3bfgpfBq3ZWG0/edit).
266 |
267 | The ID of this document is `1T3MdwUvqCL3jrh3d3VCXQ8xE0UqRzI3bfgpfBq3ZWG0`.
268 |
269 | Let's re-execute the entire pipeline with the updated data.
270 |
271 | For the same query "When is the next cohort?". What's the ID of the top matching result?
272 |
273 |
274 |
275 | ## Submit the results
276 |
277 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2024/homework/hw5
278 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
279 |
--------------------------------------------------------------------------------
/cohorts/2024/05-orchestration/parse-faq-llm.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "id": "4cd1eaa8-3424-41ad-9cf2-3e8548712865",
7 | "metadata": {},
8 | "outputs": [],
9 | "source": [
10 | "import io\n",
11 | "\n",
12 | "import requests\n",
13 | "import docx"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 2,
19 | "id": "8180e7e4-b90d-4900-a59b-d22e5d6537c4",
20 | "metadata": {},
21 | "outputs": [],
22 | "source": [
23 | "def clean_line(line):\n",
24 | " line = line.strip()\n",
25 | " line = line.strip('\\uFEFF')\n",
26 | " return line\n",
27 | "\n",
28 | "def read_faq(file_id):\n",
29 | " url = f'https://docs.google.com/document/d/{file_id}/export?format=docx'\n",
30 | " \n",
31 | " response = requests.get(url)\n",
32 | " response.raise_for_status()\n",
33 | " \n",
34 | " with io.BytesIO(response.content) as f_in:\n",
35 | " doc = docx.Document(f_in)\n",
36 | "\n",
37 | " questions = []\n",
38 | "\n",
39 | " question_heading_style = 'heading 2'\n",
40 | " section_heading_style = 'heading 1'\n",
41 | " \n",
42 | " heading_id = ''\n",
43 | " section_title = ''\n",
44 | " question_title = ''\n",
45 | " answer_text_so_far = ''\n",
46 | " \n",
47 | " for p in doc.paragraphs:\n",
48 | " style = p.style.name.lower()\n",
49 | " p_text = clean_line(p.text)\n",
50 | " \n",
51 | " if len(p_text) == 0:\n",
52 | " continue\n",
53 | " \n",
54 | " if style == section_heading_style:\n",
55 | " section_title = p_text\n",
56 | " continue\n",
57 | " \n",
58 | " if style == question_heading_style:\n",
59 | " answer_text_so_far = answer_text_so_far.strip()\n",
60 | " if answer_text_so_far != '' and section_title != '' and question_title != '':\n",
61 | " questions.append({\n",
62 | " 'text': answer_text_so_far,\n",
63 | " 'section': section_title,\n",
64 | " 'question': question_title,\n",
65 | " })\n",
66 | " answer_text_so_far = ''\n",
67 | " \n",
68 | " question_title = p_text\n",
69 | " continue\n",
70 | " \n",
71 | " answer_text_so_far += '\\n' + p_text\n",
72 | " \n",
73 | " answer_text_so_far = answer_text_so_far.strip()\n",
74 | " if answer_text_so_far != '' and section_title != '' and question_title != '':\n",
75 | " questions.append({\n",
76 | " 'text': answer_text_so_far,\n",
77 | " 'section': section_title,\n",
78 | " 'question': question_title,\n",
79 | " })\n",
80 | "\n",
81 | " return questions"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 3,
87 | "id": "7d3c2dd7-f64a-4dc7-a4e3-3e8aadfa720f",
88 | "metadata": {},
89 | "outputs": [],
90 | "source": [
91 | "faq_documents = {\n",
92 | " 'llm-zoomcamp': '1m2KexowAXTmexfC5rVTCSnaShvdUQ8Ag2IEiwBDHxN0',\n",
93 | "}"
94 | ]
95 | },
96 | {
97 | "cell_type": "code",
98 | "execution_count": 4,
99 | "id": "f94efe26-05e8-4ae5-a0fa-0a8e16852816",
100 | "metadata": {},
101 | "outputs": [
102 | {
103 | "name": "stdout",
104 | "output_type": "stream",
105 | "text": [
106 | "llm-zoomcamp\n"
107 | ]
108 | }
109 | ],
110 | "source": [
111 | "documents = []\n",
112 | "\n",
113 | "for course, file_id in faq_documents.items():\n",
114 | " print(course)\n",
115 | " course_documents = read_faq(file_id)\n",
116 | " documents.append({'course': course, 'documents': course_documents})"
117 | ]
118 | },
119 | {
120 | "cell_type": "code",
121 | "execution_count": null,
122 | "id": "1b21af5c-2f6d-49e7-92e9-ca229e2473b9",
123 | "metadata": {},
124 | "outputs": [],
125 | "source": []
126 | }
127 | ],
128 | "metadata": {
129 | "kernelspec": {
130 | "display_name": "Python 3 (ipykernel)",
131 | "language": "python",
132 | "name": "python3"
133 | },
134 | "language_info": {
135 | "codemirror_mode": {
136 | "name": "ipython",
137 | "version": 3
138 | },
139 | "file_extension": ".py",
140 | "mimetype": "text/x-python",
141 | "name": "python",
142 | "nbconvert_exporter": "python",
143 | "pygments_lexer": "ipython3",
144 | "version": "3.12.3"
145 | }
146 | },
147 | "nbformat": 4,
148 | "nbformat_minor": 5
149 | }
150 |
--------------------------------------------------------------------------------
/cohorts/2024/README.md:
--------------------------------------------------------------------------------
1 | # LLM Zoomcamp 2024 Edition
2 |
3 |
4 | Important links:
5 |
6 | - [Pre-Course Q&A Stream](https://www.youtube.com/watch?v=YuxVHZ88hfg&list=PL3MmuxUbc_hKiIVNf7DeEt_tGjypOYtKV)
7 | - [Course Launch Stream](https://www.youtube.com/watch?v=ifpqpB1ksGc)
8 | - [2024 Edition Youtube Playlist](https://www.youtube.com/playlist?list=PL3MmuxUbc_hKiIVNf7DeEt_tGjypOYtKV)
9 | - [Course management platform](https://courses.datatalks.club/llm-zoomcamp-2024/)
10 |
11 | [**LLM Zoomcamp 2024 Competition**](https://github.com/DataTalksClub/llm-zoomcamp/tree/main/cohorts/2024/competition#llm-zoomcamp-2024-competition)
12 |
13 | * Deadline: September 30, 2024
14 | * Practice and receive additional points for the course!
15 |
16 | [**Module 1: Introduction to LLMs and RAG**](01-intro)
17 |
18 | * [Homework](01-intro/homework.md)
19 | * [Solution](01-intro/homework_solution.ipynb)
20 |
21 | [**Module 2: Open-source LLMs and self-hosting LLMs**](02-open-source)
22 |
23 | * [Homework and solution](02-open-source/homework.md)
24 |
25 | [**Module 3: Vector databases**](03-vector-search)
26 |
27 | * [Homework and solution](03-vector-search/homework.md)
28 |
29 | [**Module 4: Evaluation and monitoring**](04-monitoring)
30 |
31 | * [Module explainer](https://www.loom.com/share/1dd375ec4b0d458fabdfc2b841089031)
32 | * [Homework](04-monitoring/homework.md)
33 |
34 | **Office hours**
35 |
36 | * [Office hours 1](https://www.youtube.com/watch?v=q4Mb4SN-doo)
37 | * [Office hours 2](https://www.youtube.com/watch?v=lre6h7vqz7A)
38 | * [Office hours 3 and 4](https://www.loom.com/share/b57b995f79364da68da1d1826a766794)
39 |
--------------------------------------------------------------------------------
/cohorts/2024/competition/README.md:
--------------------------------------------------------------------------------
1 | # LLM Zoomcamp 2024 Competition
2 |
3 | In the competition, you need to use LLMs to solve high school mathematics problems.
4 | Your task is to develop models that can accurately solve these problems and submit your predictions.
5 |
6 | For more details, visit the [competition page](https://www.kaggle.com/competitions/llm-zoomcamp-2024-competition/overview).
7 |
8 |
9 | ## Getting started
10 |
11 | Getting started code: [starter_notebook.ipynb](starter_notebook.ipynb)
12 |
13 | You will need to install langchain for this code:
14 |
15 | ```bash
16 | pip install -qU langchain-openai langchain
17 | ```
18 |
19 | Thanks [Blaq](https://www.linkedin.com/in/chinonsoodiaka/) for contibuting the notebook!
20 |
21 | Note that the solution is not deterministic: when you run
22 | it again on the same record, sometimes the solution is different
23 | from the initial run.
24 |
25 | Which might be more a feature than a bug:
26 | what if you run it multuple times and get the majority vote?
27 |
28 | ## Community solutions
29 |
30 | - Pastor Solo - getting started notebook on Kaggle - https://www.kaggle.com/code/pastorsoto/starter-notebook
31 | - Slava Shen - chain of thoughts - https://www.kaggle.com/code/vyacheslavshen/double-check-with-llms
32 |
33 | ## Evaluation
34 |
35 | We use accuracy as the evaluation metric. Sometimes multiple
36 | answers are correct. In this case, a solution is correct if
37 | it matches at least one of the possible answers.
38 |
39 | You can find the code for evaluation in [scorer.py](scorer.py) - it's taken [from kaggle](https://www.kaggle.com/code/dremovd/accuracy-multiple-correct?scriptVersionId=158029538)
40 | and this is exactly the code we use in the competition.
41 |
--------------------------------------------------------------------------------
/cohorts/2024/competition/scorer.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import numpy as np
3 |
4 |
5 | class ParticipantVisibleError(Exception):
6 | # If you want an error message to be shown to participants, you must raise the error as a ParticipantVisibleError
7 | # All other errors will only be shown to the competition host. This helps prevent unintentional leakage of solution data.
8 | pass
9 |
10 |
11 | def score(solution: pd.DataFrame, submission: pd.DataFrame, row_id_column_name: str) -> float:
12 | '''
13 | Accuracy that works with multiple correct answers.
14 | '''
15 | solution = solution.set_index(row_id_column_name, drop=True)
16 | submission = submission.set_index(row_id_column_name, drop=True)
17 | submission = submission.loc[solution.index]
18 |
19 | target_column = 'answer'
20 | assert target_column in solution.columns
21 | assert target_column in submission.columns
22 |
23 | # This fix is needed because submission is loaded with default parameters
24 | # Pandas magically converts string column into float
25 | def fix_suffix(value):
26 | if value.endswith('.0'):
27 | return value[:-2]
28 | else:
29 | return value
30 |
31 | submission[target_column] = submission[target_column].astype(str)
32 | submission[target_column] = submission[target_column].apply(fix_suffix)
33 |
34 |
35 | def convert_to_list(value):
36 | values = [v.strip() for v in value.strip().lstrip('[').rstrip(']').split(',')]
37 | return values
38 |
39 | solution[target_column] = solution[target_column].astype(str).apply(convert_to_list)
40 |
41 | correct = [
42 | submit_answer in correct_answer
43 | for correct_answer, submit_answer in zip(
44 | solution[target_column].values,
45 | submission[target_column].values
46 | )
47 | ]
48 |
49 | return np.mean(correct)
--------------------------------------------------------------------------------
/cohorts/2024/competition/starter_notebook_submission.csv:
--------------------------------------------------------------------------------
1 | problem_id,answer
2 | 11919,12.0
3 | 8513,285.0
4 | 7887,4.0
5 | 5272,6.0
6 | 8295,13.0
7 | 3219,15.0
8 | 7235,55.0
9 | 3688,21.0
10 | 6116,2412.0
11 | 4720,34.0
12 | 12122,40.8
13 | 4311,4.0
14 | 8283,7.0
15 | 8347,2.0
16 | 4170,220.0
17 | 4,21.0
18 | 8307,150.0
19 | 7108,544.0
20 | 7775,800.0
21 | 7680,216.0
22 | 8780,1680.0
23 | 8707,2.25
24 | 7863,5.0
25 | 12036,66.0
26 | 4569,3.0
27 | 8134,21.0
28 | 160,3.0
29 | 2869,70.0
30 | 3309,10.0
31 | 6941,0.462
32 | 4880,6.0
33 | 5126,0.5
34 | 7059,0.0
35 | 10649,45.0
36 | 10357,1.0
37 | 2445,10.0
38 | 5755,27.9
39 | 4849,0.0
40 | 1216,46.0
41 | 7787,77.0
42 | 2405,3.0
43 | 3041,6.0
44 | 10411,222240.0
45 | 7081,328.0
46 | 6018,4.0
47 | 8948,80.0
48 | 4658,54.0
49 | 11679,64.0
50 | 5390,99.2
51 | 5319,-4.0
52 | 6907,2.5
53 | 9695,5.0
54 | 12092,100.0
55 | 8458,20.0
56 | 7136,31.0
57 | 11922,8.4
58 | 6101,1350.0
59 | 245,63.0
60 | 7880,10.0
61 | 12166,4.0
62 | 8116,12.0
63 | 13554,520.0
64 | 4249,66.0
65 | 12184,3.0
66 | 5232,-4.0
67 | 9499,40980.0
68 | 4908,24.0
69 | 7452,5.0
70 | 13512,10.75
71 | 9253,6000.0
72 | 12338,4.0
73 | 4478,3.0
74 | 5170,-5.0
75 | 3122,515.0
76 | 10457,15.0
77 | 2370,10.0
78 | 8670,6.25
79 | 9446,40.0
80 | 8083,1.0
81 | 5321,-6.0
82 | 9388,0.0
83 | 8443,8.0
84 | 8138,600.0
85 | 12084,23.0
86 | 3305,11.0
87 | 4810,23.0
88 | 25,0.361
89 | 217,10.0
90 | 1421,14563.0
91 | 6914,1.0
92 | 4724,23.0
93 | 10460,26.0
94 | 1324,40.0
95 | 5268,3.0
96 | 5164,6.0
97 | 3519,650.0
98 | 7934,12.0
99 | 9390,0.0
100 | 7137,22.0
101 | 5914,300.0
102 |
--------------------------------------------------------------------------------
/cohorts/2024/project.md:
--------------------------------------------------------------------------------
1 | ## Course Project
2 |
3 | The goal of this project is to apply everything we learned
4 | in this course and build an end-to-end RAG project.
5 |
6 | Remember that to pass the project, you must evaluate 3 peers. If you don't do that, your project can't be considered compelete.
7 |
8 |
9 | ## Submitting
10 |
11 | ### Project Attempt #1
12 |
13 | * Project: https://courses.datatalks.club/llm-zoomcamp-2024/project/project1
14 | * Review: https://courses.datatalks.club/llm-zoomcamp-2024/project/project1/eval
15 |
16 |
17 | ### Project Attempt #2
18 |
19 | * Project: https://courses.datatalks.club/llm-zoomcamp-2024/project/project2
20 | * Review: https://courses.datatalks.club/llm-zoomcamp-2024/project/project2/eval
21 |
22 |
23 | > **Important**: update your "Certificate name" here: https://courses.datatalks.club/llm-zoomcamp-2024/enrollment -
24 | this is what we will use when generating certificates for you.
25 |
26 |
27 | ## Evaluation criteria
28 |
29 | See [here](../../project.md#evaluation-criteria)
--------------------------------------------------------------------------------
/cohorts/2024/workshops/dlt.md:
--------------------------------------------------------------------------------
1 | # Open source data ingestion for RAGs with dlt
2 |
3 | Video: https://www.youtube.com/watch?v=qUNyfR_X2Mo
4 |
5 | Homework solution: https://drive.google.com/file/d/1M1dKtAO-v3oYIztqMS8fXlLsBnqcmA-O/view?usp=sharing
6 |
7 | In this hands-on workshop, we’ll learn how to build a data ingestion pipeline using dlt to load data from a REST API into LanceDB so you can have an always up to date RAG.
8 |
9 | We’ll cover the following steps:
10 |
11 | * Extract data from REST APIs
12 | * Loading and vectorizing into LanceDB, which unlike other vector DBs stores the data _and_ the embeddings
13 | * Incremental loading
14 |
15 | By the end of this workshop, you’ll be able to write a portable, OSS data pipeline for your RAG that you can deploy anywhere, such as python notebooks, virtual machines, or orchestrators like Airflow, Dagster or Mage.
16 |
17 |
18 | # Resources
19 |
20 | * Slides: [dlt-LLM-Zoomcamp.pdf](https://github.com/user-attachments/files/16131729/dlt.LLM.Zoomcamp.pdf)
21 | * [Google Colab notebook](https://colab.research.google.com/drive/1nNOybHdWQiwUUuJFZu__xvJxL_ADU3xl?usp=sharing) - make a copy to follow along!
22 |
23 | ---
24 |
25 | # Homework
26 |
27 | In the workshop, we extracted contents from two pages in notion titled "Workshop: Benefits and Perks" and "Workshop: Working hours, PTO, and Vacation".
28 |
29 | Repeat the same process for a third page titled "Homework: Employee handbook" (hidden from public view, but accessible via API key):
30 |
31 | 1. Modify the REST API source to extract only this page.
32 | 2. Write the output into a separate table called "homework".
33 | 3. Remember to update the table name in all cells where you connect to a lancedb table.
34 |
35 | To do this you can use the [workshop Colab](https://colab.research.google.com/drive/1nNOybHdWQiwUUuJFZu__xvJxL_ADU3xl?usp=sharing) as a basis.
36 |
37 | Now, answer the following questions:
38 |
39 | ## Q1. Rows in LanceDB
40 |
41 | How many rows does the lancedb table "notion_pages__homework" have?
42 |
43 | * 14
44 | * 15
45 | * 16
46 | * 17
47 |
48 | ## Q2. Running the Pipeline: Last edited time
49 |
50 | In the demo, we created an incremental dlt resource `rest_api_notion_incremental` that keeps track of `last_edited_time`. What value does it store after you've run your pipeline once? (Hint: you will be able to get this value by performing some aggregation function on the column `last_edited_time` of the table)
51 |
52 | * `Timestamp('2024-07-05 22:34:00+0000', tz='UTC') (OR "2024-07-05T22:34:00.000Z")`
53 | * `Timestamp('2024-07-05 23:33:00+0000', tz='UTC') (OR "2024-07-05T23:33:00.000Z")`
54 | * `Timestamp('2024-07-05 23:52:00+0000', tz='UTC') (OR "2024-07-05T23:52:00.000Z")`
55 | * `Timestamp('2024-07-05 22:56:00+0000', tz='UTC') (OR "2024-07-05T22:56:00.000Z")`
56 |
57 |
58 | ## Q3. Ask the Assistant
59 |
60 | Find out with the help of the AI assistant: how many PTO days are the employees entitled to in a year?
61 |
62 | * 20
63 | * 25
64 | * 30
65 | * 35
66 |
67 | ## Submit the results
68 |
69 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2024/homework/workshop1
70 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
71 |
--------------------------------------------------------------------------------
/cohorts/2025/01-intro/homework.md:
--------------------------------------------------------------------------------
1 | ## Homework: Introduction
2 |
3 | In this homework, we'll learn more about search and use Elastic Search for practice.
4 |
5 | > It's possible that your answers won't match exactly. If it's the case, select the closest one.
6 |
7 |
8 | ## Q1. Running Elastic
9 |
10 | Run Elastic Search 8.17.6, and get the cluster information. If you run it on localhost, this is how you do it:
11 |
12 | ```bash
13 | curl localhost:9200
14 | ```
15 |
16 | What's the `version.build_hash` value?
17 |
18 |
19 | ## Getting the data
20 |
21 | Now let's get the FAQ data. You can run this snippet:
22 |
23 | ```python
24 | import requests
25 |
26 | docs_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main/01-intro/documents.json?raw=1'
27 | docs_response = requests.get(docs_url)
28 | documents_raw = docs_response.json()
29 |
30 | documents = []
31 |
32 | for course in documents_raw:
33 | course_name = course['course']
34 |
35 | for doc in course['documents']:
36 | doc['course'] = course_name
37 | documents.append(doc)
38 | ```
39 |
40 | Note that you need to have the `requests` library:
41 |
42 | ```bash
43 | pip install requests
44 | ```
45 |
46 | ## Q2. Indexing the data
47 |
48 | Index the data in the same way as was shown in the course videos. Make the `course` field a keyword and the rest should be text.
49 |
50 | Don't forget to install the ElasticSearch client for Python:
51 |
52 | ```bash
53 | pip install elasticsearch
54 | ```
55 |
56 | Which function do you use for adding your data to elastic?
57 |
58 | * `insert`
59 | * `index`
60 | * `put`
61 | * `add`
62 |
63 | ## Q3. Searching
64 |
65 | Now let's search in our index.
66 |
67 | We will execute a query "How do execute a command on a Kubernetes pod?".
68 |
69 | Use only `question` and `text` fields and give `question` a boost of 4, and use `"type": "best_fields"`.
70 |
71 | What's the score for the top ranking result?
72 |
73 | * 84.50
74 | * 64.50
75 | * 44.50
76 | * 24.50
77 |
78 | Look at the `_score` field.
79 |
80 | ## Q4. Filtering
81 |
82 | Now ask a different question: "How do copy a file to a Docker container?".
83 |
84 | This time we are only interested in questions from `machine-learning-zoomcamp`.
85 |
86 | Return 3 results. What's the 3rd question returned by the search engine?
87 |
88 | * How do I debug a docker container?
89 | * How do I copy files from a different folder into docker container’s working directory?
90 | * How do Lambda container images work?
91 | * How can I annotate a graph?
92 |
93 | ## Q5. Building a prompt
94 |
95 | Now we're ready to build a prompt to send to an LLM.
96 |
97 | Take the records returned from Elasticsearch in Q4 and use this template to build the context. Separate context entries by two linebreaks (`\n\n`)
98 | ```python
99 | context_template = """
100 | Q: {question}
101 | A: {text}
102 | """.strip()
103 | ```
104 |
105 | Now use the context you just created along with the "How do I execute a command in a running docker container?" question
106 | to construct a prompt using the template below:
107 |
108 | ```
109 | prompt_template = """
110 | You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.
111 | Use only the facts from the CONTEXT when answering the QUESTION.
112 |
113 | QUESTION: {question}
114 |
115 | CONTEXT:
116 | {context}
117 | """.strip()
118 | ```
119 |
120 | What's the length of the resulting prompt? (use the `len` function)
121 |
122 | * 946
123 | * 1446
124 | * 1946
125 | * 2446
126 |
127 | ## Q6. Tokens
128 |
129 | When we use the OpenAI Platform, we're charged by the number of
130 | tokens we send in our prompt and receive in the response.
131 |
132 | The OpenAI python package uses `tiktoken` for tokenization:
133 |
134 | ```bash
135 | pip install tiktoken
136 | ```
137 |
138 | Let's calculate the number of tokens in our query:
139 |
140 | ```python
141 | encoding = tiktoken.encoding_for_model("gpt-4o")
142 | ```
143 |
144 | Use the `encode` function. How many tokens does our prompt have?
145 |
146 | * 120
147 | * 220
148 | * 320
149 | * 420
150 |
151 | Note: to decode back a token into a word, you can use the `decode_single_token_bytes` function:
152 |
153 | ```python
154 | encoding.decode_single_token_bytes(63842)
155 | ```
156 |
157 | ## Bonus: generating the answer (ungraded)
158 |
159 | Let's send the prompt to OpenAI. What's the response?
160 |
161 | Note: you can replace OpenAI with Ollama. See module 2.
162 |
163 | ## Bonus: calculating the costs (ungraded)
164 |
165 | Suppose that on average per request we send 150 tokens and receive back 250 tokens.
166 |
167 | How much will it cost to run 1000 requests?
168 |
169 | You can see the prices [here](https://openai.com/api/pricing/)
170 |
171 | On June 17, the prices for gpt4o are:
172 |
173 | * Input: $0.005 / 1K tokens
174 | * Output: $0.015 / 1K tokens
175 |
176 | You can redo the calculations with the values you got in Q6 and Q7.
177 |
178 |
179 | ## Submit the results
180 |
181 | * Submit your results here: https://courses.datatalks.club/llm-zoomcamp-2025/homework/hw1
182 | * It's possible that your answers won't match exactly. If it's the case, select the closest one.
183 |
--------------------------------------------------------------------------------
/cohorts/2025/README.md:
--------------------------------------------------------------------------------
1 | # LLM Zoomcamp 2025 Edition
2 |
3 | Important links:
4 |
5 | - Pre-Course Q&A Stream: [video](https://www.youtube.com/live/8lgiOLMMKcY), [summary](/cohorts/2025/pre-course-q-a-stream-summary.md)
6 | - Course Launch Stream: [video](https://www.youtube.com/live/FgnelhEJFj0), [summary](/cohorts/2025/course-launch-stream-summary.md)
7 | - [2025 Edition Youtube Playlist](https://www.youtube.com/playlist?list=PL3MmuxUbc_hIoBpuc900htYF4uhEAbaT-)
8 | - [Course management platform](https://courses.datatalks.club/llm-zoomcamp-2025/)
9 |
10 |
11 | [**Module 1: Introduction to LLMs and RAG**](01-intro)
12 |
13 | * [Homework](01-intro/homework.md)
14 |
15 |
16 |
--------------------------------------------------------------------------------
/cohorts/2025/course-launch-stream-summary.md:
--------------------------------------------------------------------------------
1 | # Key Takeaways from the LLM Zoomcamp 2025 Launch Stream
2 |
3 | [](https://youtu.be/FgnelhEJFj0)
4 |
5 | > **[Watch the LLM Zoomcamp 2025 Launch Stream](https://youtu.be/FgnelhEJFj0)**
6 |
7 | ---
8 |
9 | ## Table of Contents
10 |
11 | - [Quick Summary](#quick-summary)
12 | - [Meet the Team](#meet-the-2025-team)
13 | - [Prerequisites](#prerequisites)
14 | - [Course Architecture](#course-architecture)
15 | - [Module Breakdown](#module-breakdown)
16 | - [Timeline & Deadlines](#timeline--deadlines)
17 | - [Getting Help](#getting-help)
18 | - [Earning Points](#earning-points)
19 | - [Communication Channels](#communication-channels)
20 | - [Sponsors & Support](#sponsors--support)
21 | - [FAQ Highlights](#faq-highlights)
22 | - [Next Steps](#next-steps)
23 |
24 | ---
25 |
26 | ## Quick Summary
27 |
28 |
29 | Key Takeaways (Click to expand)
30 |
31 | * **Central project**: Build a production-ready RAG chatbot
32 | * **Skills required**: Python, CLI, Git, Docker—nothing more
33 | * **Support workflow**: FAQ → Slack search → bot → channel (no tags)
34 | * **Earn points** by contributing to FAQ and sharing progress publicly
35 | * **No GPUs needed** for the main camp; open-source spin-off covers that
36 | * **Capstone & peer review** are mandatory for certificate—start gathering data now
37 | * **Budget**: ~$10 OpenAI credit covers the entire course
38 |
39 |
40 |
41 | ## Meet the 2025 Team
42 |
43 | | Instructor | Role | Expertise |
44 | |------------|------|-----------|
45 | | **[Alexey Grigorev](https://github.com/alexeygrigorev)** | Host & General Guidance | Course Creator, ML Engineering |
46 | | **[Kacper Łukowski](https://github.com/kacperlukawski)** | Vector Search Module | Qdrant Expert |
47 | | **Timur S** | Best Practices Module | Production ML Systems |
48 | | **Phoenix Expert** | Monitoring Module | ML Observability (name TBA) |
49 |
50 | ## Prerequisites
51 |
52 | ### Required Skills
53 | - **Python basics** (one-day refresher is sufficient)
54 | - **Command-line & Git** confidence
55 | - **Docker** installed and working
56 |
57 | ### Need a Refresher?
58 | - **Python**: Any weekend tutorial will do
59 | - **Docker**: Check out the [Data Engineering Zoomcamp Docker lesson](https://github.com/DataTalksClub/data-engineering-zoomcamp/tree/main/01-docker-terraform)
60 | - **Git**: [GitHub's Git Handbook](https://guides.github.com/introduction/git-handbook/)
61 |
62 | ## Course Architecture
63 |
64 | The entire Zoomcamp revolves around building a **production-grade RAG (Retrieval-Augmented Generation) chatbot** that answers student questions from the course FAQ.
65 |
66 | ### What You'll Build:
67 | 1. **Document Ingestion** → Text + vector indexing
68 | 2. **Smart Retrieval** → Find most relevant snippets
69 | 3. **LLM Integration** → Generate context-aware answers
70 | 4. **Production Monitoring** → Track quality, latency, and costs
71 |
72 | ## Module Breakdown
73 |
74 | | Week | Module | Focus |
75 | |------|--------|-------|
76 | | 1 | **Intro & RAG Foundations** | Core concepts, basic implementation |
77 | | 2 | **Vector vs Text Search** | Hybrid search strategies |
78 | | 3 | **Evaluation Techniques** | Measuring RAG performance |
79 | | 4 | **Monitoring with Phoenix** | Production observability |
80 | | 5 | **Best Practices & Guardrails** | Security, reliability |
81 | | 6-7 | **Capstone Project** | Build your own RAG system |
82 | | 8 | **Peer Review** | Evaluate classmates' projects |
83 | ## Timeline & Deadlines
84 |
85 | ### Content Delivery
86 | - **Pre-recorded videos** in organized playlists:
87 | - **[Main 2025 Playlist](https://youtube.com/playlist?list=PL3MmuxUbc_hIoBpuc900htYF4uhEAbaT-&si=uwC6I0wFePjdmLdp)**
88 | - **[Legacy 2024 Content](https://youtube.com/playlist?list=PL3MmuxUbc_hKiIVNf7DeEt_tGjypOYtKV&si=l7lTHbVAUHks2AMP)**
89 |
90 | ### Homework & Submissions
91 | - **Platform**: [DataTalks.Club Course Platform](https://courses.datatalks.club/llm-zoomcamp-2025/)
92 | - **Scoring**: Points-based system with public leaderboard
93 | - **Deadline**: 3 weeks after each module launch
94 |
95 | ### Certificate Requirements
96 | - Complete all homework assignments
97 | - Build and submit capstone project (2 weeks)
98 | - Complete peer review process (1 week)
99 | - Minimum point threshold (TBA)
100 |
101 | ## Getting Help
102 |
103 | ### Support Workflow (Follow This Order!)
104 |
105 | 1. **Search the [FAQ Document](https://docs.google.com/document/d/1m2KexowAXTmexfC5rVTCSnaShvdUQ8Ag2IEiwBDHxN0/edit?usp=sharing)** first
106 | 2. **Search [Slack](https://datatalks.club/slack.html) history** for similar questions
107 | 3. **Ask the Slack bot** (uses the same RAG pipeline you're building!)
108 | 4. **Post in `#course-llm-zoomcamp`** (**NEVER tag instructors directly**)
109 |
110 | ### How to Ask Good Questions
111 | - Include error messages and code snippets
112 | - Mention what you've already tried
113 | - Use thread replies to keep channels organized
114 |
115 | ## Earning Points
116 |
117 | ### Ways to Boost Your Score:
118 | - **Contribute to FAQ**: Add solved issues and solutions
119 | - **Share publicly**: Post progress on LinkedIn/Twitter with **#LLMZoomcamp**
120 | - **Limit**: Up to 7 social media links per module count toward score
121 | - **Quality over quantity**: Thoughtful posts get more engagement
122 |
123 | ### Content Ideas:
124 | - Weekly progress updates
125 | - Code snippets and explanations
126 | - Challenges you overcame
127 | - Creative applications of course concepts
128 |
129 | ## Communication Channels
130 |
131 | | Channel | Purpose | Link |
132 | |---------|---------|------|
133 | | **Telegram** | Announcements only | [Join Channel](https://t.me/llm_zoomcamp) |
134 | | **Slack** | Questions & peer help | [Join Workspace](https://datatalks.club/slack.html) |
135 | | **YouTube** | Video content | [Course Playlist](https://youtube.com/playlist?list=PL3MmuxUbc_hIoBpuc900htYF4uhEAbaT-&si=uwC6I0wFePjdmLdp) |
136 | | **GitHub** | Course materials | [Main Repository](https://github.com/DataTalksClub/llm-zoomcamp) |
137 |
138 | ### Communication Etiquette:
139 | - Always reply in **threads** to keep channels clean
140 | - Search before asking
141 | - Be respectful and helpful to peers
142 | - Don't tag instructors directly
143 |
144 | ## Sponsors & Support
145 |
146 | ### Course Sponsors
147 | - **[Arize AI](https://github.com/Arize-ai/phoenix)**
148 | - **[dltHub](https://github.com/dlt-hub/dlt)**
149 | - **[Qdrant](https://github.com/qdrant/qdrant)**
150 |
151 | *These sponsors keep the course completely free for everyone!*
152 |
153 | ### Support Alexey
154 | If you find value in this course, consider supporting via [GitHub Sponsors](https://github.com/sponsors/alexeygrigorev).
155 |
156 | ## FAQ Highlights
157 |
158 |
159 | Why no agents in the main course?
160 |
161 | **Current situation**: Agent frameworks evolve "every day," making it risky to lock the course to unstable APIs.
162 |
163 | **Future plans**:
164 | - **AI-Dev Tools Course** planned for **September 2025**
165 | - **2,100+ sign-ups** already confirmed interest
166 | - **Will cover**: Agentic search, LangGraph, CrewAI, agent guardrails
167 | - **Expect**: Workshop teasers during this cohort
168 |
169 | **More info**: [AI Dev Tools Zoomcamp Repository](https://github.com/DataTalksClub/ai-dev-tools-zoomcamp)
170 |
171 |
172 |
173 |
174 | Do I need GPUs?
175 |
176 | **Main LLM Zoomcamp**:
177 | - **No GPUs needed**
178 | - **~$10 OpenAI credit** covers everything
179 | - **Uses hosted models**: OpenAI, Anthropic, Groq, etc.
180 |
181 | **Open-Source LLM Mini-Course** (June/July 2025):
182 | - **Free GPU quotas** provided by Saturn Cloud & AMD
183 | - **Local models**: Llama 3, DeepSeek, etc.
184 | - **Topics**: Quantization, vLLM, LoRA fine-tuning
185 |
186 | **More info**: [Open-Source LLM Zoomcamp](https://github.com/DataTalksClub/open-source-llm-zoomcamp)
187 |
188 |
189 |
190 |
191 | How is LLM monitoring different from traditional MLOps?
192 |
193 | **Shared aspects**:
194 | - Uptime & latency tracking
195 | - Performance regression detection
196 | - Post-deployment monitoring
197 |
198 | **LLM-specific metrics**:
199 | - **Cost per call/token**
200 | - **Hallucination detection** (via eval sets, heuristics, human feedback)
201 | - **Prompt/response drift** (style/length changes indicating model updates)
202 | - **Content risk**: PII leaks, toxicity detection
203 |
204 | **Tools**: Phoenix (open-source) for dashboards and budget alerts
205 |
206 |
207 |
208 |
209 | Local vs Hosted Models: Which to choose?
210 |
211 | | Aspect | Hosted API | Local/Self-hosted |
212 | |--------|------------|-------------------|
213 | | **Setup** | Single HTTP call | Download 4-40GB weights |
214 | | **Scaling** | Provider handles it | You manage infrastructure |
215 | | **Cost** | Pay per usage | Higher upfront, lower long-term |
216 | | **Control** | Limited customization | Full control, no data sharing |
217 | | **Models** | Latest frontier models | Open-source alternatives |
218 | | **Customization** | API parameters only | LoRA fine-tuning possible |
219 |
220 | **Course approach**: Prototype with GPT-4o, then compare with local Llama 3
221 |
222 |
223 |
224 |
225 | Job market advice for LLM engineers
226 |
227 | **Show, don't tell**:
228 | - Publish notebooks and blog posts
229 | - Create short demo videos (Loom)
230 | - Deploy working RAG pipelines
231 |
232 | **Specialize wisely**:
233 | - RAG evaluation techniques
234 | - Retrieval optimization
235 | - LLM cost monitoring
236 | - Content safety & guardrails
237 |
238 | **Network via "learning in public"**:
239 | - Use **#LLMZoomCamp** hashtag
240 | - Consistent LinkedIn/Twitter posts
241 | - Engage with course community
242 |
243 | **Portfolio > certificates**:
244 | - Capstone GitHub repo
245 | - Regular social media updates
246 | - Video walkthroughs of projects
247 |
248 |
249 |
250 |
251 | Capstone project guidelines
252 |
253 | **Start early**:
254 | - Gather domain corpus (docs, Slack dumps, PDFs)
255 | - Begin data cleaning and chunking
256 | - Choose a problem you're passionate about
257 |
258 | **Requirements preview**:
259 | - Working RAG demonstration
260 | - Evaluation notebook with metrics
261 | - README with cost analysis
262 | - Monitoring screenshots
263 | - 3-minute video walkthrough
264 |
265 | **Peer review process**:
266 | - 2 weeks for building
267 | - 1 week for reviewing 3 classmates' projects
268 | - Mandatory for certification
269 |
270 | **Detailed rubric**: Will be published mid-cohort on the course platform
271 |
272 |
273 |
274 | ## Next Steps
275 |
276 | 1. **[Star the GitHub repo](https://github.com/DataTalksClub/llm-zoomcamp)** (helps with visibility!)
277 | 2. **Skim Module 1** content to get familiar
278 | 3. **Install Docker** and verify it works
279 | 4. **Join communication channels**:
280 | - [Slack workspace](https://datatalks.club/slack.html)
281 | - [Telegram channel](https://t.me/llm_zoomcamp)
282 | 5. **Bookmark the [FAQ document](https://docs.google.com/document/d/1m2KexowAXTmexfC5rVTCSnaShvdUQ8Ag2IEiwBDHxN0/edit?usp=sharing)**
283 |
284 | ### Week 1 Goals:
285 | - **Watch Module 1 videos**
286 | - **Complete first homework**
287 | - **Start thinking about capstone dataset**
288 | - **Share your journey** with #LLMZoomCamp
289 |
290 | ### Long-term Success:
291 | - **Consistent engagement** with course materials
292 | - **Active participation** in community discussions
293 | - **Regular progress sharing** on social media
294 | - **Early capstone planning** and data preparation
295 |
296 | ## Quick Links Reference
297 |
298 | | Resource | Link |
299 | |----------|------|
300 | | **Main Repository** | https://github.com/DataTalksClub/llm-zoomcamp |
301 | | **Course Platform** | https://courses.datatalks.club/llm-zoomcamp-2025/ |
302 | | **2025 Playlist** | https://youtube.com/playlist?list=PL3MmuxUbc_hIoBpuc900htYF4uhEAbaT-&si=uwC6I0wFePjdmLdp |
303 | | **FAQ Document** | https://docs.google.com/document/d/1m2KexowAXTmexfC5rVTCSnaShvdUQ8Ag2IEiwBDHxN0/edit?usp=sharing |
304 | | **Slack Workspace** | https://datatalks.club/slack.html |
305 | | **Telegram Channel** | https://t.me/llm_zoomcamp |
306 | | **Project Guidelines** | https://github.com/DataTalksClub/llm-zoomcamp/blob/main/cohorts/2025/project.md |
307 | | **Support Alexey** | https://github.com/sponsors/alexeygrigorev |
308 |
--------------------------------------------------------------------------------
/cohorts/2025/pre-course-q-a-stream-summary.md:
--------------------------------------------------------------------------------
1 | # Key Takeaways from the LLM Zoomcamp 2025 Pre-Course Live Q&A
2 |
3 | [](https://youtu.be/8lgiOLMMKcY)
4 |
5 | > **[Watch the LLM Zoomcamp 2025 Pre-Course Live Q&A](https://youtu.be/8lgiOLMMKcY)**
6 |
7 | ## 1. Do you think LLMs are a lasting technology or are they just a passing trend like the metaverse or NFTs?
8 |
9 | **Answer:** While there’s certainly hype around LLMs, they’ve already become deeply integrated into daily workflows—used for coding, personal productivity, and prototype development. Even after the hype subsides, the underlying tools and techniques (like RAG pipelines and vector search) will remain valuable. Future models and interfaces may evolve, but the core capabilities of LLMs are here to stay.
10 |
11 | ## 2. What prerequisites would set me up for success in the course and help me get the best out of it?
12 |
13 | **Answer:** You should be comfortable with:
14 |
15 | * General programming (ideally in Python)
16 | * Command-line tools
17 | * Connecting services (e.g., spinning up ElasticSearch or similar)
18 | No deep machine-learning or advanced software-engineering background is required, but familiarity with basic scripting and package installation will make the coursework smoother.
19 |
20 | ## 3. Is it beneficial if I do the course again this year even though I completed it last year?
21 |
22 | **Answer:** Yes. The curriculum has been updated with fewer but deeper modules, new evaluation/monitoring tooling (Phoenix instead of Grafana), and likely a new vector-search backend. You’ll also get to experiment with the latest LLMs and compete in a fresh challenge exercise.
23 |
24 | ## 4. Will the course help me implement RAG from a live database?
25 |
26 | **Answer:** Most likely yes. Whether your data is in a transactional database or a knowledge-base store, the course teaches you how to connect to your data source, chunk and index content, and build a RAG application. The exact workflow may vary by database type, but the principles carry over.
27 |
28 | ## 5. Are we going to do any agentic AI development in this course?
29 |
30 | **Answer:** Not as part of the core modules. There **will** likely be an optional parallel workshop on agentic workflows in June, but agent development is not formally included in this year’s curriculum.
31 |
32 | ## 6. Will this course include MLOps (LM Ops) content?
33 |
34 | **Answer:** To a degree. The monitoring module covers key LM Ops practices (metrics, cost tracking, query logging), but full deployment and continuous-training pipelines are reserved for the separate Open Source LLM Zoom Camp.
35 |
36 | ## 7. What will be the infrastructure cost, and can I run everything locally without cloud resources?
37 |
38 | **Answer:**
39 |
40 | * **Local:** 100 % feasible—you can use tools like Llama.cpp or Gro to run models on your own machine.
41 | * **Cloud APIs:** Costs are modest. For OpenAI, \~1 million tokens in/out costs around \$10 total. Gro offers a free tier for basic experimentation.
42 |
43 | ## 8. Will this course cover MCP (Model Context Protocol)?
44 |
45 | **Answer:** No, MCP (and other emerging protocols) are not in this year’s syllabus. As with agentic AI, these topics may surface in a future specialized offering once industry practices stabilize.
46 |
47 | ## 9. Do we discuss evaluating LLM-based applications, generating metrics, and setting up guardrails?
48 |
49 | **Answer:**
50 |
51 | * **Evaluation metrics:** Yes. You’ll learn classical IR metrics (e.g., MRR, recall) for search and how to use LLMs themselves as “judges” for end-to-end RAG evaluation.
52 | * **Guardrails:** No formal guardrail framework is included, though monitoring best practices will help you detect and respond to undesired behavior.
53 |
54 | ## 10. Will we cover chunking techniques in the course?
55 |
56 | **Answer:** Yes and no. You’ll see how data is pre-chunked in the example repo and learn best practices for chunk size and strategy—but actual implementation and experimentation with chunking are left as part of your hands-on project work.
57 |
58 | ## 11. Is the RAG pipeline included in the course?
59 |
60 | **Answer:** Absolutely. RAG is the central focus: indexing, retrieval, prompt construction, and response handling are all core modules, and you’ll build full pipelines from scratch.
61 |
62 | ## 12. Can different programming languages like JavaScript be used for this course?
63 |
64 | **Answer:** The taught examples use Python, but you’re welcome to implement your project in another language (e.g., JavaScript). You’ll just need to provide clear installation and usage instructions (npm commands, environment setup) so peers can run and review your work.
65 |
66 | ## 13. Can we expect a complex project, and learn from examples?
67 |
68 | **Answer:** Project complexity is up to you. The course provides exemplar student projects (food-search RAG, recipe recommenders, etc.) to illustrate scope and quality. You then pick your own data and extend the RAG concepts to a domain of your choice.
69 |
70 | ## 14. As someone new, how do I navigate the GitHub repo structure?
71 |
72 | **Answer:**
73 |
74 | 1. Open the repo’s README and follow the module links in order.
75 | 2. Click each module’s folder to access videos and homework.
76 | 3. Use the “Project Attempts” section to browse past student projects and peer-review guidelines.
77 |
78 | ## 15. What is the estimated weekly time investment for the course?
79 |
80 | **Answer:** Roughly **10 hours per week**:
81 |
82 | * Module videos + readings: \~4 hours
83 | * Homework/project work: \~6 hours
84 |
85 | ## 16. How long does the course run and when does it end?
86 |
87 | **Answer:** It spans **10 weeks** total:
88 |
89 | * 2 weeks for the Intro module
90 | * 1 week each for Modules 2–5
91 | * 3 weeks for the final project period
92 | Expect to finish by late summer.
93 |
94 | ## 17. How much will it cost to complete the course using Gro or OpenAI APIs?
95 |
96 | **Answer:**
97 |
98 | * **Gro:** Free tier available, suitable for initial experiments.
99 | * **OpenAI:** Approximately \$10–\$20 for 1 million tokens in + out; in practice you’ll spend far less than your API quota.
100 |
101 | ## 18. Can you explain the steps for enrolling and completing the course?
102 |
103 | **Answer:**
104 |
105 | 1. **Star & Fork** the GitHub repo to show support.
106 | 2. **Sign up** on the repo’s landing page (click “Sign up” button).
107 | 3. **Join** the community (Telegram/Slack) for announcements.
108 | 4. **Attend** the launch stream (May 27) for a content overview.
109 | 5. **Weekly:** Watch that week’s module videos, complete homework, submit via the platform.
110 | 6. **Final project:** Build and document your RAG application; peer-review others.
111 | 7. **Certificate:** Earned upon successful project submission and peer reviews.
112 |
--------------------------------------------------------------------------------
/cohorts/2025/project.md:
--------------------------------------------------------------------------------
1 | ## Course Project
2 |
3 | The goal of this project is to apply everything we learned
4 | in this course and build an end-to-end RAG project.
5 |
6 | Remember that to pass the project, you must evaluate 3 peers. If you don't do that, your project can't be considered compelete.
7 |
8 |
9 | ## Submitting
10 |
11 | ### Project Attempt #1
12 |
13 | * Project: https://courses.datatalks.club/llm-zoomcamp-2025/project/project1
14 | * Review: https://courses.datatalks.club/llm-zoomcamp-2025/project/project1/eval
15 |
16 |
17 | ### Project Attempt #2
18 |
19 | * Project: https://courses.datatalks.club/llm-zoomcamp-2025/project/project2
20 | * Review: https://courses.datatalks.club/llm-zoomcamp-2025/project/project2/eval
21 |
22 |
23 | > **Important**: update your "Certificate name" here: https://courses.datatalks.club/llm-zoomcamp-2025/enrollment -
24 | this is what we will use when generating certificates for you.
25 |
26 |
27 | ## Evaluation criteria
28 |
29 | See [here](../../project.md#evaluation-criteria)
--------------------------------------------------------------------------------
/etc/chunking.md:
--------------------------------------------------------------------------------
1 | ## Chunking
2 |
3 | I asked ChatGPT how we can chunk a YouTube transcript
4 | and this is what it answered:
5 |
6 | Retrieval Augmented Generation (RAG) is a powerful method for enhancing the capabilities of Language Models by providing them access to external data sources. This approach is particularly effective when dealing with unstructured datasets like YouTube video transcripts, where the content is not organized in a clear question-and-answer format. Let's explore various strategies for chunking these transcripts, both using heuristics and leveraging LLMs for intelligent chunking.
7 |
8 | ### Chunking Strategies
9 |
10 | Chunking is the process of breaking down a large document into smaller, manageable pieces that can be processed by a language model. Effective chunking is crucial for RAG because it directly influences the relevance and accuracy of the information retrieved.
11 |
12 | #### Heuristic-based Chunking
13 |
14 | 1. **Fixed-size Chunking**
15 | - **Fixed Word Count:** Divide the transcript into chunks of a specific number of words (e.g., 200-500 words). This method is simple and ensures uniform chunk sizes.
16 | - **Fixed Time Intervals:** For video transcripts, segment the text based on time intervals (e.g., every 2 minutes of video content).
17 | - **Fixed Sentence Count:** Break the transcript into chunks containing a set number of sentences (e.g., 5-10 sentences).
18 |
19 | 2. **Semantic Boundaries**
20 | - **Pause-based Chunking:** Utilize pauses or silences in the video (detected by timestamps in the transcript) to delineate chunks, assuming pauses often indicate topic shifts.
21 | - **Speaker Turn Chunking:** Divide the transcript at speaker changes, which can be useful in interviews or panel discussions.
22 |
23 | 3. **Structural Segmentation**
24 | - **Paragraph-based Chunking:** Use natural paragraph breaks as chunk boundaries, assuming these breaks reflect changes in topic or subtopics.
25 | - **Section Headers:** If available, use any section headers or titles in the transcript to define chunk boundaries.
26 |
27 | #### LLM-based Intelligent Chunking
28 |
29 | 1. **Thematic Chunking**
30 | - **Topic Modeling:** Use LLMs to identify and segment the transcript into coherent topics or themes. Each chunk would then represent a distinct topic.
31 | - **Content Summarization:** Summarize the transcript using LLMs to identify key points and divide the text based on these summary insights.
32 |
33 | 2. **Contextual Segmentation**
34 | - **Semantic Similarity:** Use embeddings to compute semantic similarity and create chunks where the text remains contextually consistent. LLMs can help refine these chunks by ensuring thematic coherence.
35 | - **Dynamic Chunking:** Allow the LLM to dynamically adjust chunk sizes based on content density, ensuring that dense or complex sections are adequately represented.
36 |
37 | 3. **Hierarchical Structuring**
38 | - **Sectioning:** Ask the LLM to automatically divide the transcript into sections with headers, providing an outline-like structure. This can involve creating a hierarchical representation of the content.
39 | - **Content Categorization:** LLMs can categorize content into predefined categories (e.g., introduction, explanation, conclusion), structuring chunks accordingly.
40 |
41 | 4. **Intent-based Chunking**
42 | - **Question Generation:** Use LLMs to generate potential questions from the transcript and organize chunks based on these questions, mimicking a Q&A format.
43 | - **Information Retrieval Intent:** Analyze user queries to tailor chunks that directly address likely information retrieval needs, improving retrieval efficiency.
44 |
45 | ### Implementing Chunking for RAG
46 |
47 | Here’s how you can implement these chunking strategies in a RAG workflow:
48 |
49 | 1. **Preprocessing:**
50 | - **Transcription:** Convert audio to text using a speech-to-text model if starting from raw video/audio.
51 | - **Cleaning:** Remove unnecessary filler words, irrelevant content, and transcription errors.
52 |
53 | 2. **Chunking:**
54 | - Apply one or more chunking strategies to segment the transcript into meaningful units.
55 | - Consider using a combination of heuristic and LLM-based methods for a balanced approach.
56 |
57 | 3. **Indexing:**
58 | - Convert chunks into embeddings using a suitable model (e.g., BERT, Sentence Transformers) and index them for efficient retrieval.
59 |
60 | 4. **Retrieval:**
61 | - For a given query, retrieve relevant chunks based on semantic similarity, keyword matching, or a combination of retrieval methods.
62 |
63 | 5. **Generation:**
64 | - Use an LLM to generate answers or outputs by combining retrieved chunks with the query context.
65 |
66 | ### Example Workflow for YouTube Transcript
67 |
68 | Let's walk through an example workflow using a YouTube video transcript:
69 |
70 | 1. **Transcription & Cleaning:**
71 | - Convert video to text, clean up non-essential parts, and ensure accuracy.
72 |
73 | 2. **Chunking:**
74 | - **Heuristic:** Break the text every 2 minutes of video time and by speaker turns.
75 | - **Intelligent:** Use an LLM to divide the text into sections with headings like "Introduction," "Key Concepts," "Case Studies," etc.
76 |
77 | 3. **Indexing:**
78 | - Create embeddings for each chunk and index them in a database like Elasticsearch or a vector store.
79 |
80 | 4. **Query Handling:**
81 | - When a user submits a query, retrieve relevant chunks using semantic search.
82 |
83 | 5. **Answer Generation:**
84 | - The LLM processes the query and the retrieved chunks to generate a cohesive and accurate response.
85 |
86 | ### Tools and Techniques for Implementation
87 |
88 | - **Language Models:** GPT-4, BERT, T5, or domain-specific LLMs for intelligent chunking.
89 | - **Vector Stores:** FAISS, Milvus, Pinecone for indexing and retrieval.
90 | - **Embedding Models:** Sentence-BERT, Universal Sentence Encoder for chunk embedding.
91 | - **Speech-to-Text:** Google Speech-to-Text, Whisper by OpenAI for initial transcription.
92 |
93 | ### Conclusion
94 |
95 | Effective chunking strategies are key to harnessing the full potential of RAG in unstructured datasets like YouTube transcripts. By using both heuristic and intelligent approaches, you can ensure that the language model receives relevant context for generating accurate and informative responses. The choice of chunking strategy should align with the specific use case and characteristics of the dataset, allowing for flexible and efficient retrieval processes.
96 |
--------------------------------------------------------------------------------
/images/llm-zoomcamp-2025.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DataTalksClub/llm-zoomcamp/b9d8bd63621736c75fa8d6d0def5ad6656c0b981/images/llm-zoomcamp-2025.jpg
--------------------------------------------------------------------------------
/images/llm-zoomcamp.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DataTalksClub/llm-zoomcamp/b9d8bd63621736c75fa8d6d0def5ad6656c0b981/images/llm-zoomcamp.jpg
--------------------------------------------------------------------------------
/images/qdrant.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DataTalksClub/llm-zoomcamp/b9d8bd63621736c75fa8d6d0def5ad6656c0b981/images/qdrant.png
--------------------------------------------------------------------------------
/images/saturn-cloud.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DataTalksClub/llm-zoomcamp/b9d8bd63621736c75fa8d6d0def5ad6656c0b981/images/saturn-cloud.png
--------------------------------------------------------------------------------
/learning-in-public.md:
--------------------------------------------------------------------------------
1 | # Learning in public
2 |
3 | Most people learn in private: they consume content but don't tell
4 | anyone about it. There's nothing wrong with it.
5 |
6 | But we want to encourage you to document your progress and
7 | share it publicly on social media.
8 |
9 | It helps you get noticed and will lead to:
10 |
11 | * Expanding your network: meeting new people and making new friends
12 | * Being invited to meetups, conferences and podcasts
13 | * Landing a job or getting clients
14 | * Many other good things
15 |
16 | Here's a more compresensive reading on why you want to do it: https://github.com/readme/guides/publishing-your-work
17 |
18 |
19 | ## Learning in Public for Zoomcamps
20 |
21 | When you submit your homework or project, you can also submit
22 | learning in public posts:
23 |
24 |  25 |
26 | You can watch this video to see how your learning in public posts may look like:
27 |
28 |
29 |
25 |
26 | You can watch this video to see how your learning in public posts may look like:
27 |
28 |
29 |  30 |
31 |
32 |
33 | Send a PR if you want to suggest improvements for this document
--------------------------------------------------------------------------------
/project.md:
--------------------------------------------------------------------------------
1 | # Projects
2 |
3 | * Video: https://www.loom.com/share/8f99d25893de4fb8aaa95c0395c740b6
4 | * Office hours: https://www.youtube.com/watch?v=pA9S1mTqAwU
5 |
6 | In order to receive a certificate of completion for the course, you need
7 | to deliver a project. There are two attempts for that.
8 |
9 | [Submit your project here](cohorts/2025/project.md)
10 |
11 |
12 | ## Objective
13 |
14 | The goal of this project is to apply everything we have learned
15 | in this course to build an end-to-end RAG application.
16 |
17 |
18 | ## Problem statement
19 |
20 | For the project, we ask you to build an end-to-end RAG project.
21 |
22 | For that, you need:
23 |
24 | * Select a dataset that you're interested in (see [Datasets](#datasets) for examples and ideas)
25 | * Ingest the data into a knowledge base
26 | * Implement the RAG flow: query the knowledge base, build the prompt, send the promt to an LLM
27 | * Evaluate the performance of your RAG flow
28 | * Create an interface for the application
29 | * Collect user feedback and monitor your application
30 |
31 |
32 | ## Project Documentation
33 |
34 | Your project rises or falls with its documentation. Hence, here are some general recommendations:
35 |
36 | * **Write for a Broader Audience 📝**: Assume the reader has no prior knowledge of the course materials. This way, your documentation will be accessible not only to evaluators but also to anyone interested in your project.
37 | * **Include Evaluation Criteria 🎯**: Make it easier for evaluators to assess your work by clearly mentioning each criterion in your README. Include relevant screenshots to visually support your points.
38 | * **Think of Future Opportunities 🚀**: Imagine that potential hiring managers will look at your projects. Make it straightforward for them to understand what the project is about and what you contributed. Highlight key features and your role in the project.
39 | * **Be Detailed and Comprehensive 📋**: Include as much detail as possible in the README file. Explain the setup, the functionality, and the workflow of your project. Tools like ChatGPT or other LLMs can assist you in expanding and refining your documentation.
40 | * **Provide Clear Setup Instructions ⚙️**: Include step-by-step instructions on how to set up and run your project locally. Make sure to cover dependencies, configurations, and any other requirements needed to get your project up and running.
41 | * **Use Visuals and Examples 🖼️**: Wherever possible, include diagrams, screenshots, or GIFs to illustrate key points. Use examples to show how to use your project, demonstrate common use cases, and provide sample inputs and expected outputs.
42 | * **App Preview Video 🎥**: Consider adding a short preview video of your app in action to the README. For example, if you're using Streamlit, you can easily record a screencast from the app's top-right menu ([Streamlit Guide](https://docs.streamlit.io/develop/concepts/architecture/app-chrome)). Once you saved the video file locally, you can just drag & drop it into the online GitHub editor of your README to add it ([Ref](https://stackoverflow.com/a/4279746)).
43 | * **Organize with Sub-Files 🗂️**: If your documentation becomes lengthy, consider splitting it into sub-files and linking them in your README. This keeps the main README clean and neat while providing additional detailed information in separate files (e.g., `setup.md`, `usage.md`, `contributing.md`).
44 | * **Keep It Updated 🔄**: As your project evolves, make sure your documentation reflects any changes or updates. Outdated documentation can confuse readers and diminish the credibility of your project.
45 |
46 | Remember, clear and comprehensive documentation not only helps others but is also a valuable reference for yourself in the future.
47 |
48 |
49 | ## Technologies
50 |
51 | You don't have to limit yourself to technologies covered in the course. You can use alternatives as well:
52 |
53 | * LLM: OpenAI, Ollama, Groq, AWS Bedrock, etc
54 | * Knowledge base: any text, relational or vector database, including in-memory ones like we implemented in the course or SQLite
55 | * Monitoring: Grafana, Kibana, Streamlit, dash, etc
56 | * Interface: Streamlit, dash, Flask, FastAPI, Django, etc (could be UI or API)
57 | * Ingestion pipeline: Mage, dlt, Airflow, Prefect, python script, etc
58 |
59 | If you use a tool that wasn't covered in the course, be sure to give a very detailed explanation
60 | of what that tool does and how to use it.
61 |
62 | If you're not certain about some tools, ask in Slack.
63 |
64 | ## Tips and best practices
65 |
66 | * It's better to create a separate GitHub repository for your project
67 | * Give your project a meaningful title, e.g. "DataTalksClub Zoomcamp Q&A system" or "Nutrition Facts Chat"
68 |
69 |
70 | ## Peer reviewing
71 |
72 | > [!IMPORTANT]
73 | > To evaluate the projects, we'll use peer reviewing. This is a great opportunity for you to learn from each other.
74 | > * To get points for your project, you need to evaluate 3 projects of your peers
75 | > * You get 3 extra points for each evaluation
76 |
77 | ### Review Tips
78 |
79 | * The reviewer is given a public GitHut repo link and a `commit-hash`
80 | * to see the code state of the repo at the provided commit hash, use the following URL:
81 | * `https://github.com/{username}/{repo-name}/tree/{commit-hash}`
82 | * It's recommended to clone the repository for the review. To clone the project at the commit hash:
83 | ```bash
84 | git clone https://github.com/{username}/{repo-name}.git
85 | git reset --hard {commit-hash}
86 | ```
87 |
88 | ## Evaluation Criteria
89 |
90 | * Problem description
91 | * 0 points: The problem is not described
92 | * 1 point: The problem is described but briefly or unclearly
93 | * 2 points: The problem is well-described and it's clear what problem the project solves
94 | * RAG flow
95 | * 0 points: No knowledge base or LLM is used
96 | * 1 point: No knowledge base is used, and the LLM is queried directly
97 | * 2 points: Both a knowledge base and an LLM are used in the RAG flow
98 | * Retrieval evaluation
99 | * 0 points: No evaluation of retrieval is provided
100 | * 1 point: Only one retrieval approach is evaluated
101 | * 2 points: Multiple retrieval approaches are evaluated, and the best one is used
102 | * RAG evaluation
103 | * 0 points: No evaluation of RAG is provided
104 | * 1 point: Only one RAG approach (e.g., one prompt) is evaluated
105 | * 2 points: Multiple RAG approaches are evaluated, and the best one is used
106 | * Interface
107 | * 0 points: No way to interact with the application at all
108 | * 1 point: Command line interface, a script, or a Jupyter notebook
109 | * 2 points: UI (e.g., Streamlit), web application (e.g., Django), or an API (e.g., built with FastAPI)
110 | * Ingestion pipeline
111 | * 0 points: No ingestion
112 | * 1 point: Semi-automated ingestion of the dataset into the knowledge base, e.g., with a Jupyter notebook
113 | * 2 points: Automated ingestion with a Python script or a special tool (e.g., Mage, dlt, Airflow, Prefect)
114 | * Monitoring
115 | * 0 points: No monitoring
116 | * 1 point: User feedback is collected OR there's a monitoring dashboard
117 | * 2 points: User feedback is collected and there's a dashboard with at least 5 charts
118 | * Containerization
119 | * 0 points: No containerization
120 | * 1 point: Dockerfile is provided for the main application OR there's a docker-compose for the dependencies only
121 | * 2 points: Everything is in docker-compose
122 | * Reproducibility
123 | * 0 points: No instructions on how to run the code, the data is missing, or it's unclear how to access it
124 | * 1 point: Some instructions are provided but are incomplete, OR instructions are clear and complete, the code works, but the data is missing
125 | * 2 points: Instructions are clear, the dataset is accessible, it's easy to run the code, and it works. The versions for all dependencies are specified.
126 | * Best practices
127 | * [ ] Hybrid search: combining both text and vector search (at least evaluating it) (1 point)
128 | * [ ] Document re-ranking (1 point)
129 | * [ ] User query rewriting (1 point)
130 | * Bonus points (not covered in the course)
131 | * [ ] Deployment to the cloud (2 points)
132 | * [ ] Up to 3 extra bonus points if you want to award for something extra (write in feedback for what)
133 |
134 |
135 | ## Project ideas
136 |
137 | ### Datasets
138 |
139 | Here are some datasets for your projects and potential things you can do with them
140 |
141 | * DTC data:
142 | * Slack dump: book of the week channel, course channels, career questions, etc
143 | * DTC website with book of the week archives
144 | * DTC Podcast: transcripts
145 | * Wikis
146 | * any subsets of Wikipedia
147 | * any wiki-like data source
148 | * notion notes
149 | * Articles
150 | * Index and answer questions from one or multiple articles
151 | * Transcripts
152 | * Podcast transcripts
153 | * YouTube video transcripts
154 | * Books
155 | * Sci-fi, fiction, or non-fiction books
156 | * Slide Decks and pictures
157 | * OCR and index slide decks (gpt-4o-mini can do that)
158 | * Describe and index pictures
159 | * Add more here above this line - send a PR!
160 | * Or just ask ChatGPT (see more ideas [here in this example](https://chatgpt.com/share/70b51c12-e41c-4312-831d-04f489a17f1e))
161 |
162 | You can also generate a dataset with an LLM:
163 |
164 | * If you have a dataset but you can't publicly release it, you can generate a similar one with an LLM
165 | * Or you can simply think what kind of a dataset you want to have and generate it
166 |
167 | Note that your dataset doesn't have to be in thr Q&A form. Check [etc/chunking.md](etc/chunking.md) to learn more about chunking.
168 |
169 |
170 | ## Cheating and plagiarism
171 |
172 | Plagiarism in any form is not allowed. Examples of plagiarism:
173 |
174 | * Taking somebody's else notebooks and projects (in full or partly) and using it for your project
175 | * Re-using your own projects (in full or partly) from other courses and bootcamps
176 | * Re-using your appempt 1 project as attempt 2 if you passed attempt 1
177 | * Re-using your project from the previous iterations of the course
178 |
179 | Violating any of this will result in 0 points for this project.
180 |
181 | Re-using some parts of the code from the course is allowed.
182 |
--------------------------------------------------------------------------------
30 |
31 |
32 |
33 | Send a PR if you want to suggest improvements for this document
--------------------------------------------------------------------------------
/project.md:
--------------------------------------------------------------------------------
1 | # Projects
2 |
3 | * Video: https://www.loom.com/share/8f99d25893de4fb8aaa95c0395c740b6
4 | * Office hours: https://www.youtube.com/watch?v=pA9S1mTqAwU
5 |
6 | In order to receive a certificate of completion for the course, you need
7 | to deliver a project. There are two attempts for that.
8 |
9 | [Submit your project here](cohorts/2025/project.md)
10 |
11 |
12 | ## Objective
13 |
14 | The goal of this project is to apply everything we have learned
15 | in this course to build an end-to-end RAG application.
16 |
17 |
18 | ## Problem statement
19 |
20 | For the project, we ask you to build an end-to-end RAG project.
21 |
22 | For that, you need:
23 |
24 | * Select a dataset that you're interested in (see [Datasets](#datasets) for examples and ideas)
25 | * Ingest the data into a knowledge base
26 | * Implement the RAG flow: query the knowledge base, build the prompt, send the promt to an LLM
27 | * Evaluate the performance of your RAG flow
28 | * Create an interface for the application
29 | * Collect user feedback and monitor your application
30 |
31 |
32 | ## Project Documentation
33 |
34 | Your project rises or falls with its documentation. Hence, here are some general recommendations:
35 |
36 | * **Write for a Broader Audience 📝**: Assume the reader has no prior knowledge of the course materials. This way, your documentation will be accessible not only to evaluators but also to anyone interested in your project.
37 | * **Include Evaluation Criteria 🎯**: Make it easier for evaluators to assess your work by clearly mentioning each criterion in your README. Include relevant screenshots to visually support your points.
38 | * **Think of Future Opportunities 🚀**: Imagine that potential hiring managers will look at your projects. Make it straightforward for them to understand what the project is about and what you contributed. Highlight key features and your role in the project.
39 | * **Be Detailed and Comprehensive 📋**: Include as much detail as possible in the README file. Explain the setup, the functionality, and the workflow of your project. Tools like ChatGPT or other LLMs can assist you in expanding and refining your documentation.
40 | * **Provide Clear Setup Instructions ⚙️**: Include step-by-step instructions on how to set up and run your project locally. Make sure to cover dependencies, configurations, and any other requirements needed to get your project up and running.
41 | * **Use Visuals and Examples 🖼️**: Wherever possible, include diagrams, screenshots, or GIFs to illustrate key points. Use examples to show how to use your project, demonstrate common use cases, and provide sample inputs and expected outputs.
42 | * **App Preview Video 🎥**: Consider adding a short preview video of your app in action to the README. For example, if you're using Streamlit, you can easily record a screencast from the app's top-right menu ([Streamlit Guide](https://docs.streamlit.io/develop/concepts/architecture/app-chrome)). Once you saved the video file locally, you can just drag & drop it into the online GitHub editor of your README to add it ([Ref](https://stackoverflow.com/a/4279746)).
43 | * **Organize with Sub-Files 🗂️**: If your documentation becomes lengthy, consider splitting it into sub-files and linking them in your README. This keeps the main README clean and neat while providing additional detailed information in separate files (e.g., `setup.md`, `usage.md`, `contributing.md`).
44 | * **Keep It Updated 🔄**: As your project evolves, make sure your documentation reflects any changes or updates. Outdated documentation can confuse readers and diminish the credibility of your project.
45 |
46 | Remember, clear and comprehensive documentation not only helps others but is also a valuable reference for yourself in the future.
47 |
48 |
49 | ## Technologies
50 |
51 | You don't have to limit yourself to technologies covered in the course. You can use alternatives as well:
52 |
53 | * LLM: OpenAI, Ollama, Groq, AWS Bedrock, etc
54 | * Knowledge base: any text, relational or vector database, including in-memory ones like we implemented in the course or SQLite
55 | * Monitoring: Grafana, Kibana, Streamlit, dash, etc
56 | * Interface: Streamlit, dash, Flask, FastAPI, Django, etc (could be UI or API)
57 | * Ingestion pipeline: Mage, dlt, Airflow, Prefect, python script, etc
58 |
59 | If you use a tool that wasn't covered in the course, be sure to give a very detailed explanation
60 | of what that tool does and how to use it.
61 |
62 | If you're not certain about some tools, ask in Slack.
63 |
64 | ## Tips and best practices
65 |
66 | * It's better to create a separate GitHub repository for your project
67 | * Give your project a meaningful title, e.g. "DataTalksClub Zoomcamp Q&A system" or "Nutrition Facts Chat"
68 |
69 |
70 | ## Peer reviewing
71 |
72 | > [!IMPORTANT]
73 | > To evaluate the projects, we'll use peer reviewing. This is a great opportunity for you to learn from each other.
74 | > * To get points for your project, you need to evaluate 3 projects of your peers
75 | > * You get 3 extra points for each evaluation
76 |
77 | ### Review Tips
78 |
79 | * The reviewer is given a public GitHut repo link and a `commit-hash`
80 | * to see the code state of the repo at the provided commit hash, use the following URL:
81 | * `https://github.com/{username}/{repo-name}/tree/{commit-hash}`
82 | * It's recommended to clone the repository for the review. To clone the project at the commit hash:
83 | ```bash
84 | git clone https://github.com/{username}/{repo-name}.git
85 | git reset --hard {commit-hash}
86 | ```
87 |
88 | ## Evaluation Criteria
89 |
90 | * Problem description
91 | * 0 points: The problem is not described
92 | * 1 point: The problem is described but briefly or unclearly
93 | * 2 points: The problem is well-described and it's clear what problem the project solves
94 | * RAG flow
95 | * 0 points: No knowledge base or LLM is used
96 | * 1 point: No knowledge base is used, and the LLM is queried directly
97 | * 2 points: Both a knowledge base and an LLM are used in the RAG flow
98 | * Retrieval evaluation
99 | * 0 points: No evaluation of retrieval is provided
100 | * 1 point: Only one retrieval approach is evaluated
101 | * 2 points: Multiple retrieval approaches are evaluated, and the best one is used
102 | * RAG evaluation
103 | * 0 points: No evaluation of RAG is provided
104 | * 1 point: Only one RAG approach (e.g., one prompt) is evaluated
105 | * 2 points: Multiple RAG approaches are evaluated, and the best one is used
106 | * Interface
107 | * 0 points: No way to interact with the application at all
108 | * 1 point: Command line interface, a script, or a Jupyter notebook
109 | * 2 points: UI (e.g., Streamlit), web application (e.g., Django), or an API (e.g., built with FastAPI)
110 | * Ingestion pipeline
111 | * 0 points: No ingestion
112 | * 1 point: Semi-automated ingestion of the dataset into the knowledge base, e.g., with a Jupyter notebook
113 | * 2 points: Automated ingestion with a Python script or a special tool (e.g., Mage, dlt, Airflow, Prefect)
114 | * Monitoring
115 | * 0 points: No monitoring
116 | * 1 point: User feedback is collected OR there's a monitoring dashboard
117 | * 2 points: User feedback is collected and there's a dashboard with at least 5 charts
118 | * Containerization
119 | * 0 points: No containerization
120 | * 1 point: Dockerfile is provided for the main application OR there's a docker-compose for the dependencies only
121 | * 2 points: Everything is in docker-compose
122 | * Reproducibility
123 | * 0 points: No instructions on how to run the code, the data is missing, or it's unclear how to access it
124 | * 1 point: Some instructions are provided but are incomplete, OR instructions are clear and complete, the code works, but the data is missing
125 | * 2 points: Instructions are clear, the dataset is accessible, it's easy to run the code, and it works. The versions for all dependencies are specified.
126 | * Best practices
127 | * [ ] Hybrid search: combining both text and vector search (at least evaluating it) (1 point)
128 | * [ ] Document re-ranking (1 point)
129 | * [ ] User query rewriting (1 point)
130 | * Bonus points (not covered in the course)
131 | * [ ] Deployment to the cloud (2 points)
132 | * [ ] Up to 3 extra bonus points if you want to award for something extra (write in feedback for what)
133 |
134 |
135 | ## Project ideas
136 |
137 | ### Datasets
138 |
139 | Here are some datasets for your projects and potential things you can do with them
140 |
141 | * DTC data:
142 | * Slack dump: book of the week channel, course channels, career questions, etc
143 | * DTC website with book of the week archives
144 | * DTC Podcast: transcripts
145 | * Wikis
146 | * any subsets of Wikipedia
147 | * any wiki-like data source
148 | * notion notes
149 | * Articles
150 | * Index and answer questions from one or multiple articles
151 | * Transcripts
152 | * Podcast transcripts
153 | * YouTube video transcripts
154 | * Books
155 | * Sci-fi, fiction, or non-fiction books
156 | * Slide Decks and pictures
157 | * OCR and index slide decks (gpt-4o-mini can do that)
158 | * Describe and index pictures
159 | * Add more here above this line - send a PR!
160 | * Or just ask ChatGPT (see more ideas [here in this example](https://chatgpt.com/share/70b51c12-e41c-4312-831d-04f489a17f1e))
161 |
162 | You can also generate a dataset with an LLM:
163 |
164 | * If you have a dataset but you can't publicly release it, you can generate a similar one with an LLM
165 | * Or you can simply think what kind of a dataset you want to have and generate it
166 |
167 | Note that your dataset doesn't have to be in thr Q&A form. Check [etc/chunking.md](etc/chunking.md) to learn more about chunking.
168 |
169 |
170 | ## Cheating and plagiarism
171 |
172 | Plagiarism in any form is not allowed. Examples of plagiarism:
173 |
174 | * Taking somebody's else notebooks and projects (in full or partly) and using it for your project
175 | * Re-using your own projects (in full or partly) from other courses and bootcamps
176 | * Re-using your appempt 1 project as attempt 2 if you passed attempt 1
177 | * Re-using your project from the previous iterations of the course
178 |
179 | Violating any of this will result in 0 points for this project.
180 |
181 | Re-using some parts of the code from the course is allowed.
182 |
--------------------------------------------------------------------------------