24 | 25 | 26 | ## 정렬 병합 조인 27 | 28 | 정렬 병합 조인이란 각각의 테이블을 조인할 필드 기준으로 정렬하고 정렬이 끝난 이후에 조인 작업을 수행하는 조인입니다. 아래 그림에선 '접수일자'를 기준으로 각각의 테이블을 정렬한 뒤 조인 작업을 수행하는 것을 볼 수 있습니다 29 | - 정렬을 위한 영역에 따라 효율에 큰 차이 발생 30 | - 조인 연산자가 '='이 아닌 경우 nested loop 조인보다 유리한 경우 많음 31 | 32 |
33 | 34 |  35 | 36 |
37 |
38 | 39 | ## 해시 조인 40 | 해시 조인이란 해시 알고리즘을 이용해서 데이터를 메모리에 올려놓고 메모리에서 조인하는 방법입니다. 테이블 크기가 메모리에 올릴 수 없는 크기라서 디스크를 사용하는 비용이 추가되는 경우가 아니라면 보통 중첩 루프 조인보다 더 효율적입니다. 또한 해싱을 이용하여 조인하기 때문에 대용량 데이터를 다룰 때 정렬 병합보다(대용량 데이터 정렬시 부하) 대용량 처리에 유리합니다. 41 | - 조인 연산자가 '='일때만 사용 가능합니다. 42 | 43 | 44 | -------------------------------------------------------------------------------- /DB/조인의-종류.md: -------------------------------------------------------------------------------- 1 | # 조인의 종류 2 | 3 | ## 조인이란? 4 | - 조인(join): 하나의 테이블이 아닌 두 개 이상의 테이블을 묶어서 하나의 결과물을 만드는 쿼리입니다. 5 | - MongoDB에서는 조인을 lookup이라는 쿼리로 처리하는데, 이는 관계형 데이터베이스보다 성능이 떨어지기 때문에 여러 테이블을 조인하는 작업이 많을 경우 MongoDB보다는 관계형 데이터베이스를 써야 합니다. 6 | ## 조인의 종류 7 | 8 | 9 | ### 내부 조인 10 | 두 테이블 간에 교집합을 나타냅니다. ON 조건을 만족하는 행을 두 테이블에서 가져와 하나의 테이블로 출력합니다. 11 | 12 | 13 |  14 | 15 | ``` 16 | SELECT * FROM TableA A 17 | INNER JOIN TableB B 18 | ON A.key = B.key 19 | ``` 20 | - 예시 21 | ``` 22 | SELECT Sales.*, Countries.Country 23 | FROM Sales JOIN Countries 24 | ON Sales.CountryID = Countries.ID 25 | ``` 26 |  27 | 28 | 29 | ### 왼쪽 조인 30 | 테이블 B의 일치하는 부분의 레코드와 함께 테이블 A를 기준으로 완전한 레코드 집합을 생성합니다. 만약 테이블 B에 일치하는 항목이 없으면 해당 값은 null 값이 됩니다. 31 | 32 | 33 |  34 | ``` 35 | SELECT * FROM TableA A 36 | LEFT JOIN TableB B 37 | ON A.key = B.key 38 | ``` 39 | - 예시 40 | ``` 41 | SELECT Sales.*, Countries.Country 42 | FROM Sales LEFT JOIN Countries 43 | ON Sales.CountryID = Countries.ID 44 | ``` 45 |  46 | 47 | 48 | ### 오른쪽 조인 49 | 테이블 A에서 일치하는 부분의 레코드와 함께 테이블 B를 기준으로 완전한 레코드 집합을 생성합니다. 만약 테이블 A에 일치하는 항목이 없으면 해당 값은 null 값이 됩니다. 50 | 51 | 52 |  53 | ``` 54 | SELECT * FROM TableA A 55 | RIGHT JOIN TableB B 56 | ON A.key = B.key 57 | ``` 58 | - 예시 59 | ``` 60 | SELECT Sales.*, Countries.Country 61 | FROM Sales RIGHT JOIN Countries 62 | ON Sales.CountryID = Countries.ID 63 | ``` 64 |  65 | 66 | 67 | ### 합집합 조인(전체 조인) 68 | 양쪽 테이블에서 일치하는 레코드와 함께 테이블 A와 테이블 B의 모든 레코드 집합을 생성합니다. 이 때 일치하는 항목이 없으면 누락된 쪽에 null 값이 포함되어 출력됩니다. 69 | 70 | 71 |  72 | ``` 73 | SELECT * FROM TableA A 74 | FULL OUTER JOIN TableB B ON 75 | A.key = B.key 76 | ``` 77 | - 예시 78 | ``` 79 | SELECT * FROM Sales A LEFT JOIN Countries B ON A.CountryID = B.ID 80 | UNION 81 | SELECT * FROM Sales A RIGHT JOIN Countries B ON A.CountryID = B.ID 82 | // mysql은 FULL OUTER JOIN을 지원하지 않아 두 테이블을 왼쪽 조인, 오른쪽 조인한 결과에 UNION을 사용하여 구할 수 있습니다. 83 | ``` 84 |  -------------------------------------------------------------------------------- /DB/테이블-관계.md: -------------------------------------------------------------------------------- 1 | ## 관계 2 | 3 | 데이터베이스에서는 두 개의 엔티티간의 관계를 정의해야 한다.
4 | 관계를 표기하기 위해서는 몇가지 개념을 알고 있어야한다. 5 | 6 | 1. 관계명 : 관계의 이름
7 | 
8 | 관계명이란 엔티티가 관계에 참여하는 형태를 지칭하는 이름으로, 두 개의 엔티티에 대한 것이기 때문에 하나의 관계는 2개의 현재형으로 표현한 관계명을 가진다. 9 | 2. 관계 차수
10 | 두 개의 엔티티 관계에서 참여자의 수를 표현하는 것을 관계차수라고 한다. 가장 일반적인 관계차수 표현방법은 1:1, 1:N, N:N이다. 11 | 3. 관계 선택 사양
12 | 관계에서 항상 참여해야 하는지(필수관계인지) 아니면 참여할 수도 있는지(선택관계인지)에 대한 것을 관계 선택 사양이라고 한다.
13 |

14 | 15 | * 학생은 수업을 들을 수도있고 안들을 수도 있다. 16 | * 학생 엔티티를 기준으로 학생-수업 관계는 선택 참여이다. 17 | * 학생이 듣지 않는 수업은 존재할 수 없다. 18 | * 수업 엔티티는 학생 엔티티와의 관계가 필수적이기 때문에 수업 엔티티를 기준으로 수업-학생 관계는 필수 참여가 된다. 19 | 20 |
21 | 22 | ## 테이블 관계 23 | 24 | ### 1 : 1 (일대일 관계) 25 | 
26 | 1 : 1 관계란 참조하는 테이블의 row와 참조되는 table의 row가 단 하나의 관계를 가지는 것을 의미한다. 27 | * Users 테이블과 Phonebook 테이블이 있다고 가정한다. 28 | * Users 테이블은 ID, name, phone_id를 가지고 있다. 29 | * 이 중 phone_id는 외래키(foreign key)로써, Phonebook 테이블의 ID 와 연결되어 있다. 30 | * 각 전화번호가 단 한 명의 유저와 연결되어 있고 그 반대도 동일하다면, Users 테이블과 Phonebook 테이블은 1:1 관계(One-to-one relationship)이다. 31 | 32 |
33 | 34 | ### 1 : N 관계 35 |  36 | 하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우이다. 37 | * Users 테이블과 Phonebook 테이블의 관계를 다음과 같이 가정한다. 38 | * 이 구조에서는 한 명의 유저가 여러 전화번호를 가질 수 있다. 39 | * 그러나 여러명의 유저가 하나의 전화번호를 가질 수는 없다. 40 | * 이런 1:N(일대다) 관계는 관계형 데이터베이스에서 가장 많이 사용한다. 41 | 42 |
43 | 44 | ### N:M 관계 45 | 여러 개의 레코드가 다른 테이블의 여러 개의 레코드와 관계가 있는 경우이다. 46 |  47 | 48 | * N:M(다대다) 관계를 위해 스키마를 디자인할 때에는, Join 테이블을 만들어 관리한다. 49 | * 위에 처럼 customer과 package 테이블이 있다고 가정해보자. 50 | * 고객 한 명은 여러개의 여행 상품을 구매할 수 있다. 여행 상품 하나는 여러 명의 고객이 구매할 수 있다. 51 | * 이러면 다대다 관계가 성립한다. 52 | * 이 모양은 두 개의 일대다 관계와 그 모양이 같다. 53 | * 두 개의 테이블과 1:N(일대다) 관계를 형성하는 새로운 테이블로 N:M(다대다) 관계를 나타낼 수 있다. 54 | 55 |  56 | * customer_package 테이블에서는 고객 한 명이 여러 개의 여행 상품을 가질 수 있고, 여행 상품 하나가 여러 개의 고객을 가질 수 있다. 57 | * 조인 테이블을 생성하더라도, 조인 테이블을 위한 기본키(여기서는 ID)는 반드시 있어야 한다. 58 | 59 | ### 만약 조인 테이블이 없다면 생기는 문제???? 60 | 61 | 1. 데이터를 조회하는데 많은 비용이 발생하게 된다. 62 | 2. 데이터를 수정할 때 두 곳에 수정이 잘 되었는지 확인이 불편하다. 63 | 3. 필드에 저장되는 데이터의 크기를 설정해야하는데 엄청 커지게 되고 데이터가 저장되지 못할 수 도 있다. 64 | 65 |
66 | 67 | ### 자기참조 관계(Self Referencing Relationship) 68 |  69 | * 자기 자신을 참조하는 관계이다. 70 | * 만약 추천인이 누군지 파악하기 위해서 자신의 테이블을 참조할 수 있다. 71 | * 한 명의 유저(user_id)는 한 명의 추천인(recommend_id)를 가질 수 있다. 72 | * 그러나 여러 명이 한 명의 유저를 추천인으로 등록할 수 있다. 73 | * 이 관계는 1:N(일대다) 관계와 유사하다고 생각할 수 있다. 74 | * 하지만 일대단 관계는 서로 다른 테이블의 관계를 나타낼 때 표현하는 방법이다. -------------------------------------------------------------------------------- /DB/필드-타입.md: -------------------------------------------------------------------------------- 1 | ### 데이터베이스 용어 2 | 3 |
4 | 5 |  6 | 7 | * 엔티티 : 엔티티 는 현실 세계에 존재하는 것을 데이터베이스 상에서 표현하기 위해 사용하는 추상적인 개념이다. 일종의 비유라고 할 수 있다. 8 | + 약한 엔티티 : A가 혼자서는 존재하지 못하고 B의 존재 여부에 따라 종속적이면 A는 약한 엔티티이다. 9 | + 강한 엔티티 : 이 때 B가 강한 엔티티이다. 10 | + 엔티티 셋 : 하나 이상의 엔티티들의 모임 11 | * 릴레이션 : 데이터베이스에서 정보를 구분하여 저장하는 기본 단위이다. 엔티티에 관한 데이터를 데이터베이스는 릴레이션 하나에 담아서 관리한다. 12 | + 릴레이션은 관계형 데이터베이스에서 테이블 이라고 불린다. (MySQL의 구조는 레코드-테이블-데이터베이스) 13 | + NoSQL 데이터베이스에서는 컬렉션 이라고 불린다. (MongoDB의 구조는 도큐먼트-컬렉션-데이터베이스) 14 | * 속성 : 릴레이션에서 관리하는 구체적이며 고유한 이름을 갖는 정보이다. 즉, 엔티티를 설명하는 특성을 속성이라고 한다. 이러한 특성들은 각각의 엔티티마다 다를 수 있고, 이를 통해 엔티티를 구별할 수 있다. 15 | * 도메인 : 릴레이션에 포함된 각각의 속성들이 가질 수 있는 값의 집합을 말한다. 16 | * 필드 : 필드는 엑셀에서 열에 해당하는 가장 작은 단위의 데이터를 의미한다. 이 필드는 엔티티의 속성을 표현한다. 17 | * 레코드 : 레코드는 논리적으로 연관된 필드의 집합을 의미하며, 엑셀의 행 row에 해당된다. 튜플이라고 불리기도 한다. 여기서 각각의 필드는 특정한 데이터 타입과 크기가 지정되어 있습니다. 즉, 여러 행이 모여 한 열을 이루듯이 여러 필드가 모여 한 레코드를 이루는 것이죠. 18 | 19 |
20 | 21 | ### 엔티티와 레코드의 차이점 22 | 레코드는 실제 데이터베이스 상에 저장되어 있는 값들의 모임을 말한다. 반면에, 엔티티는 현실 세계에 존재하는 객체를 표현하기 위해 비유적으로 사용된다. 23 | 24 | ### 필드와 속성의 차이점 25 | 데이터베이스에서 필드와 속성은 본질적으로 같은 것을 이야기 한다. 고객 엔티티에서 customer_id, name, age, class는 고객이라는 엔티티의 고유한 속성들이다. 이 속성들은 다른 테이블/엔티티와의 관계에 대해 이야기할 때, 필드라고 불려질 수 있다. 26 | 27 | ## 필드 타입 28 |  29 | 30 |
31 | 32 | ### Numeric types(숫자형 타입) 33 | 34 | 1. 정수형 타입 : 작은 범위의 정수들을 저장할 때 쓰는 데이터 타입. 35 | * TINYINT : 최소 -128 ~ 최대 127 까지의 정수를 저장할 수 있는 타입이다. (1byte) 36 | * SMALLINT : SINGED와 UNSIGNED에 따라 저장할 수 있는 수의 범위가 다르다. (2byte) 37 | + SMALLINT SIGNED : -32768 ~ 32767 38 | + SMALLINT UNSIGNED : 0 ~ 65535 39 | * MEDIUMINT : 더 넓은 범위를 나타내는 데이터 타입이다. (3byte) 40 | + MEDIUMINT SIGNED : -8388608 ~ 8388607 41 | + MEDIUMINT UNSIGNED : 0 ~ 16777215 42 | * INT : MEDIUMINT 보다 더 넓은 범위를 나타낸다. (4byte) 43 | + INT SIGNED : -2147483648 ~ 2147483647 44 | + INT UNSIGNED : 0 ~ 4294967295 45 | * BIGINT : 아주 큰 범위의 정수를 저장하는 데이터 타입이다. (8byte) 46 | + BIGINT SIGNED : -9223372036854775808 ~ 9223372036854775807 47 | + BIGINT UNSIGNED : 0 ~ 18446744073709551615 48 | 49 |
50 | 51 | 2. 실수형 타입 : 소수점이 붙어있는 수를 저장하기 위한 타입을 실수형 타입이라고 한다. 52 | * DECIMAL : 일반적으로 자주 쓰이는 실수형 타입 중 하나로 보통 DECIMAL(M, D)의 형식으로 나타낸다. 여기서 M은 최대로 쓸 수 있는 전체 숫자의 자리수이고, D는 최대로 쓸 수 있는 소수점 뒤에 있는 자리의 수를 의미한다.
53 | ex) DECIMAL (5, 2)라면 -999.99 부터 999.99 까지의 실수를 나타낼 수 있다. 54 | * FLOAT : -3.402823466E+38 ~ -1.175494351E-38, 0, 1.175494351E-38 ~ 3.402823466E+38 55 | 범위의 실수들을 나타낼 수 있는 데이터 타입이다. 56 | * DOUBLE : -1.7976931348623157E+308 ~ -2.2250738585072014E-308, 0, 2.2250738585072014E-308 ~ 1.7976931348623157E+308
57 | FLOAT에 비해 더 넓은 범위의 수를 나타낼 수 있을 뿐만 아니라, 그 정밀도 또한 더 높은 타입이다. 58 | 59 | 60 |
61 | 62 | 63 | ### 날짜 및 시간 타입(Date and Time Types) 64 | 65 | 66 | 1. DATE : 날짜를 저장하는 데이터 타입. (3byte) 67 | 68 | ’2022-03-01’ 이런 형식의 연, 월, 일 순으로 값을 나타낸다. 69 | 70 | 2. DATETIME : 날짜와 시간을 저장하는 데이터 타입. (8byte) 71 | 72 | ’2020-03-01 20:27:00’ 이런 식으로 연, 월, 일, 시, 분, 초를 나타낸다. 73 | 74 | 3. TIMESTAMP : 날짜와 시간을 저장하는 데이터 타입. 75 | 76 | ’2020-03-01 20:27:00’ 이런 식으로 연, 월, 일, 시, 분, 초를 + 타임 존(time_zone) 정보도 함께 저장한다. 77 | 78 | 4. TIME : 시간을 나타내는 데이터 타입. 79 | 80 | ’20:29:31’ 형식으로 ‘시:분:초’를 나타낸다. 81 | 82 | 83 |
84 | 85 | 86 | ### 문자열 타입(String type) 87 | 88 | 1. CHAR : 문자열을 나타내는 기본 타입으로 Character의 줄임말. 89 | * CHAR 타입의 괄호 안에는 0부터 255까지의 숫자를 적을 수 있다. 90 | * 고정 길이 문자열이어서 무조건 선언한 길이 값으로 고정 된다. 91 | * char(100)으로 선언한 후 10글자를 저장해도 100바이트로 저장한다. 92 | 2. VARCHAR : Character Varing의 줄임말로 가변 문자열이란 뜻이다. 93 | * 가변 길이 문자열이므로 0 ~ 65535 사이의 값으로 지정할 수 있다. 94 | * 10글자의 이메일을 저장할 경우 10글자에 해당하는 바이트 + 길이기록용 1바이트로 저장하게 된다. 95 | 3. TEXT 와 BLOB : 큰 데이터를 저장할 때 쓰는 타입이다. 96 | * TEXT : 큰 문자열 저장에 쓰며 주로 게시판의 본문을 저장할 때 쓴다. 97 | * BLOB : 이미지, 동영상 등 큰 데이터 저장에 쓴다. 98 | 4. ENUM과 SET : 문자열을 열거한 타입이다. 99 | * ENUM : ENUM('x-small', 'small', 'medium', 'large', 'x-large') 형태로 쓰인다. 100 | * 이 중에서 하나만 선택하는 단일 선택만 가능하다. 101 | * ENUM 리스트에 없는 잘못된 값을 삽입하면 빈 문자열이 대신 삽입된다. 102 | * ENUM을 이용하면 x-small 등이 0,1 등으로 매핑되어 메모리를 적게 사용하는 이점이 있다. 103 | * ENUM은 최대 65535개의 요소들을 넣을 수 있다. 104 | * SET : ENUM과 비슷하지만 여러 개의 데이터를 선택할 수 있고 비트 단위의 연산을 할 수 있으며 최대 64개의 요소를 집어넣을 수 있다. 105 | -------------------------------------------------------------------------------- /DB/해시-조인-단계.md: -------------------------------------------------------------------------------- 1 | # 해시 조인 단계 2 | 3 | 메모리에 해시 테이블을 생성하여 조인을 실행하는 해시 조인은 빌드 단계, 프로브 단계로 나뉩니다. (MySql) 4 | 5 |
6 | 7 | ## 예시로 사용할 쿼리 8 | ``` 9 | SELECT 10 | given_name, country_name 11 | FROM 12 | persons 13 | JOIN 14 | countries 15 | ON 16 | persons.country_id = countries.country_id; 17 | ``` 18 | 19 | ## 빌드 단계 20 | 21 | MySql에서 조인을 실행시 조인 속성을 해시 테이블 키로 사용하여 입력 중 하나의 행이 저장되는 In Memory Hash Table을 빌드합니다. 이 때 해시 테이블 키로 사용되는 속성은 조인하는 두 개의 테이블 중 바이트가 더 작은 테이블의 속성입니다. 22 | 23 | 예시 쿼리를 수행할 때 빌드 단계는 다음 그림과 같습니다. (countries 테이블의 바이트가 더 작다고 가정) 24 | 25 |  26 | 27 |
28 | 29 | ## 프로브 단계 30 | 31 | 프로브 단계에선 메모리에 올라가지 않은 다른 테이블의 속성으로 행과 일치하는 해시 테이블을 조사합니다. 각 일치에 대해 결합 된 행이 클라이언트로 전송되고, 일치하는 행을 찾기 위해 일정한 시간 조회를 사용하여 각 입력을 한 번 씩 만 스캔한 것을 알 수 있습니다. 32 | 33 | 예시 쿼리를 수행할 때 프로브 단계는 다음 그림과 같습니다. (나머지 테이블인 persons테이블의 country_id로 해시 테이블 조회) 34 | 35 |  36 | 37 |
38 | 39 | ## 빌드 입력이 메모리 크기보다 크다면? 40 | 41 | 만약 빌드 단계에서 해시 테이블 키로 사용된 테이블인 countries 테이블의 크기가 메모리 크기 보다 크다면 어떻게 메모리내에 해시 테이블을 만들고 조인을 수행할까요? 42 | 43 | 빌드 단계에서 설정된 버퍼 메모리가 가득 차면 서버는 나머지 빌드 입력을 디스크의 여러 청크 파일에 기록하게 됩니다. 이 때 디스크에 기록하는 해시 함수는 메모리에서 테이블을 만들때 사용한 해시 함수와는 다른 함수를 사용합니다. (hash_2) 44 | 45 |  46 | 47 | 48 | 이렇게 되면 메모리에서 일치하는 행을 찾지 못했더라도 디스크에 기록된 빌드 입력의 청크 파일에서 일치하는 행을 찾을 수 있기 때문에 프로브 입력의 각 행도 청크 파일 세트에 기록합니다. 49 | 50 | 행이 기록되는 청크 파일은 빌드 입력이 디스크에 기록 될 때 사용되는 동일한 해시 함수 및 공식을 사용하여 결정됩니다 이렇게 하면 두 입력 사이에 일치하는 행이 동일한 청크 파일 쌍에 위치하게됩니다. 51 | 52 |  53 | 54 | 위의 모든 단계가 끝났다면 이제 메모리에 존재하는 테이블로 먼저 프로브 단계를 수행하고 완료되면 디스크에서 메모리에 올릴 청크 파일을 읽기 시작합니다. 일반적으로 첫 번째 청크 파일 세트를 빌드 및 프로브 입력으로 사용하여 다시 빌드 및 프로브 단계를 수행합니다. 55 | 56 | ## MySql 버젼별 해시 조인 변경 사항 57 | - 8.0.18 -> 8.0.20 58 | - 원래 동등 조인(equi-join conditions) 에서만 해시 조인이 가능했지만 8.0.20 부터 가능하고 동등 조인이 아닌 조건은 조인이 실행 된 후 필터로 적용됨. 59 | - outer join 에서 해시 조인 사용 가능. 또한 조인 SQL 문 중 anti join(not exists) 나 semi join(in 절 서브쿼리) 가 포함되어 있어도 가능 -------------------------------------------------------------------------------- /DataStructure/README.md: -------------------------------------------------------------------------------- 1 | # 자료구조 2 | 3 | - [복잡도](https://github.com/HanKwanJin/CS_Study/blob/main/DataStructure/복잡도.md) 4 | - 시간복잡도와 공간복잡도 5 | - 자료구조에서의 시간복잡도 -------------------------------------------------------------------------------- /DataStructure/복잡도.md: -------------------------------------------------------------------------------- 1 | # 시간 복잡도와 공간 복잡도 2 | 3 | 시간 복잡도(Time Complexity)와 공간 복잡도(Space Complexity)는 알고리즘의 성능을 분석하는 데 중요한 개념입니다. 4 | 5 | 시간 복잡도는 알고리즘이 문제를 해결하는 데 걸리는 시간을 분석하는 것으로, 입력 크기에 대한 함수로 표현됩니다. 예를 들어, 정렬 알고리즘의 시간 복잡도는 n(log n)이며, n은 입력 배열의 크기입니다. 시간 복잡도는 최악, 평균, 최선의 경우 모두 고려할 수 있습니다. 6 | 7 | 공간 복잡도는 알고리즘이 사용하는 메모리 공간의 양을 분석하는 것으로, 입력 크기에 대한 함수로 표현됩니다. 예를 들어, 배열을 정렬하는 알고리즘의 공간 복잡도는 O(n)입니다. 공간 복잡도도 시간 복잡도와 마찬가지로 최악, 평균, 최선의 경우 모두 고려할 수 있습니다. 8 | 9 | 알고리즘의 성능을 분석할 때, 시간 복잡도와 공간 복잡도는 모두 고려해야 합니다. 보통은 시간 복잡도가 더 중요하다고 생각되지만, 일부 경우에는 공간 복잡도가 중요한 경우도 있습니다. 예를 들어, 모바일 기기나 임베디드 시스템에서는 메모리가 제한되어 있기 때문에 공간 복잡도가 중요해질 수 있습니다. 10 | 11 | 12 | # 자료구조에서의 시간 복잡도 13 | 14 |  15 | 16 | 참고로, 여기서 n은 자료구조의 크기를 의미하고, m은 간선의 수를 의미합니다. 또한, 이 표는 자료구조의 구현 방식에 따라 다를 수 있으며, 최악의 경우를 나타낸 것입니다. -------------------------------------------------------------------------------- /DataStructure/연결리스트와배열.md: -------------------------------------------------------------------------------- 1 | # 연결리스트 2 | 3 | 연결 리스트(linked list)는 자료를 노드(node)라는 단위로 나누어 각 노드가 다음 노드를 가리키는 방식으로 자료를 저장하는 자료구조입니다. 연결 리스트는 다음과 같은 특징을 가집니다. 4 | 5 | - 각 노드는 데이터와 다음 노드를 가리키는 포인터(pointer)로 이루어져 있습니다. 6 | 7 | - 데이터의 삽입과 삭제가 용이합니다. 8 | 9 | - 데이터를 순차적으로 탐색하는 데에는 O(n)의 시간 복잡도가 필요합니다. 10 | 11 | 연결 리스트는 크게 단일 연결 리스트(Singly Linked List)와 이중 연결 리스트(Doubly Linked List)로 구분됩니다. 12 | 13 | - 단일 연결 리스트 : 각 노드는 다음 노드를 가리키는 포인터만을 가지고 있습니다. 따라서, 다음 노드로의 순방향 탐색은 용이하지만, 이전 노드로의 역방향 탐색은 불가능합니다. 14 | 15 | - 이중 연결 리스트 : 각 노드는 이전 노드와 다음 노드를 가리키는 포인터를 모두 가지고 있습니다. 따라서, 순방향과 역방향 모두 탐색이 가능합니다. 16 | 17 | 연결 리스트는 배열과는 다르게 특정 인덱스로 바로 접근할 수 없습니다. 따라서, 연결 리스트에서는 탐색을 위해 선형적으로 각 노드를 순회하는 방법을 사용합니다. 이는 배열에 비해 탐색 시간이 느리지만, 데이터의 삽입과 삭제가 용이하므로, 데이터의 변경이 빈번히 일어나는 상황에서 유용합니다. 18 | 19 | 20 | ## 자바로 구현한 연결리스트 21 | 22 | ### 단일 연결리스트 23 | ```java 24 | public class LinkedList { 25 | private Node head; 26 | 27 | private static class Node { 28 | int data; 29 | Node next; 30 | 31 | public Node(int data) { 32 | this.data = data; 33 | this.next = null; 34 | } 35 | } 36 | 37 | public void add(int data) { 38 | Node newNode = new Node(data); 39 | 40 | if (head == null) { 41 | head = newNode; 42 | } else { 43 | Node temp = head; 44 | while (temp.next != null) { 45 | temp = temp.next; 46 | } 47 | temp.next = newNode; 48 | } 49 | } 50 | 51 | public void remove(int data) { 52 | if (head == null) { 53 | return; 54 | } 55 | 56 | if (head.data == data) { 57 | head = head.next; 58 | } else { 59 | Node prev = head; 60 | Node curr = head.next; 61 | 62 | while (curr != null && curr.data != data) { 63 | prev = curr; 64 | curr = curr.next; 65 | } 66 | 67 | if (curr != null) { 68 | prev.next = curr.next; 69 | } 70 | } 71 | } 72 | 73 | public void printList() { 74 | Node temp = head; 75 | while (temp != null) { 76 | System.out.print(temp.data + " "); 77 | temp = temp.next; 78 | } 79 | System.out.println(); 80 | } 81 | } 82 | ``` 83 | 84 | ### 이중 연결리스트 85 | 86 | ```java 87 | public class DoublyLinkedList { 88 | private Node head; 89 | 90 | private static class Node { 91 | int data; 92 | Node prev; 93 | Node next; 94 | 95 | public Node(int data) { 96 | this.data = data; 97 | this.prev = null; 98 | this.next = null; 99 | } 100 | } 101 | 102 | public void add(int data) { 103 | Node newNode = new Node(data); 104 | 105 | if (head == null) { 106 | head = newNode; 107 | } else { 108 | Node temp = head; 109 | while (temp.next != null) { 110 | temp = temp.next; 111 | } 112 | temp.next = newNode; 113 | newNode.prev = temp; 114 | } 115 | } 116 | 117 | public void remove(int data) { 118 | if (head == null) { 119 | return; 120 | } 121 | 122 | if (head.data == data) { 123 | head = head.next; 124 | head.prev = null; 125 | } else { 126 | Node curr = head.next; 127 | 128 | while (curr != null && curr.data != data) { 129 | curr = curr.next; 130 | } 131 | 132 | if (curr != null) { 133 | curr.prev.next = curr.next; 134 | if (curr.next != null) { 135 | curr.next.prev = curr.prev; 136 | } 137 | } 138 | } 139 | } 140 | 141 | public void printList() { 142 | Node temp = head; 143 | while (temp != null) { 144 | System.out.print(temp.data + " "); 145 | temp = temp.next; 146 | } 147 | System.out.println(); 148 | } 149 | } 150 | 151 | ``` 152 | 153 | # 배열 154 | 155 | 배열은 동일한 자료형의 데이터를 순차적으로 저장하는 자료구조입니다. 배열은 크기가 고정되어 있어서 생성 후에 크기를 변경할 수 없습니다. 배열의 각 요소는 인덱스를 통해 접근할 수 있으며, 인덱스는 0부터 시작합니다. 156 | 157 | 배열의 장점은 인덱스를 이용하여 빠르게 요소에 접근할 수 있다는 것입니다. 또한, 메모리 상에 연속적으로 저장되기 때문에, 캐시 지역성을 활용하여 성능을 높일 수 있습니다. 158 | 159 | 하지만 배열은 크기가 고정되어 있기 때문에, 크기가 변경되거나 요소가 추가/삭제될 경우 새로운 배열을 생성하고 모든 요소를 복사해야 하므로, 이에 따른 오버헤드가 발생할 수 있습니다. 또한, 중간에 요소를 추가/삭제하는 것이 불편하며, 연결 리스트와 같은 다른 자료구조에 비해 삽입/삭제에 대한 시간 복잡도가 높습니다. 160 | 161 | # 연결리스트와 배열 비교 162 | 163 | 연결리스트와 배열은 모두 데이터를 저장하는 자료구조이지만, 내부적으로는 다른 방식으로 동작합니다. 이들의 차이점은 다음과 같습니다. 164 | 165 | ## 크기 166 | 배열은 생성 시에 크기가 결정되며, 크기를 변경할 수 없습니다. 연결리스트는 요소의 개수에 따라 크기가 동적으로 변경됩니다. 167 | 168 | ## 삽입/삭제 169 | 170 | 배열은 크기가 고정되어 있으므로, 중간에 요소를 삽입/삭제하는 것이 불편합니다. 삽입/삭제 시에 새로운 배열을 생성하고 기존 요소를 복사해야 하므로, 이에 따른 오버헤드가 발생합니다. 연결리스트는 중간에 요소를 삽입/삭제하는 것이 쉽고 빠르며, 이에 따른 오버헤드가 거의 없습니다. 171 | 172 | ## 접근 173 | 174 | 배열은 인덱스를 이용하여 빠르게 요소에 접근할 수 있습니다. 연결리스트는 특정 요소에 접근하기 위해서는 처음부터 순서대로 검색해야 하므로, 배열에 비해 상대적으로 느립니다. 175 | 176 | ## 메모리 관리 177 | 178 | 배열은 연속적인 메모리 공간을 사용하므로, 메모리 상에 구조가 빈틈 없이 저장됩니다. 반면에 연결리스트는 각 노드가 메모리 공간에 분산되어 저장되기 때문에, 메모리 상의 빈틈이 발생할 수 있습니다. 179 | 180 | 따라서, 배열은 크기가 고정되어 있고 접근 속도가 빠르지만, 삽입/삭제에 대한 오버헤드가 크며, 동적으로 크기가 변경되지 않습니다. 반면에 연결리스트는 크기가 동적으로 변경되며, 삽입/삭제가 용이하지만, 접근 속도가 배열에 비해 느리며, 메모리 상의 빈틈이 발생할 수 있습니다. -------------------------------------------------------------------------------- /Network/ARP.md: -------------------------------------------------------------------------------- 1 | ## ARP (Address Resolution Protocol) 2 | ARP란 IP 주소를 MAC 주소와 매칭 시키기 위한 프로토콜이다. 3 | 4 | - IP 주소 (32 bits): 보낸 주소에서 도착지 주소까지 경로를 찾기 위해 필요한 주소로 때떄로 변할 수 있다. 5 | - MAC 주소 (48 bits): 한 주소 내에 다양한 기기들이 있을 때, 해당기기들이 각각 어떤 기기들인지 식별하기 위해 필요한 주소로 변하지 않는다. 6 | 7 | 컴퓨터와 컴퓨터 간의 통신은 IP 주소를 기반으로 통신한다고 알고 있지만, 정확히 이야기하자면 IP 주소에서 ARP를 통해 MAC 주소를 찾아 MAC 주소를 기반으로 통신하는 것이다. 8 | 9 | 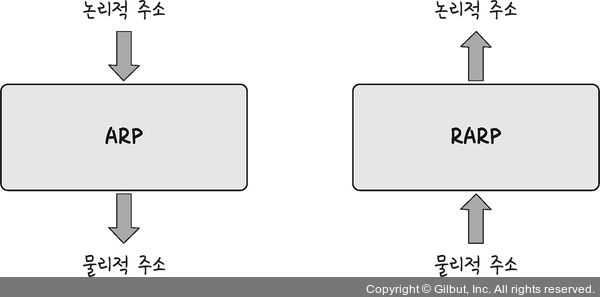 10 | ARP를 통해 가상 주소인 IP 주소를 실제 주소인 MAC 주소로 변환할 수 있다. 반대로 MAC 주소를 IP 주소로 변환하는 것은 RARP를 통해 가능하다. 11 |
12 |
13 | 14 | ## 통신할 때 MAC 주소가 필요한 이유 15 | 우리가 미국에서 서울에 살고 있는 상우의 컴퓨터와 통신을 하고 싶다고 가정하자. 이때 상우가 알려준 IP 주소가 상우의 컴퓨터라는 사실을 보증할 수가 없다. 유동 IP의 특징으로 인해 IP 자체가 변동될 수 있기 때문이다. 결국 절대 변하지 않는 하드웨어의 고유 주소 번호가 필요한데, 그것이 바로 MAC 주소다. 16 | 17 | ## 통신할 때 IP 주소가 필요한 이유 18 | MAC 주소는 데이터 링크 계층 프로토콜이므로 통신할 상대방이 나와 가까운 곳에 있다면 괜찮지만, 한국에서 미국에 있는 A 컴퓨터에 데이터가 가기 위해서는 나와 연결된 어떤 컴퓨터에게 데이터를 넘겨야 하는지 MAC 주소로 판단하기 어렵다. 이를 해결하기 위해 IP 주소가 필요하다. IP 주소는 전체적인 맵을 보고 방향성을 알려주는 역할을 한다고 생각하면 된다. IP 주소는 네트워크 주소와 호스트 주소로 나뉘므로 실생활에서 우편물이나 택배를 보낼 때 사용하는 계층형 주소 원리와 유사하기 때문이다. -------------------------------------------------------------------------------- /Network/HTTP2.md: -------------------------------------------------------------------------------- 1 | # HTTP/2 2 | 3 | HTTP/2는 SPDY 프로토콜에서 파생된 HTTP/1.x 보다 지연 시간을 줄이고 응답 시간을 더 빠르게 할 수 있으며 **멀티플렉싱, 헤더 압축, 서버 푸시, 요청의 우선순위 처리**를 지원하는 프로토콜입니다. 4 | 5 | ## 멀티플렉싱(Multiplexing) 6 | 7 | 멀티플렉싱이란 여러 개의 스트림을 사용하여 송수신한다는 것을 의미합니다. 이를 통해서 특정 스트림의 패킷이 손실되더라도 해당 스트림에만 영향을 미치고 나머지 스트림에는 영향을 미치지 않고 동작합니다. 8 | 9 | >**스트림(stream)** 이란 시간이 지남에 따라 사용할 수 있게 되는 일련의 데이터 요소를 가리키는 데이터 흐름을 의미합니다. 10 | 11 | ### HTTP 1.x 의 HOL Blocking 문제 해결 12 | 13 |
 14 |
15 | 그림에서 보이듯이 HTTP1.1 까지는 한번에 하나의 파일만 전송이 가능했습니다. 이로인해서 여러 파일을 전송 할 경우, 앞에 있는 파일의 전송이 늦어질수록 전체 파일 전송 시간이 늘어나는 문제가 발생했습니다. HTTP/2에서는 여러 파일을 한번에 병렬 전송하여서 이러한 문제를 해결하였습니다.
16 |
17 | ## 헤더 압축
18 |
19 | 이전 헤더의 내용과 중복되는 필드를 재전송 안하고 데이터를 절약합니다. 또한 기존 HTTP Header 가 Plain Text이었지만, HTTP/2 에서는 **허프만 코딩(Huffman Coding)** 을 이용한 HPACK 압축방식을 이용하여서 데이터 전송 효율을 높였습니다.
20 |
21 | >허프만코딩(Huffman Coding)이란 데이터 문자의 빈도에 따라서 다른 길이의 부호를 사용하는 알고리즘입니다.
22 |
23 | ## 서버 푸시
24 |
25 | 
26 |
27 | HTTP/1.1에서는 클라이언트가 서버에 요청을 해야 파일을 다운 받았지만 HTTP/2는 클라이언트 요청 없이 서버가 따로 리소스를 푸시할 수 있습니다.
28 |
29 | ## 스트림 우선순위
30 |
31 | 멀티플렉싱을 할 수 있게 되면서 스트림들의 우선순위를 지정할 필요가 생겼습니다. 클라이언트는 우선순위 지정을 위해서 '우선순위 지정 트리'를 사용하여 서버의 스트림처리 우선순위를 지정할 수 있습니다. 서버는 우선순위가 높은 응답이 클라이언트에 우선적으로 전달될 수 있도록 대역폭을 설정합니다.
32 |
33 |
34 |
14 |
15 | 그림에서 보이듯이 HTTP1.1 까지는 한번에 하나의 파일만 전송이 가능했습니다. 이로인해서 여러 파일을 전송 할 경우, 앞에 있는 파일의 전송이 늦어질수록 전체 파일 전송 시간이 늘어나는 문제가 발생했습니다. HTTP/2에서는 여러 파일을 한번에 병렬 전송하여서 이러한 문제를 해결하였습니다.
16 |
17 | ## 헤더 압축
18 |
19 | 이전 헤더의 내용과 중복되는 필드를 재전송 안하고 데이터를 절약합니다. 또한 기존 HTTP Header 가 Plain Text이었지만, HTTP/2 에서는 **허프만 코딩(Huffman Coding)** 을 이용한 HPACK 압축방식을 이용하여서 데이터 전송 효율을 높였습니다.
20 |
21 | >허프만코딩(Huffman Coding)이란 데이터 문자의 빈도에 따라서 다른 길이의 부호를 사용하는 알고리즘입니다.
22 |
23 | ## 서버 푸시
24 |
25 | 
26 |
27 | HTTP/1.1에서는 클라이언트가 서버에 요청을 해야 파일을 다운 받았지만 HTTP/2는 클라이언트 요청 없이 서버가 따로 리소스를 푸시할 수 있습니다.
28 |
29 | ## 스트림 우선순위
30 |
31 | 멀티플렉싱을 할 수 있게 되면서 스트림들의 우선순위를 지정할 필요가 생겼습니다. 클라이언트는 우선순위 지정을 위해서 '우선순위 지정 트리'를 사용하여 서버의 스트림처리 우선순위를 지정할 수 있습니다. 서버는 우선순위가 높은 응답이 클라이언트에 우선적으로 전달될 수 있도록 대역폭을 설정합니다.
32 |
33 |
34 | 35 | >참고자료 36 | https://jins-dev.tistory.com/entry/HTTP2-%ED%8A%B9%EC%A7%95%EB%93%A4%EC%97%90-%EB%8C%80%ED%95%9C-%EC%A0%95%EB%A6%AC 37 | https://velog.io/@taesunny/HTTP2HTTP-2.0-%EC%A0%95%EB%A6%AC#http2 38 | -------------------------------------------------------------------------------- /Network/HTTP3.md: -------------------------------------------------------------------------------- 1 | # HTTP3란? 2 | 3 |
 4 |
5 | HTTP/3은 TCP를 기반으로 한 HTTP/2와 다르게 QUIC이라는 계층 위에서 돌아가며, TCP 기반이 아닌 UDP 기반으로 돌아갑니다. 또한, HTTP/2에서 장점이었던 멀티플렉싱을 가지고 있으며 초기 연결 설정 시 지연 시간 감소라는 장점이 있습니다.
6 |
7 | # QUIC란?
8 |
9 |
4 |
5 | HTTP/3은 TCP를 기반으로 한 HTTP/2와 다르게 QUIC이라는 계층 위에서 돌아가며, TCP 기반이 아닌 UDP 기반으로 돌아갑니다. 또한, HTTP/2에서 장점이었던 멀티플렉싱을 가지고 있으며 초기 연결 설정 시 지연 시간 감소라는 장점이 있습니다.
6 |
7 | # QUIC란?
8 |
9 |  10 |
11 |
10 |
11 |  12 |
13 | HTTP/3에서는 QUIC 위에서 돌아간다고 하였는데요. QUIC의 장점은 어떤 것들이 있는지 알아보겠습니다.
14 |
15 | ## QUIC 장점
16 |
17 | - 암호화가 프로토콜의 일부기능으로 포함되어 있습니다.
18 |
19 | - 스트림 연결과 암호화 스펙등을 포함한 모든 핸드쉐이크 단일 요청/응답으로 끝납니다.
20 |
21 | - 패킷이 개별적으로 암호화되며, 다른 데이터 부분의 패킷을 기다릴 필요가 없습니다.
22 |
23 | - 통신이 멀티플렉싱 되며 이를 통해 HOL Blocking을 해결합니다.
24 |
25 | - QUIC는 운영체제 커널과 독립적으로 응용 프로그램 공간 내에서 구현할 수 있으며, 덕분에 데이터의 이동에 따른 컨텍스트 전환에 의한 오버헤드가 없어집니다.
26 |
27 | - Source Address와 상관없이 서버에 대한 연결을 고유하게 식별하는 연결 식별자가 포함되어 있어, IP 주소가 변경되더라도 커넥션을 유지할 수 있습니다.
28 |
29 | - 순방향 오류 수정 매커니즘(FEC, Forward Error Correction)이 적용되어 있어서 전송한 패킷이 손실되었다면 수신 측에서 에러를 검출하고 수정하는 방식으로 열악한 네트워크 환경에서도 낮은 패킷 손실률을 자랑합니다.
30 |
31 |
--------------------------------------------------------------------------------
/Network/HTTPS.md:
--------------------------------------------------------------------------------
1 | # HTTPS란?
2 |
3 | 먼저 HTTP란 HyperText Transfer Protocol의 약자로, 하이퍼텍스트를 전송하기 위해 사용되는 통신 규약입니다. HTTPS는 애플리케이션 계층과 전송 계층 사이에 신뢰 계층인 SSL/TLS 계층을 넣은 신뢰할 수 있는 HTTP 요청입니다. HTTPS를 사용하면 **서버와 클라이언트 사이의 모든 통신 내용이 암호화**됩니다. 추가로 HTTP/2는 HTTPS 위에서 동작합니다.
4 |
5 | ## SSL/TLS
6 |
7 | SSL/TLS는 전송 계층에서 보안을 제공하는 프로토콜입니다. 서버와 클라이언트가 통신할 때 SSL/TLS를 통해 제 3자가 메시지를 도청하거나 변조하지 못하도록 합니다.
8 |
9 | ## 동작 과정
10 |
11 | 공개키 암호화 방식과 공개키 방식이 느리다는 단점을 보완한 대칭키 암호화 방식을 함께 사용합니다. 공개키 방식으로 대칭키를 전달하고, 서로 공유된 대칭키를 가지고 통신하게 됩니다.
12 |
13 | ### 공개키 방식
14 |
15 | - A키로 암호화를 하면 B키로 복호화 할 수 있습니다.
16 |
17 | - B키로 암호화를 하면 A키로 복호화 할 수 있습니다.
18 |
19 | - 둘 중 하나를 비공개키 혹은 개인키라 불리며 이는 자신만 가지고 있고 공개되지 않습니다.
20 |
21 | - 나머지 하나는 공개키라 불리며 타인에게 제공합니다. 공개키는 유출이 되어도 비공개키를 모르면 복호화 할 수 없기 때문에 안전합니다.
22 |
23 | ### 대칭키 방식
24 |
25 | - 암호화를 할 때 사용하는 비밀번호를 키라고 합니다. 대칭키는 동일한 키로 암호화, 복호화가 가능합니다.
26 |
27 | - 대칭키는 매번 랜덤으로 생성되어 누출되어도 다음번에 사용할 때에는 다른 키가 사용되기 때문에 안전합니다.
28 |
29 | - 공개키보다 빠르게 통신할 수 있습니다.
30 |
31 | 이러한 방식을 적용하려면 인증서를 발급받아서 서버에 적용시켜야 합니다. 인증서는 사용자가 접속한 서버가 우리가 의도한 서버가 맞는지를 보장하는 역할을 합니다. 이러한 인증서를 발급하는 기관을 CA(Certificate authority)라고 부릅니다.
32 |
33 |
34 | ### 인증서 발급 과정
35 |
36 |
12 |
13 | HTTP/3에서는 QUIC 위에서 돌아간다고 하였는데요. QUIC의 장점은 어떤 것들이 있는지 알아보겠습니다.
14 |
15 | ## QUIC 장점
16 |
17 | - 암호화가 프로토콜의 일부기능으로 포함되어 있습니다.
18 |
19 | - 스트림 연결과 암호화 스펙등을 포함한 모든 핸드쉐이크 단일 요청/응답으로 끝납니다.
20 |
21 | - 패킷이 개별적으로 암호화되며, 다른 데이터 부분의 패킷을 기다릴 필요가 없습니다.
22 |
23 | - 통신이 멀티플렉싱 되며 이를 통해 HOL Blocking을 해결합니다.
24 |
25 | - QUIC는 운영체제 커널과 독립적으로 응용 프로그램 공간 내에서 구현할 수 있으며, 덕분에 데이터의 이동에 따른 컨텍스트 전환에 의한 오버헤드가 없어집니다.
26 |
27 | - Source Address와 상관없이 서버에 대한 연결을 고유하게 식별하는 연결 식별자가 포함되어 있어, IP 주소가 변경되더라도 커넥션을 유지할 수 있습니다.
28 |
29 | - 순방향 오류 수정 매커니즘(FEC, Forward Error Correction)이 적용되어 있어서 전송한 패킷이 손실되었다면 수신 측에서 에러를 검출하고 수정하는 방식으로 열악한 네트워크 환경에서도 낮은 패킷 손실률을 자랑합니다.
30 |
31 |
--------------------------------------------------------------------------------
/Network/HTTPS.md:
--------------------------------------------------------------------------------
1 | # HTTPS란?
2 |
3 | 먼저 HTTP란 HyperText Transfer Protocol의 약자로, 하이퍼텍스트를 전송하기 위해 사용되는 통신 규약입니다. HTTPS는 애플리케이션 계층과 전송 계층 사이에 신뢰 계층인 SSL/TLS 계층을 넣은 신뢰할 수 있는 HTTP 요청입니다. HTTPS를 사용하면 **서버와 클라이언트 사이의 모든 통신 내용이 암호화**됩니다. 추가로 HTTP/2는 HTTPS 위에서 동작합니다.
4 |
5 | ## SSL/TLS
6 |
7 | SSL/TLS는 전송 계층에서 보안을 제공하는 프로토콜입니다. 서버와 클라이언트가 통신할 때 SSL/TLS를 통해 제 3자가 메시지를 도청하거나 변조하지 못하도록 합니다.
8 |
9 | ## 동작 과정
10 |
11 | 공개키 암호화 방식과 공개키 방식이 느리다는 단점을 보완한 대칭키 암호화 방식을 함께 사용합니다. 공개키 방식으로 대칭키를 전달하고, 서로 공유된 대칭키를 가지고 통신하게 됩니다.
12 |
13 | ### 공개키 방식
14 |
15 | - A키로 암호화를 하면 B키로 복호화 할 수 있습니다.
16 |
17 | - B키로 암호화를 하면 A키로 복호화 할 수 있습니다.
18 |
19 | - 둘 중 하나를 비공개키 혹은 개인키라 불리며 이는 자신만 가지고 있고 공개되지 않습니다.
20 |
21 | - 나머지 하나는 공개키라 불리며 타인에게 제공합니다. 공개키는 유출이 되어도 비공개키를 모르면 복호화 할 수 없기 때문에 안전합니다.
22 |
23 | ### 대칭키 방식
24 |
25 | - 암호화를 할 때 사용하는 비밀번호를 키라고 합니다. 대칭키는 동일한 키로 암호화, 복호화가 가능합니다.
26 |
27 | - 대칭키는 매번 랜덤으로 생성되어 누출되어도 다음번에 사용할 때에는 다른 키가 사용되기 때문에 안전합니다.
28 |
29 | - 공개키보다 빠르게 통신할 수 있습니다.
30 |
31 | 이러한 방식을 적용하려면 인증서를 발급받아서 서버에 적용시켜야 합니다. 인증서는 사용자가 접속한 서버가 우리가 의도한 서버가 맞는지를 보장하는 역할을 합니다. 이러한 인증서를 발급하는 기관을 CA(Certificate authority)라고 부릅니다.
32 |
33 |
34 | ### 인증서 발급 과정
35 |
36 |  37 |
38 | 1. 인터넷 사이트는 자신의 정보와 공개키를 인증기관에 제출합니다.
39 |
40 | 2. 인증기관은 제출된 데이터 검증절차를 거쳐 개인키로 사이트에서 제출한 정보를 암호화 한 뒤 인증서를 발급합니다.
41 |
42 | 3. 인증기관은 웹 브라우저에게 자신의 공개키를 제공합니다.
43 |
44 | ### 사용자가 사이트에 접속할 경우
45 |
46 |
37 |
38 | 1. 인터넷 사이트는 자신의 정보와 공개키를 인증기관에 제출합니다.
39 |
40 | 2. 인증기관은 제출된 데이터 검증절차를 거쳐 개인키로 사이트에서 제출한 정보를 암호화 한 뒤 인증서를 발급합니다.
41 |
42 | 3. 인증기관은 웹 브라우저에게 자신의 공개키를 제공합니다.
43 |
44 | ### 사용자가 사이트에 접속할 경우
45 |
46 |  47 |
48 | 1. 사용자가 사이트에 접속하면 자신의 인증서를 웹 브라우저에게 보냅니다.
49 |
50 | 2. 웹 브라우저는 미리 받았던 인증기관의 공개키로 인증서를 해독하여 검증합니다. 그러면 사이트의 정보와 사이트의 공개키를 알 수 있게 됩니다.
51 |
52 | 3. 이렇게 얻은 사이트 공개키로 대칭키를 암호화해서 다시 사이트에 보냅니다.
53 |
54 | 4. 사이트는 개인키로 암호문을 해독하여 대칭키를 얻게 되고, 이제 대칭키로 데이터를 주고받을 수 있게 됩니다.
55 |
56 | 5. 세션이 종료되면 대칭키는 폐기됩니다.
57 |
58 |
47 |
48 | 1. 사용자가 사이트에 접속하면 자신의 인증서를 웹 브라우저에게 보냅니다.
49 |
50 | 2. 웹 브라우저는 미리 받았던 인증기관의 공개키로 인증서를 해독하여 검증합니다. 그러면 사이트의 정보와 사이트의 공개키를 알 수 있게 됩니다.
51 |
52 | 3. 이렇게 얻은 사이트 공개키로 대칭키를 암호화해서 다시 사이트에 보냅니다.
53 |
54 | 4. 사이트는 개인키로 암호문을 해독하여 대칭키를 얻게 되고, 이제 대칭키로 데이터를 주고받을 수 있게 됩니다.
55 |
56 | 5. 세션이 종료되면 대칭키는 폐기됩니다.
57 |
58 | 59 | >**[Reference]**
60 | https://devdy.tistory.com/14 -------------------------------------------------------------------------------- /Network/HTTP/1.1.md: -------------------------------------------------------------------------------- 1 | ## HTTP/1.0과 HTTP/1.1이 다른점 2 |
3 | 4 |
 5 |
6 |
7 | 1. 커넥션 유지(Persistent Connection)
5 |
6 |
7 | 1. 커넥션 유지(Persistent Connection) 8 | HTTP/1.0에 제일 큰 단점이라고 하면 nonPersistent라는 점이다. 하지만 HTTP1.1부터는 다르다. 9 | * 요청 헤더 connection:keep-alive 속성으로 지속적 연결 상태(persistent connection)을 유지한다. 10 | * 요청을 할 때마다 연결하지 않고 기존의 연결을 재사용하는 방식으로 HTTP/1.1부터는 지속적 연결 상태가 기본이고 해제하기 위해서는 명시적으로 요청 헤더를 수정해야 한다. 11 | 2. 파이프라이닝(Pipelining) 12 | * 파이프 라이닝이 존재하지 않을 때는 HTTP 요청이 순차적으로 이루어진다. 13 | * 파이프 라이닝이 생긴 이후 부터는 동시에 요청하고 이에 대해 각각 응답을 받아 처리한다. 14 | 3. 호스트 헤더 (Host Header) 15 | * HTTP 1.0 환경에서는 하나의 IP에 여러 개의 도메인을 운영할 수 없다. 도메인 마다 IP를 구분해서 준비해야 한다. 도메인만큼 서버의 개수도 늘어날 수 밖에 없는 구조이다. 16 | * HTTP 1.1 에서 Host 헤더의 추가를 통해 비로소 버츄얼 호스팅이 가능해졌다. 17 | 4. 강력한 인증 절차 (Improved Authentication Procedure) 18 | * proxy-authentication 19 | * proxy-authorization
20 | HTTP 1.1에 추가된 헤더이다. 이것은 클라이언트와 서버 사이에 프록시가 위치한 경우 프록시가 사용자의 인증을 요구할 수 있다. 21 | 22 | 23 |
24 | 25 | ## HTTP/1.1의 단점 26 | 27 | ### HOL(Head of Line) blocking: 특정 응답의 지연 28 |
 29 |
29 | 30 | 네트워크에서 같은 큐에 있는 패킷이 그 첫 번째 패킷에 의해 지연될 때 발생하는 성능 저하 현상이다. 31 | 32 |
33 | 34 | * 예를 들면 식당에가서 제일 먼저 돈까스를 시킨후에 라면, 콜라를 시켰다. 35 | * 근데 돈까스가 나올 때 까지 라면과 콜라를 주지 않는 것이다. 36 | * 더 큰 문제는 만약 돈까스 재료가 부족해 가계에서 돈까스 재료를 사러가야 한다. 37 | * 하지만 재료가 도착해 돈까스를 만들 때 까지 라면과 콜라를 주지 않는다. 38 | * 그럼 배고픈 학생들이 화가 난다. 39 | * 이게 HOL blocking이다. 40 | 41 |
42 | 43 | ### 왜 순서대로 응답을 줘야 할까? 44 | 웹 서버는 Pipelining 을 통해 한번에 여러 개의 요청을 받을 수 있으나, 응답 순서는 요청 순에 따라야 함이 HTTP 프로토콜의 규칙이 존재한다!! 45 | 46 |
47 | 48 | ### 무거운 헤더 구조 49 | HTTP/1.1의 헤더에는 많은 메타 정보들이 저장되어 있다. 클라이언트가 서버로 보내는 HTTP 요청은 매 요청 때마다 중복된 헤더 값을 전송하게 되며 서버 도메인에 관련된 쿠키 정보도 헤더에 함께 포함되어 전송된다. 이러한 반복적인 헤더 전송, 쿠키 정보로 인한 헤더 크기 증가가 HTTP/1.1의 단점이다. -------------------------------------------------------------------------------- /Network/Hop-By-Hop.md: -------------------------------------------------------------------------------- 1 | # 홉바이홉 통신 2 | 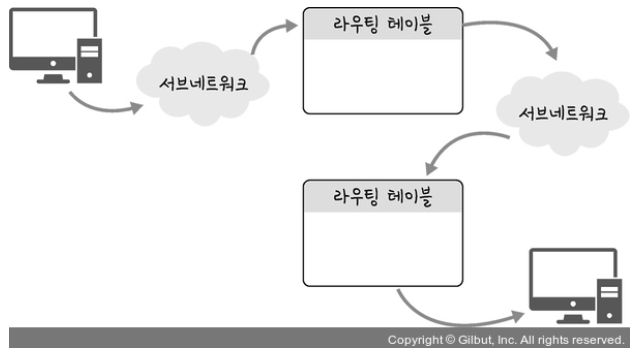 3 | - IP 주소를 통해 통신하는 과정 4 | - 각각의 라우터에 있는 라우팅 테이블의 IP를 기반으로 패킷을 전달하고 다시 전달해나감 5 | - 통신 장치에 있는 **라우팅 테이블**의 IP를 통해 시작 주소부터 시작하여 다음 IP로 계속해서 이동하는 **라우팅** 과정을 거쳐 패킷이 최종 목적지까지 도달하는 통신 6 | 7 | 8 | **라우팅** : IP 주소를 찾아가는 과정 9 |
10 |
11 | 12 |  13 | **라우팅 테이블** : 송신지에서 수신지까지 도달하기 위해 사용되며 라우터에 들어가 있는 목적지 정보들과 그 목적지로 가기 위한 방법이 들어 있는 리스트 14 |
15 |
16 | 17 | 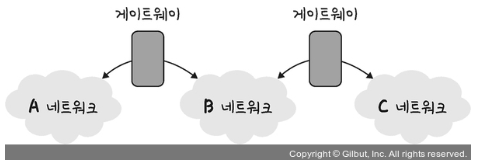 18 | 19 | **게이트웨이** : 서로 다른 통신망, 프로토콜을 사용하는 네트워크 간의 통신을 가능하게 하는 관문 역할을 하는 컴퓨터나 소프트웨어를 두루 일컫는 용어 20 | 사용자는 인터넷에 접속하기 위해 수많은 톨게이트인 게이트웨이를 거쳐야 하며 게이트웨이는 서로 다른 네트워크상의 통신 프로토콜을 변환해주는 역할을 하기도함 21 | 22 | -> 게이트웨이를 확인하는방법 = 라우팅 테이플을 통해 볼 수 있음. cmd창에서 netstat -r명령어를 통해 확인가능 23 | 24 | 25 | 26 | 27 | -------------------------------------------------------------------------------- /Network/IP-Address.md: -------------------------------------------------------------------------------- 1 | ## IPv4 vs IPv6 2 | IP 주소는 IPv4와 IPv6로 나뉜다. 3 | |구분|IPv4|IPv6| 4 | |---|---|---| 5 | |주소 길이|32비트|128비트| 6 | |주소 개수|약 43억개|2^128개| 7 | |표시 방법|8비트씩 4부분 10진수 표시|16비트씩 8부분 16진수 표시| 8 | |주소할당 방식|A, B, C, D 등의 클래스 단위 비순차 할당|네트워크 규모 및 단말기 수 따른 순차적 할당| 9 | |브로드캐스트 주소|있음|없음| 10 | |보안|IPSec 프로토콜 별도 설치|확장기능에서 기본적으로 제공| 11 |
12 | 13 | 14 | ## 클래스 기반 할당 방식 15 |  16 | 네트워크 주소와 호스트 주소에 따라 A, B, C, D, E 다섯 개의 클래스로 나누어 사용합니다. 17 | 18 | (클래스는 하나의 IP 주소에서 네트워크 영역과 호스트 영역을 나누는 방법을 의미합니다.) 19 | 20 | - 클래스 A, B, C : 일대일 통신으로 사용 21 | - 클래스 D : 멀티캐스트 통신으로 사용 22 | - 클래스 E : 앞으로 사용할 예비용 23 |
24 | 25 | 26 | 클래스 A로 12.0.0.0이란 네트워크를 부여받았다고 해보자. 그렇다면 12.0.0.1 ~ 12.255.255.254의 호스트 주소를 부여받은 것이다. 27 | 28 | 왜냐하면 첫번재 주소인 12.0.0.0은 네트워크 구별 주소이고 29 | 마지막 주소인 12.255.255.255는 브로드캐스트용 주소이기 때문이다. 30 | 31 | 이 방식은 버리는 주소가 많다는 단점이 있었고 이를 해소하기 이에 DHCP와 IPv6, NAT이 등장했다. 32 | 33 |
34 | 35 | ## DHCP (Dynamic Host Configuration Protocl) 36 | DHCP는 IP 주소 및 기타 통신 매개변수를 자동으로 할당하기 위한 네트워크 관리 프로토콜이다. 이 기술을 통해 네트워크 장치의 IP 주소를 수동으로 설정할 필요 없이 인터넷에 접속할 때마다 자동으로 IP 주소를 할당할 수 있다. 37 | 38 | 많은 라우터와 게이트웨이 장비에 DHCP 기능이 있으며 이를 통해 대부분의 가정용 네트워크에서 IP 주소를 할당한다. 39 | 40 |
41 | 42 | ## NAT (Network Address Translation) 43 | NAT는 사설 네트워크에 속한 여러 개의 호스트가하나의 공인 IP 주소를 사용하여 인터넷에 접속하기 위해 사용한다. 44 | 45 | 즉, 외부망과 내부망을 나눠주는 기능을 한다 . 46 | 47 | ex) 공유기 48 | 49 |  50 | 51 | - NAT 특징 52 | - 내부에서 외부로 통신 가능 53 | - 외부에서 내부로 통신 불가 54 | 55 | - NAT 장점 56 | - 하나의 공인IP로 여러 사설 IP를 사용가능. 절약. 57 | - 사내망 IP주소를 외부로 알리지 않음으로서 외부로 부터의 침입/공격 차단 58 | 59 | - NAT 단점 60 | - 네트워크 복잡성 증가 61 | - 네트워크 지연 영향 62 | 63 | -------------------------------------------------------------------------------- /Network/README.md: -------------------------------------------------------------------------------- 1 | # 네트워크 2 | 3 | - [TCP/IP 애플리케이션 계층](https://github.com/HanKwanJin/CS_Study/blob/main/Network/TCP/IP-애플리케이션-계층.md) 4 | - IP 란? 5 | - TCP 란? 6 | - TCP/IP 4계층과 OSI 7계층의 차이 7 | - 애플리케이션 계층 8 | - HTTP 9 | - SMTP, POP, IMAP 10 | - FTP 11 | - SSH 12 | - DNS 13 | - [TCP/IP 인터넷 계층](https://github.com/HanKwanJin/CS_Study/blob/main/Network/TCP/IP-인터넷-계층.md) 14 | - TCP/IP 인터넷 계층 15 | - IP 16 | - IPv4 패킷의 구조 17 | - ARP 18 | - ARP 패킷 구조 19 | - ICMP 20 | - ICMP가 필요한 이유 21 | - ICMP의 용도 22 | - [HTTP/2](https://github.com/HanKwanJin/CS_Study/blob/main/Network/HTTP2.md) 23 | - HTTP/2 24 | - 멀티플렉싱 25 | - HTTP 1.x의 HOL Blocking 문제 해결 26 | - 헤더 압축 27 | - 서버 푸시 28 | - 스트림 우선순위 29 | - [HTTPS](https://github.com/HanKwanJin/CS_Study/blob/main/Network/HTTP2.md) 30 | - HTTPS란? 31 | - SSL/TLS 32 | - 동작과정 33 | - 공개키 방식 34 | - 대칭키 방식 35 | - 인증서 발급 과정 36 | - 사용자가 사이트에 접속할 경우 37 | - [HTTP/3](https://github.com/HanKwanJin/CS_Study/blob/main/Network/HTTP3.md) 38 | - HTTP3란? 39 | - QUIC란? 40 | - QUIC 장점 41 | - [ARP](https://github.com/HanKwanJin/CS_Study/blob/main/Network/ARP.md) 42 | - ARP란? 43 | - 통신할 때 MAC 주소가 필요한 이유 44 | - 통신할 때 IP 주소가 필요한 이유 45 | - [Hop-By-Hop](https://github.com/HanKwanJin/CS_Study/blob/main/Network/Hop-By-Hop.md) 46 | - 라우팅 47 | - 라우팅 테이블 48 | - 게이트웨이 49 | - [어플리케이션 계층을 처리하는 기기](https://github.com/HanKwanJin/CS_Study/blob/main/Network/어플리케이션-계층을-처리하는-기기.md) 50 | - L7 스위치란? 51 | - 로드 밸런싱이란? 52 | - L4 스위치와 L7 스위치의 차이 53 | - L7 스위치의 헬스체크 기능 54 | - [Hop-By-Hop](https://github.com/HanKwanJin/CS_Study/blob/main/Network/Hop-By-Hop.md) 55 | - 라우팅 56 | - 라우팅 테이블 57 | - 게이트웨이 58 | - [IP-Address](https://github.com/HanKwanJin/CS_Study/blob/main/Network/IP-Address.md) 59 | - IPv4 vs IPv6 60 | - 클래스 기반 할당 방식 61 | - DHCP 62 | - NAT 63 | - [인터넷 계층을 처리하는 기기](https://github.com/HanKwanJin/CS_Study/blob/main/Network/인터넷-계층을-처리하는-기기.md) 64 | - 라우터 65 | - L3 스위치 66 | - 방화벽 67 | - [데이터 링크 계층을 처리하는 기기](https://github.com/HanKwanJin/CS_Study/blob/main/Network/데이터-링크-계층을-처리하는-기기.md) 68 | - 브리지 69 | - L2 스위치 70 | - [물리 계층을 처리하는 기기](https://github.com/HanKwanJin/CS_Study/blob/main/Network/물리-계층을-처리하는-기기.md) 71 | - 허브 72 | - 리피터 73 | - NIC 74 | - AP 75 | -------------------------------------------------------------------------------- /Network/TCP.IP-PDU.md: -------------------------------------------------------------------------------- 1 | # PDU (Protocol Data Unit) 2 | 3 | ***네트워크의 어떠한 계층에서 계층으로 데이터가 전달될 때, 한 덩어리의 단위를 PDU라고 한다.*** 4 | - 데이터 통신에서 상위 계층이 전달한 데이터에 붙이는 제어 정보 5 | - PDU는 제어 관련 정보들이 포함된 '헤더(header)', 데이터를 의미하는 'pay load'로 구성되어 있는데 계층마다 부르는 이름이 다르다. 6 | - 애플리케이션 계층 : 메시지 - 데이터라고도 한다고 함. 7 | - 전송 계층 : 세그먼트(TCP), 데이터그램(UDP) 8 | - 인터넷 계층 : 패킷(IP) 9 | - 링크 계층 : 프레임(데이터 링크 계층), 비트(물리 계층) 10 | 11 |  12 |
13 | **위 그림에서 data는 message와 같다.** 14 | 15 | ## PDU 구성 16 | - SDU(Service Data Unit) : 전송하려는 데이터 17 | - PCI(Protocol Control Information) : 제어 정보, 송신자와 수신자 주소나 오류코드 제어 정보 등이 있음. (데이터에 제어 정보를 붙이는 것을 캡슐화라고 함) 18 | ``` 19 | SDU + PCI = PDU 20 | ``` 21 | 22 | ## 참고 23 | - PDU 중 아래 계층인 비트로 송수신하는 것이 모든 PDU 중 가장 빠르고 효율성이 높다. 24 | - 하지만 애플리케이션 계층에선 문자열을 기반으로 송수신을 하는데, 그 이유는 헤더에 authorization 값 등 다른 값들을 넣는 확장이 쉽기 때문이다. 25 | --- 26 | ### 이미지 출처 27 | https://m.blog.naver.com/yeopil-yoon/221315395527 28 | 29 | 30 | -------------------------------------------------------------------------------- /Network/TCP.IP-계층-간-송수신.md: -------------------------------------------------------------------------------- 1 | # 계층 간 송수신 과정 2 | ``` 3 | 컴퓨터를 통해 다른 컴퓨터로 데이터를 요청한다면?
4 | -> HTTP를 통해 웹 서버에 있는 데이터를 요청한다면? 5 | 6 | 어떤 일이 일어나는지에 대하여 입니다. 7 | ``` 8 |  9 | 10 | 애플리케이션 계층에서 전송 걔층으로 보내는 요청(request) 값들이 ***캡슐화 과정***을 거쳐 전달되고, 다시 링크 계층을 통해 해당 서버와 통신을 하고, 해당 서버의 링크 계층으로부터 애플리케이션까지 ***비캡슐화 과정***을 거쳐 데이터가 전송됨 11 | 12 | 13 | --- 14 | ## **간단한 복습** 15 | 16 | ### 애플리케이션 계층 17 | - FTP, HTTP, SSH, SMTP, DNS 등등 18 | - 응용 프로그램이 사용되는 프로토콜 계층 19 | - 웹 서비스나 이메일 등 서비스를 실질적으로 사람들에게 제공하는 단계 20 |
21 | - FTP : 장치와 장치간의 파일을 전송하는 데 사용되는 표준 프로토콜 22 | - SSH : 보안되지 않은 네트워크에서 네트워크 서비스를 안전하게 운영하기 위한 암호화 네트워크 프로토콜 23 | - HTTP : WWW를 위한 데이터 통신의 기초이자 웹 사이트를 이용하는데 사용하는 프로토콜 24 | - DNS : 도메인 이름과 IP 주소를 매핑해주는 서버 -> IP 주소가 바뀌어도 사용자들에게 똑같은 도메인 주소로 서비스 25 | 26 | ### 전송계층 27 | - 송신자와 수신자를 연결하는 통신 서비스 제공 28 | - 연결 지향 데이터 스트림, 신뢰성, 흐름 제어 지원 29 | - 애플리케이션과 인터넷 계층 사이 데이터가 전달될 때의 중계 역할 30 |
31 | 예로는 TCP, UDP가 있다. 32 | - TCP 33 | - 패킷 사이의 순서를 보장 34 | - 연결 지향 프로토콜로 연결해 신뢰성을 구축하고 수신 여부를 확인 35 | - 가상회선 패킷 교환 방식 사용 36 | - UDP 37 | - 순서를 보장하지 않음 38 | - 수신 여부를 확인하지 않고, 단순히 데이터만 줌 39 | - 데이터그램 패킷 교환 방식 사용 40 | 41 | ### 인터넷 계층 42 | - 장치로부터 받은 네트워크 패킷을 IP 주소로 지정된 목적지로 전송하기 위해 사용되는 계층 43 | - IP, ARP, ICMP 등등 44 | - 패킷을 수신해야 할 상대의 주소를 지정해 데이터를 전달 45 | - 상대방이 제대로 받았는지에 대해 보장하지 않는 비연결형적인 특징을 가지고 있음 46 | 47 | ### 링크 계층(network access) 48 | - 전선, 광섬유, 무선 등으로 실질적으로 데이터를 전달하고, 장치 간에 신호를 주고 받는 규칙을 정하는 계층 -> **네트워크 접근 계층** 49 | - 물리 계층과 데이터 링크 계층으로 나뉘어진다. 50 | - 물리 계층 51 | - 무선 LAN / 유선 LAN을 통해 0,1로 이루어진 데이터를 보냄 52 | - 데이터 링크 계층 53 | - 이더넷 프레임을 통해 에러 확인 / 흐름 제어 / 접근 제어 담당 54 | --- 55 | 56 | ## 캡슐화 과정 57 | 상위 계층의 헤더와 데이터를 하위 계층의 데이터 부분에 포함시키고, 해당 계층의 헤더를 삽입하는 과정 58 | 59 |  60 | 61 | 1. 애플리케이션 계층의 데이터가 전송 계층으로 전달되면서 "**세그먼트 또는 데이터그램**"화 되며 TCP(L4) 헤더가 붙음 62 | 2. 인터넷 계층으로 가면서 IP(L3) 헤더가 붙여지며 "**패킷**"화 됨 63 | 3. 링크 계층으로 전달되면서 프레임 헤더와 프레임 트레일러가 붙어 "**프레임**"화 됨 64 | 65 | ## 비캡슐화 과정 66 | 하위 계층에서 상위 계층으로 가며 각 계층의 헤더 부분을 제거하는 과정 67 | 68 | 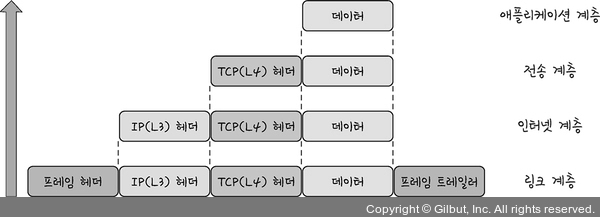 69 | 70 | 1. 링크 계층에서 프레임화된 데이터를 패킷화 71 | 2. 세그먼트, 데이터 그램화 72 | 3. 메시지화 73 | 74 | 즉, 캡슐화의 역순으로 생각하면 된다.
75 | ### ***이후 최종적으로 사용자에게 애플리케이션의 PDU인 메시지로 전달됨*** 76 | 77 | --- 78 | ### 이미지 출처 79 | https://thebook.io/080326/ 80 | 81 | -------------------------------------------------------------------------------- /Network/TCP.IP-링크-계층.md: -------------------------------------------------------------------------------- 1 | # 링크 계층 2 | - 전선, 광섬유, 무선 등으로 실질적으로 데이터를 전달하고, 장치 간에 신호를 주고받는 **규칙**을 정하는 계층 3 | - "네트워크 접근 계층" 이라고도 함 4 | - 인접한 네트워크 노드끼리 데이터를 전송하는 기능과 절차 제공 5 | - 대표적인 프로토콜로 **이더넷**이 있다. 6 | 7 | ### 물리 계층 / 데이터 링크 계층 8 | 이를 물리 계층과 데이터 링크 계층으로 나누기도 한다. 9 | - 물리 계층 10 | - 무선 LAN과 유선 LAN을 통해 0과 1로 이루어진 데이터를 보내는 계층 11 | - 데이터 링크 계층 12 | - **이더넷** 프레임을 통해 에러 확인, 흐름 제어, 접근 제어를 담당하는 계층 13 | 14 | ## 유선 LAN (IEEE802.3) 15 | 유선 LAN을 이루는 이더넷은 IEEE803.2 라는 프로토콜을 따르며 전이중화 통신을 씀 16 | 17 | ### 전이중화 통신 (Full Duplex) 18 | - 양쪽 장치가 동시에 송수신할 수 있는 방식 19 | - 송신로와 수신로로 나누어 데이터를 주고 받으며, 현대의 고속 이더넷은 이 방식을 기반으로 통신한다. 20 | - 동시에 양방향 전송을 하기 위해 4선식 전송로로 되어있다. 21 | - 2선식 전송로에서도 시분할 방식 등과 같은 멀티플렉싱(데이터 전송에서 두개 이상의 데이터원이 공통의 전송매체를 공유하게 되는 기능)을 이용하여 통신이 가능한데, 이를 사용하면 마치 4선식 전송로인 것처럼 전이중화 통신이 가능해진다. 22 | 23 | 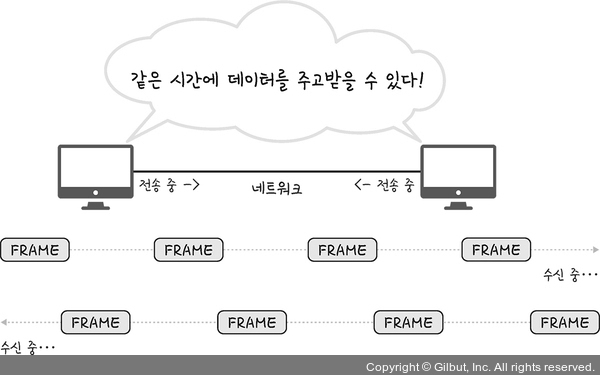 24 | 25 | ### CSMA/CD (Carrier Sense Multiple Access with Collision Detection) 26 | - 이전의 유선 LAN의 반이중화 통신 중 하나의 방식 27 | - **데이터를 '보낸 이후' 충돌이 발생하면 일정 시간 이후 재전송하는 방식** 28 | - 수신로와 송신로를 따로 두지 않고 한 경로를 기반으로 데이터를 보내기에 데이터를 보낼 때 충돌이 발생함을 대비 29 | 30 | 1. 이더넷 환경에서 통신을 하고 싶은 PC나 서버는 먼저 네트워크 상에 통신이 일어나는지 확인 (캐리어[1]가 있는지 검사) 31 | 2. 네트워크 통신이 일어나고 있으면(캐리어를 감지하면) 데이터를 보내지 않고 대기 32 | 3. 네트워크 통신이 일어나고 있지 않으면 데이터를 네트워크 상에 보낸다. 33 | 4. 캐리어가 감지되지 않았을 때, 두 PC 혹은 서버가 데이터를 동시에 보내면 이 경우를 Multiple Access(다중접근)라고 한다. 34 | 5. 위와 같이 데이터를 동시에 보내다가 부딪히는 경우 충돌(Collision)이 발생했다고 함. 35 | 6. 만약 충돌이 일어나면 데이터를 전송한 PC나 서버는 랜덤 시간 대기한 뒤 다시 데이터 전송 36 | 7. 이런 충돌이 15번 일어나면 통신을 끊는다. 37 | 38 | * 참고 : https://security-nanglam.tistory.com/193 39 | --- 40 | [1]캐리어 : carrier sense - 네트워크 상에 나타나는 신호 41 | 42 | ## 유선 LAN을 이루는 케이블 43 | 유선 LAN을 이루는 케이블은 TP케이블이라고 하는 트위스트 페어 케이블과 광섬유 케이블이 있다. 44 | 45 | ### 트위스트 페어 케이블 (twisted pair cable) 46 | 여덟개의 구리선을 두 개씩 꼬아서 묶은 케이블 47 |  48 |
49 | 케이블은 구리선을 실드 처리하지 않고 덮은 UTP 케이블과 실드 처리하고 덮은 STP로 이루어진다. 우리가 흔히 보는 케이블은 UTP 케이블이며, LAN 케이블이라고 한다.
50 | 51 | 
52 | (와이파이 연결하는 케이블 생각하면 된다.) 53 | 54 | ### 광섬유 케이블 55 | - 광섬유로 만든 케이블 56 | - 레이저를 이용해 통신하기에 구리선과는 비교할 수 없을 만큼의 장거리 및 고속 통신이 가능함. 57 | - 보통 100Gbps의 데이터를 전송하며, 광섬유 내부와 외부를 다른 밀도의 유리나 플라스틱 섬유로 제작해 한 번 들어간 빛이 내부에서 계속적으로 반사되며 전진하여 반대편 끝가지 가는 원리 58 | 59 | 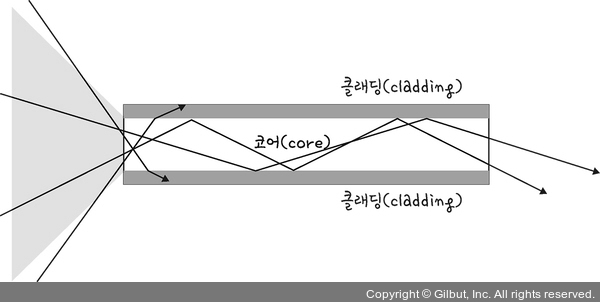
60 | 빛의 굴절률이 높은 부분을 코어(core)라고 하고, 낮은 부분을 클래딩이라고 한다. 61 | 62 | ## 무선 LAN (IEEE802.11) 63 | 무선 LAN 장치는 수신과 송신에 같은 채널을 사용하기 때문에 반이중화 통신을 사용한다. 64 | 65 | ### 반이중화 통신 (Half Duplex) 66 | - 서로 통신할 수는 있지만, 동시에는 통신할 수 없고 한 번에 한 방향만 통신할 수 있다. 67 | - 하나의 데이터를 받기까지 전송이 제한됨 68 | - 즉 장치가 신호를 수신하기 시작하면 응답하기 전에는 전송이 완료될 때까지 대기 69 | - 충돌이 발생하여 메시지가 손실되거나 왜곡될 수 있기 때문에 충돌 방지 시스템 필요 70 | 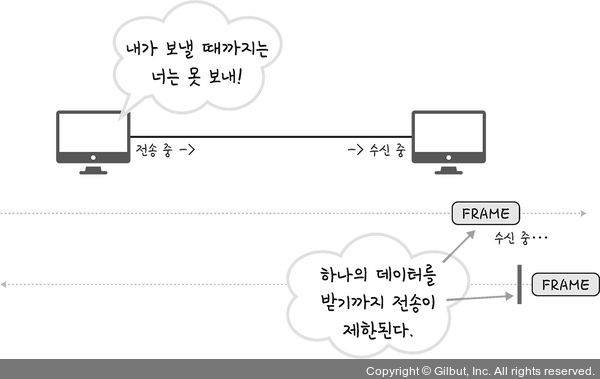 71 | 72 | ### CSMA/CA (Carrier Sense Multiple Access with Collision Avoidance) 73 | 반이중화 통신 중 하나로 장치에서 데이터를 보내기 전, 캐리어 감지 등으로 사전에 가능한 한 충돌을 방지하는 방식을 사용 74 | - CSMA/CD의 변형, 무선 환경에서 사용하는 Media Access 방법(알고리즘) 75 | - ACK 프레임 사용 76 |
77 | - CSMA/CA의 과정 78 | 1. 데이터를 송신하기 전, 무선 매체를 살핌 79 | 2. 캐리어 감지 : 회선이 비어있는지 확인 80 | 3. **IFS(Inter Frame Space)**: 랜덤 값을 기반으로 정해진 시간만큼 기다리며, 무선 매체가 사용 중이면 점점 그 간격을 늘려가며 대기 81 | 4. 이후에 데이터 전송 82 | 83 | **[참고]** 이와 반대되는 전이중화 통신은 양방향 통신이 가능하므로 충돌 가능성이 없기 때문에 충돌을 감지하거나 방지하는 메커니즘이 필요하지 않음 84 | 85 | ## 무선 LAN을 이루는 주파수 86 | 무선 LAN (WLAN, Wireless Local Area Network)은 무선 신호 전달 방식을 이용해 2대 이상의 장치를 연결한다. 87 | - 비유도 매체인 공기에 주파수를 쏘아 무선 통신망 구축 88 | - 주파수 대역 : 2.4GHz or 5GHz 중 하나 사용 89 | - 2.4GHz : 장애물에 강한 특성을 가졌지만 전자레인지, 무선 등 전파 간섭이 일어나는 경우가 많음 90 | - 5GHz : 사용할 수 있는 채널 수도 많고 동시에 사용할 수 있기에 상대적으로 깨끗한 전파 환경 구축 가능
91 | (되도록이면 5GHz 사용하는 것이 좋음) 92 | 93 | ### 와이파이(wifi) 94 | 전자기기들이 무선 LAN 신호에 연결할 수 있게 하는 기술 95 | - 무선 접속 장치(AP, Access Point)가 있어야 함 - 공유기 96 | - 유선 LAN에 흐르는 신호를 무선 LAN 신호로 변환해 신호가 닿는 범위 내에서 무선 인터넷 사용 가능 97 | - 무선 LAN을 이용한 기술은 wifi 외에도 지그비, 블루투스 등이 있다. 98 | 99 | ### BSS (Basic Service Set) 100 | 기본 서비스 집합을 의미하며, 단순 공유기를 통해 네트워크에 접속하는 것이 아닌 동일 BSS 내에 있는 AP들과 장치들이 서로 통신이 가능한 구조 101 |
근거리 무선 통신을 제공하며, 하나의 AP만을 기반으로 구축되어 사용자가 한 곳에서 다른 곳으로 자유롭게 이동하며 네트워크에 접속하는 것은 불가능 102 | 103 | ### ESS (Extended Service Set) 104 | 하나 이상의 연결된 BSS 그룹 105 | - 장거리 무선 통신을 제공 106 | - BSS 보다 많은 가용성과 이동성 지원 107 | - 사용자는 한 장소에서 다른 장소로 이동하며 중단 없이 네트워크에 계속 연결 가능 108 | 109 | 
110 | 111 | ## 이더넷 프레임 112 | 데이터 링크 계층은 이더넷 프레임을 통해 전달받은 데이터의 에러를 검출하고 캡슐화하며 다음과 같은 구조를 가진다. 113 | 
114 | 115 | - Preamble : 이더넷 프레임의 시작을 알림 116 | - SFD(Start Frame Delimiter) : 다음 byte부터 MAC 주소 필드가 시작됨을 알림 117 | - DMAC, SMAC : 수신, 송신 MAC 주소 118 | - EtherType : 데이터 계층 위의 계층은 IP 프로토콜을 정의 119 | - ex) IPv4, IPv6 120 | - Payload : 전달받은 데이터 121 | - CRC : 에러 확인 비트 122 | 123 | **!![용어]!!
124 | MAC 주소 : 컴퓨터나 노트북 등 각 장치에는 네트워크에 연결하기 위한 장치(LAN 카드)가 있는데, 이를 구별하기 위한 식별번호를 말함. 6bytes(48bits)로 구성됨** 125 | 126 | --- 127 | ### 이미지 출처
128 | 129 | 나머지 : https://thebook.io/080326/ 130 | 131 | 132 | 133 | -------------------------------------------------------------------------------- /Network/TCP.IP-전송-계층.md: -------------------------------------------------------------------------------- 1 | # TCP/IP 전송 계층 2 | 3 | - 송신자와 수신자를 연결하는 통신 서비스 제공 4 | - 연결 지향 데이터 스트림 지원, 신뢰성, 흐름 제어 제공 5 | - 애플리케이션과 인터넷 계층 사이 데이터 전달의 중계 역할 6 | - 대표적으로 TCP, UDP가 있다. 7 | - TCP (Transmission Control Protocol) 8 | - 패킷[1] 사이 순서를 보장하고 연결지향 프로토콜을 사용해 연결하여 신뢰성을 구축해서 수신 여부를 확인하며 '가상회선 패킷 교환 방식' 사용 9 | - UDP (User Datagram Protocol) 10 | - 순서를 보장하지 않고 수신 여부를 확인하지 않으며, 단순히 데이터만 주는 '데이터그램 패킷 교환 방식' 사용 11 | - 요약 : 데이터의 전달을 담당 12 | 13 | --- 14 | [1] 패킷 : 각 계층이 데이터를 프로토콜에 따라 처리하고 헤어들 추가한 데이터 단위 15 | 16 | ## 가상회선 패킷 교환 방식 17 | 각 패킷에 가상회선 식별자가 포함되며, 모든 패킷을 전송하면 가상회선이 해제되고 전송된 순서대로 도착한다. 18 | 19 |  20 | 21 | 위 그림을 보면 가상회선이 있고, 그 길을 따라 순서대로 이동하는 것을 볼 수 있다. 22 | 23 | ## 데이터그램 패킷 교환 방식 24 | 패킷이 독립적으로 이동하며 최적의 경로를 선택하여 간다. 25 | 하나의 메시지에서 분할된 여러개의 패킷은 서로 다른 경로로 전달될 수도 있으며 도착하는 순서가 정해져있지 않다. 26 | 27 |  28 | 29 | 위 그림을 보면 패킷이 독립적으로 해당 패킷의 최적의 경로를 선택하여 가고, 도착하는 순서가 '다를 수도' 있다는 것을 볼 수 있다. 30 | 31 | ## TCP 연결 성립 과정 32 | TCP는 신뢰성을 확보할 때 '3-way handshake'라는 작업을 진행한다. 33 | 이 작업으로 신뢰성이 구축되고, 데이터를 전송한다. UDP는 이 과정이 없어 신뢰성이 없는 계층이라 불린다. 34 | 35 |  36 | 37 | ### SYN[2] 단게 (#1) 38 | 클라이언트는 서버에 ISN[3]을 담아 SYN을 보낸다. ISN은 새로운 TCP연결의 첫 번째 패킷에 할당된 임의의 시퀀스 번호이다. (장치마다 다를 수 있음) 39 | ### SYN + ACK[4] 단계 (#2) 40 | 서버는 클라이언트에 SYN을 수신하고 서버의 ISN을 보내며 승인번호로 클라이언트의 ISN+1을 반환 41 | ### ASK 단계 (#3) 42 | 클라이언트가 서버에서 반환한 ISN+1 한 값(승인번호)을 담아 ACK를 서버에 보냄 43 | 44 | --- 45 | [2] SYN : SYNchronization - 연결 요청 플래그, 다른 컴퓨터로 전송된 TCP패킷으로 연결이 이루어 지도록 요청
46 | [3] ACK : ACKnowledgement - 응답 플래그, 다른 컴퓨터나 네트워크 장치가 다른 컴퓨터에 SYN/ACK 또는 다른 요청을 보낸 것을 확인한 응답
47 | [4] ISN : Initial Sequence Numbers - 초기 네트워크 연결을 할 때 할당된 32비트 고유 시퀀스 번호 48 | 49 | ## TCP 연결 해제 과정 50 | TCP가 연결을 해제할 때는 4-way handshake 과정을 거침 51 | 52 |  53 | 54 | ### FIN_WAIT_1 55 | 먼저 클라이언트가 연결을 닫으려 할 때 FIN으로 설정된 세그먼트[5]를 보냄. 그리고 클라이언트는 FIN-WAIT-1 상태로 들어가고 서버의 응답 대기 56 | ### CLOSE_WAIT 57 | 서버는 클라이언트로 ACK라는 승인 세그먼트를 전송. 이후 CLOSE-WAIT 상태로 전환하고 클라이언트가 전송을 받으면 FIN-WAIT-2로 전환 58 | ### LAST_ACK 59 | 서버가 ACK를 보내고 일정 시간 이후 클라이언트에 FIN이라는 세그먼트 전송 60 | ### TIME_WAIT[6] 61 | 클라이언트가 TIME_WAIT 상태가 되고 다시 서버로 ACK를 전송하여 서버는 CLOSED 상태가 됨. 이후 어느 정도의 시간을 대기하면 연결이 닫히고, 클라이언트와 서버의 모든 자원 연결 해제 62 | 63 | [TIME_WAIT] 일정 시간이 지나고 연결을 닫는 이유 64 | 1. 지연된 패킷이 발생할 경우를 대비 65 | - 패킷이 늦게 도달하고 이를 처리하지 못하면 데이터 무결성[7] 문제 발생(일부 데이터만 들어오는 현상) 66 | 2. 두 장치 연결이 닫혔는지 확인 67 | - server의 LAST_ACK 상태에서 ACK를 클라이언트에게서 받으면 CLOSE 상태로 들어가는데, 어떤 문제로 LAST_ACK 상태에서 닫히면 새로운 연결을 하려고 할 때, 장치는 계속 LAST_ACK로 되어있기 때문에 오류가 발생한다. 68 | 69 | --- 70 | [5] Segment : TCP로 연결된 세션간의 전달되는 데이터 단위
71 | [6] TIME_WAIT : 소켓이 바로 소멸되지 않고 일정 시간 유지되는 상태
72 | [7] 데이터 무결성(data integrity) : 데이터의 정확성과 일관성을 유지하고 보증하는 것 73 | 74 | --- 75 | ### 이미지 출처 76 | [패킷 교환 방식] https://mangkyu.tistory.com/15 77 | [TCP 연결 및 해제] https://seongonion.tistory.com/74 78 | -------------------------------------------------------------------------------- /Network/TCP/IP-HTTP/1.0.md: -------------------------------------------------------------------------------- 1 | ## HTTP란? 2 |
3 | 4 | * HTTP(Hyper Text Transfer Protocol)는 인터넷에서 주로 사용하는 데이터를 송수신하기 위한 프로토콜이다. 5 | * 애플리케이션 계층으로서 웹 서비스 통신에 사용된다. 6 | 7 |
8 | 9 | ## HTTP/1.0이란? 10 | 11 |
 12 |
12 | 13 | 14 | 15 | * HTTP/1.0 은 기본적으로 한 연결당 하나의 요청을 처리하도록 설계되었다. 즉, TCP 세션을 지속적으로 유지할 수가 없다. 16 | * HTTP/1.0은 매번 데이터를 요청하고 수신할 때마다 새로운 TCP 세션을 맺어야 한다. 17 | * HTTP/1.0은 Non-persistent HTTP이다. 18 | * 1996년에 만들어졌다. 19 | 20 |
21 | 22 | ## HTTP/1.0의 단점 23 | 24 | ### RTT 증가 25 | 26 | 서버로부터 파일을 가져올 때마다 TCP의 3-웨이 핸드셰이크를 계속해서 열어야 하기 때문에 RTT가 증가한다. 27 | 28 |
29 | 30 | ## RTT 증가 해결방법 31 | 32 | 매번 연결할 때마다 RTT가 증가하니 서버에 부담이 많이 가고 사용자 응답 시간이 길어졌다. 이를 해결하기 위해 이미지 스플리팅, 코드 압축, 이미지 Base64 인코딩을 사용한다. 33 | 34 |
35 | 36 | ### 이미지 스프라이트 37 | 38 | 많은 이미지를 한번에 다운로드 받게 되면 과부하가 걸리기 때문에 많은 이미지가 합쳐 있는 하나의 이미지를 다운로드 받고, 이를 기반으로 background-image의 position을 이용하여 이미지를 표기하는 방법이다. 39 | 40 | * 책에는 이미지 스플리팅이라고 하지만 요즘 이미지 스프라이트라고 부른다고 한다. 41 | 42 | * 웹의 경우에서는 "여러 개의 이미지를 하나의 이미지로 만들어 놓는 것"을 의미한다. 43 | 44 | 45 |
 46 |
47 | 이렇게 4개의 아이콘을 하나로 합쳐서 다운 받는 것이다.
48 |
49 | ```
50 | 네이버
51 | 페이스북
52 | 구글
53 | 카카오
54 | ```
55 | ```
56 | a::after {
57 | content: "";
58 | display: block;
59 | width: 28px;
60 | height: 28px;
61 | background-image: url(./asset/images/css_sprites.png);
62 | }
63 |
64 | .naver::after {
65 | background-position: -58px -58px;
66 | }
67 |
68 | .fb::after {
69 | background-position: -10px -10px;
70 | }
71 |
72 | .google::after {
73 | background-position: -58px -10px;
74 | }
75 |
76 | .kakao::after {
77 | background-position: -10px -58px;
78 | }
79 | ```
80 | 이렇게 background를 이용해 4개를 합쳐서 가져온다.
81 |
46 |
47 | 이렇게 4개의 아이콘을 하나로 합쳐서 다운 받는 것이다.
48 |
49 | ```
50 | 네이버
51 | 페이스북
52 | 구글
53 | 카카오
54 | ```
55 | ```
56 | a::after {
57 | content: "";
58 | display: block;
59 | width: 28px;
60 | height: 28px;
61 | background-image: url(./asset/images/css_sprites.png);
62 | }
63 |
64 | .naver::after {
65 | background-position: -58px -58px;
66 | }
67 |
68 | .fb::after {
69 | background-position: -10px -10px;
70 | }
71 |
72 | .google::after {
73 | background-position: -58px -10px;
74 | }
75 |
76 | .kakao::after {
77 | background-position: -10px -58px;
78 | }
79 | ```
80 | 이렇게 background를 이용해 4개를 합쳐서 가져온다.
81 | 82 | 출처 : https://velog.io/@untiring_dev/HTMLCSS-Day31.-%EC%9D%B4%EB%AF%B8%EC%A7%80-%EC%8A%A4%ED%94%84%EB%9D%BC%EC%9D%B4%ED%8A%B8-%EA%B8%B0%EB%B2%95 83 | 84 |
85 | 86 | ### 코드 압축 87 | 88 | 코드 압축은 코드를 압축해서 개행 문자, 빈칸을 없애서 코드의 크기를 최소화하는 방법이다.
89 | 책에서의 예시를 보면 모든 코드의 띄어쓰기와 개행문자를 없에고 ,로 대체한다. 90 | 91 | ### 이미지 Base64 인코딩 92 | * 이미지 파일을 64진법으로 이루어진 문자열로 인코딩하는 방법이다.
93 | * 이 방법을 사용하면 서버와의 연결을 열고 이미지에 대해 서버에 HTTP 요청을 할 필요가 없다는 장점이 있다.
94 | * 하지만 Base64 문자열로 변환할 경우 37% 정도 크기가 더 커지는 단점이 있다. 95 | * 이런 단점에도 사용하는 이유는 Base64는 모든 가능한 바이트값을 신뢰할 수없는 통신 채널을 통해 바이너리 데이터를 안전하게 전송할 수 있게 하는 것이다. 96 | * Base64는 어떤 문자와 기호를 쓰느냐에 따라 다양한 변종이 있지만, 대부분 처음 62개는 알파벳 A-Z, a-z와 0-9를 사용하며 마지막 두 개를 어떤 기호를 쓰느냐의 차이만 있습니다. 97 |  98 | 인코딩을 하는 과정을 보여주는 예시이다. -------------------------------------------------------------------------------- /Network/TCP/IP-애플리케이션-계층.md: -------------------------------------------------------------------------------- 1 | ## TCP/IP 애플리케이션 계층 2 | 3 | ## IP (Internet Protocol) 란? 4 | 5 | IP는, 패킷 데이터들을 최대한 빨리 특정 목적지 주소로 보내는 프로토콜이다. 6 | (패킷 전달 여부를 보증하지 않으며, 패킷은 보낸 순서와 받는 순서가 다를 수 있다.) 7 | 8 | ## TCP (Transmission Control Protocl) 란? 9 | 10 | TCP는 패킷을 정상적으로 받을 수 있도록 하는 프로토콜이다. 11 | (패킷 전달 여부를 보증하고, 패킷을 송신 순서대로 받게 해준다) 12 | 단 IP 보다 느리다. 13 | 14 | ## TCP/IP 4계층과 OSI 7계층의 차이 15 | 16 | * OSI 7계층 17 | + 특정 네트워킹 시스템에서 일어나는 일을 계층을 활용해 시각적으로 쉽게 설명할 수 있다. 18 | + 응용프로그램 개발 시 다른 어떤 계층에 작업이 필요한지 쉽게 파악할 수 있다. 19 | + IT 기업이 고객에게 신제품을 설명할 때 OSI 모형을 많이 활용한다고 한다. 20 | 에플리케이션 계층 -> 프레젠테이션 계층 -> 세션 계층 -> 전송 계층 -> 네트워크 계층 -> 데이터 링크 계층 -> 물리 계층 21 | 22 | * TCP/IP 4계층 23 | + TCP/IP는 현재의 인터넷에서 컴퓨터들이 서로 정보를 주고받는데 쓰이는 통신규약의 모음이다. 24 | + 하드웨어, 운영체제, 접속매체에 관계없이 동작할 수 있는 개방성을 가진다. 25 | 애플리케이션 계층 -> 전송 계층 -> 인터넷 계층 -> 링크 계층층 26 | 27 | ## 애플리케이션 계층 28 | 29 | FTP, HTTP, SSH, SMTP, DNS 등을 응용 프로그램이 사용되는 프로토콜 계층이며 웹 서비스, 이메일 등 서비스를 실질적으로 사람들에게 제공하는 층이다. 30 | 31 | ### HTTP 32 | 33 | * 웹 브라우저는 웹 서버로 특정 웹 페이지를 요청하면 웹 서버가 해당 페이지의 내용을 HTML 형식으로 응답한다. 34 | * 웹 브라우저가 서버로부터 받은 데이터를 해석하여 화면을 그린 후 사용자에게 보내준다. 35 | * 이 때 더 필요한 정보가 있으면 서버에게 다시 요청하고 서버는 응답한다. 36 | * HTTP는 상태 정보를 저장하지 않는 통신 형태이다. (Stateless) 무상태 프로토콜 37 | 38 | ### SMTP, POP, IMAP 39 | 40 | * 이와 같은 프로토콜들은 이메일을 송수신할 때 사용한다. 41 | * 이메일을 발신할 때는 SMTP를 사용하고, 수신할 때는 POP를 사용한다. 42 | * SMTP는 발신할 때 플러스 발신자의 메일 서버에서 수신자의 서버로 메일을 중계할 때도 사용한다. 43 | * SMTP는 Stateful 프로토콜이다. 44 | * 저장된 메일을 확인 할 때는 POP 프로토콜 사용. 메일 건수나 용량 확인, 메일 삭제와 같은 처리도 POP가 실행. 현재는 POP3가 쓰인다. 45 | * IMAP 프로토콜은 POP 프로토콜과 달리 클라이언트가 메일을 수신하더라고 메일 서버에서 수신한 메일을 지우지 않고 보관한다. 그래서 휴대기기에서 많이 사용한다. 46 | 47 | ### FTP 48 | 49 | * 파일 전송 프로토콜이다. 인터넷에 연결될 서버에 파일을 전송할 때 사용된다. 50 | * 웹 서버로 웹 페이지를 전송할 때 자주 쓰인다. 51 | * FTP는 크게 파일을 주고 받기 위한 데이터 커넥션과 명령어를 보내기 위한 컨트롤 커넥션 두 가지 접속 형태를 사용해요. 52 | 53 | ### SSH 54 | 55 | * 보안되지 않은 네트워크에서 네트워크 서비스를 안전하게 운영하기 위한 암호화 네트워크 프로토콜이다. 56 | * 물리적으로 먼 거리에 있는 서버들을 관리할 때 이 프로토콜을 사용하는 것이 일반적이라고 한다. 57 | 58 | ### DNS 59 | 60 | 도메인 이름과 IP 주소를 매핑해주는 서버 61 | www.naver.com에 DNS 쿼리가 오면 [ROOT DNS] -> [.com DNS] -> [.NAVER DNS] -> [.www DNS] 과정을 거쳐 완벽한 주소를 찾아 IP 주소를 매핑한다. 62 | 63 | -------------------------------------------------------------------------------- /Network/TCP/IP-인터넷-계층.md: -------------------------------------------------------------------------------- 1 | ## TCP/IP 인터넷 계층 2 | 3 | * 인터넷 계층은 장치로부터 받은 네트워크 패킷을 IP 주소로 지정된 목적지로 전송하기 위해 사용되는 계층이다. 4 | * IP, ARP, ICMP 등이 있으며 패킷을 수신해야 할 상대의 주소를 지정하여 데이터를 전달한다. 5 | * 상대방이 제대로 받았는지에 대해 보장하지 않는 비연결형적인 특징을 가지고 있다. 6 | 7 | ## IP 8 | 9 | ### IPv4 패킷의 구조 10 | 11 |
 12 |
12 | 13 | 14 | 1. VER (4bits) : IP의 version을 나타낸다. 15 | 2. HLEN 혹은 IHL (4bits) : IP헤더의 크기를 나타낸다. 16 | 3. TOS (Type of Service) (8bits) : 요구되는 서비스 타입이다. 17 | 4. Total Length (16bits) : IP헤더와 데이터를 포함한 IP패킷의 크기를 나타낸다. 18 | 5. Identification 혹은 Fragment Identification (16bits) : 데이터링크의 MTU size에 따라 조각화된 패킷을 복원하기 위한 식별자이다 19 | 6. Flags 혹은 Fragmentation Flags (3bits) : 20 | + 첫번째 bit는 무조건 0 21 | + 두번째 bit는 DF(Don't Fragment) bit로 이 값이 1이면 패킷을 조각화 하지 않는다. 22 | + 마지막 bit는 MF(More Fragment) bit로 분활된 패킷이 마지막일 경우 0 이고 추가로 더 있을 경우는 1이다. 23 | 7. FO (Fragmentation Offset) (13bits) : 분할된 Fragment가 원래 데이터에서 어떤 위치였는지 나타내는 값으로 단위는 8-byte(8옥텟)이다. 24 | 8. TTL(Time to live) (8bits) : 패킷이 네트워크 상에 얼마나 오래 살아남을 수 있는지를 알려주는 값이다. 25 | 9. Protocol (8bits) : 다음 상위계층(전송계층)의 프로토콜이 무엇인지 나타낸다. 26 | 10. Header checksum (16bits) : IP헤더가 손상되지 않았다는 것을 보증하기 위한 checksum이다. 27 | 11. Source IP address (32bits) : 출발지 IP주소이다. 28 | 12. Destination IP address (32bits) : 목적지 IP 주소이다. 29 | 13. Options (0~40bytes) : 가변길이를 갖는 옵션 값은, 일반적으로는 사용되지 않고 테스트나 디버그 등의 용도로 사용된다. 30 | * 단일 바이트 옵션 31 | + 옵션 종료(end of option) 32 | + 무 동작(no operation) 33 | * 다중 바이트 옵션 34 | + 경로 기록 옵션 (record route) 35 | + 엄격한 발신지 경로 옵션 (strict source route) 36 | + 느슨한 발신지 경로 옵션 (loose source route) 37 | + 타임스탬프 (Timestamp) 38 | 39 |
40 | 41 | ## ARP 42 | 43 | ### ARP 패킷 구조 44 | 45 |
 46 |
47 |
46 |
47 | 48 | ARP는 Address Resolution Protocol의 약자로 IP 주소를 MAC 주소와 매칭 시키기 위한 프로토콜입니다. 49 | 50 | 어떤 호스트나 라우터가 다른 호스타나 라우터에 보낼 IP 데이터그램을 가지고 있다면 송신자는 수신자의 논리 주소인 IP 주소를 가지고 있다. 그러나 IP 데이터그램은 물리적인 네트워크를 통과하기 위해 프레임 내에 캡슐화되어야 한다.
51 | 즉, 송신자는 수신자의 물리 주소(MAC)를 알아야 한다.
52 | ARP는 IP 프로토콜로부터 논리 주소를 받아 이를 해당하는 물리 주소로 변환한 후 데이터링크 계층에 전달한다!!! 53 | 54 | * ARP 요청은 브로드캐스트로 모든 곳에 요청하지만 응답은 유니캐스트로 목적지와 출발지만 소통한다. 55 | 56 |
57 | 58 | ## ICMP 59 | 60 |
 61 |
62 | 인터넷 제어 메시지 프로토콜이라고 한다.
63 | 이것은 네트워크 내 장치가 데이터 전송과 관련된 문제를 전달하기 위해 사용하는 프로토콜이다.
64 |
65 | ### ICMP가 필요한 이유
66 |
67 | IP 프로토콜은 TCP 처럼 흐름 제어와 혼잡 제어 메커니즘이없다. 하지만 호스트는 간혹 라우터나 다른 호스트가 동작하고 있는지 알 필요가 있다. 이 단점을 보완하고자 ICMP가 생겼다.
68 |
69 | ### ICMP의 용도
70 |
71 | 인터넷 제어 메시지 프로토콜(ICMP)는 오류 보고 및 네트워크 진단 수행에 사용됩니다. 오류 보고 프로세스에서 ICMP는 데이터가 제대로 오지 않을 때 수신자에서 발신자에게 메시지를 보냅니다. 진단 프로세스 내에서 ICMP는 데이터 전송 방법에 대한 정보를 제공하기 위해 핑 및 트레이스라우트에서 사용하는 메시지를 보내는 데 사용됩니다.
72 |
73 | * 오류 보고 메시지 (Error-reporting messages)
74 | + 목적지 도달 불가 (Destination unreachable) : 라우터가 데이터그램을 전달할 수 없거나 호스트가 데이터그램을 배달 수 없을 때 라우터나 호스트는 데이터그램을 시작했던 발신지 호스트에게 목적지 도달 불가 메시지를 낸다.
75 | + 발신지 억제 (Source quench) : 라우터나 목적지 호스트에서 혼잡으로 인해 데이터그램이 폐기되었음을 발신지에게 알린다.
76 | + 시간 경과 (Time exceeded) : 수명 필드를 감소한 후 이 값이 0이 되면 발생, 정해진 시간 내에 모든 단편을 받지 못했으면 이미 수신된 단편을 폐기하고 메시지 발생
77 | + 매개변수 문제 (Parameter Problem) : 목적지 호스트가 데이터그램의 필드에서 불명확하거나 빠진 값을 발견하게 되면 발생
78 | + 재지정 (Redirection) : 쉽게 말하면 목적지 까지 더 빠른 길을 찾기 위한 오류 보고 메시지이다.
79 |
80 | * 질의 메시지 (Query Message)
81 | + 에코 요청과 응답 (echo request and reply) : 호스트와 라우터가 서로 통신할 수 있는지 결정할 때 사용한다.
82 | + 타임스탬프 요청과 응답 (timestamp request and reply) : IP 데이터그램이 둘 사이를 지나가는 데 필요한 왕복 시간을 결정할 수 있다.
83 |
--------------------------------------------------------------------------------
/Network/데이터-링크-계층을-처리하는-기기.md:
--------------------------------------------------------------------------------
1 | 데이터 링크 계층은 OSI (Open Systems Interconnection) 모델에서 두 번째 계층으로, 물리 계층과 네트워크 계층 사이에 위치합니다. 데이터 링크 계층은 데이터 전송 중 오류를 검사하고 수정하며, 데이터 흐름을 관리합니다.
2 |
3 | # 브리지
4 |
5 | 브리지는 같은 네트워크 안에 있는 여러 세그먼트를 연결하는 역할을 합니다. 브리지는 데이터 프레임의 목적지 MAC 주소를 보고 판단하여, 다른 세그먼트로 전송할지 말지를 결정합니다.
6 |
7 | # L2 스위치
8 |
9 | 스위치는 브리지와 비슷한 역할을 하지만, 브리지보다 더 빠른 속도로 데이터 프레임을 처리할 수 있습니다. 스위치는 데이터 프레임의 목적지 MAC 주소를 보고 해당 포트로 데이터를 전송합니다.
10 |
--------------------------------------------------------------------------------
/Network/물리-계층을-처리하는-기기.md:
--------------------------------------------------------------------------------
1 | # 허브
2 |
3 | 허브는 물리 계층에서 동작하는 기기로, 네트워크에 연결된 모든 기기에게 수신된 데이터를 브로드캐스트합니다. 이로 인해, 동일한 데이터가 여러 기기로 전송되어 네트워크 성능에 악영향을 미칩니다. 따라서, 현재는 대부분의 네트워크에서 스위치로 대체되었습니다.
4 |
5 | # 리피터
6 |
7 | 리피터는 물리 계층에서 동작하는 기기로, 신호의 감쇠를 보상하여 신호를 증폭시켜 전송 거리를 늘리는 역할을 합니다. 리피터는 단지 신호를 증폭하므로, 네트워크 대역폭을 효율적으로 사용하지 못합니다. 따라서, 현재는 대부분의 네트워크에서 사용되지 않습니다.
8 |
9 | # NIC
10 |
11 | NIC(Network Interface Card)란, 컴퓨터와 네트워크 간에 연결을 담당하는 카드를 의미합니다. NIC는 이더넷, 와이파이, 블루투스 등 다양한 방식으로 컴퓨터와 네트워크를 연결할 수 있습니다. NIC를 통해 컴퓨터는 인터넷과 같은 네트워크 상의 다른 장치들과 통신이 가능해지며, 데이터를 주고받을 수 있습니다.
12 |
13 | # AP
14 |
15 | AP(Access Point)란, 무선 네트워크에서 기기가 접속할 수 있는 지점을 의미합니다. AP는 라우터와 같은 역할을 하며, 무선 신호를 발생시켜 무선 기기들이 인터넷에 접속할 수 있도록 합니다. AP는 유선 네트워크와 연결되어 있으며, 무선 신호를 발생시켜 무선 기기들이 인터넷에 접속할 수 있도록 합니다.
16 |
--------------------------------------------------------------------------------
/Network/어플리케이션-계층을-처리하는-기기.md:
--------------------------------------------------------------------------------
1 | # L7 스위치란?
2 |
3 | L7 스위치는 OSI 참조 모델에서 7계층인 애플리케이션 계층(Application Layer)에서 동작하는 네트워크 장비입니다. L7 스위치는 애플리케이션 계층에서 동작하기 때문에 다양한 프로토콜과 어플리케이션의 세부적인 정보를 파악하여 네트워크 데이터 흐름을 제어할 수 있습니다.
4 |
5 | L7 스위치는 일반적으로 로드 밸런싱과 같은 기능을 수행하며, 이를 위해 HTTP, FTP, SMTP, DNS 등과 같은 여러 프로토콜과 어플리케이션의 데이터를 분석하고 가중치 기반의 라우팅, 속도 제어, 보안 등의 기능을 제공합니다.
6 |
7 | 또한, L7 스위치는 SSL 인증서를 사용하여 HTTPS 트래픽을 처리하거나, 세션 트래킹과 같은 기능으로 사용자의 세션을 유지하고, 이를 통해 클러스터링과 같은 기술을 사용하여 고가용성을 제공할 수 있습니다.
8 |
9 | 요약하자면, L7 스위치는 애플리케이션 계층에서 동작하며, 다양한 프로토콜과 어플리케이션의 세부적인 정보를 파악하여 네트워크 데이터 흐름을 제어하고, 로드 밸런싱, 속도 제어, 보안 등의 기능을 제공합니다. 이를 통해 네트워크 환경에서 안정성과 성능을 보장할 수 있습니다.
10 |
11 | ## 로드 밸런싱(Locd Balancing)이란?
12 |
13 | 로드 밸런싱(Load Balancing)은 여러 대의 서버에게 부하를 분산시켜주는 기술입니다. 이를 통해 서버의 성능과 안정성을 향상시킬 수 있습니다.
14 |
15 | 로드 밸런싱은 클라이언트 요청을 여러 대의 서버에 분산시켜 처리하고, 서버의 부하 상태를 모니터링하여 부하가 적은 서버로 요청을 분산시키는 방식으로 동작합니다. 이를 통해 한 대의 서버로 모든 요청이 집중되는 현상을 방지하고, 서버의 부하를 분산하여 전체적인 성능을 향상시킵니다.
16 |
17 | 로드 밸런싱 기술에는 여러 종류가 있으며, 대표적으로는 하드웨어 기반 로드 밸런서와 소프트웨어 기반 로드 밸런서가 있습니다. 하드웨어 기반 로드 밸런서는 전용 장비를 사용하여 성능이 높으며, 소프트웨어 기반 로드 밸런서는 가상 서버 환경에서 사용 가능하며, 클라우드 환경에서는 대부분 소프트웨어 기반 로드 밸런서를 사용합니다.
18 |
19 | 로드 밸런싱은 대규모 서비스를 제공하는 웹 사이트나 어플리케이션, 데이터베이스 클러스터링 등에서 널리 사용되며, 고성능, 고가용성, 확장성을 제공합니다.
20 |
21 | # L4 스위치와 L7 스위치의 차이
22 |
23 | L4 스위치와 L7 스위치는 OSI 참조 모델에서 각각 4계층(전송 계층)과 7계층(애플리케이션 계층)에서 동작하는 네트워크 장비입니다.
24 |
25 | L4 스위치는 주로 전송 계층에서 동작합니다. 즉, TCP/UDP와 같은 전송 계층 프로토콜을 기반으로 동작합니다. L4 스위치는 IP 주소와 포트 번호를 기반으로 데이터 패킷을 분석하고, 다중 서버로 부하를 분산하는 기능을 제공합니다. 주로 로드 밸런싱과 같은 기능을 수행합니다.
26 |
27 | 반면, L7 스위치는 애플리케이션 계층에서 동작합니다. 즉, HTTP, FTP, SMTP, DNS 등과 같은 여러 프로토콜과 어플리케이션의 데이터를 분석하고 가중치 기반의 라우팅, 속도 제어, 보안 등의 기능을 제공합니다. L7 스위치는 L4 스위치의 기능에 더해, 애플리케이션에 대한 자세한 분석을 수행할 수 있습니다.
28 |
29 | 따라서, L4 스위치는 전송 계층에서 동작하며 IP 주소와 포트 번호를 기반으로 데이터 패킷을 분석하고, L7 스위치는 애플리케이션 계층에서 동작하며, 다양한 프로토콜과 어플리케이션의 세부적인 정보를 파악하여 네트워크 데이터 흐름을 제어합니다. 또한, L7 스위치는 로드 밸런싱과 함께, SSL 인증서를 사용하여 HTTPS 트래픽을 처리하거나, 세션 트래킹과 같은 기능으로 사용자의 세션을 유지하고, 이를 통해 클러스터링과 같은 기술을 사용하여 고가용성을 제공할 수 있습니다.
30 |
31 | # L7 스위치의 헬스체크 기능
32 |
33 | L7 스위치는 헬스체크(Health Check) 기능을 제공합니다. 이 기능은 로드 밸런싱을 수행하는 서버의 상태를 주기적으로 확인하여, 서버가 정상적으로 작동하고 있는지 여부를 판단합니다. 서버의 장애나 다운 상태를 미리 파악하여, 문제가 발생한 서버에 대한 트래픽을 분산시키지 않고 다른 정상 서버로만 분산시키기 때문에, 서비스의 가용성과 신뢰성을 높일 수 있습니다.
34 |
35 | 보통 L7 스위치의 헬스체크는 HTTP나 HTTPS 요청을 보내는 방식으로 동작합니다. L7 스위치는 일정 주기마다 웹 서버에 HTTP GET 요청을 보내고, 서버가 정상적인 응답을 반환하는지 여부를 확인합니다. 만약 서버가 응답하지 않거나, 오류가 발생한 경우 L7 스위치는 해당 서버로의 트래픽을 제외시키고, 다른 정상 서버로만 트래픽을 분산시킵니다.
36 |
37 | 또한, L7 스위치는 헬스체크 기능을 통해 서버의 부하량을 측정할 수도 있습니다. 서버의 부하량이 일정 수준 이상인 경우, L7 스위치는 해당 서버로의 트래픽을 줄이거나, 전체 트래픽을 분산시키는 등의 조치를 취할 수 있습니다. 이를 통해 서버의 부하를 분산시키고, 서비스의 안정성을 유지할 수 있습니다.
--------------------------------------------------------------------------------
/Network/인터넷-계층을-처리하는-기기.md:
--------------------------------------------------------------------------------
1 | # 라우터
2 |
3 | 인터넷 상에서 데이터를 전송할 때, 데이터가 다른 네트워크로 전송될 때마다 IP 주소를 이용하여 목적지를 찾아가는데, 이 과정에서 패킷을 처리하는 기기입니다.
4 |
5 | # L3 스위치
6 |
7 | 네트워크 상에서 데이터가 전송될 때, 목적지를 찾아가는 과정에서 패킷을 처리하는 기기입니다. 라우터와 달리, 같은 네트워크 상에서 패킷이 전송될 때만 작동합니다.
8 |
9 | # 방화벽
10 |
11 | 인터넷 상에서 데이터를 전송할 때, 보안성을 위해 패킷을 검사하고 차단하는 기기입니다. 네트워크 보안에 매우 중요한 역할을 합니다.
12 |
13 | ---
14 |
15 | 이러한 기기들은 인터넷 상에서 데이터를 안전하고 정확하게 전송하기 위해 매우 중요한 역할을 합니다.
--------------------------------------------------------------------------------
/OS/CPU-스케줄링-알고리즘.md:
--------------------------------------------------------------------------------
1 | # CPU 스케줄러
2 |
3 | 운영체제는 CPU 스케줄링을 통해 Ready Queue에 있는 어떤 프로세스에 CPU를 할당할 것인지 결정합니다. CPU 스케줄링 알고리즘은 비선점형과 선점형으로 나눌 수 있습니다. **비선점형으로는 FCFS, SJF, 우선순위 스케줄링**이있고 **선점형으로는 RR, SRF, 다단계 큐 스케줄링**이 있습니다.
4 |
5 | # 비선점형 방식
6 |
7 | 비선점형 방식은 일단 CPU가 한 프로세스에 할당되면, 그 프로세스가 종료 또는 I/O 처리를 위해 스스로 CPU 소유권을 포기할 때 까지 CPU를 점유합니다. 강제로 프로세스를 중지하지 않기 때문에 컨텍스트 스위칭으로 인한 부하가 적습니다.
8 |
9 | ## FCFS(First Come, First Served)
10 |
11 | 가장 먼저 온 것을 가장 먼저 처리하는 알고리즘입니다.
12 |
13 | >**문제점**
61 |
62 | 인터넷 제어 메시지 프로토콜이라고 한다.
63 | 이것은 네트워크 내 장치가 데이터 전송과 관련된 문제를 전달하기 위해 사용하는 프로토콜이다.
64 |
65 | ### ICMP가 필요한 이유
66 |
67 | IP 프로토콜은 TCP 처럼 흐름 제어와 혼잡 제어 메커니즘이없다. 하지만 호스트는 간혹 라우터나 다른 호스트가 동작하고 있는지 알 필요가 있다. 이 단점을 보완하고자 ICMP가 생겼다.
68 |
69 | ### ICMP의 용도
70 |
71 | 인터넷 제어 메시지 프로토콜(ICMP)는 오류 보고 및 네트워크 진단 수행에 사용됩니다. 오류 보고 프로세스에서 ICMP는 데이터가 제대로 오지 않을 때 수신자에서 발신자에게 메시지를 보냅니다. 진단 프로세스 내에서 ICMP는 데이터 전송 방법에 대한 정보를 제공하기 위해 핑 및 트레이스라우트에서 사용하는 메시지를 보내는 데 사용됩니다.
72 |
73 | * 오류 보고 메시지 (Error-reporting messages)
74 | + 목적지 도달 불가 (Destination unreachable) : 라우터가 데이터그램을 전달할 수 없거나 호스트가 데이터그램을 배달 수 없을 때 라우터나 호스트는 데이터그램을 시작했던 발신지 호스트에게 목적지 도달 불가 메시지를 낸다.
75 | + 발신지 억제 (Source quench) : 라우터나 목적지 호스트에서 혼잡으로 인해 데이터그램이 폐기되었음을 발신지에게 알린다.
76 | + 시간 경과 (Time exceeded) : 수명 필드를 감소한 후 이 값이 0이 되면 발생, 정해진 시간 내에 모든 단편을 받지 못했으면 이미 수신된 단편을 폐기하고 메시지 발생
77 | + 매개변수 문제 (Parameter Problem) : 목적지 호스트가 데이터그램의 필드에서 불명확하거나 빠진 값을 발견하게 되면 발생
78 | + 재지정 (Redirection) : 쉽게 말하면 목적지 까지 더 빠른 길을 찾기 위한 오류 보고 메시지이다.
79 |
80 | * 질의 메시지 (Query Message)
81 | + 에코 요청과 응답 (echo request and reply) : 호스트와 라우터가 서로 통신할 수 있는지 결정할 때 사용한다.
82 | + 타임스탬프 요청과 응답 (timestamp request and reply) : IP 데이터그램이 둘 사이를 지나가는 데 필요한 왕복 시간을 결정할 수 있다.
83 |
--------------------------------------------------------------------------------
/Network/데이터-링크-계층을-처리하는-기기.md:
--------------------------------------------------------------------------------
1 | 데이터 링크 계층은 OSI (Open Systems Interconnection) 모델에서 두 번째 계층으로, 물리 계층과 네트워크 계층 사이에 위치합니다. 데이터 링크 계층은 데이터 전송 중 오류를 검사하고 수정하며, 데이터 흐름을 관리합니다.
2 |
3 | # 브리지
4 |
5 | 브리지는 같은 네트워크 안에 있는 여러 세그먼트를 연결하는 역할을 합니다. 브리지는 데이터 프레임의 목적지 MAC 주소를 보고 판단하여, 다른 세그먼트로 전송할지 말지를 결정합니다.
6 |
7 | # L2 스위치
8 |
9 | 스위치는 브리지와 비슷한 역할을 하지만, 브리지보다 더 빠른 속도로 데이터 프레임을 처리할 수 있습니다. 스위치는 데이터 프레임의 목적지 MAC 주소를 보고 해당 포트로 데이터를 전송합니다.
10 |
--------------------------------------------------------------------------------
/Network/물리-계층을-처리하는-기기.md:
--------------------------------------------------------------------------------
1 | # 허브
2 |
3 | 허브는 물리 계층에서 동작하는 기기로, 네트워크에 연결된 모든 기기에게 수신된 데이터를 브로드캐스트합니다. 이로 인해, 동일한 데이터가 여러 기기로 전송되어 네트워크 성능에 악영향을 미칩니다. 따라서, 현재는 대부분의 네트워크에서 스위치로 대체되었습니다.
4 |
5 | # 리피터
6 |
7 | 리피터는 물리 계층에서 동작하는 기기로, 신호의 감쇠를 보상하여 신호를 증폭시켜 전송 거리를 늘리는 역할을 합니다. 리피터는 단지 신호를 증폭하므로, 네트워크 대역폭을 효율적으로 사용하지 못합니다. 따라서, 현재는 대부분의 네트워크에서 사용되지 않습니다.
8 |
9 | # NIC
10 |
11 | NIC(Network Interface Card)란, 컴퓨터와 네트워크 간에 연결을 담당하는 카드를 의미합니다. NIC는 이더넷, 와이파이, 블루투스 등 다양한 방식으로 컴퓨터와 네트워크를 연결할 수 있습니다. NIC를 통해 컴퓨터는 인터넷과 같은 네트워크 상의 다른 장치들과 통신이 가능해지며, 데이터를 주고받을 수 있습니다.
12 |
13 | # AP
14 |
15 | AP(Access Point)란, 무선 네트워크에서 기기가 접속할 수 있는 지점을 의미합니다. AP는 라우터와 같은 역할을 하며, 무선 신호를 발생시켜 무선 기기들이 인터넷에 접속할 수 있도록 합니다. AP는 유선 네트워크와 연결되어 있으며, 무선 신호를 발생시켜 무선 기기들이 인터넷에 접속할 수 있도록 합니다.
16 |
--------------------------------------------------------------------------------
/Network/어플리케이션-계층을-처리하는-기기.md:
--------------------------------------------------------------------------------
1 | # L7 스위치란?
2 |
3 | L7 스위치는 OSI 참조 모델에서 7계층인 애플리케이션 계층(Application Layer)에서 동작하는 네트워크 장비입니다. L7 스위치는 애플리케이션 계층에서 동작하기 때문에 다양한 프로토콜과 어플리케이션의 세부적인 정보를 파악하여 네트워크 데이터 흐름을 제어할 수 있습니다.
4 |
5 | L7 스위치는 일반적으로 로드 밸런싱과 같은 기능을 수행하며, 이를 위해 HTTP, FTP, SMTP, DNS 등과 같은 여러 프로토콜과 어플리케이션의 데이터를 분석하고 가중치 기반의 라우팅, 속도 제어, 보안 등의 기능을 제공합니다.
6 |
7 | 또한, L7 스위치는 SSL 인증서를 사용하여 HTTPS 트래픽을 처리하거나, 세션 트래킹과 같은 기능으로 사용자의 세션을 유지하고, 이를 통해 클러스터링과 같은 기술을 사용하여 고가용성을 제공할 수 있습니다.
8 |
9 | 요약하자면, L7 스위치는 애플리케이션 계층에서 동작하며, 다양한 프로토콜과 어플리케이션의 세부적인 정보를 파악하여 네트워크 데이터 흐름을 제어하고, 로드 밸런싱, 속도 제어, 보안 등의 기능을 제공합니다. 이를 통해 네트워크 환경에서 안정성과 성능을 보장할 수 있습니다.
10 |
11 | ## 로드 밸런싱(Locd Balancing)이란?
12 |
13 | 로드 밸런싱(Load Balancing)은 여러 대의 서버에게 부하를 분산시켜주는 기술입니다. 이를 통해 서버의 성능과 안정성을 향상시킬 수 있습니다.
14 |
15 | 로드 밸런싱은 클라이언트 요청을 여러 대의 서버에 분산시켜 처리하고, 서버의 부하 상태를 모니터링하여 부하가 적은 서버로 요청을 분산시키는 방식으로 동작합니다. 이를 통해 한 대의 서버로 모든 요청이 집중되는 현상을 방지하고, 서버의 부하를 분산하여 전체적인 성능을 향상시킵니다.
16 |
17 | 로드 밸런싱 기술에는 여러 종류가 있으며, 대표적으로는 하드웨어 기반 로드 밸런서와 소프트웨어 기반 로드 밸런서가 있습니다. 하드웨어 기반 로드 밸런서는 전용 장비를 사용하여 성능이 높으며, 소프트웨어 기반 로드 밸런서는 가상 서버 환경에서 사용 가능하며, 클라우드 환경에서는 대부분 소프트웨어 기반 로드 밸런서를 사용합니다.
18 |
19 | 로드 밸런싱은 대규모 서비스를 제공하는 웹 사이트나 어플리케이션, 데이터베이스 클러스터링 등에서 널리 사용되며, 고성능, 고가용성, 확장성을 제공합니다.
20 |
21 | # L4 스위치와 L7 스위치의 차이
22 |
23 | L4 스위치와 L7 스위치는 OSI 참조 모델에서 각각 4계층(전송 계층)과 7계층(애플리케이션 계층)에서 동작하는 네트워크 장비입니다.
24 |
25 | L4 스위치는 주로 전송 계층에서 동작합니다. 즉, TCP/UDP와 같은 전송 계층 프로토콜을 기반으로 동작합니다. L4 스위치는 IP 주소와 포트 번호를 기반으로 데이터 패킷을 분석하고, 다중 서버로 부하를 분산하는 기능을 제공합니다. 주로 로드 밸런싱과 같은 기능을 수행합니다.
26 |
27 | 반면, L7 스위치는 애플리케이션 계층에서 동작합니다. 즉, HTTP, FTP, SMTP, DNS 등과 같은 여러 프로토콜과 어플리케이션의 데이터를 분석하고 가중치 기반의 라우팅, 속도 제어, 보안 등의 기능을 제공합니다. L7 스위치는 L4 스위치의 기능에 더해, 애플리케이션에 대한 자세한 분석을 수행할 수 있습니다.
28 |
29 | 따라서, L4 스위치는 전송 계층에서 동작하며 IP 주소와 포트 번호를 기반으로 데이터 패킷을 분석하고, L7 스위치는 애플리케이션 계층에서 동작하며, 다양한 프로토콜과 어플리케이션의 세부적인 정보를 파악하여 네트워크 데이터 흐름을 제어합니다. 또한, L7 스위치는 로드 밸런싱과 함께, SSL 인증서를 사용하여 HTTPS 트래픽을 처리하거나, 세션 트래킹과 같은 기능으로 사용자의 세션을 유지하고, 이를 통해 클러스터링과 같은 기술을 사용하여 고가용성을 제공할 수 있습니다.
30 |
31 | # L7 스위치의 헬스체크 기능
32 |
33 | L7 스위치는 헬스체크(Health Check) 기능을 제공합니다. 이 기능은 로드 밸런싱을 수행하는 서버의 상태를 주기적으로 확인하여, 서버가 정상적으로 작동하고 있는지 여부를 판단합니다. 서버의 장애나 다운 상태를 미리 파악하여, 문제가 발생한 서버에 대한 트래픽을 분산시키지 않고 다른 정상 서버로만 분산시키기 때문에, 서비스의 가용성과 신뢰성을 높일 수 있습니다.
34 |
35 | 보통 L7 스위치의 헬스체크는 HTTP나 HTTPS 요청을 보내는 방식으로 동작합니다. L7 스위치는 일정 주기마다 웹 서버에 HTTP GET 요청을 보내고, 서버가 정상적인 응답을 반환하는지 여부를 확인합니다. 만약 서버가 응답하지 않거나, 오류가 발생한 경우 L7 스위치는 해당 서버로의 트래픽을 제외시키고, 다른 정상 서버로만 트래픽을 분산시킵니다.
36 |
37 | 또한, L7 스위치는 헬스체크 기능을 통해 서버의 부하량을 측정할 수도 있습니다. 서버의 부하량이 일정 수준 이상인 경우, L7 스위치는 해당 서버로의 트래픽을 줄이거나, 전체 트래픽을 분산시키는 등의 조치를 취할 수 있습니다. 이를 통해 서버의 부하를 분산시키고, 서비스의 안정성을 유지할 수 있습니다.
--------------------------------------------------------------------------------
/Network/인터넷-계층을-처리하는-기기.md:
--------------------------------------------------------------------------------
1 | # 라우터
2 |
3 | 인터넷 상에서 데이터를 전송할 때, 데이터가 다른 네트워크로 전송될 때마다 IP 주소를 이용하여 목적지를 찾아가는데, 이 과정에서 패킷을 처리하는 기기입니다.
4 |
5 | # L3 스위치
6 |
7 | 네트워크 상에서 데이터가 전송될 때, 목적지를 찾아가는 과정에서 패킷을 처리하는 기기입니다. 라우터와 달리, 같은 네트워크 상에서 패킷이 전송될 때만 작동합니다.
8 |
9 | # 방화벽
10 |
11 | 인터넷 상에서 데이터를 전송할 때, 보안성을 위해 패킷을 검사하고 차단하는 기기입니다. 네트워크 보안에 매우 중요한 역할을 합니다.
12 |
13 | ---
14 |
15 | 이러한 기기들은 인터넷 상에서 데이터를 안전하고 정확하게 전송하기 위해 매우 중요한 역할을 합니다.
--------------------------------------------------------------------------------
/OS/CPU-스케줄링-알고리즘.md:
--------------------------------------------------------------------------------
1 | # CPU 스케줄러
2 |
3 | 운영체제는 CPU 스케줄링을 통해 Ready Queue에 있는 어떤 프로세스에 CPU를 할당할 것인지 결정합니다. CPU 스케줄링 알고리즘은 비선점형과 선점형으로 나눌 수 있습니다. **비선점형으로는 FCFS, SJF, 우선순위 스케줄링**이있고 **선점형으로는 RR, SRF, 다단계 큐 스케줄링**이 있습니다.
4 |
5 | # 비선점형 방식
6 |
7 | 비선점형 방식은 일단 CPU가 한 프로세스에 할당되면, 그 프로세스가 종료 또는 I/O 처리를 위해 스스로 CPU 소유권을 포기할 때 까지 CPU를 점유합니다. 강제로 프로세스를 중지하지 않기 때문에 컨텍스트 스위칭으로 인한 부하가 적습니다.
8 |
9 | ## FCFS(First Come, First Served)
10 |
11 | 가장 먼저 온 것을 가장 먼저 처리하는 알고리즘입니다.
12 |
13 | >**문제점**14 | 한 프로세스가 지나치게 오랫동안 CPU를 점유하는 것도 허용하기에 준비 큐에서 오래 기다리게 되는 호위 효과(convoy effect)가 발생할 수 있습니다. 15 | 16 | ## SJF(Shortest Job First) 17 | 18 | 최단 작업 우선 스케줄링 알고리즘으로 실행 시간이 가장 짧은 프로세스를 가장 먼저 실행하는 알고리즘입니다.주어진 프로세스 집합에 대해 최소의 평균 대기 시간을 가집니다. 19 | 20 | >**문제점**
21 | 짧은 시간을 가진 프로세스만 실행되어 긴 시간을 가진 프로세스가 실행되지 않는 현상(starvation)이 발생할 수 있습니다. 22 | 23 | 24 | ## 우선순위 25 | 26 | 기존 SJF 스케줄링의 긴 시간을 가진 프로세스가 실행되지 않는 단점을 오래된 작업일수록 우선순위를 높이는 방법(aging)을 통해서 보완한 알고리즘입니다. 27 | 28 | # 선점형 방식 29 | 30 | 선점형 방식은 현대 운영체제가 쓰는 방식으로 CPU를 점유하고 있는 프로세스를 알고리즘에 의해 중단시키고 강제로 다른 프로세스에 CPU 소유권을 할당하는 방식입니다. 잦은 컨텍스트 스위칭으로 인해 부하가 발생할 수 있습니다. 31 | 32 | ## RR(Round Robin) 33 | 34 | 라운드 로빈은 각 프로세스에 동일한 CPU 할당 시간을 부여해서 해당 시간 동안만 CPU를 이용하게 합니다. 주어진 시간 안에 끝나지 않으면 다시 준비 큐의 뒤로 가는 알고리즘입니다.
35 | 할당 시간을 q라 할 때, n개의 프로세스가 있다면 어떠한 프로세스도 (n-1)*q 시간 이상 기다리지 않아도 됩니다. q가 너무 크면 FCFS처럼 동작하고 q가 너무 작으면 잦은 컨텍스트 스위칭이 발생합니다. 36 | 37 | ## SRF(Shortest Remaining time First) 38 | 39 | SJF는 중간에 실행 시간이 더 짧은 작업이 들어와도 기존 작업을 모두 수행하고 그 다음 작업을 수행하는 비선점 방식이지만 SRF는 중간에 더 짧은 작업이 들어오면 수행하던 프로세스를 중지하고 해당 프로세스를 수행하는 알고리즘입니다. 40 | 41 | ## 다단계 큐 스케줄링(Multilevel Queue Scheduling) 42 | 43 | 다단계 큐는 우선순위에 따른 준비 큐를 여러 개 사용하고, 큐마다 라운드 로빈, FCFS 등 다른 스케줄링 알고리즘을 적용한 것을 말합니다. 큐 간의 프로세스 이동이 안되므로 스케줄링 부담이 적지만 유연성이 떨어집니다. 44 | 45 | ## 다단계 피드백 큐 스케줄링(Multilevel Feedback Queue Scheduling) 46 | 47 | 다단계 피드백 큐 스케줄링 알고리즘은 큐 간의 프로세스 이동하는 것을 허용합니다. -------------------------------------------------------------------------------- /OS/IPC.md: -------------------------------------------------------------------------------- 1 | # 멀티 프로세싱과 멀티 프로세스 차이 2 | 3 | 멀티프로세싱(Multiprocessing)은 하나의 컴퓨터 시스템에서 여러 개의 프로세서(CPU)를 사용하여 동시에 여러 개의 작업을 처리하는 기술을 말합니다. 이를 통해 병렬 처리가 가능해져서 시스템 성능을 향상시킬 수 있습니다. 예를 들어, 대규모 데이터 처리나 고성능 컴퓨팅 분야에서 멀티프로세싱이 활용됩니다. 4 | 5 | 반면에, 멀티프로세스(Multiprocess)는 하나의 컴퓨터 시스템에서 여러 개의 프로세스(Process)를 생성하여 각각 독립적으로 실행하는 것을 말합니다. 이를 통해 하나의 응용프로그램을 여러 개의 프로세스로 분할하여 병렬처리할 수 있습니다. 멀티프로세스를 사용하면 각 프로세스는 독립적인 메모리 공간을 가지며, 서로 영향을 미치지 않고 동작할 수 있습니다. 멀티프로세스는 안정성과 보안성이 높아서, 예를 들어 서버나 클러스터링 시스템에서 사용됩니다. 6 | 7 | 따라서, 멀티프로세싱은 다수의 프로세서를 이용한 동시 처리 기술을 말하고, 멀티프로세스는 하나의 시스템에서 여러 개의 프로세스를 생성하여 동작하는 기술을 말합니다. 8 | 9 | 10 | # IPC란? 11 | 12 | IPC는 Interprocess Communication의 약자로, 프로세스 간에 데이터를 전달하고 상호작용하기 위한 메커니즘을 말합니다. 13 | 14 | 더 자세히 말하자면, IPC는 멀티 프로세스 환경에서 프로세스 간 통신을 위해 사용됩니다. 하나의 운영체제에서 여러 개의 프로세스가 동시에 실행될 때, 각각의 프로세스는 독립적으로 실행되며 다른 프로세스와 상호작용할 필요가 있습니다. 이때 IPC를 사용하여 프로세스 간 데이터를 전송하고 동기화할 수 있습니다. 15 | 16 | # IPC를 구현하는 방법들 17 | 18 | ## PIPE 19 | 20 | 두 프로세스 간에 단방향 통신을 가능하게 하는 일종의 버퍼입니다. 일반적으로 부모 프로세스와 자식 프로세스 간에 사용됩니다. 21 | 22 | 23 | ### 익명 PIPE 24 | 25 | 단방향 통신만 가능하며, 일반적으로 부모 프로세스와 자식 프로세스 사이에서 사용됩니다. 익명 파이프는 pipe() 함수를 사용하여 생성됩니다 26 | 27 | ### 명명된 PIPE 28 | 29 | 이름을 가진 파이프로서, 클라이언트와 서버 사이에 양방향 통신이 가능합니다. 명명된 파이프는 프로세스들 사이에서 파일처럼 공유될 수 있습니다. mkfifo() 함수를 사용하여 생성할 수 있습니다. 30 | 31 | ## 메시지 큐 32 | 33 | 프로세스 간에 메시지를 전송하고 수신하기 위한 큐입니다. 각 메시지는 특정한 우선순위를 가지며, 우선순위가 높은 메시지가 먼저 처리됩니다. 34 | 35 | ## 공유 메모리 36 | 37 | 두 개 이상의 프로세스가 동시에 접근할 수 있는 메모리 영역입니다. 이 방법은 빠른 속도로 데이터를 공유할 수 있지만, 데이터 일관성을 유지하기 위해 동기화가 필요합니다. 38 | 39 | ## 소켓 40 | 41 | 두 프로세스 간에 네트워크 소켓을 통해 통신하는 방법입니다. 소켓은 인터넷에서 TCP/IP 프로토콜을 사용하여 통신할 수 있습니다. 42 | 43 | # IPC 주의할 점 44 | 45 | IPC는 프로세스 간에 데이터를 안전하고 효율적으로 공유하는 데 중요한 역할을 합니다. 하지만, 데이터 일관성을 유지하고 동기화를 보장하기 위해서는 적절한 IPC 메커니즘을 선택하고 사용하는 것이 중요합니다. -------------------------------------------------------------------------------- /OS/README.md: -------------------------------------------------------------------------------- 1 | # 운영체제 2 | 3 | - [운영체제의 역할과 구조](https://github.com/HanKwanJin/CS_Study/blob/main/OS/운영체제의-역할과-구조.md) 4 | - 운영체제란? 5 | - 운영체제의 역할 6 | - 운영체제의 구조 7 | - 커널 8 | - 시스템 콜 9 | - [컴퓨터의 요소](https://github.com/HanKwanJin/CS_Study/blob/main/OS/컴퓨터의-요소.md) 10 | - CPU 11 | - 제어장치 12 | - 레지스터 13 | - 산술논리연산장치 14 | - CPU의 연산 처리 과정 15 | - 인터럽트 16 | - 하드웨어 인터럽트 17 | - 소프트웨어 인터럽트 18 | - DMA 컨트롤러 19 | - 메모리 20 | - 타이머 21 | - 디바이스 컨트롤러 22 | - [프로세스](https://github.com/HanKwanJin/CS_Study/blob/main/OS/프로세스.md) 23 | - 프로세스란? 24 | - 프로세스의 상태 25 | - 프로세스의 메모리 구조 26 | - PCB란? 27 | - PCB에 포함되는 정보 28 | - 컨텍스트 스위칭 29 | - [스레드](https://github.com/HanKwanJin/CS_Study/blob/main/OS/스레드.md) 30 | - 스레드란? 31 | - 스레드마다 스택을 독립적으로 할당하는 이유 32 | - 스레드마다 PC 레지스터를 독립적으로 할당하는 이유 33 | - [멀티 프로세스와 멀티 스레드](https://github.com/HanKwanJin/CS_Study/blob/main/OS/멀티프로세스와-멀티스레드.md) 34 | - 멀티 프로세스란? 35 | - 멀티 프로세스 장점 36 | - 멀티 프로세스 단점 37 | - 멀티 스레드란? 38 | - 멀티 스레드 장점 39 | - 멀티 스레드 단점 40 | - 멀티 프로세스 vs 멀티 스레드 41 | - [공유 자원과 임계 영역](https://github.com/HanKwanJin/CS_Study/blob/main/OS/공유-자원과-임계-영역.md) 42 | - 공유 자원이란? 43 | - 임계 영역이란? 44 | - 임계 영역 해결 조건 45 | - 임계 영역 해결 방법 46 | - 뮤텍스 47 | - 세마포어 48 | - 모니터 49 | - 뮤텍스와 세마포어의 차이점 50 | - 교착 상태란? 51 | - [CPU 스케줄링 알고리즘](https://github.com/HanKwanJin/CS_Study/blob/main/OS/CPU-스케줄링-알고리즘.md) 52 | - CPU 스케줄러 53 | - 비선점형 방식 54 | - FCFS 55 | - SJF 56 | - 우선순위 57 | - 선점형 방식 58 | - RR 59 | - SRF 60 | - 다단계 큐 스케줄링 61 | - 다단계 피드백 큐 스케줄링 62 | - [IPC](https://github.com/HanKwanJin/CS_Study/blob/main/OS/IPC.md) 63 | - 멀티 프로세싱과 멀티 프로세스 차이 64 | - IPC란? 65 | - IPC를 구현하는 방법들 66 | - PIPE 67 | - 메시지 큐 68 | - 공유 메모리 69 | - 소켓 70 | - IPC 주의할 점 -------------------------------------------------------------------------------- /OS/공유-자원과-임계-영역.md: -------------------------------------------------------------------------------- 1 | # 공유 자원(Shared Resource)이란? 2 | 3 | 공유 자원은 시스템 안에서 각 프로세스, 스레드가 함께 접근할 수 있는 모니터, 프린터, 메모리, 파일, 데이터 등의 자원이나 변수 등을 말합니다. 공유 자원은 공동으로 이용되기 때문에 두 개 이상의 프로세스가 동시에 읽거나 쓰는 상황이 발생합니다. 이런 상황을 경쟁 상태(race condition)이라 합니다. 4 | 5 | # 임계 영역(Critical Section)이란? 6 | 7 | 임계 영역은 공유 자원 접근 순서에 따라 실행 결과가 달라지는 프로그램의 영역을 말합니다. 그렇기 때문에 임계 구역에서는 프로세스들이 동시에 작업을 하면 안됩니다. 8 | 9 | ## 임계 영역 해결 조건 10 | 11 | - 상호 배제(Mutual Exclusion): 한 프로세스가 임계 영역에 들어가면 다른 프로세스는 임계 영역에 들어갈 수 없습니다. 12 | 13 | - 한정 대기(Bounded Wating): 어떤 프로세스도 영원히 임계 영역에 들어가지 못하면 안됩니다. 14 | 15 | - 진행의 융통성(Progress Flexibility): 한 프로세스가 다른 프로세스의 일을 방해해서는 안됩니다. 16 | 17 | # 임계 영역 해결 방법 18 | 19 | 임계 영역을 해결하는 방법으로는 크게 뮤텍스, 세마포어, 모니터 세 가지가 있습니다. 이 방법 모두 임계 영역 해결 조건들을 만족합니다. 20 | 21 | ## 뮤텍스(Mutex) 22 | 23 | - 뮤텍스는 임계 영역을 가진 스레드들의 실행 시간이 서로 겹치지 않고 각각 단독으로 실행(상호 배제) 되도록 하는 기술입니다. 24 | 25 | - 공유 자원을 사용하기 전에 잠금을 설정하면 다른 스레드는 잠긴 코드 영역에 접근할 수 없습니다. 다 사용한 후에는 잠금 해제(Unlock)를 통해 다른 스레드가 접근 가능하게 됩니다. 26 | 27 | - 뮤텍스는 잠금 또는 잠금 해제 중에 한 가지 상태만을 가집니다. 28 | 29 | ## 세마포어(Semaphore) 30 | 31 | - 공유 자원에 접근할 수 있는 프로세스의 최대 허용치 만큼 동시에 사용자가 접근할 수 있습니다. 32 | 33 | - 세마포어에는 조건 변수가 없고 프로세스가 세마포어 값을 수정할 때 다른 프로세스는 동시에 세마포어 값을 수정할 수 없습니다. 34 | 35 | - 각 프로세스는 세마포어의 값을 확인하고 변경할 수 있습니다. 자원이 사용하지 않는 상태가 되면 대기하던 프로세스가 즉시 자원을 사용합니다. 하지만 이미 다른 프로세스에 의해 사용중이라는 사실을 알게 되면, 재시도 하기 전에 일정시간 대기해야 합니다. 36 | 37 | ## 모니터(Monitor) 38 | 39 | - 모니터는 둘 이상의 스레드나 프로세스가 공유 자원에 안전하게 접근할 수 있도록 공유 자원을 숨기고 해당 접근에 대해 인터페이스만 제공합니다. 40 | 41 | - 모니터는 모니터큐를 통해 공유 자원에 대한 작업들을 순차적으로 처리합니다. 42 | 43 | 44 | # 뮤텍스와 세마포어의 차이점 45 | 46 | 가장 큰 차이점은 동기화 대상의 개수입니다. 47 | 48 | - 뮤텍스는 동기화 대상이 1개일 때 사용합니다. 49 | 50 | - 세마포어는 동기화 대상이 1개 이상일 때 사용합니다. 51 | 52 | 세마포어는 뮤텍스가 될 수 있지만, 뮤텍스는 세마포어가 될 수 없습니다. 53 | 54 | - 뮤텍스는 0, 1로 이루어진 이진 상태를 가지므로 바이너리 세마포어(Binary Semaphore)라고 할 수 있습니다. 55 | 56 | 뮤텍스는 소유하고 있는 스레드만이 해당 뮤텍스를 해제할 수 있습니다. 반면, 세마포어는 해당 세마포어를 소유하지 않는 스레드가 세마포어를 해제할 수 있습니다. 57 | 58 | # 교착 상태(Deadlock)란? 59 | 60 | 교착 상태는 두 개 이상의 프로세스들이 서로가 가진 자원을 기다리며 중단된 상태를 말합니다. -------------------------------------------------------------------------------- /OS/멀티프로세스와-멀티스레드.md: -------------------------------------------------------------------------------- 1 | # 멀티 프로세스란? 2 | 3 | 멀티 프로세스는 하나의 프로그램을 여러 개의 프로세스로 구성하여, 각 프로세스가 하나의 작업을 처리하는 것을 의미합니다. 4 | 5 | 각 프로세스 간 메모리 구분이 필요하거나 독립된 주소 공간을 가져야 할 때 사용합니다. 6 | 7 | ## 멀티 프로세스 장점 8 | 9 | - 하나의 프로세스에 문제가 생겨도, 전체적인 프로그램은 동작합니다. 작업 속도가 느려지는 손해가 발생하더라도 정지되거나 하는 문제가 발생하지 않습니다. 10 | 11 | ## 멀티 프로세스 단점 12 | 13 | - 프로세스 끼리는 공유하는 메모리가 없는 독립된 메모리 영역이기 때문에 컨텍스트 스위칭에 많은 비용이 발생합니다. 14 | 15 | >**복습!!**
16 | >프로세스 내용에서 다룬 컨텍스트 스위칭 과정에서 캐시 메모리 초기화 같은 **캐시미스**라는 비용이 발생합니다. 17 | 18 | # 멀티 스레드란? 19 | 20 | 하나의 프로그램을 여러 개의 스레드로 구성하고, 각 스레드가 하나의 작업을 처리하는 것을 의미합니다. 21 | 22 | 프로세스는 한 개일 수도 여러 개일 수도 있습니다. 23 | 24 | ## 멀티 스레드 장점 25 | 26 | - 메모리 공간과 시스템 자원 소모가 감소하여 자원의 효율성이 증대됩니다. 27 | 28 | - 스레드는 프로세스 메모리의 코드, 데이터, 힙 영역을 공유하고 있으므로, 프로세스 간의 통신(IPC)보다 스레드 간의 통신 응답 속도가 빠릅니다. 29 | 30 | - 스레드의 컨텍스트 스위칭은 프로세스 컨텍스트 스위칭과는 다르게 캐시 메모리를 비워줄 필요가 없기 때문에 더 빠릅니다. 31 | 32 | 33 | ## 멀티 스레드 단점 34 | 35 | - 자원을 공유하기 때문에 동기화 문제(병목 현상, 데드락)가 발생할 수 있습니다. 36 | 37 | - 주의 깊은 설계가 필요하고 디버깅이 어렵습니다. 불필요한 부분까지 동기화하면 대기시간으로 인해 성능 저하가 발생합니다. 38 | 39 | - 하나의 스레드에 문제가 생기면 전체 프로세스가 영향을 받습니다. 40 | 41 | - 단일 프로세스 시스템의 경우 효과를 기대하기 어렵습니다. 42 | 43 | >**동기화 문제(Synchronization Issue)란?**
44 | 여러 스레드가 함께 공유 변수를 사용할 경우, 발생할 수 있는 충돌을 동기화 문제라고 합니다. 45 | 46 | # 멀티 프로세스 vs 멀티 스레드 47 | 48 | 둘을 비교하면서 정리해보겠습니다. 49 | 50 | - 멀티 스레드는 멀티 프로세스 보다 적은 메모리 공간을 차지하고 컨텍스트 스위칭이 빠른 장점이 있지만, 동기화 문제와 하나의 스레드 장애로 전체 스레드가 종료될 수 있는 위험이 있습니다. 51 | 52 | - 반면에 멀티 프로세스는 하나의 프로세스가 죽더라도 다른 프로세스에 영향을 주지 않아 안정성이 높지만, 멀티 스레드 보다 많은 메모리 공간과 CPU 시간을 차지하는 단점이 있습니다. -------------------------------------------------------------------------------- /OS/메모리-계층.md: -------------------------------------------------------------------------------- 1 | # 메모리 계층 2 | 메모리 계층은 레지스터, 캐시, 메모리, 저장장치로 구성되어 있다. 3 | 4 | 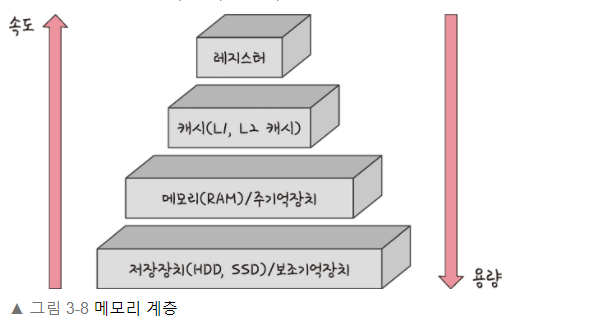 5 | 6 | - **레지스터** : CPU 안에 있는 작은 메모리. 휘발성, 속도 가장 빠름, 기억 용량이 가장 적음 7 | - **캐시** : L1, L2 캐시를 지칭. 휘발성, 속도 빠름, 기억 용량 적음 8 | - **주기억장치** : RAM을 지칭. 휘발성, 속도 보통, 기억 용량 보통 9 | - **보조기억장치** : HDD, SSD를 일컬으며 비휘발성, 속도 낮음, 기억 용량 많음 10 | 11 | 계층이 위로 올라갈수록 용량이 작아지고 속도가 빨라지므로 가격도 비싸진다. 12 |
13 |
14 | 15 | ## 계층이 존재하는 이유 16 | **경제성과 캐시성** 때문이다. 17 |
ex) 16GB RAM은 8만원이면 살 수 있다. 하지만 16GB SSD는 훨씬 더 싼 가격에 살 수 있다. 이러한 경제성 때문에 계층을 두어 관리하는 것이다. 18 | # 19 |
20 | 21 | ## 캐시 22 | 데이터를 미리 복사해 놓는 임시 저장소이자 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리 23 |
24 | -> 이를 통해 데이터를 접근하는 시간이 오래 걸리는 경우를 해결하고 무언가를 다시 계산하는 시간을 절약할 수 있음 25 | 26 | - **캐싱** 27 | : 속도 차이를 해결하기 위해 계층과 계층 사이에 있는 계층 28 |
-> 예를 들어 캐시 메모리와 보조기억장치 사이에 있는 주기억장치를 보조기억장치의 캐싱 계층이라한다. 29 | 30 | - **지역성** 31 | : 데이터 접근이 시간적, 혹은 공간적으로 가깝게 일어나는 것 32 | - 시간 지역성 : 최근 사용한 데이터에 다시 접근하려는 특성 33 |
ex) for문의 변수 i 34 | - 공간 지역성 : 최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성 35 |
ex) for문 안의 배열 36 |
37 |
38 | 39 | - **캐시히트와 캐시미스** 40 |
캐시에서 원하는 데이터를 찾았다면 캐시히트라고 하며, 41 | 해당 데이터가 캐시에 없다면 주메모리로 가서 데이터를 찾아오는 것을 캐시미스라고 한다. 42 | 43 | 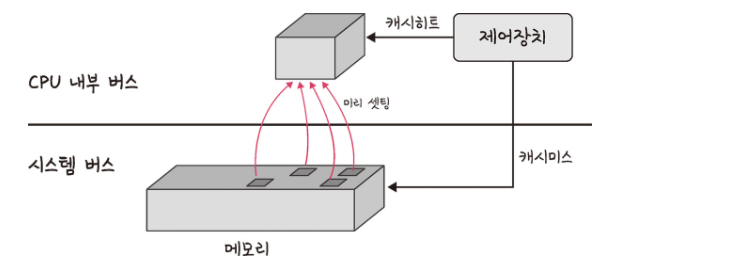 44 |
캐시히트의 경우 데이터를 제어장치를 거쳐 가져오게 되는데, *CPU 내부 버스*를 기반으로 작동하기 때문에 빠르다.
반면 캐시미스의 경우 메모리에서 가져오게 되는데, 이는 *시스템 버스*를 기반으로 작동하기 때문에 느리다. 45 | 46 | 47 | 48 | - **웹 브라우저의 캐시** 49 |
웹 브라우저의 캐시는 보통 사용자의 커스텀 정보나 인증 모듈 관련 사항들을 웹 브라우저에 저장해서 추후 서버에 요청할 때 자신을 나타내는 아이덴티티나 중복 요청 방지를 위해 쓰인다. 50 | |종류|만료기한|저장 공간|사용처| 51 | |---|---|---|---| 52 | |쿠키|있음|4KB|다시 보지 않음 팝업| 53 | |로컬 스토리지|없음|5MB|자동 로그인| 54 | |세션 스토리지|없음|5MB|비로그인 장바구니| 55 | 56 | - 로컬 스토리지와 세션 스토리지의 차이점 57 |
로컬 스토리지는 웹 브라우저를 닫아도 유지되고, 세션 스토리지는 탭을 닫을 때 해당 데이터가 삭제된다. 58 |
59 | - **데이터베이스의 캐싱 계층** 60 |
데이터베이스 시스템을 구축할 때 메인 데이터베이스 위에 레디스(redis) 데이터베이스 계층을 **캐싱 계층**으로 두어 성능을 향상시키기도 한다. 61 | 62 |  -------------------------------------------------------------------------------- /OS/메모리-관리.md: -------------------------------------------------------------------------------- 1 | # 메모리 관리 2 | ## 가상 메모리 virtual memory 3 | 컴퓨터가 실제로 이용 가능한 메모리 자원을 추상화하여 이를 사용하는 사용자들에게 매우 큰 메모리로 보이게 만드는 것 4 |  5 | 가상으로 주어진 주소를 가상 주소(논리 주소)라고 하며, 실제 메모리상에 있는 주소를 실제 주소(물리 주소)라고 한다. 6 | 7 | 가상 주소는 메모리관리장치(MMU)에 의해 실제 주소로 변환되며, 이 덕분에 사용자는 실제 주소를 의식할 필요 없이 프로그램을 구축할수 있다. 8 | 9 | 가상 메모리는 **페이지 테이블**로 관리 되며, 속도 향상을 위해 **TLB**를 사용한다. 10 | 11 | - TLB란? : 메모리와 CPU 사이에 있는 주소 변환을 위한 캐시입니다. 페이지 테이블에 있는 리스트를 보관하며 CPU가 페이지 테이블까지 가지 않도록 해 속도를 향상시킬 수 있는 캐시 계층이다. 12 | 13 | ### **스와핑** 14 | 가상 메모리에는 존재하지만 실제 메모리인 RAM에는 없는 데이터나 코드에 접근 할 경우 페이지 폴트가 발생하는데, 이 때 메모리에서 당장 사용하지 않는 영역을 하드디스크로 옮기고 하드디스크의 일부분으르 마치 메모리처럼 불러와 쓰는 것을 스와핑(swapping)이라고 한다. 15 | 16 | - 페이지 폴트란? 17 |
프로세스의 주소 공간에는 존재하지만 지금 이 컴퓨터의 RAM에는 없는 데이터에 접근했을 경우 발생하는 것 18 | 19 |
20 | 21 | 22 | ## 스레싱 thrashing 23 | 스레싱은 메모리의 페이지 폴트율이 높은 것을 의미한다. 24 | 이는 컴퓨터의 심각한 성능 저하를 초래하기 때문에 이를 해결하기 위한 방법으로는 메모리를 늘리거나, HDD를 SSD로 바꾸는 방법이 있다. 25 | 운영체제에서 이를 해결할 수 있는 방법은 **작업 세트**와 **PFF**가 있다. 26 | 27 | ### **작업 세트** 28 | 작업 세트는 프로세스의 과거 사용 이력인 지역성을 통해 결정된 페이지 집합을 만들어서 미리 메모리에 로드하는 것이다. 미리 메모리에 로드하면 탐색에 드는 비용을 줄일 수 있고 스와핑 또한 줄일 수 있다. 29 | 30 | ### **PFF** 31 | PFF(Page Fault Frequency)는 페이지 폴트 빈도를 조절하는 방법으로 상한선에 도달하면 프레임을 늘리고 하한선에 도달하면 프레임을 줄이는 것이다. 32 | 33 | 34 |
35 | 36 | ## 메모리 할당 37 | 메모리에 프로그램을 할당할 때는 시작 메모리 위치, 메모리의 할당 크기를 기반으로 할당하는데, 연속 할당과 불연속 할당으로 나뉜다. 38 | 39 | ### **연속 할당** 40 | 연속 할당은 메모리에 연속적으로 공간을 할당하는 것을 말한다. 41 |  42 | 43 | - 고정 분할 방식 44 |
45 | 고정 분할 방식은 메모리를 미리 나누어 관리하는 방식이며, 내부 단편화가 발생한다. 46 | 47 | - 가변 분할 방식 48 |
49 | 가별 분할 방식은 매 시점 프로그램의 크기에 맞게 동적으로 메모리를 나눠 사용하는 방식으로, 외부 단편화가 발생할 수 있다. 50 | - 최초적합: 위쪽이나 아래쪽에서부터 시작해서 홀을 찾으면 바로 할당 51 | 52 | - 최적접합: 프로세스의 크기 이상인 공간 중 가장 작은 홀부터 할당 53 | 54 | - 최악접합: 프로세스의 크기와 가장 많이 차이가 나는 홀에 할당 55 | 56 | ### **불연속 할당** 57 | - 페이징 58 |
59 | 동일한 크기의 페이지 단위로 나누어 메모리의 서로 다른 위치에 프로세스를 할당하는 것을 말한다. 홀의 크기가 균일하지만 주소 변환이 복잡해진다. 60 | 61 | - 세그멘테이션 62 |
63 | 세그멘테이션은 페이지 단위가 아닌 의미 단위인 세그먼트(segment)로 나누는 방식을 말한다. 공유와 보안 측면에서 좋지만 홀 크기가 균일하지 않은 문제가 발생된다. 64 | 65 | - 페이지드 세그멘테이션 66 |
67 | 페이지드 세그멘테이션은 공유나 보안을 의미 단위의 세그먼트로 나누고, 물리적 메모리는 페이지로 나누는 것을 말한다. 68 | 69 |
70 | 71 | 72 | ## 페이지 교체 알고리즘 73 | 페이지 교체 알고리즘을 기반으로 스와핑이 일어나기 때문에 스와핑이 많이 일어나지 않도록 설계되어야 한다. 74 | 75 | - 오프라인 알고리즘 : 먼 미래에 참조되는 페이지와 현재 할당하는 페이지를 바꾸는 알고리즘이며, 다른 알고리즘과의 성능 비교에 대한 기준을 제공한다. 76 | 77 | - FIFO(First In First Out) : 가장 먼저 온 페이지를 교체 영역에 가장 먼저 놓는 방법. 78 | 79 | - LRU(Least Recentle Used) : 참조가 가장 오래된 페이지를 바꾸는 것. 80 | 81 | - NUR(Not Used Recently) : LRU에서 발전한 알고리즘으로 clock 알고리즘이라고도 하며 시계방향으로 돌면서 0비트를 찾고 0을 찾은 순간 해당 프로세스를 교체하고 해당 부분을 1로 바꾸는 알고리즘이다. 82 | 83 | - LFU(Least Frequently Used) : 가장 참조 횟수가 적은 페이지를 교체하는 것. -------------------------------------------------------------------------------- /OS/스레드.md: -------------------------------------------------------------------------------- 1 | # 스레드(thread)란? 2 | 3 | 스레드는 프로세스의 실행 가능한 가장 작은 단위입니다. 프로세스는 여러 스레드를 가질 수 있습니다. 4 | 5 | 코드, 데이터, 스택, 힙을 각각 생성하는 프로세스와는 달리 스레드는 스택을 제외한 코드, 데이터, 힙은 스레드끼리 공유합니다. 스레드는 독립적인 작업을 수행하기 위해 각자의 스택과 PC 레지스터 값을 갖습니다. 6 | 7 | ## 스레드마다 스택을 독립적으로 할당하는 이유 8 | 9 | 스택 영역이 독립적이라는 것은 독립적인 함수 호출이 가능하다는 것입니다. 따라서 스레드의 독립적인 실행을 하기 위해 독립된 스택을 할당합니다. 10 | 11 | ## 스레드마다 PC 레지스터를 독립적으로 할당하는 이유 12 | 13 | PC는 스레드가 어디까지 수행했는지와 다음으로 실행해야하는 부분을 알 수 있습니다. 스레드는 CPU를 할당 받았다가 스케줄러에 의해 다시 선점 당합니다. 이때 명령어가 연속적으로 수행되지 못하기 때문에 어느 부분까지 진행 되었는지를 기억할 필요가 있습니다. 따라서 독립된 PC 레지스터를 할당합니다. -------------------------------------------------------------------------------- /OS/운영체제의-역할과-구조.md: -------------------------------------------------------------------------------- 1 | # 운영체제(OS, Operating System)란? 2 | 3 | - 시스템 자원을 효율적으로 관리하며, 사용자가 컴퓨터를 편리하고 효과적으로 사용할 수 있도록 환경을 제공하는 여러 프로그램의 모임입니다. 4 | 5 | - 사용자와 하드웨어 간의 인터페이스로서 동작하는 시스템 소프트웨어입니다. 6 | 7 | - 대표적인 운영체제로는 Windows, Mac, Unix, Linux가 있습니다. 8 | 9 | # 운영체제의 역할 10 | 11 | **응용 프로그램**이 요청하는 **시스템 자원**을 효율적으로 분배하고 관리합니다. 12 | 13 | - 시스템 자원: 컴퓨터 하드웨어와 같은 개념으로 CPU, 메모리, 입출력 장치, 저장 매체 등 시스템에서 사용할 수 있는 자원을 의미합니다. 14 | 15 | - 응용 프로그램: 운영체제를 제외한 나머지 소프트웨어입니다.
(소프트웨어 = 운영체제 + 응용 프로그램) 16 | 17 |  18 | 19 | >사진 출처: https://electricalfundablog.com/operating-system-os-functions-types-resource-management/ 20 | 21 | 1. **CPU 스케줄링과 프로세스 관리**: CPU 소유권을 어떤 프로세스에 할당할지, 프로세스의 생성과 삭제, 자원 할당 및 반환을 관리합니다. 22 | 23 | 2. **메모리 관리**: 한정된 메모리를 어떤 프로세스에 얼만큼 할당해야 하는지 관리합니다. 24 | 25 | 3. **디스크 파일 관리**: 디스크 파일을 어떠한 방법으로 보관할지 관리합니다. 26 | 27 | 4. **I/O 디바이스 관리**: I/O 디바이스들인 마우스, 키보드와 컴퓨터 간에 데이터를 주고받는 것을 관리합니다. 28 | 29 | # 운영체제의 구조 30 | 31 |  32 | >사진 출처: https://math-coding.tistory.com/80 33 | 34 | GUI, 시스템 콜, 커널, 드라이버 부분이 운영체제에 해당됩니다. 35 | 36 | - 드라이버: 하드웨어를 제어하기 위한 소프트웨어입니다. 37 | 38 | ## 커널(Kernel) 39 | 40 | - 운영체제는 규모가 매우 큰 프로그램입니다. 운영체제의 모든 부분을 메모리에 올려놓는 것은 매우 비효율적입니다. 따라서, 운영체제는 필요한 부분만을 메모리에 올려서 사용하게 되는데, 이 때 **메모리에 상주하는 운영체제의 핵심 부분**을 **커널**이라고 합니다. 41 | 42 | - 시스템 콜 인터페이스를 제공하며 보안, 메모리, 프로세스, 파일 시스템, I/O 디바이스, I/O 요청 관리 등 운영체제의 중요한 역할을 담당합니다. 43 | 44 | ## 시스템 콜(System Call) 45 | 46 | - 사용자는 운영체제의 기능을 담당하는 커널에 직접 접근할 수 없습니다. 그래서 사용자와 커널 사이에 인터페이스 역할이 필요한데, 시스템 콜이 바로 이 역할을 합니다. 47 | 48 | - 즉, 응용 프로그램이 시스템 자원에 직접 접근하여 필요한 기능을 사용할 수 있도록 해주는 함수를 의미합니다. -------------------------------------------------------------------------------- /OS/컴퓨터의-요소.md: -------------------------------------------------------------------------------- 1 | # CPU(Central Processing Unit) 2 | 3 | CPU는 사람의 두뇌와 같이 입력장치로부터 자료를 받아 연산하고 그 결과를 출력장치로 보내는 일련의 과정을 제어 및 조정하는 핵심 장치입니다. CPU는 **제어장치, 레지스터, 산술논리연산장치로 구성**됩니다. 4 | 5 | ## 제어장치(CU, Control Unit) 6 | 7 | 컴퓨터에 있는 모든 장치들의 동작을 지시하고 제어하는 장치입니다. 명령 레지스터에서 읽어 들인 명령어를 해석하고, 해당하는 장치에 제어 신호를 보내 정확하게 실행하도록 지시합니다. 프로그램 카운터(PC), 명령어 레지스터(IR), 부호기(제어신호 발생기), 명령어 해독기, 번지 해독기 등으로 구성됩니다. 8 | 9 | ## 레지스터 10 | 11 | 레지스터는 CPU 안에 있는 매우 빠른 임시기억장치입니다. CPU는 자체적으로 데이터를 저장할 방법이 없기 때문에 레지스터를 거쳐서 데이터를 전달합니다. 12 | 13 | ## 산술논리연산장치(ALU, Arithmetic Logic Unit) 14 | 15 | 산술논리연산장치는 제어장치의 명령에 따라 실제로 연산을 수행하는 장치입니다. 16 | 17 | ### CPU의 연산 처리 과정 18 | 19 | 1. 제어장치가 메모리와 레지스터에 계산할 값을 로드합니다. 20 | 21 | 2. 제어장치가 레지스터에 있는 값을 계산하라고 산술논리연산장치에 명령합니다. 22 | 23 | 3. 제어장치가 (2)에서 계산된 값을 다시 레지스터에서 메모리로 저장합니다. 24 | 25 | ## 인터럽트 26 | 27 | 인터럽트는 어떤 신호가 들어왔을 때 CPU를 잠깐 정지시키는 것을 의미합니다. 인터럽트는 키보드, 마우스 등 IO 디바이스로 인한 인터럽트, 0으로 숫자를 나누는 산술 연산에서의 인터럽트, 프로세스 오류 등으로 발생합니다. 28 | 29 | ### 하드웨어 인터럽트 30 | 31 | - 키보드를 연결하거나 마우스를 연결하는 일 등의 IO 디바이스에서 발생하는 인터럽트입니다. 32 | 33 | ### 소프트웨어 인터럽트 34 | 35 | - 소프트웨어 인터럽트는 트랩(trap)이라고도 하며, 프로세스 오류 등으로 프로세스가 시스템 콜을 호출할 때 발생합니다. 36 | 37 | # DMA 컨트롤러 38 | 39 | DMA란 Direct Memory Access로 DMA 컨트롤러는 I/O 디바이스가 메모리에 직접 접근할 수 있도록 하는 하드웨어 장치를 말합니다. CPU에 몰리는 인터럽트 때문에 생기는 부하를 막아주며 하나의 작업을 CPU와 DMA 컨트롤러가 동시에 하는 것을 방지합니다. 40 | 41 | # 메모리 42 | 43 | 메모리는 전자회로에서 데이터나 상태, 명령어 등을 기록하는 장치입니다. CPU는 계산을 담당하고 메모리는 기억을 담당합니다. 44 | 45 | # 타이머 46 | 47 | 타이머는 시간이 많이 걸리는 프로그램이 작동할 때 제한을 걸기 위해 존재합니다. 48 | 49 | # 디바이스 컨트롤러 50 | 51 | 컴퓨터와 연결되어 있는 I/O 디바이스들의 작은 CPU를 말합니다. 52 | 53 | -------------------------------------------------------------------------------- /OS/프로세스.md: -------------------------------------------------------------------------------- 1 | # 프로세스란? 2 | 프로세스(Process)는 컴퓨터에서 실행되고 있는 프로그램을 말하며 CPU 스케줄링의 대상이 되는 작업(task)과 같은 의미로 쓰입니다. 3 | 4 | # 프로세스의 상태 5 | 6 | ## 생성 상태 7 | 8 | 생성 상태(create)는 프로세스가 생성된 상태를 의미하며 fork() 또는 exec() 함수를 통해 생성합니다. 이때 PCB가 할당됩니다. 9 | 10 | - fork() : 부모 프로세스의 주소 공간을 그대로 복사하며, 새로운 자식 프로세스를 생성하는 함수입니다. 11 | 12 | - exec() : 새롭게 프로세스를 생성하는 함수입니다. 13 | 14 | ## 대기 상태 15 | 16 | 대기 상태(ready)는 메모리 공간이 충분하면 메모리를 할당받고 아니면 아닌 상태로 대기하고 있으며 CPU 스케줄러로부터 CPU 소유권이 넘어오기를 기다리는 상태입니다. 17 | 18 | ## 대기 중단 상태 19 | 20 | 대기 중단 상태(ready suspended)는 메모리 부족으로 일시 중단된 상태입니다. 21 | 22 | ## 실행 상태 23 | 24 | 실행 상태(running)는 필요한 자원 및 프로세스를 모두 할당 받은 상태입니다. CPU를 차지하고 작업을 실행 중인 상태입니다. 25 | 26 | ## 중단 상태 27 | 28 | 중단 상태(blocked)는 어떤 이벤트가 발생한 이후 기다리며 프로세스가 차단된 상태입니다. 29 | 30 | ## 일시 중단 상태 31 | 32 | 일시 중단 상태(blocked suspended)는 대기 중단과 유사합니다. 중단된 상태에서 프로세스가 실행되려고 했지만 메모리 부족으로 일시 중단된 상태입니다. 33 | 34 | ## 종료 상태 35 | 36 | 종료 상태(reminated)는 메모리와 CPU 소유권을 모두 놓고 가는 상태입니다. 37 | 38 | # 프로세스의 메모리 구조 39 | 40 | ## 스택 41 | 42 | 스택에는 지역변수, 매개변수, 함수가 저장되고 컴파일 시에 크기가 결정되며 **동적** 인 특징을 갖습니다. 43 | 44 | 스택은 함수가 함수를 재귀적으로 호출하면서 동적으로 크기가 늘어날 수 있습니다. 이때, 힙과 스택의 메모리 영역이 겹치면 안 되기 때문에 힙과 스택 사이의 공간을 비워 놓습니다. 45 | 46 | ## 힙 47 | 48 | 힙은 동적 데이터 영역이며 프로그램 동작(런타임)시에 크기가 결정됩니다. 스택과 마찬가지로 힙도 **동적** 인 특징을 갖습니다. 49 | 50 | 예시로는 벡터와 같은 동적 배열은 힙에 동적 할당됩니다. 또한 스택에서 포인터 변수를 할당하면 포인터가 가리키는 힙 영역의 임의의 공간부터 원하는 크기만큼 할당해서 사용합니다. 51 | 52 | ## 데이터 영역 53 | 54 | 데이터 영역에는 전역변수와 정적변수가 저장됩니다. 이 변수들은 프로그램이 시작될 때 할당되고 프로그램이 종료 되면 소멸합니다. 55 | 56 | 데이터 영역은 BSS(blcok stated symbol) 영역과 Data 영역으로 나뉩니다. BSS 영역은 초기화가 되지 않은 변수가 0으로 초기화되어 저장되고 Data 영역(data segment)은 0이 아닌 다른 값으로 할당된 변수들이 저장됩니다. 57 | 58 | ## 코드 영역 59 | 60 | 코드 영역은 실행할 프로그램의 코드가 저장됩니다. 이 영역은 수정 불가능한 기계어로 저장되어 있으면 정적인 특징을 가집니다. CPU는 이 영역에서 명령어를 하나씩 가져와 처리하게 됩니다. 61 | 62 | # PCB(Process Control Block)란? 63 | 64 | PCB는 운영체제에서 프로세스에 대한 메타데이터를 저장한 **데이터** 또는 **프로세스 제어 블록**이라고 부릅니다. 프로세스가 생성되면 운영체제는 해당 PCB를 생성합니다. PCB는 중요한 정보를 포함하고 있기 때문에 일반 사용자가 접근하지 못하도록 커널 스택의 가장 앞부분에서 관리됩니다. 65 | 66 | # PCB에 포함되는 정보 67 | 68 | ## 프로세스 스케줄링 상태 69 | **준비**, **일시중단** 프로세스가 CPU에 대한 소유권을 얻은 이후 또는 이후 경과된 시간과 같은 기타 스케줄링 정보 70 | 71 | ## 프로세스 ID 72 | 프로세스를 구분하는 ID, 해당 프로세스의 자식 프로세스의 ID도 포함 73 | 74 | ## 프로세스 권한 75 | 컴퓨터 자원 또는 I/O 디바이스에 대한 권한 정보 76 | 77 | ## 프로그램 카운터 78 | 프로세스에서 실행해야 할 다음 명령어의 주소에 대한 포인터 79 | 80 | ## CPU 레지스터 81 | 프로세스를 실행하기 위해 저장해야 할 레지스터에 대한 정보 82 | 83 | ## CPU 스케줄링 정보 84 | CPU 스케줄러에 의해 중단된 시간 등에 대한 정보 85 | 86 | ## 계정 정보 87 | 프로세스 실행에 사용된 CPU 사용량, 실행한 유저의 정보 88 | 89 | ## I/O 상태 정보 90 | 프로세스에 할당된 I/O 디바이스 목록 91 | 92 | # 컨텍스트 스위칭 93 | 94 | 컨텍스트 스위칭(context switching)은 PCB를 교환하는 과정을 말합니다. 한 프로세스에 할당된 시간이 끝나거나 인터럽트에 의해 발생합니다. 95 | 96 | > 컨텍스트(context)란 CPU가 해당 프로세스를 실행하기 위한 해당 프로세스의 정보입니다. 97 | 98 | 컨텍스트는 프로세스의 PCB에 저장되고 컨텍스트 스위칭 때 PCB의 정보를 읽어 CPU가 전에 프로세스가 진행됐던 상태를 이어서 수행이 가능합니다. 99 | 100 | 컨텍스트 스위칭이 일어날 때 유휴 시간(idle time)이 발생합니다. 또한 컨텍스트 스위칭에 드는 비용이 존재하는데 이를 **캐시미스**라고 합니다. 101 | 102 | - 캐시미스: 컨텍스트 스위칭이 일어날 때 프로세스가 가지고 있는 메모리 주소가 그대로 있으면 잘못된 주소 변환이 생기므로 캐시클리어 과정을 겪게 되고 이 때문에 캐시미스가 발생합니다. 103 | 104 | - 스레드에서의 컨텍스트 스위칭: 스레드에서도 컨텍스트 스위칭이 발생합니다. 스레드는 스택 영역을 제외한 모든 메모리를 공유하기 때문에 스레드 컨텍스트 스위칭의 경우 비용이 더 적고 시간도 더 적게 걸립니다. -------------------------------------------------------------------------------- /README.md: -------------------------------------------------------------------------------- 1 | # CS Study 2 | 3 | 면접을 위한 CS 전공지식 노트 - 저자 주홍철, 길벗 4 |
 5 |
6 | 해당 스터디는 '면접을 위한 CS 전공지식 노트' 목차와 내용을 참고해서 진행됩니다.
7 |
8 | # 스터디 멤버
9 |
10 | |
5 |
6 | 해당 스터디는 '면접을 위한 CS 전공지식 노트' 목차와 내용을 참고해서 진행됩니다.
7 |
8 | # 스터디 멤버
9 |
10 | |  |
|  |
|  |
|  |
|  |
|  |
11 | | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: |
12 | | [동동](https://github.com/HanKwanJin) | [헤론](https://github.com/Heron-Woong) | [아리](https://github.com/zer0silver) | [연](https://github.com/leeys1218) | [데옹](https://github.com/seongddiyong) | [나단](https://github.com/nathan29849)
13 |
14 | # :memo: 글 목록
15 | - [운영체제](https://github.com/HanKwanJin/CS_Study/tree/main/OS)
16 | - 네트워크
17 | - 데이터베이스
18 | - 자료구조
19 | - 개발자 상식
20 |
21 | # 스터디 방식
22 |
23 | CS 개념
24 | 1. 정리하고 싶은 CS 주제를 정하고 이슈를 만든다.
25 |
|
11 | | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: |
12 | | [동동](https://github.com/HanKwanJin) | [헤론](https://github.com/Heron-Woong) | [아리](https://github.com/zer0silver) | [연](https://github.com/leeys1218) | [데옹](https://github.com/seongddiyong) | [나단](https://github.com/nathan29849)
13 |
14 | # :memo: 글 목록
15 | - [운영체제](https://github.com/HanKwanJin/CS_Study/tree/main/OS)
16 | - 네트워크
17 | - 데이터베이스
18 | - 자료구조
19 | - 개발자 상식
20 |
21 | # 스터디 방식
22 |
23 | CS 개념
24 | 1. 정리하고 싶은 CS 주제를 정하고 이슈를 만든다.
25 | (ex. 프로세스와 스레드, 이슈번호 #1) 26 | 27 | 2. 이슈 번호에 맞게 브랜치를 만든다. 28 |
(ex. git switch -C os/#1/process-thread) 29 | 30 | 3. 이슈 주제에 맞게 개념 정리하고 commit 한다. 이때 커밋 메시지에 [#이슈 번호를 넣어준다] 31 |
(ex. git commit -m "os: [#1] 프로세스 내용 작성") 32 | 33 | 4. 본인이 생각한 내용들을 다 작성하면 Pull Request 한다. 34 | 35 | 5. 다른 사람들은 작성한 내용을 바탕으로 comment를 보낸다. (궁금한점, 내용에서 표현이 잘못된 부분, 추가했으면 하는 내용 등등) 36 | 37 | 6. 본인이 추가 설명을 해줄때 참고할 수 있는 내용이나 영상 링크가 있다면 추가해준다. 38 | 39 | CS 면접 40 | 1. CS 개념에 대해서 정리하고 PR 까지 마무리 됐다면 해당 주제에 대한 질문으로 이슈를 만든다. 41 |
(ex. 프로세스와 스레드의 차이점은 무엇인가요?) 42 | 43 | 2. 질문에 대한 본인만의 말로 답변을 남기고 다른 사람들의 답변도 참고한다. 다른 사람이 남긴 답변에서 좋았던 점과 아쉬운 점 등을 자유롭게 comment를 남긴다. 44 | --------------------------------------------------------------------------------