├── .github
├── ISSUE_TEMPLATE
│ ├── bug_report.md
│ └── feature_request.md
└── workflows
│ └── ubuntu.yml
├── .gitignore
├── .gitmodules
├── CODE_OF_CONDUCT.md
├── LICENSE
├── README.md
├── build.py
├── dingo
├── MetabolicNetwork.py
├── PolytopeSampler.py
├── __init__.py
├── __main__.py
├── bindings
│ ├── bindings.cpp
│ ├── bindings.h
│ └── hmc_sampling.h
├── illustrations.py
├── loading_models.py
├── nullspace.py
├── parser.py
├── preprocess.py
├── pyoptinterface_based_impl.py
├── scaling.py
├── utils.py
└── volestipy.pyx
├── doc
├── aconta_ppc_copula.png
├── e_coli_aconta.png
└── logo
│ └── dingo.jpg
├── ext_data
├── e_coli_core.json
├── e_coli_core.mat
├── e_coli_core.xml
├── e_coli_core_dingo.mat
└── matlab_model_wrapper.m
├── poetry.lock
├── pyproject.toml
├── setup.py
├── tests
├── correlation.py
├── fba.py
├── full_dimensional.py
├── max_ball.py
├── preprocess.py
├── rounding.py
├── sampling.py
├── sampling_no_multiphase.py
└── scaling.py
└── tutorials
├── CONTRIBUTING.md
├── README.md
├── dingo_tutorial.ipynb
└── figs
├── branches_github.png
├── fork.png
└── pr.png
/.github/ISSUE_TEMPLATE/bug_report.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Bug report
3 | about: Create a report to help us improve
4 | title: ''
5 | labels: ''
6 | assignees: ''
7 |
8 | ---
9 |
10 | **Describe the bug**
11 | A clear and concise description of what the bug is.
12 |
13 | **To Reproduce**
14 | Steps to reproduce the behavior:
15 | 1. Go to '...'
16 | 2. Click on '....'
17 | 3. Scroll down to '....'
18 | 4. See error
19 |
20 | **Expected behavior**
21 | A clear and concise description of what you expected to happen.
22 |
23 | **Screenshots**
24 | If applicable, add screenshots to help explain your problem.
25 |
26 | **Desktop (please complete the following information):**
27 | - OS: [e.g. iOS]
28 | - Browser [e.g. chrome, safari]
29 | - Version [e.g. 22]
30 |
31 | **Smartphone (please complete the following information):**
32 | - Device: [e.g. iPhone6]
33 | - OS: [e.g. iOS8.1]
34 | - Browser [e.g. stock browser, safari]
35 | - Version [e.g. 22]
36 |
37 | **Additional context**
38 | Add any other context about the problem here.
39 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/feature_request.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Feature request
3 | about: Suggest an idea for this project
4 | title: ''
5 | labels: ''
6 | assignees: ''
7 |
8 | ---
9 |
10 | **Is your feature request related to a problem? Please describe.**
11 | A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
12 |
13 | **Describe the solution you'd like**
14 | A clear and concise description of what you want to happen.
15 |
16 | **Describe alternatives you've considered**
17 | A clear and concise description of any alternative solutions or features you've considered.
18 |
19 | **Additional context**
20 | Add any other context or screenshots about the feature request here.
21 |
--------------------------------------------------------------------------------
/.github/workflows/ubuntu.yml:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021-2022 Vissarion Fisikopoulos
5 |
6 | # Licensed under GNU LGPL.3, see LICENCE file
7 |
8 | name: dingo-ubuntu
9 |
10 | on: [push, pull_request]
11 |
12 | jobs:
13 | build:
14 |
15 | runs-on: ubuntu-latest
16 | strategy:
17 | matrix:
18 | #python-version: [2.7, 3.5, 3.6, 3.7, 3.8]
19 | python-version: [3.8]
20 |
21 | steps:
22 | - uses: actions/checkout@v2
23 | - name: Set up Python ${{ matrix.python-version }}
24 | uses: actions/setup-python@v2
25 | with:
26 | python-version: ${{ matrix.python-version }}
27 | - name: Load submodules
28 | run: |
29 | git submodule update --init;
30 | - name: Download and unzip the boost library
31 | run: |
32 | wget -O boost_1_76_0.tar.bz2 https://archives.boost.io/release/1.76.0/source/boost_1_76_0.tar.bz2;
33 | tar xjf boost_1_76_0.tar.bz2;
34 | rm boost_1_76_0.tar.bz2;
35 | - name: Download and unzip the lp-solve library
36 | run: |
37 | wget https://sourceforge.net/projects/lpsolve/files/lpsolve/5.5.2.11/lp_solve_5.5.2.11_source.tar.gz
38 | tar xzvf lp_solve_5.5.2.11_source.tar.gz
39 | rm lp_solve_5.5.2.11_source.tar.gz
40 | - name: Install dependencies
41 | run: |
42 | sudo apt-get install libsuitesparse-dev;
43 | curl -sSL https://install.python-poetry.org | python3 - --version 1.3.2;
44 | poetry --version
45 | poetry show -v
46 | source $(poetry env info --path)/bin/activate
47 | poetry install;
48 | pip3 install numpy scipy;
49 | - name: Run tests
50 | run: |
51 | poetry run python3 tests/fba.py;
52 | poetry run python3 tests/full_dimensional.py;
53 | poetry run python3 tests/max_ball.py;
54 | poetry run python3 tests/scaling.py;
55 | poetry run python3 tests/sampling.py;
56 | poetry run python3 tests/sampling_no_multiphase.py;
57 | # currently we do not test with gurobi
58 | # python3 tests/fast_implementation_test.py;
59 |
60 | #run all tests
61 | #python -m unittest discover test
62 | #TODO: use pytest
63 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | build
2 | dist
3 | boost_1_76_0
4 | dingo.egg-info
5 | *.pyc
6 | *.so
7 | volestipy.cpp
8 | volestipy.egg-info
9 | *.npy
10 | .ipynb_checkpoints/
11 | .vscode
12 | venv
13 | lp_solve_5.5/
14 | .devcontainer/
15 | .github/dependabot.yml
--------------------------------------------------------------------------------
/.gitmodules:
--------------------------------------------------------------------------------
1 | [submodule "eigen"]
2 | path = eigen
3 | url = https://gitlab.com/libeigen/eigen.git
4 | branch = 3.3
5 | [submodule "volesti"]
6 | path = volesti
7 | url = https://github.com/GeomScale/volesti.git
8 | branch = develop
9 |
--------------------------------------------------------------------------------
/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | # Contributor Covenant Code of Conduct
2 |
3 | ## Our Pledge
4 |
5 | We as members, contributors, and leaders pledge to make participation in our
6 | community a harassment-free experience for everyone, regardless of age, body
7 | size, visible or invisible disability, ethnicity, sex characteristics, gender
8 | identity and expression, level of experience, education, socio-economic status,
9 | nationality, personal appearance, race, religion, or sexual identity
10 | and orientation.
11 |
12 | We pledge to act and interact in ways that contribute to an open, welcoming,
13 | diverse, inclusive, and healthy community.
14 |
15 | ## Our Standards
16 |
17 | Examples of behavior that contributes to a positive environment for our
18 | community include:
19 |
20 | * Demonstrating empathy and kindness toward other people
21 | * Being respectful of differing opinions, viewpoints, and experiences
22 | * Giving and gracefully accepting constructive feedback
23 | * Accepting responsibility and apologizing to those affected by our mistakes,
24 | and learning from the experience
25 | * Focusing on what is best not just for us as individuals, but for the
26 | overall community
27 |
28 | Examples of unacceptable behavior include:
29 |
30 | * The use of sexualized language or imagery, and sexual attention or
31 | advances of any kind
32 | * Trolling, insulting or derogatory comments, and personal or political attacks
33 | * Public or private harassment
34 | * Publishing others' private information, such as a physical or email
35 | address, without their explicit permission
36 | * Other conduct which could reasonably be considered inappropriate in a
37 | professional setting
38 |
39 | ## Enforcement Responsibilities
40 |
41 | Community leaders are responsible for clarifying and enforcing our standards of
42 | acceptable behavior and will take appropriate and fair corrective action in
43 | response to any behavior that they deem inappropriate, threatening, offensive,
44 | or harmful.
45 |
46 | Community leaders have the right and responsibility to remove, edit, or reject
47 | comments, commits, code, wiki edits, issues, and other contributions that are
48 | not aligned to this Code of Conduct, and will communicate reasons for moderation
49 | decisions when appropriate.
50 |
51 | ## Scope
52 |
53 | This Code of Conduct applies within all community spaces, and also applies when
54 | an individual is officially representing the community in public spaces.
55 | Examples of representing our community include using an official e-mail address,
56 | posting via an official social media account, or acting as an appointed
57 | representative at an online or offline event.
58 |
59 | ## Enforcement
60 |
61 | Instances of abusive, harassing, or otherwise unacceptable behavior may be
62 | reported to the community leaders responsible for enforcement at
63 | geomscale@gmail.com.
64 | All complaints will be reviewed and investigated promptly and fairly.
65 |
66 | All community leaders are obligated to respect the privacy and security of the
67 | reporter of any incident.
68 |
69 | ## Enforcement Guidelines
70 |
71 | Community leaders will follow these Community Impact Guidelines in determining
72 | the consequences for any action they deem in violation of this Code of Conduct:
73 |
74 | ### 1. Correction
75 |
76 | **Community Impact**: Use of inappropriate language or other behavior deemed
77 | unprofessional or unwelcome in the community.
78 |
79 | **Consequence**: A private, written warning from community leaders, providing
80 | clarity around the nature of the violation and an explanation of why the
81 | behavior was inappropriate. A public apology may be requested.
82 |
83 | ### 2. Warning
84 |
85 | **Community Impact**: A violation through a single incident or series
86 | of actions.
87 |
88 | **Consequence**: A warning with consequences for continued behavior. No
89 | interaction with the people involved, including unsolicited interaction with
90 | those enforcing the Code of Conduct, for a specified period of time. This
91 | includes avoiding interactions in community spaces as well as external channels
92 | like social media. Violating these terms may lead to a temporary or
93 | permanent ban.
94 |
95 | ### 3. Temporary Ban
96 |
97 | **Community Impact**: A serious violation of community standards, including
98 | sustained inappropriate behavior.
99 |
100 | **Consequence**: A temporary ban from any sort of interaction or public
101 | communication with the community for a specified period of time. No public or
102 | private interaction with the people involved, including unsolicited interaction
103 | with those enforcing the Code of Conduct, is allowed during this period.
104 | Violating these terms may lead to a permanent ban.
105 |
106 | ### 4. Permanent Ban
107 |
108 | **Community Impact**: Demonstrating a pattern of violation of community
109 | standards, including sustained inappropriate behavior, harassment of an
110 | individual, or aggression toward or disparagement of classes of individuals.
111 |
112 | **Consequence**: A permanent ban from any sort of public interaction within
113 | the community.
114 |
115 | ## Attribution
116 |
117 | This Code of Conduct is adapted from the [Contributor Covenant][homepage],
118 | version 2.0, available at
119 | https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
120 |
121 | Community Impact Guidelines were inspired by [Mozilla's code of conduct
122 | enforcement ladder](https://github.com/mozilla/diversity).
123 |
124 | [homepage]: https://www.contributor-covenant.org
125 |
126 | For answers to common questions about this code of conduct, see the FAQ at
127 | https://www.contributor-covenant.org/faq. Translations are available at
128 | https://www.contributor-covenant.org/translations.
129 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | GNU LESSER GENERAL PUBLIC LICENSE
2 | Version 3, 29 June 2007
3 |
4 | Copyright (C) 2007 Free Software Foundation, Inc.
5 | Everyone is permitted to copy and distribute verbatim copies
6 | of this license document, but changing it is not allowed.
7 |
8 |
9 | This version of the GNU Lesser General Public License incorporates
10 | the terms and conditions of version 3 of the GNU General Public
11 | License, supplemented by the additional permissions listed below.
12 |
13 | 0. Additional Definitions.
14 |
15 | As used herein, "this License" refers to version 3 of the GNU Lesser
16 | General Public License, and the "GNU GPL" refers to version 3 of the GNU
17 | General Public License.
18 |
19 | "The Library" refers to a covered work governed by this License,
20 | other than an Application or a Combined Work as defined below.
21 |
22 | An "Application" is any work that makes use of an interface provided
23 | by the Library, but which is not otherwise based on the Library.
24 | Defining a subclass of a class defined by the Library is deemed a mode
25 | of using an interface provided by the Library.
26 |
27 | A "Combined Work" is a work produced by combining or linking an
28 | Application with the Library. The particular version of the Library
29 | with which the Combined Work was made is also called the "Linked
30 | Version".
31 |
32 | The "Minimal Corresponding Source" for a Combined Work means the
33 | Corresponding Source for the Combined Work, excluding any source code
34 | for portions of the Combined Work that, considered in isolation, are
35 | based on the Application, and not on the Linked Version.
36 |
37 | The "Corresponding Application Code" for a Combined Work means the
38 | object code and/or source code for the Application, including any data
39 | and utility programs needed for reproducing the Combined Work from the
40 | Application, but excluding the System Libraries of the Combined Work.
41 |
42 | 1. Exception to Section 3 of the GNU GPL.
43 |
44 | You may convey a covered work under sections 3 and 4 of this License
45 | without being bound by section 3 of the GNU GPL.
46 |
47 | 2. Conveying Modified Versions.
48 |
49 | If you modify a copy of the Library, and, in your modifications, a
50 | facility refers to a function or data to be supplied by an Application
51 | that uses the facility (other than as an argument passed when the
52 | facility is invoked), then you may convey a copy of the modified
53 | version:
54 |
55 | a) under this License, provided that you make a good faith effort to
56 | ensure that, in the event an Application does not supply the
57 | function or data, the facility still operates, and performs
58 | whatever part of its purpose remains meaningful, or
59 |
60 | b) under the GNU GPL, with none of the additional permissions of
61 | this License applicable to that copy.
62 |
63 | 3. Object Code Incorporating Material from Library Header Files.
64 |
65 | The object code form of an Application may incorporate material from
66 | a header file that is part of the Library. You may convey such object
67 | code under terms of your choice, provided that, if the incorporated
68 | material is not limited to numerical parameters, data structure
69 | layouts and accessors, or small macros, inline functions and templates
70 | (ten or fewer lines in length), you do both of the following:
71 |
72 | a) Give prominent notice with each copy of the object code that the
73 | Library is used in it and that the Library and its use are
74 | covered by this License.
75 |
76 | b) Accompany the object code with a copy of the GNU GPL and this license
77 | document.
78 |
79 | 4. Combined Works.
80 |
81 | You may convey a Combined Work under terms of your choice that,
82 | taken together, effectively do not restrict modification of the
83 | portions of the Library contained in the Combined Work and reverse
84 | engineering for debugging such modifications, if you also do each of
85 | the following:
86 |
87 | a) Give prominent notice with each copy of the Combined Work that
88 | the Library is used in it and that the Library and its use are
89 | covered by this License.
90 |
91 | b) Accompany the Combined Work with a copy of the GNU GPL and this license
92 | document.
93 |
94 | c) For a Combined Work that displays copyright notices during
95 | execution, include the copyright notice for the Library among
96 | these notices, as well as a reference directing the user to the
97 | copies of the GNU GPL and this license document.
98 |
99 | d) Do one of the following:
100 |
101 | 0) Convey the Minimal Corresponding Source under the terms of this
102 | License, and the Corresponding Application Code in a form
103 | suitable for, and under terms that permit, the user to
104 | recombine or relink the Application with a modified version of
105 | the Linked Version to produce a modified Combined Work, in the
106 | manner specified by section 6 of the GNU GPL for conveying
107 | Corresponding Source.
108 |
109 | 1) Use a suitable shared library mechanism for linking with the
110 | Library. A suitable mechanism is one that (a) uses at run time
111 | a copy of the Library already present on the user's computer
112 | system, and (b) will operate properly with a modified version
113 | of the Library that is interface-compatible with the Linked
114 | Version.
115 |
116 | e) Provide Installation Information, but only if you would otherwise
117 | be required to provide such information under section 6 of the
118 | GNU GPL, and only to the extent that such information is
119 | necessary to install and execute a modified version of the
120 | Combined Work produced by recombining or relinking the
121 | Application with a modified version of the Linked Version. (If
122 | you use option 4d0, the Installation Information must accompany
123 | the Minimal Corresponding Source and Corresponding Application
124 | Code. If you use option 4d1, you must provide the Installation
125 | Information in the manner specified by section 6 of the GNU GPL
126 | for conveying Corresponding Source.)
127 |
128 | 5. Combined Libraries.
129 |
130 | You may place library facilities that are a work based on the
131 | Library side by side in a single library together with other library
132 | facilities that are not Applications and are not covered by this
133 | License, and convey such a combined library under terms of your
134 | choice, if you do both of the following:
135 |
136 | a) Accompany the combined library with a copy of the same work based
137 | on the Library, uncombined with any other library facilities,
138 | conveyed under the terms of this License.
139 |
140 | b) Give prominent notice with the combined library that part of it
141 | is a work based on the Library, and explaining where to find the
142 | accompanying uncombined form of the same work.
143 |
144 | 6. Revised Versions of the GNU Lesser General Public License.
145 |
146 | The Free Software Foundation may publish revised and/or new versions
147 | of the GNU Lesser General Public License from time to time. Such new
148 | versions will be similar in spirit to the present version, but may
149 | differ in detail to address new problems or concerns.
150 |
151 | Each version is given a distinguishing version number. If the
152 | Library as you received it specifies that a certain numbered version
153 | of the GNU Lesser General Public License "or any later version"
154 | applies to it, you have the option of following the terms and
155 | conditions either of that published version or of any later version
156 | published by the Free Software Foundation. If the Library as you
157 | received it does not specify a version number of the GNU Lesser
158 | General Public License, you may choose any version of the GNU Lesser
159 | General Public License ever published by the Free Software Foundation.
160 |
161 | If the Library as you received it specifies that a proxy can decide
162 | whether future versions of the GNU Lesser General Public License shall
163 | apply, that proxy's public statement of acceptance of any version is
164 | permanent authorization for you to choose that version for the
165 | Library.
166 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | **dingo** is a Python package that analyzes metabolic networks.
4 | It relies on high dimensional sampling with Markov Chain Monte Carlo (MCMC)
5 | methods and fast optimization methods to analyze the possible states of a
6 | metabolic network. To perform MCMC sampling, `dingo` relies on the `C++` library
7 | [volesti](https://github.com/GeomScale/volume_approximation), which provides
8 | several algorithms for sampling convex polytopes.
9 | `dingo` also performs two standard methods to analyze the flux space of a
10 | metabolic network, namely Flux Balance Analysis and Flux Variability Analysis.
11 |
12 | `dingo` is part of [GeomScale](https://geomscale.github.io/) project.
13 |
14 | [](https://github.com/GeomScale/dingo/actions?query=workflow%3Adingo-ubuntu)
15 | [](https://colab.research.google.com/github/GeomScale/dingo/blob/develop/tutorials/dingo_tutorial.ipynb)
16 | [](https://gitter.im/GeomScale/community?utm_source=share-link&utm_medium=link&utm_campaign=share-link)
17 |
18 |
19 | ## Installation
20 |
21 | **Note:** Python version should be 3.8.x. You can check this by running the following command in your terminal:
22 | ```bash
23 | python --version
24 | ```
25 | If you have a different version of Python installed, you'll need to install it ([start here](https://linuxize.com/post/how-to-install-python-3-8-on-ubuntu-18-04/)) and update-alternatives ([start here](https://linuxhint.com/update_alternatives_ubuntu/))
26 |
27 | **Note:** If you are using `GitHub Codespaces`. Start [here](https://docs.github.com/en/codespaces/setting-up-your-project-for-codespaces/adding-a-dev-container-configuration/setting-up-your-python-project-for-codespaces) to set the python version. Once your Python version is `3.8.x` you can start following the below instructions.
28 |
29 |
30 |
31 | To load the submodules that dingo uses, run
32 |
33 | ````bash
34 | git submodule update --init
35 | ````
36 |
37 | You will need to download and unzip the Boost library:
38 | ```
39 | wget -O boost_1_76_0.tar.bz2 https://archives.boost.io/release/1.76.0/source/boost_1_76_0.tar.bz2
40 | tar xjf boost_1_76_0.tar.bz2
41 | rm boost_1_76_0.tar.bz2
42 | ```
43 |
44 | You will also need to download and unzip the lpsolve library:
45 | ```
46 | wget https://sourceforge.net/projects/lpsolve/files/lpsolve/5.5.2.11/lp_solve_5.5.2.11_source.tar.gz
47 | tar xzvf lp_solve_5.5.2.11_source.tar.gz
48 | rm lp_solve_5.5.2.11_source.tar.gz
49 | ```
50 |
51 | Then, you need to install the dependencies for the PySPQR library; for Debian/Ubuntu Linux, run
52 |
53 | ```bash
54 | sudo apt-get update -y
55 | sudo apt-get install -y libsuitesparse-dev
56 | ```
57 |
58 | To install the Python dependencies, `dingo` is using [Poetry](https://python-poetry.org/),
59 | ```
60 | curl -sSL https://install.python-poetry.org | python3 - --version 1.3.2
61 | poetry shell
62 | poetry install
63 | ```
64 |
65 | You can install the [Gurobi solver](https://www.gurobi.com/) for faster linear programming optimization. Run
66 |
67 | ```
68 | pip3 install -i https://pypi.gurobi.com gurobipy
69 | ```
70 |
71 | Then, you will need a [license](https://www.gurobi.com/downloads/end-user-license-agreement-academic/). For more information, we refer to the Gurobi [download center](https://www.gurobi.com/downloads/).
72 |
73 |
74 |
75 |
76 | ## Unit tests
77 |
78 | Now, you can run the unit tests by the following commands (with the default solver `highs`):
79 | ```
80 | python3 tests/fba.py
81 | python3 tests/full_dimensional.py
82 | python3 tests/max_ball.py
83 | python3 tests/scaling.py
84 | python3 tests/rounding.py
85 | python3 tests/sampling.py
86 | ```
87 |
88 | If you have installed Gurobi successfully, then run
89 | ```
90 | python3 tests/fba.py gurobi
91 | python3 tests/full_dimensional.py gurobi
92 | python3 tests/max_ball.py gurobi
93 | python3 tests/scaling.py gurobi
94 | python3 tests/rounding.py gurobi
95 | python3 tests/sampling.py gurobi
96 | ```
97 |
98 | ## Tutorial
99 |
100 | You can have a look at our [Google Colab notebook](https://colab.research.google.com/github/GeomScale/dingo/blob/develop/tutorials/dingo_tutorial.ipynb)
101 | on how to use `dingo`.
102 |
103 |
104 | ## Documentation
105 |
106 |
107 | It quite simple to use dingo in your code. In general, dingo provides two classes:
108 |
109 | - `metabolic_network` represents a metabolic network
110 | - `polytope_sampler` can be used to sample from the flux space of a metabolic network or from a general convex polytope.
111 |
112 | The following script shows how you could sample steady states of a metabolic network with dingo. To initialize a metabolic network object you have to provide the path to the `json` file as those in [BiGG](http://bigg.ucsd.edu/models) dataset or the `mat` file (using the `matlab` wrapper in folder `/ext_data` to modify a standard `mat` file of a model as those in BiGG dataset):
113 |
114 | ```python
115 | from dingo import MetabolicNetwork, PolytopeSampler
116 |
117 | model = MetabolicNetwork.from_json('path/to/model_file.json')
118 | sampler = PolytopeSampler(model)
119 | steady_states = sampler.generate_steady_states()
120 | ```
121 |
122 | `dingo` can also load a model given in `.sbml` format using the following command,
123 |
124 | ```python
125 | model = MetabolicNetwork.from_sbml('path/to/model_file.sbml')
126 | ```
127 |
128 | The output variable `steady_states` is a `numpy` array that contains the steady states of the model column-wise. You could ask from the `sampler` for more statistical guarantees on sampling,
129 |
130 | ```python
131 | steady_states = sampler.generate_steady_states(ess=2000, psrf = True)
132 | ```
133 |
134 | The `ess` stands for the effective sample size (ESS) (default value is `1000`) and the `psrf` is a flag to request an upper bound equal to 1.1 for the value of the *potential scale reduction factor* of each marginal flux (default option is `False`).
135 |
136 | You could also ask for parallel MMCS algorithm,
137 |
138 | ```python
139 | steady_states = sampler.generate_steady_states(ess=2000, psrf = True,
140 | parallel_mmcs = True, num_threads = 2)
141 | ```
142 |
143 | The default option is to run the sequential [Multiphase Monte Carlo Sampling algorithm](https://arxiv.org/abs/2012.05503) (MMCS) algorithm.
144 |
145 | **Tip**: After the first run of MMCS algorithm the polytope stored in object `sampler` is usually more rounded than the initial one. Thus, the function `generate_steady_states()` becomes more efficient from run to run.
146 |
147 |
148 | #### Rounding the polytope
149 |
150 | `dingo` provides three methods to round a polytope: (i) Bring the polytope to John position by apllying to it the transformation that maps the largest inscribed ellipsoid of the polytope to the unit ball, (ii) Bring the polytope to near-isotropic position by using uniform sampling with Billiard Walk, (iii) Apply to the polytope the transformation that maps the smallest enclosing ellipsoid of a uniform sample from the interior of the polytope to the unit ball.
151 |
152 | ```python
153 | from dingo import MetabolicNetwork, PolytopeSampler
154 |
155 | model = MetabolicNetwork.from_json('path/to/model_file.json')
156 | sampler = PolytopeSampler(model)
157 | A, b, N, N_shift = sampler.get_polytope()
158 |
159 | A_rounded, b_rounded, Tr, Tr_shift = sampler.round_polytope(A, b, method="john_position")
160 | A_rounded, b_rounded, Tr, Tr_shift = sampler.round_polytope(A, b, method="isotropic_position")
161 | A_rounded, b_rounded, Tr, Tr_shift = sampler.round_polytope(A, b, method="min_ellipsoid")
162 | ```
163 |
164 | Then, to sample from the rounded polytope, the user has to call the following static method of PolytopeSampler class,
165 |
166 | ```python
167 | samples = sample_from_polytope(A_rounded, b_rounded)
168 | ```
169 |
170 | Last you can map the samples back to steady states,
171 |
172 | ```python
173 | from dingo import map_samples_to_steady_states
174 |
175 | steady_states = map_samples_to_steady_states(samples, N, N_shift, Tr, Tr_shift)
176 | ```
177 |
178 | #### Other MCMC sampling methods
179 |
180 | To use any other MCMC sampling method that `dingo` provides you can use the following piece of code:
181 |
182 | ```python
183 | sampler = polytope_sampler(model)
184 | steady_states = sampler.generate_steady_states_no_multiphase() #default parameters (method = 'billiard_walk', n=1000, burn_in=0, thinning=1)
185 | ```
186 |
187 | The MCMC methods that dingo (through `volesti` library) provides are the following: (i) 'cdhr': Coordinate Directions Hit-and-Run, (ii) 'rdhr': Random Directions Hit-and-Run,
188 | (iii) 'billiard_walk', (iv) 'ball_walk', (v) 'dikin_walk', (vi) 'john_walk', (vii) 'vaidya_walk'.
189 |
190 |
191 |
192 | #### Switch the linear programming solver
193 |
194 | We use `pyoptinterface` to interface with the linear programming solvers. To switch the solver that `dingo` uses, you can use the `set_default_solver` function. The default solver is `highs` and you can switch to `gurobi` by running,
195 |
196 | ```python
197 | from dingo import set_default_solver
198 | set_default_solver("gurobi")
199 | ```
200 |
201 | You can also switch to other solvers that `pyoptinterface` supports, but we recommend using `highs` or `gurobi`. If you have issues with the solver, you can check the `pyoptinterface` [documentation](https://metab0t.github.io/PyOptInterface/getting_started.html).
202 |
203 | ### Apply FBA and FVA methods
204 |
205 | To apply FVA and FBA methods you have to use the class `metabolic_network`,
206 |
207 | ```python
208 | from dingo import MetabolicNetwork
209 |
210 | model = MetabolicNetwork.from_json('path/to/model_file.json')
211 | fva_output = model.fva()
212 |
213 | min_fluxes = fva_output[0]
214 | max_fluxes = fva_output[1]
215 | max_biomass_flux_vector = fva_output[2]
216 | max_biomass_objective = fva_output[3]
217 | ```
218 |
219 | The output of FVA method is tuple that contains `numpy` arrays. The vectors `min_fluxes` and `max_fluxes` contains the minimum and the maximum values of each flux. The vector `max_biomass_flux_vector` is the optimal flux vector according to the biomass objective function and `max_biomass_objective` is the value of that optimal solution.
220 |
221 | To apply FBA method,
222 |
223 | ```python
224 | fba_output = model.fba()
225 |
226 | max_biomass_flux_vector = fba_output[0]
227 | max_biomass_objective = fba_output[1]
228 | ```
229 |
230 | while the output vectors are the same with the previous example.
231 |
232 |
233 |
234 | ### Set the restriction in the flux space
235 |
236 | FVA and FBA, restrict the flux space to the set of flux vectors that have an objective value equal to the optimal value of the function. dingo allows for a more relaxed option where you could ask for flux vectors that have an objective value equal to at least a percentage of the optimal value,
237 |
238 | ```python
239 | model.set_opt_percentage(90)
240 | fva_output = model.fva()
241 |
242 | # the same restriction in the flux space holds for the sampler
243 | sampler = polytope_sampler(model)
244 | steady_states = sampler.generate_steady_states()
245 | ```
246 |
247 | The default percentage is `100%`.
248 |
249 |
250 |
251 | ### Change the objective function
252 |
253 | You could also set an alternative objective function. For example, to maximize the 1st reaction of the model,
254 |
255 | ```python
256 | n = model.num_of_reactions()
257 | obj_fun = np.zeros(n)
258 | obj_fun[0] = 1
259 | model.objective_function(obj_fun)
260 |
261 | # apply FVA using the new objective function
262 | fva_output = model.fva()
263 | # sample from the flux space by restricting
264 | # the fluxes according to the new objective function
265 | sampler = polytope_sampler(model)
266 | steady_states = sampler.generate_steady_states()
267 | ```
268 |
269 |
270 |
271 | ### Plot flux marginals
272 |
273 | The generated steady states can be used to estimate the marginal density function of each flux. You can plot the histogram using the samples,
274 |
275 | ```python
276 | from dingo import plot_histogram
277 |
278 | model = MetabolicNetwork.from_json('path/to/e_coli_core.json')
279 | sampler = PolytopeSampler(model)
280 | steady_states = sampler.generate_steady_states(ess = 3000)
281 |
282 | # plot the histogram for the 14th reaction in e-coli (ACONTa)
283 | reactions = model.reactions
284 | plot_histogram(
285 | steady_states[13],
286 | reactions[13],
287 | n_bins = 60,
288 | )
289 | ```
290 |
291 | The default number of bins is 60. dingo uses the package `matplotlib` for plotting.
292 |
293 | 
294 |
295 | ### Plot a copula between two fluxes
296 |
297 | The generated steady states can be used to estimate and plot the copula between two fluxes. You can plot the copula using the samples,
298 |
299 | ```python
300 | from dingo import plot_copula
301 |
302 | model = MetabolicNetwork.from_json('path/to/e_coli_core.json')
303 | sampler = PolytopeSampler(model)
304 | steady_states = sampler.generate_steady_states(ess = 3000)
305 |
306 | # plot the copula between the 13th (PPC) and the 14th (ACONTa) reaction in e-coli
307 | reactions = model.reactions
308 |
309 | data_flux2=[steady_states[12],reactions[12]]
310 | data_flux1=[steady_states[13],reactions[13]]
311 |
312 | plot_copula(data_flux1, data_flux2, n=10)
313 | ```
314 |
315 | The default number of cells is 5x5=25. dingo uses the package `plotly` for plotting.
316 |
317 | 
318 |
319 |
320 |
--------------------------------------------------------------------------------
/build.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | # See if Cython is installed
4 | try:
5 | from Cython.Build import cythonize
6 | # Do nothing if Cython is not available
7 | except ImportError:
8 | # Got to provide this function. Otherwise, poetry will fail
9 | def build(setup_kwargs):
10 | pass
11 |
12 |
13 | # Cython is installed. Compile
14 | else:
15 | from setuptools import Extension
16 | from setuptools.dist import Distribution
17 | from distutils.command.build_ext import build_ext
18 |
19 | # This function will be executed in setup.py:
20 | def build(setup_kwargs):
21 | # The file you want to compile
22 | extensions = ["dingo/volestipy.pyx"]
23 |
24 | # gcc arguments hack: enable optimizations
25 | os.environ["CFLAGS"] = [
26 | "-std=c++17",
27 | "-O3",
28 | "-DBOOST_NO_AUTO_PTR",
29 | "-ldl",
30 | "-lm",
31 | ]
32 |
33 | # Build
34 | setup_kwargs.update(
35 | {
36 | "ext_modules": cythonize(
37 | extensions,
38 | language_level=3,
39 | compiler_directives={"linetrace": True},
40 | ),
41 | "cmdclass": {"build_ext": build_ext},
42 | }
43 | )
44 |
--------------------------------------------------------------------------------
/dingo/MetabolicNetwork.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 | # Copyright (c) 2021 Vissarion Fisikopoulos
6 | # Copyright (c) 2024 Ke Shi
7 |
8 | # Licensed under GNU LGPL.3, see LICENCE file
9 |
10 | import numpy as np
11 | import sys
12 | from typing import Dict
13 | import cobra
14 | from dingo.loading_models import read_json_file, read_mat_file, read_sbml_file, parse_cobra_model
15 | from dingo.pyoptinterface_based_impl import fba,fva,inner_ball,remove_redundant_facets
16 |
17 | class MetabolicNetwork:
18 | def __init__(self, tuple_args):
19 |
20 | self._parameters = {}
21 | self._parameters["opt_percentage"] = 100
22 | self._parameters["distribution"] = "uniform"
23 | self._parameters["nullspace_method"] = "sparseQR"
24 | self._parameters["solver"] = None
25 |
26 | if len(tuple_args) != 10:
27 | raise Exception(
28 | "An unknown input format given to initialize a metabolic network object."
29 | )
30 |
31 | self._lb = tuple_args[0]
32 | self._ub = tuple_args[1]
33 | self._S = tuple_args[2]
34 | self._metabolites = tuple_args[3]
35 | self._reactions = tuple_args[4]
36 | self._biomass_index = tuple_args[5]
37 | self._objective_function = tuple_args[6]
38 | self._medium = tuple_args[7]
39 | self._medium_indices = tuple_args[8]
40 | self._exchanges = tuple_args[9]
41 |
42 | try:
43 | if self._biomass_index is not None and (
44 | self._lb.size != self._ub.size
45 | or self._lb.size != self._S.shape[1]
46 | or len(self._metabolites) != self._S.shape[0]
47 | or len(self._reactions) != self._S.shape[1]
48 | or self._objective_function.size != self._S.shape[1]
49 | or (self._biomass_index < 0)
50 | or (self._biomass_index > self._objective_function.size)
51 | ):
52 | raise Exception(
53 | "Wrong tuple format given to initialize a metabolic network object."
54 | )
55 | except LookupError as error:
56 | raise error.with_traceback(sys.exc_info()[2])
57 |
58 | @classmethod
59 | def from_json(cls, arg):
60 | if (not isinstance(arg, str)) or (arg[-4:] != "json"):
61 | raise Exception(
62 | "An unknown input format given to initialize a metabolic network object."
63 | )
64 |
65 | return cls(read_json_file(arg))
66 |
67 | @classmethod
68 | def from_mat(cls, arg):
69 | if (not isinstance(arg, str)) or (arg[-3:] != "mat"):
70 | raise Exception(
71 | "An unknown input format given to initialize a metabolic network object."
72 | )
73 |
74 | return cls(read_mat_file(arg))
75 |
76 | @classmethod
77 | def from_sbml(cls, arg):
78 | if (not isinstance(arg, str)) and ((arg[-3:] == "xml") or (arg[-4] == "sbml")):
79 | raise Exception(
80 | "An unknown input format given to initialize a metabolic network object."
81 | )
82 |
83 | return cls(read_sbml_file(arg))
84 |
85 | @classmethod
86 | def from_cobra_model(cls, arg):
87 | if (not isinstance(arg, cobra.core.model.Model)):
88 | raise Exception(
89 | "An unknown input format given to initialize a metabolic network object."
90 | )
91 |
92 | return cls(parse_cobra_model(arg))
93 |
94 | def fva(self):
95 | """A member function to apply the FVA method on the metabolic network."""
96 |
97 | return fva(
98 | self._lb,
99 | self._ub,
100 | self._S,
101 | self._objective_function,
102 | self._parameters["opt_percentage"],
103 | self._parameters["solver"]
104 | )
105 |
106 | def fba(self):
107 | """A member function to apply the FBA method on the metabolic network."""
108 | return fba(self._lb, self._ub, self._S, self._objective_function, self._parameters["solver"])
109 |
110 | @property
111 | def lb(self):
112 | return self._lb
113 |
114 | @property
115 | def ub(self):
116 | return self._ub
117 |
118 | @property
119 | def S(self):
120 | return self._S
121 |
122 | @property
123 | def metabolites(self):
124 | return self._metabolites
125 |
126 | @property
127 | def reactions(self):
128 | return self._reactions
129 |
130 | @property
131 | def biomass_index(self):
132 | return self._biomass_index
133 |
134 | @property
135 | def objective_function(self):
136 | return self._objective_function
137 |
138 | @property
139 | def medium(self):
140 | return self._medium
141 |
142 | @property
143 | def exchanges(self):
144 | return self._exchanges
145 |
146 | @property
147 | def parameters(self):
148 | return self._parameters
149 |
150 | @property
151 | def get_as_tuple(self):
152 | return (
153 | self._lb,
154 | self._ub,
155 | self._S,
156 | self._metabolites,
157 | self._reactions,
158 | self._biomass_index,
159 | self._objective_function,
160 | self._medium,
161 | self._inter_medium,
162 | self._exchanges
163 | )
164 |
165 | def num_of_reactions(self):
166 | return len(self._reactions)
167 |
168 | def num_of_metabolites(self):
169 | return len(self._metabolites)
170 |
171 | @lb.setter
172 | def lb(self, value):
173 | self._lb = value
174 |
175 | @ub.setter
176 | def ub(self, value):
177 | self._ub = value
178 |
179 | @S.setter
180 | def S(self, value):
181 | self._S = value
182 |
183 | @metabolites.setter
184 | def metabolites(self, value):
185 | self._metabolites = value
186 |
187 | @reactions.setter
188 | def reactions(self, value):
189 | self._reactions = value
190 |
191 | @biomass_index.setter
192 | def biomass_index(self, value):
193 | self._biomass_index = value
194 |
195 | @objective_function.setter
196 | def objective_function(self, value):
197 | self._objective_function = value
198 |
199 |
200 | @medium.setter
201 | def medium(self, medium: Dict[str, float]) -> None:
202 | """Set the constraints on the model exchanges.
203 |
204 | `model.medium` returns a dictionary of the bounds for each of the
205 | boundary reactions, in the form of `{rxn_id: rxn_bound}`, where `rxn_bound`
206 | specifies the absolute value of the bound in direction of metabolite
207 | creation (i.e., lower_bound for `met <--`, upper_bound for `met -->`)
208 |
209 | Parameters
210 | ----------
211 | medium: dict
212 | The medium to initialize. medium should be a dictionary defining
213 | `{rxn_id: bound}` pairs.
214 | """
215 |
216 | def set_active_bound(reaction: str, reac_index: int, bound: float) -> None:
217 | """Set active bound.
218 |
219 | Parameters
220 | ----------
221 | reaction: cobra.Reaction
222 | Reaction to set
223 | bound: float
224 | Value to set bound to. The bound is reversed and set as lower bound
225 | if reaction has reactants (metabolites that are consumed). If reaction
226 | has reactants, it seems the upper bound won't be set.
227 | """
228 | if any(x < 0 for x in list(self._S[:, reac_index])):
229 | self._lb[reac_index] = -bound
230 | elif any(x > 0 for x in list(self._S[:, reac_index])):
231 | self._ub[reac_index] = bound
232 |
233 | # Set the given media bounds
234 | media_rxns = []
235 | exchange_rxns = frozenset(self.exchanges)
236 | for rxn_id, rxn_bound in medium.items():
237 | if rxn_id not in exchange_rxns:
238 | logger.warning(
239 | f"{rxn_id} does not seem to be an an exchange reaction. "
240 | f"Applying bounds anyway."
241 | )
242 | media_rxns.append(rxn_id)
243 |
244 | reac_index = self._reactions.index(rxn_id)
245 |
246 | set_active_bound(rxn_id, reac_index, rxn_bound)
247 |
248 | frozen_media_rxns = frozenset(media_rxns)
249 |
250 | # Turn off reactions not present in media
251 | for rxn_id in exchange_rxns - frozen_media_rxns:
252 | """
253 | is_export for us, needs to check on the S
254 | order reactions to their lb and ub
255 | """
256 | # is_export = rxn.reactants and not rxn.products
257 | reac_index = self._reactions.index(rxn_id)
258 | products = np.any(self._S[:,reac_index] > 0)
259 | reactants_exist = np.any(self._S[:,reac_index] < 0)
260 | is_export = True if not products and reactants_exist else False
261 | set_active_bound(
262 | rxn_id, reac_index, min(0.0, -self._lb[reac_index] if is_export else self._ub[reac_index])
263 | )
264 |
265 | def set_solver(self, solver: str):
266 | self._parameters["solver"] = solver
267 |
268 | def set_nullspace_method(self, value):
269 |
270 | self._parameters["nullspace_method"] = value
271 |
272 | def set_opt_percentage(self, value):
273 |
274 | self._parameters["opt_percentage"] = value
275 |
276 | def shut_down_reaction(self, index_val):
277 |
278 | if (
279 | (not isinstance(index_val, int))
280 | or index_val < 0
281 | or index_val >= self._S.shape[1]
282 | ):
283 | raise Exception("The input does not correspond to a proper reaction index.")
284 |
285 | self._lb[index_val] = 0
286 | self._ub[index_val] = 0
287 |
--------------------------------------------------------------------------------
/dingo/PolytopeSampler.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 | # Copyright (c) 2024 Ke Shi
6 |
7 | # Licensed under GNU LGPL.3, see LICENCE file
8 |
9 |
10 | import numpy as np
11 | import warnings
12 | import math
13 | from dingo.MetabolicNetwork import MetabolicNetwork
14 | from dingo.utils import (
15 | map_samples_to_steady_states,
16 | get_matrices_of_low_dim_polytope,
17 | get_matrices_of_full_dim_polytope,
18 | )
19 |
20 | from dingo.pyoptinterface_based_impl import fba,fva,inner_ball,remove_redundant_facets
21 |
22 | from volestipy import HPolytope
23 |
24 |
25 | class PolytopeSampler:
26 | def __init__(self, metabol_net):
27 |
28 | if not isinstance(metabol_net, MetabolicNetwork):
29 | raise Exception("An unknown input object given for initialization.")
30 |
31 | self._metabolic_network = metabol_net
32 | self._A = []
33 | self._b = []
34 | self._N = []
35 | self._N_shift = []
36 | self._T = []
37 | self._T_shift = []
38 | self._parameters = {}
39 | self._parameters["nullspace_method"] = "sparseQR"
40 | self._parameters["opt_percentage"] = self.metabolic_network.parameters[
41 | "opt_percentage"
42 | ]
43 | self._parameters["distribution"] = "uniform"
44 | self._parameters["first_run_of_mmcs"] = True
45 | self._parameters["remove_redundant_facets"] = True
46 |
47 | self._parameters["tol"] = 1e-06
48 | self._parameters["solver"] = None
49 |
50 | def get_polytope(self):
51 | """A member function to derive the corresponding full dimensional polytope
52 | and a isometric linear transformation that maps the latter to the initial space.
53 | """
54 |
55 | if (
56 | self._A == []
57 | or self._b == []
58 | or self._N == []
59 | or self._N_shift == []
60 | or self._T == []
61 | or self._T_shift == []
62 | ):
63 |
64 | (
65 | max_flux_vector,
66 | max_objective,
67 | ) = self._metabolic_network.fba()
68 |
69 | if (
70 | self._parameters["remove_redundant_facets"]
71 | ):
72 |
73 | A, b, Aeq, beq = remove_redundant_facets(
74 | self._metabolic_network.lb,
75 | self._metabolic_network.ub,
76 | self._metabolic_network.S,
77 | self._metabolic_network.objective_function,
78 | self._parameters["opt_percentage"],
79 | self._parameters["solver"],
80 | )
81 | else:
82 |
83 | (
84 | min_fluxes,
85 | max_fluxes,
86 | max_flux_vector,
87 | max_objective,
88 | ) = self._metabolic_network.fva()
89 |
90 | A, b, Aeq, beq = get_matrices_of_low_dim_polytope(
91 | self._metabolic_network.S,
92 | self._metabolic_network.lb,
93 | self._metabolic_network.ub,
94 | min_fluxes,
95 | max_fluxes,
96 | )
97 |
98 | if (
99 | A.shape[0] != b.size
100 | or A.shape[1] != Aeq.shape[1]
101 | or Aeq.shape[0] != beq.size
102 | ):
103 | raise Exception("Preprocess for full dimensional polytope failed.")
104 |
105 | A = np.vstack((A, -self._metabolic_network.objective_function))
106 |
107 | b = np.append(
108 | b,
109 | -np.floor(max_objective / self._parameters["tol"])
110 | * self._parameters["tol"]
111 | * self._parameters["opt_percentage"]
112 | / 100,
113 | )
114 |
115 | (
116 | self._A,
117 | self._b,
118 | self._N,
119 | self._N_shift,
120 | ) = get_matrices_of_full_dim_polytope(A, b, Aeq, beq)
121 |
122 | n = self._A.shape[1]
123 | self._T = np.eye(n)
124 | self._T_shift = np.zeros(n)
125 |
126 | return self._A, self._b, self._N, self._N_shift
127 |
128 | def generate_steady_states(
129 | self, ess=1000, psrf=False, parallel_mmcs=False, num_threads=1
130 | ):
131 | """A member function to sample steady states.
132 |
133 | Keyword arguments:
134 | ess -- the target effective sample size
135 | psrf -- a boolean flag to request PSRF smaller than 1.1 for all marginal fluxes
136 | parallel_mmcs -- a boolean flag to request the parallel mmcs
137 | num_threads -- the number of threads to use for parallel mmcs
138 | """
139 |
140 | self.get_polytope()
141 |
142 | P = HPolytope(self._A, self._b)
143 |
144 | self._A, self._b, Tr, Tr_shift, samples = P.mmcs(
145 | ess, psrf, parallel_mmcs, num_threads, self._parameters["solver"]
146 | )
147 |
148 | if self._parameters["first_run_of_mmcs"]:
149 | steady_states = map_samples_to_steady_states(
150 | samples, self._N, self._N_shift
151 | )
152 | self._parameters["first_run_of_mmcs"] = False
153 | else:
154 | steady_states = map_samples_to_steady_states(
155 | samples, self._N, self._N_shift, self._T, self._T_shift
156 | )
157 |
158 | self._T = np.dot(self._T, Tr)
159 | self._T_shift = np.add(self._T_shift, Tr_shift)
160 |
161 | return steady_states
162 |
163 | def generate_steady_states_no_multiphase(
164 | self, method = 'billiard_walk', n=1000, burn_in=0, thinning=1, variance=1.0, bias_vector=None, ess=1000
165 | ):
166 | """A member function to sample steady states.
167 |
168 | Keyword arguments:
169 | method -- An MCMC method to sample, i.e. {'billiard_walk', 'cdhr', 'rdhr', 'ball_walk', 'dikin_walk', 'john_walk', 'vaidya_walk', 'gaussian_hmc_walk', 'exponential_hmc_walk', 'hmc_leapfrog_gaussian', 'hmc_leapfrog_exponential'}
170 | n -- the number of steady states to sample
171 | burn_in -- the number of points to burn before sampling
172 | thinning -- the walk length of the chain
173 | """
174 |
175 | self.get_polytope()
176 |
177 | P = HPolytope(self._A, self._b)
178 |
179 | if bias_vector is None:
180 | bias_vector = np.ones(self._A.shape[1], dtype=np.float64)
181 | else:
182 | bias_vector = bias_vector.astype('float64')
183 |
184 | samples = P.generate_samples(method.encode('utf-8'), n, burn_in, thinning, variance, bias_vector, self._parameters["solver"], ess)
185 | samples_T = samples.T
186 |
187 | steady_states = map_samples_to_steady_states(
188 | samples_T, self._N, self._N_shift
189 | )
190 |
191 | return steady_states
192 |
193 | @staticmethod
194 | def sample_from_polytope(
195 | A, b, ess=1000, psrf=False, parallel_mmcs=False, num_threads=1, solver=None
196 | ):
197 | """A static function to sample from a full dimensional polytope.
198 |
199 | Keyword arguments:
200 | A -- an mxn matrix that contains the normal vectors of the facets of the polytope row-wise
201 | b -- a m-dimensional vector, s.t. A*x <= b
202 | ess -- the target effective sample size
203 | psrf -- a boolean flag to request PSRF smaller than 1.1 for all marginal fluxes
204 | parallel_mmcs -- a boolean flag to request the parallel mmcs
205 | num_threads -- the number of threads to use for parallel mmcs
206 | """
207 |
208 | P = HPolytope(A, b)
209 |
210 | A, b, Tr, Tr_shift, samples = P.mmcs(
211 | ess, psrf, parallel_mmcs, num_threads, solver
212 | )
213 |
214 |
215 | return samples
216 |
217 | @staticmethod
218 | def sample_from_polytope_no_multiphase(
219 | A, b, method = 'billiard_walk', n=1000, burn_in=0, thinning=1, variance=1.0, bias_vector=None, solver=None, ess=1000
220 | ):
221 | """A static function to sample from a full dimensional polytope with an MCMC method.
222 |
223 | Keyword arguments:
224 | A -- an mxn matrix that contains the normal vectors of the facets of the polytope row-wise
225 | b -- a m-dimensional vector, s.t. A*x <= b
226 | method -- An MCMC method to sample, i.e. {'billiard_walk', 'cdhr', 'rdhr', 'ball_walk', 'dikin_walk', 'john_walk', 'vaidya_walk', 'gaussian_hmc_walk', 'exponential_hmc_walk', 'hmc_leapfrog_gaussian', 'hmc_leapfrog_exponential'}
227 | n -- the number of steady states to sample
228 | burn_in -- the number of points to burn before sampling
229 | thinning -- the walk length of the chain
230 | """
231 | if bias_vector is None:
232 | bias_vector = np.ones(A.shape[1], dtype=np.float64)
233 | else:
234 | bias_vector = bias_vector.astype('float64')
235 |
236 | P = HPolytope(A, b)
237 |
238 | samples = P.generate_samples(method.encode('utf-8'), n, burn_in, thinning, variance, bias_vector, solver, ess)
239 |
240 | samples_T = samples.T
241 | return samples_T
242 |
243 | @staticmethod
244 | def round_polytope(
245 | A, b, method = "john_position", solver = None
246 | ):
247 | P = HPolytope(A, b)
248 | A, b, Tr, Tr_shift, round_value = P.rounding(method, solver)
249 |
250 | return A, b, Tr, Tr_shift
251 |
252 | @staticmethod
253 | def sample_from_fva_output(
254 | min_fluxes,
255 | max_fluxes,
256 | objective_function,
257 | max_objective,
258 | S,
259 | opt_percentage=100,
260 | ess=1000,
261 | psrf=False,
262 | parallel_mmcs=False,
263 | num_threads=1,
264 | solver = None
265 | ):
266 | """A static function to sample steady states when the output of FVA is given.
267 |
268 | Keyword arguments:
269 | min_fluxes -- minimum values of the fluxes, i.e., a n-dimensional vector
270 | max_fluxes -- maximum values for the fluxes, i.e., a n-dimensional vector
271 | objective_function -- the objective function
272 | max_objective -- the maximum value of the objective function
273 | S -- stoichiometric matrix
274 | opt_percentage -- consider solutions that give you at least a certain
275 | percentage of the optimal solution (default is to consider
276 | optimal solutions only)
277 | ess -- the target effective sample size
278 | psrf -- a boolean flag to request PSRF smaller than 1.1 for all marginal fluxes
279 | parallel_mmcs -- a boolean flag to request the parallel mmcs
280 | num_threads -- the number of threads to use for parallel mmcs
281 | """
282 |
283 | A, b, Aeq, beq = get_matrices_of_low_dim_polytope(
284 | S, min_fluxes, max_fluxes, opt_percentage, tol
285 | )
286 |
287 | A = np.vstack((A, -objective_function))
288 | b = np.append(
289 | b,
290 | -(opt_percentage / 100)
291 | * self._parameters["tol"]
292 | * math.floor(max_objective / self._parameters["tol"]),
293 | )
294 |
295 | A, b, N, N_shift = get_matrices_of_full_dim_polytope(A, b, Aeq, beq)
296 |
297 | P = HPolytope(A, b)
298 |
299 | A, b, Tr, Tr_shift, samples = P.mmcs(
300 | ess, psrf, parallel_mmcs, num_threads, solver
301 | )
302 |
303 | steady_states = map_samples_to_steady_states(samples, N, N_shift)
304 |
305 | return steady_states
306 |
307 | @property
308 | def A(self):
309 | return self._A
310 |
311 | @property
312 | def b(self):
313 | return self._b
314 |
315 | @property
316 | def T(self):
317 | return self._T
318 |
319 | @property
320 | def T_shift(self):
321 | return self._T_shift
322 |
323 | @property
324 | def N(self):
325 | return self._N
326 |
327 | @property
328 | def N_shift(self):
329 | return self._N_shift
330 |
331 | @property
332 | def metabolic_network(self):
333 | return self._metabolic_network
334 |
335 | def facet_redundancy_removal(self, value):
336 | self._parameters["remove_redundant_facets"] = value
337 |
338 | def set_solver(self, solver):
339 | self._parameters["solver"] = solver
340 |
341 | def set_distribution(self, value):
342 |
343 | self._parameters["distribution"] = value
344 |
345 | def set_nullspace_method(self, value):
346 |
347 | self._parameters["nullspace_method"] = value
348 |
349 | def set_tol(self, value):
350 |
351 | self._parameters["tol"] = value
352 |
353 | def set_opt_percentage(self, value):
354 |
355 | self._parameters["opt_percentage"] = value
356 |
--------------------------------------------------------------------------------
/dingo/__init__.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 |
6 | # Licensed under GNU LGPL.3, see LICENCE file
7 |
8 | import numpy as np
9 | import sys
10 | import os
11 | import pickle
12 | from dingo.loading_models import read_json_file
13 | from dingo.nullspace import nullspace_dense, nullspace_sparse
14 | from dingo.scaling import gmscale
15 | from dingo.utils import (
16 | apply_scaling,
17 | remove_almost_redundant_facets,
18 | map_samples_to_steady_states,
19 | get_matrices_of_low_dim_polytope,
20 | get_matrices_of_full_dim_polytope,
21 | )
22 | from dingo.illustrations import (
23 | plot_copula,
24 | plot_histogram,
25 | )
26 | from dingo.parser import dingo_args
27 | from dingo.MetabolicNetwork import MetabolicNetwork
28 | from dingo.PolytopeSampler import PolytopeSampler
29 |
30 | from dingo.pyoptinterface_based_impl import fba, fva, inner_ball, remove_redundant_facets, set_default_solver
31 |
32 | from volestipy import HPolytope
33 |
34 |
35 | def get_name(args_network):
36 |
37 | position = [pos for pos, char in enumerate(args_network) if char == "/"]
38 |
39 | if args_network[-4:] == "json":
40 | if position == []:
41 | name = args_network[0:-5]
42 | else:
43 | name = args_network[(position[-1] + 1) : -5]
44 | elif args_network[-3:] == "mat":
45 | if position == []:
46 | name = args_network[0:-4]
47 | else:
48 | name = args_network[(position[-1] + 1) : -4]
49 |
50 | return name
51 |
52 |
53 | def dingo_main():
54 | """A function that (a) reads the inputs using argparse package, (b) calls the proper dingo pipeline
55 | and (c) saves the outputs using pickle package
56 | """
57 |
58 | args = dingo_args()
59 |
60 | if args.metabolic_network is None and args.polytope is None and not args.histogram:
61 | raise Exception(
62 | "You have to give as input either a model or a polytope derived from a model."
63 | )
64 |
65 | if args.metabolic_network is None and ((args.fva) or (args.fba)):
66 | raise Exception("You have to give as input a model to apply FVA or FBA method.")
67 |
68 | if args.output_directory == None:
69 | output_path_dir = os.getcwd()
70 | else:
71 | output_path_dir = args.output_directory
72 |
73 | if os.path.isdir(output_path_dir) == False:
74 | os.mkdir(output_path_dir)
75 |
76 | # Move to the output directory
77 | os.chdir(output_path_dir)
78 |
79 | set_default_solver(args.solver)
80 |
81 | if args.model_name is None:
82 | if args.metabolic_network is not None:
83 | name = get_name(args.metabolic_network)
84 | else:
85 | name = args.model_name
86 |
87 | if args.histogram:
88 |
89 | if args.steady_states is None:
90 | raise Exception(
91 | "A path to a pickle file that contains steady states of the model has to be given."
92 | )
93 |
94 | if args.metabolites_reactions is None:
95 | raise Exception(
96 | "A path to a pickle file that contains the names of the metabolites and the reactions of the model has to be given."
97 | )
98 |
99 | if int(args.reaction_index) <= 0:
100 | raise Exception("The index of the reaction has to be a positive integer.")
101 |
102 | file = open(args.steady_states, "rb")
103 | steady_states = pickle.load(file)
104 | file.close()
105 |
106 | file = open(args.metabolites_reactions, "rb")
107 | model = pickle.load(file)
108 | file.close()
109 |
110 | reactions = model.reactions
111 |
112 | if int(args.reaction_index) > len(reactions):
113 | raise Exception(
114 | "The index of the reaction has not to be exceed the number of reactions."
115 | )
116 |
117 | if int(args.n_bins) <= 0:
118 | raise Exception("The number of bins has to be a positive integer.")
119 |
120 | plot_histogram(
121 | steady_states[int(args.reaction_index) - 1],
122 | reactions[int(args.reaction_index) - 1],
123 | int(args.n_bins),
124 | )
125 |
126 | elif args.fva:
127 |
128 | if args.metabolic_network[-4:] == "json":
129 | model = MetabolicNetwork.fom_json(args.metabolic_network)
130 | elif args.metabolic_network[-3:] == "mat":
131 | model = MetabolicNetwork.fom_mat(args.metabolic_network)
132 | else:
133 | raise Exception("An unknown format file given.")
134 |
135 | model.set_solver(args.solver)
136 |
137 | result_obj = model.fva()
138 |
139 | with open("dingo_fva_" + name + ".pckl", "wb") as dingo_fva_file:
140 | pickle.dump(result_obj, dingo_fva_file)
141 |
142 | elif args.fba:
143 |
144 | if args.metabolic_network[-4:] == "json":
145 | model = MetabolicNetwork.fom_json(args.metabolic_network)
146 | elif args.metabolic_network[-3:] == "mat":
147 | model = MetabolicNetwork.fom_mat(args.metabolic_network)
148 | else:
149 | raise Exception("An unknown format file given.")
150 |
151 | model.set_solver(args.solver)
152 |
153 | result_obj = model.fba()
154 |
155 | with open("dingo_fba_" + name + ".pckl", "wb") as dingo_fba_file:
156 | pickle.dump(result_obj, dingo_fba_file)
157 |
158 | elif args.metabolic_network is not None:
159 |
160 | if args.metabolic_network[-4:] == "json":
161 | model = MetabolicNetwork.fom_json(args.metabolic_network)
162 | elif args.metabolic_network[-3:] == "mat":
163 | model = MetabolicNetwork.fom_mat(args.metabolic_network)
164 | else:
165 | raise Exception("An unknown format file given.")
166 |
167 | sampler = PolytopeSampler(model)
168 |
169 | if args.preprocess_only:
170 |
171 | sampler.get_polytope()
172 |
173 | polytope_info = (
174 | sampler,
175 | name,
176 | )
177 |
178 | with open("dingo_model_" + name + ".pckl", "wb") as dingo_model_file:
179 | pickle.dump(model, dingo_model_file)
180 |
181 | with open(
182 | "dingo_polytope_sampler_" + name + ".pckl", "wb"
183 | ) as dingo_polytope_file:
184 | pickle.dump(polytope_info, dingo_polytope_file)
185 |
186 | else:
187 |
188 | steady_states = sampler.generate_steady_states(
189 | int(args.effective_sample_size),
190 | args.psrf_check,
191 | args.parallel_mmcs,
192 | int(args.num_threads),
193 | )
194 |
195 | polytope_info = (
196 | sampler,
197 | name,
198 | )
199 |
200 | with open("dingo_model_" + name + ".pckl", "wb") as dingo_model_file:
201 | pickle.dump(model, dingo_model_file)
202 |
203 | with open(
204 | "dingo_polytope_sampler_" + name + ".pckl", "wb"
205 | ) as dingo_polytope_file:
206 | pickle.dump(polytope_info, dingo_polytope_file)
207 |
208 | with open(
209 | "dingo_steady_states_" + name + ".pckl", "wb"
210 | ) as dingo_steadystates_file:
211 | pickle.dump(steady_states, dingo_steadystates_file)
212 |
213 | else:
214 |
215 | file = open(args.polytope, "rb")
216 | input_obj = pickle.load(file)
217 | file.close()
218 | sampler = input_obj[0]
219 |
220 | if isinstance(sampler, PolytopeSampler):
221 |
222 | steady_states = sampler.generate_steady_states(
223 | int(args.effective_sample_size),
224 | args.psrf_check,
225 | args.parallel_mmcs,
226 | int(args.num_threads),
227 | )
228 |
229 | else:
230 | raise Exception("The input file has to be generated by dingo package.")
231 |
232 | if args.model_name is None:
233 | name = input_obj[-1]
234 |
235 | polytope_info = (
236 | sampler,
237 | name,
238 | )
239 |
240 | with open(
241 | "dingo_polytope_sampler" + name + "_improved.pckl", "wb"
242 | ) as dingo_polytope_file:
243 | pickle.dump(polytope_info, dingo_polytope_file)
244 |
245 | with open("dingo_steady_states_" + name + ".pckl", "wb") as dingo_network_file:
246 | pickle.dump(steady_states, dingo_network_file)
247 |
248 |
249 | if __name__ == "__main__":
250 |
251 | dingo_main()
252 |
--------------------------------------------------------------------------------
/dingo/__main__.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 |
6 | # Licensed under GNU LGPL.3, see LICENCE file
7 |
8 | from dingo import dingo_main
9 |
10 | dingo_main()
11 |
--------------------------------------------------------------------------------
/dingo/bindings/bindings.cpp:
--------------------------------------------------------------------------------
1 | // This is binding file for the C++ library volesti
2 | // volesti (volume computation and sampling library)
3 |
4 | // Copyright (c) 2012-2021 Vissarion Fisikopoulos
5 | // Copyright (c) 2018-2021 Apostolos Chalkis
6 |
7 | // Contributed and/or modified by Haris Zafeiropoulos
8 | // Contributed and/or modified by Pedro Zuidberg Dos Martires
9 |
10 | // Licensed under GNU LGPL.3, see LICENCE file
11 |
12 | #include
13 | #include
14 | #include
15 | #include "bindings.h"
16 | #include "hmc_sampling.h"
17 |
18 |
19 | using namespace std;
20 |
21 | // >>> Main HPolytopeCPP class; compute_volume(), rounding() and generate_samples() volesti methods are included <<<
22 |
23 | // Here is the initialization of the HPolytopeCPP class
24 | HPolytopeCPP::HPolytopeCPP() {}
25 | HPolytopeCPP::HPolytopeCPP(double *A_np, double *b_np, int n_hyperplanes, int n_variables){
26 |
27 | MT A;
28 | VT b;
29 | A.resize(n_hyperplanes,n_variables);
30 | b.resize(n_hyperplanes);
31 |
32 | int index = 0;
33 | for (int i = 0; i < n_hyperplanes; i++){
34 | b(i) = b_np[i];
35 | for (int j=0; j < n_variables; j++){
36 | A(i,j) = A_np[index];
37 | index++;
38 | }
39 | }
40 |
41 | HP = Hpolytope(n_variables, A, b);
42 | }
43 | // Use a destructor for the HPolytopeCPP object
44 | HPolytopeCPP::~HPolytopeCPP(){}
45 |
46 | ////////// Start of "compute_volume" //////////
47 | double HPolytopeCPP::compute_volume(char* vol_method, char* walk_method,
48 | int walk_len, double epsilon, int seed) const {
49 |
50 | double volume;
51 |
52 | if (strcmp(vol_method,"sequence_of_balls") == 0){
53 | if (strcmp(walk_method,"uniform_ball") == 0){
54 | volume = volume_sequence_of_balls(HP, epsilon, walk_len);
55 | } else if (strcmp(walk_method,"CDHR") == 0){
56 | volume = volume_sequence_of_balls(HP, epsilon, walk_len);
57 | } else if (strcmp(walk_method,"RDHR") == 0){
58 | volume = volume_sequence_of_balls(HP, epsilon, walk_len);
59 | }
60 | }
61 | else if (strcmp(vol_method,"cooling_gaussian") == 0){
62 | if (strcmp(walk_method,"gaussian_ball") == 0){
63 | volume = volume_cooling_gaussians(HP, epsilon, walk_len);
64 | } else if (strcmp(walk_method,"gaussian_CDHR") == 0){
65 | volume = volume_cooling_gaussians(HP, epsilon, walk_len);
66 | } else if (strcmp(walk_method,"gaussian_RDHR") == 0){
67 | volume = volume_cooling_gaussians(HP, epsilon, walk_len);
68 | }
69 | } else if (strcmp(vol_method,"cooling_balls") == 0){
70 | if (strcmp(walk_method,"uniform_ball") == 0){
71 | volume = volume_cooling_balls(HP, epsilon, walk_len).second;
72 | } else if (strcmp(walk_method,"CDHR") == 0){
73 | volume = volume_cooling_balls(HP, epsilon, walk_len).second;
74 | } else if (strcmp(walk_method,"RDHR") == 0){
75 | volume = volume_cooling_balls(HP, epsilon, walk_len).second;
76 | } else if (strcmp(walk_method,"billiard") == 0){
77 | volume = volume_cooling_balls(HP, epsilon, walk_len).second;
78 | }
79 | }
80 | return volume;
81 | }
82 | ////////// End of "compute_volume()" //////////
83 |
84 |
85 | ////////// Start of "generate_samples()" //////////
86 | double HPolytopeCPP::apply_sampling(int walk_len,
87 | int number_of_points,
88 | int number_of_points_to_burn,
89 | char* method,
90 | double* inner_point,
91 | double radius,
92 | double* samples,
93 | double variance_value,
94 | double* bias_vector_,
95 | int ess){
96 |
97 | RNGType rng(HP.dimension());
98 | HP.normalize();
99 | int d = HP.dimension();
100 | Point starting_point;
101 | VT inner_vec(d);
102 |
103 | for (int i = 0; i < d; i++){
104 | inner_vec(i) = inner_point[i];
105 | }
106 |
107 | Point inner_point2(inner_vec);
108 | CheBall = std::pair(inner_point2, radius);
109 | HP.set_InnerBall(CheBall);
110 | starting_point = inner_point2;
111 | std::list rand_points;
112 |
113 | NT variance = variance_value;
114 |
115 | if (strcmp(method, "cdhr") == 0) { // cdhr
116 | uniform_sampling(rand_points, HP, rng, walk_len, number_of_points,
117 | starting_point, number_of_points_to_burn);
118 | } else if (strcmp(method, "rdhr") == 0) { // rdhr
119 | uniform_sampling(rand_points, HP, rng, walk_len, number_of_points,
120 | starting_point, number_of_points_to_burn);
121 | } else if (strcmp(method, "billiard_walk") == 0) { // accelerated_billiard
122 | uniform_sampling(rand_points, HP, rng, walk_len,
123 | number_of_points, starting_point,
124 | number_of_points_to_burn);
125 | } else if (strcmp(method, "ball_walk") == 0) { // ball walk
126 | uniform_sampling(rand_points, HP, rng, walk_len, number_of_points,
127 | starting_point, number_of_points_to_burn);
128 | } else if (strcmp(method, "dikin_walk") == 0) { // dikin walk
129 | uniform_sampling(rand_points, HP, rng, walk_len, number_of_points,
130 | starting_point, number_of_points_to_burn);
131 | } else if (strcmp(method, "john_walk") == 0) { // john walk
132 | uniform_sampling(rand_points, HP, rng, walk_len, number_of_points,
133 | starting_point, number_of_points_to_burn);
134 | } else if (strcmp(method, "vaidya_walk") == 0) { // vaidya walk
135 | uniform_sampling(rand_points, HP, rng, walk_len, number_of_points,
136 | starting_point, number_of_points_to_burn);
137 | } else if (strcmp(method, "mmcs") == 0) { // vaidya walk
138 | MT S;
139 | int total_ess;
140 | //TODO: avoid passing polytopes as non-const references
141 | const Hpolytope HP_const = HP;
142 | mmcs(HP_const, ess, S, total_ess, walk_len, rng);
143 | samples = S.data();
144 | } else if (strcmp(method, "gaussian_hmc_walk") == 0) { // Gaussian sampling with exact HMC walk
145 | NT a = NT(1)/(NT(2)*variance);
146 | gaussian_sampling(rand_points, HP, rng, walk_len, number_of_points, a,
147 | starting_point, number_of_points_to_burn);
148 | } else if (strcmp(method, "exponential_hmc_walk") == 0) { // exponential sampling with exact HMC walk
149 | VT c(d);
150 | for (int i = 0; i < d; i++){
151 | c(i) = bias_vector_[i];
152 | }
153 | Point bias_vector(c);
154 | exponential_sampling(rand_points, HP, rng, walk_len, number_of_points, bias_vector, variance,
155 | starting_point, number_of_points_to_burn);
156 | } else if (strcmp(method, "hmc_leapfrog_gaussian") == 0) { // HMC with Gaussian distribution
157 | rand_points = hmc_leapfrog_gaussian(walk_len, number_of_points, number_of_points_to_burn, variance, starting_point, HP);
158 | } else if (strcmp(method, "hmc_leapfrog_exponential") == 0) { // HMC with exponential distribution
159 | VT c(d);
160 | for (int i = 0; i < d; i++) {
161 | c(i) = bias_vector_[i];
162 | }
163 | Point bias_vector(c);
164 |
165 | rand_points = hmc_leapfrog_exponential(walk_len, number_of_points, number_of_points_to_burn, variance, bias_vector, starting_point, HP);
166 |
167 | }
168 |
169 | else {
170 | throw std::runtime_error("This function must not be called.");
171 | }
172 |
173 | if (strcmp(method, "mmcs") != 0) {
174 | // The following block of code allows us to copy the sampled points
175 | auto n_si=0;
176 | for (auto it_s = rand_points.cbegin(); it_s != rand_points.cend(); it_s++){
177 | for (auto i = 0; i != it_s->dimension(); i++){
178 | samples[n_si++] = (*it_s)[i];
179 | }
180 | }
181 | }
182 | return 0.0;
183 | }
184 | ////////// End of "generate_samples()" //////////
185 |
186 |
187 | void HPolytopeCPP::get_polytope_as_matrices(double* new_A, double* new_b) const {
188 |
189 | int n_hyperplanes = HP.num_of_hyperplanes();
190 | int n_variables = HP.dimension();
191 |
192 | int n_si = 0;
193 | MT A_to_copy = HP.get_mat();
194 | for (int i = 0; i < n_hyperplanes; i++){
195 | for (int j = 0; j < n_variables; j++){
196 | new_A[n_si++] = A_to_copy(i, j);
197 | }
198 | }
199 |
200 | // create the new_b vector
201 | VT new_b_temp = HP.get_vec();
202 | for (int i=0; i < n_hyperplanes; i++){
203 | new_b[i] = new_b_temp[i];
204 | }
205 |
206 | }
207 |
208 |
209 | void HPolytopeCPP::mmcs_initialize(int d, int ess, bool psrf_check, bool parallelism, int num_threads) {
210 |
211 | mmcs_set_of_parameters = mmcs_params(d, ess, psrf_check, parallelism, num_threads);
212 |
213 | }
214 |
215 |
216 | double HPolytopeCPP::mmcs_step(double* inner_point, double radius, int &N) {
217 |
218 | HP.normalize();
219 | int d = HP.dimension();
220 |
221 | VT inner_vec(d);
222 | NT max_s;
223 |
224 | for (int i = 0; i < d; i++){
225 | inner_vec(i) = inner_point[i];
226 | }
227 |
228 | Point inner_point2(inner_vec);
229 | CheBall = std::pair(inner_point2, radius);
230 |
231 | HP.set_InnerBall(CheBall);
232 |
233 | RNGType rng(d);
234 |
235 |
236 | if (mmcs_set_of_parameters.request_rounding && mmcs_set_of_parameters.rounding_completed)
237 | {
238 | mmcs_set_of_parameters.req_round_temp = false;
239 | }
240 |
241 | if (mmcs_set_of_parameters.req_round_temp)
242 | {
243 | mmcs_set_of_parameters.nburns = mmcs_set_of_parameters.num_rounding_steps / mmcs_set_of_parameters.window + 1;
244 | }
245 | else
246 | {
247 | mmcs_set_of_parameters.nburns = mmcs_set_of_parameters.max_num_samples / mmcs_set_of_parameters.window + 1;
248 | }
249 |
250 | NT L = NT(6) * std::sqrt(NT(d)) * CheBall.second;
251 | AcceleratedBilliardWalk WalkType(L);
252 |
253 | unsigned int Neff_sampled;
254 | MT TotalRandPoints;
255 | if (mmcs_set_of_parameters.parallelism)
256 | {
257 | mmcs_set_of_parameters.complete = perform_parallel_mmcs_step(HP, rng, mmcs_set_of_parameters.walk_length,
258 | mmcs_set_of_parameters.Neff,
259 | mmcs_set_of_parameters.max_num_samples,
260 | mmcs_set_of_parameters.window,
261 | Neff_sampled, mmcs_set_of_parameters.total_samples,
262 | mmcs_set_of_parameters.num_rounding_steps,
263 | TotalRandPoints, CheBall.first, mmcs_set_of_parameters.nburns,
264 | mmcs_set_of_parameters.num_threads,
265 | mmcs_set_of_parameters.req_round_temp, L);
266 | }
267 | else
268 | {
269 | mmcs_set_of_parameters.complete = perform_mmcs_step(HP, rng, mmcs_set_of_parameters.walk_length, mmcs_set_of_parameters.Neff,
270 | mmcs_set_of_parameters.max_num_samples, mmcs_set_of_parameters.window,
271 | Neff_sampled, mmcs_set_of_parameters.total_samples,
272 | mmcs_set_of_parameters.num_rounding_steps, TotalRandPoints, CheBall.first,
273 | mmcs_set_of_parameters.nburns, mmcs_set_of_parameters.req_round_temp, WalkType);
274 | }
275 |
276 | mmcs_set_of_parameters.store_ess(mmcs_set_of_parameters.phase) = Neff_sampled;
277 | mmcs_set_of_parameters.store_nsamples(mmcs_set_of_parameters.phase) = mmcs_set_of_parameters.total_samples;
278 | mmcs_set_of_parameters.phase++;
279 | mmcs_set_of_parameters.Neff -= Neff_sampled;
280 | std::cout << "phase " << mmcs_set_of_parameters.phase << ": number of correlated samples = " << mmcs_set_of_parameters.total_samples << ", effective sample size = " << Neff_sampled;
281 | mmcs_set_of_parameters.total_neff += Neff_sampled;
282 |
283 | mmcs_set_of_parameters.samples.conservativeResize(d, mmcs_set_of_parameters.total_number_of_samples_in_P0 + mmcs_set_of_parameters.total_samples);
284 | for (int i = 0; i < mmcs_set_of_parameters.total_samples; i++)
285 | {
286 | mmcs_set_of_parameters.samples.col(i + mmcs_set_of_parameters.total_number_of_samples_in_P0) =
287 | mmcs_set_of_parameters.T * TotalRandPoints.row(i).transpose() + mmcs_set_of_parameters.T_shift;
288 | }
289 |
290 | N = mmcs_set_of_parameters.total_number_of_samples_in_P0 + mmcs_set_of_parameters.total_samples;
291 | mmcs_set_of_parameters.total_number_of_samples_in_P0 += mmcs_set_of_parameters.total_samples;
292 |
293 | if (!mmcs_set_of_parameters.complete)
294 | {
295 | if (mmcs_set_of_parameters.request_rounding && !mmcs_set_of_parameters.rounding_completed)
296 | {
297 | VT shift(d), s(d);
298 | MT V(d, d), S(d, d), round_mat;
299 | for (int i = 0; i < d; ++i)
300 | {
301 | shift(i) = TotalRandPoints.col(i).mean();
302 | }
303 |
304 | for (int i = 0; i < mmcs_set_of_parameters.total_samples; ++i)
305 | {
306 | TotalRandPoints.row(i) = TotalRandPoints.row(i) - shift.transpose();
307 | }
308 |
309 | Eigen::BDCSVD svd(TotalRandPoints, Eigen::ComputeFullV);
310 | s = svd.singularValues() / svd.singularValues().minCoeff();
311 |
312 | if (s.maxCoeff() >= 2.0)
313 | {
314 | for (int i = 0; i < s.size(); ++i)
315 | {
316 | if (s(i) < 2.0)
317 | {
318 | s(i) = 1.0;
319 | }
320 | }
321 | V = svd.matrixV();
322 | }
323 | else
324 | {
325 | s = VT::Ones(d);
326 | V = MT::Identity(d, d);
327 | }
328 | max_s = s.maxCoeff();
329 | S = s.asDiagonal();
330 | round_mat = V * S;
331 |
332 | mmcs_set_of_parameters.round_it++;
333 | HP.shift(shift);
334 | HP.linear_transformIt(round_mat);
335 | mmcs_set_of_parameters.T_shift += mmcs_set_of_parameters.T * shift;
336 | mmcs_set_of_parameters.T = mmcs_set_of_parameters.T * round_mat;
337 |
338 | std::cout << ", ratio of the maximum singilar value over the minimum singular value = " << max_s << std::endl;
339 |
340 | if (max_s <= mmcs_set_of_parameters.s_cutoff || mmcs_set_of_parameters.round_it > mmcs_set_of_parameters.num_its)
341 | {
342 | mmcs_set_of_parameters.rounding_completed = true;
343 | }
344 | }
345 | else
346 | {
347 | std::cout<<"\n";
348 | }
349 | }
350 | else if (!mmcs_set_of_parameters.psrf_check)
351 | {
352 | NT max_psrf = univariate_psrf(mmcs_set_of_parameters.samples).maxCoeff();
353 | std::cout << "\n[5]total ess " << mmcs_set_of_parameters.total_neff << ": number of correlated samples = " << mmcs_set_of_parameters.samples.cols()<(mmcs_set_of_parameters.samples).maxCoeff() << std::endl;
355 | std::cout<<"\n\n";
356 | return 1.5;
357 | }
358 | else
359 | {
360 | TotalRandPoints.resize(0, 0);
361 | NT max_psrf = univariate_psrf(mmcs_set_of_parameters.samples).maxCoeff();
362 |
363 | if (max_psrf < 1.1 && mmcs_set_of_parameters.total_neff >= mmcs_set_of_parameters.fixed_Neff) {
364 | std::cout << "\n[4]total ess " << mmcs_set_of_parameters.total_neff << ": number of correlated samples = " << mmcs_set_of_parameters.samples.cols()<(mmcs_set_of_parameters.samples).maxCoeff() << std::endl;
366 | std::cout<<"\n\n";
367 | return 1.5;
368 | }
369 | std::cerr << "\n [1]maximum marginal PSRF: " << max_psrf << std::endl;
370 |
371 | while (max_psrf > 1.1 && mmcs_set_of_parameters.total_neff >= mmcs_set_of_parameters.fixed_Neff) {
372 |
373 | mmcs_set_of_parameters.Neff += mmcs_set_of_parameters.store_ess(mmcs_set_of_parameters.skip_phase);
374 | mmcs_set_of_parameters.total_neff -= mmcs_set_of_parameters.store_ess(mmcs_set_of_parameters.skip_phase);
375 |
376 | mmcs_set_of_parameters.total_number_of_samples_in_P0 -= mmcs_set_of_parameters.store_nsamples(mmcs_set_of_parameters.skip_phase);
377 | N -= mmcs_set_of_parameters.store_nsamples(mmcs_set_of_parameters.skip_phase);
378 |
379 | MT S = mmcs_set_of_parameters.samples;
380 | mmcs_set_of_parameters.samples.resize(d, mmcs_set_of_parameters.total_number_of_samples_in_P0);
381 | mmcs_set_of_parameters.samples =
382 | S.block(0, mmcs_set_of_parameters.store_nsamples(mmcs_set_of_parameters.skip_phase), d, mmcs_set_of_parameters.total_number_of_samples_in_P0);
383 |
384 | mmcs_set_of_parameters.skip_phase++;
385 |
386 | max_psrf = univariate_psrf(mmcs_set_of_parameters.samples).maxCoeff();
387 |
388 | std::cerr << "[2]maximum marginal PSRF: " << max_psrf << std::endl;
389 | std::cerr << "[2]total ess: " << mmcs_set_of_parameters.total_neff << std::endl;
390 |
391 | if (max_psrf < 1.1 && mmcs_set_of_parameters.total_neff >= mmcs_set_of_parameters.fixed_Neff) {
392 | return 1.5;
393 | }
394 | }
395 | std::cout << "[3]total ess " << mmcs_set_of_parameters.total_neff << ": number of correlated samples = " << mmcs_set_of_parameters.samples.cols()<(mmcs_set_of_parameters.samples).maxCoeff() << std::endl;
397 | std::cout<<"\n\n";
398 | return 0.0;
399 | }
400 |
401 | return 0.0;
402 | }
403 |
404 | void HPolytopeCPP::get_mmcs_samples(double* T_matrix, double* T_shift, double* samples) {
405 |
406 | int n_variables = HP.dimension();
407 |
408 | int t_mat_index = 0;
409 | for (int i = 0; i < n_variables; i++){
410 | for (int j = 0; j < n_variables; j++){
411 | T_matrix[t_mat_index++] = mmcs_set_of_parameters.T(i, j);
412 | }
413 | }
414 |
415 | // create the shift vector
416 | for (int i = 0; i < n_variables; i++){
417 | T_shift[i] = mmcs_set_of_parameters.T_shift[i];
418 | }
419 |
420 | int N = mmcs_set_of_parameters.samples.cols();
421 |
422 | int t_si = 0;
423 | for (int i = 0; i < n_variables; i++){
424 | for (int j = 0; j < N; j++){
425 | samples[t_si++] = mmcs_set_of_parameters.samples(i, j);
426 | }
427 | }
428 | mmcs_set_of_parameters.samples.resize(0,0);
429 | }
430 |
431 |
432 | ////////// Start of "rounding()" //////////
433 | void HPolytopeCPP::apply_rounding(int rounding_method, double* new_A, double* new_b,
434 | double* T_matrix, double* shift, double &round_value,
435 | double* inner_point, double radius){
436 |
437 | // make a copy of the initial HP which will be used for the rounding step
438 | auto P(HP);
439 | RNGType rng(P.dimension());
440 | P.normalize();
441 |
442 |
443 |
444 | // read the inner point provided by the user and the radius
445 | int d = P.dimension();
446 | VT inner_vec(d);
447 |
448 | for (int i = 0; i < d; i++){
449 | inner_vec(i) = inner_point[i];
450 | }
451 |
452 | Point inner_point2(inner_vec);
453 | CheBall = std::pair(inner_point2, radius);
454 | P.set_InnerBall(CheBall);
455 |
456 | // set the output variable of the rounding step
457 | round_result round_res;
458 |
459 | // walk length will always be equal to 2
460 | int walk_len = 2;
461 |
462 | // run the rounding method
463 | if (rounding_method == 1) { // max ellipsoid
464 | round_res = inscribed_ellipsoid_rounding(P, CheBall.first);
465 |
466 | } else if (rounding_method == 2) { // isotropization
467 | round_res = svd_rounding(P, CheBall, 1, rng);
468 | } else if (rounding_method == 3) { // min ellipsoid
469 | round_res = min_sampling_covering_ellipsoid_rounding(P,
470 | CheBall,
471 | walk_len,
472 | rng);
473 | } else {
474 | throw std::runtime_error("Unknown rounding method.");
475 | }
476 |
477 | // create the new_A matrix
478 | MT A_to_copy = P.get_mat();
479 | int n_hyperplanes = P.num_of_hyperplanes();
480 | int n_variables = P.dimension();
481 |
482 | auto n_si = 0;
483 | for (int i = 0; i < n_hyperplanes; i++){
484 | for (int j = 0; j < n_variables; j++){
485 | new_A[n_si++] = A_to_copy(i,j);
486 | }
487 | }
488 |
489 | // create the new_b vector
490 | VT new_b_temp = P.get_vec();
491 | for (int i=0; i < n_hyperplanes; i++){
492 | new_b[i] = new_b_temp[i];
493 | }
494 |
495 | // create the T matrix
496 | MT T_matrix_temp = get<0>(round_res);
497 | auto t_si = 0;
498 | for (int i = 0; i < n_variables; i++){
499 | for (int j = 0; j < n_variables; j++){
500 | T_matrix[t_si++] = T_matrix_temp(i,j);
501 | }
502 | }
503 |
504 | // create the shift vector
505 | VT shift_temp = get<1>(round_res);
506 | for (int i = 0; i < n_variables; i++){
507 | shift[i] = shift_temp[i];
508 | }
509 |
510 | // get the round val value from the rounding step and print int
511 | round_value = get<2>(round_res);
512 |
513 | }
514 | ////////// End of "rounding()" //////////
515 |
--------------------------------------------------------------------------------
/dingo/bindings/bindings.h:
--------------------------------------------------------------------------------
1 | // This is binding file for the C++ library volesti
2 | // volesti (volume computation and sampling library)
3 |
4 | // Copyright (c) 2012-2021 Vissarion Fisikopoulos
5 | // Copyright (c) 2018-2021 Apostolos Chalkis
6 |
7 | // Contributed and/or modified by Haris Zafeiropoulos
8 | // Contributed and/or modified by Pedro Zuidberg Dos Martires
9 |
10 | // Licensed under GNU LGPL.3, see LICENCE file
11 |
12 |
13 | #ifndef VOLESTIBINDINGS_H
14 | #define VOLESTIBINDINGS_H
15 |
16 | #define DISABLE_NLP_ORACLES
17 | #include
18 | // from SOB volume - exactly the same for CG and CB methods
19 | #include
20 | #include
21 | #include "random_walks.hpp"
22 | #include "random.hpp"
23 | #include "random/uniform_int.hpp"
24 | #include "random/normal_distribution.hpp"
25 | #include "random/uniform_real_distribution.hpp"
26 | #include "volume/volume_sequence_of_balls.hpp"
27 | #include "volume/volume_cooling_gaussians.hpp"
28 | #include "volume/volume_cooling_balls.hpp"
29 | #include "sampling/mmcs.hpp"
30 | #include "sampling/parallel_mmcs.hpp"
31 | #include "diagnostics/univariate_psrf.hpp"
32 |
33 | //from generate_samples, some extra headers not already included
34 | #include
35 | #include "sampling/sampling.hpp"
36 | #include "ode_solvers/ode_solvers.hpp"
37 |
38 | // for rounding
39 | #include "preprocess/min_sampling_covering_ellipsoid_rounding.hpp"
40 | #include "preprocess/svd_rounding.hpp"
41 | #include "preprocess/inscribed_ellipsoid_rounding.hpp"
42 |
43 | typedef double NT;
44 | typedef Cartesian Kernel;
45 | typedef typename Kernel::Point Point;
46 | typedef HPolytope Hpolytope;
47 | typedef typename Hpolytope::MT MT;
48 | typedef typename Hpolytope::VT VT;
49 | typedef BoostRandomNumberGenerator RNGType;
50 |
51 |
52 | template
53 | struct mmcs_parameters
54 | {
55 | public:
56 |
57 | mmcs_parameters() {}
58 |
59 | mmcs_parameters(int d, int ess, bool _psrf_check, bool _parallelism, int _num_threads)
60 | : T(MT::Identity(d,d))
61 | , T_shift(VT::Zero(d))
62 | , store_ess(VT::Zero(50))
63 | , store_nsamples(VT::Zero(50))
64 | , skip_phase(0)
65 | , num_rounding_steps(20*d)
66 | , walk_length(1)
67 | , num_its(20)
68 | , Neff(ess)
69 | , fixed_Neff(ess)
70 | , phase(0)
71 | , window(100)
72 | , max_num_samples(100 * d)
73 | , round_it(1)
74 | , total_number_of_samples_in_P0(0)
75 | , total_neff(0)
76 | , num_threads(_num_threads)
77 | , psrf_check(_psrf_check)
78 | , parallelism(_parallelism)
79 | , complete(false)
80 | , request_rounding(true)
81 | , rounding_completed(false)
82 | , s_cutoff(NT(3))
83 | {
84 | req_round_temp = request_rounding;
85 | }
86 |
87 | MT T;
88 | MT samples;
89 | VT T_shift;
90 | VT store_ess;
91 | VT store_nsamples;
92 | unsigned int skip_phase;
93 | unsigned int num_rounding_steps;
94 | unsigned int walk_length;
95 | unsigned int num_its;
96 | int Neff;
97 | int fixed_Neff;
98 | unsigned int phase;
99 | unsigned int window;
100 | unsigned int max_num_samples;
101 | unsigned int total_samples;
102 | unsigned int nburns;
103 | unsigned int round_it;
104 | unsigned int total_number_of_samples_in_P0;
105 | unsigned int total_neff;
106 | unsigned int num_threads;
107 | bool psrf_check;
108 | bool parallelism;
109 | bool complete;
110 | bool request_rounding;
111 | bool rounding_completed;
112 | bool req_round_temp;
113 | NT s_cutoff;
114 | };
115 |
116 |
117 | // This is the HPolytopeCPP class; the main volesti class that is running the compute_volume(), rounding() and sampling() methods
118 | class HPolytopeCPP{
119 |
120 | public:
121 |
122 | std::pair CheBall;
123 |
124 | // regarding the rounding step
125 | typedef std::tuple round_result;
126 | typedef mmcs_parameters mmcs_params;
127 |
128 | mmcs_params mmcs_set_of_parameters;
129 |
130 | // The class and its main specs
131 | HPolytopeCPP();
132 | HPolytopeCPP(double *A, double *b, int n_hyperplanes, int n_variables);
133 |
134 | Hpolytope HP;
135 | // Here we use the "~" destructor; this way we avoid a memory leak.
136 | ~HPolytopeCPP();
137 |
138 | // the compute_volume() function
139 | double compute_volume(char* vol_method, char* walk_method, int walk_len, double epsilon, int seed) const;
140 |
141 | // the apply_sampling() function
142 | double apply_sampling(int walk_len, int number_of_points, int number_of_points_to_burn,
143 | char* method, double* inner_point, double radius, double* samples,
144 | double variance_value, double* bias_vector, int ess);
145 |
146 | void mmcs_initialize(int d, int ess, bool psrf_check, bool parallelism, int num_threads);
147 |
148 | double mmcs_step(double* inner_point_for_c, double radius, int &N);
149 |
150 | void get_mmcs_samples(double* T_matrix, double* T_shift, double* samples);
151 |
152 | void get_polytope_as_matrices(double* new_A, double* new_b) const;
153 |
154 | // the rounding() function
155 | void apply_rounding(int rounding_method, double* new_A, double* new_b, double* T_matrix,
156 | double* shift, double &round_value, double* inner_point, double radius);
157 |
158 | };
159 |
160 |
161 | #endif
162 |
--------------------------------------------------------------------------------
/dingo/bindings/hmc_sampling.h:
--------------------------------------------------------------------------------
1 | #include "ode_solvers/ode_solvers.hpp"
2 | #include "random_walks.hpp"
3 |
4 | template std::list hmc_leapfrog_gaussian(int walk_len,
5 | int number_of_points,
6 | int number_of_points_to_burn,
7 | NT variance,
8 | Point starting_point,
9 | Polytope HP) {
10 |
11 | int d = HP.dimension();
12 | std::list rand_points;
13 | typedef GaussianFunctor::GradientFunctor NegativeGradientFunctor;
14 | typedef GaussianFunctor::FunctionFunctor NegativeLogprobFunctor;
15 | typedef BoostRandomNumberGenerator RandomNumberGenerator;
16 | typedef LeapfrogODESolver Solver;
17 |
18 | unsigned rng_seed = std::chrono::system_clock::now().time_since_epoch().count();
19 | RandomNumberGenerator rng(rng_seed);
20 |
21 | GaussianFunctor::parameters params(starting_point, 2 / (variance * variance), NT(-1));
22 | NegativeGradientFunctor F(params);
23 | NegativeLogprobFunctor f(params);
24 | HamiltonianMonteCarloWalk::parameters hmc_params(F, d);
25 |
26 | HamiltonianMonteCarloWalk::Walkhmc(&HP, starting_point, F, f, hmc_params);
27 |
28 | // burning points
29 | for (int i = 0; i < number_of_points_to_burn ; i++) {
30 | hmc.apply(rng, walk_len);
31 | }
32 |
33 | // actual sampling
34 | for (int i = 0; i < number_of_points ; i++) {
35 | hmc.apply(rng, walk_len);
36 | rand_points.push_back(hmc.x);
37 | }
38 | return rand_points;
39 | }
40 |
41 | template std::list hmc_leapfrog_exponential(int walk_len,
42 | int number_of_points,
43 | int number_of_points_to_burn,
44 | NT variance,
45 | Point bias_vector,
46 | Point starting_point,
47 | Polytope HP) {
48 |
49 | int d = HP.dimension();
50 | std::list rand_points;
51 | typedef ExponentialFunctor::GradientFunctor NegativeGradientFunctor;
52 | typedef ExponentialFunctor::FunctionFunctor NegativeLogprobFunctor;
53 | typedef BoostRandomNumberGenerator RandomNumberGenerator;
54 | typedef LeapfrogODESolver Solver;
55 |
56 | unsigned rng_seed = std::chrono::system_clock::now().time_since_epoch().count();
57 | RandomNumberGenerator rng(rng_seed);
58 |
59 | ExponentialFunctor::parameters params(bias_vector, 2 / (variance * variance));
60 |
61 | NegativeGradientFunctor F(params);
62 | NegativeLogprobFunctor f(params);
63 | HamiltonianMonteCarloWalk::parameters hmc_params(F, d);
64 |
65 | HamiltonianMonteCarloWalk::Walkhmc(&HP, starting_point, F, f, hmc_params);
66 |
67 |
68 | // burning points
69 | for (int i = 0; i < number_of_points_to_burn ; i++) {
70 | hmc.apply(rng, walk_len);
71 | }
72 | // actual sampling
73 | for (int i = 0; i < number_of_points ; i++) {
74 | hmc.apply(rng, walk_len);
75 | rand_points.push_back(hmc.x);
76 | }
77 | return rand_points;
78 | }
79 |
80 |
81 |
--------------------------------------------------------------------------------
/dingo/illustrations.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2022 Apostolos Chalkis, Vissarion Fisikopoulos, Elias Tsigaridas
5 |
6 | # Licensed under GNU LGPL.3, see LICENCE file
7 |
8 | import numpy as np
9 | import matplotlib.pyplot as plt
10 | import plotly.graph_objects as go
11 | import plotly.io as pio
12 | import plotly.express as px
13 | from dingo.utils import compute_copula
14 | import plotly.figure_factory as ff
15 | from scipy.cluster import hierarchy
16 |
17 | def plot_copula(data_flux1, data_flux2, n = 5, width = 900 , height = 600, export_format = "svg"):
18 | """A Python function to plot the copula between two fluxes
19 |
20 | Keyword arguments:
21 | data_flux1: A list that contains: (i) the vector of the measurements of the first reaction,
22 | (ii) the name of the first reaction
23 | data_flux2: A list that contains: (i) the vector of the measurements of the second reaction,
24 | (ii) the name of the second reaction
25 | n: The number of cells
26 | """
27 |
28 | flux1 = data_flux1[0]
29 | flux2 = data_flux2[0]
30 | copula = compute_copula(flux1, flux2, n)
31 |
32 | fig = go.Figure(
33 | data = [go.Surface(z=copula)],
34 | layout = go.Layout(
35 | height = height,
36 | width = width,
37 | )
38 | )
39 |
40 |
41 | fig.update_layout(
42 | title = 'Copula between '+ data_flux1[1] + ' and ' + data_flux2[1],
43 | scene = dict(
44 | xaxis_title= data_flux1[1],
45 | yaxis_title= data_flux2[1],
46 | zaxis_title="prob, mass"
47 | ),
48 | margin=dict(r=30, b=30, l=30, t=50))
49 |
50 | fig.layout.template = None
51 |
52 | fig.show()
53 | fig_name = data_flux1[1] + "_" + data_flux2[1] + "_copula." + export_format
54 |
55 | camera = dict(
56 | up=dict(x=0, y=0, z=1),
57 | center=dict(x=0, y=0, z=0),
58 | eye=dict(x=1.25, y=1.25, z=1.25)
59 | )
60 |
61 | fig.update_layout(scene_camera=camera)
62 | fig.to_image(format = export_format, engine="kaleido")
63 | pio.write_image(fig, fig_name, scale=2)
64 |
65 |
66 | def plot_histogram(reaction_fluxes, reaction, n_bins=40):
67 | """A Python function to plot the histogram of a certain reaction flux.
68 |
69 | Keyword arguments:
70 | reaction_fluxes -- a vector that contains sampled fluxes of a reaction
71 | reaction -- a string with the name of the reacion
72 | n_bins -- the number of bins for the histogram
73 | """
74 |
75 | plt.figure(figsize=(7, 7))
76 |
77 | n, bins, patches = plt.hist(
78 | reaction_fluxes, bins=n_bins, density=False, facecolor="red", ec="black"
79 | )
80 |
81 | plt.xlabel("Flux (mmol/gDW/h)", fontsize=16)
82 | plt.ylabel("Frequency (#samples: " + str(reaction_fluxes.size) + ")", fontsize=14)
83 | plt.grid(True)
84 | plt.title("Reaction: " + reaction, fontweight="bold", fontsize=18)
85 | plt.axis([np.amin(reaction_fluxes), np.amax(reaction_fluxes), 0, np.amax(n) * 1.2])
86 |
87 | plt.show()
88 |
89 |
90 |
91 | def plot_corr_matrix(corr_matrix, reactions, removed_reactions=[], format="svg"):
92 | """A Python function to plot the heatmap of a model's pearson correlation matrix.
93 |
94 | Keyword arguments:
95 | corr_matrix -- A matrix produced from the "correlated_reactions" function
96 | reactions -- A list with the model's reactions
97 | removed_reactions -- A list with the removed reactions in case of a preprocess.
98 | If provided removed reactions are not plotted.
99 | """
100 |
101 | sns_colormap = [[0.0, '#3f7f93'],
102 | [0.1, '#6397a7'],
103 | [0.2, '#88b1bd'],
104 | [0.3, '#acc9d2'],
105 | [0.4, '#d1e2e7'],
106 | [0.5, '#f2f2f2'],
107 | [0.6, '#f6cdd0'],
108 | [0.7, '#efa8ad'],
109 | [0.8, '#e8848b'],
110 | [0.9, '#e15e68'],
111 | [1.0, '#da3b46']]
112 |
113 | if removed_reactions != 0:
114 | for reaction in reactions:
115 | index = reactions.index(reaction)
116 | if reaction in removed_reactions:
117 | reactions[index] = None
118 |
119 | fig = px.imshow(corr_matrix,
120 | color_continuous_scale = sns_colormap,
121 | x = reactions, y = reactions, origin="upper")
122 |
123 | fig.update_layout(
124 | xaxis=dict(tickfont=dict(size=5)),
125 | yaxis=dict(tickfont=dict(size=5)),
126 | width=900, height=900, plot_bgcolor="rgba(0,0,0,0)")
127 |
128 | fig.update_traces(xgap=1, ygap=1, hoverongaps=False)
129 |
130 | fig.show()
131 |
132 | fig_name = "CorrelationMatrix." + format
133 | pio.write_image(fig, fig_name, scale=2)
134 |
135 |
136 |
137 | def plot_dendrogram(dissimilarity_matrix, reactions , plot_labels=False, t=2.0, linkage="ward"):
138 | """A Python function to plot the dendrogram of a dissimilarity matrix.
139 |
140 | Keyword arguments:
141 | dissimilarity_matrix -- A matrix produced from the "cluster_corr_reactions" function
142 | reactions -- A list with the model's reactions
143 | plot_labels -- A boolean variable that if True plots the reactions labels in the dendrogram
144 | t -- A threshold that defines a threshold that cuts the dendrogram
145 | at a specific height and colors the occuring clusters accordingly
146 | linkage -- linkage defines the type of linkage.
147 | Available linkage types are: single, average, complete, ward.
148 | """
149 |
150 | fig = ff.create_dendrogram(dissimilarity_matrix,
151 | labels=reactions,
152 | linkagefun=lambda x: hierarchy.linkage(x, linkage),
153 | color_threshold=t)
154 | fig.update_layout(width=800, height=800)
155 |
156 | if plot_labels == False:
157 | fig.update_layout(
158 | xaxis=dict(
159 | showticklabels=False,
160 | ticks="") )
161 | else:
162 | fig.update_layout(
163 | xaxis=dict(
164 | title_font=dict(size=10),
165 | tickfont=dict(size=8) ),
166 | yaxis=dict(
167 | title_font=dict(size=10),
168 | tickfont=dict(size=8) ) )
169 |
170 | fig.show()
171 |
172 |
173 |
174 | def plot_graph(G, pos):
175 | """A Python function to plot a graph created from a correlation matrix.
176 |
177 | Keyword arguments:
178 | G -- A graph produced from the "graph_corr_matrix" function.
179 | pos -- A layout for the corresponding graph.
180 | """
181 |
182 | fig = go.Figure()
183 |
184 | for u, v, data in G.edges(data=True):
185 | x0, y0 = pos[u]
186 | x1, y1 = pos[v]
187 |
188 | edge_color = 'blue' if data['weight'] > 0 else 'red'
189 |
190 | fig.add_trace(go.Scatter(x=[x0, x1], y=[y0, y1], mode='lines',
191 | line=dict(width=abs(data['weight']) * 1,
192 | color=edge_color), hoverinfo='none',
193 | showlegend=False))
194 |
195 | for node in G.nodes():
196 | x, y = pos[node]
197 | node_name = G.nodes[node].get('name', f'Node {node}')
198 |
199 | fig.add_trace(go.Scatter(x=[x], y=[y], mode='markers',
200 | marker=dict(size=10),
201 | text=[node_name],
202 | textposition='top center',
203 | name = node_name,
204 | showlegend=False))
205 |
206 | fig.update_layout(width=800, height=800)
207 | fig.show()
--------------------------------------------------------------------------------
/dingo/loading_models.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 | # Copyright (c) 2021 Haris Zafeiropoulos
6 |
7 | # Licensed under GNU LGPL.3, see LICENCE file
8 |
9 | import json
10 | import numpy as np
11 | import cobra
12 |
13 | def read_json_file(input_file):
14 | """A Python function to Read a Bigg json file and returns,
15 | (a) lower/upper flux bounds
16 | (b) the stoichiometric matrix S (dense format)
17 | (c) the list of the metabolites
18 | (d) the list of reactions
19 | (e) the index of the biomass pseudoreaction
20 | (f) the objective function to maximize the biomass pseudoreaction
21 |
22 | Keyword arguments:
23 | input_file -- a json file that contains the information about a mettabolic network, for example see http://bigg.ucsd.edu/models
24 | """
25 |
26 | try:
27 | cobra.io.load_matlab_model( input_file )
28 | except:
29 | cobra_config = cobra.Configuration()
30 | cobra_config.solver = 'glpk'
31 |
32 | model = cobra.io.load_json_model( input_file )
33 |
34 | return (parse_cobra_model( model ))
35 |
36 | def read_mat_file(input_file):
37 | """A Python function based on the to read a .mat file and returns,
38 | (a) lower/upper flux bounds
39 | (b) the stoichiometric matrix S (dense format)
40 | (c) the list of the metabolites
41 | (d) the list of reactions
42 | (e) the index of the biomass pseudoreaction
43 | (f) the objective function to maximize the biomass pseudoreaction
44 |
45 | Keyword arguments:
46 | input_file -- a mat file that contains a MATLAB structure with the information about a mettabolic network, for example see http://bigg.ucsd.edu/models
47 | """
48 | try:
49 | cobra.io.load_matlab_model( input_file )
50 | except:
51 | cobra_config = cobra.Configuration()
52 | cobra_config.solver = 'glpk'
53 |
54 | model = cobra.io.load_matlab_model( input_file )
55 |
56 | return (parse_cobra_model( model ))
57 |
58 | def read_sbml_file(input_file):
59 | """A Python function, based on the cobra.io.read_sbml_model() function of cabrapy
60 | and the extract_polytope() function of PolyRound
61 | (https://gitlab.com/csb.ethz/PolyRound/-/blob/master/PolyRound/static_classes/parse_sbml_stoichiometry.py)
62 | to read an SBML file (.xml) and return:
63 | (a) lower/upper flux bounds
64 | (b) the stoichiometric matrix S (dense format)
65 | (c) the list of the metabolites
66 | (d) the list of reactions
67 | (e) the index of the biomass pseudoreaction
68 | (f) the objective function to maximize the biomass pseudoreaction
69 |
70 | Keyword arguments:
71 | input_file -- a xml file that contains an SBML model with the information about a mettabolic network, for example see:
72 | https://github.com/VirtualMetabolicHuman/AGORA/blob/master/CurrentVersion/AGORA_1_03/AGORA_1_03_sbml/Abiotrophia_defectiva_ATCC_49176.xml
73 | """
74 | try:
75 | cobra.io.read_sbml_model( input_file )
76 | except:
77 | cobra_config = cobra.Configuration()
78 | cobra_config.solver = 'glpk'
79 |
80 | model = cobra.io.read_sbml_model( input_file )
81 |
82 | return (parse_cobra_model( model ))
83 |
84 | def parse_cobra_model(cobra_model):
85 |
86 | inf_bound=1e5
87 |
88 | metabolites = [ metabolite.id for metabolite in cobra_model.metabolites ]
89 | reactions = [ reaction.id for reaction in cobra_model.reactions ]
90 |
91 | S = cobra.util.array.create_stoichiometric_matrix(cobra_model)
92 |
93 | lb = []
94 | ub = []
95 | biomass_function = np.zeros( len(cobra_model.reactions) )
96 |
97 | for index, reaction in enumerate(cobra_model.reactions):
98 |
99 | if reaction.objective_coefficient==1:
100 | biomass_index = index
101 | biomass_function[index] = 1
102 |
103 | if reaction.bounds[0] == float("-inf"):
104 | lb.append( -inf_bound )
105 | else:
106 | lb.append( reaction.bounds[0] )
107 |
108 | if reaction.bounds[1] == float("inf"):
109 | ub.append( inf_bound )
110 | else:
111 | ub.append( reaction.bounds[1] )
112 |
113 | lb = np.asarray(lb)
114 | ub = np.asarray(ub)
115 |
116 | biomass_function = np.asarray(biomass_function)
117 | biomass_function = np.asarray(biomass_function, dtype="float")
118 | biomass_function = np.ascontiguousarray(biomass_function, dtype="float")
119 |
120 | lb = np.asarray(lb, dtype="float")
121 | lb = np.ascontiguousarray(lb, dtype="float")
122 |
123 | ub = np.asarray(ub, dtype="float")
124 | ub = np.ascontiguousarray(ub, dtype="float")
125 |
126 | medium = cobra_model.medium
127 | inter_medium = {}
128 |
129 | for index, reaction in enumerate(cobra_model.reactions):
130 | for ex_reaction in medium.keys():
131 | if ex_reaction == reaction.id:
132 | inter_medium[ex_reaction] = index
133 |
134 | exchanges_cobra_reactions = cobra_model.exchanges
135 | exchanges = []
136 | for reac in exchanges_cobra_reactions:
137 | exchanges.append(reac.id)
138 |
139 |
140 | return lb, ub, S, metabolites, reactions, biomass_index, biomass_function, medium, inter_medium, exchanges
141 |
142 |
143 |
144 |
145 |
146 |
--------------------------------------------------------------------------------
/dingo/nullspace.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 | # Copyright (c) 2021 Haris Zafeiropoulos
6 |
7 | # Licensed under GNU LGPL.3, see LICENCE file
8 |
9 | import numpy as np
10 | from scipy import linalg
11 | import sparseqr
12 | import scipy.sparse.linalg
13 |
14 |
15 | # Build a Python function to compute the nullspace of the stoichiometric matrix and a shifting to the origin
16 | def nullspace_dense(Aeq, beq):
17 | """A Python function to compute the matrix of the right nullspace of the augmented stoichiometric
18 | matrix and a shifting to the origin
19 | (a) Solves the equation Aeq x = beq,
20 | (b) Computes the nullspace of Aeq
21 |
22 | Keyword arguments:
23 | Aeq -- the mxn augmented row-wise stoichiometric matrix
24 | beq -- a m-dimensional vector
25 | """
26 |
27 | N_shift = np.linalg.lstsq(Aeq, beq, rcond=None)[0]
28 | N = linalg.null_space(Aeq)
29 |
30 | return N, N_shift
31 |
32 |
33 | def nullspace_sparse(Aeq, beq):
34 | """A Python function to compute the matrix of the right nullspace of the augmented stoichiometric
35 | matrix, exploiting that the matrix is in sparse format, and a shifting to the origin.
36 | The function uses the python wrapper PySPQR for the SuiteSparseQR library to compute the QR decomposition of matrix Aeq
37 | (a) Solves the equation Aeq x = beq,
38 | (b) Computes the nullspace of Aeq
39 |
40 | Keyword arguments:
41 | Aeq -- the mxn augmented row-wise stoichiometric matrix
42 | beq -- a m-dimensional vector
43 | """
44 |
45 | N_shift = np.linalg.lstsq(Aeq, beq, rcond=None)[0]
46 | Aeq = Aeq.T
47 | Aeq = scipy.sparse.csc_matrix(Aeq)
48 |
49 | # compute the QR decomposition of the Aeq_transposed
50 | Q, R, E, rank = sparseqr.qr(Aeq)
51 |
52 | # convert the matrices to dense format
53 | Q = Q.todense()
54 | R = R.todense()
55 | Aeq = Aeq.todense()
56 |
57 | if rank == 0:
58 |
59 | # Take the first n columns of Q where n is the number of columns of Aeq
60 | N = Q[:, : Aeq.shape[1]]
61 |
62 | else:
63 |
64 | # Take the last n-r columns of Q to derive the right nullspace of Aeq
65 | N = Q[:, rank:]
66 |
67 | N = np.asarray(N, dtype="float")
68 | N = np.ascontiguousarray(N, dtype="float")
69 |
70 | return N, N_shift
71 |
--------------------------------------------------------------------------------
/dingo/parser.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 | # Copyright (c) 2021 Haris Zafeiropoulos
6 |
7 | # Licensed under GNU LGPL.3, see LICENCE file
8 |
9 | import argparse
10 |
11 |
12 | def dingo_args():
13 | parser = argparse.ArgumentParser()
14 |
15 | parser = argparse.ArgumentParser(
16 | description="a parser to read the inputs of dingo package \
17 | dingo is a Python library for the analysis of \
18 | metabolic networks developed by the \
19 | GeomScale group - https://geomscale.github.io/ ",
20 | usage="%(prog)s [--help | -h] : help \n\n \
21 | The default method is to generate uniformly distributed steady states of the given model:\n\
22 | 1. provide just your metabolic model: \n \
23 | python -m dingo -i path_to_my_model \n\n \
24 | 2. or ask for more: \n \
25 | python -m dingo -i path_to_my_model -n 2000 -s gurobi \n \
26 | \n\n\
27 | You could give a full dimensional polytope derived from a model by dingo and saved to a `pickle` file:\n\
28 | python -m dingo -poly path_to_pickle_file -n 1000 \n \
29 | \n\n \
30 | You could ask for FVA or FBA methods:\n \
31 | python -m dingo -i path_to_my_model -fva True\n \
32 | \n\n\
33 | We recommend to use gurobi library for more stable and fast computations.",
34 | )
35 |
36 | parser._action_groups.pop()
37 |
38 | required = parser.add_argument_group("required arguments")
39 |
40 | optional = parser.add_argument_group("optional arguments")
41 | optional.add_argument(
42 | "--metabolic_network",
43 | "-i",
44 | help="the path to a metabolic network as a .json or a .mat file.",
45 | required=False,
46 | default=None,
47 | metavar="",
48 | )
49 |
50 | optional.add_argument(
51 | "--unbiased_analysis",
52 | "-unbiased",
53 | help="a boolean flag to ignore the objective function in preprocessing. Multiphase Monte Carlo Sampling algorithm will sample steady states but not restricted to optimal solutions. The default value is False.",
54 | required=False,
55 | default=False,
56 | metavar="",
57 | )
58 |
59 | optional.add_argument(
60 | "--polytope",
61 | "-poly",
62 | help="the path to a pickle file generated by dingo that contains a full dimensional polytope derived from a model. This file could be used to sample more steady states of a preprocessed metabolic network.",
63 | required=False,
64 | default=None,
65 | metavar="",
66 | )
67 |
68 | optional.add_argument(
69 | "--model_name",
70 | "-name",
71 | help="The name of the input model.",
72 | required=False,
73 | default=None,
74 | metavar="",
75 | )
76 |
77 | optional.add_argument(
78 | "--histogram",
79 | "-hist",
80 | help="A boolean flag to request a histogram for a certain reaction flux.",
81 | required=False,
82 | default=False,
83 | metavar="",
84 | )
85 |
86 | optional.add_argument(
87 | "--steady_states",
88 | "-st",
89 | help="A path to a pickle file that was generated by dingo and contains steady states of a model.",
90 | required=False,
91 | default=None,
92 | metavar="",
93 | )
94 |
95 | optional.add_argument(
96 | "--metabolites_reactions",
97 | "-mr",
98 | help="A path to a pickle file that was generated by dingo and contains the names of the metabolites and the reactions of a model.",
99 | required=False,
100 | default=None,
101 | metavar="",
102 | )
103 |
104 | optional.add_argument(
105 | "--n_bins",
106 | "-bins",
107 | help="The number of bins if a histogram is requested. The default value is 40.",
108 | required=False,
109 | default=40,
110 | metavar="",
111 | )
112 |
113 | optional.add_argument(
114 | "--reaction_index",
115 | "-reaction_id",
116 | help="The index of the reaction to plot the histogram of its fluxes. The default index is 1.",
117 | required=False,
118 | default=1,
119 | metavar="",
120 | )
121 |
122 | optional.add_argument(
123 | "--fva",
124 | "-fva",
125 | help="a boolean flag to request FVA method. The default value is False.",
126 | required=False,
127 | default=False,
128 | metavar="",
129 | )
130 |
131 | optional.add_argument(
132 | "--opt_percentage",
133 | "-opt",
134 | help="consider solutions that give you at least a certain percentage of the optimal solution in FVA method. The default is to consider optimal solutions only.",
135 | required=False,
136 | default=100,
137 | metavar="",
138 | )
139 |
140 | optional.add_argument(
141 | "--fba",
142 | "-fba",
143 | help="a boolean flag to request FBA method. The default value is False.",
144 | required=False,
145 | default=False,
146 | metavar="",
147 | )
148 |
149 | optional.add_argument(
150 | "--preprocess_only",
151 | "-preprocess",
152 | help="perform only preprocess to compute the full dimensional polytope from a model.",
153 | required=False,
154 | default=False,
155 | metavar="",
156 | )
157 |
158 | optional.add_argument(
159 | "--effective_sample_size",
160 | "-n",
161 | help="the minimum effective sample size per marginal of the sample that the Multiphase Monte Carlo Sampling algorithm will return. The default value is 1000.",
162 | required=False,
163 | default=1000,
164 | metavar="",
165 | )
166 |
167 | optional.add_argument(
168 | "--output_directory",
169 | "-o",
170 | help="the output directory for the dingo output",
171 | required=False,
172 | default=None,
173 | metavar="",
174 | )
175 |
176 | optional.add_argument(
177 | "--psrf_check",
178 | "-psrf",
179 | help="a boolean flag to request psrf < 1.1 for each marginal of the sample that the Multiphase Monte Carlo Sampling algorithm will return. The default value is `False`.",
180 | required=False,
181 | default=False,
182 | metavar="",
183 | )
184 |
185 | optional.add_argument(
186 | "--parallel_mmcs",
187 | "-pmmcs",
188 | help="a boolean flag to request sampling with parallel Multiphase Monte Carlo Sampling algorithm. The default value is `false`.",
189 | required=False,
190 | default=False,
191 | metavar="",
192 | )
193 |
194 | optional.add_argument(
195 | "--num_threads",
196 | "-nt",
197 | help="the number of threads to be used in parallel Multiphase Monte Carlo Sampling algorithm. The default number is 2.",
198 | required=False,
199 | default=2,
200 | metavar="",
201 | )
202 |
203 | optional.add_argument(
204 | "--distribution",
205 | "-d",
206 | help="the distribution to sample from the flux space of the metabolic network. Choose among `uniform`, `gaussian` and `exponential` distribution. The default value is `uniform`.",
207 | required=False,
208 | default="uniform",
209 | metavar="",
210 | )
211 |
212 | optional.add_argument(
213 | "--solver",
214 | "-s",
215 | help="the solver to use for the linear programs. Choose between `highs` and `gurobi` (faster computations --- it needs a licence). The default value is `highs`.",
216 | required=False,
217 | default="highs",
218 | metavar="",
219 | )
220 |
221 | args = parser.parse_args()
222 | return args
223 |
--------------------------------------------------------------------------------
/dingo/preprocess.py:
--------------------------------------------------------------------------------
1 |
2 | import cobra
3 | import cobra.manipulation
4 | from collections import Counter
5 | from dingo import MetabolicNetwork, PolytopeSampler
6 | from dingo.utils import correlated_reactions
7 | import numpy as np
8 |
9 |
10 | class PreProcess:
11 |
12 | def __init__(self, model, tol = 1e-6, open_exchanges = False, verbose = False):
13 |
14 | """
15 | model -- parameter gets a cobra model as input
16 |
17 | tol -- parameter gets a cutoff value used to classify
18 | zero-flux and mle reactions and compare FBA solutions
19 | before and after reactions removal
20 |
21 | open_exchanges -- parameter is used in the function that identifies blocked reactions
22 | It controls whether or not to open all exchange reactions
23 | to very high flux ranges.
24 |
25 | verbose -- A boolean type variable that if True
26 | additional information for preprocess is printed.
27 | """
28 |
29 | self._model = model
30 | self._tol = tol
31 |
32 | self._open_exchanges = open_exchanges
33 | self._verbose = verbose
34 |
35 | if self._tol > 1e-6 and verbose == True:
36 | print("Tolerance value set to",self._tol,"while default value is 1e-6. A looser check will be performed")
37 |
38 | self._objective = self._objective_function()
39 | self._initial_reactions = self._initial()
40 | self._reaction_bounds_dict = self._reaction_bounds_dictionary()
41 | self._essential_reactions = self._essentials()
42 | self._zero_flux_reactions = self._zero_flux()
43 | self._blocked_reactions = self._blocked()
44 | self._mle_reactions = self._metabolically_less_efficient()
45 | self._removed_reactions = []
46 |
47 |
48 | def _objective_function(self):
49 | """
50 | A function used to find the objective function of a model
51 | """
52 |
53 | objective = str(self._model.summary()._objective)
54 | self._objective = objective.split(" ")[1]
55 |
56 | return self._objective
57 |
58 |
59 | def _initial(self):
60 | """
61 | A function used to find reaction ids of a model
62 | """
63 |
64 | self._initial_reactions = [ reaction.id for reaction in \
65 | self._model.reactions ]
66 |
67 | return self._initial_reactions
68 |
69 |
70 | def _reaction_bounds_dictionary(self):
71 | """
72 | A function used to create a dictionary that maps
73 | reactions with their corresponding bounds. It is used to
74 | later restore bounds to their wild-type values
75 | """
76 |
77 | self._reaction_bounds_dict = { }
78 |
79 | for reaction_id in self._initial_reactions:
80 | bounds = self._model.reactions.get_by_id(reaction_id).bounds
81 | self._reaction_bounds_dict[reaction_id] = bounds
82 |
83 | return self._reaction_bounds_dict
84 |
85 |
86 | def _essentials(self):
87 | """
88 | A function used to find all the essential reactions
89 | and append them into a list. Essential reactions are
90 | the ones that are required for growth. If removed the
91 | objective function gets zeroed.
92 | """
93 |
94 | self._essential_reactions = [ reaction.id for reaction in \
95 | cobra.flux_analysis.find_essential_reactions(self._model) ]
96 |
97 | return self._essential_reactions
98 |
99 |
100 | def _zero_flux(self):
101 | """
102 | A function used to find zero-flux reactions.
103 | “Zero-flux” reactions cannot carry a flux while maintaining
104 | at least 90% of the maximum growth rate.
105 | These reactions have both a min and a max flux equal to 0,
106 | when running a FVA analysis with the fraction of optimum set to 90%
107 | """
108 |
109 | tol = self._tol
110 |
111 | fva = cobra.flux_analysis.flux_variability_analysis(self._model, fraction_of_optimum=0.9)
112 | zero_flux = fva.loc[ (abs(fva['minimum']) < tol ) & (abs(fva['maximum']) < tol)]
113 | self._zero_flux_reactions = zero_flux.index.tolist()
114 |
115 | return self._zero_flux_reactions
116 |
117 |
118 | def _blocked(self):
119 | """
120 | A function used to find blocked reactions.
121 | "Blocked" reactions that cannot carry a flux in any condition.
122 | These reactions can not have any flux other than 0
123 | """
124 |
125 | self._blocked_reactions = cobra.flux_analysis.find_blocked_reactions(self._model, open_exchanges=self._open_exchanges)
126 | return self._blocked_reactions
127 |
128 |
129 | def _metabolically_less_efficient(self):
130 | """
131 | A function used to find metabolically less efficient reactions.
132 | "Metabolically less efficient" require a reduction in growth rate if used
133 | These reactions are found when running an FBA and setting the
134 | optimal growth rate as the lower bound of the objective function (in
135 | this case biomass production. After running an FVA with the fraction of optimum
136 | set to 0.95, the reactions that have no flux are the metabolically less efficient.
137 | """
138 |
139 | tol = self._tol
140 |
141 | fba_solution = self._model.optimize()
142 |
143 | wt_lower_bound = self._model.reactions.get_by_id(self._objective).lower_bound
144 | self._model.reactions.get_by_id(self._objective).lower_bound = fba_solution.objective_value
145 |
146 | fva = cobra.flux_analysis.flux_variability_analysis(self._model, fraction_of_optimum=0.95)
147 | mle = fva.loc[ (abs(fva['minimum']) < tol ) & (abs(fva['maximum']) < tol)]
148 | self._mle_reactions = mle.index.tolist()
149 |
150 | self._model.reactions.get_by_id(self._objective).lower_bound = wt_lower_bound
151 |
152 | return self._mle_reactions
153 |
154 |
155 | def _remove_model_reactions(self):
156 | """
157 | A function used to set the lower and upper bounds of certain reactions to 0
158 | (it turns off reactions)
159 | """
160 |
161 | for reaction in self._removed_reactions:
162 | self._model.reactions.get_by_id(reaction).lower_bound = 0
163 | self._model.reactions.get_by_id(reaction).upper_bound = 0
164 |
165 | return self._model
166 |
167 |
168 | def reduce(self, extend=False):
169 | """
170 | A function that calls the "remove_model_reactions" function
171 | and removes blocked, zero-flux and metabolically less efficient
172 | reactions from the model.
173 |
174 | Then it finds the remaining reactions in the model after
175 | exclusion of the essential reactions.
176 |
177 | When the "extend" parameter is set to True, the function performes
178 | an additional check to remove further reactions. These reactions
179 | are the ones that if knocked-down, they do not affect the value
180 | of the objective function. Reactions are removed in an ordered way.
181 | The ones with the least overall correlation in a correlation matrix
182 | are removed first. These reactions are removed one by one from the model.
183 | If this removal produces an infeasible solution (or a solution of 0)
184 | to the objective function, these reactions are restored to their initial bounds.
185 |
186 | A dingo-type tuple is then created from the cobra model
187 | using the "cobra_dingo_tuple" function.
188 |
189 | The outputs are
190 | (a) A list of the removed reactions ids
191 | (b) A reduced dingo model
192 | """
193 |
194 | # create a list from the combined blocked, zero-flux, mle reactions
195 | blocked_mle_zero = self._blocked_reactions + self._mle_reactions + self._zero_flux_reactions
196 | list_removed_reactions = list(set(blocked_mle_zero))
197 | self._removed_reactions = list_removed_reactions
198 |
199 | # remove these reactions from the model
200 | self._remove_model_reactions()
201 |
202 | remained_reactions = list((Counter(self._initial_reactions)-Counter(self._removed_reactions)).elements())
203 | remained_reactions = list((Counter(remained_reactions)-Counter(self._essential_reactions)).elements())
204 |
205 | tol = self._tol
206 |
207 | if extend != False and extend != True:
208 | raise Exception("Wrong Input to extend parameter")
209 |
210 | elif extend == False:
211 |
212 | if self._verbose == True:
213 | print(len(self._removed_reactions), "of the", len(self._initial_reactions), \
214 | "reactions were removed from the model with extend set to", extend)
215 |
216 | # call this functon to convert cobra to dingo model
217 | self._dingo_model = MetabolicNetwork.from_cobra_model(self._model)
218 | return self._removed_reactions, self._dingo_model
219 |
220 | elif extend == True:
221 |
222 | reduced_dingo_model = MetabolicNetwork.from_cobra_model(self._model)
223 | reactions = reduced_dingo_model.reactions
224 | sampler = PolytopeSampler(reduced_dingo_model)
225 | steady_states = sampler.generate_steady_states()
226 |
227 | # calculate correlation matrix with additional filtering from copula indicator
228 | corr_matrix = correlated_reactions(
229 | steady_states,
230 | pearson_cutoff = 0,
231 | indicator_cutoff = 0,
232 | cells = 10,
233 | cop_coeff = 0.3,
234 | lower_triangle = False)
235 |
236 | # convert pearson values to absolute values
237 | abs_array = abs(corr_matrix)
238 | # sum absolute pearson values per row
239 | sum_array = np.sum((abs_array), axis=1)
240 | # get indices of ordered sum values
241 | order_sum_indices = np.argsort(sum_array)
242 |
243 | fba_solution_before = self._model.optimize().objective_value
244 |
245 | # count additional reactions with a possibility of removal
246 | additional_removed_reactions_count = 0
247 |
248 | # find additional reactions with a possibility of removal
249 | for index in order_sum_indices:
250 | if reactions[index] in remained_reactions:
251 | reaction = reactions[index]
252 |
253 | # perform a knock-out and check the output
254 | self._model.reactions.get_by_id(reaction).lower_bound = 0
255 | self._model.reactions.get_by_id(reaction).upper_bound = 0
256 |
257 | try:
258 | fba_solution_after = self._model.optimize().objective_value
259 | if (abs(fba_solution_after - fba_solution_before) > tol):
260 | # restore bounds
261 | self._model.reactions.get_by_id(reaction).bounds = self._reaction_bounds_dict[reaction]
262 |
263 | # if system has no solution
264 | except:
265 | self._model.reactions.get_by_id(reaction).bounds = self._reaction_bounds_dict[reaction]
266 |
267 | finally:
268 | if (fba_solution_after != None) and (abs(fba_solution_after - fba_solution_before) < tol):
269 | self._removed_reactions.append(reaction)
270 | additional_removed_reactions_count += 1
271 | else:
272 | # restore bounds
273 | self._model.reactions.get_by_id(reaction).bounds = self._reaction_bounds_dict[reaction]
274 |
275 |
276 | if self._verbose == True:
277 | print(len(self._removed_reactions), "of the", len(self._initial_reactions), \
278 | "reactions were removed from the model with extend set to", extend)
279 | print(additional_removed_reactions_count, "additional reaction(s) removed")
280 |
281 | # call this functon to convert cobra to dingo model
282 | self._dingo_model = MetabolicNetwork.from_cobra_model(self._model)
283 | return self._removed_reactions, self._dingo_model
284 |
--------------------------------------------------------------------------------
/dingo/pyoptinterface_based_impl.py:
--------------------------------------------------------------------------------
1 | import pyoptinterface as poi
2 | from pyoptinterface import highs, gurobi, copt, mosek
3 | import numpy as np
4 | import sys
5 |
6 | default_solver = "highs"
7 |
8 | def set_default_solver(solver_name):
9 | global default_solver
10 | default_solver = solver_name
11 |
12 | def get_solver(solver_name):
13 | solvers = {"highs": highs, "gurobi": gurobi, "copt": copt, "mosek": mosek}
14 | if solver_name in solvers:
15 | return solvers[solver_name]
16 | else:
17 | raise Exception("An unknown solver {solver_name} is requested.")
18 |
19 | def dot(c, x):
20 | return poi.quicksum(c[i] * x[i] for i in range(len(x)) if abs(c[i]) > 1e-12)
21 |
22 |
23 | def fba(lb, ub, S, c, solver_name=None):
24 | """A Python function to perform fba using PyOptInterface LP modeler
25 | Returns an optimal solution and its value for the following linear program:
26 | max c*v, subject to,
27 | Sv = 0, lb <= v <= ub
28 |
29 | Keyword arguments:
30 | lb -- lower bounds for the fluxes, i.e., a n-dimensional vector
31 | ub -- upper bounds for the fluxes, i.e., a n-dimensional vector
32 | S -- the mxn stoichiometric matrix, s.t. Sv = 0
33 | c -- the linear objective function, i.e., a n-dimensional vector
34 | solver_name -- the solver to use, i.e., a string of the solver name (if None, the default solver is used)
35 | """
36 |
37 | if lb.size != S.shape[1] or ub.size != S.shape[1]:
38 | raise Exception(
39 | "The number of reactions must be equal to the number of given flux bounds."
40 | )
41 | if c.size != S.shape[1]:
42 | raise Exception(
43 | "The length of the linear objective function must be equal to the number of reactions."
44 | )
45 |
46 | m = S.shape[0]
47 | n = S.shape[1]
48 | optimum_value = 0
49 | optimum_sol = np.zeros(n)
50 | try:
51 | if solver_name is None:
52 | solver_name = default_solver
53 | SOLVER = get_solver(solver_name)
54 | # Create a model
55 | model = SOLVER.Model()
56 | model.set_model_attribute(poi.ModelAttribute.Silent, True)
57 |
58 | # Create variables and set lb <= v <= ub
59 | v = np.empty(n, dtype=object)
60 | for i in range(n):
61 | v[i] = model.add_variable(lb=lb[i], ub=ub[i])
62 |
63 | # Add the constraints Sv = 0
64 | for i in range(m):
65 | model.add_linear_constraint(dot(S[i], v), poi.Eq, 0)
66 |
67 | # Set the objective function
68 | obj = dot(c, v)
69 | model.set_objective(obj, sense=poi.ObjectiveSense.Maximize)
70 |
71 | # Optimize model
72 | model.optimize()
73 |
74 | # If optimized
75 | status = model.get_model_attribute(poi.ModelAttribute.TerminationStatus)
76 | if status == poi.TerminationStatusCode.OPTIMAL:
77 | optimum_value = model.get_value(obj)
78 | for i in range(n):
79 | optimum_sol[i] = model.get_value(v[i])
80 | return optimum_sol, optimum_value
81 |
82 | except poi.TerminationStatusCode.NUMERICAL_ERROR as e:
83 | print(f"A numerical error occurred: {e}")
84 | except poi.TerminationStatusCode.OTHER_ERROR as e:
85 | print(f"An error occurred: {e}")
86 | except Exception as e:
87 | print(f"An unexpected error occurred: {e}")
88 |
89 |
90 | def fva(lb, ub, S, c, opt_percentage=100, solver_name=None):
91 | """A Python function to perform fva using PyOptInterface LP modeler
92 | Returns the value of the optimal solution for all the following linear programs:
93 | min/max v_i, for all coordinates i=1,...,n, subject to,
94 | Sv = 0, lb <= v <= ub
95 |
96 | Keyword arguments:
97 | lb -- lower bounds for the fluxes, i.e., a n-dimensional vector
98 | ub -- upper bounds for the fluxes, i.e., a n-dimensional vector
99 | S -- the mxn stoichiometric matrix, s.t. Sv = 0
100 | c -- the objective function to maximize
101 | opt_percentage -- consider solutions that give you at least a certain
102 | percentage of the optimal solution (default is to consider
103 | optimal solutions only)
104 | solver_name -- the solver to use, i.e., a string of the solver name (if None, the default solver is used)
105 | """
106 |
107 | if lb.size != S.shape[1] or ub.size != S.shape[1]:
108 | raise Exception(
109 | "The number of reactions must be equal to the number of given flux bounds."
110 | )
111 |
112 | # declare the tolerance that highs and gurobi work properly (we found it experimentally)
113 | tol = 1e-06
114 |
115 | m = S.shape[0]
116 | n = S.shape[1]
117 |
118 | max_biomass_flux_vector, max_biomass_objective = fba(lb, ub, S, c, solver_name)
119 |
120 | min_fluxes = []
121 | max_fluxes = []
122 |
123 | adjusted_opt_threshold = (
124 | (opt_percentage / 100) * tol * np.floor(max_biomass_objective / tol)
125 | )
126 |
127 | try:
128 | if solver_name is None:
129 | solver_name = default_solver
130 | SOLVER = get_solver(solver_name)
131 | # Create a model
132 | model = SOLVER.Model()
133 | model.set_model_attribute(poi.ModelAttribute.Silent, True)
134 |
135 | # Create variables and set lb <= v <= ub
136 | v = np.empty(n, dtype=object)
137 | for i in range(n):
138 | v[i] = model.add_variable(lb=lb[i], ub=ub[i])
139 |
140 | # Add the constraints Sv = 0
141 | for i in range(m):
142 | model.add_linear_constraint(dot(S[i], v), poi.Eq, 0)
143 |
144 | # add an additional constraint to impose solutions with at least `opt_percentage` of the optimal solution
145 | model.add_linear_constraint(dot(c, v), poi.Geq, adjusted_opt_threshold)
146 |
147 | for i in range(n):
148 | # Set the objective function
149 | obj = poi.ExprBuilder(v[i])
150 |
151 | model.set_objective(obj, sense=poi.ObjectiveSense.Minimize)
152 |
153 | # Optimize model
154 | model.optimize()
155 |
156 | # If optimized
157 | status = model.get_model_attribute(poi.ModelAttribute.TerminationStatus)
158 | if status == poi.TerminationStatusCode.OPTIMAL:
159 | # Get the min objective value
160 | min_objective = model.get_value(v[i])
161 | min_fluxes.append(min_objective)
162 | else:
163 | min_fluxes.append(lb[i])
164 |
165 | # Likewise, for the maximum, optimize model
166 | model.set_objective(obj, sense=poi.ObjectiveSense.Maximize)
167 |
168 | # Again if optimized
169 | model.optimize()
170 | status = model.get_model_attribute(poi.ModelAttribute.TerminationStatus)
171 | if status == poi.TerminationStatusCode.OPTIMAL:
172 | # Get the max objective value
173 | max_objective = model.get_value(v[i])
174 | max_fluxes.append(max_objective)
175 | else:
176 | max_fluxes.append(ub[i])
177 |
178 | # Make lists of fluxes numpy arrays
179 | min_fluxes = np.asarray(min_fluxes)
180 | max_fluxes = np.asarray(max_fluxes)
181 |
182 | return (
183 | min_fluxes,
184 | max_fluxes,
185 | max_biomass_flux_vector,
186 | max_biomass_objective,
187 | )
188 |
189 | except poi.TerminationStatusCode.NUMERICAL_ERROR as e:
190 | print(f"A numerical error occurred: {e}")
191 | except poi.TerminationStatusCode.OTHER_ERROR as e:
192 | print(f"An error occurred: {e}")
193 | except Exception as e:
194 | print(f"An unexpected error occurred: {e}")
195 |
196 |
197 | def inner_ball(A, b, solver_name=None):
198 | """A Python function to compute the maximum inscribed ball in the given polytope using PyOptInterface LP modeler
199 | Returns the optimal solution for the following linear program:
200 | max r, subject to,
201 | a_ix + r||a_i|| <= b, i=1,...,n
202 |
203 | Keyword arguments:
204 | A -- an mxn matrix that contains the normal vectors of the facets of the polytope row-wise
205 | b -- a m-dimensional vector
206 | solver_name -- the solver to use, i.e., a string of the solver name (if None, the default solver is used)
207 | """
208 |
209 | extra_column = []
210 |
211 | m = A.shape[0]
212 | n = A.shape[1]
213 |
214 | for i in range(A.shape[0]):
215 | entry = np.linalg.norm(A[i])
216 | extra_column.append(entry)
217 |
218 | column = np.asarray(extra_column)
219 | A_expand = np.c_[A, column]
220 |
221 | if solver_name is None:
222 | solver_name = default_solver
223 | SOLVER = get_solver(solver_name)
224 | model = SOLVER.Model()
225 | model.set_model_attribute(poi.ModelAttribute.Silent, True)
226 |
227 | # Create variables where x[n] is the radius
228 | x = np.empty(n + 1, dtype=object)
229 | for i in range(n + 1):
230 | x[i] = model.add_variable()
231 |
232 | # Add the constraints a_ix + r||a_i|| <= b
233 | for i in range(m):
234 | model.add_linear_constraint(dot(A_expand[i], x), poi.Leq, b[i])
235 |
236 | # Set the objective function
237 | obj = poi.ExprBuilder(x[n])
238 | model.set_objective(obj, sense=poi.ObjectiveSense.Maximize)
239 |
240 | # Optimize model
241 | model.optimize()
242 |
243 | # Get the center point and the radius of max ball from the solution of LP
244 | point = [model.get_value(x[i]) for i in range(n)]
245 |
246 | # Get radius
247 | r = model.get_value(obj)
248 |
249 | # And check whether the computed radius is negative
250 | if r < 0:
251 | raise Exception(
252 | "The radius calculated has negative value. The polytope is infeasible or something went wrong with the solver"
253 | )
254 | else:
255 | return point, r
256 |
257 |
258 | def set_model(n, lb, ub, Aeq, beq, A, b, solver_name=None):
259 | """
260 | A helper function of remove_redundant_facets function
261 | Create a PyOptInterface model with given PyOptInterface variables, equality constraints, inequality constraints and solver name
262 | but without an objective function.
263 | """
264 | # Create a model
265 | if solver_name is None:
266 | solver_name = default_solver
267 | SOLVER = get_solver(solver_name)
268 | model = SOLVER.Model()
269 | model.set_model_attribute(poi.ModelAttribute.Silent, True)
270 |
271 | # Create variables
272 | x = np.empty(n, dtype=object)
273 | for i in range(n):
274 | x[i] = model.add_variable(lb=lb[i], ub=ub[i])
275 |
276 | # Add the equality constraints
277 | for i in range(Aeq.shape[0]):
278 | model.add_linear_constraint(dot(Aeq[i], x), poi.Eq, beq[i])
279 |
280 | # Add the inequality constraints
281 | for i in range(A.shape[0]):
282 | model.add_linear_constraint(dot(A[i], x), poi.Leq, b[i])
283 |
284 | return model, x
285 |
286 |
287 | def remove_redundant_facets(lb, ub, S, c, opt_percentage=100, solver_name=None):
288 | """A function to find and remove the redundant facets and to find
289 | the facets with very small offset and to set them as equalities
290 |
291 | Keyword arguments:
292 | lb -- lower bounds for the fluxes, i.e., a n-dimensional vector
293 | ub -- upper bounds for the fluxes, i.e., a n-dimensional vector
294 | S -- the mxn stoichiometric matrix, s.t. Sv = 0
295 | c -- the objective function to maximize
296 | opt_percentage -- consider solutions that give you at least a certain
297 | percentage of the optimal solution (default is to consider
298 | optimal solutions only)
299 | solver_name -- the solver to use, i.e., a string of the solver name (if None, the default solver is used)
300 | """
301 |
302 | if lb.size != S.shape[1] or ub.size != S.shape[1]:
303 | raise Exception(
304 | "The number of reactions must be equal to the number of given flux bounds."
305 | )
306 |
307 | # declare the tolerance that highs and gurobi work properly (we found it experimentally)
308 | redundant_facet_tol = 1e-07
309 | tol = 1e-06
310 |
311 | m = S.shape[0]
312 | n = S.shape[1]
313 |
314 | # [v,-v] <= [ub,-lb]
315 | A = np.zeros((2 * n, n), dtype="float")
316 | A[0:n] = np.eye(n)
317 | A[n:] -= np.eye(n, n, dtype="float")
318 |
319 | b = np.concatenate((ub, -lb), axis=0)
320 | b = np.ascontiguousarray(b, dtype="float")
321 |
322 | beq = np.zeros(m)
323 |
324 | Aeq_res = S
325 | beq_res = np.array(beq)
326 | b_res = []
327 | A_res = np.empty((0, n), float)
328 |
329 | max_biomass_flux_vector, max_biomass_objective = fba(lb, ub, S, c, solver_name)
330 | val = -np.floor(max_biomass_objective / tol) * tol * opt_percentage / 100
331 |
332 | start = np.zeros(n)
333 |
334 | try:
335 |
336 | # initialize
337 | indices_iter = range(n)
338 | removed = 1
339 | offset = 1
340 | facet_left_removed = np.zeros(n, dtype=bool)
341 | facet_right_removed = np.zeros(n, dtype=bool)
342 |
343 | # Loop until no redundant facets are found
344 | while removed > 0 or offset > 0:
345 | removed = 0
346 | offset = 0
347 | indices = indices_iter
348 | indices_iter = []
349 |
350 | Aeq = np.array(Aeq_res)
351 | beq = np.array(beq_res)
352 |
353 | A_res = np.empty((0, n), dtype=float)
354 | b_res = []
355 |
356 | model_iter, v = set_model(n, lb, ub, Aeq, beq, np.array([-c]), [val], solver_name)
357 |
358 | for cnt, i in enumerate(indices):
359 |
360 | redundant_facet_right = True
361 | redundant_facet_left = True
362 |
363 | if cnt > 0:
364 | last_idx = indices[cnt-1]
365 | model_iter.set_variable_attribute(
366 | v[last_idx], poi.VariableAttribute.LowerBound, lb[last_idx]
367 | )
368 | model_iter.set_variable_attribute(
369 | v[last_idx], poi.VariableAttribute.UpperBound, ub[last_idx]
370 | )
371 |
372 | # objective function
373 | obj = poi.ExprBuilder(v[i])
374 |
375 | # maximize v_i (right)
376 | model_iter.set_objective(obj, sense=poi.ObjectiveSense.Maximize)
377 | model_iter.optimize()
378 |
379 | # if optimized
380 | status = model_iter.get_model_attribute(
381 | poi.ModelAttribute.TerminationStatus
382 | )
383 | if status == poi.TerminationStatusCode.OPTIMAL:
384 | # get the maximum objective value
385 | max_objective = model_iter.get_value(obj)
386 | else:
387 | max_objective = ub[i]
388 |
389 | # if this facet was not removed in a previous iteration
390 | if not facet_right_removed[i]:
391 | # Relax the inequality
392 | model_iter.set_variable_attribute(
393 | v[i], poi.VariableAttribute.UpperBound, ub[i] + 1
394 | )
395 |
396 | # Solve the model
397 | model_iter.optimize()
398 |
399 | status = model_iter.get_model_attribute(
400 | poi.ModelAttribute.TerminationStatus
401 | )
402 | if status == poi.TerminationStatusCode.OPTIMAL:
403 | # Get the max objective value with relaxed inequality
404 |
405 | max_objective2 = model_iter.get_value(obj)
406 | if np.abs(max_objective2 - max_objective) > redundant_facet_tol:
407 | redundant_facet_right = False
408 | else:
409 | removed += 1
410 | facet_right_removed[i] = True
411 |
412 | # Reset the inequality
413 | model_iter.set_variable_attribute(
414 | v[i], poi.VariableAttribute.UpperBound, ub[i]
415 | )
416 |
417 | # minimum v_i (left)
418 | model_iter.set_objective(obj, sense=poi.ObjectiveSense.Minimize)
419 | model_iter.optimize()
420 |
421 | # If optimized
422 | status = model_iter.get_model_attribute(
423 | poi.ModelAttribute.TerminationStatus
424 | )
425 | if status == poi.TerminationStatusCode.OPTIMAL:
426 | # Get the min objective value
427 | min_objective = model_iter.get_value(obj)
428 | else:
429 | min_objective = lb[i]
430 |
431 | # if this facet was not removed in a previous iteration
432 | if not facet_left_removed[i]:
433 | # Relax the inequality
434 | model_iter.set_variable_attribute(
435 | v[i], poi.VariableAttribute.LowerBound, lb[i] - 1
436 | )
437 |
438 | # Solve the model
439 | model_iter.optimize()
440 |
441 | status = model_iter.get_model_attribute(
442 | poi.ModelAttribute.TerminationStatus
443 | )
444 | if status == poi.TerminationStatusCode.OPTIMAL:
445 | # Get the min objective value with relaxed inequality
446 | min_objective2 = model_iter.get_value(obj)
447 | if np.abs(min_objective2 - min_objective) > redundant_facet_tol:
448 | redundant_facet_left = False
449 | else:
450 | removed += 1
451 | facet_left_removed[i] = True
452 |
453 | if (not redundant_facet_left) or (not redundant_facet_right):
454 | width = abs(max_objective - min_objective)
455 |
456 | # Check whether the offset in this dimension is small (and set an equality)
457 | if width < redundant_facet_tol:
458 | offset += 1
459 | Aeq_res = np.vstack((Aeq_res, A[i]))
460 | beq_res = np.append(beq_res, min(max_objective, min_objective))
461 | # Remove the bounds on this dimension
462 | ub[i] = sys.float_info.max
463 | lb[i] = -sys.float_info.max
464 | else:
465 | # store this dimension
466 | indices_iter.append(i)
467 |
468 | if not redundant_facet_left:
469 | # Not a redundant inequality
470 | A_res = np.append(A_res, np.array([A[n + i]]), axis=0)
471 | b_res.append(b[n + i])
472 | else:
473 | lb[i] = -sys.float_info.max
474 |
475 | if not redundant_facet_right:
476 | # Not a redundant inequality
477 | A_res = np.append(A_res, np.array([A[i]]), axis=0)
478 | b_res.append(b[i])
479 | else:
480 | ub[i] = sys.float_info.max
481 | else:
482 | # Remove the bounds on this dimension
483 | ub[i] = sys.float_info.max
484 | lb[i] = -sys.float_info.max
485 |
486 | b_res = np.asarray(b_res, dtype="float")
487 | A_res = np.asarray(A_res, dtype="float")
488 | A_res = np.ascontiguousarray(A_res, dtype="float")
489 | return A_res, b_res, Aeq_res, beq_res
490 |
491 | except poi.TerminationStatusCode.NUMERICAL_ERROR as e:
492 | print(f"A numerical error occurred: {e}")
493 | except poi.TerminationStatusCode.OTHER_ERROR as e:
494 | print(f"An error occurred: {e}")
495 | except Exception as e:
496 | print(f"An unexpected error occurred: {e}")
497 |
--------------------------------------------------------------------------------
/dingo/scaling.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 | # Copyright (c) 2021 Haris Zafeiropoulos
6 |
7 | # Licensed under GNU LGPL.3, see LICENCE file
8 |
9 | import numpy as np
10 | import scipy.sparse as sp
11 | from scipy.sparse import diags
12 | import math
13 |
14 |
15 | def gmscale(A, scltol):
16 | """This function is a python translation of the matlab cobra script you may find here:
17 | https://github.com/opencobra/cobratoolbox/blob/master/src/analysis/subspaces/gmscale.m
18 | Computes a scaling qA for the matrix A such that the computations in the polytope P = {x | qAx <= b}
19 | are numerically more stable
20 |
21 | Keyword arguments:
22 | A -- a mxn matrix
23 | scltol -- should be in the range (0.0, 1.0) to declare the desired accuracy. The maximum accuracy corresponds to 1.
24 | """
25 |
26 | m = A.shape[0]
27 | n = A.shape[1]
28 | A = np.abs(A)
29 | A_t = A.T ## We will work with the transpose matrix as numpy works on row based
30 | maxpass = 10
31 | aratio = 1e50
32 | damp = 1e-4
33 | small = 1e-8
34 | rscale = np.ones((m, 1))
35 | cscale = np.ones((n, 1))
36 |
37 | # Main loop
38 | for npass in range(maxpass):
39 |
40 | rscale[rscale == 0] = 1
41 | sparse = sp.csr_matrix(1.0 / rscale)
42 | r_diagonal_elements = np.asarray(sparse.todense())
43 | Rinv = diags(r_diagonal_elements[0].T, shape=(m, m)).toarray()
44 |
45 | SA = np.dot(Rinv, A)
46 | SA_T = SA.T
47 |
48 | J, I = SA_T.nonzero()
49 | V = SA.T[SA.T > 0]
50 | invSA = sp.csr_matrix((1.0 / V, (J, I)), shape=(n, m)).T
51 |
52 | cmax = np.max(SA, axis=0)
53 | cmin = np.max(invSA, axis=0).data
54 | cmin = 1.0 / (cmin + 2.2204e-16)
55 |
56 | sratio = np.max(cmax / cmin)
57 |
58 | if npass > 0:
59 | c_product = np.multiply(
60 | np.max((np.array((cmin.data, damp * cmax))), axis=0), cmax
61 | )
62 | cscale = np.sqrt(c_product)
63 |
64 | check = aratio * scltol
65 |
66 | if npass >= 2 and sratio >= check:
67 | break
68 |
69 | if npass == maxpass:
70 | break
71 |
72 | aratio = sratio
73 |
74 | # Set new row scales for the next pass.
75 | cscale[cscale == 0] = 1
76 | sparse = sp.csr_matrix(1.0 / cscale)
77 | c_diagonal_elements = np.asarray(sparse.todense())
78 |
79 | Cinv = diags(c_diagonal_elements[0].T, shape=(n, n)).toarray()
80 | SA = np.dot(A, Cinv)
81 | SA_T = SA.T
82 |
83 | J, I = SA_T.nonzero()
84 | V = SA.T[SA.T > 0]
85 | invSA = sp.csr_matrix((1.0 / V, (J, I)), shape=(n, m)).T
86 |
87 | rmax = np.max(SA, axis=1)
88 | rmin = np.max(invSA, axis=1).data
89 | tmp = rmin + 2.2204e-16
90 | rmin = 1.0 / tmp
91 |
92 | r_product = np.multiply(
93 | np.max((np.array((rmin.data, damp * rmax))), axis=0), rmax
94 | )
95 | rscale = np.sqrt(r_product)
96 |
97 | # End of main loop
98 |
99 | # Reset column scales so the biggest element in each scaled column will be 1.
100 | # Again, allow for empty rows and columns.
101 | rscale[rscale == 0] = 1
102 | sparse = sp.csr_matrix(1.0 / rscale)
103 | r_diagonal_elements = np.asarray(sparse.todense())
104 | Rinv = diags(r_diagonal_elements[0].T, shape=(m, m)).toarray()
105 |
106 | SA = np.dot(Rinv, A)
107 | SA_T = SA.T
108 | J, I = SA_T.nonzero()
109 | V = SA.T[SA.T > 0]
110 |
111 | cscale = np.max(SA, axis=0)
112 | cscale[cscale == 0] = 1
113 |
114 | return cscale, rscale
115 |
--------------------------------------------------------------------------------
/dingo/utils.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 |
6 | # Licensed under GNU LGPL.3, see LICENCE file
7 |
8 | import numpy as np
9 | import math
10 | import scipy.sparse as sp
11 | from scipy.sparse import diags
12 | from dingo.scaling import gmscale
13 | from dingo.nullspace import nullspace_dense, nullspace_sparse
14 | from scipy.cluster import hierarchy
15 | from networkx.algorithms.components import connected_components
16 | import networkx as nx
17 |
18 | def compute_copula(flux1, flux2, n):
19 | """A Python function to estimate the copula between two fluxes
20 |
21 | Keyword arguments:
22 | flux1: A vector that contains the measurements of the first reaxtion flux
23 | flux2: A vector that contains the measurements of the second reaxtion flux
24 | n: The number of cells
25 | """
26 |
27 | N = flux1.size
28 | copula = np.zeros([n,n], dtype=float)
29 |
30 | I1 = np.argsort(flux1)
31 | I2 = np.argsort(flux2)
32 |
33 | grouped_flux1 = np.zeros(N)
34 | grouped_flux2 = np.zeros(N)
35 |
36 | for j in range(n):
37 | rng = range((j*math.floor(N/n)),((j+1)*math.floor(N/n)))
38 | grouped_flux1[I1[rng]] = j
39 | grouped_flux2[I2[rng]] = j
40 |
41 | for i in range(n):
42 | for j in range(n):
43 | copula[i,j] = sum((grouped_flux1==i) *( grouped_flux2==j))
44 |
45 | copula = copula / N
46 | return copula
47 |
48 |
49 | def apply_scaling(A, b, cs, rs):
50 | """A Python function to apply the scaling computed by the function `gmscale` to a convex polytope
51 |
52 | Keyword arguments:
53 | A -- an mxn matrix that contains the normal vectors of the facets of the polytope row-wise
54 | b -- a m-dimensional vector
55 | cs -- a scaling vector for the matrix A
56 | rs -- a scaling vector for the vector b
57 | """
58 |
59 | m = rs.shape[0]
60 | n = cs.shape[0]
61 | r_diagonal_matrix = diags(1 / rs, shape=(m, m)).toarray()
62 | c_diagonal_matrix = diags(1 / cs, shape=(n, n)).toarray()
63 |
64 | new_A = np.dot(r_diagonal_matrix, np.dot(A, c_diagonal_matrix))
65 | new_b = np.dot(r_diagonal_matrix, b)
66 |
67 | return new_A, new_b, c_diagonal_matrix
68 |
69 |
70 | def remove_almost_redundant_facets(A, b):
71 | """A Python function to remove the facets of a polytope with norm smaller than 1e-06
72 |
73 | Keyword arguments:
74 | A -- an mxn matrix that contains the normal vectors of the facets of the polytope row-wise
75 | b -- a m-dimensional vector
76 | """
77 |
78 | new_A = []
79 | new_b = []
80 |
81 | for i in range(A.shape[0]):
82 | entry = np.linalg.norm(
83 | A[
84 | i,
85 | ]
86 | )
87 | if entry < 1e-06:
88 | continue
89 | else:
90 | new_A.append(A[i, :])
91 | new_b.append(b[i])
92 |
93 | new_A = np.array(new_A)
94 | new_b = np.array(new_b)
95 |
96 | return new_A, new_b
97 |
98 |
99 | # Map the points samples on the (rounded) full dimensional polytope, back to the initial one to obtain the steady states of the metabolic network
100 | def map_samples_to_steady_states(samples, N, N_shift, T=None, T_shift=None):
101 | """A Python function to map back to the initial space the sampled points from a full dimensional polytope derived by two
102 | linear transformation of a low dimensional polytope, to obtain the steady states of the metabolic network
103 |
104 | Keyword arguments:
105 | samples -- an nxN matrix that contains sample points column-wise
106 | N, N_shift -- the matrix and the vector of the linear transformation applied on the low dimensional polytope to derive the full dimensional polytope
107 | T, T_shift -- the matrix and the vector of the linear transformation applied on the full dimensional polytope
108 | """
109 |
110 | extra_2 = np.full((samples.shape[1], N.shape[0]), N_shift)
111 | if T is None or T_shift is None:
112 | steady_states = N.dot(samples) + extra_2.T
113 | else:
114 | extra_1 = np.full((samples.shape[1], samples.shape[0]), T_shift)
115 | steady_states = N.dot(T.dot(samples) + extra_1.T) + extra_2.T
116 |
117 | return steady_states
118 |
119 |
120 | def get_matrices_of_low_dim_polytope(S, lb, ub, min_fluxes, max_fluxes):
121 | """A Python function to derive the matrices A, Aeq and the vectors b, beq of the low dimensional polytope,
122 | such that A*x <= b and Aeq*x = beq.
123 |
124 | Keyword arguments:
125 | samples -- an nxN matrix that contains sample points column-wise
126 | S -- the stoichiometric matrix
127 | lb -- lower bounds for the fluxes, i.e., a n-dimensional vector
128 | ub -- upper bounds for the fluxes, i.e., a n-dimensional vector
129 | min_fluxes -- minimum values of the fluxes, i.e., a n-dimensional vector
130 | max_fluxes -- maximum values for the fluxes, i.e., a n-dimensional vector
131 | """
132 |
133 | n = S.shape[1]
134 | m = S.shape[0]
135 | beq = np.zeros(m)
136 | Aeq = S
137 |
138 | A = np.zeros((2 * n, n), dtype="float")
139 | A[0:n] = np.eye(n)
140 | A[n:] -= np.eye(n, n, dtype="float")
141 |
142 | b = np.concatenate((ub, -lb), axis=0)
143 | b = np.asarray(b, dtype="float")
144 | b = np.ascontiguousarray(b, dtype="float")
145 |
146 | for i in range(n):
147 |
148 | width = abs(max_fluxes[i] - min_fluxes[i])
149 |
150 | # Check whether we keep or not the equality
151 | if width < 1e-07:
152 | Aeq = np.vstack(
153 | (
154 | Aeq,
155 | A[
156 | i,
157 | ],
158 | )
159 | )
160 | beq = np.append(beq, min(max_fluxes[i], min_fluxes[i]))
161 |
162 | return A, b, Aeq, beq
163 |
164 |
165 | def get_matrices_of_full_dim_polytope(A, b, Aeq, beq):
166 | """A Python function to derive the matrix A and the vector b of the full dimensional polytope,
167 | such that Ax <= b given a low dimensional polytope.
168 |
169 | Keyword arguments:
170 | A -- an mxn matrix that contains the normal vectors of the facets of the polytope row-wise
171 | b -- a m-dimensional vector, s.t. A*x <= b
172 | Aeq -- an kxn matrix that contains the normal vectors of hyperplanes row-wise
173 | beq -- a k-dimensional vector, s.t. Aeq*x = beq
174 | """
175 |
176 | nullspace_res = nullspace_sparse(Aeq, beq)
177 | N = nullspace_res[0]
178 | N_shift = nullspace_res[1]
179 |
180 | if A.shape[1] != N.shape[0] or N.shape[0] != N_shift.size or N.shape[1] <= 1:
181 | raise Exception(
182 | "The computation of the matrix of the right nullspace of the stoichiometric matrix failed."
183 | )
184 |
185 | product = np.dot(A, N_shift)
186 | b = np.subtract(b, product)
187 | A = np.dot(A, N)
188 |
189 | res = remove_almost_redundant_facets(A, b)
190 | A = res[0]
191 | b = res[1]
192 |
193 | try:
194 | res = gmscale(A, 0.99)
195 | res = apply_scaling(A, b, res[0], res[1])
196 | A = res[0]
197 | b = res[1]
198 | N = np.dot(N, res[2])
199 |
200 | res = remove_almost_redundant_facets(A, b)
201 | A = res[0]
202 | b = res[1]
203 | except:
204 | print("gmscale failed to compute a good scaling.")
205 |
206 | return A, b, N, N_shift
207 |
208 |
209 |
210 | def correlated_reactions(steady_states, reactions=[], pearson_cutoff = 0.90, indicator_cutoff = 10,
211 | cells = 10, cop_coeff = 0.3, lower_triangle = True, verbose = False):
212 | """A Python function to calculate the pearson correlation matrix of a model
213 | and filter values based on the copula's indicator
214 |
215 | Keyword arguments:
216 | steady_states -- A numpy array of the generated steady states fluxes
217 | reactions -- A list with the model's reactions
218 | pearson_cutoff -- A cutoff to filter reactions based on pearson coefficient
219 | indicator_cutoff -- A cutoff to filter reactions based on indicator value
220 | cells -- Number of cells to compute the copula
221 | cop_coeff -- A value that narrows or widens the width of the copula's diagonal
222 | lower_triangle -- A boolean variable that if True plots only the lower triangular matrix
223 | verbose -- A boolean variable that if True additional information is printed as an output.
224 | """
225 |
226 | if cop_coeff > 0.4 or cop_coeff < 0.2:
227 | raise Exception("Input value to cop_coeff parameter must be between 0.2 and 0.4")
228 |
229 | # calculate coefficients to access red and blue copula mass
230 | cop_coeff_1 = cop_coeff
231 | cop_coeff_2 = 1 - cop_coeff
232 | cop_coeff_3 = 1 + cop_coeff
233 |
234 | # compute correlation matrix
235 | corr_matrix = np.corrcoef(steady_states, rowvar=True)
236 |
237 | # replace not assigned values with 0
238 | corr_matrix[np.isnan(corr_matrix)] = 0
239 |
240 | # create a copy of correlation matrix to replace/filter values
241 | filtered_corr_matrix = corr_matrix.copy()
242 |
243 | # find indices of correlation matrix where correlation does not occur
244 | no_corr_indices = np.argwhere((filtered_corr_matrix < pearson_cutoff) & (filtered_corr_matrix > -pearson_cutoff))
245 |
246 | # replace values from the correlation matrix that do not overcome
247 | # the pearson cutoff with 0
248 | for i in range(0, no_corr_indices.shape[0]):
249 | index1 = no_corr_indices[i][0]
250 | index2 = no_corr_indices[i][1]
251 |
252 | filtered_corr_matrix[index1, index2] = 0
253 |
254 | # if user does not provide an indicator cutoff then do not proceed
255 | # with the filtering of the correlation matrix
256 | if indicator_cutoff == 0:
257 | if lower_triangle == True:
258 | filtered_corr_matrix[np.triu_indices(filtered_corr_matrix.shape[0], 1)] = np.nan
259 | np.fill_diagonal(filtered_corr_matrix, 1)
260 | return filtered_corr_matrix
261 | else:
262 | np.fill_diagonal(filtered_corr_matrix, 1)
263 | return filtered_corr_matrix
264 | else:
265 | # a dictionary that will store for each filtered reaction combination,
266 | # the pearson correlation value, the copula's indicator value
267 | # and the correlation classification
268 | indicator_dict = {}
269 |
270 | # keep only the lower triangle
271 | corr_matrix = np.tril(corr_matrix)
272 | # replace diagonal values with 0
273 | np.fill_diagonal(corr_matrix, 0)
274 |
275 | # find indices of correlation matrix where correlation occurs
276 | corr_indices = np.argwhere((corr_matrix > pearson_cutoff) | (corr_matrix < -pearson_cutoff))
277 |
278 | # compute copula for each set of correlated reactions
279 | for i in range(0, corr_indices.shape[0]):
280 |
281 | index1 = corr_indices[i][0]
282 | index2 = corr_indices[i][1]
283 |
284 | reaction1 = reactions[index1]
285 | reaction2 = reactions[index2]
286 |
287 | flux1 = steady_states[index1]
288 | flux2 = steady_states[index2]
289 |
290 | copula = compute_copula(flux1, flux2, cells)
291 | rows, cols = copula.shape
292 |
293 | red_mass = 0
294 | blue_mass = 0
295 | indicator = 0
296 |
297 | for row in range(rows):
298 | for col in range(cols):
299 | # values in the diagonal
300 | if ((row-col >= -cop_coeff_1*rows) & (row-col <= cop_coeff_1*rows)):
301 | # values near the top left and bottom right corner
302 | if ((row+col < cop_coeff_2*rows) | (row+col > cop_coeff_3*rows)):
303 | red_mass = red_mass + copula[row][col]
304 | else:
305 | # values near the top right and bottom left corner
306 | if ((row+col >= cop_coeff_2*rows-1) & (row+col <= cop_coeff_3*rows-1)):
307 | blue_mass = blue_mass + copula[row][col]
308 |
309 | indicator = (red_mass+1e-9) / (blue_mass+1e-9)
310 |
311 | # classify specific pair of reactions as positive or negative
312 | # correlated based on indicator cutoff
313 | if indicator > indicator_cutoff:
314 | pearson = filtered_corr_matrix[index1, index2]
315 | indicator_dict[reaction1 + "~" + reaction2] = {'pearson': pearson,
316 | 'indicator': indicator,
317 | 'classification': "positive"}
318 |
319 | elif indicator < 1/indicator_cutoff:
320 | pearson = filtered_corr_matrix[index1, index2]
321 | indicator_dict[reaction1 + "~" + reaction2] = {'pearson': pearson,
322 | 'indicator': indicator,
323 | 'classification': "negative"}
324 |
325 | # if they do not overcome the cutoff replace their corresponding
326 | # value in the correlation matrix with 0
327 | else:
328 | filtered_corr_matrix[index1, index2] = 0
329 | filtered_corr_matrix[index2, index1] = 0
330 | pearson = filtered_corr_matrix[index1, index2]
331 | indicator_dict[reaction1 + "~" + reaction2] = {'pearson': pearson,
332 | 'indicator': indicator,
333 | 'classification': "no correlation"}
334 |
335 | if verbose == True:
336 | print("Completed process of",i+1,"from",corr_indices.shape[0],"copulas")
337 |
338 | if lower_triangle == True:
339 | filtered_corr_matrix[np.triu_indices(filtered_corr_matrix.shape[0], 1)] = np.nan
340 | np.fill_diagonal(filtered_corr_matrix, 1)
341 | return filtered_corr_matrix, indicator_dict
342 |
343 | else:
344 | np.fill_diagonal(filtered_corr_matrix, 1)
345 | return filtered_corr_matrix, indicator_dict
346 |
347 |
348 |
349 | def cluster_corr_reactions(correlation_matrix, reactions, linkage="ward",
350 | t = 4.0, correction=True):
351 | """A Python function for hierarchical clustering of the correlation matrix
352 |
353 | Keyword arguments:
354 | correlation_matrix -- A numpy 2D array of a correlation matrix
355 | reactions -- A list with the model's reactions
356 | linkage -- linkage defines the type of linkage.
357 | Available linkage types are: single, average, complete, ward.
358 | t -- A threshold that defines a threshold that cuts the dendrogram
359 | at a specific height and produces clusters
360 | correction -- A boolean variable that if True converts the values of the
361 | the correlation matrix to absolute values.
362 | """
363 |
364 | # function to return a nested list with grouped reactions based on clustering
365 | def clusters_list(reactions, labels):
366 | clusters = []
367 | unique_labels = np.unique(labels)
368 | for label in unique_labels:
369 | cluster = []
370 | label_where = np.where(labels == label)[0]
371 | for where in label_where:
372 | cluster.append(reactions[where])
373 | clusters.append(cluster)
374 | return clusters
375 |
376 | if correction == True:
377 | dissimilarity_matrix = 1 - abs(correlation_matrix)
378 | else:
379 | dissimilarity_matrix = 1 - correlation_matrix
380 |
381 | Z = hierarchy.linkage(dissimilarity_matrix, linkage)
382 | labels = hierarchy.fcluster(Z, t, criterion='distance')
383 |
384 | clusters = clusters_list(reactions, labels)
385 | return dissimilarity_matrix, labels, clusters
386 |
387 |
388 |
389 | def graph_corr_matrix(correlation_matrix, reactions, correction=True,
390 | clusters=[], subgraph_nodes = 5):
391 | """A Python function that creates the main graph and its subgraphs
392 | from a correlation matrix.
393 |
394 | Keyword arguments:
395 | correlation_matrix -- A numpy 2D array of a correlation matrix.
396 | reactions -- A list with the model's reactions.
397 | correction -- A boolean variable that if True converts the values of the
398 | the correlation matrix to absolute values.
399 | clusters -- A nested list with clustered reactions created from the "" function.
400 | subgraph_nodes -- A variable that specifies a cutoff for a graph's nodes.
401 | It filters subgraphs with low number of nodes..
402 | """
403 |
404 | graph_matrix = correlation_matrix.copy()
405 | np.fill_diagonal(graph_matrix, 0)
406 |
407 | if correction == True:
408 | graph_matrix = abs(graph_matrix)
409 |
410 | G = nx.from_numpy_array(graph_matrix)
411 | G = nx.relabel_nodes(G, lambda x: reactions[x])
412 |
413 | pos = nx.spring_layout(G)
414 | unconnected_nodes = list(nx.isolates(G))
415 | G.remove_nodes_from(unconnected_nodes)
416 | G_nodes = G.nodes()
417 |
418 | graph_list = []
419 | layout_list = []
420 |
421 | graph_list.append(G)
422 | layout_list.append(pos)
423 |
424 | subgraphs = [G.subgraph(c) for c in connected_components(G)]
425 | H_nodes_list = []
426 |
427 | for i in range(len(subgraphs)):
428 | if len(subgraphs[i].nodes()) > subgraph_nodes and len(subgraphs[i].nodes()) != len(G_nodes):
429 | H = G.subgraph(subgraphs[i].nodes())
430 | for cluster in clusters:
431 | if H.has_node(cluster[0]) and H.nodes() not in H_nodes_list:
432 | H_nodes_list.append(H.nodes())
433 |
434 | pos = nx.spring_layout(H)
435 | graph_list.append(H)
436 | layout_list.append(pos)
437 |
438 | return graph_list, layout_list
--------------------------------------------------------------------------------
/dingo/volestipy.pyx:
--------------------------------------------------------------------------------
1 | # This is a cython wrapper for the C++ library volesti
2 | # volesti (volume computation and sampling library)
3 |
4 | # Copyright (c) 2012-2021 Vissarion Fisikopoulos
5 | # Copyright (c) 2018-2021 Apostolos Chalkis
6 | # Copyright (c) 2020-2021 Pedro Zuidberg Dos Martires
7 | # Copyright (c) 2020-2021 Haris Zafeiropoulos
8 | # Copyright (c) 2024 Ke Shi
9 |
10 | # Licensed under GNU LGPL.3, see LICENCE file
11 |
12 | #!python
13 | #cython: language_level=3
14 | #cython: boundscheck=False
15 | #cython: wraparound=False
16 |
17 | # Global dependencies
18 | import os
19 | import sys
20 | import numpy as np
21 | cimport numpy as np
22 | from cpython cimport bool
23 |
24 | # For the read the json format BIGG files function
25 | import json
26 | import scipy.io
27 | # ----------------------------------------------------------------------------------
28 |
29 | from dingo.pyoptinterface_based_impl import inner_ball
30 |
31 | # Set the time
32 | def get_time_seed():
33 | import random
34 | import time
35 | return int(time.time())
36 |
37 |
38 | ################################################################################
39 | # Classes for the volesti C++ code #
40 | ################################################################################
41 |
42 | # Get classes from the bindings.h file
43 | cdef extern from "bindings.h":
44 |
45 | # The HPolytopeCPP class along with its functions
46 | cdef cppclass HPolytopeCPP:
47 |
48 | # Initialization
49 | HPolytopeCPP() except +
50 | HPolytopeCPP(double *A, double *b, int n_hyperplanes, int n_variables) except +
51 |
52 | # Compute volume
53 | double compute_volume(char* vol_method, char* walk_method, int walk_len, double epsilon, int seed);
54 |
55 | # Random sampling
56 | double apply_sampling(int walk_len, int number_of_points, int number_of_points_to_burn, \
57 | char* method, double* inner_point, double radius, double* samples, \
58 | double variance_value, double* bias_vector, int ess)
59 |
60 | # Initialize the parameters for the (m)ultiphase (m)onte (c)arlo (s)ampling algorithm
61 | void mmcs_initialize(unsigned int d, int ess, int psrf_check, int parallelism, int num_threads);
62 |
63 | # Perform a step of (m)ultiphase (m)onte (c)arlo (s)ampling algorithm
64 | double mmcs_step(double* inner_point_for_c, double radius, int &N);
65 |
66 | # Get the samples and the transformation matrices from (m)ultiphase (m)onte (c)arlo (s)ampling algorithm
67 | void get_mmcs_samples(double* T_matrix, double* T_shift, double* samples);
68 |
69 | void get_polytope_as_matrices(double* new_A, double* new_b);
70 |
71 | # Rounding H-Polytope
72 | void apply_rounding(int rounding_method, double* new_A, double* new_b, double* T_matrix, \
73 | double* shift, double &round_value, double* inner_point, double radius);
74 |
75 | # The lowDimPolytopeCPP class along with its functions
76 | cdef cppclass lowDimHPolytopeCPP:
77 |
78 | # Initialization
79 | lowDimHPolytopeCPP() except +
80 | lowDimHPolytopeCPP(double *A, double *b, double *Aeq, double *beq, int n_rows_of_A, int n_cols_of_A, int n_row_of_Aeq, int n_cols_of_Aeq) except +
81 |
82 | # Get full dimensional polytope
83 | int full_dimensiolal_polytope(double* N_extra_trans, double* shift, double* A_full_extra_trans, double* b_full)
84 |
85 | # Lists with the methods supported by volesti for volume approximation and random walk
86 | volume_methods = ["sequence_of_balls".encode("UTF-8"), "cooling_gaussian".encode("UTF-8"), "cooling_balls".encode("UTF-8")]
87 | walk_methods = ["uniform_ball".encode("UTF-8"), "CDHR".encode("UTF-8"), "RDHR".encode("UTF-8"), "gaussian_ball".encode("UTF-8"), \
88 | "gaussian_CDHR".encode("UTF-8"), "gaussian_RDHR".encode("UTF-8"), "uniform_ball".encode("UTF-8"), "billiard".encode("UTF-8")]
89 | rounding_methods = ["min_ellipsoid".encode("UTF-8"), "svd".encode("UTF-8"), "max_ellipsoid".encode("UTF-8")]
90 |
91 | # Build the HPolytope class
92 | cdef class HPolytope:
93 |
94 | cdef HPolytopeCPP polytope_cpp
95 | cdef double[:,::1] _A
96 | cdef double[::1] _b
97 |
98 | # Set the specs of the class
99 | def __cinit__(self, double[:,::1] A, double[::1] b):
100 | self._A = A
101 | self._b = b
102 | n_hyperplanes, n_variables = A.shape[0], A.shape[1]
103 | self.polytope_cpp = HPolytopeCPP(&A[0,0], &b[0], n_hyperplanes, n_variables)
104 |
105 | # This is where the volesti functions are getting their python interface; first the compute_volume() function
106 | def compute_volume(self, walk_len = 2, epsilon = 0.05, vol_method = "sequence_of_balls", walk_method = "uniform_ball", \
107 | np.npy_int32 seed=get_time_seed()):
108 |
109 | vol_method = vol_method.encode("UTF-8")
110 | walk_method = walk_method.encode("UTF-8")
111 |
112 | if vol_method in volume_methods:
113 | if walk_method in walk_methods:
114 | return self.polytope_cpp.compute_volume(vol_method, walk_method, walk_len, epsilon, seed)
115 | else:
116 | raise Exception('"{}" is not implemented to walk methods. Available methods are: {}'.format(walk_method, walk_methods))
117 | else:
118 | raise Exception('"{}" is not implemented to compute volume. Available methods are: {}'.format(vol_method, volume_methods))
119 |
120 | # Likewise, the generate_samples() function
121 | def generate_samples(self, method, number_of_points, number_of_points_to_burn, walk_len,
122 | variance_value, bias_vector, solver = None, ess = 1000):
123 |
124 | n_variables = self._A.shape[1]
125 | cdef double[:,::1] samples = np.zeros((number_of_points, n_variables), dtype = np.float64, order = "C")
126 |
127 | # Get max inscribed ball for the initial polytope
128 | temp_center, radius = inner_ball(self._A, self._b, solver)
129 |
130 | cdef double[::1] inner_point_for_c = np.asarray(temp_center)
131 |
132 | cdef double[::1] bias_vector_ = np.asarray(bias_vector)
133 |
134 | self.polytope_cpp.apply_sampling(walk_len, number_of_points, number_of_points_to_burn, \
135 | method, &inner_point_for_c[0], radius, &samples[0,0], \
136 | variance_value, &bias_vector_[0], ess)
137 | return np.asarray(samples)
138 |
139 |
140 | # The rounding() function; as in compute_volume, more than one method is available for this step
141 | def rounding(self, rounding_method = 'john_position', solver = None):
142 |
143 | # Get the dimensions of the items about to build
144 | n_hyperplanes, n_variables = self._A.shape[0], self._A.shape[1]
145 |
146 | # Set the variables of those items; notice that they are all cdef type, except for the last one, which is used
147 | # both as a C++ and a Python variable
148 | cdef double[:,::1] new_A = np.zeros((n_hyperplanes, n_variables), dtype=np.float64, order="C")
149 | cdef double[::1] new_b = np.zeros(n_hyperplanes, dtype=np.float64, order="C")
150 | cdef double[:,::1] T_matrix = np.zeros((n_variables, n_variables), dtype=np.float64, order="C")
151 | cdef double[::1] shift = np.zeros((n_variables), dtype=np.float64, order="C")
152 | cdef double round_value
153 |
154 | # Get max inscribed ball for the initial polytope
155 | center, radius = inner_ball(self._A, self._b, solver)
156 |
157 | cdef double[::1] inner_point_for_c = np.asarray(center)
158 |
159 | if rounding_method == 'john_position':
160 | int_method = 1
161 | elif rounding_method == 'isotropic_position':
162 | int_method = 2
163 | elif rounding_method == 'min_ellipsoid':
164 | int_method = 3
165 | else:
166 | raise RuntimeError("Uknown rounding method")
167 |
168 | self.polytope_cpp.apply_rounding(int_method, &new_A[0,0], &new_b[0], &T_matrix[0,0], &shift[0], round_value, &inner_point_for_c[0], radius)
169 |
170 | return np.asarray(new_A),np.asarray(new_b),np.asarray(T_matrix),np.asarray(shift),np.asarray(round_value)
171 |
172 |
173 | # (m)ultiphase (m)onte (c)arlo (s)ampling algorithm to generate steady states of a metabolic network
174 | def mmcs(self, ess = 1000, psrf_check = True, parallelism = False, num_threads = 2, solver = None):
175 |
176 | n_hyperplanes, n_variables = self._A.shape[0], self._A.shape[1]
177 |
178 | cdef double[:,::1] new_A = np.zeros((n_hyperplanes, n_variables), dtype=np.float64, order="C")
179 | cdef double[::1] new_b = np.zeros(n_hyperplanes, dtype=np.float64, order="C")
180 | cdef double[:,::1] T_matrix = np.zeros((n_variables, n_variables), dtype=np.float64, order="C")
181 | cdef double[::1] T_shift = np.zeros((n_variables), dtype=np.float64, order="C")
182 | cdef int N_samples
183 | cdef int N_ess = ess
184 | cdef bint check_psrf = bool(psrf_check) # restrict variables to {0,1} using Python's rules
185 | cdef bint parallel = bool(parallelism)
186 |
187 | self.polytope_cpp.mmcs_initialize(n_variables, ess, check_psrf, parallel, num_threads)
188 |
189 | # Get max inscribed ball for the initial polytope
190 | temp_center, radius = inner_ball(self._A, self._b, solver)
191 | cdef double[::1] inner_point_for_c = np.asarray(temp_center)
192 |
193 | while True:
194 |
195 | check = self.polytope_cpp.mmcs_step(&inner_point_for_c[0], radius, N_samples)
196 |
197 | if check > 1.0 and check < 2.0:
198 | break
199 |
200 | self.polytope_cpp.get_polytope_as_matrices(&new_A[0,0], &new_b[0])
201 | new_temp_c, radius = inner_ball(np.asarray(new_A), np.asarray(new_b), solver)
202 | inner_point_for_c = np.asarray(new_temp_c)
203 |
204 | cdef double[:,::1] samples = np.zeros((n_variables, N_samples), dtype=np.float64, order="C")
205 | self.polytope_cpp.get_mmcs_samples(&T_matrix[0,0], &T_shift[0], &samples[0,0])
206 | self.polytope_cpp.get_polytope_as_matrices(&new_A[0,0], &new_b[0])
207 |
208 | return np.asarray(new_A), np.asarray(new_b), np.asarray(T_matrix), np.asarray(T_shift), np.asarray(samples)
209 |
210 | def A(self):
211 | return np.asarray(self._A)
212 |
213 | def b(self):
214 | return np.asarray(self._b)
215 |
216 | def dimension(self):
217 | return self._A.shape[1]
218 |
--------------------------------------------------------------------------------
/doc/aconta_ppc_copula.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GeomScale/dingo/cdcb43c888b496ef3b86c1916ae60459dfecace4/doc/aconta_ppc_copula.png
--------------------------------------------------------------------------------
/doc/e_coli_aconta.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GeomScale/dingo/cdcb43c888b496ef3b86c1916ae60459dfecace4/doc/e_coli_aconta.png
--------------------------------------------------------------------------------
/doc/logo/dingo.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GeomScale/dingo/cdcb43c888b496ef3b86c1916ae60459dfecace4/doc/logo/dingo.jpg
--------------------------------------------------------------------------------
/ext_data/e_coli_core.mat:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GeomScale/dingo/cdcb43c888b496ef3b86c1916ae60459dfecace4/ext_data/e_coli_core.mat
--------------------------------------------------------------------------------
/ext_data/e_coli_core_dingo.mat:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GeomScale/dingo/cdcb43c888b496ef3b86c1916ae60459dfecace4/ext_data/e_coli_core_dingo.mat
--------------------------------------------------------------------------------
/ext_data/matlab_model_wrapper.m:
--------------------------------------------------------------------------------
1 | path_to_model = '';
2 | model = load(strcat(path_to_model, '.mat'));
3 |
4 | fldnames = fieldnames(model);
5 |
6 | dingo_model = struct;
7 | dingo_model.S = model.(fldnames{1}).S;
8 | dingo_model.lb = model.(fldnames{1}).lb;
9 | dingo_model.ub = model.(fldnames{1}).ub;
10 | dingo_model.c = model.(fldnames{1}).c;
11 | dingo_model.index_obj = find(dingo_model.c == 1);
12 | dingo_model.rxns = model.(fldnames{1}).rxns;
13 | dingo_model.mets = model.(fldnames{1}).mets;
14 |
15 | save('dingo_model.mat', 'dingo_model')
16 |
17 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.poetry]
2 | name = "dingo"
3 | version = "0.1.0"
4 | description = "A python library for metabolic networks sampling and analysis. dingo is part of GeomScale project"
5 | authors = ["Apostolos Chalkis "]
6 | build = 'build.py'
7 |
8 | [tool.poetry.dependencies]
9 | python = "^3.8"
10 | sparseqr = {git = "https://github.com/yig/PySPQR.git"}
11 | simplejson = "^3.17.2"
12 | Cython = "^0.29.22"
13 | numpy = "^1.20.1"
14 | scipy = "^1.6.1"
15 | argparse = "^1.4.0"
16 | matplotlib = "^3.4.1"
17 | cobra = "^0.26.0"
18 | plotly = "^5.11.0"
19 | kaleido = "0.2.1"
20 | pyoptinterface = {version = "^0.2.7", extras = ["highs"]}
21 | networkx = "3.1"
22 |
23 | [tool.poetry.dev-dependencies]
24 |
25 | [build-system]
26 | requires = ["poetry-core>=1.0.0", "cython", "numpy==1.20.1"]
27 | build-backend = "poetry.core.masonry.api"
28 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 | # Copyright (c) 2024 Vissarion Fisikopoulos
6 |
7 | # Licensed under GNU LGPL.3, see LICENCE file
8 |
9 | # This is the setup Python script for building the dingo library
10 |
11 | from distutils.core import setup
12 | from distutils.core import Extension
13 | from Cython.Build import cythonize
14 | from os.path import join
15 | import numpy
16 | import os
17 |
18 | # information about the dingo library
19 | version = "0.1.0"
20 | license = ("LGPL3",)
21 | packages = ["dingo"]
22 | description = "A python library for metabolic networks sampling and analysis"
23 | author = "Apostolos Chalkis"
24 | author_email = "tolis.chal@gmail.com"
25 | name = "dingo"
26 |
27 |
28 | source_directory_list = ["dingo", join("dingo", "bindings")]
29 |
30 | compiler_args = ["-std=c++17", "-O3", "-DBOOST_NO_AUTO_PTR", "-ldl", "-lm", "-fopenmp"]
31 | lp_solve_compiler_args = ["-DYY_NEVER_INTERACTIVE", "-DLoadInverseLib=0", "-DLoadLanguageLib=0",
32 | "-DRoleIsExternalInvEngine", "-DINVERSE_ACTIVE=3", "-DLoadableBlasLib=0"]
33 |
34 | link_args = ["-O3", "-fopenmp"]
35 |
36 | extra_volesti_include_dirs = [
37 | # include binding files
38 | join("dingo", "bindings"),
39 | # the volesti code uses some external classes.
40 | # external directories we need to add
41 | join("eigen"),
42 | join("boost_1_76_0"),
43 | join("boost_1_76_0", "boost"),
44 | join("lp_solve_5.5"),
45 | join("lp_solve_5.5", "bfp"),
46 | join("lp_solve_5.5", "bfp", "bfp_LUSOL"),
47 | join("lp_solve_5.5", "bfp", "bfp_LUSOL", "LUSOL"),
48 | join("lp_solve_5.5", "colamd"),
49 | join("lp_solve_5.5", "shared"),
50 | join("volesti", "external"),
51 | join("volesti", "external", "minimum_ellipsoid"),
52 | # include and add the directories on the "include" directory
53 | join("volesti", "include"),
54 | join("volesti", "include", "convex_bodies"),
55 | join("volesti", "include", "random_walks"),
56 | join("volesti", "include", "volume"),
57 | join("volesti", "include", "generators"),
58 | join("volesti", "include", "cartesian_geom"),
59 | ]
60 |
61 | src_files = ["lp_solve_5.5/bfp/bfp_LUSOL/lp_LUSOL.c"
62 | , "lp_solve_5.5/bfp/bfp_LUSOL/LUSOL/lusol.c"
63 | , "lp_solve_5.5/colamd/colamd.c"
64 | , "lp_solve_5.5/ini.c"
65 | , "lp_solve_5.5/shared/commonlib.c"
66 | , "lp_solve_5.5/shared/mmio.c"
67 | , "lp_solve_5.5/shared/myblas.c"
68 | , "lp_solve_5.5/lp_crash.c"
69 | , "lp_solve_5.5/lp_Hash.c"
70 | , "lp_solve_5.5/lp_lib.c"
71 | , "lp_solve_5.5/lp_matrix.c"
72 | , "lp_solve_5.5/lp_MDO.c"
73 | , "lp_solve_5.5/lp_mipbb.c"
74 | , "lp_solve_5.5/lp_MPS.c"
75 | , "lp_solve_5.5/lp_params.c"
76 | , "lp_solve_5.5/lp_presolve.c"
77 | , "lp_solve_5.5/lp_price.c"
78 | , "lp_solve_5.5/lp_pricePSE.c"
79 | , "lp_solve_5.5/lp_report.c"
80 | , "lp_solve_5.5/lp_scale.c"
81 | , "lp_solve_5.5/lp_simplex.c"
82 | , "lp_solve_5.5/lp_SOS.c"
83 | , "lp_solve_5.5/lp_utils.c"
84 | , "lp_solve_5.5/lp_wlp.c"
85 | , "dingo/volestipy.pyx"
86 | , "dingo/bindings/bindings.cpp"]
87 |
88 | # Return the directory that contains the NumPy *.h header files.
89 | # Extension modules that need to compile against NumPy should use this
90 | # function to locate the appropriate include directory.
91 | extra_include_dirs = [numpy.get_include()]
92 |
93 | ext_module = Extension(
94 | "volestipy",
95 | language="c++",
96 | sources=src_files,
97 | include_dirs=extra_include_dirs + extra_volesti_include_dirs,
98 | extra_compile_args=compiler_args + lp_solve_compiler_args,
99 | extra_link_args=link_args,
100 | )
101 | print("The Extension function is OK.")
102 |
103 | ext_modules = cythonize([ext_module], gdb_debug=False)
104 | print("The cythonize function ran fine!")
105 |
106 | setup(
107 | version=version,
108 | author=author,
109 | author_email=author_email,
110 | name=name,
111 | packages=packages,
112 | ext_modules=ext_modules,
113 | )
114 |
115 | print("Installation of dingo completed.")
116 |
--------------------------------------------------------------------------------
/tests/correlation.py:
--------------------------------------------------------------------------------
1 |
2 | from dingo.utils import correlated_reactions
3 | from dingo import MetabolicNetwork, PolytopeSampler
4 | import numpy as np
5 | import unittest
6 |
7 | class TestCorrelation(unittest.TestCase):
8 |
9 | def test_correlation(self):
10 |
11 | dingo_model = MetabolicNetwork.from_json('ext_data/e_coli_core.json')
12 | reactions = dingo_model.reactions
13 |
14 | sampler = PolytopeSampler(dingo_model)
15 | steady_states = sampler.generate_steady_states()
16 |
17 | # calculate correlation matrix with filtering from copula indicator
18 | corr_matrix, indicator_dict = correlated_reactions(steady_states,
19 | reactions = reactions,
20 | indicator_cutoff = 5,
21 | pearson_cutoff = 0.999999,
22 | lower_triangle = False,
23 | verbose = False)
24 |
25 | # sum values in the diagonal of the correlation matrix ==> 95*pearson ==> 95*1
26 | self.assertTrue(np.trace(corr_matrix) == len(reactions))
27 | # rows and columns must be equal to model reactions
28 | self.assertTrue(corr_matrix.shape[0] == len(reactions))
29 | self.assertTrue(corr_matrix.shape[1] == len(reactions))
30 |
31 |
32 | dingo_model = MetabolicNetwork.from_json('ext_data/e_coli_core.json')
33 | reactions = dingo_model.reactions
34 |
35 | sampler = PolytopeSampler(dingo_model)
36 | steady_states = sampler.generate_steady_states()
37 |
38 | # calculate correlation matrix without filtering from copula indicator
39 | corr_matrix = correlated_reactions(steady_states,
40 | indicator_cutoff = 0,
41 | pearson_cutoff = 0,
42 | lower_triangle = True,
43 | verbose = False)
44 |
45 | # sum values in the diagonal of the correlation matrix ==> 95*pearson ==> 95*1
46 | self.assertTrue(np.trace(corr_matrix) == len(reactions))
47 | # rows and columns must be equal to model reactions
48 | self.assertTrue(corr_matrix.shape[0] == len(reactions))
49 | self.assertTrue(corr_matrix.shape[1] == len(reactions))
50 |
51 |
52 | if __name__ == "__main__":
53 | unittest.main()
54 |
--------------------------------------------------------------------------------
/tests/fba.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 | # Copyright (c) 2024 Ke Shi
6 |
7 | # Licensed under GNU LGPL.3, see LICENCE file
8 |
9 | import unittest
10 | import os
11 | import sys
12 | from dingo import MetabolicNetwork
13 | from dingo.pyoptinterface_based_impl import set_default_solver
14 |
15 | class TestFba(unittest.TestCase):
16 |
17 | def test_fba_json(self):
18 |
19 | input_file_json = os.getcwd() + "/ext_data/e_coli_core.json"
20 | model = MetabolicNetwork.from_json(input_file_json)
21 | res = model.fba()
22 |
23 | self.assertTrue(abs(res[1] - 0.8739215067486387) < 1e-03)
24 |
25 | def test_fba_mat(self):
26 |
27 | input_file_mat = os.getcwd() + "/ext_data/e_coli_core.mat"
28 | model = MetabolicNetwork.from_mat(input_file_mat)
29 |
30 | res = model.fba()
31 |
32 | self.assertTrue(abs(res[1] - 0.8739215067486387) < 1e-03)
33 |
34 | def test_fba_sbml(self):
35 |
36 | input_file_sbml = os.getcwd() + "/ext_data/e_coli_core.xml"
37 | model = MetabolicNetwork.from_sbml(input_file_sbml)
38 |
39 | res = model.fba()
40 |
41 | self.assertTrue(abs(res[1] - 0.8739215067486387) < 1e-03)
42 |
43 | def test_modify_medium(self):
44 |
45 | input_file_sbml = os.getcwd() + "/ext_data/e_coli_core.xml"
46 | model = MetabolicNetwork.from_sbml(input_file_sbml)
47 |
48 | initial_medium = model.medium
49 | initial_fba = model.fba()[-1]
50 |
51 | e_coli_core_medium_compound_indices = {
52 | "EX_co2_e" : 46,
53 | "EX_glc__D_e" : 51,
54 | "EX_h_e" : 54,
55 | "EX_h2o_e" : 55,
56 | "EX_nh4_e" : 58,
57 | "EX_o2_e" : 59,
58 | "EX_pi_e" : 60
59 | }
60 |
61 | glc_index = model.reactions.index("EX_glc__D_e")
62 | o2_index = model.reactions.index("EX_o2_e")
63 |
64 | new_media = initial_medium.copy()
65 | new_media["EX_glc__D_e"] = 1.5
66 | new_media["EX_o2_e"] = -0.5
67 |
68 | model.medium = new_media
69 |
70 | updated_media = model.medium
71 | updated_medium_indices = {}
72 | for reac in updated_media:
73 | updated_medium_indices[reac] = model.reactions.index(reac)
74 |
75 | self.assertTrue(updated_medium_indices == e_coli_core_medium_compound_indices)
76 |
77 | self.assertTrue(model.lb[glc_index] == -1.5 and model.lb[o2_index] == 0.5)
78 |
79 | self.assertTrue(initial_fba - model.fba()[-1] > 0)
80 |
81 |
82 | if __name__ == "__main__":
83 | if len(sys.argv) > 1:
84 | set_default_solver(sys.argv[1])
85 | sys.argv.pop(1)
86 | unittest.main()
87 |
--------------------------------------------------------------------------------
/tests/full_dimensional.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 | # Copyright (c) 2021 Vissarion Fisikopoulos
6 | # Copyright (c) 2024 Ke Shi
7 |
8 | # Licensed under GNU LGPL.3, see LICENCE file
9 |
10 | import unittest
11 | import os
12 | import sys
13 | from dingo import MetabolicNetwork, PolytopeSampler
14 | from dingo.pyoptinterface_based_impl import set_default_solver
15 |
16 | class TestFullDim(unittest.TestCase):
17 |
18 | def test_get_full_dim_json(self):
19 |
20 | input_file_json = os.getcwd() + "/ext_data/e_coli_core.json"
21 |
22 | model = MetabolicNetwork.from_json( input_file_json )
23 | sampler = self.get_polytope_from_model_without_redundancy_removal(model)
24 |
25 | self.assertEqual(sampler.A.shape[0], 175)
26 | self.assertEqual(sampler.A.shape[1], 24)
27 |
28 | sampler = self.get_polytope_from_model_with_redundancy_removal(model)
29 |
30 | self.assertEqual(sampler.A.shape[0], 26)
31 | self.assertEqual(sampler.A.shape[1], 24)
32 |
33 | def test_get_full_dim_sbml(self):
34 |
35 | input_file_sbml = os.getcwd() + "/ext_data/e_coli_core.xml"
36 | model = MetabolicNetwork.from_sbml( input_file_sbml )
37 | sampler = self.get_polytope_from_model_without_redundancy_removal( model )
38 |
39 | self.assertEqual(sampler.A.shape[0], 175)
40 | self.assertEqual(sampler.A.shape[1], 24)
41 |
42 | sampler = self.get_polytope_from_model_with_redundancy_removal(model)
43 |
44 | self.assertEqual(sampler.A.shape[0], 26)
45 | self.assertEqual(sampler.A.shape[1], 24)
46 |
47 | def test_get_full_dim_mat(self):
48 |
49 | input_file_mat = os.getcwd() + "/ext_data/e_coli_core.mat"
50 | model = MetabolicNetwork.from_mat( input_file_mat )
51 | sampler = self.get_polytope_from_model_without_redundancy_removal( model )
52 |
53 | self.assertEqual(sampler.A.shape[0], 175)
54 | self.assertEqual(sampler.A.shape[1], 24)
55 |
56 | sampler = self.get_polytope_from_model_with_redundancy_removal(model)
57 |
58 | self.assertEqual(sampler.A.shape[0], 26)
59 | self.assertEqual(sampler.A.shape[1], 24)
60 |
61 | @staticmethod
62 | def get_polytope_from_model_without_redundancy_removal (met_model):
63 |
64 | sampler = PolytopeSampler(met_model)
65 | sampler.facet_redundancy_removal(False)
66 | sampler.get_polytope()
67 |
68 | return sampler
69 |
70 | @staticmethod
71 | def get_polytope_from_model_with_redundancy_removal (met_model):
72 |
73 | sampler = PolytopeSampler(met_model)
74 | sampler.get_polytope()
75 |
76 | return sampler
77 |
78 | if __name__ == "__main__":
79 | if len(sys.argv) > 1:
80 | set_default_solver(sys.argv[1])
81 | sys.argv.pop(1)
82 | unittest.main()
83 |
--------------------------------------------------------------------------------
/tests/max_ball.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 | # Copyright (c) 2021 Vissarion Fisikopoulos
6 | # Copyright (c) 2024 Ke Shi
7 |
8 | # Licensed under GNU LGPL.3, see LICENCE file
9 |
10 | import unittest
11 | import os
12 | import sys
13 | import scipy
14 | import numpy as np
15 | from dingo import MetabolicNetwork, PolytopeSampler
16 | from dingo.pyoptinterface_based_impl import inner_ball, set_default_solver
17 | from dingo.scaling import gmscale
18 |
19 |
20 | class TestMaxBall(unittest.TestCase):
21 |
22 | def test_simple(self):
23 | m = 2
24 | n = 5
25 | A = np.zeros((2 * n, n), dtype="float")
26 | A[0:n] = np.eye(n)
27 | A[n:] -= np.eye(n, n, dtype="float")
28 | b = np.ones(2 * n, dtype="float")
29 |
30 | max_ball = inner_ball(A, b)
31 |
32 | self.assertTrue(abs(max_ball[1] - 1) < 1e-04)
33 |
34 | if __name__ == "__main__":
35 | if len(sys.argv) > 1:
36 | set_default_solver(sys.argv[1])
37 | sys.argv.pop(1)
38 | unittest.main()
39 |
--------------------------------------------------------------------------------
/tests/preprocess.py:
--------------------------------------------------------------------------------
1 |
2 | from cobra.io import load_json_model
3 | from dingo import MetabolicNetwork
4 | from dingo.preprocess import PreProcess
5 | import unittest
6 | import numpy as np
7 |
8 | class TestPreprocess(unittest.TestCase):
9 |
10 | def test_preprocess(self):
11 |
12 | # load cobra model
13 | cobra_model = load_json_model("ext_data/e_coli_core.json")
14 |
15 | # convert cobra to dingo model
16 | initial_dingo_model = MetabolicNetwork.from_cobra_model(cobra_model)
17 |
18 | # perform an FBA to find the initial FBA solution
19 | initial_fba_solution = initial_dingo_model.fba()[1]
20 |
21 |
22 | # call the reduce function from the PreProcess class
23 | # with extend=False to remove reactions from the model
24 | obj = PreProcess(cobra_model, tol=1e-5, open_exchanges=False, verbose=False)
25 | removed_reactions, final_dingo_model = obj.reduce(extend=False)
26 |
27 | # calculate the count of removed reactions with extend set to False
28 | removed_reactions_count = len(removed_reactions)
29 | self.assertTrue( 46 - removed_reactions_count == 0 )
30 |
31 | # calculate the count of reactions with bounds equal to 0
32 | # with extend set to False from the dingo model
33 | dingo_removed_reactions = np.sum((final_dingo_model.lb == 0) & (final_dingo_model.ub == 0))
34 | self.assertTrue( 46 - dingo_removed_reactions == 0 )
35 |
36 | # perform an FBA to check the solution after reactions removal
37 | final_fba_solution = final_dingo_model.fba()[1]
38 | self.assertTrue(abs(final_fba_solution - initial_fba_solution) < 1e-03)
39 |
40 |
41 | # load models in cobra and dingo format again to restore bounds
42 | cobra_model = load_json_model("ext_data/e_coli_core.json")
43 |
44 | # convert cobra to dingo model
45 | initial_dingo_model = MetabolicNetwork.from_cobra_model(cobra_model)
46 |
47 | # call the reduce function from the PreProcess class
48 | # with extend=True to remove additional reactions from the model
49 | obj = PreProcess(cobra_model, tol=1e-6, open_exchanges=False, verbose=False)
50 | removed_reactions, final_dingo_model = obj.reduce(extend=True)
51 |
52 | # calculate the count of removed reactions with extend set to True
53 | removed_reactions_count = len(removed_reactions)
54 | self.assertTrue( 46 - removed_reactions_count <= 0 )
55 |
56 | # calculate the count of reactions with bounds equal to 0
57 | # with extend set to True from the dingo model
58 | dingo_removed_reactions = np.sum((final_dingo_model.lb == 0) & (final_dingo_model.ub == 0))
59 | self.assertTrue( 46 - dingo_removed_reactions <= 0 )
60 |
61 | # perform an FBA to check the result after reactions removal
62 | final_fba_solution = final_dingo_model.fba()[1]
63 | self.assertTrue(abs(final_fba_solution - initial_fba_solution) < 1e-03)
64 |
65 |
66 | if __name__ == "__main__":
67 | unittest.main()
68 |
69 |
--------------------------------------------------------------------------------
/tests/rounding.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2022 Apostolos Chalkis
5 | # Copyright (c) 2022-2024 Vissarion Fisikopoulos
6 | # Copyright (c) 2022 Haris Zafeiropoulos
7 | # Copyright (c) 2024 Ke Shi
8 |
9 | # Licensed under GNU LGPL.3, see LICENCE file
10 |
11 | import unittest
12 | import os
13 | import sys
14 | import numpy as np
15 | from dingo import MetabolicNetwork, PolytopeSampler
16 | from dingo.pyoptinterface_based_impl import set_default_solver
17 |
18 | def test_rounding(self, method_str):
19 |
20 | input_file_json = os.getcwd() + "/ext_data/e_coli_core.json"
21 | model = MetabolicNetwork.from_json( input_file_json )
22 | sampler = PolytopeSampler(model)
23 |
24 | A, b, N, N_shift = sampler.get_polytope()
25 |
26 | A_rounded, b_rounded, Tr, Tr_shift = sampler.round_polytope(A, b, method = method_str)
27 |
28 | self.assertTrue( A_rounded.shape[0] == 26 )
29 | self.assertTrue( A_rounded.shape[1] == 24 )
30 |
31 | self.assertTrue( b.size == 26 )
32 | self.assertTrue( N_shift.size == 95 )
33 | self.assertTrue( b_rounded.size == 26 )
34 | self.assertTrue( Tr_shift.size == 24 )
35 |
36 |
37 | self.assertTrue( N.shape[0] == 95 )
38 | self.assertTrue( N.shape[1] == 24 )
39 |
40 | self.assertTrue( Tr.shape[0] == 24 )
41 | self.assertTrue( Tr.shape[1] == 24 )
42 |
43 | samples = sampler.sample_from_polytope_no_multiphase(
44 | A_rounded, b_rounded, method = 'billiard_walk', n=1000, burn_in=10, thinning=1
45 | )
46 |
47 | Tr_shift = Tr_shift.reshape(Tr_shift.shape[0], 1)
48 | Tr_shift_mat = np.full((samples.shape[0], samples.shape[1]), Tr_shift)
49 | Tr_samples = Tr.dot(samples) + Tr_shift_mat
50 |
51 | all_points_in = True
52 | for i in range(Tr_samples.shape[1]):
53 | if np.any(A.dot(Tr_samples[:,i]) - b > 1e-05):
54 | all_points_in = False
55 | break
56 |
57 | self.assertTrue( all_points_in )
58 |
59 | class TestSampling(unittest.TestCase):
60 |
61 | def test_rounding_min_ellipsoid(self):
62 | test_rounding(self, "min_ellipsoid")
63 |
64 | def test_rounding_john_position(self):
65 | test_rounding(self, "john_position")
66 |
67 | if __name__ == "__main__":
68 | if len(sys.argv) > 1:
69 | set_default_solver(sys.argv[1])
70 | sys.argv.pop(1)
71 | unittest.main()
--------------------------------------------------------------------------------
/tests/sampling.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2022 Apostolos Chalkis
5 | # Copyright (c) 2022 Vissarion Fisikopoulos
6 | # Copyright (c) 2022 Haris Zafeiropoulos
7 | # Copyright (c) 2024 Ke Shi
8 |
9 | # Licensed under GNU LGPL.3, see LICENCE file
10 |
11 | import unittest
12 | import os
13 | import sys
14 | from dingo import MetabolicNetwork, PolytopeSampler
15 | from dingo.pyoptinterface_based_impl import set_default_solver
16 |
17 |
18 | class TestSampling(unittest.TestCase):
19 |
20 | def test_sample_json(self):
21 |
22 | input_file_json = os.getcwd() + "/ext_data/e_coli_core.json"
23 | model = MetabolicNetwork.from_json( input_file_json )
24 | sampler = PolytopeSampler(model)
25 |
26 | steady_states = sampler.generate_steady_states(ess = 20000, psrf = True)
27 |
28 | self.assertTrue( steady_states.shape[0] == 95 )
29 | self.assertTrue( abs( steady_states[12].mean() - 2.504 ) < 1e-02 )
30 |
31 |
32 | def test_sample_mat(self):
33 |
34 | input_file_mat = os.getcwd() + "/ext_data/e_coli_core.mat"
35 | model = MetabolicNetwork.from_mat(input_file_mat)
36 | sampler = PolytopeSampler(model)
37 |
38 | steady_states = sampler.generate_steady_states(ess = 20000, psrf = True)
39 |
40 | self.assertTrue( steady_states.shape[0] == 95 )
41 | self.assertTrue( abs( steady_states[12].mean() - 2.504 ) < 1e-02 )
42 |
43 |
44 | def test_sample_sbml(self):
45 |
46 | input_file_sbml = os.getcwd() + "/ext_data/e_coli_core.xml"
47 | model = MetabolicNetwork.from_sbml( input_file_sbml )
48 | sampler = PolytopeSampler(model)
49 |
50 | steady_states = sampler.generate_steady_states(ess = 20000, psrf = True)
51 |
52 | self.assertTrue( steady_states.shape[0] == 95 )
53 | self.assertTrue( abs( steady_states[12].mean() - 2.504 ) < 1e-02 )
54 |
55 |
56 |
57 | if __name__ == "__main__":
58 | if len(sys.argv) > 1:
59 | set_default_solver(sys.argv[1])
60 | sys.argv.pop(1)
61 | unittest.main()
62 |
--------------------------------------------------------------------------------
/tests/sampling_no_multiphase.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2022 Apostolos Chalkis
5 | # Copyright (c) 2022 Vissarion Fisikopoulos
6 | # Copyright (c) 2022 Haris Zafeiropoulos
7 | # Copyright (c) 2024 Ke Shi
8 |
9 | # Licensed under GNU LGPL.3, see LICENCE file
10 |
11 | import unittest
12 | import os
13 | import sys
14 | from dingo import MetabolicNetwork, PolytopeSampler
15 | from dingo.pyoptinterface_based_impl import set_default_solver
16 |
17 | def sampling(model, testing_class):
18 | sampler = PolytopeSampler(model)
19 |
20 | #Gaussian hmc sampling
21 | steady_states = sampler.generate_steady_states_no_multiphase(method = 'mmcs', ess=1000)
22 |
23 | testing_class.assertTrue( steady_states.shape[0] == 95 )
24 | testing_class.assertTrue( steady_states.shape[1] == 1000 )
25 |
26 | #Gaussian hmc sampling
27 | steady_states = sampler.generate_steady_states_no_multiphase(method = 'gaussian_hmc_walk', n=500)
28 |
29 | testing_class.assertTrue( steady_states.shape[0] == 95 )
30 | testing_class.assertTrue( steady_states.shape[1] == 500 )
31 |
32 | #exponential hmc sampling
33 | steady_states = sampler.generate_steady_states_no_multiphase(method = 'exponential_hmc_walk', n=500, variance=50)
34 |
35 | testing_class.assertTrue( steady_states.shape[0] == 95 )
36 | testing_class.assertTrue( steady_states.shape[1] == 500 )
37 |
38 | #hmc sampling with Gaussian distribution
39 | steady_states = sampler.generate_steady_states_no_multiphase(method = 'hmc_leapfrog_gaussian', n=500)
40 |
41 | testing_class.assertTrue( steady_states.shape[0] == 95 )
42 | testing_class.assertTrue( steady_states.shape[1] == 500 )
43 |
44 | #hmc sampling with exponential distribution
45 | steady_states = sampler.generate_steady_states_no_multiphase(method = 'hmc_leapfrog_exponential', n=500, variance=50)
46 |
47 | testing_class.assertTrue( steady_states.shape[0] == 95 )
48 | testing_class.assertTrue( steady_states.shape[1] == 500 )
49 |
50 | #steady_states[12].mean() seems to have a lot of discrepancy between experiments, so we won't check the mean for now
51 | #self.assertTrue( abs( steady_states[12].mean() - 2.504 ) < 1e-03 )
52 |
53 | class TestSampling(unittest.TestCase):
54 |
55 | def test_sample_json(self):
56 |
57 | input_file_json = os.getcwd() + "/ext_data/e_coli_core.json"
58 | model = MetabolicNetwork.from_json( input_file_json )
59 | sampling(model, self)
60 |
61 | def test_sample_mat(self):
62 |
63 | input_file_mat = os.getcwd() + "/ext_data/e_coli_core.mat"
64 | model = MetabolicNetwork.from_mat(input_file_mat)
65 | sampling(model, self)
66 |
67 | def test_sample_sbml(self):
68 |
69 | input_file_sbml = os.getcwd() + "/ext_data/e_coli_core.xml"
70 | model = MetabolicNetwork.from_sbml( input_file_sbml )
71 | sampling(model, self)
72 |
73 |
74 |
75 | if __name__ == "__main__":
76 | if len(sys.argv) > 1:
77 | set_default_solver(sys.argv[1])
78 | sys.argv.pop(1)
79 | unittest.main()
80 |
--------------------------------------------------------------------------------
/tests/scaling.py:
--------------------------------------------------------------------------------
1 | # dingo : a python library for metabolic networks sampling and analysis
2 | # dingo is part of GeomScale project
3 |
4 | # Copyright (c) 2021 Apostolos Chalkis
5 | # Copyright (c) 2021 Vissarion Fisikopoulos
6 |
7 | # Licensed under GNU LGPL.3, see LICENCE file
8 |
9 | import unittest
10 | import os
11 | import sys
12 | import scipy
13 | import numpy as np
14 | from dingo import MetabolicNetwork
15 | from dingo.scaling import gmscale
16 | from dingo.pyoptinterface_based_impl import set_default_solver
17 |
18 |
19 | class TestScaling(unittest.TestCase):
20 |
21 | def test_scale_json(self):
22 |
23 | input_file_json = os.getcwd() + "/ext_data/e_coli_core.json"
24 |
25 | model = MetabolicNetwork.from_json(input_file_json)
26 |
27 | json_res = gmscale(model.S, 0.99)
28 |
29 | self.assertTrue(abs(scipy.linalg.norm(json_res[0]) - 15.285577732002883) < 1e-03)
30 | self.assertTrue(abs(scipy.linalg.norm(json_res[1]) - 23.138373030721855) < 1e-03)
31 |
32 | def test_scale_mat(self):
33 |
34 | input_file_mat = os.getcwd() + "/ext_data/e_coli_core.mat"
35 |
36 | model = MetabolicNetwork.from_mat(input_file_mat)
37 |
38 | mat_res = gmscale(model.S, 0.99)
39 |
40 | self.assertTrue(abs(scipy.linalg.norm(mat_res[0]) - 15.285577732002883) < 1e-03)
41 | self.assertTrue(abs(scipy.linalg.norm(mat_res[1]) - 23.138373030721855) < 1e-03)
42 |
43 | def test_scale_sbml(self):
44 |
45 | input_file_sbml = os.getcwd() + "/ext_data/e_coli_core.xml"
46 |
47 | model = MetabolicNetwork.from_sbml(input_file_sbml)
48 |
49 | sbml_res = gmscale(model.S, 0.99)
50 |
51 | self.assertTrue(abs(scipy.linalg.norm(sbml_res[0]) - 15.285577732002883) < 1e-03)
52 | self.assertTrue(abs(scipy.linalg.norm(sbml_res[1]) - 23.138373030721855) < 1e-03)
53 |
54 |
55 | if __name__ == "__main__":
56 | if len(sys.argv) > 1:
57 | set_default_solver(sys.argv[1])
58 | sys.argv.pop(1)
59 | unittest.main()
60 |
--------------------------------------------------------------------------------
/tutorials/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing to `dingo`
2 |
3 | :+1::tada: First off, thanks for taking the time to contribute! :tada::+1:
4 |
5 | The following is a set of guidelines for contributing to dingo,
6 | which are hosted in the [GeomScale Organization](https://github.com/GeomScale) on GitHub.
7 | These are mostly guidelines, not rules.
8 | Use your best judgment, and feel free to propose changes to this document in a pull request.
9 |
10 | ## Table of Contents
11 |
12 | * [Prerequisites (how to start)](#prerequisites-how-to-start)
13 | * [Testing the development branch of `dingo` (get the tools ready)](#testing-the-development-branch-of-dingo-get-the-tools-ready)
14 | * [Fork `dingo` repository (this is your repo now!)](#fork-dingo-repository-this-is-your-repo-now)
15 | + [Verify if your fork works (optional)](#verify-if-your-fork-works-optional)
16 | * [Working with `dingo` (get ready to contribute)](#working-with-dingo-get-ready-to-contribute)
17 | + [GitFlow workflow](#gitflow-workflow)
18 | + [Create new branch for your work](#create-new-branch-for-your-work)
19 | + [Verify your new branch (optional)](#verify-your-new-branch-optional)
20 | * [Modify the branch (implement, implement, implement)](#modify-the-branch-implement-implement-implement)
21 | + [Tests](#tests)
22 | + [Push](#push)
23 | * [Pull request (the joy of sharing)](#pull-request-the-joy-of-sharing)
24 | * [Review (ok this is not an exam)](#review-ok-this-is-not-an-exam)
25 |
26 | ## Prerequisites (how to start)
27 |
28 | * git (see [Getting Started with Git](https://help.github.com/en/github/using-git/getting-started-with-git-and-github))
29 | * a compiler to run tests - gcc, clang, etc.
30 | * configured GitHub account
31 |
32 | Other helpful links:
33 |
34 | * http://git-scm.com/documentation
35 | * https://help.github.com/articles/set-up-git
36 | * https://opensource.com/article/18/1/step-step-guide-git
37 |
38 | ## Testing the development branch of dingo (get the tools ready)
39 |
40 | Clone the repository,
41 |
42 | git clone git@github.com:geomscale/dingo.git dingo
43 | cd dingo
44 | git branch -vv
45 |
46 | the last command should tell you that you are in `develop` branch.
47 |
48 | Now you need to get the `volesti` sumbodule that `dingo` makes use of.
49 |
50 | To do so, you need to run
51 |
52 | git submodule update --init
53 |
54 | Now get the `boost` library:
55 |
56 | wget -O boost_1_76_0.tar.bz2 https://archives.boost.io/release/1.76.0/source/boost_1_76_0.tar.bz2
57 | tar xjf boost_1_76_0.tar.bz2
58 | rm boost_1_76_0.tar.bz2
59 |
60 | And now you are ready to compile `dingo`
61 |
62 | python setup.py install --user
63 |
64 | Once the last command is completed, you may check if everythings is fine by running some `dingo` tests
65 |
66 | python tests/unit_tests.py
67 |
68 |
69 | If everything is ok, you will see something like this:
70 |
71 | [](https://asciinema.org/a/3IwNykajlDGEndX2rUtc0D2Ag)
72 |
73 | ## Fork `dingo` repository (this is your repo now!)
74 |
75 | You can't work directly in the original `dingo` repository, therefore you should create your fork of this library.
76 | This way you can modify the code and when the job is done send a pull request to merge your changes with the original
77 | repository.
78 |
79 | 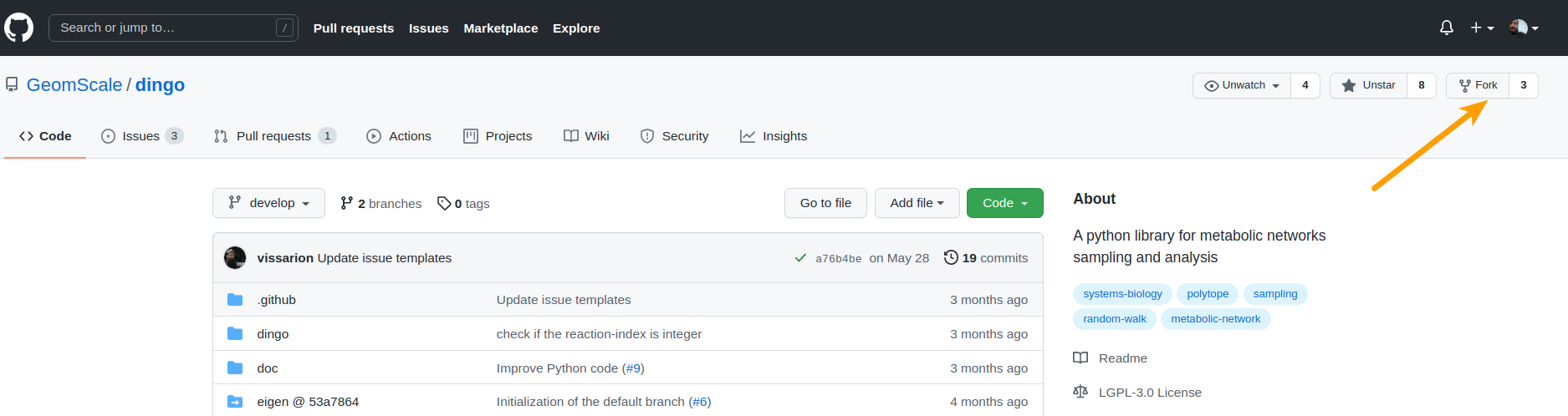
80 |
81 | 1. login on `GitHub`
82 | 2. go to [dingo repository](https://github.com/GeomScale/dingo)
83 | 3. click the 'Fork' button
84 | 4. choose your profile
85 | 5. wait
86 | 6. ready to contribute!
87 |
88 | More info: [Forking Projects](https://guides.github.com/activities/forking/)
89 |
90 | ### Verify if your fork works (optional)
91 |
92 | Go out of `dingo` directory
93 |
94 | cd ..
95 |
96 | clone your repository and checkout develop branch
97 |
98 | git clone git@github.com:hariszaf/dingo.git dingo_fork
99 | cd dingo_fork
100 | git checkout develop
101 | git branch -vv
102 | git pull
103 |
104 | In this case `hariszaf` was the user's name who had forked `dingo`. Make sure you replace this with your own.
105 |
106 | To see the so far commits, simply run:
107 |
108 | git log
109 | gitk
110 |
111 | For now you should see exactly the same commits as in `dingo` repository.
112 |
113 | ## Working with `dingo` (get ready to contribute)
114 |
115 | ### GitFlow workflow
116 |
117 | `dingo` is using the [GitFlow](http://nvie.com/posts/a-successful-git-branching-model/) workflow.
118 | It's because it is very well suited to collaboration and scaling the development team.
119 | Each repository using this model should contain two main branches:
120 |
121 | * master - release-ready version of the library
122 | * develop - development version of the library
123 |
124 | and could contain various supporting branches for new features and hotfixes.
125 |
126 | As a contributor you'll most likely be adding new features or fixing bugs in the development version of the library.
127 | This means that for each contribution you should create a new branch originating from the develop branch,
128 | modify it and send a pull request in order to merge it, again with the develop branch.
129 |
130 | ### Create new branch for your work
131 |
132 | Make sure you're in develop branch running
133 |
134 | git branch -vv
135 |
136 | you should see something like this:
137 |
138 | * develop a76b4be [origin/develop] Update issue templates
139 |
140 | Now you should pick **a name for your new branch that doesn't already exist**.
141 | The following returns a list of all the existing remote branches
142 |
143 | git branch -a
144 |
145 | Alternatively, you can check them on `GitHub`.
146 |
147 | Assume you want to add some new functionality.
148 | Then you have to create a new branch e.g. `feature/my_cool_new_feature`
149 |
150 | Create new local branch
151 |
152 | git branch feature/my_cool_new_feature
153 | git checkout feature/my_cool_new_feature
154 |
155 | push it to your fork
156 |
157 | git push -u my_fork feature/my_cool_new_feature
158 |
159 | Note that the `-u` switch also sets up the tracking of the remote branch.
160 | Your new branch now is created!
161 |
162 | ### Verify your new branch (optional)
163 |
164 | Now if you check the branches present on your repository
165 | you'll see the `develop` and `master` branches as well as the one you just created
166 |
167 | ```bash
168 | user@mypc:~/dingo$git branch -vv
169 | develop f82fcce [origin/develop] Revert "Revert "Update issue templates""
170 | * dingo_tutorial 1806b75 [origin/dingo_tutorial] notebook moved under /tutorials
171 | pairs 17d6d0b [origin/pairs] ignore notebook checkpoints
172 | ```
173 |
174 | Note that without the `-u` switch you wouldn't see the tracking information for your new branch.
175 |
176 | Your newly created remote branch is also available on GitHub
177 | on your fork repository!
178 |
179 | 
180 |
181 | Notice, we are **not** on the `dingo` repository under the `GeomScale` organization, but on the user's personal account.
182 |
183 | ## Modify the branch (implement, implement, implement)
184 |
185 | Before contributiong to a library by adding a new feature, or a bugfix, or improving documentation,
186 | it is always wise to interact with the community of developers, for example by opening an issue.
187 |
188 | ### Tests
189 |
190 | Tests are placed in the `test` directory and use the [doctest](https://github.com/onqtam/doctest) library.
191 |
192 | It is recommended to add new test whenever you contribute a new functionality/feature.
193 | Also if your contribution is a bugfix then consider adding this case to the test-suite.
194 |
195 | ### Push
196 |
197 | At the end, push your changes to the remote branch
198 |
199 | git push my_fork feature/my_cool_new_feature
200 |
201 | or if your local branch is tracking the remote one, just
202 |
203 | git push
204 |
205 | ## Pull request (the joy of sharing)
206 |
207 | After pushing your work you should be able to see it on `GitHub`.
208 |
209 | Click "Compare and pull request" button or the "New pull request" button.
210 |
211 | Add title and description
212 |
213 | 
214 |
215 | and click the "Create pull request" button.
216 |
217 | ## Review (ok this is not an exam)
218 |
219 | After creating a pull request your code will be reviewed. You can propose one or more reviewers
220 | by clicking on the "Reviewers" button
221 |
222 | 
223 |
224 | If there are no objections your changes will be merged.
225 | Otherwise you'll see some comments under the pull request and/or under specific lines of your code.
226 | Then you have to make the required changes, commit them and push to your branch.
227 | Those changes will automatically be a part of the same pull request. This procedure will be repeated until the code
228 | is ready for merging.
229 |
230 | If you're curious how it looks like you may see one of the open or closed
231 | [pull requests](https://github.com/GeomScale/dingo/pulls).
--------------------------------------------------------------------------------
/tutorials/README.md:
--------------------------------------------------------------------------------
1 | # `dingo` tutorials
2 |
3 | In this directory, you will find material about how to use `dingo` but also on how you could contribute to this open source project.
4 |
5 |
--------------------------------------------------------------------------------
/tutorials/figs/branches_github.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GeomScale/dingo/cdcb43c888b496ef3b86c1916ae60459dfecace4/tutorials/figs/branches_github.png
--------------------------------------------------------------------------------
/tutorials/figs/fork.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GeomScale/dingo/cdcb43c888b496ef3b86c1916ae60459dfecace4/tutorials/figs/fork.png
--------------------------------------------------------------------------------
/tutorials/figs/pr.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GeomScale/dingo/cdcb43c888b496ef3b86c1916ae60459dfecace4/tutorials/figs/pr.png
--------------------------------------------------------------------------------