├── README.md
├── paper reading
├── robust query
│ ├── Benchmarking Query Execution Robustness.md
│ ├── Anorexic Plan Diagrams.md
│ ├── Proactive Re-Optimization.md
│ ├── Smooth Scan.md
│ ├── Exact Cardinality Query Optimization.md
│ ├── Flow-join.md
│ ├── Plan Bouquets.md
│ └── Robust query processing Mission possible.md
├── dbms
│ ├── New distributed db architecture.md
│ ├── NoSQL Database.md
│ ├── Pravega.md
│ ├── Neo4j Concept.md
│ ├── postgres
│ │ ├── LLVM JIT-Compiling.md
│ │ ├── 监控.md
│ │ └── 选择率注入的实现.md
│ ├── Oracle RAC.md
│ ├── Lakehouse Technology as the Future of Data Warehouse.md
│ ├── A distributed in-memory kv system on heterogeneous cluster.md
│ ├── Graph vs Relational.md
│ ├── FoundationDB.md
│ ├── Flexible-Storage-Model.md
│ ├── DB of future.md
│ ├── Spanner.md
│ ├── Dima.md
│ ├── SQL Query over Mulit Engine.md
│ ├── Fast Durability.md
│ ├── Scalable Garbage Collection for In-Memory.md
│ ├── mysql
│ │ └── 性能参数相关调优.md
│ ├── Accelerating Relational Databases by RDMA.md
│ ├── Modern Column-Oriented Database Systems.md
│ └── innoDb.md
├── ai
│ └── Cost Prediction using RNN.md
├── crowdsource
│ ├── CrowdER.md
│ ├── Training for Relation Extraction.md
│ ├── Crowdsource data management.md
│ ├── Crowd-Based Selections and Joins.md
│ └── Cost-Effective Data Annotation.md
├── data structure
│ ├── Skip-List.md
│ ├── R-Tree.md
│ ├── Ttree or Btree.md
│ ├── Adaptive Radix Tree.md
│ ├── B-tree-locking.md
│ ├── LSM Tree.md
│ └── X-Tree.md
├── cloud
│ ├── Serverless Databaes.md
│ ├── 云计算概念技术与架构.md
│ └── Above the Clouds - A Berkeley View of Cloud Computing.md
├── os
│ ├── CPU.md
│ ├── Performance Bottleneck.md
│ ├── Linux Storage.md
│ └── Memory Management.md
├── query
│ ├── SQLFlow.md
│ ├── State Representations for Query Optimization.md
│ ├── join size estimation.md
│ ├── How Good Are Query Optimizers.md
│ ├── Is Query Optimization a solved problem.md
│ ├── Hyper-Pipelining Query Execution.md
│ ├── Multi-Core, Main-Memory Joins.md
│ ├── Optimize Join With Reinforcement Learning.md
│ ├── SQL Plan Management.md
│ └── An End-to-End Learning-based Cost Estimator.md
├── distributed
│ ├── Flexible Paxos.md
│ ├── Percolator.md
│ └── Distributed Transaction.md
├── benchmark
│ ├── Fair Benchmarking Considered Difficult.md
│ └── Benchmark.md
└── how-to-read-cs-paper.md
├── 03 compilation
└── 3-compilation-notes.md
├── 17 parallel join
├── 17-hashjoin.md
└── 17-sort-merge-join.md
├── 15 query exec
└── 15-query-exec.md
├── 12 logging
└── 12-logging-notes.md
├── 09 storage
└── 09-storage-notes.md
├── 02 in-memory db
└── 2-imdb-notes.md
├── 22 optimizer
└── 22-optimizer.md
└── 04 concurrency control
├── 4-occ-notes.md
└── 5-mvcc-notes.md
/README.md:
--------------------------------------------------------------------------------
1 | # Advanced-Database-Systems-Learning
2 |
3 | Notes of [CMU 15-271](https://15721.courses.cs.cmu.edu/spring2019/) and relevant papers on database
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
--------------------------------------------------------------------------------
/paper reading/robust query/Benchmarking Query Execution Robustness.md:
--------------------------------------------------------------------------------
1 | ## Benchmarking Query Execution Robustness
2 |
3 | 1. 作者认为 robustness可以分三类:
4 | - **optimizer** robustness: 当预期条件变化时,优化器仍能选出好的执行计划
5 | - **execution** robustness: 对于同一个给定的计划,执行引擎可以在不同的运行时场景下 都能高效地处理
6 | - **workload management** robustness: 当查询实际性能比预期低时,整个系统受影响的程度
7 | 2.
8 |
9 |
--------------------------------------------------------------------------------
/paper reading/dbms/New distributed db architecture.md:
--------------------------------------------------------------------------------
1 | ## 新一代分布式数据库架构
2 |
3 | > 偶数
4 |
5 | 主要就讲述了一下发展历史,没有很特别的。
6 |
7 | 1. 历史:
8 |
9 | - Navigational DBMS
10 | - 关系型
11 | - MPP
12 | - 云原生
13 |
14 | 2. 分布式数据库核心组件
15 |
16 | - 解释器、优化器
17 | - 执行器
18 | - 资源管理器
19 | - 调度器
20 | - 事务管理器
21 | - 锁管理器
22 | - 容错服务
23 |
24 | 3. 硬件架构
25 |
26 | - 共享内存
27 | - 共享存储
28 | - 无共享
29 |
30 | 4. 无共享:
31 |
32 | - Greenplum:多个Segment host与Master host相连
33 | - Postgres-XL/XC:有全局的事务管理器
34 |
35 | 5. 存储计算分离:
36 |
37 | 基于一个分布式文件系统或者分布式KV;但是存储的只读缺陷(如HDFS)导致ACID等实现不好(不适合交易型场景)。
38 |
39 | - Hive
40 | - SparkSQL
41 | - Impala
42 | - Presto
43 |
44 | 6. 云原生:
45 |
46 | 基于多集群共享数据 + 存储与计算分离
47 |
48 |
49 |
--------------------------------------------------------------------------------
/paper reading/dbms/NoSQL Database.md:
--------------------------------------------------------------------------------
1 | ## Survey on NoSQL Database
2 |
3 | 1. **问题**:在云计算和大数据时代,传统关系型数据库面临的挑战:
4 | - 低延时的高并发读写
5 | - 高效的大数据存储
6 | - 高可扩展性和高可用性
7 | - 更低的管理与运维费用
8 |
9 | 2. NoSQL中的**Data Model**
10 | - **Key-Value**: 结构简单,比关系型数据库更快,支持大容量的存储与高并发
11 | - **Column-oriented**: 只用访问query查询的列,减少了系统I/O;相同的数据类型,压缩比率更高
12 | - **Document**: 和KV型很相似,通常是JSON或XML格式;而且支持二级索引 来方便上层应用的存取
13 |
14 | 3. 依据CAP理论的数据库分类
15 |
16 | - CA:
17 |
18 | 通过**Replication**来保证数据的一致性与可用性,如 Vertica(Column-oriented)
19 |
20 | - CP:
21 |
22 | 数据存储在分布式的结点中,并且确保这些节点数据的一致性,如BigTable, HyperTable, HBase(Column-oriented), MongoDB(Document), MemcacheDB, Berkeley DB(Key-value)
23 |
24 | - AP:
25 |
26 | 有 CouchDB(Document), Tokyo Cabinet(Key-value)
27 |
28 |
--------------------------------------------------------------------------------
/paper reading/ai/Cost Prediction using RNN.md:
--------------------------------------------------------------------------------
1 | ## Cost Prediction using RNN
2 |
3 | 1. 预测查询开销的意义:
4 |
5 | - **准入控制** admission control:比如*Q-Cop - Avoiding bad query mixes to minimize client timeouts under heavy loads(2010)*中指出的,在负载超过服务器容量的时候,系统需要智能地决定要处理哪些请求,防止性能的过度降级
6 | - **查询调度** query scheduling : 比如*iCBS: Incremental Costbased Scheduling under Piecewise Linear SLAs (2011)*中提出的 一种 感知代价的调度算法iCBS,并将 服务水平协议SLA 纳入代价的考虑中(在云环境中,云服务提供商在不同的客户之间会提供不同级别的服务,这也取决于用户自身的需求)
7 | - **资源管理** resource management: 更合理地分配、管理硬件资源
8 | - **查询监控** query monitoring: 能够观察或预测数据库系统与查询执行相关的各种指标与参数
9 |
10 | 2. 问题:
11 |
12 | 以往的方案一般都是将代价映射为**逻辑单位**,与执行时间本身难以直接转换。且预测时可能需要一些运行时中间结果的信息,这些是**无法预先获取**到的。
13 |
14 | 3. 相关工作:
15 |
16 | - *Predicting Multiple Metrics for Queries: Better Decisions Enabled by Machine Learning (2009)*
17 |
18 | 利用机器学习,来预测查询的多种指标,包括执行时间、访问记录数、磁盘IO。文中对比了多种机器学习方法——聚类、PCA、CCA、KCCA (Kernel Canonical Correlation Analysis)
19 |
20 | - *Database Meets Deep Learning: Challenges and Opportunities (2016)*
21 |
22 |
23 |
24 | -
--------------------------------------------------------------------------------
/paper reading/crowdsource/CrowdER.md:
--------------------------------------------------------------------------------
1 | ## Crowdsourcing Entity Resolution
2 |
3 | 1. Entity resolution:在数据库中,找到 指向同一个实体的不同记录。(整合多数据源时很重要)比如两个产品,一个的产品名字段是"ipad 2 16GB",另一个叫"iPad二代 16GB",但它们代表的是现实世界中的同一种实体。
4 | 2. 提出一种人机混合的方式来处理批量的验证任务。其中,机器负责对所有数据进行粗略的处理再传递,人类只负责验证最可能匹配的(实体)对。
5 | 3. 使用了一种 两层的启发式方法(two-tiered heuristic) 来创建批处理任务。
6 | 4. 背景:
7 | - 在众包平台(雇佣普通人去做简单的、不需要专业知识的任务)上,去重de-duplication 是一个重要的应用。从而,Entity resolution的任务可转化为 在支持众包查询处理的系统(如CrowdDb或Qurk)中的query。参考——CrowdDB: Answering Queries with Crowdsourcing
8 | - CrowdDB: 使用人的输入通过众包来处理(无法被DBMS或搜索引擎回答的)查询请求,
9 | 5. 已提出基于机器的自动化算法:**Machine-based**
10 | - Jaccard **similarity**:与B交集的大小与并集大小的比值。可以把两个记录视作两个集合,当相似度超过特定阈值后,即可认为是相同的实体。
11 | - 基于**机器学习**,将之视作分类问题,训练出 重复/不重复 的分类器。将一对记录表示为 由属性相似度组成的特征向量(部分属性)。
12 |
13 | 6. 人机混合:**Hybrid Human-Machine**
14 | - 先基于机器进行剪枝,再人力检查(HIT: Human Intelligence Tasks)剩余的难以分辨的pairs。
15 | - 关键在于 **HIT Generation**:将 记录对 结合到 HIT 的过程
16 | - 两种**HIT Generation**:1. 基于对pair的;2. 基于簇cluster的
17 |
18 | 7. 基于簇cluster的HIT Generation 可转化为 k-clique edge covering problem。图中每个顶点代表一条记录,每条边代表一对记录,clique是一个图中两两相连的一个点集。当且仅当 clique可以覆盖相应的边时,基于簇的HIT 才可以check一对记录。
19 |
20 | 故问题转化为找到 可以覆盖图中所有边的、最少的k-clique(大小不超过k)。
21 |
22 |
23 |
24 |
--------------------------------------------------------------------------------
/paper reading/dbms/Pravega.md:
--------------------------------------------------------------------------------
1 | ## 流存储——Pravega
2 |
3 | 参考https://www.infoq.cn/article/u8gDitPJ28mY-JL6izQT
4 |
5 | **数据流实时存储的解决方案**
6 |
7 | 大数据处理架构:
8 |
9 | - Lambda架构:大数据平台 = 批处理层(使用HDFS提供高吞吐的数据访问) + 流处理层(使用消息队列系统) + 应用服务层,从而整合离线计算和实时计算
10 | - Kappa架构:将批处理层、流处理层简化为一致性的流处理
11 | - Google Dataflow模型:将批处理——有限数据流 视为流处理——无限数据流的特例,旨在消除流和批的界限
12 |
13 | 目前大数据流处理系统存在以下问题:
14 |
15 | > 计算是原生的流计算,而存储却不是原生的流存储
16 |
17 | 所以流存储的需求包括:
18 |
19 | - 将数据视为连续和无限
20 | - 能够应对延迟与乱序到达的情况
21 | - 能够通过自动弹性伸缩数据采集、存储和处理能力
22 | - 有检查点确保每个上层应用能保存并恢复原来的使用状态
23 |
24 | 和其他存储类型的对比:
25 |
26 | - 块存储:结构化数据、关系型数据库
27 | - 文件存储:非结构化数据、NoSQL数据库、文件共享、发布与订阅
28 | - 对象存储:非结构化数据、REST数据、语义上无线扩展、多站点部署
29 | - 流存储:append-only、低时延、规模无限、尾部读写、检查点
30 |
31 | Pravega基本概念:
32 |
33 | - **Events**: 客户端以**Event**的形式来读写数据,每一个**Event**都有一个路由键(Routing Key),用于给同一类事件进行分组(比如可以是 传感器的机器ID、或者数据采集时间)
34 | - **Stream**: 由***segment***(本质是append-only的字节序列,内部包含一个个的**Event**)组成,可具备 支持事务以及可扩展等特性,作为数据层(Data plane);,而**Stream**就是在segments的基础上引入了一个控制层(Control plane, 其中controller需要实现Stream的生命周期管理、事务管理),将不同的segments根据应用需求组成数据流
35 | - **Scope**: 可理解为**Stream**的命名空间,即在同一个Scope内的流,其名称是唯一的;可用作租户管理
36 | - **Writer**, **Reader**, **Reader Group**: 支持同一个reader group下的读者并行从一个数据流中读取数据
37 |
38 |
39 |
40 |
41 |
42 |
--------------------------------------------------------------------------------
/paper reading/data structure/Skip-List.md:
--------------------------------------------------------------------------------
1 | ## Skip Lists: Done Right
2 |
3 | 1. Skip list 是支持快速搜索的链表式结构。其主要优点,就是可以跟红黑树、AVL等平衡树一样,做到比较稳定地插入、查询与删除。理论插入查询删除的算法时间复杂度为O(logN)。但它比起平衡树的优点是 查询一个区间 和 删除一个区间很方便。
4 |
5 | 2. **问题**:最近几年人们对 跳表的性能持怀疑态度,因为跳表对cache的支持不如B树等结构。但是一个好的实现就可以解决这些问题,
6 |
7 | 3. 传统实现:
8 |
9 | 
10 |
11 | 相当于在最底部的链表中 跳着提取出一些结点作为 一级索引;再从一级索引中 跳着选一些作为二级索引…每个node都有自己的高度,比如'42'的高度为2,'53'的高度为3,'11'的高度为1。
12 |
13 | 如果把上图的跳表顺时针旋转45°,再去除重复的边,就可以得到一个搜索二叉树:
14 |
15 | 
16 |
17 | 由于不需要实现自平衡 self-balancing,跳表的实现比红黑树等简单。
18 |
19 | 实际实现中,垂直方向的连接不是链表;整个跳表只有一个单链表,而每个单链表的结点 是一个array(包含其上面的结点)。但如果使用动态数组的话,很容易发生cache miss,所以推荐固定代销的数组。
20 |
21 | 4. 优点:
22 | - 插入速度很快,不需要旋转等操作
23 | - 比自平衡树 和 哈希表 实现起来更容易
24 | - 可以在常数时间内取得下一个元素(二叉搜索树通过中序遍历取得下一个元素需要对数时间,哈希表需要线性时间)
25 | - 很容易修改跳表算法 来适应特定需求(如 带索引的跳表、带键的优先队列)
26 | - 无锁化很简单
27 | - 在持久化的存储中表现的更好(比起AVL树)
28 |
29 | 5. 对cache的支持
30 |
31 | - **Memory Pool**
32 |
33 | - **Flat Array**
34 |
35 | - **Unrolled List**
36 |
37 | 
--------------------------------------------------------------------------------
/paper reading/cloud/Serverless Databaes.md:
--------------------------------------------------------------------------------
1 | ## Serverless Databaes
2 |
3 | 1. 分布式数据库 + 云计算资源管理(k8s这一套)
4 |
5 | 软件系统:
6 |
7 | - 分布式数据库(OpenGauss还不是真正的分布式数据库,目前只是主从)
8 |
9 | - 云存储(Share disk,有状态的东西放在云存储;使用的是**Ceph**分布式存储集群)
10 |
11 | 共享存储的一致性怎么保证?——这里他们只有了一份实际的存储,只需要保证和cache一致就行了
12 |
13 | 虚拟化资源管理
14 |
15 | - 虚拟化平台:k8s
16 | - **资源调度器**:软件监测(怎么知道服务器压力大了,),自适应的资源分配方案
17 |
18 | 2. K8s集群中:
19 |
20 | - 最上层是 **Cluster Operator**
21 | - 根据租户需求来创建MasterSlave集群
22 | - 为MasterSlave集群分配共享存储
23 | - 对不同的租户进行资源隔离
24 | - 中间是 **MasterSlave Controller**
25 | - 周期性检测pod资源情况
26 | - 支持**主从节点的scale-up**
27 | - 支持**从节点的scale-out**
28 | - 最底层是Ceph分布式存储
29 |
30 | 3. 监控方法
31 |
32 | - USE法(utilization, saturation, errors)
33 | - perf: Linux的性能事件
34 | - 火焰图(CPU profiling)
35 | - 冷火焰图(off CPU profiling)
36 |
37 | 4. 监控的资源
38 |
39 | **硬件资源**
40 |
41 | - CPU
42 | - 内存
43 | - IO
44 | - 网络
45 | - 存储设备
46 |
47 | **软件资源**
48 |
49 | - 文件描述符
50 | - Kernel mutex
51 | - process/thread capacity
52 | - User mutex
53 |
54 | 5. 资源分配方法
55 |
56 | 如何做到自适应?
57 |
58 | 1. 根据建模直接分配(Quasar)
59 | 2. Auto-Scaling
60 | - 阈值法
61 | - 强化学习
62 | - 控制论
63 | - 时间序列分析
64 |
65 |
--------------------------------------------------------------------------------
/paper reading/data structure/R-Tree.md:
--------------------------------------------------------------------------------
1 | ## R-TREES: A DYNAMIC INDEX STRUCTURE FOR SPATIAL SEARCHING
2 |
3 | 1. **问题**:空间数据对象 通常覆盖多维空间的一片区域,用点坐标来表示不是很好。比如常用的操作——搜索一个区域内的所有object,这些都需要能高效地获取到。而传统的索引,如hash(不能范围搜索)、B-tree和ISAM(空间是多维的)都不适用空间多维数据。
4 |
5 | 2. R树(R-tree)是一种将B树扩展到多维情况下得到的数据结构。
6 |
7 | R树表示由二维或者更高维区域组成的数据,我们把它们称为数据区。一个R树的 **内部结点** 对应于 某个**内部区域**,或称“区域”。原则上,区域可以是任意形状,虽然实际中它经常为矩形或其他简单形状。
8 |
9 | 
10 |
11 | 上图(a)中的 内部结点(R3, R4, R5)就代表(b)中的一个区域,被包含在区域R1中,而R8, R9, R10就是空间数据对象。其中,区域被称为***Bounding Box*** (一般是矩形,可以不是矩形)。我们可以通过 一个object的***Minimum Bounding Box***来表示该object。
12 |
13 | 3. 示例:
14 |
15 | 
16 |
17 | 对于*house1*, *road1*, *road2*,它们被完全包在Bounding Box((0, 0), (60, 50))中。
18 |
19 | 
20 |
21 | 注意:结点中的**bounding box**可以重叠
22 |
23 | 4. 射线法:
24 |
25 | 地理围栏一般是多边形,如何判断点在多边形内部呢?可以通过射线法来判断点是否在多边形内部。从该点出发沿着X轴画一条射线,依次判断该射线与每条边的交点,并统计交点个数,如果交点数为奇数,则在多边形内部;如果交点数是偶数,则在外部。
--------------------------------------------------------------------------------
/paper reading/dbms/Neo4j Concept.md:
--------------------------------------------------------------------------------
1 | ## Graph Database Applications and Concepts with Neo4j
2 |
3 | 1. Core Concepts:
4 | - **Node**
5 | - 通过**Relationship**连接到其他节点
6 | - 可以具有一个或多个**Property**
7 | - **Relationship**
8 | - 连接两个**Node**
9 | - 有方向
10 | - 可以具有一个或多个**Property**
11 | - **Property**
12 | - 可存储为 Key-Value对
13 | 2. 应用:
14 | - **Social Graph**
15 | - **Recommender System**
16 | - **Bioinformatics**
17 |
18 | 3. Query:
19 |
20 | 图查询取出数据的一个基本操作是 **traversal**,其与 SQL的主要区别是 traversal是一个局部的操作;图中没有全局邻接的索引,而是每个顶点与边 存储与之相邻对象的索引 (只有在找起始点时,才会使用全局索引)。故整个图的大小 不会影响traversal的性能,而SQL的join操作就会受表大小的影响。
21 |
22 | 目前图数据库 没有用于 traversal和insertion操作的 标准语言。目前Neo4j支持的有 Java API, REST接口, Gremlin语言 和 Cypher语言。
23 |
24 | - Gremlin: 是领域特定语言 domain-Specific Language,基于Groovy实现
25 | - Cypher: 是声明式图查询语言 declarative graph query language
26 |
27 | 4. Transaction Management:
28 | - 所有对Neo4j数据的改变都包含在事务中
29 | - Query可能可以看到 其他事务的修改
30 | - 事务中 只有写锁才会被获取并持有
31 | - 锁是在 node和relationship级别 获取的
32 | - 核心事务管理系统中有死锁检测
33 |
34 | 5. 高可用性:
35 |
36 | 通过coordination和replication实现master-slave模式,依赖于Zookeeper进行结点间的协调。
37 |
38 | 6. **Conclusion**:
39 |
40 | 图数据库的使用不是为了取代关系型数据库,只有当需要 高度连接的动态数据模型 a dynamic data model that represents highly connected data,才有用图数据库的必要。
41 |
42 |
--------------------------------------------------------------------------------
/paper reading/dbms/postgres/LLVM JIT-Compiling.md:
--------------------------------------------------------------------------------
1 | ## JIT-Compiling SQL Queries in PostgreSQL Using LLVM
2 |
3 | > 来源于:2017 PGCon
4 | >
5 | > 可参考https://llvm.org/devmtg/2016-09/slides/Melnik-PostgreSQLLLVM.pdf
6 |
7 | 1. Motivation:
8 |
9 | 在CPU计算密集的场景中,比如对对大批量的数据进行filter,则实际在内核执行时 每行元组都要进行一次表达式的函数调用(要进行interpret)。
10 |
11 | 比如这个例子:`SELECT COUNT(*) FROM t1 WHERE (x+y)>20`,采用解释的方式执行,则解释的开销占到了总执行时间的56%;若使用LLVM生成代码,则该部分开销只会占6%。核心思想就是减少函数的反复调用,而是通过LLVM把这部分反复调用的代码在一个函数内进行实现,从而完成运算。
12 |
13 | 2. 主要针对 一些复杂的分析性查询,其瓶颈不在磁盘IO 反而在CPU上。
14 |
15 | 3. 解释执行的示例:
16 |
17 | 以filter `X+Y < 1`为例
18 |
19 | 
20 |
21 | 其对应的函数调用代码为
22 |
23 | ```c
24 | P = indirect call ExecEvalFunc() {
25 | X = indirect call ExecEvalFunc();
26 | Y = indirect call ExecEvalFunc();
27 | return int8pl(X, Y)
28 | };
29 | C = indirect call ExecEvalConst(1);
30 | return int8lt(P, C)
31 | ```
32 |
33 | 每次的indirect call就是get_next()虚函数,而JIT可以通过内联来避免函数调用。
34 |
35 | 4. JIT执行的流程
36 |
37 | \*.c文件(pg的backend目录下)通过**clang**生成\*.bc的LLVM中间代码文件,在通过**llvm-link**生成backend.bc,在经过**opt**阶段 来防止全局状态变量的重复。PostgreSQL服务启动时,将中间代码装载进buffer中;JIT阶段再将LLVM模块编译为nayive code来执行。
38 |
39 | 5. 执行模型的变化:
40 |
41 | 从原先volcano的pull-based,变为push-based的模型,从底层结点向上推送元组。
42 |
43 | 6.
44 |
45 |
--------------------------------------------------------------------------------
/paper reading/dbms/Oracle RAC.md:
--------------------------------------------------------------------------------
1 | ## Oracle RAC
2 |
3 | ### Cache Fusion
4 |
5 | 首先Oracle RAC是一个share everything的分布式数据库(既共享内存数据、又共享存储;也可以理解为share-disk + share-buffer);那么内存共享就是通过Cache Fusion将数据从一个节点的bufferpool传到其它节点。
6 |
7 | 相关术语:
8 |
9 | 1. cache coherency:即维持 buffer中数据块在不同实例上的一致性
10 |
11 | 2. multi version consistency model:包括数据块的当前版本、以及其他读一致的版本。
12 |
13 | 注意:当前版本包括已提交以及未提交的数据更新。比如用户在实例节点A更新了不存在于任何一个实例上的数据块,则该块会从底层磁盘读入缓冲区。如果另外一个实例B请求读取该数据块,此时Oracle会生成一个该块的Consistent Read副本(通过节点A的当前版本以及undo log生成),并将该副本发送到请求实例上。
14 |
15 | 3. global cache service(GCS):Cache Fusion 的核心组件。全局缓存服务负责了实例之间 数据块的传输,主要功能是**记录数据块的状态和存储位置**,需要维护全局缓存存储区内的缓存一致性,确保一个实例在任何时刻要修改一个数据块时,都会获得一个全局锁资源。
16 |
17 | 4. global enqueue service(GES):包含了所有 非基于cache fushion的实例间操作,比如元数据的并发控制。
18 |
19 | 5. global resource directory(GRD):GCS + GES 一起维护的全局资源,存放在每个实例的**SGA**中。GRD可以视作一个分布式内存数据库,存放的是cache中所有block 的信息。比如 某一块最新版本的存放位置,块的模式等。同时GRD是分布式的,也就是每个实例上会存放部分的数据(而非全量)。
20 |
21 | 两种共享模式:
22 |
23 | 1. Read-Sharing:查询存于其它节点的buffer。保证 某个数据块如果已被某节点读取过,则之后其它节点访问都不需要从磁盘读取。
24 |
25 | 需要保障数据读取的一致性,本质是通过MVCC实现。
26 |
27 | 2. Write-Sharing:更新存于其它节点的buffer。节点A先通过GCS找到块的存放节点为B,节点B此时生成并保存该块的一个副本(用于自己的后续读),然后释放所有权(该块的ownership转交给节点A了,**A会给该块加上排它锁**,谁更新就是谁的所有权,块由其所有者进行刷脏),将该块发送给A(可能是脏块)。
28 |
29 | 节点间如何提高通信效率:
30 |
31 | 1. 使用定长的消息格式,并使用高速硬件加速网络传输(所以RAC部署需要专用物理机)
32 | 2. 一次buffer的获取永远只会涉及三个节点(请求节点、管理节点、持有节点),不会随着集群规模扩大而膨胀
33 | 3. 高频访问页面的元数据信息移至本地,减少对管理节点的重复访问
34 |
35 |
--------------------------------------------------------------------------------
/paper reading/dbms/Lakehouse Technology as the Future of Data Warehouse.md:
--------------------------------------------------------------------------------
1 | ## Lakehouse Technology as the Future of Data Warehouse
2 |
3 | > 第37届CCF数据库学术会议,Matei Zaharia
4 |
5 | 1. 现今,数据存在的最大挑战:
6 |
7 | - Quality
8 | - Staleness
9 |
10 | 导致数据分析师大部分时间花在 理解数据上
11 |
12 | 2. 发展历程
13 |
14 | - 1980s,发展出了Data Warehouse。从数据库系统中 ETL 得到数据,最红用于 BI 或者报表
15 | - 2010s,发展出了 Data lake。用低成本的存储(S3,HDFS)来保存raw data(结构化/半结构化/非结构化),通过ETL/ELT 将数据装载到 Warehouse中
16 |
17 | 3. 数据湖存在的问题:**系统架构更复杂**。
18 |
19 | - 多种不同语义、不同sql dialect的存储系统
20 | - ETL步骤可能带来问题
21 |
22 | 4. **Lakehouse**:新提出的技术,metadata层 + 新的查询引擎 + 面向ML优化的数据访问
23 |
24 | 5. **metadata层**
25 |
26 | 数据湖通常就是 一系列文件的集合。所以元数据层会记录哪些文件是表的一部分,提供更丰富的数据管理功能
27 |
28 | 参考现有系统:Delta lake, Iceberg, HIVE
29 |
30 | **去读Delta lake的论文**
31 |
32 | 6. **查询引擎**
33 |
34 | 性能优化:
35 |
36 | - Caching:针对热数据。比如通过SSD或memory进行cache
37 | - 辅助数据结构:统计数据、索引。比如通过min/max信息,可以跳过一些文件数据
38 | - data layout:尽量减小IO。比如Z-ordering,针对multi-dimension的访问
39 | - 向量化执行引擎:发挥现代CPU的优势。
40 |
41 | 7. 面向ML优化的数据访问
42 |
43 | 和sql workload不同,机器学习的workload需要通过非SQL代码(Tensorflow、XGBoost)来处理大量数据;而且基于JDBC的SQL接口 在这种数量规模上太慢了。
44 |
45 | Lakehouse则对ML提供了以下特性:
46 |
47 | - Use time travel来实现版本控制,从而也可以进行可重复的实验
48 | - 使用事务来对表进行可靠的更新
49 | - 通过流式IO,来获取到最新数据
50 |
51 | 8. Q&A
52 |
53 | - 使用GPU,或使用Ethernet带来更高带宽
54 | - 列式存储,smaller object带来的好处——读取每个文件的cost,可以参考Uber的机器学习框架
55 |
56 |
--------------------------------------------------------------------------------
/paper reading/dbms/A distributed in-memory kv system on heterogeneous cluster.md:
--------------------------------------------------------------------------------
1 | ## A distributed in-memory key-value store system on heterogeneous CPU–GPU cluster
2 |
3 | 1. **问题**:同构的多核CPU系统 与KV存储系统的特性不匹配,因为无法提供**高数据并行度** 以及 **高内存带宽**;**有限的计算核心** 不满足唯一的数据处理任务的需求;**cache的层次结构**不适合 大的工作数据集。
4 |
5 | 2. **Contribution**:
6 |
7 | - 索引操作是 IMKV 处理系统中主要开销之一,但与传统的多核架构不匹配。所以需要把 该任务迁移到 一个能提供高数据并行度与高内存带宽的架构上。
8 | - 设计了 *Mega-KV*,将索引的数据结构及相应操作 交给GPU处理,并通过一个针对GPU优化的哈希表与算法,来达到前所未有的性能。
9 | - 设计了一个 周期性的调度算法,对于不同的索引操作 使用不同的调度策略,来最小化响应时延、最大化吞吐量。
10 | - 设计了实时的功率管理方案 ,通过动态地调整CPU和GPU的频率,来节省功耗。
11 | - 在异构的CPU-GPU集群上评估了*Mega-KV*,其具有接近线性的课扩展性。
12 |
13 | 3. 实现细节:
14 |
15 | - **Decoupling index data structure from key-value items**
16 | - **GPU-optimized cuckoo hash table**
17 | - **Periodic GPU scheduling**
18 | - **Dynamic frequency scaling**
19 |
20 | 4. **Background**:
21 |
22 | - **key-value store**
23 |
24 | 通常IMKV存储系统是在分布式下实现,通过一致性hash来划分不同的节点,而每个IMKV节点是独立工作的。
25 |
26 | 三种基本query:
27 |
28 | - GET(key)
29 | - SET(key, value)
30 | - DELETE(key)
31 |
32 | workflow中的四个主要操作:
33 |
34 | - **Network processing**:网络I/O,协议解析
35 | - **Memory management**:内存分配、淘汰策略(如redis中的引用计数算法 和 LRU算法)
36 | - **Index operations**:搜索、插入、删除
37 | - **Read key-value item in memory**:仅GET
38 |
39 | 索引操作的瓶颈包括:**访问索引结构本身**、**访问存储的kv项**。而**内存的随机访问** 决定了索引的访问时间,因为大数据集的索引可能有几百MB,无法装入CPU的cache。
40 |
41 | -
--------------------------------------------------------------------------------
/paper reading/dbms/Graph vs Relational.md:
--------------------------------------------------------------------------------
1 | ## A Comparison of a Graph Database and a Relational Database
2 |
3 | 1. **Motivation**: 对比 如MySQL的关系型数据库 和 如Neo4j的图数据库 哪一种更适合数据起源追踪系统data provenance system
4 |
5 | 即 在最终决定数据的存储方式前,通过一系列基准测试来比较 关系型模型 和 图模型。
6 |
7 | 2. **Related Work**:
8 |
9 | - *Should you go beyond relational databases*(2009)中提出,一个DBA如何决定 是否要从关系型转到NoSQL。满足以下条件的数据 可能更适合NoSQL:(数据起源 就符合下述条件)
10 | 1. 表有很多列,但是有几列 只有少数row才用得到
11 | 2. 有属性表 attribute tables
12 | 3. 有很多 多对多关系
13 | 4. 具有 树状的特征
14 | 5. 表模式经常变动
15 |
16 | 3. **Conclusion**:
17 |
18 | 对于数据起源追踪系统来说,在生产环境的图数据库还有些尚未成熟,尽管它搜索速度很快,但缺乏支持 是其最大的缺点。
19 |
20 | 4. 实验设计
21 | - **客观基准测试** Objective Benchmarks
22 |
23 | 包括 给定query的处理速度、磁盘空间需求、可扩展性。
24 |
25 | 每个query都模拟 数据起源追踪的过程,query的 **参数随机生成**;在每个数据库中执行10次,去掉最大和最小值,取平均(保证 cache或系统进程活动 不会影响时间)
26 |
27 | - **主观评测** Subjective Measures
28 |
29 | 包括以下:
30 |
31 | - 成熟度/支持的级别 Maturity/Level of Support
32 |
33 | 成熟度即 该系统有多老,经过了多彻底完整的测试。系统越成熟,使用的人越多,工业界、学术界也越多人讨论。
34 |
35 | - 编程友好性 Ease of Programming
36 |
37 | 友好性取决于任务类型,当需要Graph traversal时,图数据库更方便,而MySQL可能需要包括循环或递归 来完成。
38 |
39 | 通常关系型数据库 可以存储图数据,但图数据库 通常会让关系型数据更难理解。
40 |
41 | - 弹性 Flexibility
42 |
43 | Neo4j是轻量且高效的,通常能在服务器上保持良好的性能;MySQL则是大型的服务器应用,存在于大规模的多用户环境中。
44 |
45 | Neo4j的schema可变性很强;MySQL的则较弱。
46 |
47 | - 安全性 Security
48 |
49 | Neo4j没有内置的安全支持,假设运行环境是可信的,用户管理需要在应用层实现。
50 |
51 |
52 |
53 |
--------------------------------------------------------------------------------
/03 compilation/3-compilation-notes.md:
--------------------------------------------------------------------------------
1 | ## Query Compilation
2 |
3 | 1. in-memory database(内存数据库):相比于传统的寄语磁盘的DBMS,IMDB要快很多
4 | - 使用IMDB后,唯一增加throughput的方法就是**减少执行的指令数**(比如想增加10倍的吞吐量,DBMS需要减少90%的指令)
5 | 2. **code specialization**: 生成的代码对应DBMS的一个特定任务。生成代码的方法有两种:
6 | - Transpilation: 先把关系型查询计划转化为C/C++ 代码,然后用传统的编译器来生成本地代码
7 | - JIT Compilation:针对查询生成**Intermediate Representation** (中间语言),IR可以 (通过即时编译器) 快速编译生成本地代码
8 | 3. 查询处理:
9 | - tuple-at-a-time: 每个操作符通过调用子结点的***next()***方法来获取下一个要处理的**tuple**
10 | - operator-at-a-time: 每个操作符会把它所有的输出结果物化(materialiation),供它的父结点操作符使用
11 | - vector-at-a-time: 每个操作符通过调用子结点的***next()***方法来获取下一个要处理的**数据块**
12 | 4. 流程一览:
13 | - **SQL查询**经过***Parser***,得到**AST**(抽象语法树)
14 | - **AST**传到***Binder***,***Binder***与***System catalog***(元数据)交互,处理后得到**Annotated AST**(标注语法树)
15 | - **Annotated AST**发送至***Optimizer***(优化器),***Optimizer***通过***System catalog***的信息 计算估计代价,得到**Physical plan**(物理执行计划)
16 | - **physical plan**发送至**Compiler**,得到**Native code**
17 |
18 | 5. 关系型操作符很方便用来解释查询过程,但执行起来不是最高效的。
19 | 6. 使用**LLVM**(底层虚拟机)将内存中的queries编译为本地代码
20 | - LLVM是一个模块化和可重复使用的编译器和工具技术的集合
21 | - 能够进行程序语言的编译期优化、链接优化、在线编译优化、代码生成
22 | - LLVM的编译时间随着query的大小(join/predicate/aggregation的数量) 超线性增长—— 对于OLTP应用无所谓,对于OLAP是大问题。
23 |
24 | 7. Adaptive Execution
25 | - 生成query的LLVM中间语言
26 | - 在解释器中执行中间语言
27 | - 在后台对query进行编译(编译耗时相对较长)
28 | - 编译完成后,从解释执行过程无缝切换到编译后本地代码的执行
29 |
30 | 8. 查询的编译很有用,但是实现起来不容易
31 | 9. MemSQL2016版的query编译实现最好。——任何新的DBMS想有竞争力,必须实现query编译。
32 | 10.
--------------------------------------------------------------------------------
/paper reading/data structure/Ttree or Btree.md:
--------------------------------------------------------------------------------
1 | ## T-Tree or B-Tree: Main Memory Database Index Structure Revisited
2 |
3 | 1. **问题**:T树被广泛认为是适合 内存型数据库的索引结构,但是大多数研究没有考虑**并发控制**concurrency control.
4 |
5 | 2. **结论**:当使用并发控制时,B树的变种——B链树 B-link Tree 比T树表现得更好。因为T树需要的锁操作更多,而上锁和解锁的代价很高。
6 |
7 | 3. [B-link Tree](https://sciencedirect.xilesou.top/science/article/pii/0022000086900218/pdf?md5=fafabf86d6f6aced3c490eacb5d30d46&pid=1-s2.0-0022000086900218-main.pdf&_valck=1):
8 |
9 |
10 |
11 | 4. T-tail Tree:
12 |
13 | **结点设计**:参考[06 index-notes](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/06%20index/6-index-notes.md)
14 |
15 | 对T树的改进。当T树结点溢出时,允许一个额外的结点链接到该结点,从而延迟树的旋转操作。树的旋转是由于结点的上溢和下溢造成的,即 对**固定大小的结点**进行插入或删除Key的操作造成的。所以,在T-tail Tree中,一个结点允许有一个T-tail。
16 |
17 | 
18 |
19 | 当插入满结点时,就为其创建一个tail结点,接着所有该结点的插入 都在tail上进行。只有当tail结点也满了,才说该T结点是完全满。当删除导致结点下溢时,tail结点的key会补充进来。
20 |
21 | 5. T-tail Tree采用的锁机制:
22 |
23 | - S-lock
24 | - SIX-lock
25 | - X-lock
26 |
27 | T-tail Tree的两种并发访问方式:
28 |
29 | - 悲观:参考[Concurrent search and insertion in AVL trees](https://ieeexplore.ieee.xilesou.top/abstract/document/1675680/)
30 |
31 | 搜索时 从根结点到边界结点bounding node 使用 lock-coupling;更新时 所有从关键结点 critical node(边界结点最近的祖先,且该祖先结点的平衡因子为±1)到边界结点 上使用SIX-lock,以备树的旋转。如果后面发生了树的旋转,SIX-lock 就转化为 X-lock.
32 |
33 | - 乐观:搜索时不会锁,更新时 同一时间最多锁一个结点。只有当插入一个*完全满*的结点时,才会(互斥)锁住整棵树(固定状态)。
34 |
35 | 6. 基本Cost的评估:
36 |
37 | 
38 |
39 |
40 |
41 |
--------------------------------------------------------------------------------
/paper reading/robust query/Anorexic Plan Diagrams.md:
--------------------------------------------------------------------------------
1 | ## On the Production of Anorexic Plan Diagrams
2 |
3 | By Kun
4 |
5 | 1. **Motivation**: 计划图(Plan Diagram)是数据库优化器在关系选择率空间内对于可执行计划的选择的可视化枚举。在过去的研究中发现,对于工业级别的数据库引擎来说,生成的计划图过于复杂和紧密,可选择的执行计划数量很多,但大部分计划占据的选择率空间很小。因此,期望对这样复杂的计划图进行一定程度的缩减,减少可执行计划的数量的同时,也不会对计划图在参数化查询优化问题中的表现产生影响。
6 |
7 | 2. **Contribution**:
8 |
9 | - 计划图缩减问题是NP-Hard问题,可规约于集合覆盖问题
10 | - 提出了CostGreedy算法,复杂度为O(nm),n为计划个数,m为图中的查询点个数,n<q,并根据代价随选择率递增原理,查找点q第一象限内的点q',更新belong(q')=cur(q)
30 | 2. 建立计划集合S={S1,S2,...,Sn},集合内包含可覆盖点
31 | 3. 遍历计划集合,从最大的计划i 开始(|Si| 最大),对每个Sj(Sj in S)移除Si中的点,若移除后为空集,移除Sj;从S中去除Si,将i加入最终剩余计划集合C中,重复该过程,直至S为空集
32 | 4. 最终的C即为缩减结果
--------------------------------------------------------------------------------
/paper reading/dbms/FoundationDB.md:
--------------------------------------------------------------------------------
1 | ## FoundationDB
2 |
3 | 参考:
4 |
5 | 1. FoundationDB: A Distributed Unbundled Transactional Key Value Store
6 | 2. FoundationDB Record Layer: A Multi-Tenant Structured Datastore
7 | 3. https://apple.github.io/foundationdb/index.html
8 |
9 | FoundationDB是苹果内部使用的分布式数据库,主要特性包括:
10 |
11 | - 多模:可以存储各种格式类型的数据
12 | - 易扩展:部署、管理、扩容方便
13 | - 高性能:商业化的产品级硬件即可支持高负载
14 | - 弹性应用架构:应用即可以DB直接交互,也可以与上层的无状态层进行交互(提供更多特性)
15 |
16 | FDB本质是一个分布式、有序的KV存储,并在此之上提供了基于乐观并发控制的事务特性(NoSQL的扩展性 + ACID -> NewSQL)。系统逻辑上由两个集群组成(两层均可独立地扩展):
17 |
18 | - 数据层(Data Plane): 负责存储数据、处理事务
19 | - 控制层(Control Plane): 作为集群的协调者,包含了元数据管理、集群监控、与事务号分配等工作
20 |
21 | > FDB 的模拟测试框架是它的特别之处,可以做到在单线程的条件下 快速模拟集群的各种故障,所以能保证系统是确定性的(deterministic),也就是所有问题都是可复现的(在同样输入的情况下);从而保证了在快速发布新版本、引入新特性时,系统仍能保持稳定。
22 |
23 | 一个产品化的数据库需要考虑什么问题?
24 |
25 | - 数据持久性
26 | - 数据分片
27 | - 负载均衡
28 | - 集群管理
29 | - 宕机检测与恢复
30 | - 副本分布
31 | - 集群同步
32 | - 过载状态下的运行
33 | - 横向扩展
34 | - 并发与任务调度
35 | - 系统部署与升级、配置管理
36 |
37 | 为了从更高层次来阐述这些问题的解决方案,得先了解FDB架构的设计理念:
38 |
39 | - Divide-and-Conquer: 将 事务管理(写入路径) 与 分布式存储(读取路径)分离开来,并且二者可以单独扩展,还有其他不同的组件负责不同的任务,如时间戳管理、冲突检测、日志记录等
40 | - Make failure a common case: **在分布式系统中,故障认为是常态而不是一个小概率的异常**。在FDB的事务管理中,并不是尝试解决所有的失败场景,而是主动地进行重启恢复
41 | - Fail fast and recover fast: 为了提升可用性,FDB尽可能地降低MTTR(平均恢复时间),也就是上一点所提到的重启恢复【论文中提到,生产环境下的恢复用时少于5s】
42 | - Simulation testing: 引入了随机化、确定性的测试框架,不仅更容易发现深层次的bug,也能改进代码质量和开发效率
43 |
44 | ------
45 |
46 | ### 事务
47 |
48 | MVCC读 + 乐观并发写,可序列化的事务
49 |
50 |
51 |
52 | -----------
53 |
54 | [未解决的一些问题](https://apple.github.io/foundationdb/known-limitations.html):
55 |
56 | - 大事务:
57 | - 长事务:目前不支持执行时间超过5s的长事务,如果需要长事务,建议在应用层进行乐观验证;如果需要长读事务,建议在上层维护快照版本;
58 | -
--------------------------------------------------------------------------------
/paper reading/dbms/Flexible-Storage-Model.md:
--------------------------------------------------------------------------------
1 | ## Bridging the Archipelago between Row-Stores and Column-Stores for Hybrid Workloads
2 |
3 | 1. 当DBMS既要适合OLTP,又要适合OLAP,称为HTAP(hybrid transactional-analytical processing)
4 | - 支持现代OLTP要求的 **高吞吐量和低延迟**
5 | - 支持复杂的、长时间的OLAP查询——包括 hot(事务型) 和 cold(历史型)数据的操作
6 | - **难点**:在OLAP获取 旧数据和新数据 的同时,执行事务更新数据库
7 | 2. 使用一个统一的架构来连接OLAP与OLTP之间的鸿沟——基于DBMS未来访问元组的方式,使用**混合结构(hybrid layout)**来存储数据表:
8 | - hot tuple(热点元组,最近时间内经常会发生变化): 以针对OLTP操作优化的方式存储
9 | - cold tuple: 以更方便OLAP查询的方式存储
10 | 3. Storage Model:存储模型
11 | - NSM(N-ary Storage Model):对于单个元组,DBMS将其所有属性以**连续(contiguously)**的方式存储(行存)
12 | - 适合OLTP型工作,因为事务中的queries 倾向于 **一次对一个独立的entity进行操作**
13 | - 不适合OLAP,因为分析型queries 倾向于 一次获取一个表中多个entities的属性(子集),而NSM读表时,只能是tuple-at-a-time(可参考 [query-compilation](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/03%20compilation/3-compilation-notes.md)),即 以元组为中心的方式——浪费 **I/O** 以及 **内存带宽** 去访问 不必要的属性
14 | - DSM(Decomposition Storage Model):对于数据表的一个属性,DBMS将**该属性的所有值**以**连续**的方式存储(列存)
15 | - 适合OLAP,因为DBMS只需要取到query需要的属性值,以attribute-at-a-time的方式;提高CPU效率——lower interpretation overhead & skipping unnecessary attributes
16 | - 不适合OLTP,比如插入时,需要把元组的属性值放在分别的存储位置
17 | - FSM(Flexible Storage Model):一种混合存储结构。适合OLTP和OLAP,即HTAP
18 | 4. FSM的构成:
19 | 1. **tile tuple**: 最基础的单元。为 **一个元组若干个属性的集合**。
20 | 2. **physical tile**: a set of ***tile tuples***
21 | 3. **tile group**: a set of ***physical tiles***
22 | 4. table: a set of ***tile group*** 由Storage Manager管理
23 |
24 | 5. FSM保存元组的过程
25 | - 当元组存储在FSM的数据库中时,它的存储结构会随着时间而改变。
26 | - 一开始所有新tuples进来时,都是以行存的形式
27 | - 随着这些tuples逐渐变为历史数据,会重新组织为OLAP友好型的垂直划分
28 | - (re-organization过程)先把这些元组**复制**到新结构的***tile group***中,在把表中原来的的***tile group***与***新的tile group***进行交换——整个过程在后台运行,且是事务安全的
--------------------------------------------------------------------------------
/paper reading/os/CPU.md:
--------------------------------------------------------------------------------
1 | ## CPU
2 |
3 | 1. 多任务操作系统分为非抢占式 和 抢占式多任务,大多数现代操作系统是 **抢占式**的(也就是说 调度器会决定什么时候停止一个进程,同时挑选出另一个进程运行)。
4 |
5 | 2. 现有的Linux调度策略(也就是选择一个新进程的策略)
6 |
7 | ```c
8 | #define SCHED_NORMAL 0 // 默认的调度策略
9 | #define SCHED_FIFO 1 // 针对实时进程的先进先出调度,适合对时间性要求比较高但每次运行时间比较短的进程
10 | #define SCHED_RR 2 // 针对的是实时进程的时间片轮转调度,适合每次运行时间比较长得进程
11 | #define SCHED_BATCH 3 // 针对批处理进程的调度,适合那些非交互性且对cpu使用密集的进程
12 | /* SCHED_ISO: reserved but not implemented yet */
13 | #define SCHED_IDLE 5 // 适用于优先级较低的后台进程
14 | ```
15 |
16 | 3. 普通进程的CFS算法
17 |
18 | 在 pick_next_entity函数中,调用了wakeup_preempt_entity,其主要作用是 根据进程的**虚拟时间**以及**权重**的结算进程的粒度,以判断其是否需要抢占(返回0或1);同时会保证每个进程可以运行一个最小的时间粒度。
19 |
20 | 4. Nice值
21 |
22 | ```
23 | F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
24 | 4 S 0 20312 20304 0 80 0 - 29050 wait pts/0 00:00:00 bash
25 | 0 R 0 20356 20312 0 80 0 - 37234 - pts/0 00:00:00 ps
26 |
27 | ```
28 |
29 | > F:flag,标识了进程拥有的权限,4即为superuser
30 | >
31 | > S:stat,状态(R-Running,S-Sleep,T-Stop,Z-Zombie)
32 | >
33 | > UID:执行者的身份
34 | >
35 | > PID:进程ID
36 | >
37 | > PPID:父进程ID
38 | >
39 | > C:CPU百分比
40 | >
41 | > PRI:priority,优先级,越小越优先
42 | >
43 | > NI:nice,进程优先级的修正数值
44 | >
45 | > ADDR:address,程序在内存的哪个部分
46 | >
47 | > SZ:使用的内存大小
48 | >
49 | > WCHAN:是否运行中
50 | >
51 | > TTY:终端位置
52 | >
53 | > TIME:使用的CPU时间
54 | >
55 | > CMD:运行的指令
56 |
57 | 通过`ps -el`可以看到进程NI列即为nice值;PRI列表示的是进程的优先级,是一个整数,它是调度器选择进程运行的基础。
58 |
59 | CFS直接分配的不是时间片,而是**CPU使用比**,这个比例会收到nice值影响,nice值低比重就高,nice高比重就低。
60 |
61 | 普通进程的优先级分为
62 |
63 | - 静态优先级:不会随时间而变化。只能通过*系统调用nice(value)* 进行修改
64 | - 动态优先级:即PRIO。
65 |
66 | 总的来说可以通过 nice这个系统调用来改变进程的优先级。
67 |
68 | 5.
69 |
70 |
--------------------------------------------------------------------------------
/paper reading/robust query/Proactive Re-Optimization.md:
--------------------------------------------------------------------------------
1 | ## Proactive Re-Optimization
2 |
3 | SIGMOD 2005
4 |
5 | 1. **Motivation**: 传统优化器采用plan-first execute-next的方式执行查询, 这很大依赖中间结果估计的准确度 来选出好的执行计划。 而随着大数据时代,优化器没有跟上数据库系统对非常大的数据集执行复杂查询的能力,很容易选择次优的计划,导致运行时性能显著下降;学界对应的方法也无非 更好的统计数据、新的优化算法、自适应的执行架构。
6 |
7 | 作者认为比较有前景的办法是 *re-optimization*——优化阶段与执行阶段是相互交织的。然而前人提出的re-optimizer都是采用的 被动方式(reactive),即 先使用传统优化器来生成计划,然后记录运行时统计信息,并根据执行期间在计划中检测到的估计错误 以及 因此产生的次优度 做出相应调整;这样会带来以下缺点:
8 |
9 | - 优化器可能选择 那些性能很大依赖于不确定统计信息 的执行计划,导致很可能发生 重优化
10 | - 当触发重优化 并 切换计划时,流水线中完成的部分工作将丢失
11 | - 在查询执行期间快速准确地收集统计信息的能力是有限的。因此,当重优化被触发时,优化器可能会犯新的错误,导致潜在的性能退化
12 |
13 | 2. **Contribution**:
14 |
15 | - 提出一种主动的(proactive) 重优化方案来解决以上问题,这个框架原型称为 **Rio**
16 | - 根据统计估计值计算出 *Bounding Boxes*,来表示这些估计值中的不确定性
17 | - 在优化阶段,通过*Bounding Boxes* 来生成**健壮和可切换的计划**,以最小化重新优化的需要 和 流水线工作的损失
18 | - 把 **随机样本处理** 与 **常规查询执行**相结合,在运行时快速、准确、高效地收集统计信息
19 |
20 | 3. **相关工作**
21 |
22 | - **被动的重优化**:*Efficient Mid-Query Re-Optimization of Sub-Optimal Query Execution Plans (1998)* 提出的**ReOpt**,*Robust Query Processing through Progressive Optimization (2004)*提出的**POP**框架
23 | - **用区间的估计来代替确切点估计**:*Least Expected Cost Query Optimization (1999)*提出的最小期望代价(Least Expected Cost),*Novel Query Optimization and Evaluation Techniques (2003)*提出的误差感知优化(Error-Aware Optimization),*Parametric Query Optimization (1992)*、*Distributed Query Adaptation and Its Trade-offs (2003)*等研究的参数化查询
24 | - **健壮的基数估计** RCE:*Towards a Robust Query Optimizer: A Principled and Practical Approach (2005)* 使用随机采样作为基数估计来应对不确定性,并探索了性能的可预测性。但是,RCE没有考虑将 随机采样和常规的查询执行合在一起,或者在join之间传播随机采样的结果。
25 |
26 | 4. **核心流程**
27 |
28 | 
29 |
30 | 1. Bounding Box的生成:
31 |
32 | Bounding Box本质是用来表示统计数据的不确定性。
33 |
34 | 2.
35 |
36 | 5.
--------------------------------------------------------------------------------
/paper reading/os/Performance Bottleneck.md:
--------------------------------------------------------------------------------
1 | ## Performance Bottleneck
2 |
3 | > 【High Performance TiDB】Lesson 03:通过工具寻找 TiDB 瓶颈
4 |
5 | 1. 性能的定义
6 |
7 | 性能 = 产出 ÷ 资源消耗
8 |
9 | 产出:
10 |
11 | - 每秒查询率 (QPS)
12 | - 数据吞吐量 (Bytes)
13 |
14 | 资源消耗:
15 |
16 | - CPU
17 | - 磁盘IO
18 | - 网络IO
19 | - 流量
20 |
21 | 2. 资源消耗的设计目标:
22 |
23 | 让最紧缺的资源消耗满。
24 |
25 | 3. 流水线:达到 资源-时间轴 重叠的效果
26 |
27 | 比如以下三种情况的对比:
28 |
29 | 1. 整个大任务分为 Encode、Write,其中Encode消耗CPU,耗时100s;Write消耗IO,耗时70s,共170s
30 | 2. 整个大任务划分为10个小任务,交替进行,即 Encode(Block0) 10s、Write(Block0) 7s、Encode(Block1) 10s、Write(Block1) 7s... 共170s
31 | 3. 小任务间流水线进行,即 Encode(Block0) 10s、Write(Block0) + Encode(Block1) 10s、Write(Block1) + Encode(Block2) 10s ... Write(Block9),共107s
32 |
33 | 4. 流水线Batch的粒度
34 |
35 | - 小粒度
36 | - batch总量相对变多了,锁竞争可能开销变大,总的提交代价相对也变大了
37 | - 运行时占用资源小,整体资源使用峰值低
38 | - 单次失败代价更低
39 | - 大粒度
40 | - 整体占用资源较多
41 | - 单次失败代价更大
42 | - 首尾的batch不能受益
43 | - 通常吞吐更好,但latency更高
44 |
45 | 例一. 于HDD上进行文件拷贝,HDD寻道时间3-6ms,随机读写的最大QPS为 400-800,读写带宽为 100 MB/s —— 100MB / 800 ≈ 100KB,所以Batch的粒度不能小于100KB,否则造成性能下降(吞吐达不到100MB/s)。
46 |
47 | 例二. 将数据划分块,并发进行编码,使用互斥锁对块状态 加锁,在高竞争状态,mutex的QPS约为 10-20万,则总吞吐不会高于 10万*batch粒度;若batch块大小为4KB,则整体吞吐不高于 400MB/s。
48 |
49 | 5. 瓶颈类型
50 |
51 | - CPU
52 |
53 | - CPU usage高
54 |
55 | 只能减少计算的开销:比如用更优的算法,通过cache中间结果减少重复计算
56 |
57 | - CPU load高
58 |
59 | - 线程太多,频繁切换导致:考虑跨线程的交互是否必要
60 | - 等IO,可以在top中看到**iowait**比较高:说明IO是限制性能的瓶颈
61 |
62 | - IO
63 |
64 | - IOPS上限
65 |
66 | 减少读写次数,提高cache的hit率
67 |
68 | - IO带宽上限
69 |
70 | 减少磁盘读写的流量:比如采用 更紧凑的数据存储格式、更小的读写放大()
71 |
72 | - fsync次数上限(通过工具来查看)
73 |
74 | 减少fsync次数:可以采用group commit
75 |
76 | - Network
77 |
78 | - 网卡带宽上限(千兆网卡、万兆网卡):降低传输的数据量(紧凑的数据格式、计算下推)
79 | - send/recv系统调用太频繁:批量进行发送与接收
80 |
81 | 6. 工具使用可参考其他几篇
--------------------------------------------------------------------------------
/paper reading/query/SQLFlow.md:
--------------------------------------------------------------------------------
1 | ## SQLFlow: A Bridge between SQL and Machine Learning
2 |
3 | 1. **场景**:工业中的AI系统通常是 end-to-end 的机器学习工作流。这里的流程是包括:从web UI开始,再是日志收集器 log collector (如 [Fluentd](https://www.fluentd.org/)),日志流聚集器 log streams aggregator (如 Kafka),接着到 数据库,最后是机器学习系统 (如TensorFlow, PyTorch等)。
4 |
5 | 注意区分 **end-to-end解决方案** 与 **end-to-end学习**
6 |
7 | > Generally, end-to-end solutions are used with vendors that offer comprehensive systems that keep pace with a business’s ever-changing infrastructure requirements, and the changing demands of the IT sector itself. End-to-end suppliers generally handle all of a system's hardware and software, including installation, implementation, and maintenance. An end-to-end solution might cover everything from the client interface to data storage.
8 | >
9 | > end-to-end学习,其实就是从一端(输入,原始数据)到另一端(输出,结果)的意思。也就是说,端到端意味着,模型的输入是原始的数据,模型的输出是我们想要的结果。通过缩减人工预处理和后序处理,尽可能是模型从原始输入到最终输出,**使模型有更多根据数据 自动调节的空间,增加模型的整体契合度**。
10 |
11 | 目前有些数据库系统 扩展了自己的dialect 来支持机器学习,比如谷歌的BigQuery 增加了 CREATE MODEL语句 用来训练模型。但这些存在缺点如下:
12 |
13 | - 把 end-to-end ML 用户固定在特定的数据库系统上,如果要切换数据库,需要重写整个ML方案
14 | - 大部分不开源,难有社区贡献
15 | - 都基于现存 数据库的计算基础结构,无法使用向 Kubernetes 的集群计算技术做到容错和可扩展
16 |
17 | 2. **Contribution**:
18 |
19 | - SQLFlow 使用sql语言(而不是Python之类的语言,这样适合所有编程人员),高效地描述了 这样的机器学习流程
20 | - SQLFlow可以桥接多种数据库系统(Mysql, Hive, Alibaba MaxCompute) 和 多种机器学习引擎(TensorFlow, XGBoost, sklearn)
21 | - 发明了一种 collaborative parsing算法
22 | - SQLFlow 将一个sql程序 编译为 Kubernetes原生的工作流,以方便容错处理 与云端部署
23 |
24 | 3. **实现细节**:
25 |
26 | - **Collaborative Parsing**
27 |
28 | 可以使用任何开源的parser,如MySQL/TiDB, HiveQL, Clacite Parser. 使用goyacc编写,只能理解 TO TRAIN, PREDICT, EXPLAIN从句。
29 |
30 | - **Two-Tier Compilation**
31 |
32 | SQLFlow表现为 两层编译的架构。上层将 SQL程序 翻译为 YAML,其中每条SQL语句为一个step。而当每个step在容器中执行时,将SQL翻译为一个Python程序并运行。
33 |
34 | 如果是普通SQL语句,生成的Python程序会 将其直接提交到数据库系统中;如果是经过SQLFolw扩展的语句,则生成的Python程序会 获取数据、提取特征、启动ML任务。
--------------------------------------------------------------------------------
/paper reading/query/State Representations for Query Optimization.md:
--------------------------------------------------------------------------------
1 | ## Learning State Representations for Query Optimization with Deep Reinforcement Learning
2 |
3 | 1. **Motivation**:
4 |
5 | 在数据库领域,查询优化仍然是一个难题。因此尝试探索强化学习在 查询优化上的应用。
6 |
7 | 2. **Challenge**:
8 |
9 | 状态转移函数(决定了当前子查询状态 如何与下一个operation结合 到达下一个状态)如何定义?
10 |
11 | 3. **Contribution**:
12 | - 开发了一种训练模型的方法,该模型学习以增量方式 *incrementally* 生成每个子查询的中间结果 的简洁表示。模型的输入为 **子查询**与**新的操作**,从而来预测 结果子查询的属性,再根据这些性质 可以推断子查询的基数。
13 | - 提出使用强化学习,通过Markov过程建模 来增量式地 构建query plan,其中每个决策 都基于对应状态的属性。
14 |
15 | 4. 实现细节:
16 |
17 | - 模型概况
18 |
19 | 
20 |
21 | 图中的初始状态为 *t*,通过强化学习 选择出动作,使得模型转变到新状态 *t+1*;每个Action对应一个operation,每个State会包含 子查询中间结果的表示。通过 *NNST*,状态转移函数(是一个神经网络),来生成中间结果的representation。*NNST*以时间t的子查询表示法为输入,输出为时间t+1的子查询表示法。
22 |
23 | 该方法的关键在于,使用一个**有限长度的向量 来 表示每个状态**,并且**使用深度学习模型来 学习 状态转移函数**。(很多场景下的强化学习是已知 状态和状态转移函数的,比如围棋中,棋子在棋盘的位置是可知的,状态转移 也就是从一个棋盘到下一个棋盘的变化 是很清晰明了的)
24 |
25 | - 学习 Query的表示法
26 |
27 | 给定数据库*D*,查询*Q*,可以将(Q, D)转化为特征向量,以特征向量为输入、基数结果为输出,来训练深度神经网络;但是该方法中,特征向量的大小 会随D和Q的复杂度上升 而增大,从而会产生很大的稀疏向量,训练集需要很大才行。
28 |
29 | 因此,采用一种循环的方式。
30 |
31 | 
32 |
33 | 其中, *NNST*: (ht, at) → ht+1为状态转移函数,ht为子查询的特征向量表示(不是人为赋值的,是模型自我学习得到的),at为ht上的*single relation operation*。 *NNObserved*学习 从子查询representation 到一组观测到的变量 的映射。在训练中,通过后向传播来调整两个函数的权重。
34 |
35 | 在使用循环的*NNST*模型之前,需要先学习得到另一个函数,*NNinit*;其输入为 (*x0*, *a0*),其中*x0*为一个能表示数据库D属性的向量, *a0*为*single relation operator*,其输出为 **执行*a0*的子查询的基数**。对于D中的每个属性,使用以下特征来定义*x0*:最小值、最大值、域的大小、一维直方图的representation
36 |
37 | 5. Future Work: 通过结合强化学习模型,来学习得到 最优的执行计划。
--------------------------------------------------------------------------------
/paper reading/dbms/DB of future.md:
--------------------------------------------------------------------------------
1 | ## 未来的数据库
2 |
3 | > 总结自:TiDB —— 未来的数据库是什么样的?
4 |
5 | 1. **例子**:
6 |
7 | 创业公司一开始 MySQL+Redis缓存层,随着业务增长越来越快,发现底层MySQL容量有限,难以扩展 =>
8 |
9 | 尝试分库分表,Redis集群(业务并发量大,单机Redis的话 网卡、内存容量扛不住) =>
10 |
11 | MySQL做分片扩容,每隔一段时间就要折腾一次
12 |
13 | **痛点**:
14 |
15 | - **受限的扩展能力**
16 |
17 | 分库分表、“伪分布式”方案(看上去可以做水平扩展,但需要DBA花费大量精力去维护),Cloud-Native(表面上可水平扩展,但是是受限的)
18 |
19 | - **碎片化**
20 |
21 | 后端有各种各样的数据库来面对不同场景(MongoDB、HBase、Cassandra),为什么现在Kafka很重要——作为不同数据库间Pipeline的同步方案;还有在线 与 离线分析
22 |
23 | - **在线业务与分析脱节**
24 |
25 | 流式数据处理的方案(Flink、Spark Streaming)不是很灵活,当业务发生变化时,很难做匹配的修改调整;而且在线业务 和 流式处理业务很可能是两拨人在负责
26 |
27 | 2. **Real-time** HTAP
28 |
29 | **特点**:
30 |
31 | - 业务透明的无限水平扩展能力
32 | - 业务层不需要妥协:跟原来操作RDBMS一样
33 | - 支持SQL
34 | - 支持分布式事务
35 | - 支持复杂查询
36 | - 高可用——故障自恢复:比如主节点挂了,不需要手动重启
37 | - 高性能的实时分析:必须有列式存储引擎
38 | - Hybrid workload下,实时的OLAP不会影响OLTP事务
39 |
40 | 3. 场景:
41 |
42 | 智能规划预算,Self-driving
43 |
44 | - 自动识别workload,根据workload来自动扩/缩容
45 |
46 | 预感峰值到来(比如 快开学的教务系统),则自动启动机器,为热数据创建更多副本 并 重分布数据,提前扩容;当峰值过去之后,再自动回收机器
47 |
48 | - 感知业务特点,根据访问特点决定分布
49 |
50 | 比如数据带有明显的地理特征,系统自动根据将数据的地理特征 在不同的Data Center放置
51 |
52 | - 感知查询类型 和 访问频率,从而决定使用**不同类型的存储介质**
53 |
54 | 冷数据自动转移到S3这种便宜的存储介质,热数据放在高配的闪存上
55 |
56 | > S3: Simple Storage Service
57 | >
58 | > A simple web services interface that you can use to store and retrieve any amount of data, at any time, from anywhere on the web. It gives any developer access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure
59 |
60 | 4. 数据层的智能调度能力:**Serverless**
61 |
62 | > 无服务器计算是指 构建和运行**不需要服务器管理**的应用程序。
63 | >
64 | > 过去是“构建一个框架运行在一台服务器上,对多个事件进行响应”,Serverless则变为“构建或使用一个微服务或微功能来响应一个事件”
65 |
66 | 目前行业可能更多处在容器 Docker + Kubernetes,利用IaaS、PaaS和SaaS来快速搭建部署应用。
67 |
68 | 也就是设计系统时候,不能说我这个系统是跑在Unix、Windows上之类的,而应该是把**云的基础设施**当做操作系统,未来数据库是跑在Kubernetes上、某个公有云的环境下。
--------------------------------------------------------------------------------
/paper reading/dbms/Spanner.md:
--------------------------------------------------------------------------------
1 | ## Spanner: Google’s Globally Distributed Database
2 |
3 | 1. **介绍**:
4 |
5 | - Spanner 是可横向扩展的、全球分布式数据库。
6 | - a database that shards data across many sets of Paxos state machine (每个状态机都在数据中心里)
7 | - 从一个类似BigTable的多版本的Key-Value存储演变成了一个带有时间属性的多版本数据库
8 | - 应用程序可以在细粒度上对 数据的副本数 进行动态的控制:
9 | - which datacenters contain which data
10 | - how far data is from its users (控制 读取数据时延)
11 | - how far replicas are from each other (控制 写入数据时延)
12 | - how many replicas are maintained (控制 可用性和读取性能)
13 | - 提供外部一致性读写 和 基于某个时间戳的跨数据库的全球一致性读
14 | 2. **实现**:
15 | - Spanner通过目录 *directory* 来管理数据的副本 replication 和本地性 locality,目录也是spanner中数据移动的基本单元
16 | - 一个Spanner的部署称为一个*universe*
17 | - Spanner以*zones*(是部署管理 以及 **物理隔离**的基本单元,在一个数据中心可能有一个或者多个zone) 的形式进行组织。每个zone相当于一个BigTable的一个部署集群,一个zone都有一个ZoneMaster和上百数千个的 *spanserver*;ZoneMaster将数据分配给spanserver,spanserver将数据提供给各个Client端。Client端利用每个zone中的*location proxy*来定位 给自己提供数据的 spanserver。
18 |
19 | 3. **软件栈** Spanserver Software Stack
20 |
21 | 自下而上的软件栈
22 |
23 | - **Colossus**
24 |
25 | *Tablet*的状态存储在一系列 以B-Tree组织的文件 和 WAL(Write-Ahead-Log)文件中,所有这些文件都存储在名为*Colossus* (GFS的继任者)的分布式文件系统中。
26 |
27 | - **tablet**
28 |
29 | each spanserver is responsible for between 100 and 1000 instances of a data structure called a *tablet*,tablet实现 (key:string, timestamp:int64) → string 的映射;会将**时间戳信息也记录到key**中,更像是一个支持多版本数据的数据库,而不是一个单纯的KV型
30 |
31 | - **Paxos state machine**
32 |
33 | 为了支持replication,每个spanserver 都会 在*tablet*上实现一个Paxos状态机。每个状态机存储 在对应的tablet中 存储该状态机的元数据 和 日志。该Paxos实现 支持 long-lived leaders with time-based leader leases.
34 |
35 | - **Lock Table**
36 |
37 | 每个 spanserver通过一个lock table 来实现并发控制。Lock table 中有 **两阶段锁** 的状态,将 一个范围内的所有keys 映射到 lock states.
38 |
39 | - **Transaction Manager**
40 |
41 | 每个 spanserver通过一个Transaction Manager 来实现 分布式事务。该transaction manager作为participant leader;Paxos Group中的其他的replica(leader之外的副本)作为participant slaves。
42 |
43 |
--------------------------------------------------------------------------------
/17 parallel join/17-hashjoin.md:
--------------------------------------------------------------------------------
1 | 1. 并行联接算法:使用多线程联接两个关系表
2 | - **hash join**
3 |
4 | - **sort-merge join**
5 |
6 | - nested-loop join
7 |
8 | - Simple Nested-Loops Join:
9 |
10 | ```
11 | for each row r in R
12 | for each row s in S
13 | if r和s 满足联接条件
14 | output tuple
15 | ```
16 | 优化器一般会选择 **联接列含有索引**的表作为内部表
17 |
18 | 由于 **内部表扫描次数总是索引的高度**,所以当 R和S联接列都有索引且索引高度相同时,**选择记录少的表作为外部表**
19 |
20 | - Block Nested-Loops Join: 针对没有索引的联接情况,使用join buffer来减少内部循环读取表的次数
21 |
22 |
23 |
24 | 2. 许多面向OLTP的DBMS没有实现hash联接,小规模结果的**带索引嵌套循环联接(index nested-loop join)**基本与hash联接 等价
25 | 3. 联接算法的目标:
26 | - 最小化同步,避免上(闩)锁
27 | - 最小化CPU缓存miss,使工作线程满足数据的局部性
28 | - Cache 和 TLB(快表)的性能
29 | - 时间与空间的局部性
30 |
31 | 4. hash join 是 **OLAP**型DBMS 中**最重要**的操作,要尽可能利用多核来加速;分为三个阶段(假设R 联接 S):
32 | - Partition (可选):对用于联接的key(字段的值)使用hash,将R和S的元组分为不同的集合
33 | - 可以减少第二阶段Build时的cache miss。理想情况下,partition的代价 比 cache miss的代价更小
34 | - 非阻塞式划分法:(1) 所有线程一起更新一个**全局的划分集**,需要上锁来同步 (2) 每个线程拥有**自己的划分集**,在所有线程完成后,要把这些划分集合并在一起
35 | - 阻塞式划分法(radix hash join):需多次扫描产生划分
36 | - Build:扫描关系R(元组 或 划分),根据联接的key建立*哈希表T*
37 | - hash函数——速度 与 碰撞 的trade-off
38 | - CRC-32 (1975)
39 | - MurmurHash (2018)
40 | - Google CityHash (2011)
41 | - CLHash (2016)
42 | - hash模式——空间大的哈希表 与 碰撞后额外的查找指令 的trade-off
43 | - 开放链式:哈希表的每个槽中 维护一个链表
44 | - 线性探测:碰撞时,线性地查找下个空位(需要表的空间比较大)
45 | - Robin Hood:(线性探测的变式)每个Key会记录自己离最优位置的距离(比如key1 本来应该在 [2] 的位置,现在保存在[4],距离就为2);当插入key2时,若key2在 [4]的距离为3,**大于**key1的距离2,则**key2会取代key1的位置**,key1往后挪(*劫富济贫*)
46 | - Cuckoo:使用多个不同的hash函数对应多个hash表。在插入时,随便挑选一个有空槽的表,若都没有空槽,从这些表中驱逐出一个元素,重新hash找到新位置——若进入无限循环,需要重建表;查找的时间复杂度永远是O(1)
47 | - Probe:对于S的每个元组*x*,在*哈希表T*中查找*x*的联接key值。若找到匹配的,则输出联接的元组
48 | - 如果R和S经过划分,则可以给每个线程分配一个独立的partition
49 | - 当key很有可能不在hash表中,可使用**Bloom Filter(布隆过滤器)**来加速——如果检测结果为是,该元素**不一定**在集合中;但如果检测结果为否,该元素**一定不在**集合中
--------------------------------------------------------------------------------
/paper reading/distributed/Flexible Paxos.md:
--------------------------------------------------------------------------------
1 | ## Flexible Paxos: Quorum intersection revisited
2 |
3 | 1. Paxos
4 |
5 | 包括两个阶段,都需要保证majority agreement才能继续,其中quorum指的是参与者的子集。而Paxos的安全性与活性(liveness ) 是基于 任意两个quorums都会有交集(只要满足majority,显然就会有交集;不过也有其他的quorum方案被提出)。
6 |
7 | 三个角色:
8 |
9 | - proposer: wishes to have a particular value chosen
10 | - acceptor: agrees and persists decided values
11 | - learner: wishing to learn the decided value
12 |
13 | 两个阶段:
14 |
15 | - Phase 1 - **Prepare & Promise**
16 | 1. Proposer 选择唯一提议号*p*,并向Acceptor发送 *prepare(p)*
17 | 2. Acceptor接收到*p*,如果*p*是最高的提议号,则将*p*写入到持久化存储,并且回复 *promise(p', v')*,其中(p', v')为最后一次接受的提议
18 | 3. 当Proposer 收到大多数Acceptor的*promise*时,进入第二阶段。否则,Proposer 会用更大的提议号重试。
19 | - Phase 2 - **Propose & Accept**
20 | 1. Proposer 选定值 *v*。
21 |
22 | **Liveness**
23 |
24 | > A liveness property states that, under certain conditions, some event will ultimately occur.
25 | >
26 | > **Safety** and **liveness** are two important kinds of properties provided by all distributed systems. Informally, safety guarantees promise that nothing bad happens, while liveness guarantees promise that something good eventually happens. Every distributed system makes some form of safety and liveness guarantees, and some are stronger than others. For example, **atomic consistency** guarantees that operations will appear to happen instantaneously across the system (safety) but operations won’t always succeed in the presence of network partitions (liveness, in the form of availability).
27 |
28 | 2. Multi-Paxos
29 |
30 | 实际中的使用,是希望一连串的值能够达到一致,即Multi-Paxos。所以一般使用 Paxos的第一阶段**election** 来选出*leader*,使用 Paxos的第二阶段**replication** 来记录一连串的值。只有当*leader*与quorum交互 并 等待它们接收值后,该值才能被提交。
31 |
32 | 3. FPaxos (Flexible Paxos)
33 |
34 | 在Paxos的每个阶段,都不需要majority quorum,即无交集的quorum是安全的。当然,如果选择有交集的quorum就和原Paxos等价。
35 |
36 | 其优势就在于 可以减小replication阶段需要保证参与的结点数,由于leader不需要等待大多数接受,所以减小了系统的等待时延。这样的代价是 **减少了可用性**(leader宕机后的恢复过程)。
37 |
38 | 4.
39 |
40 |
--------------------------------------------------------------------------------
/paper reading/query/join size estimation.md:
--------------------------------------------------------------------------------
1 | ## Two-Level Sampling for Join Size Estimation
2 |
3 | 1. **背景**:Join size的估计在查询优化中十分关键,因为中间结果的大小 是查询计划代价(CPU时间,I/O代价,分布式引擎的通信代价)的一个决定性因素。 *Efficient join query evaluation in a parallel database system* 中指出中间结果的大小 很大程度决定了使用哪个join算法最好,尤其在分布式环境中。
4 |
5 | **Challenge**: join查询通常都包含 在**查询期间**才知道的 特定的选择谓词,因此统计信息时无法考虑这些谓词。
6 |
7 | 2. **Contribution**: 提出一种 基于**两级采样*two-level sampling***的 join size估计。且实现简单,只需要扫描一趟数据,只依赖基础的统计信息——Lk范数 ℓk-norms、**频繁命中项** heavy hitters。
8 |
9 | 3. **Conclusion**:在以下join—— 主-外键join,多对多join,多表join中,该算法比先前算法表现得都要好。
10 |
11 | 4. **Related Work**对比:
12 |
13 | - **Sketching based**: 对每个表在join的属性上 构建一个概述 sketch。当没有谓词时,给出的是join的精确大小;缺点有:
14 |
15 | 1. 当**有谓词时,性能急剧下降**,因为添加一个谓词 等价于 在原基础上多一张表的join(查询时创建的虚表)
16 | 2. 对虚表 构建sketch 只适用于**谓词属性的域 domain比较小**的情况
17 |
18 | - **Synopsis**: 通过 小波变换的信号处理技术,对数据进行有损压缩,建立一个由所有数据形成的多维数组,提取该数组的概要synopsis. 缺点有:
19 |
20 | 1. 谓词只能是 **等于equality** 或 **有范围约束range constraint**
21 | 2. 当属性的domain很大 或 数据维数很高时,压缩的效果很低
22 |
23 | - **Random sampling**: 对域大小、谓词形式/多少 不敏感。只需要在采样的样本上应用谓词,然后使用样本中符合谓词的元组 来进行join size 的估计。
24 |
25 | 采样既可以在离线阶段进行,也可以在给定query的期间进行;前者在查询时的开销更小,后者对于选择性的谓词更有效。
26 |
27 | 5. 两种最重要的join类型:
28 |
29 | - PK-FK
30 | - many-many,比如微博中的(Follower, Followee)
31 |
32 | 6. 已有的采样方法:(sampling是并行的)
33 |
34 | - Independent Bernoulli sampling
35 |
36 | 最简单的,每个元组具有独立的概率p。估计值为|SA⋈SB|/p2
37 |
38 | 只适用于PK-FK join,且该PK-FK关系必须是有向无环图。
39 |
40 | - Correlated sampling
41 |
42 | 独立采样算法忽视了两个表之间的连接关系。相关采样法Correlated sampling通过哈希函数来生成相互关联的样本。h: [u] -> [0, 1],为随机哈希函数。当一个元组的连接属性值为*v* 且 *h(v) < p* 时,该元组就放入样本中。估计值为|SA⋈SB|/p
43 |
44 | - End-biased sampling
45 |
46 | 与相关采样法类似,在其基础上引入了频率 frequency 的信息;认为一个 join value *v* 的采样概率与其频率 成正比。
47 |
48 | - Index-assisted sampling
49 |
50 | 基于索引的采样,使得采样更加集中于 与query相关的元组。
51 |
52 | 7. **Future work**: 将该估计方法 整合到大型分布式查询处理引擎中。
53 |
54 |
55 |
56 |
--------------------------------------------------------------------------------
/paper reading/data structure/Adaptive Radix Tree.md:
--------------------------------------------------------------------------------
1 | ## The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases
2 |
3 | 1. **问题**:对于内存数据库,索引结构的性能是关键瓶颈。传统的平衡二叉搜索树 在现代硬件上不够高效(包括T树,即使是cache友好的B+树 在更新操作也需要更高的代价),因为没有最好地利用CPU cache,而且由于比较的结果不能预测,会造成更多的流水线 stalls。哈希表够快,但是只支持单点查询。
4 | 2. **Contribution**: 提出 ART,自适应的 radix tree (即trie,就是压缩前缀树;但是trie更着重于字符串型的key,**这里使用radix是为了强调适用于多数据类型的基数排序原理**)。
5 | - Space efficient,自适应地为内部节点选择紧凑而有效的数据结构,解决了radix树常见的空间消耗问题
6 | - 数据有序,支持范围查询、前缀查询等
7 | - 描述了 常见的内置数据类型如何在 radix tree中**有序存储**
8 | - 将ART整合到 HyPer中,通过现实中的事务处理 证明了其优越的性能
9 |
10 | 3. **Related Work**:
11 |
12 | - 在基于磁盘的数据库系统中,B+树最普遍
13 | - 对于内存数据库,提出了 红黑树、T树
14 | - 由于 类二叉搜索树的 利用cache性能很差,提出了 针对cache优化的B+树变种 (G. Graefe and P.-A. Larson, “B-tree indexes and CPU caches,” in ICDE, 2001.)
15 | - 使用 SIMD指令减少比较的次数,也减少了 cache miss
16 | - 提出 FAST(Fast Architecture Sensitive Tree) ,使用了SIMD, cache line, page block 来最大化利用cache和内存带宽
17 |
18 | > 每个高速缓存行完全是在一个突发读操作周期中进行填充或者下载的。即使处理器只存取一个字节的存储器,高速缓存控制器也启动整个存取器访问周期并请求整个数据块。缓存行第一个字节的地址总是突发周期尺寸的倍数。缓存行的起始位置总是与突发周期的开头保持一致。
19 | >
20 | > 当从内存中取单元到cache中时,会一次取一个cache line大小的内存区域到cache中,然后存进相应的cache line中。
21 |
22 | - Burst trie 使用trie结点作为树的上层结构,当一个子树的元素很少时,就转化为链表;HAT-trie把链表替换为哈希表
23 |
24 | 4. **实现细节**:
25 |
26 | - ART的自适应结点 不会影响最终的树高度(因为 radix tree高度只有key的长度决定,而不是元素的个数)
27 |
28 | - 两种结点类型
29 |
30 | - **Inner Node**: 将partial key映射到其他结点
31 |
32 | 由两个List组成,一个List存放key部分,一个存放指向下一个结点的指针部分。
33 |
34 | 有Node4, Node16, Node48, Node256 四种大小的内部结点。
35 |
36 | - **Leaf Node**: 存储key对应的value
37 |
38 | 如果是非unique的key,即一个key可对应多个value的情况,可在key后附加元组标识符。
39 |
40 | - **Binary-comparable keys**
41 |
42 | 可以直接比较内存中的二进制表示形式
43 |
44 | 1. 无符号整数:只需要考虑大小端即可
45 | 2. 有符号整数:补码形式需要重新排序,对于b位的有符号整数x,可转化为 x XOR 2b-1
46 | 3. IEEE 754 浮点数:根据定义重新计算即可
47 | 4. 字符串:对于Unicode的比较规则很复杂
48 | 5. Null: 赋予特定的次序
49 | 6. 复合key: 分别对每个属性进行转换即可
50 |
51 | 5. **Future Work**: 支持并发更新;计划研发一个latch-free的同步方案,如使用CAS机制
52 |
53 |
--------------------------------------------------------------------------------
/paper reading/crowdsource/Training for Relation Extraction.md:
--------------------------------------------------------------------------------
1 | ## Self-Crowdsourcing Training for Relation Extraction
2 |
3 | 1. **问题**:指导crowd worker的例子和问题
4 | 2. **Contribution**:
5 | - 介绍了一种 众包的self-training策略
6 | - 提出一种 针对关系抽取 RE的人机合作训练框架(人类和机器的标注都会在迭代中 逐渐改进)
7 | 1. 使用自动分类器,从样本中自动选出一个*less-noisy*的子集
8 | 2. 使用该子集 训练标注器 annotator
9 | 3. 使用标注后的数据 再迭代地训练分类器
10 | - 在标准基准测试下,只比 state-of-the-art的方法性能差一点
11 |
12 | 3. Relation Extraction:
13 |
14 | > Relationship extraction is the task of extracting semantic relationships from a text. Extracted relationships usually occur between two or more entities of a certain type (e.g. Person, Organization, Location) and fall into a number of semantic categories (e.g. married to, employed by, lives in).
15 |
16 | 4. Distant Supervision (DS):
17 |
18 | 2009年Mintz等人提出了**远程监督**方法,借助外部知识库 Knowledge-Base (如 wiki, Freebase) 为数据提供标签,从而省去人工标注的麻烦。Mintz提出一个假设,如果知识库中存在某个实体对的某种关系,那么所有包含此对实体的数据都表达这个关系。理论上,这让关系抽取的工作大大简化。
19 |
20 | 但远程监督也有副作用(噪声很大),因为不用人为的标注,只能机械地依赖外部知识库,而外部知识库会将同一对实体的所有情况都会标注一种关系,其标签的准确度就会大大的降低。
21 |
22 | 5. **Related Work**:
23 |
24 | - 把 DS data 和少量通过众包得到的人类标注数据 结合起来,提高准确率
25 | - 通过 主动学习active learning(针对数据标签较少或打标签“代价”较高的场景)来选择给众包的最好样本
26 | - 通过 *Gated Instruction*来训练crowd worker
27 |
28 | 6. **实现细节**:
29 |
30 | 为什么叫Self-Crowdsourcing Training?-> 因为想要通过分类器的得分来训练crowd worker。
31 |
32 | - **Silver Standard Mining**
33 |
34 | 基于有噪声的数据集 DS,以及一个由众包标注的数据集 CS。首先,将CS分为三部分:
35 |
36 | - CSI: 用于给crowd worker的指引。先在DS上训练出分类器C,再用分类器C来标注CS样本。选择预测分数最高的 Top NI个 作为CSI
37 | - CSQ: 用于句子标注的问题。从 CS-CSI的集合中再选择 Top Nq个样本作为CSQ
38 | - CSA: 用于 收集 训练后的标注器 所标注的标签。即CS中剩下分数最低的样本,交给crowd worker
39 |
40 | - **Training Schema**
41 |
42 | 训练标注器分为两步:
43 |
44 | 1. **User Instruction**: 首先定义关系的类型,接着告诉crowd worker一系列的例子,比如定义 *Has nationality of* 不是 *live in* 或 *was born in*;这样有利于不同专业水平的人 来训练标注器
45 | 2. **Interactive QA**: 给workers交互式的多选任务,并智能纠正他们的错误——告诉他们哪里错了
46 |
47 | 7. **Future work**: 将该方法推广到 其他更简单或更难的任务上。
--------------------------------------------------------------------------------
/paper reading/robust query/Smooth Scan.md:
--------------------------------------------------------------------------------
1 | ## Smooth Scan: Robust Access Path Selection without Cardinality Estimation
2 |
3 | 1. **Motivation**:
4 |
5 | 2. **Contribution**:
6 | - 提出新的*smooth access path*算子,该算子可以根据**运行时的统计信息**,从一种实现过渡到另外一种实现
7 | - 实现了一种对不用感知统计信息的算子——Smooth Scan,根据运行时selectivity的变化,来进行*index scan*和*full scan*的动态过渡转化(morph)
8 | - 对Smooth Scan策略在最坏情况下的性能保障 提供了理论分析
9 |
10 | 3. 不同的扫描算法:
11 | - 全表扫描:当没有其他access path,或者access path的**选择率很高**时,会使用全表扫描
12 | - 索引扫描:是**随机读取**(所以如果选择率很高的话,索引扫会发生很多次随机读取,导致性能下降)
13 | - 排序扫描:先利用索引找到所有满足条件的元组id,再对id排序,从而利用预读取来达到(近似)顺序扫描的效果;但是无法利用B树索引的有序性,来进行一个range query
14 |
15 | 4. 流程:
16 |
17 | 在*index scan*到*full scan*的过渡中,有三种模式。
18 |
19 | 1. Index scan: 当存在索引时,首先还是会从索引扫描开始。过程中,会持续关注结果集的cardinality,达到阈值时,进入下一个状态;
20 |
21 | 2. Entire page probe: 通过CPU开销来换取IO的开销,会分析每个装载的page中满足条件的元组(原本的index scan只会取该page中索引指向的那一条记录);
22 |
23 | 3. Flattening: 结果集越来越大时,**Smooth Scan**会将随机IO的代价 分摊到 用顺序读代替随机读上,原理就是每次回预取邻近的page,做一个顺序读;结果集继续增大,则可以逐渐地flatten,从而过渡为近似的full scan
24 |
25 | 预期达到的效果如下:(虽然当选择率比较低时,一开始比走纯索引慢,但是随选择率上升,执行时间更平滑)
26 |
27 | 
28 |
29 | 5. 策略
30 | - **Greedy**: 当选择率很高时,Smooth Scan的morphing size会随每一次索引访问而扩大;显然,如果选择率没那么高,会带来额外开销
31 | - **Selectivity increase**: 当检测到选择率上升(局部大于全局)时,会扩大morphing size;没有上升,则不变
32 | - **Elastic**: 比如在大数据集的场景,由于数据分布的偏度,元组在磁盘中可能有分布稀疏和密集的区域;所以弹性策略,当局部的选择率高于全局时(密集区),会扩大过渡区morphing size,反之亦然。
33 | 6. **Morphing**触发时机
34 | - Optimizer driven: 当结果集的cardinality超过优化器的估计时,开始使用Smooth Scan
35 | - SLA driven
36 | - Eager: 所有access path都使用Smooth Scan的算法
37 | 7. 实现设计
38 | - **Page** **ID** **cache**: 保存读取过的page,bitmap的结构(每个bit对应一个page)从而Smooth Scan每次只读取之前没有访问过的page
39 | - **Tuple ID cache**: 如果是从Mode0开始的,需要保证后来不会重复读取到之前读过的元组,也是bitmap结构
40 | - **Result cache**: 是hash的结构。当索引可以保证query需求的顺序时,需要先要对每个叶子节点页面的tupleID 进行Result Cache的hash probe,再进行index probe;如果该元组在cache中找到了,则直接返回,否则正常从磁盘中读取
41 | - **Memory management**: 对于bitmap结构,通常几百GB的数据最多只要几MB的内存;但是result cache可能会增长得很大,思想是对其进行partition,写到临时文件中(根据B树根节点来决定划分的数量)
--------------------------------------------------------------------------------
/paper reading/robust query/Exact Cardinality Query Optimization.md:
--------------------------------------------------------------------------------
1 | ## Exact Cardinality Query Optimization with Bounded Execution Cost
2 |
3 | SIGMOD, 2019
4 |
5 | 1. Motivation: 还是优化器估计不准确,导致的次优计划问题。
6 |
7 | 2. 相关术语:
8 |
9 | - **ECQO**(Exact Cardinality Query Optimization)
10 |
11 | 在*Exact cardinality query optimization for optimizer testing (2009)*中被提出。通过一个probe阶段来得到 精确基数大小,来生成最优计划。
12 |
13 | 给定查询q,代价模型c,如何在没有可靠的基数估计模型
14 |
15 | 这里基于了一个假设:当知道了精确的基数大小后,代价模型c的估计本身是可靠的。这个假设不一定总成立,但*Predicting query execution time: Are optimizer cost models really unusable? (2013)*中指出了,比起代价模型本身,**基数估计的问题更大**。
16 |
17 | 比如在*How good are query optimizers, really? (2015)*中,就比较了不同优化器在精确基数的条件下 产出的计划。
18 |
19 | 前人提出的ECQO算法大部分都是需要 遍历得到计划搜索空间出现过的所有中间表的大小,但缺少运行时性能的保障,比如执行到最差计划可能会导致占用大量系统资源。
20 |
21 | - **Probe Query** 和 **Probe Order**
22 |
23 | 试探查询的作用是 获取中间结果的精确基数。试探顺序是指 执行试探查询时的Join顺序,比如可能对应bushy tree的顺序。这个过程的额外开销很大!所以得考虑离线执行。
24 |
25 | 3. Contribution:
26 |
27 | - 提出了一种ECQO算法,通过部分生成 大的中间结果表,来减少执行的开销
28 | - 证明了算法执行代价上界 为最有代价的函数(类似于SpillBound的MSO)
29 | - 通过实验证明了比前人工作的优越性(使用了Join Order Benchmark)
30 |
31 | 4. **核心流程**:
32 |
33 | 为了避免直接跑完大的中间表,肯定要给其一个限定的执行预算。所以,这里的思想是:只生成部分的中间表(文章中通过`limit`子句来实现),得到一个基数的下界,也能计算出对应计划的代价下界。
34 |
35 | 实际流程是**迭代式**的:
36 |
37 | 1. 从最小的代价假设出发,逐渐增加代价预算来执行Probe Query(这一点和SpillBound一样)
38 | 2. 每一轮迭代,都能通过执行Probe Query获取到基数信息(文章使用的是Pg的Explain Analyze功能 来实现获取中间结果的大小)
39 | 3. 根据基数信息,自底向上地计算代价下界;然后再自顶向下地计算 每张表的*剩余部分代价*,即生成最终结果的代价。这两步的结果构成了整体代价的下界
40 | 4. 每张表都有对应的状态*status*
41 | - pending
42 | -
43 | 5.
44 |
45 | 伪代码
46 |
47 | ```c
48 | 输入:查询q, 代价预算增长系数t
49 | SafeECQO(q, a)
50 | // 初始化表的元数据
51 | R = getRelInfo(q)
52 | // 初始化每个表的代价预算
53 | b = getBudget(q)
54 | while r.status
55 | // 基数试探的join顺序
56 | p = calcProbeOrder(q, R, b)
57 | if p != null
58 | // 在限定的代价内执行p
59 | card = safeExecute(p, b)
60 | // 更新基数下界
61 | updateCard(p, b, card, R)
62 | updateCost(q, R)
63 | // 更新表状态
64 | updateStatus(q, R, b ,false)
65 | else
66 | // 增加预算
67 | b = b * a
68 | // 更新表状态
69 | updateStatus(q, R, b ,true)
70 | end if
71 | end while
72 | end func
73 | ```
74 |
75 |
76 |
77 | 5. updateCard() 更新基数的过程
78 |
79 | 6. updateCost() 更新代价的过程
80 |
81 |
--------------------------------------------------------------------------------
/paper reading/data structure/B-tree-locking.md:
--------------------------------------------------------------------------------
1 | [TOC]
2 |
3 |
4 |
5 | ## A Survey of B-Tree Locking Techniques
6 |
7 | ### Introduction
8 |
9 | 1. 索引的本质就是 key->information的映射
10 | 2. B树还支持 **范围查询**、**基于排序的查询执行算法**(如: [Sort-Merge Join](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/17%20parallel%20join/17-sort-merge-join.md))
11 | 3. 在B-tree的并发保护中,要区分
12 | - **B-tree内容**的保护 与 **B-tree结构**的保护
13 | - **线程之间**的隔离 与 **用户事务之间**的隔离
14 | 4. 常规:
15 | - Shared locks(S,共享锁) 和 Exclusive locks(X,独占/排他锁)
16 | - 锁被 **线程** 或 **事务** 持有
17 |
18 | ### B-Tree Locking的两种形式
19 |
20 | 同一个事务中的两个线程,应该"看到"相同的数据库内容。即,一个线程不应该看到中间态或不完整的数据结构。
21 |
22 | 0. 两种形式:
23 | - 多事务查询/ 修改数据库内容以及B-tree索引 的并发控制
24 | - 多线程修改内存中的B-tree数据结构 (缓冲池中 基于磁盘的B-tree结点的 镜像) 的并发控制
25 |
26 | 1. 以上两种通常由 **Locks** & **Latches** 实现
27 |
28 | - lock 通过 数据页/B-tree键/B-tree键区间 上的 **读/写锁** 来分离事务
29 |
30 | - 注意:悲观锁和乐观锁是一种概念/思想,不能与数据库的锁机制(行锁、表锁、排他锁、共享锁)混为一谈。
31 |
32 | - 在DBMS中,悲观锁正是利用数据库本身提供的锁机制来实现的。每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁
33 | - 不是数据库本身的锁(用户自己实现的一种锁机制),是利用数据比较结果来当做抽象的锁。实现方法包括 **版本号**、**时间戳**
34 |
35 | - 行锁 vs 表锁:
36 |
37 | | | 表锁 | 行锁 |
38 | | ---------- | ---------- | ---------- |
39 | | 开销 | 小,加锁块 | 大,加锁慢 |
40 | | 死锁 | 不会 | 会 |
41 | | 粒度 | 大 | 小 |
42 | | 锁冲突概率 | 高 | 低 |
43 | | 并发度 | 低 | 高 |
44 |
45 | - latch 负责分离 访问缓冲池B-tree页、缓冲池管理表、所有内存中数据结构 的多线程。比如,在 一个线程修改lock manager的哈希表时,需要获取 write latch (即使是同一个事务中的多线程也会发生冲突)
46 |
47 | - 
48 |
49 | 2. 数据库恢复:
50 | - 在等待**全局事务协调器(global [transaction coordinator](https://stackoverflow.com/questions/1253836/whats-the-difference-between-a-transaction-coordinator-and-a-transaction-manage))**——(a server for managing distributed transactions)做出决定期间,不需要latch;但是需要持有locks来保证本地事务(local txn)会服从全局协调的最终决定。
51 | - 在**事务回滚**时,必须持有locks,如: 向一个事务保存点(savepoint, 不必重新提交所有语句) 部分回滚时(回滚完成后,释放**回滚语句使用的锁**;即释放次保存点后获得的表级锁和行级锁,但之前的数据所依然保留)。
52 | - 由latch(而不是lock)保护的操作是: 改变B-tree的结构,如 B-tree的结点分裂,均衡邻居结点。
53 |
54 | 3. 保护B-tree物理结构:
55 | - 在buffer pool的一个数据页镜像,当在被一个线程读取时,禁止另一个线程向它写(类似于 临界区的保护)
56 | - 在跟随B-tree索引从父结点到子结点时,另一个线程不能使当前的pointer(一个页标识符, page identifier)失效,如回收(de-allocate)子结点的页空间。由于在进行I/O (将磁盘中子结点的数据页读入buffer pool中)时,不建议持有latch (否则 临界区会变得很长)
57 | -
--------------------------------------------------------------------------------
/paper reading/benchmark/Fair Benchmarking Considered Difficult.md:
--------------------------------------------------------------------------------
1 | ## Fair Benchmarking Considered Difficult: Common Pitfalls In Database Performance Testing
2 |
3 | 1. **Motivation**: 性能测试表面上看上去很客观公正,但事实上有 许多不同的方法可以让基准测试结果 在一个系统上比另一个更优(可能是有意的,也可能是无意的)。
4 |
5 | 2. **Contribution**:
6 |
7 | - 对于软件系统可再现的基准测试方法 进行了研究
8 | - 基于以上研究的方法,探索了如何将其应用到数据库测试场景,并且讨论了在数据库测试中通常可能犯的问题
9 | - 讨论了如何 辨别并避免以上问题,从而可以在不同的系统、算法间进行公平的比较
10 |
11 | 3. 相关工作:
12 |
13 | - 通用Benchmarking
14 |
15 | 通常实验过程包括这几个步骤:实验计划与建立、实验执行、数据收集、数据分析和结果表示。而在统计型数据分析中,常见的问题包括:“精心挑选”的数据集、隐藏一些极端情况。
16 |
17 | 在计算机科学领域,*The Art of Computer Systems Performance Analysis: Techniques for Experimental Design, Measurement, Simulation and Modeling* 一书中给出了这么两个定义
18 |
19 | - Mistake: 对于Benchmark执行不利的选择,但是是无意的。 比如,测试workload不能很好地反映真实生产环境的情况。
20 | - Game: 故意操作实验过程 来得到一个特定的结果。比如,实验时的软硬件环境不同。
21 |
22 | 而在高性能计算(HPC)领域,*Scientific Benchmarking of Parallel Computing Systems (2015)* 提出了12条Benchmark测试规则。其作者也强调了 实验结果的可解释性;因为这样才提供了足够的信息,让学者能够理解实验,得出自己的结论,评估其确定性,从而对结果进行归纳。
23 |
24 | 在 系统安全领域, *Benchmarking Crimes: An Emerging Threat in Systems Security (2018)*指出了Benchmark中的错误会威胁到实验结果的有效性,一定程度阻碍研究的发展。
25 |
26 | - 数据库Benchmarking
27 |
28 | *Benchmark Handbook: For Database and Transaction Processing Systems (1992)* 提出了一些测试时的要点:
29 |
30 | - 数据应以指定的方式生成
31 | - 结果报告应包括资源利用率和数据库磁盘空间
32 | - 准确的硬软件配置
33 | - 有效的查询计划
34 | - 收集统计信息的开销
35 | - 随时间变化的内存使用情况
36 | - 运行时间、CPU时间、IO操作次数
37 |
38 | 现今的TPC测试则成为了新标准,参考TPC Benchmark C Standard Specification、TPC Benchmark H (Decision Support) Standard Specification。而对于特定的数据库,比如SQLite, *The Dangers and Complexities of SQLite Benchmarking (2017)* 中也指出 通过一个参数的设置,事务吞吐量的变化可达到28倍,而相关的16篇论文没有一篇报告了它们实验结果的所需参数。
39 |
40 | 4. ***Checklist***
41 | - Benchmark选择
42 | - 能覆盖整个评估空间
43 | - 证明选取Benchmark子集的合理性
44 | - Benchmark能够突出相应评估的功能
45 | - 可重现
46 | - 硬件配置
47 | - DBMS参数与版本
48 | - 源代码 / 二进制文件
49 | - 数据、表模式、查询
50 | - 优化
51 | - 编译选项
52 | - 系统参数
53 | - 可比较的调优
54 | - 不同的数据
55 | - 多种workload
56 | - 程序预热(Cold / Warm / Hot runs)
57 | - 区分冷运行和热运行
58 | - 冷运行:清空OS和CPU的缓存
59 | - 热运行:初始的运行结果直接忽略掉
60 | - 预处理
61 | - 确保系统之间的预处理相同
62 | - 注意自动的索引创建
63 | - 保证正确性
64 | - 验证结果
65 | - 测试不同的数据集
66 | - 边界情况的讨论
67 | - 收集结果
68 | - 多运行几次防止其他干扰
69 | - 检查多次运行结果的方差/标准差
70 | - 报告具有稳健性的指标(如中位数、置信区间)
--------------------------------------------------------------------------------
/paper reading/dbms/Dima.md:
--------------------------------------------------------------------------------
1 | ## A Distributed In-Memory Similarity-Based Query Processing System
2 |
3 | 1. **问题**:现有的算法或系统不是完全开发好的 full-fledged,不支持复杂的数据分析;且这些算法 要么不支持大规模地数据分析, 要么 负载上不均衡。
4 | 2. **Contribution**: 第一个支持基于相似度的分布式内存型查询处理系统。
5 | - 扩展了SQL编程接口,支持**similarity search**和**similarity join**
6 | - 设计了selectable **signatures**,当两条record的签名相同时,它们就近似匹配;从而避免分布式系统中高代价的数据转换
7 | - 构造了 基于签名的全局和本地索引,支持高效的search和join;同时可以自适应地选择签名来负载均衡
8 | - 无缝集成到Spark中,并在Spark中开发了有效的优化查询
9 |
10 | 3. 细节实现:
11 |
12 | - 基于相似度的查询:
13 | 1. **Set-Based Similarity**: 对record进行分词 得到一个token集合,再对比集合的相似度,可使用 Jaccard、余弦、DICE
14 | 2. **Character-Based Similarity**: 如使用 编辑距离edit distance (由一个单词w1转换为另一个单词w2 所需要的最少**单字符编辑操作**次数,包括删除、插入、替换)
15 | 3. **Similarity Search**: 给定查询*s*,相似度函数*f*,阈值*T*,找到所有使*f(r, s, T)*为真的 元组*r*
16 | 4. **Similarity Join**: 给定表R 和表S,找到所有使*f(r, s, T)*为真的 元组对*(r, s)*
17 |
18 | - **Selectable Signatures**:
19 |
20 | 对于每条record *r*,生成两种indexing signature(来源于元组r)和 两种probing signature(来源于查询s):
21 |
22 | - **Indexing Segment Signature**
23 |
24 | 将*r*划分为*n*个不相交的段 *seg1*,*seg2*… *segn*. **( segi, i, r )**即为一个indexing segment signature. 而*r*的索引段签名集合 即为*n*个的并。
25 |
26 | *n*的大小可根据 为Jaccard设定的阈值*T* 计算得到。如果**集合s** 与 **集合r** 相似,那么s最多有 **minMatchCnt** = Math.floor( (1-*T*)/*T* \* |r| )个 和r不匹配的token. 所以当我们把 r划分为 **minMatchCnt**+1 段时,若s与r相似,则s与r **至少有1个段**相同。 (一个segment都不相同,一定不相似,从而可以剪枝)
27 |
28 | 在划分时,要保持token的全局顺序,不同record中相同的token必须在同一个段内。可以用哈希函数*h*,将token *t*映射到 第*h(t)*段中。
29 |
30 | - **Indexing Deletion Signature**
31 |
32 | 对于每个索引段签名,生成一个indexing deletion signature,即 **( delik , i, |r| )**,其中 delik 是将 segi 删除掉第k个token 所得到的子集。
33 |
34 | - **Probing Segment Signatures for Length l**
35 |
36 | 如果**记录s** 和**记录r**相似,则s长度必须和r不能差太大;r的长度|r| 应该在区间 [ |s|\**T*, |s|/*T* ] 内。
37 |
38 | 对于长度为l的记录,Probing segment signatures即 **( segi, i, l )**
39 |
40 | - **Probing Deletion Signatures for Length l**
41 |
42 | 即 **( deli, i, l )**.
43 |
44 | 重点在于 **剪枝**Pruning,找到 r和s不匹配token数的阈值,超出该阈值则不可能相似。
45 |
46 | - **Distributed Indexing**
47 |
48 | 不同的query会规定不同的阈值,故在offline阶段,需要建立local index;再用**Frequency Table**记录每个签名的频率,从而建立 一个从signature映射到 包含该signature的划分 的global index (不需要用hash表,只需要固定的hash函数将 签名 映射到 划分)
49 |
50 |
--------------------------------------------------------------------------------
/paper reading/dbms/postgres/监控.md:
--------------------------------------------------------------------------------
1 | ## PostgreSQL监控
2 |
3 | > 参考《PostgreSQL监控实战——基于Pigsty解决实际监控问题》
4 |
5 | 1. 根据Google的[SRE](https://github.com/captn3m0/google-sre-ebook)(Site Reliability Engineering),监控指标可分为四类:
6 |
7 | - **饱和度**
8 |
9 | 给定资源的使用量。
10 |
11 | - 基础:
12 | - 基础资源使用率
13 | - 打开的文件句柄数
14 | - TCP连接数
15 | - 业务:
16 | - 核心功能使用率
17 | - 集群数据均衡度
18 | - 队列长度
19 |
20 | - **延迟**
21 |
22 | 衡量完成操作所需时间。
23 |
24 | - 基础:
25 | - IO wait
26 | - 网络延迟
27 | - 业务:
28 | - 核心功能延迟
29 | - 集群数据同步延迟
30 |
31 | - **流量**
32 |
33 | 衡量组件和系统的“繁忙程度”。
34 |
35 | - 基础:
36 | - 磁盘流量
37 | - 网卡流量
38 | - 业务:
39 | - 核心功能请求速率
40 |
41 | - **错误**
42 |
43 | 了解组件的运行状况、未能正确地响应请求的频率。
44 |
45 | - 基础:
46 | - 宕机
47 | - 进程存活
48 | - 业务:
49 | - 核心功能错误
50 | - 基础数据丢失
51 | - 可用实例数占比
52 | - 上游依赖错误
53 | - 日志错误
54 |
55 | 2. pigsty重要的监控指标:
56 |
57 | 1. **数据库负载** Load
58 |
59 | 衡量了数据库的负载程度,定义为:活跃事务时长占CPU总可用时间的比例(类比了CPU的利用率)。 Load在0~40%之间为低负载,40%~70%为中负载,70%以上就为高负载。
60 |
61 | 那么为什么Load采取了这个指标,而不是其他的定义?[官方文档](https://pigsty.cc/zh/blog/2020/05/29/postgresql%E7%9A%84kpi/)给出了如下解释:
62 |
63 | 如果使用CPU或IO等机器指标的话,它们确实一定程度可以反映数据库的负载;但如果瓶颈在数据库系统自身上,比如锁冲突之类的,此时底层的硬件资源利用率 就难以衡量数据库本身的饱和度了。
64 |
65 | 如果使用QPS、TPS等流量指标,是很难进行横向比较的,因为简单的查询与复杂的查询都只会算作一个Query。
66 |
67 | 对于RT这种延迟指标,也是比较有参考价值的,因为理论上Load越大,平均的响应时间肯定会越长,但是它也只能定性的指出系统的负载变化趋势,不能定量地给出负载到底多大。
68 |
69 | 2. **数据库饱和度** Saturation
70 |
71 | 衡量了数据库整体资源利用率。这里考虑的是数据库如果是非独占式部署,其他应用也会占用CPU资源,此时就应该取Load和CPU利用率二者的最大值 来衡量整体的资源利用率。
72 |
73 | 那么饱和度一个很大的作用就是 进行**水位的评估**(可以根据业务的周期性,来选择过去一周/一月的水位情况),从而看是否需要扩缩容、调整配置等。
74 |
75 | 3. **主从复制延迟**
76 |
77 | 4. **查询响应时间(平均)**Query RT
78 |
79 | 5. **活跃的后端进程数**
80 |
81 | 6. **年龄**
82 |
83 | 7. **CPU使用率**
84 |
85 | 8. **每秒查询数 QPS**
86 |
87 | 9. **连接池排队**
88 |
89 | 10. **错误日志数**
90 |
91 | 3. 对于应用程序来说,QPS和RT是最关注的指标;对于DBA来说,饱和度是最关注的指标。
92 |
93 | 4. 监控数据的来源:
94 |
95 | - **数据库**(包括Pg本身的监控、系统目录信息、日志中的统计信息)
96 | - **中间件**
97 | - **操作系统**
98 | - **负载均衡器**(如HAproxy的监控指标)
99 |
100 | 5. 如何针对操作系统内核进行参数调优?——可参考tuned调参工具(CentOS)。
101 |
102 | 6. 对于常用的通用监控方案还有:[zabbix](https://www.zabbix.com/)和[Prometheus](https://prometheus.io/),可以进一步了解。
--------------------------------------------------------------------------------
/paper reading/os/Linux Storage.md:
--------------------------------------------------------------------------------
1 | ## Linux Storage
2 |
3 | 1. VFS (Virtual File System)
4 |
5 | Linux内核里提供文件系统接口 给**用户态应用程序**的一个虚拟文件系统层。也就是不管是访问什么文件,也不管使用的是什么文件系统(ext2/ ext3/ ext4/ Minix),基本都可以统一地使用诸如open(), read()和write()这样的接口
6 |
7 | 2. 概念
8 |
9 | - SuperBlock: 文件系统的第一个Block,描述文件系统的元信息
10 | - Mount Tree: 访问文件系统必须通过mount point去访问
11 | - File System: 文件系统必须向VFS注册自己的类型,并实现mount方法
12 | - Inode: 也就是Index node,每个有一个全局唯一(对于一个文件系统)的inode号
13 | - dentry: 目录也是一种文件,包含文件与子目录,以及它们对应的inode号
14 | - Opened file: 当进程打开一个文件,VFS会创建一个文件实体,并在进程的open file table中分配一个对应的index,即文件描述符fd
15 |
16 | 3. 文件系统的组成
17 |
18 | - superblock
19 | - inode bitmap: 作为inode table的索引,保存了 已分配 / 未分配的inode信息
20 | - data block bitmap
21 | - inode tables
22 | - data blocks: 真正存储数据的数据块
23 |
24 | 4. inode
25 |
26 | - 文件元信息
27 | - 文件数据的存储位置
28 |
29 | 对于大文件的支持:
30 |
31 | - ext2: 通过多级指针的方式,但是对大文件还是不太友好,因为要用很多指针去指向
32 | - ext4: 通过extent树
33 |
34 | 琐碎文件导致inode超出范围,可能会创建文件失败。
35 |
36 | 5. dentry
37 |
38 |
39 |
40 | 6. 链接
41 |
42 | - 硬链接:不能跨分区,因为它只相当于文件的别名 (inode在同一个文件系统中才唯一)
43 |
44 | 对于 `ln 1.txt 3.txt`,dentry如下:
45 |
46 | | name | inode |
47 | | ----- | ------- |
48 | | 1.txt | 123 |
49 | | 2.txt | 456 |
50 | | 3.txt | **123** |
51 |
52 | 假设进程A 与 进程B打开了同一个文件1.txt,进程C打开了硬链接3.txt;则A和B的file指针**包含的是同一个dentry**,C的file指针**是另一个dentry**,但**两个dentry的成员inode是同一个**。
53 |
54 | - 软链接:又叫符号链接,这个文件包含了另一个文件的路径名;可以链接不同文件系统的文件,可以理解为windows的快捷方式
55 |
56 | 对于 `ln -s 1.txt 3.txt`,dentry如下:
57 |
58 | | name | inode |
59 | | ----- | ------- |
60 | | 1.txt | 123 |
61 | | 2.txt | 456 |
62 | | 3.txt | **789** |
63 |
64 | 比如用"rm"命令删除文件时,删除的只是原文件的路径和inode之间的关联,而不是这个inode本身,文件的内容依然存在于磁盘中,因而只能算是"unlink"。所以直接关联inode的hard link不受影响,而关联原文件路径的soft link此时相当于是一个dangling reference
65 |
66 | 注意:硬链接不能link目录,软链接可以。
67 |
68 | 7. 不要混用buffer I/O和 direct I/O,比如进程A用buffer IO 读取文件,会有page cache,从而接着不用进行磁盘的IO;但是进程B通过direct IO修改了磁盘上的文件,会导致进程A仍需要进行磁盘的IO。
69 |
70 | 8. buffer IO 从磁盘中读取到缓冲区,会将对应的page标记为dirty;每次做这个操作时,会检查系统的脏页数量是否过多,如果超出阈值,会执行balance_dirty_page的操作,此时原本异步的IO也会变成同步的。
71 |
72 | 9. Block层
73 |
74 | - BIO: 包含了 数据在磁盘上的位置 以及 在内存上的位置信息
75 | - Request
76 | - cmd
77 |
78 | 10. IO调度器
79 |
80 | 11. 三种队列类型
81 |
82 | 1. blk-sq(以前磁盘速度慢,瓶颈在磁盘上)
83 | 2. blk-mq:支持随CPU核数的线性扩展
84 | 3. raw
85 |
86 | 12. 工具:
87 |
88 | - perf stat
89 | - BPF tool(效率高)
90 | - iostat
91 | - blktrace
92 |
93 |
--------------------------------------------------------------------------------
/17 parallel join/17-sort-merge-join.md:
--------------------------------------------------------------------------------
1 | 1. SIMD(Single Instruction, Multiple Data): 单指令多数据流(一条指令操作多个数据)
2 |
3 | - 是一种指令集,允许CPU同时在多个数据上进行操作
4 |
5 | - 帮助CPU实现数据并行,提高运算效率
6 |
7 | - 以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。
8 |
9 | - 而在SIMD型的CPU中,指令译码后几个执行部件**同时访问内存**,**一次性获得所有操作数进行运算**。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。
10 |
11 | - 例如:
12 |
13 | ```
14 | X := {8,7,6,5,4,3,2,1}
15 | Y := {1,1,1,1,1,1,1,1}
16 | for i:=0; i500),但几乎不可能可以准确预测
12 |
13 | 3. 分支预测:对于下面这个SQL有两种代码实现
14 |
15 | ```
16 | SELECT * FROM table
17 | WHERE key >= $(low)
18 | AND key <= $(high)
19 | ```
20 |
21 | - 分支型:
22 |
23 | ```
24 | i = 0
25 | for t in table:
26 | key = t.key
27 | if (key>=low) && (key<=high):
28 | // 把符合条件的元组放在输出的数组中
29 | copy(t, output[i])
30 | i = i + 1
31 | ```
32 |
33 | - 非分支型:
34 |
35 | ```
36 | i = 0
37 | for t in table:
38 | // 不管符不符合条件
39 | // 先直接把元组放在输出的数组中
40 | copy(t, output[i])
41 | key = t.key
42 | // 这里原ppt的代码可能有误
43 | m = (key>=low && k<=high)? 1:0
44 | // 符合条件就向数组下个位置移动
45 | // 不符合不动,等待被覆盖
46 | i = i + m
47 | ```
48 |
49 | 经测试对比可发现,非分支型的所花费的平均CPU时钟周期比分支型**少**。
50 |
51 | 4. DBMS在对一个值进行操作前,需要检查其数据类型:通过很长的switch语句实现,也带来了更多难以预测的分支
52 | 5. **processing model**:决定了DBMS如何执行一个查询计划(对于不同类型有不同的trade-offs)
53 | - Iterator model: (又称为Pipeline model)
54 | - 每个查询操作符(如选择,连接,投影等)对应有一个**next()**方法
55 | - 每次调用时,返回**一个(single)元组**或空标记(null marker, 说明没有更多的了)
56 | - 查询操作符在一个for循环里,调用其子结点的next()方法,来其emit()的元组,然后对获取到的元组进行处理
57 | - 一些操作符(连接,子查询,order by)可能会**阻塞**直到子结点输出**所有的元组**
58 | - Materialization model:
59 | - 每个查询操作符**一次性**处理其输入,并**一次性**发送所有输出
60 | - 操作符将其输出作为一个结果**物化(materialize)**
61 | - DBMS会将一些hint下推/下移,避免扫描过多元组(比如有比较严格的选择时,优先执行)
62 | - 输出结果可以是 whole tuples(NSM) 或 subsets of columns(DSM)——参考([Flexible-Storage-Model](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/Flexible-Storage-Model.md))
63 | - 适合OLTP的工作(一次只会查询少量的元组,更少的函数调用),不适合OLAP查询(产生过大的中间表/中间结果)
64 | - Vectorized/Batch model:
65 | - 每个查询操作符对应有一个**next()**方法
66 | - 每次发送**一批(batch)元组**,而不是单个
67 | - 一批的大小可由硬件决定,或查询的性质决定
68 | - 适合OLAP查询(比起*Iterator*减少了每个操作符的函数调用 )
69 |
70 | 6. Plan Processing Direction:
71 | - 自顶向下:
72 | - 从根结点开始,从子结点拉取(pull)数据
73 | - 元组通过函数调用传递
74 | - 自底向上:
75 | - 从叶结点开始向父结点推送(push)数据
76 |
77 | 7. 查询内的并行:两种技术之间不互斥
78 | - 操作符内(Horizontal):比如一个选择操作符,可以根据数据的不同子集,分解(decompose)为多个独立的选择操作符,最后在通过**exchange**操作合并选择结果。
79 | - 操作符间(Vertical):在流式处理系统中更常见,又叫**流水线并行**(pipelined parallelism)
80 |
81 |
--------------------------------------------------------------------------------
/paper reading/crowdsource/Crowdsource data management.md:
--------------------------------------------------------------------------------
1 | ## Crowdsourced Data Management: A Survey
2 |
3 | 1. 众包数据管理主要问题:
4 |
5 | - **质量**quality
6 |
7 | 恶意worker给出错误答案、worker缺乏相关经验,会导致众包得到的结果包含很多噪声。可对worker进行建模,再通过以下方法来提高结果的质量:
8 |
9 | - worker elimination:消除低质量的worker
10 | - answer aggregation:将同一个任务分配给多个worker再聚合他们的答案
11 | - task assignment:将任务分配给合适的worker
12 |
13 | - **开销**cost
14 |
15 | 把整个任务直接全交给人力来做,很贵。有以下方法来控制开销:
16 |
17 | - 剪枝:可参考[Crowdsourcing Entity Resolution](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper reading/crowdsource/CrowdER.md)中提出的人机混合的c处理方式
18 |
19 | - 任务选择:为众包任务划分优先顺序
20 |
21 | - 答案推断:只把原任务的子集众包出去,根据收集到的大男来推断其他任务的答案
22 |
23 | - 根据特定的operator(众包操作)来设计开销控制
24 |
25 | **operator**:如[sort和join](https://arxiv.xilesou.top/pdf/1109.6881.pdf)。其中,sort用于如用户对产品的打分、评价、投票等,join用于两个数据集的整合和去重,如entity resolution。
26 |
27 | sort的实现:1. **Comparison-based**;2. **Rating-based**;3. **Hybrid Algorithm**,先使用基于评分机制的sort并生成一个列表L,再使用基于比较机制来迭代地修正L大小为S的子集,其中迭代数决定了最终答案的准确率。选取子集有三个方法——随机法、置信度法、滑动窗口法。
28 |
29 | join的实现:设两张表分别为***R***和***S***。1. **Simple Join**,worker直接判断两个元组是否满足谓词条件,总HIT任务量为|***R***|\*|***S***|;2. **Naive Batching**,worker一次性选出多对元组是否满足,总HIT任务量为|***R***|\*|***S***|/b,b为一批次的大小; 3. **Smart Batching**,分为两列,一列来自表***R***,一列来自表***S***,让worker去进行连线匹配,总HIT任务量为|***R***|\*|***S***|/(r*s),r和s分别为两列的选项数。(看实际例子理解比较容易)
30 |
31 | 
32 |
33 |
34 |
35 | - **等待时间**latency:
36 |
37 | 可能会花费很长时间。策略如下:
38 |
39 | - 用更高的价格去雇佣
40 |
41 | - latency modeling:1. 轮次模型:任务分多轮发布,每一轮的时间可视作常数;整体等待时间可用任务的轮数来描述。2. 统计模型:从先前的众包任务来建立统计模型,再来预测下次整体等待时间。
42 |
43 | - Budget Allocation Strategy:采用基于动态规划的预算分配算法(多项式时间复杂度),来最小化latency。之前的研究通常关注cost和accuracy,要么是 在给定最大的问题数下 使准确率最大化、要么是 在给定的准确率阈值下 使问题数最小化。而 *An Optimal-Latency Budget Allocation Strategy for Crowdsourced MAXIMUM Operations* 中关注latency的指标。
44 |
45 | 通过竞赛图tournament graph(通过在无向完全图中为每个边分配方向而获得的有向图)定义了MinLatency Problem。事实上,只需要是完全图,不需要有向性。
46 |
47 | 设图G(ci−1 , ci): 由ci−1个顶点形成的、有ci个团(clique,满足两两之间有边连接的顶点的集合)的图。
48 |
49 | 
50 |
51 | 每一轮的winner会进入下一轮(一个tournament只会有一个winner)。其中,winner可由reliable worker layer (RWL) 的算法决定,用以消除人为的误差或主观性,如[Dynamic max discovery with the crowd](http://ilpubs.stanford.edu:8090/1032/2/winner-long.pdf)提出的。
52 |
53 | - 其他
54 |
55 | - **任务设计**Task Design:包括任务类型(单选/多选/评分/聚类/打标签)、任务设置(定价格/时间约束/质量控制)。
56 | - **特定操作**specialized operators:每种operator可对应一种或多种任务类型。比如Filtering、Find等对应单选,CrowdMiner对应标签。
57 |
58 |
59 |
60 |
--------------------------------------------------------------------------------
/paper reading/crowdsource/Crowd-Based Selections and Joins.md:
--------------------------------------------------------------------------------
1 | ## Optimizing Queries with Crowd-Based Selections and Joins
2 |
3 | 1. **问题**:(现有系统,如CrowdDB/ Qurk/ Deco)
4 | - 树形模型只能提供表级连接 粗粒度的优化,限制了不同join的元组能有有不同的join次序。
5 | - 主要关注经济上的开销,忽略了lower latency 和higher quality的优化目标(见 [Crowdsourced Data Management)](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/crowdsource/Crowdsource%20data%20management.md)
6 |
7 | 2. **Contribution**:
8 |
9 | - **采用基于图的查询模型,提供更细粒度的查询优化**
10 |
11 | 在SQL中加入众包操作,提出CQL。请求发起者requester 可以使用CQL DDL来让crowd填写或收集需要的数据,使用CQL DML对数据进行众包操作(如crowdsourced selection/ join)
12 |
13 | 根据给出的CQL查询,可以构建一个图模型,其顶点为表中的一个元组、每条边根据join/ selection的谓词来连接两个顶点;从而提供元组级的查询优化
14 |
15 | - **基于图模型 使用统一的框架来进行多目标的最优化**
16 |
17 | 1. 使用图模型来描述task selection问题(证为NP-hard),提出xx算法来**减少cost**
18 | 2. 在一轮中,尽量同时问 不能被其他答案推出的 问题,从而减少轮数,**减少了latency**(但是 cost 和 latency 之间有tradeoff)
19 | 3. 提出一个适合不同类型任务的 task assignment 和 truth inference的框架,**提高quality**
20 |
21 | 3. **Conclusion**: 通过模拟与现实实验,证明了CDB众包数据库系统在cost/ latency/ quality 上的优越性。
22 |
23 | 4. **细节**:
24 |
25 | - **FILL**和**COLLECT**的数据清洗:
26 |
27 | 首先为用户提供自动补全功能,以减少同一个实体不同的说法;接着使用crowdsourced entity resolution (详见[CrowdER](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/crowdsource/CrowdER.md))。
28 |
29 | - **Join**的图模型:
30 |
31 | 每条边的权重是 两个元组tx和ty分别的两个属性tx[Ci]和ty[Cj]匹配的概率。比如使用Jaccard相似度,两个属性值的相似度越大;相似度即为边的权值,如果 权值*w(e)*<阈值*ε*,则去除该条边(匹配的可能性很小)。
32 |
33 | 为方便计算,假设边的权重(即匹配概率)是独立的。设有*N*个连接谓词的CQL query对应模型图*G*,若*G*中有*N*条边的连通子图包含query谓词的每一条边,则该子图称为一个**Candidate**. (必须要准确有*N*条边,不能多不能少)。
34 |
35 | 如果一条边不在任何Candidate中,则称该条边是无效的。可以使用深度优先遍历 来检查某条边是否在一个candidate中。所有无效的边可以从图中被去除。
36 |
37 | 接着让crowd来决定每条边是否符合对应的谓词,如果符合,将该条边标蓝;如果不符合,则标红。最后,有*N*条蓝边的Candidate就是答案。(不需要把所有边问出来,有可能一条边标红,与之相关的几条也会断掉)
38 |
39 | - **Cost Control**: 通过task selection实现
40 | - 已知边的颜色
41 | - Chain Join: 每张表最多和两张表相连接,且不形成环路
42 |
43 | 使用深度优先算法找到有N条蓝色边的链BLUE Chain,这些边必须作为问题给crowd。
44 |
45 | 再通过最小割 min-cut算法,找到必须作为问题的红色边,从而其它的红色边 可以被剪枝。
46 |
47 | - Star Join: 一张中心表与其他所有表连接
48 |
49 | - Tree Join: 无环路,可转换为Chain Join
50 |
51 | - Graph Join: 有环路,可转换为Tree Join
52 |
53 | - 未知边的颜色
54 |
55 | 使用贪婪算法来找到 覆盖S个样本的最少边数(NP-hard问题),需要生成很多样本,代价很高 =》基于期望的方法,若剪去一条边会造成其他的边invalid,则该边的 剪枝期望 pruning expectation为 (1-*w(e)*) * 造成invalid边的数目。最后可得到总的每条边的剪枝期望,从大到小排列 即可。
56 |
57 | - 给定预算
58 |
59 | 5. **Future Work**:
60 |
61 | - Join时的匹配概率 不是独立分布的(可能有正相关或负相关等关系)
62 |
63 |
64 |
65 |
--------------------------------------------------------------------------------
/paper reading/cloud/云计算概念技术与架构.md:
--------------------------------------------------------------------------------
1 | ## 云计算
2 |
3 | > 云计算 概念、技术与架构
4 |
5 | 1. 云能够提供的收益
6 |
7 | - 降低投资、开销成比例:减少或彻底消除前期IT投资,包括软硬件的采购与运维成本;可以使用 **可测得的运营支出 来代替 预期资本投入**。
8 | - 用户的可测收益:
9 |
10 | - 短期按需访问的计算资源
11 | - 感觉上可拥有无限的计算资源
12 | - 可以方便地在细粒度上调整IT资源,比如磁盘增10G或减10G
13 | - 基础设施抽象化,可以方便地迁移
14 |
15 | - 提高的**可用性和可靠性**:与企业的自身利益直接相关,可参考云提供商的SLA保证条款
16 |
17 | 2. 云交付模型
18 |
19 | - IaaS
20 |
21 | 一个典型的IaaS环境中的主要IT资源就是虚拟服务器,其租用通常是指定硬件需求:处理器能力、内存大小、存储空间。
22 |
23 | 用户需要:**配置环境**、**开发自己的应用程序**
24 |
25 | - PaaS
26 |
27 | 一般是已经部署好或配置好的IT资源。
28 |
29 | 用户需要:**开发部分或全部自己的应用程序**
30 |
31 | - SaaS
32 |
33 | 直接把软件程序定义为云服务。
34 |
35 | > 订阅者无需购买硬件和中间件,无需实施、维护、更新、运维和管理成本,连接网络即可使用,决策和投入成本降到最低。由此SaaS 软件更容易拥有大量客户,形成规模。
36 |
37 |
38 |
39 | - 基于三种基本模型的变种
40 |
41 | - 存储即服务
42 | - 数据库即服务
43 | - 安全即服务
44 | - 通信即服务
45 | - ......
46 |
47 | 3. 云部署模型
48 |
49 | - 公有云
50 |
51 | 由第三方云提供者拥有的 可公共访问的云环境。
52 |
53 | - 社区云
54 |
55 | 只能由特定的云用户社区访问。具备**业务相关性或者隶属关系的单位组织**建设社区云的可能性更大一些,因为一方面能降低各自的费用,另一方面能共享信息。
56 |
57 | 实际的应用比如:由卫生部牵头,联合各家医院组建区域医疗社区云,各家医院通过社区云共享病例和各种检测化验数据,这能极大地降低患者的就医费用。
58 |
59 | - 私有云
60 |
61 | 由一家组织单独拥有的。注意云端的实际部署有两种情况:一是部署在单位内部(如机房),称为**本地私有云**;二是托管在别处(如阿里云端),称为**托管私有云**(又叫 hosted cloud 或 dedicated cloud)。
62 |
63 | 托管私有云是把云端托管在第三方机房或者其他云端,计算设备可以自己购买,也可以租用第三方云端的计算资源,消费者所在的企业一般**通过专线与托管的云端建立连接**,或者利用叠加网络技术在因特网上建立安全通道(VPN),以便降低专线费用。(http://c.biancheng.net/view/3795.html)
64 |
65 | 实际的应用比如:企业私有办公云,用云终端替换传统的办公计算机,程序和数据全部放在云端,并为每个员工创建一个登录云端的账号。
66 |
67 | - 混合云
68 |
69 | 由多个云部署模型组成的云环境。比如用户把 处理敏感数据的服务部署在私有云,其他服务部署在公有云(之间的网络连接为 公共云提供商提供的高速专线,或者是第三方的 VPN)。企业部署混合云的步骤一般是先“私”后“公”。
70 |
71 | 4. 虚拟化技术
72 |
73 | 物理IT资源 转换为 虚拟IT资源:
74 |
75 | - 物理服务器 -> 虚拟服务器
76 | - 物理存储设备 -> 虚拟存储设备 、 虚拟磁盘
77 | - 物理路由器、交换机 -> 虚拟网络
78 | - 物理电源UPS、电源分配单元 -> 虚拟UPS
79 |
80 | **服务器整合** server consolidation:通过虚拟化技术 允许不同的虚拟服务器共享同一个物理服务器,从而可以提高 **硬件利用率**、负载均衡、**可用IT资源**的优化。
81 |
82 | **资源复制**:创建虚拟服务器的本质就是 生成虚拟磁盘镜像,即磁盘内容的二进制副本;可以方便实现虚拟服务器的复制、迁移、备份。
83 |
84 | 两种虚拟化:
85 |
86 | - 基于操作系统的虚拟化:虚拟化软件装在宿主操作系统之上。
87 | - 基于硬件的虚拟化:虚拟化软件装在物理主机硬件之上。
88 |
89 | 5. 云存储
90 |
91 | 常见数据存储逻辑单元:
92 |
93 | - 文件:分组存放于文件夹中的文件;如iSCSI
94 | - 块:最低等级、最接近硬件,可被独立访问的最小单位;如NFS
95 | - 数据集:基于表形式的;如DMBS的api
96 | - 对象:数据以及其元信息;如基于HTTP的CRUD
97 |
98 | 6.
99 |
100 | 7. 基本架构
101 |
102 | - 负载分布
103 | - 资源池
104 | - 动态可扩展
105 | - 弹性资源容量
106 | - 服务负载均衡
107 | - 云爆发
108 | - 弹性磁盘供给
109 | - 冗余存储
110 |
111 | 8. 高级架构
112 |
113 | - 虚拟机监控器集群
114 | - 负载均衡的虚拟服务器实例
115 | - 不中断服务重定位
116 | - 零宕机
117 | - 云负载
118 | - 资源预留
119 | - 动态故障检测与恢复
120 | - 裸机供给
121 | - 快速供给存储负载管理
122 |
123 | 9. 服务质量指标
--------------------------------------------------------------------------------
/paper reading/dbms/SQL Query over Mulit Engine.md:
--------------------------------------------------------------------------------
1 | ## MuSQLE: Distributed SQL Query Execution Over Multiple Engine Environments
2 |
3 | 1. **问题**:过多的框架技术 带来了系统的 **异构性** 与 **复杂性**,所以多引擎的分析 在学术界和工业界都变得越来越重要,即数据存在于多个完全独立的引擎上,需要结合在一起做复杂的分析查询。
4 |
5 | 目前的解决方案是 通过以中间件为中心来 优化多引擎的查询,但是需要 **手动地把每个基础引擎的算子、代价模型 给整合起来**。
6 |
7 | 2. **Contribution**
8 |
9 | - 提出了一个通用的SQL引擎API,可以用于多引擎查询优化
10 | - 将API整合到 基于代价的多引擎查询优化器中。优化器运行在逻辑层,物理层优化与join的执行 由引擎自身决定。
11 | - 系统整合了三大引擎:SparkSQL, PostgreSQL, MemSQL。
12 |
13 | 3. **相关工作**
14 |
15 | - SparkSQL
16 |
17 | - PrestoDB
18 |
19 | - Apache Drill
20 |
21 | 支持基于SQL的无结构数据存储 查询。不使用独立的代价模型、统计数据,避免 在本地执行更快的情况下,仍然执行多个子查询。
22 |
23 | - BigDAWG
24 |
25 | 提出 islands of information,每个岛对应一个数据模型、查询语言、数据管理系统。每个查询通过 Single-Island 或 Multi-Island Planning进行优化。
26 |
27 | - CloudMdsQL
28 |
29 | 提供函数式的类SQL语言,可以使用单独一个query来查询异构的数据存储。重点关注每个数据存储的本地查询语言和引擎的用法。
30 |
31 | - QUEPA
32 |
33 | 提出了 Augmented search 和 Augmented exploration两种新的查询方法。
34 |
35 | - SQL++
36 | - MISO
37 |
38 | 4. 架构
39 |
40 | 
41 |
42 | 右上角的*Metastore* 负责存储每张表的schema以及位置。*SQL Parser*模块 与*Metastore*进行交互来验证用户查询的有效性 并 创建query graph。
43 |
44 | *Multi-engine Optimizer*接收query graph,找到最优的执行计划(考虑因素包括:算子的顺序、查询子图的引擎选择、中间结果的移动),其输出的 执行计划 即为一棵 由SQL与move operator(负责不同引擎中间结果的传输) 组成的树。
45 |
46 | Engine API则使得优化器能够真正地与不同的引擎进行交互。
47 |
48 | 5. **Engine API**
49 |
50 | 分为两类
51 |
52 | - **Execution**
53 |
54 | 有以下函数
55 |
56 | 1. 发送一个SQL查询到指定的引擎(扩展JDBC 和 ODBC),查询结果放在Spark DataFrame中,可以传输到到其它引擎。
57 | 2.
58 |
59 | - **Estimation**
60 |
61 | 有以下函数
62 |
63 | 1. 类似于EXPLAIN语句,获取到 执行时间估计、结果表的统计信息。大部分引擎会返回 **执行计划**、**结果行数**、**执行开销(磁盘与CPU)**。
64 | 2. 获取将Spark DataFrame装载到引擎的估计时间,约等于 表大小*引擎传输速率
65 | 3. 将表与统计信息 相关联(当SQL查询需要用到中间结果,但是对应引擎没有执行的统计信息)
66 |
67 |
68 | 6. 查询优化
69 |
70 | DPccp、DPhyp(参考 G. Moerkotte and T. Neumann, “Dynamic programming strikes back,” in SIGMOD, 2008.),通过自底向上连接 查询子图 来减少搜索空间(每张表用顶点表示,边来记录join条件)
71 |
72 | > **csg-cmp-pair **(connected subgraph-connected complement subgraph)
73 | >
74 | > 设G=(V, E)为join graph,S1、S2为V的两个无交集的子集(且均连通)。如果存在边(u, v)∈E,使得u∈S1,v∈S2,则(S1, S2)为 **csg-cmp-pair**。
75 |
76 | 每个csg-cmp对 代表了 csg与cmp的 join操作。
77 |
78 | 论文拓展了DPhyp算法,来找到多引擎查询的最优join顺序。
79 |
80 | 7. Cost model
81 |
82 | | 描述 |
83 | | ---------------------------------- |
84 | | 读取一行数据的开销 |
85 | | 写入一行数据的开销 |
86 | | 做一次hash的开销 |
87 | | 广播发送一行数据的开销 |
88 | | 一次CPU比较的开销 |
89 | | 集群的核心数(决定了并行的任务数) |
90 | | 表的partition数 |
91 | | 表的行数 |
92 | | Spark的shuffle partition数 |
93 |
94 |
--------------------------------------------------------------------------------
/paper reading/robust query/Flow-join.md:
--------------------------------------------------------------------------------
1 | ## Flow-join: Adaptive skew handling for distributed joins over high-speed networks
2 |
3 | 1. 问题:分布式join的scalability会受到数据倾斜(skew)的影响,即某单台服务器节点上会处理大部分的输入,导致整个分布式查询变慢
4 |
5 | 2. **Contribution**:
6 | - 在对输入partition的同时,检测heavy hitter,只需要很小的开销
7 | - 可以在运行时调整redistribution策略 , 从而能适用于heavy hitter的key子集;通过广播对应的元组,避免heavy hitter集中在一台服务器上
8 | - 基于以上两种机制,提出Flow-Join,利用RDMA来shuffle数据;同时区分开本地与分布式的并行度,
9 | - 使用 Symmetric Fragment Replicate的redistribution策略,来应对两个输入端相互关联的数据偏度
10 |
11 | 3. 存在问题示例:
12 |
13 | 
14 |
15 | 4. Heavy Hitter检测算法:
16 |
17 | 基于*Efficient computation of frequent and top-k elements in data streams* *(2019)* 的SpaceSaving algorithm,该算法不能保证其找到的元组都是频繁项,但是多广播一些元组不会对性能有很大问题。
18 |
19 | 
20 |
21 | 5. Join流程:假设*R*作为build端输入,*S*作为probe端输入。传统上来说,通常是小的表作为build端,从而哈希表占用空间会小一点。
22 |
23 | 1. Exchange *R*
24 |
25 | 对于*R*中每个元组
26 |
27 | - 更新近似直方图
28 | - 根据阈值判断heavy hitter:如果是,则将该元组插入到local哈希表中;若不是,则将该元组发送到对应的节点
29 | - 创建*R*的全局heavy hitter list
30 |
31 | 2. Exchange *S*
32 |
33 | 对于*S*中每个元组
34 |
35 | - 更新近似直方图
36 | - 根据阈值判断heavy hitter:
37 | - 如果是在*S*中的倾斜,对该元组进行物化
38 | - 如果是在*R*中的倾斜而不是*S*中的,广播该*S*的元组到所有节点
39 | - 都不是,则将该元组发送到对应的节点
40 | - 创建*S*的全局heavy hitter list
41 |
42 | 3. Handle skew (当*S*中存在倾斜才需要)
43 |
44 | 1. 对*R*中不是heavy hitter,但需要和*S*的heavy hitter做join 的元组进行广播(与物化后的*S*的元组做join)
45 | 2. 通过**Symmetric Fragment Replicate**的重分布策略,对join key既是R heavy hitter、也是S heavy hitter的元组进行redistribute
46 |
47 | 6. **Symmetric Fragment Replicate**
48 |
49 | 原于论文 *A symmetric fragment and replicate algorithm for distributed joins 1993.*
50 |
51 | 
52 |
53 | Servers replicate heavy hitters for one input across rows, while those of the other input are replicated across columns. 保证一端输出的每个heavy hitter元组 和 另一个输出端的heavy hitter元组 能进行join。
54 |
55 | 7. 相关工作的对比
56 |
57 | - *Practical skew handling in parallel joins 1992.*
58 |
59 | 最早提出 对于 heavy hitter的join对象进行replication,不过这里的partition是基于range的。
60 |
61 | - *Handling data skew in parallel joins in shared-nothing systems 2008.*
62 |
63 | 将上述思想应用于hash的partition,需要详细的数据统计信息,来提前知道倾斜的数据值(非运行时),可能会有很大误差。
64 |
65 | - *Tuple routing strategies for distributed eddies 2003.*
66 |
67 | 核心思想: routes tuples between operators,从而解决operator的压力不均衡;但是不能解决数据倾斜的问题,比如一个很大的partition里可能全是同一个heavy hitter 的值
68 |
69 | - Track join: Distributed joins with minimal network traffic
70 |
71 | 引入track阶段,来决定每个join的值应该路由到哪里,做到最小的网络流量;但是track阶段本身是一个独立的分布式join,对数据倾斜同样敏感
72 |
73 | - *Frequent item computation on a chip 2011*
74 |
75 | 利用了FPGA,在硬件中计算频繁项;对本文算法的性能有很大提升,
76 |
77 |
--------------------------------------------------------------------------------
/12 logging/12-logging-notes.md:
--------------------------------------------------------------------------------
1 | ## Logging
2 |
3 | 1. Recovery => 在failure下保证了
4 |
5 | - **数据库的一致性**consistency:数据库从一个一致性状态变到另一个一致性状态。
6 |
7 | 注意以下几个一致性的含义区别
8 |
9 | 1. 多副本的一致性:分布式系统中,在多副本的情况下,如何保证各个副本间数据的一致性。
10 |
11 | 2. 一致性hash:普通的负载均衡的hash算法 是对服务器的数量进行取模,但这样当缓存服务器数量发生变化时,几乎所有缓存的位置都会发生改变,怎样才能尽量减少受影响的缓存?
12 |
13 | 使用一致性哈希算法时,服务器的数量如果发生改变,并不是所有缓存都会失效,而是只有部分缓存会失效,前端的缓存仍然能分担整个系统的压力,而不至于所有压力都在同一时间集中到后端服务器上。
14 |
15 | 3. CAP理论的一致性:在分布式系统中的所有数据备份,在同一时刻是否同样的值。
16 |
17 | 4. ACID里的一致性:a transaction can only bring the database from one valid state to another, maintaining database invariants: any data written to the database must be valid according to all **defined rules**, including *constraints, cascades, triggers*
18 |
19 | - **事务的原子性**atomicity:Series of database operations in an atomic transaction will either all occur (a successful operation), or none will occur (an unsuccessful operation). 要么完成,要么都不完成
20 |
21 | - **事务的持久性**durability:对数据的修改就是永久的,即便系统故障也不会丢失。
22 |
23 | 2. Recovery算法分为两部分
24 |
25 | - 在事务处理过程中,保证DBMS能从宕机后恢复的措施。
26 | - 在宕机后,使数据库恢复到ACD状态的措施。
27 |
28 | 3. 日志分为两种:
29 |
30 | - **物理日志**:记录数据库中某条record的变化(如 存储 属性变化前后的值)——支持所有并发控制方案
31 | - **逻辑日志**:记录事务执行的高层操作(如 UPDATE, DELETE, INSERT)——更快但不通用
32 |
33 | -----
34 |
35 | 逻辑日志 向每条日志record写的数据 比物理日志少。但是当有并发事务时,通过逻辑日记来恢复很难,因为 1. 难以确定宕机前 数据库哪一部分被修改;2. 耗时长,因为需要(根据逻辑日志)重新执行每一个事务
36 |
37 | 4. **面向磁盘的日志&恢复**disk oriented:
38 |
39 | 标准——Algorithms for Recovery and Isolation Exploiting Semantic 基于语义的恢复与隔离算法,[ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks](https://blog.acolyer.org/2016/01/08/aries/)
40 |
41 | - **Write-Ahead Logging** (WAL 预写日志):在数据写入到(磁盘上的)数据库之前,先写入到在稳定存储介质上的日志(即非内存)。每条日志记录(log record)对应一个唯一的标志(Logging Sequence Number,LSN 日志序列号)。DBMS通过 存储在内存(如缓冲池)和外存的 LSN 决定 系统中几乎所有东西的 **顺序**。
42 | - Repeating History During **Redo**:重启时,把数据库恢复到崩溃前的一个状态。
43 | - Logging Changes During **Undo**:在日志中记录undo撤销动作
44 |
45 | 5. **恢复三阶段**:
46 | 1. **Analysis**:读取WAL来确定 停机时 缓冲池中的脏页 和 进行中的事务。
47 | 2. **Redo**:从日志中一个合适的起点开始,重复所有的动作。同时把redo的每一步记录到日志中,以防恢复时再次崩溃。
48 | 3. **Undo**:回滚在停机前 未提交事务的动作。
49 |
50 | 6. 事务中最慢的一步 通常是 等待DBMS把log record刷到磁盘上。要么是一个timeout到了,要么是缓冲池满了,就进行一次flush。可参考 [InnoDB](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/innoDb.md)的笔记。
51 |
52 | 7. [内存数据库](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/02%20in-memory%20db/2-imdb-notes.md)的recovery相对简单,因为不用考虑脏页问题,不需要存储undo记录。VoltDB是一种面向内存的DBMS,不包含传统的面向磁盘的DBMS组件,如缓冲池等。
53 |
54 | 8. Non-volatile memory(NVM,非易失存储器),读写性能接近DRAM、掉电可以保存数据。但现在DBMS架构在设计之初都是建立在易失性内存上的,也就是基于由易失性DRAM和非易失性HDD/[SSD](https://zhuanlan.zhihu.com/p/43362595)组成的双层存储架构。
55 |
56 | | | SSD | HDD |
57 | | ------------- |-------------| -----|
58 | | 容量 |较小 | 大 |
59 | | 价格 | 贵 | 便宜 |
60 | | 随机存取 | 极快 | 一般 |
61 | | 写入次数 | 有限制(每个NAND Block都有擦写次数的限制,当超过这个次数时,该Block可能就不能用了) | 无限制(机械硬盘的寿命按小时算) |
62 | | 磁盘阵列 | 可以 | 很难 |
63 | | 数据恢复 | 难 | 简单 |
64 |
65 |
--------------------------------------------------------------------------------
/paper reading/how-to-read-cs-paper.md:
--------------------------------------------------------------------------------
1 | ## [How to Read a CS Research Paper](https://people.cs.pitt.edu/~litman/courses/cs2710/papers/howtoreadacspaper.pdf)
2 |
3 | ### 论文介绍
4 |
5 | 1. CS论文可发表为
6 |
7 | - **technical reports**
8 | - **conference papers**
9 | - **journal papers**
10 | - **book chapters**
11 |
12 | 通常作者会将一篇会议论文的信息进行扩展,写成一篇技术报告。几篇会议论文的结果可以合并再扩展成一篇期刊论文。会议论文也可以被扩展,写成书的一个章节。
13 |
14 | 2. CS论文三种类型
15 |
16 | - theoretical
17 |
18 | 描述一个理论或算法,为某个假说提供数学证明。
19 |
20 | - engineering
21 |
22 | 介绍某种算法、系统或应用的实现。通常需要包括 对系统的评估。
23 |
24 | - empirical
25 |
26 | 描述验证某个假说的一个实验。
27 |
28 | 3. 好的论文应该有
29 | - 论文研究的问题陈述清晰,描述了其重要性 以及 更广泛的影响。
30 | - 对实验、系统或理论的清晰介绍
31 | - 对实验结果的详细描述与**分析**
32 | - 作者对 future work 有独到的见解
33 | - 描述了相关研究,以及正确的引用
34 |
35 | ------
36 |
37 | ### 如何读
38 |
39 | 1. 读 introduction,找到**问题陈述**、**理论重要性**、**广泛影响**。
40 | 2. 读 method (experiment/ system description),提问:
41 | - 对于文章中的例子 是否能给出反例?
42 | - 方法是否描述清楚了?能否总结方法的步骤?
43 | - work是否解决了问题?
44 | - 方法是否合理?
45 | - 方法是否客观?
46 |
47 | 3. 语言问题
48 |
49 | > Computer science papers are often written in English by non-native speakers of English. Syntactic errors or awkwardness of phrasing do not indicate that the research is bad; you should try distinguish between the writing style and the research itself.
50 |
51 | ----
52 |
53 | [Three-Pass Approach](https://web.stanford.edu/class/ee384m/Handouts/HowtoReadPaper.pdf)
54 |
55 | 1. **第一遍:**(5分钟)
56 |
57 | - 仔细读 title, abstract, and introduction
58 | - 只读每小节标题
59 | - 读conclusion
60 | - 浏览引用文献
61 |
62 | 回答5C:
63 |
64 | - **Category**:什么类型的文章?
65 | - **Context**:基于什么理论?
66 | - **Correctness**:是否成立?
67 | - **Contributions**:主要贡献是什么?
68 | - **Clarity**:写得好吗?
69 |
70 | 再决定是否要更深入阅读。
71 |
72 | 通常一篇文章 需要在第一遍阅读 就让读者把握大意,五分钟内知道亮度在哪。
73 |
74 | 2. **第二遍:**(1小时)
75 | - 仔细看图表
76 | - 标记没有读过的引用文献,用于更深入阅读
77 |
78 | 3. **第三遍:**(2-5小时)
79 | - 可以根据记忆重建文章结构
80 | - 知道该方法的优势和劣势
81 | - 指出文章中 隐含的假设、缺少对相关研究的引用
82 |
83 | ----
84 |
85 | ### 做文献综述 LITERATURE SURVEY
86 |
87 | 做文献综述可以检验阅读论文的水平。
88 |
89 | 1. 使用 [Google Scholar](http://scholar.hedasudi.com/) 或 [CiteSeer](https://citeseerx.ist.psu.edu/) 搜索3-5篇该领域**近期的**论文,运气好可以找到综述。
90 | 2. 在文献中,找到 共用的引用、重复出现的作者名;再根据这些信息 下载关键的论文。去作者官网看看最近的进展,同时也可以找到该领域的顶级会议top conferences。
91 | 3. 去这些顶级会议的网站,浏览最近的进展。
92 |
93 | ---
94 |
95 | ### 相关阅读
96 |
97 | [Writing reviews for systems conferences](http://people.inf.ethz.ch/troscoe/pubs/review-writing.pdf)
98 |
99 | [Whitesides’ Group: Writing a Paper](http://www.che.iitm.ac.in/misc/dd/writepaper.pdf)
100 |
101 | [Research Skills](http://research.microsoft.com/simonpj/Papers/givinga-talk/giving-a-talk.htm)
102 |
103 | -----
104 |
105 | ### 三大顶会
106 |
107 | 1. **[SIGMOD](http://www.sigmod.org/)**(Special Interest Group On Management Of Data)——美国计算机协会ACM
108 | 2. **[VLDB](http://www.vldb.org/)**(Very Large Data Base)——欧洲的数据库会议
109 | 3. **[ICDE](http://www.icde.org/)**(International Conference On Data Engineering)——IEEE的数据库会议
--------------------------------------------------------------------------------
/paper reading/dbms/postgres/选择率注入的实现.md:
--------------------------------------------------------------------------------
1 | ## 选择率注入的实现
2 |
3 | 选择率 即指谓词条件过滤之后保留的元组数占过滤之前元组数的比例。为了实现Worringer中Plan Diagram,我们需要对一条SQL查询语句中的谓词选择率进行注入(在`EXPLAIN`中),从而通过指定谓词条件的过滤程度 来查看最后执行计划的不同。
4 |
5 | PostgreSQL的选择率估计可以分为两类:
6 |
7 | - **restriction_selectivity**:主要是对于filter谓词,如`eqsel =` 、`neqsel <>`、`scalarltsel <`等
8 | - **join_selectivity**:主要是对于join谓词,如`eqjoinsel =` 、`neqjoinsel <>`、`scalarltjoinsel <`等
9 |
10 | 而实际计算选择率是通过`function manager`调用 在[`pg_proc`系统表](https://www.postgresql.org/docs/11/catalog-pg-proc.html)中注册的计算函数。但是如果你自己实现一个新的过滤谓词、但没有在pg_proc中注册对应存储过程的话,就无法通过`get_oprrest(operatorid)` 函数获取到 计算选择率的**存储过程的OID**(这里oprrest是operator restriction的缩写),当OID不存在时,返回的是默认选择率0.5。
11 |
12 | 那么首先如何实现一个选择率注入的操作符呢?这里分两种情况来讨论:
13 |
14 | 1. 对于filter谓词的注入,可以通过模拟来实现,比如对于表`t1`的数值类型字段`value`,我们是可以通过原生直方图的估计来实现的,当然前提是这个数据分布是比较好的(在我们的实验中,如TPC-H,`orders`表的`o_totalprice`字段、`partsupp`的`ps_supplycost`字段等的模拟选择率平均误差均在0.03%左右,事实上也证明了目前直方图估计在普通场景中,已经足够好了,就像[IS QUERY OPTIMIZATION A “SOLVED” PROBLEM](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/query/Is%20Query%20Optimization%20a%20solved%20problem.md)中所说的一样)。
15 |
16 | 而如果不存在直方图统计信息或想更加精确的话,则要修改Pg的parser与optimizer对选择率进行注入。对此,Worringer中的语法如下
17 |
18 | `EXPLAIN SELECT * FROM t1 JOIN t2 ON t1.id=t2.id WHERE t1.value~0.3` 事实上,这里的`value`字段本身以及约束条件是不重要的,所以即使`t1`上原本的SQL语句有两个约束条件,如:`SELECT * FROM t1 JOIN t2 ON t1.id=t2.id WHERE t1.value < ? and t1.value2 > ?`像这种条件如果不存在多列统计信息,优化器是会假设它们的选择率是相互独立的;不过如果我们关心的是这张表的选择率本身 对于最终优化得到的JOIN算法与顺序(比如可以运用在执行器的自适应执行框架中,参考[Plan Bouquets](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/robust%20query/Plan%20Bouquets.md)),那么通过注入的方式就是合适的,因为不需要实际执行,只需要考虑选择率的影响。
19 |
20 | 具体修改源码的流程可分为以下几步:
21 |
22 | 1. 修改`scan.l` 与 `gram.y`文件:这里的过程实际上是在`raw_parser(const chr *str)`函数中,会分别通过由**Lex**与**Yacc**生成的代码(`scan.c`和`gram.h`、`gram.c`) 来进行词法和语法分析,从而生成语法树。
23 |
24 | `scan.l`文件中主要是通过正则表达是来对输入的字符串进行模式匹配,生成token序列;而`gram.y`是通过token序列来匹配语法结构。(实际中词法基本是完善的,所以我们实现时,是先修改的语法规则,再看是否缺少词法规则)
25 |
26 | 2. 系统表的修改:这里的`~`可以理解为新实现的操作符,需要对[系统表pg_operator](http://www.postgres.org/docs/11/catalog-pg-operator.html)进行修改,其中重要的是`oprrest`字段的实现,由于该操作符不需要实际被执行,其他字段则需要符合语义即可。
27 |
28 | 系统表或系统视图这些元数据在pg中本质也是普通的表或视图,然而创建普通表/视图又需要对系统表进行对应的修改,所以最开始的系统表或系统视图 都是由`genbki.pl`脚本生成的`postgres.bki`文件来完成。BKI文件的全称是*backend interface*,在`initdb`的时候,它不需要走SQL的那套流程,而是以Bootstrap模式执行。
29 |
30 | 如果要直接修改系统表的话,注意不能直接修改`postgres.bki`文件,因为该文件是由对应的.h头文件与.dat数据文件 通过perl脚本生成的。所以我们需要对应修改的是`pg_proc.dat` 或 `pg_operator.dat`,修改后编译,再通过`initdb`来初始化数据库。
31 |
32 | 3. 实现injectsel的函数:由于function manager (`fmgr`)会通过oid找到在`selfuncs.c`中注册的函数来计算选择率,所以需要对应实现。当然实现很简单,将第二个操作数(即注入的选择率)包装成Datum类型返回出去即可。
33 |
34 | 2. 对于join谓词的注入,则无法通过模拟来完成,因为JOIN条件操作数都是变量,很难直接利用统计信息。不过还是一定程度可以利用统计信息,比如等值连接`eqjoinsel`,对JOIN两列的高频值单独统计比较,最终选择率估计分为四个部分计算:
35 |
36 | - NULL值比例
37 | - 高频值数组中匹配的比例
38 | - 高频值数组中不匹配的比例
39 | - 其他值
40 |
41 | 这里设计的注入语法是:`EXPLAIN SELECT * FROM t1 JOIN t2 ON t1.id=t2.id:0.03 JOIN t3 ON t1.id2=t3.id`,join的选择率是针对Cartesian product而言的,假设t1有100条元组,t2有200条元组,那么这里认为 注入`t1.id=t2.id`的join结果基数大小是600。
42 |
43 | 同理,修改对应的语法规则,不同的是,此处需要对`A_Expr`的数据结构进行修改,加入对选择率注入 的属性。
44 |
45 |
46 |
47 |
--------------------------------------------------------------------------------
/paper reading/query/How Good Are Query Optimizers.md:
--------------------------------------------------------------------------------
1 | ## How Good Are Query Optimizers, Really?
2 |
3 | 1. **问题**:
4 | - Cardinality estimator有多好?什么时候 估计偏差太大 会导致query变慢?
5 | - 一个准确的cost model 对于整个查询优化过程有多重要?
6 | - 枚举的plan space需要多大才行?
7 |
8 | 2. **Contribution**:
9 | - 设计了一个有挑战性的workload,Join Order Benchmark(JOB),由来自 IMDB的21个表组成,并提供了33个查询模板和113个查询。查询中的连接关系大小范围为 5到15个。
10 | - 第一个 使用真实的数据和查询 且end-to-end 的 join order问题研究。
11 | - 通过 量化 **cardinality estimation**, **cost model**, **plan enumeration algorithm** 对查询性能的贡献,为一个查询优化器的完整设计 提供guideline(可以避免许多糟糕设计)。
12 |
13 | 3. PostgreSQL:
14 |
15 | PostgreSQL的优化器 遵循教科书上的架构。
16 |
17 | - **Join order**通过动态规划来列举(包括bushy tree,但不包括cross product)
18 |
19 | - **Cost model**,由于PostgreSQL是面向磁盘的,其Cost model 结合考虑了CPU 和 I/O的代价,并赋予各自一定权重。而一个Operator的cost 则是 访问磁盘页面(包括顺序和随机)数量 和 在内存中处理数据量 的加权和。
20 |
21 | > PostgreSQL官方文档中——
22 | >
23 | > Unfortunately, there is no well-defined method for determining ideal values for the cost variables. They are best treated as averages over the entire mix of queries that a particular installation will receive. This means that changing them on the basis of just a few experiments is very risky.
24 |
25 | - 基表的**基数估计** 使用直方图(分位数统计),最常见的值以及它们的频率,还有domain的基数。每个属性的统计信息 都通过 *analyze*命令 使用关系的sample(参考 [Two-level Sampling](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/query/join%20size%20estimation.md))来计算。基数估计基于以下假设:
26 |
27 | - 一致性 uniformity: 除了最常出现的值,其他的值都认为出现次数相同
28 | - 独立性 independence: 在属性上会使用的谓词 是独立的
29 | - 容斥原理 principle of inclusion: join key的域会有重叠,从而更小的domain能在更大的domain中找到匹配
30 |
31 | 4. 实现细节:
32 |
33 | - When do bad estimates lead to slow queries?
34 |
35 | 查询优化 和数据库的物理设计 紧密联系:索引的类型和数量 严重影响了plan的搜索空间,从而影响了 系统对基数估计误差 cardinality misestimate 的敏感度。
36 |
37 | 在实验中,我们将 (有误差的)基数估计 注入到不同的数据库系统中,最后比较 有误差和无误差的基数估计 的执行时间。有很少数的query 在使用无误差的估计后 反而更慢了,这是因为 Cost model本身的误差。
38 |
39 | 观察那些没有在合理时间内执行完的query,它们通常都有共同问题:**当基数估计的非常小时**,PostgreSQL的优化器就会 采用 nested-loop join(因为PostgreSQL 完全基于cost来选择join算法,有可能计算出嵌套循环的cost更小,但这样风险很大 high-risk),然而实际的基数很大。
40 |
41 | 另外,当我们**加入其它索引** 如外键 在属性上时,查询优化问题 会变得更困难。当然并不是说 加入索引反而查得变慢了(偶尔会有这样的情况),整体性能一般都会显著增加,但是 **索引变多,access path就更复杂,优化器也更难优化**。
42 |
43 | - How important is an accurate cost model for the overall query optimization process?
44 |
45 | Cost model 为 从搜索空间中选择哪些plans 提供了指导。目前系统中的代价模型都很复杂,比如PostgreSQL中的代价模型 超过4000行的C代码,里面考虑到了各种因素,如:部分关联的索引访问、元组大小 等。
46 |
47 | 通过替换 PostgreSQL中的cost model来实验,比如替换的cost function为 简单地只考虑query会产生的元组数。实验证明,**cost model的差别造成的影响 远小于 基数估计误差的影响**。
48 |
49 | 实验中 提出了针对*main-memory*的代价函数,即 不考虑I/O,只考虑 每个operator会得到的元组数目。
50 |
51 | - How large does the enumerated plan space need to be?
52 |
53 | 即 plan enumeration algorithm,有 exhaustive的 也有 heuristic的;它们考虑的 候选计划 数量(即搜索空间大小)不同。
54 |
55 | 实验使用 一个独立的query optimizer,实现了 DP 以及一系列的启发式算法。实验证明,**基数估计误差 对性能的算法 大于 启发式**,bushy tree的穷举法 比起只对子搜索空间枚举法 对性能的帮助要大一点,但不显著。
56 |
57 | 5. **Future work**:
58 | - 更深入的实验,比如 研究复杂的access path 的tradeoff
59 | - 本文主要基于内存型的设定,可以研究磁盘型的,以及分布式的数据库
60 | - 对于多索引的环境,数据库系统可以结合 更多先进的估计算法(在文献中提及的),还可以增加 运行时与优化器的interaction
61 |
62 |
63 |
64 |
--------------------------------------------------------------------------------
/paper reading/query/Is Query Optimization a solved problem.md:
--------------------------------------------------------------------------------
1 | ## IS QUERY OPTIMIZATION A “SOLVED” PROBLEM?
2 |
3 | [原文链接](http://wp.sigmod.org/?p=1075)
4 |
5 | 首先,作者认为 查询优化的"万恶之源"在于 对中间结果大小的估计上(基数,cardinality)。通常来说,在给定的基数下,**代价模型**本身可能最多带来30%的误差;然而**基数估计**可以带来比这高几个数量级的误差。
6 |
7 | 尽管 学者们提出了很多改进的统计学方法(如 直方图等),并且也确实大大地提升了选择率的估计准确度,然而其他地方(如没办法用统计数据)带来的巨大误差 使得这些提升就没很大作用了。
8 |
9 | > 所以作者说 如果审文章时看到 对于谓词直方图的改进,很可能直接把它拒了:sweat_smile:,因为现有在这方面的技术已经足够了。
10 |
11 | 基数估计的误差究竟主要在哪?
12 |
13 | - Host variable / parameter marker,也就是Prepared statement里面的占位符参数(参考[DB2的优化器](https://www.ibm.com/developerworks/data/library/techarticle/dm-0606fechner/index.html)):由于Prepared statement可能会在不知道参数值的情况进行预编译(通常用平均值来估计),所以会带来很大误差
14 |
15 | > `PreparedStatement` is a sub-interface of `Statement` and allows the usage of **parameter markers** (= placeholders; in other programming languages such placeholders are called **host variables**) -- in contrast to `Statement`. In the case of a `PreparedStatement`, the SQL statement to execute -- parameter markers included -- is first compiled, then values are bound to the parameter markers, and finally the SQL statement is executed
16 |
17 | 在这个问题上,主要有PQO(Parametric Query Optimization)问题的探讨。
18 |
19 | - Join谓词的选择率
20 |
21 | 目前在join选择率估计上的创新工作很少,大部分仍然使用两个join列最大基数的倒数作为选择率(System R开创的),也就是 假设一个较小列的域 是较大列的子集(不过这对于有外键约束的列确实成立,但一般情况下 **join的交集很大程度 随join语义本身的不同 而变化**)。
22 |
23 | 又比如对于非等值条件的join(A JOIN B on A.a < B.b),选择率的估计可能也无从下手,比如在pg中这种情况就直接使用了 DEFAULT_INEQ_SEL作为默认选择率。
24 |
25 | - 把各种选择率结合起来 计算最后基数的过程
26 |
27 | 当谓词包含了多个列的filter时,就需要考虑列与列之间的相关联程度。然而很多优化器会假设多个filter之间是相互独立的,也就是 最终选择率 等于 多个filter选择率的积。作者对这个假设的评价是:大部分时候成立,偶尔不成立。在错误的时候,肯定会发生基数的低估(under-estimation),这一般比高估更严重,因为会导致优化器选择一些基数较少时的特定操作,而实际运行时却发现性能退化很大。
28 |
29 | 所以后来很多数据库系统支持 多列统计信息 ***column group statistics***。比如在pg中,有着两种类型的[统计数据](http://www.postgres.cn/docs/12/view-pg-stats-ext.html):
30 |
31 | - STATS_EXT_NDISTINCT:也就是N列组合起来后 去除重复行的元组数(而普通单列的distinct统计是 除去NULL值后的去重行数)。在源代码中可以看到,会遍历每一种情况并生成对应统计信息。官方文档则指出,如果该值大于零,则为组合中不同值的估计数量;如果小于零,则为不同值数量的负数除以行数。
32 | - STATS_EXT_DEPENDENCIES:函数依赖度。Functional dependency的正式定义是 如果属性A的每一个值 在属性B上有且仅有一个与之对应的值,则称 **属性B函数依赖于A,而属性A函数决定了B**,写做 A → B。不过pg中记录的是一种 函数依赖度,定义为——两个属性之间满足函数依赖的值 所占总行数的比例。通过这个统计值,可以减少依赖列之间 原本由独立性假设带来的估计误差。
33 |
34 | 事实上,对于多列的组合查询,pg还有 [Bloom](https://github.com/digoal/blog/blob/master/201605/20160523_01.md)、[GIN](https://github.com/digoal/blog/blob/master/201702/20170205_01.md)等[多列索引](https://www.postgresql.org/docs/current/indexes-multicolumn.html)。
35 |
36 | 相对应的,学术界也提出了不同的方法来识别schema中 列组合的关联。比如
37 |
38 | - *CORDS: Automatic Discovery of Correlations and Soft Functional Dependencies (2004)*,在查询执行前,会先从数据中进行采样,然后搜索任意两列的关联性。
39 | - *Consistent selectivity estimation via maximum entropy (2007)*,其认为*CORDS*只考虑了列与列两两之间的关联(一定程度上也减小了算法的复杂度),而没有三列、四列等作为整体之间的关联。其提出的方案是——使用CORDS的输出作为 应该维护联合统计信息的 *column groups*,从而优化器利用 *column groups*的统计信息 来避免由于独立性假设带来的误差;然后通过查询的feedback机制,来校正错误的选择性估计。
40 |
41 | 作者还提出了 **冗余谓词**的问题,很多开发人员在编写查询时会认为 提供更多的谓词 可以让DBMS更好地完成任务,为了证明这一点,给出了下面这个例子:
42 |
43 | > 一个开发人员问他:这两个查询只在一个谓词上有所不同,然而原始查询在几秒钟内运行,而带有额外谓词的查询则耗时一个多小时,这是啥情况。
44 | >
45 | > 于是作者首先检查了两个结果的基数估计值,发现 慢的那个查询基数估计值比快的估计值小7了个数量级。当被问到附加谓词在哪一列时,开发人员解释说,这是一个复合键,由投保人姓氏的前四个字母、第一个和中间的首字母、邮政编码和他/她的社保号码的最后四个数字组成,但**原始查询已经在上述这些列都有谓词了**!所以这个多余的谓词条件 带来了 1/107的选择率低估(原表共107行)。
46 | >
47 | > 尽管添加谓词在执行时可能是有利的(有索引的话),但它可能直接让 不能检测到谓词冗余的优化器失去了作用。
48 |
49 | 综上,作者的呼吁是—— 研究优化器的学者应该关心解决真正重要的问题,而不是在已经解决得比较好的问题是 “精益求精”。
--------------------------------------------------------------------------------
/09 storage/09-storage-notes.md:
--------------------------------------------------------------------------------
1 | ## Storage Model & Data layout
2 |
3 | 1. 不同类型数据的表示:
4 |
5 | - INTEGER / BIGINT / SMALLINT / TINYINT
6 |
7 | 使用C/C++中的表示形式
8 |
9 | - FLOAT / REAL(不能存储精确数值) vs. NUMERIC / DECIMAL(存储精确数值)
10 |
11 | 前者为IEEE-754标准,后者为[定点十进制数 fixed-point decimal](http://www-inst.eecs.berkeley.edu/~cs61c/sp06/handout/fixedpt.html) 如Postgres中的实现:
12 |
13 | ```c
14 | typedef unsigned char NumericDigit;
15 | typedef struct {
16 | int ndigits; // 数字的数量
17 | int weight; // 首位的权
18 | int scale; // 缩放系数
19 | int sign; // 正/负/NaN
20 | NumericDigit *digits; // 实际数字的存储
21 | } numeric;
22 | ```
23 |
24 | - TIME / DATE / TIMESTAMP
25 |
26 | 32/64位的整形,Unix epoch (从1970年1月1日(UTC/GMT的午夜)开始所经过的毫秒/微秒数)
27 |
28 | - VARCHAR / VARBINARY / TEXT / BLOB
29 |
30 | 指针指向数据,头部带有长度和下一段的地址 以及数据类型
31 |
32 | 
33 |
34 | 2. NULL类型表示:
35 |
36 | - 特殊值
37 |
38 | - Null Column Bitmap Header:
39 |
40 | 在元组头部存 一个bitmap,来表示该元组哪些属性位null
41 |
42 | - Per Attribute Null Flag
43 |
44 | 会浪费空间,因为每个属性多一个bit 需要重新字对齐
45 |
46 | 3. 字对齐的元组:(与结构体的字节对齐类似)
47 |
48 | - padding: 在属性的后面补充空的bits
49 |
50 | 
51 |
52 | - reordering: 重新排序,最后可能也需要padding
53 |
54 | 两种方法的性能对比:(插入测试)
55 |
56 | | 对齐方式 | 平均吞吐量 |
57 | | ---------- | ------------ |
58 | | 无对齐 | 0.523 MB/sec |
59 | | padding | 11.7 MB/sec |
60 | | reordering | 814.8 MB/sec |
61 |
62 | 4. 存储模型: 可参考 **[Flexible-Storage-Model](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/engine/Flexible-Storage-Model.md)**
63 |
64 | - N-ary Storage Model (NSM)
65 |
66 | 物理存储的选择:
67 |
68 | 1. **Heap-Organized Tables**
69 |
70 | 元组存储在 叫做**堆**的blocks中,不需要有序
71 |
72 | 2. **Index-Organized Tables**
73 |
74 | 元组存储在自己的主键索引中,和聚集索引不相同。
75 |
76 | 优点:
77 |
78 | - 插入、更新、删除快(适合OLTP)
79 | - 适合查询整个元组
80 | - 可以使用面向索引的存储
81 |
82 | 缺点:
83 |
84 | - 不适合扫描表的大部分 以及 只查询一部分属性
85 |
86 | - Decomposition Storage Model (DSM)
87 |
88 | 优点:
89 |
90 | - 只读取需要的数据,减少无用的工作
91 | - 压缩更好
92 |
93 | 缺点:
94 |
95 | - 插入、更新、删除慢,因为元组需要分裂或者拼接
96 |
97 | - Hybrid Storage Model
98 |
99 | 两种选择:
100 |
101 | - Separate Execution Engines: 对NSM和DSM 分别使用最合适的执行引擎。返回结果时需要合并两个引擎的结果,从而对外表现在逻辑上是一个数据库。如果一个事务跨执行引擎,需要引入同步机制。
102 |
103 | 如何确定哪些数据存入DSM中?
104 |
105 | - Manual: 由DBA指定哪个表存入DSM中
106 | - Off-line: DBMS离线监控访问日志,然后决定哪些数据移入DSM
107 | - On-line: DBMS在运行期监控数据库访问,然后决定哪些数据移入DSM
108 |
109 | - Single, Flexible Architecture: 只用单一的执行引擎,同时适合NSM和DSM
110 |
111 | 5. 表模式的更改 Schema Changes:
112 |
113 | - 添加列
114 |
115 | - NSM: Copy tuples into new region of memory
116 | - DSM: 直接创建一个新列
117 |
118 | - 删除列
119 |
120 | - NSM 1: Copy tuples into new region of memory
121 | - NSM 2: 标记列为 deprecated,后期再清理
122 | - DSM: 直接删除列 释放内存
123 |
124 | - 更改列
125 |
126 | 检查改变是否合法
127 |
128 | 6. 索引操作
129 |
130 | - 创建索引
131 |
132 | - 扫描整个表、填充索引
133 |
134 | - 当一个事务在建立索引时,另一个事务需要记录修改表的裱花
135 | - 当扫描完成后,锁住表;整合扫描过程中表的变更
136 |
137 | - 删除索引
138 |
139 | - 从catalog中直接删除索引(逻辑上删除)
140 | - 只有当删除该索引的事务 commit后才变得不可见
141 |
142 | 7.
143 |
144 |
--------------------------------------------------------------------------------
/paper reading/dbms/Fast Durability.md:
--------------------------------------------------------------------------------
1 | ## Fast Databases with Fast Durability and Recovery Through Multicore Parallelism
2 |
3 | 1. **问题**:现代的高速内存型数据库可以支持OLTP的 高事务处理率,但是宕机后的recovery需要很长的时间。
4 |
5 | 2. **Contribution**: 不使用replication,在更短的时间内恢复一个大型数据库(内存型数据库)。
6 |
7 | 3. 多核内存数据库——可以支持OLTP的高事务率,但宕机后的恢复比较麻烦。普通的**logging**和**checkpoint**技术 会让 普通情况的执行 变慢,但频繁的磁盘同步 使得在只降低可接受的吞吐量 的情况下,能支持高负荷量。
8 |
9 | 4. **Replication** can allow one site to step in for another, but even replicated databases must write data to persistent storage to survive correlated failures, and performance matters for both persistence and recovery.
10 |
11 | 要注意区别Replication 和 Duplication:
12 |
13 | In database technology, replication is a **repeated activity** where as duplication is a **one time event**. I want to replicate TableA on Server1 to Server2 TableA continuously. so if server1.tableA changes values so does Server2.TableA. Duplication means I create Server1.TableA once on Server2.TableA. And as Server1.TableA changes, Server2.TableA does not and get out of sync. So I guess it would be dependent on the context in which the words are used. Replication is repetitive/scheduled event, duplication is a one time
14 |
15 | 5. **Logging**: 在Silo的基础上,添加了 Log truncation,并使得replay的并行度更高。
16 |
17 | - 由**workers** 和 **loggers**一起负责
18 |
19 | **loggers**即单独的logging线程,专门负责logging, checkpointing 和 housekeeping
20 |
21 | **workers**在事务提交时 生成log record,再把这些record传给**loggers**;**loggers**就把这些日志持久化到磁盘,当通过*fsync*成功提交到磁盘后,**loggers**会通知**workers**,从而**workers**可以把事务执行的结果告诉客户端。
22 |
23 | 将**worker**划分为不相交的子集,每个worker子集分配一个**logger**,通过**core pinning**保证logger与对应的workers在同一个CPU上运行,使得在一个socket上的log buffer 只会在该socket中被访问。
24 |
25 | > Processor affinity, or CPU ***pinning*** or "cache affinity", enables the binding and unbinding of a process or a thread to a central processing unit (CPU) or a range of CPUs, so that the process or thread will execute only on the designated CPU or CPUs rather than any CPU, can improve the performance of your code by increasing the percentage of local memory accesses.
26 | >
27 | > The **Socket** is a hardware on the motherboard which accepts the CPU for its mounting on the motherboard. The Socket thereby connects the CPU with the motherboard circuitry. One socket accepts exactly one CPU.
28 |
29 | - **Value** logging vs. **Operation** logging
30 |
31 | 使用**Value logging**,即日志包含 每个事务输出的 key与value(而不是执行的操作和参数)。其缺点是 会记录更多的日志数据,事务执行较慢;但恢复时的并行性很好,最终只用保留 **TID**最大的值(**TID**对应了写的次序)。
32 |
33 | 通过添加硬件 使得**Value logging**的I/O不是瓶颈。
34 |
35 | - **Buffer Management**:
36 |
37 | 当log buffer满了 或者 一个新的epoch开始时,worker就把buffer给flush到其对应的logger。一个日志文件即 把不同worker传来的buffer该连接起来(不需要按特定顺序)。
38 |
39 | 6. **Checkpoint**: 检查点之间的距离越小,recovery需要replay的日志数据越少。
40 |
41 | - 内存数据库必须周期性地保存检查点,才能让恢复的过程更快,并支持日志截取 log truncation(防止log文件被填满)。
42 |
43 | - 每个checkpoint disk有一个checkpointer线程,有checkpoint manager 为每个checkpointer分配数据库不同的slice.
44 |
45 | - Checkpointer会按key的顺序(根据索引树)遍历自己负责的slice,写下每条经过的record.
46 |
47 | - 检查点不一定必须是 数据库在某一点的一致的快照。因此,需要在恢复检查点后,再replay一部分的日志。
48 |
49 | - **Cleanup**: 当检查点完成后,需要删除不需要的旧文件。
50 |
51 | Logger把日志存在同个文件夹下的一系列文件中。新的条目写入名为**data.log**的文件,隔一定周期(比如每100个epoch),logger将该文件改名为**old_data.e**,*e*为该文件包含的最大epoch号。
52 |
53 | 而所有**e**小于当前epoch号的文件 即可被删除。
54 |
55 | - Log replay的代价比checkpoint 的代价高,故通过增加checkpoint 的频率,来减少log replay
56 |
57 | 7. **Future Work**:
58 |
59 | - 更弹性的 checkpoint方案,当log文件不会增长太快时,可以延缓checkpoint。
60 |
61 |
--------------------------------------------------------------------------------
/paper reading/robust query/Plan Bouquets.md:
--------------------------------------------------------------------------------
1 | ## Plan Bouquets
2 |
3 | 1. **Motivation**:
4 |
5 | OLAP查询的选择率估计经常与实际相差很大 -> 错误的执行计划选择 -> 响应时间很长。
6 |
7 | 导致选择率估计误差的原因有:过时的统计信息、复杂的谓词、算子树的误差传递放大、属性值的独立性分布假设。而且在一些远程数据源的场景中,统计信息很有可能是根本获取不到的。
8 |
9 | 2. 为应对选择率估计误差问题,前人提出的方法:
10 |
11 | - 改进统计信息
12 |
13 | - 基于反馈的调整
14 |
15 | - 识别对于估计误差更健壮的执行计划 (robust plan)
16 |
17 | - 运行时计划切换:
18 |
19 | - *Robust Query Processing through Progressive Optimization (2004)* 提出的POP(progressive query optimization,渐进式查询优化)
20 |
21 | - *Proactive Re-Optimization (2005)* 提出的Rio框架,在常规的查询处理过程中加入随机采样,以在执行期间快速准确地估计出统计信息;比起传统的Robust cardinality estimation多引入了重新优化的步骤
22 |
23 | 
24 |
25 |
26 |
27 | 3. 本文与相关工作的不同之处:
28 |
29 | 1. 本文提出的Plan Bouquet方法看上去和上述两种plan-switching方法很相似(本质确实是 **plan-switching**),但有两个关键的不同之处(也是优势所在):
30 |
31 | - 上述方法以优化器的估计值作为起点,如果估计值误差非常的话,会进行彻底的重新优化;但本文方法是从选择率空间的原点开始(与优化器无关),这带来的好处是保证了执行策略的可重复性
32 |
33 | - 上述方法都是基于启发式,无法给出性能退化的边界。
34 |
35 | 2. 比起PQO,如 *Progressive Parametric Query Optimization (2009)*,都是在执行前 通过搜索选择率空间 来得到一个执行计划集合,但是PQO的本质是为了节省对于输入查询的优化时间(在给定了参数之后),而本文方法是强调 降低易错选择率带来的 worst case 性能下降。
36 |
37 | 3. 比起 plan-morphing的过渡方式,如 *A pay-as-you-go framework for query execution feedback (2008)*,通过运行时 收集额外地cardinality信息(引入了较小的额外开销),来调整接下来执行计划的结构。但本文的方法不会在执行一个计划P的期间,去调整P的结构。
38 |
39 | 另外提一句,In any system that exploits execution feedback for query optimization, there are issues such as **maintenance policy** for updates, **replacement policy** for the feedback cache etc. 不过这些问题与原文研究的无关,没有深入探讨。
40 |
41 | 4. 核心流程:
42 |
43 | 
44 |
45 | 1. 确定易错的选择率空间
46 | 2. 生成*POSP*(parametric optimal set of plans),以及POSP最小代价的函数曲线,称作*PIC*(POSP infimum curve)
47 | 3. 将*PIC*基于执行代价离散化,从而可以从POSP中识别出最终需要的计划集,称之为Bouquet
48 | 4. 从第一条(原点算起)代价等高线开始,从当前点在的等高线上的计划开始,执行该计划,并监控执行期间是否达到了预算。若超出预算,则进入下个计划的执行
49 |
50 | 5. 主要问题:
51 |
52 | 1. 如何确定哪个谓词是易错的选择率?
53 | - 通过建模好的规则来确定,参考*Efficient Mid-Query Re-Optimization of Sub-Optimal Query Execution Plans (1998)*
54 | 2. 如何生成期望选择率的查询,从而让优化器给出相应执行计划?
55 | 3. 如何找到POSP?
56 | 4. 如何保证POSP的计划数不会太多?
57 | 5. 运行时,如何判断是否达到了预算?如何切换执行计划?
58 |
59 | 6. 修改数据库的那些模块功能?
60 |
61 | 即数据库引擎需要支持:
62 |
63 | - 在查询优化时,注入选择率(对应5.2)
64 | - 带预算的部分执行(对应5.5)
65 | - 运行时对选择率变化的监控(对应5.5)
66 |
67 | 7. 不足之处:
68 |
69 | - 如果可以知道估计误差比较小,那么事实上把优化器的估计值作为起始点的话 会收敛的更快;所以如果能够先验地知道 比如优化器会低估选择率,bouquet的方法也能够选择该起始点 从而更快收敛
70 |
71 | - 不适用于 对时延敏感的TP查询 (也就是适合AP分析),不适用事务中。所以比较适合归档数据库的决策分析之类。
72 |
73 | - DBA无法使用hint,不过可以参考*Optimizer with Oracle Database 12c Release 2 (2017)* 白皮书中的 Adaptive Query Optimization,毕竟在商业数据库中也引入了类似技术
74 |
75 | > By far the biggest change to the optimizer in Oracle Database 12c is Adaptive Query Optimization. Adaptive Query Optimization is a set of capabilities that enable the optimizer to make run-time adjustments to execution plans and discover additional information that can lead to better statistics. This new approach is extremely helpful when existing statistics are not sufficient to generate an optimal plan
76 |
77 | 
78 |
79 | - 对于属性值的分布情况有健壮性,但是如果数据集大小增大很多的话,原来的选择率空间就不再适用。因此,未来可能要考虑如何做到增量式地计算bouquet
80 |
81 | - 当易错选择率维度上升时,复杂度也会呈指数爆炸。不过复杂的查询也不一定代表易错的选择率也很多,比如对于 ‘属性值 op 常量’的谓词,现有技术已经能估计地比较准了;再比如对于PK-FK的join也可以考虑在PK表都能找到匹配;还可以计算 POSP代价函数的偏导数,找到影响较小的自变量 从而忽略之
--------------------------------------------------------------------------------
/02 in-memory db/2-imdb-notes.md:
--------------------------------------------------------------------------------
1 | ## In Memory Database
2 |
3 | 1. Disk-oriented DBMS(面向磁盘):
4 |
5 | - 主要存储位置是在HDD, SSD上,数据库分为固定大小的块——称为**slotted pages**
6 |
7 | - 使用在内存中的缓存池,缓存来自磁盘的块(表现为一个个page)
8 |
9 | - 当一个查询想访问一个page P (通过一个Page Table查询得到)时,DBMS先检查P是否在缓存池中:若不在,则DBMS从磁盘中取出页面P,并复制P放在缓冲池的一帧(frame)中 —> 若无空的frame,则按一定的替换原则evict一个在缓存池的page (此时应该还要更新page table,原PPT中没提到) —> 若该page是dirty(被修改过),则要将对应修改后的内容写回磁盘;未修改过就不用管。
10 |
11 | - 需要设置lock(锁)和latch(闩锁)来为txns(transactions)保证ACID,二者区别: (参考[B-tree Locking](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/B-tree-locking.md))
12 |
13 | | 作用 | Locks | Latches |
14 | | ---- | --------------------------------- | -------------------------------- |
15 | | 隔离 | 用户事务 | 线程 |
16 | | 保护 | 数据库内容 | 内存中的数据结构 |
17 | | 持续 | 整个事务 | 临界区critical section |
18 | | 死锁 | 检测(wait-for图、timeout) 与 解除 | 避免(编码时的规范,如加锁的顺序) |
19 | | 存在 | Lock Manager(哈希表) | 受保护数据结构 |
20 |
21 | - latch可以分为互斥锁和读写锁,主要是保证并发线程操作临界资源的正确性
22 | - lock对象一般用来锁定数据库的表、页、行,在事务commit或rollback后才释放
23 |
24 | 2. In-memory database: 又叫Main-memory database
25 |
26 | - 不需要将数据库存为slotted pages,但是仍然会把元组放在block/page中
27 | - 为什么**不用mmap**(把数据库文件映射到内存中,让OS来负责数据在需要时的换入换出)—— 因为mmap无法在精细粒度上控制内存中的内容:
28 | 1. 无法非阻塞地访问内存
29 | 2. 在磁盘上的表示形式要和在内存中的相同
30 | 3. DBMS无法知道一个page是否在内存中
31 | 4. 与mmap相关的系统调用无法移植
32 | - 仍需要**WAL**(预写日志系统,提高IO效率——在数据写入到数据库之前,先写入到日志,在将日志记录变更到存储器中)
33 | - 仍需要设立检查点**checkpoint**来加快恢复
34 |
35 | 3. 对比:
36 |
37 | | | 内存数据库 | Right-aligned |
38 | | :----------- | :------------ | :------------|
39 | | 数据存储 | 行、列存储,段-分区式存储模型,不要求数据在内存中连续 | 行、列存储,在磁盘上连续存放 |
40 | | 缓冲管理 | 无 | 有 |
41 | | 并发控制 | 较大粒度的锁,如库级、表级;或乐观锁机制 | 为了提高事务的并发度,一般支持多粒度和多类型的锁 |
42 | | 恢复机制 | 备份、日志、检查点技术;预提交、组提交等提交方式;用稳定内存来存储log record | 备份、日志、检查点、保存点 |
43 | | 索引结构 | T树、hash | B树、hash |
44 | | 查询优化 | 基于处理器代价、cache代价 | 基于I/O代价 |
45 |
46 | 4. 各种树的对比:具体参考
47 |
48 | - [T树](http://www.memdb.com/paper.pdf):由AVL树(自平衡二叉查找树)和B树发展而来,既有AVL树的二分查找特性,又有B树良好的更新和存储特性。
49 |
50 | > T树索引用来实现关键字的范围查询。T树是一棵特殊平衡的二叉树(AVL),它的每个节点存储了按键值排序的一组关键字。T树除了较高的节点空间占有率,遍历一棵树的查找算法在复杂程度和执行时间上也占有优势。
51 | >
52 | > 参考:https://blog.csdn.net/u013815649/article/details/51940548
53 |
54 | - [R树](http://www-db.deis.unibo.it/courses/SI-LS/papers/Gut84.pdf):是一种空间索引数据结构,用于处理多维数据的数据结构。
55 |
56 | 空间数据对象通常会覆盖多维空间的区域,不便于使用点坐标来表示。空间数据中的一个常用操作是 搜索一个区域内的 所有对象。
57 |
58 | 而经典的一维数据库索引 不适合多维的空间搜索。1. 基于精确值匹配的数据结构,比如hash表,在范围查询不适用。2. 基于一维顺序的数据结构,比如B树、ISAM索引,不能适用 多维的搜索空间。
59 |
60 | > 多维索引技术的历史可以追溯到20世纪70年代中期。就在那个时候,诸如Cell算法、四叉树和k-d树等各种索引技术纷纷问世,但它们的效果都不尽人意。在GIS和CAD系统对空间索引技术的需求推动下,Guttman于1984年提出了R树索引结构,发表了《R树:一种空间查询的动态索引结构》,它是一种高度平衡的树,由中间节点和页节点组成,实际数据对象的最小外接矩形存储在页节点中,中间节点通过聚集其低层节点的外接矩形形成,包含所有这些外接矩形。其后,人们在此基础上针对不同空间运算提出了不同改进,才形成了一个繁荣的索引树族,是目前流行的空间索引。。
61 | > 原文链接:https://blog.csdn.net/windgs_yf/article/details/86534384
62 |
63 | - [X树](https://kops.uni-konstanz.de/bitstream/handle/123456789/5734/The_X_Tree.pdf):线性数组和层状的R树的杂合体。
64 |
65 | 5. Cache性能优化:cache失效时CPU需要等待从内存中读取数据。
66 |
67 | 基本思想:**对数据划分,使得划分结果能够放入cache,以提高cache命中率。**
68 |
69 | - [radix-cluster算法](http://www.vldb.org/conf/1999/P5.pdf):通过多路运算将一个关系划分为多个cluster,最后将两个join的关系划分为 小于cache大小的cluster。
70 | - 处理projection:(1)pre-projection,先投影,再连接;(2)post-projection,先连接,再投影。(3)先生成join-index——[oid, oid],然后再计算投影列,生成查询结果。如果关系中的元组太多,每个列都不能放入cache内,则进行projection时,随机查找会引起很多次cache失效。
--------------------------------------------------------------------------------
/paper reading/robust query/Robust query processing Mission possible.md:
--------------------------------------------------------------------------------
1 | ## Robust query processing Mission possible
2 |
3 | 1. 问题:数据库查询可能面临的性能降级是巨大的(比起 在优化过程知道所有精确的输入值,较差的情况可能达到几个数量级的差距)。[比较常见的](https://www.dagstuhl.de/en/program/calendar/semhp/?semnr=10381)原因包括
4 |
5 | - 基数估计误差
6 | - workload波动大
7 | - 并发控制冲突
8 | - 严格的资源管理
9 |
10 | 因此提出了Robust Query Processing,近年来的工作考虑到以下环境因素:
11 |
12 | - 内存使用量:buffer pool、heap
13 | - 并发的磁盘操作导致IO带宽的变化
14 | - 并发控制导致的锁
15 | - 检测当前执行计划的问题
16 | - CPU可用核心数
17 | - Access path的变化
18 | - 网络拥堵情况
19 | - Query之间相互影响,比如热点行、事务日志冲突
20 |
21 | 2. Robust不同粒度的分类:
22 | - **Operator**:算子级别,比如以下几篇论文
23 | - **Smooth Scan**: 自适应的access path选择,可以平滑地在**顺序扫描** 和 **索引扫描**之间转化。
24 | - **G-join**: 将常见的join算法(NL, hash, sort-merge)给合并到一个统一的框架中,从而优化器不用决定选择哪个
25 | - **[Flow-join](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/robust%20query/Flow-join.md)**: 用于解决分布式join下的data skew现象。思想是:trade off communication for computation;在初始的运行阶段中,会找到高命中的元组(通过小数据量的近似直方图),再通过**广播**这些元组 来避免失衡
26 | - **Eddies framework**: 见下篇论文的相关工作
27 | - **Plan**:粒度提升到整个计划上。当输入的参数值只有运行期才知道时,目前的优化器通常都是 使用有代表性的值(如平均数、中位数)来估计这个参数的分布情况,这样做很容易误差太大
28 | - **Least Expected Cost**(LEC) plan: 会计算输入参数全分布的期望值,其在整个参数的分布空间上计算代价的期望值,而非只计算输入固定参数后计划的代价,从而在计划层面上分摊了基数估计误差带来的开销。
29 | - **SEER**
30 | - **Execution**:主要是保证Maximum Sub-Optimality(**MSO**),即整个选择率空间中,最差情况下的性能下降
31 | - **Plan Bouquet**
32 | - **SpillBoud**
33 | - **Cost Model**:要注意和基数本身关注点不同——cardinality本身是用来衡量数据的分布和关联特征;而代价模型本身是衡量底层硬件和物理操作的指标
34 |
35 | 3. 未来方向:
36 | - **Plan cost function**: 前人的工作中,一般都认为代价函数应该与selectivity呈单调关系(比如,选择出的元组越多,cost越高)。参考*A Concave Path to Low-overhead Robust Query Processing (2018)*
37 | - **Query-graph sensitive robustness**: 查询图可能呈现出不同结构,比如chain, cycle, star, clique;比如 链状的就比星状的 **优化选择更少**,更容易保证高性能地执行
38 | - **Robustness benchmark**: 像TPC-DS的是只测性能;而最近的一些benchmark如**OptMark**, **JOB**, **OTT**也没有考虑robustness的方面
39 | - **ML for component selection**: 在不同运行的场景下,可以使用不同的组件;但如何根据运行环境去做出选择判断——可以结合机器学习。参考 *F. Hueske. Specification and Optimization of Analytical Data Flows (2016)*.
40 | - **Graceful** **performance** **degradation**: 现有问题是,当运行环境发生微小的改变时(通常是硬件的资源上,文章没给出具体例子,我的理解是比如可用内存突然变小了,或参考概述前文的environments),性能会急剧退化。如何设计出一个算法,对于其中所有性能相关的参数,都可以优雅地进行降级(该算法需要可以被理论证明的)。
41 |
42 | 4. 来自 Dagstuhl Seminar (2012),在当时提出 值得探索的方向
43 | - Smooth operations: 可参考 [Smooth Scan](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/robust%20query/Smooth%20Scan.md)
44 | - Opportunistic query processing: 不是单一地执行一个计划,而是选出多个不同计划并行执行、
45 | - Run-time join order selection: 主要是通过利用执行期间得到的中间结果,从而使优化、执行两阶段交织进行,并减小技术估计误差
46 | - Robust plans: 通过smooth operator让整个计划能有健壮性的保障(不过这里说的robust plan和我理解的不太相同,有另一种理解是 计划本身具备健壮性,这里是通过smooth operation来进行运行时计划的平滑过渡)
47 | - Assessing robustness of query execution plans: 比较执行计划健壮性的指标
48 | - Testing adaptive execution: 试着比较 自适应执行方法对性能的影响 以及 基数估计误差带来的性能影响
49 | - Pro-active physical design: 通过持续的workload分析,来逐渐地调整数据库的物理设计(核心假设是 workload有共性、周期性)
50 | - Adaptive partitioning: 根据当前的workload来调整底层的partition(当然也属于physical design的一部分)
51 | - Adaptive resource allocation: 比如运行时的动态内存分配、动态workload调节、自适应地控制并发执行
52 | - Physical database design without workload knowledge: 在数据批量导入期间来决定 数据库的物理设计
53 | - Weather prediction: 通过分析当前workload,以及当前系统状态的参数,来控制当前系统性能预期
54 | - Lazy parallelization: 静态的优化阶段 给出的并行执行计划是有不小风险的,因为(1) 确切的总工作量是无法预知的;(2) 数据倾斜问题对并行有影响;(3) 运行时的可用资源也是不确定的。所以,可以考虑将是否并行给延到执行阶段决定
55 | - Pause and resume: 通过pause与resume,使得 重复或浪费的工作最少(甚至可以通过undo一些操作 来恢复到可以resume的阶段)
56 | - Physical database design in query optimization: 将一部分数据库的物理设计 放在查询优化阶段来做。比如把索引创建给延迟到优化阶段,即只有当创建索引有好处时,才会相应地创建
57 |
58 |
--------------------------------------------------------------------------------
/paper reading/crowdsource/Cost-Effective Data Annotation.md:
--------------------------------------------------------------------------------
1 | ## Cost-Effective Data Annotation using Game-Based Crowdsourcing
2 |
3 | 1. **问题**:现存的数据标注方案,要么对于大数据集的开销很高,要么容易产生噪声结果。
4 |
5 | 2. **Contribution**:
6 |
7 | - 提出一种性价比高的标注方法,生成高质量的规则来 在保证label质量的情况下 减少cost。先生成候选规则,再设计CrowdGame 基于**覆盖率**和**准确率**来选出高质量的规则。引入两组crowd worker: 一组作为**rule generator** 负责检验 规则是否有效;另一组作为**rule refuter** 负责检验 一条数据标注的标签是否正确,从而可以得出某些规则的coverage是否足够
8 |
9 | - 引入 规则的损失,来平衡**覆盖率**和**准确率***
10 |
11 | - 以 Entity matching 和 relation extraction作为实验数据集,证明了方法比 state-of-the-art方案 在元组级别众包 tuple-level
12 | crowdsourcing 以及 基于机器学习的标签规则 ML-based consolidation of labeling rules 上 的优越性。
13 |
14 | - 框架:
15 |
16 | 
17 |
18 | 3. **Challenge**:
19 |
20 | - *coverage* 和 *precision*的tradeoff —— 定义包含两个因素的损失函数 loss
21 | - *rule precision estimation* —— 使用贝叶斯估计将 **rule validation** 和 **tuple checking** 结合起来 (把rule validation的结果作为先验概率,再通过实际的tuple checking作为后验概率来修正)
22 | - 选择众包任务 来最小化loss —— 采用 minimax策略,提出了高效的task selection算法。**Rule generator**作为*minimizer*,使loss最小化;**Rule refuter**作为*maximizer*,使检验数据的loss最大化(反复进行这两项,直到众包预算用尽)
23 |
24 | > Minimax算法又名极小化极大算法,是一种找出失败的最大可能性中的最小值的算法。Minimax算法常用于棋类等由两方较量的游戏和程序,这类程序由两个游戏者轮流,每次执行一个步骤。我们众所周知的五子棋、象棋等都属于这类程序,所以说Minimax算法是基于搜索的博弈算法的基础。该算法是一种零总和算法,即一方要在可选的选项中选择将其优势最大化的选择,而另一方则选择令对手优势最小化的方法。
25 |
26 | 4. 实现细节:
27 |
28 | - **Labeling Rule**:
29 |
30 | Labeling Rule 即 将元组 映射为 标签或nil 的一个函数,一个规则 *rj*所有映射值不为nil的输入元组集合 即为该规则的 covered set。
31 |
32 | 使用Labeling Rule来标注 输入的元组 可分为两个阶段:
33 |
34 | 1. **Crowdsourced rule generation**
35 |
36 | 旨在生成高质量的规则(覆盖率 和 准确率)。首先构建候选规则,可以通过 hand-crafted(由领域专家生成,对于大数据集不适合) 或 *weak-supervision*(由算法生成,如Distant Supervision) 来构建。
37 |
38 | 同时 覆盖率 和 准确率之间存在tradeoff:有些场景更需要precision,比如在Entity Matching任务中,正确标签可能偏斜度 skew很大(比如7个元组标签为1,只有1个标签为-1),此时规则就不能有太大误差;另一些场景可能为了减少开支,尽量提高coverage。因此,引入 规则集*R*的损失函数(里面有一个 0≤ *γ* ≤1,作为人为定义的 覆盖率和准确率的preference)。
39 |
40 | 最终规则的生成 可视为一个最优化问题。
41 |
42 | 2. **Data annotation using rules**
43 |
44 | 使用Labeling Rule来标注数据,对于没有被cover的元组,使用传统的众包方法来进行元组级别的标注。
45 |
46 | - **Two-pronged task scheme**
47 |
48 | 双支众包任务方案——先利用crowd直接验证一条规则的有效性,作为粗糙的预估;再通过 基于已验证的规则进行*tuple checking*任务,作为更精确的后验评估。为了达到此目的,提出了*rule validation*任务类型。因为 crowd很可能产生 False Positive(错的当做对的)的误报(因为 当规则不适用时,很容易忽略 negative的例子),所以同样需要 细粒度的tuple checking任务。
49 |
50 | - **A game-based crowdsourcing approach**
51 |
52 | 预算是固定的,所以要平衡 *rule validation*和*tuple checking* 两种类型任务。引入一种基于博弈的众包方法*CROWDAGME*,如框架图中心所示,两组worker,一组负责*rule validation*的称为*RuleGen*,一组负责*tuple checking*的称为*RuleRef*。因此可以视为一个 基于规则集的损失函数的 两方博弈*two-player game*;*RuleGen*作为minimizer,最小化损失;*RuleRef*作为maximizer,最大化损失。
53 |
54 | (GAN 对抗式生成网络 在训练时也使用了minimax框架,用于图像和文本处理中)
55 |
56 | - **Task selection**
57 |
58 | 迭代式的众包算法,每轮迭代包含两步:*RuleGen*和*RuleRef*。使用 通用的 *batch mode*,每次选取一批任务,一起放上众包平台。
59 |
60 | 算法输入为
61 |
62 | - **candidate rules**
63 | - **tuples to be labeled**
64 | - **budget**
65 | - **crowdsourcing batch**
66 |
67 | 输出为 a set of generated rules 生成规则集。
68 |
69 | - **Candidate Rules for Entity Matching**
70 |
71 | 构造 candidate *blocking rules*,目前大部分方法是基于结构化的数据。提出方法 自动识别 关键词对*keyword pair*,可以有效地 从未处理文本中分别出 *record pairs*。
72 |
73 | 通过 词移距离*Word Mover’s Distance* (基于NLP中的词嵌入,词映射为一个词向量,在这个向量空间中,语义相似的词之间距离会比较小),从元组对中 可识别出 关键词对。
74 |
75 | - **Candidate Rules for Relation Extraction**
76 |
77 | 使用 *Distant Supervision*来找到规则,使用 point-wise mutual information 来决定两个连续的词能否形成一个词组。
78 |
79 | - 实验的指标
80 | - rule coverage
81 | - FN rate
82 | - precision
83 | - recall
84 | - F1 score
85 | - crowd cost
--------------------------------------------------------------------------------
/paper reading/os/Memory Management.md:
--------------------------------------------------------------------------------
1 | ## 内存管理
2 |
3 | 1. 存储层次:
4 |
5 | 1. 寄存器 (ns)
6 | 2. CPU缓存 (10ns)
7 | 3. 主存 (100ns)
8 | 4. 外存 (ms)
9 |
10 | 如果要达到极致的性能优化,就有必要关注L1、L2、L3的cache,比如nginx的绑核操作、pthread调度。
11 |
12 | 2. 从进程的角度来看,内存分为:**内核态**、**用户态** 两个部分。
13 |
14 | 用户态的内存划分为:
15 |
16 | - Stack
17 | - Memory mapping segment
18 | - heap
19 | - bss segment(未初始化的全局变量和局部静态变量)
20 | - data segment(经过初始化的全局变量和局部静态变量)
21 | - text segment(程序源代码编译后的机器指令)
22 |
23 | 内核态的内存划分为:
24 |
25 | - 直接映射的物理页帧
26 | - VMALLOC
27 | - 持久映射
28 | - 高端映射
29 |
30 | 3. 虚拟内存(逻辑上对程序物理内存的抽象)
31 |
32 | 物理内存按大小被分成页框、页,每块物理内存可以被映射为一个或多个虚拟内存页。这块映射关系,由操作系统的页表来保存,页表是有层级的。层级最低的页表,保存实际页面的物理地址,较高层级的页表包含指向低层级页表的物理地址,指向顶级的页表的地址,驻留在寄存器中。
33 |
34 | 每次访问可以使用更易理解的虚拟地址,让CPU转换成实际的物理地址访问内存,降低了直接使用、管理物理内存的门槛。
35 |
36 | 4. 驻留内存 Resident Memory
37 |
38 | 指那些 **被映射到进程虚拟内存空间的 物理内存**。一般我们所讲的进程占用了多少内存,其实就是说的占用了多少驻留内存而不是多少虚拟内存
39 |
40 | 5. TOP指令内存参数的区别
41 |
42 | - **VIRT**:进程的虚拟(地址)空间大小,其包含进程实际使用的大小(申请的堆栈), 使用mmap映射的大小,包括外设RAM, 还有映射到本进程的文件(例如动态库),还有进程间的共享内存。所以VIRT 表示的是**当前这个进程能够访问到的所有空间大小**
43 | - **RES**:表示**进程的常驻内存大小**,准确表示当前有多少物理内存被这个进程消费,这个和MEM是对应的, 这个大小永远要比VIRT小,因为程序大部分使用到c库。所以说,**看进程在运行过程中占用了多少内存应该看RES的值而不是VIRT的值**。
44 | - **SHR**:表示的是**进程占用的共享内存大小**,**多少VIRT 实际可以共享的**(包括内存和动态库),举例动态库,SHR的值不总代表整个库都是常驻内存的,因为有些程序使用到c库的部分函数,但整个库是被映射到进程的,并且计算到VIRT和SHR,但是只有该库的一部分被使用到
45 |
46 | 6. 举例:
47 |
48 | 
49 |
50 | - A1、A2、A3和A4是进程A的驻留内存
51 | - B1、B2和B3是进程B的驻留内存
52 | - TOP中进程A的 *VIRT* 是**A1、A2、A3、A4以及灰色部分所有空间的总和**(上面的那块,不是系统物理内存的那块)
53 | - 而进程A虚拟内存空间中的A4和进程B虚拟内存空间中的B3都映射到了物理内存空间的A4/B3部分,是因为程序会依赖于很多外部的动态库(.so),比如libc.so、libld.so等等。这些动态库在内存中仅仅会保存/映射一份,如果某个进程运行时需要这个动态库,那么动态加载器会将这块内存映射到对应进程的虚拟内存空间中。多个进展之间通过共享内存的方式相互通信也会出现这样的情况。这么一来,就会出**现不同进程的虚拟内存空间会映射到相同的物理内存空间**。也就是共享内存,用*SHR* 来表示。
54 |
55 | 7. 虚拟内存 和 swap分区
56 |
57 | windows的虚拟内存 对应 linux的swap分区,不同点在于windows即使物理内存没有用完也会去用到虚拟内存,而Linux不一样 Linux只有当物理内存用完的时候才会去动用swap分区。
58 |
59 | 该篇笔记 虚拟内存 指的就是Linux的虚拟内存。
60 |
61 | 8. 虚拟内存的好处
62 |
63 | - 有助于**进程进行内存管理**:
64 |
65 | - 比如 进程访问内存时,都要通过页表来寻址,操作系统在页表的各个项目上添加各种访问权限标识位,就可以实现内存的权限控制
66 | - 每个进程都认为自己获取的内存是一块连续的地址,在编写应用程序时,就不用考虑大块地址的分配,总是认为系统有足够的大块内存即可
67 |
68 | - **数据共享**
69 |
70 | 只需要将各个进程的虚拟内存地址指向系统分配的共享内存地址即可;从而同一个库不用加载两次
71 |
72 | - **swap**
73 |
74 | Linux 中可以使用 SWAP 分区,在分配物理内存,但可用内存不足时,将暂时不用的内存数据先放到磁盘上,让有需要的进程先使用,等进程再需要使用这些数据时,再将这些数据加载到内存中
75 |
76 | 9. 多线程对虚拟内存的消耗
77 |
78 | 每个线程都有自己的缓冲区来解决多线程内存分配的竞争,比如在JVM中:
79 |
80 | - 堆是JVM中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了new对象的开销是比较大的
81 | - 为了提升对象内存分配的效率,对于所创建的线程都会分配一块独立的空间TLAB(Thread Local Allocation Buffer),在TLAB上分配对象时不需要加锁,因此JVM在给线程的对象分配内存时会尽量的在TLAB上分配
82 | - TLAB是在 Eden区开辟的一小块线程私有区域 (TLAB大小取决于Eden space的大小)
83 |
84 | 10. 内存工具:
85 | - Valgrind:由内核以及基于内核的其他调试工具组成。内核类似于一个框架,它模拟了一个CPU环境,并提供服务给其他工具;而其他工具则类似于插件,利用内核提供的服务完成各种特定的内存调试任务。(可用来检测**内存泄漏**)
86 | - strace:跟踪系统调用的执行。最简单的方式,它可以从头到尾跟踪binary的执行,然后以一行文本输出系统调用的名字,参数和返回值。(可以用来看对于内存相关的系统函数调用)
87 | - MAT:JVM工具,通过堆得dump,来分析内存使用、对象引用等情况
88 |
89 | ------------
90 |
91 | 1. 堆和栈的区别
92 |
93 | | | 栈 | 堆 |
94 | | -------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
95 | | 管理方式 | 操作系统自动分配 | 程序人员控制 |
96 | | 空间 | 向低地址扩展,栈顶的地址和栈的最大容量是系统预先规定好的 | 高地址扩展。通常系统是用链表来存储空闲内存地址的。 |
97 | | 分配效率 | 高。操作系统提供的,会在底层堆栈提供支持,分配专门的寄存器存放栈的地址,包括压栈出栈也都有专门的指令执行 | 较低。例如分配一块内存,库函数会按照一定的算法在堆内存空间中搜索可用的足够大的内存空间,如果没有足够大的连续空间,则需要操作系统来重新整理堆内存,这样才有机会分到足够大小的空间,然后才返回 |
98 |
99 |
--------------------------------------------------------------------------------
/paper reading/benchmark/Benchmark.md:
--------------------------------------------------------------------------------
1 | ## Benchmark
2 |
3 | 1. TPC-C:
4 |
5 | OLTP的基准测试,也就是关注事务处理性能这一块,其性能由吞吐率衡量,单位是 tpm (transactions per minute)。
6 |
7 | 模拟了一个比较复杂并具有代表意义的OLTP应用环境:假设有一个大型商品批发商,它拥有若干个分布在不同区域的商品库;每个仓库负责为10个销售点供货;每个销售点为3000个客户提供服务;每个客户平均一个订单有10项产品;所有订单中约1%的产品在其直接所属的仓库中没有存货,需要由其他区域的仓库来供货。同时,每个仓库都要维护公司销售的十万种商品的库存记录。
8 |
9 | | 事务类型 | 解释 | 事务混合比 |
10 | | ------------ | -------------------------------- | ---------- |
11 | | New-Order | 客户输入一笔新的订货交易 | 最多45% |
12 | | Payment | 更新客户账户余额以反映其支付状况 | 最少43% |
13 | | Delivery | 发货(模拟批处理交易) | 最少4% |
14 | | Order-Status | 查询客户最近交易的状态 | 最少4% |
15 | | Stock-Level | 查询仓库库存状况 | 最少4% |
16 |
17 | 五种事务类型分别如下:
18 |
19 | - NewOrder: 是TPCC测试中的核心事务,特点是读写混合、高频发生并需要保证响应时间满足用户在线实时下单。并且为了模拟真实应用中,会有1%的NewOrder事务发生回退,代表订单的取消。
20 |
21 | - Payment: Payment事务代表客户对订单付款行为,并且需要更新客户账户余额,以及将交易记录更新到地区和仓库的销售统计信息中,特点是读写混合、高频发生且同样需要保证响应时间满足在线交易。
22 |
23 | - Delivery: 代表批量配送订单,对响应时间的要求较为宽松。
24 |
25 | - OrderStatus: 即模拟客户去查询自己最近一次订单的交易状态,为只读查询。
26 |
27 | - StockLevel: 查看系统的库存状态,该事务频率较低,且对响应时间要求不高。
28 |
29 | 2. [TPC-H](http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-h_v2.17.3.pdf):
30 |
31 | OLAP的基准测试,也就是关注分析处理性能这一块,包括 22 个查询(Q1~Q22),其主要评价指标是各个查询的响应时间,即从提交查询到结果返回所需时间。也可用 一个小时内能够完成的复杂交易数量 来衡量。
32 |
33 | 其schema如下
34 |
35 | 
36 |
37 | 几个查询的示例
38 |
39 | ```sql
40 | Q1:
41 | # 查询lineItems的一个定价总结报告。在单个表lineitem上查询某个时间段内,对已经付款的、已经运送的等各类商品进行统计,包括业务量的计费、发货、折扣、税、平均价格等信息
42 | select
43 | l_returnflag, //返回标志
44 | l_linestatus,
45 | sum(l_quantity) as sum_qty, //总的数量
46 | sum(l_extendedprice) as sum_base_price, //聚集函数操作
47 | sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
48 | sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
49 | avg(l_quantity) as avg_qty,
50 | avg(l_extendedprice) as avg_price,
51 | avg(l_discount) as avg_disc,
52 | count(*) as count_order //每个分组所包含的行数
53 | from
54 | lineitem
55 | where
56 | l_shipdate <= date'1998-12-01' - interval '90' day //时间段是随机生成的
57 | group by //分组操作
58 | l_returnflag,
59 | l_linestatus
60 | order by //排序操作
61 | l_returnflag,
62 | l_linestatus;
63 | ```
64 |
65 | ```sql
66 | Q2:
67 | 获得最小代价的供货商。得到给定的区域内,对于指定的零件(某一类型和大小的零件),哪个供应者能以最低的价格供应它,就可以选择哪个供应者来订货
68 | select
69 | s_acctbal, s_name, n_name, p_partkey, p_mfgr, s_address, s_phone, s_comment /*查询供应者的帐户余额、名字、国家、零件的号码、生产者、供应者的地址、电话号码、备注信息 */
70 | from
71 | part, supplier, partsupp, nation, region //五表连接
72 | where
73 | p_partkey = ps_partkey
74 | and s_suppkey = ps_suppkey
75 | and p_size = [SIZE] //指定大小,在区间[1, 50]内随机选择
76 | and p_type like '%[TYPE]' //指定类型,在TPC-H标准指定的范围内随机选择
77 | and s_nationkey = n_nationkey
78 | and n_regionkey = r_regionkey
79 | and r_name = '[REGION]' //指定地区,在TPC-H标准指定的范围内随机选择
80 | and ps_supplycost = ( //子查询
81 | select
82 | min(ps_supplycost) //聚集函数
83 | from
84 | partsupp, supplier, nation, region //与父查询的表有重叠
85 | where
86 | p_partkey = ps_partkey
87 | and s_suppkey = ps_suppkey
88 | and s_nationkey = n_nationkey
89 | and n_regionkey = r_regionkey
90 | and r_name = '[REGION]'
91 | )
92 | order by //排序
93 | s_acctbal desc,
94 | n_name,
95 | s_name,
96 | p_partkey;
97 | ```
98 |
99 |
100 |
101 | 3.
--------------------------------------------------------------------------------
/paper reading/data structure/LSM Tree.md:
--------------------------------------------------------------------------------
1 | ## LSM-Tree (Log-Structured Merge Tree)
2 |
3 | 1. 实际中应用:
4 | - **NoSQL**
5 | - BigTable
6 | - HBase
7 | - Cassandra
8 | - MongoDB
9 | - **Storage Engine**
10 | - LevelDB
11 | - RocksDB
12 | - NewSQL
13 | - TiKV
14 | - CockroachDB
15 |
16 | 2. 原本的LSM-Tree:
17 |
18 | 
19 |
20 | - Out-of-place update
21 | - Optimized for write: 单纯的append,很快
22 | - Sacrifice read: 一次读取可能有多次I/O,直到找到为止
23 | - Not optimized for space: 有很多过期数据,浪费一定空间(在merge阶段中回收)
24 | - Require data reorganization: merge / compaction
25 |
26 | 3. 现代结构(Level structure):
27 |
28 | 
29 |
30 | - **Read**:
31 |
32 | - **Point query**
33 |
34 | 有Read amplification问题,最差情况的I/O:2*(N-1+L0的文件数)。
35 |
36 | 优化:
37 |
38 | - Page cache / Block cache
39 |
40 | - Bloom filter (通过 filter 来减少不必要的 I/O,**不支持范围查询**)
41 |
42 | Level的每个文件有一个布隆过滤器,来确定该文件有没有这个key,有可能有的情况才会去读。
43 |
44 | - **Range query**
45 |
46 |
47 |
48 | 优化:
49 |
50 | - Parallel Seeks
51 | - Prefix bloom filter (RocksDB): like 'xx%'
52 | - SuRF (Sufficient Range Filter): Level-Ordered Unary Degree Sequence 的Trie树,节省内存
53 |
54 | - **Write**:
55 |
56 | - **Compaction**: 基本都是在**读放大**、**写放大**和**空间放大**这三者间做 trade-off
57 |
58 | > - 写放大
59 | > Write Amplification : 写放大,假设每秒写入10MB的数据,但观察到硬盘的写入是30MB/s,那么写放大就是3。写分为立即写和延迟写,比如redo log是立即写,传统基于B-Tree数据库刷脏页和LSM Compaction是延迟写。redo log使用direct IO写时至少以512字节对齐,假如log记录为100字节,磁盘需要写入512字节,写放大为5。
60 | > - 读放大
61 | > Read Amplification : 读放大,对应于一个简单query需要读取硬盘的次数。比如一个简单query读取了5个页面,发生了5次IO,那么读放大就是 5。假如B-Tree的非叶子节点都缓存在内存中,point read-amp 为1,一次磁盘读取就可以获取到Leaf Block;short range read-amp 为1~2,1~2次磁盘读取可以获取到所需的Leaf Block。
62 | > - 空间放大
63 | > Space Amplification : 空间放大,假设我需要存储10MB数据,但实际硬盘占用了30MB,那么空间放大就是3。有比较多的因素会影响空间放大,比如在Compaction过程中需要临时存储空间,空间碎片,Block中有效数据的比例小,旧版本数据未及时删除等等。
64 |
65 | - **Leveled**
66 |
67 | 向Ln层的压缩 将Ln-1层的数据 归并到Ln层,会重写先前 合并到Ln的数据。
68 |
69 | 最小化空间放大 和 读放大,
70 |
71 | - **Tired**
72 |
73 | 最小化写放大,但牺牲 读放大 和 空间放大
74 |
75 | 按照箭头的序号,插入一条kv记录时,kv先存入Log中;然后该条kv再插入到**有序的***MemTable*(保存了最近的更新)中。当日志文件达到一定大小的,对应的*MemTable*就会被转化为一个只读的*ImmutableMemTable*。接着创建新的日志文件和*MemTable*,同时后台会把 *ImmutableMemTable*保存为在磁盘上有序的*SSTable*。( Ln-1 is the Delta of Ln)
76 |
77 | 4. **Pipelined Compaction**
78 |
79 | 具体步骤:
80 |
81 | 1. Read data blocks
82 | 2. Checksum
83 | 3. Decompress
84 | 4. Merge sort
85 | 5. Compress
86 | 6. Re-checksum
87 | 7. Write to disk
88 |
89 | 5. **PebblesDB**
90 |
91 | 通过 **Guard**将key空间划分为多个不相交的单元,减小了写放大。
92 |
93 | 6. **WiscKey**
94 |
95 | *Separating Keys from Values in SSD - conscious storage*
96 |
97 | Compaction = 排序 + GC (只有Key是需要有序的,**通过Key-Value的分离,使得排序和垃圾回收分开进行**)
98 |
99 | KV分离的新问题:
100 |
101 | - 每次查询可能需要额外的一次I/O:WiscKey的LSM Tree较小,可直接存入内存
102 | - 范围查询需要随机I/O:利用SSD的并行I/O特性,进行prefetch
103 | - 将value日志和WAL结合
104 | - crash后的一致性
105 |
106 | **垃圾回收**
107 |
108 | LevelDB等之类LSM-tree的存储系统对于对象的删除只是追加删除标记,延期至sstable compaction的时候回收那些无效数据。
109 |
110 | > https://zhuanlan.zhihu.com/p/38810568
111 | >
112 | > log区有两个指针 head和tail。head指向当前新数据待写入的位置,而tail则指向当前待回收的位置。
113 | >
114 | > 当触发垃圾回收时,从tail位置读取一条记录,并从元数据判断其是否已经被删除:
115 | >
116 | > - 如果是,则tail向前移动至下一条记录
117 | > - 如果不是,则将该记录写入至head位置,接下来再将tail移动至下一条记录
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
--------------------------------------------------------------------------------
/paper reading/data structure/X-Tree.md:
--------------------------------------------------------------------------------
1 | ## The X-tree: An Index Structure for High-Dimensional Data
2 |
3 | 1. **问题**:高维数据的索引在很多应用中 变得越来越重要,然而当前所流行的R*-tree在很高维度的情况下 性能会急剧下降,其主要问题在于 Bounding Box的重叠。
4 |
5 | 2. **Contribution**:
6 |
7 | - 提出 X-树结构,使用了一种最小化overlap的算法来 分裂结点
8 | - 通过实验证明,当数据维度高于2时,X-树 比 TV-树和R*-树都要快
9 |
10 | 3. **实现细节**:
11 |
12 | - 使用了**基于R-树的结构**
13 |
14 | 因为不只要对 空间点数据进行索引,也要对扩展的空间数据进行索引,而R-树就同时适合这两种类型。
15 |
16 | - Overlap的定义
17 |
18 | 
19 |
20 | 如果查询的点遵守均匀分布,则Overlap可以定义为 超矩形交集的并÷超矩形的并;但如果查询的点不均匀、可能聚集在一些地方,则需要用 带权重的Overlap
21 |
22 | - X-树结构
23 |
24 | 
25 |
26 | - **Data node**
27 |
28 | 包含 **最小边界矩形** Minimum Bounding Rectangle、**指向实际数据的指针**。
29 |
30 | - **Directory node**
31 |
32 | 包含 **MBR**、**sub-MBR**
33 |
34 | - **SuperNode**
35 |
36 | large directory nodes of variable size(块大小的倍数)。目的是 防止directory分裂后形成低效的结构
37 |
38 | - **插入算法**
39 |
40 | ```c++
41 | int X_DirectoryNode::insert(DataObject obj, X_Node **new_node)
42 | {
43 | SET_OF_MBR *s1, *s2;
44 | X_Node *follow, *new_son;
45 | int return_value;
46 | // 找到数据插入的子树
47 | follow = choose_subtree(obj);
48 | // 将数据对象插入子树
49 | return_value = follow->insert(obj, &new_son);
50 | // 更新原子结点的MBR
51 | update_mbr(follow->calc_mbr());
52 | if (return_value == SPLIT){
53 | // 向当前结点插入子结点的MBR
54 | add_mbr(new_son->calc_mbr());
55 | if (num_of_mbrs() > CAPACITY){
56 | // 上溢出
57 | if (split(mbrs, s1, s2) == TRUE){
58 | // 可以做到最小化overlap的split
59 | set_mbrs(s1);
60 | *new_node = new X_DirectoryNode(s2);
61 | return SPLIT;
62 | } else {
63 | // 没有好的split方法
64 | *new_node = new X_SuperNode();
65 | (*new_node)->set_mbrs(mbrs);
66 | return SUPERNODE;
67 | }
68 | }
69 | } else if (return_value == SUPERNODE){ /
70 | // 如果follow结点称为超结点
71 | remove_son(follow);
72 | insert_son(new_son);
73 | }
74 | return NO_SPLIT;
75 | }
76 | ```
77 |
78 | - **Split算法**:返回是否可以最小化overlap
79 |
80 | ```c++
81 | bool X_DirectoryNode::split(SET_OF_MBR *in, SET_OF_MBR *out1, SET_OF_MBR *out2)
82 | {
83 | SET_OF_MBR t1, t2;
84 | MBR r1, r2;
85 | // 先尝试拓扑分裂
86 | topological_split(in, t1, t2);
87 | r1 = t1->calc_mbr(); r2 = t2->calc_mbr();
88 | // 测试overlap是否超出指标
89 | if (overlap(r1, r2) > MAX_OVERLAP)
90 | {
91 | // 尝试最小化overlap分裂
92 | overlap_minimal_split(in, t1, t2);
93 | // 测试结点是否平衡
94 | if (t1->num_of_mbrs() < MIN_FANOUT || t2->num_of_mbrs() < MIN_FANOUT) {
95 | // 都失败则生成supernode
96 | return FALSE;
97 | }
98 | }
99 | *out1 = t1;
100 | *out2 = t2;
101 | return TRUE;
102 | }
103 | ```
104 |
105 |
106 |
107 | 4. **Related Work**:
108 |
109 | - **Point transformation**
110 | - kdB-tree
111 | - grid file
112 |
113 | - 利用真实的高维空间数据是 **高度关联的**且**聚集的**特性,来进行降维 从而再使用传统的多维索引
114 | - Fastmap
115 | - multidimensional scaling
116 | - principal component analysis (PCA)
117 | - factor analysis
118 | - SS-树(基于R-树的索引结构)
119 | - 在大多数高维空间数据集中,只有小部分的维度承载了大部分的数据
120 | - TV-树: higher fanout and smaller directory
--------------------------------------------------------------------------------
/paper reading/query/Hyper-Pipelining Query Execution.md:
--------------------------------------------------------------------------------
1 | ## MonetDB/X100: Hyper-Pipelining Query Execution
2 |
3 | 1. **问题**:在计算密集型的应用(如 decision support、OLAP)中,数据库系统在现代CPU上只能取得较低的 IPC(instructions-per-cycle) 。一般来说,这些workload的计算都是相对独立的,从而CPU可以充分地进行并行流水线;但是 大多数DBMS采取的架构 **阻止了编译器使用最关键的性能优化技术**,从而导致了 低CPU效率。
4 | 2. **Contribution**:
5 | - 分析了内存数据库 MonetDB 以及其MIL查询语言 的性能
6 | - 提议将 MonetDB的 column-wise execution和 Volcano-style pipelining的增量式 materialization结合起来
7 | - 设计并实现了一个MonetDB新的查询引擎 X100,采用了一个 向量化的查询处理模型
8 |
9 | 3. 实现细节:
10 |
11 | - X100的**目标**
12 |
13 | - 在高CPU效率下 处理大量查询
14 | - 对于不同领域的应用具有可扩展性,如 数据挖掘、多媒体检索,且达到相同的高效率
15 | - 可根据disk的大小进行规模扩展
16 |
17 | - **架构**
18 |
19 | 
20 |
21 | - 不同的**bottleneck**
22 |
23 | - **Disk**
24 |
25 | X100的 ColumnBM I/O子系统 针对高效的顺序访问。使用了 **vertically fragmented**的data layout 来减少带宽的需求,有时也会引入轻量的数据压缩。
26 |
27 | - **RAM**
28 |
29 | 和Disk一样使用了 垂直的数据布局 以及 压缩数据来节省空间与带宽。包括了 平台相关的优化,比如 SSE(Streaming SIMD Extensions) 预取与 数据移动 的汇编指令。
30 |
31 | > SSE defines two types of operations; scalar and packed. Scalar operation only operates on the least-significant data element (bit 0~31), and packed operation computes all four elements in parallel. SSE instructions have a suffix -ss for scalar operations (*Single Scalar*) and -ps for packed operations (*Parallel Scalar*).
32 | >
33 | > **Prefetch Instructions**
34 | >
35 | > The prefetch instructions provide cache hints to fetch data to the L1 and/or L2 cache before the program actually needs the data. This **minimizes the data access latency**. These instructions are executed asynchronously, therefore, program **executions are not stalled while prefetching**.
36 |
37 | - **Cache**
38 |
39 | 基于 *vectorized processing*的模型,使用了 Volcano-like execution pipeline。X100执行原语的基本单元 是 cache常驻数据的垂直小块 small vertical chunks(比如1000个值)。cache是唯一不用考虑带宽的,因此压缩/解压的过程 发生在RAM与cache的边界上。
40 |
41 | - **CPU**
42 |
43 | 向量化的primitives,处理每个元组是独立的。
44 |
45 | - **执行实例**
46 |
47 | 
48 |
49 | 1. **Scan**操作符 从Monet BAT(Binary Association Table,包含了[*oid*, *value*]。BAT是一个两列的表,一列为 *Head*,另一列为 *Tail*)中 以vector-at-a-time的形式 取出数据。**只有查询相关的属性才会被扫描**。
50 | 2. **Select**操作符 创建了一个 *selection-vector*,该向量里是 匹配谓词的元组位置。
51 | 3. **Projection**操作符计算了最后aggregation需要的表达式。
52 | 4. 通过*map*原语 计算出相关元组,需要将 *selection-vector*传播到**Aggr**操作符(如虚线框所示)。
53 |
54 | - **数据存储**
55 |
56 | 
57 |
58 | 垂直存储的缺点是 **update cost越来越高**(一条row的更新 需要对每一列做一次I/O)。X100通过 将每个垂直片视作不可变对象immutable object 来规避这个问题,update则记录在delta区域。
59 |
60 | 如图中的delete操作,它把要删除的元组ID #5放入了 删除列表;insert操作 则会直接append,从而都只需要一次I/O。当delta区的大小 超过了整个表的一定比例,数据就会重新组织——清空delta区 使垂直片处于最新状态。
61 |
62 | 垂直存储的优点是 **如果查询会访问很多元组但又不需要所有的属性,则会节省带宽(RAM以及I/O带宽)**。同时 X100还通过 *lightweight compression* 来进一步减少 带宽需求。
63 |
64 | > **Memory bandwidth** is the rate at which data can be read from or stored into a semiconductor memory by a processor.
65 | >
66 | > Memory bandwidth that is advertised for a given memory or system is usually the maximum theoretical bandwidth. In practice the observed memory bandwidth will be less than (and is guaranteed not to exceed) the advertised bandwidth.
67 |
68 | 4. Related Work:
69 |
70 | - **Volcano**
71 |
72 | Volcano - an extensible and parallel query evaluation system, 1994
73 |
74 | - **MonetDB**
75 |
76 | Monet: A Next-Generation DBMS Kernel For Query-Intensive Applications, 2002
77 |
78 | - **block-at-a-time** query
79 |
80 | Buffering accesses to memory-resident index structures, 2003
81 |
82 | Buffering database operations for enhanced instruction cache performance, 2004
83 |
84 |
--------------------------------------------------------------------------------
/22 optimizer/22-optimizer.md:
--------------------------------------------------------------------------------
1 | ## Optimizer I
2 |
3 | 1. 没有优化器能真正产生"最优"计划:是[NP-完全问题](http://www.matrix67.com/blog/archives/105)
4 | - 使用**估计(estimation)**来预测真实的开销
5 | - 使用**启发算法(heuristics)**来限制搜索空间
6 |
7 | 2. 逻辑代数表达式 ------optimizer-----> 最优的、等价物理代数表达式
8 |
9 | - 关系代数表达式等价:两个关系代数表达式 在 **任何**(不能只是存在一个)合法的数据库实例上执行时 产生的元组集合相同。如:
10 |
11 | (A ⨝ (B ⨝ C)) = (B ⨝ (A ⨝ C))
12 |
13 | 3. 五个设计原则
14 | - 最优化粒度 Optimization Granularity
15 | - 最优化时机 Optimization Timing
16 | - 预编译语句 Prepared Statements
17 | - 计划稳定性 Plan Stability
18 | - 搜索终点 Search Termination
19 |
20 | 4. Optimization Granularity:
21 |
22 | - 单Query:
23 | - 搜索空间小
24 | - DBMS通常不会重用query之间的结果
25 | - 代价模型要考虑 是什么正在运行
26 | - 多Query:
27 | - 搜索空间大
28 | - 当有相似查询时,效率更高
29 | - 对于 数据/中间结果共享的情况 很实用
30 |
31 | 5. Optimization Timing
32 |
33 | - 静态:
34 | - 在**执行前**,就选择最佳计划
35 | - 计划的质量 取决于 代价模型的准确度
36 | - 在prepared stmts的帮助下,能分摊到各个执行上
37 | - 动态:
38 | - 在query执行时,动态选择计划
39 | - 多执行时会有 重优化(re-optimize)
40 | - 难以实现
41 | - 适应式/混合式:
42 | - 用一种静态算法编译
43 | - 若 **估计的误差 > 阈值**,重优化
44 |
45 | 6. Prepared Statements:三种选择
46 |
47 |  ==》
==》 48 |
49 | - 重优化:每次调用查询时都进行优化;难以重用已经存在的计划
50 | - 多计划:对于 params 不同值 生成多种plan
51 | - 平均计划:选择一个param的平均值,每次调用都用这个平均值
52 |
53 | 7. Plan Stability:三种选择
54 |
55 | - Hints:允许DBA给optimizer一些优化提示
56 | - Fixed Optimizer Versions:
57 | - Backwards-Compatible Plans:
58 |
59 | 8. Search Termination:三种方式
60 |
61 | - 定时:超过预设时间就停止优化
62 | - 阈值:直到找到 有比阈值更低代价的 plan
63 | - 穷尽:没有更多plan的变化方法
64 |
65 | 9. **最优化搜索策略**:
66 | - 启发式
67 | - 启发式 + 基于代价的联接顺序搜索(Cost-based join search)
68 | - 随机化算法
69 | - 分层(Stratified)搜索:Planning is done in multiple stages
70 | - 统一(unified)搜索:Perform query planning all at once
71 |
72 | 10. 启发式:
73 |
74 | - 尽早执行更严格的选择
75 |
76 | - 在联接前执行所有选择
77 |
78 | - 对 **projection/predicate/limit** 下推(pushdown)
79 |
80 | - 基于 基数的 联接顺序排序
81 |
82 | -----
83 |
84 | 优点:
85 |
86 | - 易实现,易调试
87 | - 对于简单查询很快
88 |
89 | 缺点:
90 |
91 | - 在估计一个计划的预期成效时,需要依赖魔法常量
92 | - 当操作符有复杂的依赖时,几乎不能生成好的计划
93 |
94 | 11. 启发式 + 基于代价的联接顺序搜索:
95 |
96 | - 初始优化使用静态的规则实现
97 |
98 | - 然后使用动态规划 来决定表联接的最佳顺序: 使用 分治法搜索来 自底向上(Bottom-up) 规划
99 |
100 | ------
101 |
102 | 优点:
103 |
104 | - 不用穷举搜索,通常也可以找到合理的执行计划
105 |
106 | 缺点:
107 |
108 | - 同 启发式
109 | - left-deep join tree 不一定总是最优的(只能串行 join,并且由于产生了大量的中间临时表;还有另外一种join order叫做 **bushy join tree**,可以并行)
110 | - 需要考虑 代价模型中数据的物理性质
111 |
112 | 12. 随机化算法:(如Postgres的遗传算法)
113 |
114 | - 在所有可能的执行计划构成的**解空间(solution space)**中随机搜索
115 | - 直到达到一个cost的阈值,或者经过一定长度的时间
116 |
117 | ------
118 |
119 | 模拟退火(simulated annealing)算法:
120 |
121 | - 起始点为 纯启发式规则
122 | - 计算不同操作符的排列组合(如交换两个表的联接顺序):
123 | - 只要减少cost,接受之
124 | - 当cost增加时,**有小概率会接受**之(防止陷入到局部极优值的解,而找不到全局最优解)
125 | - 如果会违反结果正确性(比如排序的顺序),拒绝之
126 |
127 | ------
128 |
129 | 优点:
130 |
131 | - 防止局部最优解
132 | - 低内存占用(不需要保留历史记录)
133 |
134 | 缺点:
135 |
136 | - 当DBMS选了某个方案后,难以得知它为什么要这么选
137 | - 需要额外的工作来验证算法的确定性
138 | - 需要实现 正确性的判断规则(保证每一轮变化的结果都是正确的)
139 |
140 | 13. 分层搜索:
141 |
142 | - 根据变换规则重写**逻辑查询(logical query)**:不考虑代价
143 | - 进入动态规划阶段来优化
144 |
145 | -------
146 |
147 | 优点:
148 |
149 | - 实际表现很好
150 |
151 | 缺点:
152 |
153 | - 难以指定变换的优先级
154 | - 规则是大问题
155 |
156 | 14. 统一搜索:(以Volcano 优化器为例)
157 |
158 | - 易于添加新的操作、新的等价规则
159 | - 把 数据的物理属性 当做第一成员
160 | - **自顶向下**:使用**分支定界(branch-and-bound)**搜索
161 |
162 | ----------
163 |
164 | 优点:
165 |
166 | - 使用声明式(declarative)规则来进行变换
167 | - 更好地扩展性
168 |
169 | 缺点:
170 |
171 | - 不易修改predicate
172 | - 在优化搜索前,所有等价类都被完全展开 来 生成所有的逻辑运算符
173 |
174 | 15. 查询优化很困难,甚至NoSQL一开始都没去实现它。
175 |
176 |
--------------------------------------------------------------------------------
/paper reading/query/Multi-Core, Main-Memory Joins.md:
--------------------------------------------------------------------------------
1 | ## Multi-Core, Main-Memory Joins: Sort vs. Hash Revisited
2 |
3 | 1. **问题**:随着多核体系架构的到来,人们认为sort-merge join比radix-hash join要更好(参考**[17 parallel join](https://github.com/F-ca7/Advanced-Database-Systems-Learning/tree/master/17%20parallel%20join)**),因为有 SIMD指令(当SIMD宽度足够时,sort-merge更快) 和 NUMA (*Non Uniform Memory Access Architecture*)架构。
4 |
5 | > NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(后称Remote Access)。
6 |
7 | 2. **Contribution**:
8 |
9 | - 证明了 大部分时候radix-hash 仍然比sort-merge快,只有当 涉及大量数据时,sort-merge的性能才接近radix-hash。
10 |
11 | - 给出了 在现代处理器上 其他数据操作(除join外)的见解
12 | - 给出了两种join的最快实现算法
13 | - 解释了影响算法选择的因素
14 |
15 | 3. **Related Work**:
16 |
17 | - 一旦硬件支持矢量指令,且宽度足够(如 具有256位及以上AVX的SIMD),sort-merge很容易击败 radix-hash. 参考 *Sort vs. hash revisited: Fast join implementation on modern multi-core CPUs*(2009)
18 | - 在 基于NUMA的实现中,即使不使用SIMD指令,sort-merge也可以比radix-hash快。参考 *Massively parallel sort-merge joins in main memory multi-core database systems*(2012)
19 | - **parallel radix join**
20 | - no-partitioning 的radix join. 参考 *Design and evaluation of main memory hash join algorithms for multi-core CPUs*(2011)
21 |
22 | 4. 影响算法的因素:
23 |
24 | - 输入大小 *input size*:
25 |
26 | 表的相对和绝对大小都对性能有很大的影响。随着大小的增长,关于 只有hash才会扫过数据多趟 的假设被打破,实验表明 sort-merge一样要过多趟数据,性能也会相应降低。
27 |
28 | - 并行度 *degree of parallelism*:
29 |
30 | 当并行度增加时,merge tree中的冲突也会变多。
31 |
32 | - cache竞争 cache contention:
33 |
34 | > **Cache contention** occurs when two or more CPUs alternately and repeatedly update the same **cache** line. This may be due to. memory **contention**, in which two or more CPUs try to update the same variables.
35 |
36 | - SIMD性能:
37 |
38 | 硬件特性起着很大的作用,并且发现SIMD寄存器的宽度并不是唯一的相关因素。更复杂的SIMD设计所固有的 **复杂硬件逻辑 hardware logic** 和**信号传播延迟 signal propagation delay** 可能导致延迟大于一个周期,从而限制了SIMD的优势。
39 |
40 | 5. 并行sort-merge:
41 |
42 | sort-merge join主要的cost就在排序上,通常使用归并排序。
43 |
44 | 1. **Run Generation**
45 |
46 | 使用 **排序网络** sorting network,奇偶归并排序网络也是一种比较器个数为O(n*logn*logn)的排序网络。它和归并排序几乎相同,不同的只是合并的过程。普通归并排序的O(n)合并过程显然是依赖于数据的,奇偶归并排序可以把这个合并过程改成非数据依赖型,但复杂度将变高。这个合并过程本身也是递归的。
47 |
48 | 2. **Merging Sorted Runs**
49 |
50 | 使用 双调合并 Bitonic Merge Networks来合并大的列表。
51 |
52 | > 对于两个元素x,y,如果x<=y,则x,y都位于双调序列的递增部分,而递减部分没有元素,如果x>=y,则x,y都位于双调序列的递减部分,而递增部分没有元素,于是x和y构成一个双调序列。因此,任何无序的序列都是由若干个只有2个元素的双调序列连接而成。
53 | >
54 | > 于是,对于一个无序序列,我们按照递增和递减顺序合并相邻的双调序列,按照双调序列的定义,通过连接递增和递减序列得到的序列是双调的。最终,我们可以将若干个只有2个元素的双调序列合并成1个有n个元素的双调序列。
55 | >
56 |
57 | 6. Cache conscious sort join
58 |
59 | 分为三个阶段:
60 |
61 | - **寄存器内排序 in-register**
62 |
63 | 对应了 Run Generation
64 |
65 | - **高速缓存内排序 in-cache**
66 |
67 | 对应了 双调排序
68 |
69 | - **高速缓存外排序 out-of-cache**
70 |
71 | 继续merge直到所有数据有序(超出了cache的大小,需要到内存中排序)
72 |
73 | 7. Hash join
74 |
75 | 随机访问内存,会导致缓存miss(当hash表大于cache时,基本上每次访问hash表都会发生cache miss),可通过partition来解决。
76 |
77 | - **Radix Partitioning**
78 |
79 | 在Partition阶段 考虑到 TLB translation look-aside buffers(**地址变换高速缓存**,省去了一次访问内存的时间)的影响。*Radix Partitioning*把每个元组写到他们对应的划分中:
80 |
81 | ```c#
82 | foreach input tuple t do
83 | k := hash(t)
84 | p[k][pos[k]] = t
85 | pos[k]++
86 | ```
87 |
88 | - **Software-Managed Buffers**
89 |
90 | 先分配一组buffer,其中每个buffer供输出的划分使用(可容纳*N*个元组),当buffer满了后再拷贝到最终的目的地。
91 |
92 | 有两层好处:1. 更少的趟数能达到同样
93 |
94 | 在本文实现中,就使用了Software-Managed Buffers,其中N的大小恰好使buffer装入一个cache line(64 bytes)
95 |
96 | 8. 具体join算法
97 |
98 | - Sort-Merge **m-way**
99 |
100 | - Sort-Merge **m-pass**
101 |
102 | - Massively Parallel Sort-Merge **mpsm**
103 |
104 | 通过Software-Managed Buffer对R进行划分,将R分配给不同NUMA的区域或线程,每个线程对自己区域内的数据进行排序。
105 |
106 | - Radix Hash **radix**
107 |
108 | - No-Partitioning Hash **n-part**
109 |
110 | 将关系**R**和**S**划分为大小相等的部分,分配给工作线程。每个worker把负责的关系**R**的元组填充到hash表,再在**S**中找到匹配的元组。
--------------------------------------------------------------------------------
/04 concurrency control/4-occ-notes.md:
--------------------------------------------------------------------------------
1 | ## Optimistic Concurrency Control
2 |
3 | 1. 减少 由于使用对话式API 造成的stall:
4 |
5 | - **Prepared Statement**:消除了query准备的开销(query preparation overhead)
6 |
7 | > Overhead——overhead is any combination of excess or indirect computation time, memory, bandwidth, or other resources that are required to perform a specific task.
8 |
9 | - **Query Batches**:减少网络的往返次数
10 |
11 | - **Stored Procedures**:同时减少 准备的开销和网络的时延
12 |
13 | 数据库系统中,一组为了完成特定功能的 SQL 语句集,这些SQL语句集存储在数据库中,经过第一次编译后,后续调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
14 |
15 | 2. **Prepared Statement**的优点
16 | - Less overhead for parsing the statement each time it is executed. 很多时候数据库执行的语句都是一样的,只是 WHERE的条件不一样/ UPDATE 设的值不一样 等。
17 | - Protection against SQL injection attacks. 语句中使用了占位符,规定了sql语句的结构。用户可以设置"?"的值,但是不能改变sql语句的结构。因此可以防sql注入。
18 |
19 | 3. **Stored Procedures**的优点
20 |
21 | - 减少应用程序与数据库服务器之间的 网络往返
22 | - 由于query预编译好并存储在DBMS中,可以提高性能
23 | - 可以在不同应用中被 复用
24 | - 发生冲突时,服务端的事务会重启
25 |
26 | **Stored Procedures**的缺点
27 |
28 | - 不是大部分开发者都会写SQL/PSM代码
29 | - 在应用程序的范围之外,难以管理版本与调试
30 | - 不一定能移植到别的DBMS
31 | - DBA不会授予权限
32 |
33 | 4. 并发控制方案:
34 |
35 | - Two-Phase Locking (2PL 两阶段锁 **悲观**):假设事务之间会发生冲突,当要访问数据库对象时,必须获得锁。
36 | - Timestamp Ordering (T/O 基于时间戳 **乐观**):假设事务之间的冲突概率很小,访问数据库对象时不需要获得锁;而是在提交时检查是否有冲突。
37 |
38 | 
39 |
40 | 5. **2PL** ——早期的数据库已经通过严格两阶段锁协议(S2PL,Strict Two-Phase Locking)实现了完全的串行化隔离(Serializable Isolation),即正在进行读操作的数据阻塞对应写操作,写操作阻塞所有操作(包括读操作和写操作)。但存在死锁现象:
41 | - **死锁检测** Deadlock Detection:
42 | 1. 每个事务维护一个队列,队列元素是所有持有 该事务等待的锁 的其他事务。
43 | 2. 一个独立的线程会检查所有的队列是否存在死锁。
44 | 3. 发现死锁时,使用启发式算法来决定终止(kill)哪个事务。
45 | - **死锁预防** Deadlock Prevention:
46 |
47 | 6. **Basic 基于时间戳** 协议如下
48 |
49 | - 每个事务到达DBMS时,分配一个唯一的时间戳
50 |
51 | - DBMS为 每一个元组 维护最后一个读/写该元组的事务 对应的时间戳
52 |
53 | - 每次事务访问元组时,会对比元组的时间戳和自己的时间戳,来检测冲突(每次都检测,不是乐观)
54 |
55 | - DBMS需要把一个元组拷贝到 事务的**私有空间**private workspace 来实现**可重复读**repeatable reads
56 |
57 | > Read uncommitted(读未提交):事务中的修改,即使没有提交,在其他事务也都是可见的。结果:产生脏读。
58 |
59 | > Read committed(读已提交):一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的。这个级别有时候也叫做不可重复读,因为在**一个事务中执行多次相同的查询**,可能会得到**不一样的结果**。因为在这多次读之间可能有其他事务更改这个数据,每次读到的数据都是已经提交的。结果:产生不可重复读。
60 |
61 | > Repeatable read(可重复读):解决了脏读,也保证了在同一个事务中多次读取同样记录的结果是一致的。但是理论上,可重复读隔离级别还是无法解决另外一个幻读的问题,指的是当某个事务在读取某个范围内的记录时,另外一个事务也在该范围内插入了新的记录或删除了原有的记录,当之前的事务再次读取该范围内的记录时,好像产生幻觉。结果:产生幻读。
62 |
63 | > Serializable(可串行化):它通过强制事务**串行执行**,避免了前面说的幻读的问题,但由于读取的每行数据都加锁,会导致大量的锁征用问题,因此性能也最差。
64 |
65 | -----
66 |
67 | ### 乐观并发控制
68 |
69 | 把所有改变保存在私有空间中,在提交时才检查冲突再合并。
70 |
71 | 7. 三个阶段:
72 |
73 | - Read Phase: (不是字面上的只有读操作) 把事务要访问的元组拷贝到私有空间,来实现可重复读;同时还要记录它读/写的集合。
74 |
75 | - Validation Phase: 当事务**COMMIT**时,DBMS检查它是否与其他事务发生冲突。每个事务需要按顺序(global order)获取 其**写集合**对应record的锁。
76 |
77 | - Backward Validation: 检查正在提交的事务的 读/写集合 是否与其他**已提交**的事务有交集。
78 |
79 | 
80 |
81 | - Forward Validation: 检查正在提交的事务的 读/写集合 是否与其他**未提交**的事务有交集。
82 |
83 | 
84 |
85 | - Write Phase: DBMS应用 事务write的修改,并使这些修改对其他事务可见。每个record更新成功后,该事务要释放对应的锁。
86 |
87 | 8. [时间戳分配](https://dspace.mit.edu/bitstream/handle/1721.1/100022/Devadas_Staring%20into.pdf)
88 | - Mutex:最坏的选择
89 | - Atomic Addition:使用CAS(compare-and-swap)来递增一个全局变量
90 | - Batched Atomic Addition:Needs a back-off mechanism to prevent fast burn
91 | - Hardware Clock: The CPU maintains an internal clock (not wall clock) that is synchronized across all cores. Intel only. 未来CPU中不一定存在硬件时钟
92 | - Hardware Counter:目前CPU中未实现
93 |
94 | 9. [Silo](https://github.com/stephentu/silo)内存型数据库,使用并行的Backward Validation实现可串行化的OCC。两个核心思想:
95 | - 避免对 **只读事务**的**共享内存** 的所有**写操作**
96 | - 使用epoch来进行批量时间戳分配
97 |
98 | 10. Silo实现细节如下:
99 | - Epoch
100 | - 时间被划分为**定长**的epoch(40ms)
101 | - 在同一个epoch内开始的事务 最终会在同一个epoch的末尾**一起提交**
102 | - 若事务时长超过1个epoch,则要自己刷新才能进入下一个epoch
103 | - 工作线程只需要在每个epoch的开始和结束 进行同步
104 | - Transaction ID
105 | - 每一个工作线程 会基于当前epoch号以及已赋值批次的下一个值 来生成唯一的事务ID号
106 | - Garbage Collection
107 | - 协作式线程的垃圾回收Cooperative threads GC
108 | - 每个工作线程 通过一个**reclamation epoch** 标记一个已删除的对象 (这是一个[内存型数据库](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/02%20in-memory%20db/2-imdb-notes.md))
109 | - Range Query
110 | - 通过 记录事务在索引上的scan集合 来解决幻读问题
111 | - 在 validation phase 重新执行扫描,看索引是否发生变化
112 | - Have to include virtual entries for keys that do not exist in the index to prevent two threads from trying to insert the same key.
113 |
114 |
115 |
116 |
--------------------------------------------------------------------------------
/paper reading/cloud/Above the Clouds - A Berkeley View of Cloud Computing.md:
--------------------------------------------------------------------------------
1 | ## Above the Clouds: A Berkeley View of Cloud Computing
2 |
3 | 2009
4 |
5 | 1. 什么是云计算?
6 |
7 | 云计算指:通过网络,将应用程序 以及相应的数据中心中的硬件与系统 作为服务提供。
8 |
9 | 其中,**把应用程序本身作为服务 是称为SaaS,而数据中心的软硬件称为 云 Cloud**。
10 |
11 | 2. 为什么云计算在近年腾飞,而以前的尝试却失败了?
12 |
13 | 从硬件的角度看,云计算在以下三方面有创新之处:
14 |
15 | 1. 可按需提供无限计算资源的假象,消除了云计算用户提前计划资源调配的需要
16 | 2. 允许企业从小规模做起,只有在需求增加时才增加硬件资源
17 | 3. 根据需要在短期内(例如按天存储)为计算资源的付费,并根据需要对它们进行释放
18 |
19 | 过去在效用计算(utility computing,服务提供商提供客户需要的计算资源和基础设施管理,并根据应用所占用的资源情况进行计费,而不是仅仅按照速率进行收费)上的努力失败了,作者认为 是因为 云计算这三个关键特征中的一个或两个缺失了。
20 |
21 | 3. 成为云计算提供商需要什么条件?为什么一家公司会考虑成为云计算提供商?
22 |
23 | 以下原因可能让一家公司会考虑成为云计算提供商:
24 |
25 | - **更高利润**:大型数据中心 花在硬件、网络带宽、电力上的消费 只有中型数据中心的1/5到1/7;且软件开发和部署的固定成本 可以由在更多的机器上运行而分摊。因此一家足够大的公司可以利用这些规模经济,提供远低于中型公司成本的服务,同时还能获得可观的利润
26 | - **利用现有投入**:在现有基础设施之上来构建云计算服务,以较低的成本增量提供新的收入流,有助于分摊数据中心的大量投入
27 | - **特许经营权**franchise:比如Microsoft Azure为将其企业应用程序的现有客户 迁移到云环境提供了更方便的路径
28 | - **向现任者发起挑战**
29 | - **利用客户关系**:像IBM Global Services 这样的IT组织有广泛的客户关系,那么提供品牌化的云计算产品可以为这些客户提供一条没有担忧的迁移路径,从而保护双方的投资
30 | - **自己成为平台**:比如Facebook使用插件化的App这一举措非常适合云计算(其一个基础设施提供商就是[Joyent](https://www.joyent.com/))
31 |
32 | 4. 云计算带来了哪些新机遇?
33 |
34 | 5. 如何当前的云计算产品进行分类?特定产品的类别不同,其技术和业务挑战有是否有相应不同?
35 |
36 | 6. 云计算带来了哪些新的经济模式?服务运营商如何决定 是转移到云计算 还是 留在私有数据中心?
37 |
38 | 云计算下的经济模式特点:
39 |
40 | - 云计算支持的细粒度经济模型使**决策更具流动性**,特别是云提供的**弹性有助于转移风险**
41 | - 尽管硬件资源成本继续下降,但它们的下降速度是裱花的;例如,计算和存储成本的下降速度要快于WAN。云计算可以记录这些变化,并其传递给客户,比他们建设自己的数据中心更高效,从而使支出与实际资源使用更接近
42 | - 在决定是否将现有服务移动到云上时,还必须检查预期的平均资源利用率和峰值资源利用率,特别是当应用程序可能具有高度可变的资源需求峰值时;对购买设备的实际利用率的实际限制;以及所需的各种运营成本根据所考虑的云环境的类型而有所不同
43 |
44 | 是否迁移到云的成本比较:
45 |
46 | - 按单独资源付费
47 | - 电力、冷却和物理设备成本
48 | - 运维成本
49 |
50 | 7. 云计算的十大障碍是什么?克服这些障碍相应的机遇有哪些?
51 |
52 | 1. **服务可用性:**
53 |
54 | 作者认为,实现极高可用性的唯一可行解决方案是多个云计算供应商。高可用性计算社区长期以来一直奉行“没有单点故障”原则,然而,由单公司负责云计算服务实际上也是一种单故障点。即使公司在不同的地理区域拥有多个数据中心,使用不同的网络供应商,它也可能拥有通用的软件基础设施和会计系统,甚至公司可能倒闭。如果没有针对这种情况的业务连续性战略,大客户将不愿意迁移到云计算。
55 |
56 | 另一个可用性的障碍是 DDoS攻击。云计算将攻击目标从SaaS供应商转移到效用计算供应商,后者通过弹性可以更容易地吸收攻击,而且也可能已经将DDoS保护作为核心能力。
57 |
58 | 2. **数据的锁定**(data lock-in):
59 |
60 | 客户无法轻松地从一个地方提取数据 放到另一个地方。由于担心从云中提取数据的难度很大,一些组织无法采用云计算。
61 |
62 | 这种lock-in可能对云计算供应商有利,但云计算用户很容易受到价格上涨、可靠性、甚至供应商倒闭的影响。
63 |
64 | > 可参考[供应商锁定](https://zhuanlan.zhihu.com/p/350736696) vender lock-in:
65 | >
66 | > 是指切换到其他供应商的成本非常高、以至于客户不得不继续使用原始供应商的情况。由于财政压力、人手不足,或需要避免业务运营中断,客户可能在产品或服务质量不佳时被锁定。
67 |
68 | 一种解决方案是 将API标准化,从而SaaS开发人员可以跨多个云计算提供商部署服务和数据。但是这样做可能会导致 云产品的定价相互**竞次**(race-to-the-bottom),也就是比谁更能达到底线,肯定会损害云计算供应商的利益。对此,作者提出了两个看法:
69 |
70 | - 云服务的质量和价格都是同等重要的,所以顾客不一定会选择价格最低的服务。比如当今一些互联网服务供应商的价格比其他供应商高出10倍,因为他们更可靠,并提供额外的服务来提高可用性。
71 | - 标准化的API还支持一种新的模型——相同的软件基础设施可以在私有云和公共云中使用。从而支持 **激增计算**(surge computing),即使用公共云来处理 由于临时突增的工作负载而无法在私有云轻松完成的任务
72 |
73 | > 最近看到[这篇博文](https://www.intercom.com/blog/ten-technical-strategies-to-avoid-when-scaling-your-startup-and-five-to-embrace)则指出,目前对于大部分企业来说 需要避免多云架构,因为这属于一种过早优化( premature optimization),除非是像Apple或Netflix的企业、或者已经占据了互联网大量流量。更合理的应该是选择一个好的云供应商。
74 | >
75 | > We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.
76 |
77 | 3. **数据保密性和可审核性**(Confidentiality and Auditability):
78 |
79 | 作者相信,要使云计算环境像绝大多数内部IT环境一样安全,没有任何根本性的障碍,许多问题可以通过已知的技术(如加密存储、虚拟局域网和网络中间件设备 如防火墙、数据包过滤器)。例如,在将数据放入云中之前对其进行加密,可能比在本地数据中心中对进行加密更安全。
80 |
81 | 4. **数据传输瓶颈:**
82 |
83 | 如今的应用程序继续变得更加数据密集,数据传输成本成为一个重要问题。云用户和云供应商必须如果想把成本降到最低,就要考虑系统各个层次的布局和流量的影响。
84 |
85 | 一种解决方案就是 直接运输磁盘。Jim Gray指出传输大量数据最便宜的方法是通过隔夜快递 发送磁盘甚至整个计算机。尽管磁盘或计算机的制造商无法保证这种运输方式的可靠性,但Gray在大约400次尝试中只经历了一次失败(甚至可以通过以类似RAID的方式传送带有冗余数据的磁盘来缓解这一问题)。
86 |
87 | 其次,由于像亚马逊、谷歌和微软这样的公司发送的数据可能比接收的数据多得多,因此入口带宽的成本可能要低得多,所以可以考虑**异地归档和备份**服务。因此,例如,如果每周的完整备份是通过运送物理磁盘来移动的,而压缩后的每日增量备份通过网络发送,那么云计算可能可以提供价格合理的异地备份服务。并且,一旦归档数据进入云中,就能提供更多的新服务。比如为归档数据创建可搜索的索引,或对所有存档照片执行图像识别 从而进行分组。
88 |
89 | 还有更激进的思路是 尝试更快地降低广域网带宽的成本。据估计,广域网带宽成本的三分之二是高端路由器的成本,而只有三分之一是光纤成本,所以有研究在寻找高端分布式路由器的低成本替代品。
90 |
91 | 5. **性能的不可预测性**:
92 |
93 | 从经验上来看,在云计算中,多个虚拟机可以很好地共享CPU和内存,但IO方面的问题很大。
94 |
95 | 一种可能是使用闪存来减少IO的相互干扰。闪存在断电时可以保存信息,且不像磁盘需要转动来访问,速度更快。与磁盘相比,闪存每秒可以支持更多的I/O,因此随机I/O workload的多个虚拟机,可以在同一台物理机上更好地共存。
96 |
97 | 6. **可扩展的存储:**
98 |
99 | 如何创建一个存储系统与云的优势结合起来。即满足在资源管理方面对**可伸缩性**、**数据持久性**和**高可用性**的期望
100 |
101 | 7. **大型分布式系统存在的Bug:**
102 |
103 | 大型分布式系统中出现的bug,很多都无法在小规模的环境下复现,所以不得不在大规模生产环境中进行debug。
104 |
105 | 相应的方法比如:依靠云环境的虚拟化,来获取有价值的错误信息。
106 |
107 | 8. **快速扩缩容**:
108 |
109 | 存储、网络是现用现付(pay as you go)的,都是按使用的大小计算,如何能在不违反SLA的情况下 快速扩缩容来节省成本?
110 |
111 | 9. **声誉共同体**(Reputation Fate Sharing):一个客户的不良行为会影响整个云的声誉。例如,垃圾邮件防范服务将EC2 IP地址列入黑名单,可能会对其他应用造成影响。相对应的,另一个问题是法律责任的转移问题,也就是云计算提供商希望法律责任由客户承担而不是转移给他们(即发送垃圾邮件的公司应该承担责任,而不是Amazon本身)。
112 |
113 | 10. **软件许可:**
114 |
115 | 许多云供应商基于开源软件开发的原因,部分就是由于商业软件不适合效用计算的场景。
116 |
117 | 所以未来要么开源软件继续越来越受欢迎,要么商业软件公司就要对云环境下的许可作出相应调整。
118 |
119 | 8. 未来的应用软件、基础设施和硬件的设计应该做出哪些改变,以适应云计算的需求和机遇?
120 |
121 | - 软件:出售给企业客户 和 给云计算有不同的定价。
122 | - 基础设施:需要意识到 不是在裸金属上运行,而是在虚拟机中。
123 | - 硬件:
124 | - 需要面向多个机架的规模设计
125 | - 可以将内存、存储器和网络的空闲部分置于低功耗模式来做到能耗均衡
126 | - 提高数据中心交换机 和 WAN路由器的带宽,且降低成本
--------------------------------------------------------------------------------
/paper reading/dbms/Scalable Garbage Collection for In-Memory.md:
--------------------------------------------------------------------------------
1 | ## Scalable Garbage Collection for In-Memory MVCC Systems
2 |
3 | 1. **问题**:支持HTAP的数据库系统通常都使用MVCC,而MVCC会产生很多过期的元组版本,最终需要被回收。但是我们发现HTAP中的GC通常是一个性能瓶颈。在长query中,最先进的GC方法的粒度过粗,从而版本的数量会迅速增加 使得整个系统变慢;同时 标准的后台清理方法 会使系统的工作量突增。
4 |
5 | 2. **Contribution**:
6 |
7 | - 提出一种创新的GC方法,*Steam*,来剪枝过时的版本,可以无缝地融合到事务处理过程中,使得GC的开销最小
8 | - 该方法可以处理混合的workload,并在OLTP上 与state-of-the-art方法进行对比
9 |
10 | 3. **实现细节**:
11 |
12 | - GC的恶性循环
13 |
14 | 
15 |
16 | 在长事务中,所有使用到的version都不能被丢弃,而版本链越长,每次取得版本对应的数据就越慢,从而事务执行时间就越长,导致版本仍不能被回收,从而形成了恶性循环。
17 |
18 | - **Basic Design**
19 |
20 | *Steam*基于HyPer的MVCC实现来扩展,使其更加的robust和scalable。开始一个新事务时,系统把它添加到 *active transaction*列表后。当一个事务提交后,系统再将其移动至 *committed transaction*列表。
21 |
22 | 以上的两个list都隐式地 按事务的时间顺序排序,从而可以高效地取到 最小的 开始时间戳(即*active transaction*列表的第一个),则 *committed transaction*中 *commitId* ≤ min(*startTs*)的版本可被安全回收。
23 |
24 | 下面的实现重点关注三个方面:**scalability**, **long-running transaction**, **memory-efficient**
25 |
26 | - **Scalable Synchronization** —— scalability
27 |
28 | 前面提到的list方法可以在常数时间内进行GC,但是其可扩展性非常有限,因为 维护两个全局列表需要全局的mutex。因此,需要避免全局的数据竞争。如Hekaton使用一个 latch-free的transaction map来避免全局互斥锁。
29 |
30 | 而*Steam*遵循了 最好使用不需要同步的算法 的范式 (Latch-free synchronization in database systems: Silver bullet or fool’s gold? 2017)。它使用多条线程来分别管理 事务不相交的子集,每条线程会暴露给外部 自己本地的最小值(使用一个64位的atomic整型存储),如果当前线程没有 活动中的事务,则将值设置为最大的整型;因此只要扫描一次所有线程的本地最小值,就可知道全局的可回收的最小值。
31 |
32 | 
33 |
34 | 为了防止线程处于空闲状态而导致 GC被延迟,调度器会周期性地检查线程是否进入空闲状态、如果有必要的话进行GC
35 |
36 | - **Eager Pruning of Obsolete Versions** —— long-running transaction
37 |
38 | 
39 |
40 | 在遍历版本链时,无用的版本会使长事务变得更慢;因此设计了 Eager Pruning of Obsolete Versions,在版本不被活动中的事务所需要时,将它们都移除。
41 |
42 | 当一个线程进入版本链时,使用如下算法来剪枝掉过时的版本:
43 |
44 | ```c
45 | input: 有序的active timestamps
46 | output: 剪枝后的version chain
47 | curVer := getFirstVersion(chain)
48 | for a in A
49 | visVer := retrieveVisbleVersion(a, chain)
50 | for v in (curVer, visVer)
51 | // 保证最后一个版本包含了所有属性
52 | if v.attrs不是visVer.attrs的子集
53 | merge(v, visVer)
54 | chain.remove(v)
55 | curVer = visVer
56 | ```
57 |
58 | 因为只会在版本record中保存 发生改变的属性(节省内存),所以需要检查visVer是否包含了所有v的属性,若v有多出来的属性,则将其合并到最终版本中。在*Steam*中,每次一个元组更新时就会相应有一次prune(也就是版本链要加入新版本的时候)。
59 |
60 | - **Layout of Version Records** —— memory-efficient
61 |
62 | 一条版本的record 应该是空间上和计算上高效的,由3部分组成:
63 |
64 | - *Common Header*
65 |
66 | 包括
67 |
68 | - Type {如Insert/Update/Delete}
69 | - Version {可见性,在提交时Version就设置为提交时的时间戳}
70 | - RelationId {当事务回滚时,使用RelationId 和 TupleId 来恢复关系中的元组}
71 |
72 | - *Additional Fields*
73 |
74 | 包括
75 |
76 | - Next Pointer {版本链中指向下一个版本}
77 | - TupleId
78 | - NumTuples
79 | - AttributeMask {每个bit对应该表的一个属性}
80 |
81 | - *Payload*
82 |
83 | 包括
84 |
85 | - BeforeImages {只保存改变的属性}
86 | - Tuple Ids {可以复用Next Pointer来更好地管理批量插入}
87 |
88 |
89 |
90 | 4. **Related Work**:
91 | - **Tracking Level**
92 |
93 | 最细的粒度是**元组级别**,GC在扫描过每个元组后识别出 过时的版本(通常使用一个后台的清理进程来周期性清理)。
94 |
95 | 有些系统**基于事务**来管理版本。由同一个事务创建的版本 使用相同的commit时间戳,所以可以同时找到多个过时版本 并清理。
96 |
97 | 而**基于epoch**的系统 将多个事务同一个epoch中,epoch可根据 已分配内存或版本号数目的阈值 来判断是否进入下一个epoch。
98 |
99 | 最粗的粒度是**表级别**。只对 规定了特定操作的workload适用,比如 stored procedures 和 prepared statements;因此比较少用。
100 |
101 | - **Frequency and Precision**
102 |
103 | Frequency and precision indicate how quickly and thoroughly a GC identifies and cleans obsolete versions.
104 |
105 | *HANA* 和 *Hekaton* 就使用了**后台线程**(周期性调起用于GC),但是如果频率不够高的话,GC的决定就可能基于过时的信息。
106 |
107 | *BOHM* 则以**batch**的形式来管理执行事务,在每个batch的末尾来GC,保证该batch的每个事务已经完成。
108 |
109 | 而GC的彻底程度 取决于 GC如何辨别version是否可回收。**基于时间戳**的identification 不如 **基于区间**的方法 彻底。
110 |
111 | - **Version Storage**
112 |
113 | 大多数系统将version records存储在一个全局的数据结构中,如哈希表,从而可以 独立地回收单个版本。
114 |
115 | *HyPer* 和 *Steam*直接将版本保存在事务内,即 ***Undo Log***。当事务落后于high watermark是,其所有版本都可以一起回收。总之,用Undo log作为版本的存储也很好,因为Undo log是本来就需要用来回滚的。
116 |
117 | > 高水位(high watermark),通常被用在流式处理领域(比如Apache Flink、Apache Spark等),以表征元素或事件在基于时间层面上的进度。一个比较经典的表述为:流式系统保证在水位t时刻,创建时间(event time)= t'且t' ≤ t 的所有事件都已经到达或被观测到。
118 |
119 | *Hekaton*的版本管理则很特别,它不使用连续的表空间;元组的版本只能通过索引来访问( does not distinguish between a version record and a tuple)。唯一一个在探讨的系统中 使用O2N来排序的;O2N会使 写-写冲突检测更加昂贵,因为事务需要遍历整条版本链 来检测发生冲突的版本。
120 |
121 | - **Identification**
122 |
123 | commit时间戳是单调分配的,则很容易识别过时的版本。
124 |
125 | *HANA* 和 *Steam* 使用一种更细粒度、基于区间的方式,保证版本链长度最小,只是实现起来复杂。*HANA* 使用一个*引用计数表* 来追踪所有开始与同一时刻的事务——*Global STS Tracker*
126 |
127 | - **Removal**
128 |
129 | *HANA*中 整个GC是由专门的后台线程 周期性完成的。*Hekaton* 则在事务处理过程中就可以 进行version的清除,但这只适用于O2N的顺序。
130 |
131 | *HyPer*和*Steam*则在**前台**进行GC任务,将GC任务分散在 事务处理的过程间。一旦发现过时的版本,就会在每次commit后将它们回收。
132 |
133 |
--------------------------------------------------------------------------------
/paper reading/dbms/mysql/性能参数相关调优.md:
--------------------------------------------------------------------------------
1 | ## Mysql性能参数相关调优
2 |
3 | 影响性能的参数可分为三个方面(对于参数本身的含义可参考https://dev.mysql.com/doc/refman/8.0/en/server-system-variables.html):
4 | - 数据库连接
5 | - 内存
6 | - IO
7 |
8 | 1. **数据库连接**
9 |
10 | - `back_log:` The number of outstanding connection requests MySQL can have.
11 |
12 | 当Mysql的主线程在短时间内收到大量的连接器请求时,该参数起作用,可以理解为它决定了MySQL未处理的TCP连接的队列大小(所以肯定不能超过操作系统本身的limit)。因此,如果确实在短时间可能有大量连接时,需要将该参数调大一些。
13 |
14 | > 内核参数`net.ipv4.tcp_max_syn_backlog`定义了处于`SYN_RECV`的TCP最大连接数,当处于`SYN_RECV`状态的TCP连接数超过`tcp_max_syn_backlog`后,会丢弃后续的SYN报文
15 | >
16 | > 如果想临时修改,可以使用`sysctl -w net.ipv4.tcp_max_syn_backlog = 2048`命令,但重启后会丢失;想永久保留配置,可以编辑`/etc/sysctl.conf`:net.ipv4.tcp_max_syn_backlog = 2048,执行`sysctl -p`命令默认从`/etc/sysctl.conf`中加载系统参数。
17 |
18 | 其默认值为`max_connections`,但要注意和`max_connections`参数的区别。`max_connections`参数决定了最大的客户端连接数,当连接超过该数值时,会报错too many connections。
19 |
20 | - `table_open_cache`: The number of open tables for all threads. Increasing this value increases the number of file descriptors that **mysqld** requires.
21 |
22 | 该参数太小的话,性能会下降;太大的话,可能会OOM。当`Opened_table`的值太大时(且不经常使用`FLUSH TBALES`命令来强制关闭所有打开的表,该命令同时也会清楚prepared statement的缓存),说明`table_open_cache`太小。
23 |
24 | 该参数与`max_connections`参数相关联,对于单个进程来说,OS会对文件描述符的数量作出限制(Linux内核会为每一个进程在/proc/ 建立一个以其pid为名的目录来保存进程的相关信息,而子目录fd保了该进程打开的所有文件的描述符)。需要注意,查询产生的临时文件也是需要消耗fd的。
25 |
26 | > 使用命令`mysqladmin status -u root -p`后,会显示如下信息:
27 | >
28 | > | Key | Value |
29 | > | ---------------------- | ------- |
30 | > | Uptime | 3594760 |
31 | > | Threads | 1 |
32 | > | Questions | 240458 |
33 | > | Slow queries | 0 |
34 | > | Opens | 1265 |
35 | > | Flush tables | 1 |
36 | > | Opened_tables | 942 |
37 | > | Queries per second avg | 0.066 |
38 | >
39 | > 可以看到Opened_tables的值,但数据库中表的数量明明远小于942,为什么呈现该值?——这是因为,MySQL是多线程的架构,为了避免多个会话在用一张表上有不同的状态,并发的会话中 表都是独立被打开的,所以也会导致额外的内存消耗,但这对于性能是有一定提升的。
40 |
41 |
42 |
43 | - `thread_cache_size`: How many threads the server should cache for reuse.
44 |
45 | 也就是可以复用的线程缓存池大小。如果新连接很多的话,需要把这个参数设得足够大。
46 |
47 | 默认计算公式是`8 + (max_connections / 100)`。
48 |
49 | - `interactive_timeout`: The number of seconds the server waits for activity on an **interactive** connection before closing it.
50 |
51 | - `wait_timeout`: The number of seconds the server waits for activity on a **noninteractive** connection before closing it.
52 |
53 | 2. **内存**
54 |
55 | - `innodb_buffer_pool_size`: The size in bytes of the buffer pool, the memory area where InnoDB caches **table** and **index** data.
56 |
57 | 缓冲池越大,则访问多次同一张表需要的IO就越少。根据官方文档的建议,数据库独占的服务器上,**缓冲池大小应设置为计算机物理内存大小的80%**。
58 |
59 | 默认值为128MB,最大值则取决于CPU架构。注意:缓冲池大小需要是 innodb_buffer_pool_chunk_size \* innodb_buffer_pool_instances 的整数倍。
60 |
61 | - `innodb_buffer_pool_instances`: The number of regions that the InnoDB buffer pool is divided into. For systems with buffer pools in the multi-gigabyte range, dividing the buffer pool into separate instances can improve concurrency, by reducing contention as different threads read and write to cached pages.
62 |
63 | 开启多个内存缓冲池,把需要缓冲的页面hash到不同的缓冲池中,每个缓冲池管理自己的free list(如flush list, LRU等数据结构),从而进行并行的内存读写。
64 |
65 | 默认值为8,如果`innodb_buffer_pool_size`小于1GB的话,该值为1。
66 |
67 | - `join_buffer_size`: The minimum size of the buffer that is used for plain index scans, range index scans, and joins that do not use indexes and thus perform full table scans.
68 |
69 | 当explain时,join出现ALL、INDEX、RANGE的时候,就需要使用到buffer(8.0的Hash Join也是在join buffer中以创建哈希表)。通常想加速JOIN的话,就是直接给join字段加索引,但这也取决于JOIN算法。
70 |
71 | 当使用 Block Nested-Loop 时,因为所有元组需要的列 都必须保存在buffer中,所以用较大的join buffer是有意义的。
72 |
73 | 当使用 Batched Key Access 时,buffer大小决定了 每次向存储引擎发送查询key的batch大小。buffer越大的话,则对右表查询的顺序访问比例就越大,从而提升性能。
74 |
75 | 建议是 全局变量的值设置相对小一点,如果会话中需要进行大join的话,再对绘画变量进行设置。
76 |
77 | - `tmp_table_size`: The maximum size of internal in-memory temporary tables.
78 |
79 | 对于用户自己创建的内存表,该参数是不起作用的。不过临时表的大小同时也受`max_heap_table_size`的限制,一旦超过二者的较小值时,内存中的临时表就会变为磁盘表。
80 |
81 | 3. **IO**
82 |
83 | - `sync_binlog`: Controls how often the MySQL server synchronizes the binary log to disk. 分为0/1/N 三种情况。
84 |
85 | 值为0时,MySQL不会强制对binlog刷盘,而是由操作系统自己去做,性能上确实是最好的,但是对于断电和宕机的情况,可能会有已提交的事务未被写入到磁盘上的binlog。
86 |
87 | 值为1时,每次事务提交前,都会强制binlog落盘。
88 |
89 | 值为N时,只有当 一组有N个事务的提交组完成时,才会强制binlog落盘。
90 |
91 | - `innodb_flush_logs_at_trx_commit`: Controls the balance between strict ACID compliance for commit operations and higher performance that is possible when commit-related I/O operations are rearranged and done in batches. 分为0/1/2 三种情况。这里的日志指的就是InnoDB的redo log。
92 |
93 | 值为0时,**每秒**写入并强制落一次日志到磁盘。
94 |
95 | 值为1时,**每次事务提交**时,日志都会被写入并刷到磁盘上。
96 |
97 | 值为1时,每次事务提交时日志会被写入,每秒会把日志刷到磁盘上。
98 |
99 | - `innodb_io_capacity`: Defines the number of I/O operations per second (IOPS) available to InnoDB background tasks, such as flushing pages from the buffer pool and merging data from the change buffer.
100 |
101 | 可以理解为InnoDB的整体IO能力,应该将其设置为系统可达到的IOPS大小;InnoDB会根据该值来为后台任务分配估计的IO带宽。在设置时,需要考虑workload的写负荷。
102 |
103 | InnoDB 默认值是200。[官方文档](https://dev.mysql.com/doc/refman/8.0/en/innodb-configuring-io-capacity.html)指出,对于消费级的硬盘(通常转速5400rpm或7200rpm),100就够了;低端的SSD,设为200就足够了;高端的SSD(总线连接的),可以设到1000。
104 |
105 | > 理论最大IOPS的计算:
106 | >
107 | > IOPS = 1000 ms / (寻道时间 + 旋转延迟),
108 | >
109 | > 对于7200 rpm的STAT硬盘,假设平均物理寻道时间是9ms,而平均旋转延迟大约为 (60\*1000/7200) / 2 = 4.17ms,IOPS = 1000 / (9 + 4.17) = 76。不过实际IOPS还受其他因素的影响,如IO负载(是顺序 还是随机、读写的比例)、磁盘驱动、操作系统等。
110 |
111 | - `innodb_io_capacity_max`: Defines a maximum number of IOPS performed by InnoDB background tasks in such situations.
112 |
113 | 当flush的刷盘落后时,InnoDB可以更主动地 以高于`innodb_io_capacity`的IOPS速率进行刷盘。
114 |
115 |
--------------------------------------------------------------------------------
/paper reading/query/Optimize Join With Reinforcement Learning.md:
--------------------------------------------------------------------------------
1 | ## Learning to Optimize Join Queries With Deep Reinforcement Learning
2 |
3 | 1. **问题**:目前优化器大多数都是利用 启发式算法来剪枝搜索空间,当 代价模型cost model是线性时,启发式算法可以适用;但当cost有 非线性项时,文章指出 启发式的结果会离最优化较远。因此,需要一种由数据驱动 data-driven-way的策略 (根据特定的数据集 和 query)来缩小搜索空间。
4 |
5 | 2. **Contribution**:
6 | - 提出了一种 基于强化学习的优化器 DQ
7 | - 实现了三种版本的DQ,很容易地集成到现有的DBMS中,包括 Apache Calcite, PostgreSQL, SparkSQL
8 | - 实验证明,DQ可以达到 原生查询优化器 优化后的代价 和 执行时间,但是在经过学习后,执行速度上显著更快
9 |
10 | 3. **Related Work**:
11 |
12 | 机器学习在数据库中的应用仍然是今年的热点辩题,且这个有争议的话题仍会在接下来几年持续下去。——什么问题适合ML的解决方案?文章认为 查询优化是其中的一个sub-area,即该问题很难解决 且 性能的数量级非常关键;即使是糟糕的学习方案 也只是会让执行变慢,而不会导致错误的执行结果。
13 |
14 | - **Cost Function Learning**
15 |
16 | 前人的工作 试图通过 execution的feedback 来修正优化器,如 LEO optimizer(DB2中,2003年),通过feedback来修正cost model (其底层代价模型是基于直方图的)。Leis等人在评估了各种优化器策略的效果后,指出 challenge仍是 **feedback**和**cost estimation errors**。
17 |
18 | 而*Cost Function Learning* 即通过基于统计的学习 来修正或替换现有的cost model。
19 |
20 | 作者使用神经网络来预测 单关系谓词的选择率,结果很成功,但是对于一个domain大小为10k的属性,需要有1000个query作为训练集;且难适用于 字符串或其他非数值的数据类型 。
21 |
22 | - **Learning in Query Optimization**
23 |
24 | Ortiz等人使用**RL**来 学习queries的representation (2018);也有人使用 **DNN**来进行 基数估计 cardinality estimates (2015,2018);Marcus等人 提出了基于RL的join optimizer (2018),但其实验的查询类型比本文少。
25 |
26 | 本文将 Q-learning的动态规划 整合到标准查询优化器中,从而可以进行off-policy learning。
27 |
28 | > On-policy: The agent learned and the agent interacting with the environment is the same. —— SARSA
29 | >
30 | > Off-policy: The agent learned and the agent interacting with the environment is different. —— Q-Learning
31 | >
32 | > In SARSA, the agent learns optimal policy and behaves **using the same policy** such as ε-greedy policy. **Because the update policy is the same to the behavior policy, so SARSA is on-policy.**
33 | >
34 | > In Q-Learning, the agent learns optimal policy **using absolute greedy policy** and behaves using **other policies** such as ε-greedy policy. **Because the update policy is different to the behavior policy, so Q-Learning is off-policy.**
35 |
36 | 原本Marcus等人利用On-policy的方法需要8000个query训练样本,才能达到原生的效果;而DQ 利用off-policy的Q-Learning,只需要80个query样本,降低了两个数量级。
37 |
38 | - **Adaptive Query Optimization**
39 |
40 | 自适应查询处理—— *Adaptive query processing Foundations and Trends® in Databases* (2007),执行期重优化查询——Proactive re-optimization (2005).
41 |
42 | 本文研究的优化是基于固定的数据库fixed database,而DQ提供的自适应性 只是workload级别的(无法是tuple级别的)。
43 |
44 | - **Join Optimization At Scale**
45 |
46 | *Adaptive optimization of very large join queries* (2018)中,研究了 大规模的join查询优化。可以使用随机化randomized 的方法,如 QuickPick算法 和 遗传算法,当表到达一定数量后,商用的优化器中就会使用这些方法。但是这一类方法 对于同一个查询的性能可能有很大变化。
47 |
48 | > QuickPick performs biased sampling by selecting edges from the join graph and adding the respective joins to the query plan.
49 |
50 | 还有松弛启发式方法 是 在简化的假设下来解决问题,如 贪心搜索时 避免笛卡尔积,这是 IK-KBZ算法的前提(*Optimization of non-recursive queries*, 1986)。现有的启发式算法不能很好地解决所有非线性项,而正是机器学习 可以对此有所帮助。
51 |
52 | 4. **实现细节**:
53 |
54 | - **Join Order Benchmark** (JOB)
55 |
56 | 参考 *How good are query optimizers, really* (2015)。由来自 IMDB 的 21 个表组成,并提供了 33个查询模板 和 113个查询。查询中的连接关系大小范围为 5~15。
57 |
58 | - **Query Graph**
59 |
60 | 无向图,关系*R*为顶点,连接谓词*p*为边,记*kG*为G的连通分量数。则 join 两个子计划 subplan,即 选择两个连接的顶点,并将合并为一个顶点。
61 |
62 | - **Markov Decision Process** 马尔可夫决策过程
63 |
64 | 每个join query都可以用 Query Graph来描述。
65 |
66 | | 符号 | 定义 |
67 | | --------------- | --------------------------------------- |
68 | | 状态 *G* | Query graph,是决策过程的一个状态 state |
69 | | 动作 *c* | 即 join |
70 | | 下一个状态 *G’* | 经过一次join的query graph |
71 | | *J(c)* | 评估join的代价模型 |
72 |
73 | 状态转移 state transition *P(G, c)*即为顶点合并的过程,而奖励 reward 定义为负的代价 即 -J。
74 |
75 | MDP的输出为 **将给定query graph 映射到 最佳的下一次join 的函数**。
76 |
77 | - **Greedy Operator Optimization**
78 |
79 | 朴素的优化算法,主流程分三步 (1)从query graph开始;(2)找到最低代价的join;(3)更新query graph;重复以上直到最后只有一个顶点。但是贪婪算法 **不会考虑局部决策对未来的影响**,而有的时候 需要牺牲短期收益 来获取长期利益。
80 | $$
81 | \frac{\partial J(\theta)}{\partial \theta_i} = \frac{1}{m}\sum_{k=1}^{m}[x^{(k)T}\theta - y^{(k)} ](x_i^{(k)}) + \frac{1}{m}\lambda\theta_i
82 | $$
83 |
84 | - **Long Term Reward**
85 |
86 | 考虑最优化问题
87 | $$
88 | V(G)=min\sum_{i = 0}^{t}J(c_{i})
89 | $$
90 | Q函数的递归定义
91 | $$
92 | Q(G,c)=J(c)+min_{c'}Q(G',C')
93 | $$
94 | 使用 强化学习来接近全局的Q-function,可以得到join优化的多项式时间算法。
95 |
96 | - 应用 RL
97 |
98 | 选择Q-Learning(而不是其他强化学习)的三个理由:
99 |
100 | 1. Q-Learning允许我们 在训练时 利用最优的子结构 optimal substructure,从而大大减少需要的数据
101 | 2. 比起Policy-Learning,Q-Learning 在每个subplan中会输出 每个join的分数 *score*,而不是直接输出最优的join选择
102 | 3. 评分模型支持 TopK 排序,不是简单地得到最优的plan
103 |
104 | *Deep reinforcement learning with double q-learning (2016)* 中提出了Q-Learning的变种,留给Future work
105 |
106 | - 模型训练
107 |
108 | 使用 多层感知器神经网络(MLP) 来表示 Q-function。基于经验,使用 **两层MLP** 可以在适中的时间内训练得到最好的效果(使用SGD算法进行训练)
109 |
110 | - 模型使用
111 |
112 | 在完成训练后,DQ 可以接受纯文本的 SQL 查询语句,将其解析为抽象语法树,对树进行特征化,并在每次候选连接获得评分时调用神经网络。最后,可以使用来自实际执行的反馈定期重新调整 DQ。
113 |
114 | - Fine-tuning
115 |
116 | 在深度学习中,实践中由于数据集不够大,很少有人从头开始训练网络。常见的做法是使用预训练的网络,来重新fine-tuning(也叫微调)。
117 |
118 | 而DQ可以在执行的过程,通过fine-tuning来 再训练自己,从而更适合运行环境。
119 |
120 | - 三种Cost Model
121 | - CM1: 适合内存型数据库
122 | - CM2: 额外考虑 有限内存内的hash join(超出阈值,需要考虑 partition的开销)
123 | - CM3: 额外考虑 复用 已建好的hash表
124 | - 进行对比的baseline
125 | - QuickPick1000: 选择1000个随机join计划中最好的
126 | - IK-KBZ: 多项式时间启发式方法,将query graph拆解为链状,再进行排序
127 | - Right-deep
128 | - Left-deep
129 | - Zig-zag
130 | - Exhaustive with the indicated plan shapes
131 |
132 |
133 |
134 |
--------------------------------------------------------------------------------
/paper reading/dbms/Accelerating Relational Databases by RDMA.md:
--------------------------------------------------------------------------------
1 | ## Accelerating Relational Databases by Leveraging Remote Memory and RDMA
2 |
3 | 1. **问题**:内存不足的时候,RDBMS需要强制使用SSD或HDD,极大地降低了性能
4 |
5 | 2. **Contribution**:
6 |
7 | - 研究了 SMP(Symmetric Multi-Processing 对称多处理架构) RDBMS 如何利用 **RDMA**和集群中的**remote memory** 来提高性能
8 | - 将 通过RDMA的remote memory,抽象为轻量的文件API;从而可以轻松地整合到现有的RDBMS中
9 | - 在SQL Server中实现 并进行benchmark测试
10 |
11 | 3. **RDMA**:
12 |
13 | Remote Direct Memory Access,远程直接数据存取,就是为了解决网络传输中 **服务器端数据处理的延迟** 而产生的 现代化高性能网络通信技术。Direct: 没有内核的参与,内容都在网卡上;Memory: 在用户空间虚拟内存与RNIC网卡直接进行数据传输不涉及到系统内核,没有额外的数据移动和复制。
14 |
15 | > 传统的TCP/IP网络通信,数据需要通过用户空间发送到远程机器的用户空间。*数据发送方* 需要把数据从**用户应用空间Buffer**复制到**内核空间的Socket Buffer**中。然后**内核空间中添加数据包头**,进行数据封装。通过一系列多层网络协议的数据包处理工作。数据才被发送到到**网卡中的缓冲区**进行网络传输。*消息接受方* 接受从远程机器发送的数据包后,要将数据包从**网卡缓冲区**中复制数据到**Socket Buffer**。然后经过一系列的网络协议进行数据包的解析,解析后的数据被复制到相应位置的**用户空间Buffer**。这个时候再进行系统上下文切换,用户应用程序才被调用。
16 |
17 | TCP/IP通过内核发送消息的劣势:
18 |
19 | - **低性能**:通过内核传递 导致很高的 **数据移动** 和 **数据复制**的开销
20 | - **低灵活**:所有网络通信协议通过内核传递,很难支持**新的网络协议** 和 **新的消息通信协议** 以及 **发送和接收接口**
21 |
22 | RDMA优势:
23 |
24 | - **低时延**
25 | - **低CPU开销**
26 | 1. 应用程序可以访问远程主机内存而 **不消耗远程主机中的CPU资源**;远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。
27 | 2. 远程主机的CPU的**缓存(cache)**不会被访问的内存内容所填充。
28 | - **高带宽**
29 |
30 | 三类RDMA网络硬件实现:
31 |
32 | - Infiniband:专为RDMA设计的网络,从硬件级别保证可靠传输 ;需要支持该技术的NIC和交换机
33 | - RoCE:基于以太网的RDMA技术,支持在标准以太网基础设施(**交换机**)上使用RDMA
34 | - iWARP:基于以太网的RDMA技术 (**RDMA over TCP/IP**)
35 |
36 | 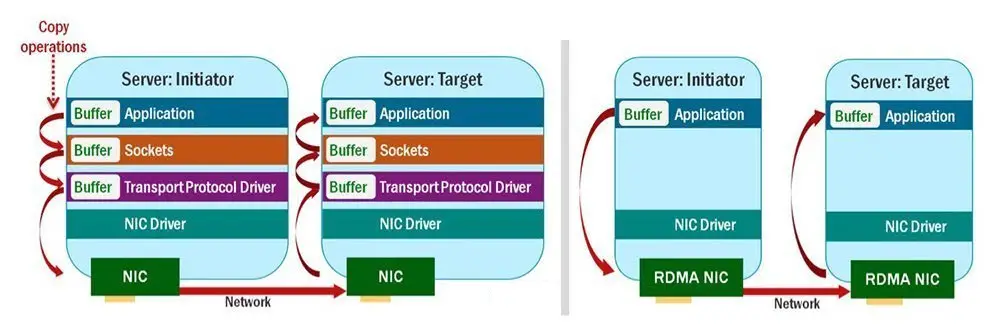
37 |
38 | 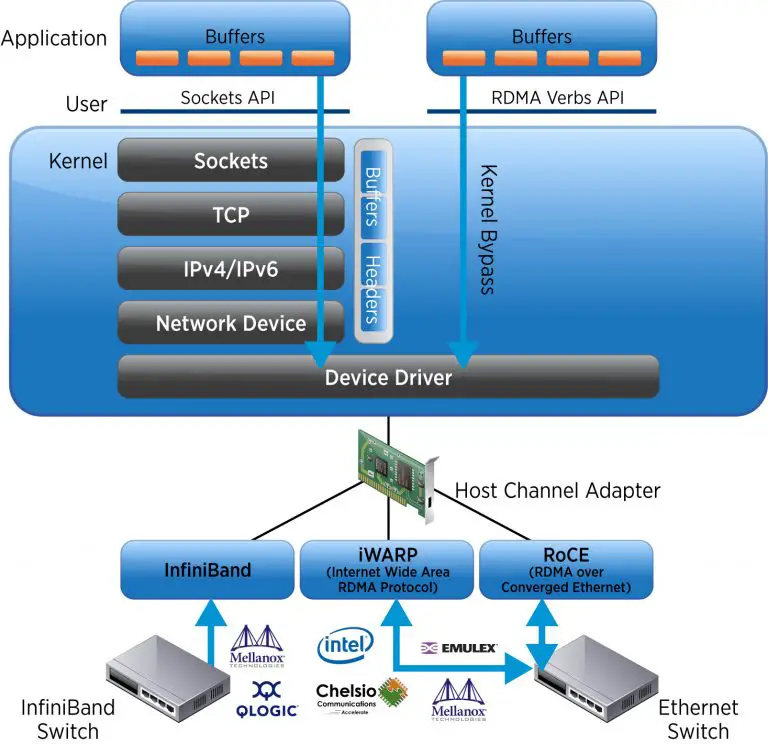
39 |
40 | 三种队列:
41 |
42 | - 发送队列(SQ)
43 | - 接收队列(RQ)
44 | - 完成队列(CQ)
45 |
46 | RDMA是基于消息的传输协议,数据传输都是异步操作
47 |
48 | **读操作**:
49 |
50 | - 本质上是Pull操作,远程系统内存里的数据拉到本地系统的内存里
51 | - Receiver 提供 **虚拟地址** 和 目标内存的**remote_key**
52 | - Sender 是完全被动的,不会接受任何通知
53 |
54 | **写操作**:
55 |
56 | - 本质上是Push操作,把本地系统内存里的数据推到远程系统的内存里
57 | - Sender 提供 **虚拟地址** 和 目标内存的**remote_key**
58 | - Receiver 是完全被动的,不会接受任何通知
59 |
60 | 具体工作流程:Work Request -> Work Queue -> Hardware -> Completion Queue -> Work Completion
61 |
62 | 1. 当应用需要通信时,就会创建一条Channel连接(建立在本端和远端应用之间),每条Channel的首尾端点是一对Queue Pair - SQ和RQ
63 | 2. Queue Pair 会被映射到应用的虚拟地址空间,使得应用直接通过它访问RNIC网卡
64 | 3. CQ用来知会用户 WQ上的消息已经被处理完
65 | 4. 提供了一套软件传输接口,方便用户创建传输请求Work Request(描述了应用希望传输到 Channel另一端的消息内容)
66 |
67 | 4. 细节实现:
68 |
69 | - **Remote Memory**
70 |
71 | 四种实现选择(本文使用的是**In-memory blocks**)
72 |
73 | - **Byte-addressable**: 远端内存以**字节寻址**,允许现存的系统无缝地将本机内存扩展到远端内存(和OS提供的虚拟内存类似)
74 | - **In-memory blocks**: 远端内存 被分为固定大小的块(大小可自定),应用程序通过**唯一的标识符**、**offset**和**读/写数据的大小** 来访问一个block;从而允许读取block中单独的一些字节,而不用读取整个block
75 | - **In-memory files**: 操作系统允许将一部分物理内存 挂载为文件系统,如Linux的**ramfs** 和windows的**Ramdisk**。数据库的设计本身就是高效地处理文件
76 | - **In-memory Key-value store**: 应用只用put和get的API来交互,隐藏了 内存管理 与 远端读写的实现细节
77 |
78 | 文件API与RDMA操作的对应关系:
79 |
80 | | 文件操作 | RDMA实现 |
81 | | ----------------------------- | ----------------------- |
82 | | Create (ServerEndpoint, Size) | Obtain lease on MRs |
83 | | Open | Connect to server |
84 | | Read/Write (Offset, Size) | RDMA read/write |
85 | | Close | Disconnect from server |
86 | | Delete | Relinquish lease on MRs |
87 |
88 | - **Architecture**
89 |
90 | 
91 |
92 | 通过 **Memory Broker**记录集群中内存的使用情况,每台Server都会向 **Memory Broker**报告可用的内存。Server *Mi*将可用的内存切分为固定大小的Memory Region 作为带序号的Block。*Mi*上的一个内存代理进程 **保证available memory不会分配给本机的其他进程**,固定可用的MR,将MR注册到本地的网卡,并从操作系统的角度标记为不可用。
93 |
94 | 当某台DB server内存不足时,可以向**Broker**请求 远程的MR,**Broker**来决定哪一台Server *Mi* 来提供MR(其机制类似于Zookeeper,具有容错性 与 高可用性)。
95 |
96 | - **Preregistration of MRs**
97 |
98 | 最大的挑战在于,SQL Server的缓冲池 不是一片连续的内存,且大小可能动态变化。又由于 只有一个内存分配器来 处理 **缓冲池的内存请求** 以及 **其他SQL Server组件的内存请求**,则连续的大片内存中 既有缓冲池的内存,又有其他引擎组件使用的内存;故 如果静态地注册整个缓冲池,可能会直接包含了整个DBMS的地址空间,**会包含大量RDMA不会传输的内存块**。
99 |
100 | - **I/O Micro benchmark**
101 |
102 | 通过**SQLIO**(一个磁盘基准测试工具)来评估随机/顺序读的性能。参考SQLIO Disk Subsystem Benchmark Tool, http://www.microsoft.com/en-us/download/details.aspx?id=20163.
103 |
104 | - 四个场景
105 |
106 | **性能提升**、**remote memory实现的复杂度** 以及 **整合到DBMS的容易度** 三者的tradeoff。
107 |
108 | - **Extending the Caches**
109 |
110 | 数据库有多种cache: procedure cache(存储 **优化后的执行计划**、**部分执行结果**)、buffer pool cache… 当cache大小达到临界值时,就要淘汰策略。这里,可以不直接丢弃 淘汰的entry,而是把该entry放到remote memory中;当再次访问它时,会比在磁盘上读取更快
111 |
112 | - **Spilling Temporary Data**
113 |
114 | 在执行复杂查询时,DBMS会产生许多临时数据,如果数据量太大,需要把中间结果保存到文件中(比如 SQL Server的 TempDB,Oracle的Temporary Tablespaces)。
115 |
116 | - **In-Memory Semantic Caching**
117 |
118 | 如 非聚集索引、部分索引(*Generalized partial indexes. 1995*)、物化视图等的cache。
119 |
120 | - **Priming the Buffer Pool**
121 |
122 | 云数据库通常使用多个副本 来保证高可用性。典型的,主copy进程处理 读取/更新的事务,其他副本通过 逻辑或物理的replication 来与主节点保持一致。
123 |
124 | *primary-secondary swap*(从节点 变为 主节点)可能会发生,当workload在 新选举出来的主节点上执行时,其缓冲池是冷启动的,故性能会有很大损失。
125 |
126 | 故对于物理replication的数据库,可以使用高速的RDMA传输 来预热(warm up)缓冲池——使用原主节点的缓冲池内容,通过push或根据需要来fetch。
127 |
128 | ---------------
129 |
130 | 1. 参考 PolarFS: An Ultra-low Latency and Failure Resilient Distributed File System for Shared Storage Cloud Database
131 |
132 | PolarDB——存储与计算分离的分布式数据库,PolarFS作为具有低延迟和高可用能力的分布式文件系统,使得PolarDB在分布式多副本架构下仍然能够发挥出极致的性能。
133 |
134 | 2. 存储管理单元分为三层:
135 |
136 | - Volume: 存放了具体文件系统实例的元数据
137 | - Chunk: 数据分布的最小粒度,
138 | - Block: Chunk会被进一步划分为多个Block
139 |
140 | 3. PolarFS编译到数据库内核,替换标准的文件系统接口;数据处理在用户空间完成,避免了传统文件系统从内核空间至用户空间的消息传递开销
141 |
--------------------------------------------------------------------------------
/paper reading/dbms/Modern Column-Oriented Database Systems.md:
--------------------------------------------------------------------------------
1 | ## The Design and Implementation of Modern Column-Oriented Database Systems
2 |
3 | 1. 列式数据库在OLAP上更快的原因:
4 |
5 | - Columns read on demand: 减少了IO的量
6 |
7 | - Batch execution: 以一个chunk进行计算,对locality有优势
8 |
9 | - Compression: 比如int类型的压缩(部分高位可能都是0)
10 |
11 | - Vectorization: SIMD
12 |
13 | - Codegen: 在列式数据库上更简单
14 |
15 | > 在运行时根据逻辑动态的生成可执行代码,那么对于java平台来说,就是动态的生成类实现
16 |
17 | 
18 |
19 | 
20 |
21 | - Late materialization: 带有filter条件的query,可以先进行filter的运算,知道哪些行有效,再进一步取需要的字段被过滤出来的值。可参考 *Materialization Strategies in a Column-Oriented DBMS, 2007*
22 |
23 | - Block IO: IO块的单位可以增大
24 |
25 | - Rough index: 粗略的索引,定位到感兴趣的块(传统的index是 B树 / Bitmap);
26 |
27 | - Inverted index
28 |
29 | - Join index
30 |
31 | - Database cracking: 数据分成很多块,可以选择某种行的排序方式(如 按照A列排序、按照B列排序,可以有多个排序的副本,对应不同的索引);可以和AI结合起来,根据query自动调整排序方式。可参考[Database Cracking](https://stratos.seas.harvard.edu/files/IKM_CIDR07.pdf)
32 |
33 | > Index maintenance should be a byroduct of query processing, not of updates. Continuously reacting on query requests brings the powerful property of self-organization.
34 |
35 | - FPGA, GPU: GPU加速的[DB](https://www.omnisci.com/blog)
36 |
37 | 2. 列式存储更新:
38 |
39 | - SQL Server
40 |
41 | 
42 |
43 | - Immutable storage中的数据未排序
44 |
45 | 优点:直接append
46 |
47 | 缺点:不能二分查找
48 |
49 | - Delta Store在内存中,使用B+树的结构
50 |
51 | - 更新的代价高
52 |
53 | - Vertica
54 |
55 | 
56 |
57 | - **C-store**
58 |
59 | *C-Store: A Column-oriented DBMS, 2005*
60 |
61 | 一个模块WS负责处理快速写入,另一个模块RS负责提供高效的查询 ,通过Tuple Mover,将 WS 中的数据同步到 RS 中。
62 |
63 | 
64 |
65 | - **Projection as Index**
66 |
67 | 存数据会存多份,通过*Projection*快速得到结果
68 |
69 | - **Sorted WOS and ROS**
70 |
71 | 写优化区、读优化区
72 |
73 | - **DV** - Delete vector
74 |
75 | 删除通过Delete vector进行,不会更新树的结构
76 |
77 | 3. **Join**实现:
78 |
79 | 最直接的Hash Join:
80 |
81 | Join的输入只包含 predicate涉及的列,所以 Hash表会更紧凑,Cache miss也会更小。而Join的输出为两个输入列匹配的 位置对,其中输出的左列会按顺序排列,右列则不会(因为通常使用左列来迭代遍历)。
82 |
83 |
84 |
85 | > 对比传统Oracle的hash join:
86 | >
87 | > 1. 首先Oracle会根据参数HASH_AREA_SIZE、DB_BLOCK_SIZE和HASH_MULTIBLOCK_IO_COUNT的值来决定Hash Partition的数量(**一个Hash Table是由多个Hash Partition所组成,而一个Hash Partition又是由多个Hash Bucket所组成**)
88 | > 2. 数据量较小的那个**表A** 会被Oracle选为哈希连接的驱动结果集
89 | > 3. 接着Oracle会遍历A,读取**A**中的每一条记录,并对S中的每一条记录按照Join的列 做哈希运算;会使用两个内置哈希函数,分别记算出hash_value_1和hash_value_2
90 | > 4. 然后Oracle会按照hash_value_1的值把相应的S中的对应记录存储在不同Hash Partition的不同Hash Bucket里,同时和该记录存储在一起的还有该记录用hash_func_2计算出来的hash_value_2的值。注意,存储在Hash Bucket里的记录并不是目标表的完整行记录,而是只需要存储位于目标SQL中的跟目标表相关的查询列和连接列就足够了;**把S所对应的每一个Hash Partition记为Ai**,内存放不下的那部分Hash Partition会放在磁盘上
91 | > 5. Oracle会遍历B,读取B中的每一条记录,并对B中的每一条记录按照连接列做哈希运算,这个哈希运算和步骤3中的哈希运算是一模一样的,即这个哈希运算还是会用步骤3中的hash_func_1和hash_func_2,并且也会计算出两个哈希值hash_value_1和hash_value_2;接着Oracle会按照该记录所对应的哈希值hash_value_1去**Ai**里找匹配的Hash Bucket;如果能找到匹配的Hash Bucket,则Oracle还会遍历该Hash Bucket中的每一条记录,并会校验存储于该Hash Bucket中的每一条记录的连接列,看是否是真的匹配
92 |
93 | **改进:** *Dimitris Tsirogiannis, Stavros Harizopoulos, Mehul A. Shah, Janet L. Wiener, and Goetz Graefe. Query processing techniques for solid state drives. In Proceedings of the ACM SIGMOD Conference on Management of Data, pages 59–72, 2009.* 使用Jive Join,通过额外增加两次join输出数据的排序(大部分数据库系统都有实现外部排序算法),来使得 所有列可以被依次迭代。
94 |
95 | 进一步研究表明:不需要完整的排序。由于存储介质上划分为多个连续的block,单个block内的随机访问 比 跨block的随机访问 要快得多。故数据库不需要对 *position list*进行完整地排序,只需要将其划分到storage的block上,在每个划分内 position是无序的,从而用于 **提取值的列** 是按block的顺序进行访问,而不是严格按 position的顺序。
96 |
97 | 4. **Insert / Update / Delete**
98 |
99 | 比起行式存储,列式存储 对更新操作 更敏感。若每一列单独存在一个文件中,则关系表中的一条元组会存储在多个文件中;即使只更新一行数据 也要进行多次I/O。
100 |
101 | CStore和MonetDB 将架构分解为 **read-store**来管理数据的主题,**write-store**来管理最近的更新(通常在内存中,更新周期性地传到**read-store**中)。如MonetDB 为每个base column附加两个辅助列,用于存储待定的insert和delete。这种存储delta方法的缺点是,query需要先访问read-store获取基表信息,再访问write-store合并更新(insert使用MergeUnion,delete使用MergeDiff,消耗CPU资源)。
102 |
103 | VectorWise系统使用新的数据结构—— **Positional Delta Trees**来存储delta。当一个query提交时,首先找到表的哪个位置受影响,把merge操作 从查询期 转移到 更新期,符合read-optimized的流程。**Positional Delta Trees**是一种计数型B树,可以在对数复杂度下 记录最新的位置。delta可以利用计算机的层次架构进行分层设计。可参考 *Positional update handling in column stores. In Proceedings of the ACM SIGMOD Conference on Management of Data, pages 543–554, 2010.*
104 |
105 | 而Hyper系统 同时对OLTP和OLAP上有较好的支持,主要依赖 硬件辅助的 page shadowing技术 来避免更新时锁住页面。
106 |
107 | > Shadow paging is a copy-on-write technique for avoiding in-place updates of pages. Instead, when a page is to be modified, a *shadow page* is allocated. Since the shadow page has no references (from other pages on disk), it can be modified liberally, without concern for consistency constraints, etc. When the page is ready to become durable, all pages that referred to the original are updated to refer to the new replacement page instead. Because the page is "activated" only when it is ready, it is **atomic**.
108 |
109 | 5. **Group-by**
110 |
111 | 基于hash table。通常使用compact hash table,只用group的属性才会被使用到。
112 |
113 | 6. **Aggregation**
114 |
115 | 聚合操作可以很好地利用列式存储,比如sum( ), min( ), avg( )等可以只扫描相关的列,最大化利用内存带宽(byte/s)。
116 |
117 | 7. **Indexing**
118 |
119 | CStore提出了projection的概念,为每个表创建多个副本,每个副本根据不同的属性排序(每个副本不一定包含整个表的所有属性)。由于列存储的压缩很好,所以多个副本不会占用太大空间。而projection的数量和种类 取决于workload,太多projection会导致更新的代价变高。
120 |
121 | 另一种列存储的索引是 zonemap,在每一个page上存储轻量的元信息(如min/max),从而减少读取没有符合条件元组page次数,加速了扫描。
122 |
123 |
124 |
125 |
--------------------------------------------------------------------------------
/paper reading/query/SQL Plan Management.md:
--------------------------------------------------------------------------------
1 | ## SQL Plan Management
2 |
3 | ### Oracle中的SPM
4 |
5 | 1. SPM的三个核心:
6 |
7 | - **Plan capture**
8 |
9 | 创建SQL计划的baseline,保存在**SQL Management Base**(SMB)中
10 |
11 | - **Plan selection**
12 |
13 | 保证有baseline的SQL查询只会使用已经Accepted的执行计划,优化器找到的新执行计划会暂时保存会Unaccepted状态
14 |
15 | - **Plan evolution**
16 |
17 | 对于一条SQL,评估所有Unaccepted状态的执行计划(根据文档,该评估过程在夜间执行,因为本质是要把这些计划跑一边),如果验证为有性能提升,则把对应计划标记为Accepted状态
18 |
19 | 2. 使用SPM的查询流程(在Oracle11g中,本质是一种保守的计划选择策略)可参考[Oracle白皮书](https://www.oracle.com/technetwork/database/bi-datawarehousing/twp-sql-plan-mgmt-12c-1963237.pdf):
20 |
21 | 1. SQL语句先编译(hard parse)成计划,然后通过CBO优化选出最低代价的执行计划P0
22 |
23 | 2. 如果该SQL语句存在计划baseline,优化器则把P0与baseline中的计划对比,进入3
24 |
25 | 3. 如果 找到对应的计划P1 且**标志位为Accepted状态**,则使用P1;如果baseline中没有P0对应的计划,则对比baseline中所有Accepted状态的计划,选出最低代价的计划P2,进入4
26 |
27 | 4. 如果P0的代价比P2低,则P0会被添加到baseline中,且状态为**Not-Accepted**。此时执行计划仍然选择的是P2,[因为P0在没有被验证不会造成性能退化之前,是不会被真正使用的](https://blogs.oracle.com/optimizer/sql-plan-management-part-2-of-4-spm-aware-optimizer)(当验证成功P0更优时,则进行演化 **Evolve**)
28 |
29 | 5. 如果整个数据库系统发生较大的变化 且影响到目前所有Accepted状态的计划,则这些计划不可再利用(无法再复现),此时会选择优化器原本生成的最低代价计划
30 |
31 | 数据库系统可能发生的变化(都可能导致相同的SQL语句生成新的执行计划,尽管大部分新计划的性能是会有改进的,但仍有一些会发生性能上的退化):
32 |
33 | - 手动/自动地更新了统计信息
34 | - 增加/删除了字段的索引
35 | - 修改了优化器相关的参数
36 | - 数据库系统的升级
37 |
38 | 3. SQL profile(10g) 和 SQL plan baseline(11g)的区别
39 |
40 | - SQL profile通常由SQL Tuning Advisor生成,包含了一些辅助信息,来最小化优化器的误差(主要是基数估计的误差),从而更大可能选择到最优计划,而不是强迫优化器去选哪个特定的计划 或 从哪些特定的计划中选择。但**无法保证计划的稳定性**
41 | - SQL plan baseline是由一系列的accepted plans组成集合。当查询语句被解析后,会从这个集合里选出最优计划;如果在CBO阶段找到了不在集合中 且代价更低的计划,优化器会把它添加到not-accepted状态的计划历史中,但该计划暂时不会被使用(直到evolve过程)
42 | - 所以,当希望系统能快速根据新的统计信息做出调整时,就可以用SQL profile;当你需要更保守的计划执行,就可以使用SQL plan baseline
43 |
44 | 4. Plan cache 和 SPM的区别
45 |
46 | Plan cache顾名思义是执行计划的缓存。本质就是相同的SQL语句采用的执行计划给缓存起来,跳过解析、优化的步骤。
47 |
48 | 比如对于Oracle,Sql语句的parsing分为 硬解析(hard parse) 和 软解析(soft parse),还有soft soft parse。软解析 即通过Sql语句hash 从cache中使用对应执行计划。
49 |
50 | 
51 |
52 | 对于PostgreSQL,pg只提供prepared statement的cache(session级别)。(pg对于存储过程也实现了plan cache,PL/sql的解释器会把SQL语句以prepared statement的形式存储)
53 |
54 | - 对于无参数的prepared stmt,第一次执行时会生成计划 并 保存到cache中,以后在执行到这个stmt会重用执行计划
55 | - 对于带参的prepared stmt,pg采用如下策略(在[德哥的博客](https://github.com/digoal/blog/blob/master/201606/20160617_01.md)中,指出了这样做可以避免plan cache的倾斜):
56 | - 前五次执行时,每次会根据输入的参数来生成执行计划称作custom plan,然后记录下**总的custom plan的代价与数量**。
57 | - 第六次开始执行时,生成一个不依赖参数的执行计划并保存起来——称作generic plan。如果generic plan的代价小于之前所有custom plan的平均代价的1.1倍,则采用generic plan;否则重新根据参数生成新的custom plan,更新总的custom plan的代价与数量。
58 |
59 | 在Mysql中,同样也只有[prepared stmt的cache](https://dev.mysql.com/doc/refman/8.0/en/statement-caching.html)(以及存储过程),既支持SQL语句,也支持C/S二进制协议。由`max_prepared_stmt_count`系统变量来控制cache的语句数量。
60 |
61 | 对于TiDB的[执行计划缓存](https://docs.pingcap.com/zh/tidb/stable/sql-prepare-plan-cache),其支持prepared请求与execute请求(session级别),通过LRU链表实现缓存。这里其无法应对参数取值变化情况(如下),所以TiDB的plan cache适用于 查询编译耗时占比较高且执行计划不容易变的业务场景。(2020-10-22 prepared plan cache选项默认开启)
62 |
63 | > 比如查询过滤条件为 `where a < ?`,假如第一次执行 `Execute` 时用的参数值为 1,此时优化器生成最优的 `IndexScan` 执行计划放入缓存,在后续执行 `Exeucte` 时参数变为 10000,此时 `TableScan` 可能才是更优执行计划,但由于执行计划缓存,执行时还是会使用先前生成的 `IndexScan`
64 |
65 | 阿里云的PolarDB-X,其[执行计划管理](https://help.aliyun.com/document_detail/144299.html)也有相应文档。(默认开启plan cache,且这里将SPM与Plan Cache整合在了一起)对于到来的SQL查询,会对SQL做参数化处理,即把常量参数用`?`占位符替换。注意:这里PolarDB-X的**plan cache**和SPM都是用参数化后的SQL语句作为Key(而不是原本的语句)。
66 |
67 | - 与Mysql和TiDB不同,plan cache会缓存所有SQL计划
68 | - SPM仅对复杂查询SQL进行处理(可能认为这一类查询退化的可能性更大);如果是简单查询,不会进入SPM这一阶段
69 | - 在其SPM中,每个SQL对应的一个baseline中包含一个或多个执行计划。实际使用中,会根据当时的参数选择其中代价最小的执行计划来执行。也就是类似于 PQO(参数化查询优化)问题
70 |
71 |
72 | ------
73 |
74 | ### Aurora PG的[Query Plan Management](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraPostgreSQL.Optimize.html)
75 |
76 | 1. **Motivation**:迁移到Aurora postgreSQL的企业用户需要在系统升级或更改时 能有**稳定的性能**。
77 |
78 | 2. 改变查询执行计划的因素(通常不在预料内):
79 |
80 | - 优化器统计信息的改变
81 | - planner配置参数的更新
82 | - schema的改变,比如 增减了索引
83 | - 绑定变量的改变
84 | - 数据库版本的更新
85 |
86 | 3. QPM的目标:
87 |
88 | - **计划稳定性**:当系统发生如上述改变时,防止计划的退化
89 | - **计划自适应性**:自动检测新的最低代价计划,自动控制新计划何时能够被使用
90 |
91 | 4. 工作流程:
92 |
93 | 
94 |
95 | 1. 还是先由优化器生成SQL对应的最低代价计划P0
96 | 2. 如果没启用QPM,则直接执行P0;若启用了,则进入下一步
97 | 3. 先判断是否属于 受管理的SQL语句,不属于则直接执行P0
98 | 4. 进入计划捕获阶段
99 | 5. 如果QPM未开启 `use_plan_baselines ` 选项,则执行P0
100 | 6. 如果P0 不属于存储中的计划,优化器会捕获并保存P0 并且 标记为 unapproved 状态,进入第7步;如果属于(且为approved状态),进入第8步
101 | 7. 如果P0不是禁用状态,直接执行P0(用户可以手动设置 **直接执行**任何估计成本低于指定阈值的unapproved计划);如果是的,进入下一步
102 | 8. 如果这个受管理的SQL语句有对应 已启用且有效的首选计划(**preferred**标记,可能有多个首选计划,会重新估计每个首选计划的代价;注意**preferred**和**approved**是不同的 ),然后优化器会执行最低代价的计划;如果没有首选计划,进入下一步
103 | 9. 如果不存在或无法重新创建首选计划,则优化器会重新计算每个approved计划的代价,然后选择代价最低的approved计划。如果既没有preferred计划,又没有approved计划,那就只能跑P0了
104 |
105 | 整体看来,流程和Oracle的SPM基本类似。
106 |
107 | 5. 受管理的语句 (Managed Statement)
108 |
109 | 类似于上文polardb-x中提到的参数化语句,这里同样会对SQL语句进行规格化:
110 |
111 | - 去除头部注释块
112 | - 去除EXPLAIN相关
113 | - 去除尾部多余空格
114 | - 去除字面量
115 | - 保留token之间的空格 以及原本大小写,方便阅读
116 |
117 | 比如,语句`/*Leading comment*/ EXPLAIN SELECT /* Query 1 */ * FROM t WHERE x > 7 AND y = 1;` 会被规格化为 `SELECT /* Query 1 */ * FROM t WHERE x > CONST AND y = CONST; `,最后根据规格化后的语句进行Hash操作。
118 |
119 | 6. [最佳实践](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraPostgreSQL.Optimize.BestPractice.html)
120 |
121 | **Proactive**:在验证了新计划确实执行更快后,可以手动置为approved状态,从而主动的防止性能退化。实践如下:
122 |
123 | 1. 在**开发环境中**,确定对性能或系统吞吐量影响最大的SQL语句,手动捕获特定SQL语句的计划
124 | 2. 从开发环境**导出捕获的计划**,并将其**导入到生产环境**中
125 | 3. 在生产中,运行应用程序并强制使用approved的计划
126 | 4. 对优化器生成的unapproved计划进行分析,**主动将性能更好的计划设置为approved状态**
127 |
128 | **Reactive**:监视运行中的应用,从而检测导致性能下降的计划;检测到时,可以手动**reject掉**或**修复**错误的计划。
129 |
130 | 1. 在应用程序运行时,强制使用受管理的计划,并自动将优化器新发现的计划添加为unapproved计划
131 | 2. 监控运行中程序可能发生的性能退化
132 | 3. 发现计划性能退化时,将该计划设置为reject状态。下次优化器运行SQL语句时,会自动忽略reject的计划,并使用其他approved计划
133 | 4. 如果想对退化的计划进行**修复**,则可以考虑使用pg_hint_plan 扩展来尝试改进计划
--------------------------------------------------------------------------------
/04 concurrency control/5-mvcc-notes.md:
--------------------------------------------------------------------------------
1 | ## Multi-Version Concurrency Control
2 |
3 | 1. COMPARE-AND-SWAP(CAS):使用了3个基本操作数——内存地址V,旧的预期值A,要修改的新值B。更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B。
4 |
5 | 在Java中:synchronized就是悲观锁,CAS操作就是乐观锁。
6 |
7 | CAS缺点:
8 |
9 | - ABA问题:如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。
10 |
11 | ——解决思路:使用**版本号**version
12 |
13 | - 循环时间长开销大:自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
14 |
15 | ——解决思路:jvm支持处理器的**pause指令**。pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率
16 |
17 | - 只能保证一个共享变量的原子操作:对多个共享变量操作时,循环CAS就无法保证操作的原子性
18 |
19 | ——解决思路:**锁synchronized** 或 把多个共享变量合并成一个共享变量来操作,如java的AtomicReference类可以把多个变量放在一个对象里来进行CAS操作
20 |
21 | 2. 隔离级别 Isolation Level:
22 |
23 | 
24 |
25 | 主流数据库考虑到串行化效果与并发性能的平衡,一般默认隔离级别都介于RC与RR之间
26 |
27 | - Read Uncommitted -> Read Committed -> Repeatable Reads -> Serializable
28 |
29 | - **Cursor Stability** (DB2的默认隔离级别): 强度介于Read Committed和Repeatable Reads 之间,DBMS的cursor会在当前记录上维护一个锁,直到移向下一条记录。有些情况下,可以防止丢失更新异常 lost update anomaly。
30 |
31 | **丢失更新异常**:txn2 先写A,txn1后写A;但txn1先提交,txn2后提交;导致txn2的写A操作丢失。
32 |
33 | - **Snapshot Isolation** (Oracle的最高隔离级别 **快照隔离** SI): 保证同一个事务中的读操作 会读到一个一致的数据库快照(在事务开始时的)。容易遇到写偏序异常Write Skew Anomaly
34 |
35 | 写偏序"黑白球"问题——两个并行事务都基于自己读到的数据集去覆盖另一部分数据集,在串行化情况下两个事务无论何种先后顺序,最终将达到一致状态,但SI隔离级别下无法实现。
36 |
37 | 
38 |
39 | 3. MVCC: DBMS为数据库中的一个逻辑对象 维护多个物理版本
40 |
41 | - 当一个事务写入一个对象时,DBMS会创建 该对象的一个新版本
42 | - 当一个事务读取一个对象时,会读取 该事务开始时 此对象的最新版本
43 |
44 | 优点:
45 |
46 | - 写者 不会阻塞 读者
47 | - 只读事务 在不需要锁的情况下 就可以读到 一致的数据库快照
48 |
49 | 4. 元组格式的设计
50 |
51 | | 属性 | 含义 |
52 | | -------- | ------------------------------------------------------------ |
53 | | Txn_Id | 唯一的事务id |
54 | | Begin_Ts | 开始时间戳 |
55 | | End_Ts | 结束时间戳 |
56 | | Pointer | 指向下一个版本create a latch-free version chain per logical tuple |
57 | | … | 其他metadata |
58 | | Data | 具体数据 |
59 |
60 | 5. **时间戳顺序**:(MVTO Multi-Version Timestamp Ordering)
61 |
62 | 元组新增一个Read_Ts属性:Use “read-ts” field in the header to keep track of the timestamp of the last txn that read it.
63 |
64 | 在元组没有锁的情况,事务只能读取 其id在Begin_Ts和End_Ts之间的版本,同时更新该元组的Read_Ts。
65 |
66 | 6. **Pointer**:通过pointer 为每一个 逻辑元组 创建一个 不需要闩锁latch-free 的**版本链version chain**
67 |
68 | - DBMS可以通过版本链,在运行期间,找到对一个事务可见的version
69 | - 索引 总是指向 版本链的头结点
70 |
71 | 版本链有两种顺序,在性能上有不同的trade-off:
72 |
73 | - Oldest-to-Newest (O2N):
74 | - Newest-to-Oldest (N2O):
75 |
76 | 7. **版本存储** Version Storage:
77 |
78 | - Append-Only: 新版本 会直接附加在 同一个表空间
79 |
80 | | Main Table | KEY | VALUE | POINTER |
81 | | ------------- | ---- | ----- | ------------- |
82 | | A1 | X | 100 | A2 |
83 | | A2 | X | 200 | A3 |
84 | | B1 | Y | 0 | nil |
85 | | A3 | X | 300 | nil |
86 |
87 | 同一个(逻辑)元组每次更新,会在表中插入一个新的(物理)版本。老的指向新的。
88 |
89 | - Time-Travel: 老版本会复制到 一个独立的表空间Time-Travel Table
90 |
91 | | Main Table | KEY | VALUE | POINTER |
92 | | ------------- | ---- | ----- | ---------------------------- |
93 | | A3 | X | 300 | A2 in Time-Travel |
94 | | B1 | Y | 0 | nil |
95 |
96 | | Time-Travel Table | KEY | VALUE | POINTER |
97 | | ----------------- | ---- | ----- | ------------- |
98 | | A1 | X | 100 | nil |
99 | | A2 | X | 200 | A1 |
100 |
101 | 新的指向老的。
102 |
103 | - Delta: 被修改属性的原始值会拷贝到 一个独立的delta record space
104 |
105 | | Main Table | KEY | VALUE | POINTER |
106 | | ------------- | ---- | ----- | ---------------------- |
107 | | A3 | X | 300 | A2 in Delta |
108 | | B1 | Y | 0 | nil |
109 |
110 | | Delta Storage | DELTA | POINTER |
111 | | ------------- | ------------ | ------------- |
112 | | A1 | (VALUE->100) | 100 |
113 | | A2 | (VALUE->200) | A1 |
114 |
115 | 8. **垃圾回收** Garbage Collection:
116 |
117 | DBMS需要 随着时间推移 删除**可以回收的**物理版本。
118 |
119 | - 没有 active的事务 可以看到该版本——快照隔离
120 | - 该版本由一个 已结束的事务创建
121 |
122 | 9. 两种层面的GC:
123 |
124 | - 元组级 Tuple-level:
125 |
126 | 1. Background Vacuuming: 独立的线程 会周期性地扫描表,寻找可回收的版本。
127 | 2. Cooperative Cleaning: 工作线程在 遍历版本链 时,找到可回收的版本。只适用于**O2N**。
128 |
129 | - 事务级 Transaction-level:
130 |
131 | 每个事务会记录 自己的 读/写集合。由DBMS来决定 一个已完成的事务 创建的所有版本 什么时候不可见。
132 |
133 | 注意 时间戳到达最大值的问题。
134 |
135 | > If the DBMS reaches the max value for its timestamps, it will have to wrap around and start at zero. This will make all previous versions be in the "future" from new transactions.
136 |
137 | Postgres的解决方法:当系统即将达到Txn_id的最大值时,停止接收新命令。在每个元组头部设置flag,标志其为过去的状态。而任何新的Txn_id都比过去状态的元组要新。
138 |
139 | 10. **索引管理** Index Management:
140 |
141 | - 主键索引——总是指向版本链的头结点。DBMS更新 主键索引的频率,取决于 系统是否 在一个元组更新时 就创建新版本。当一个事务更新元组的主键属性时,会等同于 先执行一次**DELETE**,再执行一次**INSERT**。
142 |
143 | - 辅助索引——较为复杂。可以使用 **Logical Pointers**(每个元组有一个固定不变的标识符)或 **Physical Pointers**
144 |
145 | -----
146 |
147 | ### 具体实现
148 |
149 | 11. SAP HANA—— In-memory **HTAP** DBMS with time-travel version storage (N2O)
150 |
151 | > 一种内存数据平台,可以作为内部预置型设备部署,也可以部署在云端。这是一个革命性的平台,最适合执行实时分析,开发和部署实时应用程序。
152 | >
153 | - 支持 乐观 以及 悲观的 MVCC
154 |
155 | - Time-travel表中存储最新的版本
156 |
157 | - 使用[混合存储layout](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/Flexible-Storage-Model.md)(行+列式)
158 |
159 | **版本存储**:
160 |
161 | - 在main table中存储最老的版本
162 |
163 | - 每一个元组维护一个 flag 来标记是否有newer version
164 |
165 | - 通过一个 hash 表,key为**record的identifier**,value为**版本链的头结点**。
166 |
167 | 12.
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
--------------------------------------------------------------------------------
/paper reading/dbms/innoDb.md:
--------------------------------------------------------------------------------
1 | ## InnoDB存储引擎
2 |
3 | 1. MySql由以下几部分组成:
4 | - 连接池 Connection Pool
5 | - 管理服务和工具 Management Service & Utilities(如备份, 恢复, 安全, 数据迁移等)
6 | - Sql接口 Sql Interface(DML: 数据操作语言(insert/update/delete), DDL: 数据定义语言(create), Triggers等)
7 | - 查询分析器 Parser
8 | - 优化器 Optimizer
9 | - 缓存与缓冲 Cache & Buffer
10 | - 插件式存储引擎 Pluggable Storage Engine (如MyISAM, InnoDB, NDB等)
11 | - 物理文件 File System
12 | 2. 存储引擎是**基于表**的,不是基于数据库的!插件式的架构提供了一系列标准的管理和服务支持,存储引擎是底层**物理结构**的实现。
13 | 3. InnoDb(默认的存储引擎)的特点:
14 | - 支持ACID事务 (不是所有存储引擎都支持事务)
15 | - 行锁设计
16 | - 支持外键
17 | - 非锁定读(默认读取不会产生锁)
18 | - 使用多版本并发控制(MVCC), 使用next-key locking 避免幻读
19 | - 插入缓冲(insert buffer) => **性能提升**、二次写(double write) => 数据页的**可靠性**、自适应哈希索引(adaptive hash index)、预读(read ahead)
20 | - 采用聚集(cluster)的方式存储数据; 每张表的存储都按主键顺序进行存放(没有主键时, 会为每行生成一个6byte的ROWID作为主键)
21 | - InnoDb更适合OLTP, MyISAM更适合OLAP
22 |
23 | 4. InnoDB采用**多线程**模型,运行时有多个后台线程,它们分别负责不同的任务:
24 |
25 | - Master线程: 负责将缓冲池的数据**异步刷新**到磁盘,保证数据的一致性。包括脏页(内存数据页和磁盘数据页上的内容不一致)的刷新、合并插入缓冲(INSERT buffer)、UNDO页(分为insert undo log和update undo log用Undo Log来实现MVCC)的回收等。
26 |
27 | - IO线程: 使用AIO(Async)来处理写IO请求,以提高数据库性能。IO线程负责的是这些IO请求的回调。可使用SHOW ENGINE INNODB STATUS查看:
28 |
29 | 
30 |
31 | - Purge线程: 为什么需要Purge——得从并发机制说起,InnoDB的多版本一致性读是采用了基于回滚段的的方式。无论是更新还是删除,都只是设置记录上的deleted bit标记位,而不是真正的删除记录;后续这些记录的真正删除, 是通过Purge后台线程实现。
32 |
33 | Purge: Purge parses and processes **undo log** pages from the **history list** for the purpose of removing clustered and secondary index records that were marked for deletion (by previous DELETE statements) and are no longer required for **MVCC** or **rollback**. Purge frees undo log pages from the history list after processing them.
34 |
35 | - Page Cleaner线程: InnoDB 1.2.x版本引入,将原本Master线程中的脏页刷新操作放到单独的线程中完成,减轻对于用户查询的阻塞。
36 |
37 | 5. 基于磁盘的DBMS通常使用**缓冲池**技术来提高整体性能。
38 |
39 | - 数据库读取页时,首先把从磁盘读到的页存放到缓冲池中;下一次再读相同的页时,先判断页是否在缓冲池中,若是则命中,若不是则再从磁盘读。
40 | - 数据库修改页时,首先修改缓冲池中的页,然后再以一定的频率刷新到磁盘上。不是每次页更新就会将页从缓冲池刷到磁盘!是通过**checkpoint**机制刷新回磁盘。checkpoint需要决定每次刷新多少页到磁盘、每次从哪里取脏页、什么时间触发。InnoDB中有两种checkpoint:
41 | 1. Sharp Checkpoint: 在数据库关闭时,将所有脏页刷新回磁盘。
42 | 2. Fuzzy Checkpoint: 运行时,只刷新一部分脏页;否则可用性会受到影响。
43 | - 多个缓冲池实例,每个page根据**哈希来平均分配**到不同的实例中——减少了数据库内部的资源竞争,增加数据库的并发能力。
44 |
45 | 
46 |
47 | - 缓冲池通过**LRU**算法来管理。最频繁使用的页在LRU列表的前端,当没有空位存放新读取的页时,收件释放LRU列表尾部的页。此外,InnoDB采用了**midpoint insertion**策略——新读取的页不是直接放到首部,而是放到midpoint的位置(默认是列表长度的5/8处)。在分割点前的列表称作new列表,可视作是最为活跃的热点数据。
48 |
49 | 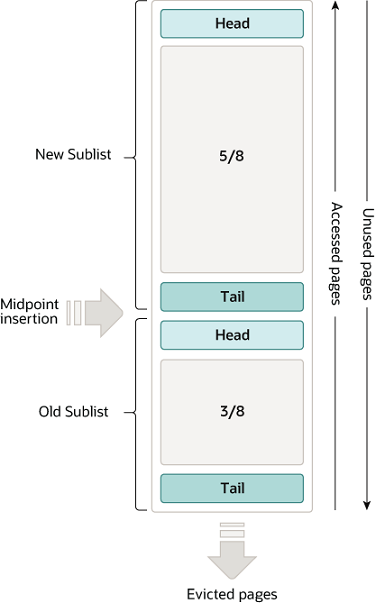
50 |
51 | 直接用朴素的LRU算法有什么劣势?当某些Sql操作需要访问表中的许多页甚至全部页时,而这些页通常又仅在这次查询中需要,并不是活跃的热点数据。如果直接放入LRU首部,就很可能把原本需要的热点数据页移除。
52 |
53 | 下图中,pct决定midpoint的位置,37即37%(3/8),即新页插入到LRU尾端37%的位置;time表示页读取到midpoint后要等待多久才被加入到new列表中:
54 |
55 | 
56 |
57 | - 支持压缩页的功能,即把原16KB的页压缩为1/2/4/8KB,并通过unzip_LRU列表管理。不同的表压缩比率不同,所以会有的表页大小为8KB,有的为4KB,如何从缓冲池分配内存?——unzip_LRU列表对不同大小的页会分别管理,并且使用伙伴(buddy)算法分配内存。
58 |
59 |
60 |
61 | 6. Master线程:
62 |
63 | - 最高的优先级别
64 |
65 | - 由多个loop组成: 主循环、后台循环、刷新循环 flush、暂停循环 suspend。
66 |
67 | - 主循环包括两类操作:每1秒执行的操作和每10秒执行的操作(通过thread.sleep实现,故并不精确)。
68 |
69 | 每1秒的操作(依次)包括: 日志缓冲刷新到磁盘(总是,即使事务还未提交,日志也会刷新到redo log中)、合并插入缓冲(可能,会判断当前的IO压力)、刷新缓冲池中的脏页到磁盘(可能,会判断脏页的比例是否超过阈值)、如果没有用户活动则切换到后台循环。
70 |
71 | - 后台循环,在数据库空闲时或数据库关闭时发生,包括: 删除无用的undo页(总是)、合并插入缓冲(总是)、跳回到主循环(总是)、不断刷新页知道符合条件(可能,会跳转到flush loop中)
72 |
73 | -----
74 |
75 | 新版本的优化点:
76 |
77 | - 引入参数innodb_io_capacity,用来表示磁盘IO的吞吐量,并用其控制**刷新缓冲区脏页**的数量和**合并插入缓冲**的数量(原本刷新脏页的数量、以及合并插入缓冲的数量是有上限的)。若使用SSD类磁盘,即存储设备IO速度较快时,可以将innodb_io_capacity调高,使之匹配磁盘IO吞吐量。
78 |
79 | - 引入参数innodb_adaptive_flushing,影响每秒刷新脏页的数量。原本刷新规则是——当脏页在缓冲池的比例小于innodb_max_dirty_pages_pct时,不刷新脏页;大于时,刷新100个脏页。现在是——通过判断redo log的速度来决定最合适的刷新脏页数量。
80 |
81 | 注: innodb事务日志包括redo log和undo log。redo log是重做日志,提供前滚操作;undo log是回滚日志,提供回滚操作。Redo log写入磁盘时,必须进行一次操作系统fsync操作,防止redo log只是写入操作系统磁盘缓存中。一般情况下,对硬盘的write操作,更新的只是内存中的页缓存,而脏页面不会立即更新到硬盘中。
82 |
83 | The [redo log](https://dev.mysql.com/doc/refman/5.5/en/innodb-redo-log.html) is a disk-based data structure used during crash recovery to correct data written by incomplete transactions. During normal operations, the redo log encodes requests to change table data that result from SQL statements or low-level API calls. Modifications that did not finish updating the data files before an unexpected shutdown are replayed automatically during initialization, and before the connections are accepted.
84 |
85 | - 引入参数innodb_purge_batch_size,控制每次full_purge回收的undo页的数量。
86 |
87 | 7. 插入缓冲: 对于非聚集索引的插入或更新,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,若在,则直接插入索引页;若**不在,则先放入到一个Insert Buffer对象中**(Changes are only recorded in the change buffer when the relevant page from the secondary index is not in the **buffer pool**)。
88 |
89 | - 使用的两个前提: 1. 索引是辅助索引(二级索引) secondary index——插入时,数据库中该非聚集索引已经插到叶子结点,但实际上其只是存放在另一个位置,然后再以一定频率进行Insert Buffer对象和辅助索引页子结点的merge;2. 索引不是unique——因为在插入缓冲时,不会去查找索引页来判断插入记录的唯一性
90 |
91 | 注: 二级索引——按照每张表创建的索引列创建一棵B+树,叶子节点并不包含行记录的全部数据(一张表可以有0/1/n个辅助索引)。查找过程为:遍历辅助索引→找到叶节点→找到指针获取主键索引的主键→通过主键索引找到对应的页→找到一个完整的行记录。
92 |
93 | ----------
94 |
95 | insert buffer现在变为**change buffer**,因为现在除了INSERT,还支持UPDATE和DELETE的DML语句。删除的两步: 1. 将一条元组标记为已删除;2. 真正将记录删除。
96 |
97 | - 其数据结构为一棵**B+树**。以前版本是一张表有一棵Insert Buffer B+树,现在是全局只有一棵,负责所有表的辅助索引进行插入缓冲。
98 |
99 | 其**非叶结点**存放的是查询的search key。search key的属性包括4字节的space,表示待插入记录所在表的表id(每张表有一个唯一的space id);1字节的marker,兼容作用;4字节的offset,表示页所在的偏移量。
100 |
101 | 当一个secondary index要插入到page(space_id, offset)时,如果该page不在缓冲池中,则会先构造一个search key,再查询Insert Buffer B+树,再将该条record插入到树的叶子结点中。
102 |
103 | 8. double write:(有些文件系统本身就提供了部分写失效的防范机制,就不需要开启double write)
104 |
105 | - 部分写失效 partial page write: 正在写入某个页到表中,比如16KB的页只写了前4KB,就发生了宕机,则会导致数据丢失
106 |
107 | - double write的两部分——**内存中**的double write buffer和**磁盘上**共享表空间中连续的128个page。(连续空间 => 顺序写 => 效率高)
108 |
109 | - 共享表空间:InnoDB的所有数据保存在一个单独的表空间里面,而这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所以其大小限制不再是文件大小的限制(**优点**),而是其自身的限制。
110 | - 独立表空间:每一个表都将会生成以独立的文件方式来进行存储,每一个表都有一个.frm表描述(结构)文件,还有一个.ibd文件。
111 |
112 | 当要刷新脏页时,不直接写磁盘;通过**memcpy**函数将脏页复制到内存中的double write buffer,之后通过double write buffer再分2次,每次写入1MB到共享表空间doublewirte中,然后马上调用fsync函数,同步到磁盘上。
113 |
114 | 如果写入磁盘时崩溃,可以从共享表空间中的doublewirte中找到该page的副本,将其复制到表空间文件,再应用重做日志。
115 |
116 | 9. 自适应哈希索引 AHI:
117 |
118 |
--------------------------------------------------------------------------------
/paper reading/query/An End-to-End Learning-based Cost Estimator.md:
--------------------------------------------------------------------------------
1 | ## An End-to-End Learning-based Cost Estimator
2 |
3 | 1. **问题**:传统基于经验的 代价和基数估计方法 无法提供高质量的估计结果,因为它们 不能有效地把握多表之间的关联。而现有的基于学习的方法有以下不足,
4 | - 关注基数的估计,没有对cost进行估计
5 | - 要么不够轻量,要么很难表示复杂的结构(如 复杂谓词)
6 | 2. **Contribution**:
7 |
8 | - **基于树结构的模型**,开发了一个 高效的 端到端 基于学习的Cost Estimator,可以同时进行 **代价和基数** 的估计
9 |
10 | - 提出高效的 **特征提取与编码**技术,在特征提取过程中 会结合考虑 query 和 physical execution,并将提取出的特征 应用到 树结构模型中,利用树结构来估计 cost和cardinality
11 |
12 | - 对于带有string类型的谓词,提出一种高效编码字符串值的方法。设计了一种基于pattern的方法 来嵌入字符串值
13 |
14 | > 特征嵌入,将数据转换(降维)为固定大小的特征表示(矢量),以便于处理和计算。embedding的主要目的是对(稀疏)特征进行降维,它降维的方式可以类比为一个全连接层(没有激活函数),通过 embedding 层的权重矩阵计算来降低维度。
15 |
16 | - 在真实数据集上进行实验,证明了该方法比现有方法的优越性
17 |
18 | 3. 实现细节:
19 |
20 | - Estimator架构
21 |
22 | dataset + queries → Query Optimizer → **Training Data Generator** → **Feature Extractor** → **Tree-structured Model**
23 |
24 | - **Training Data Generator**
25 |
26 | 根据数据集可能的join graph 以及 workload对应的谓词 生成一些query,接着对于每个query 通过优化器获得物理执行计划 (在DBMS中 使用计划分析工具),并获得真实的cost和cardinality。一条训练数据为一个三元组:<物理执行计划,该计划真实cost,该计划真实cardinality>
27 |
28 | - **Feature Extractor**
29 |
30 | 从query plan中提取有用的特征 (如 操作符 和 谓词),然后query plan中每个结点会编码为 特征向量feature vector,对于简单的特征(如 Operation: Nested Loop, Index Scan…; TableName; Operator)使用**one-hot** vector来编码得到向量;对于复杂的特征(如 LIKE谓词),直接将该每条元组\ 通过一对一映射 得到一个向量。向量再组成tensor,最后形成向量树,
31 |
32 | > one-hot是比较常用的文本特征特征提取的方法。**用N个bit来编码N个状态**,**保证每个样本中的每个特征只有1位处于状态1,其他都是0**。解决了分类器处理离散数据困难的问题。
33 |
34 | - **Tree-structured Model**
35 |
36 | - **Representation Memory Pool**
37 |
38 | 在处理query时,存储 **subplan** 到 **representation** 的映射。(就是在动态规划时 子任务结果的存储)
39 |
40 | - **Feature extraction and encoding**
41 |
42 | query node → node vector → tree-structured vector
43 |
44 | 
45 |
46 | **影响查询代价的因素主要有四种**,所以要提取出这些特征。
47 |
48 | - **Operation**
49 |
50 | 每个结点都有
51 |
52 | *Join* (Hash/ Merge/ Nested Loop Join);*Scan* (Sequential/ Bitmap Heap/ Index/ Bitmap Index/ Index Only Scan);*Sort* (Hash/ Merge Sort);*Aggregation* (Plain/ Hash Aggregation)
53 |
54 | 使用one-hot vector编码,比如1号结点操作类型是Nested Loop,其Operation编码为0001
55 |
56 | - **Predicate**
57 |
58 | join condition (a.movie_id = b.movie_id) 或 filter condition ('year > 1998')。一个谓词由三部分组成,*column*, *operator*, *operand*;前两者用one-hot vector编码,数值型*operand* 通过规格化的浮点数来编码,
59 |
60 | ----
61 |
62 | 字符串型*operand* 通过 基于embedding的方式——可以表示同一个元组中一起出现的字符串。两种字符串型的谓词,一种精确匹配型(= / IN),一种是模式匹配型(LIKE)。对所有的字符串子串 进行预训练,而不是对workload中出现的原始字符串进行编码;具体是通过对子字符串的泛化,生成一些规则,这些规则 **可以从数据集中提取出query workload的所有关键词**。再提取出满足规则的子串 来训练模型。
63 |
64 | - **Rule Generation**
65 |
66 | 一条规则由三部分构成(借助DSL的概念),*Pattern*(匹配数据集中元组的子字符串), *String Function*(决定 提取子字符串中哪个关键词), *Size*(待提取关键词的长度)。此处的*String Function*仅有两种——*Prefix*和*Suffix*
67 |
68 | 给定一个谓词中的keyword 以及 一个数据集中的string,先找到该字符串所有能匹配keyword的子串。对于每个匹配的子串,生成所有将 **keyword映射到子串**的pattern(通过穷举 Pattern的组合)。
69 |
70 | 再根据候选规则,找到最优的规则集合(使用最少的规则 来覆盖workload中的关键词)。是集合覆盖问题(SCP)的减弱版。
71 |
72 | > 给定一个集合U以及U内元素构成的若干各小类集合S,目标是找到S 的一个子集,该子集满足所含元素包含了U中的所有的元素且使小类集合个数最少。例如,U={1,2,3,4,5},S={{1,2},{3,4},{2,4,5},{4,5}},找到集合能满足条件的可以有O={{1,2},{3,4}{4,5}}或是O={{1,2},{3,4},{2,4,5}},
73 |
74 | - **String Indexing**
75 |
76 | 使用 前缀以及后缀trie树索引来存储 字符串→编码 的映射,通过*Prefix*函数提取出的子字符串就放入前缀树,*Suffix*函数提取出的子字符串就放入后缀树,叶子结点就存储字符串的向量表示(即 对应的编码)。
77 |
78 | Online Searching的过程中,会有不在dictionary的查询字符串;若它是前缀搜索(LIKE s%),则搜索该query string的最长前缀,其他同理。即在dictionary中选择 最长的可以匹配的,作为其表示。
79 |
80 | -----
81 |
82 | 如4号结点的filter为 info = 'top 250 rank' ,从Dictionary中找到top 250 rank的表示法,故4号结点的Predicate编码为 000000100000 0001 0.14,0.43,…,0.92
83 |
84 | - **Metadata**
85 |
86 | 列、表、索引的集合,分别都使用 one-hot向量来表示。(有些结点可能没有谓词,所以需要对 metadata也要进行编码)比如5号结点,没有谓词,所以其Predicate编码全部用0填充;其Table Name为movie_info_idx,故编码为0010
87 |
88 | - **Sample Bitmap**
89 |
90 | 固定长度的 0-1向量,每一位表示 对应的元组是否满足query node的谓词条件(满足为1,不满足为0)。如图中的9号结点,production_year>2010的只有第二条元组,故9号结点的Sample_Bitmap编码为0100
91 |
92 | - **Model Design**
93 |
94 | 模型有三层:*embedding layer*, *representation layer*, *estimation layer*
95 |
96 | 
97 |
98 | - **Embedding Layer**
99 |
100 | Sparse vector → dense vector,使用 一个ReLU激活的全连接层 来嵌入 *Operation*, *Metadata*和*Sample Bitmap*,
101 |
102 | 对于 *Predicate*,使用 Tree Pooling来编码(其中树的结构和 谓词树一样)。其中,叶子结点为全连接神经网络,**OR**使用最大池化层,**AND**使用最小池化层。因此,只有叶子结点才需要训练,容易做到高效的batch training;同时模型收敛更快,性能更好。
103 |
104 | - **Representation Layer**
105 |
106 | 第一个问题 information vanishing: 查询计划中的上层结点 无法捕捉到下层结点之间的关联。
107 |
108 | 第二个问题 space explosion: 如果要存储足量的信息 来保留表之间的关联,需要大量的存储空间和中间结果。
109 |
110 | 在表示层使用了 循环神经网络(RNN),作为一个连接网络,它决定了哪些信息会被传递。如果 表示模型representation model使用朴素神经网络,会有梯度消失和梯度爆炸的问题。因此使用**LSTM**来解决这个问题。
111 |
112 | > RNNs理论上是可以将以前的信息与当前的任务进行连接,例如使用以前的视频帧来帮助网络理解当前帧。理论上RNN可以通过调参来解决“长依赖”问题。但是在实践过程中RNNs无法学习到这种特征。可参考 *Learning Long-Term Dependencies with Gradient Descent is Difficult* (1994)
113 | >
114 | > Long Short Term Memory networks(以下简称LSTMs),一种特殊的RNN网络,该网络设计出来是为了解决长依赖问题。LSTMs的核心是细胞状态,用贯穿细胞的水平线表示。
115 | >
116 | > 细胞状态像传送带一样。它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNNs。即图中 *Gt-1* 到 *Gt*这一条水平线。
117 | >
118 | > LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息。门能够有选择性的决定让哪些信息通过。其实门的结构很简单,就是一个sigmoid层和一个点乘操作的组合。
119 | >
120 | > LSTM由三个门来控制细胞状态,这三个门分别称为**忘记门**、**输入门**和**输出门**。
121 |
122 | 如图中,*Gt*即为长记忆的通道,*ft* 决定了在长记忆中要遗忘哪些信息(第一步就是决定细胞状态需要丢弃哪些信息),*kt1* 决定了在长记忆中要加入哪些信息(第二步先通过一个输入门来决定更新哪些信息,再通过一个tanh层得到新的候选细胞信息),*kt2* 决定了记忆同道中的哪些信息应该当做子计划的representation
123 |
124 | - **Estimation Layer**
125 |
126 | 两层全连接神经网络,使用ReLU激活函数,输出层为sigmoid 预测归一化后的基数与代价。
127 |
128 | 由于需要同时预测两个,使用**多任务学习 multitask learning**(参考 Multitask learning. Machine Learning, 1994),其中最常用的一种实现策略是 Parameter sharing,同时训练多个任务,这些任务的模型共享部分神经网络层。
129 |
130 | > 只专注于单个模型可能会忽略一些相关任务中可能提升目标任务的潜在信息,通过进行一定程度的共享不同任务之间的参数,可能会使原任务泛化更好。
131 |
132 |
133 |
134 |
--------------------------------------------------------------------------------
/paper reading/distributed/Distributed Transaction.md:
--------------------------------------------------------------------------------
1 | ## Distributed Transactions
2 |
3 | 1. 首先,对于单机数据库上的事务,其包含一个或多个数据库操作,但逻辑上构成一个整体;那么我们知道,这些操作要么全部执行成功,要么全部不执行。所以也有事务的 **ACID**(*Atomicity*, *Consistency*, *Isolation*, Durability) 特性。
4 |
5 | 对于单机(单分区)事务,其一致性、隔离性主要是通过**并发控制**实现的;可以使用 基于锁的并发控制,比如两阶段锁;基于时间戳排序,也就是事务操作能否执行 取决于是否有更晚时间戳的事务已经提交。
6 |
7 | 2. 但是对于分布式事务,一个事务要跨越多个节点,单分区事务的并发控制方案 就不再适用。比如网购时候,订单系统和库存系统很可能就在不同的节点上,仅适用单分区事务的并发控制方案 无法得知本地外的其他节点事务是否成功提交。
8 |
9 | 所以引入原子提交的概念:原子提交不允许参与者之间发生分歧,也就是只要有一个参与者投票反对,事务就不能提交。其本质就是对这个问题达成共识——**是否要执行当前被提议的事务**?
10 |
11 | 3. 两阶段提交
12 |
13 | 两类节点
14 |
15 | - **协调者**:(一个)协调者负责保存状态,收集投票
16 |
17 | - **参与者**:其余节点即为参与者,通常每个参与者负责一个分区(互不相交的数据集合)
18 |
19 | 两个阶段
20 |
21 | - **准备** *prepare*:*协调**者* Propose消息告诉*参与者* 新事务;*参与者* 如果可以提交自己那部分的事务,就投赞成票,否则投反对票中止事务。
22 | - **提交/中止** *commit/abort*:只要有任何一个*参与者* 投反对票中止事务,则*协调者* 会向所有*参与者* 发送Abort消息。也就是只有当参与者都投赞成票时,协调者 才向它们发送Commit消息。
23 |
24 | 4. 下面考虑几种故障场景
25 |
26 | 首先考虑参与者,如果在准备阶段发生故障的话,则协调者会中止事务,因为没收到所有的赞成票,所以会影响可用性。像Spanner的话,为改进可用性问题,选择了在Paxos组上执行2PC 而非单节点。
27 |
28 | 如果它是在接受了Propose后挂掉,则恢复后,需要follow协调者的最终决定(因为不知道其他节点是否会abort),在此之前,该参与者不能处理请求,否则可能会有数据不一致的情况。
29 |
30 | 下面考虑协调者的故障。如果协调者在收集投票后、广播最终结果前发生故障,会导致所有参与者进入未决状态。因为参与者不知道协调者的决定,也不知道其他参与者是否已经收到了事务结果。那么解决方法 很自然,就是解决方案——在参与者中选举新的协调者,重新收集结果后,再做出最后决定。
31 |
32 | 如果 协调者没能向发送所有参与者发送最终消息,就发生故障。则可以在参与者中选举新的协调者,询问那条事务的执行情况,做出决定。注意 **参与者的状态转化**:当参与者在投了赞同票 然后未能收到协调者commit/abort的消息(超时)后,它可以向其他参与者pi询问结果,有可能收到以下三种回复:
33 |
34 | - pi已收到了协调者的最终决定
35 | - pi在上一阶段投了反对票,即中止了
36 | - 同样也在等待最终决定(处于未决状态)=> 如果所有p都处于未决状态,那就有必要选举新的协调者
37 |
38 | 但是如果 协调者和参与者一起故障,且故障的参与者接受到了最终消息并执行,那么在重新选举出新的协调者并决定时,可能造成数据不一致。就比如协调者向参与者1 发送rollback,然后挂掉了;参与者1 rollback成功后,也挂掉了;然后在参与者2 、3、4中选出新的协调者,由于他们都不知道那条事务的执行结果,所以重新投票后发现可以提交,从而导致了数据不一致
39 |
40 | 5. 这里需要讨论一下 两个概念 就是平常说的所谓分布式一致性算法 2PC 和 Paxos有什么区别,或者说他们是同一个类型、解决同一个问题的算法吗?
41 |
42 | 首先,举一个分布式数据库的例子 https://www.zhihu.com/question/275845393/answer/385349629。分布式数据库一般采用数据的**partition**和**replication**来提高整体的与高可用特性。单机数据库的账户表中存储了A与B两个账户。在分布式数据库中,将A与B存储在不同节点,称为partition;对于每个数据数据保存多份副本(副本在不同节点),称为replication,如A的三个副本为A1、A2和A3,B的副本为B1、B2和B3。这样原先在一个节点的数据A与B,被分到了6个节点。
43 |
44 | 那么从前面说的2PC中,我们也知道 两阶段提交 可以保证多个分片上操作的原子性,要么全部成功,要么全部失败;也就是A转钱给B,要么A-100同时B+100,要么都不变。而Paxos 或者 Raft,是用于保证同一个数据分片的多个副本的一致性,其在工程上的实现是**多个replication副本**对数据的操作序列达成一致。而且一个很明显的不同就在于,2PC中只有所有节点成功,整个事务才成功,但Paxos只要认为majority成功就行;这也体现出单纯的2PC不具备高可用,因为一个节点挂了,整个事务就阻塞住了,也就不可用了。
45 |
46 | 关于这两者也有相应的学术名称,2PC成为**consistency**算法(也就是一致性),Paxos成为**consensus**算法(也就是共识算法),那是以为两者是一个完全互补的关系,就像之前说的Spanner在paxos组上进行两阶段提交?事实上不是,Lamport在*[Consensus on Transaction Commit](https://lamport.azurewebsites.net/video/consensus-on-transaction-commit.pdf)*这篇论文中就指出了,两阶段提交是基于Paxos提交的一个退化版情形。也就是说 完全可以在Paxos算法之上创建一个新算法来代替2PC,也有相应的论文**Paxos Commit**。
47 |
48 | 6. 三阶段提交的话,则把两阶段提交的准备阶段 划分为 提议+准备两个阶段,网上也有称为 CanCommit 和 PreCommit 的说法。
49 |
50 | - **提议** *propose*:*协调者* Propose消息告诉*参与者* 新事务并收集投票
51 |
52 | - **准备** *prepare*:如果投票通过,则*协调者* 发送Prepare消息,参与者会执行事务操作(写入undo和redo log),返回ACK;否则(比如有参与者投反对票,或参与者超时未回复)发送Abort消息并结束流程
53 |
54 | - **提交/中止** *commit/abort*:*协调者* 通知*参与者* 提交事务;如果协调者 没有在超时时间内收到所有ACK,则向所有参与者发送Abort,参与者利用undo log进行回滚
55 |
56 | **解决的问题**:
57 |
58 | 解决了阻塞问题。比起2PC,3PC在参与者端额外引入了超时机制,从而如果参与者Prepare成功但无法及时收到来自协调者的信息,他会默认执行commit,而不会一直持有事务资源并处于阻塞状态。
59 |
60 | **未解决的问题**:
61 |
62 | 发生**网络分区**的情况(有些地方也说 3PC是需要假设节点间的延迟与响应时间是有界的,这也是一个意思;如果延迟高到一定程度,那也等同于发生了网络分区),Prepare阶段参与者节点A/B/C无法与协调者通信,导致A/B收到了prepare、但C没有;结果发生超时后,A/B提交了事务(因为A和B收不到协调者的Abort消息,按刚才的说法,超时后默认就commit了),但C中止了,即产生了矛盾。
63 |
64 | 7. 前面我们提过,Spanner是在paxos共识组上进行两阶段提交,但是在真正深入了解之前,我发现很容易将几个事务实现概念弄混。就比如 之前提到的TrueTime,高精度的物理时钟API,它在事务管理中扮演的是什么角色?
65 |
66 | 首先简单讲一下它的架构,这里的Zone可以理解为物理隔离的单位,每个zone里面有一个**zonemaster**和成百上千个**spanserver**,其中zonemaster负责给spanserver分配数据,spanserver才是真正处理用户请求的服务器;而location proxy顾名思义 会在客户向spanserver发送请求前,根据距离、延迟、负载等信息,决定访问哪个spanserver。
67 |
68 | 深入来看spanserver,它是真正负责读写数据的地方,每个spanserver包含多个tablet,tablet可以理解为一个表的某些行,其数据结构也是kv的(key string, timestamp int)->string,(TiDB就是参照这套来搞)。同时,一个spanserver上的**每个tablet 都维护了一个Paxos状态机**,从而在每个paxos组中也会有一个leader,事实上这里paxos是进行的binlog的同步,也就是每个paxos提议的对象是binlog record。可以看到,每个leader上有lock table以及transaction manager,也就是现在所需要关注的对象。
69 |
70 | 从Spanner的论文中可以知道,Lock table通过两阶段锁实现并发控制(悲观,为长事务设计,比如报表生成),Transaction Manager: 负责跨分片(跨Paxos group)的分布式事务,通过两阶段提交实现。其实这里可以把将一个个paxos group想像成单独的一个个节点,但是不能把paxos组的leader跟协调者弄混了,准确的说 只有leader节点会参与2PC,而协调者会由发起事务的client来决定。之前提到过两阶段提交存在单点故障问题,这里即使paxos leader宕机了,也可以很快用follower代替。
71 |
72 | 8. 那么之前提到的TrueTime到底是起什么作用?我们知道TrueTime它是用来生成全局时间戳的,而时间戳的本质就是为了建立事务的顺序关系。所以spanner所支持的三种事务类型中,只要是涉及时间戳的获取,就是由TrueTime API所支持的;并且,前面的tablet也提到是kv结构的,事实上key由两部分组成:一部分是字符串的键,另一部分就是该条记录的时间戳。那么为什么不能像TiDB那样 从 PD 获取一个全局唯一递增的时间戳作为当前事务的唯一事务 ID,这是因为 Spanner是跨全球的节点,引入一个单点的全局时间会带来很高的延迟影响。
73 |
74 | 三种事务类型:
75 |
76 | - **读写事务**:需要加锁(悲观并发控制),以下考虑写操作:
77 |
78 | 1. 确定写操作涉及的所有group,从中选取一个协调者
79 |
80 | 2. 所有节点首先获取写锁
81 |
82 | 3. 协调者生成本次事务的写入时间戳(需满足比之前任何事务的时间戳更大)
83 |
84 | 4. Leaders(不管是不是协调者)将客户端提交的数据,通过paxos写入到副本binlog;注意:这里和一般的2PC不同,spanner的客户端是直接向对应的leader发送提交的数据,不管是协调者还是参与者;只不过参与者收到提交的数据后,会发送给协调者一个prepare回复
85 | 5. 协调者收到所有参与者的prepare消息后,连带自己的Prepare以及Commit一起持久化,然后告知Client成功Commit
86 | 6. 最后是通知参与者commit,并释放锁。当然这里的commit不仅仅是本地的commit,而是paxos组要进行commit
87 |
88 | - **只读事务**:无锁,可以在副本上进行;基于TrueTime实现了多版本的无锁读,即使当前的spanserver挂掉了,仍可以基于truetime从副本中读取
89 |
90 | - **快照读**:客户端可以指定快照读的时间戳 或 时间戳过期的时间点,无锁
91 |
92 | 9. Percolator 同样是 Google 提出的分布式事务解决方案,构建在 BigTable 上,像TiDB乐观事务的实现就是基于Percolator模型。
93 |
94 | 在进行读写事务时,分以下几步:
95 |
96 | 1. 在所有写操作的行中,选出**一行**作为Primary,其余涉及的行全称为secondary,在写入Lock列之前会检查是否已有锁;且在事务开始后,检查Write列是否有新的写操作已经提交(即发生冲突)
97 | 2. Primary上好锁后,给secondary上锁,这里的锁会指向primary锁(也就是指向Account1)
98 | 3. 提交阶段的CommitTs > StartTs,更新Write列,删除Lock列
99 | 4. 如果Primary提交失败,整个事务回滚
100 |
101 | 10. TiDB 中事务 基于Percolator使用两阶段提交,分为 Prewrite 和 Commit 两个阶段;可以看到,在commit之前,在TiDB这边 buffer 所有的 update/delete 操作;但TiDB本身是无状态的,只能把最后的修改结果交给TiKV去判断冲突。
102 |
103 | 并发事务频繁修改同一行时,乐观事务的性能由于冲突可能会很差,本质因为乐观事务 基于并发事务不常修改同一行的假设,从而跳过获取行锁来提升性能。
104 |
105 | 所以TiDB后续也引入了悲观事务,当TiDB 收到来自客户端的更新数据的请求时,TiDB 向 TiKV 发起加悲观锁请求,该锁会持久化到 TiKV。当然,引入悲观锁的话,需要做好死锁的检测,终止特定的事务使整体能继续推进。
106 |
107 | 在High Performance TiDB中,也提到了一下几点性能优化:
108 |
109 | - **基于的假设:**
110 | - 写冲突小
111 | - 需要恢复场景很少(但不能完全忽略)
112 |
113 | - **异步提交:**
114 | - 如果prewrite成功,可以直接返回client成功
115 | - 代价是恢复阶段更复杂,且需要保存所有的secondary key,内存占用会上升
116 |
117 | - Batch IO
118 |
119 | - 在MVCC中,对于占用空间小的值,直接保存在元信息的Lock或Write列(减少磁盘读写)
120 |
121 |
122 |
123 |
--------------------------------------------------------------------------------
48 |
49 | - 重优化:每次调用查询时都进行优化;难以重用已经存在的计划
50 | - 多计划:对于 params 不同值 生成多种plan
51 | - 平均计划:选择一个param的平均值,每次调用都用这个平均值
52 |
53 | 7. Plan Stability:三种选择
54 |
55 | - Hints:允许DBA给optimizer一些优化提示
56 | - Fixed Optimizer Versions:
57 | - Backwards-Compatible Plans:
58 |
59 | 8. Search Termination:三种方式
60 |
61 | - 定时:超过预设时间就停止优化
62 | - 阈值:直到找到 有比阈值更低代价的 plan
63 | - 穷尽:没有更多plan的变化方法
64 |
65 | 9. **最优化搜索策略**:
66 | - 启发式
67 | - 启发式 + 基于代价的联接顺序搜索(Cost-based join search)
68 | - 随机化算法
69 | - 分层(Stratified)搜索:Planning is done in multiple stages
70 | - 统一(unified)搜索:Perform query planning all at once
71 |
72 | 10. 启发式:
73 |
74 | - 尽早执行更严格的选择
75 |
76 | - 在联接前执行所有选择
77 |
78 | - 对 **projection/predicate/limit** 下推(pushdown)
79 |
80 | - 基于 基数的 联接顺序排序
81 |
82 | -----
83 |
84 | 优点:
85 |
86 | - 易实现,易调试
87 | - 对于简单查询很快
88 |
89 | 缺点:
90 |
91 | - 在估计一个计划的预期成效时,需要依赖魔法常量
92 | - 当操作符有复杂的依赖时,几乎不能生成好的计划
93 |
94 | 11. 启发式 + 基于代价的联接顺序搜索:
95 |
96 | - 初始优化使用静态的规则实现
97 |
98 | - 然后使用动态规划 来决定表联接的最佳顺序: 使用 分治法搜索来 自底向上(Bottom-up) 规划
99 |
100 | ------
101 |
102 | 优点:
103 |
104 | - 不用穷举搜索,通常也可以找到合理的执行计划
105 |
106 | 缺点:
107 |
108 | - 同 启发式
109 | - left-deep join tree 不一定总是最优的(只能串行 join,并且由于产生了大量的中间临时表;还有另外一种join order叫做 **bushy join tree**,可以并行)
110 | - 需要考虑 代价模型中数据的物理性质
111 |
112 | 12. 随机化算法:(如Postgres的遗传算法)
113 |
114 | - 在所有可能的执行计划构成的**解空间(solution space)**中随机搜索
115 | - 直到达到一个cost的阈值,或者经过一定长度的时间
116 |
117 | ------
118 |
119 | 模拟退火(simulated annealing)算法:
120 |
121 | - 起始点为 纯启发式规则
122 | - 计算不同操作符的排列组合(如交换两个表的联接顺序):
123 | - 只要减少cost,接受之
124 | - 当cost增加时,**有小概率会接受**之(防止陷入到局部极优值的解,而找不到全局最优解)
125 | - 如果会违反结果正确性(比如排序的顺序),拒绝之
126 |
127 | ------
128 |
129 | 优点:
130 |
131 | - 防止局部最优解
132 | - 低内存占用(不需要保留历史记录)
133 |
134 | 缺点:
135 |
136 | - 当DBMS选了某个方案后,难以得知它为什么要这么选
137 | - 需要额外的工作来验证算法的确定性
138 | - 需要实现 正确性的判断规则(保证每一轮变化的结果都是正确的)
139 |
140 | 13. 分层搜索:
141 |
142 | - 根据变换规则重写**逻辑查询(logical query)**:不考虑代价
143 | - 进入动态规划阶段来优化
144 |
145 | -------
146 |
147 | 优点:
148 |
149 | - 实际表现很好
150 |
151 | 缺点:
152 |
153 | - 难以指定变换的优先级
154 | - 规则是大问题
155 |
156 | 14. 统一搜索:(以Volcano 优化器为例)
157 |
158 | - 易于添加新的操作、新的等价规则
159 | - 把 数据的物理属性 当做第一成员
160 | - **自顶向下**:使用**分支定界(branch-and-bound)**搜索
161 |
162 | ----------
163 |
164 | 优点:
165 |
166 | - 使用声明式(declarative)规则来进行变换
167 | - 更好地扩展性
168 |
169 | 缺点:
170 |
171 | - 不易修改predicate
172 | - 在优化搜索前,所有等价类都被完全展开 来 生成所有的逻辑运算符
173 |
174 | 15. 查询优化很困难,甚至NoSQL一开始都没去实现它。
175 |
176 |
--------------------------------------------------------------------------------
/paper reading/query/Multi-Core, Main-Memory Joins.md:
--------------------------------------------------------------------------------
1 | ## Multi-Core, Main-Memory Joins: Sort vs. Hash Revisited
2 |
3 | 1. **问题**:随着多核体系架构的到来,人们认为sort-merge join比radix-hash join要更好(参考**[17 parallel join](https://github.com/F-ca7/Advanced-Database-Systems-Learning/tree/master/17%20parallel%20join)**),因为有 SIMD指令(当SIMD宽度足够时,sort-merge更快) 和 NUMA (*Non Uniform Memory Access Architecture*)架构。
4 |
5 | > NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(后称Remote Access)。
6 |
7 | 2. **Contribution**:
8 |
9 | - 证明了 大部分时候radix-hash 仍然比sort-merge快,只有当 涉及大量数据时,sort-merge的性能才接近radix-hash。
10 |
11 | - 给出了 在现代处理器上 其他数据操作(除join外)的见解
12 | - 给出了两种join的最快实现算法
13 | - 解释了影响算法选择的因素
14 |
15 | 3. **Related Work**:
16 |
17 | - 一旦硬件支持矢量指令,且宽度足够(如 具有256位及以上AVX的SIMD),sort-merge很容易击败 radix-hash. 参考 *Sort vs. hash revisited: Fast join implementation on modern multi-core CPUs*(2009)
18 | - 在 基于NUMA的实现中,即使不使用SIMD指令,sort-merge也可以比radix-hash快。参考 *Massively parallel sort-merge joins in main memory multi-core database systems*(2012)
19 | - **parallel radix join**
20 | - no-partitioning 的radix join. 参考 *Design and evaluation of main memory hash join algorithms for multi-core CPUs*(2011)
21 |
22 | 4. 影响算法的因素:
23 |
24 | - 输入大小 *input size*:
25 |
26 | 表的相对和绝对大小都对性能有很大的影响。随着大小的增长,关于 只有hash才会扫过数据多趟 的假设被打破,实验表明 sort-merge一样要过多趟数据,性能也会相应降低。
27 |
28 | - 并行度 *degree of parallelism*:
29 |
30 | 当并行度增加时,merge tree中的冲突也会变多。
31 |
32 | - cache竞争 cache contention:
33 |
34 | > **Cache contention** occurs when two or more CPUs alternately and repeatedly update the same **cache** line. This may be due to. memory **contention**, in which two or more CPUs try to update the same variables.
35 |
36 | - SIMD性能:
37 |
38 | 硬件特性起着很大的作用,并且发现SIMD寄存器的宽度并不是唯一的相关因素。更复杂的SIMD设计所固有的 **复杂硬件逻辑 hardware logic** 和**信号传播延迟 signal propagation delay** 可能导致延迟大于一个周期,从而限制了SIMD的优势。
39 |
40 | 5. 并行sort-merge:
41 |
42 | sort-merge join主要的cost就在排序上,通常使用归并排序。
43 |
44 | 1. **Run Generation**
45 |
46 | 使用 **排序网络** sorting network,奇偶归并排序网络也是一种比较器个数为O(n*logn*logn)的排序网络。它和归并排序几乎相同,不同的只是合并的过程。普通归并排序的O(n)合并过程显然是依赖于数据的,奇偶归并排序可以把这个合并过程改成非数据依赖型,但复杂度将变高。这个合并过程本身也是递归的。
47 |
48 | 2. **Merging Sorted Runs**
49 |
50 | 使用 双调合并 Bitonic Merge Networks来合并大的列表。
51 |
52 | > 对于两个元素x,y,如果x<=y,则x,y都位于双调序列的递增部分,而递减部分没有元素,如果x>=y,则x,y都位于双调序列的递减部分,而递增部分没有元素,于是x和y构成一个双调序列。因此,任何无序的序列都是由若干个只有2个元素的双调序列连接而成。
53 | >
54 | > 于是,对于一个无序序列,我们按照递增和递减顺序合并相邻的双调序列,按照双调序列的定义,通过连接递增和递减序列得到的序列是双调的。最终,我们可以将若干个只有2个元素的双调序列合并成1个有n个元素的双调序列。
55 | >
56 |
57 | 6. Cache conscious sort join
58 |
59 | 分为三个阶段:
60 |
61 | - **寄存器内排序 in-register**
62 |
63 | 对应了 Run Generation
64 |
65 | - **高速缓存内排序 in-cache**
66 |
67 | 对应了 双调排序
68 |
69 | - **高速缓存外排序 out-of-cache**
70 |
71 | 继续merge直到所有数据有序(超出了cache的大小,需要到内存中排序)
72 |
73 | 7. Hash join
74 |
75 | 随机访问内存,会导致缓存miss(当hash表大于cache时,基本上每次访问hash表都会发生cache miss),可通过partition来解决。
76 |
77 | - **Radix Partitioning**
78 |
79 | 在Partition阶段 考虑到 TLB translation look-aside buffers(**地址变换高速缓存**,省去了一次访问内存的时间)的影响。*Radix Partitioning*把每个元组写到他们对应的划分中:
80 |
81 | ```c#
82 | foreach input tuple t do
83 | k := hash(t)
84 | p[k][pos[k]] = t
85 | pos[k]++
86 | ```
87 |
88 | - **Software-Managed Buffers**
89 |
90 | 先分配一组buffer,其中每个buffer供输出的划分使用(可容纳*N*个元组),当buffer满了后再拷贝到最终的目的地。
91 |
92 | 有两层好处:1. 更少的趟数能达到同样
93 |
94 | 在本文实现中,就使用了Software-Managed Buffers,其中N的大小恰好使buffer装入一个cache line(64 bytes)
95 |
96 | 8. 具体join算法
97 |
98 | - Sort-Merge **m-way**
99 |
100 | - Sort-Merge **m-pass**
101 |
102 | - Massively Parallel Sort-Merge **mpsm**
103 |
104 | 通过Software-Managed Buffer对R进行划分,将R分配给不同NUMA的区域或线程,每个线程对自己区域内的数据进行排序。
105 |
106 | - Radix Hash **radix**
107 |
108 | - No-Partitioning Hash **n-part**
109 |
110 | 将关系**R**和**S**划分为大小相等的部分,分配给工作线程。每个worker把负责的关系**R**的元组填充到hash表,再在**S**中找到匹配的元组。
--------------------------------------------------------------------------------
/04 concurrency control/4-occ-notes.md:
--------------------------------------------------------------------------------
1 | ## Optimistic Concurrency Control
2 |
3 | 1. 减少 由于使用对话式API 造成的stall:
4 |
5 | - **Prepared Statement**:消除了query准备的开销(query preparation overhead)
6 |
7 | > Overhead——overhead is any combination of excess or indirect computation time, memory, bandwidth, or other resources that are required to perform a specific task.
8 |
9 | - **Query Batches**:减少网络的往返次数
10 |
11 | - **Stored Procedures**:同时减少 准备的开销和网络的时延
12 |
13 | 数据库系统中,一组为了完成特定功能的 SQL 语句集,这些SQL语句集存储在数据库中,经过第一次编译后,后续调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
14 |
15 | 2. **Prepared Statement**的优点
16 | - Less overhead for parsing the statement each time it is executed. 很多时候数据库执行的语句都是一样的,只是 WHERE的条件不一样/ UPDATE 设的值不一样 等。
17 | - Protection against SQL injection attacks. 语句中使用了占位符,规定了sql语句的结构。用户可以设置"?"的值,但是不能改变sql语句的结构。因此可以防sql注入。
18 |
19 | 3. **Stored Procedures**的优点
20 |
21 | - 减少应用程序与数据库服务器之间的 网络往返
22 | - 由于query预编译好并存储在DBMS中,可以提高性能
23 | - 可以在不同应用中被 复用
24 | - 发生冲突时,服务端的事务会重启
25 |
26 | **Stored Procedures**的缺点
27 |
28 | - 不是大部分开发者都会写SQL/PSM代码
29 | - 在应用程序的范围之外,难以管理版本与调试
30 | - 不一定能移植到别的DBMS
31 | - DBA不会授予权限
32 |
33 | 4. 并发控制方案:
34 |
35 | - Two-Phase Locking (2PL 两阶段锁 **悲观**):假设事务之间会发生冲突,当要访问数据库对象时,必须获得锁。
36 | - Timestamp Ordering (T/O 基于时间戳 **乐观**):假设事务之间的冲突概率很小,访问数据库对象时不需要获得锁;而是在提交时检查是否有冲突。
37 |
38 | 
39 |
40 | 5. **2PL** ——早期的数据库已经通过严格两阶段锁协议(S2PL,Strict Two-Phase Locking)实现了完全的串行化隔离(Serializable Isolation),即正在进行读操作的数据阻塞对应写操作,写操作阻塞所有操作(包括读操作和写操作)。但存在死锁现象:
41 | - **死锁检测** Deadlock Detection:
42 | 1. 每个事务维护一个队列,队列元素是所有持有 该事务等待的锁 的其他事务。
43 | 2. 一个独立的线程会检查所有的队列是否存在死锁。
44 | 3. 发现死锁时,使用启发式算法来决定终止(kill)哪个事务。
45 | - **死锁预防** Deadlock Prevention:
46 |
47 | 6. **Basic 基于时间戳** 协议如下
48 |
49 | - 每个事务到达DBMS时,分配一个唯一的时间戳
50 |
51 | - DBMS为 每一个元组 维护最后一个读/写该元组的事务 对应的时间戳
52 |
53 | - 每次事务访问元组时,会对比元组的时间戳和自己的时间戳,来检测冲突(每次都检测,不是乐观)
54 |
55 | - DBMS需要把一个元组拷贝到 事务的**私有空间**private workspace 来实现**可重复读**repeatable reads
56 |
57 | > Read uncommitted(读未提交):事务中的修改,即使没有提交,在其他事务也都是可见的。结果:产生脏读。
58 |
59 | > Read committed(读已提交):一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的。这个级别有时候也叫做不可重复读,因为在**一个事务中执行多次相同的查询**,可能会得到**不一样的结果**。因为在这多次读之间可能有其他事务更改这个数据,每次读到的数据都是已经提交的。结果:产生不可重复读。
60 |
61 | > Repeatable read(可重复读):解决了脏读,也保证了在同一个事务中多次读取同样记录的结果是一致的。但是理论上,可重复读隔离级别还是无法解决另外一个幻读的问题,指的是当某个事务在读取某个范围内的记录时,另外一个事务也在该范围内插入了新的记录或删除了原有的记录,当之前的事务再次读取该范围内的记录时,好像产生幻觉。结果:产生幻读。
62 |
63 | > Serializable(可串行化):它通过强制事务**串行执行**,避免了前面说的幻读的问题,但由于读取的每行数据都加锁,会导致大量的锁征用问题,因此性能也最差。
64 |
65 | -----
66 |
67 | ### 乐观并发控制
68 |
69 | 把所有改变保存在私有空间中,在提交时才检查冲突再合并。
70 |
71 | 7. 三个阶段:
72 |
73 | - Read Phase: (不是字面上的只有读操作) 把事务要访问的元组拷贝到私有空间,来实现可重复读;同时还要记录它读/写的集合。
74 |
75 | - Validation Phase: 当事务**COMMIT**时,DBMS检查它是否与其他事务发生冲突。每个事务需要按顺序(global order)获取 其**写集合**对应record的锁。
76 |
77 | - Backward Validation: 检查正在提交的事务的 读/写集合 是否与其他**已提交**的事务有交集。
78 |
79 | 
80 |
81 | - Forward Validation: 检查正在提交的事务的 读/写集合 是否与其他**未提交**的事务有交集。
82 |
83 | 
84 |
85 | - Write Phase: DBMS应用 事务write的修改,并使这些修改对其他事务可见。每个record更新成功后,该事务要释放对应的锁。
86 |
87 | 8. [时间戳分配](https://dspace.mit.edu/bitstream/handle/1721.1/100022/Devadas_Staring%20into.pdf)
88 | - Mutex:最坏的选择
89 | - Atomic Addition:使用CAS(compare-and-swap)来递增一个全局变量
90 | - Batched Atomic Addition:Needs a back-off mechanism to prevent fast burn
91 | - Hardware Clock: The CPU maintains an internal clock (not wall clock) that is synchronized across all cores. Intel only. 未来CPU中不一定存在硬件时钟
92 | - Hardware Counter:目前CPU中未实现
93 |
94 | 9. [Silo](https://github.com/stephentu/silo)内存型数据库,使用并行的Backward Validation实现可串行化的OCC。两个核心思想:
95 | - 避免对 **只读事务**的**共享内存** 的所有**写操作**
96 | - 使用epoch来进行批量时间戳分配
97 |
98 | 10. Silo实现细节如下:
99 | - Epoch
100 | - 时间被划分为**定长**的epoch(40ms)
101 | - 在同一个epoch内开始的事务 最终会在同一个epoch的末尾**一起提交**
102 | - 若事务时长超过1个epoch,则要自己刷新才能进入下一个epoch
103 | - 工作线程只需要在每个epoch的开始和结束 进行同步
104 | - Transaction ID
105 | - 每一个工作线程 会基于当前epoch号以及已赋值批次的下一个值 来生成唯一的事务ID号
106 | - Garbage Collection
107 | - 协作式线程的垃圾回收Cooperative threads GC
108 | - 每个工作线程 通过一个**reclamation epoch** 标记一个已删除的对象 (这是一个[内存型数据库](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/02%20in-memory%20db/2-imdb-notes.md))
109 | - Range Query
110 | - 通过 记录事务在索引上的scan集合 来解决幻读问题
111 | - 在 validation phase 重新执行扫描,看索引是否发生变化
112 | - Have to include virtual entries for keys that do not exist in the index to prevent two threads from trying to insert the same key.
113 |
114 |
115 |
116 |
--------------------------------------------------------------------------------
/paper reading/cloud/Above the Clouds - A Berkeley View of Cloud Computing.md:
--------------------------------------------------------------------------------
1 | ## Above the Clouds: A Berkeley View of Cloud Computing
2 |
3 | 2009
4 |
5 | 1. 什么是云计算?
6 |
7 | 云计算指:通过网络,将应用程序 以及相应的数据中心中的硬件与系统 作为服务提供。
8 |
9 | 其中,**把应用程序本身作为服务 是称为SaaS,而数据中心的软硬件称为 云 Cloud**。
10 |
11 | 2. 为什么云计算在近年腾飞,而以前的尝试却失败了?
12 |
13 | 从硬件的角度看,云计算在以下三方面有创新之处:
14 |
15 | 1. 可按需提供无限计算资源的假象,消除了云计算用户提前计划资源调配的需要
16 | 2. 允许企业从小规模做起,只有在需求增加时才增加硬件资源
17 | 3. 根据需要在短期内(例如按天存储)为计算资源的付费,并根据需要对它们进行释放
18 |
19 | 过去在效用计算(utility computing,服务提供商提供客户需要的计算资源和基础设施管理,并根据应用所占用的资源情况进行计费,而不是仅仅按照速率进行收费)上的努力失败了,作者认为 是因为 云计算这三个关键特征中的一个或两个缺失了。
20 |
21 | 3. 成为云计算提供商需要什么条件?为什么一家公司会考虑成为云计算提供商?
22 |
23 | 以下原因可能让一家公司会考虑成为云计算提供商:
24 |
25 | - **更高利润**:大型数据中心 花在硬件、网络带宽、电力上的消费 只有中型数据中心的1/5到1/7;且软件开发和部署的固定成本 可以由在更多的机器上运行而分摊。因此一家足够大的公司可以利用这些规模经济,提供远低于中型公司成本的服务,同时还能获得可观的利润
26 | - **利用现有投入**:在现有基础设施之上来构建云计算服务,以较低的成本增量提供新的收入流,有助于分摊数据中心的大量投入
27 | - **特许经营权**franchise:比如Microsoft Azure为将其企业应用程序的现有客户 迁移到云环境提供了更方便的路径
28 | - **向现任者发起挑战**
29 | - **利用客户关系**:像IBM Global Services 这样的IT组织有广泛的客户关系,那么提供品牌化的云计算产品可以为这些客户提供一条没有担忧的迁移路径,从而保护双方的投资
30 | - **自己成为平台**:比如Facebook使用插件化的App这一举措非常适合云计算(其一个基础设施提供商就是[Joyent](https://www.joyent.com/))
31 |
32 | 4. 云计算带来了哪些新机遇?
33 |
34 | 5. 如何当前的云计算产品进行分类?特定产品的类别不同,其技术和业务挑战有是否有相应不同?
35 |
36 | 6. 云计算带来了哪些新的经济模式?服务运营商如何决定 是转移到云计算 还是 留在私有数据中心?
37 |
38 | 云计算下的经济模式特点:
39 |
40 | - 云计算支持的细粒度经济模型使**决策更具流动性**,特别是云提供的**弹性有助于转移风险**
41 | - 尽管硬件资源成本继续下降,但它们的下降速度是裱花的;例如,计算和存储成本的下降速度要快于WAN。云计算可以记录这些变化,并其传递给客户,比他们建设自己的数据中心更高效,从而使支出与实际资源使用更接近
42 | - 在决定是否将现有服务移动到云上时,还必须检查预期的平均资源利用率和峰值资源利用率,特别是当应用程序可能具有高度可变的资源需求峰值时;对购买设备的实际利用率的实际限制;以及所需的各种运营成本根据所考虑的云环境的类型而有所不同
43 |
44 | 是否迁移到云的成本比较:
45 |
46 | - 按单独资源付费
47 | - 电力、冷却和物理设备成本
48 | - 运维成本
49 |
50 | 7. 云计算的十大障碍是什么?克服这些障碍相应的机遇有哪些?
51 |
52 | 1. **服务可用性:**
53 |
54 | 作者认为,实现极高可用性的唯一可行解决方案是多个云计算供应商。高可用性计算社区长期以来一直奉行“没有单点故障”原则,然而,由单公司负责云计算服务实际上也是一种单故障点。即使公司在不同的地理区域拥有多个数据中心,使用不同的网络供应商,它也可能拥有通用的软件基础设施和会计系统,甚至公司可能倒闭。如果没有针对这种情况的业务连续性战略,大客户将不愿意迁移到云计算。
55 |
56 | 另一个可用性的障碍是 DDoS攻击。云计算将攻击目标从SaaS供应商转移到效用计算供应商,后者通过弹性可以更容易地吸收攻击,而且也可能已经将DDoS保护作为核心能力。
57 |
58 | 2. **数据的锁定**(data lock-in):
59 |
60 | 客户无法轻松地从一个地方提取数据 放到另一个地方。由于担心从云中提取数据的难度很大,一些组织无法采用云计算。
61 |
62 | 这种lock-in可能对云计算供应商有利,但云计算用户很容易受到价格上涨、可靠性、甚至供应商倒闭的影响。
63 |
64 | > 可参考[供应商锁定](https://zhuanlan.zhihu.com/p/350736696) vender lock-in:
65 | >
66 | > 是指切换到其他供应商的成本非常高、以至于客户不得不继续使用原始供应商的情况。由于财政压力、人手不足,或需要避免业务运营中断,客户可能在产品或服务质量不佳时被锁定。
67 |
68 | 一种解决方案是 将API标准化,从而SaaS开发人员可以跨多个云计算提供商部署服务和数据。但是这样做可能会导致 云产品的定价相互**竞次**(race-to-the-bottom),也就是比谁更能达到底线,肯定会损害云计算供应商的利益。对此,作者提出了两个看法:
69 |
70 | - 云服务的质量和价格都是同等重要的,所以顾客不一定会选择价格最低的服务。比如当今一些互联网服务供应商的价格比其他供应商高出10倍,因为他们更可靠,并提供额外的服务来提高可用性。
71 | - 标准化的API还支持一种新的模型——相同的软件基础设施可以在私有云和公共云中使用。从而支持 **激增计算**(surge computing),即使用公共云来处理 由于临时突增的工作负载而无法在私有云轻松完成的任务
72 |
73 | > 最近看到[这篇博文](https://www.intercom.com/blog/ten-technical-strategies-to-avoid-when-scaling-your-startup-and-five-to-embrace)则指出,目前对于大部分企业来说 需要避免多云架构,因为这属于一种过早优化( premature optimization),除非是像Apple或Netflix的企业、或者已经占据了互联网大量流量。更合理的应该是选择一个好的云供应商。
74 | >
75 | > We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.
76 |
77 | 3. **数据保密性和可审核性**(Confidentiality and Auditability):
78 |
79 | 作者相信,要使云计算环境像绝大多数内部IT环境一样安全,没有任何根本性的障碍,许多问题可以通过已知的技术(如加密存储、虚拟局域网和网络中间件设备 如防火墙、数据包过滤器)。例如,在将数据放入云中之前对其进行加密,可能比在本地数据中心中对进行加密更安全。
80 |
81 | 4. **数据传输瓶颈:**
82 |
83 | 如今的应用程序继续变得更加数据密集,数据传输成本成为一个重要问题。云用户和云供应商必须如果想把成本降到最低,就要考虑系统各个层次的布局和流量的影响。
84 |
85 | 一种解决方案就是 直接运输磁盘。Jim Gray指出传输大量数据最便宜的方法是通过隔夜快递 发送磁盘甚至整个计算机。尽管磁盘或计算机的制造商无法保证这种运输方式的可靠性,但Gray在大约400次尝试中只经历了一次失败(甚至可以通过以类似RAID的方式传送带有冗余数据的磁盘来缓解这一问题)。
86 |
87 | 其次,由于像亚马逊、谷歌和微软这样的公司发送的数据可能比接收的数据多得多,因此入口带宽的成本可能要低得多,所以可以考虑**异地归档和备份**服务。因此,例如,如果每周的完整备份是通过运送物理磁盘来移动的,而压缩后的每日增量备份通过网络发送,那么云计算可能可以提供价格合理的异地备份服务。并且,一旦归档数据进入云中,就能提供更多的新服务。比如为归档数据创建可搜索的索引,或对所有存档照片执行图像识别 从而进行分组。
88 |
89 | 还有更激进的思路是 尝试更快地降低广域网带宽的成本。据估计,广域网带宽成本的三分之二是高端路由器的成本,而只有三分之一是光纤成本,所以有研究在寻找高端分布式路由器的低成本替代品。
90 |
91 | 5. **性能的不可预测性**:
92 |
93 | 从经验上来看,在云计算中,多个虚拟机可以很好地共享CPU和内存,但IO方面的问题很大。
94 |
95 | 一种可能是使用闪存来减少IO的相互干扰。闪存在断电时可以保存信息,且不像磁盘需要转动来访问,速度更快。与磁盘相比,闪存每秒可以支持更多的I/O,因此随机I/O workload的多个虚拟机,可以在同一台物理机上更好地共存。
96 |
97 | 6. **可扩展的存储:**
98 |
99 | 如何创建一个存储系统与云的优势结合起来。即满足在资源管理方面对**可伸缩性**、**数据持久性**和**高可用性**的期望
100 |
101 | 7. **大型分布式系统存在的Bug:**
102 |
103 | 大型分布式系统中出现的bug,很多都无法在小规模的环境下复现,所以不得不在大规模生产环境中进行debug。
104 |
105 | 相应的方法比如:依靠云环境的虚拟化,来获取有价值的错误信息。
106 |
107 | 8. **快速扩缩容**:
108 |
109 | 存储、网络是现用现付(pay as you go)的,都是按使用的大小计算,如何能在不违反SLA的情况下 快速扩缩容来节省成本?
110 |
111 | 9. **声誉共同体**(Reputation Fate Sharing):一个客户的不良行为会影响整个云的声誉。例如,垃圾邮件防范服务将EC2 IP地址列入黑名单,可能会对其他应用造成影响。相对应的,另一个问题是法律责任的转移问题,也就是云计算提供商希望法律责任由客户承担而不是转移给他们(即发送垃圾邮件的公司应该承担责任,而不是Amazon本身)。
112 |
113 | 10. **软件许可:**
114 |
115 | 许多云供应商基于开源软件开发的原因,部分就是由于商业软件不适合效用计算的场景。
116 |
117 | 所以未来要么开源软件继续越来越受欢迎,要么商业软件公司就要对云环境下的许可作出相应调整。
118 |
119 | 8. 未来的应用软件、基础设施和硬件的设计应该做出哪些改变,以适应云计算的需求和机遇?
120 |
121 | - 软件:出售给企业客户 和 给云计算有不同的定价。
122 | - 基础设施:需要意识到 不是在裸金属上运行,而是在虚拟机中。
123 | - 硬件:
124 | - 需要面向多个机架的规模设计
125 | - 可以将内存、存储器和网络的空闲部分置于低功耗模式来做到能耗均衡
126 | - 提高数据中心交换机 和 WAN路由器的带宽,且降低成本
--------------------------------------------------------------------------------
/paper reading/dbms/Scalable Garbage Collection for In-Memory.md:
--------------------------------------------------------------------------------
1 | ## Scalable Garbage Collection for In-Memory MVCC Systems
2 |
3 | 1. **问题**:支持HTAP的数据库系统通常都使用MVCC,而MVCC会产生很多过期的元组版本,最终需要被回收。但是我们发现HTAP中的GC通常是一个性能瓶颈。在长query中,最先进的GC方法的粒度过粗,从而版本的数量会迅速增加 使得整个系统变慢;同时 标准的后台清理方法 会使系统的工作量突增。
4 |
5 | 2. **Contribution**:
6 |
7 | - 提出一种创新的GC方法,*Steam*,来剪枝过时的版本,可以无缝地融合到事务处理过程中,使得GC的开销最小
8 | - 该方法可以处理混合的workload,并在OLTP上 与state-of-the-art方法进行对比
9 |
10 | 3. **实现细节**:
11 |
12 | - GC的恶性循环
13 |
14 | 
15 |
16 | 在长事务中,所有使用到的version都不能被丢弃,而版本链越长,每次取得版本对应的数据就越慢,从而事务执行时间就越长,导致版本仍不能被回收,从而形成了恶性循环。
17 |
18 | - **Basic Design**
19 |
20 | *Steam*基于HyPer的MVCC实现来扩展,使其更加的robust和scalable。开始一个新事务时,系统把它添加到 *active transaction*列表后。当一个事务提交后,系统再将其移动至 *committed transaction*列表。
21 |
22 | 以上的两个list都隐式地 按事务的时间顺序排序,从而可以高效地取到 最小的 开始时间戳(即*active transaction*列表的第一个),则 *committed transaction*中 *commitId* ≤ min(*startTs*)的版本可被安全回收。
23 |
24 | 下面的实现重点关注三个方面:**scalability**, **long-running transaction**, **memory-efficient**
25 |
26 | - **Scalable Synchronization** —— scalability
27 |
28 | 前面提到的list方法可以在常数时间内进行GC,但是其可扩展性非常有限,因为 维护两个全局列表需要全局的mutex。因此,需要避免全局的数据竞争。如Hekaton使用一个 latch-free的transaction map来避免全局互斥锁。
29 |
30 | 而*Steam*遵循了 最好使用不需要同步的算法 的范式 (Latch-free synchronization in database systems: Silver bullet or fool’s gold? 2017)。它使用多条线程来分别管理 事务不相交的子集,每条线程会暴露给外部 自己本地的最小值(使用一个64位的atomic整型存储),如果当前线程没有 活动中的事务,则将值设置为最大的整型;因此只要扫描一次所有线程的本地最小值,就可知道全局的可回收的最小值。
31 |
32 | 
33 |
34 | 为了防止线程处于空闲状态而导致 GC被延迟,调度器会周期性地检查线程是否进入空闲状态、如果有必要的话进行GC
35 |
36 | - **Eager Pruning of Obsolete Versions** —— long-running transaction
37 |
38 | 
39 |
40 | 在遍历版本链时,无用的版本会使长事务变得更慢;因此设计了 Eager Pruning of Obsolete Versions,在版本不被活动中的事务所需要时,将它们都移除。
41 |
42 | 当一个线程进入版本链时,使用如下算法来剪枝掉过时的版本:
43 |
44 | ```c
45 | input: 有序的active timestamps
46 | output: 剪枝后的version chain
47 | curVer := getFirstVersion(chain)
48 | for a in A
49 | visVer := retrieveVisbleVersion(a, chain)
50 | for v in (curVer, visVer)
51 | // 保证最后一个版本包含了所有属性
52 | if v.attrs不是visVer.attrs的子集
53 | merge(v, visVer)
54 | chain.remove(v)
55 | curVer = visVer
56 | ```
57 |
58 | 因为只会在版本record中保存 发生改变的属性(节省内存),所以需要检查visVer是否包含了所有v的属性,若v有多出来的属性,则将其合并到最终版本中。在*Steam*中,每次一个元组更新时就会相应有一次prune(也就是版本链要加入新版本的时候)。
59 |
60 | - **Layout of Version Records** —— memory-efficient
61 |
62 | 一条版本的record 应该是空间上和计算上高效的,由3部分组成:
63 |
64 | - *Common Header*
65 |
66 | 包括
67 |
68 | - Type {如Insert/Update/Delete}
69 | - Version {可见性,在提交时Version就设置为提交时的时间戳}
70 | - RelationId {当事务回滚时,使用RelationId 和 TupleId 来恢复关系中的元组}
71 |
72 | - *Additional Fields*
73 |
74 | 包括
75 |
76 | - Next Pointer {版本链中指向下一个版本}
77 | - TupleId
78 | - NumTuples
79 | - AttributeMask {每个bit对应该表的一个属性}
80 |
81 | - *Payload*
82 |
83 | 包括
84 |
85 | - BeforeImages {只保存改变的属性}
86 | - Tuple Ids {可以复用Next Pointer来更好地管理批量插入}
87 |
88 |
89 |
90 | 4. **Related Work**:
91 | - **Tracking Level**
92 |
93 | 最细的粒度是**元组级别**,GC在扫描过每个元组后识别出 过时的版本(通常使用一个后台的清理进程来周期性清理)。
94 |
95 | 有些系统**基于事务**来管理版本。由同一个事务创建的版本 使用相同的commit时间戳,所以可以同时找到多个过时版本 并清理。
96 |
97 | 而**基于epoch**的系统 将多个事务同一个epoch中,epoch可根据 已分配内存或版本号数目的阈值 来判断是否进入下一个epoch。
98 |
99 | 最粗的粒度是**表级别**。只对 规定了特定操作的workload适用,比如 stored procedures 和 prepared statements;因此比较少用。
100 |
101 | - **Frequency and Precision**
102 |
103 | Frequency and precision indicate how quickly and thoroughly a GC identifies and cleans obsolete versions.
104 |
105 | *HANA* 和 *Hekaton* 就使用了**后台线程**(周期性调起用于GC),但是如果频率不够高的话,GC的决定就可能基于过时的信息。
106 |
107 | *BOHM* 则以**batch**的形式来管理执行事务,在每个batch的末尾来GC,保证该batch的每个事务已经完成。
108 |
109 | 而GC的彻底程度 取决于 GC如何辨别version是否可回收。**基于时间戳**的identification 不如 **基于区间**的方法 彻底。
110 |
111 | - **Version Storage**
112 |
113 | 大多数系统将version records存储在一个全局的数据结构中,如哈希表,从而可以 独立地回收单个版本。
114 |
115 | *HyPer* 和 *Steam*直接将版本保存在事务内,即 ***Undo Log***。当事务落后于high watermark是,其所有版本都可以一起回收。总之,用Undo log作为版本的存储也很好,因为Undo log是本来就需要用来回滚的。
116 |
117 | > 高水位(high watermark),通常被用在流式处理领域(比如Apache Flink、Apache Spark等),以表征元素或事件在基于时间层面上的进度。一个比较经典的表述为:流式系统保证在水位t时刻,创建时间(event time)= t'且t' ≤ t 的所有事件都已经到达或被观测到。
118 |
119 | *Hekaton*的版本管理则很特别,它不使用连续的表空间;元组的版本只能通过索引来访问( does not distinguish between a version record and a tuple)。唯一一个在探讨的系统中 使用O2N来排序的;O2N会使 写-写冲突检测更加昂贵,因为事务需要遍历整条版本链 来检测发生冲突的版本。
120 |
121 | - **Identification**
122 |
123 | commit时间戳是单调分配的,则很容易识别过时的版本。
124 |
125 | *HANA* 和 *Steam* 使用一种更细粒度、基于区间的方式,保证版本链长度最小,只是实现起来复杂。*HANA* 使用一个*引用计数表* 来追踪所有开始与同一时刻的事务——*Global STS Tracker*
126 |
127 | - **Removal**
128 |
129 | *HANA*中 整个GC是由专门的后台线程 周期性完成的。*Hekaton* 则在事务处理过程中就可以 进行version的清除,但这只适用于O2N的顺序。
130 |
131 | *HyPer*和*Steam*则在**前台**进行GC任务,将GC任务分散在 事务处理的过程间。一旦发现过时的版本,就会在每次commit后将它们回收。
132 |
133 |
--------------------------------------------------------------------------------
/paper reading/dbms/mysql/性能参数相关调优.md:
--------------------------------------------------------------------------------
1 | ## Mysql性能参数相关调优
2 |
3 | 影响性能的参数可分为三个方面(对于参数本身的含义可参考https://dev.mysql.com/doc/refman/8.0/en/server-system-variables.html):
4 | - 数据库连接
5 | - 内存
6 | - IO
7 |
8 | 1. **数据库连接**
9 |
10 | - `back_log:` The number of outstanding connection requests MySQL can have.
11 |
12 | 当Mysql的主线程在短时间内收到大量的连接器请求时,该参数起作用,可以理解为它决定了MySQL未处理的TCP连接的队列大小(所以肯定不能超过操作系统本身的limit)。因此,如果确实在短时间可能有大量连接时,需要将该参数调大一些。
13 |
14 | > 内核参数`net.ipv4.tcp_max_syn_backlog`定义了处于`SYN_RECV`的TCP最大连接数,当处于`SYN_RECV`状态的TCP连接数超过`tcp_max_syn_backlog`后,会丢弃后续的SYN报文
15 | >
16 | > 如果想临时修改,可以使用`sysctl -w net.ipv4.tcp_max_syn_backlog = 2048`命令,但重启后会丢失;想永久保留配置,可以编辑`/etc/sysctl.conf`:net.ipv4.tcp_max_syn_backlog = 2048,执行`sysctl -p`命令默认从`/etc/sysctl.conf`中加载系统参数。
17 |
18 | 其默认值为`max_connections`,但要注意和`max_connections`参数的区别。`max_connections`参数决定了最大的客户端连接数,当连接超过该数值时,会报错too many connections。
19 |
20 | - `table_open_cache`: The number of open tables for all threads. Increasing this value increases the number of file descriptors that **mysqld** requires.
21 |
22 | 该参数太小的话,性能会下降;太大的话,可能会OOM。当`Opened_table`的值太大时(且不经常使用`FLUSH TBALES`命令来强制关闭所有打开的表,该命令同时也会清楚prepared statement的缓存),说明`table_open_cache`太小。
23 |
24 | 该参数与`max_connections`参数相关联,对于单个进程来说,OS会对文件描述符的数量作出限制(Linux内核会为每一个进程在/proc/ 建立一个以其pid为名的目录来保存进程的相关信息,而子目录fd保了该进程打开的所有文件的描述符)。需要注意,查询产生的临时文件也是需要消耗fd的。
25 |
26 | > 使用命令`mysqladmin status -u root -p`后,会显示如下信息:
27 | >
28 | > | Key | Value |
29 | > | ---------------------- | ------- |
30 | > | Uptime | 3594760 |
31 | > | Threads | 1 |
32 | > | Questions | 240458 |
33 | > | Slow queries | 0 |
34 | > | Opens | 1265 |
35 | > | Flush tables | 1 |
36 | > | Opened_tables | 942 |
37 | > | Queries per second avg | 0.066 |
38 | >
39 | > 可以看到Opened_tables的值,但数据库中表的数量明明远小于942,为什么呈现该值?——这是因为,MySQL是多线程的架构,为了避免多个会话在用一张表上有不同的状态,并发的会话中 表都是独立被打开的,所以也会导致额外的内存消耗,但这对于性能是有一定提升的。
40 |
41 |
42 |
43 | - `thread_cache_size`: How many threads the server should cache for reuse.
44 |
45 | 也就是可以复用的线程缓存池大小。如果新连接很多的话,需要把这个参数设得足够大。
46 |
47 | 默认计算公式是`8 + (max_connections / 100)`。
48 |
49 | - `interactive_timeout`: The number of seconds the server waits for activity on an **interactive** connection before closing it.
50 |
51 | - `wait_timeout`: The number of seconds the server waits for activity on a **noninteractive** connection before closing it.
52 |
53 | 2. **内存**
54 |
55 | - `innodb_buffer_pool_size`: The size in bytes of the buffer pool, the memory area where InnoDB caches **table** and **index** data.
56 |
57 | 缓冲池越大,则访问多次同一张表需要的IO就越少。根据官方文档的建议,数据库独占的服务器上,**缓冲池大小应设置为计算机物理内存大小的80%**。
58 |
59 | 默认值为128MB,最大值则取决于CPU架构。注意:缓冲池大小需要是 innodb_buffer_pool_chunk_size \* innodb_buffer_pool_instances 的整数倍。
60 |
61 | - `innodb_buffer_pool_instances`: The number of regions that the InnoDB buffer pool is divided into. For systems with buffer pools in the multi-gigabyte range, dividing the buffer pool into separate instances can improve concurrency, by reducing contention as different threads read and write to cached pages.
62 |
63 | 开启多个内存缓冲池,把需要缓冲的页面hash到不同的缓冲池中,每个缓冲池管理自己的free list(如flush list, LRU等数据结构),从而进行并行的内存读写。
64 |
65 | 默认值为8,如果`innodb_buffer_pool_size`小于1GB的话,该值为1。
66 |
67 | - `join_buffer_size`: The minimum size of the buffer that is used for plain index scans, range index scans, and joins that do not use indexes and thus perform full table scans.
68 |
69 | 当explain时,join出现ALL、INDEX、RANGE的时候,就需要使用到buffer(8.0的Hash Join也是在join buffer中以创建哈希表)。通常想加速JOIN的话,就是直接给join字段加索引,但这也取决于JOIN算法。
70 |
71 | 当使用 Block Nested-Loop 时,因为所有元组需要的列 都必须保存在buffer中,所以用较大的join buffer是有意义的。
72 |
73 | 当使用 Batched Key Access 时,buffer大小决定了 每次向存储引擎发送查询key的batch大小。buffer越大的话,则对右表查询的顺序访问比例就越大,从而提升性能。
74 |
75 | 建议是 全局变量的值设置相对小一点,如果会话中需要进行大join的话,再对绘画变量进行设置。
76 |
77 | - `tmp_table_size`: The maximum size of internal in-memory temporary tables.
78 |
79 | 对于用户自己创建的内存表,该参数是不起作用的。不过临时表的大小同时也受`max_heap_table_size`的限制,一旦超过二者的较小值时,内存中的临时表就会变为磁盘表。
80 |
81 | 3. **IO**
82 |
83 | - `sync_binlog`: Controls how often the MySQL server synchronizes the binary log to disk. 分为0/1/N 三种情况。
84 |
85 | 值为0时,MySQL不会强制对binlog刷盘,而是由操作系统自己去做,性能上确实是最好的,但是对于断电和宕机的情况,可能会有已提交的事务未被写入到磁盘上的binlog。
86 |
87 | 值为1时,每次事务提交前,都会强制binlog落盘。
88 |
89 | 值为N时,只有当 一组有N个事务的提交组完成时,才会强制binlog落盘。
90 |
91 | - `innodb_flush_logs_at_trx_commit`: Controls the balance between strict ACID compliance for commit operations and higher performance that is possible when commit-related I/O operations are rearranged and done in batches. 分为0/1/2 三种情况。这里的日志指的就是InnoDB的redo log。
92 |
93 | 值为0时,**每秒**写入并强制落一次日志到磁盘。
94 |
95 | 值为1时,**每次事务提交**时,日志都会被写入并刷到磁盘上。
96 |
97 | 值为1时,每次事务提交时日志会被写入,每秒会把日志刷到磁盘上。
98 |
99 | - `innodb_io_capacity`: Defines the number of I/O operations per second (IOPS) available to InnoDB background tasks, such as flushing pages from the buffer pool and merging data from the change buffer.
100 |
101 | 可以理解为InnoDB的整体IO能力,应该将其设置为系统可达到的IOPS大小;InnoDB会根据该值来为后台任务分配估计的IO带宽。在设置时,需要考虑workload的写负荷。
102 |
103 | InnoDB 默认值是200。[官方文档](https://dev.mysql.com/doc/refman/8.0/en/innodb-configuring-io-capacity.html)指出,对于消费级的硬盘(通常转速5400rpm或7200rpm),100就够了;低端的SSD,设为200就足够了;高端的SSD(总线连接的),可以设到1000。
104 |
105 | > 理论最大IOPS的计算:
106 | >
107 | > IOPS = 1000 ms / (寻道时间 + 旋转延迟),
108 | >
109 | > 对于7200 rpm的STAT硬盘,假设平均物理寻道时间是9ms,而平均旋转延迟大约为 (60\*1000/7200) / 2 = 4.17ms,IOPS = 1000 / (9 + 4.17) = 76。不过实际IOPS还受其他因素的影响,如IO负载(是顺序 还是随机、读写的比例)、磁盘驱动、操作系统等。
110 |
111 | - `innodb_io_capacity_max`: Defines a maximum number of IOPS performed by InnoDB background tasks in such situations.
112 |
113 | 当flush的刷盘落后时,InnoDB可以更主动地 以高于`innodb_io_capacity`的IOPS速率进行刷盘。
114 |
115 |
--------------------------------------------------------------------------------
/paper reading/query/Optimize Join With Reinforcement Learning.md:
--------------------------------------------------------------------------------
1 | ## Learning to Optimize Join Queries With Deep Reinforcement Learning
2 |
3 | 1. **问题**:目前优化器大多数都是利用 启发式算法来剪枝搜索空间,当 代价模型cost model是线性时,启发式算法可以适用;但当cost有 非线性项时,文章指出 启发式的结果会离最优化较远。因此,需要一种由数据驱动 data-driven-way的策略 (根据特定的数据集 和 query)来缩小搜索空间。
4 |
5 | 2. **Contribution**:
6 | - 提出了一种 基于强化学习的优化器 DQ
7 | - 实现了三种版本的DQ,很容易地集成到现有的DBMS中,包括 Apache Calcite, PostgreSQL, SparkSQL
8 | - 实验证明,DQ可以达到 原生查询优化器 优化后的代价 和 执行时间,但是在经过学习后,执行速度上显著更快
9 |
10 | 3. **Related Work**:
11 |
12 | 机器学习在数据库中的应用仍然是今年的热点辩题,且这个有争议的话题仍会在接下来几年持续下去。——什么问题适合ML的解决方案?文章认为 查询优化是其中的一个sub-area,即该问题很难解决 且 性能的数量级非常关键;即使是糟糕的学习方案 也只是会让执行变慢,而不会导致错误的执行结果。
13 |
14 | - **Cost Function Learning**
15 |
16 | 前人的工作 试图通过 execution的feedback 来修正优化器,如 LEO optimizer(DB2中,2003年),通过feedback来修正cost model (其底层代价模型是基于直方图的)。Leis等人在评估了各种优化器策略的效果后,指出 challenge仍是 **feedback**和**cost estimation errors**。
17 |
18 | 而*Cost Function Learning* 即通过基于统计的学习 来修正或替换现有的cost model。
19 |
20 | 作者使用神经网络来预测 单关系谓词的选择率,结果很成功,但是对于一个domain大小为10k的属性,需要有1000个query作为训练集;且难适用于 字符串或其他非数值的数据类型 。
21 |
22 | - **Learning in Query Optimization**
23 |
24 | Ortiz等人使用**RL**来 学习queries的representation (2018);也有人使用 **DNN**来进行 基数估计 cardinality estimates (2015,2018);Marcus等人 提出了基于RL的join optimizer (2018),但其实验的查询类型比本文少。
25 |
26 | 本文将 Q-learning的动态规划 整合到标准查询优化器中,从而可以进行off-policy learning。
27 |
28 | > On-policy: The agent learned and the agent interacting with the environment is the same. —— SARSA
29 | >
30 | > Off-policy: The agent learned and the agent interacting with the environment is different. —— Q-Learning
31 | >
32 | > In SARSA, the agent learns optimal policy and behaves **using the same policy** such as ε-greedy policy. **Because the update policy is the same to the behavior policy, so SARSA is on-policy.**
33 | >
34 | > In Q-Learning, the agent learns optimal policy **using absolute greedy policy** and behaves using **other policies** such as ε-greedy policy. **Because the update policy is different to the behavior policy, so Q-Learning is off-policy.**
35 |
36 | 原本Marcus等人利用On-policy的方法需要8000个query训练样本,才能达到原生的效果;而DQ 利用off-policy的Q-Learning,只需要80个query样本,降低了两个数量级。
37 |
38 | - **Adaptive Query Optimization**
39 |
40 | 自适应查询处理—— *Adaptive query processing Foundations and Trends® in Databases* (2007),执行期重优化查询——Proactive re-optimization (2005).
41 |
42 | 本文研究的优化是基于固定的数据库fixed database,而DQ提供的自适应性 只是workload级别的(无法是tuple级别的)。
43 |
44 | - **Join Optimization At Scale**
45 |
46 | *Adaptive optimization of very large join queries* (2018)中,研究了 大规模的join查询优化。可以使用随机化randomized 的方法,如 QuickPick算法 和 遗传算法,当表到达一定数量后,商用的优化器中就会使用这些方法。但是这一类方法 对于同一个查询的性能可能有很大变化。
47 |
48 | > QuickPick performs biased sampling by selecting edges from the join graph and adding the respective joins to the query plan.
49 |
50 | 还有松弛启发式方法 是 在简化的假设下来解决问题,如 贪心搜索时 避免笛卡尔积,这是 IK-KBZ算法的前提(*Optimization of non-recursive queries*, 1986)。现有的启发式算法不能很好地解决所有非线性项,而正是机器学习 可以对此有所帮助。
51 |
52 | 4. **实现细节**:
53 |
54 | - **Join Order Benchmark** (JOB)
55 |
56 | 参考 *How good are query optimizers, really* (2015)。由来自 IMDB 的 21 个表组成,并提供了 33个查询模板 和 113个查询。查询中的连接关系大小范围为 5~15。
57 |
58 | - **Query Graph**
59 |
60 | 无向图,关系*R*为顶点,连接谓词*p*为边,记*kG*为G的连通分量数。则 join 两个子计划 subplan,即 选择两个连接的顶点,并将合并为一个顶点。
61 |
62 | - **Markov Decision Process** 马尔可夫决策过程
63 |
64 | 每个join query都可以用 Query Graph来描述。
65 |
66 | | 符号 | 定义 |
67 | | --------------- | --------------------------------------- |
68 | | 状态 *G* | Query graph,是决策过程的一个状态 state |
69 | | 动作 *c* | 即 join |
70 | | 下一个状态 *G’* | 经过一次join的query graph |
71 | | *J(c)* | 评估join的代价模型 |
72 |
73 | 状态转移 state transition *P(G, c)*即为顶点合并的过程,而奖励 reward 定义为负的代价 即 -J。
74 |
75 | MDP的输出为 **将给定query graph 映射到 最佳的下一次join 的函数**。
76 |
77 | - **Greedy Operator Optimization**
78 |
79 | 朴素的优化算法,主流程分三步 (1)从query graph开始;(2)找到最低代价的join;(3)更新query graph;重复以上直到最后只有一个顶点。但是贪婪算法 **不会考虑局部决策对未来的影响**,而有的时候 需要牺牲短期收益 来获取长期利益。
80 | $$
81 | \frac{\partial J(\theta)}{\partial \theta_i} = \frac{1}{m}\sum_{k=1}^{m}[x^{(k)T}\theta - y^{(k)} ](x_i^{(k)}) + \frac{1}{m}\lambda\theta_i
82 | $$
83 |
84 | - **Long Term Reward**
85 |
86 | 考虑最优化问题
87 | $$
88 | V(G)=min\sum_{i = 0}^{t}J(c_{i})
89 | $$
90 | Q函数的递归定义
91 | $$
92 | Q(G,c)=J(c)+min_{c'}Q(G',C')
93 | $$
94 | 使用 强化学习来接近全局的Q-function,可以得到join优化的多项式时间算法。
95 |
96 | - 应用 RL
97 |
98 | 选择Q-Learning(而不是其他强化学习)的三个理由:
99 |
100 | 1. Q-Learning允许我们 在训练时 利用最优的子结构 optimal substructure,从而大大减少需要的数据
101 | 2. 比起Policy-Learning,Q-Learning 在每个subplan中会输出 每个join的分数 *score*,而不是直接输出最优的join选择
102 | 3. 评分模型支持 TopK 排序,不是简单地得到最优的plan
103 |
104 | *Deep reinforcement learning with double q-learning (2016)* 中提出了Q-Learning的变种,留给Future work
105 |
106 | - 模型训练
107 |
108 | 使用 多层感知器神经网络(MLP) 来表示 Q-function。基于经验,使用 **两层MLP** 可以在适中的时间内训练得到最好的效果(使用SGD算法进行训练)
109 |
110 | - 模型使用
111 |
112 | 在完成训练后,DQ 可以接受纯文本的 SQL 查询语句,将其解析为抽象语法树,对树进行特征化,并在每次候选连接获得评分时调用神经网络。最后,可以使用来自实际执行的反馈定期重新调整 DQ。
113 |
114 | - Fine-tuning
115 |
116 | 在深度学习中,实践中由于数据集不够大,很少有人从头开始训练网络。常见的做法是使用预训练的网络,来重新fine-tuning(也叫微调)。
117 |
118 | 而DQ可以在执行的过程,通过fine-tuning来 再训练自己,从而更适合运行环境。
119 |
120 | - 三种Cost Model
121 | - CM1: 适合内存型数据库
122 | - CM2: 额外考虑 有限内存内的hash join(超出阈值,需要考虑 partition的开销)
123 | - CM3: 额外考虑 复用 已建好的hash表
124 | - 进行对比的baseline
125 | - QuickPick1000: 选择1000个随机join计划中最好的
126 | - IK-KBZ: 多项式时间启发式方法,将query graph拆解为链状,再进行排序
127 | - Right-deep
128 | - Left-deep
129 | - Zig-zag
130 | - Exhaustive with the indicated plan shapes
131 |
132 |
133 |
134 |
--------------------------------------------------------------------------------
/paper reading/dbms/Accelerating Relational Databases by RDMA.md:
--------------------------------------------------------------------------------
1 | ## Accelerating Relational Databases by Leveraging Remote Memory and RDMA
2 |
3 | 1. **问题**:内存不足的时候,RDBMS需要强制使用SSD或HDD,极大地降低了性能
4 |
5 | 2. **Contribution**:
6 |
7 | - 研究了 SMP(Symmetric Multi-Processing 对称多处理架构) RDBMS 如何利用 **RDMA**和集群中的**remote memory** 来提高性能
8 | - 将 通过RDMA的remote memory,抽象为轻量的文件API;从而可以轻松地整合到现有的RDBMS中
9 | - 在SQL Server中实现 并进行benchmark测试
10 |
11 | 3. **RDMA**:
12 |
13 | Remote Direct Memory Access,远程直接数据存取,就是为了解决网络传输中 **服务器端数据处理的延迟** 而产生的 现代化高性能网络通信技术。Direct: 没有内核的参与,内容都在网卡上;Memory: 在用户空间虚拟内存与RNIC网卡直接进行数据传输不涉及到系统内核,没有额外的数据移动和复制。
14 |
15 | > 传统的TCP/IP网络通信,数据需要通过用户空间发送到远程机器的用户空间。*数据发送方* 需要把数据从**用户应用空间Buffer**复制到**内核空间的Socket Buffer**中。然后**内核空间中添加数据包头**,进行数据封装。通过一系列多层网络协议的数据包处理工作。数据才被发送到到**网卡中的缓冲区**进行网络传输。*消息接受方* 接受从远程机器发送的数据包后,要将数据包从**网卡缓冲区**中复制数据到**Socket Buffer**。然后经过一系列的网络协议进行数据包的解析,解析后的数据被复制到相应位置的**用户空间Buffer**。这个时候再进行系统上下文切换,用户应用程序才被调用。
16 |
17 | TCP/IP通过内核发送消息的劣势:
18 |
19 | - **低性能**:通过内核传递 导致很高的 **数据移动** 和 **数据复制**的开销
20 | - **低灵活**:所有网络通信协议通过内核传递,很难支持**新的网络协议** 和 **新的消息通信协议** 以及 **发送和接收接口**
21 |
22 | RDMA优势:
23 |
24 | - **低时延**
25 | - **低CPU开销**
26 | 1. 应用程序可以访问远程主机内存而 **不消耗远程主机中的CPU资源**;远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。
27 | 2. 远程主机的CPU的**缓存(cache)**不会被访问的内存内容所填充。
28 | - **高带宽**
29 |
30 | 三类RDMA网络硬件实现:
31 |
32 | - Infiniband:专为RDMA设计的网络,从硬件级别保证可靠传输 ;需要支持该技术的NIC和交换机
33 | - RoCE:基于以太网的RDMA技术,支持在标准以太网基础设施(**交换机**)上使用RDMA
34 | - iWARP:基于以太网的RDMA技术 (**RDMA over TCP/IP**)
35 |
36 | 
37 |
38 | 
39 |
40 | 三种队列:
41 |
42 | - 发送队列(SQ)
43 | - 接收队列(RQ)
44 | - 完成队列(CQ)
45 |
46 | RDMA是基于消息的传输协议,数据传输都是异步操作
47 |
48 | **读操作**:
49 |
50 | - 本质上是Pull操作,远程系统内存里的数据拉到本地系统的内存里
51 | - Receiver 提供 **虚拟地址** 和 目标内存的**remote_key**
52 | - Sender 是完全被动的,不会接受任何通知
53 |
54 | **写操作**:
55 |
56 | - 本质上是Push操作,把本地系统内存里的数据推到远程系统的内存里
57 | - Sender 提供 **虚拟地址** 和 目标内存的**remote_key**
58 | - Receiver 是完全被动的,不会接受任何通知
59 |
60 | 具体工作流程:Work Request -> Work Queue -> Hardware -> Completion Queue -> Work Completion
61 |
62 | 1. 当应用需要通信时,就会创建一条Channel连接(建立在本端和远端应用之间),每条Channel的首尾端点是一对Queue Pair - SQ和RQ
63 | 2. Queue Pair 会被映射到应用的虚拟地址空间,使得应用直接通过它访问RNIC网卡
64 | 3. CQ用来知会用户 WQ上的消息已经被处理完
65 | 4. 提供了一套软件传输接口,方便用户创建传输请求Work Request(描述了应用希望传输到 Channel另一端的消息内容)
66 |
67 | 4. 细节实现:
68 |
69 | - **Remote Memory**
70 |
71 | 四种实现选择(本文使用的是**In-memory blocks**)
72 |
73 | - **Byte-addressable**: 远端内存以**字节寻址**,允许现存的系统无缝地将本机内存扩展到远端内存(和OS提供的虚拟内存类似)
74 | - **In-memory blocks**: 远端内存 被分为固定大小的块(大小可自定),应用程序通过**唯一的标识符**、**offset**和**读/写数据的大小** 来访问一个block;从而允许读取block中单独的一些字节,而不用读取整个block
75 | - **In-memory files**: 操作系统允许将一部分物理内存 挂载为文件系统,如Linux的**ramfs** 和windows的**Ramdisk**。数据库的设计本身就是高效地处理文件
76 | - **In-memory Key-value store**: 应用只用put和get的API来交互,隐藏了 内存管理 与 远端读写的实现细节
77 |
78 | 文件API与RDMA操作的对应关系:
79 |
80 | | 文件操作 | RDMA实现 |
81 | | ----------------------------- | ----------------------- |
82 | | Create (ServerEndpoint, Size) | Obtain lease on MRs |
83 | | Open | Connect to server |
84 | | Read/Write (Offset, Size) | RDMA read/write |
85 | | Close | Disconnect from server |
86 | | Delete | Relinquish lease on MRs |
87 |
88 | - **Architecture**
89 |
90 | 
91 |
92 | 通过 **Memory Broker**记录集群中内存的使用情况,每台Server都会向 **Memory Broker**报告可用的内存。Server *Mi*将可用的内存切分为固定大小的Memory Region 作为带序号的Block。*Mi*上的一个内存代理进程 **保证available memory不会分配给本机的其他进程**,固定可用的MR,将MR注册到本地的网卡,并从操作系统的角度标记为不可用。
93 |
94 | 当某台DB server内存不足时,可以向**Broker**请求 远程的MR,**Broker**来决定哪一台Server *Mi* 来提供MR(其机制类似于Zookeeper,具有容错性 与 高可用性)。
95 |
96 | - **Preregistration of MRs**
97 |
98 | 最大的挑战在于,SQL Server的缓冲池 不是一片连续的内存,且大小可能动态变化。又由于 只有一个内存分配器来 处理 **缓冲池的内存请求** 以及 **其他SQL Server组件的内存请求**,则连续的大片内存中 既有缓冲池的内存,又有其他引擎组件使用的内存;故 如果静态地注册整个缓冲池,可能会直接包含了整个DBMS的地址空间,**会包含大量RDMA不会传输的内存块**。
99 |
100 | - **I/O Micro benchmark**
101 |
102 | 通过**SQLIO**(一个磁盘基准测试工具)来评估随机/顺序读的性能。参考SQLIO Disk Subsystem Benchmark Tool, http://www.microsoft.com/en-us/download/details.aspx?id=20163.
103 |
104 | - 四个场景
105 |
106 | **性能提升**、**remote memory实现的复杂度** 以及 **整合到DBMS的容易度** 三者的tradeoff。
107 |
108 | - **Extending the Caches**
109 |
110 | 数据库有多种cache: procedure cache(存储 **优化后的执行计划**、**部分执行结果**)、buffer pool cache… 当cache大小达到临界值时,就要淘汰策略。这里,可以不直接丢弃 淘汰的entry,而是把该entry放到remote memory中;当再次访问它时,会比在磁盘上读取更快
111 |
112 | - **Spilling Temporary Data**
113 |
114 | 在执行复杂查询时,DBMS会产生许多临时数据,如果数据量太大,需要把中间结果保存到文件中(比如 SQL Server的 TempDB,Oracle的Temporary Tablespaces)。
115 |
116 | - **In-Memory Semantic Caching**
117 |
118 | 如 非聚集索引、部分索引(*Generalized partial indexes. 1995*)、物化视图等的cache。
119 |
120 | - **Priming the Buffer Pool**
121 |
122 | 云数据库通常使用多个副本 来保证高可用性。典型的,主copy进程处理 读取/更新的事务,其他副本通过 逻辑或物理的replication 来与主节点保持一致。
123 |
124 | *primary-secondary swap*(从节点 变为 主节点)可能会发生,当workload在 新选举出来的主节点上执行时,其缓冲池是冷启动的,故性能会有很大损失。
125 |
126 | 故对于物理replication的数据库,可以使用高速的RDMA传输 来预热(warm up)缓冲池——使用原主节点的缓冲池内容,通过push或根据需要来fetch。
127 |
128 | ---------------
129 |
130 | 1. 参考 PolarFS: An Ultra-low Latency and Failure Resilient Distributed File System for Shared Storage Cloud Database
131 |
132 | PolarDB——存储与计算分离的分布式数据库,PolarFS作为具有低延迟和高可用能力的分布式文件系统,使得PolarDB在分布式多副本架构下仍然能够发挥出极致的性能。
133 |
134 | 2. 存储管理单元分为三层:
135 |
136 | - Volume: 存放了具体文件系统实例的元数据
137 | - Chunk: 数据分布的最小粒度,
138 | - Block: Chunk会被进一步划分为多个Block
139 |
140 | 3. PolarFS编译到数据库内核,替换标准的文件系统接口;数据处理在用户空间完成,避免了传统文件系统从内核空间至用户空间的消息传递开销
141 |
--------------------------------------------------------------------------------
/paper reading/dbms/Modern Column-Oriented Database Systems.md:
--------------------------------------------------------------------------------
1 | ## The Design and Implementation of Modern Column-Oriented Database Systems
2 |
3 | 1. 列式数据库在OLAP上更快的原因:
4 |
5 | - Columns read on demand: 减少了IO的量
6 |
7 | - Batch execution: 以一个chunk进行计算,对locality有优势
8 |
9 | - Compression: 比如int类型的压缩(部分高位可能都是0)
10 |
11 | - Vectorization: SIMD
12 |
13 | - Codegen: 在列式数据库上更简单
14 |
15 | > 在运行时根据逻辑动态的生成可执行代码,那么对于java平台来说,就是动态的生成类实现
16 |
17 | 
18 |
19 | 
20 |
21 | - Late materialization: 带有filter条件的query,可以先进行filter的运算,知道哪些行有效,再进一步取需要的字段被过滤出来的值。可参考 *Materialization Strategies in a Column-Oriented DBMS, 2007*
22 |
23 | - Block IO: IO块的单位可以增大
24 |
25 | - Rough index: 粗略的索引,定位到感兴趣的块(传统的index是 B树 / Bitmap);
26 |
27 | - Inverted index
28 |
29 | - Join index
30 |
31 | - Database cracking: 数据分成很多块,可以选择某种行的排序方式(如 按照A列排序、按照B列排序,可以有多个排序的副本,对应不同的索引);可以和AI结合起来,根据query自动调整排序方式。可参考[Database Cracking](https://stratos.seas.harvard.edu/files/IKM_CIDR07.pdf)
32 |
33 | > Index maintenance should be a byroduct of query processing, not of updates. Continuously reacting on query requests brings the powerful property of self-organization.
34 |
35 | - FPGA, GPU: GPU加速的[DB](https://www.omnisci.com/blog)
36 |
37 | 2. 列式存储更新:
38 |
39 | - SQL Server
40 |
41 | 
42 |
43 | - Immutable storage中的数据未排序
44 |
45 | 优点:直接append
46 |
47 | 缺点:不能二分查找
48 |
49 | - Delta Store在内存中,使用B+树的结构
50 |
51 | - 更新的代价高
52 |
53 | - Vertica
54 |
55 | 
56 |
57 | - **C-store**
58 |
59 | *C-Store: A Column-oriented DBMS, 2005*
60 |
61 | 一个模块WS负责处理快速写入,另一个模块RS负责提供高效的查询 ,通过Tuple Mover,将 WS 中的数据同步到 RS 中。
62 |
63 | 
64 |
65 | - **Projection as Index**
66 |
67 | 存数据会存多份,通过*Projection*快速得到结果
68 |
69 | - **Sorted WOS and ROS**
70 |
71 | 写优化区、读优化区
72 |
73 | - **DV** - Delete vector
74 |
75 | 删除通过Delete vector进行,不会更新树的结构
76 |
77 | 3. **Join**实现:
78 |
79 | 最直接的Hash Join:
80 |
81 | Join的输入只包含 predicate涉及的列,所以 Hash表会更紧凑,Cache miss也会更小。而Join的输出为两个输入列匹配的 位置对,其中输出的左列会按顺序排列,右列则不会(因为通常使用左列来迭代遍历)。
82 |
83 |
84 |
85 | > 对比传统Oracle的hash join:
86 | >
87 | > 1. 首先Oracle会根据参数HASH_AREA_SIZE、DB_BLOCK_SIZE和HASH_MULTIBLOCK_IO_COUNT的值来决定Hash Partition的数量(**一个Hash Table是由多个Hash Partition所组成,而一个Hash Partition又是由多个Hash Bucket所组成**)
88 | > 2. 数据量较小的那个**表A** 会被Oracle选为哈希连接的驱动结果集
89 | > 3. 接着Oracle会遍历A,读取**A**中的每一条记录,并对S中的每一条记录按照Join的列 做哈希运算;会使用两个内置哈希函数,分别记算出hash_value_1和hash_value_2
90 | > 4. 然后Oracle会按照hash_value_1的值把相应的S中的对应记录存储在不同Hash Partition的不同Hash Bucket里,同时和该记录存储在一起的还有该记录用hash_func_2计算出来的hash_value_2的值。注意,存储在Hash Bucket里的记录并不是目标表的完整行记录,而是只需要存储位于目标SQL中的跟目标表相关的查询列和连接列就足够了;**把S所对应的每一个Hash Partition记为Ai**,内存放不下的那部分Hash Partition会放在磁盘上
91 | > 5. Oracle会遍历B,读取B中的每一条记录,并对B中的每一条记录按照连接列做哈希运算,这个哈希运算和步骤3中的哈希运算是一模一样的,即这个哈希运算还是会用步骤3中的hash_func_1和hash_func_2,并且也会计算出两个哈希值hash_value_1和hash_value_2;接着Oracle会按照该记录所对应的哈希值hash_value_1去**Ai**里找匹配的Hash Bucket;如果能找到匹配的Hash Bucket,则Oracle还会遍历该Hash Bucket中的每一条记录,并会校验存储于该Hash Bucket中的每一条记录的连接列,看是否是真的匹配
92 |
93 | **改进:** *Dimitris Tsirogiannis, Stavros Harizopoulos, Mehul A. Shah, Janet L. Wiener, and Goetz Graefe. Query processing techniques for solid state drives. In Proceedings of the ACM SIGMOD Conference on Management of Data, pages 59–72, 2009.* 使用Jive Join,通过额外增加两次join输出数据的排序(大部分数据库系统都有实现外部排序算法),来使得 所有列可以被依次迭代。
94 |
95 | 进一步研究表明:不需要完整的排序。由于存储介质上划分为多个连续的block,单个block内的随机访问 比 跨block的随机访问 要快得多。故数据库不需要对 *position list*进行完整地排序,只需要将其划分到storage的block上,在每个划分内 position是无序的,从而用于 **提取值的列** 是按block的顺序进行访问,而不是严格按 position的顺序。
96 |
97 | 4. **Insert / Update / Delete**
98 |
99 | 比起行式存储,列式存储 对更新操作 更敏感。若每一列单独存在一个文件中,则关系表中的一条元组会存储在多个文件中;即使只更新一行数据 也要进行多次I/O。
100 |
101 | CStore和MonetDB 将架构分解为 **read-store**来管理数据的主题,**write-store**来管理最近的更新(通常在内存中,更新周期性地传到**read-store**中)。如MonetDB 为每个base column附加两个辅助列,用于存储待定的insert和delete。这种存储delta方法的缺点是,query需要先访问read-store获取基表信息,再访问write-store合并更新(insert使用MergeUnion,delete使用MergeDiff,消耗CPU资源)。
102 |
103 | VectorWise系统使用新的数据结构—— **Positional Delta Trees**来存储delta。当一个query提交时,首先找到表的哪个位置受影响,把merge操作 从查询期 转移到 更新期,符合read-optimized的流程。**Positional Delta Trees**是一种计数型B树,可以在对数复杂度下 记录最新的位置。delta可以利用计算机的层次架构进行分层设计。可参考 *Positional update handling in column stores. In Proceedings of the ACM SIGMOD Conference on Management of Data, pages 543–554, 2010.*
104 |
105 | 而Hyper系统 同时对OLTP和OLAP上有较好的支持,主要依赖 硬件辅助的 page shadowing技术 来避免更新时锁住页面。
106 |
107 | > Shadow paging is a copy-on-write technique for avoiding in-place updates of pages. Instead, when a page is to be modified, a *shadow page* is allocated. Since the shadow page has no references (from other pages on disk), it can be modified liberally, without concern for consistency constraints, etc. When the page is ready to become durable, all pages that referred to the original are updated to refer to the new replacement page instead. Because the page is "activated" only when it is ready, it is **atomic**.
108 |
109 | 5. **Group-by**
110 |
111 | 基于hash table。通常使用compact hash table,只用group的属性才会被使用到。
112 |
113 | 6. **Aggregation**
114 |
115 | 聚合操作可以很好地利用列式存储,比如sum( ), min( ), avg( )等可以只扫描相关的列,最大化利用内存带宽(byte/s)。
116 |
117 | 7. **Indexing**
118 |
119 | CStore提出了projection的概念,为每个表创建多个副本,每个副本根据不同的属性排序(每个副本不一定包含整个表的所有属性)。由于列存储的压缩很好,所以多个副本不会占用太大空间。而projection的数量和种类 取决于workload,太多projection会导致更新的代价变高。
120 |
121 | 另一种列存储的索引是 zonemap,在每一个page上存储轻量的元信息(如min/max),从而减少读取没有符合条件元组page次数,加速了扫描。
122 |
123 |
124 |
125 |
--------------------------------------------------------------------------------
/paper reading/query/SQL Plan Management.md:
--------------------------------------------------------------------------------
1 | ## SQL Plan Management
2 |
3 | ### Oracle中的SPM
4 |
5 | 1. SPM的三个核心:
6 |
7 | - **Plan capture**
8 |
9 | 创建SQL计划的baseline,保存在**SQL Management Base**(SMB)中
10 |
11 | - **Plan selection**
12 |
13 | 保证有baseline的SQL查询只会使用已经Accepted的执行计划,优化器找到的新执行计划会暂时保存会Unaccepted状态
14 |
15 | - **Plan evolution**
16 |
17 | 对于一条SQL,评估所有Unaccepted状态的执行计划(根据文档,该评估过程在夜间执行,因为本质是要把这些计划跑一边),如果验证为有性能提升,则把对应计划标记为Accepted状态
18 |
19 | 2. 使用SPM的查询流程(在Oracle11g中,本质是一种保守的计划选择策略)可参考[Oracle白皮书](https://www.oracle.com/technetwork/database/bi-datawarehousing/twp-sql-plan-mgmt-12c-1963237.pdf):
20 |
21 | 1. SQL语句先编译(hard parse)成计划,然后通过CBO优化选出最低代价的执行计划P0
22 |
23 | 2. 如果该SQL语句存在计划baseline,优化器则把P0与baseline中的计划对比,进入3
24 |
25 | 3. 如果 找到对应的计划P1 且**标志位为Accepted状态**,则使用P1;如果baseline中没有P0对应的计划,则对比baseline中所有Accepted状态的计划,选出最低代价的计划P2,进入4
26 |
27 | 4. 如果P0的代价比P2低,则P0会被添加到baseline中,且状态为**Not-Accepted**。此时执行计划仍然选择的是P2,[因为P0在没有被验证不会造成性能退化之前,是不会被真正使用的](https://blogs.oracle.com/optimizer/sql-plan-management-part-2-of-4-spm-aware-optimizer)(当验证成功P0更优时,则进行演化 **Evolve**)
28 |
29 | 5. 如果整个数据库系统发生较大的变化 且影响到目前所有Accepted状态的计划,则这些计划不可再利用(无法再复现),此时会选择优化器原本生成的最低代价计划
30 |
31 | 数据库系统可能发生的变化(都可能导致相同的SQL语句生成新的执行计划,尽管大部分新计划的性能是会有改进的,但仍有一些会发生性能上的退化):
32 |
33 | - 手动/自动地更新了统计信息
34 | - 增加/删除了字段的索引
35 | - 修改了优化器相关的参数
36 | - 数据库系统的升级
37 |
38 | 3. SQL profile(10g) 和 SQL plan baseline(11g)的区别
39 |
40 | - SQL profile通常由SQL Tuning Advisor生成,包含了一些辅助信息,来最小化优化器的误差(主要是基数估计的误差),从而更大可能选择到最优计划,而不是强迫优化器去选哪个特定的计划 或 从哪些特定的计划中选择。但**无法保证计划的稳定性**
41 | - SQL plan baseline是由一系列的accepted plans组成集合。当查询语句被解析后,会从这个集合里选出最优计划;如果在CBO阶段找到了不在集合中 且代价更低的计划,优化器会把它添加到not-accepted状态的计划历史中,但该计划暂时不会被使用(直到evolve过程)
42 | - 所以,当希望系统能快速根据新的统计信息做出调整时,就可以用SQL profile;当你需要更保守的计划执行,就可以使用SQL plan baseline
43 |
44 | 4. Plan cache 和 SPM的区别
45 |
46 | Plan cache顾名思义是执行计划的缓存。本质就是相同的SQL语句采用的执行计划给缓存起来,跳过解析、优化的步骤。
47 |
48 | 比如对于Oracle,Sql语句的parsing分为 硬解析(hard parse) 和 软解析(soft parse),还有soft soft parse。软解析 即通过Sql语句hash 从cache中使用对应执行计划。
49 |
50 | 
51 |
52 | 对于PostgreSQL,pg只提供prepared statement的cache(session级别)。(pg对于存储过程也实现了plan cache,PL/sql的解释器会把SQL语句以prepared statement的形式存储)
53 |
54 | - 对于无参数的prepared stmt,第一次执行时会生成计划 并 保存到cache中,以后在执行到这个stmt会重用执行计划
55 | - 对于带参的prepared stmt,pg采用如下策略(在[德哥的博客](https://github.com/digoal/blog/blob/master/201606/20160617_01.md)中,指出了这样做可以避免plan cache的倾斜):
56 | - 前五次执行时,每次会根据输入的参数来生成执行计划称作custom plan,然后记录下**总的custom plan的代价与数量**。
57 | - 第六次开始执行时,生成一个不依赖参数的执行计划并保存起来——称作generic plan。如果generic plan的代价小于之前所有custom plan的平均代价的1.1倍,则采用generic plan;否则重新根据参数生成新的custom plan,更新总的custom plan的代价与数量。
58 |
59 | 在Mysql中,同样也只有[prepared stmt的cache](https://dev.mysql.com/doc/refman/8.0/en/statement-caching.html)(以及存储过程),既支持SQL语句,也支持C/S二进制协议。由`max_prepared_stmt_count`系统变量来控制cache的语句数量。
60 |
61 | 对于TiDB的[执行计划缓存](https://docs.pingcap.com/zh/tidb/stable/sql-prepare-plan-cache),其支持prepared请求与execute请求(session级别),通过LRU链表实现缓存。这里其无法应对参数取值变化情况(如下),所以TiDB的plan cache适用于 查询编译耗时占比较高且执行计划不容易变的业务场景。(2020-10-22 prepared plan cache选项默认开启)
62 |
63 | > 比如查询过滤条件为 `where a < ?`,假如第一次执行 `Execute` 时用的参数值为 1,此时优化器生成最优的 `IndexScan` 执行计划放入缓存,在后续执行 `Exeucte` 时参数变为 10000,此时 `TableScan` 可能才是更优执行计划,但由于执行计划缓存,执行时还是会使用先前生成的 `IndexScan`
64 |
65 | 阿里云的PolarDB-X,其[执行计划管理](https://help.aliyun.com/document_detail/144299.html)也有相应文档。(默认开启plan cache,且这里将SPM与Plan Cache整合在了一起)对于到来的SQL查询,会对SQL做参数化处理,即把常量参数用`?`占位符替换。注意:这里PolarDB-X的**plan cache**和SPM都是用参数化后的SQL语句作为Key(而不是原本的语句)。
66 |
67 | - 与Mysql和TiDB不同,plan cache会缓存所有SQL计划
68 | - SPM仅对复杂查询SQL进行处理(可能认为这一类查询退化的可能性更大);如果是简单查询,不会进入SPM这一阶段
69 | - 在其SPM中,每个SQL对应的一个baseline中包含一个或多个执行计划。实际使用中,会根据当时的参数选择其中代价最小的执行计划来执行。也就是类似于 PQO(参数化查询优化)问题
70 |
71 |
72 | ------
73 |
74 | ### Aurora PG的[Query Plan Management](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraPostgreSQL.Optimize.html)
75 |
76 | 1. **Motivation**:迁移到Aurora postgreSQL的企业用户需要在系统升级或更改时 能有**稳定的性能**。
77 |
78 | 2. 改变查询执行计划的因素(通常不在预料内):
79 |
80 | - 优化器统计信息的改变
81 | - planner配置参数的更新
82 | - schema的改变,比如 增减了索引
83 | - 绑定变量的改变
84 | - 数据库版本的更新
85 |
86 | 3. QPM的目标:
87 |
88 | - **计划稳定性**:当系统发生如上述改变时,防止计划的退化
89 | - **计划自适应性**:自动检测新的最低代价计划,自动控制新计划何时能够被使用
90 |
91 | 4. 工作流程:
92 |
93 | 
94 |
95 | 1. 还是先由优化器生成SQL对应的最低代价计划P0
96 | 2. 如果没启用QPM,则直接执行P0;若启用了,则进入下一步
97 | 3. 先判断是否属于 受管理的SQL语句,不属于则直接执行P0
98 | 4. 进入计划捕获阶段
99 | 5. 如果QPM未开启 `use_plan_baselines ` 选项,则执行P0
100 | 6. 如果P0 不属于存储中的计划,优化器会捕获并保存P0 并且 标记为 unapproved 状态,进入第7步;如果属于(且为approved状态),进入第8步
101 | 7. 如果P0不是禁用状态,直接执行P0(用户可以手动设置 **直接执行**任何估计成本低于指定阈值的unapproved计划);如果是的,进入下一步
102 | 8. 如果这个受管理的SQL语句有对应 已启用且有效的首选计划(**preferred**标记,可能有多个首选计划,会重新估计每个首选计划的代价;注意**preferred**和**approved**是不同的 ),然后优化器会执行最低代价的计划;如果没有首选计划,进入下一步
103 | 9. 如果不存在或无法重新创建首选计划,则优化器会重新计算每个approved计划的代价,然后选择代价最低的approved计划。如果既没有preferred计划,又没有approved计划,那就只能跑P0了
104 |
105 | 整体看来,流程和Oracle的SPM基本类似。
106 |
107 | 5. 受管理的语句 (Managed Statement)
108 |
109 | 类似于上文polardb-x中提到的参数化语句,这里同样会对SQL语句进行规格化:
110 |
111 | - 去除头部注释块
112 | - 去除EXPLAIN相关
113 | - 去除尾部多余空格
114 | - 去除字面量
115 | - 保留token之间的空格 以及原本大小写,方便阅读
116 |
117 | 比如,语句`/*Leading comment*/ EXPLAIN SELECT /* Query 1 */ * FROM t WHERE x > 7 AND y = 1;` 会被规格化为 `SELECT /* Query 1 */ * FROM t WHERE x > CONST AND y = CONST; `,最后根据规格化后的语句进行Hash操作。
118 |
119 | 6. [最佳实践](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraPostgreSQL.Optimize.BestPractice.html)
120 |
121 | **Proactive**:在验证了新计划确实执行更快后,可以手动置为approved状态,从而主动的防止性能退化。实践如下:
122 |
123 | 1. 在**开发环境中**,确定对性能或系统吞吐量影响最大的SQL语句,手动捕获特定SQL语句的计划
124 | 2. 从开发环境**导出捕获的计划**,并将其**导入到生产环境**中
125 | 3. 在生产中,运行应用程序并强制使用approved的计划
126 | 4. 对优化器生成的unapproved计划进行分析,**主动将性能更好的计划设置为approved状态**
127 |
128 | **Reactive**:监视运行中的应用,从而检测导致性能下降的计划;检测到时,可以手动**reject掉**或**修复**错误的计划。
129 |
130 | 1. 在应用程序运行时,强制使用受管理的计划,并自动将优化器新发现的计划添加为unapproved计划
131 | 2. 监控运行中程序可能发生的性能退化
132 | 3. 发现计划性能退化时,将该计划设置为reject状态。下次优化器运行SQL语句时,会自动忽略reject的计划,并使用其他approved计划
133 | 4. 如果想对退化的计划进行**修复**,则可以考虑使用pg_hint_plan 扩展来尝试改进计划
--------------------------------------------------------------------------------
/04 concurrency control/5-mvcc-notes.md:
--------------------------------------------------------------------------------
1 | ## Multi-Version Concurrency Control
2 |
3 | 1. COMPARE-AND-SWAP(CAS):使用了3个基本操作数——内存地址V,旧的预期值A,要修改的新值B。更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B。
4 |
5 | 在Java中:synchronized就是悲观锁,CAS操作就是乐观锁。
6 |
7 | CAS缺点:
8 |
9 | - ABA问题:如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。
10 |
11 | ——解决思路:使用**版本号**version
12 |
13 | - 循环时间长开销大:自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
14 |
15 | ——解决思路:jvm支持处理器的**pause指令**。pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率
16 |
17 | - 只能保证一个共享变量的原子操作:对多个共享变量操作时,循环CAS就无法保证操作的原子性
18 |
19 | ——解决思路:**锁synchronized** 或 把多个共享变量合并成一个共享变量来操作,如java的AtomicReference类可以把多个变量放在一个对象里来进行CAS操作
20 |
21 | 2. 隔离级别 Isolation Level:
22 |
23 | 
24 |
25 | 主流数据库考虑到串行化效果与并发性能的平衡,一般默认隔离级别都介于RC与RR之间
26 |
27 | - Read Uncommitted -> Read Committed -> Repeatable Reads -> Serializable
28 |
29 | - **Cursor Stability** (DB2的默认隔离级别): 强度介于Read Committed和Repeatable Reads 之间,DBMS的cursor会在当前记录上维护一个锁,直到移向下一条记录。有些情况下,可以防止丢失更新异常 lost update anomaly。
30 |
31 | **丢失更新异常**:txn2 先写A,txn1后写A;但txn1先提交,txn2后提交;导致txn2的写A操作丢失。
32 |
33 | - **Snapshot Isolation** (Oracle的最高隔离级别 **快照隔离** SI): 保证同一个事务中的读操作 会读到一个一致的数据库快照(在事务开始时的)。容易遇到写偏序异常Write Skew Anomaly
34 |
35 | 写偏序"黑白球"问题——两个并行事务都基于自己读到的数据集去覆盖另一部分数据集,在串行化情况下两个事务无论何种先后顺序,最终将达到一致状态,但SI隔离级别下无法实现。
36 |
37 | 
38 |
39 | 3. MVCC: DBMS为数据库中的一个逻辑对象 维护多个物理版本
40 |
41 | - 当一个事务写入一个对象时,DBMS会创建 该对象的一个新版本
42 | - 当一个事务读取一个对象时,会读取 该事务开始时 此对象的最新版本
43 |
44 | 优点:
45 |
46 | - 写者 不会阻塞 读者
47 | - 只读事务 在不需要锁的情况下 就可以读到 一致的数据库快照
48 |
49 | 4. 元组格式的设计
50 |
51 | | 属性 | 含义 |
52 | | -------- | ------------------------------------------------------------ |
53 | | Txn_Id | 唯一的事务id |
54 | | Begin_Ts | 开始时间戳 |
55 | | End_Ts | 结束时间戳 |
56 | | Pointer | 指向下一个版本create a latch-free version chain per logical tuple |
57 | | … | 其他metadata |
58 | | Data | 具体数据 |
59 |
60 | 5. **时间戳顺序**:(MVTO Multi-Version Timestamp Ordering)
61 |
62 | 元组新增一个Read_Ts属性:Use “read-ts” field in the header to keep track of the timestamp of the last txn that read it.
63 |
64 | 在元组没有锁的情况,事务只能读取 其id在Begin_Ts和End_Ts之间的版本,同时更新该元组的Read_Ts。
65 |
66 | 6. **Pointer**:通过pointer 为每一个 逻辑元组 创建一个 不需要闩锁latch-free 的**版本链version chain**
67 |
68 | - DBMS可以通过版本链,在运行期间,找到对一个事务可见的version
69 | - 索引 总是指向 版本链的头结点
70 |
71 | 版本链有两种顺序,在性能上有不同的trade-off:
72 |
73 | - Oldest-to-Newest (O2N):
74 | - Newest-to-Oldest (N2O):
75 |
76 | 7. **版本存储** Version Storage:
77 |
78 | - Append-Only: 新版本 会直接附加在 同一个表空间
79 |
80 | | Main Table | KEY | VALUE | POINTER |
81 | | ------------- | ---- | ----- | ------------- |
82 | | A1 | X | 100 | A2 |
83 | | A2 | X | 200 | A3 |
84 | | B1 | Y | 0 | nil |
85 | | A3 | X | 300 | nil |
86 |
87 | 同一个(逻辑)元组每次更新,会在表中插入一个新的(物理)版本。老的指向新的。
88 |
89 | - Time-Travel: 老版本会复制到 一个独立的表空间Time-Travel Table
90 |
91 | | Main Table | KEY | VALUE | POINTER |
92 | | ------------- | ---- | ----- | ---------------------------- |
93 | | A3 | X | 300 | A2 in Time-Travel |
94 | | B1 | Y | 0 | nil |
95 |
96 | | Time-Travel Table | KEY | VALUE | POINTER |
97 | | ----------------- | ---- | ----- | ------------- |
98 | | A1 | X | 100 | nil |
99 | | A2 | X | 200 | A1 |
100 |
101 | 新的指向老的。
102 |
103 | - Delta: 被修改属性的原始值会拷贝到 一个独立的delta record space
104 |
105 | | Main Table | KEY | VALUE | POINTER |
106 | | ------------- | ---- | ----- | ---------------------- |
107 | | A3 | X | 300 | A2 in Delta |
108 | | B1 | Y | 0 | nil |
109 |
110 | | Delta Storage | DELTA | POINTER |
111 | | ------------- | ------------ | ------------- |
112 | | A1 | (VALUE->100) | 100 |
113 | | A2 | (VALUE->200) | A1 |
114 |
115 | 8. **垃圾回收** Garbage Collection:
116 |
117 | DBMS需要 随着时间推移 删除**可以回收的**物理版本。
118 |
119 | - 没有 active的事务 可以看到该版本——快照隔离
120 | - 该版本由一个 已结束的事务创建
121 |
122 | 9. 两种层面的GC:
123 |
124 | - 元组级 Tuple-level:
125 |
126 | 1. Background Vacuuming: 独立的线程 会周期性地扫描表,寻找可回收的版本。
127 | 2. Cooperative Cleaning: 工作线程在 遍历版本链 时,找到可回收的版本。只适用于**O2N**。
128 |
129 | - 事务级 Transaction-level:
130 |
131 | 每个事务会记录 自己的 读/写集合。由DBMS来决定 一个已完成的事务 创建的所有版本 什么时候不可见。
132 |
133 | 注意 时间戳到达最大值的问题。
134 |
135 | > If the DBMS reaches the max value for its timestamps, it will have to wrap around and start at zero. This will make all previous versions be in the "future" from new transactions.
136 |
137 | Postgres的解决方法:当系统即将达到Txn_id的最大值时,停止接收新命令。在每个元组头部设置flag,标志其为过去的状态。而任何新的Txn_id都比过去状态的元组要新。
138 |
139 | 10. **索引管理** Index Management:
140 |
141 | - 主键索引——总是指向版本链的头结点。DBMS更新 主键索引的频率,取决于 系统是否 在一个元组更新时 就创建新版本。当一个事务更新元组的主键属性时,会等同于 先执行一次**DELETE**,再执行一次**INSERT**。
142 |
143 | - 辅助索引——较为复杂。可以使用 **Logical Pointers**(每个元组有一个固定不变的标识符)或 **Physical Pointers**
144 |
145 | -----
146 |
147 | ### 具体实现
148 |
149 | 11. SAP HANA—— In-memory **HTAP** DBMS with time-travel version storage (N2O)
150 |
151 | > 一种内存数据平台,可以作为内部预置型设备部署,也可以部署在云端。这是一个革命性的平台,最适合执行实时分析,开发和部署实时应用程序。
152 | >
153 | - 支持 乐观 以及 悲观的 MVCC
154 |
155 | - Time-travel表中存储最新的版本
156 |
157 | - 使用[混合存储layout](https://github.com/F-ca7/Advanced-Database-Systems-Learning/blob/master/paper%20reading/Flexible-Storage-Model.md)(行+列式)
158 |
159 | **版本存储**:
160 |
161 | - 在main table中存储最老的版本
162 |
163 | - 每一个元组维护一个 flag 来标记是否有newer version
164 |
165 | - 通过一个 hash 表,key为**record的identifier**,value为**版本链的头结点**。
166 |
167 | 12.
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
--------------------------------------------------------------------------------
/paper reading/dbms/innoDb.md:
--------------------------------------------------------------------------------
1 | ## InnoDB存储引擎
2 |
3 | 1. MySql由以下几部分组成:
4 | - 连接池 Connection Pool
5 | - 管理服务和工具 Management Service & Utilities(如备份, 恢复, 安全, 数据迁移等)
6 | - Sql接口 Sql Interface(DML: 数据操作语言(insert/update/delete), DDL: 数据定义语言(create), Triggers等)
7 | - 查询分析器 Parser
8 | - 优化器 Optimizer
9 | - 缓存与缓冲 Cache & Buffer
10 | - 插件式存储引擎 Pluggable Storage Engine (如MyISAM, InnoDB, NDB等)
11 | - 物理文件 File System
12 | 2. 存储引擎是**基于表**的,不是基于数据库的!插件式的架构提供了一系列标准的管理和服务支持,存储引擎是底层**物理结构**的实现。
13 | 3. InnoDb(默认的存储引擎)的特点:
14 | - 支持ACID事务 (不是所有存储引擎都支持事务)
15 | - 行锁设计
16 | - 支持外键
17 | - 非锁定读(默认读取不会产生锁)
18 | - 使用多版本并发控制(MVCC), 使用next-key locking 避免幻读
19 | - 插入缓冲(insert buffer) => **性能提升**、二次写(double write) => 数据页的**可靠性**、自适应哈希索引(adaptive hash index)、预读(read ahead)
20 | - 采用聚集(cluster)的方式存储数据; 每张表的存储都按主键顺序进行存放(没有主键时, 会为每行生成一个6byte的ROWID作为主键)
21 | - InnoDb更适合OLTP, MyISAM更适合OLAP
22 |
23 | 4. InnoDB采用**多线程**模型,运行时有多个后台线程,它们分别负责不同的任务:
24 |
25 | - Master线程: 负责将缓冲池的数据**异步刷新**到磁盘,保证数据的一致性。包括脏页(内存数据页和磁盘数据页上的内容不一致)的刷新、合并插入缓冲(INSERT buffer)、UNDO页(分为insert undo log和update undo log用Undo Log来实现MVCC)的回收等。
26 |
27 | - IO线程: 使用AIO(Async)来处理写IO请求,以提高数据库性能。IO线程负责的是这些IO请求的回调。可使用SHOW ENGINE INNODB STATUS查看:
28 |
29 | 
30 |
31 | - Purge线程: 为什么需要Purge——得从并发机制说起,InnoDB的多版本一致性读是采用了基于回滚段的的方式。无论是更新还是删除,都只是设置记录上的deleted bit标记位,而不是真正的删除记录;后续这些记录的真正删除, 是通过Purge后台线程实现。
32 |
33 | Purge: Purge parses and processes **undo log** pages from the **history list** for the purpose of removing clustered and secondary index records that were marked for deletion (by previous DELETE statements) and are no longer required for **MVCC** or **rollback**. Purge frees undo log pages from the history list after processing them.
34 |
35 | - Page Cleaner线程: InnoDB 1.2.x版本引入,将原本Master线程中的脏页刷新操作放到单独的线程中完成,减轻对于用户查询的阻塞。
36 |
37 | 5. 基于磁盘的DBMS通常使用**缓冲池**技术来提高整体性能。
38 |
39 | - 数据库读取页时,首先把从磁盘读到的页存放到缓冲池中;下一次再读相同的页时,先判断页是否在缓冲池中,若是则命中,若不是则再从磁盘读。
40 | - 数据库修改页时,首先修改缓冲池中的页,然后再以一定的频率刷新到磁盘上。不是每次页更新就会将页从缓冲池刷到磁盘!是通过**checkpoint**机制刷新回磁盘。checkpoint需要决定每次刷新多少页到磁盘、每次从哪里取脏页、什么时间触发。InnoDB中有两种checkpoint:
41 | 1. Sharp Checkpoint: 在数据库关闭时,将所有脏页刷新回磁盘。
42 | 2. Fuzzy Checkpoint: 运行时,只刷新一部分脏页;否则可用性会受到影响。
43 | - 多个缓冲池实例,每个page根据**哈希来平均分配**到不同的实例中——减少了数据库内部的资源竞争,增加数据库的并发能力。
44 |
45 | 
46 |
47 | - 缓冲池通过**LRU**算法来管理。最频繁使用的页在LRU列表的前端,当没有空位存放新读取的页时,收件释放LRU列表尾部的页。此外,InnoDB采用了**midpoint insertion**策略——新读取的页不是直接放到首部,而是放到midpoint的位置(默认是列表长度的5/8处)。在分割点前的列表称作new列表,可视作是最为活跃的热点数据。
48 |
49 | 
50 |
51 | 直接用朴素的LRU算法有什么劣势?当某些Sql操作需要访问表中的许多页甚至全部页时,而这些页通常又仅在这次查询中需要,并不是活跃的热点数据。如果直接放入LRU首部,就很可能把原本需要的热点数据页移除。
52 |
53 | 下图中,pct决定midpoint的位置,37即37%(3/8),即新页插入到LRU尾端37%的位置;time表示页读取到midpoint后要等待多久才被加入到new列表中:
54 |
55 | 
56 |
57 | - 支持压缩页的功能,即把原16KB的页压缩为1/2/4/8KB,并通过unzip_LRU列表管理。不同的表压缩比率不同,所以会有的表页大小为8KB,有的为4KB,如何从缓冲池分配内存?——unzip_LRU列表对不同大小的页会分别管理,并且使用伙伴(buddy)算法分配内存。
58 |
59 |
60 |
61 | 6. Master线程:
62 |
63 | - 最高的优先级别
64 |
65 | - 由多个loop组成: 主循环、后台循环、刷新循环 flush、暂停循环 suspend。
66 |
67 | - 主循环包括两类操作:每1秒执行的操作和每10秒执行的操作(通过thread.sleep实现,故并不精确)。
68 |
69 | 每1秒的操作(依次)包括: 日志缓冲刷新到磁盘(总是,即使事务还未提交,日志也会刷新到redo log中)、合并插入缓冲(可能,会判断当前的IO压力)、刷新缓冲池中的脏页到磁盘(可能,会判断脏页的比例是否超过阈值)、如果没有用户活动则切换到后台循环。
70 |
71 | - 后台循环,在数据库空闲时或数据库关闭时发生,包括: 删除无用的undo页(总是)、合并插入缓冲(总是)、跳回到主循环(总是)、不断刷新页知道符合条件(可能,会跳转到flush loop中)
72 |
73 | -----
74 |
75 | 新版本的优化点:
76 |
77 | - 引入参数innodb_io_capacity,用来表示磁盘IO的吞吐量,并用其控制**刷新缓冲区脏页**的数量和**合并插入缓冲**的数量(原本刷新脏页的数量、以及合并插入缓冲的数量是有上限的)。若使用SSD类磁盘,即存储设备IO速度较快时,可以将innodb_io_capacity调高,使之匹配磁盘IO吞吐量。
78 |
79 | - 引入参数innodb_adaptive_flushing,影响每秒刷新脏页的数量。原本刷新规则是——当脏页在缓冲池的比例小于innodb_max_dirty_pages_pct时,不刷新脏页;大于时,刷新100个脏页。现在是——通过判断redo log的速度来决定最合适的刷新脏页数量。
80 |
81 | 注: innodb事务日志包括redo log和undo log。redo log是重做日志,提供前滚操作;undo log是回滚日志,提供回滚操作。Redo log写入磁盘时,必须进行一次操作系统fsync操作,防止redo log只是写入操作系统磁盘缓存中。一般情况下,对硬盘的write操作,更新的只是内存中的页缓存,而脏页面不会立即更新到硬盘中。
82 |
83 | The [redo log](https://dev.mysql.com/doc/refman/5.5/en/innodb-redo-log.html) is a disk-based data structure used during crash recovery to correct data written by incomplete transactions. During normal operations, the redo log encodes requests to change table data that result from SQL statements or low-level API calls. Modifications that did not finish updating the data files before an unexpected shutdown are replayed automatically during initialization, and before the connections are accepted.
84 |
85 | - 引入参数innodb_purge_batch_size,控制每次full_purge回收的undo页的数量。
86 |
87 | 7. 插入缓冲: 对于非聚集索引的插入或更新,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,若在,则直接插入索引页;若**不在,则先放入到一个Insert Buffer对象中**(Changes are only recorded in the change buffer when the relevant page from the secondary index is not in the **buffer pool**)。
88 |
89 | - 使用的两个前提: 1. 索引是辅助索引(二级索引) secondary index——插入时,数据库中该非聚集索引已经插到叶子结点,但实际上其只是存放在另一个位置,然后再以一定频率进行Insert Buffer对象和辅助索引页子结点的merge;2. 索引不是unique——因为在插入缓冲时,不会去查找索引页来判断插入记录的唯一性
90 |
91 | 注: 二级索引——按照每张表创建的索引列创建一棵B+树,叶子节点并不包含行记录的全部数据(一张表可以有0/1/n个辅助索引)。查找过程为:遍历辅助索引→找到叶节点→找到指针获取主键索引的主键→通过主键索引找到对应的页→找到一个完整的行记录。
92 |
93 | ----------
94 |
95 | insert buffer现在变为**change buffer**,因为现在除了INSERT,还支持UPDATE和DELETE的DML语句。删除的两步: 1. 将一条元组标记为已删除;2. 真正将记录删除。
96 |
97 | - 其数据结构为一棵**B+树**。以前版本是一张表有一棵Insert Buffer B+树,现在是全局只有一棵,负责所有表的辅助索引进行插入缓冲。
98 |
99 | 其**非叶结点**存放的是查询的search key。search key的属性包括4字节的space,表示待插入记录所在表的表id(每张表有一个唯一的space id);1字节的marker,兼容作用;4字节的offset,表示页所在的偏移量。
100 |
101 | 当一个secondary index要插入到page(space_id, offset)时,如果该page不在缓冲池中,则会先构造一个search key,再查询Insert Buffer B+树,再将该条record插入到树的叶子结点中。
102 |
103 | 8. double write:(有些文件系统本身就提供了部分写失效的防范机制,就不需要开启double write)
104 |
105 | - 部分写失效 partial page write: 正在写入某个页到表中,比如16KB的页只写了前4KB,就发生了宕机,则会导致数据丢失
106 |
107 | - double write的两部分——**内存中**的double write buffer和**磁盘上**共享表空间中连续的128个page。(连续空间 => 顺序写 => 效率高)
108 |
109 | - 共享表空间:InnoDB的所有数据保存在一个单独的表空间里面,而这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所以其大小限制不再是文件大小的限制(**优点**),而是其自身的限制。
110 | - 独立表空间:每一个表都将会生成以独立的文件方式来进行存储,每一个表都有一个.frm表描述(结构)文件,还有一个.ibd文件。
111 |
112 | 当要刷新脏页时,不直接写磁盘;通过**memcpy**函数将脏页复制到内存中的double write buffer,之后通过double write buffer再分2次,每次写入1MB到共享表空间doublewirte中,然后马上调用fsync函数,同步到磁盘上。
113 |
114 | 如果写入磁盘时崩溃,可以从共享表空间中的doublewirte中找到该page的副本,将其复制到表空间文件,再应用重做日志。
115 |
116 | 9. 自适应哈希索引 AHI:
117 |
118 |
--------------------------------------------------------------------------------
/paper reading/query/An End-to-End Learning-based Cost Estimator.md:
--------------------------------------------------------------------------------
1 | ## An End-to-End Learning-based Cost Estimator
2 |
3 | 1. **问题**:传统基于经验的 代价和基数估计方法 无法提供高质量的估计结果,因为它们 不能有效地把握多表之间的关联。而现有的基于学习的方法有以下不足,
4 | - 关注基数的估计,没有对cost进行估计
5 | - 要么不够轻量,要么很难表示复杂的结构(如 复杂谓词)
6 | 2. **Contribution**:
7 |
8 | - **基于树结构的模型**,开发了一个 高效的 端到端 基于学习的Cost Estimator,可以同时进行 **代价和基数** 的估计
9 |
10 | - 提出高效的 **特征提取与编码**技术,在特征提取过程中 会结合考虑 query 和 physical execution,并将提取出的特征 应用到 树结构模型中,利用树结构来估计 cost和cardinality
11 |
12 | - 对于带有string类型的谓词,提出一种高效编码字符串值的方法。设计了一种基于pattern的方法 来嵌入字符串值
13 |
14 | > 特征嵌入,将数据转换(降维)为固定大小的特征表示(矢量),以便于处理和计算。embedding的主要目的是对(稀疏)特征进行降维,它降维的方式可以类比为一个全连接层(没有激活函数),通过 embedding 层的权重矩阵计算来降低维度。
15 |
16 | - 在真实数据集上进行实验,证明了该方法比现有方法的优越性
17 |
18 | 3. 实现细节:
19 |
20 | - Estimator架构
21 |
22 | dataset + queries → Query Optimizer → **Training Data Generator** → **Feature Extractor** → **Tree-structured Model**
23 |
24 | - **Training Data Generator**
25 |
26 | 根据数据集可能的join graph 以及 workload对应的谓词 生成一些query,接着对于每个query 通过优化器获得物理执行计划 (在DBMS中 使用计划分析工具),并获得真实的cost和cardinality。一条训练数据为一个三元组:<物理执行计划,该计划真实cost,该计划真实cardinality>
27 |
28 | - **Feature Extractor**
29 |
30 | 从query plan中提取有用的特征 (如 操作符 和 谓词),然后query plan中每个结点会编码为 特征向量feature vector,对于简单的特征(如 Operation: Nested Loop, Index Scan…; TableName; Operator)使用**one-hot** vector来编码得到向量;对于复杂的特征(如 LIKE谓词),直接将该每条元组\ 通过一对一映射 得到一个向量。向量再组成tensor,最后形成向量树,
31 |
32 | > one-hot是比较常用的文本特征特征提取的方法。**用N个bit来编码N个状态**,**保证每个样本中的每个特征只有1位处于状态1,其他都是0**。解决了分类器处理离散数据困难的问题。
33 |
34 | - **Tree-structured Model**
35 |
36 | - **Representation Memory Pool**
37 |
38 | 在处理query时,存储 **subplan** 到 **representation** 的映射。(就是在动态规划时 子任务结果的存储)
39 |
40 | - **Feature extraction and encoding**
41 |
42 | query node → node vector → tree-structured vector
43 |
44 | 
45 |
46 | **影响查询代价的因素主要有四种**,所以要提取出这些特征。
47 |
48 | - **Operation**
49 |
50 | 每个结点都有
51 |
52 | *Join* (Hash/ Merge/ Nested Loop Join);*Scan* (Sequential/ Bitmap Heap/ Index/ Bitmap Index/ Index Only Scan);*Sort* (Hash/ Merge Sort);*Aggregation* (Plain/ Hash Aggregation)
53 |
54 | 使用one-hot vector编码,比如1号结点操作类型是Nested Loop,其Operation编码为0001
55 |
56 | - **Predicate**
57 |
58 | join condition (a.movie_id = b.movie_id) 或 filter condition ('year > 1998')。一个谓词由三部分组成,*column*, *operator*, *operand*;前两者用one-hot vector编码,数值型*operand* 通过规格化的浮点数来编码,
59 |
60 | ----
61 |
62 | 字符串型*operand* 通过 基于embedding的方式——可以表示同一个元组中一起出现的字符串。两种字符串型的谓词,一种精确匹配型(= / IN),一种是模式匹配型(LIKE)。对所有的字符串子串 进行预训练,而不是对workload中出现的原始字符串进行编码;具体是通过对子字符串的泛化,生成一些规则,这些规则 **可以从数据集中提取出query workload的所有关键词**。再提取出满足规则的子串 来训练模型。
63 |
64 | - **Rule Generation**
65 |
66 | 一条规则由三部分构成(借助DSL的概念),*Pattern*(匹配数据集中元组的子字符串), *String Function*(决定 提取子字符串中哪个关键词), *Size*(待提取关键词的长度)。此处的*String Function*仅有两种——*Prefix*和*Suffix*
67 |
68 | 给定一个谓词中的keyword 以及 一个数据集中的string,先找到该字符串所有能匹配keyword的子串。对于每个匹配的子串,生成所有将 **keyword映射到子串**的pattern(通过穷举 Pattern的组合)。
69 |
70 | 再根据候选规则,找到最优的规则集合(使用最少的规则 来覆盖workload中的关键词)。是集合覆盖问题(SCP)的减弱版。
71 |
72 | > 给定一个集合U以及U内元素构成的若干各小类集合S,目标是找到S 的一个子集,该子集满足所含元素包含了U中的所有的元素且使小类集合个数最少。例如,U={1,2,3,4,5},S={{1,2},{3,4},{2,4,5},{4,5}},找到集合能满足条件的可以有O={{1,2},{3,4}{4,5}}或是O={{1,2},{3,4},{2,4,5}},
73 |
74 | - **String Indexing**
75 |
76 | 使用 前缀以及后缀trie树索引来存储 字符串→编码 的映射,通过*Prefix*函数提取出的子字符串就放入前缀树,*Suffix*函数提取出的子字符串就放入后缀树,叶子结点就存储字符串的向量表示(即 对应的编码)。
77 |
78 | Online Searching的过程中,会有不在dictionary的查询字符串;若它是前缀搜索(LIKE s%),则搜索该query string的最长前缀,其他同理。即在dictionary中选择 最长的可以匹配的,作为其表示。
79 |
80 | -----
81 |
82 | 如4号结点的filter为 info = 'top 250 rank' ,从Dictionary中找到top 250 rank的表示法,故4号结点的Predicate编码为 000000100000 0001 0.14,0.43,…,0.92
83 |
84 | - **Metadata**
85 |
86 | 列、表、索引的集合,分别都使用 one-hot向量来表示。(有些结点可能没有谓词,所以需要对 metadata也要进行编码)比如5号结点,没有谓词,所以其Predicate编码全部用0填充;其Table Name为movie_info_idx,故编码为0010
87 |
88 | - **Sample Bitmap**
89 |
90 | 固定长度的 0-1向量,每一位表示 对应的元组是否满足query node的谓词条件(满足为1,不满足为0)。如图中的9号结点,production_year>2010的只有第二条元组,故9号结点的Sample_Bitmap编码为0100
91 |
92 | - **Model Design**
93 |
94 | 模型有三层:*embedding layer*, *representation layer*, *estimation layer*
95 |
96 | 
97 |
98 | - **Embedding Layer**
99 |
100 | Sparse vector → dense vector,使用 一个ReLU激活的全连接层 来嵌入 *Operation*, *Metadata*和*Sample Bitmap*,
101 |
102 | 对于 *Predicate*,使用 Tree Pooling来编码(其中树的结构和 谓词树一样)。其中,叶子结点为全连接神经网络,**OR**使用最大池化层,**AND**使用最小池化层。因此,只有叶子结点才需要训练,容易做到高效的batch training;同时模型收敛更快,性能更好。
103 |
104 | - **Representation Layer**
105 |
106 | 第一个问题 information vanishing: 查询计划中的上层结点 无法捕捉到下层结点之间的关联。
107 |
108 | 第二个问题 space explosion: 如果要存储足量的信息 来保留表之间的关联,需要大量的存储空间和中间结果。
109 |
110 | 在表示层使用了 循环神经网络(RNN),作为一个连接网络,它决定了哪些信息会被传递。如果 表示模型representation model使用朴素神经网络,会有梯度消失和梯度爆炸的问题。因此使用**LSTM**来解决这个问题。
111 |
112 | > RNNs理论上是可以将以前的信息与当前的任务进行连接,例如使用以前的视频帧来帮助网络理解当前帧。理论上RNN可以通过调参来解决“长依赖”问题。但是在实践过程中RNNs无法学习到这种特征。可参考 *Learning Long-Term Dependencies with Gradient Descent is Difficult* (1994)
113 | >
114 | > Long Short Term Memory networks(以下简称LSTMs),一种特殊的RNN网络,该网络设计出来是为了解决长依赖问题。LSTMs的核心是细胞状态,用贯穿细胞的水平线表示。
115 | >
116 | > 细胞状态像传送带一样。它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNNs。即图中 *Gt-1* 到 *Gt*这一条水平线。
117 | >
118 | > LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息。门能够有选择性的决定让哪些信息通过。其实门的结构很简单,就是一个sigmoid层和一个点乘操作的组合。
119 | >
120 | > LSTM由三个门来控制细胞状态,这三个门分别称为**忘记门**、**输入门**和**输出门**。
121 |
122 | 如图中,*Gt*即为长记忆的通道,*ft* 决定了在长记忆中要遗忘哪些信息(第一步就是决定细胞状态需要丢弃哪些信息),*kt1* 决定了在长记忆中要加入哪些信息(第二步先通过一个输入门来决定更新哪些信息,再通过一个tanh层得到新的候选细胞信息),*kt2* 决定了记忆同道中的哪些信息应该当做子计划的representation
123 |
124 | - **Estimation Layer**
125 |
126 | 两层全连接神经网络,使用ReLU激活函数,输出层为sigmoid 预测归一化后的基数与代价。
127 |
128 | 由于需要同时预测两个,使用**多任务学习 multitask learning**(参考 Multitask learning. Machine Learning, 1994),其中最常用的一种实现策略是 Parameter sharing,同时训练多个任务,这些任务的模型共享部分神经网络层。
129 |
130 | > 只专注于单个模型可能会忽略一些相关任务中可能提升目标任务的潜在信息,通过进行一定程度的共享不同任务之间的参数,可能会使原任务泛化更好。
131 |
132 |
133 |
134 |
--------------------------------------------------------------------------------
/paper reading/distributed/Distributed Transaction.md:
--------------------------------------------------------------------------------
1 | ## Distributed Transactions
2 |
3 | 1. 首先,对于单机数据库上的事务,其包含一个或多个数据库操作,但逻辑上构成一个整体;那么我们知道,这些操作要么全部执行成功,要么全部不执行。所以也有事务的 **ACID**(*Atomicity*, *Consistency*, *Isolation*, Durability) 特性。
4 |
5 | 对于单机(单分区)事务,其一致性、隔离性主要是通过**并发控制**实现的;可以使用 基于锁的并发控制,比如两阶段锁;基于时间戳排序,也就是事务操作能否执行 取决于是否有更晚时间戳的事务已经提交。
6 |
7 | 2. 但是对于分布式事务,一个事务要跨越多个节点,单分区事务的并发控制方案 就不再适用。比如网购时候,订单系统和库存系统很可能就在不同的节点上,仅适用单分区事务的并发控制方案 无法得知本地外的其他节点事务是否成功提交。
8 |
9 | 所以引入原子提交的概念:原子提交不允许参与者之间发生分歧,也就是只要有一个参与者投票反对,事务就不能提交。其本质就是对这个问题达成共识——**是否要执行当前被提议的事务**?
10 |
11 | 3. 两阶段提交
12 |
13 | 两类节点
14 |
15 | - **协调者**:(一个)协调者负责保存状态,收集投票
16 |
17 | - **参与者**:其余节点即为参与者,通常每个参与者负责一个分区(互不相交的数据集合)
18 |
19 | 两个阶段
20 |
21 | - **准备** *prepare*:*协调**者* Propose消息告诉*参与者* 新事务;*参与者* 如果可以提交自己那部分的事务,就投赞成票,否则投反对票中止事务。
22 | - **提交/中止** *commit/abort*:只要有任何一个*参与者* 投反对票中止事务,则*协调者* 会向所有*参与者* 发送Abort消息。也就是只有当参与者都投赞成票时,协调者 才向它们发送Commit消息。
23 |
24 | 4. 下面考虑几种故障场景
25 |
26 | 首先考虑参与者,如果在准备阶段发生故障的话,则协调者会中止事务,因为没收到所有的赞成票,所以会影响可用性。像Spanner的话,为改进可用性问题,选择了在Paxos组上执行2PC 而非单节点。
27 |
28 | 如果它是在接受了Propose后挂掉,则恢复后,需要follow协调者的最终决定(因为不知道其他节点是否会abort),在此之前,该参与者不能处理请求,否则可能会有数据不一致的情况。
29 |
30 | 下面考虑协调者的故障。如果协调者在收集投票后、广播最终结果前发生故障,会导致所有参与者进入未决状态。因为参与者不知道协调者的决定,也不知道其他参与者是否已经收到了事务结果。那么解决方法 很自然,就是解决方案——在参与者中选举新的协调者,重新收集结果后,再做出最后决定。
31 |
32 | 如果 协调者没能向发送所有参与者发送最终消息,就发生故障。则可以在参与者中选举新的协调者,询问那条事务的执行情况,做出决定。注意 **参与者的状态转化**:当参与者在投了赞同票 然后未能收到协调者commit/abort的消息(超时)后,它可以向其他参与者pi询问结果,有可能收到以下三种回复:
33 |
34 | - pi已收到了协调者的最终决定
35 | - pi在上一阶段投了反对票,即中止了
36 | - 同样也在等待最终决定(处于未决状态)=> 如果所有p都处于未决状态,那就有必要选举新的协调者
37 |
38 | 但是如果 协调者和参与者一起故障,且故障的参与者接受到了最终消息并执行,那么在重新选举出新的协调者并决定时,可能造成数据不一致。就比如协调者向参与者1 发送rollback,然后挂掉了;参与者1 rollback成功后,也挂掉了;然后在参与者2 、3、4中选出新的协调者,由于他们都不知道那条事务的执行结果,所以重新投票后发现可以提交,从而导致了数据不一致
39 |
40 | 5. 这里需要讨论一下 两个概念 就是平常说的所谓分布式一致性算法 2PC 和 Paxos有什么区别,或者说他们是同一个类型、解决同一个问题的算法吗?
41 |
42 | 首先,举一个分布式数据库的例子 https://www.zhihu.com/question/275845393/answer/385349629。分布式数据库一般采用数据的**partition**和**replication**来提高整体的与高可用特性。单机数据库的账户表中存储了A与B两个账户。在分布式数据库中,将A与B存储在不同节点,称为partition;对于每个数据数据保存多份副本(副本在不同节点),称为replication,如A的三个副本为A1、A2和A3,B的副本为B1、B2和B3。这样原先在一个节点的数据A与B,被分到了6个节点。
43 |
44 | 那么从前面说的2PC中,我们也知道 两阶段提交 可以保证多个分片上操作的原子性,要么全部成功,要么全部失败;也就是A转钱给B,要么A-100同时B+100,要么都不变。而Paxos 或者 Raft,是用于保证同一个数据分片的多个副本的一致性,其在工程上的实现是**多个replication副本**对数据的操作序列达成一致。而且一个很明显的不同就在于,2PC中只有所有节点成功,整个事务才成功,但Paxos只要认为majority成功就行;这也体现出单纯的2PC不具备高可用,因为一个节点挂了,整个事务就阻塞住了,也就不可用了。
45 |
46 | 关于这两者也有相应的学术名称,2PC成为**consistency**算法(也就是一致性),Paxos成为**consensus**算法(也就是共识算法),那是以为两者是一个完全互补的关系,就像之前说的Spanner在paxos组上进行两阶段提交?事实上不是,Lamport在*[Consensus on Transaction Commit](https://lamport.azurewebsites.net/video/consensus-on-transaction-commit.pdf)*这篇论文中就指出了,两阶段提交是基于Paxos提交的一个退化版情形。也就是说 完全可以在Paxos算法之上创建一个新算法来代替2PC,也有相应的论文**Paxos Commit**。
47 |
48 | 6. 三阶段提交的话,则把两阶段提交的准备阶段 划分为 提议+准备两个阶段,网上也有称为 CanCommit 和 PreCommit 的说法。
49 |
50 | - **提议** *propose*:*协调者* Propose消息告诉*参与者* 新事务并收集投票
51 |
52 | - **准备** *prepare*:如果投票通过,则*协调者* 发送Prepare消息,参与者会执行事务操作(写入undo和redo log),返回ACK;否则(比如有参与者投反对票,或参与者超时未回复)发送Abort消息并结束流程
53 |
54 | - **提交/中止** *commit/abort*:*协调者* 通知*参与者* 提交事务;如果协调者 没有在超时时间内收到所有ACK,则向所有参与者发送Abort,参与者利用undo log进行回滚
55 |
56 | **解决的问题**:
57 |
58 | 解决了阻塞问题。比起2PC,3PC在参与者端额外引入了超时机制,从而如果参与者Prepare成功但无法及时收到来自协调者的信息,他会默认执行commit,而不会一直持有事务资源并处于阻塞状态。
59 |
60 | **未解决的问题**:
61 |
62 | 发生**网络分区**的情况(有些地方也说 3PC是需要假设节点间的延迟与响应时间是有界的,这也是一个意思;如果延迟高到一定程度,那也等同于发生了网络分区),Prepare阶段参与者节点A/B/C无法与协调者通信,导致A/B收到了prepare、但C没有;结果发生超时后,A/B提交了事务(因为A和B收不到协调者的Abort消息,按刚才的说法,超时后默认就commit了),但C中止了,即产生了矛盾。
63 |
64 | 7. 前面我们提过,Spanner是在paxos共识组上进行两阶段提交,但是在真正深入了解之前,我发现很容易将几个事务实现概念弄混。就比如 之前提到的TrueTime,高精度的物理时钟API,它在事务管理中扮演的是什么角色?
65 |
66 | 首先简单讲一下它的架构,这里的Zone可以理解为物理隔离的单位,每个zone里面有一个**zonemaster**和成百上千个**spanserver**,其中zonemaster负责给spanserver分配数据,spanserver才是真正处理用户请求的服务器;而location proxy顾名思义 会在客户向spanserver发送请求前,根据距离、延迟、负载等信息,决定访问哪个spanserver。
67 |
68 | 深入来看spanserver,它是真正负责读写数据的地方,每个spanserver包含多个tablet,tablet可以理解为一个表的某些行,其数据结构也是kv的(key string, timestamp int)->string,(TiDB就是参照这套来搞)。同时,一个spanserver上的**每个tablet 都维护了一个Paxos状态机**,从而在每个paxos组中也会有一个leader,事实上这里paxos是进行的binlog的同步,也就是每个paxos提议的对象是binlog record。可以看到,每个leader上有lock table以及transaction manager,也就是现在所需要关注的对象。
69 |
70 | 从Spanner的论文中可以知道,Lock table通过两阶段锁实现并发控制(悲观,为长事务设计,比如报表生成),Transaction Manager: 负责跨分片(跨Paxos group)的分布式事务,通过两阶段提交实现。其实这里可以把将一个个paxos group想像成单独的一个个节点,但是不能把paxos组的leader跟协调者弄混了,准确的说 只有leader节点会参与2PC,而协调者会由发起事务的client来决定。之前提到过两阶段提交存在单点故障问题,这里即使paxos leader宕机了,也可以很快用follower代替。
71 |
72 | 8. 那么之前提到的TrueTime到底是起什么作用?我们知道TrueTime它是用来生成全局时间戳的,而时间戳的本质就是为了建立事务的顺序关系。所以spanner所支持的三种事务类型中,只要是涉及时间戳的获取,就是由TrueTime API所支持的;并且,前面的tablet也提到是kv结构的,事实上key由两部分组成:一部分是字符串的键,另一部分就是该条记录的时间戳。那么为什么不能像TiDB那样 从 PD 获取一个全局唯一递增的时间戳作为当前事务的唯一事务 ID,这是因为 Spanner是跨全球的节点,引入一个单点的全局时间会带来很高的延迟影响。
73 |
74 | 三种事务类型:
75 |
76 | - **读写事务**:需要加锁(悲观并发控制),以下考虑写操作:
77 |
78 | 1. 确定写操作涉及的所有group,从中选取一个协调者
79 |
80 | 2. 所有节点首先获取写锁
81 |
82 | 3. 协调者生成本次事务的写入时间戳(需满足比之前任何事务的时间戳更大)
83 |
84 | 4. Leaders(不管是不是协调者)将客户端提交的数据,通过paxos写入到副本binlog;注意:这里和一般的2PC不同,spanner的客户端是直接向对应的leader发送提交的数据,不管是协调者还是参与者;只不过参与者收到提交的数据后,会发送给协调者一个prepare回复
85 | 5. 协调者收到所有参与者的prepare消息后,连带自己的Prepare以及Commit一起持久化,然后告知Client成功Commit
86 | 6. 最后是通知参与者commit,并释放锁。当然这里的commit不仅仅是本地的commit,而是paxos组要进行commit
87 |
88 | - **只读事务**:无锁,可以在副本上进行;基于TrueTime实现了多版本的无锁读,即使当前的spanserver挂掉了,仍可以基于truetime从副本中读取
89 |
90 | - **快照读**:客户端可以指定快照读的时间戳 或 时间戳过期的时间点,无锁
91 |
92 | 9. Percolator 同样是 Google 提出的分布式事务解决方案,构建在 BigTable 上,像TiDB乐观事务的实现就是基于Percolator模型。
93 |
94 | 在进行读写事务时,分以下几步:
95 |
96 | 1. 在所有写操作的行中,选出**一行**作为Primary,其余涉及的行全称为secondary,在写入Lock列之前会检查是否已有锁;且在事务开始后,检查Write列是否有新的写操作已经提交(即发生冲突)
97 | 2. Primary上好锁后,给secondary上锁,这里的锁会指向primary锁(也就是指向Account1)
98 | 3. 提交阶段的CommitTs > StartTs,更新Write列,删除Lock列
99 | 4. 如果Primary提交失败,整个事务回滚
100 |
101 | 10. TiDB 中事务 基于Percolator使用两阶段提交,分为 Prewrite 和 Commit 两个阶段;可以看到,在commit之前,在TiDB这边 buffer 所有的 update/delete 操作;但TiDB本身是无状态的,只能把最后的修改结果交给TiKV去判断冲突。
102 |
103 | 并发事务频繁修改同一行时,乐观事务的性能由于冲突可能会很差,本质因为乐观事务 基于并发事务不常修改同一行的假设,从而跳过获取行锁来提升性能。
104 |
105 | 所以TiDB后续也引入了悲观事务,当TiDB 收到来自客户端的更新数据的请求时,TiDB 向 TiKV 发起加悲观锁请求,该锁会持久化到 TiKV。当然,引入悲观锁的话,需要做好死锁的检测,终止特定的事务使整体能继续推进。
106 |
107 | 在High Performance TiDB中,也提到了一下几点性能优化:
108 |
109 | - **基于的假设:**
110 | - 写冲突小
111 | - 需要恢复场景很少(但不能完全忽略)
112 |
113 | - **异步提交:**
114 | - 如果prewrite成功,可以直接返回client成功
115 | - 代价是恢复阶段更复杂,且需要保存所有的secondary key,内存占用会上升
116 |
117 | - Batch IO
118 |
119 | - 在MVCC中,对于占用空间小的值,直接保存在元信息的Lock或Write列(减少磁盘读写)
120 |
121 |
122 |
123 |
--------------------------------------------------------------------------------