├── src
├── __init__.py
└── models
│ ├── __init__.py
│ ├── mlp.py
│ ├── transformer_block.py
│ ├── attention.py
│ └── transformer.py
├── requirements.txt
├── LICENSE
├── config
└── config.py
├── scripts
├── generate_text.py
├── data_download.py
├── train_transformer.py
└── data_preprocess.py
├── data_loader
└── data_loader.py
└── README.md
/src/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | --extra-index-url https://download.pytorch.org/whl/cu118
2 | torch
3 | torchvision
4 | torchaudio
5 | numpy
6 | h5py
7 | requests
8 | tqdm
9 | zstandard
10 | tiktoken
--------------------------------------------------------------------------------
/src/models/__init__.py:
--------------------------------------------------------------------------------
1 | # This file makes the 'src.models' directory a Python package.
2 | from .mlp import MLP
3 | from .attention import Head, MultiHeadAttention
4 | from .transformer_block import Block
5 | from .transformer import Transformer
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2025 Fareed Khan
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/config/config.py:
--------------------------------------------------------------------------------
1 | # --- Configuration ---
2 |
3 | # Define vocabulary size and transformer configuration (3 Billion)
4 | VOCAB_SIZE = 50304 # Number of unique tokens in the vocabulary
5 | CONTEXT_LENGTH = 512 # Maximum sequence length for the model
6 | N_EMBED = 2048 # Dimension of the embedding space
7 | N_HEAD = 16 # Number of attention heads in each transformer block
8 | N_BLOCKS = 64 # Number of transformer blocks in the model
9 |
10 | # Paths to training and development datasets
11 | TRAIN_PATH = "data/train/pile_train.h5" # File path for the training dataset
12 | DEV_PATH = "data/val/pile_dev.h5" # File path for the validation dataset
13 |
14 | # Transformer training parameters
15 | T_BATCH_SIZE = 32 # Number of samples per training batch
16 | T_CONTEXT_LENGTH = 16 # Context length for training batches
17 | T_TRAIN_STEPS = 200000 # Total number of training steps
18 | T_EVAL_STEPS = 1000 # Frequency (in steps) to perform evaluation
19 | T_EVAL_ITERS = 250 # Number of iterations to evaluate the model
20 | T_LR_DECAY_STEP = 50000 # Step at which to decay the learning rate
21 | T_LR = 5e-4 # Initial learning rate for training
22 | T_LR_DECAYED = 5e-5 # Learning rate after decay
23 | T_OUT_PATH = "models/transformer_B.pt" # Path to save the trained model
24 |
25 | # Device configuration
26 | DEVICE = 'cuda'
27 |
28 | # Store all configurations in a dictionary for easy access and modification
29 | default_config = {
30 | 'vocab_size': VOCAB_SIZE,
31 | 'context_length': CONTEXT_LENGTH,
32 | 'n_embed': N_EMBED,
33 | 'n_head': N_HEAD,
34 | 'n_blocks': N_BLOCKS,
35 | 'train_path': TRAIN_PATH,
36 | 'dev_path': DEV_PATH,
37 | 't_batch_size': T_BATCH_SIZE,
38 | 't_context_length': T_CONTEXT_LENGTH,
39 | 't_train_steps': T_TRAIN_STEPS,
40 | 't_eval_steps': T_EVAL_STEPS,
41 | 't_eval_iters': T_EVAL_ITERS,
42 | 't_lr_decay_step': T_LR_DECAY_STEP,
43 | 't_lr': T_LR,
44 | 't_lr_decayed': T_LR_DECAYED,
45 | 't_out_path': T_OUT_PATH,
46 | 'device': DEVICE,
47 | }
--------------------------------------------------------------------------------
/scripts/generate_text.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import tiktoken
3 | import argparse
4 | from config.config import default_config as config
5 | from src.models.transformer import Transformer # Assuming your Transformer class is in this module
6 |
7 | def generate_text(model_path: str, input_text: str, max_new_tokens: int = 100, device: str = 'cuda') -> str:
8 | """
9 | Generates text using a pre-trained Transformer model.
10 |
11 | Args:
12 | model_path (str): Path to the saved model checkpoint.
13 | input_text (str): The initial text to start generation from.
14 | max_new_tokens (int): The maximum number of new tokens to generate.
15 | device (str): 'cuda' or 'cpu', the device to run the model on.
16 |
17 | Returns:
18 | str: The generated text.
19 | """
20 | # Load the model checkpoint
21 | checkpoint = torch.load(model_path, map_location=torch.device(device))
22 |
23 | # Initialize the model using the configuration from config.py
24 | model = Transformer(
25 | n_head=config['n_head'],
26 | n_embed=config['n_embed'],
27 | context_length=config['context_length'],
28 | vocab_size=config['vocab_size'],
29 | N_BLOCKS=config['n_blocks']
30 | )
31 | model.load_state_dict(checkpoint['model_state_dict'])
32 | model.eval().to(device)
33 |
34 | # Load the tokenizer
35 | enc = tiktoken.get_encoding("r50k_base")
36 |
37 | start_ids = enc.encode_ordinary(input_text)
38 | context = torch.tensor(start_ids, dtype=torch.long, device=device).unsqueeze(0)
39 |
40 | # Generation process
41 | with torch.no_grad():
42 | generated_tokens = model.generate(context, max_new_tokens=max_new_tokens)[0].tolist()
43 |
44 | # Decode the generated tokens
45 | output_text = enc.decode(generated_tokens)
46 |
47 | return output_text
48 |
49 | def main() -> None:
50 | parser = argparse.ArgumentParser(description="Generate text using a pre-trained Transformer model.")
51 | parser.add_argument('--model_path', type=str, help='Path to the saved model checkpoint.')
52 | parser.add_argument('--input_text', type=str, help='The initial text to start generation from.')
53 | parser.add_argument('--max_new_tokens', type=int, default=100, help='Maximum number of new tokens to generate.')
54 |
55 | args = parser.parse_args()
56 |
57 | generated = generate_text(args.model_path, args.input_text, args.max_new_tokens, config['device'])
58 | print(f"Generated text:\n{generated}")
59 |
60 | if __name__ == "__main__":
61 | main()
62 |
--------------------------------------------------------------------------------
/src/models/mlp.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from torch import Tensor
4 |
5 | class MLP(nn.Module):
6 | """
7 | A simple Multi-Layer Perceptron with one hidden layer.
8 |
9 | This module is used within the Transformer block for feed-forward processing.
10 | It expands the input embedding size, applies a ReLU activation, and then projects it back
11 | to the original embedding size.
12 |
13 | Args:
14 | n_embed (int): The dimensionality of the input embedding.
15 | """
16 | def __init__(self, n_embed: int) -> None:
17 | """
18 | Initializes the MLP module.
19 |
20 | Args:
21 | n_embed (int): The dimensionality of the input embedding.
22 | """
23 | super().__init__()
24 | self.hidden = nn.Linear(n_embed, 4 * n_embed) # Linear layer to expand embedding size
25 | self.relu = nn.ReLU() # ReLU activation function
26 | self.proj = nn.Linear(4 * n_embed, n_embed) # Linear layer to project back to original size
27 |
28 | def forward(self, x: Tensor) -> Tensor:
29 | """
30 | Forward pass through the MLP.
31 |
32 | Args:
33 | x (torch.Tensor): Input tensor of shape (B, T, C), where B is batch size,
34 | T is sequence length, and C is embedding size.
35 |
36 | Returns:
37 | torch.Tensor: Output tensor of the same shape as the input.
38 | """
39 | x = self.forward_embedding(x)
40 | x = self.project_embedding(x)
41 | return x
42 |
43 | def forward_embedding(self, x: Tensor) -> Tensor:
44 | """
45 | Applies the hidden linear layer followed by ReLU activation.
46 |
47 | Args:
48 | x (torch.Tensor): Input tensor.
49 |
50 | Returns:
51 | torch.Tensor: Output after the hidden layer and ReLU.
52 | """
53 | x = self.relu(self.hidden(x))
54 | return x
55 |
56 | def project_embedding(self, x: Tensor) -> Tensor:
57 | """
58 | Applies the projection linear layer.
59 |
60 | Args:
61 | x (torch.Tensor): Input tensor.
62 |
63 | Returns:
64 | torch.Tensor: Output after the projection layer.
65 | """
66 | x = self.proj(x)
67 | return x
68 |
69 | if __name__ == '__main__':
70 | # Example Usage (optional, for testing the module independently)
71 | batch_size = 2
72 | sequence_length = 3
73 | embedding_dim = 16
74 | input_tensor = torch.randn(batch_size, sequence_length, embedding_dim)
75 |
76 | mlp_module = MLP(n_embed=embedding_dim)
77 | output_tensor = mlp_module(input_tensor)
78 |
79 | print("MLP Input Shape:", input_tensor.shape)
80 | print("MLP Output Shape:", output_tensor.shape)
--------------------------------------------------------------------------------
/src/models/transformer_block.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from src.models.attention import MultiHeadAttention
4 | from src.models.mlp import MLP
5 |
6 | class Block(nn.Module):
7 | """
8 | A single Transformer block.
9 |
10 | This block consists of a multi-head attention layer followed by an MLP,
11 | with layer normalization and residual connections.
12 |
13 | Args:
14 | n_head (int): The number of attention heads in the multi-head attention layer.
15 | n_embed (int): The dimensionality of the input embedding.
16 | context_length (int): The maximum length of the input sequence.
17 | """
18 | def __init__(self, n_head: int, n_embed: int, context_length: int) -> None:
19 | """
20 | Initializes the Transformer block.
21 |
22 | Args:
23 | n_head (int): The number of attention heads.
24 | n_embed (int): The dimensionality of the embedding space.
25 | context_length (int): The maximum sequence length.
26 | """
27 | super().__init__()
28 | self.ln1 = nn.LayerNorm(n_embed)
29 | self.attn = MultiHeadAttention(n_head, n_embed, context_length)
30 | self.ln2 = nn.LayerNorm(n_embed)
31 | self.mlp = MLP(n_embed)
32 |
33 | def forward(self, x: torch.Tensor) -> torch.Tensor:
34 | """
35 | Forward pass through the Transformer block.
36 |
37 | Args:
38 | x (torch.Tensor): Input tensor.
39 |
40 | Returns:
41 | torch.Tensor: Output tensor after the block.
42 | """
43 | # Apply multi-head attention with residual connection
44 | x = x + self.attn(self.ln1(x))
45 | # Apply MLP with residual connection
46 | x = x + self.mlp(self.ln2(x))
47 | return x
48 |
49 | def forward_embedding(self, x: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
50 | """
51 | Forward pass focusing on the embedding and attention parts.
52 |
53 | Args:
54 | x (torch.Tensor): Input tensor.
55 |
56 | Returns:
57 | tuple: A tuple containing the output after MLP embedding and the residual.
58 | """
59 | res = x + self.attn(self.ln1(x))
60 | x = self.mlp.forward_embedding(self.ln2(res))
61 | return x, res
62 |
63 | if __name__ == '__main__':
64 | # Example Usage (optional, for testing the module independently)
65 | batch_size = 2
66 | sequence_length = 5
67 | embedding_dim = 32
68 | num_heads = 4
69 | context_len = 5
70 | input_tensor = torch.randn(batch_size, sequence_length, embedding_dim)
71 |
72 | transformer_block = Block(n_head=num_heads, n_embed=embedding_dim, context_length=context_len)
73 | output_tensor = transformer_block(input_tensor)
74 |
75 | print("Transformer Block Input Shape:", input_tensor.shape)
76 | print("Transformer Block Output Shape:", output_tensor.shape)
--------------------------------------------------------------------------------
/data_loader/data_loader.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import h5py
4 | from typing import Iterator, Tuple
5 |
6 | def get_batch_iterator(data_path: str, batch_size: int, context_length: int, device: str = "cpu") -> Iterator[Tuple[torch.Tensor, torch.Tensor]]:
7 | """
8 | Creates an iterator for generating batches of data from an HDF5 file.
9 |
10 | Args:
11 | data_path (str): Path to the HDF5 file containing tokenized data.
12 | batch_size (int): Number of sequences in each batch.
13 | context_length (int): Length of each sequence.
14 | device (str, optional): Device to load the data onto ('cpu' or 'cuda'). Defaults to "cpu".
15 |
16 | Yields:
17 | tuple: A tuple containing input sequences (xb) and target sequences (yb).
18 | """
19 | # Open the HDF5 file in read mode
20 | with h5py.File(data_path, 'r') as hdf5_file:
21 |
22 | # Extract the dataset of tokenized sequences
23 | dataset = hdf5_file['tokens']
24 |
25 | # Get the total size of the dataset
26 | dataset_size = dataset.shape[0]
27 |
28 | # Calculate the number of examples (sequences) that can be made from the data
29 | n_examples = (dataset_size - 1) // context_length
30 |
31 | # Create an array of indices for examples and shuffle them for randomness
32 | example_idxs = np.arange(n_examples)
33 | np.random.shuffle(example_idxs)
34 |
35 | # Initialize epoch counter and example counter
36 | epochs = 0
37 | counter = 0
38 |
39 | while True:
40 | # Check if the current batch exceeds the number of available examples
41 | if counter + batch_size > n_examples:
42 | # Shuffle the indices again and reset the counter to 0
43 | np.random.shuffle(example_idxs)
44 | counter = 0
45 | print(f"Finished epoch {epochs}") # Print epoch number when an epoch finishes
46 | epochs += 1 # Increment the epoch counter
47 |
48 | # Select a batch of random indices to generate sequences
49 | random_indices = example_idxs[counter:counter+batch_size] * context_length
50 |
51 | # Retrieve sequences from the dataset based on the random indices
52 | random_samples = torch.tensor(np.array([dataset[idx:idx+context_length+1] for idx in random_indices]))
53 |
54 | # Separate the input sequences (xb) and target sequences (yb)
55 | xb = random_samples[:, :context_length].to(device) # Input sequence (first half of the random sample)
56 | yb = random_samples[:, 1:context_length+1].to(device) # Target sequence (second half of the random sample)
57 |
58 | # Increment the counter to move to the next batch
59 | counter += batch_size
60 |
61 | # Yield the input and target sequences as a tuple for the current batch
62 | yield xb, yb
63 |
64 | if __name__ == '__main__':
65 | # Example Usage (requires a dummy HDF5 file for testing)
66 | # Create a dummy HDF5 file
67 | import os
68 | dummy_data_path = "dummy_data.h5"
69 | if not os.path.exists(dummy_data_path):
70 | with h5py.File(dummy_data_path, 'w') as f:
71 | f.create_dataset('tokens', data=np.arange(1000))
72 |
73 | batch_size = 4
74 | context_length = 10
75 | for xb, yb in get_batch_iterator(dummy_data_path, batch_size, context_length):
76 | print("Input Batch Shape:", xb.shape)
77 | print("Target Batch Shape:", yb.shape)
78 | break
--------------------------------------------------------------------------------
/scripts/data_download.py:
--------------------------------------------------------------------------------
1 | import os
2 | import argparse
3 | import requests
4 | from tqdm import tqdm
5 | from typing import List
6 |
7 | # Base URL for the dataset files
8 | BASE_URL = "https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main"
9 | VAL_URL = f"{BASE_URL}/val.jsonl.zst" # URL for the validation dataset
10 | TRAIN_URLS = [f"{BASE_URL}/train/{i:02d}.jsonl.zst" for i in range(65)] # URLs for 65 training files (adjust the range if needed)
11 |
12 | def download_file(url: str, file_name: str) -> None:
13 | """
14 | Downloads a file from the given URL and saves it with the specified file name.
15 | Displays a progress bar using tqdm.
16 |
17 | Args:
18 | url (str): The URL of the file to download.
19 | file_name (str): The local path where the file will be saved.
20 | """
21 | print(f"Downloading: {file_name}...")
22 | response = requests.get(url, stream=True) # Stream the file content
23 | total_size = int(response.headers.get('content-length', 0)) # Get total file size if available
24 | block_size = 1024 # Size of each block for the progress bar
25 | with open(file_name, 'wb') as f: # Open file for writing in binary mode
26 | for chunk in tqdm(response.iter_content(block_size), total=total_size // block_size, desc="Downloading", leave=True):
27 | f.write(chunk) # Write each chunk to the file
28 |
29 | def download_dataset(val_url: str, train_urls: List[str], val_dir: str, train_dir: str, max_train_files: int) -> None:
30 | """
31 | Manages downloading of the dataset, including both validation and training files.
32 |
33 | Args:
34 | val_url (str): URL for the validation dataset.
35 | train_urls (list): List of URLs for the training dataset files.
36 | val_dir (str): Directory where the validation file will be stored.
37 | train_dir (str): Directory where the training files will be stored.
38 | max_train_files (int): Maximum number of training files to download.
39 | """
40 | # Define the path for the validation file
41 | val_file_path = os.path.join(val_dir, "val.jsonl.zst")
42 | if not os.path.exists(val_file_path): # Check if the validation file already exists
43 | print(f"Validation file not found. Downloading from {val_url}...")
44 | download_file(val_url, val_file_path) # Download the validation file
45 | else:
46 | print("Validation data already present. Skipping download.")
47 |
48 | # Loop through the training file URLs and download if not already present
49 | for idx, url in enumerate(train_urls[:max_train_files]): # Limit to max_train_files
50 | file_name = f"{idx:02d}.jsonl.zst" # Format file name (e.g., 00.jsonl.zst)
51 | file_path = os.path.join(train_dir, file_name) # Construct the full file path
52 | if not os.path.exists(file_path): # Check if the file already exists
53 | print(f"Training file {file_name} not found. Downloading...")
54 | download_file(url, file_path) # Download the training file
55 | else:
56 | print(f"Training file {file_name} already present. Skipping download.")
57 |
58 | def main() -> None:
59 | """
60 | Main function to parse arguments and orchestrate the dataset download process.
61 | """
62 | # Parse command-line arguments using argparse
63 | parser = argparse.ArgumentParser(description="Download PILE dataset.") # Description of the script
64 | parser.add_argument('--train_max', type=int, default=1, help="Max number of training files to download.") # Max training files
65 | parser.add_argument('--train_dir', default="data/train", help="Directory for storing training data.") # Training directory
66 | parser.add_argument('--val_dir', default="data/val", help="Directory for storing validation data.") # Validation directory
67 |
68 | args = parser.parse_args() # Parse the arguments provided by the user
69 |
70 | # Ensure directories for training and validation data exist
71 | os.makedirs(args.train_dir, exist_ok=True) # Create training directory if it doesn't exist
72 | os.makedirs(args.val_dir, exist_ok=True) # Create validation directory if it doesn't exist
73 |
74 | # Start downloading the dataset
75 | download_dataset(VAL_URL, TRAIN_URLS, args.val_dir, args.train_dir, args.train_max)
76 |
77 | print("Dataset downloaded successfully.") # Indicate successful download
78 |
79 | if __name__ == "__main__":
80 | # Entry point of the script
81 | main()
--------------------------------------------------------------------------------
/src/models/attention.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | import math
5 |
6 | class Head(nn.Module):
7 | """
8 | A single attention head.
9 |
10 | This module calculates attention scores and applies them to the values.
11 | It includes key, query, and value projections, and uses causal masking
12 | to prevent attending to future tokens.
13 |
14 | Args:
15 | head_size (int): The dimensionality of the key, query, and value projections.
16 | n_embed (int): The dimensionality of the input embedding.
17 | context_length (int): The maximum length of the input sequence, used for causal masking.
18 | """
19 | def __init__(self, head_size: int, n_embed: int, context_length: int) -> None:
20 | """
21 | Initializes the attention head.
22 |
23 | Args:
24 | head_size (int): The dimensionality of the key, query, and value projections.
25 | n_embed (int): The dimensionality of the input embedding.
26 | context_length (int): The maximum length of the input sequence.
27 | """
28 | super().__init__()
29 | self.key = nn.Linear(n_embed, head_size, bias=False) # Key projection
30 | self.query = nn.Linear(n_embed, head_size, bias=False) # Query projection
31 | self.value = nn.Linear(n_embed, head_size, bias=False) # Value projection
32 | # Lower triangular matrix for causal masking
33 | self.register_buffer('tril', torch.tril(torch.ones(context_length, context_length)))
34 |
35 | def forward(self, x: torch.Tensor) -> torch.Tensor:
36 | """
37 | Forward pass through the attention head.
38 |
39 | Args:
40 | x (torch.Tensor): Input tensor of shape (B, T, C).
41 |
42 | Returns:
43 | torch.Tensor: Output tensor after applying attention.
44 | """
45 | B, T, C = x.shape
46 | head_size = self.key.out_features
47 | k = self.key(x) # (B, T, head_size)
48 | q = self.query(x) # (B, T, head_size)
49 | scale_factor = 1 / math.sqrt(head_size)
50 | # Calculate attention weights: (B, T, head_size) @ (B, head_size, T) -> (B, T, T)
51 | attn_weights = q @ k.transpose(-2, -1) * scale_factor
52 | # Apply causal masking
53 | attn_weights = attn_weights.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
54 | attn_weights = F.softmax(attn_weights, dim=-1)
55 | v = self.value(x) # (B, T, head_size)
56 | # Apply attention weights to values
57 | out = attn_weights @ v # (B, T, T) @ (B, T, head_size) -> (B, T, head_size)
58 | return out
59 |
60 | class MultiHeadAttention(nn.Module):
61 | """
62 | Multi-Head Attention module.
63 |
64 | This module combines multiple attention heads in parallel. The outputs of each head
65 | are concatenated to form the final output.
66 |
67 | Args:
68 | n_head (int): The number of parallel attention heads.
69 | n_embed (int): The dimensionality of the input embedding.
70 | context_length (int): The maximum length of the input sequence.
71 | """
72 | def __init__(self, n_head: int, n_embed: int, context_length: int) -> None:
73 | """
74 | Initializes the multi-head attention module.
75 |
76 | Args:
77 | n_head (int): The number of parallel attention heads.
78 | n_embed (int): The dimensionality of the input embedding.
79 | context_length (int): The maximum length of the input sequence.
80 | """
81 | super().__init__()
82 | self.heads = nn.ModuleList([Head(n_embed // n_head, n_embed, context_length) for _ in range(n_head)])
83 |
84 | def forward(self, x: torch.Tensor) -> torch.Tensor:
85 | """
86 | Forward pass through the multi-head attention.
87 |
88 | Args:
89 | x (torch.Tensor): Input tensor of shape (B, T, C).
90 |
91 | Returns:
92 | torch.Tensor: Output tensor after concatenating the outputs of all heads.
93 | """
94 | # Concatenate the output of each head along the last dimension (C)
95 | x = torch.cat([h(x) for h in self.heads], dim=-1)
96 | return x
97 |
98 | if __name__ == '__main__':
99 | # Example Usage (optional, for testing the module independently)
100 | batch_size = 2
101 | sequence_length = 5
102 | embedding_dim = 32
103 | num_heads = 4
104 | context_len = 5
105 | input_tensor = torch.randn(batch_size, sequence_length, embedding_dim)
106 |
107 | multihead_attn = MultiHeadAttention(n_head=num_heads, n_embed=embedding_dim, context_length=context_len)
108 | output_tensor = multihead_attn(input_tensor)
109 |
110 | print("MultiHeadAttention Input Shape:", input_tensor.shape)
111 | print("MultiHeadAttention Output Shape:", output_tensor.shape)
112 |
--------------------------------------------------------------------------------
/src/models/transformer.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | from src.models.transformer_block import Block
5 |
6 | class Transformer(nn.Module):
7 | """
8 | The main Transformer model.
9 |
10 | This class combines token and position embeddings with a sequence of Transformer blocks
11 | and a final linear layer for language modeling.
12 |
13 | Args:
14 | n_head (int): The number of attention heads in each transformer block.
15 | n_embed (int): The dimensionality of the embedding space.
16 | context_length (int): The maximum length of the input sequence.
17 | vocab_size (int): The size of the vocabulary.
18 | N_BLOCKS (int): The number of transformer blocks in the model.
19 | """
20 | def __init__(self, n_head: int, n_embed: int, context_length: int, vocab_size: int, N_BLOCKS: int) -> None:
21 | """
22 | Initializes the Transformer model.
23 |
24 | Args:
25 | n_head (int): Number of attention heads.
26 | n_embed (int): Embedding dimension.
27 | context_length (int): Maximum sequence length.
28 | vocab_size (int): Size of the vocabulary.
29 | N_BLOCKS (int): Number of transformer blocks.
30 | """
31 | super().__init__()
32 | self.context_length = context_length
33 | self.N_BLOCKS = N_BLOCKS
34 | self.token_embed = nn.Embedding(vocab_size, n_embed)
35 | self.position_embed = nn.Embedding(context_length, n_embed)
36 | self.attn_blocks = nn.ModuleList([Block(n_head, n_embed, context_length) for _ in range(N_BLOCKS)])
37 | self.layer_norm = nn.LayerNorm(n_embed)
38 | self.lm_head = nn.Linear(n_embed, vocab_size)
39 | self.register_buffer('pos_idxs', torch.arange(context_length))
40 |
41 | def _pre_attn_pass(self, idx: torch.Tensor) -> torch.Tensor:
42 | """
43 | Combines token and position embeddings.
44 |
45 | Args:
46 | idx (torch.Tensor): Input token indices.
47 |
48 | Returns:
49 | torch.Tensor: Sum of token and position embeddings.
50 | """
51 | B, T = idx.shape
52 | tok_embedding = self.token_embed(idx)
53 | pos_embedding = self.position_embed(self.pos_idxs[:T])
54 | return tok_embedding + pos_embedding
55 |
56 | def forward(self, idx: torch.Tensor, targets: torch.Tensor = None) -> tuple[torch.Tensor, torch.Tensor | None]:
57 | """
58 | Forward pass through the Transformer.
59 |
60 | Args:
61 | idx (torch.Tensor): Input token indices.
62 | targets (torch.Tensor, optional): Target token indices for loss calculation. Defaults to None.
63 |
64 | Returns:
65 | tuple: Logits and loss (if targets are provided).
66 | """
67 | x = self._pre_attn_pass(idx)
68 | for block in self.attn_blocks:
69 | x = block(x)
70 | x = self.layer_norm(x)
71 | logits = self.lm_head(x)
72 | loss = None
73 | if targets is not None:
74 | B, T, C = logits.shape
75 | flat_logits = logits.view(B * T, C)
76 | targets = targets.view(B * T).long()
77 | loss = F.cross_entropy(flat_logits, targets)
78 | return logits, loss
79 |
80 | def forward_embedding(self, idx: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
81 | """
82 | Forward pass focusing on the embedding and attention blocks.
83 |
84 | Args:
85 | idx (torch.Tensor): Input token indices.
86 |
87 | Returns:
88 | tuple: Output after attention blocks and the residual.
89 | """
90 | x = self._pre_attn_pass(idx)
91 | residual = x
92 | for block in self.attn_blocks:
93 | x, residual = block.forward_embedding(x)
94 | return x, residual
95 |
96 | def generate(self, idx: torch.Tensor, max_new_tokens: int) -> torch.Tensor:
97 | """
98 | Generates new tokens given a starting sequence.
99 |
100 | Args:
101 | idx (torch.Tensor): Initial sequence of token indices.
102 | max_new_tokens (int): Number of tokens to generate.
103 |
104 | Returns:
105 | torch.Tensor: The extended sequence of tokens.
106 | """
107 | for _ in range(max_new_tokens):
108 | idx_cond = idx[:, -self.context_length:]
109 | logits, _ = self(idx_cond)
110 | logits = logits[:, -1, :]
111 | probs = F.softmax(logits, dim=-1)
112 | idx_next = torch.multinomial(probs, num_samples=1)
113 | idx = torch.cat((idx, idx_next), dim=1)
114 | return idx
115 |
116 | if __name__ == '__main__':
117 | # Example Usage (optional, for testing the module independently)
118 | batch_size = 2
119 | sequence_length = 5
120 | vocab_size = 100
121 | embedding_dim = 32
122 | num_heads = 4
123 | num_blocks = 2
124 | context_len = 5
125 | input_indices = torch.randint(0, vocab_size, (batch_size, sequence_length))
126 |
127 | transformer_model = Transformer(n_head=num_heads, n_embed=embedding_dim, context_length=context_len, vocab_size=vocab_size, N_BLOCKS=num_blocks)
128 | logits, loss = transformer_model(input_indices, targets=input_indices) # Using input as target for simplicity
129 |
130 | print("Transformer Logits Shape:", logits.shape)
131 | print("Transformer Loss:", loss)
132 |
133 | # Example of generating tokens
134 | start_indices = input_indices[:, :1] # Take the first token of each sequence as start
135 | generated_tokens = transformer_model.generate(start_indices, max_new_tokens=5)
136 | print("Generated Tokens Shape:", generated_tokens.shape)
--------------------------------------------------------------------------------
/scripts/train_transformer.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | import os
4 | from tqdm import tqdm
5 | import numpy as np
6 | from config.config import default_config as config
7 | from src.models.transformer import Transformer
8 | from data_loader.data_loader import get_batch_iterator
9 | from typing import Dict
10 |
11 | # --- Initialize the Model and Print Parameters ---
12 |
13 | model = Transformer(
14 | n_head=config['n_head'],
15 | n_embed=config['n_embed'],
16 | context_length=config['context_length'],
17 | vocab_size=config['vocab_size'],
18 | N_BLOCKS=config['n_blocks']
19 | ).to(config['device'])
20 |
21 | # Print the total number of parameters
22 | total_params = sum(p.numel() for p in model.parameters())
23 | print(f"Total number of parameters in the model: {total_params:,}")
24 |
25 | # --- Optimizer Setup and Loss Tracking ---
26 |
27 | # Set up the AdamW optimizer with the specified learning rate.
28 | optimizer = torch.optim.AdamW(model.parameters(), lr=config['t_lr'])
29 |
30 | # List to track loss values during training.
31 | losses = []
32 |
33 | # Define a window size for averaging recent losses in the training loop.
34 | AVG_WINDOW = 64
35 |
36 | # Helper function to estimate the average loss for training and development data.
37 | @torch.no_grad()
38 | def estimate_loss(steps: int) -> Dict[str, float]:
39 | """
40 | Evaluate the model on training and development datasets and calculate average loss.
41 |
42 | Args:
43 | steps (int): Number of steps to evaluate.
44 |
45 | Returns:
46 | dict: Dictionary containing average losses for 'train' and 'dev' splits.
47 | """
48 | out = {}
49 | model.eval() # Set the model to evaluation mode.
50 |
51 | for split in ['train', 'dev']:
52 | # Select the appropriate data path for the current split.
53 | data_path = config['train_path'] if split == 'train' else config['dev_path']
54 |
55 | # Create a batch iterator for evaluation.
56 | batch_iterator_eval = get_batch_iterator(
57 | data_path, config['t_batch_size'], config['t_context_length'], device=config['device']
58 | )
59 |
60 | # Initialize a tensor to track loss values for each evaluation step.
61 | losses_eval = torch.zeros(steps)
62 | for k in range(steps):
63 | try:
64 | # Fetch a batch and calculate the loss.
65 | xb, yb = next(batch_iterator_eval)
66 | _, loss = model(xb, yb)
67 | losses_eval[k] = loss.item()
68 | except StopIteration:
69 | # Handle the case where the data iterator ends early.
70 | print(f"Warning: Iterator for {split} ended early.")
71 | break
72 |
73 | # Compute the mean loss for the current split.
74 | out[split] = losses_eval[:k + 1].mean()
75 |
76 | model.train() # Restore the model to training mode.
77 | return out
78 |
79 | # --- Training Loop ---
80 |
81 | # Create a batch iterator for the training data.
82 | batch_iterator = get_batch_iterator(
83 | config['train_path'],
84 | config['t_batch_size'],
85 | config['t_context_length'],
86 | device=config['device']
87 | )
88 |
89 | # Create a progress bar to monitor training progress.
90 | pbar = tqdm(range(config['t_train_steps']))
91 | for step in pbar:
92 | try:
93 | # Fetch a batch of input and target data.
94 | xb, yb = next(batch_iterator)
95 |
96 | # Perform a forward pass and compute the loss.
97 | _, loss = model(xb, yb)
98 |
99 | # Record the loss for tracking.
100 | losses.append(loss.item())
101 | pbar.set_description(f"Train loss: {np.mean(losses[-AVG_WINDOW:]):.4f}")
102 |
103 | # Backpropagate the loss and update the model parameters.
104 | optimizer.zero_grad(set_to_none=True)
105 | loss.backward()
106 | optimizer.step()
107 |
108 | # Periodically evaluate the model on training and development data.
109 | if step % config['t_eval_steps'] == 0:
110 | evaluation_losses = estimate_loss(config['t_eval_iters'])
111 | train_loss = evaluation_losses['train']
112 | dev_loss = evaluation_losses['dev']
113 | print(f"Step: {step}, Train loss: {train_loss:.4f}, Dev loss: {dev_loss:.4f}")
114 |
115 | # Decay the learning rate at the specified step.
116 | if step == config['t_lr_decay_step']:
117 | print('Decaying learning rate')
118 | for g in optimizer.param_groups:
119 | g['lr'] = config['t_lr_decayed']
120 | except StopIteration:
121 | # Handle the case where the training data iterator ends early.
122 | print("Training data iterator finished early.")
123 | break
124 |
125 | # --- Save Model and Final Evaluation ---
126 |
127 | # Create the output directory if it does not exist.
128 | os.makedirs(config['t_out_path'].split('/')[0], exist_ok=True)
129 |
130 | # Perform a final evaluation of the model on training and development datasets.
131 | evaluation_losses = estimate_loss(200)
132 | train_loss = evaluation_losses['train']
133 | dev_loss = evaluation_losses['dev']
134 |
135 | # Ensure unique model save path in case the file already exists.
136 | modified_model_out_path = config['t_out_path']
137 | save_tries = 0
138 | while os.path.exists(modified_model_out_path):
139 | save_tries += 1
140 | model_out_name = os.path.splitext(config['t_out_path'])[0]
141 | modified_model_out_path = model_out_name + f"_{save_tries}" + ".pt"
142 |
143 | # Save the model's state dictionary, optimizer state, and training metadata.
144 | torch.save(
145 | {
146 | 'model_state_dict': model.state_dict(),
147 | 'optimizer_state_dict': optimizer.state_dict(),
148 | 'losses': losses,
149 | 'train_loss': train_loss,
150 | 'dev_loss': dev_loss,
151 | 'steps': len(losses),
152 | },
153 | modified_model_out_path
154 | )
155 | print(f"Saved model to {modified_model_out_path}")
156 | print(f"Finished training. Train loss: {train_loss:.4f}, Dev loss: {dev_loss:.4f}")
--------------------------------------------------------------------------------
/scripts/data_preprocess.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import zstandard as zstd
4 | import tiktoken
5 | import h5py
6 | from tqdm import tqdm
7 | import argparse
8 | from typing import Optional
9 |
10 | def process_files(input_dir: str, output_file: str, tokenizer_name: str, max_data: Optional[int] = None) -> None:
11 | """
12 | Process a specified number of lines from each .jsonl.zst file in the input directory
13 | and save encoded tokens to an HDF5 file.
14 |
15 | Args:
16 | input_dir (str): Directory containing input .jsonl.zst files.
17 | output_file (str): Path to the output HDF5 file.
18 | tokenizer_name (str): Name of the tiktoken tokenizer to use (e.g., 'r50k_base').
19 | max_data (int, optional): Maximum number of lines to process from each file.
20 | If None, process all lines.
21 | """
22 | # Print processing strategy based on max_data
23 | if max_data is not None:
24 | print(f"You have chosen max_data = {max_data}. Processing only the top {max_data} JSON objects from each file.")
25 | else:
26 | print("Processing all available JSON objects from each file.")
27 |
28 | # Load the tokenizer using the provided tokenizer name
29 | enc = tiktoken.get_encoding(tokenizer_name)
30 |
31 | # Create an HDF5 file for output
32 | with h5py.File(output_file, 'w') as out_f:
33 | # Initialize the dataset for storing tokenized data
34 | dataset = out_f.create_dataset('tokens', (0,), maxshape=(None,), dtype='i')
35 | start_index = 0 # Track the starting index for the next batch of tokens
36 |
37 | # Process each .jsonl.zst file in the input directory
38 | for filename in sorted(os.listdir(input_dir)):
39 | if filename.endswith(".jsonl.zst"): # Only process .jsonl.zst files
40 | in_file = os.path.join(input_dir, filename)
41 | print(f"Processing: {in_file}")
42 |
43 | processed_lines = 0 # Counter for processed lines in the current file
44 |
45 | # Open the compressed .jsonl.zst file for reading
46 | with zstd.open(in_file, 'rt', encoding='utf-8') as in_f:
47 | # Iterate over each line in the file
48 | for line in tqdm(in_f, desc=f"Processing {filename}", total=max_data if max_data is not None else None):
49 | try:
50 | # Parse the line as JSON
51 | data = json.loads(line)
52 | text = data.get('text') # Extract the 'text' field from the JSON object
53 |
54 | if text:
55 | # Tokenize the text and append an end-of-text token
56 | encoded = enc.encode(text + "<|endoftext|>", allowed_special={'<|endoftext|>'})
57 | encoded_len = len(encoded)
58 |
59 | # Resize the dataset to accommodate new tokens
60 | end_index = start_index + encoded_len
61 | dataset.resize(dataset.shape[0] + encoded_len, axis=0)
62 |
63 | # Store the encoded tokens in the dataset
64 | dataset[start_index:end_index] = encoded
65 | start_index = end_index # Update the start index
66 | else:
67 | # Warn if 'text' key is missing in the JSON object
68 | print(f"Warning: 'text' key missing in line from {filename}")
69 | except json.JSONDecodeError:
70 | # Handle JSON decoding errors
71 | print(f"Warning: Could not decode JSON from line in {filename}")
72 | except Exception as e:
73 | # Handle any other errors
74 | print(f"An error occurred while processing line in {filename}: {e}")
75 |
76 | processed_lines += 1
77 | # Stop processing if max_data limit is reached
78 | if max_data is not None and processed_lines >= max_data:
79 | break
80 |
81 | def main():
82 | """
83 | Main function to parse arguments, validate directories, and process files.
84 | """
85 | # Parse command-line arguments
86 | parser = argparse.ArgumentParser(description="Preprocess PILE dataset files and save tokens to HDF5.")
87 | parser.add_argument("--train_dir", type=str, default="data/train", help="Directory containing training .jsonl.zst files.")
88 | parser.add_argument("--val_dir", type=str, default="data/val", help="Directory containing validation .jsonl.zst files.")
89 | parser.add_argument("--out_train_file", type=str, default="data/train/pile_train.h5", help="Path to the output training HDF5 file.")
90 | parser.add_argument("--out_val_file", type=str, default="data/val/pile_dev.h5", help="Path to the output validation HDF5 file.")
91 | parser.add_argument("--tokenizer_name", type=str, default="r50k_base", help="Name of the tiktoken tokenizer to use.")
92 | parser.add_argument("--max_data", type=int, default=1000, help="Maximum number of json objects to process from each file in both train and val datasets (default: 1000).")
93 |
94 | args = parser.parse_args()
95 |
96 | # Validate the existence of the training and validation directories
97 | if not os.path.isdir(args.train_dir):
98 | print(f"Error: Training directory not found: {args.train_dir}")
99 | return
100 | if not os.path.isdir(args.val_dir):
101 | print(f"Error: Validation directory not found: {args.val_dir}")
102 | return
103 |
104 | # Process training data
105 | print("Starting training data preprocessing...")
106 | process_files(args.train_dir, args.out_train_file, args.tokenizer_name, args.max_data)
107 | print("Training data preprocessing complete.")
108 |
109 | # Process validation data
110 | print("Starting validation data preprocessing...")
111 | process_files(args.val_dir, args.out_val_file, args.tokenizer_name, args.max_data)
112 | print("Validation data preprocessing complete.")
113 |
114 | # Entry point of the script
115 | if __name__ == "__main__":
116 | main()
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 |
4 |
5 |
6 | # Train LLM From Scratch
7 |
8 |    [](#step-by-step-code-explanation)
9 |
10 | **I am Looking for a PhD position in AI**. Take a look at my [Resume](https://drive.google.com/file/d/1Q_iklJ1RVGSb-Pdey8BHy3k8IF3UJv0z/view?usp=sharing) or [GitHub](https://github.com/FareedKhan-dev)
11 |
12 |
13 |
14 | I implemented a transformer model from scratch using PyTorch, based on the paper [Attention is All You Need](https://arxiv.org/abs/1706.03762). You can use my scripts to train your own **billion** or **million** parameter LLM using a single GPU.
15 |
16 | Below is the output of the trained 13 million parameter LLM:
17 |
18 | ```
19 | In ***1978, The park was returned to the factory-plate that
20 | the public share to the lower of the electronic fence that
21 | follow from the Station's cities. The Canal of ancient Western
22 | nations were confined to the city spot. The villages were directly
23 | linked to cities in China that revolt that the US budget and in
24 | Odambinais is uncertain and fortune established in rural areas.
25 | ```
26 |
27 | ## Table of Contents
28 | - [Training Data Info](#training-data-info)
29 | - [Prerequisites and Training Time](#prerequisites-and-training-time)
30 | - [Code Structure](#code-structure)
31 | - [Usage](#usage)
32 | - [Step by Step Code Explanation](#step-by-step-code-explanation)
33 | - [Importing Libraries](#importing-libraries)
34 | - [Preparing the Training Data](#preparing-the-training-data)
35 | - [Transformer Overview](#transformer-overview)
36 | - [Multi Layer Perceptron (MLP)](#multi-layer-perceptron-mlp)
37 | - [Single Head Attention](#single-head-attention)
38 | - [Multi Head Attention](#multi-head-attention)
39 | - [Transformer Block](#transformer-block)
40 | - [The Final Model](#the-final-model)
41 | - [Batch Processing](#batch-processing)
42 | - [Training Parameters](#training-parameters)
43 | - [Training the Model](#training-the-model)
44 | - [Saving the Trained Model](#saving-the-trained-model)
45 | - [Training Loss](#training-loss)
46 | - [Generating Text](#generating-text)
47 | - [What’s Next](#whats-next)
48 |
49 | ## Training Data Info
50 |
51 | Training data is from the Pile dataset, which is a diverse, open-source, and large-scale dataset for training language models. The Pile dataset is a collection of 22 diverse datasets, including text from books, articles, websites, and more. The total size of the Pile dataset is 825GB, Below is the sample of the training data:
52 |
53 | ```python
54 | Line: 0
55 | {
56 | "text": "Effect of sleep quality ... epilepsy.",
57 | "meta": {
58 | "pile_set_name": "PubMed Abstracts"
59 | }
60 | }
61 |
62 | Line: 1
63 | {
64 | "text": "LLMops a new GitHub Repository ...",
65 | "meta": {
66 | "pile_set_name": "Github"
67 | }
68 | }
69 | ```
70 |
71 | ## Prerequisites and Training Time
72 |
73 | Make sure you have a basic understanding of object-oriented programming (OOP), neural networks (NN) and PyTorch to understand the code. Below are some resources to help you get started:
74 |
75 | | Topic | Video Link |
76 | |---------------------|-----------------------------------------------------------|
77 | | OOP | [OOP Video](https://www.youtube.com/watch?v=Ej_02ICOIgs&pp=ygUKb29wIHB5dGhvbg%3D%3D) |
78 | | Neural Network | [Neural Network Video](https://www.youtube.com/watch?v=Jy4wM2X21u0&pp=ygUbbmV1cmFsIG5ldHdvcmsgcHl0aG9uIHRvcmNo) |
79 | | Pytorch | [Pytorch Video](https://www.youtube.com/watch?v=V_xro1bcAuA&pp=ygUbbmV1cmFsIG5ldHdvcmsgcHl0aG9uIHRvcmNo) |
80 |
81 | You will need a GPU to train your model. Colab or Kaggle T4 will work for training a 13+ million-parameter model, but they will fail for billion-parameter training. Take a look at the comparison:
82 |
83 | | GPU Name | Memory | Data Size | 2B LLM Training | 13M LLM Training | Max Practical LLM Size (Training) |
84 | |--------------------------|--------|-----------|-----------------|------------------|-----------------------------------|
85 | | NVIDIA A100 | 40 GB | Large | ✔ | ✔ | ~6B–8B |
86 | | NVIDIA V100 | 16 GB | Medium | ✘ | ✔ | ~2B |
87 | | AMD Radeon VII | 16 GB | Medium | ✘ | ✔ | ~1.5B–2B |
88 | | NVIDIA RTX 3090 | 24 GB | Large | ✔ | ✔ | ~3.5B–4B |
89 | | Tesla P100 | 16 GB | Medium | ✘ | ✔ | ~1.5B–2B |
90 | | NVIDIA RTX 3080 | 10 GB | Medium | ✘ | ✔ | ~1.2B |
91 | | AMD RX 6900 XT | 16 GB | Large | ✘ | ✔ | ~2B |
92 | | NVIDIA GTX 1080 Ti | 11 GB | Medium | ✘ | ✔ | ~1.2B |
93 | | Tesla T4 | 16 GB | Small | ✘ | ✔ | ~1.5B–2B |
94 | | NVIDIA Quadro RTX 8000 | 48 GB | Large | ✔ | ✔ | ~8B–10B |
95 | | NVIDIA RTX 4070 | 12 GB | Medium | ✘ | ✔ | ~1.5B |
96 | | NVIDIA RTX 4070 Ti | 12 GB | Medium | ✘ | ✔ | ~1.5B |
97 | | NVIDIA RTX 4080 | 16 GB | Medium | ✘ | ✔ | ~2B |
98 | | NVIDIA RTX 4090 | 24 GB | Large | ✔ | ✔ | ~4B |
99 | | NVIDIA RTX 4060 Ti | 8 GB | Small | ✘ | ✔ | ~1B |
100 | | NVIDIA RTX 4060 | 8 GB | Small | ✘ | ✔ | ~1B |
101 | | NVIDIA RTX 4050 | 6 GB | Small | ✘ | ✔ | ~0.75B |
102 | | NVIDIA RTX 3070 | 8 GB | Small | ✘ | ✔ | ~1B |
103 | | NVIDIA RTX 3060 Ti | 8 GB | Small | ✘ | ✔ | ~1B |
104 | | NVIDIA RTX 3060 | 12 GB | Medium | ✘ | ✔ | ~1.5B |
105 | | NVIDIA RTX 3050 | 8 GB | Small | ✘ | ✔ | ~1B |
106 | | NVIDIA GTX 1660 Ti | 6 GB | Small | ✘ | ✔ | ~0.75B |
107 | | AMD RX 7900 XTX | 24 GB | Large | ✔ | ✔ | ~3.5B–4B |
108 | | AMD RX 7900 XT | 20 GB | Large | ✔ | ✔ | ~3B |
109 | | AMD RX 7800 XT | 16 GB | Medium | ✘ | ✔ | ~2B |
110 | | AMD RX 7700 XT | 12 GB | Medium | ✘ | ✔ | ~1.5B |
111 | | AMD RX 7600 | 8 GB | Small | ✘ | ✔ | ~1B |
112 |
113 | The 13M LLM training is the training of a 13+ million-parameter model, and the 2B LLM training is the training of a 2+ billion-parameter model. The data size is categorized as small, medium, and large. The small data size is around 1 GB, the medium data size is around 5 GB, and the large data size is around 10 GB.
114 |
115 | ## Code Structure
116 |
117 | The codebase is organized as follows:
118 | ```bash
119 | train-llm-from-scratch/
120 | ├── src/
121 | │ ├── models/
122 | │ │ ├── mlp.py # Definition of the Multi-Layer Perceptron (MLP) module
123 | │ │ ├── attention.py # Definitions for attention mechanisms (single-head, multi-head)
124 | │ │ ├── transformer_block.py # Definition of a single Transformer block
125 | │ │ ├── transformer.py # Definition of the main Transformer model
126 | ├── config/
127 | │ └── config.py # Contains default configurations (model parameters, file paths, etc.)
128 | ├── data_loader/
129 | │ └── data_loader.py # Contains functions for creating data loaders/iterators
130 | ├── scripts/
131 | │ ├── train_transformer.py # Script for training the Transformer model
132 | │ ├── data_download.py # Script for downloading the dataset
133 | │ ├── data_preprocess.py # Script for preprocessing the downloaded data
134 | │ ├── generate_text.py # Script for generating text using a trained model
135 | ├── data/ # Directory to store the dataset
136 | │ ├── train/ # Contains training data
137 | │ └── val/ # Contains validation data
138 | ├── models/ # Directory where trained models are saved
139 | ```
140 |
141 | `scripts/` directory contains scripts for downloading the dataset, preprocessing the data, training the model, and generating text using the trained model. `src/models/` directory contains the implementation of the transformer model, multi-layer perceptron (MLP), attention mechanisms, and transformer blocks.`config/` directory contains the configuration file with default parameters. `data_loader/` directory contains functions for creating data loaders/iterators.
142 |
143 | ## Usage
144 |
145 | Clone the repository and navigate to the directory:
146 | ```bash
147 | git clone https://github.com/FareedKhan-dev/train-llm-from-scratch.git
148 | cd train-llm-from-scratch
149 | ```
150 |
151 | if you encounter any issues regarding the imports, make sure to change pythonpath to the root directory of the project:
152 | ```bash
153 | export PYTHONPATH="${PYTHONPATH}:/path/to/train-llm-from-scratch"
154 |
155 | # or if you are already in the train-llm-from-scratch directory
156 | export PYTHONPATH="$PYTHONPATH:."
157 | ```
158 |
159 | Install the required dependencies:
160 | ```bash
161 | pip install -r requirements.txt
162 | ```
163 |
164 | You can modify the transformer architecture under `src/models/transformer.py` and the training configurations under `config/config.py`.
165 |
166 |
167 | To download the training data, run:
168 | ```bash
169 | python scripts/data_download.py
170 | ```
171 |
172 | The script supports the following arguments:
173 | * `--train_max`: Maximum number of training files to download. Default is 1 (Max equal to 30) Each file is around 11 GB.
174 | * `--train_dir`: Directory for storing training data. Default is `data/train`.
175 | * `--val_dir`: Directory for storing validation data. Default is `data/val`.
176 |
177 | To preprocess the downloaded data, run:
178 | ```bash
179 | python scripts/data_preprocess.py
180 | ```
181 |
182 | The script supports the following arguments:
183 | - `--train_dir`: Directory where the training data files are stored (default is `data/train`).
184 | - `--val_dir`: Directory where the validation data files are stored (default is `data/val`).
185 | - `--out_train_file`: Path to store the processed training data in HDF5 format (default is `data/train/pile_train.h5`).
186 | - `--out_val_file`: Path to store the processed validation data in HDF5 format (default is `data/val/pile_dev.h5`).
187 | - `--tokenizer_name`: Name of the tokenizer to use for processing the data (default is `r50k_base`).
188 | - `--max_data`: Maximum number of JSON objects ([lines](#training-data-info)) to process from each dataset (both train and validation). The default is 1000.
189 |
190 | Now that the data is preprocessed, you can train the 13 million parameter llm by changing the configuration in `config/config.py` to this:
191 |
192 | ```python
193 | # Define vocabulary size and transformer configuration (3 Billion)
194 | VOCAB_SIZE = 50304 # Number of unique tokens in the vocabulary
195 | CONTEXT_LENGTH = 128 # Maximum sequence length for the model
196 | N_EMBED = 128 # Dimension of the embedding space
197 | N_HEAD = 8 # Number of attention heads in each transformer block
198 | N_BLOCKS = 1 # Number of transformer blocks in the model
199 | ```
200 |
201 | To train the model, run:
202 | ```bash
203 | python scripts/train_transformer.py
204 | ```
205 |
206 | It will start training the model and save the trained model in the `models/` default directory or the directory specified in the configuration file.
207 |
208 | To generate text using the trained model, run:
209 | ```bash
210 | python scripts/generate_text.py --model_path models/your_model.pth --input_text hi
211 | ```
212 |
213 | The script supports the following arguments:
214 | - `--model_path`: Path to the trained model.
215 | - `--input_text`: Initial text prompt for generating new text.
216 | - `--max_new_tokens`: Maximum number of tokens to generate (default is 100).
217 |
218 | It will generate text based on the input prompt using the trained model.
219 |
220 | ## Step by Step Code Explanation
221 |
222 | This section is for those who want to understand the code in detail. I will explain the code step by step, starting from importing the libraries to training the model and generating text.
223 |
224 | Previously, I wrote an article on Medium about creating a [2.3+ million-parameter](https://levelup.gitconnected.com/building-a-million-parameter-llm-from-scratch-using-python-f612398f06c2) LLM using the Tiny Shakespeare dataset, but the output didn’t make sense. Here is a sample output:
225 |
226 | ```bash
227 | # 2.3 Million Parameter LLM Output
228 | ZELBETH:
229 | Sey solmenter! tis tonguerered if
230 | Vurint as steolated have loven OID the queend refore
231 | Are been, good plmp:
232 |
233 | Proforne, wiftes swleen, was no blunderesd a a quain beath!
234 | Tybell is my gateer stalk smend as be matious dazest
235 | ```
236 |
237 | I had a thought, what if I make the transformer architecture smaller and less complex, and the training data more diverse? Then, how big of a model could a single person, using their nearly dead GPU, create in terms of parameters that can speak proper grammar and generate text that makes some sense?
238 |
239 | I found that **13+ million-parameter** models are enough to start making sense in terms of proper grammar and punctuation, which is a positive point. This means we can use a very specific dataset to further fine-tune our previously trained model for a narrowed task. We might end up with a model under 1 billion parameters or even around 500 million parameters that is perfect for our specific use case, especially for running it on private data securely.
240 |
241 | I recommend you **first train a 13+ million-parameter** model using the script available in my GitHub repository. You will get results within one day, instead of waiting for a longer time, or if your local GPU might not be strong enough to train a billion-parameter model.
242 |
243 | ### Importing Libraries
244 |
245 | Let’s import the required libraries that will be used throughout this blog:
246 |
247 | ```python
248 | # PyTorch for deep learning functions and tensors
249 | import torch
250 | import torch.nn as nn
251 | import torch.nn.functional as F
252 |
253 | # Numerical operations and arrays handling
254 | import numpy as np
255 |
256 | # Handling HDF5 files
257 | import h5py
258 |
259 | # Operating system and file management
260 | import os
261 |
262 | # Command-line argument parsing
263 | import argparse
264 |
265 | # HTTP requests and interactions
266 | import requests
267 |
268 | # Progress bar for loops
269 | from tqdm import tqdm
270 |
271 | # JSON handling
272 | import json
273 |
274 | # Zstandard compression library
275 | import zstandard as zstd
276 |
277 | # Tokenization library for large language models
278 | import tiktoken
279 |
280 | # Math operations (used for advanced math functions)
281 | import math
282 | ```
283 |
284 | ### Preparing the Training Data
285 |
286 | Our training dataset needs to be diverse, containing information from different domains, and The Pile is the right choice for it. Although it is 825 GB in size, we will stick to only a small portion of it, i.e., 5%–10%. Let’s first download the dataset and see how it works. I will be downloading the version available on [HuggingFace](https://huggingface.co/datasets/monology/pile-uncopyrighted).
287 |
288 | ```python
289 | # Download validation dataset
290 | !wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/val.jsonl.zst
291 |
292 | # Download the first part of the training dataset
293 | !wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/00.jsonl.zst
294 |
295 | # Download the second part of the training dataset
296 | !wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/01.jsonl.zst
297 |
298 | # Download the third part of the training dataset
299 | !wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/02.jsonl.zst
300 | ```
301 |
302 | It will take some time to download, but you can also limit the training dataset to just one file, `00.jsonl.zst`, instead of three. It is already split into train/val/test. Once it's done, make sure to place the files correctly in their respective directories.
303 |
304 | ```python
305 | import os
306 | import shutil
307 | import glob
308 |
309 | # Define directory structure
310 | train_dir = "data/train"
311 | val_dir = "data/val"
312 |
313 | # Create directories if they don't exist
314 | os.makedirs(train_dir, exist_ok=True)
315 | os.makedirs(val_dir, exist_ok=True)
316 |
317 | # Move all train files (e.g., 00.jsonl.zst, 01.jsonl.zst, ...)
318 | train_files = glob.glob("*.jsonl.zst")
319 | for file in train_files:
320 | if file.startswith("val"):
321 | # Move validation file
322 | dest = os.path.join(val_dir, file)
323 | else:
324 | # Move training file
325 | dest = os.path.join(train_dir, file)
326 | shutil.move(file, dest)
327 |
328 | Our dataset is in the .jsonl.zst format, which is a compressed file format commonly used for storing large datasets. It combines JSON Lines (.jsonl), where each line represents a valid JSON object, with Zstandard (.zst) compression. Let's read a sample of one of the downloaded files and see how it looks.
329 |
330 | in_file = "data/val/val.jsonl.zst" # Path to our validation file
331 |
332 | with zstd.open(in_file, 'r') as in_f:
333 | for i, line in tqdm(enumerate(in_f)): # Read first 5 lines
334 | data = json.loads(line)
335 | print(f"Line {i}: {data}") # Print the raw data for inspection
336 | if i == 2:
337 | break
338 | ```
339 |
340 | The output of the above code is this:
341 |
342 | ```python
343 | #### OUTPUT ####
344 | Line: 0
345 | {
346 | "text": "Effect of sleep quality ... epilepsy.",
347 | "meta": {
348 | "pile_set_name": "PubMed Abstracts"
349 | }
350 | }
351 |
352 | Line: 1
353 | {
354 | "text": "LLMops a new GitHub Repository ...",
355 | "meta": {
356 | "pile_set_name": "Github"
357 | }
358 | }
359 | ```
360 |
361 | Now we need to encode (tokenize) our dataset. Our goal is to have an LLM that can at least output proper words. For that, we need to use an already available tokenizer. We will use the tiktoken open-source tokenizer by OpenAI. We will use the r50k_base tokenizer, which is used for the ChatGPT (GPT-3) model, to tokenize our dataset.
362 |
363 | We need to create a function for this to avoid duplication, as we will be tokenizing both the train and validation datasets.
364 |
365 | ```python
366 | def process_files(input_dir, output_file):
367 | """
368 | Process all .zst files in the specified input directory and save encoded tokens to an HDF5 file.
369 |
370 | Args:
371 | input_dir (str): Directory containing input .zst files.
372 | output_file (str): Path to the output HDF5 file.
373 | """
374 | with h5py.File(output_file, 'w') as out_f:
375 | # Create an expandable dataset named 'tokens' in the HDF5 file
376 | dataset = out_f.create_dataset('tokens', (0,), maxshape=(None,), dtype='i')
377 | start_index = 0
378 |
379 | # Iterate through all .zst files in the input directory
380 | for filename in sorted(os.listdir(input_dir)):
381 | if filename.endswith(".jsonl.zst"):
382 | in_file = os.path.join(input_dir, filename)
383 | print(f"Processing: {in_file}")
384 |
385 | # Open the .zst file for reading
386 | with zstd.open(in_file, 'r') as in_f:
387 | # Iterate through each line in the compressed file
388 | for line in tqdm(in_f, desc=f"Processing {filename}"):
389 | # Load the line as JSON
390 | data = json.loads(line)
391 |
392 | # Append the end-of-text token to the text and encode it
393 | text = data['text'] + "<|endoftext|>"
394 | encoded = enc.encode(text, allowed_special={'<|endoftext|>'})
395 | encoded_len = len(encoded)
396 |
397 | # Calculate the end index for the new tokens
398 | end_index = start_index + encoded_len
399 |
400 | # Expand the dataset size and store the encoded tokens
401 | dataset.resize(dataset.shape[0] + encoded_len, axis=0)
402 | dataset[start_index:end_index] = encoded
403 |
404 | # Update the start index for the next batch of tokens
405 | start_index = end_index
406 | ```
407 |
408 | There are two important points regarding this function:
409 |
410 | 1. We are storing the tokenized data in an HDF5 file, which allows us flexibility for quicker data access while training the model.
411 |
412 | 2. Appending the `<|endoftext|>` token marks the end of each text sequence, signaling to the model that it has reached the end of a meaningful context, which helps in generating coherent outputs.
413 |
414 | Now we can simply encode our train and validation datasets using:
415 |
416 | ```python
417 | # Define tokenized data output directories
418 | out_train_file = "data/train/pile_train.h5"
419 | out_val_file = "data/val/pile_dev.h5"
420 |
421 | # Loading tokenizer of (GPT-3/GPT-2 Model)
422 | enc = tiktoken.get_encoding('r50k_base')
423 |
424 | # Process training data
425 | process_files(train_dir, out_train_file)
426 |
427 | # Process validation data
428 | process_files(val_dir, out_val_file)
429 | ```
430 |
431 | Let’s take a look at the sample of our tokenized data:
432 |
433 | ```python
434 | with h5py.File(out_val_file, 'r') as file:
435 | # Access the 'tokens' dataset
436 | tokens_dataset = file['tokens']
437 |
438 | # Print the dtype of the dataset
439 | print(f"Dtype of 'tokens' dataset: {tokens_dataset.dtype}")
440 |
441 | # load and print the first few elements of the dataset
442 | print("First few elements of the 'tokens' dataset:")
443 | print(tokens_dataset[:10]) # First 10 token
444 | ```
445 |
446 | The output of the above code is this:
447 |
448 | ```python
449 | #### OUTPUT ####
450 | Dtype of 'tokens' dataset: int32
451 |
452 | First few elements of the 'tokens' dataset:
453 | [ 2725 6557 83 23105 157 119 229 77 5846 2429]
454 | ```
455 | We have prepared our dataset for training. Now we will code the transformer architecture and look into its theory correspondingly.
456 |
457 | ### Transformer Overview
458 |
459 | Let’s have a quick look at how a transformer architecture is used to process and understand text. It works by breaking text into smaller pieces called tokens and predicting the next token in the sequence. A transformer has many layers, called transformer blocks, stacked on top of each other, with a final layer at the end to make the prediction.
460 |
461 | Each transformer block has two main components:
462 |
463 | * **Self-Attention Heads**: These figure out which parts of the input are most important for the model to focus on. For example, when processing a sentence, the attention heads can highlight relationships between words, such as how a pronoun relates to the noun it refers to.
464 |
465 | * **MLP (Multi-Layer Perceptron)**: This is a simple feed-forward neural network. It takes the information emphasized by the attention heads and processes it further. The MLP has an input layer that receives data from the attention heads, a hidden layer that adds complexity to the processing, and an output layer that passes the results to the next transformer block.
466 |
467 | Together, the attention heads act as the “what to think about” part, while the MLP is the “how to think about it” part. Stacking many transformer blocks allows the model to understand complex patterns and relationships in the text, but this is not always guaranteed.
468 |
469 | Instead of looking at the original paper diagram, let’s visualize a simpler and easier architecture diagram that we will be coding.
470 |
471 | ](https://cdn-images-1.medium.com/max/11808/1*QXmeA-H52C-p82AwawslbQ.png)
472 |
473 | Let’s read through the flow of our architecture that we will be coding:
474 |
475 | 1. Input tokens are converted to embeddings and combined with position information.
476 |
477 | 2. The model has 64 identical transformer blocks that process data sequentially.
478 |
479 | 3. Each block first runs multi-head attention to look at relationships between tokens.
480 |
481 | 4. Each block then processes data through an MLP that expands and then compresses the data.
482 |
483 | 5. Each step uses residual connections (shortcuts) to help information flow.
484 |
485 | 6. Layer normalization is used throughout to stabilize training.
486 |
487 | 7. The attention mechanism calculates which tokens should pay attention to each other.
488 |
489 | 8. The MLP expands the data to 4x size, applies ReLU, and then compresses it back down.
490 |
491 | 9. The model uses 16 attention heads to capture different types of relationships.
492 |
493 | 10. The final layer converts the processed data into vocabulary-sized predictions.
494 |
495 | 11. The model generates text by repeatedly predicting the next most likely token.
496 |
497 | ### Multi Layer Perceptron (MLP)
498 |
499 | MLP is a fundamental building block within the transformer’s feed-forward network. Its role is to introduce non-linearity and learn complex relationships within the embedded representations. When defining an MLP module, an important parameter is n_embed, which defines the dimensionality of the input embedding.
500 |
501 | The MLP typically consists of a hidden linear layer that expands the input dimension by a factor (often 4, which we will use), followed by a non-linear activation function, commonly ReLU. This structure allows our network to learn more complex features. Finally, a projection linear layer maps the expanded representation back to the original embedding dimension. This sequence of transformations enables the MLP to refine the representations learned by the attention mechanism.
502 |
503 | ](https://cdn-images-1.medium.com/max/4866/1*GXxiLMW4kUXqOEimBA7g0A.png)
504 |
505 | ```python
506 | # --- MLP (Multi-Layer Perceptron) Class ---
507 |
508 | class MLP(nn.Module):
509 | """
510 | A simple Multi-Layer Perceptron with one hidden layer.
511 |
512 | This module is used within the Transformer block for feed-forward processing.
513 | It expands the input embedding size, applies a ReLU activation, and then projects it back
514 | to the original embedding size.
515 | """
516 | def __init__(self, n_embed):
517 | super().__init__()
518 | self.hidden = nn.Linear(n_embed, 4 * n_embed) # Linear layer to expand embedding size
519 | self.relu = nn.ReLU() # ReLU activation function
520 | self.proj = nn.Linear(4 * n_embed, n_embed) # Linear layer to project back to original size
521 |
522 | def forward(self, x):
523 | """
524 | Forward pass through the MLP.
525 |
526 | Args:
527 | x (torch.Tensor): Input tensor of shape (B, T, C), where B is batch size,
528 | T is sequence length, and C is embedding size.
529 |
530 | Returns:
531 | torch.Tensor: Output tensor of the same shape as the input.
532 | """
533 | x = self.forward_embedding(x)
534 | x = self.project_embedding(x)
535 | return x
536 |
537 | def forward_embedding(self, x):
538 | """
539 | Applies the hidden linear layer followed by ReLU activation.
540 |
541 | Args:
542 | x (torch.Tensor): Input tensor.
543 |
544 | Returns:
545 | torch.Tensor: Output after the hidden layer and ReLU.
546 | """
547 | x = self.relu(self.hidden(x))
548 | return x
549 |
550 | def project_embedding(self, x):
551 | """
552 | Applies the projection linear layer.
553 |
554 | Args:
555 | x (torch.Tensor): Input tensor.
556 |
557 | Returns:
558 | torch.Tensor: Output after the projection layer.
559 | """
560 | x = self.proj(x)
561 | return x
562 | ```
563 |
564 | We just coded our MLP part, where the __init__ method initializes a hidden linear layer that expands the input embedding size (n_embed) and a projection layer that reduces it back. ReLU activation is applied after the hidden layer. The forward method defines the data flow through these layers, applying the hidden layer and ReLU via forward_embedding, and the projection layer via project_embedding.
565 |
566 | ### Single Head Attention
567 |
568 | The attention head is the core part of our model. Its purpose is to focus on relevant parts of the input sequence. When defining a Head module, some important parameters are head_size, n_embed, and context_length. The head_size parameter determines the dimensionality of the key, query, and value projections, influencing the representational capacity of the attention mechanism.
569 |
570 | The input embedding dimension n_embed defines the size of the input to these projection layers. context_length is used to create a causal mask, ensuring that the model only attends to preceding tokens.
571 |
572 | Within the Head, linear layers (nn.Linear) for key, query, and value are initialized without bias. A lower triangular matrix (tril) of size context_length x context_length is registered as a buffer to implement causal masking, preventing the attention mechanism from attending to future tokens.
573 |
574 | ](https://cdn-images-1.medium.com/max/5470/1*teNwEhicq9ebVURiMS8WkA.png)
575 |
576 | ```python
577 | # --- Attention Head Class ---
578 |
579 | class Head(nn.Module):
580 | """
581 | A single attention head.
582 |
583 | This module calculates attention scores and applies them to the values.
584 | It includes key, query, and value projections, and uses causal masking
585 | to prevent attending to future tokens.
586 | """
587 | def __init__(self, head_size, n_embed, context_length):
588 | super().__init__()
589 | self.key = nn.Linear(n_embed, head_size, bias=False) # Key projection
590 | self.query = nn.Linear(n_embed, head_size, bias=False) # Query projection
591 | self.value = nn.Linear(n_embed, head_size, bias=False) # Value projection
592 | # Lower triangular matrix for causal masking
593 | self.register_buffer('tril', torch.tril(torch.ones(context_length, context_length)))
594 |
595 | def forward(self, x):
596 | """
597 | Forward pass through the attention head.
598 |
599 | Args:
600 | x (torch.Tensor): Input tensor of shape (B, T, C).
601 |
602 | Returns:
603 | torch.Tensor: Output tensor after applying attention.
604 | """
605 | B, T, C = x.shape
606 | k = self.key(x) # (B, T, head_size)
607 | q = self.query(x) # (B, T, head_size)
608 | scale_factor = 1 / math.sqrt(C)
609 | # Calculate attention weights: (B, T, head_size) @ (B, head_size, T) -> (B, T, T)
610 | attn_weights = q @ k.transpose(-2, -1) * scale_factor
611 | # Apply causal masking
612 | attn_weights = attn_weights.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
613 | attn_weights = F.softmax(attn_weights, dim=-1)
614 | v = self.value(x) # (B, T, head_size)
615 | # Apply attention weights to values
616 | out = attn_weights @ v # (B, T, T) @ (B, T, head_size) -> (B, T, head_size)
617 | return out
618 | ```
619 |
620 | Our attention head class’s __init__ method initializes linear layers for key, query, and value projections, each projecting the input embedding (n_embed) to head_size. A lower triangular matrix based on context_length is used for causal masking. The forward method calculates attention weights by scaling the dot product of the query and key, applies the causal mask, normalizes the weights using softmax, and computes the weighted sum of the values to produce the attention output.
621 |
622 | ### Multi Head Attention
623 |
624 | To capture diverse relationships within the input sequence, we are going to use the concept of multi-head attention. The MultiHeadAttention module manages multiple independent attention heads operating in parallel.
625 |
626 | The key parameter here is n_head, which determines the number of parallel attention heads. The input embedding dimension (n_embed) and context_length are also necessary to instantiate the individual attention heads. Each head processes the input independently, projecting it into a lower-dimensional subspace of size n_embed // n_head. By having multiple heads, the model can attend to different aspects of the input simultaneously.
627 |
628 | ](https://cdn-images-1.medium.com/max/6864/1*fa-YjrZdtbpuCLp7An99dg.png)
629 |
630 | ```python
631 | # --- Multi-Head Attention Class ---
632 |
633 | class MultiHeadAttention(nn.Module):
634 | """
635 | Multi-Head Attention module.
636 |
637 | This module combines multiple attention heads in parallel. The outputs of each head
638 | are concatenated to form the final output.
639 | """
640 | def __init__(self, n_head, n_embed, context_length):
641 | super().__init__()
642 | self.heads = nn.ModuleList([Head(n_embed // n_head, n_embed, context_length) for _ in range(n_head)])
643 |
644 | def forward(self, x):
645 | """
646 | Forward pass through the multi-head attention.
647 |
648 | Args:
649 | x (torch.Tensor): Input tensor of shape (B, T, C).
650 |
651 | Returns:
652 | torch.Tensor: Output tensor after concatenating the outputs of all heads.
653 | """
654 | # Concatenate the output of each head along the last dimension (C)
655 | x = torch.cat([h(x) for h in self.heads], dim=-1)
656 | return x
657 | ```
658 |
659 | Now that we have defined the MultiHeadAttention class, which combines multiple attention heads, the __init__ method initializes a list of Head instances (a total of n_head), each with a head_size of n_embed // n_head. The forward method applies each attention head to the input x and concatenates their outputs along the last dimension, merging the information learned by each head.
660 |
661 | ### Transformer Block
662 |
663 | To create a billion-parameter model, we definitely need a deep architecture. For that, we need to code a transformer block and stack them. The key parameters of a block are n_head, n_embed, and context_length. Each block comprises a multi-head attention layer and a feed-forward network (MLP), with layer normalization applied before each and residual connections after each.
664 |
665 | Layer normalization, parameterized by the embedding dimension n_embed, helps stabilize training. The multi-head attention mechanism, as described before, takes n_head, n_embed, and context_length. The MLP also utilizes the embedding dimension n_embed. These components work together to process the input and learn complex patterns.
666 |
667 | ](https://cdn-images-1.medium.com/max/6942/1*uLWGajZc6StnQHfZjcb6eA.png)
668 |
669 | ```python
670 | # --- Transformer Block Class ---
671 |
672 | class Block(nn.Module):
673 | """
674 | A single Transformer block.
675 |
676 | This block consists of a multi-head attention layer followed by an MLP,
677 | with layer normalization and residual connections.
678 | """
679 | def __init__(self, n_head, n_embed, context_length):
680 | super().__init__()
681 | self.ln1 = nn.LayerNorm(n_embed)
682 | self.attn = MultiHeadAttention(n_head, n_embed, context_length)
683 | self.ln2 = nn.LayerNorm(n_embed)
684 | self.mlp = MLP(n_embed)
685 |
686 | def forward(self, x):
687 | """
688 | Forward pass through the Transformer block.
689 |
690 | Args:
691 | x (torch.Tensor): Input tensor.
692 |
693 | Returns:
694 | torch.Tensor: Output tensor after the block.
695 | """
696 | # Apply multi-head attention with residual connection
697 | x = x + self.attn(self.ln1(x))
698 | # Apply MLP with residual connection
699 | x = x + self.mlp(self.ln2(x))
700 | return x
701 |
702 | def forward_embedding(self, x):
703 | """
704 | Forward pass focusing on the embedding and attention parts.
705 |
706 | Args:
707 | x (torch.Tensor): Input tensor.
708 |
709 | Returns:
710 | tuple: A tuple containing the output after MLP embedding and the residual.
711 | """
712 | res = x + self.attn(self.ln1(x))
713 | x = self.mlp.forward_embedding(self.ln2(res))
714 | return x, res
715 | ```
716 |
717 | Our Block class represents a single transformer block. The __init__ method initializes layer normalization layers (ln1, ln2), a MultiHeadAttention module, and an MLP module, all parameterized by n_head, n_embed, and context_length.
718 |
719 | The forward method implements the block's forward pass, applying layer normalization and multi-head attention with a residual connection, followed by another layer normalization and the MLP, again with a residual connection. The forward_embedding method provides an alternative forward pass focused on the attention and initial MLP embedding stages.
720 |
721 | ### The Final Model
722 |
723 | So far, we have coded small components of the transformer model. Next, we integrate token and position embeddings with a series of transformer blocks to perform sequence-to-sequence tasks. To do that, we need to code several key parameters: n_head, n_embed, context_length, vocab_size, and N_BLOCKS.
724 |
725 | vocab_size determines the size of the token embedding layer, mapping each token to a dense vector of size n_embed. The context_length parameter is important for the position embedding layer, which encodes the position of each token in the input sequence, also with dimension n_embed. The number of attention heads (n_head) and the number of blocks (N_BLOCKS) dictate the depth and complexity of the network.
726 |
727 | These parameters collectively define the architecture and capacity of the transformer model, so let’s code it.
728 |
729 | ](https://cdn-images-1.medium.com/max/5418/1*0XXd_R2EOhkKCQDfqUQg0w.png)
730 |
731 | ```python
732 | # --- Transformer Model Class ---
733 |
734 | class Transformer(nn.Module):
735 | """
736 | The main Transformer model.
737 |
738 | This class combines token and position embeddings with a sequence of Transformer blocks
739 | and a final linear layer for language modeling.
740 | """
741 | def __init__(self, n_head, n_embed, context_length, vocab_size, N_BLOCKS):
742 | super().__init__()
743 | self.context_length = context_length
744 | self.N_BLOCKS = N_BLOCKS
745 | self.token_embed = nn.Embedding(vocab_size, n_embed)
746 | self.position_embed = nn.Embedding(context_length, n_embed)
747 | self.attn_blocks = nn.ModuleList([Block(n_head, n_embed, context_length) for _ in range(N_BLOCKS)])
748 | self.layer_norm = nn.LayerNorm(n_embed)
749 | self.lm_head = nn.Linear(n_embed, vocab_size)
750 | self.register_buffer('pos_idxs', torch.arange(context_length))
751 |
752 | def _pre_attn_pass(self, idx):
753 | """
754 | Combines token and position embeddings.
755 |
756 | Args:
757 | idx (torch.Tensor): Input token indices.
758 |
759 | Returns:
760 | torch.Tensor: Sum of token and position embeddings.
761 | """
762 | B, T = idx.shape
763 | tok_embedding = self.token_embed(idx)
764 | pos_embedding = self.position_embed(self.pos_idxs[:T])
765 | return tok_embedding + pos_embedding
766 |
767 | def forward(self, idx, targets=None):
768 | """
769 | Forward pass through the Transformer.
770 |
771 | Args:
772 | idx (torch.Tensor): Input token indices.
773 | targets (torch.Tensor, optional): Target token indices for loss calculation. Defaults to None.
774 |
775 | Returns:
776 | tuple: Logits and loss (if targets are provided).
777 | """
778 | x = self._pre_attn_pass(idx)
779 | for block in self.attn_blocks:
780 | x = block(x)
781 | x = self.layer_norm(x)
782 | logits = self.lm_head(x)
783 | loss = None
784 | if targets is not None:
785 | B, T, C = logits.shape
786 | flat_logits = logits.view(B * T, C)
787 | targets = targets.view(B * T).long()
788 | loss = F.cross_entropy(flat_logits, targets)
789 | return logits, loss
790 |
791 | def forward_embedding(self, idx):
792 | """
793 | Forward pass focusing on the embedding and attention blocks.
794 |
795 | Args:
796 | idx (torch.Tensor): Input token indices.
797 |
798 | Returns:
799 | tuple: Output after attention blocks and the residual.
800 | """
801 | x = self._pre_attn_pass(idx)
802 | residual = x
803 | for block in self.attn_blocks:
804 | x, residual = block.forward_embedding(x)
805 | return x, residual
806 |
807 | def generate(self, idx, max_new_tokens):
808 | """
809 | Generates new tokens given a starting sequence.
810 |
811 | Args:
812 | idx (torch.Tensor): Initial sequence of token indices.
813 | max_new_tokens (int): Number of tokens to generate.
814 |
815 | Returns:
816 | torch.Tensor: The extended sequence of tokens.
817 | """
818 | for _ in range(max_new_tokens):
819 | idx_cond = idx[:, -self.context_length:]
820 | logits, _ = self(idx_cond)
821 | logits = logits[:, -1, :]
822 | probs = F.softmax(logits, dim=-1)
823 | idx_next = torch.multinomial(probs, num_samples=1)
824 | idx = torch.cat((idx, idx_next), dim=1)
825 | return idx
826 | ```
827 |
828 | Our Transformer class `__init__` method initializes token and position embedding layers (token_embed, position_embed), a sequence of Block modules (attn_blocks), a final layer normalization layer (layer_norm), and a linear layer for language modeling (lm_head).
829 |
830 | The _pre_attn_pass method combines token and position embeddings. The forward method processes the input sequence through the embedding layers and the series of transformer blocks, applies final layer normalization, and generates logits. It also calculates the loss if targets are provided. The forward_embedding method provides an intermediate forward pass up to the output of the attention blocks, and the generate method implements token generation.
831 |
832 | ### Batch Processing
833 |
834 | When we train a deep learning model on big data, we process it in batches due to GPU availability. So, let’s create a get_batch_iterator function, taking the data_path to an HDF5 file, the desired batch_size, the context_length for each sequence, and the device to load the data onto.
835 |
836 | The batch_size determines how many sequences are processed in parallel during training, while the context_length specifies the length of each input sequence. The data_path points to the location of the training data.
837 |
838 | ```python
839 | # --- Data Loading Utility ---
840 |
841 | def get_batch_iterator(data_path, batch_size, context_length, device="gpu"):
842 | """
843 | Creates an iterator for generating batches of data from an HDF5 file.
844 |
845 | Args:
846 | data_path (str): Path to the HDF5 file containing tokenized data.
847 | batch_size (int): Number of sequences in each batch.
848 | context_length (int): Length of each sequence.
849 | device (str, optional): Device to load the data onto ('cpu' or 'cuda'). Defaults to "cpu".
850 |
851 | Yields:
852 | tuple: A tuple containing input sequences (xb) and target sequences (yb).
853 | """
854 | # Open the HDF5 file in read mode
855 | with h5py.File(data_path, 'r') as hdf5_file:
856 |
857 | # Extract the dataset of tokenized sequences
858 | dataset = hdf5_file['tokens']
859 |
860 | # Get the total size of the dataset
861 | dataset_size = dataset.shape[0]
862 |
863 | # Calculate the number of examples (sequences) that can be made from the data
864 | n_examples = (dataset_size - 1) // context_length
865 |
866 | # Create an array of indices for examples and shuffle them for randomness
867 | example_idxs = np.arange(n_examples)
868 | np.random.shuffle(example_idxs)
869 |
870 | # Initialize epoch counter and example counter
871 | epochs = 0
872 | counter = 0
873 |
874 | while True:
875 | # Check if the current batch exceeds the number of available examples
876 | if counter + batch_size > n_examples:
877 | # Shuffle the indices again and reset the counter to 0
878 | np.random.shuffle(example_idxs)
879 | counter = 0
880 | print(f"Finished epoch {epochs}") # Print epoch number when an epoch finishes
881 | epochs += 1 # Increment the epoch counter
882 |
883 | # Select a batch of random indices to generate sequences
884 | random_indices = example_idxs[counter:counter+batch_size] * context_length
885 |
886 | # Retrieve sequences from the dataset based on the random indices
887 | random_samples = torch.tensor(np.array([dataset[idx:idx+context_length+1] for idx in random_indices]))
888 |
889 | # Separate the input sequences (xb) and target sequences (yb)
890 | xb = random_samples[:, :context_length].to(device) # Input sequence (first half of the random sample)
891 | yb = random_samples[:, 1:context_length+1].to(device) # Target sequence (second half of the random sample)
892 |
893 | # Increment the counter to move to the next batch
894 | counter += batch_size
895 |
896 | # Yield the input and target sequences as a tuple for the current batch
897 | yield xb, yb
898 | ```
899 | Our get_batch_iterator function handles the loading and batching of training data. It takes data_path, batch_size, context_length, and device as input. The function opens the HDF5 file, shuffles the data, and then enters an infinite loop to generate batches. In each iteration, it selects a random subset of the data to form a batch of input sequences (xb) and their corresponding target sequences (yb).
900 |
901 | ### Training Parameters
902 |
903 | Now that we have coded our model, we need to define the training parameters, such as the number of heads, blocks, and more, along with the data path.
904 |
905 | ```python
906 | # --- Configuration ---
907 |
908 | # Define vocabulary size and transformer configuration
909 | VOCAB_SIZE = 50304 # Number of unique tokens in the vocabulary
910 | CONTEXT_LENGTH = 512 # Maximum sequence length for the model
911 | N_EMBED = 2048 # Dimension of the embedding space
912 | N_HEAD = 16 # Number of attention heads in each transformer block
913 | N_BLOCKS = 64 # Number of transformer blocks in the model
914 |
915 | # Paths to training and development datasets
916 | TRAIN_PATH = "data/train/pile_val.h5" # File path for the training dataset
917 | DEV_PATH = "data/val/pile_val.h5" # File path for the validation dataset
918 |
919 | # Transformer training parameters
920 | T_BATCH_SIZE = 32 # Number of samples per training batch
921 | T_CONTEXT_LENGTH = 16 # Context length for training batches
922 | T_TRAIN_STEPS = 200000 # Total number of training steps
923 | T_EVAL_STEPS = 1000 # Frequency (in steps) to perform evaluation
924 | T_EVAL_ITERS = 250 # Number of iterations to evaluate the model
925 | T_LR_DECAY_STEP = 50000 # Step at which to decay the learning rate
926 | T_LR = 5e-4 # Initial learning rate for training
927 | T_LR_DECAYED = 5e-5 # Learning rate after decay
928 | T_OUT_PATH = "models/transformer_B.pt" # Path to save the trained model
929 |
930 | # Device configuration
931 | DEVICE = 'cuda'
932 |
933 | # Store all configurations in a dictionary for easy access and modification
934 | default_config = {
935 | 'vocab_size': VOCAB_SIZE,
936 | 'context_length': CONTEXT_LENGTH,
937 | 'n_embed': N_EMBED,
938 | 'n_head': N_HEAD,
939 | 'n_blocks': N_BLOCKS,
940 | 'train_path': TRAIN_PATH,
941 | 'dev_path': DEV_PATH,
942 | 't_batch_size': T_BATCH_SIZE,
943 | 't_context_length': T_CONTEXT_LENGTH,
944 | 't_train_steps': T_TRAIN_STEPS,
945 | 't_eval_steps': T_EVAL_STEPS,
946 | 't_eval_iters': T_EVAL_ITERS,
947 | 't_lr_decay_step': T_LR_DECAY_STEP,
948 | 't_lr': T_LR,
949 | 't_lr_decayed': T_LR_DECAYED,
950 | 't_out_path': T_OUT_PATH,
951 | 'device': DEVICE,
952 | }
953 | ```
954 |
955 | For most of the parameters, I have used the most common values and also stored them in a dictionary for easy access. Here, the parameters are for a billion-parameter model. If you want to train a model with millions of parameters, you can reduce the main parameters, which include CONTEXT_LENGTH, N_EMBED, N_HEAD, and N_BLOCKS. However, you can also run the million-parameter model script in my GitHub repository.
956 |
957 | ### Training the Model
958 |
959 | Let's initialize our transformer model and check its total number of parameters.
960 | ```python
961 | # --- Initialize the Model and Print Parameters ---
962 |
963 | model = Transformer(
964 | n_head=config['n_head'],
965 | n_embed=config['n_embed'],
966 | context_length=config['context_length'],
967 | vocab_size=config['vocab_size'],
968 | N_BLOCKS=config['n_blocks']
969 | ).to(config['device'])
970 |
971 |
972 | # Print the total number of parameters
973 | total_params = sum(p.numel() for p in model.parameters())
974 | print(f"Total number of parameters in the model: {total_params:,}")
975 |
976 |
977 | #### OUTPUT ####
978 | 2,141,346,251
979 | ```
980 |
981 | Now that we have 2 Billion parameter model, we need to define our Adam optimizer and loss tracking function, which will help us track the progress of our model throughout the training.
982 |
983 | ```python
984 | # --- Optimizer Setup and Loss Tracking ---
985 |
986 | # Set up the AdamW optimizer with the specified learning rate.
987 | optimizer = torch.optim.AdamW(model.parameters(), lr=config['t_lr'])
988 |
989 | # List to track loss values during training.
990 | losses = []
991 |
992 | # Define a window size for averaging recent losses in the training loop.
993 | AVG_WINDOW = 64
994 |
995 | # Helper function to estimate the average loss for training and development data.
996 | @torch.no_grad()
997 | def estimate_loss(steps):
998 | """
999 | Evaluate the model on training and development datasets and calculate average loss.
1000 |
1001 | Args:
1002 | steps (int): Number of steps to evaluate.
1003 |
1004 | Returns:
1005 | dict: Dictionary containing average losses for 'train' and 'dev' splits.
1006 | """
1007 | out = {}
1008 | model.eval() # Set the model to evaluation mode.
1009 |
1010 | for split in ['train', 'dev']:
1011 | # Select the appropriate data path for the current split.
1012 | data_path = config['train_path'] if split == 'train' else config['dev_path']
1013 |
1014 | # Create a batch iterator for evaluation.
1015 | batch_iterator_eval = get_batch_iterator(
1016 | data_path, config['t_batch_size'], config['t_context_length'], device=config['device']
1017 | )
1018 |
1019 | # Initialize a tensor to track loss values for each evaluation step.
1020 | losses_eval = torch.zeros(steps)
1021 | for k in range(steps):
1022 | try:
1023 | # Fetch a batch and calculate the loss.
1024 | xb, yb = next(batch_iterator_eval)
1025 | _, loss = model(xb, yb)
1026 | losses_eval[k] = loss.item()
1027 | except StopIteration:
1028 | # Handle the case where the data iterator ends early.
1029 | print(f"Warning: Iterator for {split} ended early.")
1030 | break
1031 |
1032 | # Compute the mean loss for the current split.
1033 | out[split] = losses_eval[:k + 1].mean()
1034 |
1035 | model.train() # Restore the model to training mode.
1036 | return out
1037 | ```
1038 |
1039 | We will now initialize our batch processing function and training loop, which will start our training.
1040 |
1041 | ```python
1042 | # --- Training Loop ---
1043 |
1044 | # Create a batch iterator for the training data.
1045 | batch_iterator = get_batch_iterator(
1046 | config['train_path'],
1047 | config['t_batch_size'],
1048 | config['t_context_length'],
1049 | device=config['device']
1050 | )
1051 |
1052 | # Create a progress bar to monitor training progress.
1053 | pbar = tqdm(range(config['t_train_steps']))
1054 | for step in pbar:
1055 | try:
1056 | # Fetch a batch of input and target data.
1057 | xb, yb = next(batch_iterator)
1058 |
1059 | # Perform a forward pass and compute the loss.
1060 | _, loss = model(xb, yb)
1061 |
1062 | # Record the loss for tracking.
1063 | losses.append(loss.item())
1064 | pbar.set_description(f"Train loss: {np.mean(losses[-AVG_WINDOW:]):.4f}")
1065 |
1066 | # Backpropagate the loss and update the model parameters.
1067 | optimizer.zero_grad(set_to_none=True)
1068 | loss.backward()
1069 | optimizer.step()
1070 |
1071 | # Periodically evaluate the model on training and development data.
1072 | if step % config['t_eval_steps'] == 0:
1073 | train_loss, dev_loss = estimate_loss(config['t_eval_iters']).values()
1074 | print(f"Step: {step}, Train loss: {train_loss:.4f}, Dev loss: {dev_loss:.4f}")
1075 |
1076 | # Decay the learning rate at the specified step.
1077 | if step == config['t_lr_decay_step']:
1078 | print('Decaying learning rate')
1079 | for g in optimizer.param_groups:
1080 | g['lr'] = config['t_lr_decayed']
1081 | except StopIteration:
1082 | # Handle the case where the training data iterator ends early.
1083 | print("Training data iterator finished early.")
1084 | break
1085 | ```
1086 | ### Saving the Trained Model
1087 |
1088 | Since our training loop has the ability to handle errors, in case the loop throws any error, it will save our partially trained model to avoid loss. Once the training is complete, we can save our trained model to use it later for inference.
1089 |
1090 | ```python
1091 | # --- Save Model and Final Evaluation ---
1092 |
1093 | # Perform a final evaluation of the model on training and development datasets.
1094 | train_loss, dev_loss = estimate_loss(200).values()
1095 |
1096 | # Ensure unique model save path in case the file already exists.
1097 | modified_model_out_path = config['t_out_path']
1098 | save_tries = 0
1099 | while os.path.exists(modified_model_out_path):
1100 | save_tries += 1
1101 | model_out_name = os.path.splitext(config['t_out_path'])[0]
1102 | modified_model_out_path = model_out_name + f"_{save_tries}" + ".pt"
1103 |
1104 | # Save the model's state dictionary, optimizer state, and training metadata.
1105 | torch.save(
1106 | {
1107 | 'model_state_dict': model.state_dict(),
1108 | 'optimizer_state_dict': optimizer.state_dict(),
1109 | 'losses': losses,
1110 | 'train_loss': train_loss,
1111 | 'dev_loss': dev_loss,
1112 | 'steps': len(losses),
1113 | },
1114 | modified_model_out_path
1115 | )
1116 | print(f"Saved model to {modified_model_out_path}")
1117 | print(f"Finished training. Train loss: {train_loss:.4f}, Dev loss: {dev_loss:.4f}")
1118 | ```
1119 | The final training loss for the billion-parameter model is 0.2314, and the dev loss is 0.643.
1120 |
1121 | ### Training Loss
1122 |
1123 | When I plot the loss of both the million- and billion-parameter models, they look very different.
1124 |
1125 | 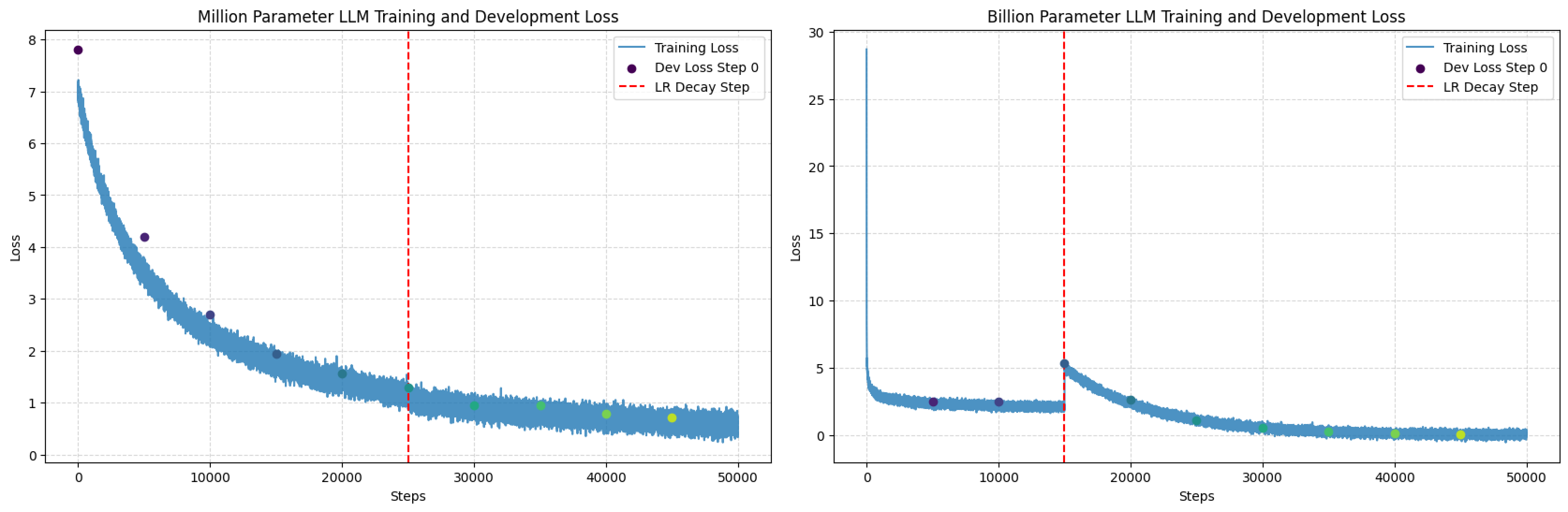
1126 |
1127 | The billion-parameter model starts with a much higher loss and fluctuates a lot at the beginning. It goes down quickly at first, but then wobbles before becoming smoother. This shows that the bigger model has a harder time finding the right way to learn at the start. It might need more data and careful settings. When the learning rate is lowered (the red line), the loss goes down more steadily, showing that this helps it fine-tune.
1128 |
1129 | The million-parameter model’s loss goes down more easily from the start. It doesn’t fluctuate as much as the bigger model. When the learning rate is lowered, it doesn’t change the curve as much. This is likely because the smaller model is simpler to train and finds a good solution faster. The big difference shows how much harder it is to train very large models. They need different methods and maybe more time to learn well.
1130 |
1131 | We now have our saved model. We can finally use it for inference and see how it generates text. 😓
1132 |
1133 | ### Generating Text
1134 |
1135 | Let’s create a function to generate text from our saved model, which takes the saved model path and the encoder as inputs and returns the generated text.
1136 |
1137 | ```python
1138 | def generate_text(model_path, input_text, max_length=512, device="gpu"):
1139 | """
1140 | Generate text using a pre-trained model based on the given input text.
1141 |
1142 | Args:
1143 | - model_path (str): Path to the model checkpoint.
1144 | - device (torch.device): Device to load the model on (e.g., 'cpu' or 'cuda').
1145 | - input_text (str): The input text to seed the generation.
1146 | - max_length (int, optional): Maximum length of generated text. Defaults to 512.
1147 |
1148 | Returns:
1149 | - str: The generated text.
1150 | """
1151 |
1152 | # Load the model checkpoint
1153 | checkpoint = torch.load(model_path)
1154 |
1155 | # Initialize the model (you should ensure that the Transformer class is defined elsewhere)
1156 | model = Transformer().to(device)
1157 |
1158 | # Load the model's state dictionary
1159 | model.load_state_dict(checkpoint['model_state_dict'])
1160 |
1161 | # Load the tokenizer for the GPT model (we use 'r50k_base' for GPT models)
1162 | enc = tiktoken.get_encoding('r50k_base')
1163 |
1164 | # Encode the input text along with the end-of-text token
1165 | input_ids = torch.tensor(
1166 | enc.encode(input_text, allowed_special={'<|endoftext|>'}),
1167 | dtype=torch.long
1168 | )[None, :].to(device) # Add batch dimension and move to the specified device
1169 |
1170 | # Generate text with the model using the encoded input
1171 | with torch.no_grad():
1172 | # Generate up to 'max_length' tokens of text
1173 | generated_output = model.generate(input_ids, max_length)
1174 |
1175 | # Decode the generated tokens back into text
1176 | generated_text = enc.decode(generated_output[0].tolist())
1177 |
1178 | return generated_text
1179 | ```
1180 |
1181 | The transformer we defined earlier needs to be called here to load the architecture, and then we load the saved model as the state in that architecture.
1182 |
1183 | Let’s first observe what both the million and billion-parameter models generate without providing any input, and see what they generate randomly.
1184 |
1185 | ```python
1186 | # Defining the file paths for the pre-trained models
1187 | Billion_model_path = 'models/transformer_B.pt' # Path to the Billion model
1188 | Million_model_path = 'models/transformer_M.pt' # Path to the Million model
1189 |
1190 | # Using '<|endoftext|>' as input to the models (acts as a prompt that allows the models to generate text freely)
1191 | input_text = "<|endoftext|>"
1192 |
1193 | # Call the function to generate text based on the input text using the Billion model
1194 | B_output = generate_text(Billion_model_path, input_text)
1195 |
1196 | # Call the function to generate text based on the input text using the Million model
1197 | M_output = generate_text(Million_model_path, input_text)
1198 |
1199 | # Print the output generated by both models
1200 | print(B_output) # Output from the Billion model
1201 | print(M_output) # Output from the Million model
1202 | ```
1203 |
1204 | | **Million Parameter Output** | **Billion Parameter Output** |
1205 | |------------------------------|------------------------------|
1206 | | In 1978, The park was returned to the factory-plate that the public share to the lower of the electronic fence that follow from the Station's cities. The Canal of ancient Western nations were confined to the city spot. The villages were directly linked to cities in China that revolt that the US budget and in Odambinais is uncertain and fortune established in rural areas. | There are two miles east coast from 1037 and 73 million refugees (hypotetus) as the same men and defeated Harvard, and Croft. At right east and West Nile's Mediterranean Sea jets. It was found there a number of parties, blacksmith, musician and boutique hospitality and inspire the strain delivered Canadians have already killed, rural branches with coalition railholder against Abyssy. |
1207 |
1208 |
1209 | Both LLMs are able to generate clear and accurate words when the context is short and simple. For example, in the million-parameter output, the phrase **“The villages were directly linked to cities in China”** makes sense and conveys a clear idea. It is easy to understand and logically connects the villages to the cities.
1210 |
1211 | However, when the context becomes longer and more complex, the clarity begins to fade. In the billion-parameter output, sentences like **“There are two miles east coast from 1037 and 73 million refugees (hypotetus)”** and **“blacksmith, musician and boutique hospitality and inspire the strain delivered Canadians”** become harder to follow. The ideas seem disjointed, and the sentence structure doesn’t flow naturally. While the words used might still be correct, the overall meaning becomes confusing and unclear.
1212 |
1213 | The positive point is that the 13+ million-parameter LLM also starts generating some kind of meaningful content with correct word spelling. For instance, when I use the subject input text, it starts generating an email for me. Although, obviously, broader text doesn’t provide meaningful results, take a look at the output:
1214 |
1215 | ```python
1216 | # Input text
1217 | input_text "Subject: "
1218 |
1219 | # Call the Million parameter Mod
1220 | m_output = generate_text(Million_model_path, input_text)
1221 |
1222 | print(m_output) # Output from the Million model
1223 | ```
1224 | | **Million Parameter LLM Output** |
1225 | |--------------------------------------------------------------------------------------------------|
1226 | | Subject: ClickPaper-summary Study for Interview
Good morning, I hope this message finds you well, as the sun gently peeks through the clouds, ... |
1227 |
1228 | Our million parameter model gives us the motivation that we can have a very narrow, goal-oriented LLM under 1B in size, while our 1B trained model shows us that the architecture needs to be coded in great depth with proper consideration. Otherwise, it won’t improve training or performance compared to the million-parameter model. It will just overfit the data unless you have a deep architecture for the billion-sized model.
1229 |
1230 | # What’s Next
1231 |
1232 | I recommend that you create the 13+ million-parameter model and then start scaling it by adding the next 100 parameters, improving its ability to handle shorter contexts. It’s up to you how many more parameters you want to train for specific tasks. Then, for the remaining parameters under 1B, try fine-tuning the model on domain-specific data, such as writing emails or essays, and see how it generates the text.
1233 |
1234 |
1235 |
1236 | Wanna chat on something? [My Linkedin](https://www.linkedin.com/in/fareed-khan-dev/)
1237 |
1238 | ## Star History
1239 |
1240 | [](https://star-history.com/#FareedKhan-dev/train-llm-from-scratch&Date)
1241 |
--------------------------------------------------------------------------------