├── README.md
├── ctr_data.txt
├── deep nn ctr prediction
├── CTR_prediction_LR_FM_CCPM_PNN.ipynb
├── DeepFM.py
├── DeepFM_NFM_DeepCTR.ipynb
├── run_dfm.ipynb
├── wide_and_deep_model_criteo.ipynb
└── wide_and_deep_model_official.ipynb
└── 从FM推演各深度学习CTR预估模型(附代码).pdf
/README.md:
--------------------------------------------------------------------------------
1 | # CTR_NN
2 | CTR prediction using Neural Network methods
3 | 基于深度学习的CTR预估,从FM推演各深度学习CTR预估模型(附代码)
4 |
5 | 详情请参见博文[《从FM推演各深度学习CTR预估模型(附代码)》](https://blog.csdn.net/han_xiaoyang/article/details/81031961)
6 | 部分代码参考[lambdaji](https://github.com/lambdaji)同学,对此表示感谢
7 |
8 | 代码所需数据可在ctr_data.txt中的网盘地址中下载到。
9 |
--------------------------------------------------------------------------------
/ctr_data.txt:
--------------------------------------------------------------------------------
1 | 链接: https://pan.baidu.com/s/1tIhlbWaVHbKoLd4XAwrUDw 密码: veww
2 |
--------------------------------------------------------------------------------
/deep nn ctr prediction/DeepFM.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 | #!/usr/bin/env python
3 | """
4 | #1 Input pipline using Dataset high level API, Support parallel and prefetch reading
5 | #2 Train pipline using Coustom Estimator by rewriting model_fn
6 | #3 Support distincted training using TF_CONFIG
7 | #4 Support export_model for TensorFlow Serving
8 |
9 | 方便迁移到其他算法上,只要修改input_fn and model_fn
10 |
11 | """
12 | #from __future__ import absolute_import
13 | #from __future__ import division
14 | #from __future__ import print_function
15 |
16 | #import argparse
17 | import shutil
18 | #import sys
19 | import os
20 | import json
21 | import glob
22 | from datetime import date, timedelta
23 | from time import time
24 | #import gc
25 | #from multiprocessing import Process
26 |
27 | #import math
28 | import random
29 | import pandas as pd
30 | import numpy as np
31 | import tensorflow as tf
32 |
33 | #################### CMD Arguments ####################
34 | FLAGS = tf.app.flags.FLAGS
35 | tf.app.flags.DEFINE_integer("dist_mode", 0, "distribuion mode {0-loacal, 1-single_dist, 2-multi_dist}")
36 | tf.app.flags.DEFINE_string("ps_hosts", '', "Comma-separated list of hostname:port pairs")
37 | tf.app.flags.DEFINE_string("worker_hosts", '', "Comma-separated list of hostname:port pairs")
38 | tf.app.flags.DEFINE_string("job_name", '', "One of 'ps', 'worker'")
39 | tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
40 | tf.app.flags.DEFINE_integer("num_threads", 16, "Number of threads")
41 | tf.app.flags.DEFINE_integer("feature_size", 0, "Number of features")
42 | tf.app.flags.DEFINE_integer("field_size", 0, "Number of fields")
43 | tf.app.flags.DEFINE_integer("embedding_size", 32, "Embedding size")
44 | tf.app.flags.DEFINE_integer("num_epochs", 10, "Number of epochs")
45 | tf.app.flags.DEFINE_integer("batch_size", 64, "Number of batch size")
46 | tf.app.flags.DEFINE_integer("log_steps", 1000, "save summary every steps")
47 | tf.app.flags.DEFINE_float("learning_rate", 0.0005, "learning rate")
48 | tf.app.flags.DEFINE_float("l2_reg", 0.0001, "L2 regularization")
49 | tf.app.flags.DEFINE_string("loss_type", 'log_loss', "loss type {square_loss, log_loss}")
50 | tf.app.flags.DEFINE_string("optimizer", 'Adam', "optimizer type {Adam, Adagrad, GD, Momentum}")
51 | tf.app.flags.DEFINE_string("deep_layers", '256,128,64', "deep layers")
52 | tf.app.flags.DEFINE_string("dropout", '0.5,0.5,0.5', "dropout rate")
53 | tf.app.flags.DEFINE_boolean("batch_norm", False, "perform batch normaization (True or False)")
54 | tf.app.flags.DEFINE_float("batch_norm_decay", 0.9, "decay for the moving average(recommend trying decay=0.9)")
55 | tf.app.flags.DEFINE_string("data_dir", '', "data dir")
56 | tf.app.flags.DEFINE_string("dt_dir", '', "data dt partition")
57 | tf.app.flags.DEFINE_string("model_dir", '', "model check point dir")
58 | tf.app.flags.DEFINE_string("servable_model_dir", '', "export servable model for TensorFlow Serving")
59 | tf.app.flags.DEFINE_string("task_type", 'train', "task type {train, infer, eval, export}")
60 | tf.app.flags.DEFINE_boolean("clear_existing_model", False, "clear existing model or not")
61 |
62 | #1 1:0.5 2:0.03519 3:1 4:0.02567 7:0.03708 8:0.01705 9:0.06296 10:0.18185 11:0.02497 12:1 14:0.02565 15:0.03267 17:0.0247 18:0.03158 20:1 22:1 23:0.13169 24:0.02933 27:0.18159 31:0.0177 34:0.02888 38:1 51:1 63:1 132:1 164:1 236:1
63 | def input_fn(filenames, batch_size=32, num_epochs=1, perform_shuffle=False):
64 | print('Parsing', filenames)
65 | def decode_libsvm(line):
66 | #columns = tf.decode_csv(value, record_defaults=CSV_COLUMN_DEFAULTS)
67 | #features = dict(zip(CSV_COLUMNS, columns))
68 | #labels = features.pop(LABEL_COLUMN)
69 | columns = tf.string_split([line], ' ')
70 | labels = tf.string_to_number(columns.values[0], out_type=tf.float32)
71 | splits = tf.string_split(columns.values[1:], ':')
72 | id_vals = tf.reshape(splits.values,splits.dense_shape)
73 | feat_ids, feat_vals = tf.split(id_vals,num_or_size_splits=2,axis=1)
74 | feat_ids = tf.string_to_number(feat_ids, out_type=tf.int32)
75 | feat_vals = tf.string_to_number(feat_vals, out_type=tf.float32)
76 | #feat_ids = tf.reshape(feat_ids,shape=[-1,FLAGS.field_size])
77 | #for i in range(splits.dense_shape.eval()[0]):
78 | # feat_ids.append(tf.string_to_number(splits.values[2*i], out_type=tf.int32))
79 | # feat_vals.append(tf.string_to_number(splits.values[2*i+1]))
80 | #return tf.reshape(feat_ids,shape=[-1,field_size]), tf.reshape(feat_vals,shape=[-1,field_size]), labels
81 | return {"feat_ids": feat_ids, "feat_vals": feat_vals}, labels
82 |
83 | # Extract lines from input files using the Dataset API, can pass one filename or filename list
84 | dataset = tf.data.TextLineDataset(filenames).map(decode_libsvm, num_parallel_calls=10).prefetch(500000) # multi-thread pre-process then prefetch
85 |
86 | # Randomizes input using a window of 256 elements (read into memory)
87 | if perform_shuffle:
88 | dataset = dataset.shuffle(buffer_size=256)
89 |
90 | # epochs from blending together.
91 | dataset = dataset.repeat(num_epochs)
92 | dataset = dataset.batch(batch_size) # Batch size to use
93 |
94 | #return dataset.make_one_shot_iterator()
95 | iterator = dataset.make_one_shot_iterator()
96 | batch_features, batch_labels = iterator.get_next()
97 | #return tf.reshape(batch_ids,shape=[-1,field_size]), tf.reshape(batch_vals,shape=[-1,field_size]), batch_labels
98 | return batch_features, batch_labels
99 |
100 | def model_fn(features, labels, mode, params):
101 | """Bulid Model function f(x) for Estimator."""
102 | #------hyperparameters----
103 | field_size = params["field_size"]
104 | feature_size = params["feature_size"]
105 | embedding_size = params["embedding_size"]
106 | l2_reg = params["l2_reg"]
107 | learning_rate = params["learning_rate"]
108 | #batch_norm_decay = params["batch_norm_decay"]
109 | #optimizer = params["optimizer"]
110 | layers = map(int, params["deep_layers"].split(','))
111 | dropout = map(float, params["dropout"].split(','))
112 |
113 | #------bulid weights------
114 | FM_B = tf.get_variable(name='fm_bias', shape=[1], initializer=tf.constant_initializer(0.0))
115 | print "FM_B", FM_B.get_shape()
116 | FM_W = tf.get_variable(name='fm_w', shape=[feature_size], initializer=tf.glorot_normal_initializer())
117 | print "FM_W", FM_W.get_shape()
118 | # F
119 | FM_V = tf.get_variable(name='fm_v', shape=[feature_size, embedding_size], initializer=tf.glorot_normal_initializer())
120 | # F * E
121 | print "FM_V", FM_V.get_shape()
122 | #------build feaure-------
123 | feat_ids = features['feat_ids']
124 | print "feat_ids", feat_ids.get_shape()
125 | feat_ids = tf.reshape(feat_ids,shape=[-1,field_size]) # None * f/K * K
126 | print "feat_ids", feat_ids.get_shape()
127 | feat_vals = features['feat_vals']
128 | print "feat_vals", feat_vals.get_shape()
129 | feat_vals = tf.reshape(feat_vals,shape=[-1,field_size]) # None * f/K * K
130 | print "feat_vals", feat_vals.get_shape()
131 |
132 | #------build f(x)------
133 | with tf.variable_scope("First-order"):
134 | feat_wgts = tf.nn.embedding_lookup(FM_W, feat_ids) # None * f/K * K
135 | print "feat_wgts", feat_wgts.get_shape()
136 | y_w = tf.reduce_sum(tf.multiply(feat_wgts, feat_vals),1)
137 |
138 | with tf.variable_scope("Second-order"):
139 | embeddings = tf.nn.embedding_lookup(FM_V, feat_ids) # None * f/K * K * E
140 | print "embeddings", embeddings.get_shape()
141 | feat_vals = tf.reshape(feat_vals, shape=[-1, field_size, 1]) # None * f/K * K * 1 ?
142 | print "feat_vals", feat_vals.get_shape()
143 | embeddings = tf.multiply(embeddings, feat_vals) #vij*xi
144 | print "embeddings", embeddings.get_shape()
145 | sum_square = tf.square(tf.reduce_sum(embeddings,1)) # None * K * E
146 | print "sum_square", sum_square.get_shape()
147 | square_sum = tf.reduce_sum(tf.square(embeddings),1)
148 | print "square_sum", square_sum.get_shape()
149 | y_v = 0.5*tf.reduce_sum(tf.subtract(sum_square, square_sum),1) # None * 1
150 |
151 | with tf.variable_scope("Deep-part"):
152 | if FLAGS.batch_norm:
153 | #normalizer_fn = tf.contrib.layers.batch_norm
154 | #normalizer_fn = tf.layers.batch_normalization
155 | if mode == tf.estimator.ModeKeys.TRAIN:
156 | train_phase = True
157 | #normalizer_params = {'decay': batch_norm_decay, 'center': True, 'scale': True, 'updates_collections': None, 'is_training': True, 'reuse': None}
158 | else:
159 | train_phase = False
160 | #normalizer_params = {'decay': batch_norm_decay, 'center': True, 'scale': True, 'updates_collections': None, 'is_training': False, 'reuse': True}
161 | else:
162 | normalizer_fn = None
163 | normalizer_params = None
164 |
165 | deep_inputs = tf.reshape(embeddings,shape=[-1,field_size*embedding_size]) # None * (F*K)
166 | for i in range(len(layers)):
167 | #if FLAGS.batch_norm:
168 | # deep_inputs = batch_norm_layer(deep_inputs, train_phase=train_phase, scope_bn='bn_%d' %i)
169 | #normalizer_params.update({'scope': 'bn_%d' %i})
170 | deep_inputs = tf.contrib.layers.fully_connected(inputs=deep_inputs, num_outputs=layers[i], \
171 | #normalizer_fn=normalizer_fn, normalizer_params=normalizer_params, \
172 | weights_regularizer=tf.contrib.layers.l2_regularizer(l2_reg), scope='mlp%d' % i)
173 | if FLAGS.batch_norm:
174 | deep_inputs = batch_norm_layer(deep_inputs, train_phase=train_phase, scope_bn='bn_%d' %i) #放在RELU之后 https://github.com/ducha-aiki/caffenet-benchmark/blob/master/batchnorm.md#bn----before-or-after-relu
175 | if mode == tf.estimator.ModeKeys.TRAIN:
176 | deep_inputs = tf.nn.dropout(deep_inputs, keep_prob=dropout[i]) #Apply Dropout after all BN layers and set dropout=0.8(drop_ratio=0.2)
177 | #deep_inputs = tf.layers.dropout(inputs=deep_inputs, rate=dropout[i], training=mode == tf.estimator.ModeKeys.TRAIN)
178 |
179 | y_deep = tf.contrib.layers.fully_connected(inputs=deep_inputs, num_outputs=1, activation_fn=tf.identity, \
180 | weights_regularizer=tf.contrib.layers.l2_regularizer(l2_reg), scope='deep_out')
181 | y_d = tf.reshape(y_deep,shape=[-1])
182 | #sig_wgts = tf.get_variable(name='sigmoid_weights', shape=[layers[-1]], initializer=tf.glorot_normal_initializer())
183 | #sig_bias = tf.get_variable(name='sigmoid_bias', shape=[1], initializer=tf.constant_initializer(0.0))
184 | #deep_out = tf.nn.xw_plus_b(deep_inputs,sig_wgts,sig_bias,name='deep_out')
185 |
186 | with tf.variable_scope("DeepFM-out"):
187 | #y_bias = FM_B * tf.ones_like(labels, dtype=tf.float32) # None * 1 warning;这里不能用label,否则调用predict/export函数会出错,train/evaluate正常;初步判断estimator做了优化,用不到label时不传
188 | y_bias = FM_B * tf.ones_like(y_d, dtype=tf.float32) # None * 1
189 | y = y_bias + y_w + y_v + y_d
190 | pred = tf.sigmoid(y)
191 |
192 | predictions={"prob": pred}
193 | export_outputs = {tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY: tf.estimator.export.PredictOutput(predictions)}
194 | # Provide an estimator spec for `ModeKeys.PREDICT`
195 | if mode == tf.estimator.ModeKeys.PREDICT:
196 | return tf.estimator.EstimatorSpec(
197 | mode=mode,
198 | predictions=predictions,
199 | export_outputs=export_outputs)
200 |
201 | #------bulid loss------
202 | loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=y, labels=labels)) + \
203 | l2_reg * tf.nn.l2_loss(FM_W) + \
204 | l2_reg * tf.nn.l2_loss(FM_V) #+ \ l2_reg * tf.nn.l2_loss(sig_wgts)
205 |
206 | # Provide an estimator spec for `ModeKeys.EVAL`
207 | eval_metric_ops = {
208 | "auc": tf.metrics.auc(labels, pred)
209 | }
210 | if mode == tf.estimator.ModeKeys.EVAL:
211 | return tf.estimator.EstimatorSpec(
212 | mode=mode,
213 | predictions=predictions,
214 | loss=loss,
215 | eval_metric_ops=eval_metric_ops)
216 |
217 | #------bulid optimizer------
218 | if FLAGS.optimizer == 'Adam':
219 | optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate, beta1=0.9, beta2=0.999, epsilon=1e-8)
220 | elif FLAGS.optimizer == 'Adagrad':
221 | optimizer = tf.train.AdagradOptimizer(learning_rate=learning_rate, initial_accumulator_value=1e-8)
222 | elif FLAGS.optimizer == 'Momentum':
223 | optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=0.95)
224 | elif FLAGS.optimizer == 'ftrl':
225 | optimizer = tf.train.FtrlOptimizer(learning_rate)
226 |
227 | train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())
228 |
229 | # Provide an estimator spec for `ModeKeys.TRAIN` modes
230 | if mode == tf.estimator.ModeKeys.TRAIN:
231 | return tf.estimator.EstimatorSpec(
232 | mode=mode,
233 | predictions=predictions,
234 | loss=loss,
235 | train_op=train_op)
236 |
237 | # Provide an estimator spec for `ModeKeys.EVAL` and `ModeKeys.TRAIN` modes.
238 | #return tf.estimator.EstimatorSpec(
239 | # mode=mode,
240 | # loss=loss,
241 | # train_op=train_op,
242 | # predictions={"prob": pred},
243 | # eval_metric_ops=eval_metric_ops)
244 |
245 | def batch_norm_layer(x, train_phase, scope_bn):
246 | bn_train = tf.contrib.layers.batch_norm(x, decay=FLAGS.batch_norm_decay, center=True, scale=True, updates_collections=None, is_training=True, reuse=None, scope=scope_bn)
247 | bn_infer = tf.contrib.layers.batch_norm(x, decay=FLAGS.batch_norm_decay, center=True, scale=True, updates_collections=None, is_training=False, reuse=True, scope=scope_bn)
248 | z = tf.cond(tf.cast(train_phase, tf.bool), lambda: bn_train, lambda: bn_infer)
249 | return z
250 |
251 | def set_dist_env():
252 | if FLAGS.dist_mode == 1: # 本地分布式测试模式1 chief, 1 ps, 1 evaluator
253 | ps_hosts = FLAGS.ps_hosts.split(',')
254 | chief_hosts = FLAGS.chief_hosts.split(',')
255 | task_index = FLAGS.task_index
256 | job_name = FLAGS.job_name
257 | print('ps_host', ps_hosts)
258 | print('chief_hosts', chief_hosts)
259 | print('job_name', job_name)
260 | print('task_index', str(task_index))
261 | # 无worker参数
262 | tf_config = {
263 | 'cluster': {'chief': chief_hosts, 'ps': ps_hosts},
264 | 'task': {'type': job_name, 'index': task_index }
265 | }
266 | print(json.dumps(tf_config))
267 | os.environ['TF_CONFIG'] = json.dumps(tf_config)
268 | elif FLAGS.dist_mode == 2: # 集群分布式模式
269 | ps_hosts = FLAGS.ps_hosts.split(',')
270 | worker_hosts = FLAGS.worker_hosts.split(',')
271 | chief_hosts = worker_hosts[0:1] # get first worker as chief
272 | worker_hosts = worker_hosts[2:] # the rest as worker
273 | task_index = FLAGS.task_index
274 | job_name = FLAGS.job_name
275 | print('ps_host', ps_hosts)
276 | print('worker_host', worker_hosts)
277 | print('chief_hosts', chief_hosts)
278 | print('job_name', job_name)
279 | print('task_index', str(task_index))
280 | # use #worker=0 as chief
281 | if job_name == "worker" and task_index == 0:
282 | job_name = "chief"
283 | # use #worker=1 as evaluator
284 | if job_name == "worker" and task_index == 1:
285 | job_name = 'evaluator'
286 | task_index = 0
287 | # the others as worker
288 | if job_name == "worker" and task_index > 1:
289 | task_index -= 2
290 |
291 | tf_config = {
292 | 'cluster': {'chief': chief_hosts, 'worker': worker_hosts, 'ps': ps_hosts},
293 | 'task': {'type': job_name, 'index': task_index }
294 | }
295 | print(json.dumps(tf_config))
296 | os.environ['TF_CONFIG'] = json.dumps(tf_config)
297 |
298 | def main(_):
299 | tr_files = glob.glob("%s/tr*libsvm" % FLAGS.data_dir)
300 | random.shuffle(tr_files)
301 | print("tr_files:", tr_files)
302 | va_files = glob.glob("%s/va*libsvm" % FLAGS.data_dir)
303 | print("va_files:", va_files)
304 | te_files = glob.glob("%s/te*libsvm" % FLAGS.data_dir)
305 | print("te_files:", te_files)
306 |
307 | if FLAGS.clear_existing_model:
308 | try:
309 | shutil.rmtree(FLAGS.model_dir)
310 | except Exception as e:
311 | print(e, "at clear_existing_model")
312 | else:
313 | print("existing model cleaned at %s" % FLAGS.model_dir)
314 |
315 | set_dist_env()
316 |
317 | model_params = {
318 | "field_size": FLAGS.field_size,
319 | "feature_size": FLAGS.feature_size,
320 | "embedding_size": FLAGS.embedding_size,
321 | "learning_rate": FLAGS.learning_rate,
322 | "batch_norm_decay": FLAGS.batch_norm_decay,
323 | "l2_reg": FLAGS.l2_reg,
324 | "deep_layers": FLAGS.deep_layers,
325 | "dropout": FLAGS.dropout
326 | }
327 | config = tf.estimator.RunConfig().replace(session_config = tf.ConfigProto(device_count={'GPU':0, 'CPU':FLAGS.num_threads}),
328 | log_step_count_steps=FLAGS.log_steps, save_summary_steps=FLAGS.log_steps)
329 | DeepFM = tf.estimator.Estimator(model_fn=model_fn, model_dir=FLAGS.model_dir, params=model_params, config=config)
330 |
331 | if FLAGS.task_type == 'train':
332 | train_spec = tf.estimator.TrainSpec(input_fn=lambda: input_fn(tr_files, num_epochs=FLAGS.num_epochs, batch_size=FLAGS.batch_size))
333 | eval_spec = tf.estimator.EvalSpec(input_fn=lambda: input_fn(va_files, num_epochs=1, batch_size=FLAGS.batch_size), steps=None, start_delay_secs=1000, throttle_secs=1200)
334 | tf.estimator.train_and_evaluate(DeepFM, train_spec, eval_spec)
335 | elif FLAGS.task_type == 'eval':
336 | DeepFM.evaluate(input_fn=lambda: input_fn(va_files, num_epochs=1, batch_size=FLAGS.batch_size))
337 | elif FLAGS.task_type == 'infer':
338 | preds = DeepFM.predict(input_fn=lambda: input_fn(te_files, num_epochs=1, batch_size=FLAGS.batch_size), predict_keys="prob")
339 | with open(FLAGS.data_dir+"/pred.txt", "w") as fo:
340 | for prob in preds:
341 | fo.write("%f\n" % (prob['prob']))
342 | elif FLAGS.task_type == 'export':
343 | #feature_spec = tf.feature_column.make_parse_example_spec(feature_columns)
344 | #feature_spec = {
345 | # 'feat_ids': tf.FixedLenFeature(dtype=tf.int64, shape=[None, FLAGS.field_size]),
346 | # 'feat_vals': tf.FixedLenFeature(dtype=tf.float32, shape=[None, FLAGS.field_size])
347 | #}
348 | #serving_input_receiver_fn = tf.estimator.export.build_parsing_serving_input_receiver_fn(feature_spec)
349 | feature_spec = {
350 | 'feat_ids': tf.placeholder(dtype=tf.int64, shape=[None, FLAGS.field_size], name='feat_ids'),
351 | 'feat_vals': tf.placeholder(dtype=tf.float32, shape=[None, FLAGS.field_size], name='feat_vals')
352 | }
353 | serving_input_receiver_fn = tf.estimator.export.build_raw_serving_input_receiver_fn(feature_spec)
354 | DeepFM.export_savedmodel(FLAGS.servable_model_dir, serving_input_receiver_fn)
355 |
356 | if __name__ == "__main__":
357 | #------check Arguments------
358 | if FLAGS.dt_dir == "":
359 | FLAGS.dt_dir = (date.today() + timedelta(-1)).strftime('%Y%m%d')
360 | FLAGS.model_dir = FLAGS.model_dir + FLAGS.dt_dir
361 | #FLAGS.data_dir = FLAGS.data_dir + FLAGS.dt_dir
362 |
363 | print('task_type ', FLAGS.task_type)
364 | print('model_dir ', FLAGS.model_dir)
365 | print('data_dir ', FLAGS.data_dir)
366 | print('dt_dir ', FLAGS.dt_dir)
367 | print('num_epochs ', FLAGS.num_epochs)
368 | print('feature_size ', FLAGS.feature_size)
369 | print('field_size ', FLAGS.field_size)
370 | print('embedding_size ', FLAGS.embedding_size)
371 | print('batch_size ', FLAGS.batch_size)
372 | print('deep_layers ', FLAGS.deep_layers)
373 | print('dropout ', FLAGS.dropout)
374 | print('loss_type ', FLAGS.loss_type)
375 | print('optimizer ', FLAGS.optimizer)
376 | print('learning_rate ', FLAGS.learning_rate)
377 | print('batch_norm_decay ', FLAGS.batch_norm_decay)
378 | print('batch_norm ', FLAGS.batch_norm)
379 | print('l2_reg ', FLAGS.l2_reg)
380 |
381 | tf.logging.set_verbosity(tf.logging.INFO)
382 | tf.app.run()
383 |
--------------------------------------------------------------------------------
/deep nn ctr prediction/DeepFM_NFM_DeepCTR.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## CTR预估(2)\n",
8 | "\n",
9 | "资料&&代码整理by[@寒小阳](https://blog.csdn.net/han_xiaoyang)(hanxiaoyang.ml@gmail.com)\n",
10 | "\n",
11 | "reference:\n",
12 | "* [《广告点击率预估是怎么回事?》](https://zhuanlan.zhihu.com/p/23499698)\n",
13 | "* [从ctr预估问题看看f(x)设计—DNN篇](https://zhuanlan.zhihu.com/p/28202287)\n",
14 | "* [Atomu2014 product_nets](https://github.com/Atomu2014/product-nets)"
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "同样以criteo数据为例,我们来看看深度学习的应用。"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | "### 特征工程\n",
29 | "特征工程是比较重要的数据处理过程,这里对criteo数据依照[paddlepaddle做ctr预估特征工程](https://github.com/PaddlePaddle/models/blob/develop/deep_fm/preprocess.py)完成特征工程"
30 | ]
31 | },
32 | {
33 | "cell_type": "code",
34 | "execution_count": 1,
35 | "metadata": {
36 | "collapsed": true
37 | },
38 | "outputs": [],
39 | "source": [
40 | "#coding=utf8\n",
41 | "\"\"\"\n",
42 | "特征工程参考(https://github.com/PaddlePaddle/models/blob/develop/deep_fm/preprocess.py)完成\n",
43 | "-对数值型特征,normalize处理\n",
44 | "-对类别型特征,对长尾(出现频次低于200)的进行过滤\n",
45 | "\"\"\"\n",
46 | "import os\n",
47 | "import sys\n",
48 | "import random\n",
49 | "import collections\n",
50 | "import argparse\n",
51 | "from multiprocessing import Pool as ThreadPool\n",
52 | "\n",
53 | "# 13个连续型列,26个类别型列\n",
54 | "continous_features = range(1, 14)\n",
55 | "categorial_features = range(14, 40)\n",
56 | "\n",
57 | "# 对连续值进行截断处理(取每个连续值列的95%分位数)\n",
58 | "continous_clip = [20, 600, 100, 50, 64000, 500, 100, 50, 500, 10, 10, 10, 50]\n",
59 | "\n",
60 | "\n",
61 | "class CategoryDictGenerator:\n",
62 | " \"\"\"\n",
63 | " 类别型特征编码字典\n",
64 | " \"\"\"\n",
65 | "\n",
66 | " def __init__(self, num_feature):\n",
67 | " self.dicts = []\n",
68 | " self.num_feature = num_feature\n",
69 | " for i in range(0, num_feature):\n",
70 | " self.dicts.append(collections.defaultdict(int))\n",
71 | "\n",
72 | " def build(self, datafile, categorial_features, cutoff=0):\n",
73 | " with open(datafile, 'r') as f:\n",
74 | " for line in f:\n",
75 | " features = line.rstrip('\\n').split('\\t')\n",
76 | " for i in range(0, self.num_feature):\n",
77 | " if features[categorial_features[i]] != '':\n",
78 | " self.dicts[i][features[categorial_features[i]]] += 1\n",
79 | " for i in range(0, self.num_feature):\n",
80 | " self.dicts[i] = filter(lambda x: x[1] >= cutoff, self.dicts[i].items())\n",
81 | " self.dicts[i] = sorted(self.dicts[i], key=lambda x: (-x[1], x[0]))\n",
82 | " vocabs, _ = list(zip(*self.dicts[i]))\n",
83 | " self.dicts[i] = dict(zip(vocabs, range(1, len(vocabs) + 1)))\n",
84 | " self.dicts[i][''] = 0\n",
85 | "\n",
86 | " def gen(self, idx, key):\n",
87 | " if key not in self.dicts[idx]:\n",
88 | " res = self.dicts[idx]['']\n",
89 | " else:\n",
90 | " res = self.dicts[idx][key]\n",
91 | " return res\n",
92 | "\n",
93 | " def dicts_sizes(self):\n",
94 | " return map(len, self.dicts)\n",
95 | "\n",
96 | "\n",
97 | "class ContinuousFeatureGenerator:\n",
98 | " \"\"\"\n",
99 | " 对连续值特征做最大最小值normalization\n",
100 | " \"\"\"\n",
101 | "\n",
102 | " def __init__(self, num_feature):\n",
103 | " self.num_feature = num_feature\n",
104 | " self.min = [sys.maxint] * num_feature\n",
105 | " self.max = [-sys.maxint] * num_feature\n",
106 | "\n",
107 | " def build(self, datafile, continous_features):\n",
108 | " with open(datafile, 'r') as f:\n",
109 | " for line in f:\n",
110 | " features = line.rstrip('\\n').split('\\t')\n",
111 | " for i in range(0, self.num_feature):\n",
112 | " val = features[continous_features[i]]\n",
113 | " if val != '':\n",
114 | " val = int(val)\n",
115 | " if val > continous_clip[i]:\n",
116 | " val = continous_clip[i]\n",
117 | " self.min[i] = min(self.min[i], val)\n",
118 | " self.max[i] = max(self.max[i], val)\n",
119 | "\n",
120 | " def gen(self, idx, val):\n",
121 | " if val == '':\n",
122 | " return 0.0\n",
123 | " val = float(val)\n",
124 | " return (val - self.min[idx]) / (self.max[idx] - self.min[idx])\n",
125 | "\n",
126 | "\n",
127 | "def preprocess(input_dir, output_dir):\n",
128 | " \"\"\"\n",
129 | " 对连续型和类别型特征进行处理\n",
130 | " \"\"\"\n",
131 | " \n",
132 | " dists = ContinuousFeatureGenerator(len(continous_features))\n",
133 | " dists.build(input_dir + 'train.txt', continous_features)\n",
134 | "\n",
135 | " dicts = CategoryDictGenerator(len(categorial_features))\n",
136 | " dicts.build(input_dir + 'train.txt', categorial_features, cutoff=150)\n",
137 | "\n",
138 | " output = open(output_dir + 'feature_map','w')\n",
139 | " for i in continous_features:\n",
140 | " output.write(\"{0} {1}\\n\".format('I'+str(i), i))\n",
141 | " dict_sizes = dicts.dicts_sizes()\n",
142 | " categorial_feature_offset = [dists.num_feature]\n",
143 | " for i in range(1, len(categorial_features)+1):\n",
144 | " offset = categorial_feature_offset[i - 1] + dict_sizes[i - 1]\n",
145 | " categorial_feature_offset.append(offset)\n",
146 | " for key, val in dicts.dicts[i-1].iteritems():\n",
147 | " output.write(\"{0} {1}\\n\".format('C'+str(i)+'|'+key, categorial_feature_offset[i - 1]+val+1))\n",
148 | "\n",
149 | " random.seed(0)\n",
150 | "\n",
151 | " # 90%的数据用于训练,10%的数据用于验证\n",
152 | " with open(output_dir + 'tr.libsvm', 'w') as out_train:\n",
153 | " with open(output_dir + 'va.libsvm', 'w') as out_valid:\n",
154 | " with open(input_dir + 'train.txt', 'r') as f:\n",
155 | " for line in f:\n",
156 | " features = line.rstrip('\\n').split('\\t')\n",
157 | "\n",
158 | " feat_vals = []\n",
159 | " for i in range(0, len(continous_features)):\n",
160 | " val = dists.gen(i, features[continous_features[i]])\n",
161 | " feat_vals.append(str(continous_features[i]) + ':' + \"{0:.6f}\".format(val).rstrip('0').rstrip('.'))\n",
162 | "\n",
163 | " for i in range(0, len(categorial_features)):\n",
164 | " val = dicts.gen(i, features[categorial_features[i]]) + categorial_feature_offset[i]\n",
165 | " feat_vals.append(str(val) + ':1')\n",
166 | "\n",
167 | " label = features[0]\n",
168 | " if random.randint(0, 9999) % 10 != 0:\n",
169 | " out_train.write(\"{0} {1}\\n\".format(label, ' '.join(feat_vals)))\n",
170 | " else:\n",
171 | " out_valid.write(\"{0} {1}\\n\".format(label, ' '.join(feat_vals)))\n",
172 | "\n",
173 | " with open(output_dir + 'te.libsvm', 'w') as out:\n",
174 | " with open(input_dir + 'test.txt', 'r') as f:\n",
175 | " for line in f:\n",
176 | " features = line.rstrip('\\n').split('\\t')\n",
177 | "\n",
178 | " feat_vals = []\n",
179 | " for i in range(0, len(continous_features)):\n",
180 | " val = dists.gen(i, features[continous_features[i] - 1])\n",
181 | " feat_vals.append(str(continous_features[i]) + ':' + \"{0:.6f}\".format(val).rstrip('0').rstrip('.'))\n",
182 | "\n",
183 | " for i in range(0, len(categorial_features)):\n",
184 | " val = dicts.gen(i, features[categorial_features[i] - 1]) + categorial_feature_offset[i]\n",
185 | " feat_vals.append(str(val) + ':1')\n",
186 | "\n",
187 | " out.write(\"{0} {1}\\n\".format(label, ' '.join(feat_vals)))"
188 | ]
189 | },
190 | {
191 | "cell_type": "code",
192 | "execution_count": null,
193 | "metadata": {},
194 | "outputs": [
195 | {
196 | "name": "stdout",
197 | "output_type": "stream",
198 | "text": [
199 | "开始数据处理与特征工程...\n"
200 | ]
201 | }
202 | ],
203 | "source": [
204 | "input_dir = './criteo_data/'\n",
205 | "output_dir = './criteo_data/'\n",
206 | "print(\"开始数据处理与特征工程...\")\n",
207 | "preprocess(input_dir, output_dir)"
208 | ]
209 | },
210 | {
211 | "cell_type": "code",
212 | "execution_count": 8,
213 | "metadata": {},
214 | "outputs": [
215 | {
216 | "name": "stdout",
217 | "output_type": "stream",
218 | "text": [
219 | "0 1:0.2 2:0.028192 3:0.07 4:0.56 5:0.000562 6:0.056 7:0.04 8:0.86 9:0.094 10:0.25 11:0.2 12:0 13:0.56 14:1 169:1 631:1 1414:1 2534:1 2584:1 4239:1 4991:1 5060:1 5064:1 7141:1 8818:1 9906:1 11250:1 11377:1 12951:1 13833:1 13883:1 14817:1 15204:1 15327:1 16118:1 16128:1 16183:1 17289:1 17361:1\r\n",
220 | "1 1:0 2:0.004975 3:0.11 4:0 5:1.373375 6:0 7:0 8:0.14 9:0 10:0 11:0 12:0 13:0 14:1 181:1 543:1 1379:1 2534:1 2582:1 3632:1 4990:1 5061:1 5217:1 6925:1 8726:1 9705:1 11250:1 11605:1 12849:1 13835:1 13971:1 14816:1 15202:1 15224:1 16118:1 16129:1 16148:1 17280:1 17320:1\r\n",
221 | "0 1:0.1 2:0.008292 3:0.28 4:0.14 5:0.000016 6:0.002 7:0.21 8:0.14 9:0.786 10:0.125 11:0.4 12:0 13:0.02 14:1 209:1 632:1 1491:1 2534:1 2582:1 2719:1 4995:1 5060:1 5069:1 6960:1 8820:1 9727:1 11249:1 11471:1 12933:1 13834:1 13927:1 14817:1 15204:1 15328:1 16118:1 16129:1 16185:1 17282:1 17364:1\r\n",
222 | "1 1:0 2:0.003317 3:0.04 4:0.5 5:0.504031 6:0.222 7:0.02 8:0.72 9:0.16 10:0 11:0.1 12:0 13:0.5 14:1 156:1 529:1 1377:1 2534:1 2583:1 3768:1 4990:1 5060:1 5247:1 7131:1 8711:1 9893:1 11250:1 11361:1 12827:1 13835:1 13888:1 14816:1 15202:1 15207:1 16118:1 16129:1 16145:1 17280:1 17320:1\r\n",
223 | "0 1:0 2:0.004975 3:0.28 4:0.14 5:0.022766 6:0.058 7:0.05 8:0.28 9:0.464 10:0 11:0.3 12:0 13:0.14 15:1 142:1 528:1 1376:1 2535:1 2582:1 2659:1 4997:1 5060:1 5064:1 7780:1 8710:1 9703:1 11250:1 11324:1 12826:1 13834:1 13861:1 14817:1 15203:1 15206:1 16118:1 16128:1 16746:1 17282:1 17320:1\r\n"
224 | ]
225 | }
226 | ],
227 | "source": [
228 | "!head -5 ./criteo_data/tr.libsvm"
229 | ]
230 | },
231 | {
232 | "cell_type": "markdown",
233 | "metadata": {},
234 | "source": [
235 | "### DeepFM\n",
236 | "reference:[常见的计算广告点击率预估算法总结](https://zhuanlan.zhihu.com/p/29053940)\n",
237 | "\n",
238 | "DeepFM结合了wide and deep和FM,其实就是把PNN和WDL结合了。原始的Wide and Deep,Wide的部分只是LR,构造线性关系,Deep部分建模更高阶的关系,所以在Wide and Deep中还需要做一些特征的东西,如Cross Column的工作,FM是可以建模二阶关系达到Cross column的效果,DeepFM就是把FM和NN结合,无需再对特征做诸如Cross Column的工作了。\n",
239 | "\n",
240 | "FM部分如下:\n",
241 | "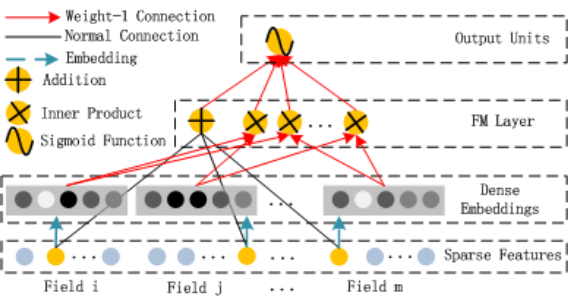\n",
242 | "\n",
243 | "Deep部分如下:\n",
244 | "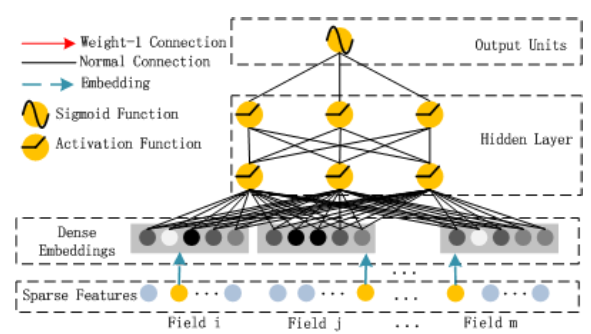\n",
245 | "\n",
246 | "总体结构图:\n",
247 | "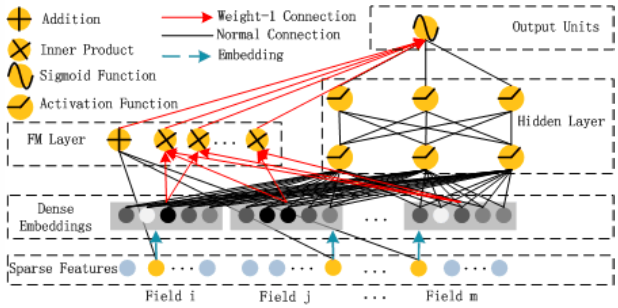\n",
248 | "\n",
249 | "DeepFM相对于FNN、PNN,能够利用其Deep部分建模更高阶信息(二阶以上),而相对于Wide and Deep能够减少特征工程的部分工作,wide部分类似FM建模一、二阶特征间关系, 算是NN和FM的一个很好的结合,另外不同的是如下图,DeepFM的wide和deep部分共享embedding向量空间,wide和deep均可以更新embedding部分"
250 | ]
251 | },
252 | {
253 | "cell_type": "code",
254 | "execution_count": null,
255 | "metadata": {
256 | "collapsed": true
257 | },
258 | "outputs": [],
259 | "source": [
260 | "# %load DeepFM.py\n",
261 | "#!/usr/bin/env python\n",
262 | "\"\"\"\n",
263 | "#1 Input pipline using Dataset high level API, Support parallel and prefetch reading\n",
264 | "#2 Train pipline using Coustom Estimator by rewriting model_fn\n",
265 | "#3 Support distincted training using TF_CONFIG\n",
266 | "#4 Support export_model for TensorFlow Serving\n",
267 | "\n",
268 | "方便迁移到其他算法上,只要修改input_fn and model_fn\n",
269 | "by lambdaji\n",
270 | "\"\"\"\n",
271 | "#from __future__ import absolute_import\n",
272 | "#from __future__ import division\n",
273 | "#from __future__ import print_function\n",
274 | "\n",
275 | "#import argparse\n",
276 | "import shutil\n",
277 | "#import sys\n",
278 | "import os\n",
279 | "import json\n",
280 | "import glob\n",
281 | "from datetime import date, timedelta\n",
282 | "from time import time\n",
283 | "#import gc\n",
284 | "#from multiprocessing import Process\n",
285 | "\n",
286 | "#import math\n",
287 | "import random\n",
288 | "import pandas as pd\n",
289 | "import numpy as np\n",
290 | "import tensorflow as tf\n",
291 | "\n",
292 | "#################### CMD Arguments ####################\n",
293 | "FLAGS = tf.app.flags.FLAGS\n",
294 | "tf.app.flags.DEFINE_integer(\"dist_mode\", 0, \"distribuion mode {0-loacal, 1-single_dist, 2-multi_dist}\")\n",
295 | "tf.app.flags.DEFINE_string(\"ps_hosts\", '', \"Comma-separated list of hostname:port pairs\")\n",
296 | "tf.app.flags.DEFINE_string(\"worker_hosts\", '', \"Comma-separated list of hostname:port pairs\")\n",
297 | "tf.app.flags.DEFINE_string(\"job_name\", '', \"One of 'ps', 'worker'\")\n",
298 | "tf.app.flags.DEFINE_integer(\"task_index\", 0, \"Index of task within the job\")\n",
299 | "tf.app.flags.DEFINE_integer(\"num_threads\", 16, \"Number of threads\")\n",
300 | "tf.app.flags.DEFINE_integer(\"feature_size\", 0, \"Number of features\")\n",
301 | "tf.app.flags.DEFINE_integer(\"field_size\", 0, \"Number of fields\")\n",
302 | "tf.app.flags.DEFINE_integer(\"embedding_size\", 32, \"Embedding size\")\n",
303 | "tf.app.flags.DEFINE_integer(\"num_epochs\", 10, \"Number of epochs\")\n",
304 | "tf.app.flags.DEFINE_integer(\"batch_size\", 64, \"Number of batch size\")\n",
305 | "tf.app.flags.DEFINE_integer(\"log_steps\", 1000, \"save summary every steps\")\n",
306 | "tf.app.flags.DEFINE_float(\"learning_rate\", 0.0005, \"learning rate\")\n",
307 | "tf.app.flags.DEFINE_float(\"l2_reg\", 0.0001, \"L2 regularization\")\n",
308 | "tf.app.flags.DEFINE_string(\"loss_type\", 'log_loss', \"loss type {square_loss, log_loss}\")\n",
309 | "tf.app.flags.DEFINE_string(\"optimizer\", 'Adam', \"optimizer type {Adam, Adagrad, GD, Momentum}\")\n",
310 | "tf.app.flags.DEFINE_string(\"deep_layers\", '256,128,64', \"deep layers\")\n",
311 | "tf.app.flags.DEFINE_string(\"dropout\", '0.5,0.5,0.5', \"dropout rate\")\n",
312 | "tf.app.flags.DEFINE_boolean(\"batch_norm\", False, \"perform batch normaization (True or False)\")\n",
313 | "tf.app.flags.DEFINE_float(\"batch_norm_decay\", 0.9, \"decay for the moving average(recommend trying decay=0.9)\")\n",
314 | "tf.app.flags.DEFINE_string(\"data_dir\", '', \"data dir\")\n",
315 | "tf.app.flags.DEFINE_string(\"dt_dir\", '', \"data dt partition\")\n",
316 | "tf.app.flags.DEFINE_string(\"model_dir\", '', \"model check point dir\")\n",
317 | "tf.app.flags.DEFINE_string(\"servable_model_dir\", '', \"export servable model for TensorFlow Serving\")\n",
318 | "tf.app.flags.DEFINE_string(\"task_type\", 'train', \"task type {train, infer, eval, export}\")\n",
319 | "tf.app.flags.DEFINE_boolean(\"clear_existing_model\", False, \"clear existing model or not\")\n",
320 | "\n",
321 | "#1 1:0.5 2:0.03519 3:1 4:0.02567 7:0.03708 8:0.01705 9:0.06296 10:0.18185 11:0.02497 12:1 14:0.02565 15:0.03267 17:0.0247 18:0.03158 20:1 22:1 23:0.13169 24:0.02933 27:0.18159 31:0.0177 34:0.02888 38:1 51:1 63:1 132:1 164:1 236:1\n",
322 | "def input_fn(filenames, batch_size=32, num_epochs=1, perform_shuffle=False):\n",
323 | " print('Parsing', filenames)\n",
324 | " def decode_libsvm(line):\n",
325 | " #columns = tf.decode_csv(value, record_defaults=CSV_COLUMN_DEFAULTS)\n",
326 | " #features = dict(zip(CSV_COLUMNS, columns))\n",
327 | " #labels = features.pop(LABEL_COLUMN)\n",
328 | " columns = tf.string_split([line], ' ')\n",
329 | " labels = tf.string_to_number(columns.values[0], out_type=tf.float32)\n",
330 | " splits = tf.string_split(columns.values[1:], ':')\n",
331 | " id_vals = tf.reshape(splits.values,splits.dense_shape)\n",
332 | " feat_ids, feat_vals = tf.split(id_vals,num_or_size_splits=2,axis=1)\n",
333 | " feat_ids = tf.string_to_number(feat_ids, out_type=tf.int32)\n",
334 | " feat_vals = tf.string_to_number(feat_vals, out_type=tf.float32)\n",
335 | " #feat_ids = tf.reshape(feat_ids,shape=[-1,FLAGS.field_size])\n",
336 | " #for i in range(splits.dense_shape.eval()[0]):\n",
337 | " # feat_ids.append(tf.string_to_number(splits.values[2*i], out_type=tf.int32))\n",
338 | " # feat_vals.append(tf.string_to_number(splits.values[2*i+1]))\n",
339 | " #return tf.reshape(feat_ids,shape=[-1,field_size]), tf.reshape(feat_vals,shape=[-1,field_size]), labels\n",
340 | " return {\"feat_ids\": feat_ids, \"feat_vals\": feat_vals}, labels\n",
341 | "\n",
342 | " # Extract lines from input files using the Dataset API, can pass one filename or filename list\n",
343 | " dataset = tf.data.TextLineDataset(filenames).map(decode_libsvm, num_parallel_calls=10).prefetch(500000) # multi-thread pre-process then prefetch\n",
344 | "\n",
345 | " # Randomizes input using a window of 256 elements (read into memory)\n",
346 | " if perform_shuffle:\n",
347 | " dataset = dataset.shuffle(buffer_size=256)\n",
348 | "\n",
349 | " # epochs from blending together.\n",
350 | " dataset = dataset.repeat(num_epochs)\n",
351 | " dataset = dataset.batch(batch_size) # Batch size to use\n",
352 | "\n",
353 | " #return dataset.make_one_shot_iterator()\n",
354 | " iterator = dataset.make_one_shot_iterator()\n",
355 | " batch_features, batch_labels = iterator.get_next()\n",
356 | " #return tf.reshape(batch_ids,shape=[-1,field_size]), tf.reshape(batch_vals,shape=[-1,field_size]), batch_labels\n",
357 | " return batch_features, batch_labels\n",
358 | "\n",
359 | "def model_fn(features, labels, mode, params):\n",
360 | " \"\"\"Bulid Model function f(x) for Estimator.\"\"\"\n",
361 | " #------hyperparameters----\n",
362 | " field_size = params[\"field_size\"]\n",
363 | " feature_size = params[\"feature_size\"]\n",
364 | " embedding_size = params[\"embedding_size\"]\n",
365 | " l2_reg = params[\"l2_reg\"]\n",
366 | " learning_rate = params[\"learning_rate\"]\n",
367 | " #batch_norm_decay = params[\"batch_norm_decay\"]\n",
368 | " #optimizer = params[\"optimizer\"]\n",
369 | " layers = map(int, params[\"deep_layers\"].split(','))\n",
370 | " dropout = map(float, params[\"dropout\"].split(','))\n",
371 | "\n",
372 | " #------bulid weights------\n",
373 | " FM_B = tf.get_variable(name='fm_bias', shape=[1], initializer=tf.constant_initializer(0.0))\n",
374 | " FM_W = tf.get_variable(name='fm_w', shape=[feature_size], initializer=tf.glorot_normal_initializer())\n",
375 | " # F\n",
376 | " FM_V = tf.get_variable(name='fm_v', shape=[feature_size, embedding_size], initializer=tf.glorot_normal_initializer())\n",
377 | " # F * E \n",
378 | " #------build feaure-------\n",
379 | " feat_ids = features['feat_ids']\n",
380 | " feat_ids = tf.reshape(feat_ids,shape=[-1,field_size]) # None * f/K * K\n",
381 | " feat_vals = features['feat_vals']\n",
382 | " feat_vals = tf.reshape(feat_vals,shape=[-1,field_size]) # None * f/K * K\n",
383 | "\n",
384 | " #------build f(x)------\n",
385 | " with tf.variable_scope(\"First-order\"):\n",
386 | " feat_wgts = tf.nn.embedding_lookup(FM_W, feat_ids) # None * f/K * K\n",
387 | " y_w = tf.reduce_sum(tf.multiply(feat_wgts, feat_vals),1) \n",
388 | "\n",
389 | " with tf.variable_scope(\"Second-order\"):\n",
390 | " embeddings = tf.nn.embedding_lookup(FM_V, feat_ids) # None * f/K * K * E\n",
391 | " feat_vals = tf.reshape(feat_vals, shape=[-1, field_size, 1]) # None * f/K * K * 1 ?\n",
392 | " embeddings = tf.multiply(embeddings, feat_vals) #vij*xi \n",
393 | " sum_square = tf.square(tf.reduce_sum(embeddings,1)) # None * K * E\n",
394 | " square_sum = tf.reduce_sum(tf.square(embeddings),1)\n",
395 | " y_v = 0.5*tf.reduce_sum(tf.subtract(sum_square, square_sum),1)\t# None * 1\n",
396 | "\n",
397 | " with tf.variable_scope(\"Deep-part\"):\n",
398 | " if FLAGS.batch_norm:\n",
399 | " #normalizer_fn = tf.contrib.layers.batch_norm\n",
400 | " #normalizer_fn = tf.layers.batch_normalization\n",
401 | " if mode == tf.estimator.ModeKeys.TRAIN:\n",
402 | " train_phase = True\n",
403 | " #normalizer_params = {'decay': batch_norm_decay, 'center': True, 'scale': True, 'updates_collections': None, 'is_training': True, 'reuse': None}\n",
404 | " else:\n",
405 | " train_phase = False\n",
406 | " #normalizer_params = {'decay': batch_norm_decay, 'center': True, 'scale': True, 'updates_collections': None, 'is_training': False, 'reuse': True}\n",
407 | " else:\n",
408 | " normalizer_fn = None\n",
409 | " normalizer_params = None\n",
410 | "\n",
411 | " deep_inputs = tf.reshape(embeddings,shape=[-1,field_size*embedding_size]) # None * (F*K)\n",
412 | " for i in range(len(layers)):\n",
413 | " #if FLAGS.batch_norm:\n",
414 | " # deep_inputs = batch_norm_layer(deep_inputs, train_phase=train_phase, scope_bn='bn_%d' %i)\n",
415 | " #normalizer_params.update({'scope': 'bn_%d' %i})\n",
416 | " deep_inputs = tf.contrib.layers.fully_connected(inputs=deep_inputs, num_outputs=layers[i], \\\n",
417 | " #normalizer_fn=normalizer_fn, normalizer_params=normalizer_params, \\\n",
418 | " weights_regularizer=tf.contrib.layers.l2_regularizer(l2_reg), scope='mlp%d' % i)\n",
419 | " if FLAGS.batch_norm:\n",
420 | " deep_inputs = batch_norm_layer(deep_inputs, train_phase=train_phase, scope_bn='bn_%d' %i) #放在RELU之后 https://github.com/ducha-aiki/caffenet-benchmark/blob/master/batchnorm.md#bn----before-or-after-relu\n",
421 | " if mode == tf.estimator.ModeKeys.TRAIN:\n",
422 | " deep_inputs = tf.nn.dropout(deep_inputs, keep_prob=dropout[i]) #Apply Dropout after all BN layers and set dropout=0.8(drop_ratio=0.2)\n",
423 | " #deep_inputs = tf.layers.dropout(inputs=deep_inputs, rate=dropout[i], training=mode == tf.estimator.ModeKeys.TRAIN)\n",
424 | "\n",
425 | " y_deep = tf.contrib.layers.fully_connected(inputs=deep_inputs, num_outputs=1, activation_fn=tf.identity, \\\n",
426 | " weights_regularizer=tf.contrib.layers.l2_regularizer(l2_reg), scope='deep_out')\n",
427 | " y_d = tf.reshape(y_deep,shape=[-1])\n",
428 | " #sig_wgts = tf.get_variable(name='sigmoid_weights', shape=[layers[-1]], initializer=tf.glorot_normal_initializer())\n",
429 | " #sig_bias = tf.get_variable(name='sigmoid_bias', shape=[1], initializer=tf.constant_initializer(0.0))\n",
430 | " #deep_out = tf.nn.xw_plus_b(deep_inputs,sig_wgts,sig_bias,name='deep_out')\n",
431 | "\n",
432 | " with tf.variable_scope(\"DeepFM-out\"):\n",
433 | " #y_bias = FM_B * tf.ones_like(labels, dtype=tf.float32) # None * 1 warning;这里不能用label,否则调用predict/export函数会出错,train/evaluate正常;初步判断estimator做了优化,用不到label时不传\n",
434 | " y_bias = FM_B * tf.ones_like(y_d, dtype=tf.float32) # None * 1\n",
435 | " y = y_bias + y_w + y_v + y_d\n",
436 | " pred = tf.sigmoid(y)\n",
437 | "\n",
438 | " predictions={\"prob\": pred}\n",
439 | " export_outputs = {tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY: tf.estimator.export.PredictOutput(predictions)}\n",
440 | " # Provide an estimator spec for `ModeKeys.PREDICT`\n",
441 | " if mode == tf.estimator.ModeKeys.PREDICT:\n",
442 | " return tf.estimator.EstimatorSpec(\n",
443 | " mode=mode,\n",
444 | " predictions=predictions,\n",
445 | " export_outputs=export_outputs)\n",
446 | "\n",
447 | " #------bulid loss------\n",
448 | " loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=y, labels=labels)) + \\\n",
449 | " l2_reg * tf.nn.l2_loss(FM_W) + \\\n",
450 | " l2_reg * tf.nn.l2_loss(FM_V) #+ \\ l2_reg * tf.nn.l2_loss(sig_wgts)\n",
451 | "\n",
452 | " # Provide an estimator spec for `ModeKeys.EVAL`\n",
453 | " eval_metric_ops = {\n",
454 | " \"auc\": tf.metrics.auc(labels, pred)\n",
455 | " }\n",
456 | " if mode == tf.estimator.ModeKeys.EVAL:\n",
457 | " return tf.estimator.EstimatorSpec(\n",
458 | " mode=mode,\n",
459 | " predictions=predictions,\n",
460 | " loss=loss,\n",
461 | " eval_metric_ops=eval_metric_ops)\n",
462 | "\n",
463 | " #------bulid optimizer------\n",
464 | " if FLAGS.optimizer == 'Adam':\n",
465 | " optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate, beta1=0.9, beta2=0.999, epsilon=1e-8)\n",
466 | " elif FLAGS.optimizer == 'Adagrad':\n",
467 | " optimizer = tf.train.AdagradOptimizer(learning_rate=learning_rate, initial_accumulator_value=1e-8)\n",
468 | " elif FLAGS.optimizer == 'Momentum':\n",
469 | " optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=0.95)\n",
470 | " elif FLAGS.optimizer == 'ftrl':\n",
471 | " optimizer = tf.train.FtrlOptimizer(learning_rate)\n",
472 | "\n",
473 | " train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())\n",
474 | "\n",
475 | " # Provide an estimator spec for `ModeKeys.TRAIN` modes\n",
476 | " if mode == tf.estimator.ModeKeys.TRAIN:\n",
477 | " return tf.estimator.EstimatorSpec(\n",
478 | " mode=mode,\n",
479 | " predictions=predictions,\n",
480 | " loss=loss,\n",
481 | " train_op=train_op)\n",
482 | "\n",
483 | " # Provide an estimator spec for `ModeKeys.EVAL` and `ModeKeys.TRAIN` modes.\n",
484 | " #return tf.estimator.EstimatorSpec(\n",
485 | " # mode=mode,\n",
486 | " # loss=loss,\n",
487 | " # train_op=train_op,\n",
488 | " # predictions={\"prob\": pred},\n",
489 | " # eval_metric_ops=eval_metric_ops)\n",
490 | "\n",
491 | "def batch_norm_layer(x, train_phase, scope_bn):\n",
492 | " bn_train = tf.contrib.layers.batch_norm(x, decay=FLAGS.batch_norm_decay, center=True, scale=True, updates_collections=None, is_training=True, reuse=None, scope=scope_bn)\n",
493 | " bn_infer = tf.contrib.layers.batch_norm(x, decay=FLAGS.batch_norm_decay, center=True, scale=True, updates_collections=None, is_training=False, reuse=True, scope=scope_bn)\n",
494 | " z = tf.cond(tf.cast(train_phase, tf.bool), lambda: bn_train, lambda: bn_infer)\n",
495 | " return z\n",
496 | "\n",
497 | "def set_dist_env():\n",
498 | " if FLAGS.dist_mode == 1: # 本地分布式测试模式1 chief, 1 ps, 1 evaluator\n",
499 | " ps_hosts = FLAGS.ps_hosts.split(',')\n",
500 | " chief_hosts = FLAGS.chief_hosts.split(',')\n",
501 | " task_index = FLAGS.task_index\n",
502 | " job_name = FLAGS.job_name\n",
503 | " print('ps_host', ps_hosts)\n",
504 | " print('chief_hosts', chief_hosts)\n",
505 | " print('job_name', job_name)\n",
506 | " print('task_index', str(task_index))\n",
507 | " # 无worker参数\n",
508 | " tf_config = {\n",
509 | " 'cluster': {'chief': chief_hosts, 'ps': ps_hosts},\n",
510 | " 'task': {'type': job_name, 'index': task_index }\n",
511 | " }\n",
512 | " print(json.dumps(tf_config))\n",
513 | " os.environ['TF_CONFIG'] = json.dumps(tf_config)\n",
514 | " elif FLAGS.dist_mode == 2: # 集群分布式模式\n",
515 | " ps_hosts = FLAGS.ps_hosts.split(',')\n",
516 | " worker_hosts = FLAGS.worker_hosts.split(',')\n",
517 | " chief_hosts = worker_hosts[0:1] # get first worker as chief\n",
518 | " worker_hosts = worker_hosts[2:] # the rest as worker\n",
519 | " task_index = FLAGS.task_index\n",
520 | " job_name = FLAGS.job_name\n",
521 | " print('ps_host', ps_hosts)\n",
522 | " print('worker_host', worker_hosts)\n",
523 | " print('chief_hosts', chief_hosts)\n",
524 | " print('job_name', job_name)\n",
525 | " print('task_index', str(task_index))\n",
526 | " # use #worker=0 as chief\n",
527 | " if job_name == \"worker\" and task_index == 0:\n",
528 | " job_name = \"chief\"\n",
529 | " # use #worker=1 as evaluator\n",
530 | " if job_name == \"worker\" and task_index == 1:\n",
531 | " job_name = 'evaluator'\n",
532 | " task_index = 0\n",
533 | " # the others as worker\n",
534 | " if job_name == \"worker\" and task_index > 1:\n",
535 | " task_index -= 2\n",
536 | "\n",
537 | " tf_config = {\n",
538 | " 'cluster': {'chief': chief_hosts, 'worker': worker_hosts, 'ps': ps_hosts},\n",
539 | " 'task': {'type': job_name, 'index': task_index }\n",
540 | " }\n",
541 | " print(json.dumps(tf_config))\n",
542 | " os.environ['TF_CONFIG'] = json.dumps(tf_config)\n",
543 | "\n",
544 | "def main(_):\n",
545 | " tr_files = glob.glob(\"%s/tr*libsvm\" % FLAGS.data_dir)\n",
546 | " random.shuffle(tr_files)\n",
547 | " print(\"tr_files:\", tr_files)\n",
548 | " va_files = glob.glob(\"%s/va*libsvm\" % FLAGS.data_dir)\n",
549 | " print(\"va_files:\", va_files)\n",
550 | " te_files = glob.glob(\"%s/te*libsvm\" % FLAGS.data_dir)\n",
551 | " print(\"te_files:\", te_files)\n",
552 | "\n",
553 | " if FLAGS.clear_existing_model:\n",
554 | " try:\n",
555 | " shutil.rmtree(FLAGS.model_dir)\n",
556 | " except Exception as e:\n",
557 | " print(e, \"at clear_existing_model\")\n",
558 | " else:\n",
559 | " print(\"existing model cleaned at %s\" % FLAGS.model_dir)\n",
560 | "\n",
561 | " set_dist_env()\n",
562 | "\n",
563 | " model_params = {\n",
564 | " \"field_size\": FLAGS.field_size,\n",
565 | " \"feature_size\": FLAGS.feature_size,\n",
566 | " \"embedding_size\": FLAGS.embedding_size,\n",
567 | " \"learning_rate\": FLAGS.learning_rate,\n",
568 | " \"batch_norm_decay\": FLAGS.batch_norm_decay,\n",
569 | " \"l2_reg\": FLAGS.l2_reg,\n",
570 | " \"deep_layers\": FLAGS.deep_layers,\n",
571 | " \"dropout\": FLAGS.dropout\n",
572 | " }\n",
573 | " config = tf.estimator.RunConfig().replace(session_config = tf.ConfigProto(device_count={'GPU':0, 'CPU':FLAGS.num_threads}),\n",
574 | " log_step_count_steps=FLAGS.log_steps, save_summary_steps=FLAGS.log_steps)\n",
575 | " DeepFM = tf.estimator.Estimator(model_fn=model_fn, model_dir=FLAGS.model_dir, params=model_params, config=config)\n",
576 | "\n",
577 | " if FLAGS.task_type == 'train':\n",
578 | " train_spec = tf.estimator.TrainSpec(input_fn=lambda: input_fn(tr_files, num_epochs=FLAGS.num_epochs, batch_size=FLAGS.batch_size))\n",
579 | " eval_spec = tf.estimator.EvalSpec(input_fn=lambda: input_fn(va_files, num_epochs=1, batch_size=FLAGS.batch_size), steps=None, start_delay_secs=1000, throttle_secs=1200)\n",
580 | " tf.estimator.train_and_evaluate(DeepFM, train_spec, eval_spec)\n",
581 | " elif FLAGS.task_type == 'eval':\n",
582 | " DeepFM.evaluate(input_fn=lambda: input_fn(va_files, num_epochs=1, batch_size=FLAGS.batch_size))\n",
583 | " elif FLAGS.task_type == 'infer':\n",
584 | " preds = DeepFM.predict(input_fn=lambda: input_fn(te_files, num_epochs=1, batch_size=FLAGS.batch_size), predict_keys=\"prob\")\n",
585 | " with open(FLAGS.data_dir+\"/pred.txt\", \"w\") as fo:\n",
586 | " for prob in preds:\n",
587 | " fo.write(\"%f\\n\" % (prob['prob']))\n",
588 | " elif FLAGS.task_type == 'export':\n",
589 | " #feature_spec = tf.feature_column.make_parse_example_spec(feature_columns)\n",
590 | " #feature_spec = {\n",
591 | " # 'feat_ids': tf.FixedLenFeature(dtype=tf.int64, shape=[None, FLAGS.field_size]),\n",
592 | " # 'feat_vals': tf.FixedLenFeature(dtype=tf.float32, shape=[None, FLAGS.field_size])\n",
593 | " #}\n",
594 | " #serving_input_receiver_fn = tf.estimator.export.build_parsing_serving_input_receiver_fn(feature_spec)\n",
595 | " feature_spec = {\n",
596 | " 'feat_ids': tf.placeholder(dtype=tf.int64, shape=[None, FLAGS.field_size], name='feat_ids'),\n",
597 | " 'feat_vals': tf.placeholder(dtype=tf.float32, shape=[None, FLAGS.field_size], name='feat_vals')\n",
598 | " }\n",
599 | " serving_input_receiver_fn = tf.estimator.export.build_raw_serving_input_receiver_fn(feature_spec)\n",
600 | " DeepFM.export_savedmodel(FLAGS.servable_model_dir, serving_input_receiver_fn)\n",
601 | "\n",
602 | "if __name__ == \"__main__\":\n",
603 | " #------check Arguments------\n",
604 | " if FLAGS.dt_dir == \"\":\n",
605 | " FLAGS.dt_dir = (date.today() + timedelta(-1)).strftime('%Y%m%d')\n",
606 | " FLAGS.model_dir = FLAGS.model_dir + FLAGS.dt_dir\n",
607 | " #FLAGS.data_dir = FLAGS.data_dir + FLAGS.dt_dir\n",
608 | "\n",
609 | " print('task_type ', FLAGS.task_type)\n",
610 | " print('model_dir ', FLAGS.model_dir)\n",
611 | " print('data_dir ', FLAGS.data_dir)\n",
612 | " print('dt_dir ', FLAGS.dt_dir)\n",
613 | " print('num_epochs ', FLAGS.num_epochs)\n",
614 | " print('feature_size ', FLAGS.feature_size)\n",
615 | " print('field_size ', FLAGS.field_size)\n",
616 | " print('embedding_size ', FLAGS.embedding_size)\n",
617 | " print('batch_size ', FLAGS.batch_size)\n",
618 | " print('deep_layers ', FLAGS.deep_layers)\n",
619 | " print('dropout ', FLAGS.dropout)\n",
620 | " print('loss_type ', FLAGS.loss_type)\n",
621 | " print('optimizer ', FLAGS.optimizer)\n",
622 | " print('learning_rate ', FLAGS.learning_rate)\n",
623 | " print('batch_norm_decay ', FLAGS.batch_norm_decay)\n",
624 | " print('batch_norm ', FLAGS.batch_norm)\n",
625 | " print('l2_reg ', FLAGS.l2_reg)\n",
626 | "\n",
627 | " tf.logging.set_verbosity(tf.logging.INFO)\n",
628 | " tf.app.run()\n"
629 | ]
630 | },
631 | {
632 | "cell_type": "code",
633 | "execution_count": null,
634 | "metadata": {},
635 | "outputs": [
636 | {
637 | "name": "stdout",
638 | "output_type": "stream",
639 | "text": [
640 | "('task_type ', 'train')\n",
641 | "('model_dir ', './criteo_model20180503')\n",
642 | "('data_dir ', './criteo_data')\n",
643 | "('dt_dir ', '20180503')\n",
644 | "('num_epochs ', 1)\n",
645 | "('feature_size ', 117581)\n",
646 | "('field_size ', 39)\n",
647 | "('embedding_size ', 32)\n",
648 | "('batch_size ', 256)\n",
649 | "('deep_layers ', '400,400,400')\n",
650 | "('dropout ', '0.5,0.5,0.5')\n",
651 | "('loss_type ', 'log_loss')\n",
652 | "('optimizer ', 'Adam')\n",
653 | "('learning_rate ', 0.0005)\n",
654 | "('batch_norm_decay ', 0.9)\n",
655 | "('batch_norm ', False)\n",
656 | "('l2_reg ', 0.0001)\n",
657 | "('tr_files:', ['./criteo_data/tr.libsvm'])\n",
658 | "('va_files:', ['./criteo_data/va.libsvm'])\n",
659 | "('te_files:', ['./criteo_data/te.libsvm'])\n",
660 | "INFO:tensorflow:Using config: {'_save_checkpoints_secs': 600, '_session_config': device_count {\n",
661 | " key: \"CPU\"\n",
662 | " value: 8\n",
663 | "}\n",
664 | "device_count {\n",
665 | " key: \"GPU\"\n",
666 | "}\n",
667 | ", '_keep_checkpoint_max': 5, '_task_type': 'worker', '_is_chief': True, '_cluster_spec': , '_save_checkpoints_steps': None, '_keep_checkpoint_every_n_hours': 10000, '_service': None, '_num_ps_replicas': 0, '_tf_random_seed': None, '_master': '', '_num_worker_replicas': 1, '_task_id': 0, '_log_step_count_steps': 1000, '_model_dir': './criteo_model', '_save_summary_steps': 1000}\n",
668 | "INFO:tensorflow:Running training and evaluation locally (non-distributed).\n",
669 | "INFO:tensorflow:Start train and evaluate loop. The evaluate will happen after 1200 secs (eval_spec.throttle_secs) or training is finished.\n",
670 | "('Parsing', ['./criteo_data/tr.libsvm'])\n",
671 | "INFO:tensorflow:Create CheckpointSaverHook.\n",
672 | "2018-05-04 23:34:53.147375: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA\n",
673 | "INFO:tensorflow:Saving checkpoints for 1 into ./criteo_model/model.ckpt.\n",
674 | "INFO:tensorflow:loss = 0.6947804, step = 1\n",
675 | "INFO:tensorflow:loss = 0.51585126, step = 101 (4.948 sec)\n",
676 | "INFO:tensorflow:loss = 0.4950318, step = 201 (4.408 sec)\n",
677 | "INFO:tensorflow:loss = 0.5462832, step = 301 (4.357 sec)\n",
678 | "INFO:tensorflow:loss = 0.5671505, step = 401 (4.368 sec)\n",
679 | "INFO:tensorflow:loss = 0.45424744, step = 501 (4.300 sec)\n",
680 | "INFO:tensorflow:loss = 0.5399899, step = 601 (4.274 sec)\n",
681 | "INFO:tensorflow:loss = 0.49540266, step = 701 (4.234 sec)\n",
682 | "INFO:tensorflow:loss = 0.5175852, step = 801 (4.294 sec)\n",
683 | "INFO:tensorflow:loss = 0.4686305, step = 901 (4.314 sec)\n",
684 | "INFO:tensorflow:global_step/sec: 22.8576\n",
685 | "INFO:tensorflow:loss = 0.5371931, step = 1001 (4.254 sec)\n",
686 | "INFO:tensorflow:loss = 0.49340367, step = 1101 (4.243 sec)\n",
687 | "INFO:tensorflow:loss = 0.49719507, step = 1201 (4.346 sec)\n",
688 | "INFO:tensorflow:loss = 0.48593232, step = 1301 (4.225 sec)\n",
689 | "INFO:tensorflow:loss = 0.48725832, step = 1401 (4.238 sec)\n",
690 | "INFO:tensorflow:loss = 0.4386774, step = 1501 (4.361 sec)\n",
691 | "INFO:tensorflow:loss = 0.49065983, step = 1601 (4.312 sec)\n",
692 | "INFO:tensorflow:loss = 0.53164876, step = 1701 (4.272 sec)\n",
693 | "INFO:tensorflow:loss = 0.40944415, step = 1801 (4.286 sec)\n",
694 | "INFO:tensorflow:loss = 0.521611, step = 1901 (4.270 sec)\n",
695 | "INFO:tensorflow:global_step/sec: 23.327\n",
696 | "INFO:tensorflow:loss = 0.49082595, step = 2001 (4.317 sec)\n",
697 | "INFO:tensorflow:loss = 0.50453734, step = 2101 (4.302 sec)\n",
698 | "INFO:tensorflow:loss = 0.49503702, step = 2201 (4.369 sec)\n",
699 | "INFO:tensorflow:loss = 0.45685932, step = 2301 (4.326 sec)\n",
700 | "INFO:tensorflow:loss = 0.47562104, step = 2401 (4.326 sec)\n",
701 | "INFO:tensorflow:loss = 0.5106457, step = 2501 (4.366 sec)\n",
702 | "INFO:tensorflow:loss = 0.4949795, step = 2601 (4.408 sec)\n",
703 | "INFO:tensorflow:loss = 0.4684176, step = 2701 (4.442 sec)\n",
704 | "INFO:tensorflow:loss = 0.43745354, step = 2801 (4.457 sec)\n",
705 | "INFO:tensorflow:loss = 0.48600715, step = 2901 (4.490 sec)\n",
706 | "INFO:tensorflow:global_step/sec: 22.7801\n",
707 | "INFO:tensorflow:loss = 0.4853104, step = 3001 (4.412 sec)\n",
708 | "INFO:tensorflow:loss = 0.49764964, step = 3101 (4.420 sec)\n",
709 | "INFO:tensorflow:loss = 0.4432894, step = 3201 (4.496 sec)\n",
710 | "INFO:tensorflow:loss = 0.46213925, step = 3301 (4.479 sec)\n",
711 | "INFO:tensorflow:loss = 0.4637582, step = 3401 (4.582 sec)\n",
712 | "INFO:tensorflow:loss = 0.46756223, step = 3501 (4.504 sec)\n",
713 | "INFO:tensorflow:loss = 0.46732077, step = 3601 (4.464 sec)\n"
714 | ]
715 | }
716 | ],
717 | "source": [
718 | "!python DeepFM.py --task_type=train \\\n",
719 | " --learning_rate=0.0005 \\\n",
720 | " --optimizer=Adam \\\n",
721 | " --num_epochs=1 \\\n",
722 | " --batch_size=256 \\\n",
723 | " --field_size=39 \\\n",
724 | " --feature_size=117581 \\\n",
725 | " --deep_layers=400,400,400 \\\n",
726 | " --dropout=0.5,0.5,0.5 \\\n",
727 | " --log_steps=1000 \\\n",
728 | " --num_threads=8 \\\n",
729 | " --model_dir=./criteo_model/DeepFM \\\n",
730 | " --data_dir=./criteo_data"
731 | ]
732 | },
733 | {
734 | "cell_type": "markdown",
735 | "metadata": {},
736 | "source": [
737 | "### NFM\n",
738 | "reference:
[从ctr预估问题看看f(x)设计—DNN篇](https://zhuanlan.zhihu.com/p/28202287)
[深度学习在CTR预估中的应用](https://zhuanlan.zhihu.com/p/35484389)\n",
739 | "\n",
740 | "NFM = LR + Embedding + Bi-Interaction Pooling + MLP\n",
741 | "\n",
742 | "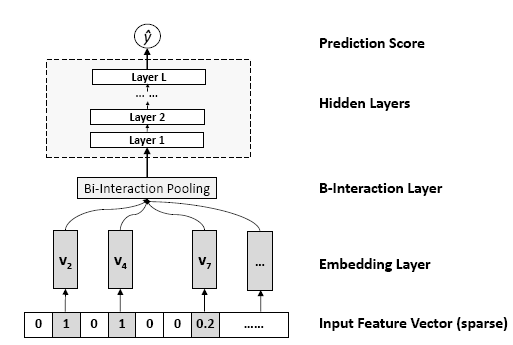\n",
743 | "\n",
744 | "对不同特征做相同维数的embedding向量。接下来,这些embedding向量两两做element-wise的相乘运算得到B-interaction layer。(element-wide运算举例: (1,2,3)element-wide相乘(4,5,6)结果是(4,10,18)。)\n",
745 | "\n",
746 | "B-interaction Layer 得到的是一个和embedding维数相同的向量。然后后面接几个隐藏层输出结果。\n",
747 | "\n",
748 | "大家思考一下,如果B-interaction layer后面不接隐藏层,直接把向量的元素相加输出结果, 就是一个FM,现在后面增加了隐藏层,相当于做了更高阶的FM,更加增强了非线性表达能力。\n",
749 | "\n",
750 | "NFM 在 embedding 做了 bi-interaction 操作来做特征的交叉处理,优点是网络参数从 n 直接压缩到 k(比 FNN 和 DeepFM 的 f\\*k 还少),降低了网络复杂度,能够加速网络的训练得到模型;但同时这种方法也可能带来较大的信息损失。"
751 | ]
752 | },
753 | {
754 | "cell_type": "code",
755 | "execution_count": null,
756 | "metadata": {
757 | "collapsed": true
758 | },
759 | "outputs": [],
760 | "source": [
761 | "# %load NFM.py\n",
762 | "#!/usr/bin/env python\n",
763 | "\"\"\"\n",
764 | "TensorFlow Implementation of <> with the fellowing features:\n",
765 | "#1 Input pipline using Dataset high level API, Support parallel and prefetch reading\n",
766 | "#2 Train pipline using Coustom Estimator by rewriting model_fn\n",
767 | "#3 Support distincted training by TF_CONFIG\n",
768 | "#4 Support export model for TensorFlow Serving\n",
769 | "\n",
770 | "by lambdaji\n",
771 | "\"\"\"\n",
772 | "#from __future__ import absolute_import\n",
773 | "#from __future__ import division\n",
774 | "#from __future__ import print_function\n",
775 | "\n",
776 | "#import argparse\n",
777 | "import shutil\n",
778 | "#import sys\n",
779 | "import os\n",
780 | "import json\n",
781 | "import glob\n",
782 | "from datetime import date, timedelta\n",
783 | "from time import time\n",
784 | "#import gc\n",
785 | "#from multiprocessing import Process\n",
786 | "\n",
787 | "#import math\n",
788 | "import random\n",
789 | "import pandas as pd\n",
790 | "import numpy as np\n",
791 | "import tensorflow as tf\n",
792 | "\n",
793 | "#################### CMD Arguments ####################\n",
794 | "FLAGS = tf.app.flags.FLAGS\n",
795 | "tf.app.flags.DEFINE_integer(\"dist_mode\", 0, \"distribuion mode {0-loacal, 1-single_dist, 2-multi_dist}\")\n",
796 | "tf.app.flags.DEFINE_string(\"ps_hosts\", '', \"Comma-separated list of hostname:port pairs\")\n",
797 | "tf.app.flags.DEFINE_string(\"worker_hosts\", '', \"Comma-separated list of hostname:port pairs\")\n",
798 | "tf.app.flags.DEFINE_string(\"job_name\", '', \"One of 'ps', 'worker'\")\n",
799 | "tf.app.flags.DEFINE_integer(\"task_index\", 0, \"Index of task within the job\")\n",
800 | "tf.app.flags.DEFINE_integer(\"num_threads\", 16, \"Number of threads\")\n",
801 | "tf.app.flags.DEFINE_integer(\"feature_size\", 0, \"Number of features\")\n",
802 | "tf.app.flags.DEFINE_integer(\"field_size\", 0, \"Number of fields\")\n",
803 | "tf.app.flags.DEFINE_integer(\"embedding_size\", 64, \"Embedding size\")\n",
804 | "tf.app.flags.DEFINE_integer(\"num_epochs\", 10, \"Number of epochs\")\n",
805 | "tf.app.flags.DEFINE_integer(\"batch_size\", 128, \"Number of batch size\")\n",
806 | "tf.app.flags.DEFINE_integer(\"log_steps\", 1000, \"save summary every steps\")\n",
807 | "tf.app.flags.DEFINE_float(\"learning_rate\", 0.05, \"learning rate\")\n",
808 | "tf.app.flags.DEFINE_float(\"l2_reg\", 0.001, \"L2 regularization\")\n",
809 | "tf.app.flags.DEFINE_string(\"loss_type\", 'log_loss', \"loss type {square_loss, log_loss}\")\n",
810 | "tf.app.flags.DEFINE_string(\"optimizer\", 'Adam', \"optimizer type {Adam, Adagrad, GD, Momentum}\")\n",
811 | "tf.app.flags.DEFINE_string(\"deep_layers\", '128,64', \"deep layers\")\n",
812 | "tf.app.flags.DEFINE_string(\"dropout\", '0.5,0.8,0.8', \"dropout rate\")\n",
813 | "tf.app.flags.DEFINE_boolean(\"batch_norm\", False, \"perform batch normaization (True or False)\")\n",
814 | "tf.app.flags.DEFINE_float(\"batch_norm_decay\", 0.9, \"decay for the moving average(recommend trying decay=0.9)\")\n",
815 | "tf.app.flags.DEFINE_string(\"data_dir\", '', \"data dir\")\n",
816 | "tf.app.flags.DEFINE_string(\"dt_dir\", '', \"data dt partition\")\n",
817 | "tf.app.flags.DEFINE_string(\"model_dir\", '', \"model check point dir\")\n",
818 | "tf.app.flags.DEFINE_string(\"servable_model_dir\", '', \"export servable model for TensorFlow Serving\")\n",
819 | "tf.app.flags.DEFINE_string(\"task_type\", 'train', \"task type {train, infer, eval, export}\")\n",
820 | "tf.app.flags.DEFINE_boolean(\"clear_existing_model\", False, \"clear existing model or not\")\n",
821 | "\n",
822 | "#1 1:0.5 2:0.03519 3:1 4:0.02567 7:0.03708 8:0.01705 9:0.06296 10:0.18185 11:0.02497 12:1 14:0.02565 15:0.03267 17:0.0247 18:0.03158 20:1 22:1 23:0.13169 24:0.02933 27:0.18159 31:0.0177 34:0.02888 38:1 51:1 63:1 132:1 164:1 236:1\n",
823 | "def input_fn(filenames, batch_size=32, num_epochs=1, perform_shuffle=False):\n",
824 | " print('Parsing', filenames)\n",
825 | " def decode_libsvm(line):\n",
826 | " #columns = tf.decode_csv(value, record_defaults=CSV_COLUMN_DEFAULTS)\n",
827 | " #features = dict(zip(CSV_COLUMNS, columns))\n",
828 | " #labels = features.pop(LABEL_COLUMN)\n",
829 | " columns = tf.string_split([line], ' ')\n",
830 | " labels = tf.string_to_number(columns.values[0], out_type=tf.float32)\n",
831 | " splits = tf.string_split(columns.values[1:], ':')\n",
832 | " id_vals = tf.reshape(splits.values,splits.dense_shape)\n",
833 | " feat_ids, feat_vals = tf.split(id_vals,num_or_size_splits=2,axis=1)\n",
834 | " feat_ids = tf.string_to_number(feat_ids, out_type=tf.int32)\n",
835 | " feat_vals = tf.string_to_number(feat_vals, out_type=tf.float32)\n",
836 | " return {\"feat_ids\": feat_ids, \"feat_vals\": feat_vals}, labels\n",
837 | "\n",
838 | " # Extract lines from input files using the Dataset API, can pass one filename or filename list\n",
839 | " dataset = tf.data.TextLineDataset(filenames).map(decode_libsvm, num_parallel_calls=10).prefetch(500000) # multi-thread pre-process then prefetch\n",
840 | "\n",
841 | " # Randomizes input using a window of 256 elements (read into memory)\n",
842 | " if perform_shuffle:\n",
843 | " dataset = dataset.shuffle(buffer_size=256)\n",
844 | "\n",
845 | " # epochs from blending together.\n",
846 | " dataset = dataset.repeat(num_epochs)\n",
847 | " dataset = dataset.batch(batch_size) # Batch size to use\n",
848 | "\n",
849 | " iterator = dataset.make_one_shot_iterator()\n",
850 | " batch_features, batch_labels = iterator.get_next()\n",
851 | " #return tf.reshape(batch_ids,shape=[-1,field_size]), tf.reshape(batch_vals,shape=[-1,field_size]), batch_labels\n",
852 | " return batch_features, batch_labels\n",
853 | "\n",
854 | "def model_fn(features, labels, mode, params):\n",
855 | " \"\"\"Bulid Model function f(x) for Estimator.\"\"\"\n",
856 | " #------hyperparameters----\n",
857 | " field_size = params[\"field_size\"]\n",
858 | " feature_size = params[\"feature_size\"]\n",
859 | " embedding_size = params[\"embedding_size\"]\n",
860 | " l2_reg = params[\"l2_reg\"]\n",
861 | " learning_rate = params[\"learning_rate\"]\n",
862 | " #optimizer = params[\"optimizer\"]\n",
863 | " layers = map(int, params[\"deep_layers\"].split(','))\n",
864 | " dropout = map(float, params[\"dropout\"].split(','))\n",
865 | "\n",
866 | " #------bulid weights------\n",
867 | " Global_Bias = tf.get_variable(name='bias', shape=[1], initializer=tf.constant_initializer(0.0))\n",
868 | " Feat_Bias = tf.get_variable(name='linear', shape=[feature_size], initializer=tf.glorot_normal_initializer())\n",
869 | " Feat_Emb = tf.get_variable(name='emb', shape=[feature_size,embedding_size], initializer=tf.glorot_normal_initializer())\n",
870 | "\n",
871 | " #------build feaure-------\n",
872 | " feat_ids = features['feat_ids']\n",
873 | " feat_ids = tf.reshape(feat_ids,shape=[-1,field_size])\n",
874 | " feat_vals = features['feat_vals']\n",
875 | " feat_vals = tf.reshape(feat_vals,shape=[-1,field_size])\n",
876 | "\n",
877 | " #------build f(x)------\n",
878 | " with tf.variable_scope(\"Linear-part\"):\n",
879 | " feat_wgts = tf.nn.embedding_lookup(Feat_Bias, feat_ids) \t\t# None * F * 1\n",
880 | " y_linear = tf.reduce_sum(tf.multiply(feat_wgts, feat_vals),1)\n",
881 | "\n",
882 | " with tf.variable_scope(\"BiInter-part\"):\n",
883 | " embeddings = tf.nn.embedding_lookup(Feat_Emb, feat_ids) \t\t# None * F * K\n",
884 | " feat_vals = tf.reshape(feat_vals, shape=[-1, field_size, 1])\n",
885 | " embeddings = tf.multiply(embeddings, feat_vals) \t\t\t\t# vij * xi\n",
886 | " sum_square_emb = tf.square(tf.reduce_sum(embeddings,1))\n",
887 | " square_sum_emb = tf.reduce_sum(tf.square(embeddings),1)\n",
888 | " deep_inputs = 0.5*tf.subtract(sum_square_emb, square_sum_emb)\t# None * K\n",
889 | "\n",
890 | " with tf.variable_scope(\"Deep-part\"):\n",
891 | " if mode == tf.estimator.ModeKeys.TRAIN:\n",
892 | " train_phase = True\n",
893 | " else:\n",
894 | " train_phase = False\n",
895 | "\n",
896 | " if mode == tf.estimator.ModeKeys.TRAIN:\n",
897 | " deep_inputs = tf.nn.dropout(deep_inputs, keep_prob=dropout[0]) \t\t\t\t\t\t# None * K\n",
898 | " for i in range(len(layers)):\n",
899 | " deep_inputs = tf.contrib.layers.fully_connected(inputs=deep_inputs, num_outputs=layers[i], \\\n",
900 | " weights_regularizer=tf.contrib.layers.l2_regularizer(l2_reg), scope='mlp%d' % i)\n",
901 | "\n",
902 | " if FLAGS.batch_norm:\n",
903 | " deep_inputs = batch_norm_layer(deep_inputs, train_phase=train_phase, scope_bn='bn_%d' %i) #放在RELU之后 https://github.com/ducha-aiki/caffenet-benchmark/blob/master/batchnorm.md#bn----before-or-after-relu\n",
904 | " if mode == tf.estimator.ModeKeys.TRAIN:\n",
905 | " deep_inputs = tf.nn.dropout(deep_inputs, keep_prob=dropout[i]) #Apply Dropout after all BN layers and set dropout=0.8(drop_ratio=0.2)\n",
906 | " #deep_inputs = tf.layers.dropout(inputs=deep_inputs, rate=dropout[i], training=mode == tf.estimator.ModeKeys.TRAIN)\n",
907 | "\n",
908 | " y_deep = tf.contrib.layers.fully_connected(inputs=deep_inputs, num_outputs=1, activation_fn=tf.identity, \\\n",
909 | " weights_regularizer=tf.contrib.layers.l2_regularizer(l2_reg), scope='deep_out')\n",
910 | " y_d = tf.reshape(y_deep,shape=[-1])\n",
911 | "\n",
912 | " with tf.variable_scope(\"NFM-out\"):\n",
913 | " #y_bias = Global_Bias * tf.ones_like(labels, dtype=tf.float32) # None * 1 warning;这里不能用label,否则调用predict/export函数会出错,train/evaluate正常;初步判断estimator做了优化,用不到label时不传\n",
914 | " y_bias = Global_Bias * tf.ones_like(y_d, dtype=tf.float32) \t# None * 1\n",
915 | " y = y_bias + y_linear + y_d\n",
916 | " pred = tf.sigmoid(y)\n",
917 | "\n",
918 | " predictions={\"prob\": pred}\n",
919 | " export_outputs = {tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY: tf.estimator.export.PredictOutput(predictions)}\n",
920 | " # Provide an estimator spec for `ModeKeys.PREDICT`\n",
921 | " if mode == tf.estimator.ModeKeys.PREDICT:\n",
922 | " return tf.estimator.EstimatorSpec(\n",
923 | " mode=mode,\n",
924 | " predictions=predictions,\n",
925 | " export_outputs=export_outputs)\n",
926 | "\n",
927 | " #------bulid loss------\n",
928 | " loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=y, labels=labels)) + \\\n",
929 | " l2_reg * tf.nn.l2_loss(Feat_Bias) + l2_reg * tf.nn.l2_loss(Feat_Emb)\n",
930 | "\n",
931 | " # Provide an estimator spec for `ModeKeys.EVAL`\n",
932 | " eval_metric_ops = {\n",
933 | " \"auc\": tf.metrics.auc(labels, pred)\n",
934 | " }\n",
935 | " if mode == tf.estimator.ModeKeys.EVAL:\n",
936 | " return tf.estimator.EstimatorSpec(\n",
937 | " mode=mode,\n",
938 | " predictions=predictions,\n",
939 | " loss=loss,\n",
940 | " eval_metric_ops=eval_metric_ops)\n",
941 | "\n",
942 | " #------bulid optimizer------\n",
943 | " if FLAGS.optimizer == 'Adam':\n",
944 | " optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate, beta1=0.9, beta2=0.999, epsilon=1e-8)\n",
945 | " elif FLAGS.optimizer == 'Adagrad':\n",
946 | " optimizer = tf.train.AdagradOptimizer(learning_rate=learning_rate, initial_accumulator_value=1e-8)\n",
947 | " elif FLAGS.optimizer == 'Momentum':\n",
948 | " optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=0.95)\n",
949 | " elif FLAGS.optimizer == 'ftrl':\n",
950 | " optimizer = tf.train.FtrlOptimizer(learning_rate)\n",
951 | "\n",
952 | " train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())\n",
953 | "\n",
954 | " # Provide an estimator spec for `ModeKeys.TRAIN` modes\n",
955 | " if mode == tf.estimator.ModeKeys.TRAIN:\n",
956 | " return tf.estimator.EstimatorSpec(\n",
957 | " mode=mode,\n",
958 | " predictions=predictions,\n",
959 | " loss=loss,\n",
960 | " train_op=train_op)\n",
961 | "\n",
962 | " # Provide an estimator spec for `ModeKeys.EVAL` and `ModeKeys.TRAIN` modes.\n",
963 | " #return tf.estimator.EstimatorSpec(\n",
964 | " # mode=mode,\n",
965 | " # loss=loss,\n",
966 | " # train_op=train_op,\n",
967 | " # predictions={\"prob\": pred},\n",
968 | " # eval_metric_ops=eval_metric_ops)\n",
969 | "\n",
970 | "def batch_norm_layer(x, train_phase, scope_bn):\n",
971 | " bn_train = tf.contrib.layers.batch_norm(x, decay=FLAGS.batch_norm_decay, center=True, scale=True, updates_collections=None, is_training=True, reuse=None, scope=scope_bn)\n",
972 | " bn_infer = tf.contrib.layers.batch_norm(x, decay=FLAGS.batch_norm_decay, center=True, scale=True, updates_collections=None, is_training=False, reuse=True, scope=scope_bn)\n",
973 | " z = tf.cond(tf.cast(train_phase, tf.bool), lambda: bn_train, lambda: bn_infer)\n",
974 | " return z\n",
975 | "\n",
976 | "def set_dist_env():\n",
977 | " if FLAGS.dist_mode == 1: # 本地分布式测试模式1 chief, 1 ps, 1 evaluator\n",
978 | " ps_hosts = FLAGS.ps_hosts.split(',')\n",
979 | " chief_hosts = FLAGS.chief_hosts.split(',')\n",
980 | " task_index = FLAGS.task_index\n",
981 | " job_name = FLAGS.job_name\n",
982 | " print('ps_host', ps_hosts)\n",
983 | " print('chief_hosts', chief_hosts)\n",
984 | " print('job_name', job_name)\n",
985 | " print('task_index', str(task_index))\n",
986 | " # 无worker参数\n",
987 | " tf_config = {\n",
988 | " 'cluster': {'chief': chief_hosts, 'ps': ps_hosts},\n",
989 | " 'task': {'type': job_name, 'index': task_index }\n",
990 | " }\n",
991 | " print(json.dumps(tf_config))\n",
992 | " os.environ['TF_CONFIG'] = json.dumps(tf_config)\n",
993 | " elif FLAGS.dist_mode == 2: # 集群分布式模式\n",
994 | " ps_hosts = FLAGS.ps_hosts.split(',')\n",
995 | " worker_hosts = FLAGS.worker_hosts.split(',')\n",
996 | " chief_hosts = worker_hosts[0:1] # get first worker as chief\n",
997 | " worker_hosts = worker_hosts[2:] # the rest as worker\n",
998 | " task_index = FLAGS.task_index\n",
999 | " job_name = FLAGS.job_name\n",
1000 | " print('ps_host', ps_hosts)\n",
1001 | " print('worker_host', worker_hosts)\n",
1002 | " print('chief_hosts', chief_hosts)\n",
1003 | " print('job_name', job_name)\n",
1004 | " print('task_index', str(task_index))\n",
1005 | " # use #worker=0 as chief\n",
1006 | " if job_name == \"worker\" and task_index == 0:\n",
1007 | " job_name = \"chief\"\n",
1008 | " # use #worker=1 as evaluator\n",
1009 | " if job_name == \"worker\" and task_index == 1:\n",
1010 | " job_name = 'evaluator'\n",
1011 | " task_index = 0\n",
1012 | " # the others as worker\n",
1013 | " if job_name == \"worker\" and task_index > 1:\n",
1014 | " task_index -= 2\n",
1015 | "\n",
1016 | " tf_config = {\n",
1017 | " 'cluster': {'chief': chief_hosts, 'worker': worker_hosts, 'ps': ps_hosts},\n",
1018 | " 'task': {'type': job_name, 'index': task_index }\n",
1019 | " }\n",
1020 | " print(json.dumps(tf_config))\n",
1021 | " os.environ['TF_CONFIG'] = json.dumps(tf_config)\n",
1022 | "\n",
1023 | "def main(_):\n",
1024 | " tr_files = glob.glob(\"%s/tr*libsvm\" % FLAGS.data_dir)\n",
1025 | " random.shuffle(tr_files)\n",
1026 | " print(\"tr_files:\", tr_files)\n",
1027 | " va_files = glob.glob(\"%s/va*libsvm\" % FLAGS.data_dir)\n",
1028 | " print(\"va_files:\", va_files)\n",
1029 | " te_files = glob.glob(\"%s/te*libsvm\" % FLAGS.data_dir)\n",
1030 | " print(\"te_files:\", te_files)\n",
1031 | "\n",
1032 | " if FLAGS.clear_existing_model:\n",
1033 | " try:\n",
1034 | " shutil.rmtree(FLAGS.model_dir)\n",
1035 | " except Exception as e:\n",
1036 | " print(e, \"at clear_existing_model\")\n",
1037 | " else:\n",
1038 | " print(\"existing model cleaned at %s\" % FLAGS.model_dir)\n",
1039 | "\n",
1040 | " set_dist_env()\n",
1041 | "\n",
1042 | " model_params = {\n",
1043 | " \"field_size\": FLAGS.field_size,\n",
1044 | " \"feature_size\": FLAGS.feature_size,\n",
1045 | " \"embedding_size\": FLAGS.embedding_size,\n",
1046 | " \"learning_rate\": FLAGS.learning_rate,\n",
1047 | " \"l2_reg\": FLAGS.l2_reg,\n",
1048 | " \"deep_layers\": FLAGS.deep_layers,\n",
1049 | " \"dropout\": FLAGS.dropout\n",
1050 | " }\n",
1051 | " config = tf.estimator.RunConfig().replace(session_config = tf.ConfigProto(device_count={'GPU':0, 'CPU':FLAGS.num_threads}),\n",
1052 | " log_step_count_steps=FLAGS.log_steps, save_summary_steps=FLAGS.log_steps)\n",
1053 | " DeepFM = tf.estimator.Estimator(model_fn=model_fn, model_dir=FLAGS.model_dir, params=model_params, config=config)\n",
1054 | "\n",
1055 | " if FLAGS.task_type == 'train':\n",
1056 | " train_spec = tf.estimator.TrainSpec(input_fn=lambda: input_fn(tr_files, num_epochs=FLAGS.num_epochs, batch_size=FLAGS.batch_size))\n",
1057 | " eval_spec = tf.estimator.EvalSpec(input_fn=lambda: input_fn(va_files, num_epochs=1, batch_size=FLAGS.batch_size), steps=None, start_delay_secs=1000, throttle_secs=1200)\n",
1058 | " tf.estimator.train_and_evaluate(DeepFM, train_spec, eval_spec)\n",
1059 | " elif FLAGS.task_type == 'eval':\n",
1060 | " DeepFM.evaluate(input_fn=lambda: input_fn(va_files, num_epochs=1, batch_size=FLAGS.batch_size))\n",
1061 | " elif FLAGS.task_type == 'infer':\n",
1062 | " preds = DeepFM.predict(input_fn=lambda: input_fn(te_files, num_epochs=1, batch_size=FLAGS.batch_size), predict_keys=\"prob\")\n",
1063 | " with open(FLAGS.data_dir+\"/pred.txt\", \"w\") as fo:\n",
1064 | " for prob in preds:\n",
1065 | " fo.write(\"%f\\n\" % (prob['prob']))\n",
1066 | " elif FLAGS.task_type == 'export':\n",
1067 | " #feature_spec = tf.feature_column.make_parse_example_spec(feature_columns)\n",
1068 | " #feature_spec = {\n",
1069 | " # 'feat_ids': tf.FixedLenFeature(dtype=tf.int64, shape=[None, FLAGS.field_size]),\n",
1070 | " # 'feat_vals': tf.FixedLenFeature(dtype=tf.float32, shape=[None, FLAGS.field_size])\n",
1071 | " #}\n",
1072 | " #serving_input_receiver_fn = tf.estimator.export.build_parsing_serving_input_receiver_fn(feature_spec)\n",
1073 | " feature_spec = {\n",
1074 | " 'feat_ids': tf.placeholder(dtype=tf.int64, shape=[None, FLAGS.field_size], name='feat_ids'),\n",
1075 | " 'feat_vals': tf.placeholder(dtype=tf.float32, shape=[None, FLAGS.field_size], name='feat_vals')\n",
1076 | " }\n",
1077 | " serving_input_receiver_fn = tf.estimator.export.build_raw_serving_input_receiver_fn(feature_spec)\n",
1078 | " DeepFM.export_savedmodel(FLAGS.servable_model_dir, serving_input_receiver_fn)\n",
1079 | "\n",
1080 | "if __name__ == \"__main__\":\n",
1081 | " #------check Arguments------\n",
1082 | " if FLAGS.dt_dir == \"\":\n",
1083 | " FLAGS.dt_dir = (date.today() + timedelta(-1)).strftime('%Y%m%d')\n",
1084 | " FLAGS.model_dir = FLAGS.model_dir + FLAGS.dt_dir\n",
1085 | " #FLAGS.data_dir = FLAGS.data_dir + FLAGS.dt_dir\n",
1086 | "\n",
1087 | " print('task_type ', FLAGS.task_type)\n",
1088 | " print('model_dir ', FLAGS.model_dir)\n",
1089 | " print('data_dir ', FLAGS.data_dir)\n",
1090 | " print('dt_dir ', FLAGS.dt_dir)\n",
1091 | " print('num_epochs ', FLAGS.num_epochs)\n",
1092 | " print('feature_size ', FLAGS.feature_size)\n",
1093 | " print('field_size ', FLAGS.field_size)\n",
1094 | " print('embedding_size ', FLAGS.embedding_size)\n",
1095 | " print('batch_size ', FLAGS.batch_size)\n",
1096 | " print('deep_layers ', FLAGS.deep_layers)\n",
1097 | " print('dropout ', FLAGS.dropout)\n",
1098 | " print('loss_type ', FLAGS.loss_type)\n",
1099 | " print('optimizer ', FLAGS.optimizer)\n",
1100 | " print('learning_rate ', FLAGS.learning_rate)\n",
1101 | " print('l2_reg ', FLAGS.l2_reg)\n",
1102 | "\n",
1103 | " tf.logging.set_verbosity(tf.logging.INFO)\n",
1104 | " tf.app.run()"
1105 | ]
1106 | },
1107 | {
1108 | "cell_type": "code",
1109 | "execution_count": null,
1110 | "metadata": {
1111 | "scrolled": false
1112 | },
1113 | "outputs": [
1114 | {
1115 | "name": "stdout",
1116 | "output_type": "stream",
1117 | "text": [
1118 | "('task_type ', 'train')\n",
1119 | "('model_dir ', './criteo_model/NFM20180504')\n",
1120 | "('data_dir ', './criteo_data')\n",
1121 | "('dt_dir ', '20180504')\n",
1122 | "('num_epochs ', 1)\n",
1123 | "('feature_size ', 117581)\n",
1124 | "('field_size ', 39)\n",
1125 | "('embedding_size ', 64)\n",
1126 | "('batch_size ', 256)\n",
1127 | "('deep_layers ', '400,400,400')\n",
1128 | "('dropout ', '0.5,0.5,0.5')\n",
1129 | "('loss_type ', 'log_loss')\n",
1130 | "('optimizer ', 'Adam')\n",
1131 | "('learning_rate ', 0.0005)\n",
1132 | "('l2_reg ', 0.001)\n",
1133 | "('tr_files:', ['./criteo_data/tr.libsvm'])\n",
1134 | "('va_files:', ['./criteo_data/va.libsvm'])\n",
1135 | "('te_files:', ['./criteo_data/te.libsvm'])\n",
1136 | "INFO:tensorflow:Using config: {'_save_checkpoints_secs': 600, '_session_config': device_count {\n",
1137 | " key: \"CPU\"\n",
1138 | " value: 8\n",
1139 | "}\n",
1140 | "device_count {\n",
1141 | " key: \"GPU\"\n",
1142 | "}\n",
1143 | ", '_keep_checkpoint_max': 5, '_task_type': 'worker', '_is_chief': True, '_cluster_spec': , '_save_checkpoints_steps': None, '_keep_checkpoint_every_n_hours': 10000, '_service': None, '_num_ps_replicas': 0, '_tf_random_seed': None, '_master': '', '_num_worker_replicas': 1, '_task_id': 0, '_log_step_count_steps': 1000, '_model_dir': './criteo_model/NFM', '_save_summary_steps': 1000}\n",
1144 | "INFO:tensorflow:Running training and evaluation locally (non-distributed).\n",
1145 | "INFO:tensorflow:Start train and evaluate loop. The evaluate will happen after 1200 secs (eval_spec.throttle_secs) or training is finished.\n",
1146 | "('Parsing', ['./criteo_data/tr.libsvm'])\n",
1147 | "INFO:tensorflow:Create CheckpointSaverHook.\n",
1148 | "2018-05-05 09:12:20.744054: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA\n",
1149 | "INFO:tensorflow:Saving checkpoints for 1 into ./criteo_model/NFM/model.ckpt.\n",
1150 | "INFO:tensorflow:loss = 0.74344236, step = 1\n",
1151 | "INFO:tensorflow:loss = 0.52700615, step = 101 (12.126 sec)\n",
1152 | "INFO:tensorflow:loss = 0.53884023, step = 201 (8.622 sec)\n",
1153 | "INFO:tensorflow:loss = 0.5741194, step = 301 (8.680 sec)\n",
1154 | "INFO:tensorflow:loss = 0.59511054, step = 401 (8.699 sec)\n",
1155 | "INFO:tensorflow:loss = 0.47535682, step = 501 (8.683 sec)\n",
1156 | "INFO:tensorflow:loss = 0.5811361, step = 601 (9.074 sec)\n",
1157 | "INFO:tensorflow:loss = 0.5244339, step = 701 (9.141 sec)\n",
1158 | "INFO:tensorflow:loss = 0.5584926, step = 801 (9.293 sec)\n",
1159 | "INFO:tensorflow:loss = 0.51474106, step = 901 (9.456 sec)\n",
1160 | "INFO:tensorflow:global_step/sec: 10.8086\n",
1161 | "INFO:tensorflow:loss = 0.5706619, step = 1001 (8.749 sec)\n",
1162 | "INFO:tensorflow:loss = 0.523185, step = 1101 (9.152 sec)\n",
1163 | "INFO:tensorflow:loss = 0.5341173, step = 1201 (8.163 sec)\n",
1164 | "INFO:tensorflow:loss = 0.5158627, step = 1301 (8.788 sec)\n",
1165 | "INFO:tensorflow:loss = 0.51566017, step = 1401 (8.700 sec)\n",
1166 | "INFO:tensorflow:loss = 0.4592861, step = 1501 (8.962 sec)\n",
1167 | "INFO:tensorflow:loss = 0.50802827, step = 1601 (8.990 sec)\n",
1168 | "INFO:tensorflow:loss = 0.5538678, step = 1701 (8.596 sec)\n",
1169 | "INFO:tensorflow:loss = 0.4346152, step = 1801 (8.267 sec)\n",
1170 | "INFO:tensorflow:loss = 0.5406091, step = 1901 (8.907 sec)\n",
1171 | "INFO:tensorflow:global_step/sec: 11.4221\n",
1172 | "INFO:tensorflow:loss = 0.5177407, step = 2001 (9.026 sec)\n",
1173 | "INFO:tensorflow:loss = 0.50947416, step = 2101 (10.118 sec)\n",
1174 | "INFO:tensorflow:loss = 0.5290449, step = 2201 (8.635 sec)\n",
1175 | "INFO:tensorflow:loss = 0.48367974, step = 2301 (9.689 sec)\n",
1176 | "INFO:tensorflow:loss = 0.5103478, step = 2401 (9.785 sec)\n",
1177 | "INFO:tensorflow:loss = 0.5290227, step = 2501 (9.748 sec)\n",
1178 | "INFO:tensorflow:loss = 0.5219102, step = 2601 (9.889 sec)\n",
1179 | "INFO:tensorflow:loss = 0.5131693, step = 2701 (10.787 sec)\n",
1180 | "INFO:tensorflow:loss = 0.47013655, step = 2801 (11.150 sec)\n",
1181 | "INFO:tensorflow:loss = 0.5133655, step = 2901 (12.453 sec)\n",
1182 | "INFO:tensorflow:global_step/sec: 9.68192\n",
1183 | "INFO:tensorflow:loss = 0.5253961, step = 3001 (11.027 sec)\n",
1184 | "INFO:tensorflow:loss = 0.53593737, step = 3101 (10.576 sec)\n",
1185 | "INFO:tensorflow:loss = 0.47377995, step = 3201 (9.975 sec)\n",
1186 | "INFO:tensorflow:loss = 0.5179897, step = 3301 (9.655 sec)\n",
1187 | "INFO:tensorflow:loss = 0.5014092, step = 3401 (8.827 sec)\n",
1188 | "INFO:tensorflow:loss = 0.50651914, step = 3501 (9.877 sec)\n",
1189 | "INFO:tensorflow:loss = 0.4893608, step = 3601 (7.170 sec)\n",
1190 | "INFO:tensorflow:loss = 0.5037479, step = 3701 (7.128 sec)\n",
1191 | "INFO:tensorflow:loss = 0.46921813, step = 3801 (7.062 sec)\n",
1192 | "INFO:tensorflow:loss = 0.5224898, step = 3901 (6.815 sec)\n",
1193 | "INFO:tensorflow:global_step/sec: 11.7165\n",
1194 | "INFO:tensorflow:loss = 0.5555479, step = 4001 (8.265 sec)\n",
1195 | "INFO:tensorflow:loss = 0.53638494, step = 4101 (9.037 sec)\n",
1196 | "INFO:tensorflow:loss = 0.58234245, step = 4201 (8.601 sec)\n",
1197 | "INFO:tensorflow:loss = 0.57939863, step = 4301 (8.564 sec)\n",
1198 | "INFO:tensorflow:loss = 0.51434916, step = 4401 (8.940 sec)\n",
1199 | "INFO:tensorflow:loss = 0.5549449, step = 4501 (8.833 sec)\n",
1200 | "INFO:tensorflow:loss = 0.5062487, step = 4601 (8.651 sec)\n",
1201 | "INFO:tensorflow:loss = 0.5529063, step = 4701 (8.658 sec)\n",
1202 | "INFO:tensorflow:loss = 0.49861303, step = 4801 (8.808 sec)\n",
1203 | "INFO:tensorflow:loss = 0.54094946, step = 4901 (8.782 sec)\n",
1204 | "INFO:tensorflow:global_step/sec: 11.413\n",
1205 | "INFO:tensorflow:loss = 0.49571908, step = 5001 (8.745 sec)\n",
1206 | "INFO:tensorflow:loss = 0.5437416, step = 5101 (8.432 sec)\n",
1207 | "INFO:tensorflow:loss = 0.5013172, step = 5201 (8.366 sec)\n",
1208 | "INFO:tensorflow:loss = 0.50875455, step = 5301 (8.017 sec)\n",
1209 | "INFO:tensorflow:loss = 0.5869225, step = 5401 (8.335 sec)\n",
1210 | "INFO:tensorflow:loss = 0.5402778, step = 5501 (8.121 sec)\n",
1211 | "INFO:tensorflow:loss = 0.52757925, step = 5601 (8.187 sec)\n",
1212 | "INFO:tensorflow:loss = 0.48195118, step = 5701 (7.991 sec)\n",
1213 | "INFO:tensorflow:loss = 0.4779031, step = 5801 (7.904 sec)\n",
1214 | "INFO:tensorflow:loss = 0.5278434, step = 5901 (7.916 sec)\n",
1215 | "INFO:tensorflow:global_step/sec: 12.3543\n",
1216 | "INFO:tensorflow:loss = 0.5329895, step = 6001 (7.673 sec)\n",
1217 | "INFO:tensorflow:loss = 0.5151729, step = 6101 (7.622 sec)\n",
1218 | "INFO:tensorflow:loss = 0.62112814, step = 6201 (7.493 sec)\n",
1219 | "INFO:tensorflow:loss = 0.48736763, step = 6301 (7.491 sec)\n",
1220 | "INFO:tensorflow:loss = 0.45068923, step = 6401 (7.353 sec)\n",
1221 | "INFO:tensorflow:loss = 0.51698387, step = 6501 (7.221 sec)\n",
1222 | "INFO:tensorflow:loss = 0.5078758, step = 6601 (7.112 sec)\n",
1223 | "INFO:tensorflow:loss = 0.53784084, step = 6701 (7.051 sec)\n",
1224 | "INFO:tensorflow:loss = 0.568355, step = 6801 (6.848 sec)\n",
1225 | "INFO:tensorflow:Saving checkpoints for 6863 into ./criteo_model/NFM/model.ckpt.\n",
1226 | "INFO:tensorflow:loss = 0.5869765, step = 6901 (7.007 sec)\n",
1227 | "INFO:tensorflow:global_step/sec: 13.877\n",
1228 | "INFO:tensorflow:loss = 0.50776565, step = 7001 (6.864 sec)\n",
1229 | "INFO:tensorflow:Saving checkpoints for 7034 into ./criteo_model/NFM/model.ckpt.\n",
1230 | "INFO:tensorflow:Loss for final step: 0.66966015.\n",
1231 | "('Parsing', ['./criteo_data/va.libsvm'])\n",
1232 | "INFO:tensorflow:Starting evaluation at 2018-05-05-01:22:35\n",
1233 | "INFO:tensorflow:Restoring parameters from ./criteo_model/NFM/model.ckpt-7034\n",
1234 | "INFO:tensorflow:Finished evaluation at 2018-05-05-01:22:58\n",
1235 | "INFO:tensorflow:Saving dict for global step 7034: auc = 0.7614266, global_step = 7034, loss = 0.50850546\n",
1236 | "('Parsing', ['./criteo_data/tr.libsvm'])\n",
1237 | "INFO:tensorflow:Create CheckpointSaverHook.\n",
1238 | "INFO:tensorflow:Restoring parameters from ./criteo_model/NFM/model.ckpt-7034\n",
1239 | "INFO:tensorflow:Saving checkpoints for 7035 into ./criteo_model/NFM/model.ckpt.\n",
1240 | "INFO:tensorflow:loss = 0.53954387, step = 7035\n",
1241 | "INFO:tensorflow:loss = 0.506534, step = 7135 (10.071 sec)\n",
1242 | "INFO:tensorflow:loss = 0.5184156, step = 7235 (8.270 sec)\n",
1243 | "INFO:tensorflow:loss = 0.5448781, step = 7335 (8.497 sec)\n",
1244 | "INFO:tensorflow:loss = 0.58426636, step = 7435 (7.031 sec)\n",
1245 | "INFO:tensorflow:loss = 0.4775302, step = 7535 (7.547 sec)\n",
1246 | "INFO:tensorflow:loss = 0.57145935, step = 7635 (8.272 sec)\n",
1247 | "INFO:tensorflow:loss = 0.52330667, step = 7735 (7.936 sec)\n",
1248 | "INFO:tensorflow:loss = 0.52791095, step = 7835 (7.510 sec)\n",
1249 | "INFO:tensorflow:loss = 0.5160444, step = 7935 (7.842 sec)\n",
1250 | "INFO:tensorflow:global_step/sec: 12.3632\n",
1251 | "INFO:tensorflow:loss = 0.54860413, step = 8035 (7.911 sec)\n",
1252 | "INFO:tensorflow:loss = 0.5232839, step = 8135 (8.025 sec)\n",
1253 | "INFO:tensorflow:loss = 0.5313403, step = 8235 (7.744 sec)\n",
1254 | "INFO:tensorflow:loss = 0.5083723, step = 8335 (8.124 sec)\n",
1255 | "INFO:tensorflow:loss = 0.5127937, step = 8435 (7.833 sec)\n",
1256 | "INFO:tensorflow:loss = 0.45451465, step = 8535 (8.071 sec)\n",
1257 | "INFO:tensorflow:loss = 0.5148269, step = 8635 (8.239 sec)\n",
1258 | "INFO:tensorflow:loss = 0.5475166, step = 8735 (8.724 sec)\n",
1259 | "INFO:tensorflow:loss = 0.4436438, step = 8835 (7.380 sec)\n",
1260 | "INFO:tensorflow:loss = 0.527986, step = 8935 (6.852 sec)\n",
1261 | "INFO:tensorflow:global_step/sec: 12.8544\n",
1262 | "INFO:tensorflow:loss = 0.5004729, step = 9035 (6.800 sec)\n",
1263 | "INFO:tensorflow:loss = 0.5152983, step = 9135 (6.864 sec)\n",
1264 | "INFO:tensorflow:loss = 0.5443342, step = 9235 (6.611 sec)\n",
1265 | "INFO:tensorflow:loss = 0.48795786, step = 9335 (8.363 sec)\n",
1266 | "INFO:tensorflow:loss = 0.50839627, step = 9435 (8.677 sec)\n",
1267 | "INFO:tensorflow:loss = 0.53861755, step = 9535 (8.617 sec)\n",
1268 | "INFO:tensorflow:loss = 0.5102945, step = 9635 (8.498 sec)\n",
1269 | "INFO:tensorflow:loss = 0.49490649, step = 9735 (8.507 sec)\n",
1270 | "INFO:tensorflow:loss = 0.46887958, step = 9835 (8.529 sec)\n",
1271 | "INFO:tensorflow:loss = 0.5098571, step = 9935 (8.540 sec)\n",
1272 | "INFO:tensorflow:global_step/sec: 12.2224\n",
1273 | "INFO:tensorflow:loss = 0.5108617, step = 10035 (8.612 sec)\n",
1274 | "INFO:tensorflow:loss = 0.5259123, step = 10135 (8.646 sec)\n",
1275 | "INFO:tensorflow:loss = 0.49567312, step = 10235 (8.585 sec)\n",
1276 | "INFO:tensorflow:loss = 0.50952077, step = 10335 (9.826 sec)\n",
1277 | "INFO:tensorflow:loss = 0.50462925, step = 10435 (8.775 sec)\n",
1278 | "INFO:tensorflow:loss = 0.49131048, step = 10535 (8.954 sec)\n",
1279 | "INFO:tensorflow:loss = 0.51161194, step = 10635 (8.810 sec)\n",
1280 | "INFO:tensorflow:loss = 0.49189892, step = 10735 (8.735 sec)\n",
1281 | "INFO:tensorflow:loss = 0.45244217, step = 10835 (8.599 sec)\n",
1282 | "INFO:tensorflow:loss = 0.5231385, step = 10935 (8.917 sec)\n",
1283 | "INFO:tensorflow:global_step/sec: 11.2768\n",
1284 | "INFO:tensorflow:loss = 0.5461174, step = 11035 (8.829 sec)\n",
1285 | "INFO:tensorflow:loss = 0.5328863, step = 11135 (8.628 sec)\n",
1286 | "INFO:tensorflow:loss = 0.5831222, step = 11235 (8.300 sec)\n",
1287 | "INFO:tensorflow:loss = 0.5753766, step = 11335 (7.912 sec)\n",
1288 | "INFO:tensorflow:loss = 0.5203026, step = 11435 (8.527 sec)\n",
1289 | "INFO:tensorflow:loss = 0.55177057, step = 11535 (8.694 sec)\n",
1290 | "INFO:tensorflow:loss = 0.5044052, step = 11635 (8.612 sec)\n",
1291 | "INFO:tensorflow:loss = 0.54929847, step = 11735 (8.030 sec)\n",
1292 | "INFO:tensorflow:loss = 0.5100083, step = 11835 (8.013 sec)\n",
1293 | "INFO:tensorflow:loss = 0.54684854, step = 11935 (8.033 sec)\n",
1294 | "INFO:tensorflow:global_step/sec: 12.0882\n",
1295 | "INFO:tensorflow:loss = 0.49854505, step = 12035 (7.976 sec)\n",
1296 | "INFO:tensorflow:loss = 0.5296041, step = 12135 (8.307 sec)\n",
1297 | "INFO:tensorflow:loss = 0.5118119, step = 12235 (8.437 sec)\n",
1298 | "INFO:tensorflow:loss = 0.5206564, step = 12335 (8.180 sec)\n",
1299 | "INFO:tensorflow:loss = 0.56792927, step = 12435 (8.102 sec)\n",
1300 | "INFO:tensorflow:loss = 0.53202826, step = 12535 (8.284 sec)\n"
1301 | ]
1302 | }
1303 | ],
1304 | "source": [
1305 | "!python NFM.py --task_type=train \\\n",
1306 | " --learning_rate=0.0005 \\\n",
1307 | " --optimizer=Adam \\\n",
1308 | " --num_epochs=1 \\\n",
1309 | " --batch_size=256 \\\n",
1310 | " --field_size=39 \\\n",
1311 | " --feature_size=117581 \\\n",
1312 | " --deep_layers=400,400,400 \\\n",
1313 | " --dropout=0.5,0.5,0.5 \\\n",
1314 | " --log_steps=1000 \\\n",
1315 | " --num_threads=8 \\\n",
1316 | " --model_dir=./criteo_model/NFM \\\n",
1317 | " --data_dir=./criteo_data"
1318 | ]
1319 | },
1320 | {
1321 | "cell_type": "markdown",
1322 | "metadata": {
1323 | "collapsed": true
1324 | },
1325 | "source": [
1326 | "### DeepCTR\n",
1327 | "充分利用图像带来的视觉影响,结合图像信息(通过CNN抽取)和业务特征一起判断点击率大小\n",
1328 | "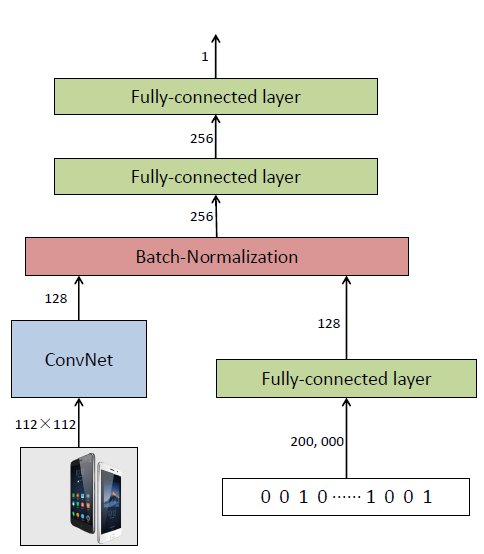"
1329 | ]
1330 | },
1331 | {
1332 | "cell_type": "code",
1333 | "execution_count": null,
1334 | "metadata": {
1335 | "collapsed": true
1336 | },
1337 | "outputs": [],
1338 | "source": [
1339 | "# %load train_with_googlenet.py\n",
1340 | "from keras.models import Sequential\n",
1341 | "from keras.layers.core import Dense, Dropout, Activation, Flatten, Reshape\n",
1342 | "from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D\n",
1343 | "from keras.optimizers import SGD, Adadelta, Adagrad\n",
1344 | "from keras.layers import Embedding,Merge\n",
1345 | "from keras.callbacks import ModelCheckpoint\n",
1346 | "import keras\n",
1347 | "from keras.preprocessing import image\n",
1348 | "import numpy as np\n",
1349 | "import sys, os, re\n",
1350 | "from keras.applications.inception_v3 import InceptionV3, preprocess_input\n",
1351 | "\n",
1352 | "#定义VGG卷积神经网络\n",
1353 | "def GoogleInceptionV3():\n",
1354 | " model = InceptionV3(weights='imagenet', include_top=False)\n",
1355 | " model.trainable = False\n",
1356 | "\n",
1357 | " return model\n",
1358 | "\n",
1359 | "#加载field和feature信息\n",
1360 | "def load_field_feature_meta(field_info_file):\n",
1361 | " field_feature_dic = {}\n",
1362 | " for line in open(field_info_file):\n",
1363 | " contents = line.strip().split(\"\\t\")\n",
1364 | " field_id = int(contents[1])\n",
1365 | " feature_count = int(contents[4])\n",
1366 | " field_feature_dic[field_id] = feature_count\n",
1367 | " return field_feature_dic\n",
1368 | "\n",
1369 | "#CTR特征做embedding\n",
1370 | "def CTR_embedding(field_feature_dic):\n",
1371 | " emd = []\n",
1372 | " for field_id in range(len(field_feature_dic)):\n",
1373 | " # 先把离散特征embedding到稠密的层\n",
1374 | " tmp_model = Sequential()\n",
1375 | " #留一个位置给rare\n",
1376 | " input_dims = field_feature_dic[field_id]+1\n",
1377 | " if input_dims>16:\n",
1378 | " dense_dim = 16\n",
1379 | " else:\n",
1380 | " dense_dim = input_dims\n",
1381 | " tmp_model.add(Dense(dense_dim, input_dim=input_dims))\n",
1382 | " emd.append(tmp_model)\n",
1383 | " return emd\n",
1384 | "\n",
1385 | "#总的网络结构\n",
1386 | "def full_network(field_feature_dic):\n",
1387 | " print \"GoogleNet model loading\"\n",
1388 | " googleNet_model = GoogleInceptionV3()\n",
1389 | " image_model = Flatten()(googleNet_model.outputs)\n",
1390 | " image_model = Dense(256)(image_model)\n",
1391 | " \n",
1392 | " print \"GoogleNet model loaded\"\n",
1393 | " print \"initialize embedding model\"\n",
1394 | " print \"loading fields info...\"\n",
1395 | " emd = CTR_embedding(field_feature_dic)\n",
1396 | " print \"embedding model done!\"\n",
1397 | " print \"initialize full model...\"\n",
1398 | " full_model = Sequential()\n",
1399 | " full_input = [image_model] + emd\n",
1400 | " full_model.add(Merge(full_input, mode='concat'))\n",
1401 | " #批规范化\n",
1402 | " full_model.add(keras.layers.normalization.BatchNormalization())\n",
1403 | " #全连接层\n",
1404 | " full_model.add(Dense(128))\n",
1405 | " full_model.add(Dropout(0.4))\n",
1406 | " full_model.add(Activation('relu'))\n",
1407 | " #全连接层\n",
1408 | " full_model.add(Dense(128))\n",
1409 | " full_model.add(Dropout(0.4))\n",
1410 | " #最后的分类\n",
1411 | " full_model.add(Dense(1))\n",
1412 | " full_model.add(Activation('sigmoid'))\n",
1413 | " #编译整个模型\n",
1414 | " full_model.compile(loss='binary_crossentropy',\n",
1415 | " optimizer='adadelta',\n",
1416 | " metrics=['binary_accuracy','fmeasure'])\n",
1417 | " #输出模型每一层的信息\n",
1418 | " full_model.summary()\n",
1419 | " return full_model\n",
1420 | "\n",
1421 | "\n",
1422 | "#图像预处理\n",
1423 | "def vgg_image_preoprocessing(image):\n",
1424 | " img = image.load_img(image, target_size=(299, 299))\n",
1425 | " x = image.img_to_array(img)\n",
1426 | " x = np.expand_dims(x, axis=0)\n",
1427 | " x = preprocess_input(x)\n",
1428 | " return x\n",
1429 | "\n",
1430 | "#CTR特征预处理\n",
1431 | "def ctr_feature_preprocessing(field_feature_string):\n",
1432 | " contents = field_feature_string.strip().split(\" \")\n",
1433 | " feature_dic = {}\n",
1434 | " for content in contents:\n",
1435 | " field_id, feature_id, num = content.split(\":\")\n",
1436 | " feature_dic[int(field_id)] = int(feature_id)\n",
1437 | " return feature_dic\n",
1438 | "\n",
1439 | "#产出用于训练的一个batch数据\n",
1440 | "def generate_batch_from_file(in_f, field_feature_dic, batch_num, skip_lines=0):\n",
1441 | " #初始化x和y\n",
1442 | " img_x = []\n",
1443 | " x = []\n",
1444 | " for field_id in range(len(field_feature_dic)):\n",
1445 | " x.append(np.zeros((batch_num, int(field_feature_dic[field_id])+1)))\n",
1446 | " y = [0.0]*batch_num\n",
1447 | " round_num = 1\n",
1448 | "\n",
1449 | " while True:\n",
1450 | " line_count = 0\n",
1451 | " skips = 0\n",
1452 | " f = open(in_f)\n",
1453 | " for line in f:\n",
1454 | " if(skip_lines>0 and round_num==1):\n",
1455 | " if skips < skip_lines:\n",
1456 | " skips += 1\n",
1457 | " continue\n",
1458 | " if (line_count+1)%batch_num == 0:\n",
1459 | " contents = line.strip().split(\"\\t\")\n",
1460 | " img_name = \"images/\"+re.sub(r'.jpg.*', '.jpg', contents[1].split(\"/\")[-1])\n",
1461 | " if not os.path.isfile(img_name):\n",
1462 | " continue\n",
1463 | " #初始化最后一个样本\n",
1464 | " try:\n",
1465 | " img_input = vgg_image_preoprocessing(img_name)\n",
1466 | " except:\n",
1467 | " continue\n",
1468 | " #图片特征填充\n",
1469 | " img_x.append(img_input)\n",
1470 | " #ctr特征填充\n",
1471 | " ctr_feature_dic = ctr_feature_preprocessing(contents[2])\n",
1472 | " for field_id in ctr_feature_dic:\n",
1473 | " x[field_id][line_count][ctr_feature_dic[field_id]] = 1.0\n",
1474 | " #填充y值\n",
1475 | " y[line_count] = int(contents[0])\n",
1476 | " #print \"shape is\", np.array(img_x).shape\n",
1477 | " yield ([np.array(img_x)]+x, y)\n",
1478 | "\n",
1479 | " img_x = []\n",
1480 | " x = []\n",
1481 | " for field_id in range(len(field_feature_dic)):\n",
1482 | " x.append(np.zeros((batch_num, int(field_feature_dic[field_id])+1)))\n",
1483 | " y = [0.0]*batch_num\n",
1484 | " line_count = 0\n",
1485 | " else: \n",
1486 | " contents = line.strip().split(\"\\t\")\n",
1487 | " img_name = \"images/\"+re.sub(r'.jpg.*', '.jpg', contents[1].split(\"/\")[-1])\n",
1488 | " if not os.path.isfile(img_name):\n",
1489 | " continue\n",
1490 | " try:\n",
1491 | " img_input = vgg_image_preoprocessing(img_name)\n",
1492 | " except:\n",
1493 | " continue\n",
1494 | " #图片特征填充\n",
1495 | " img_x.append(img_input)\n",
1496 | " #ctr特征填充\n",
1497 | " ctr_feature_dic = ctr_feature_preprocessing(contents[2])\n",
1498 | " for field_id in ctr_feature_dic:\n",
1499 | " x[field_id][line_count][ctr_feature_dic[field_id]] = 1.0\n",
1500 | " #填充y值\n",
1501 | " y[line_count] = int(contents[0])\n",
1502 | " line_count += 1\n",
1503 | " f.close()\n",
1504 | " round_num += 1\n",
1505 | "\n",
1506 | "def train_network(skip_lines, batch_num, field_info_file, data_file, weight_file):\n",
1507 | " print \"starting train whole network...\\n\"\n",
1508 | " field_feature_dic = load_field_feature_meta(field_info_file)\n",
1509 | " full_model = full_network(field_feature_dic)\n",
1510 | " if os.path.isfile(weight_file):\n",
1511 | " full_model.load_weights(weight_file)\n",
1512 | " checkpointer = ModelCheckpoint(filepath=weight_file, save_best_only=False, verbose=1, period=3)\n",
1513 | " full_model.fit_generator(generate_batch_from_file(data_file, field_feature_dic, batch_num, skip_lines),samples_per_epoch=1280, nb_epoch=100000, callbacks=[checkpointer])\n",
1514 | "\n",
1515 | "if __name__ == '__main__':\n",
1516 | " skip_lines = sys.argv[1]\n",
1517 | " batch_num = sys.argv[2]\n",
1518 | " field_info_file = sys.argv[3]\n",
1519 | " data_file = sys.argv[4]\n",
1520 | " weight_file = sys.argv[5]\n",
1521 | " train_network(int(skip_lines), int(batch_num), field_info_file, data_file, weight_file)"
1522 | ]
1523 | },
1524 | {
1525 | "cell_type": "code",
1526 | "execution_count": null,
1527 | "metadata": {
1528 | "collapsed": true
1529 | },
1530 | "outputs": [],
1531 | "source": []
1532 | }
1533 | ],
1534 | "metadata": {
1535 | "kernelspec": {
1536 | "display_name": "Python 2",
1537 | "language": "python",
1538 | "name": "python2"
1539 | },
1540 | "language_info": {
1541 | "codemirror_mode": {
1542 | "name": "ipython",
1543 | "version": 2
1544 | },
1545 | "file_extension": ".py",
1546 | "mimetype": "text/x-python",
1547 | "name": "python",
1548 | "nbconvert_exporter": "python",
1549 | "pygments_lexer": "ipython2",
1550 | "version": "2.7.10"
1551 | }
1552 | },
1553 | "nbformat": 4,
1554 | "nbformat_minor": 2
1555 | }
1556 |
--------------------------------------------------------------------------------
/deep nn ctr prediction/run_dfm.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {
7 | "collapsed": true
8 | },
9 | "outputs": [],
10 | "source": [
11 | "#======config=========\n",
12 | "\n",
13 | "SUB_DIR = \"./\"\n",
14 | "\n",
15 | "\n",
16 | "NUM_SPLITS = 3\n",
17 | "RANDOM_SEED = 233\n",
18 | "\n",
19 | "# types of columns of the dataset dataframe\n",
20 | "CATEGORICAL_COLS = [\n",
21 | " 'pass_identity', #category\n",
22 | "'bdg_age_range',#category\n",
23 | "'eight_crowd', #category\n",
24 | "'bdg_consumption_level', #category\n",
25 | "'h_channels_s',#category\n",
26 | "'setup_ele',#category\n",
27 | "'setup_meituan',#category\n",
28 | "'bdg_professioin',#category \n",
29 | "'poi_1',\n",
30 | "'poi_2',\n",
31 | "'poi_3',\n",
32 | "'poi_4',\n",
33 | "'poi_5',\n",
34 | "]\n",
35 | "\n",
36 | "NUMERIC_COLS = ['user_health_value',\n",
37 | "'privilege_sensitive',\n",
38 | "'avg_total_price_a',\n",
39 | "'avg_total_price_q',\n",
40 | "'avg_total_price_m',\n",
41 | "'avg_total_price_s',\n",
42 | "'avg_pay_price_a',\n",
43 | "'avg_pay_price_q',\n",
44 | "'avg_pay_price_m',\n",
45 | "'avg_pay_price_s',\n",
46 | "'wuyouhui_order_ratio_a',\n",
47 | "'wuyouhui_order_ratio_q',\n",
48 | "'wuyouhui_order_ratio_m',\n",
49 | "'wuyouhui_order_ratio_s',\n",
50 | "'order_rate',\n",
51 | "'privilege_sensitive.1',\n",
52 | "'next_month_avg_ue',\n",
53 | "'this_month_avg_ue',\n",
54 | "'price_preference_score',\n",
55 | "'service_preference_score',\n",
56 | "'resource_preference_score',\n",
57 | "'total_coupon_price',\n",
58 | "'total_coupon_balance',\n",
59 | "'total_coupon_used_ratio_a',\n",
60 | "'total_coupon_used_ratio_q',\n",
61 | "'total_coupon_used_ratio_m',\n",
62 | "'total_coupon_used_ratio_s',\n",
63 | "'price_preference_score.1',\n",
64 | "'visit_frequency_q',\n",
65 | "'total_order_q',\n",
66 | "'net_worth_score',\n",
67 | "'wuliu_order_ratio_a',\n",
68 | "'total_shop_butie_ratio_m',\n",
69 | "'tizao_total_order_dinner_q',\n",
70 | "'shop_concentration_q',\n",
71 | "'avg_profit_a',\n",
72 | "'sum_shop_butie_m',\n",
73 | "'first_day',\n",
74 | "'tizao_med_pay_price_dinner_q',\n",
75 | "'total_shop_butie_ratio_q',\n",
76 | "'sum_shop_butie_s',\n",
77 | "'max_delivery_price_m',\n",
78 | "'total_shop_butie_ratio_a',\n",
79 | "'min_delivery_price_q',\n",
80 | "'max_delivery_price_a',\n",
81 | "'avg_net_profit_a',\n",
82 | "'max_delivery_price_q',\n",
83 | "'avg_wuliu_take_out_time_s',\n",
84 | "'avg_wuliu_take_out_time_q',\n",
85 | "'avg_wuliu_dis_s',\n",
86 | "'last_delay_day_a',\n",
87 | "'shop_concentration_a',\n",
88 | "'loss_ratio_q',\n",
89 | "'avg_net_profit_q',\n",
90 | "'tizao_avg_pay_price_dinner_q',\n",
91 | "'min_delivery_price_a',\n",
92 | "'loss_ratio_m',\n",
93 | "'tizao_total_order_dinner_s',\n",
94 | "'lat_1',\n",
95 | "'lat_2',\n",
96 | "'lat_3',\n",
97 | "'lat_4',\n",
98 | "'lat_5',\n",
99 | "'lat_6',\n",
100 | "'lat_7',\n",
101 | "'lat_8',\n",
102 | "'lat_9',\n",
103 | "'lat_10',\n",
104 | "'lng_1',\n",
105 | "'lng_2',\n",
106 | "'lng_3',\n",
107 | "'lng_4',\n",
108 | "'lng_5',\n",
109 | "'lng_6',\n",
110 | "'lng_7',\n",
111 | "'lng_8',\n",
112 | "'lng_9',\n",
113 | "'lng_10',\n",
114 | "'doc_0',\n",
115 | "'doc_1',\n",
116 | "'doc_2',\n",
117 | "'doc_3',\n",
118 | "'doc_4',\n",
119 | "'doc_5',\n",
120 | "'doc_6',\n",
121 | "'doc_7',\n",
122 | "'doc_8',\n",
123 | "'doc_9',\n",
124 | "'doc_10',\n",
125 | "'doc_11',\n",
126 | "'doc_12',\n",
127 | "'doc_13',\n",
128 | "'doc_14',\n",
129 | "'doc_15',\n",
130 | "'doc_16',\n",
131 | "'doc_17',\n",
132 | "'doc_18',\n",
133 | "'doc_19',\n",
134 | "]\n",
135 | "\n",
136 | "IGNORE_COLS = []\n",
137 | "\n",
138 | "\n"
139 | ]
140 | },
141 | {
142 | "cell_type": "code",
143 | "execution_count": 2,
144 | "metadata": {
145 | "collapsed": true
146 | },
147 | "outputs": [],
148 | "source": [
149 | "from __future__ import unicode_literals\n",
150 | "import pandas as pd\n",
151 | "import numpy as np\n",
152 | "import json\n",
153 | "import sys\n",
154 | "from sklearn.model_selection import train_test_split\n",
155 | "import xgboost as xgb\n",
156 | "import sklearn\n",
157 | "import os\n",
158 | "import tensorflow as tf\n",
159 | "from sklearn.preprocessing import StandardScaler\n",
160 | "%matplotlib inline\n",
161 | "from sklearn.utils import shuffle\n",
162 | "\n",
163 | "\n",
164 | "import numpy as np\n",
165 | "import pandas as pd\n",
166 | "from sklearn.model_selection import *\n",
167 | "\n",
168 | "\n",
169 | "\n",
170 | "\n",
171 | "\n",
172 | "def gini(actual, pred):\n",
173 | " assert (len(actual) == len(pred))\n",
174 | " #np.c_是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等,类似于pandas中的merge()。\n",
175 | " all = np.asarray(np.c_[actual, pred, np.arange(len(actual))], dtype=np.float)\n",
176 | " #np.arange创建等差数组,其实是生成index:0~n-1\n",
177 | " #pred 列取负数:-1 * all[:, 1]\n",
178 | " all = all[np.lexsort((all[:, 2], -1 * all[:, 1]))] #把pred列的分数由高到低排序\n",
179 | " totalLosses = all[:, 0].sum()\n",
180 | " giniSum = all[:, 0].cumsum().sum() / totalLosses\n",
181 | "\n",
182 | " giniSum -= (len(actual) + 1) / 2.\n",
183 | " return giniSum / len(actual)\n",
184 | "\n",
185 | "def gini_norm(actual, pred):\n",
186 | " return gini(actual, pred) / gini(actual, actual)\n",
187 | "\n",
188 | "\n",
189 | "def custom_error(preds, dtrain):\n",
190 | " labels = dtrain.get_label()\n",
191 | " \n",
192 | "\n",
193 | " return 'gini_norm',gini_norm(labels,preds)\n",
194 | "\n",
195 | "\n",
196 | "df_train = shuffle(pd.read_pickle(\"./df_train_scaled.pickle\"))\n",
197 | "#标准化连续值\n",
198 | "df_train[NUMERIC_COLS] = StandardScaler().fit_transform(df_train[NUMERIC_COLS])\n",
199 | "train_X,test_X = train_test_split(df_train,test_size = 0.2,random_state = 233)\n"
200 | ]
201 | },
202 | {
203 | "cell_type": "code",
204 | "execution_count": 3,
205 | "metadata": {
206 | "collapsed": true
207 | },
208 | "outputs": [],
209 | "source": [
210 | "#==========data_reader========\n",
211 | "\n",
212 | "class FeatureDictionary(object):\n",
213 | " def __init__(self, trainfile=None, testfile=None,\n",
214 | " dfTrain=None, dfTest=None, numeric_cols=[], ignore_cols=[]):\n",
215 | " assert not ((trainfile is None) and (dfTrain is None)), \"trainfile or dfTrain at least one is set\"\n",
216 | " assert not ((trainfile is not None) and (dfTrain is not None)), \"only one can be set\"\n",
217 | " assert not ((testfile is None) and (dfTest is None)), \"testfile or dfTest at least one is set\"\n",
218 | " assert not ((testfile is not None) and (dfTest is not None)), \"only one can be set\"\n",
219 | " self.trainfile = trainfile\n",
220 | " self.testfile = testfile\n",
221 | " self.dfTrain = dfTrain\n",
222 | " self.dfTest = dfTest\n",
223 | " self.numeric_cols = numeric_cols\n",
224 | " self.ignore_cols = ignore_cols\n",
225 | " self.gen_feat_dict()\n",
226 | "\n",
227 | " def gen_feat_dict(self):\n",
228 | " if self.dfTrain is None:\n",
229 | " dfTrain = pd.read_csv(self.trainfile)\n",
230 | " else:\n",
231 | " dfTrain = self.dfTrain\n",
232 | " if self.dfTest is None:\n",
233 | " dfTest = pd.read_csv(self.testfile)\n",
234 | " else:\n",
235 | " dfTest = self.dfTest\n",
236 | " df = pd.concat([dfTrain, dfTest]) #首尾相连\n",
237 | " self.feat_dict = {}\n",
238 | " tc = 0\n",
239 | " for col in df.columns:\n",
240 | " if col in self.ignore_cols:\n",
241 | " continue\n",
242 | " if col in self.numeric_cols:\n",
243 | " # map to a single index\n",
244 | " self.feat_dict[col] = tc\n",
245 | " tc += 1\n",
246 | " else:\n",
247 | " us = df[col].unique()\n",
248 | " self.feat_dict[col] = dict(zip(us, range(tc, len(us)+tc)))\n",
249 | " tc += len(us)\n",
250 | " self.feat_dim = tc\n",
251 | "\n",
252 | "\n",
253 | "class DataParser(object):\n",
254 | " def __init__(self, feat_dict):\n",
255 | " self.feat_dict = feat_dict\n",
256 | "\n",
257 | " def parse(self, infile=None, df=None, has_label=False):\n",
258 | " assert not ((infile is None) and (df is None)), \"infile or df at least one is set\"\n",
259 | " assert not ((infile is not None) and (df is not None)), \"only one can be set\"\n",
260 | " if infile is None:\n",
261 | " dfi = df.copy()\n",
262 | " else:\n",
263 | " dfi = pd.read_csv(infile)\n",
264 | " if has_label:\n",
265 | " y = dfi[\"l3\"].values.tolist()\n",
266 | " dfi.drop([\"l3\"], axis=1, inplace=True)\n",
267 | " else:\n",
268 | " ids = dfi.index.tolist()\n",
269 | " \n",
270 | " # dfi for feature index\n",
271 | " # dfv for feature value which can be either binary (1/0) or float (e.g., 10.24)\n",
272 | " dfv = dfi.copy()\n",
273 | " for col in dfi.columns:\n",
274 | " if col in self.feat_dict.ignore_cols:\n",
275 | " dfi.drop(col, axis=1, inplace=True)\n",
276 | " dfv.drop(col, axis=1, inplace=True)\n",
277 | " continue\n",
278 | " \n",
279 | " if col in self.feat_dict.numeric_cols:\n",
280 | " dfi[col] = self.feat_dict.feat_dict[col]\n",
281 | " else:\n",
282 | " dfi[col] = dfi[col].map(self.feat_dict.feat_dict[col])\n",
283 | " dfv[col] = 1.\n",
284 | "\n",
285 | " # list of list of feature indices of each sample in the dataset\n",
286 | " Xi = dfi.values.tolist()\n",
287 | " # list of list of feature values of each sample in the dataset\n",
288 | " Xv = dfv.values.tolist()\n",
289 | " if has_label:\n",
290 | " return Xi, Xv, y\n",
291 | " else:\n",
292 | " return Xi, Xv, ids\n",
293 | " \n",
294 | " \n"
295 | ]
296 | },
297 | {
298 | "cell_type": "code",
299 | "execution_count": null,
300 | "metadata": {
301 | "collapsed": true
302 | },
303 | "outputs": [],
304 | "source": []
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": 4,
309 | "metadata": {
310 | "collapsed": true
311 | },
312 | "outputs": [],
313 | "source": [
314 | "from matplotlib import pyplot as plt\n",
315 | "from sklearn.metrics import make_scorer\n",
316 | "from sklearn.model_selection import StratifiedKFold\n",
317 | "import tensorflow as tf\n",
318 | "\n",
319 | "gini_scorer = make_scorer(gini_norm, greater_is_better=True, needs_proba=True)\n",
320 | "from sklearn.model_selection import train_test_split\n",
321 | "\n",
322 | "def _load_data():\n",
323 | " \n",
324 | " \n",
325 | " dfTrain = train_X\n",
326 | " #dfTest = \n",
327 | "\n",
328 | "\n",
329 | " cols = [c for c in dfTrain.columns if c not in [\"l3\"]]\n",
330 | "\n",
331 | " X_train = dfTrain[cols].values\n",
332 | " y_train = dfTrain[\"l3\"].values\n",
333 | " dfTest = test_X[cols]\n",
334 | " X_test = dfTest[cols].values\n",
335 | " ids_test = dfTest.index.tolist()\n",
336 | " cat_features_indices = [i for i,c in enumerate(cols) if c in CATEGORICAL_COLS]\n",
337 | "\n",
338 | " return dfTrain, dfTest, X_train, y_train, X_test, ids_test, cat_features_indices\n",
339 | "\n",
340 | "\n",
341 | "def _run_base_model_dfm(dfTrain, dfTest, folds, dfm_params):\n",
342 | " fd = FeatureDictionary(dfTrain=dfTrain, dfTest=dfTest,\n",
343 | " numeric_cols=NUMERIC_COLS,\n",
344 | " ignore_cols=IGNORE_COLS)\n",
345 | " data_parser = DataParser(feat_dict=fd)\n",
346 | " Xi_train, Xv_train, y_train = data_parser.parse(df=dfTrain, has_label=True)\n",
347 | " Xi_test, Xv_test, ids_test = data_parser.parse(df=dfTest)\n",
348 | "\n",
349 | " dfm_params[\"feature_size\"] = fd.feat_dim\n",
350 | " dfm_params[\"field_size\"] = len(Xi_train[0])\n",
351 | "\n",
352 | " y_train_meta = np.zeros((dfTrain.shape[0], 1), dtype=float)\n",
353 | " y_test_meta = np.zeros((dfTest.shape[0], 1), dtype=float)\n",
354 | " _get = lambda x, l: [x[i] for i in l]\n",
355 | " gini_results_cv = np.zeros(len(folds), dtype=float)\n",
356 | " gini_results_epoch_train = np.zeros((len(folds), dfm_params[\"epoch\"]), dtype=float)\n",
357 | " gini_results_epoch_valid = np.zeros((len(folds), dfm_params[\"epoch\"]), dtype=float)\n",
358 | "\n",
359 | " for i, (train_idx, valid_idx) in enumerate(folds):\n",
360 | " #valid_idx = valid_idx[:1024]\n",
361 | " Xi_train_, Xv_train_, y_train_ = _get(Xi_train, train_idx), _get(Xv_train, train_idx), _get(y_train, train_idx)\n",
362 | " Xi_valid_, Xv_valid_, y_valid_ = _get(Xi_train, valid_idx), _get(Xv_train, valid_idx), _get(y_train, valid_idx)\n",
363 | "\n",
364 | " dfm = DeepFM(**dfm_params)\n",
365 | " dfm.fit(Xi_train_, Xv_train_, y_train_, Xi_valid_, Xv_valid_, y_valid_)\n",
366 | " #dfm.fit(Xi_train_, Xv_train_, y_train_, Xi_valid_, Xv_valid_, y_valid_,early_stopping=True)\n",
367 | " y_train_meta[valid_idx,0]= dfm.predict(Xi_valid_, Xv_valid_)\n",
368 | " y_test_meta[:,0] += dfm.predict(Xi_test, Xv_test)\n",
369 | "\n",
370 | " gini_results_cv[i] = gini_norm(y_valid_, y_train_meta[valid_idx])\n",
371 | " gini_results_epoch_train[i] = dfm.train_result\n",
372 | " gini_results_epoch_valid[i] = dfm.valid_result\n",
373 | "\n",
374 | " y_test_meta /= float(len(folds))\n",
375 | "\n",
376 | " # save result\n",
377 | " if dfm_params[\"use_fm\"] and dfm_params[\"use_deep\"]:\n",
378 | " clf_str = \"DeepFM\"\n",
379 | " elif dfm_params[\"use_fm\"]:\n",
380 | " clf_str = \"FM\"\n",
381 | " elif dfm_params[\"use_deep\"]:\n",
382 | " clf_str = \"DNN\"\n",
383 | " print(\"%s: %.5f (%.5f)\"%(clf_str, gini_results_cv.mean(), gini_results_cv.std()))\n",
384 | " filename = \"%s_Mean%.5f_Std%.5f.csv\"%(clf_str, gini_results_cv.mean(), gini_results_cv.std())\n",
385 | " _save_result(ids_test, y_test_meta, filename)\n",
386 | "\n",
387 | " _plot_fig(gini_results_epoch_train, gini_results_epoch_valid, clf_str)\n",
388 | "\n",
389 | " return y_train_meta, y_test_meta\n",
390 | "\n",
391 | "def _save_result(ids, y_pred, filename=\"dfm_res.csv\"):\n",
392 | " pd.DataFrame({\"id\": ids, \"target\": y_pred.flatten()}).to_csv(\n",
393 | " os.path.join(SUB_DIR, filename), index=False, float_format=\"%.5f\")\n",
394 | "\n",
395 | "\n",
396 | "\n",
397 | "def _plot_fig(train_results, valid_results, model_name):\n",
398 | " colors = [\"red\", \"blue\", \"green\"]\n",
399 | " xs = np.arange(1, train_results.shape[1]+1)\n",
400 | " plt.figure()\n",
401 | " legends = []\n",
402 | " for i in range(train_results.shape[0]):\n",
403 | " plt.plot(xs, train_results[i], color=colors[i], linestyle=\"solid\", marker=\"o\")\n",
404 | " plt.plot(xs, valid_results[i], color=colors[i], linestyle=\"dashed\", marker=\"o\")\n",
405 | " legends.append(\"train-%d\"%(i+1))\n",
406 | " legends.append(\"valid-%d\"%(i+1))\n",
407 | " plt.xlabel(\"Epoch\")\n",
408 | " plt.ylabel(\"Normalized Gini\")\n",
409 | " plt.title(\"%s\"%model_name)\n",
410 | " plt.legend(legends)\n",
411 | " plt.savefig(\"./fig/%s.png\"%model_name)\n",
412 | " plt.close()\n",
413 | "\n",
414 | "\n",
415 | "\n"
416 | ]
417 | },
418 | {
419 | "cell_type": "code",
420 | "execution_count": 5,
421 | "metadata": {
422 | "collapsed": true
423 | },
424 | "outputs": [],
425 | "source": [
426 | "from DeepFM import DeepFM\n",
427 | "from ipykernel import kernelapp as app\n",
428 | "\n"
429 | ]
430 | },
431 | {
432 | "cell_type": "code",
433 | "execution_count": 6,
434 | "metadata": {
435 | "collapsed": true
436 | },
437 | "outputs": [],
438 | "source": [
439 | "def accuracy(actual, pred):\n",
440 | " dfm_res= []\n",
441 | " for i in pred:\n",
442 | " if i >0.5:\n",
443 | " dfm_res.append(1)\n",
444 | " else:\n",
445 | " dfm_res.append(0)\n",
446 | " print \"pred: %d , actual: %d , total : %d\" % (sum(dfm_res),sum(actual),len(pred))\n",
447 | " \n",
448 | " s = sklearn.metrics.accuracy_score(actual,dfm_res)\n",
449 | " return s\n",
450 | "def gini_norm(actual, pred):\n",
451 | " dfm_res= []\n",
452 | " for i in pred:\n",
453 | " if i >0.5:\n",
454 | " dfm_res.append(1)\n",
455 | " else:\n",
456 | " dfm_res.append(0)\n",
457 | " print \"pred: %d , actual: %d , total : %d\" % (sum(dfm_res),sum(actual),len(pred))\n",
458 | " return gini(actual, pred) / gini(actual, actual)\n"
459 | ]
460 | },
461 | {
462 | "cell_type": "code",
463 | "execution_count": 7,
464 | "metadata": {
465 | "collapsed": true
466 | },
467 | "outputs": [],
468 | "source": [
469 | "# load data\n",
470 | "dfTrain, dfTest, X_train, y_train, X_test, ids_test, cat_features_indices = _load_data()\n",
471 | "\n",
472 | "# folds\n",
473 | "folds = list(StratifiedKFold(n_splits=NUM_SPLITS, shuffle=True,\n",
474 | " random_state=RANDOM_SEED).split(X_train, y_train))\n",
475 | "fd = FeatureDictionary(dfTrain=dfTrain, dfTest=dfTest,\n",
476 | " numeric_cols=NUMERIC_COLS,\n",
477 | " ignore_cols=IGNORE_COLS)\n",
478 | "data_parser = DataParser(feat_dict=fd)\n",
479 | "Xi_train, Xv_train, y_train = data_parser.parse(df=dfTrain, has_label=True)\n",
480 | "Xi_test, Xv_test, ids_test = data_parser.parse(df=dfTest)\n",
481 | "\n",
482 | "\n"
483 | ]
484 | },
485 | {
486 | "cell_type": "code",
487 | "execution_count": 8,
488 | "metadata": {},
489 | "outputs": [
490 | {
491 | "data": {
492 | "text/plain": [
493 | "((79996, 111), (79996, 111), (19999, 111), (19999, 111))"
494 | ]
495 | },
496 | "execution_count": 8,
497 | "metadata": {},
498 | "output_type": "execute_result"
499 | }
500 | ],
501 | "source": [
502 | "np.array(Xi_train).shape,np.array(Xv_train).shape,np.array(Xi_test).shape,np.array(Xv_test).shape"
503 | ]
504 | },
505 | {
506 | "cell_type": "code",
507 | "execution_count": null,
508 | "metadata": {
509 | "collapsed": true
510 | },
511 | "outputs": [],
512 | "source": []
513 | },
514 | {
515 | "cell_type": "code",
516 | "execution_count": null,
517 | "metadata": {
518 | "collapsed": true
519 | },
520 | "outputs": [],
521 | "source": []
522 | },
523 | {
524 | "cell_type": "code",
525 | "execution_count": 9,
526 | "metadata": {
527 | "scrolled": false
528 | },
529 | "outputs": [
530 | {
531 | "name": "stdout",
532 | "output_type": "stream",
533 | "text": [
534 | "#params: 765214\n",
535 | "pred: 8033 , actual: 10660 , total : 53330\n",
536 | "pred: 3944 , actual: 5331 , total : 26666\n",
537 | "[1] train-result=0.7680, valid-result=0.7543 [8.3 s]\n",
538 | "pred: 9347 , actual: 10660 , total : 53330\n",
539 | "pred: 4710 , actual: 5331 , total : 26666\n",
540 | "[2] train-result=0.8349, valid-result=0.7991 [8.1 s]\n",
541 | "pred: 9861 , actual: 10660 , total : 53330\n",
542 | "pred: 4886 , actual: 5331 , total : 26666\n",
543 | "[3] train-result=0.8969, valid-result=0.8317 [8.1 s]\n",
544 | "pred: 9507 , actual: 10660 , total : 53330\n",
545 | "pred: 4696 , actual: 5331 , total : 26666\n",
546 | "[4] train-result=0.9345, valid-result=0.8383 [8.1 s]\n",
547 | "pred: 9182 , actual: 10660 , total : 53330\n",
548 | "pred: 4401 , actual: 5331 , total : 26666\n",
549 | "[5] train-result=0.9587, valid-result=0.8359 [9.1 s]\n",
550 | "pred: 10541 , actual: 10660 , total : 53330\n",
551 | "pred: 5546 , actual: 5331 , total : 26666\n",
552 | "[6] train-result=0.9638, valid-result=0.8349 [8.0 s]\n",
553 | "pred: 9715 , actual: 10660 , total : 53330\n",
554 | "pred: 4688 , actual: 5331 , total : 26666\n",
555 | "[7] train-result=0.9802, valid-result=0.8341 [8.2 s]\n",
556 | "pred: 10069 , actual: 10660 , total : 53330\n",
557 | "pred: 5044 , actual: 5331 , total : 26666\n",
558 | "[8] train-result=0.9839, valid-result=0.8274 [8.2 s]\n",
559 | "pred: 10305 , actual: 10660 , total : 53330\n",
560 | "pred: 4905 , actual: 5331 , total : 26666\n",
561 | "[9] train-result=0.9903, valid-result=0.8100 [8.2 s]\n",
562 | "pred: 10528 , actual: 10660 , total : 53330\n",
563 | "pred: 5293 , actual: 5331 , total : 26666\n",
564 | "[10] train-result=0.9919, valid-result=0.8079 [8.3 s]\n",
565 | "pred: 5290 , actual: 5331 , total : 26666\n",
566 | "#params: 765214\n",
567 | "pred: 9621 , actual: 10661 , total : 53331\n",
568 | "pred: 4924 , actual: 5330 , total : 26665\n",
569 | "[1] train-result=0.7868, valid-result=0.7766 [7.9 s]\n",
570 | "pred: 11382 , actual: 10661 , total : 53331\n",
571 | "pred: 5799 , actual: 5330 , total : 26665\n",
572 | "[2] train-result=0.8877, valid-result=0.8423 [8.1 s]\n",
573 | "pred: 10695 , actual: 10661 , total : 53331\n",
574 | "pred: 5531 , actual: 5330 , total : 26665\n",
575 | "[3] train-result=0.9368, valid-result=0.8506 [8.1 s]\n",
576 | "pred: 9707 , actual: 10661 , total : 53331\n",
577 | "pred: 4559 , actual: 5330 , total : 26665\n",
578 | "[4] train-result=0.9674, valid-result=0.8439 [9.0 s]\n",
579 | "pred: 10272 , actual: 10661 , total : 53331\n",
580 | "pred: 5328 , actual: 5330 , total : 26665\n",
581 | "[5] train-result=0.9787, valid-result=0.8396 [8.3 s]\n",
582 | "pred: 10319 , actual: 10661 , total : 53331\n",
583 | "pred: 5426 , actual: 5330 , total : 26665\n",
584 | "[6] train-result=0.9847, valid-result=0.8295 [8.2 s]\n",
585 | "pred: 11098 , actual: 10661 , total : 53331\n",
586 | "pred: 5768 , actual: 5330 , total : 26665\n",
587 | "[7] train-result=0.9876, valid-result=0.8230 [8.2 s]\n",
588 | "pred: 10643 , actual: 10661 , total : 53331\n",
589 | "pred: 5421 , actual: 5330 , total : 26665\n",
590 | "[8] train-result=0.9916, valid-result=0.8206 [8.1 s]\n",
591 | "pred: 10649 , actual: 10661 , total : 53331\n",
592 | "pred: 5494 , actual: 5330 , total : 26665\n",
593 | "[9] train-result=0.9933, valid-result=0.8068 [8.2 s]\n",
594 | "pred: 10871 , actual: 10661 , total : 53331\n",
595 | "pred: 5211 , actual: 5330 , total : 26665\n",
596 | "[10] train-result=0.9940, valid-result=0.7594 [8.2 s]\n",
597 | "pred: 5203 , actual: 5330 , total : 26665\n",
598 | "#params: 765214\n",
599 | "pred: 10416 , actual: 10661 , total : 53331\n",
600 | "pred: 5244 , actual: 5330 , total : 26665\n",
601 | "[1] train-result=0.7843, valid-result=0.7856 [8.1 s]\n",
602 | "pred: 11299 , actual: 10661 , total : 53331\n",
603 | "pred: 5768 , actual: 5330 , total : 26665\n",
604 | "[2] train-result=0.8748, valid-result=0.8424 [9.1 s]\n",
605 | "pred: 10895 , actual: 10661 , total : 53331\n",
606 | "pred: 5626 , actual: 5330 , total : 26665\n",
607 | "[3] train-result=0.9259, valid-result=0.8534 [8.1 s]\n",
608 | "pred: 10141 , actual: 10661 , total : 53331\n",
609 | "pred: 4960 , actual: 5330 , total : 26665\n",
610 | "[4] train-result=0.9596, valid-result=0.8591 [8.2 s]\n",
611 | "pred: 10014 , actual: 10661 , total : 53331\n",
612 | "pred: 4927 , actual: 5330 , total : 26665\n",
613 | "[5] train-result=0.9753, valid-result=0.8509 [8.2 s]\n",
614 | "pred: 10020 , actual: 10661 , total : 53331\n",
615 | "pred: 4649 , actual: 5330 , total : 26665\n",
616 | "[6] train-result=0.9829, valid-result=0.8431 [8.2 s]\n",
617 | "pred: 10149 , actual: 10661 , total : 53331\n",
618 | "pred: 4504 , actual: 5330 , total : 26665\n",
619 | "[7] train-result=0.9861, valid-result=0.8289 [8.2 s]\n",
620 | "pred: 10462 , actual: 10661 , total : 53331\n",
621 | "pred: 4851 , actual: 5330 , total : 26665\n",
622 | "[8] train-result=0.9915, valid-result=0.8169 [8.1 s]\n",
623 | "pred: 10611 , actual: 10661 , total : 53331\n",
624 | "pred: 5303 , actual: 5330 , total : 26665\n",
625 | "[9] train-result=0.9933, valid-result=0.8119 [9.0 s]\n",
626 | "pred: 11024 , actual: 10661 , total : 53331\n",
627 | "pred: 5573 , actual: 5330 , total : 26665\n",
628 | "[10] train-result=0.9942, valid-result=0.7954 [8.2 s]\n",
629 | "pred: 5568 , actual: 5330 , total : 26665\n",
630 | "DeepFM: 0.78661 (0.02043)\n"
631 | ]
632 | }
633 | ],
634 | "source": [
635 | "# ------------------ DeepFM Model ------------------\n",
636 | "\n",
637 | "dfm_params = {\n",
638 | " \"use_fm\": True,\n",
639 | " \"use_deep\": True,\n",
640 | " \"embedding_size\": 8,\n",
641 | " \"dropout_fm\": [1, 1],\n",
642 | " \"deep_layers\": [32], \n",
643 | " \"dropout_deep\": [0.5, 0.5, 0.5],\n",
644 | " \"deep_layers_activation\": tf.nn.sigmoid,\n",
645 | " \"epoch\": 10,\n",
646 | " \"batch_size\": 1024,\n",
647 | " \"learning_rate\": 0.004,\n",
648 | " \"optimizer_type\": \"adam\",\n",
649 | " \"batch_norm\": 1,\n",
650 | " \"batch_norm_decay\": 0.997,\n",
651 | " \"l2_reg\": 0.01,\n",
652 | " \"verbose\": True,\n",
653 | " \"eval_metric\": gini_norm, \n",
654 | " \"random_seed\": RANDOM_SEED,\n",
655 | " \"use_sample_weights\": True,\n",
656 | " \"sample_weights_dict\":{0:1,1:2},\n",
657 | " \n",
658 | "}\n",
659 | "y_train_dfm, y_test_dfm = _run_base_model_dfm(dfTrain, dfTest, folds, dfm_params)\n",
660 | "\n",
661 | "# # ------------------ FM Model ------------------\n",
662 | "# fm_params = dfm_params.copy()\n",
663 | "# fm_params[\"use_deep\"] = False\n",
664 | "# y_train_fm, y_test_fm = _run_base_model_dfm(dfTrain, dfTest, folds, fm_params)\n",
665 | "\n",
666 | "\n",
667 | "# # ------------------ DNN Model ------------------\n",
668 | "# dnn_params = dfm_params.copy()\n",
669 | "# dnn_params[\"use_fm\"] = False\n",
670 | "# y_train_dnn, y_test_dnn = _run_base_model_dfm(dfTrain, dfTest, folds, dnn_params)\n",
671 | "\n",
672 | "\n",
673 | "\n",
674 | "\n"
675 | ]
676 | }
677 | ],
678 | "metadata": {
679 | "kernelspec": {
680 | "display_name": "Python 2",
681 | "language": "python",
682 | "name": "python2"
683 | },
684 | "language_info": {
685 | "codemirror_mode": {
686 | "name": "ipython",
687 | "version": 2
688 | },
689 | "file_extension": ".py",
690 | "mimetype": "text/x-python",
691 | "name": "python",
692 | "nbconvert_exporter": "python",
693 | "pygments_lexer": "ipython2",
694 | "version": "2.7.14"
695 | }
696 | },
697 | "nbformat": 4,
698 | "nbformat_minor": 2
699 | }
700 |
--------------------------------------------------------------------------------
/deep nn ctr prediction/wide_and_deep_model_criteo.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 宽度深度模型/wide and deep model"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## 介绍\n",
15 | "\n",
16 | "在之前的代码里大家看到了如何用tensorflow自带的op来构建灵活的神经网络,这里用tf中的高级接口,用更简单的方式完成wide&deep模型。\n",
17 | "\n",
18 | "大家都知道google官方给出的典型wide&deep模型结构如下:\n",
19 | "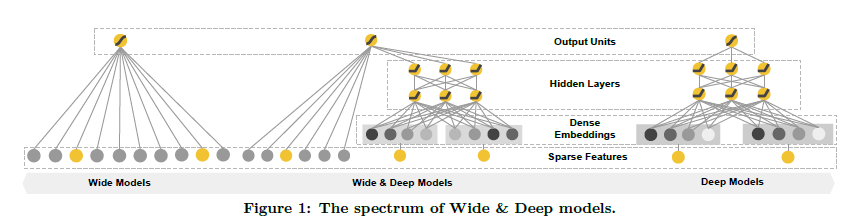\n",
20 | "\n",
21 | "更一般的拼接模型ctr预估结构可以如下:\n",
22 | "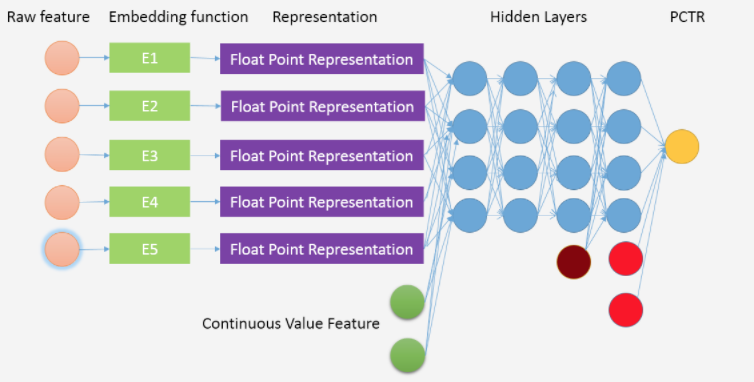"
23 | ]
24 | },
25 | {
26 | "cell_type": "markdown",
27 | "metadata": {},
28 | "source": [
29 | "## 导入工具库"
30 | ]
31 | },
32 | {
33 | "cell_type": "code",
34 | "execution_count": 1,
35 | "metadata": {},
36 | "outputs": [
37 | {
38 | "name": "stdout",
39 | "output_type": "stream",
40 | "text": [
41 | "Using TensorFlow version 1.4.0\n",
42 | "\n",
43 | "Feature columns are: ['I1', 'I2', 'I3', 'I4', 'I5', 'I6', 'I7', 'I8', 'I9', 'I10', 'I11', 'I12', 'I13', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9', 'C10', 'C11', 'C12', 'C13', 'C14', 'C15', 'C16', 'C17', 'C18', 'C19', 'C20', 'C21', 'C22', 'C23', 'C24', 'C25', 'C26'] \n",
44 | "\n",
45 | "Columns and data as a dict: {'C19': 'f6a3e43b', 'C18': 'bd17c3da', 'C13': '7203f04e', 'C12': '79507c6b', 'C11': '77212bd7', 'C10': 'ceb10289', 'C17': '8efede7f', 'C16': '49013ffe', 'C15': '2c14c412', 'C14': '07d13a8f', 'I9': 475, 'I8': 17, 'I1': 0, 'I3': 1, 'I2': 127, 'I5': 1683, 'I4': 3, 'I7': 26, 'I6': 19, 'C9': 'a73ee510', 'C8': '0b153874', 'C3': '11c9d79e', 'C2': '8947f767', 'C1': '05db9164', 'C7': '18671b18', 'C6': 'fbad5c96', 'C5': '4cf72387', 'C4': '52a787c8', 'C22': 'ad3062eb', 'C23': 'c7dc6720', 'C20': 'a458ea53', 'C21': '35cd95c9', 'C26': '49d68486', 'C24': '3fdb382b', 'C25': '010f6491', 'I11': 9, 'I10': 0, 'I13': 3, 'I12': 0} \n",
46 | "\n"
47 | ]
48 | }
49 | ],
50 | "source": [
51 | "from __future__ import absolute_import\n",
52 | "from __future__ import division\n",
53 | "from __future__ import print_function\n",
54 | "\n",
55 | "import time\n",
56 | "\n",
57 | "import tensorflow as tf\n",
58 | "\n",
59 | "tf.logging.set_verbosity(tf.logging.INFO)\n",
60 | "print(\"Using TensorFlow version %s\\n\" % (tf.__version__))\n",
61 | "\n",
62 | "# 我们这里使用的是criteo数据集,X的部分包括13个连续值列和26个类别型值的列\n",
63 | "CONTINUOUS_COLUMNS = [\"I\"+str(i) for i in range(1,14)] # 1-13 inclusive\n",
64 | "CATEGORICAL_COLUMNS = [\"C\"+str(i) for i in range(1,27)] # 1-26 inclusive\n",
65 | "# 标签是clicked\n",
66 | "LABEL_COLUMN = [\"clicked\"]\n",
67 | "\n",
68 | "# 训练集由 label列 + 连续值列 + 离散值列 构成\n",
69 | "TRAIN_DATA_COLUMNS = LABEL_COLUMN + CONTINUOUS_COLUMNS + CATEGORICAL_COLUMNS\n",
70 | "#TEST_DATA_COLUMNS = CONTINUOUS_COLUMNS + CATEGORICAL_COLUMNS\n",
71 | "\n",
72 | "# 特征列就是 连续值列+离散值列\n",
73 | "FEATURE_COLUMNS = CONTINUOUS_COLUMNS + CATEGORICAL_COLUMNS\n",
74 | "\n",
75 | "# 输出一些信息\n",
76 | "print('Feature columns are: ', FEATURE_COLUMNS, '\\n')\n",
77 | "\n",
78 | "# 数据示例\n",
79 | "sample = [ 0, 127, 1, 3, 1683, 19, 26, 17, 475, 0, 9, 0, 3, \"05db9164\", \"8947f767\", \"11c9d79e\", \"52a787c8\", \"4cf72387\", \"fbad5c96\", \"18671b18\", \"0b153874\", \"a73ee510\", \"ceb10289\", \"77212bd7\", \"79507c6b\", \"7203f04e\", \"07d13a8f\", \"2c14c412\", \"49013ffe\", \"8efede7f\", \"bd17c3da\", \"f6a3e43b\", \"a458ea53\", \"35cd95c9\", \"ad3062eb\", \"c7dc6720\", \"3fdb382b\", \"010f6491\", \"49d68486\"]\n",
80 | "\n",
81 | "print('Columns and data as a dict: ', dict(zip(FEATURE_COLUMNS, sample)), '\\n')"
82 | ]
83 | },
84 | {
85 | "cell_type": "markdown",
86 | "metadata": {},
87 | "source": [
88 | "## 输入文件解析\n",
89 | "\n",
90 | "我们把数据送进`Reader`然后从文件里一次读一个batch \n",
91 | "\n",
92 | "对`_input_fn()`函数做了特殊的封装处理,使得它更适合不同类型的文件读取\n",
93 | "\n",
94 | "注意一下:这里的文件是直接通过tensorflow读取的,我们没有用pandas这种工具,也没有一次性把所有数据读入内存,这样对于非常大规模的数据文件训练,是合理的。"
95 | ]
96 | },
97 | {
98 | "cell_type": "markdown",
99 | "metadata": {},
100 | "source": [
101 | "### 关于input_fn函数\n",
102 | "\n",
103 | "这个函数定义了我们怎么读取数据用于训练和测试。这里的返回结果是一个pair对,第一个元素是列名到具体取值的映射字典,第二个元素是label的序列。\n",
104 | "\n",
105 | "抽象一下,大概是这么个东西 `map(column_name => [Tensor of values]) , [Tensor of labels])`\n",
106 | "\n",
107 | "举个例子就长这样:\n",
108 | "\n",
109 | " { \n",
110 | " 'age': [ 39, 50, 38, 53, 28, … ], \n",
111 | " 'marital_status': [ 'Married-civ-spouse', 'Never-married', 'Widowed', 'Widowed' … ],\n",
112 | " ...\n",
113 | " 'gender': ['Male', 'Female', 'Male', 'Male', 'Female',, … ], \n",
114 | " } , \n",
115 | " [ 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1]"
116 | ]
117 | },
118 | {
119 | "cell_type": "markdown",
120 | "metadata": {},
121 | "source": [
122 | "### High-level structure of input functions for CSV-style data\n",
123 | "1. Queue file(s)\n",
124 | "2. Read a batch of data from the next file\n",
125 | "3. Create record defaults, generally 0 for continuous values, and \"\" for categorical. You can use named types if you prefer\n",
126 | "4. Decode the CSV and restructure it to be appropriate for the graph's input format\n",
127 | " * `zip()` column headers with the data\n",
128 | " * `pop()` off the label column(s)\n",
129 | " * Remove/pop any unneeded column(s)\n",
130 | " * Run `tf.expand_dims()` on categorical columns\n",
131 | " 5. Return the pair: `(feature_dict, label_array)`\n",
132 | " "
133 | ]
134 | },
135 | {
136 | "cell_type": "code",
137 | "execution_count": 2,
138 | "metadata": {},
139 | "outputs": [
140 | {
141 | "name": "stdout",
142 | "output_type": "stream",
143 | "text": [
144 | "input function configured\n"
145 | ]
146 | }
147 | ],
148 | "source": [
149 | "BATCH_SIZE = 2000\n",
150 | "\n",
151 | "def generate_input_fn(filename, batch_size=BATCH_SIZE):\n",
152 | " def _input_fn():\n",
153 | " filename_queue = tf.train.string_input_producer([filename])\n",
154 | " reader = tf.TextLineReader()\n",
155 | " # 只读batch_size行\n",
156 | " key, value = reader.read_up_to(filename_queue, num_records=batch_size)\n",
157 | " \n",
158 | " # 1个int型的label, 13个连续值, 26个字符串类型\n",
159 | " cont_defaults = [ [0] for i in range(1,14) ]\n",
160 | " cate_defaults = [ [\" \"] for i in range(1,27) ]\n",
161 | " label_defaults = [ [0] ]\n",
162 | " column_headers = TRAIN_DATA_COLUMNS\n",
163 | " \n",
164 | " # 第一列数据是label\n",
165 | " record_defaults = label_defaults + cont_defaults + cate_defaults\n",
166 | "\n",
167 | " # 解析读出的csv数据\n",
168 | " # 我们要手动把数据和header去zip在一起\n",
169 | " columns = tf.decode_csv(\n",
170 | " value, record_defaults=record_defaults)\n",
171 | " \n",
172 | " # 最终是列名到数据张量的映射字典\n",
173 | " all_columns = dict(zip(column_headers, columns))\n",
174 | " \n",
175 | " # 弹出和保存label标签\n",
176 | " labels = all_columns.pop(LABEL_COLUMN[0])\n",
177 | " \n",
178 | " # 其余列就是特征\n",
179 | " features = all_columns \n",
180 | "\n",
181 | " # 类别型的列我们要做一个类似one-hot的扩展操作\n",
182 | " for feature_name in CATEGORICAL_COLUMNS:\n",
183 | " features[feature_name] = tf.expand_dims(features[feature_name], -1)\n",
184 | "\n",
185 | " return features, labels\n",
186 | "\n",
187 | " return _input_fn\n",
188 | "\n",
189 | "print('input function configured')"
190 | ]
191 | },
192 | {
193 | "cell_type": "markdown",
194 | "metadata": {},
195 | "source": [
196 | "## 构建特征列\n",
197 | "这个部分我们来看一下用tensorflow的高级接口,如何方便地对特征进行处理"
198 | ]
199 | },
200 | {
201 | "cell_type": "markdown",
202 | "metadata": {},
203 | "source": [
204 | "#### 稀疏列/Sparse Columns\n",
205 | "我们先构建稀疏列(针对类别型)\n",
206 | "\n",
207 | "对于所有类别取值都清楚的我们用`sparse_column_with_keys()`处理\n",
208 | "\n",
209 | "对于类别可能比较多,没办法枚举的可以试试用`sparse_column_with_hash_bucket()`处理这个映射"
210 | ]
211 | },
212 | {
213 | "cell_type": "code",
214 | "execution_count": 3,
215 | "metadata": {
216 | "scrolled": true
217 | },
218 | "outputs": [
219 | {
220 | "name": "stdout",
221 | "output_type": "stream",
222 | "text": [
223 | "Wide/Sparse columns configured\n"
224 | ]
225 | }
226 | ],
227 | "source": [
228 | "# Sparse base columns.\n",
229 | "# C1 = tf.contrib.layers.sparse_column_with_hash_bucket('C1', hash_bucket_size=1000)\n",
230 | "# C2 = tf.contrib.layers.sparse_column_with_hash_bucket('C2', hash_bucket_size=1000)\n",
231 | "# C3 = tf.contrib.layers.sparse_column_with_hash_bucket('C3', hash_bucket_size=1000)\n",
232 | "# ...\n",
233 | "# Cn = tf.contrib.layers.sparse_column_with_hash_bucket('Cn', hash_bucket_size=1000)\n",
234 | "# wide_columns = [C1, C2, C3, ... , Cn]\n",
235 | "\n",
236 | "wide_columns = []\n",
237 | "for name in CATEGORICAL_COLUMNS:\n",
238 | " wide_columns.append(tf.contrib.layers.sparse_column_with_hash_bucket(\n",
239 | " name, hash_bucket_size=1000))\n",
240 | "\n",
241 | "print('Wide/Sparse columns configured')"
242 | ]
243 | },
244 | {
245 | "cell_type": "markdown",
246 | "metadata": {},
247 | "source": [
248 | "#### 连续值列/Continuous columns\n",
249 | "通过`real_valued_column()`设定连续值列"
250 | ]
251 | },
252 | {
253 | "cell_type": "code",
254 | "execution_count": 4,
255 | "metadata": {},
256 | "outputs": [
257 | {
258 | "name": "stdout",
259 | "output_type": "stream",
260 | "text": [
261 | "deep/continuous columns configured\n"
262 | ]
263 | }
264 | ],
265 | "source": [
266 | "# Continuous base columns.\n",
267 | "# I1 = tf.contrib.layers.real_valued_column(\"I1\")\n",
268 | "# I2 = tf.contrib.layers.real_valued_column(\"I2\")\n",
269 | "# I3 = tf.contrib.layers.real_valued_column(\"I3\")\n",
270 | "# ...\n",
271 | "# In = tf.contrib.layers.real_valued_column(\"In\")\n",
272 | "# deep_columns = [I1, I2, I3, ... , In]\n",
273 | "\n",
274 | "deep_columns = []\n",
275 | "for name in CONTINUOUS_COLUMNS:\n",
276 | " deep_columns.append(tf.contrib.layers.real_valued_column(name))\n",
277 | "\n",
278 | "print('deep/continuous columns configured')"
279 | ]
280 | },
281 | {
282 | "cell_type": "markdown",
283 | "metadata": {},
284 | "source": [
285 | "#### 特征工程变换\n",
286 | "因为这是一份做过脱敏处理的数据,所以我们做下面的2个操作\n",
287 | " \n",
288 | "* **分桶/bucketizing** 对连续值离散化和分桶\n",
289 | "* **生成交叉特征/feature crossing** 对2列或者多列去构建交叉组合特征(注意只有离散的特征才能交叉,所以如果连续值特征要用这个处理,要先离散化) "
290 | ]
291 | },
292 | {
293 | "cell_type": "code",
294 | "execution_count": 5,
295 | "metadata": {},
296 | "outputs": [
297 | {
298 | "name": "stdout",
299 | "output_type": "stream",
300 | "text": [
301 | "Transformations complete\n"
302 | ]
303 | }
304 | ],
305 | "source": [
306 | "# No known Transformations. Can add some if desired. \n",
307 | "# Examples from other datasets are shown below.\n",
308 | "\n",
309 | "# age_buckets = tf.contrib.layers.bucketized_column(age,\n",
310 | "# boundaries=[ 18, 25, 30, 35, 40, 45, 50, 55, 60, 65 ])\n",
311 | "# education_occupation = tf.contrib.layers.crossed_column([education, occupation], \n",
312 | "# hash_bucket_size=int(1e4))\n",
313 | "# age_race_occupation = tf.contrib.layers.crossed_column([age_buckets, race, occupation], \n",
314 | "# hash_bucket_size=int(1e6))\n",
315 | "# country_occupation = tf.contrib.layers.crossed_column([native_country, occupation], \n",
316 | "# hash_bucket_size=int(1e4))\n",
317 | "\n",
318 | "print('Transformations complete')"
319 | ]
320 | },
321 | {
322 | "cell_type": "markdown",
323 | "metadata": {},
324 | "source": [
325 | "### Group feature columns into 2 objects\n",
326 | "\n",
327 | "The wide columns are the sparse, categorical columns that we specified, as well as our hashed, bucket, and feature crossed columns. \n",
328 | "\n",
329 | "The deep columns are composed of embedded categorical columns along with the continuous real-valued columns. **Column embeddings** transform a sparse, categorical tensor into a low-dimensional and dense real-valued vector. The embedding values are also trained along with the rest of the model. For more information about embeddings, see the TensorFlow tutorial on [Vector Representations Words](https://www.tensorflow.org/tutorials/word2vec/), or [Word Embedding](https://en.wikipedia.org/wiki/Word_embedding) on Wikipedia.\n",
330 | "\n",
331 | "The higher the dimension of the embedding is, the more degrees of freedom the model will have to learn the representations of the features. We are starting with an 8-dimension embedding for simplicity, but later you can come back and increase the dimensionality if you wish.\n",
332 | "\n"
333 | ]
334 | },
335 | {
336 | "cell_type": "code",
337 | "execution_count": 6,
338 | "metadata": {
339 | "scrolled": true
340 | },
341 | "outputs": [
342 | {
343 | "name": "stdout",
344 | "output_type": "stream",
345 | "text": [
346 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
347 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
348 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
349 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
350 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
351 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
352 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
353 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
354 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
355 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
356 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
357 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
358 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
359 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
360 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
361 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
362 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
363 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
364 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
365 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
366 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
367 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
368 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
369 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
370 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
371 | "WARNING:tensorflow:The default stddev value of initializer will change from \"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after 2017/02/25.\n",
372 | "wide and deep columns configured\n"
373 | ]
374 | }
375 | ],
376 | "source": [
377 | "# Wide columns and deep columns.\n",
378 | "# wide_columns = [gender, race, native_country,\n",
379 | "# education, occupation, workclass,\n",
380 | "# marital_status, relationship,\n",
381 | "# age_buckets, education_occupation,\n",
382 | "# age_race_occupation, country_occupation]\n",
383 | "\n",
384 | "# deep_columns = [\n",
385 | "# tf.contrib.layers.embedding_column(workclass, dimension=8),\n",
386 | "# tf.contrib.layers.embedding_column(education, dimension=8),\n",
387 | "# tf.contrib.layers.embedding_column(marital_status, dimension=8),\n",
388 | "# tf.contrib.layers.embedding_column(gender, dimension=8),\n",
389 | "# tf.contrib.layers.embedding_column(relationship, dimension=8),\n",
390 | "# tf.contrib.layers.embedding_column(race, dimension=8),\n",
391 | "# tf.contrib.layers.embedding_column(native_country, dimension=8),\n",
392 | "# tf.contrib.layers.embedding_column(occupation, dimension=8),\n",
393 | "# age,\n",
394 | "# education_num,\n",
395 | "# capital_gain,\n",
396 | "# capital_loss,\n",
397 | "# hours_per_week,\n",
398 | "# ]\n",
399 | "\n",
400 | "# Embeddings for wide columns into deep columns\n",
401 | "for col in wide_columns:\n",
402 | " deep_columns.append(tf.contrib.layers.embedding_column(col, \n",
403 | " dimension=8))\n",
404 | "\n",
405 | "print('wide and deep columns configured')"
406 | ]
407 | },
408 | {
409 | "cell_type": "markdown",
410 | "metadata": {},
411 | "source": [
412 | "## 构建模型\n",
413 | "\n",
414 | "你可以根据实际情况构建“宽模型”、“深模型”、“深度宽度模型”\n",
415 | "\n",
416 | "* **Wide**: 相当于逻辑回归\n",
417 | "* **Deep**: 相当于多层感知器\n",
418 | "* **Wide & Deep**: 组合两种结构\n",
419 | "\n",
420 | "这里有2个参数`hidden_units` 或者 `dnn_hidden_units`可以指定隐层的节点个数,比如`[12, 20, 15]`构建3层神经元个数分别为12、20、15的隐层。"
421 | ]
422 | },
423 | {
424 | "cell_type": "code",
425 | "execution_count": 7,
426 | "metadata": {},
427 | "outputs": [
428 | {
429 | "name": "stdout",
430 | "output_type": "stream",
431 | "text": [
432 | "Model directory = ./models/model_WIDE_AND_DEEP_1525425429\n",
433 | "WARNING:tensorflow:From :37: calling __init__ (from tensorflow.contrib.learn.python.learn.estimators.dnn_linear_combined) with fix_global_step_increment_bug=False is deprecated and will be removed after 2017-04-15.\n",
434 | "Instructions for updating:\n",
435 | "Please set fix_global_step_increment_bug=True and update training steps in your pipeline. See pydoc for details.\n",
436 | "INFO:tensorflow:Using config: {'_save_checkpoints_secs': None, '_num_ps_replicas': 0, '_keep_checkpoint_max': 5, '_task_type': None, '_is_chief': True, '_cluster_spec': , '_model_dir': './models/model_WIDE_AND_DEEP_1525425429', '_save_checkpoints_steps': 100, '_keep_checkpoint_every_n_hours': 10000, '_session_config': None, '_tf_random_seed': None, '_save_summary_steps': 100, '_environment': 'local', '_num_worker_replicas': 0, '_task_id': 0, '_log_step_count_steps': 100, '_tf_config': gpu_options {\n",
437 | " per_process_gpu_memory_fraction: 1.0\n",
438 | "}\n",
439 | ", '_evaluation_master': '', '_master': ''}\n",
440 | "estimator built\n"
441 | ]
442 | }
443 | ],
444 | "source": [
445 | "def create_model_dir(model_type):\n",
446 | " # 返回类似这样的结果 models/model_WIDE_AND_DEEP_1493043407\n",
447 | " return './models/model_' + model_type + '_' + str(int(time.time()))\n",
448 | "\n",
449 | "# 指定模型文件夹\n",
450 | "def get_model(model_type, model_dir):\n",
451 | " print(\"Model directory = %s\" % model_dir)\n",
452 | " \n",
453 | " # 对checkpoint去做设定\n",
454 | " runconfig = tf.contrib.learn.RunConfig(\n",
455 | " save_checkpoints_secs=None,\n",
456 | " save_checkpoints_steps = 100,\n",
457 | " )\n",
458 | " \n",
459 | " m = None\n",
460 | " \n",
461 | " # 宽模型\n",
462 | " if model_type == 'WIDE':\n",
463 | " m = tf.contrib.learn.LinearClassifier(\n",
464 | " model_dir=model_dir, \n",
465 | " feature_columns=wide_columns)\n",
466 | "\n",
467 | " # 深度模型\n",
468 | " if model_type == 'DEEP':\n",
469 | " m = tf.contrib.learn.DNNClassifier(\n",
470 | " model_dir=model_dir,\n",
471 | " feature_columns=deep_columns,\n",
472 | " hidden_units=[100, 50, 25])\n",
473 | "\n",
474 | " # 宽度深度模型\n",
475 | " if model_type == 'WIDE_AND_DEEP':\n",
476 | " m = tf.contrib.learn.DNNLinearCombinedClassifier(\n",
477 | " model_dir=model_dir,\n",
478 | " linear_feature_columns=wide_columns,\n",
479 | " dnn_feature_columns=deep_columns,\n",
480 | " dnn_hidden_units=[100, 70, 50, 25],\n",
481 | " config=runconfig)\n",
482 | " \n",
483 | " print('estimator built')\n",
484 | " \n",
485 | " return m\n",
486 | " \n",
487 | "\n",
488 | "MODEL_TYPE = 'WIDE_AND_DEEP'\n",
489 | "model_dir = create_model_dir(model_type=MODEL_TYPE)\n",
490 | "m = get_model(model_type=MODEL_TYPE, model_dir=model_dir)"
491 | ]
492 | },
493 | {
494 | "cell_type": "code",
495 | "execution_count": 8,
496 | "metadata": {},
497 | "outputs": [
498 | {
499 | "data": {
500 | "text/plain": [
501 | "True"
502 | ]
503 | },
504 | "execution_count": 8,
505 | "metadata": {},
506 | "output_type": "execute_result"
507 | }
508 | ],
509 | "source": [
510 | "# 评估\n",
511 | "from tensorflow.contrib.learn.python.learn import evaluable\n",
512 | "isinstance(m, evaluable.Evaluable)"
513 | ]
514 | },
515 | {
516 | "cell_type": "markdown",
517 | "metadata": {},
518 | "source": [
519 | "## 拟合与模型训练\n",
520 | "\n",
521 | "执行`fit()`函数训练模型,可以试试不同的`train_steps`和`BATCH_SIZE`参数,会影响速度和结果"
522 | ]
523 | },
524 | {
525 | "cell_type": "code",
526 | "execution_count": 9,
527 | "metadata": {
528 | "collapsed": true
529 | },
530 | "outputs": [],
531 | "source": [
532 | "# 训练文件与测试文件\n",
533 | "train_file = \"./criteo_data/criteo_train.txt\"\n",
534 | "eval_file = \"./criteo_data/criteo_test.txt\""
535 | ]
536 | },
537 | {
538 | "cell_type": "code",
539 | "execution_count": 10,
540 | "metadata": {
541 | "scrolled": true
542 | },
543 | "outputs": [
544 | {
545 | "name": "stdout",
546 | "output_type": "stream",
547 | "text": [
548 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
549 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
550 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
551 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
552 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
553 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
554 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
555 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
556 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
557 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
558 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
559 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
560 | "WARNING:tensorflow:Rank of input Tensor (1) should be the same as output_rank (2) for column. Will attempt to expand dims. It is highly recommended that you resize your input, as this behavior may change.\n",
561 | "WARNING:tensorflow:Casting labels to bool.\n",
562 | "WARNING:tensorflow:Casting labels to bool.\n",
563 | "INFO:tensorflow:Create CheckpointSaverHook.\n",
564 | "INFO:tensorflow:Saving checkpoints for 2 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
565 | "INFO:tensorflow:loss = 383.61926, step = 2\n",
566 | "INFO:tensorflow:Saving checkpoints for 104 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
567 | "INFO:tensorflow:global_step/sec: 23.1193\n",
568 | "INFO:tensorflow:loss = 0.52519834, step = 202 (7.250 sec)\n",
569 | "INFO:tensorflow:Saving checkpoints for 206 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
570 | "INFO:tensorflow:global_step/sec: 28.1098\n",
571 | "INFO:tensorflow:Saving checkpoints for 308 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
572 | "INFO:tensorflow:global_step/sec: 34.8379\n",
573 | "INFO:tensorflow:loss = 0.52586925, step = 402 (5.846 sec)\n",
574 | "INFO:tensorflow:Saving checkpoints for 410 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
575 | "INFO:tensorflow:global_step/sec: 32.676\n",
576 | "INFO:tensorflow:Saving checkpoints for 512 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
577 | "INFO:tensorflow:global_step/sec: 34.5047\n",
578 | "INFO:tensorflow:loss = 0.50194484, step = 602 (5.955 sec)\n",
579 | "INFO:tensorflow:Saving checkpoints for 614 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
580 | "INFO:tensorflow:global_step/sec: 34.8302\n",
581 | "INFO:tensorflow:Saving checkpoints for 716 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
582 | "INFO:tensorflow:global_step/sec: 32.3302\n",
583 | "INFO:tensorflow:loss = 0.53253466, step = 802 (6.003 sec)\n",
584 | "INFO:tensorflow:Saving checkpoints for 818 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
585 | "INFO:tensorflow:global_step/sec: 34.7999\n",
586 | "INFO:tensorflow:Saving checkpoints for 920 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
587 | "INFO:tensorflow:global_step/sec: 34.8958\n",
588 | "INFO:tensorflow:loss = 0.5117367, step = 1002 (5.747 sec)\n",
589 | "INFO:tensorflow:Saving checkpoints for 1022 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
590 | "INFO:tensorflow:global_step/sec: 32.8373\n",
591 | "INFO:tensorflow:Saving checkpoints for 1124 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
592 | "INFO:tensorflow:global_step/sec: 34.6937\n",
593 | "INFO:tensorflow:loss = 0.50721353, step = 1202 (5.966 sec)\n",
594 | "INFO:tensorflow:Saving checkpoints for 1226 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
595 | "INFO:tensorflow:global_step/sec: 35.1806\n",
596 | "INFO:tensorflow:Saving checkpoints for 1328 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
597 | "INFO:tensorflow:global_step/sec: 32.6754\n",
598 | "INFO:tensorflow:loss = 0.5044991, step = 1402 (5.916 sec)\n",
599 | "INFO:tensorflow:Saving checkpoints for 1430 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
600 | "INFO:tensorflow:global_step/sec: 34.8313\n",
601 | "INFO:tensorflow:Saving checkpoints for 1532 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
602 | "INFO:tensorflow:global_step/sec: 32.7576\n",
603 | "INFO:tensorflow:loss = 0.5024924, step = 1602 (5.969 sec)\n",
604 | "INFO:tensorflow:Saving checkpoints for 1634 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
605 | "INFO:tensorflow:global_step/sec: 34.8521\n",
606 | "INFO:tensorflow:Saving checkpoints for 1736 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
607 | "INFO:tensorflow:global_step/sec: 35.2324\n",
608 | "INFO:tensorflow:loss = 0.5241726, step = 1802 (5.717 sec)\n",
609 | "INFO:tensorflow:Saving checkpoints for 1838 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
610 | "INFO:tensorflow:global_step/sec: 33.0927\n",
611 | "INFO:tensorflow:Saving checkpoints for 1940 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
612 | "INFO:tensorflow:global_step/sec: 34.9787\n",
613 | "INFO:tensorflow:loss = 0.52364856, step = 2002 (5.918 sec)\n",
614 | "INFO:tensorflow:Saving checkpoints for 2042 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
615 | "INFO:tensorflow:global_step/sec: 35.3599\n",
616 | "INFO:tensorflow:Saving checkpoints for 2144 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
617 | "INFO:tensorflow:global_step/sec: 32.9638\n",
618 | "INFO:tensorflow:loss = 0.5026111, step = 2202 (5.891 sec)\n",
619 | "INFO:tensorflow:Saving checkpoints for 2246 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
620 | "INFO:tensorflow:global_step/sec: 35.0174\n",
621 | "INFO:tensorflow:Saving checkpoints for 2348 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
622 | "INFO:tensorflow:global_step/sec: 34.9178\n",
623 | "INFO:tensorflow:loss = 0.5019771, step = 2402 (5.738 sec)\n",
624 | "INFO:tensorflow:Saving checkpoints for 2450 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
625 | "INFO:tensorflow:global_step/sec: 32.9129\n",
626 | "INFO:tensorflow:Saving checkpoints for 2552 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
627 | "INFO:tensorflow:global_step/sec: 35.285\n",
628 | "INFO:tensorflow:loss = 0.4845492, step = 2602 (5.912 sec)\n",
629 | "INFO:tensorflow:Saving checkpoints for 2654 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
630 | "INFO:tensorflow:global_step/sec: 34.8518\n",
631 | "INFO:tensorflow:Saving checkpoints for 2756 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
632 | "INFO:tensorflow:global_step/sec: 33.0218\n",
633 | "INFO:tensorflow:loss = 0.51637685, step = 2802 (5.920 sec)\n",
634 | "INFO:tensorflow:Saving checkpoints for 2858 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
635 | "INFO:tensorflow:global_step/sec: 35.0541\n",
636 | "INFO:tensorflow:Saving checkpoints for 2960 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
637 | "INFO:tensorflow:global_step/sec: 32.9527\n",
638 | "INFO:tensorflow:loss = 0.50076705, step = 3002 (5.927 sec)\n",
639 | "INFO:tensorflow:Saving checkpoints for 3062 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
640 | "INFO:tensorflow:global_step/sec: 34.8167\n",
641 | "INFO:tensorflow:Saving checkpoints for 3164 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
642 | "INFO:tensorflow:global_step/sec: 34.7644\n",
643 | "INFO:tensorflow:loss = 0.49627173, step = 3202 (5.769 sec)\n",
644 | "INFO:tensorflow:Saving checkpoints for 3266 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
645 | "INFO:tensorflow:global_step/sec: 32.4713\n",
646 | "INFO:tensorflow:Saving checkpoints for 3368 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
647 | "INFO:tensorflow:global_step/sec: 34.9586\n",
648 | "INFO:tensorflow:loss = 0.4953499, step = 3402 (5.974 sec)\n",
649 | "INFO:tensorflow:Saving checkpoints for 3470 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
650 | "INFO:tensorflow:global_step/sec: 35.249\n",
651 | "INFO:tensorflow:Saving checkpoints for 3572 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
652 | "INFO:tensorflow:global_step/sec: 33.069\n",
653 | "INFO:tensorflow:loss = 0.49573877, step = 3602 (5.892 sec)\n",
654 | "INFO:tensorflow:Saving checkpoints for 3674 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
655 | "INFO:tensorflow:global_step/sec: 34.7109\n",
656 | "INFO:tensorflow:Saving checkpoints for 3776 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
657 | "INFO:tensorflow:global_step/sec: 34.9269\n",
658 | "INFO:tensorflow:loss = 0.5173947, step = 3802 (5.770 sec)\n",
659 | "INFO:tensorflow:Saving checkpoints for 3878 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
660 | "INFO:tensorflow:global_step/sec: 32.7293\n",
661 | "INFO:tensorflow:Saving checkpoints for 3980 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
662 | "INFO:tensorflow:global_step/sec: 35.3551\n",
663 | "INFO:tensorflow:loss = 0.5168913, step = 4002 (5.907 sec)\n",
664 | "INFO:tensorflow:Saving checkpoints for 4082 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
665 | "INFO:tensorflow:global_step/sec: 35.5056\n",
666 | "INFO:tensorflow:Saving checkpoints for 4184 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
667 | "INFO:tensorflow:global_step/sec: 32.5982\n",
668 | "INFO:tensorflow:loss = 0.4942948, step = 4202 (5.909 sec)\n",
669 | "INFO:tensorflow:Saving checkpoints for 4286 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
670 | "INFO:tensorflow:global_step/sec: 34.9633\n",
671 | "INFO:tensorflow:Saving checkpoints for 4388 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
672 | "INFO:tensorflow:global_step/sec: 35.1609\n",
673 | "INFO:tensorflow:loss = 0.49204993, step = 4402 (5.732 sec)\n",
674 | "INFO:tensorflow:Saving checkpoints for 4490 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
675 | "INFO:tensorflow:global_step/sec: 33.0157\n",
676 | "INFO:tensorflow:Saving checkpoints for 4592 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
677 | "INFO:tensorflow:global_step/sec: 34.5001\n",
678 | "INFO:tensorflow:loss = 0.47883478, step = 4602 (5.962 sec)\n",
679 | "INFO:tensorflow:Saving checkpoints for 4694 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
680 | "INFO:tensorflow:global_step/sec: 32.7373\n",
681 | "INFO:tensorflow:Saving checkpoints for 4796 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
682 | "INFO:tensorflow:global_step/sec: 34.6698\n",
683 | "INFO:tensorflow:loss = 0.51010066, step = 4802 (5.964 sec)\n",
684 | "INFO:tensorflow:Saving checkpoints for 4898 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
685 | "INFO:tensorflow:global_step/sec: 34.7543\n",
686 | "INFO:tensorflow:Saving checkpoints for 5000 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
687 | "INFO:tensorflow:global_step/sec: 32.8706\n",
688 | "INFO:tensorflow:loss = 0.496355, step = 5002 (5.952 sec)\n",
689 | "INFO:tensorflow:Saving checkpoints for 5102 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
690 | "INFO:tensorflow:global_step/sec: 35.1737\n",
691 | "INFO:tensorflow:loss = 0.48928428, step = 5202 (5.082 sec)\n",
692 | "INFO:tensorflow:Saving checkpoints for 5204 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
693 | "INFO:tensorflow:global_step/sec: 35.1487\n",
694 | "INFO:tensorflow:Saving checkpoints for 5306 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
695 | "INFO:tensorflow:global_step/sec: 32.471\n",
696 | "INFO:tensorflow:loss = 0.4903523, step = 5402 (5.954 sec)\n",
697 | "INFO:tensorflow:Saving checkpoints for 5408 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
698 | "INFO:tensorflow:global_step/sec: 34.9119\n",
699 | "INFO:tensorflow:Saving checkpoints for 5510 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
700 | "INFO:tensorflow:global_step/sec: 34.9811\n",
701 | "INFO:tensorflow:loss = 0.49182308, step = 5602 (5.744 sec)\n",
702 | "INFO:tensorflow:Saving checkpoints for 5612 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
703 | "INFO:tensorflow:global_step/sec: 32.6137\n",
704 | "INFO:tensorflow:Saving checkpoints for 5714 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
705 | "INFO:tensorflow:global_step/sec: 34.7582\n",
706 | "INFO:tensorflow:loss = 0.51414853, step = 5802 (5.969 sec)\n",
707 | "INFO:tensorflow:Saving checkpoints for 5816 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
708 | "INFO:tensorflow:global_step/sec: 32.8651\n",
709 | "INFO:tensorflow:Saving checkpoints for 5918 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
710 | "INFO:tensorflow:global_step/sec: 34.7809\n",
711 | "INFO:tensorflow:loss = 0.5147529, step = 6002 (5.956 sec)\n",
712 | "INFO:tensorflow:Saving checkpoints for 6020 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
713 | "INFO:tensorflow:global_step/sec: 35.0825\n",
714 | "INFO:tensorflow:Saving checkpoints for 6122 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
715 | "INFO:tensorflow:global_step/sec: 33.0911\n",
716 | "INFO:tensorflow:loss = 0.491095, step = 6202 (5.899 sec)\n",
717 | "INFO:tensorflow:Saving checkpoints for 6224 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
718 | "INFO:tensorflow:global_step/sec: 34.835\n",
719 | "INFO:tensorflow:Saving checkpoints for 6326 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
720 | "INFO:tensorflow:global_step/sec: 34.4511\n",
721 | "INFO:tensorflow:loss = 0.4875968, step = 6402 (5.800 sec)\n",
722 | "INFO:tensorflow:Saving checkpoints for 6428 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
723 | "INFO:tensorflow:global_step/sec: 33.0431\n",
724 | "INFO:tensorflow:Saving checkpoints for 6530 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
725 | "INFO:tensorflow:global_step/sec: 35.0124\n",
726 | "INFO:tensorflow:loss = 0.47473788, step = 6602 (5.911 sec)\n",
727 | "INFO:tensorflow:Saving checkpoints for 6632 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
728 | "INFO:tensorflow:global_step/sec: 34.8711\n",
729 | "INFO:tensorflow:Saving checkpoints for 6734 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
730 | "INFO:tensorflow:global_step/sec: 32.5408\n",
731 | "INFO:tensorflow:loss = 0.50613326, step = 6802 (5.974 sec)\n",
732 | "INFO:tensorflow:Saving checkpoints for 6836 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
733 | "INFO:tensorflow:global_step/sec: 34.79\n",
734 | "INFO:tensorflow:Saving checkpoints for 6938 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
735 | "INFO:tensorflow:global_step/sec: 34.9317\n",
736 | "INFO:tensorflow:loss = 0.49292383, step = 7002 (5.766 sec)\n",
737 | "INFO:tensorflow:Saving checkpoints for 7040 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
738 | "INFO:tensorflow:global_step/sec: 32.6444\n",
739 | "INFO:tensorflow:Saving checkpoints for 7142 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
740 | "INFO:tensorflow:global_step/sec: 34.7767\n",
741 | "INFO:tensorflow:loss = 0.4855942, step = 7202 (5.964 sec)\n",
742 | "INFO:tensorflow:Saving checkpoints for 7244 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
743 | "INFO:tensorflow:global_step/sec: 35.0477\n",
744 | "INFO:tensorflow:Saving checkpoints for 7346 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
745 | "INFO:tensorflow:global_step/sec: 32.8509\n",
746 | "INFO:tensorflow:loss = 0.4879568, step = 7402 (5.923 sec)\n",
747 | "INFO:tensorflow:Saving checkpoints for 7448 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
748 | "INFO:tensorflow:global_step/sec: 34.9138\n",
749 | "INFO:tensorflow:Saving checkpoints for 7550 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
750 | "INFO:tensorflow:global_step/sec: 34.951\n",
751 | "INFO:tensorflow:loss = 0.48870382, step = 7602 (5.758 sec)\n",
752 | "INFO:tensorflow:Saving checkpoints for 7652 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
753 | "INFO:tensorflow:global_step/sec: 32.7741\n",
754 | "INFO:tensorflow:Saving checkpoints for 7754 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
755 | "INFO:tensorflow:global_step/sec: 35.1165\n",
756 | "INFO:tensorflow:loss = 0.51130104, step = 7802 (5.925 sec)\n",
757 | "INFO:tensorflow:Saving checkpoints for 7856 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
758 | "INFO:tensorflow:global_step/sec: 34.895\n",
759 | "INFO:tensorflow:Saving checkpoints for 7958 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
760 | "INFO:tensorflow:global_step/sec: 32.9485\n",
761 | "INFO:tensorflow:loss = 0.5131527, step = 8002 (5.928 sec)\n",
762 | "INFO:tensorflow:Saving checkpoints for 8060 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
763 | "INFO:tensorflow:global_step/sec: 34.8513\n",
764 | "INFO:tensorflow:Saving checkpoints for 8162 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
765 | "INFO:tensorflow:global_step/sec: 33.2702\n",
766 | "INFO:tensorflow:loss = 0.48932356, step = 8202 (5.903 sec)\n",
767 | "INFO:tensorflow:Saving checkpoints for 8264 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
768 | "INFO:tensorflow:global_step/sec: 35.1738\n",
769 | "INFO:tensorflow:Saving checkpoints for 8366 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
770 | "INFO:tensorflow:global_step/sec: 35.1566\n",
771 | "INFO:tensorflow:loss = 0.48442444, step = 8402 (5.708 sec)\n",
772 | "INFO:tensorflow:Saving checkpoints for 8468 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
773 | "INFO:tensorflow:global_step/sec: 33.1651\n",
774 | "INFO:tensorflow:Saving checkpoints for 8570 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
775 | "INFO:tensorflow:global_step/sec: 35.1729\n",
776 | "INFO:tensorflow:loss = 0.47236505, step = 8602 (5.889 sec)\n",
777 | "INFO:tensorflow:Saving checkpoints for 8672 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
778 | "INFO:tensorflow:global_step/sec: 34.3996\n",
779 | "INFO:tensorflow:Saving checkpoints for 8774 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
780 | "INFO:tensorflow:global_step/sec: 33.2737\n",
781 | "INFO:tensorflow:loss = 0.5052763, step = 8802 (5.944 sec)\n",
782 | "INFO:tensorflow:Saving checkpoints for 8876 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
783 | "INFO:tensorflow:global_step/sec: 34.9456\n",
784 | "INFO:tensorflow:Saving checkpoints for 8978 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
785 | "INFO:tensorflow:global_step/sec: 34.8424\n",
786 | "INFO:tensorflow:loss = 0.49116126, step = 9002 (5.758 sec)\n",
787 | "INFO:tensorflow:Saving checkpoints for 9080 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
788 | "INFO:tensorflow:global_step/sec: 32.615\n",
789 | "INFO:tensorflow:Saving checkpoints for 9182 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
790 | "INFO:tensorflow:global_step/sec: 34.5405\n",
791 | "INFO:tensorflow:loss = 0.4835304, step = 9202 (5.983 sec)\n",
792 | "INFO:tensorflow:Saving checkpoints for 9284 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
793 | "INFO:tensorflow:global_step/sec: 32.7099\n",
794 | "INFO:tensorflow:Saving checkpoints for 9386 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
795 | "INFO:tensorflow:global_step/sec: 35.586\n",
796 | "INFO:tensorflow:loss = 0.4846368, step = 9402 (5.897 sec)\n",
797 | "INFO:tensorflow:Saving checkpoints for 9488 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
798 | "INFO:tensorflow:global_step/sec: 35.0763\n",
799 | "INFO:tensorflow:Saving checkpoints for 9590 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
800 | "INFO:tensorflow:global_step/sec: 32.8913\n",
801 | "INFO:tensorflow:loss = 0.4866239, step = 9602 (5.927 sec)\n",
802 | "INFO:tensorflow:Saving checkpoints for 9692 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
803 | "INFO:tensorflow:global_step/sec: 34.9176\n",
804 | "INFO:tensorflow:Saving checkpoints for 9794 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
805 | "INFO:tensorflow:global_step/sec: 34.8555\n",
806 | "INFO:tensorflow:loss = 0.51006484, step = 9802 (5.754 sec)\n",
807 | "INFO:tensorflow:Saving checkpoints for 9896 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
808 | "INFO:tensorflow:global_step/sec: 31.9199\n",
809 | "INFO:tensorflow:Saving checkpoints for 9998 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
810 | "INFO:tensorflow:global_step/sec: 35.0719\n",
811 | "INFO:tensorflow:loss = 0.51255614, step = 10002 (6.015 sec)\n",
812 | "INFO:tensorflow:Saving checkpoints for 10100 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
813 | "INFO:tensorflow:global_step/sec: 35.0625\n",
814 | "INFO:tensorflow:Saving checkpoints for 10202 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
815 | "INFO:tensorflow:global_step/sec: 32.8023\n",
816 | "INFO:tensorflow:loss = 0.48584107, step = 10202 (5.930 sec)\n",
817 | "INFO:tensorflow:Saving checkpoints for 10304 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
818 | "INFO:tensorflow:global_step/sec: 34.5218\n",
819 | "INFO:tensorflow:loss = 0.48140407, step = 10402 (5.125 sec)\n",
820 | "INFO:tensorflow:Saving checkpoints for 10406 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
821 | "INFO:tensorflow:global_step/sec: 35.6643\n",
822 | "INFO:tensorflow:Saving checkpoints for 10508 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
823 | "INFO:tensorflow:global_step/sec: 32.9589\n",
824 | "INFO:tensorflow:loss = 0.47275436, step = 10602 (5.871 sec)\n",
825 | "INFO:tensorflow:Saving checkpoints for 10610 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
826 | "INFO:tensorflow:global_step/sec: 34.9231\n",
827 | "INFO:tensorflow:Saving checkpoints for 10712 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
828 | "INFO:tensorflow:global_step/sec: 35.1866\n",
829 | "INFO:tensorflow:loss = 0.5033426, step = 10802 (5.726 sec)\n",
830 | "INFO:tensorflow:Saving checkpoints for 10814 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
831 | "INFO:tensorflow:global_step/sec: 32.9069\n",
832 | "INFO:tensorflow:Saving checkpoints for 10916 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
833 | "INFO:tensorflow:global_step/sec: 35.0843\n",
834 | "INFO:tensorflow:loss = 0.4893472, step = 11002 (5.930 sec)\n",
835 | "INFO:tensorflow:Saving checkpoints for 11018 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
836 | "INFO:tensorflow:global_step/sec: 34.8252\n",
837 | "INFO:tensorflow:Saving checkpoints for 11120 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
838 | "INFO:tensorflow:global_step/sec: 32.8465\n",
839 | "INFO:tensorflow:loss = 0.48183277, step = 11202 (5.936 sec)\n",
840 | "INFO:tensorflow:Saving checkpoints for 11222 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
841 | "INFO:tensorflow:global_step/sec: 35.0827\n",
842 | "INFO:tensorflow:Saving checkpoints for 11324 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
843 | "INFO:tensorflow:global_step/sec: 34.8579\n",
844 | "INFO:tensorflow:loss = 0.48213634, step = 11402 (5.755 sec)\n",
845 | "INFO:tensorflow:Saving checkpoints for 11426 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
846 | "INFO:tensorflow:global_step/sec: 32.733\n",
847 | "INFO:tensorflow:Saving checkpoints for 11528 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
848 | "INFO:tensorflow:global_step/sec: 35.2039\n",
849 | "INFO:tensorflow:loss = 0.48272803, step = 11602 (5.919 sec)\n",
850 | "INFO:tensorflow:Saving checkpoints for 11630 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
851 | "INFO:tensorflow:global_step/sec: 32.9725\n",
852 | "INFO:tensorflow:Saving checkpoints for 11732 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
853 | "INFO:tensorflow:global_step/sec: 34.789\n",
854 | "INFO:tensorflow:loss = 0.506504, step = 11802 (5.931 sec)\n",
855 | "INFO:tensorflow:Saving checkpoints for 11834 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
856 | "INFO:tensorflow:global_step/sec: 35.24\n",
857 | "INFO:tensorflow:Saving checkpoints for 11936 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
858 | "INFO:tensorflow:global_step/sec: 32.5431\n",
859 | "INFO:tensorflow:loss = 0.51041526, step = 12002 (5.935 sec)\n",
860 | "INFO:tensorflow:Saving checkpoints for 12038 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
861 | "INFO:tensorflow:global_step/sec: 35.3221\n",
862 | "INFO:tensorflow:Saving checkpoints for 12140 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
863 | "INFO:tensorflow:global_step/sec: 34.7584\n",
864 | "INFO:tensorflow:loss = 0.4840238, step = 12202 (5.747 sec)\n",
865 | "INFO:tensorflow:Saving checkpoints for 12242 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
866 | "INFO:tensorflow:global_step/sec: 32.6937\n",
867 | "INFO:tensorflow:Saving checkpoints for 12344 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
868 | "INFO:tensorflow:global_step/sec: 34.9127\n",
869 | "INFO:tensorflow:loss = 0.48007318, step = 12402 (5.950 sec)\n",
870 | "INFO:tensorflow:Saving checkpoints for 12446 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
871 | "INFO:tensorflow:global_step/sec: 35.1066\n",
872 | "INFO:tensorflow:Saving checkpoints for 12548 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
873 | "INFO:tensorflow:global_step/sec: 32.0939\n",
874 | "INFO:tensorflow:loss = 0.4707959, step = 12602 (6.005 sec)\n",
875 | "INFO:tensorflow:Saving checkpoints for 12650 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
876 | "INFO:tensorflow:global_step/sec: 34.3398\n",
877 | "INFO:tensorflow:Saving checkpoints for 12752 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
878 | "INFO:tensorflow:global_step/sec: 32.6643\n",
879 | "INFO:tensorflow:loss = 0.50073105, step = 12802 (5.998 sec)\n",
880 | "INFO:tensorflow:Saving checkpoints for 12854 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
881 | "INFO:tensorflow:global_step/sec: 35.1485\n",
882 | "INFO:tensorflow:Saving checkpoints for 12956 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
883 | "INFO:tensorflow:global_step/sec: 35.2198\n",
884 | "INFO:tensorflow:loss = 0.48709363, step = 13002 (5.706 sec)\n",
885 | "INFO:tensorflow:Saving checkpoints for 13058 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
886 | "INFO:tensorflow:global_step/sec: 32.6911\n",
887 | "INFO:tensorflow:Saving checkpoints for 13160 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
888 | "INFO:tensorflow:global_step/sec: 34.894\n",
889 | "INFO:tensorflow:loss = 0.47868958, step = 13202 (5.958 sec)\n",
890 | "INFO:tensorflow:Saving checkpoints for 13262 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
891 | "INFO:tensorflow:global_step/sec: 35.0573\n",
892 | "INFO:tensorflow:Saving checkpoints for 13364 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
893 | "INFO:tensorflow:global_step/sec: 32.7856\n",
894 | "INFO:tensorflow:loss = 0.4787089, step = 13402 (5.923 sec)\n",
895 | "INFO:tensorflow:Saving checkpoints for 13466 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
896 | "INFO:tensorflow:global_step/sec: 35.5471\n",
897 | "INFO:tensorflow:Saving checkpoints for 13568 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
898 | "INFO:tensorflow:global_step/sec: 35.0263\n",
899 | "INFO:tensorflow:loss = 0.4809025, step = 13602 (5.705 sec)\n",
900 | "INFO:tensorflow:Saving checkpoints for 13670 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
901 | "INFO:tensorflow:global_step/sec: 32.7781\n",
902 | "INFO:tensorflow:Saving checkpoints for 13772 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
903 | "INFO:tensorflow:global_step/sec: 34.9871\n",
904 | "INFO:tensorflow:loss = 0.50386125, step = 13802 (5.930 sec)\n",
905 | "INFO:tensorflow:Saving checkpoints for 13874 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
906 | "INFO:tensorflow:global_step/sec: 34.986\n",
907 | "INFO:tensorflow:Saving checkpoints for 13976 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
908 | "INFO:tensorflow:global_step/sec: 32.8169\n",
909 | "INFO:tensorflow:loss = 0.5093261, step = 14002 (5.930 sec)\n",
910 | "INFO:tensorflow:Saving checkpoints for 14078 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
911 | "INFO:tensorflow:global_step/sec: 34.668\n",
912 | "INFO:tensorflow:Saving checkpoints for 14180 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
913 | "INFO:tensorflow:global_step/sec: 35.005\n",
914 | "INFO:tensorflow:loss = 0.48381323, step = 14202 (5.775 sec)\n",
915 | "INFO:tensorflow:Saving checkpoints for 14282 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
916 | "INFO:tensorflow:global_step/sec: 32.7084\n",
917 | "INFO:tensorflow:Saving checkpoints for 14384 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
918 | "INFO:tensorflow:global_step/sec: 34.8872\n",
919 | "INFO:tensorflow:loss = 0.48138177, step = 14402 (5.949 sec)\n",
920 | "INFO:tensorflow:Saving checkpoints for 14486 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
921 | "INFO:tensorflow:global_step/sec: 35.2346\n",
922 | "INFO:tensorflow:Saving checkpoints for 14588 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
923 | "INFO:tensorflow:global_step/sec: 32.659\n",
924 | "INFO:tensorflow:loss = 0.4707154, step = 14602 (5.931 sec)\n",
925 | "INFO:tensorflow:Saving checkpoints for 14690 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
926 | "INFO:tensorflow:global_step/sec: 34.4108\n",
927 | "INFO:tensorflow:Saving checkpoints for 14792 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
928 | "INFO:tensorflow:global_step/sec: 34.6803\n",
929 | "INFO:tensorflow:loss = 0.502075, step = 14802 (5.819 sec)\n",
930 | "INFO:tensorflow:Saving checkpoints for 14894 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
931 | "INFO:tensorflow:global_step/sec: 32.757\n",
932 | "INFO:tensorflow:Saving checkpoints for 14996 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
933 | "INFO:tensorflow:global_step/sec: 34.6987\n",
934 | "INFO:tensorflow:loss = 0.48955604, step = 15002 (5.961 sec)\n",
935 | "INFO:tensorflow:Saving checkpoints for 15098 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
936 | "INFO:tensorflow:global_step/sec: 32.9673\n",
937 | "INFO:tensorflow:Saving checkpoints for 15200 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
938 | "INFO:tensorflow:global_step/sec: 35.2175\n",
939 | "INFO:tensorflow:loss = 0.4818753, step = 15202 (5.903 sec)\n",
940 | "INFO:tensorflow:Saving checkpoints for 15302 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
941 | "INFO:tensorflow:global_step/sec: 34.6938\n",
942 | "INFO:tensorflow:loss = 0.48233324, step = 15402 (5.121 sec)\n",
943 | "INFO:tensorflow:Saving checkpoints for 15404 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
944 | "INFO:tensorflow:global_step/sec: 32.9636\n",
945 | "INFO:tensorflow:Saving checkpoints for 15506 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
946 | "INFO:tensorflow:global_step/sec: 34.8218\n",
947 | "INFO:tensorflow:loss = 0.4845931, step = 15602 (5.931 sec)\n",
948 | "INFO:tensorflow:Saving checkpoints for 15608 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
949 | "INFO:tensorflow:global_step/sec: 34.4433\n",
950 | "INFO:tensorflow:Saving checkpoints for 15710 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
951 | "INFO:tensorflow:global_step/sec: 32.8916\n",
952 | "INFO:tensorflow:loss = 0.50622445, step = 15802 (5.968 sec)\n",
953 | "INFO:tensorflow:Saving checkpoints for 15812 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
954 | "INFO:tensorflow:global_step/sec: 35.0151\n",
955 | "INFO:tensorflow:Saving checkpoints for 15914 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
956 | "INFO:tensorflow:global_step/sec: 34.5828\n",
957 | "INFO:tensorflow:loss = 0.51010966, step = 16002 (5.775 sec)\n",
958 | "INFO:tensorflow:Saving checkpoints for 16016 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
959 | "INFO:tensorflow:global_step/sec: 32.9331\n",
960 | "INFO:tensorflow:Saving checkpoints for 16118 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
961 | "INFO:tensorflow:global_step/sec: 35.1875\n",
962 | "INFO:tensorflow:loss = 0.4836615, step = 16202 (5.902 sec)\n",
963 | "INFO:tensorflow:Saving checkpoints for 16220 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
964 | "INFO:tensorflow:global_step/sec: 32.8104\n",
965 | "INFO:tensorflow:Saving checkpoints for 16322 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
966 | "INFO:tensorflow:global_step/sec: 34.8741\n",
967 | "INFO:tensorflow:loss = 0.48098013, step = 16402 (5.958 sec)\n",
968 | "INFO:tensorflow:Saving checkpoints for 16424 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
969 | "INFO:tensorflow:global_step/sec: 34.8091\n",
970 | "INFO:tensorflow:Saving checkpoints for 16526 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
971 | "INFO:tensorflow:global_step/sec: 32.5486\n",
972 | "INFO:tensorflow:loss = 0.4695204, step = 16602 (5.969 sec)\n",
973 | "INFO:tensorflow:Saving checkpoints for 16628 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
974 | "INFO:tensorflow:global_step/sec: 35.0424\n",
975 | "INFO:tensorflow:Saving checkpoints for 16730 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
976 | "INFO:tensorflow:global_step/sec: 34.8442\n",
977 | "INFO:tensorflow:loss = 0.50164527, step = 16802 (5.755 sec)\n",
978 | "INFO:tensorflow:Saving checkpoints for 16832 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
979 | "INFO:tensorflow:global_step/sec: 32.7707\n",
980 | "INFO:tensorflow:Saving checkpoints for 16934 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
981 | "INFO:tensorflow:global_step/sec: 35.0926\n",
982 | "INFO:tensorflow:loss = 0.48918447, step = 17002 (5.921 sec)\n",
983 | "INFO:tensorflow:Saving checkpoints for 17036 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
984 | "INFO:tensorflow:global_step/sec: 35.2155\n",
985 | "INFO:tensorflow:Saving checkpoints for 17138 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
986 | "INFO:tensorflow:global_step/sec: 33.0074\n",
987 | "INFO:tensorflow:loss = 0.47913647, step = 17202 (5.906 sec)\n",
988 | "INFO:tensorflow:Saving checkpoints for 17240 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
989 | "INFO:tensorflow:global_step/sec: 35.1414\n",
990 | "INFO:tensorflow:Saving checkpoints for 17342 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
991 | "INFO:tensorflow:global_step/sec: 35.1936\n",
992 | "INFO:tensorflow:loss = 0.47959447, step = 17402 (5.718 sec)\n",
993 | "INFO:tensorflow:Saving checkpoints for 17444 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
994 | "INFO:tensorflow:global_step/sec: 32.6898\n",
995 | "INFO:tensorflow:Saving checkpoints for 17546 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
996 | "INFO:tensorflow:global_step/sec: 34.8186\n",
997 | "INFO:tensorflow:loss = 0.48204988, step = 17602 (5.954 sec)\n",
998 | "INFO:tensorflow:Saving checkpoints for 17648 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
999 | "INFO:tensorflow:global_step/sec: 35.1228\n",
1000 | "INFO:tensorflow:Saving checkpoints for 17750 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1001 | "INFO:tensorflow:global_step/sec: 32.0315\n",
1002 | "INFO:tensorflow:loss = 0.5047125, step = 17802 (5.994 sec)\n",
1003 | "INFO:tensorflow:Saving checkpoints for 17852 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1004 | "INFO:tensorflow:global_step/sec: 35.1292\n",
1005 | "INFO:tensorflow:Saving checkpoints for 17954 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1006 | "INFO:tensorflow:global_step/sec: 34.8264\n",
1007 | "INFO:tensorflow:loss = 0.50951916, step = 18002 (5.747 sec)\n",
1008 | "INFO:tensorflow:Saving checkpoints for 18056 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1009 | "INFO:tensorflow:global_step/sec: 33.1272\n",
1010 | "INFO:tensorflow:Saving checkpoints for 18158 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1011 | "INFO:tensorflow:global_step/sec: 34.8218\n",
1012 | "INFO:tensorflow:loss = 0.48249555, step = 18202 (5.922 sec)\n",
1013 | "INFO:tensorflow:Saving checkpoints for 18260 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1014 | "INFO:tensorflow:global_step/sec: 34.8553\n",
1015 | "INFO:tensorflow:Saving checkpoints for 18362 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1016 | "INFO:tensorflow:global_step/sec: 32.9885\n",
1017 | "INFO:tensorflow:loss = 0.47924712, step = 18402 (5.926 sec)\n",
1018 | "INFO:tensorflow:Saving checkpoints for 18464 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1019 | "INFO:tensorflow:global_step/sec: 34.8848\n",
1020 | "INFO:tensorflow:Saving checkpoints for 18566 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1021 | "INFO:tensorflow:global_step/sec: 33.395\n",
1022 | "INFO:tensorflow:loss = 0.46886802, step = 18602 (5.893 sec)\n",
1023 | "INFO:tensorflow:Saving checkpoints for 18668 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1024 | "INFO:tensorflow:global_step/sec: 35.2775\n",
1025 | "INFO:tensorflow:Saving checkpoints for 18770 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1026 | "INFO:tensorflow:global_step/sec: 35.5929\n",
1027 | "INFO:tensorflow:loss = 0.5005961, step = 18802 (5.667 sec)\n",
1028 | "INFO:tensorflow:Saving checkpoints for 18872 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1029 | "INFO:tensorflow:global_step/sec: 32.9238\n",
1030 | "INFO:tensorflow:Saving checkpoints for 18974 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1031 | "INFO:tensorflow:global_step/sec: 35.0456\n",
1032 | "INFO:tensorflow:loss = 0.4847619, step = 19002 (5.913 sec)\n",
1033 | "INFO:tensorflow:Saving checkpoints for 19076 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1034 | "INFO:tensorflow:global_step/sec: 35.0182\n",
1035 | "INFO:tensorflow:Saving checkpoints for 19178 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1036 | "INFO:tensorflow:global_step/sec: 32.9734\n",
1037 | "INFO:tensorflow:loss = 0.47770432, step = 19202 (5.922 sec)\n",
1038 | "INFO:tensorflow:Saving checkpoints for 19280 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1039 | "INFO:tensorflow:global_step/sec: 35.4214\n",
1040 | "INFO:tensorflow:Saving checkpoints for 19382 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1041 | "INFO:tensorflow:global_step/sec: 34.6074\n",
1042 | "INFO:tensorflow:loss = 0.4758588, step = 19402 (5.731 sec)\n",
1043 | "INFO:tensorflow:Saving checkpoints for 19484 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1044 | "INFO:tensorflow:global_step/sec: 32.7778\n",
1045 | "INFO:tensorflow:Saving checkpoints for 19586 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1046 | "INFO:tensorflow:global_step/sec: 35.1873\n",
1047 | "INFO:tensorflow:loss = 0.48031697, step = 19602 (5.924 sec)\n",
1048 | "INFO:tensorflow:Saving checkpoints for 19688 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1049 | "INFO:tensorflow:global_step/sec: 33.0876\n",
1050 | "INFO:tensorflow:Saving checkpoints for 19790 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1051 | "INFO:tensorflow:global_step/sec: 35.0324\n",
1052 | "INFO:tensorflow:loss = 0.5011429, step = 19802 (5.911 sec)\n",
1053 | "INFO:tensorflow:Saving checkpoints for 19892 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1054 | "INFO:tensorflow:global_step/sec: 34.3502\n",
1055 | "INFO:tensorflow:Saving checkpoints for 19994 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1056 | "INFO:tensorflow:global_step/sec: 32.73\n",
1057 | "INFO:tensorflow:loss = 0.50794, step = 20002 (5.994 sec)\n",
1058 | "INFO:tensorflow:Saving checkpoints for 20002 into ./models/model_WIDE_AND_DEEP_1525425429/model.ckpt.\n",
1059 | "INFO:tensorflow:Loss for final step: 0.50794.\n",
1060 | "fit done\n"
1061 | ]
1062 | }
1063 | ],
1064 | "source": [
1065 | "# This can be found with\n",
1066 | "# wc -l train.csv\n",
1067 | "train_sample_size = 2000000\n",
1068 | "train_steps = train_sample_size/BATCH_SIZE*20\n",
1069 | "\n",
1070 | "m.fit(input_fn=generate_input_fn(train_file, BATCH_SIZE), steps=train_steps)\n",
1071 | "\n",
1072 | "print('fit done')"
1073 | ]
1074 | },
1075 | {
1076 | "cell_type": "markdown",
1077 | "metadata": {},
1078 | "source": [
1079 | "## 评估模型准确率\n",
1080 | "评估准确率"
1081 | ]
1082 | },
1083 | {
1084 | "cell_type": "code",
1085 | "execution_count": null,
1086 | "metadata": {
1087 | "scrolled": true
1088 | },
1089 | "outputs": [],
1090 | "source": [
1091 | "eval_sample_size = 500000 # this can be found with a 'wc -l eval.csv'\n",
1092 | "eval_steps = eval_sample_size/BATCH_SIZE\n",
1093 | "\n",
1094 | "results = m.evaluate(input_fn=generate_input_fn(eval_file), \n",
1095 | " steps=eval_steps)\n",
1096 | "print('evaluate done')\n",
1097 | "\n",
1098 | "print('Accuracy: %s' % results['accuracy'])\n",
1099 | "print(results)"
1100 | ]
1101 | },
1102 | {
1103 | "cell_type": "markdown",
1104 | "metadata": {},
1105 | "source": [
1106 | "进行预估"
1107 | ]
1108 | },
1109 | {
1110 | "cell_type": "code",
1111 | "execution_count": null,
1112 | "metadata": {},
1113 | "outputs": [],
1114 | "source": [
1115 | "def pred_fn():\n",
1116 | " sample = [ 0, 127, 1, 3, 1683, 19, 26, 17, 475, 0, 9, 0, 3, \"05db9164\", \"8947f767\", \"11c9d79e\", \"52a787c8\", \"4cf72387\", \"fbad5c96\", \"18671b18\", \"0b153874\", \"a73ee510\", \"ceb10289\", \"77212bd7\", \"79507c6b\", \"7203f04e\", \"07d13a8f\", \"2c14c412\", \"49013ffe\", \"8efede7f\", \"bd17c3da\", \"f6a3e43b\", \"a458ea53\", \"35cd95c9\", \"ad3062eb\", \"c7dc6720\", \"3fdb382b\", \"010f6491\", \"49d68486\"]\n",
1117 | " sample_dict = dict(zip(FEATURE_COLUMNS, sample))\n",
1118 | " \n",
1119 | " for feature_name in CATEGORICAL_COLUMNS:\n",
1120 | " sample_dict[feature_name] = tf.expand_dims(sample_dict[feature_name], -1)\n",
1121 | " \n",
1122 | " for feature_name in CONTINUOUS_COLUMNS:\n",
1123 | " sample_dict[feature_name] = tf.constant(sample_dict[feature_name], dtype=tf.int32)\n",
1124 | " print(sample_dict)\n",
1125 | "\n",
1126 | " return sample_dict\n",
1127 | "\n",
1128 | "m.predict(input_fn=pred_fn)"
1129 | ]
1130 | }
1131 | ],
1132 | "metadata": {
1133 | "kernelspec": {
1134 | "display_name": "Python 2",
1135 | "language": "python",
1136 | "name": "python2"
1137 | },
1138 | "language_info": {
1139 | "codemirror_mode": {
1140 | "name": "ipython",
1141 | "version": 2
1142 | },
1143 | "file_extension": ".py",
1144 | "mimetype": "text/x-python",
1145 | "name": "python",
1146 | "nbconvert_exporter": "python",
1147 | "pygments_lexer": "ipython2",
1148 | "version": "2.7.14"
1149 | }
1150 | },
1151 | "nbformat": 4,
1152 | "nbformat_minor": 2
1153 | }
1154 |
--------------------------------------------------------------------------------
/deep nn ctr prediction/wide_and_deep_model_official.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 宽度深度模型模板"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "讲一个用tensorflow高级接口搭建wide and deep model的案例,然后切到ctr预估问题中"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | "reference:[google官方案例](https://github.com/tensorflow/models/tree/master/official/wide_deep)"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": 1,
34 | "metadata": {
35 | "collapsed": false
36 | },
37 | "outputs": [
38 | {
39 | "name": "stdout",
40 | "output_type": "stream",
41 | "text": [
42 | "--2018-05-05 09:41:10-- https://raw.githubusercontent.com/tensorflow/models/master/official/wide_deep/data_download.py\n",
43 | "Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.228.133\n",
44 | "Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.228.133|:443... connected.\n",
45 | "HTTP request sent, awaiting response... 200 OK\n",
46 | "Length: 2357 (2.3K) [text/plain]\n",
47 | "Saving to: ‘data_download.py’\n",
48 | "\n",
49 | "100%[======================================>] 2,357 --.-K/s in 0s \n",
50 | "\n",
51 | "2018-05-05 09:41:11 (48.5 MB/s) - ‘data_download.py’ saved [2357/2357]\n",
52 | "\n"
53 | ]
54 | }
55 | ],
56 | "source": [
57 | "!wget https://raw.githubusercontent.com/tensorflow/models/master/official/wide_deep/data_download.py"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": null,
63 | "metadata": {
64 | "collapsed": true
65 | },
66 | "outputs": [],
67 | "source": [
68 | "# %load data_download.py\n",
69 | "# Copyright 2017 The TensorFlow Authors. All Rights Reserved.\n",
70 | "#\n",
71 | "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
72 | "# you may not use this file except in compliance with the License.\n",
73 | "# You may obtain a copy of the License at\n",
74 | "#\n",
75 | "# http://www.apache.org/licenses/LICENSE-2.0\n",
76 | "#\n",
77 | "# Unless required by applicable law or agreed to in writing, software\n",
78 | "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
79 | "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
80 | "# See the License for the specific language governing permissions and\n",
81 | "# limitations under the License.\n",
82 | "# ==============================================================================\n",
83 | "\"\"\"Download and clean the Census Income Dataset.\"\"\"\n",
84 | "\n",
85 | "from __future__ import absolute_import\n",
86 | "from __future__ import division\n",
87 | "from __future__ import print_function\n",
88 | "\n",
89 | "import argparse\n",
90 | "import os\n",
91 | "import sys\n",
92 | "\n",
93 | "from six.moves import urllib\n",
94 | "import tensorflow as tf\n",
95 | "\n",
96 | "DATA_URL = 'https://archive.ics.uci.edu/ml/machine-learning-databases/adult'\n",
97 | "TRAINING_FILE = 'adult.data'\n",
98 | "TRAINING_URL = '%s/%s' % (DATA_URL, TRAINING_FILE)\n",
99 | "EVAL_FILE = 'adult.test'\n",
100 | "EVAL_URL = '%s/%s' % (DATA_URL, EVAL_FILE)\n",
101 | "\n",
102 | "parser = argparse.ArgumentParser()\n",
103 | "\n",
104 | "parser.add_argument(\n",
105 | " '--data_dir', type=str, default='/tmp/census_data',\n",
106 | " help='Directory to download census data')\n",
107 | "\n",
108 | "\n",
109 | "def _download_and_clean_file(filename, url):\n",
110 | " \"\"\"Downloads data from url, and makes changes to match the CSV format.\"\"\"\n",
111 | " temp_file, _ = urllib.request.urlretrieve(url)\n",
112 | " with tf.gfile.Open(temp_file, 'r') as temp_eval_file:\n",
113 | " with tf.gfile.Open(filename, 'w') as eval_file:\n",
114 | " for line in temp_eval_file:\n",
115 | " line = line.strip()\n",
116 | " line = line.replace(', ', ',')\n",
117 | " if not line or ',' not in line:\n",
118 | " continue\n",
119 | " if line[-1] == '.':\n",
120 | " line = line[:-1]\n",
121 | " line += '\\n'\n",
122 | " eval_file.write(line)\n",
123 | " tf.gfile.Remove(temp_file)\n",
124 | "\n",
125 | "\n",
126 | "def main(_):\n",
127 | " if not tf.gfile.Exists(FLAGS.data_dir):\n",
128 | " tf.gfile.MkDir(FLAGS.data_dir)\n",
129 | "\n",
130 | " training_file_path = os.path.join(FLAGS.data_dir, TRAINING_FILE)\n",
131 | " _download_and_clean_file(training_file_path, TRAINING_URL)\n",
132 | "\n",
133 | " eval_file_path = os.path.join(FLAGS.data_dir, EVAL_FILE)\n",
134 | " _download_and_clean_file(eval_file_path, EVAL_URL)\n",
135 | "\n",
136 | "\n",
137 | "if __name__ == '__main__':\n",
138 | " FLAGS, unparsed = parser.parse_known_args()\n",
139 | " tf.app.run(argv=[sys.argv[0]] + unparsed)\n"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 5,
145 | "metadata": {
146 | "collapsed": true
147 | },
148 | "outputs": [],
149 | "source": [
150 | "!python data_download.py"
151 | ]
152 | },
153 | {
154 | "cell_type": "code",
155 | "execution_count": 3,
156 | "metadata": {
157 | "collapsed": false
158 | },
159 | "outputs": [
160 | {
161 | "name": "stdout",
162 | "output_type": "stream",
163 | "text": [
164 | "--2018-05-05 09:41:52-- https://raw.githubusercontent.com/tensorflow/models/master/official/wide_deep/wide_deep.py\n",
165 | "Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.228.133\n",
166 | "Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.228.133|:443... connected.\n",
167 | "HTTP request sent, awaiting response... 200 OK\n",
168 | "Length: 9540 (9.3K) [text/plain]\n",
169 | "Saving to: ‘wide_deep.py’\n",
170 | "\n",
171 | "100%[======================================>] 9,540 --.-K/s in 0s \n",
172 | "\n",
173 | "2018-05-05 09:41:53 (91.5 MB/s) - ‘wide_deep.py’ saved [9540/9540]\n",
174 | "\n"
175 | ]
176 | }
177 | ],
178 | "source": [
179 | "!wget https://raw.githubusercontent.com/tensorflow/models/master/official/wide_deep/wide_deep.py"
180 | ]
181 | },
182 | {
183 | "cell_type": "code",
184 | "execution_count": null,
185 | "metadata": {
186 | "collapsed": true
187 | },
188 | "outputs": [],
189 | "source": [
190 | "# %load wide_deep.py\n",
191 | "# Copyright 2017 The TensorFlow Authors. All Rights Reserved.\n",
192 | "#\n",
193 | "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
194 | "# you may not use this file except in compliance with the License.\n",
195 | "# You may obtain a copy of the License at\n",
196 | "#\n",
197 | "# http://www.apache.org/licenses/LICENSE-2.0\n",
198 | "#\n",
199 | "# Unless required by applicable law or agreed to in writing, software\n",
200 | "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
201 | "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
202 | "# See the License for the specific language governing permissions and\n",
203 | "# limitations under the License.\n",
204 | "# ==============================================================================\n",
205 | "\"\"\"Example code for TensorFlow Wide & Deep Tutorial using tf.estimator API.\"\"\"\n",
206 | "from __future__ import absolute_import\n",
207 | "from __future__ import division\n",
208 | "from __future__ import print_function\n",
209 | "\n",
210 | "import os\n",
211 | "import shutil\n",
212 | "\n",
213 | "from absl import app as absl_app\n",
214 | "from absl import flags\n",
215 | "import tensorflow as tf # pylint: disable=g-bad-import-order\n",
216 | "\n",
217 | "from official.utils.flags import core as flags_core\n",
218 | "from official.utils.logs import hooks_helper\n",
219 | "from official.utils.misc import model_helpers\n",
220 | "\n",
221 | "\n",
222 | "_CSV_COLUMNS = [\n",
223 | " 'age', 'workclass', 'fnlwgt', 'education', 'education_num',\n",
224 | " 'marital_status', 'occupation', 'relationship', 'race', 'gender',\n",
225 | " 'capital_gain', 'capital_loss', 'hours_per_week', 'native_country',\n",
226 | " 'income_bracket'\n",
227 | "]\n",
228 | "\n",
229 | "_CSV_COLUMN_DEFAULTS = [[0], [''], [0], [''], [0], [''], [''], [''], [''], [''],\n",
230 | " [0], [0], [0], [''], ['']]\n",
231 | "\n",
232 | "_NUM_EXAMPLES = {\n",
233 | " 'train': 32561,\n",
234 | " 'validation': 16281,\n",
235 | "}\n",
236 | "\n",
237 | "\n",
238 | "LOSS_PREFIX = {'wide': 'linear/', 'deep': 'dnn/'}\n",
239 | "\n",
240 | "\n",
241 | "def define_wide_deep_flags():\n",
242 | " \"\"\"Add supervised learning flags, as well as wide-deep model type.\"\"\"\n",
243 | " flags_core.define_base()\n",
244 | "\n",
245 | " flags.adopt_module_key_flags(flags_core)\n",
246 | "\n",
247 | " flags.DEFINE_enum(\n",
248 | " name=\"model_type\", short_name=\"mt\", default=\"wide_deep\",\n",
249 | " enum_values=['wide', 'deep', 'wide_deep'],\n",
250 | " help=\"Select model topology.\")\n",
251 | "\n",
252 | " flags_core.set_defaults(data_dir='/tmp/census_data',\n",
253 | " model_dir='/tmp/census_model',\n",
254 | " train_epochs=40,\n",
255 | " epochs_between_evals=2,\n",
256 | " batch_size=40)\n",
257 | "\n",
258 | "\n",
259 | "def build_model_columns():\n",
260 | " \"\"\"Builds a set of wide and deep feature columns.\"\"\"\n",
261 | " # Continuous columns\n",
262 | " age = tf.feature_column.numeric_column('age')\n",
263 | " education_num = tf.feature_column.numeric_column('education_num')\n",
264 | " capital_gain = tf.feature_column.numeric_column('capital_gain')\n",
265 | " capital_loss = tf.feature_column.numeric_column('capital_loss')\n",
266 | " hours_per_week = tf.feature_column.numeric_column('hours_per_week')\n",
267 | "\n",
268 | " education = tf.feature_column.categorical_column_with_vocabulary_list(\n",
269 | " 'education', [\n",
270 | " 'Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',\n",
271 | " 'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',\n",
272 | " '5th-6th', '10th', '1st-4th', 'Preschool', '12th'])\n",
273 | "\n",
274 | " marital_status = tf.feature_column.categorical_column_with_vocabulary_list(\n",
275 | " 'marital_status', [\n",
276 | " 'Married-civ-spouse', 'Divorced', 'Married-spouse-absent',\n",
277 | " 'Never-married', 'Separated', 'Married-AF-spouse', 'Widowed'])\n",
278 | "\n",
279 | " relationship = tf.feature_column.categorical_column_with_vocabulary_list(\n",
280 | " 'relationship', [\n",
281 | " 'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried',\n",
282 | " 'Other-relative'])\n",
283 | "\n",
284 | " workclass = tf.feature_column.categorical_column_with_vocabulary_list(\n",
285 | " 'workclass', [\n",
286 | " 'Self-emp-not-inc', 'Private', 'State-gov', 'Federal-gov',\n",
287 | " 'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'])\n",
288 | "\n",
289 | " # To show an example of hashing:\n",
290 | " occupation = tf.feature_column.categorical_column_with_hash_bucket(\n",
291 | " 'occupation', hash_bucket_size=1000)\n",
292 | "\n",
293 | " # Transformations.\n",
294 | " age_buckets = tf.feature_column.bucketized_column(\n",
295 | " age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])\n",
296 | "\n",
297 | " # Wide columns and deep columns.\n",
298 | " base_columns = [\n",
299 | " education, marital_status, relationship, workclass, occupation,\n",
300 | " age_buckets,\n",
301 | " ]\n",
302 | "\n",
303 | " crossed_columns = [\n",
304 | " tf.feature_column.crossed_column(\n",
305 | " ['education', 'occupation'], hash_bucket_size=1000),\n",
306 | " tf.feature_column.crossed_column(\n",
307 | " [age_buckets, 'education', 'occupation'], hash_bucket_size=1000),\n",
308 | " ]\n",
309 | "\n",
310 | " wide_columns = base_columns + crossed_columns\n",
311 | "\n",
312 | " deep_columns = [\n",
313 | " age,\n",
314 | " education_num,\n",
315 | " capital_gain,\n",
316 | " capital_loss,\n",
317 | " hours_per_week,\n",
318 | " tf.feature_column.indicator_column(workclass),\n",
319 | " tf.feature_column.indicator_column(education),\n",
320 | " tf.feature_column.indicator_column(marital_status),\n",
321 | " tf.feature_column.indicator_column(relationship),\n",
322 | " # To show an example of embedding\n",
323 | " tf.feature_column.embedding_column(occupation, dimension=8),\n",
324 | " ]\n",
325 | "\n",
326 | " return wide_columns, deep_columns\n",
327 | "\n",
328 | "\n",
329 | "def build_estimator(model_dir, model_type):\n",
330 | " \"\"\"Build an estimator appropriate for the given model type.\"\"\"\n",
331 | " wide_columns, deep_columns = build_model_columns()\n",
332 | " hidden_units = [100, 75, 50, 25]\n",
333 | "\n",
334 | " # Create a tf.estimator.RunConfig to ensure the model is run on CPU, which\n",
335 | " # trains faster than GPU for this model.\n",
336 | " run_config = tf.estimator.RunConfig().replace(\n",
337 | " session_config=tf.ConfigProto(device_count={'GPU': 0}))\n",
338 | "\n",
339 | " if model_type == 'wide':\n",
340 | " return tf.estimator.LinearClassifier(\n",
341 | " model_dir=model_dir,\n",
342 | " feature_columns=wide_columns,\n",
343 | " config=run_config)\n",
344 | " elif model_type == 'deep':\n",
345 | " return tf.estimator.DNNClassifier(\n",
346 | " model_dir=model_dir,\n",
347 | " feature_columns=deep_columns,\n",
348 | " hidden_units=hidden_units,\n",
349 | " config=run_config)\n",
350 | " else:\n",
351 | " return tf.estimator.DNNLinearCombinedClassifier(\n",
352 | " model_dir=model_dir,\n",
353 | " linear_feature_columns=wide_columns,\n",
354 | " dnn_feature_columns=deep_columns,\n",
355 | " dnn_hidden_units=hidden_units,\n",
356 | " config=run_config)\n",
357 | "\n",
358 | "\n",
359 | "def input_fn(data_file, num_epochs, shuffle, batch_size):\n",
360 | " \"\"\"Generate an input function for the Estimator.\"\"\"\n",
361 | " assert tf.gfile.Exists(data_file), (\n",
362 | " '%s not found. Please make sure you have run data_download.py and '\n",
363 | " 'set the --data_dir argument to the correct path.' % data_file)\n",
364 | "\n",
365 | " def parse_csv(value):\n",
366 | " print('Parsing', data_file)\n",
367 | " columns = tf.decode_csv(value, record_defaults=_CSV_COLUMN_DEFAULTS)\n",
368 | " features = dict(zip(_CSV_COLUMNS, columns))\n",
369 | " labels = features.pop('income_bracket')\n",
370 | " return features, tf.equal(labels, '>50K')\n",
371 | "\n",
372 | " # Extract lines from input files using the Dataset API.\n",
373 | " dataset = tf.data.TextLineDataset(data_file)\n",
374 | "\n",
375 | " if shuffle:\n",
376 | " dataset = dataset.shuffle(buffer_size=_NUM_EXAMPLES['train'])\n",
377 | "\n",
378 | " dataset = dataset.map(parse_csv, num_parallel_calls=5)\n",
379 | "\n",
380 | " # We call repeat after shuffling, rather than before, to prevent separate\n",
381 | " # epochs from blending together.\n",
382 | " dataset = dataset.repeat(num_epochs)\n",
383 | " dataset = dataset.batch(batch_size)\n",
384 | " return dataset\n",
385 | "\n",
386 | "\n",
387 | "def export_model(model, model_type, export_dir):\n",
388 | " \"\"\"Export to SavedModel format.\n",
389 | "\n",
390 | " Args:\n",
391 | " model: Estimator object\n",
392 | " model_type: string indicating model type. \"wide\", \"deep\" or \"wide_deep\"\n",
393 | " export_dir: directory to export the model.\n",
394 | " \"\"\"\n",
395 | " wide_columns, deep_columns = build_model_columns()\n",
396 | " if model_type == 'wide':\n",
397 | " columns = wide_columns\n",
398 | " elif model_type == 'deep':\n",
399 | " columns = deep_columns\n",
400 | " else:\n",
401 | " columns = wide_columns + deep_columns\n",
402 | " feature_spec = tf.feature_column.make_parse_example_spec(columns)\n",
403 | " example_input_fn = (\n",
404 | " tf.estimator.export.build_parsing_serving_input_receiver_fn(feature_spec))\n",
405 | " model.export_savedmodel(export_dir, example_input_fn)\n",
406 | "\n",
407 | "\n",
408 | "def run_wide_deep(flags_obj):\n",
409 | " \"\"\"Run Wide-Deep training and eval loop.\n",
410 | "\n",
411 | " Args:\n",
412 | " flags_obj: An object containing parsed flag values.\n",
413 | " \"\"\"\n",
414 | "\n",
415 | " # Clean up the model directory if present\n",
416 | " shutil.rmtree(flags_obj.model_dir, ignore_errors=True)\n",
417 | " model = build_estimator(flags_obj.model_dir, flags_obj.model_type)\n",
418 | "\n",
419 | " train_file = os.path.join(flags_obj.data_dir, 'adult.data')\n",
420 | " test_file = os.path.join(flags_obj.data_dir, 'adult.test')\n",
421 | "\n",
422 | " # Train and evaluate the model every `flags.epochs_between_evals` epochs.\n",
423 | " def train_input_fn():\n",
424 | " return input_fn(\n",
425 | " train_file, flags_obj.epochs_between_evals, True, flags_obj.batch_size)\n",
426 | "\n",
427 | " def eval_input_fn():\n",
428 | " return input_fn(test_file, 1, False, flags_obj.batch_size)\n",
429 | "\n",
430 | " loss_prefix = LOSS_PREFIX.get(flags_obj.model_type, '')\n",
431 | " train_hooks = hooks_helper.get_train_hooks(\n",
432 | " flags_obj.hooks, batch_size=flags_obj.batch_size,\n",
433 | " tensors_to_log={'average_loss': loss_prefix + 'head/truediv',\n",
434 | " 'loss': loss_prefix + 'head/weighted_loss/Sum'})\n",
435 | "\n",
436 | " # Train and evaluate the model every `flags.epochs_between_evals` epochs.\n",
437 | " for n in range(flags_obj.train_epochs // flags_obj.epochs_between_evals):\n",
438 | " model.train(input_fn=train_input_fn, hooks=train_hooks)\n",
439 | " results = model.evaluate(input_fn=eval_input_fn)\n",
440 | "\n",
441 | " # Display evaluation metrics\n",
442 | " print('Results at epoch', (n + 1) * flags_obj.epochs_between_evals)\n",
443 | " print('-' * 60)\n",
444 | "\n",
445 | " for key in sorted(results):\n",
446 | " print('%s: %s' % (key, results[key]))\n",
447 | "\n",
448 | " if model_helpers.past_stop_threshold(\n",
449 | " flags_obj.stop_threshold, results['accuracy']):\n",
450 | " break\n",
451 | "\n",
452 | " # Export the model\n",
453 | " if flags_obj.export_dir is not None:\n",
454 | " export_model(model, flags_obj.model_type, flags_obj.export_dir)\n",
455 | "\n",
456 | "\n",
457 | "def main(_):\n",
458 | " run_wide_deep(flags.FLAGS)\n",
459 | "\n",
460 | "\n",
461 | "if __name__ == '__main__':\n",
462 | " tf.logging.set_verbosity(tf.logging.INFO)\n",
463 | " define_wide_deep_flags()\n",
464 | " absl_app.run(main)\n"
465 | ]
466 | },
467 | {
468 | "cell_type": "code",
469 | "execution_count": null,
470 | "metadata": {
471 | "collapsed": true
472 | },
473 | "outputs": [],
474 | "source": [
475 | "!python wide_deep.py"
476 | ]
477 | }
478 | ],
479 | "metadata": {
480 | "kernelspec": {
481 | "display_name": "Python 2",
482 | "language": "python",
483 | "name": "python2"
484 | },
485 | "language_info": {
486 | "codemirror_mode": {
487 | "name": "ipython",
488 | "version": 2
489 | },
490 | "file_extension": ".py",
491 | "mimetype": "text/x-python",
492 | "name": "python",
493 | "nbconvert_exporter": "python",
494 | "pygments_lexer": "ipython2",
495 | "version": "2.7.5"
496 | }
497 | },
498 | "nbformat": 4,
499 | "nbformat_minor": 2
500 | }
501 |
--------------------------------------------------------------------------------
/从FM推演各深度学习CTR预估模型(附代码).pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/HanXiaoyang/CTR_NN/1ed817baa4c0e660f1235ca6199f311874a11c27/从FM推演各深度学习CTR预估模型(附代码).pdf
--------------------------------------------------------------------------------