\n",
224 | "\n",
237 | "\n",
238 | " \n",
239 | "
\n",
315 | "
"
316 | ],
317 | "text/plain": [
318 | " reviewerID asin reviewerName helpful \\\n",
319 | "0 A3EBHHCZO6V2A4 5555991584 Amaranth \"music fan\" [3, 3] \n",
320 | "1 AZPWAXJG9OJXV 5555991584 bethtexas [0, 0] \n",
321 | "2 A38IRL0X2T4DPF 5555991584 bob turnley [2, 2] \n",
322 | "3 A22IK3I6U76GX0 5555991584 Calle [1, 1] \n",
323 | "4 A1AISPOIIHTHXX 5555991584 Cloud \"...\" [1, 1] \n",
324 | "\n",
325 | " reviewText overall \\\n",
326 | "0 It's hard to believe \"Memory of Trees\" came ou... 5 \n",
327 | "1 A clasically-styled and introverted album, Mem... 5 \n",
328 | "2 I never thought Enya would reach the sublime h... 5 \n",
329 | "3 This is the third review of an irish album I w... 5 \n",
330 | "4 Enya, despite being a successful recording art... 4 \n",
331 | "\n",
332 | " summary unixReviewTime reviewTime \n",
333 | "0 Enya's last great album 1158019200 09 12, 2006 \n",
334 | "1 Enya at her most elegant 991526400 06 3, 2001 \n",
335 | "2 The best so far 1058140800 07 14, 2003 \n",
336 | "3 Ireland produces good music. 957312000 05 3, 2000 \n",
337 | "4 4.5; music to dream to 1200528000 01 17, 2008 "
338 | ]
339 | },
340 | "execution_count": 6,
341 | "metadata": {},
342 | "output_type": "execute_result"
343 | }
344 | ],
345 | "source": [
346 | "df = pd.read_json(r'reviews_Digital_Music_5.json',lines=True)\n",
347 | "df.head()"
348 | ]
349 | },
350 | {
351 | "cell_type": "code",
352 | "execution_count": 7,
353 | "id": "891bd472",
354 | "metadata": {},
355 | "outputs": [
356 | {
357 | "data": {
358 | "text/html": [
359 | "| \n", 241 | " | reviewerID | \n", 242 | "asin | \n", 243 | "reviewerName | \n", 244 | "helpful | \n", 245 | "reviewText | \n", 246 | "overall | \n", 247 | "summary | \n", 248 | "unixReviewTime | \n", 249 | "reviewTime | \n", 250 | "
|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", 255 | "A3EBHHCZO6V2A4 | \n", 256 | "5555991584 | \n", 257 | "Amaranth \"music fan\" | \n", 258 | "[3, 3] | \n", 259 | "It's hard to believe \"Memory of Trees\" came ou... | \n", 260 | "5 | \n", 261 | "Enya's last great album | \n", 262 | "1158019200 | \n", 263 | "09 12, 2006 | \n", 264 | "
| 1 | \n", 267 | "AZPWAXJG9OJXV | \n", 268 | "5555991584 | \n", 269 | "bethtexas | \n", 270 | "[0, 0] | \n", 271 | "A clasically-styled and introverted album, Mem... | \n", 272 | "5 | \n", 273 | "Enya at her most elegant | \n", 274 | "991526400 | \n", 275 | "06 3, 2001 | \n", 276 | "
| 2 | \n", 279 | "A38IRL0X2T4DPF | \n", 280 | "5555991584 | \n", 281 | "bob turnley | \n", 282 | "[2, 2] | \n", 283 | "I never thought Enya would reach the sublime h... | \n", 284 | "5 | \n", 285 | "The best so far | \n", 286 | "1058140800 | \n", 287 | "07 14, 2003 | \n", 288 | "
| 3 | \n", 291 | "A22IK3I6U76GX0 | \n", 292 | "5555991584 | \n", 293 | "Calle | \n", 294 | "[1, 1] | \n", 295 | "This is the third review of an irish album I w... | \n", 296 | "5 | \n", 297 | "Ireland produces good music. | \n", 298 | "957312000 | \n", 299 | "05 3, 2000 | \n", 300 | "
| 4 | \n", 303 | "A1AISPOIIHTHXX | \n", 304 | "5555991584 | \n", 305 | "Cloud \"...\" | \n", 306 | "[1, 1] | \n", 307 | "Enya, despite being a successful recording art... | \n", 308 | "4 | \n", 309 | "4.5; music to dream to | \n", 310 | "1200528000 | \n", 311 | "01 17, 2008 | \n", 312 | "
\n",
360 | "\n",
373 | "\n",
374 | " \n",
375 | "
\n",
409 | "
"
410 | ],
411 | "text/plain": [
412 | " reviewText overall\n",
413 | "0 It's hard to believe \"Memory of Trees\" came ou... 5\n",
414 | "1 A clasically-styled and introverted album, Mem... 5\n",
415 | "2 I never thought Enya would reach the sublime h... 5\n",
416 | "3 This is the third review of an irish album I w... 5\n",
417 | "4 Enya, despite being a successful recording art... 4"
418 | ]
419 | },
420 | "execution_count": 7,
421 | "metadata": {},
422 | "output_type": "execute_result"
423 | }
424 | ],
425 | "source": [
426 | "df = df[['reviewText','overall']]\n",
427 | "df.head()"
428 | ]
429 | },
430 | {
431 | "cell_type": "code",
432 | "execution_count": 8,
433 | "id": "788cc587",
434 | "metadata": {},
435 | "outputs": [],
436 | "source": [
437 | "sentiment = {1:'negative',2:'negative',3:'negative', 4:'positive',5:'positive'}"
438 | ]
439 | },
440 | {
441 | "cell_type": "code",
442 | "execution_count": 10,
443 | "id": "c7a8f268",
444 | "metadata": {},
445 | "outputs": [
446 | {
447 | "data": {
448 | "text/html": [
449 | "| \n", 377 | " | reviewText | \n", 378 | "overall | \n", 379 | "
|---|---|---|
| 0 | \n", 384 | "It's hard to believe \"Memory of Trees\" came ou... | \n", 385 | "5 | \n", 386 | "
| 1 | \n", 389 | "A clasically-styled and introverted album, Mem... | \n", 390 | "5 | \n", 391 | "
| 2 | \n", 394 | "I never thought Enya would reach the sublime h... | \n", 395 | "5 | \n", 396 | "
| 3 | \n", 399 | "This is the third review of an irish album I w... | \n", 400 | "5 | \n", 401 | "
| 4 | \n", 404 | "Enya, despite being a successful recording art... | \n", 405 | "4 | \n", 406 | "
\n",
450 | "\n",
463 | "\n",
464 | " \n",
465 | "
\n",
499 | "
"
500 | ],
501 | "text/plain": [
502 | " reviewText sentiment\n",
503 | "0 It's hard to believe \"Memory of Trees\" came ou... positive\n",
504 | "1 A clasically-styled and introverted album, Mem... positive\n",
505 | "2 I never thought Enya would reach the sublime h... positive\n",
506 | "3 This is the third review of an irish album I w... positive\n",
507 | "4 Enya, despite being a successful recording art... positive"
508 | ]
509 | },
510 | "execution_count": 10,
511 | "metadata": {},
512 | "output_type": "execute_result"
513 | }
514 | ],
515 | "source": [
516 | "df['sentiment'] = df['overall'].map(sentiment)\n",
517 | "df = df[['reviewText','sentiment']]\n",
518 | "df.head()"
519 | ]
520 | },
521 | {
522 | "cell_type": "code",
523 | "execution_count": 11,
524 | "id": "af390d43",
525 | "metadata": {},
526 | "outputs": [
527 | {
528 | "name": "stdout",
529 | "output_type": "stream",
530 | "text": [
531 | "['negative', 'positive']\n",
532 | " negative positive\n",
533 | "38430 0.0 1.0\n",
534 | "12842 0.0 1.0\n",
535 | "6965 0.0 1.0\n",
536 | "8671 0.0 1.0\n",
537 | "15755 0.0 1.0\n",
538 | "['negative', 'positive']\n",
539 | " negative positive\n",
540 | "50214 0.0 1.0\n",
541 | "53169 1.0 0.0\n",
542 | "4119 0.0 1.0\n",
543 | "37339 1.0 0.0\n",
544 | "23168 1.0 0.0\n",
545 | "downloading pretrained BERT model (uncased_L-12_H-768_A-12.zip)...\n",
546 | "[██████████████████████████████████████████████████]\n",
547 | "extracting pretrained BERT model...\n",
548 | "done.\n",
549 | "\n",
550 | "cleanup downloaded zip...\n",
551 | "done.\n",
552 | "\n",
553 | "preprocessing train...\n",
554 | "language: en\n"
555 | ]
556 | },
557 | {
558 | "data": {
559 | "text/html": [
560 | "\n",
561 | "\n"
573 | ],
574 | "text/plain": [
575 | "| \n", 467 | " | reviewText | \n", 468 | "sentiment | \n", 469 | "
|---|---|---|
| 0 | \n", 474 | "It's hard to believe \"Memory of Trees\" came ou... | \n", 475 | "positive | \n", 476 | "
| 1 | \n", 479 | "A clasically-styled and introverted album, Mem... | \n", 480 | "positive | \n", 481 | "
| 2 | \n", 484 | "I never thought Enya would reach the sublime h... | \n", 485 | "positive | \n", 486 | "
| 3 | \n", 489 | "This is the third review of an irish album I w... | \n", 490 | "positive | \n", 491 | "
| 4 | \n", 494 | "Enya, despite being a successful recording art... | \n", 495 | "positive | \n", 496 | "
 12 |
13 | ## Encoder?
14 |
15 | - Transformer에서 Encoder는 여러 개를 쌓아서 사용
16 | - Multi-Head Attention과 Feed Forward
17 |
18 | ### Attention 복습
19 |
20 | [https://wikidocs.net/22893](https://wikidocs.net/22893)
21 |
22 | Attention(Q, K, V) = Attention value
23 |
24 | 1. Query에 대해서 모든 Key와의 유사도 계산
25 | 2. 유사도를 Key에 매핑된 Value에 반영
26 | 3. 적용된 Value를 모두 더하면 -> Attention value
27 |
28 | ### Self-Attention
29 |
30 | - 단어 그대로 Attention을 자기 자신에게 수행한다는 의미
31 | - Q=K=V=입력 문장의 모든 단어 벡터들
32 | - 입력 문장 내의 단어들끼리 유사도를 구함. 각 단어의 표현들은 문장 안에 있는 다른 모든 단어의 표현과 연결해 단어가 문장 내에서 갖는 의미를 이해
33 | - 특정 단어와 문장 내에 있는 모든 단어가 어떤 연관이 있는지를 이해하면 좀 더 좋은 표현을 학습하는데 도움이 됨.
34 | - 무작위 초기화 된 가중치 행렬 W^Q, W^K, W^V을 만들고 입력 행렬 X에 곱해서 Q, K, V를 생성. 가중치 행렬들은 학습 과정에서 업데이트 됨.
35 | - Q와 K의 내적을 구하고 sqrt(d_k)로 나누기 때문에 Scale-dot product attention이라고도 함.
36 | 1. 쿼리(Q) 행렬과 키(K^T) 행렬의 내적 연산을 수행
37 | - Q와 K^T간의 내적을 계산하면 **유사도**를 구할 수 있음
38 | - 문장의 각 단어가 다른 모든 단어와 얼마나 유사한지 파악하는데 도움을 줌
39 | 2. QK^T 행렬을 키 벡터 차원(sqrt(d_k))의 제곱근값으로 나누기
40 | - 안정적인 경사값을 얻을 수 있음
41 | 3. Softmax 함수로 Normalizing
42 | - 2번까지의 값은 unnormalized form
43 | - 행 별로 softmax
44 | - softmax 함수로 normalizing하면 전체 합이 1, 각각의 값은 0~1 사이. 확률값으로 이해가능
45 | - score matrix: 각각의 단어가 문장 전체의 단어와 얼마나 연관이 있는지 확률로 알 수 있음
46 | 4. Attention(Z) 행렬 구하기
47 | - Normalized Similarity * V
48 | - Similarity를 Value를 Weight sum!
49 |
50 | ### Multi-head Attention(MHA)
51 |
52 | Attention이 단어 의미 사이의 연관을 잘 찾는다면 좋은 결과가 나오지만, 그렇지 않는다면 문장의 의미가 잘못 해석될 수도 있음. MHA는 여러 개의 Attention을 사용하여 정확한 문장의 의미를 이해하는데 도움을 준다. 구체적인 방법으로는 MHA의 결과로 나온 각각의 Attention vector를 concat하고 새로운 가중치 행렬 W^0를 곱하는 방법을 사용한다. (Attention head의 최종 결과는 Attention head의 원래 크기이므로 크기를 줄이기 위해 W_0을 곱하는 것)
53 |
54 | → 옮긴이의 코멘트에는 “헤드를 여러 개 사용해 어텐션을 사용할 경우 단일 헤드를 사용하는 경우보다 오분류가 일어날 위험을 줄이는 것으로 해석할 수 있다.”라고 되어있는데, Attention 결과의 앙상블 개념으로 생각하면 좋을 것 같습니다.
55 |
56 | ### Positional Encoding
57 |
58 | RNN은 순차적으로 들어가지만 Transformer는 병렬로 들어가기 때문에 구조에서 오는 순서 정보가 없음. 이를 해결하기 위해서 부가적으로 Positional Encoding을 추가해 줌. 논문의 저자들은 다음의 식을 사용함.
59 |
60 |
12 |
13 | ## Encoder?
14 |
15 | - Transformer에서 Encoder는 여러 개를 쌓아서 사용
16 | - Multi-Head Attention과 Feed Forward
17 |
18 | ### Attention 복습
19 |
20 | [https://wikidocs.net/22893](https://wikidocs.net/22893)
21 |
22 | Attention(Q, K, V) = Attention value
23 |
24 | 1. Query에 대해서 모든 Key와의 유사도 계산
25 | 2. 유사도를 Key에 매핑된 Value에 반영
26 | 3. 적용된 Value를 모두 더하면 -> Attention value
27 |
28 | ### Self-Attention
29 |
30 | - 단어 그대로 Attention을 자기 자신에게 수행한다는 의미
31 | - Q=K=V=입력 문장의 모든 단어 벡터들
32 | - 입력 문장 내의 단어들끼리 유사도를 구함. 각 단어의 표현들은 문장 안에 있는 다른 모든 단어의 표현과 연결해 단어가 문장 내에서 갖는 의미를 이해
33 | - 특정 단어와 문장 내에 있는 모든 단어가 어떤 연관이 있는지를 이해하면 좀 더 좋은 표현을 학습하는데 도움이 됨.
34 | - 무작위 초기화 된 가중치 행렬 W^Q, W^K, W^V을 만들고 입력 행렬 X에 곱해서 Q, K, V를 생성. 가중치 행렬들은 학습 과정에서 업데이트 됨.
35 | - Q와 K의 내적을 구하고 sqrt(d_k)로 나누기 때문에 Scale-dot product attention이라고도 함.
36 | 1. 쿼리(Q) 행렬과 키(K^T) 행렬의 내적 연산을 수행
37 | - Q와 K^T간의 내적을 계산하면 **유사도**를 구할 수 있음
38 | - 문장의 각 단어가 다른 모든 단어와 얼마나 유사한지 파악하는데 도움을 줌
39 | 2. QK^T 행렬을 키 벡터 차원(sqrt(d_k))의 제곱근값으로 나누기
40 | - 안정적인 경사값을 얻을 수 있음
41 | 3. Softmax 함수로 Normalizing
42 | - 2번까지의 값은 unnormalized form
43 | - 행 별로 softmax
44 | - softmax 함수로 normalizing하면 전체 합이 1, 각각의 값은 0~1 사이. 확률값으로 이해가능
45 | - score matrix: 각각의 단어가 문장 전체의 단어와 얼마나 연관이 있는지 확률로 알 수 있음
46 | 4. Attention(Z) 행렬 구하기
47 | - Normalized Similarity * V
48 | - Similarity를 Value를 Weight sum!
49 |
50 | ### Multi-head Attention(MHA)
51 |
52 | Attention이 단어 의미 사이의 연관을 잘 찾는다면 좋은 결과가 나오지만, 그렇지 않는다면 문장의 의미가 잘못 해석될 수도 있음. MHA는 여러 개의 Attention을 사용하여 정확한 문장의 의미를 이해하는데 도움을 준다. 구체적인 방법으로는 MHA의 결과로 나온 각각의 Attention vector를 concat하고 새로운 가중치 행렬 W^0를 곱하는 방법을 사용한다. (Attention head의 최종 결과는 Attention head의 원래 크기이므로 크기를 줄이기 위해 W_0을 곱하는 것)
53 |
54 | → 옮긴이의 코멘트에는 “헤드를 여러 개 사용해 어텐션을 사용할 경우 단일 헤드를 사용하는 경우보다 오분류가 일어날 위험을 줄이는 것으로 해석할 수 있다.”라고 되어있는데, Attention 결과의 앙상블 개념으로 생각하면 좋을 것 같습니다.
55 |
56 | ### Positional Encoding
57 |
58 | RNN은 순차적으로 들어가지만 Transformer는 병렬로 들어가기 때문에 구조에서 오는 순서 정보가 없음. 이를 해결하기 위해서 부가적으로 Positional Encoding을 추가해 줌. 논문의 저자들은 다음의 식을 사용함.
59 |
60 |  61 |
62 | 위치 인코딩 P를 계산 + 임베딩 행렬 X
63 |
64 | ### Feed Forward Network(FFN)
65 |
66 | 2개의 Dense + ReLU activation function. Attention 행렬을 입력받아 Encoder 표현을 출력함.
67 |
68 | ### Add와 Norm
69 |
70 | - sublayer에서 MHA의 input과 output을 서로 연결
71 | - sublayer에서 FFN의 input과 output을 서로 연결
72 | - Layer Normalization + Residual Connection
73 | - Layer Normalization: 각 layer의 값이 크게 변화하는 것을 방지해 모델을 더 빠르게 학습할 수 있게 함
74 | - Residual Connection: Vision의 ResNet에서 보던 구조. Skip Connection이라고도 하는데 기존 학습 정보를 보존하고 추가적인 정보만 학습하기 때문에 학습이 쉬워지고, 수렴이 빨라진다. [참고](https://daeun-computer-uneasy.tistory.com/28)
75 |
76 | ## Decoder?
77 |
78 | - Encoder의 결과값을 가져와서 Decoder의 입력값으로 사용하여 타깃을 생성
79 | - Decoder는 **이전 Decoder의 출력**과 **Encoder의 출력**을 입력으로 사용함
80 | - \
61 |
62 | 위치 인코딩 P를 계산 + 임베딩 행렬 X
63 |
64 | ### Feed Forward Network(FFN)
65 |
66 | 2개의 Dense + ReLU activation function. Attention 행렬을 입력받아 Encoder 표현을 출력함.
67 |
68 | ### Add와 Norm
69 |
70 | - sublayer에서 MHA의 input과 output을 서로 연결
71 | - sublayer에서 FFN의 input과 output을 서로 연결
72 | - Layer Normalization + Residual Connection
73 | - Layer Normalization: 각 layer의 값이 크게 변화하는 것을 방지해 모델을 더 빠르게 학습할 수 있게 함
74 | - Residual Connection: Vision의 ResNet에서 보던 구조. Skip Connection이라고도 하는데 기존 학습 정보를 보존하고 추가적인 정보만 학습하기 때문에 학습이 쉬워지고, 수렴이 빨라진다. [참고](https://daeun-computer-uneasy.tistory.com/28)
75 |
76 | ## Decoder?
77 |
78 | - Encoder의 결과값을 가져와서 Decoder의 입력값으로 사용하여 타깃을 생성
79 | - Decoder는 **이전 Decoder의 출력**과 **Encoder의 출력**을 입력으로 사용함
80 | - \ 60 |
61 | *출처 [Understanding the Bert Model](https://medium.com/analytics-vidhya/understanding-the-bert-model-a04e1c7933a9)*
62 |
63 | #### 문장 임베딩 추출
64 |
65 | `[CLS]` 토큰의 표현은 전제 문장의 집계 표현을 보유하게 되므로, **문장의 표현**은 `[CLS]` 토큰에 해당하는 `R_[CLS]` 표현 벡터가 된다.
66 |
67 | - `[CLS]` 토큰의 표현을 문장 표현으로 사용하는 것이 항상 좋은 생각은 아니다. 문장의 표현을 얻는 효율적인 방법은 모든 토큰의 표현을 평균화하거나 풀링하는 것이다. _Cf. 4장_
68 |
69 | - 매우 유사한 방식으로 학습셋에 있는 모든 문장의 벡터 표현을 계산하여 모든 문장의 문장 표현을 얻은 후에는 해당 표현을 입력으로 제공하고 분류기로 학습해 감정 분석 작업을 수행할 수 있다.
70 |
71 | ### Hugging Face Transformer
72 |
73 | Hugging Face의 오픈 소스 라이브러리 `transformers`와 사전 학습된 BERT 모델을 사용해, 문장에 있는 모든 단어의 문맥화된 단어 임베딩 생성하기
74 |
75 | - Hugging Face : 자연어 기술의 민주화를 추구하는 조직
76 | - `transformers` : 파이토치 및 텐서플로와 모두 호환, NLP 및 NLU 태스크에 강력, 100개 이상의 언어로 사전 학습된 수천 개의 모델 포함
77 |
78 | #### BERT의 최상위 인코더 계층인 12번째 인코더에서만 임베딩을 얻는 방법
79 |
80 | - 💻 [최종 인코더 계층에서만 임베딩을 추출하는 실습 코드](../../codes/3-2_generating_BERT_embedding.ipynb) *Cf. Google Colab / Python 3.x*
81 |
82 | - 코드 흐름
83 |
84 | 1. 설치 및 다운로드
85 | - `transformers` 설치
86 | - 사전 학습된 BERT *model* 다운로드
87 | - 위 모델을 사전 학습시키는 데 사용된 *tokenizer* 다운로드
88 |
89 | 2. 입력 전처리
90 |
91 | - *tokenizer*를 이용해 문장 토큰화
92 | - *attention_mask* 생성
93 | - *token_ids*로 변환
94 |
95 | 3. 임베딩 추출
96 |
97 | - *token_ids* 및 *attention_mask*를 *model*에 입력하고 임베딩 획득
98 |
99 | - *model*은 두 값으로 구성된 튜플 반환
100 |
101 | ```
102 | last_hidden_state, pooler_output = model(token_ids, attention_mask = attention_mask)
103 | ```
104 |
105 | `last_hidden_state` : 최종 인코더 계층(12번째 인코더)에서만 얻은 모든 토큰의 표현 벡터
106 |
107 | `pooler_output` : 최종 인코더 계층의 `[CLS]` 토큰 표현을 나타내며 선형 및 tanh 활성화 함수에 의해 계산
108 |
109 | 📌 `last_hidden_state[0][0]` vs. `pooler_output`
110 |
111 | - https://github.com/huggingface/transformers/issues/7540
112 |
113 | *Cf. 책에서는 last_hidden_state를 hidden_rep로, pooler_output을 cls_head라고 기술했다.*
114 |
115 | #### BERT의 모든 인코더 레이어에서 임베딩을 추출하는 방법
116 |
117 | - 최종 인코더 레이어(마지막 계층의 은닉 상태)에서만 얻은 임베딩(표현 벡터) 사용 **vs.** 다른 인코더 레이어에서 얻은 임베딩 고려
118 |
119 | ➡︎ 모든 인코더 레이어(모든 은닉 상태)에서 얻은 임베딩도 고려하자!
120 |
121 | | 속성 | 표기 | F1 스코어 |
122 | | :----------------------------: | :-------------: | :-------: |
123 | | 임베딩 | h_0 | 91.0 |
124 | | 마지막에서 두 번째 레이어 | h_11 | 95.6 |
125 | | 마지막 레이어 | h_12 | 94.9 |
126 | | 마지막 4개 레이어의 가중합 | h_9 to h_12 | 95.9 |
127 | | **마지막 4개 레이어의 연결값** | **h_9 to h_12** | **96.1** |
128 | | 12개 레이어의 가중합 | h_1 to h_12 | 95.5 |
129 |
130 |
60 |
61 | *출처 [Understanding the Bert Model](https://medium.com/analytics-vidhya/understanding-the-bert-model-a04e1c7933a9)*
62 |
63 | #### 문장 임베딩 추출
64 |
65 | `[CLS]` 토큰의 표현은 전제 문장의 집계 표현을 보유하게 되므로, **문장의 표현**은 `[CLS]` 토큰에 해당하는 `R_[CLS]` 표현 벡터가 된다.
66 |
67 | - `[CLS]` 토큰의 표현을 문장 표현으로 사용하는 것이 항상 좋은 생각은 아니다. 문장의 표현을 얻는 효율적인 방법은 모든 토큰의 표현을 평균화하거나 풀링하는 것이다. _Cf. 4장_
68 |
69 | - 매우 유사한 방식으로 학습셋에 있는 모든 문장의 벡터 표현을 계산하여 모든 문장의 문장 표현을 얻은 후에는 해당 표현을 입력으로 제공하고 분류기로 학습해 감정 분석 작업을 수행할 수 있다.
70 |
71 | ### Hugging Face Transformer
72 |
73 | Hugging Face의 오픈 소스 라이브러리 `transformers`와 사전 학습된 BERT 모델을 사용해, 문장에 있는 모든 단어의 문맥화된 단어 임베딩 생성하기
74 |
75 | - Hugging Face : 자연어 기술의 민주화를 추구하는 조직
76 | - `transformers` : 파이토치 및 텐서플로와 모두 호환, NLP 및 NLU 태스크에 강력, 100개 이상의 언어로 사전 학습된 수천 개의 모델 포함
77 |
78 | #### BERT의 최상위 인코더 계층인 12번째 인코더에서만 임베딩을 얻는 방법
79 |
80 | - 💻 [최종 인코더 계층에서만 임베딩을 추출하는 실습 코드](../../codes/3-2_generating_BERT_embedding.ipynb) *Cf. Google Colab / Python 3.x*
81 |
82 | - 코드 흐름
83 |
84 | 1. 설치 및 다운로드
85 | - `transformers` 설치
86 | - 사전 학습된 BERT *model* 다운로드
87 | - 위 모델을 사전 학습시키는 데 사용된 *tokenizer* 다운로드
88 |
89 | 2. 입력 전처리
90 |
91 | - *tokenizer*를 이용해 문장 토큰화
92 | - *attention_mask* 생성
93 | - *token_ids*로 변환
94 |
95 | 3. 임베딩 추출
96 |
97 | - *token_ids* 및 *attention_mask*를 *model*에 입력하고 임베딩 획득
98 |
99 | - *model*은 두 값으로 구성된 튜플 반환
100 |
101 | ```
102 | last_hidden_state, pooler_output = model(token_ids, attention_mask = attention_mask)
103 | ```
104 |
105 | `last_hidden_state` : 최종 인코더 계층(12번째 인코더)에서만 얻은 모든 토큰의 표현 벡터
106 |
107 | `pooler_output` : 최종 인코더 계층의 `[CLS]` 토큰 표현을 나타내며 선형 및 tanh 활성화 함수에 의해 계산
108 |
109 | 📌 `last_hidden_state[0][0]` vs. `pooler_output`
110 |
111 | - https://github.com/huggingface/transformers/issues/7540
112 |
113 | *Cf. 책에서는 last_hidden_state를 hidden_rep로, pooler_output을 cls_head라고 기술했다.*
114 |
115 | #### BERT의 모든 인코더 레이어에서 임베딩을 추출하는 방법
116 |
117 | - 최종 인코더 레이어(마지막 계층의 은닉 상태)에서만 얻은 임베딩(표현 벡터) 사용 **vs.** 다른 인코더 레이어에서 얻은 임베딩 고려
118 |
119 | ➡︎ 모든 인코더 레이어(모든 은닉 상태)에서 얻은 임베딩도 고려하자!
120 |
121 | | 속성 | 표기 | F1 스코어 |
122 | | :----------------------------: | :-------------: | :-------: |
123 | | 임베딩 | h_0 | 91.0 |
124 | | 마지막에서 두 번째 레이어 | h_11 | 95.6 |
125 | | 마지막 레이어 | h_12 | 94.9 |
126 | | 마지막 4개 레이어의 가중합 | h_9 to h_12 | 95.9 |
127 | | **마지막 4개 레이어의 연결값** | **h_9 to h_12** | **96.1** |
128 | | 12개 레이어의 가중합 | h_1 to h_12 | 95.5 |
129 |
130 | 구글 BERT의 정석 그림 3-5 서로 다른 레이어의 임베딩 속성으로 도출한 F1 스코어
131 |
132 | - 💻 [모든 인코더 레이어에서 임베딩 추출하는 실습 코드](../../codes/3-3_extracting_embeddings_from_all_encoder_layers_of_BERT.ipynb) *Cf. Google Colab / Python 3.x*
133 |
134 | - BERT의 최상위 인코더 계층인 12번째 인코더에서만 임베딩을 얻는 코드와 유사하고, 다른 점은 다음과 같다 :
135 |
136 | - 사전 학습된 BERT 모델을 다운로드 받을 때
137 |
138 | 모든 인코더 레이어에서 임베딩을 얻기 위해, `output_hidden_states = True` 로 설정한다.
139 |
140 | - 임베딩을 가져올 때
141 |
142 | 모델은 hidden_state를 추가하여, 2개가 아닌 3개의 값이 있는 튜플을 반환한다.
143 |
144 | ```
145 | last_hidden_state, pooler_output, hidden_states = model(token_ids, attention_mask = attention_mask)
146 | ```
147 |
148 | `last_hidden_state` 와 `pooler_output` 의 값은 최상위 인코더 계층에서만 임베딩을 얻는 경우와 동일하고, `hidden_states`가 추가된다.
149 |
150 | `hidden_states` : 모든 인코더 계층에서 얻은 모든 토큰의 표현 포함
151 |
152 | - 입력 임베딩 레이어 *h_0*에서 *h_12*까지 모든 인코더 레이어의 표현을 포함하는 13개의 값을 포함하는 튜플
153 |
154 | *hidden_states[i]는 i번째 레이어 h_i에서 얻은 모든 토큰의 표현 벡터를 가진다. => hidden_states[12]==last_hidden_state*
155 |
156 | ## 정리
157 |
158 | - 사전 학습된 BERT 모델을 다음 두 가지 방법으로 사용할 수 있다.
159 |
160 | - 임베딩을 추출해 특징 추출기로 사용한다.
161 |
162 | - 사전 학습된 BERT 모델을 다운스트림 태스크에 맞게 파인 튜닝한다.
163 |
164 | _Cf. 이 문서에서는 임베딩을 추출하는 방법만 다뤘다._
165 |
166 | - 사전 학습된 BERT에서 단어 및 문장 임베딩(표현)을 추출할 수 있다.
167 |
168 | - 단어의 벡터 표현
169 | - 최종 인코더는 문장에 있는 모든 토큰(단어)의 최종 표현 벡터(임베딩)을 반환한다.
170 | - 문장의 벡터 표현
171 | - `[CLS]` 토큰의 표현은 전체 문장의 집계 표현을 보유하게 된다.
172 |
173 | - 사전 학습된 BERT 모델에서 임베딩을 추출할 때 어떤 레이어에서 얻은 임베딩을 사용해야 할까?
174 |
175 | - 최종 인코더 레이어(마지막 계층의 은닉 상태)에서만 얻은 임베딩
176 | - 모든 인코더 레이어(모든 은닉 상태)에서 얻은 임베딩
177 |
178 | - 실습 코드
179 |
180 | - 저자의 깃허브 저장소
181 | - [3.03. Generating BERT embedding .ipynb](https://github.com/PacktPublishing/Getting-Started-with-Google-BERT/blob/main/Chapter03/3.03.%20Generating%20BERT%20embedding%20.ipynb)
182 | - [3.04. Extracting embeddings from all encoder layers of BERT.ipynb](https://github.com/PacktPublishing/Getting-Started-with-Google-BERT/blob/main/Chapter03/3.04.%20Extracting%20embeddings%20from%20all%20encoder%20layers%20of%20BERT.ipynb)
183 |
184 | - 버전 업데이트를 반영하고, 한글 설명을 추가한 코드 *Cf. Google Colab / Python 3.x*
185 |
186 | - [최종 인코더 계층에서만 임베딩 추출](../../codes/3-2_generating_BERT_embedding.ipynb)
187 |
188 | - [모든 인코더 레이어에서 임베딩 추출](../../codes/3-3_extracting_embeddings_from_all_encoder_layers_of_BERT.ipynb)
189 |
190 | ## 참고 자료
191 |
192 | - 구글 BERT의 정석 [book](http://www.yes24.com/Product/Goods/104491152)
193 |
--------------------------------------------------------------------------------
/summaries/chapter03/chapter03_finetuning.md:
--------------------------------------------------------------------------------
1 | # 다운스트림 태스크를 위한 BERT 파인 튜닝 방법
2 |
3 | 처음부터 학습하는 것이 아니라 Pretrained Model을 사용하여 학습
4 |
5 | - 텍스트 분류
6 | - 자연어 추론(NLI)
7 | - 개체명 인식(NER)
8 | - 질문-응답
9 |
10 | ## 텍스트 분류
11 |
12 | - Tokenization(Special Tokens 추가)
13 | - R_[CLS]를 문장의 표현으로 사용
14 | - Classifier(softmax)에 넣고 감정 분석
15 |
16 | Fine-tuning 하면서 Model Weight를 조절하는 방법은 두 가지
17 |
18 | 1. 분류 계층과 함께 사전 학습된 BERT 모델의 가중치를 업데이트
19 | 2. Pretrained BERT가 아니라 Classifier weight만 업데이트. Feature Extractor로 사용(Model Freeze)
20 |
21 | Feature Extractor로 사용하는 것과 무엇이 다를까? Model Free
22 |
23 | ### 감정 분석을 위한 BERT 파인 튜닝
24 |
25 | IMDB Dataset은 영화 리뷰 텍스트와 리뷰의 감정 레이블로 구성
26 |
27 | ```python
28 | from transfomers import BertForSequenceClassification, BertTokenizerFast, Trainer,
29 | TrainingArguments
30 | from nlp import load_dataset
31 | import torch
32 | import numpy as np
33 |
34 | # Data loading
35 | # download from GDrive
36 | dataset = load_dataset('csv', data_files='./imdbs.csv', split='train')
37 | type(dataset) # nlp.arrow_dataset.Dataset
38 | dataset = dataset.train_test_split(test_size=0.3)
39 |
40 | train_set = dataset['train']
41 | test_set = dataset['test']
42 |
43 | model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
44 | tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
45 |
46 | # ---------------
47 | tokens = [ '[CLS]', 'I', 'love', 'Paris', '[SEP]' ]
48 | inputs_ids = [101, 1045, 2293, 3000, 102]
49 | token_type_ids = [0, 0, 0, 0, 0] #Segment Embedding
50 | attention_mask = [1, 1, 1, 1, 1]
51 |
52 | tokenizer('I love Paris') # Same as above
53 |
54 | tokenizer(['I love Paris', 'birds fly', 'snow fall'], padding=True, max_length=5)
55 | # ---------------
56 | def preprocess(data):
57 | return tokenizer(data['text'], padding=True, truncation=True)
58 |
59 | train_set = train_set.map(preprocess, batched=True, batch_size=len(train_set))
60 | test_set = test_set.map(preprocess, batched=True, batch_size=len(test_set))
61 |
62 | train_set.set_format('torch', columns=['input_ids', 'attention_mask', 'label'])
63 | test_set.set_format('torch', columns=['input_ids', 'attention_mask', 'label'])
64 |
65 | batch_size = 8
66 | epochs = 2
67 |
68 | warmup_steps = 500
69 | weight_decay = 0.01
70 |
71 | training_args = TrainingArguments(
72 | output_dir='./results',
73 | num_train_epochs=epochs,
74 | per_device_train_batch_size=batch_size,
75 | per_device_eval_batch_size=batch_size,
76 | warmup_steps=warmup_steps,
77 | weight_decay=weight_decay,
78 | evaluate_during_training=True,
79 | logging_dir='./logs',
80 | )
81 |
82 | trainer = Trainer(
83 | model=model,
84 | args=training_args,
85 | train_dataset=train_set,
86 | eval_dataset=test_set
87 | )
88 |
89 | trainer.train()
90 | trainer.evaluate()
91 | ```
92 |
93 | ## 자연어 추론
94 |
95 | - Natural Language Inference
96 | - 가정이 주어진 전제에 참인지 거짓인지 중립인지 여부를 결정하는 태스크
97 | - (전제, 가설)에 대한 레이블이 주어짐
98 | - 전제와 가설 사이를 `[SEP]`으로 구분
99 | - `[CLS]` 토큰의 임베딩의 Classifier에 입력하면 참, 거짓, 중립일 확률을 반환
100 |
101 | ## 질문-응답(QA Task)
102 |
103 | - 목표: 주어진 질문에 대한 단락에서 답을 추출
104 | - BERT의 입력은 Question-Paragraph Pair
105 | - BERT는 Paragraph에서 Answer에 해당하는 텍스트의 범위를 반환해야 함
106 | - 단락 내 답의 시작과 끝 토큰의 확률을 구하면 답을 추출할 수 있음
107 | - 시작 벡터 S, 끝 벡터 E(Trainable)
108 | - Token 표현 벡터 R과 시작 벡터 S 사이의 내적 계산 → Softmax
109 | - 비슷하게 끝 벡터 E에 대해서도 학습
110 |
111 | ```python
112 | from transformer import BertForQuestionAnswering, BertTokenizer
113 |
114 | model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-fine-tuned-squad')
115 | tokenizer = BertTokenizer.from_pretrained('bert-large-uncased-whole-word-masking-fine-tuned-squad')
116 |
117 | question = "면역 체계는 무엇입니까?"
118 | paragraph = "면역 체계는 질병으로부터 보호하는 유기체 내의 다양한 생물학적 구조와 과정의 시스템입니다. 제대로 기능하려면 면역 체계가 바이러스에서 기생충에 이르기까지 병원균으로 알려진 다양한 물질을 탐지하고 유기체의 건강한 조직과 구별해야 합니다."
119 |
120 | question = '[CLS]' + question + '[SEP]'
121 | paragraph = paragraph + '[SEP]'
122 |
123 | question_tokens = tokenizer.tokenize(question)
124 | paragraph_tokens = tokenizer.tokenize(paragraph)
125 |
126 | tokens = question_tokens + paragraph_tokens
127 | input_ids = tokenizer.convert_to_ids(tokens)
128 |
129 | segment_ids = [0] * len(question_tokens)
130 | segment_ids += [1] * len(paragraph_tokens)
131 |
132 | input_ids = torch.tensor([input_ids])
133 | segment_ids = torch.tensor([segment_ids])
134 |
135 | start_scores, end_scores = model(input_ids, token_type_ids=segment_ids)
136 |
137 | start_index = torch.argmax(start_scores)
138 | end_index = torch.argmax(end_scores)
139 |
140 | print(' '.join(tokens[start_index:end_index+1]))
141 | ```
142 |
143 | ## 개체명 인식(NER)
144 |
145 | - 개체명을 미리 정의된 범주로 분류
146 | - 앞에 `[CLS]` 끝에 `[SEP]` 토큰 추가
147 | - BERT 모델에 토큰을 입력하고 표현 벡터 반환
148 | - Classifier에 입력
149 | - Classifier는 개체명이 속한 범주를 반환
150 |
151 | # 텐서플로 2와 머신러닝으로 시작하는 자연어 처리
152 |
153 | - LM이란 단어들의 시퀀스에 대한 확률 분포
154 | - 단어들의 모임(시퀀스)가 있을 때 해당 단어의 모음이 어떤 확률로 등장하는지를 나타내는 값
155 | - BERT Fine tuning 예시
156 | - 언어적 용인 가능성(Linguistic Acceptability)
157 | - 자연어 추론(Natural Language Inference)
158 | - 유사도 예측(Similiarity Predicition)
159 | - 감정 분석(Sentiment Analysis)
160 | - 개체명 인식(Named Entity Recognition)
161 | - 기계독해(Reading Comprehension)
162 | - BERT 파생모델 분류
163 | 1. BERT를 개선하려고 노력한 모델. 성능 향상, 속도 개선, 메모리 최적화 등 a.g.) SpanBERT, RoBERTa, ERNIE
164 | 2. BERT의 알고리즘 문제를 실험적으로 증명하며 개선하려는 모델 a.g.) XLNet
165 | 3. BERT를 NLP가 아닌 다른 분야에 사용하는 모델 a.g.) VideoBERT, VisualBERT
166 |
167 | # Questions
168 |
169 | ## 현업에서 Fine-tuning 어떻게 하는지?
170 | - https://klue-benchmark.com/
171 | - https://huffon.github.io/2019/11/16/glue/
172 | - https://gluebenchmark.com/
173 | - https://korquad.github.io/
174 | - https://blog.naver.com/skelterlabs/222025030327
175 |
176 |
177 | ## Weight를 freezing 하면 어떤 효과가 있는지?
178 | Layer Freezing을 한다는 것은 accuracy를 크게 떨어뜨리지 않으면서 computation cost를 절약하는 것이 목적이다. Dropout이나 Stochastic Depth 같은 것을 보면 모든 layer를 학습시키지 않으면서 네트워크를 효과적으로 학습할 수 있다는 것을 볼 수 있다.
179 |
180 | ### FreezeOut
181 | Vision 관련 논문. Pretraining 후에 Fine-tuning을 통해서 최종 Task에 맞는 Weight를 업데이트 함. 이 때, 앞쪽 layer들이 대부분 budget을 많이 차지하는 것에 비해 Parameter가 적고 상당히 간단한 설정으로 수렴하는데, 이는 대부분의 Parameter들이 있는 이후에 나오는 layer들에 비해서 fine-tuning이 필요하지는 않다고 가정할 수 있음. 이미 local minimum에 도달했다고 볼 수 있다.
182 |
183 | VGG에서의 실험결과에서 FreezeOut이 잘 맞지 않는 것으로 나타났는데, skip connection(dense나 residual도)이 FreezeOut이 동작 가능하게 해주는 중요한 요소인 것 같다고 함 → NLP에 적용했을 때는?
184 |
185 | ### References
186 | - https://raphaelb.org/posts/freezing-bert
187 | - https://analyticsindiamag.com/what-does-freezing-a-layer-mean-and-how-does-it-help-in-fine-tuning-neural-networks/
188 | - https://stats.stackexchange.com/questions/393168/what-does-it-mean-to-freeze-or-unfreeze-a-model/393171
189 | - https://arxiv.org/pdf/1706.04983.pdf
190 |
191 | # References
192 |
193 | https://mccormickml.com/2020/03/10/question-answering-with-a-fine-tuned-BERT/
194 |
--------------------------------------------------------------------------------
/summaries/chapter04/Chapter04_ALBERT_suyeon.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Gubuzeong/Getting-Started-with-Google-BERT/ae04bb9d23b4423749f121162df878972989e23c/summaries/chapter04/Chapter04_ALBERT_suyeon.pdf
--------------------------------------------------------------------------------
/summaries/chapter04/Chapter04_ELECTRA.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Gubuzeong/Getting-Started-with-Google-BERT/ae04bb9d23b4423749f121162df878972989e23c/summaries/chapter04/Chapter04_ELECTRA.pdf
--------------------------------------------------------------------------------
/summaries/chapter04/chapter04_SpanBERT.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Chapter 4 BERT 파생 모델 2
4 |
5 | 이번 장에서 다루는 BERT의 다양한 형태의 파생 모델
6 |
7 | - ALBERT
8 | - RoBERTa
9 | - ELECTRA
10 | - SpanBERT
11 |
12 | ## SpanBERT
13 |
14 | 📄 **[SpanBERT: Improving Pre-training by Representing and Predicting Spans](https://arxiv.org/pdf/1907.10529.pdf)**
15 |
16 | SpanBERT란 text span을 더 잘 표현하고 예측하기 위해 설계된 사전 학습 기법이다.
17 |
18 | - 다음과 같은 방식으로 BERT를 확장하였다.
19 |
20 | | | SpanBERT | BERT |
21 | | :-------------------------------------------: | :------------------------------------: | :-------------------------------------: |
22 | | **마스킹 방법** | 연속된 랜덤 spans 마스킹 | 랜덤 토큰 마스킹 |
23 | | **마스킹된 토큰 예측하기 위해 사용하는 표현** | span 경계 표현을 학습시켜서 예측 (SBO) | 마스킹된 개별 토큰의 표현을 이용해 예측 |
24 |
25 |  57 |
58 | ## TinyBERT 학습
59 |
60 | - General Distillation
61 | - Task-specific Distillation
62 |
63 | ### General Distillation
64 |
65 | - 사전 학습 단계를 의미
66 | - Large BERT를 Teacher로 사용하고 Student model에게 지식을 전달
67 | - 모든 layer에 증류 적용
68 | - 증류 후 Student BERT는 Teacher의 지식으로 구성, 사전 학습된 Student BERT를 General TinyBERT라고 부름
69 | - Downstream task를 위해 General TinyBERT를 Fine-tuning 할 수 있음
70 |
71 | ### Task-specific Distillation
72 |
73 | - Fine-tuning
74 | - 특정 Task를 위해 General TinyBERT를 Fine-tuning
75 | - Teacher model을 먼저 Fine-tuning, 다시 General TinyBERT로 Distillation 진행
76 | - Fine-tuning 단계에서 Distillation을 하려면 더 많은 dataset 필요 → Data Augmentation
77 |
78 | ### Data Augmentation
79 |
80 | Tokenized sentence X의 각각 모든 단어에 대해,
81 |
82 | 1. X[i]가 단일 단어인지 확인. 단일 단어라면 [MASK] 토큰으로 masking. BERT-base로 masked token을 예측. 확률이 높은 상위 K개의 단어 candidates에 저장
83 | 2. X[i]가 단일 단어가 아니면 masking 하지 않음. GloVe Embedding을 사용해 X[i]와 가장 유사한 K 단어 확인하고 candidates에 저장. p~Uniform(0,1)에서 값 p를 무작위로 추출하고, threshold를 p_t = 0.4로 설정
84 | 3. p가 p_t보다 작거나 같으면 X_masked[i]를 후보 목록의 임의 단어로 교체
85 | 4. p가 p_t보다 크면 교체 안함
86 |
87 | - N번 반복하면 N개의 Augmented sentence가 생성
88 | - Augmented Data를 사용하여 General TinyBERT를 Fine-tuning
89 | - TinyBERT는 BERT-base 모델보다,
90 | - 96%의 추론 효율 향상
91 | - 7.5배 작음
92 | - 9.4배 빠름
93 |
94 | ## BERT에서 신경망으로 지식 전달
95 |
96 | - BERT에서 간단한 신경망으로 Distillation이 가능할까?
97 | - Teacher model - Pretrained BERT(여기서는 BERT-large)
98 | - Teacher model을 Downstream task에 맞게 fine-tuning
99 | - Student model - Bi-LSTM
100 | - Bi-LSTM은 양방향으로 문장을 읽음
101 | - 순방향, 역방향 hidden state를 FFN에 넣고 logit 출력
102 | - softmax → 확률
103 |
104 | ### Student network training
105 |
106 | - 일단 Teacher부터 Fine-tuning
107 | - L = a * L_student + b * L_distillation
108 | - L_distillation = MSE(Z^T, Z^S) → Soft target, Soft prediction에 대한 MSE
109 | - L_student: Hard target, Hard prediction에 대한 cross-entropy
110 | - Teacher BERT에서 Student Network로 KD를 수행하려면 큰 데이터셋 필요
111 | - Task-agnostic Data Augmentation
112 |
113 | ## Data Augmentation
114 |
115 | - Masking
116 | - POS based word replacement
117 | - n-gram sampling
118 |
119 | ### Masking
120 |
121 | - TinyBERT의 DA 방법
122 |
123 | ### POS based word replacement
124 |
125 | - p_pos 확률로 문장의 한 단어를 같은 품사 다른 단어로 대체
126 |
127 | ### n-gram Sampling
128 |
129 | - p_ng 확률로 문장에서 n-gram을 random sampling
130 | - n은 1~5까지 무작위
131 |
132 | ### Data Augmentation Process
133 |
134 | - X_i ~ Uniform(0,1)
135 | - X_i < p_mask이면 w_i 단어를 masking
136 | - p_mask ≤ X_i p_mask + p_pos이면 POS word replacement를 진행
137 | - Masking과 POS based WR은 겹치지 않음. 둘 중 하나만 적용 가능
138 | - 이 단계 이후, p_ng 확률로 n-gram sampling
139 | - N번 수행 → N개의 새로운 Augmented data
140 |
141 | 문장이 아니라 문장 쌍이라면?
142 |
143 | - 문장 1 합성 + 문장 2 유지
144 | - 문장 1 유지 + 문장 2 합성
145 | - 문장 1 합성 + 문장 2 합성
146 |
147 | 이런 식으로 Augmentation 가능
--------------------------------------------------------------------------------
/summaries/chapter06/chapter06_텍스트_요약을_위한_BERTSUM_탐색_(1).md:
--------------------------------------------------------------------------------
1 | # Chapter 6: 텍스트 요약을 위한 BERTSUM 탐색
2 |
3 | > Speaker: 남수연
4 |
5 |
6 | # 텍스트 요약
7 |
8 | NLP 분야의 주요 연구 분야 중 하나로, 주어진 긴 텍스트를 요약하는 것. 긴 문서, 뉴스 기사, 법률 문서, 블로그 게시물 등 다양한 영역에서 널리 사용됨.
9 |
10 | # 텍스트 요약 방식 이해하기
11 |
12 | 아래와 같은 텍스트를 요약해야 한다고 해보자.
13 |
14 | ```
15 | 나는 어제 신촌에서 동아리 운영진 동기 언니와 10시간 내내 먹었다. 점심으로
16 | 진돈부리를 가려고 했지만 딱 어제 휴업하는 바람에 반서울에 갔는데 엄청 맛있었다.
17 | 다음에 또 와야겠다고 생각했다. 후식으로 파이홀에 가서 오레오말차가나슈파이와 얼그
18 | 레이가나슈파이를 먹었다. 역시 다음에 또 와야겠다고 생각했다. 저녁으로 돈우마미에
19 | 가서 사케동을 먹었다. 가라아게 4조각을 시켰는데 서비스로 한 조각을 더 주셔서
20 | 돈우마미는 참 좋은 가게라는 생각이 들었다. 마지막으로 아워즈에 가서 칵테일을 조
21 | 졌다. 줄리엣이라는 칵테일을 주문했는데 요맘때 복숭아맛과 딸기맛을 섞어놓은 것 같은
22 | 것이 정말 정말 맛있었다. 정신을 차려보니 9시 30분이어서 허겁지겁 버스를 타고
23 | 집에 왔더니 월요일이 스터디 하는 날이랜다. 어이가 없어서 헛웃음이 나왔지만 지금
24 | 웃을 때가 아니므로 열심히 스터디 준비를 하는 중이다.
25 | ```
26 |
27 | ## 추출 요약
28 |
29 | 주어진 텍스트 안에서 중요한 문장만 추출해 요약한다. 입력의 문장 중 중요도가 높은 순으로 N개의 문장을 뽑는 식이다.
30 |
31 | ```
32 | 나는 어제 신촌에서 동아리 운영진 동기 언니와 10시간 내내 먹었다. 점심으로
33 | 진돈부리를 가려고 했는데 딱 어제만 휴업하는 바람에 반서울에 갔는데 엄청 맛있
34 | 었다. 후식으로 파이홀에 가서 오레오말차가나슈 파이와 얼그레이가나슈파이를 먹었다.
35 | 마지막으로 아워즈에 가서 칵테일을 조졌다. 어이가 없어서 헛웃음이 나왔지만 지금
36 | 웃을 때가 아니므로 열심히 스터디 준비를 하는 중이다.
37 | ```
38 |
39 | ## 생성 요약
40 |
41 | 주어진 텍스트를 의역해서 원래 문서에 포함되지 않은 문장으로 요약을 만든다.
42 |
43 | ```
44 | 어제의 나는 동아리 언니와 10시간동안 쉬지 않고 먹었다. 정신을 차려보니 발등에
45 | 불이 떨어진 상태여서 열심히 스터디 준비를 하는 중이다.
46 | ```
47 |
48 | ## Summary
49 |
50 | | | 추출 요약 | 생성 요약 |
51 | | --- | --- | --- |
52 | | 입력 문장을 그대로 사용하는가? | O | X |
53 | | 정보 누락 정도 | 많음 | 적음 |
54 | | 컴퓨팅 리소스 필요량 | 적음 | 많음 |
55 | | 학습 시간 필요량 | 적음 | 많음 |
56 |
57 | # 텍스트 요약에 맞춘 BERT 파인 튜닝
58 |
59 | ## BERT을 활용한 추출 요약
60 |
61 | 사전학습된 BERT를 사용해 추출 요약 태스크를 진행하려면 BERT 모델 입력 데이터 형태를 수정해야 한다. BERT 모델의 입력 데이터를 수정하여 각 문장의 표현을 얻는 방법에 대해 알아보자.
62 |
63 | - BERT 복습
64 | 1. 입력 문장을 토큰 형태로 변경한다.
65 | 2. 첫 문장의 시작 부분에만 `[CLS]` 토큰을 모든 문장의 마지막 부분에 `[SEP]` 토큰을 추가한다.
66 | 3. 입력 토큰을 토큰 임베딩, 세그먼트 임베딩, 위치 임베딩, 총 3개의 임베딩 레이어 형태로 각각 변환한다.
67 | 4. 모든 임베딩을 더한 다음 BERT에 입력한다.
68 | 5. BERT는 아웃풋으로 모든 토큰의 표현 벡터를 출력한다.
69 |
70 |
71 |
72 | ### 1) 토큰 임베딩
73 |
74 | 텍스트 요약 태스크에서는 BERT 모델에 여러 문장을 입력하고 입력한 모든 문장에 대한 표현이 필요하다. **모든 문장의 시작 부분에 `[CLS]` 토큰을 추가**하면 모든 문장에 대한 표현을 얻을 수 있다. 이 `[CLS]` 토큰은 각 문장을 대표하는 토큰으로서 문장의 특징을 뽑아낼 때 사용할 것이다.
75 |
76 | ```python
77 | input = ["[CLS]", "ban", "seoul", "[SEP]", "[CLS]", "pie", "hole", "[SEP]", "[CLS]", "don", "umami", "[SEP]"]
78 | ```
79 |
80 | ### 2) 세그먼트 임베딩
81 |
82 | 세그먼트 임베딩은 입력을 $E_A, E_B$ 형태로 반환한다. 그보다 훨씬 많은 수의 문장이 입력으로 들어오는 텍스트 요약 태스크에서는 $E_A, E_B$ 만으로 어떻게 문장을 구분할 수 있을까?
83 |
84 | 인터벌 세그먼트 임베딩을 통해 홀수번째 문장에서 발생한 토큰은 $E_A$, 짝수번째 문장에서 발생한 토큰은 $E_B$에 매핑한다. 한 문장을 앞뒤의 문장들과 구분하기만 하면 되므로 이런 방법을 사용할 수 있다.
85 |
86 | ### 3) 위치 임베딩
87 |
88 | 위치 임베딩은 모든 토큰의 위치 정보에 대한 임베딩값으로, 기존 방식과 동일하다.
89 |
90 | ## BERTSUM
91 |
92 | 
93 |
94 | BERT 모델을 사용해 입력 데이터 형식을 변경해서 텍스트 요약에 특화되도록 만든 모델을 BERTSUM이라고 한다. 처음부터 BERT를 학습시킬 필요는 없으며, 이미 사전학습된 BERT 모델에 앞서 설명한 입력 데이터 형태로 변경하여 파인 튜닝하면 된다.
95 |
96 | ### 1) 분류기가 있는 BERTSUM
97 |
98 |
99 | **모든 문장의 표현을 받아서 각 문장의 중요도를 판단하는 분류기 레이어**를 ****BERT에 이어붙인다. 분류기는 각 문장을 요약에 포함시킬지 여부에 대한 확률을 제공한다. Linear Layer 하나만 사용하며, BERT의 아웃풋을 분류기 레이어에 넣어 나온 값에 sigmoid 활성화 함수를 취한 값을 target으로 활용한다. 이렇게 계산된 target과 정답을 BCE를 통해 loss를 계산한다. loss 값을 최소화하도록 BERT 모델과 분류기 레이어를 함께 학습시킨다.
100 |
101 | $$
102 | \hat{Y} = \sigma(W_oT_i + b_o)
103 | $$
104 |
105 | ### 2) 🌟 트랜스포머와 LSTM을 활용한 BERTSUM
106 |
107 | **(1) 문장 간 트랜스포머(inter-sentence transformer)를 활용한 BERTSUM**
108 |
109 | 논문에 따르면 다른 2개의 Summarization layer보다 훨씬 좋은 결과를 보여주는 방법이다. BERT의 결과인 문장 표현 $R$을 트랜스포머 레이어에 입력한다. 트랜스포머는 BERT에서 얻은 표현을 가져와 은닉 상태로 변환하는데, 이 때 도입되는 트랜스포머는 문장 간 Attention을 계산하고 문장 단위가 아닌 전체 문서 관점에서 요약 태스크를 수행한다.
110 |
111 | BERT에서 얻은 문장 표현 R에 위치 임베딩 값을 추가하여 트랜스포머의 인코더에 입력한다($h^0=PosEmb(R)$) . 인코더 $l$에서 서브레이어는 다음과 같이 표현한다.
112 |
113 | 
114 |
115 | 최상위 인코더를 $L$, 최상위 인코더에서 나온 은닉 상태를 $h^L$이라고 했을 때 문장의 포함 여부를 계산하는 식은 다음과 같다.
116 |
117 | 
118 |
119 | **(2) LSTM을 활용한 BERTSUM**
120 |
121 | BERT의 last hidden layer에 RNN을 활용하면 성능이 좋을 수 있다는 논문을 참고하여 실험을 진행했으며, 훈련 과정을 안정화하기 위해 단순 LSTM이 아닌 pergate layer nomarlization을 사용했다.
122 |
123 | BERT에서 얻은 문장 $i$에 대한 표현 $R_i$를 LSTM에 입력하면 LSTM 셀은 은닉 상태 $h_i$를 출력한다. sigmoid에 $h_i$를 입력하면 각 문장을 요약에 포함시킬지에 대한 확률을 반환한다.
124 |
125 | 
126 |
127 | ### 참고: summarization layers에 대한 ROUGE 성능 평가
128 |
129 | 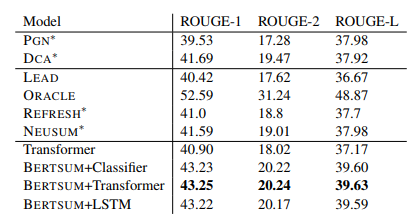
130 |
131 | # References
132 |
133 | [[논문 리뷰] Fine-tune BERT for Extractive Summarization](https://medium.com/@eyfydsyd97/bert%EB%A5%BC-%ED%99%9C%EC%9A%A9%ED%95%9C-%ED%85%8D%EC%8A%A4%ED%8A%B8-%EC%9A%94%EC%95%BD-text-summary-b582b5cc7d)
134 |
135 | [BERT를 활용한 한국어 문서 추출요약 봇](https://velog.io/@raqoon886/KorBertSum-SummaryBot)
136 |
--------------------------------------------------------------------------------
/summaries/chapter06/chapter6_BERTSUM(2)_0hee0.md:
--------------------------------------------------------------------------------
1 | # Chapter 6 텍스트 요약을 위한 BERTSUM 탐색
2 |
3 | BERTSUM: 텍스트 요약에 맞춰 파인 튜닝된 BERT 모델
4 |
5 | ## BERTSUM 모델의 성능
6 |
7 | BERTSUM 모델의 성능은 ROUGE 점수를 사용하여 평가
8 |
9 | ### ROUGE 평가 지표
10 |
11 | **ROUGE(Recall-oriented Understudy for Gisting Evalutation)**
12 |
13 | - 텍스트 요약과 기계 번역 태스크를 평가하는 데 사용하는 평가 지표
14 | - 「[ROUGE: A Package for Automatic Evaluation of Summaries](https://aclanthology.org/W04-1013/)」
15 |
16 | ROUGE의 다섯 가지 평가 지표 형태
17 |
18 | - ROUGE-N
19 | - ROUGE-L
20 | - ROUGE-W
21 | - ROUGE-S
22 | - ROUGE-SU
23 |
24 | *Cf. [ROUGE-an Evaluation Metric for Text Summarization](https://ilmoirfan.com/rouge-an-evaluation-metric-for-text-summarization/)*
25 |
26 | #### ROUGE-N
27 |
28 | 후보 요약(예측한 요약)과 참조 요약(실제 요약) 간의 n-gram 재현율(recall)
29 |
30 | ```
31 | 재현율 = (예측한 요약 결과와 실제 요약 사이의 서로 겹치는 n-gram 총 수) / (실제 요약의 n-gram의 총 수)
32 | ```
33 |
34 | *ROUGE-1(uni-gram)과 ROUGE-2(bi-gram)가 가장 많이 쓰인다.*
35 |
36 | #### ROUGE-L
37 |
38 | **가장 긴 공통 하위 시퀀스(LCS)**를 기반으로 하며, F-measure를 사용해 측정
39 |
40 | ### BERTSUM을 사용한 요약 태스크의 ROUGE 점수
41 |
42 | - 분류기, 트랜스포머, LSTM을 BERT에 적용한 BERTSUM 모델을 사용한 **추출 요약** 태스크의 ROUGE 점수
43 |
44 | *[Yang Liu. 2019. Fine-tune BERT for Extractive Summarization](https://arxiv.org/abs/1903.10318) 에서 CNN/DailyMail 테스트 데이터를 이용해 측정한 결과 (25/3/2019)*
45 |
46 | *Cf. https://github.com/nlpyang/BertSum*
47 |
48 | | 모델 | ROUGE-1 | ROUGE-2 | ROUGE-L |
49 | | :---------------------: | :-------: | :-------: | :-------: |
50 | | Transformer Baseline | 40.9 | 18.02 | 37.17 |
51 | | BERTSUM+classifier | 43.23 | 20.22 | 39.60 |
52 | | **BERTSUM+transformer** | **43.25** | **20.24** | **39.63** |
53 | | BERTSUM+LSTM | 43.22 | 20.17 | 39.59 |
54 |
55 | - BERTSUMABS 모델로 **생성 요약** 태스크를 수행했을 때의 ROUGE 점수
56 |
57 | *[Yang Liu, Mirella Lapata. 2019. Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345) 에서 CNN/DailyMail 테스트 데이터를 이용해 측정한 결과 (20/8/2019)*
58 |
59 | *Cf. https://github.com/nlpyang/PreSumm*
60 |
61 | | 모델 | ROUGE-1 | ROUGE-2 | ROUGE-L |
62 | | :--------: | :-----: | :-----: | :-----: |
63 | | BERTSUMABS | 41.72 | 19.39 | 38.76 |
64 |
65 | ## BERTSUM 모델 학습
66 |
67 | ```python
68 | # Google Colab / Python 3.x / GPU
69 |
70 | %%capture
71 | !pip install pytorch_pretrained_bert
72 | !pip install torch==1.1.0 pytorch_transformers tensorboardX multiprocess pyrouge
73 | !pip install googleDriveFileDownloader
74 |
75 | cd /content/
76 |
77 | # BERTSUM 연구원들이 오픈 소스로 제공한 학습 코드
78 | !git clone https://github.com/nlpyang/BertSum.git
79 |
80 | # 데이터셋 다운로드 (전처리된 CNN/DailyMail 뉴스 데이터)
81 | cd /content/BertSum/bert_data/
82 | ### 다운로드 및 압축 해제 ###
83 |
84 | # BERTSUM 모델 학습
85 | cd /content/BertSum/src
86 |
87 | '''
88 | First run: For the first time, you should use single-GPU, so the code can download the BERT model. Change -visible_gpus 0,1,2 -gpu_ranks 0,1,2 -world_size 3 to -visible_gpus 0 -gpu_ranks 0 -world_size 1, after downloading, you could kill the process and rerun the code with multi-GPUs.
89 | '''
90 |
91 | # BERTSUM + classifier (number of parameters: 109483009)
92 | !python train.py -mode train -encoder classifier -dropout 0.1 -bert_data_path ../bert_data/cnndm -model_path ../models/bert_classifier -lr 2e-3 -visible_gpus 0 -gpu_ranks 0 -world_size 1 -report_every 50 -save_checkpoint_steps 1000 -batch_size 3000 -decay_method noam -train_steps 50 -accum_count 2 -log_file ../logs/bert_classifier -use_interval true -warmup_steps 10000
93 |
94 | # BERTSUM + transformer (* number of parameters: 120512513)
95 | !python train.py -mode train -encoder transformer -dropout 0.1 -bert_data_path ../bert_data/cnndm -model_path ../models/bert_transformer -lr 2e-3 -visible_gpus 0 -gpu_ranks 0 -world_size 1 -report_every 50 -save_checkpoint_steps 1000 -batch_size 3000 -decay_method noam -train_steps 50 -accum_count 2 -log_file ../logs/bert_transformer -use_interval true -warmup_steps 10000 -ff_size 2048 -inter_layers 2 -heads 8
96 |
97 | # BERTSUM + lstm (* number of parameters: 113041921)
98 | !python train.py -mode train -encoder rnn -dropout 0.1 -bert_data_path ../bert_data/cnndm -model_path ../models/bert_rnn -lr 2e-3 -visible_gpus 0 -gpu_ranks 0 -world_size 1 -report_every 50 -save_checkpoint_steps 1000 -batch_size 3000 -decay_method noam -train_steps 50 -accum_count 2 -log_file ../logs/bert_rnn -use_interval true -warmup_steps 10000 -rnn_size 768 -dropout 0.1
99 | ```
100 |
101 | ```
102 | usage: train.py [-h] [-encoder {classifier,transformer,rnn,baseline}]
103 | [-mode {train,validate,test}] [-bert_data_path BERT_DATA_PATH]
104 | [-model_path MODEL_PATH] [-result_path RESULT_PATH]
105 | [-temp_dir TEMP_DIR] [-bert_config_path BERT_CONFIG_PATH]
106 | [-batch_size BATCH_SIZE] [-use_interval [USE_INTERVAL]]
107 | [-hidden_size HIDDEN_SIZE] [-ff_size FF_SIZE] [-heads HEADS]
108 | [-inter_layers INTER_LAYERS] [-rnn_size RNN_SIZE]
109 | [-param_init PARAM_INIT]
110 | [-param_init_glorot [PARAM_INIT_GLOROT]] [-dropout DROPOUT]
111 | [-optim OPTIM] [-lr LR] [-beßta1 BETA1] [-beta2 BETA2]
112 | [-decay_method DECAY_METHOD] [-warmup_steps WARMUP_STEPS]
113 | [-max_grad_norm MAX_GRAD_NORM]
114 | [-save_checkpoint_steps SAVE_CHECKPOINT_STEPS]
115 | [-accum_count ACCUM_COUNT] [-world_size WORLD_SIZE]
116 | [-report_every REPORT_EVERY] [-train_steps TRAIN_STEPS]
117 | [-recall_eval [RECALL_EVAL]] [-visible_gpus VISIBLE_GPUS]
118 | [-gpu_ranks GPU_RANKS] [-log_file LOG_FILE] [-dataset DATASET]
119 | [-seed SEED] [-test_all [TEST_ALL]] [-test_from TEST_FROM]
120 | [-train_from TRAIN_FROM] [-report_rouge [REPORT_ROUGE]]
121 | [-block_trigram [BLOCK_TRIGRAM]]
122 | ```
123 |
124 | ## 참고 자료
125 |
126 | - 구글 BERT의 정석 [book](http://www.yes24.com/Product/Goods/104491152)
127 | - [Fine-tune BERT for Extractive Summarization (BERTSUM) github repository](https://github.com/nlpyang/BertSum)
128 | - [ROUGE-an Evaluation Metric for Text Summarization](https://ilmoirfan.com/rouge-an-evaluation-metric-for-text-summarization/)
129 |
130 |
--------------------------------------------------------------------------------
/summaries/chapter07/chapter07_M-BERT.md:
--------------------------------------------------------------------------------
1 | # Chapter 7. 다른 언어에 BERT 적용하기
2 |
3 | BERT를 영어가 아닌 다른 언어에도 적용할 수 있을까? 아래 모델을 통해서 BERT를 통해 다국어 표현을 어떻게 얻을 수 있는지 알아보자.
4 |
5 | - M-BERT(multilingual-BERT)
6 | - XLM(cross-lingual language model)
7 | - XLM-R(XLM-RoBERTa)
8 |
9 |
10 |
11 | ## M-BERT 이해하기
12 |
13 | **BERT**
14 |
15 | - Datasets: 영어 위키피디아, 토론토 책 말뭉치
16 | - PreTrain Task: MLM, NSP
17 |
18 | **M-BERT**
19 |
20 | - Datasets: 104개 언어 위키피디아
21 | - 각 언어들간의 비중이 다르다 -> overfitting을 방지하기 위해 언어별 under/over sampling 적용
22 | - 104개 언어, 11만개의 워드피스(BPE와 유사하지만 likelihood 사용하는 인코딩)
23 | - PreTrain Task: MLM, NSP
24 |
25 |
26 |
27 | M-BERT는 교차 언어를 고려하지 않고도 다른 언어들의 표현을 이해할 수 있다.
28 |
29 |
30 |
31 | ### NLI task 평가로 알아보는 M-BERT 평가하기
32 |
33 | - 두 문장(가설, 전제)을 바탕으로, 가설이 주어진 전제에 따라 진실/거짓/중립 여부를 판단하는 것
34 | - 일반적으로 SNLI(Stanford natural language inference) datasets 사용
35 | - 다국어 NLI 평가를 위해서는 교차 언어 자연어 추론(XNLI: cross-linugal NLI)사용
36 | - MultiNLI 말뭉치에서 약 43만개의 영어 문장 쌍을 사용
37 | - 평가셋을 위해 7,500개의 문장 쌍을 사용하며, 이를 15개의 서로 다른 언어로 번역하여 11만개의 문장 쌍을 사용
38 |
39 |
40 |
41 | 다양한 설정에서 NLI task를 수행해 M-BERT를 평가한다.
42 |
43 | #### 제로샷(zero-shot)
44 |
45 | - Fine-tuning: 영어 학습셋
46 | - Validation: 모든 언어 테스트셋
47 | - 영어로 학습하고 모든 언어로 평가
48 | - M-BERT의 교차 언어 능력을 이해하는데 도움
49 |
50 |
51 |
52 | #### 번역-테스트(Translate-Test)
53 |
54 | - Fine-tuning: 영어 학습셋
55 | - Validation: 영어로 번역된 테스트셋
56 | - 영어로 학습하고 영어로 평가
57 |
58 |
59 |
60 | #### 번역-학습(Translate-Train)
61 |
62 | - Fine-tuning: 영어에서 다른 언어로 번역된 학습셋
63 | - Validation: 모든 언어 테스트셋
64 | - 다른 언어로 학습하고 모든 언어로 평가
65 |
66 |
67 |
68 | #### 번역-학습-모두(Translate-Train-All)
69 |
70 | - Fine-tuning: 영어에서 다른 **모든 언어**로 번역된 학습셋
71 | - Validation: 모든 언어 테스트셋
72 | - 모든 언어로 학습하고 모든 언어로 평가
73 |
74 |
75 |
76 | | 모델 | 설정 | 영어 | 중국어 | 스페인어 | 독일어 | 아랍어 | 우루드어 |
77 | | ------------ | --------------- | ---- | ------ | -------- | ------ | ------ | -------- |
78 | | BERT-cased | Translate-Train | 81.9 | 76.6 | 77.8 | 75.9 | 70.7 | 61.6 |
79 | | BERT-uncased | Translate-Train | 81.4 | 74.2 | 77.3 | 75.2 | 70.5 | 61.7 |
80 | | BERT-uncased | Translate-Test | 81.4 | 70.1 | 74.9 | 74.4 | 70.4 | 62.1 |
81 | | BERT-uncased | Zero-shot | 81.4 | 74.3 | 74.3 | 70.3 | 60.1 | 58.3 |
82 |
83 | > M-BERT 모델은 제로샷을 포함해 모든 조건에서 좋은 성능을 보여준다.
84 |
85 |
86 |
87 | ### M-BERT는 다국어 표현이 어떻게 가능한가??
88 |
89 | 다른 언어들을 다 섞어서 학습한 것 뿐인데 어떻게 다국어 표현이 가능한 건지?
90 |
91 |
92 |
93 | #### 어휘 중복 효과?
94 |
95 | - 언어 간에 중복되는 어휘 때문??
96 |
97 | - overlap으로 파인튜닝 언어/평가 언어 간에 겹치는 워드피스 토큰 계산
98 | $$
99 | \left| \dfrac{E_{train}\cap E_{eva1}}{E_{train}\cup E_{era1}}\right|
100 | $$
101 |
102 | - 16개의 모든 언어 쌍에 대해 제로샷 F1 score를 계산한 결과 어휘 중복(overlap)이 적을 때에도 제로샷 F1이 높았음
103 |
104 | > zeroshot 지식 전이는 어휘 중복에 영향을 받지 않는다
105 | >
106 | > M-BERT가 다른 언어와의 관계성을 고려해 일반화를 잘 한다 = 단순한 어휘 암기가 아니라 다국어 표현을 더 깊게 학습한다
107 |
108 |
109 |
110 | #### 스크립트에 대한 일반화?
111 |
112 | - 서로 다른 스크립트를 따르는 언어들 사이에서도 일반화가 잘 될까?
113 |
114 | > 일부 언어 쌍의 스크립트에서는 일반화가 잘 되지만, 모든 언어에서 적용되지는 않는다.
115 |
116 |
117 |
118 | #### 유형학적 특징에 대한 일반화?
119 |
120 | - 주어, 동사, 목적어 등의 단어 순서가 다른 언어들 사이에서도 일반화가 잘 될까?
121 |
122 | > M-BERT의 zeroshot 전이는 단어 순서가 동일한 언어에서 더 잘 작동한다.
123 | >
124 | > M-BERT의 일반화 능력은 언어 간의 유형학적 유사성에 따라 달라진다 = M-BERT가 체계적인 변환을 학습하는 것은 아님
125 |
126 |
127 |
128 | #### 언어 유사성의 효과?
129 |
130 | - WALS: 문법, 어휘 및 음운 속성과 같은 언어의 구조적 속성을 포함하는 대규모 데이터베이스
131 | - WALS 공통 특징 수가 많을 수록 제로샷 정확도가 높은 경향
132 |
133 | > M-BERT는 유사한 언어 구조를 공유하는 언어 사이에서 더 잘 일반화된다
134 |
135 |
136 |
137 | #### 코드 스위칭과 음차의 효과?
138 |
139 | **코드 스위칭**
140 |
141 | - 다른 언어를 혼합하거나 교대로 사용하는 것
142 | - ex) Korean은 굉장히 kind하고 polite한 것 같아.
143 |
144 | **음차**
145 |
146 | - 발음하는 그대로 쓴거
147 | - ex) 코리안은 굉장히 카인드하고 폴라이트한 것 같아.
148 |
149 |
150 |
151 | M-BERT에서 코드 스위칭과 음차를 어떻게 다룰까?
152 |
153 | - 코드 스위칭된 힌디어/영어 UD 말뭉치를 사용
154 | - 음차: 힌디어 텍스트는 라틴 문자로 작성된다.
155 | - 코드 스위칭: 라틴어의 힌디어 텍스트가 데바나가리어 스크립트로 변환되어 재작성된다.
156 |
157 | | 말뭉치 | 평가셋 | 정확도 |
158 | | ------------------------ | ----------- | ------ |
159 | | 음차 | 음차 | 85.64 |
160 | | 단일 언어(영어 + 힌디어) | 음차 | 50.41 |
161 | | 코드 스위칭 | 코드 스위칭 | 90.56 |
162 | | 단일 언어(영어 + 힌디어) | 코드 스위칭 | 86.59 |
163 |
164 | > M-BERT는 음차 텍스트와 비교해 코드 스위칭 텍스트에서 수행 능력이 좋다
165 |
166 |
167 |
168 | #### 결론
169 |
170 | - M-BERT의 일반화 가능성은 어휘 중복에 의존하지 않는다.
171 | - M-BERT의 일반화 가능성은 유형학 및 언어 유사성에 따라 다르다.
172 | - M-BERT는 코드 스위칭 텍스트를 처리할 수 있지만 음차 텍스트는 처리할 수 없다.
173 |
174 |
175 |
176 | ## XLM
177 |
178 | - 다국어를 목표로 BERT를 사전학습 시킨 모델로 M-BERT보다 다국어 표현 학습을 할 때 성능이 더 뛰어나다
179 |
180 | - 단일 언어 / 병렬 데이터셋을 사용해 사전 학습된다
181 | - 병렬 데이터셋: 언어 쌍의 텍스트(2개의 다른 언어로 된 동일한 텍스트)
182 | - 단일 언어 데이터셋: 위키피디아
183 | - 병렬 데이터셋: 다국어 유엔 말뭉치(MultiUN), 개방형 병렬 말뭉치(OPUS), IIT 봄베이 말뭉치 등의 여러 소스
184 |
185 | - BPE 사용
186 |
187 | - 언어 임베딩을 사용해서 해당 토큰이 어떤 언어인지 알려준다
188 |
189 |
190 |
191 | ### CLM
192 |
193 | - 인과 언어 모델링(CLM: Causal Language Modeling)
194 |
195 | - 이전 단어셋을 바탕으로 현재 단어의 확률 예측
196 |
197 |
198 |
199 | ### MLM
200 |
201 | - 마스크 언어 모델링(MLM: Masked Language Modeling)
202 |
203 | - BERT에서는 NSP를 위해 두 개의 문장 쌍을 입력했지만, XLM에서는 임의의 문장을 모델에 입력할 수 있다(총 토큰의 길이는 256)
204 | - 단어의 빈도수에 따라 샘플링 빈도가 달라진다(sqrt(1/빈도수)의 다항분포에서 샘플링)
205 |
206 |
207 |
208 | ### TLM
209 |
210 | - 번역 언어 모델링(TLM: Translation Language Modeling)
211 |
212 | - 서로 다른 두 언어/동일한 내용의 텍스트로 구성된 병렬 교차 언어 데이터를 이용
213 | - Masked token을 맞추는 것은 MLM과 동일하지만, 교차 언어 표현을 학습시키려는 의도
214 | - 마스크된 토큰을 맞추기 위해서 다른 언어의 표현을 이해할 수 있다(교차 언어 표현이 정렬(align)된다)
215 |
216 |
217 |
218 | ### XLM 사전 학습
219 |
220 | - CLM or MLM
221 | - 단일 언어 데이터셋
222 | - 총 256개의 토큰으로 된 임의의 문장
223 | - TLM + MLM
224 | - TLM의 경우 병렬 데이터셋 사용
225 |
226 |
227 |
228 | ### XLM 평가
229 |
230 | 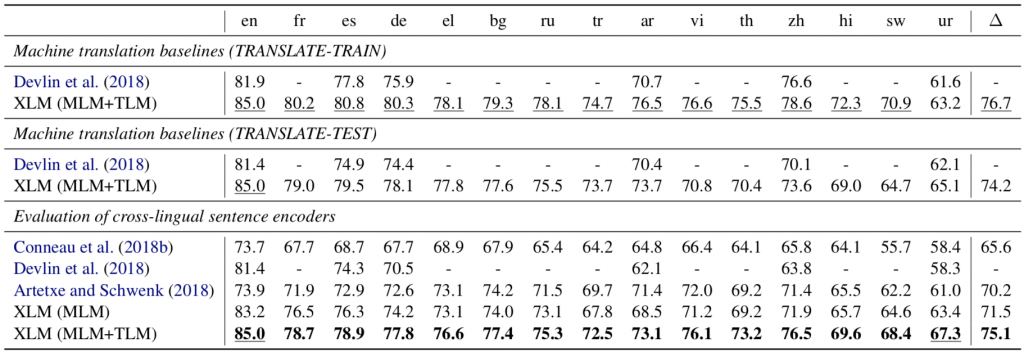
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 |
239 |
240 |
--------------------------------------------------------------------------------
/summaries/chapter07/chapter07_XLMR_multilingual.md:
--------------------------------------------------------------------------------
1 | # Chapter 7 다른 언어에 BERT 적용하기
2 |
3 | ## XLM-R 이해하기
4 |
5 | - XLM에서 몇 가지를 보완한 확장 버전
6 | - XLM-RoBERTa
7 | - 자료가 적은 언어의 경우 병렬 데이터셋을 구하는 것이 쉽지 않아 MLM만 학습
8 | - 커먼 크롤 데이터셋에서 별도 레이블이 없는 100개의 언어 텍스트를 필터링하여 얻은 2.5TB의 데이터셋으로 학습
9 | - 비중이 적은 언어는 oversampling
10 | - Common crawl이 Wikipedia에 비해 자료가 적은 언어에서 데이터가 더 많음
11 | - Sentencepiece Tokenizer, 25만 개의 Token
12 | - Model Architecture
13 | - XLM-R_base: 12개의 Encoder layers, 12개의 Attention heads, 768 Hidden size
14 | - XLM-R: 24개의 Encoder layers, 16개의 Attention heads, 1024 Hidden size
15 | - M-BERT와 XLM보다 더 뛰어난 성능
16 | - XLM-R의 교차 언어 분류 태스크로 모델을 평가
17 | - 15개의 서로 다른 XNLI 데이터셋으로 평가
18 | - 가장 낮은 점수인 스웨덴어에서 M-BERT 50.4% → XLM-R 73.9%
19 | - XLM-R의 평균 정확도가 80.9%로 다른 모델보다 비교적 높음
20 |
21 | ## 언어별 BERT
22 |
23 | - 여러 언어 대신 특정 단일 언어만 이용해 BERT 학습
24 |
25 | ### 프랑스어 FlauBERT
26 |
27 | - 사용 말뭉치: Wikipedia, 도서, 내부 크롤링, WMT19, OPUS(오픈 소스 병렬 코퍼스)의 프랑스어 텍스트 등의 24개
28 | - Moses Tokenizer: URL, 날짜 등을 포함한 특수 토큰 보존
29 | - 전처리 및 토큰화 후 BPE 사용, vocab building
30 | - 50,000개의 Token
31 | - MLM만 수행, Dynamic masking 사용
32 | - small-cased, base-uncased, base-cased, large-cased
33 | - HuggingFace에서 사용 가능
34 | - FLUE(French Language Understanding Evaluation)
35 | - CLS-FR
36 | - PAWS-X-FR
37 | - XNLI-FR
38 | - French Treebank
39 | - FrechSemEval
40 |
41 | ### 스페인어 BETO
42 |
43 | - WWM(Whole Word Masking) + MLM
44 | - POS, NER-C, MLDoc, PAWS-X, XNLI로 테스트
45 | - HuggingFace에서 사용 가능
46 |
47 | ```python
48 | from transformers import pipeline
49 |
50 | predict_mask = pipeline(
51 | "fill-mask",
52 | model = "dccuchile/bert-base-spanish-wwm-uncased",
53 | tokenizer = "dccuchile/bert-base-spanish-wwm-uncased"
54 | )
55 |
56 | result = predict_mask('[MASK] los caminos llevan a Roma')
57 | ```
58 |
59 | ### 네덜란드어 BERTje
60 |
61 | - WWM과 MLM 및 SOP를 동시에 진행
62 | - 사용 말뭉치: TwNC(네덜란드 뉴스 말뭉치), SoNAR-500(다중 장르 참조 말뭉치), 네덜란드 위키피디아 텍스트, 웹 뉴스 및 서적
63 | - 100만 번의 iteration으로 학습
64 | - HuggingFace에서 사용 가능
65 |
66 | ### 독일어 BERT
67 |
68 | - Cloud TPU v2에서 9일 동안 Wikipedia text, 뉴스, OpenLegalData
69 |
70 | ### 중국어 BERT
71 |
72 | - 12개의 Encoder layers, 12개의 Attention heads, 768개의 hidden unit, 110M
73 | - WWM + MLM
74 | - WWM을 사용해 pretrain → 하위 단어가 masking 되면 하위 단어를 포함하는 전체 단어를 마스킹
75 | - LTP(Language Technology Platform)를 사용
76 | - LTP는 단어 분할, 형태소 분석, 구문 분석을 수행하는데 사용
77 | - 중국어 단어 경계를 식별하는 데도 이용
78 |
79 | ### 일본어 BERT
80 |
81 | - 일본어 Wikipedia를 사용해 WWM으로 학습
82 | - MeCab으로 Tokenization → Wordpiece Tokenizer로 subword를 얻음
83 |
84 | ### 핀란드어 FinBERT
85 |
86 | - M-BERT보다 성능이 좋음
87 | - Wikipedia에서 핀란드 텍스트의 비중은 3%에 불과
88 | - FinBERT는 핀란드어 뉴스 기사, 온라인 토론 및 인터넷 크롤링 텍스트로 학습
89 | - FinBERT-cased, FinBERT-uncased
90 | - WWM을 이용해 MLM과 NSP로 Pretrained
91 |
92 | ### 이탈리아어 UmBERTo
93 |
94 | - RoBERTa 아키텍쳐를 따름
95 | - MLM Task시에 Dynamic Masking 사용
96 | - NSP 제거 MLM만 사용
97 | - 큰 batch size 사용
98 | - Byte-level BPE Tokenizer
99 | - RoBERTa에 Sentencepiece + WWM 사용
100 |
101 | ### 포르투갈어 BERTimbau
102 |
103 | - brWaC: 포르투갈어 대규모 오픈 소스 말뭉치
104 | - WWM + MLM 100만 iteration
105 |
106 | ### 러시아어 RuBERT
107 |
108 | - M-BERT에서 Knowledge Distillation
109 | - 학습 전에 Word Embedding을 제외하고 RuBERT의 변수를 M-BERT 모델의 변수로 초기화
110 | - 러시아어 Wikipedia text와 뉴스 기사를 사용해 학습
111 | - Subword NMT로 텍스트를 subword로 나누는 데 사용
112 | - RuBERT의 Subword vocab은 M-BERT의 vocab에 비해 더 길고 더 많은 러시아어롤 구성
113 | - M-BERT와 RuBERT 어휘 모두에서 나타나는 일반적인 단어는 M-BERT의 임베딩으로 직접 사용 가능
--------------------------------------------------------------------------------
/summaries/chapter08/S-BERT.md:
--------------------------------------------------------------------------------
1 | # Sentence-BERT 및 domain-BERT 살펴보기
2 |
3 | > Speaker: 남수연(@mori8)
4 | >
5 | > 회사에서 molrae 쓰는 중
6 |
7 | ## Sentence-BERT
8 |
9 | Sentence-BERT는 vanila BERT/RoBERTa를 fine-tuning하여 문장 임베딩 성능을 우수하게 개선한 모델이다. BERT/RoBERTa는 STS 태스크에서도 좋은 성능을 보여주었지만 매우 큰 연산 비용이 단점이었는데, Sentence-BERT는 학습하는 데 20분이 채 걸리지 않으면서 다른 문장 임베딩보다 좋은 성능을 자랑한다.
10 |
11 |
12 |
13 | ### 등장 배경
14 |
15 | **기존의 BERT로는 large-scale의 유사도 비교, 클러스터링, 정보 검색 등에 많은 시간 비용이 들어간다.**
16 |
17 | - BERT로 유사한 두 문장을 찾으려면 두 개의 문장을 한 개의 BERT 모델에 넣어야 유사도가 평가된다.
18 | - 따라서 문장이 10000개 있으면 10C2 번의 연산 후에 유사도 랭킹을 얻을 수 있다.
19 | - 클러스터링이나 검색에서는 각 문장을 벡터 공간에 매핑하는데, BERT를 이용할 때는 단어 표현을 평균내거나 `[CLS]` 토큰의 값을 이용하지만 이랬을 때의 결과는 각 단어의 GloVe 벡터를 평균낸 것보다 나쁘다.
20 |
21 |
22 |
23 | ## Sentence-BERT의 문장 임베딩
24 |
25 | 1. BERT의 `[CLS]` 토큰의 표현 벡터를 문장 표현으로 사용한다.
26 | 2. BERT의 모든 단어의 표현 벡터를 평균 풀링하여 만든 벡터를 문장 표현으로 사용한다.
27 | 3. BERT의 모든 단어의 표현 벡터를 최대 풀링하여 만든 벡터를 문장 표현으로 사용한다.
28 |
29 | Sentence-BERT(이후 SBERT로 표기)는 BERT의 출력에 풀링 연산을 추가한 모델이며, 풀링 방법은 `[CLS]` 토큰의 결과를 사용하는 방법, 모든 출력 벡터를 평균내어 사용, 출력 벡터의 max-over-time*을 계산해 사용하는 방법이 있다. 기본적으로 SBERT는 평균 풀링을 사용하며, 평균 풀링으로 문장 표현을 얻으면 이 표현은 본질적으로 모든 단어의 의미를 갖는다. 반면 최대 풀링으로 문장 표현을 얻을 경우 문장 표현은 본질적으로 중요한 단어의 의미를 갖는다.
30 |
31 | > Max-over-time pooling: 문장의 길이가 다 다르면 문장마다의 feature map 개수가 달라지는데, 모든 문장마다 하나의 값을 갖도록 feature map 벡터 중 가장 큰 값 하나만 사용하는 것
32 |
33 |
34 |
35 | ## Fine Tuning 전략: 문장 쌍 분류, 회귀 태스크
36 |
37 | 신체의 일부를 공유하는 샴 쌍둥이처럼, 샴 네트워크는 두 네트워크가 weight를 공유한다. SBERT는 동일한 사전 학습된 BERT 모델 2개를 사용하여 문장 1의 토큰은 한 BERT로, 문장 2의 토큰은 또 다른 BERT로 입력하고 주어진 문장의 표현을 계산한다. 두 문장을 `[SEP]`으로 구분하여 한 BERT 모델에 같이 집어넣는 게 아니라, 같은 가중치를 갖는 서로 다른 BERT 모델 2개에 각각 넣는 것이다.
38 |
39 |
40 |
41 | ## Objective Functions
42 |
43 | 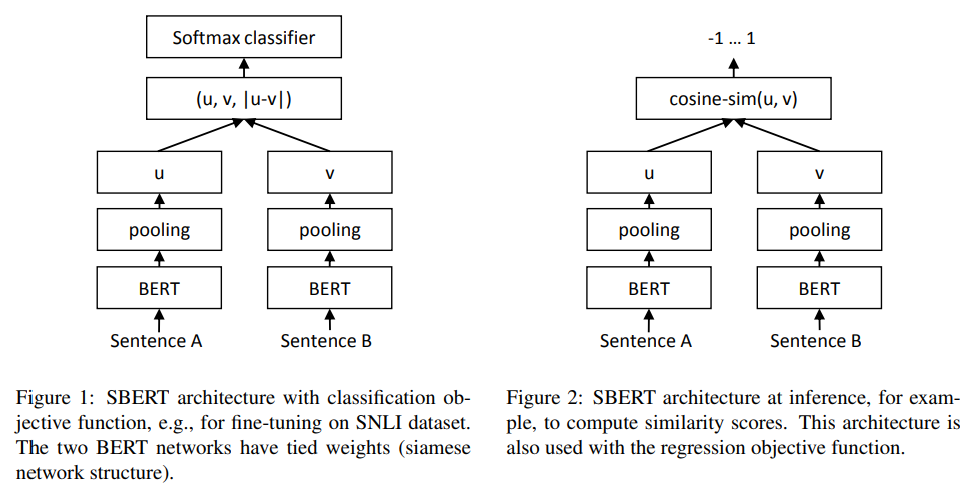
44 |
45 | SBERT 모델의 구조는 학습 데이터에 따라 다르다. 아래 구조에 따라 목적 함수와 모델 구조를 달리 하였다.
46 |
47 | - 두 문장의 출력값인 u, v 그리고 element-wise 차이값인 |u-v|를 concatenate한 후 파라미터를 추가하여 학습한다.
48 | - 실제 inference할 때나, regression 방식의 loss function을 쓸 때는 cosine-similarity를 이용한다. Training할 때, 계산된 cosine similarity와 gold label 간의 MSE를 minimize하는 방식으로 학습했다.
49 |
50 |
51 |
52 | ### Classification Objective Function
53 |
54 | 두 문장이 유사한지(1), 유사하지 않은지(0) 판단하는 태스크를 위한 모델이다. 두 문장 임베딩 *u*와 *v*를 그 차이 ∣*u*−*v*∣와 concat해 3*n* 차원의 텐서를 만들고, 이를 가중치 *W**t*∈R3*n*×*k*에 곱한다. 이를 softmax함수에 넣으면 *k*개 label에 대한 분류 작업이 가능해진다. loss는 cross-entropy로 설정했다.
55 |
56 | $$O=softmax(W_t(u,v,∣u−v∣))$$
57 |
58 |
59 |
60 | ### Regression Objective Function
61 |
62 | 회귀 태스크의 목표는 주어진 두 문장 사이의 의미 유사도를 예측하는 것이다. 두 문장의 임베딩($u$, $v$) 사이의 코사인 유사도를 계산한다.
63 |
64 |
65 |
66 | ### Triplet Objective Function
67 |
68 | #### Siamese, Triplet의 등장 배경: One-shot
69 |
70 | 조금의 데이터만으로도 학습할 수 있도록 하는 것이 `Few-shot`, 한 장의 사진만으로 학습하도록 하자는 게 `One-shot`
71 |
72 |
73 |
74 | $$max(∣∣s_a−s_p∣∣−∣∣s_a−s_n∣∣+ϵ,0)$$
75 |
76 | anchor/positive/negative 문장 *a*,*p*,*n*에 대해 triplet loss는 모델이 *a*와 *p* 사이 거리가 *a*와 *n*사이 거리보다 작게 하도록 학습시킨다. $s_x$는 문장 *x*의 임베딩이고, ∣∣⋅∣∣은 거리고, *ϵ*은 margin이다. margin은 *s**p*가 *s**n*보다 최소한 *ϵ*만큼 *s**a*에 가깝도록 하는 장치이다. 이 논문에서는 Euclidean 거리를 단위로 *ϵ*=1로 설정했다.
77 |
78 |
79 |
80 | ## Evaluation
81 |
82 | 
83 |
84 | - 보다시피 BERT의 output을 그대로 쓰는 건 성능이 별로다. InferSent* - GloVe보다 못한 걸 알 수 있다.
85 | - 제안된 siamese 네트워크 구조와 fine-tuning 메커니즘은 InferSent나 Universal Sentence Encoder를 유의미하게 앞서는 결과를 내었다. SBERT가 좋은 성적을 내지 못한 유일한 데이터셋은 SICK-R이다.
86 | - Universal Sentence Encoder는 뉴스, QA 페이지, 토론 포럼처럼 SICK-R 벤치마킹에 적합한 데이터셋에 학습되었다. 반면 SBERT는 위키피디아와 NLI 데이터에만 학습되었다.
87 | - SRoBERTa는 성능이 좋긴 한데, SBERT에 비해 큰 차이를 보이진 않았다.
88 |
89 | > InferSent는 siamse BiLSTM에 max pooling을 적용한 문장 임베딩 모델
90 |
91 |
92 |
93 | ## References
94 |
95 | - https://velog.io/@ysn003/%EB%85%BC%EB%AC%B8-Sentence-BERT-Sentence-Embeddings-using-Siamese-BERT-Networks
96 | - http://mlgalaxy.blogspot.com/2020/09/sentence-bert-sentence-embeddings-using.html
97 | - https://tyami.github.io/deep%20learning/Siamese-neural-networks/
98 |
--------------------------------------------------------------------------------
/summaries/chapter08/chapter08_domain-BERT.md:
--------------------------------------------------------------------------------
1 | # Chapter 8 sentence-BERT 및 domain-BERT 살펴보기
2 |
3 | ## 내용
4 |
5 | - sentence-BERT
6 | - 지식 증류로 다국어 임베딩 학습
7 | - domain-BERT (ClinicalBERT 및 BioBERT)
8 |
9 | ## 지식 증류를 이용한 다국어 임베딩 학습
10 |
11 | *Q. 영어 외의 다른 언어에는 어떻게 sentence-BERT를 사용할까?*
12 |
13 | *A. sentence-BERT에서 생성된 단일 언어 문장 임베딩을 **지식 증류**를 통해 다국어로 만들어 다양한 언어에 sentence-BERT를 적용할 수 있다.*
14 |
15 | sentence-BERT 지식 ➡︎ 다국어 모델 (e.g. XLM-R) ➡︎ 다국어 모델이 사전 학습된 sentence-BERT와 동일한 임베딩 형성
16 |
17 | 학생 모델 S로 계산한 소스 문장(s_j) 표현과 타깃 문장(t_j) 표현 모두 교사 모델 T로 계산한 소스 문장(s_j) 표현과 동일해지는 방향으로 다음 속성을 학습
18 |
19 | 1. 벡터 공간이 언어 간 정렬 i.e., 다른 언어의 같은 문장은 가까이 위치
20 | 2. 교사 모델 T로 계산한 소스 언어의 벡터 공간 특성을 채택하여 다른 언어로 전이
21 |
22 |
23 |
24 | 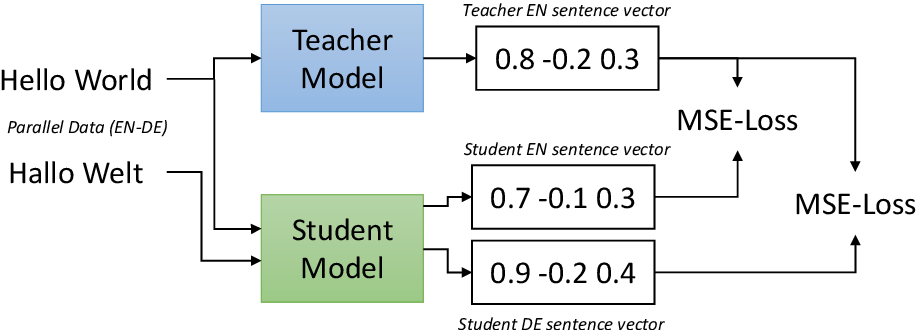
57 |
58 | ## TinyBERT 학습
59 |
60 | - General Distillation
61 | - Task-specific Distillation
62 |
63 | ### General Distillation
64 |
65 | - 사전 학습 단계를 의미
66 | - Large BERT를 Teacher로 사용하고 Student model에게 지식을 전달
67 | - 모든 layer에 증류 적용
68 | - 증류 후 Student BERT는 Teacher의 지식으로 구성, 사전 학습된 Student BERT를 General TinyBERT라고 부름
69 | - Downstream task를 위해 General TinyBERT를 Fine-tuning 할 수 있음
70 |
71 | ### Task-specific Distillation
72 |
73 | - Fine-tuning
74 | - 특정 Task를 위해 General TinyBERT를 Fine-tuning
75 | - Teacher model을 먼저 Fine-tuning, 다시 General TinyBERT로 Distillation 진행
76 | - Fine-tuning 단계에서 Distillation을 하려면 더 많은 dataset 필요 → Data Augmentation
77 |
78 | ### Data Augmentation
79 |
80 | Tokenized sentence X의 각각 모든 단어에 대해,
81 |
82 | 1. X[i]가 단일 단어인지 확인. 단일 단어라면 [MASK] 토큰으로 masking. BERT-base로 masked token을 예측. 확률이 높은 상위 K개의 단어 candidates에 저장
83 | 2. X[i]가 단일 단어가 아니면 masking 하지 않음. GloVe Embedding을 사용해 X[i]와 가장 유사한 K 단어 확인하고 candidates에 저장. p~Uniform(0,1)에서 값 p를 무작위로 추출하고, threshold를 p_t = 0.4로 설정
84 | 3. p가 p_t보다 작거나 같으면 X_masked[i]를 후보 목록의 임의 단어로 교체
85 | 4. p가 p_t보다 크면 교체 안함
86 |
87 | - N번 반복하면 N개의 Augmented sentence가 생성
88 | - Augmented Data를 사용하여 General TinyBERT를 Fine-tuning
89 | - TinyBERT는 BERT-base 모델보다,
90 | - 96%의 추론 효율 향상
91 | - 7.5배 작음
92 | - 9.4배 빠름
93 |
94 | ## BERT에서 신경망으로 지식 전달
95 |
96 | - BERT에서 간단한 신경망으로 Distillation이 가능할까?
97 | - Teacher model - Pretrained BERT(여기서는 BERT-large)
98 | - Teacher model을 Downstream task에 맞게 fine-tuning
99 | - Student model - Bi-LSTM
100 | - Bi-LSTM은 양방향으로 문장을 읽음
101 | - 순방향, 역방향 hidden state를 FFN에 넣고 logit 출력
102 | - softmax → 확률
103 |
104 | ### Student network training
105 |
106 | - 일단 Teacher부터 Fine-tuning
107 | - L = a * L_student + b * L_distillation
108 | - L_distillation = MSE(Z^T, Z^S) → Soft target, Soft prediction에 대한 MSE
109 | - L_student: Hard target, Hard prediction에 대한 cross-entropy
110 | - Teacher BERT에서 Student Network로 KD를 수행하려면 큰 데이터셋 필요
111 | - Task-agnostic Data Augmentation
112 |
113 | ## Data Augmentation
114 |
115 | - Masking
116 | - POS based word replacement
117 | - n-gram sampling
118 |
119 | ### Masking
120 |
121 | - TinyBERT의 DA 방법
122 |
123 | ### POS based word replacement
124 |
125 | - p_pos 확률로 문장의 한 단어를 같은 품사 다른 단어로 대체
126 |
127 | ### n-gram Sampling
128 |
129 | - p_ng 확률로 문장에서 n-gram을 random sampling
130 | - n은 1~5까지 무작위
131 |
132 | ### Data Augmentation Process
133 |
134 | - X_i ~ Uniform(0,1)
135 | - X_i < p_mask이면 w_i 단어를 masking
136 | - p_mask ≤ X_i p_mask + p_pos이면 POS word replacement를 진행
137 | - Masking과 POS based WR은 겹치지 않음. 둘 중 하나만 적용 가능
138 | - 이 단계 이후, p_ng 확률로 n-gram sampling
139 | - N번 수행 → N개의 새로운 Augmented data
140 |
141 | 문장이 아니라 문장 쌍이라면?
142 |
143 | - 문장 1 합성 + 문장 2 유지
144 | - 문장 1 유지 + 문장 2 합성
145 | - 문장 1 합성 + 문장 2 합성
146 |
147 | 이런 식으로 Augmentation 가능
--------------------------------------------------------------------------------
/summaries/chapter06/chapter06_텍스트_요약을_위한_BERTSUM_탐색_(1).md:
--------------------------------------------------------------------------------
1 | # Chapter 6: 텍스트 요약을 위한 BERTSUM 탐색
2 |
3 | > Speaker: 남수연
4 |
5 |
6 | # 텍스트 요약
7 |
8 | NLP 분야의 주요 연구 분야 중 하나로, 주어진 긴 텍스트를 요약하는 것. 긴 문서, 뉴스 기사, 법률 문서, 블로그 게시물 등 다양한 영역에서 널리 사용됨.
9 |
10 | # 텍스트 요약 방식 이해하기
11 |
12 | 아래와 같은 텍스트를 요약해야 한다고 해보자.
13 |
14 | ```
15 | 나는 어제 신촌에서 동아리 운영진 동기 언니와 10시간 내내 먹었다. 점심으로
16 | 진돈부리를 가려고 했지만 딱 어제 휴업하는 바람에 반서울에 갔는데 엄청 맛있었다.
17 | 다음에 또 와야겠다고 생각했다. 후식으로 파이홀에 가서 오레오말차가나슈파이와 얼그
18 | 레이가나슈파이를 먹었다. 역시 다음에 또 와야겠다고 생각했다. 저녁으로 돈우마미에
19 | 가서 사케동을 먹었다. 가라아게 4조각을 시켰는데 서비스로 한 조각을 더 주셔서
20 | 돈우마미는 참 좋은 가게라는 생각이 들었다. 마지막으로 아워즈에 가서 칵테일을 조
21 | 졌다. 줄리엣이라는 칵테일을 주문했는데 요맘때 복숭아맛과 딸기맛을 섞어놓은 것 같은
22 | 것이 정말 정말 맛있었다. 정신을 차려보니 9시 30분이어서 허겁지겁 버스를 타고
23 | 집에 왔더니 월요일이 스터디 하는 날이랜다. 어이가 없어서 헛웃음이 나왔지만 지금
24 | 웃을 때가 아니므로 열심히 스터디 준비를 하는 중이다.
25 | ```
26 |
27 | ## 추출 요약
28 |
29 | 주어진 텍스트 안에서 중요한 문장만 추출해 요약한다. 입력의 문장 중 중요도가 높은 순으로 N개의 문장을 뽑는 식이다.
30 |
31 | ```
32 | 나는 어제 신촌에서 동아리 운영진 동기 언니와 10시간 내내 먹었다. 점심으로
33 | 진돈부리를 가려고 했는데 딱 어제만 휴업하는 바람에 반서울에 갔는데 엄청 맛있
34 | 었다. 후식으로 파이홀에 가서 오레오말차가나슈 파이와 얼그레이가나슈파이를 먹었다.
35 | 마지막으로 아워즈에 가서 칵테일을 조졌다. 어이가 없어서 헛웃음이 나왔지만 지금
36 | 웃을 때가 아니므로 열심히 스터디 준비를 하는 중이다.
37 | ```
38 |
39 | ## 생성 요약
40 |
41 | 주어진 텍스트를 의역해서 원래 문서에 포함되지 않은 문장으로 요약을 만든다.
42 |
43 | ```
44 | 어제의 나는 동아리 언니와 10시간동안 쉬지 않고 먹었다. 정신을 차려보니 발등에
45 | 불이 떨어진 상태여서 열심히 스터디 준비를 하는 중이다.
46 | ```
47 |
48 | ## Summary
49 |
50 | | | 추출 요약 | 생성 요약 |
51 | | --- | --- | --- |
52 | | 입력 문장을 그대로 사용하는가? | O | X |
53 | | 정보 누락 정도 | 많음 | 적음 |
54 | | 컴퓨팅 리소스 필요량 | 적음 | 많음 |
55 | | 학습 시간 필요량 | 적음 | 많음 |
56 |
57 | # 텍스트 요약에 맞춘 BERT 파인 튜닝
58 |
59 | ## BERT을 활용한 추출 요약
60 |
61 | 사전학습된 BERT를 사용해 추출 요약 태스크를 진행하려면 BERT 모델 입력 데이터 형태를 수정해야 한다. BERT 모델의 입력 데이터를 수정하여 각 문장의 표현을 얻는 방법에 대해 알아보자.
62 |
63 | - BERT 복습
64 | 1. 입력 문장을 토큰 형태로 변경한다.
65 | 2. 첫 문장의 시작 부분에만 `[CLS]` 토큰을 모든 문장의 마지막 부분에 `[SEP]` 토큰을 추가한다.
66 | 3. 입력 토큰을 토큰 임베딩, 세그먼트 임베딩, 위치 임베딩, 총 3개의 임베딩 레이어 형태로 각각 변환한다.
67 | 4. 모든 임베딩을 더한 다음 BERT에 입력한다.
68 | 5. BERT는 아웃풋으로 모든 토큰의 표현 벡터를 출력한다.
69 |
70 |
71 |
72 | ### 1) 토큰 임베딩
73 |
74 | 텍스트 요약 태스크에서는 BERT 모델에 여러 문장을 입력하고 입력한 모든 문장에 대한 표현이 필요하다. **모든 문장의 시작 부분에 `[CLS]` 토큰을 추가**하면 모든 문장에 대한 표현을 얻을 수 있다. 이 `[CLS]` 토큰은 각 문장을 대표하는 토큰으로서 문장의 특징을 뽑아낼 때 사용할 것이다.
75 |
76 | ```python
77 | input = ["[CLS]", "ban", "seoul", "[SEP]", "[CLS]", "pie", "hole", "[SEP]", "[CLS]", "don", "umami", "[SEP]"]
78 | ```
79 |
80 | ### 2) 세그먼트 임베딩
81 |
82 | 세그먼트 임베딩은 입력을 $E_A, E_B$ 형태로 반환한다. 그보다 훨씬 많은 수의 문장이 입력으로 들어오는 텍스트 요약 태스크에서는 $E_A, E_B$ 만으로 어떻게 문장을 구분할 수 있을까?
83 |
84 | 인터벌 세그먼트 임베딩을 통해 홀수번째 문장에서 발생한 토큰은 $E_A$, 짝수번째 문장에서 발생한 토큰은 $E_B$에 매핑한다. 한 문장을 앞뒤의 문장들과 구분하기만 하면 되므로 이런 방법을 사용할 수 있다.
85 |
86 | ### 3) 위치 임베딩
87 |
88 | 위치 임베딩은 모든 토큰의 위치 정보에 대한 임베딩값으로, 기존 방식과 동일하다.
89 |
90 | ## BERTSUM
91 |
92 | 
93 |
94 | BERT 모델을 사용해 입력 데이터 형식을 변경해서 텍스트 요약에 특화되도록 만든 모델을 BERTSUM이라고 한다. 처음부터 BERT를 학습시킬 필요는 없으며, 이미 사전학습된 BERT 모델에 앞서 설명한 입력 데이터 형태로 변경하여 파인 튜닝하면 된다.
95 |
96 | ### 1) 분류기가 있는 BERTSUM
97 |
98 |
99 | **모든 문장의 표현을 받아서 각 문장의 중요도를 판단하는 분류기 레이어**를 ****BERT에 이어붙인다. 분류기는 각 문장을 요약에 포함시킬지 여부에 대한 확률을 제공한다. Linear Layer 하나만 사용하며, BERT의 아웃풋을 분류기 레이어에 넣어 나온 값에 sigmoid 활성화 함수를 취한 값을 target으로 활용한다. 이렇게 계산된 target과 정답을 BCE를 통해 loss를 계산한다. loss 값을 최소화하도록 BERT 모델과 분류기 레이어를 함께 학습시킨다.
100 |
101 | $$
102 | \hat{Y} = \sigma(W_oT_i + b_o)
103 | $$
104 |
105 | ### 2) 🌟 트랜스포머와 LSTM을 활용한 BERTSUM
106 |
107 | **(1) 문장 간 트랜스포머(inter-sentence transformer)를 활용한 BERTSUM**
108 |
109 | 논문에 따르면 다른 2개의 Summarization layer보다 훨씬 좋은 결과를 보여주는 방법이다. BERT의 결과인 문장 표현 $R$을 트랜스포머 레이어에 입력한다. 트랜스포머는 BERT에서 얻은 표현을 가져와 은닉 상태로 변환하는데, 이 때 도입되는 트랜스포머는 문장 간 Attention을 계산하고 문장 단위가 아닌 전체 문서 관점에서 요약 태스크를 수행한다.
110 |
111 | BERT에서 얻은 문장 표현 R에 위치 임베딩 값을 추가하여 트랜스포머의 인코더에 입력한다($h^0=PosEmb(R)$) . 인코더 $l$에서 서브레이어는 다음과 같이 표현한다.
112 |
113 | 
114 |
115 | 최상위 인코더를 $L$, 최상위 인코더에서 나온 은닉 상태를 $h^L$이라고 했을 때 문장의 포함 여부를 계산하는 식은 다음과 같다.
116 |
117 | 
118 |
119 | **(2) LSTM을 활용한 BERTSUM**
120 |
121 | BERT의 last hidden layer에 RNN을 활용하면 성능이 좋을 수 있다는 논문을 참고하여 실험을 진행했으며, 훈련 과정을 안정화하기 위해 단순 LSTM이 아닌 pergate layer nomarlization을 사용했다.
122 |
123 | BERT에서 얻은 문장 $i$에 대한 표현 $R_i$를 LSTM에 입력하면 LSTM 셀은 은닉 상태 $h_i$를 출력한다. sigmoid에 $h_i$를 입력하면 각 문장을 요약에 포함시킬지에 대한 확률을 반환한다.
124 |
125 | 
126 |
127 | ### 참고: summarization layers에 대한 ROUGE 성능 평가
128 |
129 | 
130 |
131 | # References
132 |
133 | [[논문 리뷰] Fine-tune BERT for Extractive Summarization](https://medium.com/@eyfydsyd97/bert%EB%A5%BC-%ED%99%9C%EC%9A%A9%ED%95%9C-%ED%85%8D%EC%8A%A4%ED%8A%B8-%EC%9A%94%EC%95%BD-text-summary-b582b5cc7d)
134 |
135 | [BERT를 활용한 한국어 문서 추출요약 봇](https://velog.io/@raqoon886/KorBertSum-SummaryBot)
136 |
--------------------------------------------------------------------------------
/summaries/chapter06/chapter6_BERTSUM(2)_0hee0.md:
--------------------------------------------------------------------------------
1 | # Chapter 6 텍스트 요약을 위한 BERTSUM 탐색
2 |
3 | BERTSUM: 텍스트 요약에 맞춰 파인 튜닝된 BERT 모델
4 |
5 | ## BERTSUM 모델의 성능
6 |
7 | BERTSUM 모델의 성능은 ROUGE 점수를 사용하여 평가
8 |
9 | ### ROUGE 평가 지표
10 |
11 | **ROUGE(Recall-oriented Understudy for Gisting Evalutation)**
12 |
13 | - 텍스트 요약과 기계 번역 태스크를 평가하는 데 사용하는 평가 지표
14 | - 「[ROUGE: A Package for Automatic Evaluation of Summaries](https://aclanthology.org/W04-1013/)」
15 |
16 | ROUGE의 다섯 가지 평가 지표 형태
17 |
18 | - ROUGE-N
19 | - ROUGE-L
20 | - ROUGE-W
21 | - ROUGE-S
22 | - ROUGE-SU
23 |
24 | *Cf. [ROUGE-an Evaluation Metric for Text Summarization](https://ilmoirfan.com/rouge-an-evaluation-metric-for-text-summarization/)*
25 |
26 | #### ROUGE-N
27 |
28 | 후보 요약(예측한 요약)과 참조 요약(실제 요약) 간의 n-gram 재현율(recall)
29 |
30 | ```
31 | 재현율 = (예측한 요약 결과와 실제 요약 사이의 서로 겹치는 n-gram 총 수) / (실제 요약의 n-gram의 총 수)
32 | ```
33 |
34 | *ROUGE-1(uni-gram)과 ROUGE-2(bi-gram)가 가장 많이 쓰인다.*
35 |
36 | #### ROUGE-L
37 |
38 | **가장 긴 공통 하위 시퀀스(LCS)**를 기반으로 하며, F-measure를 사용해 측정
39 |
40 | ### BERTSUM을 사용한 요약 태스크의 ROUGE 점수
41 |
42 | - 분류기, 트랜스포머, LSTM을 BERT에 적용한 BERTSUM 모델을 사용한 **추출 요약** 태스크의 ROUGE 점수
43 |
44 | *[Yang Liu. 2019. Fine-tune BERT for Extractive Summarization](https://arxiv.org/abs/1903.10318) 에서 CNN/DailyMail 테스트 데이터를 이용해 측정한 결과 (25/3/2019)*
45 |
46 | *Cf. https://github.com/nlpyang/BertSum*
47 |
48 | | 모델 | ROUGE-1 | ROUGE-2 | ROUGE-L |
49 | | :---------------------: | :-------: | :-------: | :-------: |
50 | | Transformer Baseline | 40.9 | 18.02 | 37.17 |
51 | | BERTSUM+classifier | 43.23 | 20.22 | 39.60 |
52 | | **BERTSUM+transformer** | **43.25** | **20.24** | **39.63** |
53 | | BERTSUM+LSTM | 43.22 | 20.17 | 39.59 |
54 |
55 | - BERTSUMABS 모델로 **생성 요약** 태스크를 수행했을 때의 ROUGE 점수
56 |
57 | *[Yang Liu, Mirella Lapata. 2019. Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345) 에서 CNN/DailyMail 테스트 데이터를 이용해 측정한 결과 (20/8/2019)*
58 |
59 | *Cf. https://github.com/nlpyang/PreSumm*
60 |
61 | | 모델 | ROUGE-1 | ROUGE-2 | ROUGE-L |
62 | | :--------: | :-----: | :-----: | :-----: |
63 | | BERTSUMABS | 41.72 | 19.39 | 38.76 |
64 |
65 | ## BERTSUM 모델 학습
66 |
67 | ```python
68 | # Google Colab / Python 3.x / GPU
69 |
70 | %%capture
71 | !pip install pytorch_pretrained_bert
72 | !pip install torch==1.1.0 pytorch_transformers tensorboardX multiprocess pyrouge
73 | !pip install googleDriveFileDownloader
74 |
75 | cd /content/
76 |
77 | # BERTSUM 연구원들이 오픈 소스로 제공한 학습 코드
78 | !git clone https://github.com/nlpyang/BertSum.git
79 |
80 | # 데이터셋 다운로드 (전처리된 CNN/DailyMail 뉴스 데이터)
81 | cd /content/BertSum/bert_data/
82 | ### 다운로드 및 압축 해제 ###
83 |
84 | # BERTSUM 모델 학습
85 | cd /content/BertSum/src
86 |
87 | '''
88 | First run: For the first time, you should use single-GPU, so the code can download the BERT model. Change -visible_gpus 0,1,2 -gpu_ranks 0,1,2 -world_size 3 to -visible_gpus 0 -gpu_ranks 0 -world_size 1, after downloading, you could kill the process and rerun the code with multi-GPUs.
89 | '''
90 |
91 | # BERTSUM + classifier (number of parameters: 109483009)
92 | !python train.py -mode train -encoder classifier -dropout 0.1 -bert_data_path ../bert_data/cnndm -model_path ../models/bert_classifier -lr 2e-3 -visible_gpus 0 -gpu_ranks 0 -world_size 1 -report_every 50 -save_checkpoint_steps 1000 -batch_size 3000 -decay_method noam -train_steps 50 -accum_count 2 -log_file ../logs/bert_classifier -use_interval true -warmup_steps 10000
93 |
94 | # BERTSUM + transformer (* number of parameters: 120512513)
95 | !python train.py -mode train -encoder transformer -dropout 0.1 -bert_data_path ../bert_data/cnndm -model_path ../models/bert_transformer -lr 2e-3 -visible_gpus 0 -gpu_ranks 0 -world_size 1 -report_every 50 -save_checkpoint_steps 1000 -batch_size 3000 -decay_method noam -train_steps 50 -accum_count 2 -log_file ../logs/bert_transformer -use_interval true -warmup_steps 10000 -ff_size 2048 -inter_layers 2 -heads 8
96 |
97 | # BERTSUM + lstm (* number of parameters: 113041921)
98 | !python train.py -mode train -encoder rnn -dropout 0.1 -bert_data_path ../bert_data/cnndm -model_path ../models/bert_rnn -lr 2e-3 -visible_gpus 0 -gpu_ranks 0 -world_size 1 -report_every 50 -save_checkpoint_steps 1000 -batch_size 3000 -decay_method noam -train_steps 50 -accum_count 2 -log_file ../logs/bert_rnn -use_interval true -warmup_steps 10000 -rnn_size 768 -dropout 0.1
99 | ```
100 |
101 | ```
102 | usage: train.py [-h] [-encoder {classifier,transformer,rnn,baseline}]
103 | [-mode {train,validate,test}] [-bert_data_path BERT_DATA_PATH]
104 | [-model_path MODEL_PATH] [-result_path RESULT_PATH]
105 | [-temp_dir TEMP_DIR] [-bert_config_path BERT_CONFIG_PATH]
106 | [-batch_size BATCH_SIZE] [-use_interval [USE_INTERVAL]]
107 | [-hidden_size HIDDEN_SIZE] [-ff_size FF_SIZE] [-heads HEADS]
108 | [-inter_layers INTER_LAYERS] [-rnn_size RNN_SIZE]
109 | [-param_init PARAM_INIT]
110 | [-param_init_glorot [PARAM_INIT_GLOROT]] [-dropout DROPOUT]
111 | [-optim OPTIM] [-lr LR] [-beßta1 BETA1] [-beta2 BETA2]
112 | [-decay_method DECAY_METHOD] [-warmup_steps WARMUP_STEPS]
113 | [-max_grad_norm MAX_GRAD_NORM]
114 | [-save_checkpoint_steps SAVE_CHECKPOINT_STEPS]
115 | [-accum_count ACCUM_COUNT] [-world_size WORLD_SIZE]
116 | [-report_every REPORT_EVERY] [-train_steps TRAIN_STEPS]
117 | [-recall_eval [RECALL_EVAL]] [-visible_gpus VISIBLE_GPUS]
118 | [-gpu_ranks GPU_RANKS] [-log_file LOG_FILE] [-dataset DATASET]
119 | [-seed SEED] [-test_all [TEST_ALL]] [-test_from TEST_FROM]
120 | [-train_from TRAIN_FROM] [-report_rouge [REPORT_ROUGE]]
121 | [-block_trigram [BLOCK_TRIGRAM]]
122 | ```
123 |
124 | ## 참고 자료
125 |
126 | - 구글 BERT의 정석 [book](http://www.yes24.com/Product/Goods/104491152)
127 | - [Fine-tune BERT for Extractive Summarization (BERTSUM) github repository](https://github.com/nlpyang/BertSum)
128 | - [ROUGE-an Evaluation Metric for Text Summarization](https://ilmoirfan.com/rouge-an-evaluation-metric-for-text-summarization/)
129 |
130 |
--------------------------------------------------------------------------------
/summaries/chapter07/chapter07_M-BERT.md:
--------------------------------------------------------------------------------
1 | # Chapter 7. 다른 언어에 BERT 적용하기
2 |
3 | BERT를 영어가 아닌 다른 언어에도 적용할 수 있을까? 아래 모델을 통해서 BERT를 통해 다국어 표현을 어떻게 얻을 수 있는지 알아보자.
4 |
5 | - M-BERT(multilingual-BERT)
6 | - XLM(cross-lingual language model)
7 | - XLM-R(XLM-RoBERTa)
8 |
9 |
10 |
11 | ## M-BERT 이해하기
12 |
13 | **BERT**
14 |
15 | - Datasets: 영어 위키피디아, 토론토 책 말뭉치
16 | - PreTrain Task: MLM, NSP
17 |
18 | **M-BERT**
19 |
20 | - Datasets: 104개 언어 위키피디아
21 | - 각 언어들간의 비중이 다르다 -> overfitting을 방지하기 위해 언어별 under/over sampling 적용
22 | - 104개 언어, 11만개의 워드피스(BPE와 유사하지만 likelihood 사용하는 인코딩)
23 | - PreTrain Task: MLM, NSP
24 |
25 |
26 |
27 | M-BERT는 교차 언어를 고려하지 않고도 다른 언어들의 표현을 이해할 수 있다.
28 |
29 |
30 |
31 | ### NLI task 평가로 알아보는 M-BERT 평가하기
32 |
33 | - 두 문장(가설, 전제)을 바탕으로, 가설이 주어진 전제에 따라 진실/거짓/중립 여부를 판단하는 것
34 | - 일반적으로 SNLI(Stanford natural language inference) datasets 사용
35 | - 다국어 NLI 평가를 위해서는 교차 언어 자연어 추론(XNLI: cross-linugal NLI)사용
36 | - MultiNLI 말뭉치에서 약 43만개의 영어 문장 쌍을 사용
37 | - 평가셋을 위해 7,500개의 문장 쌍을 사용하며, 이를 15개의 서로 다른 언어로 번역하여 11만개의 문장 쌍을 사용
38 |
39 |
40 |
41 | 다양한 설정에서 NLI task를 수행해 M-BERT를 평가한다.
42 |
43 | #### 제로샷(zero-shot)
44 |
45 | - Fine-tuning: 영어 학습셋
46 | - Validation: 모든 언어 테스트셋
47 | - 영어로 학습하고 모든 언어로 평가
48 | - M-BERT의 교차 언어 능력을 이해하는데 도움
49 |
50 |
51 |
52 | #### 번역-테스트(Translate-Test)
53 |
54 | - Fine-tuning: 영어 학습셋
55 | - Validation: 영어로 번역된 테스트셋
56 | - 영어로 학습하고 영어로 평가
57 |
58 |
59 |
60 | #### 번역-학습(Translate-Train)
61 |
62 | - Fine-tuning: 영어에서 다른 언어로 번역된 학습셋
63 | - Validation: 모든 언어 테스트셋
64 | - 다른 언어로 학습하고 모든 언어로 평가
65 |
66 |
67 |
68 | #### 번역-학습-모두(Translate-Train-All)
69 |
70 | - Fine-tuning: 영어에서 다른 **모든 언어**로 번역된 학습셋
71 | - Validation: 모든 언어 테스트셋
72 | - 모든 언어로 학습하고 모든 언어로 평가
73 |
74 |
75 |
76 | | 모델 | 설정 | 영어 | 중국어 | 스페인어 | 독일어 | 아랍어 | 우루드어 |
77 | | ------------ | --------------- | ---- | ------ | -------- | ------ | ------ | -------- |
78 | | BERT-cased | Translate-Train | 81.9 | 76.6 | 77.8 | 75.9 | 70.7 | 61.6 |
79 | | BERT-uncased | Translate-Train | 81.4 | 74.2 | 77.3 | 75.2 | 70.5 | 61.7 |
80 | | BERT-uncased | Translate-Test | 81.4 | 70.1 | 74.9 | 74.4 | 70.4 | 62.1 |
81 | | BERT-uncased | Zero-shot | 81.4 | 74.3 | 74.3 | 70.3 | 60.1 | 58.3 |
82 |
83 | > M-BERT 모델은 제로샷을 포함해 모든 조건에서 좋은 성능을 보여준다.
84 |
85 |
86 |
87 | ### M-BERT는 다국어 표현이 어떻게 가능한가??
88 |
89 | 다른 언어들을 다 섞어서 학습한 것 뿐인데 어떻게 다국어 표현이 가능한 건지?
90 |
91 |
92 |
93 | #### 어휘 중복 효과?
94 |
95 | - 언어 간에 중복되는 어휘 때문??
96 |
97 | - overlap으로 파인튜닝 언어/평가 언어 간에 겹치는 워드피스 토큰 계산
98 | $$
99 | \left| \dfrac{E_{train}\cap E_{eva1}}{E_{train}\cup E_{era1}}\right|
100 | $$
101 |
102 | - 16개의 모든 언어 쌍에 대해 제로샷 F1 score를 계산한 결과 어휘 중복(overlap)이 적을 때에도 제로샷 F1이 높았음
103 |
104 | > zeroshot 지식 전이는 어휘 중복에 영향을 받지 않는다
105 | >
106 | > M-BERT가 다른 언어와의 관계성을 고려해 일반화를 잘 한다 = 단순한 어휘 암기가 아니라 다국어 표현을 더 깊게 학습한다
107 |
108 |
109 |
110 | #### 스크립트에 대한 일반화?
111 |
112 | - 서로 다른 스크립트를 따르는 언어들 사이에서도 일반화가 잘 될까?
113 |
114 | > 일부 언어 쌍의 스크립트에서는 일반화가 잘 되지만, 모든 언어에서 적용되지는 않는다.
115 |
116 |
117 |
118 | #### 유형학적 특징에 대한 일반화?
119 |
120 | - 주어, 동사, 목적어 등의 단어 순서가 다른 언어들 사이에서도 일반화가 잘 될까?
121 |
122 | > M-BERT의 zeroshot 전이는 단어 순서가 동일한 언어에서 더 잘 작동한다.
123 | >
124 | > M-BERT의 일반화 능력은 언어 간의 유형학적 유사성에 따라 달라진다 = M-BERT가 체계적인 변환을 학습하는 것은 아님
125 |
126 |
127 |
128 | #### 언어 유사성의 효과?
129 |
130 | - WALS: 문법, 어휘 및 음운 속성과 같은 언어의 구조적 속성을 포함하는 대규모 데이터베이스
131 | - WALS 공통 특징 수가 많을 수록 제로샷 정확도가 높은 경향
132 |
133 | > M-BERT는 유사한 언어 구조를 공유하는 언어 사이에서 더 잘 일반화된다
134 |
135 |
136 |
137 | #### 코드 스위칭과 음차의 효과?
138 |
139 | **코드 스위칭**
140 |
141 | - 다른 언어를 혼합하거나 교대로 사용하는 것
142 | - ex) Korean은 굉장히 kind하고 polite한 것 같아.
143 |
144 | **음차**
145 |
146 | - 발음하는 그대로 쓴거
147 | - ex) 코리안은 굉장히 카인드하고 폴라이트한 것 같아.
148 |
149 |
150 |
151 | M-BERT에서 코드 스위칭과 음차를 어떻게 다룰까?
152 |
153 | - 코드 스위칭된 힌디어/영어 UD 말뭉치를 사용
154 | - 음차: 힌디어 텍스트는 라틴 문자로 작성된다.
155 | - 코드 스위칭: 라틴어의 힌디어 텍스트가 데바나가리어 스크립트로 변환되어 재작성된다.
156 |
157 | | 말뭉치 | 평가셋 | 정확도 |
158 | | ------------------------ | ----------- | ------ |
159 | | 음차 | 음차 | 85.64 |
160 | | 단일 언어(영어 + 힌디어) | 음차 | 50.41 |
161 | | 코드 스위칭 | 코드 스위칭 | 90.56 |
162 | | 단일 언어(영어 + 힌디어) | 코드 스위칭 | 86.59 |
163 |
164 | > M-BERT는 음차 텍스트와 비교해 코드 스위칭 텍스트에서 수행 능력이 좋다
165 |
166 |
167 |
168 | #### 결론
169 |
170 | - M-BERT의 일반화 가능성은 어휘 중복에 의존하지 않는다.
171 | - M-BERT의 일반화 가능성은 유형학 및 언어 유사성에 따라 다르다.
172 | - M-BERT는 코드 스위칭 텍스트를 처리할 수 있지만 음차 텍스트는 처리할 수 없다.
173 |
174 |
175 |
176 | ## XLM
177 |
178 | - 다국어를 목표로 BERT를 사전학습 시킨 모델로 M-BERT보다 다국어 표현 학습을 할 때 성능이 더 뛰어나다
179 |
180 | - 단일 언어 / 병렬 데이터셋을 사용해 사전 학습된다
181 | - 병렬 데이터셋: 언어 쌍의 텍스트(2개의 다른 언어로 된 동일한 텍스트)
182 | - 단일 언어 데이터셋: 위키피디아
183 | - 병렬 데이터셋: 다국어 유엔 말뭉치(MultiUN), 개방형 병렬 말뭉치(OPUS), IIT 봄베이 말뭉치 등의 여러 소스
184 |
185 | - BPE 사용
186 |
187 | - 언어 임베딩을 사용해서 해당 토큰이 어떤 언어인지 알려준다
188 |
189 |
190 |
191 | ### CLM
192 |
193 | - 인과 언어 모델링(CLM: Causal Language Modeling)
194 |
195 | - 이전 단어셋을 바탕으로 현재 단어의 확률 예측
196 |
197 |
198 |
199 | ### MLM
200 |
201 | - 마스크 언어 모델링(MLM: Masked Language Modeling)
202 |
203 | - BERT에서는 NSP를 위해 두 개의 문장 쌍을 입력했지만, XLM에서는 임의의 문장을 모델에 입력할 수 있다(총 토큰의 길이는 256)
204 | - 단어의 빈도수에 따라 샘플링 빈도가 달라진다(sqrt(1/빈도수)의 다항분포에서 샘플링)
205 |
206 |
207 |
208 | ### TLM
209 |
210 | - 번역 언어 모델링(TLM: Translation Language Modeling)
211 |
212 | - 서로 다른 두 언어/동일한 내용의 텍스트로 구성된 병렬 교차 언어 데이터를 이용
213 | - Masked token을 맞추는 것은 MLM과 동일하지만, 교차 언어 표현을 학습시키려는 의도
214 | - 마스크된 토큰을 맞추기 위해서 다른 언어의 표현을 이해할 수 있다(교차 언어 표현이 정렬(align)된다)
215 |
216 |
217 |
218 | ### XLM 사전 학습
219 |
220 | - CLM or MLM
221 | - 단일 언어 데이터셋
222 | - 총 256개의 토큰으로 된 임의의 문장
223 | - TLM + MLM
224 | - TLM의 경우 병렬 데이터셋 사용
225 |
226 |
227 |
228 | ### XLM 평가
229 |
230 | 
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 |
239 |
240 |
--------------------------------------------------------------------------------
/summaries/chapter07/chapter07_XLMR_multilingual.md:
--------------------------------------------------------------------------------
1 | # Chapter 7 다른 언어에 BERT 적용하기
2 |
3 | ## XLM-R 이해하기
4 |
5 | - XLM에서 몇 가지를 보완한 확장 버전
6 | - XLM-RoBERTa
7 | - 자료가 적은 언어의 경우 병렬 데이터셋을 구하는 것이 쉽지 않아 MLM만 학습
8 | - 커먼 크롤 데이터셋에서 별도 레이블이 없는 100개의 언어 텍스트를 필터링하여 얻은 2.5TB의 데이터셋으로 학습
9 | - 비중이 적은 언어는 oversampling
10 | - Common crawl이 Wikipedia에 비해 자료가 적은 언어에서 데이터가 더 많음
11 | - Sentencepiece Tokenizer, 25만 개의 Token
12 | - Model Architecture
13 | - XLM-R_base: 12개의 Encoder layers, 12개의 Attention heads, 768 Hidden size
14 | - XLM-R: 24개의 Encoder layers, 16개의 Attention heads, 1024 Hidden size
15 | - M-BERT와 XLM보다 더 뛰어난 성능
16 | - XLM-R의 교차 언어 분류 태스크로 모델을 평가
17 | - 15개의 서로 다른 XNLI 데이터셋으로 평가
18 | - 가장 낮은 점수인 스웨덴어에서 M-BERT 50.4% → XLM-R 73.9%
19 | - XLM-R의 평균 정확도가 80.9%로 다른 모델보다 비교적 높음
20 |
21 | ## 언어별 BERT
22 |
23 | - 여러 언어 대신 특정 단일 언어만 이용해 BERT 학습
24 |
25 | ### 프랑스어 FlauBERT
26 |
27 | - 사용 말뭉치: Wikipedia, 도서, 내부 크롤링, WMT19, OPUS(오픈 소스 병렬 코퍼스)의 프랑스어 텍스트 등의 24개
28 | - Moses Tokenizer: URL, 날짜 등을 포함한 특수 토큰 보존
29 | - 전처리 및 토큰화 후 BPE 사용, vocab building
30 | - 50,000개의 Token
31 | - MLM만 수행, Dynamic masking 사용
32 | - small-cased, base-uncased, base-cased, large-cased
33 | - HuggingFace에서 사용 가능
34 | - FLUE(French Language Understanding Evaluation)
35 | - CLS-FR
36 | - PAWS-X-FR
37 | - XNLI-FR
38 | - French Treebank
39 | - FrechSemEval
40 |
41 | ### 스페인어 BETO
42 |
43 | - WWM(Whole Word Masking) + MLM
44 | - POS, NER-C, MLDoc, PAWS-X, XNLI로 테스트
45 | - HuggingFace에서 사용 가능
46 |
47 | ```python
48 | from transformers import pipeline
49 |
50 | predict_mask = pipeline(
51 | "fill-mask",
52 | model = "dccuchile/bert-base-spanish-wwm-uncased",
53 | tokenizer = "dccuchile/bert-base-spanish-wwm-uncased"
54 | )
55 |
56 | result = predict_mask('[MASK] los caminos llevan a Roma')
57 | ```
58 |
59 | ### 네덜란드어 BERTje
60 |
61 | - WWM과 MLM 및 SOP를 동시에 진행
62 | - 사용 말뭉치: TwNC(네덜란드 뉴스 말뭉치), SoNAR-500(다중 장르 참조 말뭉치), 네덜란드 위키피디아 텍스트, 웹 뉴스 및 서적
63 | - 100만 번의 iteration으로 학습
64 | - HuggingFace에서 사용 가능
65 |
66 | ### 독일어 BERT
67 |
68 | - Cloud TPU v2에서 9일 동안 Wikipedia text, 뉴스, OpenLegalData
69 |
70 | ### 중국어 BERT
71 |
72 | - 12개의 Encoder layers, 12개의 Attention heads, 768개의 hidden unit, 110M
73 | - WWM + MLM
74 | - WWM을 사용해 pretrain → 하위 단어가 masking 되면 하위 단어를 포함하는 전체 단어를 마스킹
75 | - LTP(Language Technology Platform)를 사용
76 | - LTP는 단어 분할, 형태소 분석, 구문 분석을 수행하는데 사용
77 | - 중국어 단어 경계를 식별하는 데도 이용
78 |
79 | ### 일본어 BERT
80 |
81 | - 일본어 Wikipedia를 사용해 WWM으로 학습
82 | - MeCab으로 Tokenization → Wordpiece Tokenizer로 subword를 얻음
83 |
84 | ### 핀란드어 FinBERT
85 |
86 | - M-BERT보다 성능이 좋음
87 | - Wikipedia에서 핀란드 텍스트의 비중은 3%에 불과
88 | - FinBERT는 핀란드어 뉴스 기사, 온라인 토론 및 인터넷 크롤링 텍스트로 학습
89 | - FinBERT-cased, FinBERT-uncased
90 | - WWM을 이용해 MLM과 NSP로 Pretrained
91 |
92 | ### 이탈리아어 UmBERTo
93 |
94 | - RoBERTa 아키텍쳐를 따름
95 | - MLM Task시에 Dynamic Masking 사용
96 | - NSP 제거 MLM만 사용
97 | - 큰 batch size 사용
98 | - Byte-level BPE Tokenizer
99 | - RoBERTa에 Sentencepiece + WWM 사용
100 |
101 | ### 포르투갈어 BERTimbau
102 |
103 | - brWaC: 포르투갈어 대규모 오픈 소스 말뭉치
104 | - WWM + MLM 100만 iteration
105 |
106 | ### 러시아어 RuBERT
107 |
108 | - M-BERT에서 Knowledge Distillation
109 | - 학습 전에 Word Embedding을 제외하고 RuBERT의 변수를 M-BERT 모델의 변수로 초기화
110 | - 러시아어 Wikipedia text와 뉴스 기사를 사용해 학습
111 | - Subword NMT로 텍스트를 subword로 나누는 데 사용
112 | - RuBERT의 Subword vocab은 M-BERT의 vocab에 비해 더 길고 더 많은 러시아어롤 구성
113 | - M-BERT와 RuBERT 어휘 모두에서 나타나는 일반적인 단어는 M-BERT의 임베딩으로 직접 사용 가능
--------------------------------------------------------------------------------
/summaries/chapter08/S-BERT.md:
--------------------------------------------------------------------------------
1 | # Sentence-BERT 및 domain-BERT 살펴보기
2 |
3 | > Speaker: 남수연(@mori8)
4 | >
5 | > 회사에서 molrae 쓰는 중
6 |
7 | ## Sentence-BERT
8 |
9 | Sentence-BERT는 vanila BERT/RoBERTa를 fine-tuning하여 문장 임베딩 성능을 우수하게 개선한 모델이다. BERT/RoBERTa는 STS 태스크에서도 좋은 성능을 보여주었지만 매우 큰 연산 비용이 단점이었는데, Sentence-BERT는 학습하는 데 20분이 채 걸리지 않으면서 다른 문장 임베딩보다 좋은 성능을 자랑한다.
10 |
11 |
12 |
13 | ### 등장 배경
14 |
15 | **기존의 BERT로는 large-scale의 유사도 비교, 클러스터링, 정보 검색 등에 많은 시간 비용이 들어간다.**
16 |
17 | - BERT로 유사한 두 문장을 찾으려면 두 개의 문장을 한 개의 BERT 모델에 넣어야 유사도가 평가된다.
18 | - 따라서 문장이 10000개 있으면 10C2 번의 연산 후에 유사도 랭킹을 얻을 수 있다.
19 | - 클러스터링이나 검색에서는 각 문장을 벡터 공간에 매핑하는데, BERT를 이용할 때는 단어 표현을 평균내거나 `[CLS]` 토큰의 값을 이용하지만 이랬을 때의 결과는 각 단어의 GloVe 벡터를 평균낸 것보다 나쁘다.
20 |
21 |
22 |
23 | ## Sentence-BERT의 문장 임베딩
24 |
25 | 1. BERT의 `[CLS]` 토큰의 표현 벡터를 문장 표현으로 사용한다.
26 | 2. BERT의 모든 단어의 표현 벡터를 평균 풀링하여 만든 벡터를 문장 표현으로 사용한다.
27 | 3. BERT의 모든 단어의 표현 벡터를 최대 풀링하여 만든 벡터를 문장 표현으로 사용한다.
28 |
29 | Sentence-BERT(이후 SBERT로 표기)는 BERT의 출력에 풀링 연산을 추가한 모델이며, 풀링 방법은 `[CLS]` 토큰의 결과를 사용하는 방법, 모든 출력 벡터를 평균내어 사용, 출력 벡터의 max-over-time*을 계산해 사용하는 방법이 있다. 기본적으로 SBERT는 평균 풀링을 사용하며, 평균 풀링으로 문장 표현을 얻으면 이 표현은 본질적으로 모든 단어의 의미를 갖는다. 반면 최대 풀링으로 문장 표현을 얻을 경우 문장 표현은 본질적으로 중요한 단어의 의미를 갖는다.
30 |
31 | > Max-over-time pooling: 문장의 길이가 다 다르면 문장마다의 feature map 개수가 달라지는데, 모든 문장마다 하나의 값을 갖도록 feature map 벡터 중 가장 큰 값 하나만 사용하는 것
32 |
33 |
34 |
35 | ## Fine Tuning 전략: 문장 쌍 분류, 회귀 태스크
36 |
37 | 신체의 일부를 공유하는 샴 쌍둥이처럼, 샴 네트워크는 두 네트워크가 weight를 공유한다. SBERT는 동일한 사전 학습된 BERT 모델 2개를 사용하여 문장 1의 토큰은 한 BERT로, 문장 2의 토큰은 또 다른 BERT로 입력하고 주어진 문장의 표현을 계산한다. 두 문장을 `[SEP]`으로 구분하여 한 BERT 모델에 같이 집어넣는 게 아니라, 같은 가중치를 갖는 서로 다른 BERT 모델 2개에 각각 넣는 것이다.
38 |
39 |
40 |
41 | ## Objective Functions
42 |
43 | 
44 |
45 | SBERT 모델의 구조는 학습 데이터에 따라 다르다. 아래 구조에 따라 목적 함수와 모델 구조를 달리 하였다.
46 |
47 | - 두 문장의 출력값인 u, v 그리고 element-wise 차이값인 |u-v|를 concatenate한 후 파라미터를 추가하여 학습한다.
48 | - 실제 inference할 때나, regression 방식의 loss function을 쓸 때는 cosine-similarity를 이용한다. Training할 때, 계산된 cosine similarity와 gold label 간의 MSE를 minimize하는 방식으로 학습했다.
49 |
50 |
51 |
52 | ### Classification Objective Function
53 |
54 | 두 문장이 유사한지(1), 유사하지 않은지(0) 판단하는 태스크를 위한 모델이다. 두 문장 임베딩 *u*와 *v*를 그 차이 ∣*u*−*v*∣와 concat해 3*n* 차원의 텐서를 만들고, 이를 가중치 *W**t*∈R3*n*×*k*에 곱한다. 이를 softmax함수에 넣으면 *k*개 label에 대한 분류 작업이 가능해진다. loss는 cross-entropy로 설정했다.
55 |
56 | $$O=softmax(W_t(u,v,∣u−v∣))$$
57 |
58 |
59 |
60 | ### Regression Objective Function
61 |
62 | 회귀 태스크의 목표는 주어진 두 문장 사이의 의미 유사도를 예측하는 것이다. 두 문장의 임베딩($u$, $v$) 사이의 코사인 유사도를 계산한다.
63 |
64 |
65 |
66 | ### Triplet Objective Function
67 |
68 | #### Siamese, Triplet의 등장 배경: One-shot
69 |
70 | 조금의 데이터만으로도 학습할 수 있도록 하는 것이 `Few-shot`, 한 장의 사진만으로 학습하도록 하자는 게 `One-shot`
71 |
72 |
73 |
74 | $$max(∣∣s_a−s_p∣∣−∣∣s_a−s_n∣∣+ϵ,0)$$
75 |
76 | anchor/positive/negative 문장 *a*,*p*,*n*에 대해 triplet loss는 모델이 *a*와 *p* 사이 거리가 *a*와 *n*사이 거리보다 작게 하도록 학습시킨다. $s_x$는 문장 *x*의 임베딩이고, ∣∣⋅∣∣은 거리고, *ϵ*은 margin이다. margin은 *s**p*가 *s**n*보다 최소한 *ϵ*만큼 *s**a*에 가깝도록 하는 장치이다. 이 논문에서는 Euclidean 거리를 단위로 *ϵ*=1로 설정했다.
77 |
78 |
79 |
80 | ## Evaluation
81 |
82 | 
83 |
84 | - 보다시피 BERT의 output을 그대로 쓰는 건 성능이 별로다. InferSent* - GloVe보다 못한 걸 알 수 있다.
85 | - 제안된 siamese 네트워크 구조와 fine-tuning 메커니즘은 InferSent나 Universal Sentence Encoder를 유의미하게 앞서는 결과를 내었다. SBERT가 좋은 성적을 내지 못한 유일한 데이터셋은 SICK-R이다.
86 | - Universal Sentence Encoder는 뉴스, QA 페이지, 토론 포럼처럼 SICK-R 벤치마킹에 적합한 데이터셋에 학습되었다. 반면 SBERT는 위키피디아와 NLI 데이터에만 학습되었다.
87 | - SRoBERTa는 성능이 좋긴 한데, SBERT에 비해 큰 차이를 보이진 않았다.
88 |
89 | > InferSent는 siamse BiLSTM에 max pooling을 적용한 문장 임베딩 모델
90 |
91 |
92 |
93 | ## References
94 |
95 | - https://velog.io/@ysn003/%EB%85%BC%EB%AC%B8-Sentence-BERT-Sentence-Embeddings-using-Siamese-BERT-Networks
96 | - http://mlgalaxy.blogspot.com/2020/09/sentence-bert-sentence-embeddings-using.html
97 | - https://tyami.github.io/deep%20learning/Siamese-neural-networks/
98 |
--------------------------------------------------------------------------------
/summaries/chapter08/chapter08_domain-BERT.md:
--------------------------------------------------------------------------------
1 | # Chapter 8 sentence-BERT 및 domain-BERT 살펴보기
2 |
3 | ## 내용
4 |
5 | - sentence-BERT
6 | - 지식 증류로 다국어 임베딩 학습
7 | - domain-BERT (ClinicalBERT 및 BioBERT)
8 |
9 | ## 지식 증류를 이용한 다국어 임베딩 학습
10 |
11 | *Q. 영어 외의 다른 언어에는 어떻게 sentence-BERT를 사용할까?*
12 |
13 | *A. sentence-BERT에서 생성된 단일 언어 문장 임베딩을 **지식 증류**를 통해 다국어로 만들어 다양한 언어에 sentence-BERT를 적용할 수 있다.*
14 |
15 | sentence-BERT 지식 ➡︎ 다국어 모델 (e.g. XLM-R) ➡︎ 다국어 모델이 사전 학습된 sentence-BERT와 동일한 임베딩 형성
16 |
17 | 학생 모델 S로 계산한 소스 문장(s_j) 표현과 타깃 문장(t_j) 표현 모두 교사 모델 T로 계산한 소스 문장(s_j) 표현과 동일해지는 방향으로 다음 속성을 학습
18 |
19 | 1. 벡터 공간이 언어 간 정렬 i.e., 다른 언어의 같은 문장은 가까이 위치
20 | 2. 교사 모델 T로 계산한 소스 언어의 벡터 공간 특성을 채택하여 다른 언어로 전이
21 |
22 |
23 |
24 |  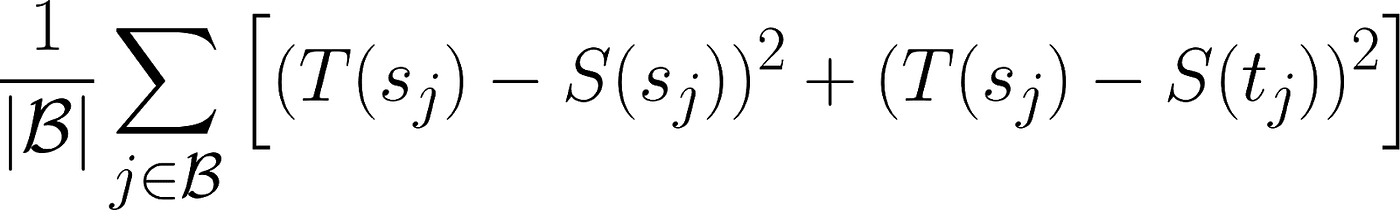 25 |
26 | : 미니배치 B에 대한 평균 제곱 오차(MSE)들을 최소화하도록 학생 네트워크 학습
27 |
28 | ## domain-BERT
29 |
30 | *BERT : 일반 위키피디아 말뭉치를 사용해 BERT를 사전 학습시키고 이를 파인튜닝해 다운스트림 태스크에 사용*
31 |
32 | 일반 위키피디아 말뭉치에서 사전학습된 BERT 사용 vs 특정 도메인 말뭉치에서 BERT를 처음부터 학습
33 |
34 | ➡︎ BERT가 특정(일반 위키피디아 말뭉치에 없을 수도 있는) 도메인 임베딩을 학습시키는데 도움
35 |
36 | ### ClinicalBERT
37 |
38 | 📄 [ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission](https://arxiv.org/pdf/1904.05342.pdf)
39 |
40 | 임상 텍스트의 콘텍스트 표현을 이해하기 위해 대규모 임상 말뭉치에서 사전학습된 임상 domain-BERT 모델
41 |
42 |
25 |
26 | : 미니배치 B에 대한 평균 제곱 오차(MSE)들을 최소화하도록 학생 네트워크 학습
27 |
28 | ## domain-BERT
29 |
30 | *BERT : 일반 위키피디아 말뭉치를 사용해 BERT를 사전 학습시키고 이를 파인튜닝해 다운스트림 태스크에 사용*
31 |
32 | 일반 위키피디아 말뭉치에서 사전학습된 BERT 사용 vs 특정 도메인 말뭉치에서 BERT를 처음부터 학습
33 |
34 | ➡︎ BERT가 특정(일반 위키피디아 말뭉치에 없을 수도 있는) 도메인 임베딩을 학습시키는데 도움
35 |
36 | ### ClinicalBERT
37 |
38 | 📄 [ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission](https://arxiv.org/pdf/1904.05342.pdf)
39 |
40 | 임상 텍스트의 콘텍스트 표현을 이해하기 위해 대규모 임상 말뭉치에서 사전학습된 임상 domain-BERT 모델
41 |
42 | 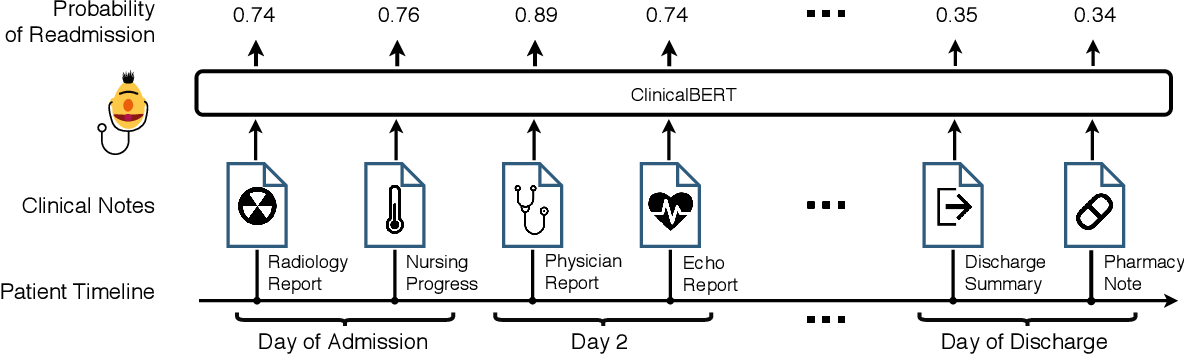 43 |
44 | #### 사전 학습
45 |
46 | - Medical Information Mart for Intensive Care III (MIMIC-III) dataset 사용
47 |
48 | - BERT와 마찬가지로 MLM과 NSP 태스크를 이용해 사전 학습
49 |
50 | #### 파인 튜닝
51 |
52 | 재입원 예측, 입원 기간, 사망 위험 추정, 진단 예측 등 다양한 다운스트림 태스크에 맞춰 파인 튜닝
53 |
54 | 
55 |
56 |
43 |
44 | #### 사전 학습
45 |
46 | - Medical Information Mart for Intensive Care III (MIMIC-III) dataset 사용
47 |
48 | - BERT와 마찬가지로 MLM과 NSP 태스크를 이용해 사전 학습
49 |
50 | #### 파인 튜닝
51 |
52 | 재입원 예측, 입원 기간, 사망 위험 추정, 진단 예측 등 다양한 다운스트림 태스크에 맞춰 파인 튜닝
53 |
54 | 
55 |
56 |  57 |
58 | *e.g. 30일 이내 재입원 예측 테스크*
59 |
60 | - 사전학습된 ClincalBERT에 임상 메모를 입력하고 임상 메모의 표현 반환
61 | - `[CLS]` 토큰의 표현을 가져와 분류기(피드포워드 + 시그모이드 활성화 함수)에 입력
62 | - 분류기는 30일 이내에 환자가 다시 입원할 확률 반환
63 |
64 | #### Empirical Study
65 |
66 | **Empirical Study I: Language Modeling and Clinical Word Similarity**
67 |
68 | - Clinical language model에서 ClinicalBERT가 BERT보다 좋은 성능
69 |
70 |
57 |
58 | *e.g. 30일 이내 재입원 예측 테스크*
59 |
60 | - 사전학습된 ClincalBERT에 임상 메모를 입력하고 임상 메모의 표현 반환
61 | - `[CLS]` 토큰의 표현을 가져와 분류기(피드포워드 + 시그모이드 활성화 함수)에 입력
62 | - 분류기는 30일 이내에 환자가 다시 입원할 확률 반환
63 |
64 | #### Empirical Study
65 |
66 | **Empirical Study I: Language Modeling and Clinical Word Similarity**
67 |
68 | - Clinical language model에서 ClinicalBERT가 BERT보다 좋은 성능
69 |
70 |  71 |
72 | - 임상 단어 유사도 추출
73 |
74 | - ClinicalBERT에서 배운 표현을 경험적으로 평가하기 위해 의학 용어 표현 계산
75 |
76 |
71 |
72 | - 임상 단어 유사도 추출
73 |
74 | - ClinicalBERT에서 배운 표현을 경험적으로 평가하기 위해 의학 용어 표현 계산
75 |
76 |  77 |
78 | - 신체기관이 서로 관련된 의학 용어끼리 가까이 있는 것을 확인 가능
79 |
80 | ➡︎ ClinicalBERT의 표현이 의학 용어에 대한 콘텍스트 정보를 갖고 있음을 나타냄
81 |
82 | **Empirical Study II: 30-Day Hospital Readmission Prediction**
83 |
84 | - Scalable Readmission Prediction
85 |
86 | **💡 BERT 최대 토큰의 길이 512보다 더 많은 토큰으로 구성된 경우?**
87 |
88 | - 512보다 더 많은 토큰으로 구성된 긴 시퀀스를 여러 서브시퀀스로 분할
89 | - 각 서브시퀀스를 모델에 입력한 후 모든 서브시퀀스를 개별적으로 예측
90 | - 다음 식을 이용해 점수 계산 :
77 |
78 | - 신체기관이 서로 관련된 의학 용어끼리 가까이 있는 것을 확인 가능
79 |
80 | ➡︎ ClinicalBERT의 표현이 의학 용어에 대한 콘텍스트 정보를 갖고 있음을 나타냄
81 |
82 | **Empirical Study II: 30-Day Hospital Readmission Prediction**
83 |
84 | - Scalable Readmission Prediction
85 |
86 | **💡 BERT 최대 토큰의 길이 512보다 더 많은 토큰으로 구성된 경우?**
87 |
88 | - 512보다 더 많은 토큰으로 구성된 긴 시퀀스를 여러 서브시퀀스로 분할
89 | - 각 서브시퀀스를 모델에 입력한 후 모든 서브시퀀스를 개별적으로 예측
90 | - 다음 식을 이용해 점수 계산 :  91 | - 재입원 예측과 관련된 서브시퀀스 : 확률이 높은 것
92 | - 노이즈가 포함된 서브시퀀스 방지를 위해 평균 확률 사용
93 | - 평균 확률에 중요성 부여
94 |
95 | ### BioBERT
96 |
97 | 📄 [BioBERT: a pre-trained biomedical language representation model for biomedical text mining](https://arxiv.org/pdf/1901.08746.pdf)
98 |
99 | 생물 의학 텍스트 이해를 위해 대규모 생물 의학 코퍼스에서 사전학습된 생물 의학 domain-BERT
100 |
101 | 
102 |
103 | #### 사전 학습
104 |
105 | - 생물 의학 도메인 텍스트를 이용해 사전학습
106 |
107 | - PubMed, PMC
108 |
109 | - 사전학습 전에 먼저, 영어 위키피디아 및 토론토 책 말뭉치 데이터셋으로 구성된 일반 도메인 말뭉치를 사용해 사전 학습된 일반 BERT로 BioBERT의 가중치 초기화
110 |
111 | - 워드피스 토크나이저로 토큰화
112 |
113 | - 생물 의학 코퍼스의 새로운 어휘를 사용하는 대신, BERT 기반 모델에서 사용되는 원래 어휘로 워드피스 어휘를 구성
114 |
115 | - BioBERT와 BERT 간의 호환성
116 |
117 | - 본 적 없는 단어도 원래 BERT 기반 어휘를 사용해 표현하고 파인튜닝
118 |
119 | - 대소문자가 있는 어휘를 사용하는 것이 다운스트림 태스크에서 더 좋은 성능을 얻을 수 있음을 발견
120 |
121 | #### 파인 튜닝
122 |
123 | 📌 코드 [github.com/dmis-lab/biobert](https://github.com/dmis-lab/biobert?fbclid=IwAR3te48b9-SsBBmybH8MrQMLxX5RlDbYTfpBZQGLp5ki1B8jq-2M15t3skA)
124 |
125 | **개체명 인식(NER) 태스크를 위한 BioBERT**
126 |
127 | - 생물 의학 코퍼스에서 특정 도메인의 다양한 고유명사 인식
128 | - BERT를 파인튜닝하는 법과 동일
129 | - 데이터셋
130 | - 질병 관련된 개체명: NCBI, 2010 i2b2/VA, BC5CDR
131 | - 약물 및 화학 관련된 개체명: BC5CDR, BC4CHEMD
132 | - 유전자와 관련된 개체명: BC2GM, JNLPBA
133 | - 종과 관련된 개체명: LINNAEUS, Species-800
134 |
135 | **관계 추출(RE)을 위한 BioBERT**
136 |
137 | - 생물 의학 코퍼스에서 명명된 개체들의 관계 분류
138 |
139 | - `[CLS]` 토큰 표현을 사용하는 BERT의 sentence classifier 사용
140 |
141 | **질문-응답(QA)을 위한 BioBERT**
142 |
143 | - BioASQ 데이터셋으로 파인튜닝
144 | - 생물 의학 질문-응답 데이터셋으로 널리 사용
145 | - SQuAD의 형식과 동일
146 | - BERT를 파인튜닝하는 법과 동일
147 |
148 |
--------------------------------------------------------------------------------
/summaries/chapter09/chapter09_BART.md:
--------------------------------------------------------------------------------
1 | # Chapter 9.2~
2 |
3 | BART에 대해서 알아보고 Hugging Face의 BERT관련 라이브러리를 다룬다.
4 |
5 |
6 |
7 | ## BART
8 |
9 | BERT는 bidirection encoder로 MASK token을 예측하는데, 이러한 구조로 인해 generation task에서 BERT의 사용이 어렵다. 왜냐하면 각각의 MASK token이 softmax/피드포워드 네트워크를 통해 독립적으로 예측되기 때문이다.
10 |
11 | GPT는 autoregressive한 구조로 다음 token을 예측할 수 있지만, BERT처럼 bidirection이 아니다.
12 |
13 |
14 |
15 | ### BART Architecture
16 |
17 | 그래서 두 architecture를 합친다.
18 |
19 | 
20 |
21 | BART는 BERT와 GPU 모델의 구조를 결합하였기 때문에, bidirection으로 문장을 살펴보며 attention representation을 얻어 디코더를 통해 seq2seq 구조로 generation을 수행한다.
22 |
23 | **이 때문에 MLM과는 달리 여러 task에 대해 응용성이 높다**
24 |
25 |
26 |
27 | BART는 seq2seq transformer 구조를 사용했고, GeLUs 활성화 함수를 사용한다. (파라미터 초기화는 N(0, 0.2)) 인코더와 디코더의 layer 수는 같으며, bsae model은 6 layer, large model은 12 layer를 사용한다. 기존의 트랜스포머 디코더와 동일하게, 디코더의 각 레이어에서는 인코더의 마지막 hidden layer와 cross-attention을 한다.
28 |
29 | > self-attention: keys와 values가 queries와 똑같은 임베딩에서 나왔을 때
30 | >
31 | > cross-attention: keys와 values가 queires와 다른 임베딩에서 나왔을 때
32 |
33 |
34 |
35 | ### 노이징 기술 (Pretraining BART)
36 |
37 | BART에서 알아볼 수 있는 핵심은 noising 기술의 유연함이다. 다양한 변형 noising 기법들을 적용시킬 수 있으며, 이 중에서는 문장의 순서를 바꾸거나, 길이를 변경하는 등의 방법론도 있다. 가장 좋은 성능을 보이는 노이징 기법은 문장의 순서를 랜덤하게 섞고, 임의의 길이의 텍스트를 단일 마스크 토큰으로 교체하는 것이다.
38 |
39 | > 모델이 전체적인 문장 길이에 대해 학습해야 하고, 변형된 입력에 많은 집중을 요구하는 효과가 있다고 한다.
40 |
41 |
42 |
43 | 
44 |
45 | **토큰 마스킹(Token Masking)**
46 |
47 | - 랜덤하게 바뀐 [MASK] 토큰 맞추기
48 |
49 | **토큰 삭제(Token Deletion)**
50 |
51 | - 토큰이 랜덤하게 제거된다.
52 | - 모델은 어떤 위치의 토큰이 없어졌는지에 대해서도 맞춰야 한다.
53 |
54 | **토큰 채우기(Text Infilling)**
55 |
56 | - 람다 3을 따르는 포아송 분포에서 span의 길이가 샘플링되고, 각 span은 한개의 [MASK] 토큰으로 치환된다.
57 | - span의 길이가 0일 때도 [MASK] 토큰이 생성된다.
58 | - 모델은 [MASK]에 해당하는 단어들을 맞춰야 한다. 즉 얼마나 많은 토큰이 없어졌는지 예측해야 한다.
59 |
60 | **문장 셔플(Sentence Permutation)**
61 |
62 | - 문장의 순서를 랜덤으로 섞는다.
63 | - 모델은 섞인 토큰들을 원래의 순서로 배열해야 한다. (XLnet에서 영감)
64 |
65 | **문서 회전(Document Rotation)**
66 |
67 | - 하나의 토큰이 랜덤하게 선택되고, 해당 토큰이 문서의 시작지점이 된다.
68 | - 모델은 해당 문서의 시작점을 찾아야 한다.
69 |
70 |
71 |
72 | ### Fine-tuning BART
73 |
74 | 번역 테스크?? 몇개의 추가적인 transformer 레이어를 쌓아 올리는 것으로 기계 번역의 새로운 방법론을 제시하기도 하였음. 추가된 레이어는 외국어를 noise가 적용된 영어로 번역하는 것이 학습되며, BART 전반적으로 학습되게 되어 BART를 사전 학습된 target-side 언어 모델로 사용ㅎ나다. WMT 루마니안-영어 벤치마크에서 1.1 BELU만큼 성능이 향상되었다고 한다.
75 |
76 |
77 |
78 | 
79 |
80 |
81 |
82 | **Sequence Classification Tasks - 시퀀스 단위의 분류 문제**
83 |
84 | - 시퀀스 분류 문제. BERT에서 [CLS] 토큰으로 classification task를 수행하는 것에서 영감. BART에서는 디코더에서 마지막 토큰을 추가하여 해당 토큰의 representation이 전체 입력과 attention을 수행할 수 있게 한다. -> output은 모든 입력을 반영
85 |
86 | - CoLA: 문장이 문법적으로나 영어적으로 합당한지 분류
87 |
88 | **Token Classification Tasks - 토큰 단위의 분류 문제**
89 |
90 | - 디코더 가장 위의 hidden state를 각 토큰의 representation으로 사용 -> classification
91 | - SQuAD: 정답에 해당되는 start point, end point 토큰 찾기
92 |
93 | **Sequence Generation Tasks - 시퀀스 생성 문제**
94 |
95 | - Abstractive QA(question answering), 요약 등의 generation task
96 | - 이러한 테스크는 입력 시퀀스의 내용을 조정하는 특징이 있는데, denoising pre-training objective와 밀접하게 연관되어 있다고 한다.
97 |
98 | **Machine Translation**
99 |
100 | - 몇개의 추가적인 transformer layer를 쌓아 올려 기계 번역의 새로운 방법론 제시 -> BART 전체를 decoder로 사용
101 | - BART 인코더의 embedding layer를 새롭게 초기화된 인코더로 교체 -> 해당 인코더를 학습시키는 것으로 영어가 아닌 다른 단어들을 영어로 매핑하여 BART가 외국어를 denoise할 수 있게 한다.
102 | - 인코더를 2가지 step으로 학습시킨다.
103 | - BART 모델의 output에 대한 cross-entropy loss 사용
104 | - step1) 새롭게 초기화된 인코더, BART의 positional embedding, 첫번째 인코더 layer의 self-attention input projection matrix 학습
105 | - step2) 모든 모델 parameter를 작은 iteration으로 학습
106 |
107 |
108 |
109 | ### Comparing pre-training objectives
110 |
111 | 실험한 언어 모델의 종류
112 |
113 | - Language Model
114 | - Permuted Language Model
115 | - Masked Language Model
116 | - Multitask Masked Language Model
117 | - Masked Seq2Seq
118 |
119 |
120 |
121 | **Tasks**
122 |
123 | **SQuAD**
124 |
125 | - 위키 문단에 대한 QA task로, 위키피디아에서 가져온 본문과 질문이 주어지면, 주어진 본문으로부터 정답에 해당되는 span을 찾아야 한다. -> BART에서는 start point, end point의 두개를 예측하는 분류기 사용
126 |
127 | **MNLI**
128 |
129 | - NLI task와 비슷하며, 이전 문장과 이후 문장의 관계 성립 예측. -> BART에서는 두 개의 문장을 [EOS] token으로 합치고, [EOS] 토큰의 representation으로 classification 수행
130 |
131 | **[ELI5](https://facebookresearch.github.io/ELI5/)**
132 |
133 | - Long form QA task.
134 |
135 | **[XSum](https://arxiv.org/pdf/1808.08745v1.pdf)**
136 |
137 | - 뉴스 요약 테스크 -> 함축된 요약을 만들어야 한다.
138 |
139 | **ConvAI2**
140 |
141 | - 대화의 답변 만들기 -> context와 화자가 주어진다.
142 |
143 | **CNN/DM**
144 |
145 | - 뉴스 요약 테스크 -> 요약본이 입력 문서와 밀접하게 연관되어 있어 XSum과는 약간 다르다.
146 |
147 | 
148 |
149 |
150 |
151 | ### Result
152 |
153 | - **Performance of pre-training methods varies significantly across tasks**
154 |
155 | - **Token masking is crucial**
156 |
157 | - **Left-to-right pre-training improves generation**
158 |
159 | - **Bidirectional encoders are crucial for SQuAD**
160 |
161 | - **The pre-training objective is not the only important factor**
162 |
163 | - **Pure language models perform best on ELI5**
164 |
165 | - **BART achieves the most consistently strong performance.**
166 |
167 |
168 |
169 |
170 |
171 | ## BERT 라이브러리 탐색
172 |
173 | BERT 관련 모델을 쉽게 학습하거나 pre train model을 쉽게 사용 할 수 있는 라이브러리들이 있다.
174 |
175 |
176 |
177 | ### ktrain
178 |
179 | https://github.com/amaiya/ktrain
180 |
181 |
182 |
183 | ### bert-as-service
184 |
185 | https://github.com/hanxiao/bert-as-service
186 |
187 |
--------------------------------------------------------------------------------
/summaries/chapter09/chapter09_VideoBERT.md:
--------------------------------------------------------------------------------
1 | # Chapter 9. VideoBERT
2 |
3 | ## VideoBert로 언어 및 비디오 표현 학습
4 |
5 | **VideoBERT** 📄 [VideoBERT: A Joint Model for Video and Language Representation Learning](https://arxiv.org/pdf/1904.01766.pdf)
6 |
7 | 
8 |
9 | - 영상과 언어의 표현을 동시에 배우는 최초의 BERT 모델
10 | - 이미지 캡션 생성, 비디오 캡션, 비디오의 다음 프레임 예측 등과 같은 태스크에 사용
11 |
12 | ### VideoBERT 사전 학습
13 |
14 | - **MLM(cloze 태스크)과 언어-시각(linguistic-visual) 정렬이라는 새로운 태스크를 사용하여 사전학습**
15 |
16 | - 데이터: 교육용 비디오(e.g., 요리 비디오)
17 |
18 | - 교육자의 말과 해당 시각 자료(영상)가 서로 일치해 언어와 비디오의 표현을 동시에 배우는데 도움
19 |
20 | - 비디오에서 언어 토큰과 시각 토큰을 추출하여 학습에 사용
21 |
22 | - 언어 토큰 추출 방법
23 |
24 | 1. 비디오에 사용된 오디오를 추출
25 |
26 | 2. 오디오를 텍스트로 변환
27 |
28 | **자동 음성 인식**(automatic speech recognition) 툴킷을 활용
29 | _Cf. https://cloud.google.com/speech-to-text_
30 |
31 | 3. 텍스트를 토큰화하면 언어 토큰 생성
32 |
33 | - 시각 토큰 추출 방법
34 |
35 | 1. 비디오의 이미지 프레임을 20fps(초당 프레임)로 샘플링
36 | 2. 이미지 프레임을 1.5초의 구간으로 시각 토큰들로 변환
37 |
38 | - 입력 토큰
39 |
40 | 1. 언어와 시각 토큰 결합
41 |
42 | 특수 토큰 `[>]` 으로 언어 및 시각적 토큰 결합
43 |
44 | 2. 언어 토큰의 시작 부분에 `[CLS]` 토큰 추가, 시각 토큰 끝에만 `[SEP]` 토큰 추가
45 |
46 | 3. 언어 및 시각 토큰 중 몇 가지 토큰들을 무작위로 마스킹
47 |
48 | - **cloze 태스크**
49 |
50 | - VideoBERT에서 반환된 마스크된 표현을 분류기(피드포워드 + 소프트맥스)에 입력하면, 분류기는 마스크된 토큰 예측
51 |
52 | 
53 |
54 | - **언어-시각 정렬**
55 |
56 | - NSP 태스크와 유사한 분류 태스크
57 |
58 | - 언어와 시각 토큰이 시간적으로 서로 정렬되어 있는지 예측
59 |
60 | = 텍스트(언어 토큰)가 비디오(시각적 토큰)와 일치하는지 여부 예측
61 |
62 | - `[CLS]` 토큰의 표현을 가져온 다음 주어진 언어 및 시각 토큰이 일시적으로 정렬되는지 여부를 분류하는 분류기에 입력
63 |
64 | _Cf. NSP는 `[CLS]` 표현을 이용해 주어진 문장 다음에 출현하는 문장이 다음 문장인지 예측_
65 |
66 | - **최종 사전 학습 목표**
67 |
68 | - 세 가지 목표: 텍스트, 비디오, 비디오-텍스트
69 |
70 | - **텍스트**
71 |
72 | 언어 토큰을 마스킹하고 마스크 언어 토큰을 예측하도록 모델을 학습시켜서 모델이 언어 표현을 더 잘 이해하도록 함
73 |
74 | - **비디오**
75 |
76 | 시각 토큰을 마스킹하고 마스크된 시각 토큰을 예측하도록 모델을 학습시켜서 모델이 비디오 표현을 더 잘 이해하도록 함
77 |
78 | - **비디오-텍스트**
79 |
80 | 언어 및 시각적 토큰을 마스킹하고 모델을 학습시켜 언어 및 시각 토큰을 예측하고, 언어-시각 정렬을 학습하게 해서 모델이 언어와 시각 토큰 간의 관계를 이해하게 함
81 |
82 | - 최종 사전 학습 목표: 세 가지 방법을 모두 활용한 가중치 조합
83 | - 4개의 TPU를 사용해 2일 동안 50만 번 반복해 최종 사전 학습 목표를 수행하며 학습
84 |
85 | ### 데이터 소스 및 전처리
86 |
87 | **데이터셋**
88 |
89 | - 유튜브의 교육용 비디오 사용
90 |
91 | - 유튜브 동영상 주석(annotation) 시스템을 이용해 요리와 관련된 유튜브 동영상 추출
92 |
93 | - 15분 미만 영상 길이, 31만 2000개의 동영상
94 |
95 | - 유튜브 API에서 제공하는 자동 음성 인식 도구(ASR)를 사용해 텍스트 추출
96 |
97 | - 텍스트를 타임 스탬프와 함께 갖고오기 위함 (비디오에 사용된 언어에 대한 정보도 반환)
98 |
99 | - 31만 2000개의 동영상 중 18만 개의 동영상에만 ASR을 적용할 수 있었고, 그 중 영어로 된 동영상은 12만개로 추정
100 |
101 | ➡︎ 텍스트 및 비디오-텍스트 목표를 위해 12만 개의 비디오만 사용하고, 비디오 목표는 31만 2000개의 비디오 사용
102 |
103 | **비디오 및 언어 전처리**
104 |
105 | - 시각 토큰
106 | 1. 비디오의 이미지 프레임을 20fps(초당 프레임)로 샘플링
107 | 2. 이미지 프레임을 1.5초의 구간으로 시각 토큰들로 변환 (= 30-frame clip 생성)
108 | 3. 각 30-frame clip에 사전 학습된 비디오 컨볼루셔널 뉴럴넷을 적용해 특징 추출
109 | 3. 계층적 k-평균 알고리즘을 적용해 시각 특징 토큰화
110 | - 언어 토큰
111 | 1. 상용 LSTM 기반 언어 모델을 이용해 각 ASR 단어 시퀀스에 구두점을 추가하여 단어 스트림을 문장으로 나눔
112 | 2. 각 문장에 대해 BERT의 텍스트 전처리와 동일한 방식을 따르며, 텍스트 토큰화
113 |
114 | > 💡 자연스럽게 문장으로 나뉘는 언어와 달리, 비디오는 어떻게 의미론적으로 나눌까?
115 | >
116 | > - 휴리스틱 사용
117 | > - ASR 문장이 존재할 경우, 문장의 시작 및 종료 timestamp 사이에 해당하는 비디오 토큰을 세그먼트로 취급
118 | > - ASR 문장이 존재하지 않을 경우, 하나의 세그먼트를 16개의 토큰으로 취급
119 |
120 | ### VideoBERT의 응용
121 |
122 | 사전학습된 VideoBERT 모델을 사용해 다양한 다운스트림 태스크에 맞춰 파인튜닝
123 |
124 | - 시각 토큰을 입력해 상위 3개의 다음 시각 토큰 예측
125 | - 텍스트가 주어지면 해당하는 비디오 생성
126 | - 비디오에 자막 생성
127 |
128 | ## Transformers in vision
129 |
130 | 📄 [Transformers in Vision: A Survey](https://arxiv.org/pdf/2101.01169.pdf)
131 |
132 | - Computer Vision 분야에서 Transformer가 활용된 연구들 정리한 survey paper
133 |
134 | ### Background
135 |
136 | RNN to Transformer in NLP ⇨ CNN에 self-attention 적용 ⇨ Transformer 모델 자체를 CV 태스크에 사용
137 |
138 | ### Task
139 |
140 | 
141 |
142 | ***Table 1 from Transformers in Vision: A survey***
143 |
144 | *A summary of key design choices adopted in different variants of transformers for a representative set of computer vision applications. The main changes relate to specific loss function choices, architectural modifications, different position embeddings and variations in input data modalities.*
145 |
146 | ### Model
147 |
148 | #### Transformers for Multi-Modal Tasks
149 |
150 | *Multi-modal learning: 다양한 데이터 타입, 데이터 형태, 다양한 특성을 갖는 데이터를 사용하는 학습법*
151 |
152 | - Transformer 모델은 vision-language 태스크에도 광범위하게 사용
153 | - visual question answering (VQA)
154 | - visual commonsense reasoning (VCR)
155 | - cross-modal retrieval
156 | - image captioning
157 |
158 | 
159 |
160 | *An overview of Transformer models used for multi-modal tasks in computer vision*
161 |
162 | #### Vision Transformer (ViT)
163 |
164 | 📄 [AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE](https://arxiv.org/pdf/2010.11929.pdf)
165 |
166 | 
167 |
168 | - CNN 구조였던 computer vision 문제를 Transformer 구조로 대체
169 | - Transformer 구조를 사용한 Architecture가 수 많은 SOTA를 찍고 있으며, **ViT 논문이 그 시작점**
170 | - Transformer 구조를 활용하여 image classification을 수행한 방법론
171 | - 더 많은 데이터를 더 적은 비용으로 사전 학습
172 |
173 | - 구조
174 |
175 | - Transformer encoder 사용
176 | - 한 이미지를 여러 patch로 분할 (patch를 단어같이 취급)
177 | - patch, classification token, position embedding을 입력하여 최종 classification 결과 생성
178 |
179 | > CNN vs Transformer
180 | >
181 | > - Layer
182 | >
183 | > - CNN: 이미지 전체의 정보를 통합하기 위해서는 몇 개의 layer 통과
184 | > - Transformer: 하나의 layer로 전체 이미지 정보 통합 가능
185 | >
186 | > - Inductive bias
187 | >
188 | > _새로운 데이터에 대해 좋은 성능을 내기 위해 모델에 사전적으로 주어지는 가정_
189 | >
190 | > - CNN: 2차원의 지역적인 특성 유지, 학습 후 weight 고정
191 | >
192 | > → 인접한 픽셀 간 강한 상관관계가 있다는 특징을 살려 inductive bias가 적절하게 만들어짐으로써 이미지 특징 효과적 추출
193 | >
194 | > - Transformer: 1차원 벡터로 만든 후 self attention (2차원의 지역적인 정보 유지 x), weight가 input에 따라 유동적으로 변함
195 | >
196 | > → inductive bias가 적고, 모델의 자유도가 높아 데이터로부터 더 많은 정보를 얻을 수 있음
197 |
198 | - 한계
199 |
200 | - 학습 데이터가 충분하지 않을 경우 CNN 모델보다 성능 감소 (∵ inductive bias ↓)
201 |
202 | ➡︎ 대용량의 학습 자원과 데이터가 필요
203 |
204 | #### Data efficient image Transformer (DeiT)
205 |
206 | 📄 [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
207 |
208 | - 많은 데이터가 필요한 ViT 한계 극복
209 | - Knowledge Distilation
210 | - Data Augmentation
211 |
212 | ## 참고 자료
213 |
214 | #### 개념
215 |
216 | - [Multimodal Deep Learning](https://towardsdatascience.com/multimodal-deep-learning-ce7d1d994f4)
217 |
218 | #### 세미나
219 |
220 | - [DMQA Transformer in Computer Vision](http://dmqm.korea.ac.kr/activity/seminar/316)
221 |
222 | #### 논문
223 |
224 | - [VideoBERT: A Joint Model for Video and Language Representation Learning](https://arxiv.org/pdf/1904.01766.pdf)
225 | - [Transformers in Vision: A Survey](https://arxiv.org/pdf/2101.01169.pdf)
226 | - **리뷰**
227 | - [Transformers in Vision: A Survey [1] Transformer 소개 & Transformers for Image Recognition](https://hoya012.github.io/blog/Vision-Transformer-1/)
228 | - [AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE](https://arxiv.org/pdf/2010.11929.pdf)
229 | - **리뷰**
230 | - https://engineer-mole.tistory.com/133
231 | - https://kmhana.tistory.com/27
232 |
233 | #### 책
234 |
235 | - [구글 BERT의 정석](http://www.yes24.com/Product/Goods/104491152)
236 |
--------------------------------------------------------------------------------
/summaries/chapter10/chapter10_kobert_kogpt2_kobart.md:
--------------------------------------------------------------------------------
1 | # Chapter 10 한국어 언어 모델: KoBERT, KoGPT2, KoBART
2 |
3 | - 다국어 모델들은 한국어 데이터의 부족 때문에 좋은 성능을 보이지 못함
4 |
5 | ## KoBERT
6 |
7 | - 한국어 위키피디아에서 500만 개의 문장과 5400만 개의 단어 학습
8 | - Huggingface, MXNet-Gluon, ONNX 등 여러 플랫폼에서 사용 가능
9 | - Sentencepiece를 이용해 Tokenizer 학습
10 | - 8,002개의 vocab size
11 |
12 | ## KoGPT2
13 |
14 | - 한국어에 특화된 GPT-2 모델
15 | - 주어진 텍스트를 기반으로 다음 단어를 잘 예측할 수 있도록 학습됨
16 | - 문장 생성에 최적화
17 | - 125M parameter
18 | - 한국어 위키피디아, 뉴스, 모두의 말뭉치 v1.0, 청와대 국민청원 등 40GB의 한국어 텍스트 사용
19 | - BPE Tokenizer
20 | - 51,200 vocab
21 | - 이모티콘, 이모지도 추가
22 |
23 | ## KoBART
24 |
25 | - text infilling 노이즈 함수만 적용
26 | - 40GB 이상의 한국어 텍스트로 사전 학습
27 | - Denoising AutoEncoder
28 | - 6 encoder layers
29 | - 6 decoder layers
30 | - 16 attention heads
31 | - 768 FFN hidden unit
32 | - 120M parameters
--------------------------------------------------------------------------------
91 | - 재입원 예측과 관련된 서브시퀀스 : 확률이 높은 것
92 | - 노이즈가 포함된 서브시퀀스 방지를 위해 평균 확률 사용
93 | - 평균 확률에 중요성 부여
94 |
95 | ### BioBERT
96 |
97 | 📄 [BioBERT: a pre-trained biomedical language representation model for biomedical text mining](https://arxiv.org/pdf/1901.08746.pdf)
98 |
99 | 생물 의학 텍스트 이해를 위해 대규모 생물 의학 코퍼스에서 사전학습된 생물 의학 domain-BERT
100 |
101 | 
102 |
103 | #### 사전 학습
104 |
105 | - 생물 의학 도메인 텍스트를 이용해 사전학습
106 |
107 | - PubMed, PMC
108 |
109 | - 사전학습 전에 먼저, 영어 위키피디아 및 토론토 책 말뭉치 데이터셋으로 구성된 일반 도메인 말뭉치를 사용해 사전 학습된 일반 BERT로 BioBERT의 가중치 초기화
110 |
111 | - 워드피스 토크나이저로 토큰화
112 |
113 | - 생물 의학 코퍼스의 새로운 어휘를 사용하는 대신, BERT 기반 모델에서 사용되는 원래 어휘로 워드피스 어휘를 구성
114 |
115 | - BioBERT와 BERT 간의 호환성
116 |
117 | - 본 적 없는 단어도 원래 BERT 기반 어휘를 사용해 표현하고 파인튜닝
118 |
119 | - 대소문자가 있는 어휘를 사용하는 것이 다운스트림 태스크에서 더 좋은 성능을 얻을 수 있음을 발견
120 |
121 | #### 파인 튜닝
122 |
123 | 📌 코드 [github.com/dmis-lab/biobert](https://github.com/dmis-lab/biobert?fbclid=IwAR3te48b9-SsBBmybH8MrQMLxX5RlDbYTfpBZQGLp5ki1B8jq-2M15t3skA)
124 |
125 | **개체명 인식(NER) 태스크를 위한 BioBERT**
126 |
127 | - 생물 의학 코퍼스에서 특정 도메인의 다양한 고유명사 인식
128 | - BERT를 파인튜닝하는 법과 동일
129 | - 데이터셋
130 | - 질병 관련된 개체명: NCBI, 2010 i2b2/VA, BC5CDR
131 | - 약물 및 화학 관련된 개체명: BC5CDR, BC4CHEMD
132 | - 유전자와 관련된 개체명: BC2GM, JNLPBA
133 | - 종과 관련된 개체명: LINNAEUS, Species-800
134 |
135 | **관계 추출(RE)을 위한 BioBERT**
136 |
137 | - 생물 의학 코퍼스에서 명명된 개체들의 관계 분류
138 |
139 | - `[CLS]` 토큰 표현을 사용하는 BERT의 sentence classifier 사용
140 |
141 | **질문-응답(QA)을 위한 BioBERT**
142 |
143 | - BioASQ 데이터셋으로 파인튜닝
144 | - 생물 의학 질문-응답 데이터셋으로 널리 사용
145 | - SQuAD의 형식과 동일
146 | - BERT를 파인튜닝하는 법과 동일
147 |
148 |
--------------------------------------------------------------------------------
/summaries/chapter09/chapter09_BART.md:
--------------------------------------------------------------------------------
1 | # Chapter 9.2~
2 |
3 | BART에 대해서 알아보고 Hugging Face의 BERT관련 라이브러리를 다룬다.
4 |
5 |
6 |
7 | ## BART
8 |
9 | BERT는 bidirection encoder로 MASK token을 예측하는데, 이러한 구조로 인해 generation task에서 BERT의 사용이 어렵다. 왜냐하면 각각의 MASK token이 softmax/피드포워드 네트워크를 통해 독립적으로 예측되기 때문이다.
10 |
11 | GPT는 autoregressive한 구조로 다음 token을 예측할 수 있지만, BERT처럼 bidirection이 아니다.
12 |
13 |
14 |
15 | ### BART Architecture
16 |
17 | 그래서 두 architecture를 합친다.
18 |
19 | 
20 |
21 | BART는 BERT와 GPU 모델의 구조를 결합하였기 때문에, bidirection으로 문장을 살펴보며 attention representation을 얻어 디코더를 통해 seq2seq 구조로 generation을 수행한다.
22 |
23 | **이 때문에 MLM과는 달리 여러 task에 대해 응용성이 높다**
24 |
25 |
26 |
27 | BART는 seq2seq transformer 구조를 사용했고, GeLUs 활성화 함수를 사용한다. (파라미터 초기화는 N(0, 0.2)) 인코더와 디코더의 layer 수는 같으며, bsae model은 6 layer, large model은 12 layer를 사용한다. 기존의 트랜스포머 디코더와 동일하게, 디코더의 각 레이어에서는 인코더의 마지막 hidden layer와 cross-attention을 한다.
28 |
29 | > self-attention: keys와 values가 queries와 똑같은 임베딩에서 나왔을 때
30 | >
31 | > cross-attention: keys와 values가 queires와 다른 임베딩에서 나왔을 때
32 |
33 |
34 |
35 | ### 노이징 기술 (Pretraining BART)
36 |
37 | BART에서 알아볼 수 있는 핵심은 noising 기술의 유연함이다. 다양한 변형 noising 기법들을 적용시킬 수 있으며, 이 중에서는 문장의 순서를 바꾸거나, 길이를 변경하는 등의 방법론도 있다. 가장 좋은 성능을 보이는 노이징 기법은 문장의 순서를 랜덤하게 섞고, 임의의 길이의 텍스트를 단일 마스크 토큰으로 교체하는 것이다.
38 |
39 | > 모델이 전체적인 문장 길이에 대해 학습해야 하고, 변형된 입력에 많은 집중을 요구하는 효과가 있다고 한다.
40 |
41 |
42 |
43 | 
44 |
45 | **토큰 마스킹(Token Masking)**
46 |
47 | - 랜덤하게 바뀐 [MASK] 토큰 맞추기
48 |
49 | **토큰 삭제(Token Deletion)**
50 |
51 | - 토큰이 랜덤하게 제거된다.
52 | - 모델은 어떤 위치의 토큰이 없어졌는지에 대해서도 맞춰야 한다.
53 |
54 | **토큰 채우기(Text Infilling)**
55 |
56 | - 람다 3을 따르는 포아송 분포에서 span의 길이가 샘플링되고, 각 span은 한개의 [MASK] 토큰으로 치환된다.
57 | - span의 길이가 0일 때도 [MASK] 토큰이 생성된다.
58 | - 모델은 [MASK]에 해당하는 단어들을 맞춰야 한다. 즉 얼마나 많은 토큰이 없어졌는지 예측해야 한다.
59 |
60 | **문장 셔플(Sentence Permutation)**
61 |
62 | - 문장의 순서를 랜덤으로 섞는다.
63 | - 모델은 섞인 토큰들을 원래의 순서로 배열해야 한다. (XLnet에서 영감)
64 |
65 | **문서 회전(Document Rotation)**
66 |
67 | - 하나의 토큰이 랜덤하게 선택되고, 해당 토큰이 문서의 시작지점이 된다.
68 | - 모델은 해당 문서의 시작점을 찾아야 한다.
69 |
70 |
71 |
72 | ### Fine-tuning BART
73 |
74 | 번역 테스크?? 몇개의 추가적인 transformer 레이어를 쌓아 올리는 것으로 기계 번역의 새로운 방법론을 제시하기도 하였음. 추가된 레이어는 외국어를 noise가 적용된 영어로 번역하는 것이 학습되며, BART 전반적으로 학습되게 되어 BART를 사전 학습된 target-side 언어 모델로 사용ㅎ나다. WMT 루마니안-영어 벤치마크에서 1.1 BELU만큼 성능이 향상되었다고 한다.
75 |
76 |
77 |
78 | 
79 |
80 |
81 |
82 | **Sequence Classification Tasks - 시퀀스 단위의 분류 문제**
83 |
84 | - 시퀀스 분류 문제. BERT에서 [CLS] 토큰으로 classification task를 수행하는 것에서 영감. BART에서는 디코더에서 마지막 토큰을 추가하여 해당 토큰의 representation이 전체 입력과 attention을 수행할 수 있게 한다. -> output은 모든 입력을 반영
85 |
86 | - CoLA: 문장이 문법적으로나 영어적으로 합당한지 분류
87 |
88 | **Token Classification Tasks - 토큰 단위의 분류 문제**
89 |
90 | - 디코더 가장 위의 hidden state를 각 토큰의 representation으로 사용 -> classification
91 | - SQuAD: 정답에 해당되는 start point, end point 토큰 찾기
92 |
93 | **Sequence Generation Tasks - 시퀀스 생성 문제**
94 |
95 | - Abstractive QA(question answering), 요약 등의 generation task
96 | - 이러한 테스크는 입력 시퀀스의 내용을 조정하는 특징이 있는데, denoising pre-training objective와 밀접하게 연관되어 있다고 한다.
97 |
98 | **Machine Translation**
99 |
100 | - 몇개의 추가적인 transformer layer를 쌓아 올려 기계 번역의 새로운 방법론 제시 -> BART 전체를 decoder로 사용
101 | - BART 인코더의 embedding layer를 새롭게 초기화된 인코더로 교체 -> 해당 인코더를 학습시키는 것으로 영어가 아닌 다른 단어들을 영어로 매핑하여 BART가 외국어를 denoise할 수 있게 한다.
102 | - 인코더를 2가지 step으로 학습시킨다.
103 | - BART 모델의 output에 대한 cross-entropy loss 사용
104 | - step1) 새롭게 초기화된 인코더, BART의 positional embedding, 첫번째 인코더 layer의 self-attention input projection matrix 학습
105 | - step2) 모든 모델 parameter를 작은 iteration으로 학습
106 |
107 |
108 |
109 | ### Comparing pre-training objectives
110 |
111 | 실험한 언어 모델의 종류
112 |
113 | - Language Model
114 | - Permuted Language Model
115 | - Masked Language Model
116 | - Multitask Masked Language Model
117 | - Masked Seq2Seq
118 |
119 |
120 |
121 | **Tasks**
122 |
123 | **SQuAD**
124 |
125 | - 위키 문단에 대한 QA task로, 위키피디아에서 가져온 본문과 질문이 주어지면, 주어진 본문으로부터 정답에 해당되는 span을 찾아야 한다. -> BART에서는 start point, end point의 두개를 예측하는 분류기 사용
126 |
127 | **MNLI**
128 |
129 | - NLI task와 비슷하며, 이전 문장과 이후 문장의 관계 성립 예측. -> BART에서는 두 개의 문장을 [EOS] token으로 합치고, [EOS] 토큰의 representation으로 classification 수행
130 |
131 | **[ELI5](https://facebookresearch.github.io/ELI5/)**
132 |
133 | - Long form QA task.
134 |
135 | **[XSum](https://arxiv.org/pdf/1808.08745v1.pdf)**
136 |
137 | - 뉴스 요약 테스크 -> 함축된 요약을 만들어야 한다.
138 |
139 | **ConvAI2**
140 |
141 | - 대화의 답변 만들기 -> context와 화자가 주어진다.
142 |
143 | **CNN/DM**
144 |
145 | - 뉴스 요약 테스크 -> 요약본이 입력 문서와 밀접하게 연관되어 있어 XSum과는 약간 다르다.
146 |
147 | 
148 |
149 |
150 |
151 | ### Result
152 |
153 | - **Performance of pre-training methods varies significantly across tasks**
154 |
155 | - **Token masking is crucial**
156 |
157 | - **Left-to-right pre-training improves generation**
158 |
159 | - **Bidirectional encoders are crucial for SQuAD**
160 |
161 | - **The pre-training objective is not the only important factor**
162 |
163 | - **Pure language models perform best on ELI5**
164 |
165 | - **BART achieves the most consistently strong performance.**
166 |
167 |
168 |
169 |
170 |
171 | ## BERT 라이브러리 탐색
172 |
173 | BERT 관련 모델을 쉽게 학습하거나 pre train model을 쉽게 사용 할 수 있는 라이브러리들이 있다.
174 |
175 |
176 |
177 | ### ktrain
178 |
179 | https://github.com/amaiya/ktrain
180 |
181 |
182 |
183 | ### bert-as-service
184 |
185 | https://github.com/hanxiao/bert-as-service
186 |
187 |
--------------------------------------------------------------------------------
/summaries/chapter09/chapter09_VideoBERT.md:
--------------------------------------------------------------------------------
1 | # Chapter 9. VideoBERT
2 |
3 | ## VideoBert로 언어 및 비디오 표현 학습
4 |
5 | **VideoBERT** 📄 [VideoBERT: A Joint Model for Video and Language Representation Learning](https://arxiv.org/pdf/1904.01766.pdf)
6 |
7 | 
8 |
9 | - 영상과 언어의 표현을 동시에 배우는 최초의 BERT 모델
10 | - 이미지 캡션 생성, 비디오 캡션, 비디오의 다음 프레임 예측 등과 같은 태스크에 사용
11 |
12 | ### VideoBERT 사전 학습
13 |
14 | - **MLM(cloze 태스크)과 언어-시각(linguistic-visual) 정렬이라는 새로운 태스크를 사용하여 사전학습**
15 |
16 | - 데이터: 교육용 비디오(e.g., 요리 비디오)
17 |
18 | - 교육자의 말과 해당 시각 자료(영상)가 서로 일치해 언어와 비디오의 표현을 동시에 배우는데 도움
19 |
20 | - 비디오에서 언어 토큰과 시각 토큰을 추출하여 학습에 사용
21 |
22 | - 언어 토큰 추출 방법
23 |
24 | 1. 비디오에 사용된 오디오를 추출
25 |
26 | 2. 오디오를 텍스트로 변환
27 |
28 | **자동 음성 인식**(automatic speech recognition) 툴킷을 활용
29 | _Cf. https://cloud.google.com/speech-to-text_
30 |
31 | 3. 텍스트를 토큰화하면 언어 토큰 생성
32 |
33 | - 시각 토큰 추출 방법
34 |
35 | 1. 비디오의 이미지 프레임을 20fps(초당 프레임)로 샘플링
36 | 2. 이미지 프레임을 1.5초의 구간으로 시각 토큰들로 변환
37 |
38 | - 입력 토큰
39 |
40 | 1. 언어와 시각 토큰 결합
41 |
42 | 특수 토큰 `[>]` 으로 언어 및 시각적 토큰 결합
43 |
44 | 2. 언어 토큰의 시작 부분에 `[CLS]` 토큰 추가, 시각 토큰 끝에만 `[SEP]` 토큰 추가
45 |
46 | 3. 언어 및 시각 토큰 중 몇 가지 토큰들을 무작위로 마스킹
47 |
48 | - **cloze 태스크**
49 |
50 | - VideoBERT에서 반환된 마스크된 표현을 분류기(피드포워드 + 소프트맥스)에 입력하면, 분류기는 마스크된 토큰 예측
51 |
52 | 
53 |
54 | - **언어-시각 정렬**
55 |
56 | - NSP 태스크와 유사한 분류 태스크
57 |
58 | - 언어와 시각 토큰이 시간적으로 서로 정렬되어 있는지 예측
59 |
60 | = 텍스트(언어 토큰)가 비디오(시각적 토큰)와 일치하는지 여부 예측
61 |
62 | - `[CLS]` 토큰의 표현을 가져온 다음 주어진 언어 및 시각 토큰이 일시적으로 정렬되는지 여부를 분류하는 분류기에 입력
63 |
64 | _Cf. NSP는 `[CLS]` 표현을 이용해 주어진 문장 다음에 출현하는 문장이 다음 문장인지 예측_
65 |
66 | - **최종 사전 학습 목표**
67 |
68 | - 세 가지 목표: 텍스트, 비디오, 비디오-텍스트
69 |
70 | - **텍스트**
71 |
72 | 언어 토큰을 마스킹하고 마스크 언어 토큰을 예측하도록 모델을 학습시켜서 모델이 언어 표현을 더 잘 이해하도록 함
73 |
74 | - **비디오**
75 |
76 | 시각 토큰을 마스킹하고 마스크된 시각 토큰을 예측하도록 모델을 학습시켜서 모델이 비디오 표현을 더 잘 이해하도록 함
77 |
78 | - **비디오-텍스트**
79 |
80 | 언어 및 시각적 토큰을 마스킹하고 모델을 학습시켜 언어 및 시각 토큰을 예측하고, 언어-시각 정렬을 학습하게 해서 모델이 언어와 시각 토큰 간의 관계를 이해하게 함
81 |
82 | - 최종 사전 학습 목표: 세 가지 방법을 모두 활용한 가중치 조합
83 | - 4개의 TPU를 사용해 2일 동안 50만 번 반복해 최종 사전 학습 목표를 수행하며 학습
84 |
85 | ### 데이터 소스 및 전처리
86 |
87 | **데이터셋**
88 |
89 | - 유튜브의 교육용 비디오 사용
90 |
91 | - 유튜브 동영상 주석(annotation) 시스템을 이용해 요리와 관련된 유튜브 동영상 추출
92 |
93 | - 15분 미만 영상 길이, 31만 2000개의 동영상
94 |
95 | - 유튜브 API에서 제공하는 자동 음성 인식 도구(ASR)를 사용해 텍스트 추출
96 |
97 | - 텍스트를 타임 스탬프와 함께 갖고오기 위함 (비디오에 사용된 언어에 대한 정보도 반환)
98 |
99 | - 31만 2000개의 동영상 중 18만 개의 동영상에만 ASR을 적용할 수 있었고, 그 중 영어로 된 동영상은 12만개로 추정
100 |
101 | ➡︎ 텍스트 및 비디오-텍스트 목표를 위해 12만 개의 비디오만 사용하고, 비디오 목표는 31만 2000개의 비디오 사용
102 |
103 | **비디오 및 언어 전처리**
104 |
105 | - 시각 토큰
106 | 1. 비디오의 이미지 프레임을 20fps(초당 프레임)로 샘플링
107 | 2. 이미지 프레임을 1.5초의 구간으로 시각 토큰들로 변환 (= 30-frame clip 생성)
108 | 3. 각 30-frame clip에 사전 학습된 비디오 컨볼루셔널 뉴럴넷을 적용해 특징 추출
109 | 3. 계층적 k-평균 알고리즘을 적용해 시각 특징 토큰화
110 | - 언어 토큰
111 | 1. 상용 LSTM 기반 언어 모델을 이용해 각 ASR 단어 시퀀스에 구두점을 추가하여 단어 스트림을 문장으로 나눔
112 | 2. 각 문장에 대해 BERT의 텍스트 전처리와 동일한 방식을 따르며, 텍스트 토큰화
113 |
114 | > 💡 자연스럽게 문장으로 나뉘는 언어와 달리, 비디오는 어떻게 의미론적으로 나눌까?
115 | >
116 | > - 휴리스틱 사용
117 | > - ASR 문장이 존재할 경우, 문장의 시작 및 종료 timestamp 사이에 해당하는 비디오 토큰을 세그먼트로 취급
118 | > - ASR 문장이 존재하지 않을 경우, 하나의 세그먼트를 16개의 토큰으로 취급
119 |
120 | ### VideoBERT의 응용
121 |
122 | 사전학습된 VideoBERT 모델을 사용해 다양한 다운스트림 태스크에 맞춰 파인튜닝
123 |
124 | - 시각 토큰을 입력해 상위 3개의 다음 시각 토큰 예측
125 | - 텍스트가 주어지면 해당하는 비디오 생성
126 | - 비디오에 자막 생성
127 |
128 | ## Transformers in vision
129 |
130 | 📄 [Transformers in Vision: A Survey](https://arxiv.org/pdf/2101.01169.pdf)
131 |
132 | - Computer Vision 분야에서 Transformer가 활용된 연구들 정리한 survey paper
133 |
134 | ### Background
135 |
136 | RNN to Transformer in NLP ⇨ CNN에 self-attention 적용 ⇨ Transformer 모델 자체를 CV 태스크에 사용
137 |
138 | ### Task
139 |
140 | 
141 |
142 | ***Table 1 from Transformers in Vision: A survey***
143 |
144 | *A summary of key design choices adopted in different variants of transformers for a representative set of computer vision applications. The main changes relate to specific loss function choices, architectural modifications, different position embeddings and variations in input data modalities.*
145 |
146 | ### Model
147 |
148 | #### Transformers for Multi-Modal Tasks
149 |
150 | *Multi-modal learning: 다양한 데이터 타입, 데이터 형태, 다양한 특성을 갖는 데이터를 사용하는 학습법*
151 |
152 | - Transformer 모델은 vision-language 태스크에도 광범위하게 사용
153 | - visual question answering (VQA)
154 | - visual commonsense reasoning (VCR)
155 | - cross-modal retrieval
156 | - image captioning
157 |
158 | 
159 |
160 | *An overview of Transformer models used for multi-modal tasks in computer vision*
161 |
162 | #### Vision Transformer (ViT)
163 |
164 | 📄 [AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE](https://arxiv.org/pdf/2010.11929.pdf)
165 |
166 | 
167 |
168 | - CNN 구조였던 computer vision 문제를 Transformer 구조로 대체
169 | - Transformer 구조를 사용한 Architecture가 수 많은 SOTA를 찍고 있으며, **ViT 논문이 그 시작점**
170 | - Transformer 구조를 활용하여 image classification을 수행한 방법론
171 | - 더 많은 데이터를 더 적은 비용으로 사전 학습
172 |
173 | - 구조
174 |
175 | - Transformer encoder 사용
176 | - 한 이미지를 여러 patch로 분할 (patch를 단어같이 취급)
177 | - patch, classification token, position embedding을 입력하여 최종 classification 결과 생성
178 |
179 | > CNN vs Transformer
180 | >
181 | > - Layer
182 | >
183 | > - CNN: 이미지 전체의 정보를 통합하기 위해서는 몇 개의 layer 통과
184 | > - Transformer: 하나의 layer로 전체 이미지 정보 통합 가능
185 | >
186 | > - Inductive bias
187 | >
188 | > _새로운 데이터에 대해 좋은 성능을 내기 위해 모델에 사전적으로 주어지는 가정_
189 | >
190 | > - CNN: 2차원의 지역적인 특성 유지, 학습 후 weight 고정
191 | >
192 | > → 인접한 픽셀 간 강한 상관관계가 있다는 특징을 살려 inductive bias가 적절하게 만들어짐으로써 이미지 특징 효과적 추출
193 | >
194 | > - Transformer: 1차원 벡터로 만든 후 self attention (2차원의 지역적인 정보 유지 x), weight가 input에 따라 유동적으로 변함
195 | >
196 | > → inductive bias가 적고, 모델의 자유도가 높아 데이터로부터 더 많은 정보를 얻을 수 있음
197 |
198 | - 한계
199 |
200 | - 학습 데이터가 충분하지 않을 경우 CNN 모델보다 성능 감소 (∵ inductive bias ↓)
201 |
202 | ➡︎ 대용량의 학습 자원과 데이터가 필요
203 |
204 | #### Data efficient image Transformer (DeiT)
205 |
206 | 📄 [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
207 |
208 | - 많은 데이터가 필요한 ViT 한계 극복
209 | - Knowledge Distilation
210 | - Data Augmentation
211 |
212 | ## 참고 자료
213 |
214 | #### 개념
215 |
216 | - [Multimodal Deep Learning](https://towardsdatascience.com/multimodal-deep-learning-ce7d1d994f4)
217 |
218 | #### 세미나
219 |
220 | - [DMQA Transformer in Computer Vision](http://dmqm.korea.ac.kr/activity/seminar/316)
221 |
222 | #### 논문
223 |
224 | - [VideoBERT: A Joint Model for Video and Language Representation Learning](https://arxiv.org/pdf/1904.01766.pdf)
225 | - [Transformers in Vision: A Survey](https://arxiv.org/pdf/2101.01169.pdf)
226 | - **리뷰**
227 | - [Transformers in Vision: A Survey [1] Transformer 소개 & Transformers for Image Recognition](https://hoya012.github.io/blog/Vision-Transformer-1/)
228 | - [AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE](https://arxiv.org/pdf/2010.11929.pdf)
229 | - **리뷰**
230 | - https://engineer-mole.tistory.com/133
231 | - https://kmhana.tistory.com/27
232 |
233 | #### 책
234 |
235 | - [구글 BERT의 정석](http://www.yes24.com/Product/Goods/104491152)
236 |
--------------------------------------------------------------------------------
/summaries/chapter10/chapter10_kobert_kogpt2_kobart.md:
--------------------------------------------------------------------------------
1 | # Chapter 10 한국어 언어 모델: KoBERT, KoGPT2, KoBART
2 |
3 | - 다국어 모델들은 한국어 데이터의 부족 때문에 좋은 성능을 보이지 못함
4 |
5 | ## KoBERT
6 |
7 | - 한국어 위키피디아에서 500만 개의 문장과 5400만 개의 단어 학습
8 | - Huggingface, MXNet-Gluon, ONNX 등 여러 플랫폼에서 사용 가능
9 | - Sentencepiece를 이용해 Tokenizer 학습
10 | - 8,002개의 vocab size
11 |
12 | ## KoGPT2
13 |
14 | - 한국어에 특화된 GPT-2 모델
15 | - 주어진 텍스트를 기반으로 다음 단어를 잘 예측할 수 있도록 학습됨
16 | - 문장 생성에 최적화
17 | - 125M parameter
18 | - 한국어 위키피디아, 뉴스, 모두의 말뭉치 v1.0, 청와대 국민청원 등 40GB의 한국어 텍스트 사용
19 | - BPE Tokenizer
20 | - 51,200 vocab
21 | - 이모티콘, 이모지도 추가
22 |
23 | ## KoBART
24 |
25 | - text infilling 노이즈 함수만 적용
26 | - 40GB 이상의 한국어 텍스트로 사전 학습
27 | - Denoising AutoEncoder
28 | - 6 encoder layers
29 | - 6 decoder layers
30 | - 16 attention heads
31 | - 768 FFN hidden unit
32 | - 120M parameters
--------------------------------------------------------------------------------
SpanBERT와 BERT
26 |
27 | 🤔 기존 많은 NLP tasks는 **두 개 이상의 text span의 관계 추론**을 포함했고, 이는 self supervision tasks를 더 어렵게 했다.
28 |
29 | ➡︎ SpanBERT는 **span-level** 사전학습 방식으로 항상 BERT보다 좋은 성능을 낸다.
30 |
31 | - 특히 span selection tasks에서 뛰어난 성능을 보인다.
32 |
33 | - question answering
34 | - coreference resolution (상호참조해결)
35 | - 데이터를 더 추가하거나 모델 크기를 키우지 않고, 좋은 사전학습 tasks와 objectives만으로도 좋은 성능을 낼 수 있다는 의의가 있다.
36 |
37 | ### Model
38 |
39 | - 연속된 랜덤 spans 마스킹
40 | - span boundary objective (SBO) 도입
41 |
42 | - 단일 연속 text segment 샘플링 ➡︎ BERT의 NSP 생략
43 |
44 | #### Span Masking
45 |
46 | `masking spans of full words using a geometric distribution based masking scheme`
47 |
48 | - 주어진 토큰 시퀀스 *X=(x1,…,xn)* 에서 masking budget(e.g. 15% of X)이 다 사용될 때까지 text span 샘플링
49 |
50 | 1. 각 iteration 마다 span length(단어 개수)를 샘플링
51 |
52 | - 짧은 span으로 치우친 geometric distribution *𝓵 ~ Geo(p)* 에서 샘플링
53 |
54 | 2. 마스킹될 span의 시작점을 랜덤(균일)하게 뽑는다.
55 |
56 | 완전한 단어 seqeunce를 샘플링한다. (subword tokens X)
57 |
58 | 3. span에 있는 모든 토큰들을 [MASK] 또는 sampled tokens로 대체한다. (span-level masking)
59 |
60 | *Cf. BERT는 80-10-10% 로 각 토큰을 개별적으로 대체*
61 |
62 | #### Span Boundary Objective (SBO)
63 |
64 | `optimizing an auxiliary span boundary objective (SBO) in addition to MLM`
65 |
66 | span selection model은 일반적으로 boundary 토큰을 이용하여 span의 고정된 길이 표현을 생성한다.
67 |
68 | ➡︎ **boundary 토큰의 표현만을 이용해 masked span의 각 토큰을 예측하는 Span boundary objective(SBO)** 도입했다.
69 |
70 | - SBO는 모델이 fine-tuning 시에 쉽게 접근할 수 있는 boundary 토큰에 span-level 정보를 저장하게 하여 span selection model을 지원한다.
71 |
72 | - span에 있는 마스킹된 토큰 `xi` *(target token: xi)* 을 예측하는 방법
73 | - xs와 xe를 각각 마스킹된 토큰에 대한 표현의 시작과 종료 지점이라고 할 때, 다음 3개의 값을 사용한다.
74 | - external boundary tokens `xs−1` and `xe+1`
75 | - position embedding of the target token `pi−s+1` (left boundary token xs-1로부터 상대 위치)
76 |
77 | - 3개의 값을 2 layer feed-forward network with GeLU activations and layer normalization 에 입력하여 얻은 출력값을 사용한다.
78 |
79 | - SpanBERT의 손실함수는 MLM과 SBO loss *(cross-entropy loss)*를 더한 값이다.
80 |
81 | #### Single-Sequence Training
82 |
83 | BERT의 examples는 두 개의 text sequence *(X_A, X_B)* 를 사용하고, 두 sequence의 연결 여부를 예측*(NSP)*하게 모델을 학습시켰다. *(bi-sequence training with NSP)*
84 |
85 | 하지만 single-sequence training이 bi-sequence training with NSP보다 우수했고, 이유는 다음과 같을 것이라고 가정했다.
86 |
87 | *: bi-sequence training은 모델이 더 긴 범위의 features를 학습하는 것을 방해하고, 결과적으로 많은 downstream tasks 에서 성능을 저하시킨다.*
88 |
89 | ➡︎ **NSP objective과 two-segment sampling procedure를 모두 제거하고,** 두 개의 half-segments를 합쳐서 n개의 토큰이 아닌,
90 |
91 | **최대 n=512의 토큰의 단일 연속 segment를 샘플링**해서 다양한 downstream tasks의 성능을 향상시켰다.
92 |
93 | ---
94 |
95 | 
96 |
97 | SpanBERT 학습 과정
98 |
99 | ### Tasks
100 |
101 | - Extractive Question Answering
102 | - 짧은 글과 질문을 입력한 후에 글에서 답으로 연속적인 text span을 선택하는 task
103 |
104 | - Coreference Resolution
105 |
106 | - 동일한 개체(entity)를 표현하는 다양한 단어(mention)들을 찾아 연결해주는 task
107 |
108 | *[Coreference Resolution 관련 설명 및 논문이 정리된 블로그](https://jjdeeplearning.tistory.com/26)*
109 |
110 | - Relation Extraction
111 |
112 | - 두 span이 들어있는 한 문장이 주어졌을 때 42개의 사전 정의된 관계 타입으로부터 span 사이의 관계를 예측하는 task
113 |
114 | - GLUE
115 |
116 | - General Language Understanding Evaluation (GLUE) benchmark는 9개의 sentence-level 분류 tasks로 구성
117 |
118 | ### Results
119 |
120 | - SpanBERT는 거의 모든 task에 대해 BERT보다 뛰어나다.
121 | - SpanBERT는 특히 extractive question answering에 좋다.
122 | - single-sequence training이 bi-sequence with NSP 보다 상당히 잘 작동한다.
123 |
124 | ### Summary
125 |
126 | - 이 논문은 span 기반 사전 학습 방식인 SpanBERT를 제시했다.
127 |
128 | - SpanBERT는 BERT를 확장했다.
129 |
130 | (1) random 토큰 대신, 연속적인 랜덤 span을 마스킹한다.
131 |
132 | (2) 개별 토큰 표현이 아닌, span 경계 표현을 학습시켜 마스킹된 span의 전체 내용을 예측한다.
133 |
134 | - SpanBERT는 여러 task에 대해 모든 BERT baselines를 뛰어넘었다.
135 |
136 | - SpanBERT는 span selection tasks에 특히 좋은 성능을 보인다.
137 |
138 | ## 사전 학습된 SpanBERT를 질문-응답 태스크에 적용하기
139 |
140 | ```python
141 | from transformers import pipeline
142 |
143 | qa_pipeline = pipeline(
144 | "question-answering",
145 | model="mrm8488/spanbert-large-finetuned-squadv2",
146 | tokenizer="SpanBERT/spanbert-large-cased"
147 | )
148 |
149 | results = qa_pipeline({
150 | 'question': "What is machine learning?",
151 | 'context': "Machine learning is a subset of artificial intelligence. It is widely for creating a variety of applications such as email filtering and computer vision"
152 | })
153 |
154 | print(results['answer']) # a subset of artificial intelligence
155 | ```
156 |
157 | *SpanBert는 텍스트 범위를 예측하는 작업에 많이 사용된다.*
158 |
159 | ## 참고 자료
160 |
161 | - 구글 BERT의 정석 [book](http://www.yes24.com/Product/Goods/104491152)
--------------------------------------------------------------------------------
/summaries/chapter04/chapter04_roberta.md:
--------------------------------------------------------------------------------
1 | # Chatper 4 BERT의 파생 모델 1
2 |
3 | 이 챕터에서 다루는 BERT의 파생 모델들
4 |
5 | - ALBERT
6 | - RoBERTa
7 | - ELECTRA
8 | - SpanBERT
9 |
10 | ## RoBERTa
11 |
12 | - Robustly Optimized BERT pre-training Approach
13 | - BERT가 충분히 학습되지 않았음을 확인
14 | - BERT와의 차이
15 | - MLM에서 Dynamic Masking 사용
16 | - NSP 제거
17 | - 배치 크기 증가
18 | - BBPE Tokenizer 사용
19 |
20 | ### Dynamic Masking
21 |
22 | - Static Masking
23 | - BERT에서 Masking은 전처리 단계에서 한 번만 수행
24 | - Epoch 별로 동일한 Masking을 예측
25 | - Dynamic Masking
26 | - 문장 10개를 복사
27 | - 각각의 복사된 문장에 대해 무작위로 15%의 확률로 Masking
28 | - 40 Epoch이면 1,2,3,4,...,10,1,2,3,...와 같이 학습시킴
29 |
30 | ### NSP 제거
31 |
32 | - 연구원들은 NSP가 BERT에 유용하지 않다는 것을 발견
33 | - Ablation Study
34 | 1. Segment-Pair + NSP: NSP를 사용해서 BERT 학습. 원래 BERT 모델 학습 방법과 유사
35 | 2. Sentence-Pair + NSP: NSP를 사용해서 BERT 학습. 입력은 한 문서의 연속된 부분 또는 다른 문서에서 추출한 문장을 쌍으로 구성
36 | 3. Full Sentences: NSP를 사용하지 않고 BERT 학습. 입력은 하나 이상의 문서에서 지속적으로 샘플링한 결과를 사용. 하나의 문서에서 마지막까지 샘플링하면 다음 문서로 넘어감.
37 | 4. Doc Sentences: NSP를 사용하지 않고 BERT 학습. Full Sentences와 비슷하지만 입력값은 하나의 문서에서만 샘플링한 결과를 입력.
38 | - Results
39 |
40 | | Model | SQuAD 1.1/2.0 | MNLI-m | SST-2 | RACE |
41 | | -------------- | ------------- | ------ | ----- | ---- |
42 | | Segment-Pair | 90.4/78.7 | 84 | 92.9 | 64.2 |
43 | | Sentence-Pair | 88.7/76.2 | 82.9 | 92.1 | 63.0 |
44 | | Full-Sentences | 90.4/79.1 | 84.7 | 92.5 | 64.8 |
45 | | Doc-Sentences | 90.6/79.7 | 84.7 | 92.7 | 65.6 |
46 |
47 | - 결론적으로 NSP를 제거하는 것이 성능이 더 좋더라!
48 | - 성능은 Full-Sentences보다 Doc-Sentences가 더 좋지만 RoBERTa에서는 Doc-Sentences의 경우 문서에 따라 배치 크기가 달라지기 때문에 Full-Sentences를 사용하여 학습
49 |
50 | ### 더 많은 데이터로 학습
51 |
52 | - BERT에서 사용한 데이터는 16GB
53 | - RoBERTa에서 사용한 데이터는 160GB
54 |
55 | ### 큰 배치 크기로 학습
56 |
57 | - BERT: 256개 배치로 1M Step Pretrain
58 | - RoBERTa: 8000개 배치로 0.3M Step Pretrain
59 | - 배치 크기를 키우면
60 | - 학습 속도를 높일 수 있고,
61 | - 모델의 성능도 향상
62 |
63 | ### BBPE Tokenizer
64 |
65 | - BERT는 Wordpiece Tokenizer 사용
66 | - 캐릭터가 아니라 Byte 형태의 시퀀스 사용
67 | - BERT는 vocab size 30000, BBPE는 50000
68 |
69 | ```python
70 | from transformers import RobertaConfig, RobertaTokenizer
71 |
72 | model = RobertaModel.from_pretrained('roberta-base')
73 | model.config
74 |
75 | tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
76 | tokenizer.tokenize('It was a great day')
77 | ```
78 |
79 | ### Summary
80 |
81 | - RoBERTa는 BERT의 파생모델
82 | - MLM Task로만 학습
83 | - Static Masking
84 | - 큰 Batch size
85 | - BBPE Tokenizer
86 |
87 | ## References
88 |
89 | - https://jeongukjae.github.io/posts/3-roberta-review/
90 | - https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=jjys9047&logNo=221671424019
91 | - https://brunch.co.kr/@choseunghyek/7
--------------------------------------------------------------------------------
/summaries/chapter05/chapter05_DistilBERT.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Gubuzeong/Getting-Started-with-Google-BERT/ae04bb9d23b4423749f121162df878972989e23c/summaries/chapter05/chapter05_DistilBERT.pdf
--------------------------------------------------------------------------------
/summaries/chapter05/chapter05_TinyBERT.md:
--------------------------------------------------------------------------------
1 | # Chapter 5 BERT 파생 모델 2: 지식 증류 기반
2 |
3 | ## TinyBERT
4 |
5 | - Teacher model의 output layer 말고도 embedding, encoder layers에서 KD
6 | - 중간 layer에서의 지식도 전달
7 | - Student가 Teacher로부터 더 많은 것을 배울 수 있음
8 | - Attention Matrix는 언어 정보를 캡슐화하므로(?) Teacher의 Attention Matrix에서 Student에게 지식을 전달하면 도움이 많이 됨
9 | - 사전학습 뿐만 아니라 fine-tuning에서도 KD
10 | - (Teacher-Student) 아키텍쳐는 동일하지만 layer수가 다름
11 | - Embedding vector size d = 312
12 | - Teacher BERT
13 | - index 0 - Embedding layer
14 | - index 1 - 첫번째 encoder layer
15 | - index n - n번째 encoder layer
16 | - index n + 1 - prediction layer
17 | - 교사의 n번째 layer에서 학생의 m번째 layer로 지식을 전달
18 |
19 | ### Transformer layer distillation
20 |
21 | - Attention-based Distillation
22 | - Hidden state-based Distillation
23 |
24 | ### Attention-based Distillation
25 |
26 | - Attention Matrix에 대한 지식을 Teacher → Student 이전
27 | - Attention Matrix에는 언어 구문, 상호 참조 정보 등과 같은 정보가 포함됨
28 | - Student attention matrix와 Teacher attention matrix 사이의 MSE를 최소화 해 Student 학습
29 | - L_att = (sum(MSE(A_i^S, A_i^T)) / h
30 | - h: attention head 수
31 | - A_i^S: Student BERT의 ith head의 attention matrix
32 | - A_i^T: Teacher BERT의 ith head의 attention matrix
33 | - MSE는 Mean Squared Error
34 | - 정규화(Normalization)하지 않은 (Softmax가 없는) Attention Matrix 사용 → 비정규화된 Attention Matrix가 더 좋은 성능을 내고, 수렴 속도도 빠름
35 |
36 | ### Hidden state-based Distillation
37 |
38 | - Hidden state는 기본적으로 Encoder의 출력, representation vector
39 | - H^S와 H^T의 차원이 다를 수 있음
40 | - L_hidden = MSE(H^SW_h, H^T)
41 | - W_h는 학습을 통해 달라지는 값. H^S를 H^T와 같은 공간에 있을 수 있도록 선형변환
42 |
43 | ### Embedding layer Distillation
44 |
45 | - Hidden state와 유사하게 차원이 다를 수 있기 때문에 W_e로 선형 변환
46 | - L_embedding = MSE(E^SW_e, E^T)
47 |
48 | ### Prediction layer Distillation
49 |
50 | - Teacher model에서 생성한 최종 logit으로 학습. DistilBERT와 유사
51 | - Soft target - Soft prediction 사이의 Cross-entropy loss를 minimize
52 | - L_pred = -softmax(Z^T)* log_softmax(Z^S)
53 |
54 | ### 최종 loss function
55 |
56 |
57 |
58 | ## TinyBERT 학습
59 |
60 | - General Distillation
61 | - Task-specific Distillation
62 |
63 | ### General Distillation
64 |
65 | - 사전 학습 단계를 의미
66 | - Large BERT를 Teacher로 사용하고 Student model에게 지식을 전달
67 | - 모든 layer에 증류 적용
68 | - 증류 후 Student BERT는 Teacher의 지식으로 구성, 사전 학습된 Student BERT를 General TinyBERT라고 부름
69 | - Downstream task를 위해 General TinyBERT를 Fine-tuning 할 수 있음
70 |
71 | ### Task-specific Distillation
72 |
73 | - Fine-tuning
74 | - 특정 Task를 위해 General TinyBERT를 Fine-tuning
75 | - Teacher model을 먼저 Fine-tuning, 다시 General TinyBERT로 Distillation 진행
76 | - Fine-tuning 단계에서 Distillation을 하려면 더 많은 dataset 필요 → Data Augmentation
77 |
78 | ### Data Augmentation
79 |
80 | Tokenized sentence X의 각각 모든 단어에 대해,
81 |
82 | 1. X[i]가 단일 단어인지 확인. 단일 단어라면 [MASK] 토큰으로 masking. BERT-base로 masked token을 예측. 확률이 높은 상위 K개의 단어 candidates에 저장
83 | 2. X[i]가 단일 단어가 아니면 masking 하지 않음. GloVe Embedding을 사용해 X[i]와 가장 유사한 K 단어 확인하고 candidates에 저장. p~Uniform(0,1)에서 값 p를 무작위로 추출하고, threshold를 p_t = 0.4로 설정
84 | 3. p가 p_t보다 작거나 같으면 X_masked[i]를 후보 목록의 임의 단어로 교체
85 | 4. p가 p_t보다 크면 교체 안함
86 |
87 | - N번 반복하면 N개의 Augmented sentence가 생성
88 | - Augmented Data를 사용하여 General TinyBERT를 Fine-tuning
89 | - TinyBERT는 BERT-base 모델보다,
90 | - 96%의 추론 효율 향상
91 | - 7.5배 작음
92 | - 9.4배 빠름
93 |
94 | ## BERT에서 신경망으로 지식 전달
95 |
96 | - BERT에서 간단한 신경망으로 Distillation이 가능할까?
97 | - Teacher model - Pretrained BERT(여기서는 BERT-large)
98 | - Teacher model을 Downstream task에 맞게 fine-tuning
99 | - Student model - Bi-LSTM
100 | - Bi-LSTM은 양방향으로 문장을 읽음
101 | - 순방향, 역방향 hidden state를 FFN에 넣고 logit 출력
102 | - softmax → 확률
103 |
104 | ### Student network training
105 |
106 | - 일단 Teacher부터 Fine-tuning
107 | - L = a * L_student + b * L_distillation
108 | - L_distillation = MSE(Z^T, Z^S) → Soft target, Soft prediction에 대한 MSE
109 | - L_student: Hard target, Hard prediction에 대한 cross-entropy
110 | - Teacher BERT에서 Student Network로 KD를 수행하려면 큰 데이터셋 필요
111 | - Task-agnostic Data Augmentation
112 |
113 | ## Data Augmentation
114 |
115 | - Masking
116 | - POS based word replacement
117 | - n-gram sampling
118 |
119 | ### Masking
120 |
121 | - TinyBERT의 DA 방법
122 |
123 | ### POS based word replacement
124 |
125 | - p_pos 확률로 문장의 한 단어를 같은 품사 다른 단어로 대체
126 |
127 | ### n-gram Sampling
128 |
129 | - p_ng 확률로 문장에서 n-gram을 random sampling
130 | - n은 1~5까지 무작위
131 |
132 | ### Data Augmentation Process
133 |
134 | - X_i ~ Uniform(0,1)
135 | - X_i < p_mask이면 w_i 단어를 masking
136 | - p_mask ≤ X_i p_mask + p_pos이면 POS word replacement를 진행
137 | - Masking과 POS based WR은 겹치지 않음. 둘 중 하나만 적용 가능
138 | - 이 단계 이후, p_ng 확률로 n-gram sampling
139 | - N번 수행 → N개의 새로운 Augmented data
140 |
141 | 문장이 아니라 문장 쌍이라면?
142 |
143 | - 문장 1 합성 + 문장 2 유지
144 | - 문장 1 유지 + 문장 2 합성
145 | - 문장 1 합성 + 문장 2 합성
146 |
147 | 이런 식으로 Augmentation 가능
--------------------------------------------------------------------------------
/summaries/chapter06/chapter06_텍스트_요약을_위한_BERTSUM_탐색_(1).md:
--------------------------------------------------------------------------------
1 | # Chapter 6: 텍스트 요약을 위한 BERTSUM 탐색
2 |
3 | > Speaker: 남수연
4 |
5 |
6 | # 텍스트 요약
7 |
8 | NLP 분야의 주요 연구 분야 중 하나로, 주어진 긴 텍스트를 요약하는 것. 긴 문서, 뉴스 기사, 법률 문서, 블로그 게시물 등 다양한 영역에서 널리 사용됨.
9 |
10 | # 텍스트 요약 방식 이해하기
11 |
12 | 아래와 같은 텍스트를 요약해야 한다고 해보자.
13 |
14 | ```
15 | 나는 어제 신촌에서 동아리 운영진 동기 언니와 10시간 내내 먹었다. 점심으로
16 | 진돈부리를 가려고 했지만 딱 어제 휴업하는 바람에 반서울에 갔는데 엄청 맛있었다.
17 | 다음에 또 와야겠다고 생각했다. 후식으로 파이홀에 가서 오레오말차가나슈파이와 얼그
18 | 레이가나슈파이를 먹었다. 역시 다음에 또 와야겠다고 생각했다. 저녁으로 돈우마미에
19 | 가서 사케동을 먹었다. 가라아게 4조각을 시켰는데 서비스로 한 조각을 더 주셔서
20 | 돈우마미는 참 좋은 가게라는 생각이 들었다. 마지막으로 아워즈에 가서 칵테일을 조
21 | 졌다. 줄리엣이라는 칵테일을 주문했는데 요맘때 복숭아맛과 딸기맛을 섞어놓은 것 같은
22 | 것이 정말 정말 맛있었다. 정신을 차려보니 9시 30분이어서 허겁지겁 버스를 타고
23 | 집에 왔더니 월요일이 스터디 하는 날이랜다. 어이가 없어서 헛웃음이 나왔지만 지금
24 | 웃을 때가 아니므로 열심히 스터디 준비를 하는 중이다.
25 | ```
26 |
27 | ## 추출 요약
28 |
29 | 주어진 텍스트 안에서 중요한 문장만 추출해 요약한다. 입력의 문장 중 중요도가 높은 순으로 N개의 문장을 뽑는 식이다.
30 |
31 | ```
32 | 나는 어제 신촌에서 동아리 운영진 동기 언니와 10시간 내내 먹었다. 점심으로
33 | 진돈부리를 가려고 했는데 딱 어제만 휴업하는 바람에 반서울에 갔는데 엄청 맛있
34 | 었다. 후식으로 파이홀에 가서 오레오말차가나슈 파이와 얼그레이가나슈파이를 먹었다.
35 | 마지막으로 아워즈에 가서 칵테일을 조졌다. 어이가 없어서 헛웃음이 나왔지만 지금
36 | 웃을 때가 아니므로 열심히 스터디 준비를 하는 중이다.
37 | ```
38 |
39 | ## 생성 요약
40 |
41 | 주어진 텍스트를 의역해서 원래 문서에 포함되지 않은 문장으로 요약을 만든다.
42 |
43 | ```
44 | 어제의 나는 동아리 언니와 10시간동안 쉬지 않고 먹었다. 정신을 차려보니 발등에
45 | 불이 떨어진 상태여서 열심히 스터디 준비를 하는 중이다.
46 | ```
47 |
48 | ## Summary
49 |
50 | | | 추출 요약 | 생성 요약 |
51 | | --- | --- | --- |
52 | | 입력 문장을 그대로 사용하는가? | O | X |
53 | | 정보 누락 정도 | 많음 | 적음 |
54 | | 컴퓨팅 리소스 필요량 | 적음 | 많음 |
55 | | 학습 시간 필요량 | 적음 | 많음 |
56 |
57 | # 텍스트 요약에 맞춘 BERT 파인 튜닝
58 |
59 | ## BERT을 활용한 추출 요약
60 |
61 | 사전학습된 BERT를 사용해 추출 요약 태스크를 진행하려면 BERT 모델 입력 데이터 형태를 수정해야 한다. BERT 모델의 입력 데이터를 수정하여 각 문장의 표현을 얻는 방법에 대해 알아보자.
62 |
63 | - BERT 복습
64 | 1. 입력 문장을 토큰 형태로 변경한다.
65 | 2. 첫 문장의 시작 부분에만 `[CLS]` 토큰을 모든 문장의 마지막 부분에 `[SEP]` 토큰을 추가한다.
66 | 3. 입력 토큰을 토큰 임베딩, 세그먼트 임베딩, 위치 임베딩, 총 3개의 임베딩 레이어 형태로 각각 변환한다.
67 | 4. 모든 임베딩을 더한 다음 BERT에 입력한다.
68 | 5. BERT는 아웃풋으로 모든 토큰의 표현 벡터를 출력한다.
69 |
70 |
71 |
72 | ### 1) 토큰 임베딩
73 |
74 | 텍스트 요약 태스크에서는 BERT 모델에 여러 문장을 입력하고 입력한 모든 문장에 대한 표현이 필요하다. **모든 문장의 시작 부분에 `[CLS]` 토큰을 추가**하면 모든 문장에 대한 표현을 얻을 수 있다. 이 `[CLS]` 토큰은 각 문장을 대표하는 토큰으로서 문장의 특징을 뽑아낼 때 사용할 것이다.
75 |
76 | ```python
77 | input = ["[CLS]", "ban", "seoul", "[SEP]", "[CLS]", "pie", "hole", "[SEP]", "[CLS]", "don", "umami", "[SEP]"]
78 | ```
79 |
80 | ### 2) 세그먼트 임베딩
81 |
82 | 세그먼트 임베딩은 입력을 $E_A, E_B$ 형태로 반환한다. 그보다 훨씬 많은 수의 문장이 입력으로 들어오는 텍스트 요약 태스크에서는 $E_A, E_B$ 만으로 어떻게 문장을 구분할 수 있을까?
83 |
84 | 인터벌 세그먼트 임베딩을 통해 홀수번째 문장에서 발생한 토큰은 $E_A$, 짝수번째 문장에서 발생한 토큰은 $E_B$에 매핑한다. 한 문장을 앞뒤의 문장들과 구분하기만 하면 되므로 이런 방법을 사용할 수 있다.
85 |
86 | ### 3) 위치 임베딩
87 |
88 | 위치 임베딩은 모든 토큰의 위치 정보에 대한 임베딩값으로, 기존 방식과 동일하다.
89 |
90 | ## BERTSUM
91 |
92 | 
93 |
94 | BERT 모델을 사용해 입력 데이터 형식을 변경해서 텍스트 요약에 특화되도록 만든 모델을 BERTSUM이라고 한다. 처음부터 BERT를 학습시킬 필요는 없으며, 이미 사전학습된 BERT 모델에 앞서 설명한 입력 데이터 형태로 변경하여 파인 튜닝하면 된다.
95 |
96 | ### 1) 분류기가 있는 BERTSUM
97 |
98 |
99 | **모든 문장의 표현을 받아서 각 문장의 중요도를 판단하는 분류기 레이어**를 ****BERT에 이어붙인다. 분류기는 각 문장을 요약에 포함시킬지 여부에 대한 확률을 제공한다. Linear Layer 하나만 사용하며, BERT의 아웃풋을 분류기 레이어에 넣어 나온 값에 sigmoid 활성화 함수를 취한 값을 target으로 활용한다. 이렇게 계산된 target과 정답을 BCE를 통해 loss를 계산한다. loss 값을 최소화하도록 BERT 모델과 분류기 레이어를 함께 학습시킨다.
100 |
101 | $$
102 | \hat{Y} = \sigma(W_oT_i + b_o)
103 | $$
104 |
105 | ### 2) 🌟 트랜스포머와 LSTM을 활용한 BERTSUM
106 |
107 | **(1) 문장 간 트랜스포머(inter-sentence transformer)를 활용한 BERTSUM**
108 |
109 | 논문에 따르면 다른 2개의 Summarization layer보다 훨씬 좋은 결과를 보여주는 방법이다. BERT의 결과인 문장 표현 $R$을 트랜스포머 레이어에 입력한다. 트랜스포머는 BERT에서 얻은 표현을 가져와 은닉 상태로 변환하는데, 이 때 도입되는 트랜스포머는 문장 간 Attention을 계산하고 문장 단위가 아닌 전체 문서 관점에서 요약 태스크를 수행한다.
110 |
111 | BERT에서 얻은 문장 표현 R에 위치 임베딩 값을 추가하여 트랜스포머의 인코더에 입력한다($h^0=PosEmb(R)$) . 인코더 $l$에서 서브레이어는 다음과 같이 표현한다.
112 |
113 | 
114 |
115 | 최상위 인코더를 $L$, 최상위 인코더에서 나온 은닉 상태를 $h^L$이라고 했을 때 문장의 포함 여부를 계산하는 식은 다음과 같다.
116 |
117 | 
118 |
119 | **(2) LSTM을 활용한 BERTSUM**
120 |
121 | BERT의 last hidden layer에 RNN을 활용하면 성능이 좋을 수 있다는 논문을 참고하여 실험을 진행했으며, 훈련 과정을 안정화하기 위해 단순 LSTM이 아닌 pergate layer nomarlization을 사용했다.
122 |
123 | BERT에서 얻은 문장 $i$에 대한 표현 $R_i$를 LSTM에 입력하면 LSTM 셀은 은닉 상태 $h_i$를 출력한다. sigmoid에 $h_i$를 입력하면 각 문장을 요약에 포함시킬지에 대한 확률을 반환한다.
124 |
125 | 
126 |
127 | ### 참고: summarization layers에 대한 ROUGE 성능 평가
128 |
129 | 
130 |
131 | # References
132 |
133 | [[논문 리뷰] Fine-tune BERT for Extractive Summarization](https://medium.com/@eyfydsyd97/bert%EB%A5%BC-%ED%99%9C%EC%9A%A9%ED%95%9C-%ED%85%8D%EC%8A%A4%ED%8A%B8-%EC%9A%94%EC%95%BD-text-summary-b582b5cc7d)
134 |
135 | [BERT를 활용한 한국어 문서 추출요약 봇](https://velog.io/@raqoon886/KorBertSum-SummaryBot)
136 |
--------------------------------------------------------------------------------
/summaries/chapter06/chapter6_BERTSUM(2)_0hee0.md:
--------------------------------------------------------------------------------
1 | # Chapter 6 텍스트 요약을 위한 BERTSUM 탐색
2 |
3 | BERTSUM: 텍스트 요약에 맞춰 파인 튜닝된 BERT 모델
4 |
5 | ## BERTSUM 모델의 성능
6 |
7 | BERTSUM 모델의 성능은 ROUGE 점수를 사용하여 평가
8 |
9 | ### ROUGE 평가 지표
10 |
11 | **ROUGE(Recall-oriented Understudy for Gisting Evalutation)**
12 |
13 | - 텍스트 요약과 기계 번역 태스크를 평가하는 데 사용하는 평가 지표
14 | - 「[ROUGE: A Package for Automatic Evaluation of Summaries](https://aclanthology.org/W04-1013/)」
15 |
16 | ROUGE의 다섯 가지 평가 지표 형태
17 |
18 | - ROUGE-N
19 | - ROUGE-L
20 | - ROUGE-W
21 | - ROUGE-S
22 | - ROUGE-SU
23 |
24 | *Cf. [ROUGE-an Evaluation Metric for Text Summarization](https://ilmoirfan.com/rouge-an-evaluation-metric-for-text-summarization/)*
25 |
26 | #### ROUGE-N
27 |
28 | 후보 요약(예측한 요약)과 참조 요약(실제 요약) 간의 n-gram 재현율(recall)
29 |
30 | ```
31 | 재현율 = (예측한 요약 결과와 실제 요약 사이의 서로 겹치는 n-gram 총 수) / (실제 요약의 n-gram의 총 수)
32 | ```
33 |
34 | *ROUGE-1(uni-gram)과 ROUGE-2(bi-gram)가 가장 많이 쓰인다.*
35 |
36 | #### ROUGE-L
37 |
38 | **가장 긴 공통 하위 시퀀스(LCS)**를 기반으로 하며, F-measure를 사용해 측정
39 |
40 | ### BERTSUM을 사용한 요약 태스크의 ROUGE 점수
41 |
42 | - 분류기, 트랜스포머, LSTM을 BERT에 적용한 BERTSUM 모델을 사용한 **추출 요약** 태스크의 ROUGE 점수
43 |
44 | *[Yang Liu. 2019. Fine-tune BERT for Extractive Summarization](https://arxiv.org/abs/1903.10318) 에서 CNN/DailyMail 테스트 데이터를 이용해 측정한 결과 (25/3/2019)*
45 |
46 | *Cf. https://github.com/nlpyang/BertSum*
47 |
48 | | 모델 | ROUGE-1 | ROUGE-2 | ROUGE-L |
49 | | :---------------------: | :-------: | :-------: | :-------: |
50 | | Transformer Baseline | 40.9 | 18.02 | 37.17 |
51 | | BERTSUM+classifier | 43.23 | 20.22 | 39.60 |
52 | | **BERTSUM+transformer** | **43.25** | **20.24** | **39.63** |
53 | | BERTSUM+LSTM | 43.22 | 20.17 | 39.59 |
54 |
55 | - BERTSUMABS 모델로 **생성 요약** 태스크를 수행했을 때의 ROUGE 점수
56 |
57 | *[Yang Liu, Mirella Lapata. 2019. Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345) 에서 CNN/DailyMail 테스트 데이터를 이용해 측정한 결과 (20/8/2019)*
58 |
59 | *Cf. https://github.com/nlpyang/PreSumm*
60 |
61 | | 모델 | ROUGE-1 | ROUGE-2 | ROUGE-L |
62 | | :--------: | :-----: | :-----: | :-----: |
63 | | BERTSUMABS | 41.72 | 19.39 | 38.76 |
64 |
65 | ## BERTSUM 모델 학습
66 |
67 | ```python
68 | # Google Colab / Python 3.x / GPU
69 |
70 | %%capture
71 | !pip install pytorch_pretrained_bert
72 | !pip install torch==1.1.0 pytorch_transformers tensorboardX multiprocess pyrouge
73 | !pip install googleDriveFileDownloader
74 |
75 | cd /content/
76 |
77 | # BERTSUM 연구원들이 오픈 소스로 제공한 학습 코드
78 | !git clone https://github.com/nlpyang/BertSum.git
79 |
80 | # 데이터셋 다운로드 (전처리된 CNN/DailyMail 뉴스 데이터)
81 | cd /content/BertSum/bert_data/
82 | ### 다운로드 및 압축 해제 ###
83 |
84 | # BERTSUM 모델 학습
85 | cd /content/BertSum/src
86 |
87 | '''
88 | First run: For the first time, you should use single-GPU, so the code can download the BERT model. Change -visible_gpus 0,1,2 -gpu_ranks 0,1,2 -world_size 3 to -visible_gpus 0 -gpu_ranks 0 -world_size 1, after downloading, you could kill the process and rerun the code with multi-GPUs.
89 | '''
90 |
91 | # BERTSUM + classifier (number of parameters: 109483009)
92 | !python train.py -mode train -encoder classifier -dropout 0.1 -bert_data_path ../bert_data/cnndm -model_path ../models/bert_classifier -lr 2e-3 -visible_gpus 0 -gpu_ranks 0 -world_size 1 -report_every 50 -save_checkpoint_steps 1000 -batch_size 3000 -decay_method noam -train_steps 50 -accum_count 2 -log_file ../logs/bert_classifier -use_interval true -warmup_steps 10000
93 |
94 | # BERTSUM + transformer (* number of parameters: 120512513)
95 | !python train.py -mode train -encoder transformer -dropout 0.1 -bert_data_path ../bert_data/cnndm -model_path ../models/bert_transformer -lr 2e-3 -visible_gpus 0 -gpu_ranks 0 -world_size 1 -report_every 50 -save_checkpoint_steps 1000 -batch_size 3000 -decay_method noam -train_steps 50 -accum_count 2 -log_file ../logs/bert_transformer -use_interval true -warmup_steps 10000 -ff_size 2048 -inter_layers 2 -heads 8
96 |
97 | # BERTSUM + lstm (* number of parameters: 113041921)
98 | !python train.py -mode train -encoder rnn -dropout 0.1 -bert_data_path ../bert_data/cnndm -model_path ../models/bert_rnn -lr 2e-3 -visible_gpus 0 -gpu_ranks 0 -world_size 1 -report_every 50 -save_checkpoint_steps 1000 -batch_size 3000 -decay_method noam -train_steps 50 -accum_count 2 -log_file ../logs/bert_rnn -use_interval true -warmup_steps 10000 -rnn_size 768 -dropout 0.1
99 | ```
100 |
101 | ```
102 | usage: train.py [-h] [-encoder {classifier,transformer,rnn,baseline}]
103 | [-mode {train,validate,test}] [-bert_data_path BERT_DATA_PATH]
104 | [-model_path MODEL_PATH] [-result_path RESULT_PATH]
105 | [-temp_dir TEMP_DIR] [-bert_config_path BERT_CONFIG_PATH]
106 | [-batch_size BATCH_SIZE] [-use_interval [USE_INTERVAL]]
107 | [-hidden_size HIDDEN_SIZE] [-ff_size FF_SIZE] [-heads HEADS]
108 | [-inter_layers INTER_LAYERS] [-rnn_size RNN_SIZE]
109 | [-param_init PARAM_INIT]
110 | [-param_init_glorot [PARAM_INIT_GLOROT]] [-dropout DROPOUT]
111 | [-optim OPTIM] [-lr LR] [-beßta1 BETA1] [-beta2 BETA2]
112 | [-decay_method DECAY_METHOD] [-warmup_steps WARMUP_STEPS]
113 | [-max_grad_norm MAX_GRAD_NORM]
114 | [-save_checkpoint_steps SAVE_CHECKPOINT_STEPS]
115 | [-accum_count ACCUM_COUNT] [-world_size WORLD_SIZE]
116 | [-report_every REPORT_EVERY] [-train_steps TRAIN_STEPS]
117 | [-recall_eval [RECALL_EVAL]] [-visible_gpus VISIBLE_GPUS]
118 | [-gpu_ranks GPU_RANKS] [-log_file LOG_FILE] [-dataset DATASET]
119 | [-seed SEED] [-test_all [TEST_ALL]] [-test_from TEST_FROM]
120 | [-train_from TRAIN_FROM] [-report_rouge [REPORT_ROUGE]]
121 | [-block_trigram [BLOCK_TRIGRAM]]
122 | ```
123 |
124 | ## 참고 자료
125 |
126 | - 구글 BERT의 정석 [book](http://www.yes24.com/Product/Goods/104491152)
127 | - [Fine-tune BERT for Extractive Summarization (BERTSUM) github repository](https://github.com/nlpyang/BertSum)
128 | - [ROUGE-an Evaluation Metric for Text Summarization](https://ilmoirfan.com/rouge-an-evaluation-metric-for-text-summarization/)
129 |
130 |
--------------------------------------------------------------------------------
/summaries/chapter07/chapter07_M-BERT.md:
--------------------------------------------------------------------------------
1 | # Chapter 7. 다른 언어에 BERT 적용하기
2 |
3 | BERT를 영어가 아닌 다른 언어에도 적용할 수 있을까? 아래 모델을 통해서 BERT를 통해 다국어 표현을 어떻게 얻을 수 있는지 알아보자.
4 |
5 | - M-BERT(multilingual-BERT)
6 | - XLM(cross-lingual language model)
7 | - XLM-R(XLM-RoBERTa)
8 |
9 |
10 |
11 | ## M-BERT 이해하기
12 |
13 | **BERT**
14 |
15 | - Datasets: 영어 위키피디아, 토론토 책 말뭉치
16 | - PreTrain Task: MLM, NSP
17 |
18 | **M-BERT**
19 |
20 | - Datasets: 104개 언어 위키피디아
21 | - 각 언어들간의 비중이 다르다 -> overfitting을 방지하기 위해 언어별 under/over sampling 적용
22 | - 104개 언어, 11만개의 워드피스(BPE와 유사하지만 likelihood 사용하는 인코딩)
23 | - PreTrain Task: MLM, NSP
24 |
25 |
26 |
27 | M-BERT는 교차 언어를 고려하지 않고도 다른 언어들의 표현을 이해할 수 있다.
28 |
29 |
30 |
31 | ### NLI task 평가로 알아보는 M-BERT 평가하기
32 |
33 | - 두 문장(가설, 전제)을 바탕으로, 가설이 주어진 전제에 따라 진실/거짓/중립 여부를 판단하는 것
34 | - 일반적으로 SNLI(Stanford natural language inference) datasets 사용
35 | - 다국어 NLI 평가를 위해서는 교차 언어 자연어 추론(XNLI: cross-linugal NLI)사용
36 | - MultiNLI 말뭉치에서 약 43만개의 영어 문장 쌍을 사용
37 | - 평가셋을 위해 7,500개의 문장 쌍을 사용하며, 이를 15개의 서로 다른 언어로 번역하여 11만개의 문장 쌍을 사용
38 |
39 |
40 |
41 | 다양한 설정에서 NLI task를 수행해 M-BERT를 평가한다.
42 |
43 | #### 제로샷(zero-shot)
44 |
45 | - Fine-tuning: 영어 학습셋
46 | - Validation: 모든 언어 테스트셋
47 | - 영어로 학습하고 모든 언어로 평가
48 | - M-BERT의 교차 언어 능력을 이해하는데 도움
49 |
50 |
51 |
52 | #### 번역-테스트(Translate-Test)
53 |
54 | - Fine-tuning: 영어 학습셋
55 | - Validation: 영어로 번역된 테스트셋
56 | - 영어로 학습하고 영어로 평가
57 |
58 |
59 |
60 | #### 번역-학습(Translate-Train)
61 |
62 | - Fine-tuning: 영어에서 다른 언어로 번역된 학습셋
63 | - Validation: 모든 언어 테스트셋
64 | - 다른 언어로 학습하고 모든 언어로 평가
65 |
66 |
67 |
68 | #### 번역-학습-모두(Translate-Train-All)
69 |
70 | - Fine-tuning: 영어에서 다른 **모든 언어**로 번역된 학습셋
71 | - Validation: 모든 언어 테스트셋
72 | - 모든 언어로 학습하고 모든 언어로 평가
73 |
74 |
75 |
76 | | 모델 | 설정 | 영어 | 중국어 | 스페인어 | 독일어 | 아랍어 | 우루드어 |
77 | | ------------ | --------------- | ---- | ------ | -------- | ------ | ------ | -------- |
78 | | BERT-cased | Translate-Train | 81.9 | 76.6 | 77.8 | 75.9 | 70.7 | 61.6 |
79 | | BERT-uncased | Translate-Train | 81.4 | 74.2 | 77.3 | 75.2 | 70.5 | 61.7 |
80 | | BERT-uncased | Translate-Test | 81.4 | 70.1 | 74.9 | 74.4 | 70.4 | 62.1 |
81 | | BERT-uncased | Zero-shot | 81.4 | 74.3 | 74.3 | 70.3 | 60.1 | 58.3 |
82 |
83 | > M-BERT 모델은 제로샷을 포함해 모든 조건에서 좋은 성능을 보여준다.
84 |
85 |
86 |
87 | ### M-BERT는 다국어 표현이 어떻게 가능한가??
88 |
89 | 다른 언어들을 다 섞어서 학습한 것 뿐인데 어떻게 다국어 표현이 가능한 건지?
90 |
91 |
92 |
93 | #### 어휘 중복 효과?
94 |
95 | - 언어 간에 중복되는 어휘 때문??
96 |
97 | - overlap으로 파인튜닝 언어/평가 언어 간에 겹치는 워드피스 토큰 계산
98 | $$
99 | \left| \dfrac{E_{train}\cap E_{eva1}}{E_{train}\cup E_{era1}}\right|
100 | $$
101 |
102 | - 16개의 모든 언어 쌍에 대해 제로샷 F1 score를 계산한 결과 어휘 중복(overlap)이 적을 때에도 제로샷 F1이 높았음
103 |
104 | > zeroshot 지식 전이는 어휘 중복에 영향을 받지 않는다
105 | >
106 | > M-BERT가 다른 언어와의 관계성을 고려해 일반화를 잘 한다 = 단순한 어휘 암기가 아니라 다국어 표현을 더 깊게 학습한다
107 |
108 |
109 |
110 | #### 스크립트에 대한 일반화?
111 |
112 | - 서로 다른 스크립트를 따르는 언어들 사이에서도 일반화가 잘 될까?
113 |
114 | > 일부 언어 쌍의 스크립트에서는 일반화가 잘 되지만, 모든 언어에서 적용되지는 않는다.
115 |
116 |
117 |
118 | #### 유형학적 특징에 대한 일반화?
119 |
120 | - 주어, 동사, 목적어 등의 단어 순서가 다른 언어들 사이에서도 일반화가 잘 될까?
121 |
122 | > M-BERT의 zeroshot 전이는 단어 순서가 동일한 언어에서 더 잘 작동한다.
123 | >
124 | > M-BERT의 일반화 능력은 언어 간의 유형학적 유사성에 따라 달라진다 = M-BERT가 체계적인 변환을 학습하는 것은 아님
125 |
126 |
127 |
128 | #### 언어 유사성의 효과?
129 |
130 | - WALS: 문법, 어휘 및 음운 속성과 같은 언어의 구조적 속성을 포함하는 대규모 데이터베이스
131 | - WALS 공통 특징 수가 많을 수록 제로샷 정확도가 높은 경향
132 |
133 | > M-BERT는 유사한 언어 구조를 공유하는 언어 사이에서 더 잘 일반화된다
134 |
135 |
136 |
137 | #### 코드 스위칭과 음차의 효과?
138 |
139 | **코드 스위칭**
140 |
141 | - 다른 언어를 혼합하거나 교대로 사용하는 것
142 | - ex) Korean은 굉장히 kind하고 polite한 것 같아.
143 |
144 | **음차**
145 |
146 | - 발음하는 그대로 쓴거
147 | - ex) 코리안은 굉장히 카인드하고 폴라이트한 것 같아.
148 |
149 |
150 |
151 | M-BERT에서 코드 스위칭과 음차를 어떻게 다룰까?
152 |
153 | - 코드 스위칭된 힌디어/영어 UD 말뭉치를 사용
154 | - 음차: 힌디어 텍스트는 라틴 문자로 작성된다.
155 | - 코드 스위칭: 라틴어의 힌디어 텍스트가 데바나가리어 스크립트로 변환되어 재작성된다.
156 |
157 | | 말뭉치 | 평가셋 | 정확도 |
158 | | ------------------------ | ----------- | ------ |
159 | | 음차 | 음차 | 85.64 |
160 | | 단일 언어(영어 + 힌디어) | 음차 | 50.41 |
161 | | 코드 스위칭 | 코드 스위칭 | 90.56 |
162 | | 단일 언어(영어 + 힌디어) | 코드 스위칭 | 86.59 |
163 |
164 | > M-BERT는 음차 텍스트와 비교해 코드 스위칭 텍스트에서 수행 능력이 좋다
165 |
166 |
167 |
168 | #### 결론
169 |
170 | - M-BERT의 일반화 가능성은 어휘 중복에 의존하지 않는다.
171 | - M-BERT의 일반화 가능성은 유형학 및 언어 유사성에 따라 다르다.
172 | - M-BERT는 코드 스위칭 텍스트를 처리할 수 있지만 음차 텍스트는 처리할 수 없다.
173 |
174 |
175 |
176 | ## XLM
177 |
178 | - 다국어를 목표로 BERT를 사전학습 시킨 모델로 M-BERT보다 다국어 표현 학습을 할 때 성능이 더 뛰어나다
179 |
180 | - 단일 언어 / 병렬 데이터셋을 사용해 사전 학습된다
181 | - 병렬 데이터셋: 언어 쌍의 텍스트(2개의 다른 언어로 된 동일한 텍스트)
182 | - 단일 언어 데이터셋: 위키피디아
183 | - 병렬 데이터셋: 다국어 유엔 말뭉치(MultiUN), 개방형 병렬 말뭉치(OPUS), IIT 봄베이 말뭉치 등의 여러 소스
184 |
185 | - BPE 사용
186 |
187 | - 언어 임베딩을 사용해서 해당 토큰이 어떤 언어인지 알려준다
188 |
189 |
190 |
191 | ### CLM
192 |
193 | - 인과 언어 모델링(CLM: Causal Language Modeling)
194 |
195 | - 이전 단어셋을 바탕으로 현재 단어의 확률 예측
196 |
197 |
198 |
199 | ### MLM
200 |
201 | - 마스크 언어 모델링(MLM: Masked Language Modeling)
202 |
203 | - BERT에서는 NSP를 위해 두 개의 문장 쌍을 입력했지만, XLM에서는 임의의 문장을 모델에 입력할 수 있다(총 토큰의 길이는 256)
204 | - 단어의 빈도수에 따라 샘플링 빈도가 달라진다(sqrt(1/빈도수)의 다항분포에서 샘플링)
205 |
206 |
207 |
208 | ### TLM
209 |
210 | - 번역 언어 모델링(TLM: Translation Language Modeling)
211 |
212 | - 서로 다른 두 언어/동일한 내용의 텍스트로 구성된 병렬 교차 언어 데이터를 이용
213 | - Masked token을 맞추는 것은 MLM과 동일하지만, 교차 언어 표현을 학습시키려는 의도
214 | - 마스크된 토큰을 맞추기 위해서 다른 언어의 표현을 이해할 수 있다(교차 언어 표현이 정렬(align)된다)
215 |
216 |
217 |
218 | ### XLM 사전 학습
219 |
220 | - CLM or MLM
221 | - 단일 언어 데이터셋
222 | - 총 256개의 토큰으로 된 임의의 문장
223 | - TLM + MLM
224 | - TLM의 경우 병렬 데이터셋 사용
225 |
226 |
227 |
228 | ### XLM 평가
229 |
230 | 
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 |
239 |
240 |
--------------------------------------------------------------------------------
/summaries/chapter07/chapter07_XLMR_multilingual.md:
--------------------------------------------------------------------------------
1 | # Chapter 7 다른 언어에 BERT 적용하기
2 |
3 | ## XLM-R 이해하기
4 |
5 | - XLM에서 몇 가지를 보완한 확장 버전
6 | - XLM-RoBERTa
7 | - 자료가 적은 언어의 경우 병렬 데이터셋을 구하는 것이 쉽지 않아 MLM만 학습
8 | - 커먼 크롤 데이터셋에서 별도 레이블이 없는 100개의 언어 텍스트를 필터링하여 얻은 2.5TB의 데이터셋으로 학습
9 | - 비중이 적은 언어는 oversampling
10 | - Common crawl이 Wikipedia에 비해 자료가 적은 언어에서 데이터가 더 많음
11 | - Sentencepiece Tokenizer, 25만 개의 Token
12 | - Model Architecture
13 | - XLM-R_base: 12개의 Encoder layers, 12개의 Attention heads, 768 Hidden size
14 | - XLM-R: 24개의 Encoder layers, 16개의 Attention heads, 1024 Hidden size
15 | - M-BERT와 XLM보다 더 뛰어난 성능
16 | - XLM-R의 교차 언어 분류 태스크로 모델을 평가
17 | - 15개의 서로 다른 XNLI 데이터셋으로 평가
18 | - 가장 낮은 점수인 스웨덴어에서 M-BERT 50.4% → XLM-R 73.9%
19 | - XLM-R의 평균 정확도가 80.9%로 다른 모델보다 비교적 높음
20 |
21 | ## 언어별 BERT
22 |
23 | - 여러 언어 대신 특정 단일 언어만 이용해 BERT 학습
24 |
25 | ### 프랑스어 FlauBERT
26 |
27 | - 사용 말뭉치: Wikipedia, 도서, 내부 크롤링, WMT19, OPUS(오픈 소스 병렬 코퍼스)의 프랑스어 텍스트 등의 24개
28 | - Moses Tokenizer: URL, 날짜 등을 포함한 특수 토큰 보존
29 | - 전처리 및 토큰화 후 BPE 사용, vocab building
30 | - 50,000개의 Token
31 | - MLM만 수행, Dynamic masking 사용
32 | - small-cased, base-uncased, base-cased, large-cased
33 | - HuggingFace에서 사용 가능
34 | - FLUE(French Language Understanding Evaluation)
35 | - CLS-FR
36 | - PAWS-X-FR
37 | - XNLI-FR
38 | - French Treebank
39 | - FrechSemEval
40 |
41 | ### 스페인어 BETO
42 |
43 | - WWM(Whole Word Masking) + MLM
44 | - POS, NER-C, MLDoc, PAWS-X, XNLI로 테스트
45 | - HuggingFace에서 사용 가능
46 |
47 | ```python
48 | from transformers import pipeline
49 |
50 | predict_mask = pipeline(
51 | "fill-mask",
52 | model = "dccuchile/bert-base-spanish-wwm-uncased",
53 | tokenizer = "dccuchile/bert-base-spanish-wwm-uncased"
54 | )
55 |
56 | result = predict_mask('[MASK] los caminos llevan a Roma')
57 | ```
58 |
59 | ### 네덜란드어 BERTje
60 |
61 | - WWM과 MLM 및 SOP를 동시에 진행
62 | - 사용 말뭉치: TwNC(네덜란드 뉴스 말뭉치), SoNAR-500(다중 장르 참조 말뭉치), 네덜란드 위키피디아 텍스트, 웹 뉴스 및 서적
63 | - 100만 번의 iteration으로 학습
64 | - HuggingFace에서 사용 가능
65 |
66 | ### 독일어 BERT
67 |
68 | - Cloud TPU v2에서 9일 동안 Wikipedia text, 뉴스, OpenLegalData
69 |
70 | ### 중국어 BERT
71 |
72 | - 12개의 Encoder layers, 12개의 Attention heads, 768개의 hidden unit, 110M
73 | - WWM + MLM
74 | - WWM을 사용해 pretrain → 하위 단어가 masking 되면 하위 단어를 포함하는 전체 단어를 마스킹
75 | - LTP(Language Technology Platform)를 사용
76 | - LTP는 단어 분할, 형태소 분석, 구문 분석을 수행하는데 사용
77 | - 중국어 단어 경계를 식별하는 데도 이용
78 |
79 | ### 일본어 BERT
80 |
81 | - 일본어 Wikipedia를 사용해 WWM으로 학습
82 | - MeCab으로 Tokenization → Wordpiece Tokenizer로 subword를 얻음
83 |
84 | ### 핀란드어 FinBERT
85 |
86 | - M-BERT보다 성능이 좋음
87 | - Wikipedia에서 핀란드 텍스트의 비중은 3%에 불과
88 | - FinBERT는 핀란드어 뉴스 기사, 온라인 토론 및 인터넷 크롤링 텍스트로 학습
89 | - FinBERT-cased, FinBERT-uncased
90 | - WWM을 이용해 MLM과 NSP로 Pretrained
91 |
92 | ### 이탈리아어 UmBERTo
93 |
94 | - RoBERTa 아키텍쳐를 따름
95 | - MLM Task시에 Dynamic Masking 사용
96 | - NSP 제거 MLM만 사용
97 | - 큰 batch size 사용
98 | - Byte-level BPE Tokenizer
99 | - RoBERTa에 Sentencepiece + WWM 사용
100 |
101 | ### 포르투갈어 BERTimbau
102 |
103 | - brWaC: 포르투갈어 대규모 오픈 소스 말뭉치
104 | - WWM + MLM 100만 iteration
105 |
106 | ### 러시아어 RuBERT
107 |
108 | - M-BERT에서 Knowledge Distillation
109 | - 학습 전에 Word Embedding을 제외하고 RuBERT의 변수를 M-BERT 모델의 변수로 초기화
110 | - 러시아어 Wikipedia text와 뉴스 기사를 사용해 학습
111 | - Subword NMT로 텍스트를 subword로 나누는 데 사용
112 | - RuBERT의 Subword vocab은 M-BERT의 vocab에 비해 더 길고 더 많은 러시아어롤 구성
113 | - M-BERT와 RuBERT 어휘 모두에서 나타나는 일반적인 단어는 M-BERT의 임베딩으로 직접 사용 가능
--------------------------------------------------------------------------------
/summaries/chapter08/S-BERT.md:
--------------------------------------------------------------------------------
1 | # Sentence-BERT 및 domain-BERT 살펴보기
2 |
3 | > Speaker: 남수연(@mori8)
4 | >
5 | > 회사에서 molrae 쓰는 중
6 |
7 | ## Sentence-BERT
8 |
9 | Sentence-BERT는 vanila BERT/RoBERTa를 fine-tuning하여 문장 임베딩 성능을 우수하게 개선한 모델이다. BERT/RoBERTa는 STS 태스크에서도 좋은 성능을 보여주었지만 매우 큰 연산 비용이 단점이었는데, Sentence-BERT는 학습하는 데 20분이 채 걸리지 않으면서 다른 문장 임베딩보다 좋은 성능을 자랑한다.
10 |
11 |
12 |
13 | ### 등장 배경
14 |
15 | **기존의 BERT로는 large-scale의 유사도 비교, 클러스터링, 정보 검색 등에 많은 시간 비용이 들어간다.**
16 |
17 | - BERT로 유사한 두 문장을 찾으려면 두 개의 문장을 한 개의 BERT 모델에 넣어야 유사도가 평가된다.
18 | - 따라서 문장이 10000개 있으면 10C2 번의 연산 후에 유사도 랭킹을 얻을 수 있다.
19 | - 클러스터링이나 검색에서는 각 문장을 벡터 공간에 매핑하는데, BERT를 이용할 때는 단어 표현을 평균내거나 `[CLS]` 토큰의 값을 이용하지만 이랬을 때의 결과는 각 단어의 GloVe 벡터를 평균낸 것보다 나쁘다.
20 |
21 |
22 |
23 | ## Sentence-BERT의 문장 임베딩
24 |
25 | 1. BERT의 `[CLS]` 토큰의 표현 벡터를 문장 표현으로 사용한다.
26 | 2. BERT의 모든 단어의 표현 벡터를 평균 풀링하여 만든 벡터를 문장 표현으로 사용한다.
27 | 3. BERT의 모든 단어의 표현 벡터를 최대 풀링하여 만든 벡터를 문장 표현으로 사용한다.
28 |
29 | Sentence-BERT(이후 SBERT로 표기)는 BERT의 출력에 풀링 연산을 추가한 모델이며, 풀링 방법은 `[CLS]` 토큰의 결과를 사용하는 방법, 모든 출력 벡터를 평균내어 사용, 출력 벡터의 max-over-time*을 계산해 사용하는 방법이 있다. 기본적으로 SBERT는 평균 풀링을 사용하며, 평균 풀링으로 문장 표현을 얻으면 이 표현은 본질적으로 모든 단어의 의미를 갖는다. 반면 최대 풀링으로 문장 표현을 얻을 경우 문장 표현은 본질적으로 중요한 단어의 의미를 갖는다.
30 |
31 | > Max-over-time pooling: 문장의 길이가 다 다르면 문장마다의 feature map 개수가 달라지는데, 모든 문장마다 하나의 값을 갖도록 feature map 벡터 중 가장 큰 값 하나만 사용하는 것
32 |
33 |
34 |
35 | ## Fine Tuning 전략: 문장 쌍 분류, 회귀 태스크
36 |
37 | 신체의 일부를 공유하는 샴 쌍둥이처럼, 샴 네트워크는 두 네트워크가 weight를 공유한다. SBERT는 동일한 사전 학습된 BERT 모델 2개를 사용하여 문장 1의 토큰은 한 BERT로, 문장 2의 토큰은 또 다른 BERT로 입력하고 주어진 문장의 표현을 계산한다. 두 문장을 `[SEP]`으로 구분하여 한 BERT 모델에 같이 집어넣는 게 아니라, 같은 가중치를 갖는 서로 다른 BERT 모델 2개에 각각 넣는 것이다.
38 |
39 |
40 |
41 | ## Objective Functions
42 |
43 | 
44 |
45 | SBERT 모델의 구조는 학습 데이터에 따라 다르다. 아래 구조에 따라 목적 함수와 모델 구조를 달리 하였다.
46 |
47 | - 두 문장의 출력값인 u, v 그리고 element-wise 차이값인 |u-v|를 concatenate한 후 파라미터를 추가하여 학습한다.
48 | - 실제 inference할 때나, regression 방식의 loss function을 쓸 때는 cosine-similarity를 이용한다. Training할 때, 계산된 cosine similarity와 gold label 간의 MSE를 minimize하는 방식으로 학습했다.
49 |
50 |
51 |
52 | ### Classification Objective Function
53 |
54 | 두 문장이 유사한지(1), 유사하지 않은지(0) 판단하는 태스크를 위한 모델이다. 두 문장 임베딩 *u*와 *v*를 그 차이 ∣*u*−*v*∣와 concat해 3*n* 차원의 텐서를 만들고, 이를 가중치 *W**t*∈R3*n*×*k*에 곱한다. 이를 softmax함수에 넣으면 *k*개 label에 대한 분류 작업이 가능해진다. loss는 cross-entropy로 설정했다.
55 |
56 | $$O=softmax(W_t(u,v,∣u−v∣))$$
57 |
58 |
59 |
60 | ### Regression Objective Function
61 |
62 | 회귀 태스크의 목표는 주어진 두 문장 사이의 의미 유사도를 예측하는 것이다. 두 문장의 임베딩($u$, $v$) 사이의 코사인 유사도를 계산한다.
63 |
64 |
65 |
66 | ### Triplet Objective Function
67 |
68 | #### Siamese, Triplet의 등장 배경: One-shot
69 |
70 | 조금의 데이터만으로도 학습할 수 있도록 하는 것이 `Few-shot`, 한 장의 사진만으로 학습하도록 하자는 게 `One-shot`
71 |
72 |
73 |
74 | $$max(∣∣s_a−s_p∣∣−∣∣s_a−s_n∣∣+ϵ,0)$$
75 |
76 | anchor/positive/negative 문장 *a*,*p*,*n*에 대해 triplet loss는 모델이 *a*와 *p* 사이 거리가 *a*와 *n*사이 거리보다 작게 하도록 학습시킨다. $s_x$는 문장 *x*의 임베딩이고, ∣∣⋅∣∣은 거리고, *ϵ*은 margin이다. margin은 *s**p*가 *s**n*보다 최소한 *ϵ*만큼 *s**a*에 가깝도록 하는 장치이다. 이 논문에서는 Euclidean 거리를 단위로 *ϵ*=1로 설정했다.
77 |
78 |
79 |
80 | ## Evaluation
81 |
82 | 
83 |
84 | - 보다시피 BERT의 output을 그대로 쓰는 건 성능이 별로다. InferSent* - GloVe보다 못한 걸 알 수 있다.
85 | - 제안된 siamese 네트워크 구조와 fine-tuning 메커니즘은 InferSent나 Universal Sentence Encoder를 유의미하게 앞서는 결과를 내었다. SBERT가 좋은 성적을 내지 못한 유일한 데이터셋은 SICK-R이다.
86 | - Universal Sentence Encoder는 뉴스, QA 페이지, 토론 포럼처럼 SICK-R 벤치마킹에 적합한 데이터셋에 학습되었다. 반면 SBERT는 위키피디아와 NLI 데이터에만 학습되었다.
87 | - SRoBERTa는 성능이 좋긴 한데, SBERT에 비해 큰 차이를 보이진 않았다.
88 |
89 | > InferSent는 siamse BiLSTM에 max pooling을 적용한 문장 임베딩 모델
90 |
91 |
92 |
93 | ## References
94 |
95 | - https://velog.io/@ysn003/%EB%85%BC%EB%AC%B8-Sentence-BERT-Sentence-Embeddings-using-Siamese-BERT-Networks
96 | - http://mlgalaxy.blogspot.com/2020/09/sentence-bert-sentence-embeddings-using.html
97 | - https://tyami.github.io/deep%20learning/Siamese-neural-networks/
98 |
--------------------------------------------------------------------------------
/summaries/chapter08/chapter08_domain-BERT.md:
--------------------------------------------------------------------------------
1 | # Chapter 8 sentence-BERT 및 domain-BERT 살펴보기
2 |
3 | ## 내용
4 |
5 | - sentence-BERT
6 | - 지식 증류로 다국어 임베딩 학습
7 | - domain-BERT (ClinicalBERT 및 BioBERT)
8 |
9 | ## 지식 증류를 이용한 다국어 임베딩 학습
10 |
11 | *Q. 영어 외의 다른 언어에는 어떻게 sentence-BERT를 사용할까?*
12 |
13 | *A. sentence-BERT에서 생성된 단일 언어 문장 임베딩을 **지식 증류**를 통해 다국어로 만들어 다양한 언어에 sentence-BERT를 적용할 수 있다.*
14 |
15 | sentence-BERT 지식 ➡︎ 다국어 모델 (e.g. XLM-R) ➡︎ 다국어 모델이 사전 학습된 sentence-BERT와 동일한 임베딩 형성
16 |
17 | 학생 모델 S로 계산한 소스 문장(s_j) 표현과 타깃 문장(t_j) 표현 모두 교사 모델 T로 계산한 소스 문장(s_j) 표현과 동일해지는 방향으로 다음 속성을 학습
18 |
19 | 1. 벡터 공간이 언어 간 정렬 i.e., 다른 언어의 같은 문장은 가까이 위치
20 | 2. 교사 모델 T로 계산한 소스 언어의 벡터 공간 특성을 채택하여 다른 언어로 전이
21 |
22 |
23 |
24 | 
43 |
44 | #### 사전 학습
45 |
46 | - Medical Information Mart for Intensive Care III (MIMIC-III) dataset 사용
47 |
48 | - BERT와 마찬가지로 MLM과 NSP 태스크를 이용해 사전 학습
49 |
50 | #### 파인 튜닝
51 |
52 | 재입원 예측, 입원 기간, 사망 위험 추정, 진단 예측 등 다양한 다운스트림 태스크에 맞춰 파인 튜닝
53 |
54 | 
55 |
56 |
57 |
58 | *e.g. 30일 이내 재입원 예측 테스크*
59 |
60 | - 사전학습된 ClincalBERT에 임상 메모를 입력하고 임상 메모의 표현 반환
61 | - `[CLS]` 토큰의 표현을 가져와 분류기(피드포워드 + 시그모이드 활성화 함수)에 입력
62 | - 분류기는 30일 이내에 환자가 다시 입원할 확률 반환
63 |
64 | #### Empirical Study
65 |
66 | **Empirical Study I: Language Modeling and Clinical Word Similarity**
67 |
68 | - Clinical language model에서 ClinicalBERT가 BERT보다 좋은 성능
69 |
70 |
71 |
72 | - 임상 단어 유사도 추출
73 |
74 | - ClinicalBERT에서 배운 표현을 경험적으로 평가하기 위해 의학 용어 표현 계산
75 |
76 |
77 |
78 | - 신체기관이 서로 관련된 의학 용어끼리 가까이 있는 것을 확인 가능
79 |
80 | ➡︎ ClinicalBERT의 표현이 의학 용어에 대한 콘텍스트 정보를 갖고 있음을 나타냄
81 |
82 | **Empirical Study II: 30-Day Hospital Readmission Prediction**
83 |
84 | - Scalable Readmission Prediction
85 |
86 | **💡 BERT 최대 토큰의 길이 512보다 더 많은 토큰으로 구성된 경우?**
87 |
88 | - 512보다 더 많은 토큰으로 구성된 긴 시퀀스를 여러 서브시퀀스로 분할
89 | - 각 서브시퀀스를 모델에 입력한 후 모든 서브시퀀스를 개별적으로 예측
90 | - 다음 식을 이용해 점수 계산 :
91 | - 재입원 예측과 관련된 서브시퀀스 : 확률이 높은 것
92 | - 노이즈가 포함된 서브시퀀스 방지를 위해 평균 확률 사용
93 | - 평균 확률에 중요성 부여
94 |
95 | ### BioBERT
96 |
97 | 📄 [BioBERT: a pre-trained biomedical language representation model for biomedical text mining](https://arxiv.org/pdf/1901.08746.pdf)
98 |
99 | 생물 의학 텍스트 이해를 위해 대규모 생물 의학 코퍼스에서 사전학습된 생물 의학 domain-BERT
100 |
101 | 
102 |
103 | #### 사전 학습
104 |
105 | - 생물 의학 도메인 텍스트를 이용해 사전학습
106 |
107 | - PubMed, PMC
108 |
109 | - 사전학습 전에 먼저, 영어 위키피디아 및 토론토 책 말뭉치 데이터셋으로 구성된 일반 도메인 말뭉치를 사용해 사전 학습된 일반 BERT로 BioBERT의 가중치 초기화
110 |
111 | - 워드피스 토크나이저로 토큰화
112 |
113 | - 생물 의학 코퍼스의 새로운 어휘를 사용하는 대신, BERT 기반 모델에서 사용되는 원래 어휘로 워드피스 어휘를 구성
114 |
115 | - BioBERT와 BERT 간의 호환성
116 |
117 | - 본 적 없는 단어도 원래 BERT 기반 어휘를 사용해 표현하고 파인튜닝
118 |
119 | - 대소문자가 있는 어휘를 사용하는 것이 다운스트림 태스크에서 더 좋은 성능을 얻을 수 있음을 발견
120 |
121 | #### 파인 튜닝
122 |
123 | 📌 코드 [github.com/dmis-lab/biobert](https://github.com/dmis-lab/biobert?fbclid=IwAR3te48b9-SsBBmybH8MrQMLxX5RlDbYTfpBZQGLp5ki1B8jq-2M15t3skA)
124 |
125 | **개체명 인식(NER) 태스크를 위한 BioBERT**
126 |
127 | - 생물 의학 코퍼스에서 특정 도메인의 다양한 고유명사 인식
128 | - BERT를 파인튜닝하는 법과 동일
129 | - 데이터셋
130 | - 질병 관련된 개체명: NCBI, 2010 i2b2/VA, BC5CDR
131 | - 약물 및 화학 관련된 개체명: BC5CDR, BC4CHEMD
132 | - 유전자와 관련된 개체명: BC2GM, JNLPBA
133 | - 종과 관련된 개체명: LINNAEUS, Species-800
134 |
135 | **관계 추출(RE)을 위한 BioBERT**
136 |
137 | - 생물 의학 코퍼스에서 명명된 개체들의 관계 분류
138 |
139 | - `[CLS]` 토큰 표현을 사용하는 BERT의 sentence classifier 사용
140 |
141 | **질문-응답(QA)을 위한 BioBERT**
142 |
143 | - BioASQ 데이터셋으로 파인튜닝
144 | - 생물 의학 질문-응답 데이터셋으로 널리 사용
145 | - SQuAD의 형식과 동일
146 | - BERT를 파인튜닝하는 법과 동일
147 |
148 |
--------------------------------------------------------------------------------
/summaries/chapter09/chapter09_BART.md:
--------------------------------------------------------------------------------
1 | # Chapter 9.2~
2 |
3 | BART에 대해서 알아보고 Hugging Face의 BERT관련 라이브러리를 다룬다.
4 |
5 |
6 |
7 | ## BART
8 |
9 | BERT는 bidirection encoder로 MASK token을 예측하는데, 이러한 구조로 인해 generation task에서 BERT의 사용이 어렵다. 왜냐하면 각각의 MASK token이 softmax/피드포워드 네트워크를 통해 독립적으로 예측되기 때문이다.
10 |
11 | GPT는 autoregressive한 구조로 다음 token을 예측할 수 있지만, BERT처럼 bidirection이 아니다.
12 |
13 |
14 |
15 | ### BART Architecture
16 |
17 | 그래서 두 architecture를 합친다.
18 |
19 | 
20 |
21 | BART는 BERT와 GPU 모델의 구조를 결합하였기 때문에, bidirection으로 문장을 살펴보며 attention representation을 얻어 디코더를 통해 seq2seq 구조로 generation을 수행한다.
22 |
23 | **이 때문에 MLM과는 달리 여러 task에 대해 응용성이 높다**
24 |
25 |
26 |
27 | BART는 seq2seq transformer 구조를 사용했고, GeLUs 활성화 함수를 사용한다. (파라미터 초기화는 N(0, 0.2)) 인코더와 디코더의 layer 수는 같으며, bsae model은 6 layer, large model은 12 layer를 사용한다. 기존의 트랜스포머 디코더와 동일하게, 디코더의 각 레이어에서는 인코더의 마지막 hidden layer와 cross-attention을 한다.
28 |
29 | > self-attention: keys와 values가 queries와 똑같은 임베딩에서 나왔을 때
30 | >
31 | > cross-attention: keys와 values가 queires와 다른 임베딩에서 나왔을 때
32 |
33 |
34 |
35 | ### 노이징 기술 (Pretraining BART)
36 |
37 | BART에서 알아볼 수 있는 핵심은 noising 기술의 유연함이다. 다양한 변형 noising 기법들을 적용시킬 수 있으며, 이 중에서는 문장의 순서를 바꾸거나, 길이를 변경하는 등의 방법론도 있다. 가장 좋은 성능을 보이는 노이징 기법은 문장의 순서를 랜덤하게 섞고, 임의의 길이의 텍스트를 단일 마스크 토큰으로 교체하는 것이다.
38 |
39 | > 모델이 전체적인 문장 길이에 대해 학습해야 하고, 변형된 입력에 많은 집중을 요구하는 효과가 있다고 한다.
40 |
41 |
42 |
43 | 
44 |
45 | **토큰 마스킹(Token Masking)**
46 |
47 | - 랜덤하게 바뀐 [MASK] 토큰 맞추기
48 |
49 | **토큰 삭제(Token Deletion)**
50 |
51 | - 토큰이 랜덤하게 제거된다.
52 | - 모델은 어떤 위치의 토큰이 없어졌는지에 대해서도 맞춰야 한다.
53 |
54 | **토큰 채우기(Text Infilling)**
55 |
56 | - 람다 3을 따르는 포아송 분포에서 span의 길이가 샘플링되고, 각 span은 한개의 [MASK] 토큰으로 치환된다.
57 | - span의 길이가 0일 때도 [MASK] 토큰이 생성된다.
58 | - 모델은 [MASK]에 해당하는 단어들을 맞춰야 한다. 즉 얼마나 많은 토큰이 없어졌는지 예측해야 한다.
59 |
60 | **문장 셔플(Sentence Permutation)**
61 |
62 | - 문장의 순서를 랜덤으로 섞는다.
63 | - 모델은 섞인 토큰들을 원래의 순서로 배열해야 한다. (XLnet에서 영감)
64 |
65 | **문서 회전(Document Rotation)**
66 |
67 | - 하나의 토큰이 랜덤하게 선택되고, 해당 토큰이 문서의 시작지점이 된다.
68 | - 모델은 해당 문서의 시작점을 찾아야 한다.
69 |
70 |
71 |
72 | ### Fine-tuning BART
73 |
74 | 번역 테스크?? 몇개의 추가적인 transformer 레이어를 쌓아 올리는 것으로 기계 번역의 새로운 방법론을 제시하기도 하였음. 추가된 레이어는 외국어를 noise가 적용된 영어로 번역하는 것이 학습되며, BART 전반적으로 학습되게 되어 BART를 사전 학습된 target-side 언어 모델로 사용ㅎ나다. WMT 루마니안-영어 벤치마크에서 1.1 BELU만큼 성능이 향상되었다고 한다.
75 |
76 |
77 |
78 | 
79 |
80 |
81 |
82 | **Sequence Classification Tasks - 시퀀스 단위의 분류 문제**
83 |
84 | - 시퀀스 분류 문제. BERT에서 [CLS] 토큰으로 classification task를 수행하는 것에서 영감. BART에서는 디코더에서 마지막 토큰을 추가하여 해당 토큰의 representation이 전체 입력과 attention을 수행할 수 있게 한다. -> output은 모든 입력을 반영
85 |
86 | - CoLA: 문장이 문법적으로나 영어적으로 합당한지 분류
87 |
88 | **Token Classification Tasks - 토큰 단위의 분류 문제**
89 |
90 | - 디코더 가장 위의 hidden state를 각 토큰의 representation으로 사용 -> classification
91 | - SQuAD: 정답에 해당되는 start point, end point 토큰 찾기
92 |
93 | **Sequence Generation Tasks - 시퀀스 생성 문제**
94 |
95 | - Abstractive QA(question answering), 요약 등의 generation task
96 | - 이러한 테스크는 입력 시퀀스의 내용을 조정하는 특징이 있는데, denoising pre-training objective와 밀접하게 연관되어 있다고 한다.
97 |
98 | **Machine Translation**
99 |
100 | - 몇개의 추가적인 transformer layer를 쌓아 올려 기계 번역의 새로운 방법론 제시 -> BART 전체를 decoder로 사용
101 | - BART 인코더의 embedding layer를 새롭게 초기화된 인코더로 교체 -> 해당 인코더를 학습시키는 것으로 영어가 아닌 다른 단어들을 영어로 매핑하여 BART가 외국어를 denoise할 수 있게 한다.
102 | - 인코더를 2가지 step으로 학습시킨다.
103 | - BART 모델의 output에 대한 cross-entropy loss 사용
104 | - step1) 새롭게 초기화된 인코더, BART의 positional embedding, 첫번째 인코더 layer의 self-attention input projection matrix 학습
105 | - step2) 모든 모델 parameter를 작은 iteration으로 학습
106 |
107 |
108 |
109 | ### Comparing pre-training objectives
110 |
111 | 실험한 언어 모델의 종류
112 |
113 | - Language Model
114 | - Permuted Language Model
115 | - Masked Language Model
116 | - Multitask Masked Language Model
117 | - Masked Seq2Seq
118 |
119 |
120 |
121 | **Tasks**
122 |
123 | **SQuAD**
124 |
125 | - 위키 문단에 대한 QA task로, 위키피디아에서 가져온 본문과 질문이 주어지면, 주어진 본문으로부터 정답에 해당되는 span을 찾아야 한다. -> BART에서는 start point, end point의 두개를 예측하는 분류기 사용
126 |
127 | **MNLI**
128 |
129 | - NLI task와 비슷하며, 이전 문장과 이후 문장의 관계 성립 예측. -> BART에서는 두 개의 문장을 [EOS] token으로 합치고, [EOS] 토큰의 representation으로 classification 수행
130 |
131 | **[ELI5](https://facebookresearch.github.io/ELI5/)**
132 |
133 | - Long form QA task.
134 |
135 | **[XSum](https://arxiv.org/pdf/1808.08745v1.pdf)**
136 |
137 | - 뉴스 요약 테스크 -> 함축된 요약을 만들어야 한다.
138 |
139 | **ConvAI2**
140 |
141 | - 대화의 답변 만들기 -> context와 화자가 주어진다.
142 |
143 | **CNN/DM**
144 |
145 | - 뉴스 요약 테스크 -> 요약본이 입력 문서와 밀접하게 연관되어 있어 XSum과는 약간 다르다.
146 |
147 | 
148 |
149 |
150 |
151 | ### Result
152 |
153 | - **Performance of pre-training methods varies significantly across tasks**
154 |
155 | - **Token masking is crucial**
156 |
157 | - **Left-to-right pre-training improves generation**
158 |
159 | - **Bidirectional encoders are crucial for SQuAD**
160 |
161 | - **The pre-training objective is not the only important factor**
162 |
163 | - **Pure language models perform best on ELI5**
164 |
165 | - **BART achieves the most consistently strong performance.**
166 |
167 |
168 |
169 |
170 |
171 | ## BERT 라이브러리 탐색
172 |
173 | BERT 관련 모델을 쉽게 학습하거나 pre train model을 쉽게 사용 할 수 있는 라이브러리들이 있다.
174 |
175 |
176 |
177 | ### ktrain
178 |
179 | https://github.com/amaiya/ktrain
180 |
181 |
182 |
183 | ### bert-as-service
184 |
185 | https://github.com/hanxiao/bert-as-service
186 |
187 |
--------------------------------------------------------------------------------
/summaries/chapter09/chapter09_VideoBERT.md:
--------------------------------------------------------------------------------
1 | # Chapter 9. VideoBERT
2 |
3 | ## VideoBert로 언어 및 비디오 표현 학습
4 |
5 | **VideoBERT** 📄 [VideoBERT: A Joint Model for Video and Language Representation Learning](https://arxiv.org/pdf/1904.01766.pdf)
6 |
7 | 
8 |
9 | - 영상과 언어의 표현을 동시에 배우는 최초의 BERT 모델
10 | - 이미지 캡션 생성, 비디오 캡션, 비디오의 다음 프레임 예측 등과 같은 태스크에 사용
11 |
12 | ### VideoBERT 사전 학습
13 |
14 | - **MLM(cloze 태스크)과 언어-시각(linguistic-visual) 정렬이라는 새로운 태스크를 사용하여 사전학습**
15 |
16 | - 데이터: 교육용 비디오(e.g., 요리 비디오)
17 |
18 | - 교육자의 말과 해당 시각 자료(영상)가 서로 일치해 언어와 비디오의 표현을 동시에 배우는데 도움
19 |
20 | - 비디오에서 언어 토큰과 시각 토큰을 추출하여 학습에 사용
21 |
22 | - 언어 토큰 추출 방법
23 |
24 | 1. 비디오에 사용된 오디오를 추출
25 |
26 | 2. 오디오를 텍스트로 변환
27 |
28 | **자동 음성 인식**(automatic speech recognition) 툴킷을 활용
29 | _Cf. https://cloud.google.com/speech-to-text_
30 |
31 | 3. 텍스트를 토큰화하면 언어 토큰 생성
32 |
33 | - 시각 토큰 추출 방법
34 |
35 | 1. 비디오의 이미지 프레임을 20fps(초당 프레임)로 샘플링
36 | 2. 이미지 프레임을 1.5초의 구간으로 시각 토큰들로 변환
37 |
38 | - 입력 토큰
39 |
40 | 1. 언어와 시각 토큰 결합
41 |
42 | 특수 토큰 `[>]` 으로 언어 및 시각적 토큰 결합
43 |
44 | 2. 언어 토큰의 시작 부분에 `[CLS]` 토큰 추가, 시각 토큰 끝에만 `[SEP]` 토큰 추가
45 |
46 | 3. 언어 및 시각 토큰 중 몇 가지 토큰들을 무작위로 마스킹
47 |
48 | - **cloze 태스크**
49 |
50 | - VideoBERT에서 반환된 마스크된 표현을 분류기(피드포워드 + 소프트맥스)에 입력하면, 분류기는 마스크된 토큰 예측
51 |
52 | 
53 |
54 | - **언어-시각 정렬**
55 |
56 | - NSP 태스크와 유사한 분류 태스크
57 |
58 | - 언어와 시각 토큰이 시간적으로 서로 정렬되어 있는지 예측
59 |
60 | = 텍스트(언어 토큰)가 비디오(시각적 토큰)와 일치하는지 여부 예측
61 |
62 | - `[CLS]` 토큰의 표현을 가져온 다음 주어진 언어 및 시각 토큰이 일시적으로 정렬되는지 여부를 분류하는 분류기에 입력
63 |
64 | _Cf. NSP는 `[CLS]` 표현을 이용해 주어진 문장 다음에 출현하는 문장이 다음 문장인지 예측_
65 |
66 | - **최종 사전 학습 목표**
67 |
68 | - 세 가지 목표: 텍스트, 비디오, 비디오-텍스트
69 |
70 | - **텍스트**
71 |
72 | 언어 토큰을 마스킹하고 마스크 언어 토큰을 예측하도록 모델을 학습시켜서 모델이 언어 표현을 더 잘 이해하도록 함
73 |
74 | - **비디오**
75 |
76 | 시각 토큰을 마스킹하고 마스크된 시각 토큰을 예측하도록 모델을 학습시켜서 모델이 비디오 표현을 더 잘 이해하도록 함
77 |
78 | - **비디오-텍스트**
79 |
80 | 언어 및 시각적 토큰을 마스킹하고 모델을 학습시켜 언어 및 시각 토큰을 예측하고, 언어-시각 정렬을 학습하게 해서 모델이 언어와 시각 토큰 간의 관계를 이해하게 함
81 |
82 | - 최종 사전 학습 목표: 세 가지 방법을 모두 활용한 가중치 조합
83 | - 4개의 TPU를 사용해 2일 동안 50만 번 반복해 최종 사전 학습 목표를 수행하며 학습
84 |
85 | ### 데이터 소스 및 전처리
86 |
87 | **데이터셋**
88 |
89 | - 유튜브의 교육용 비디오 사용
90 |
91 | - 유튜브 동영상 주석(annotation) 시스템을 이용해 요리와 관련된 유튜브 동영상 추출
92 |
93 | - 15분 미만 영상 길이, 31만 2000개의 동영상
94 |
95 | - 유튜브 API에서 제공하는 자동 음성 인식 도구(ASR)를 사용해 텍스트 추출
96 |
97 | - 텍스트를 타임 스탬프와 함께 갖고오기 위함 (비디오에 사용된 언어에 대한 정보도 반환)
98 |
99 | - 31만 2000개의 동영상 중 18만 개의 동영상에만 ASR을 적용할 수 있었고, 그 중 영어로 된 동영상은 12만개로 추정
100 |
101 | ➡︎ 텍스트 및 비디오-텍스트 목표를 위해 12만 개의 비디오만 사용하고, 비디오 목표는 31만 2000개의 비디오 사용
102 |
103 | **비디오 및 언어 전처리**
104 |
105 | - 시각 토큰
106 | 1. 비디오의 이미지 프레임을 20fps(초당 프레임)로 샘플링
107 | 2. 이미지 프레임을 1.5초의 구간으로 시각 토큰들로 변환 (= 30-frame clip 생성)
108 | 3. 각 30-frame clip에 사전 학습된 비디오 컨볼루셔널 뉴럴넷을 적용해 특징 추출
109 | 3. 계층적 k-평균 알고리즘을 적용해 시각 특징 토큰화
110 | - 언어 토큰
111 | 1. 상용 LSTM 기반 언어 모델을 이용해 각 ASR 단어 시퀀스에 구두점을 추가하여 단어 스트림을 문장으로 나눔
112 | 2. 각 문장에 대해 BERT의 텍스트 전처리와 동일한 방식을 따르며, 텍스트 토큰화
113 |
114 | > 💡 자연스럽게 문장으로 나뉘는 언어와 달리, 비디오는 어떻게 의미론적으로 나눌까?
115 | >
116 | > - 휴리스틱 사용
117 | > - ASR 문장이 존재할 경우, 문장의 시작 및 종료 timestamp 사이에 해당하는 비디오 토큰을 세그먼트로 취급
118 | > - ASR 문장이 존재하지 않을 경우, 하나의 세그먼트를 16개의 토큰으로 취급
119 |
120 | ### VideoBERT의 응용
121 |
122 | 사전학습된 VideoBERT 모델을 사용해 다양한 다운스트림 태스크에 맞춰 파인튜닝
123 |
124 | - 시각 토큰을 입력해 상위 3개의 다음 시각 토큰 예측
125 | - 텍스트가 주어지면 해당하는 비디오 생성
126 | - 비디오에 자막 생성
127 |
128 | ## Transformers in vision
129 |
130 | 📄 [Transformers in Vision: A Survey](https://arxiv.org/pdf/2101.01169.pdf)
131 |
132 | - Computer Vision 분야에서 Transformer가 활용된 연구들 정리한 survey paper
133 |
134 | ### Background
135 |
136 | RNN to Transformer in NLP ⇨ CNN에 self-attention 적용 ⇨ Transformer 모델 자체를 CV 태스크에 사용
137 |
138 | ### Task
139 |
140 | 
141 |
142 | ***Table 1 from Transformers in Vision: A survey***
143 |
144 | *A summary of key design choices adopted in different variants of transformers for a representative set of computer vision applications. The main changes relate to specific loss function choices, architectural modifications, different position embeddings and variations in input data modalities.*
145 |
146 | ### Model
147 |
148 | #### Transformers for Multi-Modal Tasks
149 |
150 | *Multi-modal learning: 다양한 데이터 타입, 데이터 형태, 다양한 특성을 갖는 데이터를 사용하는 학습법*
151 |
152 | - Transformer 모델은 vision-language 태스크에도 광범위하게 사용
153 | - visual question answering (VQA)
154 | - visual commonsense reasoning (VCR)
155 | - cross-modal retrieval
156 | - image captioning
157 |
158 | 
159 |
160 | *An overview of Transformer models used for multi-modal tasks in computer vision*
161 |
162 | #### Vision Transformer (ViT)
163 |
164 | 📄 [AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE](https://arxiv.org/pdf/2010.11929.pdf)
165 |
166 | 
167 |
168 | - CNN 구조였던 computer vision 문제를 Transformer 구조로 대체
169 | - Transformer 구조를 사용한 Architecture가 수 많은 SOTA를 찍고 있으며, **ViT 논문이 그 시작점**
170 | - Transformer 구조를 활용하여 image classification을 수행한 방법론
171 | - 더 많은 데이터를 더 적은 비용으로 사전 학습
172 |
173 | - 구조
174 |
175 | - Transformer encoder 사용
176 | - 한 이미지를 여러 patch로 분할 (patch를 단어같이 취급)
177 | - patch, classification token, position embedding을 입력하여 최종 classification 결과 생성
178 |
179 | > CNN vs Transformer
180 | >
181 | > - Layer
182 | >
183 | > - CNN: 이미지 전체의 정보를 통합하기 위해서는 몇 개의 layer 통과
184 | > - Transformer: 하나의 layer로 전체 이미지 정보 통합 가능
185 | >
186 | > - Inductive bias
187 | >
188 | > _새로운 데이터에 대해 좋은 성능을 내기 위해 모델에 사전적으로 주어지는 가정_
189 | >
190 | > - CNN: 2차원의 지역적인 특성 유지, 학습 후 weight 고정
191 | >
192 | > → 인접한 픽셀 간 강한 상관관계가 있다는 특징을 살려 inductive bias가 적절하게 만들어짐으로써 이미지 특징 효과적 추출
193 | >
194 | > - Transformer: 1차원 벡터로 만든 후 self attention (2차원의 지역적인 정보 유지 x), weight가 input에 따라 유동적으로 변함
195 | >
196 | > → inductive bias가 적고, 모델의 자유도가 높아 데이터로부터 더 많은 정보를 얻을 수 있음
197 |
198 | - 한계
199 |
200 | - 학습 데이터가 충분하지 않을 경우 CNN 모델보다 성능 감소 (∵ inductive bias ↓)
201 |
202 | ➡︎ 대용량의 학습 자원과 데이터가 필요
203 |
204 | #### Data efficient image Transformer (DeiT)
205 |
206 | 📄 [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
207 |
208 | - 많은 데이터가 필요한 ViT 한계 극복
209 | - Knowledge Distilation
210 | - Data Augmentation
211 |
212 | ## 참고 자료
213 |
214 | #### 개념
215 |
216 | - [Multimodal Deep Learning](https://towardsdatascience.com/multimodal-deep-learning-ce7d1d994f4)
217 |
218 | #### 세미나
219 |
220 | - [DMQA Transformer in Computer Vision](http://dmqm.korea.ac.kr/activity/seminar/316)
221 |
222 | #### 논문
223 |
224 | - [VideoBERT: A Joint Model for Video and Language Representation Learning](https://arxiv.org/pdf/1904.01766.pdf)
225 | - [Transformers in Vision: A Survey](https://arxiv.org/pdf/2101.01169.pdf)
226 | - **리뷰**
227 | - [Transformers in Vision: A Survey [1] Transformer 소개 & Transformers for Image Recognition](https://hoya012.github.io/blog/Vision-Transformer-1/)
228 | - [AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE](https://arxiv.org/pdf/2010.11929.pdf)
229 | - **리뷰**
230 | - https://engineer-mole.tistory.com/133
231 | - https://kmhana.tistory.com/27
232 |
233 | #### 책
234 |
235 | - [구글 BERT의 정석](http://www.yes24.com/Product/Goods/104491152)
236 |
--------------------------------------------------------------------------------
/summaries/chapter10/chapter10_kobert_kogpt2_kobart.md:
--------------------------------------------------------------------------------
1 | # Chapter 10 한국어 언어 모델: KoBERT, KoGPT2, KoBART
2 |
3 | - 다국어 모델들은 한국어 데이터의 부족 때문에 좋은 성능을 보이지 못함
4 |
5 | ## KoBERT
6 |
7 | - 한국어 위키피디아에서 500만 개의 문장과 5400만 개의 단어 학습
8 | - Huggingface, MXNet-Gluon, ONNX 등 여러 플랫폼에서 사용 가능
9 | - Sentencepiece를 이용해 Tokenizer 학습
10 | - 8,002개의 vocab size
11 |
12 | ## KoGPT2
13 |
14 | - 한국어에 특화된 GPT-2 모델
15 | - 주어진 텍스트를 기반으로 다음 단어를 잘 예측할 수 있도록 학습됨
16 | - 문장 생성에 최적화
17 | - 125M parameter
18 | - 한국어 위키피디아, 뉴스, 모두의 말뭉치 v1.0, 청와대 국민청원 등 40GB의 한국어 텍스트 사용
19 | - BPE Tokenizer
20 | - 51,200 vocab
21 | - 이모티콘, 이모지도 추가
22 |
23 | ## KoBART
24 |
25 | - text infilling 노이즈 함수만 적용
26 | - 40GB 이상의 한국어 텍스트로 사전 학습
27 | - Denoising AutoEncoder
28 | - 6 encoder layers
29 | - 6 decoder layers
30 | - 16 attention heads
31 | - 768 FFN hidden unit
32 | - 120M parameters
--------------------------------------------------------------------------------