62 | 63 | ### 1.2.3 동작 파라미터화로 메서드에 코드 전달하기 64 | 65 | 자바 8에서는 메서드를 다른 메서드의 인수로 넘겨주는 기능을 제공한다. 66 | 67 | 이를 이론적으로 **동작 파라미터화**라고 부른다. 68 | 69 |
70 | 71 | ### 1.2.4 병렬성과 가변 데이터 72 | 73 | 스트림 메서드로 전달하는 코드는 다른 코드와 동시에 실행하더라도 안전하게 실행될 수 있어야 한다. 74 | 75 | 다른 코드와 동시에 실행하더라도 안전하게 실행할 수 있는 코드를 만들려면 **공유된 가변 데이터**에 접근하지 않아야 한다. 76 | 77 | syncronized를 이용해서 **공유된 가변 데이터**를 보호할 수 있으나 이는 비싼 대가를 치러야할 수 있다. 78 | 79 | 하지만 자바 8 스트림을 이용하면 기존의 자바 스레드 API 보다 쉽게 병렬성을 활용할 수 있다. 80 | 81 |
82 | 83 | `공유되지 않은 가변 데이터`, `메서드`, `함수 코드`를 다른 메서드로 전달하는 기능은 함수형 프로그래밍 패러다임의 핵심적인 사항이다. (18,19 장에서 자세히 설명한다.) 84 | 85 | 반면 명령형 프로그래밍(객체지향, 절차지향) 패러다임에서는 일련의 가변 상태로 프로그램을 정의한다. 86 | 87 |
88 | 89 | ### 1.2.5 자바가 진화해야하는 이유 90 | 91 | 언어는 하드웨어나 프로그래머 기대의 변화에 부응하는 방향으로 변화해야 한다. 92 | 93 | 자바 8에서는 **함수형 프로그래밍을 도입**함으로써 객체지향과 함수형 프로그래밍의 두 가지 패러다임의 장점을 모두 활용할 수 있게 되었다. 94 | 95 |
96 | 97 | ## 1.3 자바 함수 98 | 99 | 자바 8에서 함수 사용법은 일반적인 프로그래밍 언어의 함수 사용법과 아주 비슷하다. 프로그래밍 언어의 핵심은 **값을 바꾸는 것**이다. 100 | 101 | 전통적으로 프로그래밍 언어에서는 이 값을 일급(first-class) 값(또는 시민)이라고 부른다. 102 | 103 |
104 | 105 | 이전까지 자바 프로그래밍 언어에서는 기본값, 인스턴스만이 일급 시민이었다. 106 | 107 | 메서드와 클래스는 이 당시 일급 시민이 아니었는데, 런타임에 메서드를 전달할 수 있다면, 즉 메서드를 일급 시민으로 만들면 프로그래밍에 유용하게 활용될 수 있다. 108 | 109 | 자바 8 설계자들은 이급 시민을 일급 시민으로 바꿀 수 있는 기능을 추가했다. 110 | 111 |
112 | 113 | ### 1.3.1 메서드와 람다를 일급 시민으로 114 | 115 | 동작의 전달을 위해 익명 클래스를 만들고 메서드를 구현해서 넘길 필요 없이, 준비된 함수를 **메서드 참조** ::(’이 메서드를 값으로 사용하라’는 의미)를 이용해서 전달할 수 있다. 116 | 117 | 아래 예제를 통해 자바 8에서는 더 이상 메서드가 이급값이 아닌 일급값인 것을 확인할 수 있다. 118 | 119 |
120 | 121 | - 익명 클래스를 통한 파일 리스팅 122 | 123 | ```java 124 | // FileFilter 객체로 isHidden 메서드를 감싼 다음에 File.listFiles 메서드로 전달해야한다. 125 | File[] hiddenFiles = new File(".").listFiles(new FileFilter() { 126 | public boolean accept(File file) { 127 | return file.isHidden(); 128 | } 129 | }); 130 | ``` 131 | 132 | - **메서드 참조**를 이용한 파일 리스팅 133 | 134 | ```java 135 | // File 내부에 메서드를 참조하여 전달한다. 136 | File[] hiddenFiles = new File(".").listFiles(File::isHidden); 137 | ``` 138 |
139 | 140 | 자바 8에서는 위와 같이 기명의 메서드를 일급값으로 취급할 뿐 아니라 람다(또는 익명 함수)를 포함하여 함수도 값으로 취급할 수 있다. 141 | 142 | 예를 들어, `(int x) → x + 1`, 즉 x라는 인수로 호출하면 x+1을 반환하는 동작을 수행하도록 코드를 구현할 수 있다. 143 | 144 | 람다 문법 형식으로 구현된 프로그램을 함수형 프로그래밍, 즉 ‘함수를 일급 값으로 넘겨주는 프로그램을 구현한다’라고 한다. 145 | 146 |
147 | 148 | ### 1.3.2 코드 넘겨주기 : 예제 149 | 150 | Apple 클래스와 getColor 메서드가 있고, Apples 리스트를 포함하는 변수 inventory가 있다고 하자. 151 | 152 | 모든 녹색 사과를 선택해서 리스트를 반환하는 프로그램을 구현한다고 해보자. 153 | 154 | 또 비슷하게 150 그램 이상의 사과를 구한다고 해보자. 155 | 156 | 이처럼 특정 항목을 선택해서 반환하는 동작을 **필터**라고 한다. 157 | 158 |
159 | 160 | `자바 8 이전의 코드` 161 | 162 | ```java 163 | public static List
189 | 190 | `자바 8 이후의 코드` 191 | 192 | ```java 193 | public static boolean isGreenApple(Apple apple) { 194 | return "green".equals(apple.getColor()); 195 | } 196 | 197 | public static boolean isHeavyApple(Apple apple) { 198 | return apple.getWeight() > 150; 199 | } 200 | 201 | // 메서드가 predicate 파라미터로 전달됨 202 | public static List
242 | 243 | 아마도 자바는 filter 그리고 다음과 같은 몇몇 일반적인 라이브러리 메서드를 추가하는 방향으로 발전했을 수도 있었다. 244 | 245 | ```java 246 | static
p);
247 |
248 | filter(inventory, (Apple a) -> a.getWeight() > 150);
249 | ```
250 |
251 | 그러나 병렬성이라는 중요성 때문에 설계자들은 이와 같은 설계를 포기했다.
252 |
253 | 대신 자바 8에서 filter와 비슷한 동작을 수행하는 연산집합을 포함하는 새로운 스트림 API를 제공한다.
254 |
255 |
256 |
257 | ## 1.4 스트림
258 |
259 | 스트림 API 이전 컬렉션 API를 이용하여 다양한 로직을 처리하였을 것이다.
260 |
261 | 스트림 API를 이용하면 컬렉션 API와는 상당히 다른 방식으로 데이터를 처리할 수 있다.
262 |
263 | 컬렉션 API를 사용한 for-each 루프를 이용하여 각 요소를 반복하면서 작업을 수행했다.
264 |
265 | 이러한 방식의 반복을 `외부 반복(external iteration)`이라 한다.
266 |
267 | 반면 스트림 API를 이용하면 루프를 신경 쓸 필요가 없다. 스트림 API에서는 라이브러리 내부에서 모든 데이터가 처리된다.
268 |
269 | 이와 같은 반복을 `내부 반복(internal iteration)`이라고 한다.
270 |
271 |
272 |
273 | ### 스트림의 기능과 장점
274 |
275 | 스트림은 자주 반복되는 패턴을 제공하는데, 주어진 조건에 따라 데이터를 필터링(filtering), 추출(extracting), 그룹화(grouping) 등의 기능이 있다.
276 |
277 | 또, 컬렉션을 이용했을 때 많은 요소를 가진 목록을 반복한다면 오랜시간이 걸리지만, 스트림은 멀티코어를 활용하여 더 높은 효율을 낼 수 있다.
278 |
279 | 기존에는 멀티 스레드를 사용하여야 병렬성을 얻을 수 있었지만, 스트림은 내부적으로 리스트를 나눠 n개의 CPU로 fork한 다음 처리 후 결과를 join하는 방식을 통해 병렬성을 제공한다.
280 |
281 | ```java
282 | //순차 처리 방식의 stream
283 | inventory.stream().filter((Apple a) -> a.getWeight() > 150).collect(Collectors.toList());
284 | //병렬 처리 방식의 stream
285 | inventory.parallelStream().filter((Apple a) -> a.getWeight() > 150).collect(Collectors.toList(
286 | ```
287 |
288 |
289 |
290 |
291 | ### 자바의 병렬성과 공유되지 않은 가변 상태
292 |
293 | 자바의 병렬성은 흔히 말하듯 어렵고 쉽게 에러를 일으킨다.
294 |
295 | 자바 8에서는 **큰 스트림을 병렬로 처리할 수 있도록 라이브러리에서 작은 스트림으로 분할**한다.
296 |
297 | 또한, 라이브러리 메서드로 전달된 **메서드가 상호작용을 하지 않는다면 가변 공유 객체를 통해 공짜로 병렬성을 누릴 수 있다.**
298 |
299 | 함수형 프로그래밍에서 함수형이란 ‘**함수를 일급값으로 사용한다**’라는 의미도 있지만 부가적으로 ‘**프로그램이 실행되는 동안 컴포넌트 간에 상호작용이 일어나지 않는다**’라는 의미도 포함한다.
300 |
301 |
302 |
303 | ## 1.5 디폴트 메서드와 자바 모듈
304 |
305 | 기존 자바 기능으로는 대규모 컴포넌트 기반 프로그래밍 그리고 진화하는 시스템의 인터페이스를 적절히 대응하기 어려웠다.
306 |
307 | 자바 8에서 지원하는 `디폴트 메서드`를 이용해 기존 인터페이스를 구현하는 클래스를 바꾸지 않고도 인터페이스를 변경할 수 있다.
308 |
309 |
310 |
311 | 예를 들어 List/나 Collection/ 인터페이스는 이전에 stream이나 parallelStream 메서드를 지원하지 않았다.
312 |
313 | 이를 지원하도록 바꾸려면 인터페이스에 stream 메서드를 정의하고, 모든 구현 클래스에 추가로 메서드를 구현하여야했다.
314 |
315 | 하지만 자바 8에서 Collection 인터페이스에 stream메서드를 추가하고 이를 디폴트 메서드로 제공하여 기존 인터페이스를 쉽게 변경할 수 있었다.
316 |
317 |
318 |
319 | ### 다중 상속?
320 |
321 | 하나의 클래스에서 여러 인터페이스를 구현할 수 있으므로, 여러 인터페이스에 다중 디폴트 메서드가 존재할 수 있다는 것은 **다중 상속이 허용된다는 것일까?**
322 |
323 | 엄밀히 다중 상속은 아니지만 **어느 정도는 그렇다**. 이에 관해 C++에서 악명 높은 `다이아몬드 상속 문제`를 피할 수 있는 방법을 설명한다.
324 |
325 |
326 |
327 | ## 1.6 함수형 프로그래밍에서 가져온 다른 유용한 아이디어
328 |
329 | ### 자바에 포함된 함수형 프로그래밍의 핵심적인 두 아이디어
330 |
331 | - 메서드와 람다를 일급값으로 사용
332 | - 가변 공유 상태가 없는 병렬 실행을 이용해서 효율적이고 안전하게 함수나 메서드를 호출
333 |
334 |
335 |
336 | ### 일반적인 함수형 언어에서 프로그램을 돕는 여러 장치
337 |
338 | 1. **NPE 회피 기법을 제공**한다.
339 |
340 | 자바 8에서는 NPE(NullPointerException)을 피할 수 있도록 도와주는 Optional
347 |
348 | 2. **패턴 매칭 기법을 제공**한다.
349 |
350 | 패턴 매칭은 switch를 확장한 것으로 데이터 형식 분류와 분석을 한번에 수행할 수 있다.
351 |
352 | 자바 8은 패턴 매칭을 완벽히 제공하지 않는다. (자바 개선안으로 제안된 상태다.)
--------------------------------------------------------------------------------
/Chapter_02/README.md:
--------------------------------------------------------------------------------
1 | # 동작 파라미터화 코드 전달하기
2 |
3 |
4 | > 💡 **동작 파라미터화**란 아직은 어떻게 실행할 것인지 결정하지 않은 코드 블록을 의미한다.
5 |
6 |
7 | 즉, 코드 블록의 실행을 나중으로 미뤄진다.
8 |
9 | 예를 들어, 나중에 실행될 메서드의 인수로 코드 블록을 전달할 수 있다.
10 |
11 | 결과적으로 **코드 블록에 따라 메서드의 동작이 파라미터화** 된다.
12 |
13 |
14 |
15 | ## 2.1 변화하는 요구사항에 대응하기
16 |
17 | 1장에서 봤던 것과 같이 List
20 |
21 | ### 2.1.1 첫번째 시도 : 녹색 사과 필터링
22 |
23 | ```java
24 | enum Color {
25 | RED,
26 | GREEN
27 | }
28 |
29 | public static List
46 |
47 | ### 2.1.2 두번째 시도 : 색을 파라미터화
48 |
49 | **색을 파라미터화할 수 있도록 메서드에 파라미터를 추가**하면 변화하는 요구사항에 좀 더 우연하게 대응하는 코드를 만들 수 있다.
50 |
51 | ```java
52 | public static List
64 |
65 | 다음으로 색 이외에도 150그램을 기준으로 가벼운 사과와 무거운 사과로 구분할 수 있도록 요구사항이 추가되었다고 해보자.
66 |
67 | ```java
68 | public static List
82 |
83 | 그러나 색을 통해 필터링하는 코드와 무게를 통해 필터링하는 코드가 대부분 중복된다.
84 |
85 | 이는 소프트웨어공학의 DRY(don’t repeat yourself, 같은 것을 반복하지 말 것) 원칙을 어긴다.
86 |
87 | 이렇게 반복하게 된다면 탐색 과정에 변화가 생긴다면 탐색하는 모든 메소드를 찾아 고쳐야만 할 것이다.
88 |
89 |
90 |
91 |
92 | ### 2.1.3 세번째 시도 : 가능한 모든 속성으로 필터링
93 |
94 | ```java
95 | public static List
113 |
114 | ## 2.2 동작 파라미터화
115 |
116 | 선택 조건은 결국 사과의 어떤 속성에 기초해서 불리언 값을 반환(사과가 녹색인가? 150그램 이상인가?)하는 것이다.
117 |
118 | 참 또는 거짓을 반환하는 함수를 `프레디케이트`라고한다.
119 |
120 | 선택 조건을 결정하는 인터페이스를 정의하자.
121 |
122 | ```java
123 | interface ApplePredicate {
124 | boolean test(Apple a);
125 | }
126 | ```
127 |
128 | 이제 인터페이스를 상속받아 실제 선택 조건을 구현하는 클래스를 만들 수 있다.
129 |
130 | ```java
131 | static class AppleWeightPredicate implements ApplePredicate {
132 | @Override
133 | public boolean test(Apple apple) {
134 | return apple.getWeight() > 150;
135 | }
136 | }
137 | static class AppleColorPredicate implements ApplePredicate {
138 | @Override
139 | public boolean test(Apple apple) {
140 | return apple.getColor() == Color.GREEN;
141 | }
142 | }
143 | ```
144 |
145 | 즉, 사용하는 구현 클래스에 따라 선택 조건을 달리할 수 있게 되고, 이를 전략 패턴이라고 부른다.
146 |
147 | 전략 디자인 패턴은 전략이라고 불리는 **알고리즘을 캡슐화하는 알고리즘 패밀리를 정의해둔 다음에 런타임에 알고리즘을 선택**하는 기법이다.
148 |
149 | `filterApples` 메서드에서 `ApplePredicate` 객체를 **파라미터로 받아** test 메서드를 사용하도록 해야한다.
150 |
151 | 이렇게 **동작 파라미터화**, 즉 메서드가 다양한 전략을 받아서 내부적으로 다양한 동작을 수행할 수 있다.
152 |
153 | 이를 통해 메서드 내부에서 **컬랙션을 반복하는 로직과 컬렉션의 각 요소에 적용할 동작을 분리**할 수 있고, 이는 소프트웨어 엔지니어링적으로 큰 이득이다.
154 |
155 |
156 |
157 | ### 2.2.1 네번째 시도 : 추상적 조건으로 필터링
158 |
159 | ```java
160 | public static List
184 |
185 | ## 2.3 복잡한 과정 간소화
186 |
187 | 메서드에 새로운 동작을 전달하려면 인터페이스를 만들고, 구현하는 여러 클래스를 정의한 다음 인스턴스화해야하고 이는 상당히 번거로운 작업이다.
188 |
189 |
190 |
191 | ### 2.3.1 익명 클래스
192 |
193 | **익명 클래스**는 자바의 지역 클래스와 비슷한 개념으로 말 그대로 이름이 없는 클래스다.
194 |
195 | **익명 클래스**를 이용하면 클르새 선언과 인스턴스화를 동시에 할 수 있다. 즉, 필요한 구현을 즉석에서 만들어서 사용할 수 있다.
196 |
197 |
198 |
199 | ### 2.3.2 다섯 번째 시도 : 익명 클래스
200 |
201 | ```java
202 | List
220 |
221 | ### 2.3.3 여섯 번째 시도 : 람다 표현식 사용
222 |
223 | (람다 표현식에 관해서는 3장에서 더 자세히 다룬다.)
224 |
225 | ```java
226 | List
232 |
233 | ### 2.3.4 일곱 번째 시도 : 리스트 형식으로 추상화
234 |
235 | ```java
236 | public interface Predicate
257 |
258 | ## 2.4 실전 예제
259 |
260 | ### 2.4.1 Comparator로 정렬하기
261 |
262 | 컬렉션 정렬은 반복되는 프로그래밍 작업이다.
263 |
264 | 개발자에게는 변화하는 요구사항에 쉽게 대응할 수 있는 다양한 정렬 동작을 수행할 수 있는 코드가 필요하다.
265 |
266 | 자바 8의 `List`는 `sort` 메서드를 포함하고 있다.
267 |
268 | 다음과 같은 인터페이스를 갖는 `Comparator` 객체를 이용해서 `sort`의 동작을 파라미터화할 수 있다.
269 |
270 | 즉, `Comparator`를 구현해서 `sort`의 메서드의 동작을 다양화할 수 있다.
271 |
272 | ```java
273 | public interface Comparator
279 |
280 | 예를 들어 사과의 무게가 적은 순으로 정렬해보자.
281 |
282 | ```java
283 | inventory.sort(new Comparator
300 |
301 | ### 2.4.2 Runnable로 코드 블록 실행하기
302 |
303 | 자바 스레드를 이용하면 병렬로 코드 블록을 실행할 수 있다.
304 |
305 | 어떤 코드를 실행할 것인지 스레드에게 알려주어야 하고, 여러 스레드는 각자 다른 코드를 실행할 수 있어야 한다.
306 |
307 | 나중에 실행할 수 있는 코드를 구현할 방법이 필요하다.
308 |
309 | 자바 8까지는 `Thread` 생성자에 객체만을 전달할 수 있었으므로 보통 결과를 반환하지 않는 `run` 메소드를 포함하는 **익명 클래스가 `Runnable` 인터페이스를 구현**하도록 하는 것이 일반적인 방법이었다.
310 |
311 | ```java
312 | Thread t = new Thread(new Runnable() {
313 | @Override
314 | public void run() {
315 | System.out.println("Hello world");
316 | }
317 | });
318 | ```
319 |
320 | 자바 8에서 지원하는 람다 표현식을 이용하면 다음처럼 구현할 수 있다.
321 |
322 | ```java
323 | Thread t = new Thread(() -> System.out.println("Hello world"));
324 | ```
325 |
326 |
327 |
328 | ### 2.4.3 Callable을 결과로 반환하기
329 |
330 | `ExecutorService`를 이용하면 태스크를 스레드 풀로 보내고 결과를 `Future`로 저장할 수 있다.
331 |
332 | `ExecutorService` 인터페이스는 태스크 제출과 실행 과정의 연관성을 끊어준다.
333 |
334 | 여기서 `Callable` 인터페이스를 이용해 결과를 반환하는 태스크를 만든다.
335 |
336 | ```java
337 | public interface Callable
361 |
362 | ### 2.4.4 GUI 이벤트 처리하기
363 |
364 | 모든 동작에 반응할 수 있어야 하기 때문에 GUI 프로그래밍에서도 변화에 대응할 수 있는 유연한 코드가 필요하다.
365 |
366 | `addActionListener` 메서드에 `ActionEvent` 인터페이스를 전달하여 이벤트에 어떻게 반응할지 설정할 수 있다.
367 |
368 | 즉, `ActionEvent` 가 `addActionListener` 메서드의 동작을 파라미터화한다.
369 |
370 | ```java
371 | // GUI
372 | Button button = new Button("Send");
373 | button.addActionListener(new ActionListener() {
374 | @Override
375 | public void actionPerformed(ActionEvent e) {
376 | button.setLabel("Sent!!");
377 | }
378 | });
379 |
380 | button.addActionListener(e -> button.setLabel("Sent!!"));
381 | ```
--------------------------------------------------------------------------------
/Chapter_04/README.md:
--------------------------------------------------------------------------------
1 | # Chapter 4. 스트림 소개
2 |
3 |
4 |
5 | # 4.1 스트림이란 무엇인가?
6 |
7 | `스트림(Streams)`을 이용하면 선언형으로 컬렉션(collection) 데이터를 처리할 수 있으며, (즉, 데이터를 처리하는 임시 구현 코드를 작성하는 대신 질의로 표현할 수 있게 됨)
8 | 멀티스레드 코드를 구현하지 않아도 데이터를 **투명하게 병렬로** 처리할 수 있다.
9 |
10 |
11 |
12 | e.g., 저칼로리의 요리명을 반환하고, 칼로리를 기준으로 요리를 정렬하는 코드
13 |
14 | - 자바 7 코드
15 |
16 | ```java
17 | // 저칼로리 요리들
18 | List
39 |
40 | - 스트림을 사용한 자바 8 코드
41 |
42 | ```java
43 | import static java.util.Comparator.comparing;
44 | import static java.util.stream.Collectors.toList;
45 | List
55 |
56 | ### 스트림의 장점
57 |
58 | > `선언형`으로 코드를 구현할 수 있다.
59 |
60 | 선언형 코드와 동작 파라미터화를 통해서 변하는 요구사항에 쉽게 대응할 수 있다.
61 |
62 |
63 |
64 | > 여러 빌딩 블록 연산(filter, sorted, map, collect 등)을 연결해서 복잡한 **데이터 처리 파이프라인**을 만들 수 있다. (`조립 가능`)
65 |
66 | 여러 연산을 파이프라인으로 연결해도 여전히 가독성과 명확성이 유지된다.
67 |
68 |
69 |
70 | > 데이터 처리 과정을 `병렬화`하면서 스레드와 락을 걱정할 필요가 없으며, 성능이 좋아진다.
71 |
72 | filter, sorted, map, collect 같은 연산은 `고수준 빌딩 블록(high-level building block)`으로 이루어져 있다.
73 |
74 | 이들은 특정 스레딩 모델에 제한되지 않고 어떤 상황에서든 자유롭게 사용할 수 있다.
75 |
76 |
77 |
78 |
79 |
80 | # 4.2 스트림 시작하기
81 |
82 | ## 정의
83 |
84 | > 💡 **데이터 처리 연산**을 지원하도록 **소스**에서 추출된 **연속된 요소** (Sequence of elements)
85 |
86 |
87 |
88 | ### 연속된 요소
89 |
90 | 스트림은 컬렉션과 마찬가지로 특정 요소 형식으로 이루어진 연속된 값 집합의 인터페이스를 제공한다.
91 |
92 | 하지만 컬렉션의 주제는 데이터고, 스트림의 주제는 계산이다. (4.3절에서 자세히 다룸)
93 |
94 |
95 |
96 | ### 소스
97 |
98 | 스트림은 데이터 제공 소스(e.g., 컬렉션, 배열, I/O 자원 등)로부터 데이터를 소비한다.
99 |
100 | **정렬된 컬렉션으로 스트림을 생성하면 정렬이 그대로 유지된다.**
101 |
102 |
103 |
104 | ### 데이터 처리 연산
105 |
106 | filter, map, reduce, find, match, sort 등으로 데이터를 조작할 수 있으며,
107 | 스트림 연산은 순차적으로 또는 병렬로 실행할 수 있다.
108 |
109 |
110 |
111 |
112 | ## 주요 특성
113 |
114 | ### 파이프라이닝(pipelining)
115 |
116 | 대부분의 스트림 연산은 **스트림 자신을 반환**한다.
117 |
118 | 따라서 스트림 연산끼리 연결해서 파이프라인을 구성할 수 있으며,
119 | 덕분에 `게으름(laziness)`, `쇼트서킷(short-circuiting)` 같은 최적화도 얻을 수 있다. (5장에서 설명함)
120 |
121 |
122 |
123 | ### 내부 반복
124 |
125 | 반복자를 이용해서 명시적으로 반복하는 컬렉션과 달리, 스트림은 내부 반복을 지원한다. (4.3.2절에서 설명함)
126 |
127 |
128 |
129 |
130 |
131 | > 스트림 라이브러리에서 필터링(fliter), 추출(map), 축소(limit) 기능을 제공하므로 **직접 기능을 구현할 필요가 없으며**,
132 | > 결과적으로 스트림 API는 파이프라인을 더 최적화할 수 있는 **유연성**을 제공한다.
133 |
134 |
135 |
136 |
137 |
138 | # 4.3 스트림과 컬렉션
139 |
140 | 자바의 기존 `컬렉션`과 새로운 `스트림` 모두 연속된(sequenced, 순차적인) 요소 형식의 값을 저장하는 자료구조의 인터페이스를 제공한다.
141 |
142 |
143 |
144 | > 💡 데이터를 **언제** 계산하느냐가 둘의 가장 큰 차이다.
145 |
146 | - `컬렉션` : 현재 자료구조가 포함하는 **모든** 값을 메모리에 저장하는 자료구조
147 | - 컬렉션의 모든 요소는 컬렉션에 추가하기 전에 계산되어야 한다.
148 |
149 |
150 | - `스트림` : **요청할 때만 요소를 계산**하는 고정된 자료구조 (= 게으르게 만들어지는 컬렉션)
151 | - 사용자가 요청하는 값만 스트림에서 추출한다.
152 | - 생산자(producer)와 소비자(consumer) 관계를 형성한다.
153 |
154 |
155 |
156 |
157 | ## 4.3.1 딱 한 번만 탐색할 수 있다
158 |
159 | 스트림은 반복자와 마찬가지로 한 번만 탐색할 수 있다.
160 |
161 | **즉, 탐색된 스트림의 요소는 소비된다.**
162 |
163 |
164 |
165 | 한 번 탐색한 요소를 다시 탐색하려면 초기 데이터 소스에서 새로운 스트림을 만들어야 하는데,
166 | 이를 위해서는 컬렉션처럼 반복 사용할 수 있는 데이터 소스여야 한다.
167 |
168 |
169 |
170 | 아래 예시처럼 데이터 소스가 I/O 채널일 경우, 소스를 반복 사용할 수 없으므로 새로운 스트림을 만들 수 없다.
171 |
172 | ```java
173 | List
180 |
181 |
182 | ## 4.3.2 외부 반복과 내부 반복
183 |
184 | 컬렉션과 스트림의 또 다른 차이점은 **데이터 반복 처리 방법**이다.
185 |
186 |
187 |
188 | ### 컬렉션 - 외부 반복(external iteration)
189 |
190 | - for-each 등을 사용해서 사용자가 직접 요소를 반복해야 한다.
191 | - e.g.,
192 |
193 | ```java
194 | List
201 |
202 |  203 |
204 |
203 |
204 |
205 |
206 |
207 | ### 스트림 - 내부 반복(internal iteration)
208 |
209 | - 반복을 알아서 처리하고 결과 스트림값을 어딘가에 저장해준다.
210 | - e.g.,
211 |
212 | ```java
213 | List
223 |
224 |  225 |
226 |
225 |
226 |
227 |
228 |
229 |
230 |
231 | # 4.4 스트림 연산
232 |
233 | 스트림 인터페이스의 연산은 크게 두 가지로 구분할 수 있다.
234 |
235 | 1. `중간 연산(intermediate operation)` : 연결할 수 있는 스트림 연산 (파이프라인을 형성)
236 | 2. `최종 연산(terminal operation)` : 스트림을 닫는 연산
237 |
238 |
239 |
240 | e.g.,
241 |
242 | ```java
243 | List
251 |
252 |  253 |
254 |
253 |
254 |
255 |
256 |
257 |
258 | ## 4.4.1 중간 연산
259 |
260 | 여러 중간 연산을 연결해서 질의를 만들 수 있다.
261 |
262 |
263 |
264 | 중간 연산은 **게으르다(lazy)**.
265 |
266 | 단말 연산을 스트림 파이프라인에 실행하기 전까지는 아무 연산도 수행하지 않는다.
267 |
268 | > 💡 중간 연산을 합친 다음에 **합쳐진 중간 연산을 최종 연산으로 한 번에 처리**하기 때문이다.
269 |
270 |
271 |
272 |
273 |
274 | e.g.,
275 |
276 | ```java
277 | List
292 |
293 | 프로그램 실행 결과는 다음과 같다.
294 |
295 | ```
296 | filtering:pork
297 | mapping:pork
298 | filtering:beef
299 | mapping:beef
300 | filtering:chicken
301 | mapping:chicken
302 | [pork, beef, chicken]
303 | ```
304 |
305 |
306 |
307 | - `limit 연산`과 `쇼트서킷 기법`(5장에서 설명함) 덕분에 300 칼로리가 넘는 요리는 여러 개지만 **오직 처음 3개만 선택되었다.**
308 |
309 |
310 | - `루프 퓨전(loop fusion)` : filter와 map은 서로 다른 연산이지만 한 과정으로 병합되었다.
311 |
312 |
313 |
314 |
315 | ## 4.4.2 최종 연산
316 |
317 | 스트림 이용 과정은 세 가지로 요약할 수 있다.
318 |
319 | - 질의를 수행할 `데이터 소스` (e.g., 컬렉션)
320 | - 스트림 파이프라인을 구성할 `중간 연산` 연결
321 | - 스트림 파이프라인을 실행하고 결과를 만들 `최종 연산`
322 |
--------------------------------------------------------------------------------
/Chapter_07/README.md:
--------------------------------------------------------------------------------
1 | # Chapter 7. 병렬 데이터 처리와 성능
2 |
3 |
4 |
5 | 이전에는 데이터 컬렉션을 병렬로 처리하기가 어려웠다.
6 |
7 | 자바 7은 `포크(fork)/조인(join) 프레임워크` 기능을 제공하여 더 쉽게 병렬화를 수행하면서 에러를 최소화할 수 있도록 하였다.
8 |
9 |
10 |
11 |
12 |
13 | # 7.1 병렬 스트림
14 |
15 | 컬렉션에 `parallelStream`을 호출하면 `병렬 스트림(parallel stream)`이 생성된다.
16 |
17 | 병렬 스트림이란 각각의 스레드에서 처리할 수 있도록 **스트림 요소를 여러 청크로 분할한 스트림**으로,
18 | 모든 멀티코어 프로세서가 각각의 청크를 처리하도록 할당할 수 있다.
19 |
20 |
21 |
22 |
23 | ## 7.1.1 순차 스트림을 병렬 스트림으로 변환하기
24 |
25 | 숫자 n을 인수로 받아서 1부터 n까지의 모든 숫자의 합계를 반환하는 메서드를 구현해보자.
26 |
27 | ```java
28 | public static long sequentialSum(long n) {
29 | return Stream.iterate(1L, i -> i + 1) // 무한 자연수 스트림 생성
30 | .limit(n)
31 | .reduce(Long::sum) // 스트림 리듀싱 연산
32 | .get();
33 | }
34 | ```
35 |
36 |
37 |
38 | 순차 스트림에 `parallel` 메서드를 호출하면 기존의 함수형 리듀싱 연산이 병렬로 처리된다.
39 |
40 | ```java
41 | public static long parallelSum(long n) {
42 | return Stream.iterate(1L, i -> i + 1)
43 | .limit(n)
44 | .parallel() // 스트림을 병렬 스트림으로 변환
45 | .reduce(Long::sum)
46 | .get();
47 | }
48 | ```
49 |
50 |
51 |
52 | 1. 스트림이 여러 청크로 분할되어 있어, 리듀싱 연산을 여러 청크에 병렬로 수행할 수 있다.
53 | 2. 리듀싱 연산으로 생성된 **부분 결과를 다시 리듀싱 연산으로 합쳐서** 전체 스트림의 리듀싱 결과를 도출한다.
54 |
55 |
56 |
57 | 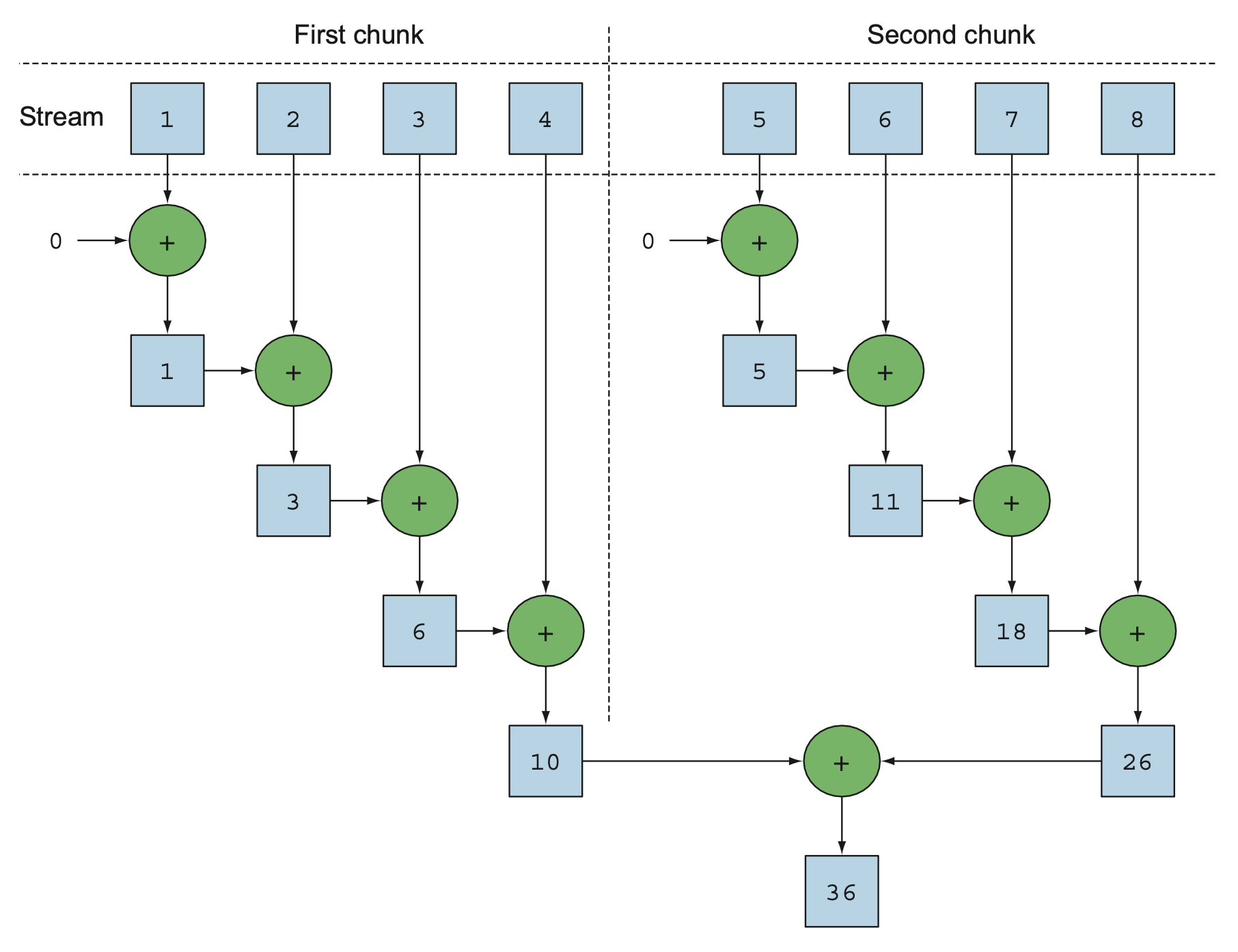 58 |
59 |
58 |
59 |
60 |
61 |
62 | ### 병렬 스트림을 순차 스트림으로 변환하기
63 |
64 | `sequential`로 병렬 스트림으르 순차 스트림으로 바꿀 수 있다.
65 |
66 |
67 |
68 | > 💡 `parallel`과 `sequential` 두 메서드 중 **최종적으로 호출된 메서드가** 전체 파이프라인에 영향을 미친다.
69 |
70 |
71 |
72 | ### 병렬 스트림에서 사용하는 스레드 풀 설정
73 |
74 | 병렬 스트림은 내부적으로 `ForkJoinPool`을 사용한다. (7.2절에서 자세히 설명)
75 |
76 | 이는 기본적으로 프로세서 수, 즉 `Runtime.getRuntime().availableProcessors()`가 반환하는 값에 상응하는 스레드를 갖는다.
77 |
78 |
79 |
80 | 아래 코드는 전역 설정 코드로, 모든 병렬 스트림 연산에 영향을 준다.
81 |
82 | ```java
83 | System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "12");
84 | ```
85 |
86 |
87 |
88 |
89 | ## 7.1.2 스트림 성능 측정
90 |
91 | `자바 마이크로벤치마크 하니스(Java Microbenchmark Harness, JMH) 라이브러리`를 통해 벤치마크를 구현하고, 위 코드들의 성능을 측정해보자.
92 |
93 | 코드 : [src/main/java/chapter07/ParallelStreamBenchmark.java](/src/main/java/chapter07/ParallelStreamBenchmark.java)
94 |
95 |
96 |
97 | 병럴화를 이용하면 순차나 반복 형식에 비해 성능이 더 좋아질 것이라고 추측했지만 그 결과는 반대였다.
98 |
99 | `전통적인 for 루프`를 사용해 반복하는 방법에 비해 `순차적 스트림`을 사용하는 버전은 4배 정도 느렸고,
100 | `병렬 스트림`을 사용하는 버전은 5배 정보나 느렸다.
101 |
102 |
103 |
104 | 병렬 스트림이 더 느렸던 이유는 다음과 같다.
105 |
106 | - 반복 결과로 박싱된 객체가 만들어지므로 숫자를 더하려면 언박싱을 해야 한다.
107 | - 반복 작업(iterate)은 병렬로 수행할 수 있는 독립 단위로 나누기가 어렵다. (본질적으로 순차적이기 때문)
108 |
109 |
110 |
111 | 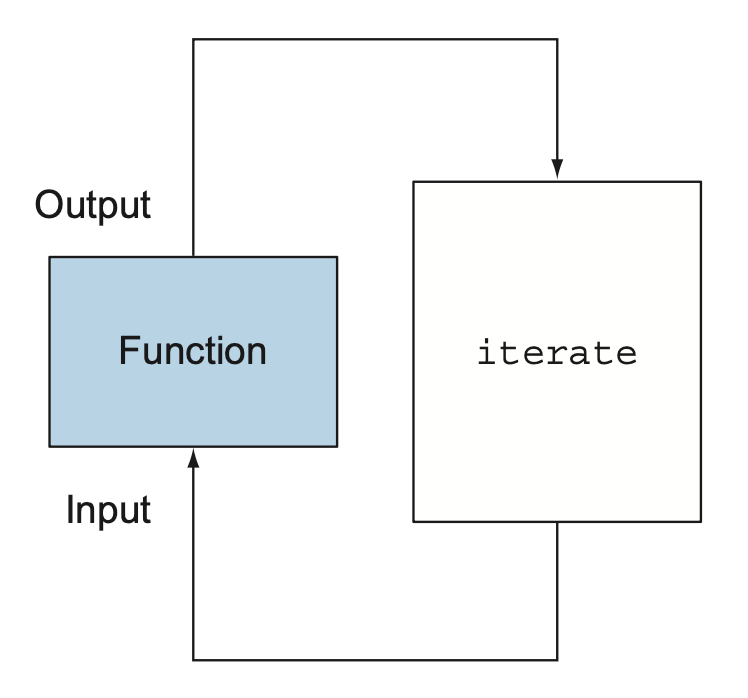 112 |
113 |
112 |
113 |
114 |
115 |
116 | 이런 상황에서는 ‘7.1.1 순차 스트림을 병렬 스트림으로 변환하기’에서의 그림처럼 리듀싱 연산이 수행되지 않는다.
117 |
118 | 리듀싱 과정을 시작하는 시점에 전체 숫자 리스트가 준비되지 않았으므로 스트림을 병렬로 처리할 수 있도록 청크로 분할할 수 없기 때문이다.
119 |
120 |
121 |
122 | 이처럼 병렬 프로그래밍을 오용하면 오히려 전체 프로그램의 성능이 더 나빠질 수 있다.
123 |
124 |
125 |
126 | ### 더 특화된 메서드 사용
127 |
128 | 5장에서 배운 `LongStream.rangeClosed`을 사용해보자.
129 |
130 | - 기본형 long을 직접 사용하므로 박싱과 언박싱 오버헤드가 사라진다.
131 | - 쉽게 청크로 분할할 수 있는 숫자 범위를 생산한다.
132 |
133 |
134 |
135 | ```java
136 | @Benchmark
137 | public long rangedSum() {
138 | return LongStream.rangeClosed(1, N)
139 | .reduce(0L, Long::sum);
140 | }
141 |
142 | // 병령 스트림
143 | @Benchmark
144 | public long parallelRangedSum() {
145 | return LongStream.rangeClosed(1, N)
146 | .parallel()
147 | .reduce(0L, Long::sum);
148 | }
149 | ```
150 |
151 |
152 |
153 | 성능을 측정해보면 기존의 iterate 팩토리 메서드로 생성한 순차 버전에 비해 숫자 스트림 처리 속도가 더 빠르다!
154 |
155 | 이번에는 ‘7.1.1 순차 스트림을 병렬 스트림으로 변환하기’에서의 그림처럼 실질적으로 리듀싱 연산이 병렬로 수행된다.
156 |
157 |
158 |
159 | > 💡 함수형 프로그래밍을 올바로 사용하면 병렬 실행의 힘을 직접적으로 얻을 수 있다.
160 |
161 |
162 |
163 | **하지만 병렬화가 완전 공짜는 아니다.**
164 |
165 | 스트림을 재귀적으로 분할해야 하고,
166 | 각 서브스트림을 서로 다른 스레드의 리듀싱 연산으로 할당하고,
167 | 이들 결과를 하나의 값으로 합쳐야 한다.
168 |
169 | 멀티코어 간의 데이터 이동은 생각보다 비싸다.
170 |
171 |
172 |
173 |
174 | ## 7.1.3 병렬 스트림의 올바른 사용법
175 |
176 | 병렬 스트림을 잘못 사용하면서 발생하는 많은 문제는 **공유된 상태를 바꾸는 알고리즘**을 사용하기 때문에 일어난다.
177 |
178 | > 💡 병렬 스트림과 병렬 계산에서는 **공유된 가변 상태를 피해야 한다.**
179 |
180 |
181 |
182 |
183 | ## 7.1.4 병렬 스트림 효과적으로 사용하기
184 |
185 | ### 확신이 서지 않으면 직접 측정하라
186 |
187 | 언제나 병렬 스트림이 순차 스트림보다 빠른 것은 아니며, 병렬 스트림의 수행 과정은 투명하지 않을 때가 많다.
188 |
189 | 순차 스트림과 병렬 스트림 중 어떤 것이 좋을지 모르겠다면 적절한 벤치마크로 직접 성능을 측정하는 것이 바람직하다.
190 |
191 |
192 |
193 | ### 박싱을 주의하라
194 |
195 | **자동 박싱과 언박싱**은 성능을 크게 저하시킬 수 있는 요소다.
196 |
197 | 자바 8은 박싱 동작을 피할 수 있도록 기본형 특화 스트림(`IntStream`, `LongStream`, `DoubleStream`)을 제공하며, 되도록이면 이들을 사용하는 것이 좋다.
198 |
199 |
200 |
201 | ### 순차 스트림보다 병렬 스트림에서 성능이 떨어지는 연산이 있다
202 |
203 | `limit`나 `findFirst`처럼 **요소의 순서에 의존하는 연산**은 병렬 스트림에서 수행하려면 비싼 비용을 치러야 한다.
204 |
205 | `findAny`는 요소의 순서와 상관없이 연산하므로 `findFirst`보다 성능이 좋다.
206 |
207 |
208 |
209 | ### 스트림에서 수행하는 전체 파이프라인 연산 비용을 고려하라
210 |
211 | 전체 스트림 파이프라인 처리 비용 = `N*Q`
212 |
213 | - `N` : 처리해야 할 요소 수
214 | - `Q` : 하나의 요소를 처리하는 데 드는 비용
215 |
216 | Q가 높아진다 → 병렬 스트림으로 성능을 개선할 수 있는 가능성이 있다.
217 |
218 |
219 |
220 | ### 소량의 데이터에서는 병렬 스트림이 도움 되지 않는다.
221 |
222 | 부가 비용을 상쇄할 수 있을 만큼의 이득을 얻지 못한다.
223 |
224 |
225 |
226 | ### 스트림을 구성하는 자료구조가 적절한지 확인하라
227 |
228 | `ArrayList`를 `LinkedList`보다 효율적으로 분할할 수 있다.
229 |
230 | - `ArrayList` : 요소를 탐색하지 않고도 리스트를 분할할 수 있다.
231 | - `LinkedList` : 분할하려면 모든 요소를 탐색해야 한다.
232 |
233 |
234 |
235 | `range 팩토리 메서드`로 만든 기본형 스트림도 쉽게 분해할 수 있다.
236 |
237 |
238 |
239 | ### 스트림의 특성과 파이프라인의 중간 연산이 스트림의 특성을 어떻게 바꾸는지에 따라 분해 과정의 성능이 달라질 수 있다
240 |
241 | `SIZED 스트림`은 정확히 같은 크기의 두 스트림으로 분해할 수 있으므로 효과적으로 스트림을 병렬 처리할 수 있다.
242 |
243 | `필터 연산`이 있으면 스트림의 길이를 예측할 수 없으므로 효과적으로 스트림을 병렬 처리할 수 있을지 알 수 없게 된다.
244 |
245 |
246 |
247 | ### 최종 연산의 병합 과정 비용을 살펴보라
248 |
249 | e.g., Collector의 combiner 메서드
250 |
251 | 병합 과정의 비용이 비싸다면 병렬 스트림으로 얻은 성능의 이익이 서브스트림의 부분 결과를 합치는 과정에서 상쇄될 수 있다.
252 |
253 |
254 |
255 | ### 병렬 스트림이 수행되는 내부 인프라구조도 살펴보라
256 |
257 | 자바 7에서 추가된 `포크/조인 프레임워크`로 병렬 스트림이 처리된다.
258 |
259 |
260 |
261 | ### 스트림 소스와 분해성
262 |
263 | 다음은 다양한 스트림 소스의 병렬화 친밀도를 요약한 것이다.
264 |
265 |
266 |
267 | 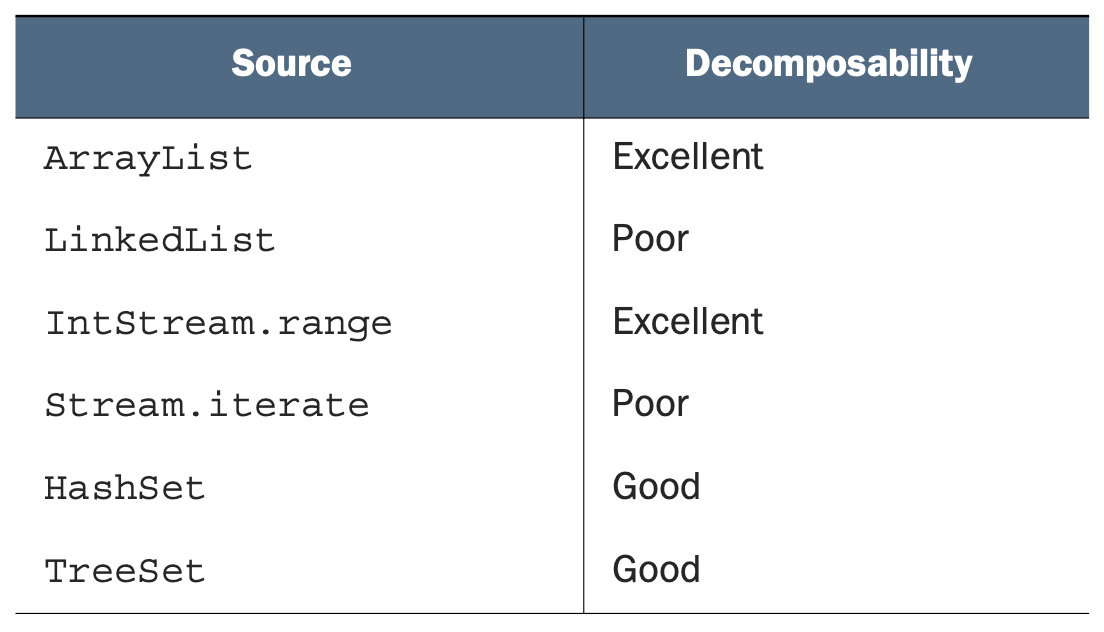 268 |
269 |
268 |
269 |
270 |
271 |
272 |
273 | # 7.2 포크/조인 프레임워크
274 |
275 | 이는 병렬화할 수 있는 작업을 **재귀적으로 작은 작업으로 분할**한 다음에 **서브태스크 각각의 결과를 합쳐서** 전체 결과를 만들도록 설계되었다.
276 |
277 |
278 |
279 | 포크/조인 프레임워크에서는 서브태스크를 스레드 풀(ForkJoinPool)의 작업자 스레드에 분산 할당하는 `ExecutorService 인터페이스`를 구현한다.
280 |
281 |
282 |
283 |
284 | ## 7.2.1 RecursiveTask 활용
285 |
286 | 스레드 풀을 이용하려면 `RecursiveTask
289 |
290 | `R`
291 |
292 | - 병렬화된 태스크가 생성하는 결과 형식
293 | - 결과가 없을 때는 RecursiveAction 형식
294 |
295 |
296 |
297 | RecursiveTask를 정의하려면 `추상 메서드 compute`를 구현해야 하는데,
298 | 이는 태스크를 서브태스크로 분할하는 로직과 더 이상 분할할 수 없을 때 개별 서브태스크의 결과를 생산할 알고리즘을 정의한다.
299 |
300 | ```
301 | // pseudo code
302 |
303 | if (태스크가 충분히 작거나 더 이상 분할할 수 없으면) {
304 | 순차적으로 태스크 계산
305 | } else {
306 | 태스크를 두 서브태스크로 분할
307 | 태스크가 다시 서브태스크로 분할되도록 이 메서드를 재귀적으로 호출함
308 | 모든 서브태스크의 연산이 완료될 때까지 기다림
309 | 각 서브태스크의 결과를 합침
310 | }
311 | ```
312 |
313 |
314 |
315 | 이 알고리즘은 `분할 후 정복(divide-and-conquer) 알고리즘`의 병렬화 버전이다.
316 |
317 |
318 |
319 | 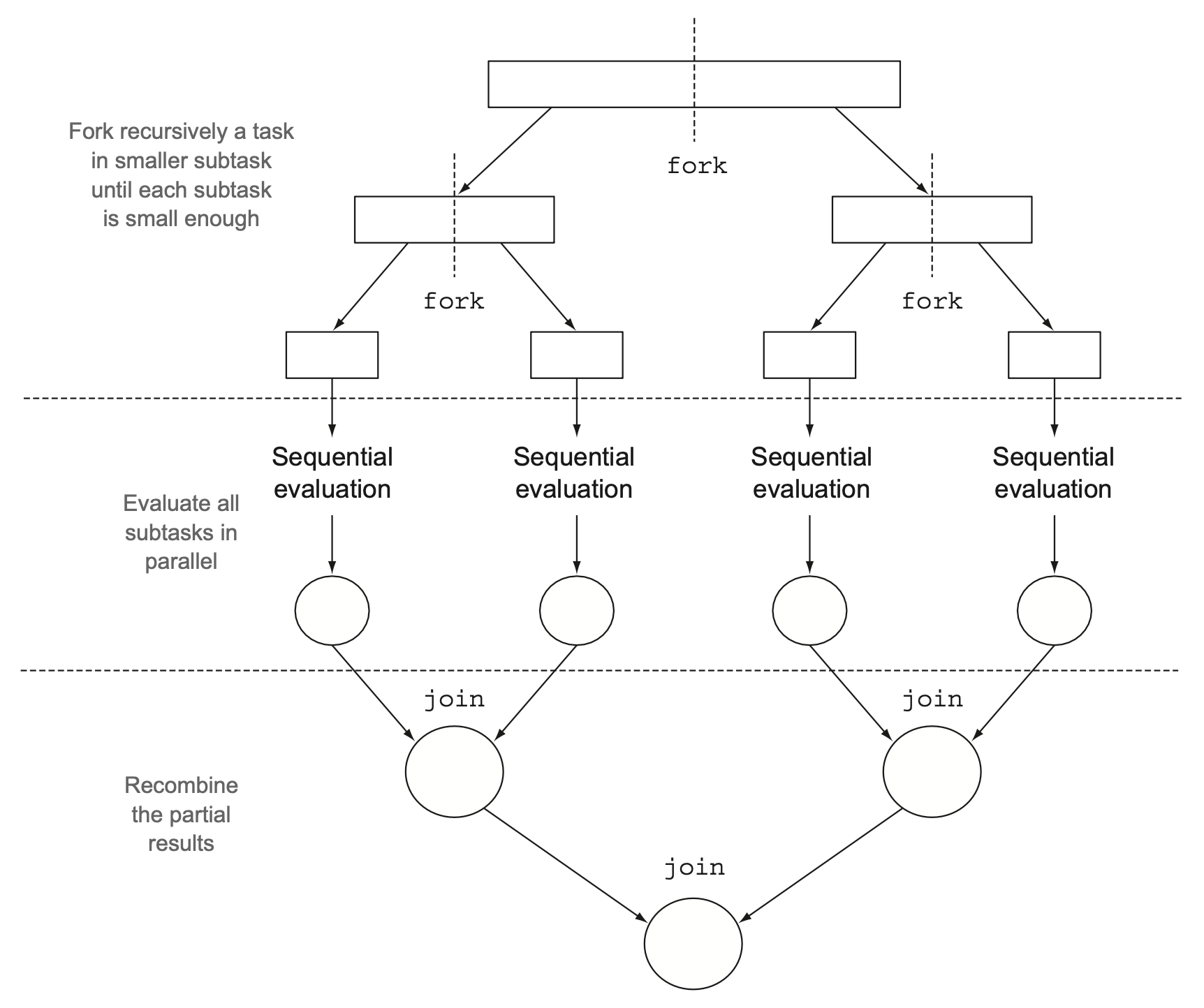 320 |
321 |
322 |
320 |
321 |
322 |
323 |
324 |
325 | ### ForkJoinSumCalculator
326 |
327 | 포크/조인 프레임워크를 이용해서 n까지의 자연수 덧셈 작업을 병렬로 수행하는 방법은 다음과 같다.
328 |
329 | 코드 : [src/main/java/chapter07/forkjoin](/src/main/java/chapter07/forkjoin)
330 |
331 |
332 |
333 | 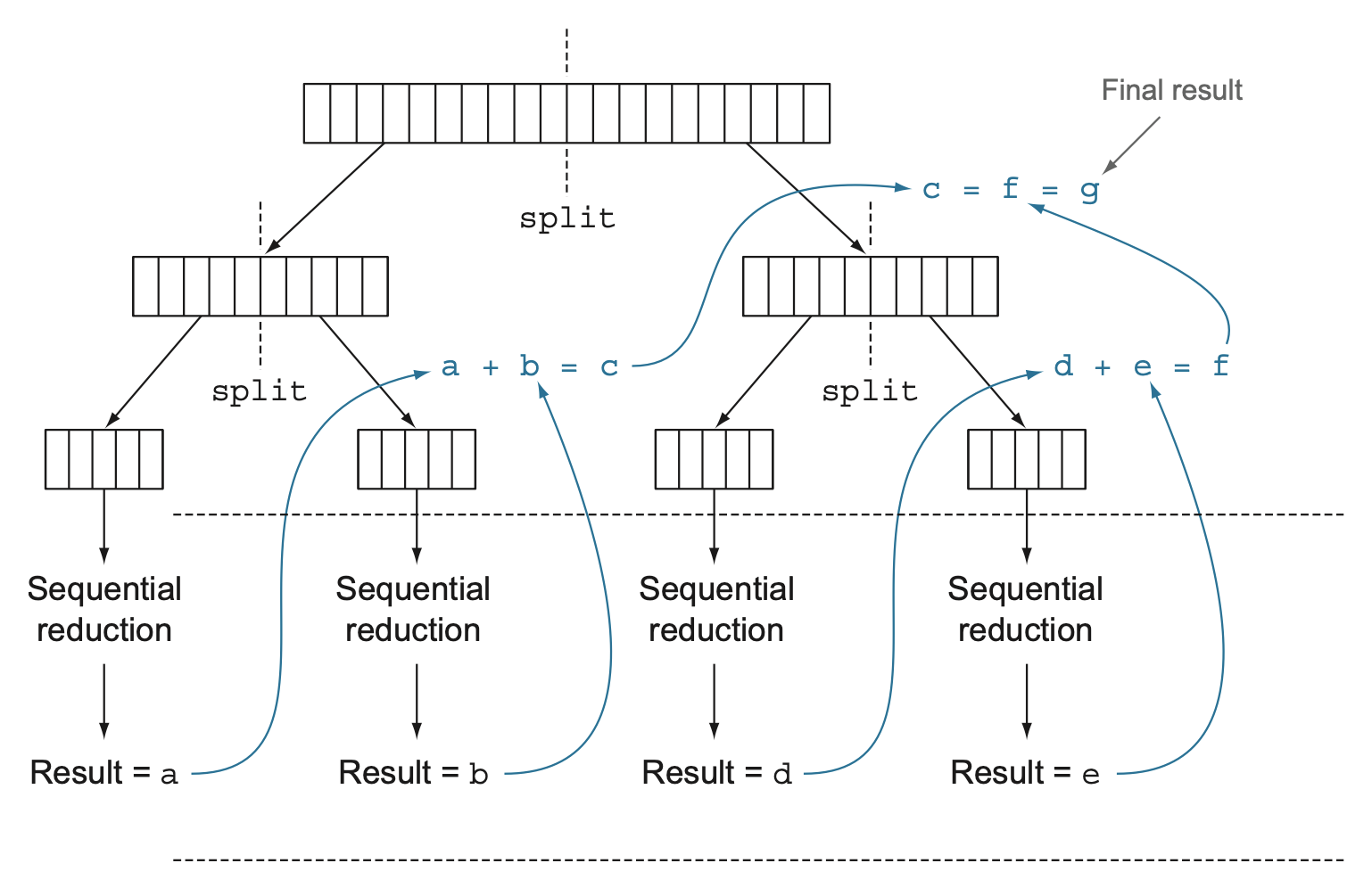 334 |
335 |
336 |
334 |
335 |
336 |
337 |
338 |
339 | 성능을 측정해보면 병렬 스트림을 이용할 때보다 성능이 나빠진 것을 볼 수 있다.
340 |
341 | 이는 `ForkJoinSumCalculator` 태스크에서 사용할 수 있도록 전체 스트림을 `long[]`으로 변환했기 때문이다.
342 |
343 |
344 |
345 |
346 | ## 7.2.2 포크/조인 프레임워크를 제대로 사용하는 방법
347 |
348 | ### 두 서브태스크가 모두 시작된 다음에 join을 호출해야 한다
349 |
350 | `join` 메서드를 태스크에 호출하면 **태스크가 생산하는 결과가 준비될 때까지** 호출자를 블록(block)시킨다.
351 |
352 |
353 |
354 | ### RecursiveTask 내에서는 ForkJoinPool의 invoke 메서드를 사용하지 말아야 한다
355 |
356 | 대신 `compute`나 `fork` 메서드를 직접 호출할 수 있다.
357 |
358 | **순차 코드에서 병렬 계산을 시작할 때만** `invoke`를 사용한다.
359 |
360 |
361 |
362 | ### 서브태스크에 fork 메서드를 호출해서 ForkJoinPool의 일정을 조절할 수 있다
363 |
364 | 왼쪽 작업과 오른쪽 작업 모두에 `fork` 메서드를 호출하는 것이 자연스러울 것 같지만
365 | 한쪽 작업에는 fork를 호출하는 것보다는 `compute`를 호출하는 것이 효율적이다.
366 |
367 | 그러면 두 서브태스크의 **한 태스크에는 같은 스레드를 재사용할 수 있으므로** 풀에서 불필요한 태스크를 할당하는 오버헤드를 피할 수 있다.
368 |
369 |
370 |
371 | ### 멀티코어에 포크/조인 프레임워크를 사용하는 것이 순차 처리보다 무조건 빠를 거라는 생각은 버려야 한다
372 |
373 | 병렬 처리로 성능을 개선하려면 태스크를 여러 독립적인 서브태스크로 분할할 수 있어야 한다.
374 |
375 | 각 서브태스크의 실행시간은 새로운 태스크를 포킹하는 데 드는 시간보다 길어야 한다.
376 |
377 |
378 |
379 |
380 | ## 7.2.3 작업 훔치기
381 |
382 | > 💡 포크/조인 분할 전략에서는 주어진 서브태스크를 더 분할할 것인지 결정할 기준을 정해야 한다.
383 |
384 |
385 |
386 | 포크/조인 프레임워크에서는 `작업 훔치기(work stealing) 기법`을 통해 ForkJoinPool의 모든 스레드를 거의 공정하게 분배한다.
387 |
388 |
389 |
390 | 각각의 스레드는 자신에게 할당된 태스크를 포함하는 `이중 연결 리스트(doubly linked list)`를 참조하면서 **작업이 끝날 때마다 큐의 헤드에서 다른 태스크를 가져와서 작업을 처리한다.**
391 |
392 | 한 스레드는 다른 스레드보다 자신에게 할당된 태스크를 더 빨리 처리할 수 있고, 할일이 없어진 스레드는 다른 스레드 큐의 꼬리에서 작업을 훔쳐온다.
393 |
394 |
395 |
396 | 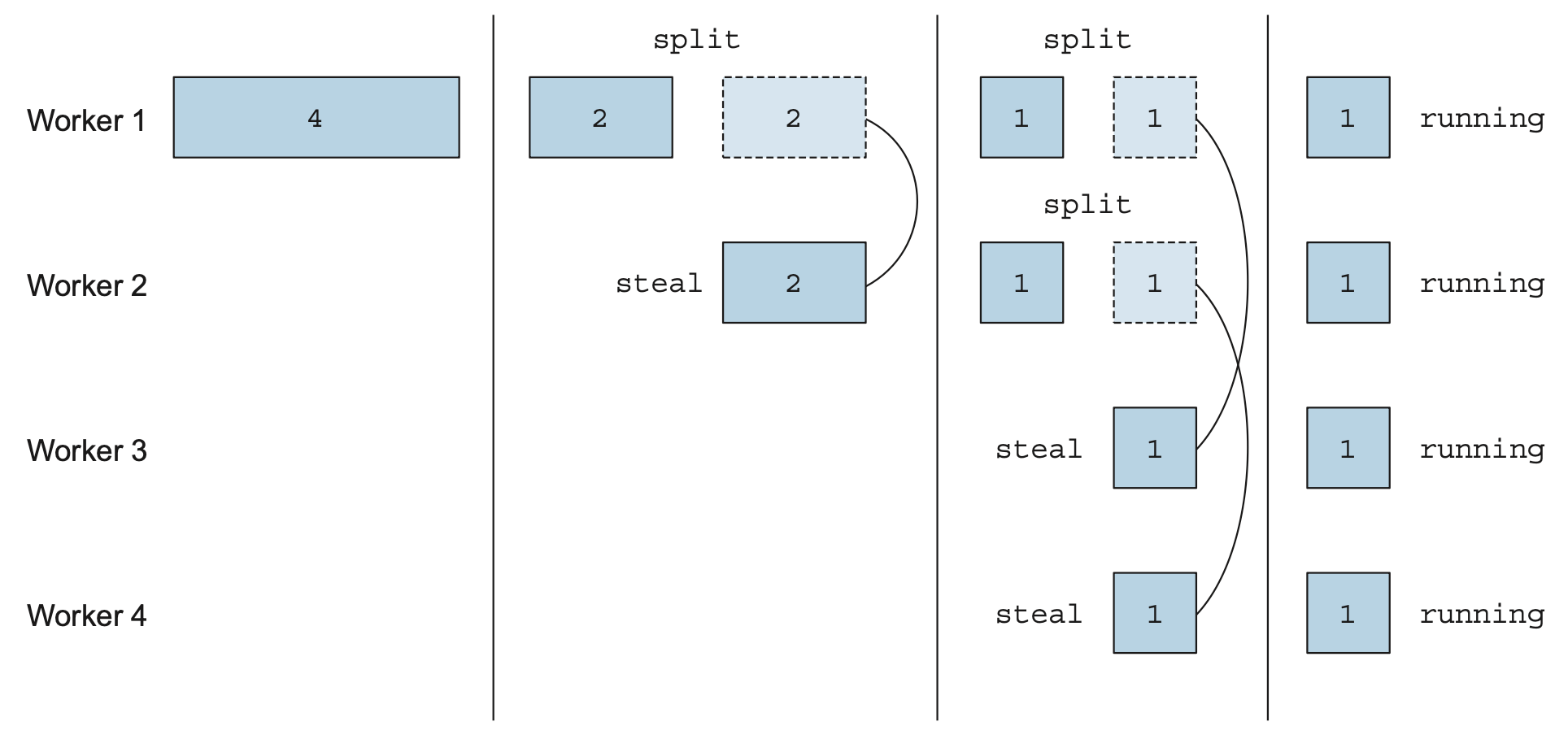 397 |
398 |
397 |
398 |
399 |
400 |
401 | 풀에 있는 작업자 스레드의 태스크를 재분배하고 균형을 맞출 때 작업 훔치기 알고리즘을 사용한다.
402 |
403 | 하지만 우리는 분할 로직을 개발하지 않고도 병렬 스트림을 이용할 수 있었다.
404 |
405 | 즉, 스트림을 자동으로 분할해주는 기능이 존재한다. (`Spliterator`)
406 |
407 |
408 |
409 |
410 |
411 | # 7.3 Spliterator 인터페이스
412 |
413 | 자바 8은 `Spliterator(splitable iterator, 분할할 수 있는 반복자)`라는 새로운 인터페이스를 제공한다.
414 |
415 | Iterator처럼 소스의 요소 탐색 기능을 제공하지만, 병렬 작업에 특화되어 있다.
416 |
417 |
418 |
419 | 자바 8은 컬렉션 프레임워크에 포함된 모든 자료구조에 사용할 수 있는 디폴트 Spliterator 구현을 제공한다.
420 |
421 | 컬렉션은 `spliterator`라는 메서드를 제공하는 Spliterator 인터페이스를 구현한다.
422 |
423 | ```java
424 | public interface Spliterator
433 |
434 |
435 | ## 7.3.1 분할 과정
436 |
437 | 스트림을 여러 스트림으로 분할하는 과정은 재귀적으로 일어난다.
438 |
439 |
440 |
441 |  442 |
443 |
442 |
443 |
444 |
445 |
446 | 이 분할 과정은 `characteristics` 메서드로 정의하는 **Spliterator의 특성**에 영향을 받는다.
447 |
448 |
449 |
450 | ### Spliterator 특성
451 |
452 |  453 |
454 |
453 |
454 |
455 |
456 |
457 |
458 | ## 7.3.2 커스텀 Spliterator 구현하기
459 |
460 | 문자열의 단어 수를 계산하는 메서드를 구현해보자.
461 |
462 | 전체 코드 : [src/main/java/chapter07/wordcount](/src/main/java/chapter07/wordcount)
463 |
464 |
465 |
466 | ### WordCounter
467 |
468 | 코드 : src/main/java/chapter07/wordcount/WordCounter.java
469 |
470 |
471 |
472 |  473 |
474 |
473 |
474 |
475 |
476 |
477 | 하지만 이것을 실행해보면 원하는 결과가 나오지 않는다.
478 |
479 | 원래 문자열을 **임의의 위치에서 둘로 나누다보니** 하나의 단어를 둘로 계산하는 상황이 발생할 수 있기 때문이다.
480 |
481 |
482 |
483 | > 💡 순차 스트림을 병렬 스트림으로 바꿀 때 스트림 분할 위치에 따라 잘못된 결과가 나올 수 있다.
484 |
485 |
486 |
487 | ### WordCounterSpliterator
488 |
489 | 문자열을 단어가 끝나는 위치에서만 분할하는 방법으로 위의 문제를 해결할 수 있다.
490 |
491 | 코드 : [src/main/java/chapter07/wordcount/WordCounterSpliterator.java](/src/main/java/chapter07/wordcount/WordCounterSpliterator.java)
492 |
493 |
494 |
495 | Spliterator는 첫 번째 탐색 시점, 첫 번째 분할 시점, 또는 첫 번째 예상 크기(estimatedSize) **요청 시점에 요소의 소스를 바인딩할 수 있다.**
496 |
497 | 이와 같은 동작을 `늦은 바인딩 Spliterator`라고 부른다.
498 |
--------------------------------------------------------------------------------
/Chapter_08/README.md:
--------------------------------------------------------------------------------
1 | # Chapter8. 컬렉션 API 개선
2 |
3 | ## 8.1 컬렉션 팩토리
4 |
5 | 자바 8 버전에서는 `Arrays.asList()` 메서드를 이용하여 리스트를 만들 수 있다.
6 |
7 | e.g.
8 |
9 | ```java
10 | List
15 |
16 | ### UnsupportedOperationException 예외 발생
17 |
18 | 내부적으로 고정된 크기의 변환할 수 있는 배열로 구현되어있기 때문에 위처럼 만든 List는 요소를 갱신하는 작업은 괜찮지만, 요소를 추가하거나 삭제하는 작업을 할 수 없다.
19 |
20 |
21 |
22 | ### 8.1.1 리스트 팩토리
23 |
24 | 자바 9에서는 List.of 팩토리 메서드를 이용해서 간단하게 리스트를 만들 수 있다.
25 |
26 | 그러나 이렇게 만들어진 리스트는 `add()`를 사용하면 `UnsupportedOperationException` 예외가 발생하며, `set()` 메서드로 아이템을 바꾸려해도 비슷한 예외가 발생한다.
27 |
28 | 이런 제약은 의도치 않게 컬렉션이 변하는 것을 막아 꼭 나쁘지만은 않다.
29 |
30 | 리스트를 바꿔야하는 상황에서는 직접 리스트를 만들면 된다.
31 |
32 |
33 |
34 | ### 오버로딩 vs 가변 인수
35 |
36 | List 인터페이스를 보면 List.of의 다양한 오버로드 버전이 있다. (Set.of와 Map.of에서도 이와 같은 패턴이 등장함)
37 |
38 | ```java
39 | static
44 |
45 | 왜 다음처럼 다중 요소를 받도록 만들지 않았을까?
46 |
47 | ```java
48 | static
58 |
59 | ### 8.1.2 집합 팩토리
60 |
61 | `List.of` 메서드와 같은 방식으로 `Set.of` 메서드를 이용해 집합을 만들 수 있다.
62 |
63 | 그러나 중복된 요소를 포함하여 만들면 예외를 발생시킨다.
64 |
65 |
66 |
67 | ### 8.1.3 맵 팩토리
68 |
69 | 맵을 만들기 위해서는 키와 값이 필요하다.
70 |
71 | `Map.of` ,`Map.ofEntries` 두가지 방법으로 맵을 초기화할 수 있다.
72 |
73 | e.g.
74 |
75 | ```java
76 | Map
85 |
86 | ## 8.2 리스트와 집합 처리
87 |
88 | 자바 8에서는 List, Set 인터페이스에 다음과 같은 메서드를 추가했다.
89 |
90 | - removeIf : 프레디케이트를 만족하는 요소를 제거한다.
91 | - replaceAll : 리스트에서 이용할 수 있는 기능으로 `UnaryOperator` 함수를 이용해 요소를 바꾼다.
92 | - sort : List 인터페이스에서 제공하는 기능으로 리스트를 정렬한다.
93 |
94 | 이 메서드들은 새로운 컬렉션을 만드는 것이 아니라 호출한 컬렉션 자체를 바꾼다.
95 |
96 |
97 |
98 | ### 8.2.1 removeIf 메서드
99 |
100 | 트랜잭션 리스트에서 숫자로 시작되는 참조 코드를 가진 트랜잭션을 삭제하는 코드가 있을 때, for-each 루프를 사용하여 트랜잭션 리스트에서 트랜잭션을 remove() 하면 에러를 일으킨다.
101 |
102 | ```java
103 | for (Transaction transaction : transactions) {
104 | if(Character.isDigit(transaction.getReferenceCode().charAt(0))) {
105 | transactions.remove(transaction);
106 | }
107 | }
108 |
109 | // 위 코드의 실질적인 코드
110 | // for-each 루프는 Iterator 객체를 사용한다.
111 | // Iterator의 상태와 transactions의 상태는 서로 동기화되지 않아 오류를 발생시킨다.
112 |
113 | for (Iterator
136 |
137 |
138 | ### 8.2.2 replaceAll 메서드
139 |
140 | 스트림 API를 이용해 리스트의 각 요소를 바꿔 새로운 객체를 만들어낼 수 있었다.
141 |
142 | 그러나 우리는 기존의 컬렉션 요소를 바꾸고 싶고, 이를 위해서라면 `removeIf` 해결 1번처럼 `iterator.set()` 을 해야만한다.
143 |
144 | replaceAll을 사용해 이를 간단히 바꿀 수 있다.
145 |
146 | ```java
147 | // a1, b1,c1 -> A1, B1, C1
148 | referenceCodes.stream().map(code -> Character.toUpperCase(code.charAt(0)) + code.substring(1))
149 | .collect(Collectors.toList())
150 | .forEach(System.out::println);
151 |
152 | // 스트림의 map과 비슷하다고 보면 된다.
153 | referenceCodes.replaceAll(code -> Character.toUpperCase(code.charAt(0)) + code.substring(1));
154 | ```
155 |
156 |
157 |
158 | ## 8.3 맵 처리
159 |
160 | 자바 8에서는 `Map` 인터페이스에 몇 가지 디폴트 메서드를 추가했다.
161 |
162 | ### 8.3.1 forEach 메서드
163 |
164 | 맵에서 키와 값을 반복하는 작업을 위해 `forEach` 메서드를 제공한다.
165 |
166 | ```java
167 | // forEach 메서드 미사용
168 | for(Map.Entry
180 |
181 | ### 8.3.2 정렬 메서드
182 |
183 | ```java
184 | Map
191 |
192 | ### HashMap 성능
193 |
194 | 기존의 맵의 항목은 많은 키가 같은 해시코드를 반환하는 상황이 되면 O(n)의 시간이 걸리는 `LinkedList`로 버킷을 반환해야 하므로 성능이 저하되었다.
195 |
196 | 최근에는 버킷이 너무 커지면 O(log(n))의 시간이 소요되는 정렬된 트리를 이용해 동적으로 치환해 충돌이 일어나는 요소 반환 성능을 개선했다.
197 |
198 | (키가 `Comparable` 형태여야 정렬된 트리를 이용할 수 있다.)
199 |
200 |
201 |
202 | ### 8.3.3 getOrDefault 메서드
203 |
204 | 키가 존재하지 않으면 결과가 널이 나오므로 문제가 될 수 있는데 `getOrDefault` 메서드는 이 문제를 해결한다.
205 |
206 | ```java
207 | Map
217 |
218 | ### 8.3.4 계산 패턴
219 |
220 | 키가 존재하는지 여부에 따라 어떤 동작을 실행하고 결과를 저장해야하는 상황이 필요한 때가 있다.
221 |
222 | 다음의 3가지 연산이 이런 상황에 도움이 된다.
223 |
224 | - `computeIfAbsent` : 제공된 키에 해당하는 값이 없으면 키를 이용해 새 값을 계산하고 맵에 추가한다.
225 | - `computeIfPresent` : 제공된 키가 존재하면 새 값을 계산하고 맵에 추가한다.
226 | - `compute` : 제공된 키로 새 값을 계산하고 맵에 저장한다.
227 |
228 |
229 |
230 | e.g., Map을 이용한 캐시 구현
231 |
232 | ```java
233 | // 캐시
234 | Map
249 |
250 | e.g. 키가 존재하지 않으면 값을 반환
251 |
252 | ```java
253 | // 키가 있었다면 영화 리스트를 반환하여 반환된 리스트에 add
254 | // 키가 없었다면 새로운 리스트에 add
255 | friendsToMovies.computeIfAbsent("Raphael", name -> new ArrayList<>()).add("Star Wars");
256 | ```
257 |
258 |
259 |
260 | ### 8.3.5 삭제 패턴
261 |
262 | 자바 8에서는 키가 특정한 값과 연관되었을 때만 항목을 제거하는 오버로드 버전 메서드를 제공한다.
263 |
264 | ```java
265 | // 자바 8 이전
266 | String key = "Raphael";
267 | String value = "Jack Reacher 2";
268 | if (favouriteMovies.containsKey(key) && Objects.equals(favouriteMovies.get(key), value)) {
269 | favouriteMovies.remove(key);
270 | return true;
271 | } else {
272 | return false;
273 | }
274 |
275 | // 자바 8 이후
276 | favouriteMovies.remove(key, value);
277 | ```
278 |
279 |
280 |
281 | ### 8.3.6 교체 패턴
282 |
283 | 맵의 항목을 바꾸는데 사용하는 메서드
284 |
285 | - `replaceAll` : BiFunction을 적용한 결과로 각 항목의 값을 교체한다.
286 | - `replace` : 키가 존재하면 맵의 값을 바꾼다. 키가 특정 값으로 매핑되었을 때만 값을 교체하는 오버로드 버전도 있다.
287 |
288 | e.g.
289 |
290 | ```java
291 | Map
299 |
300 | ### 8.3.7 합침
301 |
302 | `putAll` 메서드를 이용하여 두 맵을 합칠 수 있다.
303 |
304 | 그러나 `putAll`은 중복된 키가 있다면 제대로 동작하지 않는다.
305 |
306 | 이때는 중복된 키를 어떻게 합칠지 결정하는 `BiFunction`을 인수로 받는 `merge` 메서드를 사용한다.
307 |
308 | e.g.
309 |
310 | ```java
311 | // putAll
312 | Map
333 |
334 | ## 8.4 개선된 ConcurrentHashMap
335 |
336 | ConcurrentHashMap 클래스는 동시성 친화적이며 최신 기술을 반영했다.
337 |
338 | 내부 자료구조의 특정 부분만 잠궈 동시 추가, 갱신 작업을 허용하여 HashTable 버전에 비해 읽기 쓰기 연산 성능이 월등하다.
339 |
340 | ### 8.4.1 리듀스와 검색
341 |
342 | 스트림에서 봤던 것과 비슷한 종류의 3가지 연산을 지원한다.
343 |
344 | - `forEach` : 키,값 쌍에 주어진 액션을 실행
345 | - `reduce` : 키,값 쌍에 제공된 리듀스 함수를 이용해 결과를 합침
346 | - `search` : 널이 아닌 값을 반환할 때까지 각 키,값 쌍에 함수를 적용
347 |
348 | 모든 연산은 (키,값), (키), (값), (엔트리) 에 대해서 연산을 할 수 있도록 각종 메서드를 제공한다. (forEach, forEachKey, forEachValues, forEachEntry 등)
349 |
350 |
351 |
352 | 이 연산은 `ConcurrentHashMap`의 상태를 잠그지 않고 연산을 수행하여 연산에 제공한 함수는 계산이 진행되는 동안 바뀔 수 있는 값, 객체 등에 의존하지 않아야 한다.
353 |
354 | 또한, 연산에 병렬성 기준값을 지정해야하는데, 맵의 크기가 기준값보다 작으면 순차적으로 연산을 실행한다.
355 |
356 | 1로 지정하면 공통 스레드 풀을 이용해 병렬성을 극대화하고, `Long.MAX_VALUE`를 기준값으로 설정하면 한개의 스레드로 연산을 실행한다.
357 |
358 |
359 |
360 | e.g.
361 |
362 | ```java
363 | ConcurrentHashMap
372 |
373 | ### 8.4.2 계수
374 |
375 | 기존의 size 메서드 대신 맵의 매핑 개수를 반환하는 `mappingCount` 메서드를 제공한다.
376 |
377 | 이를 통해 매핑의 개수가 int의 범위를 넘어서는 이후의 상황을 대처할 수 있게 된다.
378 |
379 |
380 |
381 | ### 8.4.3 집합뷰
382 |
383 | `ConcurrentHashMap`을 집합 뷰로 반환하는 `keySet` 메서드를 제공한다.
384 |
385 | 맵을 바꾸면 집합도 바뀌고 집합을 바뀌면 맵도 영향을 받는다.
386 |
387 | `newKeySet`이라는 새 메서드를 이용해 `ConcurrentHashMap`으로 유지되는 집합을 만들 수도 있다.
--------------------------------------------------------------------------------
/Chapter_13/README.md:
--------------------------------------------------------------------------------
1 | # Chapter 13. 디폴트 메서드
2 |
3 |
4 |
5 | 전통적인 자바에서는 인터페이스와 관련 메서드는 한 몸처럼 구성된다.
6 |
7 | 인터페이스를 구현하는 클래스는 인터페이스에서 정의하는 모든 메서드 구현을 제공하거나 아면 슈퍼클래스의 구현을 상속받아야 한다.
8 |
9 |
10 |
11 | 따라서 만약 새로운 메서드를 추가하는 등 인터페이스를 바꾸었을 경우 이전에 해당 인터페이스를 구현했던 클래스들도 전부 고쳐야 한다는 문제가 존재한다.
12 |
13 | - **바이너리 호환성**은 유지되어 새로운 메서드 구현이 없이도 기존 클래스 파일 구현은 잘 동작한다.
14 | - 하지만 새로운 메서드를 호출하는 순간 `AbstractMethodError`가 발생하게 되며,
15 | 전체 애플리케이션을 재빌드할 경우 컴파일 에러가 발생한다.
16 |
17 |
18 |
19 | #### [참고] 바이너리 호환성, 소스 호환성, 동작 호환성
20 |
21 | - 바이너리 호환성
22 | - 뭔가를 바꾼 이후에도 에러 없이 기존 바이너리가 실행될 수 있는 상황을 말한다.
23 | - 바이너리 실행에는 인증(verification), 준비(preparation), 해석(resolution) 등의 과정이 포함된다.
24 |
25 |
26 | - 소스 호환성
27 | - 코드를 고쳐도 기존 프로그램을 성공적으로 재컴파일할 수 있음을 의미한다.
28 |
29 |
30 |
31 | - 동작 호환성
32 | - 코드를 바꾼 다음에도 같은 입력값이 주어지면 프로그램이 같은 동작을 실행한다는 의미다.
33 |
34 |
35 |
36 | ---
37 |
38 |
39 |
40 | 자바 8에서는 이 문제를 해결하기 위해 인터페이스를 정의하는 두 가지 방법을 제공한다.
41 |
42 | 1. 인터페이스 내부에 `정적 메서드(static method)`를 사용
43 | 2. 인터페이스의 기본 구현을 제공할 수 있도록 `디폴트 메서드(default method)` 기능을 사용
44 |
45 |
46 |
47 | `디폴트 메서드`를 이용하면 인터페이스의 기본 구현을 그대로 상속하므로 (즉, 바뀐 인터페이스에서 자동으로 기본 구현을 제공하므로)
48 | 인터페이스에 자유롭게 새로운 메서드를 추가할 수 있게 되며, 기존 코드를 고치지 않아도 된다.
49 |
50 |
51 |
52 |  53 |
54 |
53 |
54 |
55 |
56 |
57 |
58 |
59 | # 13.2 디폴트 메서드란 무엇인가?
60 |
61 | 자바 8에서는 호환성을 유지하면서 API를 바꿀 수 있도록 새로운 기능인 `디폴트 메서드(default method)`를 제공한다.
62 |
63 | - 인터페이스를 구현하는 클래스에서 구현하지 않은 메서드는 **인터페이스 자체에서 기본으로 제공한다.**
64 | - 디폴트 메서드는 `default`라는 키워드로 시작하며, 다른 클래스에 선언된 메서드처럼 메서드 바디를 포함한다.
65 |
66 | ```java
67 | default void sort(Comparator c) { // default 키워드는 해당 메서드가 디폴트 메서드임을 가리킴
68 | Collections.sort(this, c);
69 | }
70 | ```
71 |
72 |
73 |
74 | >💡 함수형 인터페이스는 오직 하나의 추상 메서드를 포함하는데, 디폴트 메서드는 추상 메서드에 해당하지 않는다.
75 |
76 |
77 |
78 | e.g., 모든 컬렉션에서 사용할 수 있는 `removeIf` 메서드를 추가하려면?
79 |
80 | - removeIf 메서드 : 주어진 프레디케이트와 일치하는 모든 요소를 컬렉션에서 제거하는 기능을 수행한다.
81 | - 모든 컬렉션 클래스는 `java.util.Collection` 인터페이스를 구현한다.
82 | - 따라서 Collection 인터페이스에 디폴트 메서드를 추가함으로써 소스 호환성을 유지할 수 있다.
83 |
84 | ```java
85 | default boolean removeIf(Predicate filter) {
86 | boolean removed = false;
87 | Iterator
99 |
100 |
101 | ## 추상 클래스와 자바 8의 인터페이스
102 |
103 | - 클래스는 하나의 추상 클래스만 상속받을 수 있지만 인터페이스를 여러 개 구현할 수 있다.
104 | - 추상 클래스는 인스턴스 변수(필드)로 공통 상태를 가질 수 있으나, 인터페이스는 인스턴스 변수를 가질 수 없다.
105 |
106 |
107 |
108 |
109 |
110 | # 13.3 디폴트 메서드 활용 패턴
111 |
112 | - 선택형 메서드(optional method)
113 | - 동작 다중 상속(multiple inheritance of behavior)
114 |
115 |
116 |
117 | ## 13.3.1 선택형 메서드
118 |
119 | 인터페이스를 구현하는 클래스에서 메서드의 내용이 비어있는 상황을 본 적이 있을 것이다.
120 |
121 | 디폴트 메서드를 이용하면 그러한 메서드에 기본 구현을 제공할 수 있으므로, 인터페이스를 구현하는 클래스에서 빈 구현을 제공할 필요가 없다.
122 |
123 | 따라서 불필요한 코드를 줄일 수 있다.
124 |
125 |
126 |
127 | ## 13.3.2 동작 다중 상속
128 |
129 | 디폴트 메서드를 이용하면 기존에는 불가능했던 동작 다중 상속 기능도 구현할 수 있다.
130 |
131 | 자바에서 클래스는 한 개의 다른 클래스만 상속할 수 있지만 인터페이스는 여러 개 구현할 수 있기 때문이다.
132 |
133 | #### 단일 상속
134 |
135 |  136 |
137 |
136 |
137 |
138 |
139 |
140 | #### 다중 상속
141 |
142 |  143 |
144 |
143 |
144 |
145 |
146 |
147 | ### 다중 상속 형식
148 |
149 | e.g., 자바 API에 정의된 ArrayList 클래스
150 |
151 | ```java
152 | public class ArrayList
159 |
160 | > 기능이 중복되지 않는 최소의 인터페이스를 유지한다면 우리 코드에서 동작을 쉽게 재사용하고 조합할 수 있다.
161 |
162 |
163 |
164 |
165 | ## 옳지 못한 상속
166 |
167 | 상속으로 코드 재사용 문제를 모두 해결할 수 있는 것은 아니다.
168 | e.g., 한 개의 메서드를 재사용하기 위해 100개의 메서드와 필드가 정의되어 있는 클래스를 상속받는 것
169 |
170 | 이럴 때는 `델리게이션(delegation)`, 즉 멤버 변수를 이용해서 클래스에서 필요한 메서드를 직접 호출하는 메서드를 작성하는 것이 좋다.
171 |
172 |
173 |
174 |
175 |
176 | # 13.4 해석 규칙
177 |
178 | 자바의 클래스는 하나의 부모 클래스만 상속받을 수 있지만 여러 인터페이스를 동시에 구현할 수 있다.
179 |
180 | 만약 어떤 클래스가 같은 디폴트 메서드 시그니처를 포함하는 두 인터페이스를 구현하는 상황이라면, 클래스는 어떤 인터페이스의 디폴트 메서드를 사용하게 될까?
181 |
182 |
183 |
184 | ## 13.4.1 알아야 할 세 가지 해결 규칙
185 |
186 | 다른 클래스나 인터페이스로부터 같은 시그니처를 갖는 메서드를 상속받을 때는 세 가지 규칙을 따라야 한다.
187 |
188 |
189 |
190 | > 1️⃣ 클래스가 항상 이긴다.
191 |
192 | 클래스나 슈퍼클래스에서 정의한 메서드가 디폴트 메서드보다 우선권을 갖는다.
193 |
194 |
195 |
196 | > 2️⃣ 1번 규칙 이외의 상황에서는 서브인터페이스가 이긴다.
197 |
198 | 상속관계를 갖는 인터페이스에서 같은 시그니처를 갖는 메서드를 정의할 때는 서브인터페이스가 이긴다.
199 | (즉, B가 A를 상속받는다면 B가 A를 이김)
200 |
201 |
202 |
203 | > 3️⃣ 여전히 디폴트 메서드의 우선순위가 결정되지 않았다면 여러 인터페이스를 상속받는 클래스가 명시적으로 디폴트 메서드를 오버라이드하고 호출해야 한다.
204 |
205 |
206 |
207 |
208 |
209 | ## 13.4.2 디폴트 메서드를 제공하는 서브인터페이스가 이긴다.
210 |
211 | ### 예시 1
212 |
213 | ```java
214 | public interface A {
215 | default void hello() {
216 | System.out.println("Hello from A");
217 | }
218 | }
219 |
220 | public interface B extends A {
221 | default void hello() {
222 | System.out.println("Hello from B");
223 | }
224 | }
225 |
226 | public class C implements B, A {
227 | public static void main(String[] args) {
228 | new C().hello();
229 | }
230 | }
231 | ```
232 |
233 | - B와 A는 hello라는 디폴트 메서드를 정의하며, B가 A를 상속받는다.
234 | - 클래스 C는 B와 A를 구현한다.
235 |
236 |
237 |
238 |  239 |
240 |
239 |
240 |
241 |
242 |
243 | 컴파일러는 누구의 hello 메서드 정의를 사용할까?
244 |
245 | 13.4.1의 규칙 2에서는 서브인터페이스가 이긴다고 했고, B가 A를 상속받았으므로 컴파일러는 B의 hello를 선택한다. (’Hello from B’가 출력됨)
246 |
247 |
248 |
249 | ### 예시 2
250 |
251 | C가 D를 상속받는다면 어떤 일이 일어날까?
252 |
253 | ```java
254 | public class D implements A { }
255 |
256 | public class C extends D implements B, A {
257 | public static void main(String[] args) {
258 | new C().hello();
259 | }
260 | }
261 | ```
262 |
263 |
264 |
265 |  266 |
267 |
266 |
267 |
268 |
269 |
270 | - 규칙 1에서는 클래스의 메서드 구현이 이긴다고 했다.
271 | - D는 hello를 오버라이드하지 않았고 단순히 인터페이스 A를 구현했다.
272 | - 따라서 D는 인터페이스 A의 디폴트 메서드 구현을 상속받는다.
273 |
274 |
275 | - 규칙 2에서는 **클래스나 슈퍼클래스에 메서드 정의가 없을 때는** 디폴트 메서드를 정의하는 서브인터페이스가 선택된다.
276 |
277 |
278 |
279 | 따라서 컴파일러는 인터페이스 A의 hello나 인터페이스 B의 hello 둘 중 하나를 선택해야 한다.
280 |
281 | 여기서 B가 A를 상속받는 관계이므로 이번에도 컴파일러는 B의 hello를 선택한다.
282 |
283 |
284 |
285 | ### 예시 3
286 |
287 | D가 명시적으로 A의 hello 메서드를 오버라이드한다면 어떤 일이 일어날까?
288 |
289 | ```java
290 | public class D implements A {
291 | void hello() {
292 | System.out.println("Hello from D");
293 | }
294 | }
295 |
296 | public class C extends D implements B, A {
297 | public static void main(String[] args) {
298 | new C().hello();
299 | }
300 | }
301 | ```
302 |
303 | 규칙 1에 의해 슈퍼클래스의 메서드 정의가 우선권을 갖기 때문에 ‘Hello from D’가 출력된다.
304 |
305 |
306 |
307 | 만약 D가 다음처럼 구현되었다면 A에서 디폴트 메서드를 제공함에도 불구하고 C는 hello를 구현해야 한다.
308 |
309 | ```java
310 | public class D implements A {
311 | public abstract void hello();
312 | }
313 | ```
314 |
315 |
316 |
317 |
318 | ## 13.4.3 충돌 그리고 명시적인 문제 해결
319 |
320 | 이번에는 B가 A를 상속받지 않는 상황이라고 가정하자.
321 |
322 | ```java
323 | public interface A {
324 | default void hello() {
325 | System.out.println("Hello from A");
326 | }
327 | }
328 |
329 | public interface B {
330 | default void hello() {
331 | System.out.println("Hello from B");
332 | }
333 | }
334 |
335 | public class C implements B, A { }
336 | ```
337 |
338 |
339 |
340 |  341 |
342 |
341 |
342 |
343 |
344 |
345 | 인터페이스 간에 상속관계가 없으므로 2번 규칙을 적용할 수 없기에 A와 B의 hello 메서드를 구별할 기준이 없다.
346 |
347 | 따라서 자바 컴파일러는 어떤 메서드를 호출해야 할지 알 수 없으므로 다음과 같은 에러를 발생한다.
348 |
349 | ```
350 | Error: class C inherits unrelated defaults for hello() from types B and A.
351 | ```
352 |
353 |
354 |
355 | ### 충돌 해결
356 |
357 | 클래스와 메서드 관계로 디폴트 메서드를 선택할 수 없는 상황에서는 선택할 수 있는 방법이 없다.
358 |
359 | 개발자가 직접 클래스 C에서 사용하려는 메서드를 명시적으로 선택해야 한다.
360 |
361 |
362 |
363 | 즉, 클래스 C에서 hello 메서드를 오버라이드한 다음에 호출하려는 메서드를 명시적으로 선택해야 한다.
364 |
365 | ```java
366 | public class C implements B, A {
367 | void hello() {
368 | B.super.hello();
369 | }
370 | }
371 | ```
372 |
373 |
374 |
375 |
376 | ## 13.4.4 다이아몬드 문제
377 |
378 | ### 예제 1
379 |
380 | 1️⃣ D는 B와 C 중 누구의 디폴트 메서드 정의를 상속받을까?
381 |
382 | ```java
383 | public interface A {
384 | default void hello() {
385 | System.out.println("Hello from A");
386 | }
387 | }
388 |
389 | public interface B extends A { }
390 |
391 | public interface C extends A { }
392 |
393 | public class D implements B, C {
394 | public static void main(String[] args) {
395 | new D().hello();
396 | }
397 | }
398 | ```
399 |
400 |
401 |
402 |  403 |
404 |
403 |
404 |
405 |
406 |
407 | A만 디폴트 메서드를 정의하고 있으므로 프로그램 출력 결과는 ‘Hello from A’가 된다.
408 |
409 |
410 |
411 | 2️⃣ B에도 같은 시그니처의 디폴트 메서드 hello가 있다면 2번 규칙에 의해 B가 선택된다.
412 |
413 | 3️⃣ B와 C가 모두 디폴트 메서드 hello 메서드를 정의한다면 충돌이 발생하므로, 둘 중 하나의 메서드를 명시적으로 호출해야 한다.
414 |
415 |
416 |
417 | ### 예제 2
418 |
419 | 인터페이스 C에 **추상 메서드** hello를 추가하면 어떤 일이 벌어질까?
420 |
421 | ```java
422 | public interface C extends A {
423 | void hello();
424 | }
425 | ```
426 |
427 |
428 |
429 | C는 A를 상속받으므로 C의 추상 메서드 hello가 A의 디폴트 메서드 hello보다 우선권을 갖는다.
430 |
431 | 따라서 컴파일 에러가 발생하며, 클래스 D가 어떤 hello를 사용할지 명시적으로 선택해서 에러를 해결해야 한다.
432 |
--------------------------------------------------------------------------------
/Chapter_18/README.md:
--------------------------------------------------------------------------------
1 | # Chapter 18. 함수형 관점으로 생각하기
2 |
3 |
4 |
5 | > (멀티코어 등의) 하드웨어 변경과 (데이터베이스의 질의와 비슷한 방식으로 데이터를 조작하는 등의) 프로그래머의 기대치 때문에
6 | > 결국 자바 소프트웨어 엔지니어의 프로그래밍 형식이 좀 더 `함수형`으로 다가갈 것이다.
7 |
8 |
9 |
10 | # 18.1 시스템 구현과 유지보수
11 |
12 | 함수형 프로그래밍은 `부작용 없음(no side effect)`과 `불변성(immutability)`라는 개념을 제공한다.
13 |
14 |
15 |
16 | ## 18.11 공유된 가변 데이터
17 |
18 | 많은 프로그래머는 유지보수 중 코드 크래시 디버깅 문제를 가장 많이 겪게 되며, 코드 크래시는 예상하지 못한 변숫값 때문에 발견할 수 있다.
19 |
20 | 변수가 예상하지 못한 값을 갖는 이유는 시스템이 **여러 메서드에서 공유된 가변 데이터 구조를 읽고 갱신하기 때문**이다.
21 |
22 |
23 |
24 | 공유 가변 데이터 구조를 사용하면 아래 그림처럼 프로그램 전체에서 데이터 갱신 사실을 추적하기가 어려워진다.
25 |
26 |
27 |
28 |  29 |
30 |
29 |
30 |
31 |
32 |
33 | ### 순수(pure) 메서드, 부작용 없는(side-effect free) 메서드
34 |
35 | 1. 자신을 포함하는 클래스의 상태 그리고 다른 객체의 상태를 바꾸지 않으며
36 | 2. return 문을 통해서만 자신의 결과를 반환하는 메서드를 말한다.
37 |
38 |
39 |
40 | - ‘`부작용`’은 함수 내에 포함되지 못한 기능을 말한다.
41 | - 자료구조를 고치거나 필드에 값을 할당(setter 메서드 같은 생성자 이외의 초기화 동작)
42 | - 예외 발생
43 | - 파일에 쓰기 등의 I/O 동작 수행
44 |
45 |
46 | - 불변 객체를 이용해서 부작용을 없애는 방법도 있다.
47 | - `불변 객체` : 인스턴스화한 다음에는 객체의 상태를 바꿀 수 없는 객체
48 |
49 |
50 | - 부작용 없는 시스템 컴포넌트에서는 메서드가 서로 간섭하는 일이 없으므로 잠금을 사용하지 않고도 멀티코어 병렬성을 사용할 수 있다.
51 |
52 |
53 |
54 |
55 | ## 18.1.2 선언형 프로그래밍
56 |
57 | 프로그램으로 시스템을 구현하는 방식 두 가지
58 |
59 | 1. `명령형 프로그래밍` : **작업을 ‘어떻게(how)’ 수행할 것인지**에 집중하는 형식
60 | - 고전의 객체지향 프로그래밍에서 이용하는 방식이다.
61 |
62 |
63 | 2. `선언형 프로그래밍` : **‘무엇을’ 수행할 것인지**에 집중하는 형식
64 | - 질의문 구현 방법은 라이브러리가 결정한다. (`내부 반복, internal iteration`)
65 | - e.g., 리스트에서 가장 비싼 트랜잭션을 계산하는 코드
66 |
67 | ```java
68 | Optional
73 |
74 |
75 | ## 18.1.3 왜 함수형 프로그래밍인가?
76 |
77 | 함수형 프로그래밍은 선언형 프로그래밍을 따르는 대표적인 방식이며, 부작용이 없는 계산을 지향한다.
78 |
79 | 따라서 더 쉽게 시스템을 구현하고 유지보수할 수 있게 된다.
80 |
81 |
82 |
83 |
84 |
85 | # 18.2 함수형 프로그래밍이란 무엇인가?
86 |
87 | - `함수형 프로그래밍` = 함수를 이용하는 프로그래밍
88 |
89 |
90 | - `함수` = 수학적인 함수
91 | - 함수형 프로그래밍에서 함수는 0개 이상의 인수를 가지며,
92 | 한 개 이상의 결과를 반환하지만 **부작용이 없어야 한다.**
93 | - 자바와 같은 언어에서는 바로 수학적인 함수냐 아니냐가 메서드와 함수를 구분하는 핵심이다.
94 |
95 |
96 |
97 | #### 부작용을 포함하는 함수
98 |
99 |  100 |
101 |
100 |
101 |
102 |
103 |
104 | #### 부작용이 없는 함수
105 |
106 |  107 |
108 |
107 |
108 |
109 |
110 |
111 | > ‘함수 그리고 if-then-else 등의 수학적 표현만 사용’하는 방식을 순수 함수형 프로그래밍이라고 하며
112 | > ’**시스템의 다른 부분에 영향을 미치지 않는다면** 내부적으로는 함수형이 아닌 기능도 사용’하는 방식을 함수형 프로그래밍이라 한다.
113 |
114 |
115 |
116 |
117 | ## 18.2.1 함수형 자바
118 |
119 | 실질적으로 자바로는 완벽한 순수 함수형 프로그래밍을 구현하기 어렵기에 순수 함수형이 아니라 **함수형 프로그램**을 구현할 것이다.
120 |
121 |
122 |
123 | > 1️⃣ 함수나 메서드는 **지역 변수만을 변경해야** 함수형이라 할 수 있다.
124 |
125 |
126 |
127 | > 2️⃣ 함수나 메서드에서 참조하는 객체가 있다면 그 객체는 `불변 객체`여야 한다.
128 |
129 | 즉, 객체의 모든 필드가 `final`이어야 하고 모든 참조 필드는 불변 객체를 직접 참조해야 한다.
130 |
131 |
132 |
133 | > 3️⃣ 예외적으로 메서드 내에서 생성한 객체의 필드는 갱신할 수 있다.
134 |
135 | 단, 새로 생성한 객체의 필드 갱신이 외부에 노출되지 않아야 하고, 다음에 메서드를 다시 호출한 결과에 영향을 미치지 않아야 한다.
136 |
137 |
138 |
139 | > 4️⃣ 함수형이라면 함수나 메서드가 어떤 예외도 일으키지 않아야 한다.
140 |
141 | 예외가 발생하면 return으로 결과를 반환할 수 없게 될 수 있기 때문이다.
142 |
143 |
144 |
145 | 비정상적인 입력값(e.g., 0을 어떤 수로 나누는 상황)이 있을 때 처리되지 않은 예외를 일으키는 것이 자연스러운 방식일 것인데,
146 | 예외를 처리하는 과정에서 함수형에 위배되는 제어 흐름이 발생한다면 결국 ‘인수를 전달해서 결과를 받는다’는 모델이 깨지게 된다.
147 |
148 | 따라서 세 번째 화살표가 추가된다.
149 |
150 |
151 |
152 |  153 |
154 |
153 |
154 |
155 |
156 |
157 |
158 | 예외를 사용하지 않고 함수를 표현하려면 `Optional
165 |
166 | > 5️⃣ 비함수형 동작을 감출 수 있는 상황에서만 부작용을 포함하는 라이브러리 함수를 사용해야 한다.
167 |
168 | 즉, 먼저 자료구조를 복사한다든가 발생할 수 있는 예제를 적절하게 내부적으로 처리함으로써 자료구조의 변경을 호출자가 알 수 없도록 감춰야 한다.
169 |
170 |
171 |
172 |
173 | ## 18.2.2 참조 투명성
174 |
175 | ‘부작용을 감춰야 한다’라는 제약은 `참조 투명성(referential transparency)` 개념으로 귀결된다.
176 |
177 | 즉, **같은 인수로 함수를 호출했을 때 항상 같은 결과를 반환한다면** 참조적으로 투명한 함수라고 표현한다.
178 |
179 |
180 |
181 | 참조 투명성은 비싸거나 오랜 시간이 걸리는 연산을 기억화(memorization) 또는 캐싱(caching)을 통해 다시 계산하지 않고 저장하는 최적화 기능도 제공한다.
182 |
183 |
184 |
185 |
186 |
187 | # 18.3 재귀와 반복
188 |
189 | 순수 함수형 프로그래밍 언어에서는 while, for 같은 반복문 때문에 변화가 코드에 자연스럽게 스며들 수 있기에, 이들을 포함하지 않는다.
190 |
191 | 함수형 스타일에서는 다른 누군가가 변화를 알아차리지만 못한다면 아무 상관이 없으니 **지역 변수는 자유롭게 갱신할 수 있다.**
192 |
193 |
194 |
195 | 하지만 다음 코드처럼 for-each 루프를 사용하는 검색 알고리즘은 문제가 될 수 있다.
196 |
197 | ```java
198 | public void searchForGold(List
210 |
211 | `재귀`를 통해 프로그램을 구현함으로써 이러한 문제를 해결할 수 있다.
212 |
213 | - 이론적으로 반복을 이용하는 모든 프로그램은 재귀로도 구현할 수 있으며, 재귀를 이용하면 변화가 일어나지 않는다.
214 | - 재귀를 이용하면 루프 단계마다 갱신되는 반복 변수를 제거할 수 있다.
215 |
216 |
217 |
218 | e.g., 팩토리얼
219 |
220 | > 1️⃣ 반복 방식의 팩토리얼
221 |
222 | ```java
223 | // 매 반복마다 변수 r과 i가 갱신됨
224 | static int factorialIterative(int n) {
225 | int r = 1;
226 | for (int i = 1; i <= n; i++) {
227 | r *= i;
228 | }
229 | return r;
230 | }
231 | ```
232 |
233 |
234 |
235 | > 2️⃣ 재귀 방식의 팩토리얼
236 |
237 | ```java
238 | // 최종 연산 : n과 재귀 호출의 결과값의 곱셈
239 | static int factorialRecursive(long n) {
240 | return n == 1 ? 1 : n * factorialRecursive(n - 1);
241 | }
242 | ```
243 |
244 |
245 |
246 | 일반적으로 반복 코드보다 재귀 코드가 더 비싸다.
247 |
248 | 함수를 호출할 때마다 호출 스택에 각 호출시 생성되는 정보를 저장할 새로운 스택 프레임이 만들어지기 때문이다.
249 |
250 | 즉, 재귀 팩토리얼에서는 입력값에 비례해서 메모리 사용량이 증가하게 된다.
251 |
252 |
253 |
254 |  255 |
256 |
255 |
256 |
257 |
258 |
259 | > 3️⃣ 꼬리 호출 최적화
260 |
261 | 위 재귀에 대한 해결책으로 함수형 언어에서는 `꼬리 호출 최적화(tail-call optimization)`를 제공한다.
262 |
263 | ```java
264 | static long factorialTailRecursive(long n) {
265 | return factorialHelper(1, n);
266 | }
267 |
268 | // 꼬리 재귀 (재귀 호출이 가장 마지막에서 이루어짐)
269 | static long factorialHelper(long acc, long n) {
270 | return n == 1 ? acc : factorialHelper(acc * n, n - 1);
271 | }
272 | ```
273 |
274 |
275 |
276 |  277 |
278 |
277 |
278 |
279 |
280 |
281 | - `일반 재귀` : 중간 결과를 각각 저장해야 한다.
282 | - `꼬리 재귀` : 컴파일러가 하나의 스택 프레임을 재활용할 가능성이 생긴다.
283 |
284 |
285 |
286 | 하지만 자바는 이와 같은 최적화를 제공하진 않는다.
287 |
288 | 그럼에도 여전히 고전적인 재귀보다는 여러 컴파일러 최적화 여지를 남겨둘 수 있는 꼬리 재귀를 적용하는 것이 좋다.
289 |
290 | 스칼라, 그루비 같은 최신 JVM 언어는 이와 같은 재귀를 반복으로 변환하는 최적화를 제공한다.
291 |
292 |
293 |
294 | > 4️⃣ 스트림 팩토리얼
295 |
296 | 자바 8에서는 반복을 스트림으로 대체해서 변화를 피할 수 있다.
297 |
298 | ```java
299 | static int factorialStreams(long n) {
300 | return LongStream.rangeClosed(1, n)
301 | .reduce(1, (long a, long b) -> a * b);
302 | }
303 | ```
304 |
--------------------------------------------------------------------------------
/Chapter_19/README.md:
--------------------------------------------------------------------------------
1 | # Chapter 19. 함수형 프로그래밍 기법
2 |
3 |
4 |
5 | # 19.1 함수는 모든 곳에 존재한다.
6 |
7 | `함수형 언어` 프로그래머는 함수나 메서드가 수학의 함수처럼 부작용 없이 동작함을 의미하는 `함수형 프로그래밍`이라는 용어를 좀 더 폭넓게 사용한다.
8 |
9 | 즉, 함수를 마치 일반값처럼 사용해서 인수로 전달하거나, 결과로 반환받거나, 자료구조에 저장할 수 있음을 의미한다.
10 |
11 |
12 |
13 | 일반값처럼 취급할 수 있는 함수를 `일급 함수(first-class function)`이라고 한다.
14 |
15 | **메서드 참조**를 만들거나, **람다 표현식**으로 직접 함숫값을 표현해서 메서드를 함숫값으로 사용할 수 있다.
16 |
17 | ```java
18 | Function
22 |
23 | #### [ 참고 ] 일급 객체
24 |
25 | 아래 세 가지를 충족하는 객체를 말한다.
26 |
27 | 1. 변수에 할당할 수 있어야 한다.
28 | 2. 객체의 인자로 넘길 수 있어야 한다.
29 | 3. 객체의 리턴값으로 리턴할 수 있어야 한다.
30 |
31 |
32 |
33 |
34 | ## 19.1.1 고차원 함수
35 |
36 | 하나 이상의 동작을 수행하는 함수를 `고차원 함수(highter-order functions)`라 부른다.
37 |
38 | - 하나 이상의 함수를 인수로 받음
39 | - 함수를 결과로 반환
40 |
41 |
42 |
43 | 자바 8에서는 함수를 인수로 전달할 수 있을 뿐 아니라 결과로 반환하고,
44 | 지역 변수로 할당하거나, 구조체로 삽입할 수 있으므로 자바 8의 함수도 고차원 함수라고 할 수 있다.
45 |
46 |
47 |
48 | e.g., `Comparator.comparing` : 함수를 인수로 받아 다른 함수를 반환한다.
49 |
50 | ```java
51 | Comparator
55 |
56 |  57 |
58 |
57 |
58 |
59 |
60 |
61 | ### 부작용과 고차원 함수
62 |
63 | 고차원 함수나 메서드를 구현할 때 어떤 인수가 전달될지 알 수 없으므로 **인수가 부작용을 포함할 가능성**을 염두에 두어야 한다.
64 |
65 | 부작용을 포함하는 함수를 사용하면 부정확한 결과가 발생하거나 race condition 때문에 예상치 못한 결과가 발생할 수 있다.
66 |
67 | 함수를 인수로 받아 사용하면서 코드가 정확히 어떤 작업을 수행하고 프로그램의 상태를 어떻게 바꿀지 예측하기 어려워지며 디버깅도 어려워진다.
68 |
69 | 따라서 인수로 전달된 함수가 어떤 부작용을 포함하게 될지 정확하게 문서화하는 것이 좋다.
70 |
71 |
72 |
73 |
74 | ## 19.1.2 커링
75 |
76 | `커링(currying)`은 함수를 모듈화하고 코드를 재사용하는 데 도움을 준다.
77 |
78 |
79 |
80 | 커링은 x와 y라는 두 인수를 받는 `함수 f`를 `한 개의 인수를 받는 g라는 함수로 대체`하는 기법이다.
81 |
82 | 이때 g라는 함수 역시 하나의 인수를 받는 함수를 반환한다.
83 |
84 | 함수 g와 원래 함수 f가 최종적으로 반환하는 값은 같다. 즉, f(x, y) = (g(x))(y)가 성립한다.
85 |
86 |
87 |
88 | e.g., 국제화 단위 변환 문제
89 |
90 | ```java
91 | // f: 변환 요소, b: 기준치 조정 요소
92 | static DoubleUnaryOperator curriedConverter(double f, double b) {
93 | return (double x) -> x * f + b;
94 | }
95 |
96 | // 위 메서드에 변환 요소(f)와 기준치(b)만 넘겨주면 원하는 작업을 수행할 함수가 반환됨
97 | DoubleUnaryOperator convertCtoF = curriedConverter(9.0/5, 32);
98 | DoubleUnaryOperator convertUSDtoGBP = curriedConverter(0.6, 0);
99 | ```
100 |
101 |
102 |
103 | 이런 방식으로 변환 로직을 재활용할 수 있으며 다양한 변환 요소로 다양한 함수를 만들 수 있다.
104 |
105 |
106 |
107 |
108 |
109 | # 19.2 영속 자료구조
110 |
111 | 함수형 프로그램에서 사용하는 자료구조는 함수형 자료구조, 불변 자료구조 또는 `영속(persistent) 자료구조`라고 부른다.
112 |
113 |
114 |
115 | 함수형 메서드에서는 전역 자료구조나 인수로 전달된 구조를 갱신할 수 없다.
116 |
117 | 자료구조를 바꾼다면 같은 메서드를 두 번 호출했을 때 결과가 달라지면서 참조 투명성에 위배되고 인수를 결과로 단순하게 매핑할 수 있는 능력이 상실되기 때문이다.
118 |
119 |
120 |
121 | ## 19.2.1 파괴적인 갱신과 함수형
122 |
123 | e.g., A에서 B까지 기차여행을 의미하는 가변 TrainJourney 클래스
124 |
125 | ```java
126 | class TrainJourney {
127 | public int price;
128 | public TrainJourney onward;
129 | public TrainJourney(int p, TrainJourney t) {
130 | price = p;
131 | onward = t;
132 | }
133 | }
134 | ```
135 |
136 | 두 개의 TrainJourney 객체를 연결해서 하나의 여행을 만들고자 한다.
137 |
138 |
139 |
140 | ### 파괴적인 append
141 |
142 | ```java
143 | // 기차여행을 연결(link)
144 | // firstJourney가 secondJourney를 포함하면서 파괴적인 갱신(firstJourney의 변경)이 일어남
145 | static TrainJourney link(TrainJourney a, TrainJourney b) {
146 | if (a == null) return b;
147 | TrainJourney t = a;
148 | while (t.onward != null) {
149 | t = t.onward;
150 | }
151 | t.onward = b;
152 | return a;
153 | }
154 | ```
155 |
156 |
157 |
158 |  159 |
160 |
159 |
160 |
161 |
162 |
163 | ### 함수형 append
164 |
165 | 계산 결과를 표현할 자료구조가 필요하면 기존의 자료구조를 갱신하지 않도록 새로운 자료구조를 만들어야 한다.
166 |
167 | ```java
168 | // a가 n 요소(새로운 노드)의 시퀀스고 b가 m 요소(TrainJourney b과 공유되는 요소의 시퀀스라면,
169 | // n+m 요소의 시퀀스를 반환
170 | static TrainJourney append(TrainJourney a, TrainJourney b) {
171 | return a == null ? b : new TrainJourney(a.price, append(a.onward, b));
172 | }
173 | ```
174 |
175 |
176 |
177 |  178 |
179 |
178 |
179 |
180 |
181 |
182 |
183 | ## 19.2.2 트리를 사용한 예제
184 |
185 | HashMap 같은 인터페이스를 구현할 때는 이진 탐색 트리가 사용된다.
186 |
187 | 아래 예제는 문자열 키와 int값을 포함한다.
188 |
189 | ```java
190 | class Tree {
191 | private String key;
192 | private int val;
193 | private Tree left, right;
194 | public Tree(String k, int v, Tree l, Tree r) {
195 | key = k; val = v; left = l;, right = r;
196 | }
197 | }
198 |
199 | class TreeProcessor {
200 | public static int lookup(String k, int defaultval, Tree t) {
201 | if (t == null) return defaultval;
202 | if (k.equals(t.key)) return t.val;
203 | return lookup(k, defaultval,
204 | k.compareTo(t.key) < 0 ? t.left : t.right);
205 | }
206 | // 트리의 다른 작업을 처리하는 기타 메서드
207 | }
208 | ```
209 |
210 |
211 |
212 | 주어진 키와 연관된 값을 어떻게 갱신할 수 있을까?
213 |
214 | 아래 두 가지 update 버전 모두 기존 트리를 변경한다. (즉, 트리에 저장된 맵의 모든 사용자가 **변경에 영향을 받음**)
215 |
216 | ```java
217 | public static void update(String k, int newval, Tree t) {
218 | if (t == null) { /* 새로운 노드 추가 */ }
219 | else if (k.equals(t.key)) t.val = newval;
220 | else update(k, newval, k.compareTo(t.key) < 0 ? t.left : t.right);
221 | }
222 | ```
223 |
224 | ```java
225 | public static Tree update(String k, int newval, Tree t) {
226 | if (t == null) t = new Tree(k, newval, null, null);
227 | else if (k.equals(t.key)) t.val = newval;
228 | else if (k.compareTo(t.key) < 0) t.left = update(k, newval, t.left);
229 | else t.right = update(k, newval, t.right);
230 | return t;
231 | }
232 | ```
233 |
234 |
235 |
236 | > 모든 사용자가 같은 자료구조를 공유하며 프로그램에서 누군가 자료구조를 갱신했을 때 영향을 받는다.
237 |
238 |
239 |
240 |
241 | ## 19.2.3 함수형 접근법 사용
242 |
243 | 위의 트리 문제를 함수형으로 처리해보고자 한다.
244 |
245 | 1. 새로운 키/값 쌍을 저장할 새로운 노드를 만들어야 한다.
246 | 2. 트리의 루트에서 새로 생성한 노드의 경로에 있는 노드들도 새로 만들어야 한다.
247 |
248 | ```java
249 | public static Tree fupdate(String k, int newval, Tree t) {
250 | return (t == null) ?
251 | new Tree(k, newval, null, null) :
252 | k.equals(t.key) ?
253 | new Tree(k, nweval, t.left, t.right) :
254 | k.compareTo(t.key) < 0 ?
255 | new Tree(t.key, t.val, fupdate(k, newval, t.left), t.right) :
256 | new Tree(t.key, t.val, t.left, fupdate(k, newval, t.right));
257 | }
258 | ```
259 |
260 |
261 |
262 | fupdate에서는 기존의 트리를 갱신하는 것이 아니라 새로운 트리를 만든다.
263 |
264 | 그리고 **인수를 이용해서 가능한 한 많은 정보를 공유한다.**
265 |
266 |
267 |
268 |  269 |
270 |
269 |
270 |
271 |
272 |
273 |
274 | 이와 같이 **저장된 값이 다른 누군가에 의해 영향을 받지 않는 상태**의 함수형 자료구조를 `영속(persistent)`이라고 한다.
275 |
276 | ‘`결과 자료구조를 바꾸지 말라`’는 것이 자료구조를 사용하는 모든 사용자에게 요구하는 단 한 가지 조건이다.
277 |
278 | - 이 조건을 무시한다면 fupdate로 전달된 자료구조에 의도치 않은 그리고 원치 않은 갱신이 일어난다.
279 | - 이 법칙 덕분에 조금 다른 구조체 간의 공통부분을 공유할 수 있다.
280 |
281 |
282 |
283 |
284 |
285 | # 19.4 패턴 매칭
286 |
287 | 함수형 프로그래밍을 구분하는 또 하나의 중요한 특징으로 (구조적인) `패턴 매칭(pattern matching)`을 들 수 있다.
288 | *(이는 정규표현식 그리고 정규표현식과 관련된 패턴 매칭과는 다름)*
289 |
290 | 자료형이 복잡해지면 이러한 작업을 처리하는 데 필요한 코드(if-then-else나 switch문 등)의 양이 증가하는데, 패턴 매칭을 통해 불필요한 잡동사니를 줄일 수 있다.
291 |
292 |
293 |
294 | ### 트리 탐색 예제
295 |
296 | 숫자와 바이너리 연산자로 구성된 간단한 수학언어가 있다고 가정하자.
297 |
298 | ```java
299 | class Expr { ... }
300 | class Number extends Expr { int val; ... }
301 | class BinOp extends Expr { String opname; Expr left, right; ... }
302 | ```
303 |
304 |
305 |
306 | 표현식을 단순화하는 메서드를 구현해야 한다고 하자.
307 |
308 | e.g., 5 + 0은 5로 단순화할 수 있음
309 | → `new BinOp(”+”, new Number(5), new Number(0))`은 `Number(5)`로 단순화할 수 있음
310 |
311 | ```java
312 | Expr simplifyExpression(Expr expr) {
313 | if (expr instanceof BinOp)
314 | && ((BinOp)expr).opname.equals("+"))
315 | && ((BinOp)expr).right instanceof Number
316 | && ...
317 | && ... ) {
318 | return (BinOp)expr.left;
319 | }
320 | ...
321 | }
322 | ```
323 |
324 | 코드가 깔끔하지 못하다.
325 |
326 |
327 |
328 |
329 | ## 19.4.1 방문자 디자인 패턴
330 |
331 | 자바에서는 `방문자 디자인 패턴(visitor design pattern)`으로 자료형을 언랩할 수 있으며,
332 | 특히 특정 데이터 형식을 ‘방문’하는 알고리즘을 캡슐화하는 클래스를 따로 만들 수 있다.
333 |
334 |
335 |
336 | 방문자 패턴의 동작 과정
337 |
338 | 1. `방문자 클래스`는 지정된 데이터 형식의 인스턴스를 입력으로 받는다.
339 | 2. 방문자 클래스가 인스턴스의 모든 멤버에 접근한다.
340 | 3. SimplifyExprVisitor를 인수로 받는 `accept`를 BinOp에 추가한 다음, BinOp 자신을 SimplifyExprVisitor로 전달한다.
341 |
342 |
343 |
344 | ```java
345 | class BinOp extends Expr {
346 | ...
347 | public Expr accept(SimplifyExprVisitor v) {
348 | return v.visit(this);
349 | }
350 | }
351 | ```
352 |
353 |
354 |
355 | 이제 SimplifyExprVisitor는 BinOp 객체를 언랩할 수 있다.
356 |
357 | ```java
358 | public class SimplifyExprVisitor {
359 | ...
360 | public Expr visit(BinOp e) {
361 | if ("+".equals(e.opname) && e.right instanceof Number && ...) {
362 | return e.left;
363 | }
364 | return e;
365 | }
366 | }
367 | ```
368 |
369 |
370 |
371 |
372 | ## 19.4.2 패턴 매칭의 힘
373 |
374 | 패턴 매칭으로 조금 더 단순하게 문제를 해결할 수 있다.
375 |
376 | 수식을 표현하는 Expr이라는 자료형이 주어졌을 때 스칼라 프로그래밍 언어로는 다음처럼 수식을 분해하는 코드를 구현할 수 있다. (자바는 패턴 매칭을 지원하지 않음)
377 |
378 | ```scala
379 | def simplifyExpression(expr: Expr): Expr = expr match {
380 | case BinOp("+", e, Number((0)) => e // 0 더하기
381 | case BinOp("*", e, Number(1)) => e // 1 곱하기
382 | case BinOp("/", e, Number(1)) => e // 1로 나누기
383 | case _ => expr // expr를 단순화할 수 없음
384 | }
385 | ```
386 |
387 | - 스칼라는 표현지향, 자바는 구문지향
388 | - 패턴 매칭을 지원하는 언어의 가장 큰 실용적인 장점은 커다란 switch문이나 if-then-else 문을 피할 수 있는 것이다.
389 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Modern-Java-in-Action
2 |
3 | [Modern Java in Action : 전문가를 위한 자바 8, 9, 10 기법 가이드](http://www.yes24.com/Product/Goods/77125987?pid=123487&cosemkid=go15646485055614872&gclid=Cj0KCQiA2-2eBhClARIsAGLQ2RnfiJRiNBVIJE4-RqUStA8sxbbPufA-nPNX5vp8FqJbyzkGq_XjvR4aAuAhEALw_wcB)를
4 | 읽고, 그 내용과 개념을 정리한 레포지토리입니다.
5 |
6 | 잘못된 내용은 이슈와 PR로 알려주세요 🥰
7 |
8 |
9 |
10 | ## 📌 Modern Java in Action : 전문가를 위한 자바 8, 9, 10 기법 가이드
11 |
12 | ### Part Ⅰ 기초
13 |
14 | - [Chapter 1 - 자바 8, 9, 10, 11 : 무슨 일이 일어나고 있는가](/Chapter_01)
15 | - [Chapter 2 - 동작 파라미터화 코드 전달하기](/Chapter_02)
16 | - [Chapter 3 - 람다 표현식](/Chapter_03)
17 |
18 | ### Part Ⅱ 함수형 데이터 처리
19 |
20 | - [Chapter 4 - 스트림 소개](/Chapter_04)
21 | - [Chapter 5 - 스트림 활용](/Chapter_05)
22 | - [Chapter 6 - 스트림으로 데이터 수집](/Chapter_06)
23 | - [Chapter 7 - 병렬 데이터 처리와 성능](/Chapter_07)
24 |
25 | ### Part Ⅲ 스트림과 람다를 이용한 효과적 프로그래밍
26 |
27 | - [Chapter 8 - 컬렉션 API 개선](/Chapter_08)
28 | - [Chapter 9 - 리팩터링, 테스팅, 디버깅](/Chapter_09)
29 | - [Chapter 10 - 람다를 이용한 도메인 전용 언어](/Chapter_10)
30 |
31 | ### Part Ⅳ 매일 자바와 함께
32 |
33 | - [Chapter 11 - null 대신 Optional 클래스](/Chapter_11)
34 | - Chapter 12 - 새로운 날짜와 시간 API
35 | - [Chapter 13 - 디폴트 메서드](/Chapter_13)
36 | - Chapter 14 - 자바 모듈 시스템
37 |
38 | ### Part Ⅴ 개선된 자바 동시성
39 |
40 | - Chapter 15 - CompletableFuture와 리액티브 프로그래밍 컨셉의 기초
41 | - Chapter 16 - CompletableFuture : 안정적 비동기 프로그래밍
42 | - Chapter 17 - 리액티브 프로그래밍
43 |
44 | ### Part Ⅵ 함수형 프로그래밍과 자바 진화의 미래
45 |
46 | - [Chapter 18 - 함수형 관점으로 생각하기](/Chapter_18)
47 | - [Chapter 19 - 함수형 프로그래밍 기법](/Chapter_19)
48 | - Chapter 20 - OOP와 FP의 조화 : 자바와 스칼라 비교
49 | - Chapter 21 - 결론 그리고 자바의 미래
50 |
--------------------------------------------------------------------------------
/build.gradle:
--------------------------------------------------------------------------------
1 | /*
2 | plugins {
3 | id 'java'
4 | }
5 |
6 | group 'org.example'
7 | version '1.0-SNAPSHOT'
8 |
9 | repositories {
10 | mavenCentral()
11 | }
12 |
13 | dependencies {
14 | testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
15 | testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
16 | }
17 |
18 | test {
19 | useJUnitPlatform()
20 | }
21 | //*/
22 |
23 | // for src/main/java/chapter07/ParallelStreamBenchmark.java
24 | //*
25 | plugins {
26 | id 'java-library'
27 | id 'maven-publish'
28 | }
29 |
30 | repositories {
31 | mavenLocal()
32 | maven {
33 | url = uri('https://repo.maven.apache.org/maven2/')
34 | }
35 | }
36 |
37 | dependencies {
38 | api 'org.openjdk.jmh:jmh-core:1.21'
39 | api 'org.openjdk.jmh:jmh-generator-annprocess:1.21'
40 | api 'io.reactivex.rxjava2:rxjava:2.2.2'
41 | api 'com.typesafe.akka:akka-actor_2.12:2.5.16'
42 | api 'com.typesafe.akka:akka-stream_2.12:2.5.16'
43 | api 'junit:junit:4.12'
44 | }
45 |
46 | group = 'manning'
47 | version = '2.0'
48 | description = 'modernjavainaction'
49 | java.sourceCompatibility = JavaVersion.VERSION_1_8
50 |
51 | publishing {
52 | publications {
53 | maven(MavenPublication) {
54 | from(components.java)
55 | }
56 | }
57 | }
58 |
59 | tasks.withType(JavaCompile) {
60 | options.encoding = 'UTF-8'
61 | }
62 |
63 | tasks.withType(Javadoc) {
64 | options.encoding = 'UTF-8'
65 | }
66 | //*/
67 |
--------------------------------------------------------------------------------
/gradle/wrapper/gradle-wrapper.jar:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/IT-Book-Organization/Modern-Java-in-Action/f4163364a1eb408136c8e35d39c11fdacf391b0c/gradle/wrapper/gradle-wrapper.jar
--------------------------------------------------------------------------------
/gradle/wrapper/gradle-wrapper.properties:
--------------------------------------------------------------------------------
1 | distributionBase=GRADLE_USER_HOME
2 | distributionPath=wrapper/dists
3 | distributionUrl=https\://services.gradle.org/distributions/gradle-7.4-bin.zip
4 | zipStoreBase=GRADLE_USER_HOME
5 | zipStorePath=wrapper/dists
6 |
--------------------------------------------------------------------------------
/gradlew:
--------------------------------------------------------------------------------
1 | #!/bin/sh
2 |
3 | #
4 | # Copyright © 2015-2021 the original authors.
5 | #
6 | # Licensed under the Apache License, Version 2.0 (the "License");
7 | # you may not use this file except in compliance with the License.
8 | # You may obtain a copy of the License at
9 | #
10 | # https://www.apache.org/licenses/LICENSE-2.0
11 | #
12 | # Unless required by applicable law or agreed to in writing, software
13 | # distributed under the License is distributed on an "AS IS" BASIS,
14 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | # See the License for the specific language governing permissions and
16 | # limitations under the License.
17 | #
18 |
19 | ##############################################################################
20 | #
21 | # Gradle start up script for POSIX generated by Gradle.
22 | #
23 | # Important for running:
24 | #
25 | # (1) You need a POSIX-compliant shell to run this script. If your /bin/sh is
26 | # noncompliant, but you have some other compliant shell such as ksh or
27 | # bash, then to run this script, type that shell name before the whole
28 | # command line, like:
29 | #
30 | # ksh Gradle
31 | #
32 | # Busybox and similar reduced shells will NOT work, because this script
33 | # requires all of these POSIX shell features:
34 | # * functions;
35 | # * expansions «$var», «${var}», «${var:-default}», «${var+SET}»,
36 | # «${var#prefix}», «${var%suffix}», and «$( cmd )»;
37 | # * compound commands having a testable exit status, especially «case»;
38 | # * various built-in commands including «command», «set», and «ulimit».
39 | #
40 | # Important for patching:
41 | #
42 | # (2) This script targets any POSIX shell, so it avoids extensions provided
43 | # by Bash, Ksh, etc; in particular arrays are avoided.
44 | #
45 | # The "traditional" practice of packing multiple parameters into a
46 | # space-separated string is a well documented source of bugs and security
47 | # problems, so this is (mostly) avoided, by progressively accumulating
48 | # options in "$@", and eventually passing that to Java.
49 | #
50 | # Where the inherited environment variables (DEFAULT_JVM_OPTS, JAVA_OPTS,
51 | # and GRADLE_OPTS) rely on word-splitting, this is performed explicitly;
52 | # see the in-line comments for details.
53 | #
54 | # There are tweaks for specific operating systems such as AIX, CygWin,
55 | # Darwin, MinGW, and NonStop.
56 | #
57 | # (3) This script is generated from the Groovy template
58 | # https://github.com/gradle/gradle/blob/master/subprojects/plugins/src/main/resources/org/gradle/api/internal/plugins/unixStartScript.txt
59 | # within the Gradle project.
60 | #
61 | # You can find Gradle at https://github.com/gradle/gradle/.
62 | #
63 | ##############################################################################
64 |
65 | # Attempt to set APP_HOME
66 |
67 | # Resolve links: $0 may be a link
68 | app_path=$0
69 |
70 | # Need this for daisy-chained symlinks.
71 | while
72 | APP_HOME=${app_path%"${app_path##*/}"} # leaves a trailing /; empty if no leading path
73 | [ -h "$app_path" ]
74 | do
75 | ls=$( ls -ld "$app_path" )
76 | link=${ls#*' -> '}
77 | case $link in #(
78 | /*) app_path=$link ;; #(
79 | *) app_path=$APP_HOME$link ;;
80 | esac
81 | done
82 |
83 | APP_HOME=$( cd "${APP_HOME:-./}" && pwd -P ) || exit
84 |
85 | APP_NAME="Gradle"
86 | APP_BASE_NAME=${0##*/}
87 |
88 | # Add default JVM options here. You can also use JAVA_OPTS and GRADLE_OPTS to pass JVM options to this script.
89 | DEFAULT_JVM_OPTS='"-Xmx64m" "-Xms64m"'
90 |
91 | # Use the maximum available, or set MAX_FD != -1 to use that value.
92 | MAX_FD=maximum
93 |
94 | warn () {
95 | echo "$*"
96 | } >&2
97 |
98 | die () {
99 | echo
100 | echo "$*"
101 | echo
102 | exit 1
103 | } >&2
104 |
105 | # OS specific support (must be 'true' or 'false').
106 | cygwin=false
107 | msys=false
108 | darwin=false
109 | nonstop=false
110 | case "$( uname )" in #(
111 | CYGWIN* ) cygwin=true ;; #(
112 | Darwin* ) darwin=true ;; #(
113 | MSYS* | MINGW* ) msys=true ;; #(
114 | NONSTOP* ) nonstop=true ;;
115 | esac
116 |
117 | CLASSPATH=$APP_HOME/gradle/wrapper/gradle-wrapper.jar
118 |
119 |
120 | # Determine the Java command to use to start the JVM.
121 | if [ -n "$JAVA_HOME" ] ; then
122 | if [ -x "$JAVA_HOME/jre/sh/java" ] ; then
123 | # IBM's JDK on AIX uses strange locations for the executables
124 | JAVACMD=$JAVA_HOME/jre/sh/java
125 | else
126 | JAVACMD=$JAVA_HOME/bin/java
127 | fi
128 | if [ ! -x "$JAVACMD" ] ; then
129 | die "ERROR: JAVA_HOME is set to an invalid directory: $JAVA_HOME
130 |
131 | Please set the JAVA_HOME variable in your environment to match the
132 | location of your Java installation."
133 | fi
134 | else
135 | JAVACMD=java
136 | which java >/dev/null 2>&1 || die "ERROR: JAVA_HOME is not set and no 'java' command could be found in your PATH.
137 |
138 | Please set the JAVA_HOME variable in your environment to match the
139 | location of your Java installation."
140 | fi
141 |
142 | # Increase the maximum file descriptors if we can.
143 | if ! "$cygwin" && ! "$darwin" && ! "$nonstop" ; then
144 | case $MAX_FD in #(
145 | max*)
146 | MAX_FD=$( ulimit -H -n ) ||
147 | warn "Could not query maximum file descriptor limit"
148 | esac
149 | case $MAX_FD in #(
150 | '' | soft) :;; #(
151 | *)
152 | ulimit -n "$MAX_FD" ||
153 | warn "Could not set maximum file descriptor limit to $MAX_FD"
154 | esac
155 | fi
156 |
157 | # Collect all arguments for the java command, stacking in reverse order:
158 | # * args from the command line
159 | # * the main class name
160 | # * -classpath
161 | # * -D...appname settings
162 | # * --module-path (only if needed)
163 | # * DEFAULT_JVM_OPTS, JAVA_OPTS, and GRADLE_OPTS environment variables.
164 |
165 | # For Cygwin or MSYS, switch paths to Windows format before running java
166 | if "$cygwin" || "$msys" ; then
167 | APP_HOME=$( cygpath --path --mixed "$APP_HOME" )
168 | CLASSPATH=$( cygpath --path --mixed "$CLASSPATH" )
169 |
170 | JAVACMD=$( cygpath --unix "$JAVACMD" )
171 |
172 | # Now convert the arguments - kludge to limit ourselves to /bin/sh
173 | for arg do
174 | if
175 | case $arg in #(
176 | -*) false ;; # don't mess with options #(
177 | /?*) t=${arg#/} t=/${t%%/*} # looks like a POSIX filepath
178 | [ -e "$t" ] ;; #(
179 | *) false ;;
180 | esac
181 | then
182 | arg=$( cygpath --path --ignore --mixed "$arg" )
183 | fi
184 | # Roll the args list around exactly as many times as the number of
185 | # args, so each arg winds up back in the position where it started, but
186 | # possibly modified.
187 | #
188 | # NB: a `for` loop captures its iteration list before it begins, so
189 | # changing the positional parameters here affects neither the number of
190 | # iterations, nor the values presented in `arg`.
191 | shift # remove old arg
192 | set -- "$@" "$arg" # push replacement arg
193 | done
194 | fi
195 |
196 | # Collect all arguments for the java command;
197 | # * $DEFAULT_JVM_OPTS, $JAVA_OPTS, and $GRADLE_OPTS can contain fragments of
198 | # shell script including quotes and variable substitutions, so put them in
199 | # double quotes to make sure that they get re-expanded; and
200 | # * put everything else in single quotes, so that it's not re-expanded.
201 |
202 | set -- \
203 | "-Dorg.gradle.appname=$APP_BASE_NAME" \
204 | -classpath "$CLASSPATH" \
205 | org.gradle.wrapper.GradleWrapperMain \
206 | "$@"
207 |
208 | # Use "xargs" to parse quoted args.
209 | #
210 | # With -n1 it outputs one arg per line, with the quotes and backslashes removed.
211 | #
212 | # In Bash we could simply go:
213 | #
214 | # readarray ARGS < <( xargs -n1 <<<"$var" ) &&
215 | # set -- "${ARGS[@]}" "$@"
216 | #
217 | # but POSIX shell has neither arrays nor command substitution, so instead we
218 | # post-process each arg (as a line of input to sed) to backslash-escape any
219 | # character that might be a shell metacharacter, then use eval to reverse
220 | # that process (while maintaining the separation between arguments), and wrap
221 | # the whole thing up as a single "set" statement.
222 | #
223 | # This will of course break if any of these variables contains a newline or
224 | # an unmatched quote.
225 | #
226 |
227 | eval "set -- $(
228 | printf '%s\n' "$DEFAULT_JVM_OPTS $JAVA_OPTS $GRADLE_OPTS" |
229 | xargs -n1 |
230 | sed ' s~[^-[:alnum:]+,./:=@_]~\\&~g; ' |
231 | tr '\n' ' '
232 | )" '"$@"'
233 |
234 | exec "$JAVACMD" "$@"
235 |
--------------------------------------------------------------------------------
/gradlew.bat:
--------------------------------------------------------------------------------
1 | @rem
2 | @rem Copyright 2015 the original author or authors.
3 | @rem
4 | @rem Licensed under the Apache License, Version 2.0 (the "License");
5 | @rem you may not use this file except in compliance with the License.
6 | @rem You may obtain a copy of the License at
7 | @rem
8 | @rem https://www.apache.org/licenses/LICENSE-2.0
9 | @rem
10 | @rem Unless required by applicable law or agreed to in writing, software
11 | @rem distributed under the License is distributed on an "AS IS" BASIS,
12 | @rem WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | @rem See the License for the specific language governing permissions and
14 | @rem limitations under the License.
15 | @rem
16 |
17 | @if "%DEBUG%" == "" @echo off
18 | @rem ##########################################################################
19 | @rem
20 | @rem Gradle startup script for Windows
21 | @rem
22 | @rem ##########################################################################
23 |
24 | @rem Set local scope for the variables with windows NT shell
25 | if "%OS%"=="Windows_NT" setlocal
26 |
27 | set DIRNAME=%~dp0
28 | if "%DIRNAME%" == "" set DIRNAME=.
29 | set APP_BASE_NAME=%~n0
30 | set APP_HOME=%DIRNAME%
31 |
32 | @rem Resolve any "." and ".." in APP_HOME to make it shorter.
33 | for %%i in ("%APP_HOME%") do set APP_HOME=%%~fi
34 |
35 | @rem Add default JVM options here. You can also use JAVA_OPTS and GRADLE_OPTS to pass JVM options to this script.
36 | set DEFAULT_JVM_OPTS="-Xmx64m" "-Xms64m"
37 |
38 | @rem Find java.exe
39 | if defined JAVA_HOME goto findJavaFromJavaHome
40 |
41 | set JAVA_EXE=java.exe
42 | %JAVA_EXE% -version >NUL 2>&1
43 | if "%ERRORLEVEL%" == "0" goto execute
44 |
45 | echo.
46 | echo ERROR: JAVA_HOME is not set and no 'java' command could be found in your PATH.
47 | echo.
48 | echo Please set the JAVA_HOME variable in your environment to match the
49 | echo location of your Java installation.
50 |
51 | goto fail
52 |
53 | :findJavaFromJavaHome
54 | set JAVA_HOME=%JAVA_HOME:"=%
55 | set JAVA_EXE=%JAVA_HOME%/bin/java.exe
56 |
57 | if exist "%JAVA_EXE%" goto execute
58 |
59 | echo.
60 | echo ERROR: JAVA_HOME is set to an invalid directory: %JAVA_HOME%
61 | echo.
62 | echo Please set the JAVA_HOME variable in your environment to match the
63 | echo location of your Java installation.
64 |
65 | goto fail
66 |
67 | :execute
68 | @rem Setup the command line
69 |
70 | set CLASSPATH=%APP_HOME%\gradle\wrapper\gradle-wrapper.jar
71 |
72 |
73 | @rem Execute Gradle
74 | "%JAVA_EXE%" %DEFAULT_JVM_OPTS% %JAVA_OPTS% %GRADLE_OPTS% "-Dorg.gradle.appname=%APP_BASE_NAME%" -classpath "%CLASSPATH%" org.gradle.wrapper.GradleWrapperMain %*
75 |
76 | :end
77 | @rem End local scope for the variables with windows NT shell
78 | if "%ERRORLEVEL%"=="0" goto mainEnd
79 |
80 | :fail
81 | rem Set variable GRADLE_EXIT_CONSOLE if you need the _script_ return code instead of
82 | rem the _cmd.exe /c_ return code!
83 | if not "" == "%GRADLE_EXIT_CONSOLE%" exit 1
84 | exit /b 1
85 |
86 | :mainEnd
87 | if "%OS%"=="Windows_NT" endlocal
88 |
89 | :omega
90 |
--------------------------------------------------------------------------------
/settings.gradle:
--------------------------------------------------------------------------------
1 | rootProject.name = 'Modern-Java-in-Action'
2 |
3 |
--------------------------------------------------------------------------------
/src/main/java/chapter01/FilteringApples.java:
--------------------------------------------------------------------------------
1 | package chapter01;
2 |
3 | import java.util.ArrayList;
4 | import java.util.Arrays;
5 | import java.util.List;
6 | import java.util.function.Predicate;
7 | import java.util.stream.Collectors;
8 |
9 | public class FilteringApples {
10 |
11 | public static void main(String... args) {
12 | List