├── 1-feedforward_network
├── README.md
└── images
│ ├── feedforward-network-figure0.jpg
│ ├── feedforward-network-figure1.jpg
│ ├── feedforward-network-figure10.jpg
│ ├── feedforward-network-figure11.jpg
│ ├── feedforward-network-figure12.jpg
│ ├── feedforward-network-figure13.jpg
│ ├── feedforward-network-figure14.jpg
│ ├── feedforward-network-figure15.jpg
│ ├── feedforward-network-figure16.jpg
│ ├── feedforward-network-figure17.jpg
│ ├── feedforward-network-figure18.jpg
│ ├── feedforward-network-figure19.jpg
│ ├── feedforward-network-figure2.jpg
│ ├── feedforward-network-figure20.jpg
│ ├── feedforward-network-figure21.jpg
│ ├── feedforward-network-figure22.jpg
│ ├── feedforward-network-figure23.jpg
│ ├── feedforward-network-figure24.jpg
│ ├── feedforward-network-figure3.jpg
│ ├── feedforward-network-figure4.jpg
│ ├── feedforward-network-figure5.jpg
│ ├── feedforward-network-figure6.jpg
│ ├── feedforward-network-figure7.jpg
│ ├── feedforward-network-figure8.jpg
│ └── feedforward-network-figure9.jpg
├── 10-seq2seq
├── README.md
└── images
│ ├── _seq2seq-figure1_.jpg
│ ├── _seq2seq-figure2.jpg
│ ├── _seq2seq-figure3.jpg
│ ├── seq2seq-figure1.jpg
│ ├── seq2seq-figure10.jpg
│ ├── seq2seq-figure11.jpg
│ ├── seq2seq-figure12.jpg
│ ├── seq2seq-figure13.jpg
│ ├── seq2seq-figure14.jpg
│ ├── seq2seq-figure15.jpg
│ ├── seq2seq-figure16.jpg
│ ├── seq2seq-figure17.jpg
│ ├── seq2seq-figure18.jpg
│ ├── seq2seq-figure19.jpg
│ ├── seq2seq-figure2.jpg
│ ├── seq2seq-figure20.jpg
│ ├── seq2seq-figure3.jpg
│ ├── seq2seq-figure4.jpg
│ ├── seq2seq-figure5.jpg
│ ├── seq2seq-figure6.jpg
│ ├── seq2seq-figure7.jpg
│ ├── seq2seq-figure8.jpg
│ └── seq2seq-figure9.jpg
├── 100-LLM-Survey
└── README.md
├── 11-attentions
├── README.md
├── attention-extension.md
├── decoder_demo.py
├── encoder_demo.py
└── images
│ ├── attention-figure-eg.jpg
│ ├── attention-figure1.jpg
│ ├── attention-figure10.jpg
│ ├── attention-figure11.jpg
│ ├── attention-figure12.jpg
│ ├── attention-figure13.jpg
│ ├── attention-figure14.jpg
│ ├── attention-figure15.jpg
│ ├── attention-figure16.jpg
│ ├── attention-figure17.jpg
│ ├── attention-figure18.jpg
│ ├── attention-figure19.jpg
│ ├── attention-figure2.jpg
│ ├── attention-figure20.jpg
│ ├── attention-figure21.jpg
│ ├── attention-figure22.jpg
│ ├── attention-figure3.jpg
│ ├── attention-figure4.jpg
│ ├── attention-figure5.jpg
│ ├── attention-figure6.jpg
│ ├── attention-figure7.jpg
│ ├── attention-figure8.jpg
│ ├── attention-figure9.jpg
│ ├── encoder_shaped.onnx
│ ├── flash-attention-figure1.jpg
│ ├── flash-attention-simple-0.png
│ ├── flash-attention-simple-1.png
│ ├── flash-attention-simple-2.png
│ ├── flash-attention-simple-3.png
│ ├── flash-attention1-softmax-trick.png
│ ├── flash-attention2-backward.png
│ ├── flash-attention2-forward.png
│ ├── flash-attention2-softmax-trick.png
│ ├── flash_attention1-algorithm1.png
│ ├── flash_attention1-algorithm2.png
│ ├── flash_attention1-algorithm3.png
│ ├── flash_attention1-algorithm4.png
│ ├── flash_attention1_algorithm0.jpg
│ ├── gqa-figure1.jpg
│ ├── gqa-figure2.jpg
│ ├── mla1.png
│ ├── mla2.png
│ ├── mla3.png
│ ├── page-attention0.gif
│ ├── page-attention1.gif
│ ├── page-attention2.gif
│ ├── page-attention3.gif
│ ├── ring-attention-figure2.png
│ ├── safe-softmax.png
│ ├── standard_attention0.png
│ └── vllm-figure0.png
├── 12-weight-initialization
├── README.md
└── images
│ ├── glorot-formula1.jpg
│ ├── glorot-formula2.jpg
│ ├── weight-init-figure1.jpg
│ └── weight-init-figure2.jpg
├── 13-optimizers
├── README.md
└── images
│ ├── optimizer-algorithm1.jpg
│ ├── optimizer-algorithm10.jpg
│ ├── optimizer-algorithm11.jpg
│ ├── optimizer-algorithm12.jpg
│ ├── optimizer-algorithm13.jpg
│ ├── optimizer-algorithm14.jpg
│ ├── optimizer-algorithm15.jpg
│ ├── optimizer-algorithm2.jpg
│ ├── optimizer-algorithm3.jpg
│ ├── optimizer-algorithm4.jpg
│ ├── optimizer-algorithm5.jpg
│ ├── optimizer-algorithm6.jpg
│ ├── optimizer-algorithm7.jpg
│ ├── optimizer-algorithm8.jpg
│ ├── optimizer-algorithm9.jpg
│ ├── optimizer-figure1.jpg
│ ├── optimizer-figure10.jpg
│ ├── optimizer-figure2.jpg
│ ├── optimizer-figure3.jpg
│ ├── optimizer-figure4.jpg
│ ├── optimizer-figure5.jpg
│ ├── optimizer-figure6.jpg
│ ├── optimizer-figure7.jpg
│ ├── optimizer-figure8.jpg
│ ├── optimizer-figure9.jpg
│ ├── optimizer-formula1.jpg
│ ├── optimizer-formula2.jpg
│ ├── optimizer-formula3.jpg
│ ├── optimizer-gif1.gif
│ ├── optimizer-gif2.gif
│ ├── optimizer-gif3.gif
│ ├── optimizer-gif4.gif
│ ├── optimizer-gif5.gif
│ └── optimizer-gif6.gif
├── 14-regularization
├── README.md
└── images
│ ├── figure1.png
│ ├── figure2.png
│ ├── figure3.png
│ ├── figure4.png
│ └── figure5.png
├── 15-deep-learning-tuning-guide
└── README.md
├── 16-learning_rate
└── README.md
├── 2-back_propagation
├── README.md
└── images
│ ├── back-propagation-figure1.jpg
│ ├── back-propagation-figure10.jpg
│ ├── back-propagation-figure11.jpg
│ ├── back-propagation-figure12.jpg
│ ├── back-propagation-figure13.jpg
│ ├── back-propagation-figure14.jpg
│ ├── back-propagation-figure15.jpg
│ ├── back-propagation-figure16.jpg
│ ├── back-propagation-figure17.jpg
│ ├── back-propagation-figure18.jpg
│ ├── back-propagation-figure19.jpg
│ ├── back-propagation-figure2.jpg
│ ├── back-propagation-figure20.jpg
│ ├── back-propagation-figure21.jpg
│ ├── back-propagation-figure22.jpg
│ ├── back-propagation-figure23.jpg
│ ├── back-propagation-figure3.jpg
│ ├── back-propagation-figure4.jpg
│ ├── back-propagation-figure5.jpg
│ ├── back-propagation-figure6.jpg
│ ├── back-propagation-figure7.jpg
│ ├── back-propagation-figure8.jpg
│ ├── back-propagation-figure9.jpg
│ ├── back-propagation-formula1.jpg
│ ├── back-propagation-gif1.gif
│ └── back-propagation-gif2.gif
├── 20-pytorch-tensor
├── README.md
├── images
│ └── tensor-figure1.jpg
└── test_tensor.py
├── 21-pytorch-autograd
├── README.md
├── images
│ ├── autograd-figure1.jpg
│ ├── autograd-figure2.jpg
│ ├── autograd-figure3.jpg
│ ├── autograd-gif1.gif
│ └── autograd-gif2.gif
└── test_autograd.py
├── 22-pytorch-module
├── README.md
└── test_module.py
├── 23-training-examples
├── README.md
├── decoder.md
├── encoder.md
├── kvcache_decode_demo.py
├── train_decoder_demo.py
└── transformer.md
├── 24-pytorch-optimizer
└── README.md
├── 25-pytorch-lr-scheduler
├── README.md
└── images
│ ├── lr-figure1.jpg
│ ├── lr-figure10.jpg
│ ├── lr-figure2.jpg
│ ├── lr-figure3.jpg
│ ├── lr-figure4.jpg
│ ├── lr-figure5.jpg
│ ├── lr-figure6.jpg
│ ├── lr-figure7.jpg
│ ├── lr-figure8.jpg
│ └── lr-figure9.jpg
├── 26-pytorch-dataloader
└── README.md
├── 27-pytorch-model-save
└── README.md
├── 28-pytorch-tensorboard
└── README.md
├── 29-pytorch-graph-mode
├── README.md
└── images
│ └── pytorch-patterns-figure1.jpg
├── 3-bp_example_demo
├── README.md
└── images
│ ├── bp-example-figure1.jpg
│ ├── bp-example-figure2.jpg
│ ├── bp-example-figure3.jpg
│ ├── bp-example-figure4.jpg
│ ├── bp-example-figure5.jpg
│ ├── bp-example-figure6.jpg
│ ├── bp-example-formula1.jpg
│ ├── bp-example-formula2.jpg
│ ├── bp-example-formula3.jpg
│ └── bp-example-formula4.jpg
├── 30-training_examples_cv
├── README.md
├── extract_ILSVRC.sh
├── main.py
└── requirements.txt
├── 31-stable-diffusion
├── README.md
├── SDXL.md
└── VAE.md
├── 33-stable-diffusion
├── README.md
├── SDXL.md
└── VAE.md
├── 4-convolution_neural_network
├── README.md
└── images
│ ├── cnn-figure1.jpg
│ ├── cnn-figure10.jpg
│ ├── cnn-figure11.jpg
│ ├── cnn-figure12.jpg
│ ├── cnn-figure13.jpg
│ ├── cnn-figure14.jpg
│ ├── cnn-figure15.jpg
│ ├── cnn-figure16.jpg
│ ├── cnn-figure17.jpg
│ ├── cnn-figure18.jpg
│ ├── cnn-figure2.jpg
│ ├── cnn-figure3.jpg
│ ├── cnn-figure4.jpg
│ ├── cnn-figure5.jpg
│ ├── cnn-figure6.jpg
│ ├── cnn-figure7.jpg
│ ├── cnn-figure8.jpg
│ ├── cnn-figure9.jpg
│ ├── cnn-formula1.jpg
│ ├── cnn-formula2.jpg
│ ├── cnn-formula3.jpg
│ ├── cnn-formula4.jpg
│ ├── cnn-formula5.jpg
│ ├── cnn-gif1.gif
│ ├── cnn-gif2.gif
│ ├── cnn-gif3.gif
│ ├── cnn-gif4.gif
│ ├── cnn-gif5.gif
│ └── cnn-gif6.gif
├── 40-nlp_bert
├── images
│ ├── figure1.jpg
│ ├── figure10.jpg
│ ├── figure11.jpg
│ ├── figure12.jpg
│ ├── figure13.jpg
│ ├── figure2.jpg
│ ├── figure3.jpg
│ ├── figure4.jpg
│ ├── figure5.jpg
│ ├── figure6.jpg
│ ├── figure7.jpg
│ ├── figure8.jpg
│ └── figure9.jpg
└── ner.md
├── 41-nlp_t5
├── images
│ ├── figure1.jpg
│ ├── figure10.jpg
│ ├── figure11.jpg
│ ├── figure12.jpg
│ ├── figure13.jpg
│ ├── figure14.jpg
│ ├── figure15.jpg
│ ├── figure16.jpg
│ ├── figure2.jpg
│ ├── figure3.jpg
│ ├── figure4.jpg
│ ├── figure5.jpg
│ ├── figure6.jpg
│ ├── figure7.jpg
│ ├── figure8.jpg
│ └── figure9.jpg
├── question-answering.md
└── squard_v2_output.tar.gz
├── 42-nlp-gpt
├── README.md
└── images
│ ├── gpt3-figure1.png
│ ├── gpt3-figure2.png
│ ├── gpt3-figure3.png
│ ├── gpt3-figure4.png
│ ├── gpt3-figure5.png
│ └── gpt3-figure6.png
├── 43-scaling-law
└── README.md
├── 44-distribute-training
└── README.md
├── 45-LLM-History
├── README.md
└── images
│ ├── figure1.png
│ ├── figure10.png
│ ├── figure11.png
│ ├── figure12.png
│ ├── figure13.png
│ ├── figure14.png
│ ├── figure15.png
│ ├── figure16.png
│ ├── figure17.png
│ ├── figure18.png
│ ├── figure19.png
│ ├── figure2.png
│ ├── figure20.png
│ ├── figure21.png
│ ├── figure22.png
│ ├── figure23.png
│ ├── figure24.png
│ ├── figure25.png
│ ├── figure26.png
│ ├── figure27.png
│ ├── figure3.png
│ ├── figure4.png
│ ├── figure5.png
│ ├── figure6.png
│ ├── figure7.png
│ ├── figure8.png
│ └── figure9.png
├── 46-LLM-GPT-Extension
├── README.md
├── image-1.png
├── image.png
└── images
│ ├── image-1.png
│ ├── image-2.png
│ ├── image-3.png
│ ├── image-4.png
│ ├── image-5.png
│ ├── image-6.png
│ ├── image-7.png
│ └── image.png
├── 46-LLM-Llama
├── Llama-2-7b-hf
│ ├── added_tokens.json
│ ├── config.json
│ ├── configuration.json
│ ├── generation_config.json
│ ├── model.safetensors.index.json
│ ├── special_tokens_map.json
│ ├── tokenizer.json
│ ├── tokenizer.model
│ └── tokenizer_config.json
├── README.md
├── image-1.png
├── image-10.png
├── image-2.png
├── image-3.png
├── image-4.png
├── image-5.png
├── image-6.png
├── image-7.png
├── image-8.png
├── image-9.png
└── image.png
├── 47-LLM-DeepSeek-Structure
├── README.md
├── image-1.png
├── image-10.png
├── image-11.png
├── image-12.png
├── image-13.png
├── image-14.png
├── image-15.png
├── image-16.png
├── image-17.png
├── image-18.png
├── image-19.png
├── image-2.png
├── image-20.png
├── image-21.png
├── image-22.png
├── image-23.png
├── image-24.png
├── image-3.png
├── image-4.png
├── image-5.png
├── image-6.png
├── image-7.png
├── image-8.png
├── image-9.png
└── image.png
├── 48-LLM-deepseek-r1-training
├── DeepSeekR1-Analyze.md
├── README.md
├── image-1.png
├── image-2.png
├── image-3.png
├── image-4.png
├── image-5.png
├── image.png
└── images
│ ├── image-1.png
│ ├── image-10.png
│ ├── image-11.png
│ ├── image-12.png
│ ├── image-13.png
│ ├── image-14.png
│ ├── image-15.png
│ ├── image-16.png
│ ├── image-17.png
│ ├── image-18.png
│ ├── image-19.png
│ ├── image-2.png
│ ├── image-3.png
│ ├── image-4.png
│ ├── image-5.png
│ ├── image-6.png
│ ├── image-7.png
│ ├── image-8.png
│ ├── image-9.png
│ └── image.png
├── 49-PPO-GRPO
├── README.md
├── __pycache__
│ └── rl_brain.cpython-312.pyc
├── image-1.png
├── image-10.png
├── image-11.png
├── image-12.png
├── image-13.png
├── image-14.png
├── image-15.png
├── image-2.png
├── image-3.png
├── image-4.png
├── image-5.png
├── image-6.png
├── image-7.png
├── image-8.png
├── image-9.png
├── image.png
├── ppo.py
├── rl_brain.py
└── rl_train.py
├── 5-deep_learning_model
└── README.md
├── 50-Chain-of-Thought
├── README.md
├── image-1.png
├── image-2.png
├── image-3.png
├── image-4.png
├── image-5.png
└── image.png
├── 6-pytorch_install
├── README.md
└── images
│ ├── pytorch-figure1.jpg
│ ├── pytorch-figure2.jpg
│ └── pytorch-figure3.jpg
├── 7-operators
├── README.md
└── images
│ ├── op-figure1.jpg
│ ├── op-figure10.jpg
│ ├── op-figure11.jpg
│ ├── op-figure12.jpg
│ ├── op-figure13.jpg
│ ├── op-figure14.jpg
│ ├── op-figure15.jpg
│ ├── op-figure16.jpg
│ ├── op-figure2.jpg
│ ├── op-figure3.jpg
│ ├── op-figure4.jpg
│ ├── op-figure5.jpg
│ ├── op-figure6.jpg
│ ├── op-figure7.jpg
│ ├── op-figure8.jpg
│ └── op-figure9.jpg
├── 8-activation_functions
├── README.md
└── images
│ ├── op-activation-figure1.jpg
│ ├── op-activation-figure10.jpg
│ ├── op-activation-figure11.jpg
│ ├── op-activation-figure12.jpg
│ ├── op-activation-figure13.jpg
│ ├── op-activation-figure2.jpg
│ ├── op-activation-figure3.jpg
│ ├── op-activation-figure4.jpg
│ ├── op-activation-figure5.jpg
│ ├── op-activation-figure6.jpg
│ ├── op-activation-figure7.jpg
│ ├── op-activation-figure8.jpg
│ ├── op-activation-figure9.jpg
│ ├── op-activation-formula1.jpg
│ ├── op-activation-formula2.jpg
│ └── op-activation-formula3.jpg
├── 9-recurrent_neural_network
├── README.md
└── images
│ ├── gru.gif
│ ├── lstm.gif
│ ├── rnn-figure1.jpg
│ ├── rnn-figure10.jpg
│ ├── rnn-figure11.jpg
│ ├── rnn-figure12.jpg
│ ├── rnn-figure13.jpg
│ ├── rnn-figure14.jpg
│ ├── rnn-figure15.jpg
│ ├── rnn-figure16.jpg
│ ├── rnn-figure17.jpg
│ ├── rnn-figure18.jpg
│ ├── rnn-figure2.jpg
│ ├── rnn-figure3.jpg
│ ├── rnn-figure4.jpg
│ ├── rnn-figure5.jpg
│ ├── rnn-figure6.jpg
│ ├── rnn-figure7.jpg
│ ├── rnn-figure8.jpg
│ ├── rnn-figure9.jpg
│ ├── rnn-gif1.gif
│ ├── rnn-gif10.gif
│ ├── rnn-gif2.gif
│ ├── rnn-gif3.gif
│ ├── rnn-gif4.gif
│ ├── rnn-gif5.gif
│ ├── rnn-gif6.gif
│ ├── rnn-gif7.gif
│ ├── rnn-gif8.gif
│ ├── rnn-gif9.gif
│ └── rnn.gif
├── LICENSE
├── README.md
└── position_embedding
├── README.md
├── images
├── figure1.jpg
├── figure10.jpg
├── figure11.jpg
├── figure12.jpg
├── figure13.jpg
├── figure14.jpg
├── figure15.jpg
├── figure16.jpg
├── figure2.jpg
├── figure3.jpg
├── figure4.jpg
├── figure5.jpg
├── figure6.jpg
├── figure7.jpg
├── figure8.jpg
└── figure9.jpg
├── relative_position_embedding.py
└── rope.py
/1-feedforward_network/images/feedforward-network-figure0.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure0.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure1.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure10.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure11.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure12.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure13.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure14.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure15.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure15.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure16.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure16.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure17.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure17.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure18.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure18.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure19.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure19.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure2.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure20.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure20.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure21.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure21.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure22.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure22.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure23.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure23.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure24.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure24.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure3.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure4.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure5.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure6.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure7.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure8.jpg
--------------------------------------------------------------------------------
/1-feedforward_network/images/feedforward-network-figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/1-feedforward_network/images/feedforward-network-figure9.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/_seq2seq-figure1_.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/_seq2seq-figure1_.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/_seq2seq-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/_seq2seq-figure2.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/_seq2seq-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/_seq2seq-figure3.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure1.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure10.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure11.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure12.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure13.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure14.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure15.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure15.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure16.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure16.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure17.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure17.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure18.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure18.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure19.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure19.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure2.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure20.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure20.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure3.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure4.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure5.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure6.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure7.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure8.jpg
--------------------------------------------------------------------------------
/10-seq2seq/images/seq2seq-figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/10-seq2seq/images/seq2seq-figure9.jpg
--------------------------------------------------------------------------------
/100-LLM-Survey/README.md:
--------------------------------------------------------------------------------
1 | # 论文链接
2 |
3 | - [论文链接](https://arxiv.org/pdf/2303.18223)
--------------------------------------------------------------------------------
/11-attentions/decoder_demo.py:
--------------------------------------------------------------------------------
1 | '''
2 | Llama 2 是一个 纯 Decoder 架构 的模型,没有 Encoder。
3 |
4 | 每个 Decoder 层包含 Masked Self-Attention 和 Feed-Forward Network。
5 |
6 | 使用因果掩码(Causal Mask)确保模型在生成时只能看到当前及之前的位置。
7 | '''
8 |
9 | import torch
10 | import torch.nn as nn
11 | import torch.nn.functional as F
12 |
13 | import torch
14 | import torch.nn as nn
15 | import torch.nn.functional as F
16 |
17 | class Llama2DecoderLayer(nn.Module):
18 | def __init__(self, d_model, nhead, dim_feedforward, dropout=0.1):
19 | super(Llama2DecoderLayer, self).__init__()
20 | self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
21 | self.linear1 = nn.Linear(d_model, dim_feedforward)
22 | self.linear2 = nn.Linear(dim_feedforward, d_model)
23 | self.norm1 = nn.LayerNorm(d_model)
24 | self.norm2 = nn.LayerNorm(d_model)
25 | self.dropout = nn.Dropout(dropout)
26 |
27 | def forward(self, tgt, tgt_mask=None):
28 | # Masked Self-Attention
29 | attn_output, _ = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask)
30 | tgt = tgt + self.dropout(attn_output)
31 | tgt = self.norm1(tgt)
32 |
33 | # Feed-Forward Network
34 | ff_output = self.linear2(self.dropout(F.gelu(self.linear1(tgt))))
35 | tgt = tgt + self.dropout(ff_output)
36 | tgt = self.norm2(tgt)
37 |
38 | return tgt
39 |
40 | class Llama2Decoder(nn.Module):
41 | def __init__(self, d_model, nhead, num_layers, dim_feedforward, dropout=0.1):
42 | super(Llama2Decoder, self).__init__()
43 | self.layers = nn.ModuleList([
44 | Llama2DecoderLayer(d_model, nhead, dim_feedforward, dropout)
45 | for _ in range(num_layers)
46 | ])
47 |
48 | def forward(self, tgt, tgt_mask=None):
49 | for layer in self.layers:
50 | tgt = layer(tgt, tgt_mask)
51 | return tgt
52 |
53 | def decoder_run():
54 | # 定义模型参数
55 | d_model = 512
56 | nhead = 8
57 | num_layers = 1
58 | dim_feedforward = 2048
59 | dropout = 0.1
60 |
61 | # 实例化模型
62 | model = Llama2Decoder(d_model, nhead, num_layers, dim_feedforward, dropout)
63 |
64 | # 创建示例输入
65 | tgt = torch.rand(10, 32, d_model) # (sequence_length, batch_size, d_model)
66 | tgt_mask = torch.triu(torch.ones(10, 10) * float('-inf'), diagonal=1) # 因果掩码
67 |
68 | # 前向传播
69 | output = model(tgt, tgt_mask)
70 | print(output.shape) # 输出形状: (10, 32, 512)
71 |
72 | def onnx_export():
73 | # 定义模型参数
74 | d_model = 512
75 | nhead = 8
76 | num_layers = 6
77 | dim_feedforward = 2048
78 | dropout = 0.1
79 |
80 | # 实例化模型
81 | model = Llama2Decoder(d_model, nhead, num_layers, dim_feedforward, dropout)
82 |
83 | # 设置模型为评估模式
84 | model.eval()
85 |
86 | # 创建示例输入(固定形状)
87 | sequence_length = 10
88 | batch_size = 32
89 | tgt = torch.rand(sequence_length, batch_size, d_model) # 固定形状 (10, 32, 512)
90 | tgt_mask = torch.triu(torch.ones(sequence_length, sequence_length) * float('-inf'), diagonal=1) # 固定形状 (10, 10)
91 |
92 | # 导出模型为 ONNX 格式(静态形状)
93 | torch.onnx.export(
94 | model, # 模型
95 | (tgt, tgt_mask), # 模型输入(元组形式)
96 | "llama2_decoder_static.onnx", # 导出的 ONNX 文件名
97 | input_names=["tgt", "tgt_mask"], # 输入名称
98 | output_names=["output"], # 输出名称
99 | opset_version=13, # ONNX opset 版本
100 | verbose=True # 打印导出日志
101 | )
102 |
103 | print("模型已成功导出为 llama2_decoder_static.onnx")
104 |
105 | def onnx_shape_infer_and_simplify():
106 | import onnx
107 | from onnx import shape_inference
108 | from onnxsim import simplify
109 |
110 | # 加载导出的 ONNX 模型
111 | onnx_model = onnx.load("llama2_decoder_static.onnx")
112 |
113 | # 进行形状推理
114 | onnx_model = shape_inference.infer_shapes(onnx_model)
115 |
116 | # 简化模型
117 | simplified_model, check = simplify(onnx_model)
118 | # 检查简化是否成功
119 | if check:
120 | print("模型简化成功!")
121 | else:
122 | print("模型简化失败!")
123 |
124 | # 保存简化后的模型
125 | onnx.save(simplified_model, "llama2_decoder_static_shaped_simplified.onnx")
126 |
127 |
128 | if __name__ == '__main__':
129 | # decoder_run()
130 | # onnx_export()
131 | onnx_shape_infer_and_simplify()
132 |
133 |
134 |
135 |
136 |
--------------------------------------------------------------------------------
/11-attentions/encoder_demo.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from transformers import BertModel, BertConfig
3 | import logging
4 |
5 | logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(filename)s - %(funcName)s - %(levelname)s - %(message)s')
6 | logger = logging.getLogger(__name__)
7 |
8 | class SingleLayerBertEncoder(torch.nn.Module):
9 | def __init__(self, config):
10 | super(SingleLayerBertEncoder, self).__init__()
11 | self.embeddings = BertModel.from_pretrained('bert-base-uncased', config=config).embeddings
12 | self.encoder_layer = BertModel.from_pretrained('bert-base-uncased', config=config).encoder.layer[0]
13 |
14 | def forward(self, input_ids, attention_mask=None):
15 | # 获取嵌入输出
16 | embedding_output = self.embeddings(input_ids)
17 | # 使用单层编码器进行处理
18 | encoder_outputs = self.encoder_layer(hidden_states=embedding_output,
19 | attention_mask=attention_mask)
20 | return encoder_outputs[0] # 返回最后一层隐藏状态
21 |
22 |
23 | def export_encoder_onnx():
24 | # 加载预训练的BERT配置
25 | config = BertConfig.from_pretrained('bert-base-uncased')
26 | model = SingleLayerBertEncoder(config)
27 |
28 | # 设置模型为评估模式
29 | model.eval()
30 |
31 | # 准备示例输入数据
32 | input_ids = torch.tensor([[101, 2023, 2003, 1037, 7354, 102]]) # 示例输入ID
33 | attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1]]) # 示例注意力掩码
34 |
35 | # 导出模型到ONNX
36 | torch.onnx.export(model,
37 | args=(input_ids, attention_mask),
38 | f="single_layer_bert_encoder.onnx",
39 | input_names=['input_ids', 'attention_mask'],
40 | output_names=['output'],
41 | opset_version=11,
42 | do_constant_folding=True,
43 | dynamic_axes={'input_ids': {0: 'batch_size', 1: 'sequence'},
44 | 'attention_mask': {0: 'batch_size', 1: 'sequence'},
45 | 'output': {0: 'batch_size', 1: 'sequence'}})
46 |
47 | logger.info("单层BERT编码器已成功导出为ONNX格式")
48 |
49 | def run_encoder_onnx():
50 | from transformers import BertTokenizer
51 | import numpy as np
52 | import onnxruntime as ort
53 |
54 | # 加载分词器
55 | tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
56 |
57 | # 准备输入文本
58 | text = "Here is a sample sentence for the encoder."
59 | inputs = tokenizer(text, return_tensors='pt')
60 |
61 | # 将PyTorch张量转换为NumPy数组
62 | input_ids = inputs['input_ids'].numpy()
63 | attention_mask = inputs['attention_mask'].numpy()
64 |
65 | # 创建ONNX运行时会话
66 | ort_session = ort.InferenceSession("single_layer_bert_encoder.onnx")
67 |
68 | # 运行模型
69 | outputs = ort_session.run(
70 | None, # 计算图中的输出节点名称;None表示返回所有输出
71 | {"input_ids": input_ids, "attention_mask": attention_mask},
72 | )
73 |
74 | # 输出是一个列表,其中包含了模型的所有输出
75 | output = outputs[0]
76 |
77 | logger.info("Model output:", output)
78 |
79 | def onnx_shape_inference():
80 | import onnx
81 | from onnx import shape_inference
82 |
83 | # 加载原始模型
84 | model_path = "single_layer_bert_encoder.onnx"
85 | model = onnx.load(model_path)
86 |
87 | # 对模型进行形状推理
88 | inferred_model = shape_inference.infer_shapes(model)
89 |
90 | # 保存带有形状信息的模型(可选)
91 | onnx.save(inferred_model, "single_layer_bert_encoder_with_shapes.onnx")
92 |
93 | # 打印模型的计算图及形状信息
94 | logger.info(onnx.helper.printable_graph(inferred_model.graph))
95 |
96 | if __name__ == '__main__':
97 | export_encoder_onnx() # 导出模型
98 | # run_encoder_onnx()
99 | # onnx_shape_inference()
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure-eg.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure-eg.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure1.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure10.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure11.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure12.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure13.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure14.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure15.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure15.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure16.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure16.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure17.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure17.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure18.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure18.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure19.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure19.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure2.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure20.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure20.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure21.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure21.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure22.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure22.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure3.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure4.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure5.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure6.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure7.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure8.jpg
--------------------------------------------------------------------------------
/11-attentions/images/attention-figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/attention-figure9.jpg
--------------------------------------------------------------------------------
/11-attentions/images/encoder_shaped.onnx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/encoder_shaped.onnx
--------------------------------------------------------------------------------
/11-attentions/images/flash-attention-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash-attention-figure1.jpg
--------------------------------------------------------------------------------
/11-attentions/images/flash-attention-simple-0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash-attention-simple-0.png
--------------------------------------------------------------------------------
/11-attentions/images/flash-attention-simple-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash-attention-simple-1.png
--------------------------------------------------------------------------------
/11-attentions/images/flash-attention-simple-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash-attention-simple-2.png
--------------------------------------------------------------------------------
/11-attentions/images/flash-attention-simple-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash-attention-simple-3.png
--------------------------------------------------------------------------------
/11-attentions/images/flash-attention1-softmax-trick.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash-attention1-softmax-trick.png
--------------------------------------------------------------------------------
/11-attentions/images/flash-attention2-backward.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash-attention2-backward.png
--------------------------------------------------------------------------------
/11-attentions/images/flash-attention2-forward.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash-attention2-forward.png
--------------------------------------------------------------------------------
/11-attentions/images/flash-attention2-softmax-trick.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash-attention2-softmax-trick.png
--------------------------------------------------------------------------------
/11-attentions/images/flash_attention1-algorithm1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash_attention1-algorithm1.png
--------------------------------------------------------------------------------
/11-attentions/images/flash_attention1-algorithm2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash_attention1-algorithm2.png
--------------------------------------------------------------------------------
/11-attentions/images/flash_attention1-algorithm3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash_attention1-algorithm3.png
--------------------------------------------------------------------------------
/11-attentions/images/flash_attention1-algorithm4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash_attention1-algorithm4.png
--------------------------------------------------------------------------------
/11-attentions/images/flash_attention1_algorithm0.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/flash_attention1_algorithm0.jpg
--------------------------------------------------------------------------------
/11-attentions/images/gqa-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/gqa-figure1.jpg
--------------------------------------------------------------------------------
/11-attentions/images/gqa-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/gqa-figure2.jpg
--------------------------------------------------------------------------------
/11-attentions/images/mla1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/mla1.png
--------------------------------------------------------------------------------
/11-attentions/images/mla2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/mla2.png
--------------------------------------------------------------------------------
/11-attentions/images/mla3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/mla3.png
--------------------------------------------------------------------------------
/11-attentions/images/page-attention0.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/page-attention0.gif
--------------------------------------------------------------------------------
/11-attentions/images/page-attention1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/page-attention1.gif
--------------------------------------------------------------------------------
/11-attentions/images/page-attention2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/page-attention2.gif
--------------------------------------------------------------------------------
/11-attentions/images/page-attention3.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/page-attention3.gif
--------------------------------------------------------------------------------
/11-attentions/images/ring-attention-figure2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/ring-attention-figure2.png
--------------------------------------------------------------------------------
/11-attentions/images/safe-softmax.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/safe-softmax.png
--------------------------------------------------------------------------------
/11-attentions/images/standard_attention0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/standard_attention0.png
--------------------------------------------------------------------------------
/11-attentions/images/vllm-figure0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/11-attentions/images/vllm-figure0.png
--------------------------------------------------------------------------------
/12-weight-initialization/images/glorot-formula1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/12-weight-initialization/images/glorot-formula1.jpg
--------------------------------------------------------------------------------
/12-weight-initialization/images/glorot-formula2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/12-weight-initialization/images/glorot-formula2.jpg
--------------------------------------------------------------------------------
/12-weight-initialization/images/weight-init-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/12-weight-initialization/images/weight-init-figure1.jpg
--------------------------------------------------------------------------------
/12-weight-initialization/images/weight-init-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/12-weight-initialization/images/weight-init-figure2.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm1.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm10.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm11.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm12.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm13.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm14.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm15.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm15.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm2.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm3.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm4.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm5.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm6.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm7.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm8.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-algorithm9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-algorithm9.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-figure1.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-figure10.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-figure2.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-figure3.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-figure4.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-figure5.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-figure6.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-figure7.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-figure8.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-figure9.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-formula1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-formula1.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-formula2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-formula2.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-formula3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-formula3.jpg
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-gif1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-gif1.gif
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-gif2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-gif2.gif
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-gif3.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-gif3.gif
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-gif4.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-gif4.gif
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-gif5.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-gif5.gif
--------------------------------------------------------------------------------
/13-optimizers/images/optimizer-gif6.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/13-optimizers/images/optimizer-gif6.gif
--------------------------------------------------------------------------------
/14-regularization/README.md:
--------------------------------------------------------------------------------
1 | # 1 正则化概念
2 | 机器学习中的一个核心问题是设计不仅在训练数据上表现好,并且能在新输入上泛化好的算法。在机器学习中,许多策略显式地被设计来减少测试误差(可能会以增大训练误差为代价),这些策略被统称为正则化。
3 |
4 | **思考:只有深度学习才有正则化吗?**
5 |
6 | - 正则化在深度学习的出现前就已经被使用了数十年。
7 | - 线性模型,如线性回归和逻辑回归可以使用简单、直接、有效的正则化策略。
8 |
9 | # 2 什么情况下容易出现过拟合
10 | 正则化在以下情况下容易出现:
11 |
12 | - 数据集规模相对较小:当训练数据集的规模相对较小时,模型容易过拟合。这是因为较小的数据集可能无法很好地捕捉到真实数据的复杂性,导致模型过度依赖训练数据中的噪声和异常点。在这种情况下,引入正则化可以限制模型的复杂度,减少过拟合的风险。
13 |
14 | - 特征维度较高:当输入特征的维度较高时,模型也容易过拟合。高维特征空间中的线性模型往往有很大的参数空间,可以灵活地适应训练数据,但也容易产生过多的参数,从而增加过拟合的可能性。正则化可以帮助减少模型参数的数量,使模型更加简洁且泛化性能更好。
15 |
16 | - 模型复杂度较高:如果模型具有较大的容量,例如深度神经网络具有大量的隐藏层和参数,那么模型更容易过拟合。复杂模型具有较强的表达能力,可以学习到更多数据中的细节和噪声,但也容易在训练数据上表现出很好的性能而在新数据上表现较差。正则化可以限制模型的复杂度,平衡模型的拟合能力和泛化能力。
17 |
18 | 总的来说,正则化在数据集规模较小、特征维度较高和模型复杂度较高等情况下容易出现,并且可以有效地控制模型的过拟合。
19 |
20 | # 3 常见的正则化方法
21 |
22 | ## 3.1 参数范数惩罚
23 | 许多正则化方法通过对目标函数J(loss函数) 添加一个参数范数惩罚Ω(),限制模型(如神经网络、线性回归或逻辑回归)的学习能力。我们将正则化后的目标函数记为 $\tilde{J}$ :
24 |
25 | 
26 |
27 | **思考:所有weight的权重衰减系数相同吗?**
28 |
29 | ## 3.2 数据集增强
30 | 让机器学习模型泛化得更好的最好办法是使用更多的数据进行训练。当然,在实践中,我们拥有的数据量是很有限的。解决这个问题的一种方法是创建假数据并
31 | 添加到训练集中。对于一些机器学习任务,创建新的假数据相当简单。
32 |
33 | **cv 中常见的数据增强手段**
34 | - Geometric Transformations:图像翻转,裁剪,旋转和平移等等,
35 | - Color Space Transformations:对比度,锐化,白平衡,色彩抖动,随机色彩处理和许多其他技术来更改图像的色彩空间。
36 | - Mixup就是将两张图像进行mix操作,提供数据的丰富性;
37 | - Cutmix就是将一部分区域cut掉但不填充0像素而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配。
38 | - Mosaic:是将四张图片进行随机裁剪,再拼接到一张图上作为训练数据,这样做的好处是丰富了图片的背景。
39 |
40 | **nlp 中常见的数据增强手段**
41 | - 词汇替换
42 | - 使用正则表达式应用的简单模式匹配变
43 | - 在文本中注入噪声,来生成新的文本
44 | - 在句子中随机交换任意两个单词
45 |
46 | ## 3.3 标签平滑(label smoothing)
47 | 标签平滑(label smoothing)通过把确切分类目标从0 和1 替换成 $\frac{ϵ}{k -1}$ 和 $1 - ϵ$ ,正则化具有k 个输出的softmax 函数的模型。标准交叉熵损失可以用在这些非确切目标的输出上。使用softmax 函数和明确目标的最大似然学习可能永远不会收敛——softmax 函数永远无法真正预测0 概率或1 概率,因此它会继续学习越来越大的权重,使预测更极端。使用如权重衰减等其他正则化策略能够防止这种情况。标签平滑的优势是能够防止模型追求确切概率而不影响模型学习正确分类。这种策略自20 世纪80 年代就已经被使用,并在现代神经网络继续保持显著特色.
48 |
49 | **思考:为什么是 $\frac{ϵ}{k -1}$ 呢?
50 |
51 | ## 3.4 droupout
52 | Dropout指在训练神经网络过程中随机丢掉一部分神经元来减少神经网络复杂度,从而防止过拟合。Dropout实现方法很简单:在每次迭代训练中,以一定概率随机屏蔽每一层中若干神经元,用余下神经元所构成网络来继续训练。
53 |
54 | 
55 |
56 | 上图是Dropout示意图,左边是完整的神经网络,右边是应用了Dropout之后的网络结构。应用Dropout之后,会将标了× 的神经元从网络中删除,让它们不向后面的层传递信号。在学习过程中,丢弃哪些神经元是随机决定,因此模型不会过度依赖某些神经元,能一定程度上抑制过拟合。
57 |
58 | **思考:训练和推理时dropout 有何不同???**
59 |
60 | ## 3.5 dropconnet
61 | DropConnect的思想也很简单,与Dropout不同的是,它不是随机将隐含层节点的输出清0,而是将节点中的每个与其相连的输入权值以1-p的概率清0。(一个是输出,一个是输入);
62 |
63 | 
64 |
65 | **思考:dropout 和 dropblock 多用于全连接层,那卷积层呢?**
66 |
67 |
68 | ## 3.6 dropblock
69 |
70 | 
71 |
72 | 如果对原图进行dropout正则化,b图上的黑色的点即是导致失活的特征点。此时因为后续是卷积核来进行特征的提取,卷积核是具有感受野的。特征图上,相邻元素在空间上共享语义信息,所以并不影响有效特征的提取。并没阻止学习到有效特征,就失去了正则化的效果。那dropblock为什么在卷积网络上可以有效果?根据以上的猜测,要丢掉有效特征的方法就是将有效特征点与相邻点都丢掉。这样形成一整块整块(block)的丢掉有效特征。也就是dropblock的由来。丢掉整块的有效特征,强化其他位置的特征点学习到丢失掉的位置的语义信息。这样使得整个模型更具有鲁棒性。
73 |
74 | ## 3.7 其它正则化方法
75 |
76 | 
--------------------------------------------------------------------------------
/14-regularization/images/figure1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/14-regularization/images/figure1.png
--------------------------------------------------------------------------------
/14-regularization/images/figure2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/14-regularization/images/figure2.png
--------------------------------------------------------------------------------
/14-regularization/images/figure3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/14-regularization/images/figure3.png
--------------------------------------------------------------------------------
/14-regularization/images/figure4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/14-regularization/images/figure4.png
--------------------------------------------------------------------------------
/14-regularization/images/figure5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/14-regularization/images/figure5.png
--------------------------------------------------------------------------------
/16-learning_rate/README.md:
--------------------------------------------------------------------------------
1 | - [链接](https://github.com/Elvin-Ma/deep_learning_training_techniques/tree/main/learning-rate)
2 |
3 | -[]()
--------------------------------------------------------------------------------
/2-back_propagation/README.md:
--------------------------------------------------------------------------------
1 | # 1 概念理解
2 |
3 | ## 1.1 神经网络训练流程概述
4 |
5 | 当我们使用前馈神经网络(feedforward neural network)接收输入 x 并产生输出 y 时,信息通过网络向前流动。输入 x 提供初始信息,然后传播到每一层的隐藏单元,最终产生输出 y。这称之为前向传播(forward propagation)。
6 | 在训练过程中,前向传播可以持续向前直到它产生一个**标量** 的 损失函数 $J(\theta)$ 。
7 | 反向传播(back propagation)算法经常简称为backprop,允许来自代价函数的信息通过网络向后流动,以便计算梯度。
8 |
9 | ## 1.2 反向传播的定义
10 | 反向传播(英语:Backpropagation,意为**误差**反向传播,缩写为BP)是对多层人工神经网络进行梯度下降的算法,也就是用**链式法则**以网络每层的**权重**为变量计算**损失函数**的梯度,以**更新权重**来最小化损失函数。
11 |
12 | # 2 梯度下降算法简述
13 | - 多元函数 f 的梯度定义为:
14 | 
15 |
16 | - 梯度有一个非常重要的性质:**函数f沿梯度方向增加(上升)最快, 函数f沿负梯度方向减小(下降)最快。**
17 |
18 | - 梯度下降法(SGD)算法, :
19 | 
20 |
21 | - 梯度下降法效果展示:
22 | 
23 |
24 | - 梯度下降法代码展示:
25 | ```python
26 | #coding:utf8
27 |
28 | def fun(x,y):
29 | return x*x + y*y + 2*x +2
30 |
31 | def dfun_x(x,y):
32 | return 2*x + 2
33 |
34 | def dfun_y(x,y):
35 | return 2*y
36 |
37 | if __name__ == '__main__':
38 | x = 1
39 | y = 4
40 | lr = 0.01
41 | iters = 4000
42 |
43 | for iter in range(iters):
44 | x = x - lr* dfun_x(x, y)
45 | y = y - lr* dfun_y(x, y)
46 | print('loss = ', fun(x, y))
47 | print('x=',x)
48 | print('y=',y)
49 | ```
50 |
51 | # 3 BP 或 深度神经网络训练需要明确的几个概念
52 |
53 | 一个典型的深度神经网络图如下:
54 | 
55 |
56 | 进一步,一个深度学习模型中的所有数据可划分为如下类别:
57 | - 权重(weight) 或 参数(parameter)
58 | - 激活(activation)
59 | - 超参
60 |
61 | **思考:请分析上图中参数的类别 ???**
62 |
63 | 再进一步,按照逻辑先后顺序反向传播算法(BP 算法)可划分为两个阶段:
64 | - 激励传播(反向传播)
65 | - 权重更新
66 |
67 | **思考: 反向传播的目的是求 激活的梯度 还是 权重的梯度 ???**
68 | **思考: 我们需要同时计算出 激活的梯度 和 权重的梯度吗 ???**
69 |
70 | # 4 链式求导法则
71 | 一个深度神经网络可以理解为一个复杂的复合函数:
72 | $$x = f(w); y = f(x); loss = f(y)$$
73 |
74 | 当计算 $\frac{\partial loss}{\partial w}$ 时就需要用到链式求导, 链式求导有两种情况需要考虑:
75 |
76 | - 情况一:无分支
77 | 
78 |
79 | - 情况二:存在分支
80 | 
81 |
82 | **===== 有了以上背景知识,我们就可以进行反向传播(back propagation) 的计算了。======**
83 |
84 | # 5 BP 流程图示
85 | 在前馈神经网络最后,网络的输出信号 y 与目标值(label)进行比较,这个目标值可以在训练数据集中找到。这个差异(difference)被称为输出层神经元的误差信号 $\delta$ 。
86 |
87 | 
88 |
89 | 直接计算内部神经元的误差信号是不可能的,因为这些神经元的输出值是未知的。多层网络的有效训练方法长时间以来一直未知。直到上世纪八十年代中期,反向传播算法才被提出。其思想是将误差信号 d(在单个训练步骤中计算得出)传播回所有输出信号作为该神经元的输入的神经元中。
90 |
91 | 
92 |
93 | 用于传播误差的权重系数 $w_{mn}$ 等于计算输出值时使用的权重系数。只是数据流的方向改变了(信号依次从输出传播到输入)。这种技术适用于所有网络层。如果传播的误差来自多个神经元,则进行相加。下面是示例图解:
94 |
95 | 
96 |
97 | 当计算完每个神经元的误差信号后,可以修改每个神经元输入节点的权重系数。
98 |
99 | - 第一层权重修改:
100 | 
101 | 
102 | 
103 |
104 | - 第二层权重修改:
105 | 
106 | 
107 |
108 | - 第三层权重修改:
109 | 
110 |
111 | **思考:权重的梯度什么时候计算的 ??**
112 |
113 | # 6 反向传播数学推导
114 | ## 6.1 反向传播目的确认
115 | 
116 |
117 | ## 6.2 线性连接层 weight 的梯度
118 | 
119 |
120 | ## 6.3 激活函数 input 的梯度
121 | 
122 |
123 | ## 6.4 激活函数 output 的梯度
124 | - 求解过程
125 | 
126 |
127 | - 公式化简
128 | 
129 |
130 | - 最终形式
131 | 
132 |
133 | ## 6.5 下层激活 input(z' and z'') 梯度求解
134 | 1. 下层是output的情况:
135 | 
136 |
137 | 2. 下层是中间层的情况:
138 | 
139 |
140 | # 7 反向传播总结
141 | - 所有激活梯度求解
142 | 
143 |
144 | - 所有权重梯度求解
145 | 
146 |
147 | 损失C对W的权重有两部分,一部分是第一项,激活函数Z对W的偏导数(a), 此项其实就是前向传播,另一个是第二项,C对激活函数Z的偏导数,此项就是反向传播。
148 |
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure1.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure10.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure11.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure12.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure13.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure14.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure15.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure15.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure16.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure16.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure17.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure17.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure18.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure18.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure19.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure19.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure2.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure20.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure20.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure21.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure21.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure22.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure22.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure23.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure23.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure3.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure4.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure5.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure6.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure7.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure8.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-figure9.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-formula1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-formula1.jpg
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-gif1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-gif1.gif
--------------------------------------------------------------------------------
/2-back_propagation/images/back-propagation-gif2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/2-back_propagation/images/back-propagation-gif2.gif
--------------------------------------------------------------------------------
/20-pytorch-tensor/images/tensor-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/20-pytorch-tensor/images/tensor-figure1.jpg
--------------------------------------------------------------------------------
/20-pytorch-tensor/test_tensor.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | def reshape_demo():
4 | data0 = torch.randn(4,5)
5 |
6 | data1 =data0.reshape(5,4)
7 |
8 | print(data0.shape)
9 | def reshape_view():
10 | data0 = torch.randn(4,5)
11 |
12 | data1 =data0.view(5,4)
13 |
14 | print(data0.shape)
15 |
16 | def reshape_transpose():
17 | data0 = torch.randn(4,5) # stride = (5, 1) --> (2, 4, 3) --> (12, 3, 1)
18 |
19 | data1 =data0.T # 数据不会真正搬迁,但是stride 会变化。stride 对应做转置 : (1,5)
20 |
21 | data2 = data1.contiguous() #
22 |
23 | print(data0.shape)
24 |
25 |
26 | if __name__ == '__main__':
27 |
28 | # reshape_demo()
29 | # reshape_view()
30 | reshape_transpose()
31 | print("run test_tensor.py successfully !!!")
--------------------------------------------------------------------------------
/21-pytorch-autograd/images/autograd-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/21-pytorch-autograd/images/autograd-figure1.jpg
--------------------------------------------------------------------------------
/21-pytorch-autograd/images/autograd-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/21-pytorch-autograd/images/autograd-figure2.jpg
--------------------------------------------------------------------------------
/21-pytorch-autograd/images/autograd-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/21-pytorch-autograd/images/autograd-figure3.jpg
--------------------------------------------------------------------------------
/21-pytorch-autograd/images/autograd-gif1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/21-pytorch-autograd/images/autograd-gif1.gif
--------------------------------------------------------------------------------
/21-pytorch-autograd/images/autograd-gif2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/21-pytorch-autograd/images/autograd-gif2.gif
--------------------------------------------------------------------------------
/21-pytorch-autograd/test_autograd.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | torch.no_grad()
4 |
5 | torch.optim
6 | def grad_accumulate():
7 | # torch.seed()
8 | x = torch.ones(5) # input tensor
9 | label = torch.zeros(3) # expected output
10 | w = torch.randn(5, 3, requires_grad=True) # requires_grad
11 | b = torch.randn(3, requires_grad=True)
12 | output = torch.matmul(x, w)+b # 全连接层
13 |
14 | loss = torch.nn.functional.binary_cross_entropy_with_logits(output, label)
15 | loss.backward(retain_graph=True) # 反向传播:求梯度
16 | print(f"Grad for w first time = {w.grad}")
17 | # print(f"Gradient function for z = {output.grad_fn}")
18 | # print(f"Gradient function for loss = {loss.grad_fn}")
19 | # w.grad.zero_() # 清空梯度,直接置0
20 | # w.grad = None # 置None,原tensor里的显存就释放掉了
21 | # with torch.no_grad():
22 | w.copy_(w - 0.01 * w.grad)
23 |
24 | # loss.backward(retain_graph=True) # 新算出来的结果,不是替换原来的值,而是累加到原来的值上
25 | print(f"Grad for w first time = {w.grad}")
26 |
27 |
28 | def inplace_demo():
29 | data1 = torch.randn(3, 4)
30 | data1.requires_grad = True
31 |
32 | data2 = data1 + 2
33 |
34 | data2.mul_(2) # 直接+2
35 | loss = data2.var() #
36 |
37 | loss.backward()
38 |
39 |
40 | def inplace_demo_v2():
41 | # y = torch.randn(5, 5, requires_grad=True)
42 |
43 | with torch.no_grad():
44 | data1 = torch.randn(3, 4)
45 | data1.requires_grad = True
46 |
47 | data1.mul_(2)
48 |
49 | data1.backward(torch.randn_like(data1))
50 |
51 | # loss = data1.var() #
52 |
53 | # loss.backward()
54 |
55 | def autograd_demo_v1():
56 | torch.manual_seed(0) #
57 | x = torch.ones(5, requires_grad=True) # input
58 | w = torch.randn(5, 5, requires_grad=True) # weight
59 | b = torch.randn_like(x)
60 | label = torch.Tensor([0, 0, 1, 0, 0])
61 |
62 | for i in range(100):
63 | # w.requires_grad=True # True
64 | # if w.grad is not None:
65 | # w.grad.zero_()
66 |
67 | z = torch.matmul(w, x) + b # linear layer
68 | output = torch.sigmoid(z)
69 | # output.register_hook(hook)
70 | output.retain_grad() # tensor([-0.0405, -0.0722, -0.1572, 0.3101, -0.0403]
71 | loss = (output-label).var() # l2 loss
72 | loss.backward()
73 | # print(w.grad)
74 | print("loss: ", loss)
75 | # w.sub_(0.05 * w.grad)
76 | # w = w - 0.8 * w.grad # 改了w 的属性了
77 | with torch.no_grad():
78 | w.sub_(0.05 * w.grad)
79 |
80 | w.grad =None
81 |
82 | # w.data.sub_(w.grad)
83 | # w.grad = None
84 |
85 | # print("w")
86 | # print("w")
87 | # w.retain_grad()
88 | # with torch.no_grad():
89 | # w = w - 0.05 * w.grad
90 |
91 | grad_list = []
92 | def hook_func(grad):
93 | grad_list.append(grad)
94 | return grad + 5
95 |
96 |
97 | # torch.Tensor
98 | def hook_demo():
99 | # return 0.001*grad
100 | c = 5
101 | a = torch.Tensor([1, 2, 3])
102 | a.requires_grad = True
103 | a.register_hook(hook_func)
104 | b = a.mul(c)
105 | b.var().backward()
106 | import ipdb; ipdb.set_trace()
107 | print(f"==========")
108 |
109 | class Exp(torch.autograd.Function):
110 | @staticmethod
111 | def forward(ctx, i):
112 | result = i.exp()
113 | ctx.save_for_backward(result)
114 | return result
115 |
116 | @staticmethod
117 | def backward(ctx, grad_output):
118 | result, = ctx.saved_tensors
119 | return grad_output * result
120 |
121 | if __name__ == "__main__":
122 | # grad_accumulate()
123 | # inplace_demo()
124 | # inplace_demo_v2()
125 | # autograd_demo_v1()
126 | hook_demo()
--------------------------------------------------------------------------------
/22-pytorch-module/test_module.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 |
5 |
6 | class Model(nn.Module):
7 | def __init__(self):
8 | super().__init__()
9 | self.linear1 = nn.Linear(5, 10) # k : 5, n : 10
10 | self.linear2 = nn.Linear(10, 5)
11 |
12 | def forward(self, x):
13 | import ipdb; ipdb.set_trace()
14 | x = F.relu(self.linear1(x))
15 | return F.relu(self.linear2(x))
16 |
17 | class MyModule(torch.nn.Module):
18 | def __init__(self, k, n):
19 | super().__init__()
20 | self.linear1 = nn.Linear(k, n) # k : 5, n : 10
21 | self.linear2 = nn.Linear(n, k)
22 | self.act1 = nn.GELU()
23 | self.act2 = nn.Sigmoid()
24 | self.loss = torch.nn.MSELoss()
25 |
26 | def forward(self, input, label):
27 | output = self.linear1(input)
28 | output = self.act1(output)
29 | output = self.linear2(output)
30 | output = self.act2(output)
31 | loss = self.loss(output, label)
32 | return loss
33 |
34 | def nn_demo():
35 | '''
36 | 1. 数据准备:输入数据 + lable 数据
37 | 2. 网络结构的搭建:激活函数 + 损失函数 + 权重初始化;
38 | 3. 优化器选择;
39 | 4. 训练策略:学习率的控制 + 梯度清0 + 更新权重 + 正则化;
40 | '''
41 |
42 | model = MyModule(2, 3).cuda() # H2D -->
43 | input = torch.tensor([5, 10]).reshape(1, 2).to(torch.float32).cuda()
44 | label = torch.tensor([0.01, 0.99]).reshape(1, 2).cuda()
45 | optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
46 |
47 | for i in range(100):
48 | # optimizer.zero_grad()
49 | model.zero_grad()
50 | loss = model(input, label)
51 | loss.backward()
52 | optimizer.step()
53 | print(loss)
54 |
55 | if __name__ == '__main__':
56 | nn_demo()
57 |
58 |
59 |
60 |
61 |
--------------------------------------------------------------------------------
/23-training-examples/decoder.md:
--------------------------------------------------------------------------------
1 | # Decoder
2 |
3 | ```python
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.functional as F
7 |
8 | class MultiHeadAttention(nn.Module):
9 | def __init__(self, d_model, num_heads):
10 | super(MultiHeadAttention, self).__init__()
11 | self.d_model = d_model
12 | self.num_heads = num_heads
13 | self.head_dim = d_model // num_heads
14 |
15 | assert self.head_dim * num_heads == d_model, "d_model must be divisible by num_heads"
16 |
17 | self.wq = nn.Linear(d_model, d_model)
18 | self.wk = nn.Linear(d_model, d_model)
19 | self.wv = nn.Linear(d_model, d_model)
20 | self.fc = nn.Linear(d_model, d_model)
21 |
22 | def forward(self, query, key, value, mask=None):
23 | batch_size = query.size(0)
24 |
25 | # Linear transformation
26 | Q = self.wq(query)
27 | K = self.wk(key)
28 | V = self.wv(value)
29 |
30 | # Split into multiple heads
31 | Q = Q.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
32 | K = K.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
33 | V = V.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
34 |
35 | # Scaled Dot-Product Attention
36 | scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
37 | if mask is not None:
38 | scores = scores.masked_fill(mask == 0, float('-inf'))
39 |
40 | attn_weights = F.softmax(scores, dim=-1)
41 | attn_output = torch.matmul(attn_weights, V)
42 |
43 | # Concatenate heads
44 | attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
45 |
46 | # Final linear layer
47 | output = self.fc(attn_output)
48 |
49 | return output
50 |
51 | class FeedForward(nn.Module):
52 | def __init__(self, d_model, d_ff):
53 | super(FeedForward, self).__init__()
54 | self.fc1 = nn.Linear(d_model, d_ff)
55 | self.fc2 = nn.Linear(d_ff, d_model)
56 |
57 | def forward(self, x):
58 | return self.fc2(F.relu(self.fc1(x)))
59 |
60 | class DecoderLayer(nn.Module):
61 | def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
62 | super(DecoderLayer, self).__init__()
63 | self.self_attn = MultiHeadAttention(d_model, num_heads)
64 | self.feed_forward = FeedForward(d_model, d_ff)
65 | self.norm1 = nn.LayerNorm(d_model)
66 | self.norm2 = nn.LayerNorm(d_model)
67 | self.dropout = nn.Dropout(dropout)
68 |
69 | def forward(self, x, mask=None):
70 | # Self-attention
71 | attn_output = self.self_attn(x, x, x, mask)
72 | x = x + self.dropout(attn_output)
73 | x = self.norm1(x)
74 |
75 | # Feed-forward network
76 | ff_output = self.feed_forward(x)
77 | x = x + self.dropout(ff_output)
78 | x = self.norm2(x)
79 |
80 | return x
81 |
82 | class TransformerDecoder(nn.Module):
83 | def __init__(self, num_layers, d_model, num_heads, d_ff, dropout=0.1):
84 | super(TransformerDecoder, self).__init__()
85 | self.layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
86 |
87 | def forward(self, x, mask=None):
88 | for layer in self.layers:
89 | x = layer(x, mask)
90 | return x
91 |
92 | # 运行案例
93 | if __name__ == "__main__":
94 | # 定义模型参数
95 | num_layers = 2
96 | d_model = 64
97 | num_heads = 4
98 | d_ff = 128
99 | dropout = 0.1
100 |
101 | # 创建模型
102 | decoder = TransformerDecoder(num_layers, d_model, num_heads, d_ff, dropout)
103 |
104 | # 创建输入数据 (batch_size, seq_len, d_model)
105 | batch_size = 2
106 | seq_len = 10
107 | x = torch.rand(batch_size, seq_len, d_model)
108 |
109 | # 创建掩码 (batch_size, seq_len, seq_len)
110 | mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0).expand(batch_size, -1, -1)
111 |
112 | # 前向传播
113 | output = decoder(x, mask)
114 |
115 | print("Input shape:", x.shape)
116 | print("Output shape:", output.shape)
117 | ```
--------------------------------------------------------------------------------
/23-training-examples/encoder.md:
--------------------------------------------------------------------------------
1 | # Encoder layer
2 |
3 | ```
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.functional as F
7 |
8 | class MultiHeadAttention(nn.Module):
9 | def __init__(self, embed_size, heads):
10 | super(MultiHeadAttention, self).__init__()
11 | self.embed_size = embed_size
12 | self.heads = heads
13 | self.head_dim = embed_size // heads
14 |
15 | assert (self.head_dim * heads == embed_size), "Embedding size needs to be divisible by heads"
16 |
17 | self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
18 | self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
19 | self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
20 | self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
21 |
22 | def forward(self, values, keys, query, mask):
23 | N = query.shape[0]
24 | value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
25 |
26 | # Split the embedding into self.heads different pieces
27 | values = values.reshape(N, value_len, self.heads, self.head_dim)
28 | keys = keys.reshape(N, key_len, self.heads, self.head_dim)
29 | queries = query.reshape(N, query_len, self.heads, self.head_dim)
30 |
31 | values = self.values(values)
32 | keys = self.keys(keys)
33 | queries = self.queries(queries)
34 |
35 | energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
36 | # queries shape: (N, query_len, heads, heads_dim)
37 | # keys shape: (N, key_len, heads, heads_dim)
38 | # energy shape: (N, heads, query_len, key_len)
39 |
40 | if mask is not None:
41 | energy = energy.masked_fill(mask == 0, float("-1e20"))
42 |
43 | attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
44 |
45 | out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
46 | N, query_len, self.heads * self.head_dim
47 | )
48 | # attention shape: (N, heads, query_len, key_len)
49 | # values shape: (N, value_len, heads, heads_dim)
50 | # out after matrix multiply: (N, query_len, heads, head_dim), then flatten last two dimensions
51 |
52 | out = self.fc_out(out)
53 | return out
54 |
55 | class TransformerBlock(nn.Module):
56 | def __init__(self, embed_size, heads, dropout, forward_expansion):
57 | super(TransformerBlock, self).__init__()
58 | self.attention = MultiHeadAttention(embed_size, heads)
59 | self.norm1 = nn.LayerNorm(embed_size)
60 | self.norm2 = nn.LayerNorm(embed_size)
61 |
62 | self.feed_forward = nn.Sequential(
63 | nn.Linear(embed_size, forward_expansion * embed_size),
64 | nn.ReLU(),
65 | nn.Linear(forward_expansion * embed_size, embed_size),
66 | )
67 |
68 | self.dropout = nn.Dropout(dropout)
69 |
70 | def forward(self, value, key, query, mask):
71 | attention = self.attention(value, key, query, mask)
72 |
73 | # Add skip connection, run through normalization and finally dropout
74 | x = self.dropout(self.norm1(attention + query))
75 | forward = self.feed_forward(x)
76 | out = self.dropout(self.norm2(forward + x))
77 | return out
78 |
79 | class Encoder(nn.Module):
80 | def __init__(
81 | self,
82 | src_vocab_size,
83 | embed_size,
84 | num_layers,
85 | heads,
86 | device,
87 | forward_expansion,
88 | dropout,
89 | max_length,
90 | ):
91 | super(Encoder, self).__init__()
92 | self.embed_size = embed_size
93 | self.device = device
94 | self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
95 | self.position_embedding = nn.Embedding(max_length, embed_size)
96 |
97 | self.layers = nn.ModuleList(
98 | [
99 | TransformerBlock(
100 | embed_size,
101 | heads,
102 | dropout=dropout,
103 | forward_expansion=forward_expansion,
104 | )
105 | for _ in range(num_layers)
106 | ]
107 | )
108 |
109 | self.dropout = nn.Dropout(dropout)
110 |
111 | def forward(self, x, mask):
112 | N, seq_length = x.shape
113 | positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
114 | out = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))
115 |
116 | for layer in self.layers:
117 | out = layer(out, out, out, mask)
118 |
119 | return out
120 | ```
--------------------------------------------------------------------------------
/23-training-examples/train_decoder_demo.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.optim as optim
4 |
5 | class CausalMiniLlama(nn.Module):
6 | def __init__(self, vocab_size, d_model=64, n_head=2):
7 | super().__init__()
8 | self.d_model = d_model
9 | self.n_head = n_head
10 |
11 | # 嵌入层
12 | self.embed = nn.Embedding(vocab_size, d_model)
13 |
14 | # 因果自注意力
15 | self.self_attn = nn.MultiheadAttention(
16 | embed_dim=d_model,
17 | num_heads=n_head,
18 | batch_first=False # 输入格式为 (seq_len, batch, features)
19 | )
20 |
21 | # 前馈网络
22 | self.ffn = nn.Sequential(
23 | nn.Linear(d_model, d_model*4),
24 | nn.ReLU(),
25 | nn.Linear(d_model*4, d_model)
26 | )
27 |
28 | # 输出层
29 | self.lm_head = nn.Linear(d_model, vocab_size)
30 |
31 | self.Q = nn.Linear(d_model, d_model)
32 |
33 | # 缓存因果掩码(动态生成)
34 | self.causal_mask = None
35 |
36 | def _generate_causal_mask(self, sz):
37 | """生成下三角布尔掩码 (False表示允许注意力)"""
38 | return torch.triu(torch.ones(sz, sz) == 1, diagonal=1).bool()
39 |
40 | def forward(self, x):
41 | # 输入形状: [seq_len, batch_size]
42 | seq_len = x.size(0)
43 | x = self.embed(x) # [seq_len, batch, d_model]
44 |
45 | # 生成因果掩码
46 | if self.causal_mask is None or self.causal_mask.size(0) != seq_len:
47 | self.causal_mask = self._generate_causal_mask(seq_len).to(x.device)
48 |
49 | # 执行因果注意力
50 | attn_out, _ = self.self_attn(
51 | query=x,
52 | key=x,
53 | value=x,
54 | attn_mask=self.causal_mask[:seq_len, :seq_len]
55 | )
56 |
57 | ffn_out = self.ffn(attn_out)
58 | return self.lm_head(ffn_out) # [seq_len, batch, vocab_size]
59 |
60 | # 使用之前定义的分词器和训练流程(需稍作调整)
61 | class CharTokenizer:
62 | def __init__(self, corpus):
63 | self.chars = ['', ''] + sorted(list(set(corpus)))
64 | self.vocab = {c:i for i,c in enumerate(self.chars)}
65 | self.ivocab = {i:c for i,c in enumerate(self.chars)}
66 |
67 | def encode(self, text):
68 | return [self.vocab.get(c, self.vocab['']) for c in text]
69 |
70 | def decode(self, ids):
71 | return ''.join([self.ivocab[i] for i in ids if i != self.vocab['']])
72 |
73 | # 训练配置
74 | corpus = ("中国的首都位于北京北京是政治文化中心首都有天安门")
75 | tokenizer = CharTokenizer(corpus)
76 | vocab_size = len(tokenizer.chars)
77 | seq_length = 5 # 输入序列长度
78 |
79 | # 数据预处理(滑动窗口)
80 | sentences = corpus.split('')[:-1]
81 | inputs, targets = [], []
82 | for sent in sentences:
83 | sent += ''
84 | for i in range(len(sent) - seq_length):
85 | inputs.append(sent[i:i+seq_length])
86 | targets.append(sent[i+1:i+1+seq_length])
87 |
88 | # 初始化因果模型
89 | model = CausalMiniLlama(vocab_size)
90 | optimizer = optim.Adam(model.parameters(), lr=0.001)
91 |
92 | # 训练循环(带因果注意力)
93 | for epoch in range(100):
94 | total_loss = 0
95 | for seq_in, seq_out in zip(inputs, targets):
96 | x = torch.tensor(tokenizer.encode(seq_in)).unsqueeze(1) # [seq_len, 1]
97 | y = torch.tensor(tokenizer.encode(seq_out))
98 |
99 | optimizer.zero_grad()
100 | logits = model(x)
101 | loss = nn.CrossEntropyLoss()(logits.view(-1, vocab_size), y.view(-1))
102 | loss.backward()
103 | optimizer.step()
104 | total_loss += loss.item()
105 |
106 | if (epoch+1) % 20 == 0:
107 | print(f"Epoch {epoch+1}, Loss: {total_loss/len(inputs):.4f}")
108 |
109 | # 生成函数(保持因果性)
110 | def generate(prompt, max_len=50):
111 | model.eval()
112 | input_ids = tokenizer.encode(prompt)
113 |
114 | # 填充对齐
115 | if len(input_ids) < seq_length:
116 | pad_id = tokenizer.vocab['']
117 | input_ids = [pad_id]*(seq_length - len(input_ids)) + input_ids
118 | else:
119 | input_ids = input_ids[-seq_length:]
120 |
121 | eos_id = tokenizer.vocab['']
122 |
123 | with torch.no_grad():
124 | for _ in range(max_len):
125 | x = torch.tensor(input_ids[-seq_length:]).unsqueeze(1)
126 | logits = model(x) # [seq_len, 1, vocab]
127 |
128 | # 只取最后一个位置的预测
129 | next_id = torch.argmax(logits[-1, 0]).item()
130 | input_ids.append(next_id) # 追加到input里
131 |
132 | if next_id == eos_id:
133 | break
134 |
135 | return tokenizer.decode(input_ids).split('')[0] + ''
136 |
137 | # 测试生成
138 | print(generate("中国的首")) # 输出示例:中国的首都位于北京
--------------------------------------------------------------------------------
/25-pytorch-lr-scheduler/images/lr-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/25-pytorch-lr-scheduler/images/lr-figure1.jpg
--------------------------------------------------------------------------------
/25-pytorch-lr-scheduler/images/lr-figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/25-pytorch-lr-scheduler/images/lr-figure10.jpg
--------------------------------------------------------------------------------
/25-pytorch-lr-scheduler/images/lr-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/25-pytorch-lr-scheduler/images/lr-figure2.jpg
--------------------------------------------------------------------------------
/25-pytorch-lr-scheduler/images/lr-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/25-pytorch-lr-scheduler/images/lr-figure3.jpg
--------------------------------------------------------------------------------
/25-pytorch-lr-scheduler/images/lr-figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/25-pytorch-lr-scheduler/images/lr-figure4.jpg
--------------------------------------------------------------------------------
/25-pytorch-lr-scheduler/images/lr-figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/25-pytorch-lr-scheduler/images/lr-figure5.jpg
--------------------------------------------------------------------------------
/25-pytorch-lr-scheduler/images/lr-figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/25-pytorch-lr-scheduler/images/lr-figure6.jpg
--------------------------------------------------------------------------------
/25-pytorch-lr-scheduler/images/lr-figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/25-pytorch-lr-scheduler/images/lr-figure7.jpg
--------------------------------------------------------------------------------
/25-pytorch-lr-scheduler/images/lr-figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/25-pytorch-lr-scheduler/images/lr-figure8.jpg
--------------------------------------------------------------------------------
/25-pytorch-lr-scheduler/images/lr-figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/25-pytorch-lr-scheduler/images/lr-figure9.jpg
--------------------------------------------------------------------------------
/28-pytorch-tensorboard/README.md:
--------------------------------------------------------------------------------
1 | # 1 tensorboard 介绍
2 | [torch 链接](https://pytorch.org/docs/stable/tensorboard.html?highlight=tensorboard)
3 | - board:展板
4 | - tensorflow 率先采用个
5 | - 效果很好,pytorch 也采用了这个 -->
6 | - 只要我们把我们需要保存的信息 dump 成tensorboard支持的格式就行;
7 | - pytorch 里面还有一个叫 tensorboardX 的东西,和 tensorboard 很类似,我们用tensorboard就行
8 |
9 | # 2 安装方式
10 | - 我们安装好了 tensorflow 的话,tensorboard会自动安装;
11 | - pip install tensorboard
12 |
13 |
14 | # 3 抓取log
15 |
16 | ## 3.1 import SummaryWriter
17 | ```python
18 | import torch
19 | import torchvision
20 | # from torch.utils.tensorboard import SummaryWriter
21 | from torch.utils.tensorboard import SummaryWriter
22 | from torchvision import datasets, transforms
23 | import numpy as np
24 | import torch.nn as nn
25 | import torch.optim as optim
26 | ```
27 |
28 | ## 3.2 plot scalar
29 | ```python
30 | def add_scalar():
31 | writer = SummaryWriter("scalar_log")
32 | for n_iter in range(200, 300):
33 | # writer.add_scalars('Loss/train', {"a":n_iter * 2, "b": n_iter*n_iter}, n_iter)
34 | writer.add_scalar('Loss/test1', 200, n_iter)
35 | # writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
36 | # writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
37 | ```
38 |
39 | ## 3.3 plot loss and accuracy
40 | ```python
41 |
42 | writer = SummaryWriter("run")
43 |
44 | # Log the running loss averaged per batch
45 | writer.add_scalars('Training vs. Validation Loss',
46 | { 'Training' : avg_train_loss, 'Validation' : avg_val_loss },
47 | epoch * len(training_loader) + i)
48 |
49 | ```
50 |
51 | # 4 执行方式:
52 | tensorboard --logdir=./log
53 | tensorboard --logdir dir_name
54 | python -m tensorboard.main --logdir=./logs
55 |
56 | # 5 查看graph
57 | ```python
58 | def add_graph():
59 | import torchvision.models as models
60 | net = models.resnet50(pretrained=False)
61 | writer = SummaryWriter("graph_log")
62 | writer.add_graph(net, torch.rand(16, 3, 224, 224))
63 | writer.flush()
64 | writer.close()
65 | ```
66 |
67 | # 6 查看特征图
68 | ```python
69 | def add_image():
70 | # Writer will output to ./runs/ directory by default
71 | # --logdir=./runs
72 | writer = SummaryWriter("mtn_log")
73 |
74 | transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
75 | trainset = datasets.MNIST('mnist_train', train=True, download=True, transform=transform)
76 | trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
77 | model = torchvision.models.resnet50(False)
78 | torch.onnx.export(model, torch.randn(64, 3, 224, 224), "resnet50_ttt.onnx")
79 | # Have ResNet model take in grayscale rather than RGB
80 | model.conv1 = torch.nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
81 | images, labels = next(iter(trainloader)) # 拿到 输入 和label
82 |
83 | print("============images shape: ", images.shape)
84 | output = model.conv1(images)
85 | output = output[:, 0, :, :].reshape(64, 1, 14, 14).expand(64, 3, 14, 14)
86 | print("============output shape: ", output.shape)
87 |
88 |
89 | grid = torchvision.utils.make_grid(images)
90 | grid = torchvision.utils.make_grid(output)
91 | writer.add_image('output', grid, 0) # 保存图片
92 | # writer.add_graph(model, images) # 保存模型
93 | writer.close()
94 | ```
95 |
96 | # 7 性能分析profiler
97 | ```python
98 | # Non-default profiler schedule allows user to turn profiler on and off
99 | # on different iterations of the training loop;
100 | # trace_handler is called every time a new trace becomes available
101 | def trace_handler(prof):
102 | print(prof.key_averages().table(
103 | sort_by="self_cuda_time_total", row_limit=-1))
104 | # prof.export_chrome_trace("/tmp/test_trace_" + str(prof.step_num) + ".json")
105 |
106 | with torch.profiler.profile(
107 | activities=[
108 | torch.profiler.ProfilerActivity.CPU,
109 | torch.profiler.ProfilerActivity.CUDA,
110 | ],
111 |
112 | # In this example with wait=1, warmup=1, active=2, repeat=1,
113 | # profiler will skip the first step/iteration,
114 | # start warming up on the second, record
115 | # the third and the forth iterations,
116 | # after which the trace will become available
117 | # and on_trace_ready (when set) is called;
118 | # the cycle repeats starting with the next step
119 |
120 | schedule=torch.profiler.schedule(
121 | wait=1,
122 | warmup=1,
123 | active=2,
124 | repeat=1),
125 | on_trace_ready=trace_handler
126 | # on_trace_ready=torch.profiler.tensorboard_trace_handler('./log')
127 | # used when outputting for tensorboard
128 | ) as p:
129 | for iter in range(N):
130 | code_iteration_to_profile(iter)
131 | # send a signal to the profiler that the next iteration has started
132 | p.step()
133 | ```
134 |
--------------------------------------------------------------------------------
/29-pytorch-graph-mode/images/pytorch-patterns-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/29-pytorch-graph-mode/images/pytorch-patterns-figure1.jpg
--------------------------------------------------------------------------------
/3-bp_example_demo/images/bp-example-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/3-bp_example_demo/images/bp-example-figure1.jpg
--------------------------------------------------------------------------------
/3-bp_example_demo/images/bp-example-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/3-bp_example_demo/images/bp-example-figure2.jpg
--------------------------------------------------------------------------------
/3-bp_example_demo/images/bp-example-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/3-bp_example_demo/images/bp-example-figure3.jpg
--------------------------------------------------------------------------------
/3-bp_example_demo/images/bp-example-figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/3-bp_example_demo/images/bp-example-figure4.jpg
--------------------------------------------------------------------------------
/3-bp_example_demo/images/bp-example-figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/3-bp_example_demo/images/bp-example-figure5.jpg
--------------------------------------------------------------------------------
/3-bp_example_demo/images/bp-example-figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/3-bp_example_demo/images/bp-example-figure6.jpg
--------------------------------------------------------------------------------
/3-bp_example_demo/images/bp-example-formula1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/3-bp_example_demo/images/bp-example-formula1.jpg
--------------------------------------------------------------------------------
/3-bp_example_demo/images/bp-example-formula2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/3-bp_example_demo/images/bp-example-formula2.jpg
--------------------------------------------------------------------------------
/3-bp_example_demo/images/bp-example-formula3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/3-bp_example_demo/images/bp-example-formula3.jpg
--------------------------------------------------------------------------------
/3-bp_example_demo/images/bp-example-formula4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/3-bp_example_demo/images/bp-example-formula4.jpg
--------------------------------------------------------------------------------
/30-training_examples_cv/extract_ILSVRC.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | #
3 | # script to extract ImageNet dataset
4 | # ILSVRC2012_img_train.tar (about 138 GB)
5 | # ILSVRC2012_img_val.tar (about 6.3 GB)
6 | # make sure ILSVRC2012_img_train.tar & ILSVRC2012_img_val.tar in your current directory
7 | #
8 | # Adapted from:
9 | # https://github.com/facebook/fb.resnet.torch/blob/master/INSTALL.md
10 | # https://gist.github.com/BIGBALLON/8a71d225eff18d88e469e6ea9b39cef4
11 | #
12 | # imagenet/train/
13 | # ├── n01440764
14 | # │ ├── n01440764_10026.JPEG
15 | # │ ├── n01440764_10027.JPEG
16 | # │ ├── ......
17 | # ├── ......
18 | # imagenet/val/
19 | # ├── n01440764
20 | # │ ├── ILSVRC2012_val_00000293.JPEG
21 | # │ ├── ILSVRC2012_val_00002138.JPEG
22 | # │ ├── ......
23 | # ├── ......
24 | #
25 | #
26 | # Make imagnet directory
27 | #
28 | mkdir imagenet
29 | #
30 | # Extract the training data:
31 | #
32 | # Create train directory; move .tar file; change directory
33 | mkdir imagenet/train && mv ILSVRC2012_img_train.tar imagenet/train/ && cd imagenet/train
34 | # Extract training set; remove compressed file
35 | tar -xvf ILSVRC2012_img_train.tar && rm -f ILSVRC2012_img_train.tar
36 | #
37 | # At this stage imagenet/train will contain 1000 compressed .tar files, one for each category
38 | #
39 | # For each .tar file:
40 | # 1. create directory with same name as .tar file
41 | # 2. extract and copy contents of .tar file into directory
42 | # 3. remove .tar file
43 | find . -name "*.tar" | while read NAME ; do mkdir -p "${NAME%.tar}"; tar -xvf "${NAME}" -C "${NAME%.tar}"; rm -f "${NAME}"; done
44 | #
45 | # This results in a training directory like so:
46 | #
47 | # imagenet/train/
48 | # ├── n01440764
49 | # │ ├── n01440764_10026.JPEG
50 | # │ ├── n01440764_10027.JPEG
51 | # │ ├── ......
52 | # ├── ......
53 | #
54 | # Change back to original directory
55 | cd ../..
56 | #
57 | # Extract the validation data and move images to subfolders:
58 | #
59 | # Create validation directory; move .tar file; change directory; extract validation .tar; remove compressed file
60 | mkdir imagenet/val && mv ILSVRC2012_img_val.tar imagenet/val/ && cd imagenet/val && tar -xvf ILSVRC2012_img_val.tar && rm -f ILSVRC2012_img_val.tar
61 | # get script from soumith and run; this script creates all class directories and moves images into corresponding directories
62 | wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bash
63 | #
64 | # This results in a validation directory like so:
65 | #
66 | # imagenet/val/
67 | # ├── n01440764
68 | # │ ├── ILSVRC2012_val_00000293.JPEG
69 | # │ ├── ILSVRC2012_val_00002138.JPEG
70 | # │ ├── ......
71 | # ├── ......
72 | #
73 | #
74 | # Check total files after extract
75 | #
76 | # $ find train/ -name "*.JPEG" | wc -l
77 | # 1281167
78 | # $ find val/ -name "*.JPEG" | wc -l
79 | # 50000
80 | #
81 |
--------------------------------------------------------------------------------
/30-training_examples_cv/requirements.txt:
--------------------------------------------------------------------------------
1 | torch
2 | torchvision
3 |
--------------------------------------------------------------------------------
/31-stable-diffusion/SDXL.md:
--------------------------------------------------------------------------------
1 | # SDXL
2 |
3 |
4 |
5 | # 参考链接
6 | - [Stable Diffusion XL 核心基础知识](https://zhuanlan.zhihu.com/p/643420260)
7 | - [sd3 展望](https://www.zhihu.com/question/645441220/answer/3410329468)
8 |
--------------------------------------------------------------------------------
/31-stable-diffusion/VAE.md:
--------------------------------------------------------------------------------
1 | # VAE
2 | - [论文链接](https://arxiv.org/pdf/1312.6114.pdf)
3 |
4 | # 1 VAE 的作用 (数据压缩和数据生成)
5 | ## 1.1 数据压缩
6 | 数据压缩也可以成为数据降维,一般情况下数据的维度都是高维的,比如手写数字(28*28=784维),如果数据维度的输入,机器的处理量将会很大, 而数据经过降维以后,如果保留了原有数据的主要信息,那么我们就可以用降维的数据进行机器学习模型的训练和预测,由于数据量大大缩减,训练和预测的时间效率将大为提高。还有一种好处就是我们可以将数据降维至2D或3D以便于观察分布情况。
7 | 平常最常用到的就是PCA(主成分分析法:将原来的三维空间投影到方差最大且线性无关的两个方向或者说将原矩阵进行单位正交基变换以保留最大的信息量)。
8 |
9 | 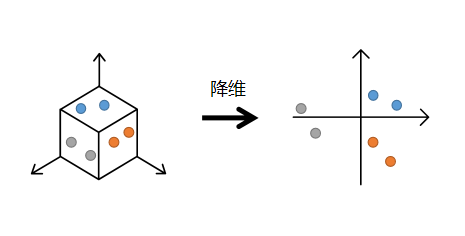
10 |
11 | ## 1.2 数据生成
12 | 近年来最火的生成模型莫过于GAN和VAE,这两种模型在实践中体现出极好的性能。
13 | 所谓数据的生成,就是经过样本训练后,**人为输入或随机输入数据**,得到一个类似于样本的结果。
14 | 比如样本为很多个人脸,生成结果就是一些人脸,但这些人脸是从未出现过的全新的人脸。又或者输入很多的手写数字,得到的结果也是一些手写数字。而给出的数据可能是一个或多个随机数,或者一个分布。然后经过神经网络,将输入的数据进行放大,得到结果。
15 |
16 | ## 1.3 数据压缩与数据生成的关系
17 | 在数据生成过程中要输入一些数进去,可是这些数字**不能是随随便便的数字**吧,至少得有一定的规律性才能让神经网络进行学习(就像要去破译密码,总得知道那些个密码符号表示的含义是什么才可以吧)。
18 | 那如何获得输入数字(或者说密码)的规律呢。这就是数据压缩过程我们所要考虑的问题,我们想要获得数据经过压缩后满足什么规律,在VAE中,我们将这种规律用概率的形式表示。在经过一系列数学研究后:我们最终获得了**数据压缩的分布规律**,这样我们就可以**根据这个规律去抽取样本进行生成**,生成的结果一定是类似于样本的数据。
19 |
20 | 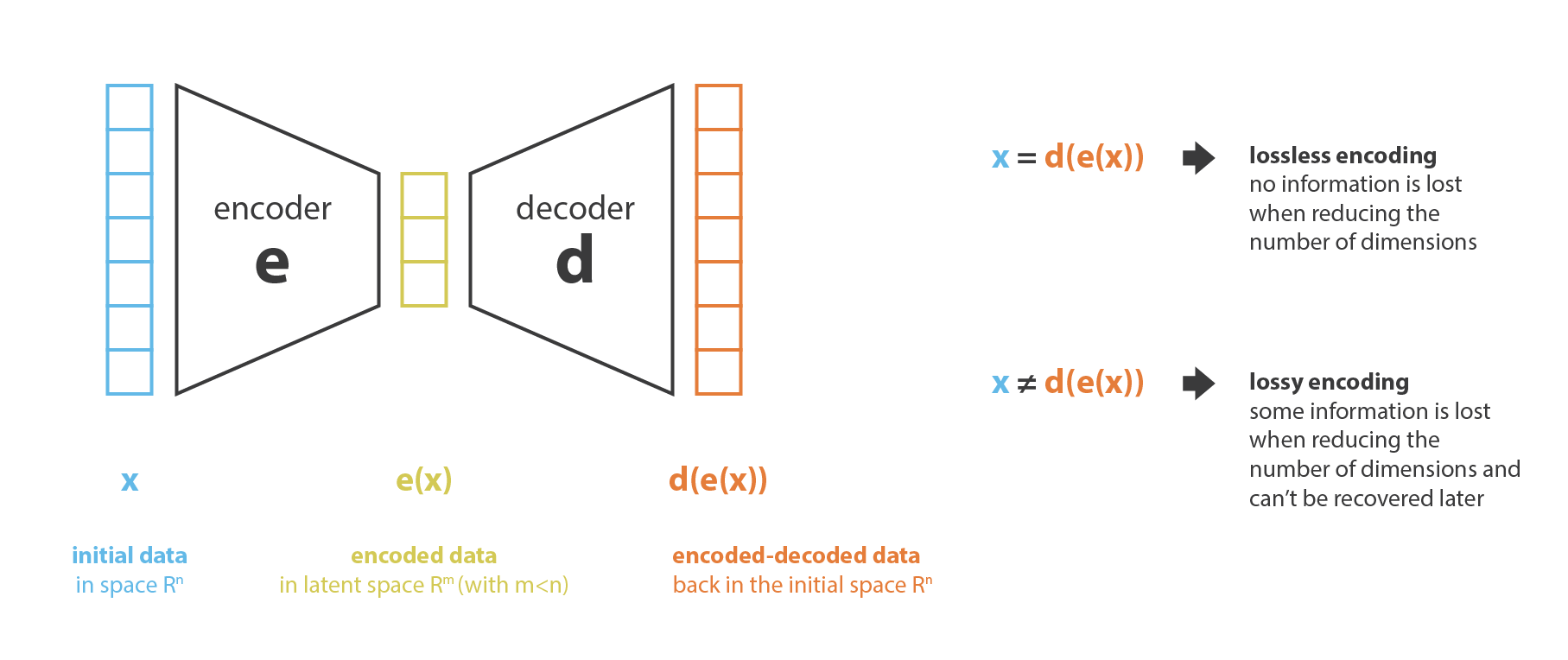
21 |
22 | ## 1.4 example
23 | 在前面讲解过,将图片进行某种编码,我们将原来 28*28 = 784 维的图片编码为2维的高斯分布(也可以不是2维,只是为了好可视化), 二维平面的中心就是图片的二维高斯分布的
24 | $μ(1)$ 和 $μ(2)$ ,表示椭圆的中心(注意:这里其实不是椭圆,我们只是把最较大概率的部分框出来)。
25 |
26 | 假设一共有5个图片(手写数字0-4),则在隐空间中一共有5个二维正态分布(椭圆),如果生成过程中**在坐标中取的点**接近蓝色区域,则说明,最后的生成结果接近数字0,如果在蓝色和黑色交界处,则结果介于0和1之间。
27 |
28 | 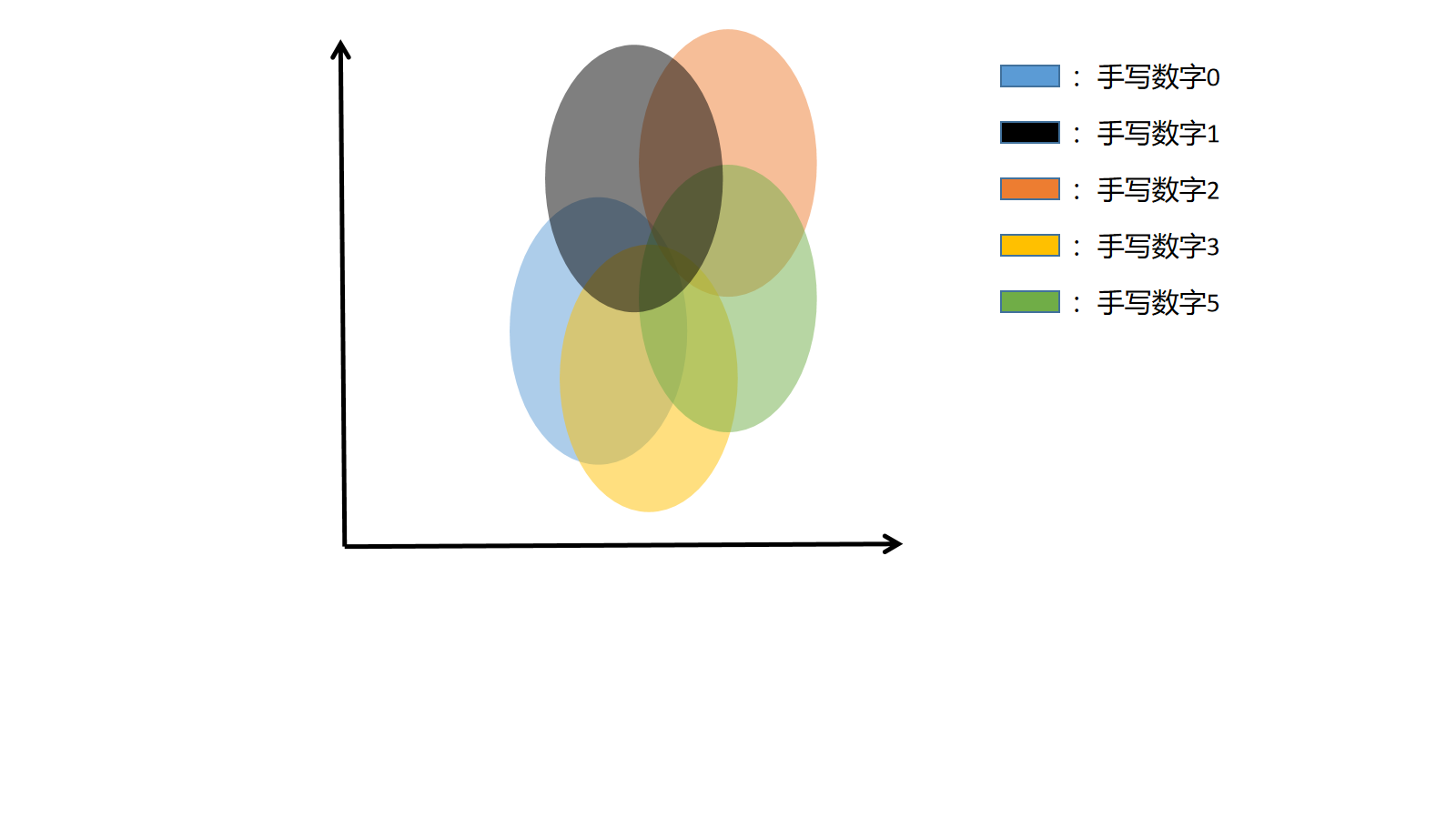
29 |
30 | ## 1.5 可能出现的问题
31 | **问题**:如果每个椭圆离得特别远会发生什么???
32 |
33 | **答案**:椭圆之间完全没有交集。
34 |
35 | **结果**:假如随机取数据的时候,**取的数据不在任何椭圆里**,最后的生成的结果将会非常离谱,根本不知道生成模型生成了什么东西,我们称这种现象为过拟合,因此,我们必须要让这些个椭圆**尽可能的推叠在一起**,并且**尽可能占满整个空间的位置**,防止生成不属于任何分类的图片。后面我们会介绍如何将椭圆尽可能堆叠。
36 |
37 | 在解决上面问题后,我们就得到了一个较为标准的数据压缩形态,这样我们就可以放心采样进行数据生成。
38 |
39 | ## 1.6 VAE 要点总结
40 | 到现在为止,VAE框架已经形成:
41 | - 隐空间(latent space)有规律可循,长的像的图片离得近;
42 | - 隐空间随便拿个点解码之后,得到的点**有意义**;
43 | - 隐空间中对应不同标签的点不会离得很远,但也不会离得太近(因为每个高斯的中心部分因为被采样次数多必须特色鲜明,不能跟别的类别的高斯中心离得太近)(VAE做生成任务的基础);
44 | - 隐空间对应相同标签的点离得比较近,但又不会聚成超小的小簇,然而也不会有相聚甚远的情况(VAE做分类任务的基础);
45 |
46 | # 2 理论推导VAE
47 | 怎么去求那么复杂的高斯分布也就是隐空间呢??? 这个问题与变分推断遇到的几乎一样。
48 |
49 | ## 2.1 引入变分
50 | 在变分推断中,我们想要通过样本x来估计关于z的分布,也就是后验,用概率的语言描述就是:p(z|x)。根据贝叶斯公式:
51 |
52 | $$p(z \mid x)=\frac{p(x \mid z) p(z)}{p(x)}$$
53 |
54 | p(x)不能直接求, 所以直接贝叶斯这个方法报废,于是我们寻找新的方法. 这时我们想到了变分法,用另一个分布 $Q(z \mid x)$ 来估计 $p(z \mid x, \theta)$ , 变分自编码器的变分就来源于此.
55 | *(注释:求泛函极值的方法称为变分法)*
56 | *(注释2:对于给定的值x∈[x0, x1],两个可取函数y(x)和y0(x),函数y(x)在y0(x)处的变分或函数的变分被定义为它们之差,即y(x) - y0(x)。这个变分表示了函数y(x)相对于y0(x)的变化或偏离程度。)*
57 |
58 | 用一个函数去近似另一个函数,可以看作从概率密度函数所在的函数空间到实数域R的一个函数f,自变量是Q的密度函数,因变量是Q与真实后验密度函数的“距离”,而这一个f关于概率密度函数的“导数”就叫做 **变分** ,我们每次降低这个距离,让Q接近真实的后验,就是让概率密度函数朝着“导数“的负方向进行函数空间的梯度下降。所以叫做变分推断。
59 |
60 | 变分推断和变分自编码器的最终目标是相同的,都是将 $Q(z \mid x)$ 尽量去近似 $p(z \mid x, \theta)$ , 我们知道有一种距离可以量化两种分布的差异Kullback-Leibler divergence—KL散度,我们要尽量减小KL散度。
61 |
62 | ##
63 | 在这种情况下,我们可以让变分近似后验是一个具有对角协方差结构的多元高斯:
64 |
65 | # 4 参考文献
66 | - [vae 导读](https://www.cnblogs.com/lvzhiyi/p/15822716.html)
67 | - [vae 导读2](https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73)
68 | - [vae 参考3](https://zhuanlan.zhihu.com/p/34998569)
69 |
70 |
71 |
--------------------------------------------------------------------------------
/33-stable-diffusion/SDXL.md:
--------------------------------------------------------------------------------
1 | # SDXL
2 |
3 |
4 |
5 | # 参考链接
6 | - [Stable Diffusion XL 核心基础知识](https://zhuanlan.zhihu.com/p/643420260)
7 | - [sd3 展望](https://www.zhihu.com/question/645441220/answer/3410329468)
8 |
--------------------------------------------------------------------------------
/33-stable-diffusion/VAE.md:
--------------------------------------------------------------------------------
1 | # VAE
2 | - [论文链接](https://arxiv.org/pdf/1312.6114.pdf)
3 |
4 | # 1 VAE 的作用 (数据压缩和数据生成)
5 | ## 1.1 数据压缩
6 | 数据压缩也可以成为数据降维,一般情况下数据的维度都是高维的,比如手写数字(28*28=784维),如果数据维度的输入,机器的处理量将会很大, 而数据经过降维以后,如果保留了原有数据的主要信息,那么我们就可以用降维的数据进行机器学习模型的训练和预测,由于数据量大大缩减,训练和预测的时间效率将大为提高。还有一种好处就是我们可以将数据降维至2D或3D以便于观察分布情况。
7 | 平常最常用到的就是PCA(主成分分析法:将原来的三维空间投影到方差最大且线性无关的两个方向或者说将原矩阵进行单位正交基变换以保留最大的信息量)。
8 |
9 | 
10 |
11 | ## 1.2 数据生成
12 | 近年来最火的生成模型莫过于GAN和VAE,这两种模型在实践中体现出极好的性能。
13 | 所谓数据的生成,就是经过样本训练后,**人为输入或随机输入数据**,得到一个类似于样本的结果。
14 | 比如样本为很多个人脸,生成结果就是一些人脸,但这些人脸是从未出现过的全新的人脸。又或者输入很多的手写数字,得到的结果也是一些手写数字。而给出的数据可能是一个或多个随机数,或者一个分布。然后经过神经网络,将输入的数据进行放大,得到结果。
15 |
16 | ## 1.3 数据压缩与数据生成的关系
17 | 在数据生成过程中要输入一些数进去,可是这些数字**不能是随随便便的数字**吧,至少得有一定的规律性才能让神经网络进行学习(就像要去破译密码,总得知道那些个密码符号表示的含义是什么才可以吧)。
18 | 那如何获得输入数字(或者说密码)的规律呢。这就是数据压缩过程我们所要考虑的问题,我们想要获得数据经过压缩后满足什么规律,在VAE中,我们将这种规律用概率的形式表示。在经过一系列数学研究后:我们最终获得了**数据压缩的分布规律**,这样我们就可以**根据这个规律去抽取样本进行生成**,生成的结果一定是类似于样本的数据。
19 |
20 | 
21 |
22 | ## 1.4 example
23 | 在前面讲解过,将图片进行某种编码,我们将原来 28*28 = 784 维的图片编码为2维的高斯分布(也可以不是2维,只是为了好可视化), 二维平面的中心就是图片的二维高斯分布的
24 | $μ(1)$ 和 $μ(2)$ ,表示椭圆的中心(注意:这里其实不是椭圆,我们只是把最较大概率的部分框出来)。
25 |
26 | 假设一共有5个图片(手写数字0-4),则在隐空间中一共有5个二维正态分布(椭圆),如果生成过程中**在坐标中取的点**接近蓝色区域,则说明,最后的生成结果接近数字0,如果在蓝色和黑色交界处,则结果介于0和1之间。
27 |
28 | 
29 |
30 | ## 1.5 可能出现的问题
31 | **问题**:如果每个椭圆离得特别远会发生什么???
32 |
33 | **答案**:椭圆之间完全没有交集。
34 |
35 | **结果**:假如随机取数据的时候,**取的数据不在任何椭圆里**,最后的生成的结果将会非常离谱,根本不知道生成模型生成了什么东西,我们称这种现象为过拟合,因此,我们必须要让这些个椭圆**尽可能的推叠在一起**,并且**尽可能占满整个空间的位置**,防止生成不属于任何分类的图片。后面我们会介绍如何将椭圆尽可能堆叠。
36 |
37 | 在解决上面问题后,我们就得到了一个较为标准的数据压缩形态,这样我们就可以放心采样进行数据生成。
38 |
39 | ## 1.6 VAE 要点总结
40 | 到现在为止,VAE框架已经形成:
41 | - 隐空间(latent space)有规律可循,长的像的图片离得近;
42 | - 隐空间随便拿个点解码之后,得到的点**有意义**;
43 | - 隐空间中对应不同标签的点不会离得很远,但也不会离得太近(因为每个高斯的中心部分因为被采样次数多必须特色鲜明,不能跟别的类别的高斯中心离得太近)(VAE做生成任务的基础);
44 | - 隐空间对应相同标签的点离得比较近,但又不会聚成超小的小簇,然而也不会有相聚甚远的情况(VAE做分类任务的基础);
45 |
46 | # 2 理论推导VAE
47 | 怎么去求那么复杂的高斯分布也就是隐空间呢??? 这个问题与变分推断遇到的几乎一样。
48 |
49 | ## 2.1 引入变分
50 | 在变分推断中,我们想要通过样本x来估计关于z的分布,也就是后验,用概率的语言描述就是:p(z|x)。根据贝叶斯公式:
51 |
52 | $$p(z \mid x)=\frac{p(x \mid z) p(z)}{p(x)}$$
53 |
54 | p(x)不能直接求, 所以直接贝叶斯这个方法报废,于是我们寻找新的方法. 这时我们想到了变分法,用另一个分布 $Q(z \mid x)$ 来估计 $p(z \mid x, \theta)$ , 变分自编码器的变分就来源于此.
55 | *(注释:求泛函极值的方法称为变分法)*
56 | *(注释2:对于给定的值x∈[x0, x1],两个可取函数y(x)和y0(x),函数y(x)在y0(x)处的变分或函数的变分被定义为它们之差,即y(x) - y0(x)。这个变分表示了函数y(x)相对于y0(x)的变化或偏离程度。)*
57 |
58 | 用一个函数去近似另一个函数,可以看作从概率密度函数所在的函数空间到实数域R的一个函数f,自变量是Q的密度函数,因变量是Q与真实后验密度函数的“距离”,而这一个f关于概率密度函数的“导数”就叫做 **变分** ,我们每次降低这个距离,让Q接近真实的后验,就是让概率密度函数朝着“导数“的负方向进行函数空间的梯度下降。所以叫做变分推断。
59 |
60 | 变分推断和变分自编码器的最终目标是相同的,都是将 $Q(z \mid x)$ 尽量去近似 $p(z \mid x, \theta)$ , 我们知道有一种距离可以量化两种分布的差异Kullback-Leibler divergence—KL散度,我们要尽量减小KL散度。
61 |
62 | ##
63 | 在这种情况下,我们可以让变分近似后验是一个具有对角协方差结构的多元高斯:
64 |
65 | # 4 参考文献
66 | - [vae 导读](https://www.cnblogs.com/lvzhiyi/p/15822716.html)
67 | - [vae 导读2](https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73)
68 | - [vae 参考3](https://zhuanlan.zhihu.com/p/34998569)
69 |
70 |
71 |
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure1.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure10.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure11.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure12.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure13.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure14.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure15.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure15.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure16.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure16.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure17.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure17.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure18.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure18.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure2.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure3.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure4.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure5.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure6.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure7.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure8.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-figure9.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-formula1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-formula1.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-formula2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-formula2.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-formula3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-formula3.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-formula4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-formula4.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-formula5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-formula5.jpg
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-gif1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-gif1.gif
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-gif2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-gif2.gif
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-gif3.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-gif3.gif
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-gif4.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-gif4.gif
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-gif5.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-gif5.gif
--------------------------------------------------------------------------------
/4-convolution_neural_network/images/cnn-gif6.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/4-convolution_neural_network/images/cnn-gif6.gif
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure1.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure10.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure11.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure12.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure13.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure2.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure3.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure4.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure5.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure6.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure7.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure8.jpg
--------------------------------------------------------------------------------
/40-nlp_bert/images/figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/40-nlp_bert/images/figure9.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure1.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure10.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure11.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure12.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure13.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure14.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure15.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure15.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure16.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure16.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure2.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure3.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure4.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure5.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure6.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure7.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure8.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/images/figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/images/figure9.jpg
--------------------------------------------------------------------------------
/41-nlp_t5/squard_v2_output.tar.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/41-nlp_t5/squard_v2_output.tar.gz
--------------------------------------------------------------------------------
/42-nlp-gpt/images/gpt3-figure1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/42-nlp-gpt/images/gpt3-figure1.png
--------------------------------------------------------------------------------
/42-nlp-gpt/images/gpt3-figure2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/42-nlp-gpt/images/gpt3-figure2.png
--------------------------------------------------------------------------------
/42-nlp-gpt/images/gpt3-figure3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/42-nlp-gpt/images/gpt3-figure3.png
--------------------------------------------------------------------------------
/42-nlp-gpt/images/gpt3-figure4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/42-nlp-gpt/images/gpt3-figure4.png
--------------------------------------------------------------------------------
/42-nlp-gpt/images/gpt3-figure5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/42-nlp-gpt/images/gpt3-figure5.png
--------------------------------------------------------------------------------
/42-nlp-gpt/images/gpt3-figure6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/42-nlp-gpt/images/gpt3-figure6.png
--------------------------------------------------------------------------------
/43-scaling-law/README.md:
--------------------------------------------------------------------------------
1 | # Scaling Laws for Neural Language Models
2 |
3 | - [论文地址](https://arxiv.org/pdf/2001.08361)
4 |
5 | - [论文地址-CN](https://yiyibooks.cn/arxiv/2001.08361v1/index.html)
6 |
--------------------------------------------------------------------------------
/44-distribute-training/README.md:
--------------------------------------------------------------------------------
1 | # How to training realy large model
2 |
3 | - [课件链接](https://github.com/Elvin-Ma/distributed_training)
--------------------------------------------------------------------------------
/45-LLM-History/images/figure1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure1.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure10.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure11.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure12.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure13.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure13.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure14.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure15.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure15.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure16.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure16.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure17.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure17.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure18.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure18.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure19.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure19.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure2.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure20.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure20.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure21.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure21.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure22.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure22.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure23.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure23.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure24.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure24.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure25.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure25.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure26.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure26.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure27.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure27.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure3.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure4.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure5.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure6.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure7.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure8.png
--------------------------------------------------------------------------------
/45-LLM-History/images/figure9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/45-LLM-History/images/figure9.png
--------------------------------------------------------------------------------
/46-LLM-GPT-Extension/image-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-GPT-Extension/image-1.png
--------------------------------------------------------------------------------
/46-LLM-GPT-Extension/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-GPT-Extension/image.png
--------------------------------------------------------------------------------
/46-LLM-GPT-Extension/images/image-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-GPT-Extension/images/image-1.png
--------------------------------------------------------------------------------
/46-LLM-GPT-Extension/images/image-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-GPT-Extension/images/image-2.png
--------------------------------------------------------------------------------
/46-LLM-GPT-Extension/images/image-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-GPT-Extension/images/image-3.png
--------------------------------------------------------------------------------
/46-LLM-GPT-Extension/images/image-4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-GPT-Extension/images/image-4.png
--------------------------------------------------------------------------------
/46-LLM-GPT-Extension/images/image-5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-GPT-Extension/images/image-5.png
--------------------------------------------------------------------------------
/46-LLM-GPT-Extension/images/image-6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-GPT-Extension/images/image-6.png
--------------------------------------------------------------------------------
/46-LLM-GPT-Extension/images/image-7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-GPT-Extension/images/image-7.png
--------------------------------------------------------------------------------
/46-LLM-GPT-Extension/images/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-GPT-Extension/images/image.png
--------------------------------------------------------------------------------
/46-LLM-Llama/Llama-2-7b-hf/added_tokens.json:
--------------------------------------------------------------------------------
1 | {
2 | "": 32000
3 | }
4 |
--------------------------------------------------------------------------------
/46-LLM-Llama/Llama-2-7b-hf/config.json:
--------------------------------------------------------------------------------
1 | {
2 | "architectures": [
3 | "LlamaForCausalLM"
4 | ],
5 | "bos_token_id": 1,
6 | "eos_token_id": 2,
7 | "hidden_act": "silu",
8 | "hidden_size": 4096,
9 | "initializer_range": 0.02,
10 | "intermediate_size": 11008,
11 | "max_position_embeddings": 4096,
12 | "model_type": "llama",
13 | "num_attention_heads": 32,
14 | "num_hidden_layers": 32,
15 | "num_key_value_heads": 32,
16 | "pad_token_id": 0,
17 | "pretraining_tp": 1,
18 | "rms_norm_eps": 1e-05,
19 | "rope_scaling": null,
20 | "tie_word_embeddings": false,
21 | "torch_dtype": "float16",
22 | "transformers_version": "4.31.0.dev0",
23 | "use_cache": true,
24 | "vocab_size": 32000
25 | }
26 |
--------------------------------------------------------------------------------
/46-LLM-Llama/Llama-2-7b-hf/configuration.json:
--------------------------------------------------------------------------------
1 | {
2 | "framework": "pytorch",
3 | "task": "text-generation",
4 | "model": {
5 | "type": "llama2"
6 | },
7 | "pipeline": {
8 | "type": "llama2-text-generation-pipeline"
9 | }
10 | }
--------------------------------------------------------------------------------
/46-LLM-Llama/Llama-2-7b-hf/generation_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "_from_model_config": true,
3 | "bos_token_id": 1,
4 | "eos_token_id": 2,
5 | "pad_token_id": 32000,
6 | "temperature": 0.9,
7 | "top_p": 0.6,
8 | "transformers_version": "4.31.0.dev0"
9 | }
10 |
--------------------------------------------------------------------------------
/46-LLM-Llama/Llama-2-7b-hf/special_tokens_map.json:
--------------------------------------------------------------------------------
1 | {
2 | "bos_token": {
3 | "content": "",
4 | "lstrip": false,
5 | "normalized": true,
6 | "rstrip": false,
7 | "single_word": false
8 | },
9 | "eos_token": {
10 | "content": "",
11 | "lstrip": false,
12 | "normalized": true,
13 | "rstrip": false,
14 | "single_word": false
15 | },
16 | "pad_token": "",
17 | "unk_token": {
18 | "content": "",
19 | "lstrip": false,
20 | "normalized": true,
21 | "rstrip": false,
22 | "single_word": false
23 | }
24 | }
25 |
--------------------------------------------------------------------------------
/46-LLM-Llama/Llama-2-7b-hf/tokenizer.model:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/Llama-2-7b-hf/tokenizer.model
--------------------------------------------------------------------------------
/46-LLM-Llama/Llama-2-7b-hf/tokenizer_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "add_bos_token": true,
3 | "add_eos_token": false,
4 | "bos_token": {
5 | "__type": "AddedToken",
6 | "content": "",
7 | "lstrip": false,
8 | "normalized": true,
9 | "rstrip": false,
10 | "single_word": false
11 | },
12 | "clean_up_tokenization_spaces": false,
13 | "eos_token": {
14 | "__type": "AddedToken",
15 | "content": "",
16 | "lstrip": false,
17 | "normalized": true,
18 | "rstrip": false,
19 | "single_word": false
20 | },
21 | "legacy": false,
22 | "model_max_length": 1000000000000000019884624838656,
23 | "pad_token": null,
24 | "sp_model_kwargs": {},
25 | "tokenizer_class": "LlamaTokenizer",
26 | "unk_token": {
27 | "__type": "AddedToken",
28 | "content": "",
29 | "lstrip": false,
30 | "normalized": true,
31 | "rstrip": false,
32 | "single_word": false
33 | }
34 | }
35 |
--------------------------------------------------------------------------------
/46-LLM-Llama/image-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/image-1.png
--------------------------------------------------------------------------------
/46-LLM-Llama/image-10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/image-10.png
--------------------------------------------------------------------------------
/46-LLM-Llama/image-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/image-2.png
--------------------------------------------------------------------------------
/46-LLM-Llama/image-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/image-3.png
--------------------------------------------------------------------------------
/46-LLM-Llama/image-4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/image-4.png
--------------------------------------------------------------------------------
/46-LLM-Llama/image-5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/image-5.png
--------------------------------------------------------------------------------
/46-LLM-Llama/image-6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/image-6.png
--------------------------------------------------------------------------------
/46-LLM-Llama/image-7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/image-7.png
--------------------------------------------------------------------------------
/46-LLM-Llama/image-8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/image-8.png
--------------------------------------------------------------------------------
/46-LLM-Llama/image-9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/image-9.png
--------------------------------------------------------------------------------
/46-LLM-Llama/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/46-LLM-Llama/image.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-1.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-10.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-11.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-12.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-13.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-13.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-14.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-15.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-15.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-16.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-16.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-17.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-17.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-18.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-18.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-19.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-19.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-2.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-20.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-20.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-21.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-21.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-22.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-22.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-23.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-23.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-24.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-24.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-3.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-4.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-5.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-6.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-7.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-8.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image-9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image-9.png
--------------------------------------------------------------------------------
/47-LLM-DeepSeek-Structure/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/47-LLM-DeepSeek-Structure/image.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/image-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/image-1.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/image-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/image-2.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/image-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/image-3.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/image-4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/image-4.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/image-5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/image-5.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/image.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-1.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-10.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-11.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-12.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-13.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-13.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-14.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-15.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-15.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-16.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-16.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-17.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-17.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-18.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-18.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-19.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-19.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-2.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-3.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-4.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-5.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-6.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-7.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-8.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image-9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image-9.png
--------------------------------------------------------------------------------
/48-LLM-deepseek-r1-training/images/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/48-LLM-deepseek-r1-training/images/image.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/__pycache__/rl_brain.cpython-312.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/__pycache__/rl_brain.cpython-312.pyc
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-1.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-10.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-11.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-12.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-13.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-13.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-14.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-15.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-15.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-2.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-3.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-4.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-5.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-6.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-7.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-8.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image-9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image-9.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/49-PPO-GRPO/image.png
--------------------------------------------------------------------------------
/49-PPO-GRPO/rl_train.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import matplotlib.pyplot as plt
3 | import gym
4 | import torch
5 | from rl_brain import PPO
6 |
7 | device = torch.device('cuda') if torch.cuda.is_available() \
8 | else torch.device('cpu')
9 |
10 | # ----------------------------------------- #
11 | # 参数设置
12 | # ----------------------------------------- #
13 |
14 | num_episodes = 100 # 总迭代次数
15 | gamma = 0.9 # 折扣因子
16 | actor_lr = 1e-3 # 策略网络的学习率
17 | critic_lr = 1e-2 # 价值网络的学习率
18 | n_hiddens = 16 # 隐含层神经元个数
19 | env_name = 'CartPole-v1'
20 | return_list = [] # 保存每个回合的return
21 |
22 | # ----------------------------------------- #
23 | # 环境加载
24 | # ----------------------------------------- #
25 |
26 | env = gym.make(env_name, render_mode="human")
27 | n_states = env.observation_space.shape[0] # 状态数 4
28 | n_actions = env.action_space.n # 动作数 2
29 |
30 | # ----------------------------------------- #
31 | # 模型构建
32 | # ----------------------------------------- #
33 |
34 | agent = PPO(n_states=n_states, # 状态数
35 | n_hiddens=n_hiddens, # 隐含层数
36 | n_actions=n_actions, # 动作数
37 | actor_lr=actor_lr, # 策略网络学习率
38 | critic_lr=critic_lr, # 价值网络学习率
39 | lmbda = 0.95, # 优势函数的缩放因子
40 | epochs = 10, # 一组序列训练的轮次
41 | eps = 0.2, # PPO中截断范围的参数
42 | gamma=gamma, # 折扣因子
43 | device = device
44 | )
45 |
46 | # ----------------------------------------- #
47 | # 训练--回合更新 on_policy
48 | # ----------------------------------------- #
49 |
50 | for i in range(num_episodes):
51 |
52 | state = env.reset()[0] # 环境重置
53 | done = False # 任务完成的标记
54 | episode_return = 0 # 累计每回合的reward
55 |
56 | # 构造数据集,保存每个回合的状态数据
57 | transition_dict = {
58 | 'states': [],
59 | 'actions': [],
60 | 'next_states': [],
61 | 'rewards': [],
62 | 'dones': [],
63 | }
64 |
65 | while not done:
66 | action = agent.take_action(state) # 动作选择
67 | next_state, reward, done, _, _ = env.step(action) # 环境更新
68 | # 保存每个时刻的状态\动作\...
69 | transition_dict['states'].append(state)
70 | transition_dict['actions'].append(action)
71 | transition_dict['next_states'].append(next_state)
72 | transition_dict['rewards'].append(reward)
73 | transition_dict['dones'].append(done)
74 | # 更新状态
75 | state = next_state
76 | # 累计回合奖励
77 | episode_return += reward
78 |
79 | # 保存每个回合的return
80 | return_list.append(episode_return)
81 | # 模型训练
82 | agent.learn(transition_dict)
83 |
84 | # 打印回合信息
85 | print(f'iter:{i}, return:{np.mean(return_list[-10:])}')
86 |
87 | # -------------------------------------- #
88 | # 绘图
89 | # -------------------------------------- #
90 |
91 | plt.plot(return_list)
92 | plt.title('return')
93 | plt.show()
--------------------------------------------------------------------------------
/5-deep_learning_model/README.md:
--------------------------------------------------------------------------------
1 | # 1 什么是深度学习模型
2 | 深度学习模型是一种机器学习模型,它由多个**神经网络层(layer)** 组成,这些层之间存在着多层的**非线性转换关系**。深度学习模型通过学习大量数据来提取和学习数据的高级特征表示,从而对输入数据进行分类、回归、生成等任务。
3 |
4 | 工程上,常将**神经网络层(layer)** 抽象成计算机上可执行的**算子**如Conv2d、matmul、relu、sigmoid等,这些算子通过张量(Tensor)相互连接,组合成一张有向无环图,这个图就是我们常说的深度学习网络图,也称为深度学习模型图。
5 |
6 | 指的主要的是,深度学习网络图中的算子有很多种类,有些算子并不能和 传统的 MLP中的神经网络层相对应,但也是很重要的,如reshape、permute、add、sconcat等。
7 |
8 | # 2 下载一个预训练好的深度学习模型
9 | - [深度学习预训练模型下载](https://github.com/onnx/models)
10 |
11 | # 3 可视化这个深度学习模型
12 | - [深度学习模型可视化](https://netron.app/)
13 |
--------------------------------------------------------------------------------
/50-Chain-of-Thought/image-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/50-Chain-of-Thought/image-1.png
--------------------------------------------------------------------------------
/50-Chain-of-Thought/image-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/50-Chain-of-Thought/image-2.png
--------------------------------------------------------------------------------
/50-Chain-of-Thought/image-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/50-Chain-of-Thought/image-3.png
--------------------------------------------------------------------------------
/50-Chain-of-Thought/image-4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/50-Chain-of-Thought/image-4.png
--------------------------------------------------------------------------------
/50-Chain-of-Thought/image-5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/50-Chain-of-Thought/image-5.png
--------------------------------------------------------------------------------
/50-Chain-of-Thought/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/50-Chain-of-Thought/image.png
--------------------------------------------------------------------------------
/6-pytorch_install/README.md:
--------------------------------------------------------------------------------
1 | # 1 pytorch 官网
2 | [](https://pytorch.org/)
3 |
4 | # 2 pytorch 简介
5 | ## 2.1 认识pytorch
6 | - [nvidia- pytorch](https://www.nvidia.cn/glossary/data-science/pytorch/)
7 |
8 | ## 2.2 pytorch 软件栈
9 | 
10 |
11 | # 3 pytorch install
12 | - [安装最新版本](https://pytorch.org/)
13 |
14 | - [安装指定版本](https://pytorch.org/get-started/previous-versions/)
15 |
16 | - [driver 与cuda 版本的对应关系](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html)
17 |
18 | - 查看自己电脑的driver
19 | ```python
20 | nvidia-smi
21 | ```
22 |
23 | # 4 nvidia 相关软件库
24 | ## 4.1 显卡驱动
25 | 显卡驱动的作用就是用来驱动显卡的,这是电脑硬件中所对应的一个软件。通过添加驱动程序计算机中的硬件就能正常的工作,当然不同的硬件使用的驱动程序也不一样。显卡对应的就是显卡驱动。
26 |
27 | - [nvidia driver](https://www.nvidia.cn/Download/Find.aspx?lang=cn)
28 |
29 | ## 4.2 cuda
30 | 统一计算设备架构(Compute Unified Device Architecture, CUDA),是由NVIDIA推出的通用并行计算架构。解决的是用更加廉价的设备资源,实现更高效的并行计算。 和中央处理器(Central Processing Unit, CPU)相对,图形处理器(Graphics Processing Unit, GPU)是显卡的核心芯片。而cuda正是英伟达开发的GPU的编程接口!
31 |
32 | - [cuda download](https://developer.nvidia.com/cuda-toolkit-archive)
33 |
34 | ## 4.3 cudnn
35 | cuDNN(CUDA Deep Neural Network library):是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。.如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库。总结来说,CPU适合串行计算,擅长逻辑控制。GPU擅长并行高强度并行计算,适用于AI算法的训练学习!
36 |
37 | - [cudnn download](https://developer.nvidia.com/rdp/cudnn-archive)
38 |
39 | # 5 cuda and driver compatible
40 | - [cuda and driver compatible](https://docs.nvidia.com/deploy/cuda-compatibility/index.html#binary-compatibility__table-toolkit-driver)
41 |
42 | # 5 GPU
43 | ## 5.1 GPU 加速原理
44 | 
45 |
46 | ## 5.2 先进GPU 白皮书
47 | - [H100](https://resources.nvidia.com/en-us-tensor-core)
48 | - [A100](https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/HGX/a100-80gb-hgx-a100-datasheet-us-nvidia-1485640-r6-web.pdf)
49 |
--------------------------------------------------------------------------------
/6-pytorch_install/images/pytorch-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/6-pytorch_install/images/pytorch-figure1.jpg
--------------------------------------------------------------------------------
/6-pytorch_install/images/pytorch-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/6-pytorch_install/images/pytorch-figure2.jpg
--------------------------------------------------------------------------------
/6-pytorch_install/images/pytorch-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/6-pytorch_install/images/pytorch-figure3.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure1.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure10.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure11.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure12.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure13.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure14.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure15.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure15.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure16.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure16.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure2.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure3.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure4.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure5.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure6.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure7.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure8.jpg
--------------------------------------------------------------------------------
/7-operators/images/op-figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/7-operators/images/op-figure9.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure1.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure10.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure11.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure12.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure13.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure2.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure3.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure4.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure5.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure6.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure7.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure8.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-figure9.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-formula1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-formula1.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-formula2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-formula2.jpg
--------------------------------------------------------------------------------
/8-activation_functions/images/op-activation-formula3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/8-activation_functions/images/op-activation-formula3.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/gru.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/gru.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/lstm.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/lstm.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure1.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure10.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure11.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure12.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure13.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure14.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure15.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure15.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure16.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure16.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure17.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure17.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure18.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure18.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure2.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure3.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure4.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure5.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure6.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure7.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure8.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-figure9.jpg
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-gif1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-gif1.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-gif10.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-gif10.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-gif2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-gif2.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-gif3.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-gif3.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-gif4.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-gif4.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-gif5.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-gif5.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-gif6.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-gif6.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-gif7.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-gif7.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-gif8.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-gif8.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn-gif9.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn-gif9.gif
--------------------------------------------------------------------------------
/9-recurrent_neural_network/images/rnn.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/9-recurrent_neural_network/images/rnn.gif
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # deep_learning_theory
2 | Summary of deep learning theory
3 |
4 |
5 |
6 | ## Lessons Additions and Adjustments
7 |
8 | ### 内容补充:
9 |
10 | | 序号 | 补充内容 | 状态 |
11 | | :--: | :----------------------------------------------------------- | :--: |
12 | | 001 | update:softmax 激活函数的导数引出一下(雅可比矩阵) | 0 |
13 | | 002 | add:Norm 讲解的时候,未加入最新的 DyT([Transformers without normalization](https://yiyibooks.cn/arxiv/2503.10622v1/index.html)) | 0 |
14 | | 004 | add:DeepNorm 补充 | 0 |
15 | | 005 | add:PyTorch 等框架模型结构中的参数类型和数据整理(我的笔记) | 0 |
16 | | 006 | 思考:工程如何实现训练和推理不同的模块或者算子(那个 training 参数和具体的算子结构) | 0 |
17 | | 007 | | 0 |
18 |
19 |
20 |
21 | ### 调整建议:
22 |
23 | | 序号 | 调整建议 | 状态 |
24 | | :--: | :----------------------------------------------------------- | :--: |
25 | | 001 | updata:torch 的 Tensor 中,数据有 metadata 和 storage 之分(之前讲成 rawdata,但官网未使用这种叫法) [torch.Srorage](https://pytorch.org/docs/stable/storage.html) | 0 |
26 | | 002 | 优化:前后知识交叉部分可以切回到原理快速回顾一下(比如:训练模式与Norm和Dropout、torch的数据结构与一些基础算子等) | 0 |
27 | | | | |
28 | | | | |
29 | | | | |
30 |
31 |
--------------------------------------------------------------------------------
/position_embedding/images/figure1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure1.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure10.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure11.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure12.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure13.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure14.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure15.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure15.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure16.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure16.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure2.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure3.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure4.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure5.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure6.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure7.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure8.jpg
--------------------------------------------------------------------------------
/position_embedding/images/figure9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Elvin-Ma/deep_learning_theory/52ab6d137cad6cd84564f0a4b5a41a1795846bf2/position_embedding/images/figure9.jpg
--------------------------------------------------------------------------------
/position_embedding/relative_position_embedding.py:
--------------------------------------------------------------------------------
1 | import math
2 | import torch
3 | from torch import nn
4 |
5 | class T5RelativePositionBias(nn.Module):
6 | def __init__(self, num_heads, relative_attention_num_buckets=32):
7 | super().__init__()
8 | self.num_heads = num_heads
9 | self.relative_attention_num_buckets = relative_attention_num_buckets
10 |
11 | # 定义可学习的相对位置偏置参数
12 | self.relative_attention_bias = nn.Embedding(
13 | relative_attention_num_buckets, num_heads
14 | )
15 |
16 | def _relative_position_bucket(self, relative_position):
17 | """
18 | 将相对位置映射到离散的桶(bucket)
19 | """
20 | num_buckets = self.relative_attention_num_buckets
21 | ret = 0
22 |
23 | # 处理正向和负向相对位置
24 | n = -relative_position
25 | n = torch.max(n, torch.zeros_like(n))
26 |
27 | # 分桶策略
28 | max_exact = num_buckets // 2
29 | is_small = n < max_exact
30 |
31 | val_if_large = max_exact + (
32 | torch.log(n.float() / max_exact) /
33 | torch.log(torch.tensor(num_buckets / max_exact)) *
34 | (num_buckets - max_exact)
35 | ).to(torch.long)
36 |
37 | val_if_large = torch.min(
38 | val_if_large,
39 | torch.full_like(val_if_large, num_buckets - 1)
40 | )
41 |
42 | ret += torch.where(is_small, n, val_if_large)
43 | return ret
44 |
45 | def forward(self, query_len, key_len):
46 | """
47 | 生成相对位置偏置矩阵
48 | Args:
49 | query_len: 查询序列长度
50 | key_len: 键序列长度
51 | Returns:
52 | bias: [num_heads, query_len, key_len]
53 | """
54 | # 生成相对位置矩阵
55 | context_position = torch.arange(query_len)[:, None]
56 | memory_position = torch.arange(key_len)[None, :]
57 | relative_position = memory_position - context_position
58 |
59 | # 映射到桶索引
60 | rp_bucket = self._relative_position_bucket(relative_position)
61 |
62 | # 查表获取偏置值
63 | values = self.relative_attention_bias(rp_bucket)
64 | values = values.permute([2, 0, 1]) # [heads, q_len, k_len]
65 | return values
66 |
67 | class T5Attention(nn.Module):
68 | def __init__(self, d_model, num_heads):
69 | super().__init__()
70 | self.num_heads = num_heads
71 | self.d_head = d_model // num_heads
72 |
73 | # 初始化相对位置编码模块
74 | self.relative_position = T5RelativePositionBias(num_heads)
75 |
76 | # 初始化Q/K/V投影层
77 | self.q = nn.Linear(d_model, d_model)
78 | self.k = nn.Linear(d_model, d_model)
79 | self.v = nn.Linear(d_model, d_model)
80 |
81 | def forward(self, hidden_states):
82 | batch_size, seq_len, _ = hidden_states.shape
83 |
84 | # 计算Q/K/V
85 | q = self.q(hidden_states) # [batch, seq, d_model]
86 | k = self.k(hidden_states)
87 | v = self.v(hidden_states)
88 |
89 | # 拆分多头
90 | q = q.view(batch_size, seq_len, self.num_heads, self.d_head).transpose(1, 2)
91 | k = k.view(batch_size, seq_len, self.num_heads, self.d_head).transpose(1, 2)
92 | v = v.view(batch_size, seq_len, self.num_heads, self.d_head).transpose(1, 2)
93 |
94 | # 计算注意力分数
95 | scores = torch.matmul(q, k.transpose(-1, -2)) / math.sqrt(self.d_head)
96 |
97 | # 添加相对位置偏置
98 | rel_pos_bias = self.relative_position(seq_len, seq_len)
99 | scores += rel_pos_bias
100 |
101 | # 计算注意力权重
102 | attn_weights = torch.softmax(scores, dim=-1)
103 |
104 | # 应用注意力到V
105 | context = torch.matmul(attn_weights, v)
106 | context = context.transpose(1, 2).reshape(batch_size, seq_len, -1)
107 | return context
108 |
109 | if __name__ == '__main__':
110 | # 创建一个T5Attention实例
111 | attention = T5Attention(d_model=512, num_heads=8)
112 |
113 | # 假设输入是一个[batch, seq, d_model]的tensor
114 | input_tensor = torch.randn(1, 32, 512)
115 |
116 | # 应用T5Attention
117 | output = attention(input_tensor)
118 |
119 | print(output.shape)
--------------------------------------------------------------------------------
/position_embedding/rope.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import math
4 |
5 | class RotaryPositionEmbedding(nn.Module):
6 | def __init__(self, dim, max_seq_len=2048):
7 | super().__init__()
8 | self.dim = dim
9 | self.max_seq_len = max_seq_len
10 | inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2).float() / dim))
11 | self.register_buffer('inv_freq', inv_freq)
12 |
13 | def forward(self, seq_len, device):
14 | seq = torch.arange(seq_len, device=device).float()
15 | freqs = torch.einsum('i,j->ij', seq, self.inv_freq)
16 | freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # Convert to complex numbers
17 | return freqs_cis
18 |
19 | def apply_rotary_pos_emb(q, k, freqs_cis):
20 | q_embed = q * freqs_cis
21 | k_embed = k * freqs_cis
22 | return q_embed, k_embed
23 |
24 | # 示例使用
25 | if __name__ == "__main__":
26 | dim = 64 # 位置编码的维度
27 | max_seq_len = 2048 # 最大序列长度
28 | seq_len = 128 # 当前序列长度
29 |
30 | rotary_emb = RotaryPositionEmbedding(dim, max_seq_len)
31 | freqs_cis = rotary_emb(seq_len, device='cpu')
32 |
33 | # 假设 q 和 k 是来自 Transformer 的查询和键
34 | q = torch.randn(seq_len, dim // 2, 2) # 实部和虚部
35 | k = torch.randn(seq_len, dim // 2, 2) # 实部和虚部
36 |
37 | # 将 q 和 k 转换为复数
38 | q_complex = torch.complex(q[..., 0], q[..., 1])
39 | k_complex = torch.complex(k[..., 0], k[..., 1])
40 |
41 | q_embed_complex, k_embed_complex = apply_rotary_pos_emb(q_complex, k_complex, freqs_cis)
42 |
43 | # 将复数结果转换回实部和虚部
44 | q_embed = torch.stack((q_embed_complex.real, q_embed_complex.imag), dim=-1)
45 | k_embed = torch.stack((k_embed_complex.real, k_embed_complex.imag), dim=-1)
46 |
47 | print("Query with Rotary Position Embedding (Real):\n", q_embed[..., 0])
48 | print("Query with Rotary Position Embedding (Imag):\n", q_embed[..., 1])
49 | print("Key with Rotary Position Embedding (Real):\n", k_embed[..., 0])
50 | print("Key with Rotary Position Embedding (Imag):\n", k_embed[..., 1])
--------------------------------------------------------------------------------