├── .gitignore
├── LICENSE
├── README.md
├── README_Adversarial Robustness Libraries.md
├── README_Commercial Platforms.md
├── README_Data Labelling Tools and Frameworks.md
├── README_Data Pipeline ETL Frameworks.md
├── README_Data Science Notebook Frameworks.md
├── README_Data Storage Optimisation.md
├── README_Data Stream Processing.md
├── README_Ethical_AI.md
├── README_Explaining Black Box Models.md
├── README_Feature Engineering Automation.md
├── README_Feature Stores.md
├── README_Function as a Service Frameworks.md
├── README_Industrial Strength NLP.md
├── README_ML Computation load distribution frameworks.md
├── README_Model Orchestration & Deployment Frameworks.md
├── README_Model and Data Versioning.md
├── README_Model serialisation formats.md
├── README_Neural Architecture Search.md
├── README_Optimized calculation frameworks.md
├── README_Privacy Preserving Machine Learning.md
├── README_Training & Indutrial Visualisation.md
├── _config.yml
└── images
├── DSWorkflow.JPG
├── FullMlopsNeuro.JPG
├── Recent_Poll_PipelineAI_July2019_1.JPG
├── Small_DataScience_Project.JPG
├── awesome.svg
├── bosstown.gif
├── mleng.png
├── mlops1.png
└── video.png
/.gitignore:
--------------------------------------------------------------------------------
1 | # Compiled source #
2 | ###################
3 | *.com
4 | *.class
5 | *.dll
6 | *.exe
7 | *.o
8 | *.so
9 |
10 | # Packages #
11 | ############
12 | # it's better to unpack these files and commit the raw source
13 | # git has its own built in compression methods
14 | *.7z
15 | *.dmg
16 | *.gz
17 | *.iso
18 | *.jar
19 | *.rar
20 | *.tar
21 | *.zip
22 |
23 | # Logs and databases #
24 | ######################
25 | *.log
26 | *.sql
27 | *.sqlite
28 |
29 | # OS generated files #
30 | ######################
31 | .DS_Store
32 | .DS_Store?
33 | ._*
34 | .Spotlight-V100
35 | .Trashes
36 | ehthumbs.db
37 | Thumbs.db
38 |
39 | # Python
40 | __pycache__
41 | *.pyc
42 |
43 | # Logs
44 | logs
45 | *.log
46 | npm-debug.log*
47 | yarn-debug.log*
48 | yarn-error.log*
49 |
50 | # Runtime data
51 | pids
52 | *.pid
53 | *.seed
54 | *.pid.lock
55 |
56 | # Directory for instrumented libs generated by jscoverage/JSCover
57 | lib-cov
58 |
59 | # Coverage directory used by tools like istanbul
60 | coverage
61 |
62 | # nyc test coverage
63 | .nyc_output
64 |
65 | # Grunt intermediate storage (http://gruntjs.com/creating-plugins#storing-task-files)
66 | .grunt
67 |
68 | # Bower dependency directory (https://bower.io/)
69 | bower_components
70 |
71 | # node-waf configuration
72 | .lock-wscript
73 |
74 | # Compiled binary addons (http://nodejs.org/api/addons.html)
75 | build/Release
76 |
77 | # Dependency directories
78 | node_modules/
79 |
80 | # Tags
81 | tags
82 | tags.*
83 | .tags
84 | .tags.*
85 |
86 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2020 DeepHiveMind
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | Special Note: _courtsey thanks to The Institute for Ethical AI & Machine Learning
16 |
17 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
18 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
19 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
20 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
21 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
22 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
23 | SOFTWARE.
24 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Production machine learning system| Real World ML System | Enterprise AI Platform MLOps
2 | This repository intends to offers
3 | - A Real-world *vision and recipe* of the `design, development and operation` of **production machine learning systems & operation**.
4 | - A curated list of tools, frameworks and open source libraries that helps AI/ML Engineers `Deploy, monitor, version, scale, and secure` production machine learning.
5 | - A *Recipe/prescription* of constituents, constructs and tools for to build & opertaionize a **comprehensive, operational & production Machine learning ecosystem** .Any good **Enterprise AI Platform** must intend to stich/chain together these constructs and tools under its hood. Genrally 'Enterprise AI Platforms', such as ```H20.ai, Alteryx, HopsML, Neu.ro, PipelineAI, DataRobot ``` etc, are powered by **Custom MLOPS** with the objective to *attempt to offer* essential high level MLOps constructs.
6 | - A Deep Dive View into:
7 | - ML Model Reproducitbility and Versioning
8 | - Production Machine Learning Orchestration
9 | - Explainablility of Black Box Models (a pillar of AI Trust)
10 | - **Ethical AI (a pillar of AI Trust)** with adequate deatiling around ```Ethical AI Frameworks, Codes of Ethics, Guidelines, Regulations``` et al. [Ethical AI](/README_Ethical_AI.md).
11 | - Target Audience:
12 | - Entereprise Architects / AI ML Solution Architects
13 | - AI Researcher
14 | - Data Scientists
15 | - AI/ML Engineers
16 | - AI Platform Engineers
17 | - DevOps Engineers
18 |
19 | ***
20 | **A Quick Rundown:**
21 |
22 | - [INSPIRATION for MLOPS](#INSPIRATION_for_MLOPS)
23 | - [WHY DO WE NEED MLOPS?](#WHY-DO-WE-NEED-MLOPS)
24 | - [EVOLUTION JOURNEY IN AI MATURITY CURVE](#EVOLUTION-IN-AI-MATURITY-JOURNEY)
25 | - [INDUSTRY SURVEY](#INDUSTRY-SURVEY)
26 | - [HIDDEN TECH DEBT IN REAL WORLD ML SYSTEM](#HIDDEN-TECH-DEBT-IN-REAL-WORLD-ML-SYSTEM)
27 | - [MLOPS VS DATAOPS VS AIOPS VS PLATFORMOPS](#MLOPS-VS-DATAOPS-VS-AIOPS-VS-PLATFORMOPS)
28 | - [STATE OF MACHINE LEARNING OPERATIONS IN Y2019](#STATE-OF-MACHINE-LEARNING-OPERATIONS-IN-Y2019)
29 | - [MLOPS Reference Architecture](#MLOPS-Reference-Architecture)
30 | - [High level constructs of MLOPS](#High-level-constructs-of-Real-World-MLOPS)
31 | - [Detail References to the Constructs and Tools of MLOPS](#Detail-References-to-the-Constructs-and-Tools-of-MLOPS)
32 | - [MLOPS Architecture based on KUBEFLOW](#MLOPS-Architecture-based-on-KUBEFLOW)
33 | - [Train and Serve TensorFlow Models at Scale with KUBERNETES and KUBEFLOW](#Train-and-Serve-TensorFlow-Models-at-Scale-with-Kubernetes-and-Kubeflow)
34 | - [Docker - Containerizatioin of AI Modules](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/1-docker)
35 | - [Kubernetes - K8S for AI](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/2-kubernetes)
36 | - [Helm Charts on K8S for AI complex deployment](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/3-helm)
37 | - [Kubeflow for AI MLOPS](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/4-kubeflow)
38 | - [JupyterHub on K8S- AI Build Notebook](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/5-jupyterhub)
39 | - [TFJob- K8S custom kind for AI Training on GPU/CPU/TPU](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/6-tfjob)
40 | - [Distributed Tensorflow](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/7-distributed-tensorflow)
41 | - [Hyperparameters Sweep with Helm](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/8-hyperparam-sweep)
42 | - [AI Model Serving for prediction/scoring](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/9-serving)
43 | - [Integrating AzureML and AWS SageMaker with KubeFlow to create E2E MLOPS Pipeline](#Integrating-AzureML-and-AWS-SageMaker-with-KubeFlow-to-create-E2E-MLOPS-Pipeline)
44 |
45 | - [Deep Dive into AI/ML SECURITY](#Deep-Dive-into-AI-SECURITY)
46 |
47 | - [Product Machine Learning System Y2019 A Video](#Product-Machine-Learning-System-Y2019-A-Video)
48 | ***
49 |
50 | # INSPIRATION for MLOPS
51 |
52 | ## WHY DO WE NEED MLOPS**
53 |
54 | Three Pronged Answer
55 | ***
56 | ```
57 |
58 | - EVOLUTION JOURNEY IN AI MATURITY CURVE
59 | {AS the Organizations advance in their AI Maturity journey, complexities start growing expoenentially}
60 |
61 | - HIDDEN TECH DEBT IN REAL WORLD ML SYSTEM
62 | {by _Google NIPS 2015}
63 |
64 | - STATE OF MACHINE LEANRNING OPERATIONS IN Y2019
65 | {Survey conducted by PipelineAI in July 2019 on State of Machine learning Operations}
66 |
67 | The aforementioned pointers are explained in below segments.
68 | ```
69 | ### INDUSTRY SURVEY
70 |
71 | But, before we resort to a deep dive into these aforementioned 3 PRONGED answers, Let us have a sneak peek into couple of the *interesting suerveys* conducted -
72 |
73 | A. "Only 20% of ML Models in the enterprise making into the production environments"
74 | _ [from 3073 AI Aware CXO-level executive surveyed](https://www.activestate.com/wp-content/uploads/2018/10/webinar-slides-mlops.pdf)
75 |
76 | B. The Story of Enterprise Machine Learning: "It took me 3 weeks to develop the model. It has been > 11 months, and it's still not deployed."
77 | _ [Ref Source: The Linux foundation CD.FONDATION](https://cd.foundation/blog/2020/02/11/announcing-the-cd-foundation-mlops-sig/)
78 |
79 | C. [The State of Affairs in MACHINE LEARNING OPERATIONS- Y'2019 Survey](#STATE-OF-MACHINE-LEARNING-OPERATIONS-IN-Y2019)
80 |
81 |
82 | ***
83 | ### EVOLUTION IN AI MATURITY JOURNEY
84 |
85 | - ***AS the Organizations advance in their AI Maturity journey, complexities start growing expoenentially.***
86 | - ***SMALL DATA SCIENCE PROJECTS/DataScience POC/MVP* has lesser complexities, than the *ENTERPRISE DATA SCIENCE SYSTEM***.
87 |
88 |
89 | Let us have a sneak peek into the Journey of any Org through various stages of AI Maturity, and related complexities
90 | ```
91 | "THE BEGINERS LUCK" (stage 1)
92 |
93 | --> "WHEN THE RUBBER HITS THE ROAD" (stage 2)
94 |
95 | --> "THE PROLIFERATION" (Stage 3)
96 | ```
97 | -- *[STAGE 1.]* **'THE BEGINERS LUCK STAGE**
98 |
99 | A *Simple ML workflow* does relatively very well with *SMALL DATA SCIENCE PROJECTS/POC/MVP*
100 | ``` 'Build/Prepare' --> 'Train' --> 'Evaluate'--> 'Deploy' --> 'UI' (a simple WebApp) ```
101 |
102 | As the focus is
103 | - Focus is on the deployment of the Model (accepted with success criteria),
104 | - Enable the registry of its inference in Real time,
105 | - Enable a simple PWA UI for the Visualization.
106 |
107 | THEREFORE, the SIMPLE WORKFLOW which worked pretty well for 'SMALL DATA SCIENCE PROJECTS' starts failing and crumbling under the complexities of 'ENTERPRISE DATA SCIENCE SYSTEM'.
108 |
109 |
110 |
111 | -- *[STAGE 2.]* **'WHEN THE RUBBER HITS THE ROAD' SATGE**
112 |
113 | As and when, the SMALL DATA SCIENCE PROJECTS/POC/MVPPOC/MVP hits the REAL WORLD SYSTEM, it starts facing new set of Challenges, and focus shifts to following
114 |
115 | - **Need to Re-Train**: After Pushing Your Model to Production, Your Model is already Out of Date. Google updates its SEO model/algorithm on average 500 times per year. [Ref](https://www.seoblog.com/google-penguin-panda-refresh/#:~:text=Of%20course%2C%20these%20are%20not,average%20500%20times%20per%20year.)
116 |
117 | - **Slow**: Need to Quantize and Speed Up Predictions
118 |
119 | - **Biased**: Needs to Validate Trained ML Binary/ Service/ servable in any form for Bias detection Before Pushing
120 |
121 | - **AI/ML Service Routing (If Broken)**: Need to A/B Test/ Multi Armed Bandit in Production
122 |
123 | - **Security Vulnerability (If Hacked)**: Need to Train With Data Privacy (All your Data & other security is for a toss now as the Makert exposed AI Model has the essence of the underlying data.
124 |
125 | - **Monitoring performance of the model** due to Data drift & concept drift
126 |
127 |
128 | A *Slightly Matured Workflow* does the work -
129 | ```'Build/Prepare' --> 'Train' --> 'Evaluate'--> 'Deploy' --> 'UI' (a PWA WebApp)** --> 'Monitor' --> Retraining pathway ```
130 |
131 | |**SMALL/MID SIZE DATA SCIENCE PROJECTS**| **ENTERPRISE DATA SCIENCE SYSTEM**|
132 | | :---: | :---:|
133 | | Workflow | Workflow|
134 | |||
135 | | Workflow Job well done | Still lot missing in the Workflow :smiley:|
136 |
137 | -- *[STAGE 3.]* **'THE PROLIFERATION' STAGE**
138 |
139 | But, as the Data Science (DS) requirements, demand for DS productionization, multiple DS Teams grows, whole lot of new issues starts popping up in explonential manner for large **ENTERPRISE DATA SCIENCE SYSTEM**. Such as,
140 |
141 | - Heterogeneity and Scale PROLIFERATION
142 | - Possibly differing engines proliferation (Spark, TensorFlow, Caffe, PyTorch, Sci-kitLearn, etc.). Multiple siloed DS Team would start using their own preferred DS tools.
143 | - Different languages proliferation (Python, Java, Scala, R ..)
144 | - Different Inference vs Training engines
145 | - Training can be frequently batch
146 | - Inference (Prediction, Model Serving) can be REST endpoint/custom code, streaming engine, micro-batch, etc.
147 | - Feature manipulation done at training needs to be replicated (or factored in) at inference
148 | - Each engine presents its own scale opportunities/issues
149 |
150 | - Increased complexities in flow of Data (One Centralized DataLake team, and multiple DS Team clamouring)
151 | - ML Team heavy dependence on data team for multiple data dimensions @variety, @Veracity, @Volume and @variability
152 |
153 | - Serving Models become increasingly harder
154 | - multiple DS Team,
155 | - multiple DS Tools,
156 | - multiple Serving requirements
157 |
158 | - Infrastructure needs, its governance complexities starts growing rapidly
159 | - Mutiple SERVING requirements,
160 | - Mutiple TRAINING requirements,
161 | - Mutiple DATA processing requirements,
162 | - Mutiple VISUALIZATION requirements etc
163 | *@varied frequency, @varied technologies, @varied Infra types**
164 |
165 | - when stuff goes wrong it's hard to trace back,
166 |
167 | - Compliance, Regulations…
168 | - Model Risk Management in Financial Services
169 | - GDPR on Reproducing and Explaining ML Decisions
170 | - Fairness Monitoring
171 |
172 | - & many More (See, whole lot of issues large Enterprise starts facing @exponential rate!!)
173 |
174 | A Fully Matured Custom MLOPS workflow is required to handle challenges of large *ENTERPRISE DATA SCIENCE SYSTEM*.
175 |
176 | **MLOPS IS THE SILVER BULLET!**
177 | ***
178 |
179 | ***
180 | ### HIDDEN TECH DEBT IN REAL WORLD ML SYSTEM
181 |
182 |
# HIDDEN TECH DEBT IN ML SYSTEM- NIPS/GOOGLE 2015
183 |
184 |
# Only a SMALL FRACTION of REAL-WORLD ML SYSTEMs is composed of the ML CODE
[HIDDEN TECH DEBT IN ML SYSTEM- NIPS/GOOGLE 2015](https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf)
193 |
194 |
195 |
# Hardest part of AI isn't AI, but it's Data & productionization
196 |
197 |
# Productionization/Industralization Machine Learning Systems
198 |
199 | **MLOPS IS THE SILVER BULLET!**
200 | ***
201 |
202 | ***
203 |
204 | # MLOPS VS DATAOPS VS AIOPS VS PLATFORMOPS
205 |
206 | DevOps fits everywhere in IT landscape as like salt. Infact, DevOps dons multiple avataar in the broader perspective of Enterprise AI & Data Platform landscape -
207 |
208 | - **MLOps** is the application DevOps for AI, ML & Analytics foundation for to help Data Scientists in managing ML Lifecycle (building-training-deployment-Inferenece-monitroing-Trust lifecycle). I.e., MLOps is the practice of applying DevOps to help automate, manage, and audit machine learning (ML) workflows.
209 | “MLOps (a compound of “machine learning” and “operations”) is a practice for collaboration and communication between data scientists and operations professionals to help manage production ML (or deep learning) lifecycle". – Wiki
210 | ```
211 | - MLOps = f(CI, CD, CT, CS, uS) in AI/ML field
212 | - CI == Continuous Integration of entire solution blocks in E2E ML Lifecycle
213 | - CD == Consistent deployment of entire solution blocks in E2E ML Lifecycle
214 | - CT == Continuous retraining & serving (deployment as AIaaS, binary, pruned end point) pathway for entire solution blocks in E2E ML Lifecycle
215 | - CS == Continuous Data pipeline for Real-time/Batch/Microbatch for Inference/Scoring of the model in production
216 | - uS == Microservice governance of entire solution blocks in E2E ML Lifecycle
217 |
218 | New generation MLOPS is composed of DataOps as well. :)
219 | ```
220 | - **DataOps** is the application DevOps for data foundation for to help Data Engineers in managing Data Lifecycle.
221 | DataOps is a collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across an organization. -Gartner
222 | ```
223 | - DataOps = f(CI, CD, CO, uS) in Data Engineering field
224 | - CI == Continuous Integration of entire solution blocks in Data Engineering Lifecycle
225 | - CD == Consistent deployment of entire solution blocks in Data Engineering Lifecycle
226 | - CO == Continuous Orachsetration pathway for entire solution blocks in Data Engineering Lifecycle
227 | - uS == Microservice governance of entire solution blocks in Data Engineering Lifecycle
228 |
229 | ```
230 | - The term **AIOps** stands for “artificial intelligence for IT operations” Originally coined by Gartner in 2017, the term refers to the way data and information from an IT environment are managed by an IT team–in this case, using AI. It's the application DevOps for for IT operations assited by AI. I.e., ***AIOps == AI powered ITOps***
231 | ```
232 | - AIOps = f(CI, CD, SIEM, uS) in Infrastructure Monitoring & Management field
233 | - CI == Continuous Integration of entire solution blocks in IT operations Lifecycle
234 | - CD == Consistent deployment of entire solution blocks in IT operations Lifecycle
235 | - SIEM == SIEM (Security Information and Event Management) pathway
236 | - uS == Microservice governance of entire solution blocks in IT operations Lifecycle
237 | ```
238 | - **PlatformOps** - Any Enterprise Platform is driven by PlatformOps for Building-Rolling_upgrade-Deployment of Platform in customer’s preferred choice of Infrastructure in accelerated fashion with ‘consistent deployment’ theme.
239 |
240 |
241 |
242 | # STATE OF MACHINE LEARNING OPERATIONS IN Y2019
243 |
244 | Survey conducted by PipelineAI in July 2019: State of Machine learning Operations -
245 |
246 |
247 | **Custom MLOPS IS THE SILVER BULLET!**
248 | ***
249 |
250 |
251 | # High level constructs of Real World MLOPS
252 |
253 | Any **"Enterprise Data Science System" / "Enterprise AI Platform"** must intend to stich/chain together at least the essential & high level constructs of MLOPS under its hood. Genrally "Enterprise AI Platform", such as H20.ai/Alteryx/HopsML/PipelineAI etc are powered by **Custom MLOPS** with the objective to *attempt to offer* following key high level AI/ML constructs:
254 | - [AI ML Dataset Annotation](#AI-ML-Dataset-Annotation)
255 | - [AI ML Pipeline](#AI/ML-Pipeline)
256 | - [Automated ML](#Automated-ML)
257 | - [Comprehensive AI Governance](#Comprehensive-AI-Governance)
258 | - [ML Operation COST Optimization SERVERLESS MLOPS](#ML-Operation-COST-Optimization-SERVERLESS-MLOPS)
259 | - [Data and AI CI CD Operations](#Data-and-AI-CI-CD-Operations)
260 | - [Comprehensive Data Operations DataOps](#Comprehensive-Data-Operations-DataOps)
261 |
262 | #### AI ML Dataset Annotation
263 | ```
264 | --o 'Image Annotation framework' (VoTT, LabelImg, VIA )
265 | --o 'NLP/ Text Annotation framework' (spacy, explosion.ai,)
266 | --o 'Audio & Speech Annotation framework' (Web-Based Audio Sequencer, CrowdCurio/audio-annotator, annotationpro)
267 | --o 'Ontology/Knowledge Graph Annotation framework' (Apache Jena)
268 | ```
269 |
270 | #### AI ML Pipeline
271 | ```
272 | --> 'Build/Prepare' - A Notebook/ Visual AI Studio with dockerized support for underlying
273 | - AI/ML Libraries (e.g., TF/PyTorch/SparkML/XGboost/0
274 | - EDA libraries,
275 | - Pre-processing libraries, such as
276 | - Data Augmentation Libraries,
277 | - Adversarial Robustness Libraries,
278 | - Translational/Angular variance et al.
279 |
280 | --> 'Train' - Computation load distribution frameworks for '
281 |
282 | - Distributed Training (e.g., using Horovod or Sonner or custom template)
283 | - Standalone tarining
284 | - with support for real time Training Visualization(e.g., TensorBoard/VisualDL)
285 | - on accelerated neural network hardware NVIDIA GPU/Google TPU/CPU with the leverage of NVIDIA GPU-accelerated libraries (CUDA, CuDNN)
286 |
287 | --> 'Evaluate'
288 |
289 | --> 'Model Serialization & Quantization' (e.g.,Using TF-Serving, ONNX Runtime, Seldon Core et al)
290 | - Serializaion support for Protobuff, hdf5, pickle et al
291 | - Serialization interoperability
292 | - Model binary/servable quantization & Pruning
293 |
294 | --> 'Deploy'
295 | - AI-as-a-Service -RESTful/gRPC API, or,
296 | - Binary Servables, or,
297 | - Edge deployment,
298 | - Mobile deployment
299 | - model versioning for model updates (with "Rollback option" to previous version)
300 |
301 | --> 'AI Inference Service Routing' (e.g.,'Service Mesh' like Istio)
302 |
303 | --> 'Monitor' (Data drift & Concept drift with Alert)
304 |
305 | --> 'Automated Re-training pathway' (e.g., ORACHESTRATOR - Apache Airflow, Kubeflow-pipeline, Databricks MLFlow, Apache Beam)
306 |
307 | --> 'User Interface' (PWA/ MobileApp / Web App)
308 | ```
309 |
310 | #### Automated ML
311 | ```
312 | 'HPO' - Hyper Parameter Optimization,
313 | 'Randmoized/Grid Serach',
314 | 'NAS' - Neural Architecture Search,
315 | 'AutoML'
316 | ```
317 |
318 | #### Comprehensive AI Governance
319 | ```
320 | --o 'AI TRUST'
321 | - Explainable AI,
322 | - Ethical AI,
323 | - Fair AI,
324 | - Feature Management & Stoarge,
325 | - Dataset processing transformation persistence,
326 | - Model and Data Versioning,
327 |
328 | --o 'AI Collaboration, Sharing & Exchange'
329 | Authenticated, Authroized and Logging based Market place for sharing & exchange of MODELS and Model related artefacts
330 | - AI/ML APIs,
331 | - Fature Set,
332 | - Training metrics,
333 | - Model Binaries,
334 | - Notebook /Model Code,
335 |
336 | --o 'AI Security'
337 | - Privacy Preserving Machine Learning
338 | - Differntial Privacy (offered by libraries such as Tensorflow Privacy)
339 | - ε-differentially private algorithms (Google's Differential Privacy)
340 | - Homomorphic Encryption / Data privacy in Real World AI/ML system (Intel n-Graph with Tensorflow, or, Microsoft SEAL)
341 | - AI/ML API Security
342 | - AI/ML RESTful or gRPC end point Authentication & Authorization
343 | - AI/ML Federated User Pool & Identity Pool management (FIdM/ FIM)
344 | - DevSecOps (Security as Code) for AI/ML Application devleopment, deployment, monitoring,
345 |
346 | --o 'AI Scalability'
347 | - Autoamted Load Balancing,
348 | - Service Routing, AutoScaling,
349 | - MultiZone Replication,
350 | - Caching
351 |
352 | --o 'AI Inference Model Update/ Roll out' Mechanism
353 | - Blue Green Deployment
354 | - Canary Deployment
355 | - Multi Armed Bandit Deployment
356 | - A/B
357 |
358 | ```
359 |
360 | #### ML Operation COST Optimization SERVERLESS MLOPS
361 | ```
362 |
363 | --o 'Serverless Framework'
364 | - FaaS: Apache OpenWhish/ OpenFaas,
365 | - KNative
366 |
367 | --o 'Hybrid Computing/ processing'
368 | - Local Edge Processing (EdgeX/AWS Greegrass Core/Azure IoT Core/GCP IoT Core)
369 | - Centralized Cloud Processing (AWS/Azure/GCP)
370 |
371 | --o 'Modular Plug & Play of AI/ML system' leveraging
372 | - Microservice (uS) governance framework' [API Gateway, uS Service Mesh, Automated uS Service Discovery & Registry, uS Service Config, uS service internal communication protocol etc]
373 | - Containerization & CaaS (Docker, Kubernetes)
374 | --o Optimized calculation frameworks (cuDF/ cuML)
375 |
376 | ```
377 |
378 | #### Data and AI CI CD Operations
379 | ```
380 | o 'REQUIREMENT & AGILE COLLABORATION TOOLS' (Jira/ Confluence)
381 | o 'SCM TOOLS (GIT - GitHub/GitLab)
382 | o 'CI ENGINE' (Jeknis/ Travis CI)
383 | o 'BUILD TOOLS' (Maven/ Grunt / Wheel)
384 | o 'UNIT TESTING TOOLS' (PyTest/ JUnit / Mocha / Jasmine)
385 | o 'CODE COVERAGE TOOLS' (SonarQube)
386 | o 'CD PIPELINE/FRAMEWORK- 1' ( Ansible/ Chef / Puppet)
387 | o 'ARTEFACT REPOSITORY MANAGER TOOLS' (Nexus/ Artefactory)
388 | o 'FUNCTIONAL TESTING TOOLS' ('Selenium')
389 | o 'SECURITY SCAN TESTING (SAST/DAST) TOOLS' (CheckMarx/ Fortify / BalckDuck)
390 | o ''CD PIPELINE/FRAMEWORK- 2' Containerized & Container orachasteration by Container-as-a-Service ' (Containerization - Docker, CaaS -Kubernetes, IaC - Terraform)
391 | ```
392 |
393 |
394 | #### Comprehensive Data Operations DataOps
395 | ```
396 | --o 'Data pipelines & ETL'
397 | --o 'Data Stream Processing'
398 | --o 'Data storage & Optimization'
399 | --o 'Data Intertcive Querying Interface'
400 | --o 'Data TRUST'
401 | ```
402 |
403 | # MLOPS Reference Architecture
404 |
405 | MLOPS Reference Architecture from One of visionary AI platform with specialized service offering in MLOPS:
406 |
407 |
408 | Reference: [Neuomation AI Platform](https://neu.ro/) | Neuromation has a specialized niche Offering in Remote MLOPS.
409 |
410 |
411 |
412 | # Detail References to the Constructs and Tools of MLOPS
413 |
414 | **Please note:**
415 |
416 | - The below matrix serve as the Index table.
417 | - Please click on hyperlinks of the respective items to delve deep into it.
418 | - Please keep checking your compass (this index table) for to seamlessly steer your way to the next mile of this wonderful matrix.
419 |
420 | | | | | |
421 | |-|-|-|-|
422 | | [🧵 Data pipelines & ETL](/README_Data%20Pipeline%20ETL%20Frameworks.md)| [💸 Data Stream Processing](/README_Data%20Stream%20Processing.md) |[🗞️ Data storage](/README_Data%20Storage%20Optimisation.md) |[🏷️ Data Labelling](/README_Data%20Labelling%20Tools%20and%20Frameworks.md)|
423 | | [🌀 Feature engineering](README_Feature%20Engineering%20Automation.md)| [🎁 Feature Stores](/README_Feature%20Stores.md)| [📓 Reproducible Notebooks](/README_Data%20Science%20Notebook%20Frameworks.md)|[🏁 Model Orchestration & Deployment Framework](/README_Model%20Orchestration%20%26%20Deployment%20Frameworks.md)|
424 | | [🗺️ ML Training Computation distribution](https://github.com/DeepHiveMind/EnterpriseAI_Platform_MLOps/blob/master/README_ML%20Computation%20load%20distribution%20frameworks.md) | [📊 ML Training & Indutrial Visualisation frameworks](/README_ML%20Computation%20load%20distribution%20frameworks.md) |[⚔ Adversarial Robustness](README_Adversarial%20Robustness%20Libraries.md) |[📥 Model serialisation](/README_Model%20serialisation%20formats.md) |
425 | |[🔍 Explaining predictions & models](/README_Explaining%20Black%20Box%20Models.md) | [🔏 Privacy preserving ML](/README_Privacy%20Preserving%20Machine%20Learning.md) | [📜 Model & data versioning](/README_Model%20and%20Data%20Versioning.md)| [🧮 Optimized calculation frameworks](/README_Optimized%20calculation%20frameworks.md) |
426 | |[🤖 AutoML](/README_Neural%20Architecture%20Search.md)| [📡 Functions as a service](README_Function%20as%20a%20Service%20Frameworks.md) | [🔠 Industry-strength NLP](/README_Industrial%20Strength%20NLP.md) | [💰 Commercial Platforms](/README_Commercial%20Platforms.md) |
427 |
428 |
429 | # MLOPS Architecture based on KUBEFLOW
430 |
431 | - High level conceptual MLOPS solutions orchasterated by KUBEFLOW (Muliple technology blocks for Enterprise level MLOPS):
432 |
433 |
434 |
435 | - Serverless MLFLOW by amalgamation of KUBEFLOW & KNative:
436 |
437 |
438 |
439 |
440 |
441 | - Runtime TRAINING Visulization of Deep NN Models supported by Kubeflow leveraging TensorBoard: A Visual of TensorBoard for TRAINING Visualization:
442 |
443 |
444 |
445 | ## Train and Serve TensorFlow Models at Scale with KUBERNETES and KUBEFLOW
446 |
447 | #### Hands On Content Summary
448 |
449 | | | Module | Description |
450 | | --- | --- | --- |
451 | |0| **[Introduction](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/0-intro)** | Introduction to this workshop. Motivations and goals.|
452 | |1| **[Docker - Containerizatioin of AI Modules](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/1-docker)** | Docker and containers 101.|
453 | |2| **[Kubernetes - K8S for AI](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/2-kubernetes)** | Kubernetes important concepts overview.|
454 | |3| **[Helm Charts on K8S for AI complex deployment](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/3-helm)** | Introduction to Helm |
455 | |4| **[Kubeflow for AI MLOPS](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/4-kubeflow)** | Introduction to Kubeflow and how to deploy it in your cluster.|
456 | |5| **[JupyterHub on K8S- AI Build Notebook](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/5-jupyterhub)** | Learn how to run JupyterHub to create and manage Jupyter notebooks using Kubeflow |
457 | |6| **[TFJob- K8S custom kind for AI Training on GPU/CPU/TPU](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/6-tfjob)** | Introduction to `TFJob` and how to use it to deploy a simple TensorFlow training.|
458 | |7| **[Distributed Tensorflow](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/7-distributed-tensorflow)** | Learn how to deploy and monitor distributed TensorFlow trainings with `TFJob`|
459 | |8| **[Hyperparameters Sweep with Helm](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/8-hyperparam-sweep)** | Using Helm to deploy a large number of trainings testing different hypothesis, and TensorBoard to monitor and compare the results |
460 | |9| **[AI Model Serving for prediction/scoring](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/9-serving)** | Using TensorFlow Serving to serve predictions |
461 | |10| **[Going Further](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/10-going-further)** | Links and resources to go further: Autoscaling, Distributed Storage etc. |
462 |
463 | #### Integrating AzureML and AWS SageMaker with KubeFlow to create E2E MLOPS Pipeline
464 | ##### HYBRID MACHINE LEARNING WORKFLOW
465 | | | Module | Description |
466 | | --- | --- | --- |
467 | |0| **[Integrating AzureML with KubeFlow](https://www.kubeflow.org/docs/azure/azureendtoend/)** | Running AzureML on top of KubeFlow for E2E MLOPS|
468 | |0| **[Integrating AWS SageMaker with KubeFlow](https://aws.amazon.com/blogs/machine-learning/introducing-amazon-sagemaker-components-for-kubeflow-pipelines/)** | Running AWS SageMaker on top of KubeFlow for E2E MLOPS|
469 | |0| **[How CISCO uses AWS SageMaker and KubeFlow](https://aws.amazon.com/blogs/machine-learning/cisco-uses-amazon-sagemaker-and-kubeflow-to-create-a-hybrid-machine-learning-workflow/)** | How CISCO leverages AWS SageMaker and KubeFlow to drive Hybrid ML workflow for E2E MLOPS|
470 |
471 | # Deep Dive into AI SECURITY
472 | 'AI Security' is now often being discussed a lot, and is increasingly becoming a point of concern as, in a technical parlance, AI/ML model endpoints are been exploited as attack-vector / vulnerability vector. *AI/ML Model endpoint Privacy* | *Data Privacy in Real World AI/ML System* | *Lack of Comprehensive adoption of DevSecOps Pipeline in Real World AI/ML system* et al.
473 |
474 | #### Why AI SECURITY is important
475 | - AI/ML Models are getting deployed on edge devices / edge gateways / Fog devices / Mobiles for offline predictions (owing to rapid proliferation of IIoT/ CIoT)
476 | - Agile, Dynamic Security Perimeter of AI/ML Serving end points
477 | - AI/ML Models gets exposed to real data, and inferencing of models can expose sensitive information
478 | - AI/ML Models generally are not trained on Masked data
479 | - AI/ML Model endpoint security (owing to uS Microservice style of AI/ML serving, AI-as-a-Service)
480 | - AI/ML RESTful or gRPC end point Authentication & Authorization
481 | - AI/ML Federated User Pool & Identity Pool management (FIdM/ FIM)
482 | - Absence of DevSecOps *(Security-as-a-Code)* implementation pipeline in AI/ML Application productionization- i.e., lack of awareness for
483 | - Vulnerability Scanning while Application development, such as *SAST Vulnerability Scanning*
484 | - Vulnerability Scanning while Application deployment, such as *DAST Vulnerability Scanning*
485 | - SIEM in production (Continuous Monitoring, Threat detection and alerting, Threat remediation)
486 |
487 |
488 |
489 |
490 | #### Real World AI Comprehensive SOC Solution
491 | There is comprehensive SOC solution (SOC- Security Operation Control - Plane) for *real world AI/ML*.
492 |
493 | Real World AI/ML SOC Plane is a custom solution, and is composed of following solution components primarily:
494 |
495 | - Privacy Preserving Machine Learning
496 | - Differntial Privacy (offered by libraries such as Tensorflow Privacy)
497 | - ε-differentially private algorithms (Google's Differential Privacy)
498 | - Homomorphic Encryption (Intel n-Graph with Tensorflow, or, Microsoft SEAL)
499 | {P.S.: Homomorphic encryption is a form of encryption that allows computation on encrypted data, and is an attractive remedy to increasing concerns about *data privacy in the field of machine learning*.}
500 |
501 | - AI/ML API/Endpoint Security
502 | - AI/ML RESTful or gRPC end point Authentication & Authorization
503 | - AI/ML Federated User Pool & Identity Pool management (FIdM/ FIM)
504 |
505 | - Implementation DevSecOps (Security-as-Code) pipeline for AI/ML Application development, deployment, monitoring, Threat detection and alerting, Threat remediation
506 | - Please refer to my another repo [DevSecOps Sec-as-a-Code]() for delving deeper into the awesome world of DevSecOps.
507 |
508 |
509 |
510 | # Product Machine Learning System Y2019 A Video
511 |
512 |
513 |
514 |
515 | This VIDEO provides an overview of the motivations for machine learning operations as well as a high level overview on some of the tools in this repo.
516 |
517 |
518 |
519 |
520 |
521 |
522 |
523 | ||
524 | |:--:|
525 | |Refer to my another Repo for [DevOps Operations for ML Deep Reinforecment Learning](https://github.com/DeepHiveMind/gateway_to_DeepReinforcementLearning_DeepNN)|
526 | |Refer to my another Repo for [DevOps Operations for Blcokchain Hyperledger Fabric](https://github.com/DeepHiveMind/gateway_to_DeepReinforcementLearning_DeepNN)|
527 |
528 | # Contact info
529 |
530 | Feel free to contact me to discuss any issues, questions, or comments.
531 |
532 | My contact info can be found on my [GitHub page](https://github.com/DeepHiveMind).
533 |
534 | # License
535 |
536 | I, *The DeepHiveMind*, am providing code and resources in this repository to you under custom Copyright & license (Copyright 2019 DeepHiveMind & Creative Commons Legal Code CC0 1.0 Universal). Please Refer to the **[Copyright 2019 DeepHiveMind License]** for further details as to this. Thanks!
537 |
--------------------------------------------------------------------------------
/README_Adversarial Robustness Libraries.md:
--------------------------------------------------------------------------------
1 |
2 | # Adversarial Robustness Libraries
3 | * [AdvBox](https://github.com/advboxes/AdvBox)  - generate adversarial examples from the command line with 0 coding using PaddlePaddle, PyTorch, Caffe2, MxNet, Keras, and TensorFlow. Includes 10 attacks and also 6 defenses. Used to implement [StealthTshirt](https://github.com/advboxes/AdvBox/blob/master/applications/StealthTshirt/README.md) at DEFCON!
4 | * [Adversarial DNN Playground](https://github.com/QData/AdversarialDNN-Playground)  - think [TensorFlow Playground](https://playground.tensorflow.org/), but for Adversarial Examples! A visualization tool designed for learning and teaching - the attack library is limited in size, but it has a nice front-end to it with buttons you can press!
5 | * [AdverTorch](https://github.com/BorealisAI/advertorch)  - library for adversarial attacks / defenses specifically for PyTorch.
6 | * [Alibi Detect](https://github.com/SeldonIO/alibi-detect)  - alibi-detect is a Python package focused on outlier, adversarial and concept drift detection. The package aims to cover both online and offline detectors for tabular data, text, images and time series. The outlier detection methods should allow the user to identify global, contextual and collective outliers.
7 | * [Artificial Adversary](https://github.com/airbnb/artificial-adversary)  AirBnB's library to generate text that reads the same to a human but passes adversarial classifiers.
8 | * [CleverHans](https://github.com/tensorflow/cleverhans)  - library for testing adversarial attacks / defenses maintained by some of the most important names in adversarial ML, namely Ian Goodfellow (ex-Google Brain, now Apple) and Nicolas Papernot (Google Brain). Comes with some nice tutorials!
9 | * [DEEPSEC](https://github.com/kleincup/DEEPSEC)  - another systematic tool for attacking and defending deep learning models.
10 | * [EvadeML](https://github.com/mzweilin/EvadeML-Zoo)  - benchmarking and visualization tool for adversarial ML maintained by Weilin Xu, a PhD at University of Virginia, working with David Evans. Has a tutorial on re-implementation of one of the most important adversarial defense papers - [feature squeezing](https://arxiv.org/abs/1704.01155) (same team).
11 | * [Foolbox](https://github.com/bethgelab/foolbox)  - second biggest adversarial library. Has an even longer list of attacks - but no defenses or evaluation metrics. Geared more towards computer vision. Code easier to understand / modify than ART - also better for exploring blackbox attacks on surrogate models.
12 | * [IBM Adversarial Robustness 360 Toolbox (ART)](https://github.com/IBM/adversarial-robustness-toolbox)  - at the time of writing this is the most complete off-the-shelf resource for testing adversarial attacks and defenses. It includes a library of 15 attacks, 10 empirical defenses, and some nice evaluation metrics. Neural networks only.
13 | * [MIA](https://github.com/spring-epfl/mia)  - A library for running membership inference attacks (MIA) against machine learning models.
14 | * [Nicolas Carlini’s Adversarial ML reading list](https://nicholas.carlini.com/writing/2018/adversarial-machine-learning-reading-list.html) - not a library, but a curated list of the most important adversarial papers by one of the leading minds in Adversarial ML, Nicholas Carlini. If you want to discover the 10 papers that matter the most - I would start here.
15 | * [Robust ML](https://www.robust-ml.org/defenses/) - another robustness resource maintained by some of the leading names in adversarial ML. They specifically focus on defenses, and ones that have published code available next to papers. Practical and useful.
16 | * [TextFool](https://github.com/bogdan-kulynych/textfool)  - plausible looking adversarial examples for text generation.
17 | * [Trickster](https://github.com/spring-epfl/trickster)  - Library and experiments for attacking machine learning in discrete domains using graph search.
18 |
19 |
--------------------------------------------------------------------------------
/README_Commercial Platforms.md:
--------------------------------------------------------------------------------
1 |
2 | # Commercial Platforms
3 | * [Algorithmia](https://algorithmia.com/) - Cloud platform to build, deploy and serve machine learning models [(Video)](https://www.youtube.com/watch?v=qcsrPY0koyY)
4 | * [allegro ai Enterprise](https://allegro.ai/enterprise) - Automagical open-source ML & DL experiment manager and ML-Ops solution.
5 | * [Amazon SageMaker](https://aws.amazon.com/sagemaker/) - End-to-end machine learning development and deployment interface where you are able to build notebooks that use EC2 instances as backend, and then can host models exposed on an API
6 | * [bigml](https://bigml.com/) - E2E machine learning platform.
7 | * [cnvrg.io](https://cnvrg.io) - An end-to-end platform to manage, build and automate machine learning
8 | * [Comet.ml](http://comet.ml) - Machine learning experiment management. Free for open source and students [(Video)](https://www.youtube.com/watch?v=xaybRkapeNE)
9 | * [D2iQ KUDO for Kubeflow](https://d2iq.com/solutions/ksphere/kudo-kubeflow) - Enterprise MLOps platform that runs in the cloud, on premises (incl. air-gapped), or on the edge; based on Kubeflow and open-source [KUDO](https://kudo.dev/) operators.
10 | * [Dataiku](https://www.dataiku.com/) - Collaborative data science platform powering both self-service analytics and the operationalization of machine learning models in production.
11 | * [DataRobot](https://www.datarobot.com/) - Automated machine learning platform which enables users to build and deploy machine learning models.
12 | * [Datatron](https://datatron.com/) - Machine Learning Model Governance Platform for all your AI models in production for large Enterprises.
13 | * [Datmo](https://datmo.com/) - Workflow tools for monitoring your deployed models to experiment and optimize models in production.
14 | * [deepsense AIOps](https://aiops.deepsense.ai/) - Enhances multi-cloud & data center IT Operations via traffic analysis, risk analysis, anomaly detection, predictive maintenance, root cause analysis, service ticket analysis and event consolidation.
15 | * [Deep Cognition Deep Learning Studio](https://deepcognition.ai/) - E2E platform for deep learning.
16 | * [deepsense Safety](https://safety.deepsense.ai/) - AI-driven solution to increase worksite safety via safety procedure check, thread detection and hazardous zones monitoring.
17 | * [deepsense Quality](https://quality.deepsense.ai/) - Automating laborious quality control tasks.
18 | * [Google Cloud Machine Learning Engine](https://cloud.google.com/ml-engine/) - Managed service that enables developers and data scientists to build and bring machine learning models to production.
19 | * [IBM Watson Machine Learning](https://www.ibm.com/cloud/machine-learning) - Create, train, and deploy self-learning models using an automated, collaborative workflow.
20 | * [Labelbox](https://labelbox.com/) - Image labelling service with support for semantic segmentation (brush & superpixels), bounding boxes and nested classifications.
21 | * [Logical Clocks Hopsworks](https://www.logicalclocks.com/) - Enterprise version of Hopsworks with a Feature Store and scale-out ML pipeline design and operation.
22 | * [MCenter](https://www.parallelm.com/product/) - MLOps platform automates the deployment, ongoing optimization, and governance of machine learning applications in production.
23 | * [Microsoft Azure Machine Learning service](https://azure.microsoft.com/en-us/services/machine-learning-service/) - Build, train, and deploy models from the cloud to the edge.
24 | * [MLJAR](https://mljar.com/) - Platform for rapid prototyping, developing and deploying machine learning models.
25 | * [neptune.ml](https://neptune.ml) - community-friendly platform supporting data scientists in creating and sharing machine learning models. Neptune facilitates teamwork, infrastructure management, models comparison and reproducibility.
26 | * [Prodigy](https://prodi.gy/) - Active learning-based data annotation. Allows to train a model and pick most 'uncertain' samples for labeling from an unlabeled pool.
27 | * [Skafos](https://metismachine.com/products/) - Skafos platform bridges the gap between data science, devops and engineering; continuous deployment, automation and monitoring.
28 | * [SKIL](https://skymind.ai/platform) - Software distribution designed to help enterprise IT teams manage, deploy, and retrain machine learning models at scale.
29 | * [Skytree 16.0](http://skytree.net) - End to end machine learning platform [(Video)](https://www.youtube.com/watch?v=XuCwpnU-F1k)
30 | * [Spell](https://spell.run) - Flexible end-to-end MLOps / Machine Learning Platform. [(Video)](https://www.youtube.com/watch?v=J7xo-STHx1k)
31 | * [Talend Studio](https://www.talend.com/)
32 | * [Valohai](https://valohai.com/) - Machine orchestration, version control and pipeline management for deep learning.
--------------------------------------------------------------------------------
/README_Data Labelling Tools and Frameworks.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Data Labelling Tools and Frameworks
4 | * [COCO Annotator](https://github.com/jsbroks/coco-annotator)  - Web-based image segmentation tool for object detection, localization and keypoints
5 | * [Computer Vision Annotation Tool (CVAT)](https://github.com/opencv/cvat)  - OpenCV's web-based annotation tool for both VIDEOS and images for computer algorithms.
6 | * [Doccano](https://github.com/chakki-works/doccano)  - Open source text annotation tools for humans, providing functionality for sentiment analysis, named entity recognition, and machine translation.
7 | * [ImageTagger](https://github.com/bit-bots/imagetagger)  - Image labelling tool with support for collaboration, supporting bounding box, polygon, line, point labelling, label export, etc.
8 | * [ImgLab](https://github.com/NaturalIntelligence/imglab)  - Image annotation tool for bounding boxes with auto-suggestion and extensibility for plugins.
9 | * [Label Studio](https://github.com/heartexlabs/label-studio)  - Multi-domain data labeling and annotation tool with standardized output format
10 | * [Labelimg](https://github.com/tzutalin/labelImg)  - Open source graphical image annotation tool writen in Python using QT for graphical interface focusing primarily on bounding boxes.
11 | * [OpenLabeling](https://github.com/Cartucho/OpenLabeling)  - Open source tool for labelling images with support for labels, edges, as well as image resizing and zooming in.
12 | * [PixelAnnotationTool](https://github.com/abreheret/PixelAnnotationTool)  - Image annotation tool with ability to "colour" on the images to select labels for segmentation. Process is semi-automated with the [watershed marked algorithm of OpenCV](docs.opencv.org/3.1.0/d7/d1b/group__imgproc__misc.html#ga3267243e4d3f95165d55a618c65ac6e1)
13 | * [Semantic Segmentation Editor](https://github.com/Hitachi-Automotive-And-Industry-Lab/semantic-segmentation-editor)  - Hitachi's Open source tool for labelling camera and LIDAR data.
14 | * [Superintendent](https://github.com/janfreyberg/superintendent)  - superintendent provides an ipywidget-based interactive labelling tool for your data.
15 | * [VGG Image Annotator (VIA)](http://www.robots.ox.ac.uk/~vgg/software/via/) - A simple and standalone manual annotation software for image, audio and video. VIA runs in a web browser and does not require any installation or setup.
16 | * [Visual Object Tagging Tool (VOTT)](https://github.com/Microsoft/VoTT)  - Microsoft's Open Source electron app for labelling videos and images for object detection models (with active learning functionality)
--------------------------------------------------------------------------------
/README_Data Pipeline ETL Frameworks.md:
--------------------------------------------------------------------------------
1 | # Data Pipeline ETL Frameworks
2 | * [Apache Airflow](https://airflow.apache.org/) - Data Pipeline framework built in Python, including scheduler, DAG definition and a UI for visualisation
3 | * [Apache Nifi](https://github.com/apache/nifi)  - Apache NiFi was made for dataflow. It supports highly configurable directed graphs of data routing, transformation, and system mediation logic.
4 | * [Argo Workflows](https://github.com/argoproj/argo)  - Argo Workflows is an open source container-native workflow engine for orchestrating parallel jobs on Kubernetes. Argo Workflows is implemented as a Kubernetes CRD (Custom Resource Definition).
5 | * [Azkaban](https://azkaban.github.io/)  - Azkaban is a batch workflow job scheduler created at LinkedIn to run Hadoop jobs. Azkaban resolves the ordering through job dependencies and provides an easy to use web user interface to maintain and track your workflows.
6 | * [Chronos](https://github.com/mesos/chronos)  - More of a job scheduler for Mesos than ETL pipeline. [OUTDATED]
7 | * [Genie](https://github.com/Netflix/genie)  - Job orchestration engine to interface and trigger the execution of jobs from Hadoop-based systems
8 | * [Gokart](https://github.com/m3dev/gokart)  - Wrapper of the data pipeline Luigi
9 | * [Luigi](https://github.com/spotify/luigi)  - Luigi is a Python module that helps you build complex pipelines of batch jobs, handling dependency resolution, workflow management, visualisation, etc
10 | * [Metaflow](https://metaflow.org/)  - A framework for data scientists to easily build and manage real-life data science projects.
11 | * [Neuraxle](https://github.com/Neuraxio/Neuraxle)  - A framework for building neat pipelines, providing the right abstractions to chain your data transformation and prediction steps with data streaming, as well as doing hyperparameter searches (AutoML).
12 | * [Oozie](http://oozie.apache.org/) - Workflow scheduler for Hadoop jobs
13 | * [PipelineX](https://github.com/Minyus/pipelinex)  - Based on Kedro and MLflow. Full comparison given at https://github.com/Minyus/Python_Packages_for_Pipeline_Workflow
14 | * [Prefect Core](https://github.com/PrefectHQ/prefect)  - Workflow management system that makes it easy to take your data pipelines and add semantics like retries, logging, dynamic mapping, caching, failure notifications, and more.#
--------------------------------------------------------------------------------
/README_Data Science Notebook Frameworks.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Data Science Notebook Frameworks
4 | * [Binder](https://mybinder.org/) - Binder hosts notebooks in an executable environment (for free).
5 | * [H2O Flow](https://github.com/h2oai/h2o-flow) - Jupyter notebook-like interface for H2O to create, save and re-use "flows"
6 | * [Hydrogen](https://atom.io/packages/hydrogen) - A plugin for ATOM that enables it to become a jupyter-notebook-like interface that prints the outputs directly in the editor.
7 | * [Jupyter Notebooks](https://github.com/jupyter/notebook)  - Web interface python sandbox environments for reproducible development
8 | * [ML Workspace](https://github.com/ml-tooling/ml-workspace)  - All-in-one web IDE for machine learning and data science. Combines Jupyter, VS Code, Tensorflow, and many other tools/libraries into one Docker image.
9 | * [Papermill](https://github.com/nteract/papermill)  - Papermill is a library for parameterizing notebooks and executing them like Python scripts.
10 | * [Polynote](https://github.com/ml-tooling/ml-workspace)  - Polynote is an experimental polyglot notebook environment. Currently, it supports Scala and Python (with or without Spark), SQL, and Vega.
11 | * [RMarkdown](https://github.com/rstudio/rmarkdown)  - The rmarkdown package is a next generation implementation of R Markdown based on Pandoc.
12 | * [Stencila](https://github.com/stencila/stencila)  - Stencila is a platform for creating, collaborating on, and sharing data driven content. Content that is transparent and reproducible.
13 | * [Voilà](https://github.com/voila-dashboards/voila)  - Voilà turns Jupyter notebooks into standalone web applications that can e.g. be used as dashboards.
14 |
15 |
--------------------------------------------------------------------------------
/README_Data Storage Optimisation.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Data Storage Optimisation
4 | * [Alluxio](https://www.alluxio.org/docs/1.8/en/Overview.html) - A virtual distributed storage system that bridges the gab between computation frameworks and storage systems.
5 | * [Apache Arrow](https://arrow.apache.org/) - In-memory columnar representation of data compatible with Pandas, Hadoop-based systems, etc
6 | * [Apache Druid](https://github.com/apache/druid)  - A high performance real-time analytics database. https://druid.apache.org/. [An introduction to Druid, your Interactive Analytics at (big) Scale](https://towardsdatascience.com/introduction-to-druid-4bf285b92b5a).
7 | * [Apache Ignite](https://github.com/apache/ignite)  - A memory-centric distributed database, caching, and processing platform for transactional, analytical, and streaming workloads delivering in-memory speeds at petabyte scale. [TensorFlow on Apache Ignite](https://blog.tensorflow.org/2019/02/tensorflow-on-apache-ignite.html), [Distributed ML in Apache Ignite](https://www.youtube.com/watch?v=Xt4PWQ__YPw)
8 | * [Apache Kafka](https://kafka.apache.org/) - Distributed streaming platform framework
9 | * [Apache Parquet](https://parquet.apache.org/) - On-disk columnar representation of data compatible with Pandas, Hadoop-based systems, etc
10 | * [Apache Pinot](https://github.com/apache/incubator-pinot)  - A realtime distributed OLAP datastore https://pinot.apache.org. [Comparison of the Open Source OLAP Systems for Big Data: ClickHouse, Druid, and Pinot](https://medium.com/@leventov/comparison-of-the-open-source-olap-systems-for-big-data-clickhouse-druid-and-pinot-8e042a5ed1c7).
11 | * [BayesDB](http://probcomp.csail.mit.edu/software/bayesdb/) - Database that allows for built-in non-parametric Bayesian model discovery and queryingi for data on a database-like interface - [(Video)](https://www.youtube.com/watch?v=2ws84s6iD1o)
12 | * [ClickHouse](https://clickhouse.yandex/)  - ClickHouse is an open source column oriented database management system supported by Yandex - [(Video)](https://
13 | * [EdgeDB](https://edgedb.com/) - NoSQL interface for Postgres that allows for object interaction to data stored
14 | * [HopsFS](https://github.com/hopshadoop/hops)  - HDFS-compatible file system with scale-out strongly consistent metadata.
15 | * [InfluxDB](https://github.com/influxdata/influxdb)  Scalable datastore for metrics, events, and real-time analytics.
16 | * [TimescaleDB](https://github.com/timescale/timescaledb)  An open-source time-series SQL database optimized for fast ingest and complex queries. Packaged as a PostgreSQL extension. [Time-series ML in TimescaleDB](https://docs.timescale.com/latest/tutorials/tutorial-forecasting)
17 | www.youtube.com/watch?v=zbjub8BQPyE)
--------------------------------------------------------------------------------
/README_Data Stream Processing.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Data Stream Processing
4 | * [Apache Flink](https://github.com/apache/flink)  - Open source stream processing framework with powerful stream and batch processing capabilities.
5 | * [Apache Samza](http://samza.apache.org/)  - Distributed stream processing framework. It uses Apache Kafka for messaging, and Apache Hadoop YARN to provide fault tolerance, processor isolation, security, and resource management.
6 | * [Brooklin](https://github.com/linkedin/Brooklin/)  - Distributed stream processing framework. It uses Apache Kafka for messaging, and Apache Hadoop YARN to provide fault tolerance, processor isolation, security, and resource management.
7 | * [Faust](https://github.com/robinhood/faust)  - Streaming library built on top of Python's Asyncio library using the async kafka client inspired by the kafka streaming library.
8 | * [Kafka Streams](https://kafka.apache.org/documentation/streams/)  - Kafka client library for buliding applications and microservices where the input and output are stored in kafka clusters
9 | * [Spark Streaming](https://spark.apache.org/streaming/)  - Micro-batch processing for streams using the apache spark framework as a backend supporting stateful exactly-once semantics
--------------------------------------------------------------------------------
/README_Ethical_AI.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
Ethical AI (AI Trust) Priciples
6 |
7 |
8 | (Unethical Bahviour of AI!!)
9 |
10 |
11 |
12 |
13 | ## Ethical AI (AI Trust)
14 |
15 | As AI systems become more prevalent in society, we face bigger and tougher societal challenges. Given many of these challenges have not been faced before, practitioners will face scenarios that will require dealing with hard ethical and societal questions.
16 |
17 | There has been a large amount of content published which attempts to address these issues through “Principles”, “Ethics Frameworks”, “Checklists” and beyond. However navigating the broad number of resources is not easy.
18 |
19 | This repository aims to simplify this by mapping the ecosystem of Principles, codes of ethics, standards and regulation being put in place around artificial intelligence.
20 |
21 | ## Quick links to sections in this page
22 |
23 | | | | |
24 | |-|-|-|
25 | |[🔍 High Level Frameworks & Principles](#high-level-frameworks-and-principles) |[🔏 Processes & Checklists](#processes-and-checklists) | [🔨 Interactive & Practical Tools](#interactive-and-practical-tools)|
26 | |[⚔ Regulation and Policy](#regulation-and-policy)|[📜 Industry standards initiatives](#industry-standards-initiatives)|[📚 Online Courses](#online-courses-and-learning-resources)|[🤖 Research and Industry References](#research-and-industry-reference)|
27 | |||
28 |
29 | ## Other relevant resources
30 |
31 |
32 |
33 |
34 | You can join the Machine Learning Engineer newsletter. You will receive updates on open source frameworks, tutorials and articles curated by machine learning professionals.
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 | ## High Level Frameworks and Principles
45 |
46 | * [AI & Machine Learning 8 principles for Responsible ML](https://ethical.institute/principles.html) - The Institute for Ethical AI & Machine Learning has put together 8 principles for responsible machine learning that are to be adopted by individuals and delivery teams designing, building and operating machine learning systems.
47 |
48 | * [An Evaluation of Principles - The Ethics of Ethics](https://arxiv.org/ftp/arxiv/papers/1903/1903.03425.pdf) - A research paper that analyses multiple Ethics principles
49 |
50 | * [From What to How: An initial review of publicly available AI Ethics Tools, Methods and Research to translate principles into practices](https://arxiv.org/abs/1905.06876) - A paper published by the UK Digital Catapult that aims to identify and present the gap between principles and their practical applications.
51 |
52 | * [European Commission's Principles for Trustworthy AI](https://ec.europa.eu/futurium/en/ai-alliance-consultation) - The Ethics Principles for Trustworthy Artificial Intelligence (AI) is a document prepared by the High-Level Expert Group on Artificial Intelligence (AI HLEG). This independent expert group was set up by the European Commission in June 2018, as part of the AI strategy announced earlier that year.
53 |
54 | * [UK Government's Data Ethics Framework Principles](https://www.gov.uk/government/publications/data-ethics-framework/data-ethics-framework) - A resource put together by the Department for Digital, Culture, Media and Sport (DCMS) which outlines an overview of data ethics, together with a 7-principle framework.
55 |
56 |
57 | ## Processes and Checklists
58 |
59 | * [Designing Ethical AI Experiences Checklist and Agreement](https://resources.sei.cmu.edu/library/asset-view.cfm?assetid=636620) - document to guide the development of accountable, de-risked, respectful, secure, honest, and usable artificial intelligence (AI) systems with a diverse team aligned on shared ethics. Carnegie Mellon University, Software Engineering Institute.
60 |
61 | * [Ethical OS Toolkit](https://ethicalos.org/) - A toolkit that dives into 8 risk zones to assess the potential challenges that a technology team may face, together with 14 scenarios to provide examples, and 7 future-proofing strategies to help take ethical action.
62 |
63 | * [San Francisco City's Ethics & Algorithms Toolkit](https://ethicstoolkit.ai/) - A risk management framework for government leaders and staff who work with algorithms, providing a two part assessment process including an algorithmic assessment process, and a process to address the risks.
64 |
65 | * [UK Government's Data Ethics Workbook](https://www.gov.uk/government/publications/data-ethics-workbook/data-ethics-workbook) - A resource put together by the Department for Digital, Culture, Media and Sport (DCMS) which provides a set of questions that can be asked by practitioners in the public sector, which address each of the principles in their [Data Ethics Framework Principles](https://www.gov.uk/government/publications/data-ethics-framework/data-ethics-framework).
66 |
67 |
68 | * [Machine Learning Assurance](https://monitaur.ai/blog/machine-learning-assurance/) - Quick look at machine learning assurance: process of recording, understanding, verifying, and auditing machine learning models and their transactions.
69 |
70 | ## Interactive and Practical Tools
71 | * [IBM's AI Explainability 360 Open Source Toolkit](http://aix360.mybluemix.net/) - This is IBM's toolkit that includes large number of examples, research papers and demos implementing several algorithms that provide insights on fairness in machine learning systems.
72 | * [Linux Foundation AI Landscape](https://landscape.lfai.foundation/) - The official list of tools in the AI landscape curated by the Linux Foundation, which contains well maintained and used tools and frameworks.
73 | * [Taking action on digital ethics](https://www.avanade.com/en-us/thinking/research-and-insights/trendlines/digital-ethics) from Avanade
74 |
75 | * [Aequitas' Bias & Fairness Audit Toolkit](http://aequitas.dssg.io/) - The Bias Report is powered by Aequitas, an open-source bias audit toolkit for machine learning developers, analysts, and policymakers to audit machine learning models for discrimination and bias, and make informed and equitable decisions around developing and deploying predictive risk-assessment tools.
76 |
77 |
78 | * [eXplainability Toolbox](https://ethical.institute/xai.html) - The Institute for Ethical AI & Machine Learning proposal for an extended version of the traditional data science process which focuses on algorithmic bias and explainability, to ensure a baseline of risks around undesired biases can be mitigated.
79 |
80 |
81 |
82 | ## Regulation and Policy
83 |
84 | ### European Union
85 |
86 | * [Ethics Principles for Trustworthy AI](https://ec.europa.eu/futurium/en/ai-alliance-consultation) - European Commission document prepared by the High-Level Expert Group on Artificial Intelligence (AI HLEG).
87 | * [General Data Protection Regulation GDPR](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=celex%3A32016R0679) - Legal text for the EU GDPR regulation 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC
88 | * [GDPR.EU Guide](https://gdpr.eu/) - A project co-funded by the Horizon 2020 Framework programme of the EU which provides a resource for organisations and individuals researching GDPR, including a library of straightforward and up-to-date information to help organisations achieve GDPR compliance ([Legal Text](https://www.govinfo.gov/content/pkg/USCODE-2012-title5/pdf/USCODE-2012-title5-partI-chap5-subchapII-sec552a.pdf)).
89 |
90 |
91 | ### United States of America
92 |
93 | * [California Consumer Privacy Act (CCPA)](http://leginfo.legislature.ca.gov/faces/billCompareClient.xhtml?bill_id=201720180AB375) - Legal text for California's consumer privacy act
94 |
95 | * [HIPPA Health Insurance Portability and Accountability Act of 1996](https://www.hhs.gov/hipaa/for-professionals/security/laws-regulations/index.html) - The HIPAA required the secretary of the US department of health and human services (HHS) to develop regulations protecting the privacy and security of certain health information, which then HHS published what is known as the
96 | - HIPAA [Privacy Rule](https://www.hhs.gov/hipaa/for-professionals/privacy/index.html), and
97 | - HIPAA [Security Rule](https://www.hhs.gov/hipaa/for-professionals/security/index.html).
98 |
99 | * [EU-U.S. and Swiss-U.S. Privacy Shield Frameworks](https://www.privacyshield.gov/welcome) - The EU-U.S. and Swiss-U.S. Privacy Shield Frameworks were designed by the U.S. Department of Commerce and the European Commission and Swiss Administration to provide companies on both sides of the Atlantic with a mechanism to comply with data protection requirements when transferring personal data from the European Union and Switzerland to the United States in support of transatlantic commerce.
100 |
101 | * [FCR Fair Credit Reporting Act 2018](https://www.ftc.gov/enforcement/rules/rulemaking-regulatory-reform-proceedings/fair-credit-reporting-act) - The Fair Reporting Act is a federal law that regulates the collection of consumers' credit information and access to their credit reports.
102 |
103 | * [Gramm-Leach-Billey Act (for financial institutions)](https://www.ftc.gov/tips-advice/business-center/privacy-and-security/gramm-leach-bliley-act) - The Graham-Leach-Billey Act requires financial institutions (companies that offer consumers financial projects or services like loans, financial, or investment advice, or insurance) to explain their information-sharing practices to their customers and to safeguard sensitive data.
104 |
105 |
106 | * [Executive Order on Maintaining American Leadership in AI](https://www.whitehouse.gov/presidential-actions/executive-order-maintaining-american-leadership-artificial-intelligence/) - Official mandate by the President of the US to
107 |
108 | * [Privacy Act of 1974](https://www.justice.gov/opcl/privacy-act-1974) - The privacy act of 1974 which establishes a code of fair information practices that governs the collection, maintenance, use and dissemination of information about individuals that is maintained in systems of records by federal agencies.
109 |
110 | * [Privacy Protection Act of 1980](https://epic.org/privacy/ppa/) - The Privacy Protection Act of 1980 protects journalists from being required to turn over to law enforcement any work product and documentary materials, including sources, before it is disseminated to the public.
111 |
112 |
113 | ### United Kingdom
114 |
115 | * [UK Data Protection Act of 2018](http://www.legislation.gov.uk/ukpga/2018/12/contents/enacted) - The DPA 2018 enacts the GDPR into UK Law, however in doing so has included various "derogations" as permitted by the GDPR, resulting in some key differenced (which although small are not of insignificance impact and may have a greater impact after Brexit).
116 |
117 | * [The Information Commissioner's Office guide to Data Protection](https://ico.org.uk/for-organisations/guide-to-data-protection/) - This guide is for data protection officers and others who have day-to-day responsibility for data protection. It is aimed at small and medium-sized organisations, but it may be useful for larger organisations too.
118 |
119 | ## Industry standards initiatives
120 |
121 | * [ACS Code of Professional Conduct - PDF](https://www.acs.org.au/content/dam/acs/rules-and-regulations/Code-of-Professional-Conduct_v2.1.pdf) - Australian ICT (Information and Communication Technology) sector professional organization.
122 |
123 | * [IEEE Global Initiative for Ethical Considerations in Artificial Intelligence (AI) and Autonomous Systems (AS)](https://ethicsinaction.ieee.org/) - IEEE Approved Standards Projects specifically focused on the Ethically Aligned Design principles, and includes 14 (P700X) standards which cover topics from data collection to privacy, to algorithmic bias and beyond.
124 |
125 | * [ISO/IEC's Standards for Artificial Intelligence](https://www.iso.org/committee/6794475/x/catalogue/) - The ISO's initiative for Artificial Intelligence standards, which include a large set of subsequent standards ranging across Big Data, AI Terminology, Machine Learning frameworks, etc.
126 |
127 |
128 | ## Online Courses and Learning Resources
129 |
130 | * [Udacity's Secure & Private AI Course](https://www.udacity.com/course/secure-and-private-ai--ud185) - Free course by Udacity which introduces three cutting-edge technologies for privacy-preserving AI: Federated Learning, Differential Privacy, and Encrypted Computation.
131 |
132 | ## Research and Industry Reference
133 |
134 | * [Import AI](https://jack-clark.net/) - A newsletter curated by OpenAI's Jack Clark which curates the most resent and relevant AI research, as well as relevant societal issues that intersect with technical AI research.
135 |
136 |
137 | * [The Machine Learning Engineer](https://ethical.institute/mle.html) - A newsletter curated by The Institute for Ethical AI & Machine Learning that contains curated articles, tutorials and blog posts from experienced Machine Learning professionals and includes insights on best practices, tools and techniques in machine learning explainability, reproducibility, model evaluation, feature analysis and beyond.
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
--------------------------------------------------------------------------------
/README_Explaining Black Box Models.md:
--------------------------------------------------------------------------------
1 | # Explaining Black Box Models and Datasets
2 |
3 | * [Aequitas](https://github.com/dssg/aequitas)  - An open-source bias audit toolkit for data scientists, machine learning researchers, and policymakers to audit machine learning models for discrimination and bias, and to make informed and equitable decisions around developing and deploying predictive risk-assessment tools.
4 | * [Alibi](https://github.com/SeldonIO/alibi)  - Alibi is an open source Python library aimed at machine learning model inspection and interpretation. The initial focus on the library is on black-box, instance based model explanations.
5 | * [anchor](https://github.com/marcotcr/anchor)  - Code for the paper ["High precision model agnostic explanations"](https://homes.cs.washington.edu/~marcotcr/aaai18.pdf), a model-agnostic system that explains the behaviour of complex models with high-precision rules called anchors.
6 | * [captum](https://github.com/pytorch/captum)  - model interpretability and understanding library for PyTorch developed by Facebook. It contains general purpose implementations of integrated gradients, saliency maps, smoothgrad, vargrad and others for PyTorch models.
7 | * [casme](https://github.com/kondiz/casme)  - Example of using classifier-agnostic saliency map extraction on ImageNet presented on the paper ["Classifier-agnostic saliency map extraction"](https://arxiv.org/abs/1805.08249).
8 | * [ContrastiveExplanation (Foil Trees)](https://github.com/MarcelRobeer/ContrastiveExplanation)  - Python script for model agnostic contrastive/counterfactual explanations for machine learning. Accompanying code for the paper ["Contrastive Explanations with Local Foil Trees"](https://arxiv.org/abs/1806.07470).
9 | * [DeepLIFT](https://github.com/kundajelab/deeplift)  - Codebase that contains the methods in the paper ["Learning important features through propagating activation differences"](https://arxiv.org/abs/1704.02685). Here is the [slides](https://docs.google.com/file/d/0B15F_QN41VQXSXRFMzgtS01UOU0/edit?filetype=mspresentation) and the [video](https://vimeo.com/238275076) of the 15 minute talk given at ICML.
10 | * [DeepVis Toolbox](https://github.com/yosinski/deep-visualization-toolbox)  - This is the code required to run the Deep Visualization Toolbox, as well as to generate the neuron-by-neuron visualizations using regularized optimization. The toolbox and methods are described casually [here](http://yosinski.com/deepvis) and more formally in this [paper](https://arxiv.org/abs/1506.06579).
11 | * [ELI5](https://github.com/TeamHG-Memex/eli5)  - "Explain Like I'm 5" is a Python package which helps to debug machine learning classifiers and explain their predictions.
12 | * [FACETS](https://pair-code.github.io/facets/) - Facets contains two robust visualizations to aid in understanding and analyzing machine learning datasets. Get a sense of the shape of each feature of your dataset using Facets Overview, or explore individual observations using Facets Dive.
13 | * [Fairlearn](https://fairlearn.github.io)  - Fairlearn is a python toolkit to assess and mitigate unfairness in machine learning models.
14 | * [FairML](https://github.com/adebayoj/fairml)  - FairML is a python toolbox auditing the machine learning models for bias.
15 | * [fairness](https://github.com/algofairness/fairness-comparison)  - This repository is meant to facilitate the benchmarking of fairness aware machine learning algorithms based on [this paper](https://arxiv.org/abs/1802.04422).
16 | * [IBM AI Explainability 360](https://github.com/IBM/AIX360/)  - Interpretability and explainability of data and machine learning models including a comprehensive set of algorithms that cover different dimensions of explanations along with proxy explainability metrics.
17 | * [IBM AI Fairness 360](https://github.com/IBM/AIF360)  - A comprehensive set of fairness metrics for datasets and machine learning models, explanations for these metrics, and algorithms to mitigate bias in datasets and models.
18 | * [iNNvestigate](https://github.com/albermax/innvestigate)  - An open-source library for analyzing Keras models visually by methods such as [DeepTaylor-Decomposition](https://www.sciencedirect.com/science/article/pii/S0031320316303582), [PatternNet](https://openreview.net/forum?id=Hkn7CBaTW), [Saliency Maps](https://arxiv.org/abs/1312.6034), and [Integrated Gradients](https://arxiv.org/abs/1703.01365).
19 | * [Integrated-Gradients](https://github.com/ankurtaly/Integrated-Gradients)  - This repository provides code for implementing integrated gradients for networks with image inputs.
20 | * [InterpretML](https://interpret.ml/)  - InterpretML is an open-source package for training interpretable models and explaining blackbox systems.
21 | * [keras-vis](https://github.com/raghakot/keras-vis)  - keras-vis is a high-level toolkit for visualizing and debugging your trained keras neural net models. Currently supported visualizations include: Activation maximization, Saliency maps, Class activation maps.
22 | * [L2X](https://github.com/Jianbo-Lab/L2X)  - Code for replicating the experiments in the paper ["Learning to Explain: An Information-Theoretic Perspective on Model Interpretation"](https://arxiv.org/pdf/1802.07814.pdf) at ICML 2018
23 | * [Lightwood](https://github.com/mindsdb/lightwood)  - A Pytorch based framework that breaks down machine learning problems into smaller blocks that can be glued together seamlessly with an objective to build predictive models with one line of code.
24 | * [LIME](https://github.com/marcotcr/lime)  - Local Interpretable Model-agnostic Explanations for machine learning models.
25 | * [LOFO Importance](https://github.com/aerdem4/lofo-importance)  - LOFO (Leave One Feature Out) Importance calculates the importances of a set of features based on a metric of choice, for a model of choice, by iteratively removing each feature from the set, and evaluating the performance of the model, with a validation scheme of choice, based on the chosen metric.
26 | * [MindsDB](https://github.com/mindsdb/mindsdb)  - MindsDB is an Explainable AutoML framework for developers. With MindsDB you can build, train and use state of the art ML models in as simple as one line of code.
27 | * [pyBreakDown](https://github.com/MI2DataLab/pyBreakDown)  - A model agnostic tool for decomposition of predictions from black boxes. Break Down Table shows contributions of every variable to a final prediction.
28 | * [rationale](https://github.com/taolei87/rcnn/tree/master/code/rationale)  - Code to implement learning rationales behind predictions with code for paper ["Rationalizing Neural Predictions"](https://github.com/taolei87/rcnn/tree/master/code/rationale)
29 | * [responsibly](https://github.com/ResponsiblyAI/responsibly)  - Toolkit for auditing and mitigating bias and fairness of machine learning systems
30 | * [SHAP](https://github.com/slundberg/shap)  - SHapley Additive exPlanations is a unified approach to explain the output of any machine learning model.
31 | * [Skater](https://github.com/datascienceinc/Skater)  - Skater is a unified framework to enable Model Interpretation for all forms of model to help one build an Interpretable machine learning system often needed for real world use-cases
32 | * [Tensorboard's Tensorboard WhatIf](https://pair-code.github.io/what-if-tool/)  - Tensorboard screen to analyse the interactions between inference results and data inputs.
33 | * [Tensorflow's cleverhans](https://github.com/tensorflow/cleverhans)  - An adversarial example library for constructing attacks, building defenses, and benchmarking both. A python library to benchmark system's vulnerability to [adversarial examples](http://karpathy.github.io/2015/03/30/breaking-convnets/)
34 | * [tensorflow's lucid](https://github.com/tensorflow/lucid)  - Lucid is a collection of infrastructure and tools for research in neural network interpretability.
35 | * [tensorflow's Model Analysis](https://github.com/tensorflow/model-analysis)  - TensorFlow Model Analysis (TFMA) is a library for evaluating TensorFlow models. It allows users to evaluate their models on large amounts of data in a distributed manner, using the same metrics defined in their trainer.
36 | * [themis-ml](https://github.com/cosmicBboy/themis-ml)  - themis-ml is a Python library built on top of pandas and sklearn that implements fairness-aware machine learning algorithms.
37 | * [Themis](https://github.com/LASER-UMASS/Themis)  - Themis is a testing-based approach for measuring discrimination in a software system.
38 | * [TreeInterpreter](https://github.com/andosa/treeinterpreter)  - Package for interpreting scikit-learn's decision tree and random forest predictions. Allows decomposing each prediction into bias and feature contribution components as described in http://blog.datadive.net/interpreting-random-forests/.
39 | * [woe](https://github.com/boredbird/woe)  - Tools for WoE Transformation mostly used in ScoreCard Model for credit rating
40 | * [XAI - eXplainableAI](https://github.com/EthicalML/xai)  - An eXplainability toolbox for machine learning.
41 | * [mljar-supervised](https://github.com/mljar/mljar-supervised)  - An Automated Machine Learning (AutoML) python package for tabular data. It can handle: Binary Classification, MultiClass Classification and Regression. It provides feature engineering, explanations and markdown reports.
--------------------------------------------------------------------------------
/README_Feature Engineering Automation.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | # Feature Engineering Automation
5 | * [auto-sklearn](https://automl.github.io/auto-sklearn/)  - Framework to automate algorithm and hyperparameter tuning for sklearn
6 | * [AutoML-GS](https://github.com/minimaxir/automl-gs)  - Automatic feature and model search with code generation in Python, on top of common data science libraries (tensorflow, sklearn, etc)
7 | * [automl](https://github.com/ClimbsRocks/auto_ml)  - Automated feature engineering, feature/model selection, hyperparam. optimisation
8 | * [Colombus](http://i.stanford.edu/hazy/victor/columbus/) - A scalable framework to perform exploratory feature selection implemented in R
9 | * [Feature Engine](https://github.com/solegalli/feature_engine)  - Feature-engine is a Python library that contains several transformers to engineer features for use in machine learning models.
10 | * [Featuretools](https://www.featuretools.com/) - An open source framework for automated feature engineering
11 | * [sklearn-deap](https://github.com/rsteca/sklearn-deap)  Use evolutionary algorithms instead of gridsearch in scikit-learn.
12 | * [TPOT](https://epistasislab.github.io/tpot/)  - Automation of sklearn pipeline creation (including feature selection, pre-processor, etc)
13 | * [tsfresh](https://github.com/blue-yonder/tsfresh)  - Automatic extraction of relevant features from time series
14 | * [mljar-supervised](https://github.com/mljar/mljar-supervised)  - An Automated Machine Learning (AutoML) python package for tabular data. It can handle: Binary Classification, MultiClass Classification and Regression. It provides feature engineering, explanations and markdown reports.
15 |
--------------------------------------------------------------------------------
/README_Feature Stores.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Feature Stores
4 | * [Feature Store for Machine Learning (FEAST)](https://github.com/feast-dev/feast)  - Feast (Feature Store) is a tool for managing and serving machine learning features. Feast is the bridge between models and data.
5 | * [Hopsworks Feature Store](https://github.com/logicalclocks/hopsworks)  - Offline/Online Feature Store for ML [(Video)](https://www.youtube.com/watch?v=N1BjPk1smdg).
6 | * [Ivory](https://github.com/antony-a1/ivory)  - ivory defines a specification for how to store feature data and provides a set of tools for querying it. It does not provide any tooling for producing feature data in the first place. All ivory commands run as MapReduce jobs so it assumed that feature data is maintained on HDFS.
7 | * [Veri](https://github.com/bgokden/veri)  - Veri is a Feature Label Store. Feature Label store allows storing features as keys and labels as values. Querying values is only possible with knn using features. Veri also supports creating sub sample spaces of data by default.
--------------------------------------------------------------------------------
/README_Function as a Service Frameworks.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Function as a Service Frameworks
4 | * [Apache OpenWhisk](https://github.com/apache/incubator-openwhisk)  - Open source, distributed serverless platform that executes functions in response to events at any scale.
5 | * [Fission](https://github.com/fission/fission)  - (Early Alpha) Serverless functions as a service framework on Kubernetes
6 | * [Hydrosphere Mist](https://github.com/Hydrospheredata/mist)  - Serverless proxy for Apache Spark clusters
7 | * [Hydrosphere ML Lambda](https://github.com/Hydrospheredata/hydro-serving)  - Open source model management cluster for deploying, serving and monitoring machine learning models and ad-hoc algorithms with a FaaS architecture
8 | * [KNative Serving](https://github.com/knative/serving)  - Kubernetes based serverless microservices with "scale-to-zero" functionality.
9 | * [OpenFaaS](https://github.com/openfaas/faas)  - Serverless functions framework with RESTful API on Kubernetes
--------------------------------------------------------------------------------
/README_Industrial Strength NLP.md:
--------------------------------------------------------------------------------
1 |
2 | # Industrial Strength NLP
3 | * [Blackstone](https://github.com/ICLRandD/Blackstone)  - Blackstone is a spaCy model and library for processing long-form, unstructured legal text. Blackstone is an experimental research project from the Incorporated Council of Law Reporting for England and Wales' research lab, ICLR&D.
4 | * [CTRL](https://github.com/salesforce/ctrl)  - A Conditional Transformer Language Model for Controllable Generation released by SalesForce
5 | * [Facebook's XLM](https://github.com/facebookresearch/XLM)  - PyTorch original implementation of Cross-lingual Language Model Pretraining which includes BERT, XLM, NMT, XNLI, PKM, etc.
6 | * [Flair](https://github.com/zalandoresearch/flair)  - Simple framework for state-of-the-art NLP developed by Zalando which builds directly on PyTorch.
7 | * [Github's Semantic](https://github.com/github/semantic)  - Github's text library for parsing, analyzing, and comparing source code across many languages .
8 | * [GluonNLP](https://github.com/dmlc/gluon-nlp)  - GluonNLP is a toolkit that enables easy text preprocessing, datasets loading and neural models building to help you speed up your Natural Language Processing (NLP) research.
9 | * [GNES](https://github.com/gnes-ai/gnes)  - Generic Neural Elastic Search is a cloud-native semantic search system based on deep neural networks.
10 | * [Grover](https://github.com/rowanz/grover)  - Grover is a model for Neural Fake News -- both generation and detection. However, it probably can also be used for other generation tasks.
11 | * [Kashgari](https://github.com/BrikerMan/Kashgari)  - Kashgari is a simple and powerful NLP Transfer learning framework, build a state-of-art model in 5 minutes for named entity recognition (NER), part-of-speech tagging (PoS), and text classification tasks.
12 | * [OpenAI GPT-2](https://github.com/openai/gpt-2)  - OpenAI's code from their paper ["Language Models are Unsupervised Multitask Learners"](https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf).
13 | * [sense2vec](https://github.com/explosion/sense2vec)  - A Pytorch library that allows for training and using sense2vec models, which are models that leverage the same approach than word2vec, but also leverage part-of-speech attributes for each token, which allows it to be "meaning-aware"
14 | * [Snorkel](https://github.com/snorkel-team/snorkel)  - Snorkel is a system for quickly generating training data with weak supervision https://snorkel.org.
15 | * [SpaCy](https://github.com/explosion/spaCy)  - Industrial-strength natural language processing library built with python and cython by the explosion.ai team.
16 | * [Stable Baselines](https://github.com/hill-a/stable-baselines)  - A fork of OpenAI Baselines, implementations of reinforcement learning algorithms http://stable-baselines.readthedocs.io/.
17 | * [Tensorflow Lingvo](https://github.com/tensorflow/lingvo)  - A framework for building neural networks in Tensorflow, particularly sequence models. [Lingvo: A TensorFlow Framework for Sequence Modeling](https://blog.tensorflow.org/2019/02/lingvo-tensorflow-framework-for-sequence-modeling.html).
18 | * [Tensorflow Text](https://github.com/tensorflow/text)  - TensorFlow Text provides a collection of text related classes and ops ready to use with TensorFlow 2.0.
19 | * [Wav2Letter++](https://code.fb.com/ai-research/wav2letter/) - A speech to text system developed by Facebook's FAIR teams.
20 | * [YouTokenToMe](https://github.com/vkcom/youtokentome)  - YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE) [Sennrich et al.].
21 | * [🤗 Transformers](https://github.com/huggingface/transformers)  - Huggingface's library of state-of-the-art pretrained models for Natural Language Processing (NLP).
22 |
--------------------------------------------------------------------------------
/README_ML Computation load distribution frameworks.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # ML Computation load distribution frameworks
4 | * [Apache Spark MLlib](https://spark.apache.org/mllib/) - Apache Spark's scalable machine learning library in Java, Scala, Python and R
5 | * [Beam](https://github.com/apache/beam)  Apache Beam is a unified programming model for Batch and Streaming https://beam.apache.org/
6 | * [BigDL](https://bigdl-project.github.io/) - Deep learning framework on top of Spark/Hadoop to distribute data and computations across a HDFS system
7 | * [Dask](http://dask.pydata.org/en/latest/) - Distributed parallel processing framework for Pandas and NumPy computations - [(Video)](https://www.youtube.com/watch?v=RA_2qdipVng)
8 | * [DEAP](https://github.com/DEAP/deap)  - A novel evolutionary computation framework for rapid prototyping and testing of ideas. It seeks to make algorithms explicit and data structures transparent. It works in perfect harmony with parallelisation mechanisms such as multiprocessing and SCOOP.
9 | * [Hadoop Open Platform-as-a-service (HOPS)](https://www.hops.io/) - A multi-tenancy open source framework with RESTful API for data science on Hadoop which enables for Spark, Tensorflow/Keras, it is Python-first, and provides a lot of features
10 | * [Horovod](https://github.com/uber/horovod)  - Uber's distributed training framework for TensorFlow, Keras, and PyTorch
11 | * [NumPyWren](https://github.com/Vaishaal/numpywren)  - Scientific computing framework build on top of pywren to enable numpy-like distributed computations
12 | * [PyWren](http://pywren.io) - Answer the question of the "cloud button" for python function execution. It's a framework that abstracts AWS Lambda to enable data scientists to execute any Python function - [(Video)](https://www.youtube.com/watch?v=OskQytBBdJU)
13 | * [Ray](https://github.com/ray-project/ray)  - Ray is a flexible, high-performance distributed execution framework for machine learning ([VIDEO](https://www.youtube.com/watch?v=D_oz7E4v-U0))
14 | * [Vespa](https://github.com/vespa-engine/vespa)  Vespa is an engine for low-latency computation over large data sets. https://vespa.ai
15 |
--------------------------------------------------------------------------------
/README_Model Orchestration & Deployment Frameworks.md:
--------------------------------------------------------------------------------
1 | # Model Orchestration Frameworks
2 |
3 | * [Hopsworks](https://github.com/logicalclocks/hopsworks)  - Hopsworks is a data-intensive platform for the design and operation of machine learning pipelines that includes a Feature Store. [(Video)](https://www.youtube.com/watch?v=v1DrnY8caVU).
4 |
5 | * [Kubeflow](https://github.com/kubeflow/kubeflow)  - A cloud native platform for machine learning based on Google’s internal machine learning pipelines.
6 |
7 | * [Open Platform for AI](https://github.com/Microsoft/pai)  - Platform that provides complete AI model training and resource management capabilities.
8 |
9 | * [PyCaret](https://pycaret.org/) ) - low-code library for training and deploying models (scikit-learn, XGBoost, LightGBM, spaCy)
10 |
11 | * [Redis-AI](https://github.com/RedisAI/RedisAI)  - A Redis module for serving tensors and executing deep learning models. Expect changes in the API and internals.
12 |
13 |
14 | * [Skaffold](https://github.com/GoogleContainerTools/skaffold) ![]() - Skaffold is a command line tool that facilitates continuous development for Kubernetes applications. You can iterate on your application source code locally then deploy to local or remote Kubernetes clusters.
15 |
16 |
17 | # Model Deployment Frameworks
18 |
19 | - [Tensorflow Serving](httpswww.tensorflow.orgserving)  - High-performant framework to serve Tensorflow models via grpc protocol able to handle 100k requests per second per core
20 |
21 | - [Seldon](httpsgithub.comSeldonIOseldon-core)  - Open source platform for deploying and monitoring machine learning models in kubernetes - [(Video)](httpswww.youtube.comwatchv=pDlapGtecbY)
22 |
23 |
24 | - [KFServing](httpsgithub.comkubeflowkfserving)  - Serverless framework to deploy and monitor machine learning models in Kubernetes - [(Video)](httpswww.youtube.comwatchv=hGIvlFADMhU)
25 |
26 | - [NVIDIA TensorRT Inference Server](httpsgithub.comNVIDIAtensorrt-inference-server) - TensorRT Inference Server is an inference microservice that lets you serve deep learning models in production while maximizing GPU utilization.
27 | - [NVIDIA TensorRT](httpsgithub.comNVIDIATensorRT) - TensorRT is a C++ library for high performance inference on NVIDIA GPUs and deep learning accelerators.
28 |
29 |
30 | - [DeepDetect](httpsgithub.combenizdeepdetect)  - Machine Learning production server for TensorFlow, XGBoost and Cafe models written in C++ and maintained by Jolibrain
31 |
32 | - [MLeap](httpsgithub.comcombustmleap)  - Standardisation of pipeline and model serialization for Spark, Tensorflow and sklearn
33 |
34 |
35 |
36 |
37 | - [BentoML](httpsgithub.combentomlBentoML)  - BentoML is an open source framework for high performance ML model serving
38 | - [Clipper](httpsgithub.comucbriseclipper)  - Model server project from Berkeley's Rise Rise Lab which includes a standard RESTful API and supports TensorFlow, Scikit-learn and Caffe models
39 |
40 | - [Cortex](httpsgithub.comcortexlabscortex) ![]() - Cortex is an open source platform for deploying machine learning models—trained with nearly any framework—as production web services.
41 |
42 |
--------------------------------------------------------------------------------
/README_Model and Data Versioning.md:
--------------------------------------------------------------------------------
1 |
2 | # Model and Data Versioning
3 | * [Apache Marvin](https://github.com/apache/incubator-marvin)  is a platform for model deployment and versioning that hides all complexity under the hood: data scientists just need to set up the server and write their code in an extended jupyter notebook.
4 | * [Catalyst](https://github.com/catalyst-team/catalyst)  - High-level utils for PyTorch DL & RL research. It was developed with a focus on reproducibility, fast experimentation and code/ideas reusing.
5 | * [D6tflow](https://github.com/d6t/d6tflow)  - A python library that allows for building complex data science workflows on Python.
6 | * [DAGsHub](https://dagshub.com) - The home for data science collaboration. A platform, based on DVC, for data science project management and collaboration.
7 | * [Data Version Control (DVC)](https://github.com/iterative/dvc)  - A git fork that allows for version management of models.
8 | * [FGLab](https://github.com/Kaixhin/FGLab)  - Machine learning dashboard, designed to make prototyping experiments easier.
9 | * [Flor](https://github.com/ucbrise/flor/blob/master/rtd/index.rst)  - Easy to use logger and automatic version controller made for data scientists who write ML code
10 | * [Hangar](https://github.com/tensorwerk/hangar-py)  - Version control for tensor data, git-like semantics on numerical data with high speed and efficiency.
11 | * [Kedro](https://github.com/quantumblacklabs/kedro/)  - Kedro is a workflow development tool that helps you build data pipelines that are robust, scalable, deployable, reproducible and versioned. Visualization of the kedro workflows can be done by [`kedro-viz`](https://github.com/quantumblacklabs/kedro-viz)
12 | * [MLflow](https://github.com/mlflow/mlflow)  - Open source platform to manage the ML lifecycle, including experimentation, reproducibility and deployment.
13 | * [MLWatcher](https://github.com/anodot/MLWatcher)  - MLWatcher is a python agent that records a large variety of time-serie metrics of your running ML classification algorithm. It enables you to monitor in real time.
14 | * [ModelChimp](https://github.com/ModelChimp/modelchimp/)  - Framework to track and compare all the results and parameters from machine learning models [(Video)](https://vimeo.com/271246650)
15 | * [ModelDB](https://github.com/VertaAI/modeldb/)  - An open-source system to version machine learning models including their ingredients code, data, config, and environment and to track ML metadata across the model lifecycle.
16 | * [Pachyderm](https://github.com/pachyderm/pachyderm)  - Open source distributed processing framework build on Kubernetes focused mainly on dynamic building of production machine learning pipelines - [(Video)](https://www.youtube.com/watch?v=LamKVhe2RSM)
17 | * [Polyaxon](https://github.com/polyaxon/polyaxon)  - A platform for reproducible and scalable machine learning and deep learning on kubernetes. - [(Video)](https://www.youtube.com/watch?v=Iexwrka_hys)
18 | * [PredictionIO](https://github.com/apache/predictionio)  - An open source Machine Learning Server built on top of a state-of-the-art open source stack for developers and data scientists to create predictive engines for any machine learning task
19 | * [Quilt Data](https://github.com/quiltdata/quilt)  - Versioning, reproducibility and deployment of data and models.
20 | * [Sacred](https://github.com/IDSIA/sacred)  - Tool to help you configure, organize, log and reproduce machine learning experiments.
21 | * [steppy](https://github.com/neptune-ml/steppy)  - Lightweight, Python3 library for fast and reproducible machine learning experimentation. Introduces simple interface that enables clean machine learning pipeline design.
22 | * [Studio.ML](https://github.com/studioml/studio)  - Model management framework which minimizes the overhead involved with scheduling, running, monitoring and managing artifacts of your machine learning experiments.
23 | * [TRAINS](https://github.com/allegroai/trains)  - Auto-Magical Experiment Manager & Version Control for AI.
24 |
25 |
--------------------------------------------------------------------------------
/README_Model serialisation formats.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Model serialisation formats
4 | * [Java PMML API](https://github.com/jpmml) - Java libraries for consuming and producing PMML files containing models from different frameworks, including:
5 | * [pyspark2pmml](https://github.com/jpmml/pyspark2pmml)
6 | * [r2pmml](https://github.com/jpmml/r2pmml)
7 | * [sklearn2pmml](https://github.com/jpmml/jpmml-sklearn)
8 | * [sparklyr2pmml](https://github.com/jpmml/sparklyr2pmml)
9 | * [MMdnn](https://github.com/Microsoft/MMdnn)  - Cross-framework solution to convert, visualize and diagnose deep neural network models.
10 | * [Neural Network Exchange Format (NNEF)](https://www.khronos.org/nnef) - A standard format to store models across Torch, Caffe, TensorFlow, Theano, Chainer, Caffe2, PyTorch, and MXNet
11 | * [ONNX](https://github.com/onnx/onnx)  - Open Neural Network Exchange Format
12 | * [PFA](http://dmg.org/pfa/index.html) - Created by the same organisation as PMML, the Predicted Format for Analytics is an emerging standard for statistical models and data transformation engines.
13 | * [PMML](http://dmg.org/pmml/v4-3/GeneralStructure.html) - The Predictive Model Markup Language standard in XML - ([Video](https://www.youtube.com/watch?v=_5pZm2PZ8Q8))_
--------------------------------------------------------------------------------
/README_Neural Architecture Search.md:
--------------------------------------------------------------------------------
1 | # Neural Architecture Search
2 | * [Autokeras](https://github.com/jhfjhfj1/autokeras)  - AutoML library for Keras based on ["Auto-Keras: Efficient Neural Architecture Search with Network Morphism"](https://arxiv.org/abs/1806.10282).
3 | * [Determined](https://github.com/determined-ai/determined)  - Hyperparameter search and distributed training platform for deep learning (supports Tensorflow and Pytorch).
4 | * [ENAS via Parameter Sharing](https://github.com/melodyguan/enas) - Efficient Neural Architecture Search via Parameter Sharing by [authors of paper](https://arxiv.org/abs/1802.03268).
5 | * [ENAS-PyTorch](https://github.com/carpedm20/ENAS-pytorch)  - Efficient Neural Architecture Search (ENAS) in PyTorch based [on this paper](https://arxiv.org/abs/1802.03268).
6 | * [ENAS-Tensorflow](https://github.com/MINGUKKANG/ENAS-Tensorflow)  - Efficient Neural Architecture search via parameter sharing(ENAS) micro search Tensorflow code for windows user.
7 | * [Katib](https://github.com/kubeflow/katib)  - A Kubernetes-based system for Hyperparameter Tuning and Neural Architecture Search.
8 | * [Maggy](https://github.com/logicalclocks/maggy)  - Asynchronous, directed Hyperparameter search and parallel ablation studies on Apache Spark [(Video)](https://www.youtube.com/watch?v=0Hd1iYEL03w).
9 | * [Neural Architecture Search with Controller RNN](https://github.com/titu1994/neural-architecture-search)  - Basic implementation of Controller RNN from [Neural Architecture Search with Reinforcement Learning](https://arxiv.org/abs/1611.01578) and [Learning Transferable Architectures for Scalable Image Recognition](https://arxiv.org/abs/1707.07012).
10 | * [Neural Network Intelligence](https://github.com/Microsoft/nni)  - NNI (Neural Network Intelligence) is a toolkit to help users run automated machine learning (AutoML) experiments.
11 |
--------------------------------------------------------------------------------
/README_Optimized calculation frameworks.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Optimized calculation frameworks
4 | * [CuDF](https://github.com/rapidsai/cudf)  cuDF - GPU DataFrame Library http://rapids.ai
5 | * [CuML](https://github.com/rapidsai/cuml)  cuML - RAPIDS Machine Learning Library
6 | * [CuPy](https://github.com/cupy/cupy)  NumPy-like API accelerated with CUDA
7 | * [Modin](https://github.com/modin-project/modin)  - Speed up your Pandas workflows by changing a single line of code
8 | * [Numba](https://github.com/numba/numba)  - A compiler for Python array and numerical functions
9 | * [NumpyGroupies](https://github.com/ml31415/numpy-groupies)  Optimised tools for group-indexing operations: aggregated sum and more
10 | * [Weld](https://github.com/weld-project/weld)  High-performance runtime for data analytics applications, [Interview with Weld’s main contributor](https://notamonadtutorial.com/weld-accelerating-numpy-scikit-and-pandas-as-much-as-100x-with-rust-and-llvm-12ec1c630a1)
--------------------------------------------------------------------------------
/README_Privacy Preserving Machine Learning.md:
--------------------------------------------------------------------------------
1 |
2 | # Privacy Preserving Machine Learning
3 | * [Tensorflow Privacy](https://github.com/tensorflow/privacy)  - A Python library that includes implementations of TensorFlow optimizers for training machine learning models with differential privacy.
4 | * [Google's Differential Privacy](https://github.com/google/differential-privacy)  - This is a C++ library of ε-differentially private algorithms, which can be used to produce aggregate statistics over numeric data sets containing private or sensitive information.
5 | * [Intel Homomorphic Encryption Backend](https://github.com/NervanaSystems/he-transformer)  - The Intel HE transformer for nGraph is a Homomorphic Encryption (HE) backend to the Intel nGraph Compiler, Intel's graph compiler for Artificial Neural Networks.
6 | * [Microsoft SEAL](https://github.com/microsoft/SEAL)  - Microsoft SEAL is an easy-to-use open-source (MIT licensed) homomorphic encryption library developed by the Cryptography Research group at Microsoft. (Simple Encrypted Arithmetic Library or SEAL)
7 | * [PySyft](https://github.com/OpenMined/PySyft)  - A Python library for secure, private Deep Learning. PySyft decouples private data from model training, using Secure Multi-Party Computation (MPC) within PyTorch. (PySyft is managed by OpenMined community.)
8 | * [Substra](https://github.com/SubstraFoundation/substra) - Substra is an open-source framework for privacy-preserving, traceable and collaborative Machine Learning.
9 | * [TF Encrypted / TF_SEAL](https://github.com/tf-encrypted/tf-encrypted)  - A Framework for Confidential Machine Learning on Encrypted Data in TensorFlow.
10 | * [Uber SQL Differencial Privacy](https://github.com/uber/sql-differential-privacy)  - Uber's open source framework that enforces differential privacy for general-purpose SQL queries.
11 |
--------------------------------------------------------------------------------
/README_Training & Indutrial Visualisation.md:
--------------------------------------------------------------------------------
1 | # ML Training & Indutrial Visualisation Frameworks
2 | * [Bokeh](https://github.com/bokeh/bokeh)  - Bokeh is an interactive visualization library for Python that enables beautiful and meaningful visual presentation of data in modern web browsers.
3 | * [Geoplotlib](https://github.com/andrea-cuttone/geoplotlib)  - geoplotlib is a python toolbox for visualizing geographical data and making maps
4 | * [ggplot2](https://github.com/tidyverse/ggplot2)  - An implementation of the grammar of graphics for R.
5 | * [matplotlib](https://github.com/matplotlib/matplotlib)  - A Python 2D plotting library which produces publication-quality figures in a variety of hardcopy formats and interactive environments across platforms.
6 | * [Missigno](https://github.com/ResidentMario/missingno)  - missingno provides a small toolset of flexible and easy-to-use missing data visualizations and utilities that allows you to get a quick visual summary of the completeness (or lack thereof) of your dataset.
7 | * [PDPBox](https://github.com/SauceCat/PDPbox)  - This repository is inspired by ICEbox. The goal is to visualize the impact of certain features towards model prediction for any supervised learning algorithm. (now support all scikit-learn algorithms)
8 | * [Perspective](https://github.com/finos/perspective)  Streaming pivot visualization via WebAssembly https://perspective.finos.org/
9 | * [Pixiedust](https://github.com/pixiedust/pixiedust)  - PixieDust is a productivity tool for Python or Scala notebooks, which lets a developer encapsulate business logic into something easy for your customers to consume.
10 | * [Plotly Dash](https://github.com/plotly/dash)  - Dash is a Python framework for building analytical web applications without the need to write javascript.
11 | * [Plotly.py](https://github.com/plotly/plotly.py)  - An interactive, open source, and browser-based graphing library for Python.
12 | * [PyCEbox](https://github.com/AustinRochford/PyCEbox)  - Python Individual Conditional Expectation Plot Toolbox
13 | * [pygal](https://github.com/Kozea/pygal)  - pygal is a dynamic SVG charting library written in python
14 | * [Redash](https://github.com/getredash/redash)  - Redash is anopen source visualisation framework that is built to allow easy access to big datasets leveraging multiple backends.
15 | * [seaborn](https://github.com/mwaskom/seaborn)  - Seaborn is a Python visualization library based on matplotlib. It provides a high-level interface for drawing attractive statistical graphics.
16 | * [Streamlit](https://github.com/streamlit/streamlit)  - Streamlit lets you create apps for your machine learning projects with deceptively simple Python scripts. It supports hot-reloading, so your app updates live as you edit and save your file
17 | * [XKCD-style plots](http://jakevdp.github.io/blog/2013/07/10/XKCD-plots-in-matplotlib/) - An XKCD theme for matblotlib visualisations
18 | * [yellowbrick](https://github.com/DistrictDataLabs/yellowbrick)  - yellowbrick is a matplotlib-based model evaluation plots for scikit-learn and other machine learning libraries.
19 |
--------------------------------------------------------------------------------
/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-hacker
2 |
--------------------------------------------------------------------------------
/images/DSWorkflow.JPG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DeepHiveMind/EnterpriseAI_Platform_MLOps/7dbcaee0af298a631552a5ceaf0aa63ec27c3974/images/DSWorkflow.JPG
--------------------------------------------------------------------------------
/images/FullMlopsNeuro.JPG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DeepHiveMind/EnterpriseAI_Platform_MLOps/7dbcaee0af298a631552a5ceaf0aa63ec27c3974/images/FullMlopsNeuro.JPG
--------------------------------------------------------------------------------
/images/Recent_Poll_PipelineAI_July2019_1.JPG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DeepHiveMind/EnterpriseAI_Platform_MLOps/7dbcaee0af298a631552a5ceaf0aa63ec27c3974/images/Recent_Poll_PipelineAI_July2019_1.JPG
--------------------------------------------------------------------------------
/images/Small_DataScience_Project.JPG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DeepHiveMind/EnterpriseAI_Platform_MLOps/7dbcaee0af298a631552a5ceaf0aa63ec27c3974/images/Small_DataScience_Project.JPG
--------------------------------------------------------------------------------
/images/awesome.svg:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/images/bosstown.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DeepHiveMind/EnterpriseAI_Platform_MLOps/7dbcaee0af298a631552a5ceaf0aa63ec27c3974/images/bosstown.gif
--------------------------------------------------------------------------------
/images/mleng.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DeepHiveMind/EnterpriseAI_Platform_MLOps/7dbcaee0af298a631552a5ceaf0aa63ec27c3974/images/mleng.png
--------------------------------------------------------------------------------
/images/mlops1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DeepHiveMind/EnterpriseAI_Platform_MLOps/7dbcaee0af298a631552a5ceaf0aa63ec27c3974/images/mlops1.png
--------------------------------------------------------------------------------
/images/video.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/DeepHiveMind/EnterpriseAI_Platform_MLOps/7dbcaee0af298a631552a5ceaf0aa63ec27c3974/images/video.png
--------------------------------------------------------------------------------
 190 |
190 |  |
| |
135 | | Workflow Job well done | Still lot missing in the Workflow :smiley:|
136 |
137 | -- *[STAGE 3.]* **'THE PROLIFERATION' STAGE**
138 |
139 | But, as the Data Science (DS) requirements, demand for DS productionization, multiple DS Teams grows, whole lot of new issues starts popping up in explonential manner for large **ENTERPRISE DATA SCIENCE SYSTEM**. Such as,
140 |
141 | - Heterogeneity and Scale PROLIFERATION
142 | - Possibly differing engines proliferation (Spark, TensorFlow, Caffe, PyTorch, Sci-kitLearn, etc.). Multiple siloed DS Team would start using their own preferred DS tools.
143 | - Different languages proliferation (Python, Java, Scala, R ..)
144 | - Different Inference vs Training engines
145 | - Training can be frequently batch
146 | - Inference (Prediction, Model Serving) can be REST endpoint/custom code, streaming engine, micro-batch, etc.
147 | - Feature manipulation done at training needs to be replicated (or factored in) at inference
148 | - Each engine presents its own scale opportunities/issues
149 |
150 | - Increased complexities in flow of Data (One Centralized DataLake team, and multiple DS Team clamouring)
151 | - ML Team heavy dependence on data team for multiple data dimensions @variety, @Veracity, @Volume and @variability
152 |
153 | - Serving Models become increasingly harder
154 | - multiple DS Team,
155 | - multiple DS Tools,
156 | - multiple Serving requirements
157 |
158 | - Infrastructure needs, its governance complexities starts growing rapidly
159 | - Mutiple SERVING requirements,
160 | - Mutiple TRAINING requirements,
161 | - Mutiple DATA processing requirements,
162 | - Mutiple VISUALIZATION requirements etc
163 | *@varied frequency, @varied technologies, @varied Infra types**
164 |
165 | - when stuff goes wrong it's hard to trace back,
166 |
167 | - Compliance, Regulations…
168 | - Model Risk Management in Financial Services
169 | - GDPR on Reproducing and Explaining ML Decisions
170 | - Fairness Monitoring
171 |
172 | - & many More (See, whole lot of issues large Enterprise starts facing @exponential rate!!)
173 |
174 | A Fully Matured Custom MLOPS workflow is required to handle challenges of large *ENTERPRISE DATA SCIENCE SYSTEM*.
175 |
176 | **MLOPS IS THE SILVER BULLET!**
177 | ***
178 |
179 | ***
180 | ### HIDDEN TECH DEBT IN REAL WORLD ML SYSTEM
181 |
182 |
|
135 | | Workflow Job well done | Still lot missing in the Workflow :smiley:|
136 |
137 | -- *[STAGE 3.]* **'THE PROLIFERATION' STAGE**
138 |
139 | But, as the Data Science (DS) requirements, demand for DS productionization, multiple DS Teams grows, whole lot of new issues starts popping up in explonential manner for large **ENTERPRISE DATA SCIENCE SYSTEM**. Such as,
140 |
141 | - Heterogeneity and Scale PROLIFERATION
142 | - Possibly differing engines proliferation (Spark, TensorFlow, Caffe, PyTorch, Sci-kitLearn, etc.). Multiple siloed DS Team would start using their own preferred DS tools.
143 | - Different languages proliferation (Python, Java, Scala, R ..)
144 | - Different Inference vs Training engines
145 | - Training can be frequently batch
146 | - Inference (Prediction, Model Serving) can be REST endpoint/custom code, streaming engine, micro-batch, etc.
147 | - Feature manipulation done at training needs to be replicated (or factored in) at inference
148 | - Each engine presents its own scale opportunities/issues
149 |
150 | - Increased complexities in flow of Data (One Centralized DataLake team, and multiple DS Team clamouring)
151 | - ML Team heavy dependence on data team for multiple data dimensions @variety, @Veracity, @Volume and @variability
152 |
153 | - Serving Models become increasingly harder
154 | - multiple DS Team,
155 | - multiple DS Tools,
156 | - multiple Serving requirements
157 |
158 | - Infrastructure needs, its governance complexities starts growing rapidly
159 | - Mutiple SERVING requirements,
160 | - Mutiple TRAINING requirements,
161 | - Mutiple DATA processing requirements,
162 | - Mutiple VISUALIZATION requirements etc
163 | *@varied frequency, @varied technologies, @varied Infra types**
164 |
165 | - when stuff goes wrong it's hard to trace back,
166 |
167 | - Compliance, Regulations…
168 | - Model Risk Management in Financial Services
169 | - GDPR on Reproducing and Explaining ML Decisions
170 | - Fairness Monitoring
171 |
172 | - & many More (See, whole lot of issues large Enterprise starts facing @exponential rate!!)
173 |
174 | A Fully Matured Custom MLOPS workflow is required to handle challenges of large *ENTERPRISE DATA SCIENCE SYSTEM*.
175 |
176 | **MLOPS IS THE SILVER BULLET!**
177 | ***
178 |
179 | ***
180 | ### HIDDEN TECH DEBT IN REAL WORLD ML SYSTEM
181 |
182 |  246 |
247 | **Custom MLOPS IS THE SILVER BULLET!**
248 | ***
249 |
250 |
251 | # High level constructs of Real World MLOPS
252 |
253 | Any **"Enterprise Data Science System" / "Enterprise AI Platform"** must intend to stich/chain together at least the essential & high level constructs of MLOPS under its hood. Genrally "Enterprise AI Platform", such as H20.ai/Alteryx/HopsML/PipelineAI etc are powered by **Custom MLOPS** with the objective to *attempt to offer* following key high level AI/ML constructs:
254 | - [AI ML Dataset Annotation](#AI-ML-Dataset-Annotation)
255 | - [AI ML Pipeline](#AI/ML-Pipeline)
256 | - [Automated ML](#Automated-ML)
257 | - [Comprehensive AI Governance](#Comprehensive-AI-Governance)
258 | - [ML Operation COST Optimization SERVERLESS MLOPS](#ML-Operation-COST-Optimization-SERVERLESS-MLOPS)
259 | - [Data and AI CI CD Operations](#Data-and-AI-CI-CD-Operations)
260 | - [Comprehensive Data Operations DataOps](#Comprehensive-Data-Operations-DataOps)
261 |
262 | #### AI ML Dataset Annotation
263 | ```
264 | --o 'Image Annotation framework' (VoTT, LabelImg, VIA )
265 | --o 'NLP/ Text Annotation framework' (spacy, explosion.ai,)
266 | --o 'Audio & Speech Annotation framework' (Web-Based Audio Sequencer, CrowdCurio/audio-annotator, annotationpro)
267 | --o 'Ontology/Knowledge Graph Annotation framework' (Apache Jena)
268 | ```
269 |
270 | #### AI ML Pipeline
271 | ```
272 | --> 'Build/Prepare' - A Notebook/ Visual AI Studio with dockerized support for underlying
273 | - AI/ML Libraries (e.g., TF/PyTorch/SparkML/XGboost/0
274 | - EDA libraries,
275 | - Pre-processing libraries, such as
276 | - Data Augmentation Libraries,
277 | - Adversarial Robustness Libraries,
278 | - Translational/Angular variance et al.
279 |
280 | --> 'Train' - Computation load distribution frameworks for '
281 |
282 | - Distributed Training (e.g., using Horovod or Sonner or custom template)
283 | - Standalone tarining
284 | - with support for real time Training Visualization(e.g., TensorBoard/VisualDL)
285 | - on accelerated neural network hardware NVIDIA GPU/Google TPU/CPU with the leverage of NVIDIA GPU-accelerated libraries (CUDA, CuDNN)
286 |
287 | --> 'Evaluate'
288 |
289 | --> 'Model Serialization & Quantization' (e.g.,Using TF-Serving, ONNX Runtime, Seldon Core et al)
290 | - Serializaion support for Protobuff, hdf5, pickle et al
291 | - Serialization interoperability
292 | - Model binary/servable quantization & Pruning
293 |
294 | --> 'Deploy'
295 | - AI-as-a-Service -RESTful/gRPC API, or,
296 | - Binary Servables, or,
297 | - Edge deployment,
298 | - Mobile deployment
299 | - model versioning for model updates (with "Rollback option" to previous version)
300 |
301 | --> 'AI Inference Service Routing' (e.g.,'Service Mesh' like Istio)
302 |
303 | --> 'Monitor' (Data drift & Concept drift with Alert)
304 |
305 | --> 'Automated Re-training pathway' (e.g., ORACHESTRATOR - Apache Airflow, Kubeflow-pipeline, Databricks MLFlow, Apache Beam)
306 |
307 | --> 'User Interface' (PWA/ MobileApp / Web App)
308 | ```
309 |
310 | #### Automated ML
311 | ```
312 | 'HPO' - Hyper Parameter Optimization,
313 | 'Randmoized/Grid Serach',
314 | 'NAS' - Neural Architecture Search,
315 | 'AutoML'
316 | ```
317 |
318 | #### Comprehensive AI Governance
319 | ```
320 | --o 'AI TRUST'
321 | - Explainable AI,
322 | - Ethical AI,
323 | - Fair AI,
324 | - Feature Management & Stoarge,
325 | - Dataset processing transformation persistence,
326 | - Model and Data Versioning,
327 |
328 | --o 'AI Collaboration, Sharing & Exchange'
329 | Authenticated, Authroized and Logging based Market place for sharing & exchange of MODELS and Model related artefacts
330 | - AI/ML APIs,
331 | - Fature Set,
332 | - Training metrics,
333 | - Model Binaries,
334 | - Notebook /Model Code,
335 |
336 | --o 'AI Security'
337 | - Privacy Preserving Machine Learning
338 | - Differntial Privacy (offered by libraries such as Tensorflow Privacy)
339 | - ε-differentially private algorithms (Google's Differential Privacy)
340 | - Homomorphic Encryption / Data privacy in Real World AI/ML system (Intel n-Graph with Tensorflow, or, Microsoft SEAL)
341 | - AI/ML API Security
342 | - AI/ML RESTful or gRPC end point Authentication & Authorization
343 | - AI/ML Federated User Pool & Identity Pool management (FIdM/ FIM)
344 | - DevSecOps (Security as Code) for AI/ML Application devleopment, deployment, monitoring,
345 |
346 | --o 'AI Scalability'
347 | - Autoamted Load Balancing,
348 | - Service Routing, AutoScaling,
349 | - MultiZone Replication,
350 | - Caching
351 |
352 | --o 'AI Inference Model Update/ Roll out' Mechanism
353 | - Blue Green Deployment
354 | - Canary Deployment
355 | - Multi Armed Bandit Deployment
356 | - A/B
357 |
358 | ```
359 |
360 | #### ML Operation COST Optimization SERVERLESS MLOPS
361 | ```
362 |
363 | --o 'Serverless Framework'
364 | - FaaS: Apache OpenWhish/ OpenFaas,
365 | - KNative
366 |
367 | --o 'Hybrid Computing/ processing'
368 | - Local Edge Processing (EdgeX/AWS Greegrass Core/Azure IoT Core/GCP IoT Core)
369 | - Centralized Cloud Processing (AWS/Azure/GCP)
370 |
371 | --o 'Modular Plug & Play of AI/ML system' leveraging
372 | - Microservice (uS) governance framework' [API Gateway, uS Service Mesh, Automated uS Service Discovery & Registry, uS Service Config, uS service internal communication protocol etc]
373 | - Containerization & CaaS (Docker, Kubernetes)
374 | --o Optimized calculation frameworks (cuDF/ cuML)
375 |
376 | ```
377 |
378 | #### Data and AI CI CD Operations
379 | ```
380 | o 'REQUIREMENT & AGILE COLLABORATION TOOLS' (Jira/ Confluence)
381 | o 'SCM TOOLS (GIT - GitHub/GitLab)
382 | o 'CI ENGINE' (Jeknis/ Travis CI)
383 | o 'BUILD TOOLS' (Maven/ Grunt / Wheel)
384 | o 'UNIT TESTING TOOLS' (PyTest/ JUnit / Mocha / Jasmine)
385 | o 'CODE COVERAGE TOOLS' (SonarQube)
386 | o 'CD PIPELINE/FRAMEWORK- 1' ( Ansible/ Chef / Puppet)
387 | o 'ARTEFACT REPOSITORY MANAGER TOOLS' (Nexus/ Artefactory)
388 | o 'FUNCTIONAL TESTING TOOLS' ('Selenium')
389 | o 'SECURITY SCAN TESTING (SAST/DAST) TOOLS' (CheckMarx/ Fortify / BalckDuck)
390 | o ''CD PIPELINE/FRAMEWORK- 2' Containerized & Container orachasteration by Container-as-a-Service ' (Containerization - Docker, CaaS -Kubernetes, IaC - Terraform)
391 | ```
392 |
393 |
394 | #### Comprehensive Data Operations DataOps
395 | ```
396 | --o 'Data pipelines & ETL'
397 | --o 'Data Stream Processing'
398 | --o 'Data storage & Optimization'
399 | --o 'Data Intertcive Querying Interface'
400 | --o 'Data TRUST'
401 | ```
402 |
403 | # MLOPS Reference Architecture
404 |
405 | MLOPS Reference Architecture from One of visionary AI platform with specialized service offering in MLOPS:
406 |
246 |
247 | **Custom MLOPS IS THE SILVER BULLET!**
248 | ***
249 |
250 |
251 | # High level constructs of Real World MLOPS
252 |
253 | Any **"Enterprise Data Science System" / "Enterprise AI Platform"** must intend to stich/chain together at least the essential & high level constructs of MLOPS under its hood. Genrally "Enterprise AI Platform", such as H20.ai/Alteryx/HopsML/PipelineAI etc are powered by **Custom MLOPS** with the objective to *attempt to offer* following key high level AI/ML constructs:
254 | - [AI ML Dataset Annotation](#AI-ML-Dataset-Annotation)
255 | - [AI ML Pipeline](#AI/ML-Pipeline)
256 | - [Automated ML](#Automated-ML)
257 | - [Comprehensive AI Governance](#Comprehensive-AI-Governance)
258 | - [ML Operation COST Optimization SERVERLESS MLOPS](#ML-Operation-COST-Optimization-SERVERLESS-MLOPS)
259 | - [Data and AI CI CD Operations](#Data-and-AI-CI-CD-Operations)
260 | - [Comprehensive Data Operations DataOps](#Comprehensive-Data-Operations-DataOps)
261 |
262 | #### AI ML Dataset Annotation
263 | ```
264 | --o 'Image Annotation framework' (VoTT, LabelImg, VIA )
265 | --o 'NLP/ Text Annotation framework' (spacy, explosion.ai,)
266 | --o 'Audio & Speech Annotation framework' (Web-Based Audio Sequencer, CrowdCurio/audio-annotator, annotationpro)
267 | --o 'Ontology/Knowledge Graph Annotation framework' (Apache Jena)
268 | ```
269 |
270 | #### AI ML Pipeline
271 | ```
272 | --> 'Build/Prepare' - A Notebook/ Visual AI Studio with dockerized support for underlying
273 | - AI/ML Libraries (e.g., TF/PyTorch/SparkML/XGboost/0
274 | - EDA libraries,
275 | - Pre-processing libraries, such as
276 | - Data Augmentation Libraries,
277 | - Adversarial Robustness Libraries,
278 | - Translational/Angular variance et al.
279 |
280 | --> 'Train' - Computation load distribution frameworks for '
281 |
282 | - Distributed Training (e.g., using Horovod or Sonner or custom template)
283 | - Standalone tarining
284 | - with support for real time Training Visualization(e.g., TensorBoard/VisualDL)
285 | - on accelerated neural network hardware NVIDIA GPU/Google TPU/CPU with the leverage of NVIDIA GPU-accelerated libraries (CUDA, CuDNN)
286 |
287 | --> 'Evaluate'
288 |
289 | --> 'Model Serialization & Quantization' (e.g.,Using TF-Serving, ONNX Runtime, Seldon Core et al)
290 | - Serializaion support for Protobuff, hdf5, pickle et al
291 | - Serialization interoperability
292 | - Model binary/servable quantization & Pruning
293 |
294 | --> 'Deploy'
295 | - AI-as-a-Service -RESTful/gRPC API, or,
296 | - Binary Servables, or,
297 | - Edge deployment,
298 | - Mobile deployment
299 | - model versioning for model updates (with "Rollback option" to previous version)
300 |
301 | --> 'AI Inference Service Routing' (e.g.,'Service Mesh' like Istio)
302 |
303 | --> 'Monitor' (Data drift & Concept drift with Alert)
304 |
305 | --> 'Automated Re-training pathway' (e.g., ORACHESTRATOR - Apache Airflow, Kubeflow-pipeline, Databricks MLFlow, Apache Beam)
306 |
307 | --> 'User Interface' (PWA/ MobileApp / Web App)
308 | ```
309 |
310 | #### Automated ML
311 | ```
312 | 'HPO' - Hyper Parameter Optimization,
313 | 'Randmoized/Grid Serach',
314 | 'NAS' - Neural Architecture Search,
315 | 'AutoML'
316 | ```
317 |
318 | #### Comprehensive AI Governance
319 | ```
320 | --o 'AI TRUST'
321 | - Explainable AI,
322 | - Ethical AI,
323 | - Fair AI,
324 | - Feature Management & Stoarge,
325 | - Dataset processing transformation persistence,
326 | - Model and Data Versioning,
327 |
328 | --o 'AI Collaboration, Sharing & Exchange'
329 | Authenticated, Authroized and Logging based Market place for sharing & exchange of MODELS and Model related artefacts
330 | - AI/ML APIs,
331 | - Fature Set,
332 | - Training metrics,
333 | - Model Binaries,
334 | - Notebook /Model Code,
335 |
336 | --o 'AI Security'
337 | - Privacy Preserving Machine Learning
338 | - Differntial Privacy (offered by libraries such as Tensorflow Privacy)
339 | - ε-differentially private algorithms (Google's Differential Privacy)
340 | - Homomorphic Encryption / Data privacy in Real World AI/ML system (Intel n-Graph with Tensorflow, or, Microsoft SEAL)
341 | - AI/ML API Security
342 | - AI/ML RESTful or gRPC end point Authentication & Authorization
343 | - AI/ML Federated User Pool & Identity Pool management (FIdM/ FIM)
344 | - DevSecOps (Security as Code) for AI/ML Application devleopment, deployment, monitoring,
345 |
346 | --o 'AI Scalability'
347 | - Autoamted Load Balancing,
348 | - Service Routing, AutoScaling,
349 | - MultiZone Replication,
350 | - Caching
351 |
352 | --o 'AI Inference Model Update/ Roll out' Mechanism
353 | - Blue Green Deployment
354 | - Canary Deployment
355 | - Multi Armed Bandit Deployment
356 | - A/B
357 |
358 | ```
359 |
360 | #### ML Operation COST Optimization SERVERLESS MLOPS
361 | ```
362 |
363 | --o 'Serverless Framework'
364 | - FaaS: Apache OpenWhish/ OpenFaas,
365 | - KNative
366 |
367 | --o 'Hybrid Computing/ processing'
368 | - Local Edge Processing (EdgeX/AWS Greegrass Core/Azure IoT Core/GCP IoT Core)
369 | - Centralized Cloud Processing (AWS/Azure/GCP)
370 |
371 | --o 'Modular Plug & Play of AI/ML system' leveraging
372 | - Microservice (uS) governance framework' [API Gateway, uS Service Mesh, Automated uS Service Discovery & Registry, uS Service Config, uS service internal communication protocol etc]
373 | - Containerization & CaaS (Docker, Kubernetes)
374 | --o Optimized calculation frameworks (cuDF/ cuML)
375 |
376 | ```
377 |
378 | #### Data and AI CI CD Operations
379 | ```
380 | o 'REQUIREMENT & AGILE COLLABORATION TOOLS' (Jira/ Confluence)
381 | o 'SCM TOOLS (GIT - GitHub/GitLab)
382 | o 'CI ENGINE' (Jeknis/ Travis CI)
383 | o 'BUILD TOOLS' (Maven/ Grunt / Wheel)
384 | o 'UNIT TESTING TOOLS' (PyTest/ JUnit / Mocha / Jasmine)
385 | o 'CODE COVERAGE TOOLS' (SonarQube)
386 | o 'CD PIPELINE/FRAMEWORK- 1' ( Ansible/ Chef / Puppet)
387 | o 'ARTEFACT REPOSITORY MANAGER TOOLS' (Nexus/ Artefactory)
388 | o 'FUNCTIONAL TESTING TOOLS' ('Selenium')
389 | o 'SECURITY SCAN TESTING (SAST/DAST) TOOLS' (CheckMarx/ Fortify / BalckDuck)
390 | o ''CD PIPELINE/FRAMEWORK- 2' Containerized & Container orachasteration by Container-as-a-Service ' (Containerization - Docker, CaaS -Kubernetes, IaC - Terraform)
391 | ```
392 |
393 |
394 | #### Comprehensive Data Operations DataOps
395 | ```
396 | --o 'Data pipelines & ETL'
397 | --o 'Data Stream Processing'
398 | --o 'Data storage & Optimization'
399 | --o 'Data Intertcive Querying Interface'
400 | --o 'Data TRUST'
401 | ```
402 |
403 | # MLOPS Reference Architecture
404 |
405 | MLOPS Reference Architecture from One of visionary AI platform with specialized service offering in MLOPS:
406 |  407 |
408 | Reference: [Neuomation AI Platform](https://neu.ro/) | Neuromation has a specialized niche Offering in Remote MLOPS.
409 |
410 |
411 |
412 | # Detail References to the Constructs and Tools of MLOPS
413 |
414 | **Please note:**
415 |
416 | - The below matrix serve as the Index table.
417 | - Please click on hyperlinks of the respective items to delve deep into it.
418 | - Please keep checking your compass (this index table) for to seamlessly steer your way to the next mile of this wonderful matrix.
419 |
420 | | | | | |
421 | |-|-|-|-|
422 | | [🧵 Data pipelines & ETL](/README_Data%20Pipeline%20ETL%20Frameworks.md)| [💸 Data Stream Processing](/README_Data%20Stream%20Processing.md) |[🗞️ Data storage](/README_Data%20Storage%20Optimisation.md) |[🏷️ Data Labelling](/README_Data%20Labelling%20Tools%20and%20Frameworks.md)|
423 | | [🌀 Feature engineering](README_Feature%20Engineering%20Automation.md)| [🎁 Feature Stores](/README_Feature%20Stores.md)| [📓 Reproducible Notebooks](/README_Data%20Science%20Notebook%20Frameworks.md)|[🏁 Model Orchestration & Deployment Framework](/README_Model%20Orchestration%20%26%20Deployment%20Frameworks.md)|
424 | | [🗺️ ML Training Computation distribution](https://github.com/DeepHiveMind/EnterpriseAI_Platform_MLOps/blob/master/README_ML%20Computation%20load%20distribution%20frameworks.md) | [📊 ML Training & Indutrial Visualisation frameworks](/README_ML%20Computation%20load%20distribution%20frameworks.md) |[⚔ Adversarial Robustness](README_Adversarial%20Robustness%20Libraries.md) |[📥 Model serialisation](/README_Model%20serialisation%20formats.md) |
425 | |[🔍 Explaining predictions & models](/README_Explaining%20Black%20Box%20Models.md) | [🔏 Privacy preserving ML](/README_Privacy%20Preserving%20Machine%20Learning.md) | [📜 Model & data versioning](/README_Model%20and%20Data%20Versioning.md)| [🧮 Optimized calculation frameworks](/README_Optimized%20calculation%20frameworks.md) |
426 | |[🤖 AutoML](/README_Neural%20Architecture%20Search.md)| [📡 Functions as a service](README_Function%20as%20a%20Service%20Frameworks.md) | [🔠 Industry-strength NLP](/README_Industrial%20Strength%20NLP.md) | [💰 Commercial Platforms](/README_Commercial%20Platforms.md) |
427 |
428 |
429 | # MLOPS Architecture based on KUBEFLOW
430 |
431 | - High level conceptual MLOPS solutions orchasterated by KUBEFLOW (Muliple technology blocks for Enterprise level MLOPS):
432 |
433 |
407 |
408 | Reference: [Neuomation AI Platform](https://neu.ro/) | Neuromation has a specialized niche Offering in Remote MLOPS.
409 |
410 |
411 |
412 | # Detail References to the Constructs and Tools of MLOPS
413 |
414 | **Please note:**
415 |
416 | - The below matrix serve as the Index table.
417 | - Please click on hyperlinks of the respective items to delve deep into it.
418 | - Please keep checking your compass (this index table) for to seamlessly steer your way to the next mile of this wonderful matrix.
419 |
420 | | | | | |
421 | |-|-|-|-|
422 | | [🧵 Data pipelines & ETL](/README_Data%20Pipeline%20ETL%20Frameworks.md)| [💸 Data Stream Processing](/README_Data%20Stream%20Processing.md) |[🗞️ Data storage](/README_Data%20Storage%20Optimisation.md) |[🏷️ Data Labelling](/README_Data%20Labelling%20Tools%20and%20Frameworks.md)|
423 | | [🌀 Feature engineering](README_Feature%20Engineering%20Automation.md)| [🎁 Feature Stores](/README_Feature%20Stores.md)| [📓 Reproducible Notebooks](/README_Data%20Science%20Notebook%20Frameworks.md)|[🏁 Model Orchestration & Deployment Framework](/README_Model%20Orchestration%20%26%20Deployment%20Frameworks.md)|
424 | | [🗺️ ML Training Computation distribution](https://github.com/DeepHiveMind/EnterpriseAI_Platform_MLOps/blob/master/README_ML%20Computation%20load%20distribution%20frameworks.md) | [📊 ML Training & Indutrial Visualisation frameworks](/README_ML%20Computation%20load%20distribution%20frameworks.md) |[⚔ Adversarial Robustness](README_Adversarial%20Robustness%20Libraries.md) |[📥 Model serialisation](/README_Model%20serialisation%20formats.md) |
425 | |[🔍 Explaining predictions & models](/README_Explaining%20Black%20Box%20Models.md) | [🔏 Privacy preserving ML](/README_Privacy%20Preserving%20Machine%20Learning.md) | [📜 Model & data versioning](/README_Model%20and%20Data%20Versioning.md)| [🧮 Optimized calculation frameworks](/README_Optimized%20calculation%20frameworks.md) |
426 | |[🤖 AutoML](/README_Neural%20Architecture%20Search.md)| [📡 Functions as a service](README_Function%20as%20a%20Service%20Frameworks.md) | [🔠 Industry-strength NLP](/README_Industrial%20Strength%20NLP.md) | [💰 Commercial Platforms](/README_Commercial%20Platforms.md) |
427 |
428 |
429 | # MLOPS Architecture based on KUBEFLOW
430 |
431 | - High level conceptual MLOPS solutions orchasterated by KUBEFLOW (Muliple technology blocks for Enterprise level MLOPS):
432 |
433 | 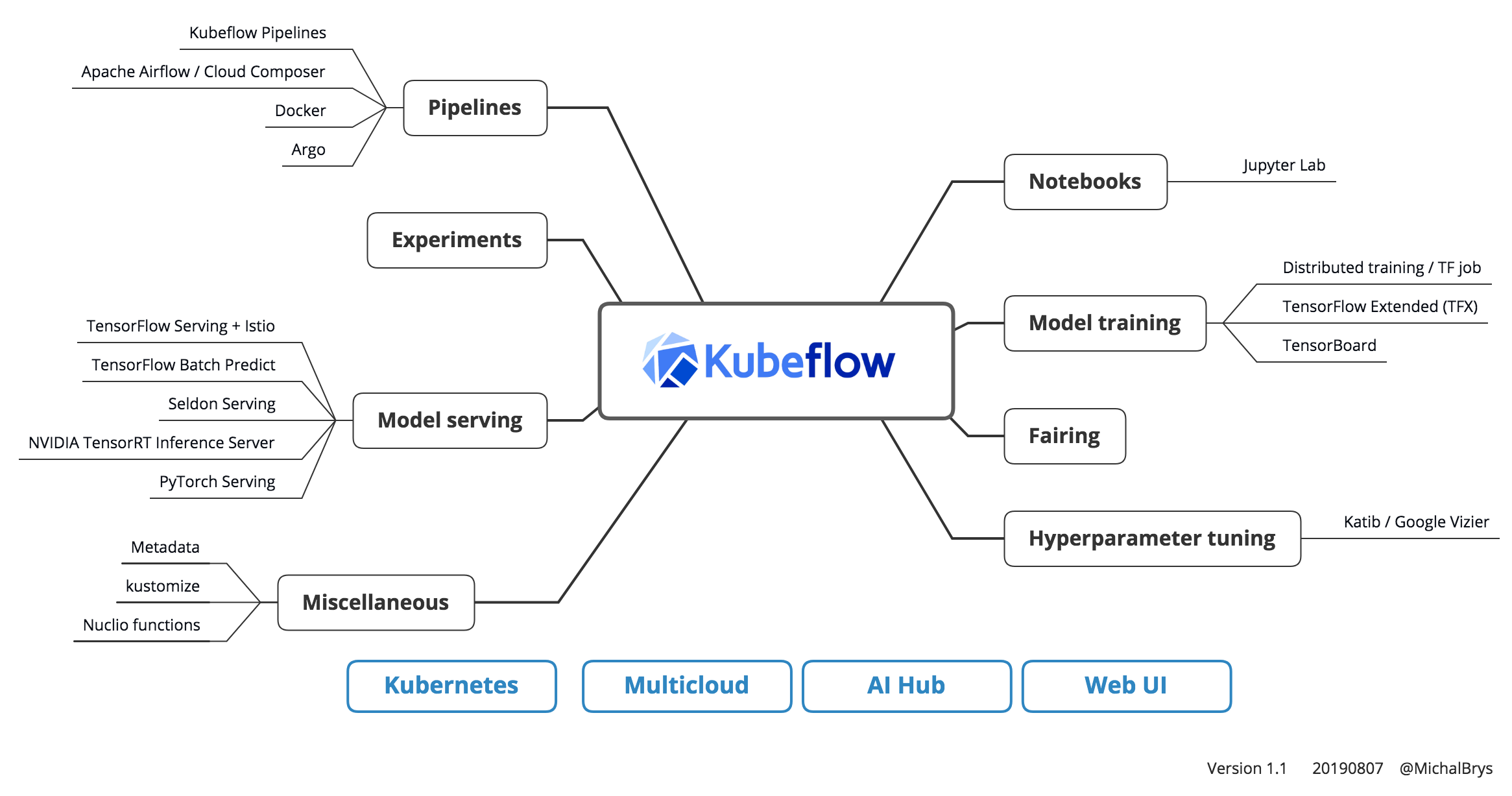 434 |
435 | - Serverless MLFLOW by amalgamation of KUBEFLOW & KNative:
436 |
437 |
434 |
435 | - Serverless MLFLOW by amalgamation of KUBEFLOW & KNative:
436 |
437 | 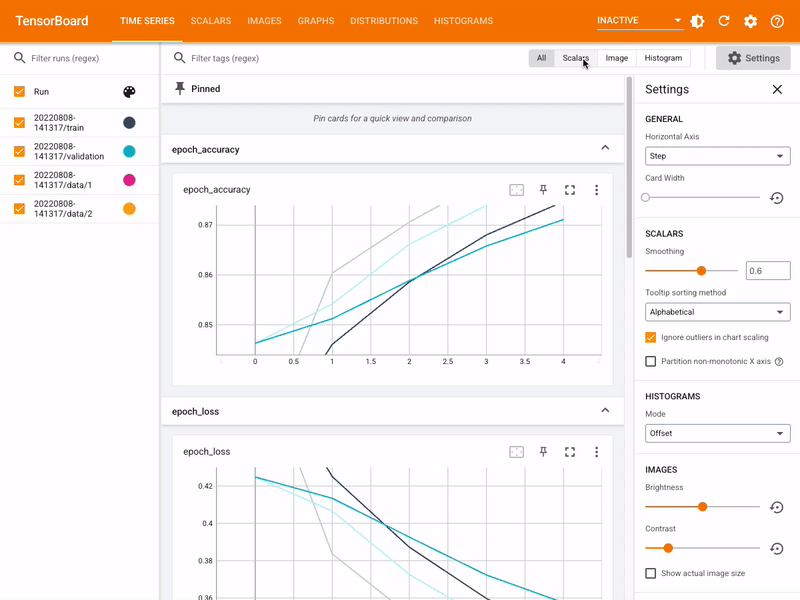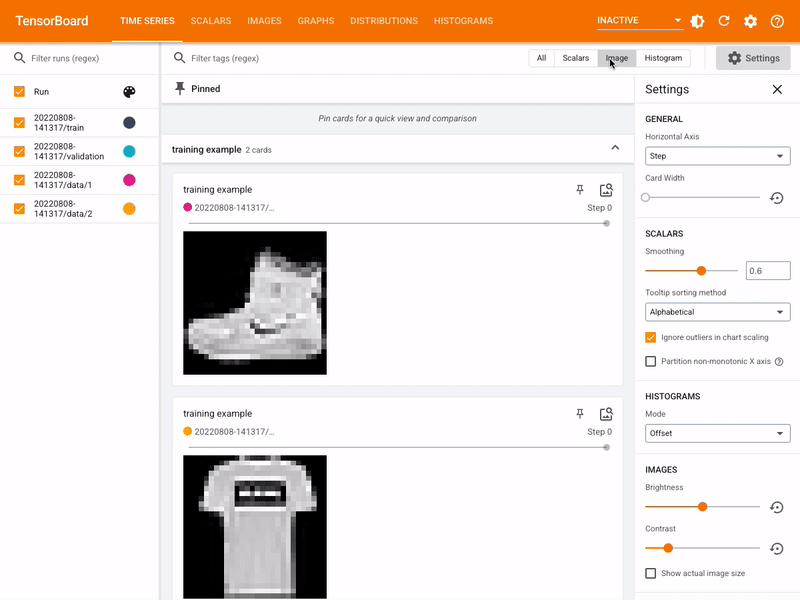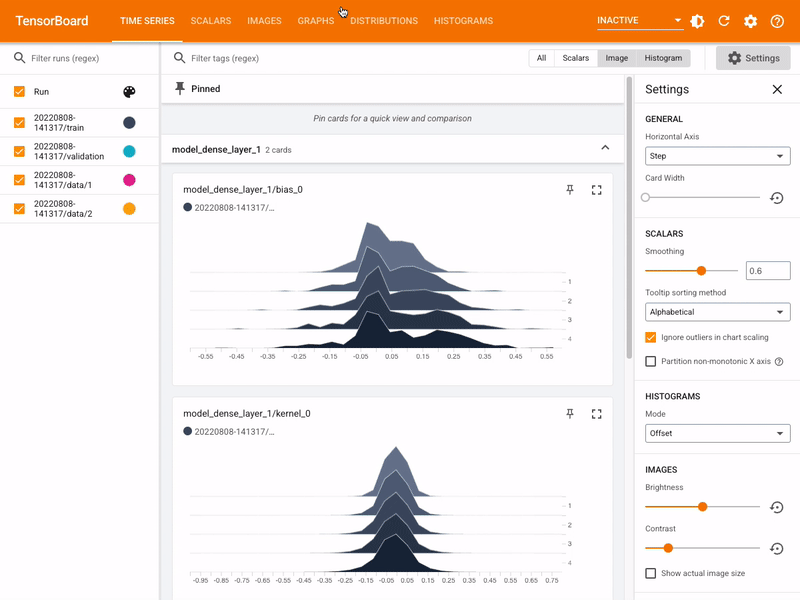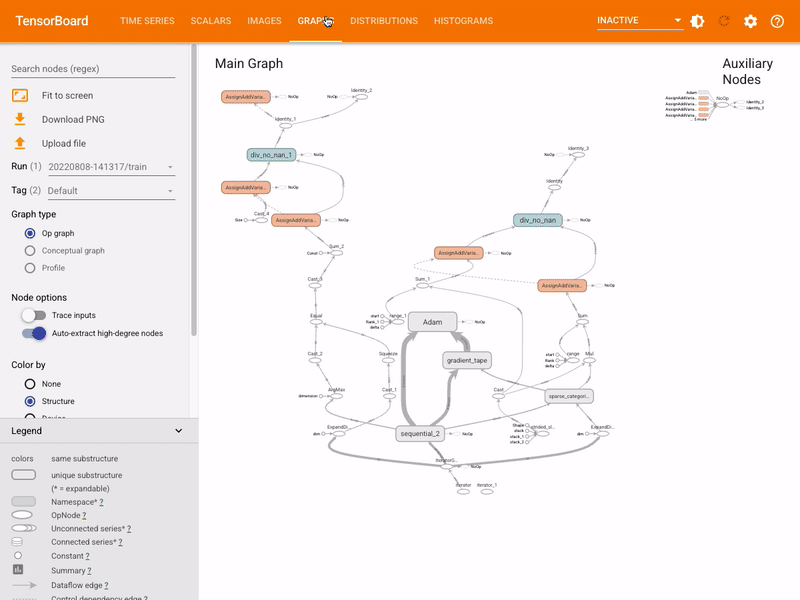 444 |
445 | ## Train and Serve TensorFlow Models at Scale with KUBERNETES and KUBEFLOW
446 |
447 | #### Hands On Content Summary
448 |
449 | | | Module | Description |
450 | | --- | --- | --- |
451 | |0| **[Introduction](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/0-intro)** | Introduction to this workshop. Motivations and goals.|
452 | |1| **[Docker - Containerizatioin of AI Modules](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/1-docker)** | Docker and containers 101.|
453 | |2| **[Kubernetes - K8S for AI](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/2-kubernetes)** | Kubernetes important concepts overview.|
454 | |3| **[Helm Charts on K8S for AI complex deployment](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/3-helm)** | Introduction to Helm |
455 | |4| **[Kubeflow for AI MLOPS](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/4-kubeflow)** | Introduction to Kubeflow and how to deploy it in your cluster.|
456 | |5| **[JupyterHub on K8S- AI Build Notebook](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/5-jupyterhub)** | Learn how to run JupyterHub to create and manage Jupyter notebooks using Kubeflow |
457 | |6| **[TFJob- K8S custom kind for AI Training on GPU/CPU/TPU](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/6-tfjob)** | Introduction to `TFJob` and how to use it to deploy a simple TensorFlow training.|
458 | |7| **[Distributed Tensorflow](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/7-distributed-tensorflow)** | Learn how to deploy and monitor distributed TensorFlow trainings with `TFJob`|
459 | |8| **[Hyperparameters Sweep with Helm](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/8-hyperparam-sweep)** | Using Helm to deploy a large number of trainings testing different hypothesis, and TensorBoard to monitor and compare the results |
460 | |9| **[AI Model Serving for prediction/scoring](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/9-serving)** | Using TensorFlow Serving to serve predictions |
461 | |10| **[Going Further](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/10-going-further)** | Links and resources to go further: Autoscaling, Distributed Storage etc. |
462 |
463 | #### Integrating AzureML and AWS SageMaker with KubeFlow to create E2E MLOPS Pipeline
464 | ##### HYBRID MACHINE LEARNING WORKFLOW
465 | | | Module | Description |
466 | | --- | --- | --- |
467 | |0| **[Integrating AzureML with KubeFlow](https://www.kubeflow.org/docs/azure/azureendtoend/)** | Running AzureML on top of KubeFlow for E2E MLOPS|
468 | |0| **[Integrating AWS SageMaker with KubeFlow](https://aws.amazon.com/blogs/machine-learning/introducing-amazon-sagemaker-components-for-kubeflow-pipelines/)** | Running AWS SageMaker on top of KubeFlow for E2E MLOPS|
469 | |0| **[How CISCO uses AWS SageMaker and KubeFlow](https://aws.amazon.com/blogs/machine-learning/cisco-uses-amazon-sagemaker-and-kubeflow-to-create-a-hybrid-machine-learning-workflow/)** | How CISCO leverages AWS SageMaker and KubeFlow to drive Hybrid ML workflow for E2E MLOPS|
470 |
471 | # Deep Dive into AI SECURITY
472 | 'AI Security' is now often being discussed a lot, and is increasingly becoming a point of concern as, in a technical parlance, AI/ML model endpoints are been exploited as attack-vector / vulnerability vector. *AI/ML Model endpoint Privacy* | *Data Privacy in Real World AI/ML System* | *Lack of Comprehensive adoption of DevSecOps Pipeline in Real World AI/ML system* et al.
473 |
474 | #### Why AI SECURITY is important
475 | - AI/ML Models are getting deployed on edge devices / edge gateways / Fog devices / Mobiles for offline predictions (owing to rapid proliferation of IIoT/ CIoT)
476 | - Agile, Dynamic Security Perimeter of AI/ML Serving end points
477 | - AI/ML Models gets exposed to real data, and inferencing of models can expose sensitive information
478 | - AI/ML Models generally are not trained on Masked data
479 | - AI/ML Model endpoint security (owing to uS Microservice style of AI/ML serving, AI-as-a-Service)
480 | - AI/ML RESTful or gRPC end point Authentication & Authorization
481 | - AI/ML Federated User Pool & Identity Pool management (FIdM/ FIM)
482 | - Absence of DevSecOps *(Security-as-a-Code)* implementation pipeline in AI/ML Application productionization- i.e., lack of awareness for
483 | - Vulnerability Scanning while Application development, such as *SAST Vulnerability Scanning*
484 | - Vulnerability Scanning while Application deployment, such as *DAST Vulnerability Scanning*
485 | - SIEM in production (Continuous Monitoring, Threat detection and alerting, Threat remediation)
486 |
487 |
488 |
489 |
490 | #### Real World AI Comprehensive SOC Solution
491 | There is comprehensive SOC solution (SOC- Security Operation Control - Plane) for *real world AI/ML*.
492 |
493 | Real World AI/ML SOC Plane is a custom solution, and is composed of following solution components primarily:
494 |
495 | - Privacy Preserving Machine Learning
496 | - Differntial Privacy (offered by libraries such as Tensorflow Privacy)
497 | - ε-differentially private algorithms (Google's Differential Privacy)
498 | - Homomorphic Encryption (Intel n-Graph with Tensorflow, or, Microsoft SEAL)
499 | {P.S.: Homomorphic encryption is a form of encryption that allows computation on encrypted data, and is an attractive remedy to increasing concerns about *data privacy in the field of machine learning*.}
500 |
501 | - AI/ML API/Endpoint Security
502 | - AI/ML RESTful or gRPC end point Authentication & Authorization
503 | - AI/ML Federated User Pool & Identity Pool management (FIdM/ FIM)
504 |
505 | - Implementation DevSecOps (Security-as-Code) pipeline for AI/ML Application development, deployment, monitoring, Threat detection and alerting, Threat remediation
506 | - Please refer to my another repo [DevSecOps Sec-as-a-Code]() for delving deeper into the awesome world of DevSecOps.
507 |
508 |
509 |
510 | # Product Machine Learning System Y2019 A Video
511 |
512 |
444 |
445 | ## Train and Serve TensorFlow Models at Scale with KUBERNETES and KUBEFLOW
446 |
447 | #### Hands On Content Summary
448 |
449 | | | Module | Description |
450 | | --- | --- | --- |
451 | |0| **[Introduction](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/0-intro)** | Introduction to this workshop. Motivations and goals.|
452 | |1| **[Docker - Containerizatioin of AI Modules](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/1-docker)** | Docker and containers 101.|
453 | |2| **[Kubernetes - K8S for AI](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/2-kubernetes)** | Kubernetes important concepts overview.|
454 | |3| **[Helm Charts on K8S for AI complex deployment](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/3-helm)** | Introduction to Helm |
455 | |4| **[Kubeflow for AI MLOPS](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/4-kubeflow)** | Introduction to Kubeflow and how to deploy it in your cluster.|
456 | |5| **[JupyterHub on K8S- AI Build Notebook](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/5-jupyterhub)** | Learn how to run JupyterHub to create and manage Jupyter notebooks using Kubeflow |
457 | |6| **[TFJob- K8S custom kind for AI Training on GPU/CPU/TPU](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/6-tfjob)** | Introduction to `TFJob` and how to use it to deploy a simple TensorFlow training.|
458 | |7| **[Distributed Tensorflow](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/7-distributed-tensorflow)** | Learn how to deploy and monitor distributed TensorFlow trainings with `TFJob`|
459 | |8| **[Hyperparameters Sweep with Helm](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/8-hyperparam-sweep)** | Using Helm to deploy a large number of trainings testing different hypothesis, and TensorBoard to monitor and compare the results |
460 | |9| **[AI Model Serving for prediction/scoring](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/9-serving)** | Using TensorFlow Serving to serve predictions |
461 | |10| **[Going Further](https://github.com/DeepHiveMind/Kubeflow-AI-Labs/tree/master/10-going-further)** | Links and resources to go further: Autoscaling, Distributed Storage etc. |
462 |
463 | #### Integrating AzureML and AWS SageMaker with KubeFlow to create E2E MLOPS Pipeline
464 | ##### HYBRID MACHINE LEARNING WORKFLOW
465 | | | Module | Description |
466 | | --- | --- | --- |
467 | |0| **[Integrating AzureML with KubeFlow](https://www.kubeflow.org/docs/azure/azureendtoend/)** | Running AzureML on top of KubeFlow for E2E MLOPS|
468 | |0| **[Integrating AWS SageMaker with KubeFlow](https://aws.amazon.com/blogs/machine-learning/introducing-amazon-sagemaker-components-for-kubeflow-pipelines/)** | Running AWS SageMaker on top of KubeFlow for E2E MLOPS|
469 | |0| **[How CISCO uses AWS SageMaker and KubeFlow](https://aws.amazon.com/blogs/machine-learning/cisco-uses-amazon-sagemaker-and-kubeflow-to-create-a-hybrid-machine-learning-workflow/)** | How CISCO leverages AWS SageMaker and KubeFlow to drive Hybrid ML workflow for E2E MLOPS|
470 |
471 | # Deep Dive into AI SECURITY
472 | 'AI Security' is now often being discussed a lot, and is increasingly becoming a point of concern as, in a technical parlance, AI/ML model endpoints are been exploited as attack-vector / vulnerability vector. *AI/ML Model endpoint Privacy* | *Data Privacy in Real World AI/ML System* | *Lack of Comprehensive adoption of DevSecOps Pipeline in Real World AI/ML system* et al.
473 |
474 | #### Why AI SECURITY is important
475 | - AI/ML Models are getting deployed on edge devices / edge gateways / Fog devices / Mobiles for offline predictions (owing to rapid proliferation of IIoT/ CIoT)
476 | - Agile, Dynamic Security Perimeter of AI/ML Serving end points
477 | - AI/ML Models gets exposed to real data, and inferencing of models can expose sensitive information
478 | - AI/ML Models generally are not trained on Masked data
479 | - AI/ML Model endpoint security (owing to uS Microservice style of AI/ML serving, AI-as-a-Service)
480 | - AI/ML RESTful or gRPC end point Authentication & Authorization
481 | - AI/ML Federated User Pool & Identity Pool management (FIdM/ FIM)
482 | - Absence of DevSecOps *(Security-as-a-Code)* implementation pipeline in AI/ML Application productionization- i.e., lack of awareness for
483 | - Vulnerability Scanning while Application development, such as *SAST Vulnerability Scanning*
484 | - Vulnerability Scanning while Application deployment, such as *DAST Vulnerability Scanning*
485 | - SIEM in production (Continuous Monitoring, Threat detection and alerting, Threat remediation)
486 |
487 |
488 |
489 |
490 | #### Real World AI Comprehensive SOC Solution
491 | There is comprehensive SOC solution (SOC- Security Operation Control - Plane) for *real world AI/ML*.
492 |
493 | Real World AI/ML SOC Plane is a custom solution, and is composed of following solution components primarily:
494 |
495 | - Privacy Preserving Machine Learning
496 | - Differntial Privacy (offered by libraries such as Tensorflow Privacy)
497 | - ε-differentially private algorithms (Google's Differential Privacy)
498 | - Homomorphic Encryption (Intel n-Graph with Tensorflow, or, Microsoft SEAL)
499 | {P.S.: Homomorphic encryption is a form of encryption that allows computation on encrypted data, and is an attractive remedy to increasing concerns about *data privacy in the field of machine learning*.}
500 |
501 | - AI/ML API/Endpoint Security
502 | - AI/ML RESTful or gRPC end point Authentication & Authorization
503 | - AI/ML Federated User Pool & Identity Pool management (FIdM/ FIM)
504 |
505 | - Implementation DevSecOps (Security-as-Code) pipeline for AI/ML Application development, deployment, monitoring, Threat detection and alerting, Threat remediation
506 | - Please refer to my another repo [DevSecOps Sec-as-a-Code]() for delving deeper into the awesome world of DevSecOps.
507 |
508 |
509 |
510 | # Product Machine Learning System Y2019 A Video
511 |
512 |  519 |
519 | 
 38 |
38 |