├── .gitignore
├── LICENSE
├── LeetCode
├── LeetCode0036有效的数独-Valid-Sudoku.ipynb
├── LeetCode0048旋转图像-Rotate-Image.ipynb
├── LeetCode0053最大子序和-Maximum-Subarray.ipynb
├── LeetCode0105从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.ipynb
├── LeetCode0123买卖股票的最佳时机III-Best-Time-to-Buy-and-Sell-Stock-III.ipynb
├── LeetCode0640求解方程-Solve-the-Equation.ipynb
└── LeetCode0768最多能完成排序的块-II-Max-Chunks-To-Make-Sorted-II.ipynb
├── OJ平台Python输入
├── Jupyter标准输入Stdin.ipynb
├── OJ在线编程常见输入输出练习场.ipynb
├── python输入方法.ipynb
└── 牛客网Python输入模板_使用stdin_可直接Jupyter运行.ipynb
├── Python数据结构与算法
├── 00_Python数据结构与算法介绍.ipynb
├── 01_array_python数组.ipynb
├── 02_lists_python列表.ipynb
├── 03_tuples_python元组.ipynb
├── 04_dictionary_python字典.ipynb
├── 05_sets_python集合.ipynb
├── 06_LinkedList链表.ipynb
└── python链表.ipynb
├── Python知识点
├── Python小知识点.ipynb
├── __new__ & __init__.ipynb
├── __str__ & __repr__.ipynb
├── _args & __kwargs.ipynb
├── class01_专有方法.ipynb
├── class02_数据属性 属性隐藏.ipynb
├── class03_实例方法、类方法、静态方法.ipynb
├── class05_super() 初始化方法 类的继承.ipynb
├── map & zip & enumerate.ipynb
├── python deque双端队列详解.ipynb
├── python忽略大小写字符串排序.ipynb
├── python格式化输出.ipynb
├── 单例模式.ipynb
├── 尾递归.ipynb
└── 栈和队列.ipynb
├── README.md
├── 剑指Offer
├── chap00_剑指Offer目录.ipynb
├── chap01_面试的流程.ipynb
├── chap02_面试需要的基础知识.ipynb
├── 二叉树.ipynb
├── 剑指Offer 名企面试官精讲典型编程题 第二版.pdf
├── 剑指Offer.ipynb
└── 牛客网剑指offer.ipynb
├── 常见算法
├── 0-1背包问题.ipynb
├── KMP算法-字符串匹配.ipynb
├── 乘法逆元.ipynb
├── 二叉树遍历_先序_中序_后序_层序.ipynb
├── 卡特兰数-Catalan.ipynb
├── 图-深度优先搜索DFS-广度优先搜索BFS.ipynb
├── 并查集.ipynb
├── 拓扑排序.ipynb
├── 排序算法总结.ipynb
├── 斐波那契数列三种时间复杂度.ipynb
├── 最小生成树-Prim算法和Kruskal算法.ipynb
├── 最长公共子串-最长公共子序列.ipynb
├── 算法目录.ipynb
├── 线段树.ipynb
├── 辗转相除法-快速幂算法-排列组合计算.ipynb
└── 高楼扔鸡蛋.ipynb
└── 算法图解
├── README.md
├── chap01-算法简介.ipynb
├── chap02-选择排序.ipynb
├── chap03-递归.ipynb
├── chap04-快速排序.ipynb
├── chap05-散列表.ipynb
├── chap06-广度优先搜索.ipynb
├── chap07-狄克斯特拉算法Dijkstra’s-algorithm.ipynb
├── chap08-贪婪算法.ipynb
├── chap09-动态规划.ipynb
├── 算法图解-compressed.pdf
└── 算法图解.pdf
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | *.egg-info/
24 | .installed.cfg
25 | *.egg
26 | MANIFEST
27 |
28 | # PyInstaller
29 | # Usually these files are written by a python script from a template
30 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
31 | *.manifest
32 | *.spec
33 |
34 | # Installer logs
35 | pip-log.txt
36 | pip-delete-this-directory.txt
37 |
38 | # Unit test / coverage reports
39 | htmlcov/
40 | .tox/
41 | .coverage
42 | .coverage.*
43 | .cache
44 | nosetests.xml
45 | coverage.xml
46 | *.cover
47 | .hypothesis/
48 | .pytest_cache/
49 |
50 | # Translations
51 | *.mo
52 | *.pot
53 |
54 | # Django stuff:
55 | *.log
56 | local_settings.py
57 | db.sqlite3
58 |
59 | # Flask stuff:
60 | instance/
61 | .webassets-cache
62 |
63 | # Scrapy stuff:
64 | .scrapy
65 |
66 | # Sphinx documentation
67 | docs/_build/
68 |
69 | # PyBuilder
70 | target/
71 |
72 | # Jupyter Notebook
73 | .ipynb_checkpoints
74 |
75 | # pyenv
76 | .python-version
77 |
78 | # celery beat schedule file
79 | celerybeat-schedule
80 |
81 | # SageMath parsed files
82 | *.sage.py
83 |
84 | # Environments
85 | .env
86 | .venv
87 | env/
88 | venv/
89 | ENV/
90 | env.bak/
91 | venv.bak/
92 |
93 | # Spyder project settings
94 | .spyderproject
95 | .spyproject
96 |
97 | # Rope project settings
98 | .ropeproject
99 |
100 | # mkdocs documentation
101 | /site
102 |
103 | # mypy
104 | .mypy_cache/
105 |
106 | # jupyter
107 | .ipynb_checkpoints
108 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2019 Evan Li
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0036有效的数独-Valid-Sudoku.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# LeetCode 36.有效的数独\n",
8 | "判断一个 9x9 的数独是否有效。只需要根据以下规则,验证已经填入的数字是否有效即可。\n",
9 | "\n",
10 | "- 数字 1-9 在每一行只能出现一次。\n",
11 | "- 数字 1-9 在每一列只能出现一次。\n",
12 | "- 数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。\n",
13 | "\n",
14 | "\n",
15 | "\n",
16 | "## 一次迭代即可进行判断\n",
17 | "\n",
18 | "### 1.首先要解决怎么判断子数独的序号\n",
19 | "\n",
20 | "如图所示,为9个子数独的标号,可以根据行和列进行确定:\n",
21 | "\n",
22 | "\n",
23 | " \n",
24 | "\n",
25 | "`box = (row // 3) * 3 + columns // 3`\n",
26 | "\n",
27 | "其中 // 取整除 - 返回商的整数部分(向下取整)\n",
28 | "\n",
29 | "### 2.分别创建集合set()用来判断行、列、子数独中是否已经出现\n",
30 | "\n",
31 | "### 3.程序如下"
32 | ]
33 | },
34 | {
35 | "cell_type": "code",
36 | "execution_count": 13,
37 | "metadata": {},
38 | "outputs": [],
39 | "source": [
40 | "class Solution(object):\n",
41 | " def isValidSudoku(self,board):\n",
42 | " \"\"\"\n",
43 | " :type board:List[List[str]]\n",
44 | " :rtype:bool\n",
45 | " \"\"\"\n",
46 | " digits = [str(i) for i in range(1,10)] #判断1-9以外的数\n",
47 | " rows = [set() for _ in range(9)] #分别保存9行出现的数\n",
48 | " cols = [set() for _ in range(9)] #分别保存9列出现的数\n",
49 | " boxes = [set() for _ in range(9)] #分别保存9个方格出现的数\n",
50 | " \n",
51 | " for r in range(9):\n",
52 | " for c in range(9):\n",
53 | " digit = board[r][c]\n",
54 | " if digit == '.':\n",
55 | " continue\n",
56 | " if digit not in digits: #出现1-9以外的数\n",
57 | " return False\n",
58 | " box = (r // 3) * 3 + c // 3 #计算子数独序号\n",
59 | " if digit in rows[r] or digit in cols[c] or digit in boxes[box]:\n",
60 | " #如果已经出现过,则输出False\n",
61 | " return False\n",
62 | " # 否则,在各个set()中添加这个数字\n",
63 | " rows[r].add(digit)\n",
64 | " rows[c].add(digit)\n",
65 | " boxes[box].add(digit)\n",
66 | " return True"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "**测试1:**"
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 15,
79 | "metadata": {},
80 | "outputs": [
81 | {
82 | "data": {
83 | "text/plain": [
84 | "True"
85 | ]
86 | },
87 | "execution_count": 15,
88 | "metadata": {},
89 | "output_type": "execute_result"
90 | }
91 | ],
92 | "source": [
93 | "board = [\n",
94 | " [\"5\",\"3\",\".\",\".\",\"7\",\".\",\".\",\".\",\".\"],\n",
95 | " [\"6\",\".\",\".\",\"1\",\"9\",\"5\",\".\",\".\",\".\"],\n",
96 | " [\".\",\"9\",\"8\",\".\",\".\",\".\",\".\",\"6\",\".\"],\n",
97 | " [\"8\",\".\",\".\",\".\",\"6\",\".\",\".\",\".\",\"3\"],\n",
98 | " [\"4\",\".\",\".\",\"8\",\".\",\"3\",\".\",\".\",\"1\"],\n",
99 | " [\"7\",\".\",\".\",\".\",\"2\",\".\",\".\",\".\",\"6\"],\n",
100 | " [\".\",\"6\",\".\",\".\",\".\",\".\",\"2\",\"8\",\".\"],\n",
101 | " [\".\",\".\",\".\",\"4\",\"1\",\"9\",\".\",\".\",\"5\"],\n",
102 | " [\".\",\".\",\".\",\".\",\"8\",\".\",\".\",\"7\",\"9\"]\n",
103 | "]\n",
104 | "s = Solution()\n",
105 | "s.isValidSudoku(board)"
106 | ]
107 | },
108 | {
109 | "cell_type": "markdown",
110 | "metadata": {},
111 | "source": [
112 | "**测试2:**"
113 | ]
114 | },
115 | {
116 | "cell_type": "code",
117 | "execution_count": 18,
118 | "metadata": {},
119 | "outputs": [
120 | {
121 | "data": {
122 | "text/plain": [
123 | "False"
124 | ]
125 | },
126 | "execution_count": 18,
127 | "metadata": {},
128 | "output_type": "execute_result"
129 | }
130 | ],
131 | "source": [
132 | "board = [\n",
133 | " [\"8\",\"3\",\".\",\".\",\"7\",\".\",\".\",\".\",\".\"],\n",
134 | " [\"6\",\".\",\".\",\"1\",\"9\",\"5\",\".\",\".\",\".\"],\n",
135 | " [\".\",\"9\",\"8\",\".\",\".\",\".\",\".\",\"6\",\".\"],\n",
136 | " [\"8\",\".\",\".\",\".\",\"6\",\".\",\".\",\".\",\"3\"],\n",
137 | " [\"4\",\".\",\".\",\"8\",\".\",\"3\",\".\",\".\",\"1\"],\n",
138 | " [\"7\",\".\",\".\",\".\",\"2\",\".\",\".\",\".\",\"6\"],\n",
139 | " [\".\",\"6\",\".\",\".\",\".\",\".\",\"2\",\"8\",\".\"],\n",
140 | " [\".\",\".\",\".\",\"4\",\"1\",\"9\",\".\",\".\",\"5\"],\n",
141 | " [\".\",\".\",\".\",\".\",\"8\",\".\",\".\",\"7\",\"9\"]\n",
142 | "]\n",
143 | "\n",
144 | "s = Solution()\n",
145 | "s.isValidSudoku(board)"
146 | ]
147 | }
148 | ],
149 | "metadata": {
150 | "kernelspec": {
151 | "display_name": "tf36",
152 | "language": "python",
153 | "name": "tf36"
154 | },
155 | "language_info": {
156 | "codemirror_mode": {
157 | "name": "ipython",
158 | "version": 3
159 | },
160 | "file_extension": ".py",
161 | "mimetype": "text/x-python",
162 | "name": "python",
163 | "nbconvert_exporter": "python",
164 | "pygments_lexer": "ipython3",
165 | "version": "3.6.8"
166 | }
167 | },
168 | "nbformat": 4,
169 | "nbformat_minor": 2
170 | }
171 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0048旋转图像-Rotate-Image.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# LeetCode0048旋转图像-Rotate-Image\n",
8 | "\n",
9 | "https://leetcode.com/problems/rotate-image/\n",
10 | "\n",
11 | "https://leetcode-cn.com/problems/rotate-image/\n",
12 | "\n"
13 | ]
14 | }
15 | ],
16 | "metadata": {
17 | "kernelspec": {
18 | "display_name": "tf36",
19 | "language": "python",
20 | "name": "tf36"
21 | },
22 | "language_info": {
23 | "codemirror_mode": {
24 | "name": "ipython",
25 | "version": 3
26 | },
27 | "file_extension": ".py",
28 | "mimetype": "text/x-python",
29 | "name": "python",
30 | "nbconvert_exporter": "python",
31 | "pygments_lexer": "ipython3",
32 | "version": "3.6.8"
33 | }
34 | },
35 | "nbformat": 4,
36 | "nbformat_minor": 2
37 | }
38 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0053最大子序和-Maximum-Subarray.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0105从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# LeetCode0105从前序与中序遍历序列构造二叉树 Construct Binary Tree from Preorder and Inorder Traversal\n",
8 | "\n",
9 | "[重建二叉树LeetCode](https://leetcode.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)\n",
10 | "\n",
11 | ">题目描述:\n",
12 | "根据一棵树的前序遍历与中序遍历构造二叉树。\n",
13 | "注意:\n",
14 | "你可以假设树中没有重复的元素。\n",
15 | "例如,给出\n",
16 | "\n",
17 | "```\n",
18 | "preorder = [3,9,20,15,7]\n",
19 | "inorder = [9,3,15,20,7]\n",
20 | "\n",
21 | "返回二叉树:\n",
22 | " 3\n",
23 | " / \\\n",
24 | " 9 20\n",
25 | " / \\\n",
26 | " 15 7\n",
27 | " \n",
28 | "preorder = [1,2,4,7,3,5,6,8]\n",
29 | "inorder = [4,7,2,1,5,3,8,6]\n",
30 | "\n",
31 | "返回二叉树:\n",
32 | " 1\n",
33 | " / \\\n",
34 | " 2 3\n",
35 | " / / \\\n",
36 | " 4 5 6\n",
37 | " \\ /\n",
38 | " 7 8\n",
39 | "```\n",
40 | "\n",
41 | ">思路:\n",
42 | ">\n",
43 | ">前序的第一个元素是根结点的值,在中序中找到该值,中序中该值的左边的元素是根结点的左子树,右边是右子树,然后递归的处理左边和右边\n",
44 | ">提示:二叉树结点,以及对二叉树的各种操作\n",
45 | "\n",
46 | "首先要知道一个结论,前序/后序+中序序列可以唯一确定一棵二叉树,所以自然而然可以用来建树。\n",
47 | "\n",
48 | "有如下特征:\n",
49 | "1. 前序中左起第一位`1`肯定是根结点,我们可以据此找到中序中根结点的位置`rootin`;\n",
50 | "2. 中序中根结点左边就是左子树结点,右边就是右子树结点,即`[左子树结点,根结点,右子树结点]`,我们就可以得出左子树结点个数为`int left = rootin - leftin;`;\n",
51 | "3. 前序中结点分布应该是:`[根结点,左子树结点,右子树结点]`;\n",
52 | "4. 根据前一步确定的左子树个数,可以确定前序中左子树结点和右子树结点的范围;\n",
53 | "5. 如果我们要前序遍历生成二叉树的话,下一层递归应该是:\n",
54 | " - 左子树:`root->left = pre_order(前序左子树范围,中序左子树范围,前序序列,中序序列);`;\n",
55 | " - 右子树:`root->right = pre_order(前序右子树范围,中序右子树范围,前序序列,中序序列);`。\n",
56 | "6. 每一层递归都要返回当前根结点`root`;\n"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 1,
62 | "metadata": {},
63 | "outputs": [
64 | {
65 | "name": "stdout",
66 | "output_type": "stream",
67 | "text": [
68 | "前序:\n",
69 | "[1, 2, 4, 7, 3, 5, 6, 8]\n",
70 | "中序:\n",
71 | "[4, 7, 2, 1, 5, 3, 8, 6]\n",
72 | "后序:\n",
73 | "[7, 4, 2, 5, 8, 6, 3, 1]\n"
74 | ]
75 | }
76 | ],
77 | "source": [
78 | "# Definition for a binary tree node.\n",
79 | "class TreeNode:\n",
80 | " def __init__(self, x):\n",
81 | " self.val = x\n",
82 | " self.left = None\n",
83 | " self.right = None\n",
84 | "\n",
85 | "class Solution:\n",
86 | " def buildTree(self, preorder, inorder):\n",
87 | " \"\"\"\n",
88 | " :type preorder: List[int]\n",
89 | " :type inorder: List[int]\n",
90 | " :rtype: TreeNode\n",
91 | " \"\"\"\n",
92 | " if not preorder or not inorder:\n",
93 | " return None\n",
94 | " x = preorder.pop(0)\n",
95 | " node = TreeNode(x)\n",
96 | " idx = inorder.index(x)\n",
97 | " \n",
98 | " node.left = self.buildTree(preorder[:idx],inorder[:idx])\n",
99 | " node.right = self.buildTree(preorder[idx:],inorder[idx+1:])\n",
100 | " #返回二叉树根节点\n",
101 | " return node\n",
102 | "\n",
103 | "#下面是打印前序、中序和后序\n",
104 | "def Preorder(root):\n",
105 | " res = []\n",
106 | " if root: #节点为None时,跳过\n",
107 | " res.append(root.val)\n",
108 | " res = res + Preorder(root.left)\n",
109 | " res = res + Preorder(root.right)\n",
110 | " return res\n",
111 | "\n",
112 | "def Inorder(root):\n",
113 | " res = []\n",
114 | " if root: #节点为None时,跳过\n",
115 | " res = res + Inorder(root.left)\n",
116 | " res.append(root.val)\n",
117 | " res = res + Inorder(root.right)\n",
118 | " return res\n",
119 | "\n",
120 | "def Postorder(root):\n",
121 | " res = []\n",
122 | " if root: #节点为None时,跳过\n",
123 | " res += Postorder(root.left)\n",
124 | " res += Postorder(root.right)\n",
125 | " res.append(root.val)\n",
126 | " return res\n",
127 | " \n",
128 | "# 测试:\n",
129 | "solu = Solution()\n",
130 | "# preorder = [3,9,20,15,7]\n",
131 | "# inorder = [9,3,15,20,7]\n",
132 | "\n",
133 | "preorder = [1,2,4,7,3,5,6,8]\n",
134 | "inorder = [4,7,2,1,5,3,8,6]\n",
135 | "\n",
136 | "node = solu.buildTree(preorder, inorder)\n",
137 | "print(\"前序:\")\n",
138 | "print(Preorder(node))\n",
139 | "print(\"中序:\")\n",
140 | "print(Inorder(node))\n",
141 | "print(\"后序:\")\n",
142 | "print(Postorder(node))"
143 | ]
144 | }
145 | ],
146 | "metadata": {
147 | "kernelspec": {
148 | "display_name": "Python 3",
149 | "language": "python",
150 | "name": "python3"
151 | },
152 | "language_info": {
153 | "codemirror_mode": {
154 | "name": "ipython",
155 | "version": 3
156 | },
157 | "file_extension": ".py",
158 | "mimetype": "text/x-python",
159 | "name": "python",
160 | "nbconvert_exporter": "python",
161 | "pygments_lexer": "ipython3",
162 | "version": "3.7.3"
163 | }
164 | },
165 | "nbformat": 4,
166 | "nbformat_minor": 2
167 | }
168 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0123买卖股票的最佳时机III-Best-Time-to-Buy-and-Sell-Stock-III.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0640求解方程-Solve-the-Equation.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0768最多能完成排序的块-II-Max-Chunks-To-Make-Sorted-II.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/OJ平台Python输入/Jupyter标准输入Stdin.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Jupyter标准输入sys.stdin\n",
8 | "\n",
9 | "https://www.reddit.com/r/Python/comments/24b3nv/programmatically_providing_input_to/\n",
10 | "\n",
11 | "**使用python io模块的StringIO将字符串替换成sys.stdin**\n",
12 | "\n",
13 | "You can change sys.stdin with any other file like object:"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 1,
19 | "metadata": {},
20 | "outputs": [],
21 | "source": [
22 | "from io import StringIO \n",
23 | "import sys\n",
24 | "\n",
25 | "doc = '''3\n",
26 | "1 2 3\n",
27 | "4 5 6\n",
28 | "7 8 9\n",
29 | "'''\n",
30 | "\n",
31 | "sys.stdin = StringIO(doc)"
32 | ]
33 | },
34 | {
35 | "cell_type": "code",
36 | "execution_count": 2,
37 | "metadata": {},
38 | "outputs": [
39 | {
40 | "name": "stdout",
41 | "output_type": "stream",
42 | "text": [
43 | "3\n",
44 | "[1, 2, 3]\n",
45 | "[4, 5, 6]\n",
46 | "[7, 8, 9]\n"
47 | ]
48 | }
49 | ],
50 | "source": [
51 | "n = int(sys.stdin.readline().strip())\n",
52 | "print(n)\n",
53 | "for i in range(n):\n",
54 | " line_str = sys.stdin.readline().strip()\n",
55 | " line = list(map(int,line_str.split()))\n",
56 | " print(line)"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 3,
62 | "metadata": {},
63 | "outputs": [
64 | {
65 | "name": "stdout",
66 | "output_type": "stream",
67 | "text": [
68 | "3\n",
69 | "7\n"
70 | ]
71 | }
72 | ],
73 | "source": [
74 | "#coding=utf-8\n",
75 | "\n",
76 | "from io import StringIO \n",
77 | "import sys\n",
78 | "\n",
79 | "doc = '''1 2\n",
80 | "3 4\n",
81 | "'''\n",
82 | "\n",
83 | "sys.stdin = StringIO(doc)\n",
84 | " \n",
85 | "if __name__ == \"__main__\":\n",
86 | " while True:\n",
87 | " try:\n",
88 | " line = sys.stdin.readline().split()\n",
89 | " a,b = list(map(int,line))\n",
90 | " print(a+b)\n",
91 | " except:\n",
92 | " break"
93 | ]
94 | }
95 | ],
96 | "metadata": {
97 | "kernelspec": {
98 | "display_name": "tf36",
99 | "language": "python",
100 | "name": "tf36"
101 | },
102 | "language_info": {
103 | "codemirror_mode": {
104 | "name": "ipython",
105 | "version": 3
106 | },
107 | "file_extension": ".py",
108 | "mimetype": "text/x-python",
109 | "name": "python",
110 | "nbconvert_exporter": "python",
111 | "pygments_lexer": "ipython3",
112 | "version": "3.6.8"
113 | }
114 | },
115 | "nbformat": 4,
116 | "nbformat_minor": 2
117 | }
118 |
--------------------------------------------------------------------------------
/OJ平台Python输入/python输入方法.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# python输入方法\n",
8 | "\n",
9 | "## 例题:找到集合 P 中的所有 ”最大“ 点的集合并输出\n",
10 | "\n",
11 | "链接:https://www.nowcoder.com/questionTerminal/e35d8c3404194cd69a88da1667ef8081\n",
12 | "\n",
13 | "来源:牛客网\n",
14 | "\n",
15 | "### 解析:\n",
16 | "只需对所有点的x坐标进行降序的排序,则第一个点一定是最大点,后面的点要想成为最大点,只需其y值大于前面的最大的y值即可。这样找到的点是根据x从大到小排列的,输出只需倒序输出就行。\n",
17 | "\n",
18 | "## python读取多行数据\n",
19 | "\n",
20 | "\n",
21 | "```\n",
22 | "5\n",
23 | "1 2\n",
24 | "5 3\n",
25 | "4 6\n",
26 | "7 5\n",
27 | "9 0\n",
28 | "```\n",
29 | "\n",
30 | "### 使用input"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": 1,
36 | "metadata": {},
37 | "outputs": [
38 | {
39 | "name": "stdin",
40 | "output_type": "stream",
41 | "text": [
42 | " 5\n",
43 | " 1 2\n",
44 | " 5 3\n",
45 | " 4 6\n",
46 | " 7 5\n",
47 | " 9 0\n"
48 | ]
49 | },
50 | {
51 | "name": "stdout",
52 | "output_type": "stream",
53 | "text": [
54 | "4 6\n",
55 | "7 5\n",
56 | "9 0\n"
57 | ]
58 | }
59 | ],
60 | "source": [
61 | "N = int(input())\n",
62 | "data = []\n",
63 | "for i in range(N):\n",
64 | " a = [int(i) for i in input().split()]\n",
65 | " data.append(a)\n",
66 | " \n",
67 | "data.sort(key=lambda t:(t[0],t[1]))\n",
68 | "myout = [data[-1]]\n",
69 | "\n",
70 | "i = N-2\n",
71 | "while(i>=0):\n",
72 | " max_end = max([t[1] for t in data[i+1:]])\n",
73 | " if data[i][1] > max_end:\n",
74 | " myout.append(data[i])\n",
75 | " i -= 1\n",
76 | "myout.sort()\n",
77 | "\n",
78 | "for i in myout:\n",
79 | " print(i[0],i[1])"
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | "### 使用sys.stdin"
87 | ]
88 | },
89 | {
90 | "cell_type": "markdown",
91 | "metadata": {},
92 | "source": [
93 | "```\n",
94 | "#coding=utf-8\n",
95 | "import sys\n",
96 | "data = []\n",
97 | "for line in sys.stdin:\n",
98 | " b = [int(i) for i in line.split()]\n",
99 | " data.append(b)\n",
100 | "\n",
101 | "N = data[0][0]\n",
102 | "pos = data[1:]\n",
103 | "\n",
104 | "print(data)\n",
105 | "print(N)\n",
106 | "print(pos)\n",
107 | "```"
108 | ]
109 | }
110 | ],
111 | "metadata": {
112 | "kernelspec": {
113 | "display_name": "tf36",
114 | "language": "python",
115 | "name": "tf36"
116 | },
117 | "language_info": {
118 | "codemirror_mode": {
119 | "name": "ipython",
120 | "version": 3
121 | },
122 | "file_extension": ".py",
123 | "mimetype": "text/x-python",
124 | "name": "python",
125 | "nbconvert_exporter": "python",
126 | "pygments_lexer": "ipython3",
127 | "version": "3.6.8"
128 | }
129 | },
130 | "nbformat": 4,
131 | "nbformat_minor": 2
132 | }
133 |
--------------------------------------------------------------------------------
/OJ平台Python输入/牛客网Python输入模板_使用stdin_可直接Jupyter运行.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 牛客网Python输入模板-使用stdin 可直接Jupyter运行\n",
8 | "\n",
9 | "## 1.方法概述:\n",
10 | "\n",
11 | "**使用sys.stdin.readline()方法进行数据输入,Jupyter中使用StringIO()方法转换**\n",
12 | "\n",
13 | "```\n",
14 | "例题:\n",
15 | "链接:https://ac.nowcoder.com/acm/contest/320/B 来源:牛客网\n",
16 | "输入:第一行包括一个数据组数t(1 <= t <= 100) 接下来每行包括两个正整数a,b(1 <= a, b <= 10^9)\n",
17 | "输出:每行的和\n",
18 | "\n",
19 | "样例输入:\n",
20 | "2\n",
21 | "1 5\n",
22 | "10 20\n",
23 | "输出:\n",
24 | "6\n",
25 | "30\n",
26 | "```\n",
27 | "\n",
28 | "## 2.模板使用\n",
29 | "\n",
30 | "下面第一行的注释使用方法:\n",
31 | "\n",
32 | "- Jupyter运行:加上的前面#\n",
33 | "- OJ平台:去掉前面的#\n",
34 | "\n",
35 | "doc中的字符替换成给定的输入"
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 1,
41 | "metadata": {},
42 | "outputs": [
43 | {
44 | "name": "stdout",
45 | "output_type": "stream",
46 | "text": [
47 | "6\n",
48 | "30\n"
49 | ]
50 | }
51 | ],
52 | "source": [
53 | "# \"\"\"\n",
54 | "from io import StringIO\n",
55 | "import sys\n",
56 | "doc = '''2\n",
57 | "1 5\n",
58 | "10 20\n",
59 | "'''\n",
60 | "sys.stdin = StringIO(doc)\n",
61 | "# \"\"\"\n",
62 | "\n",
63 | "#——————————复制的时候 从下面开始复制到牛客网OJ平台即可直接运行——————————#\n",
64 | "\n",
65 | "#coding=utf-8\n",
66 | "import sys\n",
67 | "\n",
68 | "def cal_sum(data):\n",
69 | " return sum(data)\n",
70 | "\n",
71 | "if __name__ == \"__main__\":\n",
72 | " n = int(sys.stdin.readline().strip())\n",
73 | " for _ in range(n):\n",
74 | " line = sys.stdin.readline().strip().split()\n",
75 | " data = list(map(int,line))\n",
76 | " print(cal_sum(data))"
77 | ]
78 | },
79 | {
80 | "cell_type": "markdown",
81 | "metadata": {},
82 | "source": [
83 | "### 第二种写法,使用while True的方法,可适用于不知道测试样例个数的情况\n",
84 | "\n",
85 | "注意这里的split要指定分割符号,否则会死循环(因为line为空字符串的时候也没有地方报错)"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": 2,
91 | "metadata": {},
92 | "outputs": [
93 | {
94 | "name": "stdout",
95 | "output_type": "stream",
96 | "text": [
97 | "6\n",
98 | "30\n"
99 | ]
100 | }
101 | ],
102 | "source": [
103 | "# \"\"\"\n",
104 | "from io import StringIO\n",
105 | "import sys\n",
106 | "doc = '''1 5\n",
107 | "10 20\n",
108 | "'''\n",
109 | "sys.stdin = StringIO(doc)\n",
110 | "# \"\"\"\n",
111 | "\n",
112 | "#——————————复制的时候 从下面开始复制到牛客网OJ平台即可直接运行——————————#\n",
113 | "\n",
114 | "#coding=utf-8\n",
115 | "import sys\n",
116 | "\n",
117 | "def cal_sum(data):\n",
118 | " return sum(data)\n",
119 | "\n",
120 | "if __name__ == \"__main__\":\n",
121 | " while True:\n",
122 | " try:\n",
123 | " line = sys.stdin.readline().strip().split(\" \")\n",
124 | " data = list(map(int,line))\n",
125 | " print(cal_sum(data))\n",
126 | " except:\n",
127 | " break"
128 | ]
129 | }
130 | ],
131 | "metadata": {
132 | "kernelspec": {
133 | "display_name": "tf36",
134 | "language": "python",
135 | "name": "tf36"
136 | },
137 | "language_info": {
138 | "codemirror_mode": {
139 | "name": "ipython",
140 | "version": 3
141 | },
142 | "file_extension": ".py",
143 | "mimetype": "text/x-python",
144 | "name": "python",
145 | "nbconvert_exporter": "python",
146 | "pygments_lexer": "ipython3",
147 | "version": "3.6.8"
148 | }
149 | },
150 | "nbformat": 4,
151 | "nbformat_minor": 2
152 | }
153 |
--------------------------------------------------------------------------------
/Python数据结构与算法/00_Python数据结构与算法介绍.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 数据结构概述 \n",
8 | "\n",
9 | "https://www.tutorialspoint.com/python_data_structure/python_data_structure_introduction.htm\n",
10 | "\n",
11 | "数据结构是计算机科学的基本概念,有助于编写任何语言的高效程序。 Python是一种高级,解释,交互式和面向对象的脚本语言,与其他编程语言相比,我们可以用更简单的方式研究数据结构的基础知识。 在本章中,我们将研究一般常用数据结构的简短概述,以及它们与某些特定python数据类型的关系。还有一些特定于python的数据结构被列为另一个类别。 \n",
12 | "\n",
13 | "一般数据结构 计算机科学中的各种数据结构大致分为以下两类。我们将在后续章节中详细讨论下面的每个数据结构。 \n",
14 | "\n",
15 | "## 1.线性数据结构\n",
16 | "\n",
17 | "这些是以顺序方式存储数据元素的数据结构。 \n",
18 | "\n",
19 | "### 数组Array\n",
20 | "\n",
21 | "它是与数据元素的索引配对的数据元素的顺序排列。\n",
22 | "\n",
23 | "### 链表Linked List\n",
24 | "\n",
25 | "每个数据元素都包含指向另一个元素的链接以及其中的数据。 \n",
26 | "\n",
27 | "### 栈Stack\n",
28 | "\n",
29 | "它是一种数据结构,仅遵循特定的操作顺序。 LIFO(last in First Out,后进先出)或者FILO(First in Last Out先进先出)。 \n",
30 | "\n",
31 | "### 队列Queue\n",
32 | "\n",
33 | "它与Stack类似,但操作顺序仅为FIFO(First In First Out,先进先出)。 \n",
34 | "\n",
35 | "### 矩阵Matrix\n",
36 | "\n",
37 | "二维数据结构,其中数据元素由一对索引引用。 \n",
38 | "\n",
39 | "## 2.非线性数据结构\n",
40 | "\n",
41 | "这些数据结构中没有数据元素的顺序链接。任何一对或一组数据元素都可以相互链接,并且可以在没有严格序列的情况下访问。\n",
42 | "\n",
43 | "### 二叉树Binary Tree\n",
44 | "\n",
45 | "这是一种数据结构,其中每个数据元素可以连接到最多两个其他数据元素,并以根节点开始。 \n",
46 | "\n",
47 | "### 堆Heap\n",
48 | "\n",
49 | "这是树数据结构的一种特殊情况,其中父节点中的数据严格大于/等于子节点或严格小于其子节点。 \n",
50 | "\n",
51 | "若母节点的值恒小于等于子节点的值,此堆积称为最小堆积(min heap);反之,若母节点的值恒大于等于子节点的值,此堆积称为最大堆积(max heap)。在堆积中最顶端的那一个节点,称作根节点(root node),根节点本身没有母节点(parent node)。\n",
52 | "\n",
53 | "堆的实现通过构造二叉堆(binary heap),实为二叉树的一种;由于其应用的普遍性,当不加限定时,均指该数据结构的这种实现。这种数据结构具有以下性质。\n",
54 | "\n",
55 | "- 任意节点小于(或大于)它的所有后裔,最小元(或最大元)在堆的根上(堆序性)。\n",
56 | "- 堆总是一棵完全树。即除了最底层,其他层的节点都被元素填满,且最底层尽可能地从左到右填入。\n",
57 | "\n",
58 | "将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。\n",
59 | "\n",
60 | "### 散列表/哈希表Hash Table\n",
61 | "\n",
62 | "它是一种数据结构,由使用散列函数相互关联的数组组成。它使用键而不是数据元素的索引来检索值。 \n",
63 | "\n",
64 | "### 图Graph\n",
65 | "\n",
66 | "它是顶点和节点的排列,其中一些节点通过链接相互连接。 \n",
67 | "\n",
68 | "## 3.python特定数据结构\n",
69 | "\n",
70 | "这些数据结构特定于python语言,它们为在python环境中存储不同类型的数据和更快的处理提供了更大的灵活性。 \n",
71 | "### 列表List\n",
72 | "\n",
73 | "它类似于数组,但数据元素可以是不同的数据类型。您可以在python列表中同时包含数字和字符串数据。 \n",
74 | "\n",
75 | "### 元组Tuple\n",
76 | "\n",
77 | "元组类似于列表,但它们是不可变的,这意味着元组中的值无法修改,只能读取。 \n",
78 | "\n",
79 | "### 字典Dictionary\n",
80 | "\n",
81 | "字典包含键值对作为其数据元素。 在接下来的章节中,我们将学习如何使用Python实现每个数据结构的细节。"
82 | ]
83 | }
84 | ],
85 | "metadata": {
86 | "kernelspec": {
87 | "display_name": "Python 3",
88 | "language": "python",
89 | "name": "python3"
90 | },
91 | "language_info": {
92 | "codemirror_mode": {
93 | "name": "ipython",
94 | "version": 3
95 | },
96 | "file_extension": ".py",
97 | "mimetype": "text/x-python",
98 | "name": "python",
99 | "nbconvert_exporter": "python",
100 | "pygments_lexer": "ipython3",
101 | "version": "3.7.3"
102 | }
103 | },
104 | "nbformat": 4,
105 | "nbformat_minor": 2
106 | }
107 |
--------------------------------------------------------------------------------
/Python数据结构与算法/02_lists_python列表.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python列表(Lists)\n",
8 | "\n",
9 | "https://www.tutorialspoint.com/python_data_structure/python_lists_data_structure.htm\n",
10 | "\n",
11 | "列表是Python中最通用的数据类型,可以写为方括号之间的逗号分隔值(项)列表。列表的重要一点是列表中的项不必是相同的类型,列表的元素也可以为列表(二维列表)。\n",
12 | "\n",
13 | "## 创建列表"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 1,
19 | "metadata": {
20 | "collapsed": false
21 | },
22 | "outputs": [
23 | {
24 | "name": "stdout",
25 | "output_type": "stream",
26 | "text": [
27 | "['physics', 'chemistry', 1997, 2000]\n",
28 | "[1, 2, 3, 4, 5]\n",
29 | "['a', 'b', 'c', 'd']\n",
30 | "[[11, 12, 5, 2], [15, 6, 10], [10, 8, 12, 5], [12, 15, 8, 6]]\n"
31 | ]
32 | }
33 | ],
34 | "source": [
35 | "list1 = ['physics', 'chemistry', 1997, 2000]\n",
36 | "list2 = [1, 2, 3, 4, 5 ]\n",
37 | "list3 = [\"a\", \"b\", \"c\", \"d\"]\n",
38 | "# 二维列表\n",
39 | "T = [\n",
40 | " [11, 12, 5, 2],\n",
41 | " [15, 6,10],\n",
42 | " [10, 8, 12, 5],\n",
43 | " [12,15,8,6]\n",
44 | "]\n",
45 | "# 或者写成一行\n",
46 | "# T = [[11, 12, 5, 2], [15, 6,10], [10, 8, 12, 5], [12,15,8,6]]\n",
47 | "\n",
48 | "print(list1)\n",
49 | "print(list2)\n",
50 | "print(list3)\n",
51 | "print(T)"
52 | ]
53 | },
54 | {
55 | "cell_type": "markdown",
56 | "metadata": {},
57 | "source": [
58 | "## 访问列表"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": 2,
64 | "metadata": {
65 | "collapsed": false
66 | },
67 | "outputs": [
68 | {
69 | "name": "stdout",
70 | "output_type": "stream",
71 | "text": [
72 | "list1[0]: physics\n",
73 | "list2[1:5]: [2, 3, 4, 5]\n",
74 | "[11, 12, 5, 2]\n",
75 | "10\n",
76 | "11 12 5 2 \n",
77 | "15 6 10 \n",
78 | "10 8 12 5 \n",
79 | "12 15 8 6 \n"
80 | ]
81 | }
82 | ],
83 | "source": [
84 | "print(\"list1[0]: \", list1[0])\n",
85 | "print(\"list2[1:5]: \", list2[1:5])\n",
86 | "\n",
87 | "print(T[0])\n",
88 | "print(T[1][2])\n",
89 | "for r in T:\n",
90 | " for c in r:\n",
91 | " print(c,end = \" \")\n",
92 | " print()"
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "## 插入"
100 | ]
101 | },
102 | {
103 | "cell_type": "code",
104 | "execution_count": 3,
105 | "metadata": {
106 | "collapsed": false
107 | },
108 | "outputs": [
109 | {
110 | "name": "stdout",
111 | "output_type": "stream",
112 | "text": [
113 | "['physics', 1001, 'chemistry', 1997, 2000]\n",
114 | "[[11, 12, 5, 2], [15, 6, 10], [0, 5, 11, 13, 6], [10, 8, 12, 5], [12, 15, 8, 6]]\n"
115 | ]
116 | }
117 | ],
118 | "source": [
119 | "list1.insert(1,1001)\n",
120 | "print(list1)\n",
121 | "T.insert(2, [0,5,11,13,6])\n",
122 | "print(T)"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "## 更新列表"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 1,
135 | "metadata": {
136 | "collapsed": false
137 | },
138 | "outputs": [
139 | {
140 | "name": "stdout",
141 | "output_type": "stream",
142 | "text": [
143 | "['physics', 'chemistry', 1997, 2000]\n",
144 | "['physics', 'chemistry', 2001, 2000]\n",
145 | "['physics', 'chemistry', 2001, 2000, 2019]\n",
146 | "[[11, 12, 5, 2], [15, 6, 10], [10, 8, 12, 5], [12, 15, 8, 6]]\n",
147 | "[[11, 12, 5, 2], [15, 6, 10], [11, 9], [12, 15, 8, 6]]\n",
148 | "[[11, 12, 5, 2], [15, 6, 10], [11, 7], [12, 15, 8, 6]]\n"
149 | ]
150 | }
151 | ],
152 | "source": [
153 | "# 一维列表\n",
154 | "lst = ['physics', 'chemistry', 1997, 2000]\n",
155 | "print(lst)\n",
156 | "lst[2] = 2001\n",
157 | "print(lst)\n",
158 | "lst.append(2019)\n",
159 | "print(lst)\n",
160 | "\n",
161 | "# 二维列表\n",
162 | "T = [[11, 12, 5, 2], [15, 6,10], [10, 8, 12, 5], [12,15,8,6]]\n",
163 | "print(T)\n",
164 | "\n",
165 | "T[2] = [11,9]\n",
166 | "print(T)\n",
167 | "\n",
168 | "T[2][1] = 7\n",
169 | "print(T)"
170 | ]
171 | },
172 | {
173 | "cell_type": "markdown",
174 | "metadata": {},
175 | "source": [
176 | "## 删除列表元素 del .remove"
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": 5,
182 | "metadata": {
183 | "collapsed": false
184 | },
185 | "outputs": [
186 | {
187 | "name": "stdout",
188 | "output_type": "stream",
189 | "text": [
190 | "['physics', 'chemistry', 1997, 2000]\n",
191 | "['physics', 'chemistry', 2000]\n",
192 | "['physics', 'chemistry']\n",
193 | "[[11, 12, 5, 2], [15, 6, 10], [10, 8, 12, 5], [12, 15, 8, 6]]\n",
194 | "[[15, 6, 10], [10, 8, 12, 5], [12, 15, 8, 6]]\n",
195 | "[[6, 10], [10, 8, 12, 5], [12, 15, 8, 6]]\n"
196 | ]
197 | }
198 | ],
199 | "source": [
200 | "list1 = ['physics', 'chemistry', 1997, 2000]\n",
201 | "print(list1)\n",
202 | "del(list1[2])\n",
203 | "print(list1)\n",
204 | "list1.remove(2000) #多个相同值时,从前面开始删除\n",
205 | "print(list1)\n",
206 | "\n",
207 | "T = [[11, 12, 5, 2], [15, 6,10], [10, 8, 12, 5], [12,15,8,6]]\n",
208 | "print(T)\n",
209 | "\n",
210 | "# 删除内部列表\n",
211 | "del T[0]\n",
212 | "print(T)\n",
213 | "\n",
214 | "# 删除内部列表的数据元素\n",
215 | "del T[0][0]\n",
216 | "print(T)"
217 | ]
218 | },
219 | {
220 | "cell_type": "markdown",
221 | "metadata": {},
222 | "source": [
223 | "## 列表基本操作\n",
224 | "\n",
225 | "```\n",
226 | "len, +, *, i in list, for i in list\n",
227 | "```"
228 | ]
229 | },
230 | {
231 | "cell_type": "code",
232 | "execution_count": 6,
233 | "metadata": {
234 | "collapsed": false
235 | },
236 | "outputs": [
237 | {
238 | "name": "stdout",
239 | "output_type": "stream",
240 | "text": [
241 | "3\n",
242 | "[1, 2, 3, 4, 5, 6]\n",
243 | "['Hi!', 'Hi!', 'Hi!', 'Hi!']\n",
244 | "True\n",
245 | "1\n",
246 | "2\n",
247 | "3\n"
248 | ]
249 | }
250 | ],
251 | "source": [
252 | "# len\n",
253 | "print(len([1,2,3]))\n",
254 | "\n",
255 | "# + 加号\n",
256 | "print([1, 2, 3] + [4, 5, 6])\n",
257 | "\n",
258 | "# * 乘号\n",
259 | "print(['Hi!'] * 4)\n",
260 | "\n",
261 | "# Membership 包含,输出Ture False\n",
262 | "print(3 in [1, 2, 3])\n",
263 | "\n",
264 | "# Iteration 迭代\n",
265 | "for x in [1, 2, 3]: print(x)"
266 | ]
267 | }
268 | ],
269 | "metadata": {
270 | "kernelspec": {
271 | "display_name": "Python 3",
272 | "language": "python",
273 | "name": "python3"
274 | },
275 | "language_info": {
276 | "codemirror_mode": {
277 | "name": "ipython",
278 | "version": 3
279 | },
280 | "file_extension": ".py",
281 | "mimetype": "text/x-python",
282 | "name": "python",
283 | "nbconvert_exporter": "python",
284 | "pygments_lexer": "ipython3",
285 | "version": "3.7.3"
286 | }
287 | },
288 | "nbformat": 4,
289 | "nbformat_minor": 2
290 | }
291 |
--------------------------------------------------------------------------------
/Python数据结构与算法/03_tuples_python元组.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python元组(Tuples)\n",
8 | "\n",
9 | "https://www.tutorialspoint.com/python_data_structure/python_tuples_data_structure.htm\n",
10 | "\n",
11 | "元组是一系列不可变的Python对象。 元组是序列,就像列表一样。 元组和列表之间的区别是,元组不能更改,列表可以更改。元组使用圆括号,而列表使用方括号。\n",
12 | "\n",
13 | "## 创建元组"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 1,
19 | "metadata": {},
20 | "outputs": [
21 | {
22 | "name": "stdout",
23 | "output_type": "stream",
24 | "text": [
25 | "('physics', 'chemistry', 1997, 2000)\n",
26 | "(1, 2, 3, 4, 5)\n",
27 | "('a', 'b', 'c', 'd')\n",
28 | "()\n",
29 | "(100,)\n"
30 | ]
31 | }
32 | ],
33 | "source": [
34 | "tup1 = ('physics', 'chemistry', 1997, 2000)\n",
35 | "print(tup1)\n",
36 | "tup2 = (1, 2, 3, 4, 5 )\n",
37 | "print(tup2)\n",
38 | "\n",
39 | "# 也可以不加括号\n",
40 | "tup3 = \"a\", \"b\", \"c\", \"d\"\n",
41 | "print(tup3)\n",
42 | "\n",
43 | "# 空元组\n",
44 | "tup4 = ()\n",
45 | "print(tup4)\n",
46 | "\n",
47 | "# 创建只有一个元素的元组,需要加上逗号(否则直接是int)\n",
48 | "tup5 = (100,)\n",
49 | "print(tup5)"
50 | ]
51 | },
52 | {
53 | "cell_type": "markdown",
54 | "metadata": {},
55 | "source": [
56 | "## 访问元组\n",
57 | "\n",
58 | "和list相似,直接用中括号进行索引"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": 2,
64 | "metadata": {},
65 | "outputs": [
66 | {
67 | "name": "stdout",
68 | "output_type": "stream",
69 | "text": [
70 | "physics\n",
71 | "('chemistry', 1997, 2000)\n"
72 | ]
73 | }
74 | ],
75 | "source": [
76 | "tup1 = ('physics', 'chemistry', 1997, 2000);\n",
77 | "print(tup1[0])\n",
78 | "print(tup1[1:4])"
79 | ]
80 | },
81 | {
82 | "cell_type": "markdown",
83 | "metadata": {},
84 | "source": [
85 | "## 不能更改和删除tuple元素"
86 | ]
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {},
91 | "source": [
92 | "## 元组基本操作\n",
93 | "\n",
94 | "```\n",
95 | "len, +, *, i in tuple, for i in tuple\n",
96 | "```"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": 3,
102 | "metadata": {},
103 | "outputs": [
104 | {
105 | "name": "stdout",
106 | "output_type": "stream",
107 | "text": [
108 | "3\n",
109 | "(1, 2, 3, 4, 5, 6)\n",
110 | "('Hi!', 'Hi!', 'Hi!', 'Hi!')\n",
111 | "True\n",
112 | "1\n",
113 | "2\n",
114 | "3\n"
115 | ]
116 | }
117 | ],
118 | "source": [
119 | "# len\n",
120 | "print(len((1,2,3)))\n",
121 | "\n",
122 | "# + 加号\n",
123 | "print((1,2,3)+(4,5,6))\n",
124 | "\n",
125 | "# * 乘号\n",
126 | "print(('Hi!',) * 4)\n",
127 | "\n",
128 | "# Membership 包含,输出Ture False\n",
129 | "print(3 in (1, 2, 3))\n",
130 | "\n",
131 | "# Iteration 迭代\n",
132 | "for x in (1, 2, 3): print(x)"
133 | ]
134 | }
135 | ],
136 | "metadata": {
137 | "kernelspec": {
138 | "display_name": "Python 3",
139 | "language": "python",
140 | "name": "python3"
141 | },
142 | "language_info": {
143 | "codemirror_mode": {
144 | "name": "ipython",
145 | "version": 3
146 | },
147 | "file_extension": ".py",
148 | "mimetype": "text/x-python",
149 | "name": "python",
150 | "nbconvert_exporter": "python",
151 | "pygments_lexer": "ipython3",
152 | "version": "3.7.3"
153 | }
154 | },
155 | "nbformat": 4,
156 | "nbformat_minor": 2
157 | }
158 |
--------------------------------------------------------------------------------
/Python数据结构与算法/05_sets_python集合.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python集合(Sets)\n",
8 | "\n",
9 | "https://www.tutorialspoint.com/python_data_structure/python_sets.htm\n",
10 | "\n",
11 | "数学上,集合是不按任何特定顺序排列的项目集合。 Python集类似于此数学定义,具有以下附加条件。\n",
12 | "\n",
13 | "- 集合中的元素不能重复。 \n",
14 | "- 集合中的元素是不可变的(不能修改),但整个集合是可变的。 \n",
15 | "- 没有索引附加到python集中的任何元素。因此,它们不支持任何索引或切片操作。\n",
16 | "\n",
17 | "python中的集合通常用于数学运算,如并集,交集,差异和补码等。我们可以创建一个集合,访问它的元素并执行这些数学运算。\n",
18 | "\n",
19 | "## 创建集合 set(iterable) 、 {}"
20 | ]
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": 12,
25 | "metadata": {},
26 | "outputs": [
27 | {
28 | "name": "stdout",
29 | "output_type": "stream",
30 | "text": [
31 | "{'Sat', 'Thu', 'Sun', 'Fri', 'Mon', 'Wed', 'Tue'}\n",
32 | "{'Feb', 'Jan', 'Mar'}\n",
33 | "{17, 21, 22}\n",
34 | "{'l', 'g', 'G', 'o', 'e'}\n"
35 | ]
36 | }
37 | ],
38 | "source": [
39 | "Days=set([\"Mon\",\"Tue\",\"Wed\",\"Thu\",\"Fri\",\"Sat\",\"Sun\"])\n",
40 | "Months={\"Jan\",\"Feb\",\"Mar\"}\n",
41 | "Dates={21,22,17}\n",
42 | "Google = set(\"Google\")\n",
43 | "print(Days)\n",
44 | "print(Months)\n",
45 | "print(Dates)\n",
46 | "print(Google)"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "## 访问集合\n",
54 | "\n",
55 | "我们无法访问集合中的单个值。我们只能访问所有元素,如上所示。但是我们也可以通过循环遍历集合来获得单个元素的列表。"
56 | ]
57 | },
58 | {
59 | "cell_type": "code",
60 | "execution_count": 8,
61 | "metadata": {},
62 | "outputs": [
63 | {
64 | "name": "stdout",
65 | "output_type": "stream",
66 | "text": [
67 | "Sat\n",
68 | "Thu\n",
69 | "Sun\n",
70 | "Fri\n",
71 | "Mon\n",
72 | "Wed\n",
73 | "Tue\n"
74 | ]
75 | }
76 | ],
77 | "source": [
78 | "for d in Days:\n",
79 | "\tprint(d)"
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | "## 添加元素 .add()"
87 | ]
88 | },
89 | {
90 | "cell_type": "code",
91 | "execution_count": 10,
92 | "metadata": {},
93 | "outputs": [
94 | {
95 | "name": "stdout",
96 | "output_type": "stream",
97 | "text": [
98 | "{'Sat', 'Thu', 'Sun', 'Fri', 'Mon', 'Wed', 'Tue'}\n"
99 | ]
100 | }
101 | ],
102 | "source": [
103 | "Days=set([\"Mon\",\"Tue\",\"Wed\",\"Thu\",\"Fri\",\"Sat\"])\n",
104 | "Days.add(\"Sun\")\n",
105 | "print(Days)"
106 | ]
107 | },
108 | {
109 | "cell_type": "markdown",
110 | "metadata": {},
111 | "source": [
112 | "## 移除元素 .discard()"
113 | ]
114 | },
115 | {
116 | "cell_type": "code",
117 | "execution_count": 11,
118 | "metadata": {},
119 | "outputs": [
120 | {
121 | "name": "stdout",
122 | "output_type": "stream",
123 | "text": [
124 | "{'Sat', 'Thu', 'Fri', 'Mon', 'Wed', 'Tue'}\n"
125 | ]
126 | }
127 | ],
128 | "source": [
129 | "Days=set([\"Mon\",\"Tue\",\"Wed\",\"Thu\",\"Fri\",\"Sat\"])\n",
130 | " \n",
131 | "Days.discard(\"Sun\")\n",
132 | "print(Days)"
133 | ]
134 | },
135 | {
136 | "cell_type": "markdown",
137 | "metadata": {},
138 | "source": [
139 | "## 并集 .union() 或者 |"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 2,
145 | "metadata": {},
146 | "outputs": [
147 | {
148 | "name": "stdout",
149 | "output_type": "stream",
150 | "text": [
151 | "{'Mon', 'Fri', 'Sun', 'Sat', 'Thu', 'Tue', 'Wed'}\n"
152 | ]
153 | }
154 | ],
155 | "source": [
156 | "DaysA = set([\"Mon\",\"Tue\",\"Wed\"])\n",
157 | "DaysB = set([\"Wed\",\"Thu\",\"Fri\",\"Sat\",\"Sun\"])\n",
158 | "\n",
159 | "DaysAB = DaysA.union(DaysB)\n",
160 | "print(DaysAB)"
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": 3,
166 | "metadata": {},
167 | "outputs": [
168 | {
169 | "name": "stdout",
170 | "output_type": "stream",
171 | "text": [
172 | "{'Mon', 'Fri', 'Sun', 'Sat', 'Thu', 'Tue', 'Wed'}\n"
173 | ]
174 | }
175 | ],
176 | "source": [
177 | "DaysAB = DaysA | DaysB\n",
178 | "print(DaysAB)"
179 | ]
180 | },
181 | {
182 | "cell_type": "markdown",
183 | "metadata": {},
184 | "source": [
185 | "## 交集 .intersection() 或者 &"
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": 4,
191 | "metadata": {},
192 | "outputs": [
193 | {
194 | "data": {
195 | "text/plain": [
196 | "{'Wed'}"
197 | ]
198 | },
199 | "execution_count": 4,
200 | "metadata": {},
201 | "output_type": "execute_result"
202 | }
203 | ],
204 | "source": [
205 | "DaysA.intersection(DaysB)"
206 | ]
207 | },
208 | {
209 | "cell_type": "code",
210 | "execution_count": 5,
211 | "metadata": {},
212 | "outputs": [
213 | {
214 | "data": {
215 | "text/plain": [
216 | "{'Wed'}"
217 | ]
218 | },
219 | "execution_count": 5,
220 | "metadata": {},
221 | "output_type": "execute_result"
222 | }
223 | ],
224 | "source": [
225 | "DaysA & DaysB"
226 | ]
227 | },
228 | {
229 | "cell_type": "markdown",
230 | "metadata": {},
231 | "source": [
232 | "## 差集 .difference() 或者 - (A-B = A-(A∩B)去掉公共部分)"
233 | ]
234 | },
235 | {
236 | "cell_type": "code",
237 | "execution_count": 7,
238 | "metadata": {},
239 | "outputs": [
240 | {
241 | "data": {
242 | "text/plain": [
243 | "{'Fri', 'Sat', 'Sun', 'Thu'}"
244 | ]
245 | },
246 | "execution_count": 7,
247 | "metadata": {},
248 | "output_type": "execute_result"
249 | }
250 | ],
251 | "source": [
252 | "DaysB.difference(DaysA)"
253 | ]
254 | },
255 | {
256 | "cell_type": "code",
257 | "execution_count": 6,
258 | "metadata": {},
259 | "outputs": [
260 | {
261 | "data": {
262 | "text/plain": [
263 | "{'Fri', 'Sat', 'Sun', 'Thu'}"
264 | ]
265 | },
266 | "execution_count": 6,
267 | "metadata": {},
268 | "output_type": "execute_result"
269 | }
270 | ],
271 | "source": [
272 | "DaysB -DaysA"
273 | ]
274 | },
275 | {
276 | "cell_type": "markdown",
277 | "metadata": {},
278 | "source": [
279 | "## 比较 <= 和 >="
280 | ]
281 | },
282 | {
283 | "cell_type": "code",
284 | "execution_count": 9,
285 | "metadata": {},
286 | "outputs": [
287 | {
288 | "data": {
289 | "text/plain": [
290 | "False"
291 | ]
292 | },
293 | "execution_count": 9,
294 | "metadata": {},
295 | "output_type": "execute_result"
296 | }
297 | ],
298 | "source": [
299 | "DaysB >= DaysA"
300 | ]
301 | },
302 | {
303 | "cell_type": "code",
304 | "execution_count": 11,
305 | "metadata": {},
306 | "outputs": [
307 | {
308 | "data": {
309 | "text/plain": [
310 | "True"
311 | ]
312 | },
313 | "execution_count": 11,
314 | "metadata": {},
315 | "output_type": "execute_result"
316 | }
317 | ],
318 | "source": [
319 | "set([1,2]) <= set([1,2,3,4])"
320 | ]
321 | }
322 | ],
323 | "metadata": {
324 | "kernelspec": {
325 | "display_name": "Python 3",
326 | "language": "python",
327 | "name": "python3"
328 | },
329 | "language_info": {
330 | "codemirror_mode": {
331 | "name": "ipython",
332 | "version": 3
333 | },
334 | "file_extension": ".py",
335 | "mimetype": "text/x-python",
336 | "name": "python",
337 | "nbconvert_exporter": "python",
338 | "pygments_lexer": "ipython3",
339 | "version": "3.7.3"
340 | }
341 | },
342 | "nbformat": 4,
343 | "nbformat_minor": 2
344 | }
345 |
--------------------------------------------------------------------------------
/Python数据结构与算法/python链表.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# python 链表\n",
8 | "\n",
9 | "https://www.jianshu.com/p/5875efe4748d\n",
10 | "\n",
11 | "https://blog.csdn.net/qq_39422642/article/details/78988976"
12 | ]
13 | },
14 | {
15 | "cell_type": "code",
16 | "execution_count": 5,
17 | "metadata": {},
18 | "outputs": [
19 | {
20 | "name": "stdout",
21 | "output_type": "stream",
22 | "text": [
23 | "Create a linklist\n",
24 | "1\n",
25 | "2\n",
26 | "3\n",
27 | "4\n",
28 | "5\n",
29 | "6\n",
30 | "7\n",
31 | "___________________________\n"
32 | ]
33 | },
34 | {
35 | "name": "stdin",
36 | "output_type": "stream",
37 | "text": [
38 | "Enter the index to insert 3\n",
39 | "Enter a value: 7\n"
40 | ]
41 | },
42 | {
43 | "name": "stdout",
44 | "output_type": "stream",
45 | "text": [
46 | "1\n",
47 | "2\n",
48 | "7\n",
49 | "3\n",
50 | "4\n",
51 | "5\n",
52 | "6\n",
53 | "7\n",
54 | "___________________________\n"
55 | ]
56 | },
57 | {
58 | "name": "stdin",
59 | "output_type": "stream",
60 | "text": [
61 | "Enter the index to delete 3\n"
62 | ]
63 | },
64 | {
65 | "name": "stdout",
66 | "output_type": "stream",
67 | "text": [
68 | "1\n",
69 | "2\n",
70 | "3\n",
71 | "4\n",
72 | "5\n",
73 | "6\n",
74 | "7\n"
75 | ]
76 | }
77 | ],
78 | "source": [
79 | "class ListNode(): # 初始化 构造函数 \n",
80 | " def __init__(self,value): \n",
81 | " self.value=value \n",
82 | " self.next=None\n",
83 | " \n",
84 | "def Creatlist(n): \n",
85 | " if n<=0: \n",
86 | " return False \n",
87 | " if n==1: \n",
88 | " return ListNode(1) # 只有一个节点 \n",
89 | " else: \n",
90 | " root=ListNode(1) \n",
91 | " tmp=root \n",
92 | " for i in range(2,n+1): # 一个一个的增加节点 \n",
93 | " tmp.next=ListNode(i) \n",
94 | " tmp=tmp.next \n",
95 | " return root # 返回根节点 \n",
96 | " \n",
97 | "def printlist(head): # 打印链表 (遍历) \n",
98 | " p=head \n",
99 | " while p!=None: \n",
100 | " print(p.value)\n",
101 | " p=p.next \n",
102 | " \n",
103 | "def listlen(head): # 链表长度 \n",
104 | " c=0 \n",
105 | " p=head \n",
106 | " while p!=None: \n",
107 | " c=c+1 \n",
108 | " p=p.next \n",
109 | " return c \n",
110 | " \n",
111 | "def insert(head,n): # 在n的前面插入元素 \n",
112 | " if n<1 or n>listlen(head): \n",
113 | " return \n",
114 | " \n",
115 | " p=head \n",
116 | " for i in range(1,n-1): # 循环四次到达 5 (只能一个一个节点的移动 range不包含n-1)\n",
117 | " p=p.next \n",
118 | " a=input(\"Enter a value:\") \n",
119 | " t=ListNode(value=a) \n",
120 | " t.next=p.next \n",
121 | " p.next=t \n",
122 | " return head \n",
123 | " \n",
124 | "def dellist(head,n): # 删除链表 \n",
125 | " if n<1 or n>listlen(head): \n",
126 | " return head \n",
127 | " elif n is 1: \n",
128 | " head=head.next # 删除头 \n",
129 | " else: \n",
130 | " p=head \n",
131 | " for i in range(1,n-1): \n",
132 | " p=p.next # 循环到达 2次 \n",
133 | " q=p.next \n",
134 | " p.next=q.next # 把5放在3的后面 \n",
135 | " return head \n",
136 | "\n",
137 | "def main(): \n",
138 | " print(\"Create a linklist\" )\n",
139 | " head=Creatlist(7) \n",
140 | " printlist(head) \n",
141 | " print(\"___________________________\")\n",
142 | " \n",
143 | " n1=input(\"Enter the index to insert\") \n",
144 | " n1=int(n1) \n",
145 | " insert(head,n1) \n",
146 | " printlist(head) \n",
147 | " print(\"___________________________\")\n",
148 | " \n",
149 | " n2=input(\"Enter the index to delete\") \n",
150 | " n2=int(n2) \n",
151 | " dellist(head,n2) \n",
152 | " printlist(head) \n",
153 | " \n",
154 | " \n",
155 | "if __name__=='__main__': main() # 主函数调用 "
156 | ]
157 | },
158 | {
159 | "cell_type": "code",
160 | "execution_count": null,
161 | "metadata": {},
162 | "outputs": [],
163 | "source": []
164 | }
165 | ],
166 | "metadata": {
167 | "kernelspec": {
168 | "display_name": "tf36",
169 | "language": "python",
170 | "name": "tf36"
171 | },
172 | "language_info": {
173 | "codemirror_mode": {
174 | "name": "ipython",
175 | "version": 3
176 | },
177 | "file_extension": ".py",
178 | "mimetype": "text/x-python",
179 | "name": "python",
180 | "nbconvert_exporter": "python",
181 | "pygments_lexer": "ipython3",
182 | "version": "3.6.7"
183 | }
184 | },
185 | "nbformat": 4,
186 | "nbformat_minor": 2
187 | }
188 |
--------------------------------------------------------------------------------
/Python知识点/Python小知识点.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python小知识点"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## index一个字符串的位置"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {},
21 | "outputs": [
22 | {
23 | "name": "stdout",
24 | "output_type": "stream",
25 | "text": [
26 | "6\n"
27 | ]
28 | }
29 | ],
30 | "source": [
31 | "str1 = \"Hello,Python\"\n",
32 | "str2 = \"Python\"\n",
33 | "print(str1.index(str2))"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "## 一道筛法题目\n",
41 | "\n",
42 | "假设可以不考虑计算机运行资源(如内存)的限制,以下 python3 代码的预期运行结果是:()\n",
43 | "\n",
44 | "```python\n",
45 | "import math\n",
46 | "def sieve(size):\n",
47 | " sieve= [True] * size\n",
48 | " sieve[0] = False\n",
49 | " sieve[1] = False\n",
50 | " for i in range(2, int(math.sqrt(size)) + 1):\n",
51 | " k= i * 2\n",
52 | " while k < size:\n",
53 | " sieve[k] = False\n",
54 | " k += i\n",
55 | " return sum(1 for x in sieve if x)\n",
56 | "print(sieve(10000000000))\n",
57 | "```"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 2,
63 | "metadata": {},
64 | "outputs": [
65 | {
66 | "data": {
67 | "text/plain": [
68 | "10.0"
69 | ]
70 | },
71 | "execution_count": 2,
72 | "metadata": {},
73 | "output_type": "execute_result"
74 | }
75 | ],
76 | "source": [
77 | "a=10000000000\n",
78 | "import math\n",
79 | "math.log10(a)"
80 | ]
81 | },
82 | {
83 | "cell_type": "code",
84 | "execution_count": 45,
85 | "metadata": {},
86 | "outputs": [
87 | {
88 | "name": "stdout",
89 | "output_type": "stream",
90 | "text": [
91 | "25\n",
92 | "[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]\n"
93 | ]
94 | }
95 | ],
96 | "source": [
97 | "import math\n",
98 | " \n",
99 | "def sieve(size):\n",
100 | " num = list(range(size))\n",
101 | " sieve1= [True] * size\n",
102 | " sieve1[0] = False\n",
103 | " sieve1[1] = False\n",
104 | " for i in range(2, int(math.sqrt(size)) + 1):\n",
105 | " k = i * 2\n",
106 | " while k < size:\n",
107 | " sieve1[k] = False\n",
108 | " k += i\n",
109 | " prim = [num[i] for i,x in enumerate(sieve1) if x]\n",
110 | " n = len(prim)\n",
111 | " return prim,n\n",
112 | "\n",
113 | "a,n= sieve(100)\n",
114 | "print(n)\n",
115 | "print(a)"
116 | ]
117 | },
118 | {
119 | "cell_type": "markdown",
120 | "metadata": {},
121 | "source": [
122 | "该程序是计算,前size个整数中(从0开始),素数的个数,直接查阅:\n",
123 | "\n",
124 | "https://www.wikiwand.com/en/Prime-counting_function\n",
125 | "\n",
126 | "得到10^10以内的个数为455,052,511。\n",
127 | "\n",
128 | ">筛法\n",
129 | "```\n",
130 | "用筛法求素数的基本思想是:把从1开始的、某一范围内的正整数从小到大顺序排列, 1不是素数,首先把它筛掉。\n",
131 | "剩下的数中选择最小的数是素数,然后去掉它的倍数。依次类推,直到筛子为空时结束。如有:\n",
132 | "1 2 3 4 5 6 7 8 9 10\n",
133 | "11 12 13 14 15 16 17 18 19 20\n",
134 | "21 22 23 24 25 26 27 28 29 30\n",
135 | "1不是素数,去掉。剩下的数中2最小,是素数,去掉2的倍数,余下的数是:\n",
136 | "3 5 7 9 11 13 15 17 19 21 23 25 27 29\n",
137 | "剩下的数中3最小,是素数,去掉3的倍数,如此下去直到所有的数都被筛完,求出的素数为:\n",
138 | "2 3 5 7 11 13 17 19 23 29\n",
139 | "```"
140 | ]
141 | },
142 | {
143 | "cell_type": "markdown",
144 | "metadata": {},
145 | "source": [
146 | "## return的特殊情况\n",
147 | "\n",
148 | "默认情况下,遇见 return 函数就会返回给调用者,但是 try,finally情况除外:"
149 | ]
150 | },
151 | {
152 | "cell_type": "code",
153 | "execution_count": 33,
154 | "metadata": {},
155 | "outputs": [
156 | {
157 | "name": "stdout",
158 | "output_type": "stream",
159 | "text": [
160 | "98\n",
161 | "98\n",
162 | "ok\n"
163 | ]
164 | }
165 | ],
166 | "source": [
167 | "def func(): \n",
168 | " try: \n",
169 | " print(98)\n",
170 | " return 'ok' #函数得到了一个返回值 \n",
171 | " finally: #finally语句块中的语句依然会执行 \n",
172 | " print(98) \n",
173 | "print(func())"
174 | ]
175 | },
176 | {
177 | "cell_type": "markdown",
178 | "metadata": {},
179 | "source": [
180 | "函数作为返回值返回,这其实就是闭包:"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 46,
186 | "metadata": {},
187 | "outputs": [
188 | {
189 | "name": "stdout",
190 | "output_type": "stream",
191 | "text": [
192 | "\n",
193 | "45\n"
194 | ]
195 | }
196 | ],
197 | "source": [
198 | "def lazy_sum(*args):\n",
199 | " def sum():\n",
200 | " x=0\n",
201 | " for n in args:\n",
202 | " x=x+n\n",
203 | " return x\n",
204 | " return sum\n",
205 | "\n",
206 | "lazy_sum(1,2,3,4,5,6,7,8,9) #这时候lazy_sum 并没有执行,而是返回一个指向求和的函数的函数名sum 的内存地址。\n",
207 | "f=lazy_sum(1,2,3,4,5,6,7,8,9)\n",
208 | "print(type(f))\n",
209 | "print(f()) # 调用f()函数,才真正调用了 sum 函数进行求和,"
210 | ]
211 | },
212 | {
213 | "cell_type": "markdown",
214 | "metadata": {},
215 | "source": [
216 | "返回函数列表:"
217 | ]
218 | },
219 | {
220 | "cell_type": "code",
221 | "execution_count": 49,
222 | "metadata": {},
223 | "outputs": [
224 | {
225 | "name": "stdout",
226 | "output_type": "stream",
227 | "text": [
228 | "9\n",
229 | "9\n",
230 | "9\n"
231 | ]
232 | }
233 | ],
234 | "source": [
235 | "def count():\n",
236 | " fs = []\n",
237 | " for i in range(1,4):\n",
238 | " def f():\n",
239 | " return i*i\n",
240 | " fs.append(f)\n",
241 | " return fs\n",
242 | "\n",
243 | "\n",
244 | "f1, f2, f3 = count()\n",
245 | "print(f1())\n",
246 | "print(f2())\n",
247 | "print(f3())"
248 | ]
249 | },
250 | {
251 | "cell_type": "markdown",
252 | "metadata": {},
253 | "source": [
254 | "```\n",
255 | "执行过程:\n",
256 | "当i=1, 执行for循环, 结果返回函数f的函数地址,存在列表fs中的第一个位置上。\n",
257 | "当i=2, 由于fs列表中第一个元素所指的函数中的i是count函数的局部变量,i也指向了2;然后执行for循环, 结果返回函数f的函数地址,存在列表fs中的第二个位置上。\n",
258 | "当i=3, 同理,在fs列表第一个和第二个元素所指的函数中的i变量指向了3; 然后执行for循环, 结果返回函数f的函数地址,存在列表fs中的第三个位置上。\n",
259 | "所以在调用f1()的时候,函数中的i是指向3的:\n",
260 | " f1():\n",
261 | " return 3*3\n",
262 | "同理f2(), f3()结果都为9\n",
263 | "闭包时牢记的一点就是:返回函数不要引用任何循环变量,或者后续会发生变化的变量。即包在里面的函数(本例为f()),不\n",
264 | "要引用外部函数(本例为count())的任何循环变量\n",
265 | "\n",
266 | "如果一定要引入循环变量,方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,\n",
267 | "已绑定到函数参数的值不变:\n",
268 | "```"
269 | ]
270 | },
271 | {
272 | "cell_type": "code",
273 | "execution_count": 50,
274 | "metadata": {},
275 | "outputs": [
276 | {
277 | "name": "stdout",
278 | "output_type": "stream",
279 | "text": [
280 | "1\n",
281 | "4\n",
282 | "9\n"
283 | ]
284 | }
285 | ],
286 | "source": [
287 | "def count():\n",
288 | " fs=[]\n",
289 | " for i in range(1,4):\n",
290 | " def f(j):\n",
291 | " def g():\n",
292 | " return j*j\n",
293 | " return g\n",
294 | " fs.append(f(i))\n",
295 | " return fs\n",
296 | "\n",
297 | "f1,f2,f3=count()\n",
298 | "print(f1())\n",
299 | "print(f2())\n",
300 | "print(f3())"
301 | ]
302 | }
303 | ],
304 | "metadata": {
305 | "kernelspec": {
306 | "display_name": "tf36",
307 | "language": "python",
308 | "name": "tf36"
309 | },
310 | "language_info": {
311 | "codemirror_mode": {
312 | "name": "ipython",
313 | "version": 3
314 | },
315 | "file_extension": ".py",
316 | "mimetype": "text/x-python",
317 | "name": "python",
318 | "nbconvert_exporter": "python",
319 | "pygments_lexer": "ipython3",
320 | "version": "3.6.8"
321 | }
322 | },
323 | "nbformat": 4,
324 | "nbformat_minor": 2
325 | }
326 |
--------------------------------------------------------------------------------
/Python知识点/__new__ & __init__.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# `__new__`和`__init__`\n",
8 | "\n",
9 | "[详解Python中的`__init__`和`__new__`](http://python.jobbole.com/86506/)\n",
10 | "\n",
11 | "## 1.`__init__` 方法\n",
12 | "\n",
13 | "`__init__` 方法通常用在初始化一个类实例的时候"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 13,
19 | "metadata": {},
20 | "outputs": [
21 | {
22 | "name": "stdout",
23 | "output_type": "stream",
24 | "text": [
25 | "\n"
26 | ]
27 | }
28 | ],
29 | "source": [
30 | "# -*- coding: utf-8 -*-\n",
31 | " \n",
32 | "class Person(object):\n",
33 | " \"\"\"Silly Person\"\"\"\n",
34 | " \n",
35 | " def __init__(self, name, age):\n",
36 | " self.name = name\n",
37 | " self.age = age\n",
38 | " \n",
39 | " def __str__(self):\n",
40 | " return '' % (self.name, self.age)\n",
41 | "\n",
42 | "if __name__ == '__main__':\n",
43 | " piglei = Person('piglei', 24)\n",
44 | " print(piglei)"
45 | ]
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "metadata": {},
50 | "source": [
51 | "这样便是`__init__`最普通的用法了。但`__init__`其实不是实例化一个类的时候第一个被调用 的方法。当使用 Persion(name, age) 这样的表达式来实例化一个类时,最先被调用的方法 其实是 `__new__` 方法"
52 | ]
53 | },
54 | {
55 | "cell_type": "markdown",
56 | "metadata": {},
57 | "source": [
58 | "## 2.`__new__` 方法\n",
59 | "\n",
60 | "`__new__`方法接受的参数虽然也是和`__init__`一样,但`__init__`是在类实例创建之后调用,而 `__new__`方法正是创建这个类实例的方法。"
61 | ]
62 | },
63 | {
64 | "cell_type": "markdown",
65 | "metadata": {},
66 | "source": [
67 | "python3下 原来的代码会报错:\n",
68 | "\n",
69 | "`TypeError: object() takes no parameters after defining __new__`\n",
70 | "\n",
71 | "https://stackoverflow.com/questions/34777773/typeerror-object-takes-no-parameters-after-defining-new\n",
72 | "\n",
73 | ">In Python 3.3 and later, if you're overriding both __new__ and __init__, you need to avoid passing any extra arguments to the object methods you're overriding. If you only override one of those methods, it's allowed to pass extra arguments to the other one (since that usually happens without your help).\n",
74 | "\n",
75 | ">python3.3以后,同时重写new init时,不能传入额外参数\n",
76 | "\n",
77 | "所以把下面的一行:\n",
78 | "`return super(Person, cls).__new__(cls, name, age)`\n",
79 | "\n",
80 | "改成:\n",
81 | "`return super(Person, cls).__new__(cls)`"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 18,
87 | "metadata": {},
88 | "outputs": [
89 | {
90 | "name": "stdout",
91 | "output_type": "stream",
92 | "text": [
93 | "__new__ called.\n",
94 | "__init__ called.\n",
95 | "\n"
96 | ]
97 | }
98 | ],
99 | "source": [
100 | "# -*- coding: utf-8 -*-\n",
101 | " \n",
102 | "class Person(object):\n",
103 | " \"\"\"Silly Person\"\"\"\n",
104 | " \n",
105 | " def __new__(cls, name, age):\n",
106 | " print('__new__ called.')\n",
107 | " #return super(Person, cls).__new__(cls, name, age) #这样python3会报错 改成下面的\n",
108 | "# return super(Person, cls).__new__(cls)\n",
109 | " return super().__new__(cls) #python3 的super()可以直接使用 super().xxx 代替 super(Class, self).xxx\n",
110 | " \n",
111 | " def __init__(self, name, age):\n",
112 | " print('__init__ called.')\n",
113 | " self.name = name\n",
114 | " self.age = age\n",
115 | " \n",
116 | " def __str__(self):\n",
117 | " return '' % (self.name, self.age)\n",
118 | "\n",
119 | "\n",
120 | "if __name__ == '__main__':\n",
121 | " piglei = Person('piglei', 24)\n",
122 | " print(piglei)"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "通过运行这段代码,我们可以看到,`__new__`方法的调用是发生在`__init__`之前的。其实当 你实例化一个类的时候,具体的执行逻辑是这样的:\n",
130 | "\n",
131 | "- 1.p = Person(name, age)\n",
132 | "- 2.首先执行使用name和age参数来执行Person类的`__new__`方法,这个`__new__`方法会 返回Person类的一个实例(通常情况下是使用 `super().__new__(cls)` 这样的方式),\n",
133 | "- 3.然后利用这个实例来调用类的__init__方法,上一步里面__new__产生的实例也就是 __init__里面的的 self\n",
134 | "\n",
135 | "所以,`__init__` 和 `__new__` 最主要的区别在于:\n",
136 | "\n",
137 | "- 1.`__init__` 通常用于初始化一个新实例,控制这个初始化的过程,比如添加一些属性, 做一些额外的操作,发生在类实例被创建完以后。它是实例级别的方法。\n",
138 | "- 2.`__new__` 通常用于控制生成一个新实例的过程。它是类级别的方法。\n",
139 | "\n",
140 | "但是说了这么多,__new__最通常的用法是什么呢,我们什么时候需要__new__?"
141 | ]
142 | },
143 | {
144 | "cell_type": "markdown",
145 | "metadata": {},
146 | "source": [
147 | "## 3.`__new__` 的作用\n",
148 | "\n",
149 | "依照Python官方文档的说法,`__new__`方法主要是当你继承一些不可变的class时(比如int, str, tuple), 提供给你一个自定义这些类的实例化过程的途径。还有就是实现自定义的metaclass。\n",
150 | "\n",
151 | "首先我们来看一下第一个功能,具体我们可以用int来作为一个例子:\n",
152 | "\n",
153 | "**假如我们需要一个永远都是正数的整数类型,通过集成int,我们可能会写出这样的代码。**"
154 | ]
155 | },
156 | {
157 | "cell_type": "markdown",
158 | "metadata": {},
159 | "source": [
160 | "```python\n",
161 | "class PositiveInteger(int):\n",
162 | " def __init__(self, value):\n",
163 | " super(PositiveInteger, self).__init__(self, abs(value))\n",
164 | " \n",
165 | "i = PositiveInteger(-3)\n",
166 | "print(i)\n",
167 | "```\n",
168 | "\n",
169 | "python2可以运行,\n",
170 | "\n",
171 | "warning:\n",
172 | "`DeprecationWarning: object.__init__() takes no parameters app.launch_new_instance()`\n",
173 | "\n",
174 | "python3报错\n",
175 | "\n",
176 | "但运行后会发现,结果根本不是我们想的那样,我们仍然得到了-3。这是因为对于int这种 不可变的对象,我们只有重载它的`__new__`方法才能起到自定义的作用。\n",
177 | "\n",
178 | "这是修改后的代码:"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": 34,
184 | "metadata": {},
185 | "outputs": [
186 | {
187 | "name": "stdout",
188 | "output_type": "stream",
189 | "text": [
190 | "3\n"
191 | ]
192 | }
193 | ],
194 | "source": [
195 | "class PositiveInteger(int):\n",
196 | " def __new__(cls, value):\n",
197 | " return super().__new__(cls, abs(value))\n",
198 | "\n",
199 | "i = PositiveInteger(-3)\n",
200 | "print(i)"
201 | ]
202 | },
203 | {
204 | "cell_type": "markdown",
205 | "metadata": {},
206 | "source": [
207 | "通过重载`__new__`方法,我们实现了需要的功能。\n",
208 | "\n",
209 | "另外一个作用,关于自定义metaclass。其实我最早接触__new__的时候,就是因为需要自定义 metaclass,但鉴于篇幅原因,我们下次再来讲python中的metaclass和__new__的关系。\n",
210 | "\n",
211 | "## 4.用`__new__`来实现单例\n",
212 | "\n",
213 | "事实上,当我们理解了`__new__`方法后,我们还可以利用它来做一些其他有趣的事情,比如实现 设计模式中的 单例模式(singleton) 。\n",
214 | "\n",
215 | "因为类每一次实例化后产生的过程都是通过`__new__`来控制的,所以通过重载`__new__`方法,我们 可以很简单的实现单例模式。"
216 | ]
217 | },
218 | {
219 | "cell_type": "code",
220 | "execution_count": 36,
221 | "metadata": {},
222 | "outputs": [
223 | {
224 | "name": "stdout",
225 | "output_type": "stream",
226 | "text": [
227 | "value1 value1\n",
228 | "True\n"
229 | ]
230 | }
231 | ],
232 | "source": [
233 | "class Singleton(object):\n",
234 | " def __new__(cls):\n",
235 | " # 关键在于这,每一次实例化的时候,我们都只会返回这同一个instance对象\n",
236 | " if not hasattr(cls, 'instance'):\n",
237 | " cls.instance = super(Singleton, cls).__new__(cls)\n",
238 | " return cls.instance\n",
239 | "\n",
240 | "obj1 = Singleton()\n",
241 | "obj2 = Singleton()\n",
242 | " \n",
243 | "obj1.attr1 = 'value1'\n",
244 | "print(obj1.attr1, obj2.attr1)\n",
245 | "print(obj1 is obj2)"
246 | ]
247 | },
248 | {
249 | "cell_type": "markdown",
250 | "metadata": {},
251 | "source": [
252 | "可以看到obj1和obj2是同一个实例。"
253 | ]
254 | }
255 | ],
256 | "metadata": {
257 | "kernelspec": {
258 | "display_name": "Python 3 (Ubuntu Linux)",
259 | "language": "python",
260 | "name": "python3"
261 | },
262 | "language_info": {
263 | "codemirror_mode": {
264 | "name": "ipython",
265 | "version": 3
266 | },
267 | "file_extension": ".py",
268 | "mimetype": "text/x-python",
269 | "name": "python",
270 | "nbconvert_exporter": "python",
271 | "pygments_lexer": "ipython3",
272 | "version": "3.6.7"
273 | }
274 | },
275 | "nbformat": 4,
276 | "nbformat_minor": 2
277 | }
278 |
--------------------------------------------------------------------------------
/Python知识点/__str__ & __repr__.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# `__str__` 和 `__repr__`\n",
8 | "\n",
9 | "什么是内置方法 \n",
10 | "在不是需要程序员定义,本身就存在在类中的方法就是内置方法,名字:双下方法,魔术方法,内置方法 \n",
11 | "如:init 不需要我们主动调用,而是在实例化的时候内部自动调用的。所以双下方法,都不需要我们直接调用,都有另外一种主动触发他的方法\n",
12 | "\n",
13 | "str, repr 内置方法,两者都只能返回字符串,而且都要用return\n",
14 | "\n",
15 | "## 什么情况下触发str: \n",
16 | "- 1 当你打印一个对象的时候, \n",
17 | "- 2 当你使用%格式化的时候 \n",
18 | "- 3 str() 强转数据类型的时候\n",
19 | "\n",
20 | "repr ,repr是str的备胎,有str的时候执行str,没有实现str的时候,执行repr\n",
21 | "\n",
22 | "## 什么情况触发repr \n",
23 | "- 1 repr(obj)内置函数对应的结果是repr的返回值 \n",
24 | "- 2 使用%r格式化的时候触发repr"
25 | ]
26 | },
27 | {
28 | "cell_type": "code",
29 | "execution_count": 1,
30 | "metadata": {},
31 | "outputs": [
32 | {
33 | "name": "stdout",
34 | "output_type": "stream",
35 | "text": [
36 | "1 str : python, 6 month, 20000, Mr. Jin\n",
37 | "1 str : python, 6 month, 20000, Mr. Jin\n",
38 | "1 str : python, 6 month, 20000, Mr. Jin\n",
39 | "1 repr : python, 6 month, 20000, Mr. Jin\n",
40 | "1 repr : python, 6 month, 20000, Mr. Jin\n",
41 | "----\n",
42 | "2 str : linux, 4month, 28000, Miss. Lin\n",
43 | "2 str : linux, 4month, 28000, Miss. Lin\n",
44 | "2 str : linux, 4month, 28000, Miss. Lin\n",
45 | "2 repr : linux, 4month, 28000, Miss. Lin\n",
46 | "2 repr : linux, 4month, 28000, Miss. Lin\n",
47 | "----\n"
48 | ]
49 | }
50 | ],
51 | "source": [
52 | "class Course:\n",
53 | " def __init__(self, name, period, price, teacher):\n",
54 | " self.name = name\n",
55 | " self.period = period\n",
56 | " self.price = price\n",
57 | " self.teacher = teacher\n",
58 | "\n",
59 | " def __str__(self):\n",
60 | " return 'str : {}, {}, {}, {}'.format(self.name, self.period, self.price, self.teacher)\n",
61 | "\n",
62 | " def __repr__(self):\n",
63 | " return 'repr : {}, {}, {}, {}'.format(self.name, self.period, self.price, self.teacher) # self指的是对象\n",
64 | "\n",
65 | "\n",
66 | "course_list = []\n",
67 | "python = Course('python', '6 month', 20000, 'Mr. Jin')\n",
68 | "linux = Course('linux', '4month', 28000, 'Miss. Lin')\n",
69 | "course_list.append(python)\n",
70 | "course_list.append(linux)\n",
71 | "\n",
72 | "for id, course in enumerate(course_list, 1):\n",
73 | " print(id, course) # 1 str : python, 6 month, 20000, Mr. Jin\n",
74 | " print('%s %s' % (id, course)) # 1 str : python, 6 month, 20000, Mr. Jin\n",
75 | " print(id, str(course)) # 1 str : python, 6 month, 20000, Mr. Jin\n",
76 | " print(id,repr(course)) # repr : python, 6 month, 20000, Mr. Jin #\n",
77 | " print(id,'%r' % course) # repr : python, 6 month, 20000, Mr. Jin\n",
78 | " print('----')"
79 | ]
80 | }
81 | ],
82 | "metadata": {
83 | "kernelspec": {
84 | "display_name": "Python 3 (Ubuntu Linux)",
85 | "language": "python",
86 | "name": "python3"
87 | },
88 | "language_info": {
89 | "codemirror_mode": {
90 | "name": "ipython",
91 | "version": 3
92 | },
93 | "file_extension": ".py",
94 | "mimetype": "text/x-python",
95 | "name": "python",
96 | "nbconvert_exporter": "python",
97 | "pygments_lexer": "ipython3",
98 | "version": "3.6.8"
99 | }
100 | },
101 | "nbformat": 4,
102 | "nbformat_minor": 2
103 | }
104 |
--------------------------------------------------------------------------------
/Python知识点/_args & __kwargs.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# [什么是`*args`和`**kwargs`?](https://www.cnblogs.com/fengmk2/archive/2008/04/21/1163766.html)"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [
15 | {
16 | "name": "stdout",
17 | "output_type": "stream",
18 | "text": [
19 | "args = (1, 2, 3, 4)\n",
20 | "kwargs = {}\n",
21 | "---------------------------------------\n",
22 | "args = ()\n",
23 | "kwargs = {'a': 1, 'b': 2, 'c': 3}\n",
24 | "---------------------------------------\n",
25 | "args = (1, 2, 3, 4)\n",
26 | "kwargs = {'a': 1, 'b': 2, 'c': 3}\n",
27 | "---------------------------------------\n",
28 | "args = ('a', 1, None)\n",
29 | "kwargs = {'a': 1, 'b': '2', 'c': 3}\n",
30 | "---------------------------------------\n"
31 | ]
32 | }
33 | ],
34 | "source": [
35 | "def foo(*args, **kwargs):\n",
36 | " print('args = ', args)\n",
37 | " print('kwargs = ', kwargs)\n",
38 | " print('---------------------------------------')\n",
39 | "\n",
40 | "if __name__ == '__main__':\n",
41 | " foo(1,2,3,4)\n",
42 | " foo(a=1,b=2,c=3)\n",
43 | " foo(1,2,3,4, a=1,b=2,c=3)\n",
44 | " foo('a', 1, None, a=1, b='2', c=3)"
45 | ]
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "metadata": {},
50 | "source": [
51 | "**可以看到,这两个是python中的可变参数。**\n",
52 | "\n",
53 | "- `*args`表示任何多个无名参数,它是一个tuple;\n",
54 | "- `**kwargs`表示关键字参数,它是一个dict。\n",
55 | "- 同时使用`*args`和`**kwargs`时,必须`*args`参数列要在`**kwargs`前,像foo(a=1, b='2', c=3, a', 1, None, )这样调用的话,会提示语法错误“SyntaxError: non-keyword arg after keyword arg”。\n",
56 | "\n",
57 | "**还有一个很漂亮的用法,就是创建字典:**"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 2,
63 | "metadata": {},
64 | "outputs": [
65 | {
66 | "name": "stdout",
67 | "output_type": "stream",
68 | "text": [
69 | "{'a': 1, 'b': 2, 'c': 3}\n"
70 | ]
71 | }
72 | ],
73 | "source": [
74 | "def kw_dict(**kwargs):\n",
75 | " return kwargs\n",
76 | "print(kw_dict(a=1,b=2,c=3))"
77 | ]
78 | },
79 | {
80 | "cell_type": "markdown",
81 | "metadata": {},
82 | "source": [
83 | "其实python中就带有dict类,使用dict(a=1,b=2,c=3)即可创建一个字典了。"
84 | ]
85 | },
86 | {
87 | "cell_type": "code",
88 | "execution_count": 3,
89 | "metadata": {},
90 | "outputs": [
91 | {
92 | "data": {
93 | "text/plain": [
94 | "{'a': 1, 'b': 2, 'c': 3}"
95 | ]
96 | },
97 | "execution_count": 3,
98 | "metadata": {},
99 | "output_type": "execute_result"
100 | }
101 | ],
102 | "source": [
103 | "dict(a=1,b=2,c=3)"
104 | ]
105 | }
106 | ],
107 | "metadata": {
108 | "kernelspec": {
109 | "display_name": "Python 3 (Ubuntu Linux)",
110 | "language": "python",
111 | "name": "python3"
112 | },
113 | "language_info": {
114 | "codemirror_mode": {
115 | "name": "ipython",
116 | "version": 3
117 | },
118 | "file_extension": ".py",
119 | "mimetype": "text/x-python",
120 | "name": "python",
121 | "nbconvert_exporter": "python",
122 | "pygments_lexer": "ipython3",
123 | "version": "3.6.7"
124 | }
125 | },
126 | "nbformat": 4,
127 | "nbformat_minor": 2
128 | }
129 |
--------------------------------------------------------------------------------
/Python知识点/class03_实例方法、类方法、静态方法.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 详解类class的方法:实例方法、类方法、静态方法(三)\n",
8 | "\n",
9 | "参考:https://blog.csdn.net/brucewong0516/article/details/79119551\n",
10 | "\n",
11 | "在一个类中,可能出现三种方法,实例方法、静态方法和类方法,下面来看看三种方法的不同:\n",
12 | "\n",
13 | "## 1、实例方法\n",
14 | "\n",
15 | "实例方法的第一个参数必须是”self”,实例方法只能通过类实例进行调用,这时候“self”就代表这个类实例本身。通过”self”可以直接访问实例的属性。"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 1,
21 | "metadata": {},
22 | "outputs": [
23 | {
24 | "name": "stdout",
25 | "output_type": "stream",
26 | "text": [
27 | "Bruce is 25 weights 60\n"
28 | ]
29 | }
30 | ],
31 | "source": [
32 | "class person():\n",
33 | " '''\n",
34 | " this is doc of class\n",
35 | " write doc contents here\n",
36 | " '''\n",
37 | " height = 180\n",
38 | " hobbies = []\n",
39 | " def __init__(self,name,age,weight):\n",
40 | " self.name = name\n",
41 | " self.age = age\n",
42 | " self.weight = weight\n",
43 | " def infoma(self):\n",
44 | " print('%s is %s weights %s'%(self.name,self.age,self.weight))\n",
45 | "\n",
46 | "\n",
47 | "Bruce = person('Bruce',25,60)\n",
48 | "Bruce.infoma()"
49 | ]
50 | },
51 | {
52 | "cell_type": "markdown",
53 | "metadata": {},
54 | "source": [
55 | "## 2、类方法\n",
56 | "\n",
57 | "类方法以cls作为第一个参数,cls表示类本身,定义时使用@classmethod装饰器。通过cls可以访问类的相关属性。"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 3,
63 | "metadata": {},
64 | "outputs": [],
65 | "source": [
66 | "class person(object):\n",
67 | "\n",
68 | " height = 180\n",
69 | " hobbies = []\n",
70 | " def __init__(self, name, age,weight):\n",
71 | " self.name = name\n",
72 | " self.age = age\n",
73 | " self.weight = weight\n",
74 | " @classmethod #类的装饰器\n",
75 | " def infoma(cls): #cls表示类本身,使用类参数cls\n",
76 | " print(cls.__name__)\n",
77 | " print(dir(cls))"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "直接调用类的装饰器函数,通过cls可以访问类的相关属性"
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": 5,
90 | "metadata": {},
91 | "outputs": [
92 | {
93 | "name": "stdout",
94 | "output_type": "stream",
95 | "text": [
96 | "person\n",
97 | "['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'height', 'hobbies', 'infoma']\n"
98 | ]
99 | }
100 | ],
101 | "source": [
102 | "person.infoma() "
103 | ]
104 | },
105 | {
106 | "cell_type": "markdown",
107 | "metadata": {},
108 | "source": [
109 | "也可以通过两步骤来实现,第一步实例化person,第二步调用装饰器"
110 | ]
111 | },
112 | {
113 | "cell_type": "code",
114 | "execution_count": 6,
115 | "metadata": {},
116 | "outputs": [
117 | {
118 | "name": "stdout",
119 | "output_type": "stream",
120 | "text": [
121 | "person\n",
122 | "['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'height', 'hobbies', 'infoma']\n"
123 | ]
124 | }
125 | ],
126 | "source": [
127 | "Bruce = person(\"Bruce\", 25,180)\n",
128 | "Bruce.infoma() "
129 | ]
130 | },
131 | {
132 | "cell_type": "markdown",
133 | "metadata": {},
134 | "source": [
135 | "**类方法可以通过类名访问,也可以通过实例访问**\n",
136 | "\n",
137 | "## 3、静态方法\n",
138 | "\n",
139 | "与实例方法和类方法不同,静态方法没有参数限制,既不需要实例参数,也不需要类参数,定义的时候使用@staticmethod装饰器。\n",
140 | "同类方法一样,静态法可以通过类名访问,也可以通过实例访问。"
141 | ]
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": 7,
146 | "metadata": {},
147 | "outputs": [],
148 | "source": [
149 | "class person(object):\n",
150 | "\n",
151 | " tall = 180\n",
152 | " hobbies = []\n",
153 | " def __init__(self, name, age,weight):\n",
154 | " self.name = name\n",
155 | " self.age = age\n",
156 | " self.weight = weight\n",
157 | " @staticmethod #静态方法装饰器\n",
158 | " def infoma(): #没有参数限制,既不要实例参数,也不用类参数\n",
159 | " print(person.tall)\n",
160 | " print(person.hobbies) "
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": 8,
166 | "metadata": {},
167 | "outputs": [
168 | {
169 | "name": "stdout",
170 | "output_type": "stream",
171 | "text": [
172 | "180\n",
173 | "[]\n"
174 | ]
175 | }
176 | ],
177 | "source": [
178 | "person.infoma() #静态法可以通过类名访问"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": 9,
184 | "metadata": {},
185 | "outputs": [
186 | {
187 | "name": "stdout",
188 | "output_type": "stream",
189 | "text": [
190 | "180\n",
191 | "[]\n"
192 | ]
193 | }
194 | ],
195 | "source": [
196 | "Bruce = person(\"Bruce\", 25,180) #通过实例访问\n",
197 | "Bruce.infoma() "
198 | ]
199 | },
200 | {
201 | "cell_type": "markdown",
202 | "metadata": {},
203 | "source": [
204 | "这三种方法的主要区别在于参数,实例方法被绑定到一个实例,只能通过实例进行调用;但是对于静态方法和类方法,可以通过类名和实例两种方式进行调用。"
205 | ]
206 | }
207 | ],
208 | "metadata": {
209 | "kernelspec": {
210 | "display_name": "Python 3 (Ubuntu Linux)",
211 | "language": "python",
212 | "name": "python3"
213 | },
214 | "language_info": {
215 | "codemirror_mode": {
216 | "name": "ipython",
217 | "version": 3
218 | },
219 | "file_extension": ".py",
220 | "mimetype": "text/x-python",
221 | "name": "python",
222 | "nbconvert_exporter": "python",
223 | "pygments_lexer": "ipython3",
224 | "version": "3.6.8"
225 | }
226 | },
227 | "nbformat": 4,
228 | "nbformat_minor": 2
229 | }
230 |
--------------------------------------------------------------------------------
/Python知识点/class05_super() 初始化方法 类的继承.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "参考:\n",
8 | "\n",
9 | "[【python】详解类class的继承、__init__初始化、super方法(五)](https://blog.csdn.net/brucewong0516/article/details/79121179)"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "# python super()\n",
17 | "\n",
18 | "super() 函数是用于调用父类(超类)的一个方法。\n",
19 | "\n",
20 | "super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。\n",
21 | "\n",
22 | "MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表。\n",
23 | "\n",
24 | "`super(type[, object-or-type])`\n",
25 | "\n",
26 | "- type -- 类。\n",
27 | "- object-or-type -- 类,一般是 self\n",
28 | "\n",
29 | "Python3.x 和 Python2.x 的一个区别是: \n",
30 | "\n",
31 | "**Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx** :"
32 | ]
33 | },
34 | {
35 | "cell_type": "code",
36 | "execution_count": 8,
37 | "metadata": {},
38 | "outputs": [
39 | {
40 | "name": "stdout",
41 | "output_type": "stream",
42 | "text": [
43 | "3\n"
44 | ]
45 | }
46 | ],
47 | "source": [
48 | "class A:\n",
49 | " def add(self, x):\n",
50 | " y = x+1\n",
51 | " print(y)\n",
52 | "class B(A):\n",
53 | " def add(self, x):\n",
54 | " super(B,self).add(x)\n",
55 | "# super().add(x) #同样效果\n",
56 | "b = B()\n",
57 | "b.add(2) # 3"
58 | ]
59 | },
60 | {
61 | "cell_type": "markdown",
62 | "metadata": {},
63 | "source": [
64 | "python2:\n",
65 | "\n",
66 | "```python2\n",
67 | "#!/usr/bin/python\n",
68 | "# -*- coding: UTF-8 -*-\n",
69 | " \n",
70 | "class A(object): # Python2.x 记得继承 object\n",
71 | " def add(self, x):\n",
72 | " y = x+1\n",
73 | " print y\n",
74 | "class B(A):\n",
75 | " def add(self, x):\n",
76 | " super(B, self).add(x)\n",
77 | "b = B()\n",
78 | "b.add(2) # 3\n",
79 | "```"
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | "以下展示了使用 super 函数的实例:"
87 | ]
88 | },
89 | {
90 | "cell_type": "code",
91 | "execution_count": 3,
92 | "metadata": {},
93 | "outputs": [
94 | {
95 | "name": "stdout",
96 | "output_type": "stream",
97 | "text": [
98 | "Parent\n",
99 | "Child\n",
100 | "HelloWorld from Parent\n",
101 | "Child bar fuction\n",
102 | "I'm the parent.\n"
103 | ]
104 | }
105 | ],
106 | "source": [
107 | "#!/usr/bin/python\n",
108 | "# -*- coding: UTF-8 -*-\n",
109 | " \n",
110 | "class FooParent:\n",
111 | " def __init__(self):\n",
112 | " self.parent = 'I\\'m the parent.'\n",
113 | " print ('Parent')\n",
114 | " \n",
115 | " def bar(self,message):\n",
116 | " print (\"%s from Parent\" % message)\n",
117 | "\n",
118 | "class FooChild(FooParent):\n",
119 | " def __init__(self):\n",
120 | " # super(FooChild,self) 首先找到 FooChild 的父类(就是类 FooParent),然后把类 FooChild 的对象转换为类 FooParent 的对象\n",
121 | " super(FooChild,self).__init__()\n",
122 | " print ('Child')\n",
123 | " \n",
124 | " def bar(self,message):\n",
125 | " super(FooChild, self).bar(message)\n",
126 | " print ('Child bar fuction')\n",
127 | " print (self.parent)\n",
128 | " \n",
129 | "if __name__ == '__main__':\n",
130 | " fooChild = FooChild()\n",
131 | " fooChild.bar('HelloWorld')"
132 | ]
133 | },
134 | {
135 | "cell_type": "markdown",
136 | "metadata": {},
137 | "source": [
138 | "## 构造方法、构造函数、初始化函数 `__init__`\n",
139 | "\n",
140 | "我们在学习 Python 类的时候,总会碰见书上的类中有 `__init__()` 这样一个函数,很多同学百思不得其解,其实它就是 Python 的构造方法。\n",
141 | "\n",
142 | "构造方法类似于类似 init() 这种初始化方法,来初始化新创建对象的状态,在一个对象呗创建以后会立即调用,比如像实例化一个类:\n",
143 | "\n",
144 | "实例化一个类:\n",
145 | "```\n",
146 | "f = FooBar()\n",
147 | "f.init()\n",
148 | "```\n",
149 | "使用构造方法就能让它简化成如下形式:\n",
150 | "```\n",
151 | "f = FooBar()\n",
152 | "```"
153 | ]
154 | },
155 | {
156 | "cell_type": "code",
157 | "execution_count": 1,
158 | "metadata": {},
159 | "outputs": [
160 | {
161 | "data": {
162 | "text/plain": [
163 | "42"
164 | ]
165 | },
166 | "execution_count": 1,
167 | "metadata": {},
168 | "output_type": "execute_result"
169 | }
170 | ],
171 | "source": [
172 | "class FooBar:\n",
173 | " def __init__(self):\n",
174 | " self.somevar = 42\n",
175 | "\n",
176 | "f = FooBar()\n",
177 | "f.somevar"
178 | ]
179 | },
180 | {
181 | "cell_type": "markdown",
182 | "metadata": {},
183 | "source": [
184 | "我们会发现在初始化 FooBar 中的 somevar 的值为 42 之后,实例化直接就能够调用 somevar 的值;如果说你没有用构造方法初始化值得话,就不能够调用,\n",
185 | "\n",
186 | "**构造方法中的初始值无法继承的问题。**"
187 | ]
188 | },
189 | {
190 | "cell_type": "code",
191 | "execution_count": 9,
192 | "metadata": {},
193 | "outputs": [
194 | {
195 | "name": "stdout",
196 | "output_type": "stream",
197 | "text": [
198 | "Squawk\n"
199 | ]
200 | }
201 | ],
202 | "source": [
203 | "class Bird:\n",
204 | " def __init__(self):\n",
205 | " self.hungry = True\n",
206 | " def eat(self):\n",
207 | " if self.hungry:\n",
208 | " print 'Ahahahah'\n",
209 | " else:\n",
210 | " print 'No thanks!'\n",
211 | "\n",
212 | "class SongBird(Bird):\n",
213 | " def __init__(self):\n",
214 | " self.sound = 'Squawk'\n",
215 | " def sing(self):\n",
216 | " print self.sound\n",
217 | "\n",
218 | "sb = SongBird()\n",
219 | "sb.sing() # 能正常输出\n",
220 | "# sb.eat() # 报错,因为 songgird 中没有 hungry 特性"
221 | ]
222 | }
223 | ],
224 | "metadata": {
225 | "kernelspec": {
226 | "display_name": "Python 2 (system-wide)",
227 | "language": "python",
228 | "name": "python2"
229 | },
230 | "language_info": {
231 | "codemirror_mode": {
232 | "name": "ipython",
233 | "version": 2
234 | },
235 | "file_extension": ".py",
236 | "mimetype": "text/x-python",
237 | "name": "python",
238 | "nbconvert_exporter": "python",
239 | "pygments_lexer": "ipython2",
240 | "version": "2.7.15+"
241 | }
242 | },
243 | "nbformat": 4,
244 | "nbformat_minor": 2
245 | }
246 |
--------------------------------------------------------------------------------
/Python知识点/python格式化输出.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python格式化输出(%用法和format用法)\n",
8 | "\n",
9 | "[Python格式化输出](https://www.cnblogs.com/plwang1990/p/3757549.html)\n",
10 | "\n",
11 | "[python基础_格式化输出(%用法和format用法)](https://www.cnblogs.com/fat39/p/7159881.html)\n",
12 | "\n",
13 | "## 1. 打印字符串"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 13,
19 | "metadata": {},
20 | "outputs": [
21 | {
22 | "name": "stdout",
23 | "output_type": "stream",
24 | "text": [
25 | "His name is Aviad!\n",
26 | "His name is Aviad!\n"
27 | ]
28 | }
29 | ],
30 | "source": [
31 | "print(\"His name is %s!\"%(\"Aviad\"))\n",
32 | "print(\"His name is {}!\".format(\"Aviad\"))"
33 | ]
34 | },
35 | {
36 | "cell_type": "markdown",
37 | "metadata": {},
38 | "source": [
39 | "## 2.打印整数"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": 16,
45 | "metadata": {},
46 | "outputs": [
47 | {
48 | "name": "stdout",
49 | "output_type": "stream",
50 | "text": [
51 | "He is 25 years old.\n",
52 | "He is 25 years old.\n"
53 | ]
54 | }
55 | ],
56 | "source": [
57 | "print(\"He is %d years old.\"%(25))\n",
58 | "print(\"He is {} years old.\".format(25))"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "## 3.打印浮点数"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 19,
71 | "metadata": {},
72 | "outputs": [
73 | {
74 | "name": "stdout",
75 | "output_type": "stream",
76 | "text": [
77 | "His height is 1.830000 m.\n",
78 | "His height is 1.83 m.\n",
79 | "His height is 1.830000 m.\n"
80 | ]
81 | }
82 | ],
83 | "source": [
84 | "print(\"His height is %f m.\"%(1.83)) # %f ——保留小数点后面六位有效数字\n",
85 | "print(\"His height is {} m.\".format(1.83))\n",
86 | "print(\"His height is {:f} m.\".format(1.83))"
87 | ]
88 | },
89 | {
90 | "cell_type": "markdown",
91 | "metadata": {},
92 | "source": [
93 | "## 4.打印浮点数(指定保留小数点位数)"
94 | ]
95 | },
96 | {
97 | "cell_type": "code",
98 | "execution_count": 11,
99 | "metadata": {},
100 | "outputs": [
101 | {
102 | "name": "stdout",
103 | "output_type": "stream",
104 | "text": [
105 | "His height is 1.83 m.\n",
106 | "His height is 1.83 m.\n",
107 | "His height is 1.8 m.\n"
108 | ]
109 | }
110 | ],
111 | "source": [
112 | "# 使用 %.2f\n",
113 | "\n",
114 | "print(\"His height is %.2f m.\"%(1.83))\n",
115 | "\n",
116 | "# 保留两位小数,使用format的{:.2f} \n",
117 | "\n",
118 | "print(\"His height is {:.2f} m.\".format(1.83))\n",
119 | "\n",
120 | "# 保留两位有效数字:使用format的{:.2}(没有f)\n",
121 | "\n",
122 | "print(\"His height is {:.2} m.\".format(1.83))"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "## 5.指定占位符宽度"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 12,
135 | "metadata": {},
136 | "outputs": [
137 | {
138 | "name": "stdout",
139 | "output_type": "stream",
140 | "text": [
141 | "Name: Aviad Age: 25 Height: 1.83\n",
142 | "Name: Bob Age: 30 Height: 1.78\n",
143 | "Name:Aviad Age: 25 Height: 1.83\n",
144 | "Name:Bob Age: 30 Height: 1.78\n"
145 | ]
146 | }
147 | ],
148 | "source": [
149 | "print(\"Name:%10s Age:%8d Height:%8.2f\"%(\"Aviad\",25,1.83))\n",
150 | "print(\"Name:%10s Age:%8d Height:%8.2f\"%(\"Bob\",30,1.78))\n",
151 | "\n",
152 | "print(\"Name:{:10s} Age:{:8d} Height:{:8.2f}\".format(\"Aviad\",25,1.83))\n",
153 | "print(\"Name:{:10s} Age:{:8d} Height:{:8.2f}\".format(\"Bob\",30,1.78))"
154 | ]
155 | },
156 | {
157 | "cell_type": "markdown",
158 | "metadata": {},
159 | "source": [
160 | "## 6.指定占位符宽度(左对齐)"
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": 7,
166 | "metadata": {},
167 | "outputs": [
168 | {
169 | "name": "stdout",
170 | "output_type": "stream",
171 | "text": [
172 | "Name:Aviad Age:25 Height:1.83 \n",
173 | "Name:Bob Age:30 Height:1.78 \n"
174 | ]
175 | }
176 | ],
177 | "source": [
178 | "print(\"Name:%-10s Age:%-8d Height:%-8.2f\"%(\"Aviad\",25,1.83))\n",
179 | "print(\"Name:%-10s Age:%-8d Height:%-8.2f\"%(\"Bob\",30,1.78))"
180 | ]
181 | },
182 | {
183 | "cell_type": "markdown",
184 | "metadata": {},
185 | "source": [
186 | "## 7.指定占位符(只能用0当占位符?)"
187 | ]
188 | },
189 | {
190 | "cell_type": "code",
191 | "execution_count": 17,
192 | "metadata": {},
193 | "outputs": [
194 | {
195 | "name": "stdout",
196 | "output_type": "stream",
197 | "text": [
198 | "Name:Aviad Age:00000025 Height:00001.83\n",
199 | "Name:Bob Age:00000030 Height:00001.78\n"
200 | ]
201 | }
202 | ],
203 | "source": [
204 | "print(\"Name:%-10s Age:%08d Height:%08.2f\"%(\"Aviad\",25,1.83))\n",
205 | "print(\"Name:%-10s Age:%08d Height:%08.2f\"%(\"Bob\",30,1.78))"
206 | ]
207 | },
208 | {
209 | "cell_type": "markdown",
210 | "metadata": {},
211 | "source": [
212 | "## 8.科学计数法"
213 | ]
214 | },
215 | {
216 | "cell_type": "code",
217 | "execution_count": 24,
218 | "metadata": {},
219 | "outputs": [
220 | {
221 | "name": "stdout",
222 | "output_type": "stream",
223 | "text": [
224 | "1.50e-03\n",
225 | "2.789e-05\n"
226 | ]
227 | }
228 | ],
229 | "source": [
230 | "print(format(0.0015,'.2e')) # .2为保留两位小数,e表示采用科学计数法\n",
231 | "print(format(0.0000278867,'.3e'))"
232 | ]
233 | }
234 | ],
235 | "metadata": {
236 | "kernelspec": {
237 | "display_name": "tf36",
238 | "language": "python",
239 | "name": "tf36"
240 | },
241 | "language_info": {
242 | "codemirror_mode": {
243 | "name": "ipython",
244 | "version": 3
245 | },
246 | "file_extension": ".py",
247 | "mimetype": "text/x-python",
248 | "name": "python",
249 | "nbconvert_exporter": "python",
250 | "pygments_lexer": "ipython3",
251 | "version": "3.6.8"
252 | }
253 | },
254 | "nbformat": 4,
255 | "nbformat_minor": 2
256 | }
257 |
--------------------------------------------------------------------------------
/Python知识点/单例模式.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# [由Python通过__new__实现单例模式,所想到的`__new__`和`__init__`方法的区别](https://www.cnblogs.com/qiaojushuang/p/7805973.html)\n",
8 | "\n",
9 | "单例模式是确保一个类只有一个实例,并且这个实例是自己创造的,在系统中用到的都是这个实例。单例模式是设计模式的一种,关于设计模式和单例模式更具体的内容,可以查看相关的书本\n",
10 | "\n",
11 | "下面主要说下`__new__`是用来干什么的,在Python中,`__new__`是用来创造一个类的实例的,而`__init__`是用来初始化这个实例的。既然`__new__`用来创造实例,也就需要最后返回相应类的实例,那么如果返回的是其他类的实例,结果如何呢?见下面的代码。以下代码运行后,首先打印出`NoReturn __new__`然后打印出`other instance`,最后通过`type(t)`可以看到t的类型是``,可以知道如果`__new__`中不返回本类的实例的话,是没法调用`__init__`方法的。想要返回本类的实例,只需要把以下代码中12行的`Other()`改成`super(NoReturn, cls).__new__(cls, *args, **kwargs)`即可。"
12 | ]
13 | },
14 | {
15 | "cell_type": "code",
16 | "execution_count": 8,
17 | "metadata": {},
18 | "outputs": [
19 | {
20 | "name": "stdout",
21 | "output_type": "stream",
22 | "text": [
23 | "3\n"
24 | ]
25 | }
26 | ],
27 | "source": []
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": null,
32 | "metadata": {},
33 | "outputs": [],
34 | "source": []
35 | },
36 | {
37 | "cell_type": "code",
38 | "execution_count": 2,
39 | "metadata": {},
40 | "outputs": [
41 | {
42 | "name": "stdout",
43 | "output_type": "stream",
44 | "text": [
45 | "NoReturn __new__\n",
46 | "other instance\n",
47 | "\n"
48 | ]
49 | }
50 | ],
51 | "source": [
52 | "class Other(object):\n",
53 | " val = 123\n",
54 | "\n",
55 | " def __init__(self):\n",
56 | " print ('other instance')\n",
57 | "\n",
58 | "\n",
59 | "class NoReturn(object):\n",
60 | "\n",
61 | " def __new__(cls, *args, **kwargs):\n",
62 | " print ('NoReturn __new__')\n",
63 | " return Other()\n",
64 | "\n",
65 | " def __init__(self, a):\n",
66 | " print (a)\n",
67 | " print ('NoReturn __init__')\n",
68 | "\n",
69 | "t = NoReturn(12)\n",
70 | "print (type(t))"
71 | ]
72 | },
73 | {
74 | "cell_type": "code",
75 | "execution_count": 1,
76 | "metadata": {},
77 | "outputs": [
78 | {
79 | "name": "stdout",
80 | "output_type": "stream",
81 | "text": [
82 | "NoReturn __new__\n"
83 | ]
84 | },
85 | {
86 | "ename": "TypeError",
87 | "evalue": "object() takes no parameters",
88 | "output_type": "error",
89 | "traceback": [
90 | "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
91 | "\u001b[0;31mTypeError\u001b[0m Traceback (most recent call last)",
92 | "\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 16\u001b[0m \u001b[0mprint\u001b[0m \u001b[0;34m(\u001b[0m\u001b[0;34m'NoReturn __init__'\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 17\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m---> 18\u001b[0;31m \u001b[0mt\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mNoReturn\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;36m12\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 19\u001b[0m \u001b[0mprint\u001b[0m \u001b[0;34m(\u001b[0m\u001b[0mtype\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mt\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
93 | "\u001b[0;32m\u001b[0m in \u001b[0;36m__new__\u001b[0;34m(cls, *args, **kwargs)\u001b[0m\n\u001b[1;32m 10\u001b[0m \u001b[0;32mdef\u001b[0m \u001b[0m__new__\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mcls\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m*\u001b[0m\u001b[0margs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m**\u001b[0m\u001b[0mkwargs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 11\u001b[0m \u001b[0mprint\u001b[0m \u001b[0;34m(\u001b[0m\u001b[0;34m'NoReturn __new__'\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m---> 12\u001b[0;31m \u001b[0;32mreturn\u001b[0m \u001b[0msuper\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mNoReturn\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mcls\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0m__new__\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mcls\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m*\u001b[0m\u001b[0margs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m**\u001b[0m\u001b[0mkwargs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 13\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 14\u001b[0m \u001b[0;32mdef\u001b[0m \u001b[0m__init__\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mself\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0ma\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
94 | "\u001b[0;31mTypeError\u001b[0m: object() takes no parameters"
95 | ]
96 | }
97 | ],
98 | "source": [
99 | "class Other(object):\n",
100 | " val = 123\n",
101 | "\n",
102 | " def __init__(self):\n",
103 | " print ('other instance')\n",
104 | "\n",
105 | "\n",
106 | "class NoReturn(object):\n",
107 | "\n",
108 | " def __new__(cls, *args, **kwargs):\n",
109 | " print ('NoReturn __new__')\n",
110 | " return super(NoReturn, cls).__new__(cls, *args, **kwargs)\n",
111 | "\n",
112 | " def __init__(self, a):\n",
113 | " print (a)\n",
114 | " print ('NoReturn __init__')\n",
115 | "\n",
116 | "t = NoReturn(12)\n",
117 | "print (type(t))"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": 6,
123 | "metadata": {},
124 | "outputs": [],
125 | "source": [
126 | "class SingleTon(object):\n",
127 | " _instance = {}\n",
128 | "\n",
129 | " def __new__(cls, *args, **kwargs):\n",
130 | " if cls not in cls._instance:\n",
131 | " cls._instance[cls] = super(SingleTon, cls).__new__(cls, *args, **kwargs)\n",
132 | " print (cls._instance)\n",
133 | " return cls._instance[cls]\n",
134 | "\n",
135 | "\n",
136 | "class MyClass(SingleTon):\n",
137 | " class_val = 22"
138 | ]
139 | },
140 | {
141 | "cell_type": "code",
142 | "execution_count": 9,
143 | "metadata": {},
144 | "outputs": [
145 | {
146 | "name": "stdout",
147 | "output_type": "stream",
148 | "text": [
149 | "{: <__main__.MyClass object at 0x7f463708be10>}\n"
150 | ]
151 | },
152 | {
153 | "data": {
154 | "text/plain": [
155 | "22"
156 | ]
157 | },
158 | "execution_count": 9,
159 | "metadata": {},
160 | "output_type": "execute_result"
161 | }
162 | ],
163 | "source": [
164 | "a = MyClass(12)\n",
165 | "a.class_val"
166 | ]
167 | }
168 | ],
169 | "metadata": {
170 | "kernelspec": {
171 | "display_name": "Python 3 (system-wide)",
172 | "language": "python",
173 | "name": "python3"
174 | },
175 | "language_info": {
176 | "codemirror_mode": {
177 | "name": "ipython",
178 | "version": 3
179 | },
180 | "file_extension": ".py",
181 | "mimetype": "text/x-python",
182 | "name": "python",
183 | "nbconvert_exporter": "python",
184 | "pygments_lexer": "ipython3",
185 | "version": "3.6.8"
186 | }
187 | },
188 | "nbformat": 4,
189 | "nbformat_minor": 2
190 | }
191 |
--------------------------------------------------------------------------------
/Python知识点/尾递归.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "https://www.zhihu.com/question/20761771"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [
15 | {
16 | "name": "stdout",
17 | "output_type": "stream",
18 | "text": [
19 | "3919377061614427623668052985592742430389065042819420493170692719480242247392252775480208752179017313071371501566248877239254299341332131655760767122899079117071192049598939666199865808814650408864891823186505\n"
20 | ]
21 | }
22 | ],
23 | "source": [
24 | "def fib(count, cur=0, next_=1):\n",
25 | " if count <= 1:\n",
26 | " yield cur\n",
27 | " else:\n",
28 | " # Notice that this is the tail-recursive version\n",
29 | " # of fib.\n",
30 | " yield fib(count-1, next_, cur + next_)\n",
31 | "\n",
32 | "import types\n",
33 | "\n",
34 | "def tramp(gen, *args, **kwargs):\n",
35 | " g = gen(*args, **kwargs)\n",
36 | " while isinstance(g, types.GeneratorType):\n",
37 | " g=g.__next__()\n",
38 | " return g\n",
39 | "print(tramp(fib, 996))"
40 | ]
41 | }
42 | ],
43 | "metadata": {
44 | "kernelspec": {
45 | "display_name": "tf36",
46 | "language": "python",
47 | "name": "tf36"
48 | },
49 | "language_info": {
50 | "codemirror_mode": {
51 | "name": "ipython",
52 | "version": 3
53 | },
54 | "file_extension": ".py",
55 | "mimetype": "text/x-python",
56 | "name": "python",
57 | "nbconvert_exporter": "python",
58 | "pygments_lexer": "ipython3",
59 | "version": "3.6.8"
60 | }
61 | },
62 | "nbformat": 4,
63 | "nbformat_minor": 2
64 | }
65 |
--------------------------------------------------------------------------------
/Python知识点/栈和队列.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# python数据结构与算法——栈和队列(Stack & Queue)\n",
8 | "\n",
9 | "Ref:\n",
10 | "- https://www.cnblogs.com/yangecnu/p/Introduction-Stack-and-Queue.html\n",
11 | "\n",
12 | "概念很简单,栈 (Stack)是一种后进先出(last in first off,LIFO)的数据结构,而队列(Queue)则是一种先进先出 (fisrt in first out,FIFO)的结构,如下图:\n",
13 | "\n",
14 | "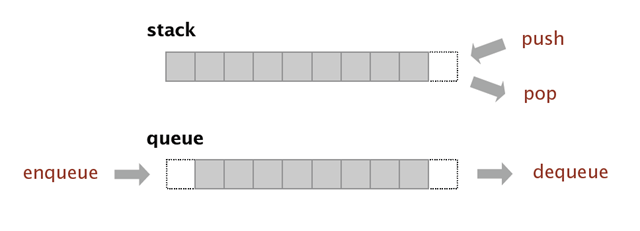"
15 | ]
16 | }
17 | ],
18 | "metadata": {
19 | "kernelspec": {
20 | "display_name": "Python 3 (system-wide)",
21 | "language": "python",
22 | "name": "python3"
23 | },
24 | "language_info": {
25 | "codemirror_mode": {
26 | "name": "ipython",
27 | "version": 3
28 | },
29 | "file_extension": ".py",
30 | "mimetype": "text/x-python",
31 | "name": "python",
32 | "nbconvert_exporter": "python",
33 | "pygments_lexer": "ipython3",
34 | "version": "3.6.8"
35 | }
36 | },
37 | "nbformat": 4,
38 | "nbformat_minor": 2
39 | }
40 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # PythonAlgorithm
2 |
3 | 全部为Jupyter Notebook格式
4 |
5 | 获取更好访问效果,请使用nbviewer链接进行查看:点击查看
6 |
7 | ## Python数据结构与算法基础
8 | ## 算法图解
9 | - [第1章 算法简介](./算法图解/chap01-算法简介.ipynb)
10 | - 二分查找
11 | - [第2章 选择排序](./算法图解/chap02-选择排序.ipynb)
12 | - 选择排序
13 | - [第3章 递归](./算法图解/chap03-递归.ipynb)
14 | - [第4章 快速排序](./算法图解/chap04-快速排序.ipynb)
15 | - [第5章 散列表](./算法图解/chap05-散列表.ipynb)
16 | - [第6章 广度优先搜索](./算法图解/chap06-广度优先搜索.ipynb)
17 | - [第7章 狄克斯特拉算法](./算法图解/chap07-狄克斯特拉算法Dijkstra’s-algorithm.ipynb)
18 | - [第8章 贪婪算法](./算法图解/chap08-贪婪算法.ipynb)
19 | - [第9章 动态规划](./算法图解/chap09-动态规划.ipynb)
20 |
21 | ## 剑指Offer
22 |
23 | ## 常见算法
24 |
25 | ## Python知识点
26 |
--------------------------------------------------------------------------------
/剑指Offer/chap00_剑指Offer目录.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "collapsed": false
7 | },
8 | "source": [
9 | "# 《剑指Offer》面试题: Python实现\n",
10 | "\n",
11 | "Github : https://github.com/JushuangQiao/Python-Offer\n",
12 | "\n",
13 | "《剑指Offer》第二版源代码(原书附):https://github.com/zhedahht/CodingInterviewChinese2\n",
14 | "\n",
15 | "\n",
16 | "# 第2章 面试基础知识\n",
17 | "\n",
18 | "## 2.2 编程语言\n",
19 | "\n",
20 | "### 面试题2 使用Python实现单例模式\n",
21 | "\n",
22 | "## 2.3 数据结构\n",
23 | "\n",
24 | "### 面试题3 二维数组中的查找\n",
25 | "\n",
26 | "### 面试题4 替换空格\n",
27 | "\n",
28 | "### 面试题5 从尾到头打印单链表\n",
29 | "\n",
30 | "### 面试题6 重建二叉树\n",
31 | "\n",
32 | "### 面试题7 用两个栈实现队列\n",
33 | "\n",
34 | "## 2.4 算法和数据操作\n",
35 | "\n",
36 | "### 面试题8 旋转数组的最小数字\n",
37 | "\n",
38 | "### 面试题9 斐波那契数列\n",
39 | "\n",
40 | "### 面试题10 二进制中1的个数\n",
41 | "\n",
42 | "# 第3章 高质量代码\n",
43 | "\n",
44 | "## 3.3 代码的完整性\n",
45 | "\n",
46 | "### 面试题11 数值的整数次方\n",
47 | "\n",
48 | "### 面试题12 打印1到最大的n位数\n",
49 | "\n",
50 | "### 面试题13 O(1)时间删除链表结点\n",
51 | "\n",
52 | "### 面试题14 调整数组顺序使寄数位于偶数前面\n",
53 | "\n",
54 | "## 3.4 代码的鲁棒性\n",
55 | "\n",
56 | "### 面试题15 链表中倒数第k个结点\n",
57 | "\n",
58 | "### 面试题16 反转链表\n",
59 | "\n",
60 | "### 面试题17 合并两个排序的链表\n",
61 | "\n",
62 | "### 面试题18 树的子结构\n",
63 | "\n",
64 | "# 第4章 解决### 面试题思路\n",
65 | "\n",
66 | "## 4.2 画图让抽象问题形象化\n",
67 | "\n",
68 | "### 面试题19 二叉树的镜像\n",
69 | "\n",
70 | "### 面试题20 顺时针打印矩阵\n",
71 | "\n",
72 | "## 4.3 举例让抽象问题具体化\n",
73 | "\n",
74 | "### 面试题21 包含min函数的栈\n",
75 | "\n",
76 | "### 面试题22 栈的压入弹出序列\n",
77 | "\n",
78 | "### 面试题23 从上往下打印二叉树\n",
79 | "\n",
80 | "### 面试题24 二叉树的后序遍历序列\n",
81 | "\n",
82 | "### 面试题25 二叉树中和为某一值的路径\n",
83 | "\n",
84 | "## 4.4 分解让复杂问题简单化\n",
85 | "\n",
86 | "### 面试题26 复杂链表的复制\n",
87 | "\n",
88 | "### 面试题27 二叉搜索树与双向链表\n",
89 | "\n",
90 | "### 面试题28 字符串的排列\n",
91 | "\n",
92 | "# 第5章 优化时间和空间效率\n",
93 | "\n",
94 | "## 5.2 时间效率\n",
95 | "\n",
96 | "### 面试题29 数组中出现次数超过一半的数字\n",
97 | "\n",
98 | "### 面试题30 最小的k个数\n",
99 | "\n",
100 | "### 面试题31 连续子数组的最大和\n",
101 | "\n",
102 | "### 面试题32 从1到n整数中1出现的次数\n",
103 | "\n",
104 | "### 面试题33 把数组排成最小的数\n",
105 | "\n",
106 | "## 5.3 时间效率与空间效率的平衡\n",
107 | "\n",
108 | "### 面试题34 丑数\n",
109 | "\n",
110 | "### 面试题35 第一个只出现一次的字符\n",
111 | "\n",
112 | "### 面试题36 数组中的逆序对\n",
113 | "\n",
114 | "### 面试题37 两个链表的第一个公共结点\n",
115 | "\n",
116 | "# 第6章 面试能力\n",
117 | "\n",
118 | "## 6.3 知识迁移能力\n",
119 | "\n",
120 | "### 面试题38 数字在排序数组中出现的次数\n",
121 | "\n",
122 | "### 面试题39 二叉树的深度\n",
123 | "\n",
124 | "### 面试题40 数组中只出现一次的数字\n",
125 | "\n",
126 | "### 面试题41 和为s的两个数字VS和为s的连续正数序列\n",
127 | "\n",
128 | "### 面试题42 翻转单词顺序与左旋转字符串\n",
129 | "\n",
130 | "## 6.4 抽象建模能力\n",
131 | "\n",
132 | "### 面试题43 n个骰子的点数\n",
133 | "\n",
134 | "### 面试题44 扑克牌的顺子\n",
135 | "\n",
136 | "### 面试题45 圆圈中最后剩下的数字\n",
137 | "\n",
138 | "## 6.5 发散思维能力\n",
139 | "\n",
140 | "### 面试题46 求## 1+2...+n\n",
141 | "\n",
142 | "### 面试题47 不用加减乘除做加法\n",
143 | "\n",
144 | "### 面试题48 不能被继承的类\n",
145 | "\n",
146 | "# 第7章 面试案例\n",
147 | "\n",
148 | "## 7.1 案例一\n",
149 | "\n",
150 | "### 面试题49 把字符串转化成整数\n",
151 | "\n",
152 | "## 7.2 案例二\n",
153 | "\n",
154 | "### 面试题50 树中两个结点的最低公共祖先\n"
155 | ]
156 | }
157 | ],
158 | "metadata": {
159 | "kernelspec": {
160 | "display_name": "Python 3 (system-wide)",
161 | "language": "python",
162 | "metadata": {
163 | "cocalc": {
164 | "description": "Python 3 programming language",
165 | "priority": 100,
166 | "url": "https://www.python.org/"
167 | }
168 | },
169 | "name": "python3"
170 | },
171 | "language_info": {
172 | "codemirror_mode": {
173 | "name": "ipython",
174 | "version": 3
175 | },
176 | "file_extension": ".py",
177 | "mimetype": "text/x-python",
178 | "name": "python",
179 | "nbconvert_exporter": "python",
180 | "pygments_lexer": "ipython3",
181 | "version": "3.6.8"
182 | }
183 | },
184 | "nbformat": 4,
185 | "nbformat_minor": 0
186 | }
--------------------------------------------------------------------------------
/剑指Offer/chap01_面试的流程.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "面试题1:赋值运算符函数\n",
8 | "\n",
9 | "题目:如下为类型CMyString的声明,请为该类型添加赋值运算符函数\n",
10 | "\n",
11 | "参考:\n",
12 | "\n",
13 | "https://github.com/zhedahht/CodingInterviewChinese2/blob/master/01_AssignmentOperator/AssignmentOperator.cpp\n",
14 | "\n",
15 | "详情见电子书第1章"
16 | ]
17 | }
18 | ],
19 | "metadata": {
20 | "kernelspec": {
21 | "display_name": "Python 3 (Ubuntu Linux)",
22 | "language": "python",
23 | "name": "python3"
24 | },
25 | "language_info": {
26 | "codemirror_mode": {
27 | "name": "ipython",
28 | "version": 3
29 | },
30 | "file_extension": ".py",
31 | "mimetype": "text/x-python",
32 | "name": "python",
33 | "nbconvert_exporter": "python",
34 | "pygments_lexer": "ipython3",
35 | "version": "3.6.7"
36 | }
37 | },
38 | "nbformat": 4,
39 | "nbformat_minor": 2
40 | }
41 |
--------------------------------------------------------------------------------
/剑指Offer/二叉树.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 2,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "# coding=utf-8\n",
10 | "\n",
11 | "\"\"\"\n",
12 | "使用先序遍历和中序遍历的结果重建二叉树\n",
13 | "\"\"\"\n",
14 | "from collections import deque\n",
15 | "\n",
16 | "class TreeNode(object):\n",
17 | " \"\"\"\n",
18 | " 二叉树结点定义\n",
19 | " \"\"\"\n",
20 | " def __init__(self, x):\n",
21 | " self.val = x\n",
22 | " self.left = None\n",
23 | " self.right = None"
24 | ]
25 | },
26 | {
27 | "cell_type": "code",
28 | "execution_count": 2,
29 | "metadata": {},
30 | "outputs": [
31 | {
32 | "name": "stdout",
33 | "output_type": "stream",
34 | "text": [
35 | "[1, 2, 3, 4, 5, 6, 7, 8]\n",
36 | "[1, 2, 4, 7, 3, 5, 6, 8]\n",
37 | "[4, 7, 2, 1, 5, 3, 8, 6]\n",
38 | "[7, 4, 2, 5, 8, 6, 3, 1]\n"
39 | ]
40 | }
41 | ],
42 | "source": [
43 | "class Tree(object):\n",
44 | " \"\"\"\n",
45 | " 二叉树\n",
46 | " \"\"\"\n",
47 | " def __init__(self):\n",
48 | " self.root = None\n",
49 | "\n",
50 | " def bfs(self):\n",
51 | " ret = []\n",
52 | " queue = deque([self.root])\n",
53 | " while queue:\n",
54 | " node = queue.popleft()\n",
55 | " if node:\n",
56 | " ret.append(node.val)\n",
57 | " queue.append(node.left)\n",
58 | " queue.append(node.right)\n",
59 | " return ret\n",
60 | "\n",
61 | " def pre_traversal(self):\n",
62 | " ret = []\n",
63 | "\n",
64 | " def traversal(head):\n",
65 | " if not head:\n",
66 | " return\n",
67 | " ret.append(head.val)\n",
68 | " traversal(head.left)\n",
69 | " traversal(head.right)\n",
70 | "\n",
71 | " traversal(self.root)\n",
72 | " return ret\n",
73 | "\n",
74 | " def in_traversal(self):\n",
75 | " ret = []\n",
76 | "\n",
77 | " def traversal(head):\n",
78 | " if not head:\n",
79 | " return\n",
80 | " traversal(head.left)\n",
81 | " ret.append(head.val)\n",
82 | " traversal(head.right)\n",
83 | "\n",
84 | " traversal(self.root)\n",
85 | " return ret\n",
86 | "\n",
87 | " def post_traversal(self):\n",
88 | " ret = []\n",
89 | "\n",
90 | " def traversal(head):\n",
91 | " if not head:\n",
92 | " return\n",
93 | " traversal(head.left)\n",
94 | " traversal(head.right)\n",
95 | " ret.append(head.val)\n",
96 | "\n",
97 | " traversal(self.root)\n",
98 | " return ret\n",
99 | "\n",
100 | "\n",
101 | "def construct_tree(preorder=None, inorder=None):\n",
102 | " \"\"\"\n",
103 | " 构建二叉树\n",
104 | " \"\"\"\n",
105 | " if not preorder or not inorder:\n",
106 | " return None\n",
107 | " index = inorder.index(preorder[0])\n",
108 | " left = inorder[0:index]\n",
109 | " right = inorder[index+1:]\n",
110 | " root = TreeNode(preorder[0])\n",
111 | " root.left = construct_tree(preorder[1:1+len(left)], left)\n",
112 | " root.right = construct_tree(preorder[-len(right):], right)\n",
113 | " return root\n",
114 | "\n",
115 | "\n",
116 | "if __name__ == '__main__':\n",
117 | " t = Tree()\n",
118 | " root = construct_tree([1, 2, 4, 7, 3, 5, 6, 8], [4, 7, 2, 1, 5, 3, 8, 6])\n",
119 | " t.root = root\n",
120 | " print(t.bfs())\n",
121 | " print(t.pre_traversal())\n",
122 | " print(t.in_traversal())\n",
123 | " print(t.post_traversal())"
124 | ]
125 | }
126 | ],
127 | "metadata": {
128 | "kernelspec": {
129 | "display_name": "Python 3 (system-wide)",
130 | "language": "python",
131 | "name": "python3"
132 | },
133 | "language_info": {
134 | "codemirror_mode": {
135 | "name": "ipython",
136 | "version": 3
137 | },
138 | "file_extension": ".py",
139 | "mimetype": "text/x-python",
140 | "name": "python",
141 | "nbconvert_exporter": "python",
142 | "pygments_lexer": "ipython3",
143 | "version": "3.6.8"
144 | }
145 | },
146 | "nbformat": 4,
147 | "nbformat_minor": 2
148 | }
149 |
--------------------------------------------------------------------------------
/剑指Offer/剑指Offer 名企面试官精讲典型编程题 第二版.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/EvanLi/PythonAlgorithm/330a9dee2fe4367e3bf63a8bf35c6ba79d101e94/剑指Offer/剑指Offer 名企面试官精讲典型编程题 第二版.pdf
--------------------------------------------------------------------------------
/剑指Offer/剑指Offer.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 剑指Offer\n",
8 | "\n",
9 | "# 1.二维数组中的查找\n",
10 | "## 题目描述\n",
11 | "\n",
12 | "在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。\n",
13 | "\n",
14 | "\n",
15 | "> 从左下角元素往上查找,右边元素是比这个元素大,上边是的元素比这个元素小。于是,target比这个元素小就往上找,比这个元素大就往右找。如果出了边界,则说明二维数组中不存在target元素。"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 1,
21 | "metadata": {
22 | "collapsed": false
23 | },
24 | "outputs": [],
25 | "source": [
26 | "# -*- coding:utf-8 -*-\n",
27 | "class Solution:\n",
28 | " # array 二维列表\n",
29 | " def Find(self, target, array):\n",
30 | " # write code here\n",
31 | " if not array:\n",
32 | " return False\n",
33 | " row,col = len(array),len(array[0])\n",
34 | "# 从左下角开始\n",
35 | " i,j = row-1,0\n",
36 | " while i >=0 and j target:\n",
40 | " i -= 1\n",
41 | " else:\n",
42 | " j +=1\n",
43 | " return False"
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {},
49 | "source": [
50 | "测试:"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 3,
56 | "metadata": {
57 | "collapsed": false
58 | },
59 | "outputs": [
60 | {
61 | "data": {
62 | "text/plain": [
63 | "True"
64 | ]
65 | },
66 | "execution_count": 3,
67 | "metadata": {},
68 | "output_type": "execute_result"
69 | }
70 | ],
71 | "source": [
72 | "array = [[1,2,3],\n",
73 | " [4,5,6],\n",
74 | " [7,8,9]]\n",
75 | "\n",
76 | "solu = Solution()\n",
77 | "solu.Find(9,array)"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "# 2.替换空格\n",
85 | "## 题目描述\n",
86 | "\n",
87 | "请实现一个函数,将一个字符串中的每个空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。"
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": 4,
93 | "metadata": {
94 | "collapsed": false
95 | },
96 | "outputs": [],
97 | "source": [
98 | "# -*- coding:utf-8 -*-\n",
99 | "class Solution:\n",
100 | " # s 源字符串\n",
101 | " def replaceSpace(self, s):\n",
102 | " # write code here\n",
103 | " l = len(s)\n",
104 | " s_out = ''\n",
105 | " for i in range(l):\n",
106 | " if(s[i]!=' '):\n",
107 | " s_out += s[i]\n",
108 | " else:\n",
109 | " s_out += \"%20\"\n",
110 | " return s_out"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {},
116 | "source": [
117 | "利用join,使用%20连接列表元素即可"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": 7,
123 | "metadata": {
124 | "collapsed": false
125 | },
126 | "outputs": [],
127 | "source": [
128 | "# -*- coding:utf-8 -*-\n",
129 | "class Solution:\n",
130 | " # s 源字符串\n",
131 | " def replaceSpace(self, s):\n",
132 | " return \"%20\".join(list(s.split(\" \")))"
133 | ]
134 | },
135 | {
136 | "cell_type": "markdown",
137 | "metadata": {},
138 | "source": [
139 | "replace函数"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 9,
145 | "metadata": {
146 | "collapsed": false
147 | },
148 | "outputs": [],
149 | "source": [
150 | "# -*- coding:utf-8 -*-\n",
151 | "class Solution:\n",
152 | " # s 源字符串\n",
153 | " def replaceSpace(self, s):\n",
154 | " # write code here\n",
155 | " return s.replace(' ','%20')"
156 | ]
157 | },
158 | {
159 | "cell_type": "markdown",
160 | "metadata": {},
161 | "source": [
162 | "正则表达式:"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": 11,
168 | "metadata": {
169 | "collapsed": false
170 | },
171 | "outputs": [],
172 | "source": [
173 | "# -*- coding:utf-8 -*-\n",
174 | "class Solution:\n",
175 | " # s 源字符串\n",
176 | " def replaceSpace(self, s):\n",
177 | " # write code here\n",
178 | " import re\n",
179 | " ret = re.compile(' ')\n",
180 | " return ret.sub('%20',s)"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 12,
186 | "metadata": {
187 | "collapsed": false
188 | },
189 | "outputs": [
190 | {
191 | "data": {
192 | "text/plain": [
193 | "'We%20Are%20Happy'"
194 | ]
195 | },
196 | "execution_count": 12,
197 | "metadata": {},
198 | "output_type": "execute_result"
199 | }
200 | ],
201 | "source": [
202 | "solu = Solution()\n",
203 | "solu.replaceSpace(\"We Are Happy\")"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {},
209 | "source": [
210 | "# 3.从尾到头打印单链表\n",
211 | "\n",
212 | "## 题目描述\n",
213 | "\n",
214 | "输入一个链表,按链表值从尾到头的顺序返回一个ArrayList。\n",
215 | "\n",
216 | "方法1:使用栈,可以使用列表模拟"
217 | ]
218 | },
219 | {
220 | "cell_type": "code",
221 | "execution_count": 17,
222 | "metadata": {
223 | "collapsed": false
224 | },
225 | "outputs": [],
226 | "source": [
227 | "# -*- coding:utf-8 -*-\n",
228 | "\n",
229 | "class ListNode:\n",
230 | " def __init__(self, x):\n",
231 | " self.val = x\n",
232 | " self.next = None\n",
233 | "\n",
234 | "class Solution:\n",
235 | " # 返回从尾部到头部的列表值序列,例如[1,2,3]\n",
236 | " def printListFromTailToHead(self, listNode):\n",
237 | " # write code here\n",
238 | " stack = []\n",
239 | " rev = []\n",
240 | " while listNode:\n",
241 | " stack.append(listNode.val)\n",
242 | " listNode = listNode.next\n",
243 | " while stack:\n",
244 | " rev.append(stack.pop())\n",
245 | " return rev"
246 | ]
247 | },
248 | {
249 | "cell_type": "markdown",
250 | "metadata": {},
251 | "source": [
252 | "方法2:直接递归"
253 | ]
254 | },
255 | {
256 | "cell_type": "code",
257 | "execution_count": 20,
258 | "metadata": {
259 | "collapsed": false
260 | },
261 | "outputs": [],
262 | "source": [
263 | "# -*- coding:utf-8 -*-\n",
264 | "\n",
265 | "class ListNode:\n",
266 | " def __init__(self, x):\n",
267 | " self.val = x\n",
268 | " self.next = None\n",
269 | "\n",
270 | "class Solution:\n",
271 | " # 返回从尾部到头部的列表值序列,例如[1,2,3]\n",
272 | " def printListFromTailToHead(self, listNode):\n",
273 | " # write code here\n",
274 | " if listNode is None:\n",
275 | " return []\n",
276 | " return self.printListFromTailToHead(listNode.next) + [listNode.val]"
277 | ]
278 | },
279 | {
280 | "cell_type": "markdown",
281 | "metadata": {},
282 | "source": [
283 | "测试:"
284 | ]
285 | },
286 | {
287 | "cell_type": "code",
288 | "execution_count": 21,
289 | "metadata": {
290 | "collapsed": false
291 | },
292 | "outputs": [
293 | {
294 | "data": {
295 | "text/plain": [
296 | "[3, 2, 1]"
297 | ]
298 | },
299 | "execution_count": 21,
300 | "metadata": {},
301 | "output_type": "execute_result"
302 | }
303 | ],
304 | "source": [
305 | "l1 = ListNode(1)\n",
306 | "l2 = ListNode(2)\n",
307 | "l3 = ListNode(3)\n",
308 | "l1.next = l2\n",
309 | "l2.next = l3\n",
310 | "\n",
311 | "solu = Solution()\n",
312 | "solu.printListFromTailToHead(l1)"
313 | ]
314 | },
315 | {
316 | "cell_type": "markdown",
317 | "metadata": {},
318 | "source": [
319 | "# 4.重建二叉树 [LeetCode](https://leetcode.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)\n",
320 | "\n",
321 | "## 题目描述\n",
322 | "\n",
323 | "输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。\n",
324 | "\n",
325 | ">思路:前序的第一个元素是根结点的值,在中序中找到该值,中序中该值的左边的元素是根结点的左子树,右边是右子树,然后递归的处理左边和右边\n",
326 | "\n",
327 | ">提示:二叉树结点,以及对二叉树的各种操作,测试代码见six.py"
328 | ]
329 | },
330 | {
331 | "cell_type": "code",
332 | "execution_count": null,
333 | "metadata": {
334 | "collapsed": false
335 | },
336 | "outputs": [],
337 | "source": [
338 | "# -*- coding:utf-8 -*-\n",
339 | "# class TreeNode:\n",
340 | "# def __init__(self, x):\n",
341 | "# self.val = x\n",
342 | "# self.left = None\n",
343 | "# self.right = None\n",
344 | "class Solution:\n",
345 | " # 返回构造的TreeNode根节点\n",
346 | " def reConstructBinaryTree(self, pre, tin):\n",
347 | " # write code here"
348 | ]
349 | }
350 | ],
351 | "metadata": {
352 | "kernelspec": {
353 | "display_name": "Python 3 (system-wide)",
354 | "language": "python",
355 | "name": "python3"
356 | },
357 | "language_info": {
358 | "codemirror_mode": {
359 | "name": "ipython",
360 | "version": 3
361 | },
362 | "file_extension": ".py",
363 | "mimetype": "text/x-python",
364 | "name": "python",
365 | "nbconvert_exporter": "python",
366 | "pygments_lexer": "ipython3",
367 | "version": "3.6.8"
368 | }
369 | },
370 | "nbformat": 4,
371 | "nbformat_minor": 2
372 | }
373 |
--------------------------------------------------------------------------------
/剑指Offer/牛客网剑指offer.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "2.二维数组中的查找\n",
8 | "\n",
9 | "题目描述\n",
10 | "\n",
11 | "在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。\n",
12 | "\n",
13 | "输入描述\n",
14 | "\n",
15 | "array: 待查找的二维数组 target:查找的数字\n",
16 | "\n",
17 | "输出描述\n",
18 | "\n",
19 | "查找到返回true,查找不到返回false"
20 | ]
21 | },
22 | {
23 | "cell_type": "markdown",
24 | "metadata": {},
25 | "source": [
26 | "暴力求解:"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 20,
32 | "metadata": {},
33 | "outputs": [],
34 | "source": [
35 | "# -*- coding:utf-8 -*-\n",
36 | "class Solution:\n",
37 | " # array 二维列表\n",
38 | " def Find(self, target, array):\n",
39 | " # write code here\n",
40 | " if not array:\n",
41 | " return False\n",
42 | " for line in array:\n",
43 | " for col in line:\n",
44 | " if target == col:\n",
45 | " return True\n",
46 | " return False"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": 23,
52 | "metadata": {},
53 | "outputs": [
54 | {
55 | "data": {
56 | "text/plain": [
57 | "True"
58 | ]
59 | },
60 | "execution_count": 23,
61 | "metadata": {},
62 | "output_type": "execute_result"
63 | }
64 | ],
65 | "source": [
66 | "array = [[1,2,3],[2,3,4],[3,4,5],[4,5,6]]\n",
67 | "target = 2\n",
68 | "s1 = Solution()\n",
69 | "s1.Find(target,array)"
70 | ]
71 | },
72 | {
73 | "cell_type": "markdown",
74 | "metadata": {},
75 | "source": [
76 | "从左下角或者右上角开始比较:"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 21,
82 | "metadata": {},
83 | "outputs": [],
84 | "source": [
85 | "# -*- coding:utf-8 -*-\n",
86 | "class Solution:\n",
87 | " # array 二维列表\n",
88 | " def Find(self, target, array):\n",
89 | " # write code here\n",
90 | " if not array:\n",
91 | " return False\n",
92 | " row,col = len(array),len(array[0])\n",
93 | "# 从左下角开始\n",
94 | " i,j = row-1,0\n",
95 | " while i >=0 and j target:\n",
99 | " i -= 1\n",
100 | " else:\n",
101 | " j +=1\n",
102 | " return False"
103 | ]
104 | },
105 | {
106 | "cell_type": "code",
107 | "execution_count": 4,
108 | "metadata": {},
109 | "outputs": [
110 | {
111 | "name": "stdout",
112 | "output_type": "stream",
113 | "text": [
114 | "Hello%20World\n"
115 | ]
116 | }
117 | ],
118 | "source": [
119 | "s = \"Hello World\"\n",
120 | "l = len(s)\n",
121 | "s_out = ''\n",
122 | "for i in range(l):\n",
123 | " if(s[i]!=' '):\n",
124 | " s_out += s[i]\n",
125 | " else:\n",
126 | " s_out += \"%20\"\n",
127 | "return s_out"
128 | ]
129 | },
130 | {
131 | "cell_type": "code",
132 | "execution_count": 7,
133 | "metadata": {},
134 | "outputs": [],
135 | "source": [
136 | "# -*- coding:utf-8 -*-\n",
137 | "class Solution:\n",
138 | " # s 源字符串\n",
139 | " def replaceSpace(self, s):\n",
140 | " # write code here\n",
141 | " s = list(s)\n",
142 | " l = len(s)\n",
143 | " for i in range(l):\n",
144 | " if(s[i] == ' '):\n",
145 | " s[i] = '%20'\n",
146 | " return ''.join(s)"
147 | ]
148 | },
149 | {
150 | "cell_type": "code",
151 | "execution_count": 11,
152 | "metadata": {},
153 | "outputs": [
154 | {
155 | "data": {
156 | "text/plain": [
157 | "'Hello%20World'"
158 | ]
159 | },
160 | "execution_count": 11,
161 | "metadata": {},
162 | "output_type": "execute_result"
163 | }
164 | ],
165 | "source": [
166 | "test1 = Solution()\n",
167 | "test1.replaceSpace(\"Hello World\")"
168 | ]
169 | }
170 | ],
171 | "metadata": {
172 | "kernelspec": {
173 | "display_name": "tf36",
174 | "language": "python",
175 | "name": "tf36"
176 | },
177 | "language_info": {
178 | "codemirror_mode": {
179 | "name": "ipython",
180 | "version": 3
181 | },
182 | "file_extension": ".py",
183 | "mimetype": "text/x-python",
184 | "name": "python",
185 | "nbconvert_exporter": "python",
186 | "pygments_lexer": "ipython3",
187 | "version": "3.6.7"
188 | }
189 | },
190 | "nbformat": 4,
191 | "nbformat_minor": 2
192 | }
193 |
--------------------------------------------------------------------------------
/常见算法/0-1背包问题.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 0-1背包问题的动态规划算法\n",
8 | "\n",
9 | "https://zhuanlan.zhihu.com/p/30959069\n",
10 | "\n",
11 | "## 1.什么是0-1背包问题(knapsack problem)\n",
12 | "\n",
13 | "给定一组多个$n$物品,每种物品都有自己的重量$w_i$和价值$v_i$\n",
14 | "\n",
15 | "在限定的总重量/总容量$C$内,选择其中若干个(也即每种物品可以选0个或1个)\n",
16 | "\n",
17 | "设计选择方案使得物品的总价值最高\n",
18 | "\n",
19 | "转换成数学语言:\n",
20 | "\n",
21 | "给定正整数$\\{(w_i,v_i)\\}_{1\\leq i\\leq n}$、给定正整数$C$,求解0-1规划问题:\n",
22 | "\n",
23 | "$$\n",
24 | "\\max \\sum_{i=1}^{n}{x_iv_i}\n",
25 | "$$\n",
26 | "s.t.,\n",
27 | "$$\n",
28 | "\\sum_{i=1}^{n}{x_iw_i}\\leq C\n",
29 | "$$\n",
30 | "$$\n",
31 | "x_i\\in\\{0,1\\}\n",
32 | "$$\n",
33 | "\n",
34 | "示例应用:处理器能力有限时间受限,任务很多,如何选择使得总效用最大?\n",
35 | "\n",
36 | "## 0-1背包问题的定性\n",
37 | "\n",
38 | "对于一般性的0-1背包,\n",
39 | "\n",
40 | "贪婪算法无法得到最优解。\n",
41 | "\n",
42 | "## 0-1背包问题的递推关系\n",
43 | "\n",
44 | "定义子问题 $P(i,W)$为:在前 $i$ 个物品中挑选总重量不超过 $W$ 的物品,每种物品至多只能挑选1个,使得总价值最大;这时的最优值记作 $m(i,W)$ ,其中 $1\\leq i\\leq n$ , $1\\leq W\\leq C$ 。\n",
45 | "\n",
46 | "考虑第 $i$个物品,无外乎两种可能:选,或者不选。\n",
47 | "\n",
48 | "* 不选的话,背包的容量不变,改变为问题$P(i-1,W)$ ;\n",
49 | "* 选的话,背包的容量变小,改变为问题$P(i-1,W-w_i)$ 。\n",
50 | "\n",
51 | "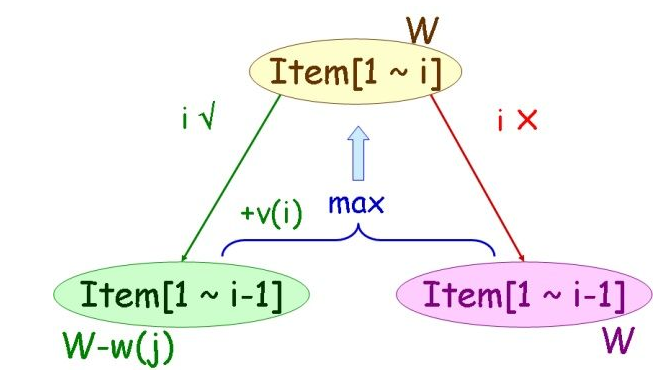\n",
52 | "\n",
53 | "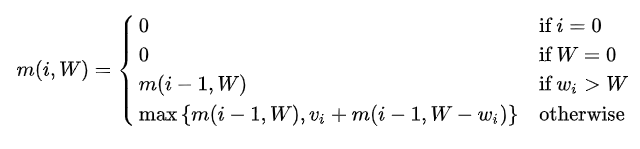"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": 4,
59 | "metadata": {},
60 | "outputs": [
61 | {
62 | "name": "stdout",
63 | "output_type": "stream",
64 | "text": [
65 | "[[0, 0, 0, 0, 0], [0, 1500, 1500, 1500, 1500], [0, 1500, 1500, 1500, 3000], [0, 1500, 1500, 2000, 3500]]\n",
66 | "3500\n"
67 | ]
68 | }
69 | ],
70 | "source": [
71 | "def knapsack_dp(value,weight,C):\n",
72 | " n =len(value)\n",
73 | " dp = [[0 for W in range(C+1)] for i in range(n+1)] #多加一行0、一列0\n",
74 | " \n",
75 | " for i in range(1,n+1):\n",
76 | " for W in range(1,C+1):\n",
77 | " if weight[i-1] > W: #当前物品重量大于背包重量,则取i-1个物品时的值\n",
78 | " dp[i][W] = dp[i-1][W]\n",
79 | " else: #当前物品重量小于背包重量,则取两者(不取这个物品、取这个物品)的最大值\n",
80 | " dp[i][W] = max(dp[i-1][W],value[i-1]+dp[i-1][W-weight[i-1]])\n",
81 | " return dp\n",
82 | "\n",
83 | "C = 4 #背包容量\n",
84 | "value = [1500,3000,2000] #物品价值\n",
85 | "weight = [1,4,3] #物品重量\n",
86 | "dp = knapsack_dp(value,weight,C)\n",
87 | "print(dp)\n",
88 | "res = 0\n",
89 | "for i in dp:\n",
90 | " res = max(res,max(i))\n",
91 | "print(res)"
92 | ]
93 | }
94 | ],
95 | "metadata": {
96 | "kernelspec": {
97 | "display_name": "Python 3",
98 | "language": "python",
99 | "name": "python3"
100 | },
101 | "language_info": {
102 | "codemirror_mode": {
103 | "name": "ipython",
104 | "version": 3
105 | },
106 | "file_extension": ".py",
107 | "mimetype": "text/x-python",
108 | "name": "python",
109 | "nbconvert_exporter": "python",
110 | "pygments_lexer": "ipython3",
111 | "version": "3.6.8"
112 | }
113 | },
114 | "nbformat": 4,
115 | "nbformat_minor": 2
116 | }
117 |
--------------------------------------------------------------------------------
/常见算法/乘法逆元.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 乘法逆元\n",
8 | "\n",
9 | "\n",
10 | "## 1.逆元简介\n",
11 | "\n",
12 | "参考:[乘法逆元-OI Wiki](https://oi-wiki.org/math/inverse/)\n",
13 | "\n",
14 | "介绍模意义下乘法运算的逆元(Modular Multiplicative Inverse),并介绍如何使用扩展欧几里德算法(Extended Euclidean algorithm)求解乘法逆元\n",
15 | "\n",
16 | "如果一个线性同余方程:\n",
17 | "\n",
18 | "$$xy \\equiv 1 \\;(\\bmod\\; p)$$\n",
19 | "\n",
20 | "则$y$称为$x \\bmod b$的逆元,记为$x^{-1}$\n",
21 | "\n",
22 | "有:\n",
23 | "\n",
24 | "$$x\\times x^{-1} \\equiv 1 \\;(\\bmod\\; p)$$\n",
25 | "\n",
26 | "例如,求5关于模14的乘法逆元:\n",
27 | "\n",
28 | "$$5\\times 3 \\equiv 1 \\;(\\bmod\\; 14)$$\n",
29 | "\n",
30 | "因此,5关于模14的乘法逆元为3。\n",
31 | "\n",
32 | "## 2.应用\n",
33 | "\n",
34 | "参考:[乘法逆元的几种计算方法](https://oi.men.ci/mul-inverse/)\n",
35 | "\n",
36 | "乘法逆元的一大应用是模意义下的除法,除法在模意义下并不是封闭的,但我们可以根据上述公式,将其转化为乘法。\n",
37 | "\n",
38 | "$$\\frac{x}{y} \\equiv x\\times y^{-1} \\;(\\bmod\\; p)$$\n",
39 | "\n",
40 | "## 3.求解方法:快速幂法\n",
41 | "\n",
42 | "### 3.1费马小定理\n",
43 | "\n",
44 | "假如a是一个整数,p是一个质数,那么$a^{p}-a$是$p$的倍数,可以表示为:\n",
45 | "\n",
46 | "$$a^{p} \\equiv a \\;(\\bmod\\; p)$$\n",
47 | "\n",
48 | "如果a不是p的倍数,这个定理也可以写成\n",
49 | "\n",
50 | "$$a^{p-1} \\equiv 1 \\;(\\bmod\\; p)$$\n",
51 | "\n",
52 | "这个书写方式更加常用"
53 | ]
54 | },
55 | {
56 | "cell_type": "code",
57 | "execution_count": 1,
58 | "metadata": {},
59 | "outputs": [
60 | {
61 | "data": {
62 | "text/plain": [
63 | "1"
64 | ]
65 | },
66 | "execution_count": 1,
67 | "metadata": {},
68 | "output_type": "execute_result"
69 | }
70 | ],
71 | "source": [
72 | "p = 221\n",
73 | "a = 38\n",
74 | "pow(a,p-1,p)"
75 | ]
76 | },
77 | {
78 | "cell_type": "markdown",
79 | "metadata": {},
80 | "source": [
81 | "### 3.2求解\n",
82 | "\n",
83 | "上述公式可变形为:\n",
84 | "\n",
85 | "$$a\\times a^{p-2} \\equiv 1 \\;(\\bmod\\; p)$$\n",
86 | "\n",
87 | "由乘法逆元的定义,$a^{p-2}$ 即为 $a$ 的乘法逆元。求乘法逆元等价于求$a^{p-2}$\n",
88 | "\n",
89 | "使用快速幂计算$a^{p-2}$,总时间复杂度为 $O(loga)$。\n",
90 | "\n",
91 | "#### 模意义下取幂与乘法逆元\n",
92 | "\n",
93 | "计算 \n",
94 | "\n",
95 | "$$x^n \\bmod\\; m$$\n",
96 | "\n",
97 | "https://oi-wiki.org/math/quick-pow/#_3\n",
98 | "\n",
99 | "快速幂的一个非常常见的应用,模意义下取幂,它可以用于计算模意义下的乘法逆元。\n",
100 | "\n",
101 | "既然我们知道取模的运算不会干涉乘法运算,因此我们只需要在计算的过程中取模即可。\n",
102 | "\n",
103 | "代码如下:"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 14,
109 | "metadata": {},
110 | "outputs": [
111 | {
112 | "name": "stdout",
113 | "output_type": "stream",
114 | "text": [
115 | "905611805\n",
116 | "333333336\n"
117 | ]
118 | }
119 | ],
120 | "source": [
121 | "def fast_pow(x,n,MOD):\n",
122 | " \"\"\"x^n对MOD取模\"\"\"\n",
123 | " res = 1\n",
124 | " x %= MOD\n",
125 | " while n > 0:\n",
126 | " if n&1: #位与=1时,n是奇数\n",
127 | " res = res * x % MOD\n",
128 | " x = x * x % MOD #base翻倍\n",
129 | " n >>= 1 #右移一位\n",
130 | " return res\n",
131 | "\n",
132 | "def mod_multi_inv(num,MOD):\n",
133 | " #模意义下的乘法逆元\n",
134 | " return fast_pow(num, MOD-2, MOD)\n",
135 | "if __name__ == \"__main__\":\n",
136 | " MOD = 10**9+7\n",
137 | " print(fast_pow(2,10000,MOD))\n",
138 | " print(mod_multi_inv(3,MOD))"
139 | ]
140 | },
141 | {
142 | "cell_type": "markdown",
143 | "metadata": {},
144 | "source": [
145 | "C++代码:\n",
146 | "\n",
147 | "- 写法一:\n",
148 | "\n",
149 | "```\n",
150 | "long long binpow(long long a, long long b, long long m) {\n",
151 | " a %= m;\n",
152 | " long long res = 1;\n",
153 | " while (b > 0) {\n",
154 | " if (b & 1) res = res * a % m;\n",
155 | " a = a * a % m;\n",
156 | " b >>= 1;\n",
157 | " }\n",
158 | " return res;\n",
159 | "}\n",
160 | "\n",
161 | "inline int inverse(const int num,long long MOD){\n",
162 | " return binpow(num, MOD - 2, MOD);\n",
163 | "}\n",
164 | "```\n",
165 | "\n",
166 | "- 写法二:\n",
167 | "\n",
168 | "```\n",
169 | "inline int pow(const int n, const int k) {\n",
170 | " long long ans = 1;\n",
171 | " for (long long num = n, t = k; t; num = num * num % MOD, t >>= 1) \n",
172 | " if (t & 1) ans = ans * num % MOD;\n",
173 | " return ans;\n",
174 | "}\n",
175 | "\n",
176 | "inline int inv(const int num) {\n",
177 | " return pow(num, MOD - 2);\n",
178 | "}\n",
179 | "```"
180 | ]
181 | },
182 | {
183 | "cell_type": "markdown",
184 | "metadata": {},
185 | "source": [
186 | "#### 除法取模\n",
187 | "\n",
188 | "$$x^n \\bmod\\; m$$\n",
189 | "\n",
190 | "$$\\frac{x}{y} \\bmod\\; MOD = x*y^{-1} \\bmod\\; MOD = ((x \\bmod\\; MOD) *(y^{-1} \\bmod\\; MOD)) \\bmod\\; MOD$$\n",
191 | "\n",
192 | "代码如下:"
193 | ]
194 | },
195 | {
196 | "cell_type": "code",
197 | "execution_count": 18,
198 | "metadata": {},
199 | "outputs": [
200 | {
201 | "name": "stdout",
202 | "output_type": "stream",
203 | "text": [
204 | "905611805\n",
205 | "333333336\n",
206 | "333333337\n"
207 | ]
208 | }
209 | ],
210 | "source": [
211 | "def fast_pow(x,n,MOD):\n",
212 | " \"\"\"x^n对MOD取模\"\"\"\n",
213 | " res = 1\n",
214 | " x %= MOD\n",
215 | " while n > 0:\n",
216 | " if n&1: #位与=1时,n是奇数\n",
217 | " res = res * x % MOD\n",
218 | " x = x * x % MOD #base翻倍\n",
219 | " n >>= 1 #右移一位\n",
220 | " return res\n",
221 | "\n",
222 | "def mod_multi_inv(num,MOD):\n",
223 | " #模意义下的乘法逆元\n",
224 | " return fast_pow(num, MOD-2, MOD)\n",
225 | "\n",
226 | "def divide_mod(num,den,MOD):\n",
227 | " #den:分母,num:分子 num/den\n",
228 | " inv_den = mod_multi_inv(den,MOD)\n",
229 | " return ((num%MOD)*inv_den)%MOD\n",
230 | "\n",
231 | "if __name__ == \"__main__\":\n",
232 | " MOD = 10**9+7\n",
233 | " print(fast_pow(2,10000,MOD))\n",
234 | " print(mod_multi_inv(3,MOD))\n",
235 | " print(divide_mod(4,3,MOD)) #4/3对1e9+7取模"
236 | ]
237 | },
238 | {
239 | "cell_type": "markdown",
240 | "metadata": {},
241 | "source": [
242 | "## 求解方法:扩展欧几里得法\n",
243 | "\n",
244 | "扩展欧几里得(EXGCD)算法可以在$O(log\\ max(a,b))$的时间内求出关于 x、y 的方程\n",
245 | "\n",
246 | "$$ax+by=gcd(a,b)$$\n",
247 | "\n",
248 | "的一组整数解\n",
249 | "\n",
250 | "当b为素数时,gcd(a,b)=1,此时有\n",
251 | "\n",
252 | "$$ax\\equiv 1 \\;(\\bmod\\; b)$$\n",
253 | "\n",
254 | "即x是a的乘法逆元"
255 | ]
256 | },
257 | {
258 | "cell_type": "markdown",
259 | "metadata": {},
260 | "source": [
261 | "C++代码:\n",
262 | "\n",
263 | "```\n",
264 | "void exgcd(const int a, const int b, int &g, int &x, int &y) {\n",
265 | " if (!b) g = a, x = 1, y = 0;\n",
266 | " else exgcd(b, a % b, g, y, x), y -= x * (a / b);\n",
267 | "}\n",
268 | "\n",
269 | "inline int inv(const int num) {\n",
270 | " int g, x, y;\n",
271 | " exgcd(num, MOD, g, x, y);\n",
272 | " return ((x % MOD) + MOD) % MOD;\n",
273 | "}\n",
274 | "```"
275 | ]
276 | },
277 | {
278 | "cell_type": "markdown",
279 | "metadata": {},
280 | "source": [
281 | "## 例题求解:\n",
282 | "\n",
283 | "[P2613 【模板】有理数取余](https://www.luogu.org/problem/P2613)\n",
284 | "\n",
285 | "题目描述\n",
286 | "给出一个有理数$c=\\frac{a}{b}$,\n",
287 | "\n",
288 | "求$c\\ \\bmod 19260817$的值。\n",
289 | "\n",
290 | "输入格式\n",
291 | "一共两行。\n",
292 | "\n",
293 | "第一行,一个整数a。\n",
294 | "第二行,一个整数b。\n",
295 | "\n",
296 | "输出格式\n",
297 | "一个整数,代表求余后的结果。如果无解,输出Angry!\n",
298 | "\n",
299 | "输入输出样例\n",
300 | "\n",
301 | "输入 #1\n",
302 | "```\n",
303 | "233\n",
304 | "666\n",
305 | "```\n",
306 | "输出 #1 \n",
307 | "```\n",
308 | "18595654\n",
309 | "```\n",
310 | "说明/提示\n",
311 | "对于所有数据,$0\\leq a,b \\leq 10^{10001}$\n",
312 | "\n",
313 | "https://www.cnblogs.com/lykkk/p/10902396.html\n",
314 | "\n"
315 | ]
316 | }
317 | ],
318 | "metadata": {
319 | "kernelspec": {
320 | "display_name": "Python 3",
321 | "language": "python",
322 | "name": "python3"
323 | },
324 | "language_info": {
325 | "codemirror_mode": {
326 | "name": "ipython",
327 | "version": 3
328 | },
329 | "file_extension": ".py",
330 | "mimetype": "text/x-python",
331 | "name": "python",
332 | "nbconvert_exporter": "python",
333 | "pygments_lexer": "ipython3",
334 | "version": "3.6.8"
335 | }
336 | },
337 | "nbformat": 4,
338 | "nbformat_minor": 2
339 | }
340 |
--------------------------------------------------------------------------------
/常见算法/卡特兰数-Catalan.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 卡特兰数\n",
8 | "\n",
9 | "[从《编程之美》买票找零问题说起,娓娓道来卡特兰数——兼爬坑指南](https://www.cnblogs.com/wuyuegb2312/p/3016878.html)\n",
10 | "\n",
11 | "《编程之美》的卡特兰数\n",
12 | "\n",
13 | " 先简单概括一下《编程之美》是如何引入和介绍卡特兰数的。\n",
14 | "\n",
15 | "问题(《编程之美》4.3买票找零):2n个人排队买票,其中n个人持50元,n个人持100元。每张票50元,且一人只买一张票。初始时售票处没有零钱找零。请问这2n个人一共有多少种排队顺序,不至于使售票处找不开钱?\n",
16 | "\n",
17 | "分析1:队伍的序号标为0,1,...,2n-1,并把50元看作左括号,100元看作右括号,合法序列即括号能完成配对的序列。对于一个合法的序列,第0个一定是左括号,它必然与某个右括号配对,记其位置为k。那么从1到k-1、k+1到2n-1也分别是两个合法序列。那么,k必然是奇数(1到k-1一共有偶数个),设k=2i+1。那么剩余括号的合法序列数为f(2i)*f(2n-2i-2)个。取i=0到n-1累加,\n",
18 | "\n",
19 | "并且令f(0)=1,再由组合数C(0,0)=0,可得\n",
20 | "\n",
21 | "$$f(2n)=\\frac{1}{n+1}C_{2n}^{n}$$\n",
22 | "\n",
23 | "至于怎么推导,《编程之美》就没有详细地说明,而是用另一个角度来解释,这个解释类似于《计算机程序设计艺术(卷一)》2.2.1节习题4的解答提到的精彩解法“反射原理”,下面是对其的概括(我所知的最早的出处是:http://bbs.csdn.net/topics/320099239)\n",
24 | "\n",
25 | " \n",
26 | "\n",
27 | "问题大意是用S表示入栈,X表示出栈,那么合法的序列有多少个(S的个数为n)\n",
28 | "显然有c(2n, n)个含S,X各n个的序列,剩下的是计算不允许的序列数(它包含正确个数的S和X,但是违背其它条件).\n",
29 | "在任何不允许的序列中,定出使得X的个数超过S的个数的第一个X的位置。然后在导致并包括这个X的部分序列中,以S代替所有的X并以X代表所有的S。结果是一个有(n+1)个S和(n-1)个X的序列。反过来,对一垢一种类型的每个序列,我们都能逆转这个过程,而且找出导致它的前一种类型的不允许序列。例如XXSXSSSXXSSS必然来自SSXSXXXXXSSS。这个对应说明,不允许的序列的个数是c(2n, n-1),因此an = c(2n, n) - c(2n, n-1)。\n",
30 | "\n",
31 | "$$\n",
32 | "f(2n)=C_{2n}^n-C_{2n}^{n-1}$$\n",
33 | "\n",
34 | "$$=\\frac{2n\\times(2n-1)...(n+2)\\times(n+1)}{n!}-\\frac{2n\\times(2n-1)...(n+2)}{(n-1)!}$$\n",
35 | "\n",
36 | "$$=\\frac{2n\\times(2n-1)...(n+2)\\times(n+1)}{n!}-\\frac{n}{n+1}\\times\\frac{2n\\times(2n-1)...(n+2)\\times(n+1)}{n!}$$\n",
37 | "\n",
38 | "$$=\\frac{1}{n+1}C_{2n}^{n}$$\n",
39 | "\n",
40 | "## 入栈出栈问题(经典问题):\n",
41 | "\n",
42 | " 对于一个无限大的栈,一共n个元素,请问有几种合法的入栈出栈形式?\n",
43 | "\n",
44 | "分析:\n",
45 | "\n",
46 | " 直接用f(2n)来求解即可。不过可以注意到,对于买票找零问题,一共是2n个人,排的是人的顺序;对于入栈出栈,是n个元素,2n次操作,排的是操作的顺序。究竟把哪个数代入,不要混淆。\n",
47 | "\n",
48 | " \n",
49 | "\n",
50 | "## 矩阵连乘问题(《编程之美》4.3扩展问题1):\n",
51 | "\n",
52 | " P = a1 * a2 * a3 * ... * an,其中ai是矩阵。根据乘法结合律,不改变矩阵的相互顺序,只用括号表示成对的乘积,试问一共有几种括号化方案?\n",
53 | "\n",
54 | "分析:\n",
55 | "\n",
56 | " n个矩阵需要连乘(n-1)次,因此需要(n-1)对括号。且这里的括号只是为了使矩阵两两结合,而不是单纯为加括号而加括号,像( (a1) * (a2)),这里将两个矩阵分别括起来是不符合要求的。因此这里如果确定了括号的顺序,那么矩阵的结合顺序也会确定,如(()())对应了(( a1* a2) * (a3 * a4))。注意到是(n-1)对括号,即(n-1)个左括号和(n-1)个右括号,那么应该使用f[2(n-1)]来计算。\n",
57 | "\n",
58 | " \n",
59 | "\n",
60 | "街区对角线问题(《编程之美》4.3扩展问题2类似题目1):\n",
61 | "\n",
62 | " 某个城市的某个居民,每天他须要走过2n个街区去上班(他在其住所以北n个街区和以东n个街区处工作)。如果他不跨越(但可以碰到)从家到办公室的对角线,那么有多少条可能的道路?\n",
63 | "\n",
64 | "分析:\n",
65 | "\n",
66 | " (图片来自维基)\n",
67 | "\n",
68 | "Catalan number 4x4 grid example.svg\n",
69 | "\n",
70 | " 为了不跨越对角线,向东走的步数时刻要大于等于向北走的步数,这些点都是处于对角线以下的。可以看出路线序列由n次向东和n次向北组成,且从第一个元素开始的任意子序列中向东次数不少于向北次数。因此方法一共是f(2n)种。\n",
71 | "\n",
72 | " 等等,似乎有什么不对。对于网络上我所见过的解答,都是到此为止;但我觉得这里有个陷阱。如果要求不跨越,并且初始点就在对角线上,这明显是个边界条件,完全可以只走上面一半,不违反“不跨越对角线”的要求,即向北走的步数时刻大于等于向东走的步数,那么真实的解应该是2*f(2n)。当然,如果这个问题真出现在面试中了,你可以和面试官探讨一下,问问这么走是否合法?注意边界条件,应该会为面试加分。\n",
73 | "\n",
74 | " \n",
75 | "\n",
76 | "## 圆上点对互连问题(《编程之美》4.3扩展问题2类似题目1):\n",
77 | "\n",
78 | " 在圆上选择2n个点,将这些点成对连接起来,且所得n条线段不相交,求可行的方法数。\n",
79 | "\n",
80 | "分析:\n",
81 | "\n",
82 | " 乍一看不能像上面三道题那样直接套公式。那么,先进行一下分析,将圆上的点依次标为P0,P1,...P2n-1。为了避免混淆,使用F(2n)表示2n个点可连成的线段数,选择Pk与P0相连(0T中无环,且任何不同两顶点间有且仅有一条路。\n",
24 | "- 定理2:T是树<=>T连通且|e|=n-1,|e|为T的边数,n为T的顶点数。\n",
25 | "- 层数:由根到某一顶点v的有向路的长度,称为顶点v的层数(level)。根树的高度就是顶点层数的最大值。\n",
26 | "- 深度:对于任意节点n,n的深度为从根到n的唯一路径长,根的深度为1。(有些定义基数为0)\n",
27 | "- 高度:对于任意节点n,n的高度为从n到一片树叶的最长路径长,所有树叶的高度为1。(有些定义基数为0)\n",
28 | "- 层数:根节点为第一层,往下依此递增。\n",
29 | " - 树中节点的最大层数称之为树的深度或者高度,所以在基数为1时树的深度=树的高度=最大层数\n",
30 | "\n",
31 | " ## [数据结构:图的存储结构之邻接矩阵](https://blog.csdn.net/jnu_simba/article/details/8866705)\n",
32 | " \n",
33 | "图的**邻接矩阵(Adjacency Matrix)**存储方式是用两个数组来表示图。一个一维的数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。\n",
34 | " \n",
35 | " 设图G有n个顶点,则邻接矩阵是一个`n*n`的方阵,定义为:\n",
36 | " \n",
37 | " 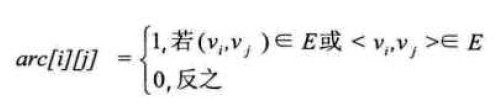\n",
38 | " \n",
39 | "### 无向图:\n",
40 | " \n",
41 | "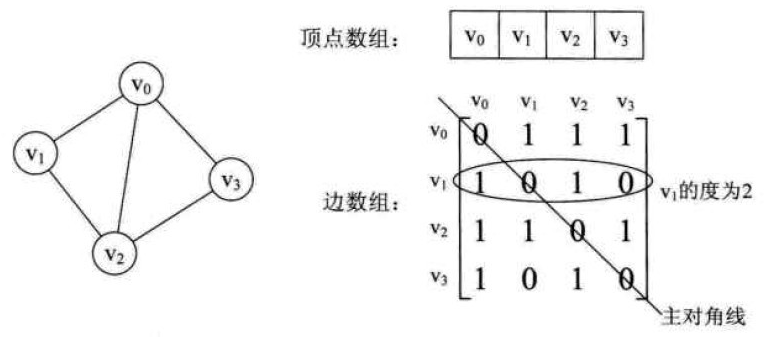\n",
42 | " \n",
43 | "### 有向图:\n",
44 | " \n",
45 | "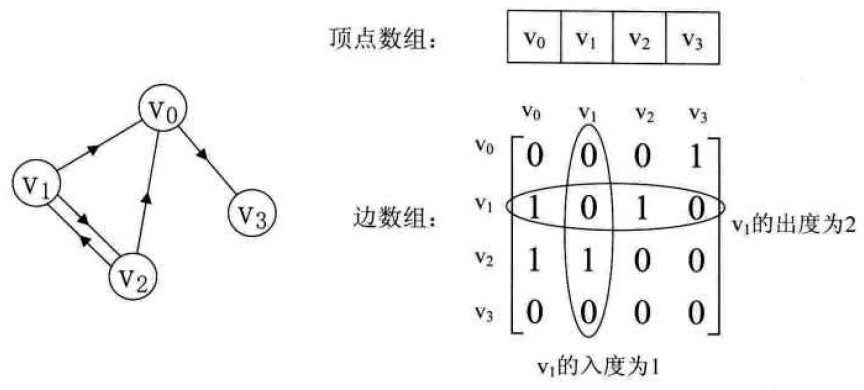\n",
46 | " \n",
47 | "\n",
48 | "## 网\n",
49 | "\n",
50 | "在图的术语中,我们提到了网的概念,也就是每条边上都带有权的图叫做网。那些这些权值就需要保存下来。\n",
51 | "\n",
52 | "设图G是网图,有n个顶点,则邻接矩阵是一个`n*n`的方阵,定义为:\n",
53 | "\n",
54 | "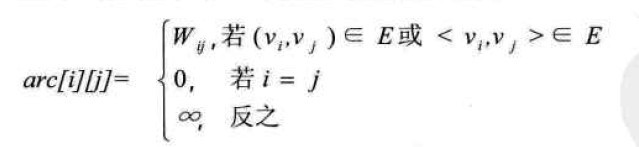\n",
55 | "\n",
56 | "### 有向图网:\n",
57 | "\n",
58 | "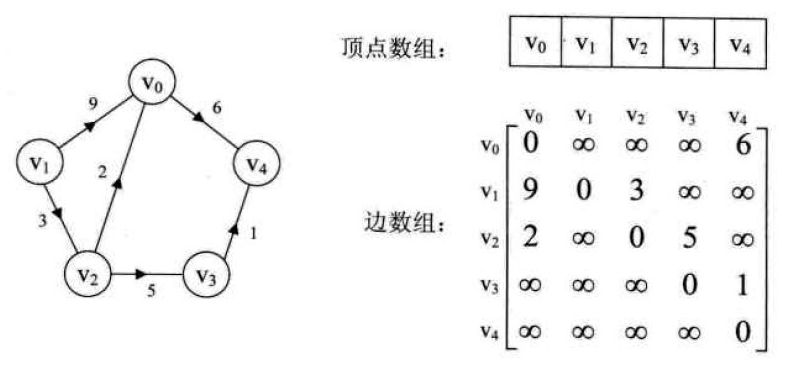\n",
59 | "\n",
60 | "## [数据结构:图的存储结构之邻接表](https://blog.csdn.net/jnu_simba/article/details/8866844)\n",
61 | "\n",
62 | "# 深度优先搜索(Depth-First-Search,DFS)\n",
63 | "\n",
64 | "求连通简单图G的一棵生成树的许多方法中,深度优先搜索(depth first search)是一个十分重要的算法。\n",
65 | "\n",
66 | "- 1.首先将根节点放入stack中。\n",
67 | "- 2.从stack中取出第一个节点,并检验它是否为目标。\n",
68 | " - 如果找到目标,则结束搜寻并回传结果。\n",
69 | " - 否则将它某一个尚未检验过的直接子节点加入stack中。\n",
70 | "- 3.重复步骤2。\n",
71 | "- 4.如果不存在未检测过的直接子节点。\n",
72 | " - 将上一级节点加入stack中。\n",
73 | " - 重复步骤2。\n",
74 | "- 5.重复步骤4。\n",
75 | "- 6.若stack为空,表示整张图都检查过了——亦即图中没有欲搜寻的目标。结束搜寻并回传“找不到目标”。\n",
76 | "\n",
77 | "基本思想:\n",
78 | "\n",
79 | " 任意选择图G的一个顶点V0作为根,通过相继地添加边来形成在顶点V0开始的路,其中每条新边都与路上的最后一个顶点以及不在路上的一个顶点相关联。\n",
80 | "\n",
81 | " 继续尽可能多地添加边到这条路。若这条路经过图G的所有顶点,则这条路即为G的一棵生成树;\n",
82 | "\n",
83 | " 若这条路没有经过G的所有顶点,不妨设形成这条路的顶点顺序V0,V1,......,Vn。则返回到路里的次最后顶点V(n-1).\n",
84 | "\n",
85 | " 若有可能,则形成在顶点v(n-1)开始的经过的还没有放过的顶点的路;\n",
86 | "\n",
87 | " 否则,返回到路里的顶点v(n-2)。\n",
88 | "\n",
89 | " 然后再试。重复这个过程,在所访问过的最后一个顶点开始,在路上次返回的顶点,只要有可能就形成新的路,直到不能添加更多的边为止。\n",
90 | "\n",
91 | " 深度优先搜索也称为回溯(back tracking)\n",
92 | "\n",
93 | "栗子:\n",
94 | "\n",
95 | " 用深度优先搜索来找出图3-9所示图G的生成树,任意地从顶点d开始,生成步骤显示在图3-10。"
96 | ]
97 | },
98 | {
99 | "cell_type": "code",
100 | "execution_count": null,
101 | "metadata": {},
102 | "outputs": [],
103 | "source": []
104 | }
105 | ],
106 | "metadata": {
107 | "kernelspec": {
108 | "display_name": "Python 3",
109 | "language": "python",
110 | "name": "python3"
111 | },
112 | "language_info": {
113 | "codemirror_mode": {
114 | "name": "ipython",
115 | "version": 3
116 | },
117 | "file_extension": ".py",
118 | "mimetype": "text/x-python",
119 | "name": "python",
120 | "nbconvert_exporter": "python",
121 | "pygments_lexer": "ipython3",
122 | "version": "3.7.3"
123 | }
124 | },
125 | "nbformat": 4,
126 | "nbformat_minor": 2
127 | }
128 |
--------------------------------------------------------------------------------
/常见算法/并查集.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 并查集\n",
8 | "\n",
9 | "背景问题:给定一些好友的关系,求这些好友关系中,存在多少个朋友圈?\n",
10 | "\n",
11 | "例如给定好友关系为:[0,1], [0, 4], [1, 2], [1, 3], [5, 6], [6, 7], [7, 5], [8, 9]。在这些朋友关系中,存在3个朋友圈,分别是\n",
12 | "\n",
13 | "【0,1,2,3,4】,【5,6,7】,【8,9】\n",
14 | "\n",
15 | "\n",
16 | "这个问题,抽象一下,就是:求一个图的连通子图的个数,即连通度是多少。\n",
17 | "\n",
18 | "- 第一种方法,采用DFS遍历这个图,遍历过程中,可以求出连通度,但是DFS对于大型图,效率缓慢。\n",
19 | "\n",
20 | "- 第二种方法,采用并查集。并查集可以说是一种算法,或者数据结构。\n",
21 | "\n",
22 | "[数据结构4——并查集(入门)](https://www.cnblogs.com/xzxl/p/7226557.html)\n",
23 | "\n",
24 | "[超有爱的并查集~](https://blog.csdn.net/niushuai666/article/details/6662911)\n",
25 | "\n",
26 | "并查集的主要思想是,对每一个连通的子图,选出根节点,作为代表。“代表”的个数,就是连通度的大小。\n",
27 | "\n",
28 | "步骤如下:\n",
29 | "\n",
30 | "1. 初始化每个节点的代表为其本身(后面,把代表叫做“父节点”)。\n",
31 | "\n",
32 | "2.针对给定的好友关系[0,1], [0, 4], [1, 2], [1, 3], [5, 6], [6, 7], [7, 5], [8, 9],更新父节点。例如给出(1,2)那么,更新2的父节点为1。\n",
33 | "\n",
34 | "3.重新更新所有节点的父节点,针对每个节点,找到其祖宗节点,即根节点。\n",
35 | "\n",
36 | "对应的步骤如下:上面的是节点本身,下面的是节点对应的父节点或根节点。\n",
37 | "\n",
38 | "```\n",
39 | "节 点:0 1 2 3 4 5 6 7 8 9\n",
40 | "父节点:0 1 2 3 4 5 6 7 8 9\n",
41 | "\n",
42 | "更新父节点:\n",
43 | "节 点:0 1 2 3 4 5 6 7 8 9\n",
44 | "父节点:0 0 1 1 0 7 5 6 8 8\n",
45 | "\n",
46 | "\n",
47 | "初始化:\n",
48 | "[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]\n",
49 | "\n",
50 | "不断更新节点:\n",
51 | "[1, 1, 2, 3, 4, 5, 6, 7, 8, 9] union(father, 0, 1)\n",
52 | "[1, 4, 2, 3, 4, 5, 6, 7, 8, 9] union(father, 0, 4)\n",
53 | "[1, 4, 2, 3, 2, 5, 6, 7, 8, 9] union(father, 1, 2)\n",
54 | "[1, 2, 3, 3, 2, 5, 6, 7, 8, 9] union(father, 1, 3)\n",
55 | "[1, 2, 3, 3, 2, 6, 6, 7, 8, 9] union(father, 5, 6)\n",
56 | "[1, 2, 3, 3, 2, 6, 7, 7, 8, 9] union(father, 6, 7)\n",
57 | "[1, 2, 3, 3, 2, 7, 7, 7, 8, 9] union(father, 7, 5)\n",
58 | "[1, 2, 3, 3, 2, 7, 7, 7, 9, 9] union(father, 8, 9)\n",
59 | "\n",
60 | "```\n"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 53,
66 | "metadata": {},
67 | "outputs": [],
68 | "source": [
69 | "def find(father, i):\n",
70 | " # father 的第i个位置表示i的父节点\n",
71 | " # 用来查找节点i的根节点\n",
72 | " if i != father[i]:\n",
73 | " father[i] = find(father, father[i])\n",
74 | " return father[i]\n",
75 | "\n",
76 | "def union(father, i, j):\n",
77 | " #连接节点i的根节点和节点j的根节点\n",
78 | " pi, pj = find(father, i), find(father, j)\n",
79 | " if pi != pj:\n",
80 | " father[pi] = pj\n",
81 | " return father\n",
82 | "\n",
83 | "def connected(father, i, j):\n",
84 | " # 判断连通性\n",
85 | " return find(father, i) == find(father, j)\n",
86 | "\n",
87 | "def union_find(nodes, edges):\n",
88 | " #nodes为节点列表,edges为关系列表\n",
89 | " # 初始化各个节点的父节点为其自身\n",
90 | " father = [0]*len(nodes)\n",
91 | " for node in nodes:\n",
92 | " father[node] = node\n",
93 | " # 连接各个node中的两个点\n",
94 | " for i,j in edges:\n",
95 | " union(father,i,j)\n",
96 | " root_of_node = [0]*len(nodes)\n",
97 | " for node in nodes:\n",
98 | " root_of_node[node] = find(father,node)\n",
99 | " out_set = {}\n",
100 | " for index,root_node in enumerate(root_of_node):\n",
101 | " if root_node in out_set:\n",
102 | " out_set[root_node].append(index)\n",
103 | " else:\n",
104 | " out_set[root_node] = [index]\n",
105 | " return root_of_node,out_set"
106 | ]
107 | },
108 | {
109 | "cell_type": "code",
110 | "execution_count": 58,
111 | "metadata": {},
112 | "outputs": [
113 | {
114 | "name": "stdout",
115 | "output_type": "stream",
116 | "text": [
117 | "[2, 2, 2]\n",
118 | "{2: [0, 1, 2]}\n"
119 | ]
120 | }
121 | ],
122 | "source": [
123 | "nodes = [i for i in range(10)]\n",
124 | "# edges = [[0, 1], [0, 4], [1, 2], [1, 3], [5, 6], [6, 7], [7, 5], [8, 9]]\n",
125 | "edges = [(0, 1), (1, 2), (0, 9), (5, 6), (6, 4), (5, 9)]\n",
126 | "# edges = [[0, 1], [1, 2]]\n",
127 | "father,out_set = union_find(nodes,edges)\n",
128 | "print(father)\n",
129 | "print(out_set)"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 32,
135 | "metadata": {},
136 | "outputs": [
137 | {
138 | "name": "stdout",
139 | "output_type": "stream",
140 | "text": [
141 | "[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]\n",
142 | "[1, 1, 2, 3, 4, 5, 6, 7, 8, 9]\n",
143 | "[1, 2, 2, 3, 4, 5, 6, 7, 8, 9]\n",
144 | "[2, 2, 9, 3, 4, 5, 6, 7, 8, 9]\n",
145 | "[2, 2, 9, 3, 4, 6, 6, 7, 8, 9]\n",
146 | "[2, 2, 9, 3, 4, 6, 4, 7, 8, 9]\n",
147 | "[2, 2, 9, 3, 9, 4, 4, 7, 8, 9]\n",
148 | "item 0 -> component 9\n",
149 | "[9, 2, 9, 3, 9, 4, 4, 7, 8, 9]\n",
150 | "item 1 -> component 9\n",
151 | "[9, 9, 9, 3, 9, 4, 4, 7, 8, 9]\n",
152 | "item 2 -> component 9\n",
153 | "[9, 9, 9, 3, 9, 4, 4, 7, 8, 9]\n",
154 | "item 3 -> component 3\n",
155 | "[9, 9, 9, 3, 9, 4, 4, 7, 8, 9]\n",
156 | "item 4 -> component 9\n",
157 | "[9, 9, 9, 3, 9, 4, 4, 7, 8, 9]\n",
158 | "item 5 -> component 9\n",
159 | "[9, 9, 9, 3, 9, 9, 4, 7, 8, 9]\n",
160 | "item 6 -> component 9\n",
161 | "[9, 9, 9, 3, 9, 9, 9, 7, 8, 9]\n",
162 | "item 7 -> component 7\n",
163 | "[9, 9, 9, 3, 9, 9, 9, 7, 8, 9]\n",
164 | "item 8 -> component 8\n",
165 | "[9, 9, 9, 3, 9, 9, 9, 7, 8, 9]\n",
166 | "item 9 -> component 9\n",
167 | "[9, 9, 9, 3, 9, 9, 9, 7, 8, 9]\n"
168 | ]
169 | }
170 | ],
171 | "source": [
172 | "n = 10\n",
173 | "data = [i for i in range(n)]\n",
174 | "connections = [(0, 1), (1, 2), (0, 9), (5, 6), (6, 4), (5, 9)]\n",
175 | "# connections = [[0, 1], [0, 4], [1, 2], [1, 3], [5, 6], [6, 7], [7, 5], [8, 9]]\n",
176 | "\n",
177 | "print(data)\n",
178 | "# union\n",
179 | "for i, j in connections:\n",
180 | " union(data, i, j)\n",
181 | " print(data)\n",
182 | "\n",
183 | "find\n",
184 | "for i in range(n):\n",
185 | " print('item', i, '-> component', find(data, i))\n",
186 | " print(data)"
187 | ]
188 | }
189 | ],
190 | "metadata": {
191 | "kernelspec": {
192 | "display_name": "tf36",
193 | "language": "python",
194 | "name": "tf36"
195 | },
196 | "language_info": {
197 | "codemirror_mode": {
198 | "name": "ipython",
199 | "version": 3
200 | },
201 | "file_extension": ".py",
202 | "mimetype": "text/x-python",
203 | "name": "python",
204 | "nbconvert_exporter": "python",
205 | "pygments_lexer": "ipython3",
206 | "version": "3.6.8"
207 | }
208 | },
209 | "nbformat": 4,
210 | "nbformat_minor": 2
211 | }
212 |
--------------------------------------------------------------------------------
/常见算法/拓扑排序.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/常见算法/斐波那契数列三种时间复杂度.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 1.递归 $O(2^n)$"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 28,
13 | "metadata": {},
14 | "outputs": [
15 | {
16 | "name": "stdout",
17 | "output_type": "stream",
18 | "text": [
19 | "2178309\n",
20 | "CPU times: user 2 s, sys: 868 µs, total: 2 s\n",
21 | "Wall time: 2.07 s\n"
22 | ]
23 | }
24 | ],
25 | "source": [
26 | "%%time\n",
27 | "def Fib(n):\n",
28 | " if n==0:\n",
29 | " return 0\n",
30 | " if n==1:\n",
31 | " return 1\n",
32 | " return Fib(n-1)+Fib(n-2)\n",
33 | "\n",
34 | "print(Fib(32))"
35 | ]
36 | },
37 | {
38 | "cell_type": "markdown",
39 | "metadata": {},
40 | "source": [
41 | "# 2.迭代算法 $O(n)$"
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": 29,
47 | "metadata": {},
48 | "outputs": [
49 | {
50 | "name": "stdout",
51 | "output_type": "stream",
52 | "text": [
53 | "2178309\n",
54 | "CPU times: user 150 µs, sys: 0 ns, total: 150 µs\n",
55 | "Wall time: 165 µs\n"
56 | ]
57 | }
58 | ],
59 | "source": [
60 | "%%time\n",
61 | "def Fib(n):\n",
62 | " a, b = 0, 1\n",
63 | " if n == 0:\n",
64 | " return a\n",
65 | " for _ in range(n - 1):\n",
66 | " a, b = b, a + b\n",
67 | " return b\n",
68 | "\n",
69 | "print(Fib(32))"
70 | ]
71 | },
72 | {
73 | "cell_type": "code",
74 | "execution_count": 30,
75 | "metadata": {},
76 | "outputs": [
77 | {
78 | "name": "stdout",
79 | "output_type": "stream",
80 | "text": [
81 | "2178309\n",
82 | "CPU times: user 145 µs, sys: 0 ns, total: 145 µs\n",
83 | "Wall time: 154 µs\n"
84 | ]
85 | }
86 | ],
87 | "source": [
88 | "%%time\n",
89 | "def Fib(n):\n",
90 | " fib = [0]*(n+1)\n",
91 | " fib[0] = 0\n",
92 | " fib[1] = 1\n",
93 | " for i in range(2,n+1):\n",
94 | " fib[i] = fib[i-1] + fib[i-2]\n",
95 | " return fib[n]\n",
96 | "\n",
97 | "print(Fib(32))"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "# 3.利用矩阵乘法 $O(logn)$\n",
105 | "\n",
106 | "$$\n",
107 | "\\begin{pmatrix}f(n) & f(n-1)\\end{pmatrix} = \\begin{pmatrix}f(n-1) & f(n-2)\\end{pmatrix} \\times \\begin{pmatrix}1 & 1 \\\\1 & 0\\end{pmatrix}\n",
108 | "$$\n",
109 | "$$\n",
110 | "= \\begin{pmatrix}f(n-2) & f(n-3)\\end{pmatrix} \\times \\begin{pmatrix}1 & 1 \\\\1 & 0\\end{pmatrix}^2\n",
111 | "$$\n",
112 | "\n",
113 | "$$\n",
114 | "= ...\n",
115 | "$$\n",
116 | "$$\n",
117 | "= \\begin{pmatrix}f(1) & f(0)\\end{pmatrix} \\times \\begin{pmatrix}1 & 1 \\\\1 & 0\\end{pmatrix}^{n-1}\n",
118 | "$$\n",
119 | "\n",
120 | "我们求一个矩阵的n-1次方即可,两个2维矩阵的乘法次数可以看作常量\n",
121 | "\n",
122 | "矩阵的n次方利用分治法,只需要$O(logn)$的复杂度就能计算出来,\n",
123 | "\n",
124 | "和常数的乘方相似:\n",
125 | "\n",
126 | "n=偶数:\n",
127 | "\n",
128 | "$$x^n = x^{\\frac{n}{2}}\\times x^{\\frac{n}{2}}$$\n",
129 | "\n",
130 | "n=奇数:\n",
131 | "\n",
132 | "$$x^n = x^{\\frac{n-1}{2}}\\times x^{\\frac{n-1}{2}} \\times x$$\n",
133 | "\n",
134 | "$$T(n) = T(n/2) + O(1)$$\n",
135 | "\n",
136 | "推出:\n",
137 | "\n",
138 | "$$T(n) = O(logn)$$"
139 | ]
140 | },
141 | {
142 | "cell_type": "markdown",
143 | "metadata": {},
144 | "source": [
145 | "## 分治法计算x的n次幂\n",
146 | "\n",
147 | "### 普通算法:"
148 | ]
149 | },
150 | {
151 | "cell_type": "code",
152 | "execution_count": 3,
153 | "metadata": {},
154 | "outputs": [
155 | {
156 | "name": "stdout",
157 | "output_type": "stream",
158 | "text": [
159 | "10715086071862673209484250490600018105614048117055336074437503883703510511249361224931983788156958581275946729175531468251871452856923140435984577574698574803934567774824230985421074605062371141877954182153046474983581941267398767559165543946077062914571196477686542167660429831652624386837205668069376\n",
160 | "CPU times: user 410 µs, sys: 0 ns, total: 410 µs\n",
161 | "Wall time: 420 µs\n"
162 | ]
163 | }
164 | ],
165 | "source": [
166 | "%%time\n",
167 | "def pow1(x,n):\n",
168 | " #计算x^n\n",
169 | " res = 1\n",
170 | " for i in range(n):\n",
171 | " res *= x\n",
172 | " return res\n",
173 | "print(pow1(2,1000))"
174 | ]
175 | },
176 | {
177 | "cell_type": "markdown",
178 | "metadata": {},
179 | "source": [
180 | "### 分治算法"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 4,
186 | "metadata": {},
187 | "outputs": [
188 | {
189 | "name": "stdout",
190 | "output_type": "stream",
191 | "text": [
192 | "114813069527425452423283320117768198402231770208869520047764273682576626139237031385665948631650626991844596463898746277344711896086305533142593135616665318539129989145312280000688779148240044871428926990063486244781615463646388363947317026040466353970904996558162398808944629605623311649536164221970332681344168908984458505602379484807914058900934776500429002716706625830522008132236281291761267883317206598995396418127021779858404042159853183251540889433902091920554957783589672039160081957216630582755380425583726015528348786419432054508915275783882625175435528800822842770817965453762184851149029376\n",
193 | "CPU times: user 121 µs, sys: 0 ns, total: 121 µs\n",
194 | "Wall time: 126 µs\n"
195 | ]
196 | }
197 | ],
198 | "source": [
199 | "%%time\n",
200 | "def pow2(x,n):\n",
201 | " #计算x^n\n",
202 | " if n == 1:\n",
203 | " return x\n",
204 | " elif n % 2 ==0:\n",
205 | " tmp = pow2(x,n/2) #// 用临时变量减少重复的运算\n",
206 | " return tmp*tmp\n",
207 | " else:\n",
208 | " tmp = pow2(x,(n-1)/2)\n",
209 | " return tmp*tmp*x\n",
210 | "\n",
211 | "print(pow2(2,2000))"
212 | ]
213 | },
214 | {
215 | "cell_type": "markdown",
216 | "metadata": {},
217 | "source": [
218 | "## 分治法计算斐波那契数列:\n",
219 | "\n",
220 | "[五种方法计算斐波那契数列的第n项](http://blog.zhengyi.one/fibonacci-in-logn.html)"
221 | ]
222 | },
223 | {
224 | "cell_type": "code",
225 | "execution_count": null,
226 | "metadata": {},
227 | "outputs": [],
228 | "source": []
229 | }
230 | ],
231 | "metadata": {
232 | "kernelspec": {
233 | "display_name": "Python 3",
234 | "language": "python",
235 | "name": "python3"
236 | },
237 | "language_info": {
238 | "codemirror_mode": {
239 | "name": "ipython",
240 | "version": 3
241 | },
242 | "file_extension": ".py",
243 | "mimetype": "text/x-python",
244 | "name": "python",
245 | "nbconvert_exporter": "python",
246 | "pygments_lexer": "ipython3",
247 | "version": "3.6.8"
248 | }
249 | },
250 | "nbformat": 4,
251 | "nbformat_minor": 2
252 | }
253 |
--------------------------------------------------------------------------------
/常见算法/最小生成树-Prim算法和Kruskal算法.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/常见算法/算法目录.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "```\n",
8 | "作者:晗江雪\n",
9 | "链接:https://www.nowcoder.com/discuss/217410?type=0&order=0&pos=1&page=1\n",
10 | "来源:牛客网\n",
11 | "\n",
12 | "基础入门班:\n",
13 | "适合人群\n",
14 | "适合0基础小白,或者基础非常薄弱的同学,左神手把手带你算法入门\n",
15 | "\n",
16 | "课程目录\n",
17 | "第一章 认识复杂度和简单排序算法\n",
18 | "时间复杂度和空间复杂度 选择排序、冒泡排序、插入排序的细节和时间复杂度分析\n",
19 | "二分法的使用和复杂度分析\n",
20 | "一道时间复杂度很低的利用异或运算解决的问题\n",
21 | "常见时间复杂度的比较\n",
22 | "详解递归函数与常见递归函数的复杂度估算(master公式)\n",
23 | "详解对数器的使用\n",
24 | "\n",
25 | "第二章 认识O(N*logN)的排序\n",
26 | "归并排序详解\n",
27 | "快速排序详解\n",
28 | "堆结构和堆排序详解\n",
29 | "\n",
30 | "第三章 详解桶排序以及排序内容大总结\n",
31 | "桶排序思想下的具体排序:计数排序、基数排序\n",
32 | "详解比较器\n",
33 | "排序内容汇总与常见坑总结\n",
34 | "工程上对排序的改进\n",
35 | "\n",
36 | "第四章 链表\n",
37 | "链表问题对于笔试和面试阶段的解题方法论\n",
38 | "常见的链表面试题目\n",
39 | "利用快慢指针\n",
40 | "哈希表和有序表在使用层次上的简单介绍\n",
41 | "\n",
42 | "第五章 二叉树\n",
43 | "详解递归函数完成二叉树的三种遍历\n",
44 | "详解非递归函数完成二叉树的三种遍历\n",
45 | "详解二叉树的序列化和反序列化(深度优先与宽度优先遍历)\n",
46 | "折纸问题\n",
47 | "判断搜索二叉树\n",
48 | "判断完全二叉树\n",
49 | "判断平衡二叉树\n",
50 | "二叉树节点的前驱节点与后继节点\n",
51 | "\n",
52 | "第六章 图\n",
53 | "图结构的表示方法\n",
54 | "图的深度优先遍历与宽度优先遍历\n",
55 | "拓扑排序问题\n",
56 | "最小生成树问题\n",
57 | "单源最短路径问题\n",
58 | "\n",
59 | "第七章 详解前缀树和贪心算法\n",
60 | "详解前缀树\n",
61 | "介绍贪心算法及其相关题目\n",
62 | "在面试中如何快速的尝试出贪心策略\n",
63 | "\n",
64 | "第八章 暴力递归\n",
65 | "常见的递归问题\n",
66 | "几种常见的尝试类型\n",
67 | "\n",
68 | "\n",
69 | "基础提升班:\n",
70 | "适合人群\n",
71 | "适合有简单入门基础,但是还达不到校招水平要求的同学,左神带你跨越学习瓶颈\n",
72 | "\n",
73 | "课程目录\n",
74 | "第一章\n",
75 | "哈希函数与哈希表\n",
76 | "位图与布隆过滤器详解\n",
77 | "一致性哈希结构\n",
78 | "\n",
79 | "第二章\n",
80 | "详解有序表(红黑树、跳表、sb树、avl树\n",
81 | "详解并查集结构的应用(岛问题)\n",
82 | "\n",
83 | "第三章\n",
84 | "KMP算法\n",
85 | "Manacher算法\n",
86 | "\n",
87 | "第四章\n",
88 | "滑动窗口的最大值与最小值更新结构\n",
89 | "单调栈结构\n",
90 | "\n",
91 | "第五章\n",
92 | "二叉树的morris遍历\n",
93 | "树形dp解题套路\n",
94 | "\n",
95 | "第六章\n",
96 | "大数据题目与空间限制题目常见解法\n",
97 | "位运算常见题目\n",
98 | "\n",
99 | "第七章\n",
100 | "从暴力递归到动态规划(上)\n",
101 | "\n",
102 | "第八章\n",
103 | "从暴力递归到动态规划(下)与社会嗑\n",
104 | "\n",
105 | "\n",
106 | "中级班\n",
107 | "适合人群\n",
108 | "适合基础比较好,刷题不熟练的同学,左神亲自带你刷题,从题目思路到代码最优家,详细讲解,带你熟悉大部分校招题目的讨论\n",
109 | "\n",
110 | "题目概括\n",
111 | "题目1-5\n",
112 | "定长绳子覆盖最多点数\n",
113 | "买苹果最少袋子数\n",
114 | "线性排列正方形的最少涂染数\n",
115 | "N阶方阵中最大正方形边长\n",
116 | "指定概率数字生成函数\n",
117 | "题目6-10\n",
118 | "给定非负整数n能形成的二叉树结构数目\n",
119 | "构成完整括号字符串的最少添加括号数\n",
120 | "求数组中差值为K的去重数字对\n",
121 | "使2个数组平均值都增加的最小操作数\n",
122 | "给定数字求可以转换出的字符串个数\n",
123 | "题目11-15\n",
124 | "合法括号序列的深度\n",
125 | "利用辅助栈对当前栈排序\n",
126 | "牛羊吃草决胜结果\n",
127 | "二叉树的路径构成的最大权值和\n",
128 | "机器打包物品最少轮数\n",
129 | "题目16-20\n",
130 | "zigzag方式打印矩阵\n",
131 | "螺旋方式打印矩阵\n",
132 | "将矩阵原地旋转90度\n",
133 | "在矩阵中查找某个数\n",
134 | "拼接字符串的最少操作数\n",
135 | "。。。。。。。。。。。\n",
136 | "\n",
137 | "\n",
138 | "高级班\n",
139 | "适合人群\n",
140 | "适合基础比较好,想冲击大厂高薪offer的同学,左神带你手撕高难度笔试面试算法真题\n",
141 | "\n",
142 | "题目概括\n",
143 | "题目1-5 \n",
144 | "路径数组统计距离i的城市数目\n",
145 | "分糖果最少数目\n",
146 | "覆盖二叉树的所有节点需要的最少相机数\n",
147 | "使字符串数组不降序的最少操作数\n",
148 | "分田地的最大价值\n",
149 | "题目6-10 \n",
150 | "得到target的最少操作数\n",
151 | "符合条件的子数组数目\n",
152 | "从 1 到 n 的数字中 1 出现的个数\n",
153 | "矩阵中最大矩形区域的1的数量\n",
154 | "N!的二进制中最低位的1的位置\n",
155 | "题目11-15\n",
156 | "完成所有的画作需要的最少时间\n",
157 | "扔棋子不摔碎的最少次数\n",
158 | "最长的连续序列的长度\n",
159 | "二叉树两个节点的最低公共祖先\n",
160 | "DC3算法生成后缀数组\n",
161 | "题目16-20 \n",
162 | "找出字符串数组中所有能两两拼接成回文串的记录\n",
163 | "在数组中挑选K个数返回所有结果中代表最大数字的结果\n",
164 | "找出数组中累加和在指定区间内的子数组个数\n",
165 | "找到离n最近的(不包括n本身)是回文数字的数\n",
166 | "计算距离邮局最近的地点的最短距离的总和\n",
167 | "。。。。。。。。。\n",
168 | "\n",
169 | "更多中高级班题目概括,详询课程顾问:1440073724(qq)\n",
170 | "\n",
171 | "\n",
172 | "\n",
173 | "***关于课程有任何问题或者不明白的地方可以留言或者私信哦~~~\n",
174 | "```"
175 | ]
176 | }
177 | ],
178 | "metadata": {
179 | "kernelspec": {
180 | "display_name": "tf36",
181 | "language": "python",
182 | "name": "tf36"
183 | },
184 | "language_info": {
185 | "codemirror_mode": {
186 | "name": "ipython",
187 | "version": 3
188 | },
189 | "file_extension": ".py",
190 | "mimetype": "text/x-python",
191 | "name": "python",
192 | "nbconvert_exporter": "python",
193 | "pygments_lexer": "ipython3",
194 | "version": "3.6.8"
195 | }
196 | },
197 | "nbformat": 4,
198 | "nbformat_minor": 2
199 | }
200 |
--------------------------------------------------------------------------------
/常见算法/线段树.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "Python 3",
14 | "language": "python",
15 | "name": "python3"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.7.3"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/常见算法/高楼扔鸡蛋.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 如何用最少的次数测出鸡蛋会在哪一层摔碎?\n",
8 | "\n",
9 | "\n",
10 | "https://www.zhihu.com/question/19690210/answer/18079633\n",
11 | "\n",
12 | "一幢 200 层的大楼,给你两个鸡蛋. 如果在第 n 层扔下鸡蛋,鸡蛋不碎,那么从前 n-1 层扔鸡蛋都不碎. 这两只鸡蛋一模一样,不碎的话可以扔无数次. 已知鸡蛋在0层扔不会碎.\n",
13 | "\n",
14 | "提出一个策略, 要**保证**能测出鸡蛋**恰好会碎**的楼层, 并使此策略在**最坏情况下所扔次数最少**.\n",
15 | "\n",
16 | "题目严谨描述:\n",
17 | "一幢 200 层的大楼,给你两个鸡蛋. 如果在第 n 层扔下鸡蛋,鸡蛋不碎,那么从前 n-1 层扔鸡蛋都不碎.\n",
18 | "这两只鸡蛋一模一样,不碎的话可以扔无数次. 已知鸡蛋在0层扔不会碎.\n",
19 | "提出一个策略, 要**保证**能测出鸡蛋**恰好会碎**的楼层, 并使此策略在**最坏情况下所扔次数最少**.\n",
20 | "\n",
21 | "搞清楚这题的意思:\n",
22 | "第一个鸡蛋用来试探, 只要它从 k 层楼扔下去没碎, 则目标就在[k+1, 200]之间了.\n",
23 | "但一旦运气不好碎了, 对于已知的区间, 我们只能用剩下一个鸡蛋从小到大一层层试,\n",
24 | "因为我们要保证策略必须成功, 不能冒险了.\n",
25 | "\n",
26 | "\"最坏情况下代价最小\"这句话十分重要, 它反映了题目的重要数学结构:\n",
27 | "我们可以把任何一种策略都看成一个决策树,\n",
28 | "每一次扔瓶子都会有两个子节点, 对应碎与不碎的情况下下一步应该扔的楼层.\n",
29 | "那么, 策略的一次执行, 是树中的一条从根往下走的路,\n",
30 | "当且仅当这条路上出现过形如 k 没碎 与 k+1 碎了的一对节点时, 路停止, 当前节点不再扩展.\n",
31 | "那么要找的是这么一棵树, 使得所有路里最长者尽量短, 也即, 要找一个最矮的决策树.\n",
32 | "\n",
33 | "再看一个节点处, 选择楼层时会发生什么.\n",
34 | "容易看出, 选择的楼层如果变高, 那么\"碎子树\"高度不减, \"不碎子树\"高度不增.\n",
35 | "同样的, 选择的楼层变矮的话, \"碎子树\"高度不增, \"不碎子树\"高度不减.\n",
36 | "\n",
37 | "这时候答案很明显了: 为了使两子树中高度最大者尽量小, 我们的选择应当使两子树高度尽量接近.\n",
38 | "最终希望的结果是, 整个二叉树尽量像一个满二叉树.\n",
39 | "\n",
40 | "假设第一次在根节点上, 我们选择扔$k$层, 其\"碎子树\"的高度显然是$k - 1$.为了考虑不碎子树的高度, 设不碎后第二次扔$m$层(显然$m > k$ ),\n",
41 | "\n",
42 | "则这个新节点的碎子树高度为 $m - k - 1$, 不碎子树高度仍然未知,但按照满二叉树的目标, 我们认为它与碎子树相同或少1就好.\n",
43 | "\n",
44 | "那么在根节点上的不碎子树的高度就是$m -k-1 + 1$, 令它与碎子树高度相同, 于是:\n",
45 | "\n",
46 | "$m - k - 1 + 1 = k - 1$ => $m = k + k - 1$\n",
47 | "\n",
48 | "也即, 如果第一次扔在k层, 第二次应该高k-1 层, 这可以有直观一点的理解:\n",
49 | "每扔一次, 就要更保守一些, 所以让区间长度少1. $[1, k) -> [k + 1, 2k - 1)$\n",
50 | "\n",
51 | "用类似刚才的分析, 可以继续得到, 下一次应该增高k - 2, 再下一次应该增高k - 3.\n",
52 | "\n",
53 | "如果大楼100层, 考虑:\n",
54 | "![[公式]](https://www.zhihu.com/equation?tex=k+%2B+%28k-1%29+%2B+%5Ccdots+%2B+1+%3D+%5Cfrac%7Bk%28k%2B1%29%7D%7B2%7D+%3D+100+%5CRightarrow+k+%5Capprox+14)\n",
55 | "\n",
56 | "所以第一次扔14层, 最坏需要14次(策略不唯一, 树的叶子可以交换位置).200层的话, 类似得到k =20.\n",
57 | "\n",
58 | "以上是数学做法...当然还有代码做法....\n",
59 | "设f(n, m)为n层楼, m个蛋所需次数, 那么它成了一道DP题..\n",
60 | "\n",
61 | "![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Beqnarray%7D%0Af%280%2C+m%29+%26+%3D+%26+0%2C+%28m+%3E%3D+1%29%5C%5C%0Af%28n%2C+1%29+%26+%3D+%26+n%2C+%28n+%3E%3D+1%29%5C%5C%0Af%28n%2C+m%29+%26+%3D+%26+%5Cmin_%7B1+%5Cle+i+%5Cle+n%7D+%5C%7B+%5Cmax%5C%7B+f%28i+-+1%2C+m+-+1%29%2C+f%28n+-+i%2C+m%29%5C%7D%5C%7D+%2B+1+%5C%5C%0A%5Cend%7Beqnarray%7D)\n",
62 | "\n",
63 | "\n",
64 | "n层楼, m个蛋扩展动态规划的解释:\n",
65 | "\n",
66 | "https://zhuanlan.zhihu.com/p/41257286"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "**python3的functools的一个自带函数, 可以对函数返回结果进行LRU cache, 下次以相同参数调用就不重复计算了**\n",
74 | "\n",
75 | "**maxsize=None 不限制大小, 其实就变成是全部都cache下来, 不考虑LRU了**"
76 | ]
77 | },
78 | {
79 | "cell_type": "code",
80 | "execution_count": 2,
81 | "metadata": {},
82 | "outputs": [],
83 | "source": [
84 | "import functools\n",
85 | "@functools.lru_cache(maxsize=None)\n",
86 | "def f(n, m): #n层楼,m个鸡蛋\n",
87 | " if n == 0:\n",
88 | " return 0\n",
89 | " if m == 1:\n",
90 | " return n\n",
91 | "\n",
92 | " ans = min([max([f(i - 1, m - 1), f(n - i, m)]) for i in range(1, n + 1)]) + 1\n",
93 | " # 先拿鸡蛋在第i层试一次(最后的+1的由来)\n",
94 | " # 鸡蛋碎,则剩余i-1楼层、m-1鸡蛋;鸡蛋不碎,则剩余n-i楼层,m个鸡蛋。找到两者中最大值\n",
95 | " # 从1到n逐个试验,找到各个最大值的最小值。\n",
96 | " return ans"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": 4,
102 | "metadata": {},
103 | "outputs": [
104 | {
105 | "name": "stdout",
106 | "output_type": "stream",
107 | "text": [
108 | "14\n",
109 | "20\n",
110 | "11\n"
111 | ]
112 | }
113 | ],
114 | "source": [
115 | "print(f(100, 2))\n",
116 | "print(f(200, 2))\n",
117 | "print(f(200,3))"
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "metadata": {},
123 | "source": [
124 | "## 优秀回答,扩展\n",
125 | "\n",
126 | "如何用最少的次数测出鸡蛋会在哪一层摔碎? - 刘遥行的回答 - 知乎\n",
127 | "\n",
128 | "https://www.zhihu.com/question/19690210/answer/514119129"
129 | ]
130 | }
131 | ],
132 | "metadata": {
133 | "kernelspec": {
134 | "display_name": "tf36",
135 | "language": "python",
136 | "name": "tf36"
137 | },
138 | "language_info": {
139 | "codemirror_mode": {
140 | "name": "ipython",
141 | "version": 3
142 | },
143 | "file_extension": ".py",
144 | "mimetype": "text/x-python",
145 | "name": "python",
146 | "nbconvert_exporter": "python",
147 | "pygments_lexer": "ipython3",
148 | "version": "3.6.8"
149 | }
150 | },
151 | "nbformat": 4,
152 | "nbformat_minor": 2
153 | }
154 |
--------------------------------------------------------------------------------
/算法图解/README.md:
--------------------------------------------------------------------------------
1 | # 算法图解 Python3代码实现
2 |
3 | ## 目录
4 |
5 | - [第1章 算法简介](./chap01-算法简介.ipynb)
6 | - 二分查找
7 | - [第2章 选择排序](./chap02-选择排序.ipynb)
8 | - 选择排序
9 | - [第3章 递归](./chap03-递归.ipynb)
10 | - [第4章 快速排序](./chap04-快速排序.ipynb)
11 | - [第5章 散列表](./chap05-散列表.ipynb)
12 | - [第6章 广度优先搜索](./chap06-广度优先搜索.ipynb)
13 | - [第7章 狄克斯特拉算法](./chap07-狄克斯特拉算法Dijkstra’s-algorithm.ipynb)
14 | - [第8章 贪婪算法](./chap08-贪婪算法.ipynb)
15 | - [第9章 动态规划](./chap09-动态规划.ipynb)
16 |
17 |
18 | Ref:
19 |
20 | ---
21 | - [随书代码](https://github.com/egonschiele/grokking_algorithms)
22 | - [算法图解的算法代码示例,用Python和Java实现](https://github.com/zhanwen/AlgorithmDiagram)
23 | - [算法图解-知乎](https://zhuanlan.zhihu.com/p/43565172)
--------------------------------------------------------------------------------
/算法图解/chap01-算法简介.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第1章 算法简介\n",
8 | "## 1.2 二分查找\n",
9 | "\n",
10 | "二分查找是一种算法,其输入是一个有序的元素列表(必须有序的原因稍后解释)。如果要查找的元素包含在列表中,二分查找返回其位置;否则返回 null 。\n",
11 | "\n",
12 | "函数 binary_search 接受一个有序数组和一个元素。如果指定的元素包含在数组中,这个函数将返回其位置。你将跟踪要在其中查找的数组部分——开始时为整个数组,你每次都检查中间的元素。\n",
13 | "\n",
14 | "算法复杂度:O(log n)"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {},
21 | "outputs": [
22 | {
23 | "name": "stdout",
24 | "output_type": "stream",
25 | "text": [
26 | "1\n",
27 | "None\n"
28 | ]
29 | }
30 | ],
31 | "source": [
32 | "def binary_search(ordered_list,item):\n",
33 | " '''二分查找'''\n",
34 | " low = 0\n",
35 | " high = len(ordered_list) - 1\n",
36 | " while low <= high:\n",
37 | " mid = int((low + high)/2) #向下取整\n",
38 | " guess =ordered_list[mid] #这次猜的值\n",
39 | " if guess == item: #猜到了\n",
40 | " return mid\n",
41 | " print(mid)\n",
42 | " if guess > item: #猜大了\n",
43 | " high = mid - 1\n",
44 | " else: # 猜小了\n",
45 | " low = mid + 1\n",
46 | " return None # 没有指定的元素\n",
47 | "\n",
48 | "my_list = [1, 3, 5, 7, 9]\n",
49 | "\n",
50 | "# 能找到对应的值\n",
51 | "print(binary_search(my_list,3))\n",
52 | "# 不能找到对应的值\n",
53 | "print(binary_search(my_list,0))"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {},
59 | "source": [
60 | "### 一些常见的大 O 运行时间\n",
61 | "\n",
62 | "下面按从快到慢的顺序列出了你经常会遇到的5种大O运行时间。\n",
63 | "\n",
64 | "- $O(log n)$,也叫对数时间,这样的算法包括二分查找。\n",
65 | "- $O(n)$,也叫线性时间,这样的算法包括简单查找。\n",
66 | "- $O(n * log n)$,这样的算法包括第4章将介绍的快速排序——一种速度较快的排序算法。\n",
67 | "- $O(n^2)$,这样的算法包括第2章将介绍的选择排序——一种速度较慢的排序算法。\n",
68 | "- $O(n!)$,这样的算法包括接下来将介绍的旅行商问题的解决方案——一种非常慢的算法。\n",
69 | "\n",
70 | "### 旅行商\n",
71 | "\n",
72 | "下面就是一个运行时间极长的算法。这个算法要解决的是计算机科学领域非常著名的旅行商问题,其计算时间增加得非常快,而有些非常聪明的人都认为没有改进空间。\n",
73 | "\n",
74 | "有一位旅行商。他需要前往5个城市。这位旅行商要前往这5个城市,同时要确保旅程最短。为此,可考虑前往这些城市的各种可能顺序。\n",
75 | "\n",
76 | "对于每种顺序,他都计算总旅程,再挑选出旅程最短的路线。5个城市有120种不同的排列方式。因此,在涉及5个城市时,解决这个问题需要执行120次操作。涉及6个城市时,需要执行720次操作(有720种不同的排列方式)。涉及7个城市时,需要执行5040次操作!\n",
77 | "\n",
78 | "推而广之,涉及n个城市时,需要执行n!(n的阶乘)次操作才能计算出结果。因此运行时间为O(n!),即阶乘时间。除非涉及的城市数很少,否则需要执行非常多的操作。如果涉及的城市数超过100,根本就不能在合理的时间内计算出结果——等你计算出结果,太阳都没了。\n",
79 | "\n",
80 | "这是计算机科学领域待解的问题之一。对于这个问题,目前还没有找到更快的算法,有些很聪明的人认为这个问题根本就没有更巧妙的算法。面对这个问题,我们能做的只是去找出近似答案,更详细的信息请参阅第10章。"
81 | ]
82 | }
83 | ],
84 | "metadata": {
85 | "kernelspec": {
86 | "display_name": "Python 3 (system-wide)",
87 | "language": "python",
88 | "name": "python3"
89 | },
90 | "language_info": {
91 | "codemirror_mode": {
92 | "name": "ipython",
93 | "version": 3
94 | },
95 | "file_extension": ".py",
96 | "mimetype": "text/x-python",
97 | "name": "python",
98 | "nbconvert_exporter": "python",
99 | "pygments_lexer": "ipython3",
100 | "version": "3.6.8"
101 | }
102 | },
103 | "nbformat": 4,
104 | "nbformat_minor": 2
105 | }
106 |
--------------------------------------------------------------------------------
/算法图解/chap02-选择排序.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第2章 选择排序\n",
8 | "\n",
9 | "## 2.2 数组和链表\n",
10 | "\n",
11 | "使用数组意味着所有待办事项在内存中都是相连的(紧靠在一起的)。有时候,需要在内存中存储一系列元素。假设你要编写一个管理待办事项的应用程序,为此需要将这些待办事项存储在内存中。\n",
12 | "\n",
13 | "现在假设你要添加第四个待办事项,但后面的那个抽屉放着别人的东西!\n",
14 | "\n",
15 | "在这种情况下,你需要请求计算机重新分配一块可容纳4个待办事项的内存,再将所有待办事项都移到那里。\n",
16 | "\n",
17 | "如果又来了一位朋友,而当前坐的地方也没有空位,你们就得再次转移!真是太麻烦了。同\n",
18 | "样,在数组中添加新元素也可能很麻烦。如果没有了空间,就得移到内存的其他地方,因此添加\n",
19 | "新元素的速度会很慢。一种解决之道是“预留座位”:即便当前只有3个待办事项,也请计算机提\n",
20 | "供10个位置,以防需要添加待办事项。这样,只要待办事项不超过10个,就无需转移。这是一个\n",
21 | "不错的权变措施,但你应该明白,它存在如下两个缺点。\n",
22 | "\n",
23 | "- 你额外请求的位置可能根本用不上,这将浪费内存。你没有使用,别人也用不了。\n",
24 | "- 待办事项超过10个后,你还得转移。\n",
25 | "\n",
26 | "因此,这种权宜措施虽然不错,但绝非完美的解决方案。对于这种问题,可使用链表来解决。\n",
27 | "\n",
28 | "### 2.2.1 链表\n",
29 | "\n",
30 | "链表的每个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串在一起。\n",
31 | "\n",
32 | "使用链表时,根本就不需要移动元素。这还可避免另一个问题。假设你与五位朋友去看一部很火的电影。你们六人想坐在一起,但看电影的人较多,没有六个在一起的座位。使用数组时有时就会遇到这样的情况。假设你要为数组分配10 000个位置,内存中有10 000个位置,但不都靠在一起。在这种情况下,你将无法为该数组分配内存!链表相当于说“我们分开来坐”,因此,只要有足够的内存空间,就能为链表分配内存。链表的优势在插入元素方面,那数组的优势又是什么呢?\n",
33 | "\n",
34 | "**链表和数组对比:**\n",
35 | "\n",
36 | "在需要读取链表的最后一个元素时,你不能直接读取,因为你不知道它所处的地址,必须先访问元素#1,从中获取元素#2的地址,再访问元素#2并从中获取元素#3的地址,以此类推,直到访问最后一个元素。需要同时读取所有元素时,链表的效率很高:你读取第一个元素,根据其中的地址再读取第二个元素,以此类推。但如果你需要跳跃,链表的效率真的很低。\n",
37 | "\n",
38 | "数组与此不同:你知道其中每个元素的地址。需要随机地读取元素时,数组的效率很高,因为可迅速找到数组的任何元素。在链表中,元素并非靠在一起的,你无法迅速计算出第五个元素的内存地址,而必须先访问第一个元素以获取第二个元素的地址,再访问第二个元素以获取第三个元素的地址,以此类推,直到访问第五个元素。\n",
39 | "\n",
40 | "|时间|数组|链表|\n",
41 | "|--|--|--|\n",
42 | "|读取|O(1)|O(n)|\n",
43 | "|插入|O(n)|O(1)|\n",
44 | "|删除|O(n)|O(1)|\n",
45 | "\n",
46 | "**在中间插入**\n",
47 | "\n",
48 | "使用链表时,插入元素很简单,只需修改它前面的那个元素指向的地址。\n",
49 | "\n",
50 | "而使用数组时,则必须将后面的元素都向后移。如果没有足够的空间,可能还得将整个数组复制到其他地方!因此,当需要在中间插入元素时,链表是更好的选择。\n",
51 | "\n",
52 | "**删除**\n",
53 | "\n",
54 | "如果你要删除元素呢?链表也是更好的选择,因为只需修改前一个元素指向的地址即可。而\n",
55 | "使用数组时,删除元素后,必须将后面的元素都向前移。\n",
56 | "不同于插入,删除元素总能成功。如果内存中没有足够的空间,插入操作可能失败,但在任\n",
57 | "何情况下都能够将元素删除。\n",
58 | "\n",
59 | "**仅当能够立即访问要删除的元素时,删除操作的运行时间才为O(1)。通常我们都记录了链表的第一个元素和最后一个元素,因此删除这些元素时运行时间为O(1)。**\n",
60 | "\n",
61 | "## 2.3 选择排序\n",
62 | "\n",
63 | "对于每个乐队,你都记录了其作品被播放的次数。你要将这个列表按播放次数从多到少的顺序排列,从而将你喜欢的乐队排序。该如何做呢?\n",
64 | "\n",
65 | "一种办法是遍历这个列表,找出作品播放次数最多的乐队,并将该乐队添加到一个新列表中。\n",
66 | "\n",
67 | "再次这样做,找出播放次数第二多的乐队。\n",
68 | "\n",
69 | "不断重复,直到最后一个。\n",
70 | "\n",
71 | "**算法复杂度 $O(n^2)$**"
72 | ]
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": 1,
77 | "metadata": {},
78 | "outputs": [
79 | {
80 | "name": "stdout",
81 | "output_type": "stream",
82 | "text": [
83 | "[2, 3, 5, 6, 10]\n"
84 | ]
85 | }
86 | ],
87 | "source": [
88 | "#查找数组中的最小数的索引\n",
89 | "def findMinIndex(array):\n",
90 | " min_val = array[0]\n",
91 | " min_index = 0\n",
92 | " for i in range(1,len(array)):\n",
93 | " if array[i] < min_val:\n",
94 | " min_val = array[i]\n",
95 | " min_index = i\n",
96 | " return min_index\n",
97 | "\n",
98 | "# 选择排序\n",
99 | "def selectSort(array):\n",
100 | " newArray = []\n",
101 | " for i in range(len(array)):\n",
102 | " min_val = findMinIndex(array)\n",
103 | " newArray.append(array.pop(min_val))\n",
104 | " return newArray\n",
105 | "\n",
106 | "print(selectSort([5,3,6,2,10]))"
107 | ]
108 | }
109 | ],
110 | "metadata": {
111 | "kernelspec": {
112 | "display_name": "Python 3 (system-wide)",
113 | "language": "python",
114 | "name": "python3"
115 | },
116 | "language_info": {
117 | "codemirror_mode": {
118 | "name": "ipython",
119 | "version": 3
120 | },
121 | "file_extension": ".py",
122 | "mimetype": "text/x-python",
123 | "name": "python",
124 | "nbconvert_exporter": "python",
125 | "pygments_lexer": "ipython3",
126 | "version": "3.6.8"
127 | }
128 | },
129 | "nbformat": 4,
130 | "nbformat_minor": 2
131 | }
132 |
--------------------------------------------------------------------------------
/算法图解/chap03-递归.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第3章 递归\n",
8 | "\n",
9 | "这两种方法的作用相同,但在我看来,第二种方法更清晰。递归只是让解决方案更清晰,并没有性能上的优势。实际上,在有些情况下,使用循环的性能更好。\n",
10 | "\n",
11 | "我很喜欢Leigh Caldwell在Stack Overflow上说的一句话:“如果使用循环,程序的性能可能更高;如果使用递归,程序可能更容易理解。如何选择要看什么对你来说更重要。([参考链接](http://stackoverflow.com/a/72694/139117))” 很多算法都使用了递归,因此理解这种概念很重要。\n",
12 | "\n",
13 | "## 3.2基线条件和递归条件\n",
14 | "\n",
15 | "由于递归函数调用自己,因此编写这样的函数时很容易出错,进而导致无限循环。例如,假设你要编写一个像下面这样倒计时的函数。\n",
16 | "```\n",
17 | "def countdown(i):\n",
18 | " print i\n",
19 | " countdown(i-1)\n",
20 | "```\n",
21 | "如果你运行上述代码,将发现一个问题:这个函数运行起来没完没了!\n",
22 | "\n",
23 | "编写递归函数时,必须告诉它何时停止递归。正因为如此,每个递归函数都有两部分:基线条件(base case)和递归条件(recursive case)。递归条件指的是函数调用自己,而基线条件则指的是函数不再调用自己,从而避免形成无限循环。\n",
24 | "\n",
25 | "我们来给函数 countdown 添加基线条件。\n",
26 | "\n",
27 | "现在,这个函数将像预期的那样运行,如下所示。"
28 | ]
29 | },
30 | {
31 | "cell_type": "code",
32 | "execution_count": 3,
33 | "metadata": {},
34 | "outputs": [
35 | {
36 | "name": "stdout",
37 | "output_type": "stream",
38 | "text": [
39 | "10\n",
40 | "9\n",
41 | "8\n",
42 | "7\n",
43 | "6\n",
44 | "5\n",
45 | "4\n",
46 | "3\n",
47 | "2\n",
48 | "1\n",
49 | "0\n"
50 | ]
51 | }
52 | ],
53 | "source": [
54 | "def countdown(i):\n",
55 | " print((i))\n",
56 | " if i <= 0:\n",
57 | " return\n",
58 | " else:\n",
59 | " countdown(i-1)\n",
60 | " \n",
61 | "countdown(10)"
62 | ]
63 | },
64 | {
65 | "cell_type": "markdown",
66 | "metadata": {},
67 | "source": [
68 | "## 3.3栈 stack\n",
69 | "\n",
70 | "本节将介绍一个重要的编程概念——调用栈(call stack)。调用栈不仅对编程来说很重要,使用递归时也必须理解这个概念。假设你去野外烧烤,并为此创建了一个待办事项清单——一叠便条。\n",
71 | "\n",
72 | "本书之前讨论数组和链表时,也有一个待办事项清单。你可将待办事项添加到该清单的任何地方,还可删除任何一个待办事项。一叠便条要简单得多:插入的待办事项放在清单的最前面;读取待办事项时,你只读取最上面的那个,并将其删除。因此这个待办事项清单只有两种操作:压入(插入)和弹出(删除并读取)。\n",
73 | "\n",
74 | "### 3.3.1 调用栈\n",
75 | "\n",
76 | "计算机在内部使用被称为调用栈的栈。我们来看看计算机是如何使用调用栈的。下面是一个简单的函数。"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 9,
82 | "metadata": {},
83 | "outputs": [
84 | {
85 | "name": "stdout",
86 | "output_type": "stream",
87 | "text": [
88 | "hello, maggie!\n",
89 | "how are you, maggie?\n",
90 | "getting ready to say bye...\n",
91 | "ok bye!\n"
92 | ]
93 | }
94 | ],
95 | "source": [
96 | "def greet(name):\n",
97 | " print(\"hello, \" + name + \"!\")\n",
98 | " greet2(name)\n",
99 | " print(\"getting ready to say bye...\")\n",
100 | " bye()\n",
101 | " \n",
102 | "#这个函数问候用户,再调用另外两个函数。这两个函数的代码如下。\n",
103 | "def greet2(name):\n",
104 | " print(\"how are you, \" + name + \"?\")\n",
105 | "def bye():\n",
106 | " print(\"ok bye!\")\n",
107 | " \n",
108 | "greet(\"maggie\")"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | "下面详细介绍调用函数时发生的情况:\n",
116 | "\n",
117 | "- 1.调用 greet(\"maggie\"),计算机为grreet函数调用分配一块内存。其中的name = maggie\n",
118 | "- 2.打印 hello, maggie!\n",
119 | "- 3.调用greet2(\"maggie\"),计算机为grreet2函数调用分配一块内存,计算机使用一个栈来表示这些内存块,第二个内存块(greet2)位于第一个内存块(greet)上面。其中的name = maggie\n",
120 | "- 4.打印how are you, maggie? ,然后从函数调用返回。此时,栈顶的内存块(greet2)被弹出。\n",
121 | "- 5.现在,栈顶的内存块是函数 greet 的,这意味着你返回到了函数 greet 。当你调用函数 greet2时,函数 greet 只执行了一部分。这是本节的一个重要概念:**调用另一个函数时,当前函数暂停并处于未完成状态**。该函数的所有变量的值都还在内存中。执行完函数 greet2 后,你回到函数greet ,并从离开的地方开始接着往下执行\n",
122 | "- 6.首先打印 getting ready to say bye\n",
123 | "- 7.再调用函数 bye 。在栈顶添加了函数 bye 的内存块。然后,你打印 ok bye! ,并从这个函数返回。\n",
124 | "- 8.现在你又回到了函数 greet 。由于没有别的事情要做,你就从函数 greet 返回。\n",
125 | "\n",
126 | "这个栈用于存储多个函数的变量,被称为调用栈。\n",
127 | "\n",
128 | "### 3.3.2 递归调用栈\n",
129 | "\n",
130 | "递归函数也使用调用栈!来看看递归函数 factorial 的调用栈。 factorial(5) 写作5!,其定义如下:5! = 5 * 4 * 3 * 2 * 1。同理, factorial(3) 为3 * 2 * 1。下面是计算阶乘的递归函数。"
131 | ]
132 | },
133 | {
134 | "cell_type": "code",
135 | "execution_count": 10,
136 | "metadata": {},
137 | "outputs": [
138 | {
139 | "data": {
140 | "text/plain": [
141 | "6"
142 | ]
143 | },
144 | "execution_count": 10,
145 | "metadata": {},
146 | "output_type": "execute_result"
147 | }
148 | ],
149 | "source": [
150 | "def fact(x):\n",
151 | " if x==1:\n",
152 | " return 1\n",
153 | " else:\n",
154 | " return x*fact(x-1)\n",
155 | " \n",
156 | "fact(3)"
157 | ]
158 | },
159 | {
160 | "cell_type": "markdown",
161 | "metadata": {},
162 | "source": [
163 | "注意,每个 fact 调用都有自己的 x 变量。在一个函数调用中不能访问另一个的 x 变量。栈在递归中扮演着重要角色。这个栈包含未完成的函数调用,每个函数调用都包含还未检查完的盒子。使用栈很方便,因为你无需自己跟踪盒子堆——栈替你这样做了。\n",
164 | "\n",
165 | "使用栈虽然很方便,但是也要付出代价:存储详尽的信息可能占用大量的内存。每个函数调用都要占用一定的内存,如果栈很高,就意味着计算机存储了大量函数调用的信息。在这种情况下,你有两种选择。\n",
166 | "- 重新编写代码,转而使用循环。\n",
167 | "- 使用尾递归。这是一个高级递归主题,不在本书的讨论范围内。另外,并非所有的语言都支持尾递归。"
168 | ]
169 | }
170 | ],
171 | "metadata": {
172 | "kernelspec": {
173 | "display_name": "Python 3 (system-wide)",
174 | "language": "python",
175 | "name": "python3"
176 | },
177 | "language_info": {
178 | "codemirror_mode": {
179 | "name": "ipython",
180 | "version": 3
181 | },
182 | "file_extension": ".py",
183 | "mimetype": "text/x-python",
184 | "name": "python",
185 | "nbconvert_exporter": "python",
186 | "pygments_lexer": "ipython3",
187 | "version": "3.6.8"
188 | }
189 | },
190 | "nbformat": 4,
191 | "nbformat_minor": 2
192 | }
193 |
--------------------------------------------------------------------------------
/算法图解/chap04-快速排序.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第4章 快速排序\n",
8 | "\n",
9 | "本章的重点是使用学到的新技能来解决问题。我们将探索分而治之(divide and conquer,D&C)——一种著名的递归式问题解决方法。\n",
10 | "\n",
11 | "本书将深入算法的核心。只能解决一种问题的算法毕竟用处有限,而D&C提供了解决问题的思路,是另一个可供你使用的工具。面对新问题时,你不再束手无策,而是自问:“使用分而治\n",
12 | "之能解决吗?”\n",
13 | "\n",
14 | "在本章末尾,你将学习第一个重要的D&C算法——快速排序。快速排序是一种排序算法,速度比第2章介绍的选择排序快得多,实属优雅代码的典范。\n",
15 | "\n",
16 | "## 4.1 分而治之\n",
17 | "\n",
18 | "如何将一块地均匀地分成方块,并确保分出的方块是最大的呢?使用D&C策略!D&C算法是递归的。使用D&C解决问题的过程包括两个步骤。\n",
19 | "\n",
20 | "- (1) 找出基线条件,这种条件必须尽可能简单。\n",
21 | "- (2) 不断将问题分解(或者说缩小规模),直到符合基线条件。\n",
22 | "\n",
23 | "假设你是农场主,有一小块土地。1680m x 640m\n",
24 | "\n",
25 | "首先,找出基线条件。最容易处理的情况是,一条边的长度是另一条边的整数倍。\n",
26 | "\n",
27 | "现在需要找出递归条件,这正是D&C的用武之地。根据D&C的定义,每次递归调用都必须缩小问题的规模。如何缩小前述问题的规模呢?我们首先找出这块地可容纳的最大方块。\n",
28 | "\n",
29 | "你可以从这块地中划出两个640 m×640 m的方块,同时余下一小块地。现在是顿悟时刻:何不对余下的那一小块地使用相同的算法呢?\n",
30 | "\n",
31 | "最初要划分的土地尺寸为1680 m×640 m,而现在要划分的土地更小,为640 m×400 m。适用于这小块地的最大方块,也是适用于整块地的最大方块。换言之,你将均匀划分1680 m×640 m\n",
32 | "土地的问题,简化成了均匀划分640 m×400 m土地的问题!\n",
33 | "```\n",
34 | "1680x640\n",
35 | "400x640\n",
36 | "400x240\n",
37 | "160x240\n",
38 | "160x80\n",
39 | "```\n",
40 | "\n",
41 | "因此,对于最初的那片土地,适用的最大方块为80 m× 80 m。\n",
42 | "\n",
43 | "这里重申一下D&C的工作原理:\n",
44 | "- (1) 找出简单的基线条件;\n",
45 | "- (2) 确定如何缩小问题的规模,使其符合基线条件。\n",
46 | "D&C并非可用于解决问题的算法,而是一种解决问题的思路。我们再来看一个例子。\n",
47 | "\n",
48 | "给定一个数字数组,计算数字之和:\n",
49 | "\n",
50 | "循环方法:"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 3,
56 | "metadata": {},
57 | "outputs": [
58 | {
59 | "name": "stdout",
60 | "output_type": "stream",
61 | "text": [
62 | "10\n"
63 | ]
64 | }
65 | ],
66 | "source": [
67 | "def sum_array(arr):\n",
68 | " total = 0\n",
69 | " for x in arr:\n",
70 | " total += x\n",
71 | " return total\n",
72 | "\n",
73 | "print(sum_array([1, 2, 3, 4]))"
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "但如何使用递归函数来完成这种任务呢?\n",
81 | "\n",
82 | "- 第一步:找出基线条件。最简单的数组什么样呢?请想想这个问题,再接着往下读。如果数组不包含任何元素或只包含一个元素,计算总和将非常容易。因此这就是基线条件。\n",
83 | "- 第二步:每次递归调用都必须离空数组更近一步。 sum([2,4,6) = 2 + sum([4,6])\n",
84 | "\n",
85 | "\n",
86 | "\n",
87 | "这个函数的运行过程如下:\n",
88 | "\n",
89 | "[](https://imgchr.com/i/et48jU)\n",
90 | "\n",
91 | "**编写涉及数组的递归函数时,基线条件通常是数组为空或只包含一个元素。陷入困境时,请检查基线条件是不是这样的。**"
92 | ]
93 | },
94 | {
95 | "cell_type": "code",
96 | "execution_count": 17,
97 | "metadata": {},
98 | "outputs": [],
99 | "source": [
100 | "def sum_array(arr):\n",
101 | " if len(arr) == 0:\n",
102 | " return 0\n",
103 | " if len(arr) == 1:\n",
104 | " return arr[0]\n",
105 | " else:\n",
106 | " return arr[0] + sum_array(arr[1:])"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": 19,
112 | "metadata": {},
113 | "outputs": [
114 | {
115 | "data": {
116 | "text/plain": [
117 | "12"
118 | ]
119 | },
120 | "execution_count": 19,
121 | "metadata": {},
122 | "output_type": "execute_result"
123 | }
124 | ],
125 | "source": [
126 | "sum_array([2,4,6])"
127 | ]
128 | },
129 | {
130 | "cell_type": "markdown",
131 | "metadata": {},
132 | "source": [
133 | "## 4.2 快速排序 Quick Sort\n",
134 | "\n",
135 | "快速排序是一种常用的排序算法,比选择排序快得多。例如,C语言标准库中的函数 qsort实现的就是快速排序。快速排序也使用了D&C。\n",
136 | "\n",
137 | "基线条件为数组为空或只包含一个元素。在这种情况下,只需原样返回数组——根本就不用排序。\n",
138 | "\n",
139 | "```\n",
140 | "def quicksort(array):\n",
141 | " if len(array) < 2:\n",
142 | " return array\n",
143 | "```\n",
144 | "\n",
145 | "快速排序,步骤如下。\n",
146 | "\n",
147 | "- (1) 选择基准值。\n",
148 | "- (2) 将数组分成两个子数组:小于基准值的元素和大于基准值的元素。\n",
149 | "- (3) 对这两个子数组进行快速排序。\n",
150 | "\n",
151 | "对于快速排序,可使用类似的推理。在基线条件中,我证明这种算法对空数组或包含一个元素的数组管用。在归纳条件中,我证明如果快速排序对包含一个元素的数组管用,对包含两个元素的数组也将管用;如果它对包含两个元素的数组管用,对包含三个元素的数组也将管用,以此类推。因此,我可以说,快速排序对任何长度的数组都管用。这里不再深入讨论归纳证明,但它很有趣,并与D&C协同发挥作用。"
152 | ]
153 | },
154 | {
155 | "cell_type": "code",
156 | "execution_count": 20,
157 | "metadata": {},
158 | "outputs": [
159 | {
160 | "name": "stdout",
161 | "output_type": "stream",
162 | "text": [
163 | "[2, 3, 5, 10]\n"
164 | ]
165 | }
166 | ],
167 | "source": [
168 | "def quicksort(array):\n",
169 | " if len(array) < 2:\n",
170 | " return array # 基线条件:为空或只包含一个元素的数组是“有序”的\n",
171 | " else:\n",
172 | " pivot = array[0] # 递归条件\n",
173 | " less = [i for i in array[1:] if i <= pivot] #由所有小于基准值的元素组成的子数组\n",
174 | " greater = [i for i in array[1:] if i > pivot] #由所有大于基准值的元素组成的子数组\n",
175 | " return quicksort(less) + [pivot] + quicksort(greater)\n",
176 | "\n",
177 | "print(quicksort([10, 5, 2, 3]))"
178 | ]
179 | },
180 | {
181 | "cell_type": "markdown",
182 | "metadata": {},
183 | "source": [
184 | "还有一种名为合并排序(merge sort)(或称归并排序)的排序算法,其运行时间为O(n log n),比选择排序快得多!快速排序的情况比较棘手,在最糟情况下,其运行时间为O(n 2 )。与选择排序一样慢!但这是最糟情况。在平均情况下,快速排序的运行时间为O(n log n)。\n",
185 | "\n",
186 | "平均情况和最糟情况:\n",
187 | "\n",
188 | "在这个示例中,层数为O(log n)(用技术术语说,调用栈的高度为O(log n)),而每层需要的时间为O(n)。因此整个算法需要的时间为O(n) * O(log n) = O(n log n)。这就是最佳情况。\n",
189 | "\n",
190 | "在最糟情况下,有O(n)层,因此该算法的运行时间为O(n) * O(n) = O(n 2 )。\n",
191 | "\n",
192 | "这里要告诉你的是,最佳情况也是平均情况。只要你每次都随机地选择一个数组元素作为基准值,快速排序的平均运行时间就将为O(n log n)。快速排序是最快的排序算法之一,也是D&C典范。"
193 | ]
194 | },
195 | {
196 | "cell_type": "markdown",
197 | "metadata": {},
198 | "source": [
199 | "## 归并排序"
200 | ]
201 | },
202 | {
203 | "cell_type": "code",
204 | "execution_count": null,
205 | "metadata": {},
206 | "outputs": [],
207 | "source": []
208 | }
209 | ],
210 | "metadata": {
211 | "kernelspec": {
212 | "display_name": "Python 3 (system-wide)",
213 | "language": "python",
214 | "name": "python3"
215 | },
216 | "language_info": {
217 | "codemirror_mode": {
218 | "name": "ipython",
219 | "version": 3
220 | },
221 | "file_extension": ".py",
222 | "mimetype": "text/x-python",
223 | "name": "python",
224 | "nbconvert_exporter": "python",
225 | "pygments_lexer": "ipython3",
226 | "version": "3.6.8"
227 | }
228 | },
229 | "nbformat": 4,
230 | "nbformat_minor": 2
231 | }
232 |
--------------------------------------------------------------------------------
/算法图解/chap05-散列表.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第5章 散列表\n",
8 | "\n",
9 | "## 5.1散列函数\n",
10 | "\n",
11 | "散列函数准确地指出了价格的存储位置,你根本不用查找!之所以能够这样,具体原因如下。\n",
12 | "\n",
13 | "- 散列函数总是将同样的输入映射到相同的索引。每次你输入avocado,得到的都是同一个数字。因此,你可首先使用它来确定将鳄梨的价格存储在什么地方,并在以后使用它来确定鳄梨的价格存储在什么地方。\n",
14 | "- 散列函数将不同的输入映射到不同的索引。avocado映射到索引4,milk映射到索引0。每种商品都映射到数组的不同位置,让你能够将其价格存储到这里。\n",
15 | "- 散列函数知道数组有多大,只返回有效的索引。如果数组包含5个元素,散列函数就不会返回无效索引100。\n",
16 | "\n",
17 | "你可能根本不需要自己去实现散列表,任一优秀的语言都提供了散列表实现。Python提供的散列表实现为字典,你可使用函数 dict 来创建散列表。\n",
18 | "\n",
19 | "在你将学习的复杂数据结构中,散列表可能是最有用的,也被称为散列映射、映射、字典和关联数组。散列表的速度很快!还记得第2章关于数组和链表的讨论吗?你可以立即获取数组中的元素,而散列表也使用数组来存储数据,因此其获取元素的速度与数组一样快。"
20 | ]
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": 1,
25 | "metadata": {},
26 | "outputs": [
27 | {
28 | "name": "stdout",
29 | "output_type": "stream",
30 | "text": [
31 | "{'apple': 0.67, 'milk': 1.49, 'avocado': 1.49}\n"
32 | ]
33 | }
34 | ],
35 | "source": [
36 | "book = dict()\n",
37 | "book[\"apple\"] = 0.67\n",
38 | "book[\"milk\"] = 1.49\n",
39 | "book[\"avocado\"] = 1.49\n",
40 | "print(book)"
41 | ]
42 | },
43 | {
44 | "cell_type": "markdown",
45 | "metadata": {},
46 | "source": [
47 | "## 5.2应用案例\n",
48 | "### 5.2.1 将散列表用于查找\n",
49 | "\n",
50 | "如电话簿"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 4,
56 | "metadata": {},
57 | "outputs": [
58 | {
59 | "name": "stdout",
60 | "output_type": "stream",
61 | "text": [
62 | "8675309\n"
63 | ]
64 | }
65 | ],
66 | "source": [
67 | "phone_book = dict()\n",
68 | "phone_book[\"jenny\"] = 8675309\n",
69 | "phone_book[\"emergency\"] = 911\n",
70 | "print(phone_book[\"jenny\"])"
71 | ]
72 | },
73 | {
74 | "cell_type": "markdown",
75 | "metadata": {},
76 | "source": [
77 | "### 5.2.2 防止重复\n",
78 | "\n",
79 | "投票记录"
80 | ]
81 | },
82 | {
83 | "cell_type": "code",
84 | "execution_count": 5,
85 | "metadata": {},
86 | "outputs": [],
87 | "source": [
88 | "voted = {}\n",
89 | "def check_voter(name):\n",
90 | " if voted.get(name):\n",
91 | " print(\"kick them out!\")\n",
92 | " else:\n",
93 | " voted[name] = True\n",
94 | " print(\"let them vote!\")"
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": 6,
100 | "metadata": {},
101 | "outputs": [
102 | {
103 | "name": "stdout",
104 | "output_type": "stream",
105 | "text": [
106 | "let them vote!\n"
107 | ]
108 | }
109 | ],
110 | "source": [
111 | "check_voter(\"tom\")"
112 | ]
113 | },
114 | {
115 | "cell_type": "code",
116 | "execution_count": 7,
117 | "metadata": {},
118 | "outputs": [
119 | {
120 | "name": "stdout",
121 | "output_type": "stream",
122 | "text": [
123 | "let them vote!\n"
124 | ]
125 | }
126 | ],
127 | "source": [
128 | "check_voter(\"mike\")"
129 | ]
130 | },
131 | {
132 | "cell_type": "code",
133 | "execution_count": 8,
134 | "metadata": {},
135 | "outputs": [
136 | {
137 | "name": "stdout",
138 | "output_type": "stream",
139 | "text": [
140 | "kick them out!\n"
141 | ]
142 | }
143 | ],
144 | "source": [
145 | "check_voter(\"mike\")"
146 | ]
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "### 5.2.3 将散列表用作缓存\n",
153 | "\n",
154 | "来看最后一个应用案例:缓存。如果你在网站工作,可能听说过进行缓存是一种不错的做法。下面简要地介绍其中的原理。假设你访问网facebook.com。\n",
155 | "\n",
156 | "- (1) 你向Facebook的服务器发出请求。\n",
157 | "- (2) 服务器做些处理,生成一个网页并将其发送给你。\n",
158 | "- (3) 你获得一个网页。\n",
159 | "\n",
160 | "如果你登录了Facebook,你看到的所有内容都是为你定制的。你每次访问facebook.com,其服务器都需考虑你感兴趣的是什么内容。但如果你没有登录,看到的将是登录页面。每个人看到的登录页面都相同。Facebook被反复要求做同样的事情:“当我注销时,请向我显示主页。”有鉴于此,它不让服务器去生成主页,而是将主页存储起来,并在需要时将其直接发送给用户。\n",
161 | "\n",
162 | "缓存是一种常用的加速方式,所有大型网站都使用缓存,而缓存的数据则存储在散列表中!Facebook不仅缓存主页,还缓存About页面、Contact页面、Terms and Conditions页面等众多其他的页面。因此,它需要将页面URL映射到页面数据。"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": 9,
168 | "metadata": {},
169 | "outputs": [],
170 | "source": [
171 | "cache = {}\n",
172 | "def get_page(url):\n",
173 | " if cache.get(url):\n",
174 | " return cache[url]\n",
175 | " else:\n",
176 | " data = get_data_from_server(url)\n",
177 | " cache[url] = data\n",
178 | " return data"
179 | ]
180 | },
181 | {
182 | "cell_type": "markdown",
183 | "metadata": {},
184 | "source": [
185 | "## 5.3 冲突\n",
186 | "\n",
187 | "前面说过,大多数语言都提供了散列表实现,你不用知道如何实现它们。有鉴于此,我就不再过多地讨论散列表的内部原理,但你依然需要考虑性能!要明白散列表的性能,你得先搞清楚什么是冲突。本节和下一节将分别介绍冲突和性能。\n",
188 | "\n",
189 | "首先,我撒了一个善意的谎。我之前告诉你的是,散列函数总是将不同的键映射到数组的不同位置。\n",
190 | "\n",
191 | "实际上,几乎不可能编写出这样的散列函数。\n",
192 | "\n",
193 | "这种情况被称为冲突(collision):给两个键分配的位置相同。这是个问题。如果你将鳄梨的价格存储到这个位置,将覆盖苹果的价格,以后再查询苹果的价格时,得到的将是鳄梨的价格!冲突很糟糕,必须要避免。处理冲突的方式很多,最简单的办法如下:如果两个键映射到了同一个位置,就在这个位置存储一个链表。\n",
194 | "\n",
195 | "这里的经验教训有两个。\n",
196 | "\n",
197 | "- 散列函数很重要。前面的散列函数将所有的键都映射到一个位置,而最理想的情况是,散列函数将键均匀地映射到散列表的不同位置。\n",
198 | "- 如果散列表存储的链表很长,散列表的速度将急剧下降。然而,如果使用的散列函数很好,这些链表就不会很长!\n",
199 | "\n",
200 | "散列函数很重要,好的散列函数很少导致冲突。那么,如何选择好的散列函数呢?这将在下一节介绍!\n",
201 | "\n",
202 | "## 5.4 性能\n",
203 | "\n",
204 | "在最糟情况下,散列表所有操作的运行时间都为O(n)——线性时间,这真的很慢。我们来将散列表同数组和链表比较一下。\n",
205 | "\n",
206 | "在平均情况下,散列表的查找(获取给定索引处的值)速度与数组一样快,而插入和删除速度与链表一样快,因此它兼具两者的优点!\n",
207 | "\n",
208 | "但在最糟情况下,散列表的各种操作的速度都很慢。因此,在使用散列表时,避开最糟情况至关重要。为此,需要避免冲突。而要避免冲突,需要有:\n",
209 | "\n",
210 | "- 较低的填装因子;\n",
211 | "- 良好的散列函数。\n",
212 | "\n",
213 | "### 5.4.1 填装因子\n",
214 | "\n",
215 | "散列表的填装因子很容易计算。\n",
216 | "\n",
217 | "散列表包含的元素数/位置总数\n",
218 | "\n",
219 | "散列表使用数组来存储数据,因此你需要计算数组中被占用的位置数。例如,下述散列表的填装因子为2/5,即0.4。\n",
220 | "\n",
221 | "\n",
222 | "\n",
223 | "不可能让每种商品都有自己的位置,因为没有足够的位置!填装因子大于1意味着商品数量超过了数组的位置数。一旦填装因子开始增大,你就需要在散列表中添加位置,这被称为调整长度(resizing)。\n",
224 | "\n",
225 | "填装因子越低,发生冲突的可能性越小,散列表的性能越高。一个不错的经验规则是:一旦填装因子大于0.7,就调整散列表的长度。\n",
226 | "\n",
227 | "你可能在想,调整散列表长度的工作需要很长时间!你说得没错,调整长度的开销很大,因此你不会希望频繁地这样做。但平均而言,即便考虑到调整长度所需的时间,散列表操作所需的时间也为O(1)。\n",
228 | "\n",
229 | "### 5.4.2 良好的散列函数\n",
230 | "\n",
231 | "良好的散列函数让数组中的值呈均匀分布。\n",
232 | "\n",
233 | "糟糕的散列函数让值扎堆,导致大量的冲突。\n",
234 | "\n",
235 | "什么样的散列函数是良好的呢?你根本不用操心——天塌下来有高个子顶着。如果你好奇,可研究一下SHA函数(本书最后一章做了简要的介绍)。你可将它用作散列函数。\n",
236 | "\n",
237 | "## 5.5 小结\n",
238 | "\n",
239 | "你几乎根本不用自己去实现散列表,因为你使用的编程语言提供了散列表实现。你可使用Python提供的散列表,并假定能够获得平均情况下的性能:常量时间。\n",
240 | "\n",
241 | "散列表是一种功能强大的数据结构,其操作速度快,还能让你以不同的方式建立数据模型。你可能很快会发现自己经常在使用它。\n",
242 | "\n",
243 | "- 你可以结合散列函数和数组来创建散列表。\n",
244 | "- 冲突很糟糕,你应使用可以最大限度减少冲突的散列函数。\n",
245 | "- 散列表的查找、插入和删除速度都非常快。\n",
246 | "- 散列表适合用于模拟映射关系。\n",
247 | "- 一旦填装因子超过0.7,就该调整散列表的长度。\n",
248 | "- 散列表可用于缓存数据(例如,在Web服务器上)。\n",
249 | "- 散列表非常适合用于防止重复。"
250 | ]
251 | }
252 | ],
253 | "metadata": {
254 | "kernelspec": {
255 | "display_name": "Python 3 (system-wide)",
256 | "language": "python",
257 | "name": "python3"
258 | },
259 | "language_info": {
260 | "codemirror_mode": {
261 | "name": "ipython",
262 | "version": 3
263 | },
264 | "file_extension": ".py",
265 | "mimetype": "text/x-python",
266 | "name": "python",
267 | "nbconvert_exporter": "python",
268 | "pygments_lexer": "ipython3",
269 | "version": "3.6.8"
270 | }
271 | },
272 | "nbformat": 4,
273 | "nbformat_minor": 2
274 | }
275 |
--------------------------------------------------------------------------------
/算法图解/chap08-贪婪算法.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第8章 贪婪算法\n",
8 | "## 8.1 教室调度问题\n",
9 | "\n",
10 | "如下课程表,你希望将尽可能多的课程安排在某间教室上。没法让这些课都在这间教室上,因为有些课的上课时间有冲突\n",
11 | "\n",
12 | "\n",
13 | "算法如下:\n",
14 | "- (1) 选出结束最早的课,它就是要在这间教室上的第一堂课。\n",
15 | "- (2) 接下来,必须选择第一堂课结束后才开始的课。同样,你选择结束最早的课,这将是要在这间教室上的第二堂课。\n",
16 | "\n",
17 | "\n",
18 | "\n",
19 | "贪婪算法很简单:每步都采取最优的做法。在这个示例中,你每次都选择结束最早的课。用专业术语说,就是你每步都选择局部最优解,最终得到的就是全局最优解。\n",
20 | "\n",
21 | "## 8.2 背包问题\n",
22 | "\n",
23 | "假设你是个贪婪的小偷,背着可装35磅(1磅≈0.45千克)重东西的背包,在商场伺机盗窃各种可装入背包的商品。你力图往背包中装入价值最高的商品,你会使用哪种算法呢?\n",
24 | "\n",
25 | "同样,你采取贪婪策略,这非常简单。\n",
26 | "- (1) 盗窃可装入背包的最贵商品。\n",
27 | "- (2) 再盗窃还可装入背包的最贵商品,以此类推。\n",
28 | "\n",
29 | "\n",
30 | "\n",
31 | "音响最贵,你把它给偷了,但背包没有空间装其他东西了。你偷到了价值3000美元的东西。如果不是偷音响,而是偷笔记本电脑和吉他,总价将为3500美元!\n",
32 | "\n",
33 | "在这里,贪婪策略显然不能获得最优解,但非常接近。下一章将介绍如何找出最优解。不过小偷去购物中心行窃时,不会强求所偷东西的总价最高,只要差不多就行了。\n",
34 | "\n",
35 | "从这个示例你得到了如下启示:在有些情况下,完美是优秀的敌人。有时候,你只需找到一个能够大致解决问题的算法,此时贪婪算法正好可派上用场,因为它们实现起来很容易,得到的结果又与正确结果相当接近。\n",
36 | "\n",
37 | "下面来看最后一个例子。在这个例子中,你别无选择,只能使用贪婪算法。\n",
38 | "\n",
39 | "## 8.3 集合覆盖问题\n",
40 | "\n",
41 | "假设你办了个广播节目,要让全美50个州的听众都收听得到。为此,你需要决定在哪些广播台播出。在每个广播台播出都需要支付费用,因此你力图在尽可能少的广播台播出。现有广播台名单如下。\n",
42 | "\n",
43 | "每个广播台都覆盖特定的区域,不同广播台的覆盖区域可能重叠。\n",
44 | "\n",
45 | "\n",
46 | "\n",
47 | "如何找出覆盖全美50个州的最小广播台集合呢?\n",
48 | "\n",
49 | "听起来很容易,但其实非常难。具体方法如下。\n",
50 | "\n",
51 | "- (1) 列出每个可能的广播台集合,这被称为幂集(power set)。可能的子集有$2^n$ 个。\n",
52 | "- (2) 在这些集合中,选出覆盖全美50个州的最小集合。\n",
53 | "\n",
54 | "问题是计算每个可能的广播台子集需要很长时间。由于可能的集合有2 n 个,因此运行时间为$O (2^n )$。如果广播台不多,只有5~10个,这是可行的。但如果广播台很多,结果将如何呢?随着广播台的增多,需要的时间将激增。假设你每秒可计算10个子集,所需的时间将如下。\n",
55 | "\n",
56 | "\n",
57 | "\n",
58 | "没有任何算法可以足够快地解决这个问题!怎么办呢?\n",
59 | "\n",
60 | "### 近似算法\n",
61 | "\n",
62 | "使用下面的贪婪算法可得到非常接近的解。\n",
63 | "- (1) 选出这样一个广播台,即它覆盖了最多的未覆盖州。即便这个广播台覆盖了一些已覆盖的州,也没有关系。\n",
64 | "- (2) 重复第一步,直到覆盖了所有的州。\n",
65 | "\n",
66 | "这是一种近似算法(approximation algorithm)。在获得精确解需要的时间太长时,可使用近似算法。判断近似算法优劣的标准如下:\n",
67 | "- 速度有多快;\n",
68 | "- 得到的近似解与最优解的接近程度。\n",
69 | "\n",
70 | "**1. 准备工作**\n",
71 | "出于简化考虑,这里假设要覆盖的州没有那么多,广播台也没有那么多。\n",
72 | "首先,创建一个列表,其中包含要覆盖的州。"
73 | ]
74 | },
75 | {
76 | "cell_type": "code",
77 | "execution_count": 1,
78 | "metadata": {},
79 | "outputs": [],
80 | "source": [
81 | "states_needed = set([\"mt\", \"wa\", \"or\", \"id\", \"nv\", \"ut\",\"ca\", \"az\"])"
82 | ]
83 | },
84 | {
85 | "cell_type": "markdown",
86 | "metadata": {},
87 | "source": [
88 | "我使用集合来表示要覆盖的州。集合类似于列表,只是同样的元素只能出现一次,即集合不能包含重复的元素。\n",
89 | "\n",
90 | "还需要有可供选择的广播台清单,我选择使用散列表来表示它。"
91 | ]
92 | },
93 | {
94 | "cell_type": "code",
95 | "execution_count": 2,
96 | "metadata": {},
97 | "outputs": [],
98 | "source": [
99 | "stations = {}\n",
100 | "stations[\"kone\"] = set([\"id\", \"nv\", \"ut\"])\n",
101 | "stations[\"ktwo\"] = set([\"wa\", \"id\", \"mt\"])\n",
102 | "stations[\"kthree\"] = set([\"or\", \"nv\", \"ca\"])\n",
103 | "stations[\"kfour\"] = set([\"nv\", \"ut\"])\n",
104 | "stations[\"kfive\"] = set([\"ca\", \"az\"])"
105 | ]
106 | },
107 | {
108 | "cell_type": "markdown",
109 | "metadata": {},
110 | "source": [
111 | "其中的键为广播台的名称,值为广播台覆盖的州。\n",
112 | "\n",
113 | "最后,需要使用一个集合来存储最终选择的广播台。"
114 | ]
115 | },
116 | {
117 | "cell_type": "code",
118 | "execution_count": 3,
119 | "metadata": {},
120 | "outputs": [],
121 | "source": [
122 | "final_stations = set()"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "**2. 计算答案**\n",
130 | "\n",
131 | "接下来需要计算要使用哪些广播台。你需要遍历所有的广播台,从中选择覆盖了最多的未覆盖州的广播台。我将这个广播台存储在best_station中。"
132 | ]
133 | },
134 | {
135 | "cell_type": "markdown",
136 | "metadata": {},
137 | "source": [
138 | "states_covered 是一个集合,包含该广播台覆盖的所有未覆盖的州。 for 循环迭代每个广播台,并确定它是否是最佳的广播台。"
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": 9,
144 | "metadata": {},
145 | "outputs": [],
146 | "source": [
147 | "while states_needed:\n",
148 | " best_station = None\n",
149 | " states_covered = set()\n",
150 | " for station, states in stations.items(): #找到覆盖未覆盖州最多的电台\n",
151 | " covered = states_needed & states\n",
152 | " if len(covered) > len(states_covered):\n",
153 | " best_station = station\n",
154 | " states_covered = covered\n",
155 | " stations -= best_station #去掉已经取出来的电台\n",
156 | " states_needed -= states_covered #去掉已经覆盖的州\n",
157 | " final_stations.add(best_station) #在结果中添加现在找到的电台"
158 | ]
159 | },
160 | {
161 | "cell_type": "code",
162 | "execution_count": 10,
163 | "metadata": {},
164 | "outputs": [
165 | {
166 | "data": {
167 | "text/plain": [
168 | "{'kfive', 'kone', 'kthree', 'ktwo'}"
169 | ]
170 | },
171 | "execution_count": 10,
172 | "metadata": {},
173 | "output_type": "execute_result"
174 | }
175 | ],
176 | "source": [
177 | "final_stations"
178 | ]
179 | },
180 | {
181 | "cell_type": "markdown",
182 | "metadata": {},
183 | "source": [
184 | "## 8.4 NP 完全问题\n",
185 | "\n",
186 | "为解决集合覆盖问题,你必须计算每个可能的集合。\n",
187 | "\n",
188 | "这可能让你想起了第1章介绍的旅行商问题。在这个问题中,旅行商需要前往5个不同的城市。他需要找出前往这5个城市的最短路径,为此,必须计算每条可能的路径。\n",
189 | "\n",
190 | "### 8.4.1 旅行商问题详解\n",
191 | "\n",
192 | "我们从城市数较少的情况着手。假设只涉及两个城市,因此可供选择的路线有两条。\n",
193 | "\n",
194 | "你可能认为这两条路线相同,难道从旧金山到马林的距离与从马林到旧金山的距离不同吗?不一定。有些城市(如旧金山)有很多单行线,因此你无法按原路返回。你可能需要离开原路行驶一两英里才能找到上高速的匝道。因此,这两条路线不一定相同。\n",
195 | "\n",
196 | "你可能心存疑惑:在旅行商问题中,必须从特定的城市出发吗?例如,假设我是旅行商。我居住在旧金山,需要前往其他4个城市,因此我将从旧金山出发。\n",
197 | "\n",
198 | "但有时候,不确定要从哪个城市出发。假设联邦快递将包裹从芝加哥发往湾区,包裹将通过航运发送到联邦快递在湾区的50个集散点之一,再装上经过不同配送点的卡车。该通过航运发送到哪个集散点呢?在这个例子中,起点就是未知的。因此,你需要通过计算为旅行商找出起点和最佳路线。\n",
199 | "\n",
200 | "在这两种情况下,运行时间是相同的。但出发城市未定时更容易处理,因此这里以这种情况为例。\n",
201 | "\n",
202 | "- 涉及两个城市时,可能的路线有两条。\n",
203 | "- 3个城市时,可能的路线有6条。\n",
204 | "- 可能的出发城市有4个,从每个城市出发时都有6条可能的路线,因此可能的路线有4 × 6 = 24条。\n",
205 | "- 涉及6个城市时,可能的路线有720条\n",
206 | "\n",
207 | "这被称为阶乘函数(factorial function),第3章介绍过。5! = 120。假设有10个城市,可能的路线有多少条呢?10! = 3 628 800。换句话说,涉及10个城市时,需要计算的可能路线超过300万条。正如你看到的,可能的路线数增加得非常快!因此,如果涉及的城市很多,根本就无法找出旅行商问题的正确解。\n",
208 | "\n",
209 | "旅行商问题和集合覆盖问题有一些共同之处:你需要计算所有的解,并从中选出最小/最短的那个。这两个问题都属于NP完全问题。\n",
210 | "\n",
211 | "NP完全问题的简单定义是,以难解著称的问题,如旅行商问题和集合覆盖问题。很多非常聪明的人都认为,根本不可能编写出可快速解决这些问题的算法。\n",
212 | "\n",
213 | "### 8.4.2 如何识别 NP 完全问题\n",
214 | "\n",
215 | "NP完全问题无处不在!如果能够判断出要解决的问题属于NP完全问题就好了,这样就不用去寻找完美的解决方案,而是使用近似算法即可。但要判断问题是不是NP完全问题很难,易于解决的问题和NP完全问题的差别通常很小。例如,前一章深入讨论了最短路径,你知道如何找出从A点到B点的最短路径。\n",
216 | "\n",
217 | "\n",
218 | "但如果要找出经由指定几个点的的最短路径,就是旅行商问题——NP完全问题。简言之,没办法判断问题是不是NP完全问题,但还是有一些蛛丝马迹可循的。\n",
219 | "\n",
220 | "- 元素较少时算法的运行速度非常快,但随着元素数量的增加,速度会变得非常慢。\n",
221 | "- 涉及“所有组合”的问题通常是NP完全问题。\n",
222 | "- 不能将问题分成小问题,必须考虑各种可能的情况。这可能是NP完全问题。\n",
223 | "- 如果问题涉及序列(如旅行商问题中的城市序列)且难以解决,它可能就是NP完全问题。\n",
224 | "- 如果问题涉及集合(如广播台集合)且难以解决,它可能就是NP完全问题。\n",
225 | "- 如果问题可转换为集合覆盖问题或旅行商问题,那它肯定是NP完全问题。\n",
226 | "\n",
227 | "## 8.5 小结\n",
228 | "\n",
229 | "- 贪婪算法寻找局部最优解,企图以这种方式获得全局最优解。\n",
230 | "- 对于NP完全问题,还没有找到快速解决方案。\n",
231 | "- 面临NP完全问题时,最佳的做法是使用近似算法。\n",
232 | "- 贪婪算法易于实现、运行速度快,是不错的近似算法。"
233 | ]
234 | }
235 | ],
236 | "metadata": {
237 | "kernelspec": {
238 | "display_name": "Python 3 (system-wide)",
239 | "language": "python",
240 | "name": "python3"
241 | },
242 | "language_info": {
243 | "codemirror_mode": {
244 | "name": "ipython",
245 | "version": 3
246 | },
247 | "file_extension": ".py",
248 | "mimetype": "text/x-python",
249 | "name": "python",
250 | "nbconvert_exporter": "python",
251 | "pygments_lexer": "ipython3",
252 | "version": "3.6.8"
253 | }
254 | },
255 | "nbformat": 4,
256 | "nbformat_minor": 2
257 | }
258 |
--------------------------------------------------------------------------------
/算法图解/算法图解-compressed.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/EvanLi/PythonAlgorithm/330a9dee2fe4367e3bf63a8bf35c6ba79d101e94/算法图解/算法图解-compressed.pdf
--------------------------------------------------------------------------------
/算法图解/算法图解.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/EvanLi/PythonAlgorithm/330a9dee2fe4367e3bf63a8bf35c6ba79d101e94/算法图解/算法图解.pdf
--------------------------------------------------------------------------------
\n",
24 | "\n",
25 | "`box = (row // 3) * 3 + columns // 3`\n",
26 | "\n",
27 | "其中 // 取整除 - 返回商的整数部分(向下取整)\n",
28 | "\n",
29 | "### 2.分别创建集合set()用来判断行、列、子数独中是否已经出现\n",
30 | "\n",
31 | "### 3.程序如下"
32 | ]
33 | },
34 | {
35 | "cell_type": "code",
36 | "execution_count": 13,
37 | "metadata": {},
38 | "outputs": [],
39 | "source": [
40 | "class Solution(object):\n",
41 | " def isValidSudoku(self,board):\n",
42 | " \"\"\"\n",
43 | " :type board:List[List[str]]\n",
44 | " :rtype:bool\n",
45 | " \"\"\"\n",
46 | " digits = [str(i) for i in range(1,10)] #判断1-9以外的数\n",
47 | " rows = [set() for _ in range(9)] #分别保存9行出现的数\n",
48 | " cols = [set() for _ in range(9)] #分别保存9列出现的数\n",
49 | " boxes = [set() for _ in range(9)] #分别保存9个方格出现的数\n",
50 | " \n",
51 | " for r in range(9):\n",
52 | " for c in range(9):\n",
53 | " digit = board[r][c]\n",
54 | " if digit == '.':\n",
55 | " continue\n",
56 | " if digit not in digits: #出现1-9以外的数\n",
57 | " return False\n",
58 | " box = (r // 3) * 3 + c // 3 #计算子数独序号\n",
59 | " if digit in rows[r] or digit in cols[c] or digit in boxes[box]:\n",
60 | " #如果已经出现过,则输出False\n",
61 | " return False\n",
62 | " # 否则,在各个set()中添加这个数字\n",
63 | " rows[r].add(digit)\n",
64 | " rows[c].add(digit)\n",
65 | " boxes[box].add(digit)\n",
66 | " return True"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "**测试1:**"
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 15,
79 | "metadata": {},
80 | "outputs": [
81 | {
82 | "data": {
83 | "text/plain": [
84 | "True"
85 | ]
86 | },
87 | "execution_count": 15,
88 | "metadata": {},
89 | "output_type": "execute_result"
90 | }
91 | ],
92 | "source": [
93 | "board = [\n",
94 | " [\"5\",\"3\",\".\",\".\",\"7\",\".\",\".\",\".\",\".\"],\n",
95 | " [\"6\",\".\",\".\",\"1\",\"9\",\"5\",\".\",\".\",\".\"],\n",
96 | " [\".\",\"9\",\"8\",\".\",\".\",\".\",\".\",\"6\",\".\"],\n",
97 | " [\"8\",\".\",\".\",\".\",\"6\",\".\",\".\",\".\",\"3\"],\n",
98 | " [\"4\",\".\",\".\",\"8\",\".\",\"3\",\".\",\".\",\"1\"],\n",
99 | " [\"7\",\".\",\".\",\".\",\"2\",\".\",\".\",\".\",\"6\"],\n",
100 | " [\".\",\"6\",\".\",\".\",\".\",\".\",\"2\",\"8\",\".\"],\n",
101 | " [\".\",\".\",\".\",\"4\",\"1\",\"9\",\".\",\".\",\"5\"],\n",
102 | " [\".\",\".\",\".\",\".\",\"8\",\".\",\".\",\"7\",\"9\"]\n",
103 | "]\n",
104 | "s = Solution()\n",
105 | "s.isValidSudoku(board)"
106 | ]
107 | },
108 | {
109 | "cell_type": "markdown",
110 | "metadata": {},
111 | "source": [
112 | "**测试2:**"
113 | ]
114 | },
115 | {
116 | "cell_type": "code",
117 | "execution_count": 18,
118 | "metadata": {},
119 | "outputs": [
120 | {
121 | "data": {
122 | "text/plain": [
123 | "False"
124 | ]
125 | },
126 | "execution_count": 18,
127 | "metadata": {},
128 | "output_type": "execute_result"
129 | }
130 | ],
131 | "source": [
132 | "board = [\n",
133 | " [\"8\",\"3\",\".\",\".\",\"7\",\".\",\".\",\".\",\".\"],\n",
134 | " [\"6\",\".\",\".\",\"1\",\"9\",\"5\",\".\",\".\",\".\"],\n",
135 | " [\".\",\"9\",\"8\",\".\",\".\",\".\",\".\",\"6\",\".\"],\n",
136 | " [\"8\",\".\",\".\",\".\",\"6\",\".\",\".\",\".\",\"3\"],\n",
137 | " [\"4\",\".\",\".\",\"8\",\".\",\"3\",\".\",\".\",\"1\"],\n",
138 | " [\"7\",\".\",\".\",\".\",\"2\",\".\",\".\",\".\",\"6\"],\n",
139 | " [\".\",\"6\",\".\",\".\",\".\",\".\",\"2\",\"8\",\".\"],\n",
140 | " [\".\",\".\",\".\",\"4\",\"1\",\"9\",\".\",\".\",\"5\"],\n",
141 | " [\".\",\".\",\".\",\".\",\"8\",\".\",\".\",\"7\",\"9\"]\n",
142 | "]\n",
143 | "\n",
144 | "s = Solution()\n",
145 | "s.isValidSudoku(board)"
146 | ]
147 | }
148 | ],
149 | "metadata": {
150 | "kernelspec": {
151 | "display_name": "tf36",
152 | "language": "python",
153 | "name": "tf36"
154 | },
155 | "language_info": {
156 | "codemirror_mode": {
157 | "name": "ipython",
158 | "version": 3
159 | },
160 | "file_extension": ".py",
161 | "mimetype": "text/x-python",
162 | "name": "python",
163 | "nbconvert_exporter": "python",
164 | "pygments_lexer": "ipython3",
165 | "version": "3.6.8"
166 | }
167 | },
168 | "nbformat": 4,
169 | "nbformat_minor": 2
170 | }
171 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0048旋转图像-Rotate-Image.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# LeetCode0048旋转图像-Rotate-Image\n",
8 | "\n",
9 | "https://leetcode.com/problems/rotate-image/\n",
10 | "\n",
11 | "https://leetcode-cn.com/problems/rotate-image/\n",
12 | "\n"
13 | ]
14 | }
15 | ],
16 | "metadata": {
17 | "kernelspec": {
18 | "display_name": "tf36",
19 | "language": "python",
20 | "name": "tf36"
21 | },
22 | "language_info": {
23 | "codemirror_mode": {
24 | "name": "ipython",
25 | "version": 3
26 | },
27 | "file_extension": ".py",
28 | "mimetype": "text/x-python",
29 | "name": "python",
30 | "nbconvert_exporter": "python",
31 | "pygments_lexer": "ipython3",
32 | "version": "3.6.8"
33 | }
34 | },
35 | "nbformat": 4,
36 | "nbformat_minor": 2
37 | }
38 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0053最大子序和-Maximum-Subarray.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0105从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# LeetCode0105从前序与中序遍历序列构造二叉树 Construct Binary Tree from Preorder and Inorder Traversal\n",
8 | "\n",
9 | "[重建二叉树LeetCode](https://leetcode.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)\n",
10 | "\n",
11 | ">题目描述:\n",
12 | "根据一棵树的前序遍历与中序遍历构造二叉树。\n",
13 | "注意:\n",
14 | "你可以假设树中没有重复的元素。\n",
15 | "例如,给出\n",
16 | "\n",
17 | "```\n",
18 | "preorder = [3,9,20,15,7]\n",
19 | "inorder = [9,3,15,20,7]\n",
20 | "\n",
21 | "返回二叉树:\n",
22 | " 3\n",
23 | " / \\\n",
24 | " 9 20\n",
25 | " / \\\n",
26 | " 15 7\n",
27 | " \n",
28 | "preorder = [1,2,4,7,3,5,6,8]\n",
29 | "inorder = [4,7,2,1,5,3,8,6]\n",
30 | "\n",
31 | "返回二叉树:\n",
32 | " 1\n",
33 | " / \\\n",
34 | " 2 3\n",
35 | " / / \\\n",
36 | " 4 5 6\n",
37 | " \\ /\n",
38 | " 7 8\n",
39 | "```\n",
40 | "\n",
41 | ">思路:\n",
42 | ">\n",
43 | ">前序的第一个元素是根结点的值,在中序中找到该值,中序中该值的左边的元素是根结点的左子树,右边是右子树,然后递归的处理左边和右边\n",
44 | ">提示:二叉树结点,以及对二叉树的各种操作\n",
45 | "\n",
46 | "首先要知道一个结论,前序/后序+中序序列可以唯一确定一棵二叉树,所以自然而然可以用来建树。\n",
47 | "\n",
48 | "有如下特征:\n",
49 | "1. 前序中左起第一位`1`肯定是根结点,我们可以据此找到中序中根结点的位置`rootin`;\n",
50 | "2. 中序中根结点左边就是左子树结点,右边就是右子树结点,即`[左子树结点,根结点,右子树结点]`,我们就可以得出左子树结点个数为`int left = rootin - leftin;`;\n",
51 | "3. 前序中结点分布应该是:`[根结点,左子树结点,右子树结点]`;\n",
52 | "4. 根据前一步确定的左子树个数,可以确定前序中左子树结点和右子树结点的范围;\n",
53 | "5. 如果我们要前序遍历生成二叉树的话,下一层递归应该是:\n",
54 | " - 左子树:`root->left = pre_order(前序左子树范围,中序左子树范围,前序序列,中序序列);`;\n",
55 | " - 右子树:`root->right = pre_order(前序右子树范围,中序右子树范围,前序序列,中序序列);`。\n",
56 | "6. 每一层递归都要返回当前根结点`root`;\n"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 1,
62 | "metadata": {},
63 | "outputs": [
64 | {
65 | "name": "stdout",
66 | "output_type": "stream",
67 | "text": [
68 | "前序:\n",
69 | "[1, 2, 4, 7, 3, 5, 6, 8]\n",
70 | "中序:\n",
71 | "[4, 7, 2, 1, 5, 3, 8, 6]\n",
72 | "后序:\n",
73 | "[7, 4, 2, 5, 8, 6, 3, 1]\n"
74 | ]
75 | }
76 | ],
77 | "source": [
78 | "# Definition for a binary tree node.\n",
79 | "class TreeNode:\n",
80 | " def __init__(self, x):\n",
81 | " self.val = x\n",
82 | " self.left = None\n",
83 | " self.right = None\n",
84 | "\n",
85 | "class Solution:\n",
86 | " def buildTree(self, preorder, inorder):\n",
87 | " \"\"\"\n",
88 | " :type preorder: List[int]\n",
89 | " :type inorder: List[int]\n",
90 | " :rtype: TreeNode\n",
91 | " \"\"\"\n",
92 | " if not preorder or not inorder:\n",
93 | " return None\n",
94 | " x = preorder.pop(0)\n",
95 | " node = TreeNode(x)\n",
96 | " idx = inorder.index(x)\n",
97 | " \n",
98 | " node.left = self.buildTree(preorder[:idx],inorder[:idx])\n",
99 | " node.right = self.buildTree(preorder[idx:],inorder[idx+1:])\n",
100 | " #返回二叉树根节点\n",
101 | " return node\n",
102 | "\n",
103 | "#下面是打印前序、中序和后序\n",
104 | "def Preorder(root):\n",
105 | " res = []\n",
106 | " if root: #节点为None时,跳过\n",
107 | " res.append(root.val)\n",
108 | " res = res + Preorder(root.left)\n",
109 | " res = res + Preorder(root.right)\n",
110 | " return res\n",
111 | "\n",
112 | "def Inorder(root):\n",
113 | " res = []\n",
114 | " if root: #节点为None时,跳过\n",
115 | " res = res + Inorder(root.left)\n",
116 | " res.append(root.val)\n",
117 | " res = res + Inorder(root.right)\n",
118 | " return res\n",
119 | "\n",
120 | "def Postorder(root):\n",
121 | " res = []\n",
122 | " if root: #节点为None时,跳过\n",
123 | " res += Postorder(root.left)\n",
124 | " res += Postorder(root.right)\n",
125 | " res.append(root.val)\n",
126 | " return res\n",
127 | " \n",
128 | "# 测试:\n",
129 | "solu = Solution()\n",
130 | "# preorder = [3,9,20,15,7]\n",
131 | "# inorder = [9,3,15,20,7]\n",
132 | "\n",
133 | "preorder = [1,2,4,7,3,5,6,8]\n",
134 | "inorder = [4,7,2,1,5,3,8,6]\n",
135 | "\n",
136 | "node = solu.buildTree(preorder, inorder)\n",
137 | "print(\"前序:\")\n",
138 | "print(Preorder(node))\n",
139 | "print(\"中序:\")\n",
140 | "print(Inorder(node))\n",
141 | "print(\"后序:\")\n",
142 | "print(Postorder(node))"
143 | ]
144 | }
145 | ],
146 | "metadata": {
147 | "kernelspec": {
148 | "display_name": "Python 3",
149 | "language": "python",
150 | "name": "python3"
151 | },
152 | "language_info": {
153 | "codemirror_mode": {
154 | "name": "ipython",
155 | "version": 3
156 | },
157 | "file_extension": ".py",
158 | "mimetype": "text/x-python",
159 | "name": "python",
160 | "nbconvert_exporter": "python",
161 | "pygments_lexer": "ipython3",
162 | "version": "3.7.3"
163 | }
164 | },
165 | "nbformat": 4,
166 | "nbformat_minor": 2
167 | }
168 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0123买卖股票的最佳时机III-Best-Time-to-Buy-and-Sell-Stock-III.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0640求解方程-Solve-the-Equation.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/LeetCode/LeetCode0768最多能完成排序的块-II-Max-Chunks-To-Make-Sorted-II.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/OJ平台Python输入/Jupyter标准输入Stdin.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Jupyter标准输入sys.stdin\n",
8 | "\n",
9 | "https://www.reddit.com/r/Python/comments/24b3nv/programmatically_providing_input_to/\n",
10 | "\n",
11 | "**使用python io模块的StringIO将字符串替换成sys.stdin**\n",
12 | "\n",
13 | "You can change sys.stdin with any other file like object:"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 1,
19 | "metadata": {},
20 | "outputs": [],
21 | "source": [
22 | "from io import StringIO \n",
23 | "import sys\n",
24 | "\n",
25 | "doc = '''3\n",
26 | "1 2 3\n",
27 | "4 5 6\n",
28 | "7 8 9\n",
29 | "'''\n",
30 | "\n",
31 | "sys.stdin = StringIO(doc)"
32 | ]
33 | },
34 | {
35 | "cell_type": "code",
36 | "execution_count": 2,
37 | "metadata": {},
38 | "outputs": [
39 | {
40 | "name": "stdout",
41 | "output_type": "stream",
42 | "text": [
43 | "3\n",
44 | "[1, 2, 3]\n",
45 | "[4, 5, 6]\n",
46 | "[7, 8, 9]\n"
47 | ]
48 | }
49 | ],
50 | "source": [
51 | "n = int(sys.stdin.readline().strip())\n",
52 | "print(n)\n",
53 | "for i in range(n):\n",
54 | " line_str = sys.stdin.readline().strip()\n",
55 | " line = list(map(int,line_str.split()))\n",
56 | " print(line)"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 3,
62 | "metadata": {},
63 | "outputs": [
64 | {
65 | "name": "stdout",
66 | "output_type": "stream",
67 | "text": [
68 | "3\n",
69 | "7\n"
70 | ]
71 | }
72 | ],
73 | "source": [
74 | "#coding=utf-8\n",
75 | "\n",
76 | "from io import StringIO \n",
77 | "import sys\n",
78 | "\n",
79 | "doc = '''1 2\n",
80 | "3 4\n",
81 | "'''\n",
82 | "\n",
83 | "sys.stdin = StringIO(doc)\n",
84 | " \n",
85 | "if __name__ == \"__main__\":\n",
86 | " while True:\n",
87 | " try:\n",
88 | " line = sys.stdin.readline().split()\n",
89 | " a,b = list(map(int,line))\n",
90 | " print(a+b)\n",
91 | " except:\n",
92 | " break"
93 | ]
94 | }
95 | ],
96 | "metadata": {
97 | "kernelspec": {
98 | "display_name": "tf36",
99 | "language": "python",
100 | "name": "tf36"
101 | },
102 | "language_info": {
103 | "codemirror_mode": {
104 | "name": "ipython",
105 | "version": 3
106 | },
107 | "file_extension": ".py",
108 | "mimetype": "text/x-python",
109 | "name": "python",
110 | "nbconvert_exporter": "python",
111 | "pygments_lexer": "ipython3",
112 | "version": "3.6.8"
113 | }
114 | },
115 | "nbformat": 4,
116 | "nbformat_minor": 2
117 | }
118 |
--------------------------------------------------------------------------------
/OJ平台Python输入/python输入方法.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# python输入方法\n",
8 | "\n",
9 | "## 例题:找到集合 P 中的所有 ”最大“ 点的集合并输出\n",
10 | "\n",
11 | "链接:https://www.nowcoder.com/questionTerminal/e35d8c3404194cd69a88da1667ef8081\n",
12 | "\n",
13 | "来源:牛客网\n",
14 | "\n",
15 | "### 解析:\n",
16 | "只需对所有点的x坐标进行降序的排序,则第一个点一定是最大点,后面的点要想成为最大点,只需其y值大于前面的最大的y值即可。这样找到的点是根据x从大到小排列的,输出只需倒序输出就行。\n",
17 | "\n",
18 | "## python读取多行数据\n",
19 | "\n",
20 | "\n",
21 | "```\n",
22 | "5\n",
23 | "1 2\n",
24 | "5 3\n",
25 | "4 6\n",
26 | "7 5\n",
27 | "9 0\n",
28 | "```\n",
29 | "\n",
30 | "### 使用input"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": 1,
36 | "metadata": {},
37 | "outputs": [
38 | {
39 | "name": "stdin",
40 | "output_type": "stream",
41 | "text": [
42 | " 5\n",
43 | " 1 2\n",
44 | " 5 3\n",
45 | " 4 6\n",
46 | " 7 5\n",
47 | " 9 0\n"
48 | ]
49 | },
50 | {
51 | "name": "stdout",
52 | "output_type": "stream",
53 | "text": [
54 | "4 6\n",
55 | "7 5\n",
56 | "9 0\n"
57 | ]
58 | }
59 | ],
60 | "source": [
61 | "N = int(input())\n",
62 | "data = []\n",
63 | "for i in range(N):\n",
64 | " a = [int(i) for i in input().split()]\n",
65 | " data.append(a)\n",
66 | " \n",
67 | "data.sort(key=lambda t:(t[0],t[1]))\n",
68 | "myout = [data[-1]]\n",
69 | "\n",
70 | "i = N-2\n",
71 | "while(i>=0):\n",
72 | " max_end = max([t[1] for t in data[i+1:]])\n",
73 | " if data[i][1] > max_end:\n",
74 | " myout.append(data[i])\n",
75 | " i -= 1\n",
76 | "myout.sort()\n",
77 | "\n",
78 | "for i in myout:\n",
79 | " print(i[0],i[1])"
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | "### 使用sys.stdin"
87 | ]
88 | },
89 | {
90 | "cell_type": "markdown",
91 | "metadata": {},
92 | "source": [
93 | "```\n",
94 | "#coding=utf-8\n",
95 | "import sys\n",
96 | "data = []\n",
97 | "for line in sys.stdin:\n",
98 | " b = [int(i) for i in line.split()]\n",
99 | " data.append(b)\n",
100 | "\n",
101 | "N = data[0][0]\n",
102 | "pos = data[1:]\n",
103 | "\n",
104 | "print(data)\n",
105 | "print(N)\n",
106 | "print(pos)\n",
107 | "```"
108 | ]
109 | }
110 | ],
111 | "metadata": {
112 | "kernelspec": {
113 | "display_name": "tf36",
114 | "language": "python",
115 | "name": "tf36"
116 | },
117 | "language_info": {
118 | "codemirror_mode": {
119 | "name": "ipython",
120 | "version": 3
121 | },
122 | "file_extension": ".py",
123 | "mimetype": "text/x-python",
124 | "name": "python",
125 | "nbconvert_exporter": "python",
126 | "pygments_lexer": "ipython3",
127 | "version": "3.6.8"
128 | }
129 | },
130 | "nbformat": 4,
131 | "nbformat_minor": 2
132 | }
133 |
--------------------------------------------------------------------------------
/OJ平台Python输入/牛客网Python输入模板_使用stdin_可直接Jupyter运行.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 牛客网Python输入模板-使用stdin 可直接Jupyter运行\n",
8 | "\n",
9 | "## 1.方法概述:\n",
10 | "\n",
11 | "**使用sys.stdin.readline()方法进行数据输入,Jupyter中使用StringIO()方法转换**\n",
12 | "\n",
13 | "```\n",
14 | "例题:\n",
15 | "链接:https://ac.nowcoder.com/acm/contest/320/B 来源:牛客网\n",
16 | "输入:第一行包括一个数据组数t(1 <= t <= 100) 接下来每行包括两个正整数a,b(1 <= a, b <= 10^9)\n",
17 | "输出:每行的和\n",
18 | "\n",
19 | "样例输入:\n",
20 | "2\n",
21 | "1 5\n",
22 | "10 20\n",
23 | "输出:\n",
24 | "6\n",
25 | "30\n",
26 | "```\n",
27 | "\n",
28 | "## 2.模板使用\n",
29 | "\n",
30 | "下面第一行的注释使用方法:\n",
31 | "\n",
32 | "- Jupyter运行:加上的前面#\n",
33 | "- OJ平台:去掉前面的#\n",
34 | "\n",
35 | "doc中的字符替换成给定的输入"
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 1,
41 | "metadata": {},
42 | "outputs": [
43 | {
44 | "name": "stdout",
45 | "output_type": "stream",
46 | "text": [
47 | "6\n",
48 | "30\n"
49 | ]
50 | }
51 | ],
52 | "source": [
53 | "# \"\"\"\n",
54 | "from io import StringIO\n",
55 | "import sys\n",
56 | "doc = '''2\n",
57 | "1 5\n",
58 | "10 20\n",
59 | "'''\n",
60 | "sys.stdin = StringIO(doc)\n",
61 | "# \"\"\"\n",
62 | "\n",
63 | "#——————————复制的时候 从下面开始复制到牛客网OJ平台即可直接运行——————————#\n",
64 | "\n",
65 | "#coding=utf-8\n",
66 | "import sys\n",
67 | "\n",
68 | "def cal_sum(data):\n",
69 | " return sum(data)\n",
70 | "\n",
71 | "if __name__ == \"__main__\":\n",
72 | " n = int(sys.stdin.readline().strip())\n",
73 | " for _ in range(n):\n",
74 | " line = sys.stdin.readline().strip().split()\n",
75 | " data = list(map(int,line))\n",
76 | " print(cal_sum(data))"
77 | ]
78 | },
79 | {
80 | "cell_type": "markdown",
81 | "metadata": {},
82 | "source": [
83 | "### 第二种写法,使用while True的方法,可适用于不知道测试样例个数的情况\n",
84 | "\n",
85 | "注意这里的split要指定分割符号,否则会死循环(因为line为空字符串的时候也没有地方报错)"
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": 2,
91 | "metadata": {},
92 | "outputs": [
93 | {
94 | "name": "stdout",
95 | "output_type": "stream",
96 | "text": [
97 | "6\n",
98 | "30\n"
99 | ]
100 | }
101 | ],
102 | "source": [
103 | "# \"\"\"\n",
104 | "from io import StringIO\n",
105 | "import sys\n",
106 | "doc = '''1 5\n",
107 | "10 20\n",
108 | "'''\n",
109 | "sys.stdin = StringIO(doc)\n",
110 | "# \"\"\"\n",
111 | "\n",
112 | "#——————————复制的时候 从下面开始复制到牛客网OJ平台即可直接运行——————————#\n",
113 | "\n",
114 | "#coding=utf-8\n",
115 | "import sys\n",
116 | "\n",
117 | "def cal_sum(data):\n",
118 | " return sum(data)\n",
119 | "\n",
120 | "if __name__ == \"__main__\":\n",
121 | " while True:\n",
122 | " try:\n",
123 | " line = sys.stdin.readline().strip().split(\" \")\n",
124 | " data = list(map(int,line))\n",
125 | " print(cal_sum(data))\n",
126 | " except:\n",
127 | " break"
128 | ]
129 | }
130 | ],
131 | "metadata": {
132 | "kernelspec": {
133 | "display_name": "tf36",
134 | "language": "python",
135 | "name": "tf36"
136 | },
137 | "language_info": {
138 | "codemirror_mode": {
139 | "name": "ipython",
140 | "version": 3
141 | },
142 | "file_extension": ".py",
143 | "mimetype": "text/x-python",
144 | "name": "python",
145 | "nbconvert_exporter": "python",
146 | "pygments_lexer": "ipython3",
147 | "version": "3.6.8"
148 | }
149 | },
150 | "nbformat": 4,
151 | "nbformat_minor": 2
152 | }
153 |
--------------------------------------------------------------------------------
/Python数据结构与算法/00_Python数据结构与算法介绍.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 数据结构概述 \n",
8 | "\n",
9 | "https://www.tutorialspoint.com/python_data_structure/python_data_structure_introduction.htm\n",
10 | "\n",
11 | "数据结构是计算机科学的基本概念,有助于编写任何语言的高效程序。 Python是一种高级,解释,交互式和面向对象的脚本语言,与其他编程语言相比,我们可以用更简单的方式研究数据结构的基础知识。 在本章中,我们将研究一般常用数据结构的简短概述,以及它们与某些特定python数据类型的关系。还有一些特定于python的数据结构被列为另一个类别。 \n",
12 | "\n",
13 | "一般数据结构 计算机科学中的各种数据结构大致分为以下两类。我们将在后续章节中详细讨论下面的每个数据结构。 \n",
14 | "\n",
15 | "## 1.线性数据结构\n",
16 | "\n",
17 | "这些是以顺序方式存储数据元素的数据结构。 \n",
18 | "\n",
19 | "### 数组Array\n",
20 | "\n",
21 | "它是与数据元素的索引配对的数据元素的顺序排列。\n",
22 | "\n",
23 | "### 链表Linked List\n",
24 | "\n",
25 | "每个数据元素都包含指向另一个元素的链接以及其中的数据。 \n",
26 | "\n",
27 | "### 栈Stack\n",
28 | "\n",
29 | "它是一种数据结构,仅遵循特定的操作顺序。 LIFO(last in First Out,后进先出)或者FILO(First in Last Out先进先出)。 \n",
30 | "\n",
31 | "### 队列Queue\n",
32 | "\n",
33 | "它与Stack类似,但操作顺序仅为FIFO(First In First Out,先进先出)。 \n",
34 | "\n",
35 | "### 矩阵Matrix\n",
36 | "\n",
37 | "二维数据结构,其中数据元素由一对索引引用。 \n",
38 | "\n",
39 | "## 2.非线性数据结构\n",
40 | "\n",
41 | "这些数据结构中没有数据元素的顺序链接。任何一对或一组数据元素都可以相互链接,并且可以在没有严格序列的情况下访问。\n",
42 | "\n",
43 | "### 二叉树Binary Tree\n",
44 | "\n",
45 | "这是一种数据结构,其中每个数据元素可以连接到最多两个其他数据元素,并以根节点开始。 \n",
46 | "\n",
47 | "### 堆Heap\n",
48 | "\n",
49 | "这是树数据结构的一种特殊情况,其中父节点中的数据严格大于/等于子节点或严格小于其子节点。 \n",
50 | "\n",
51 | "若母节点的值恒小于等于子节点的值,此堆积称为最小堆积(min heap);反之,若母节点的值恒大于等于子节点的值,此堆积称为最大堆积(max heap)。在堆积中最顶端的那一个节点,称作根节点(root node),根节点本身没有母节点(parent node)。\n",
52 | "\n",
53 | "堆的实现通过构造二叉堆(binary heap),实为二叉树的一种;由于其应用的普遍性,当不加限定时,均指该数据结构的这种实现。这种数据结构具有以下性质。\n",
54 | "\n",
55 | "- 任意节点小于(或大于)它的所有后裔,最小元(或最大元)在堆的根上(堆序性)。\n",
56 | "- 堆总是一棵完全树。即除了最底层,其他层的节点都被元素填满,且最底层尽可能地从左到右填入。\n",
57 | "\n",
58 | "将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。\n",
59 | "\n",
60 | "### 散列表/哈希表Hash Table\n",
61 | "\n",
62 | "它是一种数据结构,由使用散列函数相互关联的数组组成。它使用键而不是数据元素的索引来检索值。 \n",
63 | "\n",
64 | "### 图Graph\n",
65 | "\n",
66 | "它是顶点和节点的排列,其中一些节点通过链接相互连接。 \n",
67 | "\n",
68 | "## 3.python特定数据结构\n",
69 | "\n",
70 | "这些数据结构特定于python语言,它们为在python环境中存储不同类型的数据和更快的处理提供了更大的灵活性。 \n",
71 | "### 列表List\n",
72 | "\n",
73 | "它类似于数组,但数据元素可以是不同的数据类型。您可以在python列表中同时包含数字和字符串数据。 \n",
74 | "\n",
75 | "### 元组Tuple\n",
76 | "\n",
77 | "元组类似于列表,但它们是不可变的,这意味着元组中的值无法修改,只能读取。 \n",
78 | "\n",
79 | "### 字典Dictionary\n",
80 | "\n",
81 | "字典包含键值对作为其数据元素。 在接下来的章节中,我们将学习如何使用Python实现每个数据结构的细节。"
82 | ]
83 | }
84 | ],
85 | "metadata": {
86 | "kernelspec": {
87 | "display_name": "Python 3",
88 | "language": "python",
89 | "name": "python3"
90 | },
91 | "language_info": {
92 | "codemirror_mode": {
93 | "name": "ipython",
94 | "version": 3
95 | },
96 | "file_extension": ".py",
97 | "mimetype": "text/x-python",
98 | "name": "python",
99 | "nbconvert_exporter": "python",
100 | "pygments_lexer": "ipython3",
101 | "version": "3.7.3"
102 | }
103 | },
104 | "nbformat": 4,
105 | "nbformat_minor": 2
106 | }
107 |
--------------------------------------------------------------------------------
/Python数据结构与算法/02_lists_python列表.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python列表(Lists)\n",
8 | "\n",
9 | "https://www.tutorialspoint.com/python_data_structure/python_lists_data_structure.htm\n",
10 | "\n",
11 | "列表是Python中最通用的数据类型,可以写为方括号之间的逗号分隔值(项)列表。列表的重要一点是列表中的项不必是相同的类型,列表的元素也可以为列表(二维列表)。\n",
12 | "\n",
13 | "## 创建列表"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 1,
19 | "metadata": {
20 | "collapsed": false
21 | },
22 | "outputs": [
23 | {
24 | "name": "stdout",
25 | "output_type": "stream",
26 | "text": [
27 | "['physics', 'chemistry', 1997, 2000]\n",
28 | "[1, 2, 3, 4, 5]\n",
29 | "['a', 'b', 'c', 'd']\n",
30 | "[[11, 12, 5, 2], [15, 6, 10], [10, 8, 12, 5], [12, 15, 8, 6]]\n"
31 | ]
32 | }
33 | ],
34 | "source": [
35 | "list1 = ['physics', 'chemistry', 1997, 2000]\n",
36 | "list2 = [1, 2, 3, 4, 5 ]\n",
37 | "list3 = [\"a\", \"b\", \"c\", \"d\"]\n",
38 | "# 二维列表\n",
39 | "T = [\n",
40 | " [11, 12, 5, 2],\n",
41 | " [15, 6,10],\n",
42 | " [10, 8, 12, 5],\n",
43 | " [12,15,8,6]\n",
44 | "]\n",
45 | "# 或者写成一行\n",
46 | "# T = [[11, 12, 5, 2], [15, 6,10], [10, 8, 12, 5], [12,15,8,6]]\n",
47 | "\n",
48 | "print(list1)\n",
49 | "print(list2)\n",
50 | "print(list3)\n",
51 | "print(T)"
52 | ]
53 | },
54 | {
55 | "cell_type": "markdown",
56 | "metadata": {},
57 | "source": [
58 | "## 访问列表"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": 2,
64 | "metadata": {
65 | "collapsed": false
66 | },
67 | "outputs": [
68 | {
69 | "name": "stdout",
70 | "output_type": "stream",
71 | "text": [
72 | "list1[0]: physics\n",
73 | "list2[1:5]: [2, 3, 4, 5]\n",
74 | "[11, 12, 5, 2]\n",
75 | "10\n",
76 | "11 12 5 2 \n",
77 | "15 6 10 \n",
78 | "10 8 12 5 \n",
79 | "12 15 8 6 \n"
80 | ]
81 | }
82 | ],
83 | "source": [
84 | "print(\"list1[0]: \", list1[0])\n",
85 | "print(\"list2[1:5]: \", list2[1:5])\n",
86 | "\n",
87 | "print(T[0])\n",
88 | "print(T[1][2])\n",
89 | "for r in T:\n",
90 | " for c in r:\n",
91 | " print(c,end = \" \")\n",
92 | " print()"
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "## 插入"
100 | ]
101 | },
102 | {
103 | "cell_type": "code",
104 | "execution_count": 3,
105 | "metadata": {
106 | "collapsed": false
107 | },
108 | "outputs": [
109 | {
110 | "name": "stdout",
111 | "output_type": "stream",
112 | "text": [
113 | "['physics', 1001, 'chemistry', 1997, 2000]\n",
114 | "[[11, 12, 5, 2], [15, 6, 10], [0, 5, 11, 13, 6], [10, 8, 12, 5], [12, 15, 8, 6]]\n"
115 | ]
116 | }
117 | ],
118 | "source": [
119 | "list1.insert(1,1001)\n",
120 | "print(list1)\n",
121 | "T.insert(2, [0,5,11,13,6])\n",
122 | "print(T)"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "## 更新列表"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 1,
135 | "metadata": {
136 | "collapsed": false
137 | },
138 | "outputs": [
139 | {
140 | "name": "stdout",
141 | "output_type": "stream",
142 | "text": [
143 | "['physics', 'chemistry', 1997, 2000]\n",
144 | "['physics', 'chemistry', 2001, 2000]\n",
145 | "['physics', 'chemistry', 2001, 2000, 2019]\n",
146 | "[[11, 12, 5, 2], [15, 6, 10], [10, 8, 12, 5], [12, 15, 8, 6]]\n",
147 | "[[11, 12, 5, 2], [15, 6, 10], [11, 9], [12, 15, 8, 6]]\n",
148 | "[[11, 12, 5, 2], [15, 6, 10], [11, 7], [12, 15, 8, 6]]\n"
149 | ]
150 | }
151 | ],
152 | "source": [
153 | "# 一维列表\n",
154 | "lst = ['physics', 'chemistry', 1997, 2000]\n",
155 | "print(lst)\n",
156 | "lst[2] = 2001\n",
157 | "print(lst)\n",
158 | "lst.append(2019)\n",
159 | "print(lst)\n",
160 | "\n",
161 | "# 二维列表\n",
162 | "T = [[11, 12, 5, 2], [15, 6,10], [10, 8, 12, 5], [12,15,8,6]]\n",
163 | "print(T)\n",
164 | "\n",
165 | "T[2] = [11,9]\n",
166 | "print(T)\n",
167 | "\n",
168 | "T[2][1] = 7\n",
169 | "print(T)"
170 | ]
171 | },
172 | {
173 | "cell_type": "markdown",
174 | "metadata": {},
175 | "source": [
176 | "## 删除列表元素 del .remove"
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": 5,
182 | "metadata": {
183 | "collapsed": false
184 | },
185 | "outputs": [
186 | {
187 | "name": "stdout",
188 | "output_type": "stream",
189 | "text": [
190 | "['physics', 'chemistry', 1997, 2000]\n",
191 | "['physics', 'chemistry', 2000]\n",
192 | "['physics', 'chemistry']\n",
193 | "[[11, 12, 5, 2], [15, 6, 10], [10, 8, 12, 5], [12, 15, 8, 6]]\n",
194 | "[[15, 6, 10], [10, 8, 12, 5], [12, 15, 8, 6]]\n",
195 | "[[6, 10], [10, 8, 12, 5], [12, 15, 8, 6]]\n"
196 | ]
197 | }
198 | ],
199 | "source": [
200 | "list1 = ['physics', 'chemistry', 1997, 2000]\n",
201 | "print(list1)\n",
202 | "del(list1[2])\n",
203 | "print(list1)\n",
204 | "list1.remove(2000) #多个相同值时,从前面开始删除\n",
205 | "print(list1)\n",
206 | "\n",
207 | "T = [[11, 12, 5, 2], [15, 6,10], [10, 8, 12, 5], [12,15,8,6]]\n",
208 | "print(T)\n",
209 | "\n",
210 | "# 删除内部列表\n",
211 | "del T[0]\n",
212 | "print(T)\n",
213 | "\n",
214 | "# 删除内部列表的数据元素\n",
215 | "del T[0][0]\n",
216 | "print(T)"
217 | ]
218 | },
219 | {
220 | "cell_type": "markdown",
221 | "metadata": {},
222 | "source": [
223 | "## 列表基本操作\n",
224 | "\n",
225 | "```\n",
226 | "len, +, *, i in list, for i in list\n",
227 | "```"
228 | ]
229 | },
230 | {
231 | "cell_type": "code",
232 | "execution_count": 6,
233 | "metadata": {
234 | "collapsed": false
235 | },
236 | "outputs": [
237 | {
238 | "name": "stdout",
239 | "output_type": "stream",
240 | "text": [
241 | "3\n",
242 | "[1, 2, 3, 4, 5, 6]\n",
243 | "['Hi!', 'Hi!', 'Hi!', 'Hi!']\n",
244 | "True\n",
245 | "1\n",
246 | "2\n",
247 | "3\n"
248 | ]
249 | }
250 | ],
251 | "source": [
252 | "# len\n",
253 | "print(len([1,2,3]))\n",
254 | "\n",
255 | "# + 加号\n",
256 | "print([1, 2, 3] + [4, 5, 6])\n",
257 | "\n",
258 | "# * 乘号\n",
259 | "print(['Hi!'] * 4)\n",
260 | "\n",
261 | "# Membership 包含,输出Ture False\n",
262 | "print(3 in [1, 2, 3])\n",
263 | "\n",
264 | "# Iteration 迭代\n",
265 | "for x in [1, 2, 3]: print(x)"
266 | ]
267 | }
268 | ],
269 | "metadata": {
270 | "kernelspec": {
271 | "display_name": "Python 3",
272 | "language": "python",
273 | "name": "python3"
274 | },
275 | "language_info": {
276 | "codemirror_mode": {
277 | "name": "ipython",
278 | "version": 3
279 | },
280 | "file_extension": ".py",
281 | "mimetype": "text/x-python",
282 | "name": "python",
283 | "nbconvert_exporter": "python",
284 | "pygments_lexer": "ipython3",
285 | "version": "3.7.3"
286 | }
287 | },
288 | "nbformat": 4,
289 | "nbformat_minor": 2
290 | }
291 |
--------------------------------------------------------------------------------
/Python数据结构与算法/03_tuples_python元组.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python元组(Tuples)\n",
8 | "\n",
9 | "https://www.tutorialspoint.com/python_data_structure/python_tuples_data_structure.htm\n",
10 | "\n",
11 | "元组是一系列不可变的Python对象。 元组是序列,就像列表一样。 元组和列表之间的区别是,元组不能更改,列表可以更改。元组使用圆括号,而列表使用方括号。\n",
12 | "\n",
13 | "## 创建元组"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 1,
19 | "metadata": {},
20 | "outputs": [
21 | {
22 | "name": "stdout",
23 | "output_type": "stream",
24 | "text": [
25 | "('physics', 'chemistry', 1997, 2000)\n",
26 | "(1, 2, 3, 4, 5)\n",
27 | "('a', 'b', 'c', 'd')\n",
28 | "()\n",
29 | "(100,)\n"
30 | ]
31 | }
32 | ],
33 | "source": [
34 | "tup1 = ('physics', 'chemistry', 1997, 2000)\n",
35 | "print(tup1)\n",
36 | "tup2 = (1, 2, 3, 4, 5 )\n",
37 | "print(tup2)\n",
38 | "\n",
39 | "# 也可以不加括号\n",
40 | "tup3 = \"a\", \"b\", \"c\", \"d\"\n",
41 | "print(tup3)\n",
42 | "\n",
43 | "# 空元组\n",
44 | "tup4 = ()\n",
45 | "print(tup4)\n",
46 | "\n",
47 | "# 创建只有一个元素的元组,需要加上逗号(否则直接是int)\n",
48 | "tup5 = (100,)\n",
49 | "print(tup5)"
50 | ]
51 | },
52 | {
53 | "cell_type": "markdown",
54 | "metadata": {},
55 | "source": [
56 | "## 访问元组\n",
57 | "\n",
58 | "和list相似,直接用中括号进行索引"
59 | ]
60 | },
61 | {
62 | "cell_type": "code",
63 | "execution_count": 2,
64 | "metadata": {},
65 | "outputs": [
66 | {
67 | "name": "stdout",
68 | "output_type": "stream",
69 | "text": [
70 | "physics\n",
71 | "('chemistry', 1997, 2000)\n"
72 | ]
73 | }
74 | ],
75 | "source": [
76 | "tup1 = ('physics', 'chemistry', 1997, 2000);\n",
77 | "print(tup1[0])\n",
78 | "print(tup1[1:4])"
79 | ]
80 | },
81 | {
82 | "cell_type": "markdown",
83 | "metadata": {},
84 | "source": [
85 | "## 不能更改和删除tuple元素"
86 | ]
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {},
91 | "source": [
92 | "## 元组基本操作\n",
93 | "\n",
94 | "```\n",
95 | "len, +, *, i in tuple, for i in tuple\n",
96 | "```"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": 3,
102 | "metadata": {},
103 | "outputs": [
104 | {
105 | "name": "stdout",
106 | "output_type": "stream",
107 | "text": [
108 | "3\n",
109 | "(1, 2, 3, 4, 5, 6)\n",
110 | "('Hi!', 'Hi!', 'Hi!', 'Hi!')\n",
111 | "True\n",
112 | "1\n",
113 | "2\n",
114 | "3\n"
115 | ]
116 | }
117 | ],
118 | "source": [
119 | "# len\n",
120 | "print(len((1,2,3)))\n",
121 | "\n",
122 | "# + 加号\n",
123 | "print((1,2,3)+(4,5,6))\n",
124 | "\n",
125 | "# * 乘号\n",
126 | "print(('Hi!',) * 4)\n",
127 | "\n",
128 | "# Membership 包含,输出Ture False\n",
129 | "print(3 in (1, 2, 3))\n",
130 | "\n",
131 | "# Iteration 迭代\n",
132 | "for x in (1, 2, 3): print(x)"
133 | ]
134 | }
135 | ],
136 | "metadata": {
137 | "kernelspec": {
138 | "display_name": "Python 3",
139 | "language": "python",
140 | "name": "python3"
141 | },
142 | "language_info": {
143 | "codemirror_mode": {
144 | "name": "ipython",
145 | "version": 3
146 | },
147 | "file_extension": ".py",
148 | "mimetype": "text/x-python",
149 | "name": "python",
150 | "nbconvert_exporter": "python",
151 | "pygments_lexer": "ipython3",
152 | "version": "3.7.3"
153 | }
154 | },
155 | "nbformat": 4,
156 | "nbformat_minor": 2
157 | }
158 |
--------------------------------------------------------------------------------
/Python数据结构与算法/05_sets_python集合.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python集合(Sets)\n",
8 | "\n",
9 | "https://www.tutorialspoint.com/python_data_structure/python_sets.htm\n",
10 | "\n",
11 | "数学上,集合是不按任何特定顺序排列的项目集合。 Python集类似于此数学定义,具有以下附加条件。\n",
12 | "\n",
13 | "- 集合中的元素不能重复。 \n",
14 | "- 集合中的元素是不可变的(不能修改),但整个集合是可变的。 \n",
15 | "- 没有索引附加到python集中的任何元素。因此,它们不支持任何索引或切片操作。\n",
16 | "\n",
17 | "python中的集合通常用于数学运算,如并集,交集,差异和补码等。我们可以创建一个集合,访问它的元素并执行这些数学运算。\n",
18 | "\n",
19 | "## 创建集合 set(iterable) 、 {}"
20 | ]
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": 12,
25 | "metadata": {},
26 | "outputs": [
27 | {
28 | "name": "stdout",
29 | "output_type": "stream",
30 | "text": [
31 | "{'Sat', 'Thu', 'Sun', 'Fri', 'Mon', 'Wed', 'Tue'}\n",
32 | "{'Feb', 'Jan', 'Mar'}\n",
33 | "{17, 21, 22}\n",
34 | "{'l', 'g', 'G', 'o', 'e'}\n"
35 | ]
36 | }
37 | ],
38 | "source": [
39 | "Days=set([\"Mon\",\"Tue\",\"Wed\",\"Thu\",\"Fri\",\"Sat\",\"Sun\"])\n",
40 | "Months={\"Jan\",\"Feb\",\"Mar\"}\n",
41 | "Dates={21,22,17}\n",
42 | "Google = set(\"Google\")\n",
43 | "print(Days)\n",
44 | "print(Months)\n",
45 | "print(Dates)\n",
46 | "print(Google)"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {},
52 | "source": [
53 | "## 访问集合\n",
54 | "\n",
55 | "我们无法访问集合中的单个值。我们只能访问所有元素,如上所示。但是我们也可以通过循环遍历集合来获得单个元素的列表。"
56 | ]
57 | },
58 | {
59 | "cell_type": "code",
60 | "execution_count": 8,
61 | "metadata": {},
62 | "outputs": [
63 | {
64 | "name": "stdout",
65 | "output_type": "stream",
66 | "text": [
67 | "Sat\n",
68 | "Thu\n",
69 | "Sun\n",
70 | "Fri\n",
71 | "Mon\n",
72 | "Wed\n",
73 | "Tue\n"
74 | ]
75 | }
76 | ],
77 | "source": [
78 | "for d in Days:\n",
79 | "\tprint(d)"
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | "## 添加元素 .add()"
87 | ]
88 | },
89 | {
90 | "cell_type": "code",
91 | "execution_count": 10,
92 | "metadata": {},
93 | "outputs": [
94 | {
95 | "name": "stdout",
96 | "output_type": "stream",
97 | "text": [
98 | "{'Sat', 'Thu', 'Sun', 'Fri', 'Mon', 'Wed', 'Tue'}\n"
99 | ]
100 | }
101 | ],
102 | "source": [
103 | "Days=set([\"Mon\",\"Tue\",\"Wed\",\"Thu\",\"Fri\",\"Sat\"])\n",
104 | "Days.add(\"Sun\")\n",
105 | "print(Days)"
106 | ]
107 | },
108 | {
109 | "cell_type": "markdown",
110 | "metadata": {},
111 | "source": [
112 | "## 移除元素 .discard()"
113 | ]
114 | },
115 | {
116 | "cell_type": "code",
117 | "execution_count": 11,
118 | "metadata": {},
119 | "outputs": [
120 | {
121 | "name": "stdout",
122 | "output_type": "stream",
123 | "text": [
124 | "{'Sat', 'Thu', 'Fri', 'Mon', 'Wed', 'Tue'}\n"
125 | ]
126 | }
127 | ],
128 | "source": [
129 | "Days=set([\"Mon\",\"Tue\",\"Wed\",\"Thu\",\"Fri\",\"Sat\"])\n",
130 | " \n",
131 | "Days.discard(\"Sun\")\n",
132 | "print(Days)"
133 | ]
134 | },
135 | {
136 | "cell_type": "markdown",
137 | "metadata": {},
138 | "source": [
139 | "## 并集 .union() 或者 |"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 2,
145 | "metadata": {},
146 | "outputs": [
147 | {
148 | "name": "stdout",
149 | "output_type": "stream",
150 | "text": [
151 | "{'Mon', 'Fri', 'Sun', 'Sat', 'Thu', 'Tue', 'Wed'}\n"
152 | ]
153 | }
154 | ],
155 | "source": [
156 | "DaysA = set([\"Mon\",\"Tue\",\"Wed\"])\n",
157 | "DaysB = set([\"Wed\",\"Thu\",\"Fri\",\"Sat\",\"Sun\"])\n",
158 | "\n",
159 | "DaysAB = DaysA.union(DaysB)\n",
160 | "print(DaysAB)"
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": 3,
166 | "metadata": {},
167 | "outputs": [
168 | {
169 | "name": "stdout",
170 | "output_type": "stream",
171 | "text": [
172 | "{'Mon', 'Fri', 'Sun', 'Sat', 'Thu', 'Tue', 'Wed'}\n"
173 | ]
174 | }
175 | ],
176 | "source": [
177 | "DaysAB = DaysA | DaysB\n",
178 | "print(DaysAB)"
179 | ]
180 | },
181 | {
182 | "cell_type": "markdown",
183 | "metadata": {},
184 | "source": [
185 | "## 交集 .intersection() 或者 &"
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": 4,
191 | "metadata": {},
192 | "outputs": [
193 | {
194 | "data": {
195 | "text/plain": [
196 | "{'Wed'}"
197 | ]
198 | },
199 | "execution_count": 4,
200 | "metadata": {},
201 | "output_type": "execute_result"
202 | }
203 | ],
204 | "source": [
205 | "DaysA.intersection(DaysB)"
206 | ]
207 | },
208 | {
209 | "cell_type": "code",
210 | "execution_count": 5,
211 | "metadata": {},
212 | "outputs": [
213 | {
214 | "data": {
215 | "text/plain": [
216 | "{'Wed'}"
217 | ]
218 | },
219 | "execution_count": 5,
220 | "metadata": {},
221 | "output_type": "execute_result"
222 | }
223 | ],
224 | "source": [
225 | "DaysA & DaysB"
226 | ]
227 | },
228 | {
229 | "cell_type": "markdown",
230 | "metadata": {},
231 | "source": [
232 | "## 差集 .difference() 或者 - (A-B = A-(A∩B)去掉公共部分)"
233 | ]
234 | },
235 | {
236 | "cell_type": "code",
237 | "execution_count": 7,
238 | "metadata": {},
239 | "outputs": [
240 | {
241 | "data": {
242 | "text/plain": [
243 | "{'Fri', 'Sat', 'Sun', 'Thu'}"
244 | ]
245 | },
246 | "execution_count": 7,
247 | "metadata": {},
248 | "output_type": "execute_result"
249 | }
250 | ],
251 | "source": [
252 | "DaysB.difference(DaysA)"
253 | ]
254 | },
255 | {
256 | "cell_type": "code",
257 | "execution_count": 6,
258 | "metadata": {},
259 | "outputs": [
260 | {
261 | "data": {
262 | "text/plain": [
263 | "{'Fri', 'Sat', 'Sun', 'Thu'}"
264 | ]
265 | },
266 | "execution_count": 6,
267 | "metadata": {},
268 | "output_type": "execute_result"
269 | }
270 | ],
271 | "source": [
272 | "DaysB -DaysA"
273 | ]
274 | },
275 | {
276 | "cell_type": "markdown",
277 | "metadata": {},
278 | "source": [
279 | "## 比较 <= 和 >="
280 | ]
281 | },
282 | {
283 | "cell_type": "code",
284 | "execution_count": 9,
285 | "metadata": {},
286 | "outputs": [
287 | {
288 | "data": {
289 | "text/plain": [
290 | "False"
291 | ]
292 | },
293 | "execution_count": 9,
294 | "metadata": {},
295 | "output_type": "execute_result"
296 | }
297 | ],
298 | "source": [
299 | "DaysB >= DaysA"
300 | ]
301 | },
302 | {
303 | "cell_type": "code",
304 | "execution_count": 11,
305 | "metadata": {},
306 | "outputs": [
307 | {
308 | "data": {
309 | "text/plain": [
310 | "True"
311 | ]
312 | },
313 | "execution_count": 11,
314 | "metadata": {},
315 | "output_type": "execute_result"
316 | }
317 | ],
318 | "source": [
319 | "set([1,2]) <= set([1,2,3,4])"
320 | ]
321 | }
322 | ],
323 | "metadata": {
324 | "kernelspec": {
325 | "display_name": "Python 3",
326 | "language": "python",
327 | "name": "python3"
328 | },
329 | "language_info": {
330 | "codemirror_mode": {
331 | "name": "ipython",
332 | "version": 3
333 | },
334 | "file_extension": ".py",
335 | "mimetype": "text/x-python",
336 | "name": "python",
337 | "nbconvert_exporter": "python",
338 | "pygments_lexer": "ipython3",
339 | "version": "3.7.3"
340 | }
341 | },
342 | "nbformat": 4,
343 | "nbformat_minor": 2
344 | }
345 |
--------------------------------------------------------------------------------
/Python数据结构与算法/python链表.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# python 链表\n",
8 | "\n",
9 | "https://www.jianshu.com/p/5875efe4748d\n",
10 | "\n",
11 | "https://blog.csdn.net/qq_39422642/article/details/78988976"
12 | ]
13 | },
14 | {
15 | "cell_type": "code",
16 | "execution_count": 5,
17 | "metadata": {},
18 | "outputs": [
19 | {
20 | "name": "stdout",
21 | "output_type": "stream",
22 | "text": [
23 | "Create a linklist\n",
24 | "1\n",
25 | "2\n",
26 | "3\n",
27 | "4\n",
28 | "5\n",
29 | "6\n",
30 | "7\n",
31 | "___________________________\n"
32 | ]
33 | },
34 | {
35 | "name": "stdin",
36 | "output_type": "stream",
37 | "text": [
38 | "Enter the index to insert 3\n",
39 | "Enter a value: 7\n"
40 | ]
41 | },
42 | {
43 | "name": "stdout",
44 | "output_type": "stream",
45 | "text": [
46 | "1\n",
47 | "2\n",
48 | "7\n",
49 | "3\n",
50 | "4\n",
51 | "5\n",
52 | "6\n",
53 | "7\n",
54 | "___________________________\n"
55 | ]
56 | },
57 | {
58 | "name": "stdin",
59 | "output_type": "stream",
60 | "text": [
61 | "Enter the index to delete 3\n"
62 | ]
63 | },
64 | {
65 | "name": "stdout",
66 | "output_type": "stream",
67 | "text": [
68 | "1\n",
69 | "2\n",
70 | "3\n",
71 | "4\n",
72 | "5\n",
73 | "6\n",
74 | "7\n"
75 | ]
76 | }
77 | ],
78 | "source": [
79 | "class ListNode(): # 初始化 构造函数 \n",
80 | " def __init__(self,value): \n",
81 | " self.value=value \n",
82 | " self.next=None\n",
83 | " \n",
84 | "def Creatlist(n): \n",
85 | " if n<=0: \n",
86 | " return False \n",
87 | " if n==1: \n",
88 | " return ListNode(1) # 只有一个节点 \n",
89 | " else: \n",
90 | " root=ListNode(1) \n",
91 | " tmp=root \n",
92 | " for i in range(2,n+1): # 一个一个的增加节点 \n",
93 | " tmp.next=ListNode(i) \n",
94 | " tmp=tmp.next \n",
95 | " return root # 返回根节点 \n",
96 | " \n",
97 | "def printlist(head): # 打印链表 (遍历) \n",
98 | " p=head \n",
99 | " while p!=None: \n",
100 | " print(p.value)\n",
101 | " p=p.next \n",
102 | " \n",
103 | "def listlen(head): # 链表长度 \n",
104 | " c=0 \n",
105 | " p=head \n",
106 | " while p!=None: \n",
107 | " c=c+1 \n",
108 | " p=p.next \n",
109 | " return c \n",
110 | " \n",
111 | "def insert(head,n): # 在n的前面插入元素 \n",
112 | " if n<1 or n>listlen(head): \n",
113 | " return \n",
114 | " \n",
115 | " p=head \n",
116 | " for i in range(1,n-1): # 循环四次到达 5 (只能一个一个节点的移动 range不包含n-1)\n",
117 | " p=p.next \n",
118 | " a=input(\"Enter a value:\") \n",
119 | " t=ListNode(value=a) \n",
120 | " t.next=p.next \n",
121 | " p.next=t \n",
122 | " return head \n",
123 | " \n",
124 | "def dellist(head,n): # 删除链表 \n",
125 | " if n<1 or n>listlen(head): \n",
126 | " return head \n",
127 | " elif n is 1: \n",
128 | " head=head.next # 删除头 \n",
129 | " else: \n",
130 | " p=head \n",
131 | " for i in range(1,n-1): \n",
132 | " p=p.next # 循环到达 2次 \n",
133 | " q=p.next \n",
134 | " p.next=q.next # 把5放在3的后面 \n",
135 | " return head \n",
136 | "\n",
137 | "def main(): \n",
138 | " print(\"Create a linklist\" )\n",
139 | " head=Creatlist(7) \n",
140 | " printlist(head) \n",
141 | " print(\"___________________________\")\n",
142 | " \n",
143 | " n1=input(\"Enter the index to insert\") \n",
144 | " n1=int(n1) \n",
145 | " insert(head,n1) \n",
146 | " printlist(head) \n",
147 | " print(\"___________________________\")\n",
148 | " \n",
149 | " n2=input(\"Enter the index to delete\") \n",
150 | " n2=int(n2) \n",
151 | " dellist(head,n2) \n",
152 | " printlist(head) \n",
153 | " \n",
154 | " \n",
155 | "if __name__=='__main__': main() # 主函数调用 "
156 | ]
157 | },
158 | {
159 | "cell_type": "code",
160 | "execution_count": null,
161 | "metadata": {},
162 | "outputs": [],
163 | "source": []
164 | }
165 | ],
166 | "metadata": {
167 | "kernelspec": {
168 | "display_name": "tf36",
169 | "language": "python",
170 | "name": "tf36"
171 | },
172 | "language_info": {
173 | "codemirror_mode": {
174 | "name": "ipython",
175 | "version": 3
176 | },
177 | "file_extension": ".py",
178 | "mimetype": "text/x-python",
179 | "name": "python",
180 | "nbconvert_exporter": "python",
181 | "pygments_lexer": "ipython3",
182 | "version": "3.6.7"
183 | }
184 | },
185 | "nbformat": 4,
186 | "nbformat_minor": 2
187 | }
188 |
--------------------------------------------------------------------------------
/Python知识点/Python小知识点.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python小知识点"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## index一个字符串的位置"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {},
21 | "outputs": [
22 | {
23 | "name": "stdout",
24 | "output_type": "stream",
25 | "text": [
26 | "6\n"
27 | ]
28 | }
29 | ],
30 | "source": [
31 | "str1 = \"Hello,Python\"\n",
32 | "str2 = \"Python\"\n",
33 | "print(str1.index(str2))"
34 | ]
35 | },
36 | {
37 | "cell_type": "markdown",
38 | "metadata": {},
39 | "source": [
40 | "## 一道筛法题目\n",
41 | "\n",
42 | "假设可以不考虑计算机运行资源(如内存)的限制,以下 python3 代码的预期运行结果是:()\n",
43 | "\n",
44 | "```python\n",
45 | "import math\n",
46 | "def sieve(size):\n",
47 | " sieve= [True] * size\n",
48 | " sieve[0] = False\n",
49 | " sieve[1] = False\n",
50 | " for i in range(2, int(math.sqrt(size)) + 1):\n",
51 | " k= i * 2\n",
52 | " while k < size:\n",
53 | " sieve[k] = False\n",
54 | " k += i\n",
55 | " return sum(1 for x in sieve if x)\n",
56 | "print(sieve(10000000000))\n",
57 | "```"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 2,
63 | "metadata": {},
64 | "outputs": [
65 | {
66 | "data": {
67 | "text/plain": [
68 | "10.0"
69 | ]
70 | },
71 | "execution_count": 2,
72 | "metadata": {},
73 | "output_type": "execute_result"
74 | }
75 | ],
76 | "source": [
77 | "a=10000000000\n",
78 | "import math\n",
79 | "math.log10(a)"
80 | ]
81 | },
82 | {
83 | "cell_type": "code",
84 | "execution_count": 45,
85 | "metadata": {},
86 | "outputs": [
87 | {
88 | "name": "stdout",
89 | "output_type": "stream",
90 | "text": [
91 | "25\n",
92 | "[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]\n"
93 | ]
94 | }
95 | ],
96 | "source": [
97 | "import math\n",
98 | " \n",
99 | "def sieve(size):\n",
100 | " num = list(range(size))\n",
101 | " sieve1= [True] * size\n",
102 | " sieve1[0] = False\n",
103 | " sieve1[1] = False\n",
104 | " for i in range(2, int(math.sqrt(size)) + 1):\n",
105 | " k = i * 2\n",
106 | " while k < size:\n",
107 | " sieve1[k] = False\n",
108 | " k += i\n",
109 | " prim = [num[i] for i,x in enumerate(sieve1) if x]\n",
110 | " n = len(prim)\n",
111 | " return prim,n\n",
112 | "\n",
113 | "a,n= sieve(100)\n",
114 | "print(n)\n",
115 | "print(a)"
116 | ]
117 | },
118 | {
119 | "cell_type": "markdown",
120 | "metadata": {},
121 | "source": [
122 | "该程序是计算,前size个整数中(从0开始),素数的个数,直接查阅:\n",
123 | "\n",
124 | "https://www.wikiwand.com/en/Prime-counting_function\n",
125 | "\n",
126 | "得到10^10以内的个数为455,052,511。\n",
127 | "\n",
128 | ">筛法\n",
129 | "```\n",
130 | "用筛法求素数的基本思想是:把从1开始的、某一范围内的正整数从小到大顺序排列, 1不是素数,首先把它筛掉。\n",
131 | "剩下的数中选择最小的数是素数,然后去掉它的倍数。依次类推,直到筛子为空时结束。如有:\n",
132 | "1 2 3 4 5 6 7 8 9 10\n",
133 | "11 12 13 14 15 16 17 18 19 20\n",
134 | "21 22 23 24 25 26 27 28 29 30\n",
135 | "1不是素数,去掉。剩下的数中2最小,是素数,去掉2的倍数,余下的数是:\n",
136 | "3 5 7 9 11 13 15 17 19 21 23 25 27 29\n",
137 | "剩下的数中3最小,是素数,去掉3的倍数,如此下去直到所有的数都被筛完,求出的素数为:\n",
138 | "2 3 5 7 11 13 17 19 23 29\n",
139 | "```"
140 | ]
141 | },
142 | {
143 | "cell_type": "markdown",
144 | "metadata": {},
145 | "source": [
146 | "## return的特殊情况\n",
147 | "\n",
148 | "默认情况下,遇见 return 函数就会返回给调用者,但是 try,finally情况除外:"
149 | ]
150 | },
151 | {
152 | "cell_type": "code",
153 | "execution_count": 33,
154 | "metadata": {},
155 | "outputs": [
156 | {
157 | "name": "stdout",
158 | "output_type": "stream",
159 | "text": [
160 | "98\n",
161 | "98\n",
162 | "ok\n"
163 | ]
164 | }
165 | ],
166 | "source": [
167 | "def func(): \n",
168 | " try: \n",
169 | " print(98)\n",
170 | " return 'ok' #函数得到了一个返回值 \n",
171 | " finally: #finally语句块中的语句依然会执行 \n",
172 | " print(98) \n",
173 | "print(func())"
174 | ]
175 | },
176 | {
177 | "cell_type": "markdown",
178 | "metadata": {},
179 | "source": [
180 | "函数作为返回值返回,这其实就是闭包:"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 46,
186 | "metadata": {},
187 | "outputs": [
188 | {
189 | "name": "stdout",
190 | "output_type": "stream",
191 | "text": [
192 | "\n",
193 | "45\n"
194 | ]
195 | }
196 | ],
197 | "source": [
198 | "def lazy_sum(*args):\n",
199 | " def sum():\n",
200 | " x=0\n",
201 | " for n in args:\n",
202 | " x=x+n\n",
203 | " return x\n",
204 | " return sum\n",
205 | "\n",
206 | "lazy_sum(1,2,3,4,5,6,7,8,9) #这时候lazy_sum 并没有执行,而是返回一个指向求和的函数的函数名sum 的内存地址。\n",
207 | "f=lazy_sum(1,2,3,4,5,6,7,8,9)\n",
208 | "print(type(f))\n",
209 | "print(f()) # 调用f()函数,才真正调用了 sum 函数进行求和,"
210 | ]
211 | },
212 | {
213 | "cell_type": "markdown",
214 | "metadata": {},
215 | "source": [
216 | "返回函数列表:"
217 | ]
218 | },
219 | {
220 | "cell_type": "code",
221 | "execution_count": 49,
222 | "metadata": {},
223 | "outputs": [
224 | {
225 | "name": "stdout",
226 | "output_type": "stream",
227 | "text": [
228 | "9\n",
229 | "9\n",
230 | "9\n"
231 | ]
232 | }
233 | ],
234 | "source": [
235 | "def count():\n",
236 | " fs = []\n",
237 | " for i in range(1,4):\n",
238 | " def f():\n",
239 | " return i*i\n",
240 | " fs.append(f)\n",
241 | " return fs\n",
242 | "\n",
243 | "\n",
244 | "f1, f2, f3 = count()\n",
245 | "print(f1())\n",
246 | "print(f2())\n",
247 | "print(f3())"
248 | ]
249 | },
250 | {
251 | "cell_type": "markdown",
252 | "metadata": {},
253 | "source": [
254 | "```\n",
255 | "执行过程:\n",
256 | "当i=1, 执行for循环, 结果返回函数f的函数地址,存在列表fs中的第一个位置上。\n",
257 | "当i=2, 由于fs列表中第一个元素所指的函数中的i是count函数的局部变量,i也指向了2;然后执行for循环, 结果返回函数f的函数地址,存在列表fs中的第二个位置上。\n",
258 | "当i=3, 同理,在fs列表第一个和第二个元素所指的函数中的i变量指向了3; 然后执行for循环, 结果返回函数f的函数地址,存在列表fs中的第三个位置上。\n",
259 | "所以在调用f1()的时候,函数中的i是指向3的:\n",
260 | " f1():\n",
261 | " return 3*3\n",
262 | "同理f2(), f3()结果都为9\n",
263 | "闭包时牢记的一点就是:返回函数不要引用任何循环变量,或者后续会发生变化的变量。即包在里面的函数(本例为f()),不\n",
264 | "要引用外部函数(本例为count())的任何循环变量\n",
265 | "\n",
266 | "如果一定要引入循环变量,方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,\n",
267 | "已绑定到函数参数的值不变:\n",
268 | "```"
269 | ]
270 | },
271 | {
272 | "cell_type": "code",
273 | "execution_count": 50,
274 | "metadata": {},
275 | "outputs": [
276 | {
277 | "name": "stdout",
278 | "output_type": "stream",
279 | "text": [
280 | "1\n",
281 | "4\n",
282 | "9\n"
283 | ]
284 | }
285 | ],
286 | "source": [
287 | "def count():\n",
288 | " fs=[]\n",
289 | " for i in range(1,4):\n",
290 | " def f(j):\n",
291 | " def g():\n",
292 | " return j*j\n",
293 | " return g\n",
294 | " fs.append(f(i))\n",
295 | " return fs\n",
296 | "\n",
297 | "f1,f2,f3=count()\n",
298 | "print(f1())\n",
299 | "print(f2())\n",
300 | "print(f3())"
301 | ]
302 | }
303 | ],
304 | "metadata": {
305 | "kernelspec": {
306 | "display_name": "tf36",
307 | "language": "python",
308 | "name": "tf36"
309 | },
310 | "language_info": {
311 | "codemirror_mode": {
312 | "name": "ipython",
313 | "version": 3
314 | },
315 | "file_extension": ".py",
316 | "mimetype": "text/x-python",
317 | "name": "python",
318 | "nbconvert_exporter": "python",
319 | "pygments_lexer": "ipython3",
320 | "version": "3.6.8"
321 | }
322 | },
323 | "nbformat": 4,
324 | "nbformat_minor": 2
325 | }
326 |
--------------------------------------------------------------------------------
/Python知识点/__new__ & __init__.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# `__new__`和`__init__`\n",
8 | "\n",
9 | "[详解Python中的`__init__`和`__new__`](http://python.jobbole.com/86506/)\n",
10 | "\n",
11 | "## 1.`__init__` 方法\n",
12 | "\n",
13 | "`__init__` 方法通常用在初始化一个类实例的时候"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 13,
19 | "metadata": {},
20 | "outputs": [
21 | {
22 | "name": "stdout",
23 | "output_type": "stream",
24 | "text": [
25 | "\n"
26 | ]
27 | }
28 | ],
29 | "source": [
30 | "# -*- coding: utf-8 -*-\n",
31 | " \n",
32 | "class Person(object):\n",
33 | " \"\"\"Silly Person\"\"\"\n",
34 | " \n",
35 | " def __init__(self, name, age):\n",
36 | " self.name = name\n",
37 | " self.age = age\n",
38 | " \n",
39 | " def __str__(self):\n",
40 | " return '' % (self.name, self.age)\n",
41 | "\n",
42 | "if __name__ == '__main__':\n",
43 | " piglei = Person('piglei', 24)\n",
44 | " print(piglei)"
45 | ]
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "metadata": {},
50 | "source": [
51 | "这样便是`__init__`最普通的用法了。但`__init__`其实不是实例化一个类的时候第一个被调用 的方法。当使用 Persion(name, age) 这样的表达式来实例化一个类时,最先被调用的方法 其实是 `__new__` 方法"
52 | ]
53 | },
54 | {
55 | "cell_type": "markdown",
56 | "metadata": {},
57 | "source": [
58 | "## 2.`__new__` 方法\n",
59 | "\n",
60 | "`__new__`方法接受的参数虽然也是和`__init__`一样,但`__init__`是在类实例创建之后调用,而 `__new__`方法正是创建这个类实例的方法。"
61 | ]
62 | },
63 | {
64 | "cell_type": "markdown",
65 | "metadata": {},
66 | "source": [
67 | "python3下 原来的代码会报错:\n",
68 | "\n",
69 | "`TypeError: object() takes no parameters after defining __new__`\n",
70 | "\n",
71 | "https://stackoverflow.com/questions/34777773/typeerror-object-takes-no-parameters-after-defining-new\n",
72 | "\n",
73 | ">In Python 3.3 and later, if you're overriding both __new__ and __init__, you need to avoid passing any extra arguments to the object methods you're overriding. If you only override one of those methods, it's allowed to pass extra arguments to the other one (since that usually happens without your help).\n",
74 | "\n",
75 | ">python3.3以后,同时重写new init时,不能传入额外参数\n",
76 | "\n",
77 | "所以把下面的一行:\n",
78 | "`return super(Person, cls).__new__(cls, name, age)`\n",
79 | "\n",
80 | "改成:\n",
81 | "`return super(Person, cls).__new__(cls)`"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": 18,
87 | "metadata": {},
88 | "outputs": [
89 | {
90 | "name": "stdout",
91 | "output_type": "stream",
92 | "text": [
93 | "__new__ called.\n",
94 | "__init__ called.\n",
95 | "\n"
96 | ]
97 | }
98 | ],
99 | "source": [
100 | "# -*- coding: utf-8 -*-\n",
101 | " \n",
102 | "class Person(object):\n",
103 | " \"\"\"Silly Person\"\"\"\n",
104 | " \n",
105 | " def __new__(cls, name, age):\n",
106 | " print('__new__ called.')\n",
107 | " #return super(Person, cls).__new__(cls, name, age) #这样python3会报错 改成下面的\n",
108 | "# return super(Person, cls).__new__(cls)\n",
109 | " return super().__new__(cls) #python3 的super()可以直接使用 super().xxx 代替 super(Class, self).xxx\n",
110 | " \n",
111 | " def __init__(self, name, age):\n",
112 | " print('__init__ called.')\n",
113 | " self.name = name\n",
114 | " self.age = age\n",
115 | " \n",
116 | " def __str__(self):\n",
117 | " return '' % (self.name, self.age)\n",
118 | "\n",
119 | "\n",
120 | "if __name__ == '__main__':\n",
121 | " piglei = Person('piglei', 24)\n",
122 | " print(piglei)"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "通过运行这段代码,我们可以看到,`__new__`方法的调用是发生在`__init__`之前的。其实当 你实例化一个类的时候,具体的执行逻辑是这样的:\n",
130 | "\n",
131 | "- 1.p = Person(name, age)\n",
132 | "- 2.首先执行使用name和age参数来执行Person类的`__new__`方法,这个`__new__`方法会 返回Person类的一个实例(通常情况下是使用 `super().__new__(cls)` 这样的方式),\n",
133 | "- 3.然后利用这个实例来调用类的__init__方法,上一步里面__new__产生的实例也就是 __init__里面的的 self\n",
134 | "\n",
135 | "所以,`__init__` 和 `__new__` 最主要的区别在于:\n",
136 | "\n",
137 | "- 1.`__init__` 通常用于初始化一个新实例,控制这个初始化的过程,比如添加一些属性, 做一些额外的操作,发生在类实例被创建完以后。它是实例级别的方法。\n",
138 | "- 2.`__new__` 通常用于控制生成一个新实例的过程。它是类级别的方法。\n",
139 | "\n",
140 | "但是说了这么多,__new__最通常的用法是什么呢,我们什么时候需要__new__?"
141 | ]
142 | },
143 | {
144 | "cell_type": "markdown",
145 | "metadata": {},
146 | "source": [
147 | "## 3.`__new__` 的作用\n",
148 | "\n",
149 | "依照Python官方文档的说法,`__new__`方法主要是当你继承一些不可变的class时(比如int, str, tuple), 提供给你一个自定义这些类的实例化过程的途径。还有就是实现自定义的metaclass。\n",
150 | "\n",
151 | "首先我们来看一下第一个功能,具体我们可以用int来作为一个例子:\n",
152 | "\n",
153 | "**假如我们需要一个永远都是正数的整数类型,通过集成int,我们可能会写出这样的代码。**"
154 | ]
155 | },
156 | {
157 | "cell_type": "markdown",
158 | "metadata": {},
159 | "source": [
160 | "```python\n",
161 | "class PositiveInteger(int):\n",
162 | " def __init__(self, value):\n",
163 | " super(PositiveInteger, self).__init__(self, abs(value))\n",
164 | " \n",
165 | "i = PositiveInteger(-3)\n",
166 | "print(i)\n",
167 | "```\n",
168 | "\n",
169 | "python2可以运行,\n",
170 | "\n",
171 | "warning:\n",
172 | "`DeprecationWarning: object.__init__() takes no parameters app.launch_new_instance()`\n",
173 | "\n",
174 | "python3报错\n",
175 | "\n",
176 | "但运行后会发现,结果根本不是我们想的那样,我们仍然得到了-3。这是因为对于int这种 不可变的对象,我们只有重载它的`__new__`方法才能起到自定义的作用。\n",
177 | "\n",
178 | "这是修改后的代码:"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": 34,
184 | "metadata": {},
185 | "outputs": [
186 | {
187 | "name": "stdout",
188 | "output_type": "stream",
189 | "text": [
190 | "3\n"
191 | ]
192 | }
193 | ],
194 | "source": [
195 | "class PositiveInteger(int):\n",
196 | " def __new__(cls, value):\n",
197 | " return super().__new__(cls, abs(value))\n",
198 | "\n",
199 | "i = PositiveInteger(-3)\n",
200 | "print(i)"
201 | ]
202 | },
203 | {
204 | "cell_type": "markdown",
205 | "metadata": {},
206 | "source": [
207 | "通过重载`__new__`方法,我们实现了需要的功能。\n",
208 | "\n",
209 | "另外一个作用,关于自定义metaclass。其实我最早接触__new__的时候,就是因为需要自定义 metaclass,但鉴于篇幅原因,我们下次再来讲python中的metaclass和__new__的关系。\n",
210 | "\n",
211 | "## 4.用`__new__`来实现单例\n",
212 | "\n",
213 | "事实上,当我们理解了`__new__`方法后,我们还可以利用它来做一些其他有趣的事情,比如实现 设计模式中的 单例模式(singleton) 。\n",
214 | "\n",
215 | "因为类每一次实例化后产生的过程都是通过`__new__`来控制的,所以通过重载`__new__`方法,我们 可以很简单的实现单例模式。"
216 | ]
217 | },
218 | {
219 | "cell_type": "code",
220 | "execution_count": 36,
221 | "metadata": {},
222 | "outputs": [
223 | {
224 | "name": "stdout",
225 | "output_type": "stream",
226 | "text": [
227 | "value1 value1\n",
228 | "True\n"
229 | ]
230 | }
231 | ],
232 | "source": [
233 | "class Singleton(object):\n",
234 | " def __new__(cls):\n",
235 | " # 关键在于这,每一次实例化的时候,我们都只会返回这同一个instance对象\n",
236 | " if not hasattr(cls, 'instance'):\n",
237 | " cls.instance = super(Singleton, cls).__new__(cls)\n",
238 | " return cls.instance\n",
239 | "\n",
240 | "obj1 = Singleton()\n",
241 | "obj2 = Singleton()\n",
242 | " \n",
243 | "obj1.attr1 = 'value1'\n",
244 | "print(obj1.attr1, obj2.attr1)\n",
245 | "print(obj1 is obj2)"
246 | ]
247 | },
248 | {
249 | "cell_type": "markdown",
250 | "metadata": {},
251 | "source": [
252 | "可以看到obj1和obj2是同一个实例。"
253 | ]
254 | }
255 | ],
256 | "metadata": {
257 | "kernelspec": {
258 | "display_name": "Python 3 (Ubuntu Linux)",
259 | "language": "python",
260 | "name": "python3"
261 | },
262 | "language_info": {
263 | "codemirror_mode": {
264 | "name": "ipython",
265 | "version": 3
266 | },
267 | "file_extension": ".py",
268 | "mimetype": "text/x-python",
269 | "name": "python",
270 | "nbconvert_exporter": "python",
271 | "pygments_lexer": "ipython3",
272 | "version": "3.6.7"
273 | }
274 | },
275 | "nbformat": 4,
276 | "nbformat_minor": 2
277 | }
278 |
--------------------------------------------------------------------------------
/Python知识点/__str__ & __repr__.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# `__str__` 和 `__repr__`\n",
8 | "\n",
9 | "什么是内置方法 \n",
10 | "在不是需要程序员定义,本身就存在在类中的方法就是内置方法,名字:双下方法,魔术方法,内置方法 \n",
11 | "如:init 不需要我们主动调用,而是在实例化的时候内部自动调用的。所以双下方法,都不需要我们直接调用,都有另外一种主动触发他的方法\n",
12 | "\n",
13 | "str, repr 内置方法,两者都只能返回字符串,而且都要用return\n",
14 | "\n",
15 | "## 什么情况下触发str: \n",
16 | "- 1 当你打印一个对象的时候, \n",
17 | "- 2 当你使用%格式化的时候 \n",
18 | "- 3 str() 强转数据类型的时候\n",
19 | "\n",
20 | "repr ,repr是str的备胎,有str的时候执行str,没有实现str的时候,执行repr\n",
21 | "\n",
22 | "## 什么情况触发repr \n",
23 | "- 1 repr(obj)内置函数对应的结果是repr的返回值 \n",
24 | "- 2 使用%r格式化的时候触发repr"
25 | ]
26 | },
27 | {
28 | "cell_type": "code",
29 | "execution_count": 1,
30 | "metadata": {},
31 | "outputs": [
32 | {
33 | "name": "stdout",
34 | "output_type": "stream",
35 | "text": [
36 | "1 str : python, 6 month, 20000, Mr. Jin\n",
37 | "1 str : python, 6 month, 20000, Mr. Jin\n",
38 | "1 str : python, 6 month, 20000, Mr. Jin\n",
39 | "1 repr : python, 6 month, 20000, Mr. Jin\n",
40 | "1 repr : python, 6 month, 20000, Mr. Jin\n",
41 | "----\n",
42 | "2 str : linux, 4month, 28000, Miss. Lin\n",
43 | "2 str : linux, 4month, 28000, Miss. Lin\n",
44 | "2 str : linux, 4month, 28000, Miss. Lin\n",
45 | "2 repr : linux, 4month, 28000, Miss. Lin\n",
46 | "2 repr : linux, 4month, 28000, Miss. Lin\n",
47 | "----\n"
48 | ]
49 | }
50 | ],
51 | "source": [
52 | "class Course:\n",
53 | " def __init__(self, name, period, price, teacher):\n",
54 | " self.name = name\n",
55 | " self.period = period\n",
56 | " self.price = price\n",
57 | " self.teacher = teacher\n",
58 | "\n",
59 | " def __str__(self):\n",
60 | " return 'str : {}, {}, {}, {}'.format(self.name, self.period, self.price, self.teacher)\n",
61 | "\n",
62 | " def __repr__(self):\n",
63 | " return 'repr : {}, {}, {}, {}'.format(self.name, self.period, self.price, self.teacher) # self指的是对象\n",
64 | "\n",
65 | "\n",
66 | "course_list = []\n",
67 | "python = Course('python', '6 month', 20000, 'Mr. Jin')\n",
68 | "linux = Course('linux', '4month', 28000, 'Miss. Lin')\n",
69 | "course_list.append(python)\n",
70 | "course_list.append(linux)\n",
71 | "\n",
72 | "for id, course in enumerate(course_list, 1):\n",
73 | " print(id, course) # 1 str : python, 6 month, 20000, Mr. Jin\n",
74 | " print('%s %s' % (id, course)) # 1 str : python, 6 month, 20000, Mr. Jin\n",
75 | " print(id, str(course)) # 1 str : python, 6 month, 20000, Mr. Jin\n",
76 | " print(id,repr(course)) # repr : python, 6 month, 20000, Mr. Jin #\n",
77 | " print(id,'%r' % course) # repr : python, 6 month, 20000, Mr. Jin\n",
78 | " print('----')"
79 | ]
80 | }
81 | ],
82 | "metadata": {
83 | "kernelspec": {
84 | "display_name": "Python 3 (Ubuntu Linux)",
85 | "language": "python",
86 | "name": "python3"
87 | },
88 | "language_info": {
89 | "codemirror_mode": {
90 | "name": "ipython",
91 | "version": 3
92 | },
93 | "file_extension": ".py",
94 | "mimetype": "text/x-python",
95 | "name": "python",
96 | "nbconvert_exporter": "python",
97 | "pygments_lexer": "ipython3",
98 | "version": "3.6.8"
99 | }
100 | },
101 | "nbformat": 4,
102 | "nbformat_minor": 2
103 | }
104 |
--------------------------------------------------------------------------------
/Python知识点/_args & __kwargs.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# [什么是`*args`和`**kwargs`?](https://www.cnblogs.com/fengmk2/archive/2008/04/21/1163766.html)"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [
15 | {
16 | "name": "stdout",
17 | "output_type": "stream",
18 | "text": [
19 | "args = (1, 2, 3, 4)\n",
20 | "kwargs = {}\n",
21 | "---------------------------------------\n",
22 | "args = ()\n",
23 | "kwargs = {'a': 1, 'b': 2, 'c': 3}\n",
24 | "---------------------------------------\n",
25 | "args = (1, 2, 3, 4)\n",
26 | "kwargs = {'a': 1, 'b': 2, 'c': 3}\n",
27 | "---------------------------------------\n",
28 | "args = ('a', 1, None)\n",
29 | "kwargs = {'a': 1, 'b': '2', 'c': 3}\n",
30 | "---------------------------------------\n"
31 | ]
32 | }
33 | ],
34 | "source": [
35 | "def foo(*args, **kwargs):\n",
36 | " print('args = ', args)\n",
37 | " print('kwargs = ', kwargs)\n",
38 | " print('---------------------------------------')\n",
39 | "\n",
40 | "if __name__ == '__main__':\n",
41 | " foo(1,2,3,4)\n",
42 | " foo(a=1,b=2,c=3)\n",
43 | " foo(1,2,3,4, a=1,b=2,c=3)\n",
44 | " foo('a', 1, None, a=1, b='2', c=3)"
45 | ]
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "metadata": {},
50 | "source": [
51 | "**可以看到,这两个是python中的可变参数。**\n",
52 | "\n",
53 | "- `*args`表示任何多个无名参数,它是一个tuple;\n",
54 | "- `**kwargs`表示关键字参数,它是一个dict。\n",
55 | "- 同时使用`*args`和`**kwargs`时,必须`*args`参数列要在`**kwargs`前,像foo(a=1, b='2', c=3, a', 1, None, )这样调用的话,会提示语法错误“SyntaxError: non-keyword arg after keyword arg”。\n",
56 | "\n",
57 | "**还有一个很漂亮的用法,就是创建字典:**"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 2,
63 | "metadata": {},
64 | "outputs": [
65 | {
66 | "name": "stdout",
67 | "output_type": "stream",
68 | "text": [
69 | "{'a': 1, 'b': 2, 'c': 3}\n"
70 | ]
71 | }
72 | ],
73 | "source": [
74 | "def kw_dict(**kwargs):\n",
75 | " return kwargs\n",
76 | "print(kw_dict(a=1,b=2,c=3))"
77 | ]
78 | },
79 | {
80 | "cell_type": "markdown",
81 | "metadata": {},
82 | "source": [
83 | "其实python中就带有dict类,使用dict(a=1,b=2,c=3)即可创建一个字典了。"
84 | ]
85 | },
86 | {
87 | "cell_type": "code",
88 | "execution_count": 3,
89 | "metadata": {},
90 | "outputs": [
91 | {
92 | "data": {
93 | "text/plain": [
94 | "{'a': 1, 'b': 2, 'c': 3}"
95 | ]
96 | },
97 | "execution_count": 3,
98 | "metadata": {},
99 | "output_type": "execute_result"
100 | }
101 | ],
102 | "source": [
103 | "dict(a=1,b=2,c=3)"
104 | ]
105 | }
106 | ],
107 | "metadata": {
108 | "kernelspec": {
109 | "display_name": "Python 3 (Ubuntu Linux)",
110 | "language": "python",
111 | "name": "python3"
112 | },
113 | "language_info": {
114 | "codemirror_mode": {
115 | "name": "ipython",
116 | "version": 3
117 | },
118 | "file_extension": ".py",
119 | "mimetype": "text/x-python",
120 | "name": "python",
121 | "nbconvert_exporter": "python",
122 | "pygments_lexer": "ipython3",
123 | "version": "3.6.7"
124 | }
125 | },
126 | "nbformat": 4,
127 | "nbformat_minor": 2
128 | }
129 |
--------------------------------------------------------------------------------
/Python知识点/class03_实例方法、类方法、静态方法.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 详解类class的方法:实例方法、类方法、静态方法(三)\n",
8 | "\n",
9 | "参考:https://blog.csdn.net/brucewong0516/article/details/79119551\n",
10 | "\n",
11 | "在一个类中,可能出现三种方法,实例方法、静态方法和类方法,下面来看看三种方法的不同:\n",
12 | "\n",
13 | "## 1、实例方法\n",
14 | "\n",
15 | "实例方法的第一个参数必须是”self”,实例方法只能通过类实例进行调用,这时候“self”就代表这个类实例本身。通过”self”可以直接访问实例的属性。"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 1,
21 | "metadata": {},
22 | "outputs": [
23 | {
24 | "name": "stdout",
25 | "output_type": "stream",
26 | "text": [
27 | "Bruce is 25 weights 60\n"
28 | ]
29 | }
30 | ],
31 | "source": [
32 | "class person():\n",
33 | " '''\n",
34 | " this is doc of class\n",
35 | " write doc contents here\n",
36 | " '''\n",
37 | " height = 180\n",
38 | " hobbies = []\n",
39 | " def __init__(self,name,age,weight):\n",
40 | " self.name = name\n",
41 | " self.age = age\n",
42 | " self.weight = weight\n",
43 | " def infoma(self):\n",
44 | " print('%s is %s weights %s'%(self.name,self.age,self.weight))\n",
45 | "\n",
46 | "\n",
47 | "Bruce = person('Bruce',25,60)\n",
48 | "Bruce.infoma()"
49 | ]
50 | },
51 | {
52 | "cell_type": "markdown",
53 | "metadata": {},
54 | "source": [
55 | "## 2、类方法\n",
56 | "\n",
57 | "类方法以cls作为第一个参数,cls表示类本身,定义时使用@classmethod装饰器。通过cls可以访问类的相关属性。"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 3,
63 | "metadata": {},
64 | "outputs": [],
65 | "source": [
66 | "class person(object):\n",
67 | "\n",
68 | " height = 180\n",
69 | " hobbies = []\n",
70 | " def __init__(self, name, age,weight):\n",
71 | " self.name = name\n",
72 | " self.age = age\n",
73 | " self.weight = weight\n",
74 | " @classmethod #类的装饰器\n",
75 | " def infoma(cls): #cls表示类本身,使用类参数cls\n",
76 | " print(cls.__name__)\n",
77 | " print(dir(cls))"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "直接调用类的装饰器函数,通过cls可以访问类的相关属性"
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": 5,
90 | "metadata": {},
91 | "outputs": [
92 | {
93 | "name": "stdout",
94 | "output_type": "stream",
95 | "text": [
96 | "person\n",
97 | "['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'height', 'hobbies', 'infoma']\n"
98 | ]
99 | }
100 | ],
101 | "source": [
102 | "person.infoma() "
103 | ]
104 | },
105 | {
106 | "cell_type": "markdown",
107 | "metadata": {},
108 | "source": [
109 | "也可以通过两步骤来实现,第一步实例化person,第二步调用装饰器"
110 | ]
111 | },
112 | {
113 | "cell_type": "code",
114 | "execution_count": 6,
115 | "metadata": {},
116 | "outputs": [
117 | {
118 | "name": "stdout",
119 | "output_type": "stream",
120 | "text": [
121 | "person\n",
122 | "['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'height', 'hobbies', 'infoma']\n"
123 | ]
124 | }
125 | ],
126 | "source": [
127 | "Bruce = person(\"Bruce\", 25,180)\n",
128 | "Bruce.infoma() "
129 | ]
130 | },
131 | {
132 | "cell_type": "markdown",
133 | "metadata": {},
134 | "source": [
135 | "**类方法可以通过类名访问,也可以通过实例访问**\n",
136 | "\n",
137 | "## 3、静态方法\n",
138 | "\n",
139 | "与实例方法和类方法不同,静态方法没有参数限制,既不需要实例参数,也不需要类参数,定义的时候使用@staticmethod装饰器。\n",
140 | "同类方法一样,静态法可以通过类名访问,也可以通过实例访问。"
141 | ]
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": 7,
146 | "metadata": {},
147 | "outputs": [],
148 | "source": [
149 | "class person(object):\n",
150 | "\n",
151 | " tall = 180\n",
152 | " hobbies = []\n",
153 | " def __init__(self, name, age,weight):\n",
154 | " self.name = name\n",
155 | " self.age = age\n",
156 | " self.weight = weight\n",
157 | " @staticmethod #静态方法装饰器\n",
158 | " def infoma(): #没有参数限制,既不要实例参数,也不用类参数\n",
159 | " print(person.tall)\n",
160 | " print(person.hobbies) "
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": 8,
166 | "metadata": {},
167 | "outputs": [
168 | {
169 | "name": "stdout",
170 | "output_type": "stream",
171 | "text": [
172 | "180\n",
173 | "[]\n"
174 | ]
175 | }
176 | ],
177 | "source": [
178 | "person.infoma() #静态法可以通过类名访问"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": 9,
184 | "metadata": {},
185 | "outputs": [
186 | {
187 | "name": "stdout",
188 | "output_type": "stream",
189 | "text": [
190 | "180\n",
191 | "[]\n"
192 | ]
193 | }
194 | ],
195 | "source": [
196 | "Bruce = person(\"Bruce\", 25,180) #通过实例访问\n",
197 | "Bruce.infoma() "
198 | ]
199 | },
200 | {
201 | "cell_type": "markdown",
202 | "metadata": {},
203 | "source": [
204 | "这三种方法的主要区别在于参数,实例方法被绑定到一个实例,只能通过实例进行调用;但是对于静态方法和类方法,可以通过类名和实例两种方式进行调用。"
205 | ]
206 | }
207 | ],
208 | "metadata": {
209 | "kernelspec": {
210 | "display_name": "Python 3 (Ubuntu Linux)",
211 | "language": "python",
212 | "name": "python3"
213 | },
214 | "language_info": {
215 | "codemirror_mode": {
216 | "name": "ipython",
217 | "version": 3
218 | },
219 | "file_extension": ".py",
220 | "mimetype": "text/x-python",
221 | "name": "python",
222 | "nbconvert_exporter": "python",
223 | "pygments_lexer": "ipython3",
224 | "version": "3.6.8"
225 | }
226 | },
227 | "nbformat": 4,
228 | "nbformat_minor": 2
229 | }
230 |
--------------------------------------------------------------------------------
/Python知识点/class05_super() 初始化方法 类的继承.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "参考:\n",
8 | "\n",
9 | "[【python】详解类class的继承、__init__初始化、super方法(五)](https://blog.csdn.net/brucewong0516/article/details/79121179)"
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {},
15 | "source": [
16 | "# python super()\n",
17 | "\n",
18 | "super() 函数是用于调用父类(超类)的一个方法。\n",
19 | "\n",
20 | "super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。\n",
21 | "\n",
22 | "MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表。\n",
23 | "\n",
24 | "`super(type[, object-or-type])`\n",
25 | "\n",
26 | "- type -- 类。\n",
27 | "- object-or-type -- 类,一般是 self\n",
28 | "\n",
29 | "Python3.x 和 Python2.x 的一个区别是: \n",
30 | "\n",
31 | "**Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx** :"
32 | ]
33 | },
34 | {
35 | "cell_type": "code",
36 | "execution_count": 8,
37 | "metadata": {},
38 | "outputs": [
39 | {
40 | "name": "stdout",
41 | "output_type": "stream",
42 | "text": [
43 | "3\n"
44 | ]
45 | }
46 | ],
47 | "source": [
48 | "class A:\n",
49 | " def add(self, x):\n",
50 | " y = x+1\n",
51 | " print(y)\n",
52 | "class B(A):\n",
53 | " def add(self, x):\n",
54 | " super(B,self).add(x)\n",
55 | "# super().add(x) #同样效果\n",
56 | "b = B()\n",
57 | "b.add(2) # 3"
58 | ]
59 | },
60 | {
61 | "cell_type": "markdown",
62 | "metadata": {},
63 | "source": [
64 | "python2:\n",
65 | "\n",
66 | "```python2\n",
67 | "#!/usr/bin/python\n",
68 | "# -*- coding: UTF-8 -*-\n",
69 | " \n",
70 | "class A(object): # Python2.x 记得继承 object\n",
71 | " def add(self, x):\n",
72 | " y = x+1\n",
73 | " print y\n",
74 | "class B(A):\n",
75 | " def add(self, x):\n",
76 | " super(B, self).add(x)\n",
77 | "b = B()\n",
78 | "b.add(2) # 3\n",
79 | "```"
80 | ]
81 | },
82 | {
83 | "cell_type": "markdown",
84 | "metadata": {},
85 | "source": [
86 | "以下展示了使用 super 函数的实例:"
87 | ]
88 | },
89 | {
90 | "cell_type": "code",
91 | "execution_count": 3,
92 | "metadata": {},
93 | "outputs": [
94 | {
95 | "name": "stdout",
96 | "output_type": "stream",
97 | "text": [
98 | "Parent\n",
99 | "Child\n",
100 | "HelloWorld from Parent\n",
101 | "Child bar fuction\n",
102 | "I'm the parent.\n"
103 | ]
104 | }
105 | ],
106 | "source": [
107 | "#!/usr/bin/python\n",
108 | "# -*- coding: UTF-8 -*-\n",
109 | " \n",
110 | "class FooParent:\n",
111 | " def __init__(self):\n",
112 | " self.parent = 'I\\'m the parent.'\n",
113 | " print ('Parent')\n",
114 | " \n",
115 | " def bar(self,message):\n",
116 | " print (\"%s from Parent\" % message)\n",
117 | "\n",
118 | "class FooChild(FooParent):\n",
119 | " def __init__(self):\n",
120 | " # super(FooChild,self) 首先找到 FooChild 的父类(就是类 FooParent),然后把类 FooChild 的对象转换为类 FooParent 的对象\n",
121 | " super(FooChild,self).__init__()\n",
122 | " print ('Child')\n",
123 | " \n",
124 | " def bar(self,message):\n",
125 | " super(FooChild, self).bar(message)\n",
126 | " print ('Child bar fuction')\n",
127 | " print (self.parent)\n",
128 | " \n",
129 | "if __name__ == '__main__':\n",
130 | " fooChild = FooChild()\n",
131 | " fooChild.bar('HelloWorld')"
132 | ]
133 | },
134 | {
135 | "cell_type": "markdown",
136 | "metadata": {},
137 | "source": [
138 | "## 构造方法、构造函数、初始化函数 `__init__`\n",
139 | "\n",
140 | "我们在学习 Python 类的时候,总会碰见书上的类中有 `__init__()` 这样一个函数,很多同学百思不得其解,其实它就是 Python 的构造方法。\n",
141 | "\n",
142 | "构造方法类似于类似 init() 这种初始化方法,来初始化新创建对象的状态,在一个对象呗创建以后会立即调用,比如像实例化一个类:\n",
143 | "\n",
144 | "实例化一个类:\n",
145 | "```\n",
146 | "f = FooBar()\n",
147 | "f.init()\n",
148 | "```\n",
149 | "使用构造方法就能让它简化成如下形式:\n",
150 | "```\n",
151 | "f = FooBar()\n",
152 | "```"
153 | ]
154 | },
155 | {
156 | "cell_type": "code",
157 | "execution_count": 1,
158 | "metadata": {},
159 | "outputs": [
160 | {
161 | "data": {
162 | "text/plain": [
163 | "42"
164 | ]
165 | },
166 | "execution_count": 1,
167 | "metadata": {},
168 | "output_type": "execute_result"
169 | }
170 | ],
171 | "source": [
172 | "class FooBar:\n",
173 | " def __init__(self):\n",
174 | " self.somevar = 42\n",
175 | "\n",
176 | "f = FooBar()\n",
177 | "f.somevar"
178 | ]
179 | },
180 | {
181 | "cell_type": "markdown",
182 | "metadata": {},
183 | "source": [
184 | "我们会发现在初始化 FooBar 中的 somevar 的值为 42 之后,实例化直接就能够调用 somevar 的值;如果说你没有用构造方法初始化值得话,就不能够调用,\n",
185 | "\n",
186 | "**构造方法中的初始值无法继承的问题。**"
187 | ]
188 | },
189 | {
190 | "cell_type": "code",
191 | "execution_count": 9,
192 | "metadata": {},
193 | "outputs": [
194 | {
195 | "name": "stdout",
196 | "output_type": "stream",
197 | "text": [
198 | "Squawk\n"
199 | ]
200 | }
201 | ],
202 | "source": [
203 | "class Bird:\n",
204 | " def __init__(self):\n",
205 | " self.hungry = True\n",
206 | " def eat(self):\n",
207 | " if self.hungry:\n",
208 | " print 'Ahahahah'\n",
209 | " else:\n",
210 | " print 'No thanks!'\n",
211 | "\n",
212 | "class SongBird(Bird):\n",
213 | " def __init__(self):\n",
214 | " self.sound = 'Squawk'\n",
215 | " def sing(self):\n",
216 | " print self.sound\n",
217 | "\n",
218 | "sb = SongBird()\n",
219 | "sb.sing() # 能正常输出\n",
220 | "# sb.eat() # 报错,因为 songgird 中没有 hungry 特性"
221 | ]
222 | }
223 | ],
224 | "metadata": {
225 | "kernelspec": {
226 | "display_name": "Python 2 (system-wide)",
227 | "language": "python",
228 | "name": "python2"
229 | },
230 | "language_info": {
231 | "codemirror_mode": {
232 | "name": "ipython",
233 | "version": 2
234 | },
235 | "file_extension": ".py",
236 | "mimetype": "text/x-python",
237 | "name": "python",
238 | "nbconvert_exporter": "python",
239 | "pygments_lexer": "ipython2",
240 | "version": "2.7.15+"
241 | }
242 | },
243 | "nbformat": 4,
244 | "nbformat_minor": 2
245 | }
246 |
--------------------------------------------------------------------------------
/Python知识点/python格式化输出.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Python格式化输出(%用法和format用法)\n",
8 | "\n",
9 | "[Python格式化输出](https://www.cnblogs.com/plwang1990/p/3757549.html)\n",
10 | "\n",
11 | "[python基础_格式化输出(%用法和format用法)](https://www.cnblogs.com/fat39/p/7159881.html)\n",
12 | "\n",
13 | "## 1. 打印字符串"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": 13,
19 | "metadata": {},
20 | "outputs": [
21 | {
22 | "name": "stdout",
23 | "output_type": "stream",
24 | "text": [
25 | "His name is Aviad!\n",
26 | "His name is Aviad!\n"
27 | ]
28 | }
29 | ],
30 | "source": [
31 | "print(\"His name is %s!\"%(\"Aviad\"))\n",
32 | "print(\"His name is {}!\".format(\"Aviad\"))"
33 | ]
34 | },
35 | {
36 | "cell_type": "markdown",
37 | "metadata": {},
38 | "source": [
39 | "## 2.打印整数"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": 16,
45 | "metadata": {},
46 | "outputs": [
47 | {
48 | "name": "stdout",
49 | "output_type": "stream",
50 | "text": [
51 | "He is 25 years old.\n",
52 | "He is 25 years old.\n"
53 | ]
54 | }
55 | ],
56 | "source": [
57 | "print(\"He is %d years old.\"%(25))\n",
58 | "print(\"He is {} years old.\".format(25))"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "## 3.打印浮点数"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 19,
71 | "metadata": {},
72 | "outputs": [
73 | {
74 | "name": "stdout",
75 | "output_type": "stream",
76 | "text": [
77 | "His height is 1.830000 m.\n",
78 | "His height is 1.83 m.\n",
79 | "His height is 1.830000 m.\n"
80 | ]
81 | }
82 | ],
83 | "source": [
84 | "print(\"His height is %f m.\"%(1.83)) # %f ——保留小数点后面六位有效数字\n",
85 | "print(\"His height is {} m.\".format(1.83))\n",
86 | "print(\"His height is {:f} m.\".format(1.83))"
87 | ]
88 | },
89 | {
90 | "cell_type": "markdown",
91 | "metadata": {},
92 | "source": [
93 | "## 4.打印浮点数(指定保留小数点位数)"
94 | ]
95 | },
96 | {
97 | "cell_type": "code",
98 | "execution_count": 11,
99 | "metadata": {},
100 | "outputs": [
101 | {
102 | "name": "stdout",
103 | "output_type": "stream",
104 | "text": [
105 | "His height is 1.83 m.\n",
106 | "His height is 1.83 m.\n",
107 | "His height is 1.8 m.\n"
108 | ]
109 | }
110 | ],
111 | "source": [
112 | "# 使用 %.2f\n",
113 | "\n",
114 | "print(\"His height is %.2f m.\"%(1.83))\n",
115 | "\n",
116 | "# 保留两位小数,使用format的{:.2f} \n",
117 | "\n",
118 | "print(\"His height is {:.2f} m.\".format(1.83))\n",
119 | "\n",
120 | "# 保留两位有效数字:使用format的{:.2}(没有f)\n",
121 | "\n",
122 | "print(\"His height is {:.2} m.\".format(1.83))"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "## 5.指定占位符宽度"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 12,
135 | "metadata": {},
136 | "outputs": [
137 | {
138 | "name": "stdout",
139 | "output_type": "stream",
140 | "text": [
141 | "Name: Aviad Age: 25 Height: 1.83\n",
142 | "Name: Bob Age: 30 Height: 1.78\n",
143 | "Name:Aviad Age: 25 Height: 1.83\n",
144 | "Name:Bob Age: 30 Height: 1.78\n"
145 | ]
146 | }
147 | ],
148 | "source": [
149 | "print(\"Name:%10s Age:%8d Height:%8.2f\"%(\"Aviad\",25,1.83))\n",
150 | "print(\"Name:%10s Age:%8d Height:%8.2f\"%(\"Bob\",30,1.78))\n",
151 | "\n",
152 | "print(\"Name:{:10s} Age:{:8d} Height:{:8.2f}\".format(\"Aviad\",25,1.83))\n",
153 | "print(\"Name:{:10s} Age:{:8d} Height:{:8.2f}\".format(\"Bob\",30,1.78))"
154 | ]
155 | },
156 | {
157 | "cell_type": "markdown",
158 | "metadata": {},
159 | "source": [
160 | "## 6.指定占位符宽度(左对齐)"
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": 7,
166 | "metadata": {},
167 | "outputs": [
168 | {
169 | "name": "stdout",
170 | "output_type": "stream",
171 | "text": [
172 | "Name:Aviad Age:25 Height:1.83 \n",
173 | "Name:Bob Age:30 Height:1.78 \n"
174 | ]
175 | }
176 | ],
177 | "source": [
178 | "print(\"Name:%-10s Age:%-8d Height:%-8.2f\"%(\"Aviad\",25,1.83))\n",
179 | "print(\"Name:%-10s Age:%-8d Height:%-8.2f\"%(\"Bob\",30,1.78))"
180 | ]
181 | },
182 | {
183 | "cell_type": "markdown",
184 | "metadata": {},
185 | "source": [
186 | "## 7.指定占位符(只能用0当占位符?)"
187 | ]
188 | },
189 | {
190 | "cell_type": "code",
191 | "execution_count": 17,
192 | "metadata": {},
193 | "outputs": [
194 | {
195 | "name": "stdout",
196 | "output_type": "stream",
197 | "text": [
198 | "Name:Aviad Age:00000025 Height:00001.83\n",
199 | "Name:Bob Age:00000030 Height:00001.78\n"
200 | ]
201 | }
202 | ],
203 | "source": [
204 | "print(\"Name:%-10s Age:%08d Height:%08.2f\"%(\"Aviad\",25,1.83))\n",
205 | "print(\"Name:%-10s Age:%08d Height:%08.2f\"%(\"Bob\",30,1.78))"
206 | ]
207 | },
208 | {
209 | "cell_type": "markdown",
210 | "metadata": {},
211 | "source": [
212 | "## 8.科学计数法"
213 | ]
214 | },
215 | {
216 | "cell_type": "code",
217 | "execution_count": 24,
218 | "metadata": {},
219 | "outputs": [
220 | {
221 | "name": "stdout",
222 | "output_type": "stream",
223 | "text": [
224 | "1.50e-03\n",
225 | "2.789e-05\n"
226 | ]
227 | }
228 | ],
229 | "source": [
230 | "print(format(0.0015,'.2e')) # .2为保留两位小数,e表示采用科学计数法\n",
231 | "print(format(0.0000278867,'.3e'))"
232 | ]
233 | }
234 | ],
235 | "metadata": {
236 | "kernelspec": {
237 | "display_name": "tf36",
238 | "language": "python",
239 | "name": "tf36"
240 | },
241 | "language_info": {
242 | "codemirror_mode": {
243 | "name": "ipython",
244 | "version": 3
245 | },
246 | "file_extension": ".py",
247 | "mimetype": "text/x-python",
248 | "name": "python",
249 | "nbconvert_exporter": "python",
250 | "pygments_lexer": "ipython3",
251 | "version": "3.6.8"
252 | }
253 | },
254 | "nbformat": 4,
255 | "nbformat_minor": 2
256 | }
257 |
--------------------------------------------------------------------------------
/Python知识点/单例模式.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# [由Python通过__new__实现单例模式,所想到的`__new__`和`__init__`方法的区别](https://www.cnblogs.com/qiaojushuang/p/7805973.html)\n",
8 | "\n",
9 | "单例模式是确保一个类只有一个实例,并且这个实例是自己创造的,在系统中用到的都是这个实例。单例模式是设计模式的一种,关于设计模式和单例模式更具体的内容,可以查看相关的书本\n",
10 | "\n",
11 | "下面主要说下`__new__`是用来干什么的,在Python中,`__new__`是用来创造一个类的实例的,而`__init__`是用来初始化这个实例的。既然`__new__`用来创造实例,也就需要最后返回相应类的实例,那么如果返回的是其他类的实例,结果如何呢?见下面的代码。以下代码运行后,首先打印出`NoReturn __new__`然后打印出`other instance`,最后通过`type(t)`可以看到t的类型是``,可以知道如果`__new__`中不返回本类的实例的话,是没法调用`__init__`方法的。想要返回本类的实例,只需要把以下代码中12行的`Other()`改成`super(NoReturn, cls).__new__(cls, *args, **kwargs)`即可。"
12 | ]
13 | },
14 | {
15 | "cell_type": "code",
16 | "execution_count": 8,
17 | "metadata": {},
18 | "outputs": [
19 | {
20 | "name": "stdout",
21 | "output_type": "stream",
22 | "text": [
23 | "3\n"
24 | ]
25 | }
26 | ],
27 | "source": []
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": null,
32 | "metadata": {},
33 | "outputs": [],
34 | "source": []
35 | },
36 | {
37 | "cell_type": "code",
38 | "execution_count": 2,
39 | "metadata": {},
40 | "outputs": [
41 | {
42 | "name": "stdout",
43 | "output_type": "stream",
44 | "text": [
45 | "NoReturn __new__\n",
46 | "other instance\n",
47 | "\n"
48 | ]
49 | }
50 | ],
51 | "source": [
52 | "class Other(object):\n",
53 | " val = 123\n",
54 | "\n",
55 | " def __init__(self):\n",
56 | " print ('other instance')\n",
57 | "\n",
58 | "\n",
59 | "class NoReturn(object):\n",
60 | "\n",
61 | " def __new__(cls, *args, **kwargs):\n",
62 | " print ('NoReturn __new__')\n",
63 | " return Other()\n",
64 | "\n",
65 | " def __init__(self, a):\n",
66 | " print (a)\n",
67 | " print ('NoReturn __init__')\n",
68 | "\n",
69 | "t = NoReturn(12)\n",
70 | "print (type(t))"
71 | ]
72 | },
73 | {
74 | "cell_type": "code",
75 | "execution_count": 1,
76 | "metadata": {},
77 | "outputs": [
78 | {
79 | "name": "stdout",
80 | "output_type": "stream",
81 | "text": [
82 | "NoReturn __new__\n"
83 | ]
84 | },
85 | {
86 | "ename": "TypeError",
87 | "evalue": "object() takes no parameters",
88 | "output_type": "error",
89 | "traceback": [
90 | "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
91 | "\u001b[0;31mTypeError\u001b[0m Traceback (most recent call last)",
92 | "\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 16\u001b[0m \u001b[0mprint\u001b[0m \u001b[0;34m(\u001b[0m\u001b[0;34m'NoReturn __init__'\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 17\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m---> 18\u001b[0;31m \u001b[0mt\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mNoReturn\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;36m12\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 19\u001b[0m \u001b[0mprint\u001b[0m \u001b[0;34m(\u001b[0m\u001b[0mtype\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mt\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
93 | "\u001b[0;32m\u001b[0m in \u001b[0;36m__new__\u001b[0;34m(cls, *args, **kwargs)\u001b[0m\n\u001b[1;32m 10\u001b[0m \u001b[0;32mdef\u001b[0m \u001b[0m__new__\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mcls\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m*\u001b[0m\u001b[0margs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m**\u001b[0m\u001b[0mkwargs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 11\u001b[0m \u001b[0mprint\u001b[0m \u001b[0;34m(\u001b[0m\u001b[0;34m'NoReturn __new__'\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m---> 12\u001b[0;31m \u001b[0;32mreturn\u001b[0m \u001b[0msuper\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mNoReturn\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mcls\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0m__new__\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mcls\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m*\u001b[0m\u001b[0margs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0;34m**\u001b[0m\u001b[0mkwargs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 13\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 14\u001b[0m \u001b[0;32mdef\u001b[0m \u001b[0m__init__\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mself\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0ma\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
94 | "\u001b[0;31mTypeError\u001b[0m: object() takes no parameters"
95 | ]
96 | }
97 | ],
98 | "source": [
99 | "class Other(object):\n",
100 | " val = 123\n",
101 | "\n",
102 | " def __init__(self):\n",
103 | " print ('other instance')\n",
104 | "\n",
105 | "\n",
106 | "class NoReturn(object):\n",
107 | "\n",
108 | " def __new__(cls, *args, **kwargs):\n",
109 | " print ('NoReturn __new__')\n",
110 | " return super(NoReturn, cls).__new__(cls, *args, **kwargs)\n",
111 | "\n",
112 | " def __init__(self, a):\n",
113 | " print (a)\n",
114 | " print ('NoReturn __init__')\n",
115 | "\n",
116 | "t = NoReturn(12)\n",
117 | "print (type(t))"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": 6,
123 | "metadata": {},
124 | "outputs": [],
125 | "source": [
126 | "class SingleTon(object):\n",
127 | " _instance = {}\n",
128 | "\n",
129 | " def __new__(cls, *args, **kwargs):\n",
130 | " if cls not in cls._instance:\n",
131 | " cls._instance[cls] = super(SingleTon, cls).__new__(cls, *args, **kwargs)\n",
132 | " print (cls._instance)\n",
133 | " return cls._instance[cls]\n",
134 | "\n",
135 | "\n",
136 | "class MyClass(SingleTon):\n",
137 | " class_val = 22"
138 | ]
139 | },
140 | {
141 | "cell_type": "code",
142 | "execution_count": 9,
143 | "metadata": {},
144 | "outputs": [
145 | {
146 | "name": "stdout",
147 | "output_type": "stream",
148 | "text": [
149 | "{: <__main__.MyClass object at 0x7f463708be10>}\n"
150 | ]
151 | },
152 | {
153 | "data": {
154 | "text/plain": [
155 | "22"
156 | ]
157 | },
158 | "execution_count": 9,
159 | "metadata": {},
160 | "output_type": "execute_result"
161 | }
162 | ],
163 | "source": [
164 | "a = MyClass(12)\n",
165 | "a.class_val"
166 | ]
167 | }
168 | ],
169 | "metadata": {
170 | "kernelspec": {
171 | "display_name": "Python 3 (system-wide)",
172 | "language": "python",
173 | "name": "python3"
174 | },
175 | "language_info": {
176 | "codemirror_mode": {
177 | "name": "ipython",
178 | "version": 3
179 | },
180 | "file_extension": ".py",
181 | "mimetype": "text/x-python",
182 | "name": "python",
183 | "nbconvert_exporter": "python",
184 | "pygments_lexer": "ipython3",
185 | "version": "3.6.8"
186 | }
187 | },
188 | "nbformat": 4,
189 | "nbformat_minor": 2
190 | }
191 |
--------------------------------------------------------------------------------
/Python知识点/尾递归.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "https://www.zhihu.com/question/20761771"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [
15 | {
16 | "name": "stdout",
17 | "output_type": "stream",
18 | "text": [
19 | "3919377061614427623668052985592742430389065042819420493170692719480242247392252775480208752179017313071371501566248877239254299341332131655760767122899079117071192049598939666199865808814650408864891823186505\n"
20 | ]
21 | }
22 | ],
23 | "source": [
24 | "def fib(count, cur=0, next_=1):\n",
25 | " if count <= 1:\n",
26 | " yield cur\n",
27 | " else:\n",
28 | " # Notice that this is the tail-recursive version\n",
29 | " # of fib.\n",
30 | " yield fib(count-1, next_, cur + next_)\n",
31 | "\n",
32 | "import types\n",
33 | "\n",
34 | "def tramp(gen, *args, **kwargs):\n",
35 | " g = gen(*args, **kwargs)\n",
36 | " while isinstance(g, types.GeneratorType):\n",
37 | " g=g.__next__()\n",
38 | " return g\n",
39 | "print(tramp(fib, 996))"
40 | ]
41 | }
42 | ],
43 | "metadata": {
44 | "kernelspec": {
45 | "display_name": "tf36",
46 | "language": "python",
47 | "name": "tf36"
48 | },
49 | "language_info": {
50 | "codemirror_mode": {
51 | "name": "ipython",
52 | "version": 3
53 | },
54 | "file_extension": ".py",
55 | "mimetype": "text/x-python",
56 | "name": "python",
57 | "nbconvert_exporter": "python",
58 | "pygments_lexer": "ipython3",
59 | "version": "3.6.8"
60 | }
61 | },
62 | "nbformat": 4,
63 | "nbformat_minor": 2
64 | }
65 |
--------------------------------------------------------------------------------
/Python知识点/栈和队列.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# python数据结构与算法——栈和队列(Stack & Queue)\n",
8 | "\n",
9 | "Ref:\n",
10 | "- https://www.cnblogs.com/yangecnu/p/Introduction-Stack-and-Queue.html\n",
11 | "\n",
12 | "概念很简单,栈 (Stack)是一种后进先出(last in first off,LIFO)的数据结构,而队列(Queue)则是一种先进先出 (fisrt in first out,FIFO)的结构,如下图:\n",
13 | "\n",
14 | ""
15 | ]
16 | }
17 | ],
18 | "metadata": {
19 | "kernelspec": {
20 | "display_name": "Python 3 (system-wide)",
21 | "language": "python",
22 | "name": "python3"
23 | },
24 | "language_info": {
25 | "codemirror_mode": {
26 | "name": "ipython",
27 | "version": 3
28 | },
29 | "file_extension": ".py",
30 | "mimetype": "text/x-python",
31 | "name": "python",
32 | "nbconvert_exporter": "python",
33 | "pygments_lexer": "ipython3",
34 | "version": "3.6.8"
35 | }
36 | },
37 | "nbformat": 4,
38 | "nbformat_minor": 2
39 | }
40 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # PythonAlgorithm
2 |
3 | 全部为Jupyter Notebook格式
4 |
5 | 获取更好访问效果,请使用nbviewer链接进行查看:点击查看
6 |
7 | ## Python数据结构与算法基础
8 | ## 算法图解
9 | - [第1章 算法简介](./算法图解/chap01-算法简介.ipynb)
10 | - 二分查找
11 | - [第2章 选择排序](./算法图解/chap02-选择排序.ipynb)
12 | - 选择排序
13 | - [第3章 递归](./算法图解/chap03-递归.ipynb)
14 | - [第4章 快速排序](./算法图解/chap04-快速排序.ipynb)
15 | - [第5章 散列表](./算法图解/chap05-散列表.ipynb)
16 | - [第6章 广度优先搜索](./算法图解/chap06-广度优先搜索.ipynb)
17 | - [第7章 狄克斯特拉算法](./算法图解/chap07-狄克斯特拉算法Dijkstra’s-algorithm.ipynb)
18 | - [第8章 贪婪算法](./算法图解/chap08-贪婪算法.ipynb)
19 | - [第9章 动态规划](./算法图解/chap09-动态规划.ipynb)
20 |
21 | ## 剑指Offer
22 |
23 | ## 常见算法
24 |
25 | ## Python知识点
26 |
--------------------------------------------------------------------------------
/剑指Offer/chap00_剑指Offer目录.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "collapsed": false
7 | },
8 | "source": [
9 | "# 《剑指Offer》面试题: Python实现\n",
10 | "\n",
11 | "Github : https://github.com/JushuangQiao/Python-Offer\n",
12 | "\n",
13 | "《剑指Offer》第二版源代码(原书附):https://github.com/zhedahht/CodingInterviewChinese2\n",
14 | "\n",
15 | "\n",
16 | "# 第2章 面试基础知识\n",
17 | "\n",
18 | "## 2.2 编程语言\n",
19 | "\n",
20 | "### 面试题2 使用Python实现单例模式\n",
21 | "\n",
22 | "## 2.3 数据结构\n",
23 | "\n",
24 | "### 面试题3 二维数组中的查找\n",
25 | "\n",
26 | "### 面试题4 替换空格\n",
27 | "\n",
28 | "### 面试题5 从尾到头打印单链表\n",
29 | "\n",
30 | "### 面试题6 重建二叉树\n",
31 | "\n",
32 | "### 面试题7 用两个栈实现队列\n",
33 | "\n",
34 | "## 2.4 算法和数据操作\n",
35 | "\n",
36 | "### 面试题8 旋转数组的最小数字\n",
37 | "\n",
38 | "### 面试题9 斐波那契数列\n",
39 | "\n",
40 | "### 面试题10 二进制中1的个数\n",
41 | "\n",
42 | "# 第3章 高质量代码\n",
43 | "\n",
44 | "## 3.3 代码的完整性\n",
45 | "\n",
46 | "### 面试题11 数值的整数次方\n",
47 | "\n",
48 | "### 面试题12 打印1到最大的n位数\n",
49 | "\n",
50 | "### 面试题13 O(1)时间删除链表结点\n",
51 | "\n",
52 | "### 面试题14 调整数组顺序使寄数位于偶数前面\n",
53 | "\n",
54 | "## 3.4 代码的鲁棒性\n",
55 | "\n",
56 | "### 面试题15 链表中倒数第k个结点\n",
57 | "\n",
58 | "### 面试题16 反转链表\n",
59 | "\n",
60 | "### 面试题17 合并两个排序的链表\n",
61 | "\n",
62 | "### 面试题18 树的子结构\n",
63 | "\n",
64 | "# 第4章 解决### 面试题思路\n",
65 | "\n",
66 | "## 4.2 画图让抽象问题形象化\n",
67 | "\n",
68 | "### 面试题19 二叉树的镜像\n",
69 | "\n",
70 | "### 面试题20 顺时针打印矩阵\n",
71 | "\n",
72 | "## 4.3 举例让抽象问题具体化\n",
73 | "\n",
74 | "### 面试题21 包含min函数的栈\n",
75 | "\n",
76 | "### 面试题22 栈的压入弹出序列\n",
77 | "\n",
78 | "### 面试题23 从上往下打印二叉树\n",
79 | "\n",
80 | "### 面试题24 二叉树的后序遍历序列\n",
81 | "\n",
82 | "### 面试题25 二叉树中和为某一值的路径\n",
83 | "\n",
84 | "## 4.4 分解让复杂问题简单化\n",
85 | "\n",
86 | "### 面试题26 复杂链表的复制\n",
87 | "\n",
88 | "### 面试题27 二叉搜索树与双向链表\n",
89 | "\n",
90 | "### 面试题28 字符串的排列\n",
91 | "\n",
92 | "# 第5章 优化时间和空间效率\n",
93 | "\n",
94 | "## 5.2 时间效率\n",
95 | "\n",
96 | "### 面试题29 数组中出现次数超过一半的数字\n",
97 | "\n",
98 | "### 面试题30 最小的k个数\n",
99 | "\n",
100 | "### 面试题31 连续子数组的最大和\n",
101 | "\n",
102 | "### 面试题32 从1到n整数中1出现的次数\n",
103 | "\n",
104 | "### 面试题33 把数组排成最小的数\n",
105 | "\n",
106 | "## 5.3 时间效率与空间效率的平衡\n",
107 | "\n",
108 | "### 面试题34 丑数\n",
109 | "\n",
110 | "### 面试题35 第一个只出现一次的字符\n",
111 | "\n",
112 | "### 面试题36 数组中的逆序对\n",
113 | "\n",
114 | "### 面试题37 两个链表的第一个公共结点\n",
115 | "\n",
116 | "# 第6章 面试能力\n",
117 | "\n",
118 | "## 6.3 知识迁移能力\n",
119 | "\n",
120 | "### 面试题38 数字在排序数组中出现的次数\n",
121 | "\n",
122 | "### 面试题39 二叉树的深度\n",
123 | "\n",
124 | "### 面试题40 数组中只出现一次的数字\n",
125 | "\n",
126 | "### 面试题41 和为s的两个数字VS和为s的连续正数序列\n",
127 | "\n",
128 | "### 面试题42 翻转单词顺序与左旋转字符串\n",
129 | "\n",
130 | "## 6.4 抽象建模能力\n",
131 | "\n",
132 | "### 面试题43 n个骰子的点数\n",
133 | "\n",
134 | "### 面试题44 扑克牌的顺子\n",
135 | "\n",
136 | "### 面试题45 圆圈中最后剩下的数字\n",
137 | "\n",
138 | "## 6.5 发散思维能力\n",
139 | "\n",
140 | "### 面试题46 求## 1+2...+n\n",
141 | "\n",
142 | "### 面试题47 不用加减乘除做加法\n",
143 | "\n",
144 | "### 面试题48 不能被继承的类\n",
145 | "\n",
146 | "# 第7章 面试案例\n",
147 | "\n",
148 | "## 7.1 案例一\n",
149 | "\n",
150 | "### 面试题49 把字符串转化成整数\n",
151 | "\n",
152 | "## 7.2 案例二\n",
153 | "\n",
154 | "### 面试题50 树中两个结点的最低公共祖先\n"
155 | ]
156 | }
157 | ],
158 | "metadata": {
159 | "kernelspec": {
160 | "display_name": "Python 3 (system-wide)",
161 | "language": "python",
162 | "metadata": {
163 | "cocalc": {
164 | "description": "Python 3 programming language",
165 | "priority": 100,
166 | "url": "https://www.python.org/"
167 | }
168 | },
169 | "name": "python3"
170 | },
171 | "language_info": {
172 | "codemirror_mode": {
173 | "name": "ipython",
174 | "version": 3
175 | },
176 | "file_extension": ".py",
177 | "mimetype": "text/x-python",
178 | "name": "python",
179 | "nbconvert_exporter": "python",
180 | "pygments_lexer": "ipython3",
181 | "version": "3.6.8"
182 | }
183 | },
184 | "nbformat": 4,
185 | "nbformat_minor": 0
186 | }
--------------------------------------------------------------------------------
/剑指Offer/chap01_面试的流程.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "面试题1:赋值运算符函数\n",
8 | "\n",
9 | "题目:如下为类型CMyString的声明,请为该类型添加赋值运算符函数\n",
10 | "\n",
11 | "参考:\n",
12 | "\n",
13 | "https://github.com/zhedahht/CodingInterviewChinese2/blob/master/01_AssignmentOperator/AssignmentOperator.cpp\n",
14 | "\n",
15 | "详情见电子书第1章"
16 | ]
17 | }
18 | ],
19 | "metadata": {
20 | "kernelspec": {
21 | "display_name": "Python 3 (Ubuntu Linux)",
22 | "language": "python",
23 | "name": "python3"
24 | },
25 | "language_info": {
26 | "codemirror_mode": {
27 | "name": "ipython",
28 | "version": 3
29 | },
30 | "file_extension": ".py",
31 | "mimetype": "text/x-python",
32 | "name": "python",
33 | "nbconvert_exporter": "python",
34 | "pygments_lexer": "ipython3",
35 | "version": "3.6.7"
36 | }
37 | },
38 | "nbformat": 4,
39 | "nbformat_minor": 2
40 | }
41 |
--------------------------------------------------------------------------------
/剑指Offer/二叉树.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 2,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "# coding=utf-8\n",
10 | "\n",
11 | "\"\"\"\n",
12 | "使用先序遍历和中序遍历的结果重建二叉树\n",
13 | "\"\"\"\n",
14 | "from collections import deque\n",
15 | "\n",
16 | "class TreeNode(object):\n",
17 | " \"\"\"\n",
18 | " 二叉树结点定义\n",
19 | " \"\"\"\n",
20 | " def __init__(self, x):\n",
21 | " self.val = x\n",
22 | " self.left = None\n",
23 | " self.right = None"
24 | ]
25 | },
26 | {
27 | "cell_type": "code",
28 | "execution_count": 2,
29 | "metadata": {},
30 | "outputs": [
31 | {
32 | "name": "stdout",
33 | "output_type": "stream",
34 | "text": [
35 | "[1, 2, 3, 4, 5, 6, 7, 8]\n",
36 | "[1, 2, 4, 7, 3, 5, 6, 8]\n",
37 | "[4, 7, 2, 1, 5, 3, 8, 6]\n",
38 | "[7, 4, 2, 5, 8, 6, 3, 1]\n"
39 | ]
40 | }
41 | ],
42 | "source": [
43 | "class Tree(object):\n",
44 | " \"\"\"\n",
45 | " 二叉树\n",
46 | " \"\"\"\n",
47 | " def __init__(self):\n",
48 | " self.root = None\n",
49 | "\n",
50 | " def bfs(self):\n",
51 | " ret = []\n",
52 | " queue = deque([self.root])\n",
53 | " while queue:\n",
54 | " node = queue.popleft()\n",
55 | " if node:\n",
56 | " ret.append(node.val)\n",
57 | " queue.append(node.left)\n",
58 | " queue.append(node.right)\n",
59 | " return ret\n",
60 | "\n",
61 | " def pre_traversal(self):\n",
62 | " ret = []\n",
63 | "\n",
64 | " def traversal(head):\n",
65 | " if not head:\n",
66 | " return\n",
67 | " ret.append(head.val)\n",
68 | " traversal(head.left)\n",
69 | " traversal(head.right)\n",
70 | "\n",
71 | " traversal(self.root)\n",
72 | " return ret\n",
73 | "\n",
74 | " def in_traversal(self):\n",
75 | " ret = []\n",
76 | "\n",
77 | " def traversal(head):\n",
78 | " if not head:\n",
79 | " return\n",
80 | " traversal(head.left)\n",
81 | " ret.append(head.val)\n",
82 | " traversal(head.right)\n",
83 | "\n",
84 | " traversal(self.root)\n",
85 | " return ret\n",
86 | "\n",
87 | " def post_traversal(self):\n",
88 | " ret = []\n",
89 | "\n",
90 | " def traversal(head):\n",
91 | " if not head:\n",
92 | " return\n",
93 | " traversal(head.left)\n",
94 | " traversal(head.right)\n",
95 | " ret.append(head.val)\n",
96 | "\n",
97 | " traversal(self.root)\n",
98 | " return ret\n",
99 | "\n",
100 | "\n",
101 | "def construct_tree(preorder=None, inorder=None):\n",
102 | " \"\"\"\n",
103 | " 构建二叉树\n",
104 | " \"\"\"\n",
105 | " if not preorder or not inorder:\n",
106 | " return None\n",
107 | " index = inorder.index(preorder[0])\n",
108 | " left = inorder[0:index]\n",
109 | " right = inorder[index+1:]\n",
110 | " root = TreeNode(preorder[0])\n",
111 | " root.left = construct_tree(preorder[1:1+len(left)], left)\n",
112 | " root.right = construct_tree(preorder[-len(right):], right)\n",
113 | " return root\n",
114 | "\n",
115 | "\n",
116 | "if __name__ == '__main__':\n",
117 | " t = Tree()\n",
118 | " root = construct_tree([1, 2, 4, 7, 3, 5, 6, 8], [4, 7, 2, 1, 5, 3, 8, 6])\n",
119 | " t.root = root\n",
120 | " print(t.bfs())\n",
121 | " print(t.pre_traversal())\n",
122 | " print(t.in_traversal())\n",
123 | " print(t.post_traversal())"
124 | ]
125 | }
126 | ],
127 | "metadata": {
128 | "kernelspec": {
129 | "display_name": "Python 3 (system-wide)",
130 | "language": "python",
131 | "name": "python3"
132 | },
133 | "language_info": {
134 | "codemirror_mode": {
135 | "name": "ipython",
136 | "version": 3
137 | },
138 | "file_extension": ".py",
139 | "mimetype": "text/x-python",
140 | "name": "python",
141 | "nbconvert_exporter": "python",
142 | "pygments_lexer": "ipython3",
143 | "version": "3.6.8"
144 | }
145 | },
146 | "nbformat": 4,
147 | "nbformat_minor": 2
148 | }
149 |
--------------------------------------------------------------------------------
/剑指Offer/剑指Offer 名企面试官精讲典型编程题 第二版.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/EvanLi/PythonAlgorithm/330a9dee2fe4367e3bf63a8bf35c6ba79d101e94/剑指Offer/剑指Offer 名企面试官精讲典型编程题 第二版.pdf
--------------------------------------------------------------------------------
/剑指Offer/剑指Offer.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 剑指Offer\n",
8 | "\n",
9 | "# 1.二维数组中的查找\n",
10 | "## 题目描述\n",
11 | "\n",
12 | "在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。\n",
13 | "\n",
14 | "\n",
15 | "> 从左下角元素往上查找,右边元素是比这个元素大,上边是的元素比这个元素小。于是,target比这个元素小就往上找,比这个元素大就往右找。如果出了边界,则说明二维数组中不存在target元素。"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 1,
21 | "metadata": {
22 | "collapsed": false
23 | },
24 | "outputs": [],
25 | "source": [
26 | "# -*- coding:utf-8 -*-\n",
27 | "class Solution:\n",
28 | " # array 二维列表\n",
29 | " def Find(self, target, array):\n",
30 | " # write code here\n",
31 | " if not array:\n",
32 | " return False\n",
33 | " row,col = len(array),len(array[0])\n",
34 | "# 从左下角开始\n",
35 | " i,j = row-1,0\n",
36 | " while i >=0 and j target:\n",
40 | " i -= 1\n",
41 | " else:\n",
42 | " j +=1\n",
43 | " return False"
44 | ]
45 | },
46 | {
47 | "cell_type": "markdown",
48 | "metadata": {},
49 | "source": [
50 | "测试:"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 3,
56 | "metadata": {
57 | "collapsed": false
58 | },
59 | "outputs": [
60 | {
61 | "data": {
62 | "text/plain": [
63 | "True"
64 | ]
65 | },
66 | "execution_count": 3,
67 | "metadata": {},
68 | "output_type": "execute_result"
69 | }
70 | ],
71 | "source": [
72 | "array = [[1,2,3],\n",
73 | " [4,5,6],\n",
74 | " [7,8,9]]\n",
75 | "\n",
76 | "solu = Solution()\n",
77 | "solu.Find(9,array)"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "# 2.替换空格\n",
85 | "## 题目描述\n",
86 | "\n",
87 | "请实现一个函数,将一个字符串中的每个空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。"
88 | ]
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": 4,
93 | "metadata": {
94 | "collapsed": false
95 | },
96 | "outputs": [],
97 | "source": [
98 | "# -*- coding:utf-8 -*-\n",
99 | "class Solution:\n",
100 | " # s 源字符串\n",
101 | " def replaceSpace(self, s):\n",
102 | " # write code here\n",
103 | " l = len(s)\n",
104 | " s_out = ''\n",
105 | " for i in range(l):\n",
106 | " if(s[i]!=' '):\n",
107 | " s_out += s[i]\n",
108 | " else:\n",
109 | " s_out += \"%20\"\n",
110 | " return s_out"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "metadata": {},
116 | "source": [
117 | "利用join,使用%20连接列表元素即可"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": 7,
123 | "metadata": {
124 | "collapsed": false
125 | },
126 | "outputs": [],
127 | "source": [
128 | "# -*- coding:utf-8 -*-\n",
129 | "class Solution:\n",
130 | " # s 源字符串\n",
131 | " def replaceSpace(self, s):\n",
132 | " return \"%20\".join(list(s.split(\" \")))"
133 | ]
134 | },
135 | {
136 | "cell_type": "markdown",
137 | "metadata": {},
138 | "source": [
139 | "replace函数"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 9,
145 | "metadata": {
146 | "collapsed": false
147 | },
148 | "outputs": [],
149 | "source": [
150 | "# -*- coding:utf-8 -*-\n",
151 | "class Solution:\n",
152 | " # s 源字符串\n",
153 | " def replaceSpace(self, s):\n",
154 | " # write code here\n",
155 | " return s.replace(' ','%20')"
156 | ]
157 | },
158 | {
159 | "cell_type": "markdown",
160 | "metadata": {},
161 | "source": [
162 | "正则表达式:"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": 11,
168 | "metadata": {
169 | "collapsed": false
170 | },
171 | "outputs": [],
172 | "source": [
173 | "# -*- coding:utf-8 -*-\n",
174 | "class Solution:\n",
175 | " # s 源字符串\n",
176 | " def replaceSpace(self, s):\n",
177 | " # write code here\n",
178 | " import re\n",
179 | " ret = re.compile(' ')\n",
180 | " return ret.sub('%20',s)"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 12,
186 | "metadata": {
187 | "collapsed": false
188 | },
189 | "outputs": [
190 | {
191 | "data": {
192 | "text/plain": [
193 | "'We%20Are%20Happy'"
194 | ]
195 | },
196 | "execution_count": 12,
197 | "metadata": {},
198 | "output_type": "execute_result"
199 | }
200 | ],
201 | "source": [
202 | "solu = Solution()\n",
203 | "solu.replaceSpace(\"We Are Happy\")"
204 | ]
205 | },
206 | {
207 | "cell_type": "markdown",
208 | "metadata": {},
209 | "source": [
210 | "# 3.从尾到头打印单链表\n",
211 | "\n",
212 | "## 题目描述\n",
213 | "\n",
214 | "输入一个链表,按链表值从尾到头的顺序返回一个ArrayList。\n",
215 | "\n",
216 | "方法1:使用栈,可以使用列表模拟"
217 | ]
218 | },
219 | {
220 | "cell_type": "code",
221 | "execution_count": 17,
222 | "metadata": {
223 | "collapsed": false
224 | },
225 | "outputs": [],
226 | "source": [
227 | "# -*- coding:utf-8 -*-\n",
228 | "\n",
229 | "class ListNode:\n",
230 | " def __init__(self, x):\n",
231 | " self.val = x\n",
232 | " self.next = None\n",
233 | "\n",
234 | "class Solution:\n",
235 | " # 返回从尾部到头部的列表值序列,例如[1,2,3]\n",
236 | " def printListFromTailToHead(self, listNode):\n",
237 | " # write code here\n",
238 | " stack = []\n",
239 | " rev = []\n",
240 | " while listNode:\n",
241 | " stack.append(listNode.val)\n",
242 | " listNode = listNode.next\n",
243 | " while stack:\n",
244 | " rev.append(stack.pop())\n",
245 | " return rev"
246 | ]
247 | },
248 | {
249 | "cell_type": "markdown",
250 | "metadata": {},
251 | "source": [
252 | "方法2:直接递归"
253 | ]
254 | },
255 | {
256 | "cell_type": "code",
257 | "execution_count": 20,
258 | "metadata": {
259 | "collapsed": false
260 | },
261 | "outputs": [],
262 | "source": [
263 | "# -*- coding:utf-8 -*-\n",
264 | "\n",
265 | "class ListNode:\n",
266 | " def __init__(self, x):\n",
267 | " self.val = x\n",
268 | " self.next = None\n",
269 | "\n",
270 | "class Solution:\n",
271 | " # 返回从尾部到头部的列表值序列,例如[1,2,3]\n",
272 | " def printListFromTailToHead(self, listNode):\n",
273 | " # write code here\n",
274 | " if listNode is None:\n",
275 | " return []\n",
276 | " return self.printListFromTailToHead(listNode.next) + [listNode.val]"
277 | ]
278 | },
279 | {
280 | "cell_type": "markdown",
281 | "metadata": {},
282 | "source": [
283 | "测试:"
284 | ]
285 | },
286 | {
287 | "cell_type": "code",
288 | "execution_count": 21,
289 | "metadata": {
290 | "collapsed": false
291 | },
292 | "outputs": [
293 | {
294 | "data": {
295 | "text/plain": [
296 | "[3, 2, 1]"
297 | ]
298 | },
299 | "execution_count": 21,
300 | "metadata": {},
301 | "output_type": "execute_result"
302 | }
303 | ],
304 | "source": [
305 | "l1 = ListNode(1)\n",
306 | "l2 = ListNode(2)\n",
307 | "l3 = ListNode(3)\n",
308 | "l1.next = l2\n",
309 | "l2.next = l3\n",
310 | "\n",
311 | "solu = Solution()\n",
312 | "solu.printListFromTailToHead(l1)"
313 | ]
314 | },
315 | {
316 | "cell_type": "markdown",
317 | "metadata": {},
318 | "source": [
319 | "# 4.重建二叉树 [LeetCode](https://leetcode.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)\n",
320 | "\n",
321 | "## 题目描述\n",
322 | "\n",
323 | "输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。\n",
324 | "\n",
325 | ">思路:前序的第一个元素是根结点的值,在中序中找到该值,中序中该值的左边的元素是根结点的左子树,右边是右子树,然后递归的处理左边和右边\n",
326 | "\n",
327 | ">提示:二叉树结点,以及对二叉树的各种操作,测试代码见six.py"
328 | ]
329 | },
330 | {
331 | "cell_type": "code",
332 | "execution_count": null,
333 | "metadata": {
334 | "collapsed": false
335 | },
336 | "outputs": [],
337 | "source": [
338 | "# -*- coding:utf-8 -*-\n",
339 | "# class TreeNode:\n",
340 | "# def __init__(self, x):\n",
341 | "# self.val = x\n",
342 | "# self.left = None\n",
343 | "# self.right = None\n",
344 | "class Solution:\n",
345 | " # 返回构造的TreeNode根节点\n",
346 | " def reConstructBinaryTree(self, pre, tin):\n",
347 | " # write code here"
348 | ]
349 | }
350 | ],
351 | "metadata": {
352 | "kernelspec": {
353 | "display_name": "Python 3 (system-wide)",
354 | "language": "python",
355 | "name": "python3"
356 | },
357 | "language_info": {
358 | "codemirror_mode": {
359 | "name": "ipython",
360 | "version": 3
361 | },
362 | "file_extension": ".py",
363 | "mimetype": "text/x-python",
364 | "name": "python",
365 | "nbconvert_exporter": "python",
366 | "pygments_lexer": "ipython3",
367 | "version": "3.6.8"
368 | }
369 | },
370 | "nbformat": 4,
371 | "nbformat_minor": 2
372 | }
373 |
--------------------------------------------------------------------------------
/剑指Offer/牛客网剑指offer.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "2.二维数组中的查找\n",
8 | "\n",
9 | "题目描述\n",
10 | "\n",
11 | "在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。\n",
12 | "\n",
13 | "输入描述\n",
14 | "\n",
15 | "array: 待查找的二维数组 target:查找的数字\n",
16 | "\n",
17 | "输出描述\n",
18 | "\n",
19 | "查找到返回true,查找不到返回false"
20 | ]
21 | },
22 | {
23 | "cell_type": "markdown",
24 | "metadata": {},
25 | "source": [
26 | "暴力求解:"
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": 20,
32 | "metadata": {},
33 | "outputs": [],
34 | "source": [
35 | "# -*- coding:utf-8 -*-\n",
36 | "class Solution:\n",
37 | " # array 二维列表\n",
38 | " def Find(self, target, array):\n",
39 | " # write code here\n",
40 | " if not array:\n",
41 | " return False\n",
42 | " for line in array:\n",
43 | " for col in line:\n",
44 | " if target == col:\n",
45 | " return True\n",
46 | " return False"
47 | ]
48 | },
49 | {
50 | "cell_type": "code",
51 | "execution_count": 23,
52 | "metadata": {},
53 | "outputs": [
54 | {
55 | "data": {
56 | "text/plain": [
57 | "True"
58 | ]
59 | },
60 | "execution_count": 23,
61 | "metadata": {},
62 | "output_type": "execute_result"
63 | }
64 | ],
65 | "source": [
66 | "array = [[1,2,3],[2,3,4],[3,4,5],[4,5,6]]\n",
67 | "target = 2\n",
68 | "s1 = Solution()\n",
69 | "s1.Find(target,array)"
70 | ]
71 | },
72 | {
73 | "cell_type": "markdown",
74 | "metadata": {},
75 | "source": [
76 | "从左下角或者右上角开始比较:"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 21,
82 | "metadata": {},
83 | "outputs": [],
84 | "source": [
85 | "# -*- coding:utf-8 -*-\n",
86 | "class Solution:\n",
87 | " # array 二维列表\n",
88 | " def Find(self, target, array):\n",
89 | " # write code here\n",
90 | " if not array:\n",
91 | " return False\n",
92 | " row,col = len(array),len(array[0])\n",
93 | "# 从左下角开始\n",
94 | " i,j = row-1,0\n",
95 | " while i >=0 and j target:\n",
99 | " i -= 1\n",
100 | " else:\n",
101 | " j +=1\n",
102 | " return False"
103 | ]
104 | },
105 | {
106 | "cell_type": "code",
107 | "execution_count": 4,
108 | "metadata": {},
109 | "outputs": [
110 | {
111 | "name": "stdout",
112 | "output_type": "stream",
113 | "text": [
114 | "Hello%20World\n"
115 | ]
116 | }
117 | ],
118 | "source": [
119 | "s = \"Hello World\"\n",
120 | "l = len(s)\n",
121 | "s_out = ''\n",
122 | "for i in range(l):\n",
123 | " if(s[i]!=' '):\n",
124 | " s_out += s[i]\n",
125 | " else:\n",
126 | " s_out += \"%20\"\n",
127 | "return s_out"
128 | ]
129 | },
130 | {
131 | "cell_type": "code",
132 | "execution_count": 7,
133 | "metadata": {},
134 | "outputs": [],
135 | "source": [
136 | "# -*- coding:utf-8 -*-\n",
137 | "class Solution:\n",
138 | " # s 源字符串\n",
139 | " def replaceSpace(self, s):\n",
140 | " # write code here\n",
141 | " s = list(s)\n",
142 | " l = len(s)\n",
143 | " for i in range(l):\n",
144 | " if(s[i] == ' '):\n",
145 | " s[i] = '%20'\n",
146 | " return ''.join(s)"
147 | ]
148 | },
149 | {
150 | "cell_type": "code",
151 | "execution_count": 11,
152 | "metadata": {},
153 | "outputs": [
154 | {
155 | "data": {
156 | "text/plain": [
157 | "'Hello%20World'"
158 | ]
159 | },
160 | "execution_count": 11,
161 | "metadata": {},
162 | "output_type": "execute_result"
163 | }
164 | ],
165 | "source": [
166 | "test1 = Solution()\n",
167 | "test1.replaceSpace(\"Hello World\")"
168 | ]
169 | }
170 | ],
171 | "metadata": {
172 | "kernelspec": {
173 | "display_name": "tf36",
174 | "language": "python",
175 | "name": "tf36"
176 | },
177 | "language_info": {
178 | "codemirror_mode": {
179 | "name": "ipython",
180 | "version": 3
181 | },
182 | "file_extension": ".py",
183 | "mimetype": "text/x-python",
184 | "name": "python",
185 | "nbconvert_exporter": "python",
186 | "pygments_lexer": "ipython3",
187 | "version": "3.6.7"
188 | }
189 | },
190 | "nbformat": 4,
191 | "nbformat_minor": 2
192 | }
193 |
--------------------------------------------------------------------------------
/常见算法/0-1背包问题.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 0-1背包问题的动态规划算法\n",
8 | "\n",
9 | "https://zhuanlan.zhihu.com/p/30959069\n",
10 | "\n",
11 | "## 1.什么是0-1背包问题(knapsack problem)\n",
12 | "\n",
13 | "给定一组多个$n$物品,每种物品都有自己的重量$w_i$和价值$v_i$\n",
14 | "\n",
15 | "在限定的总重量/总容量$C$内,选择其中若干个(也即每种物品可以选0个或1个)\n",
16 | "\n",
17 | "设计选择方案使得物品的总价值最高\n",
18 | "\n",
19 | "转换成数学语言:\n",
20 | "\n",
21 | "给定正整数$\\{(w_i,v_i)\\}_{1\\leq i\\leq n}$、给定正整数$C$,求解0-1规划问题:\n",
22 | "\n",
23 | "$$\n",
24 | "\\max \\sum_{i=1}^{n}{x_iv_i}\n",
25 | "$$\n",
26 | "s.t.,\n",
27 | "$$\n",
28 | "\\sum_{i=1}^{n}{x_iw_i}\\leq C\n",
29 | "$$\n",
30 | "$$\n",
31 | "x_i\\in\\{0,1\\}\n",
32 | "$$\n",
33 | "\n",
34 | "示例应用:处理器能力有限时间受限,任务很多,如何选择使得总效用最大?\n",
35 | "\n",
36 | "## 0-1背包问题的定性\n",
37 | "\n",
38 | "对于一般性的0-1背包,\n",
39 | "\n",
40 | "贪婪算法无法得到最优解。\n",
41 | "\n",
42 | "## 0-1背包问题的递推关系\n",
43 | "\n",
44 | "定义子问题 $P(i,W)$为:在前 $i$ 个物品中挑选总重量不超过 $W$ 的物品,每种物品至多只能挑选1个,使得总价值最大;这时的最优值记作 $m(i,W)$ ,其中 $1\\leq i\\leq n$ , $1\\leq W\\leq C$ 。\n",
45 | "\n",
46 | "考虑第 $i$个物品,无外乎两种可能:选,或者不选。\n",
47 | "\n",
48 | "* 不选的话,背包的容量不变,改变为问题$P(i-1,W)$ ;\n",
49 | "* 选的话,背包的容量变小,改变为问题$P(i-1,W-w_i)$ 。\n",
50 | "\n",
51 | "\n",
52 | "\n",
53 | "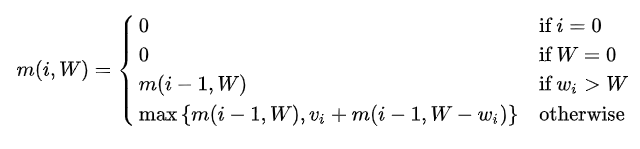"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": 4,
59 | "metadata": {},
60 | "outputs": [
61 | {
62 | "name": "stdout",
63 | "output_type": "stream",
64 | "text": [
65 | "[[0, 0, 0, 0, 0], [0, 1500, 1500, 1500, 1500], [0, 1500, 1500, 1500, 3000], [0, 1500, 1500, 2000, 3500]]\n",
66 | "3500\n"
67 | ]
68 | }
69 | ],
70 | "source": [
71 | "def knapsack_dp(value,weight,C):\n",
72 | " n =len(value)\n",
73 | " dp = [[0 for W in range(C+1)] for i in range(n+1)] #多加一行0、一列0\n",
74 | " \n",
75 | " for i in range(1,n+1):\n",
76 | " for W in range(1,C+1):\n",
77 | " if weight[i-1] > W: #当前物品重量大于背包重量,则取i-1个物品时的值\n",
78 | " dp[i][W] = dp[i-1][W]\n",
79 | " else: #当前物品重量小于背包重量,则取两者(不取这个物品、取这个物品)的最大值\n",
80 | " dp[i][W] = max(dp[i-1][W],value[i-1]+dp[i-1][W-weight[i-1]])\n",
81 | " return dp\n",
82 | "\n",
83 | "C = 4 #背包容量\n",
84 | "value = [1500,3000,2000] #物品价值\n",
85 | "weight = [1,4,3] #物品重量\n",
86 | "dp = knapsack_dp(value,weight,C)\n",
87 | "print(dp)\n",
88 | "res = 0\n",
89 | "for i in dp:\n",
90 | " res = max(res,max(i))\n",
91 | "print(res)"
92 | ]
93 | }
94 | ],
95 | "metadata": {
96 | "kernelspec": {
97 | "display_name": "Python 3",
98 | "language": "python",
99 | "name": "python3"
100 | },
101 | "language_info": {
102 | "codemirror_mode": {
103 | "name": "ipython",
104 | "version": 3
105 | },
106 | "file_extension": ".py",
107 | "mimetype": "text/x-python",
108 | "name": "python",
109 | "nbconvert_exporter": "python",
110 | "pygments_lexer": "ipython3",
111 | "version": "3.6.8"
112 | }
113 | },
114 | "nbformat": 4,
115 | "nbformat_minor": 2
116 | }
117 |
--------------------------------------------------------------------------------
/常见算法/乘法逆元.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 乘法逆元\n",
8 | "\n",
9 | "\n",
10 | "## 1.逆元简介\n",
11 | "\n",
12 | "参考:[乘法逆元-OI Wiki](https://oi-wiki.org/math/inverse/)\n",
13 | "\n",
14 | "介绍模意义下乘法运算的逆元(Modular Multiplicative Inverse),并介绍如何使用扩展欧几里德算法(Extended Euclidean algorithm)求解乘法逆元\n",
15 | "\n",
16 | "如果一个线性同余方程:\n",
17 | "\n",
18 | "$$xy \\equiv 1 \\;(\\bmod\\; p)$$\n",
19 | "\n",
20 | "则$y$称为$x \\bmod b$的逆元,记为$x^{-1}$\n",
21 | "\n",
22 | "有:\n",
23 | "\n",
24 | "$$x\\times x^{-1} \\equiv 1 \\;(\\bmod\\; p)$$\n",
25 | "\n",
26 | "例如,求5关于模14的乘法逆元:\n",
27 | "\n",
28 | "$$5\\times 3 \\equiv 1 \\;(\\bmod\\; 14)$$\n",
29 | "\n",
30 | "因此,5关于模14的乘法逆元为3。\n",
31 | "\n",
32 | "## 2.应用\n",
33 | "\n",
34 | "参考:[乘法逆元的几种计算方法](https://oi.men.ci/mul-inverse/)\n",
35 | "\n",
36 | "乘法逆元的一大应用是模意义下的除法,除法在模意义下并不是封闭的,但我们可以根据上述公式,将其转化为乘法。\n",
37 | "\n",
38 | "$$\\frac{x}{y} \\equiv x\\times y^{-1} \\;(\\bmod\\; p)$$\n",
39 | "\n",
40 | "## 3.求解方法:快速幂法\n",
41 | "\n",
42 | "### 3.1费马小定理\n",
43 | "\n",
44 | "假如a是一个整数,p是一个质数,那么$a^{p}-a$是$p$的倍数,可以表示为:\n",
45 | "\n",
46 | "$$a^{p} \\equiv a \\;(\\bmod\\; p)$$\n",
47 | "\n",
48 | "如果a不是p的倍数,这个定理也可以写成\n",
49 | "\n",
50 | "$$a^{p-1} \\equiv 1 \\;(\\bmod\\; p)$$\n",
51 | "\n",
52 | "这个书写方式更加常用"
53 | ]
54 | },
55 | {
56 | "cell_type": "code",
57 | "execution_count": 1,
58 | "metadata": {},
59 | "outputs": [
60 | {
61 | "data": {
62 | "text/plain": [
63 | "1"
64 | ]
65 | },
66 | "execution_count": 1,
67 | "metadata": {},
68 | "output_type": "execute_result"
69 | }
70 | ],
71 | "source": [
72 | "p = 221\n",
73 | "a = 38\n",
74 | "pow(a,p-1,p)"
75 | ]
76 | },
77 | {
78 | "cell_type": "markdown",
79 | "metadata": {},
80 | "source": [
81 | "### 3.2求解\n",
82 | "\n",
83 | "上述公式可变形为:\n",
84 | "\n",
85 | "$$a\\times a^{p-2} \\equiv 1 \\;(\\bmod\\; p)$$\n",
86 | "\n",
87 | "由乘法逆元的定义,$a^{p-2}$ 即为 $a$ 的乘法逆元。求乘法逆元等价于求$a^{p-2}$\n",
88 | "\n",
89 | "使用快速幂计算$a^{p-2}$,总时间复杂度为 $O(loga)$。\n",
90 | "\n",
91 | "#### 模意义下取幂与乘法逆元\n",
92 | "\n",
93 | "计算 \n",
94 | "\n",
95 | "$$x^n \\bmod\\; m$$\n",
96 | "\n",
97 | "https://oi-wiki.org/math/quick-pow/#_3\n",
98 | "\n",
99 | "快速幂的一个非常常见的应用,模意义下取幂,它可以用于计算模意义下的乘法逆元。\n",
100 | "\n",
101 | "既然我们知道取模的运算不会干涉乘法运算,因此我们只需要在计算的过程中取模即可。\n",
102 | "\n",
103 | "代码如下:"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 14,
109 | "metadata": {},
110 | "outputs": [
111 | {
112 | "name": "stdout",
113 | "output_type": "stream",
114 | "text": [
115 | "905611805\n",
116 | "333333336\n"
117 | ]
118 | }
119 | ],
120 | "source": [
121 | "def fast_pow(x,n,MOD):\n",
122 | " \"\"\"x^n对MOD取模\"\"\"\n",
123 | " res = 1\n",
124 | " x %= MOD\n",
125 | " while n > 0:\n",
126 | " if n&1: #位与=1时,n是奇数\n",
127 | " res = res * x % MOD\n",
128 | " x = x * x % MOD #base翻倍\n",
129 | " n >>= 1 #右移一位\n",
130 | " return res\n",
131 | "\n",
132 | "def mod_multi_inv(num,MOD):\n",
133 | " #模意义下的乘法逆元\n",
134 | " return fast_pow(num, MOD-2, MOD)\n",
135 | "if __name__ == \"__main__\":\n",
136 | " MOD = 10**9+7\n",
137 | " print(fast_pow(2,10000,MOD))\n",
138 | " print(mod_multi_inv(3,MOD))"
139 | ]
140 | },
141 | {
142 | "cell_type": "markdown",
143 | "metadata": {},
144 | "source": [
145 | "C++代码:\n",
146 | "\n",
147 | "- 写法一:\n",
148 | "\n",
149 | "```\n",
150 | "long long binpow(long long a, long long b, long long m) {\n",
151 | " a %= m;\n",
152 | " long long res = 1;\n",
153 | " while (b > 0) {\n",
154 | " if (b & 1) res = res * a % m;\n",
155 | " a = a * a % m;\n",
156 | " b >>= 1;\n",
157 | " }\n",
158 | " return res;\n",
159 | "}\n",
160 | "\n",
161 | "inline int inverse(const int num,long long MOD){\n",
162 | " return binpow(num, MOD - 2, MOD);\n",
163 | "}\n",
164 | "```\n",
165 | "\n",
166 | "- 写法二:\n",
167 | "\n",
168 | "```\n",
169 | "inline int pow(const int n, const int k) {\n",
170 | " long long ans = 1;\n",
171 | " for (long long num = n, t = k; t; num = num * num % MOD, t >>= 1) \n",
172 | " if (t & 1) ans = ans * num % MOD;\n",
173 | " return ans;\n",
174 | "}\n",
175 | "\n",
176 | "inline int inv(const int num) {\n",
177 | " return pow(num, MOD - 2);\n",
178 | "}\n",
179 | "```"
180 | ]
181 | },
182 | {
183 | "cell_type": "markdown",
184 | "metadata": {},
185 | "source": [
186 | "#### 除法取模\n",
187 | "\n",
188 | "$$x^n \\bmod\\; m$$\n",
189 | "\n",
190 | "$$\\frac{x}{y} \\bmod\\; MOD = x*y^{-1} \\bmod\\; MOD = ((x \\bmod\\; MOD) *(y^{-1} \\bmod\\; MOD)) \\bmod\\; MOD$$\n",
191 | "\n",
192 | "代码如下:"
193 | ]
194 | },
195 | {
196 | "cell_type": "code",
197 | "execution_count": 18,
198 | "metadata": {},
199 | "outputs": [
200 | {
201 | "name": "stdout",
202 | "output_type": "stream",
203 | "text": [
204 | "905611805\n",
205 | "333333336\n",
206 | "333333337\n"
207 | ]
208 | }
209 | ],
210 | "source": [
211 | "def fast_pow(x,n,MOD):\n",
212 | " \"\"\"x^n对MOD取模\"\"\"\n",
213 | " res = 1\n",
214 | " x %= MOD\n",
215 | " while n > 0:\n",
216 | " if n&1: #位与=1时,n是奇数\n",
217 | " res = res * x % MOD\n",
218 | " x = x * x % MOD #base翻倍\n",
219 | " n >>= 1 #右移一位\n",
220 | " return res\n",
221 | "\n",
222 | "def mod_multi_inv(num,MOD):\n",
223 | " #模意义下的乘法逆元\n",
224 | " return fast_pow(num, MOD-2, MOD)\n",
225 | "\n",
226 | "def divide_mod(num,den,MOD):\n",
227 | " #den:分母,num:分子 num/den\n",
228 | " inv_den = mod_multi_inv(den,MOD)\n",
229 | " return ((num%MOD)*inv_den)%MOD\n",
230 | "\n",
231 | "if __name__ == \"__main__\":\n",
232 | " MOD = 10**9+7\n",
233 | " print(fast_pow(2,10000,MOD))\n",
234 | " print(mod_multi_inv(3,MOD))\n",
235 | " print(divide_mod(4,3,MOD)) #4/3对1e9+7取模"
236 | ]
237 | },
238 | {
239 | "cell_type": "markdown",
240 | "metadata": {},
241 | "source": [
242 | "## 求解方法:扩展欧几里得法\n",
243 | "\n",
244 | "扩展欧几里得(EXGCD)算法可以在$O(log\\ max(a,b))$的时间内求出关于 x、y 的方程\n",
245 | "\n",
246 | "$$ax+by=gcd(a,b)$$\n",
247 | "\n",
248 | "的一组整数解\n",
249 | "\n",
250 | "当b为素数时,gcd(a,b)=1,此时有\n",
251 | "\n",
252 | "$$ax\\equiv 1 \\;(\\bmod\\; b)$$\n",
253 | "\n",
254 | "即x是a的乘法逆元"
255 | ]
256 | },
257 | {
258 | "cell_type": "markdown",
259 | "metadata": {},
260 | "source": [
261 | "C++代码:\n",
262 | "\n",
263 | "```\n",
264 | "void exgcd(const int a, const int b, int &g, int &x, int &y) {\n",
265 | " if (!b) g = a, x = 1, y = 0;\n",
266 | " else exgcd(b, a % b, g, y, x), y -= x * (a / b);\n",
267 | "}\n",
268 | "\n",
269 | "inline int inv(const int num) {\n",
270 | " int g, x, y;\n",
271 | " exgcd(num, MOD, g, x, y);\n",
272 | " return ((x % MOD) + MOD) % MOD;\n",
273 | "}\n",
274 | "```"
275 | ]
276 | },
277 | {
278 | "cell_type": "markdown",
279 | "metadata": {},
280 | "source": [
281 | "## 例题求解:\n",
282 | "\n",
283 | "[P2613 【模板】有理数取余](https://www.luogu.org/problem/P2613)\n",
284 | "\n",
285 | "题目描述\n",
286 | "给出一个有理数$c=\\frac{a}{b}$,\n",
287 | "\n",
288 | "求$c\\ \\bmod 19260817$的值。\n",
289 | "\n",
290 | "输入格式\n",
291 | "一共两行。\n",
292 | "\n",
293 | "第一行,一个整数a。\n",
294 | "第二行,一个整数b。\n",
295 | "\n",
296 | "输出格式\n",
297 | "一个整数,代表求余后的结果。如果无解,输出Angry!\n",
298 | "\n",
299 | "输入输出样例\n",
300 | "\n",
301 | "输入 #1\n",
302 | "```\n",
303 | "233\n",
304 | "666\n",
305 | "```\n",
306 | "输出 #1 \n",
307 | "```\n",
308 | "18595654\n",
309 | "```\n",
310 | "说明/提示\n",
311 | "对于所有数据,$0\\leq a,b \\leq 10^{10001}$\n",
312 | "\n",
313 | "https://www.cnblogs.com/lykkk/p/10902396.html\n",
314 | "\n"
315 | ]
316 | }
317 | ],
318 | "metadata": {
319 | "kernelspec": {
320 | "display_name": "Python 3",
321 | "language": "python",
322 | "name": "python3"
323 | },
324 | "language_info": {
325 | "codemirror_mode": {
326 | "name": "ipython",
327 | "version": 3
328 | },
329 | "file_extension": ".py",
330 | "mimetype": "text/x-python",
331 | "name": "python",
332 | "nbconvert_exporter": "python",
333 | "pygments_lexer": "ipython3",
334 | "version": "3.6.8"
335 | }
336 | },
337 | "nbformat": 4,
338 | "nbformat_minor": 2
339 | }
340 |
--------------------------------------------------------------------------------
/常见算法/卡特兰数-Catalan.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 卡特兰数\n",
8 | "\n",
9 | "[从《编程之美》买票找零问题说起,娓娓道来卡特兰数——兼爬坑指南](https://www.cnblogs.com/wuyuegb2312/p/3016878.html)\n",
10 | "\n",
11 | "《编程之美》的卡特兰数\n",
12 | "\n",
13 | " 先简单概括一下《编程之美》是如何引入和介绍卡特兰数的。\n",
14 | "\n",
15 | "问题(《编程之美》4.3买票找零):2n个人排队买票,其中n个人持50元,n个人持100元。每张票50元,且一人只买一张票。初始时售票处没有零钱找零。请问这2n个人一共有多少种排队顺序,不至于使售票处找不开钱?\n",
16 | "\n",
17 | "分析1:队伍的序号标为0,1,...,2n-1,并把50元看作左括号,100元看作右括号,合法序列即括号能完成配对的序列。对于一个合法的序列,第0个一定是左括号,它必然与某个右括号配对,记其位置为k。那么从1到k-1、k+1到2n-1也分别是两个合法序列。那么,k必然是奇数(1到k-1一共有偶数个),设k=2i+1。那么剩余括号的合法序列数为f(2i)*f(2n-2i-2)个。取i=0到n-1累加,\n",
18 | "\n",
19 | "并且令f(0)=1,再由组合数C(0,0)=0,可得\n",
20 | "\n",
21 | "$$f(2n)=\\frac{1}{n+1}C_{2n}^{n}$$\n",
22 | "\n",
23 | "至于怎么推导,《编程之美》就没有详细地说明,而是用另一个角度来解释,这个解释类似于《计算机程序设计艺术(卷一)》2.2.1节习题4的解答提到的精彩解法“反射原理”,下面是对其的概括(我所知的最早的出处是:http://bbs.csdn.net/topics/320099239)\n",
24 | "\n",
25 | " \n",
26 | "\n",
27 | "问题大意是用S表示入栈,X表示出栈,那么合法的序列有多少个(S的个数为n)\n",
28 | "显然有c(2n, n)个含S,X各n个的序列,剩下的是计算不允许的序列数(它包含正确个数的S和X,但是违背其它条件).\n",
29 | "在任何不允许的序列中,定出使得X的个数超过S的个数的第一个X的位置。然后在导致并包括这个X的部分序列中,以S代替所有的X并以X代表所有的S。结果是一个有(n+1)个S和(n-1)个X的序列。反过来,对一垢一种类型的每个序列,我们都能逆转这个过程,而且找出导致它的前一种类型的不允许序列。例如XXSXSSSXXSSS必然来自SSXSXXXXXSSS。这个对应说明,不允许的序列的个数是c(2n, n-1),因此an = c(2n, n) - c(2n, n-1)。\n",
30 | "\n",
31 | "$$\n",
32 | "f(2n)=C_{2n}^n-C_{2n}^{n-1}$$\n",
33 | "\n",
34 | "$$=\\frac{2n\\times(2n-1)...(n+2)\\times(n+1)}{n!}-\\frac{2n\\times(2n-1)...(n+2)}{(n-1)!}$$\n",
35 | "\n",
36 | "$$=\\frac{2n\\times(2n-1)...(n+2)\\times(n+1)}{n!}-\\frac{n}{n+1}\\times\\frac{2n\\times(2n-1)...(n+2)\\times(n+1)}{n!}$$\n",
37 | "\n",
38 | "$$=\\frac{1}{n+1}C_{2n}^{n}$$\n",
39 | "\n",
40 | "## 入栈出栈问题(经典问题):\n",
41 | "\n",
42 | " 对于一个无限大的栈,一共n个元素,请问有几种合法的入栈出栈形式?\n",
43 | "\n",
44 | "分析:\n",
45 | "\n",
46 | " 直接用f(2n)来求解即可。不过可以注意到,对于买票找零问题,一共是2n个人,排的是人的顺序;对于入栈出栈,是n个元素,2n次操作,排的是操作的顺序。究竟把哪个数代入,不要混淆。\n",
47 | "\n",
48 | " \n",
49 | "\n",
50 | "## 矩阵连乘问题(《编程之美》4.3扩展问题1):\n",
51 | "\n",
52 | " P = a1 * a2 * a3 * ... * an,其中ai是矩阵。根据乘法结合律,不改变矩阵的相互顺序,只用括号表示成对的乘积,试问一共有几种括号化方案?\n",
53 | "\n",
54 | "分析:\n",
55 | "\n",
56 | " n个矩阵需要连乘(n-1)次,因此需要(n-1)对括号。且这里的括号只是为了使矩阵两两结合,而不是单纯为加括号而加括号,像( (a1) * (a2)),这里将两个矩阵分别括起来是不符合要求的。因此这里如果确定了括号的顺序,那么矩阵的结合顺序也会确定,如(()())对应了(( a1* a2) * (a3 * a4))。注意到是(n-1)对括号,即(n-1)个左括号和(n-1)个右括号,那么应该使用f[2(n-1)]来计算。\n",
57 | "\n",
58 | " \n",
59 | "\n",
60 | "街区对角线问题(《编程之美》4.3扩展问题2类似题目1):\n",
61 | "\n",
62 | " 某个城市的某个居民,每天他须要走过2n个街区去上班(他在其住所以北n个街区和以东n个街区处工作)。如果他不跨越(但可以碰到)从家到办公室的对角线,那么有多少条可能的道路?\n",
63 | "\n",
64 | "分析:\n",
65 | "\n",
66 | " (图片来自维基)\n",
67 | "\n",
68 | "Catalan number 4x4 grid example.svg\n",
69 | "\n",
70 | " 为了不跨越对角线,向东走的步数时刻要大于等于向北走的步数,这些点都是处于对角线以下的。可以看出路线序列由n次向东和n次向北组成,且从第一个元素开始的任意子序列中向东次数不少于向北次数。因此方法一共是f(2n)种。\n",
71 | "\n",
72 | " 等等,似乎有什么不对。对于网络上我所见过的解答,都是到此为止;但我觉得这里有个陷阱。如果要求不跨越,并且初始点就在对角线上,这明显是个边界条件,完全可以只走上面一半,不违反“不跨越对角线”的要求,即向北走的步数时刻大于等于向东走的步数,那么真实的解应该是2*f(2n)。当然,如果这个问题真出现在面试中了,你可以和面试官探讨一下,问问这么走是否合法?注意边界条件,应该会为面试加分。\n",
73 | "\n",
74 | " \n",
75 | "\n",
76 | "## 圆上点对互连问题(《编程之美》4.3扩展问题2类似题目1):\n",
77 | "\n",
78 | " 在圆上选择2n个点,将这些点成对连接起来,且所得n条线段不相交,求可行的方法数。\n",
79 | "\n",
80 | "分析:\n",
81 | "\n",
82 | " 乍一看不能像上面三道题那样直接套公式。那么,先进行一下分析,将圆上的点依次标为P0,P1,...P2n-1。为了避免混淆,使用F(2n)表示2n个点可连成的线段数,选择Pk与P0相连(0T中无环,且任何不同两顶点间有且仅有一条路。\n",
24 | "- 定理2:T是树<=>T连通且|e|=n-1,|e|为T的边数,n为T的顶点数。\n",
25 | "- 层数:由根到某一顶点v的有向路的长度,称为顶点v的层数(level)。根树的高度就是顶点层数的最大值。\n",
26 | "- 深度:对于任意节点n,n的深度为从根到n的唯一路径长,根的深度为1。(有些定义基数为0)\n",
27 | "- 高度:对于任意节点n,n的高度为从n到一片树叶的最长路径长,所有树叶的高度为1。(有些定义基数为0)\n",
28 | "- 层数:根节点为第一层,往下依此递增。\n",
29 | " - 树中节点的最大层数称之为树的深度或者高度,所以在基数为1时树的深度=树的高度=最大层数\n",
30 | "\n",
31 | " ## [数据结构:图的存储结构之邻接矩阵](https://blog.csdn.net/jnu_simba/article/details/8866705)\n",
32 | " \n",
33 | "图的**邻接矩阵(Adjacency Matrix)**存储方式是用两个数组来表示图。一个一维的数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。\n",
34 | " \n",
35 | " 设图G有n个顶点,则邻接矩阵是一个`n*n`的方阵,定义为:\n",
36 | " \n",
37 | " 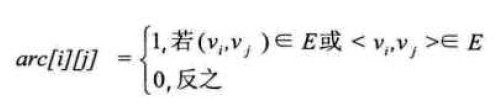\n",
38 | " \n",
39 | "### 无向图:\n",
40 | " \n",
41 | "\n",
42 | " \n",
43 | "### 有向图:\n",
44 | " \n",
45 | "\n",
46 | " \n",
47 | "\n",
48 | "## 网\n",
49 | "\n",
50 | "在图的术语中,我们提到了网的概念,也就是每条边上都带有权的图叫做网。那些这些权值就需要保存下来。\n",
51 | "\n",
52 | "设图G是网图,有n个顶点,则邻接矩阵是一个`n*n`的方阵,定义为:\n",
53 | "\n",
54 | "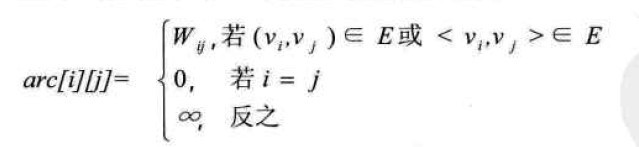\n",
55 | "\n",
56 | "### 有向图网:\n",
57 | "\n",
58 | "\n",
59 | "\n",
60 | "## [数据结构:图的存储结构之邻接表](https://blog.csdn.net/jnu_simba/article/details/8866844)\n",
61 | "\n",
62 | "# 深度优先搜索(Depth-First-Search,DFS)\n",
63 | "\n",
64 | "求连通简单图G的一棵生成树的许多方法中,深度优先搜索(depth first search)是一个十分重要的算法。\n",
65 | "\n",
66 | "- 1.首先将根节点放入stack中。\n",
67 | "- 2.从stack中取出第一个节点,并检验它是否为目标。\n",
68 | " - 如果找到目标,则结束搜寻并回传结果。\n",
69 | " - 否则将它某一个尚未检验过的直接子节点加入stack中。\n",
70 | "- 3.重复步骤2。\n",
71 | "- 4.如果不存在未检测过的直接子节点。\n",
72 | " - 将上一级节点加入stack中。\n",
73 | " - 重复步骤2。\n",
74 | "- 5.重复步骤4。\n",
75 | "- 6.若stack为空,表示整张图都检查过了——亦即图中没有欲搜寻的目标。结束搜寻并回传“找不到目标”。\n",
76 | "\n",
77 | "基本思想:\n",
78 | "\n",
79 | " 任意选择图G的一个顶点V0作为根,通过相继地添加边来形成在顶点V0开始的路,其中每条新边都与路上的最后一个顶点以及不在路上的一个顶点相关联。\n",
80 | "\n",
81 | " 继续尽可能多地添加边到这条路。若这条路经过图G的所有顶点,则这条路即为G的一棵生成树;\n",
82 | "\n",
83 | " 若这条路没有经过G的所有顶点,不妨设形成这条路的顶点顺序V0,V1,......,Vn。则返回到路里的次最后顶点V(n-1).\n",
84 | "\n",
85 | " 若有可能,则形成在顶点v(n-1)开始的经过的还没有放过的顶点的路;\n",
86 | "\n",
87 | " 否则,返回到路里的顶点v(n-2)。\n",
88 | "\n",
89 | " 然后再试。重复这个过程,在所访问过的最后一个顶点开始,在路上次返回的顶点,只要有可能就形成新的路,直到不能添加更多的边为止。\n",
90 | "\n",
91 | " 深度优先搜索也称为回溯(back tracking)\n",
92 | "\n",
93 | "栗子:\n",
94 | "\n",
95 | " 用深度优先搜索来找出图3-9所示图G的生成树,任意地从顶点d开始,生成步骤显示在图3-10。"
96 | ]
97 | },
98 | {
99 | "cell_type": "code",
100 | "execution_count": null,
101 | "metadata": {},
102 | "outputs": [],
103 | "source": []
104 | }
105 | ],
106 | "metadata": {
107 | "kernelspec": {
108 | "display_name": "Python 3",
109 | "language": "python",
110 | "name": "python3"
111 | },
112 | "language_info": {
113 | "codemirror_mode": {
114 | "name": "ipython",
115 | "version": 3
116 | },
117 | "file_extension": ".py",
118 | "mimetype": "text/x-python",
119 | "name": "python",
120 | "nbconvert_exporter": "python",
121 | "pygments_lexer": "ipython3",
122 | "version": "3.7.3"
123 | }
124 | },
125 | "nbformat": 4,
126 | "nbformat_minor": 2
127 | }
128 |
--------------------------------------------------------------------------------
/常见算法/并查集.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 并查集\n",
8 | "\n",
9 | "背景问题:给定一些好友的关系,求这些好友关系中,存在多少个朋友圈?\n",
10 | "\n",
11 | "例如给定好友关系为:[0,1], [0, 4], [1, 2], [1, 3], [5, 6], [6, 7], [7, 5], [8, 9]。在这些朋友关系中,存在3个朋友圈,分别是\n",
12 | "\n",
13 | "【0,1,2,3,4】,【5,6,7】,【8,9】\n",
14 | "\n",
15 | "\n",
16 | "这个问题,抽象一下,就是:求一个图的连通子图的个数,即连通度是多少。\n",
17 | "\n",
18 | "- 第一种方法,采用DFS遍历这个图,遍历过程中,可以求出连通度,但是DFS对于大型图,效率缓慢。\n",
19 | "\n",
20 | "- 第二种方法,采用并查集。并查集可以说是一种算法,或者数据结构。\n",
21 | "\n",
22 | "[数据结构4——并查集(入门)](https://www.cnblogs.com/xzxl/p/7226557.html)\n",
23 | "\n",
24 | "[超有爱的并查集~](https://blog.csdn.net/niushuai666/article/details/6662911)\n",
25 | "\n",
26 | "并查集的主要思想是,对每一个连通的子图,选出根节点,作为代表。“代表”的个数,就是连通度的大小。\n",
27 | "\n",
28 | "步骤如下:\n",
29 | "\n",
30 | "1. 初始化每个节点的代表为其本身(后面,把代表叫做“父节点”)。\n",
31 | "\n",
32 | "2.针对给定的好友关系[0,1], [0, 4], [1, 2], [1, 3], [5, 6], [6, 7], [7, 5], [8, 9],更新父节点。例如给出(1,2)那么,更新2的父节点为1。\n",
33 | "\n",
34 | "3.重新更新所有节点的父节点,针对每个节点,找到其祖宗节点,即根节点。\n",
35 | "\n",
36 | "对应的步骤如下:上面的是节点本身,下面的是节点对应的父节点或根节点。\n",
37 | "\n",
38 | "```\n",
39 | "节 点:0 1 2 3 4 5 6 7 8 9\n",
40 | "父节点:0 1 2 3 4 5 6 7 8 9\n",
41 | "\n",
42 | "更新父节点:\n",
43 | "节 点:0 1 2 3 4 5 6 7 8 9\n",
44 | "父节点:0 0 1 1 0 7 5 6 8 8\n",
45 | "\n",
46 | "\n",
47 | "初始化:\n",
48 | "[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]\n",
49 | "\n",
50 | "不断更新节点:\n",
51 | "[1, 1, 2, 3, 4, 5, 6, 7, 8, 9] union(father, 0, 1)\n",
52 | "[1, 4, 2, 3, 4, 5, 6, 7, 8, 9] union(father, 0, 4)\n",
53 | "[1, 4, 2, 3, 2, 5, 6, 7, 8, 9] union(father, 1, 2)\n",
54 | "[1, 2, 3, 3, 2, 5, 6, 7, 8, 9] union(father, 1, 3)\n",
55 | "[1, 2, 3, 3, 2, 6, 6, 7, 8, 9] union(father, 5, 6)\n",
56 | "[1, 2, 3, 3, 2, 6, 7, 7, 8, 9] union(father, 6, 7)\n",
57 | "[1, 2, 3, 3, 2, 7, 7, 7, 8, 9] union(father, 7, 5)\n",
58 | "[1, 2, 3, 3, 2, 7, 7, 7, 9, 9] union(father, 8, 9)\n",
59 | "\n",
60 | "```\n"
61 | ]
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": 53,
66 | "metadata": {},
67 | "outputs": [],
68 | "source": [
69 | "def find(father, i):\n",
70 | " # father 的第i个位置表示i的父节点\n",
71 | " # 用来查找节点i的根节点\n",
72 | " if i != father[i]:\n",
73 | " father[i] = find(father, father[i])\n",
74 | " return father[i]\n",
75 | "\n",
76 | "def union(father, i, j):\n",
77 | " #连接节点i的根节点和节点j的根节点\n",
78 | " pi, pj = find(father, i), find(father, j)\n",
79 | " if pi != pj:\n",
80 | " father[pi] = pj\n",
81 | " return father\n",
82 | "\n",
83 | "def connected(father, i, j):\n",
84 | " # 判断连通性\n",
85 | " return find(father, i) == find(father, j)\n",
86 | "\n",
87 | "def union_find(nodes, edges):\n",
88 | " #nodes为节点列表,edges为关系列表\n",
89 | " # 初始化各个节点的父节点为其自身\n",
90 | " father = [0]*len(nodes)\n",
91 | " for node in nodes:\n",
92 | " father[node] = node\n",
93 | " # 连接各个node中的两个点\n",
94 | " for i,j in edges:\n",
95 | " union(father,i,j)\n",
96 | " root_of_node = [0]*len(nodes)\n",
97 | " for node in nodes:\n",
98 | " root_of_node[node] = find(father,node)\n",
99 | " out_set = {}\n",
100 | " for index,root_node in enumerate(root_of_node):\n",
101 | " if root_node in out_set:\n",
102 | " out_set[root_node].append(index)\n",
103 | " else:\n",
104 | " out_set[root_node] = [index]\n",
105 | " return root_of_node,out_set"
106 | ]
107 | },
108 | {
109 | "cell_type": "code",
110 | "execution_count": 58,
111 | "metadata": {},
112 | "outputs": [
113 | {
114 | "name": "stdout",
115 | "output_type": "stream",
116 | "text": [
117 | "[2, 2, 2]\n",
118 | "{2: [0, 1, 2]}\n"
119 | ]
120 | }
121 | ],
122 | "source": [
123 | "nodes = [i for i in range(10)]\n",
124 | "# edges = [[0, 1], [0, 4], [1, 2], [1, 3], [5, 6], [6, 7], [7, 5], [8, 9]]\n",
125 | "edges = [(0, 1), (1, 2), (0, 9), (5, 6), (6, 4), (5, 9)]\n",
126 | "# edges = [[0, 1], [1, 2]]\n",
127 | "father,out_set = union_find(nodes,edges)\n",
128 | "print(father)\n",
129 | "print(out_set)"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 32,
135 | "metadata": {},
136 | "outputs": [
137 | {
138 | "name": "stdout",
139 | "output_type": "stream",
140 | "text": [
141 | "[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]\n",
142 | "[1, 1, 2, 3, 4, 5, 6, 7, 8, 9]\n",
143 | "[1, 2, 2, 3, 4, 5, 6, 7, 8, 9]\n",
144 | "[2, 2, 9, 3, 4, 5, 6, 7, 8, 9]\n",
145 | "[2, 2, 9, 3, 4, 6, 6, 7, 8, 9]\n",
146 | "[2, 2, 9, 3, 4, 6, 4, 7, 8, 9]\n",
147 | "[2, 2, 9, 3, 9, 4, 4, 7, 8, 9]\n",
148 | "item 0 -> component 9\n",
149 | "[9, 2, 9, 3, 9, 4, 4, 7, 8, 9]\n",
150 | "item 1 -> component 9\n",
151 | "[9, 9, 9, 3, 9, 4, 4, 7, 8, 9]\n",
152 | "item 2 -> component 9\n",
153 | "[9, 9, 9, 3, 9, 4, 4, 7, 8, 9]\n",
154 | "item 3 -> component 3\n",
155 | "[9, 9, 9, 3, 9, 4, 4, 7, 8, 9]\n",
156 | "item 4 -> component 9\n",
157 | "[9, 9, 9, 3, 9, 4, 4, 7, 8, 9]\n",
158 | "item 5 -> component 9\n",
159 | "[9, 9, 9, 3, 9, 9, 4, 7, 8, 9]\n",
160 | "item 6 -> component 9\n",
161 | "[9, 9, 9, 3, 9, 9, 9, 7, 8, 9]\n",
162 | "item 7 -> component 7\n",
163 | "[9, 9, 9, 3, 9, 9, 9, 7, 8, 9]\n",
164 | "item 8 -> component 8\n",
165 | "[9, 9, 9, 3, 9, 9, 9, 7, 8, 9]\n",
166 | "item 9 -> component 9\n",
167 | "[9, 9, 9, 3, 9, 9, 9, 7, 8, 9]\n"
168 | ]
169 | }
170 | ],
171 | "source": [
172 | "n = 10\n",
173 | "data = [i for i in range(n)]\n",
174 | "connections = [(0, 1), (1, 2), (0, 9), (5, 6), (6, 4), (5, 9)]\n",
175 | "# connections = [[0, 1], [0, 4], [1, 2], [1, 3], [5, 6], [6, 7], [7, 5], [8, 9]]\n",
176 | "\n",
177 | "print(data)\n",
178 | "# union\n",
179 | "for i, j in connections:\n",
180 | " union(data, i, j)\n",
181 | " print(data)\n",
182 | "\n",
183 | "find\n",
184 | "for i in range(n):\n",
185 | " print('item', i, '-> component', find(data, i))\n",
186 | " print(data)"
187 | ]
188 | }
189 | ],
190 | "metadata": {
191 | "kernelspec": {
192 | "display_name": "tf36",
193 | "language": "python",
194 | "name": "tf36"
195 | },
196 | "language_info": {
197 | "codemirror_mode": {
198 | "name": "ipython",
199 | "version": 3
200 | },
201 | "file_extension": ".py",
202 | "mimetype": "text/x-python",
203 | "name": "python",
204 | "nbconvert_exporter": "python",
205 | "pygments_lexer": "ipython3",
206 | "version": "3.6.8"
207 | }
208 | },
209 | "nbformat": 4,
210 | "nbformat_minor": 2
211 | }
212 |
--------------------------------------------------------------------------------
/常见算法/拓扑排序.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/常见算法/斐波那契数列三种时间复杂度.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 1.递归 $O(2^n)$"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 28,
13 | "metadata": {},
14 | "outputs": [
15 | {
16 | "name": "stdout",
17 | "output_type": "stream",
18 | "text": [
19 | "2178309\n",
20 | "CPU times: user 2 s, sys: 868 µs, total: 2 s\n",
21 | "Wall time: 2.07 s\n"
22 | ]
23 | }
24 | ],
25 | "source": [
26 | "%%time\n",
27 | "def Fib(n):\n",
28 | " if n==0:\n",
29 | " return 0\n",
30 | " if n==1:\n",
31 | " return 1\n",
32 | " return Fib(n-1)+Fib(n-2)\n",
33 | "\n",
34 | "print(Fib(32))"
35 | ]
36 | },
37 | {
38 | "cell_type": "markdown",
39 | "metadata": {},
40 | "source": [
41 | "# 2.迭代算法 $O(n)$"
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": 29,
47 | "metadata": {},
48 | "outputs": [
49 | {
50 | "name": "stdout",
51 | "output_type": "stream",
52 | "text": [
53 | "2178309\n",
54 | "CPU times: user 150 µs, sys: 0 ns, total: 150 µs\n",
55 | "Wall time: 165 µs\n"
56 | ]
57 | }
58 | ],
59 | "source": [
60 | "%%time\n",
61 | "def Fib(n):\n",
62 | " a, b = 0, 1\n",
63 | " if n == 0:\n",
64 | " return a\n",
65 | " for _ in range(n - 1):\n",
66 | " a, b = b, a + b\n",
67 | " return b\n",
68 | "\n",
69 | "print(Fib(32))"
70 | ]
71 | },
72 | {
73 | "cell_type": "code",
74 | "execution_count": 30,
75 | "metadata": {},
76 | "outputs": [
77 | {
78 | "name": "stdout",
79 | "output_type": "stream",
80 | "text": [
81 | "2178309\n",
82 | "CPU times: user 145 µs, sys: 0 ns, total: 145 µs\n",
83 | "Wall time: 154 µs\n"
84 | ]
85 | }
86 | ],
87 | "source": [
88 | "%%time\n",
89 | "def Fib(n):\n",
90 | " fib = [0]*(n+1)\n",
91 | " fib[0] = 0\n",
92 | " fib[1] = 1\n",
93 | " for i in range(2,n+1):\n",
94 | " fib[i] = fib[i-1] + fib[i-2]\n",
95 | " return fib[n]\n",
96 | "\n",
97 | "print(Fib(32))"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "# 3.利用矩阵乘法 $O(logn)$\n",
105 | "\n",
106 | "$$\n",
107 | "\\begin{pmatrix}f(n) & f(n-1)\\end{pmatrix} = \\begin{pmatrix}f(n-1) & f(n-2)\\end{pmatrix} \\times \\begin{pmatrix}1 & 1 \\\\1 & 0\\end{pmatrix}\n",
108 | "$$\n",
109 | "$$\n",
110 | "= \\begin{pmatrix}f(n-2) & f(n-3)\\end{pmatrix} \\times \\begin{pmatrix}1 & 1 \\\\1 & 0\\end{pmatrix}^2\n",
111 | "$$\n",
112 | "\n",
113 | "$$\n",
114 | "= ...\n",
115 | "$$\n",
116 | "$$\n",
117 | "= \\begin{pmatrix}f(1) & f(0)\\end{pmatrix} \\times \\begin{pmatrix}1 & 1 \\\\1 & 0\\end{pmatrix}^{n-1}\n",
118 | "$$\n",
119 | "\n",
120 | "我们求一个矩阵的n-1次方即可,两个2维矩阵的乘法次数可以看作常量\n",
121 | "\n",
122 | "矩阵的n次方利用分治法,只需要$O(logn)$的复杂度就能计算出来,\n",
123 | "\n",
124 | "和常数的乘方相似:\n",
125 | "\n",
126 | "n=偶数:\n",
127 | "\n",
128 | "$$x^n = x^{\\frac{n}{2}}\\times x^{\\frac{n}{2}}$$\n",
129 | "\n",
130 | "n=奇数:\n",
131 | "\n",
132 | "$$x^n = x^{\\frac{n-1}{2}}\\times x^{\\frac{n-1}{2}} \\times x$$\n",
133 | "\n",
134 | "$$T(n) = T(n/2) + O(1)$$\n",
135 | "\n",
136 | "推出:\n",
137 | "\n",
138 | "$$T(n) = O(logn)$$"
139 | ]
140 | },
141 | {
142 | "cell_type": "markdown",
143 | "metadata": {},
144 | "source": [
145 | "## 分治法计算x的n次幂\n",
146 | "\n",
147 | "### 普通算法:"
148 | ]
149 | },
150 | {
151 | "cell_type": "code",
152 | "execution_count": 3,
153 | "metadata": {},
154 | "outputs": [
155 | {
156 | "name": "stdout",
157 | "output_type": "stream",
158 | "text": [
159 | "10715086071862673209484250490600018105614048117055336074437503883703510511249361224931983788156958581275946729175531468251871452856923140435984577574698574803934567774824230985421074605062371141877954182153046474983581941267398767559165543946077062914571196477686542167660429831652624386837205668069376\n",
160 | "CPU times: user 410 µs, sys: 0 ns, total: 410 µs\n",
161 | "Wall time: 420 µs\n"
162 | ]
163 | }
164 | ],
165 | "source": [
166 | "%%time\n",
167 | "def pow1(x,n):\n",
168 | " #计算x^n\n",
169 | " res = 1\n",
170 | " for i in range(n):\n",
171 | " res *= x\n",
172 | " return res\n",
173 | "print(pow1(2,1000))"
174 | ]
175 | },
176 | {
177 | "cell_type": "markdown",
178 | "metadata": {},
179 | "source": [
180 | "### 分治算法"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 4,
186 | "metadata": {},
187 | "outputs": [
188 | {
189 | "name": "stdout",
190 | "output_type": "stream",
191 | "text": [
192 | "114813069527425452423283320117768198402231770208869520047764273682576626139237031385665948631650626991844596463898746277344711896086305533142593135616665318539129989145312280000688779148240044871428926990063486244781615463646388363947317026040466353970904996558162398808944629605623311649536164221970332681344168908984458505602379484807914058900934776500429002716706625830522008132236281291761267883317206598995396418127021779858404042159853183251540889433902091920554957783589672039160081957216630582755380425583726015528348786419432054508915275783882625175435528800822842770817965453762184851149029376\n",
193 | "CPU times: user 121 µs, sys: 0 ns, total: 121 µs\n",
194 | "Wall time: 126 µs\n"
195 | ]
196 | }
197 | ],
198 | "source": [
199 | "%%time\n",
200 | "def pow2(x,n):\n",
201 | " #计算x^n\n",
202 | " if n == 1:\n",
203 | " return x\n",
204 | " elif n % 2 ==0:\n",
205 | " tmp = pow2(x,n/2) #// 用临时变量减少重复的运算\n",
206 | " return tmp*tmp\n",
207 | " else:\n",
208 | " tmp = pow2(x,(n-1)/2)\n",
209 | " return tmp*tmp*x\n",
210 | "\n",
211 | "print(pow2(2,2000))"
212 | ]
213 | },
214 | {
215 | "cell_type": "markdown",
216 | "metadata": {},
217 | "source": [
218 | "## 分治法计算斐波那契数列:\n",
219 | "\n",
220 | "[五种方法计算斐波那契数列的第n项](http://blog.zhengyi.one/fibonacci-in-logn.html)"
221 | ]
222 | },
223 | {
224 | "cell_type": "code",
225 | "execution_count": null,
226 | "metadata": {},
227 | "outputs": [],
228 | "source": []
229 | }
230 | ],
231 | "metadata": {
232 | "kernelspec": {
233 | "display_name": "Python 3",
234 | "language": "python",
235 | "name": "python3"
236 | },
237 | "language_info": {
238 | "codemirror_mode": {
239 | "name": "ipython",
240 | "version": 3
241 | },
242 | "file_extension": ".py",
243 | "mimetype": "text/x-python",
244 | "name": "python",
245 | "nbconvert_exporter": "python",
246 | "pygments_lexer": "ipython3",
247 | "version": "3.6.8"
248 | }
249 | },
250 | "nbformat": 4,
251 | "nbformat_minor": 2
252 | }
253 |
--------------------------------------------------------------------------------
/常见算法/最小生成树-Prim算法和Kruskal算法.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "tf36",
14 | "language": "python",
15 | "name": "tf36"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.6.8"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/常见算法/算法目录.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "```\n",
8 | "作者:晗江雪\n",
9 | "链接:https://www.nowcoder.com/discuss/217410?type=0&order=0&pos=1&page=1\n",
10 | "来源:牛客网\n",
11 | "\n",
12 | "基础入门班:\n",
13 | "适合人群\n",
14 | "适合0基础小白,或者基础非常薄弱的同学,左神手把手带你算法入门\n",
15 | "\n",
16 | "课程目录\n",
17 | "第一章 认识复杂度和简单排序算法\n",
18 | "时间复杂度和空间复杂度 选择排序、冒泡排序、插入排序的细节和时间复杂度分析\n",
19 | "二分法的使用和复杂度分析\n",
20 | "一道时间复杂度很低的利用异或运算解决的问题\n",
21 | "常见时间复杂度的比较\n",
22 | "详解递归函数与常见递归函数的复杂度估算(master公式)\n",
23 | "详解对数器的使用\n",
24 | "\n",
25 | "第二章 认识O(N*logN)的排序\n",
26 | "归并排序详解\n",
27 | "快速排序详解\n",
28 | "堆结构和堆排序详解\n",
29 | "\n",
30 | "第三章 详解桶排序以及排序内容大总结\n",
31 | "桶排序思想下的具体排序:计数排序、基数排序\n",
32 | "详解比较器\n",
33 | "排序内容汇总与常见坑总结\n",
34 | "工程上对排序的改进\n",
35 | "\n",
36 | "第四章 链表\n",
37 | "链表问题对于笔试和面试阶段的解题方法论\n",
38 | "常见的链表面试题目\n",
39 | "利用快慢指针\n",
40 | "哈希表和有序表在使用层次上的简单介绍\n",
41 | "\n",
42 | "第五章 二叉树\n",
43 | "详解递归函数完成二叉树的三种遍历\n",
44 | "详解非递归函数完成二叉树的三种遍历\n",
45 | "详解二叉树的序列化和反序列化(深度优先与宽度优先遍历)\n",
46 | "折纸问题\n",
47 | "判断搜索二叉树\n",
48 | "判断完全二叉树\n",
49 | "判断平衡二叉树\n",
50 | "二叉树节点的前驱节点与后继节点\n",
51 | "\n",
52 | "第六章 图\n",
53 | "图结构的表示方法\n",
54 | "图的深度优先遍历与宽度优先遍历\n",
55 | "拓扑排序问题\n",
56 | "最小生成树问题\n",
57 | "单源最短路径问题\n",
58 | "\n",
59 | "第七章 详解前缀树和贪心算法\n",
60 | "详解前缀树\n",
61 | "介绍贪心算法及其相关题目\n",
62 | "在面试中如何快速的尝试出贪心策略\n",
63 | "\n",
64 | "第八章 暴力递归\n",
65 | "常见的递归问题\n",
66 | "几种常见的尝试类型\n",
67 | "\n",
68 | "\n",
69 | "基础提升班:\n",
70 | "适合人群\n",
71 | "适合有简单入门基础,但是还达不到校招水平要求的同学,左神带你跨越学习瓶颈\n",
72 | "\n",
73 | "课程目录\n",
74 | "第一章\n",
75 | "哈希函数与哈希表\n",
76 | "位图与布隆过滤器详解\n",
77 | "一致性哈希结构\n",
78 | "\n",
79 | "第二章\n",
80 | "详解有序表(红黑树、跳表、sb树、avl树\n",
81 | "详解并查集结构的应用(岛问题)\n",
82 | "\n",
83 | "第三章\n",
84 | "KMP算法\n",
85 | "Manacher算法\n",
86 | "\n",
87 | "第四章\n",
88 | "滑动窗口的最大值与最小值更新结构\n",
89 | "单调栈结构\n",
90 | "\n",
91 | "第五章\n",
92 | "二叉树的morris遍历\n",
93 | "树形dp解题套路\n",
94 | "\n",
95 | "第六章\n",
96 | "大数据题目与空间限制题目常见解法\n",
97 | "位运算常见题目\n",
98 | "\n",
99 | "第七章\n",
100 | "从暴力递归到动态规划(上)\n",
101 | "\n",
102 | "第八章\n",
103 | "从暴力递归到动态规划(下)与社会嗑\n",
104 | "\n",
105 | "\n",
106 | "中级班\n",
107 | "适合人群\n",
108 | "适合基础比较好,刷题不熟练的同学,左神亲自带你刷题,从题目思路到代码最优家,详细讲解,带你熟悉大部分校招题目的讨论\n",
109 | "\n",
110 | "题目概括\n",
111 | "题目1-5\n",
112 | "定长绳子覆盖最多点数\n",
113 | "买苹果最少袋子数\n",
114 | "线性排列正方形的最少涂染数\n",
115 | "N阶方阵中最大正方形边长\n",
116 | "指定概率数字生成函数\n",
117 | "题目6-10\n",
118 | "给定非负整数n能形成的二叉树结构数目\n",
119 | "构成完整括号字符串的最少添加括号数\n",
120 | "求数组中差值为K的去重数字对\n",
121 | "使2个数组平均值都增加的最小操作数\n",
122 | "给定数字求可以转换出的字符串个数\n",
123 | "题目11-15\n",
124 | "合法括号序列的深度\n",
125 | "利用辅助栈对当前栈排序\n",
126 | "牛羊吃草决胜结果\n",
127 | "二叉树的路径构成的最大权值和\n",
128 | "机器打包物品最少轮数\n",
129 | "题目16-20\n",
130 | "zigzag方式打印矩阵\n",
131 | "螺旋方式打印矩阵\n",
132 | "将矩阵原地旋转90度\n",
133 | "在矩阵中查找某个数\n",
134 | "拼接字符串的最少操作数\n",
135 | "。。。。。。。。。。。\n",
136 | "\n",
137 | "\n",
138 | "高级班\n",
139 | "适合人群\n",
140 | "适合基础比较好,想冲击大厂高薪offer的同学,左神带你手撕高难度笔试面试算法真题\n",
141 | "\n",
142 | "题目概括\n",
143 | "题目1-5 \n",
144 | "路径数组统计距离i的城市数目\n",
145 | "分糖果最少数目\n",
146 | "覆盖二叉树的所有节点需要的最少相机数\n",
147 | "使字符串数组不降序的最少操作数\n",
148 | "分田地的最大价值\n",
149 | "题目6-10 \n",
150 | "得到target的最少操作数\n",
151 | "符合条件的子数组数目\n",
152 | "从 1 到 n 的数字中 1 出现的个数\n",
153 | "矩阵中最大矩形区域的1的数量\n",
154 | "N!的二进制中最低位的1的位置\n",
155 | "题目11-15\n",
156 | "完成所有的画作需要的最少时间\n",
157 | "扔棋子不摔碎的最少次数\n",
158 | "最长的连续序列的长度\n",
159 | "二叉树两个节点的最低公共祖先\n",
160 | "DC3算法生成后缀数组\n",
161 | "题目16-20 \n",
162 | "找出字符串数组中所有能两两拼接成回文串的记录\n",
163 | "在数组中挑选K个数返回所有结果中代表最大数字的结果\n",
164 | "找出数组中累加和在指定区间内的子数组个数\n",
165 | "找到离n最近的(不包括n本身)是回文数字的数\n",
166 | "计算距离邮局最近的地点的最短距离的总和\n",
167 | "。。。。。。。。。\n",
168 | "\n",
169 | "更多中高级班题目概括,详询课程顾问:1440073724(qq)\n",
170 | "\n",
171 | "\n",
172 | "\n",
173 | "***关于课程有任何问题或者不明白的地方可以留言或者私信哦~~~\n",
174 | "```"
175 | ]
176 | }
177 | ],
178 | "metadata": {
179 | "kernelspec": {
180 | "display_name": "tf36",
181 | "language": "python",
182 | "name": "tf36"
183 | },
184 | "language_info": {
185 | "codemirror_mode": {
186 | "name": "ipython",
187 | "version": 3
188 | },
189 | "file_extension": ".py",
190 | "mimetype": "text/x-python",
191 | "name": "python",
192 | "nbconvert_exporter": "python",
193 | "pygments_lexer": "ipython3",
194 | "version": "3.6.8"
195 | }
196 | },
197 | "nbformat": 4,
198 | "nbformat_minor": 2
199 | }
200 |
--------------------------------------------------------------------------------
/常见算法/线段树.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": []
9 | }
10 | ],
11 | "metadata": {
12 | "kernelspec": {
13 | "display_name": "Python 3",
14 | "language": "python",
15 | "name": "python3"
16 | },
17 | "language_info": {
18 | "codemirror_mode": {
19 | "name": "ipython",
20 | "version": 3
21 | },
22 | "file_extension": ".py",
23 | "mimetype": "text/x-python",
24 | "name": "python",
25 | "nbconvert_exporter": "python",
26 | "pygments_lexer": "ipython3",
27 | "version": "3.7.3"
28 | }
29 | },
30 | "nbformat": 4,
31 | "nbformat_minor": 2
32 | }
33 |
--------------------------------------------------------------------------------
/常见算法/高楼扔鸡蛋.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 如何用最少的次数测出鸡蛋会在哪一层摔碎?\n",
8 | "\n",
9 | "\n",
10 | "https://www.zhihu.com/question/19690210/answer/18079633\n",
11 | "\n",
12 | "一幢 200 层的大楼,给你两个鸡蛋. 如果在第 n 层扔下鸡蛋,鸡蛋不碎,那么从前 n-1 层扔鸡蛋都不碎. 这两只鸡蛋一模一样,不碎的话可以扔无数次. 已知鸡蛋在0层扔不会碎.\n",
13 | "\n",
14 | "提出一个策略, 要**保证**能测出鸡蛋**恰好会碎**的楼层, 并使此策略在**最坏情况下所扔次数最少**.\n",
15 | "\n",
16 | "题目严谨描述:\n",
17 | "一幢 200 层的大楼,给你两个鸡蛋. 如果在第 n 层扔下鸡蛋,鸡蛋不碎,那么从前 n-1 层扔鸡蛋都不碎.\n",
18 | "这两只鸡蛋一模一样,不碎的话可以扔无数次. 已知鸡蛋在0层扔不会碎.\n",
19 | "提出一个策略, 要**保证**能测出鸡蛋**恰好会碎**的楼层, 并使此策略在**最坏情况下所扔次数最少**.\n",
20 | "\n",
21 | "搞清楚这题的意思:\n",
22 | "第一个鸡蛋用来试探, 只要它从 k 层楼扔下去没碎, 则目标就在[k+1, 200]之间了.\n",
23 | "但一旦运气不好碎了, 对于已知的区间, 我们只能用剩下一个鸡蛋从小到大一层层试,\n",
24 | "因为我们要保证策略必须成功, 不能冒险了.\n",
25 | "\n",
26 | "\"最坏情况下代价最小\"这句话十分重要, 它反映了题目的重要数学结构:\n",
27 | "我们可以把任何一种策略都看成一个决策树,\n",
28 | "每一次扔瓶子都会有两个子节点, 对应碎与不碎的情况下下一步应该扔的楼层.\n",
29 | "那么, 策略的一次执行, 是树中的一条从根往下走的路,\n",
30 | "当且仅当这条路上出现过形如 k 没碎 与 k+1 碎了的一对节点时, 路停止, 当前节点不再扩展.\n",
31 | "那么要找的是这么一棵树, 使得所有路里最长者尽量短, 也即, 要找一个最矮的决策树.\n",
32 | "\n",
33 | "再看一个节点处, 选择楼层时会发生什么.\n",
34 | "容易看出, 选择的楼层如果变高, 那么\"碎子树\"高度不减, \"不碎子树\"高度不增.\n",
35 | "同样的, 选择的楼层变矮的话, \"碎子树\"高度不增, \"不碎子树\"高度不减.\n",
36 | "\n",
37 | "这时候答案很明显了: 为了使两子树中高度最大者尽量小, 我们的选择应当使两子树高度尽量接近.\n",
38 | "最终希望的结果是, 整个二叉树尽量像一个满二叉树.\n",
39 | "\n",
40 | "假设第一次在根节点上, 我们选择扔$k$层, 其\"碎子树\"的高度显然是$k - 1$.为了考虑不碎子树的高度, 设不碎后第二次扔$m$层(显然$m > k$ ),\n",
41 | "\n",
42 | "则这个新节点的碎子树高度为 $m - k - 1$, 不碎子树高度仍然未知,但按照满二叉树的目标, 我们认为它与碎子树相同或少1就好.\n",
43 | "\n",
44 | "那么在根节点上的不碎子树的高度就是$m -k-1 + 1$, 令它与碎子树高度相同, 于是:\n",
45 | "\n",
46 | "$m - k - 1 + 1 = k - 1$ => $m = k + k - 1$\n",
47 | "\n",
48 | "也即, 如果第一次扔在k层, 第二次应该高k-1 层, 这可以有直观一点的理解:\n",
49 | "每扔一次, 就要更保守一些, 所以让区间长度少1. $[1, k) -> [k + 1, 2k - 1)$\n",
50 | "\n",
51 | "用类似刚才的分析, 可以继续得到, 下一次应该增高k - 2, 再下一次应该增高k - 3.\n",
52 | "\n",
53 | "如果大楼100层, 考虑:\n",
54 | "![[公式]](https://www.zhihu.com/equation?tex=k+%2B+%28k-1%29+%2B+%5Ccdots+%2B+1+%3D+%5Cfrac%7Bk%28k%2B1%29%7D%7B2%7D+%3D+100+%5CRightarrow+k+%5Capprox+14)\n",
55 | "\n",
56 | "所以第一次扔14层, 最坏需要14次(策略不唯一, 树的叶子可以交换位置).200层的话, 类似得到k =20.\n",
57 | "\n",
58 | "以上是数学做法...当然还有代码做法....\n",
59 | "设f(n, m)为n层楼, m个蛋所需次数, 那么它成了一道DP题..\n",
60 | "\n",
61 | "![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Beqnarray%7D%0Af%280%2C+m%29+%26+%3D+%26+0%2C+%28m+%3E%3D+1%29%5C%5C%0Af%28n%2C+1%29+%26+%3D+%26+n%2C+%28n+%3E%3D+1%29%5C%5C%0Af%28n%2C+m%29+%26+%3D+%26+%5Cmin_%7B1+%5Cle+i+%5Cle+n%7D+%5C%7B+%5Cmax%5C%7B+f%28i+-+1%2C+m+-+1%29%2C+f%28n+-+i%2C+m%29%5C%7D%5C%7D+%2B+1+%5C%5C%0A%5Cend%7Beqnarray%7D)\n",
62 | "\n",
63 | "\n",
64 | "n层楼, m个蛋扩展动态规划的解释:\n",
65 | "\n",
66 | "https://zhuanlan.zhihu.com/p/41257286"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "**python3的functools的一个自带函数, 可以对函数返回结果进行LRU cache, 下次以相同参数调用就不重复计算了**\n",
74 | "\n",
75 | "**maxsize=None 不限制大小, 其实就变成是全部都cache下来, 不考虑LRU了**"
76 | ]
77 | },
78 | {
79 | "cell_type": "code",
80 | "execution_count": 2,
81 | "metadata": {},
82 | "outputs": [],
83 | "source": [
84 | "import functools\n",
85 | "@functools.lru_cache(maxsize=None)\n",
86 | "def f(n, m): #n层楼,m个鸡蛋\n",
87 | " if n == 0:\n",
88 | " return 0\n",
89 | " if m == 1:\n",
90 | " return n\n",
91 | "\n",
92 | " ans = min([max([f(i - 1, m - 1), f(n - i, m)]) for i in range(1, n + 1)]) + 1\n",
93 | " # 先拿鸡蛋在第i层试一次(最后的+1的由来)\n",
94 | " # 鸡蛋碎,则剩余i-1楼层、m-1鸡蛋;鸡蛋不碎,则剩余n-i楼层,m个鸡蛋。找到两者中最大值\n",
95 | " # 从1到n逐个试验,找到各个最大值的最小值。\n",
96 | " return ans"
97 | ]
98 | },
99 | {
100 | "cell_type": "code",
101 | "execution_count": 4,
102 | "metadata": {},
103 | "outputs": [
104 | {
105 | "name": "stdout",
106 | "output_type": "stream",
107 | "text": [
108 | "14\n",
109 | "20\n",
110 | "11\n"
111 | ]
112 | }
113 | ],
114 | "source": [
115 | "print(f(100, 2))\n",
116 | "print(f(200, 2))\n",
117 | "print(f(200,3))"
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "metadata": {},
123 | "source": [
124 | "## 优秀回答,扩展\n",
125 | "\n",
126 | "如何用最少的次数测出鸡蛋会在哪一层摔碎? - 刘遥行的回答 - 知乎\n",
127 | "\n",
128 | "https://www.zhihu.com/question/19690210/answer/514119129"
129 | ]
130 | }
131 | ],
132 | "metadata": {
133 | "kernelspec": {
134 | "display_name": "tf36",
135 | "language": "python",
136 | "name": "tf36"
137 | },
138 | "language_info": {
139 | "codemirror_mode": {
140 | "name": "ipython",
141 | "version": 3
142 | },
143 | "file_extension": ".py",
144 | "mimetype": "text/x-python",
145 | "name": "python",
146 | "nbconvert_exporter": "python",
147 | "pygments_lexer": "ipython3",
148 | "version": "3.6.8"
149 | }
150 | },
151 | "nbformat": 4,
152 | "nbformat_minor": 2
153 | }
154 |
--------------------------------------------------------------------------------
/算法图解/README.md:
--------------------------------------------------------------------------------
1 | # 算法图解 Python3代码实现
2 |
3 | ## 目录
4 |
5 | - [第1章 算法简介](./chap01-算法简介.ipynb)
6 | - 二分查找
7 | - [第2章 选择排序](./chap02-选择排序.ipynb)
8 | - 选择排序
9 | - [第3章 递归](./chap03-递归.ipynb)
10 | - [第4章 快速排序](./chap04-快速排序.ipynb)
11 | - [第5章 散列表](./chap05-散列表.ipynb)
12 | - [第6章 广度优先搜索](./chap06-广度优先搜索.ipynb)
13 | - [第7章 狄克斯特拉算法](./chap07-狄克斯特拉算法Dijkstra’s-algorithm.ipynb)
14 | - [第8章 贪婪算法](./chap08-贪婪算法.ipynb)
15 | - [第9章 动态规划](./chap09-动态规划.ipynb)
16 |
17 |
18 | Ref:
19 |
20 | ---
21 | - [随书代码](https://github.com/egonschiele/grokking_algorithms)
22 | - [算法图解的算法代码示例,用Python和Java实现](https://github.com/zhanwen/AlgorithmDiagram)
23 | - [算法图解-知乎](https://zhuanlan.zhihu.com/p/43565172)
--------------------------------------------------------------------------------
/算法图解/chap01-算法简介.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第1章 算法简介\n",
8 | "## 1.2 二分查找\n",
9 | "\n",
10 | "二分查找是一种算法,其输入是一个有序的元素列表(必须有序的原因稍后解释)。如果要查找的元素包含在列表中,二分查找返回其位置;否则返回 null 。\n",
11 | "\n",
12 | "函数 binary_search 接受一个有序数组和一个元素。如果指定的元素包含在数组中,这个函数将返回其位置。你将跟踪要在其中查找的数组部分——开始时为整个数组,你每次都检查中间的元素。\n",
13 | "\n",
14 | "算法复杂度:O(log n)"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": 1,
20 | "metadata": {},
21 | "outputs": [
22 | {
23 | "name": "stdout",
24 | "output_type": "stream",
25 | "text": [
26 | "1\n",
27 | "None\n"
28 | ]
29 | }
30 | ],
31 | "source": [
32 | "def binary_search(ordered_list,item):\n",
33 | " '''二分查找'''\n",
34 | " low = 0\n",
35 | " high = len(ordered_list) - 1\n",
36 | " while low <= high:\n",
37 | " mid = int((low + high)/2) #向下取整\n",
38 | " guess =ordered_list[mid] #这次猜的值\n",
39 | " if guess == item: #猜到了\n",
40 | " return mid\n",
41 | " print(mid)\n",
42 | " if guess > item: #猜大了\n",
43 | " high = mid - 1\n",
44 | " else: # 猜小了\n",
45 | " low = mid + 1\n",
46 | " return None # 没有指定的元素\n",
47 | "\n",
48 | "my_list = [1, 3, 5, 7, 9]\n",
49 | "\n",
50 | "# 能找到对应的值\n",
51 | "print(binary_search(my_list,3))\n",
52 | "# 不能找到对应的值\n",
53 | "print(binary_search(my_list,0))"
54 | ]
55 | },
56 | {
57 | "cell_type": "markdown",
58 | "metadata": {},
59 | "source": [
60 | "### 一些常见的大 O 运行时间\n",
61 | "\n",
62 | "下面按从快到慢的顺序列出了你经常会遇到的5种大O运行时间。\n",
63 | "\n",
64 | "- $O(log n)$,也叫对数时间,这样的算法包括二分查找。\n",
65 | "- $O(n)$,也叫线性时间,这样的算法包括简单查找。\n",
66 | "- $O(n * log n)$,这样的算法包括第4章将介绍的快速排序——一种速度较快的排序算法。\n",
67 | "- $O(n^2)$,这样的算法包括第2章将介绍的选择排序——一种速度较慢的排序算法。\n",
68 | "- $O(n!)$,这样的算法包括接下来将介绍的旅行商问题的解决方案——一种非常慢的算法。\n",
69 | "\n",
70 | "### 旅行商\n",
71 | "\n",
72 | "下面就是一个运行时间极长的算法。这个算法要解决的是计算机科学领域非常著名的旅行商问题,其计算时间增加得非常快,而有些非常聪明的人都认为没有改进空间。\n",
73 | "\n",
74 | "有一位旅行商。他需要前往5个城市。这位旅行商要前往这5个城市,同时要确保旅程最短。为此,可考虑前往这些城市的各种可能顺序。\n",
75 | "\n",
76 | "对于每种顺序,他都计算总旅程,再挑选出旅程最短的路线。5个城市有120种不同的排列方式。因此,在涉及5个城市时,解决这个问题需要执行120次操作。涉及6个城市时,需要执行720次操作(有720种不同的排列方式)。涉及7个城市时,需要执行5040次操作!\n",
77 | "\n",
78 | "推而广之,涉及n个城市时,需要执行n!(n的阶乘)次操作才能计算出结果。因此运行时间为O(n!),即阶乘时间。除非涉及的城市数很少,否则需要执行非常多的操作。如果涉及的城市数超过100,根本就不能在合理的时间内计算出结果——等你计算出结果,太阳都没了。\n",
79 | "\n",
80 | "这是计算机科学领域待解的问题之一。对于这个问题,目前还没有找到更快的算法,有些很聪明的人认为这个问题根本就没有更巧妙的算法。面对这个问题,我们能做的只是去找出近似答案,更详细的信息请参阅第10章。"
81 | ]
82 | }
83 | ],
84 | "metadata": {
85 | "kernelspec": {
86 | "display_name": "Python 3 (system-wide)",
87 | "language": "python",
88 | "name": "python3"
89 | },
90 | "language_info": {
91 | "codemirror_mode": {
92 | "name": "ipython",
93 | "version": 3
94 | },
95 | "file_extension": ".py",
96 | "mimetype": "text/x-python",
97 | "name": "python",
98 | "nbconvert_exporter": "python",
99 | "pygments_lexer": "ipython3",
100 | "version": "3.6.8"
101 | }
102 | },
103 | "nbformat": 4,
104 | "nbformat_minor": 2
105 | }
106 |
--------------------------------------------------------------------------------
/算法图解/chap02-选择排序.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第2章 选择排序\n",
8 | "\n",
9 | "## 2.2 数组和链表\n",
10 | "\n",
11 | "使用数组意味着所有待办事项在内存中都是相连的(紧靠在一起的)。有时候,需要在内存中存储一系列元素。假设你要编写一个管理待办事项的应用程序,为此需要将这些待办事项存储在内存中。\n",
12 | "\n",
13 | "现在假设你要添加第四个待办事项,但后面的那个抽屉放着别人的东西!\n",
14 | "\n",
15 | "在这种情况下,你需要请求计算机重新分配一块可容纳4个待办事项的内存,再将所有待办事项都移到那里。\n",
16 | "\n",
17 | "如果又来了一位朋友,而当前坐的地方也没有空位,你们就得再次转移!真是太麻烦了。同\n",
18 | "样,在数组中添加新元素也可能很麻烦。如果没有了空间,就得移到内存的其他地方,因此添加\n",
19 | "新元素的速度会很慢。一种解决之道是“预留座位”:即便当前只有3个待办事项,也请计算机提\n",
20 | "供10个位置,以防需要添加待办事项。这样,只要待办事项不超过10个,就无需转移。这是一个\n",
21 | "不错的权变措施,但你应该明白,它存在如下两个缺点。\n",
22 | "\n",
23 | "- 你额外请求的位置可能根本用不上,这将浪费内存。你没有使用,别人也用不了。\n",
24 | "- 待办事项超过10个后,你还得转移。\n",
25 | "\n",
26 | "因此,这种权宜措施虽然不错,但绝非完美的解决方案。对于这种问题,可使用链表来解决。\n",
27 | "\n",
28 | "### 2.2.1 链表\n",
29 | "\n",
30 | "链表的每个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串在一起。\n",
31 | "\n",
32 | "使用链表时,根本就不需要移动元素。这还可避免另一个问题。假设你与五位朋友去看一部很火的电影。你们六人想坐在一起,但看电影的人较多,没有六个在一起的座位。使用数组时有时就会遇到这样的情况。假设你要为数组分配10 000个位置,内存中有10 000个位置,但不都靠在一起。在这种情况下,你将无法为该数组分配内存!链表相当于说“我们分开来坐”,因此,只要有足够的内存空间,就能为链表分配内存。链表的优势在插入元素方面,那数组的优势又是什么呢?\n",
33 | "\n",
34 | "**链表和数组对比:**\n",
35 | "\n",
36 | "在需要读取链表的最后一个元素时,你不能直接读取,因为你不知道它所处的地址,必须先访问元素#1,从中获取元素#2的地址,再访问元素#2并从中获取元素#3的地址,以此类推,直到访问最后一个元素。需要同时读取所有元素时,链表的效率很高:你读取第一个元素,根据其中的地址再读取第二个元素,以此类推。但如果你需要跳跃,链表的效率真的很低。\n",
37 | "\n",
38 | "数组与此不同:你知道其中每个元素的地址。需要随机地读取元素时,数组的效率很高,因为可迅速找到数组的任何元素。在链表中,元素并非靠在一起的,你无法迅速计算出第五个元素的内存地址,而必须先访问第一个元素以获取第二个元素的地址,再访问第二个元素以获取第三个元素的地址,以此类推,直到访问第五个元素。\n",
39 | "\n",
40 | "|时间|数组|链表|\n",
41 | "|--|--|--|\n",
42 | "|读取|O(1)|O(n)|\n",
43 | "|插入|O(n)|O(1)|\n",
44 | "|删除|O(n)|O(1)|\n",
45 | "\n",
46 | "**在中间插入**\n",
47 | "\n",
48 | "使用链表时,插入元素很简单,只需修改它前面的那个元素指向的地址。\n",
49 | "\n",
50 | "而使用数组时,则必须将后面的元素都向后移。如果没有足够的空间,可能还得将整个数组复制到其他地方!因此,当需要在中间插入元素时,链表是更好的选择。\n",
51 | "\n",
52 | "**删除**\n",
53 | "\n",
54 | "如果你要删除元素呢?链表也是更好的选择,因为只需修改前一个元素指向的地址即可。而\n",
55 | "使用数组时,删除元素后,必须将后面的元素都向前移。\n",
56 | "不同于插入,删除元素总能成功。如果内存中没有足够的空间,插入操作可能失败,但在任\n",
57 | "何情况下都能够将元素删除。\n",
58 | "\n",
59 | "**仅当能够立即访问要删除的元素时,删除操作的运行时间才为O(1)。通常我们都记录了链表的第一个元素和最后一个元素,因此删除这些元素时运行时间为O(1)。**\n",
60 | "\n",
61 | "## 2.3 选择排序\n",
62 | "\n",
63 | "对于每个乐队,你都记录了其作品被播放的次数。你要将这个列表按播放次数从多到少的顺序排列,从而将你喜欢的乐队排序。该如何做呢?\n",
64 | "\n",
65 | "一种办法是遍历这个列表,找出作品播放次数最多的乐队,并将该乐队添加到一个新列表中。\n",
66 | "\n",
67 | "再次这样做,找出播放次数第二多的乐队。\n",
68 | "\n",
69 | "不断重复,直到最后一个。\n",
70 | "\n",
71 | "**算法复杂度 $O(n^2)$**"
72 | ]
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": 1,
77 | "metadata": {},
78 | "outputs": [
79 | {
80 | "name": "stdout",
81 | "output_type": "stream",
82 | "text": [
83 | "[2, 3, 5, 6, 10]\n"
84 | ]
85 | }
86 | ],
87 | "source": [
88 | "#查找数组中的最小数的索引\n",
89 | "def findMinIndex(array):\n",
90 | " min_val = array[0]\n",
91 | " min_index = 0\n",
92 | " for i in range(1,len(array)):\n",
93 | " if array[i] < min_val:\n",
94 | " min_val = array[i]\n",
95 | " min_index = i\n",
96 | " return min_index\n",
97 | "\n",
98 | "# 选择排序\n",
99 | "def selectSort(array):\n",
100 | " newArray = []\n",
101 | " for i in range(len(array)):\n",
102 | " min_val = findMinIndex(array)\n",
103 | " newArray.append(array.pop(min_val))\n",
104 | " return newArray\n",
105 | "\n",
106 | "print(selectSort([5,3,6,2,10]))"
107 | ]
108 | }
109 | ],
110 | "metadata": {
111 | "kernelspec": {
112 | "display_name": "Python 3 (system-wide)",
113 | "language": "python",
114 | "name": "python3"
115 | },
116 | "language_info": {
117 | "codemirror_mode": {
118 | "name": "ipython",
119 | "version": 3
120 | },
121 | "file_extension": ".py",
122 | "mimetype": "text/x-python",
123 | "name": "python",
124 | "nbconvert_exporter": "python",
125 | "pygments_lexer": "ipython3",
126 | "version": "3.6.8"
127 | }
128 | },
129 | "nbformat": 4,
130 | "nbformat_minor": 2
131 | }
132 |
--------------------------------------------------------------------------------
/算法图解/chap03-递归.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第3章 递归\n",
8 | "\n",
9 | "这两种方法的作用相同,但在我看来,第二种方法更清晰。递归只是让解决方案更清晰,并没有性能上的优势。实际上,在有些情况下,使用循环的性能更好。\n",
10 | "\n",
11 | "我很喜欢Leigh Caldwell在Stack Overflow上说的一句话:“如果使用循环,程序的性能可能更高;如果使用递归,程序可能更容易理解。如何选择要看什么对你来说更重要。([参考链接](http://stackoverflow.com/a/72694/139117))” 很多算法都使用了递归,因此理解这种概念很重要。\n",
12 | "\n",
13 | "## 3.2基线条件和递归条件\n",
14 | "\n",
15 | "由于递归函数调用自己,因此编写这样的函数时很容易出错,进而导致无限循环。例如,假设你要编写一个像下面这样倒计时的函数。\n",
16 | "```\n",
17 | "def countdown(i):\n",
18 | " print i\n",
19 | " countdown(i-1)\n",
20 | "```\n",
21 | "如果你运行上述代码,将发现一个问题:这个函数运行起来没完没了!\n",
22 | "\n",
23 | "编写递归函数时,必须告诉它何时停止递归。正因为如此,每个递归函数都有两部分:基线条件(base case)和递归条件(recursive case)。递归条件指的是函数调用自己,而基线条件则指的是函数不再调用自己,从而避免形成无限循环。\n",
24 | "\n",
25 | "我们来给函数 countdown 添加基线条件。\n",
26 | "\n",
27 | "现在,这个函数将像预期的那样运行,如下所示。"
28 | ]
29 | },
30 | {
31 | "cell_type": "code",
32 | "execution_count": 3,
33 | "metadata": {},
34 | "outputs": [
35 | {
36 | "name": "stdout",
37 | "output_type": "stream",
38 | "text": [
39 | "10\n",
40 | "9\n",
41 | "8\n",
42 | "7\n",
43 | "6\n",
44 | "5\n",
45 | "4\n",
46 | "3\n",
47 | "2\n",
48 | "1\n",
49 | "0\n"
50 | ]
51 | }
52 | ],
53 | "source": [
54 | "def countdown(i):\n",
55 | " print((i))\n",
56 | " if i <= 0:\n",
57 | " return\n",
58 | " else:\n",
59 | " countdown(i-1)\n",
60 | " \n",
61 | "countdown(10)"
62 | ]
63 | },
64 | {
65 | "cell_type": "markdown",
66 | "metadata": {},
67 | "source": [
68 | "## 3.3栈 stack\n",
69 | "\n",
70 | "本节将介绍一个重要的编程概念——调用栈(call stack)。调用栈不仅对编程来说很重要,使用递归时也必须理解这个概念。假设你去野外烧烤,并为此创建了一个待办事项清单——一叠便条。\n",
71 | "\n",
72 | "本书之前讨论数组和链表时,也有一个待办事项清单。你可将待办事项添加到该清单的任何地方,还可删除任何一个待办事项。一叠便条要简单得多:插入的待办事项放在清单的最前面;读取待办事项时,你只读取最上面的那个,并将其删除。因此这个待办事项清单只有两种操作:压入(插入)和弹出(删除并读取)。\n",
73 | "\n",
74 | "### 3.3.1 调用栈\n",
75 | "\n",
76 | "计算机在内部使用被称为调用栈的栈。我们来看看计算机是如何使用调用栈的。下面是一个简单的函数。"
77 | ]
78 | },
79 | {
80 | "cell_type": "code",
81 | "execution_count": 9,
82 | "metadata": {},
83 | "outputs": [
84 | {
85 | "name": "stdout",
86 | "output_type": "stream",
87 | "text": [
88 | "hello, maggie!\n",
89 | "how are you, maggie?\n",
90 | "getting ready to say bye...\n",
91 | "ok bye!\n"
92 | ]
93 | }
94 | ],
95 | "source": [
96 | "def greet(name):\n",
97 | " print(\"hello, \" + name + \"!\")\n",
98 | " greet2(name)\n",
99 | " print(\"getting ready to say bye...\")\n",
100 | " bye()\n",
101 | " \n",
102 | "#这个函数问候用户,再调用另外两个函数。这两个函数的代码如下。\n",
103 | "def greet2(name):\n",
104 | " print(\"how are you, \" + name + \"?\")\n",
105 | "def bye():\n",
106 | " print(\"ok bye!\")\n",
107 | " \n",
108 | "greet(\"maggie\")"
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "metadata": {},
114 | "source": [
115 | "下面详细介绍调用函数时发生的情况:\n",
116 | "\n",
117 | "- 1.调用 greet(\"maggie\"),计算机为grreet函数调用分配一块内存。其中的name = maggie\n",
118 | "- 2.打印 hello, maggie!\n",
119 | "- 3.调用greet2(\"maggie\"),计算机为grreet2函数调用分配一块内存,计算机使用一个栈来表示这些内存块,第二个内存块(greet2)位于第一个内存块(greet)上面。其中的name = maggie\n",
120 | "- 4.打印how are you, maggie? ,然后从函数调用返回。此时,栈顶的内存块(greet2)被弹出。\n",
121 | "- 5.现在,栈顶的内存块是函数 greet 的,这意味着你返回到了函数 greet 。当你调用函数 greet2时,函数 greet 只执行了一部分。这是本节的一个重要概念:**调用另一个函数时,当前函数暂停并处于未完成状态**。该函数的所有变量的值都还在内存中。执行完函数 greet2 后,你回到函数greet ,并从离开的地方开始接着往下执行\n",
122 | "- 6.首先打印 getting ready to say bye\n",
123 | "- 7.再调用函数 bye 。在栈顶添加了函数 bye 的内存块。然后,你打印 ok bye! ,并从这个函数返回。\n",
124 | "- 8.现在你又回到了函数 greet 。由于没有别的事情要做,你就从函数 greet 返回。\n",
125 | "\n",
126 | "这个栈用于存储多个函数的变量,被称为调用栈。\n",
127 | "\n",
128 | "### 3.3.2 递归调用栈\n",
129 | "\n",
130 | "递归函数也使用调用栈!来看看递归函数 factorial 的调用栈。 factorial(5) 写作5!,其定义如下:5! = 5 * 4 * 3 * 2 * 1。同理, factorial(3) 为3 * 2 * 1。下面是计算阶乘的递归函数。"
131 | ]
132 | },
133 | {
134 | "cell_type": "code",
135 | "execution_count": 10,
136 | "metadata": {},
137 | "outputs": [
138 | {
139 | "data": {
140 | "text/plain": [
141 | "6"
142 | ]
143 | },
144 | "execution_count": 10,
145 | "metadata": {},
146 | "output_type": "execute_result"
147 | }
148 | ],
149 | "source": [
150 | "def fact(x):\n",
151 | " if x==1:\n",
152 | " return 1\n",
153 | " else:\n",
154 | " return x*fact(x-1)\n",
155 | " \n",
156 | "fact(3)"
157 | ]
158 | },
159 | {
160 | "cell_type": "markdown",
161 | "metadata": {},
162 | "source": [
163 | "注意,每个 fact 调用都有自己的 x 变量。在一个函数调用中不能访问另一个的 x 变量。栈在递归中扮演着重要角色。这个栈包含未完成的函数调用,每个函数调用都包含还未检查完的盒子。使用栈很方便,因为你无需自己跟踪盒子堆——栈替你这样做了。\n",
164 | "\n",
165 | "使用栈虽然很方便,但是也要付出代价:存储详尽的信息可能占用大量的内存。每个函数调用都要占用一定的内存,如果栈很高,就意味着计算机存储了大量函数调用的信息。在这种情况下,你有两种选择。\n",
166 | "- 重新编写代码,转而使用循环。\n",
167 | "- 使用尾递归。这是一个高级递归主题,不在本书的讨论范围内。另外,并非所有的语言都支持尾递归。"
168 | ]
169 | }
170 | ],
171 | "metadata": {
172 | "kernelspec": {
173 | "display_name": "Python 3 (system-wide)",
174 | "language": "python",
175 | "name": "python3"
176 | },
177 | "language_info": {
178 | "codemirror_mode": {
179 | "name": "ipython",
180 | "version": 3
181 | },
182 | "file_extension": ".py",
183 | "mimetype": "text/x-python",
184 | "name": "python",
185 | "nbconvert_exporter": "python",
186 | "pygments_lexer": "ipython3",
187 | "version": "3.6.8"
188 | }
189 | },
190 | "nbformat": 4,
191 | "nbformat_minor": 2
192 | }
193 |
--------------------------------------------------------------------------------
/算法图解/chap04-快速排序.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第4章 快速排序\n",
8 | "\n",
9 | "本章的重点是使用学到的新技能来解决问题。我们将探索分而治之(divide and conquer,D&C)——一种著名的递归式问题解决方法。\n",
10 | "\n",
11 | "本书将深入算法的核心。只能解决一种问题的算法毕竟用处有限,而D&C提供了解决问题的思路,是另一个可供你使用的工具。面对新问题时,你不再束手无策,而是自问:“使用分而治\n",
12 | "之能解决吗?”\n",
13 | "\n",
14 | "在本章末尾,你将学习第一个重要的D&C算法——快速排序。快速排序是一种排序算法,速度比第2章介绍的选择排序快得多,实属优雅代码的典范。\n",
15 | "\n",
16 | "## 4.1 分而治之\n",
17 | "\n",
18 | "如何将一块地均匀地分成方块,并确保分出的方块是最大的呢?使用D&C策略!D&C算法是递归的。使用D&C解决问题的过程包括两个步骤。\n",
19 | "\n",
20 | "- (1) 找出基线条件,这种条件必须尽可能简单。\n",
21 | "- (2) 不断将问题分解(或者说缩小规模),直到符合基线条件。\n",
22 | "\n",
23 | "假设你是农场主,有一小块土地。1680m x 640m\n",
24 | "\n",
25 | "首先,找出基线条件。最容易处理的情况是,一条边的长度是另一条边的整数倍。\n",
26 | "\n",
27 | "现在需要找出递归条件,这正是D&C的用武之地。根据D&C的定义,每次递归调用都必须缩小问题的规模。如何缩小前述问题的规模呢?我们首先找出这块地可容纳的最大方块。\n",
28 | "\n",
29 | "你可以从这块地中划出两个640 m×640 m的方块,同时余下一小块地。现在是顿悟时刻:何不对余下的那一小块地使用相同的算法呢?\n",
30 | "\n",
31 | "最初要划分的土地尺寸为1680 m×640 m,而现在要划分的土地更小,为640 m×400 m。适用于这小块地的最大方块,也是适用于整块地的最大方块。换言之,你将均匀划分1680 m×640 m\n",
32 | "土地的问题,简化成了均匀划分640 m×400 m土地的问题!\n",
33 | "```\n",
34 | "1680x640\n",
35 | "400x640\n",
36 | "400x240\n",
37 | "160x240\n",
38 | "160x80\n",
39 | "```\n",
40 | "\n",
41 | "因此,对于最初的那片土地,适用的最大方块为80 m× 80 m。\n",
42 | "\n",
43 | "这里重申一下D&C的工作原理:\n",
44 | "- (1) 找出简单的基线条件;\n",
45 | "- (2) 确定如何缩小问题的规模,使其符合基线条件。\n",
46 | "D&C并非可用于解决问题的算法,而是一种解决问题的思路。我们再来看一个例子。\n",
47 | "\n",
48 | "给定一个数字数组,计算数字之和:\n",
49 | "\n",
50 | "循环方法:"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 3,
56 | "metadata": {},
57 | "outputs": [
58 | {
59 | "name": "stdout",
60 | "output_type": "stream",
61 | "text": [
62 | "10\n"
63 | ]
64 | }
65 | ],
66 | "source": [
67 | "def sum_array(arr):\n",
68 | " total = 0\n",
69 | " for x in arr:\n",
70 | " total += x\n",
71 | " return total\n",
72 | "\n",
73 | "print(sum_array([1, 2, 3, 4]))"
74 | ]
75 | },
76 | {
77 | "cell_type": "markdown",
78 | "metadata": {},
79 | "source": [
80 | "但如何使用递归函数来完成这种任务呢?\n",
81 | "\n",
82 | "- 第一步:找出基线条件。最简单的数组什么样呢?请想想这个问题,再接着往下读。如果数组不包含任何元素或只包含一个元素,计算总和将非常容易。因此这就是基线条件。\n",
83 | "- 第二步:每次递归调用都必须离空数组更近一步。 sum([2,4,6) = 2 + sum([4,6])\n",
84 | "\n",
85 | "\n",
86 | "\n",
87 | "这个函数的运行过程如下:\n",
88 | "\n",
89 | "[](https://imgchr.com/i/et48jU)\n",
90 | "\n",
91 | "**编写涉及数组的递归函数时,基线条件通常是数组为空或只包含一个元素。陷入困境时,请检查基线条件是不是这样的。**"
92 | ]
93 | },
94 | {
95 | "cell_type": "code",
96 | "execution_count": 17,
97 | "metadata": {},
98 | "outputs": [],
99 | "source": [
100 | "def sum_array(arr):\n",
101 | " if len(arr) == 0:\n",
102 | " return 0\n",
103 | " if len(arr) == 1:\n",
104 | " return arr[0]\n",
105 | " else:\n",
106 | " return arr[0] + sum_array(arr[1:])"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": 19,
112 | "metadata": {},
113 | "outputs": [
114 | {
115 | "data": {
116 | "text/plain": [
117 | "12"
118 | ]
119 | },
120 | "execution_count": 19,
121 | "metadata": {},
122 | "output_type": "execute_result"
123 | }
124 | ],
125 | "source": [
126 | "sum_array([2,4,6])"
127 | ]
128 | },
129 | {
130 | "cell_type": "markdown",
131 | "metadata": {},
132 | "source": [
133 | "## 4.2 快速排序 Quick Sort\n",
134 | "\n",
135 | "快速排序是一种常用的排序算法,比选择排序快得多。例如,C语言标准库中的函数 qsort实现的就是快速排序。快速排序也使用了D&C。\n",
136 | "\n",
137 | "基线条件为数组为空或只包含一个元素。在这种情况下,只需原样返回数组——根本就不用排序。\n",
138 | "\n",
139 | "```\n",
140 | "def quicksort(array):\n",
141 | " if len(array) < 2:\n",
142 | " return array\n",
143 | "```\n",
144 | "\n",
145 | "快速排序,步骤如下。\n",
146 | "\n",
147 | "- (1) 选择基准值。\n",
148 | "- (2) 将数组分成两个子数组:小于基准值的元素和大于基准值的元素。\n",
149 | "- (3) 对这两个子数组进行快速排序。\n",
150 | "\n",
151 | "对于快速排序,可使用类似的推理。在基线条件中,我证明这种算法对空数组或包含一个元素的数组管用。在归纳条件中,我证明如果快速排序对包含一个元素的数组管用,对包含两个元素的数组也将管用;如果它对包含两个元素的数组管用,对包含三个元素的数组也将管用,以此类推。因此,我可以说,快速排序对任何长度的数组都管用。这里不再深入讨论归纳证明,但它很有趣,并与D&C协同发挥作用。"
152 | ]
153 | },
154 | {
155 | "cell_type": "code",
156 | "execution_count": 20,
157 | "metadata": {},
158 | "outputs": [
159 | {
160 | "name": "stdout",
161 | "output_type": "stream",
162 | "text": [
163 | "[2, 3, 5, 10]\n"
164 | ]
165 | }
166 | ],
167 | "source": [
168 | "def quicksort(array):\n",
169 | " if len(array) < 2:\n",
170 | " return array # 基线条件:为空或只包含一个元素的数组是“有序”的\n",
171 | " else:\n",
172 | " pivot = array[0] # 递归条件\n",
173 | " less = [i for i in array[1:] if i <= pivot] #由所有小于基准值的元素组成的子数组\n",
174 | " greater = [i for i in array[1:] if i > pivot] #由所有大于基准值的元素组成的子数组\n",
175 | " return quicksort(less) + [pivot] + quicksort(greater)\n",
176 | "\n",
177 | "print(quicksort([10, 5, 2, 3]))"
178 | ]
179 | },
180 | {
181 | "cell_type": "markdown",
182 | "metadata": {},
183 | "source": [
184 | "还有一种名为合并排序(merge sort)(或称归并排序)的排序算法,其运行时间为O(n log n),比选择排序快得多!快速排序的情况比较棘手,在最糟情况下,其运行时间为O(n 2 )。与选择排序一样慢!但这是最糟情况。在平均情况下,快速排序的运行时间为O(n log n)。\n",
185 | "\n",
186 | "平均情况和最糟情况:\n",
187 | "\n",
188 | "在这个示例中,层数为O(log n)(用技术术语说,调用栈的高度为O(log n)),而每层需要的时间为O(n)。因此整个算法需要的时间为O(n) * O(log n) = O(n log n)。这就是最佳情况。\n",
189 | "\n",
190 | "在最糟情况下,有O(n)层,因此该算法的运行时间为O(n) * O(n) = O(n 2 )。\n",
191 | "\n",
192 | "这里要告诉你的是,最佳情况也是平均情况。只要你每次都随机地选择一个数组元素作为基准值,快速排序的平均运行时间就将为O(n log n)。快速排序是最快的排序算法之一,也是D&C典范。"
193 | ]
194 | },
195 | {
196 | "cell_type": "markdown",
197 | "metadata": {},
198 | "source": [
199 | "## 归并排序"
200 | ]
201 | },
202 | {
203 | "cell_type": "code",
204 | "execution_count": null,
205 | "metadata": {},
206 | "outputs": [],
207 | "source": []
208 | }
209 | ],
210 | "metadata": {
211 | "kernelspec": {
212 | "display_name": "Python 3 (system-wide)",
213 | "language": "python",
214 | "name": "python3"
215 | },
216 | "language_info": {
217 | "codemirror_mode": {
218 | "name": "ipython",
219 | "version": 3
220 | },
221 | "file_extension": ".py",
222 | "mimetype": "text/x-python",
223 | "name": "python",
224 | "nbconvert_exporter": "python",
225 | "pygments_lexer": "ipython3",
226 | "version": "3.6.8"
227 | }
228 | },
229 | "nbformat": 4,
230 | "nbformat_minor": 2
231 | }
232 |
--------------------------------------------------------------------------------
/算法图解/chap05-散列表.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第5章 散列表\n",
8 | "\n",
9 | "## 5.1散列函数\n",
10 | "\n",
11 | "散列函数准确地指出了价格的存储位置,你根本不用查找!之所以能够这样,具体原因如下。\n",
12 | "\n",
13 | "- 散列函数总是将同样的输入映射到相同的索引。每次你输入avocado,得到的都是同一个数字。因此,你可首先使用它来确定将鳄梨的价格存储在什么地方,并在以后使用它来确定鳄梨的价格存储在什么地方。\n",
14 | "- 散列函数将不同的输入映射到不同的索引。avocado映射到索引4,milk映射到索引0。每种商品都映射到数组的不同位置,让你能够将其价格存储到这里。\n",
15 | "- 散列函数知道数组有多大,只返回有效的索引。如果数组包含5个元素,散列函数就不会返回无效索引100。\n",
16 | "\n",
17 | "你可能根本不需要自己去实现散列表,任一优秀的语言都提供了散列表实现。Python提供的散列表实现为字典,你可使用函数 dict 来创建散列表。\n",
18 | "\n",
19 | "在你将学习的复杂数据结构中,散列表可能是最有用的,也被称为散列映射、映射、字典和关联数组。散列表的速度很快!还记得第2章关于数组和链表的讨论吗?你可以立即获取数组中的元素,而散列表也使用数组来存储数据,因此其获取元素的速度与数组一样快。"
20 | ]
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": 1,
25 | "metadata": {},
26 | "outputs": [
27 | {
28 | "name": "stdout",
29 | "output_type": "stream",
30 | "text": [
31 | "{'apple': 0.67, 'milk': 1.49, 'avocado': 1.49}\n"
32 | ]
33 | }
34 | ],
35 | "source": [
36 | "book = dict()\n",
37 | "book[\"apple\"] = 0.67\n",
38 | "book[\"milk\"] = 1.49\n",
39 | "book[\"avocado\"] = 1.49\n",
40 | "print(book)"
41 | ]
42 | },
43 | {
44 | "cell_type": "markdown",
45 | "metadata": {},
46 | "source": [
47 | "## 5.2应用案例\n",
48 | "### 5.2.1 将散列表用于查找\n",
49 | "\n",
50 | "如电话簿"
51 | ]
52 | },
53 | {
54 | "cell_type": "code",
55 | "execution_count": 4,
56 | "metadata": {},
57 | "outputs": [
58 | {
59 | "name": "stdout",
60 | "output_type": "stream",
61 | "text": [
62 | "8675309\n"
63 | ]
64 | }
65 | ],
66 | "source": [
67 | "phone_book = dict()\n",
68 | "phone_book[\"jenny\"] = 8675309\n",
69 | "phone_book[\"emergency\"] = 911\n",
70 | "print(phone_book[\"jenny\"])"
71 | ]
72 | },
73 | {
74 | "cell_type": "markdown",
75 | "metadata": {},
76 | "source": [
77 | "### 5.2.2 防止重复\n",
78 | "\n",
79 | "投票记录"
80 | ]
81 | },
82 | {
83 | "cell_type": "code",
84 | "execution_count": 5,
85 | "metadata": {},
86 | "outputs": [],
87 | "source": [
88 | "voted = {}\n",
89 | "def check_voter(name):\n",
90 | " if voted.get(name):\n",
91 | " print(\"kick them out!\")\n",
92 | " else:\n",
93 | " voted[name] = True\n",
94 | " print(\"let them vote!\")"
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": 6,
100 | "metadata": {},
101 | "outputs": [
102 | {
103 | "name": "stdout",
104 | "output_type": "stream",
105 | "text": [
106 | "let them vote!\n"
107 | ]
108 | }
109 | ],
110 | "source": [
111 | "check_voter(\"tom\")"
112 | ]
113 | },
114 | {
115 | "cell_type": "code",
116 | "execution_count": 7,
117 | "metadata": {},
118 | "outputs": [
119 | {
120 | "name": "stdout",
121 | "output_type": "stream",
122 | "text": [
123 | "let them vote!\n"
124 | ]
125 | }
126 | ],
127 | "source": [
128 | "check_voter(\"mike\")"
129 | ]
130 | },
131 | {
132 | "cell_type": "code",
133 | "execution_count": 8,
134 | "metadata": {},
135 | "outputs": [
136 | {
137 | "name": "stdout",
138 | "output_type": "stream",
139 | "text": [
140 | "kick them out!\n"
141 | ]
142 | }
143 | ],
144 | "source": [
145 | "check_voter(\"mike\")"
146 | ]
147 | },
148 | {
149 | "cell_type": "markdown",
150 | "metadata": {},
151 | "source": [
152 | "### 5.2.3 将散列表用作缓存\n",
153 | "\n",
154 | "来看最后一个应用案例:缓存。如果你在网站工作,可能听说过进行缓存是一种不错的做法。下面简要地介绍其中的原理。假设你访问网facebook.com。\n",
155 | "\n",
156 | "- (1) 你向Facebook的服务器发出请求。\n",
157 | "- (2) 服务器做些处理,生成一个网页并将其发送给你。\n",
158 | "- (3) 你获得一个网页。\n",
159 | "\n",
160 | "如果你登录了Facebook,你看到的所有内容都是为你定制的。你每次访问facebook.com,其服务器都需考虑你感兴趣的是什么内容。但如果你没有登录,看到的将是登录页面。每个人看到的登录页面都相同。Facebook被反复要求做同样的事情:“当我注销时,请向我显示主页。”有鉴于此,它不让服务器去生成主页,而是将主页存储起来,并在需要时将其直接发送给用户。\n",
161 | "\n",
162 | "缓存是一种常用的加速方式,所有大型网站都使用缓存,而缓存的数据则存储在散列表中!Facebook不仅缓存主页,还缓存About页面、Contact页面、Terms and Conditions页面等众多其他的页面。因此,它需要将页面URL映射到页面数据。"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": 9,
168 | "metadata": {},
169 | "outputs": [],
170 | "source": [
171 | "cache = {}\n",
172 | "def get_page(url):\n",
173 | " if cache.get(url):\n",
174 | " return cache[url]\n",
175 | " else:\n",
176 | " data = get_data_from_server(url)\n",
177 | " cache[url] = data\n",
178 | " return data"
179 | ]
180 | },
181 | {
182 | "cell_type": "markdown",
183 | "metadata": {},
184 | "source": [
185 | "## 5.3 冲突\n",
186 | "\n",
187 | "前面说过,大多数语言都提供了散列表实现,你不用知道如何实现它们。有鉴于此,我就不再过多地讨论散列表的内部原理,但你依然需要考虑性能!要明白散列表的性能,你得先搞清楚什么是冲突。本节和下一节将分别介绍冲突和性能。\n",
188 | "\n",
189 | "首先,我撒了一个善意的谎。我之前告诉你的是,散列函数总是将不同的键映射到数组的不同位置。\n",
190 | "\n",
191 | "实际上,几乎不可能编写出这样的散列函数。\n",
192 | "\n",
193 | "这种情况被称为冲突(collision):给两个键分配的位置相同。这是个问题。如果你将鳄梨的价格存储到这个位置,将覆盖苹果的价格,以后再查询苹果的价格时,得到的将是鳄梨的价格!冲突很糟糕,必须要避免。处理冲突的方式很多,最简单的办法如下:如果两个键映射到了同一个位置,就在这个位置存储一个链表。\n",
194 | "\n",
195 | "这里的经验教训有两个。\n",
196 | "\n",
197 | "- 散列函数很重要。前面的散列函数将所有的键都映射到一个位置,而最理想的情况是,散列函数将键均匀地映射到散列表的不同位置。\n",
198 | "- 如果散列表存储的链表很长,散列表的速度将急剧下降。然而,如果使用的散列函数很好,这些链表就不会很长!\n",
199 | "\n",
200 | "散列函数很重要,好的散列函数很少导致冲突。那么,如何选择好的散列函数呢?这将在下一节介绍!\n",
201 | "\n",
202 | "## 5.4 性能\n",
203 | "\n",
204 | "在最糟情况下,散列表所有操作的运行时间都为O(n)——线性时间,这真的很慢。我们来将散列表同数组和链表比较一下。\n",
205 | "\n",
206 | "在平均情况下,散列表的查找(获取给定索引处的值)速度与数组一样快,而插入和删除速度与链表一样快,因此它兼具两者的优点!\n",
207 | "\n",
208 | "但在最糟情况下,散列表的各种操作的速度都很慢。因此,在使用散列表时,避开最糟情况至关重要。为此,需要避免冲突。而要避免冲突,需要有:\n",
209 | "\n",
210 | "- 较低的填装因子;\n",
211 | "- 良好的散列函数。\n",
212 | "\n",
213 | "### 5.4.1 填装因子\n",
214 | "\n",
215 | "散列表的填装因子很容易计算。\n",
216 | "\n",
217 | "散列表包含的元素数/位置总数\n",
218 | "\n",
219 | "散列表使用数组来存储数据,因此你需要计算数组中被占用的位置数。例如,下述散列表的填装因子为2/5,即0.4。\n",
220 | "\n",
221 | "\n",
222 | "\n",
223 | "不可能让每种商品都有自己的位置,因为没有足够的位置!填装因子大于1意味着商品数量超过了数组的位置数。一旦填装因子开始增大,你就需要在散列表中添加位置,这被称为调整长度(resizing)。\n",
224 | "\n",
225 | "填装因子越低,发生冲突的可能性越小,散列表的性能越高。一个不错的经验规则是:一旦填装因子大于0.7,就调整散列表的长度。\n",
226 | "\n",
227 | "你可能在想,调整散列表长度的工作需要很长时间!你说得没错,调整长度的开销很大,因此你不会希望频繁地这样做。但平均而言,即便考虑到调整长度所需的时间,散列表操作所需的时间也为O(1)。\n",
228 | "\n",
229 | "### 5.4.2 良好的散列函数\n",
230 | "\n",
231 | "良好的散列函数让数组中的值呈均匀分布。\n",
232 | "\n",
233 | "糟糕的散列函数让值扎堆,导致大量的冲突。\n",
234 | "\n",
235 | "什么样的散列函数是良好的呢?你根本不用操心——天塌下来有高个子顶着。如果你好奇,可研究一下SHA函数(本书最后一章做了简要的介绍)。你可将它用作散列函数。\n",
236 | "\n",
237 | "## 5.5 小结\n",
238 | "\n",
239 | "你几乎根本不用自己去实现散列表,因为你使用的编程语言提供了散列表实现。你可使用Python提供的散列表,并假定能够获得平均情况下的性能:常量时间。\n",
240 | "\n",
241 | "散列表是一种功能强大的数据结构,其操作速度快,还能让你以不同的方式建立数据模型。你可能很快会发现自己经常在使用它。\n",
242 | "\n",
243 | "- 你可以结合散列函数和数组来创建散列表。\n",
244 | "- 冲突很糟糕,你应使用可以最大限度减少冲突的散列函数。\n",
245 | "- 散列表的查找、插入和删除速度都非常快。\n",
246 | "- 散列表适合用于模拟映射关系。\n",
247 | "- 一旦填装因子超过0.7,就该调整散列表的长度。\n",
248 | "- 散列表可用于缓存数据(例如,在Web服务器上)。\n",
249 | "- 散列表非常适合用于防止重复。"
250 | ]
251 | }
252 | ],
253 | "metadata": {
254 | "kernelspec": {
255 | "display_name": "Python 3 (system-wide)",
256 | "language": "python",
257 | "name": "python3"
258 | },
259 | "language_info": {
260 | "codemirror_mode": {
261 | "name": "ipython",
262 | "version": 3
263 | },
264 | "file_extension": ".py",
265 | "mimetype": "text/x-python",
266 | "name": "python",
267 | "nbconvert_exporter": "python",
268 | "pygments_lexer": "ipython3",
269 | "version": "3.6.8"
270 | }
271 | },
272 | "nbformat": 4,
273 | "nbformat_minor": 2
274 | }
275 |
--------------------------------------------------------------------------------
/算法图解/chap08-贪婪算法.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 第8章 贪婪算法\n",
8 | "## 8.1 教室调度问题\n",
9 | "\n",
10 | "如下课程表,你希望将尽可能多的课程安排在某间教室上。没法让这些课都在这间教室上,因为有些课的上课时间有冲突\n",
11 | "\n",
12 | "\n",
13 | "算法如下:\n",
14 | "- (1) 选出结束最早的课,它就是要在这间教室上的第一堂课。\n",
15 | "- (2) 接下来,必须选择第一堂课结束后才开始的课。同样,你选择结束最早的课,这将是要在这间教室上的第二堂课。\n",
16 | "\n",
17 | "\n",
18 | "\n",
19 | "贪婪算法很简单:每步都采取最优的做法。在这个示例中,你每次都选择结束最早的课。用专业术语说,就是你每步都选择局部最优解,最终得到的就是全局最优解。\n",
20 | "\n",
21 | "## 8.2 背包问题\n",
22 | "\n",
23 | "假设你是个贪婪的小偷,背着可装35磅(1磅≈0.45千克)重东西的背包,在商场伺机盗窃各种可装入背包的商品。你力图往背包中装入价值最高的商品,你会使用哪种算法呢?\n",
24 | "\n",
25 | "同样,你采取贪婪策略,这非常简单。\n",
26 | "- (1) 盗窃可装入背包的最贵商品。\n",
27 | "- (2) 再盗窃还可装入背包的最贵商品,以此类推。\n",
28 | "\n",
29 | "\n",
30 | "\n",
31 | "音响最贵,你把它给偷了,但背包没有空间装其他东西了。你偷到了价值3000美元的东西。如果不是偷音响,而是偷笔记本电脑和吉他,总价将为3500美元!\n",
32 | "\n",
33 | "在这里,贪婪策略显然不能获得最优解,但非常接近。下一章将介绍如何找出最优解。不过小偷去购物中心行窃时,不会强求所偷东西的总价最高,只要差不多就行了。\n",
34 | "\n",
35 | "从这个示例你得到了如下启示:在有些情况下,完美是优秀的敌人。有时候,你只需找到一个能够大致解决问题的算法,此时贪婪算法正好可派上用场,因为它们实现起来很容易,得到的结果又与正确结果相当接近。\n",
36 | "\n",
37 | "下面来看最后一个例子。在这个例子中,你别无选择,只能使用贪婪算法。\n",
38 | "\n",
39 | "## 8.3 集合覆盖问题\n",
40 | "\n",
41 | "假设你办了个广播节目,要让全美50个州的听众都收听得到。为此,你需要决定在哪些广播台播出。在每个广播台播出都需要支付费用,因此你力图在尽可能少的广播台播出。现有广播台名单如下。\n",
42 | "\n",
43 | "每个广播台都覆盖特定的区域,不同广播台的覆盖区域可能重叠。\n",
44 | "\n",
45 | "\n",
46 | "\n",
47 | "如何找出覆盖全美50个州的最小广播台集合呢?\n",
48 | "\n",
49 | "听起来很容易,但其实非常难。具体方法如下。\n",
50 | "\n",
51 | "- (1) 列出每个可能的广播台集合,这被称为幂集(power set)。可能的子集有$2^n$ 个。\n",
52 | "- (2) 在这些集合中,选出覆盖全美50个州的最小集合。\n",
53 | "\n",
54 | "问题是计算每个可能的广播台子集需要很长时间。由于可能的集合有2 n 个,因此运行时间为$O (2^n )$。如果广播台不多,只有5~10个,这是可行的。但如果广播台很多,结果将如何呢?随着广播台的增多,需要的时间将激增。假设你每秒可计算10个子集,所需的时间将如下。\n",
55 | "\n",
56 | "\n",
57 | "\n",
58 | "没有任何算法可以足够快地解决这个问题!怎么办呢?\n",
59 | "\n",
60 | "### 近似算法\n",
61 | "\n",
62 | "使用下面的贪婪算法可得到非常接近的解。\n",
63 | "- (1) 选出这样一个广播台,即它覆盖了最多的未覆盖州。即便这个广播台覆盖了一些已覆盖的州,也没有关系。\n",
64 | "- (2) 重复第一步,直到覆盖了所有的州。\n",
65 | "\n",
66 | "这是一种近似算法(approximation algorithm)。在获得精确解需要的时间太长时,可使用近似算法。判断近似算法优劣的标准如下:\n",
67 | "- 速度有多快;\n",
68 | "- 得到的近似解与最优解的接近程度。\n",
69 | "\n",
70 | "**1. 准备工作**\n",
71 | "出于简化考虑,这里假设要覆盖的州没有那么多,广播台也没有那么多。\n",
72 | "首先,创建一个列表,其中包含要覆盖的州。"
73 | ]
74 | },
75 | {
76 | "cell_type": "code",
77 | "execution_count": 1,
78 | "metadata": {},
79 | "outputs": [],
80 | "source": [
81 | "states_needed = set([\"mt\", \"wa\", \"or\", \"id\", \"nv\", \"ut\",\"ca\", \"az\"])"
82 | ]
83 | },
84 | {
85 | "cell_type": "markdown",
86 | "metadata": {},
87 | "source": [
88 | "我使用集合来表示要覆盖的州。集合类似于列表,只是同样的元素只能出现一次,即集合不能包含重复的元素。\n",
89 | "\n",
90 | "还需要有可供选择的广播台清单,我选择使用散列表来表示它。"
91 | ]
92 | },
93 | {
94 | "cell_type": "code",
95 | "execution_count": 2,
96 | "metadata": {},
97 | "outputs": [],
98 | "source": [
99 | "stations = {}\n",
100 | "stations[\"kone\"] = set([\"id\", \"nv\", \"ut\"])\n",
101 | "stations[\"ktwo\"] = set([\"wa\", \"id\", \"mt\"])\n",
102 | "stations[\"kthree\"] = set([\"or\", \"nv\", \"ca\"])\n",
103 | "stations[\"kfour\"] = set([\"nv\", \"ut\"])\n",
104 | "stations[\"kfive\"] = set([\"ca\", \"az\"])"
105 | ]
106 | },
107 | {
108 | "cell_type": "markdown",
109 | "metadata": {},
110 | "source": [
111 | "其中的键为广播台的名称,值为广播台覆盖的州。\n",
112 | "\n",
113 | "最后,需要使用一个集合来存储最终选择的广播台。"
114 | ]
115 | },
116 | {
117 | "cell_type": "code",
118 | "execution_count": 3,
119 | "metadata": {},
120 | "outputs": [],
121 | "source": [
122 | "final_stations = set()"
123 | ]
124 | },
125 | {
126 | "cell_type": "markdown",
127 | "metadata": {},
128 | "source": [
129 | "**2. 计算答案**\n",
130 | "\n",
131 | "接下来需要计算要使用哪些广播台。你需要遍历所有的广播台,从中选择覆盖了最多的未覆盖州的广播台。我将这个广播台存储在best_station中。"
132 | ]
133 | },
134 | {
135 | "cell_type": "markdown",
136 | "metadata": {},
137 | "source": [
138 | "states_covered 是一个集合,包含该广播台覆盖的所有未覆盖的州。 for 循环迭代每个广播台,并确定它是否是最佳的广播台。"
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": 9,
144 | "metadata": {},
145 | "outputs": [],
146 | "source": [
147 | "while states_needed:\n",
148 | " best_station = None\n",
149 | " states_covered = set()\n",
150 | " for station, states in stations.items(): #找到覆盖未覆盖州最多的电台\n",
151 | " covered = states_needed & states\n",
152 | " if len(covered) > len(states_covered):\n",
153 | " best_station = station\n",
154 | " states_covered = covered\n",
155 | " stations -= best_station #去掉已经取出来的电台\n",
156 | " states_needed -= states_covered #去掉已经覆盖的州\n",
157 | " final_stations.add(best_station) #在结果中添加现在找到的电台"
158 | ]
159 | },
160 | {
161 | "cell_type": "code",
162 | "execution_count": 10,
163 | "metadata": {},
164 | "outputs": [
165 | {
166 | "data": {
167 | "text/plain": [
168 | "{'kfive', 'kone', 'kthree', 'ktwo'}"
169 | ]
170 | },
171 | "execution_count": 10,
172 | "metadata": {},
173 | "output_type": "execute_result"
174 | }
175 | ],
176 | "source": [
177 | "final_stations"
178 | ]
179 | },
180 | {
181 | "cell_type": "markdown",
182 | "metadata": {},
183 | "source": [
184 | "## 8.4 NP 完全问题\n",
185 | "\n",
186 | "为解决集合覆盖问题,你必须计算每个可能的集合。\n",
187 | "\n",
188 | "这可能让你想起了第1章介绍的旅行商问题。在这个问题中,旅行商需要前往5个不同的城市。他需要找出前往这5个城市的最短路径,为此,必须计算每条可能的路径。\n",
189 | "\n",
190 | "### 8.4.1 旅行商问题详解\n",
191 | "\n",
192 | "我们从城市数较少的情况着手。假设只涉及两个城市,因此可供选择的路线有两条。\n",
193 | "\n",
194 | "你可能认为这两条路线相同,难道从旧金山到马林的距离与从马林到旧金山的距离不同吗?不一定。有些城市(如旧金山)有很多单行线,因此你无法按原路返回。你可能需要离开原路行驶一两英里才能找到上高速的匝道。因此,这两条路线不一定相同。\n",
195 | "\n",
196 | "你可能心存疑惑:在旅行商问题中,必须从特定的城市出发吗?例如,假设我是旅行商。我居住在旧金山,需要前往其他4个城市,因此我将从旧金山出发。\n",
197 | "\n",
198 | "但有时候,不确定要从哪个城市出发。假设联邦快递将包裹从芝加哥发往湾区,包裹将通过航运发送到联邦快递在湾区的50个集散点之一,再装上经过不同配送点的卡车。该通过航运发送到哪个集散点呢?在这个例子中,起点就是未知的。因此,你需要通过计算为旅行商找出起点和最佳路线。\n",
199 | "\n",
200 | "在这两种情况下,运行时间是相同的。但出发城市未定时更容易处理,因此这里以这种情况为例。\n",
201 | "\n",
202 | "- 涉及两个城市时,可能的路线有两条。\n",
203 | "- 3个城市时,可能的路线有6条。\n",
204 | "- 可能的出发城市有4个,从每个城市出发时都有6条可能的路线,因此可能的路线有4 × 6 = 24条。\n",
205 | "- 涉及6个城市时,可能的路线有720条\n",
206 | "\n",
207 | "这被称为阶乘函数(factorial function),第3章介绍过。5! = 120。假设有10个城市,可能的路线有多少条呢?10! = 3 628 800。换句话说,涉及10个城市时,需要计算的可能路线超过300万条。正如你看到的,可能的路线数增加得非常快!因此,如果涉及的城市很多,根本就无法找出旅行商问题的正确解。\n",
208 | "\n",
209 | "旅行商问题和集合覆盖问题有一些共同之处:你需要计算所有的解,并从中选出最小/最短的那个。这两个问题都属于NP完全问题。\n",
210 | "\n",
211 | "NP完全问题的简单定义是,以难解著称的问题,如旅行商问题和集合覆盖问题。很多非常聪明的人都认为,根本不可能编写出可快速解决这些问题的算法。\n",
212 | "\n",
213 | "### 8.4.2 如何识别 NP 完全问题\n",
214 | "\n",
215 | "NP完全问题无处不在!如果能够判断出要解决的问题属于NP完全问题就好了,这样就不用去寻找完美的解决方案,而是使用近似算法即可。但要判断问题是不是NP完全问题很难,易于解决的问题和NP完全问题的差别通常很小。例如,前一章深入讨论了最短路径,你知道如何找出从A点到B点的最短路径。\n",
216 | "\n",
217 | "\n",
218 | "但如果要找出经由指定几个点的的最短路径,就是旅行商问题——NP完全问题。简言之,没办法判断问题是不是NP完全问题,但还是有一些蛛丝马迹可循的。\n",
219 | "\n",
220 | "- 元素较少时算法的运行速度非常快,但随着元素数量的增加,速度会变得非常慢。\n",
221 | "- 涉及“所有组合”的问题通常是NP完全问题。\n",
222 | "- 不能将问题分成小问题,必须考虑各种可能的情况。这可能是NP完全问题。\n",
223 | "- 如果问题涉及序列(如旅行商问题中的城市序列)且难以解决,它可能就是NP完全问题。\n",
224 | "- 如果问题涉及集合(如广播台集合)且难以解决,它可能就是NP完全问题。\n",
225 | "- 如果问题可转换为集合覆盖问题或旅行商问题,那它肯定是NP完全问题。\n",
226 | "\n",
227 | "## 8.5 小结\n",
228 | "\n",
229 | "- 贪婪算法寻找局部最优解,企图以这种方式获得全局最优解。\n",
230 | "- 对于NP完全问题,还没有找到快速解决方案。\n",
231 | "- 面临NP完全问题时,最佳的做法是使用近似算法。\n",
232 | "- 贪婪算法易于实现、运行速度快,是不错的近似算法。"
233 | ]
234 | }
235 | ],
236 | "metadata": {
237 | "kernelspec": {
238 | "display_name": "Python 3 (system-wide)",
239 | "language": "python",
240 | "name": "python3"
241 | },
242 | "language_info": {
243 | "codemirror_mode": {
244 | "name": "ipython",
245 | "version": 3
246 | },
247 | "file_extension": ".py",
248 | "mimetype": "text/x-python",
249 | "name": "python",
250 | "nbconvert_exporter": "python",
251 | "pygments_lexer": "ipython3",
252 | "version": "3.6.8"
253 | }
254 | },
255 | "nbformat": 4,
256 | "nbformat_minor": 2
257 | }
258 |
--------------------------------------------------------------------------------
/算法图解/算法图解-compressed.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/EvanLi/PythonAlgorithm/330a9dee2fe4367e3bf63a8bf35c6ba79d101e94/算法图解/算法图解-compressed.pdf
--------------------------------------------------------------------------------
/算法图解/算法图解.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/EvanLi/PythonAlgorithm/330a9dee2fe4367e3bf63a8bf35c6ba79d101e94/算法图解/算法图解.pdf
--------------------------------------------------------------------------------