├── .gitignore
├── README.md
└── docs
├── doc_001.md
├── doc_002.md
├── doc_004.md
└── doc_003.md
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea
2 | *swp
3 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # ML 自学者周刊
2 |
3 | 本周刊在公众号「 **进击的龙** 」每周连载,欢迎关注。
4 |
5 | ## 2019
6 |
7 | **十月**:[第 4 期](docs/doc_004.md) :high_brightness: | [第 3 期](docs/doc_003.md) | [第 2 期](docs/doc_002.md) | [第 1 期](docs/doc_001.md)
8 |
9 | ## 组织者
10 |
11 | 公子龙,自然语言处理算法工程师,经历较为丰富,学生时代在多次大型数据竞赛中斩获冠亚军,一年收入四十多万。毕业时拿过百度、腾讯、阿里、京东、美团、网易、拼多多、快手等一线互联网公司的 offer。[他的介绍](https://mp.weixin.qq.com/s/FBmYWfdh8Vi5NnVmt6M82Q)
12 |
13 | ## 加入我们
14 |
15 | 扫描二维码,关注公众号,回复「 **自学** 」加入我们。
16 |
17 |  18 |
--------------------------------------------------------------------------------
/docs/doc_001.md:
--------------------------------------------------------------------------------
1 | > 这里记录自学者的学习内容,欢迎留言投稿你的自学内容。
2 |
3 | ### 刊首语
4 |
5 | 创刊第 1 期,会一直坚持下去,希望能够做到 100 期。一直以来,同学们都在坚持分享。好的自学内容,还是放出来让大家多看看、多交流为好。欢迎投稿,每周一起学习进步!
6 |
7 | #### 学习ALBERT
8 |
9 | ALBERT A LITE BERT:是一个轻量级的 BERT 模型,和BERT比有三个变化点:
10 | - 嵌入向量参数化的因式分解不再将 one-hot 向量直接映射到大小为 H 的隐藏空间,而是先将它们映射到一个低维词嵌入空间 E,然后再映射到隐藏空间。通过这种分解,研究者可以将词嵌入参数从 O(V × H) 降低到 O(V × E + E × H),这在 H 远远大于 E 的时候,参数量减少得非常明显,减少计算量,加快计算时间。
11 | - 跨层参数共享:所有层权重共享
12 | - 句间连贯性损失:句间建模使用基于语言连贯性的损失函数。对于 ALBERT,研究者使用了一个句子顺序预测(SOP)损失函数,它会避免预测主题,而只关注建模句子之间的连贯性。
13 |
14 | #### 目标跟踪 PRCF
15 |
16 | 本文研究了池操作对视觉跟踪的影响,提出了一种新的ROI池相关滤波算法。虽然基于roi的池算法在许多基于深度学习的应用中得到了成功的应用,但是在视觉跟踪领域,尤其是在基于相关滤波的方法中,却很少考虑到它。由于相关滤波公式并不能真正提取出正样本和负样本,所以快速R-CNN等基于roi的池是不可行的。通过数学推导,给出了实现基于roi的池的另一种解决方案。提出了一种具有等式约束的相关滤波算法,通过该算法可以等价地实现基于roi的池。提出了一种求解优化问题的交替方向乘法器(ADMM)算法,并在傅里叶域中给出了一种有效的求解方法。
17 | 论文阅读笔记:http://haha-strong.com/2019/09/23/20190923-RoiCF/
18 |
19 | #### 大数据系统工程架构
20 | 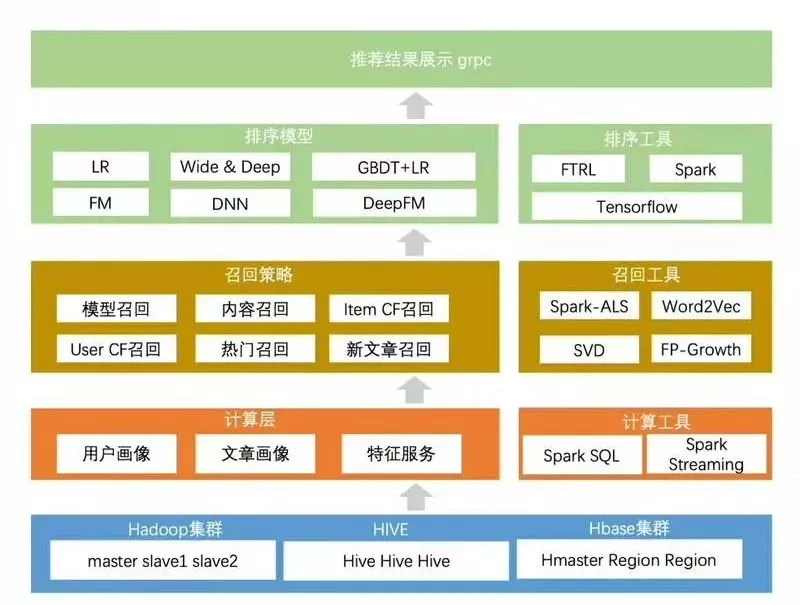
21 |
22 | #### 温习XGBoost
23 |
24 | 最近温习了 XGBoost,通过重读论文,阅读一些公众号的推送和博客,重新把公式推导了一遍,详细了解损失函数,泰勒展开,节点分裂,如果选择最优划分等具体过程,此外,了解了一些并行化的处理方式。
25 | - [公众号文章:XGBoost超详细推导,终于有人讲明白了!](https://mp.weixin.qq.com/s/7n1nzGL7r789P9sv0GEkDA)
26 | - 论文:https://arxiv.org/pdf/1603.02754.pdf
27 | - PPT:https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
28 | - 并行处理:[Parallel Gradient Boosting Decision Trees](http://zhanpengfang.github.io/418home.html)
29 |
30 | #### 小样本学习
31 |
32 | 最近老师给的任务涉及到小样本学习问题,读了以下针对小样本学习的MTL算法,交流一下我学到的东西,理解不准确的地方还望指正。
33 |
34 | Meta-Transfer Learning for Few-Shot Learning是CVPR 2019接收的论文,第一作者是新加坡国立大学的Qianru Sun,根据Papers With Code这个网站的评估,该算法截止到今天是SOTA for Few-Shot Image Classification on Fewshot-CIFAR100 - 10-Shot Learning。
35 |
36 | 元学习的架构已经被提出,并广泛应用到小样本检测问题上,元学习的核心是利用大量相似的小样本检测任务,以学习如何去适应一个新的小样本学习任务。传统的DNN网络在处理小样本学习问题时会有过拟合的问题,因此元学习通常使用浅层神经网络,但是这也限制了网络的性能。针对上述问题,这篇文章提出了一种新型的小样本检测算法,叫做MTL,它采用了一种深层神经网络用于小样本检测问题。M是指meta,代表着多种多样的任务,T是指transfer,通过学习每个任务的DNN权重的缩放和移位功能,可以实现权重的传递。
37 |
38 | 除此之外,这篇文章介绍了一种方法,该方法对于提升算法性能非常有帮助。传统的元学习方法受到两方面的限制:
39 | - 这些方法需要大量类似的任务来进行元训练,而找到大量相似任务是非常困难的;
40 | - 每个任务通常由低复杂度的浅层神经网络构成,以避免模型出现过拟合,因此无法使用更深更强大的体系结构。
41 |
42 | 1. 第一步:训练DNN网络在大尺度数据集上,并且将低层固定为特征提取器,需要注意的是,迁移给小样本学习任务的特征提取器的相关权重而不是DNN的最后一层权重。
43 | 2. 第二步:元迁移学习阶段,MTL学习特征提取神经元的缩放和移位参数,从而能够快速适应Few-shot Learning任务。具体实现过程在论文的4.2节,讲道理我只是看懂了一部分,相比于传统的方法,这篇论文在传递到小样本学习任务时,冻结迁移过来的权重,不进行更新,而其他的相关权重正常进行更新,感觉这篇文章的精髓在于这一部分的冻结操作和迁移过程的精妙操作。具体怎么迁移的,还需在继续学习下。
44 | 3. 第三步:为了提升整体学习水平,使用HT元批量学习策略。HT元批量学习策略是指挑选检测失败的案例进行附加训练,重点强调识别错误的例子,“在失败中成长”…,根据本文的试验,效果还不错。
45 |
46 | - 文章下载地址:https://arxiv.org/pdf/1812.02391v3.pdf
47 | - 文章源代码:https://github.com/y2l/meta-transfer-learning-tensorflow
48 |
49 | #### 推公式
50 |
51 | 路漫漫其修远兮,吾将上下而求索。手推牛顿法,混合高斯模型,SVM,核方法,EM,CRF,MCMC等等。这里极度推荐b站shuhuai的视频,里面的公式解析极其细致!
52 | 
53 |
--------------------------------------------------------------------------------
/docs/doc_002.md:
--------------------------------------------------------------------------------
1 | ### 刊首语
2 |
3 | 这里记录ML自学者群体,每周分享优秀的学习心得与资料。由于微信不允许外部链接,需要点击文末的「阅读原文」,才能访问文中的链接。
4 |
5 | ---
6 |
7 | ### 本期内容
8 |
9 | **目录**
10 |
11 | **一、学习心得分享**
12 | - 图像超分辨和图像高分辨的区别
13 | - 挖掘模板,辅助对话生成
14 | - 学习梯度优化算法
15 |
16 | **二、机器学习解答**
17 | - 为什么SVM不会过拟合
18 | - GBDT和XGBOOST的区别有哪些
19 | - 如何入门NLP,比较茫然
20 |
21 | **三、资料整理**
22 | - 论文类
23 | - 工具类
24 |
25 | ---
26 |
27 | ### 学习心得分享
28 |
29 | #### 图像超分辨和图像高分辨的区别
30 |
31 | 图像超分辨和图像高分辨之间的区别是:**图像超分辨描述**是图像由小到大的一个变化过程,**图像高分辨**是图像本身较大的一个状态。对于图图像的超分辨任务SR通常使用比较深的卷积神经网络编码成较高分辨率的图像过程,该方向比较难的一个点是SISR单张图像超分辨在医学、天文、安防方面有广泛使用,通常都是插值重构的方案,但是这种方法有一定局限性。
32 |
33 | 代码地址:https://github.com/lightningsoon/Residual-Dense-Net-for-Super-Resolution
34 |
35 | 论文地址:https://arxiv.org/abs/1802.08797
36 |
37 | 在上面的论文和代码中是以三个模块实现超分辨的单张功能,模块一是密集型残差网络RDB、模块二是局部特征混合LFF、模块三是LRL局部特征学习。因为卷积神经网络和图像中距离像素较远的关联关系较弱所以局部特征更能表达深度特征能力。整个RDN主要包括4个部分:隐藏特征提取网络(SFENet),残差密集模块(RDBs),密集特征融合(DFF),和最后的上采样网络(UPNet)。
38 |
39 | #### 挖掘模板,辅助对话生成
40 |
41 | EMNLP2019的一篇文章,对话领域中,训练语料(通常指的是post-response的语句对形式)较难采集。而无序的语句较容易获得。利用这些大量无监督语料,来提升机器对话回复的质量,是本文提出新的探索方向。作者将大量无序语句和少量对话语句对相结合,从无序语句中学习对话模板(template),模板涵盖了语义和语法的信息,作为先验知识,从而辅助对话response的生成。数据集采用了微博和知乎的语料,模型结构如下所示。
42 |
43 | 论文名称:Low-Resource Response Generation with Template Prior
44 |
45 | 论文地址:https://arxiv.org/abs/1909.11968
46 |
47 |
48 | #### 学习梯度优化算法
49 |
50 | 这篇博客是梯度优化算法综述,附上一些读后感。
51 | 1. SGD : 每次朝着梯度的反方向进行更新。
52 | 2. Momentum:动能积累,每次更新时候积累 SGD 的更新方向,也就是每次参数更新时,不单单考虑当前的梯度方向,还考虑之前的梯度方向,当然之前的梯度会有一个衰减因子。
53 | 3. Adagrad:自动调节学习率大小,对于频繁更新的参数,学习率小;对于很少更新的参数,学习率大。怎么判断参数频繁更新呢?可以为更新公式设置一个分母:梯度平方累加和的平方根。这样当分母越大,说明之前该参数越频繁更新,反之则很少更新。存在问题:当迭代次数多了之后,由于是累加操作,分母越来越大,学习率会变得非常小,模型更新会很慢。
54 | 4. Adadelta:作为 Adagrad 的拓展,是解决学习率消失的问题。在这里不会直接叠加之前所有的梯度平方,而是引入了一个梯度衰退的因子,使得时间久远的梯度对此刻参数更新的影响会消失。RMSProp 的思想和其类似。
55 | 5. Adam:结合 Momentum 和 Adadelta 两种优化算法的优点。对梯度的一阶矩估计(First Moment Estimation,即梯度的均值)和二阶矩估计(Second Moment Estimation,即梯度的未中心化的方差)进行综合考虑,计算出更新步长。
56 |
57 | 文章地址:http://ruder.io/optimizing-gradient-descent/
58 |
59 | ---
60 |
61 | ### 机器学习问答
62 |
63 | #### [为什么svm不会过拟合](https://www.zhihu.com/question/20178589/answer/29950675)
64 |
65 | SVM当然会过拟合,而且过度拟合的能力还非常强。首先我想说说什么叫过度拟合?就是模型学岔路了,把数据中的噪音当做有效的分类标准。
66 |
67 | 通常越是描述能力强大的模型越容易过度拟合。描述能力强的模型就像聪明人,描述能力弱的如:”一次线性模型“像傻子,如果聪明人要骗人肯定比傻子更能自圆其说对不对?而SVM的其中一个优化目标:最小化||W||,就是抑制它的描述能力,聪明人是吧,只允许你用100个字,能把事情说清楚不?
68 |
69 | 这就是为什么regularization能够对抗过度拟合,同时它也在弱化模型的描述能力。但只要能说话就能说谎,就能歪曲事实对不对?别把SVM想得太复杂,你就可以把它当做一个线性分类器,只不过它优化了分类平面与分类数据之间距离。
70 |
71 | #### [GBDT和XGBOOST的区别有哪些](https://zhuanlan.zhihu.com/p/30316845)
72 |
73 | 1. 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
74 | 2. 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
75 | 3. Xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
76 | 4. Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
77 | 5. 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
78 |
79 | #### 如何入门NLP,比较茫然
80 |
81 | 先了解什么是词向量 onehot和 word2vec,然后了解最基础的文本分类任务,跑下经典的机器学习模型和现在的cnn、rnn分类模型。这些代码都不多的,用pytorch或者tf实现下挺快的,可以照着代码敲一遍,有感觉了就离入门近一些了。再然后,看看nlp常见的任务,ner,mrc,nli,等等。对了,推荐直接跟着斯坦福的nlp公开课走一遍吧,很快的。
82 |
83 | 课程名:CS224d - Deep Learning for Natural Language Processing
84 |
85 | 课程地址:http://cs224d.stanford.edu
86 |
87 | ---
88 |
89 | ### 资料整理
90 |
91 | #### 论文类
92 | - [APDrawingGAN:人脸秒变艺术肖像画](https://mp.weixin.qq.com/s/Ok9ediwb35LzQiT9YVKfWA)
93 | - [NeurIPS 2019 | 用于弱监督图像语义分割的新型损失函数](https://mp.weixin.qq.com/s/CbORYhJQn27J0G4G6XpODw)
94 | - [Doc2EDAG:一种针对中文金融事件抽取的端到端文档级框架](https://mp.weixin.qq.com/s/irYEpq9pkeZYoSRcp4auew)
95 |
96 | #### 工具类
97 | - [三行代码提取PDF表格数据](https://mp.weixin.qq.com/s/VOU9bZTYENI0wZnP9SmAtQ)
98 | - [PyTorch 1.3发布:能在移动端部署](https://mp.weixin.qq.com/s/NNTA7B_ZZNruh01Nax26Mg)
99 | - [谷歌工程师:Tensorflow2.0 简单粗暴教程中文版](https://mp.weixin.qq.com/s/sG2Xp0vLzlW5zE1k7myB4w)
100 |
101 | ---
102 |
103 | ### 加入我们
104 |
105 | 公众号内回复「自学」,即可加入ML自学者俱乐部社群。可以投稿每周学习心得或者看到的优质学习资料,助力团体共同学习进步。
106 |
107 | ---
108 |
109 | ### 参考来源
110 |
111 | - [ML自学者俱乐部投稿](https://github.com/Dikea/ML-SelfStudy-Weekly)
112 | - [黄博的机器学习圈子](https://t.zsxq.com/eaeYv7a)
113 | - [知乎机器学习话题](https://zhihu.com)
114 |
115 | ---
116 |
117 | [点击阅读上一期内容](https://mp.weixin.qq.com/s/aqn1jN1_ZqC_KAsSLG9SYg)
118 |
--------------------------------------------------------------------------------
/docs/doc_004.md:
--------------------------------------------------------------------------------
1 | ## 刊首语
2 |
3 | > 这里记录ML自学者群体,每周分享优秀的学习心得与资料。由于微信不允许外部链接,需要点击文末的「**阅读原文**」,才能访问文中的链接。
4 |
5 |
6 |
7 | ## 本期内容
8 |
9 | **论文速递**
10 | - CVPR2019:细粒度图像识别新论文
11 | - 基于元学习和AutoML的模型压缩新方法
12 |
13 |
14 | **学习心得**
15 | - 大煌
16 | - 奔腾
17 | - 昨夜星辰
18 | - 大灵
19 | - 大鹏鹏
20 | - 安芯
21 | - 吕涛
22 |
23 |
24 | **疑问解答**
25 | - lstm激活函数为什么sigmoid和tanh同时存在
26 |
27 | ## 论文速递
28 |
29 | ### CVPR2019:细粒度图像识别新论文
30 |
31 | 论文名称:Destruction and Construction Learning for Fine-grained Image Recognition
32 |
33 | [论文地址](http://openaccess.thecvf.com/content_CVPR_2019/papers/Chen_Destruction_and_Construction_Learning_for_Fine-Grained_Image_Recognition_CVPR_2019_paper.pdf)
34 |
35 | 该文献是属于细粒度图像识别领域的。文章提到部分先前的方法需要判别性区域的标注先验信息,标注成本高昂;并且先前方法一般需增加额外模块,而这些模块在推断阶段会引入额外的计算负担。
36 |
37 | 因此文章引入“拆解与建构学习”机制使分类模块获得专家知识,其中“拆解”部分强迫分类模块着重于判别性区域的区别,“建构”部分建立各局部区域的语义关联并避免拆解带来的含噪样本引发的过拟合现象。文章工作中包括性能对比、消融实验、控制变量法参数调整实验、特征可视化等。
38 |
39 | 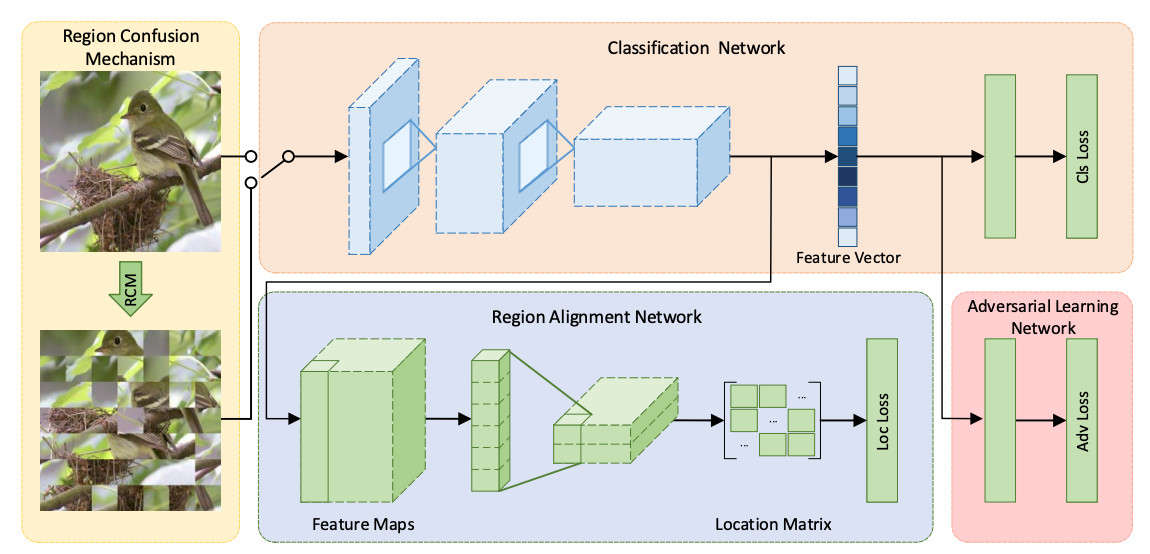
40 |
41 | 一句话概括该文献:引入“拆解与建构学习”机制,强迫分类模块着重于判别性区域的区别,并建立各局部区域的语义关联并避免拆解带来的含噪样本引发的过拟合现象,且未引入额外判别性区域标注负担和推断阶段的额外计算负担。
42 |
43 | ### 基于元学习和AutoML的模型压缩新方法
44 |
45 | 这篇文章来自于旷视。旷视内部有一个基础模型组,孙剑老师也是很看好 NAS 相关的技术,相信这篇文章无论从学术上还是工程落地上都有可以让人借鉴的地方。回到文章本身,模型剪枝算法能够减少模型计算量,实现模型压缩和加速的目的,但是模型剪枝过程中确定剪枝比例等参数的过程实在让人头痛。
46 |
47 | 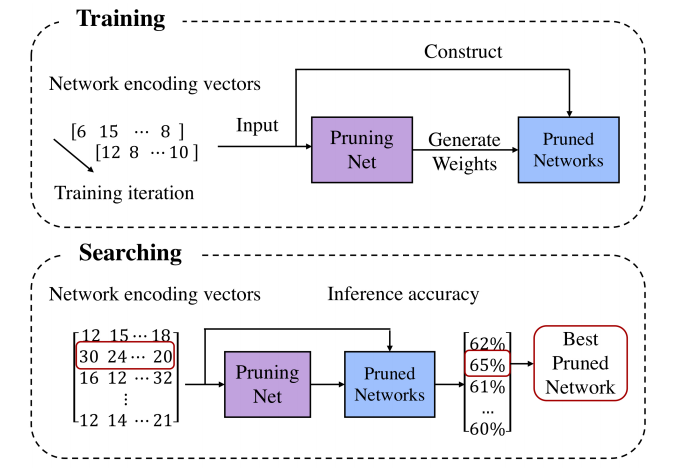
48 |
49 | 这篇文章提出了 PruningNet 的概念,自动为剪枝后的模型生成权重,从而绕过了费时的 retrain 步骤。并且能够和进化算法等搜索方法结合,通过搜索编码 network 的 coding vector,自动地根据所给约束搜索剪枝后的网络结构。和 AutoML 技术相比,这种方法并不是从头搜索,而是从已有的大模型出发,从而缩小了搜索空间,节省了搜索算力和时间。
50 |
51 |
52 | [论文地址](https://arxiv.org/abs/1903.10258)
53 | [原文地址](https://mp.weixin.qq.com/s/lc7IoOV6S2Uz5xi7cPQUqg)
54 |
55 |
56 |
57 | ## 学习心得
58 |
59 | ### 大煌
60 |
61 | 本周复现了一篇论文的代码。复现的效果没有论文的好。是一个很基础的版本,欢迎交流和探讨。[复现代码地址](https://github.com/HaHuangChan/Deep-Mating-for-Portrait-Animation)
62 |
63 | ### 奔腾
64 |
65 | 本周复习了一下概率论,具体是过了一遍叶丙成老师的玩想概率,相对国内过于注重计算,而叶老师的课程很注重概念。最简单的概念,随机变量到底是什么,如果这个不清楚的话,可以再认真学学概率,会有新的收获。
66 |
67 | ### 昨夜星辰
68 |
69 | 本周学习了词向量的三种:word2vec,fasttext,elmo。代码如下,放在笔记里面:
70 |
71 | - [word2vec](https://blog.csdn.net/weixin_43178406/article/details/102461021)
72 | - [fasttext](https://blog.csdn.net/weixin_43178406/article/details/102465629)
73 | - [elmo](https://blog.csdn.net/weixin_43178406/article/details/102522853)
74 |
75 | ### 大灵
76 |
77 | 这周了解了一下密集计数。
78 |
79 | - 聚类计数: 基于外观和运动线索等特征进行聚类,适用于视频序列,不适用于图象。 缺点:需要视频,准确率较低
80 | - 回归计数:通过检测计数 两种:一是使用计算对象的密度来预测密度图。使用高斯核将点级注释矩阵转换为密度图。挑战是确定高斯核的最佳大小,这个与对象的大小密切相关。 第二种是一瞥(glance)基于网格的计数方法(不太懂) 缺点:受物体的大小变化影响大。
81 | - 检测计数: 先检测出对象,再计算数量,比glance和子图标的表现更差。 缺点:如果对象被遮挡效果就不好,其实物体的大小对这个的影响也有,效果可能要看训练集和实际场景了。
82 |
83 |
84 | ### 大鹏鹏
85 |
86 | 本周由于在赶论文,所以自学的不多,主要看了《大话数据结构》中的第三、四章节,以及《数学之美》中的前5章。这两本书算是入门类型的书籍了,根据之前看别人的经验帖子,前者适合刷题吃力的小伙伴看,或者适合作为入门自然语言处理的启蒙教材。
87 |
88 | ### 安芯
89 |
90 | 最近对图像分析做了一个简单的小结,我个人把模型训练的相关流程简单的总结一下如下:个人研究loss和初始化对模型影响最大除模型结构之外。
91 |
92 | 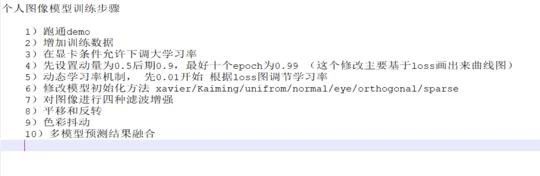
93 |
94 | ### 吕涛
95 |
96 | 本周刚开始接触机器学习,学习了贝叶斯,线性回归,决策树,KNN模型,模型的评价方法
97 | 1. 贝叶斯模型是基于概率的,通过贝叶斯方程和模糊处理,将事件的概率约等于已发生概率的积。
98 | 2. 线性回归主要采用广度摸索和深度搜索方法,对已发生事件对应的线性函数进行最优求解
99 | 3. 决策树主要通过求解不同分割点得信息熵之和,判定每次的最优分割点,最终生成决策树。
100 | 4. 模型评价主要通过不同纬度来进行,需要视情况而定,如pression,recall,auc等等
101 | 5. 知道了过拟合是什么意思,导致它产生的原因有很多,如数据太少,模型太复杂,数据分布,模型变化太快等等
102 |
103 | ## 疑问解答
104 |
105 | ### [lstm 激活函数为什么 sigmoid 和 tanh 同时存在](https://www.zhihu.com/question/46197687/answer/229098444)
106 |
107 | 其中一个原因如下:输入x经过sigmoid函数后均值在0.5左右,不利于后续激活函数的处理。
108 |
109 | 而tanh的输出在[-1,1]之间,因此相当于把输入的均值调整为0,便于后续处理。
110 |
111 | 因此,tanh一般来说总是比sigmoid函数效果更好。
112 |
113 | 除了一些特殊情况:比如你想要激活函数的输出值是一个概率时,显然sigmoid函数更好。
114 |
115 | ### 研究生阶段如何规划
116 |
117 | > 老师,您好。我现在大四学生,现在已经推免,本科和硕士专业为GIS(地理信息系统)。据我了解硕士老板是个大牛,但是其方向主要是系统应用开发,但我对数据科学这块比较感兴趣,将来也有读博打算,因为前期参加比赛和论文写作,对数据科学方面有一点了解,现在在系统的学着机器学习,请问研究生阶段该如何规划呢?
118 |
119 | 你这个问题首先存在以下方面考虑:
120 | - 第一:你是否真心喜欢你所在领域,能坚持研究几年。
121 | - 第二:你老板很牛是老板很牛,他只能会在你发论文和申请项目及开题帮助较大,写代码和推公式等活没人帮你干只有自己。
122 | - 第三:你已经推免说明成绩在前十自己自学能力ok这点自信还是要有,自信、多尝试、坚持是做好的思想基础。
123 | 系统开发和数据科学不冲突,数据科学只是系统开发一部分。GIS这个方向挺好可以做交通也可以搞地理和其他用途很广。
124 | - 第四:作为一名研究生快速成长的方式是完成自己科研任务同时选择学术方向还是工程方向的决定后再开始深入的做下去。
125 | - 第五:根据我的了解报送学生时间相对宽裕,我的建议第一年针对GIS方向完成毕业指标论文和三个大数据比赛并获奖及自己的研究生课程。第二年完成自己的系统及开发。第三年尽量在实习前做出整个基于机器学习的系统开发demo。
126 |
127 | 总结:以上的建议仅仅代表个人看法,这样做的好处
128 | - 能顺利工作和读博二选一都不影响。
129 | - 前一两年做好的数学基础在系统开发应用起来可以提高开发效率。
130 | - 面试的时候如果达到以上的水平根据我对各大公司和单位的可以直接拿到spp的提前批免得进入费力的系统面试阶段。
131 |
132 |
133 |
134 | ## 加入我们
135 |
136 | 公众号内回复「**自学**」,即可加入ML自学者俱乐部社群。可以投稿每周学习心得或者优质学习资料,助力团体共同学习进步。
137 |
138 |
139 |
140 |
141 | 
142 |
143 |
--------------------------------------------------------------------------------
/docs/doc_003.md:
--------------------------------------------------------------------------------
1 | ### 刊首语
2 |
3 | 这里记录ML自学者群体,每周分享优秀的学习心得与资料。由于微信不允许外部链接,需要点击文末的「**阅读原文**」,才能访问文中的链接。
4 |
5 | ---
6 |
7 |
8 | 前几天看到一则新闻,AI界的网红老师Siraj,遭吃瓜群众大规模打假。
9 |
10 | Siraj原本是靠在视频网站上传AI教学视频的博主,被称为AI界的最强Rapper,吸粉百万。
11 |
12 | 当然,他是为了最终能够通过粉丝的支持来进行盈利,这无可厚非。但有件事他做错了,而且是原则性错误。
13 |
14 | 首先,他的教学代码一般是从Github开源项目复制而来,而且删除了原作者的信息。更过分的事情是,他发表的论文,也是大段不加改动的,从其他论文处复制粘贴,甚至直接截图过来。
15 |
16 | 
17 |
18 | 于是成了千夫所指,人设一夜崩塌。
19 |
20 | 这个悲惨的故事,告诉我们,想要成名,还得靠脚踏实地的好好学习。来,看看大家本周都学了什么。
21 |
22 | ---
23 |
24 | ### 本期内容
25 |
26 | **心得分享**
27 |
28 | - 骨骼动作识别模型:AGC-LSTM
29 | - 对FM模型的学习
30 | - 多任务学习概述
31 | - 机器人在对话中推荐物品
32 | - 分水岭分割方法
33 |
34 | **学习周记**
35 |
36 | - Mr.WR
37 | - 贺
38 | - 君君
39 | - 千禧
40 |
41 |
42 | **资料分享**
43 |
44 | - 超轻量级人脸检测模型
45 | - 中文自然语言处理语料
46 |
47 | ---
48 |
49 | ### 自学心得
50 |
51 | #### 骨骼动作识别新模型:AGC-LSTM
52 |
53 | 本周写了一个软件著作权,并将其邮寄到中国版权保护中心。阅读动作识别综述论文,和再次阅读CVPR论文,
54 |
55 | 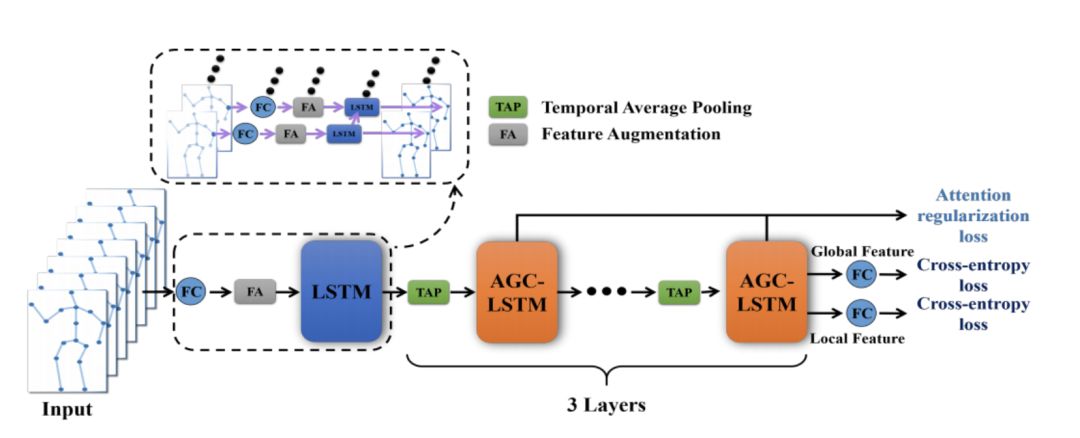
56 |
57 | 该篇论文首次提出AGC-LSTM网络。不仅能够分别的提取数据在时间和空间上的特征,而且还能查出两者之间的共现联系。在AGC-LSTM顶层,提出了一个时间分层结构,该结构不仅可以提高学习高等级表示的能力,而且还能显著的减少计算代价。
58 |
59 | 论文名称: An attention enhanced graph convolutional LSTM Network for Skeleton-Based Action Recognition
60 |
61 | [论文地址](https://arxiv.org/pdf/1902.09130.pdf)
62 |
63 | #### 对FM模型的学习
64 |
65 | 
66 |
67 |
68 | 这周学习FM模型,FM在计算广告和推荐系统中十分常用,主要优点在于考虑了特征交叉,并且算法的时间复杂度仍然还是线行的。
69 |
70 | 实际业务中,对于离散型的特征经常使用one-hot编码,传统的特征交叉方法使得特征维度扩张较为迅速,而且二阶项的系数很容易训练不充分,而在 FM 中,对于每个特征都学习了一个Embedding二阶项的系数就转化成了特征Embedding之间的内积。
71 |
72 | 在FM的论文中,比较了SVM和FM之间的优劣和FM与MF的联系,SVM 中的多项式核也可以完成特征交叉,但是并不适合高维稀疏的数据。
73 |
74 | MF可以理解为,在评分任务中,把用户对于物品的评分,分解为用户 Embedding 和物品 Embedding 的内积;
75 |
76 | FM 的重点在于二阶项的计算方式的改写(改写成线性时间),在这里附上论文和一些其他看过的博客。
77 |
78 | 论文:
79 | - [FM算法详解](https://blog.csdn.net/bitcarmanlee/article/details/52143909)
80 | - [FM模型理论和实践](https://mp.weixin.qq.com/s?__biz=MzI1MzY0MzE4Mg==&mid=2247483878&idx=1&sn=0a94aff9156bf2902096c77ca2122372&chksm=e9d01127dea79831de1d1d126549cba1996994c210d0be2ae0004b718fd348909b425fe15fe2&mpshare=1&scene=1&srcid=1009NC42Qg2PsMCADYMCjpkv&sharer_sharetime=1570587740133&sharer_shareid=32dc4a57f2d5d60ea8e4e538e6caa1b1%23rd)
81 | - [Factorization Machines](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
82 | - [推荐系统召回四模型之:全能的FM模型](https://zhuanlan.zhihu.com/p/58160982)
83 | - [前深度学习时代CTR预估模型的演化之路](https://zhuanlan.zhihu.com/p/61154299)
84 |
85 | #### 多任务学习概述
86 |
87 | 
88 |
89 |
90 | 今天介绍一下这几天看的一篇多任务概述,发表在arxiv,引用次数393。
91 |
92 | 多任务学习的直观定义是只要优化多个loss就被称之为多任务学习。为什么关注多任务,是因为我们往往只聚焦于单任务想要优化的目标,但是往往会失去一些关联信息。
93 |
94 | 从人类学习的角度来讲,在学习复杂任务之前往往会先学习一些简单的任务。从机器学习的视角来看,与主任务相关的辅助任务可以引入一些额外的信息,这些信息被称为inductive bias,我个人理解是引入了一些先验。这些先验会导致模型会更加关注能够解释多个任务的共同部分,而不是只关注解释单单一个任务,这也会使得泛化能力提高。
95 |
96 | 多任务有效的原因:
97 | 1. 同时学习多个任务会平衡在各自任务上的噪声,使得模型能够学到更好的表征;
98 | 2. 辅助任务可以引入额外信息。
99 |
100 | 如何设计辅助任务:作者在这里并没有给出一些方法论,而是给出了一些示例。如目标检测中常常同时输出目标类别和位置,情感分析中有设置预测输入句是否存在正向或负向情感词的辅助任务。
101 |
102 | 论文名称:An Overview of Multi-Task Learning
103 | in Deep Neural Networks
104 | [论文地址](https://arxiv.org/pdf/1706.05098.pdf)
105 |
106 | #### 分水岭分割方法
107 |
108 | 
109 |
110 | 最近在尝试看论文的代码,不知不觉就研究上了分水岭分割方法。并了解了一下同在scikitimage库中的随机漫步分割方法。在腾讯云上有翻译的中文文档,[地址链接](https://cloud.tencent.com/developer/section/1415081)。
111 |
112 | **分水岭算法**:对于没有噪声的图象效果很好。即使是有重叠。
113 | **随机漫步算法**:随机Walker分割基于各向异性扩散的分割算法,通常比分水岭慢,但对噪声数据和孔洞边界具有良好结果。
114 |
115 | 自己体验下来,感觉分水岭确实是一个很好的传统分割算法,而随机漫步算法进行分割感觉太消耗内存了。在图片没什么噪声的情况下两者相比应该优先选择分水岭
116 |
117 | #### 机器人在对话中推荐物品
118 |
119 | 分享SIGIR2018的一篇文章,个性化的聊天机器人在电商领域,有着可观的前景。目前的多轮对话中,机器人通常仅仅利用到了用户的历史输入信息,忽略了用户长期的偏好,从而给出一些不受欢迎的回复。而推荐系统,能够从用户历史购买的物品或者给出的评分中,学习到更多的用户喜好信息。
120 |
121 | 这篇文章,将对话和推荐两种看起来有所差异的分支结合到一起,利用深度强化学习框架,建立个性化的对话推荐机器人,从而能够优化对话体验,完成对话目标。这里所说的对话目标,是在电商场景下,成功的推荐商品给用户。
122 |
123 | 系统主要由三个部分组成:Belief Tracker, Policy Network, Recommender。
124 |
125 | 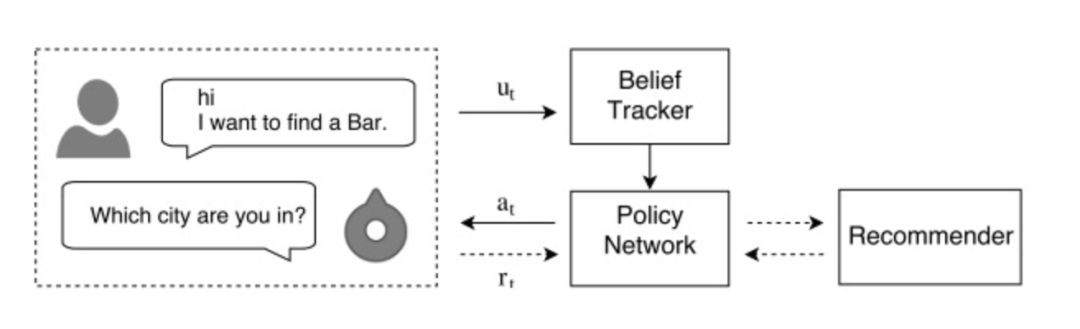
126 |
127 | 论文名称:Conversational Recommender System
128 | [论文地址](https://arxiv.org/abs/1806.03277)
129 |
130 | ---
131 |
132 | ### 学习周记
133 |
134 | #### Mr.WR
135 |
136 | 这周把吴恩达的机器学习看完了,麻省理工的stang教授的线代也看完了。机器学习的视频就是入了个门,以后还有很多东西要学,正在最后面的编程练习,感觉好多都看不懂。
137 |
138 | 接下来这周要好好研究研究,然后同时看Python深度学习这本书和林轩田的机器学习技法,争取在这周看完
139 |
140 | #### 贺
141 |
142 | 这周忙于找工作,没有太多的时间去学习,主要看了一下网易云课堂上厦门大学林子雨老师的大数据原理和应用课程的前十一章,觉得比较适合想要入门大数据以及对大数据有大致的了解的同学,这门免费课程还有配套的教程和相应的资料,确实还不错。
143 |
144 | #### 君君
145 |
146 | 在复现论文过程中,为了生成对应数据集试过的方法之一,虽然最终没有采用该方法生成数据集,不过我觉得这种勇于创新的思路值得记录下来(狗头保命)。
147 |
148 | 具体背景情况、实验图像、实现代码都详细在下面链接里面有说明,这边就不重复陈述了。[链接地址](https://blog.csdn.net/weixin_43194555/article/details/102535907)
149 |
150 | #### 千禧
151 |
152 | 最近重温了sklearn的调用,从中学习到最新版本的sklearn的细节操作,从案例中积累超参数调整的经验。这里推荐B站视频:[链接地址](https://www.bilibili.com/video/av70627602/?p=27)
153 |
154 | ---
155 |
156 | ### 优质资料
157 |
158 | #### 超轻量级人脸检测模型
159 |
160 |
161 | 一款超轻量级通用人脸检测模型,模型文件大小仅1MB,320x240输入下计算量仅90MFlops,适用于边缘计算设备、移动端设备以及PC。
162 |
163 | [项目地址](https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB)
164 |
165 | #### 中文自然语言处理语料
166 |
167 | 大规模中文自然语言处理语料,包括维基百科,新闻语料,百科问答,社区问答,翻译语料。
168 |
169 | [项目地址](https://github.com/brightmart/nlp_chinese_corpus)
170 |
171 |
172 |
173 | ---
174 |
175 | ### 加入我们
176 |
177 | 公众号内回复「自学」,即可加入ML自学者俱乐部社群。可以投稿每周学习心得或者看到的优质学习资料,助力团体共同学习进步。
178 |
179 |
180 |
181 | ---
182 |
183 | ### 参考来源
184 |
185 | - [ML自学者俱乐部投稿](https://github.com/Dikea/ML-SelfStudy-Weekly)
186 | - [黄博的机器学习圈子](https://t.zsxq.com/eaeYv7a)
187 | - [知乎机器学习话题](https://zhihu.com)
188 |
189 | [点击阅读上一期内容](https://mp.weixin.qq.com/s/ev3XfCNdM4mE55vTKukyXQ)
190 |
--------------------------------------------------------------------------------
18 |
--------------------------------------------------------------------------------
/docs/doc_001.md:
--------------------------------------------------------------------------------
1 | > 这里记录自学者的学习内容,欢迎留言投稿你的自学内容。
2 |
3 | ### 刊首语
4 |
5 | 创刊第 1 期,会一直坚持下去,希望能够做到 100 期。一直以来,同学们都在坚持分享。好的自学内容,还是放出来让大家多看看、多交流为好。欢迎投稿,每周一起学习进步!
6 |
7 | #### 学习ALBERT
8 |
9 | ALBERT A LITE BERT:是一个轻量级的 BERT 模型,和BERT比有三个变化点:
10 | - 嵌入向量参数化的因式分解不再将 one-hot 向量直接映射到大小为 H 的隐藏空间,而是先将它们映射到一个低维词嵌入空间 E,然后再映射到隐藏空间。通过这种分解,研究者可以将词嵌入参数从 O(V × H) 降低到 O(V × E + E × H),这在 H 远远大于 E 的时候,参数量减少得非常明显,减少计算量,加快计算时间。
11 | - 跨层参数共享:所有层权重共享
12 | - 句间连贯性损失:句间建模使用基于语言连贯性的损失函数。对于 ALBERT,研究者使用了一个句子顺序预测(SOP)损失函数,它会避免预测主题,而只关注建模句子之间的连贯性。
13 |
14 | #### 目标跟踪 PRCF
15 |
16 | 本文研究了池操作对视觉跟踪的影响,提出了一种新的ROI池相关滤波算法。虽然基于roi的池算法在许多基于深度学习的应用中得到了成功的应用,但是在视觉跟踪领域,尤其是在基于相关滤波的方法中,却很少考虑到它。由于相关滤波公式并不能真正提取出正样本和负样本,所以快速R-CNN等基于roi的池是不可行的。通过数学推导,给出了实现基于roi的池的另一种解决方案。提出了一种具有等式约束的相关滤波算法,通过该算法可以等价地实现基于roi的池。提出了一种求解优化问题的交替方向乘法器(ADMM)算法,并在傅里叶域中给出了一种有效的求解方法。
17 | 论文阅读笔记:http://haha-strong.com/2019/09/23/20190923-RoiCF/
18 |
19 | #### 大数据系统工程架构
20 | 
21 |
22 | #### 温习XGBoost
23 |
24 | 最近温习了 XGBoost,通过重读论文,阅读一些公众号的推送和博客,重新把公式推导了一遍,详细了解损失函数,泰勒展开,节点分裂,如果选择最优划分等具体过程,此外,了解了一些并行化的处理方式。
25 | - [公众号文章:XGBoost超详细推导,终于有人讲明白了!](https://mp.weixin.qq.com/s/7n1nzGL7r789P9sv0GEkDA)
26 | - 论文:https://arxiv.org/pdf/1603.02754.pdf
27 | - PPT:https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
28 | - 并行处理:[Parallel Gradient Boosting Decision Trees](http://zhanpengfang.github.io/418home.html)
29 |
30 | #### 小样本学习
31 |
32 | 最近老师给的任务涉及到小样本学习问题,读了以下针对小样本学习的MTL算法,交流一下我学到的东西,理解不准确的地方还望指正。
33 |
34 | Meta-Transfer Learning for Few-Shot Learning是CVPR 2019接收的论文,第一作者是新加坡国立大学的Qianru Sun,根据Papers With Code这个网站的评估,该算法截止到今天是SOTA for Few-Shot Image Classification on Fewshot-CIFAR100 - 10-Shot Learning。
35 |
36 | 元学习的架构已经被提出,并广泛应用到小样本检测问题上,元学习的核心是利用大量相似的小样本检测任务,以学习如何去适应一个新的小样本学习任务。传统的DNN网络在处理小样本学习问题时会有过拟合的问题,因此元学习通常使用浅层神经网络,但是这也限制了网络的性能。针对上述问题,这篇文章提出了一种新型的小样本检测算法,叫做MTL,它采用了一种深层神经网络用于小样本检测问题。M是指meta,代表着多种多样的任务,T是指transfer,通过学习每个任务的DNN权重的缩放和移位功能,可以实现权重的传递。
37 |
38 | 除此之外,这篇文章介绍了一种方法,该方法对于提升算法性能非常有帮助。传统的元学习方法受到两方面的限制:
39 | - 这些方法需要大量类似的任务来进行元训练,而找到大量相似任务是非常困难的;
40 | - 每个任务通常由低复杂度的浅层神经网络构成,以避免模型出现过拟合,因此无法使用更深更强大的体系结构。
41 |
42 | 1. 第一步:训练DNN网络在大尺度数据集上,并且将低层固定为特征提取器,需要注意的是,迁移给小样本学习任务的特征提取器的相关权重而不是DNN的最后一层权重。
43 | 2. 第二步:元迁移学习阶段,MTL学习特征提取神经元的缩放和移位参数,从而能够快速适应Few-shot Learning任务。具体实现过程在论文的4.2节,讲道理我只是看懂了一部分,相比于传统的方法,这篇论文在传递到小样本学习任务时,冻结迁移过来的权重,不进行更新,而其他的相关权重正常进行更新,感觉这篇文章的精髓在于这一部分的冻结操作和迁移过程的精妙操作。具体怎么迁移的,还需在继续学习下。
44 | 3. 第三步:为了提升整体学习水平,使用HT元批量学习策略。HT元批量学习策略是指挑选检测失败的案例进行附加训练,重点强调识别错误的例子,“在失败中成长”…,根据本文的试验,效果还不错。
45 |
46 | - 文章下载地址:https://arxiv.org/pdf/1812.02391v3.pdf
47 | - 文章源代码:https://github.com/y2l/meta-transfer-learning-tensorflow
48 |
49 | #### 推公式
50 |
51 | 路漫漫其修远兮,吾将上下而求索。手推牛顿法,混合高斯模型,SVM,核方法,EM,CRF,MCMC等等。这里极度推荐b站shuhuai的视频,里面的公式解析极其细致!
52 | 
53 |
--------------------------------------------------------------------------------
/docs/doc_002.md:
--------------------------------------------------------------------------------
1 | ### 刊首语
2 |
3 | 这里记录ML自学者群体,每周分享优秀的学习心得与资料。由于微信不允许外部链接,需要点击文末的「阅读原文」,才能访问文中的链接。
4 |
5 | ---
6 |
7 | ### 本期内容
8 |
9 | **目录**
10 |
11 | **一、学习心得分享**
12 | - 图像超分辨和图像高分辨的区别
13 | - 挖掘模板,辅助对话生成
14 | - 学习梯度优化算法
15 |
16 | **二、机器学习解答**
17 | - 为什么SVM不会过拟合
18 | - GBDT和XGBOOST的区别有哪些
19 | - 如何入门NLP,比较茫然
20 |
21 | **三、资料整理**
22 | - 论文类
23 | - 工具类
24 |
25 | ---
26 |
27 | ### 学习心得分享
28 |
29 | #### 图像超分辨和图像高分辨的区别
30 |
31 | 图像超分辨和图像高分辨之间的区别是:**图像超分辨描述**是图像由小到大的一个变化过程,**图像高分辨**是图像本身较大的一个状态。对于图图像的超分辨任务SR通常使用比较深的卷积神经网络编码成较高分辨率的图像过程,该方向比较难的一个点是SISR单张图像超分辨在医学、天文、安防方面有广泛使用,通常都是插值重构的方案,但是这种方法有一定局限性。
32 |
33 | 代码地址:https://github.com/lightningsoon/Residual-Dense-Net-for-Super-Resolution
34 |
35 | 论文地址:https://arxiv.org/abs/1802.08797
36 |
37 | 在上面的论文和代码中是以三个模块实现超分辨的单张功能,模块一是密集型残差网络RDB、模块二是局部特征混合LFF、模块三是LRL局部特征学习。因为卷积神经网络和图像中距离像素较远的关联关系较弱所以局部特征更能表达深度特征能力。整个RDN主要包括4个部分:隐藏特征提取网络(SFENet),残差密集模块(RDBs),密集特征融合(DFF),和最后的上采样网络(UPNet)。
38 |
39 | #### 挖掘模板,辅助对话生成
40 |
41 | EMNLP2019的一篇文章,对话领域中,训练语料(通常指的是post-response的语句对形式)较难采集。而无序的语句较容易获得。利用这些大量无监督语料,来提升机器对话回复的质量,是本文提出新的探索方向。作者将大量无序语句和少量对话语句对相结合,从无序语句中学习对话模板(template),模板涵盖了语义和语法的信息,作为先验知识,从而辅助对话response的生成。数据集采用了微博和知乎的语料,模型结构如下所示。
42 |
43 | 论文名称:Low-Resource Response Generation with Template Prior
44 |
45 | 论文地址:https://arxiv.org/abs/1909.11968
46 |
47 |
48 | #### 学习梯度优化算法
49 |
50 | 这篇博客是梯度优化算法综述,附上一些读后感。
51 | 1. SGD : 每次朝着梯度的反方向进行更新。
52 | 2. Momentum:动能积累,每次更新时候积累 SGD 的更新方向,也就是每次参数更新时,不单单考虑当前的梯度方向,还考虑之前的梯度方向,当然之前的梯度会有一个衰减因子。
53 | 3. Adagrad:自动调节学习率大小,对于频繁更新的参数,学习率小;对于很少更新的参数,学习率大。怎么判断参数频繁更新呢?可以为更新公式设置一个分母:梯度平方累加和的平方根。这样当分母越大,说明之前该参数越频繁更新,反之则很少更新。存在问题:当迭代次数多了之后,由于是累加操作,分母越来越大,学习率会变得非常小,模型更新会很慢。
54 | 4. Adadelta:作为 Adagrad 的拓展,是解决学习率消失的问题。在这里不会直接叠加之前所有的梯度平方,而是引入了一个梯度衰退的因子,使得时间久远的梯度对此刻参数更新的影响会消失。RMSProp 的思想和其类似。
55 | 5. Adam:结合 Momentum 和 Adadelta 两种优化算法的优点。对梯度的一阶矩估计(First Moment Estimation,即梯度的均值)和二阶矩估计(Second Moment Estimation,即梯度的未中心化的方差)进行综合考虑,计算出更新步长。
56 |
57 | 文章地址:http://ruder.io/optimizing-gradient-descent/
58 |
59 | ---
60 |
61 | ### 机器学习问答
62 |
63 | #### [为什么svm不会过拟合](https://www.zhihu.com/question/20178589/answer/29950675)
64 |
65 | SVM当然会过拟合,而且过度拟合的能力还非常强。首先我想说说什么叫过度拟合?就是模型学岔路了,把数据中的噪音当做有效的分类标准。
66 |
67 | 通常越是描述能力强大的模型越容易过度拟合。描述能力强的模型就像聪明人,描述能力弱的如:”一次线性模型“像傻子,如果聪明人要骗人肯定比傻子更能自圆其说对不对?而SVM的其中一个优化目标:最小化||W||,就是抑制它的描述能力,聪明人是吧,只允许你用100个字,能把事情说清楚不?
68 |
69 | 这就是为什么regularization能够对抗过度拟合,同时它也在弱化模型的描述能力。但只要能说话就能说谎,就能歪曲事实对不对?别把SVM想得太复杂,你就可以把它当做一个线性分类器,只不过它优化了分类平面与分类数据之间距离。
70 |
71 | #### [GBDT和XGBOOST的区别有哪些](https://zhuanlan.zhihu.com/p/30316845)
72 |
73 | 1. 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
74 | 2. 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
75 | 3. Xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
76 | 4. Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
77 | 5. 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
78 |
79 | #### 如何入门NLP,比较茫然
80 |
81 | 先了解什么是词向量 onehot和 word2vec,然后了解最基础的文本分类任务,跑下经典的机器学习模型和现在的cnn、rnn分类模型。这些代码都不多的,用pytorch或者tf实现下挺快的,可以照着代码敲一遍,有感觉了就离入门近一些了。再然后,看看nlp常见的任务,ner,mrc,nli,等等。对了,推荐直接跟着斯坦福的nlp公开课走一遍吧,很快的。
82 |
83 | 课程名:CS224d - Deep Learning for Natural Language Processing
84 |
85 | 课程地址:http://cs224d.stanford.edu
86 |
87 | ---
88 |
89 | ### 资料整理
90 |
91 | #### 论文类
92 | - [APDrawingGAN:人脸秒变艺术肖像画](https://mp.weixin.qq.com/s/Ok9ediwb35LzQiT9YVKfWA)
93 | - [NeurIPS 2019 | 用于弱监督图像语义分割的新型损失函数](https://mp.weixin.qq.com/s/CbORYhJQn27J0G4G6XpODw)
94 | - [Doc2EDAG:一种针对中文金融事件抽取的端到端文档级框架](https://mp.weixin.qq.com/s/irYEpq9pkeZYoSRcp4auew)
95 |
96 | #### 工具类
97 | - [三行代码提取PDF表格数据](https://mp.weixin.qq.com/s/VOU9bZTYENI0wZnP9SmAtQ)
98 | - [PyTorch 1.3发布:能在移动端部署](https://mp.weixin.qq.com/s/NNTA7B_ZZNruh01Nax26Mg)
99 | - [谷歌工程师:Tensorflow2.0 简单粗暴教程中文版](https://mp.weixin.qq.com/s/sG2Xp0vLzlW5zE1k7myB4w)
100 |
101 | ---
102 |
103 | ### 加入我们
104 |
105 | 公众号内回复「自学」,即可加入ML自学者俱乐部社群。可以投稿每周学习心得或者看到的优质学习资料,助力团体共同学习进步。
106 |
107 | ---
108 |
109 | ### 参考来源
110 |
111 | - [ML自学者俱乐部投稿](https://github.com/Dikea/ML-SelfStudy-Weekly)
112 | - [黄博的机器学习圈子](https://t.zsxq.com/eaeYv7a)
113 | - [知乎机器学习话题](https://zhihu.com)
114 |
115 | ---
116 |
117 | [点击阅读上一期内容](https://mp.weixin.qq.com/s/aqn1jN1_ZqC_KAsSLG9SYg)
118 |
--------------------------------------------------------------------------------
/docs/doc_004.md:
--------------------------------------------------------------------------------
1 | ## 刊首语
2 |
3 | > 这里记录ML自学者群体,每周分享优秀的学习心得与资料。由于微信不允许外部链接,需要点击文末的「**阅读原文**」,才能访问文中的链接。
4 |
5 |
6 |
7 | ## 本期内容
8 |
9 | **论文速递**
10 | - CVPR2019:细粒度图像识别新论文
11 | - 基于元学习和AutoML的模型压缩新方法
12 |
13 |
14 | **学习心得**
15 | - 大煌
16 | - 奔腾
17 | - 昨夜星辰
18 | - 大灵
19 | - 大鹏鹏
20 | - 安芯
21 | - 吕涛
22 |
23 |
24 | **疑问解答**
25 | - lstm激活函数为什么sigmoid和tanh同时存在
26 |
27 | ## 论文速递
28 |
29 | ### CVPR2019:细粒度图像识别新论文
30 |
31 | 论文名称:Destruction and Construction Learning for Fine-grained Image Recognition
32 |
33 | [论文地址](http://openaccess.thecvf.com/content_CVPR_2019/papers/Chen_Destruction_and_Construction_Learning_for_Fine-Grained_Image_Recognition_CVPR_2019_paper.pdf)
34 |
35 | 该文献是属于细粒度图像识别领域的。文章提到部分先前的方法需要判别性区域的标注先验信息,标注成本高昂;并且先前方法一般需增加额外模块,而这些模块在推断阶段会引入额外的计算负担。
36 |
37 | 因此文章引入“拆解与建构学习”机制使分类模块获得专家知识,其中“拆解”部分强迫分类模块着重于判别性区域的区别,“建构”部分建立各局部区域的语义关联并避免拆解带来的含噪样本引发的过拟合现象。文章工作中包括性能对比、消融实验、控制变量法参数调整实验、特征可视化等。
38 |
39 | 
40 |
41 | 一句话概括该文献:引入“拆解与建构学习”机制,强迫分类模块着重于判别性区域的区别,并建立各局部区域的语义关联并避免拆解带来的含噪样本引发的过拟合现象,且未引入额外判别性区域标注负担和推断阶段的额外计算负担。
42 |
43 | ### 基于元学习和AutoML的模型压缩新方法
44 |
45 | 这篇文章来自于旷视。旷视内部有一个基础模型组,孙剑老师也是很看好 NAS 相关的技术,相信这篇文章无论从学术上还是工程落地上都有可以让人借鉴的地方。回到文章本身,模型剪枝算法能够减少模型计算量,实现模型压缩和加速的目的,但是模型剪枝过程中确定剪枝比例等参数的过程实在让人头痛。
46 |
47 | 
48 |
49 | 这篇文章提出了 PruningNet 的概念,自动为剪枝后的模型生成权重,从而绕过了费时的 retrain 步骤。并且能够和进化算法等搜索方法结合,通过搜索编码 network 的 coding vector,自动地根据所给约束搜索剪枝后的网络结构。和 AutoML 技术相比,这种方法并不是从头搜索,而是从已有的大模型出发,从而缩小了搜索空间,节省了搜索算力和时间。
50 |
51 |
52 | [论文地址](https://arxiv.org/abs/1903.10258)
53 | [原文地址](https://mp.weixin.qq.com/s/lc7IoOV6S2Uz5xi7cPQUqg)
54 |
55 |
56 |
57 | ## 学习心得
58 |
59 | ### 大煌
60 |
61 | 本周复现了一篇论文的代码。复现的效果没有论文的好。是一个很基础的版本,欢迎交流和探讨。[复现代码地址](https://github.com/HaHuangChan/Deep-Mating-for-Portrait-Animation)
62 |
63 | ### 奔腾
64 |
65 | 本周复习了一下概率论,具体是过了一遍叶丙成老师的玩想概率,相对国内过于注重计算,而叶老师的课程很注重概念。最简单的概念,随机变量到底是什么,如果这个不清楚的话,可以再认真学学概率,会有新的收获。
66 |
67 | ### 昨夜星辰
68 |
69 | 本周学习了词向量的三种:word2vec,fasttext,elmo。代码如下,放在笔记里面:
70 |
71 | - [word2vec](https://blog.csdn.net/weixin_43178406/article/details/102461021)
72 | - [fasttext](https://blog.csdn.net/weixin_43178406/article/details/102465629)
73 | - [elmo](https://blog.csdn.net/weixin_43178406/article/details/102522853)
74 |
75 | ### 大灵
76 |
77 | 这周了解了一下密集计数。
78 |
79 | - 聚类计数: 基于外观和运动线索等特征进行聚类,适用于视频序列,不适用于图象。 缺点:需要视频,准确率较低
80 | - 回归计数:通过检测计数 两种:一是使用计算对象的密度来预测密度图。使用高斯核将点级注释矩阵转换为密度图。挑战是确定高斯核的最佳大小,这个与对象的大小密切相关。 第二种是一瞥(glance)基于网格的计数方法(不太懂) 缺点:受物体的大小变化影响大。
81 | - 检测计数: 先检测出对象,再计算数量,比glance和子图标的表现更差。 缺点:如果对象被遮挡效果就不好,其实物体的大小对这个的影响也有,效果可能要看训练集和实际场景了。
82 |
83 |
84 | ### 大鹏鹏
85 |
86 | 本周由于在赶论文,所以自学的不多,主要看了《大话数据结构》中的第三、四章节,以及《数学之美》中的前5章。这两本书算是入门类型的书籍了,根据之前看别人的经验帖子,前者适合刷题吃力的小伙伴看,或者适合作为入门自然语言处理的启蒙教材。
87 |
88 | ### 安芯
89 |
90 | 最近对图像分析做了一个简单的小结,我个人把模型训练的相关流程简单的总结一下如下:个人研究loss和初始化对模型影响最大除模型结构之外。
91 |
92 | 
93 |
94 | ### 吕涛
95 |
96 | 本周刚开始接触机器学习,学习了贝叶斯,线性回归,决策树,KNN模型,模型的评价方法
97 | 1. 贝叶斯模型是基于概率的,通过贝叶斯方程和模糊处理,将事件的概率约等于已发生概率的积。
98 | 2. 线性回归主要采用广度摸索和深度搜索方法,对已发生事件对应的线性函数进行最优求解
99 | 3. 决策树主要通过求解不同分割点得信息熵之和,判定每次的最优分割点,最终生成决策树。
100 | 4. 模型评价主要通过不同纬度来进行,需要视情况而定,如pression,recall,auc等等
101 | 5. 知道了过拟合是什么意思,导致它产生的原因有很多,如数据太少,模型太复杂,数据分布,模型变化太快等等
102 |
103 | ## 疑问解答
104 |
105 | ### [lstm 激活函数为什么 sigmoid 和 tanh 同时存在](https://www.zhihu.com/question/46197687/answer/229098444)
106 |
107 | 其中一个原因如下:输入x经过sigmoid函数后均值在0.5左右,不利于后续激活函数的处理。
108 |
109 | 而tanh的输出在[-1,1]之间,因此相当于把输入的均值调整为0,便于后续处理。
110 |
111 | 因此,tanh一般来说总是比sigmoid函数效果更好。
112 |
113 | 除了一些特殊情况:比如你想要激活函数的输出值是一个概率时,显然sigmoid函数更好。
114 |
115 | ### 研究生阶段如何规划
116 |
117 | > 老师,您好。我现在大四学生,现在已经推免,本科和硕士专业为GIS(地理信息系统)。据我了解硕士老板是个大牛,但是其方向主要是系统应用开发,但我对数据科学这块比较感兴趣,将来也有读博打算,因为前期参加比赛和论文写作,对数据科学方面有一点了解,现在在系统的学着机器学习,请问研究生阶段该如何规划呢?
118 |
119 | 你这个问题首先存在以下方面考虑:
120 | - 第一:你是否真心喜欢你所在领域,能坚持研究几年。
121 | - 第二:你老板很牛是老板很牛,他只能会在你发论文和申请项目及开题帮助较大,写代码和推公式等活没人帮你干只有自己。
122 | - 第三:你已经推免说明成绩在前十自己自学能力ok这点自信还是要有,自信、多尝试、坚持是做好的思想基础。
123 | 系统开发和数据科学不冲突,数据科学只是系统开发一部分。GIS这个方向挺好可以做交通也可以搞地理和其他用途很广。
124 | - 第四:作为一名研究生快速成长的方式是完成自己科研任务同时选择学术方向还是工程方向的决定后再开始深入的做下去。
125 | - 第五:根据我的了解报送学生时间相对宽裕,我的建议第一年针对GIS方向完成毕业指标论文和三个大数据比赛并获奖及自己的研究生课程。第二年完成自己的系统及开发。第三年尽量在实习前做出整个基于机器学习的系统开发demo。
126 |
127 | 总结:以上的建议仅仅代表个人看法,这样做的好处
128 | - 能顺利工作和读博二选一都不影响。
129 | - 前一两年做好的数学基础在系统开发应用起来可以提高开发效率。
130 | - 面试的时候如果达到以上的水平根据我对各大公司和单位的可以直接拿到spp的提前批免得进入费力的系统面试阶段。
131 |
132 |
133 |
134 | ## 加入我们
135 |
136 | 公众号内回复「**自学**」,即可加入ML自学者俱乐部社群。可以投稿每周学习心得或者优质学习资料,助力团体共同学习进步。
137 |
138 |
139 |
140 |
141 | 
142 |
143 |
--------------------------------------------------------------------------------
/docs/doc_003.md:
--------------------------------------------------------------------------------
1 | ### 刊首语
2 |
3 | 这里记录ML自学者群体,每周分享优秀的学习心得与资料。由于微信不允许外部链接,需要点击文末的「**阅读原文**」,才能访问文中的链接。
4 |
5 | ---
6 |
7 |
8 | 前几天看到一则新闻,AI界的网红老师Siraj,遭吃瓜群众大规模打假。
9 |
10 | Siraj原本是靠在视频网站上传AI教学视频的博主,被称为AI界的最强Rapper,吸粉百万。
11 |
12 | 当然,他是为了最终能够通过粉丝的支持来进行盈利,这无可厚非。但有件事他做错了,而且是原则性错误。
13 |
14 | 首先,他的教学代码一般是从Github开源项目复制而来,而且删除了原作者的信息。更过分的事情是,他发表的论文,也是大段不加改动的,从其他论文处复制粘贴,甚至直接截图过来。
15 |
16 | 
17 |
18 | 于是成了千夫所指,人设一夜崩塌。
19 |
20 | 这个悲惨的故事,告诉我们,想要成名,还得靠脚踏实地的好好学习。来,看看大家本周都学了什么。
21 |
22 | ---
23 |
24 | ### 本期内容
25 |
26 | **心得分享**
27 |
28 | - 骨骼动作识别模型:AGC-LSTM
29 | - 对FM模型的学习
30 | - 多任务学习概述
31 | - 机器人在对话中推荐物品
32 | - 分水岭分割方法
33 |
34 | **学习周记**
35 |
36 | - Mr.WR
37 | - 贺
38 | - 君君
39 | - 千禧
40 |
41 |
42 | **资料分享**
43 |
44 | - 超轻量级人脸检测模型
45 | - 中文自然语言处理语料
46 |
47 | ---
48 |
49 | ### 自学心得
50 |
51 | #### 骨骼动作识别新模型:AGC-LSTM
52 |
53 | 本周写了一个软件著作权,并将其邮寄到中国版权保护中心。阅读动作识别综述论文,和再次阅读CVPR论文,
54 |
55 | 
56 |
57 | 该篇论文首次提出AGC-LSTM网络。不仅能够分别的提取数据在时间和空间上的特征,而且还能查出两者之间的共现联系。在AGC-LSTM顶层,提出了一个时间分层结构,该结构不仅可以提高学习高等级表示的能力,而且还能显著的减少计算代价。
58 |
59 | 论文名称: An attention enhanced graph convolutional LSTM Network for Skeleton-Based Action Recognition
60 |
61 | [论文地址](https://arxiv.org/pdf/1902.09130.pdf)
62 |
63 | #### 对FM模型的学习
64 |
65 | 
66 |
67 |
68 | 这周学习FM模型,FM在计算广告和推荐系统中十分常用,主要优点在于考虑了特征交叉,并且算法的时间复杂度仍然还是线行的。
69 |
70 | 实际业务中,对于离散型的特征经常使用one-hot编码,传统的特征交叉方法使得特征维度扩张较为迅速,而且二阶项的系数很容易训练不充分,而在 FM 中,对于每个特征都学习了一个Embedding二阶项的系数就转化成了特征Embedding之间的内积。
71 |
72 | 在FM的论文中,比较了SVM和FM之间的优劣和FM与MF的联系,SVM 中的多项式核也可以完成特征交叉,但是并不适合高维稀疏的数据。
73 |
74 | MF可以理解为,在评分任务中,把用户对于物品的评分,分解为用户 Embedding 和物品 Embedding 的内积;
75 |
76 | FM 的重点在于二阶项的计算方式的改写(改写成线性时间),在这里附上论文和一些其他看过的博客。
77 |
78 | 论文:
79 | - [FM算法详解](https://blog.csdn.net/bitcarmanlee/article/details/52143909)
80 | - [FM模型理论和实践](https://mp.weixin.qq.com/s?__biz=MzI1MzY0MzE4Mg==&mid=2247483878&idx=1&sn=0a94aff9156bf2902096c77ca2122372&chksm=e9d01127dea79831de1d1d126549cba1996994c210d0be2ae0004b718fd348909b425fe15fe2&mpshare=1&scene=1&srcid=1009NC42Qg2PsMCADYMCjpkv&sharer_sharetime=1570587740133&sharer_shareid=32dc4a57f2d5d60ea8e4e538e6caa1b1%23rd)
81 | - [Factorization Machines](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
82 | - [推荐系统召回四模型之:全能的FM模型](https://zhuanlan.zhihu.com/p/58160982)
83 | - [前深度学习时代CTR预估模型的演化之路](https://zhuanlan.zhihu.com/p/61154299)
84 |
85 | #### 多任务学习概述
86 |
87 | 
88 |
89 |
90 | 今天介绍一下这几天看的一篇多任务概述,发表在arxiv,引用次数393。
91 |
92 | 多任务学习的直观定义是只要优化多个loss就被称之为多任务学习。为什么关注多任务,是因为我们往往只聚焦于单任务想要优化的目标,但是往往会失去一些关联信息。
93 |
94 | 从人类学习的角度来讲,在学习复杂任务之前往往会先学习一些简单的任务。从机器学习的视角来看,与主任务相关的辅助任务可以引入一些额外的信息,这些信息被称为inductive bias,我个人理解是引入了一些先验。这些先验会导致模型会更加关注能够解释多个任务的共同部分,而不是只关注解释单单一个任务,这也会使得泛化能力提高。
95 |
96 | 多任务有效的原因:
97 | 1. 同时学习多个任务会平衡在各自任务上的噪声,使得模型能够学到更好的表征;
98 | 2. 辅助任务可以引入额外信息。
99 |
100 | 如何设计辅助任务:作者在这里并没有给出一些方法论,而是给出了一些示例。如目标检测中常常同时输出目标类别和位置,情感分析中有设置预测输入句是否存在正向或负向情感词的辅助任务。
101 |
102 | 论文名称:An Overview of Multi-Task Learning
103 | in Deep Neural Networks
104 | [论文地址](https://arxiv.org/pdf/1706.05098.pdf)
105 |
106 | #### 分水岭分割方法
107 |
108 | 
109 |
110 | 最近在尝试看论文的代码,不知不觉就研究上了分水岭分割方法。并了解了一下同在scikitimage库中的随机漫步分割方法。在腾讯云上有翻译的中文文档,[地址链接](https://cloud.tencent.com/developer/section/1415081)。
111 |
112 | **分水岭算法**:对于没有噪声的图象效果很好。即使是有重叠。
113 | **随机漫步算法**:随机Walker分割基于各向异性扩散的分割算法,通常比分水岭慢,但对噪声数据和孔洞边界具有良好结果。
114 |
115 | 自己体验下来,感觉分水岭确实是一个很好的传统分割算法,而随机漫步算法进行分割感觉太消耗内存了。在图片没什么噪声的情况下两者相比应该优先选择分水岭
116 |
117 | #### 机器人在对话中推荐物品
118 |
119 | 分享SIGIR2018的一篇文章,个性化的聊天机器人在电商领域,有着可观的前景。目前的多轮对话中,机器人通常仅仅利用到了用户的历史输入信息,忽略了用户长期的偏好,从而给出一些不受欢迎的回复。而推荐系统,能够从用户历史购买的物品或者给出的评分中,学习到更多的用户喜好信息。
120 |
121 | 这篇文章,将对话和推荐两种看起来有所差异的分支结合到一起,利用深度强化学习框架,建立个性化的对话推荐机器人,从而能够优化对话体验,完成对话目标。这里所说的对话目标,是在电商场景下,成功的推荐商品给用户。
122 |
123 | 系统主要由三个部分组成:Belief Tracker, Policy Network, Recommender。
124 |
125 | 
126 |
127 | 论文名称:Conversational Recommender System
128 | [论文地址](https://arxiv.org/abs/1806.03277)
129 |
130 | ---
131 |
132 | ### 学习周记
133 |
134 | #### Mr.WR
135 |
136 | 这周把吴恩达的机器学习看完了,麻省理工的stang教授的线代也看完了。机器学习的视频就是入了个门,以后还有很多东西要学,正在最后面的编程练习,感觉好多都看不懂。
137 |
138 | 接下来这周要好好研究研究,然后同时看Python深度学习这本书和林轩田的机器学习技法,争取在这周看完
139 |
140 | #### 贺
141 |
142 | 这周忙于找工作,没有太多的时间去学习,主要看了一下网易云课堂上厦门大学林子雨老师的大数据原理和应用课程的前十一章,觉得比较适合想要入门大数据以及对大数据有大致的了解的同学,这门免费课程还有配套的教程和相应的资料,确实还不错。
143 |
144 | #### 君君
145 |
146 | 在复现论文过程中,为了生成对应数据集试过的方法之一,虽然最终没有采用该方法生成数据集,不过我觉得这种勇于创新的思路值得记录下来(狗头保命)。
147 |
148 | 具体背景情况、实验图像、实现代码都详细在下面链接里面有说明,这边就不重复陈述了。[链接地址](https://blog.csdn.net/weixin_43194555/article/details/102535907)
149 |
150 | #### 千禧
151 |
152 | 最近重温了sklearn的调用,从中学习到最新版本的sklearn的细节操作,从案例中积累超参数调整的经验。这里推荐B站视频:[链接地址](https://www.bilibili.com/video/av70627602/?p=27)
153 |
154 | ---
155 |
156 | ### 优质资料
157 |
158 | #### 超轻量级人脸检测模型
159 |
160 |
161 | 一款超轻量级通用人脸检测模型,模型文件大小仅1MB,320x240输入下计算量仅90MFlops,适用于边缘计算设备、移动端设备以及PC。
162 |
163 | [项目地址](https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB)
164 |
165 | #### 中文自然语言处理语料
166 |
167 | 大规模中文自然语言处理语料,包括维基百科,新闻语料,百科问答,社区问答,翻译语料。
168 |
169 | [项目地址](https://github.com/brightmart/nlp_chinese_corpus)
170 |
171 |
172 |
173 | ---
174 |
175 | ### 加入我们
176 |
177 | 公众号内回复「自学」,即可加入ML自学者俱乐部社群。可以投稿每周学习心得或者看到的优质学习资料,助力团体共同学习进步。
178 |
179 |
180 |
181 | ---
182 |
183 | ### 参考来源
184 |
185 | - [ML自学者俱乐部投稿](https://github.com/Dikea/ML-SelfStudy-Weekly)
186 | - [黄博的机器学习圈子](https://t.zsxq.com/eaeYv7a)
187 | - [知乎机器学习话题](https://zhihu.com)
188 |
189 | [点击阅读上一期内容](https://mp.weixin.qq.com/s/ev3XfCNdM4mE55vTKukyXQ)
190 |
--------------------------------------------------------------------------------