├── graph
├── test_cat.tsv
├── .DS_Store
└── test.tsv
├── overview.png
├── emb
├── .DS_Store
├── test_emb.txt
└── test_emb_ind.txt
├── src
├── .DS_Store
├── latent_summary.pkl
├── util.py
├── main_inductive.py
└── main.py
└── README.md
/graph/test_cat.tsv:
--------------------------------------------------------------------------------
1 | 0 0 4
2 | 1 5 6
3 | 2 7 8
4 |
--------------------------------------------------------------------------------
/overview.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GemsLab/MultiLENS/HEAD/overview.png
--------------------------------------------------------------------------------
/emb/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GemsLab/MultiLENS/HEAD/emb/.DS_Store
--------------------------------------------------------------------------------
/graph/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GemsLab/MultiLENS/HEAD/graph/.DS_Store
--------------------------------------------------------------------------------
/src/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GemsLab/MultiLENS/HEAD/src/.DS_Store
--------------------------------------------------------------------------------
/src/latent_summary.pkl:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GemsLab/MultiLENS/HEAD/src/latent_summary.pkl
--------------------------------------------------------------------------------
/graph/test.tsv:
--------------------------------------------------------------------------------
1 | 0 2 1
2 | 1 0 1
3 | 1 2 5
4 | 1 5 1
5 | 2 8 5
6 | 3 0 5
7 | 3 4 1
8 | 3 6 1
9 | 4 0 1
10 | 4 3 1
11 | 4 7 5
12 | 7 0 1
13 |
--------------------------------------------------------------------------------
/src/util.py:
--------------------------------------------------------------------------------
1 | import numpy as np, networkx as nx
2 | import scipy.sparse
3 |
4 | class RepMethod():
5 | def __init__(self, bucket_max_value = None, method="hetero", num_buckets = None, use_other_features = False, operators = None,
6 | use_total = 0):
7 | self.method = method
8 | self.bucket_max_value = bucket_max_value
9 | self.num_buckets = num_buckets
10 | self.use_other_features = use_other_features
11 | self.operators = operators
12 | self.use_total = use_total
13 |
14 |
15 | class Graph():
16 | def __init__(self, adj_matrix = None, num_nodes = None, max_id = None, directed = False, neighbor_list = None,
17 | num_buckets = None, base_features = None, cat_dict = None, id_cat_dict = None, unique_cat = None, check_eq = True):
18 | # self.nx_graph = nx_graph
19 | self.adj_matrix = adj_matrix
20 | self.num_nodes = num_nodes
21 | self.max_id = max_id
22 | self.base_features = base_features
23 | self.unique_cat = unique_cat
24 | self.directed = directed
25 | self.num_buckets = num_buckets
26 |
27 | self. neighbor_list = neighbor_list
28 | self.cat_dict = cat_dict
29 | self.id_cat_dict = id_cat_dict
30 | self.check_eq = check_eq
31 |
32 |
33 | def get_delimiter(input_file_path):
34 | delimiter = " "
35 | if ".csv" in input_file_path:
36 | delimiter = ","
37 | elif ".tsv" in input_file_path:
38 | delimiter = "\t"
39 | else:
40 | sys.exit('Format not supported.')
41 |
42 | return delimiter
43 |
44 |
45 | def write_embedding(rep, output_file_path):
46 | N, K = rep.shape
47 |
48 | fOut = open(output_file_path, 'w')
49 | fOut.write(str(N) + ' ' + str(K) + '\n')
50 |
51 | for i in range(N):
52 | cur_line = ' '.join([str(np.round(ii, 6)) for ii in rep[i,:]])
53 | fOut.write(str(i) + ' ' + cur_line + '\n')
54 |
55 | fOut.close()
56 |
57 | return
58 |
59 |
60 | def read_embedding(input_file_path):
61 |
62 | fIn = open(input_file_path, 'r')
63 | N, K = fIn.readline().split(' ')
64 |
65 | rep = np.zeros((int(N), int(K)))
66 |
67 | for line in fIn.readlines():
68 | parts = line.strip().split(' ')
69 | rep[int(parts[0]),:] = [float(ele) for ele in parts[1:]]
70 |
71 |
72 | return rep
73 |
74 |
--------------------------------------------------------------------------------
/emb/test_emb.txt:
--------------------------------------------------------------------------------
1 | 9 26
2 | 0 1.850588 0.830303 -0.191896 -1.045115 0.505562 -0.200553 -0.050742 0.13008 3.053755 1.433569 -0.041825 -1.78883 -0.094202 0.089586 -0.459508 -0.309663 -0.11008 4.866181 2.22298 0.121998 0.05738 2.989983 -0.308342 -0.771511 -0.265161 0.491672
3 | 1 1.207391 -1.041898 0.126836 -0.047614 0.20108 0.967246 0.191076 0.189968 1.986099 -1.576634 -0.158664 0.161196 1.013833 1.562144 0.347487 -0.345401 0.01183 3.145423 -1.64266 -1.225175 -3.435987 -0.479035 1.606629 0.03074 -0.480261 0.1073
4 | 2 1.188927 0.931284 0.089476 -0.004928 -1.120979 0.403132 0.194414 -0.181278 1.91365 1.80887 0.097809 0.765877 1.351447 -0.421045 0.770864 0.39684 0.192125 2.953462 3.391384 0.03733 -1.149727 -1.662207 -1.414858 1.096449 0.322216 -0.792043
5 | 3 1.541783 -0.948771 -0.094118 0.014943 -0.073187 -0.172418 -0.618337 -0.337874 2.5019 -1.497652 -0.284534 0.18921 0.107144 -0.477646 -0.974225 0.808616 0.120295 3.988445 -2.647114 -0.410472 0.669848 -0.570027 -1.046523 -1.542457 1.035089 -0.694214
6 | 4 1.54687 -0.447575 0.671183 0.533284 -0.30057 -0.728973 0.295225 0.238886 2.489298 -0.986318 1.031641 0.670041 -0.66237 -1.136445 0.493327 -0.607405 -0.193471 3.963646 -2.033719 1.867637 1.288111 -1.023158 -0.773682 1.35929 -0.758336 0.823649
7 | 5 0.451265 -0.023006 -1.259903 0.367417 -0.008656 -0.075931 0.127082 0.042334 0.697913 0.189865 -2.03451 0.350973 -0.466462 0.054177 0.397503 0.197009 -0.853154 1.073465 0.53663 -3.199775 1.000627 -0.488686 0.578496 0.847164 1.107696 1.141338
8 | 6 0.451265 -0.023006 -1.259903 0.367417 -0.008656 -0.075931 0.127082 0.042334 0.675869 0.110825 -2.04555 0.352309 -0.615303 -0.199929 0.062071 -0.397289 0.804648 1.1152 0.10538 -2.937997 1.942738 -0.203464 0.380247 0.061913 -1.357843 -0.927939
9 | 7 0.74425 0.536652 0.348272 0.632578 0.905468 0.09093 0.388578 -0.32813 1.21809 0.428394 0.820024 0.099353 -1.686427 0.981121 0.622814 0.55406 0.21437 1.977655 0.234332 1.678586 1.164126 0.527168 2.891226 0.903616 0.674615 -0.804256
10 | 8 0.424346 0.920717 0.189408 0.81788 0.15575 0.278821 -0.648462 0.242351 0.565392 1.353081 0.359149 1.64749 -0.239997 0.629258 -1.11555 -0.323173 -0.148373 0.848442 2.115553 0.914508 0.711768 -2.470263 1.300451 -1.864505 -0.332716 0.605318
11 |
--------------------------------------------------------------------------------
/emb/test_emb_ind.txt:
--------------------------------------------------------------------------------
1 | 9 26
2 | 0 1.850588 0.830303 -0.191896 -1.045115 0.505562 -0.200553 -0.050742 0.13008 3.053755 1.433569 -0.041825 -1.78883 -0.094202 0.089586 -0.459508 -0.309663 -0.11008 4.866181 2.22298 0.121998 0.05738 2.989983 -0.308342 -0.771511 -0.265161 0.491672
3 | 1 1.207391 -1.041898 0.126836 -0.047614 0.20108 0.967246 0.191076 0.189968 1.986099 -1.576634 -0.158664 0.161196 1.013833 1.562144 0.347487 -0.345401 0.01183 3.145423 -1.64266 -1.225175 -3.435987 -0.479035 1.606629 0.03074 -0.480261 0.1073
4 | 2 1.188927 0.931284 0.089476 -0.004928 -1.120979 0.403132 0.194414 -0.181278 1.91365 1.80887 0.097809 0.765877 1.351447 -0.421045 0.770864 0.39684 0.192125 2.953462 3.391384 0.03733 -1.149727 -1.662207 -1.414858 1.096449 0.322216 -0.792043
5 | 3 1.541783 -0.948771 -0.094118 0.014943 -0.073187 -0.172418 -0.618337 -0.337874 2.5019 -1.497652 -0.284534 0.18921 0.107144 -0.477646 -0.974225 0.808616 0.120295 3.988445 -2.647114 -0.410472 0.669848 -0.570027 -1.046523 -1.542457 1.035089 -0.694214
6 | 4 1.54687 -0.447575 0.671183 0.533284 -0.30057 -0.728973 0.295225 0.238886 2.489298 -0.986318 1.031641 0.670041 -0.66237 -1.136445 0.493327 -0.607405 -0.193471 3.963646 -2.033719 1.867637 1.288111 -1.023158 -0.773682 1.35929 -0.758336 0.823649
7 | 5 0.451265 -0.023006 -1.259903 0.367417 -0.008656 -0.075931 0.127082 0.042334 0.697913 0.189865 -2.03451 0.350973 -0.466462 0.054177 0.397503 0.197009 -0.853154 1.073465 0.53663 -3.199775 1.000627 -0.488686 0.578496 0.847164 1.107696 1.141338
8 | 6 0.451265 -0.023006 -1.259903 0.367417 -0.008656 -0.075931 0.127082 0.042334 0.675869 0.110825 -2.04555 0.352309 -0.615303 -0.199929 0.062071 -0.397289 0.804648 1.1152 0.10538 -2.937997 1.942738 -0.203464 0.380247 0.061913 -1.357843 -0.927939
9 | 7 0.74425 0.536652 0.348272 0.632578 0.905468 0.09093 0.388578 -0.32813 1.21809 0.428394 0.820024 0.099353 -1.686427 0.981121 0.622814 0.55406 0.21437 1.977655 0.234332 1.678586 1.164126 0.527168 2.891226 0.903616 0.674615 -0.804256
10 | 8 0.424346 0.920717 0.189408 0.81788 0.15575 0.278821 -0.648462 0.242351 0.565392 1.353081 0.359149 1.64749 -0.239997 0.629258 -1.11555 -0.323173 -0.148373 0.848442 2.115553 0.914508 0.711768 -2.470263 1.300451 -1.864505 -0.332716 0.605318
11 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # MultiLENS
2 |
3 |
4 | **Paper**: Di Jin, Ryan A. Rossi, Eunyee Koh, Sungchul Kim, Anup Rao, Danai Koutra. Latent Network Summarization: Bridging Network Embedding and Summarization. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2019.
5 |
6 | *Link*: https://gemslab.github.io/papers/jin-2019-latent.pdf
7 |
8 |
9 | 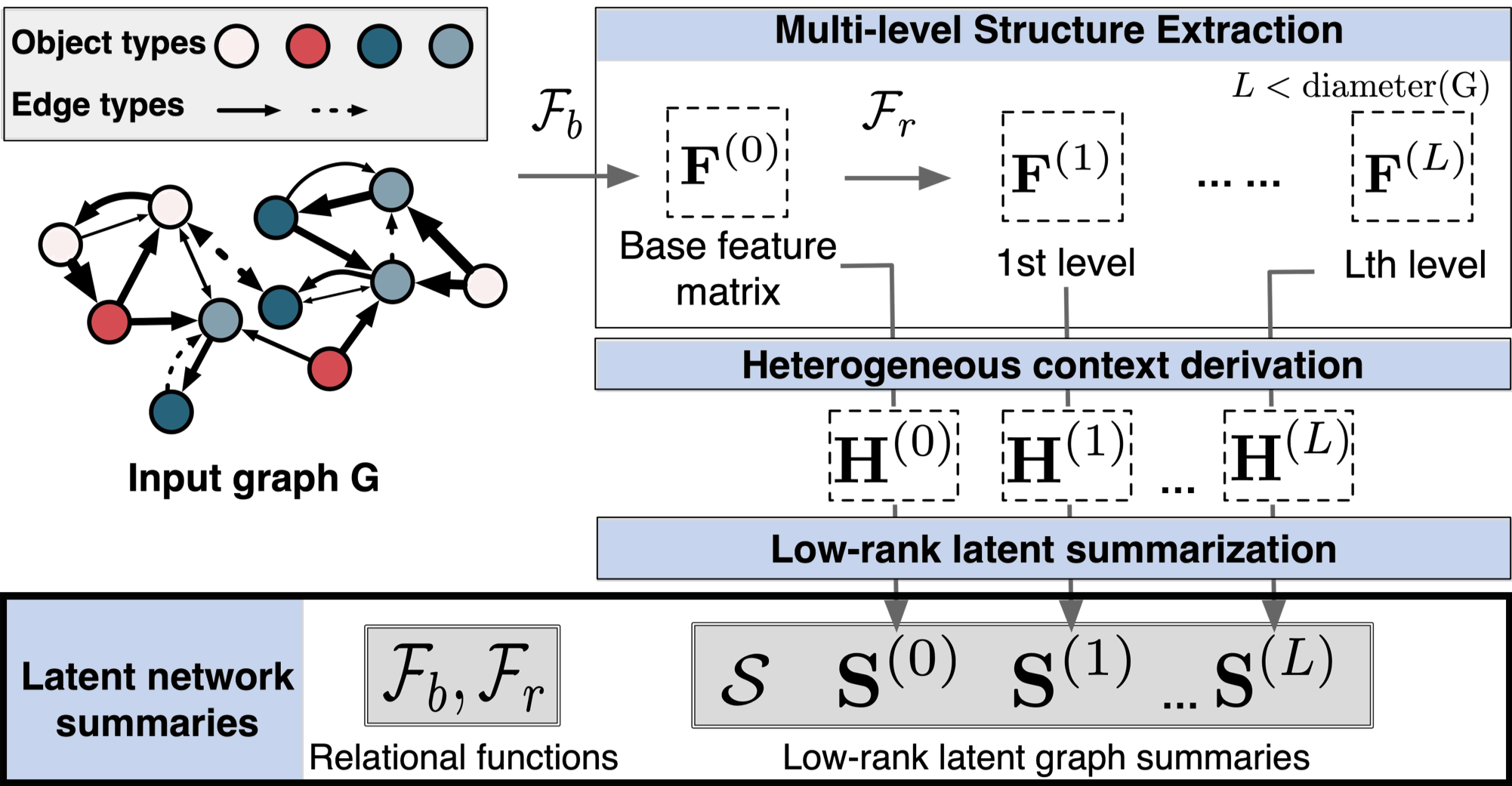 10 |
10 |
11 |
12 |
13 | **Citation (bibtex)**:
14 | ```
15 | @inproceedings{DBLP:conf/kdd/JinRKKRK19,
16 | author = {Di Jin and
17 | Ryan A. Rossi and
18 | Eunyee Koh and
19 | Sungchul Kim and
20 | Anup Rao and
21 | Danai Koutra},
22 | title = {Latent Network Summarization: Bridging Network Embedding and Summarization},
23 | booktitle = {Proceedings of the 25th {ACM} {SIGKDD} International Conference on
24 | Knowledge Discovery {\&} Data Mining, {KDD} 2019, London, UK,
25 | August 4-8, 2019},
26 | year = {2019},
27 | }
28 | ```
29 |
30 | # Code
31 |
32 | ## Inputs:
33 |
34 | MultiLENS takes two files as input, the graph file and the category file.
35 |
36 | ### Input graph file
37 | The input graph file can be either static or temporal edge list in the following format separated by tab:
38 | ```
39 | (optional)
40 | ```
41 | MultiLENS will automatically determine if the input graph is static or temporal. The edge list is assumed to be re-ordered consecutively from 0, i.e., the minimum node ID is 0, and the maximum node ID is <#node - 1>. A toy static graph is under "/graph/" directory.
42 |
43 | ### Input category file
44 | The category file is a mapping between the node ID and its type (e.g., IP, cookie, web agent) with the following format separated by tab:
45 | ```
46 |
47 | ```
48 | if the node IDs are grouped by the type, where `````` and `````` are the starting and ending node ids in type ``````
49 | For example,
50 | ```
51 | 0 0 279629
52 | 1 279630 283182
53 | ```
54 | means node 0, 1, ... 279629 are in type 0, node 279630, 279631, ... 283182 are in type 1.
55 |
56 | But if the node IDs are not grouped by the types, this implementation also supports the following format separated by tab:
57 | ```
58 |
59 | ```
60 | which is just the 1-1 mapping. The code accepts either format.
61 |
62 | ## Usage
63 |
64 | The complete command to run MultiLENS is as follows.
65 |
66 | ```
67 | python main.py --input --cat --output --dim
68 | --L <#level> --base --operators
69 | ```
70 |
71 | - input, the input graph file stated under the "Graph Input" section above. Default value: '../graph/test.tsv'
72 | - cat, the input category file stated under the "Graph Input" section above. Default value: '../graph/test_cat.tsv'
73 | - output, the ouput file path of the embeddings. Default value: '../emb/test_emb.txt'
74 | - dim, the dimension of the embeddings. Default value: 128
75 | - L, the maximum subgraph order. Default value: 2
76 | - base, the base constant of logarithm binning. Default value: 4
77 | - operators, a list of relational operators to use. Use the command such as ```--operators 'mean','sum'``` to specify which operators to use. Default value: ['mean', 'var', 'sum', 'max', 'min', 'L1', 'L2']
78 |
79 | ## Output
80 | In addition to embedding file indicated in the path ```output```, MultiLENS also outputs "latent_summary.pkl", which is the latent graph summary file that can be used for inductive learning tasks.
81 |
82 | ## Inductive learning task
83 | This repo also provides the python script to perform inductive learnings, i.e., deriving node embeddings from the latent summary on the fly. The commands to run it is as follows:
84 |
85 | ```
86 | python main_inducitve.py --input --cat --summary --output
87 | --dim --L <#level> --base --operators
88 | ```
89 |
90 | In addition to the identical arguments shown above, MultiLENS takes ```summary``` as the input:
91 |
92 | - summary, the input latent graph summary file derived on the (same/different) graph. Default value: './latent_summary.pkl'
93 | - output. Default value: './emb/test_emb_ind.txt'
94 |
95 | One may also set the variable "check_difference" in "main_inducitve.py" to compute the sum of node-wise distances (Frobenius norm) to measure graph difference.
96 |
97 |
98 | # Question & troubleshooting
99 |
100 | If you encounter any problems running the code, pls feel free to contact Di Jin (dijin@umich.edu)
101 |
102 |
103 |
--------------------------------------------------------------------------------
/src/main_inductive.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import datetime
3 | from pathlib import Path
4 | import numpy as np, scipy as sp, networkx as nx
5 | import math, time, os, sys, random
6 | from collections import deque
7 | import pickle
8 | import argparse
9 |
10 | import scipy.sparse as sps
11 | from scipy.sparse import coo_matrix
12 | from scipy.sparse.linalg import svds, eigs
13 | import sparsesvd
14 |
15 | from sklearn.decomposition import NMF, DictionaryLearning
16 | from sklearn.manifold import TSNE
17 |
18 | from collections import defaultdict
19 |
20 | from util import *
21 |
22 | def get_combined_feature_sequence(graph, rep_method, current_node, input_dense_matrix = None, feature_wid_ind = None):
23 | '''
24 | Get the combined degree/other feature sequence for a given node
25 | '''
26 | N, cur_P = input_dense_matrix.shape
27 |
28 | id_cat_dict = graph.id_cat_dict
29 | combined_feature_vector = []
30 | cur_neighbors = graph.neighbor_list[current_node][:]
31 | cur_neighbors.append(current_node)
32 |
33 | for cat in graph.cat_dict.keys():
34 |
35 | features = []
36 | for i in range(cur_P):
37 | features.append([0.0] * feature_wid_ind[i])
38 |
39 | for neighbor in cur_neighbors:
40 |
41 | if id_cat_dict[neighbor] != cat:
42 | continue
43 |
44 | try:
45 | for i in range(cur_P):
46 | node_feature = input_dense_matrix[neighbor, i]
47 |
48 | if (rep_method.num_buckets is not None) and (node_feature != 0):
49 | bucket_index = int(math.log(node_feature, rep_method.num_buckets))
50 | else:
51 | bucket_index = int(node_feature)
52 |
53 | features[i][min(bucket_index, len(features[i]) - 1)] += 1#(rep_method.alpha ** layer) * weight
54 | except Exception as e:
55 | print "Exception:", e
56 | print("Node %d has %s value %d and will not contribute to feature distribution" % (khop_neighbor, feature, node_feature))
57 | cur_feature_vector = features[0]
58 |
59 | for feature_vector in features[1:]:
60 | cur_feature_vector += feature_vector
61 |
62 | combined_feature_vector += cur_feature_vector
63 |
64 | return combined_feature_vector
65 |
66 | def get_features(graph, rep_method, input_dense_matrix = None, nodes_to_embed = None):
67 |
68 | feature_wid_sum, feature_wid_ind = get_feature_n_buckets(input_dense_matrix, num_buckets, rep_method.bucket_max_value)
69 | feature_matrix = np.zeros([graph.num_nodes, feature_wid_sum * len(graph.unique_cat)])
70 |
71 | for n in nodes_to_embed:
72 | if n % 50000 == 0:
73 | print "[Generate combined feature vetor] node: " + str(n)
74 | combined_feature_sequence = get_combined_feature_sequence(graph, rep_method, n, input_dense_matrix = input_dense_matrix, feature_wid_ind = feature_wid_ind)
75 | feature_matrix[n,:] = combined_feature_sequence
76 |
77 | return feature_matrix
78 |
79 |
80 | def get_seq_features(graph, rep_method, input_dense_matrix = None, nodes_to_embed = None):
81 |
82 | if input_dense_matrix is None:
83 | sys.exit('get_seq_features: no input matrix.')
84 |
85 | if nodes_to_embed is None:
86 | nodes_to_embed = range(graph.num_nodes)
87 | num_nodes = graph.num_nodes
88 | else:
89 | num_nodes = len(nodes_to_embed)
90 |
91 | feature_matrix = get_features(graph, rep_method, input_dense_matrix, nodes_to_embed)
92 |
93 | if graph.directed:
94 | print "[Starting to obtain features from in-components]"
95 |
96 | neighbor_list_r = construct_neighbor_list(graph.adj_matrix.transpose(), nodes_to_embed)
97 |
98 | indegree_graph = Graph(graph.adj_matrix.transpose(), max_id = graph.max_id, num_nodes = graph.num_nodes,
99 | directed = graph.directed, base_features = graph.base_features, neighbor_list = neighbor_list_r,
100 | cat_dict = graph.cat_dict, id_cat_dict = graph.id_cat_dict, unique_cat = graph.unique_cat, check_eq = graph.check_eq)
101 | base_feature_matrix_in = get_features(indegree_graph, rep_method, input_dense_matrix, nodes_to_embed = nodes_to_embed)
102 |
103 | feature_matrix = np.hstack((feature_matrix, base_feature_matrix_in))
104 |
105 | return feature_matrix
106 |
107 |
108 | def construct_cat(input_gt_path, delimiter):
109 | '''
110 | # Input: per line, 1) cat-id_init, id_end or 2) cat-id
111 | '''
112 | result = defaultdict(set)
113 | id_cat_dict = dict()
114 |
115 | fIn = open(input_gt_path, 'r')
116 | lines = fIn.readlines()
117 | for line in lines:
118 |
119 | parts = line.strip('\r\n').split(delimiter)
120 | if len(parts) == 3:
121 | cat = parts[0]
122 | node_id_start = parts[1]
123 | node_id_end = parts[2]
124 |
125 | for i in range( int(node_id_start), int(node_id_end)+1 ):
126 | result[ int(cat) ].add( i )
127 | id_cat_dict[i] = int(cat)
128 |
129 | elif len(parts) == 2:
130 | cat = parts[0]
131 | node_id = parts[1]
132 |
133 | result[int(cat)].add( int(node_id) )
134 | id_cat_dict[int(node_id)] = int(cat)
135 |
136 | else:
137 | sys.exit('Cat file format not supported')
138 |
139 | fIn.close()
140 | return result, result.keys(), id_cat_dict
141 |
142 |
143 | def search_feature_layer(graph, rep_method, base_feature_matrix = None):
144 |
145 | n,p = base_feature_matrix.shape
146 | result = np.zeros([n, p*rep_method.use_total])
147 | ops = rep_method.operators
148 |
149 | for u in range(n):
150 | if u % 50000 == 0:
151 | print '[Current_node_id] ' + str(u)
152 |
153 | neighbors = graph.neighbor_list[u]
154 |
155 | for fid in range(p):
156 |
157 | mean_v = 0.0; sum_v = 0.0; var_v = 0.0; max_v = 0.0; min_v = 0.0; sum_sq_diff = 0.0; prod_v = 1.0; L1_v = 0.0; L2_v = 0.0
158 |
159 | for v in neighbors:
160 |
161 | L1_v += abs(base_feature_matrix[u][fid] - base_feature_matrix[v][fid]) # L1
162 | diff = base_feature_matrix[u][fid] - base_feature_matrix[v][fid]
163 | L2_v += diff*diff # L2
164 | sum_sq_diff += base_feature_matrix[v][fid] * base_feature_matrix[v][fid] # var
165 | sum_v += base_feature_matrix[v][fid] # used in sum and mean
166 | if max_v < base_feature_matrix[v][fid]: # max
167 | max_v = base_feature_matrix[v][fid]
168 | if min_v > base_feature_matrix[v][fid]: # min
169 | min_v = base_feature_matrix[v][fid]
170 |
171 | deg = len(neighbors)
172 | if deg == 0:
173 | mean_v = 0
174 | var_v = 0
175 | else:
176 | mean_v = sum_v / float(deg)
177 | var_v = (sum_sq_diff / float(deg)) - (mean_v * mean_v)
178 |
179 | temp_vec = [0.0] * rep_method.use_total
180 |
181 | for idx, op in enumerate(ops):
182 | if op == 'mean':
183 | temp_vec[idx] = mean_v
184 | elif op == 'var':
185 | temp_vec[idx] = var_v
186 | elif op == 'sum':
187 | temp_vec[idx] = sum_v
188 | elif op == 'max':
189 | temp_vec[idx] = max_v
190 | elif op == 'min':
191 | temp_vec[idx] = min_v
192 | elif op == 'L1':
193 | temp_vec[idx] = L1_v
194 | elif op == 'L2':
195 | temp_vec[idx] = L2_v
196 | else:
197 | sys.exit('[Unsupported operation]')
198 |
199 | result[u, fid*rep_method.use_total:(fid+1)*rep_method.use_total] = temp_vec
200 |
201 | return result
202 |
203 |
204 | def construct_neighbor_list(adj_matrix, nodes_to_embed):
205 | result = {}
206 |
207 | for i in nodes_to_embed:
208 | result[i] = list(adj_matrix.getrow(i).nonzero()[1])
209 |
210 | return result
211 |
212 |
213 | def get_init_features(graph, base_features, nodes_to_embed):
214 | '''
215 | # set fb: sum as default.
216 | '''
217 | init_feature_matrix = np.zeros((len(nodes_to_embed), len(base_features)))
218 | adj = graph.adj_matrix
219 |
220 | if "row_col" in base_features:
221 | init_feature_matrix[:,base_features.index("row_col")] = (adj.sum(axis=0).transpose() + adj.sum(axis=1)).ravel()
222 |
223 | if "col" in base_features:
224 | init_feature_matrix[:,base_features.index("col")] = adj.sum(axis=0).transpose().ravel()
225 |
226 | if "row" in base_features:
227 | init_feature_matrix[:,base_features.index("row")] = adj.sum(axis=1).ravel()
228 |
229 | print '[Initial_feature_all finished]'
230 | return init_feature_matrix
231 |
232 |
233 | def get_feature_n_buckets(feature_matrix, num_buckets, bucket_max_value):
234 |
235 | result_sum = 0
236 | result_ind = []
237 | N, cur_P = feature_matrix.shape
238 |
239 | if num_buckets is not None:
240 | for i in range(cur_P):
241 | temp = max(bucket_max_value, int(math.log(max(max(feature_matrix[:,i]), 1), num_buckets) + 1))
242 | n_buckets = temp
243 | # print max(feature_matrix[:,i])
244 | result_sum += n_buckets
245 | result_ind.append(n_buckets)
246 | else:
247 | for i in range(cur_P):
248 | temp = max(bucket_max_value, int( max(feature_matrix[:,i]) ) + 1)
249 | n_buckets = temp
250 | result_sum += n_buckets
251 | result_ind.append(n_buckets)
252 |
253 | return result_sum, result_ind
254 |
255 |
256 |
257 | def parse_args():
258 | '''
259 | Parses the arguments.
260 | '''
261 | parser = argparse.ArgumentParser(description="Multi-Lens: Bridging Network Embedding and Summarization.")
262 |
263 | parser.add_argument('--input', nargs='?', default='../graph/test.tsv', help='Input graph file path')
264 |
265 | parser.add_argument('--cat', nargs='?', default='../graph/test_cat.tsv', help='Input node category file path')
266 |
267 | parser.add_argument('--summary', nargs='?', default='./latent_summary.pkl', help='Summary file path')
268 |
269 | parser.add_argument('--output', nargs='?', default='../emb/test_emb_ind.txt', help='Embedding file path')
270 |
271 | parser.add_argument('--test', nargs='?', default='../emb/test_emb.txt', help='Embedding file (old) path. This file is just used for testing.')
272 |
273 | parser.add_argument('--dim', type=int, default=128, help='Embedding dimension')
274 |
275 | parser.add_argument('--L', type=int, default=2, help='Subgraph level')
276 |
277 | parser.add_argument('--base', type=int, default=4, help='Base constant of logarithm histograms')
278 |
279 | parser.add_argument('--operators', default=['mean', 'var', 'sum', 'max', 'min', 'L1', 'L2'], nargs="+", help='Relational operators to use.')
280 |
281 | return parser.parse_args()
282 |
283 |
284 | def dist_cal(row1, row2):
285 | dist = np.linalg.norm(row1-row2)
286 |
287 | return dist
288 |
289 | if __name__ == '__main__':
290 |
291 | # assume the graph is directed, weighted
292 | directed = True
293 |
294 | args = parse_args()
295 |
296 | ######################################################
297 | # Base features to use
298 | ######################################################
299 |
300 | emb_write = True
301 | check_difference = False
302 |
303 | base_features = ['row', 'col', 'row_col']
304 |
305 | ###########################################
306 | # graph_2_file_path
307 | ###########################################
308 | input_graph_file_path = args.input
309 | input_gt_path = args.cat
310 | input_summary_path = args.summary
311 | input_emb_file_path = args.test
312 |
313 | output_file_path = args.output
314 |
315 | dim = args.dim
316 | L = args.L
317 | num_buckets = args.base
318 | op = args.operators
319 | print '----------------------------------'
320 | print '[Input graph (new) file] ' + input_graph_file_path
321 | print '[Input category file] ' + input_gt_path
322 | print '[Input summary (existing) file]' + input_summary_path
323 | print '[Output embedding file] ' + output_file_path
324 | print '[Embedding dimension] ' + str(dim)
325 | print '[Number of levels] ' + str(L)
326 | print '[Base of logarithm binning] ' + str(num_buckets)
327 | print '[Relational operators] ' + str(op)
328 | print '----------------------------------'
329 |
330 |
331 | pkl_file = open(input_summary_path, 'rb')
332 | g_summs = pickle.load(pkl_file)
333 | pkl_file.close()
334 |
335 |
336 | delimiter = get_delimiter(input_graph_file_path)
337 |
338 |
339 | raw = np.genfromtxt(input_graph_file_path, dtype=int)
340 | COL = raw.shape[1]
341 |
342 | if COL < 2:
343 | sys.exit('[Input format error.]')
344 | elif COL == 2:
345 | print '[unweighted graph detected.]'
346 | rows = raw[:,0]
347 | cols = raw[:,1]
348 | weis = np.ones(len(rows))
349 |
350 | elif COL == 3:
351 | print '[weighted graph detected.]'
352 | rows = raw[:,0]
353 | cols = raw[:,1]
354 | weis = raw[:,2]
355 |
356 |
357 | check_eq = True
358 | max_id = int(max(max(rows), max(cols)))
359 | num_nodes = max_id + 1
360 | print '[max_node_id] ' + str(max_id)
361 | print '[num_nodes] ' + str(num_nodes)
362 |
363 | nodes_to_embed = range(int(max_id)+1)
364 |
365 | if max(rows) != max(cols):
366 | rows = np.append(rows,max(max(rows), max(cols)))
367 | cols = np.append(cols,max(max(rows), max(cols)))
368 | weis = np.append(weis, 0)
369 | check_eq = False
370 |
371 |
372 | adj_matrix = sps.lil_matrix( sps.csc_matrix((weis, (rows, cols))) )
373 |
374 | CAT_DICT, unique_cat, ID_CAT_DICT = construct_cat(input_gt_path, delimiter)
375 |
376 | g_sums = []
377 |
378 | neighbor_list = construct_neighbor_list(adj_matrix, nodes_to_embed)
379 |
380 | graph = Graph(adj_matrix = adj_matrix, max_id = max_id, num_nodes = num_nodes, base_features = base_features, neighbor_list = neighbor_list,
381 | directed = directed, cat_dict = CAT_DICT, id_cat_dict = ID_CAT_DICT, unique_cat = unique_cat, check_eq = check_eq)
382 |
383 | init_feature_matrix = get_init_features(graph, base_features, nodes_to_embed)
384 |
385 | rep_method = RepMethod(method = "hetero", bucket_max_value = 30, num_buckets = num_buckets, operators = op, use_total = len(op))
386 |
387 |
388 | ######################################################
389 | # Step 1: get node embeddings from the summary
390 | # The number of layers we want to explore -
391 | # layer 0 is the base feature matrix
392 | # layer 1+: are the layers of higher order
393 | ############################################
394 | init_feature_matrix_seq = get_seq_features(graph, rep_method, input_dense_matrix = init_feature_matrix, nodes_to_embed = nodes_to_embed)
395 | init_gs = g_summs[0]
396 | print 'init_gs shape: ' + str(init_gs.shape)
397 | U = np.dot( init_feature_matrix_seq, np.linalg.pinv(init_gs) )
398 |
399 |
400 | feature_matrix = init_feature_matrix
401 |
402 | for i in range(L):
403 | print '[Current layer] ' + str(i)
404 |
405 | feature_matrix_new = search_feature_layer(graph, rep_method, base_feature_matrix = feature_matrix)
406 |
407 | feature_matrix_new_seq = get_seq_features(graph, rep_method, input_dense_matrix = feature_matrix_new, nodes_to_embed = nodes_to_embed)
408 |
409 | cur_gs = g_summs[i+1]
410 | print '[Summary shape] ' + str(cur_gs.shape)
411 | cur_U = np.dot( feature_matrix_new_seq, np.linalg.pinv(cur_gs) )
412 | U = np.concatenate((U, cur_U), axis=1)
413 |
414 | feature_matrix = feature_matrix_new
415 |
416 |
417 | ######################################################
418 | # Step 2: evaluate the difference (optional)
419 | ######################################################
420 |
421 |
422 | if check_difference:
423 | orig = read_embedding(input_emb_file_path)
424 | modi = U
425 |
426 | rows = orig[:,0]
427 | cols = orig[:,1]
428 |
429 | max_id_1 = orig.shape[0]
430 | max_id_2 = U.shape[0]
431 | max_id = min(max_id_1, max_id_2)
432 |
433 | ID_DIST_DICT = {}
434 | dist_total = 0
435 |
436 | for i in range(max_id):
437 | if i % 10000 == 0:
438 | print '[Current_node_id] ' + str(i)
439 | cur_row_orig = orig[i,:]
440 | cur_row_modi = modi[i,:]
441 | dist = dist_cal(cur_row_orig, cur_row_modi)
442 |
443 | ID_DIST_DICT[i] = dist
444 | dist_total += dist
445 |
446 | print '[total dist] ' + str(dist_total)
447 |
448 |
449 | if emb_write:
450 | write_embedding(U, output_file_path)
451 |
452 |
453 |
454 |
455 |
456 |
457 |
458 |
--------------------------------------------------------------------------------
/src/main.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import datetime
3 | from pathlib import Path
4 | import numpy as np, scipy as sp, networkx as nx
5 | import math, time, os, sys, random
6 | from collections import deque
7 | import pickle
8 | import argparse
9 |
10 | import scipy.sparse as sps
11 | from scipy.sparse import coo_matrix
12 | from scipy.sparse.linalg import svds, eigs
13 | import sparsesvd
14 |
15 | from collections import defaultdict
16 |
17 | from sklearn.decomposition import NMF, DictionaryLearning
18 | from sklearn.manifold import TSNE
19 |
20 | from util import *
21 |
22 |
23 | def get_combined_feature_sequence(graph, rep_method, current_node, input_dense_matrix = None, feature_wid_ind = None):
24 | '''
25 | Get the combined degree/other feature sequence for a given node
26 | '''
27 | N, cur_P = input_dense_matrix.shape
28 |
29 | id_cat_dict = graph.id_cat_dict
30 | combined_feature_vector = []
31 | cur_neighbors = graph.neighbor_list[current_node][:]
32 | cur_neighbors.append(current_node)
33 |
34 | for cat in graph.cat_dict.keys():
35 |
36 | features = []
37 | for i in range(cur_P):
38 | features.append([0.0] * feature_wid_ind[i])
39 |
40 | for neighbor in cur_neighbors:
41 | if id_cat_dict[neighbor] != cat:
42 | continue
43 | try:
44 | # print cur_P
45 | for i in range(cur_P):
46 | node_feature = input_dense_matrix[neighbor, i]
47 |
48 | if (rep_method.num_buckets is not None) and (node_feature != 0):
49 | bucket_index = int(math.log(node_feature, rep_method.num_buckets))
50 | else:
51 | bucket_index = int(node_feature)
52 |
53 | bucket_index = max(bucket_index, 0)
54 | features[i][min(bucket_index, len(features[i]) - 1)] += 1
55 |
56 | except Exception as e:
57 | print "Exception:", e
58 | cur_feature_vector = features[0]
59 |
60 | for feature_vector in features[1:]:
61 | cur_feature_vector += feature_vector
62 |
63 | combined_feature_vector += cur_feature_vector
64 |
65 | return combined_feature_vector
66 |
67 |
68 | def get_features(graph, rep_method, input_dense_matrix = None, nodes_to_embed = None):
69 |
70 | feature_wid_sum, feature_wid_ind = get_feature_n_buckets(input_dense_matrix, num_buckets, rep_method.bucket_max_value)
71 | feature_matrix = np.zeros([graph.num_nodes, feature_wid_sum * len(graph.unique_cat)])
72 |
73 | for n in nodes_to_embed:
74 | if n % 50000 == 0:
75 | print "[Generate combined feature vetor] node: " + str(n)
76 | combined_feature_sequence = get_combined_feature_sequence(graph, rep_method, n, input_dense_matrix = input_dense_matrix, feature_wid_ind = feature_wid_ind)
77 | feature_matrix[n,:] = combined_feature_sequence
78 |
79 | return feature_matrix
80 |
81 |
82 | def get_seq_features(graph, rep_method, input_dense_matrix = None, nodes_to_embed = None):
83 |
84 | if input_dense_matrix is None:
85 | sys.exit('get_seq_features: no input matrix.')
86 |
87 | if nodes_to_embed is None:
88 | nodes_to_embed = range(graph.num_nodes)
89 | num_nodes = graph.num_nodes
90 | else:
91 | num_nodes = len(nodes_to_embed)
92 |
93 | feature_matrix = get_features(graph, rep_method, input_dense_matrix, nodes_to_embed)
94 |
95 | if graph.directed:
96 | print "[Starting to obtain features from in-components]"
97 |
98 | neighbor_list_r = construct_neighbor_list(graph.adj_matrix.transpose(), nodes_to_embed)
99 |
100 | indegree_graph = Graph(graph.adj_matrix.transpose(), max_id = graph.max_id, num_nodes = graph.num_nodes,
101 | directed = graph.directed, base_features = graph.base_features, neighbor_list = neighbor_list_r,
102 | cat_dict = graph.cat_dict, id_cat_dict = graph.id_cat_dict, unique_cat = graph.unique_cat, check_eq = graph.check_eq)
103 | base_feature_matrix_in = get_features(indegree_graph, rep_method, input_dense_matrix, nodes_to_embed = nodes_to_embed)
104 |
105 | feature_matrix = np.hstack((feature_matrix, base_feature_matrix_in))
106 |
107 | return feature_matrix
108 |
109 |
110 | def construct_cat(input_gt_path, delimiter):
111 | '''
112 | # Input: per line, 1) cat-id_init, id_end or 2) cat-id
113 | '''
114 | result = defaultdict(set)
115 | id_cat_dict = dict()
116 |
117 | fIn = open(input_gt_path, 'r')
118 | lines = fIn.readlines()
119 | for line in lines:
120 |
121 | parts = line.strip('\r\n').split(delimiter)
122 | if len(parts) == 3:
123 | cat = parts[0]
124 | node_id_start = parts[1]
125 | node_id_end = parts[2]
126 |
127 | for i in range( int(node_id_start), int(node_id_end)+1 ):
128 | result[ int(cat) ].add( i )
129 | id_cat_dict[i] = int(cat)
130 |
131 | elif len(parts) == 2:
132 | cat = parts[0]
133 | node_id = parts[1]
134 |
135 | result[int(cat)].add( int(node_id) )
136 | id_cat_dict[int(node_id)] = int(cat)
137 |
138 | else:
139 | sys.exit('Cat file format not supported')
140 |
141 | fIn.close()
142 | return result, result.keys(), id_cat_dict
143 |
144 |
145 | def search_feature_layer(graph, rep_method, base_feature_matrix = None):
146 |
147 | n,p = base_feature_matrix.shape
148 | result = np.zeros([n, p*rep_method.use_total])
149 | ops = rep_method.operators
150 |
151 | for u in range(n):
152 | if u % 50000 == 0:
153 | print '[Current_node_id] ' + str(u)
154 |
155 | neighbors = graph.neighbor_list[u]
156 |
157 | for fid in range(p):
158 |
159 | mean_v = 0.0; sum_v = 0.0; var_v = 0.0; max_v = 0.0; min_v = 0.0; sum_sq_diff = 0.0; prod_v = 1.0; L1_v = 0.0; L2_v = 0.0
160 |
161 | for v in neighbors:
162 |
163 | L1_v += abs(base_feature_matrix[u][fid] - base_feature_matrix[v][fid]) # L1
164 | diff = base_feature_matrix[u][fid] - base_feature_matrix[v][fid]
165 | L2_v += diff*diff # L2
166 | sum_sq_diff += base_feature_matrix[v][fid] * base_feature_matrix[v][fid] # var
167 | sum_v += base_feature_matrix[v][fid] # used in sum and mean
168 | if max_v < base_feature_matrix[v][fid]: # max
169 | max_v = base_feature_matrix[v][fid]
170 | if min_v > base_feature_matrix[v][fid]: # min
171 | min_v = base_feature_matrix[v][fid]
172 |
173 | deg = len(neighbors)
174 | if deg == 0:
175 | mean_v = 0
176 | var_v = 0
177 | else:
178 | mean_v = sum_v / float(deg)
179 | var_v = (sum_sq_diff / float(deg)) - (mean_v * mean_v) #- 2.0*mean_v/float(deg)*sum_v
180 |
181 | temp_vec = [0.0] * rep_method.use_total
182 |
183 | for idx, op in enumerate(ops):
184 | if op == 'mean':
185 | temp_vec[idx] = mean_v
186 | elif op == 'var':
187 | temp_vec[idx] = var_v
188 | elif op == 'sum':
189 | temp_vec[idx] = sum_v
190 | elif op == 'max':
191 | temp_vec[idx] = max_v
192 | elif op == 'min':
193 | temp_vec[idx] = min_v
194 | elif op == 'L1':
195 | temp_vec[idx] = L1_v
196 | elif op == 'L2':
197 | temp_vec[idx] = L2_v
198 | else:
199 | sys.exit('[Unsupported operation]')
200 |
201 | result[u, fid*rep_method.use_total:(fid+1)*rep_method.use_total] = temp_vec
202 |
203 | return result
204 |
205 |
206 | def feature_layer_evaluation_embedding(graph, rep_method, feature_matrix = None, k = 17):
207 |
208 | temp = scipy.sparse.csc_matrix(feature_matrix)
209 | U,s,V = sparsesvd.sparsesvd(temp, k)
210 |
211 | S = np.diag(s)
212 | emb = np.dot(U.T, (S ** 0.5))
213 | g_sum = np.dot((S**0.5), V)
214 |
215 | return emb, g_sum
216 |
217 |
218 | def construct_neighbor_list(adj_matrix, nodes_to_embed):
219 | result = {}
220 |
221 | for i in nodes_to_embed:
222 | result[i] = list(adj_matrix.getrow(i).nonzero()[1])
223 |
224 | return result
225 |
226 |
227 |
228 | def get_init_features(graph, base_features, nodes_to_embed):
229 | '''
230 | # set fb: sum as default.
231 | '''
232 | init_feature_matrix = np.zeros((len(nodes_to_embed), len(base_features)))
233 | adj = graph.adj_matrix
234 |
235 | if "row_col" in base_features:
236 | init_feature_matrix[:,base_features.index("row_col")] = (adj.sum(axis=0).transpose() + adj.sum(axis=1)).ravel()
237 |
238 | if "col" in base_features:
239 | init_feature_matrix[:,base_features.index("col")] = adj.sum(axis=0).transpose().ravel()
240 |
241 | if "row" in base_features:
242 | init_feature_matrix[:,base_features.index("row")] = adj.sum(axis=1).ravel()
243 |
244 | print '[Initial_feature_all finished]'
245 | return init_feature_matrix
246 |
247 | def get_feature_n_buckets(feature_matrix, num_buckets, bucket_max_value):
248 |
249 | result_sum = 0
250 | result_ind = []
251 | N, cur_P = feature_matrix.shape
252 |
253 | if num_buckets is not None:
254 | for i in range(cur_P):
255 | temp = max(bucket_max_value, int(math.log(max(max(feature_matrix[:,i]), 1), num_buckets) + 1))
256 | n_buckets = temp
257 | # print max(feature_matrix[:,i])
258 | result_sum += n_buckets
259 | result_ind.append(n_buckets)
260 | else:
261 | for i in range(cur_P):
262 | temp = max(bucket_max_value, int( max(feature_matrix[:,i]) ) + 1)
263 | n_buckets = temp
264 | result_sum += n_buckets
265 | result_ind.append(n_buckets)
266 |
267 | return result_sum, result_ind
268 |
269 |
270 | def parse_args():
271 | '''
272 | Parses the arguments.
273 | '''
274 | parser = argparse.ArgumentParser(description="Multi-Lens: Bridging Network Embedding and Summarization.")
275 |
276 | parser.add_argument('--input', nargs='?', default='../graph/test.tsv', help='Input graph file path')
277 |
278 | parser.add_argument('--cat', nargs='?', default='../graph/test_cat.tsv', help='Input node category file path')
279 |
280 | parser.add_argument('--output', nargs='?', default='../emb/test_emb.txt', help='Embedding file path')
281 |
282 | parser.add_argument('--dim', type=int, default=128, help='Embedding dimension')
283 |
284 | parser.add_argument('--L', type=int, default=2, help='Subgraph level')
285 |
286 | parser.add_argument('--base', type=int, default=4, help='Base constant of logarithm histograms')
287 |
288 | parser.add_argument('--operators', default=['mean', 'var', 'sum', 'max', 'min', 'L1', 'L2'], nargs="+", help='Relational operators to use.')
289 |
290 | return parser.parse_args()
291 |
292 |
293 |
294 | def get_Kis(init_feature_matrix_seq, K, L):
295 |
296 | result = []
297 | rank_init = np.linalg.matrix_rank(init_feature_matrix_seq)
298 |
299 | if L == 0:
300 | result.append( min(rank_init, K) )
301 | else:
302 | l_0 = min(rank_init, K/(L+1))
303 | result.append(l_0)
304 | for i in range(L-1):
305 | result.append( K/(L+1) )
306 |
307 | result.append(K - sum(result))
308 |
309 | return result
310 |
311 |
312 |
313 | if __name__ == '__main__':
314 |
315 | # assume the graph is directed, weighted
316 | directed = True
317 |
318 | args = parse_args()
319 |
320 | ######################################################
321 | # Base features to use.
322 | ######################################################
323 |
324 | emb_write = True
325 |
326 | base_features = ['row', 'col', 'row_col']
327 |
328 | ######################################################
329 | # Parameters to setup
330 | ######################################################
331 | input_file_path = args.input
332 | input_gt_path = args.cat
333 | output_file_path = args.output
334 |
335 | dim = args.dim
336 | L = args.L
337 | num_buckets = args.base
338 | op = args.operators
339 | print '----------------------------------'
340 | print '[Input graph file] ' + input_file_path
341 | print '[Input category file] ' + input_gt_path
342 | print '[Output embedding file] ' + output_file_path
343 | print '[Embedding dimension] ' + str(dim)
344 | print '[Number of levels] ' + str(L)
345 | print '[Base of logarithm binning] ' + str(num_buckets)
346 | print '[Relational operators] ' + str(op)
347 | print '----------------------------------'
348 |
349 | ######################################################
350 | # Preprocess
351 | ######################################################
352 |
353 | delimiter = get_delimiter(input_file_path)
354 |
355 |
356 | raw = np.genfromtxt(input_file_path, dtype=int)
357 | COL = raw.shape[1]
358 |
359 | if COL < 2:
360 | sys.exit('[Input format error.]')
361 | elif COL == 2:
362 | print '[unweighted graph detected.]'
363 | rows = raw[:,0]
364 | cols = raw[:,1]
365 | weis = np.ones(len(rows))
366 |
367 | elif COL == 3:
368 | print '[weighted graph detected.]'
369 | rows = raw[:,0]
370 | cols = raw[:,1]
371 | weis = raw[:,2]
372 |
373 |
374 | check_eq = True
375 | max_id = int(max(max(rows), max(cols)))
376 | num_nodes = max_id + 1
377 | print '[max_node_id] ' + str(max_id)
378 | print '[num_nodes] ' + str(num_nodes)
379 |
380 | nodes_to_embed = range(int(max_id)+1) #[1,2]#
381 |
382 | if max(rows) != max(cols):
383 | rows = np.append(rows,max(max(rows), max(cols)))
384 | cols = np.append(cols,max(max(rows), max(cols)))
385 | weis = np.append(weis, 0)
386 | check_eq = False
387 |
388 |
389 | adj_matrix = sps.lil_matrix( sps.csc_matrix((weis, (rows, cols))))
390 | print '[shape of adj_matrix] ' + str(adj_matrix.shape)
391 |
392 | CAT_DICT, unique_cat, ID_CAT_DICT = construct_cat(input_gt_path, delimiter)
393 |
394 |
395 | ######################################################
396 | # Multi-Lens starts.
397 | ######################################################
398 |
399 | g_sums = []
400 |
401 | neighbor_list = construct_neighbor_list(adj_matrix, nodes_to_embed)
402 |
403 | graph = Graph(adj_matrix = adj_matrix, max_id = max_id, num_nodes = num_nodes, base_features = base_features,
404 | neighbor_list = neighbor_list, directed = directed, cat_dict = CAT_DICT, id_cat_dict = ID_CAT_DICT, unique_cat = unique_cat, check_eq = check_eq)
405 |
406 | rep_method = RepMethod(method = "hetero", bucket_max_value = 30, num_buckets = num_buckets, operators = op, use_total = len(op))
407 |
408 | ########################################
409 | # Step 1: get base features
410 | ########################################
411 | init_feature_matrix = get_init_features(graph, base_features, nodes_to_embed)
412 | init_feature_matrix_seq = get_seq_features(graph, rep_method, input_dense_matrix = init_feature_matrix, nodes_to_embed = nodes_to_embed)
413 |
414 | Kis = get_Kis(init_feature_matrix_seq, dim, L)
415 |
416 | feature_matrix_emb, g_sum = feature_layer_evaluation_embedding(graph, rep_method, feature_matrix = init_feature_matrix_seq, k = Kis[0])
417 |
418 | g_sums.append(g_sum)
419 |
420 |
421 | ########################################
422 | # Step 2: feature proliferation.
423 | # layer 0 is the base feature matrix
424 | # layer 1+: are the layers of higher order
425 | ########################################
426 |
427 | rep = feature_matrix_emb
428 | feature_matrix = init_feature_matrix
429 |
430 |
431 | for i in range(L):
432 | print '[Current layer] ' + str(i)
433 | print '[feature_matrix shape] ' + str(feature_matrix.shape)
434 |
435 | feature_matrix_new = search_feature_layer(graph, rep_method, base_feature_matrix = feature_matrix)
436 | feature_matrix_new_seq = get_seq_features(graph, rep_method, input_dense_matrix = feature_matrix_new, nodes_to_embed = nodes_to_embed)
437 | feature_matrix_new_emb, g_new_sum = feature_layer_evaluation_embedding(graph, rep_method, feature_matrix = feature_matrix_new_seq, k = Kis[i+1])
438 |
439 | feature_matrix = feature_matrix_new
440 | rep_new = feature_matrix_new_emb
441 | rep = np.concatenate((rep, rep_new), axis=1)
442 |
443 | g_sums.append(g_new_sum)
444 |
445 | ######################################################
446 | # Write output
447 | ######################################################
448 |
449 | print '[Multi-Lens ends. Summary sizes:]'
450 | for ele in g_sums:
451 | print ele.shape
452 |
453 | fOut = open('latent_summary.pkl', 'wb')
454 | pickle.dump(g_sums, fOut, -1)
455 | fOut.close()
456 |
457 | if emb_write:
458 | write_embedding(rep, output_file_path)
459 |
460 |
461 |
462 |
--------------------------------------------------------------------------------