├── GenerateApp
├── GuernikaModelConverter.version
├── GuernikaModelConverter_AppIcon.png
├── exportOptions.plist
└── GuernikaTools.entitlements
├── GuernikaTools
├── guernikatools
│ ├── _version.py
│ ├── __init__.py
│ ├── models
│ │ ├── layer_norm.py
│ │ ├── attention.py
│ │ └── controlnet.py
│ ├── convert
│ │ ├── convert_text_encoder.py
│ │ ├── convert_t2i_adapter.py
│ │ ├── convert_safety_checker.py
│ │ ├── convert_controlnet.py
│ │ ├── convert_vae.py
│ │ └── convert_unet.py
│ └── utils
│ │ ├── merge_lora.py
│ │ ├── utils.py
│ │ └── chunk_mlprogram.py
├── requirements.txt
├── build.sh
├── GuernikaTools.entitlements
├── setup.py
└── GuernikaTools.spec
├── GuernikaModelConverter
├── Assets.xcassets
│ ├── Contents.json
│ ├── AppIcon.appiconset
│ │ ├── AppIcon-128.png
│ │ ├── AppIcon-16.png
│ │ ├── AppIcon-256.png
│ │ ├── AppIcon-32.png
│ │ ├── AppIcon-512.png
│ │ ├── AppIcon-64.png
│ │ ├── AppIcon-1024.png
│ │ └── Contents.json
│ └── AccentColor.colorset
│ │ └── Contents.json
├── Preview Content
│ └── Preview Assets.xcassets
│ │ └── Contents.json
├── Model
│ ├── LoRAInfo.swift
│ ├── Compression.swift
│ ├── ModelOrigin.swift
│ ├── ComputeUnits.swift
│ ├── Version.swift
│ ├── Logger.swift
│ └── ConverterProcess.swift
├── GuernikaModelConverter.entitlements
├── GuernikaModelConverterApp.swift
├── Navigation
│ ├── ContentView.swift
│ ├── DetailColumn.swift
│ └── Sidebar.swift
├── Views
│ ├── CircularProgress.swift
│ ├── DestinationToolbarButton.swift
│ ├── IntegerField.swift
│ └── DecimalField.swift
├── Log
│ └── LogView.swift
├── ConvertControlNet
│ └── ConvertControlNetViewModel.swift
└── ConvertModel
│ └── ConvertModelViewModel.swift
├── GuernikaModelConverter.xcodeproj
├── project.xcworkspace
│ ├── contents.xcworkspacedata
│ └── xcshareddata
│ │ └── IDEWorkspaceChecks.plist
└── xcuserdata
│ └── guiye.xcuserdatad
│ └── xcschemes
│ └── xcschememanagement.plist
├── .github
└── FUNDING.yml
├── GuernikaModelConverterUITests
├── GuernikaModelConverterUITestsLaunchTests.swift
└── GuernikaModelConverterUITests.swift
├── GuernikaModelConverterTests
└── GuernikaModelConverterTests.swift
├── .gitignore
└── README.md
/GenerateApp/GuernikaModelConverter.version:
--------------------------------------------------------------------------------
1 | 6.5.0
2 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/_version.py:
--------------------------------------------------------------------------------
1 | __version__ = "7.0.0"
2 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/__init__.py:
--------------------------------------------------------------------------------
1 | from ._version import __version__
2 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Assets.xcassets/Contents.json:
--------------------------------------------------------------------------------
1 | {
2 | "info" : {
3 | "author" : "xcode",
4 | "version" : 1
5 | }
6 | }
7 |
--------------------------------------------------------------------------------
/GenerateApp/GuernikaModelConverter_AppIcon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GuernikaCore/GuernikaModelConverter/HEAD/GenerateApp/GuernikaModelConverter_AppIcon.png
--------------------------------------------------------------------------------
/GuernikaModelConverter/Preview Content/Preview Assets.xcassets/Contents.json:
--------------------------------------------------------------------------------
1 | {
2 | "info" : {
3 | "author" : "xcode",
4 | "version" : 1
5 | }
6 | }
7 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-128.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GuernikaCore/GuernikaModelConverter/HEAD/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-128.png
--------------------------------------------------------------------------------
/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-16.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GuernikaCore/GuernikaModelConverter/HEAD/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-16.png
--------------------------------------------------------------------------------
/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-256.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GuernikaCore/GuernikaModelConverter/HEAD/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-256.png
--------------------------------------------------------------------------------
/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-32.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GuernikaCore/GuernikaModelConverter/HEAD/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-32.png
--------------------------------------------------------------------------------
/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-512.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GuernikaCore/GuernikaModelConverter/HEAD/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-512.png
--------------------------------------------------------------------------------
/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-64.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GuernikaCore/GuernikaModelConverter/HEAD/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-64.png
--------------------------------------------------------------------------------
/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-1024.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/GuernikaCore/GuernikaModelConverter/HEAD/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/AppIcon-1024.png
--------------------------------------------------------------------------------
/GuernikaModelConverter.xcodeproj/project.xcworkspace/contents.xcworkspacedata:
--------------------------------------------------------------------------------
1 |
2 |
4 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/GuernikaTools/requirements.txt:
--------------------------------------------------------------------------------
1 | coremltools>=7.0b2
2 | diffusers[torch]
3 | torch
4 | transformers>=4.30.0
5 | scipy
6 | numpy<1.24
7 | pytest
8 | scikit-learn==1.1.2
9 | pytorch_lightning
10 | omegaconf
11 | six
12 | safetensors
13 | pyinstaller
14 |
--------------------------------------------------------------------------------
/GuernikaTools/build.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | pyinstaller GuernikaTools.spec --clean -y --distpath "../GuernikaModelConverter"
4 | codesign -s - -i com.guiyec.GuernikaModelConverter.GuernikaTools -o runtime --entitlements GuernikaTools.entitlements -f "../GuernikaModelConverter/GuernikaTools"
5 |
--------------------------------------------------------------------------------
/GuernikaModelConverter.xcodeproj/project.xcworkspace/xcshareddata/IDEWorkspaceChecks.plist:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | IDEDidComputeMac32BitWarning
6 |
7 |
8 |
9 |
--------------------------------------------------------------------------------
/GenerateApp/exportOptions.plist:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | method
6 | developer-id
7 | signingStyle
8 | automatic
9 | teamID
10 | A5ZC2LG374
11 |
12 |
13 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Model/LoRAInfo.swift:
--------------------------------------------------------------------------------
1 | //
2 | // LoRAInfo.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 11/8/23.
6 | //
7 |
8 | import Foundation
9 |
10 | struct LoRAInfo: Hashable, Identifiable {
11 | var id: URL { url }
12 | var url: URL
13 | var ratio: Double
14 |
15 | var argument: String {
16 | String(format: "%@:%0.2f", url.path(percentEncoded: false), ratio)
17 | }
18 | }
19 |
--------------------------------------------------------------------------------
/GuernikaModelConverter.xcodeproj/xcuserdata/guiye.xcuserdatad/xcschemes/xcschememanagement.plist:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | SchemeUserState
6 |
7 | GuernikaModelConverter.xcscheme_^#shared#^_
8 |
9 | orderHint
10 | 0
11 |
12 |
13 |
14 |
15 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/GuernikaModelConverter.entitlements:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | com.apple.security.cs.allow-dyld-environment-variables
6 |
7 | com.apple.security.cs.allow-jit
8 |
9 | com.apple.security.cs.disable-library-validation
10 |
11 | com.apple.security.network.client
12 |
13 |
14 |
15 |
--------------------------------------------------------------------------------
/GenerateApp/GuernikaTools.entitlements:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | com.apple.security.cs.allow-dyld-environment-variables
6 |
7 | com.apple.security.cs.allow-jit
8 |
9 | com.apple.security.cs.disable-library-validation
10 |
11 | com.apple.security.network.client
12 |
13 | com.apple.security.inherit
14 |
15 |
16 |
17 |
--------------------------------------------------------------------------------
/GuernikaTools/GuernikaTools.entitlements:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | com.apple.security.cs.allow-dyld-environment-variables
6 |
7 | com.apple.security.cs.allow-jit
8 |
9 | com.apple.security.cs.disable-library-validation
10 |
11 | com.apple.security.network.client
12 |
13 | com.apple.security.inherit
14 |
15 |
16 |
17 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Model/Compression.swift:
--------------------------------------------------------------------------------
1 | //
2 | // Compression.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 19/6/23.
6 | //
7 |
8 | import Foundation
9 |
10 | enum Compression: String, CaseIterable, Identifiable, CustomStringConvertible {
11 | case quantizied6bit
12 | case quantizied8bit
13 | case fullSize
14 |
15 | var id: String { rawValue }
16 |
17 | var description: String {
18 | switch self {
19 | case .quantizied6bit: return "6 bit"
20 | case .quantizied8bit: return "8 bit"
21 | case .fullSize: return "Full size"
22 | }
23 | }
24 | }
25 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Model/ModelOrigin.swift:
--------------------------------------------------------------------------------
1 | //
2 | // ModelOrigin.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 30/3/23.
6 | //
7 |
8 | import Foundation
9 |
10 | enum ModelOrigin: String, CaseIterable, Identifiable, CustomStringConvertible {
11 | case huggingface
12 | case diffusers
13 | case checkpoint
14 |
15 | var id: String { rawValue }
16 |
17 | var description: String {
18 | switch self {
19 | case .huggingface: return "🤗 Hugging Face"
20 | case .diffusers: return "📂 Diffusers"
21 | case .checkpoint: return "💽 Checkpoint"
22 | }
23 | }
24 | }
25 |
--------------------------------------------------------------------------------
/.github/FUNDING.yml:
--------------------------------------------------------------------------------
1 | # These are supported funding model platforms
2 |
3 | github: GuiyeC
4 | patreon: # Replace with a single Patreon username
5 | open_collective: # Replace with a single Open Collective username
6 | ko_fi: # Replace with a single Ko-fi username
7 | tidelift: # Replace with a single Tidelift platform-name/package-name e.g., npm/babel
8 | community_bridge: # Replace with a single Community Bridge project-name e.g., cloud-foundry
9 | liberapay: # Replace with a single Liberapay username
10 | issuehunt: # Replace with a single IssueHunt username
11 | otechie: # Replace with a single Otechie username
12 | lfx_crowdfunding: # Replace with a single LFX Crowdfunding project-name e.g., cloud-foundry
13 | custom: # Replace with up to 4 custom sponsorship URLs e.g., ['link1', 'link2']
14 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/GuernikaModelConverterApp.swift:
--------------------------------------------------------------------------------
1 | //
2 | // GuernikaModelConverterApp.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 19/3/23.
6 | //
7 |
8 | import SwiftUI
9 |
10 | final class AppDelegate: NSObject, NSApplicationDelegate {
11 | func applicationShouldTerminateAfterLastWindowClosed(_ sender: NSApplication) -> Bool {
12 | true
13 | }
14 | }
15 |
16 | @main
17 | struct GuernikaModelConverterApp: App {
18 | @NSApplicationDelegateAdaptor(AppDelegate.self) var delegate
19 |
20 | var body: some Scene {
21 | WindowGroup {
22 | ContentView()
23 | }.commands {
24 | SidebarCommands()
25 |
26 | CommandGroup(replacing: CommandGroupPlacement.newItem) {}
27 | }
28 | }
29 | }
30 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Assets.xcassets/AccentColor.colorset/Contents.json:
--------------------------------------------------------------------------------
1 | {
2 | "colors" : [
3 | {
4 | "color" : {
5 | "color-space" : "srgb",
6 | "components" : {
7 | "alpha" : "1.000",
8 | "blue" : "0.271",
9 | "green" : "0.067",
10 | "red" : "0.522"
11 | }
12 | },
13 | "idiom" : "mac"
14 | },
15 | {
16 | "appearances" : [
17 | {
18 | "appearance" : "luminosity",
19 | "value" : "dark"
20 | }
21 | ],
22 | "color" : {
23 | "color-space" : "srgb",
24 | "components" : {
25 | "alpha" : "1.000",
26 | "blue" : "0.271",
27 | "green" : "0.067",
28 | "red" : "0.522"
29 | }
30 | },
31 | "idiom" : "mac"
32 | }
33 | ],
34 | "info" : {
35 | "author" : "xcode",
36 | "version" : 1
37 | }
38 | }
39 |
--------------------------------------------------------------------------------
/GuernikaModelConverterUITests/GuernikaModelConverterUITestsLaunchTests.swift:
--------------------------------------------------------------------------------
1 | //
2 | // GuernikaModelConverterUITestsLaunchTests.swift
3 | // GuernikaModelConverterUITests
4 | //
5 | // Created by Guillermo Cique Fernández on 19/3/23.
6 | //
7 |
8 | import XCTest
9 |
10 | final class GuernikaModelConverterUITestsLaunchTests: XCTestCase {
11 |
12 | override class var runsForEachTargetApplicationUIConfiguration: Bool {
13 | true
14 | }
15 |
16 | override func setUpWithError() throws {
17 | continueAfterFailure = false
18 | }
19 |
20 | func testLaunch() throws {
21 | let app = XCUIApplication()
22 | app.launch()
23 |
24 | // Insert steps here to perform after app launch but before taking a screenshot,
25 | // such as logging into a test account or navigating somewhere in the app
26 |
27 | let attachment = XCTAttachment(screenshot: app.screenshot())
28 | attachment.name = "Launch Screen"
29 | attachment.lifetime = .keepAlways
30 | add(attachment)
31 | }
32 | }
33 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Navigation/ContentView.swift:
--------------------------------------------------------------------------------
1 | //
2 | // ContentView.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 19/3/23.
6 | //
7 |
8 | import SwiftUI
9 |
10 | struct ContentView: View {
11 | @State private var selection: Panel = Panel.model
12 | @State private var path = NavigationPath()
13 |
14 | var body: some View {
15 | NavigationSplitView {
16 | Sidebar(path: $path, selection: $selection)
17 | } detail: {
18 | NavigationStack(path: $path) {
19 | DetailColumn(path: $path, selection: $selection)
20 | }
21 | }
22 | .onChange(of: selection) { _ in
23 | path.removeLast(path.count)
24 | }
25 | .frame(minWidth: 800, minHeight: 500)
26 | }
27 | }
28 |
29 | struct ContentView_Previews: PreviewProvider {
30 | struct Preview: View {
31 | var body: some View {
32 | ContentView()
33 | }
34 | }
35 | static var previews: some View {
36 | Preview()
37 | }
38 | }
39 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Navigation/DetailColumn.swift:
--------------------------------------------------------------------------------
1 | //
2 | // DetailColumn.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 19/3/23.
6 | //
7 |
8 | import SwiftUI
9 |
10 | struct DetailColumn: View {
11 | @Binding var path: NavigationPath
12 | @Binding var selection: Panel
13 | @StateObject var modelConverter = ConvertModelViewModel()
14 | @StateObject var controlNetConverter = ConvertControlNetViewModel()
15 |
16 | var body: some View {
17 | switch selection {
18 | case .model:
19 | ConvertModelView(model: modelConverter)
20 | case .controlNet:
21 | ConvertControlNetView(model: controlNetConverter)
22 | case .log:
23 | LogView()
24 | }
25 | }
26 | }
27 |
28 | struct DetailColumn_Previews: PreviewProvider {
29 | struct Preview: View {
30 | @State private var selection: Panel = .model
31 |
32 | var body: some View {
33 | DetailColumn(path: .constant(NavigationPath()), selection: $selection)
34 | }
35 | }
36 | static var previews: some View {
37 | Preview()
38 | }
39 | }
40 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Model/ComputeUnits.swift:
--------------------------------------------------------------------------------
1 | //
2 | // ComputeUnits.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 30/3/23.
6 | //
7 |
8 | import Foundation
9 |
10 | enum ComputeUnits: String, CaseIterable, Identifiable, CustomStringConvertible {
11 | case cpuAndNeuralEngine, cpuAndGPU, cpuOnly, all
12 |
13 | var id: String { rawValue }
14 |
15 | var description: String {
16 | switch self {
17 | case .cpuAndNeuralEngine: return "CPU and Neural Engine"
18 | case .cpuAndGPU: return "CPU and GPU"
19 | case .cpuOnly: return "CPU only"
20 | case .all: return "All"
21 | }
22 | }
23 |
24 | var shortDescription: String {
25 | switch self {
26 | case .cpuAndNeuralEngine: return "CPU & NE"
27 | case .cpuAndGPU: return "CPU & GPU"
28 | case .cpuOnly: return "CPU"
29 | case .all: return "All"
30 | }
31 | }
32 |
33 | var asCTComputeUnits: String {
34 | switch self {
35 | case .cpuAndNeuralEngine: return "CPU_AND_NE"
36 | case .cpuAndGPU: return "CPU_AND_GPU"
37 | case .cpuOnly: return "CPU_ONLY"
38 | case .all: return "ALL"
39 | }
40 | }
41 | }
42 |
--------------------------------------------------------------------------------
/GuernikaTools/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 |
3 | from guernikatools._version import __version__
4 |
5 | setup(
6 | name='guernikatools',
7 | version=__version__,
8 | url='https://github.com/GuernikaCore/GuernikaModelConverter',
9 | description="Run Stable Diffusion on Apple Silicon with Guernika",
10 | author='Guernika',
11 | install_requires=[
12 | "coremltools>=7.0",
13 | "diffusers[torch]",
14 | "torch",
15 | "transformers>=4.30.0",
16 | "scipy",
17 | "numpy",
18 | "pytest",
19 | "scikit-learn==1.1.2",
20 | "pytorch_lightning",
21 | "OmegaConf",
22 | "six",
23 | "safetensors",
24 | "pyinstaller",
25 | ],
26 | packages=find_packages(),
27 | classifiers=[
28 | "Development Status :: 4 - Beta",
29 | "Intended Audience :: Developers",
30 | "Operating System :: MacOS :: MacOS X",
31 | "Programming Language :: Python :: 3",
32 | "Programming Language :: Python :: 3.7",
33 | "Programming Language :: Python :: 3.8",
34 | "Programming Language :: Python :: 3.9",
35 | "Topic :: Artificial Intelligence",
36 | "Topic :: Scientific/Engineering",
37 | "Topic :: Software Development",
38 | ],
39 | )
40 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Views/CircularProgress.swift:
--------------------------------------------------------------------------------
1 | //
2 | // CircularProgress.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 15/12/22.
6 | //
7 |
8 | import SwiftUI
9 |
10 | struct CircularProgress: View {
11 | var progress: Float?
12 |
13 | var body: some View {
14 | ZStack {
15 | if let progress, progress != 0 && progress != 1 {
16 | Circle()
17 | .stroke(lineWidth: 4)
18 | .opacity(0.2)
19 | .foregroundColor(Color.primary)
20 | .frame(width: 20, height: 20)
21 | Circle()
22 | .trim(from: 0, to: CGFloat(min(progress, 1)))
23 | .stroke(style: StrokeStyle(lineWidth: 4, lineCap: .round, lineJoin: .round))
24 | .foregroundColor(Color.accentColor)
25 | .rotationEffect(Angle(degrees: 270))
26 | .animation(.linear, value: progress)
27 | .frame(width: 20, height: 20)
28 | } else {
29 | ProgressView()
30 | .progressViewStyle(.circular)
31 | .scaleEffect(0.7)
32 | }
33 | }.frame(width: 24, height: 24)
34 | }
35 | }
36 |
37 | struct CircularProgress_Previews: PreviewProvider {
38 | static var previews: some View {
39 | CircularProgress(progress: 0.5)
40 | }
41 | }
42 |
--------------------------------------------------------------------------------
/GuernikaModelConverterTests/GuernikaModelConverterTests.swift:
--------------------------------------------------------------------------------
1 | //
2 | // GuernikaModelConverterTests.swift
3 | // GuernikaModelConverterTests
4 | //
5 | // Created by Guillermo Cique Fernández on 19/3/23.
6 | //
7 |
8 | import XCTest
9 | @testable import GuernikaModelConverter
10 |
11 | final class GuernikaModelConverterTests: XCTestCase {
12 |
13 | override func setUpWithError() throws {
14 | // Put setup code here. This method is called before the invocation of each test method in the class.
15 | }
16 |
17 | override func tearDownWithError() throws {
18 | // Put teardown code here. This method is called after the invocation of each test method in the class.
19 | }
20 |
21 | func testExample() throws {
22 | // This is an example of a functional test case.
23 | // Use XCTAssert and related functions to verify your tests produce the correct results.
24 | // Any test you write for XCTest can be annotated as throws and async.
25 | // Mark your test throws to produce an unexpected failure when your test encounters an uncaught error.
26 | // Mark your test async to allow awaiting for asynchronous code to complete. Check the results with assertions afterwards.
27 | }
28 |
29 | func testPerformanceExample() throws {
30 | // This is an example of a performance test case.
31 | self.measure {
32 | // Put the code you want to measure the time of here.
33 | }
34 | }
35 |
36 | }
37 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Xcode
2 | #
3 | # gitignore contributors: remember to update Global/Xcode.gitignore, Objective-C.gitignore & Swift.gitignore
4 |
5 | ## User settings
6 | xcuserdata/
7 |
8 | ## Obj-C/Swift specific
9 | *.hmap
10 |
11 | ## App packaging
12 | *.ipa
13 | *.dSYM.zip
14 | *.dSYM
15 |
16 | ## Playgrounds
17 | timeline.xctimeline
18 | playground.xcworkspace
19 |
20 | # Swift Package Manager
21 | #
22 | # Add this line if you want to avoid checking in source code from Swift Package Manager dependencies.
23 | # Packages/
24 | # Package.pins
25 | # Package.resolved
26 | # *.xcodeproj
27 | #
28 | # Xcode automatically generates this directory with a .xcworkspacedata file and xcuserdata
29 | # hence it is not needed unless you have added a package configuration file to your project
30 | .swiftpm
31 |
32 | .build/
33 |
34 | # fastlane
35 | #
36 | # It is recommended to not store the screenshots in the git repo.
37 | # Instead, use fastlane to re-generate the screenshots whenever they are needed.
38 | # For more information about the recommended setup visit:
39 | # https://docs.fastlane.tools/best-practices/source-control/#source-control
40 |
41 | fastlane/report.xml
42 | fastlane/Preview.html
43 | fastlane/screenshots/**/*.png
44 | fastlane/test_output
45 |
46 | # Code Injection
47 | #
48 | # After new code Injection tools there's a generated folder /iOSInjectionProject
49 | # https://github.com/johnno1962/injectionforxcode
50 |
51 | iOSInjectionProject/
52 | .DS_Store
53 |
54 | __pycache__
55 | GenerateApp/build
56 | GuernikaTools/build
57 | GuernikaTools/guernikatools.egg-info
58 | GuernikaModelConverter/GuernikaTools
59 | *.dmg
60 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Assets.xcassets/AppIcon.appiconset/Contents.json:
--------------------------------------------------------------------------------
1 | {
2 | "images" : [
3 | {
4 | "size" : "16x16",
5 | "idiom" : "mac",
6 | "filename" : "AppIcon-16.png",
7 | "scale" : "1x"
8 | },
9 | {
10 | "size" : "16x16",
11 | "idiom" : "mac",
12 | "filename" : "AppIcon-32.png",
13 | "scale" : "2x"
14 | },
15 | {
16 | "size" : "32x32",
17 | "idiom" : "mac",
18 | "filename" : "AppIcon-32.png",
19 | "scale" : "1x"
20 | },
21 | {
22 | "size" : "32x32",
23 | "idiom" : "mac",
24 | "filename" : "AppIcon-64.png",
25 | "scale" : "2x"
26 | },
27 | {
28 | "size" : "128x128",
29 | "idiom" : "mac",
30 | "filename" : "AppIcon-128.png",
31 | "scale" : "1x"
32 | },
33 | {
34 | "size" : "128x128",
35 | "idiom" : "mac",
36 | "filename" : "AppIcon-256.png",
37 | "scale" : "2x"
38 | },
39 | {
40 | "size" : "256x256",
41 | "idiom" : "mac",
42 | "filename" : "AppIcon-256.png",
43 | "scale" : "1x"
44 | },
45 | {
46 | "size" : "256x256",
47 | "idiom" : "mac",
48 | "filename" : "AppIcon-512.png",
49 | "scale" : "2x"
50 | },
51 | {
52 | "size" : "512x512",
53 | "idiom" : "mac",
54 | "filename" : "AppIcon-512.png",
55 | "scale" : "1x"
56 | },
57 | {
58 | "size" : "512x512",
59 | "idiom" : "mac",
60 | "filename" : "AppIcon-1024.png",
61 | "scale" : "2x"
62 | }
63 | ],
64 | "info" : {
65 | "version" : 1,
66 | "author" : "xcode"
67 | }
68 | }
--------------------------------------------------------------------------------
/GuernikaModelConverterUITests/GuernikaModelConverterUITests.swift:
--------------------------------------------------------------------------------
1 | //
2 | // GuernikaModelConverterUITests.swift
3 | // GuernikaModelConverterUITests
4 | //
5 | // Created by Guillermo Cique Fernández on 19/3/23.
6 | //
7 |
8 | import XCTest
9 |
10 | final class GuernikaModelConverterUITests: XCTestCase {
11 |
12 | override func setUpWithError() throws {
13 | // Put setup code here. This method is called before the invocation of each test method in the class.
14 |
15 | // In UI tests it is usually best to stop immediately when a failure occurs.
16 | continueAfterFailure = false
17 |
18 | // In UI tests it’s important to set the initial state - such as interface orientation - required for your tests before they run. The setUp method is a good place to do this.
19 | }
20 |
21 | override func tearDownWithError() throws {
22 | // Put teardown code here. This method is called after the invocation of each test method in the class.
23 | }
24 |
25 | func testExample() throws {
26 | // UI tests must launch the application that they test.
27 | let app = XCUIApplication()
28 | app.launch()
29 |
30 | // Use XCTAssert and related functions to verify your tests produce the correct results.
31 | }
32 |
33 | func testLaunchPerformance() throws {
34 | if #available(macOS 10.15, iOS 13.0, tvOS 13.0, watchOS 7.0, *) {
35 | // This measures how long it takes to launch your application.
36 | measure(metrics: [XCTApplicationLaunchMetric()]) {
37 | XCUIApplication().launch()
38 | }
39 | }
40 | }
41 | }
42 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Views/DestinationToolbarButton.swift:
--------------------------------------------------------------------------------
1 | //
2 | // DestinationToolbarButton.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 31/3/23.
6 | //
7 |
8 | import SwiftUI
9 |
10 | struct DestinationToolbarButton: View {
11 | @Binding var showOutputPicker: Bool
12 | var outputLocation: URL?
13 |
14 | var body: some View {
15 | ZStack(alignment: .leading) {
16 | Image(systemName: "folder")
17 | .padding(.leading, 18)
18 | .frame(width: 16)
19 | .foregroundColor(.secondary)
20 | .onTapGesture {
21 | guard let outputLocation else { return }
22 | NSWorkspace.shared.open(outputLocation)
23 | }
24 | Button {
25 | showOutputPicker = true
26 | } label: {
27 | Text(outputLocation?.lastPathComponent ?? "Select destination")
28 | .frame(minWidth: 200)
29 | }
30 | .foregroundColor(.primary)
31 | .background(Color.primary.opacity(0.1))
32 | .clipShape(RoundedRectangle(cornerRadius: 8, style: .continuous))
33 | .padding(.leading, 34)
34 | }.background {
35 | RoundedRectangle(cornerRadius: 8, style: .continuous)
36 | .stroke(.secondary, lineWidth: 1)
37 | .opacity(0.4)
38 | }
39 | .help("Destination")
40 | .padding(.trailing, 8)
41 | }
42 | }
43 |
44 | struct DestinationToolbarButton_Previews: PreviewProvider {
45 | static var previews: some View {
46 | DestinationToolbarButton(showOutputPicker: .constant(false), outputLocation: nil)
47 | }
48 | }
49 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Model/Version.swift:
--------------------------------------------------------------------------------
1 | //
2 | // Version.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 14/3/23.
6 | //
7 |
8 | import Foundation
9 |
10 | public struct Version: Comparable, Hashable, CustomStringConvertible {
11 | let components: [Int]
12 | public var major: Int {
13 | guard components.count > 0 else { return 0 }
14 | return components[0]
15 | }
16 | public var minor: Int {
17 | guard components.count > 1 else { return 0 }
18 | return components[1]
19 | }
20 | public var patch: Int {
21 | guard components.count > 2 else { return 0 }
22 | return components[2]
23 | }
24 |
25 | public var description: String {
26 | return components.map { $0.description }.joined(separator: ".")
27 | }
28 |
29 | public init(major: Int, minor: Int, patch: Int) {
30 | self.components = [major, minor, patch]
31 | }
32 |
33 | public static func == (lhs: Version, rhs: Version) -> Bool {
34 | return lhs.major == rhs.major &&
35 | lhs.minor == rhs.minor &&
36 | lhs.patch == rhs.patch
37 | }
38 |
39 | public static func < (lhs: Version, rhs: Version) -> Bool {
40 | return lhs.major < rhs.major ||
41 | (lhs.major == rhs.major && lhs.minor < rhs.minor) ||
42 | (lhs.major == rhs.major && lhs.minor == rhs.minor && lhs.patch < rhs.patch)
43 | }
44 | }
45 |
46 | extension Version: Codable {
47 | public init(from decoder: Decoder) throws {
48 | let container = try decoder.singleValueContainer()
49 | let stringValue = try container.decode(String.self)
50 | self.init(stringLiteral: stringValue)
51 | }
52 |
53 | public func encode(to encoder: Encoder) throws {
54 | var container = encoder.singleValueContainer()
55 | try container.encode(description)
56 | }
57 | }
58 |
59 | extension Version: ExpressibleByStringLiteral {
60 | public typealias StringLiteralType = String
61 |
62 | public init(stringLiteral value: StringLiteralType) {
63 | components = value.split(separator: ".").compactMap { Int($0) }
64 | }
65 | }
66 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Model/Logger.swift:
--------------------------------------------------------------------------------
1 | //
2 | // Logger.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 30/3/23.
6 | //
7 |
8 | import SwiftUI
9 |
10 | class Logger: ObservableObject {
11 | static var shared: Logger = Logger()
12 |
13 | enum LogLevel {
14 | case debug
15 | case info
16 | case warning
17 | case error
18 | case success
19 |
20 | var backgroundColor: Color {
21 | switch self {
22 | case .debug:
23 | return .secondary
24 | case .info:
25 | return .blue
26 | case .warning:
27 | return .orange
28 | case .error:
29 | return .red
30 | case .success:
31 | return .green
32 | }
33 | }
34 | }
35 |
36 | var isEmpty: Bool = true
37 | var previousContent: Text?
38 | @Published var content: Text = Text("")
39 |
40 | func append(_ line: String) {
41 | if line.starts(with: "INFO:") {
42 | append(String(line.replacing(try! Regex(#"INFO:.*:"#), with: "")), level: .info)
43 | } else if line.starts(with: "WARNING:") {
44 | append(String(line.replacing(try! Regex(#"WARNING:.*:"#), with: "")), level: .warning)
45 | } else if line.starts(with: "ERROR:") {
46 | append(String(line.replacing(try! Regex(#"ERROR:.*:"#), with: "")), level: .error)
47 | } else {
48 | append(line, level: .debug)
49 | }
50 | }
51 |
52 | func append(_ line: String, level: LogLevel) {
53 | if level == .success {
54 | if previousContent == nil {
55 | previousContent = content
56 | }
57 | content = previousContent! + Text(line + "\n").foregroundColor(level.backgroundColor)
58 | isEmpty = false
59 | print(line)
60 | } else {
61 | previousContent = nil
62 | if !line.isEmpty {
63 | content = content + Text(line + "\n").foregroundColor(level.backgroundColor)
64 | isEmpty = false
65 | print(line)
66 | }
67 | }
68 | }
69 |
70 | func clear() {
71 | content = Text("")
72 | previousContent = nil
73 | isEmpty = true
74 | }
75 | }
76 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Guernika Model Converter
2 |
3 | This repository contains a model converter compatible with [Guernika](https://apps.apple.com/app/id1660407508).
4 |
5 | ## Converting Models to Guernika
6 |
7 | **WARNING:** Xcode is required to convert models:
8 |
9 | - Make sure you have [Xcode](https://apps.apple.com/app/id497799835) installed.
10 |
11 | - Once installed run the following commands:
12 |
13 | ```shell
14 | sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer/
15 | sudo xcodebuild -license accept
16 | ```
17 |
18 | - You should now be ready to start converting models!
19 |
20 | **Step 1:** Download and install [`Guernika Model Converter`](https://huggingface.co/Guernika/CoreMLStableDiffusion/resolve/main/GuernikaModelConverter.dmg).
21 |
22 | [ ](https://huggingface.co/Guernika/CoreMLStableDiffusion/resolve/main/GuernikaModelConverter.dmg)
23 |
24 | **Step 2:** Launch `Guernika Model Converter` from your `Applications` folder, this app may take a few seconds to load.
25 |
26 | **Step 3:** Once the app has loaded you will be able to select what model you want to convert:
27 |
28 | - You can input the model identifier (e.g. CompVis/stable-diffusion-v1-4) to download from Hugging Face. You may have to log in to or register for your [Hugging Face account](https://huggingface.co), generate a [User Access Token](https://huggingface.co/settings/tokens) and use this token to set up Hugging Face API access by running `huggingface-cli login` in a Terminal window.
29 |
30 | - You can select a local model from your machine: `Select local model`
31 |
32 | - You can select a local .CKPT model from your machine: `Select CKPT`
33 |
34 |
](https://huggingface.co/Guernika/CoreMLStableDiffusion/resolve/main/GuernikaModelConverter.dmg)
23 |
24 | **Step 2:** Launch `Guernika Model Converter` from your `Applications` folder, this app may take a few seconds to load.
25 |
26 | **Step 3:** Once the app has loaded you will be able to select what model you want to convert:
27 |
28 | - You can input the model identifier (e.g. CompVis/stable-diffusion-v1-4) to download from Hugging Face. You may have to log in to or register for your [Hugging Face account](https://huggingface.co), generate a [User Access Token](https://huggingface.co/settings/tokens) and use this token to set up Hugging Face API access by running `huggingface-cli login` in a Terminal window.
29 |
30 | - You can select a local model from your machine: `Select local model`
31 |
32 | - You can select a local .CKPT model from your machine: `Select CKPT`
33 |
34 | 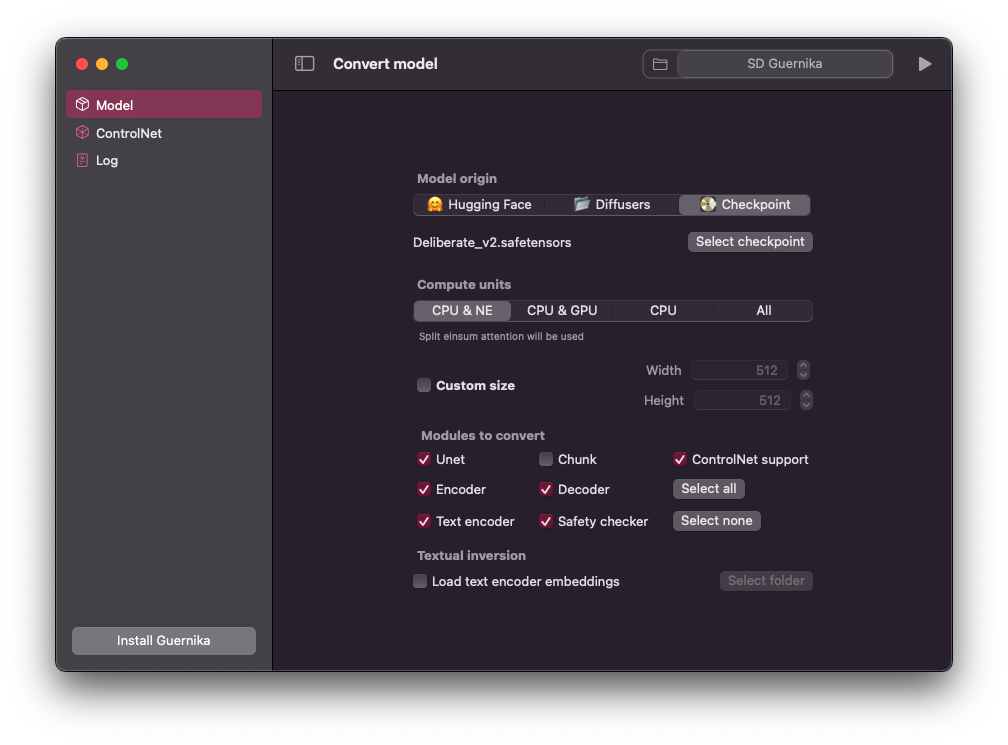 35 |
36 | **Step 4:** Once you've chosen the model you want to convert you can choose what modules to convert and/or if you want to chunk the UNet module (recommended for iOS/iPadOS devices).
37 |
38 | **Step 5:** Once you're happy with your selection click `Convert to Guernika` and wait for the app to complete conversion.
39 | **WARNING:** This command may download several GB worth of PyTorch checkpoints from Hugging Face and may take a long time to complete (15-20 minutes on an M1 machine).
40 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Log/LogView.swift:
--------------------------------------------------------------------------------
1 | //
2 | // LogView.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 30/3/23.
6 | //
7 |
8 | import SwiftUI
9 |
10 | struct LogView: View {
11 | @ObservedObject var logger = Logger.shared
12 | @State var stickToBottom: Bool = true
13 |
14 | var body: some View {
15 | VStack {
16 | if logger.isEmpty {
17 | emptyView
18 | } else {
19 | contentView
20 | }
21 | }.navigationTitle("Log")
22 | .toolbar {
23 | ToolbarItemGroup {
24 | Button {
25 | logger.clear()
26 | } label: {
27 | Image(systemName: "trash")
28 | }.help("Clear log")
29 | .disabled(logger.isEmpty)
30 | Toggle(isOn: $stickToBottom) {
31 | Image(systemName: "dock.arrow.down.rectangle")
32 | }.help("Stick to bottom")
33 | }
34 | }
35 | }
36 |
37 | @ViewBuilder
38 | var emptyView: some View {
39 | Image(systemName: "moon.zzz.fill")
40 | .resizable()
41 | .aspectRatio(contentMode: .fit)
42 | .frame(width: 72)
43 | .opacity(0.3)
44 | .padding(8)
45 | Text("Log is empty")
46 | .font(.largeTitle)
47 | .opacity(0.3)
48 | }
49 |
50 | @ViewBuilder
51 | var contentView: some View {
52 | ScrollViewReader { proxy in
53 | ScrollView {
54 | logger.content
55 | .multilineTextAlignment(.leading)
56 | .font(.body.monospaced())
57 | .textSelection(.enabled)
58 | .frame(maxWidth: .infinity, alignment: .leading)
59 | .padding()
60 |
61 | Divider().opacity(0)
62 | .id("bottom")
63 | }.onChange(of: logger.content) { _ in
64 | if stickToBottom {
65 | proxy.scrollTo("bottom", anchor: .bottom)
66 | }
67 | }.onChange(of: stickToBottom) { newValue in
68 | if newValue {
69 | proxy.scrollTo("bottom", anchor: .bottom)
70 | }
71 | }.onAppear {
72 | if stickToBottom {
73 | proxy.scrollTo("bottom", anchor: .bottom)
74 | }
75 | }
76 | }
77 | }
78 | }
79 |
80 | struct LogView_Previews: PreviewProvider {
81 | static var previews: some View {
82 | LogView()
83 | }
84 | }
85 |
--------------------------------------------------------------------------------
/GuernikaTools/GuernikaTools.spec:
--------------------------------------------------------------------------------
1 | # -*- mode: python ; coding: utf-8 -*-
2 | from PyInstaller.utils.hooks import collect_all
3 |
4 | import sys ; sys.setrecursionlimit(sys.getrecursionlimit() * 5)
5 |
6 | datas = []
7 | binaries = []
8 | hiddenimports = []
9 | tmp_ret = collect_all('regex')
10 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
11 | tmp_ret = collect_all('tqdm')
12 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
13 | tmp_ret = collect_all('requests')
14 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
15 | tmp_ret = collect_all('packaging')
16 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
17 | tmp_ret = collect_all('filelock')
18 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
19 | tmp_ret = collect_all('numpy')
20 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
21 | tmp_ret = collect_all('tokenizers')
22 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
23 | tmp_ret = collect_all('transformers')
24 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
25 | tmp_ret = collect_all('huggingface-hub')
26 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
27 | tmp_ret = collect_all('pyyaml')
28 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
29 | tmp_ret = collect_all('omegaconf')
30 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
31 | tmp_ret = collect_all('pytorch_lightning')
32 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
33 | tmp_ret = collect_all('pytorch-lightning')
34 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
35 | tmp_ret = collect_all('torch')
36 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
37 | tmp_ret = collect_all('safetensors')
38 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
39 | tmp_ret = collect_all('pillow')
40 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
41 |
42 | block_cipher = None
43 |
44 |
45 | a = Analysis(
46 | ['./guernikatools/torch2coreml.py'],
47 | pathex=[],
48 | binaries=binaries,
49 | datas=datas,
50 | hiddenimports=hiddenimports,
51 | hookspath=[],
52 | hooksconfig={},
53 | runtime_hooks=[],
54 | excludes=[],
55 | win_no_prefer_redirects=False,
56 | win_private_assemblies=False,
57 | cipher=block_cipher,
58 | noarchive=False,
59 | )
60 | pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)
61 |
62 | exe = EXE(
63 | pyz,
64 | a.scripts,
65 | a.binaries,
66 | a.zipfiles,
67 | a.datas,
68 | [],
69 | name='GuernikaTools',
70 | debug=False,
71 | bootloader_ignore_signals=False,
72 | strip=False,
73 | upx=True,
74 | upx_exclude=[],
75 | runtime_tmpdir=None,
76 | console=False,
77 | disable_windowed_traceback=False,
78 | argv_emulation=False,
79 | target_arch=None,
80 | codesign_identity=None,
81 | entitlements_file=None,
82 | )
83 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/models/layer_norm.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | import torch
7 | import torch.nn as nn
8 |
9 |
10 | # Reference: https://github.com/apple/ml-ane-transformers/blob/main/ane_transformers/reference/layer_norm.py
11 | class LayerNormANE(nn.Module):
12 | """ LayerNorm optimized for Apple Neural Engine (ANE) execution
13 |
14 | Note: This layer only supports normalization over the final dim. It expects `num_channels`
15 | as an argument and not `normalized_shape` which is used by `torch.nn.LayerNorm`.
16 | """
17 |
18 | def __init__(self,
19 | num_channels,
20 | clip_mag=None,
21 | eps=1e-5,
22 | elementwise_affine=True):
23 | """
24 | Args:
25 | num_channels: Number of channels (C) where the expected input data format is BC1S. S stands for sequence length.
26 | clip_mag: Optional float value to use for clamping the input range before layer norm is applied.
27 | If specified, helps reduce risk of overflow.
28 | eps: Small value to avoid dividing by zero
29 | elementwise_affine: If true, adds learnable channel-wise shift (bias) and scale (weight) parameters
30 | """
31 | super().__init__()
32 | # Principle 1: Picking the Right Data Format (machinelearning.apple.com/research/apple-neural-engine)
33 | self.expected_rank = len("BC1S")
34 |
35 | self.num_channels = num_channels
36 | self.eps = eps
37 | self.clip_mag = clip_mag
38 | self.elementwise_affine = elementwise_affine
39 |
40 | if self.elementwise_affine:
41 | self.weight = nn.Parameter(torch.Tensor(num_channels))
42 | self.bias = nn.Parameter(torch.Tensor(num_channels))
43 |
44 | self._reset_parameters()
45 |
46 | def _reset_parameters(self):
47 | if self.elementwise_affine:
48 | nn.init.ones_(self.weight)
49 | nn.init.zeros_(self.bias)
50 |
51 | def forward(self, inputs):
52 | input_rank = len(inputs.size())
53 |
54 | # Principle 1: Picking the Right Data Format (machinelearning.apple.com/research/apple-neural-engine)
55 | # Migrate the data format from BSC to BC1S (most conducive to ANE)
56 | if input_rank == 3 and inputs.size(2) == self.num_channels:
57 | inputs = inputs.transpose(1, 2).unsqueeze(2)
58 | input_rank = len(inputs.size())
59 |
60 | assert input_rank == self.expected_rank
61 | assert inputs.size(1) == self.num_channels
62 |
63 | if self.clip_mag is not None:
64 | inputs.clamp_(-self.clip_mag, self.clip_mag)
65 |
66 | channels_mean = inputs.mean(dim=1, keepdim=True)
67 |
68 | zero_mean = inputs - channels_mean
69 |
70 | zero_mean_sq = zero_mean * zero_mean
71 |
72 | denom = (zero_mean_sq.mean(dim=1, keepdim=True) + self.eps).rsqrt()
73 |
74 | out = zero_mean * denom
75 |
76 | if self.elementwise_affine:
77 | out = (out + self.bias.view(1, self.num_channels, 1, 1)) * self.weight.view(1, self.num_channels, 1, 1)
78 |
79 | return out
80 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Navigation/Sidebar.swift:
--------------------------------------------------------------------------------
1 | //
2 | // Sidebar.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 19/3/23.
6 | //
7 |
8 | import Cocoa
9 | import SwiftUI
10 |
11 | enum Panel: Hashable {
12 | case model
13 | case controlNet
14 | case log
15 | }
16 |
17 | struct Sidebar: View {
18 | @Binding var path: NavigationPath
19 | @Binding var selection: Panel
20 | @State var showUpdateButton: Bool = false
21 |
22 | var body: some View {
23 | List(selection: $selection) {
24 | NavigationLink(value: Panel.model) {
25 | Label("Model", systemImage: "shippingbox")
26 | }
27 | NavigationLink(value: Panel.controlNet) {
28 | Label("ControlNet", systemImage: "cube.transparent")
29 | }
30 | NavigationLink(value: Panel.log) {
31 | Label("Log", systemImage: "doc.text.below.ecg")
32 | }
33 | }
34 | .safeAreaInset(edge: .bottom, content: {
35 | VStack(spacing: 12) {
36 | if showUpdateButton {
37 | Button {
38 | NSWorkspace.shared.open(URL(string: "https://huggingface.co/Guernika/CoreMLStableDiffusion/blob/main/GuernikaModelConverter.dmg")!)
39 | } label: {
40 | Text("Update available")
41 | .frame(minWidth: 168)
42 | }.controlSize(.large)
43 | .buttonStyle(.borderedProminent)
44 | }
45 | if !FileManager.default.fileExists(atPath: "/Applications/Guernika.app") {
46 | Button {
47 | NSWorkspace.shared.open(URL(string: "macappstore://apps.apple.com/app/id1660407508")!)
48 | } label: {
49 | Text("Install Guernika")
50 | .frame(minWidth: 168)
51 | }.controlSize(.large)
52 | }
53 | }
54 | .padding(16)
55 | })
56 | .navigationTitle("Guernika Model Converter")
57 | .navigationSplitViewColumnWidth(min: 200, ideal: 200)
58 | .onAppear { checkForUpdate() }
59 | }
60 |
61 | func checkForUpdate() {
62 | Task.detached {
63 | let versionUrl = URL(string: "https://huggingface.co/Guernika/CoreMLStableDiffusion/raw/main/GuernikaModelConverter.version")!
64 | guard let lastVersionString = try? String(contentsOf: versionUrl) else { return }
65 | let lastVersion = Version(stringLiteral: lastVersionString)
66 | let currentVersionString = Bundle.main.object(forInfoDictionaryKey: "CFBundleShortVersionString") as? String ?? ""
67 | let currentVersion = Version(stringLiteral: currentVersionString)
68 | await MainActor.run {
69 | withAnimation {
70 | showUpdateButton = currentVersion < lastVersion
71 | }
72 | }
73 | }
74 | }
75 | }
76 |
77 | struct Sidebar_Previews: PreviewProvider {
78 | struct Preview: View {
79 | @State private var selection: Panel = Panel.model
80 | var body: some View {
81 | Sidebar(path: .constant(NavigationPath()), selection: $selection)
82 | }
83 | }
84 |
85 | static var previews: some View {
86 | NavigationSplitView {
87 | Preview()
88 | } detail: {
89 | Text("Detail!")
90 | }
91 | }
92 | }
93 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Views/IntegerField.swift:
--------------------------------------------------------------------------------
1 | //
2 | // IntegerField.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 23/1/22.
6 | //
7 |
8 | import SwiftUI
9 |
10 | struct LabeledIntegerField: View {
11 | @Binding var value: Int
12 | var step: Int = 1
13 | var minValue: Int?
14 | var maxValue: Int?
15 | @ViewBuilder var label: () -> Content
16 |
17 | init(
18 | _ titleKey: LocalizedStringKey,
19 | value: Binding,
20 | step: Int = 1,
21 | minValue: Int? = nil,
22 | maxValue: Int? = nil
23 | ) where Content == Text {
24 | self.init(value: value, step: step, minValue: minValue, maxValue: maxValue, label: {
25 | Text(titleKey)
26 | })
27 | }
28 |
29 | init(
30 | value: Binding,
31 | step: Int = 1,
32 | minValue: Int? = nil,
33 | maxValue: Int? = nil,
34 | @ViewBuilder label: @escaping () -> Content
35 | ) {
36 | self.label = label
37 | self.step = step
38 | self.minValue = minValue
39 | self.maxValue = maxValue
40 | self._value = value
41 | }
42 |
43 | var body: some View {
44 | LabeledContent(content: {
45 | IntegerField(
46 | value: $value,
47 | step: step,
48 | minValue: minValue,
49 | maxValue: maxValue
50 | )
51 | .frame(maxWidth: 120)
52 | }, label: label)
53 | }
54 | }
55 |
56 | struct IntegerField: View {
57 | @Binding var value: Int
58 | var step: Int = 1
59 | var minValue: Int?
60 | var maxValue: Int?
61 | @State private var text: String
62 | @FocusState private var isFocused: Bool
63 |
64 | init(
65 | value: Binding,
66 | step: Int = 1,
67 | minValue: Int? = nil,
68 | maxValue: Int? = nil
69 | ) {
70 | self.step = step
71 | self.minValue = minValue
72 | self.maxValue = maxValue
73 | self._value = value
74 | let text = String(describing: value.wrappedValue)
75 | self._text = State(wrappedValue: text)
76 | }
77 |
78 | var body: some View {
79 | HStack(spacing: 0) {
80 | TextField("", text: $text, prompt: Text("Value"))
81 | .multilineTextAlignment(.trailing)
82 | .textFieldStyle(.plain)
83 | .padding(.horizontal, 10)
84 | .submitLabel(.done)
85 | .focused($isFocused)
86 | .frame(minWidth: 70)
87 | .labelsHidden()
88 | #if !os(macOS)
89 | .keyboardType(.numberPad)
90 | #endif
91 | Stepper(label: {}, onIncrement: {
92 | if let maxValue {
93 | value = min(value + step, maxValue)
94 | } else {
95 | value += step
96 | }
97 | }, onDecrement: {
98 | if let minValue {
99 | value = max(value - step, minValue)
100 | } else {
101 | value -= step
102 | }
103 | }).labelsHidden()
104 | }
105 | #if os(macOS)
106 | .padding(3)
107 | .background(Color.primary.opacity(0.06))
108 | .clipShape(RoundedRectangle(cornerRadius: 8, style: .continuous))
109 | #else
110 | .padding(2)
111 | .background(Color.primary.opacity(0.05))
112 | .clipShape(RoundedRectangle(cornerRadius: 10, style: .continuous))
113 | #endif
114 | .onSubmit {
115 | updateValue()
116 | isFocused = false
117 | }
118 | .onChange(of: isFocused) { focused in
119 | if !focused {
120 | updateValue()
121 | }
122 | }
123 | .onChange(of: value) { _ in updateText() }
124 | .onChange(of: text) { _ in
125 | if let newValue = Int(text), value != newValue {
126 | value = newValue
127 | }
128 | }
129 | #if !os(macOS)
130 | .toolbar {
131 | if isFocused {
132 | ToolbarItem(placement: .keyboard) {
133 | HStack {
134 | Spacer()
135 | Button("Done") {
136 | isFocused = false
137 | }
138 | }
139 | }
140 | }
141 | }
142 | #endif
143 | }
144 |
145 | private func updateValue() {
146 | if let newValue = Int(text) {
147 | if let maxValue, newValue > maxValue {
148 | value = maxValue
149 | } else if let minValue, newValue < minValue {
150 | value = minValue
151 | } else {
152 | value = newValue
153 | }
154 | }
155 | }
156 |
157 | private func updateText() {
158 | text = String(describing: value)
159 | }
160 | }
161 |
162 | struct ValueField_Previews: PreviewProvider {
163 | static var previews: some View {
164 | LabeledIntegerField("Text", value: .constant(20))
165 | }
166 | }
167 |
168 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_text_encoder.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils
8 |
9 | from collections import OrderedDict, defaultdict
10 | from copy import deepcopy
11 | import gc
12 |
13 | import logging
14 |
15 | logging.basicConfig()
16 | logger = logging.getLogger(__name__)
17 | logger.setLevel(logging.INFO)
18 |
19 | import numpy as np
20 | import os
21 |
22 | import torch
23 | import torch.nn as nn
24 | import torch.nn.functional as F
25 |
26 | torch.set_grad_enabled(False)
27 |
28 |
29 | def main(tokenizer, text_encoder, args, model_name="text_encoder"):
30 | """ Converts the text encoder component of Stable Diffusion
31 | """
32 | out_path = utils.get_out_path(args, model_name)
33 | if os.path.exists(out_path):
34 | logger.info(
35 | f"`text_encoder` already exists at {out_path}, skipping conversion."
36 | )
37 | return
38 |
39 | # Create sample inputs for tracing, conversion and correctness verification
40 | text_encoder_sequence_length = tokenizer.model_max_length
41 | text_encoder_hidden_size = text_encoder.config.hidden_size
42 |
43 | sample_text_encoder_inputs = {
44 | "input_ids":
45 | torch.randint(
46 | text_encoder.config.vocab_size,
47 | (1, text_encoder_sequence_length),
48 | # https://github.com/apple/coremltools/issues/1423
49 | dtype=torch.float32,
50 | )
51 | }
52 | sample_text_encoder_inputs_spec = {
53 | k: (v.shape, v.dtype)
54 | for k, v in sample_text_encoder_inputs.items()
55 | }
56 | logger.info(f"Sample inputs spec: {sample_text_encoder_inputs_spec}")
57 |
58 | class TextEncoder(nn.Module):
59 |
60 | def __init__(self):
61 | super().__init__()
62 | self.text_encoder = text_encoder
63 |
64 | def forward(self, input_ids):
65 | return text_encoder(input_ids, return_dict=False)
66 |
67 | class TextEncoderXL(nn.Module):
68 |
69 | def __init__(self):
70 | super().__init__()
71 | self.text_encoder = text_encoder
72 |
73 | def forward(self, input_ids):
74 | output = text_encoder(input_ids, output_hidden_states=True)
75 | return (output.hidden_states[-2], output[0])
76 |
77 | reference_text_encoder = TextEncoderXL().eval() if args.model_is_sdxl else TextEncoder().eval()
78 |
79 | logger.info("JIT tracing {model_name}..")
80 | reference_text_encoder = torch.jit.trace(
81 | reference_text_encoder,
82 | (sample_text_encoder_inputs["input_ids"].to(torch.int32), ),
83 | )
84 | logger.info("Done.")
85 |
86 | sample_coreml_inputs = utils.get_coreml_inputs(sample_text_encoder_inputs)
87 | coreml_text_encoder, out_path = utils.convert_to_coreml(
88 | model_name, reference_text_encoder, sample_coreml_inputs,
89 | ["last_hidden_state", "pooled_outputs"], args.precision_full, args
90 | )
91 |
92 | # Set model metadata
93 | coreml_text_encoder.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
94 | coreml_text_encoder.license = "OpenRAIL (https://huggingface.co/spaces/CompVis/stable-diffusion-license)"
95 | coreml_text_encoder.version = args.model_version
96 | coreml_text_encoder.short_description = \
97 | "Stable Diffusion generates images conditioned on text and/or other images as input through the diffusion process. " \
98 | "Please refer to https://arxiv.org/abs/2112.10752 for details."
99 |
100 | # Set the input descriptions
101 | coreml_text_encoder.input_description["input_ids"] = "The token ids that represent the input text"
102 |
103 | # Set the output descriptions
104 | coreml_text_encoder.output_description["last_hidden_state"] = "The token embeddings as encoded by the Transformer model"
105 | coreml_text_encoder.output_description["pooled_outputs"] = "The version of the `last_hidden_state` output after pooling"
106 |
107 | # Set package version metadata
108 | coreml_text_encoder.user_defined_metadata["identifier"] = args.model_version
109 | coreml_text_encoder.user_defined_metadata["converter_version"] = __version__
110 | coreml_text_encoder.user_defined_metadata["attention_implementation"] = args.attention_implementation
111 | coreml_text_encoder.user_defined_metadata["compute_unit"] = args.compute_unit
112 | coreml_text_encoder.user_defined_metadata["hidden_size"] = str(text_encoder.config.hidden_size)
113 |
114 | coreml_text_encoder.save(out_path)
115 |
116 | logger.info(f"Saved {model_name} into {out_path}")
117 |
118 | # Parity check PyTorch vs CoreML
119 | if args.check_output_correctness:
120 | baseline_out = text_encoder(
121 | sample_text_encoder_inputs["input_ids"].to(torch.int32),
122 | return_dict=False,
123 | )[1].numpy()
124 |
125 | coreml_out = list(coreml_text_encoder.predict({
126 | k: v.numpy() for k, v in sample_text_encoder_inputs.items()
127 | }).values())[0]
128 | utils.report_correctness(baseline_out, coreml_out, "{model_name} baseline PyTorch to reference CoreML")
129 |
130 | del reference_text_encoder, coreml_text_encoder, text_encoder
131 | gc.collect()
132 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Views/DecimalField.swift:
--------------------------------------------------------------------------------
1 | //
2 | // DecimalField.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 5/2/23.
6 | //
7 |
8 | import SwiftUI
9 |
10 | extension Formatter {
11 | static let decimal: NumberFormatter = {
12 | let formatter = NumberFormatter()
13 | formatter.numberStyle = .decimal
14 | formatter.usesGroupingSeparator = false
15 | formatter.maximumFractionDigits = 2
16 | return formatter
17 | }()
18 | }
19 |
20 | struct LabeledDecimalField: View {
21 | @Binding var value: Double
22 | var step: Double = 1
23 | var minValue: Double?
24 | var maxValue: Double?
25 | @ViewBuilder var label: () -> Content
26 |
27 | init(
28 | _ titleKey: LocalizedStringKey,
29 | value: Binding,
30 | step: Double = 1,
31 | minValue: Double? = nil,
32 | maxValue: Double? = nil
33 | ) where Content == Text {
34 | self.init(value: value, step: step, minValue: minValue, maxValue: maxValue, label: {
35 | Text(titleKey)
36 | })
37 | }
38 |
39 | init(
40 | value: Binding,
41 | step: Double = 1,
42 | minValue: Double? = nil,
43 | maxValue: Double? = nil,
44 | @ViewBuilder label: @escaping () -> Content
45 | ) {
46 | self.label = label
47 | self.step = step
48 | self.minValue = minValue
49 | self.maxValue = maxValue
50 | self._value = value
51 | }
52 |
53 | var body: some View {
54 | LabeledContent(content: {
55 | DecimalField(
56 | value: $value,
57 | step: step,
58 | minValue: minValue,
59 | maxValue: maxValue
60 | )
61 | }, label: label)
62 | }
63 | }
64 |
65 | struct DecimalField: View {
66 | @Binding var value: Double
67 | var step: Double = 1
68 | var minValue: Double?
69 | var maxValue: Double?
70 | @State private var text: String
71 | @FocusState private var isFocused: Bool
72 |
73 | init(
74 | value: Binding,
75 | step: Double = 1,
76 | minValue: Double? = nil,
77 | maxValue: Double? = nil
78 | ) {
79 | self.step = step
80 | self.minValue = minValue
81 | self.maxValue = maxValue
82 | self._value = value
83 | let text = Formatter.decimal.string(from: value.wrappedValue as NSNumber) ?? ""
84 | self._text = State(wrappedValue: text)
85 | }
86 |
87 | var body: some View {
88 | HStack(spacing: 0) {
89 | TextField("", text: $text, prompt: Text("Value"))
90 | .multilineTextAlignment(.trailing)
91 | .textFieldStyle(.plain)
92 | .padding(.horizontal, 10)
93 | .submitLabel(.done)
94 | .focused($isFocused)
95 | .frame(minWidth: 70)
96 | .labelsHidden()
97 | #if !os(macOS)
98 | .keyboardType(.decimalPad)
99 | #endif
100 | Stepper(label: {}, onIncrement: {
101 | if let maxValue {
102 | value = min(value + step, maxValue)
103 | } else {
104 | value += step
105 | }
106 | }, onDecrement: {
107 | if let minValue {
108 | value = max(value - step, minValue)
109 | } else {
110 | value -= step
111 | }
112 | }).labelsHidden()
113 | }
114 | #if os(macOS)
115 | .padding(3)
116 | .background(Color.primary.opacity(0.06))
117 | .clipShape(RoundedRectangle(cornerRadius: 8, style: .continuous))
118 | #else
119 | .padding(2)
120 | .background(Color.primary.opacity(0.05))
121 | .clipShape(RoundedRectangle(cornerRadius: 10, style: .continuous))
122 | #endif
123 | .onSubmit {
124 | updateValue()
125 | isFocused = false
126 | }
127 | .onChange(of: isFocused) { focused in
128 | if !focused {
129 | updateValue()
130 | }
131 | }
132 | .onChange(of: value) { _ in updateText() }
133 | .onChange(of: text) { _ in
134 | if let newValue = Formatter.decimal.number(from: text)?.doubleValue, value != newValue {
135 | value = newValue
136 | }
137 | }
138 | #if !os(macOS)
139 | .toolbar {
140 | if isFocused {
141 | ToolbarItem(placement: .keyboard) {
142 | HStack {
143 | Spacer()
144 | Button("Done") {
145 | isFocused = false
146 | }
147 | }
148 | }
149 | }
150 | }
151 | #endif
152 | }
153 |
154 | private func updateValue() {
155 | if let newValue = Formatter.decimal.number(from: text)?.doubleValue {
156 | if let maxValue, newValue > maxValue {
157 | value = maxValue
158 | } else if let minValue, newValue < minValue {
159 | value = minValue
160 | } else {
161 | value = newValue
162 | }
163 | }
164 | }
165 |
166 | private func updateText() {
167 | text = Formatter.decimal.string(from: value as NSNumber) ?? ""
168 | }
169 | }
170 |
171 |
172 | struct DecimalField_Previews: PreviewProvider {
173 | static var previews: some View {
174 | DecimalField(value: .constant(20))
175 | .padding()
176 | }
177 | }
178 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/ConvertControlNet/ConvertControlNetViewModel.swift:
--------------------------------------------------------------------------------
1 | //
2 | // ConvertControlNetViewModel.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 30/3/23.
6 | //
7 |
8 | import SwiftUI
9 | import Combine
10 |
11 | class ConvertControlNetViewModel: ObservableObject {
12 | @Published var showSuccess: Bool = false
13 | var showError: Bool {
14 | get { error != nil }
15 | set {
16 | if !newValue {
17 | error = nil
18 | isCoreMLError = false
19 | }
20 | }
21 | }
22 | var isCoreMLError: Bool = false
23 | @Published var error: String?
24 |
25 | var isReady: Bool {
26 | switch controlNetOrigin {
27 | case .huggingface: return !huggingfaceIdentifier.isEmpty
28 | case .diffusers: return diffusersLocation != nil
29 | case .checkpoint: return checkpointLocation != nil
30 | }
31 | }
32 | @Published var process: ConverterProcess?
33 | var isRunning: Bool { process != nil }
34 |
35 | @Published var showOutputPicker: Bool = false
36 | @AppStorage("output_location") var outputLocation: URL?
37 |
38 | var controlNetOrigin: ModelOrigin {
39 | get { ModelOrigin(rawValue: controlNetOriginString) ?? .huggingface }
40 | set { controlNetOriginString = newValue.rawValue }
41 | }
42 | @AppStorage("controlnet_origin") var controlNetOriginString: String = ModelOrigin.huggingface.rawValue
43 | @AppStorage("controlnet_huggingface_identifier") var huggingfaceIdentifier: String = ""
44 | @AppStorage("controlnet_diffusers_location") var diffusersLocation: URL?
45 | @AppStorage("controlnet_checkpoint_location") var checkpointLocation: URL?
46 | var selectedControlNet: String? {
47 | switch controlNetOrigin {
48 | case .huggingface: return nil
49 | case .diffusers: return diffusersLocation?.lastPathComponent
50 | case .checkpoint: return checkpointLocation?.lastPathComponent
51 | }
52 | }
53 |
54 | var computeUnits: ComputeUnits {
55 | get { ComputeUnits(rawValue: computeUnitsString) ?? .cpuAndNeuralEngine }
56 | set { computeUnitsString = newValue.rawValue }
57 | }
58 | @AppStorage("compute_units") var computeUnitsString: String = ComputeUnits.cpuAndNeuralEngine.rawValue
59 |
60 | var compression: Compression {
61 | get { Compression(rawValue: compressionString) ?? .fullSize }
62 | set { compressionString = newValue.rawValue }
63 | }
64 | @AppStorage("controlnet_compression") var compressionString: String = Compression.fullSize.rawValue
65 |
66 | @AppStorage("custom_size") var customSize: Bool = false
67 | @AppStorage("custom_size_width") var customWidth: Int = 512
68 | @AppStorage("custom_size_height") var customHeight: Int = 512
69 | @AppStorage("controlnet_multisize") var multisize: Bool = false
70 |
71 | private var cancellables: Set = []
72 |
73 | func start() {
74 | guard checkCoreMLCompiler() else {
75 | isCoreMLError = true
76 | error = "CoreMLCompiler not available.\nMake sure you have Xcode installed and you run \"sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer/\" on a Terminal."
77 | return
78 | }
79 | do {
80 | let process = try ConverterProcess(
81 | outputLocation: outputLocation,
82 | controlNetOrigin: controlNetOrigin,
83 | huggingfaceIdentifier: huggingfaceIdentifier,
84 | diffusersLocation: diffusersLocation,
85 | checkpointLocation: checkpointLocation,
86 | computeUnits: computeUnits,
87 | customWidth: customSize && !multisize && computeUnits == .cpuAndGPU ? customWidth : nil,
88 | customHeight: customSize && !multisize && computeUnits == .cpuAndGPU ? customHeight : nil,
89 | multisize: multisize && computeUnits == .cpuAndGPU,
90 | compression: compression
91 | )
92 | process.objectWillChange
93 | .receive(on: DispatchQueue.main)
94 | .sink { _ in
95 | self.objectWillChange.send()
96 | }.store(in: &cancellables)
97 | NotificationCenter.default.publisher(for: Process.didTerminateNotification, object: process.process)
98 | .receive(on: DispatchQueue.main)
99 | .sink { _ in
100 | withAnimation {
101 | if process.didComplete {
102 | self.showSuccess = true
103 | }
104 | self.cancel()
105 | }
106 | }.store(in: &cancellables)
107 | try process.start()
108 | withAnimation {
109 | self.process = process
110 | }
111 | } catch ConverterProcess.ArgumentError.noOutputLocation {
112 | showOutputPicker = true
113 | } catch ConverterProcess.ArgumentError.noHuggingfaceIdentifier {
114 | self.error = "Enter a valid identifier"
115 | } catch ConverterProcess.ArgumentError.noDiffusersLocation {
116 | self.error = "Enter a valid location"
117 | } catch ConverterProcess.ArgumentError.noCheckpointLocation {
118 | self.error = "Enter a valid location"
119 | } catch {
120 | print(error.localizedDescription)
121 | self.error = error.localizedDescription
122 | withAnimation {
123 | cancel()
124 | }
125 | }
126 | }
127 |
128 | func cancel() {
129 | withAnimation {
130 | process?.cancel()
131 | process = nil
132 | }
133 | }
134 |
135 | func checkCoreMLCompiler() -> Bool {
136 | let process = Process()
137 | process.executableURL = URL(string: "file:///usr/bin/xcrun")
138 | process.arguments = ["coremlcompiler", "version"]
139 | do {
140 | try process.run()
141 | } catch {
142 | Logger.shared.append("coremlcompiler not found")
143 | return false
144 | }
145 | return true
146 | }
147 | }
148 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_t2i_adapter.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils
8 | from guernikatools.models import attention
9 |
10 | from diffusers import T2IAdapter
11 |
12 | from collections import OrderedDict, defaultdict
13 | from copy import deepcopy
14 | import coremltools as ct
15 | import gc
16 |
17 | import logging
18 |
19 | logging.basicConfig()
20 | logger = logging.getLogger(__name__)
21 | logger.setLevel(logging.INFO)
22 |
23 | import numpy as np
24 | import os
25 |
26 | import torch
27 | import torch.nn as nn
28 | import torch.nn.functional as F
29 |
30 | torch.set_grad_enabled(False)
31 |
32 |
33 | def main(base_adapter, args):
34 | """ Converts a T2IAdapter
35 | """
36 | out_path = utils.get_out_path(args, "t2i_adapter")
37 | if os.path.exists(out_path):
38 | logger.info(f"`t2i_adapter` already exists at {out_path}, skipping conversion.")
39 | return
40 |
41 | # Register the selected attention implementation globally
42 | attention.ATTENTION_IMPLEMENTATION_IN_EFFECT = attention.AttentionImplementations[args.attention_implementation]
43 | logger.info(f"Attention implementation in effect: {attention.ATTENTION_IMPLEMENTATION_IN_EFFECT}")
44 |
45 | # Prepare sample input shapes and values
46 | batch_size = 2 # for classifier-free guidance
47 | adapter_type = base_adapter.config.adapter_type
48 | adapter_in_channels = base_adapter.config.in_channels
49 |
50 | input_shape = (
51 | 1, # B
52 | adapter_in_channels, # C
53 | args.output_h, # H
54 | args.output_w, # W
55 | )
56 |
57 | sample_adapter_inputs = {
58 | "input": torch.rand(*input_shape, dtype=torch.float16)
59 | }
60 | sample_adapter_inputs_spec = {
61 | k: (v.shape, v.dtype)
62 | for k, v in sample_adapter_inputs.items()
63 | }
64 | logger.info(f"Sample inputs spec: {sample_adapter_inputs_spec}")
65 |
66 | # Initialize reference adapter
67 | reference_adapter = T2IAdapter(**base_adapter.config).eval()
68 | load_state_dict_summary = reference_adapter.load_state_dict(base_adapter.state_dict())
69 |
70 | # Prepare inputs
71 | baseline_sample_adapter_inputs = deepcopy(sample_adapter_inputs)
72 |
73 | # JIT trace
74 | logger.info("JIT tracing..")
75 | reference_adapter = torch.jit.trace(reference_adapter, (sample_adapter_inputs["input"].to(torch.float32), ))
76 | logger.info("Done.")
77 |
78 | if args.check_output_correctness:
79 | baseline_out = base_adapter(**baseline_sample_adapter_inputs, return_dict=False)[0].numpy()
80 | reference_out = reference_adapter(**sample_adapter_inputs)[0].numpy()
81 | utils.report_correctness(baseline_out, reference_out, "control baseline to reference PyTorch")
82 |
83 | del base_adapter
84 | gc.collect()
85 |
86 | coreml_sample_adapter_inputs = {
87 | k: v.numpy().astype(np.float16)
88 | for k, v in sample_adapter_inputs.items()
89 | }
90 |
91 | if args.multisize:
92 | input_size = args.output_h
93 | input_shape = ct.Shape(shape=(
94 | 1,
95 | adapter_in_channels,
96 | ct.RangeDim(int(input_size * 0.5), upper_bound=int(input_size * 2), default=input_size),
97 | ct.RangeDim(int(input_size * 0.5), upper_bound=int(input_size * 2), default=input_size)
98 | ))
99 |
100 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_adapter_inputs, {"input": input_shape})
101 | else:
102 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_adapter_inputs)
103 | output_names = [
104 | "adapter_res_samples_00", "adapter_res_samples_01",
105 | "adapter_res_samples_02", "adapter_res_samples_03"
106 | ]
107 | coreml_adapter, out_path = utils.convert_to_coreml(
108 | "t2i_adapter",
109 | reference_adapter,
110 | sample_coreml_inputs,
111 | output_names,
112 | args.precision_full,
113 | args
114 | )
115 | del reference_adapter
116 | gc.collect()
117 |
118 | # Set model metadata
119 | coreml_adapter.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
120 | coreml_adapter.license = "T2IAdapter (https://github.com/TencentARC/T2I-Adapter)"
121 | coreml_adapter.version = args.t2i_adapter_version
122 | coreml_adapter.short_description = \
123 | "T2IAdapter is a neural network structure to control diffusion models by adding extra conditions. " \
124 | "Please refer to https://github.com/TencentARC/T2I-Adapter for details."
125 |
126 | # Set the input descriptions
127 | coreml_adapter.input_description["input"] = "Image used to condition adapter output"
128 |
129 | # Set the output descriptions
130 | coreml_adapter.output_description["adapter_res_samples_00"] = "Residual sample from T2IAdapter"
131 | coreml_adapter.output_description["adapter_res_samples_01"] = "Residual sample from T2IAdapter"
132 | coreml_adapter.output_description["adapter_res_samples_02"] = "Residual sample from T2IAdapter"
133 | coreml_adapter.output_description["adapter_res_samples_03"] = "Residual sample from T2IAdapter"
134 |
135 | # Set package version metadata
136 | coreml_adapter.user_defined_metadata["identifier"] = args.t2i_adapter_version
137 | coreml_adapter.user_defined_metadata["converter_version"] = __version__
138 | coreml_adapter.user_defined_metadata["attention_implementation"] = args.attention_implementation
139 | coreml_adapter.user_defined_metadata["compute_unit"] = args.compute_unit
140 | coreml_adapter.user_defined_metadata["adapter_type"] = adapter_type
141 | adapter_method = conditioning_method_from(args.t2i_adapter_version)
142 | if adapter_method:
143 | coreml_adapter.user_defined_metadata["method"] = adapter_method
144 |
145 | coreml_adapter.save(out_path)
146 | logger.info(f"Saved adapter into {out_path}")
147 |
148 | # Parity check PyTorch vs CoreML
149 | if args.check_output_correctness:
150 | coreml_out = list(coreml_adapter.predict(coreml_sample_adapter_inputs).values())[0]
151 | utils.report_correctness(baseline_out, coreml_out, "control baseline PyTorch to reference CoreML")
152 |
153 | del coreml_adapter
154 | gc.collect()
155 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/ConvertModel/ConvertModelViewModel.swift:
--------------------------------------------------------------------------------
1 | //
2 | // ConvertModelViewModel.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 30/3/23.
6 | //
7 |
8 | import SwiftUI
9 | import Combine
10 |
11 | class ConvertModelViewModel: ObservableObject {
12 | @Published var showSuccess: Bool = false
13 | var showError: Bool {
14 | get { error != nil }
15 | set {
16 | if !newValue {
17 | error = nil
18 | isCoreMLError = false
19 | }
20 | }
21 | }
22 | var isCoreMLError: Bool = false
23 | @Published var error: String?
24 |
25 | var isReady: Bool {
26 | guard convertUnet || convertTextEncoder || convertVaeEncoder || convertVaeDecoder || convertSafetyChecker else {
27 | return false
28 | }
29 | switch modelOrigin {
30 | case .huggingface: return !huggingfaceIdentifier.isEmpty
31 | case .diffusers: return diffusersLocation != nil
32 | case .checkpoint: return checkpointLocation != nil
33 | }
34 | }
35 | @Published var process: ConverterProcess?
36 | var isRunning: Bool { process != nil }
37 |
38 | @Published var showOutputPicker: Bool = false
39 | @AppStorage("output_location") var outputLocation: URL?
40 | var modelOrigin: ModelOrigin {
41 | get { ModelOrigin(rawValue: modelOriginString) ?? .huggingface }
42 | set { modelOriginString = newValue.rawValue }
43 | }
44 | @AppStorage("model_origin") var modelOriginString: String = ModelOrigin.huggingface.rawValue
45 | @AppStorage("huggingface_identifier") var huggingfaceIdentifier: String = ""
46 | @AppStorage("diffusers_location") var diffusersLocation: URL?
47 | @AppStorage("checkpoint_location") var checkpointLocation: URL?
48 | var selectedModel: String? {
49 | switch modelOrigin {
50 | case .huggingface: return nil
51 | case .diffusers: return diffusersLocation?.lastPathComponent
52 | case .checkpoint: return checkpointLocation?.lastPathComponent
53 | }
54 | }
55 |
56 | var computeUnits: ComputeUnits {
57 | get { ComputeUnits(rawValue: computeUnitsString) ?? .cpuAndNeuralEngine }
58 | set { computeUnitsString = newValue.rawValue }
59 | }
60 | @AppStorage("compute_units") var computeUnitsString: String = ComputeUnits.cpuAndNeuralEngine.rawValue
61 |
62 | var compression: Compression {
63 | get { Compression(rawValue: compressionString) ?? .fullSize }
64 | set { compressionString = newValue.rawValue }
65 | }
66 | @AppStorage("compression") var compressionString: String = Compression.fullSize.rawValue
67 |
68 | @AppStorage("custom_size") var customSize: Bool = false
69 | @AppStorage("custom_size_width") var customWidth: Int = 512
70 | @AppStorage("custom_size_height") var customHeight: Int = 512
71 | @AppStorage("multisize") var multisize: Bool = false
72 |
73 | @AppStorage("convert_unet") var convertUnet: Bool = true
74 | @AppStorage("chunk_unet") var chunkUnet: Bool = false
75 | @AppStorage("controlnet_support") var controlNetSupport: Bool = true
76 | @AppStorage("convert_text_encoder") var convertTextEncoder: Bool = true
77 | @AppStorage("load_embeddings") var loadEmbeddings: Bool = false
78 | @AppStorage("embeddings_location") var embeddingsLocation: URL?
79 | @AppStorage("convert_vae_encoder") var convertVaeEncoder: Bool = true
80 | @AppStorage("convert_vae_decoder") var convertVaeDecoder: Bool = true
81 | @AppStorage("convert_safety_checker") var convertSafetyChecker: Bool = false
82 | @AppStorage("precision_full") var precisionFull: Bool = false
83 | @Published var loRAsToMerge: [LoRAInfo] = []
84 |
85 | private var cancellables: Set = []
86 |
87 | func start() {
88 | guard checkCoreMLCompiler() else {
89 | isCoreMLError = true
90 | error = "CoreMLCompiler not available.\nMake sure you have Xcode installed and you run \"sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer/\" on a Terminal."
91 | return
92 | }
93 | do {
94 | let process = try ConverterProcess(
95 | outputLocation: outputLocation,
96 | modelOrigin: modelOrigin,
97 | huggingfaceIdentifier: huggingfaceIdentifier,
98 | diffusersLocation: diffusersLocation,
99 | checkpointLocation: checkpointLocation,
100 | computeUnits: computeUnits,
101 | customWidth: customSize && !multisize && computeUnits == .cpuAndGPU ? customWidth : nil,
102 | customHeight: customSize && !multisize && computeUnits == .cpuAndGPU ? customHeight : nil,
103 | multisize: multisize && computeUnits == .cpuAndGPU,
104 | convertUnet: convertUnet,
105 | chunkUnet: chunkUnet,
106 | controlNetSupport: controlNetSupport && !multisize, // TODO: Currently not possible to have both
107 | convertTextEncoder: convertTextEncoder,
108 | embeddingsLocation: loadEmbeddings ? embeddingsLocation : nil,
109 | convertVaeEncoder: convertVaeEncoder,
110 | convertVaeDecoder: convertVaeDecoder,
111 | convertSafetyChecker: convertSafetyChecker,
112 | precisionFull: precisionFull,
113 | loRAsToMerge: loRAsToMerge,
114 | compression: compression
115 | )
116 | process.objectWillChange
117 | .receive(on: DispatchQueue.main)
118 | .sink { _ in
119 | self.objectWillChange.send()
120 | }.store(in: &cancellables)
121 | NotificationCenter.default.publisher(for: Process.didTerminateNotification, object: process.process)
122 | .receive(on: DispatchQueue.main)
123 | .sink { _ in
124 | if process.didComplete {
125 | self.showSuccess = true
126 | }
127 | self.cancel()
128 | }.store(in: &cancellables)
129 | try process.start()
130 | withAnimation {
131 | self.process = process
132 | }
133 | } catch ConverterProcess.ArgumentError.noOutputLocation {
134 | showOutputPicker = true
135 | } catch ConverterProcess.ArgumentError.noHuggingfaceIdentifier {
136 | self.error = "Enter a valid identifier"
137 | } catch ConverterProcess.ArgumentError.noDiffusersLocation {
138 | self.error = "Enter a valid location"
139 | } catch ConverterProcess.ArgumentError.noCheckpointLocation {
140 | self.error = "Enter a valid location"
141 | } catch {
142 | print(error.localizedDescription)
143 | self.error = error.localizedDescription
144 | withAnimation {
145 | cancel()
146 | }
147 | }
148 | }
149 |
150 | func cancel() {
151 | withAnimation {
152 | process?.cancel()
153 | process = nil
154 | }
155 | }
156 |
157 | func selectAll() {
158 | convertUnet = true
159 | convertTextEncoder = true
160 | convertVaeEncoder = true
161 | convertVaeDecoder = true
162 | convertSafetyChecker = true
163 | }
164 |
165 | func selectNone() {
166 | convertUnet = false
167 | convertTextEncoder = false
168 | convertVaeEncoder = false
169 | convertVaeDecoder = false
170 | convertSafetyChecker = false
171 | }
172 |
173 | func checkCoreMLCompiler() -> Bool {
174 | let process = Process()
175 | process.executableURL = URL(string: "file:///usr/bin/xcrun")
176 | process.arguments = ["coremlcompiler", "version"]
177 | do {
178 | try process.run()
179 | } catch {
180 | Logger.shared.append("coremlcompiler not found")
181 | return false
182 | }
183 | return true
184 | }
185 | }
186 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/models/attention.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 | logger = logging.getLogger(__name__)
4 | logger.setLevel(logging.INFO)
5 |
6 | import torch
7 | import torch.nn as nn
8 |
9 | from enum import Enum
10 |
11 |
12 | # Ensure minimum macOS version requirement is met for this particular model
13 | from coremltools.models.utils import _macos_version
14 | if not _macos_version() >= (13, 1):
15 | logger.warning(
16 | "!!! macOS 13.1 and newer or iOS/iPadOS 16.2 and newer is required for best performance !!!"
17 | )
18 |
19 |
20 | class AttentionImplementations(Enum):
21 | ORIGINAL = "ORIGINAL"
22 | SPLIT_EINSUM = "SPLIT_EINSUM"
23 | SPLIT_EINSUM_V2 = "SPLIT_EINSUM_V2"
24 |
25 |
26 | ATTENTION_IMPLEMENTATION_IN_EFFECT = AttentionImplementations.SPLIT_EINSUM_V2
27 |
28 |
29 | WARN_MSG = \
30 | "This `nn.Module` is intended for Apple Silicon deployment only. " \
31 | "PyTorch-specific optimizations and training is disabled"
32 |
33 | class Attention(nn.Module):
34 | """ Apple Silicon friendly version of `diffusers.models.attention.Attention`
35 | """
36 | def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.0, bias=False):
37 | super().__init__()
38 | inner_dim = dim_head * heads
39 | context_dim = context_dim if context_dim is not None else query_dim
40 |
41 | self.scale = dim_head**-0.5
42 | self.heads = heads
43 | self.dim_head = dim_head
44 |
45 | self.to_q = nn.Conv2d(query_dim, inner_dim, kernel_size=1, bias=bias)
46 | self.to_k = nn.Conv2d(context_dim, inner_dim, kernel_size=1, bias=bias)
47 | self.to_v = nn.Conv2d(context_dim, inner_dim, kernel_size=1, bias=bias)
48 | if dropout > 0:
49 | self.to_out = nn.Sequential(
50 | nn.Conv2d(inner_dim, query_dim, kernel_size=1, bias=True), nn.Dropout(dropout)
51 | )
52 | else:
53 | self.to_out = nn.Sequential(
54 | nn.Conv2d(inner_dim, query_dim, kernel_size=1, bias=True)
55 | )
56 |
57 |
58 | def forward(self, hidden_states, encoder_hidden_states=None, mask=None):
59 | if self.training:
60 | raise NotImplementedError(WARN_MSG)
61 |
62 | batch_size, dim, _, sequence_length = hidden_states.shape
63 |
64 | q = self.to_q(hidden_states)
65 | encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
66 | k = self.to_k(encoder_hidden_states)
67 | v = self.to_v(encoder_hidden_states)
68 |
69 | # Validate mask
70 | if mask is not None:
71 | expected_mask_shape = [batch_size, sequence_length, 1, 1]
72 | if mask.dtype == torch.bool:
73 | mask = mask.logical_not().float() * -1e4
74 | elif mask.dtype == torch.int64:
75 | mask = (1 - mask).float() * -1e4
76 | elif mask.dtype != torch.float32:
77 | raise TypeError(f"Unexpected dtype for mask: {mask.dtype}")
78 |
79 | if len(mask.size()) == 2:
80 | mask = mask.unsqueeze(2).unsqueeze(2)
81 |
82 | if list(mask.size()) != expected_mask_shape:
83 | raise RuntimeError(
84 | f"Invalid shape for `mask` (Expected {expected_mask_shape}, got {list(mask.size())}"
85 | )
86 |
87 | if ATTENTION_IMPLEMENTATION_IN_EFFECT == AttentionImplementations.ORIGINAL:
88 | attn = original(q, k, v, mask, self.heads, self.dim_head)
89 | elif ATTENTION_IMPLEMENTATION_IN_EFFECT == AttentionImplementations.SPLIT_EINSUM:
90 | attn = split_einsum(q, k, v, mask, self.heads, self.dim_head)
91 | elif ATTENTION_IMPLEMENTATION_IN_EFFECT == AttentionImplementations.SPLIT_EINSUM_V2:
92 | attn = split_einsum_v2(q, k, v, mask, self.heads, self.dim_head)
93 | else:
94 | raise ValueError(ATTENTION_IMPLEMENTATION_IN_EFFECT)
95 |
96 | return self.to_out(attn)
97 |
98 | def split_einsum(q, k, v, mask, heads, dim_head):
99 | """ Attention Implementation backing AttentionImplementations.SPLIT_EINSUM
100 |
101 | - Implements https://machinelearning.apple.com/research/neural-engine-transformers
102 | - Recommended for ANE
103 | - Marginally slower on GPU
104 | """
105 | mh_q = [
106 | q[:, head_idx * dim_head:(head_idx + 1) *
107 | dim_head, :, :] for head_idx in range(heads)
108 | ] # (bs, dim_head, 1, max_seq_length) * heads
109 |
110 | k = k.transpose(1, 3)
111 | mh_k = [
112 | k[:, :, :,
113 | head_idx * dim_head:(head_idx + 1) * dim_head]
114 | for head_idx in range(heads)
115 | ] # (bs, max_seq_length, 1, dim_head) * heads
116 |
117 | mh_v = [
118 | v[:, head_idx * dim_head:(head_idx + 1) *
119 | dim_head, :, :] for head_idx in range(heads)
120 | ] # (bs, dim_head, 1, max_seq_length) * heads
121 |
122 | attn_weights = [
123 | torch.einsum("bchq,bkhc->bkhq", [qi, ki]) * (dim_head**-0.5)
124 | for qi, ki in zip(mh_q, mh_k)
125 | ] # (bs, max_seq_length, 1, max_seq_length) * heads
126 |
127 | if mask is not None:
128 | for head_idx in range(heads):
129 | attn_weights[head_idx] = attn_weights[head_idx] + mask
130 |
131 | attn_weights = [
132 | aw.softmax(dim=1) for aw in attn_weights
133 | ] # (bs, max_seq_length, 1, max_seq_length) * heads
134 | attn = [
135 | torch.einsum("bkhq,bchk->bchq", wi, vi)
136 | for wi, vi in zip(attn_weights, mh_v)
137 | ] # (bs, dim_head, 1, max_seq_length) * heads
138 |
139 | attn = torch.cat(attn, dim=1) # (bs, dim, 1, max_seq_length)
140 | return attn
141 |
142 |
143 | CHUNK_SIZE = 512
144 |
145 | def split_einsum_v2(q, k, v, mask, heads, dim_head):
146 | """ Attention Implementation backing AttentionImplementations.SPLIT_EINSUM_V2
147 |
148 | - Implements https://machinelearning.apple.com/research/neural-engine-transformers
149 | - Recommended for ANE
150 | - Marginally slower on GPU
151 | - Chunks the query sequence to avoid large intermediate tensors and improves ANE performance
152 | """
153 | query_seq_length = q.size(3)
154 | num_chunks = query_seq_length // CHUNK_SIZE
155 |
156 | if num_chunks == 0:
157 | logger.info(
158 | "AttentionImplementations.SPLIT_EINSUM_V2: query sequence too short to chunk "
159 | f"({query_seq_length}<{CHUNK_SIZE}), fall back to AttentionImplementations.SPLIT_EINSUM (safe to ignore)")
160 | return split_einsum(q, k, v, mask, heads, dim_head)
161 |
162 | logger.info(
163 | "AttentionImplementations.SPLIT_EINSUM_V2: Splitting query sequence length of "
164 | f"{query_seq_length} into {num_chunks} chunks")
165 |
166 | mh_q = [
167 | q[:, head_idx * dim_head:(head_idx + 1) *
168 | dim_head, :, :] for head_idx in range(heads)
169 | ] # (bs, dim_head, 1, max_seq_length) * heads
170 |
171 | # Chunk the query sequence for each head
172 | mh_q_chunked = [
173 | [h_q[..., chunk_idx * CHUNK_SIZE:(chunk_idx + 1) * CHUNK_SIZE] for chunk_idx in range(num_chunks)]
174 | for h_q in mh_q
175 | ] # ((bs, dim_head, 1, QUERY_SEQ_CHUNK_SIZE) * num_chunks) * heads
176 |
177 | k = k.transpose(1, 3)
178 | mh_k = [
179 | k[:, :, :,
180 | head_idx * dim_head:(head_idx + 1) * dim_head]
181 | for head_idx in range(heads)
182 | ] # (bs, max_seq_length, 1, dim_head) * heads
183 |
184 | mh_v = [
185 | v[:, head_idx * dim_head:(head_idx + 1) *
186 | dim_head, :, :] for head_idx in range(heads)
187 | ] # (bs, dim_head, 1, max_seq_length) * heads
188 |
189 | attn_weights = [
190 | [
191 | torch.einsum("bchq,bkhc->bkhq", [qi_chunk, ki]) * (dim_head**-0.5)
192 | for qi_chunk in h_q_chunked
193 | ] for h_q_chunked, ki in zip(mh_q_chunked, mh_k)
194 | ] # ((bs, max_seq_length, 1, chunk_size) * num_chunks) * heads
195 |
196 | attn_weights = [
197 | [aw_chunk.softmax(dim=1) for aw_chunk in aw_chunked]
198 | for aw_chunked in attn_weights
199 | ] # ((bs, max_seq_length, 1, chunk_size) * num_chunks) * heads
200 |
201 | attn = [
202 | [
203 | torch.einsum("bkhq,bchk->bchq", wi_chunk, vi)
204 | for wi_chunk in wi_chunked
205 | ] for wi_chunked, vi in zip(attn_weights, mh_v)
206 | ] # ((bs, dim_head, 1, chunk_size) * num_chunks) * heads
207 |
208 | attn = torch.cat([
209 | torch.cat(attn_chunked, dim=3) for attn_chunked in attn
210 | ], dim=1) # (bs, dim, 1, max_seq_length)
211 |
212 | return attn
213 |
214 |
215 | def original(q, k, v, mask, heads, dim_head):
216 | """ Attention Implementation backing AttentionImplementations.ORIGINAL
217 |
218 | - Not recommended for ANE
219 | - Recommended for GPU
220 | """
221 | bs = q.size(0)
222 | mh_q = q.view(bs, heads, dim_head, -1)
223 | mh_k = k.view(bs, heads, dim_head, -1)
224 | mh_v = v.view(bs, heads, dim_head, -1)
225 |
226 | attn_weights = torch.einsum("bhcq,bhck->bhqk", [mh_q, mh_k])
227 | attn_weights.mul_(dim_head**-0.5)
228 |
229 | if mask is not None:
230 | attn_weights = attn_weights + mask
231 |
232 | attn_weights = attn_weights.softmax(dim=3)
233 |
234 | attn = torch.einsum("bhqk,bhck->bhcq", [attn_weights, mh_v])
235 | attn = attn.contiguous().view(bs, heads * dim_head, 1, -1)
236 | return attn
237 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_safety_checker.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils
8 |
9 | from collections import OrderedDict, defaultdict
10 | from copy import deepcopy
11 | import coremltools as ct
12 | import gc
13 |
14 | import logging
15 |
16 | logging.basicConfig()
17 | logger = logging.getLogger(__name__)
18 | logger.setLevel(logging.INFO)
19 |
20 | import numpy as np
21 | import os
22 |
23 | import torch
24 | import torch.nn as nn
25 | import torch.nn.functional as F
26 |
27 | torch.set_grad_enabled(False)
28 |
29 | from types import MethodType
30 |
31 |
32 | def main(pipe, args):
33 | """ Converts the Safety Checker component of Stable Diffusion
34 | """
35 | if pipe.safety_checker is None:
36 | logger.warning(
37 | f"diffusers pipeline for {args.model_version} does not have a `safety_checker` module! " \
38 | "`--convert-safety-checker` will be ignored."
39 | )
40 | return
41 |
42 | out_path = utils.get_out_path(args, "safety_checker")
43 | if os.path.exists(out_path):
44 | logger.info(f"`safety_checker` already exists at {out_path}, skipping conversion.")
45 | return
46 |
47 | sample_image = np.random.randn(
48 | 1, # B
49 | args.output_h, # H
50 | args.output_w, # w
51 | 3 # C
52 | ).astype(np.float32)
53 |
54 | # Note that pipe.feature_extractor is not an ML model. It simply
55 | # preprocesses data for the pipe.safety_checker module.
56 | safety_checker_input = pipe.feature_extractor(
57 | pipe.numpy_to_pil(sample_image),
58 | return_tensors="pt",
59 | ).pixel_values.to(torch.float32)
60 |
61 | sample_safety_checker_inputs = OrderedDict([
62 | ("clip_input", safety_checker_input),
63 | ("images", torch.from_numpy(sample_image)),
64 | ("adjustment", torch.tensor([0]).to(torch.float32)),
65 | ])
66 |
67 | sample_safety_checker_inputs_spec = {
68 | k: (v.shape, v.dtype)
69 | for k, v in sample_safety_checker_inputs.items()
70 | }
71 | logger.info(f"Sample inputs spec: {sample_safety_checker_inputs_spec}")
72 |
73 | # Patch safety_checker's forward pass to be vectorized and avoid conditional blocks
74 | # (similar to pipe.safety_checker.forward_onnx)
75 | from diffusers.pipelines.stable_diffusion import safety_checker
76 |
77 | def forward_coreml(self, clip_input, images, adjustment):
78 | """ Forward pass implementation for safety_checker
79 | """
80 |
81 | def cosine_distance(image_embeds, text_embeds):
82 | return F.normalize(image_embeds) @ F.normalize(text_embeds).transpose(0, 1)
83 |
84 | pooled_output = self.vision_model(clip_input)[1] # pooled_output
85 | image_embeds = self.visual_projection(pooled_output)
86 |
87 | special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds)
88 | cos_dist = cosine_distance(image_embeds, self.concept_embeds)
89 |
90 | special_scores = special_cos_dist - self.special_care_embeds_weights + adjustment
91 | special_care = special_scores.gt(0).float().sum(dim=1).gt(0).float()
92 | special_adjustment = special_care * 0.01
93 | special_adjustment = special_adjustment.unsqueeze(1).expand(-1, cos_dist.shape[1])
94 |
95 | concept_scores = (cos_dist - self.concept_embeds_weights) + special_adjustment
96 | has_nsfw_concepts = concept_scores.gt(0).float().sum(dim=1).gt(0)
97 |
98 | # There is a problem when converting using multisize, for now the workaround is to not filter the images
99 | # The swift implementations already filters the images checking `has_nsfw_concepts` so this should not have any impact
100 |
101 | #has_nsfw_concepts = concept_scores.gt(0).float().sum(dim=1).gt(0)[:, None, None, None]
102 |
103 | #has_nsfw_concepts_inds, _ = torch.broadcast_tensors(has_nsfw_concepts, images)
104 | #images[has_nsfw_concepts_inds] = 0.0 # black image
105 |
106 | return images, has_nsfw_concepts.float(), concept_scores
107 |
108 | baseline_safety_checker = deepcopy(pipe.safety_checker.eval())
109 | setattr(baseline_safety_checker, "forward", MethodType(forward_coreml, baseline_safety_checker))
110 |
111 | # In order to parity check the actual signal, we need to override the forward pass to return `concept_scores` which is the
112 | # output before thresholding
113 | # Reference: https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py#L100
114 | def forward_extended_return(self, clip_input, images, adjustment):
115 |
116 | def cosine_distance(image_embeds, text_embeds):
117 | normalized_image_embeds = F.normalize(image_embeds)
118 | normalized_text_embeds = F.normalize(text_embeds)
119 | return torch.mm(normalized_image_embeds, normalized_text_embeds.t())
120 |
121 | pooled_output = self.vision_model(clip_input)[1] # pooled_output
122 | image_embeds = self.visual_projection(pooled_output)
123 |
124 | special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds)
125 | cos_dist = cosine_distance(image_embeds, self.concept_embeds)
126 |
127 | adjustment = 0.0
128 |
129 | special_scores = special_cos_dist - self.special_care_embeds_weights + adjustment
130 | special_care = torch.any(special_scores > 0, dim=1)
131 | special_adjustment = special_care * 0.01
132 | special_adjustment = special_adjustment.unsqueeze(1).expand(-1, cos_dist.shape[1])
133 |
134 | concept_scores = (cos_dist - self.concept_embeds_weights) + special_adjustment
135 | has_nsfw_concepts = torch.any(concept_scores > 0, dim=1)
136 |
137 | # Don't make the images black as to align with the workaround in `forward_coreml`
138 | #images[has_nsfw_concepts] = 0.0
139 |
140 | return images, has_nsfw_concepts, concept_scores
141 |
142 | setattr(pipe.safety_checker, "forward", MethodType(forward_extended_return, pipe.safety_checker))
143 |
144 | # Trace the safety_checker model
145 | logger.info("JIT tracing..")
146 | traced_safety_checker = torch.jit.trace(baseline_safety_checker, list(sample_safety_checker_inputs.values()))
147 | logger.info("Done.")
148 | del baseline_safety_checker
149 | gc.collect()
150 |
151 | # Cast all inputs to float16
152 | coreml_sample_safety_checker_inputs = {
153 | k: v.numpy().astype(np.float16)
154 | for k, v in sample_safety_checker_inputs.items()
155 | }
156 |
157 | # Convert safety_checker model to Core ML
158 | if args.multisize:
159 | clip_size = safety_checker_input.shape[2]
160 | clip_input_shape = ct.Shape(shape=(
161 | 1,
162 | 3,
163 | ct.RangeDim(int(clip_size * 0.5), upper_bound=int(clip_size * 2), default=clip_size),
164 | ct.RangeDim(int(clip_size * 0.5), upper_bound=int(clip_size * 2), default=clip_size)
165 | ))
166 | sample_size = args.output_h
167 | input_shape = ct.Shape(shape=(
168 | 1,
169 | ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
170 | ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
171 | 3
172 | ))
173 |
174 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_safety_checker_inputs, {
175 | "clip_input": clip_input_shape, "images": input_shape
176 | })
177 | else:
178 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_safety_checker_inputs)
179 | coreml_safety_checker, out_path = utils.convert_to_coreml(
180 | "safety_checker", traced_safety_checker,
181 | sample_coreml_inputs,
182 | ["filtered_images", "has_nsfw_concepts", "concept_scores"], False, args
183 | )
184 |
185 | # Set model metadata
186 | coreml_safety_checker.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
187 | coreml_safety_checker.license = "OpenRAIL (https://huggingface.co/spaces/CompVis/stable-diffusion-license)"
188 | coreml_safety_checker.version = args.model_version
189 | coreml_safety_checker.short_description = \
190 | "Stable Diffusion generates images conditioned on text and/or other images as input through the diffusion process. " \
191 | "Please refer to https://arxiv.org/abs/2112.10752 for details."
192 |
193 | # Set the input descriptions
194 | coreml_safety_checker.input_description["clip_input"] = \
195 | "The normalized image input tensor resized to (224x224) in channels-first (BCHW) format"
196 | coreml_safety_checker.input_description["images"] = \
197 | f"Output of the vae_decoder ({pipe.vae.config.sample_size}x{pipe.vae.config.sample_size}) in channels-last (BHWC) format"
198 | coreml_safety_checker.input_description["adjustment"] = \
199 | "Bias added to the concept scores to trade off increased recall for reduce precision in the safety checker classifier"
200 |
201 | # Set the output descriptions
202 | coreml_safety_checker.output_description["filtered_images"] = \
203 | f"Identical to the input `images`. If safety checker detected any sensitive content, " \
204 | "the corresponding image is replaced with a blank image (zeros)"
205 | coreml_safety_checker.output_description["has_nsfw_concepts"] = \
206 | "Indicates whether the safety checker model found any sensitive content in the given image"
207 | coreml_safety_checker.output_description["concept_scores"] = \
208 | "Concept scores are the scores before thresholding at zero yields the `has_nsfw_concepts` output. " \
209 | "These scores can be used to tune the `adjustment` input"
210 |
211 | # Set package version metadata
212 | coreml_safety_checker.user_defined_metadata["identifier"] = args.model_version
213 | coreml_safety_checker.user_defined_metadata["converter_version"] = __version__
214 | coreml_safety_checker.user_defined_metadata["attention_implementation"] = args.attention_implementation
215 | coreml_safety_checker.user_defined_metadata["compute_unit"] = args.compute_unit
216 |
217 | coreml_safety_checker.save(out_path)
218 |
219 | if args.check_output_correctness:
220 | baseline_out = pipe.safety_checker(**sample_safety_checker_inputs)[2].numpy()
221 | coreml_out = coreml_safety_checker.predict(coreml_sample_safety_checker_inputs)["concept_scores"]
222 | utils.report_correctness(baseline_out, coreml_out, "safety_checker baseline PyTorch to reference CoreML")
223 |
224 | del traced_safety_checker, coreml_safety_checker, pipe.safety_checker
225 | gc.collect()
226 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/utils/merge_lora.py:
--------------------------------------------------------------------------------
1 | # Taken from: https://github.com/kohya-ss/sd-scripts/blob/main/networks/merge_lora.py
2 |
3 | import math
4 | import argparse
5 | import os
6 | import torch
7 | from safetensors.torch import load_file, save_file
8 |
9 | # is it possible to apply conv_in and conv_out? -> yes, newer LoCon supports it (^^;)
10 | UNET_TARGET_REPLACE_MODULE = ["Transformer2DModel", "Attention"]
11 | UNET_TARGET_REPLACE_MODULE_CONV2D_3X3 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
12 | TEXT_ENCODER_TARGET_REPLACE_MODULE = ["CLIPAttention", "CLIPMLP"]
13 | LORA_PREFIX_UNET = "lora_unet"
14 | LORA_PREFIX_TEXT_ENCODER = "lora_te"
15 |
16 | # SDXL: must starts with LORA_PREFIX_TEXT_ENCODER
17 | LORA_PREFIX_TEXT_ENCODER_1 = "lora_te1"
18 | LORA_PREFIX_TEXT_ENCODER_2 = "lora_te2"
19 |
20 | def load_state_dict(file_name, dtype):
21 | if os.path.splitext(file_name)[1] == ".safetensors":
22 | sd = load_file(file_name)
23 | else:
24 | sd = torch.load(file_name, map_location="cpu")
25 | for key in list(sd.keys()):
26 | if type(sd[key]) == torch.Tensor:
27 | sd[key] = sd[key].to(dtype)
28 | return sd
29 |
30 |
31 | def save_to_file(file_name, model, state_dict, dtype):
32 | if dtype is not None:
33 | for key in list(state_dict.keys()):
34 | if type(state_dict[key]) == torch.Tensor:
35 | state_dict[key] = state_dict[key].to(dtype)
36 |
37 | if os.path.splitext(file_name)[1] == ".safetensors":
38 | save_file(model, file_name)
39 | else:
40 | torch.save(model, file_name)
41 |
42 | def merge_to_sd_model(unet, text_encoder, text_encoder_2, models, ratios, merge_dtype=torch.float32):
43 | unet.to(merge_dtype)
44 | text_encoder.to(merge_dtype)
45 | if text_encoder_2:
46 | text_encoder_2.to(merge_dtype)
47 |
48 | layers_per_block = unet.config.layers_per_block
49 |
50 | # create module map
51 | name_to_module = {}
52 | for i, root_module in enumerate([unet, text_encoder, text_encoder_2]):
53 | if not root_module:
54 | continue
55 | if i == 0:
56 | prefix = LORA_PREFIX_UNET
57 | target_replace_modules = (
58 | UNET_TARGET_REPLACE_MODULE + UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
59 | )
60 | elif text_encoder_2:
61 | target_replace_modules = TEXT_ENCODER_TARGET_REPLACE_MODULE
62 | if i == 1:
63 | prefix = LORA_PREFIX_TEXT_ENCODER_1
64 | else:
65 | prefix = LORA_PREFIX_TEXT_ENCODER_2
66 | else:
67 | prefix = LORA_PREFIX_TEXT_ENCODER
68 | target_replace_modules = TEXT_ENCODER_TARGET_REPLACE_MODULE
69 |
70 | for name, module in root_module.named_modules():
71 | if module.__class__.__name__ == "LoRACompatibleLinear" or module.__class__.__name__ == "LoRACompatibleConv":
72 | lora_name = prefix + "." + name
73 | lora_name = lora_name.replace(".", "_")
74 | name_to_module[lora_name] = module
75 | elif module.__class__.__name__ in target_replace_modules:
76 | for child_name, child_module in module.named_modules():
77 | if child_module.__class__.__name__ == "Linear" or child_module.__class__.__name__ == "Conv2d":
78 | lora_name = prefix + "." + name + "." + child_name
79 | lora_name = lora_name.replace(".", "_")
80 | name_to_module[lora_name] = child_module
81 |
82 | for model, ratio in zip(models, ratios):
83 | print(f"Merging: {model}")
84 | lora_sd = load_state_dict(model, merge_dtype)
85 |
86 | for key in lora_sd.keys():
87 | if "lora_down" in key:
88 | up_key = key.replace("lora_down", "lora_up")
89 | alpha_key = key[: key.index("lora_down")] + "alpha"
90 |
91 | # find original module for this lora
92 | module_name = ".".join(key.split(".")[:-2]) # remove trailing ".lora_down.weight"
93 | if "input_blocks" in module_name:
94 | i = int(module_name.split("input_blocks_", 1)[1].split("_", 1)[0])
95 | block_id = (i - 1) // (layers_per_block + 1)
96 | layer_in_block_id = (i - 1) % (layers_per_block + 1)
97 | module_name = module_name.replace(f"input_blocks_{i}_0", f"down_blocks_{block_id}_resnets_{layer_in_block_id}")
98 | module_name = module_name.replace(f"input_blocks_{i}_1", f"down_blocks_{block_id}_attentions_{layer_in_block_id}")
99 | module_name = module_name.replace(f"input_blocks_{i}_2", f"down_blocks_{block_id}_resnets_{layer_in_block_id}")
100 | if "middle_block" in module_name:
101 | module_name = module_name.replace("middle_block_0", "mid_block_resnets_0")
102 | module_name = module_name.replace("middle_block_1", "mid_block_attentions_0")
103 | module_name = module_name.replace("middle_block_2", "mid_block_resnets_1")
104 | if "output_blocks" in module_name:
105 | i = int(module_name.split("output_blocks_", 1)[1].split("_", 1)[0])
106 | block_id = i // (layers_per_block + 1)
107 | layer_in_block_id = i % (layers_per_block + 1)
108 | module_name = module_name.replace(f"output_blocks_{i}_0", f"up_blocks_{block_id}_resnets_{layer_in_block_id}")
109 | module_name = module_name.replace(f"output_blocks_{i}_1", f"up_blocks_{block_id}_attentions_{layer_in_block_id}")
110 | module_name = module_name.replace(f"output_blocks_{i}_2", f"up_blocks_{block_id}_resnets_{layer_in_block_id}")
111 |
112 | module_name = module_name.replace("in_layers_0", "norm1")
113 | module_name = module_name.replace("in_layers_2", "conv1")
114 |
115 | module_name = module_name.replace("out_layers_0", "norm2")
116 | module_name = module_name.replace("out_layers_3", "conv2")
117 |
118 | module_name = module_name.replace("emb_layers_1", "time_emb_proj")
119 | module_name = module_name.replace("skip_connection", "conv_shortcut")
120 |
121 | if module_name not in name_to_module:
122 | print(f"no module found for LoRA weight: {key}")
123 | continue
124 | module = name_to_module[module_name]
125 | # print(f"apply {key} to {module}")
126 |
127 | down_weight = lora_sd[key]
128 | up_weight = lora_sd[up_key]
129 |
130 | dim = down_weight.size()[0]
131 | alpha = lora_sd.get(alpha_key, dim)
132 | scale = alpha / dim
133 |
134 | # W <- W + U * D
135 | weight = module.weight
136 | # print(module_name, down_weight.size(), up_weight.size())
137 | if len(weight.size()) == 2:
138 | # linear
139 | if len(up_weight.size()) == 4: # use linear projection mismatch
140 | up_weight = up_weight.squeeze(3).squeeze(2)
141 | down_weight = down_weight.squeeze(3).squeeze(2)
142 | weight = weight + ratio * (up_weight @ down_weight) * scale
143 | elif down_weight.size()[2:4] == (1, 1):
144 | # conv2d 1x1
145 | weight = (
146 | weight
147 | + ratio
148 | * (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)).unsqueeze(2).unsqueeze(3)
149 | * scale
150 | )
151 | else:
152 | # conv2d 3x3
153 | conved = torch.nn.functional.conv2d(down_weight.permute(1, 0, 2, 3), up_weight).permute(1, 0, 2, 3)
154 | # print(conved.size(), weight.size(), module.stride, module.padding)
155 | weight = weight + ratio * conved * scale
156 |
157 | module.weight = torch.nn.Parameter(weight)
158 |
159 |
160 | def merge_lora_models(models, ratios, merge_dtype):
161 | base_alphas = {} # alpha for merged model
162 | base_dims = {}
163 |
164 | merged_sd = {}
165 | for model, ratio in zip(models, ratios):
166 | print(f"loading: {model}")
167 | lora_sd = load_state_dict(model, merge_dtype)
168 |
169 | # get alpha and dim
170 | alphas = {} # alpha for current model
171 | dims = {} # dims for current model
172 | for key in lora_sd.keys():
173 | if "alpha" in key:
174 | lora_module_name = key[: key.rfind(".alpha")]
175 | alpha = float(lora_sd[key].detach().numpy())
176 | alphas[lora_module_name] = alpha
177 | if lora_module_name not in base_alphas:
178 | base_alphas[lora_module_name] = alpha
179 | elif "lora_down" in key:
180 | lora_module_name = key[: key.rfind(".lora_down")]
181 | dim = lora_sd[key].size()[0]
182 | dims[lora_module_name] = dim
183 | if lora_module_name not in base_dims:
184 | base_dims[lora_module_name] = dim
185 |
186 | for lora_module_name in dims.keys():
187 | if lora_module_name not in alphas:
188 | alpha = dims[lora_module_name]
189 | alphas[lora_module_name] = alpha
190 | if lora_module_name not in base_alphas:
191 | base_alphas[lora_module_name] = alpha
192 |
193 | print(f"dim: {list(set(dims.values()))}, alpha: {list(set(alphas.values()))}")
194 |
195 | # merge
196 | print(f"merging...")
197 | for key in lora_sd.keys():
198 | if "alpha" in key:
199 | continue
200 |
201 | lora_module_name = key[: key.rfind(".lora_")]
202 |
203 | base_alpha = base_alphas[lora_module_name]
204 | alpha = alphas[lora_module_name]
205 |
206 | scale = math.sqrt(alpha / base_alpha) * ratio
207 |
208 | if key in merged_sd:
209 | assert (
210 | merged_sd[key].size() == lora_sd[key].size()
211 | ), f"weights shape mismatch merging v1 and v2, different dims? / 重みのサイズが合いません。v1とv2、または次元数の異なるモデルはマージできません"
212 | merged_sd[key] = merged_sd[key] + lora_sd[key] * scale
213 | else:
214 | merged_sd[key] = lora_sd[key] * scale
215 |
216 | # set alpha to sd
217 | for lora_module_name, alpha in base_alphas.items():
218 | key = lora_module_name + ".alpha"
219 | merged_sd[key] = torch.tensor(alpha)
220 |
221 | print("merged model")
222 | print(f"dim: {list(set(base_dims.values()))}, alpha: {list(set(base_alphas.values()))}")
223 |
224 | return merged_sd
225 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/utils/utils.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from .merge_lora import merge_to_sd_model
8 |
9 | import json
10 | import argparse
11 | from collections import OrderedDict, defaultdict
12 | from copy import deepcopy
13 | import coremltools as ct
14 | from diffusers import DiffusionPipeline, StableDiffusionPipeline, StableDiffusionXLPipeline, AutoPipelineForInpainting
15 | from diffusers import T2IAdapter, StableDiffusionAdapterPipeline
16 | from diffusers import ControlNetModel, StableDiffusionControlNetPipeline, StableDiffusionXLControlNetPipeline, AutoencoderKL
17 | from diffusers.pipelines.stable_diffusion.convert_from_ckpt import download_from_original_stable_diffusion_ckpt
18 | import gc
19 |
20 | import logging
21 |
22 | logging.basicConfig()
23 | logger = logging.getLogger(__name__)
24 | logger.setLevel(logging.INFO)
25 |
26 | import numpy as np
27 | import os
28 | from os import listdir
29 | from os.path import isfile, join
30 | import tempfile
31 | import requests
32 | import shutil
33 | import time
34 | import traceback
35 |
36 | import torch
37 | import torch.nn as nn
38 | import torch.nn.functional as F
39 |
40 | torch.set_grad_enabled(False)
41 |
42 |
43 | def conditioning_method_from(identifier):
44 | if "canny" in identifier:
45 | return "canny"
46 | if "depth" in identifier:
47 | return "depth"
48 | if "pose" in identifier:
49 | return "pose"
50 | if "mlsd" in identifier:
51 | return "mlsd"
52 | if "normal" in identifier:
53 | return "normal"
54 | if "scribble" in identifier:
55 | return "scribble"
56 | if "hed" in identifier:
57 | return "hed"
58 | if "seg" in identifier:
59 | return "segmentation"
60 | return None
61 |
62 |
63 | def get_out_path(args, submodule_name):
64 | fname = f"{args.model_version}_{submodule_name}.mlpackage"
65 | fname = fname.replace("/", "_")
66 | if args.clean_up_mlpackages:
67 | temp_dir = tempfile.gettempdir()
68 | return os.path.join(temp_dir, fname)
69 | return os.path.join(args.o, fname)
70 |
71 |
72 | def get_coreml_inputs(sample_inputs, samples_shapes=None):
73 | return [
74 | ct.TensorType(
75 | name=k,
76 | shape=samples_shapes[k] if samples_shapes and k in samples_shapes else v.shape,
77 | dtype=v.numpy().dtype if isinstance(v, torch.Tensor) else v.dtype,
78 | ) for k, v in sample_inputs.items()
79 | ]
80 |
81 |
82 | ABSOLUTE_MIN_PSNR = 35
83 |
84 | def report_correctness(original_outputs, final_outputs, log_prefix):
85 | """ Report PSNR values across two compatible tensors
86 | """
87 | original_psnr = compute_psnr(original_outputs, original_outputs)
88 | final_psnr = compute_psnr(original_outputs, final_outputs)
89 |
90 | dB_change = final_psnr - original_psnr
91 | logger.info(
92 | f"{log_prefix}: PSNR changed by {dB_change:.1f} dB ({original_psnr:.1f} -> {final_psnr:.1f})"
93 | )
94 |
95 | if final_psnr < ABSOLUTE_MIN_PSNR:
96 | # raise ValueError(f"{final_psnr:.1f} dB is too low!")
97 | logger.info(f"{final_psnr:.1f} dB is too low!")
98 | else:
99 | logger.info(
100 | f"{final_psnr:.1f} dB > {ABSOLUTE_MIN_PSNR} dB (minimum allowed) parity check passed"
101 | )
102 | return final_psnr
103 |
104 |
105 | def compute_psnr(a, b):
106 | """ Compute Peak-Signal-to-Noise-Ratio across two numpy.ndarray objects
107 | """
108 | max_b = np.abs(b).max()
109 | sumdeltasq = 0.0
110 |
111 | sumdeltasq = ((a - b) * (a - b)).sum()
112 |
113 | sumdeltasq /= b.size
114 | sumdeltasq = np.sqrt(sumdeltasq)
115 |
116 | eps = 1e-5
117 | eps2 = 1e-10
118 | psnr = 20 * np.log10((max_b + eps) / (sumdeltasq + eps2))
119 |
120 | return psnr
121 |
122 |
123 | def convert_to_coreml(submodule_name, torchscript_module, coreml_inputs, output_names, precision_full, args):
124 | out_path = get_out_path(args, submodule_name)
125 |
126 | if os.path.exists(out_path):
127 | logger.info(f"Skipping export because {out_path} already exists")
128 | logger.info(f"Loading model from {out_path}")
129 |
130 | start = time.time()
131 | # Note: Note that each model load will trigger a model compilation which takes up to a few minutes.
132 | # The Swifty CLI we provide uses precompiled Core ML models (.mlmodelc) which incurs compilation only
133 | # upon first load and mitigates the load time in subsequent runs.
134 | coreml_model = ct.models.MLModel(out_path, compute_units=ct.ComputeUnit[args.compute_unit])
135 | logger.info(f"Loading {out_path} took {time.time() - start:.1f} seconds")
136 |
137 | coreml_model.compute_unit = ct.ComputeUnit[args.compute_unit]
138 | else:
139 | logger.info(f"Converting {submodule_name} to CoreML...")
140 | coreml_model = ct.convert(
141 | torchscript_module,
142 | convert_to="mlprogram",
143 | minimum_deployment_target=ct.target.macOS13,
144 | inputs=coreml_inputs,
145 | outputs=[ct.TensorType(name=name) for name in output_names],
146 | compute_units=ct.ComputeUnit[args.compute_unit],
147 | compute_precision=ct.precision.FLOAT32 if precision_full else ct.precision.FLOAT16,
148 | # skip_model_load=True,
149 | )
150 |
151 | del torchscript_module
152 | gc.collect()
153 |
154 | return coreml_model, out_path
155 |
156 |
157 | def quantize_weights(models, args):
158 | """ Quantize weights to args.quantize_nbits using a palette (look-up table)
159 | """
160 | for model_name in models:
161 | logger.info(f"Quantizing {model_name} to {args.quantize_nbits}-bit precision")
162 | out_path = get_out_path(args, model_name)
163 | _quantize_weights(
164 | out_path,
165 | model_name,
166 | args.quantize_nbits
167 | )
168 |
169 | def _quantize_weights(out_path, model_name, nbits):
170 | if os.path.exists(out_path):
171 | logger.info(f"Quantizing {model_name}")
172 | mlmodel = ct.models.MLModel(out_path, compute_units=ct.ComputeUnit.CPU_ONLY)
173 |
174 | op_config = ct.optimize.coreml.OpPalettizerConfig(
175 | mode="kmeans",
176 | nbits=nbits,
177 | )
178 |
179 | config = ct.optimize.coreml.OptimizationConfig(
180 | global_config=op_config,
181 | op_type_configs={
182 | "gather": None # avoid quantizing the embedding table
183 | }
184 | )
185 |
186 | model = ct.optimize.coreml.palettize_weights(mlmodel, config=config).save(out_path)
187 | logger.info("Done")
188 | else:
189 | logger.info(f"Skipped quantizing {model_name} (Not found at {out_path})")
190 |
191 |
192 | def bundle_resources_for_guernika(pipe, args):
193 | """
194 | - Compiles Core ML models from mlpackage into mlmodelc format
195 | - Download tokenizer resources for the text encoder
196 | """
197 | resources_dir = os.path.join(args.o, args.resources_dir_name.replace("/", "_"))
198 | if not os.path.exists(resources_dir):
199 | os.makedirs(resources_dir, exist_ok=True)
200 | logger.info(f"Created {resources_dir} for Guernika assets")
201 |
202 | # Compile model using coremlcompiler (Significantly reduces the load time for unet)
203 | for source_name, target_name in [
204 | ("text_encoder", "TextEncoder"),
205 | ("text_encoder_2", "TextEncoder2"),
206 | ("text_encoder_prior", "TextEncoderPrior"),
207 | ("vae_encoder", "VAEEncoder"),
208 | ("vae_decoder", "VAEDecoder"),
209 | ("t2i_adapter", "T2IAdapter"),
210 | ("controlnet", "ControlNet"),
211 | ("unet", "Unet"),
212 | ("unet_chunk1", "UnetChunk1"),
213 | ("unet_chunk2", "UnetChunk2"),
214 | ("safety_checker", "SafetyChecker"),
215 | ("wuerstchen_prior", "WuerstchenPrior"),
216 | ("wuerstchen_decoder", "WuerstchenDecoder"),
217 | ("wuerstchen_vqgan", "WuerstchenVQGAN")
218 |
219 | ]:
220 | source_path = get_out_path(args, source_name)
221 | if os.path.exists(source_path):
222 | target_path = _compile_coreml_model(source_path, resources_dir, target_name)
223 | logger.info(f"Compiled {source_path} to {target_path}")
224 | if source_name.startswith("text_encoder"):
225 | # Fetch and save vocabulary JSON file for text tokenizer
226 | logger.info("Downloading and saving tokenizer vocab.json")
227 | with open(os.path.join(target_path, "vocab.json"), "wb") as f:
228 | f.write(requests.get(args.text_encoder_vocabulary_url).content)
229 | logger.info("Done")
230 |
231 | # Fetch and save merged pairs JSON file for text tokenizer
232 | logger.info("Downloading and saving tokenizer merges.txt")
233 | with open(os.path.join(target_path, "merges.txt"), "wb") as f:
234 | f.write(requests.get(args.text_encoder_merges_url).content)
235 | logger.info("Done")
236 |
237 | if hasattr(args, "added_vocab") and args.added_vocab:
238 | logger.info("Saving added vocab")
239 | with open(os.path.join(target_path, "added_vocab.json"), 'w', encoding='utf-8') as f:
240 | json.dump(args.added_vocab, f, ensure_ascii=False, indent=4)
241 | else:
242 | logger.warning(
243 | f"{source_path} not found, skipping compilation to {target_name}.mlmodelc"
244 | )
245 |
246 | return resources_dir
247 |
248 |
249 | def _compile_coreml_model(source_model_path, output_dir, final_name):
250 | """ Compiles Core ML models using the coremlcompiler utility from Xcode toolchain
251 | """
252 | target_path = os.path.join(output_dir, f"{final_name}.mlmodelc")
253 | if os.path.exists(target_path):
254 | logger.warning(f"Found existing compiled model at {target_path}! Skipping..")
255 | return target_path
256 |
257 | logger.info(f"Compiling {source_model_path}")
258 | source_model_name = os.path.basename(os.path.splitext(source_model_path)[0])
259 |
260 | os.system(f"xcrun coremlcompiler compile '{source_model_path}' '{output_dir}'")
261 | compiled_output = os.path.join(output_dir, f"{source_model_name}.mlmodelc")
262 | shutil.move(compiled_output, target_path)
263 |
264 | return target_path
265 |
266 |
267 | def remove_mlpackages(args):
268 | for package_name in [
269 | "text_encoder",
270 | "text_encoder_2",
271 | "text_encoder_prior",
272 | "vae_encoder",
273 | "vae_decoder",
274 | "t2i_adapter",
275 | "controlnet",
276 | "unet",
277 | "unet_chunk1",
278 | "unet_chunk2",
279 | "safety_checker",
280 | "wuerstchen_prior",
281 | "wuerstchen_prior_chunk1",
282 | "wuerstchen_prior_chunk2",
283 | "wuerstchen_decoder",
284 | "wuerstchen_decoder_chunk1",
285 | "wuerstchen_decoder_chunk2",
286 | "wuerstchen_vqgan"
287 | ]:
288 | package_path = get_out_path(args, package_name)
289 | try:
290 | if os.path.exists(package_path):
291 | shutil.rmtree(package_path)
292 | except:
293 | traceback.print_exc()
294 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_controlnet.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils
8 | from guernikatools.models import attention, controlnet
9 |
10 | from collections import OrderedDict, defaultdict
11 | from copy import deepcopy
12 | import coremltools as ct
13 | import gc
14 |
15 | import logging
16 |
17 | logging.basicConfig()
18 | logger = logging.getLogger(__name__)
19 | logger.setLevel(logging.INFO)
20 |
21 | import numpy as np
22 | import os
23 |
24 | import torch
25 | import torch.nn as nn
26 | import torch.nn.functional as F
27 |
28 | torch.set_grad_enabled(False)
29 |
30 |
31 | def main(pipe, args):
32 | """ Converts the ControlNet component of Stable Diffusion
33 | """
34 | if not pipe.controlnet:
35 | logger.info(f"`controlnet` not available in this pipline.")
36 | return
37 |
38 | out_path = utils.get_out_path(args, "controlnet")
39 | if os.path.exists(out_path):
40 | logger.info(f"`controlnet` already exists at {out_path}, skipping conversion.")
41 | return
42 |
43 | # Register the selected attention implementation globally
44 | attention.ATTENTION_IMPLEMENTATION_IN_EFFECT = attention.AttentionImplementations[args.attention_implementation]
45 | logger.info(f"Attention implementation in effect: {attention.ATTENTION_IMPLEMENTATION_IN_EFFECT}")
46 |
47 | # Prepare sample input shapes and values
48 | batch_size = 2 # for classifier-free guidance
49 | controlnet_in_channels = pipe.controlnet.config.in_channels
50 | vae_scale_factor = 2 ** (len(pipe.vae.config.block_out_channels) - 1)
51 | height = int(args.output_h / vae_scale_factor)
52 | width = int(args.output_w / vae_scale_factor)
53 |
54 | sample_shape = (
55 | batch_size, # B
56 | controlnet_in_channels, # C
57 | height, # H
58 | width, # W
59 | )
60 |
61 | cond_shape = (
62 | batch_size, # B
63 | 3, # C
64 | args.output_h, # H
65 | args.output_w, # W
66 | )
67 |
68 | if not hasattr(pipe, "text_encoder"):
69 | raise RuntimeError(
70 | "convert_text_encoder() deletes pipe.text_encoder to save RAM. "
71 | "Please use convert_controlnet() before convert_text_encoder()")
72 |
73 | hidden_size = pipe.controlnet.config.cross_attention_dim
74 | encoder_hidden_states_shape = (
75 | batch_size,
76 | hidden_size,
77 | 1,
78 | pipe.text_encoder.config.max_position_embeddings,
79 | )
80 |
81 | # Create the scheduled timesteps for downstream use
82 | DEFAULT_NUM_INFERENCE_STEPS = 50
83 | pipe.scheduler.set_timesteps(DEFAULT_NUM_INFERENCE_STEPS)
84 |
85 | output_names = [
86 | "down_block_res_samples_00", "down_block_res_samples_01", "down_block_res_samples_02",
87 | "down_block_res_samples_03", "down_block_res_samples_04", "down_block_res_samples_05",
88 | "down_block_res_samples_06", "down_block_res_samples_07", "down_block_res_samples_08"
89 | ]
90 | sample_controlnet_inputs = [
91 | ("sample", torch.rand(*sample_shape)),
92 | ("timestep",
93 | torch.tensor([pipe.scheduler.timesteps[0].item()] *
94 | (batch_size)).to(torch.float32)),
95 | ("encoder_hidden_states", torch.rand(*encoder_hidden_states_shape)),
96 | ("controlnet_cond", torch.rand(*cond_shape))
97 | ]
98 | if hasattr(pipe.controlnet.config, "addition_embed_type") and pipe.controlnet.config.addition_embed_type == "text_time":
99 | text_embeds_shape = (
100 | batch_size,
101 | pipe.text_encoder_2.config.hidden_size,
102 | )
103 | time_ids_input = [
104 | [args.output_h, args.output_w, 0, 0, args.output_h, args.output_w],
105 | [args.output_h, args.output_w, 0, 0, args.output_h, args.output_w]
106 | ]
107 | sample_controlnet_inputs = sample_controlnet_inputs + [
108 | ("text_embeds", torch.rand(*text_embeds_shape)),
109 | ("time_ids", torch.tensor(time_ids_input).to(torch.float32)),
110 | ]
111 | else:
112 | # SDXL ControlNet does not generate these outputs
113 | output_names = output_names + ["down_block_res_samples_09", "down_block_res_samples_10", "down_block_res_samples_11"]
114 | output_names = output_names + ["mid_block_res_sample"]
115 |
116 | sample_controlnet_inputs = OrderedDict(sample_controlnet_inputs)
117 | sample_controlnet_inputs_spec = {
118 | k: (v.shape, v.dtype)
119 | for k, v in sample_controlnet_inputs.items()
120 | }
121 | logger.info(f"Sample inputs spec: {sample_controlnet_inputs_spec}")
122 |
123 | # Initialize reference controlnet
124 | reference_controlnet = controlnet.ControlNetModel(**pipe.controlnet.config).eval()
125 | load_state_dict_summary = reference_controlnet.load_state_dict(pipe.controlnet.state_dict())
126 |
127 | # Prepare inputs
128 | baseline_sample_controlnet_inputs = deepcopy(sample_controlnet_inputs)
129 | baseline_sample_controlnet_inputs[
130 | "encoder_hidden_states"] = baseline_sample_controlnet_inputs[
131 | "encoder_hidden_states"].squeeze(2).transpose(1, 2)
132 |
133 | # JIT trace
134 | logger.info("JIT tracing..")
135 | reference_controlnet = torch.jit.trace(reference_controlnet, example_kwarg_inputs=sample_controlnet_inputs)
136 | logger.info("Done.")
137 |
138 | if args.check_output_correctness:
139 | baseline_out = pipe.controlnet(**baseline_sample_controlnet_inputs, return_dict=False)[0].numpy()
140 | reference_out = reference_controlnet(**sample_controlnet_inputs)[0].numpy()
141 | utils.report_correctness(baseline_out, reference_out, "control baseline to reference PyTorch")
142 |
143 | del pipe.controlnet
144 | gc.collect()
145 |
146 | coreml_sample_controlnet_inputs = {
147 | k: v.numpy().astype(np.float16)
148 | for k, v in sample_controlnet_inputs.items()
149 | }
150 |
151 | if args.multisize:
152 | sample_size = height
153 | sample_input_shape = ct.Shape(shape=(
154 | batch_size,
155 | controlnet_in_channels,
156 | ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
157 | ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size)
158 | ))
159 |
160 | cond_size = args.output_h
161 | cond_input_shape = ct.Shape(shape=(
162 | batch_size,
163 | 3,
164 | ct.RangeDim(int(cond_size * 0.5), upper_bound=int(cond_size * 2), default=cond_size),
165 | ct.RangeDim(int(cond_size * 0.5), upper_bound=int(cond_size * 2), default=cond_size)
166 | ))
167 |
168 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_controlnet_inputs, {
169 | "sample": sample_input_shape,
170 | "controlnet_cond": cond_input_shape,
171 | })
172 | else:
173 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_controlnet_inputs)
174 | coreml_controlnet, out_path = utils.convert_to_coreml(
175 | "controlnet",
176 | reference_controlnet,
177 | sample_coreml_inputs,
178 | output_names,
179 | args.precision_full,
180 | args
181 | )
182 | del reference_controlnet
183 | gc.collect()
184 |
185 | # Set model metadata
186 | coreml_controlnet.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
187 | coreml_controlnet.license = "ControlNet (https://github.com/lllyasviel/ControlNet)"
188 | coreml_controlnet.version = args.controlnet_version
189 | coreml_controlnet.short_description = \
190 | "ControlNet is a neural network structure to control diffusion models by adding extra conditions. " \
191 | "Please refer to https://github.com/lllyasviel/ControlNet for details."
192 |
193 | # Set the input descriptions
194 | coreml_controlnet.input_description["sample"] = \
195 | "The low resolution latent feature maps being denoised through reverse diffusion"
196 | coreml_controlnet.input_description["timestep"] = \
197 | "A value emitted by the associated scheduler object to condition the model on a given noise schedule"
198 | coreml_controlnet.input_description["encoder_hidden_states"] = \
199 | "Output embeddings from the associated text_encoder model to condition to generated image on text. " \
200 | "A maximum of 77 tokens (~40 words) are allowed. Longer text is truncated. " \
201 | "Shorter text does not reduce computation."
202 | coreml_controlnet.input_description["controlnet_cond"] = \
203 | "Image used to condition ControlNet output"
204 |
205 | # Set the output descriptions
206 | coreml_controlnet.output_description["down_block_res_samples_00"] = "Residual down sample from ControlNet"
207 | coreml_controlnet.output_description["down_block_res_samples_01"] = "Residual down sample from ControlNet"
208 | coreml_controlnet.output_description["down_block_res_samples_02"] = "Residual down sample from ControlNet"
209 | coreml_controlnet.output_description["down_block_res_samples_03"] = "Residual down sample from ControlNet"
210 | coreml_controlnet.output_description["down_block_res_samples_04"] = "Residual down sample from ControlNet"
211 | coreml_controlnet.output_description["down_block_res_samples_05"] = "Residual down sample from ControlNet"
212 | coreml_controlnet.output_description["down_block_res_samples_06"] = "Residual down sample from ControlNet"
213 | coreml_controlnet.output_description["down_block_res_samples_07"] = "Residual down sample from ControlNet"
214 | coreml_controlnet.output_description["down_block_res_samples_08"] = "Residual down sample from ControlNet"
215 | if "down_block_res_samples_09" in output_names:
216 | coreml_controlnet.output_description["down_block_res_samples_09"] = "Residual down sample from ControlNet"
217 | coreml_controlnet.output_description["down_block_res_samples_10"] = "Residual down sample from ControlNet"
218 | coreml_controlnet.output_description["down_block_res_samples_11"] = "Residual down sample from ControlNet"
219 | coreml_controlnet.output_description["mid_block_res_sample"] = "Residual mid sample from ControlNet"
220 |
221 | # Set package version metadata
222 | coreml_controlnet.user_defined_metadata["identifier"] = args.controlnet_version
223 | coreml_controlnet.user_defined_metadata["converter_version"] = __version__
224 | coreml_controlnet.user_defined_metadata["attention_implementation"] = args.attention_implementation
225 | coreml_controlnet.user_defined_metadata["compute_unit"] = args.compute_unit
226 | coreml_controlnet.user_defined_metadata["hidden_size"] = str(hidden_size)
227 | controlnet_method = utils.conditioning_method_from(args.controlnet_version)
228 | if controlnet_method:
229 | coreml_controlnet.user_defined_metadata["method"] = controlnet_method
230 |
231 | coreml_controlnet.save(out_path)
232 | logger.info(f"Saved controlnet into {out_path}")
233 |
234 | # Parity check PyTorch vs CoreML
235 | if args.check_output_correctness:
236 | coreml_out = list(coreml_controlnet.predict(coreml_sample_controlnet_inputs).values())[0]
237 | utils.report_correctness(baseline_out, coreml_out, "control baseline PyTorch to reference CoreML")
238 |
239 | del coreml_controlnet
240 | gc.collect()
241 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/models/controlnet.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools.models import attention
7 | from .layer_norm import LayerNormANE
8 | from .unet import Timesteps, TimestepEmbedding, UNetMidBlock2DCrossAttn
9 | from .unet import linear_to_conv2d_map, get_down_block, get_up_block
10 |
11 | from diffusers.configuration_utils import ConfigMixin, register_to_config
12 | from diffusers import ModelMixin
13 |
14 | from enum import Enum
15 |
16 | import logging
17 |
18 | logger = logging.getLogger(__name__)
19 | logger.setLevel(logging.INFO)
20 |
21 | import math
22 |
23 | import torch
24 | import torch.nn as nn
25 | import torch.nn.functional as F
26 |
27 | # Ensure minimum macOS version requirement is met for this particular model
28 | from coremltools.models.utils import _macos_version
29 | if not _macos_version() >= (13, 1):
30 | logger.warning(
31 | "!!! macOS 13.1 and newer or iOS/iPadOS 16.2 and newer is required for best performance !!!"
32 | )
33 |
34 | class ControlNetConditioningDefaultEmbedding(nn.Module):
35 | """
36 | "Stable Diffusion uses a pre-processing method similar to VQ-GAN [11] to convert the entire dataset of 512 × 512
37 | images into smaller 64 × 64 “latent images” for stabilized training. This requires ControlNets to convert
38 | image-based conditions to 64 × 64 feature space to match the convolution size. We use a tiny network E(·) of four
39 | convolution layers with 4 × 4 kernels and 2 × 2 strides (activated by ReLU, channels are 16, 32, 64, 128,
40 | initialized with Gaussian weights, trained jointly with the full model) to encode image-space conditions ... into
41 | feature maps ..."
42 | """
43 |
44 | def __init__(
45 | self,
46 | conditioning_embedding_channels: int,
47 | conditioning_channels: int = 3,
48 | block_out_channels = (16, 32, 96, 256),
49 | ):
50 | super().__init__()
51 |
52 | self.conv_in = nn.Conv2d(conditioning_channels, block_out_channels[0], kernel_size=3, padding=1)
53 |
54 | self.blocks = nn.ModuleList([])
55 |
56 | for i in range(len(block_out_channels) - 1):
57 | channel_in = block_out_channels[i]
58 | channel_out = block_out_channels[i + 1]
59 | self.blocks.append(nn.Conv2d(channel_in, channel_in, kernel_size=3, padding=1))
60 | self.blocks.append(nn.Conv2d(channel_in, channel_out, kernel_size=3, padding=1, stride=2))
61 |
62 | self.conv_out = zero_module(
63 | nn.Conv2d(block_out_channels[-1], conditioning_embedding_channels, kernel_size=3, padding=1)
64 | )
65 |
66 | def forward(self, conditioning):
67 | embedding = self.conv_in(conditioning)
68 | embedding = F.silu(embedding)
69 |
70 | for block in self.blocks:
71 | embedding = block(embedding)
72 | embedding = F.silu(embedding)
73 |
74 | embedding = self.conv_out(embedding)
75 | return embedding
76 |
77 | class ControlNetModel(ModelMixin, ConfigMixin):
78 |
79 | @register_to_config
80 | def __init__(
81 | self,
82 | sample_size=None,
83 | in_channels=4,
84 | out_channels=4,
85 | center_input_sample=False,
86 | flip_sin_to_cos=True,
87 | freq_shift=0,
88 | down_block_types=(
89 | "CrossAttnDownBlock2D",
90 | "CrossAttnDownBlock2D",
91 | "CrossAttnDownBlock2D",
92 | "DownBlock2D",
93 | ),
94 | only_cross_attention=False,
95 | block_out_channels=(320, 640, 1280, 1280),
96 | layers_per_block=2,
97 | downsample_padding=1,
98 | mid_block_scale_factor=1,
99 | act_fn="silu",
100 | norm_num_groups=32,
101 | norm_eps=1e-5,
102 | cross_attention_dim=768,
103 | attention_head_dim=8,
104 | transformer_layers_per_block=1,
105 | conv_in_kernel=3,
106 | conv_out_kernel=3,
107 | addition_embed_type=None,
108 | addition_time_embed_dim=None,
109 | projection_class_embeddings_input_dim=None,
110 | conditioning_embedding_out_channels=(16, 32, 96, 256),
111 | **kwargs,
112 | ):
113 | if kwargs.get("dual_cross_attention", None):
114 | raise NotImplementedError
115 | if kwargs.get("num_classs_embeds", None):
116 | raise NotImplementedError
117 | if only_cross_attention:
118 | raise NotImplementedError
119 | if kwargs.get("use_linear_projection", None):
120 | logger.warning("`use_linear_projection=True` is ignored!")
121 |
122 | super().__init__()
123 | self._register_load_state_dict_pre_hook(linear_to_conv2d_map)
124 |
125 | self.sample_size = sample_size
126 | time_embed_dim = block_out_channels[0] * 4
127 |
128 | # input
129 | conv_in_padding = (conv_in_kernel - 1) // 2
130 | self.conv_in = nn.Conv2d(
131 | in_channels,
132 | block_out_channels[0],
133 | kernel_size=conv_in_kernel,
134 | padding=conv_in_padding
135 | )
136 |
137 | # time
138 | time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
139 | timestep_input_dim = block_out_channels[0]
140 | time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
141 |
142 | if addition_embed_type == "text_time":
143 | self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
144 | self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
145 | elif addition_embed_type is not None:
146 | raise NotImplementedError
147 |
148 | self.time_proj = time_proj
149 | self.time_embedding = time_embedding
150 |
151 | self.controlnet_cond_embedding = ControlNetConditioningDefaultEmbedding(
152 | conditioning_embedding_channels=block_out_channels[0],
153 | block_out_channels=conditioning_embedding_out_channels,
154 | )
155 |
156 | self.down_blocks = nn.ModuleList([])
157 | self.mid_block = None
158 | self.controlnet_down_blocks = nn.ModuleList([])
159 |
160 | if isinstance(only_cross_attention, bool):
161 | only_cross_attention = [only_cross_attention] * len(down_block_types)
162 |
163 | if isinstance(attention_head_dim, int):
164 | attention_head_dim = (attention_head_dim,) * len(down_block_types)
165 |
166 | if isinstance(transformer_layers_per_block, int):
167 | transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
168 |
169 | # down
170 | output_channel = block_out_channels[0]
171 |
172 | controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
173 | controlnet_block = zero_module(controlnet_block)
174 | self.controlnet_down_blocks.append(controlnet_block)
175 |
176 | for i, down_block_type in enumerate(down_block_types):
177 | input_channel = output_channel
178 | output_channel = block_out_channels[i]
179 | is_final_block = i == len(block_out_channels) - 1
180 |
181 | down_block = get_down_block(
182 | down_block_type,
183 | num_layers=layers_per_block,
184 | transformer_layers_per_block=transformer_layers_per_block[i],
185 | in_channels=input_channel,
186 | out_channels=output_channel,
187 | temb_channels=time_embed_dim,
188 | add_downsample=not is_final_block,
189 | resnet_eps=norm_eps,
190 | resnet_act_fn=act_fn,
191 | cross_attention_dim=cross_attention_dim,
192 | attn_num_head_channels=attention_head_dim[i],
193 | downsample_padding=downsample_padding,
194 | )
195 | self.down_blocks.append(down_block)
196 |
197 | for _ in range(layers_per_block):
198 | controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
199 | controlnet_block = zero_module(controlnet_block)
200 | self.controlnet_down_blocks.append(controlnet_block)
201 |
202 | if not is_final_block:
203 | controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
204 | controlnet_block = zero_module(controlnet_block)
205 | self.controlnet_down_blocks.append(controlnet_block)
206 |
207 | # mid
208 | mid_block_channel = block_out_channels[-1]
209 |
210 | controlnet_block = nn.Conv2d(mid_block_channel, mid_block_channel, kernel_size=1)
211 | controlnet_block = zero_module(controlnet_block)
212 | self.controlnet_mid_block = controlnet_block
213 |
214 | self.mid_block = UNetMidBlock2DCrossAttn(
215 | transformer_layers_per_block=transformer_layers_per_block[-1],
216 | in_channels=mid_block_channel,
217 | temb_channels=time_embed_dim,
218 | resnet_eps=norm_eps,
219 | resnet_act_fn=act_fn,
220 | output_scale_factor=mid_block_scale_factor,
221 | resnet_time_scale_shift="default",
222 | cross_attention_dim=cross_attention_dim,
223 | attn_num_head_channels=attention_head_dim[i],
224 | resnet_groups=norm_num_groups,
225 | )
226 |
227 | def forward(
228 | self,
229 | sample,
230 | timestep,
231 | encoder_hidden_states,
232 | controlnet_cond,
233 | text_embeds=None,
234 | time_ids=None
235 | ):
236 | # 0. Project (or look-up) time embeddings
237 | t_emb = self.time_proj(timestep)
238 | emb = self.time_embedding(t_emb)
239 |
240 | if hasattr(self.config, "addition_embed_type") and self.config.addition_embed_type == "text_time":
241 | time_embeds = self.add_time_proj(time_ids.flatten())
242 | time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
243 |
244 | add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
245 | add_embeds = add_embeds.to(emb.dtype)
246 | aug_emb = self.add_embedding(add_embeds)
247 | emb = emb + aug_emb
248 |
249 | # 1. center input if necessary
250 | if self.config.center_input_sample:
251 | sample = 2 * sample - 1.0
252 |
253 | # 2. pre-process
254 | sample = self.conv_in(sample)
255 |
256 | controlnet_cond = self.controlnet_cond_embedding(controlnet_cond)
257 |
258 | sample += controlnet_cond
259 |
260 | # 3. down
261 | down_block_res_samples = (sample, )
262 | for downsample_block in self.down_blocks:
263 | if hasattr(downsample_block, "attentions") and downsample_block.attentions is not None:
264 | sample, res_samples = downsample_block(
265 | hidden_states=sample,
266 | temb=emb,
267 | encoder_hidden_states=encoder_hidden_states
268 | )
269 | else:
270 | sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
271 |
272 | down_block_res_samples += res_samples
273 |
274 | # 4. mid
275 | sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states)
276 |
277 | # 5. Control net blocks
278 |
279 | controlnet_down_block_res_samples = ()
280 |
281 | for down_block_res_sample, controlnet_block in zip(down_block_res_samples, self.controlnet_down_blocks):
282 | down_block_res_sample = controlnet_block(down_block_res_sample)
283 | controlnet_down_block_res_samples += (down_block_res_sample, )
284 |
285 | down_block_res_samples = controlnet_down_block_res_samples
286 |
287 | mid_block_res_sample = self.controlnet_mid_block(sample)
288 |
289 | return (down_block_res_samples, mid_block_res_sample)
290 |
291 |
292 | def zero_module(module):
293 | for p in module.parameters():
294 | nn.init.zeros_(p)
295 | return module
296 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_vae.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils
8 |
9 | from collections import OrderedDict, defaultdict
10 | from copy import deepcopy
11 | import coremltools as ct
12 | import gc
13 |
14 | import logging
15 |
16 | logging.basicConfig()
17 | logger = logging.getLogger(__name__)
18 | logger.setLevel(logging.INFO)
19 |
20 | import numpy as np
21 | import os
22 |
23 | import torch
24 | import torch.nn as nn
25 | import torch.nn.functional as F
26 |
27 | torch.set_grad_enabled(False)
28 |
29 |
30 | def modify_coremltools_torch_frontend_badbmm():
31 | """
32 | Modifies coremltools torch frontend for baddbmm to be robust to the `beta` argument being of non-float dtype:
33 | e.g. https://github.com/huggingface/diffusers/blob/v0.8.1/src/diffusers/models/attention.py#L315
34 | """
35 | from coremltools.converters.mil import register_torch_op
36 | from coremltools.converters.mil.mil import Builder as mb
37 | from coremltools.converters.mil.frontend.torch.ops import _get_inputs
38 | from coremltools.converters.mil.frontend.torch.torch_op_registry import _TORCH_OPS_REGISTRY
39 | if "baddbmm" in _TORCH_OPS_REGISTRY:
40 | del _TORCH_OPS_REGISTRY["baddbmm"]
41 |
42 | @register_torch_op
43 | def baddbmm(context, node):
44 | """
45 | baddbmm(Tensor input, Tensor batch1, Tensor batch2, Scalar beta=1, Scalar alpha=1)
46 | output = beta * input + alpha * batch1 * batch2
47 | Notice that batch1 and batch2 must be 3-D tensors each containing the same number of matrices.
48 | If batch1 is a (b×n×m) tensor, batch2 is a (b×m×p) tensor, then input must be broadcastable with a (b×n×p) tensor
49 | and out will be a (b×n×p) tensor.
50 | """
51 | assert len(node.outputs) == 1
52 | inputs = _get_inputs(context, node, expected=5)
53 | bias, batch1, batch2, beta, alpha = inputs
54 |
55 | if beta.val != 1.0:
56 | # Apply scaling factor beta to the bias.
57 | if beta.val.dtype == np.int32:
58 | beta = mb.cast(x=beta, dtype="fp32")
59 | logger.warning(
60 | f"Casted the `beta`(value={beta.val}) argument of `baddbmm` op "
61 | "from int32 to float32 dtype for conversion!")
62 | bias = mb.mul(x=beta, y=bias, name=bias.name + "_scaled")
63 |
64 | context.add(bias)
65 |
66 | if alpha.val != 1.0:
67 | # Apply scaling factor alpha to the input.
68 | batch1 = mb.mul(x=alpha, y=batch1, name=batch1.name + "_scaled")
69 | context.add(batch1)
70 |
71 | bmm_node = mb.matmul(x=batch1, y=batch2, name=node.name + "_bmm")
72 | context.add(bmm_node)
73 |
74 | baddbmm_node = mb.add(x=bias, y=bmm_node, name=node.name)
75 | context.add(baddbmm_node)
76 |
77 |
78 | def encoder(pipe, args):
79 | """ Converts the VAE Encoder component of Stable Diffusion
80 | """
81 | out_path = utils.get_out_path(args, "vae_encoder")
82 | if os.path.exists(out_path):
83 | logger.info(f"`vae_encoder` already exists at {out_path}, skipping conversion.")
84 | return
85 |
86 | if not hasattr(pipe, "unet"):
87 | raise RuntimeError(
88 | "convert_unet() deletes pipe.unet to save RAM. "
89 | "Please use convert_vae_encoder() before convert_unet()")
90 |
91 | z_shape = (
92 | 1, # B
93 | 3, # C
94 | args.output_h, # H
95 | args.output_w, # w
96 | )
97 |
98 | sample_vae_encoder_inputs = {
99 | "z": torch.rand(*z_shape, dtype=torch.float16)
100 | }
101 |
102 | class VAEEncoder(nn.Module):
103 | """ Wrapper nn.Module wrapper for pipe.encode() method
104 | """
105 |
106 | def __init__(self):
107 | super().__init__()
108 | self.quant_conv = pipe.vae.quant_conv
109 | self.encoder = pipe.vae.encoder
110 |
111 | def forward(self, z):
112 | return self.quant_conv(self.encoder(z))
113 |
114 | baseline_encoder = VAEEncoder().eval()
115 |
116 | # No optimization needed for the VAE Encoder as it is a pure ConvNet
117 | traced_vae_encoder = torch.jit.trace(baseline_encoder, (sample_vae_encoder_inputs["z"].to(torch.float32), ))
118 |
119 | modify_coremltools_torch_frontend_badbmm()
120 |
121 | # TODO: For now using variable size takes too much memory and time
122 | # if args.multisize:
123 | # sample_size = args.output_h
124 | # input_shape = ct.Shape(shape=(
125 | # 1,
126 | # 3,
127 | # ct.RangeDim(lower_bound=int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
128 | # ct.RangeDim(lower_bound=int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size)
129 | # ))
130 | # sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_encoder_inputs, {"z": input_shape})
131 | # else:
132 | # sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_encoder_inputs)
133 | sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_encoder_inputs)
134 |
135 | # SDXL seems to require full precision
136 | precision_full = args.model_is_sdxl and args.model_version != "stabilityai/stable-diffusion-xl-base-1.0"
137 | coreml_vae_encoder, out_path = utils.convert_to_coreml(
138 | "vae_encoder", traced_vae_encoder, sample_coreml_inputs,
139 | ["latent"], precision_full, args
140 | )
141 |
142 | # Set model metadata
143 | coreml_vae_encoder.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
144 | coreml_vae_encoder.license = "OpenRAIL (https://huggingface.co/spaces/CompVis/stable-diffusion-license)"
145 | coreml_vae_encoder.version = args.model_version
146 | coreml_vae_encoder.short_description = \
147 | "Stable Diffusion generates images conditioned on text and/or other images as input through the diffusion process. " \
148 | "Please refer to https://arxiv.org/abs/2112.10752 for details."
149 |
150 | # Set the input descriptions
151 | coreml_vae_encoder.input_description["z"] = \
152 | "The input image to base the initial latents on normalized to range [-1, 1]"
153 |
154 | # Set the output descriptions
155 | coreml_vae_encoder.output_description["latent"] = "The latent embeddings from the unet model from the input image."
156 |
157 | # Set package version metadata
158 | coreml_vae_encoder.user_defined_metadata["identifier"] = args.model_version
159 | coreml_vae_encoder.user_defined_metadata["converter_version"] = __version__
160 | coreml_vae_encoder.user_defined_metadata["attention_implementation"] = args.attention_implementation
161 | coreml_vae_encoder.user_defined_metadata["compute_unit"] = args.compute_unit
162 | coreml_vae_encoder.user_defined_metadata["scaling_factor"] = str(pipe.vae.config.scaling_factor)
163 | # TODO: Add this key to stop using the hack when variable size works correctly
164 | coreml_vae_encoder.user_defined_metadata["supports_model_size_hack"] = "true"
165 |
166 | coreml_vae_encoder.save(out_path)
167 |
168 | logger.info(f"Saved vae_encoder into {out_path}")
169 |
170 | # Parity check PyTorch vs CoreML
171 | if args.check_output_correctness:
172 | baseline_out = baseline_encoder(z=sample_vae_encoder_inputs["z"].to(torch.float32)).detach().numpy()
173 | coreml_out = list(coreml_vae_encoder.predict({
174 | k: v.numpy() for k, v in sample_vae_encoder_inputs.items()
175 | }).values())[0]
176 | utils.report_correctness(baseline_out, coreml_out,"vae_encoder baseline PyTorch to baseline CoreML")
177 |
178 | del traced_vae_encoder, pipe.vae.encoder, coreml_vae_encoder
179 | gc.collect()
180 |
181 |
182 | def decoder(pipe, args):
183 | """ Converts the VAE Decoder component of Stable Diffusion
184 | """
185 | out_path = utils.get_out_path(args, "vae_decoder")
186 | if os.path.exists(out_path):
187 | logger.info(f"`vae_decoder` already exists at {out_path}, skipping conversion.")
188 | return
189 |
190 | if not hasattr(pipe, "unet"):
191 | raise RuntimeError(
192 | "convert_unet() deletes pipe.unet to save RAM. "
193 | "Please use convert_vae_decoder() before convert_unet()")
194 |
195 | vae_scale_factor = 2 ** (len(pipe.vae.config.block_out_channels) - 1)
196 | height = int(args.output_h / vae_scale_factor)
197 | width = int(args.output_w / vae_scale_factor)
198 | vae_latent_channels = pipe.vae.config.latent_channels
199 | z_shape = (
200 | 1, # B
201 | vae_latent_channels, # C
202 | height, # H
203 | width, # w
204 | )
205 |
206 | sample_vae_decoder_inputs = {
207 | "z": torch.rand(*z_shape, dtype=torch.float16)
208 | }
209 |
210 | class VAEDecoder(nn.Module):
211 | """ Wrapper nn.Module wrapper for pipe.decode() method
212 | """
213 |
214 | def __init__(self):
215 | super().__init__()
216 | self.post_quant_conv = pipe.vae.post_quant_conv
217 | self.decoder = pipe.vae.decoder
218 |
219 | def forward(self, z):
220 | return self.decoder(self.post_quant_conv(z))
221 |
222 | baseline_decoder = VAEDecoder().eval()
223 |
224 | # No optimization needed for the VAE Decoder as it is a pure ConvNet
225 | traced_vae_decoder = torch.jit.trace(baseline_decoder, (sample_vae_decoder_inputs["z"].to(torch.float32), ))
226 |
227 | modify_coremltools_torch_frontend_badbmm()
228 |
229 | # TODO: For now using variable size takes too much memory and time
230 | # if args.multisize:
231 | # sample_size = height
232 | # input_shape = ct.Shape(shape=(
233 | # 1,
234 | # vae_latent_channels,
235 | # ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
236 | # ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size)
237 | # ))
238 | # sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_decoder_inputs, {"z": input_shape})
239 | # else:
240 | # sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_decoder_inputs)
241 | sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_decoder_inputs)
242 |
243 | # SDXL seems to require full precision
244 | precision_full = args.model_is_sdxl and args.model_version != "stabilityai/stable-diffusion-xl-base-1.0"
245 | coreml_vae_decoder, out_path = utils.convert_to_coreml(
246 | "vae_decoder", traced_vae_decoder, sample_coreml_inputs,
247 | ["image"], precision_full, args
248 | )
249 |
250 | # Set model metadata
251 | coreml_vae_decoder.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
252 | coreml_vae_decoder.license = "OpenRAIL (https://huggingface.co/spaces/CompVis/stable-diffusion-license)"
253 | coreml_vae_decoder.version = args.model_version
254 | coreml_vae_decoder.short_description = \
255 | "Stable Diffusion generates images conditioned on text and/or other images as input through the diffusion process. " \
256 | "Please refer to https://arxiv.org/abs/2112.10752 for details."
257 |
258 | # Set the input descriptions
259 | coreml_vae_decoder.input_description["z"] = \
260 | "The denoised latent embeddings from the unet model after the last step of reverse diffusion"
261 |
262 | # Set the output descriptions
263 | coreml_vae_decoder.output_description["image"] = "Generated image normalized to range [-1, 1]"
264 |
265 | # Set package version metadata
266 | coreml_vae_decoder.user_defined_metadata["identifier"] = args.model_version
267 | coreml_vae_decoder.user_defined_metadata["converter_version"] = __version__
268 | coreml_vae_decoder.user_defined_metadata["attention_implementation"] = args.attention_implementation
269 | coreml_vae_decoder.user_defined_metadata["compute_unit"] = args.compute_unit
270 | coreml_vae_decoder.user_defined_metadata["scaling_factor"] = str(pipe.vae.config.scaling_factor)
271 | # TODO: Add this key to stop using the hack when variable size works correctly
272 | coreml_vae_decoder.user_defined_metadata["supports_model_size_hack"] = "true"
273 |
274 | coreml_vae_decoder.save(out_path)
275 |
276 | logger.info(f"Saved vae_decoder into {out_path}")
277 |
278 | # Parity check PyTorch vs CoreML
279 | if args.check_output_correctness:
280 | baseline_out = baseline_decoder(z=sample_vae_decoder_inputs["z"].to(torch.float32)).detach().numpy()
281 | coreml_out = list(coreml_vae_decoder.predict({
282 | k: v.numpy() for k, v in sample_vae_decoder_inputs.items()
283 | }).values())[0]
284 | utils.report_correctness(baseline_out, coreml_out, "vae_decoder baseline PyTorch to baseline CoreML")
285 |
286 | del traced_vae_decoder, pipe.vae.decoder, coreml_vae_decoder
287 | gc.collect()
288 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/utils/chunk_mlprogram.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools.utils import utils
7 |
8 | import argparse
9 | from collections import OrderedDict
10 |
11 | import coremltools as ct
12 | from coremltools.converters.mil import Block, Program, Var
13 | from coremltools.converters.mil.frontend.milproto.load import load as _milproto_to_pymil
14 | from coremltools.converters.mil.mil import Builder as mb
15 | from coremltools.converters.mil.mil import Placeholder
16 | from coremltools.converters.mil.mil import types as types
17 | from coremltools.converters.mil.mil.passes.helper import block_context_manager
18 | from coremltools.converters.mil.mil.passes.pass_registry import PASS_REGISTRY
19 | from coremltools.converters.mil.testing_utils import random_gen_input_feature_type
20 |
21 | import gc
22 |
23 | import logging
24 |
25 | logging.basicConfig()
26 | logger = logging.getLogger(__name__)
27 | logger.setLevel(logging.INFO)
28 |
29 | import numpy as np
30 | import os
31 | import tempfile
32 | from guernikatools import torch2coreml
33 | import shutil
34 | import time
35 |
36 |
37 | def _verify_output_correctness_of_chunks(full_model, first_chunk_model,
38 | second_chunk_model):
39 | """ Verifies the end-to-end output correctness of full (original) model versus chunked models
40 | """
41 | # Generate inputs for first chunk and full model
42 | input_dict = {}
43 | for input_desc in full_model._spec.description.input:
44 | input_dict[input_desc.name] = random_gen_input_feature_type(input_desc)
45 |
46 | # Generate outputs for first chunk and full model
47 | outputs_from_full_model = full_model.predict(input_dict)
48 | outputs_from_first_chunk_model = first_chunk_model.predict(input_dict)
49 |
50 | # Prepare inputs for second chunk model from first chunk's outputs and regular inputs
51 | second_chunk_input_dict = {}
52 | for input_desc in second_chunk_model._spec.description.input:
53 | if input_desc.name in outputs_from_first_chunk_model:
54 | second_chunk_input_dict[
55 | input_desc.name] = outputs_from_first_chunk_model[
56 | input_desc.name]
57 | else:
58 | second_chunk_input_dict[input_desc.name] = input_dict[
59 | input_desc.name]
60 |
61 | # Generate output for second chunk model
62 | outputs_from_second_chunk_model = second_chunk_model.predict(
63 | second_chunk_input_dict)
64 |
65 | # Verify correctness across all outputs from second chunk and full model
66 | for out_name in outputs_from_full_model.keys():
67 | utils.report_correctness(
68 | original_outputs=outputs_from_full_model[out_name],
69 | final_outputs=outputs_from_second_chunk_model[out_name],
70 | log_prefix=f"{out_name}")
71 |
72 |
73 | def _load_prog_from_mlmodel(model):
74 | """ Load MIL Program from an MLModel
75 | """
76 | model_spec = model.get_spec()
77 | start_ = time.time()
78 | logger.info(
79 | "Loading MLModel object into a MIL Program object (including the weights).."
80 | )
81 | prog = _milproto_to_pymil(
82 | model_spec=model_spec,
83 | specification_version=model_spec.specificationVersion,
84 | file_weights_dir=model.weights_dir,
85 | )
86 | logger.info(f"Program loaded in {time.time() - start_:.1f} seconds")
87 |
88 | return prog
89 |
90 |
91 | def _get_op_idx_split_location(prog: Program):
92 | """ Find the op that approximately bisects the graph as measure by weights size on each side
93 | """
94 | main_block = prog.functions["main"]
95 | total_size_in_mb = 0
96 |
97 | for op in main_block.operations:
98 | if op.op_type == "const" and isinstance(op.val.val, np.ndarray):
99 | size_in_mb = op.val.val.size * op.val.val.itemsize / (1024 * 1024)
100 | total_size_in_mb += size_in_mb
101 | half_size = total_size_in_mb / 2
102 |
103 | # Find the first non const op (single child), where the total cumulative size exceeds
104 | # the half size for the first time
105 | cumulative_size_in_mb = 0
106 | for op in main_block.operations:
107 | if op.op_type == "const" and isinstance(op.val.val, np.ndarray):
108 | size_in_mb = op.val.val.size * op.val.val.itemsize / (1024 * 1024)
109 | cumulative_size_in_mb += size_in_mb
110 |
111 | # Note: The condition "not op.op_type.startswith("const")" is to make sure that the
112 | # incision op is neither of type "const" nor "constexpr_*" ops that
113 | # are used to store compressed weights
114 | if (cumulative_size_in_mb > half_size and not op.op_type.startswith("const")
115 | and len(op.outputs) == 1
116 | and len(op.outputs[0].child_ops) == 1):
117 | op_idx = main_block.operations.index(op)
118 | return op_idx, cumulative_size_in_mb, total_size_in_mb
119 |
120 |
121 | def _get_first_chunk_outputs(block, op_idx):
122 | # Get the list of all vars that go across from first program (all ops from 0 to op_idx (inclusive))
123 | # to the second program (all ops from op_idx+1 till the end). These all vars need to be made the output
124 | # of the first program and the input of the second program
125 | boundary_vars = set()
126 | for i in range(op_idx + 1):
127 | op = block.operations[i]
128 | if not op.op_type.startswith("const"):
129 | for var in op.outputs:
130 | if var.val is None: # only consider non const vars
131 | for child_op in var.child_ops:
132 | child_op_idx = block.operations.index(child_op)
133 | if child_op_idx > op_idx:
134 | boundary_vars.add(var)
135 | return list(boundary_vars)
136 |
137 |
138 | @block_context_manager
139 | def _add_fp32_casts(block, boundary_vars):
140 | new_boundary_vars = []
141 | for var in boundary_vars:
142 | if var.dtype != types.fp16:
143 | new_boundary_vars.append(var)
144 | else:
145 | fp32_var = mb.cast(x=var, dtype="fp32", name=var.name)
146 | new_boundary_vars.append(fp32_var)
147 | return new_boundary_vars
148 |
149 |
150 | def _make_first_chunk_prog(prog, op_idx):
151 | """ Build first chunk by declaring early outputs and removing unused subgraph
152 | """
153 | block = prog.functions["main"]
154 | boundary_vars = _get_first_chunk_outputs(block, op_idx)
155 |
156 | # Due to possible numerical issues, cast any fp16 var to fp32
157 | new_boundary_vars = _add_fp32_casts(block, boundary_vars)
158 |
159 | block.outputs.clear()
160 | block.set_outputs(new_boundary_vars)
161 | PASS_REGISTRY["common::dead_code_elimination"](prog)
162 | return prog
163 |
164 |
165 | def _make_second_chunk_prog(prog, op_idx):
166 | """ Build second chunk by rebuilding a pristine MIL Program from MLModel
167 | """
168 | block = prog.functions["main"]
169 | block.opset_version = ct.target.iOS16
170 |
171 | # First chunk outputs are second chunk inputs (e.g. skip connections)
172 | boundary_vars = _get_first_chunk_outputs(block, op_idx)
173 |
174 | # This op will not be included in this program. Its output var will be made into an input
175 | boundary_op = block.operations[op_idx]
176 |
177 | # Add all boundary ops as inputs
178 | with block:
179 | for var in boundary_vars:
180 | new_placeholder = Placeholder(
181 | sym_shape=var.shape,
182 | dtype=var.dtype if var.dtype != types.fp16 else types.fp32,
183 | name=var.name,
184 | )
185 |
186 | block._input_dict[
187 | new_placeholder.outputs[0].name] = new_placeholder.outputs[0]
188 |
189 | block.function_inputs = tuple(block._input_dict.values())
190 | new_var = None
191 | if var.dtype == types.fp16:
192 | new_var = mb.cast(x=new_placeholder.outputs[0],
193 | dtype="fp16",
194 | before_op=var.op)
195 | else:
196 | new_var = new_placeholder.outputs[0]
197 |
198 | block.replace_uses_of_var_after_op(
199 | anchor_op=boundary_op,
200 | old_var=var,
201 | new_var=new_var,
202 | # This is needed if the program contains "constexpr_*" ops. In normal cases, there are stricter
203 | # rules for removing them, and their presence may prevent replacing this var.
204 | # However in this case, since we want to remove all the ops in chunk 1, we can safely
205 | # set this to True.
206 | force_replace=True,
207 | )
208 |
209 | PASS_REGISTRY["common::dead_code_elimination"](prog)
210 |
211 | # Remove any unused inputs
212 | new_input_dict = OrderedDict()
213 | for k, v in block._input_dict.items():
214 | if len(v.child_ops) > 0:
215 | new_input_dict[k] = v
216 | block._input_dict = new_input_dict
217 | block.function_inputs = tuple(block._input_dict.values())
218 |
219 | return prog
220 |
221 |
222 | def main(args):
223 | os.makedirs(args.o, exist_ok=True)
224 |
225 | # Check filename extension
226 | mlpackage_name = os.path.basename(args.mlpackage_path)
227 | name, ext = os.path.splitext(mlpackage_name)
228 | assert ext == ".mlpackage", f"`--mlpackage-path` (args.mlpackage_path) is not an .mlpackage file"
229 |
230 | # Load CoreML model
231 | logger.info("Loading model from {}".format(args.mlpackage_path))
232 | start_ = time.time()
233 | model = ct.models.MLModel(
234 | args.mlpackage_path,
235 | compute_units=ct.ComputeUnit.CPU_ONLY,
236 | )
237 | logger.info(
238 | f"Loading {args.mlpackage_path} took {time.time() - start_:.1f} seconds"
239 | )
240 |
241 | # Load the MIL Program from MLModel
242 | prog = _load_prog_from_mlmodel(model)
243 |
244 | # Compute the incision point by bisecting the program based on weights size
245 | op_idx, first_chunk_weights_size, total_weights_size = _get_op_idx_split_location(
246 | prog)
247 | main_block = prog.functions["main"]
248 | incision_op = main_block.operations[op_idx]
249 | logger.info(f"{args.mlpackage_path} will chunked into two pieces.")
250 | logger.info(
251 | f"The incision op: name={incision_op.name}, type={incision_op.op_type}, index={op_idx}/{len(main_block.operations)}"
252 | )
253 | logger.info(f"First chunk size = {first_chunk_weights_size:.2f} MB")
254 | logger.info(
255 | f"Second chunk size = {total_weights_size - first_chunk_weights_size:.2f} MB"
256 | )
257 |
258 | # Build first chunk (in-place modifies prog by declaring early exits and removing unused subgraph)
259 | prog_chunk1 = _make_first_chunk_prog(prog, op_idx)
260 |
261 | # Build the second chunk
262 | prog_chunk2 = _make_second_chunk_prog(_load_prog_from_mlmodel(model), op_idx)
263 |
264 | user_defined_metadata = model.user_defined_metadata
265 |
266 | if not args.check_output_correctness:
267 | # Original model no longer needed in memory
268 | del model
269 | gc.collect()
270 |
271 | # Convert the MIL Program objects into MLModels
272 | logger.info("Converting the two programs")
273 | model_chunk1 = ct.convert(
274 | prog_chunk1,
275 | convert_to="mlprogram",
276 | compute_units=ct.ComputeUnit.CPU_ONLY,
277 | minimum_deployment_target=ct.target.iOS16,
278 | )
279 | del prog_chunk1
280 | gc.collect()
281 | logger.info("Conversion of first chunk done.")
282 |
283 | model_chunk2 = ct.convert(
284 | prog_chunk2,
285 | convert_to="mlprogram",
286 | compute_units=ct.ComputeUnit.CPU_ONLY,
287 | minimum_deployment_target=ct.target.iOS16,
288 | )
289 | del prog_chunk2
290 | gc.collect()
291 | logger.info("Conversion of second chunk done.")
292 |
293 | for key in user_defined_metadata:
294 | if "com.github.apple" not in key:
295 | model_chunk1.user_defined_metadata[key] = user_defined_metadata[key]
296 | model_chunk2.user_defined_metadata[key] = user_defined_metadata[key]
297 |
298 | # Verify output correctness
299 | if args.check_output_correctness:
300 | logger.info("Verifying output correctness of chunks")
301 | _verify_output_correctness_of_chunks(
302 | full_model=model,
303 | first_chunk_model=model_chunk1,
304 | second_chunk_model=model_chunk2,
305 | )
306 |
307 | # Remove original (non-chunked) model if requested
308 | if args.remove_original:
309 | logger.info(
310 | "Removing original (non-chunked) model at {args.mlpackage_path}")
311 | shutil.rmtree(args.mlpackage_path)
312 | logger.info("Done.")
313 |
314 | # Save the chunked models to disk
315 | out_path_chunk1 = os.path.join(args.o, name + "_chunk1.mlpackage")
316 | out_path_chunk2 = os.path.join(args.o, name + "_chunk2.mlpackage")
317 | if args.clean_up_mlpackages:
318 | temp_dir = tempfile.gettempdir()
319 | out_path_chunk1 = os.path.join(temp_dir, name + "_chunk1.mlpackage")
320 | out_path_chunk2 = os.path.join(temp_dir, name + "_chunk2.mlpackage")
321 |
322 | logger.info(
323 | f"Saved chunks in {args.o} with the suffix _chunk1.mlpackage and _chunk2.mlpackage"
324 | )
325 | model_chunk1.save(out_path_chunk1)
326 | model_chunk2.save(out_path_chunk2)
327 | logger.info("Done.")
328 |
329 |
330 | if __name__ == "__main__":
331 | parser = argparse.ArgumentParser()
332 | parser.add_argument(
333 | "--mlpackage-path",
334 | required=True,
335 | help=
336 | "Path to the mlpackage file to be split into two mlpackages of approximately same file size.",
337 | )
338 | parser.add_argument(
339 | "-o",
340 | required=True,
341 | help=
342 | "Path to output directory where the two model chunks should be saved.",
343 | )
344 | parser.add_argument(
345 | "--clean-up-mlpackages",
346 | action="store_true",
347 | help="Removes mlpackages after a successful convesion.")
348 | parser.add_argument(
349 | "--remove-original",
350 | action="store_true",
351 | help=
352 | "If specified, removes the original (non-chunked) model to avoid duplicating storage."
353 | )
354 | parser.add_argument(
355 | "--check-output-correctness",
356 | action="store_true",
357 | help=
358 | ("If specified, compares the outputs of original Core ML model with that of pipelined CoreML model chunks and reports PSNR in dB. ",
359 | "Enabling this feature uses more memory. Disable it if your machine runs out of memory."
360 | ))
361 |
362 | args = parser.parse_args()
363 | main(args)
364 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_unet.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils, chunk_mlprogram
8 | from guernikatools.models import attention, unet
9 |
10 | from collections import OrderedDict, defaultdict
11 | from copy import deepcopy
12 | import coremltools as ct
13 | import gc
14 |
15 | import logging
16 |
17 | logging.basicConfig()
18 | logger = logging.getLogger(__name__)
19 | logger.setLevel(logging.INFO)
20 |
21 | import numpy as np
22 | import os
23 |
24 | import torch
25 | import torch.nn as nn
26 | import torch.nn.functional as F
27 |
28 | torch.set_grad_enabled(False)
29 |
30 |
31 | def main(pipe, args):
32 | """ Converts the UNet component of Stable Diffusion
33 | """
34 | out_path = utils.get_out_path(args, "unet")
35 |
36 | # Check if Unet was previously exported and then chunked
37 | unet_chunks_exist = all(
38 | os.path.exists(out_path.replace(".mlpackage", f"_chunk{idx+1}.mlpackage")) for idx in range(2)
39 | )
40 |
41 | if args.chunk_unet and unet_chunks_exist:
42 | logger.info("`unet` chunks already exist, skipping conversion.")
43 | del pipe.unet
44 | gc.collect()
45 | return
46 |
47 | # If original Unet does not exist, export it from PyTorch+diffusers
48 | elif not os.path.exists(out_path):
49 | # Register the selected attention implementation globally
50 | attention.ATTENTION_IMPLEMENTATION_IN_EFFECT = attention.AttentionImplementations[args.attention_implementation]
51 | logger.info(f"Attention implementation in effect: {attention.ATTENTION_IMPLEMENTATION_IN_EFFECT}")
52 |
53 | # Prepare sample input shapes and values
54 | batch_size = 2 # for classifier-free guidance
55 | unet_in_channels = pipe.unet.config.in_channels
56 | # allow converting instruct pix2pix
57 | if unet_in_channels == 8:
58 | batch_size = 3
59 | vae_scale_factor = 2 ** (len(pipe.vae.config.block_out_channels) - 1)
60 | height = int(args.output_h / vae_scale_factor)
61 | width = int(args.output_w / vae_scale_factor)
62 |
63 | sample_shape = (
64 | batch_size, # B
65 | unet_in_channels, # C
66 | height, # H
67 | width, # W
68 | )
69 |
70 | max_position_embeddings = 77
71 | if hasattr(pipe, "text_encoder") and pipe.text_encoder and pipe.text_encoder.config:
72 | max_position_embeddings = pipe.text_encoder.config.max_position_embeddings
73 | elif hasattr(pipe, "text_encoder_2") and pipe.text_encoder_2 and pipe.text_encoder_2.config:
74 | max_position_embeddings = pipe.text_encoder_2.config.max_position_embeddings
75 | else:
76 | raise RuntimeError(
77 | "convert_text_encoder() deletes pipe.text_encoder to save RAM. "
78 | "Please use convert_unet() before convert_text_encoder()")
79 |
80 | args.hidden_size = pipe.unet.config.cross_attention_dim
81 | encoder_hidden_states_shape = (
82 | batch_size,
83 | args.hidden_size,
84 | 1,
85 | max_position_embeddings,
86 | )
87 |
88 | # Create the scheduled timesteps for downstream use
89 | DEFAULT_NUM_INFERENCE_STEPS = 50
90 | pipe.scheduler.set_timesteps(DEFAULT_NUM_INFERENCE_STEPS)
91 |
92 | sample_unet_inputs = [
93 | ("sample", torch.rand(*sample_shape)),
94 | ("timestep", torch.tensor([pipe.scheduler.timesteps[0].item()] * (batch_size)).to(torch.float32)),
95 | ("encoder_hidden_states", torch.rand(*encoder_hidden_states_shape)),
96 | ]
97 |
98 | args.requires_aesthetics_score = False
99 | if hasattr(pipe.unet.config, "addition_embed_type") and pipe.unet.config.addition_embed_type == "text_time":
100 | text_embeds_shape = (
101 | batch_size,
102 | pipe.text_encoder_2.config.hidden_size,
103 | )
104 | time_ids_input = None
105 | if hasattr(pipe.config, "requires_aesthetics_score") and pipe.config.requires_aesthetics_score:
106 | args.requires_aesthetics_score = True
107 | time_ids_input = [
108 | [args.output_h, args.output_w, 0, 0, 2.5],
109 | [args.output_h, args.output_w, 0, 0, 6]
110 | ]
111 | else:
112 | time_ids_input = [
113 | [args.output_h, args.output_w, 0, 0, args.output_h, args.output_w],
114 | [args.output_h, args.output_w, 0, 0, args.output_h, args.output_w]
115 | ]
116 | sample_unet_inputs = sample_unet_inputs + [
117 | ("text_embeds", torch.rand(*text_embeds_shape)),
118 | ("time_ids", torch.tensor(time_ids_input).to(torch.float32)),
119 | ]
120 |
121 | if args.controlnet_support:
122 | block_out_channels = pipe.unet.config.block_out_channels
123 |
124 | cn_output = 0
125 | cn_height = height
126 | cn_width = width
127 |
128 | # down
129 | output_channel = block_out_channels[0]
130 | sample_unet_inputs = sample_unet_inputs + [
131 | (f"down_block_res_samples_{cn_output:02}", torch.rand(2, output_channel, cn_height, cn_width))
132 | ]
133 | cn_output += 1
134 |
135 | for i, output_channel in enumerate(block_out_channels):
136 | is_final_block = i == len(block_out_channels) - 1
137 | sample_unet_inputs = sample_unet_inputs + [
138 | (f"down_block_res_samples_{cn_output:02}", torch.rand(2, output_channel, cn_height, cn_width)),
139 | (f"down_block_res_samples_{cn_output+1:02}", torch.rand(2, output_channel, cn_height, cn_width)),
140 | ]
141 | cn_output += 2
142 | if not is_final_block:
143 | cn_height = int(cn_height / 2)
144 | cn_width = int(cn_width / 2)
145 | sample_unet_inputs = sample_unet_inputs + [
146 | (f"down_block_res_samples_{cn_output:02}", torch.rand(2, output_channel, cn_height, cn_width)),
147 | ]
148 | cn_output += 1
149 |
150 | # mid
151 | output_channel = block_out_channels[-1]
152 | sample_unet_inputs = sample_unet_inputs + [
153 | ("mid_block_res_sample", torch.rand(2, output_channel, cn_height, cn_width))
154 | ]
155 |
156 | if args.t2i_adapter_support:
157 | block_out_channels = pipe.unet.config.block_out_channels
158 |
159 | if args.model_is_sdxl:
160 | t2ia_height = int(height / 2)
161 | t2ia_width = int(width / 2)
162 | else:
163 | t2ia_height = height
164 | t2ia_width = width
165 |
166 | for i, output_channel in enumerate(block_out_channels):
167 | sample_unet_inputs = sample_unet_inputs + [
168 | (f"adapter_res_samples_{i:02}", torch.rand(2, output_channel, t2ia_height, t2ia_width)),
169 | ]
170 | if not args.model_is_sdxl or i == 1:
171 | t2ia_height = int(t2ia_height / 2)
172 | t2ia_width = int(t2ia_width / 2)
173 |
174 | multisize_inputs = None
175 | if args.multisize:
176 | sample_size = height
177 | input_shape = ct.Shape(shape=(
178 | batch_size,
179 | unet_in_channels,
180 | ct.RangeDim(lower_bound=int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
181 | ct.RangeDim(lower_bound=int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size)
182 | ))
183 | multisize_inputs = {"sample": input_shape}
184 | for k, v in sample_unet_inputs:
185 | if "res_sample" in k:
186 | v_height = v.shape[2]
187 | v_width = v.shape[3]
188 | multisize_inputs[k] = ct.Shape(shape=(
189 | 2,
190 | output_channel,
191 | ct.RangeDim(lower_bound=int(v_height * 0.5), upper_bound=int(v_height * 2), default=v_height),
192 | ct.RangeDim(lower_bound=int(v_width * 0.5), upper_bound=int(v_width * 2), default=v_width)
193 | ))
194 |
195 | sample_unet_inputs = OrderedDict(sample_unet_inputs)
196 | sample_unet_inputs_spec = {
197 | k: (v.shape, v.dtype)
198 | for k, v in sample_unet_inputs.items()
199 | }
200 | logger.info(f"Sample inputs spec: {sample_unet_inputs_spec}")
201 |
202 | # Initialize reference unet
203 | reference_unet = unet.UNet2DConditionModel(**pipe.unet.config).eval()
204 | load_state_dict_summary = reference_unet.load_state_dict(pipe.unet.state_dict())
205 |
206 | # Prepare inputs
207 | baseline_sample_unet_inputs = deepcopy(sample_unet_inputs)
208 | baseline_sample_unet_inputs[
209 | "encoder_hidden_states"] = baseline_sample_unet_inputs[
210 | "encoder_hidden_states"].squeeze(2).transpose(1, 2)
211 |
212 | if not args.check_output_correctness:
213 | del pipe.unet
214 | gc.collect()
215 |
216 | # JIT trace
217 | logger.info("JIT tracing..")
218 | reference_unet = torch.jit.trace(reference_unet, example_kwarg_inputs=sample_unet_inputs)
219 | logger.info("Done.")
220 |
221 | if args.check_output_correctness:
222 | baseline_out = pipe.unet(
223 | sample=baseline_sample_unet_inputs["sample"],
224 | timestep=baseline_sample_unet_inputs["timestep"],
225 | encoder_hidden_states=baseline_sample_unet_inputs["encoder_hidden_states"],
226 | return_dict=False
227 | )[0].detach().numpy()
228 | reference_out = reference_unet(**sample_unet_inputs)[0].detach().numpy()
229 | utils.report_correctness(baseline_out, reference_out, "unet baseline to reference PyTorch")
230 |
231 | del pipe.unet
232 | gc.collect()
233 |
234 | coreml_sample_unet_inputs = {
235 | k: v.numpy().astype(np.float16)
236 | for k, v in sample_unet_inputs.items()
237 | }
238 |
239 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_unet_inputs, multisize_inputs)
240 | precision_full = args.precision_full
241 | if not precision_full and pipe.scheduler.config.prediction_type == "v_prediction":
242 | precision_full = True
243 | logger.info(f"Full precision required: prediction_type == v_prediction")
244 | coreml_unet, out_path = utils.convert_to_coreml(
245 | "unet",
246 | reference_unet,
247 | sample_coreml_inputs,
248 | ["noise_pred"],
249 | precision_full,
250 | args
251 | )
252 | del reference_unet
253 | gc.collect()
254 |
255 | update_coreml_unet(pipe, coreml_unet, out_path, args)
256 | logger.info(f"Saved unet into {out_path}")
257 |
258 | # Parity check PyTorch vs CoreML
259 | if args.check_output_correctness:
260 | coreml_out = list(coreml_unet.predict(coreml_sample_unet_inputs).values())[0]
261 | utils.report_correctness(baseline_out, coreml_out, "unet baseline PyTorch to reference CoreML")
262 |
263 | del coreml_unet
264 | gc.collect()
265 | else:
266 | del pipe.unet
267 | gc.collect()
268 | logger.info(f"`unet` already exists at {out_path}, skipping conversion.")
269 |
270 | if args.chunk_unet and not unet_chunks_exist:
271 | logger.info("Chunking unet in two approximately equal MLModels")
272 | args.mlpackage_path = out_path
273 | args.remove_original = False
274 | chunk_mlprogram.main(args)
275 |
276 |
277 | def update_coreml_unet(pipe, coreml_unet, out_path, args):
278 | # make ControlNet/T2IAdapter inputs optional
279 | coreml_spec = coreml_unet.get_spec()
280 | for index, input_spec in enumerate(coreml_spec.description.input):
281 | if "res_sample" in input_spec.name:
282 | coreml_spec.description.input[index].type.isOptional = True
283 | coreml_unet = ct.models.MLModel(coreml_spec, skip_model_load=True, weights_dir=coreml_unet.weights_dir)
284 |
285 | # Set model metadata
286 | coreml_unet.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
287 | coreml_unet.license = "OpenRAIL (https://huggingface.co/spaces/CompVis/stable-diffusion-license)"
288 | coreml_unet.version = args.model_version
289 | coreml_unet.short_description = \
290 | "Stable Diffusion generates images conditioned on text or other images as input through the diffusion process. " \
291 | "Please refer to https://arxiv.org/abs/2112.10752 for details."
292 |
293 | # Set the input descriptions
294 | coreml_unet.input_description["sample"] = \
295 | "The low resolution latent feature maps being denoised through reverse diffusion"
296 | coreml_unet.input_description["timestep"] = \
297 | "A value emitted by the associated scheduler object to condition the model on a given noise schedule"
298 | coreml_unet.input_description["encoder_hidden_states"] = \
299 | "Output embeddings from the associated text_encoder model to condition to generated image on text. " \
300 | "A maximum of 77 tokens (~40 words) are allowed. Longer text is truncated. " \
301 | "Shorter text does not reduce computation."
302 | if hasattr(pipe, "text_encoder_2") and pipe.text_encoder_2:
303 | coreml_unet.input_description["text_embeds"] = ""
304 | coreml_unet.input_description["time_ids"] = ""
305 | if args.t2i_adapter_support:
306 | coreml_unet.input_description["adapter_res_samples_00"] = "Optional: Residual down sample from T2IAdapter"
307 | if args.controlnet_support:
308 | coreml_unet.input_description["down_block_res_samples_00"] = "Optional: Residual down sample from ControlNet"
309 | coreml_unet.input_description["mid_block_res_sample"] = "Optional: Residual mid sample from ControlNet"
310 |
311 | # Set the output descriptions
312 | coreml_unet.output_description["noise_pred"] = \
313 | "Same shape and dtype as the `sample` input. " \
314 | "The predicted noise to facilitate the reverse diffusion (denoising) process"
315 |
316 | # Set package version metadata
317 | coreml_unet.user_defined_metadata["identifier"] = args.model_version
318 | coreml_unet.user_defined_metadata["converter_version"] = __version__
319 | coreml_unet.user_defined_metadata["attention_implementation"] = args.attention_implementation
320 | coreml_unet.user_defined_metadata["compute_unit"] = args.compute_unit
321 | coreml_unet.user_defined_metadata["prediction_type"] = pipe.scheduler.config.prediction_type
322 | coreml_unet.user_defined_metadata["hidden_size"] = str(args.hidden_size)
323 | if args.requires_aesthetics_score:
324 | coreml_unet.user_defined_metadata["requires_aesthetics_score"] = "true"
325 |
326 | coreml_unet.save(out_path)
327 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Model/ConverterProcess.swift:
--------------------------------------------------------------------------------
1 | //
2 | // ConverterProcess.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 30/3/23.
6 | //
7 |
8 | import Combine
9 | import Foundation
10 |
11 | extension Process: Cancellable {
12 | public func cancel() {
13 | terminate()
14 | }
15 | }
16 |
17 | class ConverterProcess: ObservableObject {
18 | enum ArgumentError: Error {
19 | case noOutputLocation
20 | case noHuggingfaceIdentifier
21 | case noDiffusersLocation
22 | case noCheckpointLocation
23 | }
24 | enum Step: Int, Identifiable, CustomStringConvertible {
25 | case initialize = 0
26 | case loadEmbeddings
27 | case convertVaeEncoder
28 | case convertVaeDecoder
29 | case convertUnet
30 | case convertTextEncoder
31 | case convertSafetyChecker
32 | case convertControlNet
33 | case compressOutput
34 | case cleanUp
35 | case done
36 |
37 | var id: Int { rawValue }
38 |
39 | var description: String {
40 | switch self {
41 | case .initialize:
42 | return "Initialize"
43 | case .loadEmbeddings:
44 | return "Load embeddings"
45 | case .convertVaeEncoder:
46 | return "Convert Encoder"
47 | case .convertVaeDecoder:
48 | return "Convert Decoder"
49 | case .convertUnet:
50 | return "Convert Unet"
51 | case .convertTextEncoder:
52 | return "Convert Text encoder"
53 | case .convertSafetyChecker:
54 | return "Convert Safety checker"
55 | case .convertControlNet:
56 | return "Convert ControlNet"
57 | case .compressOutput:
58 | return "Compress"
59 | case .cleanUp:
60 | return "Clean up"
61 | case .done:
62 | return "Done"
63 | }
64 | }
65 | }
66 | struct StepProgress: CustomStringConvertible {
67 | let step: String
68 | let etaString: String
69 | var percentage: Float
70 |
71 | var description: String { "\(step).\(etaString)" }
72 | }
73 |
74 | let process: Process
75 | let steps: [Step]
76 | @Published var currentStep: Step = .initialize
77 | @Published var currentProgress: StepProgress?
78 | var didComplete: Bool {
79 | currentStep == .done && !process.isRunning
80 | }
81 |
82 | init(
83 | outputLocation: URL?,
84 | modelOrigin: ModelOrigin,
85 | huggingfaceIdentifier: String,
86 | diffusersLocation: URL?,
87 | checkpointLocation: URL?,
88 | computeUnits: ComputeUnits,
89 | customWidth: Int?,
90 | customHeight: Int?,
91 | multisize: Bool,
92 | convertUnet: Bool,
93 | chunkUnet: Bool,
94 | controlNetSupport: Bool,
95 | convertTextEncoder: Bool,
96 | embeddingsLocation: URL?,
97 | convertVaeEncoder: Bool,
98 | convertVaeDecoder: Bool,
99 | convertSafetyChecker: Bool,
100 | precisionFull: Bool,
101 | loRAsToMerge: [LoRAInfo] = [],
102 | compression: Compression
103 | ) throws {
104 | guard let outputLocation else {
105 | throw ArgumentError.noOutputLocation
106 | }
107 | var steps: [Step] = [.initialize]
108 | var arguments: [String] = [
109 | "-o", outputLocation.path(percentEncoded: false),
110 | "--bundle-resources-for-guernika",
111 | "--clean-up-mlpackages",
112 | "--compute-unit", "\(computeUnits.asCTComputeUnits)"
113 | ]
114 |
115 | switch modelOrigin {
116 | case .huggingface:
117 | guard !huggingfaceIdentifier.isEmpty else {
118 | throw ArgumentError.noHuggingfaceIdentifier
119 | }
120 | arguments.append("--model-version")
121 | arguments.append(huggingfaceIdentifier)
122 | arguments.append("--resources-dir-name")
123 | arguments.append(huggingfaceIdentifier)
124 | case .diffusers:
125 | guard let diffusersLocation else {
126 | throw ArgumentError.noDiffusersLocation
127 | }
128 | arguments.append("--model-location")
129 | arguments.append(diffusersLocation.path(percentEncoded: false))
130 | arguments.append("--resources-dir-name")
131 | arguments.append(diffusersLocation.lastPathComponent)
132 | arguments.append("--model-version")
133 | arguments.append(diffusersLocation.lastPathComponent)
134 | case .checkpoint:
135 | guard let checkpointLocation else {
136 | throw ArgumentError.noCheckpointLocation
137 | }
138 | arguments.append("--model-checkpoint-location")
139 | arguments.append(checkpointLocation.path(percentEncoded: false))
140 | arguments.append("--resources-dir-name")
141 | arguments.append(checkpointLocation.deletingPathExtension().lastPathComponent)
142 | arguments.append("--model-version")
143 | arguments.append(checkpointLocation.deletingPathExtension().lastPathComponent)
144 | }
145 |
146 | if computeUnits == .cpuAndGPU {
147 | arguments.append("--attention-implementation")
148 | arguments.append("ORIGINAL")
149 | } else {
150 | arguments.append("--attention-implementation")
151 | arguments.append("SPLIT_EINSUM_V2")
152 | }
153 |
154 | if let embeddingsLocation {
155 | steps.append(.loadEmbeddings)
156 | arguments.append("--embeddings-location")
157 | arguments.append(embeddingsLocation.path(percentEncoded: false))
158 | }
159 |
160 | if convertVaeEncoder {
161 | steps.append(.convertVaeEncoder)
162 | arguments.append("--convert-vae-encoder")
163 | }
164 | if convertVaeDecoder {
165 | steps.append(.convertVaeDecoder)
166 | arguments.append("--convert-vae-decoder")
167 | }
168 | if convertUnet {
169 | steps.append(.convertUnet)
170 | arguments.append("--convert-unet")
171 | if chunkUnet {
172 | arguments.append("--chunk-unet")
173 | }
174 | if controlNetSupport {
175 | arguments.append("--controlnet-support")
176 | }
177 | }
178 | if convertTextEncoder {
179 | steps.append(.convertTextEncoder)
180 | arguments.append("--convert-text-encoder")
181 | }
182 | if convertSafetyChecker {
183 | steps.append(.convertSafetyChecker)
184 | arguments.append("--convert-safety-checker")
185 | }
186 |
187 | if !loRAsToMerge.isEmpty {
188 | arguments.append("--loras-to-merge")
189 | for loRA in loRAsToMerge {
190 | arguments.append(loRA.argument)
191 | }
192 | }
193 |
194 | if #available(macOS 14.0, *) {
195 | switch compression {
196 | case .quantizied6bit:
197 | arguments.append("--quantize-nbits")
198 | arguments.append("6")
199 | if convertUnet || convertTextEncoder {
200 | steps.append(.compressOutput)
201 | }
202 | case .quantizied8bit:
203 | arguments.append("--quantize-nbits")
204 | arguments.append("8")
205 | if convertUnet || convertTextEncoder {
206 | steps.append(.compressOutput)
207 | }
208 | case .fullSize:
209 | break
210 | }
211 | }
212 |
213 | if precisionFull {
214 | arguments.append("--precision-full")
215 | }
216 |
217 | if let customWidth {
218 | arguments.append("--output-w")
219 | arguments.append(String(describing: customWidth))
220 | }
221 | if let customHeight {
222 | arguments.append("--output-h")
223 | arguments.append(String(describing: customHeight))
224 | }
225 | if multisize {
226 | arguments.append("--multisize")
227 | }
228 |
229 | let process = Process()
230 | let pipe = Pipe()
231 | process.standardOutput = pipe
232 | process.standardError = pipe
233 | process.standardInput = nil
234 |
235 | process.executableURL = Bundle.main.url(forAuxiliaryExecutable: "GuernikaTools")!
236 | print("Arguments", arguments)
237 | process.arguments = arguments
238 | self.process = process
239 | steps.append(.cleanUp)
240 | self.steps = steps
241 |
242 | pipe.fileHandleForReading.readabilityHandler = { handle in
243 | let data = handle.availableData
244 | if data.count > 0 {
245 | if let newLine = String(data: data, encoding: .utf8) {
246 | self.handleOutput(newLine)
247 | }
248 | }
249 | }
250 | }
251 |
252 | init(
253 | outputLocation: URL?,
254 | controlNetOrigin: ModelOrigin,
255 | huggingfaceIdentifier: String,
256 | diffusersLocation: URL?,
257 | checkpointLocation: URL?,
258 | computeUnits: ComputeUnits,
259 | customWidth: Int?,
260 | customHeight: Int?,
261 | multisize: Bool,
262 | compression: Compression
263 | ) throws {
264 | guard let outputLocation else {
265 | throw ArgumentError.noOutputLocation
266 | }
267 | var steps: [Step] = [.initialize, .convertControlNet]
268 | var arguments: [String] = [
269 | "-o", outputLocation.path(percentEncoded: false),
270 | "--bundle-resources-for-guernika",
271 | "--clean-up-mlpackages",
272 | "--compute-unit", "\(computeUnits.asCTComputeUnits)"
273 | ]
274 |
275 | switch controlNetOrigin {
276 | case .huggingface:
277 | guard !huggingfaceIdentifier.isEmpty else {
278 | throw ArgumentError.noHuggingfaceIdentifier
279 | }
280 | arguments.append("--controlnet-version")
281 | arguments.append(huggingfaceIdentifier)
282 | arguments.append("--resources-dir-name")
283 | arguments.append(huggingfaceIdentifier)
284 | case .diffusers:
285 | guard let diffusersLocation else {
286 | throw ArgumentError.noDiffusersLocation
287 | }
288 | arguments.append("--controlnet-location")
289 | arguments.append(diffusersLocation.path(percentEncoded: false))
290 | arguments.append("--resources-dir-name")
291 | arguments.append(diffusersLocation.lastPathComponent)
292 | arguments.append("--controlnet-version")
293 | arguments.append(diffusersLocation.lastPathComponent)
294 | case .checkpoint:
295 | guard let checkpointLocation else {
296 | throw ArgumentError.noCheckpointLocation
297 | }
298 | arguments.append("--controlnet-checkpoint-location")
299 | arguments.append(checkpointLocation.path(percentEncoded: false))
300 | arguments.append("--resources-dir-name")
301 | arguments.append(checkpointLocation.deletingPathExtension().lastPathComponent)
302 | arguments.append("--controlnet-version")
303 | arguments.append(checkpointLocation.deletingPathExtension().lastPathComponent)
304 | }
305 |
306 | if computeUnits == .cpuAndGPU {
307 | arguments.append("--attention-implementation")
308 | arguments.append("ORIGINAL")
309 | } else {
310 | arguments.append("--attention-implementation")
311 | arguments.append("SPLIT_EINSUM_V2")
312 | }
313 |
314 | if let customWidth {
315 | arguments.append("--output-w")
316 | arguments.append(String(describing: customWidth))
317 | }
318 | if let customHeight {
319 | arguments.append("--output-h")
320 | arguments.append(String(describing: customHeight))
321 | }
322 | if multisize {
323 | arguments.append("--multisize")
324 | }
325 |
326 | if #available(macOS 14.0, *) {
327 | switch compression {
328 | case .quantizied6bit:
329 | arguments.append("--quantize-nbits")
330 | arguments.append("6")
331 | steps.append(.compressOutput)
332 | case .quantizied8bit:
333 | arguments.append("--quantize-nbits")
334 | arguments.append("8")
335 | steps.append(.compressOutput)
336 | case .fullSize:
337 | break
338 | }
339 | }
340 |
341 | let process = Process()
342 | let pipe = Pipe()
343 | process.standardOutput = pipe
344 | process.standardError = pipe
345 | process.standardInput = nil
346 |
347 | process.executableURL = Bundle.main.url(forAuxiliaryExecutable: "GuernikaTools")!
348 | print("Arguments", arguments)
349 | process.arguments = arguments
350 | self.process = process
351 | steps.append(.cleanUp)
352 | self.steps = steps
353 |
354 | pipe.fileHandleForReading.readabilityHandler = { handle in
355 | let data = handle.availableData
356 | if data.count > 0 {
357 | if let newLine = String(data: data, encoding: .utf8) {
358 | self.handleOutput(newLine)
359 | }
360 | }
361 | }
362 | }
363 |
364 | private func handleOutput(_ newLine: String) {
365 | let isProgressStep = newLine.starts(with: "\r")
366 | let newLine = newLine.trimmingCharacters(in: .whitespacesAndNewlines)
367 | if isProgressStep {
368 | if
369 | let match = newLine.firstMatch(#": *?(\d*)%.*\|(.*)"#),
370 | let percentageRange = Range(match.range(at: 1), in: newLine),
371 | let percentage = Int(newLine[percentageRange]),
372 | let etaRange = Range(match.range(at: 2), in: newLine)
373 | {
374 | let etaString = String(newLine[etaRange])
375 | if newLine.starts(with: "Running MIL") || newLine.starts(with: "Running compression pass") {
376 | currentProgress = StepProgress(
377 | step: String(newLine.split(separator: ":")[0]),
378 | etaString: etaString,
379 | percentage: Float(percentage) / 100
380 | )
381 | } else {
382 | currentProgress = nil
383 | }
384 | }
385 | DispatchQueue.main.async {
386 | Logger.shared.append(newLine, level: .success)
387 | }
388 | return
389 | }
390 |
391 | if
392 | let match = newLine.firstMatch(#"INFO:.*Converting ([^\s]+)$"#),
393 | let moduleRange = Range(match.range(at: 1), in: newLine)
394 | {
395 | let module = String(newLine[moduleRange])
396 | currentProgress = nil
397 | switch module {
398 | case "vae_encoder":
399 | currentStep = .convertVaeEncoder
400 | case "vae_decoder":
401 | currentStep = .convertVaeDecoder
402 | case "unet":
403 | currentStep = .convertUnet
404 | case "text_encoder":
405 | currentStep = .convertTextEncoder
406 | case "safety_checker":
407 | currentStep = .convertSafetyChecker
408 | case "controlnet":
409 | currentStep = .convertControlNet
410 | default:
411 | break
412 | }
413 | } else if let _ = newLine.firstMatch(#"INFO:.*Loading embeddings"#) {
414 | currentProgress = nil
415 | currentStep = .loadEmbeddings
416 | } else if let _ = newLine.firstMatch(#"INFO:.*Quantizing weights"#) {
417 | currentProgress = nil
418 | currentStep = .compressOutput
419 | } else if let _ = newLine.firstMatch(#"INFO:.*Bundling resources for Guernika$"#) {
420 | currentProgress = nil
421 | currentStep = .cleanUp
422 | } else if let _ = newLine.firstMatch(#"INFO:.*MLPackages removed$"#) {
423 | currentProgress = nil
424 | currentStep = .done
425 | } else if newLine.hasPrefix("usage: GuernikaTools") || newLine.hasPrefix("GuernikaTools: error: unrecognized arguments") {
426 | print(newLine)
427 | return
428 | } else {
429 | currentProgress = nil
430 | }
431 | DispatchQueue.main.async {
432 | Logger.shared.append(newLine)
433 | }
434 | }
435 |
436 | func start() throws {
437 | guard !process.isRunning else { return }
438 | Logger.shared.append("Starting python converter", level: .info)
439 | try process.run()
440 | }
441 |
442 | func cancel() {
443 | process.cancel()
444 | }
445 | }
446 |
447 | extension String {
448 | func firstMatch(_ pattern: String) -> NSTextCheckingResult? {
449 | guard let regex = try? NSRegularExpression(pattern: pattern) else { return nil }
450 | return regex.firstMatch(in: self, options: [], range: NSRange(location: 0, length: utf16.count))
451 | }
452 | }
453 |
--------------------------------------------------------------------------------
35 |
36 | **Step 4:** Once you've chosen the model you want to convert you can choose what modules to convert and/or if you want to chunk the UNet module (recommended for iOS/iPadOS devices).
37 |
38 | **Step 5:** Once you're happy with your selection click `Convert to Guernika` and wait for the app to complete conversion.
39 | **WARNING:** This command may download several GB worth of PyTorch checkpoints from Hugging Face and may take a long time to complete (15-20 minutes on an M1 machine).
40 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Log/LogView.swift:
--------------------------------------------------------------------------------
1 | //
2 | // LogView.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 30/3/23.
6 | //
7 |
8 | import SwiftUI
9 |
10 | struct LogView: View {
11 | @ObservedObject var logger = Logger.shared
12 | @State var stickToBottom: Bool = true
13 |
14 | var body: some View {
15 | VStack {
16 | if logger.isEmpty {
17 | emptyView
18 | } else {
19 | contentView
20 | }
21 | }.navigationTitle("Log")
22 | .toolbar {
23 | ToolbarItemGroup {
24 | Button {
25 | logger.clear()
26 | } label: {
27 | Image(systemName: "trash")
28 | }.help("Clear log")
29 | .disabled(logger.isEmpty)
30 | Toggle(isOn: $stickToBottom) {
31 | Image(systemName: "dock.arrow.down.rectangle")
32 | }.help("Stick to bottom")
33 | }
34 | }
35 | }
36 |
37 | @ViewBuilder
38 | var emptyView: some View {
39 | Image(systemName: "moon.zzz.fill")
40 | .resizable()
41 | .aspectRatio(contentMode: .fit)
42 | .frame(width: 72)
43 | .opacity(0.3)
44 | .padding(8)
45 | Text("Log is empty")
46 | .font(.largeTitle)
47 | .opacity(0.3)
48 | }
49 |
50 | @ViewBuilder
51 | var contentView: some View {
52 | ScrollViewReader { proxy in
53 | ScrollView {
54 | logger.content
55 | .multilineTextAlignment(.leading)
56 | .font(.body.monospaced())
57 | .textSelection(.enabled)
58 | .frame(maxWidth: .infinity, alignment: .leading)
59 | .padding()
60 |
61 | Divider().opacity(0)
62 | .id("bottom")
63 | }.onChange(of: logger.content) { _ in
64 | if stickToBottom {
65 | proxy.scrollTo("bottom", anchor: .bottom)
66 | }
67 | }.onChange(of: stickToBottom) { newValue in
68 | if newValue {
69 | proxy.scrollTo("bottom", anchor: .bottom)
70 | }
71 | }.onAppear {
72 | if stickToBottom {
73 | proxy.scrollTo("bottom", anchor: .bottom)
74 | }
75 | }
76 | }
77 | }
78 | }
79 |
80 | struct LogView_Previews: PreviewProvider {
81 | static var previews: some View {
82 | LogView()
83 | }
84 | }
85 |
--------------------------------------------------------------------------------
/GuernikaTools/GuernikaTools.spec:
--------------------------------------------------------------------------------
1 | # -*- mode: python ; coding: utf-8 -*-
2 | from PyInstaller.utils.hooks import collect_all
3 |
4 | import sys ; sys.setrecursionlimit(sys.getrecursionlimit() * 5)
5 |
6 | datas = []
7 | binaries = []
8 | hiddenimports = []
9 | tmp_ret = collect_all('regex')
10 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
11 | tmp_ret = collect_all('tqdm')
12 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
13 | tmp_ret = collect_all('requests')
14 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
15 | tmp_ret = collect_all('packaging')
16 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
17 | tmp_ret = collect_all('filelock')
18 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
19 | tmp_ret = collect_all('numpy')
20 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
21 | tmp_ret = collect_all('tokenizers')
22 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
23 | tmp_ret = collect_all('transformers')
24 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
25 | tmp_ret = collect_all('huggingface-hub')
26 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
27 | tmp_ret = collect_all('pyyaml')
28 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
29 | tmp_ret = collect_all('omegaconf')
30 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
31 | tmp_ret = collect_all('pytorch_lightning')
32 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
33 | tmp_ret = collect_all('pytorch-lightning')
34 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
35 | tmp_ret = collect_all('torch')
36 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
37 | tmp_ret = collect_all('safetensors')
38 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
39 | tmp_ret = collect_all('pillow')
40 | datas += tmp_ret[0]; binaries += tmp_ret[1]; hiddenimports += tmp_ret[2]
41 |
42 | block_cipher = None
43 |
44 |
45 | a = Analysis(
46 | ['./guernikatools/torch2coreml.py'],
47 | pathex=[],
48 | binaries=binaries,
49 | datas=datas,
50 | hiddenimports=hiddenimports,
51 | hookspath=[],
52 | hooksconfig={},
53 | runtime_hooks=[],
54 | excludes=[],
55 | win_no_prefer_redirects=False,
56 | win_private_assemblies=False,
57 | cipher=block_cipher,
58 | noarchive=False,
59 | )
60 | pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)
61 |
62 | exe = EXE(
63 | pyz,
64 | a.scripts,
65 | a.binaries,
66 | a.zipfiles,
67 | a.datas,
68 | [],
69 | name='GuernikaTools',
70 | debug=False,
71 | bootloader_ignore_signals=False,
72 | strip=False,
73 | upx=True,
74 | upx_exclude=[],
75 | runtime_tmpdir=None,
76 | console=False,
77 | disable_windowed_traceback=False,
78 | argv_emulation=False,
79 | target_arch=None,
80 | codesign_identity=None,
81 | entitlements_file=None,
82 | )
83 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/models/layer_norm.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | import torch
7 | import torch.nn as nn
8 |
9 |
10 | # Reference: https://github.com/apple/ml-ane-transformers/blob/main/ane_transformers/reference/layer_norm.py
11 | class LayerNormANE(nn.Module):
12 | """ LayerNorm optimized for Apple Neural Engine (ANE) execution
13 |
14 | Note: This layer only supports normalization over the final dim. It expects `num_channels`
15 | as an argument and not `normalized_shape` which is used by `torch.nn.LayerNorm`.
16 | """
17 |
18 | def __init__(self,
19 | num_channels,
20 | clip_mag=None,
21 | eps=1e-5,
22 | elementwise_affine=True):
23 | """
24 | Args:
25 | num_channels: Number of channels (C) where the expected input data format is BC1S. S stands for sequence length.
26 | clip_mag: Optional float value to use for clamping the input range before layer norm is applied.
27 | If specified, helps reduce risk of overflow.
28 | eps: Small value to avoid dividing by zero
29 | elementwise_affine: If true, adds learnable channel-wise shift (bias) and scale (weight) parameters
30 | """
31 | super().__init__()
32 | # Principle 1: Picking the Right Data Format (machinelearning.apple.com/research/apple-neural-engine)
33 | self.expected_rank = len("BC1S")
34 |
35 | self.num_channels = num_channels
36 | self.eps = eps
37 | self.clip_mag = clip_mag
38 | self.elementwise_affine = elementwise_affine
39 |
40 | if self.elementwise_affine:
41 | self.weight = nn.Parameter(torch.Tensor(num_channels))
42 | self.bias = nn.Parameter(torch.Tensor(num_channels))
43 |
44 | self._reset_parameters()
45 |
46 | def _reset_parameters(self):
47 | if self.elementwise_affine:
48 | nn.init.ones_(self.weight)
49 | nn.init.zeros_(self.bias)
50 |
51 | def forward(self, inputs):
52 | input_rank = len(inputs.size())
53 |
54 | # Principle 1: Picking the Right Data Format (machinelearning.apple.com/research/apple-neural-engine)
55 | # Migrate the data format from BSC to BC1S (most conducive to ANE)
56 | if input_rank == 3 and inputs.size(2) == self.num_channels:
57 | inputs = inputs.transpose(1, 2).unsqueeze(2)
58 | input_rank = len(inputs.size())
59 |
60 | assert input_rank == self.expected_rank
61 | assert inputs.size(1) == self.num_channels
62 |
63 | if self.clip_mag is not None:
64 | inputs.clamp_(-self.clip_mag, self.clip_mag)
65 |
66 | channels_mean = inputs.mean(dim=1, keepdim=True)
67 |
68 | zero_mean = inputs - channels_mean
69 |
70 | zero_mean_sq = zero_mean * zero_mean
71 |
72 | denom = (zero_mean_sq.mean(dim=1, keepdim=True) + self.eps).rsqrt()
73 |
74 | out = zero_mean * denom
75 |
76 | if self.elementwise_affine:
77 | out = (out + self.bias.view(1, self.num_channels, 1, 1)) * self.weight.view(1, self.num_channels, 1, 1)
78 |
79 | return out
80 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Navigation/Sidebar.swift:
--------------------------------------------------------------------------------
1 | //
2 | // Sidebar.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 19/3/23.
6 | //
7 |
8 | import Cocoa
9 | import SwiftUI
10 |
11 | enum Panel: Hashable {
12 | case model
13 | case controlNet
14 | case log
15 | }
16 |
17 | struct Sidebar: View {
18 | @Binding var path: NavigationPath
19 | @Binding var selection: Panel
20 | @State var showUpdateButton: Bool = false
21 |
22 | var body: some View {
23 | List(selection: $selection) {
24 | NavigationLink(value: Panel.model) {
25 | Label("Model", systemImage: "shippingbox")
26 | }
27 | NavigationLink(value: Panel.controlNet) {
28 | Label("ControlNet", systemImage: "cube.transparent")
29 | }
30 | NavigationLink(value: Panel.log) {
31 | Label("Log", systemImage: "doc.text.below.ecg")
32 | }
33 | }
34 | .safeAreaInset(edge: .bottom, content: {
35 | VStack(spacing: 12) {
36 | if showUpdateButton {
37 | Button {
38 | NSWorkspace.shared.open(URL(string: "https://huggingface.co/Guernika/CoreMLStableDiffusion/blob/main/GuernikaModelConverter.dmg")!)
39 | } label: {
40 | Text("Update available")
41 | .frame(minWidth: 168)
42 | }.controlSize(.large)
43 | .buttonStyle(.borderedProminent)
44 | }
45 | if !FileManager.default.fileExists(atPath: "/Applications/Guernika.app") {
46 | Button {
47 | NSWorkspace.shared.open(URL(string: "macappstore://apps.apple.com/app/id1660407508")!)
48 | } label: {
49 | Text("Install Guernika")
50 | .frame(minWidth: 168)
51 | }.controlSize(.large)
52 | }
53 | }
54 | .padding(16)
55 | })
56 | .navigationTitle("Guernika Model Converter")
57 | .navigationSplitViewColumnWidth(min: 200, ideal: 200)
58 | .onAppear { checkForUpdate() }
59 | }
60 |
61 | func checkForUpdate() {
62 | Task.detached {
63 | let versionUrl = URL(string: "https://huggingface.co/Guernika/CoreMLStableDiffusion/raw/main/GuernikaModelConverter.version")!
64 | guard let lastVersionString = try? String(contentsOf: versionUrl) else { return }
65 | let lastVersion = Version(stringLiteral: lastVersionString)
66 | let currentVersionString = Bundle.main.object(forInfoDictionaryKey: "CFBundleShortVersionString") as? String ?? ""
67 | let currentVersion = Version(stringLiteral: currentVersionString)
68 | await MainActor.run {
69 | withAnimation {
70 | showUpdateButton = currentVersion < lastVersion
71 | }
72 | }
73 | }
74 | }
75 | }
76 |
77 | struct Sidebar_Previews: PreviewProvider {
78 | struct Preview: View {
79 | @State private var selection: Panel = Panel.model
80 | var body: some View {
81 | Sidebar(path: .constant(NavigationPath()), selection: $selection)
82 | }
83 | }
84 |
85 | static var previews: some View {
86 | NavigationSplitView {
87 | Preview()
88 | } detail: {
89 | Text("Detail!")
90 | }
91 | }
92 | }
93 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Views/IntegerField.swift:
--------------------------------------------------------------------------------
1 | //
2 | // IntegerField.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 23/1/22.
6 | //
7 |
8 | import SwiftUI
9 |
10 | struct LabeledIntegerField: View {
11 | @Binding var value: Int
12 | var step: Int = 1
13 | var minValue: Int?
14 | var maxValue: Int?
15 | @ViewBuilder var label: () -> Content
16 |
17 | init(
18 | _ titleKey: LocalizedStringKey,
19 | value: Binding,
20 | step: Int = 1,
21 | minValue: Int? = nil,
22 | maxValue: Int? = nil
23 | ) where Content == Text {
24 | self.init(value: value, step: step, minValue: minValue, maxValue: maxValue, label: {
25 | Text(titleKey)
26 | })
27 | }
28 |
29 | init(
30 | value: Binding,
31 | step: Int = 1,
32 | minValue: Int? = nil,
33 | maxValue: Int? = nil,
34 | @ViewBuilder label: @escaping () -> Content
35 | ) {
36 | self.label = label
37 | self.step = step
38 | self.minValue = minValue
39 | self.maxValue = maxValue
40 | self._value = value
41 | }
42 |
43 | var body: some View {
44 | LabeledContent(content: {
45 | IntegerField(
46 | value: $value,
47 | step: step,
48 | minValue: minValue,
49 | maxValue: maxValue
50 | )
51 | .frame(maxWidth: 120)
52 | }, label: label)
53 | }
54 | }
55 |
56 | struct IntegerField: View {
57 | @Binding var value: Int
58 | var step: Int = 1
59 | var minValue: Int?
60 | var maxValue: Int?
61 | @State private var text: String
62 | @FocusState private var isFocused: Bool
63 |
64 | init(
65 | value: Binding,
66 | step: Int = 1,
67 | minValue: Int? = nil,
68 | maxValue: Int? = nil
69 | ) {
70 | self.step = step
71 | self.minValue = minValue
72 | self.maxValue = maxValue
73 | self._value = value
74 | let text = String(describing: value.wrappedValue)
75 | self._text = State(wrappedValue: text)
76 | }
77 |
78 | var body: some View {
79 | HStack(spacing: 0) {
80 | TextField("", text: $text, prompt: Text("Value"))
81 | .multilineTextAlignment(.trailing)
82 | .textFieldStyle(.plain)
83 | .padding(.horizontal, 10)
84 | .submitLabel(.done)
85 | .focused($isFocused)
86 | .frame(minWidth: 70)
87 | .labelsHidden()
88 | #if !os(macOS)
89 | .keyboardType(.numberPad)
90 | #endif
91 | Stepper(label: {}, onIncrement: {
92 | if let maxValue {
93 | value = min(value + step, maxValue)
94 | } else {
95 | value += step
96 | }
97 | }, onDecrement: {
98 | if let minValue {
99 | value = max(value - step, minValue)
100 | } else {
101 | value -= step
102 | }
103 | }).labelsHidden()
104 | }
105 | #if os(macOS)
106 | .padding(3)
107 | .background(Color.primary.opacity(0.06))
108 | .clipShape(RoundedRectangle(cornerRadius: 8, style: .continuous))
109 | #else
110 | .padding(2)
111 | .background(Color.primary.opacity(0.05))
112 | .clipShape(RoundedRectangle(cornerRadius: 10, style: .continuous))
113 | #endif
114 | .onSubmit {
115 | updateValue()
116 | isFocused = false
117 | }
118 | .onChange(of: isFocused) { focused in
119 | if !focused {
120 | updateValue()
121 | }
122 | }
123 | .onChange(of: value) { _ in updateText() }
124 | .onChange(of: text) { _ in
125 | if let newValue = Int(text), value != newValue {
126 | value = newValue
127 | }
128 | }
129 | #if !os(macOS)
130 | .toolbar {
131 | if isFocused {
132 | ToolbarItem(placement: .keyboard) {
133 | HStack {
134 | Spacer()
135 | Button("Done") {
136 | isFocused = false
137 | }
138 | }
139 | }
140 | }
141 | }
142 | #endif
143 | }
144 |
145 | private func updateValue() {
146 | if let newValue = Int(text) {
147 | if let maxValue, newValue > maxValue {
148 | value = maxValue
149 | } else if let minValue, newValue < minValue {
150 | value = minValue
151 | } else {
152 | value = newValue
153 | }
154 | }
155 | }
156 |
157 | private func updateText() {
158 | text = String(describing: value)
159 | }
160 | }
161 |
162 | struct ValueField_Previews: PreviewProvider {
163 | static var previews: some View {
164 | LabeledIntegerField("Text", value: .constant(20))
165 | }
166 | }
167 |
168 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_text_encoder.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils
8 |
9 | from collections import OrderedDict, defaultdict
10 | from copy import deepcopy
11 | import gc
12 |
13 | import logging
14 |
15 | logging.basicConfig()
16 | logger = logging.getLogger(__name__)
17 | logger.setLevel(logging.INFO)
18 |
19 | import numpy as np
20 | import os
21 |
22 | import torch
23 | import torch.nn as nn
24 | import torch.nn.functional as F
25 |
26 | torch.set_grad_enabled(False)
27 |
28 |
29 | def main(tokenizer, text_encoder, args, model_name="text_encoder"):
30 | """ Converts the text encoder component of Stable Diffusion
31 | """
32 | out_path = utils.get_out_path(args, model_name)
33 | if os.path.exists(out_path):
34 | logger.info(
35 | f"`text_encoder` already exists at {out_path}, skipping conversion."
36 | )
37 | return
38 |
39 | # Create sample inputs for tracing, conversion and correctness verification
40 | text_encoder_sequence_length = tokenizer.model_max_length
41 | text_encoder_hidden_size = text_encoder.config.hidden_size
42 |
43 | sample_text_encoder_inputs = {
44 | "input_ids":
45 | torch.randint(
46 | text_encoder.config.vocab_size,
47 | (1, text_encoder_sequence_length),
48 | # https://github.com/apple/coremltools/issues/1423
49 | dtype=torch.float32,
50 | )
51 | }
52 | sample_text_encoder_inputs_spec = {
53 | k: (v.shape, v.dtype)
54 | for k, v in sample_text_encoder_inputs.items()
55 | }
56 | logger.info(f"Sample inputs spec: {sample_text_encoder_inputs_spec}")
57 |
58 | class TextEncoder(nn.Module):
59 |
60 | def __init__(self):
61 | super().__init__()
62 | self.text_encoder = text_encoder
63 |
64 | def forward(self, input_ids):
65 | return text_encoder(input_ids, return_dict=False)
66 |
67 | class TextEncoderXL(nn.Module):
68 |
69 | def __init__(self):
70 | super().__init__()
71 | self.text_encoder = text_encoder
72 |
73 | def forward(self, input_ids):
74 | output = text_encoder(input_ids, output_hidden_states=True)
75 | return (output.hidden_states[-2], output[0])
76 |
77 | reference_text_encoder = TextEncoderXL().eval() if args.model_is_sdxl else TextEncoder().eval()
78 |
79 | logger.info("JIT tracing {model_name}..")
80 | reference_text_encoder = torch.jit.trace(
81 | reference_text_encoder,
82 | (sample_text_encoder_inputs["input_ids"].to(torch.int32), ),
83 | )
84 | logger.info("Done.")
85 |
86 | sample_coreml_inputs = utils.get_coreml_inputs(sample_text_encoder_inputs)
87 | coreml_text_encoder, out_path = utils.convert_to_coreml(
88 | model_name, reference_text_encoder, sample_coreml_inputs,
89 | ["last_hidden_state", "pooled_outputs"], args.precision_full, args
90 | )
91 |
92 | # Set model metadata
93 | coreml_text_encoder.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
94 | coreml_text_encoder.license = "OpenRAIL (https://huggingface.co/spaces/CompVis/stable-diffusion-license)"
95 | coreml_text_encoder.version = args.model_version
96 | coreml_text_encoder.short_description = \
97 | "Stable Diffusion generates images conditioned on text and/or other images as input through the diffusion process. " \
98 | "Please refer to https://arxiv.org/abs/2112.10752 for details."
99 |
100 | # Set the input descriptions
101 | coreml_text_encoder.input_description["input_ids"] = "The token ids that represent the input text"
102 |
103 | # Set the output descriptions
104 | coreml_text_encoder.output_description["last_hidden_state"] = "The token embeddings as encoded by the Transformer model"
105 | coreml_text_encoder.output_description["pooled_outputs"] = "The version of the `last_hidden_state` output after pooling"
106 |
107 | # Set package version metadata
108 | coreml_text_encoder.user_defined_metadata["identifier"] = args.model_version
109 | coreml_text_encoder.user_defined_metadata["converter_version"] = __version__
110 | coreml_text_encoder.user_defined_metadata["attention_implementation"] = args.attention_implementation
111 | coreml_text_encoder.user_defined_metadata["compute_unit"] = args.compute_unit
112 | coreml_text_encoder.user_defined_metadata["hidden_size"] = str(text_encoder.config.hidden_size)
113 |
114 | coreml_text_encoder.save(out_path)
115 |
116 | logger.info(f"Saved {model_name} into {out_path}")
117 |
118 | # Parity check PyTorch vs CoreML
119 | if args.check_output_correctness:
120 | baseline_out = text_encoder(
121 | sample_text_encoder_inputs["input_ids"].to(torch.int32),
122 | return_dict=False,
123 | )[1].numpy()
124 |
125 | coreml_out = list(coreml_text_encoder.predict({
126 | k: v.numpy() for k, v in sample_text_encoder_inputs.items()
127 | }).values())[0]
128 | utils.report_correctness(baseline_out, coreml_out, "{model_name} baseline PyTorch to reference CoreML")
129 |
130 | del reference_text_encoder, coreml_text_encoder, text_encoder
131 | gc.collect()
132 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Views/DecimalField.swift:
--------------------------------------------------------------------------------
1 | //
2 | // DecimalField.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 5/2/23.
6 | //
7 |
8 | import SwiftUI
9 |
10 | extension Formatter {
11 | static let decimal: NumberFormatter = {
12 | let formatter = NumberFormatter()
13 | formatter.numberStyle = .decimal
14 | formatter.usesGroupingSeparator = false
15 | formatter.maximumFractionDigits = 2
16 | return formatter
17 | }()
18 | }
19 |
20 | struct LabeledDecimalField: View {
21 | @Binding var value: Double
22 | var step: Double = 1
23 | var minValue: Double?
24 | var maxValue: Double?
25 | @ViewBuilder var label: () -> Content
26 |
27 | init(
28 | _ titleKey: LocalizedStringKey,
29 | value: Binding,
30 | step: Double = 1,
31 | minValue: Double? = nil,
32 | maxValue: Double? = nil
33 | ) where Content == Text {
34 | self.init(value: value, step: step, minValue: minValue, maxValue: maxValue, label: {
35 | Text(titleKey)
36 | })
37 | }
38 |
39 | init(
40 | value: Binding,
41 | step: Double = 1,
42 | minValue: Double? = nil,
43 | maxValue: Double? = nil,
44 | @ViewBuilder label: @escaping () -> Content
45 | ) {
46 | self.label = label
47 | self.step = step
48 | self.minValue = minValue
49 | self.maxValue = maxValue
50 | self._value = value
51 | }
52 |
53 | var body: some View {
54 | LabeledContent(content: {
55 | DecimalField(
56 | value: $value,
57 | step: step,
58 | minValue: minValue,
59 | maxValue: maxValue
60 | )
61 | }, label: label)
62 | }
63 | }
64 |
65 | struct DecimalField: View {
66 | @Binding var value: Double
67 | var step: Double = 1
68 | var minValue: Double?
69 | var maxValue: Double?
70 | @State private var text: String
71 | @FocusState private var isFocused: Bool
72 |
73 | init(
74 | value: Binding,
75 | step: Double = 1,
76 | minValue: Double? = nil,
77 | maxValue: Double? = nil
78 | ) {
79 | self.step = step
80 | self.minValue = minValue
81 | self.maxValue = maxValue
82 | self._value = value
83 | let text = Formatter.decimal.string(from: value.wrappedValue as NSNumber) ?? ""
84 | self._text = State(wrappedValue: text)
85 | }
86 |
87 | var body: some View {
88 | HStack(spacing: 0) {
89 | TextField("", text: $text, prompt: Text("Value"))
90 | .multilineTextAlignment(.trailing)
91 | .textFieldStyle(.plain)
92 | .padding(.horizontal, 10)
93 | .submitLabel(.done)
94 | .focused($isFocused)
95 | .frame(minWidth: 70)
96 | .labelsHidden()
97 | #if !os(macOS)
98 | .keyboardType(.decimalPad)
99 | #endif
100 | Stepper(label: {}, onIncrement: {
101 | if let maxValue {
102 | value = min(value + step, maxValue)
103 | } else {
104 | value += step
105 | }
106 | }, onDecrement: {
107 | if let minValue {
108 | value = max(value - step, minValue)
109 | } else {
110 | value -= step
111 | }
112 | }).labelsHidden()
113 | }
114 | #if os(macOS)
115 | .padding(3)
116 | .background(Color.primary.opacity(0.06))
117 | .clipShape(RoundedRectangle(cornerRadius: 8, style: .continuous))
118 | #else
119 | .padding(2)
120 | .background(Color.primary.opacity(0.05))
121 | .clipShape(RoundedRectangle(cornerRadius: 10, style: .continuous))
122 | #endif
123 | .onSubmit {
124 | updateValue()
125 | isFocused = false
126 | }
127 | .onChange(of: isFocused) { focused in
128 | if !focused {
129 | updateValue()
130 | }
131 | }
132 | .onChange(of: value) { _ in updateText() }
133 | .onChange(of: text) { _ in
134 | if let newValue = Formatter.decimal.number(from: text)?.doubleValue, value != newValue {
135 | value = newValue
136 | }
137 | }
138 | #if !os(macOS)
139 | .toolbar {
140 | if isFocused {
141 | ToolbarItem(placement: .keyboard) {
142 | HStack {
143 | Spacer()
144 | Button("Done") {
145 | isFocused = false
146 | }
147 | }
148 | }
149 | }
150 | }
151 | #endif
152 | }
153 |
154 | private func updateValue() {
155 | if let newValue = Formatter.decimal.number(from: text)?.doubleValue {
156 | if let maxValue, newValue > maxValue {
157 | value = maxValue
158 | } else if let minValue, newValue < minValue {
159 | value = minValue
160 | } else {
161 | value = newValue
162 | }
163 | }
164 | }
165 |
166 | private func updateText() {
167 | text = Formatter.decimal.string(from: value as NSNumber) ?? ""
168 | }
169 | }
170 |
171 |
172 | struct DecimalField_Previews: PreviewProvider {
173 | static var previews: some View {
174 | DecimalField(value: .constant(20))
175 | .padding()
176 | }
177 | }
178 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/ConvertControlNet/ConvertControlNetViewModel.swift:
--------------------------------------------------------------------------------
1 | //
2 | // ConvertControlNetViewModel.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 30/3/23.
6 | //
7 |
8 | import SwiftUI
9 | import Combine
10 |
11 | class ConvertControlNetViewModel: ObservableObject {
12 | @Published var showSuccess: Bool = false
13 | var showError: Bool {
14 | get { error != nil }
15 | set {
16 | if !newValue {
17 | error = nil
18 | isCoreMLError = false
19 | }
20 | }
21 | }
22 | var isCoreMLError: Bool = false
23 | @Published var error: String?
24 |
25 | var isReady: Bool {
26 | switch controlNetOrigin {
27 | case .huggingface: return !huggingfaceIdentifier.isEmpty
28 | case .diffusers: return diffusersLocation != nil
29 | case .checkpoint: return checkpointLocation != nil
30 | }
31 | }
32 | @Published var process: ConverterProcess?
33 | var isRunning: Bool { process != nil }
34 |
35 | @Published var showOutputPicker: Bool = false
36 | @AppStorage("output_location") var outputLocation: URL?
37 |
38 | var controlNetOrigin: ModelOrigin {
39 | get { ModelOrigin(rawValue: controlNetOriginString) ?? .huggingface }
40 | set { controlNetOriginString = newValue.rawValue }
41 | }
42 | @AppStorage("controlnet_origin") var controlNetOriginString: String = ModelOrigin.huggingface.rawValue
43 | @AppStorage("controlnet_huggingface_identifier") var huggingfaceIdentifier: String = ""
44 | @AppStorage("controlnet_diffusers_location") var diffusersLocation: URL?
45 | @AppStorage("controlnet_checkpoint_location") var checkpointLocation: URL?
46 | var selectedControlNet: String? {
47 | switch controlNetOrigin {
48 | case .huggingface: return nil
49 | case .diffusers: return diffusersLocation?.lastPathComponent
50 | case .checkpoint: return checkpointLocation?.lastPathComponent
51 | }
52 | }
53 |
54 | var computeUnits: ComputeUnits {
55 | get { ComputeUnits(rawValue: computeUnitsString) ?? .cpuAndNeuralEngine }
56 | set { computeUnitsString = newValue.rawValue }
57 | }
58 | @AppStorage("compute_units") var computeUnitsString: String = ComputeUnits.cpuAndNeuralEngine.rawValue
59 |
60 | var compression: Compression {
61 | get { Compression(rawValue: compressionString) ?? .fullSize }
62 | set { compressionString = newValue.rawValue }
63 | }
64 | @AppStorage("controlnet_compression") var compressionString: String = Compression.fullSize.rawValue
65 |
66 | @AppStorage("custom_size") var customSize: Bool = false
67 | @AppStorage("custom_size_width") var customWidth: Int = 512
68 | @AppStorage("custom_size_height") var customHeight: Int = 512
69 | @AppStorage("controlnet_multisize") var multisize: Bool = false
70 |
71 | private var cancellables: Set = []
72 |
73 | func start() {
74 | guard checkCoreMLCompiler() else {
75 | isCoreMLError = true
76 | error = "CoreMLCompiler not available.\nMake sure you have Xcode installed and you run \"sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer/\" on a Terminal."
77 | return
78 | }
79 | do {
80 | let process = try ConverterProcess(
81 | outputLocation: outputLocation,
82 | controlNetOrigin: controlNetOrigin,
83 | huggingfaceIdentifier: huggingfaceIdentifier,
84 | diffusersLocation: diffusersLocation,
85 | checkpointLocation: checkpointLocation,
86 | computeUnits: computeUnits,
87 | customWidth: customSize && !multisize && computeUnits == .cpuAndGPU ? customWidth : nil,
88 | customHeight: customSize && !multisize && computeUnits == .cpuAndGPU ? customHeight : nil,
89 | multisize: multisize && computeUnits == .cpuAndGPU,
90 | compression: compression
91 | )
92 | process.objectWillChange
93 | .receive(on: DispatchQueue.main)
94 | .sink { _ in
95 | self.objectWillChange.send()
96 | }.store(in: &cancellables)
97 | NotificationCenter.default.publisher(for: Process.didTerminateNotification, object: process.process)
98 | .receive(on: DispatchQueue.main)
99 | .sink { _ in
100 | withAnimation {
101 | if process.didComplete {
102 | self.showSuccess = true
103 | }
104 | self.cancel()
105 | }
106 | }.store(in: &cancellables)
107 | try process.start()
108 | withAnimation {
109 | self.process = process
110 | }
111 | } catch ConverterProcess.ArgumentError.noOutputLocation {
112 | showOutputPicker = true
113 | } catch ConverterProcess.ArgumentError.noHuggingfaceIdentifier {
114 | self.error = "Enter a valid identifier"
115 | } catch ConverterProcess.ArgumentError.noDiffusersLocation {
116 | self.error = "Enter a valid location"
117 | } catch ConverterProcess.ArgumentError.noCheckpointLocation {
118 | self.error = "Enter a valid location"
119 | } catch {
120 | print(error.localizedDescription)
121 | self.error = error.localizedDescription
122 | withAnimation {
123 | cancel()
124 | }
125 | }
126 | }
127 |
128 | func cancel() {
129 | withAnimation {
130 | process?.cancel()
131 | process = nil
132 | }
133 | }
134 |
135 | func checkCoreMLCompiler() -> Bool {
136 | let process = Process()
137 | process.executableURL = URL(string: "file:///usr/bin/xcrun")
138 | process.arguments = ["coremlcompiler", "version"]
139 | do {
140 | try process.run()
141 | } catch {
142 | Logger.shared.append("coremlcompiler not found")
143 | return false
144 | }
145 | return true
146 | }
147 | }
148 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_t2i_adapter.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils
8 | from guernikatools.models import attention
9 |
10 | from diffusers import T2IAdapter
11 |
12 | from collections import OrderedDict, defaultdict
13 | from copy import deepcopy
14 | import coremltools as ct
15 | import gc
16 |
17 | import logging
18 |
19 | logging.basicConfig()
20 | logger = logging.getLogger(__name__)
21 | logger.setLevel(logging.INFO)
22 |
23 | import numpy as np
24 | import os
25 |
26 | import torch
27 | import torch.nn as nn
28 | import torch.nn.functional as F
29 |
30 | torch.set_grad_enabled(False)
31 |
32 |
33 | def main(base_adapter, args):
34 | """ Converts a T2IAdapter
35 | """
36 | out_path = utils.get_out_path(args, "t2i_adapter")
37 | if os.path.exists(out_path):
38 | logger.info(f"`t2i_adapter` already exists at {out_path}, skipping conversion.")
39 | return
40 |
41 | # Register the selected attention implementation globally
42 | attention.ATTENTION_IMPLEMENTATION_IN_EFFECT = attention.AttentionImplementations[args.attention_implementation]
43 | logger.info(f"Attention implementation in effect: {attention.ATTENTION_IMPLEMENTATION_IN_EFFECT}")
44 |
45 | # Prepare sample input shapes and values
46 | batch_size = 2 # for classifier-free guidance
47 | adapter_type = base_adapter.config.adapter_type
48 | adapter_in_channels = base_adapter.config.in_channels
49 |
50 | input_shape = (
51 | 1, # B
52 | adapter_in_channels, # C
53 | args.output_h, # H
54 | args.output_w, # W
55 | )
56 |
57 | sample_adapter_inputs = {
58 | "input": torch.rand(*input_shape, dtype=torch.float16)
59 | }
60 | sample_adapter_inputs_spec = {
61 | k: (v.shape, v.dtype)
62 | for k, v in sample_adapter_inputs.items()
63 | }
64 | logger.info(f"Sample inputs spec: {sample_adapter_inputs_spec}")
65 |
66 | # Initialize reference adapter
67 | reference_adapter = T2IAdapter(**base_adapter.config).eval()
68 | load_state_dict_summary = reference_adapter.load_state_dict(base_adapter.state_dict())
69 |
70 | # Prepare inputs
71 | baseline_sample_adapter_inputs = deepcopy(sample_adapter_inputs)
72 |
73 | # JIT trace
74 | logger.info("JIT tracing..")
75 | reference_adapter = torch.jit.trace(reference_adapter, (sample_adapter_inputs["input"].to(torch.float32), ))
76 | logger.info("Done.")
77 |
78 | if args.check_output_correctness:
79 | baseline_out = base_adapter(**baseline_sample_adapter_inputs, return_dict=False)[0].numpy()
80 | reference_out = reference_adapter(**sample_adapter_inputs)[0].numpy()
81 | utils.report_correctness(baseline_out, reference_out, "control baseline to reference PyTorch")
82 |
83 | del base_adapter
84 | gc.collect()
85 |
86 | coreml_sample_adapter_inputs = {
87 | k: v.numpy().astype(np.float16)
88 | for k, v in sample_adapter_inputs.items()
89 | }
90 |
91 | if args.multisize:
92 | input_size = args.output_h
93 | input_shape = ct.Shape(shape=(
94 | 1,
95 | adapter_in_channels,
96 | ct.RangeDim(int(input_size * 0.5), upper_bound=int(input_size * 2), default=input_size),
97 | ct.RangeDim(int(input_size * 0.5), upper_bound=int(input_size * 2), default=input_size)
98 | ))
99 |
100 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_adapter_inputs, {"input": input_shape})
101 | else:
102 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_adapter_inputs)
103 | output_names = [
104 | "adapter_res_samples_00", "adapter_res_samples_01",
105 | "adapter_res_samples_02", "adapter_res_samples_03"
106 | ]
107 | coreml_adapter, out_path = utils.convert_to_coreml(
108 | "t2i_adapter",
109 | reference_adapter,
110 | sample_coreml_inputs,
111 | output_names,
112 | args.precision_full,
113 | args
114 | )
115 | del reference_adapter
116 | gc.collect()
117 |
118 | # Set model metadata
119 | coreml_adapter.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
120 | coreml_adapter.license = "T2IAdapter (https://github.com/TencentARC/T2I-Adapter)"
121 | coreml_adapter.version = args.t2i_adapter_version
122 | coreml_adapter.short_description = \
123 | "T2IAdapter is a neural network structure to control diffusion models by adding extra conditions. " \
124 | "Please refer to https://github.com/TencentARC/T2I-Adapter for details."
125 |
126 | # Set the input descriptions
127 | coreml_adapter.input_description["input"] = "Image used to condition adapter output"
128 |
129 | # Set the output descriptions
130 | coreml_adapter.output_description["adapter_res_samples_00"] = "Residual sample from T2IAdapter"
131 | coreml_adapter.output_description["adapter_res_samples_01"] = "Residual sample from T2IAdapter"
132 | coreml_adapter.output_description["adapter_res_samples_02"] = "Residual sample from T2IAdapter"
133 | coreml_adapter.output_description["adapter_res_samples_03"] = "Residual sample from T2IAdapter"
134 |
135 | # Set package version metadata
136 | coreml_adapter.user_defined_metadata["identifier"] = args.t2i_adapter_version
137 | coreml_adapter.user_defined_metadata["converter_version"] = __version__
138 | coreml_adapter.user_defined_metadata["attention_implementation"] = args.attention_implementation
139 | coreml_adapter.user_defined_metadata["compute_unit"] = args.compute_unit
140 | coreml_adapter.user_defined_metadata["adapter_type"] = adapter_type
141 | adapter_method = conditioning_method_from(args.t2i_adapter_version)
142 | if adapter_method:
143 | coreml_adapter.user_defined_metadata["method"] = adapter_method
144 |
145 | coreml_adapter.save(out_path)
146 | logger.info(f"Saved adapter into {out_path}")
147 |
148 | # Parity check PyTorch vs CoreML
149 | if args.check_output_correctness:
150 | coreml_out = list(coreml_adapter.predict(coreml_sample_adapter_inputs).values())[0]
151 | utils.report_correctness(baseline_out, coreml_out, "control baseline PyTorch to reference CoreML")
152 |
153 | del coreml_adapter
154 | gc.collect()
155 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/ConvertModel/ConvertModelViewModel.swift:
--------------------------------------------------------------------------------
1 | //
2 | // ConvertModelViewModel.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 30/3/23.
6 | //
7 |
8 | import SwiftUI
9 | import Combine
10 |
11 | class ConvertModelViewModel: ObservableObject {
12 | @Published var showSuccess: Bool = false
13 | var showError: Bool {
14 | get { error != nil }
15 | set {
16 | if !newValue {
17 | error = nil
18 | isCoreMLError = false
19 | }
20 | }
21 | }
22 | var isCoreMLError: Bool = false
23 | @Published var error: String?
24 |
25 | var isReady: Bool {
26 | guard convertUnet || convertTextEncoder || convertVaeEncoder || convertVaeDecoder || convertSafetyChecker else {
27 | return false
28 | }
29 | switch modelOrigin {
30 | case .huggingface: return !huggingfaceIdentifier.isEmpty
31 | case .diffusers: return diffusersLocation != nil
32 | case .checkpoint: return checkpointLocation != nil
33 | }
34 | }
35 | @Published var process: ConverterProcess?
36 | var isRunning: Bool { process != nil }
37 |
38 | @Published var showOutputPicker: Bool = false
39 | @AppStorage("output_location") var outputLocation: URL?
40 | var modelOrigin: ModelOrigin {
41 | get { ModelOrigin(rawValue: modelOriginString) ?? .huggingface }
42 | set { modelOriginString = newValue.rawValue }
43 | }
44 | @AppStorage("model_origin") var modelOriginString: String = ModelOrigin.huggingface.rawValue
45 | @AppStorage("huggingface_identifier") var huggingfaceIdentifier: String = ""
46 | @AppStorage("diffusers_location") var diffusersLocation: URL?
47 | @AppStorage("checkpoint_location") var checkpointLocation: URL?
48 | var selectedModel: String? {
49 | switch modelOrigin {
50 | case .huggingface: return nil
51 | case .diffusers: return diffusersLocation?.lastPathComponent
52 | case .checkpoint: return checkpointLocation?.lastPathComponent
53 | }
54 | }
55 |
56 | var computeUnits: ComputeUnits {
57 | get { ComputeUnits(rawValue: computeUnitsString) ?? .cpuAndNeuralEngine }
58 | set { computeUnitsString = newValue.rawValue }
59 | }
60 | @AppStorage("compute_units") var computeUnitsString: String = ComputeUnits.cpuAndNeuralEngine.rawValue
61 |
62 | var compression: Compression {
63 | get { Compression(rawValue: compressionString) ?? .fullSize }
64 | set { compressionString = newValue.rawValue }
65 | }
66 | @AppStorage("compression") var compressionString: String = Compression.fullSize.rawValue
67 |
68 | @AppStorage("custom_size") var customSize: Bool = false
69 | @AppStorage("custom_size_width") var customWidth: Int = 512
70 | @AppStorage("custom_size_height") var customHeight: Int = 512
71 | @AppStorage("multisize") var multisize: Bool = false
72 |
73 | @AppStorage("convert_unet") var convertUnet: Bool = true
74 | @AppStorage("chunk_unet") var chunkUnet: Bool = false
75 | @AppStorage("controlnet_support") var controlNetSupport: Bool = true
76 | @AppStorage("convert_text_encoder") var convertTextEncoder: Bool = true
77 | @AppStorage("load_embeddings") var loadEmbeddings: Bool = false
78 | @AppStorage("embeddings_location") var embeddingsLocation: URL?
79 | @AppStorage("convert_vae_encoder") var convertVaeEncoder: Bool = true
80 | @AppStorage("convert_vae_decoder") var convertVaeDecoder: Bool = true
81 | @AppStorage("convert_safety_checker") var convertSafetyChecker: Bool = false
82 | @AppStorage("precision_full") var precisionFull: Bool = false
83 | @Published var loRAsToMerge: [LoRAInfo] = []
84 |
85 | private var cancellables: Set = []
86 |
87 | func start() {
88 | guard checkCoreMLCompiler() else {
89 | isCoreMLError = true
90 | error = "CoreMLCompiler not available.\nMake sure you have Xcode installed and you run \"sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer/\" on a Terminal."
91 | return
92 | }
93 | do {
94 | let process = try ConverterProcess(
95 | outputLocation: outputLocation,
96 | modelOrigin: modelOrigin,
97 | huggingfaceIdentifier: huggingfaceIdentifier,
98 | diffusersLocation: diffusersLocation,
99 | checkpointLocation: checkpointLocation,
100 | computeUnits: computeUnits,
101 | customWidth: customSize && !multisize && computeUnits == .cpuAndGPU ? customWidth : nil,
102 | customHeight: customSize && !multisize && computeUnits == .cpuAndGPU ? customHeight : nil,
103 | multisize: multisize && computeUnits == .cpuAndGPU,
104 | convertUnet: convertUnet,
105 | chunkUnet: chunkUnet,
106 | controlNetSupport: controlNetSupport && !multisize, // TODO: Currently not possible to have both
107 | convertTextEncoder: convertTextEncoder,
108 | embeddingsLocation: loadEmbeddings ? embeddingsLocation : nil,
109 | convertVaeEncoder: convertVaeEncoder,
110 | convertVaeDecoder: convertVaeDecoder,
111 | convertSafetyChecker: convertSafetyChecker,
112 | precisionFull: precisionFull,
113 | loRAsToMerge: loRAsToMerge,
114 | compression: compression
115 | )
116 | process.objectWillChange
117 | .receive(on: DispatchQueue.main)
118 | .sink { _ in
119 | self.objectWillChange.send()
120 | }.store(in: &cancellables)
121 | NotificationCenter.default.publisher(for: Process.didTerminateNotification, object: process.process)
122 | .receive(on: DispatchQueue.main)
123 | .sink { _ in
124 | if process.didComplete {
125 | self.showSuccess = true
126 | }
127 | self.cancel()
128 | }.store(in: &cancellables)
129 | try process.start()
130 | withAnimation {
131 | self.process = process
132 | }
133 | } catch ConverterProcess.ArgumentError.noOutputLocation {
134 | showOutputPicker = true
135 | } catch ConverterProcess.ArgumentError.noHuggingfaceIdentifier {
136 | self.error = "Enter a valid identifier"
137 | } catch ConverterProcess.ArgumentError.noDiffusersLocation {
138 | self.error = "Enter a valid location"
139 | } catch ConverterProcess.ArgumentError.noCheckpointLocation {
140 | self.error = "Enter a valid location"
141 | } catch {
142 | print(error.localizedDescription)
143 | self.error = error.localizedDescription
144 | withAnimation {
145 | cancel()
146 | }
147 | }
148 | }
149 |
150 | func cancel() {
151 | withAnimation {
152 | process?.cancel()
153 | process = nil
154 | }
155 | }
156 |
157 | func selectAll() {
158 | convertUnet = true
159 | convertTextEncoder = true
160 | convertVaeEncoder = true
161 | convertVaeDecoder = true
162 | convertSafetyChecker = true
163 | }
164 |
165 | func selectNone() {
166 | convertUnet = false
167 | convertTextEncoder = false
168 | convertVaeEncoder = false
169 | convertVaeDecoder = false
170 | convertSafetyChecker = false
171 | }
172 |
173 | func checkCoreMLCompiler() -> Bool {
174 | let process = Process()
175 | process.executableURL = URL(string: "file:///usr/bin/xcrun")
176 | process.arguments = ["coremlcompiler", "version"]
177 | do {
178 | try process.run()
179 | } catch {
180 | Logger.shared.append("coremlcompiler not found")
181 | return false
182 | }
183 | return true
184 | }
185 | }
186 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/models/attention.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 | logger = logging.getLogger(__name__)
4 | logger.setLevel(logging.INFO)
5 |
6 | import torch
7 | import torch.nn as nn
8 |
9 | from enum import Enum
10 |
11 |
12 | # Ensure minimum macOS version requirement is met for this particular model
13 | from coremltools.models.utils import _macos_version
14 | if not _macos_version() >= (13, 1):
15 | logger.warning(
16 | "!!! macOS 13.1 and newer or iOS/iPadOS 16.2 and newer is required for best performance !!!"
17 | )
18 |
19 |
20 | class AttentionImplementations(Enum):
21 | ORIGINAL = "ORIGINAL"
22 | SPLIT_EINSUM = "SPLIT_EINSUM"
23 | SPLIT_EINSUM_V2 = "SPLIT_EINSUM_V2"
24 |
25 |
26 | ATTENTION_IMPLEMENTATION_IN_EFFECT = AttentionImplementations.SPLIT_EINSUM_V2
27 |
28 |
29 | WARN_MSG = \
30 | "This `nn.Module` is intended for Apple Silicon deployment only. " \
31 | "PyTorch-specific optimizations and training is disabled"
32 |
33 | class Attention(nn.Module):
34 | """ Apple Silicon friendly version of `diffusers.models.attention.Attention`
35 | """
36 | def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.0, bias=False):
37 | super().__init__()
38 | inner_dim = dim_head * heads
39 | context_dim = context_dim if context_dim is not None else query_dim
40 |
41 | self.scale = dim_head**-0.5
42 | self.heads = heads
43 | self.dim_head = dim_head
44 |
45 | self.to_q = nn.Conv2d(query_dim, inner_dim, kernel_size=1, bias=bias)
46 | self.to_k = nn.Conv2d(context_dim, inner_dim, kernel_size=1, bias=bias)
47 | self.to_v = nn.Conv2d(context_dim, inner_dim, kernel_size=1, bias=bias)
48 | if dropout > 0:
49 | self.to_out = nn.Sequential(
50 | nn.Conv2d(inner_dim, query_dim, kernel_size=1, bias=True), nn.Dropout(dropout)
51 | )
52 | else:
53 | self.to_out = nn.Sequential(
54 | nn.Conv2d(inner_dim, query_dim, kernel_size=1, bias=True)
55 | )
56 |
57 |
58 | def forward(self, hidden_states, encoder_hidden_states=None, mask=None):
59 | if self.training:
60 | raise NotImplementedError(WARN_MSG)
61 |
62 | batch_size, dim, _, sequence_length = hidden_states.shape
63 |
64 | q = self.to_q(hidden_states)
65 | encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
66 | k = self.to_k(encoder_hidden_states)
67 | v = self.to_v(encoder_hidden_states)
68 |
69 | # Validate mask
70 | if mask is not None:
71 | expected_mask_shape = [batch_size, sequence_length, 1, 1]
72 | if mask.dtype == torch.bool:
73 | mask = mask.logical_not().float() * -1e4
74 | elif mask.dtype == torch.int64:
75 | mask = (1 - mask).float() * -1e4
76 | elif mask.dtype != torch.float32:
77 | raise TypeError(f"Unexpected dtype for mask: {mask.dtype}")
78 |
79 | if len(mask.size()) == 2:
80 | mask = mask.unsqueeze(2).unsqueeze(2)
81 |
82 | if list(mask.size()) != expected_mask_shape:
83 | raise RuntimeError(
84 | f"Invalid shape for `mask` (Expected {expected_mask_shape}, got {list(mask.size())}"
85 | )
86 |
87 | if ATTENTION_IMPLEMENTATION_IN_EFFECT == AttentionImplementations.ORIGINAL:
88 | attn = original(q, k, v, mask, self.heads, self.dim_head)
89 | elif ATTENTION_IMPLEMENTATION_IN_EFFECT == AttentionImplementations.SPLIT_EINSUM:
90 | attn = split_einsum(q, k, v, mask, self.heads, self.dim_head)
91 | elif ATTENTION_IMPLEMENTATION_IN_EFFECT == AttentionImplementations.SPLIT_EINSUM_V2:
92 | attn = split_einsum_v2(q, k, v, mask, self.heads, self.dim_head)
93 | else:
94 | raise ValueError(ATTENTION_IMPLEMENTATION_IN_EFFECT)
95 |
96 | return self.to_out(attn)
97 |
98 | def split_einsum(q, k, v, mask, heads, dim_head):
99 | """ Attention Implementation backing AttentionImplementations.SPLIT_EINSUM
100 |
101 | - Implements https://machinelearning.apple.com/research/neural-engine-transformers
102 | - Recommended for ANE
103 | - Marginally slower on GPU
104 | """
105 | mh_q = [
106 | q[:, head_idx * dim_head:(head_idx + 1) *
107 | dim_head, :, :] for head_idx in range(heads)
108 | ] # (bs, dim_head, 1, max_seq_length) * heads
109 |
110 | k = k.transpose(1, 3)
111 | mh_k = [
112 | k[:, :, :,
113 | head_idx * dim_head:(head_idx + 1) * dim_head]
114 | for head_idx in range(heads)
115 | ] # (bs, max_seq_length, 1, dim_head) * heads
116 |
117 | mh_v = [
118 | v[:, head_idx * dim_head:(head_idx + 1) *
119 | dim_head, :, :] for head_idx in range(heads)
120 | ] # (bs, dim_head, 1, max_seq_length) * heads
121 |
122 | attn_weights = [
123 | torch.einsum("bchq,bkhc->bkhq", [qi, ki]) * (dim_head**-0.5)
124 | for qi, ki in zip(mh_q, mh_k)
125 | ] # (bs, max_seq_length, 1, max_seq_length) * heads
126 |
127 | if mask is not None:
128 | for head_idx in range(heads):
129 | attn_weights[head_idx] = attn_weights[head_idx] + mask
130 |
131 | attn_weights = [
132 | aw.softmax(dim=1) for aw in attn_weights
133 | ] # (bs, max_seq_length, 1, max_seq_length) * heads
134 | attn = [
135 | torch.einsum("bkhq,bchk->bchq", wi, vi)
136 | for wi, vi in zip(attn_weights, mh_v)
137 | ] # (bs, dim_head, 1, max_seq_length) * heads
138 |
139 | attn = torch.cat(attn, dim=1) # (bs, dim, 1, max_seq_length)
140 | return attn
141 |
142 |
143 | CHUNK_SIZE = 512
144 |
145 | def split_einsum_v2(q, k, v, mask, heads, dim_head):
146 | """ Attention Implementation backing AttentionImplementations.SPLIT_EINSUM_V2
147 |
148 | - Implements https://machinelearning.apple.com/research/neural-engine-transformers
149 | - Recommended for ANE
150 | - Marginally slower on GPU
151 | - Chunks the query sequence to avoid large intermediate tensors and improves ANE performance
152 | """
153 | query_seq_length = q.size(3)
154 | num_chunks = query_seq_length // CHUNK_SIZE
155 |
156 | if num_chunks == 0:
157 | logger.info(
158 | "AttentionImplementations.SPLIT_EINSUM_V2: query sequence too short to chunk "
159 | f"({query_seq_length}<{CHUNK_SIZE}), fall back to AttentionImplementations.SPLIT_EINSUM (safe to ignore)")
160 | return split_einsum(q, k, v, mask, heads, dim_head)
161 |
162 | logger.info(
163 | "AttentionImplementations.SPLIT_EINSUM_V2: Splitting query sequence length of "
164 | f"{query_seq_length} into {num_chunks} chunks")
165 |
166 | mh_q = [
167 | q[:, head_idx * dim_head:(head_idx + 1) *
168 | dim_head, :, :] for head_idx in range(heads)
169 | ] # (bs, dim_head, 1, max_seq_length) * heads
170 |
171 | # Chunk the query sequence for each head
172 | mh_q_chunked = [
173 | [h_q[..., chunk_idx * CHUNK_SIZE:(chunk_idx + 1) * CHUNK_SIZE] for chunk_idx in range(num_chunks)]
174 | for h_q in mh_q
175 | ] # ((bs, dim_head, 1, QUERY_SEQ_CHUNK_SIZE) * num_chunks) * heads
176 |
177 | k = k.transpose(1, 3)
178 | mh_k = [
179 | k[:, :, :,
180 | head_idx * dim_head:(head_idx + 1) * dim_head]
181 | for head_idx in range(heads)
182 | ] # (bs, max_seq_length, 1, dim_head) * heads
183 |
184 | mh_v = [
185 | v[:, head_idx * dim_head:(head_idx + 1) *
186 | dim_head, :, :] for head_idx in range(heads)
187 | ] # (bs, dim_head, 1, max_seq_length) * heads
188 |
189 | attn_weights = [
190 | [
191 | torch.einsum("bchq,bkhc->bkhq", [qi_chunk, ki]) * (dim_head**-0.5)
192 | for qi_chunk in h_q_chunked
193 | ] for h_q_chunked, ki in zip(mh_q_chunked, mh_k)
194 | ] # ((bs, max_seq_length, 1, chunk_size) * num_chunks) * heads
195 |
196 | attn_weights = [
197 | [aw_chunk.softmax(dim=1) for aw_chunk in aw_chunked]
198 | for aw_chunked in attn_weights
199 | ] # ((bs, max_seq_length, 1, chunk_size) * num_chunks) * heads
200 |
201 | attn = [
202 | [
203 | torch.einsum("bkhq,bchk->bchq", wi_chunk, vi)
204 | for wi_chunk in wi_chunked
205 | ] for wi_chunked, vi in zip(attn_weights, mh_v)
206 | ] # ((bs, dim_head, 1, chunk_size) * num_chunks) * heads
207 |
208 | attn = torch.cat([
209 | torch.cat(attn_chunked, dim=3) for attn_chunked in attn
210 | ], dim=1) # (bs, dim, 1, max_seq_length)
211 |
212 | return attn
213 |
214 |
215 | def original(q, k, v, mask, heads, dim_head):
216 | """ Attention Implementation backing AttentionImplementations.ORIGINAL
217 |
218 | - Not recommended for ANE
219 | - Recommended for GPU
220 | """
221 | bs = q.size(0)
222 | mh_q = q.view(bs, heads, dim_head, -1)
223 | mh_k = k.view(bs, heads, dim_head, -1)
224 | mh_v = v.view(bs, heads, dim_head, -1)
225 |
226 | attn_weights = torch.einsum("bhcq,bhck->bhqk", [mh_q, mh_k])
227 | attn_weights.mul_(dim_head**-0.5)
228 |
229 | if mask is not None:
230 | attn_weights = attn_weights + mask
231 |
232 | attn_weights = attn_weights.softmax(dim=3)
233 |
234 | attn = torch.einsum("bhqk,bhck->bhcq", [attn_weights, mh_v])
235 | attn = attn.contiguous().view(bs, heads * dim_head, 1, -1)
236 | return attn
237 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_safety_checker.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils
8 |
9 | from collections import OrderedDict, defaultdict
10 | from copy import deepcopy
11 | import coremltools as ct
12 | import gc
13 |
14 | import logging
15 |
16 | logging.basicConfig()
17 | logger = logging.getLogger(__name__)
18 | logger.setLevel(logging.INFO)
19 |
20 | import numpy as np
21 | import os
22 |
23 | import torch
24 | import torch.nn as nn
25 | import torch.nn.functional as F
26 |
27 | torch.set_grad_enabled(False)
28 |
29 | from types import MethodType
30 |
31 |
32 | def main(pipe, args):
33 | """ Converts the Safety Checker component of Stable Diffusion
34 | """
35 | if pipe.safety_checker is None:
36 | logger.warning(
37 | f"diffusers pipeline for {args.model_version} does not have a `safety_checker` module! " \
38 | "`--convert-safety-checker` will be ignored."
39 | )
40 | return
41 |
42 | out_path = utils.get_out_path(args, "safety_checker")
43 | if os.path.exists(out_path):
44 | logger.info(f"`safety_checker` already exists at {out_path}, skipping conversion.")
45 | return
46 |
47 | sample_image = np.random.randn(
48 | 1, # B
49 | args.output_h, # H
50 | args.output_w, # w
51 | 3 # C
52 | ).astype(np.float32)
53 |
54 | # Note that pipe.feature_extractor is not an ML model. It simply
55 | # preprocesses data for the pipe.safety_checker module.
56 | safety_checker_input = pipe.feature_extractor(
57 | pipe.numpy_to_pil(sample_image),
58 | return_tensors="pt",
59 | ).pixel_values.to(torch.float32)
60 |
61 | sample_safety_checker_inputs = OrderedDict([
62 | ("clip_input", safety_checker_input),
63 | ("images", torch.from_numpy(sample_image)),
64 | ("adjustment", torch.tensor([0]).to(torch.float32)),
65 | ])
66 |
67 | sample_safety_checker_inputs_spec = {
68 | k: (v.shape, v.dtype)
69 | for k, v in sample_safety_checker_inputs.items()
70 | }
71 | logger.info(f"Sample inputs spec: {sample_safety_checker_inputs_spec}")
72 |
73 | # Patch safety_checker's forward pass to be vectorized and avoid conditional blocks
74 | # (similar to pipe.safety_checker.forward_onnx)
75 | from diffusers.pipelines.stable_diffusion import safety_checker
76 |
77 | def forward_coreml(self, clip_input, images, adjustment):
78 | """ Forward pass implementation for safety_checker
79 | """
80 |
81 | def cosine_distance(image_embeds, text_embeds):
82 | return F.normalize(image_embeds) @ F.normalize(text_embeds).transpose(0, 1)
83 |
84 | pooled_output = self.vision_model(clip_input)[1] # pooled_output
85 | image_embeds = self.visual_projection(pooled_output)
86 |
87 | special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds)
88 | cos_dist = cosine_distance(image_embeds, self.concept_embeds)
89 |
90 | special_scores = special_cos_dist - self.special_care_embeds_weights + adjustment
91 | special_care = special_scores.gt(0).float().sum(dim=1).gt(0).float()
92 | special_adjustment = special_care * 0.01
93 | special_adjustment = special_adjustment.unsqueeze(1).expand(-1, cos_dist.shape[1])
94 |
95 | concept_scores = (cos_dist - self.concept_embeds_weights) + special_adjustment
96 | has_nsfw_concepts = concept_scores.gt(0).float().sum(dim=1).gt(0)
97 |
98 | # There is a problem when converting using multisize, for now the workaround is to not filter the images
99 | # The swift implementations already filters the images checking `has_nsfw_concepts` so this should not have any impact
100 |
101 | #has_nsfw_concepts = concept_scores.gt(0).float().sum(dim=1).gt(0)[:, None, None, None]
102 |
103 | #has_nsfw_concepts_inds, _ = torch.broadcast_tensors(has_nsfw_concepts, images)
104 | #images[has_nsfw_concepts_inds] = 0.0 # black image
105 |
106 | return images, has_nsfw_concepts.float(), concept_scores
107 |
108 | baseline_safety_checker = deepcopy(pipe.safety_checker.eval())
109 | setattr(baseline_safety_checker, "forward", MethodType(forward_coreml, baseline_safety_checker))
110 |
111 | # In order to parity check the actual signal, we need to override the forward pass to return `concept_scores` which is the
112 | # output before thresholding
113 | # Reference: https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py#L100
114 | def forward_extended_return(self, clip_input, images, adjustment):
115 |
116 | def cosine_distance(image_embeds, text_embeds):
117 | normalized_image_embeds = F.normalize(image_embeds)
118 | normalized_text_embeds = F.normalize(text_embeds)
119 | return torch.mm(normalized_image_embeds, normalized_text_embeds.t())
120 |
121 | pooled_output = self.vision_model(clip_input)[1] # pooled_output
122 | image_embeds = self.visual_projection(pooled_output)
123 |
124 | special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds)
125 | cos_dist = cosine_distance(image_embeds, self.concept_embeds)
126 |
127 | adjustment = 0.0
128 |
129 | special_scores = special_cos_dist - self.special_care_embeds_weights + adjustment
130 | special_care = torch.any(special_scores > 0, dim=1)
131 | special_adjustment = special_care * 0.01
132 | special_adjustment = special_adjustment.unsqueeze(1).expand(-1, cos_dist.shape[1])
133 |
134 | concept_scores = (cos_dist - self.concept_embeds_weights) + special_adjustment
135 | has_nsfw_concepts = torch.any(concept_scores > 0, dim=1)
136 |
137 | # Don't make the images black as to align with the workaround in `forward_coreml`
138 | #images[has_nsfw_concepts] = 0.0
139 |
140 | return images, has_nsfw_concepts, concept_scores
141 |
142 | setattr(pipe.safety_checker, "forward", MethodType(forward_extended_return, pipe.safety_checker))
143 |
144 | # Trace the safety_checker model
145 | logger.info("JIT tracing..")
146 | traced_safety_checker = torch.jit.trace(baseline_safety_checker, list(sample_safety_checker_inputs.values()))
147 | logger.info("Done.")
148 | del baseline_safety_checker
149 | gc.collect()
150 |
151 | # Cast all inputs to float16
152 | coreml_sample_safety_checker_inputs = {
153 | k: v.numpy().astype(np.float16)
154 | for k, v in sample_safety_checker_inputs.items()
155 | }
156 |
157 | # Convert safety_checker model to Core ML
158 | if args.multisize:
159 | clip_size = safety_checker_input.shape[2]
160 | clip_input_shape = ct.Shape(shape=(
161 | 1,
162 | 3,
163 | ct.RangeDim(int(clip_size * 0.5), upper_bound=int(clip_size * 2), default=clip_size),
164 | ct.RangeDim(int(clip_size * 0.5), upper_bound=int(clip_size * 2), default=clip_size)
165 | ))
166 | sample_size = args.output_h
167 | input_shape = ct.Shape(shape=(
168 | 1,
169 | ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
170 | ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
171 | 3
172 | ))
173 |
174 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_safety_checker_inputs, {
175 | "clip_input": clip_input_shape, "images": input_shape
176 | })
177 | else:
178 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_safety_checker_inputs)
179 | coreml_safety_checker, out_path = utils.convert_to_coreml(
180 | "safety_checker", traced_safety_checker,
181 | sample_coreml_inputs,
182 | ["filtered_images", "has_nsfw_concepts", "concept_scores"], False, args
183 | )
184 |
185 | # Set model metadata
186 | coreml_safety_checker.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
187 | coreml_safety_checker.license = "OpenRAIL (https://huggingface.co/spaces/CompVis/stable-diffusion-license)"
188 | coreml_safety_checker.version = args.model_version
189 | coreml_safety_checker.short_description = \
190 | "Stable Diffusion generates images conditioned on text and/or other images as input through the diffusion process. " \
191 | "Please refer to https://arxiv.org/abs/2112.10752 for details."
192 |
193 | # Set the input descriptions
194 | coreml_safety_checker.input_description["clip_input"] = \
195 | "The normalized image input tensor resized to (224x224) in channels-first (BCHW) format"
196 | coreml_safety_checker.input_description["images"] = \
197 | f"Output of the vae_decoder ({pipe.vae.config.sample_size}x{pipe.vae.config.sample_size}) in channels-last (BHWC) format"
198 | coreml_safety_checker.input_description["adjustment"] = \
199 | "Bias added to the concept scores to trade off increased recall for reduce precision in the safety checker classifier"
200 |
201 | # Set the output descriptions
202 | coreml_safety_checker.output_description["filtered_images"] = \
203 | f"Identical to the input `images`. If safety checker detected any sensitive content, " \
204 | "the corresponding image is replaced with a blank image (zeros)"
205 | coreml_safety_checker.output_description["has_nsfw_concepts"] = \
206 | "Indicates whether the safety checker model found any sensitive content in the given image"
207 | coreml_safety_checker.output_description["concept_scores"] = \
208 | "Concept scores are the scores before thresholding at zero yields the `has_nsfw_concepts` output. " \
209 | "These scores can be used to tune the `adjustment` input"
210 |
211 | # Set package version metadata
212 | coreml_safety_checker.user_defined_metadata["identifier"] = args.model_version
213 | coreml_safety_checker.user_defined_metadata["converter_version"] = __version__
214 | coreml_safety_checker.user_defined_metadata["attention_implementation"] = args.attention_implementation
215 | coreml_safety_checker.user_defined_metadata["compute_unit"] = args.compute_unit
216 |
217 | coreml_safety_checker.save(out_path)
218 |
219 | if args.check_output_correctness:
220 | baseline_out = pipe.safety_checker(**sample_safety_checker_inputs)[2].numpy()
221 | coreml_out = coreml_safety_checker.predict(coreml_sample_safety_checker_inputs)["concept_scores"]
222 | utils.report_correctness(baseline_out, coreml_out, "safety_checker baseline PyTorch to reference CoreML")
223 |
224 | del traced_safety_checker, coreml_safety_checker, pipe.safety_checker
225 | gc.collect()
226 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/utils/merge_lora.py:
--------------------------------------------------------------------------------
1 | # Taken from: https://github.com/kohya-ss/sd-scripts/blob/main/networks/merge_lora.py
2 |
3 | import math
4 | import argparse
5 | import os
6 | import torch
7 | from safetensors.torch import load_file, save_file
8 |
9 | # is it possible to apply conv_in and conv_out? -> yes, newer LoCon supports it (^^;)
10 | UNET_TARGET_REPLACE_MODULE = ["Transformer2DModel", "Attention"]
11 | UNET_TARGET_REPLACE_MODULE_CONV2D_3X3 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
12 | TEXT_ENCODER_TARGET_REPLACE_MODULE = ["CLIPAttention", "CLIPMLP"]
13 | LORA_PREFIX_UNET = "lora_unet"
14 | LORA_PREFIX_TEXT_ENCODER = "lora_te"
15 |
16 | # SDXL: must starts with LORA_PREFIX_TEXT_ENCODER
17 | LORA_PREFIX_TEXT_ENCODER_1 = "lora_te1"
18 | LORA_PREFIX_TEXT_ENCODER_2 = "lora_te2"
19 |
20 | def load_state_dict(file_name, dtype):
21 | if os.path.splitext(file_name)[1] == ".safetensors":
22 | sd = load_file(file_name)
23 | else:
24 | sd = torch.load(file_name, map_location="cpu")
25 | for key in list(sd.keys()):
26 | if type(sd[key]) == torch.Tensor:
27 | sd[key] = sd[key].to(dtype)
28 | return sd
29 |
30 |
31 | def save_to_file(file_name, model, state_dict, dtype):
32 | if dtype is not None:
33 | for key in list(state_dict.keys()):
34 | if type(state_dict[key]) == torch.Tensor:
35 | state_dict[key] = state_dict[key].to(dtype)
36 |
37 | if os.path.splitext(file_name)[1] == ".safetensors":
38 | save_file(model, file_name)
39 | else:
40 | torch.save(model, file_name)
41 |
42 | def merge_to_sd_model(unet, text_encoder, text_encoder_2, models, ratios, merge_dtype=torch.float32):
43 | unet.to(merge_dtype)
44 | text_encoder.to(merge_dtype)
45 | if text_encoder_2:
46 | text_encoder_2.to(merge_dtype)
47 |
48 | layers_per_block = unet.config.layers_per_block
49 |
50 | # create module map
51 | name_to_module = {}
52 | for i, root_module in enumerate([unet, text_encoder, text_encoder_2]):
53 | if not root_module:
54 | continue
55 | if i == 0:
56 | prefix = LORA_PREFIX_UNET
57 | target_replace_modules = (
58 | UNET_TARGET_REPLACE_MODULE + UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
59 | )
60 | elif text_encoder_2:
61 | target_replace_modules = TEXT_ENCODER_TARGET_REPLACE_MODULE
62 | if i == 1:
63 | prefix = LORA_PREFIX_TEXT_ENCODER_1
64 | else:
65 | prefix = LORA_PREFIX_TEXT_ENCODER_2
66 | else:
67 | prefix = LORA_PREFIX_TEXT_ENCODER
68 | target_replace_modules = TEXT_ENCODER_TARGET_REPLACE_MODULE
69 |
70 | for name, module in root_module.named_modules():
71 | if module.__class__.__name__ == "LoRACompatibleLinear" or module.__class__.__name__ == "LoRACompatibleConv":
72 | lora_name = prefix + "." + name
73 | lora_name = lora_name.replace(".", "_")
74 | name_to_module[lora_name] = module
75 | elif module.__class__.__name__ in target_replace_modules:
76 | for child_name, child_module in module.named_modules():
77 | if child_module.__class__.__name__ == "Linear" or child_module.__class__.__name__ == "Conv2d":
78 | lora_name = prefix + "." + name + "." + child_name
79 | lora_name = lora_name.replace(".", "_")
80 | name_to_module[lora_name] = child_module
81 |
82 | for model, ratio in zip(models, ratios):
83 | print(f"Merging: {model}")
84 | lora_sd = load_state_dict(model, merge_dtype)
85 |
86 | for key in lora_sd.keys():
87 | if "lora_down" in key:
88 | up_key = key.replace("lora_down", "lora_up")
89 | alpha_key = key[: key.index("lora_down")] + "alpha"
90 |
91 | # find original module for this lora
92 | module_name = ".".join(key.split(".")[:-2]) # remove trailing ".lora_down.weight"
93 | if "input_blocks" in module_name:
94 | i = int(module_name.split("input_blocks_", 1)[1].split("_", 1)[0])
95 | block_id = (i - 1) // (layers_per_block + 1)
96 | layer_in_block_id = (i - 1) % (layers_per_block + 1)
97 | module_name = module_name.replace(f"input_blocks_{i}_0", f"down_blocks_{block_id}_resnets_{layer_in_block_id}")
98 | module_name = module_name.replace(f"input_blocks_{i}_1", f"down_blocks_{block_id}_attentions_{layer_in_block_id}")
99 | module_name = module_name.replace(f"input_blocks_{i}_2", f"down_blocks_{block_id}_resnets_{layer_in_block_id}")
100 | if "middle_block" in module_name:
101 | module_name = module_name.replace("middle_block_0", "mid_block_resnets_0")
102 | module_name = module_name.replace("middle_block_1", "mid_block_attentions_0")
103 | module_name = module_name.replace("middle_block_2", "mid_block_resnets_1")
104 | if "output_blocks" in module_name:
105 | i = int(module_name.split("output_blocks_", 1)[1].split("_", 1)[0])
106 | block_id = i // (layers_per_block + 1)
107 | layer_in_block_id = i % (layers_per_block + 1)
108 | module_name = module_name.replace(f"output_blocks_{i}_0", f"up_blocks_{block_id}_resnets_{layer_in_block_id}")
109 | module_name = module_name.replace(f"output_blocks_{i}_1", f"up_blocks_{block_id}_attentions_{layer_in_block_id}")
110 | module_name = module_name.replace(f"output_blocks_{i}_2", f"up_blocks_{block_id}_resnets_{layer_in_block_id}")
111 |
112 | module_name = module_name.replace("in_layers_0", "norm1")
113 | module_name = module_name.replace("in_layers_2", "conv1")
114 |
115 | module_name = module_name.replace("out_layers_0", "norm2")
116 | module_name = module_name.replace("out_layers_3", "conv2")
117 |
118 | module_name = module_name.replace("emb_layers_1", "time_emb_proj")
119 | module_name = module_name.replace("skip_connection", "conv_shortcut")
120 |
121 | if module_name not in name_to_module:
122 | print(f"no module found for LoRA weight: {key}")
123 | continue
124 | module = name_to_module[module_name]
125 | # print(f"apply {key} to {module}")
126 |
127 | down_weight = lora_sd[key]
128 | up_weight = lora_sd[up_key]
129 |
130 | dim = down_weight.size()[0]
131 | alpha = lora_sd.get(alpha_key, dim)
132 | scale = alpha / dim
133 |
134 | # W <- W + U * D
135 | weight = module.weight
136 | # print(module_name, down_weight.size(), up_weight.size())
137 | if len(weight.size()) == 2:
138 | # linear
139 | if len(up_weight.size()) == 4: # use linear projection mismatch
140 | up_weight = up_weight.squeeze(3).squeeze(2)
141 | down_weight = down_weight.squeeze(3).squeeze(2)
142 | weight = weight + ratio * (up_weight @ down_weight) * scale
143 | elif down_weight.size()[2:4] == (1, 1):
144 | # conv2d 1x1
145 | weight = (
146 | weight
147 | + ratio
148 | * (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)).unsqueeze(2).unsqueeze(3)
149 | * scale
150 | )
151 | else:
152 | # conv2d 3x3
153 | conved = torch.nn.functional.conv2d(down_weight.permute(1, 0, 2, 3), up_weight).permute(1, 0, 2, 3)
154 | # print(conved.size(), weight.size(), module.stride, module.padding)
155 | weight = weight + ratio * conved * scale
156 |
157 | module.weight = torch.nn.Parameter(weight)
158 |
159 |
160 | def merge_lora_models(models, ratios, merge_dtype):
161 | base_alphas = {} # alpha for merged model
162 | base_dims = {}
163 |
164 | merged_sd = {}
165 | for model, ratio in zip(models, ratios):
166 | print(f"loading: {model}")
167 | lora_sd = load_state_dict(model, merge_dtype)
168 |
169 | # get alpha and dim
170 | alphas = {} # alpha for current model
171 | dims = {} # dims for current model
172 | for key in lora_sd.keys():
173 | if "alpha" in key:
174 | lora_module_name = key[: key.rfind(".alpha")]
175 | alpha = float(lora_sd[key].detach().numpy())
176 | alphas[lora_module_name] = alpha
177 | if lora_module_name not in base_alphas:
178 | base_alphas[lora_module_name] = alpha
179 | elif "lora_down" in key:
180 | lora_module_name = key[: key.rfind(".lora_down")]
181 | dim = lora_sd[key].size()[0]
182 | dims[lora_module_name] = dim
183 | if lora_module_name not in base_dims:
184 | base_dims[lora_module_name] = dim
185 |
186 | for lora_module_name in dims.keys():
187 | if lora_module_name not in alphas:
188 | alpha = dims[lora_module_name]
189 | alphas[lora_module_name] = alpha
190 | if lora_module_name not in base_alphas:
191 | base_alphas[lora_module_name] = alpha
192 |
193 | print(f"dim: {list(set(dims.values()))}, alpha: {list(set(alphas.values()))}")
194 |
195 | # merge
196 | print(f"merging...")
197 | for key in lora_sd.keys():
198 | if "alpha" in key:
199 | continue
200 |
201 | lora_module_name = key[: key.rfind(".lora_")]
202 |
203 | base_alpha = base_alphas[lora_module_name]
204 | alpha = alphas[lora_module_name]
205 |
206 | scale = math.sqrt(alpha / base_alpha) * ratio
207 |
208 | if key in merged_sd:
209 | assert (
210 | merged_sd[key].size() == lora_sd[key].size()
211 | ), f"weights shape mismatch merging v1 and v2, different dims? / 重みのサイズが合いません。v1とv2、または次元数の異なるモデルはマージできません"
212 | merged_sd[key] = merged_sd[key] + lora_sd[key] * scale
213 | else:
214 | merged_sd[key] = lora_sd[key] * scale
215 |
216 | # set alpha to sd
217 | for lora_module_name, alpha in base_alphas.items():
218 | key = lora_module_name + ".alpha"
219 | merged_sd[key] = torch.tensor(alpha)
220 |
221 | print("merged model")
222 | print(f"dim: {list(set(base_dims.values()))}, alpha: {list(set(base_alphas.values()))}")
223 |
224 | return merged_sd
225 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/utils/utils.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from .merge_lora import merge_to_sd_model
8 |
9 | import json
10 | import argparse
11 | from collections import OrderedDict, defaultdict
12 | from copy import deepcopy
13 | import coremltools as ct
14 | from diffusers import DiffusionPipeline, StableDiffusionPipeline, StableDiffusionXLPipeline, AutoPipelineForInpainting
15 | from diffusers import T2IAdapter, StableDiffusionAdapterPipeline
16 | from diffusers import ControlNetModel, StableDiffusionControlNetPipeline, StableDiffusionXLControlNetPipeline, AutoencoderKL
17 | from diffusers.pipelines.stable_diffusion.convert_from_ckpt import download_from_original_stable_diffusion_ckpt
18 | import gc
19 |
20 | import logging
21 |
22 | logging.basicConfig()
23 | logger = logging.getLogger(__name__)
24 | logger.setLevel(logging.INFO)
25 |
26 | import numpy as np
27 | import os
28 | from os import listdir
29 | from os.path import isfile, join
30 | import tempfile
31 | import requests
32 | import shutil
33 | import time
34 | import traceback
35 |
36 | import torch
37 | import torch.nn as nn
38 | import torch.nn.functional as F
39 |
40 | torch.set_grad_enabled(False)
41 |
42 |
43 | def conditioning_method_from(identifier):
44 | if "canny" in identifier:
45 | return "canny"
46 | if "depth" in identifier:
47 | return "depth"
48 | if "pose" in identifier:
49 | return "pose"
50 | if "mlsd" in identifier:
51 | return "mlsd"
52 | if "normal" in identifier:
53 | return "normal"
54 | if "scribble" in identifier:
55 | return "scribble"
56 | if "hed" in identifier:
57 | return "hed"
58 | if "seg" in identifier:
59 | return "segmentation"
60 | return None
61 |
62 |
63 | def get_out_path(args, submodule_name):
64 | fname = f"{args.model_version}_{submodule_name}.mlpackage"
65 | fname = fname.replace("/", "_")
66 | if args.clean_up_mlpackages:
67 | temp_dir = tempfile.gettempdir()
68 | return os.path.join(temp_dir, fname)
69 | return os.path.join(args.o, fname)
70 |
71 |
72 | def get_coreml_inputs(sample_inputs, samples_shapes=None):
73 | return [
74 | ct.TensorType(
75 | name=k,
76 | shape=samples_shapes[k] if samples_shapes and k in samples_shapes else v.shape,
77 | dtype=v.numpy().dtype if isinstance(v, torch.Tensor) else v.dtype,
78 | ) for k, v in sample_inputs.items()
79 | ]
80 |
81 |
82 | ABSOLUTE_MIN_PSNR = 35
83 |
84 | def report_correctness(original_outputs, final_outputs, log_prefix):
85 | """ Report PSNR values across two compatible tensors
86 | """
87 | original_psnr = compute_psnr(original_outputs, original_outputs)
88 | final_psnr = compute_psnr(original_outputs, final_outputs)
89 |
90 | dB_change = final_psnr - original_psnr
91 | logger.info(
92 | f"{log_prefix}: PSNR changed by {dB_change:.1f} dB ({original_psnr:.1f} -> {final_psnr:.1f})"
93 | )
94 |
95 | if final_psnr < ABSOLUTE_MIN_PSNR:
96 | # raise ValueError(f"{final_psnr:.1f} dB is too low!")
97 | logger.info(f"{final_psnr:.1f} dB is too low!")
98 | else:
99 | logger.info(
100 | f"{final_psnr:.1f} dB > {ABSOLUTE_MIN_PSNR} dB (minimum allowed) parity check passed"
101 | )
102 | return final_psnr
103 |
104 |
105 | def compute_psnr(a, b):
106 | """ Compute Peak-Signal-to-Noise-Ratio across two numpy.ndarray objects
107 | """
108 | max_b = np.abs(b).max()
109 | sumdeltasq = 0.0
110 |
111 | sumdeltasq = ((a - b) * (a - b)).sum()
112 |
113 | sumdeltasq /= b.size
114 | sumdeltasq = np.sqrt(sumdeltasq)
115 |
116 | eps = 1e-5
117 | eps2 = 1e-10
118 | psnr = 20 * np.log10((max_b + eps) / (sumdeltasq + eps2))
119 |
120 | return psnr
121 |
122 |
123 | def convert_to_coreml(submodule_name, torchscript_module, coreml_inputs, output_names, precision_full, args):
124 | out_path = get_out_path(args, submodule_name)
125 |
126 | if os.path.exists(out_path):
127 | logger.info(f"Skipping export because {out_path} already exists")
128 | logger.info(f"Loading model from {out_path}")
129 |
130 | start = time.time()
131 | # Note: Note that each model load will trigger a model compilation which takes up to a few minutes.
132 | # The Swifty CLI we provide uses precompiled Core ML models (.mlmodelc) which incurs compilation only
133 | # upon first load and mitigates the load time in subsequent runs.
134 | coreml_model = ct.models.MLModel(out_path, compute_units=ct.ComputeUnit[args.compute_unit])
135 | logger.info(f"Loading {out_path} took {time.time() - start:.1f} seconds")
136 |
137 | coreml_model.compute_unit = ct.ComputeUnit[args.compute_unit]
138 | else:
139 | logger.info(f"Converting {submodule_name} to CoreML...")
140 | coreml_model = ct.convert(
141 | torchscript_module,
142 | convert_to="mlprogram",
143 | minimum_deployment_target=ct.target.macOS13,
144 | inputs=coreml_inputs,
145 | outputs=[ct.TensorType(name=name) for name in output_names],
146 | compute_units=ct.ComputeUnit[args.compute_unit],
147 | compute_precision=ct.precision.FLOAT32 if precision_full else ct.precision.FLOAT16,
148 | # skip_model_load=True,
149 | )
150 |
151 | del torchscript_module
152 | gc.collect()
153 |
154 | return coreml_model, out_path
155 |
156 |
157 | def quantize_weights(models, args):
158 | """ Quantize weights to args.quantize_nbits using a palette (look-up table)
159 | """
160 | for model_name in models:
161 | logger.info(f"Quantizing {model_name} to {args.quantize_nbits}-bit precision")
162 | out_path = get_out_path(args, model_name)
163 | _quantize_weights(
164 | out_path,
165 | model_name,
166 | args.quantize_nbits
167 | )
168 |
169 | def _quantize_weights(out_path, model_name, nbits):
170 | if os.path.exists(out_path):
171 | logger.info(f"Quantizing {model_name}")
172 | mlmodel = ct.models.MLModel(out_path, compute_units=ct.ComputeUnit.CPU_ONLY)
173 |
174 | op_config = ct.optimize.coreml.OpPalettizerConfig(
175 | mode="kmeans",
176 | nbits=nbits,
177 | )
178 |
179 | config = ct.optimize.coreml.OptimizationConfig(
180 | global_config=op_config,
181 | op_type_configs={
182 | "gather": None # avoid quantizing the embedding table
183 | }
184 | )
185 |
186 | model = ct.optimize.coreml.palettize_weights(mlmodel, config=config).save(out_path)
187 | logger.info("Done")
188 | else:
189 | logger.info(f"Skipped quantizing {model_name} (Not found at {out_path})")
190 |
191 |
192 | def bundle_resources_for_guernika(pipe, args):
193 | """
194 | - Compiles Core ML models from mlpackage into mlmodelc format
195 | - Download tokenizer resources for the text encoder
196 | """
197 | resources_dir = os.path.join(args.o, args.resources_dir_name.replace("/", "_"))
198 | if not os.path.exists(resources_dir):
199 | os.makedirs(resources_dir, exist_ok=True)
200 | logger.info(f"Created {resources_dir} for Guernika assets")
201 |
202 | # Compile model using coremlcompiler (Significantly reduces the load time for unet)
203 | for source_name, target_name in [
204 | ("text_encoder", "TextEncoder"),
205 | ("text_encoder_2", "TextEncoder2"),
206 | ("text_encoder_prior", "TextEncoderPrior"),
207 | ("vae_encoder", "VAEEncoder"),
208 | ("vae_decoder", "VAEDecoder"),
209 | ("t2i_adapter", "T2IAdapter"),
210 | ("controlnet", "ControlNet"),
211 | ("unet", "Unet"),
212 | ("unet_chunk1", "UnetChunk1"),
213 | ("unet_chunk2", "UnetChunk2"),
214 | ("safety_checker", "SafetyChecker"),
215 | ("wuerstchen_prior", "WuerstchenPrior"),
216 | ("wuerstchen_decoder", "WuerstchenDecoder"),
217 | ("wuerstchen_vqgan", "WuerstchenVQGAN")
218 |
219 | ]:
220 | source_path = get_out_path(args, source_name)
221 | if os.path.exists(source_path):
222 | target_path = _compile_coreml_model(source_path, resources_dir, target_name)
223 | logger.info(f"Compiled {source_path} to {target_path}")
224 | if source_name.startswith("text_encoder"):
225 | # Fetch and save vocabulary JSON file for text tokenizer
226 | logger.info("Downloading and saving tokenizer vocab.json")
227 | with open(os.path.join(target_path, "vocab.json"), "wb") as f:
228 | f.write(requests.get(args.text_encoder_vocabulary_url).content)
229 | logger.info("Done")
230 |
231 | # Fetch and save merged pairs JSON file for text tokenizer
232 | logger.info("Downloading and saving tokenizer merges.txt")
233 | with open(os.path.join(target_path, "merges.txt"), "wb") as f:
234 | f.write(requests.get(args.text_encoder_merges_url).content)
235 | logger.info("Done")
236 |
237 | if hasattr(args, "added_vocab") and args.added_vocab:
238 | logger.info("Saving added vocab")
239 | with open(os.path.join(target_path, "added_vocab.json"), 'w', encoding='utf-8') as f:
240 | json.dump(args.added_vocab, f, ensure_ascii=False, indent=4)
241 | else:
242 | logger.warning(
243 | f"{source_path} not found, skipping compilation to {target_name}.mlmodelc"
244 | )
245 |
246 | return resources_dir
247 |
248 |
249 | def _compile_coreml_model(source_model_path, output_dir, final_name):
250 | """ Compiles Core ML models using the coremlcompiler utility from Xcode toolchain
251 | """
252 | target_path = os.path.join(output_dir, f"{final_name}.mlmodelc")
253 | if os.path.exists(target_path):
254 | logger.warning(f"Found existing compiled model at {target_path}! Skipping..")
255 | return target_path
256 |
257 | logger.info(f"Compiling {source_model_path}")
258 | source_model_name = os.path.basename(os.path.splitext(source_model_path)[0])
259 |
260 | os.system(f"xcrun coremlcompiler compile '{source_model_path}' '{output_dir}'")
261 | compiled_output = os.path.join(output_dir, f"{source_model_name}.mlmodelc")
262 | shutil.move(compiled_output, target_path)
263 |
264 | return target_path
265 |
266 |
267 | def remove_mlpackages(args):
268 | for package_name in [
269 | "text_encoder",
270 | "text_encoder_2",
271 | "text_encoder_prior",
272 | "vae_encoder",
273 | "vae_decoder",
274 | "t2i_adapter",
275 | "controlnet",
276 | "unet",
277 | "unet_chunk1",
278 | "unet_chunk2",
279 | "safety_checker",
280 | "wuerstchen_prior",
281 | "wuerstchen_prior_chunk1",
282 | "wuerstchen_prior_chunk2",
283 | "wuerstchen_decoder",
284 | "wuerstchen_decoder_chunk1",
285 | "wuerstchen_decoder_chunk2",
286 | "wuerstchen_vqgan"
287 | ]:
288 | package_path = get_out_path(args, package_name)
289 | try:
290 | if os.path.exists(package_path):
291 | shutil.rmtree(package_path)
292 | except:
293 | traceback.print_exc()
294 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_controlnet.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils
8 | from guernikatools.models import attention, controlnet
9 |
10 | from collections import OrderedDict, defaultdict
11 | from copy import deepcopy
12 | import coremltools as ct
13 | import gc
14 |
15 | import logging
16 |
17 | logging.basicConfig()
18 | logger = logging.getLogger(__name__)
19 | logger.setLevel(logging.INFO)
20 |
21 | import numpy as np
22 | import os
23 |
24 | import torch
25 | import torch.nn as nn
26 | import torch.nn.functional as F
27 |
28 | torch.set_grad_enabled(False)
29 |
30 |
31 | def main(pipe, args):
32 | """ Converts the ControlNet component of Stable Diffusion
33 | """
34 | if not pipe.controlnet:
35 | logger.info(f"`controlnet` not available in this pipline.")
36 | return
37 |
38 | out_path = utils.get_out_path(args, "controlnet")
39 | if os.path.exists(out_path):
40 | logger.info(f"`controlnet` already exists at {out_path}, skipping conversion.")
41 | return
42 |
43 | # Register the selected attention implementation globally
44 | attention.ATTENTION_IMPLEMENTATION_IN_EFFECT = attention.AttentionImplementations[args.attention_implementation]
45 | logger.info(f"Attention implementation in effect: {attention.ATTENTION_IMPLEMENTATION_IN_EFFECT}")
46 |
47 | # Prepare sample input shapes and values
48 | batch_size = 2 # for classifier-free guidance
49 | controlnet_in_channels = pipe.controlnet.config.in_channels
50 | vae_scale_factor = 2 ** (len(pipe.vae.config.block_out_channels) - 1)
51 | height = int(args.output_h / vae_scale_factor)
52 | width = int(args.output_w / vae_scale_factor)
53 |
54 | sample_shape = (
55 | batch_size, # B
56 | controlnet_in_channels, # C
57 | height, # H
58 | width, # W
59 | )
60 |
61 | cond_shape = (
62 | batch_size, # B
63 | 3, # C
64 | args.output_h, # H
65 | args.output_w, # W
66 | )
67 |
68 | if not hasattr(pipe, "text_encoder"):
69 | raise RuntimeError(
70 | "convert_text_encoder() deletes pipe.text_encoder to save RAM. "
71 | "Please use convert_controlnet() before convert_text_encoder()")
72 |
73 | hidden_size = pipe.controlnet.config.cross_attention_dim
74 | encoder_hidden_states_shape = (
75 | batch_size,
76 | hidden_size,
77 | 1,
78 | pipe.text_encoder.config.max_position_embeddings,
79 | )
80 |
81 | # Create the scheduled timesteps for downstream use
82 | DEFAULT_NUM_INFERENCE_STEPS = 50
83 | pipe.scheduler.set_timesteps(DEFAULT_NUM_INFERENCE_STEPS)
84 |
85 | output_names = [
86 | "down_block_res_samples_00", "down_block_res_samples_01", "down_block_res_samples_02",
87 | "down_block_res_samples_03", "down_block_res_samples_04", "down_block_res_samples_05",
88 | "down_block_res_samples_06", "down_block_res_samples_07", "down_block_res_samples_08"
89 | ]
90 | sample_controlnet_inputs = [
91 | ("sample", torch.rand(*sample_shape)),
92 | ("timestep",
93 | torch.tensor([pipe.scheduler.timesteps[0].item()] *
94 | (batch_size)).to(torch.float32)),
95 | ("encoder_hidden_states", torch.rand(*encoder_hidden_states_shape)),
96 | ("controlnet_cond", torch.rand(*cond_shape))
97 | ]
98 | if hasattr(pipe.controlnet.config, "addition_embed_type") and pipe.controlnet.config.addition_embed_type == "text_time":
99 | text_embeds_shape = (
100 | batch_size,
101 | pipe.text_encoder_2.config.hidden_size,
102 | )
103 | time_ids_input = [
104 | [args.output_h, args.output_w, 0, 0, args.output_h, args.output_w],
105 | [args.output_h, args.output_w, 0, 0, args.output_h, args.output_w]
106 | ]
107 | sample_controlnet_inputs = sample_controlnet_inputs + [
108 | ("text_embeds", torch.rand(*text_embeds_shape)),
109 | ("time_ids", torch.tensor(time_ids_input).to(torch.float32)),
110 | ]
111 | else:
112 | # SDXL ControlNet does not generate these outputs
113 | output_names = output_names + ["down_block_res_samples_09", "down_block_res_samples_10", "down_block_res_samples_11"]
114 | output_names = output_names + ["mid_block_res_sample"]
115 |
116 | sample_controlnet_inputs = OrderedDict(sample_controlnet_inputs)
117 | sample_controlnet_inputs_spec = {
118 | k: (v.shape, v.dtype)
119 | for k, v in sample_controlnet_inputs.items()
120 | }
121 | logger.info(f"Sample inputs spec: {sample_controlnet_inputs_spec}")
122 |
123 | # Initialize reference controlnet
124 | reference_controlnet = controlnet.ControlNetModel(**pipe.controlnet.config).eval()
125 | load_state_dict_summary = reference_controlnet.load_state_dict(pipe.controlnet.state_dict())
126 |
127 | # Prepare inputs
128 | baseline_sample_controlnet_inputs = deepcopy(sample_controlnet_inputs)
129 | baseline_sample_controlnet_inputs[
130 | "encoder_hidden_states"] = baseline_sample_controlnet_inputs[
131 | "encoder_hidden_states"].squeeze(2).transpose(1, 2)
132 |
133 | # JIT trace
134 | logger.info("JIT tracing..")
135 | reference_controlnet = torch.jit.trace(reference_controlnet, example_kwarg_inputs=sample_controlnet_inputs)
136 | logger.info("Done.")
137 |
138 | if args.check_output_correctness:
139 | baseline_out = pipe.controlnet(**baseline_sample_controlnet_inputs, return_dict=False)[0].numpy()
140 | reference_out = reference_controlnet(**sample_controlnet_inputs)[0].numpy()
141 | utils.report_correctness(baseline_out, reference_out, "control baseline to reference PyTorch")
142 |
143 | del pipe.controlnet
144 | gc.collect()
145 |
146 | coreml_sample_controlnet_inputs = {
147 | k: v.numpy().astype(np.float16)
148 | for k, v in sample_controlnet_inputs.items()
149 | }
150 |
151 | if args.multisize:
152 | sample_size = height
153 | sample_input_shape = ct.Shape(shape=(
154 | batch_size,
155 | controlnet_in_channels,
156 | ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
157 | ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size)
158 | ))
159 |
160 | cond_size = args.output_h
161 | cond_input_shape = ct.Shape(shape=(
162 | batch_size,
163 | 3,
164 | ct.RangeDim(int(cond_size * 0.5), upper_bound=int(cond_size * 2), default=cond_size),
165 | ct.RangeDim(int(cond_size * 0.5), upper_bound=int(cond_size * 2), default=cond_size)
166 | ))
167 |
168 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_controlnet_inputs, {
169 | "sample": sample_input_shape,
170 | "controlnet_cond": cond_input_shape,
171 | })
172 | else:
173 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_controlnet_inputs)
174 | coreml_controlnet, out_path = utils.convert_to_coreml(
175 | "controlnet",
176 | reference_controlnet,
177 | sample_coreml_inputs,
178 | output_names,
179 | args.precision_full,
180 | args
181 | )
182 | del reference_controlnet
183 | gc.collect()
184 |
185 | # Set model metadata
186 | coreml_controlnet.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
187 | coreml_controlnet.license = "ControlNet (https://github.com/lllyasviel/ControlNet)"
188 | coreml_controlnet.version = args.controlnet_version
189 | coreml_controlnet.short_description = \
190 | "ControlNet is a neural network structure to control diffusion models by adding extra conditions. " \
191 | "Please refer to https://github.com/lllyasviel/ControlNet for details."
192 |
193 | # Set the input descriptions
194 | coreml_controlnet.input_description["sample"] = \
195 | "The low resolution latent feature maps being denoised through reverse diffusion"
196 | coreml_controlnet.input_description["timestep"] = \
197 | "A value emitted by the associated scheduler object to condition the model on a given noise schedule"
198 | coreml_controlnet.input_description["encoder_hidden_states"] = \
199 | "Output embeddings from the associated text_encoder model to condition to generated image on text. " \
200 | "A maximum of 77 tokens (~40 words) are allowed. Longer text is truncated. " \
201 | "Shorter text does not reduce computation."
202 | coreml_controlnet.input_description["controlnet_cond"] = \
203 | "Image used to condition ControlNet output"
204 |
205 | # Set the output descriptions
206 | coreml_controlnet.output_description["down_block_res_samples_00"] = "Residual down sample from ControlNet"
207 | coreml_controlnet.output_description["down_block_res_samples_01"] = "Residual down sample from ControlNet"
208 | coreml_controlnet.output_description["down_block_res_samples_02"] = "Residual down sample from ControlNet"
209 | coreml_controlnet.output_description["down_block_res_samples_03"] = "Residual down sample from ControlNet"
210 | coreml_controlnet.output_description["down_block_res_samples_04"] = "Residual down sample from ControlNet"
211 | coreml_controlnet.output_description["down_block_res_samples_05"] = "Residual down sample from ControlNet"
212 | coreml_controlnet.output_description["down_block_res_samples_06"] = "Residual down sample from ControlNet"
213 | coreml_controlnet.output_description["down_block_res_samples_07"] = "Residual down sample from ControlNet"
214 | coreml_controlnet.output_description["down_block_res_samples_08"] = "Residual down sample from ControlNet"
215 | if "down_block_res_samples_09" in output_names:
216 | coreml_controlnet.output_description["down_block_res_samples_09"] = "Residual down sample from ControlNet"
217 | coreml_controlnet.output_description["down_block_res_samples_10"] = "Residual down sample from ControlNet"
218 | coreml_controlnet.output_description["down_block_res_samples_11"] = "Residual down sample from ControlNet"
219 | coreml_controlnet.output_description["mid_block_res_sample"] = "Residual mid sample from ControlNet"
220 |
221 | # Set package version metadata
222 | coreml_controlnet.user_defined_metadata["identifier"] = args.controlnet_version
223 | coreml_controlnet.user_defined_metadata["converter_version"] = __version__
224 | coreml_controlnet.user_defined_metadata["attention_implementation"] = args.attention_implementation
225 | coreml_controlnet.user_defined_metadata["compute_unit"] = args.compute_unit
226 | coreml_controlnet.user_defined_metadata["hidden_size"] = str(hidden_size)
227 | controlnet_method = utils.conditioning_method_from(args.controlnet_version)
228 | if controlnet_method:
229 | coreml_controlnet.user_defined_metadata["method"] = controlnet_method
230 |
231 | coreml_controlnet.save(out_path)
232 | logger.info(f"Saved controlnet into {out_path}")
233 |
234 | # Parity check PyTorch vs CoreML
235 | if args.check_output_correctness:
236 | coreml_out = list(coreml_controlnet.predict(coreml_sample_controlnet_inputs).values())[0]
237 | utils.report_correctness(baseline_out, coreml_out, "control baseline PyTorch to reference CoreML")
238 |
239 | del coreml_controlnet
240 | gc.collect()
241 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/models/controlnet.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools.models import attention
7 | from .layer_norm import LayerNormANE
8 | from .unet import Timesteps, TimestepEmbedding, UNetMidBlock2DCrossAttn
9 | from .unet import linear_to_conv2d_map, get_down_block, get_up_block
10 |
11 | from diffusers.configuration_utils import ConfigMixin, register_to_config
12 | from diffusers import ModelMixin
13 |
14 | from enum import Enum
15 |
16 | import logging
17 |
18 | logger = logging.getLogger(__name__)
19 | logger.setLevel(logging.INFO)
20 |
21 | import math
22 |
23 | import torch
24 | import torch.nn as nn
25 | import torch.nn.functional as F
26 |
27 | # Ensure minimum macOS version requirement is met for this particular model
28 | from coremltools.models.utils import _macos_version
29 | if not _macos_version() >= (13, 1):
30 | logger.warning(
31 | "!!! macOS 13.1 and newer or iOS/iPadOS 16.2 and newer is required for best performance !!!"
32 | )
33 |
34 | class ControlNetConditioningDefaultEmbedding(nn.Module):
35 | """
36 | "Stable Diffusion uses a pre-processing method similar to VQ-GAN [11] to convert the entire dataset of 512 × 512
37 | images into smaller 64 × 64 “latent images” for stabilized training. This requires ControlNets to convert
38 | image-based conditions to 64 × 64 feature space to match the convolution size. We use a tiny network E(·) of four
39 | convolution layers with 4 × 4 kernels and 2 × 2 strides (activated by ReLU, channels are 16, 32, 64, 128,
40 | initialized with Gaussian weights, trained jointly with the full model) to encode image-space conditions ... into
41 | feature maps ..."
42 | """
43 |
44 | def __init__(
45 | self,
46 | conditioning_embedding_channels: int,
47 | conditioning_channels: int = 3,
48 | block_out_channels = (16, 32, 96, 256),
49 | ):
50 | super().__init__()
51 |
52 | self.conv_in = nn.Conv2d(conditioning_channels, block_out_channels[0], kernel_size=3, padding=1)
53 |
54 | self.blocks = nn.ModuleList([])
55 |
56 | for i in range(len(block_out_channels) - 1):
57 | channel_in = block_out_channels[i]
58 | channel_out = block_out_channels[i + 1]
59 | self.blocks.append(nn.Conv2d(channel_in, channel_in, kernel_size=3, padding=1))
60 | self.blocks.append(nn.Conv2d(channel_in, channel_out, kernel_size=3, padding=1, stride=2))
61 |
62 | self.conv_out = zero_module(
63 | nn.Conv2d(block_out_channels[-1], conditioning_embedding_channels, kernel_size=3, padding=1)
64 | )
65 |
66 | def forward(self, conditioning):
67 | embedding = self.conv_in(conditioning)
68 | embedding = F.silu(embedding)
69 |
70 | for block in self.blocks:
71 | embedding = block(embedding)
72 | embedding = F.silu(embedding)
73 |
74 | embedding = self.conv_out(embedding)
75 | return embedding
76 |
77 | class ControlNetModel(ModelMixin, ConfigMixin):
78 |
79 | @register_to_config
80 | def __init__(
81 | self,
82 | sample_size=None,
83 | in_channels=4,
84 | out_channels=4,
85 | center_input_sample=False,
86 | flip_sin_to_cos=True,
87 | freq_shift=0,
88 | down_block_types=(
89 | "CrossAttnDownBlock2D",
90 | "CrossAttnDownBlock2D",
91 | "CrossAttnDownBlock2D",
92 | "DownBlock2D",
93 | ),
94 | only_cross_attention=False,
95 | block_out_channels=(320, 640, 1280, 1280),
96 | layers_per_block=2,
97 | downsample_padding=1,
98 | mid_block_scale_factor=1,
99 | act_fn="silu",
100 | norm_num_groups=32,
101 | norm_eps=1e-5,
102 | cross_attention_dim=768,
103 | attention_head_dim=8,
104 | transformer_layers_per_block=1,
105 | conv_in_kernel=3,
106 | conv_out_kernel=3,
107 | addition_embed_type=None,
108 | addition_time_embed_dim=None,
109 | projection_class_embeddings_input_dim=None,
110 | conditioning_embedding_out_channels=(16, 32, 96, 256),
111 | **kwargs,
112 | ):
113 | if kwargs.get("dual_cross_attention", None):
114 | raise NotImplementedError
115 | if kwargs.get("num_classs_embeds", None):
116 | raise NotImplementedError
117 | if only_cross_attention:
118 | raise NotImplementedError
119 | if kwargs.get("use_linear_projection", None):
120 | logger.warning("`use_linear_projection=True` is ignored!")
121 |
122 | super().__init__()
123 | self._register_load_state_dict_pre_hook(linear_to_conv2d_map)
124 |
125 | self.sample_size = sample_size
126 | time_embed_dim = block_out_channels[0] * 4
127 |
128 | # input
129 | conv_in_padding = (conv_in_kernel - 1) // 2
130 | self.conv_in = nn.Conv2d(
131 | in_channels,
132 | block_out_channels[0],
133 | kernel_size=conv_in_kernel,
134 | padding=conv_in_padding
135 | )
136 |
137 | # time
138 | time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
139 | timestep_input_dim = block_out_channels[0]
140 | time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
141 |
142 | if addition_embed_type == "text_time":
143 | self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
144 | self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
145 | elif addition_embed_type is not None:
146 | raise NotImplementedError
147 |
148 | self.time_proj = time_proj
149 | self.time_embedding = time_embedding
150 |
151 | self.controlnet_cond_embedding = ControlNetConditioningDefaultEmbedding(
152 | conditioning_embedding_channels=block_out_channels[0],
153 | block_out_channels=conditioning_embedding_out_channels,
154 | )
155 |
156 | self.down_blocks = nn.ModuleList([])
157 | self.mid_block = None
158 | self.controlnet_down_blocks = nn.ModuleList([])
159 |
160 | if isinstance(only_cross_attention, bool):
161 | only_cross_attention = [only_cross_attention] * len(down_block_types)
162 |
163 | if isinstance(attention_head_dim, int):
164 | attention_head_dim = (attention_head_dim,) * len(down_block_types)
165 |
166 | if isinstance(transformer_layers_per_block, int):
167 | transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
168 |
169 | # down
170 | output_channel = block_out_channels[0]
171 |
172 | controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
173 | controlnet_block = zero_module(controlnet_block)
174 | self.controlnet_down_blocks.append(controlnet_block)
175 |
176 | for i, down_block_type in enumerate(down_block_types):
177 | input_channel = output_channel
178 | output_channel = block_out_channels[i]
179 | is_final_block = i == len(block_out_channels) - 1
180 |
181 | down_block = get_down_block(
182 | down_block_type,
183 | num_layers=layers_per_block,
184 | transformer_layers_per_block=transformer_layers_per_block[i],
185 | in_channels=input_channel,
186 | out_channels=output_channel,
187 | temb_channels=time_embed_dim,
188 | add_downsample=not is_final_block,
189 | resnet_eps=norm_eps,
190 | resnet_act_fn=act_fn,
191 | cross_attention_dim=cross_attention_dim,
192 | attn_num_head_channels=attention_head_dim[i],
193 | downsample_padding=downsample_padding,
194 | )
195 | self.down_blocks.append(down_block)
196 |
197 | for _ in range(layers_per_block):
198 | controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
199 | controlnet_block = zero_module(controlnet_block)
200 | self.controlnet_down_blocks.append(controlnet_block)
201 |
202 | if not is_final_block:
203 | controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
204 | controlnet_block = zero_module(controlnet_block)
205 | self.controlnet_down_blocks.append(controlnet_block)
206 |
207 | # mid
208 | mid_block_channel = block_out_channels[-1]
209 |
210 | controlnet_block = nn.Conv2d(mid_block_channel, mid_block_channel, kernel_size=1)
211 | controlnet_block = zero_module(controlnet_block)
212 | self.controlnet_mid_block = controlnet_block
213 |
214 | self.mid_block = UNetMidBlock2DCrossAttn(
215 | transformer_layers_per_block=transformer_layers_per_block[-1],
216 | in_channels=mid_block_channel,
217 | temb_channels=time_embed_dim,
218 | resnet_eps=norm_eps,
219 | resnet_act_fn=act_fn,
220 | output_scale_factor=mid_block_scale_factor,
221 | resnet_time_scale_shift="default",
222 | cross_attention_dim=cross_attention_dim,
223 | attn_num_head_channels=attention_head_dim[i],
224 | resnet_groups=norm_num_groups,
225 | )
226 |
227 | def forward(
228 | self,
229 | sample,
230 | timestep,
231 | encoder_hidden_states,
232 | controlnet_cond,
233 | text_embeds=None,
234 | time_ids=None
235 | ):
236 | # 0. Project (or look-up) time embeddings
237 | t_emb = self.time_proj(timestep)
238 | emb = self.time_embedding(t_emb)
239 |
240 | if hasattr(self.config, "addition_embed_type") and self.config.addition_embed_type == "text_time":
241 | time_embeds = self.add_time_proj(time_ids.flatten())
242 | time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
243 |
244 | add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
245 | add_embeds = add_embeds.to(emb.dtype)
246 | aug_emb = self.add_embedding(add_embeds)
247 | emb = emb + aug_emb
248 |
249 | # 1. center input if necessary
250 | if self.config.center_input_sample:
251 | sample = 2 * sample - 1.0
252 |
253 | # 2. pre-process
254 | sample = self.conv_in(sample)
255 |
256 | controlnet_cond = self.controlnet_cond_embedding(controlnet_cond)
257 |
258 | sample += controlnet_cond
259 |
260 | # 3. down
261 | down_block_res_samples = (sample, )
262 | for downsample_block in self.down_blocks:
263 | if hasattr(downsample_block, "attentions") and downsample_block.attentions is not None:
264 | sample, res_samples = downsample_block(
265 | hidden_states=sample,
266 | temb=emb,
267 | encoder_hidden_states=encoder_hidden_states
268 | )
269 | else:
270 | sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
271 |
272 | down_block_res_samples += res_samples
273 |
274 | # 4. mid
275 | sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states)
276 |
277 | # 5. Control net blocks
278 |
279 | controlnet_down_block_res_samples = ()
280 |
281 | for down_block_res_sample, controlnet_block in zip(down_block_res_samples, self.controlnet_down_blocks):
282 | down_block_res_sample = controlnet_block(down_block_res_sample)
283 | controlnet_down_block_res_samples += (down_block_res_sample, )
284 |
285 | down_block_res_samples = controlnet_down_block_res_samples
286 |
287 | mid_block_res_sample = self.controlnet_mid_block(sample)
288 |
289 | return (down_block_res_samples, mid_block_res_sample)
290 |
291 |
292 | def zero_module(module):
293 | for p in module.parameters():
294 | nn.init.zeros_(p)
295 | return module
296 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_vae.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils
8 |
9 | from collections import OrderedDict, defaultdict
10 | from copy import deepcopy
11 | import coremltools as ct
12 | import gc
13 |
14 | import logging
15 |
16 | logging.basicConfig()
17 | logger = logging.getLogger(__name__)
18 | logger.setLevel(logging.INFO)
19 |
20 | import numpy as np
21 | import os
22 |
23 | import torch
24 | import torch.nn as nn
25 | import torch.nn.functional as F
26 |
27 | torch.set_grad_enabled(False)
28 |
29 |
30 | def modify_coremltools_torch_frontend_badbmm():
31 | """
32 | Modifies coremltools torch frontend for baddbmm to be robust to the `beta` argument being of non-float dtype:
33 | e.g. https://github.com/huggingface/diffusers/blob/v0.8.1/src/diffusers/models/attention.py#L315
34 | """
35 | from coremltools.converters.mil import register_torch_op
36 | from coremltools.converters.mil.mil import Builder as mb
37 | from coremltools.converters.mil.frontend.torch.ops import _get_inputs
38 | from coremltools.converters.mil.frontend.torch.torch_op_registry import _TORCH_OPS_REGISTRY
39 | if "baddbmm" in _TORCH_OPS_REGISTRY:
40 | del _TORCH_OPS_REGISTRY["baddbmm"]
41 |
42 | @register_torch_op
43 | def baddbmm(context, node):
44 | """
45 | baddbmm(Tensor input, Tensor batch1, Tensor batch2, Scalar beta=1, Scalar alpha=1)
46 | output = beta * input + alpha * batch1 * batch2
47 | Notice that batch1 and batch2 must be 3-D tensors each containing the same number of matrices.
48 | If batch1 is a (b×n×m) tensor, batch2 is a (b×m×p) tensor, then input must be broadcastable with a (b×n×p) tensor
49 | and out will be a (b×n×p) tensor.
50 | """
51 | assert len(node.outputs) == 1
52 | inputs = _get_inputs(context, node, expected=5)
53 | bias, batch1, batch2, beta, alpha = inputs
54 |
55 | if beta.val != 1.0:
56 | # Apply scaling factor beta to the bias.
57 | if beta.val.dtype == np.int32:
58 | beta = mb.cast(x=beta, dtype="fp32")
59 | logger.warning(
60 | f"Casted the `beta`(value={beta.val}) argument of `baddbmm` op "
61 | "from int32 to float32 dtype for conversion!")
62 | bias = mb.mul(x=beta, y=bias, name=bias.name + "_scaled")
63 |
64 | context.add(bias)
65 |
66 | if alpha.val != 1.0:
67 | # Apply scaling factor alpha to the input.
68 | batch1 = mb.mul(x=alpha, y=batch1, name=batch1.name + "_scaled")
69 | context.add(batch1)
70 |
71 | bmm_node = mb.matmul(x=batch1, y=batch2, name=node.name + "_bmm")
72 | context.add(bmm_node)
73 |
74 | baddbmm_node = mb.add(x=bias, y=bmm_node, name=node.name)
75 | context.add(baddbmm_node)
76 |
77 |
78 | def encoder(pipe, args):
79 | """ Converts the VAE Encoder component of Stable Diffusion
80 | """
81 | out_path = utils.get_out_path(args, "vae_encoder")
82 | if os.path.exists(out_path):
83 | logger.info(f"`vae_encoder` already exists at {out_path}, skipping conversion.")
84 | return
85 |
86 | if not hasattr(pipe, "unet"):
87 | raise RuntimeError(
88 | "convert_unet() deletes pipe.unet to save RAM. "
89 | "Please use convert_vae_encoder() before convert_unet()")
90 |
91 | z_shape = (
92 | 1, # B
93 | 3, # C
94 | args.output_h, # H
95 | args.output_w, # w
96 | )
97 |
98 | sample_vae_encoder_inputs = {
99 | "z": torch.rand(*z_shape, dtype=torch.float16)
100 | }
101 |
102 | class VAEEncoder(nn.Module):
103 | """ Wrapper nn.Module wrapper for pipe.encode() method
104 | """
105 |
106 | def __init__(self):
107 | super().__init__()
108 | self.quant_conv = pipe.vae.quant_conv
109 | self.encoder = pipe.vae.encoder
110 |
111 | def forward(self, z):
112 | return self.quant_conv(self.encoder(z))
113 |
114 | baseline_encoder = VAEEncoder().eval()
115 |
116 | # No optimization needed for the VAE Encoder as it is a pure ConvNet
117 | traced_vae_encoder = torch.jit.trace(baseline_encoder, (sample_vae_encoder_inputs["z"].to(torch.float32), ))
118 |
119 | modify_coremltools_torch_frontend_badbmm()
120 |
121 | # TODO: For now using variable size takes too much memory and time
122 | # if args.multisize:
123 | # sample_size = args.output_h
124 | # input_shape = ct.Shape(shape=(
125 | # 1,
126 | # 3,
127 | # ct.RangeDim(lower_bound=int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
128 | # ct.RangeDim(lower_bound=int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size)
129 | # ))
130 | # sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_encoder_inputs, {"z": input_shape})
131 | # else:
132 | # sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_encoder_inputs)
133 | sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_encoder_inputs)
134 |
135 | # SDXL seems to require full precision
136 | precision_full = args.model_is_sdxl and args.model_version != "stabilityai/stable-diffusion-xl-base-1.0"
137 | coreml_vae_encoder, out_path = utils.convert_to_coreml(
138 | "vae_encoder", traced_vae_encoder, sample_coreml_inputs,
139 | ["latent"], precision_full, args
140 | )
141 |
142 | # Set model metadata
143 | coreml_vae_encoder.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
144 | coreml_vae_encoder.license = "OpenRAIL (https://huggingface.co/spaces/CompVis/stable-diffusion-license)"
145 | coreml_vae_encoder.version = args.model_version
146 | coreml_vae_encoder.short_description = \
147 | "Stable Diffusion generates images conditioned on text and/or other images as input through the diffusion process. " \
148 | "Please refer to https://arxiv.org/abs/2112.10752 for details."
149 |
150 | # Set the input descriptions
151 | coreml_vae_encoder.input_description["z"] = \
152 | "The input image to base the initial latents on normalized to range [-1, 1]"
153 |
154 | # Set the output descriptions
155 | coreml_vae_encoder.output_description["latent"] = "The latent embeddings from the unet model from the input image."
156 |
157 | # Set package version metadata
158 | coreml_vae_encoder.user_defined_metadata["identifier"] = args.model_version
159 | coreml_vae_encoder.user_defined_metadata["converter_version"] = __version__
160 | coreml_vae_encoder.user_defined_metadata["attention_implementation"] = args.attention_implementation
161 | coreml_vae_encoder.user_defined_metadata["compute_unit"] = args.compute_unit
162 | coreml_vae_encoder.user_defined_metadata["scaling_factor"] = str(pipe.vae.config.scaling_factor)
163 | # TODO: Add this key to stop using the hack when variable size works correctly
164 | coreml_vae_encoder.user_defined_metadata["supports_model_size_hack"] = "true"
165 |
166 | coreml_vae_encoder.save(out_path)
167 |
168 | logger.info(f"Saved vae_encoder into {out_path}")
169 |
170 | # Parity check PyTorch vs CoreML
171 | if args.check_output_correctness:
172 | baseline_out = baseline_encoder(z=sample_vae_encoder_inputs["z"].to(torch.float32)).detach().numpy()
173 | coreml_out = list(coreml_vae_encoder.predict({
174 | k: v.numpy() for k, v in sample_vae_encoder_inputs.items()
175 | }).values())[0]
176 | utils.report_correctness(baseline_out, coreml_out,"vae_encoder baseline PyTorch to baseline CoreML")
177 |
178 | del traced_vae_encoder, pipe.vae.encoder, coreml_vae_encoder
179 | gc.collect()
180 |
181 |
182 | def decoder(pipe, args):
183 | """ Converts the VAE Decoder component of Stable Diffusion
184 | """
185 | out_path = utils.get_out_path(args, "vae_decoder")
186 | if os.path.exists(out_path):
187 | logger.info(f"`vae_decoder` already exists at {out_path}, skipping conversion.")
188 | return
189 |
190 | if not hasattr(pipe, "unet"):
191 | raise RuntimeError(
192 | "convert_unet() deletes pipe.unet to save RAM. "
193 | "Please use convert_vae_decoder() before convert_unet()")
194 |
195 | vae_scale_factor = 2 ** (len(pipe.vae.config.block_out_channels) - 1)
196 | height = int(args.output_h / vae_scale_factor)
197 | width = int(args.output_w / vae_scale_factor)
198 | vae_latent_channels = pipe.vae.config.latent_channels
199 | z_shape = (
200 | 1, # B
201 | vae_latent_channels, # C
202 | height, # H
203 | width, # w
204 | )
205 |
206 | sample_vae_decoder_inputs = {
207 | "z": torch.rand(*z_shape, dtype=torch.float16)
208 | }
209 |
210 | class VAEDecoder(nn.Module):
211 | """ Wrapper nn.Module wrapper for pipe.decode() method
212 | """
213 |
214 | def __init__(self):
215 | super().__init__()
216 | self.post_quant_conv = pipe.vae.post_quant_conv
217 | self.decoder = pipe.vae.decoder
218 |
219 | def forward(self, z):
220 | return self.decoder(self.post_quant_conv(z))
221 |
222 | baseline_decoder = VAEDecoder().eval()
223 |
224 | # No optimization needed for the VAE Decoder as it is a pure ConvNet
225 | traced_vae_decoder = torch.jit.trace(baseline_decoder, (sample_vae_decoder_inputs["z"].to(torch.float32), ))
226 |
227 | modify_coremltools_torch_frontend_badbmm()
228 |
229 | # TODO: For now using variable size takes too much memory and time
230 | # if args.multisize:
231 | # sample_size = height
232 | # input_shape = ct.Shape(shape=(
233 | # 1,
234 | # vae_latent_channels,
235 | # ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
236 | # ct.RangeDim(int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size)
237 | # ))
238 | # sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_decoder_inputs, {"z": input_shape})
239 | # else:
240 | # sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_decoder_inputs)
241 | sample_coreml_inputs = utils.get_coreml_inputs(sample_vae_decoder_inputs)
242 |
243 | # SDXL seems to require full precision
244 | precision_full = args.model_is_sdxl and args.model_version != "stabilityai/stable-diffusion-xl-base-1.0"
245 | coreml_vae_decoder, out_path = utils.convert_to_coreml(
246 | "vae_decoder", traced_vae_decoder, sample_coreml_inputs,
247 | ["image"], precision_full, args
248 | )
249 |
250 | # Set model metadata
251 | coreml_vae_decoder.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
252 | coreml_vae_decoder.license = "OpenRAIL (https://huggingface.co/spaces/CompVis/stable-diffusion-license)"
253 | coreml_vae_decoder.version = args.model_version
254 | coreml_vae_decoder.short_description = \
255 | "Stable Diffusion generates images conditioned on text and/or other images as input through the diffusion process. " \
256 | "Please refer to https://arxiv.org/abs/2112.10752 for details."
257 |
258 | # Set the input descriptions
259 | coreml_vae_decoder.input_description["z"] = \
260 | "The denoised latent embeddings from the unet model after the last step of reverse diffusion"
261 |
262 | # Set the output descriptions
263 | coreml_vae_decoder.output_description["image"] = "Generated image normalized to range [-1, 1]"
264 |
265 | # Set package version metadata
266 | coreml_vae_decoder.user_defined_metadata["identifier"] = args.model_version
267 | coreml_vae_decoder.user_defined_metadata["converter_version"] = __version__
268 | coreml_vae_decoder.user_defined_metadata["attention_implementation"] = args.attention_implementation
269 | coreml_vae_decoder.user_defined_metadata["compute_unit"] = args.compute_unit
270 | coreml_vae_decoder.user_defined_metadata["scaling_factor"] = str(pipe.vae.config.scaling_factor)
271 | # TODO: Add this key to stop using the hack when variable size works correctly
272 | coreml_vae_decoder.user_defined_metadata["supports_model_size_hack"] = "true"
273 |
274 | coreml_vae_decoder.save(out_path)
275 |
276 | logger.info(f"Saved vae_decoder into {out_path}")
277 |
278 | # Parity check PyTorch vs CoreML
279 | if args.check_output_correctness:
280 | baseline_out = baseline_decoder(z=sample_vae_decoder_inputs["z"].to(torch.float32)).detach().numpy()
281 | coreml_out = list(coreml_vae_decoder.predict({
282 | k: v.numpy() for k, v in sample_vae_decoder_inputs.items()
283 | }).values())[0]
284 | utils.report_correctness(baseline_out, coreml_out, "vae_decoder baseline PyTorch to baseline CoreML")
285 |
286 | del traced_vae_decoder, pipe.vae.decoder, coreml_vae_decoder
287 | gc.collect()
288 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/utils/chunk_mlprogram.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools.utils import utils
7 |
8 | import argparse
9 | from collections import OrderedDict
10 |
11 | import coremltools as ct
12 | from coremltools.converters.mil import Block, Program, Var
13 | from coremltools.converters.mil.frontend.milproto.load import load as _milproto_to_pymil
14 | from coremltools.converters.mil.mil import Builder as mb
15 | from coremltools.converters.mil.mil import Placeholder
16 | from coremltools.converters.mil.mil import types as types
17 | from coremltools.converters.mil.mil.passes.helper import block_context_manager
18 | from coremltools.converters.mil.mil.passes.pass_registry import PASS_REGISTRY
19 | from coremltools.converters.mil.testing_utils import random_gen_input_feature_type
20 |
21 | import gc
22 |
23 | import logging
24 |
25 | logging.basicConfig()
26 | logger = logging.getLogger(__name__)
27 | logger.setLevel(logging.INFO)
28 |
29 | import numpy as np
30 | import os
31 | import tempfile
32 | from guernikatools import torch2coreml
33 | import shutil
34 | import time
35 |
36 |
37 | def _verify_output_correctness_of_chunks(full_model, first_chunk_model,
38 | second_chunk_model):
39 | """ Verifies the end-to-end output correctness of full (original) model versus chunked models
40 | """
41 | # Generate inputs for first chunk and full model
42 | input_dict = {}
43 | for input_desc in full_model._spec.description.input:
44 | input_dict[input_desc.name] = random_gen_input_feature_type(input_desc)
45 |
46 | # Generate outputs for first chunk and full model
47 | outputs_from_full_model = full_model.predict(input_dict)
48 | outputs_from_first_chunk_model = first_chunk_model.predict(input_dict)
49 |
50 | # Prepare inputs for second chunk model from first chunk's outputs and regular inputs
51 | second_chunk_input_dict = {}
52 | for input_desc in second_chunk_model._spec.description.input:
53 | if input_desc.name in outputs_from_first_chunk_model:
54 | second_chunk_input_dict[
55 | input_desc.name] = outputs_from_first_chunk_model[
56 | input_desc.name]
57 | else:
58 | second_chunk_input_dict[input_desc.name] = input_dict[
59 | input_desc.name]
60 |
61 | # Generate output for second chunk model
62 | outputs_from_second_chunk_model = second_chunk_model.predict(
63 | second_chunk_input_dict)
64 |
65 | # Verify correctness across all outputs from second chunk and full model
66 | for out_name in outputs_from_full_model.keys():
67 | utils.report_correctness(
68 | original_outputs=outputs_from_full_model[out_name],
69 | final_outputs=outputs_from_second_chunk_model[out_name],
70 | log_prefix=f"{out_name}")
71 |
72 |
73 | def _load_prog_from_mlmodel(model):
74 | """ Load MIL Program from an MLModel
75 | """
76 | model_spec = model.get_spec()
77 | start_ = time.time()
78 | logger.info(
79 | "Loading MLModel object into a MIL Program object (including the weights).."
80 | )
81 | prog = _milproto_to_pymil(
82 | model_spec=model_spec,
83 | specification_version=model_spec.specificationVersion,
84 | file_weights_dir=model.weights_dir,
85 | )
86 | logger.info(f"Program loaded in {time.time() - start_:.1f} seconds")
87 |
88 | return prog
89 |
90 |
91 | def _get_op_idx_split_location(prog: Program):
92 | """ Find the op that approximately bisects the graph as measure by weights size on each side
93 | """
94 | main_block = prog.functions["main"]
95 | total_size_in_mb = 0
96 |
97 | for op in main_block.operations:
98 | if op.op_type == "const" and isinstance(op.val.val, np.ndarray):
99 | size_in_mb = op.val.val.size * op.val.val.itemsize / (1024 * 1024)
100 | total_size_in_mb += size_in_mb
101 | half_size = total_size_in_mb / 2
102 |
103 | # Find the first non const op (single child), where the total cumulative size exceeds
104 | # the half size for the first time
105 | cumulative_size_in_mb = 0
106 | for op in main_block.operations:
107 | if op.op_type == "const" and isinstance(op.val.val, np.ndarray):
108 | size_in_mb = op.val.val.size * op.val.val.itemsize / (1024 * 1024)
109 | cumulative_size_in_mb += size_in_mb
110 |
111 | # Note: The condition "not op.op_type.startswith("const")" is to make sure that the
112 | # incision op is neither of type "const" nor "constexpr_*" ops that
113 | # are used to store compressed weights
114 | if (cumulative_size_in_mb > half_size and not op.op_type.startswith("const")
115 | and len(op.outputs) == 1
116 | and len(op.outputs[0].child_ops) == 1):
117 | op_idx = main_block.operations.index(op)
118 | return op_idx, cumulative_size_in_mb, total_size_in_mb
119 |
120 |
121 | def _get_first_chunk_outputs(block, op_idx):
122 | # Get the list of all vars that go across from first program (all ops from 0 to op_idx (inclusive))
123 | # to the second program (all ops from op_idx+1 till the end). These all vars need to be made the output
124 | # of the first program and the input of the second program
125 | boundary_vars = set()
126 | for i in range(op_idx + 1):
127 | op = block.operations[i]
128 | if not op.op_type.startswith("const"):
129 | for var in op.outputs:
130 | if var.val is None: # only consider non const vars
131 | for child_op in var.child_ops:
132 | child_op_idx = block.operations.index(child_op)
133 | if child_op_idx > op_idx:
134 | boundary_vars.add(var)
135 | return list(boundary_vars)
136 |
137 |
138 | @block_context_manager
139 | def _add_fp32_casts(block, boundary_vars):
140 | new_boundary_vars = []
141 | for var in boundary_vars:
142 | if var.dtype != types.fp16:
143 | new_boundary_vars.append(var)
144 | else:
145 | fp32_var = mb.cast(x=var, dtype="fp32", name=var.name)
146 | new_boundary_vars.append(fp32_var)
147 | return new_boundary_vars
148 |
149 |
150 | def _make_first_chunk_prog(prog, op_idx):
151 | """ Build first chunk by declaring early outputs and removing unused subgraph
152 | """
153 | block = prog.functions["main"]
154 | boundary_vars = _get_first_chunk_outputs(block, op_idx)
155 |
156 | # Due to possible numerical issues, cast any fp16 var to fp32
157 | new_boundary_vars = _add_fp32_casts(block, boundary_vars)
158 |
159 | block.outputs.clear()
160 | block.set_outputs(new_boundary_vars)
161 | PASS_REGISTRY["common::dead_code_elimination"](prog)
162 | return prog
163 |
164 |
165 | def _make_second_chunk_prog(prog, op_idx):
166 | """ Build second chunk by rebuilding a pristine MIL Program from MLModel
167 | """
168 | block = prog.functions["main"]
169 | block.opset_version = ct.target.iOS16
170 |
171 | # First chunk outputs are second chunk inputs (e.g. skip connections)
172 | boundary_vars = _get_first_chunk_outputs(block, op_idx)
173 |
174 | # This op will not be included in this program. Its output var will be made into an input
175 | boundary_op = block.operations[op_idx]
176 |
177 | # Add all boundary ops as inputs
178 | with block:
179 | for var in boundary_vars:
180 | new_placeholder = Placeholder(
181 | sym_shape=var.shape,
182 | dtype=var.dtype if var.dtype != types.fp16 else types.fp32,
183 | name=var.name,
184 | )
185 |
186 | block._input_dict[
187 | new_placeholder.outputs[0].name] = new_placeholder.outputs[0]
188 |
189 | block.function_inputs = tuple(block._input_dict.values())
190 | new_var = None
191 | if var.dtype == types.fp16:
192 | new_var = mb.cast(x=new_placeholder.outputs[0],
193 | dtype="fp16",
194 | before_op=var.op)
195 | else:
196 | new_var = new_placeholder.outputs[0]
197 |
198 | block.replace_uses_of_var_after_op(
199 | anchor_op=boundary_op,
200 | old_var=var,
201 | new_var=new_var,
202 | # This is needed if the program contains "constexpr_*" ops. In normal cases, there are stricter
203 | # rules for removing them, and their presence may prevent replacing this var.
204 | # However in this case, since we want to remove all the ops in chunk 1, we can safely
205 | # set this to True.
206 | force_replace=True,
207 | )
208 |
209 | PASS_REGISTRY["common::dead_code_elimination"](prog)
210 |
211 | # Remove any unused inputs
212 | new_input_dict = OrderedDict()
213 | for k, v in block._input_dict.items():
214 | if len(v.child_ops) > 0:
215 | new_input_dict[k] = v
216 | block._input_dict = new_input_dict
217 | block.function_inputs = tuple(block._input_dict.values())
218 |
219 | return prog
220 |
221 |
222 | def main(args):
223 | os.makedirs(args.o, exist_ok=True)
224 |
225 | # Check filename extension
226 | mlpackage_name = os.path.basename(args.mlpackage_path)
227 | name, ext = os.path.splitext(mlpackage_name)
228 | assert ext == ".mlpackage", f"`--mlpackage-path` (args.mlpackage_path) is not an .mlpackage file"
229 |
230 | # Load CoreML model
231 | logger.info("Loading model from {}".format(args.mlpackage_path))
232 | start_ = time.time()
233 | model = ct.models.MLModel(
234 | args.mlpackage_path,
235 | compute_units=ct.ComputeUnit.CPU_ONLY,
236 | )
237 | logger.info(
238 | f"Loading {args.mlpackage_path} took {time.time() - start_:.1f} seconds"
239 | )
240 |
241 | # Load the MIL Program from MLModel
242 | prog = _load_prog_from_mlmodel(model)
243 |
244 | # Compute the incision point by bisecting the program based on weights size
245 | op_idx, first_chunk_weights_size, total_weights_size = _get_op_idx_split_location(
246 | prog)
247 | main_block = prog.functions["main"]
248 | incision_op = main_block.operations[op_idx]
249 | logger.info(f"{args.mlpackage_path} will chunked into two pieces.")
250 | logger.info(
251 | f"The incision op: name={incision_op.name}, type={incision_op.op_type}, index={op_idx}/{len(main_block.operations)}"
252 | )
253 | logger.info(f"First chunk size = {first_chunk_weights_size:.2f} MB")
254 | logger.info(
255 | f"Second chunk size = {total_weights_size - first_chunk_weights_size:.2f} MB"
256 | )
257 |
258 | # Build first chunk (in-place modifies prog by declaring early exits and removing unused subgraph)
259 | prog_chunk1 = _make_first_chunk_prog(prog, op_idx)
260 |
261 | # Build the second chunk
262 | prog_chunk2 = _make_second_chunk_prog(_load_prog_from_mlmodel(model), op_idx)
263 |
264 | user_defined_metadata = model.user_defined_metadata
265 |
266 | if not args.check_output_correctness:
267 | # Original model no longer needed in memory
268 | del model
269 | gc.collect()
270 |
271 | # Convert the MIL Program objects into MLModels
272 | logger.info("Converting the two programs")
273 | model_chunk1 = ct.convert(
274 | prog_chunk1,
275 | convert_to="mlprogram",
276 | compute_units=ct.ComputeUnit.CPU_ONLY,
277 | minimum_deployment_target=ct.target.iOS16,
278 | )
279 | del prog_chunk1
280 | gc.collect()
281 | logger.info("Conversion of first chunk done.")
282 |
283 | model_chunk2 = ct.convert(
284 | prog_chunk2,
285 | convert_to="mlprogram",
286 | compute_units=ct.ComputeUnit.CPU_ONLY,
287 | minimum_deployment_target=ct.target.iOS16,
288 | )
289 | del prog_chunk2
290 | gc.collect()
291 | logger.info("Conversion of second chunk done.")
292 |
293 | for key in user_defined_metadata:
294 | if "com.github.apple" not in key:
295 | model_chunk1.user_defined_metadata[key] = user_defined_metadata[key]
296 | model_chunk2.user_defined_metadata[key] = user_defined_metadata[key]
297 |
298 | # Verify output correctness
299 | if args.check_output_correctness:
300 | logger.info("Verifying output correctness of chunks")
301 | _verify_output_correctness_of_chunks(
302 | full_model=model,
303 | first_chunk_model=model_chunk1,
304 | second_chunk_model=model_chunk2,
305 | )
306 |
307 | # Remove original (non-chunked) model if requested
308 | if args.remove_original:
309 | logger.info(
310 | "Removing original (non-chunked) model at {args.mlpackage_path}")
311 | shutil.rmtree(args.mlpackage_path)
312 | logger.info("Done.")
313 |
314 | # Save the chunked models to disk
315 | out_path_chunk1 = os.path.join(args.o, name + "_chunk1.mlpackage")
316 | out_path_chunk2 = os.path.join(args.o, name + "_chunk2.mlpackage")
317 | if args.clean_up_mlpackages:
318 | temp_dir = tempfile.gettempdir()
319 | out_path_chunk1 = os.path.join(temp_dir, name + "_chunk1.mlpackage")
320 | out_path_chunk2 = os.path.join(temp_dir, name + "_chunk2.mlpackage")
321 |
322 | logger.info(
323 | f"Saved chunks in {args.o} with the suffix _chunk1.mlpackage and _chunk2.mlpackage"
324 | )
325 | model_chunk1.save(out_path_chunk1)
326 | model_chunk2.save(out_path_chunk2)
327 | logger.info("Done.")
328 |
329 |
330 | if __name__ == "__main__":
331 | parser = argparse.ArgumentParser()
332 | parser.add_argument(
333 | "--mlpackage-path",
334 | required=True,
335 | help=
336 | "Path to the mlpackage file to be split into two mlpackages of approximately same file size.",
337 | )
338 | parser.add_argument(
339 | "-o",
340 | required=True,
341 | help=
342 | "Path to output directory where the two model chunks should be saved.",
343 | )
344 | parser.add_argument(
345 | "--clean-up-mlpackages",
346 | action="store_true",
347 | help="Removes mlpackages after a successful convesion.")
348 | parser.add_argument(
349 | "--remove-original",
350 | action="store_true",
351 | help=
352 | "If specified, removes the original (non-chunked) model to avoid duplicating storage."
353 | )
354 | parser.add_argument(
355 | "--check-output-correctness",
356 | action="store_true",
357 | help=
358 | ("If specified, compares the outputs of original Core ML model with that of pipelined CoreML model chunks and reports PSNR in dB. ",
359 | "Enabling this feature uses more memory. Disable it if your machine runs out of memory."
360 | ))
361 |
362 | args = parser.parse_args()
363 | main(args)
364 |
--------------------------------------------------------------------------------
/GuernikaTools/guernikatools/convert/convert_unet.py:
--------------------------------------------------------------------------------
1 | #
2 | # For licensing see accompanying LICENSE.md file.
3 | # Copyright (C) 2022 Apple Inc. All Rights Reserved.
4 | #
5 |
6 | from guernikatools._version import __version__
7 | from guernikatools.utils import utils, chunk_mlprogram
8 | from guernikatools.models import attention, unet
9 |
10 | from collections import OrderedDict, defaultdict
11 | from copy import deepcopy
12 | import coremltools as ct
13 | import gc
14 |
15 | import logging
16 |
17 | logging.basicConfig()
18 | logger = logging.getLogger(__name__)
19 | logger.setLevel(logging.INFO)
20 |
21 | import numpy as np
22 | import os
23 |
24 | import torch
25 | import torch.nn as nn
26 | import torch.nn.functional as F
27 |
28 | torch.set_grad_enabled(False)
29 |
30 |
31 | def main(pipe, args):
32 | """ Converts the UNet component of Stable Diffusion
33 | """
34 | out_path = utils.get_out_path(args, "unet")
35 |
36 | # Check if Unet was previously exported and then chunked
37 | unet_chunks_exist = all(
38 | os.path.exists(out_path.replace(".mlpackage", f"_chunk{idx+1}.mlpackage")) for idx in range(2)
39 | )
40 |
41 | if args.chunk_unet and unet_chunks_exist:
42 | logger.info("`unet` chunks already exist, skipping conversion.")
43 | del pipe.unet
44 | gc.collect()
45 | return
46 |
47 | # If original Unet does not exist, export it from PyTorch+diffusers
48 | elif not os.path.exists(out_path):
49 | # Register the selected attention implementation globally
50 | attention.ATTENTION_IMPLEMENTATION_IN_EFFECT = attention.AttentionImplementations[args.attention_implementation]
51 | logger.info(f"Attention implementation in effect: {attention.ATTENTION_IMPLEMENTATION_IN_EFFECT}")
52 |
53 | # Prepare sample input shapes and values
54 | batch_size = 2 # for classifier-free guidance
55 | unet_in_channels = pipe.unet.config.in_channels
56 | # allow converting instruct pix2pix
57 | if unet_in_channels == 8:
58 | batch_size = 3
59 | vae_scale_factor = 2 ** (len(pipe.vae.config.block_out_channels) - 1)
60 | height = int(args.output_h / vae_scale_factor)
61 | width = int(args.output_w / vae_scale_factor)
62 |
63 | sample_shape = (
64 | batch_size, # B
65 | unet_in_channels, # C
66 | height, # H
67 | width, # W
68 | )
69 |
70 | max_position_embeddings = 77
71 | if hasattr(pipe, "text_encoder") and pipe.text_encoder and pipe.text_encoder.config:
72 | max_position_embeddings = pipe.text_encoder.config.max_position_embeddings
73 | elif hasattr(pipe, "text_encoder_2") and pipe.text_encoder_2 and pipe.text_encoder_2.config:
74 | max_position_embeddings = pipe.text_encoder_2.config.max_position_embeddings
75 | else:
76 | raise RuntimeError(
77 | "convert_text_encoder() deletes pipe.text_encoder to save RAM. "
78 | "Please use convert_unet() before convert_text_encoder()")
79 |
80 | args.hidden_size = pipe.unet.config.cross_attention_dim
81 | encoder_hidden_states_shape = (
82 | batch_size,
83 | args.hidden_size,
84 | 1,
85 | max_position_embeddings,
86 | )
87 |
88 | # Create the scheduled timesteps for downstream use
89 | DEFAULT_NUM_INFERENCE_STEPS = 50
90 | pipe.scheduler.set_timesteps(DEFAULT_NUM_INFERENCE_STEPS)
91 |
92 | sample_unet_inputs = [
93 | ("sample", torch.rand(*sample_shape)),
94 | ("timestep", torch.tensor([pipe.scheduler.timesteps[0].item()] * (batch_size)).to(torch.float32)),
95 | ("encoder_hidden_states", torch.rand(*encoder_hidden_states_shape)),
96 | ]
97 |
98 | args.requires_aesthetics_score = False
99 | if hasattr(pipe.unet.config, "addition_embed_type") and pipe.unet.config.addition_embed_type == "text_time":
100 | text_embeds_shape = (
101 | batch_size,
102 | pipe.text_encoder_2.config.hidden_size,
103 | )
104 | time_ids_input = None
105 | if hasattr(pipe.config, "requires_aesthetics_score") and pipe.config.requires_aesthetics_score:
106 | args.requires_aesthetics_score = True
107 | time_ids_input = [
108 | [args.output_h, args.output_w, 0, 0, 2.5],
109 | [args.output_h, args.output_w, 0, 0, 6]
110 | ]
111 | else:
112 | time_ids_input = [
113 | [args.output_h, args.output_w, 0, 0, args.output_h, args.output_w],
114 | [args.output_h, args.output_w, 0, 0, args.output_h, args.output_w]
115 | ]
116 | sample_unet_inputs = sample_unet_inputs + [
117 | ("text_embeds", torch.rand(*text_embeds_shape)),
118 | ("time_ids", torch.tensor(time_ids_input).to(torch.float32)),
119 | ]
120 |
121 | if args.controlnet_support:
122 | block_out_channels = pipe.unet.config.block_out_channels
123 |
124 | cn_output = 0
125 | cn_height = height
126 | cn_width = width
127 |
128 | # down
129 | output_channel = block_out_channels[0]
130 | sample_unet_inputs = sample_unet_inputs + [
131 | (f"down_block_res_samples_{cn_output:02}", torch.rand(2, output_channel, cn_height, cn_width))
132 | ]
133 | cn_output += 1
134 |
135 | for i, output_channel in enumerate(block_out_channels):
136 | is_final_block = i == len(block_out_channels) - 1
137 | sample_unet_inputs = sample_unet_inputs + [
138 | (f"down_block_res_samples_{cn_output:02}", torch.rand(2, output_channel, cn_height, cn_width)),
139 | (f"down_block_res_samples_{cn_output+1:02}", torch.rand(2, output_channel, cn_height, cn_width)),
140 | ]
141 | cn_output += 2
142 | if not is_final_block:
143 | cn_height = int(cn_height / 2)
144 | cn_width = int(cn_width / 2)
145 | sample_unet_inputs = sample_unet_inputs + [
146 | (f"down_block_res_samples_{cn_output:02}", torch.rand(2, output_channel, cn_height, cn_width)),
147 | ]
148 | cn_output += 1
149 |
150 | # mid
151 | output_channel = block_out_channels[-1]
152 | sample_unet_inputs = sample_unet_inputs + [
153 | ("mid_block_res_sample", torch.rand(2, output_channel, cn_height, cn_width))
154 | ]
155 |
156 | if args.t2i_adapter_support:
157 | block_out_channels = pipe.unet.config.block_out_channels
158 |
159 | if args.model_is_sdxl:
160 | t2ia_height = int(height / 2)
161 | t2ia_width = int(width / 2)
162 | else:
163 | t2ia_height = height
164 | t2ia_width = width
165 |
166 | for i, output_channel in enumerate(block_out_channels):
167 | sample_unet_inputs = sample_unet_inputs + [
168 | (f"adapter_res_samples_{i:02}", torch.rand(2, output_channel, t2ia_height, t2ia_width)),
169 | ]
170 | if not args.model_is_sdxl or i == 1:
171 | t2ia_height = int(t2ia_height / 2)
172 | t2ia_width = int(t2ia_width / 2)
173 |
174 | multisize_inputs = None
175 | if args.multisize:
176 | sample_size = height
177 | input_shape = ct.Shape(shape=(
178 | batch_size,
179 | unet_in_channels,
180 | ct.RangeDim(lower_bound=int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size),
181 | ct.RangeDim(lower_bound=int(sample_size * 0.5), upper_bound=int(sample_size * 2), default=sample_size)
182 | ))
183 | multisize_inputs = {"sample": input_shape}
184 | for k, v in sample_unet_inputs:
185 | if "res_sample" in k:
186 | v_height = v.shape[2]
187 | v_width = v.shape[3]
188 | multisize_inputs[k] = ct.Shape(shape=(
189 | 2,
190 | output_channel,
191 | ct.RangeDim(lower_bound=int(v_height * 0.5), upper_bound=int(v_height * 2), default=v_height),
192 | ct.RangeDim(lower_bound=int(v_width * 0.5), upper_bound=int(v_width * 2), default=v_width)
193 | ))
194 |
195 | sample_unet_inputs = OrderedDict(sample_unet_inputs)
196 | sample_unet_inputs_spec = {
197 | k: (v.shape, v.dtype)
198 | for k, v in sample_unet_inputs.items()
199 | }
200 | logger.info(f"Sample inputs spec: {sample_unet_inputs_spec}")
201 |
202 | # Initialize reference unet
203 | reference_unet = unet.UNet2DConditionModel(**pipe.unet.config).eval()
204 | load_state_dict_summary = reference_unet.load_state_dict(pipe.unet.state_dict())
205 |
206 | # Prepare inputs
207 | baseline_sample_unet_inputs = deepcopy(sample_unet_inputs)
208 | baseline_sample_unet_inputs[
209 | "encoder_hidden_states"] = baseline_sample_unet_inputs[
210 | "encoder_hidden_states"].squeeze(2).transpose(1, 2)
211 |
212 | if not args.check_output_correctness:
213 | del pipe.unet
214 | gc.collect()
215 |
216 | # JIT trace
217 | logger.info("JIT tracing..")
218 | reference_unet = torch.jit.trace(reference_unet, example_kwarg_inputs=sample_unet_inputs)
219 | logger.info("Done.")
220 |
221 | if args.check_output_correctness:
222 | baseline_out = pipe.unet(
223 | sample=baseline_sample_unet_inputs["sample"],
224 | timestep=baseline_sample_unet_inputs["timestep"],
225 | encoder_hidden_states=baseline_sample_unet_inputs["encoder_hidden_states"],
226 | return_dict=False
227 | )[0].detach().numpy()
228 | reference_out = reference_unet(**sample_unet_inputs)[0].detach().numpy()
229 | utils.report_correctness(baseline_out, reference_out, "unet baseline to reference PyTorch")
230 |
231 | del pipe.unet
232 | gc.collect()
233 |
234 | coreml_sample_unet_inputs = {
235 | k: v.numpy().astype(np.float16)
236 | for k, v in sample_unet_inputs.items()
237 | }
238 |
239 | sample_coreml_inputs = utils.get_coreml_inputs(coreml_sample_unet_inputs, multisize_inputs)
240 | precision_full = args.precision_full
241 | if not precision_full and pipe.scheduler.config.prediction_type == "v_prediction":
242 | precision_full = True
243 | logger.info(f"Full precision required: prediction_type == v_prediction")
244 | coreml_unet, out_path = utils.convert_to_coreml(
245 | "unet",
246 | reference_unet,
247 | sample_coreml_inputs,
248 | ["noise_pred"],
249 | precision_full,
250 | args
251 | )
252 | del reference_unet
253 | gc.collect()
254 |
255 | update_coreml_unet(pipe, coreml_unet, out_path, args)
256 | logger.info(f"Saved unet into {out_path}")
257 |
258 | # Parity check PyTorch vs CoreML
259 | if args.check_output_correctness:
260 | coreml_out = list(coreml_unet.predict(coreml_sample_unet_inputs).values())[0]
261 | utils.report_correctness(baseline_out, coreml_out, "unet baseline PyTorch to reference CoreML")
262 |
263 | del coreml_unet
264 | gc.collect()
265 | else:
266 | del pipe.unet
267 | gc.collect()
268 | logger.info(f"`unet` already exists at {out_path}, skipping conversion.")
269 |
270 | if args.chunk_unet and not unet_chunks_exist:
271 | logger.info("Chunking unet in two approximately equal MLModels")
272 | args.mlpackage_path = out_path
273 | args.remove_original = False
274 | chunk_mlprogram.main(args)
275 |
276 |
277 | def update_coreml_unet(pipe, coreml_unet, out_path, args):
278 | # make ControlNet/T2IAdapter inputs optional
279 | coreml_spec = coreml_unet.get_spec()
280 | for index, input_spec in enumerate(coreml_spec.description.input):
281 | if "res_sample" in input_spec.name:
282 | coreml_spec.description.input[index].type.isOptional = True
283 | coreml_unet = ct.models.MLModel(coreml_spec, skip_model_load=True, weights_dir=coreml_unet.weights_dir)
284 |
285 | # Set model metadata
286 | coreml_unet.author = f"Please refer to the Model Card available at huggingface.co/{args.model_version}"
287 | coreml_unet.license = "OpenRAIL (https://huggingface.co/spaces/CompVis/stable-diffusion-license)"
288 | coreml_unet.version = args.model_version
289 | coreml_unet.short_description = \
290 | "Stable Diffusion generates images conditioned on text or other images as input through the diffusion process. " \
291 | "Please refer to https://arxiv.org/abs/2112.10752 for details."
292 |
293 | # Set the input descriptions
294 | coreml_unet.input_description["sample"] = \
295 | "The low resolution latent feature maps being denoised through reverse diffusion"
296 | coreml_unet.input_description["timestep"] = \
297 | "A value emitted by the associated scheduler object to condition the model on a given noise schedule"
298 | coreml_unet.input_description["encoder_hidden_states"] = \
299 | "Output embeddings from the associated text_encoder model to condition to generated image on text. " \
300 | "A maximum of 77 tokens (~40 words) are allowed. Longer text is truncated. " \
301 | "Shorter text does not reduce computation."
302 | if hasattr(pipe, "text_encoder_2") and pipe.text_encoder_2:
303 | coreml_unet.input_description["text_embeds"] = ""
304 | coreml_unet.input_description["time_ids"] = ""
305 | if args.t2i_adapter_support:
306 | coreml_unet.input_description["adapter_res_samples_00"] = "Optional: Residual down sample from T2IAdapter"
307 | if args.controlnet_support:
308 | coreml_unet.input_description["down_block_res_samples_00"] = "Optional: Residual down sample from ControlNet"
309 | coreml_unet.input_description["mid_block_res_sample"] = "Optional: Residual mid sample from ControlNet"
310 |
311 | # Set the output descriptions
312 | coreml_unet.output_description["noise_pred"] = \
313 | "Same shape and dtype as the `sample` input. " \
314 | "The predicted noise to facilitate the reverse diffusion (denoising) process"
315 |
316 | # Set package version metadata
317 | coreml_unet.user_defined_metadata["identifier"] = args.model_version
318 | coreml_unet.user_defined_metadata["converter_version"] = __version__
319 | coreml_unet.user_defined_metadata["attention_implementation"] = args.attention_implementation
320 | coreml_unet.user_defined_metadata["compute_unit"] = args.compute_unit
321 | coreml_unet.user_defined_metadata["prediction_type"] = pipe.scheduler.config.prediction_type
322 | coreml_unet.user_defined_metadata["hidden_size"] = str(args.hidden_size)
323 | if args.requires_aesthetics_score:
324 | coreml_unet.user_defined_metadata["requires_aesthetics_score"] = "true"
325 |
326 | coreml_unet.save(out_path)
327 |
--------------------------------------------------------------------------------
/GuernikaModelConverter/Model/ConverterProcess.swift:
--------------------------------------------------------------------------------
1 | //
2 | // ConverterProcess.swift
3 | // GuernikaModelConverter
4 | //
5 | // Created by Guillermo Cique Fernández on 30/3/23.
6 | //
7 |
8 | import Combine
9 | import Foundation
10 |
11 | extension Process: Cancellable {
12 | public func cancel() {
13 | terminate()
14 | }
15 | }
16 |
17 | class ConverterProcess: ObservableObject {
18 | enum ArgumentError: Error {
19 | case noOutputLocation
20 | case noHuggingfaceIdentifier
21 | case noDiffusersLocation
22 | case noCheckpointLocation
23 | }
24 | enum Step: Int, Identifiable, CustomStringConvertible {
25 | case initialize = 0
26 | case loadEmbeddings
27 | case convertVaeEncoder
28 | case convertVaeDecoder
29 | case convertUnet
30 | case convertTextEncoder
31 | case convertSafetyChecker
32 | case convertControlNet
33 | case compressOutput
34 | case cleanUp
35 | case done
36 |
37 | var id: Int { rawValue }
38 |
39 | var description: String {
40 | switch self {
41 | case .initialize:
42 | return "Initialize"
43 | case .loadEmbeddings:
44 | return "Load embeddings"
45 | case .convertVaeEncoder:
46 | return "Convert Encoder"
47 | case .convertVaeDecoder:
48 | return "Convert Decoder"
49 | case .convertUnet:
50 | return "Convert Unet"
51 | case .convertTextEncoder:
52 | return "Convert Text encoder"
53 | case .convertSafetyChecker:
54 | return "Convert Safety checker"
55 | case .convertControlNet:
56 | return "Convert ControlNet"
57 | case .compressOutput:
58 | return "Compress"
59 | case .cleanUp:
60 | return "Clean up"
61 | case .done:
62 | return "Done"
63 | }
64 | }
65 | }
66 | struct StepProgress: CustomStringConvertible {
67 | let step: String
68 | let etaString: String
69 | var percentage: Float
70 |
71 | var description: String { "\(step).\(etaString)" }
72 | }
73 |
74 | let process: Process
75 | let steps: [Step]
76 | @Published var currentStep: Step = .initialize
77 | @Published var currentProgress: StepProgress?
78 | var didComplete: Bool {
79 | currentStep == .done && !process.isRunning
80 | }
81 |
82 | init(
83 | outputLocation: URL?,
84 | modelOrigin: ModelOrigin,
85 | huggingfaceIdentifier: String,
86 | diffusersLocation: URL?,
87 | checkpointLocation: URL?,
88 | computeUnits: ComputeUnits,
89 | customWidth: Int?,
90 | customHeight: Int?,
91 | multisize: Bool,
92 | convertUnet: Bool,
93 | chunkUnet: Bool,
94 | controlNetSupport: Bool,
95 | convertTextEncoder: Bool,
96 | embeddingsLocation: URL?,
97 | convertVaeEncoder: Bool,
98 | convertVaeDecoder: Bool,
99 | convertSafetyChecker: Bool,
100 | precisionFull: Bool,
101 | loRAsToMerge: [LoRAInfo] = [],
102 | compression: Compression
103 | ) throws {
104 | guard let outputLocation else {
105 | throw ArgumentError.noOutputLocation
106 | }
107 | var steps: [Step] = [.initialize]
108 | var arguments: [String] = [
109 | "-o", outputLocation.path(percentEncoded: false),
110 | "--bundle-resources-for-guernika",
111 | "--clean-up-mlpackages",
112 | "--compute-unit", "\(computeUnits.asCTComputeUnits)"
113 | ]
114 |
115 | switch modelOrigin {
116 | case .huggingface:
117 | guard !huggingfaceIdentifier.isEmpty else {
118 | throw ArgumentError.noHuggingfaceIdentifier
119 | }
120 | arguments.append("--model-version")
121 | arguments.append(huggingfaceIdentifier)
122 | arguments.append("--resources-dir-name")
123 | arguments.append(huggingfaceIdentifier)
124 | case .diffusers:
125 | guard let diffusersLocation else {
126 | throw ArgumentError.noDiffusersLocation
127 | }
128 | arguments.append("--model-location")
129 | arguments.append(diffusersLocation.path(percentEncoded: false))
130 | arguments.append("--resources-dir-name")
131 | arguments.append(diffusersLocation.lastPathComponent)
132 | arguments.append("--model-version")
133 | arguments.append(diffusersLocation.lastPathComponent)
134 | case .checkpoint:
135 | guard let checkpointLocation else {
136 | throw ArgumentError.noCheckpointLocation
137 | }
138 | arguments.append("--model-checkpoint-location")
139 | arguments.append(checkpointLocation.path(percentEncoded: false))
140 | arguments.append("--resources-dir-name")
141 | arguments.append(checkpointLocation.deletingPathExtension().lastPathComponent)
142 | arguments.append("--model-version")
143 | arguments.append(checkpointLocation.deletingPathExtension().lastPathComponent)
144 | }
145 |
146 | if computeUnits == .cpuAndGPU {
147 | arguments.append("--attention-implementation")
148 | arguments.append("ORIGINAL")
149 | } else {
150 | arguments.append("--attention-implementation")
151 | arguments.append("SPLIT_EINSUM_V2")
152 | }
153 |
154 | if let embeddingsLocation {
155 | steps.append(.loadEmbeddings)
156 | arguments.append("--embeddings-location")
157 | arguments.append(embeddingsLocation.path(percentEncoded: false))
158 | }
159 |
160 | if convertVaeEncoder {
161 | steps.append(.convertVaeEncoder)
162 | arguments.append("--convert-vae-encoder")
163 | }
164 | if convertVaeDecoder {
165 | steps.append(.convertVaeDecoder)
166 | arguments.append("--convert-vae-decoder")
167 | }
168 | if convertUnet {
169 | steps.append(.convertUnet)
170 | arguments.append("--convert-unet")
171 | if chunkUnet {
172 | arguments.append("--chunk-unet")
173 | }
174 | if controlNetSupport {
175 | arguments.append("--controlnet-support")
176 | }
177 | }
178 | if convertTextEncoder {
179 | steps.append(.convertTextEncoder)
180 | arguments.append("--convert-text-encoder")
181 | }
182 | if convertSafetyChecker {
183 | steps.append(.convertSafetyChecker)
184 | arguments.append("--convert-safety-checker")
185 | }
186 |
187 | if !loRAsToMerge.isEmpty {
188 | arguments.append("--loras-to-merge")
189 | for loRA in loRAsToMerge {
190 | arguments.append(loRA.argument)
191 | }
192 | }
193 |
194 | if #available(macOS 14.0, *) {
195 | switch compression {
196 | case .quantizied6bit:
197 | arguments.append("--quantize-nbits")
198 | arguments.append("6")
199 | if convertUnet || convertTextEncoder {
200 | steps.append(.compressOutput)
201 | }
202 | case .quantizied8bit:
203 | arguments.append("--quantize-nbits")
204 | arguments.append("8")
205 | if convertUnet || convertTextEncoder {
206 | steps.append(.compressOutput)
207 | }
208 | case .fullSize:
209 | break
210 | }
211 | }
212 |
213 | if precisionFull {
214 | arguments.append("--precision-full")
215 | }
216 |
217 | if let customWidth {
218 | arguments.append("--output-w")
219 | arguments.append(String(describing: customWidth))
220 | }
221 | if let customHeight {
222 | arguments.append("--output-h")
223 | arguments.append(String(describing: customHeight))
224 | }
225 | if multisize {
226 | arguments.append("--multisize")
227 | }
228 |
229 | let process = Process()
230 | let pipe = Pipe()
231 | process.standardOutput = pipe
232 | process.standardError = pipe
233 | process.standardInput = nil
234 |
235 | process.executableURL = Bundle.main.url(forAuxiliaryExecutable: "GuernikaTools")!
236 | print("Arguments", arguments)
237 | process.arguments = arguments
238 | self.process = process
239 | steps.append(.cleanUp)
240 | self.steps = steps
241 |
242 | pipe.fileHandleForReading.readabilityHandler = { handle in
243 | let data = handle.availableData
244 | if data.count > 0 {
245 | if let newLine = String(data: data, encoding: .utf8) {
246 | self.handleOutput(newLine)
247 | }
248 | }
249 | }
250 | }
251 |
252 | init(
253 | outputLocation: URL?,
254 | controlNetOrigin: ModelOrigin,
255 | huggingfaceIdentifier: String,
256 | diffusersLocation: URL?,
257 | checkpointLocation: URL?,
258 | computeUnits: ComputeUnits,
259 | customWidth: Int?,
260 | customHeight: Int?,
261 | multisize: Bool,
262 | compression: Compression
263 | ) throws {
264 | guard let outputLocation else {
265 | throw ArgumentError.noOutputLocation
266 | }
267 | var steps: [Step] = [.initialize, .convertControlNet]
268 | var arguments: [String] = [
269 | "-o", outputLocation.path(percentEncoded: false),
270 | "--bundle-resources-for-guernika",
271 | "--clean-up-mlpackages",
272 | "--compute-unit", "\(computeUnits.asCTComputeUnits)"
273 | ]
274 |
275 | switch controlNetOrigin {
276 | case .huggingface:
277 | guard !huggingfaceIdentifier.isEmpty else {
278 | throw ArgumentError.noHuggingfaceIdentifier
279 | }
280 | arguments.append("--controlnet-version")
281 | arguments.append(huggingfaceIdentifier)
282 | arguments.append("--resources-dir-name")
283 | arguments.append(huggingfaceIdentifier)
284 | case .diffusers:
285 | guard let diffusersLocation else {
286 | throw ArgumentError.noDiffusersLocation
287 | }
288 | arguments.append("--controlnet-location")
289 | arguments.append(diffusersLocation.path(percentEncoded: false))
290 | arguments.append("--resources-dir-name")
291 | arguments.append(diffusersLocation.lastPathComponent)
292 | arguments.append("--controlnet-version")
293 | arguments.append(diffusersLocation.lastPathComponent)
294 | case .checkpoint:
295 | guard let checkpointLocation else {
296 | throw ArgumentError.noCheckpointLocation
297 | }
298 | arguments.append("--controlnet-checkpoint-location")
299 | arguments.append(checkpointLocation.path(percentEncoded: false))
300 | arguments.append("--resources-dir-name")
301 | arguments.append(checkpointLocation.deletingPathExtension().lastPathComponent)
302 | arguments.append("--controlnet-version")
303 | arguments.append(checkpointLocation.deletingPathExtension().lastPathComponent)
304 | }
305 |
306 | if computeUnits == .cpuAndGPU {
307 | arguments.append("--attention-implementation")
308 | arguments.append("ORIGINAL")
309 | } else {
310 | arguments.append("--attention-implementation")
311 | arguments.append("SPLIT_EINSUM_V2")
312 | }
313 |
314 | if let customWidth {
315 | arguments.append("--output-w")
316 | arguments.append(String(describing: customWidth))
317 | }
318 | if let customHeight {
319 | arguments.append("--output-h")
320 | arguments.append(String(describing: customHeight))
321 | }
322 | if multisize {
323 | arguments.append("--multisize")
324 | }
325 |
326 | if #available(macOS 14.0, *) {
327 | switch compression {
328 | case .quantizied6bit:
329 | arguments.append("--quantize-nbits")
330 | arguments.append("6")
331 | steps.append(.compressOutput)
332 | case .quantizied8bit:
333 | arguments.append("--quantize-nbits")
334 | arguments.append("8")
335 | steps.append(.compressOutput)
336 | case .fullSize:
337 | break
338 | }
339 | }
340 |
341 | let process = Process()
342 | let pipe = Pipe()
343 | process.standardOutput = pipe
344 | process.standardError = pipe
345 | process.standardInput = nil
346 |
347 | process.executableURL = Bundle.main.url(forAuxiliaryExecutable: "GuernikaTools")!
348 | print("Arguments", arguments)
349 | process.arguments = arguments
350 | self.process = process
351 | steps.append(.cleanUp)
352 | self.steps = steps
353 |
354 | pipe.fileHandleForReading.readabilityHandler = { handle in
355 | let data = handle.availableData
356 | if data.count > 0 {
357 | if let newLine = String(data: data, encoding: .utf8) {
358 | self.handleOutput(newLine)
359 | }
360 | }
361 | }
362 | }
363 |
364 | private func handleOutput(_ newLine: String) {
365 | let isProgressStep = newLine.starts(with: "\r")
366 | let newLine = newLine.trimmingCharacters(in: .whitespacesAndNewlines)
367 | if isProgressStep {
368 | if
369 | let match = newLine.firstMatch(#": *?(\d*)%.*\|(.*)"#),
370 | let percentageRange = Range(match.range(at: 1), in: newLine),
371 | let percentage = Int(newLine[percentageRange]),
372 | let etaRange = Range(match.range(at: 2), in: newLine)
373 | {
374 | let etaString = String(newLine[etaRange])
375 | if newLine.starts(with: "Running MIL") || newLine.starts(with: "Running compression pass") {
376 | currentProgress = StepProgress(
377 | step: String(newLine.split(separator: ":")[0]),
378 | etaString: etaString,
379 | percentage: Float(percentage) / 100
380 | )
381 | } else {
382 | currentProgress = nil
383 | }
384 | }
385 | DispatchQueue.main.async {
386 | Logger.shared.append(newLine, level: .success)
387 | }
388 | return
389 | }
390 |
391 | if
392 | let match = newLine.firstMatch(#"INFO:.*Converting ([^\s]+)$"#),
393 | let moduleRange = Range(match.range(at: 1), in: newLine)
394 | {
395 | let module = String(newLine[moduleRange])
396 | currentProgress = nil
397 | switch module {
398 | case "vae_encoder":
399 | currentStep = .convertVaeEncoder
400 | case "vae_decoder":
401 | currentStep = .convertVaeDecoder
402 | case "unet":
403 | currentStep = .convertUnet
404 | case "text_encoder":
405 | currentStep = .convertTextEncoder
406 | case "safety_checker":
407 | currentStep = .convertSafetyChecker
408 | case "controlnet":
409 | currentStep = .convertControlNet
410 | default:
411 | break
412 | }
413 | } else if let _ = newLine.firstMatch(#"INFO:.*Loading embeddings"#) {
414 | currentProgress = nil
415 | currentStep = .loadEmbeddings
416 | } else if let _ = newLine.firstMatch(#"INFO:.*Quantizing weights"#) {
417 | currentProgress = nil
418 | currentStep = .compressOutput
419 | } else if let _ = newLine.firstMatch(#"INFO:.*Bundling resources for Guernika$"#) {
420 | currentProgress = nil
421 | currentStep = .cleanUp
422 | } else if let _ = newLine.firstMatch(#"INFO:.*MLPackages removed$"#) {
423 | currentProgress = nil
424 | currentStep = .done
425 | } else if newLine.hasPrefix("usage: GuernikaTools") || newLine.hasPrefix("GuernikaTools: error: unrecognized arguments") {
426 | print(newLine)
427 | return
428 | } else {
429 | currentProgress = nil
430 | }
431 | DispatchQueue.main.async {
432 | Logger.shared.append(newLine)
433 | }
434 | }
435 |
436 | func start() throws {
437 | guard !process.isRunning else { return }
438 | Logger.shared.append("Starting python converter", level: .info)
439 | try process.run()
440 | }
441 |
442 | func cancel() {
443 | process.cancel()
444 | }
445 | }
446 |
447 | extension String {
448 | func firstMatch(_ pattern: String) -> NSTextCheckingResult? {
449 | guard let regex = try? NSRegularExpression(pattern: pattern) else { return nil }
450 | return regex.firstMatch(in: self, options: [], range: NSRange(location: 0, length: utf16.count))
451 | }
452 | }
453 |
--------------------------------------------------------------------------------