├── .DS_Store
├── GETTING_STARTED.md
├── MODEL_ZOO.md
├── README.md
├── configs
├── Base-AGW.yml
├── Base-MGN.yml
├── Base-Strongerbaseline.yml
├── Base-bagtricks.yml
├── DukeMTMC
│ ├── AGW_R101-ibn.yml
│ ├── AGW_R50-ibn.yml
│ ├── AGW_R50.yml
│ ├── AGW_S50.yml
│ ├── bagtricks_R101-ibn.yml
│ ├── bagtricks_R50-ibn.yml
│ ├── bagtricks_R50.yml
│ ├── bagtricks_S50.yml
│ ├── mgn_R50-ibn.yml
│ ├── sbs_R101-ibn.yml
│ ├── sbs_R50-ibn.yml
│ ├── sbs_R50.yml
│ └── sbs_S50.yml
├── MSMT17
│ ├── AGW_R101-ibn.yml
│ ├── AGW_R50-ibn.yml
│ ├── AGW_R50.yml
│ ├── AGW_S50.yml
│ ├── bagtricks_R101-ibn.yml
│ ├── bagtricks_R50-ibn.yml
│ ├── bagtricks_R50.yml
│ ├── bagtricks_S50.yml
│ ├── mgn_R50-ibn.yml
│ ├── mgn_R50.yml
│ ├── sbs_R101-ibn.yml
│ ├── sbs_R50-ibn.yml
│ ├── sbs_R50.yml
│ └── sbs_S50.yml
└── Market1501
│ ├── AGW_R101-ibn.yml
│ ├── AGW_R50-ibn.yml
│ ├── AGW_R50.yml
│ ├── AGW_S50.yml
│ ├── bagtricks_R101-ibn.yml
│ ├── bagtricks_R50-ibn.yml
│ ├── bagtricks_R50.yml
│ ├── bagtricks_S50.yml
│ ├── mgn_R50-ibn.yml
│ ├── sbs_R101-ibn.yml
│ ├── sbs_R50-ibn.yml
│ ├── sbs_R50.yml
│ └── sbs_S50.yml
├── demo
├── README.md
├── demo.py
├── plot_roc_with_pickle.py
├── predictor.py
├── run_demo.sh
└── visualize_result.py
├── fastreid
├── __init__.py
├── __pycache__
│ └── __init__.cpython-36.pyc
├── config
│ ├── .defaults.py.swp
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ ├── config.cpython-36.pyc
│ │ └── defaults.cpython-36.pyc
│ ├── config.py
│ └── defaults.py
├── data
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ ├── build.cpython-36.pyc
│ │ ├── common.cpython-36.pyc
│ │ └── data_utils.cpython-36.pyc
│ ├── build.py
│ ├── common.py
│ ├── data_utils.py
│ ├── datasets
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-36.pyc
│ │ │ ├── bases.cpython-36.pyc
│ │ │ ├── cuhk03.cpython-36.pyc
│ │ │ ├── dukemtmcreid.cpython-36.pyc
│ │ │ ├── market1501.cpython-36.pyc
│ │ │ ├── msmt17.cpython-36.pyc
│ │ │ ├── vehicleid.cpython-36.pyc
│ │ │ ├── veri.cpython-36.pyc
│ │ │ └── veriwild.cpython-36.pyc
│ │ ├── bases.py
│ │ ├── cuhk03.py
│ │ ├── dukemtmcreid.py
│ │ ├── market1501.py
│ │ ├── msmt17.py
│ │ ├── vehicleid.py
│ │ ├── veri.py
│ │ └── veriwild.py
│ ├── samplers
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-36.pyc
│ │ │ ├── data_sampler.cpython-36.pyc
│ │ │ └── triplet_sampler.cpython-36.pyc
│ │ ├── data_sampler.py
│ │ └── triplet_sampler.py
│ └── transforms
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ ├── autoaugment.cpython-36.pyc
│ │ ├── build.cpython-36.pyc
│ │ ├── functional.cpython-36.pyc
│ │ └── transforms.cpython-36.pyc
│ │ ├── autoaugment.py
│ │ ├── build.py
│ │ ├── functional.py
│ │ └── transforms.py
├── engine
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ ├── defaults.cpython-36.pyc
│ │ ├── hooks.cpython-36.pyc
│ │ └── train_loop.cpython-36.pyc
│ ├── defaults.py
│ ├── hooks.py
│ └── train_loop.py
├── evaluation
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ ├── evaluator.cpython-36.pyc
│ │ ├── query_expansion.cpython-36.pyc
│ │ ├── rank.cpython-36.pyc
│ │ ├── reid_evaluation.cpython-36.pyc
│ │ ├── rerank.cpython-36.pyc
│ │ ├── roc.cpython-36.pyc
│ │ └── testing.cpython-36.pyc
│ ├── evaluator.py
│ ├── query_expansion.py
│ ├── rank.py
│ ├── rank_cylib
│ │ ├── Makefile
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ └── __init__.cpython-36.pyc
│ │ ├── rank_cy.c
│ │ ├── rank_cy.cpython-36m-x86_64-linux-gnu.so
│ │ ├── rank_cy.pyx
│ │ ├── setup.py
│ │ └── test_cython.py
│ ├── reid_evaluation.py
│ ├── rerank.py
│ ├── roc.py
│ └── testing.py
├── export
│ ├── __init__.py
│ ├── tensorflow_export.py
│ └── tf_modeling.py
├── layers
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ ├── activation.cpython-36.pyc
│ │ ├── arcface.cpython-36.pyc
│ │ ├── attention.cpython-36.pyc
│ │ ├── batch_drop.cpython-36.pyc
│ │ ├── batch_norm.cpython-36.pyc
│ │ ├── circle.cpython-36.pyc
│ │ ├── context_block.cpython-36.pyc
│ │ ├── frn.cpython-36.pyc
│ │ ├── gem_pool.cpython-36.pyc
│ │ ├── non_local.cpython-36.pyc
│ │ ├── se_layer.cpython-36.pyc
│ │ └── splat.cpython-36.pyc
│ ├── activation.py
│ ├── arcface.py
│ ├── attention.py
│ ├── batch_drop.py
│ ├── batch_norm.py
│ ├── circle.py
│ ├── context_block.py
│ ├── frn.py
│ ├── gem_pool.py
│ ├── non_local.py
│ ├── se_layer.py
│ ├── splat.py
│ └── sync_bn
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ ├── batchnorm.cpython-36.pyc
│ │ ├── comm.cpython-36.pyc
│ │ └── replicate.cpython-36.pyc
│ │ ├── batchnorm.py
│ │ ├── batchnorm_reimpl.py
│ │ ├── comm.py
│ │ ├── replicate.py
│ │ └── unittest.py
├── modeling
│ ├── __init__.py
│ ├── __pycache__
│ │ └── __init__.cpython-36.pyc
│ ├── backbones
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-36.pyc
│ │ │ ├── build.cpython-36.pyc
│ │ │ ├── osnet.cpython-36.pyc
│ │ │ ├── resnest.cpython-36.pyc
│ │ │ ├── resnet.cpython-36.pyc
│ │ │ └── resnext.cpython-36.pyc
│ │ ├── build.py
│ │ ├── osnet.py
│ │ ├── resnest.py
│ │ ├── resnet.py
│ │ └── resnext.py
│ ├── heads
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-36.pyc
│ │ │ ├── bnneck_head.cpython-36.pyc
│ │ │ ├── build.cpython-36.pyc
│ │ │ └── linear_head.cpython-36.pyc
│ │ ├── bnneck_head.py
│ │ ├── build.py
│ │ ├── linear_head.py
│ │ └── reduction_head.py
│ ├── losses
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-36.pyc
│ │ │ ├── build_losses.cpython-36.pyc
│ │ │ ├── cross_entroy_loss.cpython-36.pyc
│ │ │ ├── focal_loss.cpython-36.pyc
│ │ │ └── metric_loss.cpython-36.pyc
│ │ ├── build_losses.py
│ │ ├── center_loss.py
│ │ ├── cross_entroy_loss.py
│ │ ├── focal_loss.py
│ │ └── metric_loss.py
│ └── meta_arch
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ ├── baseline.cpython-36.pyc
│ │ └── build.cpython-36.pyc
│ │ ├── baseline.py
│ │ ├── build.py
│ │ └── mgn.py
├── solver
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ ├── build.cpython-36.pyc
│ │ └── lr_scheduler.cpython-36.pyc
│ ├── build.py
│ ├── lr_scheduler.py
│ └── optim
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ ├── lamb.cpython-36.pyc
│ │ ├── lookahead.cpython-36.pyc
│ │ ├── novograd.cpython-36.pyc
│ │ ├── over9000.cpython-36.pyc
│ │ ├── radam.cpython-36.pyc
│ │ ├── ralamb.cpython-36.pyc
│ │ ├── ranger.cpython-36.pyc
│ │ └── swa.cpython-36.pyc
│ │ ├── lamb.py
│ │ ├── lookahead.py
│ │ ├── novograd.py
│ │ ├── over9000.py
│ │ ├── radam.py
│ │ ├── ralamb.py
│ │ ├── ranger.py
│ │ └── swa.py
└── utils
│ ├── __init__.py
│ ├── __pycache__
│ ├── __init__.cpython-36.pyc
│ ├── checkpoint.cpython-36.pyc
│ ├── comm.cpython-36.pyc
│ ├── events.cpython-36.pyc
│ ├── file_io.cpython-36.pyc
│ ├── history_buffer.cpython-36.pyc
│ ├── logger.cpython-36.pyc
│ ├── one_hot.cpython-36.pyc
│ ├── precision_bn.cpython-36.pyc
│ ├── registry.cpython-36.pyc
│ ├── timer.cpython-36.pyc
│ └── weight_init.cpython-36.pyc
│ ├── checkpoint.py
│ ├── comm.py
│ ├── events.py
│ ├── file_io.py
│ ├── history_buffer.py
│ ├── logger.py
│ ├── one_hot.py
│ ├── precision_bn.py
│ ├── registry.py
│ ├── summary.py
│ ├── timer.py
│ ├── visualizer.py
│ └── weight_init.py
├── projects
├── .gitkeep
├── PartialReID
│ ├── configs
│ │ ├── .partial_market.yml.swn
│ │ ├── .partial_market.yml.swo
│ │ ├── .partial_market.yml.swp
│ │ └── partial_market.yml
│ ├── partialreid
│ │ ├── .dsr_head.py.swo
│ │ ├── .dsr_head.py.swp
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-36.pyc
│ │ │ ├── config.cpython-36.pyc
│ │ │ ├── dsr_distance.cpython-36.pyc
│ │ │ ├── dsr_evaluation.cpython-36.pyc
│ │ │ ├── dsr_head.cpython-36.pyc
│ │ │ ├── partial_dataset.cpython-36.pyc
│ │ │ └── partialbaseline.cpython-36.pyc
│ │ ├── config.py
│ │ ├── dsr_distance.py
│ │ ├── dsr_evaluation.py
│ │ ├── dsr_head.py
│ │ ├── partial_dataset.py
│ │ └── partialbaseline.py
│ └── train_net.py
└── README.md
├── tests
├── __init__.py
├── dataset_test.py
├── interp_test.py
├── lr_scheduler_test.py
├── model_test.py
└── sampler_test.py
└── tools
├── export2tf.py
└── train_net.py
/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JDAI-CV/Partial-Person-ReID/fb94dbfbec1105bbc22a442702bc6e385427d416/.DS_Store
--------------------------------------------------------------------------------
/GETTING_STARTED.md:
--------------------------------------------------------------------------------
1 | # Getting Started with Fastreid
2 |
3 | ## Prepare pretrained model
4 |
5 | If you use origin ResNet, you do not need to do anything. But if you want to use ResNet_ibn, you need to download pretrain model in [here](https://drive.google.com/open?id=1thS2B8UOSBi_cJX6zRy6YYRwz_nVFI_S). And then you can put it in `~/.cache/torch/checkpoints` or anywhere you like.
6 |
7 | Then you should set the pretrain model path in `configs/Base-bagtricks.yml`.
8 |
9 | ## Compile with cython to accelerate evalution
10 |
11 | ```bash
12 | cd fastreid/evaluation/rank_cylib; make all
13 | ```
14 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
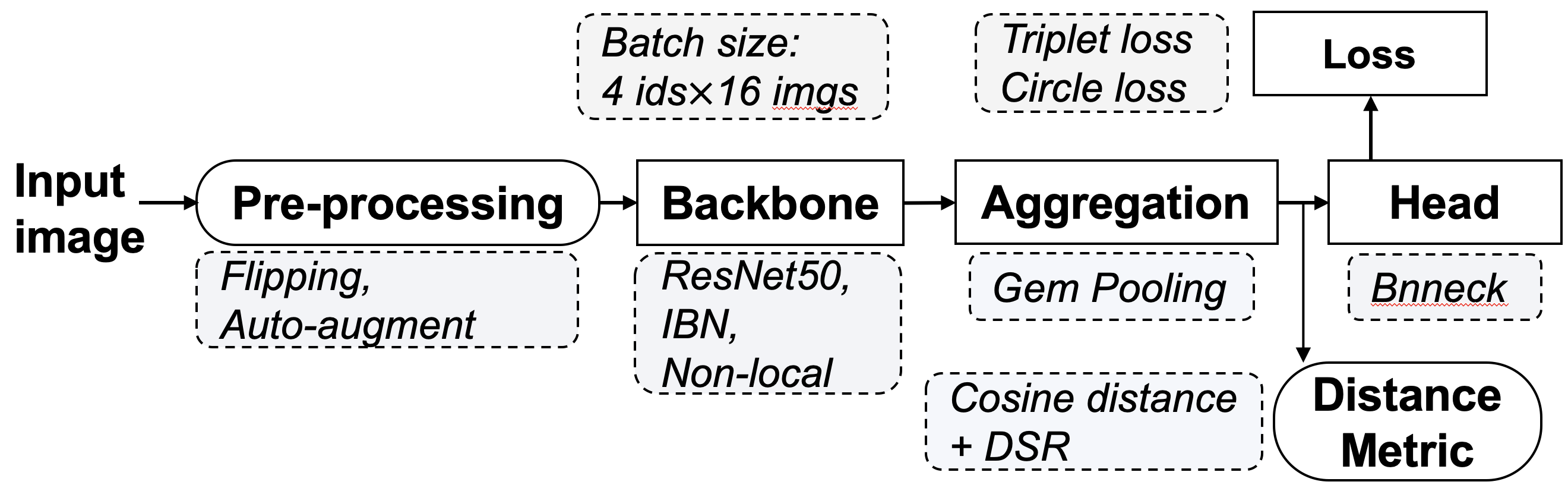
1 | # DSR in FastReID
2 | **Deep Spatial Feature Reconstruction for Partial Person Re-identification**
3 |
4 | Lingxiao He, Xingyu Liao
5 |
6 | [[`CVPR2018`](http://openaccess.thecvf.com/content_cvpr_2018/papers/He_Deep_Spatial_Feature_CVPR_2018_paper.pdf)] [[`BibTeX`](#CitingDSR)]
7 |
8 | **Foreground-aware Pyramid Reconstruction for Alignment-free Occluded Person Re-identification**
9 |
10 | Lingxiao He, Xingyu Liao
11 |
12 | [[`ICCV2019`](http://openaccess.thecvf.com/content_ICCV_2019/papers/He_Foreground-Aware_Pyramid_Reconstruction_for_Alignment-Free_Occluded_Person_Re-Identification_ICCV_2019_paper.pdf)] [[`BibTeX`](#CitingFPR)]
13 |
14 | ## Installation
15 |
16 | First install FastReID, and then put Partial Datasets in directory datasets. The whole framework of FastReID-DSR is
17 |
18 |
19 |