|Precision=TP/(TP+FP)|Recall
|
240 | | :- | :- |:-| :- |:-|
241 | | box2 |Positive| score2 |1/1|1/3|
242 | | box1 |Negative| score1 |1/2|1/3|
243 | | box3 |Positive| score3 |2/3|2/3|
244 |
245 |
246 |
247 | 这样得到一个个PR曲线上的点,然后利用插值法计算PR曲线的面积,得到class1的AP。
248 | 具体插值方法:COCO中是均匀取101个recall值即0,0.01,0.02,...,1,对于每个recall值r,precision值取所有recall>=r中的最大值$p_{interp(r)}$。
249 |
250 |
251 | 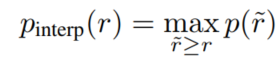 252 |
252 |
253 |
254 |
255 |  256 |
256 |
257 |
258 |
259 |  260 |
260 |
261 |
262 | 然后每个recall值区间(0-0.01,0.01-0.02,...)都对应一个矩形,将所有矩形面积加起来即为PR曲线面积,得到一个类别的AP,如下图所示。对所有类别(如COCO中80类)、所有IoU阈值(例如0.5:0.95)的AP取均值即得到最终AP。
263 |
264 | 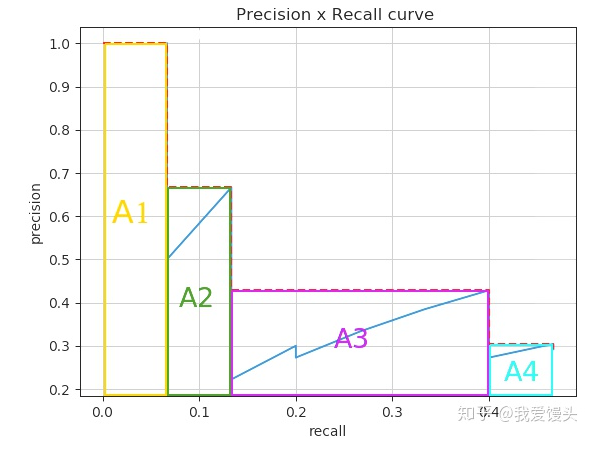 265 |
265 |
266 |
267 | **AR计算**
268 | 计算过程同AP,也是在所有IoU阈值和类别上平均。
269 | 每给定一个IoU阈值和类别,得到一个P_R曲线,当P不为0时最大的Recall作为当前Recall。
270 |
271 | ### 17、⭐IoU变种合集
272 | **IoU**
273 |
274 | 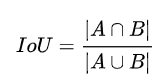 275 |
275 |
276 |
277 | **GIoU**
278 |
279 | 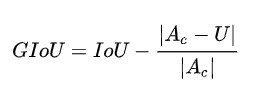 280 |
280 |
281 |
282 | $Ac$为bbox A和bbox B的最小凸集面积,U为A U B的面积,即第二项为不属于A和B的区域占最小闭包的比例。
283 | -1<=GIoU<=1,当A和B不重合,仍可以计算损失,因此可作为损失函数。
284 |
285 | 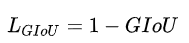 286 |
286 |
287 |
288 | ✒️优点:在不重叠的情况下,能让预测框向gt框接近。
289 |
290 | ✒️缺点:遇到A框被B框包含的情况下,GIoU相同。
291 |
292 |
293 | 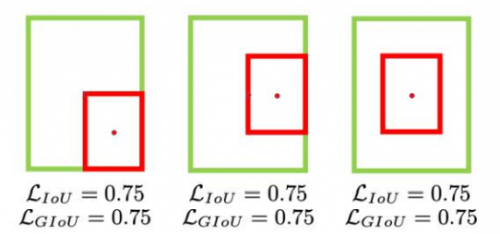 294 |
294 |
295 |
296 | **DIoU**
297 |
298 |  299 |
299 |
300 |
301 | 其中, $b$和$b^{gt}$分别代表了预测框和真实框的中心点,且$ρ$代表的是计算两个中心点间的欧式距离。$c$代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
302 |
303 | 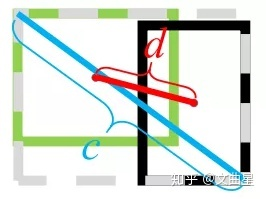 304 |
304 |
305 |
306 | $-1 < DIoU \leq 1$, 将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定
307 |
308 | ✒️优点:直接优化距离,解决GIoU包含情况。
309 |
310 | 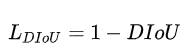 311 |
311 |
312 |
313 | **CIoU**
314 |
315 | 在DIoU的基础上考虑bbox的长宽比:
316 |
317 | 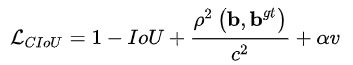 318 |
318 |
319 |
320 |
321 | 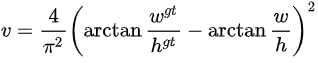 322 |
322 |
323 |
324 | $-1 \leq CIoU \leq 1$
325 |
326 | ✒️优点:考虑bbox长宽比
327 |
328 | ### 18、⭐depth-wise separable conv (深度可分离卷积)
329 | 例如$5 \ast 5 \ast 3$图片要编码为$5 \ast 5 \ast 4$ feature map,则depth-wise conv分为两步:
330 | 先是depth wise卷积,利用3个$3 \ast 3$ conv对每个通道单独进行卷积,这一步只能改变feature map长宽,不能改变通道数:
331 |
332 | 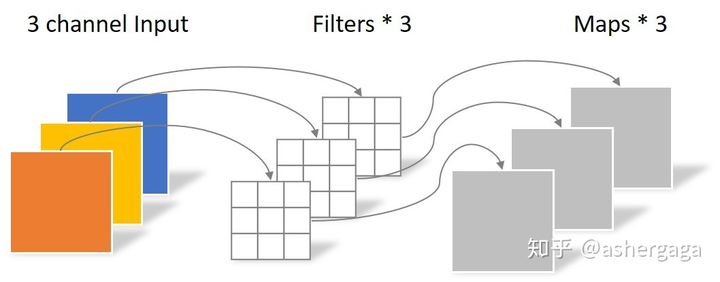 333 |
333 |
334 |
335 | 参数量:
336 |
337 | 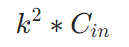 338 |
338 |
339 |
340 | 计算量:
341 |
342 |  343 |
343 |
344 |
345 | 然后是point wise卷积,利用4个$1 \ast 1 \ast 3$ conv对depth wise生成的feature map进行卷积,这一步只能改变通道数,不能改变feature map长宽:
346 |
347 | 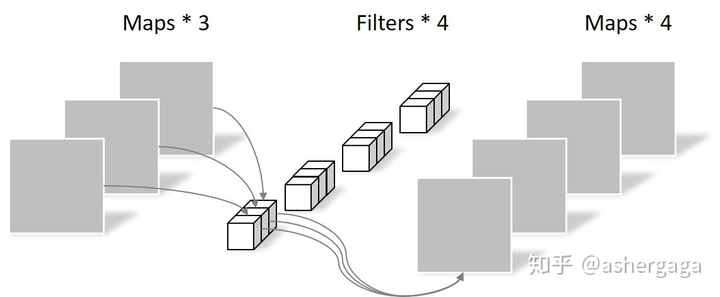 348 |
348 |
349 |
350 | 参数量:
351 |
352 | 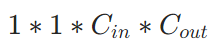 353 |
353 |
354 |
355 | 计算量:
356 |
357 | 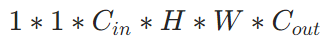 358 |
358 |
359 |
360 | 所以与一般卷积对比,总参数量和计算量:
361 | - 总参数量:常规卷积-->
362 |
363 | 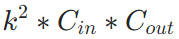 364 |
364 |
365 |
366 | , 深度可分离卷积-->
367 |
368 | 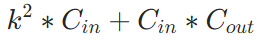 369 |
369 |
370 |
371 | - 总计算量:常规卷积-->
372 |
373 | 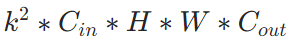 374 |
374 |
375 |
376 | , 深度可分离卷积-->
377 |
378 | 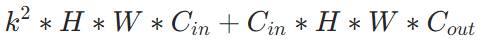 379 |
379 |
380 |
381 | ### 19、⭐检测模型里为啥用smoothL1去回归bbox
382 | 首先,对于L2 loss,其导数包含了(f(x)-Y),所以当预测值与gt差异过大时,容易梯度爆炸;
383 | 而对于L1 loss,即使训练后期预测值和gt差异较小,梯度依然为常数,损失函数将在稳定值附近波动,难以收敛到更高精度。
384 |
385 |  386 |
386 |
387 |
388 | 所以SmoothL1 loss结合了两者的优势,当预测值和gt差异较大时使用L1 loss;差异较小时使用L2 loss:
389 |
390 | 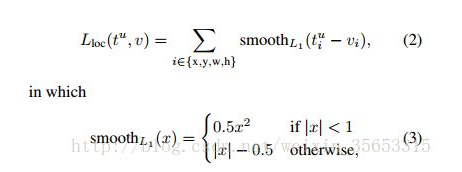 391 |
391 |
392 |
393 | ### 20、⭐Deformable conv如何实现梯度可微?
394 | 指的是对offset可微,因为offset后卷积核所在位置可能是小数,即不在feature map整数点上,所以无法求导;Deformable conv通过双线性插值实现了offset梯度可微。
395 | 用如下表达式表达常规CNN:
396 |
397 | 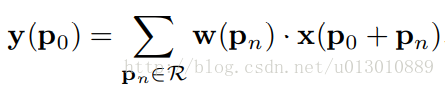 398 |
398 |
399 |
400 |
401 | 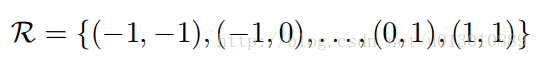 402 |
402 |
403 |
404 | 则Deformable conv可表达为:
405 |
406 | 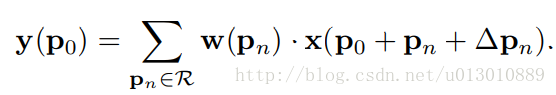 407 |
407 |
408 |
409 | $x(p_0+p_n+\Delta p_n)$可能不是整数,需要进行插值,任意点p(周围四个整数点为q)的双线性插值可表达为下式:
410 |
411 | 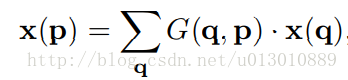 412 |
412 |
413 |
414 |
415 | 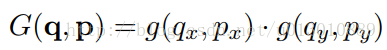 416 |
416 |
417 |
418 | 其中$g(a, b) = max(0, 1 − |a − b|)$。
419 |
420 | 则offest delta_pn求导公式为:
421 |
422 | 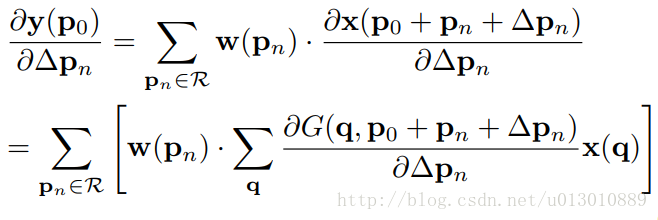 423 |
423 |
424 |
425 | 从而实现对offset的梯度可微。
426 |
427 | ### 21、⭐Swin Transformer
428 | (1)⭐**motivation**
429 | 高分辨率图像作为序列输入计算量过大问题;和nlp不同,cv里每个物体的尺度不同,而nlp里每个物体的单词长度都差不多。
430 |
431 | (2)⭐**idea**
432 | 问题一:一张图分成多个窗口,每个窗口分成多个patch,每个窗口内的多个patch相互计算自注意力;问题二:模仿CNN pooling操作,将浅层尺度patch进行path merging得到一个小的patch,实现降采样,从而得到多尺度特征。
433 |
434 | (3)⭐**method**
435 | 整体结构很像CNN,卷积被窗口自注意力代替,pooling被patch merging代替。
436 |
437 | 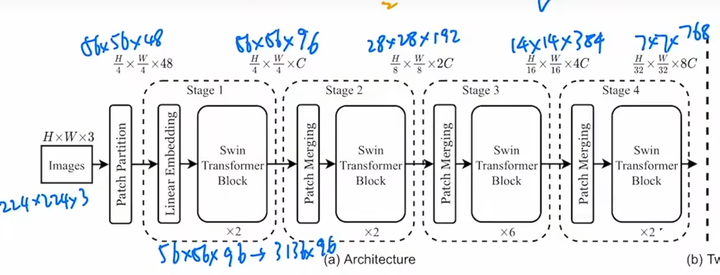 438 |
438 |
439 |
440 | - ✒️method 1: shifted window
441 |
442 | 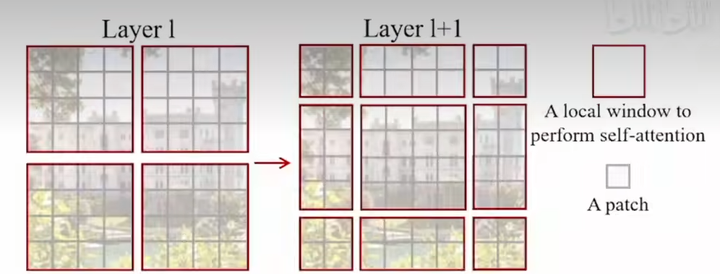 443 |
443 |
444 |
445 | 目的是让不重叠窗口区域也能有交互,操作本质是将所有窗口往右下角移动2个patch。
446 |
447 | 窗口数从4个变成了9个,计算量增大,为减小计算量,使用cyclic shift,将窗口拼接成4个窗口,另外因为拼接后A、B、C相较于原图发生了相对位置变化,所以A、B、C和其他区域是不可以进行交互的,因此引入了Mask操作。
448 |
449 | 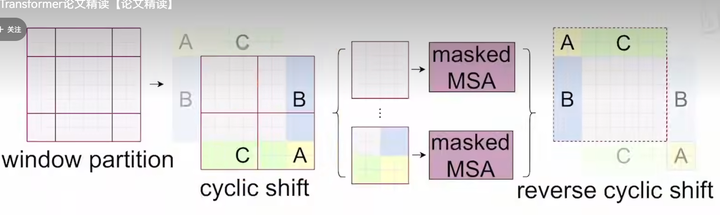 450 |
450 |
451 |
452 | Mask操作:
453 |
454 | 以3、6所在窗口的自注意力计算为例,将7\*7=49个像素展平得到长度为49的一维向量,做矩阵乘法即Q*K。
455 |
456 | 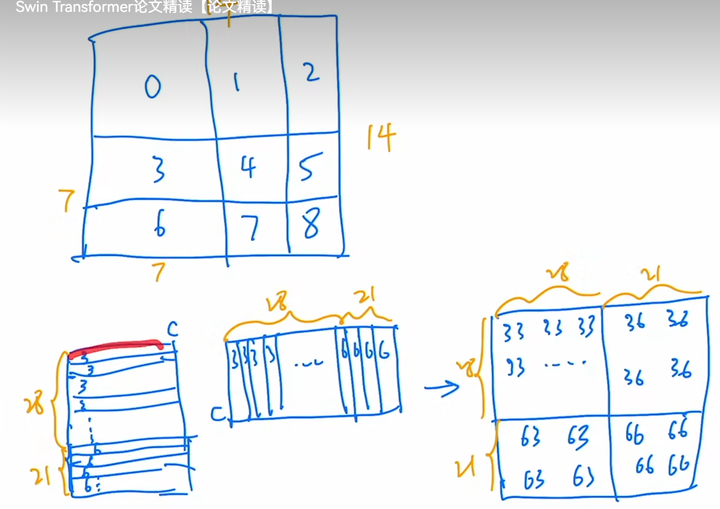 457 |
457 |
458 |
459 | 又因为3和6是不可以交互的,所以矩阵左下角和右上角应该被mask掉,Swin采用的方法是加上左下角和右上角为-100,其余位置为0的模板,这样得到的attention矩阵在softmax后就变成0了。
460 |
461 | 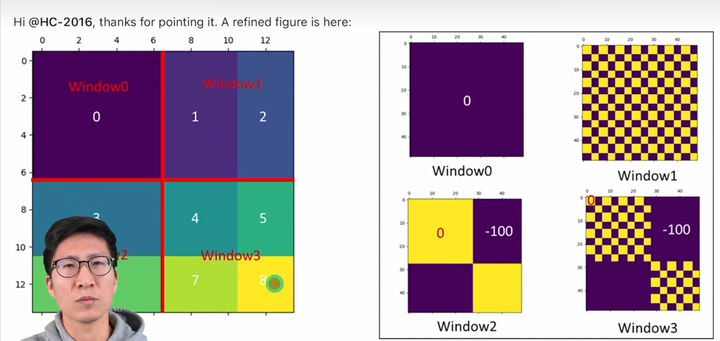 462 |
462 |
463 |
464 | - ✒️method2: patch merging
465 | 就是间隔采样,然后在通道维度上拼接
466 |
467 |  468 |
468 |
469 |
470 | (4)⭐**SwinTransformer位置编码实现**
471 |
472 | **👉核心思想就是建了一个相对位置编码embedding字典,使得相同的相对位置编码成相同的embedding。👈**
473 |
474 | 例如2\*2的patch之间的相对位置关系矩阵为2\*2\*2,相对位置范围为[-1,1]:
475 |
476 | 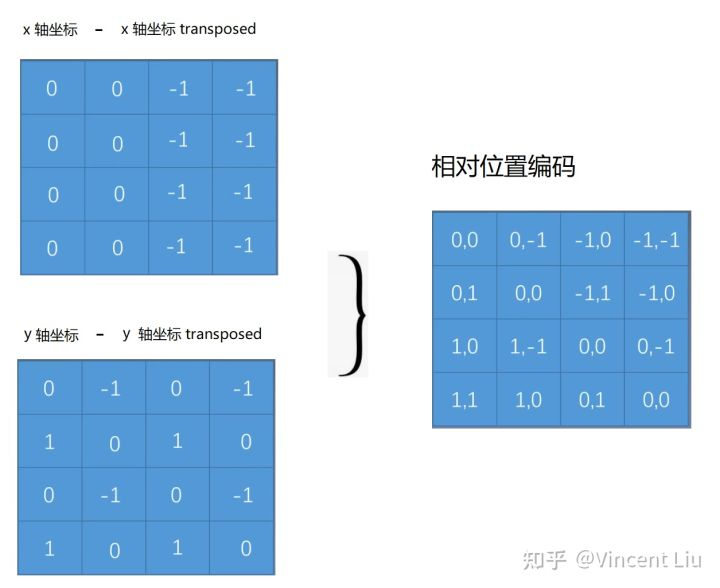 477 |
477 |
478 |
479 | 则x,y相对位置关系可用3\*3 (-1,0,1三种相对位置)的table存储所有可能的相对位置关系,并用3\*3\*embed_n表示所有相对位置对应的embedding。**为了使得索引为整数**,需要将所有相对位置变为正值:
480 |
481 |  482 |
482 |
483 |
484 | 可以通过简单的x,y相对位置相加将相对位置映射为一维,但是会出现(0,2)和(2,0)无法区分的问题,所以需要使得x,y相对位置编码不同:
485 |
486 | 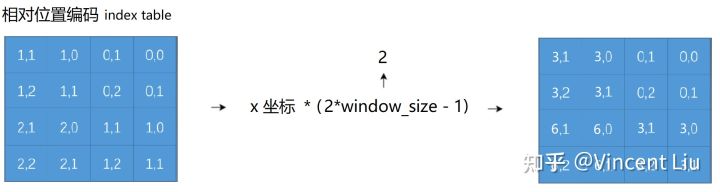 487 |
487 |
488 |
489 | 然后将x和y相对位置相加:
490 |
491 | 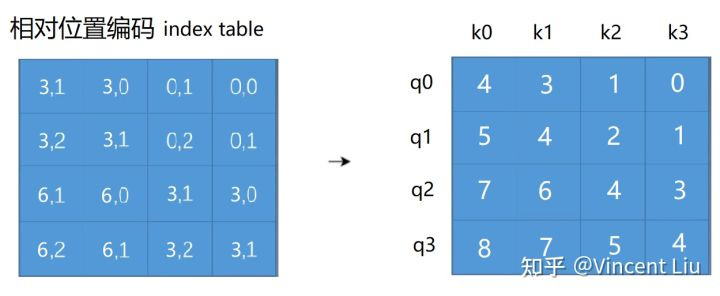 492 |
492 |
493 |
494 | 从而每个相对位置对应一个一维的值,作为相对位置embedding table的索引,获取对应位置的embedding。
495 |
496 | ### 22、⭐YOLOX核心改进:
497 |
498 | 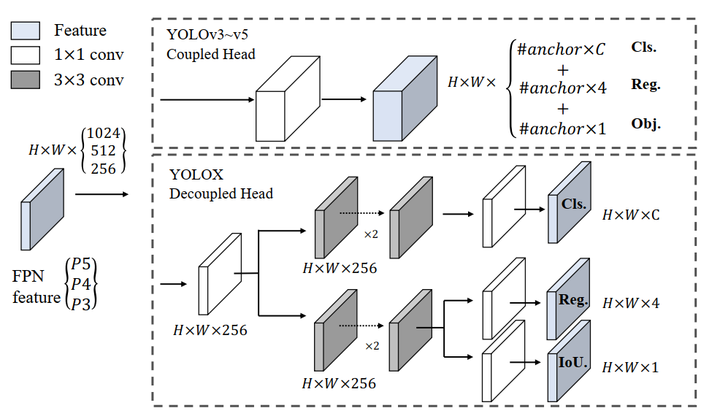 499 |
499 |
500 |
501 | (1)✒️Decoupled head:就是anchor free方法里最常用的cls head和reg head
502 |
503 | (2)✒️Anchor-free: 即类似FCOS,不同的是预测的是中心点相对于grid左上角坐标的offset值,以及bbox的长宽,将物体中心的某个区域内的点定义为正样本,并且每个尺度预测不同大小物体。
504 |
505 | (3)✒️Label assignment(SimOTA): 将prediction和gt的匹配过程建模为运输问题,使得cost最小。
506 | - cost表示:$pred_i$和$gt_j$的cls和reg loss。
507 | - 对每个gt,选择落在指定中心区域的top-k least cost predictions当作正样本,每个gt的k值不同。
508 | - 最佳正锚点数量估计:某个gt的适当正锚点数量应该与该gt回归良好的锚点数量正相关,所以对于每个gt,我们根据IoU值选择前q个预测。这些IoU值相加以表示此gt的正锚点估计数量。
509 |
510 | ### 23、⭐L1、L2正则化的区别
511 |
512 |  513 |
513 |
514 |
515 | ✒️L1正则化容易得到稀疏解,即稀疏权值矩阵,L2正则化容易得到平滑解(权值很小)。
516 |
517 | ✒️原因:a、解空间角度:二维情况,L1正则化:||w1||+||w2||,则函数图像为图中方框,显然方框的角点容易是最优解,而这些最优解都在坐标轴上,权值为0.
518 |
519 | 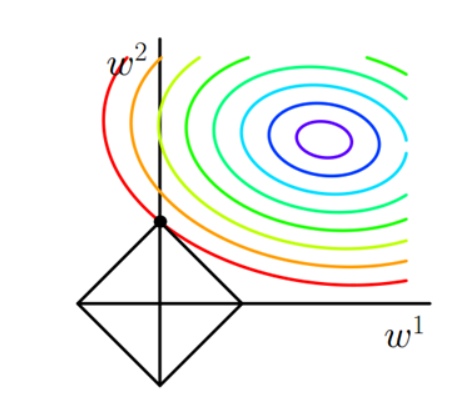 520 |
520 |
521 |
522 | b、梯度下降角度
523 | 添加正则项 $\lambda \theta^2_j$,则L对$\theta_j$的导数为$2\lambda \theta_j$,梯度更新时$\theta_j=\theta_j-2 \lambda \theta_j=(1-2 \lambda) \theta_j$,相当于每次都会乘以一个小于1的数,使得$\theta_j$越来越小。
524 |
525 | ### 24、⭐深度学习花式归一化之Batch/Layer/Instance/Group Normalization
526 | **✒️Batch Normalization**
527 | - ⭐**核心过程**:顾名思义,对一个batch内的数据计算均值和方差,将数据归一化为均值为0、方差为1的正态分布数据,最后用对数据进行缩放和偏移来还原数据本身的分布,如下图所示。
528 |
529 |  530 |
530 |
531 |
532 | - **Batch Norm 1d**
533 | 输入是b\*c, 输出是b\*c,即在每个维度上进行normalization。
534 | - **Batch Norm 2d**
535 | 例如输入是b\*c\*h\*w,则计算normlization时是对每个通道,求b*h*w内的像素求均值和方差,输出是1\*c\*1\*1。
536 |
537 | 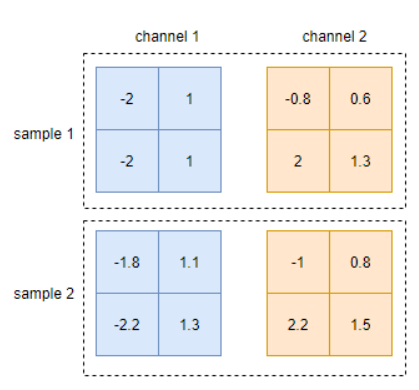 538 |
538 |
539 |
540 |
541 |  542 |
542 |
543 |
544 | - **BN测试时和训练时不同,测试时使用的是全局训练数据的滑动平均的均值和方差。**
545 | - 作用:a、防止过拟合 b、加速网络的收敛,internal covariate shift导致上层网络需要不断适应底层网络带来的分布变化 c、缓解梯度爆炸和梯度消失
546 | - 局限:依赖于batch size,适用于batch size较大的情况
547 |
548 | **✒️改进:**
549 | - Layer normalization: 对每个样本的所有特征进行归一化,如N\*C\*H\*W,对每个C\*H\*W进行归一化,得到N个均值和方差。
550 | - Instance normalization: 对每个样本的每个通道特征进行归一化,如N\*C\*H\*W,对每个H\*W进行归一化,得到N\*C个均值和方差。
551 | - Group normalization:每个样本按通道分组进行归一化,如N\*C\*H\*W,对每个C\*H\*W,在C维度上分成g组,则共有N\*g个均值和方差。
552 |
553 |
554 | 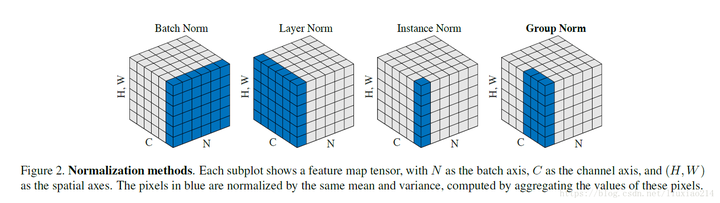 555 |
555 |
556 |
557 | ### 25、⭐深度学习常用优化器介绍
558 | 参考https://zhuanlan.zhihu.com/p/261695487,修正了其中的一些错误。
559 |
560 | (1)**⭐SGD**
561 |
562 | a. ✒️**公式**
563 |
564 | 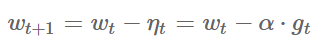 565 |
565 |
566 |
567 | 其中$\alpha$是学习率,$g_t$是当前参数的梯度。
568 |
569 | b. ✒️**优点**:每次只用一个样本更新模型参数,训练速度快。
570 |
571 | c. ✒️**缺点**:容易陷入局部最优;沿陡峭方向振荡,而沿平缓维度进展缓慢,难以迅速收敛
572 |
573 | (2) ⭐**SGD with momentum**
574 |
575 | a. ✒️**公式**
576 |
577 | 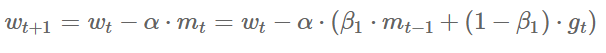 578 |
578 |
579 |
580 | 其中$m_t$为动量。
581 |
582 | b. ✒️**优点**:可借助动量跳出局部最优点。
583 |
584 | c. ✒️**缺点**:容易在局部最优点里来回振荡。
585 |
586 | (3) ⭐**AdaGrad**:经常更新的参数已经收敛得比较好了,应该减少对它的关注,即降低其学习率;对于不常更新的参数,模型学习的信息过少,应该增加对它的关注,即增大其学习率。
587 |
588 | a. ✒️**公式**
589 | $$w_{t+1}=w_t-\alpha \cdot g_t / \sqrt{V_t}=w_t-\alpha \cdot g_t / \sqrt{\sum_{\tau=1}^t g_\tau^2}$$
590 | 其中Vt是二阶动量,为累计梯度值的平方和,与参数更新频繁程度成正比。
591 |
592 | b. ✒️**优点**:稀疏数据场景下表现好;自适应调节学习率。
593 |
594 | c. ✒️**缺点**:Vt单调递增,使得学习率单调递减为0,从而使得训练过程过早结束。
595 |
596 | (4) ⭐**RMSProp**:AdaGrad的改进版,不累计所有历史梯度,而是过去一段时间窗口内的历史梯度。
597 |
598 | a. ✒️**公式**
599 | $$\begin{aligned} w_{t+1} & =w_t-\alpha \cdot g_t / \sqrt{V_t} \\ & =w_t-\alpha \cdot g_t / \sqrt{\beta_2 \cdot V_{t-1}+\left(1-\beta_2\right) g_t^2}\end{aligned}$$
600 | 即把Vt换成指数移动平均。
601 |
602 | b. ✒️**优点**:避免了二阶动量持续累积、导致训练过程提前结束的问题了。
603 |
604 | (5) ⭐**Adam**:=Adaptive + momentum,即结合了momentum一阶动量+RMSProp二阶动量。
605 |
606 | a. ✒️**公式**
607 | $$\begin{aligned} w_{t+1} & =w_t-\alpha \cdot m_t / \sqrt{V_t} \\ & =w_t-\alpha \cdot\left(\beta_1 \cdot m_{t-1}+\left(1-\beta_1\right) \cdot g_t\right) / \sqrt{\beta_2 \cdot V_{t-1}+\left(1-\beta_2\right) g_t^2}\end{aligned}$$
608 |
609 | b. ✒️**优点**:通过一阶动量和二阶动量,有效控制学习率步长和梯度方向,防止梯度的振荡和在鞍点的静止。
610 |
611 | c. ✒️**缺点**:二阶动量是固定历史时间窗口的累积,窗口的变化可能导致Vt振荡,而不是单调变化,从而导致训练后期学习率的振荡,模型不收敛,可通过
612 |
613 |
614 | 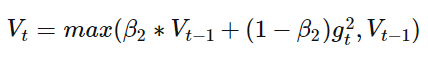 615 |
615 |
616 | 来修正,保证学习率单调递减;自适应学习率算法可能会对前期出现的特征过拟合,后期才出现的特征很难纠正前期的拟合效果,从而错过全局最优解。
617 |
618 | ***
619 | 整理这篇文章不易,喜欢的话可以关注我-->**无名氏,某乎和小红薯同名,WX:无名氏的胡言乱语。** 定期分享算法笔试、面试干货。
--------------------------------------------------------------------------------
/万字秋招算法岗深度学习八股文大全/公众号.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Icecream-blue-sky/Five-year-algorithm-interview-three-year-simulation/6a46ae7b23bf9ccad61cfc458f1237044d9d134a/万字秋招算法岗深度学习八股文大全/公众号.png
--------------------------------------------------------------------------------
/今年 IT 行业就业情况能否回春?(2023年).md:
--------------------------------------------------------------------------------
1 | 本文是2023年秋招时在逼乎写的一个高赞回答(https://www.zhihu.com/question/615395614/answer/3240396956),下面是回答原内容:
2 |
3 | **从身边人情况看不能回春。**
4 |
5 | **样本一**:坐标某C9,方向3D重建相关,一个实验室公认很强的硕士师弟论文(ICCV)、比赛(几个Kaggle金银牌、以及其它杂七杂八比赛)都有,可以说AI岗位要求的名校、顶会、比赛都有,还是科班出身,编程能力也很强。今年他主投的自动驾驶相关方向(别的相关AI方向也投了),我本来以为他预定offer收割机了,但是目前一个到手的offer都没有,只有依图过了,还是说的可能发意向;旷视可能有机会;地平线简历挂,快手一面挂;互联网如快手、淘宝也都挂了;到终面的字节、momenta在泡池子。。。我好奇地问他这些公司顶会和比赛都不看吗?他说看的很少,主要是因为方向不匹配,看到做3D的就不想要。。。这直接给我整无语了,他这简历要是放以前真的是乱杀。他尚且如此,实验室其他师弟师妹更不用说了,已经有人准备考公了。
6 |
7 | **样本二**:坐标北航计算机,公司组里的一个实习生,做的自动驾驶相关方向。每次一起吃饭,我都问他几个offer了,几乎每次都是0,最好的一次是说地平线到了终面,但是并没有offer,泡池子(可能是我那届开始的神奇操作)!
8 |
9 | **样本三**:公司除了某新业务找人外,其他部门几乎不招人了,不仅是不招正式员工,而且连实习生名额都严重缩减了。
10 |
11 | **样本四**: 语音方向某C9硕士师弟,去年和我说实验室2022届以前的师兄/姐去处都不错,都去的zoom之类的有语音岗的公司,到2023届就有几个师兄/姐找不到直接准备考公考遍了……然后到他这届也挺惨,毕竟随着疫情过去,zoom很少招人了,有语音岗的公司非常少,目前只拿了科大讯飞飞星和思必驰,华为泡池子,其他的狂挂。
12 |
13 | 只能说good luck吧,做为2023届毕业生,我非常能理解那种找不到工作的焦虑、难受,尤其是读研究生的,拼命地考研、保研上了一个更好的学校,以为凭着名校、高学历就能“飞黄腾达”,没想到碰上了3年疫情,好不容易熬过了疫情,却发现找不到工作了,本科随便去的华为,读了个研不仅去不了了,还要被要挟给13级。
14 |
15 | 这就业情况要找到好工作真的太靠运气了,但还是要努力找,**千万不要自暴自弃**,依稀记得去年四个舍友每天出寝室的最重要的事就是刷题,回到寝室的第一件事就是投简历,每个人可能都投了上百个简历。其中两个舍友还要在找工作期间被拉去做项目;我则是要一边准备小论文否则有延毕危险,一边要挤出时间刷题,没时间刷的时候就趁走路时间思考题目;另一个舍友则是被挂麻了,只有中兴过了,最后被迫投国企银行。大概是感动了上天,四个人都没实习也没啥顶会,但最后四个人找的工作都挺不错,一个去了大疆,一个去了华为,那个被挂麻了的舍友则拿了我听说的中兴ssp中的“顶薪”,我则是去了某独角兽,个人比较满意。
16 |
17 | 加油!
--------------------------------------------------------------------------------
/各互联网、银行、外企、研究所作息(供秋招同学参考).md:
--------------------------------------------------------------------------------
1 | **华为、荣耀**:一般情况下**9:30上班,一二四九点、三五六点下班,双休**,周末可申请加班,有加班费,但是据说已经很少批准了。当然这是一般情况(舍友无线部门是这样的),组与组之间加班情况方差极大,**搞预研的加班少,搞交付的则加班狠**。
2 |
3 | **大疆**:给钱多,但是加班也是真狠,**10:00左右上班,一般都得干到23:00**(舍友经常23:00后才在群里回消息),双休。另外,实习生好像加班也挺狠。
4 |
5 | **中兴:9:30左右上班,三五六点,一二四八、九点下班,周末自愿加班,可不去**。听舍友描述感觉挺养老的。
6 |
7 | **快手**:有朋友在里面做推荐算法,活特别多(一方面也证明业务多),**一般得干到晚上22:00多甚至23:00**,有双休,绩效不好直接走人。听朋友说,压力太大,下班回到家经常属于床上一躺啥也不想干的状态。最近快手开始盈利了,年终奖很给力,**人均6个月年终**。
8 |
9 | **微软苏州**:有个很厉害的学长在里面做开发,真正的**965**,并且常年居家办公,真的神仙公司。最近学长都开始一边旅游一边上班了,每个星期换个地方住。
10 |
11 | **旷视**:听朋友说方差较大,**业务部门加班较多**,但**研究院风格偏外企,很多部门965,也有的11 7 5**,但是也有那种周末加班的部门。**传言2024年零年终**。
12 |
13 | **Oppo**:听做硬件(射频方向)的朋友说加班很狠,有的说天天**加班到一两点**。
14 |
15 | **百度**:有几个在里面做产品经理的朋友,作息是**10:30前上班,21:00下班,周末加班很少**。搞**搜广推**的则听说是**10:00前上班,21:00下班**;也有**23:00下班的,周末加班**,还是蛮狠的。
16 |
17 | **美团**:也是做产品经理的,作息和百度产品经理差不多。做开发的朋友说**10 8 5**。
18 |
19 | **中国银行:8:30上班,17:30下班**,上班没啥事干,就是扣手机,下班还有2元晚餐,养老首选。上线新软件版本的时候可能让凌晨加班,但会有调休。
20 |
21 | **阿里**:开发岗位,一般**1095,双休**。年终也挺给力的,一搞金融数据分析方面的同学说有**5个月年终**。
22 |
23 | **字节**:坐标北京字节,出了名的卷,一实习学习说**10105**。
24 |
25 | **拼多多**:一般**11116**,也有本科同学去那做开发的,经常干到凌晨,然后辞职了。
26 |
27 | **量化**:听几个量化公司的朋友都说是**标准965**,钱多,但不清楚业绩压力大不大。
28 |
29 | **研究所**:听洛阳、武汉某所的朋友说,**经常加班,但是事不多**,只是硬要你待到指定时间;**有国庆加班的现象**。
30 |
31 | **地平线**:作息10105,网传的绩效361,就是30% A,60% B,10% C,10%的人绩效为0,无年终,但不会裁员。
32 |
33 | **理想**: 作息9105,去年理想赚了很多钱,发了两倍年终,但据说应届生没有年终。今年因为mega卖得不好,有裁员风险,年终估计也无了。
--------------------------------------------------------------------------------
/各公司秋招手撕代码、笔试代码题(供秋招同学参考).md:
--------------------------------------------------------------------------------
1 | **华为:** 岛屿数量(Leetcode 200);根据字符出现频率排序(Leetcode 451)。
2 | 地平线:手撕k-means。
3 |
4 | **博世:** 寻找两个正序数组的中位数(Leetcode 4);跳跃游戏(Leetcode 55)。
5 | 快手:将图像旋转任意角度;只出现一次的数字(Leetcode 136);只出现一次的数字 III(Leetcode 260)。
6 |
7 | **旷视:** 手写NMS;手写multi-head attention;代码写Focal Loss;手写RoI Align。
8 | 美团:编辑距离(Leetcode 72)。
9 |
10 | **虹软:** 笔试题有计算深度可分离卷积的参数量和FLOPS;面试无手撕代码。
11 |
12 | **字节:** 笔试题有 竞技场(牛客搜2023 字节笔试题 0512可找到)。PS:笔试题全是中等以上的,建议投提前批(无笔试)。
13 |
14 | **文远知行:**
15 | - 题一:n*n矩阵,都是0-9数字,0代表空位,相同数字一定连通,并且相同数字组成一个图案。输入k次操作,每次将图案上下左右某个方向整体移动一个单位,如果移动后出界或者被其它图案阻挡,则该次移动无效;否则改变矩阵为移动后的值。输出k次操作后的矩阵。
16 | - 题二:定义f(x,y)的矩形面积为‖x‖‖y‖,输入整数n,m,x属于1到n整数,y属于1到m整数,问n、m范围内第k大的矩形面积。
17 | - 题三:给你一个围棋盘,只有一个空格,其他都是黑棋和白棋,每次只能将任意棋子移动到空位,问最少多少次操作,使得所有的黑棋都在左半边,白棋在右半边。
18 |
19 | **网易:** 笔试题感觉是给acm选手出的,没一道做出来的,寝室全军覆没。
20 |
21 | **蔚来:** 最长递增子序列(Leetcode 300);判断一个矩阵是不是另一个的子矩阵;最长有效括号(Leetcode 32);不同路径 II(Leetcode 63)。
22 |
23 | **科大讯飞:** 笔试题 最大四边形面积(牛客);不相邻最大子序列和(牛客); 最长公共子序列(Leetcode 1143);面试无手撕代码。
24 |
25 | **京东:** 全是小写字母的字符串,长度为n,问:至少包含两个red子串的字符串种类数(google搜近期大厂笔试遇到的“好串”、“漂亮串”、“red串”题目总结)。
26 |
27 | **荣耀:** 笔试题 平方数之和(Leetcode 633);最长公共子序列(Leetcode 1143);
28 |
29 | **海康威视:** 无笔试;面试无手撕代码。
30 |
31 | **其他高频代码题汇总**: 打家劫舍 III (Leetcode337,打家劫舍系列);LCR 147 最小栈;#LCR 007 三数之和;#LCR 153 二叉树中和为目标值的路径;跳跃游戏系列;Leetcode 32 最长有效括号;Leetcode 21 合并两个有序链表;Leetcode 23 合并 K 个升序链表;Leetcode 347 前 K 个高频元素;#LCR 074 合并区间;#LCR 016 无重复字符的最长子串(各种最长最短字符串系列题,经常考);#LCR 010 和为 K 的子数组;Leetcode 704.二分查找;Leetcode 239.滑动窗口最大值;买卖股票系列;Leetcode 42.接雨水;Leetcode 135.分发糖果。
32 |
--------------------------------------------------------------------------------
/工作最常用Git命令.md:
--------------------------------------------------------------------------------
1 | ### 使用频次最高的Git命令
2 | ##### clone代码到本地
3 | ```bash
4 | git clone xxx.git
5 | 拉取最新代码,先git fetch更新所有远程仓库,再用git pull从最新的仓库拉取代码
6 | git fetch
7 | git pull
8 | ```
9 | ##### 切换分支,实际工作中经常要切换到分支进行开发
10 | ```bash
11 | 1、直接切换,但当本地有改动时无法切换,一般采用流程2
12 | git checkout $branch_name
13 | 2、缓存本地改动再切换
14 | git stash save "xxxx"
15 | git stash list
16 | git checkout $branch_name
17 | 切换回去
18 | git checkout $raw_branch_name
19 | 释放缓存,$x是多少用git stash list查看
20 | git stash apply stash@{$x} or git stash pop stash@{x}
21 | ```
22 |
23 | ##### push代码到远程仓库一般流程
24 | ```bash
25 | 查看当前代码改动
26 | git status
27 | git diff $file_path
28 | 确认改动正确后,添加改动到本地git,为了防止出错,一般逐个添加
29 | git add $file_path
30 | git commit -m "xxxx"
31 | 推送到默认的远程分支
32 | git push
33 | 也可推送到指定的远程分支,如不存在,则会新建远程分支,因此常用来新建分支
34 | git push origin $local-branch-name:$remote-branch-name
35 | ```
36 | ### 其他使用频次较低的Git命令
37 | ```bash
38 | 新建本地分支
39 | git checkout -b $branch_name
40 | 从其他分支更新指定文件,会直接覆盖原内容
41 | git checkout $branch_name -- file_path
42 | 从其他分支pull代码
43 | git pull origin $remote_branch:$local_branch
44 | 删除本地分支
45 | git branch -d $branch_name
46 | 缓存单个文件
47 | git stash -- temp.c
48 | 缓存多个文件
49 | git stash push a_file b_file c_file ...
50 | 查看所有分支
51 | git branch -a
52 | 复原文件
53 | git restore --staged filepath
54 | 撤销上次commit,但commit内容是保留在缓存中的
55 | git reset --soft HEAD^
56 | 丢弃所有uncommit的changes
57 | git reset --hard $版本号
58 | 查看上次git pull的时间
59 | date -r .git/FETCH_HEAD
60 | 比较两个分支或者commit不同
61 | git diff a b --stat
62 | 比较具体文件
63 | git diff a b filename
64 | 查看被修改的文件列表
65 | git diff --name-only a b
66 | 用于查看当前分支以及分支之间的关系和跟踪情况
67 | git branch -vv
68 | 查看最近两次两次提交
69 | git reflog -n 2
70 | 合并指定commit代码
71 | git cherry-pick $commit_id
72 | ```
--------------------------------------------------------------------------------
/普通牛马初入社会的一年.md:
--------------------------------------------------------------------------------
1 | 某个平淡的午后,突然得知比我大两岁的朋友准备生娃了,震惊之余,回想过去一年的种种离奇遭遇,瞬间感觉自己老了,尽管我才98年,所以就开始提笔写这篇文章了。
2 |
3 | ---
4 |
5 | 因为恰巧赶上了疫情后的经济寒潮,碰上史上最难一届秋招,我手上就零星几个offer,没有选择的权利,所以被迫去了最不想去的北京,进入了自动驾驶行业。
6 |
7 | 确定了工作去处后,我对未来十分憧憬,小学-初中-高中-大学-硕士,整整19年寒窗苦读,我终于逃离了“牢笼”,心想着终于可以过上自食其力的幸福生活了,但没想到**第一年就遭遇了社会的当头一棒**。
8 |
9 | ### 起
10 |
11 | 去京城前,心想着我这“乡下人”终于可以见识见识大城市了,真是满怀期待。去北京那天,我独自坐了一路高铁,第一次看到了北京的晚霞,心里的期待又多了一分。打车到出租屋时已是深夜,当我拖着行李箱顺着漆黑和狭窄的巷子拐进所住的小区时,我才第一次见识到传说中的“老破小”:楼梯过道坑坑洼洼的墙壁,积满灰与堆着各式杂物的楼梯,发黄且略显灰暗的声控灯,当然还有我那小得可怜但又贵得出奇的“小窝”。在北京的第一夜,孤独、失落、对未知的恐惧等各种感觉让我五味杂陈,心里空落落的。
12 |
13 |
14 |  15 |
16 | 北京出租屋
17 |
15 |
16 | 北京出租屋
17 |
18 |
19 | 尽管在北京生活的中后期发生了太多太多事,让我一度对生活失去信心,但不得不说,前期我真的过得挺幸福的,甚至幸福得有点不真实。
20 |
21 | 首先是在北京要好的同学很多,一来就受到了硕士同学的款待,吃了顿北京涮羊肉火锅。接着又跟着本科同学去参观了传说中的北大,在未名湖旁吹了吹风,和同学忆往昔峥嵘岁月的同时,赞叹着北大食堂的豪华以及校园环境的优美。
22 |
23 |
24 |  25 |
26 | 北大未名湖
27 |
25 |
26 | 北大未名湖
27 |
28 |
29 | 然后是玩乐。北京作为首都,有着深厚的文化底蕴,所以好玩的地方也非常多,我经历了人生很多第一次:去看了人生第一次话剧;去秦皇岛看了刘谦精彩绝伦的魔术演出;去北戴河人生第一次看海,并且看的是绝美且治愈的海上日出;去国家网球中心第一次现场看网球比赛,还看到了堪比大满贯决赛的梅总与辛纳之争;去滑了雪;去看了雪中故宫;去朝阳公园玩了浆板;去了颐和园;去了西湖;去了灵隐寺。。。还有很多很多美好回忆,现在想来也很幸福。
30 |
31 |
32 |  33 |
34 | 雪中故宫
35 |
33 |
34 | 雪中故宫
35 |
36 |
37 | 除了到处玩,从来不会做菜的我竟然喜欢上了做菜。从一开始的煎个蛋都能煎黑的菜鸡,到后来开始煎豆腐、炒白菜、蒜香鸡翅、辣子鸡、玉米炖排骨、炒豆泡等等,一开始自己都下不了嘴,后来慢慢觉得自己做得挺好吃,这让我每个周末都过得异常充实。做饭最大的幸福在于可以做自己喜欢吃的菜,一顿不够可以两顿。
38 |
39 |
40 |  41 |
42 | 和朋友一起做饭
43 |
41 |
42 | 和朋友一起做饭
43 |
44 |
45 | ### 承
46 |
47 | 当身边朋友都在苦逼的加班以至于没有生活时,我就常常感觉这快乐的生活有些许不真实,莫名担心它哪一天会结束,没想到有一天真的迎来了转折点。还是后来下定决心跳槽时,我试图回想什么时候落入这牢笼的时候,才发现那一天真的是一切痛苦的开始。
48 |
49 | 我的工作职位是传说中的自动驾驶感知算法工程师,主要负责BEV障碍物检测算法,请注意这个“主要”,看完后面的叙述你会知道它真是“主要”,必须加上这个修饰。
50 |
51 | 那一天正值海淀初雪,雪对南方人天生有种魔力,我带着初雪的喜悦去了公司,被告知调去新项目帮忙,担任的职责有个高大上的学名:后融合,简单来说就是融合多个模态(lidar、radar、纯视觉)模型的预测结果。一开始听说要用C++且做的东西是我从未做过的,我很兴奋,因为又能学到新东西,接受新的挑战了。带着这份兴奋,我短时间入门了C++,同时借着ChatGPT,我终于能帮着写些简单的函数了。
52 |
53 |
54 |  55 |
56 | 下班天桥上的雪景
57 |
55 |
56 | 下班天桥上的雪景
57 |
58 |
59 |
60 | 慢慢的,一些脏活累活开始找上我了。首先就是出差去某主机厂基地驻场,主要工作就是上车看看我们的算法效果。这是我人生第一次出差,大致流程就是跟着测试人员找各种场景测试,记录badcase,这还是我第一次上车,惊喜地发现我们的算法效果还不错。不过这次整体体验很差,一是因为流程混乱,按理说会有专门的测试人员协助我们,结果发现从拉取软件包、到编译程序、再到启动录制全都得自己来,什么文档也没有;二是因为车子出了故障,莫名在红绿灯路口误触发SOS,拔了电池重启都没用,喝了半小时刺骨且夹着冷雨的西北风后只能无赖回酒店了。
61 |
62 | 很长一段时间里,我都天真地以为派我们出差真的是为了看路测效果,后来出差多了,**发现出差的真正目的只有一个,主机厂想面对面地监视我们干活。大致就是以前的奴隶主监督着黑人摘棉花那种感觉,唯一区别是有没有鞭子,或者说鞭子是物理的还是其他形式的**。
63 |
64 | 用奴隶主形容此主机厂是一点都不过分。尤其是在如今的自动驾驶市场下,主机厂牢牢握住供应商的命脉:供应商没有车,算法只有上车才能卖钱。因此主机厂是绝对的甲方,供应商则是卑微的乙方,乙方必须卑躬屈膝,舔着脸求主子给个量产单子,哪怕是PoC(Proof of Concept,概念验证,证明你的算法是否行得通)也好,不管要求多严格、多无理,都照单全收,什么**白盒交付、主动驻场、陪同加班**都不在话下。供应商卑微地把钱搞到了,勉强生存下去,而底下的研发工程师们则累得哭爹喊娘,并且将大部分生命都浪费在讨好主机厂且与技术无关的无意义琐事上,这也是我最后离开自驾这一行的主要原因。
65 |
66 | 印象里最深的一次是做后融合的人全部被派去驻场了,也是那次驻场直接导致了我最后的离职。那一次和以往有很大不同,以往并不会严格要求你作息,你早走晚走实际上并没有太大的影响,但那一次甲方明文要求**早八晚十,一周七天**,公司某领导还在群里说是对我们的恩赐,关键是组长也来了,所以不好“旷工”。驻场的办公室就在总装车间上方,每一天都要和同事穿着和环卫工人所穿相差无几的红色马甲,闻着机油味和灰尘味路过这车间,看着严格遵守路线的寻迹小车发会呆,然后左转,总有个主播在那直播卖车,接着是爬满是高中才有的奋斗标语的楼梯,右转,走过一道长廊,每次走时都会往左侧窗外看看辛勤工作的工人们,也不知道为什么要看,最后到了,印入眼帘的是一排排没有隔板的白色桌子,桌子上是电脑、公司自己运过来的显示器(是的你没有看错,我们自己运来的)、插满插头的插线板、随意丢弃的饮料或是零食垃圾以及目光呆滞、穿着“环卫工”衣裳的牛马们。oh,对了,最深处一排可不是牛马,是某主机厂的老爷们,来监工的!
67 |
68 |
69 |  70 |
71 | 红色马甲
72 |
70 |
71 | 红色马甲
72 |
73 |
74 | **去办公室的路本不长,可每次走的时候我都觉得好长好长,每一天都比昨天对工作和生活感到更失望,仿佛路上有吸人精血的恶鬼,每次到工位时便全无干劲可言**。有人可能会好奇,你不是算法工程师吗,不就训训模型、处理数据就没事干了吗,天天早八晚十哪有那么多事做?你不说我都快忘了我是算法工程师了,因为我真的找不到那时在做的事和“算法工程师”有任何关联,我做的事随便拉个本科生都能做,根本用不着我这个百无一用的“高材生”。每天的工作只有两件,一是分析JIRA上路测反馈的Badcase,没做过后融合的人可能不知道这个分析过程有多恶心,后融合概括来说无非就是不断地写If else来给上游感知算法兜底,因此所谓分析其实就是找是哪个If else逻辑的锅,而且代码是C++的,一些难的case你要手动print调试一层一层找,当然最让人绝望的其实还是无法If else保证互相之间不打架,又称跷跷板,所以Badcase 是无穷无尽的;二是将上下游分析完成的Badcase汇成ppt,注意是格式有严格要求的一页PPT,阐述清楚问题现象、原因、修复方案及日期,我们私下里戏称为“**奏折**”,毕竟花这么大力气做这么一个花哨的东西的目的只有一个,让“皇上”能看懂并且相信我们确实解决了某个case。而项目经理每天的活就是“批阅奏折”,对自己人严加要求,动辄打回,然后给“主子”汇报今日解决多少badcase,还剩多少。
75 |
76 | 就这样撑到了第五天,我们解决了大量的badcase,甚至让主机厂的人感叹还是驻场效率高,这也直接导致了后来越来越频繁的出差,当然这是后话。“劳作”了五天,牛马都想休息了,每个人心中的怨气也积累得快要爆炸,于是组长想给我们放一天假,但上面规定是七天无休,所以只能抽签轮休。抽签的方式是微信跳一跳,也许是确实过得太压抑了,一个这么简单的游戏我们竟然玩得津津有味,最终我们平常玩得最好的四个人抽到了周六休息。第二天,我们迫不及待地开车去市里透透气,淋着小雨绕着某景点走了很久,一路上有说有笑、吐槽着公司和主机厂的xx,骂骂这个,骂骂那个,一会聊到过去,一会畅想未来,倒是颇有些“**携来百侣曾游,忆往昔峥嵘岁月稠。恰同学少年...**”的意境。好不容易被放出来,大家都不太想回去,直到晚上十点我们才赶回酒店,回去的时候还给刚下班的战友们待了肯德基还是麦当劳。周日,组长突然提议大家晚上去K歌,释放下情绪,现在看来这是个极好的提议,毕竟音乐的本质就是情感,唱歌就是情感的表达,那晚,我们四人小队或许是真的太苦闷了,鬼哭狼嚎到了凌晨两点多,凌晨三点才回到酒店。那晚让我印象最深的歌是《鲜花》,里面的歌词真是太能表达我当时的感受了,“**你那快乐吗?我期待的吗?**”,“**还记得笑吗?**”,“**可是我可惜我,把车卖了**”,以及最后的“**啊...**”,后来我多次唱过这首歌,却怎么也唱不出当时的感觉。
77 |
78 |
79 |  80 |
81 | 《鲜花》歌词
82 |
80 |
81 | 《鲜花》歌词
82 |
83 |
84 | 值得庆幸的是,公司决定后面派人来轮流驻场,因此我们又待了一周就陆续回去了,要是真待上一个月,怕是我们组当场就得解散。当然,可笑的是,后来听说因为某些原因,我们那两周解的“成吨”的badcase几乎都作废了,所以现实有时候就是个笑话。当然其间其实还发生了很多可笑又可恨的事,某公司的“恶心”行径实在是“罄竹难书”。
85 |
86 | 比如之前是某著名公司全球副总裁的某CEO,在一个平凡的周末在公司群里说周一有要事宣布,要求大家明天早上8:00到公司,虽然平时上班时间是10:00多,不去也不违反公司的任何规定,但是还是有很多人准时去了,也许这就是老牛马的服从性吧。来不及为它们感到悲哀,就听闻传说中的要事是这周开始大家要早八晚十,直到项目攻关结束。因为我们不打卡,这位CEO为了保证我们“准时”上下班,**不仅暗中命令门卫记录我们每个人上下班的时间,而且还去每个人工位拍照,记录谁谁“旷工”**,这件事让我深刻见识到了什么是中国公司的管理手段,什么是全球副总裁。
87 |
88 | 再比如某CTO在某会上被主机厂的领导辱骂之后(小道消息),开始上演离职大戏,这场戏前前后后持续了几个月,某天他又说突然不走了,说要成立某某部门,不再碰和主机厂相关的事,于是把我身边的人一一拆散,接着又真的离职了,留下这没人接的烂摊子。
89 |
90 | 再比如公司去年拖到今年的年终奖,说是只有做量产的人才有,最可笑的是,如果你跟着上面那位CTO转去某部门,不管之前你对项目贡献多大、熬了多少夜,你的年终奖都要被再拖三个月,甚至身边有反抗的同事被穿小鞋,干着最脏最累的活,年终奖系数却被降到几乎没有的地步。
91 |
92 | ### 转
93 |
94 | 那次早八晚十出差后,已是四月份,我已经有了离职的念头。公司被这一个量产搞得极其动荡,尤其是某CTO说要跑路的时候,身边的同事纷纷想离职,每天八卦的是谁谁刷了多少题,谁谁已经面了多少公司,谁谁要last day了。**那时只要一进公司,仿佛踏入一滩死水,被“死亡”的气息压得喘不过气,看谁都像行尸走肉,有时候甚至像牛头或马头人身的真牛马,对人生充满了绝望**。
95 |
96 | 当确认自己不能再承受更多失望以及想换个环境后,某天我请了一天假,认真思考到底要不要离职,主要思考了两点,一是担心我只有差不多一年经验,出去有没有人要我,能不能找到工作;二是深入想了想这公司还有没有什么我值得留恋的地方,我在手机上敲了很多字,罗列我留恋的东西,发现唯一舍不得的只有组里待我很好很好的同事们。抉择的当天晚上,我下了离职的决心,对于第一点,一年经验有没有公司要没人能说得定,不试试怎么知道,试了既能让我不再颓废,又能真正了解自己一年以来的进步;对于第二点,大厦将倾,身边人都是要离职的阵仗,而且我们小组已被某CTO拆散,所以即使我不离开,也留不住他们。
97 |
98 | 于是乎我开始了痛苦而漫长的刷题之旅。校招时,由于内部和外部的极端压力(内要毕业,外是寒冬),我并没有太多时间刷题,算上去实验室路上强行背的题,总共刷的题甚至没有超过150题,也因此错过一些本来就难得的面试机会。这次借着离职的决心,决定补齐刷题这个短板,刷题语言也由Python变成了新学的C++。从四月份下旬到七月,我由一开始的全凭心情的每周零散刷几题模式,**慢慢变成每日至少一题,时间是早晨和晚上下班,凭着“做题家”的毅力和多年来培养的“做题”能力,我把《代码随想录》完整刷了一遍,再加上leetcode上的hot100以及常考的面试题,最后刷了将近300道题吧**,“代码能力”(背题能力!)以肉眼可见的速度在提升。
99 |
100 | 补齐了这个大短板,我几乎再无短板,写简历、面试“吹牛”都是我所擅长的。写简历我大概只用了两天,由于**在BEV障碍物检测、单目3D障碍物检测、后融合、车道线等各个模块都打过杂**,我能写的东西非常多,也因此从未因为一年经验被嫌弃过,在那之前还从未想到自己厌恶的事情(到处打杂)最终却使我受益最多。另外,最让我感动的是,**相比于那寒冬得不能再寒冬的校招,人生第一次社招的面试机会异常多,几乎只要投了就有面试机会,看来早生或晚生一年也许真能逆天改命**。虽然面试机会非常多,但我还在职,所以那段时间显得异常忙碌,有时早上和晚上都有面试,白天还要上班,整个人疲惫不堪。但幸运的是面试过程都异常顺利,大都按我简历上引导的方向去提问,代码题也是几乎都做出来了,印象最深的一件事是,几乎每个面试官都会怀着好奇或是同情的心情问我为什么才一年就跳槽了,我给他们吐槽了在公司的种种离谱遭遇后,他们都非常理解我的选择,甚至有的和我一起骂该公司。
101 |
102 | ### 合
103 |
104 | 由于实在不想在这乌烟瘴气之地久留,我把面试时间都排得尽可能的紧凑,从面试到拿到大部分offer的过程只持续了不到3周。纠结了一段时间手上的offer后,我最终决定离开了自动驾驶行业,感性地选择了大多数人不会选的一个offer。这是一个非常冒险的决定,以前那个谨小慎微、多方权衡的我是绝不会做出这个选择的,但我实在厌倦了墨守陈规的生活,索性“离经叛道”了一把。
105 |
106 | 选好下一站后,我的离职速度是同事始料未及的,**从提交离职申请和交接、到请散伙饭、到离开北京、到新城市租好房、再到新公司入职,不过一周多一点而已**。没办法,我实在对一年来发生的一切太失望了,也对租房、物价过高的北京没有了任何好感,没有一丁点想留下来的欲望,北京户口我也早早地放弃了。在北京的最后一周,为了尽可能不留遗憾,我去逛了一些没逛过的景点,去鸟巢看了邓紫棋的演唱会,也是人生第一次看演唱会,和在北京的朋友一一吃饭和道别,小电驴卖给了师弟(这会是真的卖车了哈哈),房子租给了好朋友。这一周我过得无比放松,上一次这么放松还是刚来北京的时候,另外,也许是无论哪座城市,只要以打工人的角度去看都会心生厌恶,这次我以旅游的角度观察北京时,反倒觉得北京确实是个不错的城市,那么多景点、那么多好玩的去处,只可惜一点,不适合穷人。
107 |
108 |
109 |  110 |
111 | 邓紫棋演唱会
112 |
110 |
111 | 邓紫棋演唱会
112 |
113 |
114 | 现在的我已经回到了南方,在新城市、新公司生活和工作了几个月,各方面来说都比较满意,比如说租房方面,我以比北京三人合租更低的价格租到了30多平的公寓,有沙发,每天下班回家还能躺着看看电视或者打打游戏。再比如说工作方面,再也没有量产压力,没有驻场,没有那么多无聊会议,可以“心安理得”地双休,甚至第二周就碰上了团建。
115 |
116 |
117 |  118 |
119 | 团建
120 |
118 |
119 | 团建
120 |
121 |
122 | 再比如我终于又能有时间写文章,此时此刻,窗外下着大雨,电脑里放着略显悲伤的音乐,正在电脑前码字的我,再回头看看一年来的动荡岁月,真是有点“**眼看它起高楼,眼看它楼塌了**”的感觉,就像《红楼梦》里的大观园一般,一开始大家都在,热热闹闹的,大家也很有干劲,然后大leader走了,再然后隔壁组的小组长也走了,再然后同组的同事也走了,最后甚至隔壁组所有人都走光了,同组的也仅剩因为客观原因走不了的几个人,都是多么优秀的人啊,却还是免不了“群芳流散”的命运。
123 |
124 | ---
125 |
126 | 正如你所看到的,对于一个初入社会的人来说,这是多么糟糕的一年,我失望过、彷徨过,但我从来没有绝望过,正如我的座右铭“雄关漫道真如铁,而今迈步从头越”,人要向前看,向前走,不怕任何妖魔鬼怪,不怕任何失败,大不了从头再来!
127 |
128 |
129 |  130 |
130 |
131 |
132 | ---
133 | 写文章这么多年,还没有建过交流群,今天就索性建一个,就叫“无名氏的工作学习生活交流群”,主打一个“包罗万象”,大家有什么想咨询我的可以在群里问我,欢迎大家加入~
134 |
135 |
136 |  137 |
137 |
--------------------------------------------------------------------------------
/秋招算法岗手撕代码题合集(非leetcode,含答案)/2024秋招社招手撕代码题.md:
--------------------------------------------------------------------------------
1 | 最近跳槽,下面是社招时遇到的手撕代码题,**如需要答案,可提issue,视需求写**:
2 | 1. ✒️**手撕k-means(在手撕代码合集里有)和三数之和(蔚来感知算法岗)**
3 | 2. ✒️**有重复数字的二分查找(leetcode287)(赢彻感知算法岗)**
4 | 给定一个包含 n + 1 个整数的数组 nums ,其数字都在 [1, n] 范围内(包括 1 和 n),可知至少存在一个重复的整数。假设 nums 只有 一个重复的整数 ,返回 这个重复的数 。
5 | 3. ✒️**智力题(赢彻感知算法岗)**
6 | 假设你只能在一维数轴上移动,从0开始,第k步可以左右走k步,给定坐标x(整数,可能为正也可能为负),问能不能到达?最少步数是多少?
7 | 4. ✒️**多起点多终点最短路径问题(微软某算法岗)**
8 | 给定一个n*n的格子,有多个起点和多个终点,格子中可能有障碍物(不可通行),求每个起点到终点的最短距离。
9 | 5. ✒️**组成三角形的个数**
10 | 给定一个一维数组,问能组成有效三角形的个数?
11 | 6. ✒️**手写2d iou(美团无人车感知算法岗)**
12 | 手撕代码合集里有这道题。进阶问题是旋转2d iou如何计算?只需要给出思路
13 | 7. ✒️**能否组成两条平行线(美团无人车感知算法岗)**
14 | 给定n个二维空间的点的坐标(x1,y1),(x2,y2)...,问能否找到两条平行线,使所有点都在这两条平行线上?
15 | 8. ✒️**手撕二维卷积(小马智行感知算法岗)**
16 | 这题一看就是小马智行才能出得出来的题,手撕代码合集里也有这道题。实际是个套壳版:给定n*n的格子,某些格子中有炸弹,你可以在格子中行走,若距离d(整数)范围内有炸弹,则该格子不安全,求安全格子的数量。
17 | 9. ✒️**跳跃游戏(文远知行感知算法岗)**
18 | leetcode 55
19 |
--------------------------------------------------------------------------------
/秋招算法岗手撕代码题合集(非leetcode,含答案)/秋招算法岗手撕代码题合集(非leetcode,含答案).md:
--------------------------------------------------------------------------------
1 | ##### 作者: 无名氏,某乎和小红薯同名,WX:无名氏的胡言乱语。
2 | ### 1、python手动实现二维卷积(一种丑陋但容易背的写法)
3 | ```python
4 | import numpy as np
5 | def conv2d(img, in_channels, out_channels ,kernels, bias, stride=1, padding=0):
6 | N, C, H, W = img.shape
7 | kh, kw = kernels.shape
8 | p = padding
9 | assert C == in_channels, "kernels' input channels do not match with img"
10 |
11 | if p:
12 | img = np.pad(img, ((0,0),(0,0),(p,p),(p,p)), 'constant') # padding along with all axis
13 |
14 | out_h = (H + 2*padding - kh) // stride + 1
15 | out_w = (W + 2*padding - kw) // stride + 1
16 |
17 | outputs = np.zeros([N, out_channels, out_h, out_w])
18 | # print(img)
19 | for n in range(N):
20 | for out in range(out_channels):
21 | for i in range(in_channels):
22 | for h in range(out_h):
23 | for w in range(out_w):
24 | for x in range(kh):
25 | for y in range(kw):
26 | outputs[n][out][h][w] += img[n][i][h * stride + x][w * stride + y] * kernels[x][y]
27 | if i == in_channels - 1:
28 | outputs[n][out][:][:] += bias[n][out]
29 | return outputs
30 | ```
31 | ### 2、pytorch手动实现自注意力和多头自注意力
32 | from [(多头)自注意力机制的PyTorch实现 - Zzxn's Blog](https://zzxn.github.io/2020/11/03/multihead-attention-in-pytorch.html)
33 | - 自注意力
34 | ``` python
35 | from math import sqrt
36 |
37 | import torch
38 | import torch.nn as nn
39 |
40 | class SelfAttention(nn.Module):
41 | # dim_in: int
42 | # dim_k: int
43 | # dim_v: int
44 |
45 | def __init__(self, dim_in, dim_k, dim_v):
46 | super(SelfAttention, self).__init__()
47 | self.dim_in = dim_in
48 | self.dim_k = dim_k
49 | self.dim_v = dim_v
50 | self.linear_q = nn.Linear(dim_in, dim_k, bias=False)
51 | self.linear_k = nn.Linear(dim_in, dim_k, bias=False)
52 | self.linear_v = nn.Linear(dim_in, dim_v, bias=False)
53 | self._norm_fact = 1 / sqrt(dim_k)
54 |
55 | def forward(self, x):
56 | # x: batch, n, dim_in
57 | batch, n, dim_in = x.shape
58 | assert dim_in == self.dim_in
59 |
60 | q = self.linear_q(x) # batch, n, dim_k
61 | k = self.linear_k(x) # batch, n, dim_k
62 | v = self.linear_v(x) # batch, n, dim_v
63 |
64 | dist = torch.bmm(q, k.transpose(1, 2)) * self._norm_fact # batch, n, n
65 | dist = torch.softmax(dist, dim=-1) # batch, n, n
66 |
67 | att = torch.bmm(dist, v)
68 | return att
69 | ```
70 |
71 | - 多头自注意力
72 | ```python
73 | from math import sqrt
74 |
75 | import torch
76 | import torch.nn as nn
77 |
78 |
79 | class MultiHeadSelfAttention(nn.Module):
80 | # dim_in: int # input dimension
81 | # dim_k: int # key and query dimension
82 | # dim_v: int # value dimension
83 | # num_heads: int # number of heads, for each head, dim_* = dim_* // num_heads
84 |
85 | def __init__(self, dim_in, dim_k, dim_v, num_heads=8):
86 | super(MultiHeadSelfAttention, self).__init__()
87 | assert dim_k % num_heads == 0 and dim_v % num_heads == 0, "dim_k and dim_v must be multiple of num_heads"
88 | self.dim_in = dim_in
89 | self.dim_k = dim_k
90 | self.dim_v = dim_v
91 | self.num_heads = num_heads
92 | self.linear_q = nn.Linear(dim_in, dim_k, bias=False)
93 | self.linear_k = nn.Linear(dim_in, dim_k, bias=False)
94 | self.linear_v = nn.Linear(dim_in, dim_v, bias=False)
95 | self._norm_fact = 1 / sqrt(dim_k // num_heads)
96 |
97 | def forward(self, x):
98 | # x: tensor of shape (batch, n, dim_in)
99 | batch, n, dim_in = x.shape
100 | assert dim_in == self.dim_in
101 |
102 | nh = self.num_heads
103 | dk = self.dim_k // nh # dim_k of each head
104 | dv = self.dim_v // nh # dim_v of each head
105 |
106 | q = self.linear_q(x).reshape(batch, n, nh, dk).transpose(1, 2) # (batch, nh, n, dk)
107 | k = self.linear_k(x).reshape(batch, n, nh, dk).transpose(1, 2) # (batch, nh, n, dk)
108 | v = self.linear_v(x).reshape(batch, n, nh, dv).transpose(1, 2) # (batch, nh, n, dv)
109 |
110 | dist = torch.matmul(q, k.transpose(2, 3)) * self._norm_fact # batch, nh, n, n
111 | dist = torch.softmax(dist, dim=-1) # batch, nh, n, n
112 |
113 | att = torch.matmul(dist, v) # batch, nh, n, dv
114 | att = att.transpose(1, 2).reshape(batch, n, self.dim_v) # batch, n, dim_v
115 | return att
116 |
117 | ```
118 | ### 3、图像缩放
119 | #### 步骤:
120 | 1. 通过原始图像和比例因子得到新图像的大小,并用零矩阵初始化新图像。
121 | 2. 由新图像的某个像素点(x,y)映射到原始图像(x’,y’)处。
122 | 3. 对x’,y’取整得到(xx,yy)并得到(xx,yy)、(xx+1,yy)、(xx,yy+1)和(xx+1,yy+1)的值。
123 | 4. 利用双线性插值得到像素点(x,y)的值并写回新图像。
124 |
125 | 双线性插值实现:将每个像素点坐标(x,y)分解为(i+u,j+v), i,j是整数部分,u,v是小数部分,则$ f(i+u,j+v) = (1-u)(1-v) \ast f(i,j)+uv \ast f(i+1,j+1)+u(1-v)f(i+1,j)+(1-u)v \ast f(i,j+1) $。
126 |
127 | opencv实现细节:将新图像像素点映射回原图像时,$SrcX=(dstX+0.5) \ast (srcWidth/dstWidth) -0.5,SrcY=(dstY+0.5) \ast (srcHeight/dstHeight)-0.5$,使得原图像和新图像几何中心对齐。因为按原始映射方式,$5 \ast 5$图像缩放成$3 \ast 3$图像,图像中心点(1,1)映射回原图会变成(1.67,1.67)而不是(2,2)。
128 | ### 4、图像旋转实现
129 | #### 旋转矩阵:
130 |
131 |
132 |  133 |
133 |
134 |
135 | #### 实现思路:
136 | 1. 计算旋转后图像的min_x,min_y,将(min_x,min_y)作为新坐标原点(向下取整),并变换原图像坐标到新坐标系,以防止旋转后图像超出图像边界。
137 | 2. 初始化旋转后图像的0矩阵,遍历矩阵中每个点(x,y),根据旋转矩阵进行反向映射(旋转矩阵的逆,np.linalg.inv(a)),将(x,y)映射回原图(x0,y0),同样将x0和y0拆分为整数和小数部分:i+u,j+v,进行双线性插值即可。从而得到旋转后图像每个像素(x,y)的值。
138 |
139 | ### 5、RoI Pooling实现细节
140 | **RoI Pooling**需要经过两次量化实现pooling:
141 | 第一次是映射到feature map时,当位置是小数时,对坐标进行最近邻插值。
142 |
143 |
144 |  145 |
145 |
146 |
147 | 第二次是在pooling时,当RoI size不能被RoI Pooling ouputsize整除时,直接舍去小数位。如4/3=1.33,直接变为1,则RoI pooling变成对每个1*2的格子做pooling,pooling方式可选max或者average。
148 |
149 |
150 |  151 |
151 |
152 |
153 | ### 6、RoIAlign实现细节
154 | **RoIAlign**采用双线性插值避免量化带来的特征损失:
155 | 将RoI平分成outputsize*outputsize个方格,对每个方格取四个采样点,采样点的值通过双线性插值获得,最后通过对四个采样点进行max或average pooling得到最终的RoI feature。
156 |
157 |
158 |  159 |
159 |
160 |
161 | ### 7、2D/3D IoU实现
162 | ```python
163 | #核心思路:
164 | union_h = min(top_y) - max(bottom_y)
165 | union_w = min(right_x) - max(left_x)
166 | def 2d_iou(box1, box2):
167 | '''
168 | 两个框(二维)的 iou 计算
169 |
170 | 注意:左下和右上角点
171 |
172 | box:[x1, y1, x2, y2]
173 | '''
174 | # 计算重叠区域的长宽
175 | in_h = min(box1[3], box2[3]) - max(box1[1], box2[1])
176 | in_w = min(box1[2], box2[2]) - max(box1[0], box2[0])
177 | inter = 0 if in_h<0 or in_w<0 else in_h*in_w
178 | union = (box1[2] - box1[0]) * (box1[3] - box1[1]) + \
179 | (box2[2] - box2[0]) * (box2[3] - box2[1]) - inter
180 | iou = inter / union
181 | return iou
182 |
183 | # 思路类似,找到原点方向的角点以及斜对角处的角点
184 | def 3d_iou(box1, box2):
185 | '''
186 | box:[x1,y1,z1,x2,y2,z2]
187 | '''
188 | area1 = (box1[3]-box1[0])*(box1[4]-box1[1])*(box1[5]-box1[2])
189 | area2 = (box2[3]-box2[0])*(box2[4]-box2[1])*(box2[5]-box2[2])
190 | area_sum = area1 + area2
191 |
192 | #计算重叠长方体区域的两个角点[x1,y1,z1,x2,y2,z2]
193 | x1 = max(box1[0], box2[0])
194 | y1 = max(box1[1], box2[1])
195 | z1 = max(box1[2], box2[2])
196 | x2 = min(box1[3], box2[3])
197 | y2 = min(box1[4], box2[4])
198 | z2 = min(box1[5], box2[5])
199 | if x1 >= x2 or y1 >= y2 or z1 >= z2:
200 | return 0
201 | else:
202 | inter_area = (x2-x1)*(y2-y1)*(z2-z1)
203 |
204 | return inter_area/(area_sum-inter_area)
205 | ```
206 | ### 8、手撕NMS
207 | ```python
208 | import numpy as np
209 | # from https://github.com/luanshiyinyang/NMS,个人觉得很简洁的一种写法
210 | def nms(bboxes, scores, iou_thresh):
211 | """
212 | :param bboxes: 检测框列表
213 | :param scores: 置信度列表
214 | :param iou_thresh: IOU阈值
215 | :return:
216 | """
217 |
218 | x1 = bboxes[:, 0]
219 | y1 = bboxes[:, 1]
220 | x2 = bboxes[:, 2]
221 | y2 = bboxes[:, 3]
222 | areas = (y2 - y1) * (x2 - x1)
223 |
224 | # 结果列表
225 | result = []
226 | # 对检测框按照置信度进行从高到低的排序,并获取索引
227 | index = scores.argsort()[::-1]
228 | # 下面的操作为了安全,都是对索引处理
229 | while index.size > 0:
230 | # 当检测框不为空一直循环
231 | i = index[0]
232 | # 将置信度最高的加入结果列表
233 | result.append(i)
234 |
235 | # 计算其他边界框与该边界框的IOU
236 | x11 = np.maximum(x1[i], x1[index[1:]])
237 | y11 = np.maximum(y1[i], y1[index[1:]])
238 | x22 = np.minimum(x2[i], x2[index[1:]])
239 | y22 = np.minimum(y2[i], y2[index[1:]])
240 | w = np.maximum(0, x22 - x11 + 1)
241 | h = np.maximum(0, y22 - y11 + 1)
242 | overlaps = w * h
243 | ious = overlaps / (areas[i] + areas[index[1:]] - overlaps)
244 | # 只保留满足IOU阈值的索引
245 | idx = np.where(ious <= iou_thresh)[0]
246 | index = index[idx + 1] # 处理剩余的边框
247 | bboxes, scores = bboxes[result], scores[result]
248 | return bboxes, scores
249 | ```
250 | ### 9、手撕k-means
251 | ```python
252 | import numpy as np
253 |
254 |
255 | def kmeans(data, k, thresh=1, max_iterations=100):
256 | # 随机初始化k个中心点
257 | centers = data[np.random.choice(data.shape[0], k, replace=False)]
258 |
259 | for _ in range(max_iterations):
260 | # 计算每个样本到各个中心点的距离
261 | distances = np.linalg.norm(data[:, None] - centers, axis=2)
262 |
263 | # 根据距离最近的中心点将样本分配到对应的簇
264 | labels = np.argmin(distances, axis=1)
265 |
266 | # 更新中心点为每个簇的平均值
267 | new_centers = np.array([data[labels == i].mean(axis=0) for i in range(k)])
268 |
269 | # 判断中心点是否收敛,多种收敛条件可选
270 | # 条件1:中心点不再改变
271 | if np.all(centers == new_centers):
272 | break
273 | # 条件2:中心点的阈值小于某个阈值
274 | # center_change = np.linalg.norm(new_centers - centers)
275 | # if center_change < thresh:
276 | # break
277 | centers = new_centers
278 |
279 | return labels, centers
280 |
281 |
282 | # 生成一些随机数据作为示例输入
283 | data = np.random.rand(100, 2) # 100个样本,每个样本有两个特征
284 |
285 | # 手动实现K均值算法
286 | k = 3 # 聚类数为3
287 | labels, centers = kmeans(data, k)
288 |
289 | # 打印簇标签和聚类中心点
290 | print("簇标签:", labels)
291 | print("聚类中心点:", centers)
292 | ```
293 | ### 10、手撕SoftNMS
294 | ```python
295 | import numpy as np
296 |
297 | # from github, author: OneDirection9
298 | def soft_nms(dets, method='linear', iou_thr=0.3, sigma=0.5, score_thr=0.001):
299 | """Pure python implementation of soft NMS as described in the paper
300 | `Improving Object Detection With One Line of Code`_.
301 |
302 | Args:
303 | dets (numpy.array): Detection results with shape `(num, 5)`,
304 | data in second dimension are [x1, y1, x2, y2, score] respectively.
305 | method (str): Rescore method. Only can be `linear`, `gaussian`
306 | or 'greedy'.
307 | iou_thr (float): IOU threshold. Only work when method is `linear`
308 | or 'greedy'.
309 | sigma (float): Gaussian function parameter. Only work when method
310 | is `gaussian`.
311 | score_thr (float): Boxes that score less than the.
312 |
313 | Returns:
314 | numpy.array: Retained boxes.
315 |
316 | .. _`Improving Object Detection With One Line of Code`:
317 | https://arxiv.org/abs/1704.04503
318 | """
319 | if method not in ('linear', 'gaussian', 'greedy'):
320 | raise ValueError('method must be linear, gaussian or greedy')
321 |
322 | x1 = dets[:, 0]
323 | y1 = dets[:, 1]
324 | x2 = dets[:, 2]
325 | y2 = dets[:, 3]
326 |
327 | areas = (x2 - x1 + 1) * (y2 - y1 + 1)
328 | # expand dets with areas, and the second dimension is
329 | # x1, y1, x2, y2, score, area
330 | dets = np.concatenate((dets, areas[:, None]), axis=1)
331 |
332 | retained_box = []
333 | while dets.size > 0:
334 | max_idx = np.argmax(dets[:, 4], axis=0)
335 | # 将置信度最大的框放在首位
336 | dets[[0, max_idx], :] = dets[[max_idx, 0], :]
337 | retained_box.append(dets[0, :-1])
338 |
339 | xx1 = np.maximum(dets[0, 0], dets[1:, 0])
340 | yy1 = np.maximum(dets[0, 1], dets[1:, 1])
341 | xx2 = np.minimum(dets[0, 2], dets[1:, 2])
342 | yy2 = np.minimum(dets[0, 3], dets[1:, 3])
343 |
344 | w = np.maximum(xx2 - xx1 + 1, 0.0)
345 | h = np.maximum(yy2 - yy1 + 1, 0.0)
346 | inter = w * h
347 | iou = inter / (dets[0, 5] + dets[1:, 5] - inter)
348 |
349 | # 根据IoU大小降低重叠框置信度,IoU越大,置信度减小程度越大
350 | if method == 'linear':
351 | weight = np.ones_like(iou)
352 | weight[iou > iou_thr] -= iou[iou > iou_thr]
353 | elif method == 'gaussian':
354 | weight = np.exp(-(iou * iou) / sigma)
355 | else: # traditional nms
356 | weight = np.ones_like(iou)
357 | weight[iou > iou_thr] = 0
358 |
359 | dets[1:, 4] *= weight
360 | retained_idx = np.where(dets[1:, 4] >= score_thr)[0]
361 | dets = dets[retained_idx + 1, :]
362 |
363 | return np.vstack(retained_box)
364 |
365 |
366 | if __name__ == '__main__':
367 | boxes = np.array([[100, 100, 210, 210, 0.72],
368 | [250, 250, 420, 420, 0.8],
369 | [220, 220, 320, 330, 0.92],
370 | [100, 100, 210, 210, 0.72],
371 | [230, 240, 325, 330, 0.81],
372 | [220, 230, 315, 340, 0.9]], dtype=np.float32)
373 | print('soft nms result:')
374 | print(soft_nms(boxes, method='gaussian'))
375 | ```
376 | ### 11、手撕Batch Normalization
377 | ```python
378 | # 参考并更正自知乎(机器学习入坑者《Batch Normalization原理与python实现》)
379 | class MyBN:
380 | def __init__(self, momentum=0.01, eps=1e-5, feat_dim=2):
381 | """
382 | 初始化参数值
383 | :param momentum: 动量,用于计算每个batch均值和方差的滑动均值
384 | :param eps: 防止分母为0
385 | :param feat_dim: 特征维度
386 | """
387 | # 均值和方差的滑动均值
388 | self._running_mean = np.zeros(shape=(feat_dim, ))
389 | self._running_var = np.ones((shape=(feat_dim, ))
390 | # 更新self._running_xxx时的动量
391 | self._momentum = momentum
392 | # 防止分母计算为0
393 | self._eps = eps
394 | # 对应Batch Norm中需要更新的beta和gamma,采用pytorch文档中的初始化值
395 | self._beta = np.zeros(shape=(feat_dim, ))
396 | self._gamma = np.ones(shape=(feat_dim, ))
397 |
398 | def batch_norm(self, x):
399 | """
400 | BN向传播
401 | :param x: 数据
402 | :return: BN输出
403 | """
404 | if self.training:
405 | x_mean = x.mean(axis=0)
406 | x_var = x.var(axis=0)
407 | # 对应running_mean的更新公式
408 | self._running_mean = (1-self._momentum)*x_mean + self._momentum*self._running_mean
409 | self._running_var = (1-self._momentum)*x_var + self._momentum*self._running_var
410 | # 对应论文中计算BN的公式
411 | x_hat = (x-x_mean)/np.sqrt(x_var+self._eps)
412 | else:
413 | x_hat = (x-self._running_mean)/np.sqrt(self._running_var+self._eps)
414 | return self._gamma*x_hat + self._beta
415 | ```
416 | 整理这篇文章不易,喜欢的话可以关注我-->**无名氏,某乎和小红薯同名,WX:无名氏的胡言乱语。** 定期分享算法笔试、面试干货。
417 |
418 |
419 |  420 |
420 |
421 |
--------------------------------------------------------------------------------
/秋招算法岗求生“指南”(2023届面经)/秋招算法岗求生“指南”(2023届面经).md:
--------------------------------------------------------------------------------
1 | ### 2023届秋招概况
2 | 在找工作之前总听说什么算法岗灰飞烟灭,但师兄、师姐找的工作都很不错,所以从来只当乐子看,但真的轮到自己找工作时,才发现是真的灰飞烟灭。整个秋招过程,都是笼罩在国内外各大互联网公司的裁员消息纷飞的乌云下,而在这乌云下的是各公司令人寒心的招聘消息:本来以为凭学校光环随便去的华为12月多才开,如下图是当时某小组的池子群(没错就是68个候选人),12月多还没收网;腾讯迟迟不开,真正开的时候据说HC只有两位数,却收到几十万简历;科大讯飞传言收到23万份简历,但只有600个HC;往年财大气粗、疯狂招人的字节跳动HC从8000减少到2~3000。2023届总结来说就是:任总真的切切实实地把寒气传给了每个人。
3 |
4 |
5 | 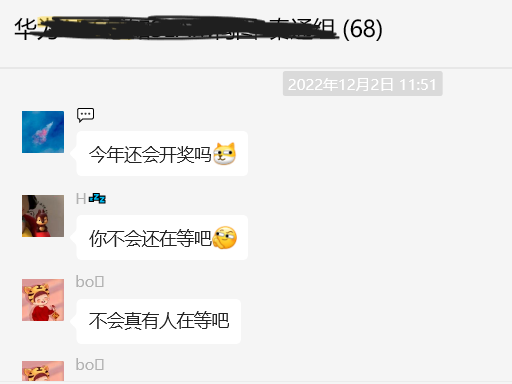 6 |
7 | 去年12月的华为某组池子群
8 |
6 |
7 | 去年12月的华为某组池子群
8 |
9 |
10 | 本来以为2024届会情况好点,但是综合身边人的情况以及上篇回答的热度来看,2024届依然是寒气逼人,所以临时起意写了这篇秋招面经,希望能对大家有些许帮助,或者至少有些心理安慰也行,毕竟去年也真的很惨。
11 |
12 |
13 |  14 |
15 | 当时秋招群最流行的表情包
16 |
14 |
15 | 当时秋招群最流行的表情包
16 |
17 |
18 | ### 个人情况
19 | 个人是某C9硕毕业,无顶会、无实习(实验室不让)、有小比赛冠军(CVPR workshop challenge这种)以及一些本科乱七八糟的奖项,研究方向是目标检测,主找自动驾驶相关岗位,最后实际上拿了2个offer(当然实际上多于这个,因为拿到了满意的offer了都放弃了),去的某小公司做自动驾驶算法,纯菜鸟一个,不喜勿喷。
20 |
21 | ### 制作简历
22 | 万丈高楼平地起,找工作第一步从制作个人简历开始。个人简历的核心是要简洁(配色朴素大方、语言精炼)、突出重点(你最想让面试官看到的东西,比如你是某比赛冠军,你需要强调这个比赛得冠军的难度,如排名1/20000000),**如图是个人秋招使用的简历,身边朋友也大都用的类似模板,想要的同学公众号回复“简历”即可免费获取**。
23 |
24 |
25 |  26 |
27 | 个人秋招时使用的简历
28 |
26 |
27 | 个人秋招时使用的简历
28 |
29 |
30 | ### 刷题与面试题准备
31 | 找工作第二步就是刷算法题和准备面试题(看各种面经、深度学习八股)。刷题先刷的剑指offer以及hot 100(leetcode hot100以及牛客网面试hot100),然后剩下的按类型(比如动态规划)查漏补缺,推荐看《代码随想录》,最后大概刷了200题,身边人的平均数量也差不多是200,最多的有500多的;深度学习八股就是按目标岗位、目标公司找面经自己整理的,面试过程中也一直在整理。
32 |
33 | ### 面试经历概括
34 | #### 小试牛刀阶段--状态:踌躇满志
35 | 准备得差不多了后,就开始正式投简历了,打算**先找不想去的或者不知名的公司小试牛刀**,演练一下“面试台词”。投了几家,发现都石沉大海,最后是中兴来学校组织了线下见面会,索性就去试试,当面投了简历,这才有了第一次面试经历(面的未来领军计划,后面再阐述细节),还是直接在现场电话面试的。记得当时面了三面,因为是人才计划,每一面人都很多,少的时候5人,多的时候8、9人,虽然最后没通过,但是利用中兴的面试刷足了面试经验,“面试台词”也是在这期间成型的。此时尚未察觉到寒气,满满都是信心,以为凭自己的学校和比赛工作肯定随便找。
36 |
37 | #### 慌不择路阶段--状态:焦虑万分
38 | 后面陆续开始投其他公司,但全都没有回应,知名的比如“学历厂”Tplink,发现不管多优秀,只要本科是211的通通没过;zoom第一批面试完后,突然冻结HC,后面批次的面试全部取消了;微软也冻结HC了,之前许诺给实习生的offer突然不给了;任总开始传播寒气,意味着往年用来保底的华为也不咋招人了。于是身边人包括我开始慌了,宿舍里、各种秋招群里开始每天都互相传播焦虑,每天我们回宿舍第一件事就是选个公司投简历(最烦的是简历不能复用或简单上传,每个公司都要重新手填一遍,极其费时),讨论最多的话题也是谁投了哪个没有、哪个公司有消息了没、哪道笔试题应该咋写等等,看的最多的APP是脉脉,写过的各种笔试题数量堪比高中试卷。**最后在各种平台如官网、牛客等投的公司可能得有7、80家,甚至100家,但有时候努力是没用的,就算再努力也只有零星几家有面试机会,大部分公司招聘网站的简历状态刷了上百遍但最后秋招结束都没有再变过**。焦虑着焦虑着,金色8月悄然逝去,步入银色9月,虽然还是一个offer没有甚至面试次数也是个位数,但好在天生“抗揍”,只要有面试机会就全力准备,因此也慢慢地积累了经验,自我介绍、竞赛介绍、项目介绍轻车熟路。
39 |
40 | #### 稳如老狗阶段--状态:渐入佳境
41 | 记不得是哪一天了,突然很久没有回应的公司有了消息,可能是最优秀的那一批人“吃饱喝足”还有些“剩菜”,也可能是有些公司就是秋招开得晚,也可能是之前情况已经差到不能再差了,反正情况突然好转,有种否极泰来、时来运转的意味(希望你们也有这一天)。从那一天后,我开始不断地收到公司邀约,因为之前积累的丰富“吹牛”经验(不断地针对面试需求修改简历、调整“面试台词”与重点“吹牛方向”),以及“视死如归”的决心(**反正已经这么差了,再差能怎样**),面试过程都意外的顺利。这个阶段最大的感受就是刷题真的很重要,很多面试题都是原题,面试编程题过了就基本成功了一半。最终三个舍友都去的大厂(大疆、华为、中兴),我去的小公司做算法,身边最厉害的那批人有的去搞量化了(唯一真神,工资奇高+965)、有的去阿里云、也有的硕士华为16级等等,而那些不算拔尖但一直在努力准备秋招的最后去处也很不错,例如OPPO、百度推荐算法、快手推荐算法、阿里等等(**也许这说明了努力还是有点用的,所以大家真的不要放弃**),也有听说秋招没找到好工作但春招找到的。当然,必须强调的是,就算是在C9,真的也有很多没找到工作的,也有很多别无选择去迪子的,另外也有挺多延毕去考公考编的,而且C9尚且如此,不敢想象更次一点的学校情况有多糟糕;也有好朋友秋招前扬言要让字节请他去工作,秋招后去了银行躺平;亦有好友因为怕被裁弃腾讯去邮储的;还有本科很厉害的、电赛国奖的一个朋友,读了个硕士,怕等不到华为,去了老家研究所躺平的。。。
42 |
43 | ### 各公司面试经验分享
44 | #### 中兴
45 | 中兴随便投的一个卖摄像头的部门,属于未来领军计划,整体偏开发,他们也不太懂深度学习,因此实际上和我的目标方向差挺多。一面电话面,自我介绍后让介绍项目,问了些细节,然后问对他们部门有啥想了解的没,简单地就过了;二面直接5个人,有问我开发问题的,就常见的C语言、C++八股,比如线程和进程区别、静态库和动态库区别、死锁、C++中vector申请内存机制,内部存储原理等,完全没准备,答得一塌糊涂;有问我算法问题的,例如YOLOv1-YOLOv5的做法与改进之处;还有HR问了些常规问题;三面好像8、9个人,用腾讯会议面的,当时看到8、9个头像都惊呆了,来的应该都是各个部门的领导以及技术负责人,整个面试过程是轮流拷打,一个人问一个问题,有问我那个比赛的最大创新点是什么,有提出一个真实场景问题(好像是摄像头里的模型、小物体如何检测),有问华为和中兴选哪个的。。结果:挂,后来让转正式批面,放弃了,纯刷经验。
46 | 据舍友说,中兴还挺躺的,活没那么多,之前传言的周六加班,实际上都是自愿的,很少人去加班。
47 |
48 | #### 快手
49 | 面了两次,整体感觉快手不太需要做cv算法的人,明明两次都投的图像岗,但是面试官都是搞推荐算法的。第一次面试时,简单介绍项目后,因为他不太懂,直接就上算法题了,做的是图像旋转任意角度(见下图,当然还要考虑旋转后图像超出原图像范围等细节问题),没做出来;第二次面试时,更离谱,几乎都在做题,做的是数组里面找唯一一个出现奇数次的数,然后进阶,找两个出现奇数次的数。结果:都是一面挂,适合做推荐算法的去投。
50 | 快手这公司还是挺能赚钱的,不过听做推荐算法的朋友说加班很猛、活多压力大,但给的钱以及公司的盈利业务也多,世事难两全。
51 |
52 |
53 | 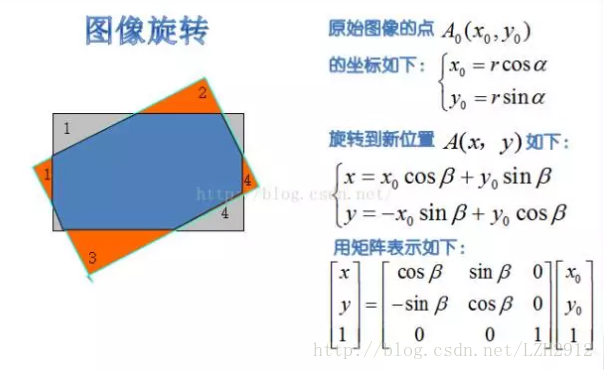 54 |
55 | 旋转图像
56 |
54 |
55 | 旋转图像
56 |
57 |
58 |
59 | #### 博世
60 | 面的新成立不久的自动驾驶部门,一面是HR面,HR小姐姐非常nice,很有礼貌;二面先英文自我介绍,然后直接做题,两道,一个是求两个升序数组的中位数,一个是跳跃游戏。结果:挂。
61 |
62 | #### 虹软
63 | 投的感知算法,有笔试题,笔试题有选择题、问答题(例如计算深度可分离卷积的参数量和FLOPS)、编程题,深度学习各种基础知识都有涉及,感觉出的很有水平,当时把能答的都写了,也不知道答得怎样,稀里糊涂就过了。一面主要在聊项目、比赛,大部分时间是我在“吹牛”,我把目标检测、小目标检测的整个发展路径、主流做法大说特说了一通;二面问了YOLOX细节以及一些场景问题,具体忘了;三面HR面。结果:拿到offer了,对这公司印象还不错,属于老牌CV公司,听说是外企风格。
64 |
65 | #### 华为
66 | 投的华为车bu某天才少年组,就是第一张图中68个备胎的“牛组”。9月多做的笔试,难度比一般公司笔试高,靠骗分过的。一面先简单复盘了笔试,然后问了问项目、比赛,然后撕了两道简单代码题——岛屿问题、把字符按频率排序,但也听说有的人撕的是hard题;二面主管面,除了问项目,还真的考察了“如何看待华为的狼性文化”,迫于生计狠狠地舔了一波(面试前背了挺久),问做过最满意的事是什么,都是些hr问题。面完不到20分钟发短信说面试通过,但是实际上绝大部分通过笔试的人面试都过了,我只不过进入了华为的超级无敌大池子,而谁也没想到的是这池子一泡就泡到了12月多,投简历前极其热情的HR,到此时对你爱搭不理、一问三不知,只一个劲地忽悠我们下周就发意向了。然后就听说了华为给人打电话说要来的话只给13级(而有的爱华等华的可怜人此时为了等华为已经放弃其他offer,这操作属实恶心)、华为车bu HC大砍(未证实,只是传言,但是很少15级指标应该是真的),最后考虑到等待风险太大以及基本上不可能拿到15级,我直接放弃等待了。
67 |
68 | 但华为的魅力还是大的,毕竟华子有应届生保护、合同期内不裁员,在这“动荡”的时期是十分稳定的存在。所以包括我舍友在内的几个朋友干脆把其他offer全放弃了,只赌华为(去的无线部门),最后他们都等到了,现在也都过的还不错,一是加班没想象的狠,9:30上班,一二四9点下班,三五6点下班,双休;二是加班有免费夜宵,挺丰盛的。
69 |
70 | #### 地平线
71 | 投的CV岗。一面让手撕k-means,还问了个场景题:如何在标注存在错误的数据上训练模型,除场景题外都答得还行,但是没想到一面后直接进池子了,秋招结束都没捞起来,当时正值地平线获一汽投资阶段,可能是不缺人才吧。个人觉得地平线前景还是可以的,毕竟芯片被制裁后,地平线的自动驾驶芯片就开始称王称霸了。
72 |
73 | #### 科大讯飞
74 | 投的CV岗。笔试据说完全不看,按简历筛进面试。一面很简单,比较不同的是让介绍DETR-based目标检测方法的做法,以及问了Swin Transformer细节(窗口注意力等);二面主管面,问得相对较深,问了Deformable conv如何实现梯度可微、Swin Transformer的positional encoding如何实现,答得不是很好。讯飞三面一直没有,舍友也一直被拖着,直到12月问我愿不愿意去。
75 |
76 | #### 海康威视
77 | 投的某摄像头部门。面试安排比较特别,每个人限制20分钟左右,到了就叫号。一面让介绍了比赛、项目,然后问了个场景题,具体忘了。当时自我感觉不错,但是后来尴尬地发现挂了,可能是因为我缺乏项目部署经验、太偏学术。PS:海康加班真的很猛。
78 |
79 | #### 万兴科技
80 | 长沙的某个小公司,据说是长沙顶薪,当时很灰心丧气,一度想去个非一线城市的小公司躺平,于是就投了万兴科技。自信满满地做了笔试,结果发现挂了。。。原因未知。
81 |
82 | #### 墨奇科技
83 | 错过了第一次笔试,和hr沟通说安排第二次笔试,但是有趣的事情发生了,墨奇的hc好像突然被砍了,很多人的意向被毁了,第二次笔试也取消了。
84 |
85 | #### shein
86 | 秋招最高贵的公司,听说清北投都挂了,反正我们寝室的都挂了。
87 |
88 | #### zoom
89 | 秋招前一直想去外企wlb的,但是没想到外企也“受寒”了。本来安排了两次笔试,我选择的第二次,但是第一次后突然说没HC了,加的zoom群的群主也劝退大家别抱希望了,第二次笔试直接取消了。
90 |
91 | #### oppo
92 | 投的影像处理相关岗的提前批,直接挂我简历,正式批投又给我秒挂。后来oppo芯片子公司哲库直接原地解散了,让选择内部转岗或者拿补偿金,实惨。
93 |
94 | #### 大疆
95 | 投的机器学习算法岗,做了笔试过了很久,最后挂了。听说很看懂学校和国奖,只有拿过国奖的舍友进了面试。
96 |
97 | #### 小红书
98 | 投的人才计划,秋招结束了也是一点消息没有。
99 |
100 | #### 极智嘉
101 | 笔试通过后,因为有其他offer,直接放弃面试了,听说很简单。
102 |
103 | #### TPLink
104 | 因为本科是211的,提前批直接没面试机会。有本硕C9的同学,面试就是简单聊天、问智力题,直接给了29k*16,非常的离谱,比华为还学历厂。
105 |
106 | #### 比亚迪
107 | 点击就送,但是也是投得早的才送,舍友投了就没理他,不知今年还能不能救广大“祖国花朵”于水火之中。
108 |
109 | #### 独角兽综合(商汤、旷视、momenta、元戎、文远智行、蔚来、禾赛、智加科技、小马智行、AutoX、图森未来等等)
110 | 大部分是自动驾驶领域的公司,行情也是大不如前了,招聘要求一个比一个卷,几乎都要顶会,挂了一大堆,就笼统说一下面试题。有让手写NMS的,有让手写RoIAlign的,有让写Focal loss公式的,有让讲AP、mAP、mmAP计算过程的,也有些场景题:训练过程中发现loss快速增大应该从哪些方面考虑?如何区分错误样本和难样本?也有针对我的比赛往深处问的,问我某个操作为啥那样做。
111 |
112 | #### 互联网综合(阿里、百度、腾讯、美团、字节、拼多多、网易等等)
113 | 都是投的CV岗,互联网大厂里的CV岗真的少得可怜,一般要有顶会或者博士学历才有机会进面试。最后都挂了,身边人投的开发岗倒是面试机会比较多,另外字节和网易的笔试是真的难,还是得投提前批(无笔试)。
114 |
115 | #### 量化
116 | 量化唯一真神,投了宽投资产等量化公司,都挂了。他们非常看重学校背景(本科和研究生),以及要求提前去实习,视实习成果决定给不给offer。身边去量化的都是很强的人,给的工资也高得吓人,个人觉得符合上述两点要求的人可以考虑考虑量化,我是秋招时才知道这个方向的。
117 |
118 | **除了以上这些也投了很多小公司,比如经纬恒润等,但大部分都没有消息,因为大公司都没HC,小公司更别提了。**
119 |
120 | ### 人生的选择
121 | 人生时时刻刻处于选择之中,这点在秋招选offer时特别明显。舍友手握TPLink、长春某所等“躺平”offer,最后却通通丢弃选择了华为;本科那个很厉害的朋友,选择不等华为,直接去老家的研究所躺平,尽管最后华为最后要给他offer;当初踌躇满志地要去字节的朋友,最后去了银行躺平;和我关系很好的师弟,当初也想做算法赚钱,最后选择了考公。这真是个魔幻的时代,孰对孰错,谁又知道呢?或许正如《向云端》里唱的那样:**真实的你在于怎么选择**。最后祝大家都有个好的归宿!
122 |
123 |
124 |  125 |
126 | 《向云端》歌词
127 |
125 |
126 | 《向云端》歌词
127 |
128 |
--------------------------------------------------------------------------------
/算法废物跳槽记2024版.md:
--------------------------------------------------------------------------------
1 | # 跳槽经验与教训:从认知到实战的全流程指南
2 |
3 | ## 非干货篇:认知准备
4 |
5 | ### 跳槽决策原则
6 | - **核心目标**:新槽需优于现状(涨薪/减压/发展前景)
7 | - **风险警示**:
8 | - 潜在工作强度升级(如1095→007)
9 | - 适应新环境/同事/Leader的隐性成本
10 | - ❗建议:未深思者建议滑走
11 |
12 | ### 前期准备清单
13 | - **算法题库**(150-200题):
14 | - 必刷:hot100 + 高频题
15 | - 推荐资料:
16 | - 📚《无名氏:万字秋招算法岗深度学习八股文大全》
17 | - 📚《无名氏:秋招算法岗手撕代码题合集》
18 | - **学术化简历**:
19 | - 撰写框架:项目背景→核心贡献→量化成果
20 | - 🎁 模板获取:WX公众号「无名氏的胡言乱语」回复"简历"
21 | - **话术演练**:
22 | - 跳槽动机应答公式 = "发展空间 + 技术匹配"
23 | - **求职渠道**:
24 | - 优先级:脉脉直聊HR > 官网投递 > 猎头
25 | - ⚠️ 猎头弊端:增加企业用人成本 → 降低录用概率
26 |
27 |
28 | ---
29 |
30 | ## 干货篇:实战指南
31 |
32 | ### 薪酬体系解构
33 | 1. **涨幅基准**
34 | - 参考依据:银行流水 + 公积金比例(例:12%→7%需补偿)
35 | - 合理区间:常规20%+,司龄长涨幅更高
36 | - 🚫 禁忌:现司调薪未满6个月者难获认可涨幅
37 |
38 | 2. **谈薪策略**
39 | - 核心资本:多offer互搏
40 | - 战术要点:
41 | - 非目标公司可作薪资谈判筹码
42 | - 协调目标公司最后发offer
43 |
44 | 3. **offer避坑清单**
45 | - 薪资结构:试用期时长/薪资折扣(如影石8折)
46 | - 福利细则:五险一金比例/年假/年终奖发放规则
47 | - 隐藏条款:竞业协议/年假折算/实际工作内容
48 |
49 | ### 操作注意事项
50 | 1. **社保续接**:离职日建议选15-20号(确保当月缴纳)
51 | 2. **竞业防御**:
52 | - 低调处理去向(尤其拼xixi等敏感企业)
53 | - 仅告知可信人员
54 | 3. **背调应对**:
55 | - 提前与直属领导达成离职共识
56 | - 预留2周交接期
57 |
58 |
59 | ---
60 |
61 | ## 结语
62 | 跳槽最大收益并非涨薪,而是**职场议价权的觉醒**:
63 | ✅ 摆脱"必须工作满X年"的思维桎梏
64 | ✅ 建立"Not a big deal"的从容心态
65 | ✅ 掌握反制企业不合理行为的底气
66 |
67 |
68 | ---
69 |
70 | ## 附录:手撕代码题精选
71 | 1. `k-means` + 三数之和(蔚来感知算法岗)
72 | 2. 带重复数字的二分查找(`LeetCode 287`,赢彻)
73 | - 问题:n+1数组找唯一重复数(1~n范围)
74 | 3. 一维数轴可达性(赢彻)
75 | - 规则:第k步可左/右走k步,求达坐标x的最少步数
76 | 4. 多起点多终点最短路径(微软)
77 | - 场景:n*n网格含障碍物,多起点→多终点
78 | 5. 有效三角形计数(数组组合问题)
79 | 6. `2D IoU`手撕(美团无人车)
80 | - 进阶:旋转IoU计算思路
81 | 7. 平行线覆盖判定(美团无人车)
82 | - 给定点集能否被两条平行线覆盖?
83 | 8. 二维卷积炸弹探测(小马智行)
84 | - 安全区域判定:d距离内有炸弹即不安全
85 | 9. 跳跃游戏(`LeetCode 55`,文远知行)
86 |
--------------------------------------------------------------------------------
 19 |
19 |  5 |
5 |  11 |
11 |  16 |
16 |  25 |
25 |  29 |
29 |  34 |
34 |  39 |
39 | 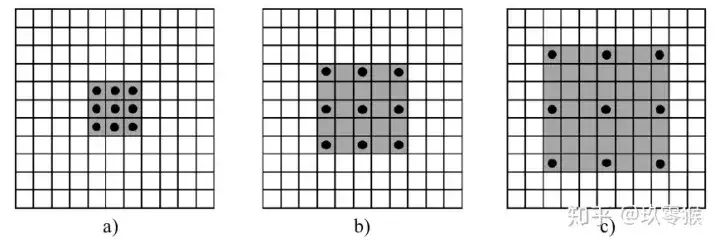 57 |
57 | 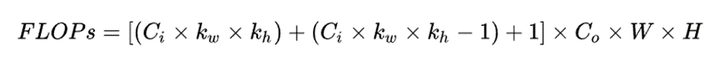 79 |
79 | 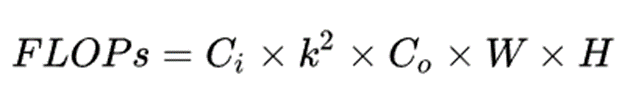 83 |
83 |  118 |
118 | 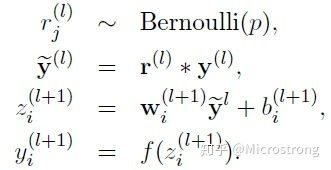 122 |
122 |  194 |
194 | 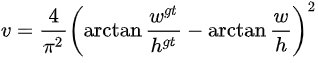 203 |
203 |