├── .gitattributes
├── ComoSVC.py
├── Content
└── put_the_checkpoint_here
├── Features.py
├── LICENSE
├── README.md
├── Readme_CN.md
├── Vocoder.py
├── como.py
├── configs
└── the_config_files
├── configs_template
└── diffusion_template.yaml
├── data_loaders.py
├── dataset
└── the_prprocessed_data
├── dataset_slice
└── if_you_need_to_slice
├── filelists
└── put_the_txt_here
├── infer_tool.py
├── inference_main.py
├── logs
└── the_log_files
├── mel_processing.py
├── meldataset.py
├── pitch_extractor.py
├── preparation_slice.py
├── preprocessing1_resample.py
├── preprocessing2_flist.py
├── preprocessing3_feature.py
├── requirements.txt
├── saver.py
├── slicer.py
├── solver.py
├── train.py
├── utils.py
├── vocoder
├── __init__.py
└── m4gan
│ ├── __init__.py
│ ├── hifigan.py
│ └── parallel_wavegan.py
└── wavenet.py
/.gitattributes:
--------------------------------------------------------------------------------
1 | # Auto detect text files and perform LF normalization
2 | * text=auto
3 |
--------------------------------------------------------------------------------
/ComoSVC.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch
3 | import torch.nn as nn
4 | import yaml
5 | from Vocoder import Vocoder
6 | from como import Como
7 |
8 |
9 | class DotDict(dict):
10 | def __getattr__(*args):
11 | val = dict.get(*args)
12 | return DotDict(val) if type(val) is dict else val
13 |
14 | __setattr__ = dict.__setitem__
15 | __delattr__ = dict.__delitem__
16 |
17 |
18 | def load_model_vocoder(
19 | model_path,
20 | device='cpu',
21 | config_path = None,
22 | total_steps=1,
23 | teacher=False
24 | ):
25 | if config_path is None:
26 | config_file = os.path.join(os.path.split(model_path)[0], 'config.yaml')
27 | else:
28 | config_file = config_path
29 |
30 | with open(config_file, "r") as config:
31 | args = yaml.safe_load(config)
32 | args = DotDict(args)
33 |
34 | # load vocoder
35 | vocoder = Vocoder(args.vocoder.type, args.vocoder.ckpt, device=device)
36 |
37 | # load model
38 | model = ComoSVC(
39 | args.data.encoder_out_channels,
40 | args.model.n_spk,
41 | args.model.use_pitch_aug,
42 | vocoder.dimension,
43 | args.model.n_layers,
44 | args.model.n_chans,
45 | args.model.n_hidden,
46 | total_steps,
47 | teacher
48 | )
49 |
50 | print(' [Loading] ' + model_path)
51 | ckpt = torch.load(model_path, map_location=torch.device(device))
52 | model.to(device)
53 | model.load_state_dict(ckpt['model'],strict=False)
54 | model.eval()
55 | return model, vocoder, args
56 |
57 |
58 | class ComoSVC(nn.Module):
59 | def __init__(
60 | self,
61 | input_channel,
62 | n_spk,
63 | use_pitch_aug=True,
64 | out_dims=128, # define in como
65 | n_layers=20,
66 | n_chans=384,
67 | n_hidden=100,
68 | total_steps=1,
69 | teacher=True
70 | ):
71 | super().__init__()
72 |
73 | self.unit_embed = nn.Linear(input_channel, n_hidden)
74 | self.f0_embed = nn.Linear(1, n_hidden)
75 | self.volume_embed = nn.Linear(1, n_hidden)
76 | self.teacher=teacher
77 |
78 | if use_pitch_aug:
79 | self.aug_shift_embed = nn.Linear(1, n_hidden, bias=False)
80 | else:
81 | self.aug_shift_embed = None
82 | self.n_spk = n_spk
83 | if n_spk is not None and n_spk > 1:
84 | self.spk_embed = nn.Embedding(n_spk, n_hidden)
85 | self.n_hidden = n_hidden
86 | self.decoder = Como(out_dims, n_layers, n_chans, n_hidden, total_steps, teacher)
87 | self.input_channel = input_channel
88 |
89 | def forward(self, units, f0, volume, spk_id = None, aug_shift = None,
90 | gt_spec=None, infer=True):
91 |
92 | '''
93 | input:
94 | B x n_frames x n_unit
95 | return:
96 | dict of B x n_frames x feat
97 | '''
98 |
99 | x = self.unit_embed(units) + self.f0_embed((1+ f0 / 700).log()) + self.volume_embed(volume)
100 |
101 | if self.n_spk is not None and self.n_spk > 1:
102 | if spk_id.shape[1] > 1:
103 | g = spk_id.reshape((spk_id.shape[0], spk_id.shape[1], 1, 1, 1)) # [N, S, B, 1, 1]
104 | g = g * self.speaker_map # [N, S, B, 1, H]
105 | g = torch.sum(g, dim=1) # [N, 1, B, 1, H]
106 | g = g.transpose(0, -1).transpose(0, -2).squeeze(0) # [B, H, N]
107 | x = x + g
108 | else:
109 | x = x + self.spk_embed(spk_id)
110 |
111 | if self.aug_shift_embed is not None and aug_shift is not None:
112 | x = x + self.aug_shift_embed(aug_shift / 5)
113 |
114 | if not infer:
115 | output = self.decoder(gt_spec,x,infer=False)
116 | else:
117 | output = self.decoder(gt_spec,x,infer=True)
118 |
119 | return output
120 |
121 |
--------------------------------------------------------------------------------
/Content/put_the_checkpoint_here:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Grace9994/CoMoSVC/2ea8e644e2c5b3a8afc0762e870b9daacf3b5be5/Content/put_the_checkpoint_here
--------------------------------------------------------------------------------
/Features.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import pyworld
4 | from fairseq import checkpoint_utils
5 |
6 |
7 | class SpeechEncoder(object):
8 | def __init__(self, vec_path="Content/checkpoint_best_legacy_500.pt", device=None):
9 | self.model = None # This is Model
10 | self.hidden_dim = 768
11 | pass
12 |
13 |
14 | def encoder(self, wav):
15 | """
16 | input: wav:[signal_length]
17 | output: embedding:[batchsize,hidden_dim,wav_frame]
18 | """
19 | pass
20 |
21 |
22 |
23 | class ContentVec768L12(SpeechEncoder):
24 | def __init__(self, vec_path="Content/checkpoint_best_legacy_500.pt", device=None):
25 | super().__init__()
26 | print("load model(s) from {}".format(vec_path))
27 | self.hidden_dim = 768
28 | models, saved_cfg, task = checkpoint_utils.load_model_ensemble_and_task(
29 | [vec_path],
30 | suffix="",
31 | )
32 | if device is None:
33 | self.dev = torch.device("cuda" if torch.cuda.is_available() else "cpu")
34 | else:
35 | self.dev = torch.device(device)
36 | self.model = models[0].to(self.dev)
37 | self.model.eval()
38 |
39 | def encoder(self, wav):
40 | feats = wav
41 | if feats.dim() == 2: # double channels
42 | feats = feats.mean(-1)
43 | assert feats.dim() == 1, feats.dim()
44 | feats = feats.view(1, -1)
45 | padding_mask = torch.BoolTensor(feats.shape).fill_(False)
46 | inputs = {
47 | "source": feats.to(wav.device),
48 | "padding_mask": padding_mask.to(wav.device),
49 | "output_layer": 12, # layer 12
50 | }
51 | with torch.no_grad():
52 | logits = self.model.extract_features(**inputs)
53 | return logits[0].transpose(1, 2)
54 |
55 |
56 |
57 | class F0Predictor(object):
58 | def compute_f0(self,wav,p_len):
59 | '''
60 | input: wav:[signal_length]
61 | p_len:int
62 | output: f0:[signal_length//hop_length]
63 | '''
64 | pass
65 |
66 | def compute_f0_uv(self,wav,p_len):
67 | '''
68 | input: wav:[signal_length]
69 | p_len:int
70 | output: f0:[signal_length//hop_length],uv:[signal_length//hop_length]
71 | '''
72 | pass
73 |
74 |
75 | class DioF0Predictor(F0Predictor):
76 | def __init__(self,hop_length=512,f0_min=50,f0_max=1100,sampling_rate=44100):
77 | self.hop_length = hop_length
78 | self.f0_min = f0_min
79 | self.f0_max = f0_max
80 | self.sampling_rate = sampling_rate
81 | self.name = "dio"
82 |
83 | def interpolate_f0(self,f0):
84 | '''
85 | 对F0进行插值处理
86 | '''
87 | vuv_vector = np.zeros_like(f0, dtype=np.float32)
88 | vuv_vector[f0 > 0.0] = 1.0
89 | vuv_vector[f0 <= 0.0] = 0.0
90 |
91 | nzindex = np.nonzero(f0)[0]
92 | data = f0[nzindex]
93 | nzindex = nzindex.astype(np.float32)
94 | time_org = self.hop_length / self.sampling_rate * nzindex
95 | time_frame = np.arange(f0.shape[0]) * self.hop_length / self.sampling_rate
96 |
97 | if data.shape[0] <= 0:
98 | return np.zeros(f0.shape[0], dtype=np.float32),vuv_vector
99 |
100 | if data.shape[0] == 1:
101 | return np.ones(f0.shape[0], dtype=np.float32) * f0[0],vuv_vector
102 |
103 | f0 = np.interp(time_frame, time_org, data, left=data[0], right=data[-1])
104 |
105 | return f0,vuv_vector
106 |
107 | def resize_f0(self,x, target_len):
108 | source = np.array(x)
109 | source[source<0.001] = np.nan
110 | target = np.interp(np.arange(0, len(source)*target_len, len(source))/ target_len, np.arange(0, len(source)), source)
111 | res = np.nan_to_num(target)
112 | return res
113 |
114 | def compute_f0(self,wav,p_len=None):
115 | if p_len is None:
116 | p_len = wav.shape[0]//self.hop_length
117 | f0, t = pyworld.dio(
118 | wav.astype(np.double),
119 | fs=self.sampling_rate,
120 | f0_floor=self.f0_min,
121 | f0_ceil=self.f0_max,
122 | frame_period=1000 * self.hop_length / self.sampling_rate,
123 | )
124 | f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.sampling_rate)
125 | for index, pitch in enumerate(f0):
126 | f0[index] = round(pitch, 1)
127 | return self.interpolate_f0(self.resize_f0(f0, p_len))[0]
128 |
129 | def compute_f0_uv(self,wav,p_len=None):
130 | if p_len is None:
131 | p_len = wav.shape[0]//self.hop_length
132 | f0, t = pyworld.dio(
133 | wav.astype(np.double),
134 | fs=self.sampling_rate,
135 | f0_floor=self.f0_min,
136 | f0_ceil=self.f0_max,
137 | frame_period=1000 * self.hop_length / self.sampling_rate,
138 | )
139 | f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.sampling_rate)
140 | for index, pitch in enumerate(f0):
141 | f0[index] = round(pitch, 1)
142 | return self.interpolate_f0(self.resize_f0(f0, p_len))
143 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 Yiwen LU
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
CoMoSVC: Consistency Model Based Singing Voice Conversion
3 |
4 | [中文文档](./Readme_CN.md)
5 |
6 |
7 | A consistency model based Singing Voice Conversion system is composed, which is inspired by [CoMoSpeech](https://github.com/zhenye234/CoMoSpeech): One-Step Speech and Singing Voice Synthesis via Consistency Model.
8 |
9 | This is an implemention of the paper [CoMoSVC](https://arxiv.org/pdf/2401.01792.pdf).
10 | ## Improvements
11 | The subjective evaluations are illustrated through the table below.
12 | 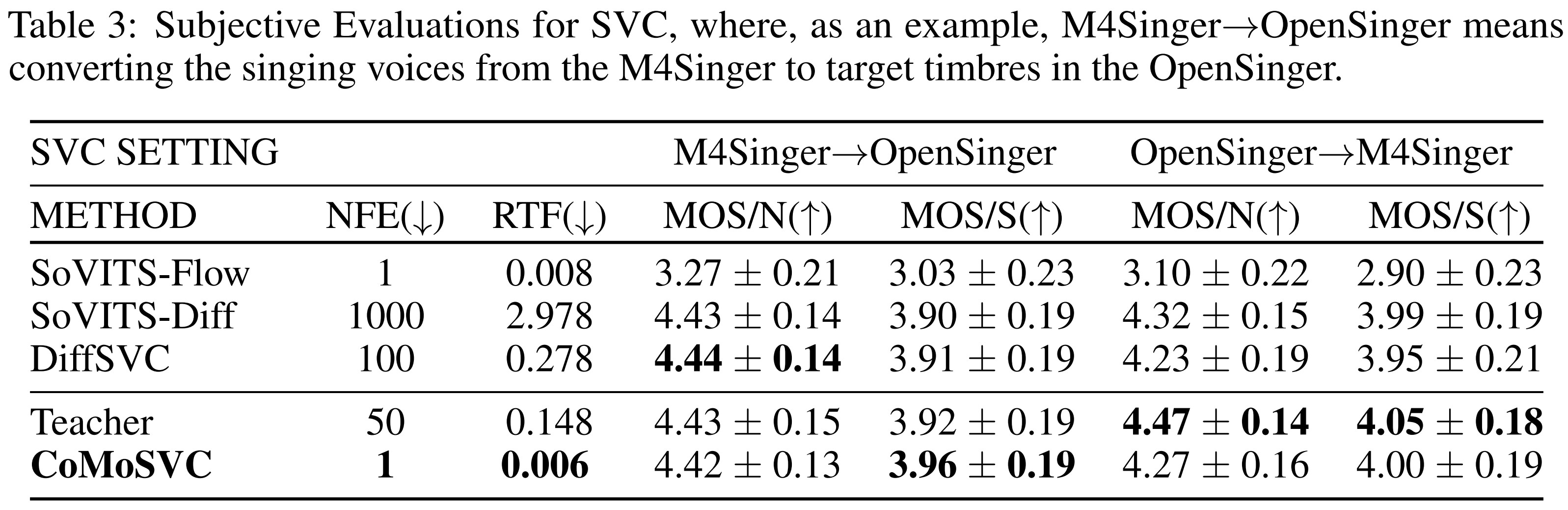 13 |
14 | ## Environment
15 | We have tested the code and it runs successfully on Python 3.8, so you can set up your Conda environment using the following command:
16 |
17 | ```shell
18 | conda create -n Your_Conda_Environment_Name python=3.8
19 | ```
20 | Then after activating your conda environment, you can install the required packages under it by:
21 |
22 | ```shell
23 | pip install -r requirements.txt
24 | ```
25 |
26 | ## Download the Checkpoints
27 | ### 1. m4singer_hifigan
28 |
29 | You should first download [m4singer_hifigan](https://drive.google.com/file/d/10LD3sq_zmAibl379yTW5M-LXy2l_xk6h/view) and then unzip the zip file by
30 | ```shell
31 | unzip m4singer_hifigan.zip
32 | ```
33 | The checkpoints of the vocoder will be in the `m4singer_hifigan` directory
34 |
35 | ### 2. ContentVec
36 | You should download the checkpoint [ContentVec](https://ibm.box.com/s/z1wgl1stco8ffooyatzdwsqn2psd9lrr) and the put it in the `Content` directory to extract the content feature.
37 |
38 | ### 3. m4singer_pe
39 | You should download the pitch_extractor checkpoint of the [m4singer_pe](https://drive.google.com/file/d/19QtXNeqUjY3AjvVycEt3G83lXn2HwbaJ/view) and then unzip the zip file by
40 |
41 | ```shell
42 | unzip m4singer_pe.zip
43 | ```
44 |
45 | ## Dataset Preparation
46 |
47 | You should first create the folders by
48 |
49 | ```shell
50 | mkdir dataset_raw
51 | mkdir dataset
52 | ```
53 | You can refer to different preparation methods based on your needs.
54 |
55 | Preparation With Slicing can help you remove the silent parts and slice the audio for stable training.
56 |
57 |
58 | ### 0. Preparation With Slicing
59 |
60 | Please place your original dataset in the `dataset_slice` directory.
61 |
62 | The original audios can be in any waveformat which should be specified in the command line. You can designate the length of slices you want, the unit of slice_size is milliseconds. The default wavformat and slice_size is mp3 and 10000 respectively.
63 |
64 | ```shell
65 | python preparation_slice.py -w your_wavformat -s slice_size
66 | ```
67 |
68 | ### 1. Preparation Without Slicing
69 |
70 | You can just place the dataset in the `dataset_raw` directory with the following file structure:
71 |
72 | ```
73 | dataset_raw
74 | ├───speaker0
75 | │ ├───xxx1-xxx1.wav
76 | │ ├───...
77 | │ └───Lxx-0xx8.wav
78 | └───speaker1
79 | ├───xx2-0xxx2.wav
80 | ├───...
81 | └───xxx7-xxx007.wav
82 | ```
83 |
84 |
85 | ## Preprocessing
86 |
87 | ### 1. Resample to 24000Hz and mono
88 |
89 | ```shell
90 | python preprocessing1_resample.py -n num_process
91 | ```
92 | num_process is the number of processes, the default num_process is 5.
93 |
94 | ### 2. Split the Training and Validation Datasets, and Generate Configuration Files.
95 |
96 | ```shell
97 | python preprocessing2_flist.py
98 | ```
99 |
100 |
101 | ### 3. Generate Features
102 |
103 | ```shell
104 | python preprocessing3_feature.py -c your_config_file -n num_processes
105 | ```
106 |
107 |
108 | ## Training
109 |
110 | ### 1. Train the Teacher Model
111 |
112 | ```shell
113 | python train.py
114 | ```
115 | The checkpoints will be saved in the `logs/teacher` directory
116 |
117 | ### 2. Train the Consistency Model
118 |
119 | If you want to adjust the config file, you can duplicate a new config file and modify some parameters.
120 |
121 |
122 | ```shell
123 | python train.py -t -c Your_new_configfile_path -p The_teacher_model_checkpoint_path
124 | ```
125 |
126 | ## Inference
127 | You should put the audios you want to convert under the `raw` directory firstly.
128 |
129 | ### Inference by the Teacher Model
130 |
131 | ```shell
132 | python inference_main.py -ts 50 -tm "logs/teacher/model_800000.pt" -tc "logs/teacher/config.yaml" -n "src.wav" -k 0 -s "target_singer"
133 | ```
134 | -ts refers to the total number of iterative steps during inference for the teacher model
135 |
136 | -tm refers to the teacher_model_path
137 |
138 | -tc refers to the teacher_config_path
139 |
140 | -n refers to the source audio
141 |
142 | -k refers to the pitch shift, it can be positive and negative (semitone) values
143 |
144 | -s refers to the target singer
145 |
146 | ### Inference by the Consistency Model
147 |
148 | ```shell
149 | python inference_main.py -ts 1 -cm "logs/como/model_800000.pt" -cc "logs/como/config.yaml" -n "src.wav" -k 0 -s "target_singer" -t
150 | ```
151 | -ts refers to the total number of iterative steps during inference for the student model
152 |
153 | -cm refers to the como_model_path
154 |
155 | -cc refers to the como_config_path
156 |
157 | -t means it is not the teacher model and you don't need to specify anything after it
158 |
--------------------------------------------------------------------------------
/Readme_CN.md:
--------------------------------------------------------------------------------
1 |
13 |
14 | ## Environment
15 | We have tested the code and it runs successfully on Python 3.8, so you can set up your Conda environment using the following command:
16 |
17 | ```shell
18 | conda create -n Your_Conda_Environment_Name python=3.8
19 | ```
20 | Then after activating your conda environment, you can install the required packages under it by:
21 |
22 | ```shell
23 | pip install -r requirements.txt
24 | ```
25 |
26 | ## Download the Checkpoints
27 | ### 1. m4singer_hifigan
28 |
29 | You should first download [m4singer_hifigan](https://drive.google.com/file/d/10LD3sq_zmAibl379yTW5M-LXy2l_xk6h/view) and then unzip the zip file by
30 | ```shell
31 | unzip m4singer_hifigan.zip
32 | ```
33 | The checkpoints of the vocoder will be in the `m4singer_hifigan` directory
34 |
35 | ### 2. ContentVec
36 | You should download the checkpoint [ContentVec](https://ibm.box.com/s/z1wgl1stco8ffooyatzdwsqn2psd9lrr) and the put it in the `Content` directory to extract the content feature.
37 |
38 | ### 3. m4singer_pe
39 | You should download the pitch_extractor checkpoint of the [m4singer_pe](https://drive.google.com/file/d/19QtXNeqUjY3AjvVycEt3G83lXn2HwbaJ/view) and then unzip the zip file by
40 |
41 | ```shell
42 | unzip m4singer_pe.zip
43 | ```
44 |
45 | ## Dataset Preparation
46 |
47 | You should first create the folders by
48 |
49 | ```shell
50 | mkdir dataset_raw
51 | mkdir dataset
52 | ```
53 | You can refer to different preparation methods based on your needs.
54 |
55 | Preparation With Slicing can help you remove the silent parts and slice the audio for stable training.
56 |
57 |
58 | ### 0. Preparation With Slicing
59 |
60 | Please place your original dataset in the `dataset_slice` directory.
61 |
62 | The original audios can be in any waveformat which should be specified in the command line. You can designate the length of slices you want, the unit of slice_size is milliseconds. The default wavformat and slice_size is mp3 and 10000 respectively.
63 |
64 | ```shell
65 | python preparation_slice.py -w your_wavformat -s slice_size
66 | ```
67 |
68 | ### 1. Preparation Without Slicing
69 |
70 | You can just place the dataset in the `dataset_raw` directory with the following file structure:
71 |
72 | ```
73 | dataset_raw
74 | ├───speaker0
75 | │ ├───xxx1-xxx1.wav
76 | │ ├───...
77 | │ └───Lxx-0xx8.wav
78 | └───speaker1
79 | ├───xx2-0xxx2.wav
80 | ├───...
81 | └───xxx7-xxx007.wav
82 | ```
83 |
84 |
85 | ## Preprocessing
86 |
87 | ### 1. Resample to 24000Hz and mono
88 |
89 | ```shell
90 | python preprocessing1_resample.py -n num_process
91 | ```
92 | num_process is the number of processes, the default num_process is 5.
93 |
94 | ### 2. Split the Training and Validation Datasets, and Generate Configuration Files.
95 |
96 | ```shell
97 | python preprocessing2_flist.py
98 | ```
99 |
100 |
101 | ### 3. Generate Features
102 |
103 | ```shell
104 | python preprocessing3_feature.py -c your_config_file -n num_processes
105 | ```
106 |
107 |
108 | ## Training
109 |
110 | ### 1. Train the Teacher Model
111 |
112 | ```shell
113 | python train.py
114 | ```
115 | The checkpoints will be saved in the `logs/teacher` directory
116 |
117 | ### 2. Train the Consistency Model
118 |
119 | If you want to adjust the config file, you can duplicate a new config file and modify some parameters.
120 |
121 |
122 | ```shell
123 | python train.py -t -c Your_new_configfile_path -p The_teacher_model_checkpoint_path
124 | ```
125 |
126 | ## Inference
127 | You should put the audios you want to convert under the `raw` directory firstly.
128 |
129 | ### Inference by the Teacher Model
130 |
131 | ```shell
132 | python inference_main.py -ts 50 -tm "logs/teacher/model_800000.pt" -tc "logs/teacher/config.yaml" -n "src.wav" -k 0 -s "target_singer"
133 | ```
134 | -ts refers to the total number of iterative steps during inference for the teacher model
135 |
136 | -tm refers to the teacher_model_path
137 |
138 | -tc refers to the teacher_config_path
139 |
140 | -n refers to the source audio
141 |
142 | -k refers to the pitch shift, it can be positive and negative (semitone) values
143 |
144 | -s refers to the target singer
145 |
146 | ### Inference by the Consistency Model
147 |
148 | ```shell
149 | python inference_main.py -ts 1 -cm "logs/como/model_800000.pt" -cc "logs/como/config.yaml" -n "src.wav" -k 0 -s "target_singer" -t
150 | ```
151 | -ts refers to the total number of iterative steps during inference for the student model
152 |
153 | -cm refers to the como_model_path
154 |
155 | -cc refers to the como_config_path
156 |
157 | -t means it is not the teacher model and you don't need to specify anything after it
158 |
--------------------------------------------------------------------------------
/Readme_CN.md:
--------------------------------------------------------------------------------
1 |
2 |
CoMoSVC: One-Step Consistency Model Based Singing Voice Conversion
3 |
4 |
5 | 基于一致性模型的歌声转换及克隆系统,可以一步diffusion采样进行歌声转换,是对论文[CoMoSVC](https://arxiv.org/pdf/2401.01792.pdf)的实现。工作基于[CoMoSpeech](https://github.com/zhenye234/CoMoSpeech): One-Step Speech and Singing Voice Synthesis via Consistency Model.
6 |
7 |
8 |
9 | # 环境配置
10 | Python 3.8环境下创建Conda虚拟环境:
11 |
12 | ```shell
13 | conda create -n Your_Conda_Environment_Name python=3.8
14 | ```
15 | 安装相关依赖库:
16 |
17 | ```shell
18 | pip install -r requirements.txt
19 | ```
20 | ## 下载checkpoints
21 | ### 1. m4singer_hifigan
22 | 下载vocoder [m4singer_hifigan](https://drive.google.com/file/d/10LD3sq_zmAibl379yTW5M-LXy2l_xk6h/view) 并解压
23 |
24 | ```shell
25 | unzip m4singer_hifigan.zip
26 | ```
27 |
28 | vocoder的checkoint将在`m4singer_hifigan`目录中
29 |
30 | ### 2. ContentVec
31 |
32 | 下载 [ContentVec](https://ibm.box.com/s/z1wgl1stco8ffooyatzdwsqn2psd9lrr) 放置在`Content`路径,以提取歌词内容特征。
33 |
34 | ### 3. m4singer_pe
35 |
36 | 下载pitch_extractor [m4singer_pe](https://drive.google.com/file/d/19QtXNeqUjY3AjvVycEt3G83lXn2HwbaJ/view) ,并解压到根目录
37 |
38 | ```shell
39 | unzip m4singer_pe.zip
40 | ```
41 |
42 |
43 | ## 数据准备
44 |
45 |
46 | 构造两个空文件夹
47 |
48 | ```shell
49 | mkdir dataset_raw
50 | mkdir dataset
51 | ```
52 |
53 | 请自行准备歌手的清唱录音数据,随后按照如下操作。
54 |
55 | ### 0. 带切片的数据准备流程
56 |
57 | 请将你的原始数据集放在 dataset_slice 目录下。
58 |
59 | 原始音频可以是任何波形格式,应在命令行中指定。你可以指定你想要的切片长度,切片大小的单位是毫秒。默认的文件格式和切片大小分别是mp3和10000。
60 |
61 | ```shell
62 | python preparation_slice.py -w 你的文件格式 -s 切片大小
63 | ```
64 |
65 | ### 1. 不带切片的数据准备流程
66 |
67 | 你可以只将数据集放在 `dataset_raw` 目录下,按照以下文件结构:
68 |
69 |
70 | ```
71 | dataset_raw
72 | ├───speaker0
73 | │ ├───xxx1-xxx1.wav
74 | │ ├───...
75 | │ └───Lxx-0xx8.wav
76 | └───speaker1
77 | ├───xx2-0xxx2.wav
78 | ├───...
79 | └───xxx7-xxx007.wav
80 | ```
81 |
82 |
83 | ## 预处理
84 |
85 | ### 1. 重采样为24000Hz和单声道
86 |
87 | ```shell
88 | python preprocessing1_resample.py -n num_process
89 | ```
90 | num_process 是进程数,默认5。
91 |
92 |
93 | ### 2. 分割训练和验证数据集,并生成配置文件
94 |
95 | ```shell
96 | python preprocessing2_flist.py
97 | ```
98 |
99 |
100 | ### 3. 生成特征
101 |
102 |
103 |
104 |
105 | 执行下面代码以提取所有特征
106 |
107 | ```shell
108 | python preprocessing3_feature.py -c your_config_file -n num_processes
109 | ```
110 |
111 |
112 |
113 |
114 | ## 训练
115 |
116 | ### 1. 训练 teacher model
117 |
118 | ```shell
119 | python train.py
120 | ```
121 | Checkpoint将存于 `logs/teacher` 目录中
122 |
123 | ### 2. 训练 consistency model
124 |
125 | #### 如果你想调整配置文件,你可以复制一个新的配置文件并修改一些参数。
126 |
127 |
128 |
129 | ```shell
130 | python train.py -t -c Your_new_configfile_path -p The_teacher_model_checkpoint_path
131 | ```
132 |
133 | ## 推理
134 |
135 | 你应该首先将你想要转换的音频放在`raw`目录下。
136 |
137 | ### 采用教师模型的推理
138 |
139 | ```shell
140 | python inference_main.py -ts 50 -tm "logs/teacher/model_800000.pt" -tc "logs/teacher/config.yaml" -n "src.wav" -k 0 -s "target_singer"
141 | ```
142 | -ts 教师模型推理时的迭代步数
143 |
144 | -tm 教师模型路径
145 |
146 | -tc 教师模型配置文件
147 |
148 | -n source音频路径
149 |
150 | -k pitch shift,可以是正负semitone值
151 |
152 | -s 目标歌手
153 |
154 |
155 |
156 | ### 采用CoMoSVC进行推理
157 |
158 | ```shell
159 | python inference_main.py -ts 1 -cm "logs/como/model_800000.pt" -cc "logs/como/config.yaml" -n "src.wav" -k 0 -s "target_singer" -t
160 | ```
161 | -ts 学生模型推理时的迭代步数
162 |
163 | -cm CoMoSVC模型路径
164 |
165 | -cc CoMoSVC模型配置文件
166 |
167 | -t 加上该参数并保留后续为空代表不是教师模型
168 |
--------------------------------------------------------------------------------
/Vocoder.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch
3 | from torchaudio.transforms import Resample
4 | from vocoder.m4gan.hifigan import HifiGanGenerator
5 |
6 | from mel_processing import mel_spectrogram, MAX_WAV_VALUE
7 | import utils
8 |
9 | class Vocoder:
10 | def __init__(self, vocoder_type, vocoder_ckpt, device = None):
11 | if device is None:
12 | device = 'cuda' if torch.cuda.is_available() else 'cpu'
13 | self.device = device # device
14 | self.vocodertype = vocoder_type
15 | if vocoder_type == 'm4-gan':
16 | self.vocoder = M4GAN(vocoder_ckpt, device = device)
17 | else:
18 | raise ValueError(f" [x] Unknown vocoder: {vocoder_type}")
19 |
20 | self.resample_kernel = {}
21 | self.vocoder_sample_rate = self.vocoder.sample_rate()
22 | self.vocoder_hop_size = self.vocoder.hop_size()
23 | self.dimension = self.vocoder.dimension()
24 |
25 | def extract(self, audio, sample_rate, keyshift=0):
26 | # resample
27 | if sample_rate == self.vocoder_sample_rate:
28 | audio_res = audio
29 | else:
30 | key_str = str(sample_rate)# 这里是24k
31 | if key_str not in self.resample_kernel:
32 | self.resample_kernel[key_str] = Resample(sample_rate, self.vocoder_sample_rate, lowpass_filter_width = 128).to(self.device)
33 |
34 | audio_res = self.resample_kernel[key_str](audio) # 对原始audio进行resample
35 |
36 | # extract
37 | mel = self.vocoder.extract(audio_res, keyshift=keyshift) # B, n_frames, bins
38 | return mel
39 |
40 | def infer(self, mel, f0):
41 | f0 = f0[:,:mel.size(1),0]
42 | audio = self.vocoder(mel,f0)
43 | return audio
44 |
45 |
46 | class M4GAN(torch.nn.Module):
47 | def __init__(self, model_path, device=None):
48 | super().__init__()
49 | if device is None:
50 | device = 'cuda' if torch.cuda.is_available() else 'cpu'
51 | self.device = device
52 | self.model_path = model_path
53 | self.model = None
54 | self.h = utils.load_config(os.path.join(os.path.split(model_path)[0], 'config.yaml'))
55 |
56 | def sample_rate(self):
57 | return self.h.audio_sample_rate
58 |
59 | def hop_size(self):
60 | return self.h.hop_size
61 |
62 | def dimension(self):
63 | return self.h.audio_num_mel_bins
64 |
65 | def extract(self, audio, keyshift=0):
66 |
67 | mel= mel_spectrogram(audio, self.h.fft_size, self.h.audio_num_mel_bins, self.h.audio_sample_rate, self.h.hop_size, self.h.win_size, self.h.fmin, self.h.fmax, keyshift=keyshift).transpose(1,2)
68 | # mel= mel_spectrogram(audio, 512, 80, 24000, 128, 512, 30, 12000, keyshift=keyshift).transpose(1,2)
69 | return mel
70 |
71 | def load_checkpoint(self, filepath, device):
72 | assert os.path.isfile(filepath)
73 | print("Loading '{}'".format(filepath))
74 | checkpoint_dict = torch.load(filepath, map_location=device)
75 | print("Complete.")
76 | return checkpoint_dict
77 |
78 |
79 | def forward(self, mel, f0):
80 | ckpt_dict = torch.load(self.model_path, map_location=self.device)
81 | state = ckpt_dict["state_dict"]["model_gen"]
82 | self.model = HifiGanGenerator(self.h).to(self.device)
83 | self.model.load_state_dict(state, strict=True)
84 | self.model.remove_weight_norm()
85 | self.model = self.model.eval()
86 | c = mel.transpose(2, 1)
87 | y = self.model(c,f0).view(-1)
88 |
89 | return y[None]
90 |
--------------------------------------------------------------------------------
/como.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | import copy
4 | from pitch_extractor import PitchExtractor
5 | from wavenet import WaveNet
6 |
7 | import numpy as np
8 | import torch
9 |
10 |
11 | class BaseModule(torch.nn.Module):
12 | def __init__(self):
13 | super(BaseModule, self).__init__()
14 |
15 | @property
16 | def nparams(self):
17 | """
18 | Returns number of trainable parameters of the module.
19 | """
20 | num_params = 0
21 | for name, param in self.named_parameters():
22 | if param.requires_grad:
23 | num_params += np.prod(param.detach().cpu().numpy().shape)
24 | return num_params
25 |
26 |
27 | def relocate_input(self, x: list):
28 | """
29 | Relocates provided tensors to the same device set for the module.
30 | """
31 | device = next(self.parameters()).device
32 | for i in range(len(x)):
33 | if isinstance(x[i], torch.Tensor) and x[i].device != device:
34 | x[i] = x[i].to(device)
35 | return x
36 |
37 |
38 | class Como(BaseModule):
39 | def __init__(self, out_dims, n_layers, n_chans, n_hidden,total_steps,teacher = True ):
40 | super().__init__()
41 | self.denoise_fn = WaveNet(out_dims, n_layers, n_chans, n_hidden)
42 | self.pe= PitchExtractor()
43 | self.teacher = teacher
44 | if not teacher:
45 | self.denoise_fn_ema = copy.deepcopy(self.denoise_fn)
46 | self.denoise_fn_pretrained = copy.deepcopy(self.denoise_fn)
47 |
48 | self.P_mean =-1.2
49 | self.P_std =1.2
50 | self.sigma_data =0.5
51 |
52 | self.sigma_min= 0.002
53 | self.sigma_max= 80
54 | self.rho=7
55 | self.N = 25
56 | self.total_steps=total_steps
57 | self.spec_min=-6
58 | self.spec_max=1.5
59 | step_indices = torch.arange(self.N)
60 | t_steps = (self.sigma_min ** (1 / self.rho) + step_indices / (self.N - 1) * (self.sigma_max ** (1 / self.rho) - self.sigma_min ** (1 / self.rho))) ** self.rho
61 | self.t_steps = torch.cat([torch.zeros_like(t_steps[:1]), self.round_sigma(t_steps)]) # round_tensorj将数据转为tensor
62 |
63 | def norm_spec(self, x):
64 | return (x - self.spec_min) / (self.spec_max - self.spec_min) * 2 - 1
65 |
66 | def denorm_spec(self, x):
67 | return (x + 1) / 2 * (self.spec_max - self.spec_min) + self.spec_min
68 |
69 | def EDMPrecond(self, x, sigma ,cond,denoise_fn):
70 | sigma = sigma.reshape(-1, 1, 1 )
71 | c_skip = self.sigma_data ** 2 / ((sigma-self.sigma_min) ** 2 + self.sigma_data ** 2)
72 | c_out = (sigma-self.sigma_min) * self.sigma_data / (sigma ** 2 + self.sigma_data ** 2).sqrt()
73 | c_in = 1 / (self.sigma_data ** 2 + sigma ** 2).sqrt()
74 | c_noise = sigma.log() / 4
75 | F_x = denoise_fn((c_in * x), c_noise.flatten(),cond)
76 | D_x = c_skip * x + c_out * (F_x .squeeze(1) )
77 | return D_x
78 |
79 | def EDMLoss(self, x_start, cond):
80 | rnd_normal = torch.randn([x_start.shape[0], 1, 1], device=x_start.device)
81 | sigma = (rnd_normal * self.P_std + self.P_mean).exp()
82 | weight = (sigma ** 2 + self.sigma_data ** 2) / (sigma * self.sigma_data) ** 2
83 | n = (torch.randn_like(x_start) ) * sigma # Generate Gaussian Noise
84 | D_yn = self.EDMPrecond(x_start + n, sigma ,cond,self.denoise_fn) # After Denoising
85 | loss = (weight * ((D_yn - x_start) ** 2))
86 | loss=loss.unsqueeze(1).unsqueeze(1)
87 | loss=loss.mean()
88 | return loss
89 |
90 | def round_sigma(self, sigma):
91 | return torch.as_tensor(sigma)
92 |
93 | def edm_sampler(self,latents, cond,num_steps=50, sigma_min=0.002, sigma_max=80, rho=7, S_churn=0, S_min=0, S_max=float('inf'), S_noise=1):
94 | # Time step discretization.
95 | step_indices = torch.arange(num_steps, device=latents.device)
96 |
97 | num_steps=num_steps + 1
98 | t_steps = (sigma_max ** (1 / rho) + step_indices / (num_steps - 1) * (sigma_min ** (1 / rho) - sigma_max ** (1 / rho))) ** rho
99 | t_steps = torch.cat([self.round_sigma(t_steps), torch.zeros_like(t_steps[:1])])
100 | # Main sampling loop.
101 | x_next = latents * t_steps[0]
102 | x_next = x_next.transpose(1,2)
103 | for i, (t_cur, t_next) in enumerate(zip(t_steps[:-1], t_steps[1:])):
104 | x_cur = x_next
105 | gamma = min(S_churn / num_steps, np.sqrt(2) - 1) if S_min <= t_cur <= S_max else 0
106 | t_hat = self.round_sigma(t_cur + gamma * t_cur)
107 | x_hat = x_cur + (t_hat ** 2 - t_cur ** 2).sqrt() * S_noise * torch.randn_like(x_cur)
108 | denoised = self.EDMPrecond(x_hat, t_hat, cond, self.denoise_fn) # mel,sigma,cond
109 | d_cur = (x_hat - denoised) / t_hat # 7th step
110 | x_next = x_hat + (t_next - t_hat) * d_cur
111 |
112 | return x_next
113 |
114 | def CTLoss_D(self,y, cond): # y is the gt_spec
115 | with torch.no_grad():
116 | mu = 0.95
117 | for p, ema_p in zip(self.denoise_fn.parameters(), self.denoise_fn_ema.parameters()):
118 | ema_p.mul_(mu).add_(p, alpha=1 - mu)
119 | n = torch.randint(1, self.N, (y.shape[0],))
120 |
121 | z = torch.randn_like(y) # Gaussian Noise
122 | tn_1 = self.c_t_d(n + 1).reshape(-1, 1, 1).to(y.device)
123 | f_theta = self.EDMPrecond(y + tn_1 * z, tn_1, cond, self.denoise_fn)
124 |
125 | with torch.no_grad():
126 | tn = self.c_t_d(n ).reshape(-1, 1, 1).to(y.device)
127 | #euler step
128 | x_hat = y + tn_1 * z
129 | denoised = self.EDMPrecond(x_hat, tn_1 , cond,self.denoise_fn_pretrained)
130 | d_cur = (x_hat - denoised) / tn_1
131 | y_tn = x_hat + (tn - tn_1) * d_cur
132 | f_theta_ema = self.EDMPrecond( y_tn, tn,cond, self.denoise_fn_ema)
133 |
134 | loss = (f_theta - f_theta_ema.detach()) ** 2 # For consistency model, lembda=1
135 | loss=loss.unsqueeze(1).unsqueeze(1)
136 | loss=loss.mean()
137 |
138 | return loss
139 |
140 | def c_t_d(self, i ):
141 | return self.t_steps[i]
142 |
143 | def get_t_steps(self,N):
144 | N=N+1
145 | step_indices = torch.arange( N ) #, device=latents.device)
146 | t_steps = (self.sigma_min ** (1 / self.rho) + step_indices / (N- 1) * (self.sigma_max ** (1 / self.rho) - self.sigma_min ** (1 / self.rho))) ** self.rho
147 |
148 | return t_steps.flip(0)# FLIP t_step
149 |
150 | def CT_sampler(self, latents, cond, t_steps=1):
151 | if t_steps ==1:
152 | t_steps=[80]
153 | else:
154 | t_steps=self.get_t_steps(t_steps)
155 | t_steps = torch.as_tensor(t_steps).to(latents.device)
156 | latents = latents * t_steps[0]
157 | latents = latents.transpose(1,2)
158 | x = self.EDMPrecond(latents, t_steps[0],cond,self.denoise_fn)
159 | for t in t_steps[1:-1]: # N-1 to 1
160 | z = torch.randn_like(x)
161 | x_tn = x + (t ** 2 - self.sigma_min ** 2).sqrt()*z
162 | x = self.EDMPrecond(x_tn, t,cond,self.denoise_fn)
163 | return x
164 |
165 | def forward(self, x, cond, infer=False):
166 |
167 | if self.teacher: # teacher model
168 | if not infer: # training
169 | x=self.norm_spec(x)
170 | loss = self.EDMLoss(x, cond)
171 | return loss
172 | else: # infer
173 | shape = (cond.shape[0], 80, cond.shape[1])
174 | x = torch.randn(shape, device=cond.device)
175 | x=self.edm_sampler(x, cond, self.total_steps)
176 | return self.denorm_spec(x)
177 | else: #Consistency distillation
178 | if not infer: # training
179 | x=self.norm_spec(x)
180 | loss = self.CTLoss_D(x, cond)
181 | return loss
182 | else: # infer
183 | shape = (cond.shape[0], 80, cond.shape[1])
184 | x = torch.randn(shape, device=cond.device) # The Input is the Random Noise
185 | x=self.CT_sampler(x,cond,self.total_steps)
186 | return self.denorm_spec(x)
187 |
188 |
189 |
--------------------------------------------------------------------------------
/configs/the_config_files:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Grace9994/CoMoSVC/2ea8e644e2c5b3a8afc0762e870b9daacf3b5be5/configs/the_config_files
--------------------------------------------------------------------------------
/configs_template/diffusion_template.yaml:
--------------------------------------------------------------------------------
1 | data:
2 | sampling_rate: 24000
3 | hop_length: 128
4 | duration: 2 # Audio duration during training, must be less than the duration of the shortest audio clip
5 | filter_length: 512
6 | win_length: 512
7 | encoder: 'vec768l12' #
8 | cnhubertsoft_gate: 10
9 | encoder_sample_rate: 16000
10 | encoder_hop_size: 320
11 | encoder_out_channels: 768 #
12 | training_files: "filelists/train.txt"
13 | validation_files: "filelists/val.txt"
14 | extensions: # List of extension included in the data collection
15 | - wav
16 | unit_interpolate_mode: "nearest"
17 | model:
18 | type: 'Diffusion'
19 | n_layers: 20
20 | n_chans: 512
21 | n_hidden: 256
22 | use_pitch_aug: true
23 | n_spk: 1 # max number of different speakers
24 | device: cuda
25 | vocoder:
26 | type: 'm4-gan'
27 | ckpt: 'm4singer_hifigan/model_ckpt_steps_1970000.ckpt'
28 | infer:
29 | method: 'dpm-solver++' #
30 | env:
31 | comodir: logs/como
32 | expdir: logs/teacher
33 | gpu_id: 0
34 | train:
35 | num_workers: 4 # If your cpu and gpu are both very strong, set to 0 may be faster!
36 | amp_dtype: fp32 # fp32, fp16 or bf16 (fp16 or bf16 may be faster if it is supported by your gpu)
37 | batch_size: 48
38 | cache_all_data: true # Save Internal-Memory or Graphics-Memory if it is false, but may be slow
39 | cache_device: 'cpu' # Set to 'cuda' to cache the data into the Graphics-Memory, fastest speed for strong gpu
40 | cache_fp16: true
41 | epochs: 100000
42 | interval_log: 10
43 | interval_val: 2000
44 | interval_force_save: 2000
45 | lr: 0.0001
46 | comolr: 0.00005
47 | decay_step: 100000
48 | gamma: 0.5
49 | weight_decay: 0
50 | save_opt: false
51 | spk:
52 | 'SPEAKER1': 0
--------------------------------------------------------------------------------
/data_loaders.py:
--------------------------------------------------------------------------------
1 | import os
2 | import random
3 |
4 | import librosa
5 | import numpy as np
6 | import torch
7 | from torch.utils.data import Dataset
8 | from tqdm import tqdm
9 |
10 | from utils import repeat_expand_2d
11 |
12 |
13 | def traverse_dir(
14 | root_dir,
15 | extensions,
16 | amount=None,
17 | str_include=None,
18 | str_exclude=None,
19 | is_pure=False,
20 | is_sort=False,
21 | is_ext=True):
22 |
23 | file_list = []
24 | cnt = 0
25 | for root, _, files in os.walk(root_dir):
26 | for file in files:
27 | if any([file.endswith(f".{ext}") for ext in extensions]):
28 | # path
29 | mix_path = os.path.join(root, file)
30 | pure_path = mix_path[len(root_dir)+1:] if is_pure else mix_path
31 |
32 | # amount
33 | if (amount is not None) and (cnt == amount):
34 | if is_sort:
35 | file_list.sort()
36 | return file_list
37 |
38 | # check string
39 | if (str_include is not None) and (str_include not in pure_path):
40 | continue
41 | if (str_exclude is not None) and (str_exclude in pure_path):
42 | continue
43 |
44 | if not is_ext:
45 | ext = pure_path.split('.')[-1]
46 | pure_path = pure_path[:-(len(ext)+1)]
47 | file_list.append(pure_path)
48 | cnt += 1
49 | if is_sort:
50 | file_list.sort()
51 | return file_list
52 |
53 |
54 | def get_data_loaders(args, whole_audio=False):
55 | data_train = AudioDataset(
56 | filelists = args.data.training_files,
57 | waveform_sec=args.data.duration,
58 | hop_size=args.data.hop_length,
59 | sample_rate=args.data.sampling_rate,
60 | load_all_data=args.train.cache_all_data,
61 | whole_audio=whole_audio,
62 | extensions=args.data.extensions,
63 | n_spk=args.model.n_spk,
64 | spk=args.spk,
65 | device=args.train.cache_device,
66 | fp16=args.train.cache_fp16,
67 | unit_interpolate_mode = args.data.unit_interpolate_mode,
68 | use_aug=True)
69 | loader_train = torch.utils.data.DataLoader(
70 | data_train ,
71 | batch_size=args.train.batch_size if not whole_audio else 1,
72 | shuffle=True,
73 | num_workers=args.train.num_workers if args.train.cache_device=='cpu' else 0,
74 | persistent_workers=(args.train.num_workers > 0) if args.train.cache_device=='cpu' else False,
75 | pin_memory=True if args.train.cache_device=='cpu' else False
76 | )
77 | data_valid = AudioDataset(
78 | filelists = args.data.validation_files,
79 | waveform_sec=args.data.duration,
80 | hop_size=args.data.hop_length,
81 | sample_rate=args.data.sampling_rate,
82 | load_all_data=args.train.cache_all_data,
83 | whole_audio=True,
84 | spk=args.spk,
85 | extensions=args.data.extensions,
86 | unit_interpolate_mode = args.data.unit_interpolate_mode,
87 | n_spk=args.model.n_spk)
88 | loader_valid = torch.utils.data.DataLoader(
89 | data_valid,
90 | batch_size=1,
91 | shuffle=False,
92 | num_workers=0,
93 | pin_memory=True
94 | )
95 | return loader_train, loader_valid
96 |
97 |
98 | class AudioDataset(Dataset):
99 | def __init__(
100 | self,
101 | filelists,
102 | waveform_sec,
103 | hop_size,
104 | sample_rate,
105 | spk,
106 | load_all_data=True,
107 | whole_audio=False,
108 | extensions=['wav'],
109 | n_spk=1,
110 | device='cpu',
111 | fp16=False,
112 | use_aug=False,
113 | unit_interpolate_mode = 'left'
114 | ):
115 | super().__init__()
116 |
117 | self.waveform_sec = waveform_sec
118 | self.sample_rate = sample_rate
119 | self.hop_size = hop_size
120 | self.filelists = filelists
121 | self.whole_audio = whole_audio
122 | self.use_aug = use_aug
123 | self.data_buffer={}
124 | self.pitch_aug_dict = {}
125 | self.unit_interpolate_mode = unit_interpolate_mode
126 | # np.load(os.path.join(self.path_root, 'pitch_aug_dict.npy'), allow_pickle=True).item()
127 | if load_all_data:
128 | print('Load all the data filelists:', filelists)
129 | else:
130 | print('Load the f0, volume data filelists:', filelists)
131 | with open(filelists,"r") as f:
132 | self.paths = f.read().splitlines()
133 | for name_ext in tqdm(self.paths, total=len(self.paths)):
134 | path_audio = name_ext
135 | duration = librosa.get_duration(filename = path_audio, sr = self.sample_rate)
136 |
137 | path_f0 = name_ext + ".f0.npy"
138 | f0,_ = np.load(path_f0,allow_pickle=True)
139 | f0 = torch.from_numpy(np.array(f0,dtype=float)).float().unsqueeze(-1).to(device)
140 |
141 | path_volume = name_ext + ".vol.npy"
142 | volume = np.load(path_volume)
143 | volume = torch.from_numpy(volume).float().unsqueeze(-1).to(device)
144 |
145 | path_augvol = name_ext + ".aug_vol.npy"
146 | aug_vol = np.load(path_augvol)
147 | aug_vol = torch.from_numpy(aug_vol).float().unsqueeze(-1).to(device)
148 |
149 | if n_spk is not None and n_spk > 1:
150 | spk_name = name_ext.split("/")[-2]
151 | spk_id = spk[spk_name] if spk_name in spk else 0
152 | if spk_id < 0 or spk_id >= n_spk:
153 | raise ValueError(' [x] Muiti-speaker traing error : spk_id must be a positive integer from 0 to n_spk-1 ')
154 | else:
155 | spk_id = 0
156 | spk_id = torch.LongTensor(np.array([spk_id])).to(device)
157 |
158 | if load_all_data:
159 | '''
160 | audio, sr = librosa.load(path_audio, sr=self.sample_rate)
161 | if len(audio.shape) > 1:
162 | audio = librosa.to_mono(audio)
163 | audio = torch.from_numpy(audio).to(device)
164 | '''
165 | path_mel = name_ext + ".mel.npy"
166 | mel = np.load(path_mel)
167 | mel = torch.from_numpy(mel).to(device)
168 |
169 | path_augmel = name_ext + ".aug_mel.npy"
170 | aug_mel,keyshift = np.load(path_augmel, allow_pickle=True)
171 | aug_mel = np.array(aug_mel,dtype=float)
172 | aug_mel = torch.from_numpy(aug_mel).to(device)
173 | self.pitch_aug_dict[name_ext] = keyshift
174 |
175 | path_units = name_ext + ".soft.pt"
176 | units = torch.load(path_units).to(device)
177 | units = units[0]
178 | units = repeat_expand_2d(units,f0.size(0),unit_interpolate_mode).transpose(0,1)
179 |
180 | if fp16:
181 | mel = mel.half()
182 | aug_mel = aug_mel.half()
183 | units = units.half()
184 |
185 | self.data_buffer[name_ext] = {
186 | 'duration': duration,
187 | 'mel': mel,
188 | 'aug_mel': aug_mel,
189 | 'units': units,
190 | 'f0': f0,
191 | 'volume': volume,
192 | 'aug_vol': aug_vol,
193 | 'spk_id': spk_id
194 | }
195 | else:
196 | path_augmel = name_ext + ".aug_mel.npy"
197 | aug_mel,keyshift = np.load(path_augmel, allow_pickle=True)
198 | self.pitch_aug_dict[name_ext] = keyshift
199 | self.data_buffer[name_ext] = {
200 | 'duration': duration,
201 | 'f0': f0,
202 | 'volume': volume,
203 | 'aug_vol': aug_vol,
204 | 'spk_id': spk_id
205 | }
206 |
207 |
208 | def __getitem__(self, file_idx):
209 | name_ext = self.paths[file_idx]
210 | data_buffer = self.data_buffer[name_ext]
211 | # check duration. if too short, then skip
212 | if data_buffer['duration'] < (self.waveform_sec + 0.1):
213 | return self.__getitem__( (file_idx + 1) % len(self.paths))
214 |
215 | # get item
216 | return self.get_data(name_ext, data_buffer)
217 |
218 | def get_data(self, name_ext, data_buffer):
219 | name = os.path.splitext(name_ext)[0]
220 | frame_resolution = self.hop_size / self.sample_rate
221 | duration = data_buffer['duration']
222 | waveform_sec = duration if self.whole_audio else self.waveform_sec
223 |
224 | # load audio
225 | idx_from = 0 if self.whole_audio else random.uniform(0, duration - waveform_sec - 0.1)
226 | start_frame = int(idx_from / frame_resolution)
227 | units_frame_len = int(waveform_sec / frame_resolution)
228 | aug_flag = random.choice([True, False]) and self.use_aug
229 | '''
230 | audio = data_buffer.get('audio')
231 | if audio is None:
232 | path_audio = os.path.join(self.path_root, 'audio', name) + '.wav'
233 | audio, sr = librosa.load(
234 | path_audio,
235 | sr = self.sample_rate,
236 | offset = start_frame * frame_resolution,
237 | duration = waveform_sec)
238 | if len(audio.shape) > 1:
239 | audio = librosa.to_mono(audio)
240 | # clip audio into N seconds
241 | audio = audio[ : audio.shape[-1] // self.hop_size * self.hop_size]
242 | audio = torch.from_numpy(audio).float()
243 | else:
244 | audio = audio[start_frame * self.hop_size : (start_frame + units_frame_len) * self.hop_size]
245 | '''
246 | # load mel
247 | mel_key = 'aug_mel' if aug_flag else 'mel'
248 | mel = data_buffer.get(mel_key)
249 | if mel is None:
250 | mel = name_ext + ".mel.npy"
251 | mel = np.load(mel)
252 | mel = mel[start_frame : start_frame + units_frame_len]
253 | mel = torch.from_numpy(mel).float()
254 | else:
255 | mel = mel[start_frame : start_frame + units_frame_len]
256 |
257 | # load f0
258 | f0 = data_buffer.get('f0')
259 | aug_shift = 0
260 | if aug_flag:
261 | aug_shift = self.pitch_aug_dict[name_ext]
262 | f0_frames = 2 ** (aug_shift / 12) * f0[start_frame : start_frame + units_frame_len]
263 |
264 | # load units
265 | units = data_buffer.get('units')
266 | if units is None:
267 | path_units = name_ext + ".soft.pt"
268 | units = torch.load(path_units)
269 | units = units[0]
270 | units = repeat_expand_2d(units,f0.size(0),self.unit_interpolate_mode).transpose(0,1)
271 |
272 | units = units[start_frame : start_frame + units_frame_len]
273 |
274 | # load volume
275 | vol_key = 'aug_vol' if aug_flag else 'volume'
276 | volume = data_buffer.get(vol_key)
277 | volume_frames = volume[start_frame : start_frame + units_frame_len]
278 |
279 | # load spk_id
280 | spk_id = data_buffer.get('spk_id')
281 |
282 | # load shift
283 | aug_shift = torch.from_numpy(np.array([[aug_shift]])).float()
284 |
285 | return dict(mel=mel, f0=f0_frames, volume=volume_frames, units=units, spk_id=spk_id, aug_shift=aug_shift, name=name, name_ext=name_ext)
286 |
287 | def __len__(self):
288 | return len(self.paths)
--------------------------------------------------------------------------------
/dataset/the_prprocessed_data:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Grace9994/CoMoSVC/2ea8e644e2c5b3a8afc0762e870b9daacf3b5be5/dataset/the_prprocessed_data
--------------------------------------------------------------------------------
/dataset_slice/if_you_need_to_slice:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Grace9994/CoMoSVC/2ea8e644e2c5b3a8afc0762e870b9daacf3b5be5/dataset_slice/if_you_need_to_slice
--------------------------------------------------------------------------------
/filelists/put_the_txt_here:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Grace9994/CoMoSVC/2ea8e644e2c5b3a8afc0762e870b9daacf3b5be5/filelists/put_the_txt_here
--------------------------------------------------------------------------------
/infer_tool.py:
--------------------------------------------------------------------------------
1 | import io
2 | import logging
3 | import os
4 | import time
5 | from pathlib import Path
6 |
7 | import librosa
8 | import numpy as np
9 |
10 | import soundfile
11 | import torch
12 | import torchaudio
13 |
14 | import utils
15 | from ComoSVC import load_model_vocoder
16 | import slicer
17 |
18 | logging.getLogger('matplotlib').setLevel(logging.WARNING)
19 |
20 |
21 | def format_wav(audio_path):
22 | if Path(audio_path).suffix == '.wav':
23 | return
24 | raw_audio, raw_sample_rate = librosa.load(audio_path, mono=True, sr=None)
25 | soundfile.write(Path(audio_path).with_suffix(".wav"), raw_audio, raw_sample_rate)
26 |
27 |
28 | def get_end_file(dir_path, end):
29 | file_lists = []
30 | for root, dirs, files in os.walk(dir_path):
31 | files = [f for f in files if f[0] != '.']
32 | dirs[:] = [d for d in dirs if d[0] != '.']
33 | for f_file in files:
34 | if f_file.endswith(end):
35 | file_lists.append(os.path.join(root, f_file).replace("\\", "/"))
36 | return file_lists
37 |
38 |
39 | def fill_a_to_b(a, b):
40 | if len(a) < len(b):
41 | for _ in range(0, len(b) - len(a)):
42 | a.append(a[0])
43 |
44 | def mkdir(paths: list):
45 | for path in paths:
46 | if not os.path.exists(path):
47 | os.mkdir(path)
48 |
49 | def pad_array(arr, target_length):
50 | current_length = arr.shape[0]
51 | if current_length >= target_length:
52 | return arr
53 | else:
54 | pad_width = target_length - current_length
55 | pad_left = pad_width // 2
56 | pad_right = pad_width - pad_left
57 | padded_arr = np.pad(arr, (pad_left, pad_right), 'constant', constant_values=(0, 0))
58 | return padded_arr
59 |
60 | def split_list_by_n(list_collection, n, pre=0):
61 | for i in range(0, len(list_collection), n):
62 | yield list_collection[i-pre if i-pre>=0 else i: i + n]
63 |
64 |
65 | class F0FilterException(Exception):
66 | pass
67 |
68 | class Svc(object):
69 | def __init__(self,
70 | diffusion_model_path="logs/como/model_8000.pt",
71 | diffusion_config_path="configs/diffusion.yaml",
72 | total_steps=1,
73 | teacher = False
74 | ):
75 |
76 | self.teacher = teacher
77 | self.total_steps=total_steps
78 | self.dev = torch.device("cuda" if torch.cuda.is_available() else "cpu")
79 | self.diffusion_model,self.vocoder,self.diffusion_args = load_model_vocoder(diffusion_model_path,self.dev,config_path=diffusion_config_path,total_steps=self.total_steps,teacher=self.teacher)
80 | self.target_sample = self.diffusion_args.data.sampling_rate
81 | self.hop_size = self.diffusion_args.data.hop_length
82 | self.spk2id = self.diffusion_args.spk
83 | self.dtype = torch.float32
84 | self.speech_encoder = self.diffusion_args.data.encoder
85 | self.unit_interpolate_mode = self.diffusion_args.data.unit_interpolate_mode if self.diffusion_args.data.unit_interpolate_mode is not None else 'left'
86 |
87 | # load hubert and model
88 |
89 | from Features import ContentVec768L12
90 | self.hubert_model = ContentVec768L12(device = self.dev)
91 | self.volume_extractor= utils.Volume_Extractor(self.hop_size)
92 |
93 |
94 |
95 | def get_unit_f0(self, wav, tran):
96 |
97 | if not hasattr(self,"f0_predictor_object") or self.f0_predictor_object is None:
98 | from Features import DioF0Predictor
99 | self.f0_predictor_object = DioF0Predictor(hop_length=self.hop_size,sampling_rate=self.target_sample)
100 | f0, uv = self.f0_predictor_object.compute_f0_uv(wav)
101 | f0 = torch.FloatTensor(f0).to(self.dev)
102 | uv = torch.FloatTensor(uv).to(self.dev)
103 |
104 | f0 = f0 * 2 ** (tran / 12)
105 | f0 = f0.unsqueeze(0)
106 | uv = uv.unsqueeze(0)
107 |
108 | wav = torch.from_numpy(wav).to(self.dev)
109 | if not hasattr(self,"audio16k_resample_transform"):
110 | self.audio16k_resample_transform = torchaudio.transforms.Resample(self.target_sample, 16000).to(self.dev)
111 | wav16k = self.audio16k_resample_transform(wav[None,:])[0]
112 |
113 | c = self.hubert_model.encoder(wav16k)
114 | c = utils.repeat_expand_2d(c.squeeze(0), f0.shape[1],self.unit_interpolate_mode)
115 | c = c.unsqueeze(0)
116 | return c, f0, uv
117 |
118 | def infer(self, speaker, tran, raw_path):
119 | torchaudio.set_audio_backend("soundfile")
120 | wav, sr = torchaudio.load(raw_path)
121 | if not hasattr(self,"audio_resample_transform") or self.audio16k_resample_transform.orig_freq != sr:
122 | self.audio_resample_transform = torchaudio.transforms.Resample(sr,self.target_sample)
123 | wav = self.audio_resample_transform(wav).numpy()[0]# (100080,)
124 | speaker_id = self.spk2id.get(speaker)
125 |
126 | if not speaker_id and type(speaker) is int:
127 | if len(self.spk2id.__dict__) >= speaker:
128 | speaker_id = speaker
129 | if speaker_id is None:
130 | raise RuntimeError("The name you entered is not in the speaker list!")
131 | sid = torch.LongTensor([int(speaker_id)]).to(self.dev).unsqueeze(0)
132 |
133 | c, f0, uv = self.get_unit_f0(wav, tran)
134 | n_frames = f0.size(1)
135 | c = c.to(self.dtype)
136 | f0 = f0.to(self.dtype)
137 | uv = uv.to(self.dtype)
138 |
139 | with torch.no_grad():
140 | start = time.time()
141 | vol = None
142 | audio = torch.FloatTensor(wav).to(self.dev)
143 | audio_mel = None
144 | vol = self.volume_extractor.extract(audio[None,:])[None,:,None].to(self.dev) if vol is None else vol[:,:,None]
145 | f0 = f0[:,:,None] # torch.Size([1, 390]) to torch.Size([1, 390, 1])
146 | c = c.transpose(-1,-2)
147 | audio_mel = self.diffusion_model(c, f0, vol,spk_id = sid,gt_spec=audio_mel,infer=True)
148 | # print("inferencetool_audiomel",audio_mel.shape)
149 | audio = self.vocoder.infer(audio_mel, f0).squeeze()
150 | use_time = time.time() - start
151 | print("inference_time is:{}".format(use_time))
152 | return audio, audio.shape[-1], n_frames
153 |
154 | def clear_empty(self):
155 | # clean up vram
156 | torch.cuda.empty_cache()
157 |
158 |
159 | def slice_inference(self,
160 | raw_audio_path,
161 | spk,
162 | tran,
163 | slice_db=-40, # -40
164 | pad_seconds=0.5,
165 | clip_seconds=0,
166 | ):
167 |
168 | wav_path = Path(raw_audio_path).with_suffix('.wav')
169 | chunks = slicer.cut(wav_path, db_thresh=slice_db)
170 | audio_data, audio_sr = slicer.chunks2audio(wav_path, chunks)
171 | per_size = int(clip_seconds*audio_sr)
172 | lg_size = 0
173 | global_frame = 0
174 | audio = []
175 | for (slice_tag, data) in audio_data:
176 | print(f'#=====segment start, {round(len(data) / audio_sr, 3)}s======')
177 | # padd
178 | length = int(np.ceil(len(data) / audio_sr * self.target_sample))
179 | if slice_tag:
180 | print('jump empty segment')
181 | _audio = np.zeros(length)
182 | audio.extend(list(pad_array(_audio, length)))
183 | global_frame += length // self.hop_size
184 | continue
185 | if per_size != 0:
186 | datas = split_list_by_n(data, per_size,lg_size)
187 | else:
188 | datas = [data]
189 | for k,dat in enumerate(datas):
190 | per_length = int(np.ceil(len(dat) / audio_sr * self.target_sample)) if clip_seconds!=0 else length
191 | if clip_seconds!=0:
192 | print(f'###=====segment clip start, {round(len(dat) / audio_sr, 3)}s======')
193 | # padd
194 | pad_len = int(audio_sr * pad_seconds)
195 | dat = np.concatenate([np.zeros([pad_len]), dat, np.zeros([pad_len])])
196 | raw_path = io.BytesIO()
197 | soundfile.write(raw_path, dat, audio_sr, format="wav")
198 | raw_path.seek(0)
199 | out_audio, out_sr, out_frame = self.infer(spk, tran, raw_path)
200 | global_frame += out_frame
201 | _audio = out_audio.cpu().numpy()
202 | pad_len = int(self.target_sample * pad_seconds)
203 | _audio = _audio[pad_len:-pad_len]
204 | _audio = pad_array(_audio, per_length)
205 | audio.extend(list(_audio))
206 | return np.array(audio)
207 |
--------------------------------------------------------------------------------
/inference_main.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import soundfile
3 | import os
4 | os.environ["CUDA_VISIBLE_DEVICES"]='1'
5 |
6 | import infer_tool
7 | from infer_tool import Svc
8 |
9 | logging.getLogger('numba').setLevel(logging.WARNING)
10 |
11 |
12 | def main():
13 | import argparse
14 |
15 | parser = argparse.ArgumentParser(description='comosvc inference')
16 | parser.add_argument('-t', '--teacher', action="store_false",help='if it is teacher model')
17 | parser.add_argument('-ts', '--total_steps', type=int,default=1,help='the total number of iterative steps during inference')
18 |
19 |
20 | parser.add_argument('--clip', type=float, default=0, help='Slicing the audios which are to be converted')
21 | parser.add_argument('-n','--clean_names', type=str, nargs='+', default=['1.wav'], help='The audios to be converted,should be put in "raw" directory')
22 | parser.add_argument('-k','--keys', type=int, nargs='+', default=[0], help='To Adjust the Key')
23 | parser.add_argument('-s','--spk_list', type=str, nargs='+', default=['singer1'], help='The target singer')
24 | parser.add_argument('-cm','--como_model_path', type=str, default="./logs/como/model_800000.pt", help='the path to checkpoint of CoMoSVC')
25 | parser.add_argument('-cc','--como_config_path', type=str, default="./logs/como/config.yaml", help='the path to config file of CoMoSVC')
26 | parser.add_argument('-tm','--teacher_model_path', type=str, default="./logs/teacher/model_800000.pt", help='the path to checkpoint of Teacher Model')
27 | parser.add_argument('-tc','--teacher_config_path', type=str, default="./logs/teacher/config.yaml", help='the path to config file of Teacher Model')
28 |
29 | args = parser.parse_args()
30 |
31 | clean_names = args.clean_names
32 | keys = args.keys
33 | spk_list = args.spk_list
34 | slice_db =-40
35 | wav_format = 'wav' # the format of the output audio
36 | pad_seconds = 0.5
37 | clip = args.clip
38 |
39 | if args.teacher:
40 | diffusion_model_path = args.teacher_model_path
41 | diffusion_config_path = args.teacher_config_path
42 | resultfolder='result_teacher'
43 | else:
44 | diffusion_model_path = args.como_model_path
45 | diffusion_config_path = args.como_config_path
46 | resultfolder='result_teacher'
47 |
48 | svc_model = Svc(diffusion_model_path,
49 | diffusion_config_path,
50 | args.total_steps,
51 | args.teacher)
52 |
53 | infer_tool.mkdir(["raw", resultfolder])
54 |
55 | infer_tool.fill_a_to_b(keys, clean_names)
56 | for clean_name, tran in zip(clean_names, keys):
57 | raw_audio_path = f"raw/{clean_name}"
58 | if "." not in raw_audio_path:
59 | raw_audio_path += ".wav"
60 | infer_tool.format_wav(raw_audio_path)
61 | for spk in spk_list:
62 | kwarg = {
63 | "raw_audio_path" : raw_audio_path,
64 | "spk" : spk,
65 | "tran" : tran,
66 | "slice_db" : slice_db,# -40
67 | "pad_seconds" : pad_seconds, # 0.5
68 | "clip_seconds" : clip, #0
69 |
70 | }
71 | audio = svc_model.slice_inference(**kwarg)
72 | step_num=diffusion_model_path.split('/')[-1].split('.')[0]
73 | if args.teacher:
74 | isdiffusion = "teacher"
75 | else:
76 | isdiffusion= "como"
77 | res_path = f'{resultfolder}/{clean_name}_{spk}_{isdiffusion}_{step_num}.{wav_format}'
78 | soundfile.write(res_path, audio, svc_model.target_sample, format=wav_format)
79 | svc_model.clear_empty()
80 |
81 | if __name__ == '__main__':
82 | main()
83 |
--------------------------------------------------------------------------------
/logs/the_log_files:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Grace9994/CoMoSVC/2ea8e644e2c5b3a8afc0762e870b9daacf3b5be5/logs/the_log_files
--------------------------------------------------------------------------------
/mel_processing.py:
--------------------------------------------------------------------------------
1 | import math
2 | import os
3 | import random
4 | import torch
5 | import torch.utils.data
6 | import torch.nn.functional as F
7 | import numpy as np
8 | from librosa.util import normalize
9 | from scipy.io.wavfile import read
10 | from librosa.filters import mel as librosa_mel_fn
11 | import pathlib
12 | from tqdm import tqdm
13 |
14 | MAX_WAV_VALUE = 32768.0
15 |
16 |
17 | def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
18 | return torch.log10(torch.clamp(x, min=clip_val) * C)
19 |
20 |
21 | def dynamic_range_decompression_torch(x, C=1):
22 | return torch.exp(x) / C
23 |
24 |
25 | def spectral_normalize_torch(magnitudes):
26 | output = dynamic_range_compression_torch(magnitudes)
27 | return output
28 |
29 |
30 | def spectral_de_normalize_torch(magnitudes):
31 | output = dynamic_range_decompression_torch(magnitudes)
32 | return output
33 |
34 |
35 | mel_basis = {}
36 | hann_window = {}
37 |
38 | def mel_spectrogram(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, keyshift=0, speed=1,center=False):
39 |
40 | factor = 2 ** (keyshift / 12)
41 | n_fft_new = int(np.round(n_fft * factor))
42 | win_size_new = int(np.round(win_size * factor))
43 | hop_length_new = int(np.round(hop_size * speed))
44 |
45 |
46 | if torch.min(y) < -1.:
47 | print('min value is ', torch.min(y))
48 | if torch.max(y) > 1.:
49 | print('max value is ', torch.max(y))
50 |
51 | global mel_basis, hann_window
52 | mel_basis_key = str(fmax)+'_'+str(y.device)
53 | if mel_basis_key not in mel_basis:
54 | mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax) # 一个mel转换器,即这是一个函数,可以用来提取mel谱
55 | mel_basis[mel_basis_key] = torch.from_numpy(mel).float().to(y.device) # 建 Mel 转换器,并将其转换为 PyTorch 的张量,并根据 y.device 将其放置在相应的设备上。
56 |
57 | keyshift_key = str(keyshift)+'_'+str(y.device)
58 | if keyshift_key not in hann_window:
59 | hann_window[keyshift_key] = torch.hann_window(win_size_new).to(y.device)
60 |
61 | pad_left = (win_size_new - hop_length_new) //2
62 | pad_right = max((win_size_new- hop_length_new + 1) //2, win_size_new - y.size(-1) - pad_left)
63 | if pad_right < y.size(-1):
64 | mode = 'reflect'
65 | else:
66 | mode = 'constant'
67 | y = torch.nn.functional.pad(y.unsqueeze(1), (pad_left, pad_right), mode = mode)
68 | y = y.squeeze(1)
69 |
70 |
71 | spec = torch.stft(y, n_fft_new, hop_length=hop_length_new, win_length=win_size_new, window=hann_window[keyshift_key],
72 | center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=False)
73 |
74 | spec = torch.sqrt(spec.pow(2).sum(-1)+(1e-9))
75 | if keyshift != 0:
76 | size = n_fft // 2 + 1
77 | resize = spec.size(1)
78 | if resize < size:
79 | spec = F.pad(spec, (0, 0, 0, size-resize))
80 | spec = spec[:, :size, :] * win_size / win_size_new
81 | spec = torch.matmul(mel_basis[mel_basis_key], spec)
82 |
83 | spec = spectral_normalize_torch(spec)
84 |
85 | return spec
86 |
87 |
88 | def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False):
89 | if torch.min(y) < -1.:
90 | print('min value is ', torch.min(y))
91 | if torch.max(y) > 1.:
92 | print('max value is ', torch.max(y))
93 |
94 | global hann_window
95 | dtype_device = str(y.dtype) + '_' + str(y.device)
96 | wnsize_dtype_device = str(win_size) + '_' + dtype_device
97 | if wnsize_dtype_device not in hann_window:
98 | hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
99 |
100 | y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
101 | y = y.squeeze(1)
102 |
103 | y_dtype = y.dtype
104 | if y.dtype == torch.bfloat16:
105 | y = y.to(torch.float32)
106 |
107 | spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
108 | center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=True)
109 | spec = torch.view_as_real(spec).to(y_dtype)
110 |
111 | spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
112 | return spec
113 |
114 |
115 |
--------------------------------------------------------------------------------
/meldataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.utils.data
3 | import torch.nn.functional as F
4 | import numpy as np
5 | from librosa.filters import mel as librosa_mel_fn
6 |
7 |
8 | def spectral_normalize_torch(magnitudes):
9 | output = dynamic_range_compression_torch(magnitudes)
10 | return output
11 |
12 | def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
13 | return torch.log10(torch.clamp(x, min=clip_val) * C)
14 |
15 |
16 | def mel_spectrogram(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, keyshift=0, speed=1,center=False):
17 |
18 | factor = 2 ** (keyshift / 12)
19 | n_fft_new = int(np.round(n_fft * factor))
20 | win_size_new = int(np.round(win_size * factor))
21 | hop_length_new = int(np.round(hop_size * speed))
22 |
23 |
24 | if torch.min(y) < -1.:
25 | print('min value is ', torch.min(y))
26 | if torch.max(y) > 1.:
27 | print('max value is ', torch.max(y))
28 |
29 | global mel_basis, hann_window
30 | mel_basis_key = str(fmax)+'_'+str(y.device)
31 | if mel_basis_key not in mel_basis:
32 | mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax) # 一个mel转换器,即这是一个函数,可以用来提取mel谱
33 | mel_basis[mel_basis_key] = torch.from_numpy(mel).float().to(y.device) # 建 Mel 转换器,并将其转换为 PyTorch 的张量,并根据 y.device 将其放置在相应的设备上。
34 |
35 | keyshift_key = str(keyshift)+'_'+str(y.device)
36 | if keyshift_key not in hann_window:
37 | hann_window[keyshift_key] = torch.hann_window(win_size_new).to(y.device)
38 |
39 | pad_left = (win_size_new - hop_length_new) //2
40 | pad_right = max((win_size_new- hop_length_new + 1) //2, win_size_new - y.size(-1) - pad_left)
41 | if pad_right < y.size(-1):
42 | mode = 'reflect'
43 | else:
44 | mode = 'constant'
45 | y = torch.nn.functional.pad(y.unsqueeze(1), (pad_left, pad_right), mode = mode)
46 | y = y.squeeze(1)
47 | spec = torch.stft(y, n_fft_new, hop_length=hop_length_new, win_length=win_size_new, window=hann_window[keyshift_key],
48 | center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=False)
49 |
50 | spec = torch.sqrt(spec.pow(2).sum(-1)+(1e-9))
51 | if keyshift != 0:
52 | size = n_fft // 2 + 1
53 | resize = spec.size(1)
54 | if resize < size:
55 | spec = F.pad(spec, (0, 0, 0, size-resize))
56 | spec = spec[:, :size, :] * win_size / win_size_new
57 | spec = torch.matmul(mel_basis[mel_basis_key], spec)
58 |
59 | spec = spectral_normalize_torch(spec)
60 |
61 | return spec
62 |
--------------------------------------------------------------------------------
/pitch_extractor.py:
--------------------------------------------------------------------------------
1 | import math
2 | import torch
3 | from torch import nn
4 | from torch.nn import Parameter
5 | import torch.onnx.operators
6 | import torch.nn.functional as F
7 | import utils
8 |
9 |
10 | class Reshape(nn.Module):
11 | def __init__(self, *args):
12 | super(Reshape, self).__init__()
13 | self.shape = args
14 |
15 | def forward(self, x):
16 | return x.view(self.shape)
17 |
18 |
19 | class Permute(nn.Module):
20 | def __init__(self, *args):
21 | super(Permute, self).__init__()
22 | self.args = args
23 |
24 | def forward(self, x):
25 | return x.permute(self.args)
26 |
27 |
28 | class LinearNorm(torch.nn.Module):
29 | def __init__(self, in_dim, out_dim, bias=True, w_init_gain='linear'):
30 | super(LinearNorm, self).__init__()
31 | self.linear_layer = torch.nn.Linear(in_dim, out_dim, bias=bias)
32 |
33 | torch.nn.init.xavier_uniform_(
34 | self.linear_layer.weight,
35 | gain=torch.nn.init.calculate_gain(w_init_gain))
36 |
37 | def forward(self, x):
38 | return self.linear_layer(x)
39 |
40 |
41 | class ConvNorm(torch.nn.Module):
42 | def __init__(self, in_channels, out_channels, kernel_size=1, stride=1,
43 | padding=None, dilation=1, bias=True, w_init_gain='linear'):
44 | super(ConvNorm, self).__init__()
45 | if padding is None:
46 | assert (kernel_size % 2 == 1)
47 | padding = int(dilation * (kernel_size - 1) / 2)
48 |
49 | self.conv = torch.nn.Conv1d(in_channels, out_channels,
50 | kernel_size=kernel_size, stride=stride,
51 | padding=padding, dilation=dilation,
52 | bias=bias)
53 |
54 | torch.nn.init.xavier_uniform_(
55 | self.conv.weight, gain=torch.nn.init.calculate_gain(w_init_gain))
56 |
57 | def forward(self, signal):
58 | conv_signal = self.conv(signal)
59 | return conv_signal
60 |
61 |
62 | def Embedding(num_embeddings, embedding_dim, padding_idx=None):
63 | m = nn.Embedding(num_embeddings, embedding_dim, padding_idx=padding_idx)
64 | nn.init.normal_(m.weight, mean=0, std=embedding_dim ** -0.5)
65 | if padding_idx is not None:
66 | nn.init.constant_(m.weight[padding_idx], 0)
67 | return m
68 |
69 |
70 | # def LayerNorm(normalized_shape, eps=1e-5, elementwise_affine=True, export=False):
71 | # # if not export and torch.cuda.is_available():
72 | # # try:
73 | # # from apex.normalization import FusedLayerNorm
74 | # # return FusedLayerNorm(normalized_shape, eps, elementwise_affine)
75 | # # except ImportError:
76 | # # pass
77 | # return torch.nn.LayerNorm(normalized_shape, eps, elementwise_affine)
78 |
79 | class LayerNorm(torch.nn.LayerNorm):
80 | """Layer normalization module.
81 | :param int nout: output dim size
82 | :param int dim: dimension to be normalized
83 | """
84 |
85 | def __init__(self, nout, dim=-1):
86 | """Construct an LayerNorm object."""
87 | super(LayerNorm, self).__init__(nout, eps=1e-12)
88 | self.dim = dim
89 |
90 | def forward(self, x):
91 | """Apply layer normalization.
92 | :param torch.Tensor x: input tensor
93 | :return: layer normalized tensor
94 | :rtype torch.Tensor
95 | """
96 | if self.dim == -1:
97 | return super(LayerNorm, self).forward(x)
98 | return super(LayerNorm, self).forward(x.transpose(1, -1)).transpose(1, -1)
99 |
100 | def Linear(in_features, out_features, bias=True):
101 | m = nn.Linear(in_features, out_features, bias)
102 | nn.init.xavier_uniform_(m.weight)
103 | if bias:
104 | nn.init.constant_(m.bias, 0.)
105 | return m
106 |
107 |
108 | class SinusoidalPositionalEmbedding(nn.Module):
109 | """This module produces sinusoidal positional embeddings of any length.
110 |
111 | Padding symbols are ignored.
112 | """
113 |
114 | def __init__(self, embedding_dim, padding_idx, init_size=1024):
115 | super().__init__()
116 | self.embedding_dim = embedding_dim
117 | self.padding_idx = padding_idx
118 | self.weights = SinusoidalPositionalEmbedding.get_embedding(
119 | init_size,
120 | embedding_dim,
121 | padding_idx,
122 | )
123 | self.register_buffer('_float_tensor', torch.FloatTensor(1))
124 |
125 | @staticmethod
126 | def get_embedding(num_embeddings, embedding_dim, padding_idx=None):
127 | """Build sinusoidal embeddings.
128 |
129 | This matches the implementation in tensor2tensor, but differs slightly
130 | from the description in Section 3.5 of "Attention Is All You Need".
131 | """
132 | half_dim = embedding_dim // 2
133 | emb = math.log(10000) / (half_dim - 1)
134 | emb = torch.exp(torch.arange(half_dim, dtype=torch.float) * -emb)
135 | emb = torch.arange(num_embeddings, dtype=torch.float).unsqueeze(1) * emb.unsqueeze(0)
136 | emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1).view(num_embeddings, -1)
137 | if embedding_dim % 2 == 1:
138 | # zero pad
139 | emb = torch.cat([emb, torch.zeros(num_embeddings, 1)], dim=1)
140 | if padding_idx is not None:
141 | emb[padding_idx, :] = 0
142 | return emb
143 |
144 | def forward(self, input, incremental_state=None, timestep=None, positions=None, **kwargs):
145 | """Input is expected to be of size [bsz x seqlen]."""
146 | bsz, seq_len = input.shape[:2]
147 | max_pos = self.padding_idx + 1 + seq_len
148 | if self.weights is None or max_pos > self.weights.size(0):
149 | # recompute/expand embeddings if needed
150 | self.weights = SinusoidalPositionalEmbedding.get_embedding(
151 | max_pos,
152 | self.embedding_dim,
153 | self.padding_idx,
154 | )
155 | self.weights = self.weights.to(self._float_tensor)
156 |
157 | if incremental_state is not None:
158 | # positions is the same for every token when decoding a single step
159 | pos = timestep.view(-1)[0] + 1 if timestep is not None else seq_len
160 | return self.weights[self.padding_idx + pos, :].expand(bsz, 1, -1)
161 |
162 | positions = utils.make_positions(input, self.padding_idx) if positions is None else positions
163 | return self.weights.index_select(0, positions.view(-1)).view(bsz, seq_len, -1).detach()
164 |
165 | def max_positions(self):
166 | """Maximum number of supported positions."""
167 | return int(1e5) # an arbitrary large number
168 |
169 |
170 | class ConvTBC(nn.Module):
171 | def __init__(self, in_channels, out_channels, kernel_size, padding=0):
172 | super(ConvTBC, self).__init__()
173 | self.in_channels = in_channels
174 | self.out_channels = out_channels
175 | self.kernel_size = kernel_size
176 | self.padding = padding
177 |
178 | self.weight = torch.nn.Parameter(torch.Tensor(
179 | self.kernel_size, in_channels, out_channels))
180 | self.bias = torch.nn.Parameter(torch.Tensor(out_channels))
181 |
182 | def forward(self, input):
183 | return torch.conv_tbc(input.contiguous(), self.weight, self.bias, self.padding)
184 |
185 |
186 | class MultiheadAttention(nn.Module):
187 | def __init__(self, embed_dim, num_heads, kdim=None, vdim=None, dropout=0., bias=True,
188 | add_bias_kv=False, add_zero_attn=False, self_attention=False,
189 | encoder_decoder_attention=False):
190 | super().__init__()
191 | self.embed_dim = embed_dim
192 | self.kdim = kdim if kdim is not None else embed_dim
193 | self.vdim = vdim if vdim is not None else embed_dim
194 | self.qkv_same_dim = self.kdim == embed_dim and self.vdim == embed_dim
195 |
196 | self.num_heads = num_heads
197 | self.dropout = dropout
198 | self.head_dim = embed_dim // num_heads
199 | assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
200 | self.scaling = self.head_dim ** -0.5
201 |
202 | self.self_attention = self_attention
203 | self.encoder_decoder_attention = encoder_decoder_attention
204 |
205 | assert not self.self_attention or self.qkv_same_dim, 'Self-attention requires query, key and ' \
206 | 'value to be of the same size'
207 |
208 | if self.qkv_same_dim:
209 | self.in_proj_weight = Parameter(torch.Tensor(3 * embed_dim, embed_dim))
210 | else:
211 | self.k_proj_weight = Parameter(torch.Tensor(embed_dim, self.kdim))
212 | self.v_proj_weight = Parameter(torch.Tensor(embed_dim, self.vdim))
213 | self.q_proj_weight = Parameter(torch.Tensor(embed_dim, embed_dim))
214 |
215 | if bias:
216 | self.in_proj_bias = Parameter(torch.Tensor(3 * embed_dim))
217 | else:
218 | self.register_parameter('in_proj_bias', None)
219 |
220 | self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
221 |
222 | if add_bias_kv:
223 | self.bias_k = Parameter(torch.Tensor(1, 1, embed_dim))
224 | self.bias_v = Parameter(torch.Tensor(1, 1, embed_dim))
225 | else:
226 | self.bias_k = self.bias_v = None
227 |
228 | self.add_zero_attn = add_zero_attn
229 |
230 | self.reset_parameters()
231 |
232 | self.enable_torch_version = False
233 | if hasattr(F, "multi_head_attention_forward"):
234 | self.enable_torch_version = True
235 | else:
236 | self.enable_torch_version = False
237 | self.last_attn_probs = None
238 |
239 | def reset_parameters(self):
240 | if self.qkv_same_dim:
241 | nn.init.xavier_uniform_(self.in_proj_weight)
242 | else:
243 | nn.init.xavier_uniform_(self.k_proj_weight)
244 | nn.init.xavier_uniform_(self.v_proj_weight)
245 | nn.init.xavier_uniform_(self.q_proj_weight)
246 |
247 | nn.init.xavier_uniform_(self.out_proj.weight)
248 | if self.in_proj_bias is not None:
249 | nn.init.constant_(self.in_proj_bias, 0.)
250 | nn.init.constant_(self.out_proj.bias, 0.)
251 | if self.bias_k is not None:
252 | nn.init.xavier_normal_(self.bias_k)
253 | if self.bias_v is not None:
254 | nn.init.xavier_normal_(self.bias_v)
255 |
256 | def forward(
257 | self,
258 | query, key, value,
259 | key_padding_mask=None,
260 | incremental_state=None,
261 | need_weights=True,
262 | static_kv=False,
263 | attn_mask=None,
264 | before_softmax=False,
265 | need_head_weights=False,
266 | enc_dec_attn_constraint_mask=None,
267 | reset_attn_weight=None
268 | ):
269 | """Input shape: Time x Batch x Channel
270 |
271 | Args:
272 | key_padding_mask (ByteTensor, optional): mask to exclude
273 | keys that are pads, of shape `(batch, src_len)`, where
274 | padding elements are indicated by 1s.
275 | need_weights (bool, optional): return the attention weights,
276 | averaged over heads (default: False).
277 | attn_mask (ByteTensor, optional): typically used to
278 | implement causal attention, where the mask prevents the
279 | attention from looking forward in time (default: None).
280 | before_softmax (bool, optional): return the raw attention
281 | weights and values before the attention softmax.
282 | need_head_weights (bool, optional): return the attention
283 | weights for each head. Implies *need_weights*. Default:
284 | return the average attention weights over all heads.
285 | """
286 | if need_head_weights:
287 | need_weights = True
288 |
289 | tgt_len, bsz, embed_dim = query.size()
290 | assert embed_dim == self.embed_dim
291 | assert list(query.size()) == [tgt_len, bsz, embed_dim]
292 |
293 | if self.enable_torch_version and incremental_state is None and not static_kv and reset_attn_weight is None:
294 | if self.qkv_same_dim:
295 | return F.multi_head_attention_forward(query, key, value,
296 | self.embed_dim, self.num_heads,
297 | self.in_proj_weight,
298 | self.in_proj_bias, self.bias_k, self.bias_v,
299 | self.add_zero_attn, self.dropout,
300 | self.out_proj.weight, self.out_proj.bias,
301 | self.training, key_padding_mask, need_weights,
302 | attn_mask)
303 | else:
304 | return F.multi_head_attention_forward(query, key, value,
305 | self.embed_dim, self.num_heads,
306 | torch.empty([0]),
307 | self.in_proj_bias, self.bias_k, self.bias_v,
308 | self.add_zero_attn, self.dropout,
309 | self.out_proj.weight, self.out_proj.bias,
310 | self.training, key_padding_mask, need_weights,
311 | attn_mask, use_separate_proj_weight=True,
312 | q_proj_weight=self.q_proj_weight,
313 | k_proj_weight=self.k_proj_weight,
314 | v_proj_weight=self.v_proj_weight)
315 |
316 | if incremental_state is not None:
317 | print('Not implemented error.')
318 | exit()
319 | else:
320 | saved_state = None
321 |
322 | if self.self_attention:
323 | # self-attention
324 | q, k, v = self.in_proj_qkv(query)
325 | elif self.encoder_decoder_attention:
326 | # encoder-decoder attention
327 | q = self.in_proj_q(query)
328 | if key is None:
329 | assert value is None
330 | k = v = None
331 | else:
332 | k = self.in_proj_k(key)
333 | v = self.in_proj_v(key)
334 |
335 | else:
336 | q = self.in_proj_q(query)
337 | k = self.in_proj_k(key)
338 | v = self.in_proj_v(value)
339 | q *= self.scaling
340 |
341 | if self.bias_k is not None:
342 | assert self.bias_v is not None
343 | k = torch.cat([k, self.bias_k.repeat(1, bsz, 1)])
344 | v = torch.cat([v, self.bias_v.repeat(1, bsz, 1)])
345 | if attn_mask is not None:
346 | attn_mask = torch.cat([attn_mask, attn_mask.new_zeros(attn_mask.size(0), 1)], dim=1)
347 | if key_padding_mask is not None:
348 | key_padding_mask = torch.cat(
349 | [key_padding_mask, key_padding_mask.new_zeros(key_padding_mask.size(0), 1)], dim=1)
350 |
351 | q = q.contiguous().view(tgt_len, bsz * self.num_heads, self.head_dim).transpose(0, 1)
352 | if k is not None:
353 | k = k.contiguous().view(-1, bsz * self.num_heads, self.head_dim).transpose(0, 1)
354 | if v is not None:
355 | v = v.contiguous().view(-1, bsz * self.num_heads, self.head_dim).transpose(0, 1)
356 |
357 | if saved_state is not None:
358 | print('Not implemented error.')
359 | exit()
360 |
361 | src_len = k.size(1)
362 |
363 | # This is part of a workaround to get around fork/join parallelism
364 | # not supporting Optional types.
365 | if key_padding_mask is not None and key_padding_mask.shape == torch.Size([]):
366 | key_padding_mask = None
367 |
368 | if key_padding_mask is not None:
369 | assert key_padding_mask.size(0) == bsz
370 | assert key_padding_mask.size(1) == src_len
371 |
372 | if self.add_zero_attn:
373 | src_len += 1
374 | k = torch.cat([k, k.new_zeros((k.size(0), 1) + k.size()[2:])], dim=1)
375 | v = torch.cat([v, v.new_zeros((v.size(0), 1) + v.size()[2:])], dim=1)
376 | if attn_mask is not None:
377 | attn_mask = torch.cat([attn_mask, attn_mask.new_zeros(attn_mask.size(0), 1)], dim=1)
378 | if key_padding_mask is not None:
379 | key_padding_mask = torch.cat(
380 | [key_padding_mask, torch.zeros(key_padding_mask.size(0), 1).type_as(key_padding_mask)], dim=1)
381 |
382 | attn_weights = torch.bmm(q, k.transpose(1, 2))
383 | attn_weights = self.apply_sparse_mask(attn_weights, tgt_len, src_len, bsz)
384 |
385 | assert list(attn_weights.size()) == [bsz * self.num_heads, tgt_len, src_len]
386 |
387 | if attn_mask is not None:
388 | if len(attn_mask.shape) == 2:
389 | attn_mask = attn_mask.unsqueeze(0)
390 | elif len(attn_mask.shape) == 3:
391 | attn_mask = attn_mask[:, None].repeat([1, self.num_heads, 1, 1]).reshape(
392 | bsz * self.num_heads, tgt_len, src_len)
393 | attn_weights = attn_weights + attn_mask
394 |
395 | if enc_dec_attn_constraint_mask is not None: # bs x head x L_kv
396 | attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
397 | attn_weights = attn_weights.masked_fill(
398 | enc_dec_attn_constraint_mask.unsqueeze(2).bool(),
399 | -1e9,
400 | )
401 | attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
402 |
403 | if key_padding_mask is not None:
404 | # don't attend to padding symbols
405 | attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
406 | attn_weights = attn_weights.masked_fill(
407 | key_padding_mask.unsqueeze(1).unsqueeze(2),
408 | -1e9,
409 | )
410 | attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
411 |
412 | attn_logits = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
413 |
414 | if before_softmax:
415 | return attn_weights, v
416 |
417 | attn_weights_float = utils.softmax(attn_weights, dim=-1)
418 | attn_weights = attn_weights_float.type_as(attn_weights)
419 | attn_probs = F.dropout(attn_weights_float.type_as(attn_weights), p=self.dropout, training=self.training)
420 |
421 | if reset_attn_weight is not None:
422 | if reset_attn_weight:
423 | self.last_attn_probs = attn_probs.detach()
424 | else:
425 | assert self.last_attn_probs is not None
426 | attn_probs = self.last_attn_probs
427 | attn = torch.bmm(attn_probs, v)
428 | assert list(attn.size()) == [bsz * self.num_heads, tgt_len, self.head_dim]
429 | attn = attn.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
430 | attn = self.out_proj(attn)
431 |
432 | if need_weights:
433 | attn_weights = attn_weights_float.view(bsz, self.num_heads, tgt_len, src_len).transpose(1, 0)
434 | if not need_head_weights:
435 | # average attention weights over heads
436 | attn_weights = attn_weights.mean(dim=0)
437 | else:
438 | attn_weights = None
439 |
440 | return attn, (attn_weights, attn_logits)
441 |
442 | def in_proj_qkv(self, query):
443 | return self._in_proj(query).chunk(3, dim=-1)
444 |
445 | def in_proj_q(self, query):
446 | if self.qkv_same_dim:
447 | return self._in_proj(query, end=self.embed_dim)
448 | else:
449 | bias = self.in_proj_bias
450 | if bias is not None:
451 | bias = bias[:self.embed_dim]
452 | return F.linear(query, self.q_proj_weight, bias)
453 |
454 | def in_proj_k(self, key):
455 | if self.qkv_same_dim:
456 | return self._in_proj(key, start=self.embed_dim, end=2 * self.embed_dim)
457 | else:
458 | weight = self.k_proj_weight
459 | bias = self.in_proj_bias
460 | if bias is not None:
461 | bias = bias[self.embed_dim:2 * self.embed_dim]
462 | return F.linear(key, weight, bias)
463 |
464 | def in_proj_v(self, value):
465 | if self.qkv_same_dim:
466 | return self._in_proj(value, start=2 * self.embed_dim)
467 | else:
468 | weight = self.v_proj_weight
469 | bias = self.in_proj_bias
470 | if bias is not None:
471 | bias = bias[2 * self.embed_dim:]
472 | return F.linear(value, weight, bias)
473 |
474 | def _in_proj(self, input, start=0, end=None):
475 | weight = self.in_proj_weight
476 | bias = self.in_proj_bias
477 | weight = weight[start:end, :]
478 | if bias is not None:
479 | bias = bias[start:end]
480 | return F.linear(input, weight, bias)
481 |
482 |
483 | def apply_sparse_mask(self, attn_weights, tgt_len, src_len, bsz):
484 | return attn_weights
485 |
486 |
487 | class Swish(torch.autograd.Function):
488 | @staticmethod
489 | def forward(ctx, i):
490 | result = i * torch.sigmoid(i)
491 | ctx.save_for_backward(i)
492 | return result
493 |
494 | @staticmethod
495 | def backward(ctx, grad_output):
496 | i = ctx.saved_variables[0]
497 | sigmoid_i = torch.sigmoid(i)
498 | return grad_output * (sigmoid_i * (1 + i * (1 - sigmoid_i)))
499 |
500 |
501 | class CustomSwish(nn.Module):
502 | def forward(self, input_tensor):
503 | return Swish.apply(input_tensor)
504 |
505 |
506 | class TransformerFFNLayer(nn.Module):
507 | def __init__(self, hidden_size, filter_size, padding="SAME", kernel_size=1, dropout=0., act='gelu'):
508 | super().__init__()
509 | self.kernel_size = kernel_size
510 | self.dropout = dropout
511 | self.act = act
512 | if padding == 'SAME':
513 | self.ffn_1 = nn.Conv1d(hidden_size, filter_size, kernel_size, padding=kernel_size // 2)
514 | elif padding == 'LEFT':
515 | self.ffn_1 = nn.Sequential(
516 | nn.ConstantPad1d((kernel_size - 1, 0), 0.0),
517 | nn.Conv1d(hidden_size, filter_size, kernel_size)
518 | )
519 | self.ffn_2 = Linear(filter_size, hidden_size)
520 | if self.act == 'swish':
521 | self.swish_fn = CustomSwish()
522 |
523 | def forward(self, x, incremental_state=None):
524 | # x: T x B x C
525 | if incremental_state is not None:
526 | assert incremental_state is None, 'Nar-generation does not allow this.'
527 | exit(1)
528 |
529 | x = self.ffn_1(x.permute(1, 2, 0)).permute(2, 0, 1)
530 | x = x * self.kernel_size ** -0.5
531 |
532 | if incremental_state is not None:
533 | x = x[-1:]
534 | if self.act == 'gelu':
535 | x = F.gelu(x)
536 | if self.act == 'relu':
537 | x = F.relu(x)
538 | if self.act == 'swish':
539 | x = self.swish_fn(x)
540 | x = F.dropout(x, self.dropout, training=self.training)
541 | x = self.ffn_2(x)
542 | return x
543 |
544 |
545 | class BatchNorm1dTBC(nn.Module):
546 | def __init__(self, c):
547 | super(BatchNorm1dTBC, self).__init__()
548 | self.bn = nn.BatchNorm1d(c)
549 |
550 | def forward(self, x):
551 | """
552 |
553 | :param x: [T, B, C]
554 | :return: [T, B, C]
555 | """
556 | x = x.permute(1, 2, 0) # [B, C, T]
557 | x = self.bn(x) # [B, C, T]
558 | x = x.permute(2, 0, 1) # [T, B, C]
559 | return x
560 |
561 |
562 | class EncSALayer(nn.Module):
563 | def __init__(self, c, num_heads, dropout, attention_dropout=0.1,
564 | relu_dropout=0.1, kernel_size=9, padding='SAME', norm='ln', act='gelu'):
565 | super().__init__()
566 | self.c = c
567 | self.dropout = dropout
568 | self.num_heads = num_heads
569 | if num_heads > 0:
570 | if norm == 'ln':
571 | self.layer_norm1 = LayerNorm(c)
572 | elif norm == 'bn':
573 | self.layer_norm1 = BatchNorm1dTBC(c)
574 | self.self_attn = MultiheadAttention(
575 | self.c, num_heads, self_attention=True, dropout=attention_dropout, bias=False,
576 | )
577 | if norm == 'ln':
578 | self.layer_norm2 = LayerNorm(c)
579 | elif norm == 'bn':
580 | self.layer_norm2 = BatchNorm1dTBC(c)
581 | self.ffn = TransformerFFNLayer(
582 | c, 4 * c, kernel_size=kernel_size, dropout=relu_dropout, padding=padding, act=act)
583 |
584 | def forward(self, x, encoder_padding_mask=None, **kwargs):
585 | layer_norm_training = kwargs.get('layer_norm_training', None)
586 | if layer_norm_training is not None:
587 | self.layer_norm1.training = layer_norm_training
588 | self.layer_norm2.training = layer_norm_training
589 | if self.num_heads > 0:
590 | residual = x
591 | x = self.layer_norm1(x)
592 | x, _, = self.self_attn(
593 | query=x,
594 | key=x,
595 | value=x,
596 | key_padding_mask=encoder_padding_mask
597 | )
598 | x = F.dropout(x, self.dropout, training=self.training)
599 | x = residual + x
600 | x = x * (1 - encoder_padding_mask.float()).transpose(0, 1)[..., None]
601 |
602 | residual = x
603 | x = self.layer_norm2(x)
604 | x = self.ffn(x)
605 | x = F.dropout(x, self.dropout, training=self.training)
606 | x = residual + x
607 | x = x * (1 - encoder_padding_mask.float()).transpose(0, 1)[..., None]
608 | return x
609 |
610 |
611 | class DecSALayer(nn.Module):
612 | def __init__(self, c, num_heads, dropout, attention_dropout=0.1, relu_dropout=0.1, kernel_size=9, act='gelu'):
613 | super().__init__()
614 | self.c = c
615 | self.dropout = dropout
616 | self.layer_norm1 = LayerNorm(c)
617 | self.self_attn = MultiheadAttention(
618 | c, num_heads, self_attention=True, dropout=attention_dropout, bias=False
619 | )
620 | self.layer_norm2 = LayerNorm(c)
621 | self.encoder_attn = MultiheadAttention(
622 | c, num_heads, encoder_decoder_attention=True, dropout=attention_dropout, bias=False,
623 | )
624 | self.layer_norm3 = LayerNorm(c)
625 | self.ffn = TransformerFFNLayer(
626 | c, 4 * c, padding='LEFT', kernel_size=kernel_size, dropout=relu_dropout, act=act)
627 |
628 | def forward(
629 | self,
630 | x,
631 | encoder_out=None,
632 | encoder_padding_mask=None,
633 | incremental_state=None,
634 | self_attn_mask=None,
635 | self_attn_padding_mask=None,
636 | attn_out=None,
637 | reset_attn_weight=None,
638 | **kwargs,
639 | ):
640 | layer_norm_training = kwargs.get('layer_norm_training', None)
641 | if layer_norm_training is not None:
642 | self.layer_norm1.training = layer_norm_training
643 | self.layer_norm2.training = layer_norm_training
644 | self.layer_norm3.training = layer_norm_training
645 | residual = x
646 | x = self.layer_norm1(x)
647 | x, _ = self.self_attn(
648 | query=x,
649 | key=x,
650 | value=x,
651 | key_padding_mask=self_attn_padding_mask,
652 | incremental_state=incremental_state,
653 | attn_mask=self_attn_mask
654 | )
655 | x = F.dropout(x, self.dropout, training=self.training)
656 | x = residual + x
657 |
658 | residual = x
659 | x = self.layer_norm2(x)
660 | if encoder_out is not None:
661 | x, attn = self.encoder_attn(
662 | query=x,
663 | key=encoder_out,
664 | value=encoder_out,
665 | key_padding_mask=encoder_padding_mask,
666 | incremental_state=incremental_state,
667 | static_kv=True,
668 | enc_dec_attn_constraint_mask=None, #utils.get_incremental_state(self, incremental_state, 'enc_dec_attn_constraint_mask'),
669 | reset_attn_weight=reset_attn_weight
670 | )
671 | attn_logits = attn[1]
672 | else:
673 | assert attn_out is not None
674 | x = self.encoder_attn.in_proj_v(attn_out.transpose(0, 1))
675 | attn_logits = None
676 | x = F.dropout(x, self.dropout, training=self.training)
677 | x = residual + x
678 |
679 | residual = x
680 | x = self.layer_norm3(x)
681 | x = self.ffn(x, incremental_state=incremental_state)
682 | x = F.dropout(x, self.dropout, training=self.training)
683 | x = residual + x
684 | # if len(attn_logits.size()) > 3:
685 | # indices = attn_logits.softmax(-1).max(-1).values.sum(-1).argmax(-1)
686 | # attn_logits = attn_logits.gather(1,
687 | # indices[:, None, None, None].repeat(1, 1, attn_logits.size(-2), attn_logits.size(-1))).squeeze(1)
688 | return x, attn_logits
689 |
690 | class PitchPredictor(torch.nn.Module):
691 | def __init__(self, idim, n_layers=5, n_chans=384, odim=2, kernel_size=5,
692 | dropout_rate=0.1, padding='SAME'):
693 | """Initilize pitch predictor module.
694 | Args:
695 | idim (int): Input dimension.
696 | n_layers (int, optional): Number of convolutional layers.
697 | n_chans (int, optional): Number of channels of convolutional layers.
698 | kernel_size (int, optional): Kernel size of convolutional layers.
699 | dropout_rate (float, optional): Dropout rate.
700 | """
701 | super(PitchPredictor, self).__init__()
702 | self.conv = torch.nn.ModuleList()
703 | self.kernel_size = kernel_size
704 | self.padding = padding
705 | for idx in range(n_layers):
706 | in_chans = idim if idx == 0 else n_chans
707 | self.conv += [torch.nn.Sequential(
708 | torch.nn.ConstantPad1d(((kernel_size - 1) // 2, (kernel_size - 1) // 2)
709 | if padding == 'SAME'
710 | else (kernel_size - 1, 0), 0),
711 | torch.nn.Conv1d(in_chans, n_chans, kernel_size, stride=1, padding=0),
712 | torch.nn.ReLU(),
713 | LayerNorm(n_chans, dim=1),
714 | torch.nn.Dropout(dropout_rate)
715 | )]
716 | self.linear = torch.nn.Linear(n_chans, odim)
717 | self.embed_positions = SinusoidalPositionalEmbedding(idim, 0, init_size=4096)
718 | self.pos_embed_alpha = nn.Parameter(torch.Tensor([1]))
719 |
720 | def forward(self, xs):
721 | """
722 |
723 | :param xs: [B, T, H]
724 | :return: [B, T, H]
725 | """
726 | positions = self.pos_embed_alpha * self.embed_positions(xs[..., 0])
727 | xs = xs + positions
728 | xs = xs.transpose(1, -1) # (B, idim, Tmax)
729 | for f in self.conv:
730 | xs = f(xs) # (B, C, Tmax)
731 | # NOTE: calculate in log domain
732 | xs = self.linear(xs.transpose(1, -1)) # (B, Tmax, H)
733 | return xs
734 |
735 |
736 | class Prenet(nn.Module):
737 | def __init__(self, in_dim=80, out_dim=256, kernel=5, n_layers=3, strides=None):
738 | super(Prenet, self).__init__()
739 | padding = kernel // 2
740 | self.layers = []
741 | self.strides = strides if strides is not None else [1] * n_layers
742 | for l in range(n_layers):
743 | self.layers.append(nn.Sequential(
744 | nn.Conv1d(in_dim, out_dim, kernel_size=kernel, padding=padding, stride=self.strides[l]),
745 | nn.ReLU(),
746 | nn.BatchNorm1d(out_dim)
747 | ))
748 | in_dim = out_dim
749 | self.layers = nn.ModuleList(self.layers)
750 | self.out_proj = nn.Linear(out_dim, out_dim)
751 |
752 | def forward(self, x):
753 | """
754 |
755 | :param x: [B, T, 80]
756 | :return: [L, B, T, H], [B, T, H]
757 | """
758 | padding_mask = x.abs().sum(-1).eq(0).data # [B, T]
759 | nonpadding_mask_TB = 1 - padding_mask.float()[:, None, :] # [B, 1, T]
760 | x = x.transpose(1, 2)
761 | hiddens = []
762 | for i, l in enumerate(self.layers):
763 | nonpadding_mask_TB = nonpadding_mask_TB[:, :, ::self.strides[i]]
764 | x = l(x) * nonpadding_mask_TB
765 | hiddens.append(x)
766 | hiddens = torch.stack(hiddens, 0) # [L, B, H, T]
767 | hiddens = hiddens.transpose(2, 3) # [L, B, T, H]
768 | x = self.out_proj(x.transpose(1, 2)) # [B, T, H]
769 | x = x * nonpadding_mask_TB.transpose(1, 2)
770 | return hiddens, x
771 |
772 |
773 | class ConvBlock(nn.Module):
774 | def __init__(self, idim=80, n_chans=256, kernel_size=3, stride=1, norm='gn', dropout=0):
775 | super().__init__()
776 | self.conv = ConvNorm(idim, n_chans, kernel_size, stride=stride)
777 | self.norm = norm
778 | if self.norm == 'bn':
779 | self.norm = nn.BatchNorm1d(n_chans)
780 | elif self.norm == 'in':
781 | self.norm = nn.InstanceNorm1d(n_chans, affine=True)
782 | elif self.norm == 'gn':
783 | self.norm = nn.GroupNorm(n_chans // 16, n_chans)
784 | elif self.norm == 'ln':
785 | self.norm = LayerNorm(n_chans // 16, n_chans)
786 | elif self.norm == 'wn':
787 | self.conv = torch.nn.utils.weight_norm(self.conv.conv)
788 | self.dropout = nn.Dropout(dropout)
789 | self.relu = nn.ReLU()
790 |
791 | def forward(self, x):
792 | """
793 |
794 | :param x: [B, C, T]
795 | :return: [B, C, T]
796 | """
797 | x = self.conv(x)
798 | if not isinstance(self.norm, str):
799 | if self.norm == 'none':
800 | pass
801 | elif self.norm == 'ln':
802 | x = self.norm(x.transpose(1, 2)).transpose(1, 2)
803 | else:
804 | x = self.norm(x)
805 | x = self.relu(x)
806 | x = self.dropout(x)
807 | return x
808 |
809 |
810 | class ConvStacks(nn.Module):
811 | def __init__(self, idim=80, n_layers=5, n_chans=256, odim=32, kernel_size=5, norm='gn',
812 | dropout=0, strides=None, res=True):
813 | super().__init__()
814 | self.conv = torch.nn.ModuleList()
815 | self.kernel_size = kernel_size
816 | self.res = res
817 | self.in_proj = Linear(idim, n_chans)
818 | if strides is None:
819 | strides = [1] * n_layers
820 | else:
821 | assert len(strides) == n_layers
822 | for idx in range(n_layers):
823 | self.conv.append(ConvBlock(
824 | n_chans, n_chans, kernel_size, stride=strides[idx], norm=norm, dropout=dropout))
825 | self.out_proj = Linear(n_chans, odim)
826 |
827 | def forward(self, x, return_hiddens=False):
828 | """
829 |
830 | :param x: [B, T, H]
831 | :return: [B, T, H]
832 | """
833 | x = self.in_proj(x)
834 | x = x.transpose(1, -1) # (B, idim, Tmax)
835 | hiddens = []
836 | for f in self.conv:
837 | x_ = f(x)
838 | x = x + x_ if self.res else x_ # (B, C, Tmax)
839 | hiddens.append(x)
840 | x = x.transpose(1, -1)
841 | x = self.out_proj(x) # (B, Tmax, H)
842 | if return_hiddens:
843 | hiddens = torch.stack(hiddens, 1) # [B, L, C, T]
844 | return x, hiddens
845 | return x
846 |
847 |
848 | class PitchExtractor(nn.Module):
849 | def __init__(self, n_mel_bins=80, conv_layers=2):
850 | super().__init__()
851 | self.hidden_size = 256
852 | self.predictor_hidden = self.hidden_size
853 | self.conv_layers = conv_layers
854 |
855 | self.mel_prenet = Prenet(n_mel_bins, self.hidden_size, strides=[1, 1, 1])
856 | if self.conv_layers > 0:
857 | self.mel_encoder = ConvStacks(
858 | idim=self.hidden_size, n_chans=self.hidden_size, odim=self.hidden_size, n_layers=self.conv_layers)
859 | self.pitch_predictor = PitchPredictor(
860 | self.hidden_size, n_chans=self.predictor_hidden,
861 | n_layers=5, dropout_rate=0.5, odim=2,
862 | padding='SAME', kernel_size=5)
863 |
864 | def forward(self, mel_input=None):
865 | ret = {}
866 | mel_hidden = self.mel_prenet(mel_input)[1]
867 | if self.conv_layers > 0:
868 | mel_hidden = self.mel_encoder(mel_hidden)
869 |
870 | ret['pitch_pred'] = pitch_pred = self.pitch_predictor(mel_hidden)
871 |
872 | # pitch_padding = mel_input.abs().sum(-1) == 0
873 | # use_uv = hparams['pitch_type'] == 'frame' and hparams['use_uv']
874 |
875 | # ret['f0_denorm_pred'] = denorm_f0(
876 | # pitch_pred[:, :, 0], (pitch_pred[:, :, 1] > 0) if use_uv else None,
877 | # hparams, pitch_padding=pitch_padding)
878 | return ret
--------------------------------------------------------------------------------
/preparation_slice.py:
--------------------------------------------------------------------------------
1 | import glob
2 | import os
3 | from pydub import AudioSegment
4 | from pydub.silence import split_on_silence
5 | from pydub.utils import make_chunks
6 | import argparse
7 | from multiprocessing import Pool
8 | from glob import glob
9 |
10 | def process(filename,wavformat,size):
11 | songname = filename.split('/')[-1].strip('.'+wavformat)
12 | singer = filename.split('/')[-2]
13 | slice_name = './dataset_raw/'+singer+'/'+songname
14 |
15 | if not os.path.exists('./dataset_raw/'+singer):
16 | os.mkdir('./dataset_raw/'+singer)
17 |
18 | # Removing the silent parts
19 | audio_segment = AudioSegment.from_file(filename) # Loading the audio
20 | list_split_on_silence = split_on_silence(
21 | audio_segment, min_silence_len=600,
22 | silence_thresh=-40,
23 | keep_silence=400)
24 | sum=audio_segment[:1]
25 | for i, chunk in enumerate(list_split_on_silence):
26 | sum=sum+chunk
27 |
28 | # Slicing
29 | chunks = make_chunks(sum, size)
30 |
31 | for i, chunk in enumerate(chunks):
32 | chunk_name=slice_name+"_{0}.wav".format(i)
33 | if not os.path.exists(chunk_name):
34 | #logger1.info(chunk_name)
35 | chunk.export(chunk_name, format="wav")
36 |
37 |
38 |
39 | if __name__ == '__main__':
40 | parser = argparse.ArgumentParser()
41 | parser.add_argument("-w","--wavformat", type=str, default="wav", help="the wavformat of original data")
42 | parser.add_argument("-s","--size", type=int, default=10000, help="the length of audio slices")
43 | args = parser.parse_args()
44 | wavformat = args.wavformat
45 | size = args.size
46 | files=glob('./dataset_slice/*/*.'+wavformat)
47 |
48 | for file in files:
49 | process(file,wavformat,size)
50 |
--------------------------------------------------------------------------------
/preprocessing1_resample.py:
--------------------------------------------------------------------------------
1 | import librosa
2 | import os,tqdm
3 | import multiprocessing as mp
4 | import soundfile as sf
5 | from glob import glob
6 | import argparse
7 |
8 | def resample_one(filename):
9 | singer=filename.split('/')[-2]
10 | songname=filename.split('/')[-1]
11 | output_path='dataset/'+singer+'/'+songname
12 | if os.path.exists(output_path):
13 | return
14 | wav, sr = librosa.load(filename, sr=24000)
15 | # normalize the volume
16 | wav = wav / (0.00001+max(abs(wav)))*0.95
17 | # write to file using soundfile
18 | try:
19 | sf.write(output_path, wav, 24000)
20 | except:
21 | print("Error writing file",output_path)
22 | return
23 |
24 | def mkdir_func(input_path):
25 | singer=input_path.split('/')[-2]
26 | out_dir = 'dataset/'+singer
27 | if not os.path.exists(out_dir):
28 | os.makedirs(out_dir)
29 |
30 | def resample_parallel(num_process):
31 | input_paths = glob('dataset_raw/*/*.wav')
32 | print("input_paths",len(input_paths))
33 | # multiprocessing with progress bar
34 | pool = mp.Pool(num_process)
35 | for _ in tqdm.tqdm(pool.imap_unordered(resample_one, input_paths), total=len(input_paths)):
36 | pass
37 |
38 | def path_parallel():
39 | input_paths = glob('dataset_raw/*/*.wav')
40 | input_paths = list(set(input_paths)) # sort
41 | print("input_paths",len(input_paths))
42 | for input_path in input_paths:
43 | mkdir_func(input_path)
44 |
45 | if __name__ == "__main__":
46 | parser = argparse.ArgumentParser()
47 | parser.add_argument("-n","--num_process", type=int, default=5, help="the number of process")
48 | args = parser.parse_args()
49 | num_process = args.num_process
50 | path_parallel()
51 | resample_parallel(num_process)
52 |
--------------------------------------------------------------------------------
/preprocessing2_flist.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import re
4 | import wave
5 | from random import shuffle
6 |
7 | from loguru import logger
8 | from tqdm import tqdm
9 |
10 | import utils
11 |
12 | pattern = re.compile(r'^[\.a-zA-Z0-9_\/]+$')
13 |
14 | def get_wav_duration(file_path):
15 | try:
16 | with wave.open(file_path, 'rb') as wav_file:
17 | # The number of frames
18 | n_frames = wav_file.getnframes()
19 | # The sampling rate
20 | framerate = wav_file.getframerate()
21 | # The duration
22 | return n_frames / float(framerate)
23 | except Exception as e:
24 | logger.error(f"Reading {file_path}")
25 | raise e
26 |
27 | if __name__ == "__main__":
28 | parser = argparse.ArgumentParser()
29 | parser.add_argument("--train_list", type=str, default="./filelists/train.txt", help="path to train list")
30 | parser.add_argument("--val_list", type=str, default="./filelists/val.txt", help="path to val list")
31 | parser.add_argument("--source_dir", type=str, default="./dataset", help="path to source dir")
32 | args = parser.parse_args()
33 |
34 | train = []
35 | val = []
36 | idx = 0
37 | spk_dict = {}
38 | spk_id = 0
39 |
40 |
41 | for speaker in tqdm(os.listdir(args.source_dir)):
42 | spk_dict[speaker] = spk_id
43 | spk_id += 1
44 | wavs = []
45 |
46 | for file_name in os.listdir(os.path.join(args.source_dir, speaker)):
47 | if not file_name.endswith("wav"):
48 | continue
49 | if file_name.startswith("."):
50 | continue
51 |
52 | file_path = "/".join([args.source_dir, speaker, file_name])
53 |
54 | if get_wav_duration(file_path) < 0.3:
55 | logger.info("Skip too short audio: " + file_path)
56 | continue
57 |
58 | wavs.append(file_path)
59 |
60 | shuffle(wavs)
61 | train += wavs[2:]
62 | val += wavs[:2]
63 |
64 | shuffle(train)
65 | shuffle(val)
66 |
67 | logger.info("Writing " + args.train_list)
68 | with open(args.train_list, "w") as f:
69 | for fname in tqdm(train):
70 | wavpath = fname
71 | f.write(wavpath + "\n")
72 |
73 | logger.info("Writing " + args.val_list)
74 | with open(args.val_list, "w") as f:
75 | for fname in tqdm(val):
76 | wavpath = fname
77 | f.write(wavpath + "\n")
78 |
79 |
80 | d_config_template = utils.load_config("configs_template/diffusion_template.yaml")
81 | d_config_template["model"]["n_spk"] = spk_id
82 |
83 | d_config_template["spk"] = spk_dict
84 |
85 |
86 | logger.info("Writing to configs/diffusion.yaml")
87 | utils.save_config("configs/diffusion.yaml",d_config_template)
88 |
--------------------------------------------------------------------------------
/preprocessing3_feature.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import logging
3 | import os
4 | import random
5 | from concurrent.futures import ProcessPoolExecutor
6 | from glob import glob
7 | from random import shuffle
8 |
9 | import librosa
10 | import numpy as np
11 | import torch
12 | import torch.multiprocessing as mp
13 | from loguru import logger
14 | from tqdm import tqdm
15 |
16 | import utils
17 | from Vocoder import Vocoder
18 | from mel_processing import spectrogram_torch
19 |
20 | logging.getLogger("numba").setLevel(logging.WARNING)
21 | logging.getLogger("matplotlib").setLevel(logging.WARNING)
22 |
23 | dconfig = utils.load_config("./configs/diffusion.yaml")
24 |
25 |
26 | def process_one(filename, hmodel, device, hop_length, sampling_rate, filter_length, win_length):
27 | wav, sr = librosa.load(filename, sr=sampling_rate)
28 | audio_norm = torch.FloatTensor(wav)
29 | audio_norm = audio_norm.unsqueeze(0)
30 | soft_path = filename + ".soft.pt"
31 | if not os.path.exists(soft_path):
32 | wav16k = librosa.resample(wav, orig_sr=sampling_rate, target_sr=16000)
33 | wav16k = torch.from_numpy(wav16k).to(device)
34 | c = hmodel.encoder(wav16k) # extract content from the pre-trained model
35 | torch.save(c.cpu(), soft_path)
36 |
37 | f0_path = filename + ".f0.npy"
38 | if not os.path.exists(f0_path):
39 | from Features import DioF0Predictor
40 | f0_predictor= DioF0Predictor(hop_length=hop_length,sampling_rate=sampling_rate)
41 | f0,uv = f0_predictor.compute_f0_uv(wav)
42 | np.save(f0_path, np.asanyarray((f0,uv),dtype=object))
43 |
44 |
45 | spec_path = filename.replace(".wav", ".spec.pt")
46 | if not os.path.exists(spec_path):
47 | # Process spectrogram
48 | # The following code can't be replaced by torch.FloatTensor(wav)
49 | # because load_wav_to_torch return a tensor that need to be normalized
50 | if sr != sampling_rate:
51 | raise ValueError("{} SR doesn't match target {} SR".format(sr,sampling_rate))
52 | spec = spectrogram_torch(
53 | audio_norm,
54 | filter_length,
55 | sampling_rate,
56 | hop_length,
57 | win_length,
58 | center=False,
59 | )
60 | spec = torch.squeeze(spec, 0)
61 | torch.save(spec, spec_path)
62 |
63 |
64 | volume_path = filename + ".vol.npy"
65 | if not os.path.exists(volume_path):
66 | volume_extractor = utils.Volume_Extractor(hop_length)
67 | volume = volume_extractor.extract(audio_norm)
68 | np.save(volume_path, volume.to('cpu').numpy())
69 |
70 |
71 | mel_path = filename + ".mel.npy"
72 | mel_extractor = Vocoder(dconfig.vocoder.type, dconfig.vocoder.ckpt, device=device)
73 |
74 | if not os.path.exists(mel_path) and mel_extractor is not None:
75 | mel_t = mel_extractor.extract(audio_norm.to(device), sampling_rate)
76 | mel = mel_t.squeeze().to('cpu').numpy()
77 | np.save(mel_path, mel)
78 |
79 | max_amp = float(torch.max(torch.abs(audio_norm))) + 1e-5
80 | max_shift = min(1, np.log10(1/max_amp))
81 | log10_vol_shift = random.uniform(-1, max_shift)
82 | keyshift = random.uniform(-5, 5)
83 |
84 | aug_mel_path = filename + ".aug_mel.npy"
85 | if not os.path.exists(aug_mel_path):
86 | aug_mel_t = mel_extractor.extract(audio_norm * (10 ** log10_vol_shift), sampling_rate, keyshift = keyshift)
87 | aug_mel = aug_mel_t.squeeze().to('cpu').numpy()
88 | np.save(aug_mel_path,np.asanyarray((aug_mel,keyshift),dtype=object))
89 |
90 | aug_vol_path = filename + ".aug_vol.npy"
91 | if not os.path.exists(aug_vol_path):
92 | aug_vol = volume_extractor.extract(audio_norm * (10 ** log10_vol_shift))
93 | np.save(aug_vol_path,aug_vol.to('cpu').numpy())
94 |
95 |
96 | def process_batch(file_chunk, hop_length, sampling_rate, filter_length, win_length, device="cpu"):
97 | logger.info("Loading speech encoder for content...")
98 | rank = mp.current_process()._identity
99 | rank = rank[0] if len(rank) > 0 else 0
100 | if torch.cuda.is_available():
101 | gpu_id = rank % torch.cuda.device_count()
102 | device = torch.device(f"cuda:{gpu_id}")
103 | logger.info(f"Rank {rank} uses device {device}")
104 | from Features import ContentVec768L12
105 | hmodel = ContentVec768L12(device = device)
106 | logger.info(f"Loaded speech encoder for rank {rank}")
107 | for filename in tqdm(file_chunk, position = rank):
108 | process_one(filename, hmodel, device, hop_length, sampling_rate, filter_length, win_length)
109 |
110 | def parallel_process(filenames, num_processes, hop_length, sampling_rate, filter_length, win_length, device):
111 | with ProcessPoolExecutor(max_workers=num_processes) as executor:
112 | tasks = []
113 | for i in range(num_processes):
114 | start = int(i * len(filenames) / num_processes)
115 | end = int((i + 1) * len(filenames) / num_processes)
116 | file_chunk = filenames[start:end]
117 | tasks.append(executor.submit(process_batch, file_chunk, hop_length, sampling_rate, filter_length, win_length,device=device))
118 | for task in tqdm(tasks, position = 0):
119 | task.result()
120 |
121 | if __name__ == "__main__":
122 | parser = argparse.ArgumentParser()
123 | parser.add_argument('-c',"--config", type=str, default='configs/diffusion.yaml', help="path to input dir")
124 | parser.add_argument(
125 | '-n','--num_processes', type=int, default=1, help='You are advised to set the number of processes to the same as the number of CPU cores')
126 | args = parser.parse_args()
127 |
128 | dconfig = utils.load_config(args.config)
129 |
130 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
131 | logger.info("Using device: " + str(device))
132 | print("Loading Mel Extractor...",dconfig.vocoder.type)
133 | # mel_extractor = Vocoder(dconfig.vocoder.type, dconfig.vocoder.ckpt, device=device)
134 |
135 | filenames = glob("./dataset/*/*.wav", recursive=True) # [:10]
136 | shuffle(filenames)
137 | mp.set_start_method("spawn", force=True)
138 |
139 | num_processes = args.num_processes
140 | if num_processes == 0:
141 | num_processes = os.cpu_count()
142 |
143 | parallel_process(filenames, num_processes, dconfig.data.hop_length, dconfig.data.sampling_rate, dconfig.data.filter_length, dconfig.data.win_length, device)
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | numpy==1.23.5
2 | pyworld
3 | scipy==1.10.0
4 | SoundFile==0.12.1
5 | librosa==0.9.1
6 | torch==2.1.0
7 | fairseq==0.12.2
8 | torchaudio
9 | tqdm
10 | loguru
11 | pydub
12 | matplotlib
13 | tensorboard
14 | tensorboardX
15 | pyyaml
--------------------------------------------------------------------------------
/saver.py:
--------------------------------------------------------------------------------
1 | '''
2 | author: wayn391@mastertones
3 | '''
4 |
5 | import datetime
6 | import os
7 | import time
8 |
9 | import matplotlib.pyplot as plt
10 | import torch
11 | import yaml
12 | from torch.utils.tensorboard import SummaryWriter
13 |
14 |
15 | class Saver(object):
16 | def __init__(
17 | self,
18 | args,
19 | save_dir,
20 | initial_global_step=-1):
21 |
22 | self.expdir = save_dir
23 | self.sample_rate = args.data.sampling_rate
24 |
25 | # cold start
26 | self.global_step = initial_global_step
27 | self.init_time = time.time()
28 | self.last_time = time.time()
29 |
30 | # makedirs
31 | os.makedirs(self.expdir, exist_ok=True)
32 |
33 | # path
34 | self.path_log_info = os.path.join(self.expdir, 'log_info.txt')
35 |
36 | # ckpt
37 | os.makedirs(self.expdir, exist_ok=True)
38 |
39 | # writer
40 | self.writer = SummaryWriter(os.path.join(self.expdir, 'logs'))
41 |
42 | # save config
43 | path_config = os.path.join(self.expdir, 'config.yaml')
44 | with open(path_config, "w") as out_config:
45 | yaml.dump(dict(args), out_config)
46 |
47 |
48 | def log_info(self, msg):
49 | '''log method'''
50 | if isinstance(msg, dict):
51 | msg_list = []
52 | for k, v in msg.items():
53 | tmp_str = ''
54 | if isinstance(v, int):
55 | tmp_str = '{}: {:,}'.format(k, v)
56 | else:
57 | tmp_str = '{}: {}'.format(k, v)
58 |
59 | msg_list.append(tmp_str)
60 | msg_str = '\n'.join(msg_list)
61 | else:
62 | msg_str = msg
63 |
64 | # dsplay
65 | print(msg_str)
66 |
67 | # save
68 | with open(self.path_log_info, 'a') as fp:
69 | fp.write(msg_str+'\n')
70 |
71 | def log_value(self, dict):
72 | for k, v in dict.items():
73 | self.writer.add_scalar(k, v, self.global_step)
74 |
75 | def log_spec(self, name, spec, spec_out, vmin=-14, vmax=3.5):
76 | spec_cat = torch.cat([(spec_out - spec).abs() + vmin, spec, spec_out], -1)
77 | spec = spec_cat[0]
78 | if isinstance(spec, torch.Tensor):
79 | spec = spec.cpu().numpy()
80 | fig = plt.figure(figsize=(12, 9))
81 | plt.pcolor(spec.T, vmin=vmin, vmax=vmax)
82 | plt.tight_layout()
83 | self.writer.add_figure(name, fig, self.global_step)
84 |
85 | def log_audio(self, dict):
86 | for k, v in dict.items():
87 | self.writer.add_audio(k, v, global_step=self.global_step, sample_rate=self.sample_rate)
88 |
89 | def get_interval_time(self, update=True):
90 | cur_time = time.time()
91 | time_interval = cur_time - self.last_time
92 | if update:
93 | self.last_time = cur_time
94 | return time_interval
95 |
96 | def get_total_time(self, to_str=True):
97 | total_time = time.time() - self.init_time
98 | if to_str:
99 | total_time = str(datetime.timedelta(
100 | seconds=total_time))[:-5]
101 | return total_time
102 |
103 | def save_model(
104 | self,
105 | model,
106 | optimizer,
107 | name='model',
108 | postfix='',
109 | to_json=False):
110 | # path
111 | if postfix:
112 | postfix = '_' + postfix
113 | path_pt = os.path.join(
114 | self.expdir , name+postfix+'.pt')
115 |
116 | # check
117 | print(' [*] model checkpoint saved: {}'.format(path_pt))
118 |
119 | # save
120 | if optimizer is not None:
121 | torch.save({
122 | 'global_step': self.global_step,
123 | 'model': model.state_dict(),
124 | 'optimizer': optimizer.state_dict()}, path_pt)
125 | else:
126 | torch.save({
127 | 'global_step': self.global_step,
128 | 'model': model.state_dict()}, path_pt)
129 |
130 |
131 | def delete_model(self, name='model', postfix=''):
132 | # path
133 | if postfix:
134 | postfix = '_' + postfix
135 | path_pt = os.path.join(
136 | self.expdir , name+postfix+'.pt')
137 |
138 | # delete
139 | if os.path.exists(path_pt):
140 | os.remove(path_pt)
141 | print(' [*] model checkpoint deleted: {}'.format(path_pt))
142 |
143 | def global_step_increment(self):
144 | self.global_step += 1
145 |
146 |
147 |
--------------------------------------------------------------------------------
/slicer.py:
--------------------------------------------------------------------------------
1 | import librosa
2 | import torch
3 | import torchaudio
4 |
5 |
6 | class Slicer:
7 | def __init__(self,
8 | sr: int,
9 | threshold: float = -40.,
10 | min_length: int = 5000,
11 | min_interval: int = 300,
12 | hop_size: int = 20,
13 | max_sil_kept: int = 5000):
14 | if not min_length >= min_interval >= hop_size:
15 | raise ValueError('The following condition must be satisfied: min_length >= min_interval >= hop_size')
16 | if not max_sil_kept >= hop_size:
17 | raise ValueError('The following condition must be satisfied: max_sil_kept >= hop_size')
18 | min_interval = sr * min_interval / 1000
19 | self.threshold = 10 ** (threshold / 20.)
20 | self.hop_size = round(sr * hop_size / 1000)
21 | self.win_size = min(round(min_interval), 4 * self.hop_size)
22 | self.min_length = round(sr * min_length / 1000 / self.hop_size)
23 | self.min_interval = round(min_interval / self.hop_size)
24 | self.max_sil_kept = round(sr * max_sil_kept / 1000 / self.hop_size)
25 |
26 | def _apply_slice(self, waveform, begin, end):
27 | if len(waveform.shape) > 1:
28 | return waveform[:, begin * self.hop_size: min(waveform.shape[1], end * self.hop_size)]
29 | else:
30 | return waveform[begin * self.hop_size: min(waveform.shape[0], end * self.hop_size)]
31 |
32 | # @timeit
33 | def slice(self, waveform):
34 | if len(waveform.shape) > 1:
35 | samples = librosa.to_mono(waveform)
36 | else:
37 | samples = waveform
38 | if samples.shape[0] <= self.min_length:
39 | return {"0": {"slice": False, "split_time": f"0,{len(waveform)}"}}
40 | rms_list = librosa.feature.rms(y=samples, frame_length=self.win_size, hop_length=self.hop_size).squeeze(0)
41 | sil_tags = []
42 | silence_start = None
43 | clip_start = 0
44 | for i, rms in enumerate(rms_list):
45 | # Keep looping while frame is silent.
46 | if rms < self.threshold:
47 | # Record start of silent frames.
48 | if silence_start is None:
49 | silence_start = i
50 | continue
51 | # Keep looping while frame is not silent and silence start has not been recorded.
52 | if silence_start is None:
53 | continue
54 | # Clear recorded silence start if interval is not enough or clip is too short
55 | is_leading_silence = silence_start == 0 and i > self.max_sil_kept
56 | need_slice_middle = i - silence_start >= self.min_interval and i - clip_start >= self.min_length
57 | if not is_leading_silence and not need_slice_middle:
58 | silence_start = None
59 | continue
60 | # Need slicing. Record the range of silent frames to be removed.
61 | if i - silence_start <= self.max_sil_kept:
62 | pos = rms_list[silence_start: i + 1].argmin() + silence_start
63 | if silence_start == 0:
64 | sil_tags.append((0, pos))
65 | else:
66 | sil_tags.append((pos, pos))
67 | clip_start = pos
68 | elif i - silence_start <= self.max_sil_kept * 2:
69 | pos = rms_list[i - self.max_sil_kept: silence_start + self.max_sil_kept + 1].argmin()
70 | pos += i - self.max_sil_kept
71 | pos_l = rms_list[silence_start: silence_start + self.max_sil_kept + 1].argmin() + silence_start
72 | pos_r = rms_list[i - self.max_sil_kept: i + 1].argmin() + i - self.max_sil_kept
73 | if silence_start == 0:
74 | sil_tags.append((0, pos_r))
75 | clip_start = pos_r
76 | else:
77 | sil_tags.append((min(pos_l, pos), max(pos_r, pos)))
78 | clip_start = max(pos_r, pos)
79 | else:
80 | pos_l = rms_list[silence_start: silence_start + self.max_sil_kept + 1].argmin() + silence_start
81 | pos_r = rms_list[i - self.max_sil_kept: i + 1].argmin() + i - self.max_sil_kept
82 | if silence_start == 0:
83 | sil_tags.append((0, pos_r))
84 | else:
85 | sil_tags.append((pos_l, pos_r))
86 | clip_start = pos_r
87 | silence_start = None
88 | # Deal with trailing silence.
89 | total_frames = rms_list.shape[0]
90 | if silence_start is not None and total_frames - silence_start >= self.min_interval:
91 | silence_end = min(total_frames, silence_start + self.max_sil_kept)
92 | pos = rms_list[silence_start: silence_end + 1].argmin() + silence_start
93 | sil_tags.append((pos, total_frames + 1))
94 | # Apply and return slices.
95 | if len(sil_tags) == 0:
96 | return {"0": {"slice": False, "split_time": f"0,{len(waveform)}"}}
97 | else:
98 | chunks = []
99 | # 第一段静音并非从头开始,补上有声片段
100 | if sil_tags[0][0]:
101 | chunks.append(
102 | {"slice": False, "split_time": f"0,{min(waveform.shape[0], sil_tags[0][0] * self.hop_size)}"})
103 | for i in range(0, len(sil_tags)):
104 | # 标识有声片段(跳过第一段)
105 | if i:
106 | chunks.append({"slice": False,
107 | "split_time": f"{sil_tags[i - 1][1] * self.hop_size},{min(waveform.shape[0], sil_tags[i][0] * self.hop_size)}"})
108 | # 标识所有静音片段
109 | chunks.append({"slice": True,
110 | "split_time": f"{sil_tags[i][0] * self.hop_size},{min(waveform.shape[0], sil_tags[i][1] * self.hop_size)}"})
111 | # 最后一段静音并非结尾,补上结尾片段
112 | if sil_tags[-1][1] * self.hop_size < len(waveform):
113 | chunks.append({"slice": False, "split_time": f"{sil_tags[-1][1] * self.hop_size},{len(waveform)}"})
114 | chunk_dict = {}
115 | for i in range(len(chunks)):
116 | chunk_dict[str(i)] = chunks[i]
117 | return chunk_dict
118 |
119 |
120 | def cut(audio_path, db_thresh=-30, min_len=5000):
121 | audio, sr = librosa.load(audio_path, sr=None)
122 | slicer = Slicer(
123 | sr=sr,
124 | threshold=db_thresh,
125 | min_length=min_len
126 | )
127 | chunks = slicer.slice(audio)
128 | return chunks
129 |
130 |
131 | def chunks2audio(audio_path, chunks):
132 | chunks = dict(chunks)
133 | audio, sr = torchaudio.load(audio_path)
134 | if len(audio.shape) == 2 and audio.shape[1] >= 2:
135 | audio = torch.mean(audio, dim=0).unsqueeze(0)
136 | audio = audio.cpu().numpy()[0]
137 | result = []
138 | for k, v in chunks.items():
139 | tag = v["split_time"].split(",")
140 | if tag[0] != tag[1]:
141 | result.append((v["slice"], audio[int(tag[0]):int(tag[1])]))
142 | return result, sr
143 |
--------------------------------------------------------------------------------
/solver.py:
--------------------------------------------------------------------------------
1 | import time
2 |
3 | import librosa
4 | import numpy as np
5 | import torch
6 | from torch import autocast
7 | from torch.cuda.amp import GradScaler
8 |
9 | import utils
10 | from saver import Saver
11 |
12 |
13 | def test(args, model, vocoder, loader_test, saver):
14 | print(' [*] testing...')
15 | model.eval()
16 |
17 | # losses
18 | test_loss = 0.
19 |
20 | # intialization
21 | num_batches = len(loader_test)
22 | rtf_all = []
23 |
24 | # run
25 | with torch.no_grad():
26 | for bidx, data in enumerate(loader_test):
27 | fn = data['name'][0].split("/")[-1]
28 | speaker = data['name'][0].split("/")[-2]
29 | print('--------')
30 | print('{}/{} - {}'.format(bidx, num_batches, fn))
31 |
32 | # unpack data
33 | for k in data.keys():
34 | if not k.startswith('name'):
35 | data[k] = data[k].to(args.device)
36 | print('>>', data['name'][0])
37 |
38 | # forward
39 | st_time = time.time()
40 | mel = model(
41 | data['units'],
42 | data['f0'],
43 | data['volume'],
44 | data['spk_id'],
45 | gt_spec= data['mel'],
46 | infer=True
47 | )
48 | signal = vocoder.infer(mel, data['f0'])
49 | ed_time = time.time()
50 |
51 | # RTF
52 | run_time = ed_time - st_time
53 | song_time = signal.shape[-1] / args.data.sampling_rate
54 | rtf = run_time / song_time
55 | print('RTF: {} | {} / {}'.format(rtf, run_time, song_time))
56 | rtf_all.append(rtf)
57 |
58 | # loss
59 | for i in range(args.train.batch_size):
60 | loss = model(
61 | data['units'],
62 | data['f0'],
63 | data['volume'],
64 | data['spk_id'],
65 | gt_spec=data['mel'],
66 | infer=False)
67 | if isinstance(loss, list):
68 | test_loss += loss[0].item()
69 | else:
70 | test_loss += loss.item()
71 |
72 | # log mel
73 | saver.log_spec(f"{speaker}_{fn}.wav", data['mel'], mel)
74 |
75 | # log audi
76 | path_audio = data['name_ext'][0]
77 | audio, sr = librosa.load(path_audio, sr=args.data.sampling_rate)
78 | if len(audio.shape) > 1:
79 | audio = librosa.to_mono(audio)
80 | audio = torch.from_numpy(audio).unsqueeze(0).to(signal)
81 | saver.log_audio({f"{speaker}_{fn}_gt.wav": audio,f"{speaker}_{fn}_pred.wav": signal})
82 | # report
83 | test_loss /= args.train.batch_size
84 | test_loss /= num_batches
85 |
86 | # check
87 | print(' [test_loss] test_loss:', test_loss)
88 | print(' Real Time Factor', np.mean(rtf_all))
89 | return test_loss
90 |
91 |
92 | # def train(args, initial_global_step, model, optimizer, scheduler, vocoder, loader_train, loader_test):
93 | def train(args, initial_global_step, model, optimizer, scheduler, vocoder, loader_train, loader_test, teacher):
94 |
95 | # saver
96 | if teacher:
97 | save_dir=args.env.expdir
98 | else:
99 | save_dir=args.env.comodir
100 |
101 | saver = Saver(args, save_dir, initial_global_step=initial_global_step)
102 |
103 | # model size
104 | params_count = utils.get_network_paras_amount({'model': model})
105 | saver.log_info('--- model size ---')
106 | saver.log_info(params_count)
107 |
108 | # run
109 | num_batches = len(loader_train)
110 | model.train()
111 | saver.log_info('======= start training =======')
112 | scaler = GradScaler()
113 | if args.train.amp_dtype == 'fp32': # fp32
114 | dtype = torch.float32
115 | elif args.train.amp_dtype == 'fp16':
116 | dtype = torch.float16
117 | elif args.train.amp_dtype == 'bf16':
118 | dtype = torch.bfloat16
119 | else:
120 | raise ValueError(' [x] Unknown amp_dtype: ' + args.train.amp_dtype)
121 | saver.log_info("epoch|batch_idx/num_batches|output_dir|batch/s|lr|time|step")
122 | for epoch in range(args.train.epochs):
123 | for batch_idx, data in enumerate(loader_train):
124 | saver.global_step_increment()
125 | optimizer.zero_grad()
126 |
127 | # unpack data
128 | for k in data.keys():
129 | if not k.startswith('name'):
130 | data[k] = data[k].to(args.device)
131 |
132 | # forward
133 | if dtype == torch.float32:
134 | loss = model(data['units'].float(), data['f0'], data['volume'], data['spk_id'],
135 | aug_shift = data['aug_shift'], gt_spec=data['mel'].float(), infer=False)
136 | else:
137 | with autocast(device_type=args.device, dtype=dtype):
138 | loss = model(data['units'], data['f0'], data['volume'], data['spk_id'],
139 | aug_shift = data['aug_shift'], gt_spec=data['mel'], infer=False)
140 | if not teacher:
141 | loss=loss*1000
142 | # loss_mel = loss[0]*50
143 | # loss_pitch = loss[1]
144 | # loss = loss_mel +loss_pitch
145 | # loss=loss*1000
146 | # handle nan loss
147 | if torch.isnan(loss):
148 | raise ValueError(' [x] nan loss ')
149 | else:
150 | # backpropagate
151 | if dtype == torch.float32:
152 | loss.backward()
153 | optimizer.step()
154 | else:
155 | scaler.scale(loss).backward()
156 | scaler.step(optimizer)
157 | scaler.update()
158 | scheduler.step()
159 |
160 | # log loss
161 | if saver.global_step % args.train.interval_log == 0:
162 | current_lr = optimizer.param_groups[0]['lr']
163 | saver.log_info(
164 | 'epoch: {} | {:3d}/{:3d} | {} | batch/s: {:.2f} | lr: {:.6} | loss: {:.3f} | time: {} | step: {}'.format(
165 | epoch,
166 | batch_idx,
167 | num_batches,
168 | save_dir,
169 | args.train.interval_log/saver.get_interval_time(),
170 | current_lr,
171 | loss.item(),
172 | saver.get_total_time(),
173 | saver.global_step
174 | )
175 | )
176 |
177 | saver.log_value({
178 | 'train/loss': loss.item()
179 | })
180 |
181 | # if not teacher:
182 | # saver.log_value({
183 | # 'train/loss_pitch': loss_pitch.item()
184 | # })
185 | # saver.log_value({
186 | # 'train/loss_mel': loss_mel.item()
187 | # })
188 |
189 | saver.log_value({
190 | 'train/lr': current_lr
191 | })
192 |
193 | # validation
194 | if saver.global_step % args.train.interval_val == 0:
195 | optimizer_save = optimizer if args.train.save_opt else None
196 |
197 | # save latest
198 | saver.save_model(model, optimizer_save, postfix=f'{saver.global_step}')
199 | last_val_step = saver.global_step - args.train.interval_val
200 | if last_val_step % args.train.interval_force_save != 0:
201 | saver.delete_model(postfix=f'{last_val_step}')
202 |
203 | # run testing set
204 | test_loss = test(args, model, vocoder, loader_test, saver)
205 |
206 | # log loss
207 | saver.log_info(
208 | ' --- --- \nloss: {:.3f}. '.format(
209 | test_loss,
210 | )
211 | )
212 |
213 | saver.log_value({
214 | 'validation/loss': test_loss
215 | })
216 |
217 | model.train()
218 |
219 |
220 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | import torch
4 | from loguru import logger
5 | from torch.optim import lr_scheduler
6 |
7 | import os
8 |
9 | from data_loaders import get_data_loaders
10 | import utils
11 | from solver import train
12 | from ComoSVC import ComoSVC
13 | from Vocoder import Vocoder
14 | from utils import load_teacher_model_with_pitch
15 | from utils import traverse_dir
16 |
17 |
18 |
19 |
20 | def parse_args(args=None, namespace=None):
21 | """Parse command-line arguments."""
22 | parser = argparse.ArgumentParser()
23 | parser.add_argument(
24 | "-c",
25 | "--config",
26 | type=str,
27 | default='configs/diffusion.yaml',
28 | help="path to the config file")
29 |
30 | parser.add_argument(
31 | "-t",
32 | "--teacher",
33 | action='store_false',
34 | help="if it is the teacher model")
35 |
36 | parser.add_argument(
37 | "-s",
38 | "--total_steps",
39 | type=int,
40 | default=1,
41 | help="the number of iterative steps during inference")
42 |
43 | parser.add_argument(
44 | "-p",
45 | "--teacher_model_path",
46 | type=str,
47 | default="logs/teacher/model_800000.pt",
48 | help="path to teacher model")
49 | return parser.parse_args(args=args, namespace=namespace)
50 |
51 |
52 | if __name__ == '__main__':
53 | # parse commands
54 | cmd = parse_args()
55 | # load config
56 | args = utils.load_config(cmd.config)
57 | logger.info(' > config:'+ cmd.config)
58 | # teacher_or_not=cmd.teacher
59 | teacher_model_path=cmd.teacher_model_path
60 | # load vocoder
61 | vocoder = Vocoder(args.vocoder.type, args.vocoder.ckpt, device=args.device)
62 |
63 |
64 | # load model
65 | if cmd.teacher:
66 | model = ComoSVC(
67 | args.data.encoder_out_channels,
68 | args.model.n_spk,
69 | args.model.use_pitch_aug,#true
70 | vocoder.dimension,
71 | args.model.n_layers,
72 | args.model.n_chans,
73 | args.model.n_hidden,
74 | cmd.total_steps,
75 | teacher=cmd.teacher
76 | )
77 |
78 | optimizer = torch.optim.AdamW(model.parameters(),lr=args.train.lr)
79 | initial_global_step, model, optimizer = utils.load_model(args.env.expdir, model, optimizer, device=args.device)
80 |
81 | else:
82 | model = ComoSVC(
83 | args.data.encoder_out_channels,
84 | args.model.n_spk,
85 | args.model.use_pitch_aug,
86 | vocoder.dimension,
87 | args.model.n_layers,
88 | args.model.n_chans,
89 | args.model.n_hidden,
90 | cmd.total_steps,
91 | teacher=cmd.teacher
92 | )
93 | model = load_teacher_model_with_pitch(model,checkpoint_dir=cmd.teacher_model_path) # teacher model path
94 |
95 |
96 | # optimizer = torch.optim.AdamW(params=model.decoder.denoise_fn.parameters())
97 | optimizer = torch.optim.AdamW(params=model.decoder.denoise_fn.parameters())
98 | path_pt = traverse_dir(args.env.comodir, ['pt'], is_ext=False)
99 | if len(path_pt)>0:
100 | initial_global_step, model, optimizer = utils.load_model(args.env.comodir, model, optimizer, device=args.device)
101 | else:
102 | initial_global_step = 0
103 |
104 |
105 | if cmd.teacher:
106 | logger.info(f' > The Teacher Model is training now.')
107 | else:
108 | logger.info(f' > The Student Model CoMoSVC is training now.')
109 |
110 |
111 |
112 | for param_group in optimizer.param_groups:
113 | if cmd.teacher:
114 | param_group['initial_lr'] = args.train.lr
115 | param_group['lr'] = args.train.lr * (args.train.gamma ** max(((initial_global_step-2)//args.train.decay_step),0) )
116 | param_group['weight_decay'] = args.train.weight_decay
117 | else:
118 | param_group['initial_lr'] = args.train.comolr
119 | param_group['lr'] = args.train.comolr * (args.train.gamma ** max(((initial_global_step-2)//args.train.decay_step),0) )
120 | param_group['weight_decay'] = args.train.weight_decay
121 | scheduler = lr_scheduler.StepLR(optimizer, step_size=args.train.decay_step, gamma=args.train.gamma,last_epoch=initial_global_step-2)
122 |
123 | # device
124 | if args.device == 'cuda':
125 | torch.cuda.set_device(args.env.gpu_id)
126 | model.to(args.device)
127 |
128 | for state in optimizer.state.values():
129 | for k, v in state.items():
130 | if torch.is_tensor(v):
131 | state[k] = v.to(args.device)
132 |
133 | # datas
134 | loader_train, loader_valid = get_data_loaders(args, whole_audio=False)
135 |
136 | train(args, initial_global_step, model, optimizer, scheduler, vocoder, loader_train, loader_valid, teacher=cmd.teacher)
137 |
138 |
139 |
--------------------------------------------------------------------------------
/utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import json
3 | import yaml
4 | import os
5 | import copy
6 | from torch.nn import functional as F
7 |
8 | def repeat_expand_2d(content, target_len, mode = 'left'):
9 | # content : [h, t]
10 | return repeat_expand_2d_left(content, target_len) if mode == 'left' else repeat_expand_2d_other(content, target_len, mode)
11 |
12 |
13 |
14 | def repeat_expand_2d_left(content, target_len):
15 | # content : [h, t]
16 |
17 | src_len = content.shape[-1]
18 | target = torch.zeros([content.shape[0], target_len], dtype=torch.float).to(content.device)
19 | temp = torch.arange(src_len+1) * target_len / src_len
20 | current_pos = 0
21 | for i in range(target_len):
22 | if i < temp[current_pos+1]:
23 | target[:, i] = content[:, current_pos]
24 | else:
25 | current_pos += 1
26 | target[:, i] = content[:, current_pos]
27 |
28 | return target
29 |
30 |
31 | # mode : 'nearest'| 'linear'| 'bilinear'| 'bicubic'| 'trilinear'| 'area'
32 | def repeat_expand_2d_other(content, target_len, mode = 'nearest'):
33 | # content : [h, t]
34 | content = content[None,:,:]
35 | target = F.interpolate(content,size=target_len,mode=mode)[0]
36 | return target
37 |
38 |
39 |
40 | def traverse_dir(
41 | root_dir,
42 | extensions,
43 | amount=None,
44 | str_include=None,
45 | str_exclude=None,
46 | is_pure=False,
47 | is_sort=False,
48 | is_ext=True):
49 |
50 | file_list = []
51 | cnt = 0
52 | for root, _, files in os.walk(root_dir):
53 | for file in files:
54 | if any([file.endswith(f".{ext}") for ext in extensions]):
55 | # path
56 | mix_path = os.path.join(root, file)
57 | pure_path = mix_path[len(root_dir)+1:] if is_pure else mix_path
58 |
59 | # amount
60 | if (amount is not None) and (cnt == amount):
61 | if is_sort:
62 | file_list.sort()
63 | return file_list
64 |
65 | # check string
66 | if (str_include is not None) and (str_include not in pure_path):
67 | continue
68 | if (str_exclude is not None) and (str_exclude in pure_path):
69 | continue
70 |
71 | if not is_ext:
72 | ext = pure_path.split('.')[-1]
73 | pure_path = pure_path[:-(len(ext)+1)]
74 | file_list.append(pure_path)
75 | cnt += 1
76 | if is_sort:
77 | file_list.sort()
78 | return file_list
79 |
80 |
81 | class DotDict(dict):
82 | def __getattr__(*args):
83 | val = dict.get(*args)
84 | return DotDict(val) if type(val) is dict else val
85 |
86 | __setattr__ = dict.__setitem__
87 | __delattr__ = dict.__delitem__
88 |
89 | def load_config(path_config):
90 | with open(path_config, "r") as config:
91 | args = yaml.safe_load(config)
92 | args = DotDict(args)
93 | return args
94 |
95 |
96 | def save_config(path_config,config):
97 | config = dict(config)
98 | with open(path_config, "w") as f:
99 | yaml.dump(config, f)
100 |
101 |
102 | class HParams():
103 | def __init__(self, **kwargs):
104 | for k, v in kwargs.items():
105 | if type(v) == dict:
106 | v = HParams(**v)
107 | self[k] = v
108 |
109 | def keys(self):
110 | return self.__dict__.keys()
111 |
112 | def items(self):
113 | return self.__dict__.items()
114 |
115 | def values(self):
116 | return self.__dict__.values()
117 |
118 | def __len__(self):
119 | return len(self.__dict__)
120 |
121 | def __getitem__(self, key):
122 | return getattr(self, key)
123 |
124 | def __setitem__(self, key, value):
125 | return setattr(self, key, value)
126 |
127 | def __contains__(self, key):
128 | return key in self.__dict__
129 |
130 | def __repr__(self):
131 | return self.__dict__.__repr__()
132 |
133 | def get(self,index):
134 | return self.__dict__.get(index)
135 |
136 |
137 | class InferHParams(HParams):
138 | def __init__(self, **kwargs):
139 | for k, v in kwargs.items():
140 | if type(v) == dict:
141 | v = InferHParams(**v)
142 | self[k] = v
143 |
144 | def __getattr__(self,index):
145 | return self.get(index)
146 |
147 |
148 | def make_positions(tensor, padding_idx):
149 | """Replace non-padding symbols with their position numbers.
150 | Position numbers begin at padding_idx+1. Padding symbols are ignored.
151 | """
152 | # The series of casts and type-conversions here are carefully
153 | # balanced to both work with ONNX export and XLA. In particular XLA
154 | # prefers ints, cumsum defaults to output longs, and ONNX doesn't know
155 | # how to handle the dtype kwarg in cumsum.
156 | mask = tensor.ne(padding_idx).int()
157 | return (
158 | torch.cumsum(mask, dim=1).type_as(mask) * mask
159 | ).long() + padding_idx
160 |
161 |
162 |
163 | class Volume_Extractor:
164 | def __init__(self, hop_size = 512):
165 | self.hop_size = hop_size
166 |
167 | def extract(self, audio): # audio: 2d tensor array
168 | if not isinstance(audio,torch.Tensor):
169 | audio = torch.Tensor(audio)
170 | n_frames = int(audio.size(-1) // self.hop_size)
171 | audio2 = audio ** 2
172 | audio2 = torch.nn.functional.pad(audio2, (int(self.hop_size // 2), int((self.hop_size + 1) // 2)), mode = 'reflect')
173 | volume = torch.nn.functional.unfold(audio2[:,None,None,:],(1,self.hop_size),stride=self.hop_size)[:,:,:n_frames].mean(dim=1)[0]
174 | volume = torch.sqrt(volume)
175 | return volume
176 |
177 |
178 | def get_hparams_from_file(config_path, infer_mode = False):
179 | with open(config_path, "r") as f:
180 | data = f.read()
181 | config = json.loads(data)
182 | hparams =HParams(**config) if not infer_mode else InferHParams(**config)
183 | return hparams
184 |
185 |
186 | def load_model(
187 | expdir,
188 | model,
189 | optimizer,
190 | name='model',
191 | postfix='',
192 | device='cpu'):
193 | if postfix == '':
194 | postfix = '_' + postfix
195 | path = os.path.join(expdir, name+postfix)
196 | path_pt = traverse_dir(expdir, ['pt'], is_ext=False)
197 | global_step = 0
198 | if len(path_pt) > 0:
199 | steps = [s[len(path):] for s in path_pt]
200 | maxstep = max([int(s) if s.isdigit() else 0 for s in steps])
201 | if maxstep >= 0:
202 | path_pt = path+str(maxstep)+'.pt'
203 | else:
204 | path_pt = path+'best.pt'
205 | print(' [*] restoring model from', path_pt)
206 | ckpt = torch.load(path_pt, map_location=torch.device(device))
207 | global_step = ckpt['global_step']
208 | model.load_state_dict(ckpt['model'], strict=False)
209 | if ckpt.get("optimizer") is not None:
210 | optimizer.load_state_dict(ckpt['optimizer'])
211 | return global_step, model, optimizer
212 |
213 | def get_network_paras_amount(model_dict):
214 | info = dict()
215 | for model_name, model in model_dict.items():
216 | # all_params = sum(p.numel() for p in model.parameters())
217 | trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
218 |
219 | info[model_name] = trainable_params
220 | return info
221 |
222 |
223 | def load_teacher_model(model,checkpoint_dir):
224 | model_resumed = torch.load(checkpoint_dir)
225 | model.load_state_dict(model_resumed['model'],strict=False)
226 |
227 | model.decoder.denoise_fn_ema = copy.deepcopy(model.decoder.denoise_fn)
228 | model.decoder.denoise_fn_pretrained= copy.deepcopy(model.decoder.denoise_fn)
229 | return model
230 |
231 |
232 | def load_teacher_model_with_pitch(model,checkpoint_dir):
233 | model_resumed = torch.load(checkpoint_dir)
234 | model_pe_resumed = torch.load('./m4singer_pe/model_ckpt_steps_280000.ckpt')['state_dict']
235 | prefix_in_ckpt ='model'
236 | model_pe_resumed = {k[len(prefix_in_ckpt) + 1:]: v for k, v in model_pe_resumed.items()
237 | if k.startswith(f'{prefix_in_ckpt}.')}
238 | model.load_state_dict(model_resumed['model'],strict=False)
239 | model.decoder.pe.load_state_dict(model_pe_resumed,strict=True)
240 | model.decoder.denoise_fn_ema = copy.deepcopy(model.decoder.denoise_fn)
241 | model.decoder.denoise_fn_pretrained= copy.deepcopy(model.decoder.denoise_fn)
242 | return model
--------------------------------------------------------------------------------
/vocoder/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Grace9994/CoMoSVC/2ea8e644e2c5b3a8afc0762e870b9daacf3b5be5/vocoder/__init__.py
--------------------------------------------------------------------------------
/vocoder/m4gan/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Grace9994/CoMoSVC/2ea8e644e2c5b3a8afc0762e870b9daacf3b5be5/vocoder/m4gan/__init__.py
--------------------------------------------------------------------------------
/vocoder/m4gan/hifigan.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | import torch.nn as nn
4 | from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
5 | from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
6 |
7 |
8 | from vocoder.m4gan.parallel_wavegan import SourceModuleHnNSF
9 | import numpy as np
10 |
11 | LRELU_SLOPE = 0.1
12 |
13 |
14 | def init_weights(m, mean=0.0, std=0.01):
15 | classname = m.__class__.__name__
16 | if classname.find("Conv") != -1:
17 | m.weight.data.normal_(mean, std)
18 |
19 |
20 | def apply_weight_norm(m):
21 | classname = m.__class__.__name__
22 | if classname.find("Conv") != -1:
23 | weight_norm(m)
24 |
25 |
26 | def get_padding(kernel_size, dilation=1):
27 | return int((kernel_size * dilation - dilation) / 2)
28 |
29 |
30 | class ResBlock1(torch.nn.Module):
31 | def __init__(self, h, channels, kernel_size=3, dilation=(1, 3, 5)):
32 | super(ResBlock1, self).__init__()
33 | self.h = h
34 | self.convs1 = nn.ModuleList([
35 | weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
36 | padding=get_padding(kernel_size, dilation[0]))),
37 | weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
38 | padding=get_padding(kernel_size, dilation[1]))),
39 | weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
40 | padding=get_padding(kernel_size, dilation[2])))
41 | ])
42 | self.convs1.apply(init_weights)
43 |
44 | self.convs2 = nn.ModuleList([
45 | weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
46 | padding=get_padding(kernel_size, 1))),
47 | weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
48 | padding=get_padding(kernel_size, 1))),
49 | weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
50 | padding=get_padding(kernel_size, 1)))
51 | ])
52 | self.convs2.apply(init_weights)
53 |
54 | def forward(self, x):
55 | for c1, c2 in zip(self.convs1, self.convs2):
56 | xt = F.leaky_relu(x, LRELU_SLOPE)
57 | xt = c1(xt)
58 | xt = F.leaky_relu(xt, LRELU_SLOPE)
59 | xt = c2(xt)
60 | x = xt + x
61 | return x
62 |
63 | def remove_weight_norm(self):
64 | for l in self.convs1:
65 | remove_weight_norm(l)
66 | for l in self.convs2:
67 | remove_weight_norm(l)
68 |
69 |
70 | class ResBlock2(torch.nn.Module):
71 | def __init__(self, h, channels, kernel_size=3, dilation=(1, 3)):
72 | super(ResBlock2, self).__init__()
73 | self.h = h
74 | self.convs = nn.ModuleList([
75 | weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
76 | padding=get_padding(kernel_size, dilation[0]))),
77 | weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
78 | padding=get_padding(kernel_size, dilation[1])))
79 | ])
80 | self.convs.apply(init_weights)
81 |
82 | def forward(self, x):
83 | for c in self.convs:
84 | xt = F.leaky_relu(x, LRELU_SLOPE)
85 | xt = c(xt)
86 | x = xt + x
87 | return x
88 |
89 | def remove_weight_norm(self):
90 | for l in self.convs:
91 | remove_weight_norm(l)
92 |
93 |
94 | class Conv1d1x1(Conv1d):
95 | """1x1 Conv1d with customized initialization."""
96 |
97 | def __init__(self, in_channels, out_channels, bias):
98 | """Initialize 1x1 Conv1d module."""
99 | super(Conv1d1x1, self).__init__(in_channels, out_channels,
100 | kernel_size=1, padding=0,
101 | dilation=1, bias=bias)
102 |
103 |
104 | class HifiGanGenerator(torch.nn.Module):
105 | def __init__(self, h, c_out=1):
106 | super(HifiGanGenerator, self).__init__()
107 | self.h = h
108 | self.num_kernels = len(h['resblock_kernel_sizes'])
109 | self.num_upsamples = len(h['upsample_rates'])
110 |
111 | if h['use_pitch_embed']:
112 | self.harmonic_num = 8
113 | self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(h['upsample_rates']))
114 | self.m_source = SourceModuleHnNSF(
115 | sampling_rate=h['audio_sample_rate'],
116 | harmonic_num=self.harmonic_num)
117 | self.noise_convs = nn.ModuleList()
118 | self.conv_pre = weight_norm(Conv1d(80, h['upsample_initial_channel'], 7, 1, padding=3))
119 | resblock = ResBlock1 if h['resblock'] == '1' else ResBlock2
120 |
121 | self.ups = nn.ModuleList()
122 | for i, (u, k) in enumerate(zip(h['upsample_rates'], h['upsample_kernel_sizes'])):
123 | c_cur = h['upsample_initial_channel'] // (2 ** (i + 1))
124 | self.ups.append(weight_norm(
125 | ConvTranspose1d(c_cur * 2, c_cur, k, u, padding=(k - u) // 2)))
126 | if h['use_pitch_embed']:
127 | if i + 1 < len(h['upsample_rates']):
128 | stride_f0 = np.prod(h['upsample_rates'][i + 1:])
129 | self.noise_convs.append(Conv1d(
130 | 1, c_cur, kernel_size=stride_f0 * 2, stride=stride_f0, padding=stride_f0 // 2))
131 | else:
132 | self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
133 |
134 | self.resblocks = nn.ModuleList()
135 | for i in range(len(self.ups)):
136 | ch = h['upsample_initial_channel'] // (2 ** (i + 1))
137 | for j, (k, d) in enumerate(zip(h['resblock_kernel_sizes'], h['resblock_dilation_sizes'])):
138 | self.resblocks.append(resblock(h, ch, k, d))
139 |
140 | self.conv_post = weight_norm(Conv1d(ch, c_out, 7, 1, padding=3))
141 | self.ups.apply(init_weights)
142 | self.conv_post.apply(init_weights)
143 |
144 | def forward(self, x, f0=None):
145 | if f0 is not None:
146 | # harmonic-source signal, noise-source signal, uv flag
147 | f0 = self.f0_upsamp(f0[:, None]).transpose(1, 2)
148 | har_source, noi_source, uv = self.m_source(f0)
149 | har_source = har_source.transpose(1, 2)
150 |
151 | x = self.conv_pre(x)
152 | for i in range(self.num_upsamples):
153 | x = F.leaky_relu(x, LRELU_SLOPE)
154 | x = self.ups[i](x)
155 | if f0 is not None:
156 | x_source = self.noise_convs[i](har_source)
157 | x_source = torch.nn.functional.relu(x_source)
158 | tmp_shape = x_source.shape[1]
159 | x_source = torch.nn.functional.layer_norm(x_source.transpose(1, -1), (tmp_shape, )).transpose(1, -1)
160 | x = x + x_source
161 | xs = None
162 | for j in range(self.num_kernels):
163 | xs_ = self.resblocks[i * self.num_kernels + j](x)
164 | if xs is None:
165 | xs = xs_
166 | else:
167 | xs += xs_
168 | x = xs / self.num_kernels
169 | x = F.leaky_relu(x)
170 | x = self.conv_post(x)
171 | x = torch.tanh(x)
172 |
173 | return x
174 |
175 | def remove_weight_norm(self):
176 | print('Removing weight norm...')
177 | for l in self.ups:
178 | remove_weight_norm(l)
179 | for l in self.resblocks:
180 | l.remove_weight_norm()
181 | remove_weight_norm(self.conv_pre)
182 | remove_weight_norm(self.conv_post)
183 |
184 |
185 | class DiscriminatorP(torch.nn.Module):
186 | def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False, use_cond=False, c_in=1):
187 | super(DiscriminatorP, self).__init__()
188 | self.use_cond = use_cond
189 | if use_cond:
190 | from utils.hparams import hparams
191 | t = hparams['hop_size']
192 | self.cond_net = torch.nn.ConvTranspose1d(80, 1, t * 2, stride=t, padding=t // 2)
193 | c_in = 2
194 |
195 | self.period = period
196 | norm_f = weight_norm if use_spectral_norm == False else spectral_norm
197 | self.convs = nn.ModuleList([
198 | norm_f(Conv2d(c_in, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
199 | norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
200 | norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
201 | norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),
202 | norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(2, 0))),
203 | ])
204 | self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
205 |
206 | def forward(self, x, mel):
207 | fmap = []
208 | if self.use_cond:
209 | x_mel = self.cond_net(mel)
210 | x = torch.cat([x_mel, x], 1)
211 | # 1d to 2d
212 | b, c, t = x.shape
213 | if t % self.period != 0: # pad first
214 | n_pad = self.period - (t % self.period)
215 | x = F.pad(x, (0, n_pad), "reflect")
216 | t = t + n_pad
217 | x = x.view(b, c, t // self.period, self.period)
218 |
219 | for l in self.convs:
220 | x = l(x)
221 | x = F.leaky_relu(x, LRELU_SLOPE)
222 | fmap.append(x)
223 | x = self.conv_post(x)
224 | fmap.append(x)
225 | x = torch.flatten(x, 1, -1)
226 |
227 | return x, fmap
228 |
229 |
230 | class MultiPeriodDiscriminator(torch.nn.Module):
231 | def __init__(self, use_cond=False, c_in=1):
232 | super(MultiPeriodDiscriminator, self).__init__()
233 | self.discriminators = nn.ModuleList([
234 | DiscriminatorP(2, use_cond=use_cond, c_in=c_in),
235 | DiscriminatorP(3, use_cond=use_cond, c_in=c_in),
236 | DiscriminatorP(5, use_cond=use_cond, c_in=c_in),
237 | DiscriminatorP(7, use_cond=use_cond, c_in=c_in),
238 | DiscriminatorP(11, use_cond=use_cond, c_in=c_in),
239 | ])
240 |
241 | def forward(self, y, y_hat, mel=None):
242 | y_d_rs = []
243 | y_d_gs = []
244 | fmap_rs = []
245 | fmap_gs = []
246 | for i, d in enumerate(self.discriminators):
247 | y_d_r, fmap_r = d(y, mel)
248 | y_d_g, fmap_g = d(y_hat, mel)
249 | y_d_rs.append(y_d_r)
250 | fmap_rs.append(fmap_r)
251 | y_d_gs.append(y_d_g)
252 | fmap_gs.append(fmap_g)
253 |
254 | return y_d_rs, y_d_gs, fmap_rs, fmap_gs
255 |
256 |
257 | class DiscriminatorS(torch.nn.Module):
258 | def __init__(self, use_spectral_norm=False, use_cond=False, upsample_rates=None, c_in=1):
259 | super(DiscriminatorS, self).__init__()
260 | self.use_cond = use_cond
261 | if use_cond:
262 | t = np.prod(upsample_rates)
263 | self.cond_net = torch.nn.ConvTranspose1d(80, 1, t * 2, stride=t, padding=t // 2)
264 | c_in = 2
265 | norm_f = weight_norm if use_spectral_norm == False else spectral_norm
266 | self.convs = nn.ModuleList([
267 | norm_f(Conv1d(c_in, 128, 15, 1, padding=7)),
268 | norm_f(Conv1d(128, 128, 41, 2, groups=4, padding=20)),
269 | norm_f(Conv1d(128, 256, 41, 2, groups=16, padding=20)),
270 | norm_f(Conv1d(256, 512, 41, 4, groups=16, padding=20)),
271 | norm_f(Conv1d(512, 1024, 41, 4, groups=16, padding=20)),
272 | norm_f(Conv1d(1024, 1024, 41, 1, groups=16, padding=20)),
273 | norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
274 | ])
275 | self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
276 |
277 | def forward(self, x, mel):
278 | if self.use_cond:
279 | x_mel = self.cond_net(mel)
280 | x = torch.cat([x_mel, x], 1)
281 | fmap = []
282 | for l in self.convs:
283 | x = l(x)
284 | x = F.leaky_relu(x, LRELU_SLOPE)
285 | fmap.append(x)
286 | x = self.conv_post(x)
287 | fmap.append(x)
288 | x = torch.flatten(x, 1, -1)
289 |
290 | return x, fmap
291 |
292 |
293 | class MultiScaleDiscriminator(torch.nn.Module):
294 | def __init__(self, use_cond=False, c_in=1):
295 | super(MultiScaleDiscriminator, self).__init__()
296 | from utils.hparams import hparams
297 | self.discriminators = nn.ModuleList([
298 | DiscriminatorS(use_spectral_norm=True, use_cond=use_cond,
299 | upsample_rates=[4, 4, hparams['hop_size'] // 16],
300 | c_in=c_in),
301 | DiscriminatorS(use_cond=use_cond,
302 | upsample_rates=[4, 4, hparams['hop_size'] // 32],
303 | c_in=c_in),
304 | DiscriminatorS(use_cond=use_cond,
305 | upsample_rates=[4, 4, hparams['hop_size'] // 64],
306 | c_in=c_in),
307 | ])
308 | self.meanpools = nn.ModuleList([
309 | AvgPool1d(4, 2, padding=1),
310 | AvgPool1d(4, 2, padding=1)
311 | ])
312 |
313 | def forward(self, y, y_hat, mel=None):
314 | y_d_rs = []
315 | y_d_gs = []
316 | fmap_rs = []
317 | fmap_gs = []
318 | for i, d in enumerate(self.discriminators):
319 | if i != 0:
320 | y = self.meanpools[i - 1](y)
321 | y_hat = self.meanpools[i - 1](y_hat)
322 | y_d_r, fmap_r = d(y, mel)
323 | y_d_g, fmap_g = d(y_hat, mel)
324 | y_d_rs.append(y_d_r)
325 | fmap_rs.append(fmap_r)
326 | y_d_gs.append(y_d_g)
327 | fmap_gs.append(fmap_g)
328 |
329 | return y_d_rs, y_d_gs, fmap_rs, fmap_gs
330 |
331 |
332 | def feature_loss(fmap_r, fmap_g):
333 | loss = 0
334 | for dr, dg in zip(fmap_r, fmap_g):
335 | for rl, gl in zip(dr, dg):
336 | loss += torch.mean(torch.abs(rl - gl))
337 |
338 | return loss * 2
339 |
340 |
341 | def discriminator_loss(disc_real_outputs, disc_generated_outputs):
342 | r_losses = 0
343 | g_losses = 0
344 | for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
345 | r_loss = torch.mean((1 - dr) ** 2)
346 | g_loss = torch.mean(dg ** 2)
347 | r_losses += r_loss
348 | g_losses += g_loss
349 | r_losses = r_losses / len(disc_real_outputs)
350 | g_losses = g_losses / len(disc_real_outputs)
351 | return r_losses, g_losses
352 |
353 |
354 | def cond_discriminator_loss(outputs):
355 | loss = 0
356 | for dg in outputs:
357 | g_loss = torch.mean(dg ** 2)
358 | loss += g_loss
359 | loss = loss / len(outputs)
360 | return loss
361 |
362 |
363 | def generator_loss(disc_outputs):
364 | loss = 0
365 | for dg in disc_outputs:
366 | l = torch.mean((1 - dg) ** 2)
367 | loss += l
368 | loss = loss / len(disc_outputs)
369 | return loss
370 |
371 |
--------------------------------------------------------------------------------
/vocoder/m4gan/parallel_wavegan.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import sys
4 | import torch.nn.functional as torch_nn_func
5 |
6 |
7 | class SineGen(torch.nn.Module):
8 | """ Definition of sine generator
9 | SineGen(samp_rate, harmonic_num = 0,
10 | sine_amp = 0.1, noise_std = 0.003,
11 | voiced_threshold = 0,
12 | flag_for_pulse=False)
13 |
14 | samp_rate: sampling rate in Hz
15 | harmonic_num: number of harmonic overtones (default 0)
16 | sine_amp: amplitude of sine-wavefrom (default 0.1)
17 | noise_std: std of Gaussian noise (default 0.003)
18 | voiced_thoreshold: F0 threshold for U/V classification (default 0)
19 | flag_for_pulse: this SinGen is used inside PulseGen (default False)
20 |
21 | Note: when flag_for_pulse is True, the first time step of a voiced
22 | segment is always sin(np.pi) or cos(0)
23 | """
24 |
25 | def __init__(self, samp_rate, harmonic_num=0,
26 | sine_amp=0.1, noise_std=0.003,
27 | voiced_threshold=0,
28 | flag_for_pulse=False):
29 | super(SineGen, self).__init__()
30 | self.sine_amp = sine_amp
31 | self.noise_std = noise_std
32 | self.harmonic_num = harmonic_num
33 | self.dim = self.harmonic_num + 1
34 | self.sampling_rate = samp_rate
35 | self.voiced_threshold = voiced_threshold
36 | self.flag_for_pulse = flag_for_pulse
37 |
38 | def _f02uv(self, f0):
39 | # generate uv signal
40 | uv = torch.ones_like(f0)
41 | uv = uv * (f0 > self.voiced_threshold)
42 | return uv
43 |
44 | def _f02sine(self, f0_values):
45 | """ f0_values: (batchsize, length, dim)
46 | where dim indicates fundamental tone and overtones
47 | """
48 | # convert to F0 in rad. The interger part n can be ignored
49 | # because 2 * np.pi * n doesn't affect phase
50 | rad_values = (f0_values / self.sampling_rate) % 1
51 |
52 | # initial phase noise (no noise for fundamental component)
53 | rand_ini = torch.rand(f0_values.shape[0], f0_values.shape[2], \
54 | device=f0_values.device)
55 | rand_ini[:, 0] = 0
56 | rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
57 |
58 | # instantanouse phase sine[t] = sin(2*pi \sum_i=1 ^{t} rad)
59 | if not self.flag_for_pulse:
60 | # for normal case
61 |
62 | # To prevent torch.cumsum numerical overflow,
63 | # it is necessary to add -1 whenever \sum_k=1^n rad_value_k > 1.
64 | # Buffer tmp_over_one_idx indicates the time step to add -1.
65 | # This will not change F0 of sine because (x-1) * 2*pi = x * 2*pi
66 | tmp_over_one = torch.cumsum(rad_values, 1) % 1
67 | tmp_over_one_idx = (tmp_over_one[:, 1:, :] -
68 | tmp_over_one[:, :-1, :]) < 0
69 | cumsum_shift = torch.zeros_like(rad_values)
70 | cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
71 |
72 | sines = torch.sin(torch.cumsum(rad_values + cumsum_shift, dim=1)
73 | * 2 * np.pi)
74 | else:
75 | # If necessary, make sure that the first time step of every
76 | # voiced segments is sin(pi) or cos(0)
77 | # This is used for pulse-train generation
78 |
79 | # identify the last time step in unvoiced segments
80 | uv = self._f02uv(f0_values)
81 | uv_1 = torch.roll(uv, shifts=-1, dims=1)
82 | uv_1[:, -1, :] = 1
83 | u_loc = (uv < 1) * (uv_1 > 0)
84 |
85 | # get the instantanouse phase
86 | tmp_cumsum = torch.cumsum(rad_values, dim=1)
87 | # different batch needs to be processed differently
88 | for idx in range(f0_values.shape[0]):
89 | temp_sum = tmp_cumsum[idx, u_loc[idx, :, 0], :]
90 | temp_sum[1:, :] = temp_sum[1:, :] - temp_sum[0:-1, :]
91 | # stores the accumulation of i.phase within
92 | # each voiced segments
93 | tmp_cumsum[idx, :, :] = 0
94 | tmp_cumsum[idx, u_loc[idx, :, 0], :] = temp_sum
95 |
96 | # rad_values - tmp_cumsum: remove the accumulation of i.phase
97 | # within the previous voiced segment.
98 | i_phase = torch.cumsum(rad_values - tmp_cumsum, dim=1)
99 |
100 | # get the sines
101 | sines = torch.cos(i_phase * 2 * np.pi)
102 | return sines
103 |
104 | def forward(self, f0):
105 | """ sine_tensor, uv = forward(f0)
106 | input F0: tensor(batchsize=1, length, dim=1)
107 | f0 for unvoiced steps should be 0
108 | output sine_tensor: tensor(batchsize=1, length, dim)
109 | output uv: tensor(batchsize=1, length, 1)
110 | """
111 | with torch.no_grad():
112 | f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim,
113 | device=f0.device)
114 | # fundamental component
115 | f0_buf[:, :, 0] = f0[:, :, 0]
116 | for idx in np.arange(self.harmonic_num):
117 | # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
118 | f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (idx + 2)
119 |
120 | # generate sine waveforms
121 | sine_waves = self._f02sine(f0_buf) * self.sine_amp
122 |
123 | # generate uv signal
124 | # uv = torch.ones(f0.shape)
125 | # uv = uv * (f0 > self.voiced_threshold)
126 | uv = self._f02uv(f0)
127 |
128 | # noise: for unvoiced should be similar to sine_amp
129 | # std = self.sine_amp/3 -> max value ~ self.sine_amp
130 | # . for voiced regions is self.noise_std
131 | noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
132 | noise = noise_amp * torch.randn_like(sine_waves)
133 |
134 | # first: set the unvoiced part to 0 by uv
135 | # then: additive noise
136 | sine_waves = sine_waves * uv + noise
137 | return sine_waves, uv, noise
138 |
139 |
140 | class PulseGen(torch.nn.Module):
141 | """ Definition of Pulse train generator
142 |
143 | There are many ways to implement pulse generator.
144 | Here, PulseGen is based on SinGen. For a perfect
145 | """
146 | def __init__(self, samp_rate, pulse_amp = 0.1,
147 | noise_std = 0.003, voiced_threshold = 0):
148 | super(PulseGen, self).__init__()
149 | self.pulse_amp = pulse_amp
150 | self.sampling_rate = samp_rate
151 | self.voiced_threshold = voiced_threshold
152 | self.noise_std = noise_std
153 | self.l_sinegen = SineGen(self.sampling_rate, harmonic_num=0, \
154 | sine_amp=self.pulse_amp, noise_std=0, \
155 | voiced_threshold=self.voiced_threshold, \
156 | flag_for_pulse=True)
157 |
158 | def forward(self, f0):
159 | """ Pulse train generator
160 | pulse_train, uv = forward(f0)
161 | input F0: tensor(batchsize=1, length, dim=1)
162 | f0 for unvoiced steps should be 0
163 | output pulse_train: tensor(batchsize=1, length, dim)
164 | output uv: tensor(batchsize=1, length, 1)
165 |
166 | Note: self.l_sine doesn't make sure that the initial phase of
167 | a voiced segment is np.pi, the first pulse in a voiced segment
168 | may not be at the first time step within a voiced segment
169 | """
170 | with torch.no_grad():
171 | sine_wav, uv, noise = self.l_sinegen(f0)
172 |
173 | # sine without additive noise
174 | pure_sine = sine_wav - noise
175 |
176 | # step t corresponds to a pulse if
177 | # sine[t] > sine[t+1] & sine[t] > sine[t-1]
178 | # & sine[t-1], sine[t+1], and sine[t] are voiced
179 | # or
180 | # sine[t] is voiced, sine[t-1] is unvoiced
181 | # we use torch.roll to simulate sine[t+1] and sine[t-1]
182 | sine_1 = torch.roll(pure_sine, shifts=1, dims=1)
183 | uv_1 = torch.roll(uv, shifts=1, dims=1)
184 | uv_1[:, 0, :] = 0
185 | sine_2 = torch.roll(pure_sine, shifts=-1, dims=1)
186 | uv_2 = torch.roll(uv, shifts=-1, dims=1)
187 | uv_2[:, -1, :] = 0
188 |
189 | loc = (pure_sine > sine_1) * (pure_sine > sine_2) \
190 | * (uv_1 > 0) * (uv_2 > 0) * (uv > 0) \
191 | + (uv_1 < 1) * (uv > 0)
192 |
193 | # pulse train without noise
194 | pulse_train = pure_sine * loc
195 |
196 | # additive noise to pulse train
197 | # note that noise from sinegen is zero in voiced regions
198 | pulse_noise = torch.randn_like(pure_sine) * self.noise_std
199 |
200 | # with additive noise on pulse, and unvoiced regions
201 | pulse_train += pulse_noise * loc + pulse_noise * (1 - uv)
202 | return pulse_train, sine_wav, uv, pulse_noise
203 |
204 |
205 | class SignalsConv1d(torch.nn.Module):
206 | """ Filtering input signal with time invariant filter
207 | Note: FIRFilter conducted filtering given fixed FIR weight
208 | SignalsConv1d convolves two signals
209 | Note: this is based on torch.nn.functional.conv1d
210 |
211 | """
212 |
213 | def __init__(self):
214 | super(SignalsConv1d, self).__init__()
215 |
216 | def forward(self, signal, system_ir):
217 | """ output = forward(signal, system_ir)
218 |
219 | signal: (batchsize, length1, dim)
220 | system_ir: (length2, dim)
221 |
222 | output: (batchsize, length1, dim)
223 | """
224 | if signal.shape[-1] != system_ir.shape[-1]:
225 | print("Error: SignalsConv1d expects shape:")
226 | print("signal (batchsize, length1, dim)")
227 | print("system_id (batchsize, length2, dim)")
228 | print("But received signal: {:s}".format(str(signal.shape)))
229 | print(" system_ir: {:s}".format(str(system_ir.shape)))
230 | sys.exit(1)
231 | padding_length = system_ir.shape[0] - 1
232 | groups = signal.shape[-1]
233 |
234 | # pad signal on the left
235 | signal_pad = torch_nn_func.pad(signal.permute(0, 2, 1), \
236 | (padding_length, 0))
237 | # prepare system impulse response as (dim, 1, length2)
238 | # also flip the impulse response
239 | ir = torch.flip(system_ir.unsqueeze(1).permute(2, 1, 0), \
240 | dims=[2])
241 | # convolute
242 | output = torch_nn_func.conv1d(signal_pad, ir, groups=groups)
243 | return output.permute(0, 2, 1)
244 |
245 |
246 | class CyclicNoiseGen_v1(torch.nn.Module):
247 | """ CyclicnoiseGen_v1
248 | Cyclic noise with a single parameter of beta.
249 | Pytorch v1 implementation assumes f_t is also fixed
250 | """
251 |
252 | def __init__(self, samp_rate,
253 | noise_std=0.003, voiced_threshold=0):
254 | super(CyclicNoiseGen_v1, self).__init__()
255 | self.samp_rate = samp_rate
256 | self.noise_std = noise_std
257 | self.voiced_threshold = voiced_threshold
258 |
259 | self.l_pulse = PulseGen(samp_rate, pulse_amp=1.0,
260 | noise_std=noise_std,
261 | voiced_threshold=voiced_threshold)
262 | self.l_conv = SignalsConv1d()
263 |
264 | def noise_decay(self, beta, f0mean):
265 | """ decayed_noise = noise_decay(beta, f0mean)
266 | decayed_noise = n[t]exp(-t * f_mean / beta / samp_rate)
267 |
268 | beta: (dim=1) or (batchsize=1, 1, dim=1)
269 | f0mean (batchsize=1, 1, dim=1)
270 |
271 | decayed_noise (batchsize=1, length, dim=1)
272 | """
273 | with torch.no_grad():
274 | # exp(-1.0 n / T) < 0.01 => n > -log(0.01)*T = 4.60*T
275 | # truncate the noise when decayed by -40 dB
276 | length = 4.6 * self.samp_rate / f0mean
277 | length = length.int()
278 | time_idx = torch.arange(0, length, device=beta.device)
279 | time_idx = time_idx.unsqueeze(0).unsqueeze(2)
280 | time_idx = time_idx.repeat(beta.shape[0], 1, beta.shape[2])
281 |
282 | noise = torch.randn(time_idx.shape, device=beta.device)
283 |
284 | # due to Pytorch implementation, use f0_mean as the f0 factor
285 | decay = torch.exp(-time_idx * f0mean / beta / self.samp_rate)
286 | return noise * self.noise_std * decay
287 |
288 | def forward(self, f0s, beta):
289 | """ Producde cyclic-noise
290 | """
291 | # pulse train
292 | pulse_train, sine_wav, uv, noise = self.l_pulse(f0s)
293 | pure_pulse = pulse_train - noise
294 |
295 | # decayed_noise (length, dim=1)
296 | if (uv < 1).all():
297 | # all unvoiced
298 | cyc_noise = torch.zeros_like(sine_wav)
299 | else:
300 | f0mean = f0s[uv > 0].mean()
301 |
302 | decayed_noise = self.noise_decay(beta, f0mean)[0, :, :]
303 | # convolute
304 | cyc_noise = self.l_conv(pure_pulse, decayed_noise)
305 |
306 | # add noise in invoiced segments
307 | cyc_noise = cyc_noise + noise * (1.0 - uv)
308 | return cyc_noise, pulse_train, sine_wav, uv, noise
309 |
310 |
311 | class SourceModuleCycNoise_v1(torch.nn.Module):
312 | """ SourceModuleCycNoise_v1
313 | SourceModule(sampling_rate, noise_std=0.003, voiced_threshod=0)
314 | sampling_rate: sampling_rate in Hz
315 |
316 | noise_std: std of Gaussian noise (default: 0.003)
317 | voiced_threshold: threshold to set U/V given F0 (default: 0)
318 |
319 | cyc, noise, uv = SourceModuleCycNoise_v1(F0_upsampled, beta)
320 | F0_upsampled (batchsize, length, 1)
321 | beta (1)
322 | cyc (batchsize, length, 1)
323 | noise (batchsize, length, 1)
324 | uv (batchsize, length, 1)
325 | """
326 |
327 | def __init__(self, sampling_rate, noise_std=0.003, voiced_threshod=0):
328 | super(SourceModuleCycNoise_v1, self).__init__()
329 | self.sampling_rate = sampling_rate
330 | self.noise_std = noise_std
331 | self.l_cyc_gen = CyclicNoiseGen_v1(sampling_rate, noise_std,
332 | voiced_threshod)
333 |
334 | def forward(self, f0_upsamped, beta):
335 | """
336 | cyc, noise, uv = SourceModuleCycNoise_v1(F0, beta)
337 | F0_upsampled (batchsize, length, 1)
338 | beta (1)
339 | cyc (batchsize, length, 1)
340 | noise (batchsize, length, 1)
341 | uv (batchsize, length, 1)
342 | """
343 | # source for harmonic branch
344 | cyc, pulse, sine, uv, add_noi = self.l_cyc_gen(f0_upsamped, beta)
345 |
346 | # source for noise branch, in the same shape as uv
347 | noise = torch.randn_like(uv) * self.noise_std / 3
348 | return cyc, noise, uv
349 |
350 |
351 | class SourceModuleHnNSF(torch.nn.Module):
352 | """ SourceModule for hn-nsf
353 | SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
354 | add_noise_std=0.003, voiced_threshod=0)
355 | sampling_rate: sampling_rate in Hz
356 | harmonic_num: number of harmonic above F0 (default: 0)
357 | sine_amp: amplitude of sine source signal (default: 0.1)
358 | add_noise_std: std of additive Gaussian noise (default: 0.003)
359 | note that amplitude of noise in unvoiced is decided
360 | by sine_amp
361 | voiced_threshold: threhold to set U/V given F0 (default: 0)
362 |
363 | Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
364 | F0_sampled (batchsize, length, 1)
365 | Sine_source (batchsize, length, 1)
366 | noise_source (batchsize, length 1)
367 | uv (batchsize, length, 1)
368 | """
369 |
370 | def __init__(self, sampling_rate, harmonic_num=0, sine_amp=0.1,
371 | add_noise_std=0.003, voiced_threshod=0):
372 | super(SourceModuleHnNSF, self).__init__()
373 |
374 | self.sine_amp = sine_amp
375 | self.noise_std = add_noise_std
376 |
377 | # to produce sine waveforms
378 | self.l_sin_gen = SineGen(sampling_rate, harmonic_num,
379 | sine_amp, add_noise_std, voiced_threshod)
380 |
381 | # to merge source harmonics into a single excitation
382 | self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
383 | self.l_tanh = torch.nn.Tanh()
384 |
385 | def forward(self, x):
386 | """
387 | Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
388 | F0_sampled (batchsize, length, 1)
389 | Sine_source (batchsize, length, 1)
390 | noise_source (batchsize, length 1)
391 | """
392 | # source for harmonic branch
393 | sine_wavs, uv, _ = self.l_sin_gen(x)
394 | sine_merge = self.l_tanh(self.l_linear(sine_wavs))
395 |
396 | # source for noise branch, in the same shape as uv
397 | noise = torch.randn_like(uv) * self.sine_amp / 3
398 | return sine_merge, noise, uv
399 |
400 |
401 | if __name__ == '__main__':
402 | source = SourceModuleCycNoise_v1(24000)
403 | x = torch.randn(16, 25600, 1)
404 |
405 |
406 |
--------------------------------------------------------------------------------
/wavenet.py:
--------------------------------------------------------------------------------
1 | import math
2 | from math import sqrt
3 |
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.functional as F
7 | from torch.nn import Mish
8 |
9 |
10 | class Conv1d(torch.nn.Conv1d):
11 | def __init__(self, *args, **kwargs):
12 | super().__init__(*args, **kwargs)
13 | nn.init.kaiming_normal_(self.weight)
14 |
15 |
16 | class SinusoidalPosEmb(nn.Module):
17 | def __init__(self, dim):
18 | super().__init__()
19 | self.dim = dim
20 |
21 | def forward(self, x):
22 | device = x.device
23 | half_dim = self.dim // 2
24 | emb = math.log(10000) / (half_dim - 1)
25 | emb = torch.exp(torch.arange(half_dim, device=device) * -emb)
26 | emb = x[:, None] * emb[None, :]
27 | emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
28 | return emb
29 |
30 |
31 | class ResidualBlock(nn.Module):
32 | def __init__(self, encoder_hidden, residual_channels, dilation):
33 | super().__init__()
34 | self.residual_channels = residual_channels
35 | self.dilated_conv = nn.Conv1d(
36 | residual_channels,
37 | 2 * residual_channels,
38 | kernel_size=3,
39 | padding=dilation,
40 | dilation=dilation
41 | )
42 | self.diffusion_projection = nn.Linear(residual_channels, residual_channels)
43 | self.conditioner_projection = nn.Conv1d(encoder_hidden, 2 * residual_channels, 1)
44 | self.output_projection = nn.Conv1d(residual_channels, 2 * residual_channels, 1)
45 |
46 | def forward(self, x, conditioner, diffusion_step):
47 | # x:[48,512,187]
48 | diffusion_step = self.diffusion_projection(diffusion_step).unsqueeze(-1) # [48, 512, 1]
49 | conditioner = self.conditioner_projection(conditioner) # [48, 1024, 187]
50 | y = x + diffusion_step # 维度分别是 [48,512,187] & [48,512,1],将diffusion_step的最后一维复制187份和x相加
51 |
52 | y = self.dilated_conv(y) + conditioner # self.dilated_conv(y)形状是[48, 1024, 187]
53 |
54 | # Using torch.split instead of torch.chunk to avoid using onnx::Slice
55 | gate, filter = torch.split(y, [self.residual_channels, self.residual_channels], dim=1)
56 | # gate和filter的形状都是[48, 512, 187]
57 | y = torch.sigmoid(gate) * torch.tanh(filter) # [48, 512, 187]
58 |
59 | y = self.output_projection(y) # [48, 1024, 187]
60 |
61 | # Using torch.split instead of torch.chunk to avoid using onnx::Slice
62 | residual, skip = torch.split(y, [self.residual_channels, self.residual_channels], dim=1)
63 | #形状都是[48, 512, 187]
64 | return (x + residual) / math.sqrt(2.0), skip
65 |
66 |
67 | class WaveNet(nn.Module):
68 | def __init__(self, in_dims=128, n_layers=20, n_chans=384, n_hidden=256):
69 | #in_dim=vocoder_dimension 512 n_hidden: 100 n_layers: 20 n_spk: 20
70 | super().__init__()
71 | self.input_projection = Conv1d(in_dims, n_chans, 1)
72 | self.diffusion_embedding = SinusoidalPosEmb(n_chans)
73 | self.mlp = nn.Sequential(
74 | nn.Linear(n_chans, n_chans * 4),
75 | Mish(),
76 | nn.Linear(n_chans * 4, n_chans)
77 | )
78 | self.residual_layers = nn.ModuleList([
79 | ResidualBlock(
80 | encoder_hidden=n_hidden,
81 | residual_channels=n_chans,
82 | dilation=1
83 | )
84 | for i in range(n_layers)
85 | ])
86 | self.skip_projection = Conv1d(n_chans, n_chans, 1)
87 | self.output_projection = Conv1d(n_chans, in_dims, 1)
88 | nn.init.zeros_(self.output_projection.weight)
89 |
90 | def forward(self, spec, diffusion_step,cond):
91 | """
92 | :param spec: [B, 1, M, T]
93 | :param diffusion_step: [B, 1]
94 | :param cond: [B, M, T]
95 | :return:
96 | """
97 | # print("spec_shape",spec.shape)
98 | # print("cond_shape",cond.shape)
99 | cond = cond.transpose(1,2) # [48,256,187]
100 | x = spec.squeeze(1)# 没有变化[48, 187, 100]
101 | x = x.transpose(1,2)
102 | x = self.input_projection(x) # [B, residual_channel, T]
103 |
104 |
105 | x = F.relu(x)
106 | diffusion_step = self.diffusion_embedding(diffusion_step)
107 | diffusion_step = self.mlp(diffusion_step)
108 | skip = []
109 | # n_layers=20,要经过20层residual layer
110 | for layer in self.residual_layers:
111 | x, skip_connection = layer(x, cond, diffusion_step)
112 | skip.append(skip_connection)
113 |
114 | x = torch.sum(torch.stack(skip), dim=0) / sqrt(len(self.residual_layers)) #[48, 512, 187]
115 | x = self.skip_projection(x)
116 | x = F.relu(x) # [48, 512, 187]
117 | x = self.output_projection(x) # [B, mel_bins, T] [48, 100, 187]
118 | # output=x[:, None, :, :]
119 | # print(output.shape)
120 | return x[:, :, :].transpose(1,2) # [48, 187, 100]
121 |
--------------------------------------------------------------------------------