11 |  12 |
12 |
13 |
14 | ### 🔧 Quick Start
15 |
16 | 1. Fork and clone the repository
17 | 2. Install dependencies: `poetry install`
18 | 3. Create a feature branch and make your changes
19 | 4. Run tests: `poetry run pytest`
20 | 5. Don't forget version bump `poetry version patch` (or minor/major) and update `CHANGELOG.md`
21 | 6. Open a pull request and describe changes and why they are needed
22 |
23 | **Most of needed/handy commands are available via `make`.**
24 | To see available commands, run:
25 | ```bash
26 | make help
27 | ```
28 |
29 | ### 🩺 Code Quality
30 |
31 | We use:
32 | - **Ruff** for linting and formatting
33 | - **Pyright** for type checking
34 | - **pytest** for testing
35 |
36 | *Please ensure your IDE is configured to use these tools for a smooth development experience.*
37 |
38 |
39 | ### 📝 Writing Good Commit Messages
40 |
41 | **We use**:
42 | - [Conventional Commits](https://www.conventionalcommits.org/en/v1.0.0/) for commit messages.
43 | - [GitMoji](https://gitmoji.dev/) for visual representation of commit types. (**OPTIONAL**)
44 | - Describe not only the change but also **why** it was made.
45 |
46 |
47 | So a generic commit message would look like this:
48 | ```
49 | feat: ✨ Add hyperspace drive support
50 | The hyperspace drive allows faster travel between galaxies.
51 |
52 | fix: 🐛 Fix formatting.
53 | ```
54 |
55 | **To make it even easier for you, use VS Code extension:**
56 | - [VSCode Conventional Commits](https://marketplace.visualstudio.com/items?itemName=vivaxy.vscode-conventional-commits) - it speed up writing commit messages in our format.
57 |
58 |
59 | ### ✅ Pull Requests CI Checks
60 |
61 | **Now project uses Github Actions for:**
62 | - Check PRs for code quality (linting, type checking, tests)
63 | - Check `dev -> main` PRs for version bump
64 | - Automatically create releases on `main` merge (PyPi and GitHub Releases)
65 |
66 |
67 | ### 🔨 Other HOW TOs:
68 |
69 |
12 |
70 |
84 |
85 | 🏁 Making a Release
71 | 72 | 1. **Prepare in `dev` branch:** 73 | ```bash 74 | poetry version patch # or minor/major 75 | # Update CHANGELOG.md 76 | git commit -am "chore: bump version to X.Y.Z" 77 | git push origin dev 78 | ``` 79 | 80 | 2. **Create PR:** `dev` → `main` 81 | 82 | 3. **Merge PR** → Automatic release! 🎉 83 |
86 |
97 |
--------------------------------------------------------------------------------
/boosty_downloader/src/application/mappers/post_mapper.py:
--------------------------------------------------------------------------------
1 | """Mapping logic for converting Boosty API post DTOs to domain Post objects."""
2 |
3 | from boosty_downloader.src.application import mappers
4 | from boosty_downloader.src.domain.post import Post
5 | from boosty_downloader.src.domain.post_data_chunks import PostDataChunkText
6 | from boosty_downloader.src.infrastructure.boosty_api.models.post.base_post_data import (
7 | BoostyPostDataExternalVideoDTO,
8 | )
9 | from boosty_downloader.src.infrastructure.boosty_api.models.post.post import PostDTO
10 | from boosty_downloader.src.infrastructure.boosty_api.models.post.post_data_types import (
11 | BoostyPostDataFileDTO,
12 | BoostyPostDataHeaderDTO,
13 | BoostyPostDataImageDTO,
14 | BoostyPostDataLinkDTO,
15 | BoostyPostDataListDTO,
16 | BoostyPostDataOkVideoDTO,
17 | BoostyPostDataTextDTO,
18 | )
19 | from boosty_downloader.src.infrastructure.boosty_api.models.post.post_data_types.post_data_ok_video import (
20 | BoostyOkVideoType,
21 | )
22 |
23 |
24 | def map_post_dto_to_domain(
25 | post_dto: PostDTO, preferred_video_quality: BoostyOkVideoType
26 | ) -> Post:
27 | """Convert a Boosty API PostDTO object to a domain Post object, mapping all data chunks to their domain representations."""
28 | post = Post(
29 | uuid=post_dto.id,
30 | title=post_dto.title,
31 | created_at=post_dto.created_at,
32 | updated_at=post_dto.updated_at,
33 | has_access=post_dto.has_access,
34 | signed_query=post_dto.signed_query,
35 | post_data_chunks=[],
36 | )
37 |
38 | for data_chunk in post_dto.data:
39 | match data_chunk:
40 | case BoostyPostDataImageDTO():
41 | post.post_data_chunks.append(mappers.to_domain_image_chunk(data_chunk))
42 | case (
43 | BoostyPostDataHeaderDTO()
44 | | BoostyPostDataLinkDTO()
45 | | BoostyPostDataTextDTO()
46 | ):
47 | text_fragments = mappers.to_domain_text_chunk(data_chunk)
48 | text_chunk = PostDataChunkText(text_fragments=text_fragments)
49 | post.post_data_chunks.append(text_chunk)
50 | case BoostyPostDataListDTO():
51 | post.post_data_chunks.append(mappers.to_domain_list_chunk(data_chunk))
52 | case BoostyPostDataFileDTO():
53 | post.post_data_chunks.append(
54 | mappers.to_domain_file_chunk(data_chunk, post.signed_query)
55 | )
56 | case BoostyPostDataOkVideoDTO():
57 | video_chunk = mappers.to_ok_boosty_video_content(
58 | data_chunk, preferred_quality=preferred_video_quality
59 | )
60 | if video_chunk is not None:
61 | post.post_data_chunks.append(video_chunk)
62 | case BoostyPostDataExternalVideoDTO():
63 | post.post_data_chunks.append(
64 | mappers.to_external_video_content(data_chunk)
65 | )
66 |
67 | return post
68 |
--------------------------------------------------------------------------------
/boosty_downloader/src/interfaces/cli_options.py:
--------------------------------------------------------------------------------
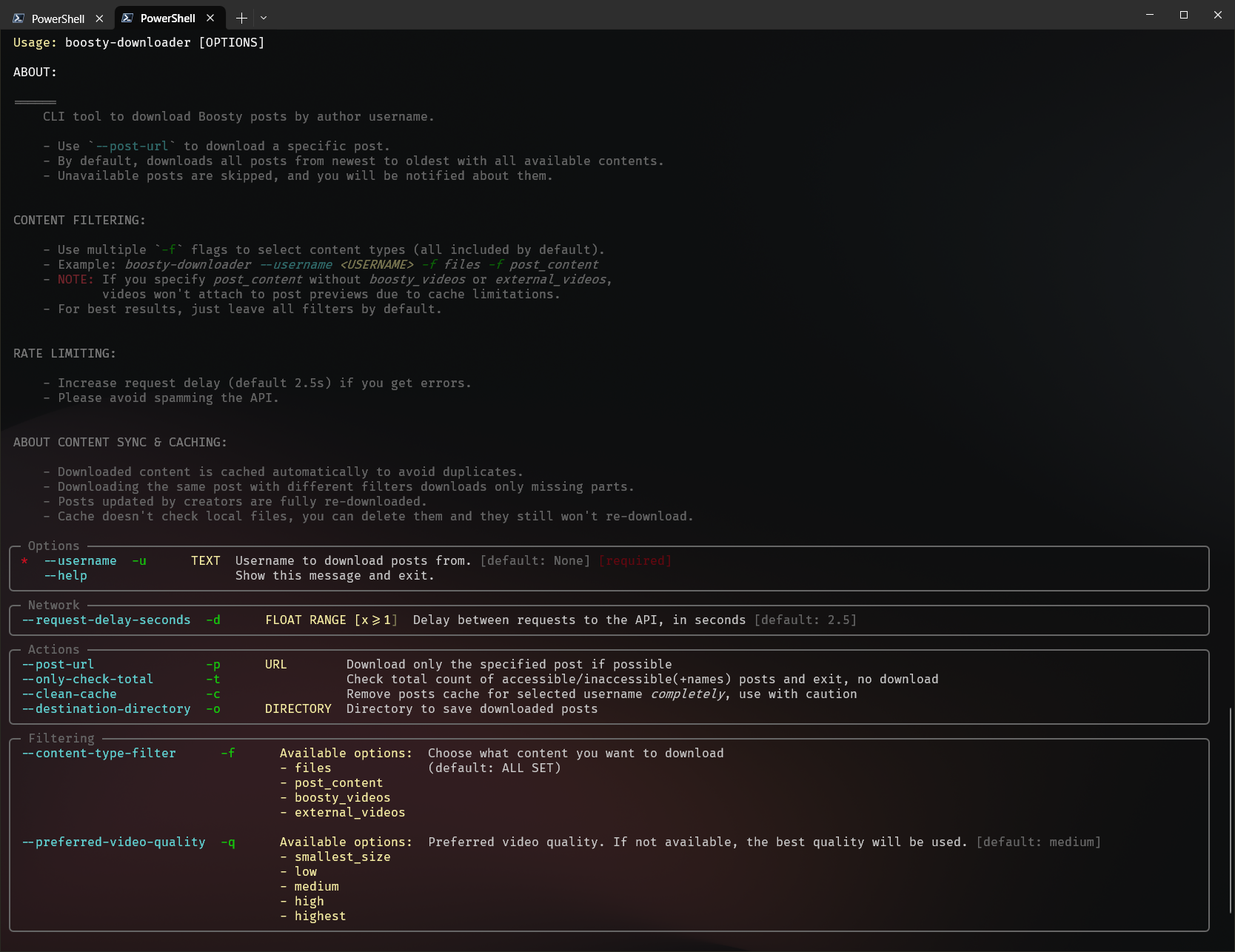
1 | """CLI option definitions for Boosty Downloader."""
2 |
3 | from pathlib import Path
4 | from typing import Annotated
5 |
6 | import typer
7 |
8 | from boosty_downloader.src.application.filtering import (
9 | DownloadContentTypeFilter,
10 | VideoQualityOption,
11 | )
12 | from boosty_downloader.src.interfaces.help_panels import HelpPanels
13 |
14 | UsernameOption = Annotated[
15 | str,
16 | typer.Option(
17 | '--username',
18 | '-u',
19 | help='Username to download posts from.',
20 | ),
21 | ]
22 |
23 | RequestDelaySecondsOption = Annotated[
24 | float,
25 | typer.Option(
26 | '--request-delay-seconds',
27 | '-d',
28 | help='Delay between requests to the API, in seconds',
29 | min=1,
30 | rich_help_panel=HelpPanels.network,
31 | ),
32 | ]
33 |
34 |
35 | ContentTypeFilterOption = Annotated[
36 | list[DownloadContentTypeFilter] | None,
37 | typer.Option(
38 | '--content-type-filter',
39 | '-f',
40 | help='Choose what content you want to download\n\n(default: ALL SET)',
41 | metavar='Available options:\n- files\n- post_content\n- boosty_videos\n- external_videos\n',
42 | show_default=False,
43 | rich_help_panel=HelpPanels.filtering,
44 | ),
45 | ]
46 |
47 |
48 | PreferredVideoQualityOption = Annotated[
49 | VideoQualityOption,
50 | typer.Option(
51 | '--preferred-video-quality',
52 | '-q',
53 | help='Preferred video quality. If not available, the best quality will be used.',
54 | metavar='Available options:\n- smallest_size\n- low\n- medium\n- high\n- highest',
55 | rich_help_panel=HelpPanels.filtering,
56 | ),
57 | ]
58 |
59 | PostUrlOption = Annotated[
60 | str | None,
61 | typer.Option(
62 | '--post-url',
63 | '-p',
64 | help='Download only the specified post if possible',
65 | metavar='URL',
66 | show_default=False,
67 | rich_help_panel=HelpPanels.actions,
68 | ),
69 | ]
70 |
71 | CheckTotalCountOption = Annotated[
72 | bool,
73 | typer.Option(
74 | '--only-check-total',
75 | '-t',
76 | help='Check total count of accessible/inaccessible(+names) posts and exit, no download',
77 | rich_help_panel=HelpPanels.actions,
78 | ),
79 | ]
80 |
81 | CleanCacheOption = Annotated[
82 | bool,
83 | typer.Option(
84 | '--clean-cache',
85 | '-c',
86 | help='Remove posts cache for selected username [italic]completely[/italic], use with caution',
87 | rich_help_panel=HelpPanels.actions,
88 | ),
89 | ]
90 |
91 | DestinationDirectoryOption = Annotated[
92 | Path | None,
93 | typer.Option(
94 | '--destination-directory',
95 | '-o',
96 | help='Directory to save downloaded posts',
97 | dir_okay=True,
98 | file_okay=False,
99 | resolve_path=True,
100 | rich_help_panel=HelpPanels.actions,
101 | show_default=False,
102 | ),
103 | ]
104 |
--------------------------------------------------------------------------------
/Makefile:
--------------------------------------------------------------------------------
1 | .PHONY: build test posts-example
2 |
3 | # Ensure that all the pipe-like commands work correctly.
4 | export PYTHONIOENCODING = utf-8
5 |
6 | help:
7 | @echo ------------------------- To run locally: ----------------------------
8 | @echo Run make deps to install dependencies
9 | @echo And to run current project locally without installation:
10 | @echo poetry run python -m boosty_downloader.main
11 | @echo . .
12 | @echo ------------------------- Available commands: ------------------------
13 | @echo Building:
14 | @echo deps - Install project dependencies using poetry
15 | @echo build - Build the project whl file
16 | @echo ----------------------------------------------------------------------
17 | @echo Code Health:
18 | @echo dev-fix - Try to fix code issues, show problems if any
19 | @echo ci-check - Run CI checks (linter/formatter/type checks)
20 | @echo types - Code type checks using pyright
21 | @echo format-check - Code format check using ruff
22 | @echo format-fix - Code format using ruff
23 | @echo lint-check - Code linting (only check)
24 | @echo lint-fix - Code linting (try to fix)
25 | @echo ----------------------------------------------------------------------
26 | @echo Testing:
27 | @echo test - Run the project unit tests
28 | @echo test-verbose - Run the project unit tests
29 | @echo test-api - Run the project API integration tests
30 | @echo test-api-verbose - Run the project API integration tests with verbose output
31 | @echo ----------------------------------------------------------------------
32 | @echo Endpoints Analysis (Only work if integration tests config available):
33 | @echo posts_example - Show posts json for defined author
34 |
35 |
36 |
37 | # ------------------------------------------------------------------------------
38 | # 📦 Distribution
39 |
40 | deps:
41 | poetry sync --no-interaction
42 |
43 | build:
44 | poetry build --no-cache
45 | @echo Build complete at /dist/
46 |
47 | # ------------------------------------------------------------------------------
48 | # 🩺 Code Health Checks
49 |
50 | dev-fix: lint-fix format-fix types
51 | ci-check: lint-check types format-check
52 |
53 | lint-check:
54 | poetry run ruff check .
55 |
56 | lint-fix:
57 | poetry run ruff check --fix .
58 |
59 | format-check:
60 | poetry run ruff format --check .
61 |
62 | format-fix:
63 | poetry run ruff format .
64 |
65 | types:
66 | poetry run pyright
67 |
68 |
69 | # ------------------------------------------------------------------------------
70 | # 🧪 Testing
71 |
72 | test:
73 | poetry run pytest test/unit/
74 |
75 | test-verbose:
76 | poetry run pytest -v test/unit/
77 |
78 | test-api:
79 | poetry run pytest test/integration/
80 |
81 | test-api-verbose:
82 | poetry run pytest -v test/integration/
83 |
84 | # ------------------------------------------------------------------------------
85 | # 🔍 Endpoints analysis
86 |
87 | posts-example:
88 | poetry run pytest ./test/integration/analysis/get_author_posts_test.py::test_get_author_posts -s -q
89 |
90 |
--------------------------------------------------------------------------------
/boosty_downloader/src/infrastructure/yaml_configuration/config.py:
--------------------------------------------------------------------------------
1 | """Configuration for the whole application"""
2 |
3 | from __future__ import annotations
4 |
5 | import sys
6 | from pathlib import Path
7 |
8 | from pydantic import BaseModel, Field, ValidationError
9 | from pydantic_settings import (
10 | BaseSettings,
11 | PydanticBaseSettingsSource,
12 | SettingsConfigDict,
13 | YamlConfigSettingsSource,
14 | )
15 |
16 | from boosty_downloader.src.infrastructure.loggers import logger_instances
17 | from boosty_downloader.src.infrastructure.yaml_configuration.sample_config import (
18 | DEFAULT_YAML_CONFIG_VALUE,
19 | )
20 |
21 |
22 | class DownloadSettings(BaseModel):
23 | """Settings for the script downloading process"""
24 |
25 | target_directory: Path = Path('./boosty-downloads')
26 |
27 |
28 | class AuthSettings(BaseModel):
29 | """Configuration for authentication (cookies and authorization headers)"""
30 |
31 | cookie: str = Field(default='', min_length=1)
32 | auth_header: str = Field(default='', min_length=1)
33 |
34 |
35 | CONFIG_LOCATION: Path = Path('config.yaml')
36 |
37 |
38 | class Config(BaseSettings):
39 | """General script configuration with subsections"""
40 |
41 | model_config = SettingsConfigDict(
42 | yaml_file=CONFIG_LOCATION,
43 | yaml_file_encoding='utf-8',
44 | )
45 |
46 | auth: AuthSettings = AuthSettings()
47 | downloading_settings: DownloadSettings = DownloadSettings()
48 |
49 | @classmethod
50 | def settings_customise_sources(
51 | cls,
52 | settings_cls: type[BaseSettings],
53 | init_settings: PydanticBaseSettingsSource,
54 | env_settings: PydanticBaseSettingsSource,
55 | dotenv_settings: PydanticBaseSettingsSource,
56 | file_secret_settings: PydanticBaseSettingsSource,
57 | ) -> tuple[PydanticBaseSettingsSource, ...]:
58 | return (
59 | YamlConfigSettingsSource(settings_cls),
60 | init_settings,
61 | env_settings,
62 | dotenv_settings,
63 | file_secret_settings,
64 | )
65 |
66 |
67 | def create_sample_config_file() -> None:
68 | """Create a sample config file if it doesn't exist."""
69 | with CONFIG_LOCATION.open(mode='w') as f:
70 | f.write(DEFAULT_YAML_CONFIG_VALUE)
71 |
72 |
73 | def init_config() -> Config:
74 | """Initialize the config file with a sample if it doesn't exist"""
75 | try:
76 | if not CONFIG_LOCATION.exists():
77 | create_sample_config_file()
78 | logger_instances.downloader_logger.error("Config doesn't exist")
79 | logger_instances.downloader_logger.success(
80 | f'Created a sample config file at {CONFIG_LOCATION.absolute()}, please fill `auth_header` and `cookie` with yours before running the app',
81 | )
82 | sys.exit(1)
83 | return Config()
84 | except ValidationError:
85 | # If can't be parsed correctly
86 | create_sample_config_file()
87 | logger_instances.downloader_logger.error(
88 | 'Config is invalid (could not be parsed)'
89 | )
90 | logger_instances.downloader_logger.error(
91 | '[bold yellow]Make sure you fill `auth_header` and `cookie` with yours, they are required[/bold yellow]',
92 | )
93 | logger_instances.downloader_logger.success(
94 | f'Recreated it at [green bold]{CONFIG_LOCATION.absolute()}[/green bold]',
95 | )
96 | sys.exit(1)
97 |
--------------------------------------------------------------------------------
/CHANGELOG.md:
--------------------------------------------------------------------------------
1 | ## 2.0.1
2 |
3 | - 🐛 Fixed image data so posts download even when width/height is missing
4 | - 🐛 Fixed download process to stop automatically after the chosen post
5 |
6 | ## 2.0.0
7 |
8 | ### ⛔ BREAKING CHANGES ⛔
9 |
10 | - Because of the new caching system, the cache database changed.
11 | If you have an existing cache, you may need to clean it first to avoid issues.
12 |
13 | The utility will automatically detect cache inconsistencies and prompt you to clean it though.
14 |
15 | I tried to figgure some sort of db migration but it is too complex for the current state of the project, so I decided to just make it a breaking change yet.
16 |
17 | If you know how I can keep migrating the cache given the fact that dbs are
18 | scattered across multiple author directories, and even possibly have different versions
19 | please let me know with an issue!
20 |
21 | - Some options were renamed but their functionality remains the same
22 |
23 | ### 🔔 New Features
24 |
25 | - 🔔 **Automatic Update Checker**
26 | You'll now be notified when a new version is available on PyPI.
27 |
28 | - 📦 **Improved Caching Layer**
29 | - Only the requested parts are cached to avoid unnecessary re-downloads/skips (before this change the post was cached entirely not just the requested parts), so now partial updates are possible.
30 | - Cache is properly **invalidated** if a post is updated by its author (will be re-downloaded).
31 | - More **robust and accurate** caching system: better handling of missing post parts.
32 |
33 | - **HTML Generation Enhancements**
34 | - New **HTML generator engine** with support for **Dark/Light modes**. 🦉
35 | - Added support for **headings and lists** in HTML output.
36 | - Added better support for styling (italic/bold/etc)
37 | - `post_content` now includes both **images AND videos** (offline only).
38 |
39 | - **Improved CLI UX**
40 | - New destination option to allow override config values.
41 | - Better help descriptions with logical **option grouping**.
42 | - More informative **post counter**: displays both accessible and inaccessible posts, with names listed for all inaccessible posts.
43 | - Enhanced **logging and error handling** for a more readable and helpful output.
44 |
45 | - **Retry Logic**
46 | - If post download fails, it will be retried up to 5 times with exponential backoff.
47 | - After 5 failed attempts, the post will be skipped and not cached.
48 |
49 | ### 🐛 Fixes
50 |
51 | - Fixed duplication problem [#12](https://github.com/Glitchy-Sheep/boosty-downloader/issues/12) (now posts are cached by UUID and have it as part of the filename, so duplication is no longer an issue)
52 | - Fixed external video downloading for unsupported formats (now format >=720p is preferred, less otherwise).
53 | - Fixed HTML generation for posts with **no content**, now it won't be created.
54 | - Resolved issues with **newline handling** in some HTML outputs.
55 | - Fixed **Ctrl+C interruption** handling with proper cleanup and messaging.
56 | - Prevented creation of **empty directories** for posts with no downloadable content.
57 | now the utility do the job only if there is one.
58 |
59 | ### 🧹 Miscellaneous
60 |
61 | - Internal **project structure refactored** for better maintainability and scalability.
62 |
63 | ## 1.0.1
64 | - Fix: 🐛 Support new boosty API response schema (as a placeholder)
65 |
66 | ## 1.0.0
67 |
68 | - First stable release
69 | - Main downloader functions such as video/post/external_video/files
70 | - Added CLI interface with typer (with customizable options)
71 |
--------------------------------------------------------------------------------
/test/unit/download_manager/ok_video_ranking_test.py:
--------------------------------------------------------------------------------
1 | from boosty_downloader.src.application.mappers import (
2 | get_best_video,
3 | get_quality_ranking,
4 | )
5 | from boosty_downloader.src.application.ok_video_ranking import (
6 | BoostyOkVideoType,
7 | BoostyOkVideoUrl,
8 | RankingDict,
9 | )
10 |
11 |
12 | def test_ranking_dict_basic_operations():
13 | ranking = RankingDict[str]()
14 | ranking['a'] = 10
15 | ranking['b'] = 20
16 | ranking['c'] = 15
17 |
18 | assert ranking['a'] == 10
19 | assert ranking['b'] == 20
20 | assert ranking['c'] == 15
21 |
22 | assert ranking.pop_max() == ('b', 20)
23 | assert ranking.pop_max() == ('c', 15)
24 | assert ranking.pop_max() == ('a', 10)
25 | assert ranking.pop_max() is None
26 |
27 |
28 | def test_ranking_dict_delete():
29 | ranking = RankingDict[str]()
30 | ranking['x'] = 5
31 | ranking['y'] = 10
32 |
33 | del ranking['x']
34 | assert 'x' not in ranking.data
35 | assert ranking.pop_max() == ('y', 10)
36 | assert ranking.pop_max() is None
37 |
38 |
39 | def test_get_quality_ranking():
40 | ranking = get_quality_ranking()
41 | assert ranking[BoostyOkVideoType.ultra_hd] == 17
42 | assert ranking[BoostyOkVideoType.lowest] == 10
43 | assert ranking.pop_max() == (BoostyOkVideoType.ultra_hd, 17)
44 | assert ranking.pop_max() == (BoostyOkVideoType.quad_hd, 16)
45 | assert ranking.pop_max() == (BoostyOkVideoType.full_hd, 15)
46 |
47 |
48 | def test_get_best_video():
49 | video_urls = [
50 | BoostyOkVideoUrl(type=BoostyOkVideoType.low, url='low.mp4'),
51 | BoostyOkVideoUrl(type=BoostyOkVideoType.medium, url='medium.mp4'),
52 | BoostyOkVideoUrl(type=BoostyOkVideoType.full_hd, url='full_hd.mp4'),
53 | ]
54 |
55 | best_video_info = get_best_video(video_urls)
56 | best_video = best_video_info[0] if best_video_info else None
57 | assert best_video is not None
58 | assert best_video.type == BoostyOkVideoType.medium # Default preference
59 | assert best_video.url == 'medium.mp4'
60 |
61 |
62 | def test_get_best_video_with_preference():
63 | video_urls = [
64 | BoostyOkVideoUrl(type=BoostyOkVideoType.low, url='low.mp4'),
65 | BoostyOkVideoUrl(type=BoostyOkVideoType.full_hd, url='full_hd.mp4'),
66 | ]
67 |
68 | best_video_info = get_best_video(
69 | video_urls, preferred_quality=BoostyOkVideoType.full_hd
70 | )
71 |
72 | best_video = best_video_info[0] if best_video_info else None
73 |
74 | assert best_video is not None
75 | assert best_video.type == BoostyOkVideoType.full_hd
76 | assert best_video.url == 'full_hd.mp4'
77 |
78 |
79 | def test_get_best_video_no_available():
80 | video_urls = [
81 | BoostyOkVideoUrl(type=BoostyOkVideoType.low, url=''), # No valid URL
82 | BoostyOkVideoUrl(type=BoostyOkVideoType.medium, url=''),
83 | ]
84 |
85 | best_video = get_best_video(video_urls)
86 | assert best_video is None
87 |
88 |
89 | def test_get_best_video_empty_list():
90 | best_video = get_best_video([])
91 | assert best_video is None
92 |
93 |
94 | def test_ranking_dict_with_duplicate_entries():
95 | ranking = RankingDict[str]()
96 | ranking['a'] = 10
97 | ranking['b'] = 20
98 | ranking['a'] = 30 # Overwriting "a" with a higher value
99 |
100 | assert ranking.pop_max() == ('a', 30)
101 | assert ranking.pop_max() == ('b', 20)
102 | assert ranking.pop_max() is None
103 |
--------------------------------------------------------------------------------
/boosty_downloader/src/infrastructure/loggers/base.py:
--------------------------------------------------------------------------------
1 | """Logger for the application."""
2 |
3 | import io
4 | import logging
5 | import sys
6 |
7 | from rich.logging import RichHandler
8 |
9 | # Detect if running in a terminal
10 | is_terminal = sys.stdout.isatty()
11 |
12 | # Ensure proper UTF-8 handling in non-interactive environments
13 | if not is_terminal and 'pytest' not in sys.modules:
14 | sys.stdout = io.TextIOWrapper(
15 | sys.stdout.buffer,
16 | encoding='utf-8',
17 | line_buffering=True,
18 | )
19 |
20 |
21 | class RichLogger:
22 | """Enhanced logger with Rich for colorful output while keeping severity levels."""
23 |
24 | def __init__(self, prefix: str) -> None:
25 | self.prefix = prefix
26 |
27 | # Avoid adding duplicate handlers
28 | handler = RichHandler(
29 | log_time_format='[%H:%M:%S]',
30 | markup=True,
31 | show_time=True,
32 | rich_tracebacks=True,
33 | show_path=False,
34 | show_level=False,
35 | )
36 |
37 | self._handler = handler
38 | self._log = logging.getLogger(prefix)
39 | self._log.setLevel(logging.DEBUG)
40 | self._log.addHandler(handler)
41 | self.console = self._handler.console
42 | self.logging_logger_obj = self._log
43 |
44 | def _log_message(
45 | self,
46 | level: int,
47 | msg: str,
48 | *,
49 | highlight: bool = True,
50 | tab_level: int = 0,
51 | ) -> None:
52 | if highlight:
53 | self._log.log(level, '\t' * tab_level + msg)
54 | else:
55 | self._handler.console.log('\t' * tab_level + msg, highlight=False)
56 |
57 | def info(self, msg: str, *, highlight: bool = True, tab_level: int = 0) -> None:
58 | prefix = f'[cyan]{self.prefix}[/cyan][blue].INFO 🔹[/blue]:'
59 | self._log_message(
60 | logging.INFO,
61 | f'{prefix} {msg}',
62 | highlight=highlight,
63 | tab_level=tab_level,
64 | )
65 |
66 | def success(self, msg: str, *, highlight: bool = True, tab_level: int = 0) -> None:
67 | prefix = f'[cyan]{self.prefix}[/cyan][green].SUCCESS ✔[/green]:'
68 | self._log_message(
69 | logging.INFO,
70 | f'{prefix} {msg}',
71 | highlight=highlight,
72 | tab_level=tab_level,
73 | )
74 |
75 | def error(self, msg: str, *, highlight: bool = True, tab_level: int = 0) -> None:
76 | prefix = f'[cyan]{self.prefix}[/cyan][bold red].ERROR ❌[/bold red]:'
77 | self._log_message(
78 | logging.ERROR,
79 | f'{prefix} {msg}',
80 | highlight=highlight,
81 | tab_level=tab_level,
82 | )
83 |
84 | def wait(self, msg: str, *, highlight: bool = True, tab_level: int = 0) -> None:
85 | prefix = f'[cyan]{self.prefix}[/cyan][yellow].WAIT ⏳[/yellow]:'
86 | self._log_message(
87 | logging.INFO,
88 | f'{prefix} {msg}',
89 | highlight=highlight,
90 | tab_level=tab_level,
91 | )
92 |
93 | def warning(self, msg: str, *, highlight: bool = True, tab_level: int = 0) -> None:
94 | prefix = f'[cyan]{self.prefix}[/cyan][bold yellow].WARNING ⚠ [/bold yellow]:'
95 | self._log_message(
96 | logging.WARNING,
97 | f'{prefix} {msg}',
98 | highlight=highlight,
99 | tab_level=tab_level,
100 | )
101 |
--------------------------------------------------------------------------------
/boosty_downloader/src/application/ok_video_ranking.py:
--------------------------------------------------------------------------------
1 | """The module provides tools to work with ok video links (selecting them) by quality."""
2 |
3 | from __future__ import annotations
4 |
5 | import heapq
6 | from typing import Generic, TypeVar
7 |
8 | from boosty_downloader.src.infrastructure.boosty_api.models.post.post_data_types.post_data_ok_video import (
9 | BoostyOkVideoType,
10 | BoostyOkVideoUrl,
11 | )
12 |
13 | KT = TypeVar('KT')
14 |
15 |
16 | class RankingDict(Generic[KT]):
17 | """A dict which also keeps track of the max value, it's not thread-safe"""
18 |
19 | def __init__(self) -> None:
20 | self.data: dict[KT, float] = {}
21 | self.max_heap: list[tuple[float, KT]] = []
22 | self.entries: dict[KT, tuple[float, KT]] = {}
23 |
24 | def __getitem__(self, key: KT) -> float:
25 | """Get the value associated with the key"""
26 | return self.data[key]
27 |
28 | def __setitem__(self, key: KT, value: float) -> None:
29 | """Set the value associated with the key"""
30 | self.data[key] = value
31 | entry = (-value, key)
32 | self.entries[key] = entry
33 | heapq.heappush(self.max_heap, entry)
34 |
35 | def __delitem__(self, key: KT) -> None:
36 | """Remove the key and its value"""
37 | if key in self.data:
38 | del self.data[key]
39 | if key in self.entries:
40 | self.entries[key] = (float('-inf'), key) # Mark as deleted
41 |
42 | def pop_max(self) -> tuple[KT, float] | None:
43 | """Pop the maximum value"""
44 | while self.max_heap:
45 | value, key = heapq.heappop(self.max_heap)
46 | if key in self.data and self.entries[key] == (value, key):
47 | del self.data[key]
48 | del self.entries[key]
49 | return key, -value # Convert back to positive
50 | return None
51 |
52 |
53 | def get_quality_ranking() -> RankingDict[BoostyOkVideoType]:
54 | """Get the ranking dict for video quality"""
55 | quality_ranking = RankingDict[BoostyOkVideoType]()
56 | quality_ranking[BoostyOkVideoType.ultra_hd] = 17
57 | quality_ranking[BoostyOkVideoType.quad_hd] = 16
58 | quality_ranking[BoostyOkVideoType.full_hd] = 15
59 | quality_ranking[BoostyOkVideoType.high] = 14
60 | quality_ranking[BoostyOkVideoType.medium] = 13
61 | quality_ranking[BoostyOkVideoType.low] = 12
62 | quality_ranking[BoostyOkVideoType.tiny] = 11
63 | quality_ranking[BoostyOkVideoType.lowest] = 10
64 | quality_ranking[BoostyOkVideoType.live_playback_dash] = 9
65 | quality_ranking[BoostyOkVideoType.live_playback_hls] = 8
66 | quality_ranking[BoostyOkVideoType.live_ondemand_hls] = 7
67 | quality_ranking[BoostyOkVideoType.live_dash] = 6
68 | quality_ranking[BoostyOkVideoType.live_hls] = 5
69 | quality_ranking[BoostyOkVideoType.hls] = 4
70 | quality_ranking[BoostyOkVideoType.dash] = 3
71 | quality_ranking[BoostyOkVideoType.dash_uni] = 2
72 | quality_ranking[BoostyOkVideoType.live_cmaf] = 1
73 |
74 | return quality_ranking
75 |
76 |
77 | def get_best_video(
78 | video_urls: list[BoostyOkVideoUrl],
79 | preferred_quality: BoostyOkVideoType = BoostyOkVideoType.medium,
80 | ) -> tuple[BoostyOkVideoUrl, BoostyOkVideoType] | None:
81 | """Select the best video format for downloading according to user's preferences"""
82 | quality_ranking: RankingDict[BoostyOkVideoType] = get_quality_ranking()
83 | quality_ranking[preferred_quality] = float('inf')
84 |
85 | video_urls_map = {video.type: video for video in video_urls}
86 |
87 | while highest_rank_video_type := quality_ranking.pop_max():
88 | highest_rank_video_type = highest_rank_video_type[0]
89 |
90 | video_url = video_urls_map.get(highest_rank_video_type)
91 | if video_url and video_url.url:
92 | return video_url, highest_rank_video_type
93 |
94 | return None
95 |
--------------------------------------------------------------------------------
/test/integration/boosty_api/boosty_api_test.py:
--------------------------------------------------------------------------------
1 | """Integration tests for Boosty API client.
2 |
3 | These tests make real requests to the Boosty API and require proper configuration.
4 |
5 | Please see test/ABOUT_TESTING.md for more details.
6 | """
7 |
8 | import pytest
9 |
10 | from boosty_downloader.src.infrastructure.boosty_api import (
11 | BoostyAPIClient,
12 | )
13 | from boosty_downloader.src.infrastructure.boosty_api.core.client import (
14 | BoostyAPINoUsernameError,
15 | BoostyAPIUnauthorizedError,
16 | )
17 | from integration.configuration import IntegrationTestConfig
18 |
19 | # For automatic fixture discovery
20 | pytest_plugins = [
21 | 'integration.fixtures',
22 | ]
23 |
24 |
25 | @pytest.mark.asyncio
26 | async def test_get_posts_existing_author_success(
27 | authorized_boosty_client: BoostyAPIClient, integration_config: IntegrationTestConfig
28 | ) -> None:
29 | """Test successful retrieval of posts from an existing author."""
30 | response = await authorized_boosty_client.get_author_posts(
31 | author_name=integration_config.boosty_existing_author, limit=5
32 | )
33 |
34 | assert response.posts is not None
35 | assert response.extra is not None
36 | assert len(response.posts) >= 0
37 |
38 |
39 | @pytest.mark.asyncio
40 | async def test_get_posts_nonexistent_author_raises_error(
41 | authorized_boosty_client: BoostyAPIClient, integration_config: IntegrationTestConfig
42 | ) -> None:
43 | """Test that requesting posts from non-existent author raises BoostyAPINoUsernameError."""
44 | with pytest.raises(BoostyAPINoUsernameError):
45 | await authorized_boosty_client.get_author_posts(
46 | author_name=integration_config.boosty_nonexistent_author, limit=5
47 | )
48 |
49 |
50 | @pytest.mark.asyncio
51 | async def test_get_posts_with_pagination(
52 | authorized_boosty_client: BoostyAPIClient, integration_config: IntegrationTestConfig
53 | ) -> None:
54 | """Test pagination functionality for author posts."""
55 | first_page = await authorized_boosty_client.get_author_posts(
56 | author_name=integration_config.boosty_existing_author, limit=2
57 | )
58 |
59 | if not first_page.extra.is_last and first_page.extra.offset:
60 | second_page = await authorized_boosty_client.get_author_posts(
61 | author_name=integration_config.boosty_existing_author,
62 | limit=2,
63 | offset=first_page.extra.offset,
64 | )
65 |
66 | # Posts should be different between pages (assuming author has more than 2 posts)
67 | first_page_ids = {post.id for post in first_page.posts}
68 | second_page_ids = {post.id for post in second_page.posts}
69 | assert first_page_ids.isdisjoint(second_page_ids), (
70 | 'Pages should contain different posts'
71 | )
72 |
73 |
74 | @pytest.mark.asyncio
75 | async def test_iterate_over_posts(
76 | authorized_boosty_client: BoostyAPIClient, integration_config: IntegrationTestConfig
77 | ) -> None:
78 | """Test the async generator for iterating over all author posts."""
79 | pages_count = 0
80 | total_posts = 0
81 |
82 | async for response in authorized_boosty_client.iterate_over_posts(
83 | author_name=integration_config.boosty_existing_author,
84 | posts_per_page=2,
85 | ):
86 | pages_count += 1
87 | total_posts += len(response.posts)
88 |
89 | # Limit iteration to avoid running too long in tests
90 | if pages_count >= 3:
91 | break
92 |
93 | assert pages_count > 0, 'Should retrieve at least one page'
94 | assert total_posts >= 0, 'Should count posts correctly'
95 |
96 |
97 | @pytest.mark.asyncio
98 | async def test_unathoirized_raises_error(
99 | invalid_auth_boosty_client: BoostyAPIClient,
100 | integration_config: IntegrationTestConfig,
101 | ) -> None:
102 | """Test that unauthorized access raises an error."""
103 | with pytest.raises(BoostyAPIUnauthorizedError):
104 | await invalid_auth_boosty_client.get_author_posts(
105 | author_name=integration_config.boosty_existing_author, limit=5
106 | )
107 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | 🐛 Hotfix
87 | 88 | 1. **From main:** 89 | ```bash 90 | git checkout -b hotfix/fix-name 91 | poetry version patch 92 | # Fix bug, update changelog 93 | ``` 94 | 95 | 2. **PR:** `hotfix/*` → `main` 96 |
3 | ![]() 4 |
4 |
 50 |
50 | 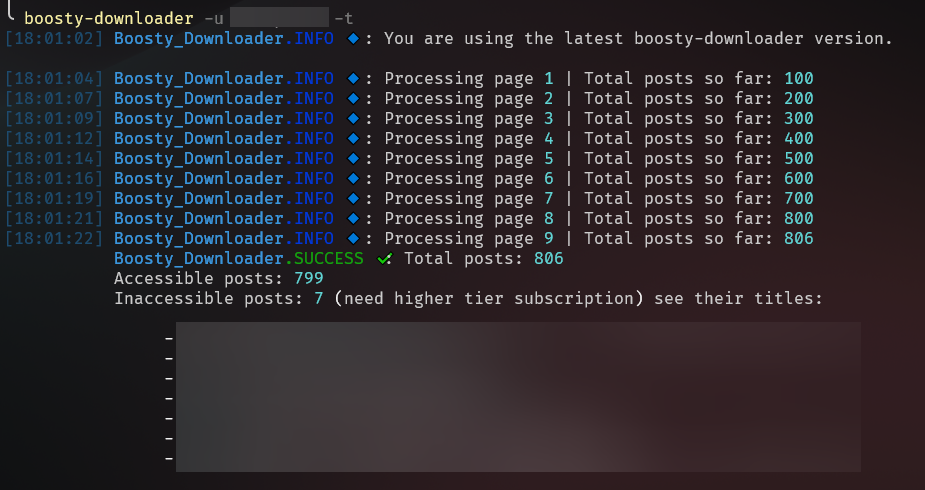 51 |
51 | 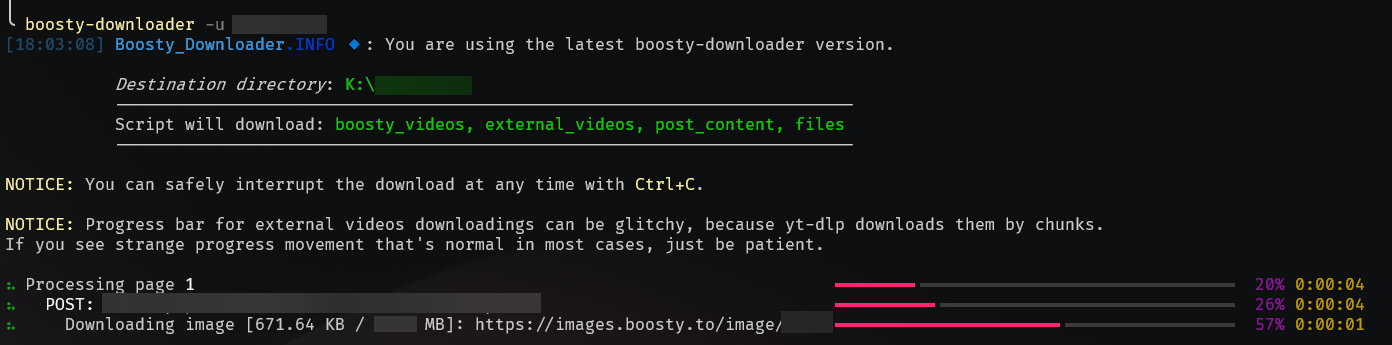 52 |
52 | 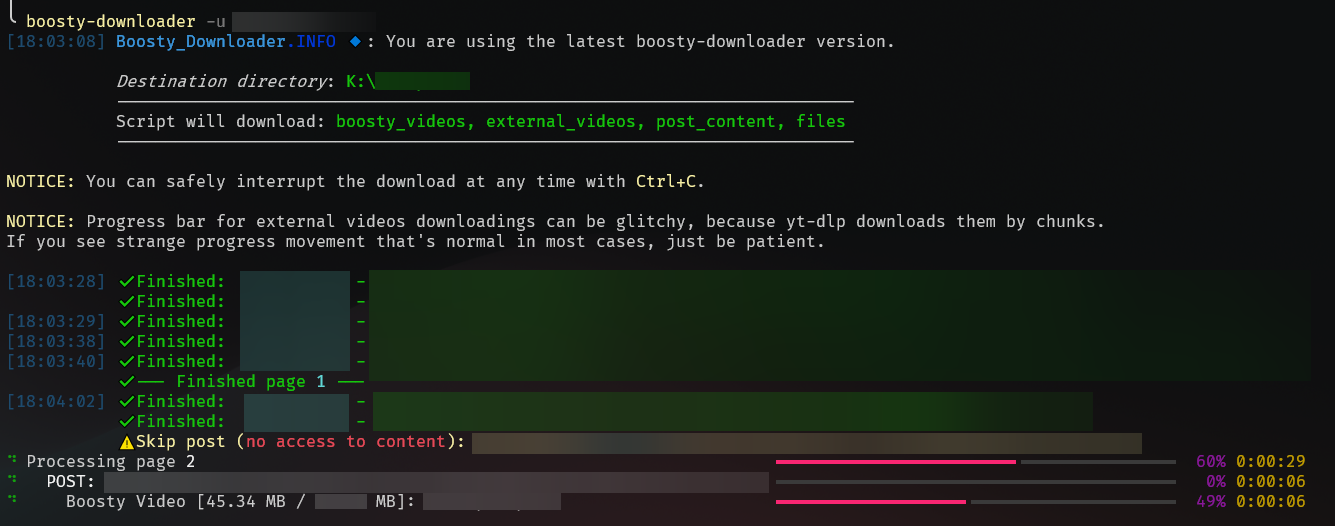 53 |
54 |
55 |
56 | ## 🛠️ Installation
57 |
58 | 1. **Install python**:
59 | - Window:
60 | ```bash
61 | winget install Python.Python.3.13
62 | ```
63 | - Linux:
64 | ```bash
65 | sudo apt-get install python3
66 | ```
67 | - macOS:
68 | ```bash
69 | brew install python
70 | ```
71 |
72 | 2. **Install the boosty-downloader package:**
73 | ```bash
74 | pip install boosty-downloader
75 | ```
76 |
77 | 3. **Run the application:**
78 | ```bash
79 | boosty-downloader --help
80 | ```
81 |
82 | ## 🚀 Configuration for Usage
83 |
84 | ### Step 1: Get the auth cookie and auth header
85 |
86 | 1. Open the [Boosty](https://boosty.to) website.
87 | 2. Click the "Sign in" button and fill you credentials.
88 | 3. Navigate to any author you have access to and scroll post a little.
89 | 4. Copy auth token and cookie from browser network tab.
90 |
91 |
53 |
54 |
55 |
56 | ## 🛠️ Installation
57 |
58 | 1. **Install python**:
59 | - Window:
60 | ```bash
61 | winget install Python.Python.3.13
62 | ```
63 | - Linux:
64 | ```bash
65 | sudo apt-get install python3
66 | ```
67 | - macOS:
68 | ```bash
69 | brew install python
70 | ```
71 |
72 | 2. **Install the boosty-downloader package:**
73 | ```bash
74 | pip install boosty-downloader
75 | ```
76 |
77 | 3. **Run the application:**
78 | ```bash
79 | boosty-downloader --help
80 | ```
81 |
82 | ## 🚀 Configuration for Usage
83 |
84 | ### Step 1: Get the auth cookie and auth header
85 |
86 | 1. Open the [Boosty](https://boosty.to) website.
87 | 2. Click the "Sign in" button and fill you credentials.
88 | 3. Navigate to any author you have access to and scroll post a little.
89 | 4. Copy auth token and cookie from browser network tab.
90 |
91 | 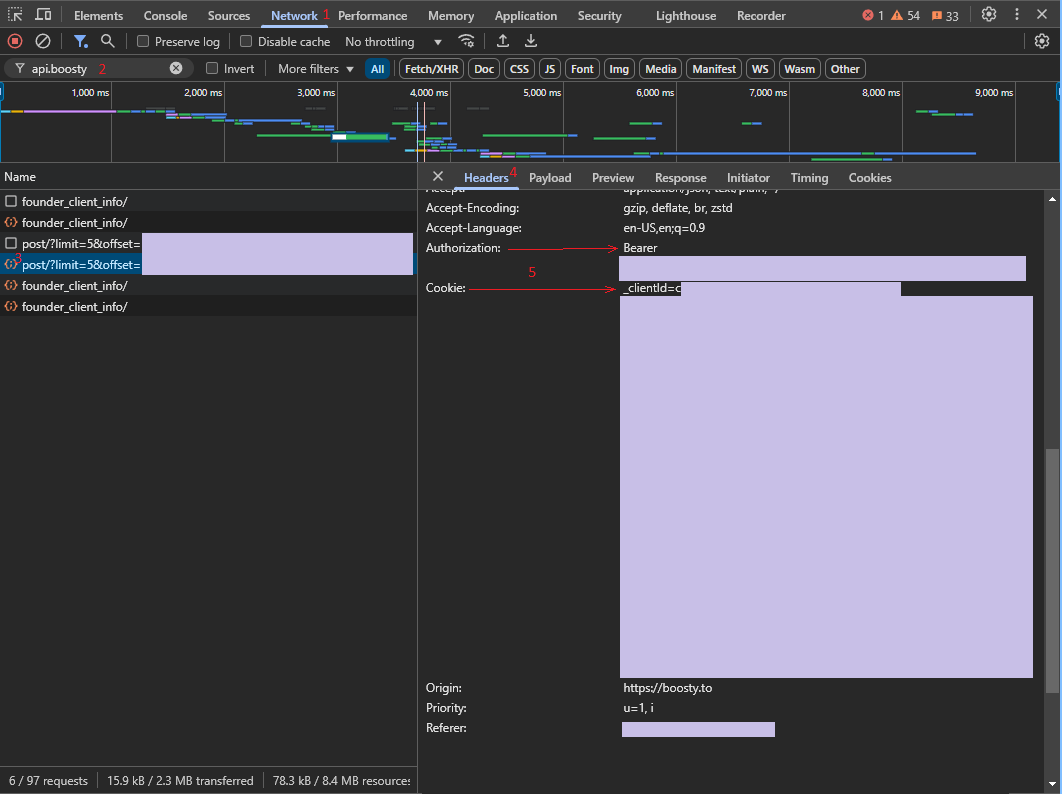 92 |
93 | ### Step 2: Paste the cookie and auth header into the config file
94 |
95 | This config will be created during first run of the app in the current working directory.
96 |
97 |
92 |
93 | ### Step 2: Paste the cookie and auth header into the config file
94 |
95 | This config will be created during first run of the app in the current working directory.
96 |
97 | 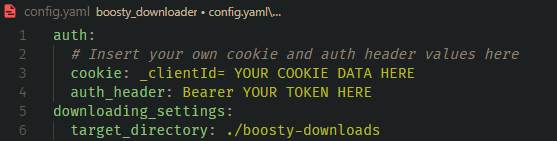 98 |
99 | ### Step 3: Run the utility
100 |
101 | Now you can just download your content with the following command:
102 |
103 | ```bash
104 | boosty-downloader --username YOUR_CREATOR_NAME
105 | ```
106 |
107 | ## 💖 Contributing
108 |
109 | If you want to contribute to this project, please see the [CONTRIBUTING.md](CONTRIBUTING.md).
110 |
111 | ## 📜 License
112 |
113 | This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
114 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Created by https://www.toptal.com/developers/gitignore/api/python
2 | # Edit at https://www.toptal.com/developers/gitignore?templates=python
3 |
4 | test/data
5 |
6 | # ------------- USER DEFINED --------------- #
7 | lab/
8 |
9 | # For local downloading tests
10 | boosty-downloads/
11 |
12 | # Credentials
13 | config.yaml
14 |
15 |
16 | ### Python ###
17 | # Byte-compiled / optimized / DLL files
18 | __pycache__/
19 | *.py[cod]
20 | *$py.class
21 |
22 | # C extensions
23 | *.so
24 |
25 | # Distribution / packaging
26 | .Python
27 | build/
28 | develop-eggs/
29 | dist/
30 | downloads/
31 | eggs/
32 | .eggs/
33 | lib/
34 | lib64/
35 | parts/
36 | sdist/
37 | var/
38 | wheels/
39 | share/python-wheels/
40 | *.egg-info/
41 | .installed.cfg
42 | *.egg
43 | MANIFEST
44 |
45 | # PyInstaller
46 | # Usually these files are written by a python script from a template
47 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
48 | *.manifest
49 | *.spec
50 |
51 | # Installer logs
52 | pip-log.txt
53 | pip-delete-this-directory.txt
54 |
55 | # Unit test / coverage reports
56 | htmlcov/
57 | .tox/
58 | .nox/
59 | .coverage
60 | .coverage.*
61 | .cache
62 | nosetests.xml
63 | coverage.xml
64 | *.cover
65 | *.py,cover
66 | .hypothesis/
67 | .pytest_cache/
68 | cover/
69 |
70 | # Translations
71 | *.mo
72 | *.pot
73 |
74 | # Django stuff:
75 | *.log
76 | local_settings.py
77 | db.sqlite3
78 | db.sqlite3-journal
79 |
80 | # Flask stuff:
81 | instance/
82 | .webassets-cache
83 |
84 | # Scrapy stuff:
85 | .scrapy
86 |
87 | # Sphinx documentation
88 | docs/_build/
89 |
90 | # PyBuilder
91 | .pybuilder/
92 | target/
93 |
94 | # Jupyter Notebook
95 | .ipynb_checkpoints
96 |
97 | # IPython
98 | profile_default/
99 | ipython_config.py
100 |
101 | # pyenv
102 | # For a library or package, you might want to ignore these files since the code is
103 | # intended to run in multiple environments; otherwise, check them in:
104 | # .python-version
105 |
106 | # pipenv
107 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
108 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
109 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
110 | # install all needed dependencies.
111 | #Pipfile.lock
112 |
113 | # poetry
114 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
115 | # This is especially recommended for binary packages to ensure reproducibility, and is more
116 | # commonly ignored for libraries.
117 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
118 | #poetry.lock
119 |
120 | # pdm
121 | # Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
122 | #pdm.lock
123 | # pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
124 | # in version control.
125 | # https://pdm.fming.dev/latest/usage/project/#working-with-version-control
126 | .pdm.toml
127 | .pdm-python
128 | .pdm-build/
129 |
130 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
131 | __pypackages__/
132 |
133 | # Celery stuff
134 | celerybeat-schedule
135 | celerybeat.pid
136 |
137 | # SageMath parsed files
138 | *.sage.py
139 |
140 | # Environments
141 | .env
142 | .venv
143 | env/
144 | venv/
145 | ENV/
146 | env.bak/
147 | venv.bak/
148 |
149 | # Spyder project settings
150 | .spyderproject
151 | .spyproject
152 |
153 | # Rope project settings
154 | .ropeproject
155 |
156 | # mkdocs documentation
157 | /site
158 |
159 | # mypy
160 | .mypy_cache/
161 | .dmypy.json
162 | dmypy.json
163 |
164 | # Pyre type checker
165 | .pyre/
166 |
167 | # pytype static type analyzer
168 | .pytype/
169 |
170 | # Cython debug symbols
171 | cython_debug/
172 |
173 | # PyCharm
174 | # JetBrains specific template is maintained in a separate JetBrains.gitignore that can
175 | # be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
176 | # and can be added to the global gitignore or merged into this file. For a more nuclear
177 | # option (not recommended) you can uncomment the following to ignore the entire idea folder.
178 | #.idea/
179 |
180 | ### Python Patch ###
181 | # Poetry local configuration file - https://python-poetry.org/docs/configuration/#local-configuration
182 | poetry.toml
183 |
184 | # ruff
185 | .ruff_cache/
186 |
187 | # LSP config files
188 | # pyrightconfig.json Make those rules crucial to the project's quality
189 |
190 | # End of https://www.toptal.com/developers/gitignore/api/python
191 |
192 |
--------------------------------------------------------------------------------
/boosty_downloader/src/application/di/app_environment.py:
--------------------------------------------------------------------------------
1 | """Defines the application environment and dependency injection context for resource management."""
2 |
3 | from contextlib import AsyncExitStack
4 | from dataclasses import dataclass
5 | from pathlib import Path
6 | from types import TracebackType
7 |
8 | import aiohttp
9 | from aiohttp.typedefs import LooseHeaders
10 | from aiohttp_retry import RetryClient, RetryOptionsBase
11 |
12 | from boosty_downloader.src.infrastructure.boosty_api.core.client import BoostyAPIClient
13 | from boosty_downloader.src.infrastructure.loggers.logger_instances import RichLogger
14 | from boosty_downloader.src.infrastructure.post_caching.post_cache import SQLitePostCache
15 | from boosty_downloader.src.interfaces.console_progress_reporter import (
16 | ProgressReporter,
17 | use_reporter,
18 | )
19 |
20 |
21 | class AppEnvironment:
22 | """Manages the application's resource initialization and cleanup, providing an async context for dependency injection."""
23 |
24 | @dataclass
25 | class Environment:
26 | """Holds initialized application resources for use within the app context."""
27 |
28 | boosty_api_client: BoostyAPIClient
29 | downloading_retry_client: RetryClient
30 | progress_reporter: ProgressReporter
31 | destination_directory: Path
32 | post_cache: SQLitePostCache
33 |
34 | @dataclass
35 | class AppConfig:
36 | """Configuration for the application environment."""
37 |
38 | author_name: str
39 | target_directory: Path
40 | boosty_headers: LooseHeaders
41 | boosty_cookies_jar: aiohttp.CookieJar
42 | retry_options: RetryOptionsBase
43 | request_delay_seconds: float
44 | logger: RichLogger
45 |
46 | def __init__(
47 | self,
48 | config: AppConfig,
49 | ) -> None:
50 | self.author_name = config.author_name
51 | self.target_directory = config.target_directory
52 | self.boosty_headers = config.boosty_headers
53 | self.boosty_cookies_jar = config.boosty_cookies_jar
54 | self.logger = config.logger
55 | self.retry_options = config.retry_options
56 | self._request_delay_seconds = config.request_delay_seconds
57 |
58 | async def __aenter__(self) -> 'Environment':
59 | """Enter the async context and initialize resources."""
60 | self._exit_stack = AsyncExitStack()
61 | await self._exit_stack.__aenter__()
62 |
63 | authorized_boosty_session = await self._exit_stack.enter_async_context(
64 | # Don't: set BASE_URL here, the BoostyAPIClient will handle it internally.
65 | # Why: this session will be used for both downloading and API requests with different bases.
66 | aiohttp.ClientSession(
67 | headers=self.boosty_headers,
68 | cookie_jar=self.boosty_cookies_jar,
69 | timeout=aiohttp.ClientTimeout(total=None),
70 | trust_env=True,
71 | )
72 | )
73 |
74 | progress_reporter = await self._exit_stack.enter_async_context(
75 | use_reporter(
76 | reporter=ProgressReporter(
77 | logger=self.logger.logging_logger_obj,
78 | console=self.logger.console,
79 | )
80 | )
81 | )
82 |
83 | authorized_retry_client = RetryClient(
84 | authorized_boosty_session, retry_options=self.retry_options
85 | )
86 |
87 | boosty_api_client = BoostyAPIClient(
88 | authorized_retry_client,
89 | request_delay_seconds=self._request_delay_seconds,
90 | )
91 |
92 | post_cache = SQLitePostCache(
93 | destination=self.target_directory / self.author_name,
94 | logger=self.logger,
95 | )
96 | post_cache.__enter__() # sync context manager
97 | self._exit_stack.callback(post_cache.__exit__, None, None, None)
98 |
99 | return self.Environment(
100 | boosty_api_client=boosty_api_client,
101 | downloading_retry_client=authorized_retry_client,
102 | progress_reporter=progress_reporter,
103 | destination_directory=self.target_directory / self.author_name,
104 | post_cache=post_cache,
105 | )
106 |
107 | async def __aexit__(
108 | self,
109 | exc_type: type[BaseException] | None,
110 | exc_val: BaseException | None,
111 | exc_tb: TracebackType | None,
112 | ) -> None:
113 | """Exit the async context and clean up resources"""
114 | await self._exit_stack.__aexit__(exc_type, exc_val, exc_tb)
115 |
--------------------------------------------------------------------------------
/boosty_downloader/src/domain/post_data_chunks.py:
--------------------------------------------------------------------------------
1 | """
2 | Module contains domain models for post data chunks.
3 |
4 | These are used to represent different parts of a post, such as text, images, etc.
5 | """
6 |
7 | from dataclasses import dataclass, field
8 | from enum import Enum
9 |
10 |
11 | @dataclass
12 | class PostDataChunkImage:
13 | """Represent an image data chunk within a post."""
14 |
15 | url: str
16 |
17 |
18 | @dataclass
19 | class PostDataChunkText:
20 | """
21 | Represent a textual data chunk within a post.
22 |
23 | It can contain multiple text fragments, each with optional styling and links.
24 |
25 | For example:
26 | - PostDataChunkText(
27 | text_fragments=[
28 | PostDataChunkText.TextFragment(text="Hello, world!", bold=True),
29 | PostDataChunkText.TextFragment(text="Visit Boosty", link_data="https://boosty.com", header_level=1),
30 | PostDataChunkText.TextFragment(text="This is a normal text."),
31 | PostDataChunkText.TextFragment(text="
98 |
99 | ### Step 3: Run the utility
100 |
101 | Now you can just download your content with the following command:
102 |
103 | ```bash
104 | boosty-downloader --username YOUR_CREATOR_NAME
105 | ```
106 |
107 | ## 💖 Contributing
108 |
109 | If you want to contribute to this project, please see the [CONTRIBUTING.md](CONTRIBUTING.md).
110 |
111 | ## 📜 License
112 |
113 | This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
114 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Created by https://www.toptal.com/developers/gitignore/api/python
2 | # Edit at https://www.toptal.com/developers/gitignore?templates=python
3 |
4 | test/data
5 |
6 | # ------------- USER DEFINED --------------- #
7 | lab/
8 |
9 | # For local downloading tests
10 | boosty-downloads/
11 |
12 | # Credentials
13 | config.yaml
14 |
15 |
16 | ### Python ###
17 | # Byte-compiled / optimized / DLL files
18 | __pycache__/
19 | *.py[cod]
20 | *$py.class
21 |
22 | # C extensions
23 | *.so
24 |
25 | # Distribution / packaging
26 | .Python
27 | build/
28 | develop-eggs/
29 | dist/
30 | downloads/
31 | eggs/
32 | .eggs/
33 | lib/
34 | lib64/
35 | parts/
36 | sdist/
37 | var/
38 | wheels/
39 | share/python-wheels/
40 | *.egg-info/
41 | .installed.cfg
42 | *.egg
43 | MANIFEST
44 |
45 | # PyInstaller
46 | # Usually these files are written by a python script from a template
47 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
48 | *.manifest
49 | *.spec
50 |
51 | # Installer logs
52 | pip-log.txt
53 | pip-delete-this-directory.txt
54 |
55 | # Unit test / coverage reports
56 | htmlcov/
57 | .tox/
58 | .nox/
59 | .coverage
60 | .coverage.*
61 | .cache
62 | nosetests.xml
63 | coverage.xml
64 | *.cover
65 | *.py,cover
66 | .hypothesis/
67 | .pytest_cache/
68 | cover/
69 |
70 | # Translations
71 | *.mo
72 | *.pot
73 |
74 | # Django stuff:
75 | *.log
76 | local_settings.py
77 | db.sqlite3
78 | db.sqlite3-journal
79 |
80 | # Flask stuff:
81 | instance/
82 | .webassets-cache
83 |
84 | # Scrapy stuff:
85 | .scrapy
86 |
87 | # Sphinx documentation
88 | docs/_build/
89 |
90 | # PyBuilder
91 | .pybuilder/
92 | target/
93 |
94 | # Jupyter Notebook
95 | .ipynb_checkpoints
96 |
97 | # IPython
98 | profile_default/
99 | ipython_config.py
100 |
101 | # pyenv
102 | # For a library or package, you might want to ignore these files since the code is
103 | # intended to run in multiple environments; otherwise, check them in:
104 | # .python-version
105 |
106 | # pipenv
107 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
108 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
109 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
110 | # install all needed dependencies.
111 | #Pipfile.lock
112 |
113 | # poetry
114 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
115 | # This is especially recommended for binary packages to ensure reproducibility, and is more
116 | # commonly ignored for libraries.
117 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
118 | #poetry.lock
119 |
120 | # pdm
121 | # Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
122 | #pdm.lock
123 | # pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
124 | # in version control.
125 | # https://pdm.fming.dev/latest/usage/project/#working-with-version-control
126 | .pdm.toml
127 | .pdm-python
128 | .pdm-build/
129 |
130 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
131 | __pypackages__/
132 |
133 | # Celery stuff
134 | celerybeat-schedule
135 | celerybeat.pid
136 |
137 | # SageMath parsed files
138 | *.sage.py
139 |
140 | # Environments
141 | .env
142 | .venv
143 | env/
144 | venv/
145 | ENV/
146 | env.bak/
147 | venv.bak/
148 |
149 | # Spyder project settings
150 | .spyderproject
151 | .spyproject
152 |
153 | # Rope project settings
154 | .ropeproject
155 |
156 | # mkdocs documentation
157 | /site
158 |
159 | # mypy
160 | .mypy_cache/
161 | .dmypy.json
162 | dmypy.json
163 |
164 | # Pyre type checker
165 | .pyre/
166 |
167 | # pytype static type analyzer
168 | .pytype/
169 |
170 | # Cython debug symbols
171 | cython_debug/
172 |
173 | # PyCharm
174 | # JetBrains specific template is maintained in a separate JetBrains.gitignore that can
175 | # be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
176 | # and can be added to the global gitignore or merged into this file. For a more nuclear
177 | # option (not recommended) you can uncomment the following to ignore the entire idea folder.
178 | #.idea/
179 |
180 | ### Python Patch ###
181 | # Poetry local configuration file - https://python-poetry.org/docs/configuration/#local-configuration
182 | poetry.toml
183 |
184 | # ruff
185 | .ruff_cache/
186 |
187 | # LSP config files
188 | # pyrightconfig.json Make those rules crucial to the project's quality
189 |
190 | # End of https://www.toptal.com/developers/gitignore/api/python
191 |
192 |
--------------------------------------------------------------------------------
/boosty_downloader/src/application/di/app_environment.py:
--------------------------------------------------------------------------------
1 | """Defines the application environment and dependency injection context for resource management."""
2 |
3 | from contextlib import AsyncExitStack
4 | from dataclasses import dataclass
5 | from pathlib import Path
6 | from types import TracebackType
7 |
8 | import aiohttp
9 | from aiohttp.typedefs import LooseHeaders
10 | from aiohttp_retry import RetryClient, RetryOptionsBase
11 |
12 | from boosty_downloader.src.infrastructure.boosty_api.core.client import BoostyAPIClient
13 | from boosty_downloader.src.infrastructure.loggers.logger_instances import RichLogger
14 | from boosty_downloader.src.infrastructure.post_caching.post_cache import SQLitePostCache
15 | from boosty_downloader.src.interfaces.console_progress_reporter import (
16 | ProgressReporter,
17 | use_reporter,
18 | )
19 |
20 |
21 | class AppEnvironment:
22 | """Manages the application's resource initialization and cleanup, providing an async context for dependency injection."""
23 |
24 | @dataclass
25 | class Environment:
26 | """Holds initialized application resources for use within the app context."""
27 |
28 | boosty_api_client: BoostyAPIClient
29 | downloading_retry_client: RetryClient
30 | progress_reporter: ProgressReporter
31 | destination_directory: Path
32 | post_cache: SQLitePostCache
33 |
34 | @dataclass
35 | class AppConfig:
36 | """Configuration for the application environment."""
37 |
38 | author_name: str
39 | target_directory: Path
40 | boosty_headers: LooseHeaders
41 | boosty_cookies_jar: aiohttp.CookieJar
42 | retry_options: RetryOptionsBase
43 | request_delay_seconds: float
44 | logger: RichLogger
45 |
46 | def __init__(
47 | self,
48 | config: AppConfig,
49 | ) -> None:
50 | self.author_name = config.author_name
51 | self.target_directory = config.target_directory
52 | self.boosty_headers = config.boosty_headers
53 | self.boosty_cookies_jar = config.boosty_cookies_jar
54 | self.logger = config.logger
55 | self.retry_options = config.retry_options
56 | self._request_delay_seconds = config.request_delay_seconds
57 |
58 | async def __aenter__(self) -> 'Environment':
59 | """Enter the async context and initialize resources."""
60 | self._exit_stack = AsyncExitStack()
61 | await self._exit_stack.__aenter__()
62 |
63 | authorized_boosty_session = await self._exit_stack.enter_async_context(
64 | # Don't: set BASE_URL here, the BoostyAPIClient will handle it internally.
65 | # Why: this session will be used for both downloading and API requests with different bases.
66 | aiohttp.ClientSession(
67 | headers=self.boosty_headers,
68 | cookie_jar=self.boosty_cookies_jar,
69 | timeout=aiohttp.ClientTimeout(total=None),
70 | trust_env=True,
71 | )
72 | )
73 |
74 | progress_reporter = await self._exit_stack.enter_async_context(
75 | use_reporter(
76 | reporter=ProgressReporter(
77 | logger=self.logger.logging_logger_obj,
78 | console=self.logger.console,
79 | )
80 | )
81 | )
82 |
83 | authorized_retry_client = RetryClient(
84 | authorized_boosty_session, retry_options=self.retry_options
85 | )
86 |
87 | boosty_api_client = BoostyAPIClient(
88 | authorized_retry_client,
89 | request_delay_seconds=self._request_delay_seconds,
90 | )
91 |
92 | post_cache = SQLitePostCache(
93 | destination=self.target_directory / self.author_name,
94 | logger=self.logger,
95 | )
96 | post_cache.__enter__() # sync context manager
97 | self._exit_stack.callback(post_cache.__exit__, None, None, None)
98 |
99 | return self.Environment(
100 | boosty_api_client=boosty_api_client,
101 | downloading_retry_client=authorized_retry_client,
102 | progress_reporter=progress_reporter,
103 | destination_directory=self.target_directory / self.author_name,
104 | post_cache=post_cache,
105 | )
106 |
107 | async def __aexit__(
108 | self,
109 | exc_type: type[BaseException] | None,
110 | exc_val: BaseException | None,
111 | exc_tb: TracebackType | None,
112 | ) -> None:
113 | """Exit the async context and clean up resources"""
114 | await self._exit_stack.__aexit__(exc_type, exc_val, exc_tb)
115 |
--------------------------------------------------------------------------------
/boosty_downloader/src/domain/post_data_chunks.py:
--------------------------------------------------------------------------------
1 | """
2 | Module contains domain models for post data chunks.
3 |
4 | These are used to represent different parts of a post, such as text, images, etc.
5 | """
6 |
7 | from dataclasses import dataclass, field
8 | from enum import Enum
9 |
10 |
11 | @dataclass
12 | class PostDataChunkImage:
13 | """Represent an image data chunk within a post."""
14 |
15 | url: str
16 |
17 |
18 | @dataclass
19 | class PostDataChunkText:
20 | """
21 | Represent a textual data chunk within a post.
22 |
23 | It can contain multiple text fragments, each with optional styling and links.
24 |
25 | For example:
26 | - PostDataChunkText(
27 | text_fragments=[
28 | PostDataChunkText.TextFragment(text="Hello, world!", bold=True),
29 | PostDataChunkText.TextFragment(text="Visit Boosty", link_data="https://boosty.com", header_level=1),
30 | PostDataChunkText.TextFragment(text="This is a normal text."),
31 | PostDataChunkText.TextFragment(text="
139 | {{ content | safe }}
140 |
141 |
142 |
158 |
159 |
160 |
--------------------------------------------------------------------------------
/boosty_downloader/src/application/use_cases/download_all_posts.py:
--------------------------------------------------------------------------------
1 | """Implements the use case for downloading all posts from a Boosty author, applying filters and caching as needed."""
2 |
3 | import asyncio
4 | from pathlib import Path
5 |
6 | from boosty_downloader.src.application.di.download_context import DownloadContext
7 | from boosty_downloader.src.application.exceptions.application_errors import (
8 | ApplicationCancelledError,
9 | ApplicationFailedDownloadError,
10 | )
11 | from boosty_downloader.src.application.use_cases.download_single_post import (
12 | DownloadSinglePostUseCase,
13 | )
14 | from boosty_downloader.src.infrastructure.boosty_api.core.client import BoostyAPIClient
15 | from boosty_downloader.src.infrastructure.path_sanitizer import (
16 | sanitize_string,
17 | )
18 |
19 |
20 | class DownloadAllPostUseCase:
21 | """
22 | Use case for downloading all user's posts.
23 |
24 | This class encapsulates the logic required to download all posts from a source.
25 | Initialize the use case and call its methods to perform the download operation.
26 |
27 | All the downloaded content parts will be saved under the specified destination path.
28 | """
29 |
30 | def __init__(
31 | self,
32 | author_name: str,
33 | boosty_api: BoostyAPIClient,
34 | destination: Path,
35 | download_context: DownloadContext,
36 | ) -> None:
37 | self.author_name = author_name
38 |
39 | self.boosty_api = boosty_api
40 | self.destination = destination
41 | self.context = download_context
42 |
43 | async def execute(self) -> None:
44 | posts_iterator = self.boosty_api.iterate_over_posts(
45 | author_name=self.author_name
46 | )
47 |
48 | current_page = 0
49 |
50 | async for page in posts_iterator:
51 | count = len(page.posts)
52 | current_page += 1
53 |
54 | page_task_id = self.context.progress_reporter.create_task(
55 | f'Got new posts: [{count}]',
56 | total=count,
57 | indent_level=0, # Each page prints without indentation
58 | )
59 |
60 | for post_dto in page.posts:
61 | if not post_dto.has_access:
62 | self.context.progress_reporter.warn(
63 | f'Skip post ([red]no access to content[/red]): {post_dto.title}'
64 | )
65 | continue
66 |
67 | # For empty titles use post ID as a fallback (first 8 chars)
68 | if len(post_dto.title) == 0:
69 | post_dto.title = f'Not title (id_{post_dto.id[:8]})'
70 |
71 | post_dto.title = (
72 | sanitize_string(post_dto.title).replace('.', '').strip()
73 | )
74 |
75 | # date - TITLE (UUID_PART) for deduplication in case of same names with different posts
76 | full_post_title = f'{post_dto.created_at.date()} - {post_dto.title} ({post_dto.id[:8]})'
77 |
78 | single_post_use_case = DownloadSinglePostUseCase(
79 | destination=self.destination / full_post_title,
80 | post_dto=post_dto,
81 | download_context=self.context,
82 | )
83 |
84 | self.context.progress_reporter.update_task(
85 | page_task_id,
86 | advance=1,
87 | description=f'Processing page [bold]{current_page}[/bold]',
88 | )
89 |
90 | max_attempts = 5
91 | delay = 1.0
92 | for attempt in range(1, max_attempts + 1):
93 | try:
94 | await single_post_use_case.execute()
95 | break
96 | except ApplicationCancelledError:
97 | raise
98 | except ApplicationFailedDownloadError as e:
99 | if attempt == max_attempts:
100 | self.context.progress_reporter.error(
101 | f'Skip post after {attempt} failed attempts: {full_post_title} ({e.message})'
102 | )
103 | else:
104 | self.context.progress_reporter.warn(
105 | f'Attempt {attempt} failed for post: {full_post_title} ({e.message}), RESOURCE: ({e.resource})'
106 | )
107 | self.context.progress_reporter.warn(
108 | f'Retrying in {delay:.1f}s... ({e.message})'
109 | )
110 | await asyncio.sleep(delay)
111 | delay = min(delay * 1.5, 10.0)
112 |
113 | self.context.progress_reporter.complete_task(page_task_id)
114 | self.context.progress_reporter.success(
115 | f'--- Finished page {current_page} ---'
116 | )
117 |
--------------------------------------------------------------------------------
/.github/workflows/release-pr-validation.yaml:
--------------------------------------------------------------------------------
1 | # This workflow runs only for dev -> main PRs to ensure that:
2 | # - CHANGELOG updated
3 | # - pyproject.toml version updated
4 | # - Version is higher than the one on PyPI
5 | name: 🔍 Release PR Validation (version checks)
6 |
7 | on:
8 | pull_request:
9 | branches:
10 | - main
11 |
12 | env:
13 | PACKAGE_NAME: "boosty-downloader"
14 |
15 | jobs:
16 | # About Inter-step Communication:
17 | # Steps share data (versions) using GitHub Actions outputs mechanism:
18 | #
19 | # Creating output: echo "key=value" >> "$GITHUB_OUTPUT"
20 | # Using output: ${{ steps.STEP_ID.outputs.key }}
21 | #
22 | version-validation:
23 | name: 📋 Version Validation (Main Branch PRs)
24 | runs-on: ubuntu-latest
25 | # if: github.event_name == 'pull_request' && github.base_ref == 'main'
26 | steps:
27 | - uses: actions/checkout@v4
28 | with:
29 | fetch-depth: 0
30 | # ref: ${{ github.event.pull_request.head.sha }}
31 |
32 | - name: 🐍 Set up Python
33 | uses: actions/setup-python@v5
34 | with:
35 | python-version: "3.12"
36 |
37 | - name: 📦 Install Poetry if missing
38 | uses: snok/install-poetry@v1
39 | with:
40 | version: 'latest'
41 |
42 | - name: Get project versions (base and head)
43 | id: get_poetry_versions
44 | run: |
45 | HEAD_VERSION=$(poetry version --short)
46 | echo "head_version=$HEAD_VERSION" >> "$GITHUB_OUTPUT"
47 | echo "Current version: $HEAD_VERSION at $(git rev-parse --short HEAD)"
48 |
49 | git switch main
50 | BASE_VERSION=$(poetry version --short)
51 | echo "base_version=$BASE_VERSION" >> "$GITHUB_OUTPUT"
52 | echo "Base version: $BASE_VERSION at $(git rev-parse --short HEAD)"
53 |
54 | git switch - -d
55 |
56 |
57 | - name: ✅ Validate version bump in pyproject.toml
58 | run: |
59 | CURRENT_VERSION="${{ steps.get_poetry_versions.outputs.head_version }}"
60 | BASE_VERSION="${{ steps.get_poetry_versions.outputs.base_version }}"
61 |
62 | if [ "$CURRENT_VERSION" == "$BASE_VERSION" ]; then
63 | echo "❌ Version not updated! Please update version in pyproject.toml"
64 | echo "Current: $CURRENT_VERSION"
65 | echo "Base: $BASE_VERSION"
66 | exit 1
67 | fi
68 |
69 | if [ "$(printf '%s\n' "$BASE_VERSION" "$CURRENT_VERSION" | sort -rV | head -n 1)" != "$CURRENT_VERSION" ]; then
70 | echo "❌ Version should be higher than base version!"
71 | echo "Current: $CURRENT_VERSION"
72 | echo "Base: $BASE_VERSION"
73 | exit 1
74 | fi
75 |
76 | echo "✅ Version correctly updated: $BASE_VERSION → $CURRENT_VERSION"
77 |
78 | - name: 📝 Check for version in CHANGELOG.md
79 | run: |
80 | if [ ! -f CHANGELOG.md ]; then
81 | echo "❌ CHANGELOG.md not found! Please create it."
82 | exit 1
83 | fi
84 | VERSION="${{ steps.get_poetry_versions.outputs.head_version }}"
85 | if ! grep -q "$VERSION" CHANGELOG.md; then
86 | echo "at $(git rev-parse --short HEAD)"
87 | echo "❌ Version $VERSION not found in CHANGELOG.md"
88 | echo "Please add changelog entry for version $VERSION"
89 | exit 1
90 | fi
91 | echo "✅ Version $VERSION found in CHANGELOG.md"
92 |
93 | - name: 🩺 Check PyPi release version compatibility
94 | run: |
95 | echo "Checking package: $PACKAGE_NAME"
96 | echo "Current version: $CURRENT_VERSION"
97 |
98 | PACKAGE_NAME="${{ env.PACKAGE_NAME }}"
99 | CURRENT_VERSION="${{ steps.get_poetry_versions.outputs.head_version }}"
100 |
101 | response=$(curl -s "https://pypi.org/pypi/$PACKAGE_NAME/json" || echo "{}")
102 |
103 | pypi_version=$(echo "$response" | jq --raw-output "select(.releases != null) | .releases | keys_unsorted | last // empty")
104 |
105 | if [ -z "$pypi_version" ] || [ "$pypi_version" = "null" ]; then
106 | echo "Package not found on PyPI or no releases available."
107 | pypi_version="0.0.0"
108 | fi
109 |
110 | echo "Latest version on PyPI: $pypi_version"
111 | echo "pypi_version=$pypi_version" >> "$GITHUB_OUTPUT"
112 |
113 | # Compare versions using sort -rV
114 | if [ "$CURRENT_VERSION" = "$pypi_version" ]; then
115 | echo "❌ Current version equals PyPI version ($CURRENT_VERSION)"
116 | echo "is_newer=false" >> "$GITHUB_OUTPUT"
117 | exit 1
118 | elif [ "$(printf '%s\n' "$pypi_version" "$CURRENT_VERSION" | sort -rV | head -n 1)" = "$CURRENT_VERSION" ]; then
119 | echo "✅ Current version ($CURRENT_VERSION) is newer than PyPI version ($pypi_version)"
120 | echo "is_newer=true" >> "$GITHUB_OUTPUT"
121 | else
122 | echo "❌ Current version ($CURRENT_VERSION) is older than PyPI version ($pypi_version)"
123 | echo "is_newer=false" >> "$GITHUB_OUTPUT"
124 | exit 1
125 | fi
126 |
--------------------------------------------------------------------------------
/boosty_downloader/src/application/mappers/link_header_text.py:
--------------------------------------------------------------------------------
1 | """
2 | Mapper for converting textual Boosty API post data chunks to domain text object.
3 |
4 | If the API responses change, this mapper may need to be updated accordingly.
5 | """
6 |
7 | import json
8 |
9 | from boosty_downloader.src.domain.post_data_chunks import PostDataChunkText
10 | from boosty_downloader.src.infrastructure.boosty_api.models.post.post_data_types import (
11 | BoostyPostDataHeaderDTO,
12 | BoostyPostDataLinkDTO,
13 | BoostyPostDataTextDTO,
14 | )
15 |
16 |
17 | def _parse_header(style_definition: str) -> int:
18 | r"""
19 | Parse header level (h1/h2/h3...) from the style definition.
20 |
21 | Style definition usually comes as a 2nd field in the "content" field of PostDataText.
22 |
23 | ```
24 | "content": "[\"Hello, world!\", \"unstyled\", <---- [[0, 0, 13]]"
25 | ```
26 | """
27 | # These values were reverse engineered from Boosty API responses.
28 | header_possible_values = {
29 | 'unstyled': 0,
30 | 'header-one': 1,
31 | 'header-two': 2,
32 | 'header-three': 3,
33 | 'header-four': 4,
34 | 'header-five': 5,
35 | 'header-six': 6,
36 | }
37 |
38 | # by default (and in other cases) have no header
39 | return header_possible_values.get(style_definition, 0)
40 |
41 |
42 | def _create_style_bitmap(
43 | text_length: int, style_array: list[list[int]]
44 | ) -> list[set[int]]:
45 | """Create bitmap of styles for each character position."""
46 | bitmap: list[set[int]] = [set() for _ in range(text_length)]
47 |
48 | for style_desc in style_array:
49 | style_id, start_idx, end_idx = style_desc
50 | for i in range(start_idx, min(end_idx, text_length)):
51 | bitmap[i].add(style_id)
52 |
53 | return bitmap
54 |
55 |
56 | def _create_text_fragments(
57 | text: str, style_bitmap: list[set[int]], header_level: int
58 | ) -> list[PostDataChunkText.TextFragment]:
59 | """Create text fragments based on style bitmap."""
60 | if not text:
61 | return []
62 |
63 | fragments: list[PostDataChunkText.TextFragment] = []
64 | current_fragment_start = 0
65 | current_styles: set[int] = style_bitmap[0] if style_bitmap else set()
66 |
67 | for i in range(1, len(text)):
68 | if i >= len(style_bitmap) or style_bitmap[i] != current_styles:
69 | fragment_text = text[current_fragment_start:i]
70 | fragment = PostDataChunkText.TextFragment(fragment_text)
71 | fragment.header_level = header_level
72 | fragment.style = _convert_style_set_to_text_style(current_styles)
73 | fragments.append(fragment)
74 |
75 | current_fragment_start = i
76 | current_styles = style_bitmap[i] if i < len(style_bitmap) else set()
77 |
78 | # Add the last fragment
79 | fragment_text = text[current_fragment_start:]
80 | fragment = PostDataChunkText.TextFragment(fragment_text)
81 | fragment.header_level = header_level
82 | fragment.style = _convert_style_set_to_text_style(current_styles)
83 | fragments.append(fragment)
84 |
85 | return fragments
86 |
87 |
88 | def _convert_style_set_to_text_style(
89 | style_set: set[int],
90 | ) -> PostDataChunkText.TextFragment.TextStyle:
91 | """Convert set of style IDs to TextStyle object."""
92 | bold = 0
93 | italic = 2
94 | underline = 4
95 |
96 | text_style = PostDataChunkText.TextFragment.TextStyle()
97 | text_style.bold = bold in style_set
98 | text_style.italic = italic in style_set
99 | text_style.underline = underline in style_set
100 |
101 | return text_style
102 |
103 |
104 | def _parse_content_field(
105 | content: str, modificator: str = ''
106 | ) -> list[PostDataChunkText.TextFragment]:
107 | def _extract_content_field(content: str) -> tuple[str, str, list[list[int]]]:
108 | r"""
109 | Extract text, style info, and style array from the content field.
110 |
111 | Boosty API returns "content" as a JSON-encoded string like this:
112 | "[\"Hello, world!\", \"unstyled\", [[0, 0, 13]]"
113 |
114 | The first part is just a text string, the other two parts are style information:
115 | - you can read about them in the _parse_style_array and _parse_header functions above.
116 | """
117 | try:
118 | parsed = json.loads(content)
119 | text = parsed[0]
120 | style_info = parsed[1]
121 | style_array = parsed[2]
122 | except json.JSONDecodeError:
123 | return content, '', []
124 | else:
125 | return text, style_info, style_array
126 |
127 | text, style_info, styles_array = _extract_content_field(content)
128 |
129 | if modificator == 'BLOCK_END':
130 | text += '\n'
131 |
132 | header_level = _parse_header(style_info)
133 | style_bitmap = _create_style_bitmap(len(text), styles_array)
134 | return _create_text_fragments(text, style_bitmap, header_level)
135 |
136 |
137 | def to_domain_text_chunk(
138 | api_textual_dto: BoostyPostDataTextDTO
139 | | BoostyPostDataHeaderDTO
140 | | BoostyPostDataLinkDTO,
141 | ) -> list[PostDataChunkText.TextFragment]:
142 | """
143 | Convert API textual data chunks to domain text fragments.
144 |
145 | It uses the PostDataText, PostDataHeader, or PostDataLink DTOs
146 | to extract the content and convert it to a list of domain text fragments.
147 | """
148 | modificator = getattr(api_textual_dto, 'modificator', '')
149 | text_fragments = _parse_content_field(api_textual_dto.content, modificator)
150 |
151 | # Attach link information to the text fragments if any is present
152 | if isinstance(api_textual_dto, BoostyPostDataLinkDTO):
153 | for fragment in text_fragments:
154 | fragment.link_url = api_textual_dto.url
155 |
156 | return text_fragments
157 |
--------------------------------------------------------------------------------
/boosty_downloader/src/infrastructure/html_reporter/html_reporter.py:
--------------------------------------------------------------------------------
1 | """HTML Reporter for generating HTML documents"""
2 |
3 | from __future__ import annotations
4 |
5 | from dataclasses import dataclass
6 | from typing import TYPE_CHECKING, TypedDict
7 |
8 | from jinja2 import Template
9 |
10 | if TYPE_CHECKING:
11 | from pathlib import Path
12 |
13 |
14 | @dataclass
15 | class NormalText:
16 | """Textual element, which can be added to the html document"""
17 |
18 | text: str
19 |
20 |
21 | @dataclass
22 | class HyperlinkText:
23 | """Hyperlink element, which can be added to the html document"""
24 |
25 | text: str
26 | url: str
27 |
28 |
29 | class TextElement(TypedDict):
30 | """Text element, which can be added to the html document"""
31 |
32 | type: str
33 | content: str
34 |
35 |
36 | class ImageElement(TypedDict):
37 | """Image element, which can be added to the html document"""
38 |
39 | type: str
40 | content: str
41 | width: int
42 |
43 |
44 | class LinkElement(TypedDict):
45 | """Link element, which can be added to the html document"""
46 |
47 | type: str
48 | content: str
49 | url: str
50 |
51 |
52 | class HTMLReport:
53 | """
54 | Representation of the document, which can be saved as an HTML file.
55 |
56 | You can add text/links/images to the document, they will be added one after another.
57 | """
58 |
59 | def __init__(self, filename: Path) -> None:
60 | self.filename = filename
61 | self.elements: list[TextElement | ImageElement | LinkElement] = []
62 |
63 | def _render_template(self) -> str:
64 | """Render the HTML document using Jinja2"""
65 | template = """
66 |
67 |
68 |
118 | {% for element in elements %}
119 | {% if element.type == 'text' %}
120 |
130 |
131 |
132 | """
133 | jinja_template = Template(template)
134 | return jinja_template.render(elements=self.elements)
135 |
136 | def new_paragraph(self) -> None:
137 | """Add an empty line between elements"""
138 | # Append a new paragraph using a proper TextElement type
139 | self.elements.append(TextElement(type='text', content='{{ element.content }}
121 | {% elif element.type == 'image' %} 122 |
123 |  124 |
124 |
125 | {% elif element.type == 'link' %}
126 | {{ element.content }}
127 | {% endif %}
128 | {% endfor %}
129 | ')) 140 | 141 | def add_text(self, text: NormalText) -> None: 142 | """Add a text to the report right after the last added element""" 143 | # Append text content using TextElement 144 | self.elements.append(TextElement(type='text', content=text.text)) 145 | 146 | def add_image(self, image_path: str, width: int = 600) -> None: 147 | """ 148 | Add an image to the report right after the last added element 149 | 150 | - width 600 is usually enough for most HTML pages 151 | """ 152 | # Append image content using ImageElement 153 | self.elements.append( 154 | ImageElement(type='image', content=image_path, width=width), 155 | ) 156 | 157 | def add_link(self, text: NormalText, url: str) -> None: 158 | """Add a link to the report right after the last added element""" 159 | # Append link content using LinkElement 160 | self.elements.append(LinkElement(type='link', content=text.text, url=url)) 161 | 162 | def save(self) -> None: 163 | """Save the whole document to the file""" 164 | html_content = self._render_template() 165 | with self.filename.open('w', encoding='utf-8') as file: 166 | file.write(html_content) 167 | -------------------------------------------------------------------------------- /boosty_downloader/src/infrastructure/file_downloader.py: -------------------------------------------------------------------------------- 1 | """Module to download files with reporting process mechanisms""" 2 | 3 | from __future__ import annotations 4 | 5 | import http 6 | import mimetypes 7 | from asyncio import CancelledError 8 | from dataclasses import dataclass 9 | from typing import TYPE_CHECKING 10 | 11 | import aiofiles 12 | from aiohttp import ClientConnectionError 13 | 14 | from boosty_downloader.src.infrastructure.path_sanitizer import ( 15 | sanitize_string, 16 | ) 17 | 18 | if TYPE_CHECKING: 19 | from collections.abc import Callable 20 | from pathlib import Path 21 | 22 | from aiohttp_retry import RetryClient 23 | 24 | 25 | @dataclass 26 | class DownloadingStatus: 27 | """ 28 | Model for status of the download. 29 | 30 | Can be used in status update callbacks. 31 | """ 32 | 33 | name: str 34 | total_bytes: int | None 35 | total_downloaded_bytes: int 36 | downloaded_bytes: int = 0 37 | 38 | 39 | @dataclass 40 | class DownloadFileConfig: 41 | """General configuration for the file download""" 42 | 43 | session: RetryClient 44 | url: str 45 | 46 | filename: str 47 | destination: Path 48 | on_status_update: Callable[[DownloadingStatus], None] = lambda _: None 49 | 50 | guess_extension: bool = True 51 | chunk_size_bytes: int = 524288 # 512 KiB 52 | 53 | 54 | class DownloadError(Exception): 55 | """Exception raised when the download failed for any reason""" 56 | 57 | message: str 58 | file: Path | None 59 | resource_url: str 60 | 61 | def __init__(self, message: str, file: Path | None, resource_url: str) -> None: 62 | super().__init__(message) 63 | self.file = file 64 | self.resource_url = resource_url 65 | 66 | 67 | class DownloadCancelledError(DownloadError): 68 | """Exception raised when the download was cancelled by the user""" 69 | 70 | def __init__(self, resource_url: str, file: Path | None = None) -> None: 71 | super().__init__('Download cancelled by user', file, resource_url=resource_url) 72 | 73 | 74 | class DownloadTimeoutError(DownloadError): 75 | """Exception raised when the download timed out""" 76 | 77 | def __init__(self, resource_url: str, file: Path | None = None) -> None: 78 | super().__init__( 79 | 'Download timed out for the destination server', 80 | file, 81 | resource_url=resource_url, 82 | ) 83 | 84 | 85 | class DownloadConnectionError(DownloadError): 86 | """Exception raised when there was a connection error during the download""" 87 | 88 | def __init__(self, resource_url: str, file: Path | None = None) -> None: 89 | super().__init__( 90 | 'Connection error during the download', file, resource_url=resource_url 91 | ) 92 | 93 | 94 | class DownloadIOFailureError(DownloadError): 95 | """Exception raised when there was an IOError during the download""" 96 | 97 | def __init__(self, resource_url: str, file: Path | None = None) -> None: 98 | super().__init__('Failed during I/O operation', file, resource_url=resource_url) 99 | 100 | 101 | class DownloadUnexpectedStatusError(DownloadError): 102 | """Exception raised when the server returned an unexpected status code""" 103 | 104 | status_code: int 105 | response_message: str 106 | 107 | def __init__(self, status: int, response_message: str, resource_url: str) -> None: 108 | super().__init__( 109 | f'Unexpected status code: {status}', file=None, resource_url=resource_url 110 | ) 111 | self.status_code = status 112 | self.response_message = response_message 113 | 114 | 115 | async def download_file( 116 | dl_config: DownloadFileConfig, 117 | ) -> Path: 118 | """Download files and report the downloading process via callback""" 119 | async with dl_config.session.get(dl_config.url) as response: 120 | if response.status != http.HTTPStatus.OK: 121 | raise DownloadUnexpectedStatusError( 122 | resource_url=dl_config.url, 123 | status=response.status, 124 | response_message=response.reason or 'No reason provided', 125 | ) 126 | 127 | filename = sanitize_string(dl_config.filename) 128 | file_path = dl_config.destination / filename 129 | 130 | content_type = response.content_type 131 | if content_type and dl_config.guess_extension: 132 | ext = mimetypes.guess_extension(content_type) 133 | if ext is not None: 134 | file_path = file_path.with_suffix(ext) 135 | 136 | total_downloaded = 0 137 | 138 | async with aiofiles.open(file_path, mode='wb') as file: 139 | total_size = response.content_length 140 | 141 | try: 142 | async for chunk in response.content.iter_chunked( 143 | dl_config.chunk_size_bytes 144 | ): 145 | total_downloaded += len(chunk) 146 | dl_config.on_status_update( 147 | DownloadingStatus( 148 | name=filename, 149 | total_bytes=total_size, 150 | total_downloaded_bytes=total_downloaded, 151 | downloaded_bytes=len(chunk), 152 | ), 153 | ) 154 | await file.write(chunk) 155 | except (CancelledError, KeyboardInterrupt) as e: 156 | raise DownloadCancelledError( 157 | file=file_path, resource_url=dl_config.url 158 | ) from e 159 | except DownloadTimeoutError as e: 160 | raise DownloadTimeoutError( 161 | file=file_path, resource_url=dl_config.url 162 | ) from e 163 | except (ConnectionResetError, BrokenPipeError, ClientConnectionError) as e: 164 | raise DownloadConnectionError( 165 | file=file_path, resource_url=dl_config.url 166 | ) from e 167 | except OSError as e: 168 | raise DownloadIOFailureError( 169 | file=file_path, resource_url=dl_config.url 170 | ) from e 171 | 172 | return file_path 173 | -------------------------------------------------------------------------------- /test/integration/fixtures.py: -------------------------------------------------------------------------------- 1 | """Shared fixtures for Boosty API integration tests.""" 2 | 3 | import logging 4 | from collections.abc import AsyncGenerator 5 | 6 | import pytest 7 | import pytest_asyncio 8 | from aiohttp import ClientSession, CookieJar 9 | from aiohttp.typedefs import LooseHeaders 10 | from aiohttp_retry import ExponentialRetry, RetryClient 11 | from pydantic import ValidationError 12 | 13 | from boosty_downloader.src.infrastructure.boosty_api.core.client import BoostyAPIClient 14 | from boosty_downloader.src.infrastructure.boosty_api.utils.auth_parsers import ( 15 | parse_session_cookie, 16 | ) 17 | from integration.configuration import IntegrationTestConfig 18 | 19 | logger = logging.getLogger(__name__) 20 | 21 | # ------------------------------------------------------------------------------ 22 | # Utilities for further fixtures 23 | 24 | 25 | @pytest.fixture(scope='session') 26 | def integration_config() -> IntegrationTestConfig: 27 | """ 28 | Provides configuration for integration tests. 29 | 30 | It loads the configuration from the environment or a configuration file. 31 | If the configuration is invalid, it logs the errors and skips the tests. 32 | """ 33 | try: 34 | return IntegrationTestConfig() # pyright: ignore[reportCallIssue] : will be loaded automatically by pydantic_settings 35 | 36 | except ValidationError as e: 37 | logger.exception('❌ Failed to load integration test config:') 38 | for err in e.errors(): 39 | loc = '.'.join(map(str, err['loc'])) 40 | msg = err['msg'] 41 | logger.exception(f' - {loc}: {msg}') 42 | pytest.skip('Integration tests require valid configuration') 43 | 44 | 45 | @pytest.fixture 46 | def boosty_headers(integration_config: IntegrationTestConfig) -> LooseHeaders: 47 | """Returns headers with authorization token for Boosty API requests.""" 48 | return { 49 | 'Authorization': integration_config.boosty_auth_token, 50 | 'Content-Type': 'application/json', 51 | } 52 | 53 | 54 | @pytest_asyncio.fixture 55 | async def boosty_cookies_jar_async( 56 | integration_config: IntegrationTestConfig, 57 | ) -> CookieJar: 58 | # This avoids 'no running event loop' error by ensuring the jar is created in an async context 59 | return parse_session_cookie(integration_config.boosty_cookies) 60 | 61 | 62 | # ------------------------------------------------------------------------------ 63 | # Different session setups 64 | 65 | 66 | @pytest_asyncio.fixture 67 | async def authorized_http_session( 68 | boosty_headers: LooseHeaders, 69 | boosty_cookies_jar_async: CookieJar, 70 | ) -> AsyncGenerator[ClientSession, None]: 71 | """Creates an HTTP session for making requests.""" 72 | session = ClientSession( 73 | headers=boosty_headers, 74 | cookie_jar=boosty_cookies_jar_async, 75 | ) 76 | yield session 77 | await session.close() 78 | 79 | 80 | @pytest_asyncio.fixture 81 | async def unauthorized_http_session() -> AsyncGenerator[ClientSession, None]: 82 | """Creates an HTTP session without authorization headers.""" 83 | session = ClientSession() 84 | yield session 85 | await session.close() 86 | 87 | 88 | @pytest_asyncio.fixture 89 | async def invalid_auth_http_session() -> AsyncGenerator[ClientSession, None]: 90 | session = ClientSession( 91 | headers={ 92 | 'Authorization': 'Bearer ' 93 | + 'a' * 64, # Looks valid (64 hex chars), but not actually valid 94 | }, 95 | ) 96 | yield session 97 | await session.close() 98 | 99 | 100 | # ------------------------------------------------------------------------------ 101 | # Clients for Boosty API 102 | 103 | 104 | @pytest_asyncio.fixture 105 | async def authorized_retry_client( 106 | authorized_http_session: ClientSession, 107 | ) -> AsyncGenerator[RetryClient, None]: 108 | """Creates a retry client for handling transient failures.""" 109 | retry_options = ExponentialRetry(attempts=3, start_timeout=1.0) 110 | client = RetryClient( 111 | client_session=authorized_http_session, 112 | retry_options=retry_options, 113 | ) 114 | yield client 115 | await client.close() 116 | 117 | 118 | @pytest_asyncio.fixture 119 | async def unauthorized_retry_client( 120 | unauthorized_http_session: ClientSession, 121 | ) -> AsyncGenerator[RetryClient, None]: 122 | """Creates a retry client without authentication for testing unauthorized scenarios.""" 123 | retry_options = ExponentialRetry(attempts=3, start_timeout=1.0) 124 | client = RetryClient( 125 | client_session=unauthorized_http_session, 126 | retry_options=retry_options, 127 | ) 128 | yield client 129 | await client.close() 130 | 131 | 132 | @pytest_asyncio.fixture 133 | async def invalid_auth_retry_client( 134 | invalid_auth_http_session: ClientSession, 135 | ) -> AsyncGenerator[RetryClient, None]: 136 | """Creates a retry client with invalid authentication for testing error handling.""" 137 | retry_options = ExponentialRetry(attempts=3, start_timeout=1.0) 138 | client = RetryClient( 139 | client_session=invalid_auth_http_session, 140 | retry_options=retry_options, 141 | ) 142 | yield client 143 | await client.close() 144 | 145 | 146 | # ------------------------------------------------------------------------------ 147 | # Clients for Boosty API 148 | 149 | 150 | @pytest_asyncio.fixture 151 | async def authorized_boosty_client( 152 | authorized_retry_client: RetryClient, 153 | ) -> BoostyAPIClient: 154 | """Creates a Boosty API client configured with authentication.""" 155 | return BoostyAPIClient(session=authorized_retry_client) 156 | 157 | 158 | @pytest_asyncio.fixture 159 | async def unauthorized_boosty_client( 160 | unauthorized_retry_client: RetryClient, 161 | ) -> BoostyAPIClient: 162 | """Creates a Boosty API client without authentication for testing unauthorized scenarios.""" 163 | return BoostyAPIClient(session=unauthorized_retry_client, request_delay_seconds=1) 164 | 165 | 166 | @pytest_asyncio.fixture 167 | async def invalid_auth_boosty_client( 168 | invalid_auth_retry_client: RetryClient, 169 | ) -> BoostyAPIClient: 170 | """Creates a Boosty API client with invalid authentication for testing error handling.""" 171 | return BoostyAPIClient(session=invalid_auth_retry_client, request_delay_seconds=1) 172 | -------------------------------------------------------------------------------- /test/unit/html_generator/html_templates_test.py: -------------------------------------------------------------------------------- 1 | from pathlib import Path 2 | 3 | from boosty_downloader.src.infrastructure.html_generator.models import ( 4 | HtmlGenChunk, 5 | HtmlGenImage, 6 | HtmlGenList, 7 | HtmlGenText, 8 | HtmlGenVideo, 9 | HtmlListItem, 10 | HtmlTextFragment, 11 | HtmlTextStyle, 12 | ) 13 | from boosty_downloader.src.infrastructure.html_generator.renderer import ( 14 | render_html, 15 | render_html_to_file, 16 | ) 17 | 18 | 19 | def test_html_generator_templates(): 20 | chunks: list[HtmlGenChunk] = [ 21 | HtmlGenText( 22 | text_fragments=[ 23 | HtmlTextFragment(text='Welcome to my Boosty!', header_level=1), 24 | HtmlTextFragment( 25 | text='This post includes various elements: text, media, and lists.', 26 | ), 27 | HtmlTextFragment(text='