├── settings
├── __init__.py
├── settings.py.example
└── settings.py
├── requirements.txt
├── .idea
└── .gitignore
├── gunicorn_config.py
├── Dockerfile
├── deploy.sh
├── logger.py
├── README.md
├── .gitignore
├── templates
└── wereadtonotion.html
├── app.py
├── weread_2_notion.py
├── weread
└── weread.py
└── notion
└── notion.py
/settings/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | requests~=2.26.0
2 | notion-client==1.0.0
3 | retrying==1.3.4
4 | Flask==2.3.2
5 | pywebio==1.8.2
6 | gunicorn==20.1.0
7 | gevent==22.10.2
--------------------------------------------------------------------------------
/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # 默认忽略的文件
2 | /shelf/
3 | /workspace.xml
4 | # 基于编辑器的 HTTP 客户端请求
5 | /httpRequests/
6 | # Datasource local storage ignored files
7 | /dataSources/
8 | /dataSources.local.xml
9 |
--------------------------------------------------------------------------------
/gunicorn_config.py:
--------------------------------------------------------------------------------
1 | bind = '0.0.0.0:80' # 绑定的IP地址和端口号
2 | # bind = '127.0.0.1:6000' # 绑定的IP地址和端口号
3 | workers = 1 # 工作进程的数量
4 | worker_class = 'gevent' # 使用gevent作为工作进程的类别
5 | timeout = 12000 # 超时时间,单位为秒
6 | accesslog = '/var/log/weread' # 访问日志的文件路径,'-' 表示输出到标准输出
7 | errorlog = '/var/log/weread' # 错误日志的文件路径,'-' 表示输出到标准输出
8 |
--------------------------------------------------------------------------------
/Dockerfile:
--------------------------------------------------------------------------------
1 | # 基于 Python 官方镜像构建 Docker 镜像
2 | FROM python:3.9-slim
3 |
4 | # 设置工作目录
5 | WORKDIR /app
6 |
7 | # 单独复制 requirements.txt,后续可以利用 Docker 缓存避免重复安装依赖
8 | COPY ./requirements.txt /app/requirements.txt
9 | RUN pip install -r requirements.txt
10 |
11 |
12 | # 将当前目录下的所有文件复制到容器的 /app 目录下
13 | COPY . /app
14 | # 暴露容器的端口
15 | EXPOSE 80
16 |
17 | # 运行应用
18 | CMD ["gunicorn", "--config", "gunicorn_config.py", "app:app"]
19 |
--------------------------------------------------------------------------------
/settings/settings.py.example:
--------------------------------------------------------------------------------
1 | NOTION_TOKEN = ''
2 | WEREAD_COOKIE = ''
3 | DATABASE_ID = ''
4 |
5 | BOOK_BLACKLIST = [
6 | '从红月开始',
7 | '修真聊天群(聊天群的日常生活)',
8 | '第一序列',
9 | '我真没想重生啊',
10 | '我有一座恐怖屋',
11 | '大王饶命',
12 | '我师兄实在太稳健了',
13 | '死而替生',
14 | '中医许阳',
15 | '这游戏也太真实了',
16 | '家父汉高祖',
17 | '吕布的人生模拟器',
18 | '学霸的黑科技系统',
19 | '黎明之剑',
20 | '我的一天有48小时',
21 | '明克街13号',
22 | ]
23 |
--------------------------------------------------------------------------------
/settings/settings.py:
--------------------------------------------------------------------------------
1 | NOTION_TOKEN = 'xxxxxxxxxxx'
2 | WEREAD_COOKIE = 'wr_fp=2533447432; wr_gid=295032143; wr_vid=23683664; wr_pf=0; wr_rt=web%40QxPpLky5s9q8MDFU8TK_AL; wr_localvid=fb3325d071696250fb37ae2; wr_name=%E8%AF%B6%E9%B8%AD; wr_avatar=https%3A%2F%2Fthirdwx.qlogo.cn%2Fmmopen%2Fvi_32%2FXpfWjDr8uAYiagxaSibFmnMh2LUJXTQrjJ8z2ve6X8J3w2CI79YSvQwic1icyHUoHVgoccckuoLxlt1cQOD87tZLfQ%2F132; wr_gender=1; RK=Ou2xAkMpZ9; ptcz=6d556d39aaf44f088fec74b97d2942db2ea837b96f5c8c603ddacec2b5e1fd45; uin=o1307317886; wr_skey=t1Gw1zJp'
3 | DATABASE_ID = 'd92bb4b8434745baa2061caf67d6ef7a'
4 |
5 | BOOK_BLACKLIST = [
6 | '从红月开始',
7 | '修真聊天群(聊天群的日常生活)',
8 | '第一序列',
9 | '我真没想重生啊',
10 | '我有一座恐怖屋',
11 | '大王饶命',
12 | '我师兄实在太稳健了',
13 | '死而替生',
14 | '中医许阳',
15 | '这游戏也太真实了',
16 | '家父汉高祖',
17 | '吕布的人生模拟器',
18 | '学霸的黑科技系统',
19 | '黎明之剑',
20 | '我的一天有48小时',
21 | '明克街13号',
22 | ]
23 |
--------------------------------------------------------------------------------
/deploy.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # 获取应用版本参数
4 | version=$1
5 |
6 | # 默认应用版本
7 | default_version="latest"
8 |
9 | # 如果没有指定版本参数,则使用默认版本
10 | if [ -z "$version" ]; then
11 | version=$default_version
12 | fi
13 |
14 | # 容器名称
15 | container_name="weread-to-notion"
16 |
17 | # 检查是否存在同名容器
18 | existing_container=$(docker ps -a --filter "name=$container_name" --format "{{.Names}}")
19 |
20 | if [ ! -z "$existing_container" ]; then
21 | # 停止并删除同名容器
22 | echo "Stopping and removing existing container: $existing_container"
23 | docker stop "$existing_container"
24 | docker rm "$existing_container"
25 | fi
26 |
27 | echo "################ Building Docker image: $container_name:$version ################"
28 | # 构建Docker镜像
29 | docker build -t "$container_name:$version" .
30 |
31 | echo "################ Starting Docker container: $container_name:$version ############"
32 | # 启动容器
33 | docker run -d -p 7000:80 --name "$container_name" "$container_name:$version"
34 |
--------------------------------------------------------------------------------
/logger.py:
--------------------------------------------------------------------------------
1 | import logging.handlers
2 | import os
3 |
4 | _logger = logging.getLogger('weread_to_notion')
5 | _logger.setLevel(logging.DEBUG)
6 |
7 | _cons_rht = logging.StreamHandler()
8 |
9 | # _log_base_dir = f'/var/log'
10 | _log_base_dir = '.'
11 |
12 | # _pid = os.getpid()
13 | log_dir = f'{_log_base_dir}/logs'
14 | if not os.path.exists(log_dir):
15 | os.makedirs(log_dir)
16 | log_file_name = 'weread_to_notion'
17 |
18 | _file_rht = logging.handlers.RotatingFileHandler(f"{log_dir}/{log_file_name}.log",
19 | maxBytes=1024 * 1024 * 1024,
20 | backupCount=100)
21 |
22 | _fmt = logging.Formatter("%(asctime)s pid:%(process)d %(filename)s:%(lineno)s %(levelname)s: %(message)s",
23 | "%Y-%m-%d %H:%M:%S")
24 |
25 | _file_rht.setFormatter(_fmt)
26 | _cons_rht.setFormatter(_fmt)
27 |
28 | _logger.addHandler(_file_rht)
29 | _logger.addHandler(_cons_rht)
30 |
31 | debug = _logger.debug
32 | info = _logger.info
33 | warning = _logger.warning
34 | error = _logger.error
35 | exception = _logger.exception
36 | critical = _logger.critical
37 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # wereadtonotion
2 |
3 | 微信读书笔记、划线等信息同步到notion数据库
4 | > 效果如下:
5 | > 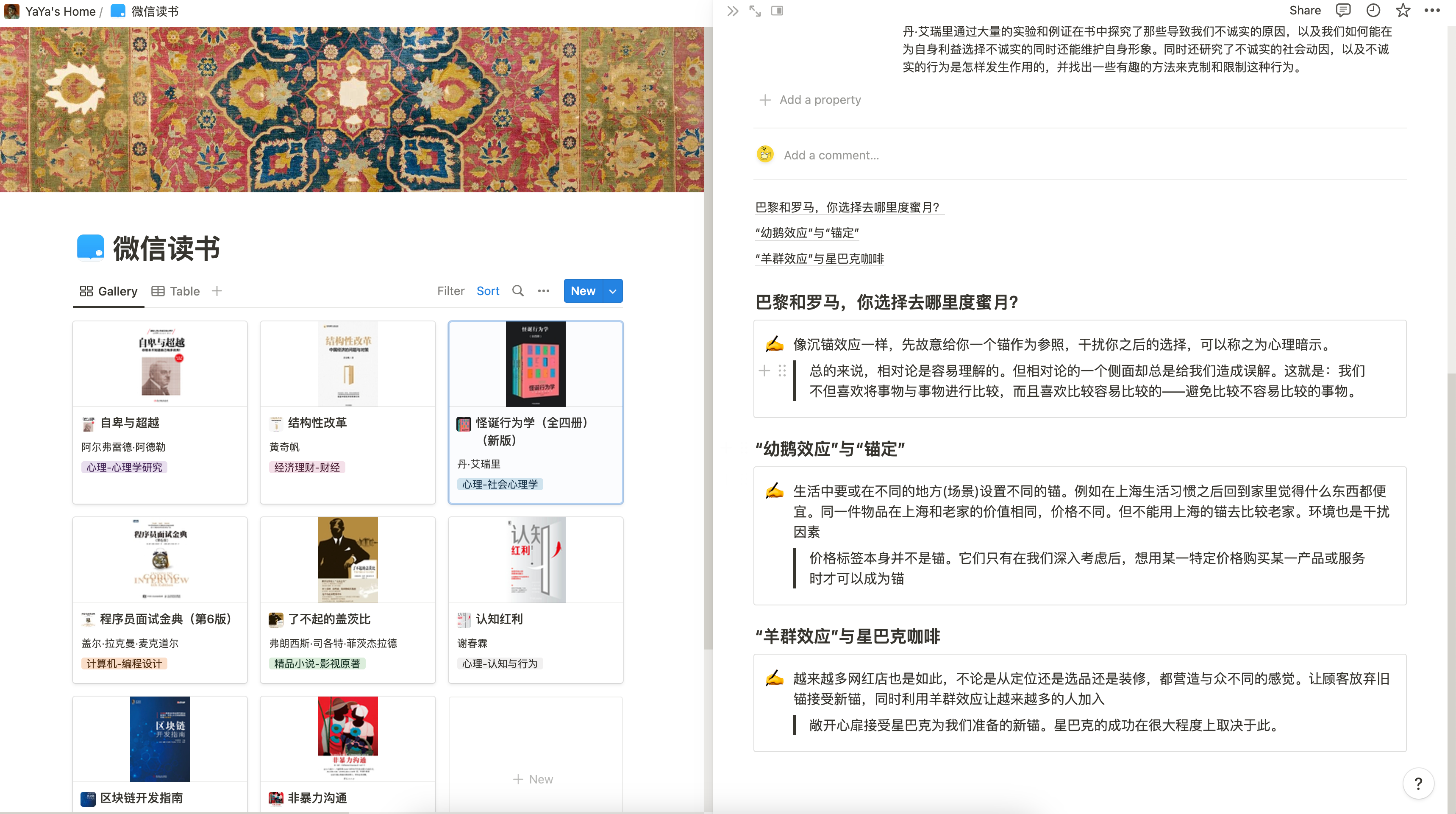
6 |
7 | *注意:不存在划线、书评等信息的书籍不会被获取、导入*
8 |
9 | ## 功能
10 |
11 | ### 已有功能
12 |
13 | 1. 导入书籍的划线、评论、笔记等信息到 Notion 数据库
14 | > 注意:不存在划线、书评等信息的书籍不会被获取、导入
15 | 2. 支持 Web 端部署执行和本机 Python 脚本运行
16 |
17 | ### TODO
18 |
19 | - [ ] 支持 Notion 增量读写
20 | - [ ] 支持用户选择书籍获取模式 [存在划线 / 书架书籍 / 全部书籍]
21 | - [ ] 单独导出功能。导出为 markdown 文件
22 | - [ ] 考虑支持自定义 Noiton 数据库结构
23 |
24 | ## 使用方法
25 |
26 | ### 1. 本地脚本运行
27 |
28 | 1. 安装依赖 `pip install -r requirements.txt`
29 | 2. 配置 settings/settings.py 文件中的信息
30 | > 1. 获取 **Notion token**
31 | > - 打开[此页面](https://www.notion.so/my-integrations)并登录
32 | > - 点击New integration 输入 name 提交.(如果已有,则点击 view integration)
33 | > - 点击show,然后copy
34 | > 2. 从微信读书中获取 cookie
35 | > - 在浏览器中打开 weread.qq.com 并登录
36 | > - 打开开发者工具(按 F12),点击 network(网络),刷新页面, 点击第一个请求,复制 cookie 的值。
37 | > 3. 准备 Noiton Database ID
38 | > - 复制[此页面](https://www.notion.so/yayya/a9b3a8dfcc0543559005a263103fc81c)到你的
39 | Notion 中,点击右上角的分享按钮,将页面分享为公开页面
40 | >- 点击页面右上角三个点,在 connections 中找到选择你的 connections。第一步中创建的 integration 的 name
41 | >- 通过 URL 找到你的 Database ID 的值。
42 | > > 例如:页面 https://www.notion.so/yayya/d92bb4b8434745baa2061caf67d6ef7a?v=b4a5bfb89e8e44868a473179ee60x851 的
43 | ID 为d92bb4b8434745baa2061caf67d6ef7a
44 | 4. 运行 `python weread_2_notion.py`
45 |
46 | ### 2. 网页端部署运行
47 |
48 | #### docker 部署(推荐)
49 |
50 | 执行脚本: `bash deploy.sh`
51 |
52 | #### 直接部署
53 |
54 | 1. 安装依赖:`python3 install -r requirement.txt`
55 | 2. 启动 Web 端: `python3 app.py`
56 |
57 | ## PS
58 |
59 | - 借鉴了大佬的[项目](https://github.com/malinkang/weread_to_notion),优化了代码结构、增加了web 端。非常感谢大佬的开源项目
60 | - 配合 NoitonNext 构建 Blog [效果](https://yaya.run/weread)非常好
61 |
62 | ## 免责申明
63 |
64 | 本工具仅作技术研究之用,请勿用于商业或违法用途,由于使用该工具导致的侵权或其它问题,该本工具不承担任何责任!
65 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | pip-wheel-metadata/
24 | share/python-wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 | MANIFEST
29 |
30 | # PyInstaller
31 | # Usually these files are written by a python script from a template
32 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
33 | *.manifest
34 | *.spec
35 |
36 | # Installer logs
37 | pip-log.txt
38 | pip-delete-this-directory.txt
39 |
40 | # Unit test / coverage reports
41 | htmlcov/
42 | .tox/
43 | .nox/
44 | .coverage
45 | .coverage.*
46 | .cache
47 | nosetests.xml
48 | coverage.xml
49 | *.cover
50 | *.py,cover
51 | .hypothesis/
52 | .pytest_cache/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | target/
76 |
77 | # Jupyter Notebook
78 | .ipynb_checkpoints
79 |
80 | # IPython
81 | profile_default/
82 | ipython_config.py
83 |
84 | # pyenv
85 | .python-version
86 |
87 | # pipenv
88 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
89 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
90 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
91 | # install all needed dependencies.
92 | #Pipfile.lock
93 |
94 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
95 | __pypackages__/
96 |
97 | # Celery stuff
98 | celerybeat-schedule
99 | celerybeat.pid
100 |
101 | # SageMath parsed files
102 | *.sage.py
103 |
104 | # Environments
105 | .env
106 | .venv
107 | env/
108 | venv/
109 | ENV/
110 | env.bak/
111 | venv.bak/
112 |
113 | # Spyder project settings
114 | .spyderproject
115 | .spyproject
116 |
117 | # Rope project settings
118 | .ropeproject
119 |
120 | # mkdocs documentation
121 | /site
122 |
123 | # mypy
124 | .mypy_cache/
125 | .dmypy.json
126 | dmypy.json
127 |
128 | # Pyre type checker
129 | .pyre/
130 |
131 |
132 | # venv
133 | .cfg
--------------------------------------------------------------------------------
/templates/wereadtonotion.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | Weread to Notion
5 |
29 |
30 |
31 |
32 |
Weread to Notion
33 |
49 |
50 |
51 |