├── 07_advanced_programmability_and_recent_updates_with_tc_cls_bpf.pdf
├── 18-eBPF-experience.pdf
├── A_pure_Go_eBPF_library.pdf
├── BPF-and-Kubernetes-Little-Helper-Minions-for-Scaling-Microservices
├── Aug19_eBPF_and_Kubernetes_Little_Helper_Minions_for_Scaling_Microservices_Daniel_Borkmann.pdf
└── index_zh.md
├── BPF_as_a_revolutionary_technology_for_the_container_landscape.pdf
├── BSidesSF2017_BPF_security_monitoring.pdf
├── Linux-Tracing-System.md
├── README.md
├── REPEAT_1_BPF_performance_analysis_at_Netflix_OPN303-R1.pdf
├── Understanding-the-eBPF-Datapath-in-Cilium
├── eBPF-and-the-Cilium-Datapath.pdf
└── index_zh.md
├── bcc-ebpf-go.md
├── bpf-co-re-btf-libbpf
└── index.md
├── bpf-enable-software-definition-kernel
└── index.md
├── bpf-prog-type.md
├── bpf_cve.md
├── bpf_intro.pdf
├── bpf_study.xmind
├── centos-8-env.md
├── cilium-ebpf-go.md
├── cilium-network-intro
├── images
│ ├── 1.png
│ ├── 10.png
│ ├── 11.png
│ ├── 12.png
│ ├── 13.png
│ ├── 14.png
│ ├── 2.png
│ ├── 3.png
│ ├── 4.png
│ ├── 5.png
│ ├── 6.png
│ ├── 7.png
│ ├── 8.png
│ └── 9.png
└── index.md
├── compile-bpf-examples
├── images
│ └── bpf-kernel-examples.png
└── index.md
├── ebpf_bcc_trace_open_ex
├── open.py
├── open_perf_output.py
├── open_perf_output_ret.py
├── open_pid.py
└── tp_open_perf_output.py
├── ebpf_network_kpath_ipvs
├── imgs
│ ├── client_ping_wireshark.png
│ ├── estimation_timer_flamgraph.png
│ ├── estimation_timer_funcgraph.png
│ ├── netcard_dev_softirq.png
│ ├── perf_kernel_cpu0.png
│ ├── ping_host_container.png
│ ├── ping_host_container_detail.png
│ ├── ping_server_pcap.png
│ ├── service_latency_high.png
│ └── timer_softirq_hist.png
├── index.md
└── 网络延时之IPVS统计定时器篇-图床.md
├── ebpf_on_windows
├── imgs
│ └── ebpf_on_windows_arch.png
└── index.md
├── ebpf_tcp_cc
├── bpf_dctcp.c
├── bpf_dctcp.skel.h
└── bpf_tcp_ca.c
├── env.md
├── ftrace
├── README.md
├── col_and_reset.sh
├── sys_connnet.sh
└── trace.log
├── fuzzing-the-berkeley-acket-filter.pdf
├── head_first_bpf.png
├── hello_falco.graffle
├── hello_falco
├── hello_falco.graffle
├── imgs
│ ├── evt_collect_display.png
│ ├── falco-extended-architecture.png
│ ├── falco_arch_cncf.png
│ ├── falcosidekick-ui.png
│ ├── k8s_audit_falco.png
│ ├── libs_2_cncf.png
│ └── libs_to_cncf_arch.png
├── index.md
└── index2.md
├── hello_kernel_module
├── Makefile
├── README.md
├── get_inst.c
├── hello.c
└── helloproc.c
├── hello_world_bpf_ex
├── Makefile_diff
├── README.md
├── hello_kern.c
└── hello_user.c
├── how-to-make-linux-microservice-aware-with-cilium-ebpf
├── bpf_-_turning_linux_into_a_microservices-aware_operating_system.pdf
├── further_readings.md
└── index.md
├── imgs
├── KProbeExecution.png
├── KProbesArchitecture.png
├── bcc-internals.png
├── bcc-intro.png
├── bcc-tools.png
├── bpf-basic-arch.png
├── ebpf-workflow-101.png
├── ebpf_60s.png
├── ebpf_on_windows_arch.png
├── evt_collect_display.png
├── falco-extended-architecture.png
├── falco_arch_cncf.png
├── falcosidekick-ui.png
├── flame.png
├── image-20200419215511484.png
├── image-20200419223334157.png
├── k8s_audit_falco.png
├── libs_2_cncf.png
├── libs_to_cncf_arch.png
├── linux-bpf-book.jpeg
├── linux_ebpf_internals.png
├── linux_kernel_event_bpf.png
└── packet-processor-xdp.png
├── katran
├── README.md
├── ebpf-ip-tun.png
└── ipip-120-all.pcap
├── kpatch_ipvs_timer
├── imgs
│ └── ipvs_timer.png
└── index.md
├── kprobe-intro-1.md
├── kprobe-intro-2.md
├── kprobe_ko_ex
├── Makefile
├── README.md
├── kprobe_example.c
├── kprobe_tcp_con.c
├── kretprobe_example.c
├── tcp_con.md
├── tcp_con.py
├── tcp_mss.py
└── tcp_mss2.py
├── linux-process-thread.md
├── linux-tracing-zine-print.pdf
├── linux-tracing-zine.pdf
├── linux_load_avg.md
├── list_process_kernel_module
├── Makefile
├── README.md
└── list_process.c
├── pid_task_module
├── Makefile
├── README.md
└── pid.c
├── replace_img_addr.sh
├── skbtracer
├── skbtracer.c
└── skbtracer.py
├── socket_filter
├── BPF_PROG_TYPE_SOCKET_FILTER.md
└── socket-filter.graffle
├── sysdig_centos_install
├── DRAIOS-GPG-KEY.public
├── draios.repo
├── epel-release-6-8.noarch.rpm
└── install.md
├── tcphash_info_module
├── Makefile
├── README.md
├── tcp_rcv.py
└── tcphash.c
├── the-art-of-writing-ebpf-programs-a-primer
└── index.md
├── trace-packet-with-tracepoint-perf-ebpf
├── icmp_trace_v2.py
├── index_en.md
├── index_zh.md
├── prob_icmp.py
├── trace_pkt_v3.py
├── traceicmpsoftirq.py
└── tracepkt_centos_7.md
├── ubuntu_kernel_compile
├── README.md
└── ubuntu-kernel-compile.md
└── xdp-project
├── README.md
├── XDP_LLC2018_redirect.pdf
├── af_xdp.md
├── xdp-the-express-data-path.pdf
├── xdp_buffer.md
└── xdp_intro_and_use_cases_sep2016.pdf
/07_advanced_programmability_and_recent_updates_with_tc_cls_bpf.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/07_advanced_programmability_and_recent_updates_with_tc_cls_bpf.pdf
--------------------------------------------------------------------------------
/18-eBPF-experience.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/18-eBPF-experience.pdf
--------------------------------------------------------------------------------
/A_pure_Go_eBPF_library.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/A_pure_Go_eBPF_library.pdf
--------------------------------------------------------------------------------
/BPF-and-Kubernetes-Little-Helper-Minions-for-Scaling-Microservices/Aug19_eBPF_and_Kubernetes_Little_Helper_Minions_for_Scaling_Microservices_Daniel_Borkmann.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/BPF-and-Kubernetes-Little-Helper-Minions-for-Scaling-Microservices/Aug19_eBPF_and_Kubernetes_Little_Helper_Minions_for_Scaling_Microservices_Daniel_Borkmann.pdf
--------------------------------------------------------------------------------
/BPF_as_a_revolutionary_technology_for_the_container_landscape.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/BPF_as_a_revolutionary_technology_for_the_container_landscape.pdf
--------------------------------------------------------------------------------
/BSidesSF2017_BPF_security_monitoring.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/BSidesSF2017_BPF_security_monitoring.pdf
--------------------------------------------------------------------------------
/Linux-Tracing-System.md:
--------------------------------------------------------------------------------
1 | # Linux Tracing System
2 |
3 | 
4 |
5 | 整体架构图,灰色为动态跟踪
6 |
7 | 
23 |
24 |
25 |
26 |
27 | ## 数据源 DataSource
28 |
29 | | | 内核 | 用户空间 |
30 | | -------- | ----------------- | ---------------------------------------------------- |
31 | | **动态** | kprobe | uprobe |
32 | | **静态** | kernel tracepoint | usdt
dtrace probes
LTTng userspace Tracing |
33 |
34 |
35 |
36 | ## 提取数据的方式 Ways to extrace data
37 |
38 | * perf
39 | * ftrace
40 | * LTTng
41 | * ebpf
42 | * SystemTap
43 | * Sysdig
44 |
45 |
46 |
47 | ## 前端界面 Frontends
48 |
49 | * perf
50 | * ftrace
51 | * trace-cmd
52 | * catapult
53 | * kernelshark
54 | * trace compass
55 | * bcc
56 | * sysdig
57 | * LTTng
58 | * SystemTap
59 |
60 |
61 |
62 | * [Linux Tracing Technologies](https://www.kernel.org/doc/html/latest/trace/index.html)
63 |
64 | * https://support.typora.io/Draw-Diagrams-With-Markdown/
65 |
66 |
--------------------------------------------------------------------------------
/REPEAT_1_BPF_performance_analysis_at_Netflix_OPN303-R1.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/REPEAT_1_BPF_performance_analysis_at_Netflix_OPN303-R1.pdf
--------------------------------------------------------------------------------
/Understanding-the-eBPF-Datapath-in-Cilium/eBPF-and-the-Cilium-Datapath.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/Understanding-the-eBPF-Datapath-in-Cilium/eBPF-and-the-Cilium-Datapath.pdf
--------------------------------------------------------------------------------
/bpf-co-re-btf-libbpf/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "BPF 二进制文件:BTF,CO-RE 和 BPF 性能工具的未来【译】"
3 | date: 2021-03-25T10:32:04+08:00
4 | keywords:
5 | - bpf
6 | - btf
7 | - core
8 | description : "BTF 和 CO-RE 这两项新技术为 BPF 成为价值十亿美元的产业铺平了道路。目前,有许多 BPF(eBPF)初创公司正在构建网络,安全性和性能产品(并且更多未浮出水面的),但是要求客户安装 LLVM,Clang 和内核头文件依赖(可能消耗超过100 MB的存储空间)是一个额外的负担。 BTF 和 CO-RE 在运行时消除了这些依赖关系,不仅使 BPF 在嵌入式 Linux 环境中更加实用,而且在任何地方都可以使用。"
9 | tags: []
10 | categories: ["BPF","foundation"]
11 | ---
12 |
13 | 作者: [Brendan Gregg](http://www.brendangregg.com/blog/index.html)
14 |
15 | ## 1. 简述
16 |
17 | BTF 和 CO-RE 这两项新技术为 BPF 成为价值十亿美元的产业铺平了道路。目前,有许多 BPF(eBPF)初创公司正在构建网络,安全性和性能产品(并且更多未浮出水面的),但是要求客户安装 LLVM,Clang 和内核头文件依赖(可能消耗超过100 MB的存储空间)是一个额外的负担。 BTF 和 CO-RE 在运行时消除了这些依赖关系,不仅使 BPF 在嵌入式 Linux 环境中更加实用,而且在任何地方都可以使用。
18 |
19 | 这些技术是:
20 |
21 | * **BTF**:BPF 类型格式,它提供结构信息以避免 Clang 和内核头文件依赖。
22 | * **CO-RE**:BPF Compile-Once Run-Everywhere,它使已编译的 BPF 字节码可重定位,从而避免了 LLVM 重新编译的需要。
23 | 仍然需要 Clang 和 LLVM 进行编译,但是结果是一个轻量级的 ELF 二进制文件,其中包含预编译的 BPF 字节码,并且可以在任何地方运行。 BCC 项目包含这些工具的集合,称为 libbpf 工具。作为示例,我移植了我开发的opensnoop(8)工具:
24 |
25 | ```bash
26 | # ./opensnoop
27 | PID COMM FD ERR PATH
28 | 27974 opensnoop 28 0 /etc/localtime
29 | 1482 redis-server 7 0 /proc/1482/stat
30 | 1657 atlas-system-ag 3 0 /proc/stat
31 | […]
32 | ```
33 |
34 |
35 | opensnoop(8)是不使用 libLLVM 或 libclang 的 ELF 二进制文件:
36 |
37 | ```bash
38 | # file opensnoop
39 | opensnoop: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/l, for GNU/Linux 3.2.0, BuildID[sha1]=b4b5320c39e5ad2313e8a371baf5e8241bb4e4ed, with debug_info, not stripped
40 |
41 | # ldd opensnoop
42 | linux-vdso.so.1 (0x00007ffddf3f1000)
43 | libelf.so.1 => /usr/lib/x86_64-linux-gnu/libelf.so.1 (0x00007f9fb7836000)
44 | libz.so.1 => /lib/x86_64-linux-gnu/libz.so.1 (0x00007f9fb7619000)
45 | libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f9fb7228000)
46 | /lib64/ld-linux-x86-64.so.2 (0x00007f9fb7c76000)
47 |
48 | # ls -lh opensnoop opensnoop.stripped
49 | -rwxr-xr-x 1 root root 645K Feb 28 23:18 opensnoop
50 | -rwxr-xr-x 1 root root 151K Feb 28 23:33 opensnoop.stripped
51 | ```
52 |
53 | ...最后文件大小仅为 151 KB。
54 |
55 | 现在想象一个 BPF 产品:BPF 代理现在可以是单个微小的二进制文件,它可以在任何具有 BTF 的内核上运行,而不是要求客户安装各种重量级(且脆弱)的依赖项。
56 |
57 | ## 2. 这是如何工作的?
58 |
59 | 这不仅仅是将 BPF 字节码保存在 ELF 中,然后将其发送到任何其他内核的问题。许多 BPF 程序会使用可从一种内核版本更改为另一种内核版本的内核结构。BPF 字节码可能仍然可以不同的内核上执行,但是其可能会读取错误的结构偏移量并打印错误输出! opensnoop(8)不会遍历内核结构,因为它可以检测稳定的跟踪点及其参数,但是许多其他工具都需要遍历内核结构。
60 |
61 | 这涉及到重定位问题,BTF 和 CO-RE 都针对 BPF 二进制文件解决了此问题。 BTF 提供类型信息,以便可以根据需要查询结构偏移量和其他详细信息,并且 CO-RE 记录需要重写 BPF 程序的哪些部分以及如何重写。 CO-RE 开发人员 Andrii Nakryiko 已撰写了很长的帖子,更深入地解释了这一点:[BPF 可移植性以及 CO-RE](https://facebookmicrosites.github.io/bpf/blog/2020/02/19/bpf-portability-and-co-re.html) ([本站地址见这里](https://www.ebpf.top/post/bpf_core/)) 和 [BTF 类型信息](https://facebookmicrosites.github.io/bpf/blog/2018/11/14/btf-enhancement.html)。
62 |
63 |
64 |
65 | ## 3. CONFIG_DEBUG_INFO_BTF = y
66 | 新的 BPF 二进制文件仅在设置了此内核配置选项后才可用。该选项为内核映像增加了约 1.5 MB(这与数百 M的 DWARF debuginfo 相比可能很小)。Ubuntu 20.10 已经将此配置选项设置为默认选项,所有其他发行版都应遵循。发行维护者的注意事项:它需要 pahole >= 1.16。
67 |
68 |
69 |
70 | ## 4. BPF 性能工具,BCC Python 和 bpftrace 的未来
71 |
72 | 对于 BPF 性能工具,你应该从运行 BCC 和 bpftrace 工具开始,然后在 bpftrace 中进行编码。 BCC 工具最终应该在后台实现上从 Python 切换到 libbpf C,但是仍然可以正常使用。现在,随着我们转向带有 BTF 和 CO-RE 的l ibbpf C,**已经不赞成使用 BCC Python 中的性能工具**(尽管我们仍需要继续完善库的功能,例如对 USDT 的支持,因此需要一段时间才能使用 Python 版本)。请注意,还有其他 BCC 用例可能会继续使用 Python 接口。 BPF 的共同维护者 Alexei Starovoitov 和我本人在 [iovisor-dev](https://lists.iovisor.org/g/iovisor-dev/topic/future_of_bcc_python_tools/77827559?p=,,,20,0,0,0::recentpostdate%2Fsticky,,,20,2,0,77827559) 上对此进行了简短的讨论。
73 |
74 | 我的 《BPF Performance Tools》书籍着重于运行 BCC 工具和在 bpftrace 中进行编码,并且这没有改变。但是,现在认为**附录 C 的 Python 编程示例已被弃用**。造成的不便,深表歉意,幸运的是,这本 880 页的书中只有 15 页相关的附录材料。
75 |
76 | bpftrace 呢?它确实支持 BTF,并且将来我们还将考虑减少其安装空间(目前可以达到 29 MB,并且我们认为它可以减小很多)。假设平均 libbpf 程序大小为 229 KB(基于当前的 libbpf 工具,已经经过 strippe),平均bpftrace 程序大小为 1KB(我图书中的工具),则有大量 bpftrace 工具加上与 libbpf 中的等效工具相比,bpftrace 二进制文件可能会占用较小的安装空间。再加上 bpftrace 版本可以随时修改。 libbpf 更适合需要自定义参数和库的更复杂,更成熟的工具。
77 |
78 | 如屏幕截图所示,BPF性能工具的未来是这样的:
79 |
80 | ```bash
81 | # ls /usr/share/bcc/tools /usr/sbin/*.bt
82 | argdist drsnoop mdflush pythongc tclobjnew
83 | bashreadline execsnoop memleak pythonstat tclstat
84 | [...]
85 | /usr/sbin/bashreadline.bt /usr/sbin/mdflush.bt /usr/sbin/tcpaccept.bt
86 | /usr/sbin/biolatency.bt /usr/sbin/naptime.bt /usr/sbin/tcpconnect.bt
87 | [...]
88 | ```
89 |
90 |
91 | ... 还有这个:
92 |
93 | ```bash
94 | # bpftrace -e 'BEGIN { printf("Hello, World!\n"); }'
95 | Attaching 1 probe...
96 | Hello, World!
97 | ^C
98 | ```
99 |
100 | ...而不是这样:
101 |
102 | ```python
103 | #!/usr/bin/python
104 |
105 | from bcc import BPF
106 | from bcc.utils import printb
107 |
108 | prog = """
109 | int hello(void *ctx) {
110 | bpf_trace_printk("Hello, World!\\n");
111 | return 0;
112 | }
113 | """
114 | [...]
115 | ```
116 |
117 | 感谢 Song Yonghong(Facebook)领导 BTF 的开发,Andrii Nakryiko(Facebook)领导 CO-RE 的开发,以及参与实现这一目标的其他所有人。
118 |
119 |
120 |
121 | 原文地址: http://www.brendangregg.com/blog/2020-11-04/bpf-co-re-btf-libbpf.html
--------------------------------------------------------------------------------
/bpf-enable-software-definition-kernel/index.md:
--------------------------------------------------------------------------------
1 | ### BPF使能软件定义内核
2 |
3 | 原文地址:http://blog.nsfocus.net/bpf-enable-software-definition-kernel
4 |
5 | [2020-03-02](http://blog.nsfocus.net/bpf-enable-software-definition-kernel/)[江国龙](http://blog.nsfocus.net/author/jiangguolong/)[BPF](http://blog.nsfocus.net/tag/bpf/), [软件定义内核](http://blog.nsfocus.net/tag/软件定义内核/)
6 |
7 | BPF通过一种软件定义的方式,将内核的行为和数据暴露给用户空间,开发者可以通过在用户空间编写BPF程序,加载到内核空间执行,进而实现对内核行为的灵活管理和控制。
8 |
9 |
10 |
11 | ## 摘要
12 |
13 | BPF通过一种软件定义的方式,将内核的行为和数据暴露给用户空间,开发者可以通过在用户空间编写BPF程序,加载到内核空间执行,进而实现对内核行为的灵活管理和控制。
14 |
15 | 在计算机系统中,包过滤器通常有一个特定的用途,那就是提供给应用程序来监控系统的网络与内核运行的相关信息。这些监控程序对于系统的开发者、运维者、或者是安全管理者,都有着重要的意义。
16 |
17 | 有了更加细粒度的网络数据和内核运行数据,对于开发者来说,就可以根据当前系统的运行情况,合理的优化程序,提高程序的性能同时降低资源开销;对于系统运维者来说,能够拿到精确全面的系统运行数据,可以更好的对系统进行监控,保证系统的可靠性与高可用性;对于安全管理者来说,可以从这些网络和内核行为中,发现异常,进而在攻击行为发生的早期,发现攻击并且能够快速的进行响应和修复。
18 |
19 | BPF(Berkeley Packet Filter)就是这样的一种包过滤器,从其诞生之初,就引起了人们的广泛关注与应用,尤其是近年来,随着微服务和云原生的发展和落地,BPF更是成为了内核开发者最受追捧的技术之一。
20 |
21 | ## 1. BPF概述
22 |
23 | BPF(BSD Packet Filter)是很早就有的Unix内核特性,最早可以追溯到1992年发表在USENIX Conference上的一篇论文[1]。作者描述了他们如何为Unix内核实现一个网络包过滤器,这种实现甚至比当时最先进的包过滤技术快20倍。
24 |
25 | 随后,得益于如此强大的性能优势,所有Unix系统都将BPF作为网络包过滤的首选技术,抛弃了消耗更多内存和性能更差的原有技术实现。后来由于BPF的理念逐渐成为主流,为各大操作系统所接受,这样早期“B”所代表的BSD便渐渐淡去,最终演化成了今天我们眼中的BPF(Berkeley Packet Filter)。比如我们熟知的Tcpdump,其底层就是依赖BPF实现的包过滤。
26 |
27 | 关于BPF的发展历史,网上已经有很多文章进行了比较详尽的解释和描述,本文就不再过多的进行介绍,感兴趣的读者可以自行搜索,或者参照参考文献[2]。
28 |
29 | 本文重点要介绍的是自2014年,对传统的BPF进行扩展进化后的BPF。得益于BPF在包过滤上的良好表现,Alexei Starovoitov对BPF进行彻底的改造,并增加了新的功能,改善了它的性能,这个新版本被命名为eBPF(extended BPF),新版本的BPF全面兼容并扩充了原有BPF的功能。因此,将传统的BPF重命名为cBPF(classical BPF),相对应的,新版本的BPF则命名为eBPF或直接称为BPF(后文所有的eBPF,均简化描述为BPF)。Linux Kernel 3.15版本开始实现对eBPF的支持。
30 |
31 | BPF针对现代硬件进行了优化和全新的设计,使其生成的指令集比cBPF解释器生成的机器码更快。这个扩展版本还将BPF VM中的寄存器数量从两个32位寄存器增加到10个64位寄存器。寄存器数量和寄存器宽度的增加为编写更复杂的程序提供了可能性,开发人员可以自由的使用函数参数交换更多的信息。这些改进使得BPF比原来的cBPF快四倍。这些改进,主要还是对网络过滤器内部处理的BPF指令集进行优化,仍然被限制在内核空间中,只有少数用户空间中的程序可以编写BPF过滤器供内核处理,比如Tcpdump和Seccomp。
32 |
33 | 除了上述的优化之外,BPF最让人兴奋的改进,是其向用户空间的开放。开发者可以在用户空间,编写BPF程序,并将其加在到内核空间执行。虽然BPF程序看起来更像内核模块,但与内核模块不同的是,BPF程序不需要开发者重新编译内核,而且保证了在内核不崩溃的情况下完成加载操作,着重强调了安全性和稳定性。BPF代码的主要贡献单位主要包括Cilium、Facebook、Red Hat以及Netronome等。
34 |
35 | 图1 Software Define Kernel
36 |
37 | BPF使得更多的内核操作可以通过用户空间的应用程序来完成,这恰恰是与软件定义的架构和理念不谋而合。软件定义强调将系统的数据平面和控制平面进行分离,控制平面实现各种各样的控制和管理逻辑,而数据平面则专注于高效快速的执行,控制平面和数据平面通过特定的接口或协议进行通信。
38 |
39 | 因此,笔者认为,BPF正是设计和实现了一种对内核进行软件定义(Software Define Kernel)的方式。控制平面是用户空间的各种BPF程序,实现BPF程序在内核的跟踪点以及执行逻辑;数据平面则是内核各种操作的执行单元,这些跟踪点可以是一个系统调用,甚至是一段确定的实现代码;控制平面和数据平面通过bpf()系统调用进行通信,将用户空间的控制平面逻辑,加在到内核空间数据平面的准确位置。
40 |
41 | 这种软件定义内核的设计和实现,极大的提高了内核行为分析与操作的灵活性、安全性和效率,降低了内核操作的技术门槛。尤其在云原生环境中,对于云原生应用的性能提升、可视化监控以及安全检测有着重要的意义。
42 |
43 | ## 2. BPF原理与架构
44 |
45 | 众所周知,Linux内核是一个事件驱动的系统设计,这意味着所有的操作都是基于事件来描述和执行的。比如打开文件是一种事件、CPU执行指令是一种事件、接收网络数据包是一种事件等等。BPF作为内核中的一个子系统,可以检查这些基于事件的信息源,并且允许开发者编写并运行在内核触发任何事件时安全执行的BPF程序。
46 |
47 | 图2 BPF在Linux中挂载示例
48 |
49 |
50 |
51 | 图3简要描述了BPF的架构及基本的工作流程。首先,开发者可以使用C语言(或者Python等其他高级程序语言)编写自己的BPF程序,然后通过LLVM或者GNU、Clang等编译器,将其编译成BPF字节码。Linux提供了一个bpf()系统调用,通过bpf()系统调用,将这段编译之后的字节码传入内核空间。
52 |
53 | 传入内核空间之后的BPF程序,并不是直接就在其指定的内核跟踪点上开始执行,而是先通过Verifier这个组件,来保证我们传入的这个BPF程序可以在内核中安全的运行。经过安全检测之后,Linux内核还为BPF字节码提供了一个实时的编译器(Just-In-Time,JIT),JIT将确认后的BPF字节码编译为对应的机器码。这样就可以在BPF指定的跟踪点上执行我们的操作逻辑了。
54 |
55 | 图3 BPF架构与流程图
56 |
57 | 那么,用户空间的应用程序怎么样拿到我们插入到内核中的BPF程序产生的数据呢?BPF是通过一种MAP的数据结构来进行数据的存储和管理的,BPF将产生的数据,通过指定的MAP数据类型进行存储,用户空间的应用程序,作为消费者,通过bpf()系统调用,从MAP数据结构中读取数据并进行相应的存储和处理。这样一个完整BPF程序的流程就完成了。
58 |
59 | ## 3. BPF Hello World
60 |
61 | 下面我们通过一个Hello World例子,来对上述各个步骤进行展开介绍。这个示例将完成下面的操作:当内核执行某一系统调用时,打印“Hello, BPF World!”字符串。
62 |
63 | 首先我们先使用C语言编写一段完成上述功能的BPF代码bpf_program.c:
64 |
65 | ```c
66 | #include
67 | #define SEC(NAME) __attribute__((section(NAME), used)) SEC("tracepoint/syscalls/sys_enter_execve")
68 |
69 | int bpf_prog(void *ctx)
70 | {
71 | char** msg[] = "Hello, BPF World!";
72 | bpf_trace_printk(msg, sizeof(msg));
73 | return** 0;
74 | }
75 |
76 | char** _license[] SEC("license") = "GPL";
77 | ```
78 |
79 | 首先,我们需要声明BPF程序什么时候执行,这里有一个跟踪点(Tracepoints)的概念,跟踪点是内核二进制代码中的静态标记,允许开发人员注入代码来检查内核的执行。代码的第4行就是指出我们这个BPF程序的跟踪点是什么。在BPF的语法中,使用SEC标识跟踪点,在本例中,我们将在检测到执行execve系统调用时运行这个BPF程序。
80 |
81 | 代码的5—9行,定义了我们在这个追踪点需要执行的操作,也就是每当内核检测到一个程序执行另一个程序时,将打印消息“Hello, BPF World!”
82 |
83 | 然后我们将使用clang将这个程序编译为成一个ELF二进制文件,这是内核能够识别的一种文件格式。clang -O2 -target bpf -c bpf_program.c -o bpf_program.o。
84 |
85 | 下面将这个已经编译好的BPF程序加载到内核中,现在我们已经编译了第一个BPF程序,我们使用内核提供的load_bpf_file方法,将上述编译好的bpf_program.o加载到内核。如下loader.c。
86 |
87 | ```c
88 | #include
89 | #include
90 | #include "bpf_load.h"`
91 |
92 | int main(int argc, char **argv)
93 | {
94 | if (load_bpf_file("hello_world_kern.o") != 0)
95 | {
96 | printf("The kernel didn't load the BPF program**\n**");
97 | return** -1;
98 | }
99 |
100 | read_trace_pipe();
101 | return0;
102 | }
103 | ```
104 |
105 | 使用如下方法编译我们loader文件。
106 |
107 | ```bash
108 | TOOLS=/kernel-src/samples/bpf
109 | INCLUDE=/kernel-src/tools/lib
110 | PERF_INCLUDE=/kernel-src/tools/perf
111 | KERNEL_TOOLS_INCLUDE=/kernel-src/tools/include/
112 |
113 | clang -o loader -lelf\
114 | -I${INCLUDE} \
115 | -I${PERF_INCLUDE} \
116 | -I${KERNEL_TOOLS_INCLUDE} \
117 | -I${TOOLS} \
118 | ${TOOLS}/bpf_load.c \
119 | loader.c
120 | ```
121 |
122 | 然后运行sudo ./loader,我们的BPF程序就已经加载到内核中了。当我们停止这个loader程序时,上述BPF程序实现自动从内核中卸载。
123 |
124 | ## 4. BPF程序类型
125 |
126 | 通过上面的Hello World示例,我们已经对BPF程序有了一个初步的认识,那么接下来我们看一下,我们都能够用BPF来做什么?Linux内核当前提供了对哪些BPF程序类型的支持。
127 |
128 | 这里可以简单的将BPF程序的类型分为两个方面:内核追踪(Tracing)和内核网络(Networking)。
129 |
130 | ### 4.1 内核追踪(Tracing)
131 |
132 | 第一类是内核跟踪。开发者可以通过BPF程序更清晰的了解系统中正在发生的事情。从前文中的介绍可以看出,BPF可以通过各种类型的追踪点(TracePoint)访问与特定程序相关的内存区域,并从正在运行的进程中提取信息并执行跟踪。这样开发者就可以获取关于系统的行为及其所运行的硬件的直接信息,甚至还可以直接访问为每个特定进程分配的资源,包括从文件描述符到CPU和内存使用情况。
133 |
134 | 图4 BPF内核行为追踪
135 |
136 |
137 |
138 | BPF对内核行为的追踪,可以通过静态的追踪点,kprobes或者是uprobes等动态的追踪点,实现整个系统的可观察性(Observability),进而可以进行系统的性能分析、调试以及安全的检测与发现。
139 |
140 | 图5 BPF Observability
141 |
142 |
143 |
144 | 在安全检测上,我们可以将BPF程序的追踪点加载到一些关键并且不是很频繁的内核行为上,比如一个新的TCP/UDP会话的创建、启动了新的进程、特权提升等,这样就可以通过对这些行为的监控,进行异常检测。
145 |
146 | 图6 BPF实现主机入侵检测
147 |
148 |
149 |
150 | ### 4.2 内核网络(Networking)
151 |
152 | 第二类程序是对内核网络的操作。BPF程序允许开发者监控并且操作计算机系统中的网络流量,这也是BPF原始设计时的核心功能点。BPF允许过滤来自网络接口的数据包,甚至完全拒绝这些数据包。不同类型的BPF程序可以加载到内核网络中不同的处理阶段。
153 |
154 | 比如,开发者可以在网络驱动程序收到包时立即将BPF程序附加到这一网络事件上,并根据特定的过滤条件,对符合条件的数据包进行处理。这种数据包的处理和过滤可以直接下沉到物理网卡上,利用网卡的处理单元(Network Processor),进一步降低主机在数据包处理上的资源开销。
155 |
156 | 当然,这种灵活的数据包处理方式有优点也有缺点。一方面,当收到数据包之后,我们在越早的阶段处理,可能在资源消耗上越有优势,但是这个时候,内核还没有将足够的信息提供我们,我们对这个数据包的信息了解的就很少,这对下一步的处理决策有着一定的影响。另一方面,我们也可以在网络事件传递到用户空间之前将BPF程序加载到网络事件上,这时,我们将拥有关于数据包的更多信息,并且有助于做出更明智的决策,但这就需要支付完全处理数据包的成本。
157 |
158 | 这里我们简单举个例子,如下图所示,在容器等虚拟化环境中,我们可以将BPF程序附着在包括物理和虚拟的网络设备上,这样就能够根据实际的业务场景以及网络通信需求,实时动态的设置和更新网络通信规则,实现对数据包的过滤。而这种包过滤,当前容器网络更多的是通过Iptables来实现的,那么一旦规模达到一定量级之后,不论是在规则管理上,还是在资源消耗上,都将带来巨大的负担和隐患。
159 |
160 | 图7 BPF实现容器网络安全
161 |
162 |
163 |
164 | BPF在网络数据包的处理上,通常会与Linux内核的另外一个重要功能XDP一起来实现。XDP(Express Data Path)是一个安全的、可编程的、高性能的、内核集成的包处理器,它位于Linux网络数据路径中,当网卡驱动程序收到包时,就会执行BPF程序,XDP程序会在尽可能早的时间点对收到的包进行删除、修改或转发到网络堆栈等操作。XDP程序是通过bpf()系统调用控制的,使用BPF程序实现相应的控制逻辑。
165 |
166 | 图8 BPF+XDP实现网络数据包过滤
167 |
168 |
169 |
170 | ## 5. BPF工具
171 |
172 | 当前BPF贡献者以及使用者,已经开发并且开源了许多实用的BPF工具。这将给我们进行BPF开发和使用带来极大的便利性。
173 |
174 | ### 5.1 BCC
175 |
176 | 前文的介绍中我们提到了,对于一个C语言实现的BPF程序,可以通过Clang、LLVM将其编译成BPF字节码,然后通过加载程序,将BPF字节码通过bpf()系统调用加载到内核中。这种用户动态的编译、加载比较麻烦,因此IO Visor开发实现了一个BPF程序工具包BCC[3]。
177 |
178 | BCC(BPF Compiler Collection)是高效创建BPF程序的工具包,BCC把上述BPF程序的编译、加载等功能都集成了起来,提供友好的接口给用户,进而方便用户的使用。它使用了(Python + Lua + C++)的混合架构,底层操作封装到C++库中,Lua提供一些辅助功能,对用户的接口使用Python提供,Python和C++之间的调用使用ctypes连接。因为使用了Python,所有抓回来的数据分析和数据呈现都非常方便。
179 |
180 | 除此之外,BCC还提供了一套现成的工具和示例供开发者使用,下图展示了当前BCC提供的各种类型的工具,当我们安装完BCC之后,进入”/usr/share/bcc/tools” 和”/usr/share/bcc/examples/”目录就可以使用这些工具。
181 |
182 | 图9 BCC工具集
183 |
184 |
185 |
186 | ```bash
187 | /usr/share/bcc/tools# ./syscount -L
188 | Tracing syscalls, printing top 10… Ctrl+C to quit.
189 | ^C[21:22:45]
190 | SYSCALL COUNT TIME (us)
191 | futex 1122 1321885751.331
192 | select 673 229961581.277
193 | poll 219 171994374.042
194 | pselect6 48 21627700.875
195 | epoll_wait 33 14026746.897
196 | wait4 120 10169962.613
197 | read 4177 1662075.764
198 | fsync 4 364937.128
199 | nanosleep 337 48387.145
200 | openat 2809 25358.704
201 | ```
202 |
203 |
204 |
205 | ### 5.2 其他工具
206 |
207 | BPFTool是一个用于检查BPF程序和MAP存储的内核实用程序。这个工具在默认情况下不会安装在任何Linux发行版上,而且它还处于开发阶段,所以需要开发者编译最支持Linux内核的版本。将随Linux内核5.1版本一起发布BPFTool版本。BPFTool的一个重要功能就是可以扫描系统,进而了解系统支持了哪些BPF特性、系统中已经加载了何种BPF程序等。比如可以查看内核的哪个版本支持了哪种BPF程序,或者是否启用了BPF JIT编译器等。
208 |
209 | BPFTrace[4]是BPF的高级跟踪语言。它允许开发者用简洁的DSL编写BPF程序,并将它们保存为脚本,开发者可以执行这些脚本,而不必在内核中手动编译和加载它们。它的灵感来自其他著名的Trace工具,比如awk和DTrace,BPFTrace将会是DTrace的一个很好的替代品。与直接使用BCC或其他BPF工具编写程序相比,使用BPFTrace的一个优点是,BPFTrace提供了许多不需要自己实现的内置功能,比如聚合信息和创建直方图等。
210 |
211 | Kubectl-trace [5]是Kubernetes命令行kubectl的一个非常棒的插件。它可以帮助开发者在Kubernetes集群中调度BPFTrace程序,而不必安装任何附加的包或模块。它通过使用trace-runner容器镜像,通过Kubernetes作业调度来实现,trace-runner镜像中已经安装了运行程序所需的所有东西,可以在DockerHub中下载使用。
212 |
213 | 图10 Kubectl-trace架构
214 |
215 |
216 |
217 | ## 6. 总结
218 |
219 | BPF机制通过在Linux内核事件的处理流程上,插入用户定义的BPF程序,实现对内核的软件定义,极大的提高了内核行为分析与操作的灵活性、安全性和效率,降低了内核操作的技术门槛。
220 |
221 | Linux容器,作为云原生环境重要的支撑技术,是Linux内核上用于隔离和管理计算机进程的一组特性的抽象,高度依赖了Linux内核的底层功能。那么从内核的角度来看,(1)内核知道所有的进程/线程运行情况;(2)通过cgroups,内核可以知道Container Runtime配置的CPU/内存/网络等资源的配额以及使用情况;(3)从namespace的层面,内核可以知道Container Runtime配置的进程隔离情况、网络堆栈的情况、容器用户等众多的信息;(4)还可以知道容器环境内网络的连接以及网络流量的情况;(5)容器对系统调用、内核功能使用等信息。
222 |
223 | 因此,对于云原生环境来讲,如果能够拿到上述内核所拥有的种种信息,对于云原生应用的性能提升、可视化监控以及安全检测有着重要的意义。
224 |
225 |
226 |
227 | ## 参考文献
228 |
229 | [1] The BSD Packet Filter: A New Architecture for User-level Packet Capture,http://www.tcpdump.org/papers/bpf-usenix93.pdf
230 |
231 | [2] eBPF 简史,https://www.ibm.com/developerworks/cn/linux/l-lo-eBPF-history/index.html
232 |
233 | [3] IO visor,https://iovisor.github.io/bcc/
234 |
235 | [4] BPFTrace,https://github.com/iovisor/bpftrace
236 |
237 | [5] Kubectl-trace,https://github.com/iovisor/kubectl-trace
238 |
239 | [5] Linux Observability with BPF,https://www.oreilly.com/library/view/linux-observability-with/9781492050193/
--------------------------------------------------------------------------------
/bpf_cve.md:
--------------------------------------------------------------------------------
1 | # BPF 安全漏洞
2 |
3 | [TOC]
4 |
5 | ## CVE-2017-16995
6 |
7 | * [CVE-2017-16995漏洞分析](http://blog.lazzzy.xyz/2018/06/05/CVE-2017-16995%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90/)
8 |
9 | ## CVE-2020-8835
10 |
11 | * [CVE-2020-8835:Linux eBPF模块verifier组件漏洞分析](https://www.anquanke.com/post/id/203284)
12 | * [CVE-2020-8835: LINUX KERNEL PRIVILEGE ESCALATION VIA IMPROPER EBPF PROGRAM VERIFICATION](https://www.thezdi.com/blog/2020/4/8/cve-2020-8835-linux-kernel-privilege-escalation-via-improper-ebpf-program-verification)
13 | * [CVE-2020-8835 pwn2own 2020 ebpf 提权漏洞分析](https://www.anquanke.com/post/id/203416)
14 | * [CVE-2020-8835 pwn2own 2020 ebpf 通过任意读写提权分析](https://xz.aliyun.com/t/7690) ***
15 |
16 | ## CVE-2020-27194
17 |
18 | * [Linux eBPF JIT权限提升漏洞(CVE-2020-27194)分析与验证](https://mp.weixin.qq.com/s/93HyZBf803WucqEUG0uI7g)
19 |
20 |
21 |
22 | ## 英文
23 |
24 | [Fuzzing for eBPF JIT bugs in the Linux kernel](https://scannell.me/fuzzing-for-ebpf-jit-bugs-in-the-linux-kernel/)
25 |
26 | [对 Linux 内核中的 eBPF JIT 漏洞进行 fuzz](https://mp.weixin.qq.com/s?__biz=Mzg5NjEyMjA5OQ==&mid=2247485138&idx=1&sn=a46c5882670192f52884395e423d7fa0&chksm=c004ab4ef77322585d00b36c60e8c8ba88ea0c590cbde51469cc31ec6a8526e66e99ef0eb5f7&scene=27&k)
27 |
28 |
29 |
30 | ## 参考
31 |
32 | https://www.qemu.org/docs/master/system/index.html
33 |
34 | https://github.com/qemu/qemu
35 |
36 | https://github.com/hugsy/gef
37 |
38 |
39 |
40 |
41 |
42 |
--------------------------------------------------------------------------------
/bpf_intro.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/bpf_intro.pdf
--------------------------------------------------------------------------------
/bpf_study.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/bpf_study.xmind
--------------------------------------------------------------------------------
/centos-8-env.md:
--------------------------------------------------------------------------------
1 | # 环境搭建
2 |
3 | ## Centos 8
4 |
5 | CentOS 8 主要改动和 [RedHat Enterprise Linux 8](https://www.oschina.net/news/106529/redhat-enterprise-linux-8-final) 是一致的,基于 **Fedora 28** 和内核版本 **4.18**, 为用户提供一个稳定的、安全的、一致的基础,跨越混合云部署,支持传统和新兴的工作负载所需的工具。更加详细的说明参见:https://www.cnbeta.com/articles/soft/892951.htm
6 |
7 | > 该版本中 eBPF 相关的特性参见:
8 | >
9 | > - 扩展 Berkeley Packet Filtering (**eBPF)** 特性使得用户空间的各个点上附加自定义程序,包括 (sockets, trace points, packet reception) ,用于接收和处理数据。目前该特性还处于特性预览阶段
10 | > - BPF Compiler Collection (**BCC**), 这是一个用来创建高效内核跟踪和操作的工具,目前处于技术预览阶段
11 | > - 支持 **IPVLAN** 虚拟网络驱动程序,用于连接多个容器
12 | > - eXpress Data Path (**XDP**), XDP for Traffic Control (**tc**), 以及 Address Family eXpress Data Path (**AF_XDP**), 可作为部分 Berkeley Packet Filtering (**eBPF)** 扩展特性,目前还是技术预览阶段,详情请看 [Section 5.3.7, “Networking”](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/8.0_release_notes/RHEL-8_0_0_release#networking_technology_preview).
13 | > - 核心支持 **eBPF** 调试的工具包括`BCC`, `PCP`, 和 `SystemTap`.
14 |
15 | 内核源码安装参见:[我需要内核的源代码](https://wiki.centos.org/zh/HowTos/I_need_the_Kernel_Source#A.2BYhaLuE9gTg2XAImBZXROKlGFaDh2hG6QTuN4AQ-)
16 |
17 | ## Vagrant
18 |
19 | [vagrant 文件](https://app.vagrantup.com/centos/boxes/8)
20 |
21 | ```bash
22 | Vagrant.configure("2") do |config|
23 | config.vm.box = "centos/8"
24 | config.vm.box_version = "1905.1"
25 | end
26 | ```
27 |
28 | 命令行方式
29 |
30 | ```bash
31 | $ vagrant init centos/8 \
32 | --box-version 1905.1
33 | $ vagrant up
34 |
35 | # yum update -y
36 | ...
37 | Installed:
38 | kernel-4.18.0-193.14.2.el8_2.x86_64 kernel-core-4.18.0-193.14.2.el8_2.x86_64 kernel-modules-4.18.0-193.14.2.el8_2.x86_64
39 | yum-utils-4.0.12-3.el8.noarch elfutils-debuginfod-client-0.178-7.el8.x86_64 centos-gpg-keys-8.2-2.2004.0.1.el8.noarch
40 | centos-repos-8.2-2.2004.0.1.el8.x86_64 grub2-tools-efi-1:2.02-87.el8_2.x86_64 libssh-config-0.9.0-4.el8.noarch
41 | libzstd-1.4.2-2.el8.x86_64 mozjs60-60.9.0-4.el8.x86_64 python3-nftables-1:0.9.3-12.el8.x86_64
42 | python3-pip-wheel-9.0.3-16.el8.noarch python3-setuptools-wheel-39.2.0-5.el8.noarch
43 | ```
44 |
45 | 默认硬盘大小为 10G,调整大小为 40G
46 |
47 | ```bash
48 | $ vagrant plugin install vagrant-disksize
49 | ```
50 |
51 | 修改后的 vagrant 文件为:
52 |
53 | ```bash
54 | $ cat Vagrantfile
55 | # -*- mode: ruby -*-
56 | # vi: set ft=ruby :
57 |
58 | # All Vagrant configuration is done below. The "2" in Vagrant.configure
59 | # configures the configuration version (we support older styles for
60 | # backwards compatibility). Please don't change it unless you know what
61 | # you're doing.
62 | Vagrant.configure("2") do |config|
63 | # The most common configuration options are documented and commented below.
64 | # For a complete reference, please see the online documentation at
65 | # https://docs.vagrantup.com.
66 |
67 | # Every Vagrant development environment requires a box. You can search for
68 | # boxes at https://vagrantcloud.com/search.
69 | config.vm.box = "centos/8"
70 | config.vm.box_version = "1905.1"
71 | config.disksize.size = "40GB"
72 |
73 | # Disable automatic box update checking. If you disable this, then
74 | # boxes will only be checked for updates when the user runs
75 | # `vagrant box outdated`. This is not recommended.
76 | # config.vm.box_check_update = false
77 |
78 | # Create a forwarded port mapping which allows access to a specific port
79 | # within the machine from a port on the host machine. In the example below,
80 | # accessing "localhost:8080" will access port 80 on the guest machine.
81 | # NOTE: This will enable public access to the opened port
82 | # config.vm.network "forwarded_port", guest: 80, host: 8080
83 |
84 | # Create a forwarded port mapping which allows access to a specific port
85 | # within the machine from a port on the host machine and only allow access
86 | # via 127.0.0.1 to disable public access
87 | # config.vm.network "forwarded_port", guest: 80, host: 8080, host_ip: "127.0.0.1"
88 |
89 | # Create a private network, which allows host-only access to the machine
90 | # using a specific IP.
91 | # config.vm.network "private_network", ip: "192.168.33.10"
92 |
93 | # Create a public network, which generally matched to bridged network.
94 | # Bridged networks make the machine appear as another physical device on
95 | # your network.
96 | # config.vm.network "public_network"
97 |
98 | # Share an additional folder to the guest VM. The first argument is
99 | # the path on the host to the actual folder. The second argument is
100 | # the path on the guest to mount the folder. And the optional third
101 | # argument is a set of non-required options.
102 | # config.vm.synced_folder "../data", "/vagrant_data"
103 |
104 | # Provider-specific configuration so you can fine-tune various
105 | # backing providers for Vagrant. These expose provider-specific options.
106 | # Example for VirtualBox:
107 | #
108 | config.vm.provider "virtualbox" do |vb|
109 | # # Display the VirtualBox GUI when booting the machine
110 | # vb.gui = true
111 | #
112 | # # Customize the amount of memory on the VM:
113 | vb.memory = "4096"
114 | end
115 | #
116 | # View the documentation for the provider you are using for more
117 | # information on available options.
118 |
119 | # Enable provisioning with a shell script. Additional provisioners such as
120 | # Puppet, Chef, Ansible, Salt, and Docker are also available. Please see the
121 | # documentation for more information about their specific syntax and use.
122 | # config.vm.provision "shell", inline: <<-SHELL
123 | # apt-get update
124 | # apt-get install -y apache2
125 | # SHELL
126 | end
127 | ```
128 |
129 |
130 |
131 | ## 测试 tcptracer-bpf
132 |
133 | tcptracer-bpf 主要用于跟踪 TCP 服务的状态跟踪(此外也实现了特定进程打开文件 fd 的事件跟踪 ),该库的亮点在于动态计算字段信息的 offset 偏移量,避免了通过引用 linux 头文件来进行连接状态信息的提取,动态计算的方式是在程序启动阶段建立本地连接获取到的事件信息来推测 sock 中各个字段信息比如源端口、目的端口等信息的 offset ,从而实现了对于内核版本的移植性。主要流程如下:
134 |
135 | 1. 在启动的时候本地建立侦听端口 127.0.0.2,然后在 127.0.0.1 设备上建立连接;
136 |
137 | 2. 在内核中使用 tcp_v{4,6}_connect 的 kprobe 探针中进行预期字段进行查找,最终确定出各个字段信息在 sock 结构中的 offset,并将将对应的 offset 保存到结构 tcptracer_status_t 中,并存入名为 tcptracer_status 的 map 结构中,实现了用户空间设置 eBPF 相关偏移量的工作;其中 tcptracer_status_t 结构中的 state 字段用于保存初始化的状态,协调用户空间的 offset 递增与 eBPF 在 kprobe 中的验证工作,在多次尝试和验证后, state 状态会被设置为 TCPTRACER_STATE_READY 状态,标志着 offset 初始化完成后;
138 |
139 | 3. 在完成 offset 初始化以后,后续的相关事件处理中,就可基于 tcptracer_status_t 中保存的 offset 信息来提取事件中的字段信息,当前的支持的字段信息如下:
140 |
141 | ```c
142 | struct tcptracer_status_t {
143 | __u64 state;
144 |
145 | /* checking */
146 | __u64 pid_tgid;
147 | __u64 what;
148 | __u64 offset_saddr;
149 | __u64 offset_daddr;
150 | __u64 offset_sport;
151 | __u64 offset_dport;
152 | __u64 offset_netns;
153 | __u64 offset_ino;
154 | __u64 offset_family;
155 | __u64 offset_daddr_ipv6;
156 |
157 | __u64 err;
158 |
159 | // 支持提取的字段信息
160 | __u32 daddr_ipv6[4];
161 | __u32 netns;
162 | __u32 saddr;
163 | __u32 daddr;
164 | __u16 sport;
165 | __u16 dport;
166 | __u16 family;
167 | __u16 padding;
168 | };
169 | ```
170 |
171 | eBPF 程序由 [tcptracer-bpf.h](https://github.com/weaveworks/tcptracer-bpf/blob/master/tcptracer-bpf.h) 和 [tcptracer-bpf.c](https://github.com/weaveworks/tcptracer-bpf/blob/master/tcptracer-bpf.c) 两个文件组成,在编译以后生产 `ebpf/tcptracer-ebpf.o` 文件,然后通过 `go-bindata` 将 `tcptracer-ebpf.o` 文件转换成 .go 文件,最后通过 go 语言导出 `pkg tracer` 供应用程序引用和使用,具体的方式可以在 `tests` 目录中的 [tracer.go](https://github.com/weaveworks/tcptracer-bpf/blob/master/tests/tracer.go) 文件中找到参考样例,其中对于 eBPF 程序操作的库为 `github.com/iovisor/gobpf/elf`。Tracer 主要结构和初始化的方式如下:
172 |
173 | ```go
174 | type Callback interface {
175 | TCPEventV4(TcpV4)
176 | TCPEventV6(TcpV6)
177 | LostV4(uint64)
178 | LostV6(uint64)
179 | }
180 |
181 | func NewTracer(cb Callback) (*Tracer, error) {
182 | // ...
183 | }
184 |
185 | type Tracer struct {
186 | m *bpflib.Module
187 | perfMapIPV4 *bpflib.PerfMap
188 | perfMapIPV6 *bpflib.PerfMap
189 | stopChan chan struct{}
190 | }
191 |
192 |
193 | // 其中 Tracer 的主要方法如下:
194 | func (t *Tracer) Start() {
195 | t.perfMapIPV4.PollStart()
196 | t.perfMapIPV6.PollStart()
197 | }
198 |
199 | func (t *Tracer) AddFdInstallWatcher(pid uint32) (err error) {
200 | var one uint32 = 1
201 | mapFdInstall := t.m.Map("fdinstall_pids")
202 | err = t.m.UpdateElement(mapFdInstall, unsafe.Pointer(&pid), unsafe.Pointer(&one), 0)
203 | return err
204 | }
205 |
206 | func (t *Tracer) RemoveFdInstallWatcher(pid uint32) (err error) {
207 | mapFdInstall := t.m.Map("fdinstall_pids")
208 | err = t.m.DeleteElement(mapFdInstall, unsafe.Pointer(&pid))
209 | return err
210 | }
211 |
212 | func (t *Tracer) Stop() {
213 | close(t.stopChan)
214 | t.perfMapIPV4.PollStop()
215 | t.perfMapIPV6.PollStop()
216 | t.m.Close()
217 | }
218 | ```
219 |
220 |
221 |
222 |
223 |
224 | 验证 tcptracer-bpf 的详细指令下:
225 |
226 | ```bash
227 | # yum install go git make -y
228 | # go get github.com/DavadDi/tcptracer-bpf
229 | # cd ~/go/src/github.com/
230 | # mv DavadDi weaveworks
231 |
232 | # From https://www.cnblogs.com/ding2016/p/11592999.html
233 | # install docker-ce
234 | # curl https://download.docker.com/linux/centos/docker-ce.repo -o /etc/yum.repos.d/docker-ce.repo
235 | # yum install https://download.docker.com/linux/fedora/30/x86_64/stable/Packages/containerd.io-1.2.6-3.3.fc30.x86_64.rpm
236 | # yum install docker-ce -y
237 |
238 | # systemctl start docker
239 |
240 | # make
241 | docker run --rm -e DEBUG=1 \
242 | -e CIRCLE_BUILD_URL= \
243 | -v /root/go/src/github.com/weaveworks/tcptracer-bpf:/src:ro \
244 | -v /root/go/src/github.com/weaveworks/tcptracer-bpf/ebpf:/dist/ \
245 | --workdir=/src \
246 | registry.qtt6.cn/paas-dev/tcptracer-bpf-builder \
247 | make -f ebpf.mk build
248 | Unable to find image 'tcptracer-bpf-builder:latest' locally
249 | latest: Pulling from dwh0403/tcptracer-bpf-builder
250 | 565884f490d9: Pull complete
251 | 978975d10f48: Pull complete
252 | 20bc768d2ae7: Pull complete
253 | a99182571ab5: Pull complete
254 | 4e052b8b7625: Pull complete
255 | Digest: sha256:f030a2c944a679fa5d7fa8da188b23e6ce972f2fa351387a24e25b2023d2e635
256 | Status: Downloaded newer image for dwh0403/tcptracer-bpf-builder:latest
257 | clang -D__KERNEL__ -D__ASM_SYSREG_H -D__BPF_TRACING__\
258 | -DCIRCLE_BUILD_URL=\"\" \
259 | -Wno-unused-value \
260 | -Wno-pointer-sign \
261 | -Wno-compare-distinct-pointer-types \
262 | -Wunused \
263 | -Wall \
264 | -Werror \
265 | -O2 -emit-llvm -c tcptracer-bpf.c \
266 | -I /usr/src/kernels/4.18.16-200.fc28.x86_64/arch/x86/include -I /usr/src/kernels/4.18.16-200.fc28.x86_64/arch/x86/include/generated -I /usr/src/kernels/4.18.16-200.fc28.x86_64/include -I /usr/src/kernels/4.18.16-200.fc28.x86_64/include/generated/uapi -I /usr/src/kernels/4.18.16-200.fc28.x86_64/arch/x86/include/uapi -I /usr/src/kernels/4.18.16-200.fc28.x86_64/include/uapi \
267 | -o - | llc -march=bpf -filetype=obj -o "/dist/tcptracer-ebpf.o"
268 | go-bindata -pkg tracer -prefix "/dist/" -modtime 1 -o "/dist/tcptracer-ebpf.go" "/dist/tcptracer-ebpf.o"
269 | sudo chown -R 0:0 ebpf
270 | cp ebpf/tcptracer-ebpf.go pkg/tracer/tcptracer-ebpf.go
271 |
272 | # cd tests
273 | # make
274 | # ./tracer
275 | # e.Timestamp, e.CPU, e.Type, e.Pid, e.Comm, e.SAddr, e.SPort, e.DAddr, e.DPort, e.NetNS
276 | 1886981614864 cpu#0 connect 15877 curl 10.0.2.15:38788 61.135.185.32:80 4026531992
277 | 1887014987197 cpu#0 close 15877 curl 10.0.2.15:38788 61.135.185.32:80 4026531992
278 |
279 | # 在另外一个窗口测试
280 | $ curl www.baidu.com
281 | ```
282 |
283 | [datadog-agent tracer-bpf](https://github.com/DataDog/https://github.com/DataDog/datadog-agent/tree/master/pkg/ebpf/tree/master/pkg/ebpf) 在上述的基础上增加了 UDP 支持,同时也增加了接受和发送字节数的统计功能。
284 |
285 | 样例程序 [**nettop**](https://github.com/DataDog/datadog-agent/tree/01fce225f1e52c97090ba0163eeb9bc0658133b4/pkg/network/nettop#toc0) 在其基础上提供了本地流量打印测试的程序。
286 |
287 |
288 |
289 | ## katran
290 |
291 | Facebook 开源的 4 层 LB 库
292 |
293 | ```
294 | # git clone https://github.com/facebookincubator/katran.git
295 | # cd katran
296 | # ./build_katran.sh
297 | ```
298 |
299 |
--------------------------------------------------------------------------------
/cilium-ebpf-go.md:
--------------------------------------------------------------------------------
1 | # Cilium ebpf go lib
2 |
3 | - [asm](https://pkg.go.dev/github.com/cilium/ebpf/asm) 包含一个基本的汇编生成器。
4 | - [link](https://pkg.go.dev/github.com/cilium/ebpf/link) 允许将附加的 eBPF 程序挂载到各类 hooks 上。
5 | - [perf](https://pkg.go.dev/github.com/cilium/ebpf/perf) 提供从 PERF_EVENT_ARRAY 读取对应的数据。
6 | - [cmd/bpf2go](https://pkg.go.dev/github.com/cilium/ebpf/cmd/bpf2go) 将 eBPF 程序嵌入到 Go 代码中。
7 |
8 | godoc 地址: https://godoc.org/github.com/cilium/ebpf
9 |
10 | ## bpf2go
11 |
12 | 可以实现将 C 代码编写的 bpf 程序编译成 Go 代码。
13 |
14 | test.c
15 |
16 | ```c
17 | // +build ignore
18 |
19 | char __license[] __attribute__((section("license"), used)) = "MIT";
20 |
21 | __attribute__((section("socket"), used)) int filter() { return 0; }
22 | ```
23 |
24 | 将 C 文件编译成 Go 代码
25 |
26 | ```bash
27 | # go build -o bpf2go
28 | # export GOPACKAGE="sock" // 定义生产 go 代码的包名
29 | # ./bpf2go -cc=clang -makebase="" -target=bpf sock test.c
30 | Compiled /root/go/src/github.com/cilium/ebpf/cmd/bpf2go/test_bpf.o
31 | Wrote /root/go/src/github.com/cilium/ebpf/cmd/bpf2go/sock_bpf.go
32 |
33 | # 最后会生成 test_bpf.o 和 sock_bpf.go
34 | ```
35 |
36 | 生成的 sock_bpf.go 完整代码如下:
37 |
38 | ```go
39 | // Code generated by bpf2go; DO NOT EDIT.
40 |
41 | package aa
42 |
43 | import (
44 | "bytes"
45 | "fmt"
46 | "io"
47 |
48 | "github.com/cilium/ebpf"
49 | )
50 |
51 | type sockSpecs struct {
52 | ProgramFilter *ebpf.ProgramSpec `ebpf:"filter"`
53 | }
54 |
55 | func newSockSpecs() (*sockSpecs, error) {
56 | reader := bytes.NewReader(_SockBytes)
57 | spec, err := ebpf.LoadCollectionSpecFromReader(reader)
58 | if err != nil {
59 | return nil, fmt.Errorf("can't load sock: %w", err)
60 | }
61 |
62 | specs := new(sockSpecs)
63 | if err := spec.Assign(specs); err != nil {
64 | return nil, fmt.Errorf("can't assign sock: %w", err)
65 | }
66 |
67 | return specs, nil
68 | }
69 |
70 | func (s *sockSpecs) CollectionSpec() *ebpf.CollectionSpec {
71 | return &ebpf.CollectionSpec{
72 | Programs: map[string]*ebpf.ProgramSpec{
73 | "filter": s.ProgramFilter,
74 | },
75 | Maps: map[string]*ebpf.MapSpec{},
76 | }
77 | }
78 |
79 | func (s *sockSpecs) Load(opts *ebpf.CollectionOptions) (*sockObjects, error) {
80 | var objs sockObjects
81 | if err := s.CollectionSpec().LoadAndAssign(&objs, opts); err != nil {
82 | return nil, err
83 | }
84 | return &objs, nil
85 | }
86 |
87 | func (s *sockSpecs) Copy() *sockSpecs {
88 | return &sockSpecs{
89 | ProgramFilter: s.ProgramFilter.Copy(),
90 | }
91 | }
92 |
93 | type sockObjects struct {
94 | ProgramFilter *ebpf.Program `ebpf:"filter"`
95 | }
96 |
97 | func (o *sockObjects) Close() error {
98 | for _, closer := range []io.Closer{
99 | o.ProgramFilter,
100 | } {
101 | if err := closer.Close(); err != nil {
102 | return err
103 | }
104 | }
105 | return nil
106 | }
107 |
108 | // Do not access this directly.
109 | var _SockBytes = []byte("0x....")
110 |
111 | ```
112 |
113 |
--------------------------------------------------------------------------------
/cilium-network-intro/images/1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/1.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/10.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/11.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/12.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/13.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/13.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/14.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/2.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/3.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/4.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/5.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/6.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/7.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/8.png
--------------------------------------------------------------------------------
/cilium-network-intro/images/9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/cilium-network-intro/images/9.png
--------------------------------------------------------------------------------
/cilium-network-intro/index.md:
--------------------------------------------------------------------------------
1 | # Cilium网络概述
2 |
3 | [toc]
4 |
5 | > 原文地址: https://mp.weixin.qq.com/s?__biz=MzIyODYzNTU2OA==&mid=2247488284&idx=1&sn=12436ea0a31daf2b2e463eced3e165dd&scene=21#wechat_redirect
6 |
7 | Cilium[1]是一种开源网络实现方案,与其他网络方案不同的是,Cilium着重强调了其在网络安全上的优势,可以透明的对Kubernetes等容器管理平台上的应用程序服务之间的网络连接进行安全防护。
8 |
9 | Cilium在设计和实现上,基于Linux的一种新的内核技术eBPF[2],可以在Linux内部动态插入强大的安全性、可见性和网络控制逻辑,相应的安全策略可以在不修改应用程序代码或容器配置的情况下进行应用和更新。
10 |
11 | Cilium在其官网上对产品的定位称为“API-aware Networking and Security”,因此可以看出,其特性主要包括这三方面:
12 |
13 | (1)提供Kubernetes中基本的网络互连互通的能力,实现容器集群中包括Pod、Service等在内的基础网络连通功能;
14 |
15 | (2)依托eBPF,实现Kubernetes中网络的可观察性以及基本的网络隔离、故障排查等安全策略;
16 |
17 | (3)依托eBPF,突破传统主机防火墙仅支持L3、L4微隔离的限制,支持基于API的网络安全过滤能力。Cilium提供了一种简单而有效的方法来定义和执行基于容器/Pod身份(Identity Based)的网络层和应用层(比如HTTP/gRPC/Kafka等)安全策略。
18 |
19 | ## 一、架构
20 |
21 | Cilium官方给出了如下的参考架构[3],Cilium位于容器编排系统和Linux Kernel之间,向上可以通过编排平台为容器进行网络以及相应的安全配置,向下可以通过在Linux内核挂载eBPF程序,来控制容器网络的转发行为以及安全策略执行。
22 |
23 | 
24 |
25 | 图1 Cilium架构
26 |
27 | 在Cilium的架构中,除了Key-Value数据存储之外,主要组件包括Cilium Agent和Cilium Operator,还有一个客户端的命令行工具Cilium CLI。
28 |
29 | Cilium Agent作为整个架构中最核心的组件,通过DaemonSet的方式,以特权容器的模式,运行在集群的每个主机上。Cilium Agent作为用户空间守护程序,通过插件与容器运行时和容器编排系统进行交互,进而为本机上的容器进行网络以及安全的相关配置。同时提供了开放的API,供其他组件进行调用。
30 |
31 | Cilium Agent在进行网络和安全的相关配置时,采用eBPF程序进行实现。Cilium Agent结合容器标识和相关的策略,生成eBPF程序,并将eBPF程序编译为字节码,将它们传递到Linux内核。
32 |
33 | 
34 |
35 | 图2 Cilium部署架构
36 |
37 | Cilium Operator 主要负责管理集群中的任务,尽可能的保证以集群为单位,而不是单独的以节点为单位进行任务处理。主要包括,通过etcd为节点之间同步资源信息、确保Pod的DNS可以被Cilium管理、集群NetworkPolicy的管理和更新等。
38 |
39 | ## 二、组网模式
40 |
41 | Cilium提供多种组网模式,默认采用基于vxlan的overlay组网。除此之外,还包括:
42 |
43 | (1)通过BGP路由的方式,实现集群间Pod的组网和互联;
44 |
45 | (2)在AWS的ENI(Elastic Network Interfaces)模式下部署使用Cilium;
46 |
47 | (3)Flannel和Cilium的集成部署;
48 |
49 | (4)采用基于ipvlan的组网,而不是默认的基于veth;
50 |
51 | (5)Cluster Mesh组网,实现跨多个Kubernetes集群的网络连通和安全性
52 |
53 | 等多种组网模式[4]。
54 |
55 | 本文将针对默认的基于vxlan的overlay组网,进行深度的原理和数据包路径分析。
56 |
57 | ## 三、Overlay组网
58 |
59 | 使用官方给出的yaml文件,通过下述命令,实现Cilium的快速部署。
60 |
61 | ```bash
62 | 1root@u18-161:~# kubectl create -f https://raw.githubusercontent.com/cilium/cilium/v1.6.5/install/kubernetes/quick-install.yaml
63 | ```
64 |
65 | 部署成功后,我们可以发现,在集群的每个主机上,启动了一个Cilium Agent(cilium-k54qt,cilium-v7fx4),整个集群启动了一个Cilium Operator(cilium-operator-cdb4d8bb6-8mj5w)。
66 |
67 | ```bash
68 | 1root@u18-161:~# kubectl get pods --all-namespaces -o wide | grep cilium
69 | 2NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
70 | 4kube-system cilium-k54qt 1/1 Running 0 80d 192.168.19.161 u18-161
71 | 5kube-system cilium-v7fx4 1/1 Running 0 80d 192.168.19.162 u18-162
72 | 7kube-system cilium-operator-cdb4d8bb6-8mj5w 1/1 Running 1 80d 192.168.19.162 u18-162
73 | ```
74 |
75 | 在这种默认的组网情况下,主机上的网络发生了以下变化:在主机的root命名空间,新增了如下图所示的四个虚拟网络接口,其中cilium_vxlan主要是处理对数据包的vxlan隧道操作,采用metadata模式,并不会为这个接口分配ip地址;cilium_host作为主机上该子网的一个网关,并且在node-161为其自动分配了ip地址10.244.0.26/32,cilium_net和cilium_host作为一对veth而创建,还有一个lxc_health。
76 |
77 | 在每个主机上,可以进入Cilium Agent,查看其隧道配置。比如进入主机node-161上的Cilium Agent cilium-k54qt,运行cilium bpf tunnel list,可以看到,其为集群中的另一台主机node-162(192.168.19.162)上的虚拟网络10.244.1.0创建了一个隧道。同样在node-162上也有一条这样的隧道配置。
78 |
79 | 
80 |
81 | 图3 Cilium默认overlay组网
82 |
83 | 接下来创建Pod1和Pod2运行于node-161,Pod3和Pod4运行于node-162。其与主机的root命名空间,通过veth-pair连接,如下图所示。
84 |
85 | 
86 |
87 | 图4 测试环境组网示例
88 |
89 | 进入Pod1,可以发现,Cilium已经为其分配了IP地址,并且设置了默认的路由,默认路由指向了本机的cilium_host。初始状态Pod内的arp表为空。
90 |
91 | ```bash
92 | 1root@u18-161:~# kubectl exec -it test-1-7cd5798f46-vzf9s -n test-1 bash
93 | 2root@test-1-7cd5798f46-vzf9s:/# route -n
94 | 3Kernel IP routing table
95 | 4Destination Gateway Genmask Flags Metric Ref Use Iface
96 | 50.0.0.0 10.244.0.26 0.0.0.0 UG 0 0 0 eth0
97 | 610.244.0.26 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
98 | 7root@test-1-7cd5798f46-vzf9s:/# arp
99 | 8root@test-1-7cd5798f46-vzf9s:/#
100 | ```
101 |
102 |
103 |
104 | 在Pod1中ping Pod2,通过抓包可以发现,Pod发出的ARP请求,其对应的ARP响应直接通过其对端的veth-pair 接口返回(52:c6:5e:ef:6e:97和5e:2d:20:9d:b1:a8是Pod1对应的veth-pair)。这个ARP响应是通过Cilium Agent通过挂载的eBPF程序实现的自动应答,并且将veth-pair对端的MAC地址返回,避免了虚拟网络中的ARP广播问题。
105 |
106 | ```bash
107 | 1No. Time Source Destination Protocol Length Info
108 | 2133 39.536478 52:c6:5e:ef:6e:97 5e:2d:20:9d:b1:a8 ARP 42 Who has 10.244.0.26? Tell 10.244.0.71
109 | 3134 39.536617 5e:2d:20:9d:b1:a8 52:c6:5e:ef:6e:97 ARP 42 10.244.0.26 is at 5e:2d:20:9d:b1:a8
110 | ```
111 |
112 | ### 3.1**主机内Pod通信**
113 |
114 | 分析完组网状态之后,那么同一个主机内,两个Pod间通信的情况,就很容易理解了。例如,Pod1向Pod2发包,其数据通路如下图所示Pod1 --> eth0 --> lxc909734ef58f7 --> lxc7c0fcdd49dd0 --> eth0 --> Pod2。
115 |
116 | 
117 |
118 | 图5 主机内Pod通信路径
119 |
120 | ### 3.2 **跨主机Pod通信**
121 |
122 | 在这种Overlay组网模式下,Pod跨节点之间的通信,通过vxlan实现隧道的封装,其数据路径如下图所示pod1 --> eth0 --> lxc909734ef58f7 --> cilium_vxlan --> eth0(node-161) --> eth0(node-162) --> cilium_vxlan --> lxc2df34a40a888 --> eth0 --> pod3。
123 |
124 | 
125 |
126 | 图6 跨主机节点Pod通信路径
127 |
128 | 我们在cilium_vxlan虚拟网络接口上抓包,如下所示。从抓包分析可以看出,Linux内核将Pod1发出的原始数据包发送到cilium_vxlan进行隧道相关的封包、解包处理,然后再将其送往主机的物理网卡eth0。
129 |
130 | 
131 |
132 | 图7 cilium_vxlan抓包
133 |
134 | 在物理网卡eth0抓包可以发现,Pod1出发的数据包经过cilium_vxlan的封装处理之后,其源目的地址已经变成物理主机node-161和node-162,这是经典的overlay封装。同时,还可以发现,cilium_vxlan除了对数据包进行了隧道封装之外,还将原始数据包进行了TLS加密处理,保障了数据包在主机外的物理网络中的安全性。
135 |
136 | 
137 |
138 | 图8 node-161 eth0抓包
139 |
140 | ## 四、API感知的安全性
141 |
142 | ### 4.1**安全可视化与分析**
143 |
144 | Cilium在1.17版本之后,推出并开源了其网络可视化组件Hubble[5],Hubble是建立在Cilium和eBPF之上,以一种完全透明的方式,提供网络基础设施通信以及应用行为的深度可视化,是一个应用于云原生工作负载,完全分布式的网络和安全可观察性平台。
145 |
146 | Hubble能够利用Cilium提供的eBPF数据路径,获得对Kubernetes应用和服务网络流量的深度可见性。这些网络流量信息可以对接Hubble CLI、UI工具,可以通过交互式的方式快速发现诊断相关的网络问题与安全问题。Hubble除了自身的监控工具,还可以对接像Prometheus、Grafana等主流的云原生监控体系,实现可扩展的监控策略。
147 |
148 | 
149 |
150 | 图9 Hubble架构图
151 |
152 | 从上图的架构以及Hubble部署可以看出,Hubble在Cilium Agent之上,以DaemonSet的方式运行自己的Agent,笔者这里的部署示例采用Hubble UI来操作和展示相关的网络以及安全数据。
153 |
154 | ```
155 | 1root@u18-163:~# kubectl get pods --all-namespaces -o wide | grep hubble
156 | 2kube-system hubble-5tvzc 1/1 Running 16 66d 10.244.1.209 u18-164
157 | 3kube-system hubble-k9ft8 1/1 Running 0 34m 10.244.0.198 u18-163
158 | 4kube-system hubble-ui-5f9fc85849-x7lnl 1/1 Running 4 67d 10.244.0.109 u18-163
159 | ```
160 |
161 |
162 |
163 | 依托于Hubble深入的对网络数据和行为的可观察性,其可以为网络和安全运维人员提供以下相关能力:
164 |
165 | **服务依赖关系和通信映射拓扑:**比如,可以知道哪些服务之间在相互通信?这些服务通信的频率是多少?服务依赖关系图是什么样的?正在进行什么HTTP调用?服务正在消费或生产哪些Kafka的Topic等。
166 |
167 | **运行时的网络监控和告警:**比如,可以知道是否有网络通信失败了?为什么通信会失败?是DNS的问题?还是应用程序得问题?还是网络问题?是在第4层(TCP)或第7层(HTTP)的发生的通信中断等;哪些服务在过去5分钟内遇到了DNS解析的问题?哪些服务最近经历了TCP连接中断或看到连接超时?TCP SYN请求的未回答率是多少?等等。
168 |
169 | **应用程序的监控:**比如,可以知道针对特定的服务或跨集群服务,HTTP 4xx或者5xx响应码速率是多少?在我的集群中HTTP请求和响应之间的第95和第99百分位延迟是多少?哪些服务的性能最差?两个服务之间的延迟是什么?等等这些问题。
170 |
171 | **安全可观察性:**比如,可以知道哪些服务的连接因为网络策略而被阻塞?从集群外部访问了哪些服务?哪些服务解析了特定的DNS名称?等等。
172 |
173 | 
174 |
175 | 图10 Hubble界面功能
176 |
177 | 从上图Hubble的界面,我们可以简单的看出其部分功能和数据,比如,可以直观的显示出网路和服务之间的通信关系,可以查看Flows的多种详细数据指标,可以查看对应的安全策略情况,可以通过namespace对观测结果进行过滤等等。
178 |
179 | ### 4.2 **微隔离**
180 |
181 | 默认情况下,Cilium与其他网络插件一样,提供了整个集群网络的完全互联互通,用户需要根据自己的应用服务情况设定相应的安全隔离策略。如下图所示,每当用户新创建一个Pod,或者新增加一条安全策略,Cilium Agent会在主机对应的虚拟网卡驱动加载相应的eBPF程序,实现网络连通以及根据安全策略对数据包进行过滤。比如,可以通过采用下面的NetworkPolicy实现一个基本的L3/L4层网络安全策略。
182 |
183 | ```yaml
184 | apiVersion: "cilium.io/v2"
185 | kind: CiliumNetworkPolicy
186 | description: "L3-L4 policy to restrict deathstar access to empire ships only"
187 | metadata:
188 | name: "rule1"
189 | spec:
190 | endpointSelector:
191 | matchLabels:
192 | org: empire
193 | class: deathstar
194 | ingress:
195 | - fromEndpoints:
196 | - matchLabels:
197 | org: empire
198 | toPorts:
199 | - ports:
200 | - port: "80"
201 | protocol: TCP
202 | ```
203 |
204 |
205 |
206 | 
207 |
208 | 图11 Cilium网络隔离方案示意图
209 |
210 | 然而,在微服务架构中,一个基于微服务的应用程序通常被分割成一些独立的服务,这些服务通过API(使用HTTP、gRPC、Kafka等轻量级协议)实现彼此的通信。因此,仅实现在L3/L4层的网络安全策略,缺乏对于微服务层的可见性以及对API的细粒度隔离访问控制,在微服务架构中是不够的。
211 |
212 | 我们可以看如下这个例子,Job Postings这个服务暴露了其服务的健康检查、以及一些增、删、改、查的API。Gordon作为一个求职者,需要访问Job Postings提供的Jobs相关信息。按照传统的L3/L4层的隔离方法,可以通过iptables -s 10.1.1.1 -p tcp –dport 80 -j ACCEPT,允许Gordon来访问Job Postings在80端口提供的HTTP服务。但是这样的网络规则,导致Gordon同样可以访问包括发布信息、修改信息、甚至是删除信息等其他接口。这样的情况肯定是我们的服务设计者所不希望发生的,同时也存在着严重的安全隐患。
213 |
214 | 
215 |
216 | 图12 L7微隔离示例
217 |
218 | 因此,实现微服务间的L7层隔离,实现其对应的API级别的访问控制,是微服务网络微隔离的一个重要部分。Cilium在为Docker和Kubernetes等基于Linux的容器框架提供了支持API层面的网络安全过滤能力。通过使用eBPF,Cilium提供了一种简单而有效的方法来定义和执行基于容器/pod身份的网络层和应用层安全策略。我们可以通过采用下面的NetworkPolicy实现一个L7层网络安全策略。
219 |
220 | 
221 |
222 | 图13 Cilium实现微服务安全
223 |
224 | ```yaml
225 | apiVersion: "cilium.io/v2"
226 | kind: CiliumNetworkPolicy
227 | description: "L7 policy to restrict access to specific HTTP call"
228 | metadata:
229 | name: "rule1"
230 | spec:
231 | endpointSelector:
232 | matchLabels:
233 | org: empire
234 | class: deathstar
235 | ingress:
236 | - fromEndpoints:
237 | - matchLabels:
238 | org: empire
239 | toPorts:
240 | - ports:
241 | - port: "80"
242 | protocol: TCP
243 | rules:
244 | http:
245 | - method: "POST"
246 | path: "/v1/request-landing"
247 | ```
248 |
249 | Cilium还提供了一种基于Proxy的实现方式,可以更方便的对L7协议进行扩展。如下图所示,Cilium Agent采用eBPF实现对数据包的重定向,将需要进行过滤的数据包首先转发至Proxy代理,Proxy代理根据其相应的过滤规则,对收到的数据包进行过滤,然后再将其发回至数据包的原始路径,而Proxy代理进行过滤的规则,则通过Cilium Agent进行下发和管理。
250 |
251 | 当需要扩展协议时,只需要在Proxy代理中,增加对新协议的处理解析逻辑以及规则处置逻辑,即可实现相应的过滤能力。
252 |
253 | 
254 |
255 | 图14 L7层访问控制协议扩展原理图
256 |
257 | ## 五、总结
258 |
259 | Cilium是一个基于eBPF和XDP的高性能网络方案,本文着重介绍了其原理以及默认的overlay组网通信。除了基本的网络通信能力外,Cilium还包含了基于eBPF的负载均衡能力,L3/L4/L7的安全策略能力等相关的内容,后续会进行更详细的实践分析。
260 |
261 |
262 |
263 | ## 参考文献
264 |
265 | ------
266 |
267 | [1] https://cilium.io
268 |
269 | [2] https://mp.weixin.qq.com/s/pPDO4NpDoIblh4taJXVuzw
270 |
271 | [3] https://cilium.readthedocs.io/en/stable/concepts/overview/
272 |
273 | [4] https://cilium.readthedocs.io/en/stable/gettingstarted/#advanced-networking
274 |
275 | [5] https://cilium.io/blog/2019/11/19/announcing-hubble/
--------------------------------------------------------------------------------
/compile-bpf-examples/images/bpf-kernel-examples.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/compile-bpf-examples/images/bpf-kernel-examples.png
--------------------------------------------------------------------------------
/ebpf_bcc_trace_open_ex/open.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | from bcc import BPF
3 |
4 | prog = """
5 | #include
6 |
7 | int trace_syscall_open(struct pt_regs *ctx, const char __user *filename, int flags) {
8 | u32 pid = bpf_get_current_pid_tgid() >> 32;
9 | u32 uid = bpf_get_current_uid_gid();
10 |
11 | char comm[TASK_COMM_LEN];
12 | bpf_get_current_comm(&comm, sizeof(comm));
13 |
14 | bpf_trace_printk("%d [%s]\\n", pid, filename);
15 | return 0;
16 | }
17 | """
18 |
19 | b = BPF(text=prog)
20 | b.attach_kprobe(event=b.get_syscall_fnname("open"), fn_name="trace_syscall_open")
21 | try:
22 | b.trace_print()
23 | except KeyboardInterrupt:
24 | exit()
25 |
--------------------------------------------------------------------------------
/ebpf_bcc_trace_open_ex/open_perf_output.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | from bcc import BPF
3 |
4 | prog = """
5 | #include // for NAME_MAX
6 |
7 | // 1 define struct
8 | struct event_data_t {
9 | u32 pid;
10 | char fname[NAME_MAX]; // max of filename
11 | };
12 |
13 | // 2. declare BPF_PERF_OUTPUT define
14 | BPF_PERF_OUTPUT(open_events);
15 |
16 | int trace_syscall_open(struct pt_regs *ctx, const char __user *filename, int flags) {
17 | u32 pid = bpf_get_current_pid_tgid() >> 32;
18 |
19 | // 3.1 define event data and fill data
20 | struct event_data_t evt = {};
21 |
22 | evt.pid = pid;
23 | bpf_probe_read(&evt.fname, sizeof(evt.fname), (void *)filename);
24 |
25 | // bpf_trace_printk("%d [%s]\\n", pid, filename); =>
26 |
27 | // 3.2 submit the event
28 | open_events.perf_submit(ctx, &evt, sizeof(evt));
29 |
30 | return 0;
31 | }
32 | """
33 |
34 | b = BPF(text=prog)
35 | b.attach_kprobe(event=b.get_syscall_fnname("open"), fn_name="trace_syscall_open")
36 |
37 | # process event
38 | def print_event(cpu, data, size):
39 | event = b["open_events"].event(data)
40 | print("Rcv Event %d, %s"%(event.pid, event.fname))
41 |
42 | # loop with callback to print_event
43 | b["open_events"].open_perf_buffer(print_event)
44 | while True:
45 | try:
46 | b.perf_buffer_poll()
47 | except KeyboardInterrupt:
48 | exit()
49 |
--------------------------------------------------------------------------------
/ebpf_bcc_trace_open_ex/open_perf_output_ret.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | from bcc import BPF
3 |
4 | prog = """
5 | #include // for NAME_MAX
6 | #include // for TASK_COMM_LEN
7 |
8 | struct event_data_t {
9 | u32 pid;
10 | u32 ret; // +add
11 | char comm[TASK_COMM_LEN];
12 | char fname[NAME_MAX];
13 | };
14 |
15 | // +add
16 | struct val_t {
17 | u64 id;
18 | const char *fname;
19 | };
20 |
21 | BPF_HASH(infotmp, u64, struct val_t);
22 | BPF_PERF_OUTPUT(open_events);
23 |
24 | int trace_syscall_open(struct pt_regs *ctx, const char __user *filename, int flags) {
25 | struct val_t val = {};
26 | u64 id = bpf_get_current_pid_tgid();
27 |
28 | val.id = id;
29 | val.fname = filename;
30 |
31 | infotmp.update(&id, &val);
32 |
33 | return 0;
34 | }
35 |
36 | int trace_syscall_open_return(struct pt_regs *ctx)
37 | {
38 | u64 id = bpf_get_current_pid_tgid();
39 | struct val_t *valp;
40 | struct event_data_t evt = {};
41 |
42 | valp = infotmp.lookup(&id);
43 | if (valp == 0) {
44 | // missed entry
45 | return 0;
46 | }
47 |
48 | evt.pid = id >> 32;
49 | evt.ret = PT_REGS_RC(ctx);
50 | bpf_probe_read(&evt.fname, sizeof(evt.fname), (void *)valp->fname);
51 | bpf_get_current_comm(&evt.comm, sizeof(evt.comm));
52 |
53 | open_events.perf_submit(ctx, &evt, sizeof(evt));
54 |
55 | infotmp.delete(&id);
56 | return 0;
57 | }
58 | """
59 |
60 | b = BPF(text=prog)
61 | b.attach_kprobe(event=b.get_syscall_fnname("open"), fn_name="trace_syscall_open")
62 | b.attach_kretprobe(event=b.get_syscall_fnname("open"), fn_name="trace_syscall_open_return")
63 |
64 | # process event
65 | def print_event(cpu, data, size):
66 | event = b["open_events"].event(data)
67 | print("[%s] %d, %s, res: %d"%(event.comm, event.pid, event.fname, event.ret))
68 |
69 | # loop with callback to print_event
70 | b["open_events"].open_perf_buffer(print_event)
71 | while True:
72 | try:
73 | b.perf_buffer_poll()
74 | except KeyboardInterrupt:
75 | exit()
76 |
--------------------------------------------------------------------------------
/ebpf_bcc_trace_open_ex/open_pid.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | from bcc import BPF
3 | import argparse # +add
4 |
5 | prog = """
6 | #include
7 |
8 | int trace_syscall_open(struct pt_regs *ctx, const char __user *filename, int flags) {
9 | u32 pid = bpf_get_current_pid_tgid() >> 32;
10 | u32 uid = bpf_get_current_uid_gid();
11 |
12 | PID_FILTER // + add PID FILTER
13 | char comm[TASK_COMM_LEN];
14 | bpf_get_current_comm(&comm, sizeof(comm));
15 |
16 | bpf_trace_printk("%d [%s]\\n", pid, filename);
17 | return 0;
18 | }
19 | """
20 |
21 | examples = """examples:
22 | ./open_pid -p 181 # only trace PID 181
23 | """
24 |
25 | parser = argparse.ArgumentParser(
26 | description="Trace open() syscalls",
27 | formatter_class=argparse.RawDescriptionHelpFormatter,
28 | epilog=examples)
29 |
30 | parser.add_argument("-p", "--pid",
31 | help="trace this PID only")
32 |
33 | args = parser.parse_args()
34 |
35 | if args.pid:
36 | prog = prog.replace('PID_FILTER',
37 | 'if (pid != %s) { return 0; }' % args.pid)
38 | else:
39 | prog = prog.replace('PID_TID_FILTER', '')
40 |
41 | b = BPF(text=prog)
42 | b.attach_kprobe(event=b.get_syscall_fnname("open"), fn_name="trace_syscall_open")
43 | try:
44 | b.trace_print()
45 | except KeyboardInterrupt:
46 | exit()
47 |
--------------------------------------------------------------------------------
/ebpf_bcc_trace_open_ex/tp_open_perf_output.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | from bcc import BPF
3 | from bcc import DEBUG_PREPROCESSOR
4 |
5 | prog = """
6 | #include // for NAME_MAX
7 |
8 | struct event_data_t {
9 | u32 pid;
10 | char fname[NAME_MAX]; // max of filename
11 | };
12 |
13 | BPF_PERF_OUTPUT(open_events);
14 |
15 | TRACEPOINT_PROBE(syscalls,sys_enter_open){
16 | u32 pid = bpf_get_current_pid_tgid() >> 32;
17 | struct event_data_t evt = {};
18 |
19 | evt.pid = pid;
20 | bpf_probe_read(&evt.fname, sizeof(evt.fname), (void *)args->filename);
21 |
22 | open_events.perf_submit((struct pt_regs *)args, &evt, sizeof(evt));
23 | return 0;
24 | }
25 | """
26 |
27 | b = BPF(text=prog, debug=DEBUG_PREPROCESSOR)
28 |
29 | # process event
30 | def print_event(cpu, data, size):
31 | event = b["open_events"].event(data)
32 | print("Rcv Event %d, %s"%(event.pid, event.fname))
33 |
34 | # loop with callback to print_event
35 | b["open_events"].open_perf_buffer(print_event)
36 | while True:
37 | try:
38 | b.perf_buffer_poll()
39 | except KeyboardInterrupt:
40 | exit()
41 |
--------------------------------------------------------------------------------
/ebpf_network_kpath_ipvs/imgs/client_ping_wireshark.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/ebpf_network_kpath_ipvs/imgs/client_ping_wireshark.png
--------------------------------------------------------------------------------
/ebpf_network_kpath_ipvs/imgs/estimation_timer_flamgraph.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/ebpf_network_kpath_ipvs/imgs/estimation_timer_flamgraph.png
--------------------------------------------------------------------------------
/ebpf_network_kpath_ipvs/imgs/estimation_timer_funcgraph.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/ebpf_network_kpath_ipvs/imgs/estimation_timer_funcgraph.png
--------------------------------------------------------------------------------
/ebpf_network_kpath_ipvs/imgs/netcard_dev_softirq.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/ebpf_network_kpath_ipvs/imgs/netcard_dev_softirq.png
--------------------------------------------------------------------------------
/ebpf_network_kpath_ipvs/imgs/perf_kernel_cpu0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/ebpf_network_kpath_ipvs/imgs/perf_kernel_cpu0.png
--------------------------------------------------------------------------------
/ebpf_network_kpath_ipvs/imgs/ping_host_container.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/ebpf_network_kpath_ipvs/imgs/ping_host_container.png
--------------------------------------------------------------------------------
/ebpf_network_kpath_ipvs/imgs/ping_host_container_detail.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/ebpf_network_kpath_ipvs/imgs/ping_host_container_detail.png
--------------------------------------------------------------------------------
/ebpf_network_kpath_ipvs/imgs/ping_server_pcap.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/ebpf_network_kpath_ipvs/imgs/ping_server_pcap.png
--------------------------------------------------------------------------------
/ebpf_network_kpath_ipvs/imgs/service_latency_high.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/ebpf_network_kpath_ipvs/imgs/service_latency_high.png
--------------------------------------------------------------------------------
/ebpf_network_kpath_ipvs/imgs/timer_softirq_hist.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/ebpf_network_kpath_ipvs/imgs/timer_softirq_hist.png
--------------------------------------------------------------------------------
/ebpf_on_windows/imgs/ebpf_on_windows_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/ebpf_on_windows/imgs/ebpf_on_windows_arch.png
--------------------------------------------------------------------------------
/ebpf_on_windows/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "在 Windows 平台上启用 eBPF【译】"
3 | date: 2021-05-11T15:04:10+08:00
4 | keywords:
5 | - windows
6 | - ebpf
7 | - ebpf-for-windows
8 | description: "今天,我们很高兴地宣布一个新的微软开源项目,以使 eBPF 在 Windows 10 和 Windows Server 2016 及以后的版本上运行。旨在让开发者在现有版本的 Windows 之上使用熟悉的eBPF工具链和应用编程接口(API)。在其他项目的基础上,该项目采用了几个现有的 eBPF 开源项目,并添加了'胶水',以使其能在Windows 上运行。"
9 | tags: ["ebpf", "windows"]
10 | categories: ["BPF"]
11 | ---
12 |
13 | ## 前言
14 |
15 | [eBPF](https://ebpf.io/) 是一项众所周知的革命性技术--提供了可编程性、可扩展性和敏捷性。eBPF 已被应用于拒绝服务保护和可观察性等场景。随着时间的推移,围绕eBPF建立了重要的工具,产品和经验生态系统。尽管最初在 Linux 内核中实现了对 eBPF 的支持,但是人们越来越关注允许 eBPF在其他操作系统上使用,并且除了内核以外,还可以扩展用户模式服务和守护程序。
16 |
17 | 今天,我们很高兴地宣布一个新的微软开源项目,以使 eBPF 在 Windows 10 和 Windows Server 2016 及以后的版本上运行。[ebpf-for-windows 项目](https://aka.ms/ebpf-for-windows)旨在让开发者在现有版本的 Windows 之上使用熟悉的eBPF工具链和应用编程接口(API)。在其他项目的基础上,该项目采用了几个现有的 eBPF 开源项目,并添加了 "胶水",以使其能在Windows 上运行。
18 |
19 | 我们宣布这个消息时,但该项目仍处于相对早期的开发阶段,因为我们的目标是与强大的 eBPF 社区合作,以确保 eBPF 在 Windows 和其他地方都可以正常工作。
20 |
21 | ## 架构概述
22 |
23 | 下图说明了该项目的结构和相关的组成部分。
24 |
25 | 
26 |
27 | 如图所示,现有的 eBPF 工具链(如 clang)可以用来从各种语言的源代码中生成 eBPF 字节码。然后,生成的字节码可以被任何应用程序使用,或者通过 Windows netsh 命令行工具手动使用,这两种工具都使用了[Libbpf API的](https://github.com/libbpf/libbpf)的共享库,相关工作仍在进行中。
28 |
29 | 该库将 eBPF 字节码发送到一个静态验证器([PREVAIL验证器](https://github.com/vbpf/ebpf-verifier)),该验证器托管在一个用户模式[保护进程中](https://docs.microsoft.com/en-us/windows/win32/services/protecting-anti-malware-services-#system-protected-process),这是一个 Windows 安全环境,允许内核组件信任一个由其信任的密钥签署的用户模式守护程序。如果字节码通过了验证器的所有安全检查,该字节码可以被加载到运行在 Windows 内核模式执行上下文中的 [uBPF解释器中](https://github.com/iovisor/ubpf),或者由 [uBPF](https://github.com/iovisor/ubpf) 即时编译器(JIT)进行编译,并将本地代码加载到内核模式执行上下文中。
30 |
31 | 安装到内核模式执行上下文的 eBPF 程序可以附加到各种钩子上,以处理事件和调用 eBPF shim 暴露的各种帮助API,它在内部包装了公共的 Windows 内核API,以允许在现有版本的 Windows 上使用 eBPF。到目前为止,已经添加了两个钩子(XDP 和 socket 套接字绑定),虽然这些是网络专用的钩子,但我们希望随着时间的推移,将添加更多的钩子和帮助函数,而不仅仅是与网络有关的*。*
32 |
33 | ## 是eBPF的fork吗?
34 |
35 | 简而言之,不是。
36 |
37 | eBPF for Windows 项目利用现有的开源项目,包括 [IOVisor uBPF项目](https://github.com/iovisor/ubpf)和 [PREVAIL验证器](https://github.com/vbpf/ebpf-verifier),通过为该代码添加Windows 特定的托管环境,在 Windows 之上运行它们。
38 |
39 | ## 是否提供Linux eBPF程序的兼容性?
40 |
41 | 其目的是为使用通用钩子和助手的代码提供源代码兼容性,这些钩子和帮助函数适用于整个操作系统的生态系统。
42 |
43 | Linux 提供了许多钩子和帮助函数,其中一些是非常具体的 Linux(如使用 Linux 内部数据结构),将不适用于其他平台。其他的钩子和帮助函数是普遍适用的,目的是支持它们用于 eBPF 程序。
44 |
45 | 同样,eBPF for Windows项目公开了[Libbpf APIs](https://github.com/libbpf/libbpf),为与eBPF程序互动的应用程序提供源代码兼容性。
46 |
47 | ## 了解更多信息并做出贡献
48 |
49 | [ebpf-for-windows 项目](https://aka.ms/ebpf-for-windows)将 eBPF 的力量带给 Windows 用户,并打算最终驻扎在 eBPF 生态系统中一个社区管理的基础上。有了你的投入和帮助,我们可以达到这个目标。
50 |
51 | 请联系我们或 [GitHub ](https://aka.ms/ebpf-for-windows)上创建一个问题。我们很高兴能继续完善和扩展 ebpf-for-windows,使每个人都能从这个项目中受益。我们渴望看到你对这个项目的发现以及它的发展。
52 |
53 |
54 | 原文地址:https://cloudblogs.microsoft.com/opensource/2021/05/10/making-ebpf-work-on-windows/
55 |
56 | 作者:[Dave Thaler](https://cloudblogs.microsoft.com/opensource/author/dave-thaler/) && [Poorna Gaddehosur](https://cloudblogs.microsoft.com/opensource/author/poorna-gaddehosur/)
57 |
58 |
--------------------------------------------------------------------------------
/ebpf_tcp_cc/bpf_dctcp.c:
--------------------------------------------------------------------------------
1 | // SPDX-License-Identifier: GPL-2.0
2 | /* Copyright (c) 2019 Facebook */
3 |
4 | /* WARNING: This implemenation is not necessarily the same
5 | * as the tcp_dctcp.c. The purpose is mainly for testing
6 | * the kernel BPF logic.
7 | */
8 |
9 | #include
10 | #include
11 | #include
12 | #include
13 | #include
14 | #include "bpf_tcp_helpers.h"
15 |
16 | char _license[] SEC("license") = "GPL";
17 |
18 | int stg_result = 0;
19 |
20 | struct {
21 | __uint(type, BPF_MAP_TYPE_SK_STORAGE);
22 | __uint(map_flags, BPF_F_NO_PREALLOC);
23 | __type(key, int);
24 | __type(value, int);
25 | } sk_stg_map SEC(".maps");
26 |
27 | #define DCTCP_MAX_ALPHA 1024U
28 |
29 | struct dctcp {
30 | __u32 old_delivered;
31 | __u32 old_delivered_ce;
32 | __u32 prior_rcv_nxt;
33 | __u32 dctcp_alpha;
34 | __u32 next_seq;
35 | __u32 ce_state;
36 | __u32 loss_cwnd;
37 | };
38 |
39 | static unsigned int dctcp_shift_g = 4; /* g = 1/2^4 */
40 | static unsigned int dctcp_alpha_on_init = DCTCP_MAX_ALPHA;
41 |
42 | static __always_inline void dctcp_reset(const struct tcp_sock *tp,
43 | struct dctcp *ca)
44 | {
45 | ca->next_seq = tp->snd_nxt;
46 |
47 | ca->old_delivered = tp->delivered;
48 | ca->old_delivered_ce = tp->delivered_ce;
49 | }
50 |
51 | SEC("struct_ops/dctcp_init")
52 | void BPF_PROG(dctcp_init, struct sock *sk)
53 | {
54 | const struct tcp_sock *tp = tcp_sk(sk);
55 | struct dctcp *ca = inet_csk_ca(sk);
56 | int *stg;
57 |
58 | ca->prior_rcv_nxt = tp->rcv_nxt;
59 | ca->dctcp_alpha = min(dctcp_alpha_on_init, DCTCP_MAX_ALPHA);
60 | ca->loss_cwnd = 0;
61 | ca->ce_state = 0;
62 |
63 | stg = bpf_sk_storage_get(&sk_stg_map, (void *)tp, NULL, 0);
64 | if (stg) {
65 | stg_result = *stg;
66 | bpf_sk_storage_delete(&sk_stg_map, (void *)tp);
67 | }
68 | dctcp_reset(tp, ca);
69 | }
70 |
71 | SEC("struct_ops/dctcp_ssthresh")
72 | __u32 BPF_PROG(dctcp_ssthresh, struct sock *sk)
73 | {
74 | struct dctcp *ca = inet_csk_ca(sk);
75 | struct tcp_sock *tp = tcp_sk(sk);
76 |
77 | ca->loss_cwnd = tp->snd_cwnd;
78 | return max(tp->snd_cwnd - ((tp->snd_cwnd * ca->dctcp_alpha) >> 11U), 2U);
79 | }
80 |
81 | SEC("struct_ops/dctcp_update_alpha")
82 | void BPF_PROG(dctcp_update_alpha, struct sock *sk, __u32 flags)
83 | {
84 | const struct tcp_sock *tp = tcp_sk(sk);
85 | struct dctcp *ca = inet_csk_ca(sk);
86 |
87 | /* Expired RTT */
88 | if (!before(tp->snd_una, ca->next_seq)) {
89 | __u32 delivered_ce = tp->delivered_ce - ca->old_delivered_ce;
90 | __u32 alpha = ca->dctcp_alpha;
91 |
92 | /* alpha = (1 - g) * alpha + g * F */
93 |
94 | alpha -= min_not_zero(alpha, alpha >> dctcp_shift_g);
95 | if (delivered_ce) {
96 | __u32 delivered = tp->delivered - ca->old_delivered;
97 |
98 | /* If dctcp_shift_g == 1, a 32bit value would overflow
99 | * after 8 M packets.
100 | */
101 | delivered_ce <<= (10 - dctcp_shift_g);
102 | delivered_ce /= max(1U, delivered);
103 |
104 | alpha = min(alpha + delivered_ce, DCTCP_MAX_ALPHA);
105 | }
106 | ca->dctcp_alpha = alpha;
107 | dctcp_reset(tp, ca);
108 | }
109 | }
110 |
111 | static __always_inline void dctcp_react_to_loss(struct sock *sk)
112 | {
113 | struct dctcp *ca = inet_csk_ca(sk);
114 | struct tcp_sock *tp = tcp_sk(sk);
115 |
116 | ca->loss_cwnd = tp->snd_cwnd;
117 | tp->snd_ssthresh = max(tp->snd_cwnd >> 1U, 2U);
118 | }
119 |
120 | SEC("struct_ops/dctcp_state")
121 | void BPF_PROG(dctcp_state, struct sock *sk, __u8 new_state)
122 | {
123 | if (new_state == TCP_CA_Recovery &&
124 | new_state != BPF_CORE_READ_BITFIELD(inet_csk(sk), icsk_ca_state))
125 | dctcp_react_to_loss(sk);
126 | /* We handle RTO in dctcp_cwnd_event to ensure that we perform only
127 | * one loss-adjustment per RTT.
128 | */
129 | }
130 |
131 | static __always_inline void dctcp_ece_ack_cwr(struct sock *sk, __u32 ce_state)
132 | {
133 | struct tcp_sock *tp = tcp_sk(sk);
134 |
135 | if (ce_state == 1)
136 | tp->ecn_flags |= TCP_ECN_DEMAND_CWR;
137 | else
138 | tp->ecn_flags &= ~TCP_ECN_DEMAND_CWR;
139 | }
140 |
141 | /* Minimal DCTP CE state machine:
142 | *
143 | * S: 0 <- last pkt was non-CE
144 | * 1 <- last pkt was CE
145 | */
146 | static __always_inline
147 | void dctcp_ece_ack_update(struct sock *sk, enum tcp_ca_event evt,
148 | __u32 *prior_rcv_nxt, __u32 *ce_state)
149 | {
150 | __u32 new_ce_state = (evt == CA_EVENT_ECN_IS_CE) ? 1 : 0;
151 |
152 | if (*ce_state != new_ce_state) {
153 | /* CE state has changed, force an immediate ACK to
154 | * reflect the new CE state. If an ACK was delayed,
155 | * send that first to reflect the prior CE state.
156 | */
157 | if (inet_csk(sk)->icsk_ack.pending & ICSK_ACK_TIMER) {
158 | dctcp_ece_ack_cwr(sk, *ce_state);
159 | bpf_tcp_send_ack(sk, *prior_rcv_nxt);
160 | }
161 | inet_csk(sk)->icsk_ack.pending |= ICSK_ACK_NOW;
162 | }
163 | *prior_rcv_nxt = tcp_sk(sk)->rcv_nxt;
164 | *ce_state = new_ce_state;
165 | dctcp_ece_ack_cwr(sk, new_ce_state);
166 | }
167 |
168 | SEC("struct_ops/dctcp_cwnd_event")
169 | void BPF_PROG(dctcp_cwnd_event, struct sock *sk, enum tcp_ca_event ev)
170 | {
171 | struct dctcp *ca = inet_csk_ca(sk);
172 |
173 | switch (ev) {
174 | case CA_EVENT_ECN_IS_CE:
175 | case CA_EVENT_ECN_NO_CE:
176 | dctcp_ece_ack_update(sk, ev, &ca->prior_rcv_nxt, &ca->ce_state);
177 | break;
178 | case CA_EVENT_LOSS:
179 | dctcp_react_to_loss(sk);
180 | break;
181 | default:
182 | /* Don't care for the rest. */
183 | break;
184 | }
185 | }
186 |
187 | SEC("struct_ops/dctcp_cwnd_undo")
188 | __u32 BPF_PROG(dctcp_cwnd_undo, struct sock *sk)
189 | {
190 | const struct dctcp *ca = inet_csk_ca(sk);
191 |
192 | return max(tcp_sk(sk)->snd_cwnd, ca->loss_cwnd);
193 | }
194 |
195 | SEC("struct_ops/tcp_reno_cong_avoid")
196 | void BPF_PROG(tcp_reno_cong_avoid, struct sock *sk, __u32 ack, __u32 acked)
197 | {
198 | struct tcp_sock *tp = tcp_sk(sk);
199 |
200 | if (!tcp_is_cwnd_limited(sk))
201 | return;
202 |
203 | /* In "safe" area, increase. */
204 | if (tcp_in_slow_start(tp)) {
205 | acked = tcp_slow_start(tp, acked);
206 | if (!acked)
207 | return;
208 | }
209 | /* In dangerous area, increase slowly. */
210 | tcp_cong_avoid_ai(tp, tp->snd_cwnd, acked);
211 | }
212 |
213 | SEC(".struct_ops")
214 | struct tcp_congestion_ops dctcp_nouse = {
215 | .init = (void *)dctcp_init,
216 | .set_state = (void *)dctcp_state,
217 | .flags = TCP_CONG_NEEDS_ECN,
218 | .name = "bpf_dctcp_nouse",
219 | };
220 |
221 | SEC(".struct_ops")
222 | struct tcp_congestion_ops dctcp = {
223 | .init = (void *)dctcp_init,
224 | .in_ack_event = (void *)dctcp_update_alpha,
225 | .cwnd_event = (void *)dctcp_cwnd_event,
226 | .ssthresh = (void *)dctcp_ssthresh,
227 | .cong_avoid = (void *)tcp_reno_cong_avoid,
228 | .undo_cwnd = (void *)dctcp_cwnd_undo,
229 | .set_state = (void *)dctcp_state,
230 | .flags = TCP_CONG_NEEDS_ECN,
231 | .name = "bpf_dctcp",
232 | };
233 |
--------------------------------------------------------------------------------
/ebpf_tcp_cc/bpf_tcp_ca.c:
--------------------------------------------------------------------------------
1 | // SPDX-License-Identifier: GPL-2.0
2 | /* Copyright (c) 2019 Facebook */
3 |
4 | #include
5 | #include
6 | #include "bpf_dctcp.skel.h"
7 | #include "bpf_cubic.skel.h"
8 |
9 | #define min(a, b) ((a) < (b) ? (a) : (b))
10 |
11 | static const unsigned int total_bytes = 10 * 1024 * 1024;
12 | static const struct timeval timeo_sec = { .tv_sec = 10 };
13 | static const size_t timeo_optlen = sizeof(timeo_sec);
14 | static int expected_stg = 0xeB9F;
15 | static int stop, duration;
16 |
17 | static int settimeo(int fd)
18 | {
19 | int err;
20 |
21 | err = setsockopt(fd, SOL_SOCKET, SO_RCVTIMEO, &timeo_sec,
22 | timeo_optlen);
23 | if (CHECK(err == -1, "setsockopt(fd, SO_RCVTIMEO)", "errno:%d\n",
24 | errno))
25 | return -1;
26 |
27 | err = setsockopt(fd, SOL_SOCKET, SO_SNDTIMEO, &timeo_sec,
28 | timeo_optlen);
29 | if (CHECK(err == -1, "setsockopt(fd, SO_SNDTIMEO)", "errno:%d\n",
30 | errno))
31 | return -1;
32 |
33 | return 0;
34 | }
35 |
36 | static int settcpca(int fd, const char *tcp_ca)
37 | {
38 | int err;
39 |
40 | err = setsockopt(fd, IPPROTO_TCP, TCP_CONGESTION, tcp_ca, strlen(tcp_ca));
41 | if (CHECK(err == -1, "setsockopt(fd, TCP_CONGESTION)", "errno:%d\n",
42 | errno))
43 | return -1;
44 |
45 | return 0;
46 | }
47 |
48 | static void *server(void *arg)
49 | {
50 | int lfd = (int)(long)arg, err = 0, fd;
51 | ssize_t nr_sent = 0, bytes = 0;
52 | char batch[1500];
53 |
54 | fd = accept(lfd, NULL, NULL);
55 | while (fd == -1) {
56 | if (errno == EINTR)
57 | continue;
58 | err = -errno;
59 | goto done;
60 | }
61 |
62 | if (settimeo(fd)) {
63 | err = -errno;
64 | goto done;
65 | }
66 |
67 | while (bytes < total_bytes && !READ_ONCE(stop)) {
68 | nr_sent = send(fd, &batch,
69 | min(total_bytes - bytes, sizeof(batch)), 0);
70 | if (nr_sent == -1 && errno == EINTR)
71 | continue;
72 | if (nr_sent == -1) {
73 | err = -errno;
74 | break;
75 | }
76 | bytes += nr_sent;
77 | }
78 |
79 | CHECK(bytes != total_bytes, "send", "%zd != %u nr_sent:%zd errno:%d\n",
80 | bytes, total_bytes, nr_sent, errno);
81 |
82 | done:
83 | if (fd != -1)
84 | close(fd);
85 | if (err) {
86 | WRITE_ONCE(stop, 1);
87 | return ERR_PTR(err);
88 | }
89 | return NULL;
90 | }
91 |
92 | static void do_test(const char *tcp_ca, const struct bpf_map *sk_stg_map)
93 | {
94 | struct sockaddr_in6 sa6 = {};
95 | ssize_t nr_recv = 0, bytes = 0;
96 | int lfd = -1, fd = -1;
97 | pthread_t srv_thread;
98 | socklen_t addrlen = sizeof(sa6);
99 | void *thread_ret;
100 | char batch[1500];
101 | int err;
102 |
103 | WRITE_ONCE(stop, 0);
104 |
105 | lfd = socket(AF_INET6, SOCK_STREAM, 0);
106 | if (CHECK(lfd == -1, "socket", "errno:%d\n", errno))
107 | return;
108 | fd = socket(AF_INET6, SOCK_STREAM, 0);
109 | if (CHECK(fd == -1, "socket", "errno:%d\n", errno)) {
110 | close(lfd);
111 | return;
112 | }
113 |
114 | if (settcpca(lfd, tcp_ca) || settcpca(fd, tcp_ca) ||
115 | settimeo(lfd) || settimeo(fd))
116 | goto done;
117 |
118 | /* bind, listen and start server thread to accept */
119 | sa6.sin6_family = AF_INET6;
120 | sa6.sin6_addr = in6addr_loopback;
121 | err = bind(lfd, (struct sockaddr *)&sa6, addrlen);
122 | if (CHECK(err == -1, "bind", "errno:%d\n", errno))
123 | goto done;
124 | err = getsockname(lfd, (struct sockaddr *)&sa6, &addrlen);
125 | if (CHECK(err == -1, "getsockname", "errno:%d\n", errno))
126 | goto done;
127 | err = listen(lfd, 1);
128 | if (CHECK(err == -1, "listen", "errno:%d\n", errno))
129 | goto done;
130 |
131 | if (sk_stg_map) {
132 | err = bpf_map_update_elem(bpf_map__fd(sk_stg_map), &fd,
133 | &expected_stg, BPF_NOEXIST);
134 | if (CHECK(err, "bpf_map_update_elem(sk_stg_map)",
135 | "err:%d errno:%d\n", err, errno))
136 | goto done;
137 | }
138 |
139 | /* connect to server */
140 | err = connect(fd, (struct sockaddr *)&sa6, addrlen);
141 | if (CHECK(err == -1, "connect", "errno:%d\n", errno))
142 | goto done;
143 |
144 | if (sk_stg_map) {
145 | int tmp_stg;
146 |
147 | err = bpf_map_lookup_elem(bpf_map__fd(sk_stg_map), &fd,
148 | &tmp_stg);
149 | if (CHECK(!err || errno != ENOENT,
150 | "bpf_map_lookup_elem(sk_stg_map)",
151 | "err:%d errno:%d\n", err, errno))
152 | goto done;
153 | }
154 |
155 | err = pthread_create(&srv_thread, NULL, server, (void *)(long)lfd);
156 | if (CHECK(err != 0, "pthread_create", "err:%d errno:%d\n", err, errno))
157 | goto done;
158 |
159 | /* recv total_bytes */
160 | while (bytes < total_bytes && !READ_ONCE(stop)) {
161 | nr_recv = recv(fd, &batch,
162 | min(total_bytes - bytes, sizeof(batch)), 0);
163 | if (nr_recv == -1 && errno == EINTR)
164 | continue;
165 | if (nr_recv == -1)
166 | break;
167 | bytes += nr_recv;
168 | }
169 |
170 | CHECK(bytes != total_bytes, "recv", "%zd != %u nr_recv:%zd errno:%d\n",
171 | bytes, total_bytes, nr_recv, errno);
172 |
173 | WRITE_ONCE(stop, 1);
174 | pthread_join(srv_thread, &thread_ret);
175 | CHECK(IS_ERR(thread_ret), "pthread_join", "thread_ret:%ld",
176 | PTR_ERR(thread_ret));
177 | done:
178 | close(lfd);
179 | close(fd);
180 | }
181 |
182 | static void test_cubic(void)
183 | {
184 | struct bpf_cubic *cubic_skel;
185 | struct bpf_link *link;
186 |
187 | cubic_skel = bpf_cubic__open_and_load();
188 | if (CHECK(!cubic_skel, "bpf_cubic__open_and_load", "failed\n"))
189 | return;
190 |
191 | link = bpf_map__attach_struct_ops(cubic_skel->maps.cubic);
192 | if (CHECK(IS_ERR(link), "bpf_map__attach_struct_ops", "err:%ld\n",
193 | PTR_ERR(link))) {
194 | bpf_cubic__destroy(cubic_skel);
195 | return;
196 | }
197 |
198 | do_test("bpf_cubic", NULL);
199 |
200 | bpf_link__destroy(link);
201 | bpf_cubic__destroy(cubic_skel);
202 | }
203 |
204 | static void test_dctcp(void)
205 | {
206 | struct bpf_dctcp *dctcp_skel;
207 | struct bpf_link *link;
208 |
209 | dctcp_skel = bpf_dctcp__open_and_load();
210 | if (CHECK(!dctcp_skel, "bpf_dctcp__open_and_load", "failed\n"))
211 | return;
212 |
213 | link = bpf_map__attach_struct_ops(dctcp_skel->maps.dctcp);
214 | if (CHECK(IS_ERR(link), "bpf_map__attach_struct_ops", "err:%ld\n",
215 | PTR_ERR(link))) {
216 | bpf_dctcp__destroy(dctcp_skel);
217 | return;
218 | }
219 |
220 | do_test("bpf_dctcp", dctcp_skel->maps.sk_stg_map);
221 | CHECK(dctcp_skel->bss->stg_result != expected_stg,
222 | "Unexpected stg_result", "stg_result (%x) != expected_stg (%x)\n",
223 | dctcp_skel->bss->stg_result, expected_stg);
224 |
225 | bpf_link__destroy(link);
226 | bpf_dctcp__destroy(dctcp_skel);
227 | }
228 |
229 | void test_bpf_tcp_ca(void)
230 | {
231 | if (test__start_subtest("dctcp"))
232 | test_dctcp();
233 | if (test__start_subtest("cubic"))
234 | test_cubic();
235 | }
236 |
--------------------------------------------------------------------------------
/ftrace/README.md:
--------------------------------------------------------------------------------
1 | # 客户端网络调用堆栈获取
2 |
3 | ## ftrace 跟踪 connect 内核细节
4 |
5 | 脚本 `sys_connnet.sh` 用于跟踪我们执行命令中的 connect 客户端连接的调用整个堆栈。
6 |
7 | 比如
8 |
9 | ```bash
10 | ./sys_connect.sh curl www.baidu.com
11 | ```
12 |
13 | 然后使用脚本 `col_and_reset.sh` 可以获取到 connect 在内核中的完整调用堆栈,并关闭 ftrace 的跟踪,最终文件保存到 `/tmp/trace.log` 文件中。
14 |
15 |
16 |
17 | 在获取到 connect 的完整调用逻辑后,我们可以使用 kprobe + bpf 技术获取到函数中的更多细节。
18 |
19 |
20 |
21 | ## 扩展
22 |
23 | [perf-tools](https://github.com/brendangregg/perf-tools)中的 [funcgraph](https://github.com/brendangregg/perf-tools/blob/master/bin/funcgraph) 对于 ftrace 的使用做了更加易用的封装,我们可以直接使用。
24 |
25 |
26 |
27 | BCC 的 [trace](https://github.com/iovisor/bcc/blob/master/tools/trace.py) 工具与 [funcgraph](https://github.com/brendangregg/perf-tools/blob/master/bin/funcgraph) 的配合对于内核函数的调用跟踪起到绝妙的配合。
28 |
29 | * [trace](https://github.com/iovisor/bcc/blob/master/tools/trace.py) 用于跟踪这个函数被谁调用的,就是函数调用的上半部分,用于确定函数被那些堆栈的调用。
30 | * [funcgraph](https://github.com/brendangregg/perf-tools/blob/master/bin/funcgraph) 则是这个函数调用了那些函数,实现调用方的完整堆栈。
--------------------------------------------------------------------------------
/ftrace/col_and_reset.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | debugfs=/sys/kernel/debug
4 |
5 | cat $debugfs/tracing/trace > /tmp/trace.log
6 |
7 | # reset again
8 | echo nop > $debugfs/tracing/current_tracer
9 | echo 0 > $debugfs/tracing/tracing_on
10 |
--------------------------------------------------------------------------------
/ftrace/sys_connnet.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | debugfs=/sys/kernel/debug
4 |
5 | # clear
6 | echo nop > $debugfs/tracing/current_tracer
7 | echo 0 > $debugfs/tracing/tracing_on
8 |
9 | # start
10 | echo $$ > $debugfs/tracing/set_ftrace_pid
11 | echo function_graph > $debugfs/tracing/current_tracer
12 |
13 | #replace test_proc_show by your function name
14 | echo __sys_connect > $debugfs/tracing/set_graph_function
15 | echo 1 > $debugfs/tracing/tracing_on
16 | exec "$@"
17 |
--------------------------------------------------------------------------------
/fuzzing-the-berkeley-acket-filter.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/fuzzing-the-berkeley-acket-filter.pdf
--------------------------------------------------------------------------------
/head_first_bpf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/head_first_bpf.png
--------------------------------------------------------------------------------
/hello_falco.graffle:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/hello_falco.graffle
--------------------------------------------------------------------------------
/hello_falco/hello_falco.graffle:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/hello_falco/hello_falco.graffle
--------------------------------------------------------------------------------
/hello_falco/imgs/evt_collect_display.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/hello_falco/imgs/evt_collect_display.png
--------------------------------------------------------------------------------
/hello_falco/imgs/falco-extended-architecture.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/hello_falco/imgs/falco-extended-architecture.png
--------------------------------------------------------------------------------
/hello_falco/imgs/falco_arch_cncf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/hello_falco/imgs/falco_arch_cncf.png
--------------------------------------------------------------------------------
/hello_falco/imgs/falcosidekick-ui.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/hello_falco/imgs/falcosidekick-ui.png
--------------------------------------------------------------------------------
/hello_falco/imgs/k8s_audit_falco.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/hello_falco/imgs/k8s_audit_falco.png
--------------------------------------------------------------------------------
/hello_falco/imgs/libs_2_cncf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/hello_falco/imgs/libs_2_cncf.png
--------------------------------------------------------------------------------
/hello_falco/imgs/libs_to_cncf_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/hello_falco/imgs/libs_to_cncf_arch.png
--------------------------------------------------------------------------------
/hello_kernel_module/Makefile:
--------------------------------------------------------------------------------
1 | obj-m := hello.o
2 |
3 | KERNELBUILD :=/lib/modules/$(shell uname -r)/build
4 |
5 | default:
6 | make -C $(KERNELBUILD) M=$(shell pwd) modules
7 | clean:
8 | rm -rf *.o *.ko *.mod.c .*.cmd *.markers *.order *.symvers .tmp_versions
9 |
10 |
--------------------------------------------------------------------------------
/hello_kernel_module/README.md:
--------------------------------------------------------------------------------
1 | # Hello kernel module
2 |
3 | ```bash
4 | # make
5 | # insmod ./hello.ko //or insmod hello.ko debug_on=1
6 | # dmesg
7 | # rmmod hello
8 |
9 | ```
10 |
11 | see also: https://blog.csdn.net/JeromeCoco/article/details/108045653
12 |
--------------------------------------------------------------------------------
/hello_kernel_module/get_inst.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include
5 | static struct kprobe kp = {
6 | .symbol_name = "kallsyms_lookup_name"
7 | };
8 |
9 | static int __init hello_init(void)
10 | {
11 | typedef unsigned long (*kallsyms_lookup_name_t)(const char *name);
12 | kallsyms_lookup_name_t kallsyms_lookup_name;
13 | int i = 0;
14 | register_kprobe(&kp);
15 | kallsyms_lookup_name = (kallsyms_lookup_name_t) kp.addr;
16 | unregister_kprobe(&kp);
17 |
18 | char *func_addr = (char *)kallsyms_lookup_name("schedule");
19 |
20 | for (i = 0; i < 5; i++)
21 | {
22 | pr_info("0x%02x ", (u8)func_addr[i]);
23 | }
24 |
25 | pr_info("fun addr 0x%lx\n", func_addr);
26 | return 0;
27 | }
28 | module_init(hello_init);
29 |
30 |
31 | static void __exit hello_exit(void)
32 | {
33 | printk("Hello World Module Exit\n");
34 | }
35 | module_exit(hello_exit);
36 |
37 |
38 | MODULE_LICENSE("GPL");
39 | MODULE_AUTHOR("dwh0403");
40 | MODULE_DESCRIPTION("hello world module");
41 | MODULE_ALIAS("hello_module");
42 |
43 |
--------------------------------------------------------------------------------
/hello_kernel_module/hello.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 |
4 | bool debug_on = 0;
5 | module_param(debug_on, bool, S_IRUSR);
6 |
7 | static int __init hello_init(void)
8 | {
9 | if (debug_on)
10 | printk("[ DEBUG ] debug info output\n");
11 | printk("Hello World Module Init\n");
12 | return 0;
13 | }
14 | module_init(hello_init);
15 |
16 |
17 | static void __exit hello_exit(void)
18 | {
19 | printk("Hello World Module Exit\n");
20 | }
21 | module_exit(hello_exit);
22 |
23 |
24 | MODULE_LICENSE("GPL");
25 | MODULE_AUTHOR("dwh0403");
26 | MODULE_DESCRIPTION("hello world module");
27 | MODULE_ALIAS("hello_module");
28 |
29 |
--------------------------------------------------------------------------------
/hello_kernel_module/helloproc.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include
5 | #include
6 | #include
7 | #include
8 | #include
9 |
10 | // from https://gist.githubusercontent.com/BrotherJing/c9c5ffdc9954d998d1336711fa3a6480/raw/52c549beca2631b857580c2860f488b26344373a/helloproc.c
11 |
12 | static char *str = NULL;
13 |
14 | static int my_proc_show(struct seq_file *m,void *v){
15 | seq_printf(m,"%s\n",str);
16 | return 0;
17 | }
18 |
19 | static ssize_t my_proc_write(struct file* file,const char __user *buffer,size_t count,loff_t *f_pos){
20 | char *tmp = kzalloc((count+1),GFP_KERNEL);
21 | if(!tmp)return -ENOMEM;
22 | if(copy_from_user(tmp,buffer,count)){
23 | kfree(tmp);
24 | return EFAULT;
25 | }
26 | kfree(str);
27 | str=tmp;
28 | return count;
29 | }
30 |
31 | static int my_proc_open(struct inode *inode,struct file *file){
32 | return single_open(file,my_proc_show,NULL);
33 | }
34 |
35 | static struct file_operations my_fops={
36 | .owner = THIS_MODULE,
37 | .open = my_proc_open,
38 | .release = single_release,
39 | .read = seq_read,
40 | .llseek = seq_lseek,
41 | .write = my_proc_write
42 | };
43 |
44 | static int __init hello_init(void){
45 | struct proc_dir_entry *entry;
46 | entry = proc_create("helloproc",0777,NULL,&my_fops);
47 | if(!entry){
48 | return -1;
49 | }else{
50 | printk(KERN_INFO "create proc file successfully\n");
51 | }
52 | return 0;
53 | }
54 |
55 | static void __exit hello_exit(void){
56 | remove_proc_entry("helloproc",NULL);
57 | printk(KERN_INFO "Goodbye world!\n");
58 | }
59 |
60 | module_init(hello_init);
61 | module_exit(hello_exit);
62 | MODULE_LICENSE("GPL");
63 |
--------------------------------------------------------------------------------
/hello_world_bpf_ex/Makefile_diff:
--------------------------------------------------------------------------------
1 | # diff -u Makefile.old Makefile
2 | --- Makefile.old 2021-09-26 03:16:16.883348130 +0000
3 | +++ Makefile 2021-09-26 03:20:46.732277872 +0000
4 | @@ -55,6 +55,7 @@
5 | tprogs-y += xdp_sample_pkts
6 | tprogs-y += ibumad
7 | tprogs-y += hbm
8 | +tprogs-y += hello
9 |
10 | # Libbpf dependencies
11 | LIBBPF = $(TOOLS_PATH)/lib/bpf/libbpf.a
12 | @@ -113,6 +114,7 @@
13 | xdp_sample_pkts-objs := xdp_sample_pkts_user.o
14 | ibumad-objs := ibumad_user.o
15 | hbm-objs := hbm.o $(CGROUP_HELPERS)
16 | +hello-objs := hello_user.o $(TRACE_HELPERS)
17 |
18 | # Tell kbuild to always build the programs
19 | always-y := $(tprogs-y)
20 | @@ -174,6 +176,7 @@
21 | always-y += hbm_out_kern.o
22 | always-y += hbm_edt_kern.o
23 | always-y += xdpsock_kern.o
24 | +always-y += hello_kern.o
25 |
26 | ifeq ($(ARCH), arm)
27 | # Strip all except -D__LINUX_ARM_ARCH__ option needed to handle linux
28 |
--------------------------------------------------------------------------------
/hello_world_bpf_ex/README.md:
--------------------------------------------------------------------------------
1 | # 介绍
2 |
3 | 参见博客文章
4 |
--------------------------------------------------------------------------------
/hello_world_bpf_ex/hello_kern.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include
5 |
6 | SEC("tracepoint/syscalls/sys_enter_execve")
7 | int bpf_hello(struct pt_regs *ctx)
8 | {
9 | char fmt[] = "Hello %s !";
10 | char comm[16];
11 | bpf_get_current_comm(&comm, sizeof(comm));
12 | bpf_trace_printk(fmt, sizeof(fmt), comm);
13 |
14 | return 0;
15 | }
16 |
17 | char _license[] SEC("license") = "GPL";
18 | u32 _version SEC("version") = LINUX_VERSION_CODE;
19 |
--------------------------------------------------------------------------------
/hello_world_bpf_ex/hello_user.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include "trace_helpers.h"
5 |
6 | int main(int ac, char **argv)
7 | {
8 | struct bpf_link *link = NULL;
9 | struct bpf_program *prog;
10 | struct bpf_object *obj;
11 | char filename[256];
12 |
13 | snprintf(filename, sizeof(filename), "%s_kern.o", argv[0]);
14 | obj = bpf_object__open_file(filename, NULL);
15 | if (libbpf_get_error(obj)) {
16 | fprintf(stderr, "ERROR: opening BPF object file failed\n");
17 | return 0;
18 | }
19 |
20 | prog = bpf_object__find_program_by_name(obj, "bpf_hello");
21 | if (!prog) {
22 | fprintf(stderr, "ERROR: finding a prog in obj file failed\n");
23 | goto cleanup;
24 | }
25 |
26 | /* load BPF program */
27 | if (bpf_object__load(obj)) {
28 | fprintf(stderr, "ERROR: loading BPF object file failed\n");
29 | goto cleanup;
30 | }
31 |
32 | link = bpf_program__attach(prog);
33 | if (libbpf_get_error(link)) {
34 | fprintf(stderr, "ERROR: bpf_program__attach failed\n");
35 | link = NULL;
36 | goto cleanup;
37 | }
38 |
39 | read_trace_pipe();
40 |
41 | cleanup:
42 | bpf_link__destroy(link);
43 | bpf_object__close(obj);
44 | return 0;
45 | }
46 |
--------------------------------------------------------------------------------
/how-to-make-linux-microservice-aware-with-cilium-ebpf/bpf_-_turning_linux_into_a_microservices-aware_operating_system.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/how-to-make-linux-microservice-aware-with-cilium-ebpf/bpf_-_turning_linux_into_a_microservices-aware_operating_system.pdf
--------------------------------------------------------------------------------
/how-to-make-linux-microservice-aware-with-cilium-ebpf/further_readings.md:
--------------------------------------------------------------------------------
1 | ## Table of Contents
2 |
3 | From: https://github.com/cilium/cilium/blob/89b622cf4e0a960e27e5b1bf9f139abee25dfea0/FURTHER_READINGS.rst
4 |
5 |
6 |
7 | - [Further Reading](https://github.com/cilium/cilium/blob/89b622cf4e0a960e27e5b1bf9f139abee25dfea0/FURTHER_READINGS.rst#toc0)
8 | - [Related Material](https://github.com/cilium/cilium/blob/89b622cf4e0a960e27e5b1bf9f139abee25dfea0/FURTHER_READINGS.rst#toc1)
9 | - [Presentations](https://github.com/cilium/cilium/blob/89b622cf4e0a960e27e5b1bf9f139abee25dfea0/FURTHER_READINGS.rst#toc2)
10 | - [Podcasts](https://github.com/cilium/cilium/blob/89b622cf4e0a960e27e5b1bf9f139abee25dfea0/FURTHER_READINGS.rst#toc3)
11 | - [Community blog posts](https://github.com/cilium/cilium/blob/89b622cf4e0a960e27e5b1bf9f139abee25dfea0/FURTHER_READINGS.rst#toc4)
12 |
13 |
14 |
15 | # Further Reading
16 |
17 |
18 |
19 | ## Related Material
20 |
21 | - [BPF for security—and chaos—in Kubernetes](https://lwn.net/Articles/790684/)
22 | - [k8s-snowflake: Configs and scripts for bootstrapping an opinionated Kubernetes cluster anywhere using Cilium plugin](https://github.com/jessfraz/k8s-snowflake)
23 | - [Using Cilium for NetworkPolicy: Kubernetes documentation on how to use Cilium to implement NetworkPolicy](https://kubernetes.io/docs/tasks/administer-cluster/cilium-network-policy/)
24 |
25 |
26 |
27 | ## Presentations
28 |
29 | - Fosdem, Brussels, 2020 - BPF as a revolutionary technology for the container landscape: [Slides](https://docs.google.com/presentation/d/1VOUcoIxgM_c6M_zAV1dLlRCjyYCMdR3tJv6CEdfLMh8/edit#slide=id.g7055f48ba8_0_0), [Video](https://fosdem.org/2020/schedule/event/containers_bpf/)
30 | - KubeCon, North America 2019 - Liberating Kubernetes from kube-proxy and iptables: [Slides](https://docs.google.com/presentation/d/1cZJ-pcwB9WG88wzhDm2jxQY4Sh8adYg0-N3qWQ8593I/edit#slide=id.g7055f48ba8_0_0), [Video](https://www.youtube.com/watch?v=bIRwSIwNHC0)
31 | - KubeCon, Europe 2019 - Using eBPF to Bring Kubernetes-Aware Security to the Linux Kernel: [Video](https://www.youtube.com/watch?v=7PXQB-1U380)
32 | - KubeCon, Europe 2019 - Transparent Chaos Testing with Envoy , Cilium and BPF: [Slides](https://static.sched.com/hosted_files/kccnceu19/54/Chaos Testing with Envoy%2C Cilium and eBPF.pdf), [Video](https://www.youtube.com/watch?v=gPvl2NDIWzY)
33 | - All Systems Go!, Berlin, Sept 2018 - Cilium - Bringing the BPF Revolution to Kubernetes Networking and Security [Slides](https://www.slideshare.net/ThomasGraf5/cilium-bringing-the-bpf-revolution-to-kubernetes-networking-and-security), [Video](https://www.youtube.com/watch?v=QmmId1QEE5k)
34 | - QCon, San Francisco 2018 - How to Make Linux Microservice-Aware with Cilium and eBPF: [Slides](https://www.slideshare.net/InfoQ/how-to-make-linux-microserviceaware-with-cilium-and-ebpf), [Video](https://www.youtube.com/watch?v=_Iq1xxNZOAo)
35 | - KubeCon, North America 2018 - Connecting Kubernetes Clusters Across Cloud Providers: [Slides](https://static.sched.com/hosted_files/kccna18/68/Connecting Multiple Kubernetes Clusters Across Cloud Providers.pdf), [Video](https://www.youtube.com/watch?v=U34lQ8KbQow)
36 | - KubeCon, North America 2018 - Implementing Least Privilege Security and Networking with BPF on Kubernetes: [Slides](https://www.slideshare.net/ThomasGraf5/accelerating-envoy-and-istio-with-cilium-and-the-linux-kernel), [Video](https://www.youtube.com/watch?v=3F_XNbhjgxY)
37 | - KubeCon, Europe 2018 - Accelerating Envoy with the Linux Kernel: [Video](https://www.youtube.com/watch?v=ER9eIXL2_14)
38 | - Open Source Summit, North America - Cilium: Networking and security for containers with BPF and XDP: [Video](https://www.youtube.com/watch?v=CcGtDMm1SJA)
39 | - DockerCon, Austin TX, Apr 2017 - Cilium - Network and Application Security with BPF and XDP: [Slides](https://www.slideshare.net/ThomasGraf5/dockercon-2017-cilium-network-and-application-security-with-bpf-and-xdp), [Video](https://www.youtube.com/watch?v=ilKlmTDdFgk)
40 | - CNCF/KubeCon Meetup, Berlin, Mar 2017 - Linux Native, HTTP Aware Network Security: [Slides](https://www.slideshare.net/ThomasGraf5/linux-native-http-aware-network-security), [Video](https://www.youtube.com/watch?v=Yf_INdTWIHI)
41 | - Docker Distributed Systems Summit, Berlin, Oct 2016: [Slides](http://www.slideshare.net/Docker/cilium-bpf-xdp-for-containers-66969823), [Video](https://www.youtube.com/watch?v=TnJF7ht3ZYc&list=PLkA60AVN3hh8oPas3cq2VA9xB7WazcIgs&index=7)
42 | - NetDev1.2, Tokyo, Sep 2016 - cls_bpf/eBPF updates since netdev 1.1: [Slides](http://borkmann.ch/talks/2016_tcws.pdf), [Video](https://youtu.be/gwzaKXWIelc?t=12m55s)
43 | - NetDev1.2, Tokyo, Sep 2016 - Advanced programmability and recent updates with tc’s cls_bpf: [Slides](http://borkmann.ch/talks/2016_netdev2.pdf), [Video](https://www.youtube.com/watch?v=GwT9hRiqdUo)
44 | - ContainerCon NA, Toronto, Aug 2016 - Fast IPv6 container networking with BPF & XDP: [Slides](http://www.slideshare.net/ThomasGraf5/cilium-fast-ipv6-container-networking-with-bpf-and-xdp)
45 |
46 |
47 |
48 | ## Podcasts
49 |
50 | - Software Gone Wild by Ivan Pepelnjak, Oct 2016: [Blog](http://blog.ipspace.net/2016/10/fast-linux-packet-forwarding-with.html), [MP3](http://media.blubrry.com/ipspace/stream.ipspace.net/nuggets/podcast/Show_64-Cilium_with_Thomas_Graf.mp3)
51 | - OVS Orbit by Ben Pfaff, May 2016: [Blog](https://ovsorbit.benpfaff.org/#e4), [MP3](https://ovsorbit.benpfaff.org/episode-4.mp3)
52 |
53 |
54 |
55 | ## Community blog posts
56 |
57 | - [Cilium for Network and Application Security with BPF and XDP, Apr 2017](https://blog.scottlowe.org/2017/04/18/black-belt-cilium/)
58 | - [Cilium, BPF and XDP, Google Open Source Blog, Nov 2016](https://opensource.googleblog.com/2016/11/cilium-networking-and-security.html)
--------------------------------------------------------------------------------
/imgs/KProbeExecution.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/KProbeExecution.png
--------------------------------------------------------------------------------
/imgs/KProbesArchitecture.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/KProbesArchitecture.png
--------------------------------------------------------------------------------
/imgs/bcc-internals.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/bcc-internals.png
--------------------------------------------------------------------------------
/imgs/bcc-intro.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/bcc-intro.png
--------------------------------------------------------------------------------
/imgs/bcc-tools.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/bcc-tools.png
--------------------------------------------------------------------------------
/imgs/bpf-basic-arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/bpf-basic-arch.png
--------------------------------------------------------------------------------
/imgs/ebpf-workflow-101.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/ebpf-workflow-101.png
--------------------------------------------------------------------------------
/imgs/ebpf_60s.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/ebpf_60s.png
--------------------------------------------------------------------------------
/imgs/ebpf_on_windows_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/ebpf_on_windows_arch.png
--------------------------------------------------------------------------------
/imgs/evt_collect_display.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/evt_collect_display.png
--------------------------------------------------------------------------------
/imgs/falco-extended-architecture.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/falco-extended-architecture.png
--------------------------------------------------------------------------------
/imgs/falco_arch_cncf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/falco_arch_cncf.png
--------------------------------------------------------------------------------
/imgs/falcosidekick-ui.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/falcosidekick-ui.png
--------------------------------------------------------------------------------
/imgs/flame.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/flame.png
--------------------------------------------------------------------------------
/imgs/image-20200419215511484.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/image-20200419215511484.png
--------------------------------------------------------------------------------
/imgs/image-20200419223334157.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/image-20200419223334157.png
--------------------------------------------------------------------------------
/imgs/k8s_audit_falco.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/k8s_audit_falco.png
--------------------------------------------------------------------------------
/imgs/libs_2_cncf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/libs_2_cncf.png
--------------------------------------------------------------------------------
/imgs/libs_to_cncf_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/libs_to_cncf_arch.png
--------------------------------------------------------------------------------
/imgs/linux-bpf-book.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/linux-bpf-book.jpeg
--------------------------------------------------------------------------------
/imgs/linux_ebpf_internals.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/linux_ebpf_internals.png
--------------------------------------------------------------------------------
/imgs/linux_kernel_event_bpf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/linux_kernel_event_bpf.png
--------------------------------------------------------------------------------
/imgs/packet-processor-xdp.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/imgs/packet-processor-xdp.png
--------------------------------------------------------------------------------
/katran/ebpf-ip-tun.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/katran/ebpf-ip-tun.png
--------------------------------------------------------------------------------
/katran/ipip-120-all.pcap:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/katran/ipip-120-all.pcap
--------------------------------------------------------------------------------
/kpatch_ipvs_timer/imgs/ipvs_timer.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/kpatch_ipvs_timer/imgs/ipvs_timer.png
--------------------------------------------------------------------------------
/kprobe_ko_ex/Makefile:
--------------------------------------------------------------------------------
1 | obj-m := kprobe_example.o
2 |
3 | KERNELBUILD :=/lib/modules/$(shell uname -r)/build
4 |
5 | default:
6 | make -C $(KERNELBUILD) M=$(shell pwd) modules
7 | clean:
8 | rm -rf *.o *.ko *.mod.c .*.cmd *.markers *.order *.symvers .tmp_versions
9 |
--------------------------------------------------------------------------------
/kprobe_ko_ex/README.md:
--------------------------------------------------------------------------------
1 | # 编译和测试
2 |
3 | Code From: kernel-src/samples/kprobes/
4 |
5 | ```bash
6 | $ make
7 | make -C /lib/modules/4.18.0-193.14.2.el8_2.x86_64/build M=/home/vagrant/kprobes modules
8 | make[1]: Entering directory '/usr/src/kernels/4.18.0-193.14.2.el8_2.x86_64'
9 | CC [M] /home/vagrant/kprobes/kprobe_example.o
10 | Building modules, stage 2.
11 | MODPOST 1 modules
12 | CC /home/vagrant/kprobes/kprobe_example.mod.o
13 | LD [M] /home/vagrant/kprobes/kprobe_example.ko
14 | make[1]: Leaving directory '/usr/src/kernels/4.18.0-193.14.2.el8_2.x86_64'
15 |
16 | # insmod kprobe_example.ko
17 |
18 | # dmesg
19 | [26537.263371] kprobe_example: loading out-of-tree module taints kernel.
20 | [26537.264006] kprobe_example: module verification failed: signature and/or required key missing - tainting kernel
21 | [26537.272969] <_do_fork> pre_handler: p->addr = 0x000000001f2d23bd, ip = ffffffff85eb02c1, flags = 0x246
22 | [26537.273726] Planted kprobe at 000000001f2d23bd
23 | [26537.273969] <_do_fork> pre_handler: p->addr = 0x000000001f2d23bd, ip = ffffffff85eb02c1, flags = 0x246
24 | [26537.274031] <_do_fork> post_handler: p->addr = 0x000000001f2d23bd, flags = 0x246
25 | [26537.274651] <_do_fork> post_handler: p->addr = 0x000000001f2d23bd, flags = 0x246
26 | [26540.939990] <_do_fork> pre_handler: p->addr = 0x000000001f2d23bd, ip = ffffffff85eb02c1, flags = 0x246
27 | [26540.941180] <_do_fork> post_handler: p->addr = 0x000000001f2d23bd, flags = 0x246
28 |
29 | # rmmod kprobe_example
30 | ```
31 |
--------------------------------------------------------------------------------
/kprobe_ko_ex/kprobe_example.c:
--------------------------------------------------------------------------------
1 | /*
2 | * NOTE: This example is works on x86 and powerpc.
3 | * Here's a sample kernel module showing the use of kprobes to dump a
4 | * stack trace and selected registers when _do_fork() is called.
5 | *
6 | * For more information on theory of operation of kprobes, see
7 | * Documentation/kprobes.txt
8 | *
9 | * You will see the trace data in /var/log/messages and on the console
10 | * whenever _do_fork() is invoked to create a new process.
11 | */
12 |
13 | #include
14 | #include
15 | #include
16 |
17 | #define MAX_SYMBOL_LEN 64
18 | static char symbol[MAX_SYMBOL_LEN] = "_do_fork";
19 | module_param_string(symbol, symbol, sizeof(symbol), 0644);
20 |
21 | /* For each probe you need to allocate a kprobe structure */
22 | static struct kprobe kp = {
23 | .symbol_name = symbol,
24 | };
25 |
26 | /* kprobe pre_handler: called just before the probed instruction is executed */
27 | static int handler_pre(struct kprobe *p, struct pt_regs *regs)
28 | {
29 | #ifdef CONFIG_X86
30 | pr_info("<%s> pre_handler: p->addr = 0x%p, ip = %lx, flags = 0x%lx\n",
31 | p->symbol_name, p->addr, regs->ip, regs->flags);
32 | #endif
33 | #ifdef CONFIG_PPC
34 | pr_info("<%s> pre_handler: p->addr = 0x%p, nip = 0x%lx, msr = 0x%lx\n",
35 | p->symbol_name, p->addr, regs->nip, regs->msr);
36 | #endif
37 | #ifdef CONFIG_MIPS
38 | pr_info("<%s> pre_handler: p->addr = 0x%p, epc = 0x%lx, status = 0x%lx\n",
39 | p->symbol_name, p->addr, regs->cp0_epc, regs->cp0_status);
40 | #endif
41 | #ifdef CONFIG_ARM64
42 | pr_info("<%s> pre_handler: p->addr = 0x%p, pc = 0x%lx,"
43 | " pstate = 0x%lx\n",
44 | p->symbol_name, p->addr, (long)regs->pc, (long)regs->pstate);
45 | #endif
46 | #ifdef CONFIG_S390
47 | pr_info("<%s> pre_handler: p->addr, 0x%p, ip = 0x%lx, flags = 0x%lx\n",
48 | p->symbol_name, p->addr, regs->psw.addr, regs->flags);
49 | #endif
50 |
51 | /* A dump_stack() here will give a stack backtrace */
52 | return 0;
53 | }
54 |
55 | /* kprobe post_handler: called after the probed instruction is executed */
56 | static void handler_post(struct kprobe *p, struct pt_regs *regs,
57 | unsigned long flags)
58 | {
59 | #ifdef CONFIG_X86
60 | pr_info("<%s> post_handler: p->addr = 0x%p, flags = 0x%lx\n",
61 | p->symbol_name, p->addr, regs->flags);
62 | #endif
63 | #ifdef CONFIG_PPC
64 | pr_info("<%s> post_handler: p->addr = 0x%p, msr = 0x%lx\n",
65 | p->symbol_name, p->addr, regs->msr);
66 | #endif
67 | #ifdef CONFIG_MIPS
68 | pr_info("<%s> post_handler: p->addr = 0x%p, status = 0x%lx\n",
69 | p->symbol_name, p->addr, regs->cp0_status);
70 | #endif
71 | #ifdef CONFIG_ARM64
72 | pr_info("<%s> post_handler: p->addr = 0x%p, pstate = 0x%lx\n",
73 | p->symbol_name, p->addr, (long)regs->pstate);
74 | #endif
75 | #ifdef CONFIG_S390
76 | pr_info("<%s> pre_handler: p->addr, 0x%p, flags = 0x%lx\n",
77 | p->symbol_name, p->addr, regs->flags);
78 | #endif
79 | }
80 |
81 | /*
82 | * fault_handler: this is called if an exception is generated for any
83 | * instruction within the pre- or post-handler, or when Kprobes
84 | * single-steps the probed instruction.
85 | */
86 | static int handler_fault(struct kprobe *p, struct pt_regs *regs, int trapnr)
87 | {
88 | pr_info("fault_handler: p->addr = 0x%p, trap #%dn", p->addr, trapnr);
89 | /* Return 0 because we don't handle the fault. */
90 | return 0;
91 | }
92 |
93 | static int __init kprobe_init(void)
94 | {
95 | int ret;
96 | kp.pre_handler = handler_pre;
97 | kp.post_handler = handler_post;
98 | kp.fault_handler = handler_fault;
99 |
100 | ret = register_kprobe(&kp);
101 | if (ret < 0) {
102 | pr_err("register_kprobe failed, returned %d\n", ret);
103 | return ret;
104 | }
105 | pr_info("Planted kprobe at %p\n", kp.addr);
106 | return 0;
107 | }
108 |
109 | static void __exit kprobe_exit(void)
110 | {
111 | unregister_kprobe(&kp);
112 | pr_info("kprobe at %p unregistered\n", kp.addr);
113 | }
114 |
115 | module_init(kprobe_init)
116 | module_exit(kprobe_exit)
117 | MODULE_LICENSE("GPL");
118 |
--------------------------------------------------------------------------------
/kprobe_ko_ex/kprobe_tcp_con.c:
--------------------------------------------------------------------------------
1 | #include // included for all kernel modules
2 | #include // included for KERN_INFO
3 | #include // included for __init and __exit macros
4 | #include // struct net_device
5 | #include // struct sk_buff
6 | #include // AF_INET
7 | #include // struct ethhdr
8 | #include // struct iphdr
9 | #include // struct tcphdr
10 | #include // for bpf kprobe/kretprobe
11 |
12 |
13 | #define MAX_ARGLEN 256
14 | #define MAX_ARGS 20
15 | #define NARGS 6
16 | #define NULL ((void *)0)
17 | typedef unsigned long args_t;
18 |
19 |
20 | #define MAX_SYMBOL_LEN 64
21 | static char symbol_tcp_conn_request[MAX_SYMBOL_LEN] = "tcp_conn_request";
22 |
23 | /* For each probe you need to allocate a kprobe structure */
24 | static struct kprobe kp_request = {
25 | .symbol_name = symbol_tcp_conn_request,
26 | };
27 |
28 | /* kprobe pre_handler: called just before the probed instruction is executed */
29 | static int kp_request_prehandler(struct kprobe *p, struct pt_regs *ctx)
30 | {
31 | struct sk_buff *skb;
32 | struct iphdr *iphdr;
33 | /* https://github.com/iovisor/bcc/blob/949a4e59175da289c2ed3dff1979da20b7aee953/src/cc/export/helpers.h
34 | #elif defined(bpf_target_x86)
35 | #define PT_REGS_PARM1(ctx) ((ctx)->di)
36 | #define PT_REGS_PARM2(ctx) ((ctx)->si)
37 | #define PT_REGS_PARM3(ctx) ((ctx)->dx)
38 | #define PT_REGS_PARM4(ctx) ((ctx)->cx)
39 | #define PT_REGS_PARM5(ctx) ((ctx)->r8)
40 | #define PT_REGS_PARM6(ctx) ((ctx)->r9)
41 | #define PT_REGS_RET(ctx) ((ctx)->sp)
42 | */
43 | skb = (void *)((ctx)->cx); // 获取 skb 参数 使用 regs_get_kernel_argument 函数更好 https://github.com/torvalds/linux/blob/6daa755f813e6aa0bcc97e352666e072b1baac25/arch/x86/include/asm/ptrace.h#L342
44 | iphdr = (struct iphdr *)(skb->head + skb->network_header);
45 |
46 | printk(KERN_INFO "[tcp_conn_request] src %x -> dst %x\n", iphdr->saddr, iphdr->daddr);
47 |
48 | return 0;
49 | }
50 |
51 |
52 | /*
53 | * fault_handler: this is called if an exception is generated for any
54 | * instruction within the pre- or post-handler, or when Kprobes
55 | * single-steps the probed instruction.
56 | */
57 | static int handler_fault(struct kprobe *p, struct pt_regs *regs, int trapnr)
58 | {
59 | pr_info("kprobe fault_handler(%s): p->addr = 0x%p, trap #%d\n", p->symbol_name, p->addr, trapnr);
60 | /* Return 0 because we don't handle the fault. */
61 | return 0;
62 | }
63 |
64 | static int __init probe_init(void)
65 | {
66 | int ret;
67 | kp_request.pre_handler = kp_request_prehandler;
68 | kp_request.fault_handler = handler_fault;
69 |
70 | ret = register_kprobe(&kp_request);
71 | if (ret < 0) {
72 | pr_err("register_kprobe tcp_conn_request failed, returned %d\n", ret);
73 | return ret;
74 | }
75 |
76 | pr_info("Planted kprobe tcp_conn_request at %p\n", kp_request.addr);
77 | return 0;
78 | }
79 |
80 | static void __exit probe_exit(void)
81 | {
82 | pr_info("kprobe at %p unregistered\n", kp_request.addr);
83 |
84 | unregister_kprobe(&kp_request);
85 | }
86 |
87 | module_init(probe_init);
88 | module_exit(probe_exit);
89 |
90 | MODULE_LICENSE("GPL");
91 | MODULE_AUTHOR("DWH");
92 | MODULE_DESCRIPTION("A kprobe_test Module");
93 |
94 |
--------------------------------------------------------------------------------
/kprobe_ko_ex/kretprobe_example.c:
--------------------------------------------------------------------------------
1 | /*
2 | * kretprobe_example.c
3 | *
4 | * Here's a sample kernel module showing the use of return probes to
5 | * report the return value and total time taken for probed function
6 | * to run.
7 | *
8 | * usage: insmod kretprobe_example.ko func=
9 | *
10 | * If no func_name is specified, _do_fork is instrumented
11 | *
12 | * For more information on theory of operation of kretprobes, see
13 | * Documentation/kprobes.txt
14 | *
15 | * Build and insert the kernel module as done in the kprobe example.
16 | * You will see the trace data in /var/log/messages and on the console
17 | * whenever the probed function returns. (Some messages may be suppressed
18 | * if syslogd is configured to eliminate duplicate messages.)
19 | */
20 |
21 | #include
22 | #include
23 | #include
24 | #include
25 | #include
26 | #include
27 |
28 | static char func_name[NAME_MAX] = "_do_fork";
29 | module_param_string(func, func_name, NAME_MAX, S_IRUGO);
30 | MODULE_PARM_DESC(func, "Function to kretprobe; this module will report the"
31 | " function's execution time");
32 |
33 | /* per-instance private data */
34 | struct my_data {
35 | ktime_t entry_stamp;
36 | };
37 |
38 | /* Here we use the entry_hanlder to timestamp function entry */
39 | static int entry_handler(struct kretprobe_instance *ri, struct pt_regs *regs)
40 | {
41 | struct my_data *data;
42 |
43 | if (!current->mm)
44 | return 1; /* Skip kernel threads */
45 |
46 | data = (struct my_data *)ri->data;
47 | data->entry_stamp = ktime_get();
48 | return 0;
49 | }
50 |
51 | /*
52 | * Return-probe handler: Log the return value and duration. Duration may turn
53 | * out to be zero consistently, depending upon the granularity of time
54 | * accounting on the platform.
55 | */
56 | static int ret_handler(struct kretprobe_instance *ri, struct pt_regs *regs)
57 | {
58 | unsigned long retval = regs_return_value(regs);
59 | struct my_data *data = (struct my_data *)ri->data;
60 | s64 delta;
61 | ktime_t now;
62 |
63 | now = ktime_get();
64 | delta = ktime_to_ns(ktime_sub(now, data->entry_stamp));
65 | pr_info("%s returned %lu and took %lld ns to execute\n",
66 | func_name, retval, (long long)delta);
67 | return 0;
68 | }
69 |
70 | static struct kretprobe my_kretprobe = {
71 | .handler = ret_handler,
72 | .entry_handler = entry_handler,
73 | .data_size = sizeof(struct my_data),
74 | /* Probe up to 20 instances concurrently. */
75 | .maxactive = 20,
76 | };
77 |
78 | static int __init kretprobe_init(void)
79 | {
80 | int ret;
81 |
82 | my_kretprobe.kp.symbol_name = func_name;
83 | ret = register_kretprobe(&my_kretprobe);
84 | if (ret < 0) {
85 | pr_err("register_kretprobe failed, returned %d\n", ret);
86 | return -1;
87 | }
88 | pr_info("Planted return probe at %s: %p\n",
89 | my_kretprobe.kp.symbol_name, my_kretprobe.kp.addr);
90 | return 0;
91 | }
92 |
93 | static void __exit kretprobe_exit(void)
94 | {
95 | unregister_kretprobe(&my_kretprobe);
96 | pr_info("kretprobe at %p unregistered\n", my_kretprobe.kp.addr);
97 |
98 | /* nmissed > 0 suggests that maxactive was set too low. */
99 | pr_info("Missed probing %d instances of %s\n",
100 | my_kretprobe.nmissed, my_kretprobe.kp.symbol_name);
101 | }
102 |
103 | module_init(kretprobe_init)
104 | module_exit(kretprobe_exit)
105 | MODULE_LICENSE("GPL");
106 |
--------------------------------------------------------------------------------
/kprobe_ko_ex/tcp_con.md:
--------------------------------------------------------------------------------
1 | 使用 kprobe 的事件 Trace
2 |
3 | int tcp_conn_request(struct request_sock_ops *rsk_ops,
4 | const struct tcp_request_sock_ops *af_ops,
5 | struct sock *sk, struct sk_buff *skb);
6 |
7 | /* x86
8 | offsetof(struct pt_regs, di),
9 | offsetof(struct pt_regs, si),
10 | offsetof(struct pt_regs, dx),
11 | offsetof(struct pt_regs, cx),
12 | offsetof(struct pt_regs, r8),
13 | offsetof(struct pt_regs, r9),
14 | */
15 |
16 | see: https://www.kernel.org/doc/html/latest/trace/kprobetrace.html
17 |
18 | ```bash
19 | $ sudo echo 'p:myprobe tcp_conn_request rsk_ops=%di af_ops=%si sk=%dx skb=%cx' > /sys/kernel/debug/tracing/kprobe_events
20 |
21 | $ sudo cat /sys/kernel/debug/tracing/events/kprobes/myprobe/format
22 | $ sudo echo 1 > /sys/kernel/debug/tracing/events/kprobes/myprobe/enable
23 | $ sudo echo 1 > tracing_on
24 |
25 | $ sudo cat /sys/kernel/debug/tracing/trace
26 | # tracer: nop
27 | #
28 | # entries-in-buffer/entries-written: 1/1 #P:16
29 | #
30 | # _-----=> irqs-off
31 | # / _----=> need-resched
32 | # | / _---=> hardirq/softirq
33 | # || / _--=> preempt-depth
34 | # ||| / delay
35 | # TASK-PID CPU# |||| TIMESTAMP FUNCTION
36 | # | | | |||| | |
37 | curl-23427 [011] d.s1 5017168.745924: myprobe: (tcp_conn_request+0x0/0x760) rsk_ops=0xffffffff8b969940 af_ops=0xffffffff8b4a2b60 sk=0xffff9581df11a6c0 skb=0xffff957324b948f8
38 |
39 | $ echo 0 > tracing_o // 关闭
40 | ```
41 |
42 |
--------------------------------------------------------------------------------
/kprobe_ko_ex/tcp_con.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 |
3 | from bcc import BPF
4 |
5 | text="""
6 | #ifndef KBUILD_MODNAME
7 | #define KBUILD_MODNAME "bcc"
8 | #endif
9 |
10 | #include
11 | #include
12 | #include
13 | #include
14 | #include
15 | #include
16 |
17 | // see https://github.com/iovisor/bcc/blob/151fe198988ce3ab10964f4fca4401978caa18f1/tools/tcpdrop.py
18 |
19 | static inline struct iphdr *skb_to_iphdr(const struct sk_buff *skb)
20 | {
21 | // unstable API. verify logic in ip_hdr() -> skb_network_header().
22 | return (struct iphdr *)(skb->head + skb->network_header);
23 | }
24 |
25 | int kprobe__tcp_conn_request(struct pt_regs *ctx) {
26 | struct sk_buff *skb = (void *)PT_REGS_PARM4(ctx);
27 | struct iphdr *ip;
28 |
29 | if (skb->protocol == htons(ETH_P_IP)) {
30 | ip = skb_to_iphdr(skb);
31 | bpf_trace_printk("src 0x%x dest 0x%x", ip->saddr, ip->daddr);
32 | }
33 |
34 | return 0;
35 | }
36 | """
37 |
38 | BPF(text=text).trace_print()
39 |
--------------------------------------------------------------------------------
/kprobe_ko_ex/tcp_mss.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 |
3 | from bcc import BPF
4 |
5 | text="""
6 | #ifndef KBUILD_MODNAME
7 | #define KBUILD_MODNAME "bcc"
8 | #endif
9 | #include
10 | #include
11 | #include
12 | #include
13 |
14 | int kretprobe__tcp_current_mss(struct pt_regs *ctx) {
15 | struct sock *sk = (void *)PT_REGS_PARM1(ctx);
16 | u32 mss = PT_REGS_RC(ctx);
17 |
18 | if (!sk) {
19 | return 0;
20 | }
21 |
22 | bpf_trace_printk("sk 0x%lx mss: %d\\n", sk, mss);
23 |
24 | return 0;
25 | }
26 | """
27 |
28 | BPF(text=text).trace_print()
29 |
--------------------------------------------------------------------------------
/kprobe_ko_ex/tcp_mss2.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 |
3 | from bcc import BPF
4 |
5 | text="""
6 |
7 | #ifndef KBUILD_MODNAME
8 | #define KBUILD_MODNAME "bcc"
9 | #endif
10 | #include
11 | #include
12 | #include
13 | #include
14 |
15 | #include "linux/netdev_features.h"
16 |
17 | static inline bool net_gso_ok2(netdev_features_t features, int gso_type)
18 | {
19 | netdev_features_t feature = gso_type << NETIF_F_GSO_SHIFT;
20 |
21 | return (features & feature) == feature;
22 | }
23 |
24 | int kretprobe__tcp_current_mss(struct pt_regs *ctx) {
25 | struct sock *sk = (void *)PT_REGS_PARM1(ctx);
26 | u32 mss = PT_REGS_RC(ctx);
27 |
28 | bool can_gso = net_gso_ok(sk->sk_route_caps, sk->sk_gso_type);
29 |
30 | if (!sk) {
31 | return 0;
32 | }
33 |
34 | bpf_trace_printk("mss: %d, can gso %d\\n", mss, can_gso);
35 |
36 | return 0;
37 | }
38 | """
39 |
40 | BPF(text=text).trace_print()
41 |
--------------------------------------------------------------------------------
/linux-process-thread.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "如何在 BPF 程序中正确地按照 PID 过滤?"
3 | date: 2020-11-17T21:20:06+08:00
4 | tags: []
5 | categories: ["BPF", "foundation"]
6 | ---
7 |
8 |
9 |
10 | ## 1. 前言
11 |
12 | 在 bpf 的实现中我们经常在内核 helper 函数 `bpf_get_current_pid_tgid()` 来进行用户空间进程 `pid` 进行过滤,那么到底如何写呢? 在 [`BCC`](https://github.com/iovisor/bcc) 项目中有不少程序直接使用 `bpf_get_current_pid_tgid()` 直接与用户空间传入的 pid 对比,也有使用 `bpf_get_current_pid_tgid() >> 32` 进行过滤的,那么使用者或者开发者到底应该使用哪种方式,这篇文章可以帮你彻底解决这类的疑惑。
13 |
14 |
15 |
16 | ## 2. Linux 进程与线程
17 |
18 | 在 Linux 系统中进程在内核空间一般用任务/Task来表示,内核中对应的结构为 `task_struct`,每个进程之间通过该结构进行资源隔离,内核中的调度器基于 `task_struct ` 结构进行调度。
19 |
20 | Linux 线程是基于进程的基础进行演进的,用户创建的线程在 Linux 内核中也会对等创建一个 `task_struct` 结构,属于同一个进程的多个线程对应的 `task_struct` 结构在底层实现了进程级别资源的共享,比如内存、信号量、文件等。
21 |
22 | 从上述实现上看 Linux 系统中的进程和线程在内核级别的实现并无不同,结构都是 `task_struct` ,调度器也一视同仁。
23 |
24 | 在创建方式上 Linux 线程通过 `clone` 函数实现,进程与线程的最底层都是通过 `do_fork` 函数实现,只是传入的参数不同。
25 |
26 | > 内核线程是另外依赖的特殊的实现,有 Linux 内核负责创建,只运行在内核态,所有内核线程共享整个内核空间地址,通过 ps 命令查看的时候以 "[]" 进行区别。
27 |
28 |
29 |
30 | ## 2.1 Linux 线程
31 |
32 | ### 线程库
33 |
34 | POSIX Thread 是以一个定义 Thread 相关函数的 API 集。Redhat 公司的 **Native POSIX Thread Library**(**NPTL**)是 [Linux内核](https://zh.wikipedia.org/wiki/Linux内核) 中实践 [POSIX Threads](https://zh.wikipedia.org/wiki/POSIX_Threads) 标准的库,参见 [wiki](https://zh.wikipedia.org/wiki/Native_POSIX_Thread_Library)。
35 |
36 | ```bash
37 | # lsb_release -a
38 | LSB Version: :core-4.1-amd64:core-4.1-noarch
39 | Distributor ID: CentOS
40 | Description: CentOS Linux release 7.6.1810 (Core)
41 | Release: 7.6.1810
42 | Codename: Core
43 |
44 | # getconf GNU_LIBPTHREAD_VERSION
45 | NPTL 2.17
46 | ```
47 |
48 | NPTL 是一个所谓的 1:1 线程函数库,用户产生的线程与内核能够分配的对象之间的联系是一对一的,这种实现也是效率和简单的折中。
49 |
50 | 当使用 `pthread_create()` 调用创建一个线程后,在内核里就相应创建了一个调度实体 `task_struct`。
51 |
52 | * 用户空间的线程 - - 负责执行线程的创建、销毁等操作;
53 |
54 | * 内核空间的线程 - - 作为调度单元;
55 |
56 |
57 |
58 | ### 2.2 Linux 线程的 PID 与 TGID
59 |
60 | 进程中第一个创建的线程称作主线程,作为线程组的 Leader,线程组的 id 使用 tgid 标识,主线程的 pid 与 tgid 相同。
61 |
62 | 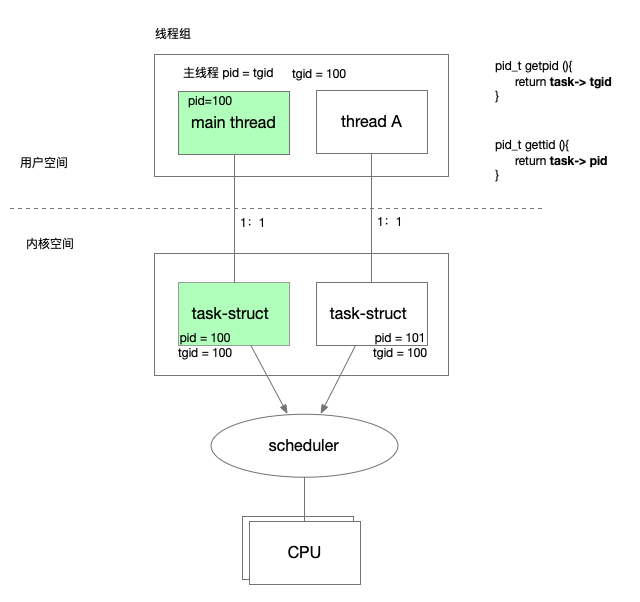
63 |
64 | 下图也通过进程创建进程和线程的异同,给了比较直观的展示:
65 |
66 | ```bash
67 | USER VIEW
68 | <-- PID 43 --> <----------------- PID 42 ----------------->
69 | +---------+
70 | | process |
71 | _| pid=42 |_
72 | _/ | tgid=42 | \_ (new thread) _
73 | _ (fork) _/ +---------+ \
74 | / +---------+
75 | +---------+ | process |
76 | | process | | pid=44 |
77 | | pid=43 | | tgid=42 |
78 | | tgid=43 | +---------+
79 | +---------+
80 | <-- PID 43 --> <--------- PID 42 --------> <--- PID 44 --->
81 | KERNEL VIEW
82 | ```
83 |
84 | `getpid` 与 `gettid` 的内核实现在文件 [kernel/sys.c](https://elixir.bootlin.com/linux/v5.8/source/kernel/sys.c#L896):
85 |
86 | ```c
87 | /**
88 | * sys_getpid - return the thread group id of the current process
89 | *
90 | * Note, despite the name, this returns the tgid not the pid. The tgid and
91 | * the pid are identical unless CLONE_THREAD was specified on clone() in
92 | * which case the tgid is the same in all threads of the same group.
93 | *
94 | * This is SMP safe as current->tgid does not change.
95 | */
96 | SYSCALL_DEFINE0(getpid)
97 | {
98 | return task_tgid_vnr(current);
99 | }
100 |
101 | /* Thread ID - the internal kernel "pid" */
102 | SYSCALL_DEFINE0(gettid)
103 | {
104 | return task_pid_vnr(current);
105 | }
106 | ```
107 |
108 | `task_tgid_vnr` 的实现参见 [linux/sched.h](https://elixir.bootlin.com/linux/v5.8/source/include/linux/sched.h#L1409), `gettid` 的情况类似:
109 |
110 | ```c
111 | static inline pid_t task_tgid_vnr(struct task_struct *tsk)
112 | {
113 | return __task_pid_nr_ns(tsk, PIDTYPE_TGID, NULL); // PIDTYPE_TGID 获取当前 task 的 tgid
114 | }
115 | ```
116 |
117 | 函数 `__task_pid_nr_ns` 参见 [kernel/pid.c](https://elixir.bootlin.com/linux/v5.8/source/kernel/pid.c#L490):
118 |
119 | ```c
120 | pid_t __task_pid_nr_ns(struct task_struct *task, enum pid_type type,
121 | struct pid_namespace *ns)
122 | {
123 | pid_t nr = 0;
124 |
125 | rcu_read_lock();
126 | if (!ns)
127 | ns = task_active_pid_ns(current);
128 | nr = pid_nr_ns(rcu_dereference(*task_pid_ptr(task, type)), ns);
129 | rcu_read_unlock();
130 |
131 | return nr;
132 | }
133 | ```
134 |
135 |
136 |
137 | ## 3. BPF 中的 PID 过滤功能
138 |
139 | 在 BPF 中内核中的函数 [`bpf_get_current_pid_tgid()`](https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#toc20):
140 |
141 | ```bash
142 | Syntax: u64 bpf_get_current_pid_tgid(void)
143 |
144 | Return: current->tgid << 32 | current->pid
145 |
146 | Returns the process ID in the lower 32 bits (kernel's view of the PID, which in user space is usually presented as the thread ID), and the thread group ID in the upper 32 bits (what user space often thinks of as the PID). By directly setting this to a u32, we discard the upper 32 bits.
147 | ```
148 |
149 | `bpf_get_current_pid_tgid` 的返回值为: `current->tgid << 32 | current->pid`,高 32 位置为 tgid ,低 32 位为 pid(tid),如果我们计划采用进程空间传统的 pid 过滤那么则可以这样写 [`tcptop.py`](https://github.com/iovisor/bcc/blob/master/tools/tcptop.py):
150 |
151 | ```c
152 | int kprobe__tcp_sendmsg(struct pt_regs *ctx, struct sock *sk,
153 | struct msghdr *msg, size_t size)
154 | {
155 | if (container_should_be_filtered()) {
156 | return 0;
157 | }
158 | u32 pid = bpf_get_current_pid_tgid() >> 32;
159 | FILTER_PID // if (pid != %s) { return 0; } 有 python 进行替换
160 |
161 | // ...
162 |
163 | }
164 | ```
165 |
166 | 如果通过 `tid` 进行过滤那么写法这样写:
167 |
168 | ```c
169 | int kprobe__tcp_sendmsg(struct pt_regs *ctx, struct sock *sk,
170 | struct msghdr *msg, size_t size)
171 | {
172 | if (container_should_be_filtered()) {
173 | return 0;
174 | }
175 | u32 tid = bpf_get_current_pid_tgid(); // 只是取低 11 位
176 | FILTER_PID // if (tid != %s) { return 0; } 有 python 进行替换
177 |
178 | // ...
179 |
180 | }
181 | ```
182 |
183 |
184 |
185 | ## 4. 参考
186 |
187 | * [linux线程与进程的理解](https://blog.csdn.net/u012218309/article/details/81912074)
188 |
189 | * [深入 Linux 多线程编程](http://senlinzhan.github.io/2017/06/10/pthread-inside/)
190 |
191 | * [If threads share the same PID, how can they be identified?](https://stackoverflow.com/questions/9305992/if-threads-share-the-same-pid-how-can-they-be-identified)
192 |
193 | * [POSIX Threads Programming](https://computing.llnl.gov/tutorials/pthreads/)
194 |
195 | * [Linux threading models compared: LinuxThreads and NPTL ](http://cs.uns.edu.ar/~jechaiz/sosd/clases/extras/03-LinuxThreads%20and%20NPTL.pdf) pdf
196 |
197 | * [The Native POSIX Thread Library for Linux](https://compas.cs.stonybrook.edu/~nhonarmand/courses/fa14/cse506.2/papers/nptl-design.pdf) pdf
--------------------------------------------------------------------------------
/linux-tracing-zine-print.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/linux-tracing-zine-print.pdf
--------------------------------------------------------------------------------
/linux-tracing-zine.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/linux-tracing-zine.pdf
--------------------------------------------------------------------------------
/list_process_kernel_module/Makefile:
--------------------------------------------------------------------------------
1 | obj-m += list_process.o
2 | KDIR ?= /lib/modules/$(shell uname -r)/build
3 |
4 | all:
5 | make -C $(KDIR) M=$(PWD) modules
6 |
7 | clean:
8 | make -C $(KDIR) M=$(PWD) clean
9 |
--------------------------------------------------------------------------------
/list_process_kernel_module/README.md:
--------------------------------------------------------------------------------
1 | # 其他资料
2 |
3 | * [Traversal process list, print kernel module pcb related fields](https://www.programmersought.com/article/20542583355/)
4 | * [梁金荣:Linux内核之话说进程](https://mp.weixin.qq.com/s/8KSB1IsvHHW7_Vo2ApYuZg)
5 | * [Learning about Linux Processes](https://linuxgazette.net/133/saha.html)
6 |
7 |
--------------------------------------------------------------------------------
/list_process_kernel_module/list_process.c:
--------------------------------------------------------------------------------
1 | #include // Needed by all modules
2 | #include // KERN_INFO
3 | #include // for_each_process, pr_info old in: #include
4 |
5 | #include
6 | #include
7 |
8 | void procs_info_print(void)
9 | {
10 | struct task_struct* task_list;
11 | size_t process_counter = 0;
12 | for_each_process(task_list) {
13 | pr_info("== %s [%d] state:%lx prio: %d static_prio %d file_count: %d \n",
14 | task_list->comm, task_list->pid,
15 | task_list->state, task_list->prio,task_list->static_prio,
16 | atomic_read((&(task_list->files)->count)));
17 |
18 | ++process_counter;
19 | }
20 | printk(KERN_INFO "== Number of process: %zu\n", process_counter);
21 | }
22 |
23 | int init_module(void)
24 | {
25 | printk(KERN_INFO "[ INIT ==\n");
26 | procs_info_print();
27 | return 0;
28 | }
29 |
30 | void cleanup_module(void)
31 | {
32 | printk(KERN_INFO "== CLEANUP ]\n");
33 | }
34 |
35 | MODULE_LICENSE("GPL");
36 |
--------------------------------------------------------------------------------
/pid_task_module/Makefile:
--------------------------------------------------------------------------------
1 | obj-m := pid.o
2 |
3 | KERNELBUILD :=/lib/modules/$(shell uname -r)/build
4 |
5 | default:
6 | make -C $(KERNELBUILD) M=$(shell pwd) modules
7 | clean:
8 | rm -rf *.o *.ko *.mod.c .*.cmd *.markers *.order *.symvers .tmp_versions
9 |
--------------------------------------------------------------------------------
/pid_task_module/README.md:
--------------------------------------------------------------------------------
1 | # Hello
2 |
3 | insmod pid=xxx
4 |
--------------------------------------------------------------------------------
/pid_task_module/pid.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include
5 | #include
6 |
7 | pid_t pid = 0;
8 | module_param(pid, int, S_IRUSR);
9 |
10 | static int __init pid_init(void)
11 | {
12 | struct pid *spid;
13 | struct task_struct *task;
14 |
15 | if (pid < 0 )
16 | {
17 | printk("[ DEBUG ] pid < 0, %d\n", pid);
18 | return 0;
19 | }
20 |
21 |
22 | spid = find_get_pid(pid);
23 | if (!spid)
24 | {
25 | printk("[ DEBUG ] find struct pid for pid %d failed\n", pid);
26 | return 0;
27 | }
28 |
29 | task = get_pid_task(spid, PIDTYPE_PID);
30 | if (!task)
31 | {
32 | printk("[ DEBUG ] find task_struct for pid %d failed\n", pid);
33 | return 0;
34 | }
35 |
36 | printk("[ DEBUG ] %s %d\n", task->comm, task->pid);
37 |
38 | return 0;
39 | }
40 |
41 | module_init(pid_init);
42 |
43 |
44 | static void __exit pid_exit(void)
45 | {
46 | printk("PID Module Exit\n");
47 | }
48 |
49 | module_exit(pid_exit);
50 |
51 | MODULE_LICENSE("GPL");
52 | MODULE_AUTHOR("dwh0403");
53 | MODULE_DESCRIPTION("print task_struct for pid");
54 | MODULE_ALIAS("pid_module");
55 |
--------------------------------------------------------------------------------
/replace_img_addr.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # mac sed -i ""
3 | # 发现 -i 需要带一个字符串,用来备份源文件
4 | sed -i "" "s/https:\/\/www\.do1618\.com\/wp-content\/uploads\/2020\/08/imgs/g" README.md
5 |
--------------------------------------------------------------------------------
/skbtracer/skbtracer.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | import sys
5 | import socket
6 | from socket import inet_ntop, AF_INET, AF_INET6
7 | from bcc import BPF
8 | import ctypes as ct
9 | import subprocess
10 | from struct import pack
11 | import argparse
12 | import time
13 | import struct
14 |
15 | examples = """examples:
16 | skbtracer.py # trace all packets
17 | skbtracer.py --proto=icmp -H 1.2.3.4 --icmpid 22 # trace icmp packet with addr=1.2.3.4 and icmpid=22
18 | skbtracer.py --proto=tcp -H 1.2.3.4 -P 22 # trace tcp packet with addr=1.2.3.4:22
19 | skbtracer.py --proto=udp -H 1.2.3.4 -P 22 # trace udp packet wich addr=1.2.3.4:22
20 | skbtracer.py -t -T -p 1 --debug -P 80 -H 127.0.0.1 --proto=tcp --kernel-stack --icmpid=100 -N 10000
21 | """
22 |
23 | parser = argparse.ArgumentParser(
24 | description="Trace any packet through TCP/IP stack",
25 | formatter_class=argparse.RawDescriptionHelpFormatter,
26 | epilog=examples)
27 |
28 | parser.add_argument("-H", "--ipaddr", type=str,
29 | help="ip address")
30 |
31 | parser.add_argument("--proto", type=str,
32 | help="tcp|udp|icmp|any ")
33 |
34 | parser.add_argument("--icmpid", type=int, default=0,
35 | help="trace icmp id")
36 |
37 | parser.add_argument("-c", "--catch-count", type=int, default=1000000,
38 | help="catch and print count")
39 |
40 | parser.add_argument("-P", "--port", type=int, default=0,
41 | help="udp or tcp port")
42 |
43 | parser.add_argument("-p", "--pid", type=int, default=0,
44 | help="trace this PID only")
45 |
46 | parser.add_argument("-N", "--netns", type=int, default=0,
47 | help="trace this Network Namespace only")
48 |
49 | parser.add_argument("--dropstack", action="store_true",
50 | help="output kernel stack trace when drop packet")
51 |
52 | parser.add_argument("--callstack", action="store_true",
53 | help="output kernel stack trace")
54 |
55 | parser.add_argument("--iptable", action="store_true",
56 | help="output iptable path")
57 |
58 | parser.add_argument("--route", action="store_true",
59 | help="output route path")
60 |
61 | parser.add_argument("--keep", action="store_true",
62 | help="keep trace packet all lifetime")
63 |
64 | parser.add_argument("-T", "--time", action="store_true",
65 | help="show HH:MM:SS timestamp")
66 |
67 | parser.add_argument("-t", "--timestamp", action="store_true",
68 | help="show timestamp in seconds at us resolution")
69 |
70 | parser.add_argument("--ebpf", action="store_true",
71 | help=argparse.SUPPRESS)
72 |
73 | parser.add_argument("--debug", action="store_true",
74 | help=argparse.SUPPRESS)
75 |
76 | args = parser.parse_args()
77 | if args.debug == True:
78 | print("pid=%d time=%d timestamp=%d ipaddr=%s port=%d netns=%d proto=%s icmpid=%d dropstack=%d" % \
79 | (args.pid,args.time,args.timestamp,args.ipaddr, args.port,args.netns,args.proto,args.icmpid, args.dropstack))
80 | sys.exit()
81 |
82 |
83 | ipproto={}
84 | #ipproto["tcp"]="IPPROTO_TCP"
85 | ipproto["tcp"]="6"
86 | #ipproto["udp"]="IPPROTO_UDP"
87 | ipproto["udp"]="17"
88 | #ipproto["icmp"]="IPPROTO_ICMP"
89 | ipproto["icmp"]="1"
90 | proto = 0 if args.proto == None else (0 if ipproto.get(args.proto) == None else ipproto[args.proto])
91 | #ipaddr=socket.htonl(struct.unpack("I",socket.inet_aton("0" if args.ipaddr == None else args.ipaddr))[0])
92 | #port=socket.htons(args.port)
93 | ipaddr=(struct.unpack("I",socket.inet_aton("0" if args.ipaddr == None else args.ipaddr))[0])
94 | port=(args.port)
95 | icmpid=socket.htons(args.icmpid)
96 |
97 | bpf_def="#define __BCC_ARGS__\n"
98 | bpf_args="#define __BCC_pid (%d)\n" % (args.pid)
99 | bpf_args+="#define __BCC_ipaddr (0x%x)\n" % (ipaddr)
100 | bpf_args+="#define __BCC_port (%d)\n" % (port)
101 | bpf_args+="#define __BCC_netns (%d)\n" % (args.netns)
102 | bpf_args+="#define __BCC_proto (%s)\n" % (proto)
103 | bpf_args+="#define __BCC_icmpid (%d)\n" % (icmpid)
104 | bpf_args+="#define __BCC_dropstack (%d)\n" % (args.dropstack)
105 | bpf_args+="#define __BCC_callstack (%d)\n" % (args.callstack)
106 | bpf_args+="#define __BCC_iptable (%d)\n" % (args.iptable)
107 | bpf_args+="#define __BCC_route (%d)\n" % (args.route)
108 | bpf_args+="#define __BCC_keep (%d)\n" % (args.keep)
109 |
110 | bpf_text=open(r"skbtracer.c", "r").read()
111 | bpf_text=bpf_def + bpf_text
112 | bpf_text=bpf_text.replace("__BCC_ARGS_DEFINE__", bpf_args)
113 |
114 | if args.ebpf == True:
115 | print("%s" % (bpf_text))
116 | sys.exit()
117 |
118 | # uapi/linux/if.h
119 | IFNAMSIZ = 16
120 |
121 | # uapi/linux/netfilter/x_tables.h
122 | XT_TABLE_MAXNAMELEN = 32
123 |
124 | # uapi/linux/netfilter.h
125 | NF_VERDICT_NAME = [
126 | 'DROP',
127 | 'ACCEPT',
128 | 'STOLEN',
129 | 'QUEUE',
130 | 'REPEAT',
131 | 'STOP',
132 | ]
133 |
134 | # uapi/linux/netfilter.h
135 | # net/ipv4/netfilter/ip_tables.c
136 | HOOKNAMES = [
137 | "PREROUTING",
138 | "INPUT",
139 | "FORWARD",
140 | "OUTPUT",
141 | "POSTROUTING",
142 | ]
143 |
144 | TCPFLAGS = [
145 | "CWR",
146 | "ECE",
147 | "URG",
148 | "ACK",
149 | "PSH",
150 | "RST",
151 | "SYN",
152 | "FIN",
153 | ]
154 |
155 | ROUTE_EVENT_IF = 0x0001
156 | ROUTE_EVENT_IPTABLE = 0x0002
157 | ROUTE_EVENT_DROP = 0x0004
158 | ROUTE_EVENT_NEW = 0x0010
159 | FUNCNAME_MAX_LEN = 64
160 |
161 | class TestEvt(ct.Structure):
162 | _fields_ = [
163 | ("func_name", ct.c_char * FUNCNAME_MAX_LEN),
164 | ("flags", ct.c_ubyte),
165 |
166 | ("ifname", ct.c_char * IFNAMSIZ),
167 | ("netns", ct.c_uint),
168 |
169 | ("dest_mac", ct.c_ubyte * 6),
170 | ("len", ct.c_uint),
171 | ("ip_version", ct.c_ubyte),
172 | ("l4_proto", ct.c_ubyte),
173 | ("tot_len", ct.c_ushort),
174 | ("saddr", ct.c_ulonglong * 2),
175 | ("daddr", ct.c_ulonglong * 2),
176 | ("icmptype", ct.c_ubyte),
177 | ("icmpid", ct.c_ushort),
178 | ("icmpseq", ct.c_ushort),
179 | ("sport", ct.c_ushort),
180 | ("dport", ct.c_ushort),
181 | ("tcpflags", ct.c_ushort),
182 | ("hook", ct.c_uint),
183 | ("pf", ct.c_ubyte),
184 | ("verdict", ct.c_uint),
185 | ("tablename", ct.c_char * XT_TABLE_MAXNAMELEN),
186 | ("ipt_delay", ct.c_ulonglong),
187 |
188 | ("skb", ct.c_ulonglong),
189 | ("pkt_type", ct.c_ubyte),
190 |
191 | ("kernel_stack_id", ct.c_int),
192 | ("kernel_ip", ct.c_ulonglong),
193 |
194 | ("start_ns", ct.c_ulonglong),
195 | ("test", ct.c_ulonglong)
196 | ]
197 |
198 |
199 | def _get(l, index, default):
200 | '''
201 | Get element at index in l or return the default
202 | '''
203 | if index < len(l):
204 | return l[index]
205 | return default
206 | def _get_tcpflags(tcpflags):
207 | flag=""
208 | start=1
209 | for index in range(len(TCPFLAGS)):
210 | if (tcpflags & (1< 0:
225 | kernel_tmp = stack_traces.walk(event.kernel_stack_id)
226 | # fix kernel stack
227 | for addr in kernel_tmp:
228 | kernel_stack.append(addr)
229 | for addr in kernel_stack:
230 | print((" %s" % b.ksym(addr)))
231 |
232 | earliest_ts = 0
233 | def time_str(event):
234 | if args.timestamp:
235 | global earliest_ts
236 | if earliest_ts == 0:
237 | earliest_ts = event.start_ns
238 | return "%-7.6f " % ((event.start_ns - earliest_ts) / 1000000000.0)
239 | elif args.time:
240 | return "%-7s " % time.strftime("%H:%M:%S")
241 | else:
242 | return "%-7s " % time.strftime("%H:%M:%S")
243 |
244 | def event_printer(cpu, data, size):
245 | # Decode event
246 | event = ct.cast(data, ct.POINTER(TestEvt)).contents
247 |
248 | if event.ip_version == 4:
249 | saddr = inet_ntop(AF_INET, pack("=I", event.saddr[0]))
250 | daddr = inet_ntop(AF_INET, pack("=I", event.daddr[0]))
251 | elif event.ip_version == 6:
252 | saddr = inet_ntop(AF_INET6, event.saddr)
253 | daddr = inet_ntop(AF_INET6, event.daddr)
254 | else:
255 | return
256 |
257 | mac_info = ''.join('%02x' % b for b in event.dest_mac)
258 |
259 | if event.l4_proto == socket.IPPROTO_TCP:
260 | pkt_info = "T_%s:%s:%u->%s:%u" % (_get_tcpflags(event.tcpflags), saddr, event.sport, daddr, event.dport)
261 | elif event.l4_proto == socket.IPPROTO_UDP:
262 | pkt_info = "U:%s:%u->%s:%u" % (saddr, event.sport, daddr, event.dport)
263 | elif event.l4_proto == socket.IPPROTO_ICMP:
264 | if event.icmptype in [8, 128]:
265 | pkt_info = "I_request:%s->%s" % (saddr, daddr)
266 | elif event.icmptype in [0, 129]:
267 | pkt_info = "I_reply:%s->%s" % (saddr, daddr)
268 | else:
269 | pkt_info = "I:%s->%s" % (saddr, daddr)
270 | else:
271 | pkt_info = "%u:%s->%s" % (event.l4_proto, saddr, daddr)
272 |
273 | iptables = ""
274 | if event.flags & ROUTE_EVENT_IPTABLE == ROUTE_EVENT_IPTABLE:
275 | verdict = _get(NF_VERDICT_NAME, event.verdict, "~UNK~")
276 | hook = _get(HOOKNAMES, event.hook, "~UNK~")
277 | iptables = "%u.%s.%s.%s " % (event.pf, event.tablename, hook, verdict)
278 |
279 | trace_info = "%x.%u:%s%s" % (event.skb, event.pkt_type, iptables, event.func_name)
280 |
281 | # Print event
282 | print("[%-8s][%-10s] %-12s %-12s %-6s %-40s %s" % (time_str(event), event.netns, event.ifname, mac_info, event.tot_len, pkt_info, trace_info))
283 | print_stack(event)
284 | args.catch_count = args.catch_count - 1
285 |
286 | global is_done
287 | if args.catch_count <= 0:
288 | is_done = True
289 |
290 | is_done = False
291 |
292 | if __name__ == "__main__":
293 | b = BPF(text=bpf_text)
294 | b["route_event"].open_perf_buffer(event_printer)
295 |
296 | print("%-10s %-12s %-12s %-12s %-6s %-40s %s" % ('time', 'NETWORK_NS', 'INTERFACE', 'DEST_MAC', 'IP_LEN', 'PKT_INFO', 'TRACE_INFO'))
297 |
298 | is_done = False;
299 | try:
300 | while is_done == False:
301 | b.kprobe_poll(1)
302 | except (KeyboardInterrupt,SystemExit):
303 | is_done = True
304 |
--------------------------------------------------------------------------------
/socket_filter/socket-filter.graffle:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/socket_filter/socket-filter.graffle
--------------------------------------------------------------------------------
/sysdig_centos_install/DRAIOS-GPG-KEY.public:
--------------------------------------------------------------------------------
1 | -----BEGIN PGP PUBLIC KEY BLOCK-----
2 | Version: GnuPG v2.0.14 (GNU/Linux)
3 |
4 | mQENBFIxRTcBCADlhdqyPuegNdtqkBCQJ6Rm22zftcLSmXms/HcsEkSqJLB4NA/o
5 | Hfnubf9yyZiucB94z6A0Y9ylL6kp75kSUEMDHFwskNRRJuKq4DykfsN5zO2HQk/k
6 | E9eZNNI7tnvs3gl9hHCV3tJvGAVxjmyH3a1hfjMp9df7hwz/PQoqj3NiKqO0awL1
7 | rwI3w8EiIRiKVzNltHMOV3z9wnNe01gpIORJ7o0vIJ1iQrL1qqd0E2lWyoImCVoV
8 | 3zTHWA9NUmTmlZ3Z9VmhjE2QRDH6cVPtk34DBifQpmBWvBPylNC7denFbv3qXV9i
9 | 0Ry2qUR5FlxwSmfb/viPMSE6xqUwrrToL/+lABEBAAG0IERyYWlvcyBJbmMuIDxz
10 | dXBwb3J0QGRyYWlvcy5jb20+iQE4BBMBAgAiBQJSMUU3AhsDBgsJCAcDAgYVCAIJ
11 | CgsEFgIDAQIeAQIXgAAKCRB0SQ/W7FHoxNifB/4h2jjhgdeRMPG3XYc8BEP1s+iX
12 | pNDAS9AgTbfc5QrSbKOn3MIz6195IQOl0Qh8U5DnPEZihFFTH9eU4kEJFITZ6SPs
13 | Y2cQZik1/fJKlU17YXB9herINcUpFK37K+Kb5YPdl98jVjguA7H7JciQVADcTe4Z
14 | 6qsNlBRxehDxYntufsyhWjcILYJGMVEy6vUNZedURA+/A8f8//S8Q4n8KI/SOi6E
15 | 0TOTA+5diqE7o2/y4t8zLijjzCMdQu+7uRxMOFpyJQscFPs3QLbBW1dlhRCrC12k
16 | SwhKOl7SYqI0bWRtJVvHIZ0PFnHF7ryZTPCurQi0W263cJNZnZoHHLOyzrtvuQEN
17 | BFIxRTcBCADPAdMeBOIION2w581IG/74k7A4XldP5aMxCVZYoU1xfT+SUWZ1B1o9
18 | ltGyQiLkILW4TnLRiufyla9I/dcF+INfnBrC4W6skem0BlI26N7xwn4Z2XnLLKoj
19 | 3VLWpL/GzLwKJXn6FZONdHk9Tcbia8eEg/Y2VeL7gY3YxwDHC6kfHGi4z1mml2lz
20 | N9ZyC+zguzwbbqpB435cGNE5iu3fvKs/DMlJG0orwSQT7FEWECjlnAjILACz6ZOq
21 | HBbANqQOwHCPeBfMse3UWwRmJ6aNl1IfUZt0Ra/gaMwcqDnMbYsUd7hzR3/9nmbj
22 | o60IHHOdt1DHMfUsRhc2YAHulJ21e1lFABEBAAGJAR8EGAECAAkFAlIxRTcCGwwA
23 | CgkQdEkP1uxR6MQCZAgAs4zsd8tJpppw+DhixII/gLWFXUWES5Uc/RcgmFf/2JYx
24 | QzusYSuamPfGLcDzNccLRErDZe1mYYILNR2V+KoSZG+9j/vHyfqEp1+TeH8dxUEp
25 | h1yHhxZ2/BFt+8HBG2L3o6a7iUE8Skj6qrr21TJr6pHNuhRyAxRYmy8+huDQletm
26 | IHJoiPjs42A9ktBlRjT/b+7+TnarEZBt/C6gqTOQX8A+Wt4D035cYW6Jhd6t8w0A
27 | tBgKUZ+P49OKrrfKITCRKZ3DR4Xg4sobx9Ype+AP30UyVSHVkEUFP45hnZDfrZ8m
28 | GefyTnhWCWhOZEH5OM4T5UEcrF5RW3jpHKUu9zfhOA==
29 | =MSyl
30 | -----END PGP PUBLIC KEY BLOCK-----
31 |
--------------------------------------------------------------------------------
/sysdig_centos_install/draios.repo:
--------------------------------------------------------------------------------
1 | [draios]
2 | name=Draios
3 | baseurl=https://download.sysdig.com/stable/rpm/$basearch
4 | enabled=1
5 | gpgcheck=1
6 | gpgkey=https://download.sysdig.com/DRAIOS-GPG-KEY.public
7 | #repo_gpgcheck=1
8 |
--------------------------------------------------------------------------------
/sysdig_centos_install/epel-release-6-8.noarch.rpm:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/sysdig_centos_install/epel-release-6-8.noarch.rpm
--------------------------------------------------------------------------------
/sysdig_centos_install/install.md:
--------------------------------------------------------------------------------
1 | # install sysdig on Linux
2 |
3 | From: https://github.com/draios/sysdig/wiki/How-to-Install-Sysdig-for-Linux
4 |
5 | **CentOS, RHEL, Fedora, Amazon Linux**
6 |
7 | 1) Trust the Draios GPG key, configure the yum repository
8 | ```
9 | rpm --import https://s3.amazonaws.com/download.draios.com/DRAIOS-GPG-KEY.public
10 | curl -s -o /etc/yum.repos.d/draios.repo https://s3.amazonaws.com/download.draios.com/stable/rpm/draios.repo
11 | ```
12 |
13 | 2) Install the EPEL repository
14 |
15 | Note: The following command is required only if DKMS is not available in the distribution. You can verify if DKMS is available with `yum list dkms`
16 |
17 | ```
18 | rpm -i https://mirror.us.leaseweb.net/epel/6/i386/epel-release-6-8.noarch.rpm
19 | ```
20 |
21 | 3) Install kernel headers
22 |
23 | **Warning**: The following command might not work with any kernel. Make sure to customize the name of the package properly
24 | ```
25 | yum -y install kernel-devel-$(uname -r)
26 | ```
27 |
28 | 4) Install sysdig
29 | ```
30 | yum -y install sysdig
31 | ```
32 |
33 |
--------------------------------------------------------------------------------
/tcphash_info_module/Makefile:
--------------------------------------------------------------------------------
1 | obj-m := tcphash.o
2 |
3 | KERNELBUILD :=/lib/modules/$(shell uname -r)/build
4 |
5 | default:
6 | make -C $(KERNELBUILD) M=$(shell pwd) modules
7 | clean:
8 | rm -rf *.o *.ko *.mod.c .*.cmd *.markers *.order *.symvers .tmp_versions
9 |
--------------------------------------------------------------------------------
/tcphash_info_module/README.md:
--------------------------------------------------------------------------------
1 | # 通过内核模块获取 tcphash_info 信息
2 |
3 | [TOC]
4 |
5 | ## 1. 测试环境
6 |
7 | ```bash
8 | # lsb_release -a
9 | LSB Version: :core-4.1-amd64:core-4.1-noarch
10 | Distributor ID: CentOS
11 | Description: CentOS Linux release 7.7.1908 (Core)
12 | Release: 7.7.1908
13 | Codename: Core
14 |
15 | # uname -a
16 | Linux bje-qtt-backend-paas-05 3.10.0-1062.9.1.el7.x86_64 #1 SMP Fri Dec 6 15:49:49 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
17 | ```
18 |
19 |
20 |
21 | ## 2. 介绍
22 |
23 | 在网络问题排查的过程中,有时候需要了解内核中保存的 tcphash_info 信息,仅仅通过 BPF 还是缺少更加细致的分析,这种情况下可以通过 kernel 模块访问到 tcphash_info 的结构体,由于是遍历会获取 lock,因此只能用于学习。
24 |
25 | 如果在生产环境排查问题,具体的写法可以参考 `__inet_lookup_established` 函数,通过参入 5 元组来进行读取,避免整个遍历带来的性能开销。
26 |
27 | ```c
28 | static inline struct sock *
29 | inet_lookup_established(struct net *net, struct inet_hashinfo *hashinfo,
30 | const __be32 saddr, const __be16 sport,
31 | const __be32 daddr, const __be16 dport,
32 | const int dif)
33 | {
34 | return __inet_lookup_established(net, hashinfo, saddr, sport, daddr,
35 | ntohs(dport), dif);
36 | }
37 |
38 | struct sock *__inet_lookup_established(struct net *net,
39 | struct inet_hashinfo *hashinfo,
40 | const __be32 saddr, const __be16 sport,
41 | const __be32 daddr, const u16 hnum,
42 | const int dif)
43 | {
44 | INET_ADDR_COOKIE(acookie, saddr, daddr)
45 | const __portpair ports = INET_COMBINED_PORTS(sport, hnum);
46 | struct sock *sk;
47 | const struct hlist_nulls_node *node;
48 | /* Optimize here for direct hit, only listening connections can
49 | * have wildcards anyways.
50 | */
51 | unsigned int hash = inet_ehashfn(net, daddr, hnum, saddr, sport);
52 | unsigned int slot = hash & hashinfo->ehash_mask;
53 | struct inet_ehash_bucket *head = &hashinfo->ehash[slot];
54 |
55 | rcu_read_lock();
56 | begin:
57 | sk_nulls_for_each_rcu(sk, node, &head->chain) {
58 | if (sk->sk_hash != hash)
59 | continue;
60 | if (likely(INET_MATCH(sk, net, acookie,
61 | saddr, daddr, ports, dif))) {
62 | if (unlikely(!atomic_inc_not_zero(&sk->sk_refcnt)))
63 | goto out;
64 | if (unlikely(!INET_MATCH(sk, net, acookie,
65 | saddr, daddr, ports, dif))) {
66 | sock_gen_put(sk);
67 | goto begin;
68 | }
69 | goto found;
70 | }
71 | }
72 | /*
73 | * if the nulls value we got at the end of this lookup is
74 | * not the expected one, we must restart lookup.
75 | * We probably met an item that was moved to another chain.
76 | */
77 | if (get_nulls_value(node) != slot)
78 | goto begin;
79 | out:
80 | sk = NULL;
81 | found:
82 | rcu_read_unlock();
83 | return sk;
84 | }
85 | EXPORT_SYMBOL_GPL(__inet_lookup_established);
86 | ```
87 |
88 |
89 |
90 | ## 3. 使用
91 |
92 | ```bash
93 | # make
94 | # inmod tcphash.ko
95 | # dmesg -T
96 | ...
97 | [Wed Jan 27 16:57:30 2021] --- Established ---
98 | [Wed Jan 27 16:57:30 2021] 89.30.135.163:512 ---> 100.100.120.13:80
99 | [Wed Jan 27 16:57:30 2021] 0.0.0.0:0 ---> 127.0.0.1:9099
100 | [Wed Jan 27 16:57:30 2021] 162.216.6.93:512 ---> 100.100.120.57:80
101 | [Wed Jan 27 16:57:30 2021] 3.136.144.7:8307 ---> 100.100.105.70:80
102 | [Wed Jan 27 16:57:30 2021] 178.13.170.109:512 ---> 100.100.105.70:80
103 |
104 | # rmmode tcphash
105 | ```
106 |
107 | ## 4. `tcp_rcv.py` 脚本说明
108 | 关于 `tcp_rcv.py` 文件是我排查 tcp_reset 过程中使用的脚本,分析过程中有比较多的干扰因素,因此我在代码中写死了源地址和目标端口,实现思路仅供参考,不是能够按照帮助说明自由组合的脚本,因为有些函数返回值不同。
109 |
110 |
--------------------------------------------------------------------------------
/tcphash_info_module/tcp_rcv.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # @lint-avoid-python-3-compatibility-imports
3 |
4 |
5 | from __future__ import print_function
6 | from bcc import BPF
7 | from time import sleep, strftime
8 | from socket import inet_ntop, AF_INET
9 | import socket, struct
10 | import argparse
11 | import ctypes as ct
12 | from struct import pack
13 |
14 | # arguments
15 | examples = """examples:
16 | ./tcp_rcv # summarize TCP RTT
17 | ./tcp_rcv -p # filter for dest port
18 | ./tcp_rcv -P # filter for src port
19 | ./tcp_rcv -a # filter for dest address
20 | ./tcp_rcv -A # filter for src address
21 | ./tcp_rcv -D # show debug bpf text
22 | """
23 |
24 | parser = argparse.ArgumentParser(
25 | description="Summarize TCP RTT as a histogram",
26 | formatter_class=argparse.RawDescriptionHelpFormatter,
27 | epilog=examples)
28 |
29 | parser.add_argument("-p", "--sport",
30 | help="filter for src port")
31 | parser.add_argument("-P", "--dport",
32 | help="filter for dest port")
33 | parser.add_argument("-a", "--saddr",
34 | help="filter for src address")
35 | parser.add_argument("-A", "--daddr",
36 | help="filter for dest address")
37 |
38 | parser.add_argument("-D", "--debug", action="store_true",
39 | help="print BPF program before starting (for debugging purposes)")
40 | parser.add_argument("--ebpf", action="store_true",
41 | help=argparse.SUPPRESS)
42 | args = parser.parse_args()
43 |
44 | # define BPF program
45 | bpf_text = """
46 | #ifndef KBUILD_MODNAME
47 | #define KBUILD_MODNAME "bcc"
48 | #endif
49 |
50 | #include
51 | #include
52 | #include
53 | #include
54 | #include
55 | #include
56 |
57 | struct ipv4_data_t
58 | {
59 | u64 ts_us;
60 | u32 pid;
61 | u32 fun_idx;
62 | u32 saddr;
63 | u32 daddr;
64 | u16 sport;
65 | u16 dport;
66 | u64 arg0;
67 | u64 arg1;
68 | u64 arg2;
69 | u32 syn;
70 | u32 fin;
71 | char task[TASK_COMM_LEN];
72 | };
73 |
74 | BPF_PERF_OUTPUT(ipv4_events);
75 |
76 | static inline struct iphdr *skb_to_iphdr(const struct sk_buff *skb)
77 | {
78 | // unstable API. verify logic in ip_hdr() -> skb_network_header().
79 | return (struct iphdr *)(skb->head + skb->network_header);
80 | }
81 |
82 | static struct tcphdr *skb_to_tcphdr(const struct sk_buff *skb)
83 | {
84 | // unstable API. verify logic in tcp_hdr() -> skb_transport_header().
85 | return (struct tcphdr *)(skb->head + skb->transport_header);
86 | }
87 |
88 | static inline int deal_skb(struct pt_regs *ctx, const struct sock *sk, const struct sk_buff *skb, int fun_idx)
89 | {
90 | u16 sport = 0;
91 | u16 dport = 0;
92 | u32 saddr = 0;
93 | u32 daddr = 0;
94 | u32 seq = 0;
95 | u32 syn = 0;
96 | u32 fin = 0;
97 | u16 family = 0;
98 | u8 ip_proto;
99 |
100 | struct iphdr *iph = skb_to_iphdr(skb);
101 | struct tcphdr *th = skb_to_tcphdr(skb);
102 |
103 | if (skb->protocol != htons(ETH_P_IP)) {
104 | return 0;
105 | }
106 |
107 | ip_proto = iph->protocol;
108 | saddr = iph->saddr;
109 | daddr = iph->daddr;
110 |
111 | sport = th->source;
112 | dport = th->dest;
113 |
114 | if (ip_proto != 0x06) {
115 | return 0;
116 | }
117 |
118 | if (ntohs(dport) != 80 && ntohs(dport) != 32193)
119 | {
120 | return 0;
121 | }
122 |
123 | if (saddr != 0x488610ac)
124 | {
125 | return 0;
126 | }
127 |
128 | SRCPORTFILTER
129 | DSTPORTFILTER
130 | SRCADDRFILTER
131 | DSTADDRFILTER
132 |
133 | sport = ntohs(sport);
134 | dport = ntohs(dport);
135 |
136 | struct ipv4_data_t data4 = {};
137 | data4.ts_us = bpf_ktime_get_ns()/1000;
138 | data4.pid = bpf_get_current_pid_tgid() >> 32;
139 | data4.fun_idx = fun_idx;
140 |
141 |
142 | data4.saddr = saddr;
143 | data4.daddr = daddr;
144 |
145 | data4.sport = sport;
146 | data4.dport = dport;
147 |
148 | data4.arg0 = (u64)sk;
149 |
150 | seq = th->seq;
151 | seq = ntohl(seq);
152 |
153 | data4.arg2 = seq;
154 | data4.arg1 = (u64)skb;
155 | // syn = th->syn;
156 | // fin = th->fin;
157 |
158 | // data4.syn = syn;
159 | // data4.fin = fin;
160 |
161 | bpf_get_current_comm(&data4.task, sizeof(data4.task));
162 | ipv4_events.perf_submit(ctx, &data4, sizeof(data4));
163 |
164 | return 0;
165 |
166 | }
167 |
168 | int trace_tcp_rcv(struct pt_regs *ctx, struct sk_buff *skb)
169 | {
170 | return deal_skb(ctx, skb->sk, skb, 100);
171 | }
172 |
173 |
174 | int trace_ip_rcv(struct pt_regs *ctx, struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
175 | {
176 | return deal_skb(ctx, skb->sk, skb, 1);
177 | }
178 |
179 | int trace_ip_rcv_finish(struct pt_regs *ctx, struct sock *sk, struct sk_buff *skb)
180 | {
181 | return deal_skb(ctx, skb->sk, skb, 2);
182 | }
183 |
184 | void trace_tcp_set_state(struct pt_regs *ctx, struct sock *sk, int state)
185 | {
186 | const struct inet_sock *inet = inet_sk(sk);
187 |
188 | u16 sport = 0;
189 | u16 dport = 0;
190 | u32 saddr = 0;
191 | u32 daddr = 0;
192 | u16 family = 0;
193 | family = sk->__sk_common.skc_family;
194 |
195 |
196 | bpf_probe_read(&dport, sizeof(dport), (void *)&inet->inet_sport);
197 | bpf_probe_read(&sport, sizeof(sport), (void *)&inet->inet_dport);
198 |
199 | bpf_probe_read(&daddr, sizeof(daddr), (void *)&inet->inet_saddr);
200 | bpf_probe_read(&saddr, sizeof(saddr), (void *)&inet->inet_daddr);
201 |
202 | if (ntohs(dport) != 80 && ntohs(dport) != 32193)
203 | {
204 | return;
205 | }
206 |
207 | if (saddr != 0x488610ac)
208 | {
209 | return;
210 | }
211 |
212 |
213 | if (family == AF_INET)
214 | {
215 | struct ipv4_data_t data4 = {};
216 | data4.ts_us = bpf_ktime_get_ns()/1000;
217 | data4.pid = bpf_get_current_pid_tgid() >> 32;
218 | data4.fun_idx = 102;
219 |
220 | data4.saddr = saddr;
221 | data4.daddr = daddr;
222 | data4.sport = be16_to_cpu(sport);
223 | data4.dport = be16_to_cpu(dport);
224 |
225 | data4.arg0 = (u64)sk;
226 | data4.arg1 = (u64)state;
227 | data4.arg2 = (u64)sk->sk_state;
228 | bpf_get_current_comm(&data4.task, sizeof(data4.task));
229 |
230 | ipv4_events.perf_submit(ctx, &data4, sizeof(data4));
231 | }
232 | }
233 |
234 | int trace_tcp_reset(struct pt_regs *ctx, struct sock *sk, struct sk_buff *skb)
235 | {
236 | return deal_skb(ctx, sk, skb, 101);
237 | }
238 |
239 | """
240 |
241 | # filter for local port
242 | if args.sport:
243 | bpf_text = bpf_text.replace('SRCPORTFILTER',
244 | """if (ntohs(sport) != %d)
245 | return 0;""" % int(args.sport))
246 | else:
247 | bpf_text = bpf_text.replace('SRCPORTFILTER', '')
248 |
249 | # filter for remote port
250 | if args.dport:
251 | bpf_text = bpf_text.replace('DSTPORTFILTER',
252 | """if (ntohs(dport) != %d)
253 | return 0;""" % int(args.dport))
254 | else:
255 | bpf_text = bpf_text.replace('DSTPORTFILTER', '')
256 |
257 | # filter for local address
258 | if args.saddr:
259 | bpf_text = bpf_text.replace('SRCADDRFILTER',
260 | """if (saddr != %d)
261 | return 0;""" % struct.unpack("=I", socket.inet_aton(args.saddr))[0])
262 | else:
263 | bpf_text = bpf_text.replace('SRCADDRFILTER', '')
264 |
265 | # filter for remote address
266 | if args.daddr:
267 | bpf_text = bpf_text.replace('DSTADDRFILTER',
268 | """if (daddr != %d)
269 | return 0;""" % struct.unpack("=I", socket.inet_aton(args.daddr))[0])
270 | else:
271 | bpf_text = bpf_text.replace('DSTADDRFILTER', '')
272 |
273 | # debug/dump ebpf enable or not
274 | if args.debug or args.ebpf:
275 | print(bpf_text)
276 | if args.ebpf:
277 | exit()
278 |
279 | TASK_COMM_LEN = 16 # linux/sched.h
280 |
281 | class RouteEvt(ct.Structure):
282 | _fields_ = [
283 | ("ts_us", ct.c_ulonglong),
284 | ("pid", ct.c_uint32),
285 | ("fun_idx", ct.c_uint32),
286 | ("saddr", ct.c_uint32),
287 | ("daddr", ct.c_uint32),
288 | ("sport", ct.c_uint16),
289 | ("dport", ct.c_uint16),
290 | ("arg0", ct.c_ulonglong),
291 | ("arg1", ct.c_ulonglong),
292 | ("arg2", ct.c_ulonglong),
293 | ("syn", ct.c_uint32),
294 | ("fin", ct.c_uint32),
295 | ("task", ct.c_char * TASK_COMM_LEN),
296 | ]
297 |
298 |
299 | def event_printer(cpu, data, size):
300 | event = b["ipv4_events"].event(data)
301 | # Decode event
302 | event = ct.cast(data, ct.POINTER(RouteEvt)).contents
303 |
304 | saddr = inet_ntop(AF_INET, pack("=I", event.saddr))
305 | daddr = inet_ntop(AF_INET, pack("=I", event.daddr))
306 |
307 | if event.fun_idx != 102:
308 | # Print event
309 | print("-%s [%10s] %d %d - [%d] %s:%d -> %s:%d 0x%x 0x%x 0x%x"
310 | % (cpu, event.task, event.ts_us, event.pid, event.fun_idx, saddr, event.sport, daddr, event.dport, event.arg0, event.arg1, event.arg2))
311 | else:
312 | # Print event
313 | print("-%s [%10s] %d %d - [%d] %s:%d -> %s:%d 0x%x %s %s syn %d fin %d"
314 | % (cpu, event.task, event.ts_us, event.pid, event.fun_idx, saddr, event.sport, daddr, event.dport, event.arg0, tcp_stat[event.arg1], tcp_stat[event.arg2]))
315 |
316 | # load BPF program
317 | b = BPF(text=bpf_text)
318 | b.attach_kprobe(event="tcp_v4_rcv", fn_name="trace_tcp_rcv")
319 |
320 | b.attach_kprobe(event="ip_rcv", fn_name="trace_ip_rcv")
321 | b.attach_kprobe(event="ip_rcv_finish", fn_name="trace_ip_rcv_finish")
322 |
323 | b.attach_kprobe(event="tcp_v4_send_reset", fn_name="trace_tcp_reset")
324 | b.attach_kprobe(event="tcp_set_state", fn_name="trace_tcp_set_state")
325 |
326 | print("Tracing tcp_v4_rcv... Hit Ctrl-C to end.")
327 |
328 | tcp_stat = ["UNKNOWN",
329 | "TCP_ESTABLISHED",
330 | "TCP_SYN_SENT",
331 | "TCP_SYN_RECV",
332 | "TCP_FIN_WAIT1",
333 | "TCP_FIN_WAIT2",
334 | "TCP_TIME_WAIT",
335 | "TCP_CLOSE",
336 | "TCP_CLOSE_WAIT",
337 | "TCP_LAST_ACK",
338 | "TCP_LISTEN",
339 | "TCP_CLOSING"]
340 |
341 | if __name__ == "__main__":
342 | b["ipv4_events"].open_perf_buffer(event_printer)
343 |
344 | while 1:
345 | try:
346 | b.perf_buffer_poll()
347 | except KeyboardInterrupt:
348 | exit()
349 |
350 |
--------------------------------------------------------------------------------
/tcphash_info_module/tcphash.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 |
5 |
6 | #define NIPQUAD(addr) \\
7 | ((unsigned char *)&addr)[0], \\
8 | ((unsigned char *)&addr)[1], \\
9 | ((unsigned char *)&addr)[2], \\
10 | ((unsigned char *)&addr)[3]
11 |
12 | #define NIPQUAD_FMT "%u.%u.%u.%u"
13 |
14 |
15 | extern struct inet_hashinfo tcp_hashinfo;
16 |
17 | /* Decides whether a bucket has any sockets in it. */
18 | static inline bool empty_bucket(int i)
19 | {
20 | return hlist_nulls_empty(&tcp_hashinfo.ehash[i].chain);
21 | }
22 |
23 | void print_tcp_socks(void)
24 | {
25 | int i = 0;
26 | struct inet_sock *inet;
27 |
28 | /* Walk hash array and lock each if not empty. */
29 | printk("--- Established ---");
30 | for (i = 0; i <= tcp_hashinfo.ehash_mask; i++) {
31 | struct sock *sk;
32 | // see struct https://elixir.bootlin.com/linux/v3.10.108/source/include/linux/tcp.h#L146
33 | struct tcp_sock *tp;
34 | struct hlist_nulls_node *node;
35 | spinlock_t *lock = inet_ehash_lockp(&tcp_hashinfo, i);
36 |
37 | /* Lockless fast path for the common case of empty buckets */
38 | if (empty_bucket(i))
39 | continue;
40 |
41 | spin_lock_bh(lock);
42 | sk_nulls_for_each(sk, node, &tcp_hashinfo.ehash[i].chain) {
43 | if (sk->sk_family != PF_INET)
44 | continue;
45 |
46 | inet = inet_sk(sk);
47 | tp = tcp_sk(sk);
48 |
49 | printk("%u.%u.%u.%u:%hu ---> %u.%u.%u.%u:%hu,ack first byte 0x%x send_next 0x%x rcv_next 0x%x\n",
50 | ((unsigned char *)&inet->inet_saddr)[0],
51 | ((unsigned char *)&inet->inet_saddr)[1],
52 | ((unsigned char *)&inet->inet_saddr)[2],
53 | ((unsigned char *)&inet->inet_saddr)[3],
54 | ntohs(inet->inet_sport),
55 | ((unsigned char *)&inet->inet_daddr)[0],
56 | ((unsigned char *)&inet->inet_daddr)[1],
57 | ((unsigned char *)&inet->inet_daddr)[2],
58 | ((unsigned char *)&inet->inet_daddr)[3],
59 | ntohs(inet->inet_dport),
60 | tp->snd_una,
61 | tp->snd_nxt,
62 | tp->rcv_nxt);
63 | }
64 | spin_unlock_bh(lock);
65 |
66 | }
67 | }
68 |
69 | static int __init tcphash_init(void)
70 | {
71 | printk("tcphash_info Module Init\n");
72 |
73 | print_tcp_socks();
74 |
75 | printk("tcphash_info Module End");
76 | return 0;
77 | }
78 | module_init(tcphash_init);
79 |
80 |
81 | static void __exit tcphash_exit(void)
82 | {
83 | printk("tcphash_info Module Exit\n");
84 | }
85 | module_exit(tcphash_exit);
86 |
87 |
88 | MODULE_LICENSE("GPL");
89 | MODULE_AUTHOR("dwh0403");
90 | MODULE_DESCRIPTION("print tcphash_info module");
91 | MODULE_ALIAS("tcphash_module");
92 |
--------------------------------------------------------------------------------
/trace-packet-with-tracepoint-perf-ebpf/icmp_trace_v2.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | import sys
5 | from socket import inet_ntop, AF_INET, AF_INET6
6 | from bcc import BPF
7 | import ctypes as ct
8 | import subprocess
9 | from struct import pack
10 | from datetime import datetime
11 |
12 | bpf_text = '''
13 | #include
14 | #include
15 | #include
16 | #include
17 | // for net struct
18 | #include
19 |
20 | #include
21 | #include
22 | #include
23 | #include
24 |
25 | #define IFNAMSIZ 16
26 | #define XT_TABLE_MAXNAMELEN 32
27 |
28 | // Event structure
29 | struct route_evt_t {
30 | char comm[TASK_COMM_LEN];
31 | char ifname[IFNAMSIZ];
32 | u64 netns;
33 | u64 ts_us;
34 | u64 fun_idx;
35 | u64 cpu;
36 |
37 | /* Packet type (IPv4 or IPv6) and address */
38 | u64 ip_version; // familiy (IPv4 or IPv6)
39 | u64 icmptype;
40 | u64 icmpid; // In practice, this is the PID of the ping process (see "ident" field in https://github.com/iputils/iputils/blob/master/ping_common.c)
41 | u64 icmpseq; // Sequence number
42 | u64 saddr[2]; // Source address. IPv4: store in saddr[0]
43 | u64 daddr[2]; // Dest address. IPv4: store in daddr[0]
44 | };
45 |
46 | BPF_PERF_OUTPUT(route_evt);
47 |
48 | #define MAC_HEADER_SIZE 14;
49 |
50 | #define member_read(destination, source_struct, source_member) \
51 | do{ \
52 | bpf_probe_read( \
53 | destination, \
54 | sizeof(source_struct->source_member), \
55 | ((char*)source_struct) + offsetof(typeof(*source_struct), source_member) \
56 | ); \
57 | } while(0)
58 |
59 | #define member_address(source_struct, source_member) \
60 | ({ \
61 | void* __ret; \
62 | __ret = (void*) (((char*)source_struct) + offsetof(typeof(*source_struct), source_member)); \
63 | __ret; \
64 | })
65 |
66 | static inline int do_trace(void* ctx, struct sk_buff* skb, int func_idx)
67 | {
68 | // Built event for userland
69 | struct route_evt_t evt = {};
70 | bpf_get_current_comm(evt.comm, TASK_COMM_LEN);
71 | evt.ts_us = bpf_ktime_get_ns()/1000;
72 | evt.fun_idx = func_idx;
73 |
74 | struct net_device *dev;
75 | member_read(&dev, skb, dev);
76 | // bpf_probe_read(&dev, sizeof(skb->dev), ((char*)skb) + offsetof(typeof(*skb), dev));
77 |
78 | // Load interface name
79 | bpf_probe_read(&evt.ifname, IFNAMSIZ, dev->name);
80 |
81 | // Compute MAC header address
82 | char* head;
83 | u16 mac_header;
84 | u16 network_header;
85 |
86 | member_read(&head, skb, head);
87 | member_read(&mac_header, skb, mac_header);
88 | member_read(&network_header, skb, network_header);
89 |
90 | if(network_header == 0) {
91 | network_header = mac_header + MAC_HEADER_SIZE;
92 | }
93 |
94 | // Compute IP Header address
95 | char *ip_header_address = head + network_header;
96 |
97 | // Abstract IPv4 / IPv6
98 | u8 proto_icmp;
99 | u8 proto_icmp_echo_request;
100 | u8 proto_icmp_echo_reply;
101 | u8 icmp_offset_from_ip_header;
102 | u8 l4proto;
103 |
104 | // Load IP protocol version
105 | bpf_probe_read(&evt.ip_version, sizeof(u8), ip_header_address);
106 | evt.ip_version = evt.ip_version >> 4 & 0xf;
107 |
108 | evt.cpu = bpf_get_smp_processor_id();
109 |
110 | // Filter IP packets
111 | if (evt.ip_version == 4) {
112 | // Load IP Header
113 | struct iphdr iphdr;
114 | bpf_probe_read(&iphdr, sizeof(iphdr), ip_header_address);
115 |
116 | // Load protocol and address
117 | icmp_offset_from_ip_header = iphdr.ihl * 4;
118 | l4proto = iphdr.protocol;
119 | evt.saddr[0] = iphdr.saddr;
120 | evt.daddr[0] = iphdr.daddr;
121 |
122 | // Load constants
123 | proto_icmp = IPPROTO_ICMP;
124 | proto_icmp_echo_request = ICMP_ECHO;
125 | proto_icmp_echo_reply = ICMP_ECHOREPLY;
126 | }
127 |
128 | // Filter ICMP packets
129 | if (l4proto != proto_icmp) {
130 | return 0;
131 | }
132 |
133 | // Compute ICMP header address and load ICMP header
134 | char* icmp_header_address = ip_header_address + icmp_offset_from_ip_header;
135 | struct icmphdr icmphdr;
136 | bpf_probe_read(&icmphdr, sizeof(icmphdr), icmp_header_address);
137 |
138 | // Filter ICMP echo request and echo reply
139 | if (icmphdr.type != proto_icmp_echo_request && icmphdr.type != proto_icmp_echo_reply) {
140 | return 0;
141 | }
142 |
143 | // Get ICMP info
144 | evt.icmptype = icmphdr.type;
145 | evt.icmpid = icmphdr.un.echo.id;
146 | evt.icmpseq = icmphdr.un.echo.sequence;
147 |
148 | // Fix endian
149 | evt.icmpid = be16_to_cpu(evt.icmpid);
150 | evt.icmpseq = be16_to_cpu(evt.icmpseq);
151 |
152 | #ifdef CONFIG_NET_NS
153 | struct net *net;
154 |
155 | // Get netns id. The code below is equivalent to: evt->netns = dev->nd_net.net->ns.inum
156 | member_read(&net, dev, nd_net);
157 | member_read(&evt.netns, net, proc_inum);
158 | #endif
159 |
160 | // Send event to userland
161 | route_evt.perf_submit(ctx, &evt, sizeof(evt));
162 |
163 | return 0;
164 | }
165 |
166 |
167 | static inline int do_trace_netif_rx(void* ctx, struct sk_buff* skb)
168 | {
169 | return do_trace(ctx,skb, 0);
170 | }
171 |
172 | static inline int do_trace_net_dev_queue(void* ctx, struct sk_buff* skb)
173 | {
174 | return do_trace(ctx,skb, 1);
175 | }
176 |
177 | static inline int do_trace_net_dev_xmit(void* ctx, struct sk_buff* skb)
178 | {
179 | return do_trace(ctx,skb, 2);
180 | }
181 |
182 | static inline int do_trace_netif_receive_skb(void* ctx, struct sk_buff* skb)
183 | {
184 | return do_trace(ctx,skb, 3);
185 | }
186 |
187 |
188 | /**
189 | * Attach to Kernel Tracepoints
190 | */
191 | TRACEPOINT_PROBE(net, netif_rx) {
192 | return do_trace_netif_rx(args, (struct sk_buff*)args->skbaddr);
193 | }
194 |
195 | TRACEPOINT_PROBE(net, net_dev_queue) {
196 | return do_trace_net_dev_queue(args, (struct sk_buff*)args->skbaddr);
197 | }
198 |
199 | TRACEPOINT_PROBE(net, net_dev_xmit) {
200 | return do_trace_net_dev_xmit(args, (struct sk_buff*)args->skbaddr);
201 | }
202 |
203 | TRACEPOINT_PROBE(net, netif_receive_skb) {
204 | return do_trace_netif_receive_skb(args, (struct sk_buff*)args->skbaddr);
205 | }
206 | '''
207 |
208 | TASK_COMM_LEN = 16 # linux/sched.h
209 | IFNAMSIZ = 16
210 |
211 | class RouteEvt(ct.Structure):
212 | _fields_ = [
213 | ("comm", ct.c_char * TASK_COMM_LEN),
214 | ("ifname", ct.c_char * IFNAMSIZ),
215 | ("netns", ct.c_ulonglong),
216 | ("ts_us", ct.c_ulonglong),
217 | ("fun_idx", ct.c_ulonglong),
218 | ("cpu", ct.c_ulonglong),
219 |
220 | # Packet type (IPv4 or IPv6) and address
221 | ("ip_version", ct.c_ulonglong),
222 | ("icmptype", ct.c_ulonglong),
223 | ("icmpid", ct.c_ulonglong),
224 | ("icmpseq", ct.c_ulonglong),
225 | ("saddr", ct.c_ulonglong * 2),
226 | ("daddr", ct.c_ulonglong * 2),
227 | ]
228 |
229 |
230 | # start_times 当前没有办法清理,只能用于短期内验证
231 | start_times = {}
232 |
233 | def event_printer(cpu, data, size):
234 | icmq_seq = 0
235 | start_us = 0
236 |
237 | # Decode event
238 | event = ct.cast(data, ct.POINTER(RouteEvt)).contents
239 |
240 |
241 | start_us = event.ts_us
242 | key = event.icmpseq + event.icmpid
243 | if start_times.has_key(key):
244 | start_us = start_times.get(key, 0)
245 | else:
246 | start_times[key] = event.ts_us
247 |
248 | # Decode address
249 | if event.ip_version == 4:
250 | saddr = inet_ntop(AF_INET, pack("=I", event.saddr[0]))
251 | daddr = inet_ntop(AF_INET, pack("=I", event.daddr[0]))
252 |
253 | # Decode direction
254 | if event.icmptype in [8, 128]:
255 | direction = "request"
256 | elif event.icmptype in [0, 129]:
257 | direction = "reply"
258 | else:
259 | return
260 |
261 | # dt = datetime.fromtimestamp(event.ts_ns // 1000000000)
262 | # data_str = dt.strftime('%Y-%m-%d %H:%M:%S')
263 | # data_str += '.' + str(int(event.ts_ns % 1000000000)).zfill(6)
264 |
265 | flow = "%s -> %s" % (saddr, daddr)
266 |
267 | delta_ms = (float(event.ts_us) - start_us) / 1000
268 |
269 | tps_name = ["netif_rx", "net_dev_queue", "net_dev_xmit", "netif_receive_skb"]
270 |
271 | fun_name = tps_name[event.fun_idx]
272 |
273 | # Print event
274 | if (delta_ms > 10.0):
275 | print "* %5s [%-12s] [%6s] %20s %16s %7s %7s %-34s" % (event.icmpseq, delta_ms, event.cpu, fun_name, event.ifname, event.icmpid, direction, flow)
276 | else:
277 | print "%7s [%-12s] [%6s] %20s %16s %7s %7s %-34s" % (event.icmpseq, delta_ms, event.cpu, fun_name, event.ifname, event.icmpid, direction, flow)
278 |
279 | if __name__ == "__main__":
280 | b = BPF(text=bpf_text)
281 | b["route_evt"].open_perf_buffer(event_printer)
282 |
283 | while True:
284 | b.kprobe_poll()
285 |
286 |
287 |
288 |
--------------------------------------------------------------------------------
/trace-packet-with-tracepoint-perf-ebpf/prob_icmp.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | bpf_text = """
3 | #include
4 | #include /* For TASK_COMM_LEN */
5 | #include
6 | #include
7 | struct probe_icmp_data_t
8 | {
9 | u64 timestamp_ns;
10 | u32 tgid;
11 | u32 pid;
12 | char comm[TASK_COMM_LEN];
13 | int v0;
14 | };
15 | BPF_PERF_OUTPUT(probe_icmp_events);
16 | static inline unsigned char *my_skb_transport_header(const struct sk_buff *skb)
17 | {
18 | return skb->head + skb->transport_header;
19 | }
20 | static inline struct icmphdr *my_icmp_hdr(const struct sk_buff *skb)
21 | {
22 | return (struct icmphdr *)my_skb_transport_header(skb);
23 | }
24 | int probe_icmp(struct pt_regs *ctx, struct sk_buff *skb)
25 | {
26 | u64 __pid_tgid = bpf_get_current_pid_tgid();
27 | u32 __tgid = __pid_tgid >> 32;
28 | u32 __pid = __pid_tgid; // implicit cast to u32 for bottom half
29 |
30 | struct probe_icmp_data_t __data = {0};
31 | __data.timestamp_ns = bpf_ktime_get_ns();
32 | __data.tgid = __tgid;
33 | __data.pid = __pid;
34 | bpf_get_current_comm(&__data.comm, sizeof(__data.comm));
35 | __be16 seq;
36 | // bpf_probe_read(&seq, sizeof(seq), &my_icmp_hdr(skb)->un.echo.sequence);
37 |
38 | void *addr = &my_icmp_hdr(skb)->un.echo.sequence;
39 | bpf_probe_read(&seq, sizeof(seq), addr);
40 |
41 | __data.v0 = (int)seq;
42 | probe_icmp_events.perf_submit(ctx, &__data, sizeof(__data));
43 | return 0;
44 | }
45 | """
46 |
47 | from bcc import BPF
48 | import ctypes as ct
49 |
50 | class Data_icmp(ct.Structure):
51 | _fields_ = [
52 | ("timestamp_ns", ct.c_ulonglong),
53 | ("tgid", ct.c_uint),
54 | ("pid", ct.c_uint),
55 | ("comm", ct.c_char * 16), # TASK_COMM_LEN
56 | ('v0', ct.c_uint),
57 | ]
58 |
59 | b = BPF(text=bpf_text)
60 |
61 | def print_icmp_event(cpu, data, size):
62 | #event = b["probe_icmp_events"].event(data)
63 | event = ct.cast(data, ct.POINTER(Data_icmp)).contents
64 | print("%-7d %-7d %-15s %s" %
65 | (event.tgid, event.pid,
66 | event.comm.decode('utf-8', 'replace'),
67 | event.v0))
68 |
69 | b.attach_kprobe(event="icmp_echo", fn_name="probe_icmp")
70 |
71 | b["probe_icmp_events"].open_perf_buffer(print_icmp_event)
72 | while 1:
73 | try:
74 | b.kprobe_poll()
75 | except KeyboardInterrupt:
76 | exit()
77 |
--------------------------------------------------------------------------------
/trace-packet-with-tracepoint-perf-ebpf/trace_pkt_v3.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 |
4 | import sys
5 | from socket import inet_ntop, AF_INET, AF_INET6
6 | from bcc import BPF
7 | import ctypes as ct
8 | import subprocess
9 | from struct import pack
10 | from datetime import datetime
11 |
12 | bpf_text = '''
13 | #include
14 | #include
15 | #include
16 | #include
17 | // for net struct
18 | #include
19 |
20 | #include
21 | #include
22 | #include
23 | #include
24 |
25 | #define IFNAMSIZ 16
26 | #define XT_TABLE_MAXNAMELEN 32
27 |
28 | // Event structure
29 | struct route_evt_t {
30 | char comm[TASK_COMM_LEN];
31 | char ifname[IFNAMSIZ];
32 | u64 netns;
33 | u64 ts_us;
34 | u64 fun_idx;
35 | u64 cpu;
36 |
37 | /* Packet type (IPv4 or IPv6) and address */
38 | u64 ip_version; // familiy (IPv4 or IPv6)
39 | u64 icmptype;
40 | u64 icmpid; // In practice, this is the PID of the ping process (see "ident" field in https://github.com/iputils/iputils/blob/master/ping_common.c)
41 | u64 icmpseq; // Sequence number
42 | u64 saddr[2]; // Source address. IPv4: store in saddr[0]
43 | u64 daddr[2]; // Dest address. IPv4: store in daddr[0]
44 | };
45 |
46 | BPF_PERF_OUTPUT(route_evt);
47 |
48 | #define MAC_HEADER_SIZE 14;
49 |
50 | #define member_read(destination, source_struct, source_member) \
51 | do{ \
52 | bpf_probe_read( \
53 | destination, \
54 | sizeof(source_struct->source_member), \
55 | ((char*)source_struct) + offsetof(typeof(*source_struct), source_member) \
56 | ); \
57 | } while(0)
58 |
59 | #define member_address(source_struct, source_member) \
60 | ({ \
61 | void* __ret; \
62 | __ret = (void*) (((char*)source_struct) + offsetof(typeof(*source_struct), source_member)); \
63 | __ret; \
64 | })
65 |
66 | static inline int do_trace(void* ctx, struct sk_buff* skb, int func_idx)
67 | {
68 | // Built event for userland
69 | struct route_evt_t evt = {};
70 | bpf_get_current_comm(evt.comm, TASK_COMM_LEN);
71 | evt.ts_us = bpf_ktime_get_ns()/1000;
72 | evt.fun_idx = func_idx;
73 |
74 | struct net_device *dev;
75 | member_read(&dev, skb, dev);
76 | // bpf_probe_read(&dev, sizeof(skb->dev), ((char*)skb) + offsetof(typeof(*skb), dev));
77 |
78 | // Load interface name
79 | bpf_probe_read(&evt.ifname, IFNAMSIZ, dev->name);
80 |
81 | // Compute MAC header address
82 | char* head;
83 | u16 mac_header;
84 | u16 network_header;
85 |
86 | member_read(&head, skb, head);
87 | member_read(&mac_header, skb, mac_header);
88 | member_read(&network_header, skb, network_header);
89 |
90 | if(network_header == 0) {
91 | network_header = mac_header + MAC_HEADER_SIZE;
92 | }
93 |
94 | // Compute IP Header address
95 | char *ip_header_address = head + network_header;
96 |
97 | // Abstract IPv4 / IPv6
98 | u8 proto_icmp;
99 | u8 proto_icmp_echo_request;
100 | u8 proto_icmp_echo_reply;
101 | u8 icmp_offset_from_ip_header;
102 | u8 l4proto;
103 |
104 | // Load IP protocol version
105 | bpf_probe_read(&evt.ip_version, sizeof(u8), ip_header_address);
106 | evt.ip_version = evt.ip_version >> 4 & 0xf;
107 |
108 | evt.cpu = bpf_get_smp_processor_id();
109 |
110 | // Filter IP packets
111 | if (evt.ip_version == 4) {
112 | // Load IP Header
113 | struct iphdr iphdr;
114 | bpf_probe_read(&iphdr, sizeof(iphdr), ip_header_address);
115 |
116 | // Load protocol and address
117 | icmp_offset_from_ip_header = iphdr.ihl * 4;
118 | l4proto = iphdr.protocol;
119 | evt.saddr[0] = iphdr.saddr;
120 | evt.daddr[0] = iphdr.daddr;
121 |
122 | // Load constants
123 | proto_icmp = IPPROTO_ICMP;
124 | proto_icmp_echo_request = ICMP_ECHO;
125 | proto_icmp_echo_reply = ICMP_ECHOREPLY;
126 | }
127 |
128 | // Filter ICMP packets
129 | if (l4proto != proto_icmp) {
130 | return 0;
131 | }
132 |
133 | // Compute ICMP header address and load ICMP header
134 | char* icmp_header_address = ip_header_address + icmp_offset_from_ip_header;
135 | struct icmphdr icmphdr;
136 | bpf_probe_read(&icmphdr, sizeof(icmphdr), icmp_header_address);
137 |
138 | // Filter ICMP echo request and echo reply
139 | if (icmphdr.type != proto_icmp_echo_request && icmphdr.type != proto_icmp_echo_reply) {
140 | return 0;
141 | }
142 |
143 | // Get ICMP info
144 | evt.icmptype = icmphdr.type;
145 | evt.icmpid = icmphdr.un.echo.id;
146 | evt.icmpseq = icmphdr.un.echo.sequence;
147 |
148 | // Fix endian
149 | evt.icmpid = be16_to_cpu(evt.icmpid);
150 | evt.icmpseq = be16_to_cpu(evt.icmpseq);
151 |
152 | #ifdef CONFIG_NET_NS
153 | struct net *net;
154 |
155 | // Get netns id. The code below is equivalent to: evt->netns = dev->nd_net.net->ns.inum
156 | member_read(&net, dev, nd_net);
157 | member_read(&evt.netns, net, proc_inum);
158 | #endif
159 |
160 | // Send event to userland
161 | route_evt.perf_submit(ctx, &evt, sizeof(evt));
162 |
163 | return 0;
164 | }
165 |
166 |
167 | static inline int do_trace_netif_rx(void* ctx, struct sk_buff* skb)
168 | {
169 | return do_trace(ctx,skb, 0);
170 | }
171 |
172 | static inline int do_trace_net_dev_queue(void* ctx, struct sk_buff* skb)
173 | {
174 | return do_trace(ctx,skb, 1);
175 | }
176 |
177 | static inline int do_trace_net_dev_xmit(void* ctx, struct sk_buff* skb)
178 | {
179 | return do_trace(ctx,skb, 2);
180 | }
181 |
182 | static inline int do_trace_netif_receive_skb(void* ctx, struct sk_buff* skb)
183 | {
184 | return do_trace(ctx,skb, 3);
185 | }
186 |
187 |
188 | /**
189 | * Attach to Kernel Tracepoints
190 | */
191 | TRACEPOINT_PROBE(net, netif_rx) {
192 | return do_trace_netif_rx(args, (struct sk_buff*)args->skbaddr);
193 | }
194 |
195 | TRACEPOINT_PROBE(net, net_dev_queue) {
196 | return do_trace_net_dev_queue(args, (struct sk_buff*)args->skbaddr);
197 | }
198 |
199 | TRACEPOINT_PROBE(net, net_dev_xmit) {
200 | return do_trace_net_dev_xmit(args, (struct sk_buff*)args->skbaddr);
201 | }
202 |
203 | TRACEPOINT_PROBE(net, netif_receive_skb) {
204 | return do_trace_netif_receive_skb(args, (struct sk_buff*)args->skbaddr);
205 | }
206 | '''
207 |
208 | TASK_COMM_LEN = 16 # linux/sched.h
209 | IFNAMSIZ = 16
210 |
211 | class RouteEvt(ct.Structure):
212 | _fields_ = [
213 | ("comm", ct.c_char * TASK_COMM_LEN),
214 | ("ifname", ct.c_char * IFNAMSIZ),
215 | ("netns", ct.c_ulonglong),
216 | ("ts_us", ct.c_ulonglong),
217 | ("fun_idx", ct.c_ulonglong),
218 | ("cpu", ct.c_ulonglong),
219 |
220 | # Packet type (IPv4 or IPv6) and address
221 | ("ip_version", ct.c_ulonglong),
222 | ("icmptype", ct.c_ulonglong),
223 | ("icmpid", ct.c_ulonglong),
224 | ("icmpseq", ct.c_ulonglong),
225 | ("saddr", ct.c_ulonglong * 2),
226 | ("daddr", ct.c_ulonglong * 2),
227 | ]
228 |
229 | def event_printer(cpu, data, size):
230 | global start_ts
231 | global icmq_seq
232 | # Decode event
233 | event = ct.cast(data, ct.POINTER(RouteEvt)).contents
234 |
235 |
236 | if icmq_seq != event.icmpseq:
237 | icmq_seq = event.icmpseq
238 | start_ts = event.ts_us
239 |
240 | # Decode address
241 | if event.ip_version == 4:
242 | saddr = inet_ntop(AF_INET, pack("=I", event.saddr[0]))
243 | daddr = inet_ntop(AF_INET, pack("=I", event.daddr[0]))
244 |
245 | # Decode direction
246 | if event.icmptype in [8, 128]:
247 | direction = "request"
248 | elif event.icmptype in [0, 129]:
249 | direction = "reply"
250 | else:
251 | return
252 |
253 | # dt = datetime.fromtimestamp(event.ts_ns // 1000000000)
254 | # data_str = dt.strftime('%Y-%m-%d %H:%M:%S')
255 | # data_str += '.' + str(int(event.ts_ns % 1000000000)).zfill(6)
256 |
257 | flow = "%s -> %s" % (saddr, daddr)
258 |
259 | delta_ms = (float(event.ts_us) - start_ts) / 1000
260 |
261 | tps_name = ["netif_rx", "net_dev_queue", "net_dev_xmit", "netif_receive_skb"]
262 |
263 | fun_name = tps_name[event.fun_idx]
264 |
265 | # Print event
266 | print "%7s [%-12s] [%6s] %20s %4s %7s %7s %-34s" % (event.icmpseq, delta_ms, event.cpu, fun_name, event.ifname, event.icmpid, direction, flow)
267 |
268 | start_ts = 0
269 | icmq_seq = 0
270 |
271 | if __name__ == "__main__":
272 | b = BPF(text=bpf_text)
273 | b["route_evt"].open_perf_buffer(event_printer)
274 |
275 | while True:
276 | b.kprobe_poll()
277 |
--------------------------------------------------------------------------------
/trace-packet-with-tracepoint-perf-ebpf/traceicmpsoftirq.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | bpf_text = """
3 | #include
4 | #include /* For TASK_COMM_LEN */
5 | #include
6 | #include
7 | struct probe_icmp_data_t
8 | {
9 | u64 timestamp_ns;
10 | u32 tgid;
11 | u32 pid;
12 | char comm[TASK_COMM_LEN];
13 | int v0;
14 | };
15 | BPF_PERF_OUTPUT(probe_icmp_events);
16 | static inline unsigned char *my_skb_transport_header(const struct sk_buff *skb)
17 | {
18 | return skb->head + skb->transport_header;
19 | }
20 | static inline struct icmphdr *my_icmp_hdr(const struct sk_buff *skb)
21 | {
22 | return (struct icmphdr *)my_skb_transport_header(skb);
23 | }
24 | int probe_icmp(struct pt_regs *ctx, struct sk_buff *skb)
25 | {
26 | u64 __pid_tgid = bpf_get_current_pid_tgid();
27 | u32 __tgid = __pid_tgid >> 32;
28 | u32 __pid = __pid_tgid; // implicit cast to u32 for bottom half
29 |
30 | struct probe_icmp_data_t __data = {0};
31 | __data.timestamp_ns = bpf_ktime_get_ns();
32 | __data.tgid = __tgid;
33 | __data.pid = __pid;
34 | bpf_get_current_comm(&__data.comm, sizeof(__data.comm));
35 | __be16 seq;
36 | void *addr = &my_icmp_hdr(skb)->un.echo.sequence;
37 | bpf_probe_read(&seq, sizeof(seq), addr);
38 |
39 | // bpf_probe_read(&seq, sizeof(seq), &my_icmp_hdr(skb)->un.echo.sequence);
40 | __data.v0 = be16_to_cpu(seq);
41 | probe_icmp_events.perf_submit(ctx, &__data, sizeof(__data));
42 | return 0;
43 | }
44 | """
45 |
46 | from bcc import BPF
47 | import ctypes as ct
48 |
49 | class Data_icmp(ct.Structure):
50 | _fields_ = [
51 | ("timestamp_ns", ct.c_ulonglong),
52 | ("tgid", ct.c_uint),
53 | ("pid", ct.c_uint),
54 | ("comm", ct.c_char * 16), # TASK_COMM_LEN
55 | ('v0', ct.c_uint),
56 | ]
57 |
58 | b = BPF(text=bpf_text)
59 |
60 | def print_icmp_event(cpu, data, size):
61 | #event = b["probe_icmp_events"].event(data)
62 | event = ct.cast(data, ct.POINTER(Data_icmp)).contents
63 | print("%-7d %-7d %-15s %s" %
64 | (event.tgid, event.pid,
65 | event.comm.decode('utf-8', 'replace'),
66 | event.v0))
67 |
68 | b.attach_kprobe(event="icmp_echo", fn_name="probe_icmp")
69 |
70 | b["probe_icmp_events"].open_perf_buffer(print_icmp_event)
71 | while 1:
72 | try:
73 | b.kprobe_poll()
74 | except KeyboardInterrupt:
75 | exit()
76 |
--------------------------------------------------------------------------------
/trace-packet-with-tracepoint-perf-ebpf/tracepkt_centos_7.md:
--------------------------------------------------------------------------------
1 | ```bash
2 | #!/usr/bin/env python
3 | # coding: utf-8
4 |
5 | # [tracer_skb]# uname -a
6 | # Linux master-147 3.10.0-957.21.3.el7.x86_64 #1 SMP Tue Jun 18 16:35:19 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
7 | # [tracer_skb]# lsb_release -a
8 | # LSB Version: :core-4.1-amd64:core-4.1-noarch
9 | # Distributor ID: CentOS
10 | # Description: CentOS Linux release 7.6.1810 (Core)
11 | # Release: 7.6.1810
12 | # Codename: Core
13 |
14 | $ perf trace --no-syscalls --event 'net:*' ping 10.81.128.16 -c1 > /dev/null
15 |
16 | 0.000 net:net_dev_queue: dev=cali6ecc40249f1 skbaddr=0xffff9eb2d36c5500 len=98
17 | 0.017 net:netif_rx: dev=eth0 skbaddr=0xffff9eb2d36c5500 len=84
18 | 0.021 net:net_dev_xmit: dev=cali6ecc40249f1 skbaddr=0xffff9eb2d36c5500 len=98 rc=0
19 | 0.024 net:netif_receive_skb: dev=eth0 skbaddr=0xffff9eb2d36c5500 len=84
20 |
21 | # ICMP echo reply
22 | 0.058 net:net_dev_queue: dev=eth0 skbaddr=0xffff9eb2d36c5d00 len=98
23 | 0.061 net:netif_rx: dev=cali6ecc40249f1 skbaddr=0xffff9eb2d36c5d00 len=84
24 | 0.063 net:net_dev_xmit: dev=eth0 skbaddr=0xffff9eb2d36c5d00 len=98 rc=0
25 | 0.065 net:netif_receive_skb: dev=cali6ecc40249f1 skbaddr=0xffff9eb2d36c5d00 len=84
26 | ```
27 |
28 |
29 |
30 | 针对 CentOS CentOS Linux release 7.6.1810 版本的 tracepkt.py
31 |
32 | ```python
33 | import sys
34 | from socket import inet_ntop, AF_INET, AF_INET6
35 | from bcc import BPF
36 | import ctypes as ct
37 | import subprocess
38 | from struct import pack
39 |
40 | bpf_text = '''
41 | #include
42 | #include
43 | #include
44 | #include
45 | // for net struct
46 | #include
47 |
48 | #include
49 | #include
50 | #include
51 | #include
52 |
53 | #define IFNAMSIZ 16
54 | #define XT_TABLE_MAXNAMELEN 32
55 |
56 | // Event structure
57 | struct route_evt_t {
58 | char comm[TASK_COMM_LEN];
59 | char ifname[IFNAMSIZ];
60 | u64 netns;
61 |
62 | /* Packet type (IPv4 or IPv6) and address */
63 | u64 ip_version; // familiy (IPv4 or IPv6)
64 | u64 icmptype;
65 | u64 icmpid; // In practice, this is the PID of the ping process (see "ident" field in https://github.com/iputils/iputils/blob/master/ping_common.c)
66 | u64 icmpseq; // Sequence number
67 | u64 saddr[2]; // Source address. IPv4: store in saddr[0]
68 | u64 daddr[2]; // Dest address. IPv4: store in daddr[0]
69 | };
70 |
71 | BPF_PERF_OUTPUT(route_evt);
72 |
73 | #define MAC_HEADER_SIZE 14;
74 |
75 | #define member_read(destination, source_struct, source_member) \
76 | do{ \
77 | bpf_probe_read( \
78 | destination, \
79 | sizeof(source_struct->source_member), \
80 | ((char*)source_struct) + offsetof(typeof(*source_struct), source_member) \
81 | ); \
82 | } while(0)
83 |
84 | #define member_address(source_struct, source_member) \
85 | ({ \
86 | void* __ret; \
87 | __ret = (void*) (((char*)source_struct) + offsetof(typeof(*source_struct), source_member)); \
88 | __ret; \
89 | })
90 |
91 | static inline int do_trace(void* ctx, struct sk_buff* skb)
92 | {
93 | // Built event for userland
94 | struct route_evt_t evt = {};
95 | bpf_get_current_comm(evt.comm, TASK_COMM_LEN);
96 |
97 | struct net_device *dev;
98 | member_read(&dev, skb, dev);
99 | // bpf_probe_read(&dev, sizeof(skb->dev), ((char*)skb) + offsetof(typeof(*skb), dev));
100 |
101 | // Load interface name
102 | bpf_probe_read(&evt.ifname, IFNAMSIZ, dev->name);
103 |
104 | // Compute MAC header address
105 | char* head;
106 | u16 mac_header;
107 | u16 network_header;
108 |
109 | member_read(&head, skb, head);
110 | member_read(&mac_header, skb, mac_header);
111 | member_read(&network_header, skb, network_header);
112 |
113 | if(network_header == 0) {
114 | network_header = mac_header + MAC_HEADER_SIZE;
115 | }
116 |
117 | // Compute IP Header address
118 | char *ip_header_address = head + network_header;
119 |
120 | // Abstract IPv4 / IPv6
121 | u8 proto_icmp;
122 | u8 proto_icmp_echo_request;
123 | u8 proto_icmp_echo_reply;
124 | u8 icmp_offset_from_ip_header;
125 | u8 l4proto;
126 |
127 | // Load IP protocol version
128 | bpf_probe_read(&evt.ip_version, sizeof(u8), ip_header_address);
129 | evt.ip_version = evt.ip_version >> 4 & 0xf;
130 |
131 | // Filter IP packets
132 | if (evt.ip_version == 4) {
133 | // Load IP Header
134 | struct iphdr iphdr;
135 | bpf_probe_read(&iphdr, sizeof(iphdr), ip_header_address);
136 |
137 | // Load protocol and address
138 | icmp_offset_from_ip_header = iphdr.ihl * 4;
139 | l4proto = iphdr.protocol;
140 | evt.saddr[0] = iphdr.saddr;
141 | evt.daddr[0] = iphdr.daddr;
142 |
143 | // Load constants
144 | proto_icmp = IPPROTO_ICMP;
145 | proto_icmp_echo_request = ICMP_ECHO;
146 | proto_icmp_echo_reply = ICMP_ECHOREPLY;
147 | }
148 |
149 | // Filter ICMP packets
150 | if (l4proto != proto_icmp) {
151 | return 0;
152 | }
153 |
154 | // Compute ICMP header address and load ICMP header
155 | char* icmp_header_address = ip_header_address + icmp_offset_from_ip_header;
156 | struct icmphdr icmphdr;
157 | bpf_probe_read(&icmphdr, sizeof(icmphdr), icmp_header_address);
158 |
159 | // Filter ICMP echo request and echo reply
160 | if (icmphdr.type != proto_icmp_echo_request && icmphdr.type != proto_icmp_echo_reply) {
161 | return 0;
162 | }
163 |
164 | // Get ICMP info
165 | evt.icmptype = icmphdr.type;
166 | evt.icmpid = icmphdr.un.echo.id;
167 | evt.icmpseq = icmphdr.un.echo.sequence;
168 |
169 | // Fix endian
170 | evt.icmpid = be16_to_cpu(evt.icmpid);
171 | evt.icmpseq = be16_to_cpu(evt.icmpseq);
172 |
173 | #ifdef CONFIG_NET_NS
174 | struct net *net;
175 |
176 | // Get netns id. The code below is equivalent to: evt->netns = dev->nd_net.net->ns.inum
177 | member_read(&net, dev, nd_net);
178 | member_read(&evt.netns, net, proc_inum);
179 | #endif
180 |
181 | // Send event to userland
182 | route_evt.perf_submit(ctx, &evt, sizeof(evt));
183 |
184 | return 0;
185 | }
186 |
187 | /**
188 | * Attach to Kernel Tracepoints
189 | */
190 | TRACEPOINT_PROBE(net, netif_rx) {
191 | return do_trace(args, (struct sk_buff*)args->skbaddr);
192 | }
193 |
194 | TRACEPOINT_PROBE(net, net_dev_queue) {
195 | return do_trace(args, (struct sk_buff*)args->skbaddr);
196 | }
197 |
198 | TRACEPOINT_PROBE(net, net_dev_xmit) {
199 | return do_trace(args, (struct sk_buff*)args->skbaddr);
200 | }
201 |
202 | TRACEPOINT_PROBE(net, netif_receive_skb) {
203 | return do_trace(args, (struct sk_buff*)args->skbaddr);
204 | }
205 | '''
206 |
207 | TASK_COMM_LEN = 16 # linux/sched.h
208 | IFNAMSIZ = 16
209 |
210 | class RouteEvt(ct.Structure):
211 | _fields_ = [
212 | ("comm", ct.c_char * TASK_COMM_LEN),
213 | ("ifname", ct.c_char * IFNAMSIZ),
214 | ("netns", ct.c_ulonglong),
215 |
216 | # Packet type (IPv4 or IPv6) and address
217 | ("ip_version", ct.c_ulonglong),
218 | ("icmptype", ct.c_ulonglong),
219 | ("icmpid", ct.c_ulonglong),
220 | ("icmpseq", ct.c_ulonglong),
221 | ("saddr", ct.c_ulonglong * 2),
222 | ("daddr", ct.c_ulonglong * 2),
223 | ]
224 |
225 | def event_printer(cpu, data, size):
226 | # Decode event
227 | event = ct.cast(data, ct.POINTER(RouteEvt)).contents
228 |
229 | # Decode address
230 | if event.ip_version == 4:
231 | saddr = inet_ntop(AF_INET, pack("=I", event.saddr[0]))
232 | daddr = inet_ntop(AF_INET, pack("=I", event.daddr[0]))
233 |
234 | # Decode direction
235 | if event.icmptype in [8, 128]:
236 | direction = "request"
237 | elif event.icmptype in [0, 129]:
238 | direction = "reply"
239 | else:
240 | return
241 |
242 | flow = "%s -> %s" % (saddr, daddr)
243 |
244 | # Print event
245 | print "[%12s] %16s %7s %-34s" % (event.netns, event.ifname, direction, flow)
246 |
247 | if __name__ == "__main__":
248 | b = BPF(text=bpf_text)
249 | b["route_evt"].open_perf_buffer(event_printer)
250 |
251 | while True:
252 | b.kprobe_poll()
253 | ```
254 |
255 |
--------------------------------------------------------------------------------
/ubuntu_kernel_compile/README.md:
--------------------------------------------------------------------------------
1 | # qemu + gdb 调试 linux 内核
2 |
3 | ubuntu 启用 ssh
4 |
5 | ```bash
6 | $ sudo apt update
7 | $ sudo apt install openssh-server
8 | $ sudo systemctl status ssh
9 | $ sudo ufw allow ssh
10 | ```
11 |
12 |
13 |
14 | 编译内核 CentOS7
15 |
16 | ```bash
17 | $ sudo yum group install "Development Tools"
18 | $ yum install ncurses-devel bison flex elfutils-libelf-devel openssl-devel
19 |
20 | $ wget http://ftp.sjtu.edu.cn/sites/ftp.kernel.org/pub/linux/kernel/v4.x/linux-4.19.172.tar.gz
21 | $ tar xzvf linux-4.19.172.tar.gz
22 | $ cd linux-4.19.172/
23 |
24 | $ make menuconfig
25 | $ nproc
26 | $ make -j 12 # make bzImage
27 |
28 | # 编译完成后内核位于以下目录
29 | ./arch/x86_64/boot/bzImage
30 | ./arch/x86/boot/bzImage
31 | ```
32 |
33 |
34 |
35 | 通过 busybox 文件系统定制 Linux
36 |
37 | ```bash
38 | # 首先安装静态依赖
39 | $ yum install -y glibc-static.x86_64 -y
40 |
41 | $ wget https://busybox.net/downloads/busybox-1.32.1.tar.bz2
42 | $ tar -xvf busybox-1.32.1.tar.bz2
43 | $ cd busybox-1.32.1/
44 |
45 | $ make menuconfig
46 | $ make && make install
47 |
48 | $ cd _install
49 | $ mkdir proc
50 | $ mkdir sys
51 | $ vim init # 内容如下
52 | $ cat init
53 | $ chmod +x init
54 | $ find . | cpio -o --format=newc > ./rootfs.img
55 | cpio: File ./rootfs.img grew, 2758144 new bytes not copied
56 | 10777 blocks
57 | $ ls -hl rootfs.img
58 | -rw-r--r-- 1 root root 5.3M Feb 2 11:23 rootfs.img
59 | ```
60 |
61 | 
62 |
63 |
64 |
65 | init 内容如下
66 |
67 | ```bash
68 | #!/bin/sh
69 | echo "{==DBG==} INIT SCRIPT"
70 | mkdir /tmp
71 | mount -t proc none /proc
72 | mount -t sysfs none /sys
73 | mount -t debugfs none /sys/kernel/debug
74 | mount -t tmpfs none /tmp
75 |
76 | mdev -s
77 | echo -e "{==DBG==} Boot took $(cut -d' ' -f1 /proc/uptime) seconds"
78 | setsid /bin/cttyhack setuidgid 1000 /bin/sh #normal user
79 | ```
80 |
81 |
82 |
83 | > 报错排查
84 | >
85 | > ```bash
86 | > /bin/ld: cannot find -lcrypt
87 | > /bin/ld: cannot find -lm
88 | > /bin/ld: cannot find -lresolv
89 | > /bin/ld: cannot find -lrt
90 | > collect2: error: ld returned 1 exit status
91 | > Note: if build needs additional libraries, put them in CONFIG_EXTRA_LDLIBS.
92 | > Example: CONFIG_EXTRA_LDLIBS="pthread dl tirpc audit pam"
93 | > ```
94 | >
95 | > 由于是静态编译可以使用 `yum provides` 命令查看
96 | >
97 | > ```bash
98 | > $ yum provides */libm.a
99 | > // ...
100 | > glibc-static-2.17-317.el7.x86_64 : C library static libraries for -static linking.
101 | > Repo : base
102 | > Matched from:
103 | > Filename : /usr/lib64/libm.a
104 | > ```
105 |
106 |
107 |
108 | ## QEMU
109 |
110 | CentOS 安装,参见[这里](https://www.qemu.org/download/)。
111 |
112 | ```bash
113 | $ sudo yum install qemu-kvm -y
114 | $ sudo which qemu-kvm
115 | /bin/qemu-kvm
116 |
117 | $ /bin/qemu-kvm --version
118 | QEMU emulator version 1.5.3 (qemu-kvm-1.5.3-175.el7_9.1), Copyright (c) 2003-2008 Fabrice Bellard
119 | ```
120 |
121 |
122 |
123 | 如果启动报错,多数是因为 BIOS 中未开启 Intel 的虚拟化技术导致,(在云厂商的机器上比如阿里的 ECS 可能禁止了虚拟化)。
124 |
125 | ```bash
126 | Could not access KVM kernel module: No such file or directory
127 | failed to initialize KVM: No such file or directory
128 | Back to tcg accelerator.
129 | ```
130 |
131 | 如果主机支持虚拟化,则可以使用以下方式解决
132 |
133 | ```bash
134 | Try with sudo modprobe kvm-intel.
135 |
136 | In order to have the module automatically loaded at the startup of the virtual machine, do the following:
137 |
138 | Edit the corresponding file from the shell with sudo vim /etc/modules.conf
139 | Possibly enter your username password.
140 | Press the key G to go to the end of the document and then o to begin inserting.
141 | Write kvm-intel and press Enter, producing a new line.
142 | Press Esc to return to the Normal mode of vim. "--INSERT--" will disappear fromthe bottom.
143 | Save the file and exit vim by writing :wq.
144 | You are done. Try to reboot and load the nested virtual machine.
145 | ```
146 |
147 |
148 |
149 | ```bash
150 | $ cp linux-4.19.172/arch/x86_64/boot/bzImage ./
151 | $ cp busybox-1.32.1/_install/rootfs.img ./
152 | ```
153 |
154 |
155 |
156 | Ubuntu 20.04
157 |
158 | ```bash
159 | $ apt install qemu qemu-utils qemu-kvm virt-manager libvirt-daemon-system libvirt-clients bridge-utils
160 | ```
161 |
162 |
163 |
164 | ```
165 | qemu-system-x86_64 -kernel ./bzImage -initrd ./rootfs.img -append "console=ttyS0" -s -S -nographic
166 | ```
167 |
168 |
169 |
170 | ## 参考
171 |
172 | * [How to compile and install Linux Kernel 5.6.9 from source code](https://www.cyberciti.biz/tips/compiling-linux-kernel-26.html)
173 | * [用qemu + gdb调试linux内核](https://www.jianshu.com/p/431d606d322c)
174 | * [QEMU+busybox 搭建Linux内核运行环境](https://www.sunxiaokong.xyz/2020-01-14/lzx-linuxkernel-qemuinit/)
175 | * [QEMU+gdb调试Linux内核全过程](https://blog.csdn.net/jasonLee_lijiaqi/article/details/80967912)
176 | * [How to Build A Custom Linux Kernel For Qemu (2015 Edition)](http://mgalgs.github.io/2015/05/16/how-to-build-a-custom-linux-kernel-for-qemu-2015-edition.html)
177 | * [qemu与qemu-kvm到底什么区别](https://www.cnblogs.com/hugetong/p/8808544.html)
178 | * [在qemu环境中用gdb调试Linux内核](https://www.cnblogs.com/wipan/p/9264979.html)
--------------------------------------------------------------------------------
/ubuntu_kernel_compile/ubuntu-kernel-compile.md:
--------------------------------------------------------------------------------
1 | # Ubuntu 内核编译
2 |
3 | 当前版本 18.04
4 |
5 | ```bash
6 | $ uname -a
7 | Linux ubuntu-bionic 4.15.0-124-generic #127-Ubuntu SMP Fri Nov 6 10:54:43 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
8 | ```
9 |
10 |
11 |
12 | 国内内核源码下载:http://ftp.sjtu.edu.cn/sites/ftp.kernel.org/pub/linux/kernel/
13 |
14 | 将 ubuntu 源替换成清华源 https://mirror.tuna.tsinghua.edu.cn/help/ubuntu/
15 |
16 | ```bash
17 | $ sudo cp /etc/apt/sources.list /etc/apt/sources.list.bk
18 | $ sudo vim /etc/apt/sources.list
19 |
20 | # 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
21 | deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
22 | # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
23 | deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
24 | # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
25 | deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
26 | # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
27 | deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
28 | # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
29 |
30 | # 预发布软件源,不建议启用
31 | # deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
32 | # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
33 |
34 | $ sudo apt-get update
35 | ```
36 |
37 |
38 |
39 | 安装依赖包
40 |
41 | ```bash
42 | $ sudo apt-get install build-essential libncurses-dev bison flex libssl-dev libelf-dev
43 |
44 | # 使用当前系统运行的配置进行编译,如果需要定制使用 make menuconfig
45 | $ sudo cp -v /boot/config-$(uname -r) .config
46 | $ sudo make -j4
47 |
48 | $ sudo make modules_install
49 | $ sudo make install
50 |
51 | # 重启电脑,查看新的内核
52 | ```
53 |
54 |
--------------------------------------------------------------------------------
/xdp-project/README.md:
--------------------------------------------------------------------------------
1 | # XDP Project
2 |
3 | * [xdp-project](https://github.com/xdp-project) include [xdp-tutorial](https://github.com/xdp-project/xdp-tutorial)
4 |
--------------------------------------------------------------------------------
/xdp-project/XDP_LLC2018_redirect.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/xdp-project/XDP_LLC2018_redirect.pdf
--------------------------------------------------------------------------------
/xdp-project/af_xdp.md:
--------------------------------------------------------------------------------
1 | AF_XDP是一个针对高性能数据包处理而优化的地址系列。
2 |
3 | 本文档假设读者熟悉BPF和XDP。如果不熟悉,Cilium项目有一个很好的参考指南,网址是http://cilium.readthedocs.io/en/latest/bpf/。
4 |
5 | 使用XDP程序中的XDP_REDIRECT操作,程序可以使用bpf_redirect_map()函数将入口帧重定向到其他启用XDP的netdevs。AF_XDP套接字使XDP程序可以将帧重定向到用户空间应用程序的内存缓冲区。
6 |
7 | 一个AF_XDP套接字(XSK)是通过正常的socket()系统调用创建的。与每个XSK相关联的是两个环:RX环和TX环。一个套接字可以在RX环上接收数据包,也可以在TX环上发送数据包。这些环分别用setockopts XDP_RX_RING和XDP_TX_RING注册和确定大小。每个套接字必须至少有一个这样的环。一个RX或TX描述符环指向内存区域中的一个数据缓冲区,称为UMEM。RX和TX可以共享同一个UMEM,这样一个数据包就不必在RX和TX之间复制。此外,如果一个数据包由于可能的重发而需要保留一段时间,可以将指向该数据包的描述符改为指向另一个数据包,并立即重新使用。这又避免了数据的复制。
8 |
9 | UMEM由许多大小相等的块组成。其中一个环中的描述符通过引用其addr来引用一个帧。addr只是整个UMEM区域内的一个偏移。用户空间使用任何它认为最合适的手段(malloc、mmap、巨页等)为这个UMEM分配内存。然后使用新的setockopt XDP_UMEM_REG向内核注册这个内存区域。UMEM也有两个环:FILL环和COMPLETION环。FILL环由应用程序用来发送addr给内核,让内核填入RX数据包。一旦收到每个数据包,这些帧的引用就会出现在RX环中。另一方面,COMPLETION环包含了内核已经完全传输的帧addr,现在可以被用户空间再次使用,用于TX或RX。因此,出现在COMPLETION环中的帧addr是之前使用TX环传输的addr。总之,RX和FILL环用于RX路径,TX和COMPLETION环用于TX路径。
10 |
11 | 然后通过bind()调用将套接字最后绑定到一个设备上,并在该设备上绑定一个特定的队列id,直到绑定完成后,流量才开始流动。
12 |
13 | 如果需要,UMEM可以在进程之间共享。如果一个进程想这样做,它只需跳过UMEM及其对应的两个环的注册,在绑定调用中设置XDP_SHARED_UMEM标志,并提交它想与之共享UMEM的进程的XSK以及自己新创建的XSK套接字。然后,新进程将在自己的RX环中接收指向这个共享UMEM的帧addr引用。请注意,由于环结构是单消费者/单生产者(出于性能考虑),新进程必须创建自己的套接字和相关的RX和TX环,因为它不能与其他进程共享。这也是每个UMEM只有一组FILL和COMPLETION环的原因。处理UMEM是一个进程的责任。
14 |
15 | 那么数据包是如何从XDP程序分发到XSK的呢?有一个叫做XSKMAP的BPF映射(或BPF_MAP_TYPE_XSKMAP全称)。用户空间程序可以在这个映射中的任意位置放置一个XSK。然后,XDP程序可以将一个数据包重定向到这个映射中的特定索引,此时XDP会验证该映射中的XSK是否确实与该设备和环号绑定。如果没有,则丢弃该数据包。如果该索引处地图为空,则数据包也会被丢弃。这也就意味着目前必须加载一个XDP程序(并且在XSKMAP里有一个XSK),才能通过XSK获得任何流量到用户空间。
16 |
17 | AF_XDP可以在两种不同的模式下工作。XDP_SKB和XDP_DRV。如果驱动程序不支持XDP,或者在加载XDP程序时明确选择了XDP_SKB,则会采用XDP_SKB模式,该模式使用SKB与通用的XDP支持一起使用,并将数据复制到用户空间。这是一种适用于任何网络设备的后备模式。另一方面,如果驱动程序对XDP有支持,则会被AF_XDP代码使用,以提供更好的性能,但仍有一份数据拷贝到用户空间。
18 |
19 |
20 |
21 | 概念
22 | 为了使用AF_XDP套接字,需要设置一些相关的对象。这些对象及其选项将在下面的章节中解释。
23 |
24 | 要想了解AF_XDP的工作原理,你也可以看看2018年的Linux Plumbers关于这个主题的论文:http://vger.kernel.org/lpc_net2018_talks/lpc18_paper_af_xdp_perf-v2.pdf。不要参考2017年关于 "AF_PACKET v4 "的论文,这是AF_XDP的第一次尝试。从那时起,几乎所有的东西都改变了。Jonathan Corbet还写了一篇关于LWN的优秀文章,"用AF_XDP加速联网"。它可以在 https://lwn.net/Articles/750845/ 找到。
25 |
26 | UMEM
27 | UMEM是一个虚拟连续内存的区域,被分割成大小相等的帧。一个UMEM与一个netdev和该netdev的一个特定的队列id相关联,它是通过使用XDP_UMEM_REG setock来创建和配置的(分块大小、净空、起始地址和大小)。它是通过使用XDP_UMEM_REG setockopt系统调用来创建和配置的(分块大小、净空、起始地址和大小)。一个UMEM通过bind()系统调用与netdev和队列id绑定。
28 |
29 | 一个AF_XDP是连接到单个UMEM的套接字,但一个UMEM可以有多个AF_XDP套接字。要共享通过一个套接字A创建的UMEM,下一个套接字B可以通过设置struct sockaddr_xdp成员sxdp_flags中的XDP_SHARED_UMEM标志,并将A的文件描述符传递给struct sockaddr_xdp成员sxdp_shared_umem_fd。
30 |
31 | UMEM有两个单生产者/单消费者环,用于在内核和用户空间应用之间转移UMEM帧的所有权。
32 |
33 | 环
34 | 有四种不同的环。FILL、COMPLETION、RX和TX。所有的环都是单生产者/单消费者,所以用户空间的应用需要显式同步多个进程/线程的读写。
35 |
36 | UMEM使用两个环。FILL和COMPLETION。每一个与UMEM相关联的socket必须有一个RX队列、TX队列或两者兼有。比如说,有一个设置有四个socket(都是做TX和RX)。那么就会有一个FILL环,一个COMPLETION环,四个TX环和四个RX环。
37 |
38 | 这些环是基于头部(生产者)/尾部(消费者)的环。生产者在结构xdp_ring producer成员指出的索引处写入数据环,并增加生产者索引。消费者在 struct xdp_ring consumer member 指明的索引处读取数据环,并增加消费者索引。
39 |
40 | 环通过_RING setockopt系统调用进行配置和创建,并使用适当的偏移量向mmap()映射到用户空间(XDP_PGOFF_RX_RING、XDP_PGOFF_TX_RING、XDP_UMEM_PGOFF_FILL_RING和XDP_UMEM_PGOFF_COMPLETION_RING)。
41 |
42 | 环的大小需要是2的幂。
43 |
44 | UMEM 填充环
45 | FILL环用于将UMEM帧的所有权从用户空间转移到内核空间。UMEM的addrs是在环中传递的。举个例子,如果UMEM是64k,每个chunk是4k,那么UMEM有16个chunk,可以传递0到64k之间的addrs。
46 |
47 | 传递给内核的帧用于入口路径(RX环)。
48 |
49 | 用户应用程序产生UMEM addrs到这个环。需要注意的是,如果在对齐的分块模式下运行应用程序,内核会屏蔽传入的addr。例如,对于一个2k大小的chunk,addr的log2(2048)LSB将被屏蔽掉,这意味着2048、2050和3000指的是同一个chunk。如果用户应用在不对齐的chunks模式下运行,那么传入的addr将不被触动。
50 |
51 | UMEM完成环
52 | COMPLETION环用于将UMEM帧的所有权从内核空间转移到用户空间。就像FILL环一样,使用UMEM索引。
53 |
54 | 从内核传递到用户空间的帧是已经发送的帧(TX环),可以被用户空间再次使用。
55 |
56 | 用户应用从这个环消耗UMEM addrs。
57 |
58 | RX环
59 | RX环是套接字的接收端。环中的每个条目是一个xdp_desc描述符结构。描述符包含UMEM偏移量(addr)和数据的长度(len)。
60 |
61 | 如果没有帧通过FILL环传递给内核,那么在RX环上就不会(或可以)出现描述符。
62 |
63 | 用户应用程序从这个环消耗xdp_desc描述符结构。
64 |
65 | TX环
66 | TX环用于发送帧。结构xdp_desc描述符被填入(索引、长度和偏移量)并传递到环中。
67 |
68 | 为了开始传输,需要一个sendmsg()系统调用。这一点将来可能会被放宽。
69 |
70 | 用户应用程序会产生结构xdp_desc描述符到这个环中。
71 |
72 |
73 |
74 | Libbpf
75 | Libbpf是一个用于eBPF和XDP的帮助库,它使这些技术的使用变得更加简单。它还在 tools/lib/bpf/xsk.h 中包含了特定的帮助函数,以方便AF_XDP的使用。它包含两种类型的函数:那些可以用来使AF_XDP套接字的设置变得更简单的函数,以及那些可以在数据平面上安全快速地访问环的函数。要查看如何使用这个API的例子,请看samples/bpf/xdpsock_usr.c中的示例应用程序,它使用libbpf进行设置和数据平面操作。
76 |
77 | 我们建议你使用这个库,除非你已经成为一个强大的用户。它将使你的程序变得更简单。
78 |
79 | XSKMAP / BPF_MAP_TYPE_XSKMAP.
80 | 在XDP侧有一个BPF映射类型BPF_MAP_TYPE_XSKMAP (XSKMAP),它与bpf_redirect_map()一起使用,将入口帧传递给socket。
81 |
82 | 用户应用程序通过bpf()系统调用将套接字插入到映射中。
83 |
84 | 请注意,如果一个XDP程序试图重定向到一个与队列配置和netdev不匹配的套接字,该帧将被丢弃。例如,AF_XDP套接字被绑定到netdev eth0和队列17。只有针对eth0和队列17执行的XDP程序才能成功地将数据传递到套接字。请参考示例应用程序(samples/bpf/)中的例子。
85 |
86 | 配置标志和套接字选项
87 | 这些是各种配置标志,可以用来控制和监视AF_XDP套接字的行为。
88 |
89 | XDP和XDP_ZERO的绑定标志。
90 | 当你绑定到一个socket时,内核会首先尝试使用零拷贝。如果不支持零拷贝,它将回到使用拷贝模式,即把所有数据包复制到用户空间。但是如果你想强制使用某种模式,你可以使用以下标志。如果你把XDP标志传递给绑定调用,内核将强制套接字进入复制模式。如果它不能使用复制模式,绑定调用将以错误的方式失败。反之,XDP_ZERO_XXX标志将强制套接字进入零拷贝模式或失败。
91 |
92 | XDP_SHARED_UMEM绑定标志
93 | 该标志使您能够将多个套接字绑定到同一个UMEM上,但前提是它们共享同一个队列id。在这种模式下,每个套接字都有自己的RX和TX环,但UMEM(与创建的第一个套接字绑定)只有一个FILL环和一个COMPLETION环。要使用这种模式,请创建第一个套接字,并以正常方式进行绑定。创建第二个套接字,并创建一个RX和一个TX环,或至少创建其中一个,但不使用FILL或COMPLETION环,因为将使用第一个套接字的环。在绑定调用中,设置XDP_SHARED_UMEM选项,并在sxdp_shared_umem_fd字段中提供初始socket的fd。你可以用这种方式附加任意数量的额外套接字。
94 |
95 | 那么一个数据包将到达哪个套接字呢?这是由XDP程序决定的。把所有的套接字都放在XSK_MAP中,只需指明你想把每个数据包发送到数组中的哪个索引。下面是一个简单的循环分发数据包的例子。
96 |
97 | ```c
98 | #include
99 | #include "bpf_helpers.h"
100 |
101 | #define MAX_SOCKS 16
102 |
103 | struct {
104 | __uint(type, BPF_MAP_TYPE_XSKMAP);
105 | __uint(max_entries, MAX_SOCKS);
106 | __uint(key_size, sizeof(int));
107 | __uint(value_size, sizeof(int));
108 | } xsks_map SEC(".maps");
109 |
110 | static unsigned int rr;
111 |
112 | SEC("xdp_sock") int xdp_sock_prog(struct xdp_md *ctx)
113 | {
114 | rr = (rr + 1) & (MAX_SOCKS - 1);
115 |
116 | return bpf_redirect_map(&xsks_map, rr, XDP_DROP);
117 | }
118 | ```
119 |
120 | 需要注意的是,由于FILL和COMPLETION环只有一组,而且是单个生产者、单个消费者环,所以需要确保多个进程或线程不会并发使用这些环。在libbpf代码中,目前还没有保护多个用户的同步基元。
121 |
122 | 如果你创建了多个绑定在同一个umem上的socket,Libbpf就会使用这种模式。然而,请注意,你需要在xsk_socket__create调用中提供XSK_LIBBPF_FLAGS__INHIBIT_PROG_LOAD libbpf_flag,并加载你自己的XDP程序,因为libbpf中没有内置的程序会为你路由流量。
123 |
124 |
125 |
126 | XDP_USE_NEED_WAKEUP 绑定标志.
127 | 这个选项增加了对一个名为need_wakeup的新标志的支持,这个标志存在于FILL环和TX环,用户空间是生产者的环。当在绑定调用中设置这个选项时,如果内核需要被syscall显式唤醒才能继续处理数据包,那么就会设置need_wakeup标志。如果该标志为0,则不需要系统调用。
128 |
129 | 如果在FILL环上设置了标志,应用程序需要调用poll()才能在RX环上继续接收数据包。例如,当内核检测到 FILL 环上没有缓冲区了,而 NIC 的 RX HW 环上也没有缓冲区了,就会发生这种情况。在这种情况下,中断会被关闭,因为网卡不能接收任何数据包(因为没有缓冲区可以放),设置 need_wakeup 标志,这样用户空间就可以在 FILL 环上放缓冲区,然后调用 poll(),这样内核驱动就可以在 HW 环上放这些缓冲区,开始接收数据包。
130 |
131 | 如果为TX环设置了标志,则意味着应用程序需要明确地通知内核发送任何放在TX环上的数据包。这可以通过poll()调用来实现,就像在RX路径中一样,或者通过调用sendto()来实现。
132 |
133 | 关于如何使用这个标志的例子可以在 samples/bpf/xdpsock_user.c中找到,一个使用libbpf helpers的例子在TX路径中是这样的。
134 |
135 | ```c
136 | if (xsk_ring_prod__needs_wakeup(&my_tx_ring))
137 | sendto(xsk_socket__fd(xsk_handle), NULL, 0, MSG_DONTWAIT, NULL, 0);
138 | ```
139 |
140 | 即,只有在设置了标志的情况下才使用syscall。
141 |
142 | 我们建议您总是启用这个模式,因为它通常会带来更好的性能,特别是当您在同一个内核上运行应用程序和驱动程序时,但如果您为应用程序和内核驱动程序使用不同的内核,也是如此,因为它减少了TX路径所需的syscall数量。
143 |
144 |
145 |
146 | XDP_{RX|TX|UMEM_FILL|UMEM_COMPLETION}_RING setockopts
147 | 这些setockopts设置了RX、TX、FILL和COMPLETION环分别应该拥有的描述符数量。RX和TX环中至少有一个环的大小是必须设置的。如果同时设置了这两个环,就可以同时接收和发送应用程序的流量,但如果只想做其中的一个环,可以只设置其中一个环来节省资源。FILL环和COMPLETION环都是必须的,因为你需要有一个UMEM与你的socket绑定。但是如果使用了XDP_SHARED_UMEM标志,那么在第一个套接字之后的任何套接字都没有UMEM,在这种情况下,不应该创建任何FILL或COMPLETION环,因为共享UMEM中的环将被使用。注意,这些环是单生产者单消费者的,所以不要试图同时从多个进程访问它们。参见XDP_SHARED_UMEM部分。
148 |
149 | 在 libbpf 中,您可以通过向 xsk_socket__create 函数的 rx 和 tx 参数分别提供 NULL 来创建 Rx-only 和 Tx-only 套接字。
150 |
151 | 如果您创建了一个仅有Tx的套接字,我们建议您不要在填充环上放置任何数据包。如果您这样做,驱动程序可能会认为您将收到一些东西,而事实上您不会收到,这可能会对性能产生负面影响。
152 |
153 | XDP_UMEM_REG setockopt
154 | 这个setockopt注册一个UMEM到socket。这是一个包含所有缓冲区的区域,数据包可以在这个区域中找到。这个调用需要一个指向这个区域起始的指针和它的大小。此外,它还有一个参数chunk_size,是UMEM被分割成的大小。目前只能是2K或4K。如果你的UMEM区域是128K,chunk大小是2K,这意味着你的UMEM区域最多只能容纳128K / 2K = 64个数据包,而你最大的数据包大小可以是2K。
155 |
156 | 还有一个选项可以设置UMEM中每个单个缓冲区的净空。如果你把它设置为N个字节,意味着数据包将从N个字节开始进入缓冲区,留下前N个字节供应用程序使用。最后一个选项是flags字段,但它将在每个UMEM标志的单独章节中处理。
157 |
158 | XDP_STATISTICS getsockopt
159 | 获取一个套接字的drop统计信息,这些信息对调试很有用。支持的统计数据如下所示。
160 |
161 | ```
162 | struct xdp_statistics {
163 | __u64 rx_dropped; /* Dropped for reasons other than invalid desc */
164 | __u64 rx_invalid_descs; /* Dropped due to invalid descriptor */
165 | __u64 tx_invalid_descs; /* Dropped due to invalid descriptor */
166 | };
167 | ```
168 |
169 | XDP_OPTIONS getsockopt.
170 | 从 XDP 套接字中获取选项。目前唯一支持的是XDP_OPTIONS_ZEROCOPY,它告诉你零拷贝是否开启。
171 |
172 | 用法
173 | 为了使用AF_XDP套接字,需要两个部分。用户空间应用程序和XDP程序。关于完整的设置和使用示例,请参考示例程序。用户空间程序是xdpsock_user.c,XDP程序是libbpf的一部分。
174 |
175 | 工具/lib/bpf/xsk.c中包含的XDP代码示例如下。
176 |
177 | ```
178 | SEC("xdp_sock") int xdp_sock_prog(struct xdp_md *ctx)
179 | {
180 | int index = ctx->rx_queue_index;
181 |
182 | // A set entry here means that the corresponding queue_id
183 | // has an active AF_XDP socket bound to it.
184 | if (bpf_map_lookup_elem(&xsks_map, &index))
185 | return bpf_redirect_map(&xsks_map, index, 0);
186 |
187 | return XDP_PASS;
188 | }
189 | ```
190 |
191 | 一个简单但性能不高的环形dequeue和enqueue可以是这样的。
192 |
193 | ```
194 | // struct xdp_rxtx_ring {
195 | // __u32 *producer;
196 | // __u32 *consumer;
197 | // struct xdp_desc *desc;
198 | // };
199 |
200 | // struct xdp_umem_ring {
201 | // __u32 *producer;
202 | // __u32 *consumer;
203 | // __u64 *desc;
204 | // };
205 |
206 | // typedef struct xdp_rxtx_ring RING;
207 | // typedef struct xdp_umem_ring RING;
208 |
209 | // typedef struct xdp_desc RING_TYPE;
210 | // typedef __u64 RING_TYPE;
211 |
212 | int dequeue_one(RING *ring, RING_TYPE *item)
213 | {
214 | __u32 entries = *ring->producer - *ring->consumer;
215 |
216 | if (entries == 0)
217 | return -1;
218 |
219 | // read-barrier!
220 |
221 | *item = ring->desc[*ring->consumer & (RING_SIZE - 1)];
222 | (*ring->consumer)++;
223 | return 0;
224 | }
225 |
226 | int enqueue_one(RING *ring, const RING_TYPE *item)
227 | {
228 | u32 free_entries = RING_SIZE - (*ring->producer - *ring->consumer);
229 |
230 | if (free_entries == 0)
231 | return -1;
232 |
233 | ring->desc[*ring->producer & (RING_SIZE - 1)] = *item;
234 |
235 | // write-barrier!
236 |
237 | (*ring->producer)++;
238 | return 0;
239 | }
240 | ```
241 |
242 | 但请使用libbpf函数,因为它们是优化过的,并可随时使用。会让你的生活更轻松。
243 |
244 | 申请书样本
245 | 其中包含了一个xdpsock基准/测试程序,演示了如何在私有UMEM中使用AF_XDP套接字。假设你想让来自4242端口的UDP流量最终进入队列16,我们将启用AF_XDP。在这里,我们使用ethtool来实现。
246 |
247 | ```
248 | ethtool -N p3p2 rx-flow-hash udp4 fn
249 | ethtool -N p3p2 flow-type udp4 src-port 4242 dst-port 4242 \
250 | action 16
251 | ```
252 |
253 | 然后在XDP_DRV模式下运行rxdrop基准可以使用。
254 |
255 | ```
256 | samples/bpf/xdpsock -i p3p2 -q 16 -r -N
257 | ```
258 |
259 | 对于XDP_SKB模式,使用开关"-S "代替"-N",所有的选项可以像往常一样用"-h "来显示。
260 |
261 | 这个示例程序使用libbpf来简化AF_XDP的设置和使用。如果你想知道AF_XDP的原始uapi到底是如何被用来做一些更高级的东西,可以看看工具/lib/bpf/xsk.[ch]中的libbpf代码。
262 |
263 |
264 |
265 | 常见问题
266 | 问:我在插座上没有看到任何流量。我做错了什么?
267 |
268 | 答:当物理网卡的netdev被初始化时,Linux通常会将该物理网卡的netdev设置为
269 | 为每个核分配一个RX和TX队列对,所以在8核系统中,队列ID 0到7将被分配,每个核分配一个。所以在8核系统中,队列id 0到7将被分配,每个核分配一个。在AF_XDP绑定调用或xsk_socket__create libbpf函数调用中,你指定了一个特定的队列id来绑定,你将在你的套接字上得到的只是朝向该队列的流量。因此,在上面的例子中,如果你绑定到队列0,你不会得到任何分配到队列1到7的流量。如果你很幸运,你会看到流量,但通常它最终会出现在你没有绑定的队列中。
270 |
271 | 有很多方法可以解决把你想要的流量送到你绑定的队列id上的问题。如果你想看到所有的流量,你可以强制netdev只有1个队列,队列id 0,然后绑定到队列0。你可以使用 ethtool 来完成这个任务。
272 |
273 | ```
274 | sudo ethtool -L <接口> combined 1
275 | ```
276 |
277 |
278 | 如果你想只看到部分流量,你可以通过 ethtool 对 NIC 进行编程,将流量过滤到一个单一的队列 id 上,你可以将 XDP 套接字绑定到这个队列上。下面是一个例子,在这个例子中,进出端口4242的UDP流量被发送到队列2。
279 |
280 | ```
281 | sudo ethtool -N rx-flow-hash udp4 fn
282 | sudo ethtool -N flow-type udp4 src-port 4242 dst-port \
283 | 4242 action 2
284 | ```
285 |
286 |
287 | 其他一些方法也是可能的,都取决于你的网卡的能力。
288 |
289 | 问:我可以用XSKMAP来实现不同内存的切换吗?
290 | 在复制模式下?
291 | 答:简短的回答是否定的,目前不支持这种方式。该
292 | XSKMAP只能用于将从队列id X进入的流量切换到绑定在同一队列id X上的套接字。XSKMAP可以包含绑定在不同队列id上的套接字,例如X和Y,但只有从队列id Y进入的流量才能被引导到绑定在同一队列id Y上的套接字上。
293 |
294 |
295 |
296 | ## 参考
297 |
298 | 1. [什么是AF_XDP Socket](https://decodezp.github.io/2019/03/26/quickwords22-af-xdp/)
--------------------------------------------------------------------------------
/xdp-project/xdp-the-express-data-path.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/xdp-project/xdp-the-express-data-path.pdf
--------------------------------------------------------------------------------
/xdp-project/xdp_intro_and_use_cases_sep2016.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DavadDi/bpf_study/09fd04b743469c27c699931c7fd73275772738a4/xdp-project/xdp_intro_and_use_cases_sep2016.pdf
--------------------------------------------------------------------------------