├── .gitignore
├── LICENSE
├── README.md
├── async_pubmed_scraper.py
├── example
├── article_data - natural language processing, cancer mRNA vaccines, sugar nanocapsules.csv
├── article_data - photonics, biophysics, biochemistry.csv
├── cli_usage_example.JPG
└── data_example.JPG
└── requirements.txt
/.gitignore:
--------------------------------------------------------------------------------
1 | .
2 | # Byte-compiled / optimized / DLL files
3 | __pycache__/
4 | *.py[cod]
5 | *$py.class
6 |
7 | # C extensions
8 | *.so
9 |
10 | # Distribution / packaging
11 | .Python
12 | build/
13 | develop-eggs/
14 | dist/
15 | downloads/
16 | eggs/
17 | .eggs/
18 | lib/
19 | lib64/
20 | parts/
21 | sdist/
22 | var/
23 | wheels/
24 | pip-wheel-metadata/
25 | share/python-wheels/
26 | *.egg-info/
27 | .installed.cfg
28 | *.egg
29 | MANIFEST
30 |
31 | # PyInstaller
32 | # Usually these files are written by a python script from a template
33 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
34 | *.manifest
35 | *.spec
36 |
37 | # Installer logs
38 | pip-log.txt
39 | pip-delete-this-directory.txt
40 |
41 | # Unit test / coverage reports
42 | htmlcov/
43 | .tox/
44 | .nox/
45 | .coverage
46 | .coverage.*
47 | .cache
48 | nosetests.xml
49 | coverage.xml
50 | *.cover
51 | *.py,cover
52 | .hypothesis/
53 | .pytest_cache/
54 |
55 | # Translations
56 | *.mo
57 | *.pot
58 |
59 | # Django stuff:
60 | *.log
61 | local_settings.py
62 | db.sqlite3
63 | db.sqlite3-journal
64 |
65 | # Flask stuff:
66 | instance/
67 | .webassets-cache
68 |
69 | # Scrapy stuff:
70 | .scrapy
71 |
72 | # Sphinx documentation
73 | docs/_build/
74 |
75 | # PyBuilder
76 | target/
77 |
78 | # Jupyter Notebook
79 | .ipynb_checkpoints
80 |
81 | # IPython
82 | profile_default/
83 | ipython_config.py
84 |
85 | # pyenv
86 | .python-version
87 |
88 | # pipenv
89 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
90 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
91 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
92 | # install all needed dependencies.
93 | #Pipfile.lock
94 |
95 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
96 | __pypackages__/
97 |
98 | # Celery stuff
99 | celerybeat-schedule
100 | celerybeat.pid
101 |
102 | # SageMath parsed files
103 | *.sage.py
104 |
105 | # Environments
106 | .env
107 | .venv
108 | env/
109 | venv/
110 | ENV/
111 | env.bak/
112 | venv.bak/
113 |
114 | # Spyder project settings
115 | .spyderproject
116 | .spyproject
117 |
118 | # Rope project settings
119 | .ropeproject
120 |
121 | # mkdocs documentation
122 | /site
123 |
124 | # mypy
125 | .mypy_cache/
126 | .dmypy.json
127 | dmypy.json
128 |
129 | # Pyre type checker
130 | .pyre/
131 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2020 Ilia Zenkov
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Asynchronous PubMed Scraper
2 |
3 | ## Quick Start
4 | Instructions for Windows. Make sure you have [python](https://www.python.org/downloads/) installed. Linux users: ```async_pubmed_scraper -h```
5 | 1) Open command prompt and change directory to the folder containing ```async_pubmed_scraper.py``` and ```keywords.txt```
6 | 2) Create a [virtual environment](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/): ```python -m pip install --user virtualenv```, ```python -m venv scraper_env```, ```.\scraper_env\Scripts\activate```
7 | 3) Install dependencies: ``` pip install -r requirements.txt```
8 | 4) Enter list of keywords to scrape, one per line, in ```keywords.txt```
9 | 5) Enter ```python async_pubmed_scraper -h``` for usage instructions and you are good to go
10 | Example: To scrape the first 10 pages of search results for your keywords from 2018 to 2020 and save the data to the file ```article_data.csv```: ```python async_pubmed_scraper --pages 10 --start 2018 --stop 2020 --output article_data```
11 |
12 | ## Example Usage and Data
13 | Collects the following data at 13 articles/second: url, title, abstract, authors, affiliations, journal, keywords, date
14 |
15 |
16 | 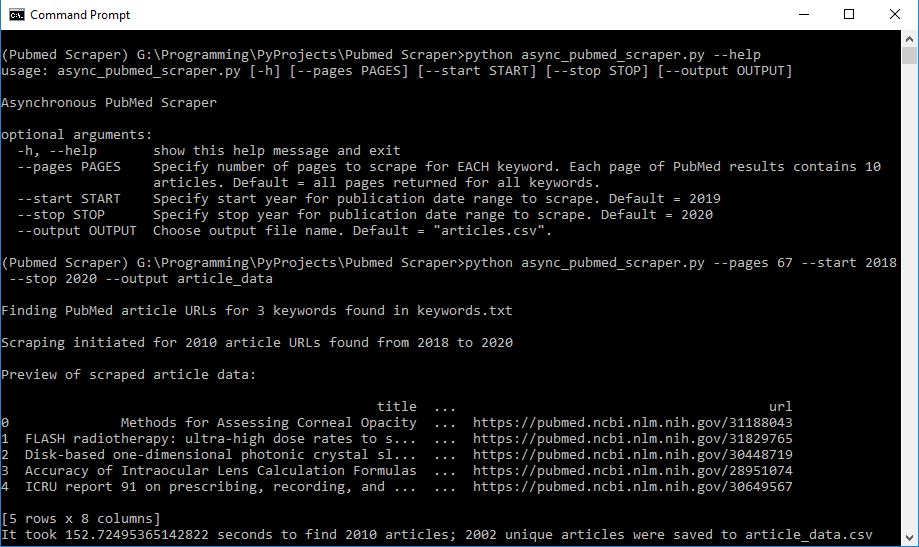 17 |
17 |  18 |
19 | ## What it does
20 |
21 | This script asynchronously scrapes PubMed - an open-access database of scholarly research articles -
22 | and saves the data to a PANDAS DataFrame which is then written to a CSV intended for further processing.
23 | This script scrapes a user-specified list of keywords for all results pages asynchronously.
24 |
25 | ## Why scrape when there's an API? Why asynchronous?
26 | PubMed provides an API - the NCBI Entrez API, also known as Entrez Programming Utilities or E-Utilities -
27 | which can be used build datasets with their search engine - however, PubMed allows only 3 URL requests per second
28 | through E-Utilities (10/second w/ API key).
29 | We're doing potentially thousands of URL requests asynchronously - depending on the amount of articles returned by the command line options specified by the user.
30 | It's much faster to download articles from all urls on all results pages in parallel compared to downloading articles page by page, article by article, waiting for the previous article request to complete before moving on to a new one. It's not unusual to see a 10x speedup with async scraping compared to regular scraping.
31 | Simply put, we're going to make our client send requests to all search queries and all resulting article URLs at the same time.
32 | Otherwise, our client will wait for the server to answer before sending the next request, so most of our script's execution time
33 | will be spent waiting for a response from the (PubMed) server.
34 |
35 | ## License
36 |
37 | [](https://github.com/IliaZenkov/async-pubmed-scraper/blob/master/LICENSE)
38 |
39 |
40 |
--------------------------------------------------------------------------------
/async_pubmed_scraper.py:
--------------------------------------------------------------------------------
1 | """
2 | Author: Ilia Zenkov
3 | Date: 9/26/2020
4 |
5 | This script asynchronously scrapes Pubmed - an open-access database of scholarly research articles -
6 | and saves the data to a DataFrame which is then written to a CSV intended for further processing
7 | This script is capable of scraping a list of keywords asynchronously
8 |
9 | Contains the following functions:
10 | make_header: Makes an HTTP request header using a random user agent
11 | get_num_pages: Finds number of pubmed results pages returned by a keyword search
12 | extract_by_article: Extracts data from a single pubmed article to a DataFrame
13 | get_pmids: Gets PMIDs of all article URLs from a single page and builds URLs to pubmed articles specified by those PMIDs
14 | build_article_urls: Async wrapper for get_pmids, creates asyncio tasks for each page of results, page by page,
15 | and stores article urls in urls: List[string]
16 | get_article_data: Async wrapper for extract_by_article, creates asyncio tasks to scrape data from each article specified by urls[]
17 |
18 | requires:
19 | BeautifulSoup4 (bs4)
20 | PANDAS
21 | requests
22 | asyncio
23 | aiohttp
24 | nest_asyncio (OPTIONAL: Solves nested async calls in jupyter notebooks)
25 | """
26 |
27 | import argparse
28 | import time
29 | from bs4 import BeautifulSoup
30 | import pandas as pd
31 | import random
32 | import requests
33 | import asyncio
34 | import aiohttp
35 | import socket
36 | import warnings; warnings.filterwarnings('ignore') # aiohttp produces deprecation warnings that don't concern us
37 | #import nest_asyncio; nest_asyncio.apply() # necessary to run nested async loops in jupyter notebooks
38 |
39 | # Use a variety of agents for our ClientSession to reduce traffic per agent
40 | # This (attempts to) avoid a ban for high traffic from any single agent
41 | # We should really use proxybroker or similar to ensure no ban
42 | user_agents = [
43 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
44 | "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:55.0) Gecko/20100101 Firefox/55.0",
45 | "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36",
46 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
47 | "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
48 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
49 | "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
50 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
51 | "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
52 | "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
53 | "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
54 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
55 | "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
56 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
57 | "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
58 | "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
59 | "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
60 | "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
61 | "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
62 | "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
63 | "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
64 | ]
65 |
66 | def make_header():
67 | '''
68 | Chooses a random agent from user_agents with which to construct headers
69 | :return headers: dict: HTTP headers to use to get HTML from article URL
70 | '''
71 | # Make a header for the ClientSession to use with one of our agents chosen at random
72 | headers = {
73 | 'User-Agent':random.choice(user_agents),
74 | }
75 | return headers
76 |
77 | async def extract_by_article(url):
78 | '''
79 | Extracts all data from a single article
80 | :param url: string: URL to a single article (i.e. root pubmed URL + PMID)
81 | :return article_data: Dict: Contains all data from a single article
82 | '''
83 | conn = aiohttp.TCPConnector(family=socket.AF_INET)
84 | headers = make_header()
85 | # Reference our articles DataFrame containing accumulated data for ALL scraped articles
86 | global articles_data
87 | async with aiohttp.ClientSession(headers=headers, connector=conn) as session:
88 | async with semaphore, session.get(url) as response:
89 | data = await response.text()
90 | soup = BeautifulSoup(data, "lxml")
91 | # Get article abstract if exists - sometimes abstracts are not available (not an error)
92 | try:
93 | abstract_raw = soup.find('div', {'class': 'abstract-content selected'}).find_all('p')
94 | # Some articles are in a split background/objectives/method/results style, we need to join these paragraphs
95 | abstract = ' '.join([paragraph.text.strip() for paragraph in abstract_raw])
96 | except:
97 | abstract = 'NO_ABSTRACT'
98 | # Get author affiliations - sometimes affiliations are not available (not an error)
99 | affiliations = [] # list because it would be difficult to split since ',' exists within an affiliation
100 | try:
101 | all_affiliations = soup.find('ul', {'class':'item-list'}).find_all('li')
102 | for affiliation in all_affiliations:
103 | affiliations.append(affiliation.get_text().strip())
104 | except:
105 | affiliations = 'NO_AFFILIATIONS'
106 | # Get article keywords - sometimes keywords are not available (not an error)
107 | try:
108 | # We need to check if the abstract section includes keywords or else we may get abstract text
109 | has_keywords = soup.find_all('strong',{'class':'sub-title'})[-1].text.strip()
110 | if has_keywords == 'Keywords:':
111 | # Taking last element in following line because occasionally this section includes text from abstract
112 | keywords = soup.find('div', {'class':'abstract' }).find_all('p')[-1].get_text()
113 | keywords = keywords.replace('Keywords:','\n').strip() # Clean it up
114 | else:
115 | keywords = 'NO_KEYWORDS'
116 | except:
117 | keywords = 'NO_KEYWORDS'
118 | try:
119 | title = soup.find('meta',{'name':'citation_title'})['content'].strip('[]')
120 | except:
121 | title = 'NO_TITLE'
122 | authors = '' # string because it's easy to split a string on ','
123 | try:
124 | for author in soup.find('div',{'class':'authors-list'}).find_all('a',{'class':'full-name'}):
125 | authors += author.text + ', '
126 | # alternative to get citation style authors (no first name e.g. I. Zenkov)
127 | # all_authors = soup.find('meta', {'name': 'citation_authors'})['content']
128 | # [authors.append(author) for author in all_authors.split(';')]
129 | except:
130 | authors = ('NO_AUTHOR')
131 | try:
132 | journal = soup.find('meta',{'name':'citation_journal_title'})['content']
133 | except:
134 | journal = 'NO_JOURNAL'
135 | try:
136 | date = soup.find('time', {'class': 'citation-year'}).text
137 | except:
138 | date = 'NO_DATE'
139 |
140 | # Format data as a dict to insert into a DataFrame
141 | article_data = {
142 | 'url': url,
143 | 'title': title,
144 | 'authors': authors,
145 | 'abstract': abstract,
146 | 'affiliations': affiliations,
147 | 'journal': journal,
148 | 'keywords': keywords,
149 | 'date': date
150 | }
151 | # Add dict containing one article's data to list of article dicts
152 | articles_data.append(article_data)
153 |
154 | async def get_pmids(page, keyword):
155 | """
156 | Extracts PMIDs of all articles from a pubmed search result, page by page,
157 | builds a url to each article, and stores all article URLs in urls: List[string]
158 | :param page: int: value of current page of a search result for keyword
159 | :param keyword: string: current search keyword
160 | :return: None
161 | """
162 | # URL to one unique page of results for a keyword search
163 | page_url = f'{pubmed_url}+{keyword}+&page={page}'
164 | headers = make_header()
165 | async with aiohttp.ClientSession(headers=headers) as session:
166 | async with session.get(page_url) as response:
167 | data = await response.text()
168 | # Parse the current page of search results from the response
169 | soup = BeautifulSoup(data, "lxml")
170 | # Find section which holds the PMIDs for all articles on a single page of search results
171 | pmids = soup.find('meta',{'name':'log_displayeduids'})['content']
172 | # alternative to get pmids: page_content = soup.find_all('div', {'class': 'docsum-content'}) + for line in page_content: line.find('a').get('href')
173 | # Extract URLs by getting PMIDs for all pubmed articles on the results page (default 10 articles/page)
174 | for pmid in pmids.split(','):
175 | url = root_pubmed_url + '/' + pmid
176 | urls.append(url)
177 |
178 | def get_num_pages(keyword):
179 | '''
180 | Gets total number of pages returned by search results for keyword
181 | :param keyword: string: search word used to search for results
182 | :return: num_pages: int: number of pages returned by search results for keyword
183 | '''
184 | # Return user specified number of pages if option was supplied
185 | if args.pages != None: return args.pages
186 |
187 | # Get search result page and wait a second for it to load
188 | # URL to the first page of results for a keyword search
189 | headers=make_header()
190 | search_url = f'{pubmed_url}+{keyword}'
191 | with requests.get(search_url,headers=headers) as response:
192 | data = response.text
193 | soup = BeautifulSoup(data, "lxml")
194 | num_pages = int((soup.find('span', {'class': 'total-pages'}).get_text()).replace(',',''))
195 | return num_pages # Can hardcode this value (e.g. 10 pages) to limit # of articles scraped per keyword
196 |
197 | async def build_article_urls(keywords):
198 | """
199 | PubMed uniquely identifies articles using a PMID
200 | e.g. https://pubmed.ncbi.nlm.nih.gov/32023415/ #shameless self plug :)
201 | Any and all articles can be identified with a single PMID
202 |
203 | Async wrapper for get_article_urls, page by page of results, for a single search keyword
204 | Creates an asyncio task for each page of search result for each keyword
205 | :param keyword: string: search word used to search for results
206 | :return: None
207 | """
208 | tasks = []
209 | for keyword in keywords:
210 | num_pages = get_num_pages(keyword)
211 | for page in range(1,num_pages+1):
212 | task = asyncio.create_task(get_pmids(page, keyword))
213 | tasks.append(task)
214 |
215 | await asyncio.gather(*tasks)
216 |
217 | async def get_article_data(urls):
218 | """
219 | Async wrapper for extract_by_article to scrape data from each article (url)
220 | :param urls: List[string]: list of all pubmed urls returned by the search keyword
221 | :return: None
222 | """
223 | tasks = []
224 | for url in urls:
225 | if url not in scraped_urls:
226 | task = asyncio.create_task(extract_by_article(url))
227 | tasks.append(task)
228 | scraped_urls.append(url)
229 |
230 | await asyncio.gather(*tasks)
231 |
232 |
233 | if __name__ == "__main__":
234 | # Set options so user can choose number of pages and publication date range to scrape, and output file name
235 | parser = argparse.ArgumentParser(description='Asynchronous PubMed Scraper')
236 | parser.add_argument('--pages', type=int, default=None, help='Specify number of pages to scrape for EACH keyword. Each page of PubMed results contains 10 articles. \n Default = all pages returned for all keywords.')
237 | parser.add_argument('--start', type=int, default=2019, help='Specify start year for publication date range to scrape. Default = 2019')
238 | parser.add_argument('--stop', type=int, default=2020, help='Specify stop year for publication date range to scrape. Default = 2020')
239 | parser.add_argument('--output', type=str, default='articles.csv',help='Choose output file name. Default = "articles.csv".')
240 | args = parser.parse_args()
241 | if args.output[-4:] != '.csv': args.output += '.csv' # ensure we save a CSV if user forgot to include format in --output option
242 | start = time.time()
243 | # This pubmed link is hardcoded to search for articles from user specified date range, defaults to 2019-2020
244 | pubmed_url = f'https://pubmed.ncbi.nlm.nih.gov/?term={args.start}%3A{args.stop}%5Bdp%5D'
245 | # The root pubmed link is used to construct URLs to scrape after PMIDs are retrieved from user specified date range
246 | root_pubmed_url = 'https://pubmed.ncbi.nlm.nih.gov'
247 | # Construct our list of keywords from a user input file to search for and extract articles from
248 | search_keywords = []
249 | with open('keywords.txt') as file:
250 | keywords = file.readlines()
251 | [search_keywords.append(keyword.strip()) for keyword in keywords]
252 | print(f'\nFinding PubMed article URLs for {len(keywords)} keywords found in keywords.txt\n')
253 | # Empty list to store all article data as List[dict]; each dict represents data from one article
254 | # This approach is considerably faster than appending article data article-by-article to a DataFrame
255 | articles_data = []
256 | # Empty list to store all article URLs
257 | urls = []
258 | # Empty list to store URLs already scraped
259 | scraped_urls = []
260 |
261 | # We use asyncio's BoundedSemaphore method to limit the number of asynchronous requests
262 | # we make to PubMed at a time to avoid a ban (and to be nice to PubMed servers)
263 | # Higher value for BoundedSemaphore yields faster scraping, and a higher chance of ban. 100-500 seems to be OK.
264 | semaphore = asyncio.BoundedSemaphore(100)
265 |
266 | # Get and run the loop to build a list of all URLs
267 | loop = asyncio.get_event_loop()
268 | loop.run_until_complete(build_article_urls(search_keywords))
269 | print(f'Scraping initiated for {len(urls)} article URLs found from {args.start} to {args.stop}\n')
270 | # Get and run the loop to get article data into a DataFrame from a list of all URLs
271 | loop = asyncio.get_event_loop()
272 | loop.run_until_complete(get_article_data(urls))
273 |
274 | # Create DataFrame to store data from all articles
275 | articles_df = pd.DataFrame(articles_data, columns=['title','abstract','affiliations','authors','journal','date','keywords','url'])
276 | print('Preview of scraped article data:\n')
277 | print(articles_df.head(5))
278 | # Save all extracted article data to CSV for further processing
279 | filename = args.output
280 | articles_df.to_csv(filename)
281 | print(f'It took {time.time() - start} seconds to find {len(urls)} articles; {len(scraped_urls)} unique articles were saved to {filename}')
282 |
283 |
--------------------------------------------------------------------------------
/example/cli_usage_example.JPG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/IliaZenkov/async-pubmed-scraper/3b3f322d9d5c2828d181a7a370d06395cb063ab7/example/cli_usage_example.JPG
--------------------------------------------------------------------------------
/example/data_example.JPG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/IliaZenkov/async-pubmed-scraper/3b3f322d9d5c2828d181a7a370d06395cb063ab7/example/data_example.JPG
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | aiohttp==3.6.2
2 | asyncio==3.4.3
3 | beautifulsoup4==4.9.1
4 | bs4==0.0.1
5 | lxml==4.5.2
6 | numpy==1.19.2
7 | pandas==1.1.2
8 | requests==2.24.0
9 |
10 |
--------------------------------------------------------------------------------
18 |
19 | ## What it does
20 |
21 | This script asynchronously scrapes PubMed - an open-access database of scholarly research articles -
22 | and saves the data to a PANDAS DataFrame which is then written to a CSV intended for further processing.
23 | This script scrapes a user-specified list of keywords for all results pages asynchronously.
24 |
25 | ## Why scrape when there's an API? Why asynchronous?
26 | PubMed provides an API - the NCBI Entrez API, also known as Entrez Programming Utilities or E-Utilities -
27 | which can be used build datasets with their search engine - however, PubMed allows only 3 URL requests per second
28 | through E-Utilities (10/second w/ API key).
29 | We're doing potentially thousands of URL requests asynchronously - depending on the amount of articles returned by the command line options specified by the user.
30 | It's much faster to download articles from all urls on all results pages in parallel compared to downloading articles page by page, article by article, waiting for the previous article request to complete before moving on to a new one. It's not unusual to see a 10x speedup with async scraping compared to regular scraping.
31 | Simply put, we're going to make our client send requests to all search queries and all resulting article URLs at the same time.
32 | Otherwise, our client will wait for the server to answer before sending the next request, so most of our script's execution time
33 | will be spent waiting for a response from the (PubMed) server.
34 |
35 | ## License
36 |
37 | [](https://github.com/IliaZenkov/async-pubmed-scraper/blob/master/LICENSE)
38 |
39 |
40 |
--------------------------------------------------------------------------------
/async_pubmed_scraper.py:
--------------------------------------------------------------------------------
1 | """
2 | Author: Ilia Zenkov
3 | Date: 9/26/2020
4 |
5 | This script asynchronously scrapes Pubmed - an open-access database of scholarly research articles -
6 | and saves the data to a DataFrame which is then written to a CSV intended for further processing
7 | This script is capable of scraping a list of keywords asynchronously
8 |
9 | Contains the following functions:
10 | make_header: Makes an HTTP request header using a random user agent
11 | get_num_pages: Finds number of pubmed results pages returned by a keyword search
12 | extract_by_article: Extracts data from a single pubmed article to a DataFrame
13 | get_pmids: Gets PMIDs of all article URLs from a single page and builds URLs to pubmed articles specified by those PMIDs
14 | build_article_urls: Async wrapper for get_pmids, creates asyncio tasks for each page of results, page by page,
15 | and stores article urls in urls: List[string]
16 | get_article_data: Async wrapper for extract_by_article, creates asyncio tasks to scrape data from each article specified by urls[]
17 |
18 | requires:
19 | BeautifulSoup4 (bs4)
20 | PANDAS
21 | requests
22 | asyncio
23 | aiohttp
24 | nest_asyncio (OPTIONAL: Solves nested async calls in jupyter notebooks)
25 | """
26 |
27 | import argparse
28 | import time
29 | from bs4 import BeautifulSoup
30 | import pandas as pd
31 | import random
32 | import requests
33 | import asyncio
34 | import aiohttp
35 | import socket
36 | import warnings; warnings.filterwarnings('ignore') # aiohttp produces deprecation warnings that don't concern us
37 | #import nest_asyncio; nest_asyncio.apply() # necessary to run nested async loops in jupyter notebooks
38 |
39 | # Use a variety of agents for our ClientSession to reduce traffic per agent
40 | # This (attempts to) avoid a ban for high traffic from any single agent
41 | # We should really use proxybroker or similar to ensure no ban
42 | user_agents = [
43 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
44 | "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:55.0) Gecko/20100101 Firefox/55.0",
45 | "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36",
46 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
47 | "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
48 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
49 | "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
50 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
51 | "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
52 | "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
53 | "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
54 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
55 | "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
56 | "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
57 | "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
58 | "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
59 | "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
60 | "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
61 | "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
62 | "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
63 | "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
64 | ]
65 |
66 | def make_header():
67 | '''
68 | Chooses a random agent from user_agents with which to construct headers
69 | :return headers: dict: HTTP headers to use to get HTML from article URL
70 | '''
71 | # Make a header for the ClientSession to use with one of our agents chosen at random
72 | headers = {
73 | 'User-Agent':random.choice(user_agents),
74 | }
75 | return headers
76 |
77 | async def extract_by_article(url):
78 | '''
79 | Extracts all data from a single article
80 | :param url: string: URL to a single article (i.e. root pubmed URL + PMID)
81 | :return article_data: Dict: Contains all data from a single article
82 | '''
83 | conn = aiohttp.TCPConnector(family=socket.AF_INET)
84 | headers = make_header()
85 | # Reference our articles DataFrame containing accumulated data for ALL scraped articles
86 | global articles_data
87 | async with aiohttp.ClientSession(headers=headers, connector=conn) as session:
88 | async with semaphore, session.get(url) as response:
89 | data = await response.text()
90 | soup = BeautifulSoup(data, "lxml")
91 | # Get article abstract if exists - sometimes abstracts are not available (not an error)
92 | try:
93 | abstract_raw = soup.find('div', {'class': 'abstract-content selected'}).find_all('p')
94 | # Some articles are in a split background/objectives/method/results style, we need to join these paragraphs
95 | abstract = ' '.join([paragraph.text.strip() for paragraph in abstract_raw])
96 | except:
97 | abstract = 'NO_ABSTRACT'
98 | # Get author affiliations - sometimes affiliations are not available (not an error)
99 | affiliations = [] # list because it would be difficult to split since ',' exists within an affiliation
100 | try:
101 | all_affiliations = soup.find('ul', {'class':'item-list'}).find_all('li')
102 | for affiliation in all_affiliations:
103 | affiliations.append(affiliation.get_text().strip())
104 | except:
105 | affiliations = 'NO_AFFILIATIONS'
106 | # Get article keywords - sometimes keywords are not available (not an error)
107 | try:
108 | # We need to check if the abstract section includes keywords or else we may get abstract text
109 | has_keywords = soup.find_all('strong',{'class':'sub-title'})[-1].text.strip()
110 | if has_keywords == 'Keywords:':
111 | # Taking last element in following line because occasionally this section includes text from abstract
112 | keywords = soup.find('div', {'class':'abstract' }).find_all('p')[-1].get_text()
113 | keywords = keywords.replace('Keywords:','\n').strip() # Clean it up
114 | else:
115 | keywords = 'NO_KEYWORDS'
116 | except:
117 | keywords = 'NO_KEYWORDS'
118 | try:
119 | title = soup.find('meta',{'name':'citation_title'})['content'].strip('[]')
120 | except:
121 | title = 'NO_TITLE'
122 | authors = '' # string because it's easy to split a string on ','
123 | try:
124 | for author in soup.find('div',{'class':'authors-list'}).find_all('a',{'class':'full-name'}):
125 | authors += author.text + ', '
126 | # alternative to get citation style authors (no first name e.g. I. Zenkov)
127 | # all_authors = soup.find('meta', {'name': 'citation_authors'})['content']
128 | # [authors.append(author) for author in all_authors.split(';')]
129 | except:
130 | authors = ('NO_AUTHOR')
131 | try:
132 | journal = soup.find('meta',{'name':'citation_journal_title'})['content']
133 | except:
134 | journal = 'NO_JOURNAL'
135 | try:
136 | date = soup.find('time', {'class': 'citation-year'}).text
137 | except:
138 | date = 'NO_DATE'
139 |
140 | # Format data as a dict to insert into a DataFrame
141 | article_data = {
142 | 'url': url,
143 | 'title': title,
144 | 'authors': authors,
145 | 'abstract': abstract,
146 | 'affiliations': affiliations,
147 | 'journal': journal,
148 | 'keywords': keywords,
149 | 'date': date
150 | }
151 | # Add dict containing one article's data to list of article dicts
152 | articles_data.append(article_data)
153 |
154 | async def get_pmids(page, keyword):
155 | """
156 | Extracts PMIDs of all articles from a pubmed search result, page by page,
157 | builds a url to each article, and stores all article URLs in urls: List[string]
158 | :param page: int: value of current page of a search result for keyword
159 | :param keyword: string: current search keyword
160 | :return: None
161 | """
162 | # URL to one unique page of results for a keyword search
163 | page_url = f'{pubmed_url}+{keyword}+&page={page}'
164 | headers = make_header()
165 | async with aiohttp.ClientSession(headers=headers) as session:
166 | async with session.get(page_url) as response:
167 | data = await response.text()
168 | # Parse the current page of search results from the response
169 | soup = BeautifulSoup(data, "lxml")
170 | # Find section which holds the PMIDs for all articles on a single page of search results
171 | pmids = soup.find('meta',{'name':'log_displayeduids'})['content']
172 | # alternative to get pmids: page_content = soup.find_all('div', {'class': 'docsum-content'}) + for line in page_content: line.find('a').get('href')
173 | # Extract URLs by getting PMIDs for all pubmed articles on the results page (default 10 articles/page)
174 | for pmid in pmids.split(','):
175 | url = root_pubmed_url + '/' + pmid
176 | urls.append(url)
177 |
178 | def get_num_pages(keyword):
179 | '''
180 | Gets total number of pages returned by search results for keyword
181 | :param keyword: string: search word used to search for results
182 | :return: num_pages: int: number of pages returned by search results for keyword
183 | '''
184 | # Return user specified number of pages if option was supplied
185 | if args.pages != None: return args.pages
186 |
187 | # Get search result page and wait a second for it to load
188 | # URL to the first page of results for a keyword search
189 | headers=make_header()
190 | search_url = f'{pubmed_url}+{keyword}'
191 | with requests.get(search_url,headers=headers) as response:
192 | data = response.text
193 | soup = BeautifulSoup(data, "lxml")
194 | num_pages = int((soup.find('span', {'class': 'total-pages'}).get_text()).replace(',',''))
195 | return num_pages # Can hardcode this value (e.g. 10 pages) to limit # of articles scraped per keyword
196 |
197 | async def build_article_urls(keywords):
198 | """
199 | PubMed uniquely identifies articles using a PMID
200 | e.g. https://pubmed.ncbi.nlm.nih.gov/32023415/ #shameless self plug :)
201 | Any and all articles can be identified with a single PMID
202 |
203 | Async wrapper for get_article_urls, page by page of results, for a single search keyword
204 | Creates an asyncio task for each page of search result for each keyword
205 | :param keyword: string: search word used to search for results
206 | :return: None
207 | """
208 | tasks = []
209 | for keyword in keywords:
210 | num_pages = get_num_pages(keyword)
211 | for page in range(1,num_pages+1):
212 | task = asyncio.create_task(get_pmids(page, keyword))
213 | tasks.append(task)
214 |
215 | await asyncio.gather(*tasks)
216 |
217 | async def get_article_data(urls):
218 | """
219 | Async wrapper for extract_by_article to scrape data from each article (url)
220 | :param urls: List[string]: list of all pubmed urls returned by the search keyword
221 | :return: None
222 | """
223 | tasks = []
224 | for url in urls:
225 | if url not in scraped_urls:
226 | task = asyncio.create_task(extract_by_article(url))
227 | tasks.append(task)
228 | scraped_urls.append(url)
229 |
230 | await asyncio.gather(*tasks)
231 |
232 |
233 | if __name__ == "__main__":
234 | # Set options so user can choose number of pages and publication date range to scrape, and output file name
235 | parser = argparse.ArgumentParser(description='Asynchronous PubMed Scraper')
236 | parser.add_argument('--pages', type=int, default=None, help='Specify number of pages to scrape for EACH keyword. Each page of PubMed results contains 10 articles. \n Default = all pages returned for all keywords.')
237 | parser.add_argument('--start', type=int, default=2019, help='Specify start year for publication date range to scrape. Default = 2019')
238 | parser.add_argument('--stop', type=int, default=2020, help='Specify stop year for publication date range to scrape. Default = 2020')
239 | parser.add_argument('--output', type=str, default='articles.csv',help='Choose output file name. Default = "articles.csv".')
240 | args = parser.parse_args()
241 | if args.output[-4:] != '.csv': args.output += '.csv' # ensure we save a CSV if user forgot to include format in --output option
242 | start = time.time()
243 | # This pubmed link is hardcoded to search for articles from user specified date range, defaults to 2019-2020
244 | pubmed_url = f'https://pubmed.ncbi.nlm.nih.gov/?term={args.start}%3A{args.stop}%5Bdp%5D'
245 | # The root pubmed link is used to construct URLs to scrape after PMIDs are retrieved from user specified date range
246 | root_pubmed_url = 'https://pubmed.ncbi.nlm.nih.gov'
247 | # Construct our list of keywords from a user input file to search for and extract articles from
248 | search_keywords = []
249 | with open('keywords.txt') as file:
250 | keywords = file.readlines()
251 | [search_keywords.append(keyword.strip()) for keyword in keywords]
252 | print(f'\nFinding PubMed article URLs for {len(keywords)} keywords found in keywords.txt\n')
253 | # Empty list to store all article data as List[dict]; each dict represents data from one article
254 | # This approach is considerably faster than appending article data article-by-article to a DataFrame
255 | articles_data = []
256 | # Empty list to store all article URLs
257 | urls = []
258 | # Empty list to store URLs already scraped
259 | scraped_urls = []
260 |
261 | # We use asyncio's BoundedSemaphore method to limit the number of asynchronous requests
262 | # we make to PubMed at a time to avoid a ban (and to be nice to PubMed servers)
263 | # Higher value for BoundedSemaphore yields faster scraping, and a higher chance of ban. 100-500 seems to be OK.
264 | semaphore = asyncio.BoundedSemaphore(100)
265 |
266 | # Get and run the loop to build a list of all URLs
267 | loop = asyncio.get_event_loop()
268 | loop.run_until_complete(build_article_urls(search_keywords))
269 | print(f'Scraping initiated for {len(urls)} article URLs found from {args.start} to {args.stop}\n')
270 | # Get and run the loop to get article data into a DataFrame from a list of all URLs
271 | loop = asyncio.get_event_loop()
272 | loop.run_until_complete(get_article_data(urls))
273 |
274 | # Create DataFrame to store data from all articles
275 | articles_df = pd.DataFrame(articles_data, columns=['title','abstract','affiliations','authors','journal','date','keywords','url'])
276 | print('Preview of scraped article data:\n')
277 | print(articles_df.head(5))
278 | # Save all extracted article data to CSV for further processing
279 | filename = args.output
280 | articles_df.to_csv(filename)
281 | print(f'It took {time.time() - start} seconds to find {len(urls)} articles; {len(scraped_urls)} unique articles were saved to {filename}')
282 |
283 |
--------------------------------------------------------------------------------
/example/cli_usage_example.JPG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/IliaZenkov/async-pubmed-scraper/3b3f322d9d5c2828d181a7a370d06395cb063ab7/example/cli_usage_example.JPG
--------------------------------------------------------------------------------
/example/data_example.JPG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/IliaZenkov/async-pubmed-scraper/3b3f322d9d5c2828d181a7a370d06395cb063ab7/example/data_example.JPG
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | aiohttp==3.6.2
2 | asyncio==3.4.3
3 | beautifulsoup4==4.9.1
4 | bs4==0.0.1
5 | lxml==4.5.2
6 | numpy==1.19.2
7 | pandas==1.1.2
8 | requests==2.24.0
9 |
10 |
--------------------------------------------------------------------------------