 3 |
3 |
2 |
3 |
6 |
7 |
8 |
9 |

13 |
14 |
 15 |
15 |  16 |
16 | 
 76 |
77 |
76 |
77 |  78 |
79 |
78 |
79 |  80 |
81 |
80 |
81 | 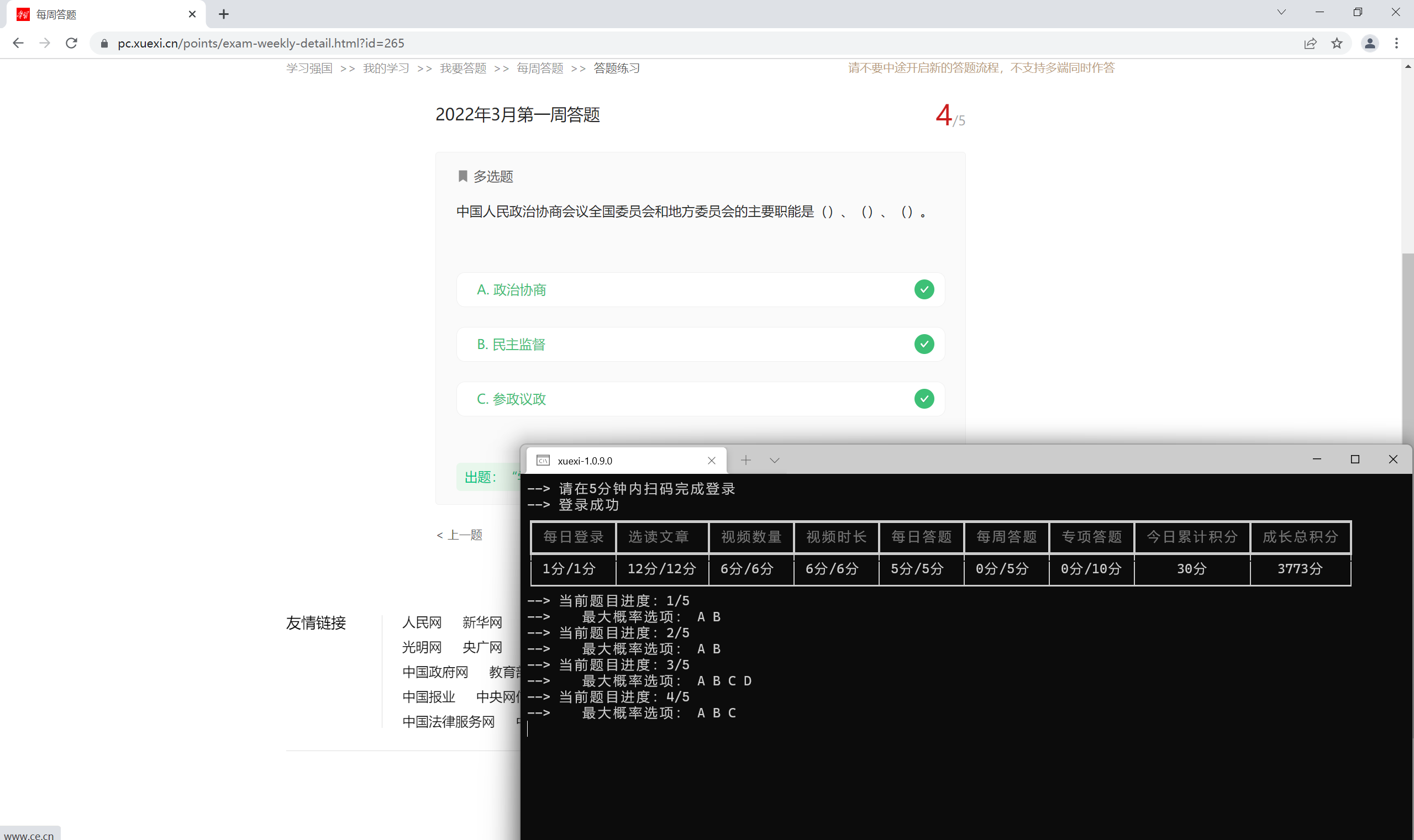 82 |
83 | # 项目结构树
84 |
85 | ```text
86 | +--custom # 自定义webdriver模块
87 | | +--xuexi_chrome.py
88 | | +--__init__.py
89 | +--data # 程序运行所需数据文件及配置文件
90 | | +--articles.json
91 | | +--lastTime.json
92 | | +--settings.json
93 | | +--videos.json
94 | +--getData # 数据获取模块
95 | | +--dataTimeOperation.py
96 | | +--get_article.py
97 | | +--get_video.py
98 | | +--version.py
99 | | +--__init__.py
100 | +--operation # 程序核心模块
101 | | +--check_version.py
102 | | +--exam.py
103 | | +--get_chromedriver.py
104 | | +--scan_article.py
105 | | +--watch_video.py
106 | | +--__init__.py
107 | +--userOperation # 用户相关模块
108 | | +--check.py
109 | | +--login.py
110 | | +--logout.py
111 | | +--__init__.py
112 | +--xuexi.py # 主程序入口
113 | +--__init__.py
114 | ```
115 |
116 | ## License
117 |
118 | [MIT](https://github.com/PRaichu/xxqg/blob/master/LICENSE)
119 |
120 | Copyright (c) 2020-present PRaichu
--------------------------------------------------------------------------------
/operation/get_chromedriver.py:
--------------------------------------------------------------------------------
1 | # -*- encoding: utf-8 -*-
2 | import re
3 | from requests import get
4 | from re import compile
5 | from subprocess import Popen, PIPE, call
6 | from traceback import format_exc
7 | from zipfile import ZipFile
8 | import winreg
9 | from json import loads
10 |
11 |
12 | def do(program_path):
13 | """
14 | 检测并更新ChromeDriver
15 | :param program_path: ChromeDriver路径(文件夹路径)
16 | :return: 执行结果 True:执行成功,False:执行失败
17 | """
18 | settings_path = 'data/settings.json'
19 | with open(settings_path, 'r', encoding='utf-8') as f:
20 | settings = f.read()
21 | settings = loads(settings)
22 | if settings['自动更新ChromeDriver'] != "true":
23 | return True
24 | try:
25 | url = 'https://registry.npmmirror.com/-/binary/chromedriver/'
26 | chrome_version = get_chrome_version() # 当前Chrome版本号(前三位)
27 | version = get_version(program_path) # 当前ChromeDriver版本号(前三位)
28 | if chrome_version != version:
29 | print('--> 当前ChromeDriver版本号和Chrome浏览器版本号不一致,准备进行更新')
30 | latest_version = get_download_version(chrome_version)
31 | download_url = url + latest_version + '/chromedriver_win32.zip' # 拼接下载链接
32 | download_chromedriver(download_url)
33 | unzip_file(program_path)
34 | print('--> ChromeDriver更新成功\n')
35 | return True
36 | except:
37 | print(str(format_exc()))
38 | print('--> 程序异常,请确保你的chrome浏览器是最新版本,然后重启脚本')
39 | call('pause', shell=True)
40 | return False
41 |
42 |
43 | def get_download_version(current_version):
44 | """
45 | 根据本地Chrome版本号获取可下载的ChromeDriver版本号
46 | :param current_version: 当前本地Chrome版本号前三位
47 | :return: 完整版本号
48 | """
49 | google_api_url = 'https://registry.npmmirror.com/-/binary/chromedriver/'
50 | rep = loads(get(google_api_url).content.decode('utf-8'))
51 | version_list = []
52 |
53 | for item in rep:
54 | letter_re = re.compile(r'[A-Za-z]', re.S)
55 | letter_res = re.findall(letter_re, item['name'])
56 | if len(letter_res):
57 | continue
58 | version_list.append(item)
59 |
60 | download_version = version_list[len(version_list) - 1]
61 | for item in version_list:
62 | if compile(r'^[1-9]\d*\.\d*.\d*').findall(item['name'])[0] == current_version:
63 | download_version = item['name'][:-1]
64 | return download_version
65 |
66 |
67 | def download_chromedriver(download_url):
68 | """
69 | 下载chromedriver
70 | :param download_url: 下载链接
71 | """
72 | file = get(download_url)
73 | with open("chromedriver.zip", 'wb') as zip_file: # 保存文件到脚本所在目录
74 | zip_file.write(file.content)
75 | print('--> ChromeDriver下载成功')
76 |
77 |
78 | def get_version(path):
79 | """
80 | 获取当前ChromeDriver版本号前三位
81 | :param path: chromedriver文件夹路径
82 | :return: 版本号前三位
83 | """
84 | import os
85 | version_info = Popen([os.path.join(path, 'chromedriver.exe'), '--version'], shell=True,
86 | stdout=PIPE).stdout.read().decode()
87 | return compile(r'^[1-9]\d*\.\d*.\d*').findall(version_info.split(' ')[1])[0]
88 |
89 |
90 | def unzip_file(path):
91 | """
92 | 解压chromedriver.zip到指定目录
93 | :param path: 解压目录
94 | """
95 | f = ZipFile('chromedriver.zip', 'r')
96 | for file in f.namelist():
97 | f.extract(file, path)
98 | f.close()
99 | print('--> 解压成功')
100 | import os
101 | os.remove('chromedriver.zip')
102 | print('--> 压缩包已删除')
103 |
104 |
105 | def get_chrome_version():
106 | """
107 | 获取当前Chrome浏览器版本号
108 | :return: 版本号前三位
109 | """
110 | version_re = compile(r'^[1-9]\d*\.\d*.\d*')
111 | try:
112 | # 从注册表中获得版本号
113 | key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, r'Software\Google\Chrome\BLBeacon')
114 | version, _ = winreg.QueryValueEx(key, 'version')
115 | return version_re.findall(version)[0] # 返回前3位版本号
116 | except WindowsError as e:
117 | print('Chrome版本检查失败:{}'.format(e))
118 |
--------------------------------------------------------------------------------
/userOperation/check.py:
--------------------------------------------------------------------------------
1 | # -*- encoding: utf-8 -*-
2 | from json import loads
3 | from enum import Enum
4 | from rich import print
5 | from rich.table import Table
6 | from datetime import datetime
7 | from selenium.webdriver.common.by import By
8 | from custom.xuexi_chrome import XuexiChrome
9 |
10 |
11 | class CheckResType(Enum):
12 | NULL = 0
13 | ARTICLE = 1
14 | VIDEO = 2
15 | ARTICLE_AND_VIDEO = 3
16 | DAILY_EXAM = 4
17 | WEEKLY_EXAM = 5
18 | SPECIAL_EXAM = 6
19 |
20 |
21 | def check_task(browser: XuexiChrome):
22 | """
23 | 检查任务项并返回给主程序
24 | :param browser: browser
25 | :return: CheckResType:任务类型
26 | """
27 | # table = PrettyTable(["每日登录", "选读文章", "视频数量", "视频时长", "每日答题", "每周答题", "专项答题", "今日累计积分", "成长总积分"])
28 | table = Table(show_header=True, header_style="bold black")
29 | table.add_column("每日登录", justify='center')
30 | table.add_column("选读文章", justify='center')
31 | table.add_column("视频数量", justify='center')
32 | table.add_column("视频时长", justify='center')
33 | table.add_column("每日答题", justify='center')
34 | table.add_column("专项答题", justify='center')
35 | table.add_column("每周答题", justify='center')
36 | table.add_column("今日累计积分", justify='center')
37 | table.add_column("成长总积分", justify='center')
38 | table_row = []
39 | settings_path = 'data/settings.json'
40 | with open(settings_path, 'r', encoding='utf-8') as f:
41 | settings = f.read()
42 | settings = loads(settings)
43 |
44 | exam_temp_path = './data/exam_temp.json'
45 | with open(exam_temp_path, 'r', encoding='utf-8') as f:
46 | exam_temp = f.read()
47 | exam_temp = loads(exam_temp)
48 |
49 | res = CheckResType.NULL
50 | browser.xuexi_get('https://www.xuexi.cn/index.html')
51 | browser.xuexi_get('https://pc.xuexi.cn/points/my-points.html')
52 |
53 | # 获取各任务项底部按钮
54 | task_buttons = browser.find_elements(by=By.CLASS_NAME, value='big')
55 |
56 | # 获取各任务项积分
57 | scores = browser.find_elements(by=By.CLASS_NAME, value='my-points-card-text')
58 | for score in scores:
59 | table_row.append(score.text.strip())
60 |
61 | # 今日积分
62 | today_points = browser.find_elements(by=By.CLASS_NAME, value='my-points-points')[1]
63 | table_row.append(today_points.text.strip())
64 | # 总积分
65 | all_points = browser.find_elements(by=By.CLASS_NAME, value='my-points-points')[0]
66 | table_row.append(all_points.text.strip())
67 |
68 | # 打印表格
69 | table.add_row(table_row[0],
70 | table_row[1],
71 | table_row[2],
72 | table_row[3],
73 | table_row[4],
74 | table_row[5],
75 | table_row[6],
76 | table_row[7] + '分',
77 | table_row[8] + '分')
78 | print(table)
79 |
80 | if settings['浏览文章'] == "true" and scores[1].text != '12分/12分':
81 | res = CheckResType.ARTICLE
82 | if settings['观看视频'] == "true" and (scores[2].text != '6分/6分' or scores[3].text != '6分/6分'):
83 | if res == CheckResType.ARTICLE:
84 | res = CheckResType.ARTICLE_AND_VIDEO
85 | else:
86 | res = CheckResType.VIDEO
87 |
88 | # 检查设置文件
89 | if settings['自动答题'] != 'true':
90 | return res
91 |
92 | day_of_week = str(datetime.now().isoweekday())
93 | if settings['每日答题'] == 'true' and res == CheckResType.NULL and task_buttons[4].text != '已完成':
94 | if settings['答题时间设置']['是否启用(关闭则每天都答题)'] != 'true' or (settings['答题时间设置']['是否启用(关闭则每天都答题)'] == 'true' and day_of_week in settings['答题时间设置']['答题类型(数字代表星期几)']['每日答题']):
95 | res = CheckResType.DAILY_EXAM
96 | if exam_temp['SPECIAL_EXAM'] == 'true' and settings['专项答题'] == 'true' and res == CheckResType.NULL and task_buttons[5].text != '已完成':
97 | if settings['答题时间设置']['是否启用(关闭则每天都答题)'] != 'true' or (settings['答题时间设置']['是否启用(关闭则每天都答题)'] == 'true' and day_of_week in settings['答题时间设置']['答题类型(数字代表星期几)']['专项答题']):
98 | res = CheckResType.SPECIAL_EXAM
99 | if exam_temp['WEEKLY_EXAM'] == 'true' and settings['每周答题'] == 'true' and res == CheckResType.NULL and task_buttons[6].text != '已完成':
100 | if settings['答题时间设置']['是否启用(关闭则每天都答题)'] != 'true' or (settings['答题时间设置']['是否启用(关闭则每天都答题)'] == 'true' and day_of_week in settings['答题时间设置']['答题类型(数字代表星期几)']['每周答题']):
101 | res = CheckResType.WEEKLY_EXAM
102 |
103 | return res
104 |
--------------------------------------------------------------------------------
/xuexi.py:
--------------------------------------------------------------------------------
1 | # -*- encoding: utf-8 -*-
2 | from json import dumps
3 | from ssl import SSLEOFError
4 | from subprocess import call
5 | from traceback import format_exc
6 | from requests.exceptions import SSLError
7 | from urllib3.exceptions import MaxRetryError
8 | from selenium import webdriver
9 | from random import randint
10 | from custom.xuexi_chrome import XuexiChrome
11 | from getData import get_article, get_video
12 | from getData.version import VERSION
13 | from userOperation import login, check
14 | from operation import scan_article, watch_video, exam, get_chromedriver, check_version
15 |
16 |
17 | def article_or_video():
18 | """
19 | 伪随机(在随机浏览文章或视频的情况下,保证文章或视频不会连续2次以上重复出现),浏览文章或视频
20 | :return: 1(文章)或2(视频)
21 | """
22 | rand = randint(1, 2)
23 | if len(randArr) >= 2 and randArr[len(randArr) - 1] + randArr[len(randArr) - 2] == 2:
24 | rand = 2
25 | elif len(randArr) >= 2 and randArr[len(randArr) - 1] + randArr[len(randArr) - 2] == 4:
26 | rand = 1
27 | randArr.append(rand)
28 | return rand
29 |
30 |
31 | def user_login():
32 | """
33 | 登录,循环执行,直到登录成功
34 | :return:
35 | """
36 | while not login.login(browser):
37 | print('--> 登录超时,正在尝试重新登录')
38 | continue
39 |
40 |
41 | def run():
42 | """
43 | 刷视频,刷题目主要部分
44 | 通过check_task()函数决定应该执行什么任务,并调用相应任务函数
45 | :return: null
46 | """
47 | while True:
48 | check_res = check.check_task(browser)
49 | if check_res == check.CheckResType.NULL:
50 | break
51 | elif check_res == check.CheckResType.ARTICLE:
52 | scan_article.scan_article(browser)
53 | elif check_res == check.CheckResType.VIDEO:
54 | watch_video.watch_video(browser)
55 | elif check_res == check.CheckResType.ARTICLE_AND_VIDEO:
56 | if article_or_video() == 1:
57 | scan_article.scan_article(browser)
58 | else:
59 | watch_video.watch_video(browser)
60 | else:
61 | exam.to_exam(browser, check_res)
62 |
63 |
64 | def finally_run():
65 | """
66 | 程序最后执行的函数,包括打印信息、关闭浏览器等
67 | """
68 | browser.quit()
69 | print(r'''
70 | __/\\\\\\\\\\\\\____/\\\________/\\\__________/\\\\\\\\\\\\__/\\\\\\\\\\\\_____/\\\\\\\\\\\\\\\_
71 | _\/\\\/////////\\\_\///\\\____/\\\/_________/\\\//////////__\/\\\////////\\\__\/\\\///////////__
72 | _\/\\\_______\/\\\___\///\\\/\\\/__________/\\\_____________\/\\\______\//\\\_\/\\\_____________
73 | _\/\\\\\\\\\\\\\\______\///\\\/___________\/\\\____/\\\\\\\_\/\\\_______\/\\\_\/\\\\\\\\\\\_____
74 | _\/\\\/////////\\\_______\/\\\____________\/\\\___\/////\\\_\/\\\_______\/\\\_\/\\\///////______
75 | _\/\\\_______\/\\\_______\/\\\____________\/\\\_______\/\\\_\/\\\_______\/\\\_\/\\\_____________
76 | _\/\\\_______\/\\\_______\/\\\____________\/\\\_______\/\\\_\/\\\_______/\\\__\/\\\_____________
77 | _\/\\\\\\\\\\\\\/________\/\\\____________\//\\\\\\\\\\\\/__\/\\\\\\\\\\\\/___\/\\\_____________
78 | _\/////////////__________\///______________\////////////____\////////////_____\///______________''')
79 |
80 | call('pause', shell=True)
81 |
82 |
83 | if __name__ == "__main__":
84 | try:
85 | from sys import exit
86 | import ctypes
87 | from os import getcwd, remove, path
88 |
89 | ctypes.windll.kernel32.SetConsoleTitleW('xuexi-{}'.format(VERSION))
90 |
91 | try:
92 | check_version.check()
93 | except (SSLEOFError, MaxRetryError, SSLError):
94 | print(str(format_exc()))
95 | print('--> \033[31m网络连接失败,请检查是否开启了VPN或代理软件,如果开启了请关闭后再试\033[0m')
96 | print('--> \033[31m当前版本:{}\033[0m'.format(VERSION))
97 | call('pause', shell=True)
98 | exit(1)
99 |
100 | if not get_chromedriver.do(getcwd()):
101 | exit(1)
102 |
103 | chrome_options = webdriver.ChromeOptions()
104 |
105 | chrome_options.add_experimental_option('useAutomationExtension', False) # 防止检测
106 | chrome_options.add_argument("--mute-audio") # 静音
107 | chrome_options.add_experimental_option('excludeSwitches', ['enable-automation', 'enable-logging']) # 防止检测、禁止打印日志
108 | chrome_options.add_argument('--disable-blink-features=AutomationControlled')
109 | chrome_options.add_argument('--ignore-certificate-errors') # 忽略证书错误
110 | chrome_options.add_argument('--ignore-ssl-errors') # 忽略ssl错误
111 | chrome_options.add_argument('–log-level=3')
112 |
113 | browser = XuexiChrome(path.join(getcwd(), 'chromedriver.exe'), options=chrome_options)
114 | browser.maximize_window()
115 |
116 | exam_temp_Path = './data/exam_temp.json'
117 | except:
118 | print(str(format_exc()))
119 | print('--> \033[31m程序异常,请尝试重启脚本\033[0m')
120 | print('--> \033[31m当前版本:{}\033[0m'.format(VERSION))
121 | call('pause', shell=True)
122 | else:
123 | try:
124 | with open(exam_temp_Path, 'w', encoding='utf-8') as f:
125 | dataDict = {
126 | 'DAILY_EXAM': 'true',
127 | 'WEEKLY_EXAM': 'true',
128 | 'SPECIAL_EXAM': 'true'
129 | }
130 | f.write(dumps(dataDict, ensure_ascii=False, indent=4))
131 |
132 | get_article.get_article()
133 | get_video.get_video()
134 | user_login()
135 | randArr = [] # 存放并用于判断随机值,防止出现连续看文章或者看视频的情况
136 | run()
137 | print('--> 任务全部完成,程序已结束')
138 | except (SSLEOFError, MaxRetryError, SSLError):
139 | print(str(format_exc()))
140 | print('--> \033[31m网络连接失败,请检查是否开启了VPN或代理软件,如果开启了请关闭后再试\033[0m')
141 | print('--> \033[31m当前版本:{}\033[0m'.format(VERSION))
142 | except:
143 | print(str(format_exc()))
144 | print('--> \033[31m程序异常,请尝试重启脚本\033[0m')
145 | print('--> \033[31m当前版本:{}\033[0m'.format(VERSION))
146 | finally:
147 | remove(exam_temp_Path)
148 | finally_run()
149 |
--------------------------------------------------------------------------------
/operation/exam.py:
--------------------------------------------------------------------------------
1 | # -*- encoding: utf-8 -*-
2 | from json import loads, dumps
3 | from traceback import format_exc
4 | from selenium.common.exceptions import WebDriverException, NoSuchElementException, UnexpectedAlertPresentException
5 | from time import sleep
6 | from random import uniform
7 | from difflib import SequenceMatcher
8 | from re import findall
9 | from selenium.webdriver.common.by import By
10 | from selenium.webdriver.remote.webelement import WebElement
11 | from custom.xuexi_chrome import XuexiChrome
12 | from userOperation import check
13 |
14 |
15 | def click(browser: XuexiChrome, element: WebElement):
16 | browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
17 | 'source': '''
18 | Object.defineProperty(navigator, 'webdriver', {
19 | get: () => undefined
20 | })
21 | window.alert = function() {
22 | return;
23 | }
24 | '''
25 | })
26 | element.click()
27 |
28 |
29 | def check_exam(browser: XuexiChrome, exam_type):
30 | """
31 | 检查可做的题目,如果本页没有则翻页查找
32 | :param browser: browser
33 | :param exam_type: 题目类型(周、专)
34 | :return: null
35 | """
36 | sleep(round(uniform(1, 2), 2))
37 | while True:
38 | flag = True # 用来记录是否答题,答题则置为False
39 | all_exams = browser.find_elements(by=By.CLASS_NAME, value='ant-btn-primary')
40 | for exam in all_exams:
41 | if exam.text == '开始答题' or exam.text == '继续答题':
42 | browser.execute_script('arguments[0].scrollIntoView();', exam)
43 | sleep(round(uniform(1, 2), 2))
44 | click(browser, exam)
45 | sleep(round(uniform(2, 4), 2))
46 | run_exam(browser)
47 | flag = False
48 | break
49 | if flag: # flag为True则执行翻页
50 | next_page = browser.find_element(by=By.CLASS_NAME, value='ant-pagination-next')
51 | browser.execute_script('arguments[0].scrollIntoView();', next_page)
52 | sleep(round(uniform(1, 2), 2))
53 | if next_page.get_attribute('aria-disabled') == 'true': # 检查翻页按钮是否可点击
54 | exam_type = None
55 | if exam_type == check.CheckResType.WEEKLY_EXAM:
56 | exam_type = 'WEEKLY_EXAM'
57 | print('--> 每周答题:已无可做题目')
58 | elif exam_type == check.CheckResType.SPECIAL_EXAM:
59 | exam_type = 'SPECIAL_EXAM'
60 | print('--> 专项答题:已无可做题目')
61 | # 如果该类型的题目已全部做完,则记录防止再次刷
62 | exam_temp_path = './data/exam_temp.json'
63 | with open(exam_temp_path, 'r', encoding='utf-8') as f:
64 | data_dict = loads(f.read())
65 | data_dict[exam_type] = 'false'
66 | with open(exam_temp_path, 'w', encoding='utf-8') as f:
67 | f.write(dumps(data_dict, ensure_ascii=False, indent=4))
68 | return
69 | click(browser, next_page)
70 | sleep(round(uniform(3, 5), 2))
71 | else:
72 | break
73 |
74 |
75 | def to_exam(browser: XuexiChrome, exam_type: check.CheckResType):
76 | """
77 | 根据参数题目类型进入对应的题目
78 | :param browser: browser
79 | :param exam_type: 题目类型(日、周、专)
80 | :return:
81 | """
82 | browser.xuexi_get('https://www.xuexi.cn/')
83 | browser.xuexi_get('https://pc.xuexi.cn/points/my-points.html')
84 | sleep(round(uniform(1, 2), 2))
85 |
86 | # 获取答题按钮族
87 | exam = browser.find_elements(by=By.CLASS_NAME, value='big')
88 | if exam_type == check.CheckResType.DAILY_EXAM:
89 | daily = exam[4]
90 | browser.execute_script('arguments[0].scrollIntoView();', daily)
91 | sleep(round(uniform(1, 2), 2))
92 | click(browser, daily)
93 | sleep(round(uniform(2, 4), 2))
94 | run_exam(browser)
95 | elif exam_type == check.CheckResType.SPECIAL_EXAM:
96 | special = exam[5]
97 | browser.execute_script('arguments[0].scrollIntoView();', special)
98 | sleep(round(uniform(1, 2), 2))
99 | click(browser, special)
100 | check_exam(browser, exam_type)
101 | elif exam_type == check.CheckResType.WEEKLY_EXAM:
102 | weekly = exam[6]
103 | browser.execute_script('arguments[0].scrollIntoView();', weekly)
104 | sleep(round(uniform(1, 2), 2))
105 | click(browser, weekly)
106 | check_exam(browser, exam_type)
107 |
108 |
109 | def select_all(options):
110 | print('--> 最大概率选项:', end='')
111 | for i in range(len(options)):
112 | print(' ' + options[i].text[0], end='')
113 | print()
114 | for i in range(len(options)):
115 | sleep(round(uniform(0.2, 0.8), 2))
116 | options[i].click()
117 |
118 |
119 | def run_exam(browser: XuexiChrome):
120 | while True:
121 | content = browser.find_element(by=By.CLASS_NAME, value='ant-breadcrumb')
122 | browser.execute_script('arguments[0].scrollIntoView();', content)
123 | sleep(round(uniform(2, 3), 2))
124 | # 题目类型
125 | question_type = browser.find_element(by=By.CLASS_NAME, value='q-header').text
126 | # print(questionType)
127 | # 当前题目的坐标
128 | question_index = int(browser.find_element(by=By.CLASS_NAME, value='big').text)
129 | # 题目总数
130 | question_count = int(findall('/(.*)', browser.find_element(by=By.CLASS_NAME, value='pager').text)[0])
131 | # 确定按钮
132 | ok_btn = browser.find_element(by=By.CLASS_NAME, value='ant-btn-primary')
133 | try:
134 | browser.find_element(by=By.CLASS_NAME, value='answer')
135 | if ok_btn.text == '下一题':
136 | ok_btn.click()
137 | sleep(round(uniform(0.2, 0.8), 2))
138 | continue
139 | except NoSuchElementException:
140 | pass
141 | # 提示按钮
142 | tip_btn = browser.find_element(by=By.CLASS_NAME, value='tips')
143 | print('--> 当前题目进度:' + str(question_index) + '/' + str(question_count))
144 | tip_btn.click()
145 | sleep(round(uniform(0.2, 0.8), 2))
146 | try:
147 | # 获取所有提示内容
148 | tips_content = browser.find_element(by=By.CLASS_NAME, value='line-feed').find_elements(by=By.TAG_NAME, value='font')
149 | sleep(round(uniform(0.2, 0.8), 2))
150 | tip_btn.click()
151 | tips = []
152 | tips.clear()
153 | for tip in tips_content:
154 | tips.append(tip.text)
155 |
156 | if '单选题' in question_type:
157 | # 选择题,获取所有选项
158 | options = browser.find_elements(by=By.CLASS_NAME, value='choosable')
159 | if len(tips) == 0:
160 | sleep(round(uniform(0.2, 0.8), 2))
161 | options[0].click()
162 | else:
163 | ans_dict = {} # 存放每个选项与提示的相似度
164 | for i in range(len(options)):
165 | ans_dict[i] = SequenceMatcher(None, tips[0], options[i].text[3:]).ratio()
166 | ans_dict = sorted(ans_dict.items(), key=lambda x: x[1], reverse=True)
167 | # print(ansDict)
168 | print('--> 最大概率选项: ' + options[ans_dict[0][0]].text[0])
169 | options[ans_dict[0][0]].click()
170 |
171 | sleep(round(uniform(0.2, 0.8), 2))
172 | ok_btn.click()
173 |
174 | elif '多选题' in question_type:
175 | # 选择题,获取所有选项
176 | options = browser.find_elements(by=By.CLASS_NAME, value='choosable')
177 | q_word = browser.find_element(by=By.CLASS_NAME, value='q-body').text
178 | bracket_count = len(findall('()', q_word))
179 | if len(options) == bracket_count:
180 | select_all(options)
181 | else:
182 | if len(tips) == 0:
183 | sleep(round(uniform(0.2, 0.8), 2))
184 | options[0].click()
185 | sleep(round(uniform(0.2, 0.8), 2))
186 | options[1].click()
187 | else:
188 | # 如果选项数量多于提示数量,则匹配出最可能的选项
189 | if len(options) > len(tips):
190 | ans = [] # 存放匹配出的最终结果
191 | for i in range(len(tips)):
192 | ans_dict = {} # 存放每个选项与提示的相似度
193 | for j in range(len(options)):
194 | ans_dict[j] = SequenceMatcher(None, tips[i], options[j].text[3:]).ratio()
195 | # print(ansDict)
196 | ans_dict = sorted(ans_dict.items(), key=lambda x: x[1], reverse=True)
197 | ans.append(ans_dict[0][0])
198 | ans = list(set(ans))
199 | # print(ans)
200 | print('--> 最大概率选项:', end='')
201 | for i in range(len(ans)):
202 | print(' ' + options[ans[i]].text[0], end='')
203 | print()
204 | for i in range(len(ans)):
205 | sleep(round(uniform(0.2, 0.8), 2))
206 | options[ans[i]].click()
207 | # 如果选项数量和提示数量相同或少于提示数量,则全选
208 | else:
209 | select_all(options)
210 |
211 | sleep(round(uniform(0.2, 0.8), 2))
212 | ok_btn.click()
213 |
214 | elif '填空题' in question_type:
215 | # 填空题,获取所有输入框
216 | blanks = browser.find_elements(by=By.CLASS_NAME, value='blank')
217 | tips_i = 0
218 | for i in range(len(blanks)):
219 | sleep(round(uniform(0.2, 0.8), 2))
220 | if len(tips) > tips_i and tips[tips_i].strip() == '':
221 | tips_i += 1
222 | try:
223 | blank_ans = tips[tips_i]
224 | except:
225 | blank_ans = '未找到提示'
226 | print('--> 第{0}空答案可能是: {1}'.format(i + 1, blank_ans))
227 | blanks[i].send_keys(blank_ans)
228 | tips_i += 1
229 |
230 | sleep(round(uniform(0.2, 0.8), 2))
231 | ok_btn.click()
232 | except UnexpectedAlertPresentException:
233 | alert = browser.switch_to.alert
234 | alert.accept()
235 | other_place = browser.find_element(by=By.ID, value='app')
236 | other_place.click()
237 | sleep(round(uniform(0.2, 0.8), 2))
238 | except WebDriverException:
239 | print(str(format_exc()))
240 | print('--> 答题异常,正在重试')
241 | other_place = browser.find_element(by=By.ID, value='app')
242 | other_place.click()
243 | sleep(round(uniform(0.2, 0.8), 2))
244 |
245 | if question_index == question_count:
246 | sleep(round(uniform(0.2, 0.8), 2))
247 | try:
248 | submit = browser.find_element(by=By.CLASS_NAME, value='submit-btn')
249 | submit.click()
250 | browser.implicitly_wait(10)
251 | sleep(round(uniform(2.6, 4.6), 2))
252 | except NoSuchElementException:
253 | submit = browser.find_element(by=By.CLASS_NAME, value='ant-btn-primary')
254 | submit.click()
255 | browser.implicitly_wait(10)
256 | sleep(round(uniform(2.6, 4.6), 2))
257 | except UnexpectedAlertPresentException:
258 | alert = browser.switch_to.alert
259 | alert.accept()
260 | print('--> 答题结束')
261 | break
262 |
--------------------------------------------------------------------------------
82 |
83 | # 项目结构树
84 |
85 | ```text
86 | +--custom # 自定义webdriver模块
87 | | +--xuexi_chrome.py
88 | | +--__init__.py
89 | +--data # 程序运行所需数据文件及配置文件
90 | | +--articles.json
91 | | +--lastTime.json
92 | | +--settings.json
93 | | +--videos.json
94 | +--getData # 数据获取模块
95 | | +--dataTimeOperation.py
96 | | +--get_article.py
97 | | +--get_video.py
98 | | +--version.py
99 | | +--__init__.py
100 | +--operation # 程序核心模块
101 | | +--check_version.py
102 | | +--exam.py
103 | | +--get_chromedriver.py
104 | | +--scan_article.py
105 | | +--watch_video.py
106 | | +--__init__.py
107 | +--userOperation # 用户相关模块
108 | | +--check.py
109 | | +--login.py
110 | | +--logout.py
111 | | +--__init__.py
112 | +--xuexi.py # 主程序入口
113 | +--__init__.py
114 | ```
115 |
116 | ## License
117 |
118 | [MIT](https://github.com/PRaichu/xxqg/blob/master/LICENSE)
119 |
120 | Copyright (c) 2020-present PRaichu
--------------------------------------------------------------------------------
/operation/get_chromedriver.py:
--------------------------------------------------------------------------------
1 | # -*- encoding: utf-8 -*-
2 | import re
3 | from requests import get
4 | from re import compile
5 | from subprocess import Popen, PIPE, call
6 | from traceback import format_exc
7 | from zipfile import ZipFile
8 | import winreg
9 | from json import loads
10 |
11 |
12 | def do(program_path):
13 | """
14 | 检测并更新ChromeDriver
15 | :param program_path: ChromeDriver路径(文件夹路径)
16 | :return: 执行结果 True:执行成功,False:执行失败
17 | """
18 | settings_path = 'data/settings.json'
19 | with open(settings_path, 'r', encoding='utf-8') as f:
20 | settings = f.read()
21 | settings = loads(settings)
22 | if settings['自动更新ChromeDriver'] != "true":
23 | return True
24 | try:
25 | url = 'https://registry.npmmirror.com/-/binary/chromedriver/'
26 | chrome_version = get_chrome_version() # 当前Chrome版本号(前三位)
27 | version = get_version(program_path) # 当前ChromeDriver版本号(前三位)
28 | if chrome_version != version:
29 | print('--> 当前ChromeDriver版本号和Chrome浏览器版本号不一致,准备进行更新')
30 | latest_version = get_download_version(chrome_version)
31 | download_url = url + latest_version + '/chromedriver_win32.zip' # 拼接下载链接
32 | download_chromedriver(download_url)
33 | unzip_file(program_path)
34 | print('--> ChromeDriver更新成功\n')
35 | return True
36 | except:
37 | print(str(format_exc()))
38 | print('--> 程序异常,请确保你的chrome浏览器是最新版本,然后重启脚本')
39 | call('pause', shell=True)
40 | return False
41 |
42 |
43 | def get_download_version(current_version):
44 | """
45 | 根据本地Chrome版本号获取可下载的ChromeDriver版本号
46 | :param current_version: 当前本地Chrome版本号前三位
47 | :return: 完整版本号
48 | """
49 | google_api_url = 'https://registry.npmmirror.com/-/binary/chromedriver/'
50 | rep = loads(get(google_api_url).content.decode('utf-8'))
51 | version_list = []
52 |
53 | for item in rep:
54 | letter_re = re.compile(r'[A-Za-z]', re.S)
55 | letter_res = re.findall(letter_re, item['name'])
56 | if len(letter_res):
57 | continue
58 | version_list.append(item)
59 |
60 | download_version = version_list[len(version_list) - 1]
61 | for item in version_list:
62 | if compile(r'^[1-9]\d*\.\d*.\d*').findall(item['name'])[0] == current_version:
63 | download_version = item['name'][:-1]
64 | return download_version
65 |
66 |
67 | def download_chromedriver(download_url):
68 | """
69 | 下载chromedriver
70 | :param download_url: 下载链接
71 | """
72 | file = get(download_url)
73 | with open("chromedriver.zip", 'wb') as zip_file: # 保存文件到脚本所在目录
74 | zip_file.write(file.content)
75 | print('--> ChromeDriver下载成功')
76 |
77 |
78 | def get_version(path):
79 | """
80 | 获取当前ChromeDriver版本号前三位
81 | :param path: chromedriver文件夹路径
82 | :return: 版本号前三位
83 | """
84 | import os
85 | version_info = Popen([os.path.join(path, 'chromedriver.exe'), '--version'], shell=True,
86 | stdout=PIPE).stdout.read().decode()
87 | return compile(r'^[1-9]\d*\.\d*.\d*').findall(version_info.split(' ')[1])[0]
88 |
89 |
90 | def unzip_file(path):
91 | """
92 | 解压chromedriver.zip到指定目录
93 | :param path: 解压目录
94 | """
95 | f = ZipFile('chromedriver.zip', 'r')
96 | for file in f.namelist():
97 | f.extract(file, path)
98 | f.close()
99 | print('--> 解压成功')
100 | import os
101 | os.remove('chromedriver.zip')
102 | print('--> 压缩包已删除')
103 |
104 |
105 | def get_chrome_version():
106 | """
107 | 获取当前Chrome浏览器版本号
108 | :return: 版本号前三位
109 | """
110 | version_re = compile(r'^[1-9]\d*\.\d*.\d*')
111 | try:
112 | # 从注册表中获得版本号
113 | key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, r'Software\Google\Chrome\BLBeacon')
114 | version, _ = winreg.QueryValueEx(key, 'version')
115 | return version_re.findall(version)[0] # 返回前3位版本号
116 | except WindowsError as e:
117 | print('Chrome版本检查失败:{}'.format(e))
118 |
--------------------------------------------------------------------------------
/userOperation/check.py:
--------------------------------------------------------------------------------
1 | # -*- encoding: utf-8 -*-
2 | from json import loads
3 | from enum import Enum
4 | from rich import print
5 | from rich.table import Table
6 | from datetime import datetime
7 | from selenium.webdriver.common.by import By
8 | from custom.xuexi_chrome import XuexiChrome
9 |
10 |
11 | class CheckResType(Enum):
12 | NULL = 0
13 | ARTICLE = 1
14 | VIDEO = 2
15 | ARTICLE_AND_VIDEO = 3
16 | DAILY_EXAM = 4
17 | WEEKLY_EXAM = 5
18 | SPECIAL_EXAM = 6
19 |
20 |
21 | def check_task(browser: XuexiChrome):
22 | """
23 | 检查任务项并返回给主程序
24 | :param browser: browser
25 | :return: CheckResType:任务类型
26 | """
27 | # table = PrettyTable(["每日登录", "选读文章", "视频数量", "视频时长", "每日答题", "每周答题", "专项答题", "今日累计积分", "成长总积分"])
28 | table = Table(show_header=True, header_style="bold black")
29 | table.add_column("每日登录", justify='center')
30 | table.add_column("选读文章", justify='center')
31 | table.add_column("视频数量", justify='center')
32 | table.add_column("视频时长", justify='center')
33 | table.add_column("每日答题", justify='center')
34 | table.add_column("专项答题", justify='center')
35 | table.add_column("每周答题", justify='center')
36 | table.add_column("今日累计积分", justify='center')
37 | table.add_column("成长总积分", justify='center')
38 | table_row = []
39 | settings_path = 'data/settings.json'
40 | with open(settings_path, 'r', encoding='utf-8') as f:
41 | settings = f.read()
42 | settings = loads(settings)
43 |
44 | exam_temp_path = './data/exam_temp.json'
45 | with open(exam_temp_path, 'r', encoding='utf-8') as f:
46 | exam_temp = f.read()
47 | exam_temp = loads(exam_temp)
48 |
49 | res = CheckResType.NULL
50 | browser.xuexi_get('https://www.xuexi.cn/index.html')
51 | browser.xuexi_get('https://pc.xuexi.cn/points/my-points.html')
52 |
53 | # 获取各任务项底部按钮
54 | task_buttons = browser.find_elements(by=By.CLASS_NAME, value='big')
55 |
56 | # 获取各任务项积分
57 | scores = browser.find_elements(by=By.CLASS_NAME, value='my-points-card-text')
58 | for score in scores:
59 | table_row.append(score.text.strip())
60 |
61 | # 今日积分
62 | today_points = browser.find_elements(by=By.CLASS_NAME, value='my-points-points')[1]
63 | table_row.append(today_points.text.strip())
64 | # 总积分
65 | all_points = browser.find_elements(by=By.CLASS_NAME, value='my-points-points')[0]
66 | table_row.append(all_points.text.strip())
67 |
68 | # 打印表格
69 | table.add_row(table_row[0],
70 | table_row[1],
71 | table_row[2],
72 | table_row[3],
73 | table_row[4],
74 | table_row[5],
75 | table_row[6],
76 | table_row[7] + '分',
77 | table_row[8] + '分')
78 | print(table)
79 |
80 | if settings['浏览文章'] == "true" and scores[1].text != '12分/12分':
81 | res = CheckResType.ARTICLE
82 | if settings['观看视频'] == "true" and (scores[2].text != '6分/6分' or scores[3].text != '6分/6分'):
83 | if res == CheckResType.ARTICLE:
84 | res = CheckResType.ARTICLE_AND_VIDEO
85 | else:
86 | res = CheckResType.VIDEO
87 |
88 | # 检查设置文件
89 | if settings['自动答题'] != 'true':
90 | return res
91 |
92 | day_of_week = str(datetime.now().isoweekday())
93 | if settings['每日答题'] == 'true' and res == CheckResType.NULL and task_buttons[4].text != '已完成':
94 | if settings['答题时间设置']['是否启用(关闭则每天都答题)'] != 'true' or (settings['答题时间设置']['是否启用(关闭则每天都答题)'] == 'true' and day_of_week in settings['答题时间设置']['答题类型(数字代表星期几)']['每日答题']):
95 | res = CheckResType.DAILY_EXAM
96 | if exam_temp['SPECIAL_EXAM'] == 'true' and settings['专项答题'] == 'true' and res == CheckResType.NULL and task_buttons[5].text != '已完成':
97 | if settings['答题时间设置']['是否启用(关闭则每天都答题)'] != 'true' or (settings['答题时间设置']['是否启用(关闭则每天都答题)'] == 'true' and day_of_week in settings['答题时间设置']['答题类型(数字代表星期几)']['专项答题']):
98 | res = CheckResType.SPECIAL_EXAM
99 | if exam_temp['WEEKLY_EXAM'] == 'true' and settings['每周答题'] == 'true' and res == CheckResType.NULL and task_buttons[6].text != '已完成':
100 | if settings['答题时间设置']['是否启用(关闭则每天都答题)'] != 'true' or (settings['答题时间设置']['是否启用(关闭则每天都答题)'] == 'true' and day_of_week in settings['答题时间设置']['答题类型(数字代表星期几)']['每周答题']):
101 | res = CheckResType.WEEKLY_EXAM
102 |
103 | return res
104 |
--------------------------------------------------------------------------------
/xuexi.py:
--------------------------------------------------------------------------------
1 | # -*- encoding: utf-8 -*-
2 | from json import dumps
3 | from ssl import SSLEOFError
4 | from subprocess import call
5 | from traceback import format_exc
6 | from requests.exceptions import SSLError
7 | from urllib3.exceptions import MaxRetryError
8 | from selenium import webdriver
9 | from random import randint
10 | from custom.xuexi_chrome import XuexiChrome
11 | from getData import get_article, get_video
12 | from getData.version import VERSION
13 | from userOperation import login, check
14 | from operation import scan_article, watch_video, exam, get_chromedriver, check_version
15 |
16 |
17 | def article_or_video():
18 | """
19 | 伪随机(在随机浏览文章或视频的情况下,保证文章或视频不会连续2次以上重复出现),浏览文章或视频
20 | :return: 1(文章)或2(视频)
21 | """
22 | rand = randint(1, 2)
23 | if len(randArr) >= 2 and randArr[len(randArr) - 1] + randArr[len(randArr) - 2] == 2:
24 | rand = 2
25 | elif len(randArr) >= 2 and randArr[len(randArr) - 1] + randArr[len(randArr) - 2] == 4:
26 | rand = 1
27 | randArr.append(rand)
28 | return rand
29 |
30 |
31 | def user_login():
32 | """
33 | 登录,循环执行,直到登录成功
34 | :return:
35 | """
36 | while not login.login(browser):
37 | print('--> 登录超时,正在尝试重新登录')
38 | continue
39 |
40 |
41 | def run():
42 | """
43 | 刷视频,刷题目主要部分
44 | 通过check_task()函数决定应该执行什么任务,并调用相应任务函数
45 | :return: null
46 | """
47 | while True:
48 | check_res = check.check_task(browser)
49 | if check_res == check.CheckResType.NULL:
50 | break
51 | elif check_res == check.CheckResType.ARTICLE:
52 | scan_article.scan_article(browser)
53 | elif check_res == check.CheckResType.VIDEO:
54 | watch_video.watch_video(browser)
55 | elif check_res == check.CheckResType.ARTICLE_AND_VIDEO:
56 | if article_or_video() == 1:
57 | scan_article.scan_article(browser)
58 | else:
59 | watch_video.watch_video(browser)
60 | else:
61 | exam.to_exam(browser, check_res)
62 |
63 |
64 | def finally_run():
65 | """
66 | 程序最后执行的函数,包括打印信息、关闭浏览器等
67 | """
68 | browser.quit()
69 | print(r'''
70 | __/\\\\\\\\\\\\\____/\\\________/\\\__________/\\\\\\\\\\\\__/\\\\\\\\\\\\_____/\\\\\\\\\\\\\\\_
71 | _\/\\\/////////\\\_\///\\\____/\\\/_________/\\\//////////__\/\\\////////\\\__\/\\\///////////__
72 | _\/\\\_______\/\\\___\///\\\/\\\/__________/\\\_____________\/\\\______\//\\\_\/\\\_____________
73 | _\/\\\\\\\\\\\\\\______\///\\\/___________\/\\\____/\\\\\\\_\/\\\_______\/\\\_\/\\\\\\\\\\\_____
74 | _\/\\\/////////\\\_______\/\\\____________\/\\\___\/////\\\_\/\\\_______\/\\\_\/\\\///////______
75 | _\/\\\_______\/\\\_______\/\\\____________\/\\\_______\/\\\_\/\\\_______\/\\\_\/\\\_____________
76 | _\/\\\_______\/\\\_______\/\\\____________\/\\\_______\/\\\_\/\\\_______/\\\__\/\\\_____________
77 | _\/\\\\\\\\\\\\\/________\/\\\____________\//\\\\\\\\\\\\/__\/\\\\\\\\\\\\/___\/\\\_____________
78 | _\/////////////__________\///______________\////////////____\////////////_____\///______________''')
79 |
80 | call('pause', shell=True)
81 |
82 |
83 | if __name__ == "__main__":
84 | try:
85 | from sys import exit
86 | import ctypes
87 | from os import getcwd, remove, path
88 |
89 | ctypes.windll.kernel32.SetConsoleTitleW('xuexi-{}'.format(VERSION))
90 |
91 | try:
92 | check_version.check()
93 | except (SSLEOFError, MaxRetryError, SSLError):
94 | print(str(format_exc()))
95 | print('--> \033[31m网络连接失败,请检查是否开启了VPN或代理软件,如果开启了请关闭后再试\033[0m')
96 | print('--> \033[31m当前版本:{}\033[0m'.format(VERSION))
97 | call('pause', shell=True)
98 | exit(1)
99 |
100 | if not get_chromedriver.do(getcwd()):
101 | exit(1)
102 |
103 | chrome_options = webdriver.ChromeOptions()
104 |
105 | chrome_options.add_experimental_option('useAutomationExtension', False) # 防止检测
106 | chrome_options.add_argument("--mute-audio") # 静音
107 | chrome_options.add_experimental_option('excludeSwitches', ['enable-automation', 'enable-logging']) # 防止检测、禁止打印日志
108 | chrome_options.add_argument('--disable-blink-features=AutomationControlled')
109 | chrome_options.add_argument('--ignore-certificate-errors') # 忽略证书错误
110 | chrome_options.add_argument('--ignore-ssl-errors') # 忽略ssl错误
111 | chrome_options.add_argument('–log-level=3')
112 |
113 | browser = XuexiChrome(path.join(getcwd(), 'chromedriver.exe'), options=chrome_options)
114 | browser.maximize_window()
115 |
116 | exam_temp_Path = './data/exam_temp.json'
117 | except:
118 | print(str(format_exc()))
119 | print('--> \033[31m程序异常,请尝试重启脚本\033[0m')
120 | print('--> \033[31m当前版本:{}\033[0m'.format(VERSION))
121 | call('pause', shell=True)
122 | else:
123 | try:
124 | with open(exam_temp_Path, 'w', encoding='utf-8') as f:
125 | dataDict = {
126 | 'DAILY_EXAM': 'true',
127 | 'WEEKLY_EXAM': 'true',
128 | 'SPECIAL_EXAM': 'true'
129 | }
130 | f.write(dumps(dataDict, ensure_ascii=False, indent=4))
131 |
132 | get_article.get_article()
133 | get_video.get_video()
134 | user_login()
135 | randArr = [] # 存放并用于判断随机值,防止出现连续看文章或者看视频的情况
136 | run()
137 | print('--> 任务全部完成,程序已结束')
138 | except (SSLEOFError, MaxRetryError, SSLError):
139 | print(str(format_exc()))
140 | print('--> \033[31m网络连接失败,请检查是否开启了VPN或代理软件,如果开启了请关闭后再试\033[0m')
141 | print('--> \033[31m当前版本:{}\033[0m'.format(VERSION))
142 | except:
143 | print(str(format_exc()))
144 | print('--> \033[31m程序异常,请尝试重启脚本\033[0m')
145 | print('--> \033[31m当前版本:{}\033[0m'.format(VERSION))
146 | finally:
147 | remove(exam_temp_Path)
148 | finally_run()
149 |
--------------------------------------------------------------------------------
/operation/exam.py:
--------------------------------------------------------------------------------
1 | # -*- encoding: utf-8 -*-
2 | from json import loads, dumps
3 | from traceback import format_exc
4 | from selenium.common.exceptions import WebDriverException, NoSuchElementException, UnexpectedAlertPresentException
5 | from time import sleep
6 | from random import uniform
7 | from difflib import SequenceMatcher
8 | from re import findall
9 | from selenium.webdriver.common.by import By
10 | from selenium.webdriver.remote.webelement import WebElement
11 | from custom.xuexi_chrome import XuexiChrome
12 | from userOperation import check
13 |
14 |
15 | def click(browser: XuexiChrome, element: WebElement):
16 | browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
17 | 'source': '''
18 | Object.defineProperty(navigator, 'webdriver', {
19 | get: () => undefined
20 | })
21 | window.alert = function() {
22 | return;
23 | }
24 | '''
25 | })
26 | element.click()
27 |
28 |
29 | def check_exam(browser: XuexiChrome, exam_type):
30 | """
31 | 检查可做的题目,如果本页没有则翻页查找
32 | :param browser: browser
33 | :param exam_type: 题目类型(周、专)
34 | :return: null
35 | """
36 | sleep(round(uniform(1, 2), 2))
37 | while True:
38 | flag = True # 用来记录是否答题,答题则置为False
39 | all_exams = browser.find_elements(by=By.CLASS_NAME, value='ant-btn-primary')
40 | for exam in all_exams:
41 | if exam.text == '开始答题' or exam.text == '继续答题':
42 | browser.execute_script('arguments[0].scrollIntoView();', exam)
43 | sleep(round(uniform(1, 2), 2))
44 | click(browser, exam)
45 | sleep(round(uniform(2, 4), 2))
46 | run_exam(browser)
47 | flag = False
48 | break
49 | if flag: # flag为True则执行翻页
50 | next_page = browser.find_element(by=By.CLASS_NAME, value='ant-pagination-next')
51 | browser.execute_script('arguments[0].scrollIntoView();', next_page)
52 | sleep(round(uniform(1, 2), 2))
53 | if next_page.get_attribute('aria-disabled') == 'true': # 检查翻页按钮是否可点击
54 | exam_type = None
55 | if exam_type == check.CheckResType.WEEKLY_EXAM:
56 | exam_type = 'WEEKLY_EXAM'
57 | print('--> 每周答题:已无可做题目')
58 | elif exam_type == check.CheckResType.SPECIAL_EXAM:
59 | exam_type = 'SPECIAL_EXAM'
60 | print('--> 专项答题:已无可做题目')
61 | # 如果该类型的题目已全部做完,则记录防止再次刷
62 | exam_temp_path = './data/exam_temp.json'
63 | with open(exam_temp_path, 'r', encoding='utf-8') as f:
64 | data_dict = loads(f.read())
65 | data_dict[exam_type] = 'false'
66 | with open(exam_temp_path, 'w', encoding='utf-8') as f:
67 | f.write(dumps(data_dict, ensure_ascii=False, indent=4))
68 | return
69 | click(browser, next_page)
70 | sleep(round(uniform(3, 5), 2))
71 | else:
72 | break
73 |
74 |
75 | def to_exam(browser: XuexiChrome, exam_type: check.CheckResType):
76 | """
77 | 根据参数题目类型进入对应的题目
78 | :param browser: browser
79 | :param exam_type: 题目类型(日、周、专)
80 | :return:
81 | """
82 | browser.xuexi_get('https://www.xuexi.cn/')
83 | browser.xuexi_get('https://pc.xuexi.cn/points/my-points.html')
84 | sleep(round(uniform(1, 2), 2))
85 |
86 | # 获取答题按钮族
87 | exam = browser.find_elements(by=By.CLASS_NAME, value='big')
88 | if exam_type == check.CheckResType.DAILY_EXAM:
89 | daily = exam[4]
90 | browser.execute_script('arguments[0].scrollIntoView();', daily)
91 | sleep(round(uniform(1, 2), 2))
92 | click(browser, daily)
93 | sleep(round(uniform(2, 4), 2))
94 | run_exam(browser)
95 | elif exam_type == check.CheckResType.SPECIAL_EXAM:
96 | special = exam[5]
97 | browser.execute_script('arguments[0].scrollIntoView();', special)
98 | sleep(round(uniform(1, 2), 2))
99 | click(browser, special)
100 | check_exam(browser, exam_type)
101 | elif exam_type == check.CheckResType.WEEKLY_EXAM:
102 | weekly = exam[6]
103 | browser.execute_script('arguments[0].scrollIntoView();', weekly)
104 | sleep(round(uniform(1, 2), 2))
105 | click(browser, weekly)
106 | check_exam(browser, exam_type)
107 |
108 |
109 | def select_all(options):
110 | print('--> 最大概率选项:', end='')
111 | for i in range(len(options)):
112 | print(' ' + options[i].text[0], end='')
113 | print()
114 | for i in range(len(options)):
115 | sleep(round(uniform(0.2, 0.8), 2))
116 | options[i].click()
117 |
118 |
119 | def run_exam(browser: XuexiChrome):
120 | while True:
121 | content = browser.find_element(by=By.CLASS_NAME, value='ant-breadcrumb')
122 | browser.execute_script('arguments[0].scrollIntoView();', content)
123 | sleep(round(uniform(2, 3), 2))
124 | # 题目类型
125 | question_type = browser.find_element(by=By.CLASS_NAME, value='q-header').text
126 | # print(questionType)
127 | # 当前题目的坐标
128 | question_index = int(browser.find_element(by=By.CLASS_NAME, value='big').text)
129 | # 题目总数
130 | question_count = int(findall('/(.*)', browser.find_element(by=By.CLASS_NAME, value='pager').text)[0])
131 | # 确定按钮
132 | ok_btn = browser.find_element(by=By.CLASS_NAME, value='ant-btn-primary')
133 | try:
134 | browser.find_element(by=By.CLASS_NAME, value='answer')
135 | if ok_btn.text == '下一题':
136 | ok_btn.click()
137 | sleep(round(uniform(0.2, 0.8), 2))
138 | continue
139 | except NoSuchElementException:
140 | pass
141 | # 提示按钮
142 | tip_btn = browser.find_element(by=By.CLASS_NAME, value='tips')
143 | print('--> 当前题目进度:' + str(question_index) + '/' + str(question_count))
144 | tip_btn.click()
145 | sleep(round(uniform(0.2, 0.8), 2))
146 | try:
147 | # 获取所有提示内容
148 | tips_content = browser.find_element(by=By.CLASS_NAME, value='line-feed').find_elements(by=By.TAG_NAME, value='font')
149 | sleep(round(uniform(0.2, 0.8), 2))
150 | tip_btn.click()
151 | tips = []
152 | tips.clear()
153 | for tip in tips_content:
154 | tips.append(tip.text)
155 |
156 | if '单选题' in question_type:
157 | # 选择题,获取所有选项
158 | options = browser.find_elements(by=By.CLASS_NAME, value='choosable')
159 | if len(tips) == 0:
160 | sleep(round(uniform(0.2, 0.8), 2))
161 | options[0].click()
162 | else:
163 | ans_dict = {} # 存放每个选项与提示的相似度
164 | for i in range(len(options)):
165 | ans_dict[i] = SequenceMatcher(None, tips[0], options[i].text[3:]).ratio()
166 | ans_dict = sorted(ans_dict.items(), key=lambda x: x[1], reverse=True)
167 | # print(ansDict)
168 | print('--> 最大概率选项: ' + options[ans_dict[0][0]].text[0])
169 | options[ans_dict[0][0]].click()
170 |
171 | sleep(round(uniform(0.2, 0.8), 2))
172 | ok_btn.click()
173 |
174 | elif '多选题' in question_type:
175 | # 选择题,获取所有选项
176 | options = browser.find_elements(by=By.CLASS_NAME, value='choosable')
177 | q_word = browser.find_element(by=By.CLASS_NAME, value='q-body').text
178 | bracket_count = len(findall('()', q_word))
179 | if len(options) == bracket_count:
180 | select_all(options)
181 | else:
182 | if len(tips) == 0:
183 | sleep(round(uniform(0.2, 0.8), 2))
184 | options[0].click()
185 | sleep(round(uniform(0.2, 0.8), 2))
186 | options[1].click()
187 | else:
188 | # 如果选项数量多于提示数量,则匹配出最可能的选项
189 | if len(options) > len(tips):
190 | ans = [] # 存放匹配出的最终结果
191 | for i in range(len(tips)):
192 | ans_dict = {} # 存放每个选项与提示的相似度
193 | for j in range(len(options)):
194 | ans_dict[j] = SequenceMatcher(None, tips[i], options[j].text[3:]).ratio()
195 | # print(ansDict)
196 | ans_dict = sorted(ans_dict.items(), key=lambda x: x[1], reverse=True)
197 | ans.append(ans_dict[0][0])
198 | ans = list(set(ans))
199 | # print(ans)
200 | print('--> 最大概率选项:', end='')
201 | for i in range(len(ans)):
202 | print(' ' + options[ans[i]].text[0], end='')
203 | print()
204 | for i in range(len(ans)):
205 | sleep(round(uniform(0.2, 0.8), 2))
206 | options[ans[i]].click()
207 | # 如果选项数量和提示数量相同或少于提示数量,则全选
208 | else:
209 | select_all(options)
210 |
211 | sleep(round(uniform(0.2, 0.8), 2))
212 | ok_btn.click()
213 |
214 | elif '填空题' in question_type:
215 | # 填空题,获取所有输入框
216 | blanks = browser.find_elements(by=By.CLASS_NAME, value='blank')
217 | tips_i = 0
218 | for i in range(len(blanks)):
219 | sleep(round(uniform(0.2, 0.8), 2))
220 | if len(tips) > tips_i and tips[tips_i].strip() == '':
221 | tips_i += 1
222 | try:
223 | blank_ans = tips[tips_i]
224 | except:
225 | blank_ans = '未找到提示'
226 | print('--> 第{0}空答案可能是: {1}'.format(i + 1, blank_ans))
227 | blanks[i].send_keys(blank_ans)
228 | tips_i += 1
229 |
230 | sleep(round(uniform(0.2, 0.8), 2))
231 | ok_btn.click()
232 | except UnexpectedAlertPresentException:
233 | alert = browser.switch_to.alert
234 | alert.accept()
235 | other_place = browser.find_element(by=By.ID, value='app')
236 | other_place.click()
237 | sleep(round(uniform(0.2, 0.8), 2))
238 | except WebDriverException:
239 | print(str(format_exc()))
240 | print('--> 答题异常,正在重试')
241 | other_place = browser.find_element(by=By.ID, value='app')
242 | other_place.click()
243 | sleep(round(uniform(0.2, 0.8), 2))
244 |
245 | if question_index == question_count:
246 | sleep(round(uniform(0.2, 0.8), 2))
247 | try:
248 | submit = browser.find_element(by=By.CLASS_NAME, value='submit-btn')
249 | submit.click()
250 | browser.implicitly_wait(10)
251 | sleep(round(uniform(2.6, 4.6), 2))
252 | except NoSuchElementException:
253 | submit = browser.find_element(by=By.CLASS_NAME, value='ant-btn-primary')
254 | submit.click()
255 | browser.implicitly_wait(10)
256 | sleep(round(uniform(2.6, 4.6), 2))
257 | except UnexpectedAlertPresentException:
258 | alert = browser.switch_to.alert
259 | alert.accept()
260 | print('--> 答题结束')
261 | break
262 |
--------------------------------------------------------------------------------