├── .gitignore
├── .gitmodules
├── CHANGELOG.md
├── LICENSE
├── README.md
├── assets
├── demo_llama3_8B_fpft.gif
└── demo_yi_34B_peft.gif
├── db
├── api_key_management.py
└── create_apikey_table.sql
├── docker
├── Dockerfile
└── README.md
├── environment.yml
├── examples
├── __init__.py
└── local_rag
│ ├── README.md
│ ├── __init__.py
│ ├── requirements.txt
│ └── run.py
├── green_bit_llm
├── __init__.py
├── args_parser.py
├── common
│ ├── __init__.py
│ ├── enum.py
│ ├── model.py
│ └── utils.py
├── evaluation
│ ├── README.md
│ ├── __init__.py
│ ├── datautils.py
│ ├── evaluate.py
│ ├── lmclass.py
│ └── utils.py
├── inference
│ ├── README.md
│ ├── __init__.py
│ ├── chat_base.py
│ ├── chat_cli.py
│ ├── conversation.py
│ ├── sim_gen.py
│ └── utils.py
├── langchain
│ ├── README.md
│ ├── __init__.py
│ ├── chat_model.py
│ ├── embedding.py
│ └── pipeline.py
├── patches
│ ├── __init__.py
│ ├── deepseek_v3_moe_patch.py
│ └── qwen3_moe_patch.py
├── routing
│ ├── __init__.py
│ └── confidence_scorer.py
├── serve
│ ├── __init__.py
│ ├── api
│ │ ├── __init__.py
│ │ └── v1
│ │ │ ├── __init__.py
│ │ │ └── fastapi_server.py
│ └── auth
│ │ ├── __init__.py
│ │ ├── api_key_auth.py
│ │ └── rate_limiter.py
├── sft
│ ├── README.md
│ ├── __init__.py
│ ├── finetune.py
│ ├── optim
│ │ ├── __init__.py
│ │ ├── adamw8bit.py
│ │ └── bnb_optimizer.py
│ ├── peft_lora.py
│ ├── peft_utils
│ │ ├── __init__.py
│ │ ├── gba_lora.py
│ │ └── model.py
│ ├── trainer.py
│ └── utils.py
└── version.py
├── requirements.txt
├── scripts
└── curl_script
├── setup.py
└── tests
├── __init__.py
├── test_langchain_chatmodel.py
├── test_langchain_embedding.py
└── test_langchain_pipeline.py
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | share/python-wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 | MANIFEST
28 |
29 | # PyInstaller
30 | # Usually these files are written by a python script from a template
31 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
32 | *.manifest
33 | *.spec
34 |
35 | # Installer logs
36 | pip-log.txt
37 | pip-delete-this-directory.txt
38 |
39 | # Unit test / coverage reports
40 | htmlcov/
41 | .tox/
42 | .nox/
43 | .coverage
44 | .coverage.*
45 | .cache
46 | nosetests.xml
47 | coverage.xml
48 | *.cover
49 | *.py,cover
50 | .hypothesis/
51 | .pytest_cache/
52 | cover/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | .pybuilder/
76 | target/
77 |
78 | # Jupyter Notebook
79 | .ipynb_checkpoints
80 |
81 | # IPython
82 | profile_default/
83 | ipython_config.py
84 |
85 | # pyenv
86 | # For a library or package, you might want to ignore these files since the code is
87 | # intended to run in multiple environments; otherwise, check them in:
88 | # .python-version
89 |
90 | # pipenv
91 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
92 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
93 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
94 | # install all needed dependencies.
95 | #Pipfile.lock
96 |
97 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
98 | __pypackages__/
99 |
100 | # Celery stuff
101 | celerybeat-schedule
102 | celerybeat.pid
103 |
104 | # SageMath parsed files
105 | *.sage.py
106 |
107 | # Environments
108 | .env
109 | .venv
110 | env/
111 | venv/
112 | ENV/
113 | env.bak/
114 | venv.bak/
115 |
116 | # Spyder project settings
117 | .spyderproject
118 | .spyproject
119 |
120 | # Rope project settings
121 | .ropeproject
122 |
123 | # mkdocs documentation
124 | /site
125 |
126 | # mypy
127 | .mypy_cache/
128 | .dmypy.json
129 | dmypy.json
130 |
131 | # Pyre type checker
132 | .pyre/
133 |
134 | # pytype static type analyzer
135 | .pytype/
136 |
137 | # Cython debug symbols
138 | cython_debug/
139 |
140 | .coverage
141 | .idea/
142 | .vscode/
143 | .mypy_cache
144 |
145 | # downloaded dataset files
146 | train/
147 | test/
148 |
149 | # Logs
150 | logs/*
151 | !logs/.gitkeep
152 |
153 | # databasegit status
154 | db/*
155 | !db/.gitkeep
--------------------------------------------------------------------------------
/.gitmodules:
--------------------------------------------------------------------------------
1 | [submodule "green_bit_llm/routing/libra_router"]
2 | path = green_bit_llm/routing/libra_router
3 | url = https://github.com/GreenBitAI/Libra-Router.git
4 |
--------------------------------------------------------------------------------
/CHANGELOG.md:
--------------------------------------------------------------------------------
1 | # Changelog
2 |
3 | All notable changes to this project will be documented in this file.
4 | The format is based on [Keep a Changelog](http://keepachangelog.com/)
5 | and this project adheres to [Semantic Versioning](http://semver.org/).
6 |
7 | ## [0.2.6] - 2025/6/4
8 |
9 | ### Updated
10 |
11 | - Fixed RoPE type missing problem in deepseek-r1-qwen3-8B model
12 | - Update README with Qwen3 model notes and Transformers compatibility details
13 |
14 | ## [0.2.5] - 2025/5/30
15 |
16 | ### Added
17 |
18 | - Model server support
19 | - Deepseek model support
20 | - Qwen-3 model support
21 | - Langchain integration
22 | - local RAG example
23 |
24 | ### Updated
25 |
26 | - Various refactoring and improvements
27 |
28 | ## [0.2.4] - 2024/06/04
29 |
30 | ### Fixed
31 |
32 | - Source distribution (was missing `requirements.txt`)
33 |
34 | ## [0.2.3] - 2024/05/26
35 |
36 | ### Added
37 |
38 | - Evaluation results
39 |
40 | ### Fixed
41 |
42 | - Changelog order and date format
43 | - URL in README for PyPI
44 |
45 | ## [0.2.2] - 2024/05/24
46 |
47 | ### Added
48 |
49 | - Evaluation results
50 |
51 | ### Fixed
52 |
53 | - Version numbering
54 |
55 | ## [0.2.1] - 2024/05/22
56 |
57 | ### Added
58 |
59 | - Missing changelog entries
60 |
61 | ### Fixed
62 |
63 | - Version numbering
64 |
65 | ## [0.2.0] - 2024/05/20
66 |
67 | ### Added
68 |
69 | - Initial support for a classical GPTQ model using the MPQLinear layer
70 | - AutoGPTQ information and commands in the repository
71 | - Support for LoRA and GPTQ evaluation
72 | - SFT comparison updates
73 | - Missing comment to the customized trainer class
74 |
75 | ### Fixed
76 |
77 | - Issue in GbaSFTTrainer for saving non-GBA models
78 | - Mismatch issue between GPTQ and LoRA
79 | - Bug preventing quant_strategy.json from being saved during SFT
80 |
81 | ### Updated
82 |
83 | - README with new AutoGPTQ and GPTQ support information
84 |
85 | ## [0.1.0] - 2024/01/05
86 |
87 | ### Added
88 |
89 | - Integration with Bitorch Engine
90 | - Full-parameter fine-tuning and PEFT support
91 | - Fast inference capabilities
92 | - Comprehensive evaluation tools and detailed model evaluation results
93 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Green-Bit-LLM
2 |
3 | This Python package uses the [Bitorch Engine](https://github.com/GreenBitAI/bitorch-engine) for efficient operations on [GreenBitAI's Low-bit Language Models (LLMs)](https://huggingface.co/GreenBitAI).
4 | It enables **high-performance inference** on both cloud-based and consumer-level GPUs, and supports **full-parameter fine-tuning** directly **using quantized LLMs**.
5 | Additionally, you can use our provided **evaluation tools** to validate the model's performance on mainstream benchmark datasets.
6 |
7 | ## News
8 | - [2025/5]
9 | - Qwen-3 and Deepseek support.
10 | - [2024/10]
11 | - Langchain integration, model server support.
12 | - [2024/04]
13 | - We have launched over **200 low-bit LLMs** in [GreenBitAI's Hugging Face Model Repo](https://huggingface.co/GreenBitAI). Our release includes highly precise 2.2/2.5/3-bit models across the LLM family, featuring LLaMA 2/3, 01-Yi, Qwen, Mistral, Phi-3 and more.
14 | - We released [Bitorch Engine](https://github.com/GreenBitAI/bitorch-engine) for **low-bit** quantized neural network operations. Our release support full parameter fine-tuning and parameter efficiency fine-tuning (PEFT), even under extremely constrained GPU resource conditions.
15 |
16 | ## LLMs
17 |
18 | We have released over 260 highly efficient 2-4 bit models across the modern LLM family, featuring Deepseek, LLaMA, Qwen, Mistral, Phi, and more.
19 | Explore all available models in our [Hugging Face repository](https://huggingface.co/GreenBitAI).
20 | green-bit-llm is also fully compatible with all 4-bit models in the AutoGPTQ series.
21 |
22 | ## Installation
23 |
24 | This package depends on [Bitorch Engine](https://github.com/GreenBitAI/bitorch-engine) and
25 | a first experimental **binary release for Linux with CUDA 12.1 is ready.**
26 | We recommend to create a conda environment to manage the installed CUDA version and other packages.
27 |
28 | ### Conda
29 |
30 | We recommend using [Miniconda](https://docs.conda.io/en/latest/miniconda.html) for a lightweight installation.
31 | Please download the installer from the official Miniconda website and follow the setup instructions.
32 |
33 | After Conda successfully installed, do the following steps:
34 |
35 | 1. Create Environment for Python 3.10 and activate it:
36 | ```bash
37 | conda create -y --name bitorch-engine python=3.10
38 | conda activate bitorch-engine
39 | ```
40 | 2. Install target CUDA version:
41 | ```bash
42 | conda install -y -c "nvidia/label/cuda-12.1.0" cuda-toolkit
43 | ```
44 | 3. Install bitorch engine:
45 |
46 | *Inference ONLY*
47 | ```bash
48 | pip install \
49 | "https://packages.greenbit.ai/whl/cu121/bitorch-engine/bitorch_engine-0.2.6-cp310-cp310-linux_x86_64.whl"
50 | ```
51 |
52 | *Training REQUIRED*
53 |
54 | Install our customized torch that allows gradients on INT tensors and install it with pip (this URL is for CUDA 12.1
55 | and Python 3.10 - you can find other versions [here](https://packages.greenbit.ai/whl/)) together with bitorch engine:
56 | ```bash
57 | pip install \
58 | "https://packages.greenbit.ai/whl/cu121/torch/torch-2.5.1-cp310-cp310-linux_x86_64.whl" \
59 | "https://packages.greenbit.ai/whl/cu121/bitorch-engine/bitorch_engine-0.2.6-cp310-cp310-linux_x86_64.whl"
60 | ```
61 |
62 | 4. Install green-bit-llm:
63 |
64 | via pypi
65 | ```bash
66 | pip install green-bit-llm
67 | ```
68 | or from source
69 | ```bash
70 | git clone https://github.com/GreenBitAI/green-bit-llm.git
71 | cd green-bit-llm
72 | pip install -r requirements.txt
73 | ```
74 |
75 | **Note: For Qwen3 model support, you need to install the development version of transformers:**
76 | ```bash
77 | pip install git+https://github.com/huggingface/transformers.git
78 | ```
79 | This installs transformers version 4.53.0.dev0 which includes the necessary Qwen3 model support.
80 |
81 | 5. Install [Flash Attention](https://github.com/Dao-AILab/flash-attention) (`flash-attn`) according to their [official instructions](https://github.com/Dao-AILab/flash-attention?tab=readme-ov-file#installation-and-features).
82 | ```bash
83 | pip install flash-attn --no-build-isolation
84 | ```
85 |
86 | ## Examples
87 |
88 | ### Simple Generation
89 |
90 | Run the simple generation script as follows:
91 |
92 | ```bash
93 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.inference.sim_gen --model GreenBitAI/Qwen-3-1.7B-layer-mix-bpw-4.0 --max-tokens 1024 --use-flash-attention-2
94 | ```
95 |
96 | ### FastAPI Model Server
97 |
98 | A high-performance HTTP API for text generation with GreenBitAI's low-bit models.
99 |
100 | #### Quick Start
101 | 1. Run:
102 | ```shell
103 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.serve.api.v1.fastapi_server --model GreenBitAI/Qwen-3-1.7B-layer-mix-bpw-4.0 --host 127.0.0.1 --port 11668
104 | ```
105 | 2. Use:
106 | ```shell
107 | # Chat
108 | curl http://localhost:11668/v1/GreenBitAI-Qwen-3-17B-layer-mix-bpw-40/chat/completions -H "Content-Type: application/json" \
109 | -d '{"model": "default_model", "messages": [{"role": "user", "content": "Hello!"}]}'
110 |
111 | # Chat stream
112 | curl http://localhost:11668/v1/GreenBitAI-Qwen-3-17B-layer-mix-bpw-40/chat/completions -H "Content-Type: application/json" \
113 | -d '{"model": "default_model", "messages": [{"role": "user", "content": "Hello!"}], "stream": "True"}'
114 | ```
115 |
116 | ### Full-parameter fine-tuning
117 |
118 | Full parameter fine-tuning of the LLaMA-3 8B model using a single GTX 3090 GPU with 24GB of graphics memory:
119 |
120 | 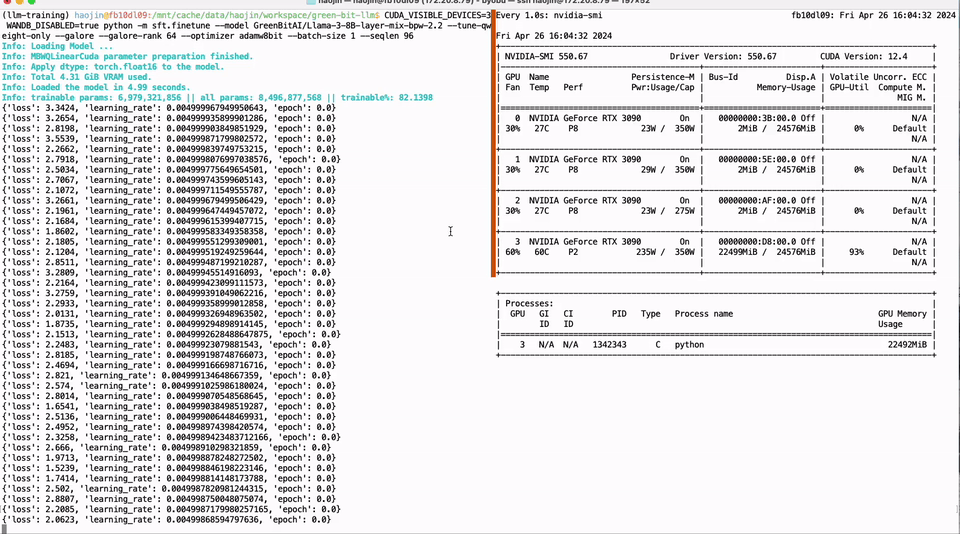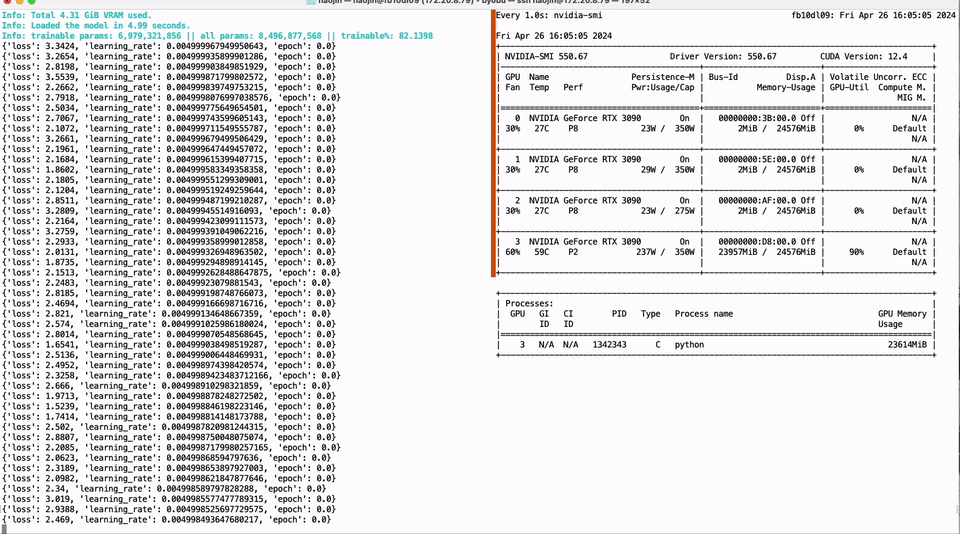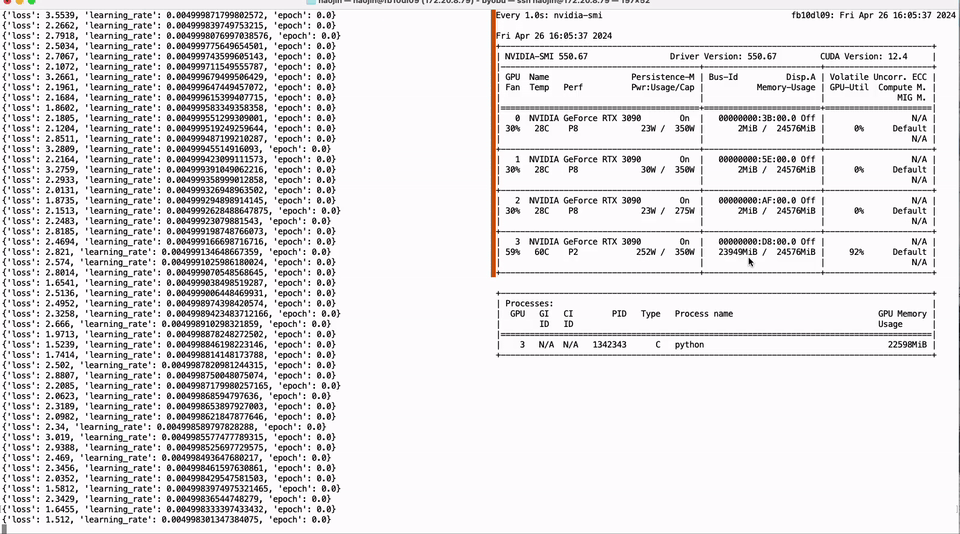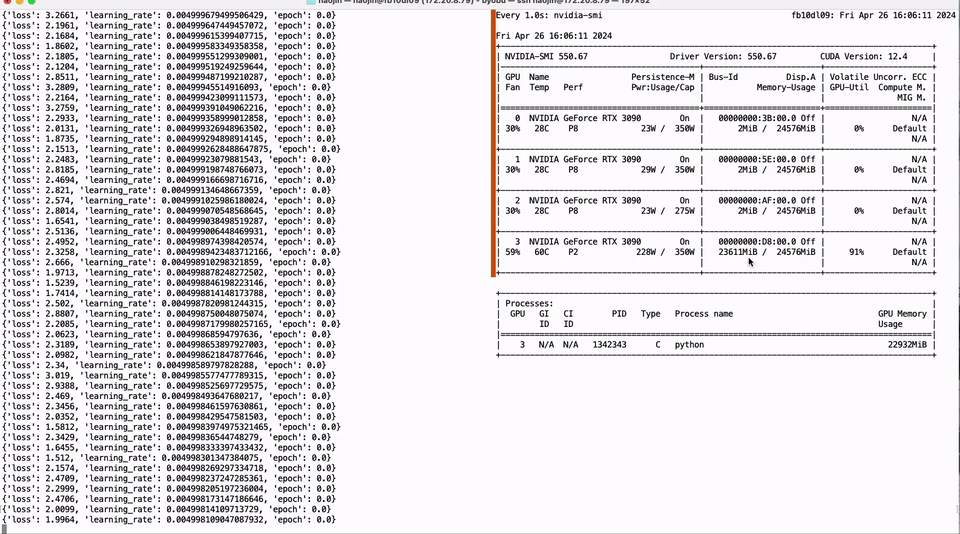 121 |
122 | Run the script as follows to fine-tune the quantized weights of the model on the target dataset.
123 | The '--tune-qweight-only' parameter determines whether to fine-tune only the quantized weights or all weights, including non-quantized ones.
124 |
125 | ```bash
126 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --optimizer DiodeMix --tune-qweight-only
127 |
128 | # AutoGPTQ model Q-SFT
129 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --tune-qweight-only --batch-size 1
130 | ```
131 |
132 | ### Parameter efficient fine-tuning
133 |
134 | PEFT of the 01-Yi 34B model using a single GTX 3090 GPU with 24GB of graphics memory:
135 |
136 |
121 |
122 | Run the script as follows to fine-tune the quantized weights of the model on the target dataset.
123 | The '--tune-qweight-only' parameter determines whether to fine-tune only the quantized weights or all weights, including non-quantized ones.
124 |
125 | ```bash
126 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --optimizer DiodeMix --tune-qweight-only
127 |
128 | # AutoGPTQ model Q-SFT
129 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --tune-qweight-only --batch-size 1
130 | ```
131 |
132 | ### Parameter efficient fine-tuning
133 |
134 | PEFT of the 01-Yi 34B model using a single GTX 3090 GPU with 24GB of graphics memory:
135 |
136 | 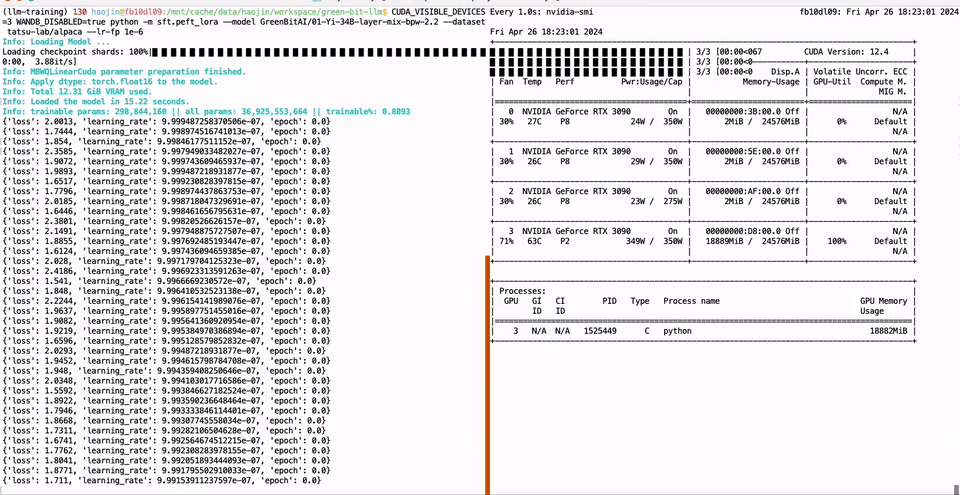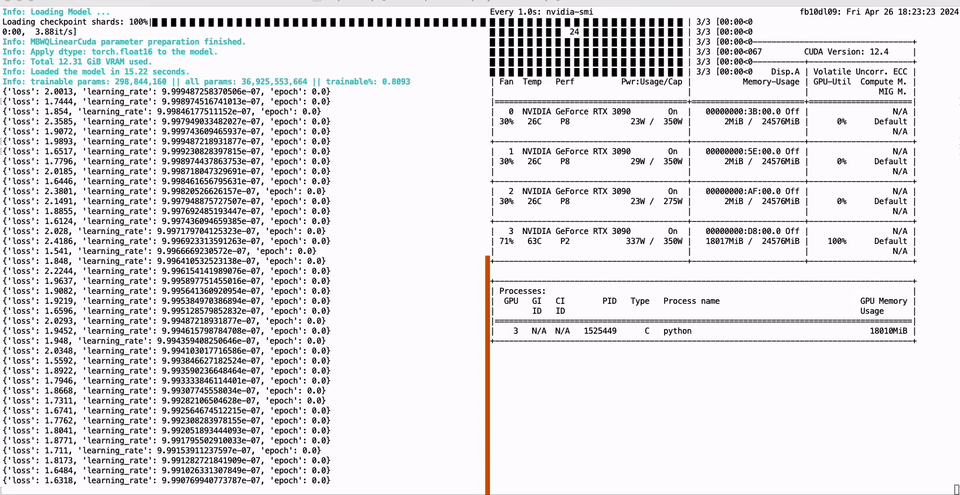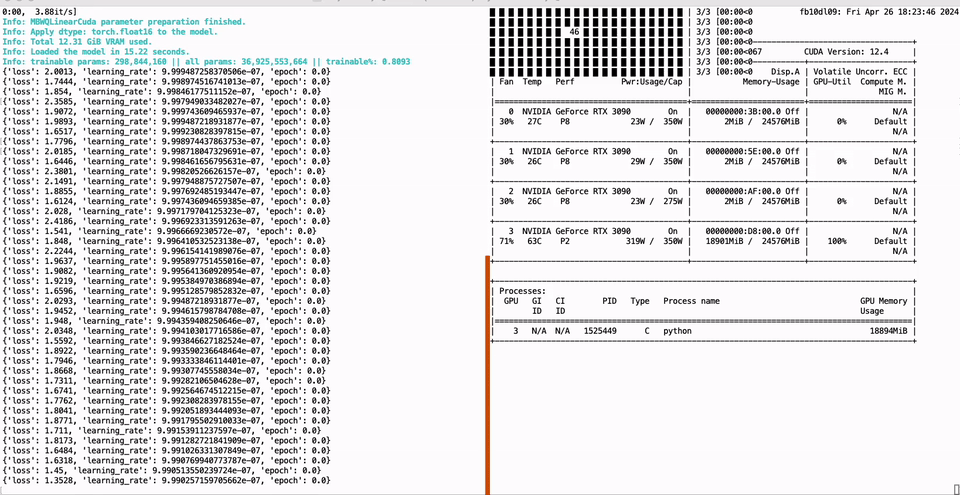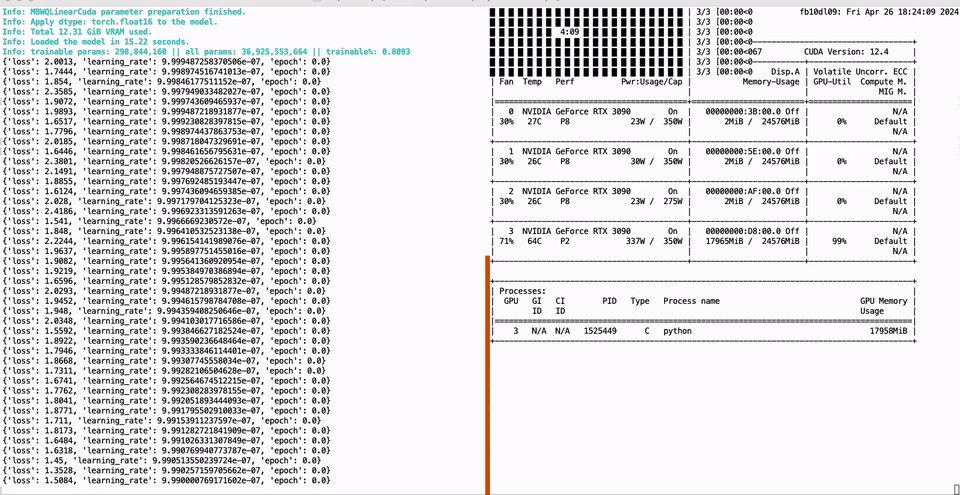 137 |
138 | ```bash
139 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --lr-fp 1e-6
140 |
141 | # AutoGPTQ model with Lora
142 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --lr-fp 1e-6
143 | ```
144 |
145 | ## Further Usage
146 |
147 | Please see the description of the [Inference](green_bit_llm/inference/README.md), [sft](green_bit_llm/sft/README.md) and [evaluation](green_bit_llm/evaluation/README.md) package for details.
148 |
149 | ## License
150 | We release our codes under the [Apache 2.0 License](LICENSE).
151 | Additionally, three packages are also partly based on third-party open-source codes. For detailed information, please refer to the description pages of the sub-projects.
152 |
--------------------------------------------------------------------------------
/assets/demo_llama3_8B_fpft.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/assets/demo_llama3_8B_fpft.gif
--------------------------------------------------------------------------------
/assets/demo_yi_34B_peft.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/assets/demo_yi_34B_peft.gif
--------------------------------------------------------------------------------
/db/create_apikey_table.sql:
--------------------------------------------------------------------------------
1 | -- z.B. sqlite3 greenbit.db < create_tables.sql
2 |
3 | -- drop tables if exists
4 | --DROP TABLE IF EXISTS api_keys;
5 | --DROP TABLE IF EXISTS users;
6 |
7 | -- Create users table
8 | CREATE TABLE IF NOT EXISTS users (
9 | id INTEGER PRIMARY KEY AUTOINCREMENT,
10 | name TEXT NOT NULL,
11 | email TEXT NOT NULL UNIQUE,
12 | organization TEXT,
13 | created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
14 | );
15 |
16 | -- Create API keys table
17 | CREATE TABLE IF NOT EXISTS api_keys (
18 | id INTEGER PRIMARY KEY AUTOINCREMENT,
19 | user_id INTEGER NOT NULL,
20 | api_key_hash TEXT NOT NULL UNIQUE,
21 | name TEXT NOT NULL,
22 | email TEXT NOT NULL,
23 | organization TEXT,
24 | tier VARCHAR(20) DEFAULT 'basic',
25 | rpm_limit INTEGER DEFAULT 60,
26 | tpm_limit INTEGER DEFAULT 40000,
27 | concurrent_requests INTEGER DEFAULT 5,
28 | max_tokens INTEGER DEFAULT 32768,
29 | permissions TEXT DEFAULT 'completion,chat',
30 | is_active BOOLEAN DEFAULT TRUE,
31 | created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
32 | last_used_at TIMESTAMP,
33 | FOREIGN KEY (user_id) REFERENCES users(id),
34 | CHECK (is_active IN (0, 1))
35 | );
36 |
37 | -- Create indexes
38 | CREATE INDEX IF NOT EXISTS idx_api_key_hash ON api_keys(api_key_hash);
39 | CREATE INDEX IF NOT EXISTS idx_user_email ON users(email);
40 | CREATE INDEX IF NOT EXISTS idx_last_used ON api_keys(last_used_at);
--------------------------------------------------------------------------------
/docker/Dockerfile:
--------------------------------------------------------------------------------
1 | ARG FROM_IMAGE="bitorch/engine"
2 | FROM ${FROM_IMAGE} as bitorch-engine-base
3 |
4 | FROM bitorch-engine-base as requirements-installed
5 | COPY "../requirements.txt" "/green-bit-llm-req.txt"
6 | RUN pip install packaging -r "/green-bit-llm-req.txt" && \
7 | rm "/green-bit-llm-req.txt" && \
8 | pip install flash-attn --no-build-isolation && \
9 | pip cache purge
10 |
11 | # clone instead of mounting makes the code in the image independent from local changes
12 | # to mount your code before building, use the target above and mount your local code
13 | FROM requirements-installed as code-cloned
14 | ARG GIT_URL="https://github.com/GreenBitAI/green-bit-llm.git"
15 | ARG GIT_BRANCH="main"
16 | ARG BUILD_TARGET="."
17 | RUN git clone \
18 | --depth 1 \
19 | --branch "${GIT_BRANCH}" \
20 | "${GIT_URL}" \
21 | /green-bit-llm && \
22 | cd /green-bit-llm && \
23 | pip install -e .
24 |
--------------------------------------------------------------------------------
/docker/README.md:
--------------------------------------------------------------------------------
1 | # Project Setup with Docker
2 |
3 | In the following, we show how to build a [Docker](https://www.docker.com/) image for this project and explain additional options.
4 |
5 | ## Build Docker Image
6 |
7 | 1. Build the bitorch engine image according to [these instructions](https://github.com/GreenBitAI/bitorch-engine/blob/HEAD/docker/README.md).
8 | 2. Now you should be able to build the image by running the following commands
9 | (if you used a custom image name or tag, you can adjust with `--build-arg FROM_IMAGE="bitorch/engine:custom-tag"`):
10 | ```bash
11 | # cd docker
12 | # you should be in this `docker` directory
13 | cp -f ../requirements.txt .
14 | docker build -t gbai/green-bit-llm .
15 | ```
16 | 3. You can now run the container, for example with this:
17 | ```bash
18 | docker run -it --rm --gpus all gbai/green-bit-llm
19 | ```
20 | 4. Alternatively, you can mount the directory `/root/.cache/huggingface/hub` which will save the downloaded model cache locally,
21 | e.g. you could use your users cache directory:
22 | ```bash
23 | docker run -it --rm --gpus all -v "${HOME}/.cache/huggingface/hub":"/root/.cache/huggingface/hub" gbai/green-bit-llm
24 | ```
25 |
26 | ## Build Options
27 |
28 | Depending on your setup, you may want to adjust some options through build arguments:
29 | - base docker image, e.g. add `--build-arg FROM_IMAGE="bitorch/engine:custom-tag"`
30 | - repository URL, e.g. add `--build-arg GIT_URL="https://github.com/MyFork/green-bit-llm.git"`
31 | - green-bit-llm branch or tag, e.g. add `--build-arg GIT_BRANCH="v1.2.3"`
32 | - if there is a problem, set the environment variable `BUILDKIT_PROGRESS=plain` to see all output
33 |
34 | ## For Development
35 |
36 | A docker image without the code cloned, e.g. for mounting a local copy of the code, can be made easily with the target `requirements-installed`:
37 | ```bash
38 | # cd docker
39 | # you should be in this `docker` directory
40 | cp -f ../requirements.txt .
41 | docker build -t gbai/green-bit-llm:no-code --target requirements-installed .
42 | docker run -it --rm --gpus all --volume "$(pwd)/..":/green-bit-llm gbai/green-bit-llm:no-code
43 | # in the docker container:
44 | cd /green-bit-llm
45 | pip install -e .
46 | ```
47 | However, this means the build results will not be persisted in the image, so you probably want to mount the same directory every time.
48 |
--------------------------------------------------------------------------------
/environment.yml:
--------------------------------------------------------------------------------
1 | name: gbai_cuda_lm
2 | channels:
3 | - conda-forge
4 | - pytorch
5 | dependencies:
6 | - python=3.9
7 | - pip=24.0
8 | - pytorch::pytorch>=2.0
9 | - pip:
10 | - sentencepiece
11 | - huggingface-hub
12 | - transformers>=4.52.4
13 | - accelerate
14 | - colorama
15 | - datasets
16 | - lm-eval==0.3.0
17 | - termcolor
18 | - pillow
19 | - requests
20 | - prompt-toolkit
21 | - rich
22 | - optimum
23 | - auto-gptq
24 | - langchain-core
25 |
--------------------------------------------------------------------------------
/examples/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/examples/__init__.py
--------------------------------------------------------------------------------
/examples/local_rag/README.md:
--------------------------------------------------------------------------------
1 | # Local RAG Demo
2 |
3 | ## Overview
4 |
5 | This project demonstrates a local implementation of Retrieval-Augmented Generation (RAG) using GreenBit models, including GreenBitPipeline, ChatGreenBit, and GreenBitEmbeddings. It showcases features such as document loading, text splitting, vector store creation, and various natural language processing tasks in a CUDA environment.
6 |
7 | ## Features
8 |
9 | - Document loading from web sources
10 | - Text splitting for efficient processing
11 | - Vector store creation using BERT embeddings
12 | - Rap battle simulation
13 | - Document summarization
14 | - Question answering
15 | - Question answering with retrieval
16 |
17 | ## Installation
18 |
19 | 1. Install the required packages:
20 | ```
21 | pip install -r requirements.txt
22 | ```
23 |
24 | 2. Ensure you have a CUDA-compatible environment set up on your system.
25 |
26 | ## Usage
27 |
28 | Run the main script to execute all tasks:
29 |
30 | ```
31 | CUDA_VISIBLE_DEVICES=0 \
32 | python -m examples.local_rag.run --model "GreenBitAI/Llama-3-8B-instruct-layer-mix-bpw-4.0" \
33 | --embedding_model "sentence-transformers/all-MiniLM-L12-v2" \
34 | --query "What are the core components of GraphRAG?" \
35 | --max_tokens 300 \
36 | --web_source "https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/"
37 | ```
38 |
39 | This will perform the following tasks:
40 | 1. Initialize the model and prepare data
41 | 2. Simulate a rap battle
42 | 3. Summarize documents based on a question
43 | 4. Perform question answering
44 | 5. Perform question answering with retrieval
45 |
46 | ## Note
47 |
48 | This implementation uses GreenBit models, which are compatible with Hugging Face's transformers library and optimized for CUDA environments. Make sure you have the appropriate CUDA setup and GreenBit model files before running the demo.
--------------------------------------------------------------------------------
/examples/local_rag/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/examples/local_rag/__init__.py
--------------------------------------------------------------------------------
/examples/local_rag/requirements.txt:
--------------------------------------------------------------------------------
1 | langchain-core
2 | langchain-community
3 | langchain-chroma
4 | langchain-text-splitters
5 | langchain-experimental
6 | beautifulsoup4
7 | pydantic
8 | sentence-transformers
--------------------------------------------------------------------------------
/examples/local_rag/run.py:
--------------------------------------------------------------------------------
1 | import re
2 | import argparse
3 | import torch
4 |
5 | from langchain_community.document_loaders import WebBaseLoader
6 | from langchain_text_splitters import RecursiveCharacterTextSplitter
7 | from langchain_chroma import Chroma
8 | from langchain_core.output_parsers import StrOutputParser
9 | from langchain_core.prompts import ChatPromptTemplate
10 | from langchain_core.runnables import RunnablePassthrough
11 |
12 | from green_bit_llm.langchain import GreenBitPipeline, ChatGreenBit, GreenBitEmbeddings
13 |
14 | import warnings
15 | warnings.filterwarnings("ignore", category=UserWarning)
16 |
17 |
18 | # Helper function to format documents
19 | def format_docs(docs):
20 | return "\n\n".join(doc.page_content for doc in docs)
21 |
22 | # Helper function to print task separators
23 | def print_task_separator(task_name):
24 | print("\n" + "="*50)
25 | print(f"Task: {task_name}")
26 | print("="*50 + "\n")
27 |
28 | def clean_output(text):
29 | # Remove all non-alphanumeric characters except periods and spaces
30 | cleaned = re.sub(r'[^a-zA-Z0-9\.\s]', ' ', text)
31 | # Replace multiple spaces with a single space
32 | cleaned = re.sub(r'\s+', ' ', cleaned).strip()
33 | # Remove any mentions of "assistant" or other unwanted words
34 | cleaned = re.sub(r'\b(assistant|correct|I apologize|mistake)\b', '', cleaned, flags=re.IGNORECASE)
35 | # Remove any remaining leading/trailing whitespace
36 | cleaned = cleaned.strip()
37 | # Ensure the first letter is capitalized
38 | cleaned = cleaned.capitalize()
39 | # Ensure the answer ends with a period
40 | if cleaned and not cleaned.endswith('.'):
41 | cleaned += '.'
42 | return cleaned
43 |
44 | def extract_answer(text):
45 | # Try to extract a single sentence answer
46 | match = re.search(r'([A-Z][^\.!?]*[\.!?])', text)
47 | if match:
48 | return match.group(1)
49 | # If no clear sentence is found, return the first 100 characters
50 | return text[:100] + '...' if len(text) > 100 else text
51 |
52 | # Load and prepare data
53 | def prepare_data(url):
54 | loader = WebBaseLoader(url)
55 | data = loader.load()
56 | text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
57 | all_splits = text_splitter.split_documents(data)
58 | return all_splits
59 |
60 | # Create vector store
61 | def create_vectorstore(documents, embedding_model):
62 | model_kwargs = {'trust_remote_code': True}
63 | encode_kwargs = {'normalize_embeddings': False}
64 |
65 | greenbit_embeddings = GreenBitEmbeddings.from_model_id(
66 | model_name=embedding_model,
67 | cache_dir="cache",
68 | multi_process=False,
69 | show_progress=False,
70 | model_kwargs=model_kwargs,
71 | encode_kwargs=encode_kwargs
72 | )
73 | return Chroma.from_documents(documents=documents, embedding=greenbit_embeddings)
74 |
75 | # Initialize GreenBit model
76 | def init_greenbit_model(model_id, max_tokens):
77 | pipeline = GreenBitPipeline.from_model_id(
78 | model_id=model_id,
79 | model_kwargs={"dtype": torch.half, "seqlen": 2048, "device_map": "auto"},
80 | pipeline_kwargs={"max_new_tokens": max_tokens, "temperature": 0.7, "do_sample": True},
81 | )
82 |
83 | return ChatGreenBit(llm=pipeline)
84 |
85 |
86 | # Task 1: Rap Battle Simulation
87 | def simulate_rap_battle(model):
88 | print_task_separator("Rap Battle Simulation")
89 | prompt = "Simulate a rap battle between rag and graphRag."
90 | response = model.invoke(prompt)
91 | print(response.content)
92 |
93 |
94 | # Task 2: Summarization
95 | def summarize_docs(model, vectorstore, question):
96 | print_task_separator("Summarization")
97 | prompt_template = "Summarize the main themes in these retrieved docs in a single, complete sentence of no more than 200 words: {docs}"
98 | prompt = ChatPromptTemplate.from_template(prompt_template)
99 |
100 | chain = (
101 | {"docs": format_docs}
102 | | prompt
103 | | model
104 | | StrOutputParser()
105 | | clean_output
106 | | extract_answer
107 | )
108 | docs = vectorstore.similarity_search(question)
109 | response = chain.invoke(docs)
110 | print(response)
111 |
112 |
113 | # Task 3: Q&A
114 | def question_answering(model, vectorstore, question):
115 | print_task_separator("Q&A")
116 | RAG_TEMPLATE = """
117 | Answer the following question based on the context provided. Give a direct and concise answer in a single, complete sentence of no more than 100 words. Do not include any additional dialogue or explanation.
118 |
119 | Context:
120 | {context}
121 |
122 | Question: {question}
123 |
124 | Answer:"""
125 |
126 | rag_prompt = ChatPromptTemplate.from_template(RAG_TEMPLATE)
127 | chain = (
128 | RunnablePassthrough.assign(context=lambda input: format_docs(input["context"]))
129 | | rag_prompt
130 | | model
131 | | StrOutputParser()
132 | | clean_output
133 | | extract_answer
134 | )
135 | docs = vectorstore.similarity_search(question)
136 | response = chain.invoke({"context": docs, "question": question})
137 | print(response)
138 |
139 |
140 | # Task 4: Q&A with Retrieval
141 | def qa_with_retrieval(model, vectorstore, question):
142 | print_task_separator("Q&A with Retrieval")
143 | RAG_TEMPLATE = """
144 | Answer the following question based on the retrieved information. Provide a direct and concise answer in a single, complete sentence of no more than 100 words. Do not include any additional dialogue or explanation.
145 |
146 | Question: {question}
147 |
148 | Answer:"""
149 |
150 | rag_prompt = ChatPromptTemplate.from_template(RAG_TEMPLATE)
151 | retriever = vectorstore.as_retriever()
152 | qa_chain = (
153 | {"context": retriever | format_docs, "question": RunnablePassthrough()}
154 | | rag_prompt
155 | | model
156 | | StrOutputParser()
157 | | clean_output
158 | | extract_answer
159 | )
160 | response = qa_chain.invoke(question)
161 | print(response)
162 |
163 |
164 |
165 | def main(model_id, embedding_model, query, max_tokens, web_source):
166 | print_task_separator("Initialization")
167 | print("Preparing data and initializing model...")
168 | # Prepare data and initialize model
169 | all_splits = prepare_data(web_source)
170 | vectorstore = create_vectorstore(all_splits, embedding_model)
171 | model = init_greenbit_model(model_id, max_tokens)
172 | print("Initialization complete.")
173 |
174 | # Execute tasks
175 | simulate_rap_battle(model)
176 | summarize_docs(model, vectorstore, query)
177 | question_answering(model, vectorstore, query)
178 | qa_with_retrieval(model, vectorstore, query)
179 |
180 | print("\nAll tasks completed.")
181 |
182 | if __name__ == "__main__":
183 | parser = argparse.ArgumentParser(description="Run NLP tasks with specified model, query, max tokens, and web source.")
184 | parser.add_argument("--model", type=str, default="GreenBitAI/Llama-3-8B-instruct-layer-mix-bpw-4.0", help="Model ID to use for the tasks")
185 | parser.add_argument("--embedding_model", type=str, default="sentence-transformers/all-MiniLM-L12-v2", help="Embedding model to use for vector store creation")
186 | parser.add_argument("--query", type=str, required=True, help="Query to use for the tasks")
187 | parser.add_argument("--max_tokens", type=int, default=200, help="Maximum number of tokens for model output (default: 200)")
188 | parser.add_argument("--web_source", type=str, default="https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/",
189 | help="URL of the web source to load data from (default: Microsoft Research blog post on GraphRAG)")
190 | args = parser.parse_args()
191 |
192 | main(args.model, args.embedding_model, args.query, args.max_tokens, args.web_source)
--------------------------------------------------------------------------------
/green_bit_llm/__init__.py:
--------------------------------------------------------------------------------
1 | from .version import __version__
2 |
--------------------------------------------------------------------------------
/green_bit_llm/args_parser.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | DEFAULT_MODEL_PATH = "GreenBitAI/Qwen-1.5-0.5B-layer-mix-bpw-2.2"
4 | DEFAULT_SEQLEN = 2048
5 |
6 |
7 | def setup_shared_arg_parser(parser_name="Shared argument parser for green-bit-llm scripts"):
8 | """Set up and return the argument parser with shared arguments."""
9 | parser = argparse.ArgumentParser(description=parser_name)
10 | parser.add_argument(
11 | "--model",
12 | type=str,
13 | default=DEFAULT_MODEL_PATH,
14 | help="The path to the local model directory or Hugging Face repo.",
15 | )
16 | parser.add_argument(
17 | "--trust-remote-code",
18 | action="store_true",
19 | help="Enable trusting remote code for tokenizer",
20 | )
21 | parser.add_argument(
22 | "--use-flash-attention-2",
23 | action="store_true",
24 | help="Enable using flash attention v2",
25 | )
26 | parser.add_argument(
27 | "--seqlen",
28 | type=int,
29 | default=DEFAULT_SEQLEN,
30 | help="Sequence length"
31 | )
32 | parser.add_argument(
33 | "--save-dir",
34 | type=str,
35 | default="output/",
36 | help="Specify save dir for eval results.",
37 | )
38 | parser.add_argument(
39 | "--save-step",
40 | type=int,
41 | default=500,
42 | help="Specify how many steps to save a checkpoint.",
43 | )
44 | parser.add_argument(
45 | "--dtype",
46 | type=str,
47 | choices=["float", "half"],
48 | default="half",
49 | help="Dtype used in optimizer.",
50 | )
51 | parser.add_argument(
52 | "--dataset",
53 | type=str,
54 | default="tatsu-lab/alpaca",
55 | help="Dataset name for finetuning",
56 | )
57 | parser.add_argument(
58 | "--optimizer",
59 | type=str,
60 | default="DiodeMix",
61 | help="Optimizer to use: 1. DiodeMix, 2. AdamW8bit"
62 | )
63 | parser.add_argument(
64 | "--batch-size",
65 | type=int,
66 | default=4,
67 | help="Batch size"
68 | )
69 | parser.add_argument("--weight_decay", type=float, default=0.0)
70 | return parser
71 |
--------------------------------------------------------------------------------
/green_bit_llm/common/__init__.py:
--------------------------------------------------------------------------------
1 | from .model import load, generate
2 |
--------------------------------------------------------------------------------
/green_bit_llm/common/enum.py:
--------------------------------------------------------------------------------
1 | from enum import Enum
2 |
3 | class LayerMode(Enum):
4 | LAYER_MIX = 1
5 | CHANNEL_MIX = 2
6 | LEGENCY = 3
7 |
8 | class TextGenMode(Enum):
9 | SEQUENCE = 1
10 | TOKEN = 2
--------------------------------------------------------------------------------
/green_bit_llm/evaluation/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/evaluation/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/evaluation/datautils.py:
--------------------------------------------------------------------------------
1 | from transformers import AutoTokenizer
2 | from datasets import load_dataset
3 | import torch
4 | import random
5 |
6 | from colorama import init, Fore, Style
7 | init(autoreset=True)
8 |
9 | def get_wikitext2(nsamples, seed, seqlen, model):
10 | """
11 | Prepares data loaders for the Wikitext-2 dataset for training and testing.
12 |
13 | Args:
14 | nsamples (int): Number of random samples to generate from the training data.
15 | seed (int): Seed for random number generator to ensure reproducibility.
16 | seqlen (int): Sequence length for each input sample.
17 | model (str): Pretrained model identifier used for tokenization.
18 |
19 | Returns:
20 | tuple: A tuple containing the training loader and tokenized test data.
21 | """
22 | print(Style.BRIGHT + Fore.CYAN + "Info: get_wikitext2")
23 | traindata = load_dataset('wikitext', 'wikitext-2-raw-v1', split='train', cache_dir="./cache/")
24 | testdata = load_dataset('wikitext', 'wikitext-2-raw-v1', split='test', cache_dir="./cache/")
25 |
26 | tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False, trust_remote_code=True)
27 | trainenc = tokenizer("\n\n".join(traindata['text']), return_tensors='pt')
28 | testenc = tokenizer("\n\n".join(testdata['text']), return_tensors='pt')
29 |
30 | random.seed(seed)
31 | trainloader = []
32 | for _ in range(nsamples):
33 | i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
34 | j = i + seqlen
35 | inp = trainenc.input_ids[:, i:j]
36 | tar = inp.clone()
37 | tar[:, :-1] = -100
38 | trainloader.append((inp, tar))
39 |
40 | return trainloader, testenc
41 |
42 |
43 | def get_ptb(nsamples, seed, seqlen, model):
44 | """
45 | Load and prepare the Penn Treebank (PTB) dataset for training and validation.
46 |
47 | Args:
48 | nsamples (int): The number of samples to generate for the training loader.
49 | seed (int): The seed value for random number generation, ensuring reproducibility.
50 | seqlen (int): The sequence length of each sample.
51 | model (str): The model identifier used to load a pre-trained tokenizer.
52 |
53 | Returns:
54 | tuple: A tuple containing the training loader and tokenized validation data.
55 | """
56 | print(Style.BRIGHT + Fore.CYAN + "Info: get_ptb")
57 | traindata = load_dataset('ptb_text_only', 'penn_treebank', split='train', cache_dir="./cache/")
58 | valdata = load_dataset('ptb_text_only', 'penn_treebank', split='validation', cache_dir="./cache/")
59 |
60 | tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False, trust_remote_code=True)
61 |
62 | trainenc = tokenizer("\n\n".join(traindata['sentence']), return_tensors='pt')
63 | testenc = tokenizer("\n\n".join(valdata['sentence']), return_tensors='pt')
64 |
65 | random.seed(seed)
66 | trainloader = []
67 | for _ in range(nsamples):
68 | i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
69 | j = i + seqlen
70 | inp = trainenc.input_ids[:, i:j]
71 | tar = inp.clone()
72 | tar[:, :-1] = -100
73 | trainloader.append((inp, tar))
74 |
75 | return trainloader, testenc
76 |
77 |
78 | def get_c4(nsamples, seed, seqlen, model):
79 | """
80 | Loads and preprocesses the C4 dataset for training and validation.
81 | Args:
82 | nsamples (int): Number of samples to generate for training.
83 | seed (int): Random seed for reproducibility.
84 | seqlen (int): The sequence length for each training sample.
85 | model (str): Model identifier for tokenizer initialization.
86 |
87 | Returns:
88 | tuple: A tuple containing training data loader and validation data tensor.
89 | """
90 | print(Style.BRIGHT + Fore.CYAN + "Info: get_c4")
91 | traindata = load_dataset(
92 | 'allenai/c4', data_files={'train': 'en/c4-train.00000-of-01024.json.gz'},
93 | split='train',
94 | cache_dir="./cache/"
95 | )
96 | valdata = load_dataset(
97 | 'allenai/c4', data_files={'validation': 'en/c4-validation.00000-of-00008.json.gz'},
98 | split='validation',
99 | cache_dir="./cache/"
100 | )
101 |
102 | tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False, trust_remote_code=True)
103 |
104 | random.seed(seed)
105 | trainloader = []
106 | for _ in range(nsamples):
107 |
108 | while True:
109 | i = random.randint(0, len(traindata) - 1)
110 | trainenc = tokenizer(traindata[i]['text'], return_tensors='pt')
111 | if trainenc.input_ids.shape[1] > seqlen + 2:
112 | break
113 |
114 | i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
115 | j = i + seqlen
116 | inp = trainenc.input_ids[:, i:j]
117 | tar = inp.clone()
118 | tar[:, :-1] = -100
119 | trainloader.append((inp, tar))
120 |
121 | random.seed(0)
122 | valenc = []
123 | for _ in range(256):
124 | while True:
125 | i = random.randint(0, len(valdata) - 1)
126 | tmp = tokenizer(valdata[i]['text'], return_tensors='pt')
127 | if tmp.input_ids.shape[1] >= seqlen:
128 | break
129 | i = random.randint(0, tmp.input_ids.shape[1] - seqlen - 1)
130 | j = i + seqlen
131 | valenc.append(tmp.input_ids[:, i:j])
132 | valenc = torch.hstack(valenc)
133 |
134 | return trainloader, valenc
135 |
136 |
137 | def get_ptb_new(nsamples, seed, seqlen, model):
138 | """
139 | Generates training and testing data loaders for the Penn Treebank dataset using a specified model tokenizer.
140 |
141 | Args:
142 | nsamples (int): Number of samples to generate in the training loader.
143 | seed (int): Random seed for reproducibility of sample selection.
144 | seqlen (int): Sequence length of each sample in the training data.
145 | model (str): Model identifier for the tokenizer (e.g., a Hugging Face model name).
146 |
147 | Returns:
148 | tuple: A tuple containing the training loader (list of tuples with input IDs and target IDs) and
149 | the tokenized test data.
150 | """
151 | print(Style.BRIGHT + Fore.CYAN + "Info: get_ptb_new")
152 | traindata = load_dataset('ptb_text_only', 'penn_treebank', split='train')
153 | testdata = load_dataset('ptb_text_only', 'penn_treebank', split='test')
154 |
155 | tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False, trust_remote_code=True)
156 |
157 | trainenc = tokenizer(" ".join(traindata["sentence"]), return_tensors="pt")
158 | testenc = tokenizer(" ".join(testdata["sentence"]), return_tensors="pt")
159 |
160 | random.seed(seed)
161 | trainloader = []
162 | for _ in range(nsamples):
163 | i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
164 | j = i + seqlen
165 | inp = trainenc.input_ids[:, i:j]
166 | tar = inp.clone()
167 | tar[:, :-1] = -100
168 | trainloader.append((inp, tar))
169 |
170 | return trainloader, testenc
171 |
172 |
173 | def get_c4_new(nsamples, seed, seqlen, model):
174 | """
175 | Load and preprocess training and validation datasets from C4 dataset, and tokenize the data.
176 |
177 | Args:
178 | nsamples (int): Number of samples to process for the training data.
179 | seed (int): Random seed for reproducibility of sample selection.
180 | seqlen (int): Length of the sequence for each input/output example.
181 | model (str): Model identifier for the tokenizer, specifying which pretrained model to use.
182 |
183 | Returns:
184 | tuple: A tuple containing two elements:
185 | - trainloader (list of tuples): A list where each tuple contains input ids and target tensors for training.
186 | - valenc (torch.Tensor): A tensor containing the tokenized validation data.
187 | """
188 | print(Style.BRIGHT + Fore.CYAN + "Info: get_c4_new")
189 | traindata = load_dataset(
190 | 'allenai/c4', data_files={'train': 'en/c4-train.00000-of-01024.json.gz'}, split='train'
191 | )
192 | valdata = load_dataset(
193 | 'allenai/c4', data_files={'validation': 'en/c4-validation.00000-of-00008.json.gz'}, split='validation'
194 | )
195 |
196 | tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False, trust_remote_code=True)
197 |
198 | random.seed(seed)
199 | trainloader = []
200 | for _ in range(nsamples):
201 | while True:
202 | i = random.randint(0, len(traindata) - 1)
203 | trainenc = tokenizer(traindata[i]["text"], return_tensors="pt")
204 | if trainenc.input_ids.shape[1] >= seqlen:
205 | break
206 | i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
207 | j = i + seqlen
208 | inp = trainenc.input_ids[:, i:j]
209 | tar = inp.clone()
210 | tar[:, :-1] = -100
211 | trainloader.append((inp, tar))
212 |
213 | valenc = tokenizer(" ".join(valdata[:1100]["text"]), return_tensors="pt")
214 | valenc = valenc.input_ids[:, : (256 * seqlen)]
215 |
216 | return trainloader, valenc
217 |
218 |
219 | def get_loaders(name, nsamples=128, seed=0, seqlen=2048, model=''):
220 | """
221 | Retrieves data loaders for different datasets based on the dataset name.
222 |
223 | Args:
224 | name (str): The name of the dataset to load, which can include specific versions like 'new'.
225 | nsamples (int): The number of samples to retrieve from the dataset.
226 | seed (int): The random seed to ensure reproducibility.
227 | seqlen (int): The sequence length of the samples.
228 | model (str): The model specification that might influence data preprocessing.
229 |
230 | Returns:
231 | DataLoader: A configured data loader for the specified dataset.
232 |
233 | Raises:
234 | ValueError: If the dataset name is not recognized or supported.
235 | """
236 | if 'wikitext2' in name:
237 | return get_wikitext2(nsamples, seed, seqlen, model)
238 | elif 'ptb' in name:
239 | if 'new' in name:
240 | return get_ptb_new(nsamples, seed, seqlen, model)
241 | else:
242 | return get_ptb(nsamples, seed, seqlen, model)
243 | elif 'c4' in name:
244 | if 'new' in name:
245 | return get_c4_new(nsamples, seed, seqlen, model)
246 | else:
247 | return get_c4(nsamples, seed, seqlen, model)
248 | else:
249 | raise ValueError(f"Only support wikitext2, c4, c4_new, ptb, ptb_new currently, but get {name}")
250 |
--------------------------------------------------------------------------------
/green_bit_llm/evaluation/evaluate.py:
--------------------------------------------------------------------------------
1 | import os
2 | import argparse
3 | import sys
4 | import warnings
5 | from pathlib import Path
6 | from tqdm import tqdm
7 |
8 | from lm_eval import evaluator
9 | from peft import PeftModel, LoraConfig, get_peft_model
10 |
11 | import torch
12 | import torch.nn as nn
13 |
14 | from green_bit_llm.evaluation.lmclass import LMClass
15 | from green_bit_llm.evaluation.utils import create_logger, add_dict_to_json_file
16 | from green_bit_llm.evaluation.datautils import get_loaders
17 | from green_bit_llm.common import load
18 | from green_bit_llm.sft.peft_utils.model import *
19 |
20 | warnings.filterwarnings('ignore')
21 |
22 | # default value for arguments
23 | DEFAULT_MODEL_PATH = "GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-2.2"
24 | DEFAULT_SEQLEN = 2048
25 | DEFAULT_RANDOM_SEED = 0
26 | DTYPE = torch.half
27 |
28 | replace_peft_lora_model_with_gba_lora_model()
29 |
30 |
31 | @torch.no_grad()
32 | def lm_evaluate(lm, args, logger):
33 | """
34 | Evaluates the language model (lm) according to the specified evaluation parameters in args.
35 | This function handles both perplexity evaluation on various datasets and few-shot learning evaluation.
36 |
37 | Parameters:
38 | lm: The language model object configured for evaluation.
39 | args: An object containing all necessary parameters and flags for evaluation, such as which datasets to use,
40 | whether to evaluate perplexity or few-shot performance, sequence length, etc.
41 | logger: A logging object used to record evaluation results and other important messages.
42 |
43 | Returns:
44 | A dictionary containing evaluation results, including perplexity values and few-shot evaluation metrics,
45 | keyed by dataset or task name.
46 | """
47 | results = {}
48 | lm.model = lm.model.to(lm.device)
49 |
50 | if args.eval_ppl:
51 | for dataset in args.ppl_tasks.split(","):
52 | dataloader, testloader = get_loaders(
53 | dataset,
54 | seed=args.seed,
55 | model=args.model,
56 | seqlen=args.seqlen,
57 | )
58 |
59 | if "c4" in dataset:
60 | testenc = testloader
61 | else:
62 | testenc = testloader.input_ids
63 |
64 | nsamples = testenc.numel() // lm.seqlen
65 | use_cache = lm.model.config.use_cache
66 | lm.model.config.use_cache = False
67 | lm.model.eval()
68 | nlls = []
69 |
70 | for i in tqdm(range(nsamples)):
71 | batch = testenc[:, (i * lm.seqlen): ((i + 1) * lm.seqlen)].to(lm.device)
72 | with torch.no_grad():
73 | outputs = lm.model.model(batch)
74 | hidden_states = outputs[0]
75 | logits = lm.model.lm_head(hidden_states)
76 | shift_logits = logits[:, :-1, :]
77 | shift_labels = testenc[:, (i * lm.seqlen): ((i + 1) * lm.seqlen)][
78 | :, 1:
79 | ].to(lm.model.lm_head.weight.device)
80 | loss_fct = nn.CrossEntropyLoss()
81 | loss = loss_fct(
82 | shift_logits.view(-1, shift_logits.size(-1)),
83 | shift_labels.view(-1),
84 | )
85 | neg_log_likelihood = loss.float() * lm.seqlen
86 | nlls.append(neg_log_likelihood)
87 |
88 | ppl = torch.exp(torch.stack(nlls).sum() / (nsamples * lm.seqlen))
89 | logger.info(f'{dataset} : {ppl.item()}')
90 | lm.model.config.use_cache = use_cache
91 | results[dataset] = ppl.item()
92 |
93 | if args.eval_few_shot and args.eval_few_shot != "":
94 | few_shot_tasks = args.few_shot_tasks.split(",")
95 |
96 | eval_results = evaluator.simple_evaluate(
97 | lm,
98 | tasks=few_shot_tasks,
99 | batch_size=args.batch_size,
100 | num_fewshot=args.num_fewshot,
101 | no_cache=True
102 | )
103 |
104 | results.update({"results": eval_results["results"]})
105 | results.update({"versions": eval_results["versions"]})
106 | logger.info(evaluator.make_table(results))
107 |
108 | return results
109 |
110 | def setup_arg_parser():
111 | """Set up and return the argument parser."""
112 | parser = argparse.ArgumentParser(description="green-bit-llm evaluate script")
113 | parser.add_argument(
114 | "--seed",
115 | type=int,
116 | default=DEFAULT_RANDOM_SEED,
117 | help="The random seed for data loader.",
118 | )
119 | parser.add_argument(
120 | "--model",
121 | type=str,
122 | default=DEFAULT_MODEL_PATH,
123 | help="The path to the local model directory or Hugging Face repo.",
124 | )
125 | parser.add_argument(
126 | "--cuda-device-id",
127 | type=str,
128 | default="0",
129 | help="CUDA device IDs.",
130 | )
131 | parser.add_argument(
132 | "--trust-remote-code",
133 | action="store_true",
134 | help="Enable trusting remote code for tokenizer.",
135 | )
136 | parser.add_argument(
137 | "--use-flash-attention-2",
138 | action="store_true",
139 | help="Enable using flash attention v2.",
140 | )
141 | parser.add_argument(
142 | "--eos-token",
143 | type=str,
144 | default="<|im_end|>",
145 | help="End of sequence token for tokenizer.",
146 | )
147 | parser.add_argument(
148 | "--seqlen",
149 | type=int,
150 | default=DEFAULT_SEQLEN,
151 | help="Sequence length."
152 | )
153 | parser.add_argument(
154 | "--eval-ppl",
155 | action="store_true",
156 | help="Evaluate LLM prediction perplexity.",
157 | )
158 | parser.add_argument(
159 | "--ppl-tasks",
160 | type=str,
161 | default="wikitext2, c4_new, ptb",
162 | help="Specify ppl evaluation task.",
163 | )
164 | parser.add_argument(
165 | "--eval-few-shot",
166 | action="store_true",
167 | help="Evaluate LLM few-shot learning ability.",
168 | )
169 | parser.add_argument(
170 | "--num-fewshot",
171 | type=int,
172 | default=0,
173 | help="Specify num of few shot examples for evaluation.",
174 | )
175 | parser.add_argument(
176 | "--few-shot-tasks",
177 | type=str,
178 | default="openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq,race,anli_r1,anli_r2,anli_r3,wic",
179 | help="Few-shot learning ability evaluation tasks.",
180 | )
181 | parser.add_argument(
182 | "--batch-size",
183 | type=int,
184 | default=16,
185 | help="Batch size for few-shot evaluation.",
186 | )
187 | parser.add_argument(
188 | "--save-dir",
189 | type=str,
190 | default="log/",
191 | help="Specify save dir for eval results.",
192 | )
193 | parser.add_argument(
194 | "--lora-dir",
195 | type=str,
196 | default=None,
197 | help="Specify lora dir for lora merge"
198 |
199 | )
200 | return parser
201 |
202 |
203 | def create_device_map(cuda_device_id):
204 | ids = cuda_device_id.split(',')
205 | # Create strings in the format "cuda:x" for each ID and put them into the collection
206 | device_map = {f"cuda:{id}" for id in ids}
207 | return device_map
208 |
209 | def main(args):
210 | if not os.path.exists(Path(args.save_dir)):
211 | os.mkdir(Path(args.save_dir))
212 |
213 | # Building configs
214 | tokenizer_config = {"trust_remote_code": True if args.trust_remote_code else None}
215 |
216 | pretrain_model_config = {
217 | "trust_remote_code": True if args.trust_remote_code else None,
218 | "attn_implementation": "flash_attention_2" if args.use_flash_attention_2 else None
219 | }
220 |
221 | if args.eos_token is not None:
222 | tokenizer_config["eos_token"] = args.eos_token
223 |
224 | model, tokenizer, config = load(
225 | args.model,
226 | tokenizer_config=tokenizer_config,
227 | dtype=DTYPE,
228 | device_map='auto',
229 | seqlen=args.seqlen,
230 | model_config=pretrain_model_config,
231 | requires_grad=False
232 | )
233 |
234 | if args.lora_dir is not None:
235 | config = LoraConfig(
236 | r=64,
237 | lora_alpha=32,
238 | target_modules=["q_proj", "v_proj", "out_proj", "up_proj"],
239 | lora_dropout=0.01,
240 | bias="none",
241 | task_type="CAUSAL_LM",
242 | )
243 | model = get_peft_model(model,config)
244 | model.load_adapter(args.lora_dir, adapter_name="default")
245 |
246 | lm = LMClass(args.model, batch_size=args.batch_size, config=config, tokenizer=tokenizer, model=model)
247 | lm.seqlen = args.seqlen
248 |
249 | logger = create_logger(Path(args.save_dir))
250 |
251 | with torch.no_grad():
252 | eval_results = lm_evaluate(lm=lm, args=args, logger=logger)
253 |
254 | eval_results = {"{}".format(args.model): eval_results}
255 |
256 | add_dict_to_json_file(file_path="{}".format(os.path.join(args.save_dir, "eval_results.json")), new_data=eval_results)
257 |
258 | if __name__ == "__main__":
259 | if not torch.cuda.is_available():
260 | print("Warning: CUDA is needed to run the model.")
261 | sys.exit(0)
262 |
263 | parser = setup_arg_parser()
264 | args = parser.parse_args()
265 |
266 | main(args)
267 |
--------------------------------------------------------------------------------
/green_bit_llm/evaluation/lmclass.py:
--------------------------------------------------------------------------------
1 | from lm_eval.base import BaseLM
2 | import torch.nn.functional as F
3 | import torch
4 |
5 | from colorama import init, Fore, Style
6 | init(autoreset=True)
7 |
8 | class LMClass(BaseLM):
9 | """
10 | Wraps a pretrained language model into a format suitable for evaluation tasks.
11 | This class adapts a given model to be used with specific language modeling evaluation tools.
12 |
13 | Args:
14 | model_name (str): Name of the language model.
15 | batch_size (int): Batch size per GPU for processing.
16 | config (dict): Configuration settings for the model.
17 | tokenizer: Tokenizer associated with the model for text processing.
18 | model (nn.Module): The pretrained neural network model.
19 | """
20 | def __init__(self, model_name, batch_size, config, tokenizer, model):
21 | # Initializes the model wrapper class with specified model and configuration
22 | super().__init__()
23 |
24 | self._device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
25 | self.model_name = model_name
26 | self.batch_size_per_gpu = batch_size
27 |
28 | self.model_config = config
29 | self.tokenizer = tokenizer
30 | self.model = model
31 | self.initial()
32 |
33 | def initial(self):
34 | # Initializes the model for inference, setting up necessary parameters such as sequence length and vocab size
35 | self.seqlen = self.model.config.max_position_embeddings
36 | self.model.eval()
37 | self.vocab_size = self.tokenizer.vocab_size
38 | print(Style.BRIGHT + Fore.CYAN + "Info: vocab size: ", self.vocab_size)
39 |
40 | @property
41 | def eot_token(self) -> str:
42 | # Returns the end-of-text token as a string
43 | return self.tokenizer.eos_token
44 |
45 | @property
46 | def eot_token_id(self):
47 | # we use EOT because end of *text* is more accurate for what we're doing than end of *sentence*
48 | return self.tokenizer.eos_token_id
49 |
50 | @property
51 | def max_length(self):
52 | # Returns the maximum length of sequences the model can handle, based on the model's configuration
53 | try:
54 | return self.gpt2.config.n_ctx
55 | except AttributeError:
56 | # gptneoconfig doesn't have n_ctx apparently
57 | return self.model.config.max_position_embeddings
58 |
59 | @property
60 | def max_gen_toks(self):
61 | # Returns the maximum number of tokens that can be generated in one go
62 | print(Style.BRIGHT + Fore.CYAN + "Info: max_gen_toks fn")
63 | return 256
64 |
65 | @property
66 | def batch_size(self):
67 | # Returns the configured batch size per GPU
68 | # TODO: fix multi-gpu
69 | return self.batch_size_per_gpu # * gpus
70 |
71 | @property
72 | def device(self):
73 | # Returns the computing device (CPU or GPU) that the model is using
74 | # TODO: fix multi-gpu
75 | return self._device
76 |
77 | def tok_encode(self, string: str):
78 | # Encodes a string into its corresponding IDs using the tokenizer
79 | return self.tokenizer.encode(string, add_special_tokens=False)
80 |
81 | def tok_encode_batch(self, strings):
82 | # Encodes a batch of strings into model inputs, handling padding and special tokens
83 | return self.tokenizer(
84 | strings,
85 | padding=True,
86 | add_special_tokens=False,
87 | return_tensors="pt",
88 | )
89 |
90 | def tok_decode(self, tokens):
91 | # Decodes a batch of token IDs back into strings
92 | return self.tokenizer.batch_decode(tokens, skip_special_tokens=True)
93 |
94 | def _model_call(self, inps):
95 | """
96 | Performs a forward pass through the model with the provided inputs and returns logits
97 |
98 | Args:
99 | inps: a torch tensor of shape [batch, sequence]
100 | the size of sequence may vary from call to call
101 | returns: a torch tensor of shape [batch, sequence, vocab] with the
102 | logits returned from the model
103 | """
104 | with torch.no_grad():
105 | return self.model(inps)["logits"]
106 |
107 | def model_batched_set(self, inps):
108 | # Processes a set of inputs in batches and returns a list of logit tensors
109 | dataset_logits = []
110 | for batch in inps:
111 | multi_logits = F.log_softmax(
112 | self._model_call(batch), dim=-1
113 | ).cpu() # [batch, padding_length, vocab]
114 | dataset_logits.append(multi_logits)
115 | return dataset_logits
116 |
117 | def _model_generate(self, context, max_length, eos_token_id):
118 | # Generates text based on a given context up to a specified maximum length
119 | return self.model.generate(
120 | context, max_length=max_length, eos_token_id=eos_token_id, do_sample=False
121 | )
122 |
--------------------------------------------------------------------------------
/green_bit_llm/evaluation/utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import json
4 | import time
5 | import logging
6 | from termcolor import colored
7 |
8 |
9 | def pattern_match(patterns, source_list):
10 | """
11 | Function to find unique matching patterns from a source list.
12 | Args:
13 | patterns: list of pattern strings to match.
14 | Returns:
15 | list: list of task name
16 | """
17 | task_names = set()
18 | for pattern in patterns:
19 | task_names.add(pattern)
20 | return list(task_names)
21 |
22 | def add_dict_to_json_file(file_path, new_data):
23 | """
24 | Update a JSON file based on the top-level keys in new_data. If the key exists, it replaces the existing content
25 | under that key. If it doesn't exist, it adds the new key with its value.
26 |
27 | Args:
28 | file_path: Path to the JSON file.
29 | new_data: Dictionary to add or update in the file.
30 | """
31 | # Initialize or load existing data
32 | if os.path.exists(file_path) and os.stat(file_path).st_size > 0:
33 | with open(file_path, 'r') as file:
34 | existing_data = json.load(file)
35 | else:
36 | existing_data = {}
37 |
38 | # Merge new data into existing data based on the top-level keys
39 | existing_data.update(new_data)
40 |
41 | # Write the updated data back to the file
42 | with open(file_path, 'w') as file:
43 | json.dump(existing_data, file, indent=4)
44 |
45 | def create_logger(output_dir, dist_rank=0, name=''):
46 | """
47 | Creates and configures a logger with console and file handlers.
48 |
49 | Args:
50 | output_dir (str): Directory where the log files will be stored.
51 | dist_rank (int): Rank of the process in distributed training. Only the master process (rank 0) will output to the console.
52 | name (str): Name of the logger, used to differentiate output if multiple loggers are used.
53 |
54 | Returns:
55 | logger: Configured logger object.
56 | """
57 | # create logger
58 | logger = logging.getLogger(name)
59 | logger.setLevel(logging.INFO)
60 | logger.propagate = False
61 |
62 | # create formatter
63 | fmt = '[%(asctime)s %(name)s] (%(filename)s %(lineno)d): %(levelname)s %(message)s'
64 | color_fmt = colored('[%(asctime)s %(name)s]', 'green') + \
65 | colored('(%(filename)s %(lineno)d)', 'yellow') + ': %(levelname)s %(message)s'
66 |
67 | # create console handlers for master process
68 | if dist_rank == 0:
69 | console_handler = logging.StreamHandler(sys.stdout)
70 | console_handler.setLevel(logging.DEBUG)
71 | console_handler.setFormatter(
72 | logging.Formatter(fmt=color_fmt, datefmt='%Y-%m-%d %H:%M:%S'))
73 | logger.addHandler(console_handler)
74 |
75 | # create file handlers
76 | file_handler = logging.FileHandler(os.path.join(output_dir, f'log_rank{dist_rank}_{int(time.time())}.txt'), mode='a')
77 | file_handler.setLevel(logging.DEBUG)
78 | file_handler.setFormatter(logging.Formatter(fmt=fmt, datefmt='%Y-%m-%d %H:%M:%S'))
79 | logger.addHandler(file_handler)
80 |
81 | return logger
82 |
83 |
--------------------------------------------------------------------------------
/green_bit_llm/inference/README.md:
--------------------------------------------------------------------------------
1 | # Inference Package for GreenBitAI's Low-bit LLMs
2 |
3 | ## Overview
4 |
5 | This package demonstrates the capabilities of [GreenBitAI's low-bit large language models (LLMs)](https://huggingface.co/GreenBitAI) through two main features:
6 | 1. Simple generation with `sim_gen.py` script.
7 | 2. A command-line interface (CLI) based chat demo using the `chat_cli.py` script.
8 |
9 | Both tools are designed for efficient natural language processing, enabling quick setups and responses using local models.
10 |
11 | ## Installation
12 |
13 | Please follow the [main installation instructions](../../README.md#installation) for how to install the packages required to run this inference package.
14 | Further packages should not be required.
15 |
16 | ## Usage
17 |
18 | ### LLMs
19 |
20 | We have released over 200 highly precise 2.2/2.5/3/4-bit models across the modern LLM family, featuring LLaMA 2/3, 01-Yi, Qwen, Mistral, Phi-3, and more.
21 |
22 | | Family | Bpw | Size | HF collection id |
23 | |:----------------:|:------------------:|:------------------------------:|:-----------------------------------------------------------------------------------------------------------------:|
24 | | Llama-3 | `4.0/3.0/2.5/2.2` | `8B/70B` | [`GreenBitAI Llama-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-3-6627bc1ec6538e3922c5d81c) |
25 | | Llama-2 | `3.0/2.5/2.2` | `7B/13B/70B` | [`GreenBitAI Llama-2`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-2-661f87e3b073ff8e48a12834) |
26 | | Qwen-1.5 | `4.0/3.0/2.5/2.2` | `0.5B/1.8B/4B/7B/14B/32B/110B` | [`GreenBitAI Qwen 1.5`](https://huggingface.co/collections/GreenBitAI/greenbitai-qwen15-661f86ea69433f3d3062c920) |
27 | | Phi-3 | `3.0/2.5/2.2` | `mini` | [`GreenBitAI Phi-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-phi-3-6628d008cdf168398a296c92) |
28 | | Mistral | `3.0/2.5/2.2` | `7B` | [`GreenBitAI Mistral`](https://huggingface.co/collections/GreenBitAI/greenbitai-mistral-661f896c45da9d8b28a193a8) |
29 | | 01-Yi | `3.0/2.5/2.2` | `6B/34B` | [`GreenBitAI 01-Yi`](https://huggingface.co/collections/GreenBitAI/greenbitai-01-yi-661f88af0648daa766d5102f) |
30 | | Llama-3-instruct | `4.0/3.0/2.5/2.2` | `8B/70B` | [`GreenBitAI Llama-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-3-6627bc1ec6538e3922c5d81c) |
31 | | Mistral-instruct | `3.0/2.5/2.2` | `7B` | [`GreenBitAI Mistral`](https://huggingface.co/collections/GreenBitAI/greenbitai-mistral-661f896c45da9d8b28a193a8) |
32 | | Phi-3-instruct | `3.0/2.5/2.2` | `mini` | [`GreenBitAI Phi-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-phi-3-6628d008cdf168398a296c92) |
33 | | Qwen-1.5-Chat | `4.0/3.0/2.5/2.2` | `0.5B/1.8B/4B/7B/14B/32B/110B` | [`GreenBitAI Qwen 1.5`](https://huggingface.co/collections/GreenBitAI/greenbitai-qwen15-661f86ea69433f3d3062c920) |
34 | | 01-Yi-Chat | `3.0/2.5/2.2` | `6B/34B` | [`GreenBitAI 01-Yi`](https://huggingface.co/collections/GreenBitAI/greenbitai-01-yi-661f88af0648daa766d5102f) |
35 |
36 |
37 | ### Simple Generation
38 |
39 | Run the simple generation script as follows:
40 |
41 | ```bash
42 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.inference.sim_gen --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --max-tokens 100 --use-flash-attention-2 --ignore-chat-template --prompt "The meaning of life is"
43 | ```
44 |
45 | This command generates text based on the provided prompt using the specified GreenBitAI model.
46 |
47 | ### CLI-Based Chat Demo
48 |
49 | To start the chat interface:
50 |
51 | ```bash
52 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.inference.chat_cli --model GreenBitAI/Qwen-1.5-1.8B-Chat-layer-mix-bpw-2.2 --use-flash-attention-2 --multiline --mouse
53 | ```
54 | This launches a rich command-line interface for interactive chatting.
55 |
56 | ## License
57 | - The scripts `conversation.py`, `chat_base.py`, and `chat_cli.py` have been modified from their original versions found in [FastChat-serve](https://github.com/lm-sys/FastChat/tree/main/fastchat/serve), which are released under the [Apache 2.0 License](https://github.com/lm-sys/FastChat/tree/main/LICENSE).
58 | - We release our changes and additions to these files under the [Apache 2.0 License](../../LICENSE).
59 |
--------------------------------------------------------------------------------
/green_bit_llm/inference/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/inference/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/inference/chat_cli.py:
--------------------------------------------------------------------------------
1 | """
2 | cli chat demo.
3 | Code based on: https://github.com/yanghaojin/FastChat/blob/greenbit/fastchat/serve/cli.py
4 | """
5 | import argparse
6 | import os
7 | import warnings
8 | warnings.filterwarnings("ignore", category=UserWarning, module='torch.nn.modules.module')
9 |
10 | import torch
11 |
12 | # Add the parent directory to sys.path
13 | from green_bit_llm.inference.utils import str_to_torch_dtype
14 |
15 | try:
16 | from green_bit_llm.inference.chat_base import chat_loop, SimpleChatIO, RichChatIO
17 | except Exception:
18 | raise Exception("Error occurred when import chat loop, ChatIO classes.")
19 |
20 |
21 | def main(args):
22 | # args setup
23 | if args.gpus:
24 | if len(args.gpus.split(",")) < args.num_gpus:
25 | raise ValueError(
26 | f"Larger --num-gpus ({args.num_gpus}) than --gpus {args.gpus}!"
27 | )
28 | # NOTE that we need to set this before any other cuda operations. Otherwise will not work.
29 | os.environ["CUDA_VISIBLE_DEVICES"] = args.gpus
30 |
31 | if not torch.cuda.is_available():
32 | raise Exception("Warning: CUDA is needed to run the model.")
33 |
34 | if args.style == "simple":
35 | chatio = SimpleChatIO(args.multiline)
36 | elif args.style == "rich":
37 | chatio = RichChatIO(args.multiline, args.mouse)
38 | else:
39 | raise ValueError(f"Invalid style for console: {args.style}")
40 |
41 | # Building configs
42 | tokenizer_config = {"trust_remote_code": True if args.trust_remote_code else None}
43 | pretrain_model_config = {
44 | "trust_remote_code": True if args.trust_remote_code else None,
45 | "attn_implementation": "flash_attention_2" if args.use_flash_attention_2 else None
46 | }
47 |
48 | if args.eos_token is not None:
49 | tokenizer_config["eos_token"] = args.eos_token
50 |
51 | # chat
52 | try:
53 | chat_loop(
54 | args.model,
55 | tokenizer_config,
56 | pretrain_model_config,
57 | args.seqlen,
58 | args.device,
59 | str_to_torch_dtype(args.dtype),
60 | args.conv_template,
61 | args.conv_system_msg,
62 | args.temperature,
63 | args.repetition_penalty,
64 | args.max_new_tokens,
65 | chatio,
66 | judge_sent_end=args.judge_sent_end,
67 | debug=args.debug,
68 | history=not args.no_history,
69 | )
70 | except KeyboardInterrupt:
71 | print("exit...")
72 |
73 |
74 | if __name__ == "__main__":
75 | parser = argparse.ArgumentParser()
76 | parser.add_argument(
77 | "--model",
78 | type=str,
79 | default="GreenBitAI/Mistral-Instruct-7B-v0.2-layer-mix-bpw-2.2",
80 | help="The path to the weights. This can be a local folder or a Hugging Face repo ID.",
81 | )
82 | parser.add_argument(
83 | "--device",
84 | type=str,
85 | choices=["cpu", "cuda"],
86 | default="cuda",
87 | help="The device type",
88 | )
89 | parser.add_argument(
90 | "--gpus",
91 | type=str,
92 | default='0',
93 | help="A single GPU like 1 or multiple GPUs like 0,2",
94 | )
95 | parser.add_argument("--num-gpus", type=int, default=1)
96 | parser.add_argument(
97 | "--dtype",
98 | type=str,
99 | choices=["float32", "float16"],
100 | help="Override the default dtype. If not set, it will use float16 on GPU and float32 on CPU.",
101 | default="float16",
102 | )
103 | parser.add_argument(
104 | "--conv-template", type=str, default=None, help="Conversation prompt template."
105 | )
106 | parser.add_argument(
107 | "--conv-system-msg", type=str, default=None, help="Conversation system message."
108 | )
109 | parser.add_argument("--temperature", type=float, default=0.7)
110 | parser.add_argument("--repetition_penalty", type=float, default=1.0)
111 | parser.add_argument("--max-new-tokens", type=int, default=256)
112 | parser.add_argument("--no-history", action="store_true", help="Disables chat history.")
113 | parser.add_argument(
114 | "--style",
115 | type=str,
116 | default="rich",
117 | choices=["simple", "rich"],
118 | help="Display style.",
119 | )
120 | parser.add_argument(
121 | "--multiline",
122 | action="store_true",
123 | help="Enable multiline input. Use ESC+Enter for newline.",
124 | )
125 | parser.add_argument(
126 | "--mouse",
127 | action="store_true",
128 | help="[Rich Style]: Enable mouse support for cursor positioning.",
129 | )
130 | parser.add_argument(
131 | "--judge-sent-end",
132 | action="store_true",
133 | help="Whether enable the correction logic that interrupts the output of sentences due to EOS.",
134 | )
135 | parser.add_argument(
136 | "--debug",
137 | action="store_true",
138 | help="Print useful debug information (e.g., prompts)",
139 | )
140 | parser.add_argument(
141 | "--eos-token",
142 | type=str,
143 | default=None,
144 | help="End of sequence token for tokenizer",
145 | )
146 | parser.add_argument(
147 | "--trust-remote-code",
148 | action="store_true",
149 | help="Enable trusting remote code",
150 | )
151 | parser.add_argument(
152 | "--seqlen", type=int, default=2048, help="Sequence length"
153 | )
154 | parser.add_argument(
155 | "--use-flash-attention-2",
156 | action="store_true",
157 | help="Enable using flash attention v2",
158 | )
159 | args = parser.parse_args()
160 | main(args)
--------------------------------------------------------------------------------
/green_bit_llm/inference/sim_gen.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import torch
4 | import torch.nn as nn
5 |
6 | import warnings
7 | warnings.filterwarnings("ignore", category=UserWarning, module='torch.nn.modules.module')
8 |
9 | from transformers import PreTrainedTokenizer
10 |
11 | from green_bit_llm.common import generate, load
12 | from green_bit_llm.args_parser import setup_shared_arg_parser
13 |
14 | # default value for arguments
15 | DEFAULT_PROMPT = None
16 | DEFAULT_MAX_TOKENS = 100
17 | DEFAULT_TEMP = 0.8
18 | DEFAULT_TOP_P = 0.95
19 | DTYPE = torch.half
20 |
21 |
22 | def setup_arg_parser():
23 | """Set up and return the argument parser."""
24 | parser = setup_shared_arg_parser("green-bit-llm inference script")
25 |
26 | parser.add_argument("--num-gpus", type=int, default=1)
27 | parser.add_argument(
28 | "--gpus",
29 | type=str,
30 | default='0',
31 | help="A single GPU like 1 or multiple GPUs like 0,2",
32 | )
33 | parser.add_argument(
34 | "--eos-token",
35 | type=str,
36 | default=None,
37 | help="End of sequence token for tokenizer",
38 | )
39 | parser.add_argument(
40 | "--max-tokens",
41 | type=int,
42 | default=DEFAULT_MAX_TOKENS,
43 | help="Maximum number of tokens to generate",
44 | )
45 | parser.add_argument(
46 | "--prompt", default=DEFAULT_PROMPT, help="Message to be processed by the model"
47 | )
48 | parser.add_argument(
49 | "--temp", type=float, default=DEFAULT_TEMP, help="Sampling temperature"
50 | )
51 | parser.add_argument(
52 | "--top-p", type=float, default=DEFAULT_TOP_P, help="Sampling top-p"
53 | )
54 | parser.add_argument(
55 | "--ignore-chat-template",
56 | action="store_true",
57 | help="Use the raw prompt without the tokenizer's chat template.",
58 | )
59 | parser.add_argument(
60 | "--use-default-chat-template",
61 | action="store_true",
62 | help="Use the default chat template",
63 | )
64 | parser.add_argument(
65 | "--enable-thinking",
66 | action="store_true",
67 | help="Enable thinking mode for Qwen-3 models.",
68 | )
69 | return parser
70 |
71 |
72 | def do_generate(args, model: nn.Module, tokenizer: PreTrainedTokenizer, prompt: str, enable_thinking: bool):
73 | """
74 | This function generates text based on a given prompt using a model and tokenizer.
75 | It handles optional pre-processing with chat templates if specified in the arguments.
76 | """
77 | if not args.ignore_chat_template and (
78 | hasattr(tokenizer, "apply_chat_template")
79 | and tokenizer.chat_template is not None
80 | ):
81 | messages = [{"role": "user", "content": prompt}]
82 | prompt = tokenizer.apply_chat_template(
83 | messages,
84 | tokenize=False,
85 | add_generation_prompt=True,
86 | enable_thinking=enable_thinking
87 | )
88 | else:
89 | prompt = prompt
90 |
91 | generate(
92 | model,
93 | tokenizer,
94 | prompt,
95 | args.temp,
96 | args.max_tokens,
97 | True,
98 | top_p=args.top_p
99 | )
100 |
101 |
102 | def main(args):
103 |
104 | if args.gpus:
105 | if len(args.gpus.split(",")) < args.num_gpus:
106 | raise ValueError(
107 | f"Larger --num-gpus ({args.num_gpus}) than --gpus {args.gpus}!"
108 | )
109 | os.environ["CUDA_VISIBLE_DEVICES"] = args.gpus
110 |
111 | if not torch.cuda.is_available():
112 | raise Exception("Warning: CUDA is needed to run the model.")
113 |
114 | # Building configs
115 | tokenizer_config = {"trust_remote_code": True if args.trust_remote_code else None}
116 | pretrain_model_config = {
117 | "trust_remote_code": True if args.trust_remote_code else None,
118 | "attn_implementation": "flash_attention_2" if args.use_flash_attention_2 else None
119 | }
120 |
121 | if args.eos_token is not None:
122 | tokenizer_config["eos_token"] = args.eos_token
123 |
124 | model, tokenizer, config = load(
125 | args.model,
126 | tokenizer_config=tokenizer_config,
127 | dtype=DTYPE,
128 | device_map='auto',
129 | seqlen=args.seqlen,
130 | model_config=pretrain_model_config,
131 | requires_grad=False
132 | )
133 |
134 | if args.use_default_chat_template:
135 | if tokenizer.chat_template is None:
136 | tokenizer.chat_template = tokenizer.default_chat_template
137 |
138 | if args.prompt is None:
139 | while True:
140 | user_input = input("Input prompt or type 'exit' to quit): ")
141 | if user_input.lower() in ['exit', 'quit']:
142 | break
143 | do_generate(args, model, tokenizer, user_input, args.enable_thinking)
144 | else:
145 | do_generate(args, model, tokenizer, args.prompt, args.enable_thinking)
146 |
147 |
148 | if __name__ == "__main__":
149 | parser = setup_arg_parser()
150 | args = parser.parse_args()
151 |
152 | main(args)
--------------------------------------------------------------------------------
/green_bit_llm/inference/utils.py:
--------------------------------------------------------------------------------
1 | from transformers.generation.logits_process import (
2 | LogitsProcessorList,
3 | RepetitionPenaltyLogitsProcessor,
4 | TemperatureLogitsWarper,
5 | TopKLogitsWarper,
6 | TopPLogitsWarper,
7 | )
8 |
9 | from .conversation import Conversation, get_conv_template
10 |
11 | # value is the search term in model name,
12 | # key is the name of conversation template
13 | CONV_TEMP_DICT = {
14 | "llama-2": "llama-2",
15 | "qwen-chat": "qwen",
16 | "yi-chat": "yi-",
17 | "mistral": "mistral",
18 | "gemma": "gemma",
19 | "llama-3": "llama-3",
20 | "phi-3": "phi-3",
21 | }
22 |
23 | # Models don't use the same configuration key for determining the maximum
24 | # sequence length. Store them here so we can sanely check them.
25 | # NOTE: The ordering here is important. Some models have two of these and we
26 | # have a preference for which value gets used.
27 | SEQUENCE_LENGTH_KEYS = [
28 | "max_position_embeddings",
29 | "max_sequence_length",
30 | "seq_length",
31 | "max_seq_len",
32 | "model_max_length",
33 | ]
34 |
35 |
36 | def is_partial_stop(output: str, stop_str: str):
37 | """Check whether the output contains a partial stop str."""
38 | for i in range(0, min(len(output), len(stop_str))):
39 | if stop_str.startswith(output[-i:]):
40 | return True
41 | return False
42 |
43 | def is_sentence_complete(output: str):
44 | """Check whether the output is a complete sentence."""
45 | end_symbols = (".", "?", "!", "...", "。", "?", "!", "…", '"', "'", "”")
46 | return output.endswith(end_symbols)
47 |
48 | def get_context_length(config):
49 | """Get the context length of a model from a huggingface model config."""
50 | rope_scaling = getattr(config, "rope_scaling", None)
51 | if rope_scaling:
52 | try:
53 | rope_scaling_factor = config.rope_scaling["factor"]
54 | except KeyError:
55 | rope_scaling_factor = 1
56 | else:
57 | rope_scaling_factor = 1
58 |
59 | for key in SEQUENCE_LENGTH_KEYS:
60 | val = getattr(config, key, None)
61 | if val is not None:
62 | return int(rope_scaling_factor * val)
63 | return 2048
64 |
65 | def get_conversation_template(model_path: str) -> Conversation:
66 | """Get and return a specific conversation template via checking its model path/model name."""
67 | for key, value in CONV_TEMP_DICT.items():
68 | # check if model path contains the value
69 | if value in model_path.lower():
70 | return get_conv_template(key)
71 | raise Exception("Invalid model path: The provided model is not supported yet.")
72 |
73 | def prepare_logits_processor(
74 | temperature: float, repetition_penalty: float, top_p: float, top_k: int
75 | ) -> LogitsProcessorList:
76 | """
77 | Creates and initializes a list of logits processors based on the specified parameters.
78 | Each processor applies a different modification to the logits during text generation,
79 | such as adjusting the sampling temperature, applying repetition penalties,
80 | or enforcing top-p and top-k constraints.
81 |
82 | Args:
83 | temperature (float): Scaling factor for logits; a value of 1.0 means no scaling.
84 | repetition_penalty (float): Penalty for repeated tokens to discourage repetition.
85 | top_p (float): The cumulative probability threshold for nucleus sampling, filters out the smallest probabilities.
86 | top_k (int): The number of highest probability logits to keep for top-k sampling.
87 |
88 | Returns:
89 | LogitsProcessorList: A configured list of logits processors.
90 | """
91 | processor_list = LogitsProcessorList()
92 | # TemperatureLogitsWarper doesn't accept 0.0, 1.0 makes it a no-op so we skip two cases.
93 | if temperature >= 1e-5 and temperature != 1.0:
94 | processor_list.append(TemperatureLogitsWarper(temperature))
95 | if repetition_penalty > 1.0:
96 | processor_list.append(RepetitionPenaltyLogitsProcessor(repetition_penalty))
97 | if 1e-8 <= top_p < 1.0:
98 | processor_list.append(TopPLogitsWarper(top_p))
99 | if top_k > 0:
100 | processor_list.append(TopKLogitsWarper(top_k))
101 | return processor_list
102 |
103 | def str_to_torch_dtype(dtype: str):
104 | """Get torch dtype via parsing the dtype string."""
105 | import torch
106 |
107 | if dtype is None:
108 | return None
109 | elif dtype == "float32":
110 | return torch.float32
111 | elif dtype == "float16":
112 | return torch.half
113 | elif dtype == "bfloat16":
114 | return torch.bfloat16
115 | else:
116 | raise ValueError(f"Unrecognized dtype: {dtype}")
117 |
118 | def is_chat_model(path):
119 | """Distinguish if the input model name contains keywords like '-chat-' or '-instrct-'"""
120 | substrings = ["-chat-", "-instruct-"]
121 | return any(substring in path for substring in substrings)
--------------------------------------------------------------------------------
/green_bit_llm/langchain/README.md:
--------------------------------------------------------------------------------
1 | # GreenBit Langchain Demos
2 |
3 | ## Overview
4 |
5 | GreenBit Langchain Demos showcase the integration of GreenBit language models with the Langchain framework, enabling powerful and flexible natural language processing capabilities.
6 |
7 | ## Installation
8 |
9 | ### Step 1: Install the green-bit-llm Package
10 |
11 | ```bash
12 | pip install green-bit-llm
13 | ```
14 |
15 | ### Step 2: Install Langchain Package
16 |
17 | ```bash
18 | pip install langchain-core
19 | ```
20 |
21 | If you want to use RAG demo, please make sure that the `sentence_transformers` python package has been installed.
22 |
23 | ```bash
24 | pip install sentence-transformers
25 | ```
26 |
27 | Ensure your system has Python3 and pip installed before proceeding.
28 |
29 | ## Usage
30 |
31 | ### Basic Example
32 |
33 | Here's a basic example of how to use the GreenBit Langchain integration:
34 |
35 | ```python
36 | from langchain_core.messages import HumanMessage
37 | from green_bit_llm.langchain import GreenBitPipeline, ChatGreenBit
38 | import torch
39 |
40 | pipeline = GreenBitPipeline.from_model_id(
41 | model_id="GreenBitAI/Llama-3-8B-instruct-layer-mix-bpw-4.0",
42 | device="cuda:0",
43 | model_kwargs={"dtype": torch.half, "device_map": 'auto', "seqlen": 2048, "requires_grad": False},
44 | pipeline_kwargs={"max_new_tokens": 100, "temperature": 0.7},
45 | )
46 |
47 | chat = ChatGreenBit(llm=pipeline)
48 |
49 | # normal generation
50 | response = chat.invoke("What is the capital of France?")
51 | print(response.content)
52 |
53 | # stream generation
54 | for chunk in chat.stream([HumanMessage(content="Tell me a story about a brave knight.")]):
55 | print(chunk.message.content, end="", flush=True)
56 |
57 | ```
58 |
--------------------------------------------------------------------------------
/green_bit_llm/langchain/__init__.py:
--------------------------------------------------------------------------------
1 | from .pipeline import GreenBitPipeline
2 | from .embedding import GreenBitEmbeddings
3 | from .chat_model import ChatGreenBit
--------------------------------------------------------------------------------
/green_bit_llm/langchain/chat_model.py:
--------------------------------------------------------------------------------
1 | from typing import Any, Dict, List, Optional, Union, Sequence, Literal, Callable, Type
2 | from pydantic import Field
3 | from langchain_core.callbacks.manager import (
4 | AsyncCallbackManagerForLLMRun,
5 | CallbackManagerForLLMRun,
6 | )
7 | from langchain_core.language_models.chat_models import BaseChatModel
8 | from langchain_core.messages import (
9 | AIMessage,
10 | BaseMessage,
11 | ChatMessage,
12 | HumanMessage,
13 | SystemMessage,
14 | )
15 | from langchain_core.outputs import ChatGeneration, ChatResult, LLMResult
16 | from langchain_core.language_models import LanguageModelInput
17 | from langchain_core.runnables import Runnable, RunnableConfig
18 | from langchain_core.tools import BaseTool
19 | from langchain_core.utils.function_calling import convert_to_openai_tool
20 |
21 | from green_bit_llm.langchain import GreenBitPipeline
22 |
23 | DEFAULT_SYSTEM_PROMPT = """You are a helpful, respectful, and honest assistant."""
24 |
25 |
26 | class ChatGreenBit(BaseChatModel):
27 | """GreenBit Chat model.
28 |
29 | Example:
30 | .. code-block:: python
31 |
32 | from green_bit_llm.langchain import GreenBitPipeline
33 |
34 | model_config = {
35 | "trust_remote_code": True,
36 | "attn_implementation": "flash_attention_2"
37 | }
38 |
39 | tokenizer_config = {"trust_remote_code": True}
40 |
41 | gb = GreenBitPipeline.from_model_id(
42 | model_id="GreenBitAI/Llama-3-8B-instruct-layer-mix-bpw-4.0",
43 | task="text-generation",
44 | pipeline_kwargs={"max_tokens": 100, "temp": 0.7},
45 | model_kwargs={
46 | "dtype": torch.half,
47 | "seqlen": 2048,
48 | "requires_grad": False,
49 | "model_config": model_config,
50 | "tokenizer_config": tokenizer_config
51 | }
52 | )
53 | """
54 |
55 | llm: GreenBitPipeline = Field(..., description="GreenBit Pipeline instance")
56 |
57 | class Config:
58 | """Configuration for this pydantic object."""
59 | arbitrary_types_allowed = True
60 |
61 | def __init__(
62 | self,
63 | llm: GreenBitPipeline,
64 | **kwargs: Any,
65 | ) -> None:
66 | """Initialize the chat model.
67 |
68 | Args:
69 | llm: GreenBit Pipeline instance
70 | **kwargs: Additional keyword arguments
71 | """
72 | # First initialize with mandatory llm field
73 | super().__init__(llm=llm, **kwargs)
74 |
75 | @property
76 | def _llm_type(self) -> str:
77 | return "greenbit-chat"
78 |
79 | def _create_chat_result(self, llm_result: LLMResult) -> ChatResult:
80 | """Convert LLM result to chat messages"""
81 | generations = []
82 | for gen in llm_result.generations:
83 | for g in gen:
84 | message = AIMessage(content=g.text.strip())
85 | chat_generation = ChatGeneration(
86 | message=message,
87 | generation_info=g.generation_info
88 | )
89 | generations.append(chat_generation)
90 | return ChatResult(generations=generations)
91 |
92 | def _messages_to_dict(self, messages: List[BaseMessage]) -> List[Dict[str, str]]:
93 | """Convert LangChain messages to dictionary format for apply_chat_template"""
94 | message_dicts = []
95 |
96 | for message in messages:
97 | if isinstance(message, SystemMessage):
98 | message_dicts.append({"role": "system", "content": message.content})
99 | elif isinstance(message, HumanMessage):
100 | message_dicts.append({"role": "user", "content": message.content})
101 | elif isinstance(message, AIMessage):
102 | message_dicts.append({"role": "assistant", "content": message.content})
103 |
104 | return message_dicts
105 |
106 | def _prepare_prompt(self, messages: List[BaseMessage], **kwargs) -> str:
107 | """Prepare prompt using apply_chat_template"""
108 | if not hasattr(self.llm.pipeline, 'tokenizer'):
109 | raise ValueError("Tokenizer not available in pipeline")
110 |
111 | tokenizer = self.llm.pipeline.tokenizer
112 | if not hasattr(tokenizer, 'apply_chat_template'):
113 | raise ValueError("Tokenizer does not support apply_chat_template")
114 |
115 | # Convert messages to dict format
116 | message_dicts = self._messages_to_dict(messages)
117 |
118 | # Prepare apply_chat_template arguments
119 | template_kwargs = {
120 | "add_generation_prompt": True,
121 | "tokenize": False, # 关键:设置为 False 确保返回字符串
122 | }
123 |
124 | # Add enable_thinking for Qwen3 models if provided
125 | enable_thinking = kwargs.get('enable_thinking')
126 | if enable_thinking is not None:
127 | template_kwargs["enable_thinking"] = enable_thinking
128 |
129 | try:
130 | result = tokenizer.apply_chat_template(message_dicts, **template_kwargs)
131 |
132 | # 确保返回字符串
133 | if isinstance(result, list):
134 | # 如果仍然返回 token IDs,解码为字符串
135 | return tokenizer.decode(result, skip_special_tokens=False)
136 | elif isinstance(result, str):
137 | return result
138 | else:
139 | raise ValueError(f"Unexpected return type from apply_chat_template: {type(result)}")
140 |
141 | except Exception as e:
142 | raise ValueError(f"Failed to apply chat template: {str(e)}")
143 |
144 | def generate(
145 | self,
146 | messages: List[BaseMessage],
147 | stop: Optional[List[str]] = None,
148 | run_manager: Optional[CallbackManagerForLLMRun] = None,
149 | **kwargs: Any,
150 | ) -> ChatResult:
151 | """Generate chat completion using the underlying pipeline"""
152 | # Prepare prompt using apply_chat_template
153 | prompt = self._prepare_prompt(messages, **kwargs)
154 |
155 | # Handle generation parameters
156 | generation_kwargs = {}
157 | if "temperature" in kwargs:
158 | generation_kwargs["temperature"] = kwargs["temperature"]
159 | if "max_new_tokens" in kwargs:
160 | generation_kwargs["max_new_tokens"] = kwargs["max_new_tokens"]
161 | elif "max_tokens" in kwargs:
162 | generation_kwargs["max_new_tokens"] = kwargs["max_tokens"]
163 |
164 | wrapped_kwargs = {
165 | "pipeline_kwargs": generation_kwargs,
166 | "stop": stop,
167 | **kwargs
168 | }
169 |
170 | # Generate using pipeline
171 | llm_result = self.llm.generate(
172 | prompts=[prompt],
173 | run_manager=run_manager,
174 | **wrapped_kwargs
175 | )
176 |
177 | return self._create_chat_result(llm_result)
178 |
179 | def _generate(
180 | self,
181 | messages: List[BaseMessage],
182 | stop: Optional[List[str]] = None,
183 | run_manager: Optional[CallbackManagerForLLMRun] = None,
184 | **kwargs: Any,
185 | ) -> ChatResult:
186 | """Generate method required by BaseChatModel"""
187 | return self.generate(messages, stop, run_manager, **kwargs)
188 |
189 | def stream(
190 | self,
191 | messages: List[BaseMessage],
192 | stop: Optional[List[str]] = None,
193 | run_manager: Optional[CallbackManagerForLLMRun] = None,
194 | **kwargs: Any,
195 | ):
196 | """Stream chat completion"""
197 | # Prepare prompt using apply_chat_template
198 | prompt = self._prepare_prompt(messages, **kwargs)
199 |
200 | # Handle generation parameters
201 | generation_kwargs = {}
202 | if "temperature" in kwargs:
203 | generation_kwargs["temperature"] = kwargs["temperature"]
204 | if "max_new_tokens" in kwargs:
205 | generation_kwargs["max_new_tokens"] = kwargs["max_new_tokens"]
206 | elif "max_tokens" in kwargs:
207 | generation_kwargs["max_new_tokens"] = kwargs["max_tokens"]
208 |
209 | wrapped_kwargs = {
210 | "pipeline_kwargs": generation_kwargs,
211 | "stop": stop,
212 | "skip_prompt": kwargs.get("skip_prompt", True),
213 | **kwargs
214 | }
215 |
216 | # Stream using pipeline
217 | for chunk in self.llm.stream(
218 | prompt,
219 | run_manager=run_manager,
220 | **wrapped_kwargs
221 | ):
222 | yield ChatGeneration(message=AIMessage(content=chunk.text))
223 |
224 | async def agenerate(
225 | self,
226 | messages: List[BaseMessage],
227 | stop: Optional[List[str]] = None,
228 | run_manager: Optional[AsyncCallbackManagerForLLMRun] = None,
229 | **kwargs: Any,
230 | ) -> ChatResult:
231 | """Async generation (not implemented)"""
232 | raise NotImplementedError("Async generation not implemented yet")
233 |
234 | async def astream(
235 | self,
236 | messages: List[BaseMessage],
237 | stop: Optional[List[str]] = None,
238 | run_manager: Optional[CallbackManagerForLLMRun] = None,
239 | **kwargs: Any,
240 | ):
241 | """Async streaming (not implemented)"""
242 | raise NotImplementedError("Async stream generation not implemented yet")
243 |
244 | def bind_tools(
245 | self,
246 | tools: Sequence[Union[Dict[str, Any], Type, Callable, BaseTool]],
247 | *,
248 | tool_choice: Optional[Union[dict, str, Literal["auto", "none"], bool]] = None,
249 | **kwargs: Any,
250 | ) -> Runnable[LanguageModelInput, BaseMessage]:
251 | """Bind tools to the chat model"""
252 | formatted_tools = [convert_to_openai_tool(tool) for tool in tools]
253 |
254 | if tool_choice is not None and tool_choice:
255 | if len(formatted_tools) != 1:
256 | raise ValueError(
257 | "When specifying `tool_choice`, you must provide exactly one "
258 | f"tool. Received {len(formatted_tools)} tools."
259 | )
260 |
261 | if isinstance(tool_choice, str):
262 | if tool_choice not in ("auto", "none"):
263 | tool_choice = {
264 | "type": "function",
265 | "function": {"name": tool_choice},
266 | }
267 | elif isinstance(tool_choice, bool):
268 | tool_choice = formatted_tools[0]
269 | elif isinstance(tool_choice, dict):
270 | if (
271 | formatted_tools[0]["function"]["name"]
272 | != tool_choice["function"]["name"]
273 | ):
274 | raise ValueError(
275 | f"Tool choice {tool_choice} was specified, but the only "
276 | f"provided tool was {formatted_tools[0]['function']['name']}."
277 | )
278 | else:
279 | raise ValueError(
280 | f"Unrecognized tool_choice type. Expected str, bool or dict. "
281 | f"Received: {tool_choice}"
282 | )
283 |
284 | kwargs["tool_choice"] = tool_choice
285 |
286 | return super().bind(tools=formatted_tools, **kwargs)
--------------------------------------------------------------------------------
/green_bit_llm/langchain/embedding.py:
--------------------------------------------------------------------------------
1 | from typing import List, Dict, Any, Optional
2 | from langchain_core.embeddings import Embeddings
3 | from pydantic import BaseModel, Field
4 |
5 | # good balance between performance and efficiency, params: 22M
6 | DEFAULT_MODEL_NAME1 = "sentence-transformers/all-MiniLM-L12-v2"
7 | # params: 110M, better NLU ability
8 | DEFAULT_MODEL_NAME2 = "sentence-transformers/all-mpnet-base-v2"
9 | # Optimized for multi-round question answering and suitable for applications
10 | # that require more complex context understanding.
11 | DEFAULT_MODEL_NAME3 = "sentence-transformers/multi-qa-MiniLM-L6-cos-v"
12 |
13 |
14 | class GreenBitEmbeddings(BaseModel, Embeddings):
15 | """GreenBit embedding model using sentence-transformers.
16 |
17 | This class provides an interface to generate embeddings using GreenBit's models,
18 | which are based on the sentence-transformers package.
19 |
20 | Attributes:
21 | model (Any): Embedding model.
22 | encode_kwargs (Dict[str, Any]): Additional keyword arguments for the encoding process.
23 | device (str): The device to use for computations (e.g., 'cuda' for GPU).
24 |
25 | Example:
26 | .. code-block:: python
27 | from reen_bit_llm.langchain import GreenBitEmbeddings
28 |
29 | embedder = GreenBitEmbeddings.from_model_id(
30 | "sentence-transformers/all-mpnet-base-v2",
31 | device="cuda",
32 | multi_process=True,
33 | model_kwargs={"cache_folder": "/path/to/cache"},
34 | encode_kwargs={"normalize_embeddings": True}
35 | )
36 |
37 | texts = ["Hello, world!", "This is a test."]
38 | document_embeddings = embedder.embed_documents(texts)
39 | query_embedding = embedder.embed_query("What is the meaning of life?")
40 | """
41 | cache_dir: Optional[str] = "~/.cache/huggingface/hub"
42 | """Path to store models.
43 | Can be also set by SENTENCE_TRANSFORMERS_HOME environment variable."""
44 | encode_kwargs: Dict[str, Any] = Field(default_factory=dict)
45 | """Keyword arguments to pass when calling the `encode` method of the Sentence
46 | Transformer model, such as `prompt_name`, `prompt`, `batch_size`, `precision`,
47 | `normalize_embeddings`, and more.
48 | See also the Sentence Transformer documentation: https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.encode"""
49 | multi_process: bool = False
50 | """Run encode() on multiple GPUs."""
51 | show_progress: bool = False
52 | """Whether to show a progress bar."""
53 | device: str = "cuda"
54 | model: Any = None
55 |
56 | def __init__(self, **data):
57 | super().__init__(**data)
58 |
59 | class Config:
60 | """Configuration for this pydantic object."""
61 |
62 | extra = "forbid"
63 |
64 | def embed_documents(self, texts: List[str]) -> List[List[float]]:
65 | """
66 | Generate embeddings for a list of documents.
67 |
68 | Args:
69 | texts (List[str]): The list of texts to embed.
70 |
71 | Returns:
72 | List[List[float]]: The list of embeddings, one for each input text.
73 | """
74 | import sentence_transformers
75 | texts = list(map(lambda x: x.replace("\n", " "), texts))
76 | if self.multi_process:
77 | pool = self.model.start_multi_process_pool()
78 | embeddings = self.model.encode_multi_process(texts, pool)
79 | sentence_transformers.SentenceTransformer.stop_multi_process_pool(pool)
80 | else:
81 | embeddings = self.model.encode(
82 | texts, show_progress_bar=self.show_progress, **self.encode_kwargs
83 | )
84 | return embeddings.tolist()
85 |
86 | def embed_query(self, text: str) -> List[float]:
87 | """
88 | Generate an embedding for a single query text.
89 |
90 | Args:
91 | text (str): The query text to embed.
92 |
93 | Returns:
94 | List[float]: The embedding for the input text.
95 | """
96 | return self.embed_documents([text])[0]
97 |
98 | @classmethod
99 | def from_model_id(
100 | cls,
101 | model_name: str = DEFAULT_MODEL_NAME1,
102 | device: str = "cuda",
103 | cache_dir: Optional[str] = "",
104 | multi_process: bool = False,
105 | show_progress: bool = False,
106 | model_kwargs: Dict[str, Any] = Field(default_factory=dict),
107 | encode_kwargs: Optional[Dict[str, Any]] = Field(default_factory=dict),
108 | **kwargs
109 | ) -> "GreenBitEmbeddings":
110 | """
111 | Create a GreenBitEmbeddings instance from a model name.
112 |
113 | Args:
114 | model_name (str): The name of the model to use.
115 | device (str): The device to use for computations (default is "cuda" for GPU).
116 | cache_dir (Optional[str]): Path to store models. Can be also set by SENTENCE_TRANSFORMERS_HOME environment variable.
117 | multi_process (bool): Run encode() on multiple GPUs.
118 | show_progress (bool): Whether to show a progress bar.
119 | model_kwargs (Optional[Dict[str, Any]]): Keyword arguments to pass to the Sentence Transformer model, such as `device`,
120 | `prompts`, `default_prompt_name`, `revision`, `trust_remote_code`, or `token`.
121 | See also the Sentence Transformer documentation: https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer
122 | encode_kwargs (Optional[Dict[str, Any]]): Keyword arguments to pass when calling the `encode` method of the SentenceTransformer model, such as `prompt_name`, `prompt`, `batch_size`, `precision`,
123 | `normalize_embeddings`, and more. See also the Sentence Transformer documentation: https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.encode
124 | **kwargs: Additional keyword arguments for the GreenBitEmbeddings constructor.
125 |
126 | Returns:
127 | GreenBitEmbeddings: An instance of GreenBitEmbeddings.
128 | """
129 | try:
130 | from sentence_transformers import SentenceTransformer
131 | except ImportError:
132 | raise ImportError(
133 | "Could not import sentence_transformers. "
134 | "Please install it with `pip install sentence-transformers`."
135 | )
136 |
137 | model = SentenceTransformer(
138 | model_name,
139 | device=device,
140 | cache_folder=cache_dir,
141 | **model_kwargs
142 | )
143 |
144 | return cls(
145 | model=model,
146 | device=device,
147 | cache_dir=cache_dir,
148 | multi_process=multi_process,
149 | show_progress=show_progress,
150 | encode_kwargs=encode_kwargs or {},
151 | **kwargs
152 | )
--------------------------------------------------------------------------------
/green_bit_llm/patches/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/patches/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/patches/deepseek_v3_moe_patch.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | # Import DeepSeek V3 components at module level
4 | try:
5 | from transformers.models.deepseek_v3.modeling_deepseek_v3 import DeepseekV3MoE
6 |
7 | DEEPSEEK_V3_AVAILABLE = True
8 | except ImportError:
9 | DeepseekV3MoE = None
10 | DEEPSEEK_V3_AVAILABLE = False
11 |
12 |
13 | class QuantizedDeepSeekV3MoE:
14 | """
15 | DeepSeekV3MoE forward method optimized for quantized models
16 | """
17 |
18 | @staticmethod
19 | def moe_token_by_token(self, hidden_states: torch.Tensor, topk_indices: torch.Tensor, topk_weights: torch.Tensor):
20 | """
21 | Quantization-friendly MoE implementation using token-by-token processing
22 | """
23 | batch_size, sequence_length, hidden_dim = hidden_states.shape
24 | total_tokens = batch_size * sequence_length
25 |
26 | # Flatten processing
27 | hidden_states_flat = hidden_states.view(-1, hidden_dim)
28 |
29 | # Initialize output with correct dtype
30 | final_hidden_states = torch.zeros_like(hidden_states_flat, dtype=topk_weights.dtype)
31 |
32 | # Pre-convert to CPU to reduce GPU-CPU transfers
33 | topk_indices_cpu = topk_indices.cpu().numpy()
34 | topk_weights_cpu = topk_weights.cpu().numpy()
35 | top_k = topk_indices.shape[-1]
36 |
37 | # Process token by token for maximum quantization compatibility
38 | for token_idx in range(total_tokens):
39 | # Get single token input - fixed batch size (1)
40 | token_input = hidden_states_flat[token_idx:token_idx + 1] # [1, hidden_dim]
41 | token_output = torch.zeros_like(token_input, dtype=topk_weights.dtype)
42 |
43 | # Get expert indices and weights for this token
44 | token_experts = topk_indices_cpu[token_idx] # [top_k]
45 | token_weights = topk_weights_cpu[token_idx] # [top_k]
46 |
47 | # Process selected experts
48 | for expert_pos in range(top_k):
49 | expert_idx = int(token_experts[expert_pos])
50 | expert_weight = float(token_weights[expert_pos])
51 |
52 | # Skip small weights for performance
53 | if expert_weight < 1e-6:
54 | continue
55 |
56 | # Call expert network - fixed batch size, quantization friendly
57 | expert_layer = self.experts[expert_idx]
58 | expert_output = expert_layer(token_input)
59 |
60 | # Weighted accumulation - simple scalar operations
61 | token_output = token_output + expert_output * expert_weight
62 |
63 | # Store result
64 | final_hidden_states[token_idx] = token_output[0]
65 |
66 | # Convert back to original dtype
67 | return final_hidden_states.type(hidden_states.dtype)
68 |
69 | @staticmethod
70 | def moe_vectorized(self, hidden_states: torch.Tensor, topk_indices: torch.Tensor, topk_weights: torch.Tensor):
71 | """
72 | Vectorized MoE implementation adapted from Qwen3 method
73 | """
74 | batch_size, sequence_length, hidden_dim = hidden_states.shape
75 | total_tokens = batch_size * sequence_length
76 |
77 | # Flatten processing
78 | hidden_states_flat = hidden_states.view(-1, hidden_dim)
79 | top_k = topk_indices.shape[-1]
80 |
81 | # Pre-allocate expert output storage - key vectorization optimization
82 | expert_outputs = torch.zeros(total_tokens, top_k, hidden_dim,
83 | dtype=topk_weights.dtype, device=hidden_states.device)
84 |
85 | # Process experts in batches - adapted for 256 experts
86 | for expert_idx in range(len(self.experts)):
87 | # Create expert mask [total_tokens, top_k]
88 | expert_mask = (topk_indices == expert_idx)
89 |
90 | if not expert_mask.any():
91 | continue
92 |
93 | # Find positions using current expert
94 | token_idx, topk_idx = torch.where(expert_mask)
95 |
96 | if len(token_idx) == 0:
97 | continue
98 |
99 | # Batch processing - key performance improvement
100 | expert_inputs = hidden_states_flat[token_idx]
101 | expert_result = self.experts[expert_idx](expert_inputs)
102 |
103 | # Store results
104 | expert_outputs[token_idx, topk_idx] = expert_result
105 |
106 | # Apply weights and sum - vectorized operations
107 | weights_expanded = topk_weights.unsqueeze(-1)
108 | final_hidden_states = (expert_outputs * weights_expanded).sum(dim=1)
109 |
110 | # Reshape back to original shape
111 | final_hidden_states = final_hidden_states.view(batch_size, sequence_length, hidden_dim)
112 |
113 | # Convert back to original dtype
114 | return final_hidden_states.type(hidden_states.dtype)
115 |
116 | @staticmethod
117 | def should_use_vectorized(self, hidden_states):
118 | """
119 | Determine whether to use vectorized method based on batch size efficiency
120 | """
121 | batch_size, seq_len, hidden_dim = hidden_states.shape
122 | total_tokens = batch_size * seq_len
123 | top_k = getattr(self, 'top_k', 6) # DeepSeek V3 default
124 |
125 | # Estimate memory requirement for expert_outputs tensor
126 | estimated_memory_mb = total_tokens * top_k * hidden_dim * 2 / (1024 * 1024) # fp16
127 |
128 | # Primary criterion: batch size efficiency
129 | if total_tokens < 64:
130 | # Too small batch, vectorization has no advantage
131 | return False, estimated_memory_mb
132 |
133 | # Optional safety check for extreme cases
134 | try:
135 | total_memory = torch.cuda.get_device_properties(0).total_memory
136 | allocated_memory = torch.cuda.memory_allocated()
137 | available_memory_mb = (total_memory - allocated_memory) / (1024 * 1024)
138 |
139 | # Only fallback if memory is really insufficient (< 20% available)
140 | memory_threshold = available_memory_mb * 0.2
141 |
142 | if estimated_memory_mb > memory_threshold:
143 | return False, estimated_memory_mb
144 |
145 | except Exception:
146 | # If cannot get memory info, don't restrict
147 | pass
148 |
149 | return True, estimated_memory_mb
150 |
151 | @staticmethod
152 | def forward_hybrid(self, hidden_states):
153 | """
154 | Hybrid strategy forward method for DeepSeek V3 MoE
155 | """
156 | # Save for residual connection and shared experts
157 | residuals = hidden_states
158 |
159 | # Route calculation - maintain DeepSeek V3's complex routing logic
160 | topk_indices, topk_weights = self.gate(hidden_states)
161 |
162 | # Choose strategy based on memory and batch size
163 | use_vectorized, estimated_mb = QuantizedDeepSeekV3MoE.should_use_vectorized(self, hidden_states)
164 |
165 | if use_vectorized:
166 | moe_output = QuantizedDeepSeekV3MoE.moe_vectorized(
167 | self, hidden_states, topk_indices, topk_weights
168 | )
169 | else:
170 | moe_output = QuantizedDeepSeekV3MoE.moe_token_by_token(
171 | self, hidden_states, topk_indices, topk_weights
172 | )
173 |
174 | # Add shared expert output - DeepSeek V3 specific feature
175 | shared_expert_output = self.shared_experts(residuals)
176 |
177 | # Final output = MoE output + shared expert output
178 | final_output = moe_output + shared_expert_output
179 |
180 | return final_output
181 |
182 | @staticmethod
183 | def forward_conservative(self, hidden_states):
184 | """
185 | Conservative forward method using only token-by-token processing
186 | """
187 | residuals = hidden_states
188 |
189 | # Route calculation
190 | topk_indices, topk_weights = self.gate(hidden_states)
191 |
192 | # Use token-by-token method for maximum compatibility
193 | moe_output = QuantizedDeepSeekV3MoE.moe_token_by_token(
194 | self, hidden_states, topk_indices, topk_weights
195 | )
196 |
197 | # Add shared expert output
198 | shared_expert_output = self.shared_experts(residuals)
199 |
200 | return moe_output + shared_expert_output
201 |
202 | @staticmethod
203 | def forward_vectorized(self, hidden_states):
204 | """
205 | Vectorized forward method for maximum performance
206 | """
207 | residuals = hidden_states
208 |
209 | # Route calculation
210 | topk_indices, topk_weights = self.gate(hidden_states)
211 |
212 | # Use vectorized method
213 | moe_output = QuantizedDeepSeekV3MoE.moe_vectorized(
214 | self, hidden_states, topk_indices, topk_weights
215 | )
216 |
217 | # Add shared expert output
218 | shared_expert_output = self.shared_experts(residuals)
219 |
220 | return moe_output + shared_expert_output
221 |
222 |
223 | def apply_deepseek_v3_moe_patch(strategy='hybrid'):
224 | """
225 | Apply DeepSeek V3 MoE patch
226 |
227 | Args:
228 | strategy: 'conservative', 'vectorized', 'hybrid'
229 | """
230 | if not DEEPSEEK_V3_AVAILABLE:
231 | print("Error: DeepSeek V3 models not available in current transformers installation")
232 | return False
233 |
234 | # Save original method
235 | if not hasattr(DeepseekV3MoE, '_original_forward'):
236 | DeepseekV3MoE._original_forward = DeepseekV3MoE.forward
237 |
238 | # Apply strategy
239 | if strategy == 'conservative':
240 | DeepseekV3MoE.forward = QuantizedDeepSeekV3MoE.forward_conservative
241 | print("Info: Applied DeepSeek V3 conservative MoE patch")
242 | elif strategy == 'vectorized':
243 | DeepseekV3MoE.forward = QuantizedDeepSeekV3MoE.forward_vectorized
244 | print("Info: Applied DeepSeek V3 vectorized MoE patch")
245 | elif strategy == 'hybrid':
246 | DeepseekV3MoE.forward = QuantizedDeepSeekV3MoE.forward_hybrid
247 | print("Info: Applied DeepSeek V3 hybrid MoE patch")
248 | else:
249 | raise ValueError(f"Unknown strategy: {strategy}")
250 |
251 | return True
252 |
253 |
254 | def restore_deepseek_v3_moe_patch():
255 | """
256 | Restore original DeepSeek V3 MoE forward method
257 | """
258 | if not DEEPSEEK_V3_AVAILABLE:
259 | return
260 |
261 | if hasattr(DeepseekV3MoE, '_original_forward'):
262 | DeepseekV3MoE.forward = DeepseekV3MoE._original_forward
263 | delattr(DeepseekV3MoE, '_original_forward')
264 | print("Info: Restored original DeepSeek V3 MoE forward method")
265 |
266 |
267 | def detect_deepseek_v3_moe_model(config):
268 | """
269 | Detect if model is DeepSeek V3 MoE
270 | """
271 | return (
272 | hasattr(config, 'model_type') and
273 | 'deepseek_v3' in config.model_type.lower() and
274 | getattr(config, 'n_routed_experts', 0) > 0
275 | )
--------------------------------------------------------------------------------
/green_bit_llm/patches/qwen3_moe_patch.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | from typing import Tuple
4 |
5 |
6 | class QuantizedQwen3MoeSparseMoeBlock:
7 | """
8 | Qwen3MoeSparseMoeBlock forward method optimized for quantized models
9 | """
10 |
11 | @staticmethod
12 | def forward(self, hidden_states: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
13 | """
14 | Quantization-friendly MoE forward implementation using vectorized strategy
15 | """
16 | batch_size, sequence_length, hidden_dim = hidden_states.shape
17 | total_tokens = batch_size * sequence_length
18 |
19 | # flat
20 | hidden_states_flat = hidden_states.reshape(total_tokens, hidden_dim)
21 |
22 | # 1. Route calculation
23 | router_logits = self.gate(hidden_states_flat)
24 | if len(router_logits.shape) > 2:
25 | router_logits = router_logits.reshape(total_tokens, -1)
26 |
27 | # 2. Calculating routing weight
28 | routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
29 |
30 | # 3. Select top experts and weights
31 | routing_weights_topk, indices_topk = torch.topk(routing_weights, self.top_k, dim=1)
32 |
33 | # 4. Normalized top weights
34 | if self.norm_topk_prob:
35 | routing_weights_topk /= routing_weights_topk.sum(dim=1, keepdim=True)
36 | routing_weights_topk = routing_weights_topk.to(hidden_states.dtype)
37 |
38 | # 5. Pre-allocated expert output storage
39 | # [total_tokens, top_k, hidden_dim]
40 | expert_outputs = torch.zeros(total_tokens, self.top_k, hidden_dim,
41 | dtype=hidden_states.dtype, device=hidden_states.device)
42 |
43 | # 6. Batch processing by experts
44 | for expert_idx in range(self.num_experts):
45 | # Create expert mask [total_tokens, top_k]
46 | expert_mask = (indices_topk == expert_idx)
47 |
48 | if not expert_mask.any():
49 | continue
50 |
51 | # Find a location using current experts
52 | token_idx, topk_idx = torch.where(expert_mask)
53 |
54 | if len(token_idx) == 0:
55 | continue
56 |
57 | # Batch Processing
58 | expert_inputs = hidden_states_flat[token_idx]
59 | expert_result = self.experts[expert_idx](expert_inputs)
60 |
61 | # Storing Results
62 | expert_outputs[token_idx, topk_idx] = expert_result
63 |
64 | # 7. Apply weights and sum
65 | # Expand weight dimension: [total_tokens, top_k, 1]
66 | weights_expanded = routing_weights_topk.unsqueeze(-1)
67 |
68 | # Weighted sum: [total_tokens, hidden_dim]
69 | final_hidden_states = (expert_outputs * weights_expanded).sum(dim=1)
70 |
71 | # 8. Reshape back to original shape
72 | final_hidden_states = final_hidden_states.view(batch_size, sequence_length, hidden_dim)
73 |
74 | return final_hidden_states, router_logits
75 |
76 | @staticmethod
77 | def forward_micro_batched(self, hidden_states: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
78 | """
79 | Quantization-friendly MoE forward implementation using micro_batched strategy
80 | """
81 | batch_size, sequence_length, hidden_dim = hidden_states.shape
82 | total_tokens = batch_size * sequence_length
83 |
84 | hidden_states_flat = hidden_states.reshape(total_tokens, hidden_dim)
85 |
86 | # Route calculation
87 | router_logits = self.gate(hidden_states_flat)
88 | if len(router_logits.shape) > 2:
89 | router_logits = router_logits.reshape(total_tokens, -1)
90 |
91 | routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
92 | routing_weights_topk, indices_topk = torch.topk(routing_weights, self.top_k, dim=1)
93 |
94 | if self.norm_topk_prob:
95 | routing_weights_topk /= routing_weights_topk.sum(dim=1, keepdim=True)
96 | routing_weights_topk = routing_weights_topk.to(hidden_states.dtype)
97 |
98 | final_hidden_states = torch.zeros_like(hidden_states_flat)
99 |
100 | # Fixed micro-batch size - quantization friendly
101 | micro_batch_size = min(8, total_tokens) # Small fixed batch size
102 |
103 | for start_idx in range(0, total_tokens, micro_batch_size):
104 | end_idx = min(start_idx + micro_batch_size, total_tokens)
105 |
106 | # Still process token by token in micro batch - maintain quantization compatibility
107 | for token_idx in range(start_idx, end_idx):
108 | token_input = hidden_states_flat[token_idx:token_idx + 1]
109 | token_output = torch.zeros_like(token_input)
110 |
111 | for expert_pos in range(self.top_k):
112 | expert_idx = indices_topk[token_idx, expert_pos].item()
113 | expert_weight = routing_weights_topk[token_idx, expert_pos].item()
114 |
115 | if expert_weight < 1e-4:
116 | continue
117 |
118 | expert_output = self.experts[expert_idx](token_input)
119 | token_output = token_output + expert_output * expert_weight
120 |
121 | final_hidden_states[token_idx] = token_output[0]
122 |
123 | final_hidden_states = final_hidden_states.view(batch_size, sequence_length, hidden_dim)
124 | return final_hidden_states, router_logits
125 |
126 | def apply_qwen3_moe_patch():
127 | """
128 | Apply the monkey patch of Qwen3MoeSparseMoeBlock
129 | """
130 | try:
131 | from transformers.models.qwen3_moe.modeling_qwen3_moe import Qwen3MoeSparseMoeBlock
132 |
133 | # Save the original method (in case we need to restore it)
134 | if not hasattr(Qwen3MoeSparseMoeBlock, '_original_forward'):
135 | Qwen3MoeSparseMoeBlock._original_forward = Qwen3MoeSparseMoeBlock.forward
136 |
137 | # Replace the forward method
138 | Qwen3MoeSparseMoeBlock.forward = QuantizedQwen3MoeSparseMoeBlock.forward
139 |
140 | print("Info: Successfully applied Qwen3MoeSparseMoeBlock patch for quantized models")
141 |
142 | except ImportError as e:
143 | print(f"Error: Could not apply Qwen3MoeSparseMoeBlock patch: {e}")
144 | print(" This might be expected if Qwen3 models are not being used")
145 |
146 | def restore_qwen3_moe_patch():
147 | """
148 | Restore the original Qwen3MoeSparseMoeBlock forward method
149 | """
150 | try:
151 | from transformers.models.qwen3_moe.modeling_qwen3_moe import Qwen3MoeSparseMoeBlock
152 |
153 | if hasattr(Qwen3MoeSparseMoeBlock, '_original_forward'):
154 | Qwen3MoeSparseMoeBlock.forward = Qwen3MoeSparseMoeBlock._original_forward
155 | delattr(Qwen3MoeSparseMoeBlock, '_original_forward')
156 | print("Info: Successfully restored original Qwen3MoeSparseMoeBlock forward method")
157 |
158 | except ImportError:
159 | pass
--------------------------------------------------------------------------------
/green_bit_llm/routing/__init__.py:
--------------------------------------------------------------------------------
1 | from .confidence_scorer import ConfidenceScorer
--------------------------------------------------------------------------------
/green_bit_llm/routing/confidence_scorer.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from green_bit_llm.routing.libra_router.ue_router import MahalanobisDistanceSeq
3 |
4 |
5 | class ConfidenceScorer:
6 | """
7 | A class to compute confidence scores based on Mahalanobis distance.
8 |
9 | Attributes:
10 | parameters_path (str): Path to the model parameters
11 | json_file_path (str): Path to the uncertainty bounds JSON file
12 | device (str): Device to run computations on ('cpu', 'cuda', 'mps')
13 |
14 | Example:
15 | confidence_scorer = ConfidenceScore(
16 | parameters_path="path/to/params",
17 | json_file_path="path/to/bounds.json",
18 | device="cuda"
19 | )
20 |
21 | confidence = confidence_scorer.calculate_confidence(hidden_states)
22 | """
23 |
24 | def __init__(
25 | self,
26 | parameters_path: str,
27 | model_id: str,
28 | device: str = "cuda"
29 | ):
30 | """
31 | Initialize the ConfidenceScore calculator.
32 |
33 | Args:
34 | parameters_path: Path to model parameters
35 | json_file_path: Path to uncertainty bounds JSON
36 | device: Computation device
37 | threshold: Confidence threshold for routing
38 | """
39 | self.parameters_path = parameters_path
40 | self.device = device
41 |
42 | # Initialize Mahalanobis distance calculator
43 | try:
44 | self.mahalanobis = MahalanobisDistanceSeq(
45 | parameters_path=parameters_path,
46 | normalize=False,
47 | model_id=model_id,
48 | device=self.device
49 | )
50 | except Exception as e:
51 | raise RuntimeError(f"Failed to initialize Mahalanobis distance calculator: {str(e)}")
52 |
53 | def calculate_confidence(
54 | self,
55 | hidden_states: torch.Tensor
56 | ) -> float:
57 | """
58 | Calculate confidence score from hidden states.
59 | Support both single input and batch input.
60 |
61 | Args:
62 | hidden_states: Model hidden states tensor
63 | return_uncertainty: Whether to return the raw uncertainty score
64 |
65 | Returns:
66 | Union[float, List[float]]: Single confidence score or list of confidence scores
67 |
68 | Raises:
69 | ValueError: If hidden states have invalid shape
70 | RuntimeError: If confidence calculation fails
71 | """
72 |
73 | try:
74 | # Calculate uncertainty using Mahalanobis distance
75 | uncertainty = self.mahalanobis(hidden_states)
76 | if uncertainty is None:
77 | raise RuntimeError("Failed to calculate uncertainty")
78 |
79 | # Normalize uncertainty if bounds are available
80 | if self.mahalanobis.ue_bounds_tensor is not None:
81 | uncertainty = self.mahalanobis.normalize_ue(
82 | uncertainty[0],
83 | self.device
84 | )
85 | else:
86 | uncertainty = uncertainty[0]
87 |
88 | # Handle both single input and batch input
89 | if uncertainty.dim() == 0: # single value
90 | confidence_score = 1.0 - uncertainty.cpu().item()
91 | return confidence_score
92 | else: # batch of values
93 | confidence_scores = 1.0 - uncertainty.cpu().tolist()
94 | return confidence_scores
95 |
96 | except Exception as e:
97 | raise RuntimeError(f"Failed to calculate confidence score: {str(e)}")
--------------------------------------------------------------------------------
/green_bit_llm/serve/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/serve/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/serve/api/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/serve/api/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/serve/api/v1/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/serve/api/v1/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/serve/auth/__init__.py:
--------------------------------------------------------------------------------
1 | from .api_key_auth import APIKeyAuth, get_api_key_auth
2 | from .rate_limiter import RateLimiter
3 |
4 | __all__ = ['APIKeyAuth', 'get_api_key_auth', 'RateLimiter']
--------------------------------------------------------------------------------
/green_bit_llm/serve/auth/api_key_auth.py:
--------------------------------------------------------------------------------
1 | import sqlite3
2 | import hashlib
3 | from typing import Optional
4 | from fastapi import HTTPException, Security
5 | from fastapi.security.api_key import APIKeyHeader
6 | from starlette.status import HTTP_403_FORBIDDEN
7 | import logging
8 | from pathlib import Path
9 | from dotenv import load_dotenv
10 | import os
11 |
12 | from .rate_limiter import RateLimiter
13 |
14 | # API key header
15 | API_KEY_HEADER = APIKeyHeader(name="X-Api-Key", auto_error=True)
16 |
17 |
18 | class APIKeyAuth:
19 | def __init__(self, db_path: str):
20 | self.db_path = db_path
21 | self.rate_limiter = RateLimiter()
22 | self.logger = logging.getLogger("greenbit_server")
23 |
24 | def get_db_connection(self):
25 | return sqlite3.connect(self.db_path)
26 |
27 | def _hash_key(self, api_key: str) -> str:
28 | """Hash the API key for database lookup."""
29 | return hashlib.blake2b(
30 | api_key.encode(),
31 | digest_size=32,
32 | salt=b"greenbit_storage",
33 | person=b"api_key_storage"
34 | ).hexdigest()
35 |
36 | def validate_api_key(self, api_key: str) -> dict:
37 | """Validate API key and return user info if valid."""
38 | try:
39 | hashed_key = self._hash_key(api_key)
40 |
41 | with self.get_db_connection() as conn:
42 | cursor = conn.cursor()
43 | cursor.execute("""
44 | SELECT
45 | ak.user_id,
46 | u.name,
47 | u.email,
48 | u.organization,
49 | ak.tier,
50 | ak.rpm_limit,
51 | ak.tpm_limit,
52 | ak.concurrent_requests,
53 | ak.max_tokens,
54 | ak.permissions,
55 | ak.is_active
56 | FROM api_keys ak
57 | JOIN users u ON ak.user_id = u.id
58 | WHERE ak.api_key_hash = ?
59 | """, (hashed_key,))
60 | result = cursor.fetchone()
61 |
62 | if not result:
63 | raise HTTPException(
64 | status_code=HTTP_403_FORBIDDEN,
65 | detail="Invalid API key"
66 | )
67 |
68 | user_info = {
69 | "user_id": result[0],
70 | "name": result[1],
71 | "email": result[2],
72 | "organization": result[3],
73 | "tier": result[4],
74 | "rpm_limit": result[5],
75 | "tpm_limit": result[6],
76 | "concurrent_requests": result[7],
77 | "max_tokens": result[8],
78 | "permissions": result[9].split(','),
79 | "is_active": bool(result[10])
80 | }
81 |
82 | if not user_info["is_active"]:
83 | raise HTTPException(
84 | status_code=HTTP_403_FORBIDDEN,
85 | detail="API key is inactive"
86 | )
87 |
88 | # Update last_used_at
89 | cursor.execute("""
90 | UPDATE api_keys
91 | SET last_used_at = CURRENT_TIMESTAMP
92 | WHERE api_key_hash = ?
93 | """, (hashed_key,))
94 | conn.commit()
95 |
96 | return user_info
97 |
98 | except sqlite3.Error as e:
99 | self.logger.error(f"Database error during API key validation: {str(e)}")
100 | raise HTTPException(status_code=500, detail="Internal server error")
101 |
102 | async def check_rate_limits(self, api_key: str, user_info: dict, estimated_tokens: Optional[int] = None):
103 | """Check all rate limits."""
104 | try:
105 | # Check RPM
106 | self.rate_limiter.check_rate_limit(api_key, user_info["rpm_limit"])
107 |
108 | # Check TPM if tokens are provided
109 | if estimated_tokens is not None:
110 | self.rate_limiter.check_token_limit(
111 | api_key,
112 | estimated_tokens,
113 | user_info["tpm_limit"]
114 | )
115 |
116 | # Try to acquire concurrent request slot
117 | await self.rate_limiter.acquire_concurrent_request(
118 | api_key,
119 | user_info["concurrent_requests"]
120 | )
121 |
122 | except Exception as e:
123 | self.logger.error(f"Rate limit check failed: {str(e)}")
124 | raise
125 |
126 | def check_permissions(self, user_info: dict, endpoint_type: str):
127 | """Check if the user has permission to access the endpoint."""
128 | if endpoint_type not in user_info["permissions"]:
129 | raise HTTPException(
130 | status_code=HTTP_403_FORBIDDEN,
131 | detail=f"No permission to access {endpoint_type} endpoint"
132 | )
133 |
134 | def check_token_limit(self, user_info: dict, requested_tokens: int):
135 | """Check if the requested tokens are within the user's limit."""
136 | if requested_tokens > user_info["max_tokens"]:
137 | raise HTTPException(
138 | status_code=HTTP_403_FORBIDDEN,
139 | detail=f"Requested tokens ({requested_tokens}) exceed maximum allowed ({user_info['max_tokens']})"
140 | )
141 |
142 |
143 | def load_api_key(env_file: str = None) -> str:
144 | """Load API key from environment file or environment variables."""
145 | if env_file and Path(env_file).exists():
146 | load_dotenv(env_file)
147 |
148 | api_key = os.getenv("LIBRA_API_KEY")
149 | if not api_key:
150 | raise HTTPException(
151 | status_code=HTTP_403_FORBIDDEN,
152 | detail="API key not found in environment"
153 | )
154 |
155 | return api_key
156 |
157 |
158 | async def get_api_key_auth(
159 | api_key: str = Security(API_KEY_HEADER),
160 | env_file: str = None,
161 | estimated_tokens: Optional[int] = None
162 | ) -> dict:
163 | """FastAPI dependency for API key authentication."""
164 | # If no API key in header, try to load from environment
165 | if not api_key:
166 | api_key = load_api_key(env_file)
167 |
168 | db_path = os.getenv("LIBRA_DB_PATH", str(Path(__file__).parent.parent.parent.parent / "db" / "greenbit.db"))
169 | auth_handler = APIKeyAuth(db_path)
170 | user_info = auth_handler.validate_api_key(api_key)
171 | await auth_handler.check_rate_limits(api_key, user_info, estimated_tokens)
172 | return user_info
--------------------------------------------------------------------------------
/green_bit_llm/serve/auth/rate_limiter.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime, timedelta
2 | from typing import Dict, List, Tuple
3 | from fastapi import HTTPException
4 | from starlette.status import HTTP_429_TOO_MANY_REQUESTS
5 | import asyncio
6 | from collections import defaultdict
7 |
8 |
9 | class RateLimiter:
10 | def __init__(self):
11 | self._request_times: Dict[str, List[datetime]] = defaultdict(list)
12 | self._token_counts: Dict[str, List[Tuple[datetime, int]]] = defaultdict(list)
13 | self._concurrent_requests: Dict[str, int] = defaultdict(int)
14 | self._locks: Dict[str, asyncio.Lock] = defaultdict(asyncio.Lock)
15 |
16 | async def acquire_concurrent_request(self, api_key: str, limit: int):
17 | """Try to acquire a concurrent request slot."""
18 | async with self._locks[api_key]:
19 | if self._concurrent_requests[api_key] >= limit:
20 | raise HTTPException(
21 | status_code=HTTP_429_TOO_MANY_REQUESTS,
22 | detail=f"Maximum concurrent requests ({limit}) exceeded"
23 | )
24 | self._concurrent_requests[api_key] += 1
25 |
26 | async def release_concurrent_request(self, api_key: str):
27 | """Release a concurrent request slot."""
28 | async with self._locks[api_key]:
29 | if self._concurrent_requests[api_key] > 0:
30 | self._concurrent_requests[api_key] -= 1
31 |
32 | def check_rate_limit(self, api_key: str, rpm_limit: int):
33 | """Check requests per minute limit."""
34 | now = datetime.now()
35 | minute_ago = now - timedelta(minutes=1)
36 |
37 | # Clean old entries
38 | self._request_times[api_key] = [
39 | time for time in self._request_times[api_key]
40 | if time > minute_ago
41 | ]
42 |
43 | # Check RPM limit
44 | if len(self._request_times[api_key]) >= rpm_limit:
45 | raise HTTPException(
46 | status_code=HTTP_429_TOO_MANY_REQUESTS,
47 | detail=f"Rate limit exceeded. Maximum {rpm_limit} requests per minute."
48 | )
49 |
50 | self._request_times[api_key].append(now)
51 |
52 | def check_token_limit(self, api_key: str, new_tokens: int, tpm_limit: int):
53 | """Check tokens per minute limit."""
54 | now = datetime.now()
55 | minute_ago = now - timedelta(minutes=1)
56 |
57 | # Clean old entries
58 | self._token_counts[api_key] = [
59 | (time, count) for time, count in self._token_counts[api_key]
60 | if time > minute_ago
61 | ]
62 |
63 | # Calculate current token usage
64 | current_tpm = sum(count for _, count in self._token_counts[api_key])
65 |
66 | # Check TPM limit
67 | if current_tpm + new_tokens > tpm_limit:
68 | raise HTTPException(
69 | status_code=HTTP_429_TOO_MANY_REQUESTS,
70 | detail=f"Token rate limit exceeded. Maximum {tpm_limit} tokens per minute."
71 | )
72 |
73 | self._token_counts[api_key].append((now, new_tokens))
--------------------------------------------------------------------------------
/green_bit_llm/sft/README.md:
--------------------------------------------------------------------------------
1 | # Finetuning GreenBitAI's Low-bit LLMs
2 |
3 | ## Overview
4 |
5 | This package demonstrates the capabilities of [GreenBitAI's low-bit large language models (LLMs)](https://huggingface.co/GreenBitAI) through two main features:
6 | 1. Full-parameter fine-tuning using quantized LLMs.
7 | 2. Parameter efficient fine-tuning
8 |
9 |
10 | ## Installation
11 |
12 | Please follow the [main installation instructions](../../README.md#installation) for how to install the packages required to run this inference package.
13 | Afterward, install the following additional libraries:
14 |
15 | ```bash
16 | pip install trl
17 | pip install -U git+https://github.com/huggingface/peft.git
18 | ```
19 |
20 | If you want to use a **8-bit customized optimizer** with the gradient low-rank projection for maximizing memory savings, you will also need to install the following package:
21 |
22 | ```bash
23 | pip install bitsandbytes galore-torch
24 | ```
25 |
26 | ## Usage
27 |
28 | ### LLMs
29 |
30 | We have released over 200 highly precise 2.2/2.5/3/4-bit models across the modern LLM family, featuring LLaMA 2/3, 01-Yi, Qwen, Mistral, Phi-3, and more. Currently, only layer-mix quantized models are supported for sft. In addition to our low-bit models, green-bit-llm is fully compatible with the AutoGPTQ series of 4-bit quantization and compression models.
31 |
32 | Happy scaling low-bit LLMs with more data!
33 |
34 | | Family | Bpw | Size | HF collection id |
35 | |:----------------:|:------------------:|:------------------------------:|:-----------------------------------------------------------------------------------------------------------------:|
36 | | Llama-3 | `4.0/3.0/2.5/2.2` | `8B/70B` | [`GreenBitAI Llama-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-3-6627bc1ec6538e3922c5d81c) |
37 | | Llama-2 | `3.0/2.5/2.2` | `7B/13B/70B` | [`GreenBitAI Llama-2`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-2-661f87e3b073ff8e48a12834) |
38 | | Qwen-1.5 | `4.0/3.0/2.5/2.2` | `0.5B/1.8B/4B/7B/14B/32B/110B` | [`GreenBitAI Qwen 1.5`](https://huggingface.co/collections/GreenBitAI/greenbitai-qwen15-661f86ea69433f3d3062c920) |
39 | | Phi-3 | `3.0/2.5/2.2` | `mini` | [`GreenBitAI Phi-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-phi-3-6628d008cdf168398a296c92) |
40 | | Mistral | `3.0/2.5/2.2` | `7B` | [`GreenBitAI Mistral`](https://huggingface.co/collections/GreenBitAI/greenbitai-mistral-661f896c45da9d8b28a193a8) |
41 | | 01-Yi | `3.0/2.5/2.2` | `6B/34B` | [`GreenBitAI 01-Yi`](https://huggingface.co/collections/GreenBitAI/greenbitai-01-yi-661f88af0648daa766d5102f) |
42 | | Llama-3-instruct | `4.0/3.0/2.5/2.2` | `8B/70B` | [`GreenBitAI Llama-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-3-6627bc1ec6538e3922c5d81c) |
43 | | Mistral-instruct | `3.0/2.5/2.2` | `7B` | [`GreenBitAI Mistral`](https://huggingface.co/collections/GreenBitAI/greenbitai-mistral-661f896c45da9d8b28a193a8) |
44 | | Phi-3-instruct | `3.0/2.5/2.2` | `mini` | [`GreenBitAI Phi-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-phi-3-6628d008cdf168398a296c92) |
45 | | Qwen-1.5-Chat | `4.0/3.0/2.5/2.2` | `0.5B/1.8B/4B/7B/14B/32B/110B` | [`GreenBitAI Qwen 1.5`](https://huggingface.co/collections/GreenBitAI/greenbitai-qwen15-661f86ea69433f3d3062c920) |
46 | | 01-Yi-Chat | `3.0/2.5/2.2` | `6B/34B` | [`GreenBitAI 01-Yi`](https://huggingface.co/collections/GreenBitAI/greenbitai-01-yi-661f88af0648daa766d5102f) |
47 |
48 |
49 | ### Full-parameter fine-tuning
50 |
51 | Run the script as follows to fine-tune the quantized weights of the model on the target dataset.
52 | The **--tune-qweight-only** parameter determines whether to fine-tune only the quantized weights or all weights, including non-quantized ones.
53 |
54 | ```bash
55 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --tune-qweight-only
56 |
57 | # AutoGPTQ model Q-SFT
58 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --tune-qweight-only --batch-size 1
59 | ```
60 | If you want to further save memory, we also support [Galore](https://github.com/jiaweizzhao/GaLore): a memory-efficient low-rank training strategy.
61 | You just need to add the **--galore** parameter in your command line. However, it's important to note that Galore requires the computation of projection matrices for the gradients, which will incur additional time costs.
62 | You can think of this as a trade-off strategy where time is exchanged for space.
63 | To select the "AdamW8bit" optimizer, simply add "--optimizer AdamW8bit" to your command line.
64 |
65 | ### Parameter efficient fine-tuning
66 |
67 | ```bash
68 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --lr-fp 1e-6
69 |
70 | # AutoGPTQ model with Lora
71 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --lr-fp 1e-6
72 | ```
73 |
74 | ### 0-Shot Evaluation of Q-SFT
75 |
76 | The 0-shot evaluations of quantized Llama 3 8B model under different fine-tuning settings are listed as an example. **Q-SFT** indicates quantized surpervised-finetuning.
77 |
78 | | Task | Bpw | Llama 3 8B Base | Llama 3 8B + LoRA | Llama 3 8B Q-SFT + Galore | Llama 3 8B + Q-SFT |
79 | |:-------------:|:--------:|:-----------------:|:-------------------:|:--------------------------:|:------------------:|
80 | | PIQA | 2.2 | 0.72 | 0.75 | 0.75 | 0.75 |
81 | | | 2.5 | 0.74 | 0.77 | 0.76 | 0.76 |
82 | | | 3.0 | 0.76 | 0.78 | 0.78 | 0.79 |
83 | | BoolQ | 2.2 | 0.74 | 0.77 | 0.77 | 0.78 |
84 | | | 2.5 | 0.75 | 0.76 | 0.76 | 0.78 |
85 | | | 3.0 | 0.78 | 0.80 | 0.79 | 0.80 |
86 | | Winogr. | 2.2 | 0.67 | 0.68 | 0.68 | 0.67 |
87 | | | 2.5 | 0.68 | 0.69 | 0.69 | 0.69 |
88 | | | 3.0 | 0.70 | 0.71 | 0.71 | 0.71 |
89 | | ARC-E | 2.2 | 0.73 | 0.77 | 0.76 | 0.75 |
90 | | | 2.5 | 0.76 | 0.77 | 0.77 | 0.76 |
91 | | | 3.0 | 0.77 | 0.79 | 0.79 | 0.79 |
92 | | ARC-C | 2.2 | 0.39 | 0.46 | 0.45 | 0.45 |
93 | | | 2.5 | 0.41 | 0.44 | 0.43 | 0.43 |
94 | | | 3.0 | 0.44 | 0.49 | 0.47 | 0.49 |
95 | | WiC | 2.2 | 0.50 | 0.50 | 0.50 | 0.50 |
96 | | | 2.5 | 0.51 | 0.50 | 0.52 | 0.51 |
97 | | | 3.0 | 0.52 | 0.52 | 0.57 | 0.60 |
98 | | Avg | 2.2 | 0.62 | 0.65 | 0.65 | 0.65 |
99 | | | 2.5 | 0.64 | 0.65 | 0.65 | 0.65 |
100 | | | 3.0 | 0.66 | 0.68 | 0.68 | 0.69 |
101 |
102 | Compared to traditional LoRA based fine-tuning, our approach streamlines engineering supply chain from fine-tuning to hardware deployment, while also enhancing performance.
103 |
104 | ### Current Limitations
105 |
106 | 1. Gradient clipping is currently unavailable for Full-parameter fine-tuning due to PyTorch's restrictions on the dtype of gradient tensors. The integer tensor type we use for qweight is not supported. We plan to address this issue gradually in the future.
107 | 2. Due to the need for deep modifications to the Python code related to the Int gradient tensor type, to ensure stability and safety, we currently do not support distributed or data parallel training. We plan to support this in the future. Stay tuned.
108 |
109 |
110 | ## License
111 | - The script 'optim/adamw8bit.py' has been modified from [GaLore repository](https://github.com/jiaweizzhao/GaLore/blob/master/galore_torch/adamw8bit.py), which is released under the Apache 2.0 License.
112 | - The script 'optim/bnb_optimizer.py' has been modified from [bitsandbytes repository](https://github.com/TimDettmers/bitsandbytes/blob/main/bitsandbytes/optim/optimizer.py), which is released under the MIT License.
113 | - We release our changes and additions to these files under the [Apache 2.0 License](../../LICENSE).
114 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/sft/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/sft/finetune.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 |
4 | import torch
5 |
6 | from transformers import PreTrainedTokenizer, TrainingArguments
7 | from datasets import load_dataset
8 | from green_bit_llm.sft.trainer import GbaSFTTrainer
9 |
10 | from green_bit_llm.common import load
11 | from green_bit_llm.args_parser import setup_shared_arg_parser
12 |
13 | import warnings
14 |
15 | warnings.filterwarnings('ignore')
16 |
17 | try:
18 | from bitorch_engine.optim import DiodeMix
19 | from bitorch_engine.layers.qlinear.nbit import MPQLinearBase
20 | except ModuleNotFoundError as e:
21 | raise Exception(f"Error occurred while importing Bitorch Engine module '{str(e)}'.")
22 |
23 | from green_bit_llm.sft.optim import AdamW8bit
24 | from green_bit_llm.sft.utils import str_to_torch_dtype, create_param_groups
25 |
26 |
27 | # default value for arguments
28 | DEFAULT_MODEL_PATH = "GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0"
29 | DEFAULT_SEQLEN = 512
30 | DEFAULT_RANDOM_SEED = 0
31 | DEFAULT_LR = 5e-6
32 | DEFAULT_LR_GALORE = 5e-5
33 | DEFAULT_LR_ADAMW8BIT = 5e-3
34 | DEFAULT_BETAS = (0.9, 0.99)
35 |
36 |
37 | def setup_arg_parser():
38 | """Set up and return the argument parser."""
39 | parser = setup_shared_arg_parser("green-bit-llm finetune script")
40 | parser.add_argument(
41 | "--seed",
42 | type=int,
43 | default=DEFAULT_RANDOM_SEED,
44 | help="The random seed for data loader.",
45 | )
46 | # GaLore parameters
47 | parser.add_argument(
48 | "--galore",
49 | action="store_true",
50 | help="Enable using galore",
51 | )
52 | parser.add_argument("--galore-rank", type=int, default=256)
53 | parser.add_argument("--galore-update-proj-gap", type=int, default=200)
54 | parser.add_argument("--galore-scale", type=float, default=0.25)
55 | parser.add_argument("--galore-proj-type", type=str, default="std")
56 |
57 | # qweight related
58 | parser.add_argument(
59 | "--tune-qweight-only",
60 | action="store_true",
61 | help="Set whether to adjust only the low-bit qweight and keep the regular parameters unchanged during the training process.",
62 | )
63 | parser.add_argument(
64 | "--lr-2bit",
65 | type=float,
66 | default=-1.0,
67 | help="Learning rate for 2-bit qweight."
68 | )
69 | parser.add_argument(
70 | "--lr-4bit",
71 | type=float,
72 | default=-1.0,
73 | help="Learning rate for 4-bit qweight."
74 | )
75 | parser.add_argument(
76 | "--lr-fp",
77 | type=float,
78 | default=DEFAULT_LR,
79 | help="Learning rate for full-precision weight."
80 | )
81 | return parser
82 |
83 |
84 | def main(args):
85 |
86 | # Building configs
87 | tokenizer_config = {"trust_remote_code": True if args.trust_remote_code else None}
88 | pretrain_model_config = {
89 | "trust_remote_code": True if args.trust_remote_code else None,
90 | "attn_implementation": "flash_attention_2" if args.use_flash_attention_2 else None
91 | }
92 |
93 | model, tokenizer, config = load(
94 | args.model,
95 | tokenizer_config=tokenizer_config,
96 | device_map='auto',
97 | seqlen=args.seqlen,
98 | model_config=pretrain_model_config,
99 | requires_grad=True,
100 | )
101 |
102 | # NOTE:
103 | # Typically, Hugging Face's Trainer does not support fine-tuning quantized models.
104 | # However, our tool supports this scenario.
105 | # Therefore, we need to delete this attribute after loading the model.
106 | if hasattr(model, 'is_quantized'):
107 | delattr(model, 'is_quantized')
108 |
109 | param_groups = create_param_groups(model, args, DEFAULT_BETAS, DEFAULT_LR_GALORE, DEFAULT_LR_ADAMW8BIT, DEFAULT_LR)
110 |
111 | model.train()
112 |
113 | dataset = load_dataset(args.dataset, split="train")
114 |
115 | if not args.galore:
116 | args.save_dir = os.path.join(args.save_dir, "finetune/common/", args.model)
117 | else:
118 | args.save_dir = os.path.join(args.save_dir, "finetune/galore/", args.model)
119 |
120 |
121 | train_args = TrainingArguments(
122 | output_dir=args.save_dir,
123 | gradient_checkpointing=True,
124 | #auto_find_batch_size=True,
125 | per_device_train_batch_size=args.batch_size,
126 | logging_steps=1,
127 | num_train_epochs=1,
128 | save_steps=args.save_step,
129 | save_total_limit=3,
130 | gradient_accumulation_steps=1,
131 | lr_scheduler_type='cosine',
132 | max_grad_norm=0, # NOTE: max_grad_norm MUST be <= 0 or None, otherwise raise dtype error due to the Int dtype of qweight.
133 | )
134 |
135 | # Optimizer
136 | if 'adamw8bit' in args.optimizer.lower():
137 | optimizer = AdamW8bit(param_groups, weight_decay=args.weight_decay, dtype=str_to_torch_dtype(args.dtype))
138 | elif 'diodemix' in args.optimizer.lower():
139 | optimizer = DiodeMix(param_groups, dtype=str_to_torch_dtype(args.dtype))
140 |
141 | optimizers = (optimizer, None)
142 |
143 | # Trainer
144 | trainer = GbaSFTTrainer(
145 | model=model,
146 | args=train_args,
147 | train_dataset=dataset,
148 | dataset_text_field="text",
149 | optimizers=optimizers,
150 | max_seq_length=args.seqlen,
151 | )
152 |
153 | trainer.train()
154 |
155 | model.save_pretrained(args.save_dir)
156 |
157 |
158 | if __name__ == "__main__":
159 | if not torch.cuda.is_available():
160 | print("Warning: CUDA is required to run the model.")
161 | sys.exit(0)
162 |
163 | parser = setup_arg_parser()
164 | args = parser.parse_args()
165 |
166 | main(args)
167 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/optim/__init__.py:
--------------------------------------------------------------------------------
1 | from .adamw8bit import AdamW8bit
--------------------------------------------------------------------------------
/green_bit_llm/sft/optim/adamw8bit.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from .bnb_optimizer import Optimizer2State
4 |
5 | try:
6 | from galore_torch.galore_projector import GaLoreProjector
7 | except ModuleNotFoundError as e:
8 | raise Exception("Error: GaLoreProjector is not available. Make sure 'galore-torch' has been installed on you system.")
9 |
10 | try:
11 | from bitorch_engine.layers.qlinear.nbit import MPQWeightParameter
12 | from bitorch_engine.utils.quant_operators import gptq_style_unpacking
13 | from bitorch_engine.layers.qlinear.nbit.cuda.utils import pack_fp_weight
14 | except ModuleNotFoundError as e:
15 | raise Exception(f"Error occurred while importing Bitorch Engine module '{str(e)}'.")
16 |
17 |
18 | class AdamW8bit(Optimizer2State):
19 | def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=.0, amsgrad=False, optim_bits=8,
20 | args=None, min_8bit_size=4096, percentile_clipping=100, block_wise=True, is_paged=False,
21 | dtype: torch.dtype = torch.float16):
22 | self.dtype = dtype
23 | super().__init__( "adam", params, lr, betas, eps, weight_decay, optim_bits, args, min_8bit_size, percentile_clipping,
24 | block_wise, is_paged=is_paged )
25 |
26 | @torch.no_grad()
27 | def step(self, closure=None):
28 | """Performs a single optimization step.
29 |
30 | Arguments:
31 | closure (callable, optional): A closure that reevaluates the model
32 | and returns the loss.
33 | """
34 | loss = None
35 | if closure is not None:
36 | with torch.enable_grad():
37 | loss = closure()
38 |
39 | if not self.initialized:
40 | self.check_overrides()
41 | self.to_gpu() # needed for fairseq pure fp16 training
42 | self.initialized = True
43 |
44 | #if self.is_paged: self.page_mng.prefetch_all()
45 | for gindex, group in enumerate(self.param_groups):
46 | for pindex, p in enumerate(group["params"]):
47 | if p.grad is None:
48 | continue
49 |
50 | state = self.state[p]
51 |
52 | if "step" not in state:
53 | state["step"] = 0
54 |
55 | if isinstance(p, MPQWeightParameter):
56 | grad = p.privileged_grad.to(self.dtype).to(p.grad.device)
57 | else:
58 | grad = p.grad.to(self.dtype)
59 |
60 | # GaLore Projection
61 | if "rank" in group:
62 | if "projector" not in state:
63 | state["projector"] = GaLoreProjector(group["rank"], update_proj_gap=group["update_proj_gap"], scale=group["scale"], proj_type=group["proj_type"])
64 |
65 | projector = state["projector"]
66 | grad = projector.project(grad, state["step"])
67 |
68 | saved_data = None
69 | if "rank" in group or isinstance(p, MPQWeightParameter):
70 | # suboptimal implementation
71 | # In the implementation mentioned, the author sets the variable p (representing model parameters) to zero,
72 | # meaning p does not change during the update step. Instead, only the gradient states are updated,
73 | # and actual weight modifications are calculated manually later in the code.
74 | saved_data = p.data.clone()
75 | p.data = torch.zeros_like(grad)
76 |
77 | if 'weight_decay' in group and group['weight_decay'] > 0:
78 | # ensure that the weight decay is not applied to the norm grad
79 | group['weight_decay_saved'] = group['weight_decay']
80 | group['weight_decay'] = 0
81 |
82 | if 'state1' not in state:
83 | self.init_state(group, p, gindex, pindex, grad)
84 |
85 | self.prefetch_state(p)
86 |
87 | self.update_step(group, p, gindex, pindex, grad)
88 |
89 | torch.cuda.synchronize()
90 |
91 | if 'weight_decay_saved' in group:
92 | group['weight_decay'] = group['weight_decay_saved']
93 | del group['weight_decay_saved']
94 |
95 | w_unpacked = None
96 | # GaLore Projection Back
97 | if "rank" in group:
98 | # now the p.data is actually: -norm_grad*lr
99 | norm_grad = projector.project_back(p.data)
100 |
101 | if isinstance(p, MPQWeightParameter):
102 | # unpack qweight
103 | p.data = saved_data
104 | w_unpacked = gptq_style_unpacking(p).to(self.dtype).to(saved_data.device)
105 | w_unpacked.add_(norm_grad)
106 | if group["weight_decay"] > 0.0:
107 | w_unpacked.add_(w_unpacked, alpha=-group['lr'] * group['weight_decay'])
108 | # pack fp weight back to Q-weight and update qweight data
109 | p.data = pack_fp_weight(w_unpacked, p)
110 | else:
111 | p.data = saved_data.add_(norm_grad)
112 | if group["weight_decay"] > 0.0:
113 | p.data.add_(p.data, alpha=-group['lr'] * group['weight_decay'])
114 | elif isinstance(p, MPQWeightParameter):
115 | # now the p.data is actually: -norm_grad*lr
116 | norm_grad = p.data.clone()
117 | # unpack qweight
118 | p.data = saved_data
119 | w_unpacked = gptq_style_unpacking(p).to(self.dtype).to(saved_data.device)
120 | w_unpacked.add_(norm_grad)
121 | if group["weight_decay"] > 0.0:
122 | w_unpacked.add_(w_unpacked, alpha=-group['lr'] * group['weight_decay'])
123 | # pack fp weight back to Q-weight and update qweight data
124 | p.data = pack_fp_weight(w_unpacked, p)
125 |
126 | # pack fp weight back to qweight
127 | if w_unpacked is not None:
128 | del w_unpacked
129 | if saved_data is not None:
130 | del saved_data
131 | if torch.cuda.is_available():
132 | torch.cuda.empty_cache()
133 |
134 | if self.is_paged:
135 | # all paged operation are asynchronous, we need
136 | # to sync to make sure all tensors are in the right state
137 | torch.cuda.synchronize()
138 |
139 | return loss
140 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/peft_lora.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 |
4 | import torch
5 |
6 | from transformers import PreTrainedTokenizer, TrainingArguments
7 | from datasets import load_dataset
8 | from peft import PeftModel, LoraConfig, get_peft_model
9 |
10 | from green_bit_llm.sft.trainer import GbaSFTTrainer
11 | from green_bit_llm.common import load
12 | from green_bit_llm.args_parser import setup_shared_arg_parser
13 | from green_bit_llm.sft.peft_utils.model import *
14 | from green_bit_llm.sft.optim import AdamW8bit
15 |
16 | import warnings
17 | warnings.filterwarnings('ignore')
18 |
19 | try:
20 | from bitorch_engine.optim import DiodeMix
21 | except ModuleNotFoundError as e:
22 | raise Exception(f"Error occurred while importing Bitorch Engine module '{str(e)}'.")
23 |
24 | from green_bit_llm.sft.utils import str_to_torch_dtype, create_param_groups
25 |
26 | # default value for arguments
27 | DEFAULT_MODEL_PATH = "GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0"
28 | DEFAULT_SEQLEN = 512
29 | DEFAULT_RANDOM_SEED = 0
30 | DEFAULT_LR = 1e-5
31 | DEFAULT_LR_GALORE = 1e-4
32 | DEFAULT_LR_FP = 1e-6
33 | DEFAULT_BETAS = (0.9, 0.999)
34 |
35 |
36 | def setup_arg_parser():
37 | """Set up and return the argument parser."""
38 | parser = setup_shared_arg_parser("green-bit-llm lora script")
39 | parser.add_argument(
40 | "--seed",
41 | type=int,
42 | default=DEFAULT_RANDOM_SEED,
43 | help="The random seed for data loader.",
44 | )
45 | # qweight related
46 | parser.add_argument(
47 | "--lr-fp",
48 | type=float,
49 | default=DEFAULT_LR_FP,
50 | help="Learning rate for full-precision weight."
51 | )
52 | parser.add_argument("--lora-rank", type=int, default=64)
53 | parser.add_argument("--lora-alpha", type=int, default=32)
54 | parser.add_argument("--lora-dropout", type=float, default=0.01)
55 | return parser
56 |
57 |
58 | def main(args):
59 |
60 | # Building configs
61 | tokenizer_config = {"trust_remote_code": True if args.trust_remote_code else None}
62 | pretrain_model_config = {
63 | "trust_remote_code": True if args.trust_remote_code else None,
64 | "attn_implementation": "flash_attention_2" if args.use_flash_attention_2 else None
65 | }
66 |
67 | model, tokenizer, config = load(
68 | args.model,
69 | tokenizer_config=tokenizer_config,
70 | device_map='auto',
71 | seqlen=args.seqlen,
72 | model_config=pretrain_model_config,
73 | requires_grad=False,
74 | )
75 |
76 | config = LoraConfig(
77 | r=args.lora_rank,
78 | lora_alpha=args.lora_alpha,
79 | target_modules=["q_proj", "v_proj", "out_proj", "down_proj", "up_proj"],
80 | lora_dropout=args.lora_dropout,
81 | bias="none",
82 | task_type="CAUSAL_LM",
83 | )
84 |
85 | replace_peft_lora_model_with_gba_lora_model()
86 |
87 | model = get_peft_model(model, config)
88 |
89 | param_groups = create_param_groups(model, args, DEFAULT_BETAS)
90 |
91 | model.train()
92 |
93 | dataset = load_dataset(args.dataset, split="train")
94 |
95 | args.save_dir = os.path.join(args.save_dir, "lora/", args.model)
96 |
97 | train_args = TrainingArguments(
98 | output_dir=args.save_dir,
99 | gradient_checkpointing=True,
100 | #auto_find_batch_size=True,
101 | per_device_train_batch_size=args.batch_size,
102 | logging_steps=1,
103 | num_train_epochs=1,
104 | gradient_accumulation_steps=1,
105 | save_steps=args.save_step,
106 | #warmup_ratio=0.05,
107 | max_grad_norm=0, # NOTE: max_grad_norm MUST be <= 0 or None, otherwise raise dtype error due to the Int dtype of qweight.
108 | )
109 |
110 | # Optimizer
111 | if 'adamw8bit' in args.optimizer.lower():
112 | optimizer = AdamW8bit(param_groups, weight_decay=args.weight_decay, lr=5e-3, dtype=str_to_torch_dtype(args.dtype))
113 | elif 'diodemix' in args.optimizer.lower():
114 | optimizer = DiodeMix(param_groups, dtype=str_to_torch_dtype(args.dtype))
115 | optimizers = (optimizer, None)
116 |
117 | for name, param in model.named_parameters():
118 | if "qweight" not in name:
119 | param.requires_grad = True
120 |
121 | trainer = GbaSFTTrainer(
122 | model=model,
123 | args=train_args,
124 | train_dataset=dataset,
125 | dataset_text_field="text",
126 | optimizers=optimizers,
127 | max_seq_length=args.seqlen,
128 | )
129 |
130 | trainer.train()
131 |
132 | model.save_pretrained(args.save_dir)
133 |
134 |
135 | if __name__ == "__main__":
136 | if not torch.cuda.is_available():
137 | print("Warning: CUDA is needed to run the model.")
138 | sys.exit(0)
139 |
140 | parser = setup_arg_parser()
141 | args = parser.parse_args()
142 |
143 | main(args)
144 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/peft_utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/sft/peft_utils/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/sft/peft_utils/gba_lora.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023-present the HuggingFace Inc. team.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | from __future__ import annotations
15 |
16 | from typing import Any, Optional
17 |
18 | ENGINE_AVAILABLE=True
19 | try:
20 | from bitorch_engine.layers.qlinear.nbit import MPQLinearBase
21 | from bitorch_engine.layers.qlinear.nbit.cuda import MPQLinearCuda, MBWQLinearCuda
22 | except ModuleNotFoundError as e:
23 | ENGINE_AVAILABLE = False
24 | raise Exception(f"Error occurred while importing Bitorch Engine module '{str(e)}'.")
25 |
26 | import torch
27 | import torch.nn as nn
28 | from transformers.pytorch_utils import Conv1D
29 |
30 | from peft.tuners.tuners_utils import BaseTunerLayer, check_adapters_to_merge
31 | from peft.tuners.lora import LoraLayer
32 |
33 |
34 | class GBALoraLayer(LoraLayer):
35 | """
36 | GBALoraLayer class extends LoraLayer to support Gradient-Based Adapter tuning for various model layers.
37 | It maintains lists of both LoRA-specific parameters and other adapter-related parameters.
38 | """
39 |
40 | # All names of layers that may contain (trainable) adapter weights
41 | adapter_layer_names = ("lora_A", "lora_B", "lora_embedding_A", "lora_embedding_B")
42 | # All names of other parameters that may contain adapter-related parameters
43 | other_param_names = ("r", "lora_alpha", "scaling", "lora_dropout")
44 |
45 | def __init__(self, base_layer: nn.Module, **kwargs) -> None:
46 | """
47 | Initializes a GBALoraLayer instance.
48 | Args:
49 | base_layer: The underlying neural network layer that LoRA is being applied to.
50 | **kwargs: Additional keyword arguments for customization.
51 |
52 | This method initializes adapter components, configures the underlying base layer, and sets the
53 | feature sizes based on the base layer type.
54 | """
55 | self.base_layer = base_layer
56 | self.r = {}
57 | self.lora_alpha = {}
58 | self.scaling = {}
59 | self.lora_dropout = nn.ModuleDict({})
60 | self.lora_A = nn.ModuleDict({})
61 | self.lora_B = nn.ModuleDict({})
62 | # For Embedding layer
63 | self.lora_embedding_A = nn.ParameterDict({})
64 | self.lora_embedding_B = nn.ParameterDict({})
65 | # Mark the weight as unmerged
66 | self._disable_adapters = False
67 | self.merged_adapters = []
68 | self.use_dora: dict[str, bool] = {}
69 | self.lora_magnitude_vector: Optional[torch.nn.ParameterDict] = None # for DoRA
70 | self._caches: dict[str, Any] = {}
71 | self.kwargs = kwargs
72 |
73 | base_layer = self.get_base_layer()
74 | if isinstance(base_layer, nn.Linear):
75 | in_features, out_features = base_layer.in_features, base_layer.out_features
76 | elif isinstance(base_layer, nn.Conv2d):
77 | in_features, out_features = base_layer.in_channels, base_layer.out_channels
78 | elif isinstance(base_layer, nn.Embedding):
79 | in_features, out_features = base_layer.num_embeddings, base_layer.embedding_dim
80 | elif isinstance(base_layer, Conv1D):
81 | in_features, out_features = (
82 | base_layer.weight.ds_shape if hasattr(base_layer.weight, "ds_shape") else base_layer.weight.shape
83 | )
84 | elif hasattr(base_layer, "infeatures") and hasattr(base_layer, "outfeatures"):
85 | # QuantLinear
86 | in_features, out_features = base_layer.infeatures, base_layer.outfeatures
87 | elif hasattr(base_layer, "input_size") and hasattr(base_layer, "output_size"):
88 | # Megatron ColumnParallelLinear,RowParallelLinear
89 | in_features, out_features = base_layer.input_size, base_layer.output_size
90 | elif hasattr(base_layer, "codebooks") and base_layer.__class__.__name__ == "QuantizedLinear":
91 | # AQLM QuantLinear
92 | in_features, out_features = base_layer.in_features, base_layer.out_features
93 | elif hasattr(base_layer, "w_bit") and base_layer.__class__.__name__ == "WQLinear_GEMM":
94 | # Awq layers
95 | in_features, out_features = base_layer.in_features, base_layer.out_features
96 | elif base_layer.__class__.__name__ == "MBWQLinearCuda":
97 | in_features, out_features = base_layer.in_channels, base_layer.out_channels
98 | elif base_layer.__class__.__name__ == "MPQLinearCuda":
99 | in_features, out_features = base_layer.in_channels, base_layer.out_channels
100 | else:
101 | raise ValueError(f"Unsupported layer type {type(base_layer)}")
102 |
103 | self.in_features = in_features
104 | self.out_features = out_features
105 |
106 |
107 | class GBALoraLinear(torch.nn.Module, GBALoraLayer):
108 | """
109 | Implements a LoRA (Low-Rank Adaptation) module integrated into a dense linear layer.
110 | This class extends functionality by allowing modifications to the layer through
111 | low-rank matrices to efficiently adapt large pre-trained models without extensive retraining.
112 | """
113 | # Lora implemented in a dense layer
114 | def __init__(
115 | self,
116 | base_layer: torch.nn.Module,
117 | adapter_name: str,
118 | r: int = 0,
119 | lora_alpha: int = 1,
120 | lora_dropout: float = 0.0,
121 | init_lora_weights: bool = True,
122 | use_rslora: bool = False,
123 | use_dora: bool = False,
124 | **kwargs,
125 | ) -> None:
126 | """
127 | Initializes the LoRA adapted layer with specific parameters and configurations.
128 |
129 | Parameters:
130 | base_layer (torch.nn.Module): The original base layer to which LoRA adjustments are applied.
131 | adapter_name (str): The name of the adapter for identification.
132 | r (int): The rank of the low-rank approximation matrices.
133 | lora_alpha (int): Scaling factor for the LoRA parameters.
134 | lora_dropout (float): Dropout rate for regularization during training.
135 | init_lora_weights (bool): Whether to initialize LoRA weights upon creation.
136 | use_rslora (bool): Indicates whether to use rank-stabilized LoRA.
137 | use_dora (bool): Indicates whether to use dynamic orthogonal regularization adapter.
138 | """
139 | super().__init__()
140 | GBALoraLayer.__init__(self, base_layer)
141 | self.fan_in_fan_out = False
142 |
143 | self._active_adapter = adapter_name
144 | self.update_layer(
145 | adapter_name,
146 | r,
147 | lora_alpha=lora_alpha,
148 | lora_dropout=lora_dropout,
149 | init_lora_weights=init_lora_weights,
150 | use_rslora=use_rslora,
151 | use_dora=use_dora,
152 | )
153 |
154 | def forward(self, x: torch.Tensor, *args, **kwargs) -> torch.Tensor:
155 | """
156 | Defines the computation performed at every call. Applies the base layer computation
157 | and modifies the output using the configured LoRA parameters.
158 |
159 | Parameters:
160 | x (torch.Tensor): The input tensor to process.
161 |
162 | Returns:
163 | torch.Tensor: The output tensor after applying the LoRA adaptation.
164 | """
165 | self._check_forward_args(x, *args, **kwargs)
166 | adapter_names = kwargs.pop("adapter_names", None)
167 |
168 | result = self.base_layer(x, *args, **kwargs)
169 | # As per Tim Dettmers, for 4bit, we need to defensively clone here.
170 | # The reason is that in some cases, an error can occur that backprop
171 | # does not work on a manipulated view. This issue may be solved with
172 | # newer PyTorch versions but this would need extensive testing to be
173 | # sure.
174 |
175 | for active_adapter in self.active_adapters:
176 | if active_adapter not in self.lora_A.keys():
177 | continue
178 | lora_A = self.lora_A[active_adapter]
179 | lora_B = self.lora_B[active_adapter]
180 | dropout = self.lora_dropout[active_adapter]
181 | scaling = self.scaling[active_adapter]
182 |
183 | requires_conversion = not torch.is_autocast_enabled()
184 | if requires_conversion:
185 | expected_dtype = result.dtype
186 | x = x.to(lora_A.weight.dtype)
187 |
188 | if not self.use_dora[active_adapter]:
189 | output = lora_B(lora_A(dropout(x))) * scaling
190 | else:
191 | output = self._apply_dora(x, lora_A, lora_B, scaling, active_adapter)
192 | if requires_conversion:
193 | output = output.to(expected_dtype)
194 |
195 | result = result + output
196 |
197 | return result
198 |
199 | def __repr__(self) -> str:
200 | """
201 | Provides a string representation of the module, enhancing the default
202 | representation with a prefix to identify it as a LoRA-adapted layer.
203 | """
204 | rep = super().__repr__()
205 | return "lora." + rep
206 |
207 |
208 | def dispatch_gba(target: torch.nn.Module, adapter_name: str, **kwargs):
209 | new_module = None
210 |
211 | if isinstance(target, BaseTunerLayer):
212 | target_base_layer = target.get_base_layer()
213 | else:
214 | target_base_layer = target
215 |
216 | if ENGINE_AVAILABLE and issubclass(type(target_base_layer), MPQLinearBase):
217 | new_module = GBALoraLinear(target_base_layer, adapter_name, **kwargs)
218 |
219 | return new_module
220 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/peft_utils/model.py:
--------------------------------------------------------------------------------
1 | import peft.peft_model
2 | from peft.tuners import lora
3 | from peft.utils import _get_submodules, PeftType
4 |
5 | from green_bit_llm.sft.peft_utils.gba_lora import dispatch_gba
6 |
7 |
8 | class GBALoraModel(lora.LoraModel):
9 | """
10 | A specialized version of LoraModel for low-rank adaptation. This class overrides the method to create new modules specifically tailored
11 | to GBA needs, by selecting appropriate backend functions to handle LoRA layers.
12 | """
13 | @staticmethod
14 | def _create_new_module(lora_config, adapter_name, target, **kwargs):
15 | """
16 | Creates a new module based on the provided configuration for LoRA and the type of target module.
17 | This method selects the correct dispatch function for integrating LoRA into the specified model layer.
18 | If no suitable module can be found, it raises an error.
19 |
20 | Args:
21 | lora_config: Configuration parameters for the LoRA adaptation.
22 | adapter_name: Identifier for the LoRA adapter.
23 | target: The target neural network layer to which LoRA should be applied.
24 | **kwargs: Additional keyword arguments.
25 |
26 | Returns:
27 | new_module: A new module with LoRA adaptation applied, or raises an error if the target is unsupported.
28 |
29 | Raises:
30 | ValueError: If the target module type is not supported by the currently available dispatchers.
31 | """
32 | # Collect dispatcher functions to decide what backend to use for the replaced LoRA layer. The order matters,
33 | # because the first match is always used. Therefore, the default layers should be checked last.
34 | dispatchers = []
35 |
36 | dispatchers.append(dispatch_gba)
37 |
38 | dispatchers.extend(
39 | [dispatch_gba]
40 | )
41 |
42 | new_module = None
43 | for dispatcher in dispatchers:
44 | new_module = dispatcher(target, adapter_name, lora_config=lora_config, **kwargs)
45 | if new_module is not None: # first match wins
46 | break
47 |
48 | if new_module is None:
49 | # no module could be matched
50 | raise ValueError(
51 | f"Target module {target} is not supported. Currently, only the following modules are supported: "
52 | "`torch.nn.Linear`, `torch.nn.Embedding`, `torch.nn.Conv2d`, `transformers.pytorch_utils.Conv1D`."
53 | )
54 |
55 | return new_module
56 |
57 | def replace_peft_lora_model_with_gba_lora_model():
58 | """
59 | Replaces the existing LoRA model in the PEFT framework with the GBA-enhanced LoRA model.
60 | This function patches the model mapping in PEFT to use `GBALoraModel` for LoRA configurations.
61 | """
62 | peft.peft_model.PEFT_TYPE_TO_MODEL_MAPPING[PeftType.LORA] = GBALoraModel
63 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/trainer.py:
--------------------------------------------------------------------------------
1 | import json
2 | import shutil
3 | import os
4 | from typing import Optional
5 |
6 | from trl import SFTTrainer
7 |
8 | from green_bit_llm.common.utils import STRATEGY_FILE_NAME
9 | from green_bit_llm.common.utils import get_model_path
10 |
11 |
12 | class GbaSFTTrainer(SFTTrainer):
13 | def save_model(self, output_dir: Optional[str] = None, _internal_call: bool = False):
14 | """
15 | Saves the model to the specified directory and also ensures that the
16 | 'quant_strategy.json' file is copied over to the same directory.
17 |
18 | Args:
19 | output_dir (Optional[str]): The directory to which the model and the
20 | 'quant_strategy.json' file should be saved.
21 | If None, the model will be saved to the default location.
22 | _internal_call (bool): A flag used to indicate whether this method was
23 | called internally by the library, which can affect
24 | certain behaviors (not used in this override).
25 |
26 | Raises:
27 | ValueError: If the expected GBA prefix is not found in the output directory path.
28 | """
29 |
30 | # Perform the original save model behavior of the superclass
31 | # out_dir should be os.path.join(args.save_dir, args.model)
32 | super().save_model(output_dir)
33 |
34 | # Define the prefix to look for in the output directory path
35 | gba_prefix = "GreenBitAI" + os.path.sep
36 | # Find the prefix in the output directory path
37 | start_index = output_dir.find(gba_prefix)
38 |
39 | if start_index == -1:
40 | config_path = os.path.join(output_dir, "config.json")
41 | if os.path.isfile(config_path):
42 | with open(config_path, 'r') as file:
43 | data = json.load(file)
44 | if "quantization_config" in data.keys():
45 | quantization_config = data["quantization_config"]
46 | if "exllama_config" in quantization_config.keys():
47 | del quantization_config["exllama_config"]
48 | if "use_exllama" in quantization_config.keys():
49 | del quantization_config["use_exllama"]
50 |
51 | with open(config_path, 'w') as file:
52 | json.dump(data, file, indent=4)
53 | return
54 |
55 | # Ensure this is executed only on the main process
56 | if not self.is_world_process_zero():
57 | return
58 |
59 | # save "quant_strategy.json" file
60 | start_pos = start_index + len(gba_prefix) - 1
61 | end_pos = output_dir.find(os.path.sep, start_pos + 1)
62 |
63 | if end_pos == -1:
64 | model_name = output_dir[start_index:]
65 | else:
66 | model_name = output_dir[start_index:end_pos]
67 |
68 | model_from_path = get_model_path(model_name)
69 | quant_strategy_file = os.path.join(model_from_path, STRATEGY_FILE_NAME)
70 | destination_path = os.path.join(output_dir, STRATEGY_FILE_NAME)
71 | shutil.copy(quant_strategy_file, destination_path)
72 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from colorama import init, Fore, Style
4 | init(autoreset=True)
5 |
6 | try:
7 | from bitorch_engine.layers.qlinear.nbit import MPQLinearBase
8 | except ModuleNotFoundError as e:
9 | raise Exception(f"Error occurred while importing Bitorch Engine module '{str(e)}'.")
10 |
11 |
12 | def str_to_torch_dtype(dtype: str):
13 | """Get torch dtype from the input data type string."""
14 | if dtype is None:
15 | return None
16 | elif dtype == "float":
17 | return torch.float
18 | elif dtype == "half":
19 | return torch.float16
20 | else:
21 | raise ValueError(f"Unsupported dtype: {dtype}")
22 |
23 |
24 | def create_device_map(cuda_device_id):
25 | ids = cuda_device_id.split(',')
26 | # Create strings in the format "cuda:x" for each ID and put them into the collection
27 | device_map = {f"cuda:{id}" for id in ids}
28 | return device_map
29 |
30 |
31 | def get_learning_rate(lr_bit, galore, default_lr_galore, default_lr):
32 | """Adaptivly get the learning rate value from the input setting parameters."""
33 | if lr_bit > 0:
34 | return lr_bit
35 | return default_lr_galore if galore else default_lr
36 |
37 |
38 | def create_param_groups(model, args, betas=(0.9, 0.999), lr_galore=1e-4, lr_adamw8b=5e-3, lr_default=1e-5):
39 | """
40 | Create parameter groups based on the bit-width of quantized weights in the model.
41 | This function categorizes parameters into groups with different learning rates and beta values
42 | for optimizers.
43 |
44 | This function also prints out the number of trainable params and all params.
45 |
46 | Args:
47 | model (nn.Module): The neural network model.
48 | args (argparse.ArgumentParser): Command line arguments for additional parameters.
49 |
50 | Returns:
51 | List[dict]: A list of dictionaries where each dictionary contains a parameter group.
52 | """
53 | params_2_bit = []
54 | params_4_bit = []
55 |
56 | regular_trainable_numel = []
57 | qweight_trainable_numel = []
58 | total_numel = []
59 | trainable_numel = []
60 |
61 | for module_name, module in model.named_modules():
62 | if issubclass(type(module), MPQLinearBase):
63 | if module.w_bit == 2:
64 | params_2_bit.append(module.qweight)
65 | qweight_trainable_numel.append(int(module.qweight.numel() * 32 / 2))
66 | elif module.w_bit == 4:
67 | params_4_bit.append(module.qweight)
68 | qweight_trainable_numel.append(int(module.qweight.numel() * 32 / 4))
69 | else:
70 | raise Exception(f"Error: Invalid qweight bit width: '{module.w_bit}'.")
71 |
72 | total_parameters = list(model.parameters())
73 | for param in total_parameters:
74 | if not hasattr(param, "qweight"):
75 | total_numel.append(param.numel())
76 | total_numel += qweight_trainable_numel
77 |
78 | if hasattr(args, 'lora_rank'): # peft
79 | param_groups = []
80 |
81 | # Create list of peft parameters
82 | params_lora = [p for n, p in model.named_parameters() if "lora" in n]
83 |
84 | for param in params_lora:
85 | if param.requires_grad:
86 | trainable_numel.append(param.numel())
87 |
88 | params_group_lora = {'params': params_lora, 'lr': args.lr_fp, 'betas': betas}
89 |
90 | param_groups.append(params_group_lora)
91 |
92 | elif hasattr(args, 'tune_qweight_only'): # full parameter finetune
93 |
94 | id_2bit_params = [id(p) for p in params_2_bit]
95 | id_4bit_params = [id(p) for p in params_4_bit]
96 | # Concatenate IDs to form a single list
97 | excluded_ids = id_2bit_params + id_4bit_params
98 |
99 | # Create list of regular parameters excluding 2-bit and 4-bit params
100 | params_regular = [p for p in model.parameters() if id(p) not in excluded_ids]
101 | for param in params_regular:
102 | if param.requires_grad:
103 | regular_trainable_numel.append(param.numel())
104 |
105 | lr_2 = get_learning_rate(
106 | args.lr_2bit,
107 | args.galore,
108 | lr_adamw8b if 'adamw8bit' in args.optimizer.lower() else lr_galore,
109 | 1e-3 if 'adamw8bit' in args.optimizer.lower() else lr_default
110 | )
111 |
112 | lr_4 = get_learning_rate(
113 | args.lr_4bit,
114 | args.galore,
115 | lr_adamw8b if 'adamw8bit' in args.optimizer.lower() else lr_galore,
116 | 1e-3 if 'adamw8bit' in args.optimizer.lower() else lr_default
117 | )
118 |
119 | params_group_2bit = {'params': params_2_bit, 'lr': lr_2, 'betas': betas}
120 | params_group_4bit = {'params': params_4_bit, 'lr': lr_4, 'betas': betas}
121 | params_group_regular = {'params': params_regular, 'lr': args.lr_fp, 'betas': betas}
122 |
123 | # Optionally add extra settings from command line arguments
124 | if args.galore:
125 | galore_settings = {
126 | 'rank': args.galore_rank,
127 | 'update_proj_gap': args.galore_update_proj_gap,
128 | 'scale': args.galore_scale,
129 | 'proj_type': args.galore_proj_type
130 | }
131 | params_group_2bit.update(galore_settings)
132 | params_group_4bit.update(galore_settings)
133 |
134 | param_groups = [
135 | params_group_2bit,
136 | params_group_4bit
137 | ]
138 |
139 | trainable_numel = qweight_trainable_numel
140 | if not args.tune_qweight_only:
141 | param_groups.append(params_group_regular)
142 | trainable_numel += regular_trainable_numel
143 | else:
144 | raise Exception("Error: invalid use case in creating param_group.")
145 |
146 | # print out trainable params info
147 | print(Style.BRIGHT + Fore.CYAN +
148 | f"Info: trainable params: {sum(trainable_numel):,d} || "
149 | f"all params: {sum(total_numel):,d} || "
150 | f"trainable%: {100 * sum(trainable_numel) / sum(total_numel):.4f}"
151 | )
152 |
153 | return param_groups
154 |
155 |
156 |
157 |
--------------------------------------------------------------------------------
/green_bit_llm/version.py:
--------------------------------------------------------------------------------
1 | __version__ = "0.2.6"
2 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | accelerate>=0.27.2
2 | colorama
3 | datasets
4 | torch>=2.0.0
5 | sentencepiece
6 | transformers>=4.52.4
7 | huggingface-hub
8 | lm-eval==0.3.0
9 | termcolor
10 | pillow
11 | requests
12 | prompt-toolkit
13 | rich
14 | optimum
15 | auto-gptq
16 | langchain-core
17 | fastapi
18 | uvicorn
19 | peewee
20 | python-dotenv
--------------------------------------------------------------------------------
/scripts/curl_script:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # Set variables for testing
4 | API_KEY="" # Replace with your actual API key
5 | HOST="172.20.8.79:8000"
6 |
7 | # Array of models to test
8 | MODELS=(
9 | "GreenBitAI-Llama-3-8B-instruct-layer-mix-bpw-40"
10 | "GreenBitAI-Qwen-25-7B-Instruct-layer-mix-bpw-40"
11 | )
12 |
13 | # Function to run tests for a specific model
14 | run_tests() {
15 | local MODEL_NAME=$1
16 | echo "Running tests for model: ${MODEL_NAME}"
17 | echo "=================================="
18 |
19 | # 1. Health Check
20 | echo "Testing Health Check Endpoint..."
21 | curl -X GET "http://${HOST}/health"
22 |
23 | # 2. Root Endpoint
24 | echo -e "\n\nTesting Root Endpoint..."
25 | curl -X GET "http://${HOST}/"
26 |
27 | # 3. Text Completion Endpoints
28 | echo -e "\n\nTesting Basic Completion..."
29 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/completions" \
30 | -H "Content-Type: application/json" \
31 | -H "X-Api-Key: ${API_KEY}" \
32 | -d '{
33 | "model": "'${MODEL_NAME}'",
34 | "prompt": "Write a story about a robot",
35 | "max_tokens": 100,
36 | "temperature": 0.7
37 | }'
38 |
39 | echo -e "\n\nTesting Streaming Completion..."
40 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/completions" \
41 | -H "Content-Type: application/json" \
42 | -H "X-Api-Key: ${API_KEY}" \
43 | -d '{
44 | "model": "'${MODEL_NAME}'",
45 | "prompt": "Write a story about a robot",
46 | "max_tokens": 200,
47 | "temperature": 0.7,
48 | "stream": true
49 | }'
50 |
51 | echo -e "\n\nTesting Batch Completion..."
52 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/completions" \
53 | -H "Content-Type: application/json" \
54 | -H "X-Api-Key: ${API_KEY}" \
55 | -d '{
56 | "model": "'${MODEL_NAME}'",
57 | "prompt": ["Tell me a joke", "Write a poem"],
58 | "max_tokens": 100,
59 | "temperature": 0.7
60 | }'
61 |
62 | # 4. Chat Completion Endpoints
63 | echo -e "\n\nTesting Basic Chat Completion..."
64 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/chat/completions" \
65 | -H "Content-Type: application/json" \
66 | -H "X-Api-Key: ${API_KEY}" \
67 | -d '{
68 | "model": "'${MODEL_NAME}'",
69 | "messages": [
70 | {"role": "system", "content": "You are a helpful assistant."},
71 | {"role": "user", "content": "What is the capital of France?"}
72 | ],
73 | "max_tokens": 100,
74 | "temperature": 0.7
75 | }'
76 |
77 | echo -e "\n\nTesting Streaming Chat Completion..."
78 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/chat/completions" \
79 | -H "Content-Type: application/json" \
80 | -H "X-Api-Key: ${API_KEY}" \
81 | -d '{
82 | "model": "'${MODEL_NAME}'",
83 | "messages": [
84 | {"role": "user", "content": "Write a story about a cat"}
85 | ],
86 | "max_tokens": 100,
87 | "temperature": 0.7,
88 | "stream": true
89 | }'
90 |
91 | echo -e "\n\nTesting Remote Confidence Scores..."
92 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/chat/completions" \
93 | -H "Content-Type: application/json" \
94 | -H "X-Api-Key: ${API_KEY}" \
95 | -d '{
96 | "model": "'${MODEL_NAME}'",
97 | "messages": [
98 | {"role": "system", "content": "You are a helpful assistant."},
99 | {"role": "user", "content": "hi"}
100 | ],
101 | "max_tokens": 1,
102 | "temperature": 0.7,
103 | "top_p": 1.0,
104 | "with_hidden_states": true,
105 | "remote_score": true
106 | }'
107 |
108 | echo -e "\n\nTesting Chat Completion with History..."
109 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/chat/completions" \
110 | -H "Content-Type: application/json" \
111 | -H "X-Api-Key: ${API_KEY}" \
112 | -d '{
113 | "model": "'${MODEL_NAME}'",
114 | "messages": [
115 | {"role": "system", "content": "You are a friendly and knowledgeable AI assistant."},
116 | {"role": "user", "content": "Tell me about Paris"},
117 | {"role": "assistant", "content": "Paris is the capital of France."},
118 | {"role": "user", "content": "What are some famous landmarks there?"}
119 | ],
120 | "max_tokens": 150,
121 | "temperature": 0.7,
122 | "top_p": 0.9
123 | }'
124 |
125 | echo -e "\n\nCompleted tests for ${MODEL_NAME}"
126 | echo "==================================\n\n"
127 | }
128 |
129 | # Run tests for each model
130 | for MODEL in "${MODELS[@]}"; do
131 | run_tests "$MODEL"
132 | done
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | import sys
2 | from pathlib import Path
3 |
4 | from setuptools import setup, find_packages
5 |
6 | package_dir = Path(__file__).parent / "green_bit_llm"
7 | with open(Path(__file__).parent / "requirements.txt") as fid:
8 | requirements = [l.strip() for l in fid.readlines()]
9 |
10 | sys.path.append(str(package_dir))
11 | from version import __version__
12 |
13 | setup(
14 | name="green-bit-llm",
15 | version=__version__,
16 | description="A toolkit for fine-tuning, inferencing, and evaluating GreenBitAI's LLMs.",
17 | long_description=open("README.md", encoding="utf-8").read(),
18 | long_description_content_type="text/markdown",
19 | author_email="team@greenbit.ai",
20 | author="GreenBitAI Contributors",
21 | url="https://github.com/GreenBitAI/green-bit-llm",
22 | license="Apache-2.0",
23 | install_requires=requirements,
24 | packages=find_packages(where=".", exclude=["tests", "tests.*", "examples", "examples.*"]),
25 | python_requires=">=3.9",
26 | data_files=[('.', ['requirements.txt'])],
27 | )
28 |
--------------------------------------------------------------------------------
/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/tests/__init__.py
--------------------------------------------------------------------------------
/tests/test_langchain_chatmodel.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from unittest.mock import MagicMock, patch
3 | from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
4 | from langchain_core.outputs import LLMResult, Generation, ChatResult, ChatGeneration
5 | from green_bit_llm.langchain import GreenBitPipeline, ChatGreenBit
6 |
7 |
8 | class TestChatGreenBit(unittest.TestCase):
9 |
10 | def setUp(self):
11 | self.mock_pipeline = MagicMock(spec=GreenBitPipeline)
12 | self.mock_pipeline.pipeline = MagicMock()
13 | self.mock_pipeline.pipeline.tokenizer = MagicMock()
14 | self.mock_pipeline.pipeline.tokenizer.apply_chat_template = MagicMock(return_value="Mocked chat template")
15 | self.chat_model = ChatGreenBit(llm=self.mock_pipeline)
16 |
17 | def test_llm_type(self):
18 | self.assertEqual(self.chat_model._llm_type, "greenbit-chat")
19 |
20 | def test_messages_to_dict(self):
21 | """Test message conversion to dictionary format"""
22 | system_message = SystemMessage(content="You are an AI assistant.")
23 | human_message = HumanMessage(content="Hello, AI!")
24 | ai_message = AIMessage(content="Hello, human!")
25 |
26 | messages = [system_message, human_message, ai_message]
27 | result = self.chat_model._messages_to_dict(messages)
28 |
29 | expected = [
30 | {"role": "system", "content": "You are an AI assistant."},
31 | {"role": "user", "content": "Hello, AI!"},
32 | {"role": "assistant", "content": "Hello, human!"}
33 | ]
34 | self.assertEqual(result, expected)
35 |
36 | def test_prepare_prompt(self):
37 | """Test prompt preparation using apply_chat_template"""
38 | messages = [
39 | SystemMessage(content="You are an AI assistant."),
40 | HumanMessage(content="Hello, AI!"),
41 | AIMessage(content="Hello, human!"),
42 | HumanMessage(content="How are you?")
43 | ]
44 |
45 | result = self.chat_model._prepare_prompt(messages)
46 |
47 | self.assertEqual(result, "Mocked chat template")
48 | self.mock_pipeline.pipeline.tokenizer.apply_chat_template.assert_called_once()
49 |
50 | # Check that the call was made with correct message format
51 | call_args = self.mock_pipeline.pipeline.tokenizer.apply_chat_template.call_args
52 | messages_arg = call_args[0][0] # First positional argument
53 | expected_messages = [
54 | {"role": "system", "content": "You are an AI assistant."},
55 | {"role": "user", "content": "Hello, AI!"},
56 | {"role": "assistant", "content": "Hello, human!"},
57 | {"role": "user", "content": "How are you?"}
58 | ]
59 | self.assertEqual(messages_arg, expected_messages)
60 |
61 | def test_prepare_prompt_with_enable_thinking(self):
62 | """Test prompt preparation with enable_thinking parameter"""
63 | messages = [HumanMessage(content="Hello, AI!")]
64 |
65 | result = self.chat_model._prepare_prompt(messages, enable_thinking=True)
66 |
67 | self.assertEqual(result, "Mocked chat template")
68 | call_args = self.mock_pipeline.pipeline.tokenizer.apply_chat_template.call_args
69 | kwargs = call_args[1] # Keyword arguments
70 | self.assertTrue(kwargs.get("enable_thinking"))
71 | self.assertTrue(kwargs.get("add_generation_prompt"))
72 |
73 | def test_prepare_prompt_no_tokenizer(self):
74 | """Test error handling when tokenizer is not available"""
75 | self.mock_pipeline.pipeline.tokenizer = None
76 | messages = [HumanMessage(content="Hello, AI!")]
77 |
78 | with self.assertRaises(ValueError) as context:
79 | self.chat_model._prepare_prompt(messages)
80 | self.assertIn("Tokenizer not available", str(context.exception))
81 |
82 | def test_prepare_prompt_no_chat_template(self):
83 | """Test error handling when apply_chat_template is not available"""
84 | del self.mock_pipeline.pipeline.tokenizer.apply_chat_template
85 | messages = [HumanMessage(content="Hello, AI!")]
86 |
87 | with self.assertRaises(ValueError) as context:
88 | self.chat_model._prepare_prompt(messages)
89 | self.assertIn("does not support apply_chat_template", str(context.exception))
90 |
91 | def test_create_chat_result(self):
92 | """Test conversion from LLM result to chat result"""
93 | llm_result = LLMResult(generations=[[Generation(text="Hello, human!")]])
94 | chat_result = self.chat_model._create_chat_result(llm_result)
95 |
96 | self.assertEqual(len(chat_result.generations), 1)
97 | self.assertIsInstance(chat_result.generations[0], ChatGeneration)
98 | self.assertEqual(chat_result.generations[0].message.content, "Hello, human!")
99 |
100 | @patch.object(ChatGreenBit, '_prepare_prompt')
101 | def test_generate(self, mock_prepare_prompt):
102 | """Test generation with mocked prompt preparation"""
103 | mock_prepare_prompt.return_value = "Mocked chat prompt"
104 | self.mock_pipeline.generate.return_value = LLMResult(generations=[[Generation(text="Generated response")]])
105 |
106 | messages = [HumanMessage(content="Hello, AI!")]
107 | result = self.chat_model.generate(messages, temperature=0.8, max_tokens=100)
108 |
109 | # Check that prompt was prepared correctly
110 | mock_prepare_prompt.assert_called_once_with(messages, temperature=0.8, max_tokens=100)
111 |
112 | # Check that pipeline.generate was called with correct arguments
113 | self.mock_pipeline.generate.assert_called_once()
114 | call_args = self.mock_pipeline.generate.call_args
115 |
116 | # Check prompts argument
117 | self.assertEqual(call_args[1]["prompts"], ["Mocked chat prompt"])
118 |
119 | # Check that result is ChatResult
120 | self.assertIsInstance(result, ChatResult)
121 | self.assertEqual(result.generations[0].message.content, "Generated response")
122 |
123 | @patch.object(ChatGreenBit, '_prepare_prompt')
124 | def test_stream(self, mock_prepare_prompt):
125 | """Test streaming with mocked prompt preparation"""
126 | mock_prepare_prompt.return_value = "Mocked chat prompt"
127 | mock_chunk1 = MagicMock()
128 | mock_chunk1.text = "Hello"
129 | mock_chunk2 = MagicMock()
130 | mock_chunk2.text = " human!"
131 | self.mock_pipeline.stream.return_value = [mock_chunk1, mock_chunk2]
132 |
133 | messages = [HumanMessage(content="Hello, AI!")]
134 | stream_result = list(self.chat_model.stream(messages, temperature=0.7))
135 |
136 | # Check that prompt was prepared correctly
137 | mock_prepare_prompt.assert_called_once_with(messages, temperature=0.7)
138 |
139 | # Check that pipeline.stream was called
140 | self.mock_pipeline.stream.assert_called_once()
141 |
142 | # Check stream results
143 | self.assertEqual(len(stream_result), 2)
144 | self.assertIsInstance(stream_result[0], ChatGeneration)
145 | self.assertEqual(stream_result[0].message.content, "Hello")
146 | self.assertEqual(stream_result[1].message.content, " human!")
147 |
148 | def test_generate_with_enable_thinking(self):
149 | """Test generation with enable_thinking parameter"""
150 | with patch.object(self.chat_model, '_prepare_prompt') as mock_prepare_prompt:
151 | mock_prepare_prompt.return_value = "Mocked chat prompt"
152 | self.mock_pipeline.generate.return_value = LLMResult(generations=[[Generation(text="Generated response")]])
153 |
154 | messages = [HumanMessage(content="Hello, AI!")]
155 | result = self.chat_model.generate(messages, enable_thinking=True)
156 |
157 | # Check that enable_thinking was passed to _prepare_prompt
158 | mock_prepare_prompt.assert_called_once_with(messages, enable_thinking=True)
159 |
160 |
161 | if __name__ == '__main__':
162 | unittest.main()
--------------------------------------------------------------------------------
/tests/test_langchain_embedding.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from typing import List
3 | from green_bit_llm.langchain import GreenBitEmbeddings
4 |
5 | class TestGreenBitEmbeddings(unittest.TestCase):
6 | def setUp(self):
7 | model_kwargs = {'trust_remote_code': True}
8 | encode_kwargs = {'normalize_embeddings': False}
9 | self.embeddings = GreenBitEmbeddings.from_model_id(
10 | model_name="sentence-transformers/all-MiniLM-L6-v2",
11 | cache_dir="cache",
12 | device="cpu",
13 | multi_process=False,
14 | model_kwargs=model_kwargs,
15 | encode_kwargs=encode_kwargs
16 | )
17 |
18 | def test_embed_documents_returns_list(self):
19 | texts = ["Hello, world!", "This is a test."]
20 | result = self.embeddings.embed_documents(texts)
21 | self.assertIsInstance(result, list)
22 |
23 | def test_embed_documents_returns_correct_number_of_embeddings(self):
24 | texts = ["Hello, world!", "This is a test."]
25 | result = self.embeddings.embed_documents(texts)
26 | self.assertEqual(len(result), len(texts))
27 |
28 | def test_embed_query_returns_list(self):
29 | query = "What is the meaning of life?"
30 | result = self.embeddings.embed_query(query)
31 | self.assertIsInstance(result, list)
32 |
33 | def test_embed_query_returns_non_empty_list(self):
34 | query = "What is the meaning of life?"
35 | result = self.embeddings.embed_query(query)
36 | self.assertTrue(len(result) > 0)
37 |
38 | if __name__ == '__main__':
39 | unittest.main()
--------------------------------------------------------------------------------
/tests/test_langchain_pipeline.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from unittest.mock import patch, MagicMock
3 | import torch
4 | from green_bit_llm.langchain import GreenBitPipeline
5 | from langchain_core.outputs import LLMResult, Generation, GenerationChunk
6 |
7 |
8 | class TestGreenBitPipeline(unittest.TestCase):
9 |
10 | @patch('green_bit_llm.langchain.pipeline.check_engine_available')
11 | @patch('green_bit_llm.langchain.pipeline.load')
12 | @patch('green_bit_llm.langchain.pipeline.pipeline')
13 | def test_from_model_id(self, mock_pipeline, mock_load, mock_check_engine):
14 | """Test pipeline creation from model ID"""
15 | # Setup
16 | mock_check_engine.return_value = True
17 | mock_model = MagicMock()
18 | mock_tokenizer = MagicMock()
19 | mock_tokenizer.pad_token = None
20 | mock_tokenizer.eos_token = "<|endoftext|>"
21 | mock_tokenizer.pad_token_id = None
22 | mock_tokenizer.eos_token_id = 50256
23 | mock_load.return_value = (mock_model, mock_tokenizer, None)
24 | mock_pipe = MagicMock()
25 | mock_pipeline.return_value = mock_pipe
26 |
27 | # Test
28 | gb_pipeline = GreenBitPipeline.from_model_id(
29 | model_id="test_model",
30 | task="text-generation",
31 | model_kwargs={"dtype": torch.float16},
32 | pipeline_kwargs={"max_length": 100}
33 | )
34 |
35 | # Assert
36 | self.assertIsInstance(gb_pipeline, GreenBitPipeline)
37 | self.assertEqual(gb_pipeline.model_id, "test_model")
38 | self.assertEqual(gb_pipeline.task, "text-generation")
39 | self.assertEqual(gb_pipeline.model_kwargs, {"dtype": torch.float16})
40 | self.assertEqual(gb_pipeline.pipeline_kwargs, {"max_length": 100})
41 | mock_check_engine.assert_called_once()
42 | mock_pipeline.assert_called_once()
43 |
44 | # Check that tokenizer pad_token was set
45 | self.assertEqual(mock_tokenizer.pad_token, "<|endoftext|>")
46 | self.assertEqual(mock_tokenizer.pad_token_id, 50256)
47 |
48 | def test_identifying_params(self):
49 | """Test identifying parameters property"""
50 | gb_pipeline = GreenBitPipeline(
51 | pipeline=MagicMock(),
52 | model_id="test_model",
53 | task="text-generation",
54 | model_kwargs={"dtype": torch.float16},
55 | pipeline_kwargs={"max_length": 100}
56 | )
57 | params = gb_pipeline._identifying_params
58 | self.assertEqual(params["model_id"], "test_model")
59 | self.assertEqual(params["task"], "text-generation")
60 | self.assertEqual(params["model_kwargs"], {"dtype": torch.float16})
61 | self.assertEqual(params["pipeline_kwargs"], {"max_length": 100})
62 |
63 | def test_llm_type(self):
64 | """Test LLM type property"""
65 | gb_pipeline = GreenBitPipeline(pipeline=MagicMock(), model_kwargs={}, pipeline_kwargs={})
66 | self.assertEqual(gb_pipeline._llm_type, "greenbit_pipeline")
67 |
68 | def test_prepare_generation_config(self):
69 | """Test generation config preparation"""
70 | mock_pipeline = MagicMock()
71 | mock_pipeline.tokenizer.pad_token_id = 0
72 | mock_pipeline.tokenizer.eos_token_id = 1
73 |
74 | gb_pipeline = GreenBitPipeline(
75 | pipeline=mock_pipeline,
76 | model_kwargs={},
77 | pipeline_kwargs={"temperature": 0.5, "max_new_tokens": 50}
78 | )
79 |
80 | config = gb_pipeline._prepare_generation_config({"temperature": 0.8})
81 |
82 | self.assertEqual(config["temperature"], 0.8) # Should override pipeline_kwargs
83 | self.assertEqual(config["max_new_tokens"], 50) # Should use pipeline default
84 | self.assertEqual(config["pad_token_id"], 0)
85 | self.assertEqual(config["eos_token_id"], 1)
86 | self.assertTrue(config["do_sample"]) # Changed default to True
87 |
88 | def test_prepare_prompt_from_text_with_chat_template(self):
89 | """Test prompt preparation from plain text using chat template"""
90 | mock_tokenizer = MagicMock()
91 | mock_tokenizer.apply_chat_template = MagicMock(
92 | return_value="<|im_start|>user\nHello<|im_end|><|im_start|>assistant\n")
93 |
94 | mock_pipeline = MagicMock()
95 | mock_pipeline.tokenizer = mock_tokenizer
96 |
97 | gb_pipeline = GreenBitPipeline(pipeline=mock_pipeline, model_kwargs={}, pipeline_kwargs={})
98 |
99 | result = gb_pipeline._prepare_prompt_from_text("Hello", enable_thinking=True)
100 |
101 | self.assertEqual(result, "<|im_start|>user\nHello<|im_end|><|im_start|>assistant\n")
102 | mock_tokenizer.apply_chat_template.assert_called_once()
103 |
104 | # Check the call arguments
105 | call_args = mock_tokenizer.apply_chat_template.call_args
106 | messages = call_args[0][0]
107 | kwargs = call_args[1]
108 |
109 | self.assertEqual(messages, [{"role": "user", "content": "Hello"}])
110 | self.assertTrue(kwargs["add_generation_prompt"])
111 | self.assertTrue(kwargs["enable_thinking"])
112 |
113 | def test_prepare_prompt_from_text_no_chat_template(self):
114 | """Test prompt preparation fallback when no chat template available"""
115 | mock_tokenizer = MagicMock()
116 | # Remove apply_chat_template method
117 | del mock_tokenizer.apply_chat_template
118 |
119 | mock_pipeline = MagicMock()
120 | mock_pipeline.tokenizer = mock_tokenizer
121 |
122 | gb_pipeline = GreenBitPipeline(pipeline=mock_pipeline, model_kwargs={}, pipeline_kwargs={})
123 |
124 | result = gb_pipeline._prepare_prompt_from_text("Hello")
125 |
126 | # Should return original text when no chat template
127 | self.assertEqual(result, "Hello")
128 |
129 | def test_prepare_prompt_from_text_template_error(self):
130 | """Test prompt preparation fallback when template application fails"""
131 | mock_tokenizer = MagicMock()
132 | mock_tokenizer.apply_chat_template = MagicMock(side_effect=Exception("Template error"))
133 |
134 | mock_pipeline = MagicMock()
135 | mock_pipeline.tokenizer = mock_tokenizer
136 |
137 | gb_pipeline = GreenBitPipeline(pipeline=mock_pipeline, model_kwargs={}, pipeline_kwargs={})
138 |
139 | result = gb_pipeline._prepare_prompt_from_text("Hello")
140 |
141 | # Should return original text when template application fails
142 | self.assertEqual(result, "Hello")
143 |
144 | @patch.object(GreenBitPipeline, '_prepare_prompt_from_text')
145 | def test_generate_with_plain_text(self, mock_prepare_prompt):
146 | """Test generation with plain text prompts"""
147 | # Setup
148 | mock_prepare_prompt.return_value = ""
149 | mock_pipeline = MagicMock()
150 | mock_pipeline.tokenizer.encode.return_value = [1, 2, 3]
151 | mock_pipeline.device = "cpu"
152 | mock_pipeline.model.generate.return_value = MagicMock(
153 | sequences=torch.tensor([[1, 2, 3, 4, 5]]),
154 | hidden_states=None
155 | )
156 | mock_pipeline.tokenizer.return_value = {
157 | 'input_ids': torch.tensor([[1, 2, 3]]),
158 | 'attention_mask': torch.tensor([[1, 1, 1]])
159 | }
160 | mock_pipeline.tokenizer.decode.return_value = "Generated text"
161 |
162 | gb_pipeline = GreenBitPipeline(
163 | pipeline=mock_pipeline,
164 | model_kwargs={},
165 | pipeline_kwargs={"max_new_tokens": 100}
166 | )
167 |
168 | # Test with plain text (should trigger chat template)
169 | result = gb_pipeline.generate(["Hello"], enable_thinking=True)
170 |
171 | # Check that prompt was processed
172 | mock_prepare_prompt.assert_called_once_with("Hello", enable_thinking=True)
173 |
174 | # Check result
175 | self.assertIsInstance(result, LLMResult)
176 | self.assertEqual(len(result.generations), 1)
177 |
178 | def test_generate_with_formatted_prompt(self):
179 | """Test generation with already formatted prompts"""
180 | # Setup
181 | mock_pipeline = MagicMock()
182 | mock_pipeline.tokenizer.encode.return_value = [1, 2, 3]
183 | mock_pipeline.device = "cpu"
184 | mock_pipeline.model.generate.return_value = MagicMock(
185 | sequences=torch.tensor([[1, 2, 3, 4, 5]]),
186 | hidden_states=None
187 | )
188 | mock_pipeline.tokenizer.return_value = {
189 | 'input_ids': torch.tensor([[1, 2, 3]]),
190 | 'attention_mask': torch.tensor([[1, 1, 1]])
191 | }
192 | mock_pipeline.tokenizer.decode.return_value = "Generated text"
193 |
194 | gb_pipeline = GreenBitPipeline(
195 | pipeline=mock_pipeline,
196 | model_kwargs={},
197 | pipeline_kwargs={"max_new_tokens": 100}
198 | )
199 |
200 | # Test with already formatted prompt (should not trigger chat template)
201 | formatted_prompt = "<|im_start|>user\nHello<|im_end|><|im_start|>assistant\n"
202 |
203 | with patch.object(gb_pipeline, '_prepare_prompt_from_text') as mock_prepare:
204 | result = gb_pipeline.generate([formatted_prompt])
205 |
206 | # Should not call _prepare_prompt_from_text for already formatted prompts
207 | mock_prepare.assert_not_called()
208 |
209 | @patch('green_bit_llm.langchain.pipeline.TextIteratorStreamer')
210 | @patch('green_bit_llm.langchain.pipeline.Thread')
211 | @patch.object(GreenBitPipeline, '_prepare_prompt_from_text')
212 | def test_stream(self, mock_prepare_prompt, mock_thread, mock_streamer):
213 | """Test streaming functionality"""
214 | # Setup
215 | mock_prepare_prompt.return_value = ""
216 | mock_pipeline = MagicMock()
217 | mock_pipeline.tokenizer.return_value = {'input_ids': torch.tensor([[1, 2, 3]])}
218 | mock_pipeline.device = "cpu"
219 |
220 | mock_streamer_instance = MagicMock()
221 | mock_streamer_instance.__iter__.return_value = iter(["Hello", " ", "world"])
222 | mock_streamer.return_value = mock_streamer_instance
223 |
224 | gb_pipeline = GreenBitPipeline(pipeline=mock_pipeline, model_kwargs={}, pipeline_kwargs={})
225 |
226 | # Test
227 | chunks = list(gb_pipeline.stream("Hi", enable_thinking=True))
228 |
229 | # Check that prompt was processed
230 | mock_prepare_prompt.assert_called_once_with("Hi", enable_thinking=True)
231 |
232 | # Assert
233 | self.assertEqual(len(chunks), 3)
234 | self.assertIsInstance(chunks[0], GenerationChunk)
235 | self.assertEqual(chunks[0].text, "Hello")
236 | self.assertEqual(chunks[1].text, " ")
237 | self.assertEqual(chunks[2].text, "world")
238 | mock_thread.assert_called_once()
239 | mock_streamer.assert_called_once()
240 |
241 | @patch.object(GreenBitPipeline, '_prepare_prompt_from_text')
242 | def test_stream_with_formatted_prompt(self, mock_prepare_prompt):
243 | """Test streaming with already formatted prompt"""
244 | # Setup
245 | mock_pipeline = MagicMock()
246 | mock_pipeline.tokenizer.return_value = {'input_ids': torch.tensor([[1, 2, 3]])}
247 | mock_pipeline.device = "cpu"
248 |
249 | gb_pipeline = GreenBitPipeline(pipeline=mock_pipeline, model_kwargs={}, pipeline_kwargs={})
250 |
251 | formatted_prompt = "<|start_header_id|>user<|end_header_id|>Hello<|eot_id|>"
252 |
253 | with patch('green_bit_llm.langchain.pipeline.TextIteratorStreamer') as mock_streamer:
254 | with patch('green_bit_llm.langchain.pipeline.Thread'):
255 | mock_streamer_instance = MagicMock()
256 | mock_streamer_instance.__iter__.return_value = iter(["Hello"])
257 | mock_streamer.return_value = mock_streamer_instance
258 |
259 | list(gb_pipeline.stream(formatted_prompt))
260 |
261 | # Should not call _prepare_prompt_from_text for already formatted prompts
262 | mock_prepare_prompt.assert_not_called()
263 |
264 |
265 | if __name__ == '__main__':
266 | unittest.main()
--------------------------------------------------------------------------------
137 |
138 | ```bash
139 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --lr-fp 1e-6
140 |
141 | # AutoGPTQ model with Lora
142 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --lr-fp 1e-6
143 | ```
144 |
145 | ## Further Usage
146 |
147 | Please see the description of the [Inference](green_bit_llm/inference/README.md), [sft](green_bit_llm/sft/README.md) and [evaluation](green_bit_llm/evaluation/README.md) package for details.
148 |
149 | ## License
150 | We release our codes under the [Apache 2.0 License](LICENSE).
151 | Additionally, three packages are also partly based on third-party open-source codes. For detailed information, please refer to the description pages of the sub-projects.
152 |
--------------------------------------------------------------------------------
/assets/demo_llama3_8B_fpft.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/assets/demo_llama3_8B_fpft.gif
--------------------------------------------------------------------------------
/assets/demo_yi_34B_peft.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/assets/demo_yi_34B_peft.gif
--------------------------------------------------------------------------------
/db/create_apikey_table.sql:
--------------------------------------------------------------------------------
1 | -- z.B. sqlite3 greenbit.db < create_tables.sql
2 |
3 | -- drop tables if exists
4 | --DROP TABLE IF EXISTS api_keys;
5 | --DROP TABLE IF EXISTS users;
6 |
7 | -- Create users table
8 | CREATE TABLE IF NOT EXISTS users (
9 | id INTEGER PRIMARY KEY AUTOINCREMENT,
10 | name TEXT NOT NULL,
11 | email TEXT NOT NULL UNIQUE,
12 | organization TEXT,
13 | created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
14 | );
15 |
16 | -- Create API keys table
17 | CREATE TABLE IF NOT EXISTS api_keys (
18 | id INTEGER PRIMARY KEY AUTOINCREMENT,
19 | user_id INTEGER NOT NULL,
20 | api_key_hash TEXT NOT NULL UNIQUE,
21 | name TEXT NOT NULL,
22 | email TEXT NOT NULL,
23 | organization TEXT,
24 | tier VARCHAR(20) DEFAULT 'basic',
25 | rpm_limit INTEGER DEFAULT 60,
26 | tpm_limit INTEGER DEFAULT 40000,
27 | concurrent_requests INTEGER DEFAULT 5,
28 | max_tokens INTEGER DEFAULT 32768,
29 | permissions TEXT DEFAULT 'completion,chat',
30 | is_active BOOLEAN DEFAULT TRUE,
31 | created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
32 | last_used_at TIMESTAMP,
33 | FOREIGN KEY (user_id) REFERENCES users(id),
34 | CHECK (is_active IN (0, 1))
35 | );
36 |
37 | -- Create indexes
38 | CREATE INDEX IF NOT EXISTS idx_api_key_hash ON api_keys(api_key_hash);
39 | CREATE INDEX IF NOT EXISTS idx_user_email ON users(email);
40 | CREATE INDEX IF NOT EXISTS idx_last_used ON api_keys(last_used_at);
--------------------------------------------------------------------------------
/docker/Dockerfile:
--------------------------------------------------------------------------------
1 | ARG FROM_IMAGE="bitorch/engine"
2 | FROM ${FROM_IMAGE} as bitorch-engine-base
3 |
4 | FROM bitorch-engine-base as requirements-installed
5 | COPY "../requirements.txt" "/green-bit-llm-req.txt"
6 | RUN pip install packaging -r "/green-bit-llm-req.txt" && \
7 | rm "/green-bit-llm-req.txt" && \
8 | pip install flash-attn --no-build-isolation && \
9 | pip cache purge
10 |
11 | # clone instead of mounting makes the code in the image independent from local changes
12 | # to mount your code before building, use the target above and mount your local code
13 | FROM requirements-installed as code-cloned
14 | ARG GIT_URL="https://github.com/GreenBitAI/green-bit-llm.git"
15 | ARG GIT_BRANCH="main"
16 | ARG BUILD_TARGET="."
17 | RUN git clone \
18 | --depth 1 \
19 | --branch "${GIT_BRANCH}" \
20 | "${GIT_URL}" \
21 | /green-bit-llm && \
22 | cd /green-bit-llm && \
23 | pip install -e .
24 |
--------------------------------------------------------------------------------
/docker/README.md:
--------------------------------------------------------------------------------
1 | # Project Setup with Docker
2 |
3 | In the following, we show how to build a [Docker](https://www.docker.com/) image for this project and explain additional options.
4 |
5 | ## Build Docker Image
6 |
7 | 1. Build the bitorch engine image according to [these instructions](https://github.com/GreenBitAI/bitorch-engine/blob/HEAD/docker/README.md).
8 | 2. Now you should be able to build the image by running the following commands
9 | (if you used a custom image name or tag, you can adjust with `--build-arg FROM_IMAGE="bitorch/engine:custom-tag"`):
10 | ```bash
11 | # cd docker
12 | # you should be in this `docker` directory
13 | cp -f ../requirements.txt .
14 | docker build -t gbai/green-bit-llm .
15 | ```
16 | 3. You can now run the container, for example with this:
17 | ```bash
18 | docker run -it --rm --gpus all gbai/green-bit-llm
19 | ```
20 | 4. Alternatively, you can mount the directory `/root/.cache/huggingface/hub` which will save the downloaded model cache locally,
21 | e.g. you could use your users cache directory:
22 | ```bash
23 | docker run -it --rm --gpus all -v "${HOME}/.cache/huggingface/hub":"/root/.cache/huggingface/hub" gbai/green-bit-llm
24 | ```
25 |
26 | ## Build Options
27 |
28 | Depending on your setup, you may want to adjust some options through build arguments:
29 | - base docker image, e.g. add `--build-arg FROM_IMAGE="bitorch/engine:custom-tag"`
30 | - repository URL, e.g. add `--build-arg GIT_URL="https://github.com/MyFork/green-bit-llm.git"`
31 | - green-bit-llm branch or tag, e.g. add `--build-arg GIT_BRANCH="v1.2.3"`
32 | - if there is a problem, set the environment variable `BUILDKIT_PROGRESS=plain` to see all output
33 |
34 | ## For Development
35 |
36 | A docker image without the code cloned, e.g. for mounting a local copy of the code, can be made easily with the target `requirements-installed`:
37 | ```bash
38 | # cd docker
39 | # you should be in this `docker` directory
40 | cp -f ../requirements.txt .
41 | docker build -t gbai/green-bit-llm:no-code --target requirements-installed .
42 | docker run -it --rm --gpus all --volume "$(pwd)/..":/green-bit-llm gbai/green-bit-llm:no-code
43 | # in the docker container:
44 | cd /green-bit-llm
45 | pip install -e .
46 | ```
47 | However, this means the build results will not be persisted in the image, so you probably want to mount the same directory every time.
48 |
--------------------------------------------------------------------------------
/environment.yml:
--------------------------------------------------------------------------------
1 | name: gbai_cuda_lm
2 | channels:
3 | - conda-forge
4 | - pytorch
5 | dependencies:
6 | - python=3.9
7 | - pip=24.0
8 | - pytorch::pytorch>=2.0
9 | - pip:
10 | - sentencepiece
11 | - huggingface-hub
12 | - transformers>=4.52.4
13 | - accelerate
14 | - colorama
15 | - datasets
16 | - lm-eval==0.3.0
17 | - termcolor
18 | - pillow
19 | - requests
20 | - prompt-toolkit
21 | - rich
22 | - optimum
23 | - auto-gptq
24 | - langchain-core
25 |
--------------------------------------------------------------------------------
/examples/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/examples/__init__.py
--------------------------------------------------------------------------------
/examples/local_rag/README.md:
--------------------------------------------------------------------------------
1 | # Local RAG Demo
2 |
3 | ## Overview
4 |
5 | This project demonstrates a local implementation of Retrieval-Augmented Generation (RAG) using GreenBit models, including GreenBitPipeline, ChatGreenBit, and GreenBitEmbeddings. It showcases features such as document loading, text splitting, vector store creation, and various natural language processing tasks in a CUDA environment.
6 |
7 | ## Features
8 |
9 | - Document loading from web sources
10 | - Text splitting for efficient processing
11 | - Vector store creation using BERT embeddings
12 | - Rap battle simulation
13 | - Document summarization
14 | - Question answering
15 | - Question answering with retrieval
16 |
17 | ## Installation
18 |
19 | 1. Install the required packages:
20 | ```
21 | pip install -r requirements.txt
22 | ```
23 |
24 | 2. Ensure you have a CUDA-compatible environment set up on your system.
25 |
26 | ## Usage
27 |
28 | Run the main script to execute all tasks:
29 |
30 | ```
31 | CUDA_VISIBLE_DEVICES=0 \
32 | python -m examples.local_rag.run --model "GreenBitAI/Llama-3-8B-instruct-layer-mix-bpw-4.0" \
33 | --embedding_model "sentence-transformers/all-MiniLM-L12-v2" \
34 | --query "What are the core components of GraphRAG?" \
35 | --max_tokens 300 \
36 | --web_source "https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/"
37 | ```
38 |
39 | This will perform the following tasks:
40 | 1. Initialize the model and prepare data
41 | 2. Simulate a rap battle
42 | 3. Summarize documents based on a question
43 | 4. Perform question answering
44 | 5. Perform question answering with retrieval
45 |
46 | ## Note
47 |
48 | This implementation uses GreenBit models, which are compatible with Hugging Face's transformers library and optimized for CUDA environments. Make sure you have the appropriate CUDA setup and GreenBit model files before running the demo.
--------------------------------------------------------------------------------
/examples/local_rag/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/examples/local_rag/__init__.py
--------------------------------------------------------------------------------
/examples/local_rag/requirements.txt:
--------------------------------------------------------------------------------
1 | langchain-core
2 | langchain-community
3 | langchain-chroma
4 | langchain-text-splitters
5 | langchain-experimental
6 | beautifulsoup4
7 | pydantic
8 | sentence-transformers
--------------------------------------------------------------------------------
/examples/local_rag/run.py:
--------------------------------------------------------------------------------
1 | import re
2 | import argparse
3 | import torch
4 |
5 | from langchain_community.document_loaders import WebBaseLoader
6 | from langchain_text_splitters import RecursiveCharacterTextSplitter
7 | from langchain_chroma import Chroma
8 | from langchain_core.output_parsers import StrOutputParser
9 | from langchain_core.prompts import ChatPromptTemplate
10 | from langchain_core.runnables import RunnablePassthrough
11 |
12 | from green_bit_llm.langchain import GreenBitPipeline, ChatGreenBit, GreenBitEmbeddings
13 |
14 | import warnings
15 | warnings.filterwarnings("ignore", category=UserWarning)
16 |
17 |
18 | # Helper function to format documents
19 | def format_docs(docs):
20 | return "\n\n".join(doc.page_content for doc in docs)
21 |
22 | # Helper function to print task separators
23 | def print_task_separator(task_name):
24 | print("\n" + "="*50)
25 | print(f"Task: {task_name}")
26 | print("="*50 + "\n")
27 |
28 | def clean_output(text):
29 | # Remove all non-alphanumeric characters except periods and spaces
30 | cleaned = re.sub(r'[^a-zA-Z0-9\.\s]', ' ', text)
31 | # Replace multiple spaces with a single space
32 | cleaned = re.sub(r'\s+', ' ', cleaned).strip()
33 | # Remove any mentions of "assistant" or other unwanted words
34 | cleaned = re.sub(r'\b(assistant|correct|I apologize|mistake)\b', '', cleaned, flags=re.IGNORECASE)
35 | # Remove any remaining leading/trailing whitespace
36 | cleaned = cleaned.strip()
37 | # Ensure the first letter is capitalized
38 | cleaned = cleaned.capitalize()
39 | # Ensure the answer ends with a period
40 | if cleaned and not cleaned.endswith('.'):
41 | cleaned += '.'
42 | return cleaned
43 |
44 | def extract_answer(text):
45 | # Try to extract a single sentence answer
46 | match = re.search(r'([A-Z][^\.!?]*[\.!?])', text)
47 | if match:
48 | return match.group(1)
49 | # If no clear sentence is found, return the first 100 characters
50 | return text[:100] + '...' if len(text) > 100 else text
51 |
52 | # Load and prepare data
53 | def prepare_data(url):
54 | loader = WebBaseLoader(url)
55 | data = loader.load()
56 | text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
57 | all_splits = text_splitter.split_documents(data)
58 | return all_splits
59 |
60 | # Create vector store
61 | def create_vectorstore(documents, embedding_model):
62 | model_kwargs = {'trust_remote_code': True}
63 | encode_kwargs = {'normalize_embeddings': False}
64 |
65 | greenbit_embeddings = GreenBitEmbeddings.from_model_id(
66 | model_name=embedding_model,
67 | cache_dir="cache",
68 | multi_process=False,
69 | show_progress=False,
70 | model_kwargs=model_kwargs,
71 | encode_kwargs=encode_kwargs
72 | )
73 | return Chroma.from_documents(documents=documents, embedding=greenbit_embeddings)
74 |
75 | # Initialize GreenBit model
76 | def init_greenbit_model(model_id, max_tokens):
77 | pipeline = GreenBitPipeline.from_model_id(
78 | model_id=model_id,
79 | model_kwargs={"dtype": torch.half, "seqlen": 2048, "device_map": "auto"},
80 | pipeline_kwargs={"max_new_tokens": max_tokens, "temperature": 0.7, "do_sample": True},
81 | )
82 |
83 | return ChatGreenBit(llm=pipeline)
84 |
85 |
86 | # Task 1: Rap Battle Simulation
87 | def simulate_rap_battle(model):
88 | print_task_separator("Rap Battle Simulation")
89 | prompt = "Simulate a rap battle between rag and graphRag."
90 | response = model.invoke(prompt)
91 | print(response.content)
92 |
93 |
94 | # Task 2: Summarization
95 | def summarize_docs(model, vectorstore, question):
96 | print_task_separator("Summarization")
97 | prompt_template = "Summarize the main themes in these retrieved docs in a single, complete sentence of no more than 200 words: {docs}"
98 | prompt = ChatPromptTemplate.from_template(prompt_template)
99 |
100 | chain = (
101 | {"docs": format_docs}
102 | | prompt
103 | | model
104 | | StrOutputParser()
105 | | clean_output
106 | | extract_answer
107 | )
108 | docs = vectorstore.similarity_search(question)
109 | response = chain.invoke(docs)
110 | print(response)
111 |
112 |
113 | # Task 3: Q&A
114 | def question_answering(model, vectorstore, question):
115 | print_task_separator("Q&A")
116 | RAG_TEMPLATE = """
117 | Answer the following question based on the context provided. Give a direct and concise answer in a single, complete sentence of no more than 100 words. Do not include any additional dialogue or explanation.
118 |
119 | Context:
120 | {context}
121 |
122 | Question: {question}
123 |
124 | Answer:"""
125 |
126 | rag_prompt = ChatPromptTemplate.from_template(RAG_TEMPLATE)
127 | chain = (
128 | RunnablePassthrough.assign(context=lambda input: format_docs(input["context"]))
129 | | rag_prompt
130 | | model
131 | | StrOutputParser()
132 | | clean_output
133 | | extract_answer
134 | )
135 | docs = vectorstore.similarity_search(question)
136 | response = chain.invoke({"context": docs, "question": question})
137 | print(response)
138 |
139 |
140 | # Task 4: Q&A with Retrieval
141 | def qa_with_retrieval(model, vectorstore, question):
142 | print_task_separator("Q&A with Retrieval")
143 | RAG_TEMPLATE = """
144 | Answer the following question based on the retrieved information. Provide a direct and concise answer in a single, complete sentence of no more than 100 words. Do not include any additional dialogue or explanation.
145 |
146 | Question: {question}
147 |
148 | Answer:"""
149 |
150 | rag_prompt = ChatPromptTemplate.from_template(RAG_TEMPLATE)
151 | retriever = vectorstore.as_retriever()
152 | qa_chain = (
153 | {"context": retriever | format_docs, "question": RunnablePassthrough()}
154 | | rag_prompt
155 | | model
156 | | StrOutputParser()
157 | | clean_output
158 | | extract_answer
159 | )
160 | response = qa_chain.invoke(question)
161 | print(response)
162 |
163 |
164 |
165 | def main(model_id, embedding_model, query, max_tokens, web_source):
166 | print_task_separator("Initialization")
167 | print("Preparing data and initializing model...")
168 | # Prepare data and initialize model
169 | all_splits = prepare_data(web_source)
170 | vectorstore = create_vectorstore(all_splits, embedding_model)
171 | model = init_greenbit_model(model_id, max_tokens)
172 | print("Initialization complete.")
173 |
174 | # Execute tasks
175 | simulate_rap_battle(model)
176 | summarize_docs(model, vectorstore, query)
177 | question_answering(model, vectorstore, query)
178 | qa_with_retrieval(model, vectorstore, query)
179 |
180 | print("\nAll tasks completed.")
181 |
182 | if __name__ == "__main__":
183 | parser = argparse.ArgumentParser(description="Run NLP tasks with specified model, query, max tokens, and web source.")
184 | parser.add_argument("--model", type=str, default="GreenBitAI/Llama-3-8B-instruct-layer-mix-bpw-4.0", help="Model ID to use for the tasks")
185 | parser.add_argument("--embedding_model", type=str, default="sentence-transformers/all-MiniLM-L12-v2", help="Embedding model to use for vector store creation")
186 | parser.add_argument("--query", type=str, required=True, help="Query to use for the tasks")
187 | parser.add_argument("--max_tokens", type=int, default=200, help="Maximum number of tokens for model output (default: 200)")
188 | parser.add_argument("--web_source", type=str, default="https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/",
189 | help="URL of the web source to load data from (default: Microsoft Research blog post on GraphRAG)")
190 | args = parser.parse_args()
191 |
192 | main(args.model, args.embedding_model, args.query, args.max_tokens, args.web_source)
--------------------------------------------------------------------------------
/green_bit_llm/__init__.py:
--------------------------------------------------------------------------------
1 | from .version import __version__
2 |
--------------------------------------------------------------------------------
/green_bit_llm/args_parser.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | DEFAULT_MODEL_PATH = "GreenBitAI/Qwen-1.5-0.5B-layer-mix-bpw-2.2"
4 | DEFAULT_SEQLEN = 2048
5 |
6 |
7 | def setup_shared_arg_parser(parser_name="Shared argument parser for green-bit-llm scripts"):
8 | """Set up and return the argument parser with shared arguments."""
9 | parser = argparse.ArgumentParser(description=parser_name)
10 | parser.add_argument(
11 | "--model",
12 | type=str,
13 | default=DEFAULT_MODEL_PATH,
14 | help="The path to the local model directory or Hugging Face repo.",
15 | )
16 | parser.add_argument(
17 | "--trust-remote-code",
18 | action="store_true",
19 | help="Enable trusting remote code for tokenizer",
20 | )
21 | parser.add_argument(
22 | "--use-flash-attention-2",
23 | action="store_true",
24 | help="Enable using flash attention v2",
25 | )
26 | parser.add_argument(
27 | "--seqlen",
28 | type=int,
29 | default=DEFAULT_SEQLEN,
30 | help="Sequence length"
31 | )
32 | parser.add_argument(
33 | "--save-dir",
34 | type=str,
35 | default="output/",
36 | help="Specify save dir for eval results.",
37 | )
38 | parser.add_argument(
39 | "--save-step",
40 | type=int,
41 | default=500,
42 | help="Specify how many steps to save a checkpoint.",
43 | )
44 | parser.add_argument(
45 | "--dtype",
46 | type=str,
47 | choices=["float", "half"],
48 | default="half",
49 | help="Dtype used in optimizer.",
50 | )
51 | parser.add_argument(
52 | "--dataset",
53 | type=str,
54 | default="tatsu-lab/alpaca",
55 | help="Dataset name for finetuning",
56 | )
57 | parser.add_argument(
58 | "--optimizer",
59 | type=str,
60 | default="DiodeMix",
61 | help="Optimizer to use: 1. DiodeMix, 2. AdamW8bit"
62 | )
63 | parser.add_argument(
64 | "--batch-size",
65 | type=int,
66 | default=4,
67 | help="Batch size"
68 | )
69 | parser.add_argument("--weight_decay", type=float, default=0.0)
70 | return parser
71 |
--------------------------------------------------------------------------------
/green_bit_llm/common/__init__.py:
--------------------------------------------------------------------------------
1 | from .model import load, generate
2 |
--------------------------------------------------------------------------------
/green_bit_llm/common/enum.py:
--------------------------------------------------------------------------------
1 | from enum import Enum
2 |
3 | class LayerMode(Enum):
4 | LAYER_MIX = 1
5 | CHANNEL_MIX = 2
6 | LEGENCY = 3
7 |
8 | class TextGenMode(Enum):
9 | SEQUENCE = 1
10 | TOKEN = 2
--------------------------------------------------------------------------------
/green_bit_llm/evaluation/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/evaluation/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/evaluation/datautils.py:
--------------------------------------------------------------------------------
1 | from transformers import AutoTokenizer
2 | from datasets import load_dataset
3 | import torch
4 | import random
5 |
6 | from colorama import init, Fore, Style
7 | init(autoreset=True)
8 |
9 | def get_wikitext2(nsamples, seed, seqlen, model):
10 | """
11 | Prepares data loaders for the Wikitext-2 dataset for training and testing.
12 |
13 | Args:
14 | nsamples (int): Number of random samples to generate from the training data.
15 | seed (int): Seed for random number generator to ensure reproducibility.
16 | seqlen (int): Sequence length for each input sample.
17 | model (str): Pretrained model identifier used for tokenization.
18 |
19 | Returns:
20 | tuple: A tuple containing the training loader and tokenized test data.
21 | """
22 | print(Style.BRIGHT + Fore.CYAN + "Info: get_wikitext2")
23 | traindata = load_dataset('wikitext', 'wikitext-2-raw-v1', split='train', cache_dir="./cache/")
24 | testdata = load_dataset('wikitext', 'wikitext-2-raw-v1', split='test', cache_dir="./cache/")
25 |
26 | tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False, trust_remote_code=True)
27 | trainenc = tokenizer("\n\n".join(traindata['text']), return_tensors='pt')
28 | testenc = tokenizer("\n\n".join(testdata['text']), return_tensors='pt')
29 |
30 | random.seed(seed)
31 | trainloader = []
32 | for _ in range(nsamples):
33 | i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
34 | j = i + seqlen
35 | inp = trainenc.input_ids[:, i:j]
36 | tar = inp.clone()
37 | tar[:, :-1] = -100
38 | trainloader.append((inp, tar))
39 |
40 | return trainloader, testenc
41 |
42 |
43 | def get_ptb(nsamples, seed, seqlen, model):
44 | """
45 | Load and prepare the Penn Treebank (PTB) dataset for training and validation.
46 |
47 | Args:
48 | nsamples (int): The number of samples to generate for the training loader.
49 | seed (int): The seed value for random number generation, ensuring reproducibility.
50 | seqlen (int): The sequence length of each sample.
51 | model (str): The model identifier used to load a pre-trained tokenizer.
52 |
53 | Returns:
54 | tuple: A tuple containing the training loader and tokenized validation data.
55 | """
56 | print(Style.BRIGHT + Fore.CYAN + "Info: get_ptb")
57 | traindata = load_dataset('ptb_text_only', 'penn_treebank', split='train', cache_dir="./cache/")
58 | valdata = load_dataset('ptb_text_only', 'penn_treebank', split='validation', cache_dir="./cache/")
59 |
60 | tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False, trust_remote_code=True)
61 |
62 | trainenc = tokenizer("\n\n".join(traindata['sentence']), return_tensors='pt')
63 | testenc = tokenizer("\n\n".join(valdata['sentence']), return_tensors='pt')
64 |
65 | random.seed(seed)
66 | trainloader = []
67 | for _ in range(nsamples):
68 | i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
69 | j = i + seqlen
70 | inp = trainenc.input_ids[:, i:j]
71 | tar = inp.clone()
72 | tar[:, :-1] = -100
73 | trainloader.append((inp, tar))
74 |
75 | return trainloader, testenc
76 |
77 |
78 | def get_c4(nsamples, seed, seqlen, model):
79 | """
80 | Loads and preprocesses the C4 dataset for training and validation.
81 | Args:
82 | nsamples (int): Number of samples to generate for training.
83 | seed (int): Random seed for reproducibility.
84 | seqlen (int): The sequence length for each training sample.
85 | model (str): Model identifier for tokenizer initialization.
86 |
87 | Returns:
88 | tuple: A tuple containing training data loader and validation data tensor.
89 | """
90 | print(Style.BRIGHT + Fore.CYAN + "Info: get_c4")
91 | traindata = load_dataset(
92 | 'allenai/c4', data_files={'train': 'en/c4-train.00000-of-01024.json.gz'},
93 | split='train',
94 | cache_dir="./cache/"
95 | )
96 | valdata = load_dataset(
97 | 'allenai/c4', data_files={'validation': 'en/c4-validation.00000-of-00008.json.gz'},
98 | split='validation',
99 | cache_dir="./cache/"
100 | )
101 |
102 | tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False, trust_remote_code=True)
103 |
104 | random.seed(seed)
105 | trainloader = []
106 | for _ in range(nsamples):
107 |
108 | while True:
109 | i = random.randint(0, len(traindata) - 1)
110 | trainenc = tokenizer(traindata[i]['text'], return_tensors='pt')
111 | if trainenc.input_ids.shape[1] > seqlen + 2:
112 | break
113 |
114 | i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
115 | j = i + seqlen
116 | inp = trainenc.input_ids[:, i:j]
117 | tar = inp.clone()
118 | tar[:, :-1] = -100
119 | trainloader.append((inp, tar))
120 |
121 | random.seed(0)
122 | valenc = []
123 | for _ in range(256):
124 | while True:
125 | i = random.randint(0, len(valdata) - 1)
126 | tmp = tokenizer(valdata[i]['text'], return_tensors='pt')
127 | if tmp.input_ids.shape[1] >= seqlen:
128 | break
129 | i = random.randint(0, tmp.input_ids.shape[1] - seqlen - 1)
130 | j = i + seqlen
131 | valenc.append(tmp.input_ids[:, i:j])
132 | valenc = torch.hstack(valenc)
133 |
134 | return trainloader, valenc
135 |
136 |
137 | def get_ptb_new(nsamples, seed, seqlen, model):
138 | """
139 | Generates training and testing data loaders for the Penn Treebank dataset using a specified model tokenizer.
140 |
141 | Args:
142 | nsamples (int): Number of samples to generate in the training loader.
143 | seed (int): Random seed for reproducibility of sample selection.
144 | seqlen (int): Sequence length of each sample in the training data.
145 | model (str): Model identifier for the tokenizer (e.g., a Hugging Face model name).
146 |
147 | Returns:
148 | tuple: A tuple containing the training loader (list of tuples with input IDs and target IDs) and
149 | the tokenized test data.
150 | """
151 | print(Style.BRIGHT + Fore.CYAN + "Info: get_ptb_new")
152 | traindata = load_dataset('ptb_text_only', 'penn_treebank', split='train')
153 | testdata = load_dataset('ptb_text_only', 'penn_treebank', split='test')
154 |
155 | tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False, trust_remote_code=True)
156 |
157 | trainenc = tokenizer(" ".join(traindata["sentence"]), return_tensors="pt")
158 | testenc = tokenizer(" ".join(testdata["sentence"]), return_tensors="pt")
159 |
160 | random.seed(seed)
161 | trainloader = []
162 | for _ in range(nsamples):
163 | i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
164 | j = i + seqlen
165 | inp = trainenc.input_ids[:, i:j]
166 | tar = inp.clone()
167 | tar[:, :-1] = -100
168 | trainloader.append((inp, tar))
169 |
170 | return trainloader, testenc
171 |
172 |
173 | def get_c4_new(nsamples, seed, seqlen, model):
174 | """
175 | Load and preprocess training and validation datasets from C4 dataset, and tokenize the data.
176 |
177 | Args:
178 | nsamples (int): Number of samples to process for the training data.
179 | seed (int): Random seed for reproducibility of sample selection.
180 | seqlen (int): Length of the sequence for each input/output example.
181 | model (str): Model identifier for the tokenizer, specifying which pretrained model to use.
182 |
183 | Returns:
184 | tuple: A tuple containing two elements:
185 | - trainloader (list of tuples): A list where each tuple contains input ids and target tensors for training.
186 | - valenc (torch.Tensor): A tensor containing the tokenized validation data.
187 | """
188 | print(Style.BRIGHT + Fore.CYAN + "Info: get_c4_new")
189 | traindata = load_dataset(
190 | 'allenai/c4', data_files={'train': 'en/c4-train.00000-of-01024.json.gz'}, split='train'
191 | )
192 | valdata = load_dataset(
193 | 'allenai/c4', data_files={'validation': 'en/c4-validation.00000-of-00008.json.gz'}, split='validation'
194 | )
195 |
196 | tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False, trust_remote_code=True)
197 |
198 | random.seed(seed)
199 | trainloader = []
200 | for _ in range(nsamples):
201 | while True:
202 | i = random.randint(0, len(traindata) - 1)
203 | trainenc = tokenizer(traindata[i]["text"], return_tensors="pt")
204 | if trainenc.input_ids.shape[1] >= seqlen:
205 | break
206 | i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
207 | j = i + seqlen
208 | inp = trainenc.input_ids[:, i:j]
209 | tar = inp.clone()
210 | tar[:, :-1] = -100
211 | trainloader.append((inp, tar))
212 |
213 | valenc = tokenizer(" ".join(valdata[:1100]["text"]), return_tensors="pt")
214 | valenc = valenc.input_ids[:, : (256 * seqlen)]
215 |
216 | return trainloader, valenc
217 |
218 |
219 | def get_loaders(name, nsamples=128, seed=0, seqlen=2048, model=''):
220 | """
221 | Retrieves data loaders for different datasets based on the dataset name.
222 |
223 | Args:
224 | name (str): The name of the dataset to load, which can include specific versions like 'new'.
225 | nsamples (int): The number of samples to retrieve from the dataset.
226 | seed (int): The random seed to ensure reproducibility.
227 | seqlen (int): The sequence length of the samples.
228 | model (str): The model specification that might influence data preprocessing.
229 |
230 | Returns:
231 | DataLoader: A configured data loader for the specified dataset.
232 |
233 | Raises:
234 | ValueError: If the dataset name is not recognized or supported.
235 | """
236 | if 'wikitext2' in name:
237 | return get_wikitext2(nsamples, seed, seqlen, model)
238 | elif 'ptb' in name:
239 | if 'new' in name:
240 | return get_ptb_new(nsamples, seed, seqlen, model)
241 | else:
242 | return get_ptb(nsamples, seed, seqlen, model)
243 | elif 'c4' in name:
244 | if 'new' in name:
245 | return get_c4_new(nsamples, seed, seqlen, model)
246 | else:
247 | return get_c4(nsamples, seed, seqlen, model)
248 | else:
249 | raise ValueError(f"Only support wikitext2, c4, c4_new, ptb, ptb_new currently, but get {name}")
250 |
--------------------------------------------------------------------------------
/green_bit_llm/evaluation/evaluate.py:
--------------------------------------------------------------------------------
1 | import os
2 | import argparse
3 | import sys
4 | import warnings
5 | from pathlib import Path
6 | from tqdm import tqdm
7 |
8 | from lm_eval import evaluator
9 | from peft import PeftModel, LoraConfig, get_peft_model
10 |
11 | import torch
12 | import torch.nn as nn
13 |
14 | from green_bit_llm.evaluation.lmclass import LMClass
15 | from green_bit_llm.evaluation.utils import create_logger, add_dict_to_json_file
16 | from green_bit_llm.evaluation.datautils import get_loaders
17 | from green_bit_llm.common import load
18 | from green_bit_llm.sft.peft_utils.model import *
19 |
20 | warnings.filterwarnings('ignore')
21 |
22 | # default value for arguments
23 | DEFAULT_MODEL_PATH = "GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-2.2"
24 | DEFAULT_SEQLEN = 2048
25 | DEFAULT_RANDOM_SEED = 0
26 | DTYPE = torch.half
27 |
28 | replace_peft_lora_model_with_gba_lora_model()
29 |
30 |
31 | @torch.no_grad()
32 | def lm_evaluate(lm, args, logger):
33 | """
34 | Evaluates the language model (lm) according to the specified evaluation parameters in args.
35 | This function handles both perplexity evaluation on various datasets and few-shot learning evaluation.
36 |
37 | Parameters:
38 | lm: The language model object configured for evaluation.
39 | args: An object containing all necessary parameters and flags for evaluation, such as which datasets to use,
40 | whether to evaluate perplexity or few-shot performance, sequence length, etc.
41 | logger: A logging object used to record evaluation results and other important messages.
42 |
43 | Returns:
44 | A dictionary containing evaluation results, including perplexity values and few-shot evaluation metrics,
45 | keyed by dataset or task name.
46 | """
47 | results = {}
48 | lm.model = lm.model.to(lm.device)
49 |
50 | if args.eval_ppl:
51 | for dataset in args.ppl_tasks.split(","):
52 | dataloader, testloader = get_loaders(
53 | dataset,
54 | seed=args.seed,
55 | model=args.model,
56 | seqlen=args.seqlen,
57 | )
58 |
59 | if "c4" in dataset:
60 | testenc = testloader
61 | else:
62 | testenc = testloader.input_ids
63 |
64 | nsamples = testenc.numel() // lm.seqlen
65 | use_cache = lm.model.config.use_cache
66 | lm.model.config.use_cache = False
67 | lm.model.eval()
68 | nlls = []
69 |
70 | for i in tqdm(range(nsamples)):
71 | batch = testenc[:, (i * lm.seqlen): ((i + 1) * lm.seqlen)].to(lm.device)
72 | with torch.no_grad():
73 | outputs = lm.model.model(batch)
74 | hidden_states = outputs[0]
75 | logits = lm.model.lm_head(hidden_states)
76 | shift_logits = logits[:, :-1, :]
77 | shift_labels = testenc[:, (i * lm.seqlen): ((i + 1) * lm.seqlen)][
78 | :, 1:
79 | ].to(lm.model.lm_head.weight.device)
80 | loss_fct = nn.CrossEntropyLoss()
81 | loss = loss_fct(
82 | shift_logits.view(-1, shift_logits.size(-1)),
83 | shift_labels.view(-1),
84 | )
85 | neg_log_likelihood = loss.float() * lm.seqlen
86 | nlls.append(neg_log_likelihood)
87 |
88 | ppl = torch.exp(torch.stack(nlls).sum() / (nsamples * lm.seqlen))
89 | logger.info(f'{dataset} : {ppl.item()}')
90 | lm.model.config.use_cache = use_cache
91 | results[dataset] = ppl.item()
92 |
93 | if args.eval_few_shot and args.eval_few_shot != "":
94 | few_shot_tasks = args.few_shot_tasks.split(",")
95 |
96 | eval_results = evaluator.simple_evaluate(
97 | lm,
98 | tasks=few_shot_tasks,
99 | batch_size=args.batch_size,
100 | num_fewshot=args.num_fewshot,
101 | no_cache=True
102 | )
103 |
104 | results.update({"results": eval_results["results"]})
105 | results.update({"versions": eval_results["versions"]})
106 | logger.info(evaluator.make_table(results))
107 |
108 | return results
109 |
110 | def setup_arg_parser():
111 | """Set up and return the argument parser."""
112 | parser = argparse.ArgumentParser(description="green-bit-llm evaluate script")
113 | parser.add_argument(
114 | "--seed",
115 | type=int,
116 | default=DEFAULT_RANDOM_SEED,
117 | help="The random seed for data loader.",
118 | )
119 | parser.add_argument(
120 | "--model",
121 | type=str,
122 | default=DEFAULT_MODEL_PATH,
123 | help="The path to the local model directory or Hugging Face repo.",
124 | )
125 | parser.add_argument(
126 | "--cuda-device-id",
127 | type=str,
128 | default="0",
129 | help="CUDA device IDs.",
130 | )
131 | parser.add_argument(
132 | "--trust-remote-code",
133 | action="store_true",
134 | help="Enable trusting remote code for tokenizer.",
135 | )
136 | parser.add_argument(
137 | "--use-flash-attention-2",
138 | action="store_true",
139 | help="Enable using flash attention v2.",
140 | )
141 | parser.add_argument(
142 | "--eos-token",
143 | type=str,
144 | default="<|im_end|>",
145 | help="End of sequence token for tokenizer.",
146 | )
147 | parser.add_argument(
148 | "--seqlen",
149 | type=int,
150 | default=DEFAULT_SEQLEN,
151 | help="Sequence length."
152 | )
153 | parser.add_argument(
154 | "--eval-ppl",
155 | action="store_true",
156 | help="Evaluate LLM prediction perplexity.",
157 | )
158 | parser.add_argument(
159 | "--ppl-tasks",
160 | type=str,
161 | default="wikitext2, c4_new, ptb",
162 | help="Specify ppl evaluation task.",
163 | )
164 | parser.add_argument(
165 | "--eval-few-shot",
166 | action="store_true",
167 | help="Evaluate LLM few-shot learning ability.",
168 | )
169 | parser.add_argument(
170 | "--num-fewshot",
171 | type=int,
172 | default=0,
173 | help="Specify num of few shot examples for evaluation.",
174 | )
175 | parser.add_argument(
176 | "--few-shot-tasks",
177 | type=str,
178 | default="openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq,race,anli_r1,anli_r2,anli_r3,wic",
179 | help="Few-shot learning ability evaluation tasks.",
180 | )
181 | parser.add_argument(
182 | "--batch-size",
183 | type=int,
184 | default=16,
185 | help="Batch size for few-shot evaluation.",
186 | )
187 | parser.add_argument(
188 | "--save-dir",
189 | type=str,
190 | default="log/",
191 | help="Specify save dir for eval results.",
192 | )
193 | parser.add_argument(
194 | "--lora-dir",
195 | type=str,
196 | default=None,
197 | help="Specify lora dir for lora merge"
198 |
199 | )
200 | return parser
201 |
202 |
203 | def create_device_map(cuda_device_id):
204 | ids = cuda_device_id.split(',')
205 | # Create strings in the format "cuda:x" for each ID and put them into the collection
206 | device_map = {f"cuda:{id}" for id in ids}
207 | return device_map
208 |
209 | def main(args):
210 | if not os.path.exists(Path(args.save_dir)):
211 | os.mkdir(Path(args.save_dir))
212 |
213 | # Building configs
214 | tokenizer_config = {"trust_remote_code": True if args.trust_remote_code else None}
215 |
216 | pretrain_model_config = {
217 | "trust_remote_code": True if args.trust_remote_code else None,
218 | "attn_implementation": "flash_attention_2" if args.use_flash_attention_2 else None
219 | }
220 |
221 | if args.eos_token is not None:
222 | tokenizer_config["eos_token"] = args.eos_token
223 |
224 | model, tokenizer, config = load(
225 | args.model,
226 | tokenizer_config=tokenizer_config,
227 | dtype=DTYPE,
228 | device_map='auto',
229 | seqlen=args.seqlen,
230 | model_config=pretrain_model_config,
231 | requires_grad=False
232 | )
233 |
234 | if args.lora_dir is not None:
235 | config = LoraConfig(
236 | r=64,
237 | lora_alpha=32,
238 | target_modules=["q_proj", "v_proj", "out_proj", "up_proj"],
239 | lora_dropout=0.01,
240 | bias="none",
241 | task_type="CAUSAL_LM",
242 | )
243 | model = get_peft_model(model,config)
244 | model.load_adapter(args.lora_dir, adapter_name="default")
245 |
246 | lm = LMClass(args.model, batch_size=args.batch_size, config=config, tokenizer=tokenizer, model=model)
247 | lm.seqlen = args.seqlen
248 |
249 | logger = create_logger(Path(args.save_dir))
250 |
251 | with torch.no_grad():
252 | eval_results = lm_evaluate(lm=lm, args=args, logger=logger)
253 |
254 | eval_results = {"{}".format(args.model): eval_results}
255 |
256 | add_dict_to_json_file(file_path="{}".format(os.path.join(args.save_dir, "eval_results.json")), new_data=eval_results)
257 |
258 | if __name__ == "__main__":
259 | if not torch.cuda.is_available():
260 | print("Warning: CUDA is needed to run the model.")
261 | sys.exit(0)
262 |
263 | parser = setup_arg_parser()
264 | args = parser.parse_args()
265 |
266 | main(args)
267 |
--------------------------------------------------------------------------------
/green_bit_llm/evaluation/lmclass.py:
--------------------------------------------------------------------------------
1 | from lm_eval.base import BaseLM
2 | import torch.nn.functional as F
3 | import torch
4 |
5 | from colorama import init, Fore, Style
6 | init(autoreset=True)
7 |
8 | class LMClass(BaseLM):
9 | """
10 | Wraps a pretrained language model into a format suitable for evaluation tasks.
11 | This class adapts a given model to be used with specific language modeling evaluation tools.
12 |
13 | Args:
14 | model_name (str): Name of the language model.
15 | batch_size (int): Batch size per GPU for processing.
16 | config (dict): Configuration settings for the model.
17 | tokenizer: Tokenizer associated with the model for text processing.
18 | model (nn.Module): The pretrained neural network model.
19 | """
20 | def __init__(self, model_name, batch_size, config, tokenizer, model):
21 | # Initializes the model wrapper class with specified model and configuration
22 | super().__init__()
23 |
24 | self._device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
25 | self.model_name = model_name
26 | self.batch_size_per_gpu = batch_size
27 |
28 | self.model_config = config
29 | self.tokenizer = tokenizer
30 | self.model = model
31 | self.initial()
32 |
33 | def initial(self):
34 | # Initializes the model for inference, setting up necessary parameters such as sequence length and vocab size
35 | self.seqlen = self.model.config.max_position_embeddings
36 | self.model.eval()
37 | self.vocab_size = self.tokenizer.vocab_size
38 | print(Style.BRIGHT + Fore.CYAN + "Info: vocab size: ", self.vocab_size)
39 |
40 | @property
41 | def eot_token(self) -> str:
42 | # Returns the end-of-text token as a string
43 | return self.tokenizer.eos_token
44 |
45 | @property
46 | def eot_token_id(self):
47 | # we use EOT because end of *text* is more accurate for what we're doing than end of *sentence*
48 | return self.tokenizer.eos_token_id
49 |
50 | @property
51 | def max_length(self):
52 | # Returns the maximum length of sequences the model can handle, based on the model's configuration
53 | try:
54 | return self.gpt2.config.n_ctx
55 | except AttributeError:
56 | # gptneoconfig doesn't have n_ctx apparently
57 | return self.model.config.max_position_embeddings
58 |
59 | @property
60 | def max_gen_toks(self):
61 | # Returns the maximum number of tokens that can be generated in one go
62 | print(Style.BRIGHT + Fore.CYAN + "Info: max_gen_toks fn")
63 | return 256
64 |
65 | @property
66 | def batch_size(self):
67 | # Returns the configured batch size per GPU
68 | # TODO: fix multi-gpu
69 | return self.batch_size_per_gpu # * gpus
70 |
71 | @property
72 | def device(self):
73 | # Returns the computing device (CPU or GPU) that the model is using
74 | # TODO: fix multi-gpu
75 | return self._device
76 |
77 | def tok_encode(self, string: str):
78 | # Encodes a string into its corresponding IDs using the tokenizer
79 | return self.tokenizer.encode(string, add_special_tokens=False)
80 |
81 | def tok_encode_batch(self, strings):
82 | # Encodes a batch of strings into model inputs, handling padding and special tokens
83 | return self.tokenizer(
84 | strings,
85 | padding=True,
86 | add_special_tokens=False,
87 | return_tensors="pt",
88 | )
89 |
90 | def tok_decode(self, tokens):
91 | # Decodes a batch of token IDs back into strings
92 | return self.tokenizer.batch_decode(tokens, skip_special_tokens=True)
93 |
94 | def _model_call(self, inps):
95 | """
96 | Performs a forward pass through the model with the provided inputs and returns logits
97 |
98 | Args:
99 | inps: a torch tensor of shape [batch, sequence]
100 | the size of sequence may vary from call to call
101 | returns: a torch tensor of shape [batch, sequence, vocab] with the
102 | logits returned from the model
103 | """
104 | with torch.no_grad():
105 | return self.model(inps)["logits"]
106 |
107 | def model_batched_set(self, inps):
108 | # Processes a set of inputs in batches and returns a list of logit tensors
109 | dataset_logits = []
110 | for batch in inps:
111 | multi_logits = F.log_softmax(
112 | self._model_call(batch), dim=-1
113 | ).cpu() # [batch, padding_length, vocab]
114 | dataset_logits.append(multi_logits)
115 | return dataset_logits
116 |
117 | def _model_generate(self, context, max_length, eos_token_id):
118 | # Generates text based on a given context up to a specified maximum length
119 | return self.model.generate(
120 | context, max_length=max_length, eos_token_id=eos_token_id, do_sample=False
121 | )
122 |
--------------------------------------------------------------------------------
/green_bit_llm/evaluation/utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import json
4 | import time
5 | import logging
6 | from termcolor import colored
7 |
8 |
9 | def pattern_match(patterns, source_list):
10 | """
11 | Function to find unique matching patterns from a source list.
12 | Args:
13 | patterns: list of pattern strings to match.
14 | Returns:
15 | list: list of task name
16 | """
17 | task_names = set()
18 | for pattern in patterns:
19 | task_names.add(pattern)
20 | return list(task_names)
21 |
22 | def add_dict_to_json_file(file_path, new_data):
23 | """
24 | Update a JSON file based on the top-level keys in new_data. If the key exists, it replaces the existing content
25 | under that key. If it doesn't exist, it adds the new key with its value.
26 |
27 | Args:
28 | file_path: Path to the JSON file.
29 | new_data: Dictionary to add or update in the file.
30 | """
31 | # Initialize or load existing data
32 | if os.path.exists(file_path) and os.stat(file_path).st_size > 0:
33 | with open(file_path, 'r') as file:
34 | existing_data = json.load(file)
35 | else:
36 | existing_data = {}
37 |
38 | # Merge new data into existing data based on the top-level keys
39 | existing_data.update(new_data)
40 |
41 | # Write the updated data back to the file
42 | with open(file_path, 'w') as file:
43 | json.dump(existing_data, file, indent=4)
44 |
45 | def create_logger(output_dir, dist_rank=0, name=''):
46 | """
47 | Creates and configures a logger with console and file handlers.
48 |
49 | Args:
50 | output_dir (str): Directory where the log files will be stored.
51 | dist_rank (int): Rank of the process in distributed training. Only the master process (rank 0) will output to the console.
52 | name (str): Name of the logger, used to differentiate output if multiple loggers are used.
53 |
54 | Returns:
55 | logger: Configured logger object.
56 | """
57 | # create logger
58 | logger = logging.getLogger(name)
59 | logger.setLevel(logging.INFO)
60 | logger.propagate = False
61 |
62 | # create formatter
63 | fmt = '[%(asctime)s %(name)s] (%(filename)s %(lineno)d): %(levelname)s %(message)s'
64 | color_fmt = colored('[%(asctime)s %(name)s]', 'green') + \
65 | colored('(%(filename)s %(lineno)d)', 'yellow') + ': %(levelname)s %(message)s'
66 |
67 | # create console handlers for master process
68 | if dist_rank == 0:
69 | console_handler = logging.StreamHandler(sys.stdout)
70 | console_handler.setLevel(logging.DEBUG)
71 | console_handler.setFormatter(
72 | logging.Formatter(fmt=color_fmt, datefmt='%Y-%m-%d %H:%M:%S'))
73 | logger.addHandler(console_handler)
74 |
75 | # create file handlers
76 | file_handler = logging.FileHandler(os.path.join(output_dir, f'log_rank{dist_rank}_{int(time.time())}.txt'), mode='a')
77 | file_handler.setLevel(logging.DEBUG)
78 | file_handler.setFormatter(logging.Formatter(fmt=fmt, datefmt='%Y-%m-%d %H:%M:%S'))
79 | logger.addHandler(file_handler)
80 |
81 | return logger
82 |
83 |
--------------------------------------------------------------------------------
/green_bit_llm/inference/README.md:
--------------------------------------------------------------------------------
1 | # Inference Package for GreenBitAI's Low-bit LLMs
2 |
3 | ## Overview
4 |
5 | This package demonstrates the capabilities of [GreenBitAI's low-bit large language models (LLMs)](https://huggingface.co/GreenBitAI) through two main features:
6 | 1. Simple generation with `sim_gen.py` script.
7 | 2. A command-line interface (CLI) based chat demo using the `chat_cli.py` script.
8 |
9 | Both tools are designed for efficient natural language processing, enabling quick setups and responses using local models.
10 |
11 | ## Installation
12 |
13 | Please follow the [main installation instructions](../../README.md#installation) for how to install the packages required to run this inference package.
14 | Further packages should not be required.
15 |
16 | ## Usage
17 |
18 | ### LLMs
19 |
20 | We have released over 200 highly precise 2.2/2.5/3/4-bit models across the modern LLM family, featuring LLaMA 2/3, 01-Yi, Qwen, Mistral, Phi-3, and more.
21 |
22 | | Family | Bpw | Size | HF collection id |
23 | |:----------------:|:------------------:|:------------------------------:|:-----------------------------------------------------------------------------------------------------------------:|
24 | | Llama-3 | `4.0/3.0/2.5/2.2` | `8B/70B` | [`GreenBitAI Llama-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-3-6627bc1ec6538e3922c5d81c) |
25 | | Llama-2 | `3.0/2.5/2.2` | `7B/13B/70B` | [`GreenBitAI Llama-2`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-2-661f87e3b073ff8e48a12834) |
26 | | Qwen-1.5 | `4.0/3.0/2.5/2.2` | `0.5B/1.8B/4B/7B/14B/32B/110B` | [`GreenBitAI Qwen 1.5`](https://huggingface.co/collections/GreenBitAI/greenbitai-qwen15-661f86ea69433f3d3062c920) |
27 | | Phi-3 | `3.0/2.5/2.2` | `mini` | [`GreenBitAI Phi-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-phi-3-6628d008cdf168398a296c92) |
28 | | Mistral | `3.0/2.5/2.2` | `7B` | [`GreenBitAI Mistral`](https://huggingface.co/collections/GreenBitAI/greenbitai-mistral-661f896c45da9d8b28a193a8) |
29 | | 01-Yi | `3.0/2.5/2.2` | `6B/34B` | [`GreenBitAI 01-Yi`](https://huggingface.co/collections/GreenBitAI/greenbitai-01-yi-661f88af0648daa766d5102f) |
30 | | Llama-3-instruct | `4.0/3.0/2.5/2.2` | `8B/70B` | [`GreenBitAI Llama-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-3-6627bc1ec6538e3922c5d81c) |
31 | | Mistral-instruct | `3.0/2.5/2.2` | `7B` | [`GreenBitAI Mistral`](https://huggingface.co/collections/GreenBitAI/greenbitai-mistral-661f896c45da9d8b28a193a8) |
32 | | Phi-3-instruct | `3.0/2.5/2.2` | `mini` | [`GreenBitAI Phi-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-phi-3-6628d008cdf168398a296c92) |
33 | | Qwen-1.5-Chat | `4.0/3.0/2.5/2.2` | `0.5B/1.8B/4B/7B/14B/32B/110B` | [`GreenBitAI Qwen 1.5`](https://huggingface.co/collections/GreenBitAI/greenbitai-qwen15-661f86ea69433f3d3062c920) |
34 | | 01-Yi-Chat | `3.0/2.5/2.2` | `6B/34B` | [`GreenBitAI 01-Yi`](https://huggingface.co/collections/GreenBitAI/greenbitai-01-yi-661f88af0648daa766d5102f) |
35 |
36 |
37 | ### Simple Generation
38 |
39 | Run the simple generation script as follows:
40 |
41 | ```bash
42 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.inference.sim_gen --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --max-tokens 100 --use-flash-attention-2 --ignore-chat-template --prompt "The meaning of life is"
43 | ```
44 |
45 | This command generates text based on the provided prompt using the specified GreenBitAI model.
46 |
47 | ### CLI-Based Chat Demo
48 |
49 | To start the chat interface:
50 |
51 | ```bash
52 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.inference.chat_cli --model GreenBitAI/Qwen-1.5-1.8B-Chat-layer-mix-bpw-2.2 --use-flash-attention-2 --multiline --mouse
53 | ```
54 | This launches a rich command-line interface for interactive chatting.
55 |
56 | ## License
57 | - The scripts `conversation.py`, `chat_base.py`, and `chat_cli.py` have been modified from their original versions found in [FastChat-serve](https://github.com/lm-sys/FastChat/tree/main/fastchat/serve), which are released under the [Apache 2.0 License](https://github.com/lm-sys/FastChat/tree/main/LICENSE).
58 | - We release our changes and additions to these files under the [Apache 2.0 License](../../LICENSE).
59 |
--------------------------------------------------------------------------------
/green_bit_llm/inference/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/inference/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/inference/chat_cli.py:
--------------------------------------------------------------------------------
1 | """
2 | cli chat demo.
3 | Code based on: https://github.com/yanghaojin/FastChat/blob/greenbit/fastchat/serve/cli.py
4 | """
5 | import argparse
6 | import os
7 | import warnings
8 | warnings.filterwarnings("ignore", category=UserWarning, module='torch.nn.modules.module')
9 |
10 | import torch
11 |
12 | # Add the parent directory to sys.path
13 | from green_bit_llm.inference.utils import str_to_torch_dtype
14 |
15 | try:
16 | from green_bit_llm.inference.chat_base import chat_loop, SimpleChatIO, RichChatIO
17 | except Exception:
18 | raise Exception("Error occurred when import chat loop, ChatIO classes.")
19 |
20 |
21 | def main(args):
22 | # args setup
23 | if args.gpus:
24 | if len(args.gpus.split(",")) < args.num_gpus:
25 | raise ValueError(
26 | f"Larger --num-gpus ({args.num_gpus}) than --gpus {args.gpus}!"
27 | )
28 | # NOTE that we need to set this before any other cuda operations. Otherwise will not work.
29 | os.environ["CUDA_VISIBLE_DEVICES"] = args.gpus
30 |
31 | if not torch.cuda.is_available():
32 | raise Exception("Warning: CUDA is needed to run the model.")
33 |
34 | if args.style == "simple":
35 | chatio = SimpleChatIO(args.multiline)
36 | elif args.style == "rich":
37 | chatio = RichChatIO(args.multiline, args.mouse)
38 | else:
39 | raise ValueError(f"Invalid style for console: {args.style}")
40 |
41 | # Building configs
42 | tokenizer_config = {"trust_remote_code": True if args.trust_remote_code else None}
43 | pretrain_model_config = {
44 | "trust_remote_code": True if args.trust_remote_code else None,
45 | "attn_implementation": "flash_attention_2" if args.use_flash_attention_2 else None
46 | }
47 |
48 | if args.eos_token is not None:
49 | tokenizer_config["eos_token"] = args.eos_token
50 |
51 | # chat
52 | try:
53 | chat_loop(
54 | args.model,
55 | tokenizer_config,
56 | pretrain_model_config,
57 | args.seqlen,
58 | args.device,
59 | str_to_torch_dtype(args.dtype),
60 | args.conv_template,
61 | args.conv_system_msg,
62 | args.temperature,
63 | args.repetition_penalty,
64 | args.max_new_tokens,
65 | chatio,
66 | judge_sent_end=args.judge_sent_end,
67 | debug=args.debug,
68 | history=not args.no_history,
69 | )
70 | except KeyboardInterrupt:
71 | print("exit...")
72 |
73 |
74 | if __name__ == "__main__":
75 | parser = argparse.ArgumentParser()
76 | parser.add_argument(
77 | "--model",
78 | type=str,
79 | default="GreenBitAI/Mistral-Instruct-7B-v0.2-layer-mix-bpw-2.2",
80 | help="The path to the weights. This can be a local folder or a Hugging Face repo ID.",
81 | )
82 | parser.add_argument(
83 | "--device",
84 | type=str,
85 | choices=["cpu", "cuda"],
86 | default="cuda",
87 | help="The device type",
88 | )
89 | parser.add_argument(
90 | "--gpus",
91 | type=str,
92 | default='0',
93 | help="A single GPU like 1 or multiple GPUs like 0,2",
94 | )
95 | parser.add_argument("--num-gpus", type=int, default=1)
96 | parser.add_argument(
97 | "--dtype",
98 | type=str,
99 | choices=["float32", "float16"],
100 | help="Override the default dtype. If not set, it will use float16 on GPU and float32 on CPU.",
101 | default="float16",
102 | )
103 | parser.add_argument(
104 | "--conv-template", type=str, default=None, help="Conversation prompt template."
105 | )
106 | parser.add_argument(
107 | "--conv-system-msg", type=str, default=None, help="Conversation system message."
108 | )
109 | parser.add_argument("--temperature", type=float, default=0.7)
110 | parser.add_argument("--repetition_penalty", type=float, default=1.0)
111 | parser.add_argument("--max-new-tokens", type=int, default=256)
112 | parser.add_argument("--no-history", action="store_true", help="Disables chat history.")
113 | parser.add_argument(
114 | "--style",
115 | type=str,
116 | default="rich",
117 | choices=["simple", "rich"],
118 | help="Display style.",
119 | )
120 | parser.add_argument(
121 | "--multiline",
122 | action="store_true",
123 | help="Enable multiline input. Use ESC+Enter for newline.",
124 | )
125 | parser.add_argument(
126 | "--mouse",
127 | action="store_true",
128 | help="[Rich Style]: Enable mouse support for cursor positioning.",
129 | )
130 | parser.add_argument(
131 | "--judge-sent-end",
132 | action="store_true",
133 | help="Whether enable the correction logic that interrupts the output of sentences due to EOS.",
134 | )
135 | parser.add_argument(
136 | "--debug",
137 | action="store_true",
138 | help="Print useful debug information (e.g., prompts)",
139 | )
140 | parser.add_argument(
141 | "--eos-token",
142 | type=str,
143 | default=None,
144 | help="End of sequence token for tokenizer",
145 | )
146 | parser.add_argument(
147 | "--trust-remote-code",
148 | action="store_true",
149 | help="Enable trusting remote code",
150 | )
151 | parser.add_argument(
152 | "--seqlen", type=int, default=2048, help="Sequence length"
153 | )
154 | parser.add_argument(
155 | "--use-flash-attention-2",
156 | action="store_true",
157 | help="Enable using flash attention v2",
158 | )
159 | args = parser.parse_args()
160 | main(args)
--------------------------------------------------------------------------------
/green_bit_llm/inference/sim_gen.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import torch
4 | import torch.nn as nn
5 |
6 | import warnings
7 | warnings.filterwarnings("ignore", category=UserWarning, module='torch.nn.modules.module')
8 |
9 | from transformers import PreTrainedTokenizer
10 |
11 | from green_bit_llm.common import generate, load
12 | from green_bit_llm.args_parser import setup_shared_arg_parser
13 |
14 | # default value for arguments
15 | DEFAULT_PROMPT = None
16 | DEFAULT_MAX_TOKENS = 100
17 | DEFAULT_TEMP = 0.8
18 | DEFAULT_TOP_P = 0.95
19 | DTYPE = torch.half
20 |
21 |
22 | def setup_arg_parser():
23 | """Set up and return the argument parser."""
24 | parser = setup_shared_arg_parser("green-bit-llm inference script")
25 |
26 | parser.add_argument("--num-gpus", type=int, default=1)
27 | parser.add_argument(
28 | "--gpus",
29 | type=str,
30 | default='0',
31 | help="A single GPU like 1 or multiple GPUs like 0,2",
32 | )
33 | parser.add_argument(
34 | "--eos-token",
35 | type=str,
36 | default=None,
37 | help="End of sequence token for tokenizer",
38 | )
39 | parser.add_argument(
40 | "--max-tokens",
41 | type=int,
42 | default=DEFAULT_MAX_TOKENS,
43 | help="Maximum number of tokens to generate",
44 | )
45 | parser.add_argument(
46 | "--prompt", default=DEFAULT_PROMPT, help="Message to be processed by the model"
47 | )
48 | parser.add_argument(
49 | "--temp", type=float, default=DEFAULT_TEMP, help="Sampling temperature"
50 | )
51 | parser.add_argument(
52 | "--top-p", type=float, default=DEFAULT_TOP_P, help="Sampling top-p"
53 | )
54 | parser.add_argument(
55 | "--ignore-chat-template",
56 | action="store_true",
57 | help="Use the raw prompt without the tokenizer's chat template.",
58 | )
59 | parser.add_argument(
60 | "--use-default-chat-template",
61 | action="store_true",
62 | help="Use the default chat template",
63 | )
64 | parser.add_argument(
65 | "--enable-thinking",
66 | action="store_true",
67 | help="Enable thinking mode for Qwen-3 models.",
68 | )
69 | return parser
70 |
71 |
72 | def do_generate(args, model: nn.Module, tokenizer: PreTrainedTokenizer, prompt: str, enable_thinking: bool):
73 | """
74 | This function generates text based on a given prompt using a model and tokenizer.
75 | It handles optional pre-processing with chat templates if specified in the arguments.
76 | """
77 | if not args.ignore_chat_template and (
78 | hasattr(tokenizer, "apply_chat_template")
79 | and tokenizer.chat_template is not None
80 | ):
81 | messages = [{"role": "user", "content": prompt}]
82 | prompt = tokenizer.apply_chat_template(
83 | messages,
84 | tokenize=False,
85 | add_generation_prompt=True,
86 | enable_thinking=enable_thinking
87 | )
88 | else:
89 | prompt = prompt
90 |
91 | generate(
92 | model,
93 | tokenizer,
94 | prompt,
95 | args.temp,
96 | args.max_tokens,
97 | True,
98 | top_p=args.top_p
99 | )
100 |
101 |
102 | def main(args):
103 |
104 | if args.gpus:
105 | if len(args.gpus.split(",")) < args.num_gpus:
106 | raise ValueError(
107 | f"Larger --num-gpus ({args.num_gpus}) than --gpus {args.gpus}!"
108 | )
109 | os.environ["CUDA_VISIBLE_DEVICES"] = args.gpus
110 |
111 | if not torch.cuda.is_available():
112 | raise Exception("Warning: CUDA is needed to run the model.")
113 |
114 | # Building configs
115 | tokenizer_config = {"trust_remote_code": True if args.trust_remote_code else None}
116 | pretrain_model_config = {
117 | "trust_remote_code": True if args.trust_remote_code else None,
118 | "attn_implementation": "flash_attention_2" if args.use_flash_attention_2 else None
119 | }
120 |
121 | if args.eos_token is not None:
122 | tokenizer_config["eos_token"] = args.eos_token
123 |
124 | model, tokenizer, config = load(
125 | args.model,
126 | tokenizer_config=tokenizer_config,
127 | dtype=DTYPE,
128 | device_map='auto',
129 | seqlen=args.seqlen,
130 | model_config=pretrain_model_config,
131 | requires_grad=False
132 | )
133 |
134 | if args.use_default_chat_template:
135 | if tokenizer.chat_template is None:
136 | tokenizer.chat_template = tokenizer.default_chat_template
137 |
138 | if args.prompt is None:
139 | while True:
140 | user_input = input("Input prompt or type 'exit' to quit): ")
141 | if user_input.lower() in ['exit', 'quit']:
142 | break
143 | do_generate(args, model, tokenizer, user_input, args.enable_thinking)
144 | else:
145 | do_generate(args, model, tokenizer, args.prompt, args.enable_thinking)
146 |
147 |
148 | if __name__ == "__main__":
149 | parser = setup_arg_parser()
150 | args = parser.parse_args()
151 |
152 | main(args)
--------------------------------------------------------------------------------
/green_bit_llm/inference/utils.py:
--------------------------------------------------------------------------------
1 | from transformers.generation.logits_process import (
2 | LogitsProcessorList,
3 | RepetitionPenaltyLogitsProcessor,
4 | TemperatureLogitsWarper,
5 | TopKLogitsWarper,
6 | TopPLogitsWarper,
7 | )
8 |
9 | from .conversation import Conversation, get_conv_template
10 |
11 | # value is the search term in model name,
12 | # key is the name of conversation template
13 | CONV_TEMP_DICT = {
14 | "llama-2": "llama-2",
15 | "qwen-chat": "qwen",
16 | "yi-chat": "yi-",
17 | "mistral": "mistral",
18 | "gemma": "gemma",
19 | "llama-3": "llama-3",
20 | "phi-3": "phi-3",
21 | }
22 |
23 | # Models don't use the same configuration key for determining the maximum
24 | # sequence length. Store them here so we can sanely check them.
25 | # NOTE: The ordering here is important. Some models have two of these and we
26 | # have a preference for which value gets used.
27 | SEQUENCE_LENGTH_KEYS = [
28 | "max_position_embeddings",
29 | "max_sequence_length",
30 | "seq_length",
31 | "max_seq_len",
32 | "model_max_length",
33 | ]
34 |
35 |
36 | def is_partial_stop(output: str, stop_str: str):
37 | """Check whether the output contains a partial stop str."""
38 | for i in range(0, min(len(output), len(stop_str))):
39 | if stop_str.startswith(output[-i:]):
40 | return True
41 | return False
42 |
43 | def is_sentence_complete(output: str):
44 | """Check whether the output is a complete sentence."""
45 | end_symbols = (".", "?", "!", "...", "。", "?", "!", "…", '"', "'", "”")
46 | return output.endswith(end_symbols)
47 |
48 | def get_context_length(config):
49 | """Get the context length of a model from a huggingface model config."""
50 | rope_scaling = getattr(config, "rope_scaling", None)
51 | if rope_scaling:
52 | try:
53 | rope_scaling_factor = config.rope_scaling["factor"]
54 | except KeyError:
55 | rope_scaling_factor = 1
56 | else:
57 | rope_scaling_factor = 1
58 |
59 | for key in SEQUENCE_LENGTH_KEYS:
60 | val = getattr(config, key, None)
61 | if val is not None:
62 | return int(rope_scaling_factor * val)
63 | return 2048
64 |
65 | def get_conversation_template(model_path: str) -> Conversation:
66 | """Get and return a specific conversation template via checking its model path/model name."""
67 | for key, value in CONV_TEMP_DICT.items():
68 | # check if model path contains the value
69 | if value in model_path.lower():
70 | return get_conv_template(key)
71 | raise Exception("Invalid model path: The provided model is not supported yet.")
72 |
73 | def prepare_logits_processor(
74 | temperature: float, repetition_penalty: float, top_p: float, top_k: int
75 | ) -> LogitsProcessorList:
76 | """
77 | Creates and initializes a list of logits processors based on the specified parameters.
78 | Each processor applies a different modification to the logits during text generation,
79 | such as adjusting the sampling temperature, applying repetition penalties,
80 | or enforcing top-p and top-k constraints.
81 |
82 | Args:
83 | temperature (float): Scaling factor for logits; a value of 1.0 means no scaling.
84 | repetition_penalty (float): Penalty for repeated tokens to discourage repetition.
85 | top_p (float): The cumulative probability threshold for nucleus sampling, filters out the smallest probabilities.
86 | top_k (int): The number of highest probability logits to keep for top-k sampling.
87 |
88 | Returns:
89 | LogitsProcessorList: A configured list of logits processors.
90 | """
91 | processor_list = LogitsProcessorList()
92 | # TemperatureLogitsWarper doesn't accept 0.0, 1.0 makes it a no-op so we skip two cases.
93 | if temperature >= 1e-5 and temperature != 1.0:
94 | processor_list.append(TemperatureLogitsWarper(temperature))
95 | if repetition_penalty > 1.0:
96 | processor_list.append(RepetitionPenaltyLogitsProcessor(repetition_penalty))
97 | if 1e-8 <= top_p < 1.0:
98 | processor_list.append(TopPLogitsWarper(top_p))
99 | if top_k > 0:
100 | processor_list.append(TopKLogitsWarper(top_k))
101 | return processor_list
102 |
103 | def str_to_torch_dtype(dtype: str):
104 | """Get torch dtype via parsing the dtype string."""
105 | import torch
106 |
107 | if dtype is None:
108 | return None
109 | elif dtype == "float32":
110 | return torch.float32
111 | elif dtype == "float16":
112 | return torch.half
113 | elif dtype == "bfloat16":
114 | return torch.bfloat16
115 | else:
116 | raise ValueError(f"Unrecognized dtype: {dtype}")
117 |
118 | def is_chat_model(path):
119 | """Distinguish if the input model name contains keywords like '-chat-' or '-instrct-'"""
120 | substrings = ["-chat-", "-instruct-"]
121 | return any(substring in path for substring in substrings)
--------------------------------------------------------------------------------
/green_bit_llm/langchain/README.md:
--------------------------------------------------------------------------------
1 | # GreenBit Langchain Demos
2 |
3 | ## Overview
4 |
5 | GreenBit Langchain Demos showcase the integration of GreenBit language models with the Langchain framework, enabling powerful and flexible natural language processing capabilities.
6 |
7 | ## Installation
8 |
9 | ### Step 1: Install the green-bit-llm Package
10 |
11 | ```bash
12 | pip install green-bit-llm
13 | ```
14 |
15 | ### Step 2: Install Langchain Package
16 |
17 | ```bash
18 | pip install langchain-core
19 | ```
20 |
21 | If you want to use RAG demo, please make sure that the `sentence_transformers` python package has been installed.
22 |
23 | ```bash
24 | pip install sentence-transformers
25 | ```
26 |
27 | Ensure your system has Python3 and pip installed before proceeding.
28 |
29 | ## Usage
30 |
31 | ### Basic Example
32 |
33 | Here's a basic example of how to use the GreenBit Langchain integration:
34 |
35 | ```python
36 | from langchain_core.messages import HumanMessage
37 | from green_bit_llm.langchain import GreenBitPipeline, ChatGreenBit
38 | import torch
39 |
40 | pipeline = GreenBitPipeline.from_model_id(
41 | model_id="GreenBitAI/Llama-3-8B-instruct-layer-mix-bpw-4.0",
42 | device="cuda:0",
43 | model_kwargs={"dtype": torch.half, "device_map": 'auto', "seqlen": 2048, "requires_grad": False},
44 | pipeline_kwargs={"max_new_tokens": 100, "temperature": 0.7},
45 | )
46 |
47 | chat = ChatGreenBit(llm=pipeline)
48 |
49 | # normal generation
50 | response = chat.invoke("What is the capital of France?")
51 | print(response.content)
52 |
53 | # stream generation
54 | for chunk in chat.stream([HumanMessage(content="Tell me a story about a brave knight.")]):
55 | print(chunk.message.content, end="", flush=True)
56 |
57 | ```
58 |
--------------------------------------------------------------------------------
/green_bit_llm/langchain/__init__.py:
--------------------------------------------------------------------------------
1 | from .pipeline import GreenBitPipeline
2 | from .embedding import GreenBitEmbeddings
3 | from .chat_model import ChatGreenBit
--------------------------------------------------------------------------------
/green_bit_llm/langchain/chat_model.py:
--------------------------------------------------------------------------------
1 | from typing import Any, Dict, List, Optional, Union, Sequence, Literal, Callable, Type
2 | from pydantic import Field
3 | from langchain_core.callbacks.manager import (
4 | AsyncCallbackManagerForLLMRun,
5 | CallbackManagerForLLMRun,
6 | )
7 | from langchain_core.language_models.chat_models import BaseChatModel
8 | from langchain_core.messages import (
9 | AIMessage,
10 | BaseMessage,
11 | ChatMessage,
12 | HumanMessage,
13 | SystemMessage,
14 | )
15 | from langchain_core.outputs import ChatGeneration, ChatResult, LLMResult
16 | from langchain_core.language_models import LanguageModelInput
17 | from langchain_core.runnables import Runnable, RunnableConfig
18 | from langchain_core.tools import BaseTool
19 | from langchain_core.utils.function_calling import convert_to_openai_tool
20 |
21 | from green_bit_llm.langchain import GreenBitPipeline
22 |
23 | DEFAULT_SYSTEM_PROMPT = """You are a helpful, respectful, and honest assistant."""
24 |
25 |
26 | class ChatGreenBit(BaseChatModel):
27 | """GreenBit Chat model.
28 |
29 | Example:
30 | .. code-block:: python
31 |
32 | from green_bit_llm.langchain import GreenBitPipeline
33 |
34 | model_config = {
35 | "trust_remote_code": True,
36 | "attn_implementation": "flash_attention_2"
37 | }
38 |
39 | tokenizer_config = {"trust_remote_code": True}
40 |
41 | gb = GreenBitPipeline.from_model_id(
42 | model_id="GreenBitAI/Llama-3-8B-instruct-layer-mix-bpw-4.0",
43 | task="text-generation",
44 | pipeline_kwargs={"max_tokens": 100, "temp": 0.7},
45 | model_kwargs={
46 | "dtype": torch.half,
47 | "seqlen": 2048,
48 | "requires_grad": False,
49 | "model_config": model_config,
50 | "tokenizer_config": tokenizer_config
51 | }
52 | )
53 | """
54 |
55 | llm: GreenBitPipeline = Field(..., description="GreenBit Pipeline instance")
56 |
57 | class Config:
58 | """Configuration for this pydantic object."""
59 | arbitrary_types_allowed = True
60 |
61 | def __init__(
62 | self,
63 | llm: GreenBitPipeline,
64 | **kwargs: Any,
65 | ) -> None:
66 | """Initialize the chat model.
67 |
68 | Args:
69 | llm: GreenBit Pipeline instance
70 | **kwargs: Additional keyword arguments
71 | """
72 | # First initialize with mandatory llm field
73 | super().__init__(llm=llm, **kwargs)
74 |
75 | @property
76 | def _llm_type(self) -> str:
77 | return "greenbit-chat"
78 |
79 | def _create_chat_result(self, llm_result: LLMResult) -> ChatResult:
80 | """Convert LLM result to chat messages"""
81 | generations = []
82 | for gen in llm_result.generations:
83 | for g in gen:
84 | message = AIMessage(content=g.text.strip())
85 | chat_generation = ChatGeneration(
86 | message=message,
87 | generation_info=g.generation_info
88 | )
89 | generations.append(chat_generation)
90 | return ChatResult(generations=generations)
91 |
92 | def _messages_to_dict(self, messages: List[BaseMessage]) -> List[Dict[str, str]]:
93 | """Convert LangChain messages to dictionary format for apply_chat_template"""
94 | message_dicts = []
95 |
96 | for message in messages:
97 | if isinstance(message, SystemMessage):
98 | message_dicts.append({"role": "system", "content": message.content})
99 | elif isinstance(message, HumanMessage):
100 | message_dicts.append({"role": "user", "content": message.content})
101 | elif isinstance(message, AIMessage):
102 | message_dicts.append({"role": "assistant", "content": message.content})
103 |
104 | return message_dicts
105 |
106 | def _prepare_prompt(self, messages: List[BaseMessage], **kwargs) -> str:
107 | """Prepare prompt using apply_chat_template"""
108 | if not hasattr(self.llm.pipeline, 'tokenizer'):
109 | raise ValueError("Tokenizer not available in pipeline")
110 |
111 | tokenizer = self.llm.pipeline.tokenizer
112 | if not hasattr(tokenizer, 'apply_chat_template'):
113 | raise ValueError("Tokenizer does not support apply_chat_template")
114 |
115 | # Convert messages to dict format
116 | message_dicts = self._messages_to_dict(messages)
117 |
118 | # Prepare apply_chat_template arguments
119 | template_kwargs = {
120 | "add_generation_prompt": True,
121 | "tokenize": False, # 关键:设置为 False 确保返回字符串
122 | }
123 |
124 | # Add enable_thinking for Qwen3 models if provided
125 | enable_thinking = kwargs.get('enable_thinking')
126 | if enable_thinking is not None:
127 | template_kwargs["enable_thinking"] = enable_thinking
128 |
129 | try:
130 | result = tokenizer.apply_chat_template(message_dicts, **template_kwargs)
131 |
132 | # 确保返回字符串
133 | if isinstance(result, list):
134 | # 如果仍然返回 token IDs,解码为字符串
135 | return tokenizer.decode(result, skip_special_tokens=False)
136 | elif isinstance(result, str):
137 | return result
138 | else:
139 | raise ValueError(f"Unexpected return type from apply_chat_template: {type(result)}")
140 |
141 | except Exception as e:
142 | raise ValueError(f"Failed to apply chat template: {str(e)}")
143 |
144 | def generate(
145 | self,
146 | messages: List[BaseMessage],
147 | stop: Optional[List[str]] = None,
148 | run_manager: Optional[CallbackManagerForLLMRun] = None,
149 | **kwargs: Any,
150 | ) -> ChatResult:
151 | """Generate chat completion using the underlying pipeline"""
152 | # Prepare prompt using apply_chat_template
153 | prompt = self._prepare_prompt(messages, **kwargs)
154 |
155 | # Handle generation parameters
156 | generation_kwargs = {}
157 | if "temperature" in kwargs:
158 | generation_kwargs["temperature"] = kwargs["temperature"]
159 | if "max_new_tokens" in kwargs:
160 | generation_kwargs["max_new_tokens"] = kwargs["max_new_tokens"]
161 | elif "max_tokens" in kwargs:
162 | generation_kwargs["max_new_tokens"] = kwargs["max_tokens"]
163 |
164 | wrapped_kwargs = {
165 | "pipeline_kwargs": generation_kwargs,
166 | "stop": stop,
167 | **kwargs
168 | }
169 |
170 | # Generate using pipeline
171 | llm_result = self.llm.generate(
172 | prompts=[prompt],
173 | run_manager=run_manager,
174 | **wrapped_kwargs
175 | )
176 |
177 | return self._create_chat_result(llm_result)
178 |
179 | def _generate(
180 | self,
181 | messages: List[BaseMessage],
182 | stop: Optional[List[str]] = None,
183 | run_manager: Optional[CallbackManagerForLLMRun] = None,
184 | **kwargs: Any,
185 | ) -> ChatResult:
186 | """Generate method required by BaseChatModel"""
187 | return self.generate(messages, stop, run_manager, **kwargs)
188 |
189 | def stream(
190 | self,
191 | messages: List[BaseMessage],
192 | stop: Optional[List[str]] = None,
193 | run_manager: Optional[CallbackManagerForLLMRun] = None,
194 | **kwargs: Any,
195 | ):
196 | """Stream chat completion"""
197 | # Prepare prompt using apply_chat_template
198 | prompt = self._prepare_prompt(messages, **kwargs)
199 |
200 | # Handle generation parameters
201 | generation_kwargs = {}
202 | if "temperature" in kwargs:
203 | generation_kwargs["temperature"] = kwargs["temperature"]
204 | if "max_new_tokens" in kwargs:
205 | generation_kwargs["max_new_tokens"] = kwargs["max_new_tokens"]
206 | elif "max_tokens" in kwargs:
207 | generation_kwargs["max_new_tokens"] = kwargs["max_tokens"]
208 |
209 | wrapped_kwargs = {
210 | "pipeline_kwargs": generation_kwargs,
211 | "stop": stop,
212 | "skip_prompt": kwargs.get("skip_prompt", True),
213 | **kwargs
214 | }
215 |
216 | # Stream using pipeline
217 | for chunk in self.llm.stream(
218 | prompt,
219 | run_manager=run_manager,
220 | **wrapped_kwargs
221 | ):
222 | yield ChatGeneration(message=AIMessage(content=chunk.text))
223 |
224 | async def agenerate(
225 | self,
226 | messages: List[BaseMessage],
227 | stop: Optional[List[str]] = None,
228 | run_manager: Optional[AsyncCallbackManagerForLLMRun] = None,
229 | **kwargs: Any,
230 | ) -> ChatResult:
231 | """Async generation (not implemented)"""
232 | raise NotImplementedError("Async generation not implemented yet")
233 |
234 | async def astream(
235 | self,
236 | messages: List[BaseMessage],
237 | stop: Optional[List[str]] = None,
238 | run_manager: Optional[CallbackManagerForLLMRun] = None,
239 | **kwargs: Any,
240 | ):
241 | """Async streaming (not implemented)"""
242 | raise NotImplementedError("Async stream generation not implemented yet")
243 |
244 | def bind_tools(
245 | self,
246 | tools: Sequence[Union[Dict[str, Any], Type, Callable, BaseTool]],
247 | *,
248 | tool_choice: Optional[Union[dict, str, Literal["auto", "none"], bool]] = None,
249 | **kwargs: Any,
250 | ) -> Runnable[LanguageModelInput, BaseMessage]:
251 | """Bind tools to the chat model"""
252 | formatted_tools = [convert_to_openai_tool(tool) for tool in tools]
253 |
254 | if tool_choice is not None and tool_choice:
255 | if len(formatted_tools) != 1:
256 | raise ValueError(
257 | "When specifying `tool_choice`, you must provide exactly one "
258 | f"tool. Received {len(formatted_tools)} tools."
259 | )
260 |
261 | if isinstance(tool_choice, str):
262 | if tool_choice not in ("auto", "none"):
263 | tool_choice = {
264 | "type": "function",
265 | "function": {"name": tool_choice},
266 | }
267 | elif isinstance(tool_choice, bool):
268 | tool_choice = formatted_tools[0]
269 | elif isinstance(tool_choice, dict):
270 | if (
271 | formatted_tools[0]["function"]["name"]
272 | != tool_choice["function"]["name"]
273 | ):
274 | raise ValueError(
275 | f"Tool choice {tool_choice} was specified, but the only "
276 | f"provided tool was {formatted_tools[0]['function']['name']}."
277 | )
278 | else:
279 | raise ValueError(
280 | f"Unrecognized tool_choice type. Expected str, bool or dict. "
281 | f"Received: {tool_choice}"
282 | )
283 |
284 | kwargs["tool_choice"] = tool_choice
285 |
286 | return super().bind(tools=formatted_tools, **kwargs)
--------------------------------------------------------------------------------
/green_bit_llm/langchain/embedding.py:
--------------------------------------------------------------------------------
1 | from typing import List, Dict, Any, Optional
2 | from langchain_core.embeddings import Embeddings
3 | from pydantic import BaseModel, Field
4 |
5 | # good balance between performance and efficiency, params: 22M
6 | DEFAULT_MODEL_NAME1 = "sentence-transformers/all-MiniLM-L12-v2"
7 | # params: 110M, better NLU ability
8 | DEFAULT_MODEL_NAME2 = "sentence-transformers/all-mpnet-base-v2"
9 | # Optimized for multi-round question answering and suitable for applications
10 | # that require more complex context understanding.
11 | DEFAULT_MODEL_NAME3 = "sentence-transformers/multi-qa-MiniLM-L6-cos-v"
12 |
13 |
14 | class GreenBitEmbeddings(BaseModel, Embeddings):
15 | """GreenBit embedding model using sentence-transformers.
16 |
17 | This class provides an interface to generate embeddings using GreenBit's models,
18 | which are based on the sentence-transformers package.
19 |
20 | Attributes:
21 | model (Any): Embedding model.
22 | encode_kwargs (Dict[str, Any]): Additional keyword arguments for the encoding process.
23 | device (str): The device to use for computations (e.g., 'cuda' for GPU).
24 |
25 | Example:
26 | .. code-block:: python
27 | from reen_bit_llm.langchain import GreenBitEmbeddings
28 |
29 | embedder = GreenBitEmbeddings.from_model_id(
30 | "sentence-transformers/all-mpnet-base-v2",
31 | device="cuda",
32 | multi_process=True,
33 | model_kwargs={"cache_folder": "/path/to/cache"},
34 | encode_kwargs={"normalize_embeddings": True}
35 | )
36 |
37 | texts = ["Hello, world!", "This is a test."]
38 | document_embeddings = embedder.embed_documents(texts)
39 | query_embedding = embedder.embed_query("What is the meaning of life?")
40 | """
41 | cache_dir: Optional[str] = "~/.cache/huggingface/hub"
42 | """Path to store models.
43 | Can be also set by SENTENCE_TRANSFORMERS_HOME environment variable."""
44 | encode_kwargs: Dict[str, Any] = Field(default_factory=dict)
45 | """Keyword arguments to pass when calling the `encode` method of the Sentence
46 | Transformer model, such as `prompt_name`, `prompt`, `batch_size`, `precision`,
47 | `normalize_embeddings`, and more.
48 | See also the Sentence Transformer documentation: https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.encode"""
49 | multi_process: bool = False
50 | """Run encode() on multiple GPUs."""
51 | show_progress: bool = False
52 | """Whether to show a progress bar."""
53 | device: str = "cuda"
54 | model: Any = None
55 |
56 | def __init__(self, **data):
57 | super().__init__(**data)
58 |
59 | class Config:
60 | """Configuration for this pydantic object."""
61 |
62 | extra = "forbid"
63 |
64 | def embed_documents(self, texts: List[str]) -> List[List[float]]:
65 | """
66 | Generate embeddings for a list of documents.
67 |
68 | Args:
69 | texts (List[str]): The list of texts to embed.
70 |
71 | Returns:
72 | List[List[float]]: The list of embeddings, one for each input text.
73 | """
74 | import sentence_transformers
75 | texts = list(map(lambda x: x.replace("\n", " "), texts))
76 | if self.multi_process:
77 | pool = self.model.start_multi_process_pool()
78 | embeddings = self.model.encode_multi_process(texts, pool)
79 | sentence_transformers.SentenceTransformer.stop_multi_process_pool(pool)
80 | else:
81 | embeddings = self.model.encode(
82 | texts, show_progress_bar=self.show_progress, **self.encode_kwargs
83 | )
84 | return embeddings.tolist()
85 |
86 | def embed_query(self, text: str) -> List[float]:
87 | """
88 | Generate an embedding for a single query text.
89 |
90 | Args:
91 | text (str): The query text to embed.
92 |
93 | Returns:
94 | List[float]: The embedding for the input text.
95 | """
96 | return self.embed_documents([text])[0]
97 |
98 | @classmethod
99 | def from_model_id(
100 | cls,
101 | model_name: str = DEFAULT_MODEL_NAME1,
102 | device: str = "cuda",
103 | cache_dir: Optional[str] = "",
104 | multi_process: bool = False,
105 | show_progress: bool = False,
106 | model_kwargs: Dict[str, Any] = Field(default_factory=dict),
107 | encode_kwargs: Optional[Dict[str, Any]] = Field(default_factory=dict),
108 | **kwargs
109 | ) -> "GreenBitEmbeddings":
110 | """
111 | Create a GreenBitEmbeddings instance from a model name.
112 |
113 | Args:
114 | model_name (str): The name of the model to use.
115 | device (str): The device to use for computations (default is "cuda" for GPU).
116 | cache_dir (Optional[str]): Path to store models. Can be also set by SENTENCE_TRANSFORMERS_HOME environment variable.
117 | multi_process (bool): Run encode() on multiple GPUs.
118 | show_progress (bool): Whether to show a progress bar.
119 | model_kwargs (Optional[Dict[str, Any]]): Keyword arguments to pass to the Sentence Transformer model, such as `device`,
120 | `prompts`, `default_prompt_name`, `revision`, `trust_remote_code`, or `token`.
121 | See also the Sentence Transformer documentation: https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer
122 | encode_kwargs (Optional[Dict[str, Any]]): Keyword arguments to pass when calling the `encode` method of the SentenceTransformer model, such as `prompt_name`, `prompt`, `batch_size`, `precision`,
123 | `normalize_embeddings`, and more. See also the Sentence Transformer documentation: https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.encode
124 | **kwargs: Additional keyword arguments for the GreenBitEmbeddings constructor.
125 |
126 | Returns:
127 | GreenBitEmbeddings: An instance of GreenBitEmbeddings.
128 | """
129 | try:
130 | from sentence_transformers import SentenceTransformer
131 | except ImportError:
132 | raise ImportError(
133 | "Could not import sentence_transformers. "
134 | "Please install it with `pip install sentence-transformers`."
135 | )
136 |
137 | model = SentenceTransformer(
138 | model_name,
139 | device=device,
140 | cache_folder=cache_dir,
141 | **model_kwargs
142 | )
143 |
144 | return cls(
145 | model=model,
146 | device=device,
147 | cache_dir=cache_dir,
148 | multi_process=multi_process,
149 | show_progress=show_progress,
150 | encode_kwargs=encode_kwargs or {},
151 | **kwargs
152 | )
--------------------------------------------------------------------------------
/green_bit_llm/patches/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/patches/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/patches/deepseek_v3_moe_patch.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | # Import DeepSeek V3 components at module level
4 | try:
5 | from transformers.models.deepseek_v3.modeling_deepseek_v3 import DeepseekV3MoE
6 |
7 | DEEPSEEK_V3_AVAILABLE = True
8 | except ImportError:
9 | DeepseekV3MoE = None
10 | DEEPSEEK_V3_AVAILABLE = False
11 |
12 |
13 | class QuantizedDeepSeekV3MoE:
14 | """
15 | DeepSeekV3MoE forward method optimized for quantized models
16 | """
17 |
18 | @staticmethod
19 | def moe_token_by_token(self, hidden_states: torch.Tensor, topk_indices: torch.Tensor, topk_weights: torch.Tensor):
20 | """
21 | Quantization-friendly MoE implementation using token-by-token processing
22 | """
23 | batch_size, sequence_length, hidden_dim = hidden_states.shape
24 | total_tokens = batch_size * sequence_length
25 |
26 | # Flatten processing
27 | hidden_states_flat = hidden_states.view(-1, hidden_dim)
28 |
29 | # Initialize output with correct dtype
30 | final_hidden_states = torch.zeros_like(hidden_states_flat, dtype=topk_weights.dtype)
31 |
32 | # Pre-convert to CPU to reduce GPU-CPU transfers
33 | topk_indices_cpu = topk_indices.cpu().numpy()
34 | topk_weights_cpu = topk_weights.cpu().numpy()
35 | top_k = topk_indices.shape[-1]
36 |
37 | # Process token by token for maximum quantization compatibility
38 | for token_idx in range(total_tokens):
39 | # Get single token input - fixed batch size (1)
40 | token_input = hidden_states_flat[token_idx:token_idx + 1] # [1, hidden_dim]
41 | token_output = torch.zeros_like(token_input, dtype=topk_weights.dtype)
42 |
43 | # Get expert indices and weights for this token
44 | token_experts = topk_indices_cpu[token_idx] # [top_k]
45 | token_weights = topk_weights_cpu[token_idx] # [top_k]
46 |
47 | # Process selected experts
48 | for expert_pos in range(top_k):
49 | expert_idx = int(token_experts[expert_pos])
50 | expert_weight = float(token_weights[expert_pos])
51 |
52 | # Skip small weights for performance
53 | if expert_weight < 1e-6:
54 | continue
55 |
56 | # Call expert network - fixed batch size, quantization friendly
57 | expert_layer = self.experts[expert_idx]
58 | expert_output = expert_layer(token_input)
59 |
60 | # Weighted accumulation - simple scalar operations
61 | token_output = token_output + expert_output * expert_weight
62 |
63 | # Store result
64 | final_hidden_states[token_idx] = token_output[0]
65 |
66 | # Convert back to original dtype
67 | return final_hidden_states.type(hidden_states.dtype)
68 |
69 | @staticmethod
70 | def moe_vectorized(self, hidden_states: torch.Tensor, topk_indices: torch.Tensor, topk_weights: torch.Tensor):
71 | """
72 | Vectorized MoE implementation adapted from Qwen3 method
73 | """
74 | batch_size, sequence_length, hidden_dim = hidden_states.shape
75 | total_tokens = batch_size * sequence_length
76 |
77 | # Flatten processing
78 | hidden_states_flat = hidden_states.view(-1, hidden_dim)
79 | top_k = topk_indices.shape[-1]
80 |
81 | # Pre-allocate expert output storage - key vectorization optimization
82 | expert_outputs = torch.zeros(total_tokens, top_k, hidden_dim,
83 | dtype=topk_weights.dtype, device=hidden_states.device)
84 |
85 | # Process experts in batches - adapted for 256 experts
86 | for expert_idx in range(len(self.experts)):
87 | # Create expert mask [total_tokens, top_k]
88 | expert_mask = (topk_indices == expert_idx)
89 |
90 | if not expert_mask.any():
91 | continue
92 |
93 | # Find positions using current expert
94 | token_idx, topk_idx = torch.where(expert_mask)
95 |
96 | if len(token_idx) == 0:
97 | continue
98 |
99 | # Batch processing - key performance improvement
100 | expert_inputs = hidden_states_flat[token_idx]
101 | expert_result = self.experts[expert_idx](expert_inputs)
102 |
103 | # Store results
104 | expert_outputs[token_idx, topk_idx] = expert_result
105 |
106 | # Apply weights and sum - vectorized operations
107 | weights_expanded = topk_weights.unsqueeze(-1)
108 | final_hidden_states = (expert_outputs * weights_expanded).sum(dim=1)
109 |
110 | # Reshape back to original shape
111 | final_hidden_states = final_hidden_states.view(batch_size, sequence_length, hidden_dim)
112 |
113 | # Convert back to original dtype
114 | return final_hidden_states.type(hidden_states.dtype)
115 |
116 | @staticmethod
117 | def should_use_vectorized(self, hidden_states):
118 | """
119 | Determine whether to use vectorized method based on batch size efficiency
120 | """
121 | batch_size, seq_len, hidden_dim = hidden_states.shape
122 | total_tokens = batch_size * seq_len
123 | top_k = getattr(self, 'top_k', 6) # DeepSeek V3 default
124 |
125 | # Estimate memory requirement for expert_outputs tensor
126 | estimated_memory_mb = total_tokens * top_k * hidden_dim * 2 / (1024 * 1024) # fp16
127 |
128 | # Primary criterion: batch size efficiency
129 | if total_tokens < 64:
130 | # Too small batch, vectorization has no advantage
131 | return False, estimated_memory_mb
132 |
133 | # Optional safety check for extreme cases
134 | try:
135 | total_memory = torch.cuda.get_device_properties(0).total_memory
136 | allocated_memory = torch.cuda.memory_allocated()
137 | available_memory_mb = (total_memory - allocated_memory) / (1024 * 1024)
138 |
139 | # Only fallback if memory is really insufficient (< 20% available)
140 | memory_threshold = available_memory_mb * 0.2
141 |
142 | if estimated_memory_mb > memory_threshold:
143 | return False, estimated_memory_mb
144 |
145 | except Exception:
146 | # If cannot get memory info, don't restrict
147 | pass
148 |
149 | return True, estimated_memory_mb
150 |
151 | @staticmethod
152 | def forward_hybrid(self, hidden_states):
153 | """
154 | Hybrid strategy forward method for DeepSeek V3 MoE
155 | """
156 | # Save for residual connection and shared experts
157 | residuals = hidden_states
158 |
159 | # Route calculation - maintain DeepSeek V3's complex routing logic
160 | topk_indices, topk_weights = self.gate(hidden_states)
161 |
162 | # Choose strategy based on memory and batch size
163 | use_vectorized, estimated_mb = QuantizedDeepSeekV3MoE.should_use_vectorized(self, hidden_states)
164 |
165 | if use_vectorized:
166 | moe_output = QuantizedDeepSeekV3MoE.moe_vectorized(
167 | self, hidden_states, topk_indices, topk_weights
168 | )
169 | else:
170 | moe_output = QuantizedDeepSeekV3MoE.moe_token_by_token(
171 | self, hidden_states, topk_indices, topk_weights
172 | )
173 |
174 | # Add shared expert output - DeepSeek V3 specific feature
175 | shared_expert_output = self.shared_experts(residuals)
176 |
177 | # Final output = MoE output + shared expert output
178 | final_output = moe_output + shared_expert_output
179 |
180 | return final_output
181 |
182 | @staticmethod
183 | def forward_conservative(self, hidden_states):
184 | """
185 | Conservative forward method using only token-by-token processing
186 | """
187 | residuals = hidden_states
188 |
189 | # Route calculation
190 | topk_indices, topk_weights = self.gate(hidden_states)
191 |
192 | # Use token-by-token method for maximum compatibility
193 | moe_output = QuantizedDeepSeekV3MoE.moe_token_by_token(
194 | self, hidden_states, topk_indices, topk_weights
195 | )
196 |
197 | # Add shared expert output
198 | shared_expert_output = self.shared_experts(residuals)
199 |
200 | return moe_output + shared_expert_output
201 |
202 | @staticmethod
203 | def forward_vectorized(self, hidden_states):
204 | """
205 | Vectorized forward method for maximum performance
206 | """
207 | residuals = hidden_states
208 |
209 | # Route calculation
210 | topk_indices, topk_weights = self.gate(hidden_states)
211 |
212 | # Use vectorized method
213 | moe_output = QuantizedDeepSeekV3MoE.moe_vectorized(
214 | self, hidden_states, topk_indices, topk_weights
215 | )
216 |
217 | # Add shared expert output
218 | shared_expert_output = self.shared_experts(residuals)
219 |
220 | return moe_output + shared_expert_output
221 |
222 |
223 | def apply_deepseek_v3_moe_patch(strategy='hybrid'):
224 | """
225 | Apply DeepSeek V3 MoE patch
226 |
227 | Args:
228 | strategy: 'conservative', 'vectorized', 'hybrid'
229 | """
230 | if not DEEPSEEK_V3_AVAILABLE:
231 | print("Error: DeepSeek V3 models not available in current transformers installation")
232 | return False
233 |
234 | # Save original method
235 | if not hasattr(DeepseekV3MoE, '_original_forward'):
236 | DeepseekV3MoE._original_forward = DeepseekV3MoE.forward
237 |
238 | # Apply strategy
239 | if strategy == 'conservative':
240 | DeepseekV3MoE.forward = QuantizedDeepSeekV3MoE.forward_conservative
241 | print("Info: Applied DeepSeek V3 conservative MoE patch")
242 | elif strategy == 'vectorized':
243 | DeepseekV3MoE.forward = QuantizedDeepSeekV3MoE.forward_vectorized
244 | print("Info: Applied DeepSeek V3 vectorized MoE patch")
245 | elif strategy == 'hybrid':
246 | DeepseekV3MoE.forward = QuantizedDeepSeekV3MoE.forward_hybrid
247 | print("Info: Applied DeepSeek V3 hybrid MoE patch")
248 | else:
249 | raise ValueError(f"Unknown strategy: {strategy}")
250 |
251 | return True
252 |
253 |
254 | def restore_deepseek_v3_moe_patch():
255 | """
256 | Restore original DeepSeek V3 MoE forward method
257 | """
258 | if not DEEPSEEK_V3_AVAILABLE:
259 | return
260 |
261 | if hasattr(DeepseekV3MoE, '_original_forward'):
262 | DeepseekV3MoE.forward = DeepseekV3MoE._original_forward
263 | delattr(DeepseekV3MoE, '_original_forward')
264 | print("Info: Restored original DeepSeek V3 MoE forward method")
265 |
266 |
267 | def detect_deepseek_v3_moe_model(config):
268 | """
269 | Detect if model is DeepSeek V3 MoE
270 | """
271 | return (
272 | hasattr(config, 'model_type') and
273 | 'deepseek_v3' in config.model_type.lower() and
274 | getattr(config, 'n_routed_experts', 0) > 0
275 | )
--------------------------------------------------------------------------------
/green_bit_llm/patches/qwen3_moe_patch.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | from typing import Tuple
4 |
5 |
6 | class QuantizedQwen3MoeSparseMoeBlock:
7 | """
8 | Qwen3MoeSparseMoeBlock forward method optimized for quantized models
9 | """
10 |
11 | @staticmethod
12 | def forward(self, hidden_states: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
13 | """
14 | Quantization-friendly MoE forward implementation using vectorized strategy
15 | """
16 | batch_size, sequence_length, hidden_dim = hidden_states.shape
17 | total_tokens = batch_size * sequence_length
18 |
19 | # flat
20 | hidden_states_flat = hidden_states.reshape(total_tokens, hidden_dim)
21 |
22 | # 1. Route calculation
23 | router_logits = self.gate(hidden_states_flat)
24 | if len(router_logits.shape) > 2:
25 | router_logits = router_logits.reshape(total_tokens, -1)
26 |
27 | # 2. Calculating routing weight
28 | routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
29 |
30 | # 3. Select top experts and weights
31 | routing_weights_topk, indices_topk = torch.topk(routing_weights, self.top_k, dim=1)
32 |
33 | # 4. Normalized top weights
34 | if self.norm_topk_prob:
35 | routing_weights_topk /= routing_weights_topk.sum(dim=1, keepdim=True)
36 | routing_weights_topk = routing_weights_topk.to(hidden_states.dtype)
37 |
38 | # 5. Pre-allocated expert output storage
39 | # [total_tokens, top_k, hidden_dim]
40 | expert_outputs = torch.zeros(total_tokens, self.top_k, hidden_dim,
41 | dtype=hidden_states.dtype, device=hidden_states.device)
42 |
43 | # 6. Batch processing by experts
44 | for expert_idx in range(self.num_experts):
45 | # Create expert mask [total_tokens, top_k]
46 | expert_mask = (indices_topk == expert_idx)
47 |
48 | if not expert_mask.any():
49 | continue
50 |
51 | # Find a location using current experts
52 | token_idx, topk_idx = torch.where(expert_mask)
53 |
54 | if len(token_idx) == 0:
55 | continue
56 |
57 | # Batch Processing
58 | expert_inputs = hidden_states_flat[token_idx]
59 | expert_result = self.experts[expert_idx](expert_inputs)
60 |
61 | # Storing Results
62 | expert_outputs[token_idx, topk_idx] = expert_result
63 |
64 | # 7. Apply weights and sum
65 | # Expand weight dimension: [total_tokens, top_k, 1]
66 | weights_expanded = routing_weights_topk.unsqueeze(-1)
67 |
68 | # Weighted sum: [total_tokens, hidden_dim]
69 | final_hidden_states = (expert_outputs * weights_expanded).sum(dim=1)
70 |
71 | # 8. Reshape back to original shape
72 | final_hidden_states = final_hidden_states.view(batch_size, sequence_length, hidden_dim)
73 |
74 | return final_hidden_states, router_logits
75 |
76 | @staticmethod
77 | def forward_micro_batched(self, hidden_states: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
78 | """
79 | Quantization-friendly MoE forward implementation using micro_batched strategy
80 | """
81 | batch_size, sequence_length, hidden_dim = hidden_states.shape
82 | total_tokens = batch_size * sequence_length
83 |
84 | hidden_states_flat = hidden_states.reshape(total_tokens, hidden_dim)
85 |
86 | # Route calculation
87 | router_logits = self.gate(hidden_states_flat)
88 | if len(router_logits.shape) > 2:
89 | router_logits = router_logits.reshape(total_tokens, -1)
90 |
91 | routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
92 | routing_weights_topk, indices_topk = torch.topk(routing_weights, self.top_k, dim=1)
93 |
94 | if self.norm_topk_prob:
95 | routing_weights_topk /= routing_weights_topk.sum(dim=1, keepdim=True)
96 | routing_weights_topk = routing_weights_topk.to(hidden_states.dtype)
97 |
98 | final_hidden_states = torch.zeros_like(hidden_states_flat)
99 |
100 | # Fixed micro-batch size - quantization friendly
101 | micro_batch_size = min(8, total_tokens) # Small fixed batch size
102 |
103 | for start_idx in range(0, total_tokens, micro_batch_size):
104 | end_idx = min(start_idx + micro_batch_size, total_tokens)
105 |
106 | # Still process token by token in micro batch - maintain quantization compatibility
107 | for token_idx in range(start_idx, end_idx):
108 | token_input = hidden_states_flat[token_idx:token_idx + 1]
109 | token_output = torch.zeros_like(token_input)
110 |
111 | for expert_pos in range(self.top_k):
112 | expert_idx = indices_topk[token_idx, expert_pos].item()
113 | expert_weight = routing_weights_topk[token_idx, expert_pos].item()
114 |
115 | if expert_weight < 1e-4:
116 | continue
117 |
118 | expert_output = self.experts[expert_idx](token_input)
119 | token_output = token_output + expert_output * expert_weight
120 |
121 | final_hidden_states[token_idx] = token_output[0]
122 |
123 | final_hidden_states = final_hidden_states.view(batch_size, sequence_length, hidden_dim)
124 | return final_hidden_states, router_logits
125 |
126 | def apply_qwen3_moe_patch():
127 | """
128 | Apply the monkey patch of Qwen3MoeSparseMoeBlock
129 | """
130 | try:
131 | from transformers.models.qwen3_moe.modeling_qwen3_moe import Qwen3MoeSparseMoeBlock
132 |
133 | # Save the original method (in case we need to restore it)
134 | if not hasattr(Qwen3MoeSparseMoeBlock, '_original_forward'):
135 | Qwen3MoeSparseMoeBlock._original_forward = Qwen3MoeSparseMoeBlock.forward
136 |
137 | # Replace the forward method
138 | Qwen3MoeSparseMoeBlock.forward = QuantizedQwen3MoeSparseMoeBlock.forward
139 |
140 | print("Info: Successfully applied Qwen3MoeSparseMoeBlock patch for quantized models")
141 |
142 | except ImportError as e:
143 | print(f"Error: Could not apply Qwen3MoeSparseMoeBlock patch: {e}")
144 | print(" This might be expected if Qwen3 models are not being used")
145 |
146 | def restore_qwen3_moe_patch():
147 | """
148 | Restore the original Qwen3MoeSparseMoeBlock forward method
149 | """
150 | try:
151 | from transformers.models.qwen3_moe.modeling_qwen3_moe import Qwen3MoeSparseMoeBlock
152 |
153 | if hasattr(Qwen3MoeSparseMoeBlock, '_original_forward'):
154 | Qwen3MoeSparseMoeBlock.forward = Qwen3MoeSparseMoeBlock._original_forward
155 | delattr(Qwen3MoeSparseMoeBlock, '_original_forward')
156 | print("Info: Successfully restored original Qwen3MoeSparseMoeBlock forward method")
157 |
158 | except ImportError:
159 | pass
--------------------------------------------------------------------------------
/green_bit_llm/routing/__init__.py:
--------------------------------------------------------------------------------
1 | from .confidence_scorer import ConfidenceScorer
--------------------------------------------------------------------------------
/green_bit_llm/routing/confidence_scorer.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from green_bit_llm.routing.libra_router.ue_router import MahalanobisDistanceSeq
3 |
4 |
5 | class ConfidenceScorer:
6 | """
7 | A class to compute confidence scores based on Mahalanobis distance.
8 |
9 | Attributes:
10 | parameters_path (str): Path to the model parameters
11 | json_file_path (str): Path to the uncertainty bounds JSON file
12 | device (str): Device to run computations on ('cpu', 'cuda', 'mps')
13 |
14 | Example:
15 | confidence_scorer = ConfidenceScore(
16 | parameters_path="path/to/params",
17 | json_file_path="path/to/bounds.json",
18 | device="cuda"
19 | )
20 |
21 | confidence = confidence_scorer.calculate_confidence(hidden_states)
22 | """
23 |
24 | def __init__(
25 | self,
26 | parameters_path: str,
27 | model_id: str,
28 | device: str = "cuda"
29 | ):
30 | """
31 | Initialize the ConfidenceScore calculator.
32 |
33 | Args:
34 | parameters_path: Path to model parameters
35 | json_file_path: Path to uncertainty bounds JSON
36 | device: Computation device
37 | threshold: Confidence threshold for routing
38 | """
39 | self.parameters_path = parameters_path
40 | self.device = device
41 |
42 | # Initialize Mahalanobis distance calculator
43 | try:
44 | self.mahalanobis = MahalanobisDistanceSeq(
45 | parameters_path=parameters_path,
46 | normalize=False,
47 | model_id=model_id,
48 | device=self.device
49 | )
50 | except Exception as e:
51 | raise RuntimeError(f"Failed to initialize Mahalanobis distance calculator: {str(e)}")
52 |
53 | def calculate_confidence(
54 | self,
55 | hidden_states: torch.Tensor
56 | ) -> float:
57 | """
58 | Calculate confidence score from hidden states.
59 | Support both single input and batch input.
60 |
61 | Args:
62 | hidden_states: Model hidden states tensor
63 | return_uncertainty: Whether to return the raw uncertainty score
64 |
65 | Returns:
66 | Union[float, List[float]]: Single confidence score or list of confidence scores
67 |
68 | Raises:
69 | ValueError: If hidden states have invalid shape
70 | RuntimeError: If confidence calculation fails
71 | """
72 |
73 | try:
74 | # Calculate uncertainty using Mahalanobis distance
75 | uncertainty = self.mahalanobis(hidden_states)
76 | if uncertainty is None:
77 | raise RuntimeError("Failed to calculate uncertainty")
78 |
79 | # Normalize uncertainty if bounds are available
80 | if self.mahalanobis.ue_bounds_tensor is not None:
81 | uncertainty = self.mahalanobis.normalize_ue(
82 | uncertainty[0],
83 | self.device
84 | )
85 | else:
86 | uncertainty = uncertainty[0]
87 |
88 | # Handle both single input and batch input
89 | if uncertainty.dim() == 0: # single value
90 | confidence_score = 1.0 - uncertainty.cpu().item()
91 | return confidence_score
92 | else: # batch of values
93 | confidence_scores = 1.0 - uncertainty.cpu().tolist()
94 | return confidence_scores
95 |
96 | except Exception as e:
97 | raise RuntimeError(f"Failed to calculate confidence score: {str(e)}")
--------------------------------------------------------------------------------
/green_bit_llm/serve/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/serve/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/serve/api/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/serve/api/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/serve/api/v1/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/serve/api/v1/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/serve/auth/__init__.py:
--------------------------------------------------------------------------------
1 | from .api_key_auth import APIKeyAuth, get_api_key_auth
2 | from .rate_limiter import RateLimiter
3 |
4 | __all__ = ['APIKeyAuth', 'get_api_key_auth', 'RateLimiter']
--------------------------------------------------------------------------------
/green_bit_llm/serve/auth/api_key_auth.py:
--------------------------------------------------------------------------------
1 | import sqlite3
2 | import hashlib
3 | from typing import Optional
4 | from fastapi import HTTPException, Security
5 | from fastapi.security.api_key import APIKeyHeader
6 | from starlette.status import HTTP_403_FORBIDDEN
7 | import logging
8 | from pathlib import Path
9 | from dotenv import load_dotenv
10 | import os
11 |
12 | from .rate_limiter import RateLimiter
13 |
14 | # API key header
15 | API_KEY_HEADER = APIKeyHeader(name="X-Api-Key", auto_error=True)
16 |
17 |
18 | class APIKeyAuth:
19 | def __init__(self, db_path: str):
20 | self.db_path = db_path
21 | self.rate_limiter = RateLimiter()
22 | self.logger = logging.getLogger("greenbit_server")
23 |
24 | def get_db_connection(self):
25 | return sqlite3.connect(self.db_path)
26 |
27 | def _hash_key(self, api_key: str) -> str:
28 | """Hash the API key for database lookup."""
29 | return hashlib.blake2b(
30 | api_key.encode(),
31 | digest_size=32,
32 | salt=b"greenbit_storage",
33 | person=b"api_key_storage"
34 | ).hexdigest()
35 |
36 | def validate_api_key(self, api_key: str) -> dict:
37 | """Validate API key and return user info if valid."""
38 | try:
39 | hashed_key = self._hash_key(api_key)
40 |
41 | with self.get_db_connection() as conn:
42 | cursor = conn.cursor()
43 | cursor.execute("""
44 | SELECT
45 | ak.user_id,
46 | u.name,
47 | u.email,
48 | u.organization,
49 | ak.tier,
50 | ak.rpm_limit,
51 | ak.tpm_limit,
52 | ak.concurrent_requests,
53 | ak.max_tokens,
54 | ak.permissions,
55 | ak.is_active
56 | FROM api_keys ak
57 | JOIN users u ON ak.user_id = u.id
58 | WHERE ak.api_key_hash = ?
59 | """, (hashed_key,))
60 | result = cursor.fetchone()
61 |
62 | if not result:
63 | raise HTTPException(
64 | status_code=HTTP_403_FORBIDDEN,
65 | detail="Invalid API key"
66 | )
67 |
68 | user_info = {
69 | "user_id": result[0],
70 | "name": result[1],
71 | "email": result[2],
72 | "organization": result[3],
73 | "tier": result[4],
74 | "rpm_limit": result[5],
75 | "tpm_limit": result[6],
76 | "concurrent_requests": result[7],
77 | "max_tokens": result[8],
78 | "permissions": result[9].split(','),
79 | "is_active": bool(result[10])
80 | }
81 |
82 | if not user_info["is_active"]:
83 | raise HTTPException(
84 | status_code=HTTP_403_FORBIDDEN,
85 | detail="API key is inactive"
86 | )
87 |
88 | # Update last_used_at
89 | cursor.execute("""
90 | UPDATE api_keys
91 | SET last_used_at = CURRENT_TIMESTAMP
92 | WHERE api_key_hash = ?
93 | """, (hashed_key,))
94 | conn.commit()
95 |
96 | return user_info
97 |
98 | except sqlite3.Error as e:
99 | self.logger.error(f"Database error during API key validation: {str(e)}")
100 | raise HTTPException(status_code=500, detail="Internal server error")
101 |
102 | async def check_rate_limits(self, api_key: str, user_info: dict, estimated_tokens: Optional[int] = None):
103 | """Check all rate limits."""
104 | try:
105 | # Check RPM
106 | self.rate_limiter.check_rate_limit(api_key, user_info["rpm_limit"])
107 |
108 | # Check TPM if tokens are provided
109 | if estimated_tokens is not None:
110 | self.rate_limiter.check_token_limit(
111 | api_key,
112 | estimated_tokens,
113 | user_info["tpm_limit"]
114 | )
115 |
116 | # Try to acquire concurrent request slot
117 | await self.rate_limiter.acquire_concurrent_request(
118 | api_key,
119 | user_info["concurrent_requests"]
120 | )
121 |
122 | except Exception as e:
123 | self.logger.error(f"Rate limit check failed: {str(e)}")
124 | raise
125 |
126 | def check_permissions(self, user_info: dict, endpoint_type: str):
127 | """Check if the user has permission to access the endpoint."""
128 | if endpoint_type not in user_info["permissions"]:
129 | raise HTTPException(
130 | status_code=HTTP_403_FORBIDDEN,
131 | detail=f"No permission to access {endpoint_type} endpoint"
132 | )
133 |
134 | def check_token_limit(self, user_info: dict, requested_tokens: int):
135 | """Check if the requested tokens are within the user's limit."""
136 | if requested_tokens > user_info["max_tokens"]:
137 | raise HTTPException(
138 | status_code=HTTP_403_FORBIDDEN,
139 | detail=f"Requested tokens ({requested_tokens}) exceed maximum allowed ({user_info['max_tokens']})"
140 | )
141 |
142 |
143 | def load_api_key(env_file: str = None) -> str:
144 | """Load API key from environment file or environment variables."""
145 | if env_file and Path(env_file).exists():
146 | load_dotenv(env_file)
147 |
148 | api_key = os.getenv("LIBRA_API_KEY")
149 | if not api_key:
150 | raise HTTPException(
151 | status_code=HTTP_403_FORBIDDEN,
152 | detail="API key not found in environment"
153 | )
154 |
155 | return api_key
156 |
157 |
158 | async def get_api_key_auth(
159 | api_key: str = Security(API_KEY_HEADER),
160 | env_file: str = None,
161 | estimated_tokens: Optional[int] = None
162 | ) -> dict:
163 | """FastAPI dependency for API key authentication."""
164 | # If no API key in header, try to load from environment
165 | if not api_key:
166 | api_key = load_api_key(env_file)
167 |
168 | db_path = os.getenv("LIBRA_DB_PATH", str(Path(__file__).parent.parent.parent.parent / "db" / "greenbit.db"))
169 | auth_handler = APIKeyAuth(db_path)
170 | user_info = auth_handler.validate_api_key(api_key)
171 | await auth_handler.check_rate_limits(api_key, user_info, estimated_tokens)
172 | return user_info
--------------------------------------------------------------------------------
/green_bit_llm/serve/auth/rate_limiter.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime, timedelta
2 | from typing import Dict, List, Tuple
3 | from fastapi import HTTPException
4 | from starlette.status import HTTP_429_TOO_MANY_REQUESTS
5 | import asyncio
6 | from collections import defaultdict
7 |
8 |
9 | class RateLimiter:
10 | def __init__(self):
11 | self._request_times: Dict[str, List[datetime]] = defaultdict(list)
12 | self._token_counts: Dict[str, List[Tuple[datetime, int]]] = defaultdict(list)
13 | self._concurrent_requests: Dict[str, int] = defaultdict(int)
14 | self._locks: Dict[str, asyncio.Lock] = defaultdict(asyncio.Lock)
15 |
16 | async def acquire_concurrent_request(self, api_key: str, limit: int):
17 | """Try to acquire a concurrent request slot."""
18 | async with self._locks[api_key]:
19 | if self._concurrent_requests[api_key] >= limit:
20 | raise HTTPException(
21 | status_code=HTTP_429_TOO_MANY_REQUESTS,
22 | detail=f"Maximum concurrent requests ({limit}) exceeded"
23 | )
24 | self._concurrent_requests[api_key] += 1
25 |
26 | async def release_concurrent_request(self, api_key: str):
27 | """Release a concurrent request slot."""
28 | async with self._locks[api_key]:
29 | if self._concurrent_requests[api_key] > 0:
30 | self._concurrent_requests[api_key] -= 1
31 |
32 | def check_rate_limit(self, api_key: str, rpm_limit: int):
33 | """Check requests per minute limit."""
34 | now = datetime.now()
35 | minute_ago = now - timedelta(minutes=1)
36 |
37 | # Clean old entries
38 | self._request_times[api_key] = [
39 | time for time in self._request_times[api_key]
40 | if time > minute_ago
41 | ]
42 |
43 | # Check RPM limit
44 | if len(self._request_times[api_key]) >= rpm_limit:
45 | raise HTTPException(
46 | status_code=HTTP_429_TOO_MANY_REQUESTS,
47 | detail=f"Rate limit exceeded. Maximum {rpm_limit} requests per minute."
48 | )
49 |
50 | self._request_times[api_key].append(now)
51 |
52 | def check_token_limit(self, api_key: str, new_tokens: int, tpm_limit: int):
53 | """Check tokens per minute limit."""
54 | now = datetime.now()
55 | minute_ago = now - timedelta(minutes=1)
56 |
57 | # Clean old entries
58 | self._token_counts[api_key] = [
59 | (time, count) for time, count in self._token_counts[api_key]
60 | if time > minute_ago
61 | ]
62 |
63 | # Calculate current token usage
64 | current_tpm = sum(count for _, count in self._token_counts[api_key])
65 |
66 | # Check TPM limit
67 | if current_tpm + new_tokens > tpm_limit:
68 | raise HTTPException(
69 | status_code=HTTP_429_TOO_MANY_REQUESTS,
70 | detail=f"Token rate limit exceeded. Maximum {tpm_limit} tokens per minute."
71 | )
72 |
73 | self._token_counts[api_key].append((now, new_tokens))
--------------------------------------------------------------------------------
/green_bit_llm/sft/README.md:
--------------------------------------------------------------------------------
1 | # Finetuning GreenBitAI's Low-bit LLMs
2 |
3 | ## Overview
4 |
5 | This package demonstrates the capabilities of [GreenBitAI's low-bit large language models (LLMs)](https://huggingface.co/GreenBitAI) through two main features:
6 | 1. Full-parameter fine-tuning using quantized LLMs.
7 | 2. Parameter efficient fine-tuning
8 |
9 |
10 | ## Installation
11 |
12 | Please follow the [main installation instructions](../../README.md#installation) for how to install the packages required to run this inference package.
13 | Afterward, install the following additional libraries:
14 |
15 | ```bash
16 | pip install trl
17 | pip install -U git+https://github.com/huggingface/peft.git
18 | ```
19 |
20 | If you want to use a **8-bit customized optimizer** with the gradient low-rank projection for maximizing memory savings, you will also need to install the following package:
21 |
22 | ```bash
23 | pip install bitsandbytes galore-torch
24 | ```
25 |
26 | ## Usage
27 |
28 | ### LLMs
29 |
30 | We have released over 200 highly precise 2.2/2.5/3/4-bit models across the modern LLM family, featuring LLaMA 2/3, 01-Yi, Qwen, Mistral, Phi-3, and more. Currently, only layer-mix quantized models are supported for sft. In addition to our low-bit models, green-bit-llm is fully compatible with the AutoGPTQ series of 4-bit quantization and compression models.
31 |
32 | Happy scaling low-bit LLMs with more data!
33 |
34 | | Family | Bpw | Size | HF collection id |
35 | |:----------------:|:------------------:|:------------------------------:|:-----------------------------------------------------------------------------------------------------------------:|
36 | | Llama-3 | `4.0/3.0/2.5/2.2` | `8B/70B` | [`GreenBitAI Llama-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-3-6627bc1ec6538e3922c5d81c) |
37 | | Llama-2 | `3.0/2.5/2.2` | `7B/13B/70B` | [`GreenBitAI Llama-2`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-2-661f87e3b073ff8e48a12834) |
38 | | Qwen-1.5 | `4.0/3.0/2.5/2.2` | `0.5B/1.8B/4B/7B/14B/32B/110B` | [`GreenBitAI Qwen 1.5`](https://huggingface.co/collections/GreenBitAI/greenbitai-qwen15-661f86ea69433f3d3062c920) |
39 | | Phi-3 | `3.0/2.5/2.2` | `mini` | [`GreenBitAI Phi-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-phi-3-6628d008cdf168398a296c92) |
40 | | Mistral | `3.0/2.5/2.2` | `7B` | [`GreenBitAI Mistral`](https://huggingface.co/collections/GreenBitAI/greenbitai-mistral-661f896c45da9d8b28a193a8) |
41 | | 01-Yi | `3.0/2.5/2.2` | `6B/34B` | [`GreenBitAI 01-Yi`](https://huggingface.co/collections/GreenBitAI/greenbitai-01-yi-661f88af0648daa766d5102f) |
42 | | Llama-3-instruct | `4.0/3.0/2.5/2.2` | `8B/70B` | [`GreenBitAI Llama-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-llama-3-6627bc1ec6538e3922c5d81c) |
43 | | Mistral-instruct | `3.0/2.5/2.2` | `7B` | [`GreenBitAI Mistral`](https://huggingface.co/collections/GreenBitAI/greenbitai-mistral-661f896c45da9d8b28a193a8) |
44 | | Phi-3-instruct | `3.0/2.5/2.2` | `mini` | [`GreenBitAI Phi-3`](https://huggingface.co/collections/GreenBitAI/greenbitai-phi-3-6628d008cdf168398a296c92) |
45 | | Qwen-1.5-Chat | `4.0/3.0/2.5/2.2` | `0.5B/1.8B/4B/7B/14B/32B/110B` | [`GreenBitAI Qwen 1.5`](https://huggingface.co/collections/GreenBitAI/greenbitai-qwen15-661f86ea69433f3d3062c920) |
46 | | 01-Yi-Chat | `3.0/2.5/2.2` | `6B/34B` | [`GreenBitAI 01-Yi`](https://huggingface.co/collections/GreenBitAI/greenbitai-01-yi-661f88af0648daa766d5102f) |
47 |
48 |
49 | ### Full-parameter fine-tuning
50 |
51 | Run the script as follows to fine-tune the quantized weights of the model on the target dataset.
52 | The **--tune-qweight-only** parameter determines whether to fine-tune only the quantized weights or all weights, including non-quantized ones.
53 |
54 | ```bash
55 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --tune-qweight-only
56 |
57 | # AutoGPTQ model Q-SFT
58 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.finetune --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --tune-qweight-only --batch-size 1
59 | ```
60 | If you want to further save memory, we also support [Galore](https://github.com/jiaweizzhao/GaLore): a memory-efficient low-rank training strategy.
61 | You just need to add the **--galore** parameter in your command line. However, it's important to note that Galore requires the computation of projection matrices for the gradients, which will incur additional time costs.
62 | You can think of this as a trade-off strategy where time is exchanged for space.
63 | To select the "AdamW8bit" optimizer, simply add "--optimizer AdamW8bit" to your command line.
64 |
65 | ### Parameter efficient fine-tuning
66 |
67 | ```bash
68 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0 --dataset tatsu-lab/alpaca --lr-fp 1e-6
69 |
70 | # AutoGPTQ model with Lora
71 | CUDA_VISIBLE_DEVICES=0 python -m green_bit_llm.sft.peft_lora --model astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit --dataset tatsu-lab/alpaca --lr-fp 1e-6
72 | ```
73 |
74 | ### 0-Shot Evaluation of Q-SFT
75 |
76 | The 0-shot evaluations of quantized Llama 3 8B model under different fine-tuning settings are listed as an example. **Q-SFT** indicates quantized surpervised-finetuning.
77 |
78 | | Task | Bpw | Llama 3 8B Base | Llama 3 8B + LoRA | Llama 3 8B Q-SFT + Galore | Llama 3 8B + Q-SFT |
79 | |:-------------:|:--------:|:-----------------:|:-------------------:|:--------------------------:|:------------------:|
80 | | PIQA | 2.2 | 0.72 | 0.75 | 0.75 | 0.75 |
81 | | | 2.5 | 0.74 | 0.77 | 0.76 | 0.76 |
82 | | | 3.0 | 0.76 | 0.78 | 0.78 | 0.79 |
83 | | BoolQ | 2.2 | 0.74 | 0.77 | 0.77 | 0.78 |
84 | | | 2.5 | 0.75 | 0.76 | 0.76 | 0.78 |
85 | | | 3.0 | 0.78 | 0.80 | 0.79 | 0.80 |
86 | | Winogr. | 2.2 | 0.67 | 0.68 | 0.68 | 0.67 |
87 | | | 2.5 | 0.68 | 0.69 | 0.69 | 0.69 |
88 | | | 3.0 | 0.70 | 0.71 | 0.71 | 0.71 |
89 | | ARC-E | 2.2 | 0.73 | 0.77 | 0.76 | 0.75 |
90 | | | 2.5 | 0.76 | 0.77 | 0.77 | 0.76 |
91 | | | 3.0 | 0.77 | 0.79 | 0.79 | 0.79 |
92 | | ARC-C | 2.2 | 0.39 | 0.46 | 0.45 | 0.45 |
93 | | | 2.5 | 0.41 | 0.44 | 0.43 | 0.43 |
94 | | | 3.0 | 0.44 | 0.49 | 0.47 | 0.49 |
95 | | WiC | 2.2 | 0.50 | 0.50 | 0.50 | 0.50 |
96 | | | 2.5 | 0.51 | 0.50 | 0.52 | 0.51 |
97 | | | 3.0 | 0.52 | 0.52 | 0.57 | 0.60 |
98 | | Avg | 2.2 | 0.62 | 0.65 | 0.65 | 0.65 |
99 | | | 2.5 | 0.64 | 0.65 | 0.65 | 0.65 |
100 | | | 3.0 | 0.66 | 0.68 | 0.68 | 0.69 |
101 |
102 | Compared to traditional LoRA based fine-tuning, our approach streamlines engineering supply chain from fine-tuning to hardware deployment, while also enhancing performance.
103 |
104 | ### Current Limitations
105 |
106 | 1. Gradient clipping is currently unavailable for Full-parameter fine-tuning due to PyTorch's restrictions on the dtype of gradient tensors. The integer tensor type we use for qweight is not supported. We plan to address this issue gradually in the future.
107 | 2. Due to the need for deep modifications to the Python code related to the Int gradient tensor type, to ensure stability and safety, we currently do not support distributed or data parallel training. We plan to support this in the future. Stay tuned.
108 |
109 |
110 | ## License
111 | - The script 'optim/adamw8bit.py' has been modified from [GaLore repository](https://github.com/jiaweizzhao/GaLore/blob/master/galore_torch/adamw8bit.py), which is released under the Apache 2.0 License.
112 | - The script 'optim/bnb_optimizer.py' has been modified from [bitsandbytes repository](https://github.com/TimDettmers/bitsandbytes/blob/main/bitsandbytes/optim/optimizer.py), which is released under the MIT License.
113 | - We release our changes and additions to these files under the [Apache 2.0 License](../../LICENSE).
114 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/sft/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/sft/finetune.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 |
4 | import torch
5 |
6 | from transformers import PreTrainedTokenizer, TrainingArguments
7 | from datasets import load_dataset
8 | from green_bit_llm.sft.trainer import GbaSFTTrainer
9 |
10 | from green_bit_llm.common import load
11 | from green_bit_llm.args_parser import setup_shared_arg_parser
12 |
13 | import warnings
14 |
15 | warnings.filterwarnings('ignore')
16 |
17 | try:
18 | from bitorch_engine.optim import DiodeMix
19 | from bitorch_engine.layers.qlinear.nbit import MPQLinearBase
20 | except ModuleNotFoundError as e:
21 | raise Exception(f"Error occurred while importing Bitorch Engine module '{str(e)}'.")
22 |
23 | from green_bit_llm.sft.optim import AdamW8bit
24 | from green_bit_llm.sft.utils import str_to_torch_dtype, create_param_groups
25 |
26 |
27 | # default value for arguments
28 | DEFAULT_MODEL_PATH = "GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0"
29 | DEFAULT_SEQLEN = 512
30 | DEFAULT_RANDOM_SEED = 0
31 | DEFAULT_LR = 5e-6
32 | DEFAULT_LR_GALORE = 5e-5
33 | DEFAULT_LR_ADAMW8BIT = 5e-3
34 | DEFAULT_BETAS = (0.9, 0.99)
35 |
36 |
37 | def setup_arg_parser():
38 | """Set up and return the argument parser."""
39 | parser = setup_shared_arg_parser("green-bit-llm finetune script")
40 | parser.add_argument(
41 | "--seed",
42 | type=int,
43 | default=DEFAULT_RANDOM_SEED,
44 | help="The random seed for data loader.",
45 | )
46 | # GaLore parameters
47 | parser.add_argument(
48 | "--galore",
49 | action="store_true",
50 | help="Enable using galore",
51 | )
52 | parser.add_argument("--galore-rank", type=int, default=256)
53 | parser.add_argument("--galore-update-proj-gap", type=int, default=200)
54 | parser.add_argument("--galore-scale", type=float, default=0.25)
55 | parser.add_argument("--galore-proj-type", type=str, default="std")
56 |
57 | # qweight related
58 | parser.add_argument(
59 | "--tune-qweight-only",
60 | action="store_true",
61 | help="Set whether to adjust only the low-bit qweight and keep the regular parameters unchanged during the training process.",
62 | )
63 | parser.add_argument(
64 | "--lr-2bit",
65 | type=float,
66 | default=-1.0,
67 | help="Learning rate for 2-bit qweight."
68 | )
69 | parser.add_argument(
70 | "--lr-4bit",
71 | type=float,
72 | default=-1.0,
73 | help="Learning rate for 4-bit qweight."
74 | )
75 | parser.add_argument(
76 | "--lr-fp",
77 | type=float,
78 | default=DEFAULT_LR,
79 | help="Learning rate for full-precision weight."
80 | )
81 | return parser
82 |
83 |
84 | def main(args):
85 |
86 | # Building configs
87 | tokenizer_config = {"trust_remote_code": True if args.trust_remote_code else None}
88 | pretrain_model_config = {
89 | "trust_remote_code": True if args.trust_remote_code else None,
90 | "attn_implementation": "flash_attention_2" if args.use_flash_attention_2 else None
91 | }
92 |
93 | model, tokenizer, config = load(
94 | args.model,
95 | tokenizer_config=tokenizer_config,
96 | device_map='auto',
97 | seqlen=args.seqlen,
98 | model_config=pretrain_model_config,
99 | requires_grad=True,
100 | )
101 |
102 | # NOTE:
103 | # Typically, Hugging Face's Trainer does not support fine-tuning quantized models.
104 | # However, our tool supports this scenario.
105 | # Therefore, we need to delete this attribute after loading the model.
106 | if hasattr(model, 'is_quantized'):
107 | delattr(model, 'is_quantized')
108 |
109 | param_groups = create_param_groups(model, args, DEFAULT_BETAS, DEFAULT_LR_GALORE, DEFAULT_LR_ADAMW8BIT, DEFAULT_LR)
110 |
111 | model.train()
112 |
113 | dataset = load_dataset(args.dataset, split="train")
114 |
115 | if not args.galore:
116 | args.save_dir = os.path.join(args.save_dir, "finetune/common/", args.model)
117 | else:
118 | args.save_dir = os.path.join(args.save_dir, "finetune/galore/", args.model)
119 |
120 |
121 | train_args = TrainingArguments(
122 | output_dir=args.save_dir,
123 | gradient_checkpointing=True,
124 | #auto_find_batch_size=True,
125 | per_device_train_batch_size=args.batch_size,
126 | logging_steps=1,
127 | num_train_epochs=1,
128 | save_steps=args.save_step,
129 | save_total_limit=3,
130 | gradient_accumulation_steps=1,
131 | lr_scheduler_type='cosine',
132 | max_grad_norm=0, # NOTE: max_grad_norm MUST be <= 0 or None, otherwise raise dtype error due to the Int dtype of qweight.
133 | )
134 |
135 | # Optimizer
136 | if 'adamw8bit' in args.optimizer.lower():
137 | optimizer = AdamW8bit(param_groups, weight_decay=args.weight_decay, dtype=str_to_torch_dtype(args.dtype))
138 | elif 'diodemix' in args.optimizer.lower():
139 | optimizer = DiodeMix(param_groups, dtype=str_to_torch_dtype(args.dtype))
140 |
141 | optimizers = (optimizer, None)
142 |
143 | # Trainer
144 | trainer = GbaSFTTrainer(
145 | model=model,
146 | args=train_args,
147 | train_dataset=dataset,
148 | dataset_text_field="text",
149 | optimizers=optimizers,
150 | max_seq_length=args.seqlen,
151 | )
152 |
153 | trainer.train()
154 |
155 | model.save_pretrained(args.save_dir)
156 |
157 |
158 | if __name__ == "__main__":
159 | if not torch.cuda.is_available():
160 | print("Warning: CUDA is required to run the model.")
161 | sys.exit(0)
162 |
163 | parser = setup_arg_parser()
164 | args = parser.parse_args()
165 |
166 | main(args)
167 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/optim/__init__.py:
--------------------------------------------------------------------------------
1 | from .adamw8bit import AdamW8bit
--------------------------------------------------------------------------------
/green_bit_llm/sft/optim/adamw8bit.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from .bnb_optimizer import Optimizer2State
4 |
5 | try:
6 | from galore_torch.galore_projector import GaLoreProjector
7 | except ModuleNotFoundError as e:
8 | raise Exception("Error: GaLoreProjector is not available. Make sure 'galore-torch' has been installed on you system.")
9 |
10 | try:
11 | from bitorch_engine.layers.qlinear.nbit import MPQWeightParameter
12 | from bitorch_engine.utils.quant_operators import gptq_style_unpacking
13 | from bitorch_engine.layers.qlinear.nbit.cuda.utils import pack_fp_weight
14 | except ModuleNotFoundError as e:
15 | raise Exception(f"Error occurred while importing Bitorch Engine module '{str(e)}'.")
16 |
17 |
18 | class AdamW8bit(Optimizer2State):
19 | def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=.0, amsgrad=False, optim_bits=8,
20 | args=None, min_8bit_size=4096, percentile_clipping=100, block_wise=True, is_paged=False,
21 | dtype: torch.dtype = torch.float16):
22 | self.dtype = dtype
23 | super().__init__( "adam", params, lr, betas, eps, weight_decay, optim_bits, args, min_8bit_size, percentile_clipping,
24 | block_wise, is_paged=is_paged )
25 |
26 | @torch.no_grad()
27 | def step(self, closure=None):
28 | """Performs a single optimization step.
29 |
30 | Arguments:
31 | closure (callable, optional): A closure that reevaluates the model
32 | and returns the loss.
33 | """
34 | loss = None
35 | if closure is not None:
36 | with torch.enable_grad():
37 | loss = closure()
38 |
39 | if not self.initialized:
40 | self.check_overrides()
41 | self.to_gpu() # needed for fairseq pure fp16 training
42 | self.initialized = True
43 |
44 | #if self.is_paged: self.page_mng.prefetch_all()
45 | for gindex, group in enumerate(self.param_groups):
46 | for pindex, p in enumerate(group["params"]):
47 | if p.grad is None:
48 | continue
49 |
50 | state = self.state[p]
51 |
52 | if "step" not in state:
53 | state["step"] = 0
54 |
55 | if isinstance(p, MPQWeightParameter):
56 | grad = p.privileged_grad.to(self.dtype).to(p.grad.device)
57 | else:
58 | grad = p.grad.to(self.dtype)
59 |
60 | # GaLore Projection
61 | if "rank" in group:
62 | if "projector" not in state:
63 | state["projector"] = GaLoreProjector(group["rank"], update_proj_gap=group["update_proj_gap"], scale=group["scale"], proj_type=group["proj_type"])
64 |
65 | projector = state["projector"]
66 | grad = projector.project(grad, state["step"])
67 |
68 | saved_data = None
69 | if "rank" in group or isinstance(p, MPQWeightParameter):
70 | # suboptimal implementation
71 | # In the implementation mentioned, the author sets the variable p (representing model parameters) to zero,
72 | # meaning p does not change during the update step. Instead, only the gradient states are updated,
73 | # and actual weight modifications are calculated manually later in the code.
74 | saved_data = p.data.clone()
75 | p.data = torch.zeros_like(grad)
76 |
77 | if 'weight_decay' in group and group['weight_decay'] > 0:
78 | # ensure that the weight decay is not applied to the norm grad
79 | group['weight_decay_saved'] = group['weight_decay']
80 | group['weight_decay'] = 0
81 |
82 | if 'state1' not in state:
83 | self.init_state(group, p, gindex, pindex, grad)
84 |
85 | self.prefetch_state(p)
86 |
87 | self.update_step(group, p, gindex, pindex, grad)
88 |
89 | torch.cuda.synchronize()
90 |
91 | if 'weight_decay_saved' in group:
92 | group['weight_decay'] = group['weight_decay_saved']
93 | del group['weight_decay_saved']
94 |
95 | w_unpacked = None
96 | # GaLore Projection Back
97 | if "rank" in group:
98 | # now the p.data is actually: -norm_grad*lr
99 | norm_grad = projector.project_back(p.data)
100 |
101 | if isinstance(p, MPQWeightParameter):
102 | # unpack qweight
103 | p.data = saved_data
104 | w_unpacked = gptq_style_unpacking(p).to(self.dtype).to(saved_data.device)
105 | w_unpacked.add_(norm_grad)
106 | if group["weight_decay"] > 0.0:
107 | w_unpacked.add_(w_unpacked, alpha=-group['lr'] * group['weight_decay'])
108 | # pack fp weight back to Q-weight and update qweight data
109 | p.data = pack_fp_weight(w_unpacked, p)
110 | else:
111 | p.data = saved_data.add_(norm_grad)
112 | if group["weight_decay"] > 0.0:
113 | p.data.add_(p.data, alpha=-group['lr'] * group['weight_decay'])
114 | elif isinstance(p, MPQWeightParameter):
115 | # now the p.data is actually: -norm_grad*lr
116 | norm_grad = p.data.clone()
117 | # unpack qweight
118 | p.data = saved_data
119 | w_unpacked = gptq_style_unpacking(p).to(self.dtype).to(saved_data.device)
120 | w_unpacked.add_(norm_grad)
121 | if group["weight_decay"] > 0.0:
122 | w_unpacked.add_(w_unpacked, alpha=-group['lr'] * group['weight_decay'])
123 | # pack fp weight back to Q-weight and update qweight data
124 | p.data = pack_fp_weight(w_unpacked, p)
125 |
126 | # pack fp weight back to qweight
127 | if w_unpacked is not None:
128 | del w_unpacked
129 | if saved_data is not None:
130 | del saved_data
131 | if torch.cuda.is_available():
132 | torch.cuda.empty_cache()
133 |
134 | if self.is_paged:
135 | # all paged operation are asynchronous, we need
136 | # to sync to make sure all tensors are in the right state
137 | torch.cuda.synchronize()
138 |
139 | return loss
140 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/peft_lora.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 |
4 | import torch
5 |
6 | from transformers import PreTrainedTokenizer, TrainingArguments
7 | from datasets import load_dataset
8 | from peft import PeftModel, LoraConfig, get_peft_model
9 |
10 | from green_bit_llm.sft.trainer import GbaSFTTrainer
11 | from green_bit_llm.common import load
12 | from green_bit_llm.args_parser import setup_shared_arg_parser
13 | from green_bit_llm.sft.peft_utils.model import *
14 | from green_bit_llm.sft.optim import AdamW8bit
15 |
16 | import warnings
17 | warnings.filterwarnings('ignore')
18 |
19 | try:
20 | from bitorch_engine.optim import DiodeMix
21 | except ModuleNotFoundError as e:
22 | raise Exception(f"Error occurred while importing Bitorch Engine module '{str(e)}'.")
23 |
24 | from green_bit_llm.sft.utils import str_to_torch_dtype, create_param_groups
25 |
26 | # default value for arguments
27 | DEFAULT_MODEL_PATH = "GreenBitAI/Qwen-1.5-1.8B-layer-mix-bpw-3.0"
28 | DEFAULT_SEQLEN = 512
29 | DEFAULT_RANDOM_SEED = 0
30 | DEFAULT_LR = 1e-5
31 | DEFAULT_LR_GALORE = 1e-4
32 | DEFAULT_LR_FP = 1e-6
33 | DEFAULT_BETAS = (0.9, 0.999)
34 |
35 |
36 | def setup_arg_parser():
37 | """Set up and return the argument parser."""
38 | parser = setup_shared_arg_parser("green-bit-llm lora script")
39 | parser.add_argument(
40 | "--seed",
41 | type=int,
42 | default=DEFAULT_RANDOM_SEED,
43 | help="The random seed for data loader.",
44 | )
45 | # qweight related
46 | parser.add_argument(
47 | "--lr-fp",
48 | type=float,
49 | default=DEFAULT_LR_FP,
50 | help="Learning rate for full-precision weight."
51 | )
52 | parser.add_argument("--lora-rank", type=int, default=64)
53 | parser.add_argument("--lora-alpha", type=int, default=32)
54 | parser.add_argument("--lora-dropout", type=float, default=0.01)
55 | return parser
56 |
57 |
58 | def main(args):
59 |
60 | # Building configs
61 | tokenizer_config = {"trust_remote_code": True if args.trust_remote_code else None}
62 | pretrain_model_config = {
63 | "trust_remote_code": True if args.trust_remote_code else None,
64 | "attn_implementation": "flash_attention_2" if args.use_flash_attention_2 else None
65 | }
66 |
67 | model, tokenizer, config = load(
68 | args.model,
69 | tokenizer_config=tokenizer_config,
70 | device_map='auto',
71 | seqlen=args.seqlen,
72 | model_config=pretrain_model_config,
73 | requires_grad=False,
74 | )
75 |
76 | config = LoraConfig(
77 | r=args.lora_rank,
78 | lora_alpha=args.lora_alpha,
79 | target_modules=["q_proj", "v_proj", "out_proj", "down_proj", "up_proj"],
80 | lora_dropout=args.lora_dropout,
81 | bias="none",
82 | task_type="CAUSAL_LM",
83 | )
84 |
85 | replace_peft_lora_model_with_gba_lora_model()
86 |
87 | model = get_peft_model(model, config)
88 |
89 | param_groups = create_param_groups(model, args, DEFAULT_BETAS)
90 |
91 | model.train()
92 |
93 | dataset = load_dataset(args.dataset, split="train")
94 |
95 | args.save_dir = os.path.join(args.save_dir, "lora/", args.model)
96 |
97 | train_args = TrainingArguments(
98 | output_dir=args.save_dir,
99 | gradient_checkpointing=True,
100 | #auto_find_batch_size=True,
101 | per_device_train_batch_size=args.batch_size,
102 | logging_steps=1,
103 | num_train_epochs=1,
104 | gradient_accumulation_steps=1,
105 | save_steps=args.save_step,
106 | #warmup_ratio=0.05,
107 | max_grad_norm=0, # NOTE: max_grad_norm MUST be <= 0 or None, otherwise raise dtype error due to the Int dtype of qweight.
108 | )
109 |
110 | # Optimizer
111 | if 'adamw8bit' in args.optimizer.lower():
112 | optimizer = AdamW8bit(param_groups, weight_decay=args.weight_decay, lr=5e-3, dtype=str_to_torch_dtype(args.dtype))
113 | elif 'diodemix' in args.optimizer.lower():
114 | optimizer = DiodeMix(param_groups, dtype=str_to_torch_dtype(args.dtype))
115 | optimizers = (optimizer, None)
116 |
117 | for name, param in model.named_parameters():
118 | if "qweight" not in name:
119 | param.requires_grad = True
120 |
121 | trainer = GbaSFTTrainer(
122 | model=model,
123 | args=train_args,
124 | train_dataset=dataset,
125 | dataset_text_field="text",
126 | optimizers=optimizers,
127 | max_seq_length=args.seqlen,
128 | )
129 |
130 | trainer.train()
131 |
132 | model.save_pretrained(args.save_dir)
133 |
134 |
135 | if __name__ == "__main__":
136 | if not torch.cuda.is_available():
137 | print("Warning: CUDA is needed to run the model.")
138 | sys.exit(0)
139 |
140 | parser = setup_arg_parser()
141 | args = parser.parse_args()
142 |
143 | main(args)
144 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/peft_utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/green_bit_llm/sft/peft_utils/__init__.py
--------------------------------------------------------------------------------
/green_bit_llm/sft/peft_utils/gba_lora.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023-present the HuggingFace Inc. team.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | from __future__ import annotations
15 |
16 | from typing import Any, Optional
17 |
18 | ENGINE_AVAILABLE=True
19 | try:
20 | from bitorch_engine.layers.qlinear.nbit import MPQLinearBase
21 | from bitorch_engine.layers.qlinear.nbit.cuda import MPQLinearCuda, MBWQLinearCuda
22 | except ModuleNotFoundError as e:
23 | ENGINE_AVAILABLE = False
24 | raise Exception(f"Error occurred while importing Bitorch Engine module '{str(e)}'.")
25 |
26 | import torch
27 | import torch.nn as nn
28 | from transformers.pytorch_utils import Conv1D
29 |
30 | from peft.tuners.tuners_utils import BaseTunerLayer, check_adapters_to_merge
31 | from peft.tuners.lora import LoraLayer
32 |
33 |
34 | class GBALoraLayer(LoraLayer):
35 | """
36 | GBALoraLayer class extends LoraLayer to support Gradient-Based Adapter tuning for various model layers.
37 | It maintains lists of both LoRA-specific parameters and other adapter-related parameters.
38 | """
39 |
40 | # All names of layers that may contain (trainable) adapter weights
41 | adapter_layer_names = ("lora_A", "lora_B", "lora_embedding_A", "lora_embedding_B")
42 | # All names of other parameters that may contain adapter-related parameters
43 | other_param_names = ("r", "lora_alpha", "scaling", "lora_dropout")
44 |
45 | def __init__(self, base_layer: nn.Module, **kwargs) -> None:
46 | """
47 | Initializes a GBALoraLayer instance.
48 | Args:
49 | base_layer: The underlying neural network layer that LoRA is being applied to.
50 | **kwargs: Additional keyword arguments for customization.
51 |
52 | This method initializes adapter components, configures the underlying base layer, and sets the
53 | feature sizes based on the base layer type.
54 | """
55 | self.base_layer = base_layer
56 | self.r = {}
57 | self.lora_alpha = {}
58 | self.scaling = {}
59 | self.lora_dropout = nn.ModuleDict({})
60 | self.lora_A = nn.ModuleDict({})
61 | self.lora_B = nn.ModuleDict({})
62 | # For Embedding layer
63 | self.lora_embedding_A = nn.ParameterDict({})
64 | self.lora_embedding_B = nn.ParameterDict({})
65 | # Mark the weight as unmerged
66 | self._disable_adapters = False
67 | self.merged_adapters = []
68 | self.use_dora: dict[str, bool] = {}
69 | self.lora_magnitude_vector: Optional[torch.nn.ParameterDict] = None # for DoRA
70 | self._caches: dict[str, Any] = {}
71 | self.kwargs = kwargs
72 |
73 | base_layer = self.get_base_layer()
74 | if isinstance(base_layer, nn.Linear):
75 | in_features, out_features = base_layer.in_features, base_layer.out_features
76 | elif isinstance(base_layer, nn.Conv2d):
77 | in_features, out_features = base_layer.in_channels, base_layer.out_channels
78 | elif isinstance(base_layer, nn.Embedding):
79 | in_features, out_features = base_layer.num_embeddings, base_layer.embedding_dim
80 | elif isinstance(base_layer, Conv1D):
81 | in_features, out_features = (
82 | base_layer.weight.ds_shape if hasattr(base_layer.weight, "ds_shape") else base_layer.weight.shape
83 | )
84 | elif hasattr(base_layer, "infeatures") and hasattr(base_layer, "outfeatures"):
85 | # QuantLinear
86 | in_features, out_features = base_layer.infeatures, base_layer.outfeatures
87 | elif hasattr(base_layer, "input_size") and hasattr(base_layer, "output_size"):
88 | # Megatron ColumnParallelLinear,RowParallelLinear
89 | in_features, out_features = base_layer.input_size, base_layer.output_size
90 | elif hasattr(base_layer, "codebooks") and base_layer.__class__.__name__ == "QuantizedLinear":
91 | # AQLM QuantLinear
92 | in_features, out_features = base_layer.in_features, base_layer.out_features
93 | elif hasattr(base_layer, "w_bit") and base_layer.__class__.__name__ == "WQLinear_GEMM":
94 | # Awq layers
95 | in_features, out_features = base_layer.in_features, base_layer.out_features
96 | elif base_layer.__class__.__name__ == "MBWQLinearCuda":
97 | in_features, out_features = base_layer.in_channels, base_layer.out_channels
98 | elif base_layer.__class__.__name__ == "MPQLinearCuda":
99 | in_features, out_features = base_layer.in_channels, base_layer.out_channels
100 | else:
101 | raise ValueError(f"Unsupported layer type {type(base_layer)}")
102 |
103 | self.in_features = in_features
104 | self.out_features = out_features
105 |
106 |
107 | class GBALoraLinear(torch.nn.Module, GBALoraLayer):
108 | """
109 | Implements a LoRA (Low-Rank Adaptation) module integrated into a dense linear layer.
110 | This class extends functionality by allowing modifications to the layer through
111 | low-rank matrices to efficiently adapt large pre-trained models without extensive retraining.
112 | """
113 | # Lora implemented in a dense layer
114 | def __init__(
115 | self,
116 | base_layer: torch.nn.Module,
117 | adapter_name: str,
118 | r: int = 0,
119 | lora_alpha: int = 1,
120 | lora_dropout: float = 0.0,
121 | init_lora_weights: bool = True,
122 | use_rslora: bool = False,
123 | use_dora: bool = False,
124 | **kwargs,
125 | ) -> None:
126 | """
127 | Initializes the LoRA adapted layer with specific parameters and configurations.
128 |
129 | Parameters:
130 | base_layer (torch.nn.Module): The original base layer to which LoRA adjustments are applied.
131 | adapter_name (str): The name of the adapter for identification.
132 | r (int): The rank of the low-rank approximation matrices.
133 | lora_alpha (int): Scaling factor for the LoRA parameters.
134 | lora_dropout (float): Dropout rate for regularization during training.
135 | init_lora_weights (bool): Whether to initialize LoRA weights upon creation.
136 | use_rslora (bool): Indicates whether to use rank-stabilized LoRA.
137 | use_dora (bool): Indicates whether to use dynamic orthogonal regularization adapter.
138 | """
139 | super().__init__()
140 | GBALoraLayer.__init__(self, base_layer)
141 | self.fan_in_fan_out = False
142 |
143 | self._active_adapter = adapter_name
144 | self.update_layer(
145 | adapter_name,
146 | r,
147 | lora_alpha=lora_alpha,
148 | lora_dropout=lora_dropout,
149 | init_lora_weights=init_lora_weights,
150 | use_rslora=use_rslora,
151 | use_dora=use_dora,
152 | )
153 |
154 | def forward(self, x: torch.Tensor, *args, **kwargs) -> torch.Tensor:
155 | """
156 | Defines the computation performed at every call. Applies the base layer computation
157 | and modifies the output using the configured LoRA parameters.
158 |
159 | Parameters:
160 | x (torch.Tensor): The input tensor to process.
161 |
162 | Returns:
163 | torch.Tensor: The output tensor after applying the LoRA adaptation.
164 | """
165 | self._check_forward_args(x, *args, **kwargs)
166 | adapter_names = kwargs.pop("adapter_names", None)
167 |
168 | result = self.base_layer(x, *args, **kwargs)
169 | # As per Tim Dettmers, for 4bit, we need to defensively clone here.
170 | # The reason is that in some cases, an error can occur that backprop
171 | # does not work on a manipulated view. This issue may be solved with
172 | # newer PyTorch versions but this would need extensive testing to be
173 | # sure.
174 |
175 | for active_adapter in self.active_adapters:
176 | if active_adapter not in self.lora_A.keys():
177 | continue
178 | lora_A = self.lora_A[active_adapter]
179 | lora_B = self.lora_B[active_adapter]
180 | dropout = self.lora_dropout[active_adapter]
181 | scaling = self.scaling[active_adapter]
182 |
183 | requires_conversion = not torch.is_autocast_enabled()
184 | if requires_conversion:
185 | expected_dtype = result.dtype
186 | x = x.to(lora_A.weight.dtype)
187 |
188 | if not self.use_dora[active_adapter]:
189 | output = lora_B(lora_A(dropout(x))) * scaling
190 | else:
191 | output = self._apply_dora(x, lora_A, lora_B, scaling, active_adapter)
192 | if requires_conversion:
193 | output = output.to(expected_dtype)
194 |
195 | result = result + output
196 |
197 | return result
198 |
199 | def __repr__(self) -> str:
200 | """
201 | Provides a string representation of the module, enhancing the default
202 | representation with a prefix to identify it as a LoRA-adapted layer.
203 | """
204 | rep = super().__repr__()
205 | return "lora." + rep
206 |
207 |
208 | def dispatch_gba(target: torch.nn.Module, adapter_name: str, **kwargs):
209 | new_module = None
210 |
211 | if isinstance(target, BaseTunerLayer):
212 | target_base_layer = target.get_base_layer()
213 | else:
214 | target_base_layer = target
215 |
216 | if ENGINE_AVAILABLE and issubclass(type(target_base_layer), MPQLinearBase):
217 | new_module = GBALoraLinear(target_base_layer, adapter_name, **kwargs)
218 |
219 | return new_module
220 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/peft_utils/model.py:
--------------------------------------------------------------------------------
1 | import peft.peft_model
2 | from peft.tuners import lora
3 | from peft.utils import _get_submodules, PeftType
4 |
5 | from green_bit_llm.sft.peft_utils.gba_lora import dispatch_gba
6 |
7 |
8 | class GBALoraModel(lora.LoraModel):
9 | """
10 | A specialized version of LoraModel for low-rank adaptation. This class overrides the method to create new modules specifically tailored
11 | to GBA needs, by selecting appropriate backend functions to handle LoRA layers.
12 | """
13 | @staticmethod
14 | def _create_new_module(lora_config, adapter_name, target, **kwargs):
15 | """
16 | Creates a new module based on the provided configuration for LoRA and the type of target module.
17 | This method selects the correct dispatch function for integrating LoRA into the specified model layer.
18 | If no suitable module can be found, it raises an error.
19 |
20 | Args:
21 | lora_config: Configuration parameters for the LoRA adaptation.
22 | adapter_name: Identifier for the LoRA adapter.
23 | target: The target neural network layer to which LoRA should be applied.
24 | **kwargs: Additional keyword arguments.
25 |
26 | Returns:
27 | new_module: A new module with LoRA adaptation applied, or raises an error if the target is unsupported.
28 |
29 | Raises:
30 | ValueError: If the target module type is not supported by the currently available dispatchers.
31 | """
32 | # Collect dispatcher functions to decide what backend to use for the replaced LoRA layer. The order matters,
33 | # because the first match is always used. Therefore, the default layers should be checked last.
34 | dispatchers = []
35 |
36 | dispatchers.append(dispatch_gba)
37 |
38 | dispatchers.extend(
39 | [dispatch_gba]
40 | )
41 |
42 | new_module = None
43 | for dispatcher in dispatchers:
44 | new_module = dispatcher(target, adapter_name, lora_config=lora_config, **kwargs)
45 | if new_module is not None: # first match wins
46 | break
47 |
48 | if new_module is None:
49 | # no module could be matched
50 | raise ValueError(
51 | f"Target module {target} is not supported. Currently, only the following modules are supported: "
52 | "`torch.nn.Linear`, `torch.nn.Embedding`, `torch.nn.Conv2d`, `transformers.pytorch_utils.Conv1D`."
53 | )
54 |
55 | return new_module
56 |
57 | def replace_peft_lora_model_with_gba_lora_model():
58 | """
59 | Replaces the existing LoRA model in the PEFT framework with the GBA-enhanced LoRA model.
60 | This function patches the model mapping in PEFT to use `GBALoraModel` for LoRA configurations.
61 | """
62 | peft.peft_model.PEFT_TYPE_TO_MODEL_MAPPING[PeftType.LORA] = GBALoraModel
63 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/trainer.py:
--------------------------------------------------------------------------------
1 | import json
2 | import shutil
3 | import os
4 | from typing import Optional
5 |
6 | from trl import SFTTrainer
7 |
8 | from green_bit_llm.common.utils import STRATEGY_FILE_NAME
9 | from green_bit_llm.common.utils import get_model_path
10 |
11 |
12 | class GbaSFTTrainer(SFTTrainer):
13 | def save_model(self, output_dir: Optional[str] = None, _internal_call: bool = False):
14 | """
15 | Saves the model to the specified directory and also ensures that the
16 | 'quant_strategy.json' file is copied over to the same directory.
17 |
18 | Args:
19 | output_dir (Optional[str]): The directory to which the model and the
20 | 'quant_strategy.json' file should be saved.
21 | If None, the model will be saved to the default location.
22 | _internal_call (bool): A flag used to indicate whether this method was
23 | called internally by the library, which can affect
24 | certain behaviors (not used in this override).
25 |
26 | Raises:
27 | ValueError: If the expected GBA prefix is not found in the output directory path.
28 | """
29 |
30 | # Perform the original save model behavior of the superclass
31 | # out_dir should be os.path.join(args.save_dir, args.model)
32 | super().save_model(output_dir)
33 |
34 | # Define the prefix to look for in the output directory path
35 | gba_prefix = "GreenBitAI" + os.path.sep
36 | # Find the prefix in the output directory path
37 | start_index = output_dir.find(gba_prefix)
38 |
39 | if start_index == -1:
40 | config_path = os.path.join(output_dir, "config.json")
41 | if os.path.isfile(config_path):
42 | with open(config_path, 'r') as file:
43 | data = json.load(file)
44 | if "quantization_config" in data.keys():
45 | quantization_config = data["quantization_config"]
46 | if "exllama_config" in quantization_config.keys():
47 | del quantization_config["exllama_config"]
48 | if "use_exllama" in quantization_config.keys():
49 | del quantization_config["use_exllama"]
50 |
51 | with open(config_path, 'w') as file:
52 | json.dump(data, file, indent=4)
53 | return
54 |
55 | # Ensure this is executed only on the main process
56 | if not self.is_world_process_zero():
57 | return
58 |
59 | # save "quant_strategy.json" file
60 | start_pos = start_index + len(gba_prefix) - 1
61 | end_pos = output_dir.find(os.path.sep, start_pos + 1)
62 |
63 | if end_pos == -1:
64 | model_name = output_dir[start_index:]
65 | else:
66 | model_name = output_dir[start_index:end_pos]
67 |
68 | model_from_path = get_model_path(model_name)
69 | quant_strategy_file = os.path.join(model_from_path, STRATEGY_FILE_NAME)
70 | destination_path = os.path.join(output_dir, STRATEGY_FILE_NAME)
71 | shutil.copy(quant_strategy_file, destination_path)
72 |
--------------------------------------------------------------------------------
/green_bit_llm/sft/utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from colorama import init, Fore, Style
4 | init(autoreset=True)
5 |
6 | try:
7 | from bitorch_engine.layers.qlinear.nbit import MPQLinearBase
8 | except ModuleNotFoundError as e:
9 | raise Exception(f"Error occurred while importing Bitorch Engine module '{str(e)}'.")
10 |
11 |
12 | def str_to_torch_dtype(dtype: str):
13 | """Get torch dtype from the input data type string."""
14 | if dtype is None:
15 | return None
16 | elif dtype == "float":
17 | return torch.float
18 | elif dtype == "half":
19 | return torch.float16
20 | else:
21 | raise ValueError(f"Unsupported dtype: {dtype}")
22 |
23 |
24 | def create_device_map(cuda_device_id):
25 | ids = cuda_device_id.split(',')
26 | # Create strings in the format "cuda:x" for each ID and put them into the collection
27 | device_map = {f"cuda:{id}" for id in ids}
28 | return device_map
29 |
30 |
31 | def get_learning_rate(lr_bit, galore, default_lr_galore, default_lr):
32 | """Adaptivly get the learning rate value from the input setting parameters."""
33 | if lr_bit > 0:
34 | return lr_bit
35 | return default_lr_galore if galore else default_lr
36 |
37 |
38 | def create_param_groups(model, args, betas=(0.9, 0.999), lr_galore=1e-4, lr_adamw8b=5e-3, lr_default=1e-5):
39 | """
40 | Create parameter groups based on the bit-width of quantized weights in the model.
41 | This function categorizes parameters into groups with different learning rates and beta values
42 | for optimizers.
43 |
44 | This function also prints out the number of trainable params and all params.
45 |
46 | Args:
47 | model (nn.Module): The neural network model.
48 | args (argparse.ArgumentParser): Command line arguments for additional parameters.
49 |
50 | Returns:
51 | List[dict]: A list of dictionaries where each dictionary contains a parameter group.
52 | """
53 | params_2_bit = []
54 | params_4_bit = []
55 |
56 | regular_trainable_numel = []
57 | qweight_trainable_numel = []
58 | total_numel = []
59 | trainable_numel = []
60 |
61 | for module_name, module in model.named_modules():
62 | if issubclass(type(module), MPQLinearBase):
63 | if module.w_bit == 2:
64 | params_2_bit.append(module.qweight)
65 | qweight_trainable_numel.append(int(module.qweight.numel() * 32 / 2))
66 | elif module.w_bit == 4:
67 | params_4_bit.append(module.qweight)
68 | qweight_trainable_numel.append(int(module.qweight.numel() * 32 / 4))
69 | else:
70 | raise Exception(f"Error: Invalid qweight bit width: '{module.w_bit}'.")
71 |
72 | total_parameters = list(model.parameters())
73 | for param in total_parameters:
74 | if not hasattr(param, "qweight"):
75 | total_numel.append(param.numel())
76 | total_numel += qweight_trainable_numel
77 |
78 | if hasattr(args, 'lora_rank'): # peft
79 | param_groups = []
80 |
81 | # Create list of peft parameters
82 | params_lora = [p for n, p in model.named_parameters() if "lora" in n]
83 |
84 | for param in params_lora:
85 | if param.requires_grad:
86 | trainable_numel.append(param.numel())
87 |
88 | params_group_lora = {'params': params_lora, 'lr': args.lr_fp, 'betas': betas}
89 |
90 | param_groups.append(params_group_lora)
91 |
92 | elif hasattr(args, 'tune_qweight_only'): # full parameter finetune
93 |
94 | id_2bit_params = [id(p) for p in params_2_bit]
95 | id_4bit_params = [id(p) for p in params_4_bit]
96 | # Concatenate IDs to form a single list
97 | excluded_ids = id_2bit_params + id_4bit_params
98 |
99 | # Create list of regular parameters excluding 2-bit and 4-bit params
100 | params_regular = [p for p in model.parameters() if id(p) not in excluded_ids]
101 | for param in params_regular:
102 | if param.requires_grad:
103 | regular_trainable_numel.append(param.numel())
104 |
105 | lr_2 = get_learning_rate(
106 | args.lr_2bit,
107 | args.galore,
108 | lr_adamw8b if 'adamw8bit' in args.optimizer.lower() else lr_galore,
109 | 1e-3 if 'adamw8bit' in args.optimizer.lower() else lr_default
110 | )
111 |
112 | lr_4 = get_learning_rate(
113 | args.lr_4bit,
114 | args.galore,
115 | lr_adamw8b if 'adamw8bit' in args.optimizer.lower() else lr_galore,
116 | 1e-3 if 'adamw8bit' in args.optimizer.lower() else lr_default
117 | )
118 |
119 | params_group_2bit = {'params': params_2_bit, 'lr': lr_2, 'betas': betas}
120 | params_group_4bit = {'params': params_4_bit, 'lr': lr_4, 'betas': betas}
121 | params_group_regular = {'params': params_regular, 'lr': args.lr_fp, 'betas': betas}
122 |
123 | # Optionally add extra settings from command line arguments
124 | if args.galore:
125 | galore_settings = {
126 | 'rank': args.galore_rank,
127 | 'update_proj_gap': args.galore_update_proj_gap,
128 | 'scale': args.galore_scale,
129 | 'proj_type': args.galore_proj_type
130 | }
131 | params_group_2bit.update(galore_settings)
132 | params_group_4bit.update(galore_settings)
133 |
134 | param_groups = [
135 | params_group_2bit,
136 | params_group_4bit
137 | ]
138 |
139 | trainable_numel = qweight_trainable_numel
140 | if not args.tune_qweight_only:
141 | param_groups.append(params_group_regular)
142 | trainable_numel += regular_trainable_numel
143 | else:
144 | raise Exception("Error: invalid use case in creating param_group.")
145 |
146 | # print out trainable params info
147 | print(Style.BRIGHT + Fore.CYAN +
148 | f"Info: trainable params: {sum(trainable_numel):,d} || "
149 | f"all params: {sum(total_numel):,d} || "
150 | f"trainable%: {100 * sum(trainable_numel) / sum(total_numel):.4f}"
151 | )
152 |
153 | return param_groups
154 |
155 |
156 |
157 |
--------------------------------------------------------------------------------
/green_bit_llm/version.py:
--------------------------------------------------------------------------------
1 | __version__ = "0.2.6"
2 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | accelerate>=0.27.2
2 | colorama
3 | datasets
4 | torch>=2.0.0
5 | sentencepiece
6 | transformers>=4.52.4
7 | huggingface-hub
8 | lm-eval==0.3.0
9 | termcolor
10 | pillow
11 | requests
12 | prompt-toolkit
13 | rich
14 | optimum
15 | auto-gptq
16 | langchain-core
17 | fastapi
18 | uvicorn
19 | peewee
20 | python-dotenv
--------------------------------------------------------------------------------
/scripts/curl_script:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # Set variables for testing
4 | API_KEY="" # Replace with your actual API key
5 | HOST="172.20.8.79:8000"
6 |
7 | # Array of models to test
8 | MODELS=(
9 | "GreenBitAI-Llama-3-8B-instruct-layer-mix-bpw-40"
10 | "GreenBitAI-Qwen-25-7B-Instruct-layer-mix-bpw-40"
11 | )
12 |
13 | # Function to run tests for a specific model
14 | run_tests() {
15 | local MODEL_NAME=$1
16 | echo "Running tests for model: ${MODEL_NAME}"
17 | echo "=================================="
18 |
19 | # 1. Health Check
20 | echo "Testing Health Check Endpoint..."
21 | curl -X GET "http://${HOST}/health"
22 |
23 | # 2. Root Endpoint
24 | echo -e "\n\nTesting Root Endpoint..."
25 | curl -X GET "http://${HOST}/"
26 |
27 | # 3. Text Completion Endpoints
28 | echo -e "\n\nTesting Basic Completion..."
29 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/completions" \
30 | -H "Content-Type: application/json" \
31 | -H "X-Api-Key: ${API_KEY}" \
32 | -d '{
33 | "model": "'${MODEL_NAME}'",
34 | "prompt": "Write a story about a robot",
35 | "max_tokens": 100,
36 | "temperature": 0.7
37 | }'
38 |
39 | echo -e "\n\nTesting Streaming Completion..."
40 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/completions" \
41 | -H "Content-Type: application/json" \
42 | -H "X-Api-Key: ${API_KEY}" \
43 | -d '{
44 | "model": "'${MODEL_NAME}'",
45 | "prompt": "Write a story about a robot",
46 | "max_tokens": 200,
47 | "temperature": 0.7,
48 | "stream": true
49 | }'
50 |
51 | echo -e "\n\nTesting Batch Completion..."
52 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/completions" \
53 | -H "Content-Type: application/json" \
54 | -H "X-Api-Key: ${API_KEY}" \
55 | -d '{
56 | "model": "'${MODEL_NAME}'",
57 | "prompt": ["Tell me a joke", "Write a poem"],
58 | "max_tokens": 100,
59 | "temperature": 0.7
60 | }'
61 |
62 | # 4. Chat Completion Endpoints
63 | echo -e "\n\nTesting Basic Chat Completion..."
64 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/chat/completions" \
65 | -H "Content-Type: application/json" \
66 | -H "X-Api-Key: ${API_KEY}" \
67 | -d '{
68 | "model": "'${MODEL_NAME}'",
69 | "messages": [
70 | {"role": "system", "content": "You are a helpful assistant."},
71 | {"role": "user", "content": "What is the capital of France?"}
72 | ],
73 | "max_tokens": 100,
74 | "temperature": 0.7
75 | }'
76 |
77 | echo -e "\n\nTesting Streaming Chat Completion..."
78 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/chat/completions" \
79 | -H "Content-Type: application/json" \
80 | -H "X-Api-Key: ${API_KEY}" \
81 | -d '{
82 | "model": "'${MODEL_NAME}'",
83 | "messages": [
84 | {"role": "user", "content": "Write a story about a cat"}
85 | ],
86 | "max_tokens": 100,
87 | "temperature": 0.7,
88 | "stream": true
89 | }'
90 |
91 | echo -e "\n\nTesting Remote Confidence Scores..."
92 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/chat/completions" \
93 | -H "Content-Type: application/json" \
94 | -H "X-Api-Key: ${API_KEY}" \
95 | -d '{
96 | "model": "'${MODEL_NAME}'",
97 | "messages": [
98 | {"role": "system", "content": "You are a helpful assistant."},
99 | {"role": "user", "content": "hi"}
100 | ],
101 | "max_tokens": 1,
102 | "temperature": 0.7,
103 | "top_p": 1.0,
104 | "with_hidden_states": true,
105 | "remote_score": true
106 | }'
107 |
108 | echo -e "\n\nTesting Chat Completion with History..."
109 | curl -X POST "http://${HOST}/v1/${MODEL_NAME}/chat/completions" \
110 | -H "Content-Type: application/json" \
111 | -H "X-Api-Key: ${API_KEY}" \
112 | -d '{
113 | "model": "'${MODEL_NAME}'",
114 | "messages": [
115 | {"role": "system", "content": "You are a friendly and knowledgeable AI assistant."},
116 | {"role": "user", "content": "Tell me about Paris"},
117 | {"role": "assistant", "content": "Paris is the capital of France."},
118 | {"role": "user", "content": "What are some famous landmarks there?"}
119 | ],
120 | "max_tokens": 150,
121 | "temperature": 0.7,
122 | "top_p": 0.9
123 | }'
124 |
125 | echo -e "\n\nCompleted tests for ${MODEL_NAME}"
126 | echo "==================================\n\n"
127 | }
128 |
129 | # Run tests for each model
130 | for MODEL in "${MODELS[@]}"; do
131 | run_tests "$MODEL"
132 | done
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | import sys
2 | from pathlib import Path
3 |
4 | from setuptools import setup, find_packages
5 |
6 | package_dir = Path(__file__).parent / "green_bit_llm"
7 | with open(Path(__file__).parent / "requirements.txt") as fid:
8 | requirements = [l.strip() for l in fid.readlines()]
9 |
10 | sys.path.append(str(package_dir))
11 | from version import __version__
12 |
13 | setup(
14 | name="green-bit-llm",
15 | version=__version__,
16 | description="A toolkit for fine-tuning, inferencing, and evaluating GreenBitAI's LLMs.",
17 | long_description=open("README.md", encoding="utf-8").read(),
18 | long_description_content_type="text/markdown",
19 | author_email="team@greenbit.ai",
20 | author="GreenBitAI Contributors",
21 | url="https://github.com/GreenBitAI/green-bit-llm",
22 | license="Apache-2.0",
23 | install_requires=requirements,
24 | packages=find_packages(where=".", exclude=["tests", "tests.*", "examples", "examples.*"]),
25 | python_requires=">=3.9",
26 | data_files=[('.', ['requirements.txt'])],
27 | )
28 |
--------------------------------------------------------------------------------
/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GreenBitAI/green-bit-llm/71a575da60524c9f7b1b04f63ad397a7c7650309/tests/__init__.py
--------------------------------------------------------------------------------
/tests/test_langchain_chatmodel.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from unittest.mock import MagicMock, patch
3 | from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
4 | from langchain_core.outputs import LLMResult, Generation, ChatResult, ChatGeneration
5 | from green_bit_llm.langchain import GreenBitPipeline, ChatGreenBit
6 |
7 |
8 | class TestChatGreenBit(unittest.TestCase):
9 |
10 | def setUp(self):
11 | self.mock_pipeline = MagicMock(spec=GreenBitPipeline)
12 | self.mock_pipeline.pipeline = MagicMock()
13 | self.mock_pipeline.pipeline.tokenizer = MagicMock()
14 | self.mock_pipeline.pipeline.tokenizer.apply_chat_template = MagicMock(return_value="Mocked chat template")
15 | self.chat_model = ChatGreenBit(llm=self.mock_pipeline)
16 |
17 | def test_llm_type(self):
18 | self.assertEqual(self.chat_model._llm_type, "greenbit-chat")
19 |
20 | def test_messages_to_dict(self):
21 | """Test message conversion to dictionary format"""
22 | system_message = SystemMessage(content="You are an AI assistant.")
23 | human_message = HumanMessage(content="Hello, AI!")
24 | ai_message = AIMessage(content="Hello, human!")
25 |
26 | messages = [system_message, human_message, ai_message]
27 | result = self.chat_model._messages_to_dict(messages)
28 |
29 | expected = [
30 | {"role": "system", "content": "You are an AI assistant."},
31 | {"role": "user", "content": "Hello, AI!"},
32 | {"role": "assistant", "content": "Hello, human!"}
33 | ]
34 | self.assertEqual(result, expected)
35 |
36 | def test_prepare_prompt(self):
37 | """Test prompt preparation using apply_chat_template"""
38 | messages = [
39 | SystemMessage(content="You are an AI assistant."),
40 | HumanMessage(content="Hello, AI!"),
41 | AIMessage(content="Hello, human!"),
42 | HumanMessage(content="How are you?")
43 | ]
44 |
45 | result = self.chat_model._prepare_prompt(messages)
46 |
47 | self.assertEqual(result, "Mocked chat template")
48 | self.mock_pipeline.pipeline.tokenizer.apply_chat_template.assert_called_once()
49 |
50 | # Check that the call was made with correct message format
51 | call_args = self.mock_pipeline.pipeline.tokenizer.apply_chat_template.call_args
52 | messages_arg = call_args[0][0] # First positional argument
53 | expected_messages = [
54 | {"role": "system", "content": "You are an AI assistant."},
55 | {"role": "user", "content": "Hello, AI!"},
56 | {"role": "assistant", "content": "Hello, human!"},
57 | {"role": "user", "content": "How are you?"}
58 | ]
59 | self.assertEqual(messages_arg, expected_messages)
60 |
61 | def test_prepare_prompt_with_enable_thinking(self):
62 | """Test prompt preparation with enable_thinking parameter"""
63 | messages = [HumanMessage(content="Hello, AI!")]
64 |
65 | result = self.chat_model._prepare_prompt(messages, enable_thinking=True)
66 |
67 | self.assertEqual(result, "Mocked chat template")
68 | call_args = self.mock_pipeline.pipeline.tokenizer.apply_chat_template.call_args
69 | kwargs = call_args[1] # Keyword arguments
70 | self.assertTrue(kwargs.get("enable_thinking"))
71 | self.assertTrue(kwargs.get("add_generation_prompt"))
72 |
73 | def test_prepare_prompt_no_tokenizer(self):
74 | """Test error handling when tokenizer is not available"""
75 | self.mock_pipeline.pipeline.tokenizer = None
76 | messages = [HumanMessage(content="Hello, AI!")]
77 |
78 | with self.assertRaises(ValueError) as context:
79 | self.chat_model._prepare_prompt(messages)
80 | self.assertIn("Tokenizer not available", str(context.exception))
81 |
82 | def test_prepare_prompt_no_chat_template(self):
83 | """Test error handling when apply_chat_template is not available"""
84 | del self.mock_pipeline.pipeline.tokenizer.apply_chat_template
85 | messages = [HumanMessage(content="Hello, AI!")]
86 |
87 | with self.assertRaises(ValueError) as context:
88 | self.chat_model._prepare_prompt(messages)
89 | self.assertIn("does not support apply_chat_template", str(context.exception))
90 |
91 | def test_create_chat_result(self):
92 | """Test conversion from LLM result to chat result"""
93 | llm_result = LLMResult(generations=[[Generation(text="Hello, human!")]])
94 | chat_result = self.chat_model._create_chat_result(llm_result)
95 |
96 | self.assertEqual(len(chat_result.generations), 1)
97 | self.assertIsInstance(chat_result.generations[0], ChatGeneration)
98 | self.assertEqual(chat_result.generations[0].message.content, "Hello, human!")
99 |
100 | @patch.object(ChatGreenBit, '_prepare_prompt')
101 | def test_generate(self, mock_prepare_prompt):
102 | """Test generation with mocked prompt preparation"""
103 | mock_prepare_prompt.return_value = "Mocked chat prompt"
104 | self.mock_pipeline.generate.return_value = LLMResult(generations=[[Generation(text="Generated response")]])
105 |
106 | messages = [HumanMessage(content="Hello, AI!")]
107 | result = self.chat_model.generate(messages, temperature=0.8, max_tokens=100)
108 |
109 | # Check that prompt was prepared correctly
110 | mock_prepare_prompt.assert_called_once_with(messages, temperature=0.8, max_tokens=100)
111 |
112 | # Check that pipeline.generate was called with correct arguments
113 | self.mock_pipeline.generate.assert_called_once()
114 | call_args = self.mock_pipeline.generate.call_args
115 |
116 | # Check prompts argument
117 | self.assertEqual(call_args[1]["prompts"], ["Mocked chat prompt"])
118 |
119 | # Check that result is ChatResult
120 | self.assertIsInstance(result, ChatResult)
121 | self.assertEqual(result.generations[0].message.content, "Generated response")
122 |
123 | @patch.object(ChatGreenBit, '_prepare_prompt')
124 | def test_stream(self, mock_prepare_prompt):
125 | """Test streaming with mocked prompt preparation"""
126 | mock_prepare_prompt.return_value = "Mocked chat prompt"
127 | mock_chunk1 = MagicMock()
128 | mock_chunk1.text = "Hello"
129 | mock_chunk2 = MagicMock()
130 | mock_chunk2.text = " human!"
131 | self.mock_pipeline.stream.return_value = [mock_chunk1, mock_chunk2]
132 |
133 | messages = [HumanMessage(content="Hello, AI!")]
134 | stream_result = list(self.chat_model.stream(messages, temperature=0.7))
135 |
136 | # Check that prompt was prepared correctly
137 | mock_prepare_prompt.assert_called_once_with(messages, temperature=0.7)
138 |
139 | # Check that pipeline.stream was called
140 | self.mock_pipeline.stream.assert_called_once()
141 |
142 | # Check stream results
143 | self.assertEqual(len(stream_result), 2)
144 | self.assertIsInstance(stream_result[0], ChatGeneration)
145 | self.assertEqual(stream_result[0].message.content, "Hello")
146 | self.assertEqual(stream_result[1].message.content, " human!")
147 |
148 | def test_generate_with_enable_thinking(self):
149 | """Test generation with enable_thinking parameter"""
150 | with patch.object(self.chat_model, '_prepare_prompt') as mock_prepare_prompt:
151 | mock_prepare_prompt.return_value = "Mocked chat prompt"
152 | self.mock_pipeline.generate.return_value = LLMResult(generations=[[Generation(text="Generated response")]])
153 |
154 | messages = [HumanMessage(content="Hello, AI!")]
155 | result = self.chat_model.generate(messages, enable_thinking=True)
156 |
157 | # Check that enable_thinking was passed to _prepare_prompt
158 | mock_prepare_prompt.assert_called_once_with(messages, enable_thinking=True)
159 |
160 |
161 | if __name__ == '__main__':
162 | unittest.main()
--------------------------------------------------------------------------------
/tests/test_langchain_embedding.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from typing import List
3 | from green_bit_llm.langchain import GreenBitEmbeddings
4 |
5 | class TestGreenBitEmbeddings(unittest.TestCase):
6 | def setUp(self):
7 | model_kwargs = {'trust_remote_code': True}
8 | encode_kwargs = {'normalize_embeddings': False}
9 | self.embeddings = GreenBitEmbeddings.from_model_id(
10 | model_name="sentence-transformers/all-MiniLM-L6-v2",
11 | cache_dir="cache",
12 | device="cpu",
13 | multi_process=False,
14 | model_kwargs=model_kwargs,
15 | encode_kwargs=encode_kwargs
16 | )
17 |
18 | def test_embed_documents_returns_list(self):
19 | texts = ["Hello, world!", "This is a test."]
20 | result = self.embeddings.embed_documents(texts)
21 | self.assertIsInstance(result, list)
22 |
23 | def test_embed_documents_returns_correct_number_of_embeddings(self):
24 | texts = ["Hello, world!", "This is a test."]
25 | result = self.embeddings.embed_documents(texts)
26 | self.assertEqual(len(result), len(texts))
27 |
28 | def test_embed_query_returns_list(self):
29 | query = "What is the meaning of life?"
30 | result = self.embeddings.embed_query(query)
31 | self.assertIsInstance(result, list)
32 |
33 | def test_embed_query_returns_non_empty_list(self):
34 | query = "What is the meaning of life?"
35 | result = self.embeddings.embed_query(query)
36 | self.assertTrue(len(result) > 0)
37 |
38 | if __name__ == '__main__':
39 | unittest.main()
--------------------------------------------------------------------------------
/tests/test_langchain_pipeline.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | from unittest.mock import patch, MagicMock
3 | import torch
4 | from green_bit_llm.langchain import GreenBitPipeline
5 | from langchain_core.outputs import LLMResult, Generation, GenerationChunk
6 |
7 |
8 | class TestGreenBitPipeline(unittest.TestCase):
9 |
10 | @patch('green_bit_llm.langchain.pipeline.check_engine_available')
11 | @patch('green_bit_llm.langchain.pipeline.load')
12 | @patch('green_bit_llm.langchain.pipeline.pipeline')
13 | def test_from_model_id(self, mock_pipeline, mock_load, mock_check_engine):
14 | """Test pipeline creation from model ID"""
15 | # Setup
16 | mock_check_engine.return_value = True
17 | mock_model = MagicMock()
18 | mock_tokenizer = MagicMock()
19 | mock_tokenizer.pad_token = None
20 | mock_tokenizer.eos_token = "<|endoftext|>"
21 | mock_tokenizer.pad_token_id = None
22 | mock_tokenizer.eos_token_id = 50256
23 | mock_load.return_value = (mock_model, mock_tokenizer, None)
24 | mock_pipe = MagicMock()
25 | mock_pipeline.return_value = mock_pipe
26 |
27 | # Test
28 | gb_pipeline = GreenBitPipeline.from_model_id(
29 | model_id="test_model",
30 | task="text-generation",
31 | model_kwargs={"dtype": torch.float16},
32 | pipeline_kwargs={"max_length": 100}
33 | )
34 |
35 | # Assert
36 | self.assertIsInstance(gb_pipeline, GreenBitPipeline)
37 | self.assertEqual(gb_pipeline.model_id, "test_model")
38 | self.assertEqual(gb_pipeline.task, "text-generation")
39 | self.assertEqual(gb_pipeline.model_kwargs, {"dtype": torch.float16})
40 | self.assertEqual(gb_pipeline.pipeline_kwargs, {"max_length": 100})
41 | mock_check_engine.assert_called_once()
42 | mock_pipeline.assert_called_once()
43 |
44 | # Check that tokenizer pad_token was set
45 | self.assertEqual(mock_tokenizer.pad_token, "<|endoftext|>")
46 | self.assertEqual(mock_tokenizer.pad_token_id, 50256)
47 |
48 | def test_identifying_params(self):
49 | """Test identifying parameters property"""
50 | gb_pipeline = GreenBitPipeline(
51 | pipeline=MagicMock(),
52 | model_id="test_model",
53 | task="text-generation",
54 | model_kwargs={"dtype": torch.float16},
55 | pipeline_kwargs={"max_length": 100}
56 | )
57 | params = gb_pipeline._identifying_params
58 | self.assertEqual(params["model_id"], "test_model")
59 | self.assertEqual(params["task"], "text-generation")
60 | self.assertEqual(params["model_kwargs"], {"dtype": torch.float16})
61 | self.assertEqual(params["pipeline_kwargs"], {"max_length": 100})
62 |
63 | def test_llm_type(self):
64 | """Test LLM type property"""
65 | gb_pipeline = GreenBitPipeline(pipeline=MagicMock(), model_kwargs={}, pipeline_kwargs={})
66 | self.assertEqual(gb_pipeline._llm_type, "greenbit_pipeline")
67 |
68 | def test_prepare_generation_config(self):
69 | """Test generation config preparation"""
70 | mock_pipeline = MagicMock()
71 | mock_pipeline.tokenizer.pad_token_id = 0
72 | mock_pipeline.tokenizer.eos_token_id = 1
73 |
74 | gb_pipeline = GreenBitPipeline(
75 | pipeline=mock_pipeline,
76 | model_kwargs={},
77 | pipeline_kwargs={"temperature": 0.5, "max_new_tokens": 50}
78 | )
79 |
80 | config = gb_pipeline._prepare_generation_config({"temperature": 0.8})
81 |
82 | self.assertEqual(config["temperature"], 0.8) # Should override pipeline_kwargs
83 | self.assertEqual(config["max_new_tokens"], 50) # Should use pipeline default
84 | self.assertEqual(config["pad_token_id"], 0)
85 | self.assertEqual(config["eos_token_id"], 1)
86 | self.assertTrue(config["do_sample"]) # Changed default to True
87 |
88 | def test_prepare_prompt_from_text_with_chat_template(self):
89 | """Test prompt preparation from plain text using chat template"""
90 | mock_tokenizer = MagicMock()
91 | mock_tokenizer.apply_chat_template = MagicMock(
92 | return_value="<|im_start|>user\nHello<|im_end|><|im_start|>assistant\n")
93 |
94 | mock_pipeline = MagicMock()
95 | mock_pipeline.tokenizer = mock_tokenizer
96 |
97 | gb_pipeline = GreenBitPipeline(pipeline=mock_pipeline, model_kwargs={}, pipeline_kwargs={})
98 |
99 | result = gb_pipeline._prepare_prompt_from_text("Hello", enable_thinking=True)
100 |
101 | self.assertEqual(result, "<|im_start|>user\nHello<|im_end|><|im_start|>assistant\n")
102 | mock_tokenizer.apply_chat_template.assert_called_once()
103 |
104 | # Check the call arguments
105 | call_args = mock_tokenizer.apply_chat_template.call_args
106 | messages = call_args[0][0]
107 | kwargs = call_args[1]
108 |
109 | self.assertEqual(messages, [{"role": "user", "content": "Hello"}])
110 | self.assertTrue(kwargs["add_generation_prompt"])
111 | self.assertTrue(kwargs["enable_thinking"])
112 |
113 | def test_prepare_prompt_from_text_no_chat_template(self):
114 | """Test prompt preparation fallback when no chat template available"""
115 | mock_tokenizer = MagicMock()
116 | # Remove apply_chat_template method
117 | del mock_tokenizer.apply_chat_template
118 |
119 | mock_pipeline = MagicMock()
120 | mock_pipeline.tokenizer = mock_tokenizer
121 |
122 | gb_pipeline = GreenBitPipeline(pipeline=mock_pipeline, model_kwargs={}, pipeline_kwargs={})
123 |
124 | result = gb_pipeline._prepare_prompt_from_text("Hello")
125 |
126 | # Should return original text when no chat template
127 | self.assertEqual(result, "Hello")
128 |
129 | def test_prepare_prompt_from_text_template_error(self):
130 | """Test prompt preparation fallback when template application fails"""
131 | mock_tokenizer = MagicMock()
132 | mock_tokenizer.apply_chat_template = MagicMock(side_effect=Exception("Template error"))
133 |
134 | mock_pipeline = MagicMock()
135 | mock_pipeline.tokenizer = mock_tokenizer
136 |
137 | gb_pipeline = GreenBitPipeline(pipeline=mock_pipeline, model_kwargs={}, pipeline_kwargs={})
138 |
139 | result = gb_pipeline._prepare_prompt_from_text("Hello")
140 |
141 | # Should return original text when template application fails
142 | self.assertEqual(result, "Hello")
143 |
144 | @patch.object(GreenBitPipeline, '_prepare_prompt_from_text')
145 | def test_generate_with_plain_text(self, mock_prepare_prompt):
146 | """Test generation with plain text prompts"""
147 | # Setup
148 | mock_prepare_prompt.return_value = ""
149 | mock_pipeline = MagicMock()
150 | mock_pipeline.tokenizer.encode.return_value = [1, 2, 3]
151 | mock_pipeline.device = "cpu"
152 | mock_pipeline.model.generate.return_value = MagicMock(
153 | sequences=torch.tensor([[1, 2, 3, 4, 5]]),
154 | hidden_states=None
155 | )
156 | mock_pipeline.tokenizer.return_value = {
157 | 'input_ids': torch.tensor([[1, 2, 3]]),
158 | 'attention_mask': torch.tensor([[1, 1, 1]])
159 | }
160 | mock_pipeline.tokenizer.decode.return_value = "Generated text"
161 |
162 | gb_pipeline = GreenBitPipeline(
163 | pipeline=mock_pipeline,
164 | model_kwargs={},
165 | pipeline_kwargs={"max_new_tokens": 100}
166 | )
167 |
168 | # Test with plain text (should trigger chat template)
169 | result = gb_pipeline.generate(["Hello"], enable_thinking=True)
170 |
171 | # Check that prompt was processed
172 | mock_prepare_prompt.assert_called_once_with("Hello", enable_thinking=True)
173 |
174 | # Check result
175 | self.assertIsInstance(result, LLMResult)
176 | self.assertEqual(len(result.generations), 1)
177 |
178 | def test_generate_with_formatted_prompt(self):
179 | """Test generation with already formatted prompts"""
180 | # Setup
181 | mock_pipeline = MagicMock()
182 | mock_pipeline.tokenizer.encode.return_value = [1, 2, 3]
183 | mock_pipeline.device = "cpu"
184 | mock_pipeline.model.generate.return_value = MagicMock(
185 | sequences=torch.tensor([[1, 2, 3, 4, 5]]),
186 | hidden_states=None
187 | )
188 | mock_pipeline.tokenizer.return_value = {
189 | 'input_ids': torch.tensor([[1, 2, 3]]),
190 | 'attention_mask': torch.tensor([[1, 1, 1]])
191 | }
192 | mock_pipeline.tokenizer.decode.return_value = "Generated text"
193 |
194 | gb_pipeline = GreenBitPipeline(
195 | pipeline=mock_pipeline,
196 | model_kwargs={},
197 | pipeline_kwargs={"max_new_tokens": 100}
198 | )
199 |
200 | # Test with already formatted prompt (should not trigger chat template)
201 | formatted_prompt = "<|im_start|>user\nHello<|im_end|><|im_start|>assistant\n"
202 |
203 | with patch.object(gb_pipeline, '_prepare_prompt_from_text') as mock_prepare:
204 | result = gb_pipeline.generate([formatted_prompt])
205 |
206 | # Should not call _prepare_prompt_from_text for already formatted prompts
207 | mock_prepare.assert_not_called()
208 |
209 | @patch('green_bit_llm.langchain.pipeline.TextIteratorStreamer')
210 | @patch('green_bit_llm.langchain.pipeline.Thread')
211 | @patch.object(GreenBitPipeline, '_prepare_prompt_from_text')
212 | def test_stream(self, mock_prepare_prompt, mock_thread, mock_streamer):
213 | """Test streaming functionality"""
214 | # Setup
215 | mock_prepare_prompt.return_value = ""
216 | mock_pipeline = MagicMock()
217 | mock_pipeline.tokenizer.return_value = {'input_ids': torch.tensor([[1, 2, 3]])}
218 | mock_pipeline.device = "cpu"
219 |
220 | mock_streamer_instance = MagicMock()
221 | mock_streamer_instance.__iter__.return_value = iter(["Hello", " ", "world"])
222 | mock_streamer.return_value = mock_streamer_instance
223 |
224 | gb_pipeline = GreenBitPipeline(pipeline=mock_pipeline, model_kwargs={}, pipeline_kwargs={})
225 |
226 | # Test
227 | chunks = list(gb_pipeline.stream("Hi", enable_thinking=True))
228 |
229 | # Check that prompt was processed
230 | mock_prepare_prompt.assert_called_once_with("Hi", enable_thinking=True)
231 |
232 | # Assert
233 | self.assertEqual(len(chunks), 3)
234 | self.assertIsInstance(chunks[0], GenerationChunk)
235 | self.assertEqual(chunks[0].text, "Hello")
236 | self.assertEqual(chunks[1].text, " ")
237 | self.assertEqual(chunks[2].text, "world")
238 | mock_thread.assert_called_once()
239 | mock_streamer.assert_called_once()
240 |
241 | @patch.object(GreenBitPipeline, '_prepare_prompt_from_text')
242 | def test_stream_with_formatted_prompt(self, mock_prepare_prompt):
243 | """Test streaming with already formatted prompt"""
244 | # Setup
245 | mock_pipeline = MagicMock()
246 | mock_pipeline.tokenizer.return_value = {'input_ids': torch.tensor([[1, 2, 3]])}
247 | mock_pipeline.device = "cpu"
248 |
249 | gb_pipeline = GreenBitPipeline(pipeline=mock_pipeline, model_kwargs={}, pipeline_kwargs={})
250 |
251 | formatted_prompt = "<|start_header_id|>user<|end_header_id|>Hello<|eot_id|>"
252 |
253 | with patch('green_bit_llm.langchain.pipeline.TextIteratorStreamer') as mock_streamer:
254 | with patch('green_bit_llm.langchain.pipeline.Thread'):
255 | mock_streamer_instance = MagicMock()
256 | mock_streamer_instance.__iter__.return_value = iter(["Hello"])
257 | mock_streamer.return_value = mock_streamer_instance
258 |
259 | list(gb_pipeline.stream(formatted_prompt))
260 |
261 | # Should not call _prepare_prompt_from_text for already formatted prompts
262 | mock_prepare_prompt.assert_not_called()
263 |
264 |
265 | if __name__ == '__main__':
266 | unittest.main()
--------------------------------------------------------------------------------