├── README.md
├── Readme_Img
├── C_Frame.png
├── Frameworks.png
├── Q_Frame.png
└── qflow.png
├── model.tar.gz
├── model
├── u2_p2
│ ├── config
│ └── model_best.tar
├── u2_p2_n2
│ ├── config
│ └── model_best.tar
├── u4_p2
│ ├── config
│ └── model_best.tar
├── u4_v2
│ ├── config
│ └── model_best.tar
├── v16_u2
│ ├── config
│ └── model_best.tar
└── v16_v2
│ ├── config
│ └── model_best.tar
├── requirements.txt
├── session_1
└── Tutorial_0_Basic_Quantum_Gate.ipynb
├── session_2
├── Tutorial_1_DataPreparation.ipynb
├── Tutorial_2_Hidden_NeuralComp.ipynb
├── Tutorial_3_Full_MNIST_Prediction.ipynb
├── Tutorial_4_QAccelerate.ipynb
└── Tutorial_5_QF-Map-Eval.ipynb
├── session_3
├── EX_1_QF_pNet.ipynb
├── EX_2_QF_hNet.ipynb
├── EX_3_QF_FB.py
├── EX_4_FFNN.ipynb
└── EX_5_VQC.ipynb
└── session_4
├── EX_6_QF_MixNN_V_U.ipynb
└── EX_7_QF_MixNN_U_V.ipynb
/README.md:
--------------------------------------------------------------------------------
1 |
2 | 
3 |
4 | [](https://jqub.github.io/categories/QF/) [](https://www.nature.com/articles/s41467-020-20729-5) [](https://arxiv.org/pdf/2012.10360.pdf) [](#)
5 |
6 |
7 | # Tutorial of Implemeting Neural Network on Quantum Computer
8 |
9 | ## News
10 | [2021/06/25] A tutorial proposal on QuantumFlow has been accepted by [**IEEE Quantum Week**](https://qce.quantum.ieee.org/). See you then virtually on Oct. 18-22, 2021.
11 |
12 | [2021/06/17] A tutorial proposal on QuantumFlow has been accepted by [**ESWEEK**](https://esweek.org/). See you then virtually on Oct. 08, 2021.
13 |
14 | [2021/06/01] The tutorial on QuantumFlow optimization is released on 06/02/2021! See Tutorial 4.
15 |
16 | [2021/05/01] The tutorial can be executed on Google CoLab now!
17 |
18 | [2021/01/17] Invited to give a talk at **ASP-DAC 2021** for this tutorial work.
19 |
20 | [2021/01/01] [QuantumFlow](https://www.nature.com/articles/s41467-020-20729-5) has been accepted by **Nature Communications**.
21 |
22 | [2020/12/30] The tutorial is released on 12/31/2020! Happy New Year and enjoy the following Tutorial.
23 |
24 | [2020/09/17] Invited to give a talk at **IBM Quantum Summit** about [QuantumFlow](https://www.nature.com/articles/s41467-020-20729-5).
25 |
26 |
27 | ## Overview
28 | Recently, we proposed the first neural network and quantum circuit co-design framework, [QuantumFlow](https://www.nature.com/articles/s41467-020-20729-5), in which we have successfully demonstrated the quantum advatages in performing the basic neural operation from O(N) to O(logN). Based on the understandings from the co-design framework, in this repo, we provide a tutorial on an end-to-end implementation of neural networks onto quantum circuits, which is base of the invited paper at **ASP-DAC 2021**, titled [When Machine Learning Meets Quantum Computers: A Case Study](https://arxiv.org/pdf/2012.10360.pdf).
29 |
30 | This repo aims to demonstrate the workflow of implementing neural network onto quantum circuit and demonstrates the functional correctness. It will provide the basis to understand [QuantumFlow](https://www.nature.com/articles/s41467-020-20729-5). The demonstration of quantum advantage will be included in the repo for [QuantumFlow](https://www.nature.com/articles/s41467-020-20729-5), which will be completed soon at [here](https://github.com/weiwenjiang/QuantumFlow).
31 |
32 | Before introducing the QuantumFlow framework, we povide the implementation of basic quantum cirucit in the following Qikist codes, which can be executed in colab [](https://colab.research.google.com/github/JQub/QuantumFlow_Tutorial/blob/main/session_1/Tutorial_0_Basic_Quantum_Gate.ipynb)
33 |
34 |
35 | ## Framework: from classical to quantum
36 | 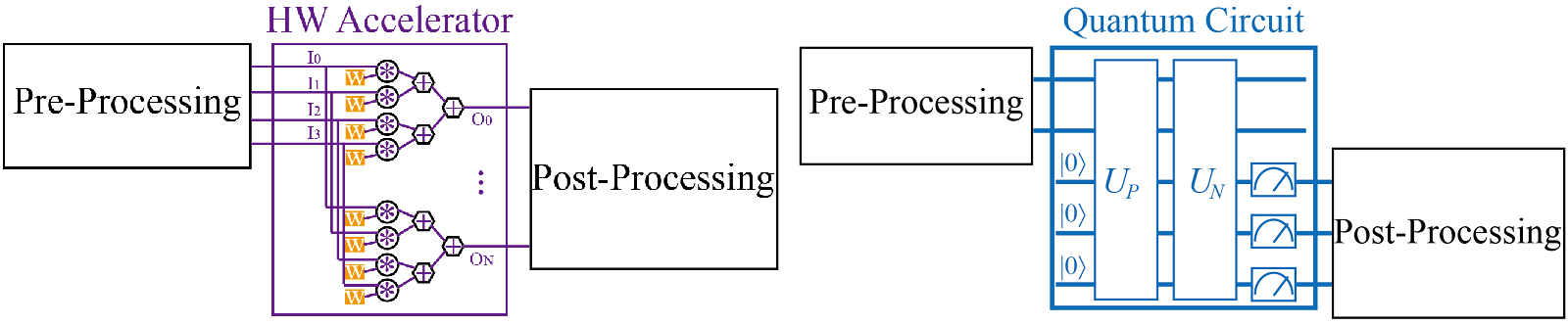
37 |
38 | In the above figure, on the left-hand, it is the design framework for classical hardware (HW) accelerators. The whole procedure will take three steps: (1) pre-processing data, (2) accelerating the neural computations, (3) post-processing data.
39 |
40 | Similarly, on the right-hand side, we can build up the workflow for quantum machine learning. It takes 5 steps to complete the whole computation: (1) **PreP** pre-processing data; (2) **UP** data encoding onto quantum, that is quantum-state preparation; (3) **UN** neural operation oracle on quantum computer; (4) **M** data readout, that is quantum measurement; (5) **PostP** post-processing data. Among these stpes, (1) and (5) are conducted on classical computer, and (2-4) are conducted on the quantum circuit.
41 |
42 | ## Tutorial 1: **PreP** + **UP**
43 |
44 | [](https://colab.research.google.com/github/JQub/QuantumFlow_Tutorial/blob/main/session_2/Tutorial_1_DataPreparation.ipynb)
45 |
46 | This tutorial demonstrates how to do data pre-preocessing and encoding it to quantum circuit using Qiskit.
47 |
48 | Let us formulate the problem as follow.
49 |
50 | **Given:** (1) One 28\*28 image from MNIST ; (2) The size to be downsampled, i.e., 4\*4
51 |
52 | **Do:** (1) Downsampling image; (2) Converting classical data to quantum data that can be encoded to quantum circuit; (3) Create quantum circuit and encode 16 pixel data to log16=4 qubits.
53 |
54 | **Check:** Whether the data is correctly encoded.
55 |
56 |
57 | ## Tutorial 2: **PreP** + **UP** + **UN**
58 |
59 | [](https://colab.research.google.com/github/JQub/QuantumFlow_Tutorial/blob/main/session_2/Tutorial_2_Hidden_NeuralComp.ipynb)
60 |
61 |
62 | This tutorial demonstrates how to use the encoded quantum circuit to perform **weighted sum** and **quadratic non-linear** operations, which are the basic operations in machine learning.
63 |
64 | Let us formulate the problem based on the output of Tutorial 1 as follow.
65 |
66 | **Given:** (1) A circuit with encoded input data **x**; (2) the trained binary weights **w** for one neural computation, which will be associated to each data.
67 |
68 | **Do:** (1) Place quantum gates on the qubits, such that it performs **(x\*w)^2/||x||**.
69 |
70 | **Check:** Whether the output data of quantum circuit and the output computed using torch on classical computer are the same.
71 |
72 |
73 |
74 | ## Tutorial 3: **PreP** + **UP** + **UN** + **M** + **PostP**
75 |
76 | [](https://colab.research.google.com/github/JQub/QuantumFlow_Tutorial/blob/main/session_2/Tutorial_3_Full_MNIST_Prediction.ipynb)
77 |
78 | This is a complete tutorial to demonstrates an end-to-end implementation of a two-layer neural network for MNIST sub-dataset of {3,6}. The first layer (hidden layer) is implemented using the one presented in Tutorial 2, and the second layer (output layer) is implemented using the P-LYR and N-LYR proposed in [QuantumFlow](https://arxiv.org/pdf/2006.14815.pdf). The model is pre-trained and the weights for hidden layer, output layer, and normalization are obtained (details will be provided in [QuantumFlow github repo](https://github.com/weiwenjiang/QuantumFlow)).
79 |
80 | Let us formulate the problem from scratch as follow.
81 |
82 | **Given:** (1) An image from MNIST; (2) The trained model.
83 |
84 | **Do:** (1) Construct the quantum circuit; (2) Perform the simulation on Qiskit or execute the circuit on IBM Quantum Processor.
85 |
86 | **Check:** Whether the prediction is correct.
87 |
88 |
89 |
90 | ## Tutorial 4: **PreP** + **UP** + **Optimized UN** + **M** + **PostP**
91 |
92 | [](https://colab.research.google.com/github/JQub/QuantumFlow_Tutorial/blob/main/session_2/Tutorial_4_QAccelerate.ipynb)
93 |
94 | This is a complete tutorial to demonstrates QuantumFlow can optimize the quantum circuit with the same function as the one created in Tutorial 3.
95 | We continously use the settings in Tutorial 3. We do the optimization on the U-Layer of two hidden neurons using the algorithm proposed in [QuantumFlow github repo](https://github.com/weiwenjiang/QuantumFlow).
96 |
97 | Let us formulate the problem from scratch as follow.
98 |
99 | **Given:** (1) An image from MNIST; (2) The trained model.
100 |
101 | **Do:** (1) Construct the quantum circuit with optimized U-Layer; (2) Perform the simulation on Qiskit or execute the circuit on IBM Quantum Processor.
102 |
103 | **Check:** Whether the prediction is correct; whether the results are almost the same with the circuit created in Tutorial 3; compare the reduction on circuit depth.
104 |
105 |
106 | ## Related work on This Tutorial
107 |
108 | The work published at Nature Communications.
109 |
110 | ```
111 | @article{jiang2021co,
112 | title={A co-design framework of neural networks and quantum circuits towards quantum advantage},
113 | author={Jiang, Weiwen and Xiong, Jinjun and Shi, Yiyu},
114 | journal={Nature communications},
115 | volume={12},
116 | number={1},
117 | pages={1--13},
118 | year={2021},
119 | publisher={Nature Publishing Group}
120 | }
121 | ```
122 |
123 | The work invited by ASP-DAC 2021.
124 |
125 | ```
126 | @article{jiang2020machine,
127 | title={When Machine Learning Meets Quantum Computers: A Case Study},
128 | author={Jiang, Weiwen and Xiong, Jinjun and Shi, Yiyu},
129 | journal={arXiv preprint arXiv:2012.10360},
130 | year={2020}
131 | }
132 | ```
133 |
134 | ## Contact
135 | **Weiwen Jiang**
136 |
137 | **Email: wjiang8@gmu.edu**
138 |
139 | **Web: https://jqub.ece.gmu.edu/**
140 |
141 | **Date: 06/17/2021**
142 |
--------------------------------------------------------------------------------
/Readme_Img/C_Frame.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JQub/QuantumFlow_Tutorial/488923974fbc783480964d857ad537b46190d277/Readme_Img/C_Frame.png
--------------------------------------------------------------------------------
/Readme_Img/Frameworks.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JQub/QuantumFlow_Tutorial/488923974fbc783480964d857ad537b46190d277/Readme_Img/Frameworks.png
--------------------------------------------------------------------------------
/Readme_Img/Q_Frame.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JQub/QuantumFlow_Tutorial/488923974fbc783480964d857ad537b46190d277/Readme_Img/Q_Frame.png
--------------------------------------------------------------------------------
/Readme_Img/qflow.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JQub/QuantumFlow_Tutorial/488923974fbc783480964d857ad537b46190d277/Readme_Img/qflow.png
--------------------------------------------------------------------------------
/model.tar.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JQub/QuantumFlow_Tutorial/488923974fbc783480964d857ad537b46190d277/model.tar.gz
--------------------------------------------------------------------------------
/model/u2_p2/config:
--------------------------------------------------------------------------------
1 | ===================== Your setting is listed as follows ======================
2 | Attribute Input
3 | device cpu
4 | interest_class 3,6
5 | img_size 4
6 | datapath /home/hzr/Software/quantum/qc_mnist/pytorch/data
7 | preprocessdata 0
8 | num_workers 0
9 | batch_size 32
10 | inference_batch_size 1
11 | neural_in_layers u:2,p:2
12 | init_lr 0.01
13 | milestones 5, 7, 9
14 | max_epoch 2
15 | resume_path
16 | test_only 0
17 | binary 0
18 | given_ang 1 -1 1 -1, -1 -1
19 | train_ang 0
20 | save_chkp 1
21 | chk_name u2_p2
22 | chk_path .
23 | ====================== Exploration will start, have fun ======================
24 | ==============================================================================
25 |
--------------------------------------------------------------------------------
/model/u2_p2/model_best.tar:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JQub/QuantumFlow_Tutorial/488923974fbc783480964d857ad537b46190d277/model/u2_p2/model_best.tar
--------------------------------------------------------------------------------
/model/u2_p2_n2/config:
--------------------------------------------------------------------------------
1 | ===================== Your setting is listed as follows ======================
2 | Attribute Input
3 | device cpu
4 | interest_class 3,6
5 | img_size 4
6 | datapath /home/hzr/Software/quantum/qc_mnist/pytorch/data
7 | preprocessdata 0
8 | num_workers 0
9 | batch_size 32
10 | inference_batch_size 1
11 | neural_in_layers u:2,p:2,n:2
12 | init_lr 0.01
13 | milestones 5, 7, 9
14 | max_epoch 2
15 | resume_path
16 | test_only 0
17 | binary 0
18 | given_ang 1, 1, 1 1
19 | train_ang 1
20 | save_chkp 1
21 | chk_name u2_p2_n2
22 | chk_path .
23 | ====================== Exploration will start, have fun ======================
24 | ==============================================================================
25 |
--------------------------------------------------------------------------------
/model/u2_p2_n2/model_best.tar:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JQub/QuantumFlow_Tutorial/488923974fbc783480964d857ad537b46190d277/model/u2_p2_n2/model_best.tar
--------------------------------------------------------------------------------
/model/u4_p2/config:
--------------------------------------------------------------------------------
1 | ===================== Your setting is listed as follows ======================
2 | Attribute Input
3 | device cpu
4 | interest_class 3,6
5 | img_size 4
6 | datapath /home/hzr/Software/quantum/qc_mnist/pytorch/data
7 | preprocessdata 0
8 | num_workers 0
9 | batch_size 32
10 | inference_batch_size 1
11 | neural_in_layers u:4,p:2
12 | init_lr 0.01
13 | milestones 5, 7, 9
14 | max_epoch 2
15 | resume_path
16 | test_only 0
17 | binary 0
18 | given_ang 1 -1 1 -1, -1 -1
19 | train_ang 0
20 | save_chkp 1
21 | chk_name u4_p2
22 | chk_path .
23 | ====================== Exploration will start, have fun ======================
24 | ==============================================================================
25 |
--------------------------------------------------------------------------------
/model/u4_p2/model_best.tar:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JQub/QuantumFlow_Tutorial/488923974fbc783480964d857ad537b46190d277/model/u4_p2/model_best.tar
--------------------------------------------------------------------------------
/model/u4_v2/config:
--------------------------------------------------------------------------------
1 | ===================== Your setting is listed as follows ======================
2 | Attribute Input
3 | device cpu
4 | interest_class 3,6
5 | img_size 4
6 | datapath /home/hzr/Software/quantum/qc_mnist/pytorch/data
7 | preprocessdata 0
8 | num_workers 0
9 | batch_size 32
10 | inference_batch_size 1
11 | neural_in_layers u:4,p2a:16,v:2
12 | init_lr 0.01
13 | milestones 5, 7, 9
14 | max_epoch 2
15 | resume_path
16 | test_only 0
17 | binary 0
18 | given_ang 1, 1, 1 1
19 | train_ang 1
20 | save_chkp 1
21 | chk_name u4_v2
22 | chk_path .
23 | ====================== Exploration will start, have fun ======================
24 | ==============================================================================
25 |
--------------------------------------------------------------------------------
/model/u4_v2/model_best.tar:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JQub/QuantumFlow_Tutorial/488923974fbc783480964d857ad537b46190d277/model/u4_v2/model_best.tar
--------------------------------------------------------------------------------
/model/v16_u2/config:
--------------------------------------------------------------------------------
1 | ===================== Your setting is listed as follows ======================
2 | Attribute Input
3 | device cpu
4 | interest_class 3,6
5 | img_size 4
6 | datapath /home/hzr/Software/quantum/qc_mnist/pytorch/data
7 | preprocessdata 0
8 | num_workers 0
9 | batch_size 32
10 | inference_batch_size 1
11 | neural_in_layers v:16,u:2
12 | init_lr 0.01
13 | milestones 5, 7, 9
14 | max_epoch 10
15 | resume_path
16 | test_only 0
17 | binary 0
18 | given_ang 1 -1 1 -1, -1 -1
19 | train_ang 0
20 | save_chkp 1
21 | chk_name v16_u2
22 | chk_path .
23 | ====================== Exploration will start, have fun ======================
24 | ==============================================================================
25 |
--------------------------------------------------------------------------------
/model/v16_u2/model_best.tar:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JQub/QuantumFlow_Tutorial/488923974fbc783480964d857ad537b46190d277/model/v16_u2/model_best.tar
--------------------------------------------------------------------------------
/model/v16_v2/config:
--------------------------------------------------------------------------------
1 | ===================== Your setting is listed as follows ======================
2 | Attribute Input
3 | device cpu
4 | interest_class 3,6
5 | img_size 4
6 | datapath /home/hzr/Software/quantum/qc_mnist/pytorch/data
7 | preprocessdata 0
8 | num_workers 0
9 | batch_size 32
10 | inference_batch_size 1
11 | neural_in_layers v:16,v:2
12 | init_lr 0.01
13 | milestones 5, 7, 9
14 | max_epoch 2
15 | resume_path
16 | test_only 0
17 | binary 0
18 | given_ang 1 -1 1 -1, -1 -1
19 | train_ang 0
20 | save_chkp 1
21 | chk_name u4_v2
22 | chk_path .
23 | ====================== Exploration will start, have fun ======================
24 | ==============================================================================
25 |
--------------------------------------------------------------------------------
/model/v16_v2/model_best.tar:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JQub/QuantumFlow_Tutorial/488923974fbc783480964d857ad537b46190d277/model/v16_v2/model_best.tar
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | pylatexenc==2.10
2 | qfnn==0.1.10
3 | qiskit==0.20.0
4 | torch==1.9.0
5 | torchvision==0.10.0
6 |
--------------------------------------------------------------------------------
/session_1/Tutorial_0_Basic_Quantum_Gate.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 2,
4 | "metadata": {
5 | "colab": {
6 | "name": "Basic Quantum Gate",
7 | "provenance": [],
8 | "collapsed_sections": [],
9 | "toc_visible": true
10 | },
11 | "kernelspec": {
12 | "name": "python3",
13 | "display_name": "Python 3.8.10 64-bit ('qf': conda)"
14 | },
15 | "language_info": {
16 | "name": "python",
17 | "version": "3.8.10",
18 | "mimetype": "text/x-python",
19 | "codemirror_mode": {
20 | "name": "ipython",
21 | "version": 3
22 | },
23 | "pygments_lexer": "ipython3",
24 | "nbconvert_exporter": "python",
25 | "file_extension": ".py"
26 | },
27 | "interpreter": {
28 | "hash": "f24048f0d5bdb0ff49c5e7c8a9899a65bc3ab13b0f32660a2227453ca6b95fd8"
29 | }
30 | },
31 | "cells": [
32 | {
33 | "cell_type": "markdown",
34 | "source": [
35 | "# Single qubit gate"
36 | ],
37 | "metadata": {
38 | "id": "XhKK71TPv07l"
39 | }
40 | },
41 | {
42 | "cell_type": "code",
43 | "execution_count": 180,
44 | "source": [
45 | "is_colab = True\n",
46 | "\n",
47 | "if is_colab:\n",
48 | " !pip install -q torch==1.9.0\n",
49 | " !pip install -q torchvision==0.10.0\n",
50 | " !pip install -q qiskit==0.20.0\n",
51 | "\n",
52 | "import torch\n",
53 | "import torchvision\n",
54 | "import qiskit \n",
55 | "from qiskit import QuantumCircuit, assemble, Aer\n",
56 | "from qiskit import execute"
57 | ],
58 | "outputs": [],
59 | "metadata": {
60 | "colab": {
61 | "base_uri": "https://localhost:8080/"
62 | },
63 | "id": "jkCtB8IiGu49",
64 | "outputId": "14892b0b-77e8-4953-b7e1-409c7ec91c3b"
65 | }
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": 181,
70 | "source": [
71 | "sim = Aer.get_backend('statevector_simulator') # Tell Qiskit how to simulate our circuit"
72 | ],
73 | "outputs": [],
74 | "metadata": {
75 | "id": "vewjYJIIL4Lu"
76 | }
77 | },
78 | {
79 | "cell_type": "markdown",
80 | "source": [
81 | "### X Gate"
82 | ],
83 | "metadata": {
84 | "id": "rge0n87hJPnt"
85 | }
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": 182,
90 | "source": [
91 | "qc = QuantumCircuit(1)\n",
92 | "initial_state = [1,0] # Define initial_state as |0>\n",
93 | "# qc.initialize(initial_state, 0) # Apply initialisation operation to the 0th qubit\n",
94 | "qc.x(0)\n",
95 | "qc.draw()"
96 | ],
97 | "outputs": [
98 | {
99 | "data": {
100 | "text/plain": " ┌───┐\nq_0: ┤ X ├\n └───┘",
101 | "text/html": " ┌───┐\nq_0: ┤ X ├\n └───┘
"
102 | },
103 | "execution_count": 182,
104 | "metadata": {},
105 | "output_type": "execute_result"
106 | }
107 | ],
108 | "metadata": {
109 | "colab": {
110 | "base_uri": "https://localhost:8080/",
111 | "height": 63
112 | },
113 | "id": "5TlRdJx4ATH9",
114 | "outputId": "f19b14f8-6892-41b0-d8f1-3ca1fdb04914"
115 | }
116 | },
117 | {
118 | "cell_type": "code",
119 | "execution_count": 183,
120 | "source": [
121 | "result = execute(qc, sim).result()\n",
122 | "out_state = result.get_statevector(qc)\n",
123 | "print(\"after X gate, the state is \",out_state)\n",
124 | "\n",
125 | "initial_state_torch = torch.tensor([initial_state])\n",
126 | "x_gate_matrix = torch.tensor([[0,1],[1,0]])\n",
127 | "out_state_torch = torch.mm(x_gate_matrix,initial_state_torch.t()) \n",
128 | "print(\"after X matrix, the state is \",out_state_torch.t()) # Display the output state vector\n",
129 | "print(\"Equal 0 if correct!\",out_state_torch.t()[0].sub(torch.tensor(out_state)))\n"
130 | ],
131 | "outputs": [
132 | {
133 | "name": "stdout",
134 | "output_type": "stream",
135 | "text": [
136 | "after X gate, the state is [0.+0.j 1.+0.j]\n",
137 | "after X matrix, the state is tensor([[0, 1]])\n",
138 | "Equal 0 if correct! tensor([0.+0.j, 0.+0.j], dtype=torch.complex128)\n"
139 | ]
140 | }
141 | ],
142 | "metadata": {
143 | "colab": {
144 | "base_uri": "https://localhost:8080/",
145 | "height": 312
146 | },
147 | "id": "EOYG4XTBIyFk",
148 | "outputId": "88d9ac16-0b36-42e0-8fa6-65e8e1b6db38"
149 | }
150 | },
151 | {
152 | "cell_type": "markdown",
153 | "source": [
154 | "### Y Gate"
155 | ],
156 | "metadata": {
157 | "id": "k8z_4_y2LYOB"
158 | }
159 | },
160 | {
161 | "cell_type": "code",
162 | "execution_count": 184,
163 | "source": [
164 | "qc = QuantumCircuit(1)\n",
165 | "initial_state = [1,0] # Define initial_state as |0>\n",
166 | "qc.y(0)\n",
167 | "qc.draw()"
168 | ],
169 | "outputs": [
170 | {
171 | "data": {
172 | "text/plain": " ┌───┐\nq_0: ┤ Y ├\n └───┘",
173 | "text/html": " ┌───┐\nq_0: ┤ Y ├\n └───┘
"
174 | },
175 | "execution_count": 184,
176 | "metadata": {},
177 | "output_type": "execute_result"
178 | }
179 | ],
180 | "metadata": {
181 | "id": "znSu1ETWLOpl"
182 | }
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": 185,
187 | "source": [
188 | "result = execute(qc, sim).result()\n",
189 | "out_state = result.get_statevector(qc)\n",
190 | "print(\"after Y gate, the state is \",out_state) # Display the output state vector\n",
191 | "\n",
192 | "initial_state_torch = torch.tensor([initial_state],dtype=torch.cfloat)\n",
193 | "y_gate_matrix = torch.tensor([[0,-1j],[1j,0]])\n",
194 | "out_state_torch = torch.mm(y_gate_matrix,initial_state_torch.t()) \n",
195 | "print(\"after Y matrix, the state is \",out_state_torch.t()) # Display the output state vector\n",
196 | "print(\"Equal 0 if correct!\",out_state_torch.t()[0].sub(torch.tensor(out_state)))"
197 | ],
198 | "outputs": [
199 | {
200 | "name": "stdout",
201 | "output_type": "stream",
202 | "text": [
203 | "after Y gate, the state is [0.-0.j 0.+1.j]\n",
204 | "after Y matrix, the state is tensor([[0.+0.j, 0.+1.j]])\n",
205 | "Equal 0 if correct! tensor([0.+0.j, 0.+0.j], dtype=torch.complex128)\n"
206 | ]
207 | }
208 | ],
209 | "metadata": {
210 | "id": "7k8E7kGDLQzM"
211 | }
212 | },
213 | {
214 | "cell_type": "markdown",
215 | "source": [
216 | "### Z Gate"
217 | ],
218 | "metadata": {
219 | "id": "1h5MwXQTLa0V"
220 | }
221 | },
222 | {
223 | "cell_type": "code",
224 | "execution_count": 186,
225 | "source": [
226 | "qc = QuantumCircuit(1)\n",
227 | "initial_state = [1,0] # Define initial_state as |0>\n",
228 | "qc.z(0)\n",
229 | "qc.draw()"
230 | ],
231 | "outputs": [
232 | {
233 | "data": {
234 | "text/plain": " ┌───┐\nq_0: ┤ Z ├\n └───┘",
235 | "text/html": " ┌───┐\nq_0: ┤ Z ├\n └───┘
"
236 | },
237 | "execution_count": 186,
238 | "metadata": {},
239 | "output_type": "execute_result"
240 | }
241 | ],
242 | "metadata": {
243 | "id": "q3vUiWKcLfdQ"
244 | }
245 | },
246 | {
247 | "cell_type": "code",
248 | "execution_count": 187,
249 | "source": [
250 | "result = execute(qc, sim).result()\n",
251 | "out_state = result.get_statevector(qc)\n",
252 | "print(\"after Z gate, the state is \",out_state) # Display the output state vector\n",
253 | "\n",
254 | "initial_state_torch = torch.tensor([initial_state])\n",
255 | "z_gate_matrix = torch.tensor([[1,0],[0,-1]])\n",
256 | "out_state_torch = torch.mm(z_gate_matrix,initial_state_torch.t()) \n",
257 | "print(\"after Z matrix, the state is \",out_state_torch.t()) # Display the output state vector\n",
258 | "print(\"Equal 0 if correct!\",out_state_torch.t()[0].sub(torch.tensor(out_state)))"
259 | ],
260 | "outputs": [
261 | {
262 | "name": "stdout",
263 | "output_type": "stream",
264 | "text": [
265 | "after Z gate, the state is [ 1.+0.j -0.+0.j]\n",
266 | "after Z matrix, the state is tensor([[1, 0]])\n",
267 | "Equal 0 if correct! tensor([0.+0.j, 0.+0.j], dtype=torch.complex128)\n"
268 | ]
269 | }
270 | ],
271 | "metadata": {
272 | "id": "BQ0O3msTLgng"
273 | }
274 | },
275 | {
276 | "cell_type": "markdown",
277 | "source": [
278 | "### H Gate"
279 | ],
280 | "metadata": {
281 | "id": "1h5MwXQTLa0V"
282 | }
283 | },
284 | {
285 | "cell_type": "code",
286 | "execution_count": 188,
287 | "source": [
288 | "qc = QuantumCircuit(1)\n",
289 | "initial_state = [1,0] # Define initial_state as |0>\n",
290 | "qc.h(0)\n",
291 | "qc.draw()"
292 | ],
293 | "outputs": [
294 | {
295 | "data": {
296 | "text/plain": " ┌───┐\nq_0: ┤ H ├\n └───┘",
297 | "text/html": " ┌───┐\nq_0: ┤ H ├\n └───┘
"
298 | },
299 | "execution_count": 188,
300 | "metadata": {},
301 | "output_type": "execute_result"
302 | }
303 | ],
304 | "metadata": {}
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": 189,
309 | "source": [
310 | "import math\n",
311 | "result = execute(qc, sim).result()\n",
312 | "out_state = result.get_statevector(qc)\n",
313 | "print(\"after H gate, the state is \",out_state) # Display the output state vector\n",
314 | "\n",
315 | "initial_state_torch = torch.tensor([initial_state],dtype=torch.double)\n",
316 | "h_gate_matrix = torch.tensor([[math.sqrt(0.5),math.sqrt(0.5)],[math.sqrt(0.5),-math.sqrt(0.5)]],dtype=torch.double)\n",
317 | "out_state_torch = torch.mm(h_gate_matrix,initial_state_torch.t()) \n",
318 | "print(\"after H matrix, the state is \",out_state_torch.t()) # Display the output state vector\n",
319 | "print(\"Equal 0 if correct!\",out_state_torch.t()[0].sub(torch.tensor(out_state)))"
320 | ],
321 | "outputs": [
322 | {
323 | "name": "stdout",
324 | "output_type": "stream",
325 | "text": [
326 | "after H gate, the state is [0.70710678+0.j 0.70710678+0.j]\n",
327 | "after H matrix, the state is tensor([[0.7071, 0.7071]], dtype=torch.float64)\n",
328 | "Equal 0 if correct! tensor([0.+0.j, 0.+0.j], dtype=torch.complex128)\n"
329 | ]
330 | }
331 | ],
332 | "metadata": {}
333 | },
334 | {
335 | "cell_type": "markdown",
336 | "source": [
337 | "### U Gate"
338 | ],
339 | "metadata": {
340 | "id": "1h5MwXQTLa0V"
341 | }
342 | },
343 | {
344 | "cell_type": "code",
345 | "execution_count": 190,
346 | "source": [
347 | "qc = QuantumCircuit(1)\n",
348 | "initial_state = [1,0] # Define initial_state as |0>\n",
349 | "qc.u(math.pi/2, 0, math.pi, 0)\n",
350 | "qc.draw()"
351 | ],
352 | "outputs": [
353 | {
354 | "data": {
355 | "text/plain": " ┌──────────────┐\nq_0: ┤ U(pi/2,0,pi) ├\n └──────────────┘",
356 | "text/html": " ┌──────────────┐\nq_0: ┤ U(pi/2,0,pi) ├\n └──────────────┘
"
357 | },
358 | "execution_count": 190,
359 | "metadata": {},
360 | "output_type": "execute_result"
361 | }
362 | ],
363 | "metadata": {}
364 | },
365 | {
366 | "cell_type": "code",
367 | "execution_count": 191,
368 | "source": [
369 | "import cmath\n",
370 | "result = execute(qc, sim).result()\n",
371 | "out_state = result.get_statevector(qc)\n",
372 | "print(\"after U gate, the state is \",out_state) # Display the output state vector\n",
373 | "\n",
374 | "initial_state_torch = torch.tensor([initial_state],dtype=torch.cdouble)\n",
375 | "para = [cmath.pi/2, 0, cmath.pi, 0]\n",
376 | "u_gate_matrix = torch.tensor([[cmath.cos(para[0]/2),-cmath.exp(-1j*para[2])*cmath.sin(para[0]/2)],\n",
377 | " [cmath.exp(1j*para[1])*cmath.sin(para[0]/2),cmath.exp(1j*(para[1]+para[2]))*cmath.cos(para[0]/2)]],dtype=torch.cdouble)\n",
378 | "out_state_torch = torch.mm(u_gate_matrix,initial_state_torch.t()) \n",
379 | "print(\"after U matrix, the state is \",out_state_torch.t()) # Display the output state vector\n",
380 | "print(\"Equal 0 if correct!\",out_state_torch.t()[0].sub(torch.tensor(out_state)))"
381 | ],
382 | "outputs": [
383 | {
384 | "name": "stdout",
385 | "output_type": "stream",
386 | "text": [
387 | "after U gate, the state is [0.70710678+0.j 0.70710678+0.j]\n",
388 | "after U matrix, the state is tensor([[0.7071+0.j, 0.7071+0.j]], dtype=torch.complex128)\n",
389 | "Equal 0 if correct! tensor([0.+0.j, 0.+0.j], dtype=torch.complex128)\n"
390 | ]
391 | }
392 | ],
393 | "metadata": {}
394 | },
395 | {
396 | "cell_type": "markdown",
397 | "source": [
398 | "# Single Qubit Gates in parallel"
399 | ],
400 | "metadata": {}
401 | },
402 | {
403 | "cell_type": "markdown",
404 | "source": [
405 | "### H Gate + H Gate"
406 | ],
407 | "metadata": {}
408 | },
409 | {
410 | "cell_type": "code",
411 | "execution_count": 192,
412 | "source": [
413 | "qc = QuantumCircuit(2)\n",
414 | "initial_state = [1,0] # Define initial_state as |0>\n",
415 | "qc.h(0)\n",
416 | "qc.h(1)\n",
417 | "qc.draw()"
418 | ],
419 | "outputs": [
420 | {
421 | "data": {
422 | "text/plain": " ┌───┐\nq_0: ┤ H ├\n ├───┤\nq_1: ┤ H ├\n └───┘",
423 | "text/html": " ┌───┐\nq_0: ┤ H ├\n ├───┤\nq_1: ┤ H ├\n └───┘
"
424 | },
425 | "execution_count": 192,
426 | "metadata": {},
427 | "output_type": "execute_result"
428 | }
429 | ],
430 | "metadata": {}
431 | },
432 | {
433 | "cell_type": "code",
434 | "execution_count": 193,
435 | "source": [
436 | "import math\n",
437 | "result = execute(qc, sim).result()\n",
438 | "out_state = result.get_statevector(qc)\n",
439 | "print(\"after gate, the state is \",out_state) # Display the output state vector\n",
440 | "\n",
441 | "initial_state_single_qubit = torch.tensor([initial_state],dtype=torch.double)\n",
442 | "initial_state_torch = torch.kron(initial_state_single_qubit,initial_state_single_qubit)\n",
443 | "\n",
444 | "h_gate_matrix = torch.tensor([[math.sqrt(0.5),math.sqrt(0.5)],[math.sqrt(0.5),-math.sqrt(0.5)]],dtype=torch.double)\n",
445 | "\n",
446 | "double_h_gate_matrix = torch.kron(h_gate_matrix,h_gate_matrix)\n",
447 | "out_state_torch = torch.mm(double_h_gate_matrix,initial_state_torch.t()) \n",
448 | "print(\"after matrix, the state is \",out_state_torch.t()) # Display the output state vector\n",
449 | "print(\"Equal 0 if correct!\",out_state_torch.t()[0].sub(torch.tensor(out_state)))"
450 | ],
451 | "outputs": [
452 | {
453 | "name": "stdout",
454 | "output_type": "stream",
455 | "text": [
456 | "after gate, the state is [0.5+0.j 0.5+0.j 0.5+0.j 0.5+0.j]\n",
457 | "after matrix, the state is tensor([[0.5000, 0.5000, 0.5000, 0.5000]], dtype=torch.float64)\n",
458 | "Equal 0 if correct! tensor([0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], dtype=torch.complex128)\n"
459 | ]
460 | }
461 | ],
462 | "metadata": {}
463 | },
464 | {
465 | "cell_type": "markdown",
466 | "source": [
467 | "### I+X -> H+Z Gate"
468 | ],
469 | "metadata": {}
470 | },
471 | {
472 | "cell_type": "code",
473 | "execution_count": 194,
474 | "source": [
475 | "qc = QuantumCircuit(2)\n",
476 | "initial_state_1 = [1,0] # Define initial_state as |0>\n",
477 | "initial_state_2 = [1,0] # Define initial_state as |1>\n",
478 | "# qc.initialize(initial_state_1, 0)\n",
479 | "# qc.initialize(initial_state_2, 1)\n",
480 | "qc.x(1)\n",
481 | "qc.barrier()\n",
482 | "qc.h(0)\n",
483 | "qc.z(1)\n",
484 | "qc.draw()"
485 | ],
486 | "outputs": [
487 | {
488 | "data": {
489 | "text/plain": " ░ ┌───┐\nq_0: ──────░─┤ H ├\n ┌───┐ ░ ├───┤\nq_1: ┤ X ├─░─┤ Z ├\n └───┘ ░ └───┘",
490 | "text/html": " ░ ┌───┐\nq_0: ──────░─┤ H ├\n ┌───┐ ░ ├───┤\nq_1: ┤ X ├─░─┤ Z ├\n └───┘ ░ └───┘
"
491 | },
492 | "execution_count": 194,
493 | "metadata": {},
494 | "output_type": "execute_result"
495 | }
496 | ],
497 | "metadata": {}
498 | },
499 | {
500 | "cell_type": "markdown",
501 | "source": [
502 | "Qiskit encoding\n",
503 | "\n",
504 | "A -----\n",
505 | "\n",
506 | "B -----\n",
507 | "\n",
508 | "|BA>"
509 | ],
510 | "metadata": {
511 | "collapsed": false,
512 | "pycharm": {
513 | "name": "#%% md\n"
514 | }
515 | }
516 | },
517 | {
518 | "cell_type": "code",
519 | "execution_count": 195,
520 | "source": [
521 | "import math\n",
522 | "result = execute(qc, sim).result()\n",
523 | "out_state = result.get_statevector(qc)\n",
524 | "print(\"after gate, the state is \",out_state) # Display the output state vector\n",
525 | "\n",
526 | "initial_state_single_qubit_1 = torch.tensor([initial_state_1],dtype=torch.double)\n",
527 | "initial_state_single_qubit_2 = torch.tensor([initial_state_2],dtype=torch.double)\n",
528 | "initial_state_torch = torch.kron(initial_state_single_qubit_2,initial_state_single_qubit_1)\n",
529 | "\n",
530 | "h_gate_matrix = torch.tensor([[math.sqrt(0.5),math.sqrt(0.5)],[math.sqrt(0.5),-math.sqrt(0.5)]],dtype=torch.double)\n",
531 | "z_gate_matrix = torch.tensor([[1,0],[0,-1]],dtype=torch.double)\n",
532 | "x_gate_matrix = torch.tensor([[0,1],[1,0]],dtype=torch.double)\n",
533 | "i_gate_matrix = torch.tensor([[1,0],[0,1]],dtype=torch.double)\n",
534 | "\n",
535 | "x_i_gate_matrix = torch.kron(x_gate_matrix,i_gate_matrix)\n",
536 | "z_h_gate_matrix = torch.kron(z_gate_matrix,h_gate_matrix)\n",
537 | "\n",
538 | "\n",
539 | "composed_gate = torch.mm(z_h_gate_matrix,x_i_gate_matrix)\n",
540 | "out_state_torch = torch.mm(composed_gate,initial_state_torch.t())\n",
541 | "\n",
542 | "\n",
543 | "print(\"after matrix, the state is \",out_state_torch.t()) # Display the output state vector\n",
544 | "print(\"Equal 0 if correct!\",out_state_torch.t()[0].sub(torch.tensor(out_state)))\n"
545 | ],
546 | "outputs": [
547 | {
548 | "name": "stdout",
549 | "output_type": "stream",
550 | "text": [
551 | "after gate, the state is [ 0. +0.j 0. +0.j -0.70710678+0.j -0.70710678+0.j]\n",
552 | "after matrix, the state is tensor([[ 0.0000, 0.0000, -0.7071, -0.7071]], dtype=torch.float64)\n",
553 | "Equal 0 if correct! tensor([0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], dtype=torch.complex128)\n"
554 | ]
555 | }
556 | ],
557 | "metadata": {}
558 | },
559 | {
560 | "cell_type": "markdown",
561 | "source": [
562 | "# Entanglement"
563 | ],
564 | "metadata": {}
565 | },
566 | {
567 | "cell_type": "markdown",
568 | "source": [
569 | "### CX Gate"
570 | ],
571 | "metadata": {}
572 | },
573 | {
574 | "cell_type": "code",
575 | "execution_count": 196,
576 | "source": [
577 | "qc = QuantumCircuit(2)\n",
578 | "initial_state_1 = [0,1] # Define initial_state as |1>\n",
579 | "# initial_state_2 = [1,0] # Define initial_state as |1>\n",
580 | "qc.initialize(initial_state_1, 0)\n",
581 | "# qc.initialize(initial_state_2, 1)\n",
582 | "qc.cx(0,1)\n",
583 | "qc.draw()"
584 | ],
585 | "outputs": [
586 | {
587 | "data": {
588 | "text/plain": " ┌─────────────────┐ \nq_0: ┤ initialize(0,1) ├──■──\n └─────────────────┘┌─┴─┐\nq_1: ───────────────────┤ X ├\n └───┘",
589 | "text/html": " ┌─────────────────┐ \nq_0: ┤ initialize(0,1) ├──■──\n └─────────────────┘┌─┴─┐\nq_1: ───────────────────┤ X ├\n └───┘
"
590 | },
591 | "execution_count": 196,
592 | "metadata": {},
593 | "output_type": "execute_result"
594 | }
595 | ],
596 | "metadata": {}
597 | },
598 | {
599 | "cell_type": "code",
600 | "execution_count": 197,
601 | "source": [
602 | "result = execute(qc, sim).result()\n",
603 | "out_state = result.get_statevector(qc)\n",
604 | "print(\"after gate, the state is \",out_state) # Display the output state vector\n",
605 | "\n",
606 | "initial_state_single_qubit_1 = torch.tensor([initial_state_1],dtype=torch.double)\n",
607 | "initial_state_single_qubit_2 = torch.tensor([initial_state_2],dtype=torch.double)\n",
608 | "initial_state_torch = torch.kron(initial_state_single_qubit_2,initial_state_single_qubit_1)\n",
609 | "\n",
610 | "cx_gate_matrix = torch.tensor([[1,0,0,0],\n",
611 | " [0,0,0,1],\n",
612 | " [0,0,1,0],\n",
613 | " [0,1,0,0]],dtype=torch.double)\n",
614 | "\n",
615 | "out_state_torch = torch.mm(cx_gate_matrix,initial_state_torch.t()) \n",
616 | "print(\"after matrix, the state is \",out_state_torch.t()) # Display the output state vector\n",
617 | "print(\"Equal 0 if correct!\",out_state_torch.t()[0].sub(torch.tensor(out_state)))\n"
618 | ],
619 | "outputs": [
620 | {
621 | "name": "stdout",
622 | "output_type": "stream",
623 | "text": [
624 | "after gate, the state is [0.+0.j 0.+0.j 0.+0.j 1.+0.j]\n",
625 | "after matrix, the state is tensor([[0., 0., 0., 1.]], dtype=torch.float64)\n",
626 | "Equal 0 if correct! tensor([0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], dtype=torch.complex128)\n"
627 | ]
628 | }
629 | ],
630 | "metadata": {}
631 | },
632 | {
633 | "cell_type": "markdown",
634 | "source": [
635 | "### CZ Gate"
636 | ],
637 | "metadata": {}
638 | },
639 | {
640 | "cell_type": "code",
641 | "execution_count": 198,
642 | "source": [
643 | "qc = QuantumCircuit(2)\n",
644 | "initial_state = [1,0] # Define initial_state as |0>\n",
645 | "qc.cz(0,1)\n",
646 | "qc.draw()"
647 | ],
648 | "outputs": [
649 | {
650 | "data": {
651 | "text/plain": " \nq_0: ─■─\n │ \nq_1: ─■─\n ",
652 | "text/html": " \nq_0: ─■─\n │ \nq_1: ─■─\n
"
653 | },
654 | "execution_count": 198,
655 | "metadata": {},
656 | "output_type": "execute_result"
657 | }
658 | ],
659 | "metadata": {}
660 | },
661 | {
662 | "cell_type": "code",
663 | "execution_count": 199,
664 | "source": [
665 | "result = execute(qc, sim).result()\n",
666 | "out_state = result.get_statevector(qc)\n",
667 | "print(\"after gate, the state is \",out_state) # Display the output state vector\n",
668 | "\n",
669 | "initial_state_single_qubit = torch.tensor([initial_state],dtype=torch.double)\n",
670 | "initial_state_torch = torch.kron(initial_state_single_qubit,initial_state_single_qubit)\n",
671 | "\n",
672 | "cz_gate_matrix = torch.tensor([[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,-1]],dtype=torch.double)\n",
673 | "\n",
674 | "out_state_torch = torch.mm(cz_gate_matrix,initial_state_torch.t()) \n",
675 | "print(\"after matrix, the state is \",out_state_torch.t()) # Display the output state vector\n",
676 | "print(\"Equal 0 if correct!\",out_state_torch.t()[0].sub(torch.tensor(out_state)))"
677 | ],
678 | "outputs": [
679 | {
680 | "name": "stdout",
681 | "output_type": "stream",
682 | "text": [
683 | "after gate, the state is [ 1.+0.j 0.+0.j 0.+0.j -0.+0.j]\n",
684 | "after matrix, the state is tensor([[1., 0., 0., 0.]], dtype=torch.float64)\n",
685 | "Equal 0 if correct! tensor([0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], dtype=torch.complex128)\n"
686 | ]
687 | }
688 | ],
689 | "metadata": {}
690 | },
691 | {
692 | "cell_type": "markdown",
693 | "source": [
694 | "### X Gate + CX Gate"
695 | ],
696 | "metadata": {}
697 | },
698 | {
699 | "cell_type": "code",
700 | "execution_count": 200,
701 | "source": [
702 | "qc = QuantumCircuit(2)\n",
703 | "initial_state = [1,0] # Define initial_state as |0>\n",
704 | "qc.x(0)\n",
705 | "qc.cx(0,1)\n",
706 | "qc.draw()"
707 | ],
708 | "outputs": [
709 | {
710 | "data": {
711 | "text/plain": " ┌───┐ \nq_0: ┤ X ├──■──\n └───┘┌─┴─┐\nq_1: ─────┤ X ├\n └───┘",
712 | "text/html": " ┌───┐ \nq_0: ┤ X ├──■──\n └───┘┌─┴─┐\nq_1: ─────┤ X ├\n └───┘
"
713 | },
714 | "execution_count": 200,
715 | "metadata": {},
716 | "output_type": "execute_result"
717 | }
718 | ],
719 | "metadata": {}
720 | },
721 | {
722 | "cell_type": "code",
723 | "execution_count": 201,
724 | "source": [
725 | "result = execute(qc, sim).result()\n",
726 | "out_state = result.get_statevector(qc)\n",
727 | "print(\"after gate, the state is \",out_state) # Display the output state vector\n",
728 | "\n",
729 | "initial_state_single_qubit = torch.tensor([initial_state],dtype=torch.double)\n",
730 | "initial_state_torch = torch.kron(initial_state_single_qubit,initial_state_single_qubit)\n",
731 | "x_gate_matrix = torch.tensor([[0,1],[1,0]],dtype=torch.double)\n",
732 | "i_gate_matrix = torch.tensor([[1,0],[0,1]],dtype=torch.double)\n",
733 | "cx_gate_matrix = torch.tensor([[1,0,0,0],\n",
734 | " [0,0,0,1],\n",
735 | " [0,0,1,0],\n",
736 | " [0,1,0,0]],dtype=torch.double)\n",
737 | "\n",
738 | "\n",
739 | "i_x_gate_matrix = torch.kron(i_gate_matrix,x_gate_matrix)\n",
740 | "\n",
741 | "composed_gate = torch.mm( cx_gate_matrix, i_x_gate_matrix)\n",
742 | "out_state_torch = torch.mm(composed_gate ,initial_state_torch.t())\n",
743 | "\n",
744 | "print(\"after matrix, the state is \",out_state_torch.t()) # Display the output state vector\n",
745 | "print(\"Equal 0 if correct!\",out_state_torch.t()[0].sub(torch.tensor(out_state)))"
746 | ],
747 | "outputs": [
748 | {
749 | "name": "stdout",
750 | "output_type": "stream",
751 | "text": [
752 | "after gate, the state is [0.+0.j 0.+0.j 0.+0.j 1.+0.j]\n",
753 | "after matrix, the state is tensor([[0., 0., 0., 1.]], dtype=torch.float64)\n",
754 | "Equal 0 if correct! tensor([0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], dtype=torch.complex128)\n"
755 | ]
756 | }
757 | ],
758 | "metadata": {}
759 | },
760 | {
761 | "cell_type": "markdown",
762 | "source": [
763 | "### H Gate + CX Gate"
764 | ],
765 | "metadata": {}
766 | },
767 | {
768 | "cell_type": "code",
769 | "execution_count": 202,
770 | "source": [
771 | "qc = QuantumCircuit(2)\n",
772 | "initial_state = [1,0] # Define initial_state as |0>\n",
773 | "qc.h(0)\n",
774 | "qc.cx(0,1)\n",
775 | "qc.draw()"
776 | ],
777 | "outputs": [
778 | {
779 | "data": {
780 | "text/plain": " ┌───┐ \nq_0: ┤ H ├──■──\n └───┘┌─┴─┐\nq_1: ─────┤ X ├\n └───┘",
781 | "text/html": " ┌───┐ \nq_0: ┤ H ├──■──\n └───┘┌─┴─┐\nq_1: ─────┤ X ├\n └───┘
"
782 | },
783 | "execution_count": 202,
784 | "metadata": {},
785 | "output_type": "execute_result"
786 | }
787 | ],
788 | "metadata": {}
789 | },
790 | {
791 | "cell_type": "markdown",
792 | "source": [
793 | "Qiskit encoding\n",
794 | "\n",
795 | "CX = [[1,0,0,0],[0,0,0,1],[0,0,1,0],[0,1,0,0]]"
796 | ],
797 | "metadata": {
798 | "collapsed": false,
799 | "pycharm": {
800 | "name": "#%% md\n"
801 | }
802 | }
803 | },
804 | {
805 | "cell_type": "code",
806 | "execution_count": 203,
807 | "source": [
808 | "import math\n",
809 | "result = execute(qc, sim).result()\n",
810 | "out_state = result.get_statevector(qc)\n",
811 | "print(\"after gate, the state is \",out_state) # Display the output state vector\n",
812 | "\n",
813 | "initial_state_single_qubit = torch.tensor([initial_state],dtype=torch.double)\n",
814 | "initial_state_torch = torch.kron(initial_state_single_qubit,initial_state_single_qubit)\n",
815 | "print(initial_state_torch)\n",
816 | "h_gate_matrix = torch.tensor([[math.sqrt(0.5),math.sqrt(0.5)],[math.sqrt(0.5),-math.sqrt(0.5)]],dtype=torch.double)\n",
817 | "i_gate_matrix = torch.tensor([[1,0],[0,1]],dtype=torch.double)\n",
818 | "cx_gate_matrix = torch.tensor([[1,0,0,0],\n",
819 | " [0,0,0,1],\n",
820 | " [0,0,1,0],\n",
821 | " [0,1,0,0]],dtype=torch.double)\n",
822 | "\n",
823 | "composed_gate = torch.kron(i_gate_matrix,h_gate_matrix)\n",
824 | "composed_gate = torch.mm(cx_gate_matrix,composed_gate)\n",
825 | "out_state_torch = torch.mm(composed_gate,initial_state_torch.t())\n",
826 | "\n",
827 | "print(\"after matrix, the state is \",out_state_torch.t()) # Display the output state vector\n",
828 | "print(\"Equal 0 if correct!\",out_state_torch.t()[0].sub(torch.tensor(out_state)))"
829 | ],
830 | "outputs": [
831 | {
832 | "name": "stdout",
833 | "output_type": "stream",
834 | "text": [
835 | "after gate, the state is [0.70710678+0.j 0. +0.j 0. +0.j 0.70710678+0.j]\n",
836 | "tensor([[1., 0., 0., 0.]], dtype=torch.float64)\n",
837 | "after matrix, the state is tensor([[0.7071, 0.0000, 0.0000, 0.7071]], dtype=torch.float64)\n",
838 | "Equal 0 if correct! tensor([0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], dtype=torch.complex128)\n"
839 | ]
840 | }
841 | ],
842 | "metadata": {
843 | "pycharm": {
844 | "name": "#%% Qiskit Encoding\n"
845 | }
846 | }
847 | }
848 | ]
849 | }
850 |
--------------------------------------------------------------------------------
/session_2/Tutorial_1_DataPreparation.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {
7 | "pycharm": {
8 | "is_executing": false
9 | },
10 | "id": "BL4fMqPQrXH-"
11 | },
12 | "outputs": [],
13 | "source": [
14 | "# !pip install -q torch==1.9.0\n",
15 | "# !pip install -q torchvision==0.10.0\n",
16 | "!pip install -q qiskit==0.20.0\n",
17 | "\n",
18 | "import warnings\n",
19 | "warnings.filterwarnings(\"ignore\", category=DeprecationWarning) \n",
20 | "\n",
21 | "import torch\n",
22 | "import torchvision\n",
23 | "from torchvision import datasets\n",
24 | "import torchvision.transforms as transforms\n",
25 | "import qiskit \n",
26 | "import sys\n",
27 | "from pathlib import Path\n",
28 | "import numpy as np\n",
29 | "import matplotlib.pyplot as plt\n",
30 | "import numpy as np\n",
31 | "from PIL import Image\n",
32 | "from matplotlib import cm\n",
33 | "import functools\n",
34 | "\n",
35 | "import warnings\n",
36 | "warnings.filterwarnings(\"ignore\", category=DeprecationWarning)\n",
37 | "print = functools.partial(print, flush=True)\n",
38 | "\n",
39 | "interest_num = [3,6]\n",
40 | "ori_img_size = 28\n",
41 | "img_size = 4\n",
42 | "# number of subprocesses to use for data loading\n",
43 | "num_workers = 0\n",
44 | "# how many samples per batch to load\n",
45 | "batch_size = 1\n",
46 | "inference_batch_size = 1\n",
47 | "\n",
48 | "\n",
49 | "\n",
50 | "# Weiwen: modify the target classes starting from 0. Say, [3,6] -> [0,1]\n",
51 | "def modify_target(target):\n",
52 | " for j in range(len(target)):\n",
53 | " for idx in range(len(interest_num)):\n",
54 | " if target[j] == interest_num[idx]:\n",
55 | " target[j] = idx\n",
56 | " break\n",
57 | " new_target = torch.zeros(target.shape[0],2)\n",
58 | " for i in range(target.shape[0]): \n",
59 | " if target[i].item() == 0: \n",
60 | " new_target[i] = torch.tensor([1,0]).clone() \n",
61 | " else:\n",
62 | " new_target[i] = torch.tensor([0,1]).clone()\n",
63 | " \n",
64 | " return target,new_target\n",
65 | "\n",
66 | "# Weiwen: select sub-set from MNIST\n",
67 | "def select_num(dataset,interest_num):\n",
68 | " labels = dataset.targets #get labels\n",
69 | " labels = labels.numpy()\n",
70 | " idx = {}\n",
71 | " for num in interest_num:\n",
72 | " idx[num] = np.where(labels == num)\n",
73 | " fin_idx = idx[interest_num[0]]\n",
74 | " for i in range(1,len(interest_num)): \n",
75 | " fin_idx = (np.concatenate((fin_idx[0],idx[interest_num[i]][0])),)\n",
76 | " \n",
77 | " fin_idx = fin_idx[0] \n",
78 | " dataset.targets = labels[fin_idx]\n",
79 | " dataset.data = dataset.data[fin_idx]\n",
80 | " dataset.targets,_ = modify_target(dataset.targets)\n",
81 | " return dataset\n",
82 | "\n",
83 | "################ Weiwen on 12-30-2020 ################\n",
84 | "# Function: ToQuantumData from Listing 1\n",
85 | "# Note: Coverting classical data to quantum data\n",
86 | "######################################################\n",
87 | "class ToQuantumData(object):\n",
88 | " def __call__(self, tensor):\n",
89 | " device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n",
90 | " data = tensor.to(device)\n",
91 | " input_vec = data.view(-1)\n",
92 | " vec_len = input_vec.size()[0]\n",
93 | " input_matrix = torch.zeros(vec_len, vec_len)\n",
94 | " input_matrix[0] = input_vec\n",
95 | " input_matrix = np.float64(input_matrix.transpose(0,1))\n",
96 | " u, s, v = np.linalg.svd(input_matrix)\n",
97 | " output_matrix = torch.tensor(np.dot(u, v))\n",
98 | " output_data = output_matrix[:, 0].view(1, img_size,img_size)\n",
99 | " return output_data\n",
100 | "\n",
101 | "################ Weiwen on 12-30-2020 ################\n",
102 | "# Function: ToQuantumData from Listing 1\n",
103 | "# Note: Coverting classical data to quantum matrix\n",
104 | "######################################################\n",
105 | "class ToQuantumMatrix(object):\n",
106 | " def __call__(self, tensor):\n",
107 | " device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n",
108 | " data = tensor.to(device)\n",
109 | " input_vec = data.view(-1)\n",
110 | " vec_len = input_vec.size()[0]\n",
111 | " input_matrix = torch.zeros(vec_len, vec_len)\n",
112 | " input_matrix[0] = input_vec\n",
113 | " input_matrix = np.float64(input_matrix.transpose(0,1))\n",
114 | " u, s, v = np.linalg.svd(input_matrix)\n",
115 | " output_matrix = torch.tensor(np.dot(u, v))\n",
116 | " return output_matrix "
117 | ]
118 | },
119 | {
120 | "cell_type": "code",
121 | "execution_count": null,
122 | "metadata": {
123 | "pycharm": {
124 | "is_executing": false
125 | },
126 | "id": "oj5JfepLrXID"
127 | },
128 | "outputs": [],
129 | "source": [
130 | "################ Weiwen on 12-30-2020 ################\n",
131 | "# Using torch to load MNIST data\n",
132 | "######################################################\n",
133 | "\n",
134 | "# convert data to torch.FloatTensor\n",
135 | "transform = transforms.Compose([transforms.Resize((ori_img_size,ori_img_size)),\n",
136 | " transforms.ToTensor()])\n",
137 | "# Path to MNIST Dataset\n",
138 | "train_data = datasets.MNIST(root='./data', train=True,\n",
139 | " download=True, transform=transform)\n",
140 | "test_data = datasets.MNIST(root='./data', train=False,\n",
141 | " download=True, transform=transform)\n",
142 | "\n",
143 | "train_data = select_num(train_data,interest_num)\n",
144 | "test_data = select_num(test_data,interest_num)\n",
145 | "\n",
146 | "# prepare data loaders\n",
147 | "train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,\n",
148 | " num_workers=num_workers, shuffle=True, drop_last=True)\n",
149 | "test_loader = torch.utils.data.DataLoader(test_data, batch_size=inference_batch_size, \n",
150 | " num_workers=num_workers, shuffle=True, drop_last=True)\n"
151 | ]
152 | },
153 | {
154 | "cell_type": "code",
155 | "execution_count": null,
156 | "metadata": {
157 | "pycharm": {
158 | "is_executing": false
159 | },
160 | "id": "Eq9L6tffrXIE"
161 | },
162 | "outputs": [],
163 | "source": [
164 | "################ Weiwen on 12-30-2020 ################\n",
165 | "# T1: Downsample the image from 28*28 to 4*4\n",
166 | "# T2: Convert classical data to quantum data which \n",
167 | "# can be encoded to the quantum states (amplitude)\n",
168 | "######################################################\n",
169 | "\n",
170 | "# Process data by hand, we can also integrate ToQuantumData into transform\n",
171 | "def data_pre_pro(img):\n",
172 | " # Print original figure\n",
173 | " img = img\n",
174 | " npimg = img.numpy()\n",
175 | " plt.imshow(np.transpose(npimg, (1, 2, 0))) \n",
176 | " plt.show()\n",
177 | " # Print resized figure\n",
178 | " image = np.asarray(npimg[0] * 255, np.uint8) \n",
179 | " im = Image.fromarray(image,mode=\"L\")\n",
180 | " im = im.resize((4,4),Image.BILINEAR) \n",
181 | " plt.imshow(im,cmap='gray',)\n",
182 | " plt.show()\n",
183 | " # Converting classical data to quantum data\n",
184 | " trans_to_tensor = transforms.ToTensor()\n",
185 | " trans_to_vector = ToQuantumData()\n",
186 | " trans_to_matrix = ToQuantumMatrix() \n",
187 | " print(\"Classical Data: {}\".format(trans_to_tensor(im).flatten()))\n",
188 | " print(\"Quantum Data: {}\".format(trans_to_vector(trans_to_tensor(im)).flatten()))\n",
189 | " return trans_to_matrix(trans_to_tensor(im)),trans_to_vector(trans_to_tensor(im))\n",
190 | "\n",
191 | "# Use the first image from test loader as example\n",
192 | "for batch_idx, (data, target) in enumerate(test_loader):\n",
193 | " torch.set_printoptions(threshold=sys.maxsize)\n",
194 | " print(\"Batch Id: {}, Target: {}\".format(batch_idx,target))\n",
195 | " quantum_matrix,qantum_data = data_pre_pro(torchvision.utils.make_grid(data))\n",
196 | " break"
197 | ]
198 | },
199 | {
200 | "cell_type": "code",
201 | "execution_count": null,
202 | "metadata": {
203 | "pycharm": {
204 | "is_executing": false
205 | },
206 | "id": "ELav6khrrXII"
207 | },
208 | "outputs": [],
209 | "source": [
210 | "################ Weiwen on 12-30-2020 ################\n",
211 | "# Do quantum state preparation and compare it with\n",
212 | "# the original data\n",
213 | "######################################################\n",
214 | "\n",
215 | "# Quantum-State Preparation in IBM Qiskit\n",
216 | "from qiskit import QuantumRegister, QuantumCircuit, ClassicalRegister\n",
217 | "from qiskit.extensions import XGate, UnitaryGate\n",
218 | "from qiskit import Aer, execute\n",
219 | "import qiskit\n",
220 | "# Input: a 4*4 matrix (data) holding 16 input data\n",
221 | "inp = QuantumRegister(4,\"in_qbit\")\n",
222 | "circ = QuantumCircuit(inp)\n",
223 | "data_matrix = quantum_matrix\n",
224 | "circ.append(UnitaryGate(data_matrix, label=\"Input\"), inp[0:4])\n",
225 | "print(circ)\n",
226 | "# Using StatevectorSimulator from the Aer provider\n",
227 | "simulator = Aer.get_backend('statevector_simulator')\n",
228 | "result = execute(circ, simulator).result()\n",
229 | "statevector = result.get_statevector(circ)\n",
230 | "\n",
231 | "print(\"Data to be encoded: \\n {}\\n\".format(qantum_data))\n",
232 | "print(\"Data read from the circuit: \\n {}\".format(statevector))"
233 | ]
234 | }
235 | ],
236 | "metadata": {
237 | "kernelspec": {
238 | "display_name": "PyCharm (qiskit_practice)",
239 | "language": "python",
240 | "name": "pycharm-8213722"
241 | },
242 | "language_info": {
243 | "codemirror_mode": {
244 | "name": "ipython",
245 | "version": 3
246 | },
247 | "file_extension": ".py",
248 | "mimetype": "text/x-python",
249 | "name": "python",
250 | "nbconvert_exporter": "python",
251 | "pygments_lexer": "ipython3",
252 | "version": "3.8.5"
253 | },
254 | "pycharm": {
255 | "stem_cell": {
256 | "cell_type": "raw",
257 | "metadata": {
258 | "collapsed": false
259 | },
260 | "source": []
261 | }
262 | },
263 | "colab": {
264 | "provenance": []
265 | }
266 | },
267 | "nbformat": 4,
268 | "nbformat_minor": 0
269 | }
--------------------------------------------------------------------------------
/session_2/Tutorial_2_Hidden_NeuralComp.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {
7 | "id": "_DmG8bKXrkkU"
8 | },
9 | "outputs": [],
10 | "source": [
11 | "# !pip install -q torch==1.9.0\n",
12 | "# !pip install -q torchvision==0.10.0\n",
13 | "\n",
14 | "!pip install -q qiskit==0.20.0\n",
15 | "\n",
16 | "import warnings\n",
17 | "warnings.filterwarnings(\"ignore\", category=DeprecationWarning) \n",
18 | "\n",
19 | "import torch\n",
20 | "import torchvision\n",
21 | "from torchvision import datasets\n",
22 | "import torchvision.transforms as transforms\n",
23 | "import torch.nn as nn\n",
24 | "import shutil\n",
25 | "import os\n",
26 | "import time\n",
27 | "import sys\n",
28 | "from pathlib import Path\n",
29 | "import numpy as np\n",
30 | "import matplotlib.pyplot as plt\n",
31 | "import numpy as np\n",
32 | "from PIL import Image\n",
33 | "from matplotlib import cm\n",
34 | "import functools\n",
35 | "from qiskit.tools.monitor import job_monitor\n",
36 | "from qiskit import QuantumRegister, QuantumCircuit, ClassicalRegister\n",
37 | "from qiskit.extensions import XGate, UnitaryGate\n",
38 | "from qiskit import Aer, execute\n",
39 | "import qiskit\n",
40 | "\n",
41 | "import warnings\n",
42 | "warnings.filterwarnings(\"ignore\", category=DeprecationWarning)\n",
43 | "print = functools.partial(print, flush=True)\n",
44 | "\n",
45 | "interest_num = [3,6]\n",
46 | "ori_img_size = 28\n",
47 | "img_size = 4\n",
48 | "# number of subprocesses to use for data loading\n",
49 | "num_workers = 0\n",
50 | "# how many samples per batch to load\n",
51 | "batch_size = 1\n",
52 | "inference_batch_size = 1\n",
53 | "\n",
54 | "\n",
55 | "# Weiwen: modify the target classes starting from 0. Say, [3,6] -> [0,1]\n",
56 | "def modify_target(target):\n",
57 | " for j in range(len(target)):\n",
58 | " for idx in range(len(interest_num)):\n",
59 | " if target[j] == interest_num[idx]:\n",
60 | " target[j] = idx\n",
61 | " break\n",
62 | " new_target = torch.zeros(target.shape[0],2)\n",
63 | " for i in range(target.shape[0]): \n",
64 | " if target[i].item() == 0: \n",
65 | " new_target[i] = torch.tensor([1,0]).clone() \n",
66 | " else:\n",
67 | " new_target[i] = torch.tensor([0,1]).clone()\n",
68 | " \n",
69 | " return target,new_target\n",
70 | "\n",
71 | "# Weiwen: select sub-set from MNIST\n",
72 | "def select_num(dataset,interest_num):\n",
73 | " labels = dataset.targets #get labels\n",
74 | " labels = labels.numpy()\n",
75 | " idx = {}\n",
76 | " for num in interest_num:\n",
77 | " idx[num] = np.where(labels == num)\n",
78 | " fin_idx = idx[interest_num[0]]\n",
79 | " for i in range(1,len(interest_num)): \n",
80 | " fin_idx = (np.concatenate((fin_idx[0],idx[interest_num[i]][0])),)\n",
81 | " \n",
82 | " fin_idx = fin_idx[0] \n",
83 | " dataset.targets = labels[fin_idx]\n",
84 | " dataset.data = dataset.data[fin_idx]\n",
85 | " dataset.targets,_ = modify_target(dataset.targets)\n",
86 | " return dataset\n",
87 | "\n",
88 | "################ Weiwen on 12-30-2020 ################\n",
89 | "# Function: ToQuantumData from Listing 1\n",
90 | "# Note: Coverting classical data to quantum data\n",
91 | "######################################################\n",
92 | "class ToQuantumData(object):\n",
93 | " def __call__(self, tensor):\n",
94 | " device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n",
95 | " data = tensor.to(device)\n",
96 | " input_vec = data.view(-1)\n",
97 | " vec_len = input_vec.size()[0]\n",
98 | " input_matrix = torch.zeros(vec_len, vec_len)\n",
99 | " input_matrix[0] = input_vec\n",
100 | " input_matrix = np.float64(input_matrix.transpose(0,1))\n",
101 | " u, s, v = np.linalg.svd(input_matrix)\n",
102 | " output_matrix = torch.tensor(np.dot(u, v))\n",
103 | " output_data = output_matrix[:, 0].view(1, img_size,img_size)\n",
104 | " return output_data\n",
105 | "\n",
106 | "################ Weiwen on 12-30-2020 ################\n",
107 | "# Function: ToQuantumData from Listing 1\n",
108 | "# Note: Coverting classical data to quantum matrix\n",
109 | "######################################################\n",
110 | "class ToQuantumMatrix(object):\n",
111 | " def __call__(self, tensor):\n",
112 | " device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n",
113 | " data = tensor.to(device)\n",
114 | " input_vec = data.view(-1)\n",
115 | " vec_len = input_vec.size()[0]\n",
116 | " input_matrix = torch.zeros(vec_len, vec_len)\n",
117 | " input_matrix[0] = input_vec\n",
118 | " input_matrix = np.float64(input_matrix.transpose(0,1))\n",
119 | " u, s, v = np.linalg.svd(input_matrix)\n",
120 | " output_matrix = torch.tensor(np.dot(u, v))\n",
121 | " return output_matrix \n",
122 | " \n",
123 | "################ Weiwen on 12-30-2020 ################\n",
124 | "# Function: fire_ibmq from Listing 6\n",
125 | "# Note: used for execute quantum circuit using \n",
126 | "# simulation or ibm quantum processor\n",
127 | "# Parameters: (1) quantum circuit; \n",
128 | "# (2) number of shots;\n",
129 | "# (3) simulation or quantum processor;\n",
130 | "# (4) backend name if quantum processor.\n",
131 | "######################################################\n",
132 | "def fire_ibmq(circuit,shots,Simulation = False,backend_name='ibmq_essex'): \n",
133 | " count_set = []\n",
134 | " if not Simulation:\n",
135 | " provider = IBMQ.get_provider('ibm-q-academic')\n",
136 | " backend = provider.get_backend(backend_name)\n",
137 | " else:\n",
138 | " backend = Aer.get_backend('qasm_simulator')\n",
139 | " job_ibm_q = execute(circuit, backend, shots=shots)\n",
140 | " job_monitor(job_ibm_q)\n",
141 | " result_ibm_q = job_ibm_q.result()\n",
142 | " counts = result_ibm_q.get_counts()\n",
143 | " return counts\n",
144 | "\n",
145 | "################ Weiwen on 12-30-2020 ################\n",
146 | "# Function: analyze from Listing 6\n",
147 | "# Note: used for analyze the count on states to \n",
148 | "# formulate the probability for each qubit\n",
149 | "# Parameters: (1) counts returned by fire_ibmq; \n",
150 | "######################################################\n",
151 | "def analyze(counts):\n",
152 | " mycount = {}\n",
153 | " for i in range(2):\n",
154 | " mycount[i] = 0\n",
155 | " for k,v in counts.items():\n",
156 | " bits = len(k) \n",
157 | " for i in range(bits): \n",
158 | " if k[bits-1-i] == \"1\":\n",
159 | " if i in mycount.keys():\n",
160 | " mycount[i] += v\n",
161 | " else:\n",
162 | " mycount[i] = v\n",
163 | " return mycount,bits\n",
164 | "\n",
165 | "################ Weiwen on 12-30-2020 ################\n",
166 | "# Function: cccz from Listing 3\n",
167 | "# Note: using the basic Toffoli gates and CZ gate\n",
168 | "# to implement cccz gate, which will flip the\n",
169 | "# sign of state |1111>\n",
170 | "# Parameters: (1) quantum circuit; \n",
171 | "# (2-4) control qubits;\n",
172 | "# (5) target qubits;\n",
173 | "# (6-7) auxiliary qubits.\n",
174 | "######################################################\n",
175 | "def cccz(circ, q1, q2, q3, q4, aux1, aux2):\n",
176 | " # Apply Z-gate to a state controlled by 4 qubits\n",
177 | " circ.ccx(q1, q2, aux1)\n",
178 | " circ.ccx(q3, aux1, aux2)\n",
179 | " circ.cz(aux2, q4)\n",
180 | " # cleaning the aux bits\n",
181 | " circ.ccx(q3, aux1, aux2)\n",
182 | " circ.ccx(q1, q2, aux1)\n",
183 | " return circ\n",
184 | "\n",
185 | "################ Weiwen on 12-30-2020 ################\n",
186 | "# Function: cccz from Listing 4\n",
187 | "# Note: using the basic Toffoli gate to implement ccccx\n",
188 | "# gate. It is used to switch the quantum states\n",
189 | "# of |11110> and |11111>.\n",
190 | "# Parameters: (1) quantum circuit; \n",
191 | "# (2-5) control qubits;\n",
192 | "# (6) target qubits;\n",
193 | "# (7-8) auxiliary qubits.\n",
194 | "######################################################\n",
195 | "def ccccx(circ, q1, q2, q3, q4, q5, aux1, aux2):\n",
196 | " circ.ccx(q1, q2, aux1)\n",
197 | " circ.ccx(q3, q4, aux2)\n",
198 | " circ.ccx(aux2, aux1, q5)\n",
199 | " # cleaning the aux bits\n",
200 | " circ.ccx(q3, q4, aux2)\n",
201 | " circ.ccx(q1, q2, aux1)\n",
202 | " return circ\n",
203 | "\n",
204 | "################ Weiwen on 12-30-2020 ################\n",
205 | "# Function: neg_weight_gate from Listing 3\n",
206 | "# Note: adding NOT(X) gate before the qubits associated\n",
207 | "# with 0 state. For example, if we want to flip \n",
208 | "# the sign of |1101>, we add X gate for q2 before\n",
209 | "# the cccz gate, as follows.\n",
210 | "# --q3-----|---\n",
211 | "# --q2----X|X--\n",
212 | "# --q1-----|---\n",
213 | "# --q0-----z---\n",
214 | "# Parameters: (1) quantum circuit; \n",
215 | "# (2) all qubits, say q0-q3;\n",
216 | "# (3) the auxiliary qubits used for cccz\n",
217 | "# (4) states, say 1101\n",
218 | "######################################################\n",
219 | "def neg_weight_gate(circ,qubits,aux,state):\n",
220 | " idx = 0\n",
221 | " # The index of qubits are reversed in terms of states.\n",
222 | " # As shown in the above example: we put X at q2 not the third position.\n",
223 | " state = state[::-1]\n",
224 | " for idx in range(len(state)):\n",
225 | " if state[idx]=='0':\n",
226 | " circ.x(qubits[idx])\n",
227 | " cccz(circ,qubits[0],qubits[1],qubits[2],qubits[3],aux[0],aux[1])\n",
228 | " for idx in range(len(state)):\n",
229 | " if state[idx]=='0':\n",
230 | " circ.x(qubits[idx])\n"
231 | ]
232 | },
233 | {
234 | "cell_type": "code",
235 | "execution_count": null,
236 | "metadata": {
237 | "id": "qeLLhENSrkka"
238 | },
239 | "outputs": [],
240 | "source": [
241 | "################ Weiwen on 12-30-2020 ################\n",
242 | "# Using torch to load MNIST data\n",
243 | "######################################################\n",
244 | "\n",
245 | "# convert data to torch.FloatTensor\n",
246 | "transform = transforms.Compose([transforms.Resize((ori_img_size,ori_img_size)),\n",
247 | " transforms.ToTensor()])\n",
248 | "# Path to MNIST Dataset\n",
249 | "train_data = datasets.MNIST(root='./data', train=True,\n",
250 | " download=True, transform=transform)\n",
251 | "test_data = datasets.MNIST(root='./data', train=False,\n",
252 | " download=True, transform=transform)\n",
253 | "\n",
254 | "train_data = select_num(train_data,interest_num)\n",
255 | "test_data = select_num(test_data,interest_num)\n",
256 | "\n",
257 | "# prepare data loaders\n",
258 | "train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,\n",
259 | " num_workers=num_workers, shuffle=True, drop_last=True)\n",
260 | "test_loader = torch.utils.data.DataLoader(test_data, batch_size=inference_batch_size, \n",
261 | " num_workers=num_workers, shuffle=True, drop_last=True)\n"
262 | ]
263 | },
264 | {
265 | "cell_type": "code",
266 | "execution_count": null,
267 | "metadata": {
268 | "id": "5ooj924Lrkkb"
269 | },
270 | "outputs": [],
271 | "source": [
272 | "################ Weiwen on 12-30-2020 ################\n",
273 | "# T1: Downsample the image from 28*28 to 4*4\n",
274 | "# T2: Convert classical data to quantum data which \n",
275 | "# can be encoded to the quantum states (amplitude)\n",
276 | "######################################################\n",
277 | "\n",
278 | "# Process data by hand, we can also integrate ToQuantumData into transform\n",
279 | "def data_pre_pro(img):\n",
280 | " # Print original figure\n",
281 | " img = img\n",
282 | " npimg = img.numpy()\n",
283 | " plt.imshow(np.transpose(npimg, (1, 2, 0))) \n",
284 | " plt.show()\n",
285 | " # Print resized figure\n",
286 | " image = np.asarray(npimg[0] * 255, np.uint8) \n",
287 | " im = Image.fromarray(image,mode=\"L\")\n",
288 | " im = im.resize((4,4),Image.BILINEAR) \n",
289 | " plt.imshow(im,cmap='gray',)\n",
290 | " plt.show()\n",
291 | " # Converting classical data to quantum data\n",
292 | " trans_to_tensor = transforms.ToTensor()\n",
293 | " trans_to_vector = ToQuantumData()\n",
294 | " trans_to_matrix = ToQuantumMatrix() \n",
295 | " print(\"Classical Data: {}\".format(trans_to_tensor(im).flatten()))\n",
296 | " print(\"Quantum Data: {}\".format(trans_to_vector(trans_to_tensor(im)).flatten()))\n",
297 | " return trans_to_matrix(trans_to_tensor(im)),trans_to_vector(trans_to_tensor(im))\n",
298 | "\n",
299 | "# Use the first image from test loader as example\n",
300 | "for batch_idx, (data, target) in enumerate(test_loader):\n",
301 | " torch.set_printoptions(threshold=sys.maxsize)\n",
302 | " print(\"Batch Id: {}, Target: {}\".format(batch_idx,target))\n",
303 | " quantum_matrix,qantum_data = data_pre_pro(torchvision.utils.make_grid(data))\n",
304 | " break"
305 | ]
306 | },
307 | {
308 | "cell_type": "code",
309 | "execution_count": null,
310 | "metadata": {
311 | "id": "q4AYSlK3rkkc"
312 | },
313 | "outputs": [],
314 | "source": [
315 | "################ Weiwen on 12-30-2020 ################\n",
316 | "# Parameters of the trained model\n",
317 | "# The training procedure will be found in another repo\n",
318 | "# https://github.com/weiwenjiang/QuantumFlow\n",
319 | "######################################################\n",
320 | "\n",
321 | "# Model initialization\n",
322 | "weight_1_1 = torch.tensor([1., 1., 1., 1., 1., 1., 1., -1., 1., -1., 1., -1., 1., 1., 1., 1.])\n",
323 | "weight_1_2 = torch.tensor([-1., -1., -1., -1., -1., -1., -1., -1., -1., 1., -1., 1., -1., -1.,-1., -1.])\n",
324 | "\n",
325 | "weight_2_1 = torch.tensor([1., -1.])\n",
326 | "norm_flag_1 = True\n",
327 | "norm_para_1 = torch.tensor(0.3060)\n",
328 | "\n",
329 | "weight_2_2 = torch.tensor([-1., -1.])\n",
330 | "norm_flag_2 = False\n",
331 | "norm_para_2 = torch.tensor(0.6940)"
332 | ]
333 | },
334 | {
335 | "cell_type": "code",
336 | "execution_count": null,
337 | "metadata": {
338 | "scrolled": true,
339 | "id": "MCEXuiGKrkkd"
340 | },
341 | "outputs": [],
342 | "source": [
343 | "################ Weiwen on 12-30-2020 ################\n",
344 | "# Quantum circuit implementation\n",
345 | "######################################################\n",
346 | "\n",
347 | "# From Listing 2: creat the qubits to hold data\n",
348 | "inp = QuantumRegister(4,\"in_qbit\")\n",
349 | "circ = QuantumCircuit(inp)\n",
350 | "data_matrix = quantum_matrix\n",
351 | "circ.append(UnitaryGate(data_matrix, label=\"Input\"), inp[0:4])\n",
352 | "\n",
353 | "# From Listing 3: create auxiliary qubits\n",
354 | "aux = QuantumRegister(2,\"aux_qbit\")\n",
355 | "circ.add_register(aux)\n",
356 | "\n",
357 | "# From Listing 4: create output qubits for the first layer (hidden neurons)\n",
358 | "hidden_neurons = QuantumRegister(1,\"hidden_qbits\")\n",
359 | "circ.add_register(hidden_neurons)\n",
360 | "\n",
361 | "# Add classical register\n",
362 | "c_reg = ClassicalRegister(1,\"reg\")\n",
363 | "circ.add_register(c_reg)\n",
364 | "\n",
365 | "# From Listing 3: to multiply inputs and weights on quantum circuit\n",
366 | "if weight_1_1.sum()<0:\n",
367 | " weight_1_1 = weight_1_1*-1\n",
368 | "idx = 0\n",
369 | "for idx in range(weight_1_1.flatten().size()[0]):\n",
370 | " if weight_1_1[idx]==-1:\n",
371 | " state = \"{0:b}\".format(idx).zfill(4)\n",
372 | " neg_weight_gate(circ,inp,aux,state)\n",
373 | " circ.barrier()\n",
374 | " \n",
375 | "# From Listing 4: applying the quadratic function on the weighted sum\n",
376 | "circ.h(inp)\n",
377 | "circ.x(inp)\n",
378 | "ccccx(circ,inp[0],inp[1],inp[2],inp[3],hidden_neurons[0],aux[0],aux[1])\n",
379 | "\n",
380 | "# Measure output of the neuron to see the result, which is not necessary for multi-layer network\n",
381 | "circ.measure(hidden_neurons,c_reg)\n",
382 | "\n",
383 | "print(circ)"
384 | ]
385 | },
386 | {
387 | "cell_type": "code",
388 | "execution_count": null,
389 | "metadata": {
390 | "id": "8_H5RAoOrkkd"
391 | },
392 | "outputs": [],
393 | "source": [
394 | "################ Weiwen on 12-30-2020 ################\n",
395 | "# Quantum simulation\n",
396 | "######################################################\n",
397 | "\n",
398 | "# From Listing 6: execute the quantum circuit to obtain the results\n",
399 | "qc_shots=1000000\n",
400 | "counts = fire_ibmq(circ,qc_shots,True)\n",
401 | "(mycount,bits) = analyze(counts)\n",
402 | "class_prob=[]\n",
403 | "for b in range(bits):\n",
404 | " class_prob.append(float(mycount[b])/qc_shots)\n",
405 | "print(class_prob)"
406 | ]
407 | },
408 | {
409 | "cell_type": "code",
410 | "execution_count": null,
411 | "metadata": {
412 | "id": "nf2WE2Vyrkke"
413 | },
414 | "outputs": [],
415 | "source": [
416 | "################ Weiwen on 12-30-2020 ################\n",
417 | "# Do the same compuation in classical computing for\n",
418 | "# comparison.\n",
419 | "######################################################\n",
420 | "\n",
421 | "input_data = qantum_data.flatten()\n",
422 | "weight_neuron_1 = weight_1_1\n",
423 | "weighted_sum_neuron_1 = (input_data*weight_neuron_1).sum()\n",
424 | "result_neuron_1 = weighted_sum_neuron_1.pow(2)/len(weight_neuron_1)\n",
425 | "\n",
426 | "print([result_neuron_1])"
427 | ]
428 | }
429 | ],
430 | "metadata": {
431 | "kernelspec": {
432 | "display_name": "Python 3",
433 | "language": "python",
434 | "name": "python3"
435 | },
436 | "language_info": {
437 | "codemirror_mode": {
438 | "name": "ipython",
439 | "version": 3
440 | },
441 | "file_extension": ".py",
442 | "mimetype": "text/x-python",
443 | "name": "python",
444 | "nbconvert_exporter": "python",
445 | "pygments_lexer": "ipython3",
446 | "version": "3.8.5"
447 | },
448 | "pycharm": {
449 | "stem_cell": {
450 | "cell_type": "raw",
451 | "metadata": {
452 | "collapsed": false
453 | },
454 | "source": []
455 | }
456 | },
457 | "colab": {
458 | "provenance": []
459 | }
460 | },
461 | "nbformat": 4,
462 | "nbformat_minor": 0
463 | }
--------------------------------------------------------------------------------
/session_2/Tutorial_3_Full_MNIST_Prediction.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "source": [
7 | "!pip install -q torch==1.8.1\n",
8 | "!pip install -q torchvision==0.4.0\n",
9 | "!pip install -q qiskit==0.20.0\n",
10 | "\n",
11 | "import warnings\n",
12 | "warnings.filterwarnings(\"ignore\", category=DeprecationWarning) \n",
13 | "\n",
14 | "import torch\n",
15 | "import torchvision\n",
16 | "from torchvision import datasets\n",
17 | "import torchvision.transforms as transforms\n",
18 | "import torch.nn as nn\n",
19 | "import shutil\n",
20 | "import os\n",
21 | "import time\n",
22 | "import sys\n",
23 | "from pathlib import Path\n",
24 | "import numpy as np\n",
25 | "import matplotlib.pyplot as plt\n",
26 | "import numpy as np\n",
27 | "from PIL import Image\n",
28 | "from matplotlib import cm\n",
29 | "import functools\n",
30 | "from qiskit.tools.monitor import job_monitor\n",
31 | "from qiskit import QuantumRegister, QuantumCircuit, ClassicalRegister\n",
32 | "from qiskit.extensions import XGate, UnitaryGate\n",
33 | "from qiskit import Aer, execute\n",
34 | "import qiskit\n",
35 | "\n",
36 | "print = functools.partial(print, flush=True)\n",
37 | "\n",
38 | "interest_num = [3,6]\n",
39 | "ori_img_size = 28\n",
40 | "img_size = 4\n",
41 | "# number of subprocesses to use for data loading\n",
42 | "num_workers = 0\n",
43 | "# how many samples per batch to load\n",
44 | "batch_size = 1\n",
45 | "inference_batch_size = 1\n",
46 | "\n",
47 | "\n",
48 | "# Weiwen: modify the target classes starting from 0. Say, [3,6] -> [0,1]\n",
49 | "def modify_target(target):\n",
50 | " for j in range(len(target)):\n",
51 | " for idx in range(len(interest_num)):\n",
52 | " if target[j] == interest_num[idx]:\n",
53 | " target[j] = idx\n",
54 | " break\n",
55 | " new_target = torch.zeros(target.shape[0],2)\n",
56 | " for i in range(target.shape[0]): \n",
57 | " if target[i].item() == 0: \n",
58 | " new_target[i] = torch.tensor([1,0]).clone() \n",
59 | " else:\n",
60 | " new_target[i] = torch.tensor([0,1]).clone()\n",
61 | " \n",
62 | " return target,new_target\n",
63 | "\n",
64 | "# Weiwen: select sub-set from MNIST\n",
65 | "def select_num(dataset,interest_num):\n",
66 | " labels = dataset.targets #get labels\n",
67 | " labels = labels.numpy()\n",
68 | " idx = {}\n",
69 | " for num in interest_num:\n",
70 | " idx[num] = np.where(labels == num)\n",
71 | " fin_idx = idx[interest_num[0]]\n",
72 | " for i in range(1,len(interest_num)): \n",
73 | " fin_idx = (np.concatenate((fin_idx[0],idx[interest_num[i]][0])),)\n",
74 | " \n",
75 | " fin_idx = fin_idx[0] \n",
76 | " dataset.targets = labels[fin_idx]\n",
77 | " dataset.data = dataset.data[fin_idx]\n",
78 | " dataset.targets,_ = modify_target(dataset.targets)\n",
79 | " return dataset\n",
80 | "\n",
81 | "################ Weiwen on 12-30-2020 ################\n",
82 | "# Function: ToQuantumData from Listing 1\n",
83 | "# Note: Coverting classical data to quantum data\n",
84 | "######################################################\n",
85 | "class ToQuantumData(object):\n",
86 | " def __call__(self, tensor):\n",
87 | " device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n",
88 | " data = tensor.to(device)\n",
89 | " input_vec = data.view(-1)\n",
90 | " vec_len = input_vec.size()[0]\n",
91 | " input_matrix = torch.zeros(vec_len, vec_len)\n",
92 | " input_matrix[0] = input_vec\n",
93 | " input_matrix = np.float64(input_matrix.transpose(0,1))\n",
94 | " u, s, v = np.linalg.svd(input_matrix)\n",
95 | " output_matrix = torch.tensor(np.dot(u, v))\n",
96 | " output_data = output_matrix[:, 0].view(1, img_size,img_size)\n",
97 | " return output_data\n",
98 | "\n",
99 | "################ Weiwen on 12-30-2020 ################\n",
100 | "# Function: ToQuantumData from Listing 1\n",
101 | "# Note: Coverting classical data to quantum matrix\n",
102 | "######################################################\n",
103 | "class ToQuantumMatrix(object):\n",
104 | " def __call__(self, tensor):\n",
105 | " device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n",
106 | " data = tensor.to(device)\n",
107 | " input_vec = data.view(-1)\n",
108 | " vec_len = input_vec.size()[0]\n",
109 | " input_matrix = torch.zeros(vec_len, vec_len)\n",
110 | " input_matrix[0] = input_vec\n",
111 | " input_matrix = np.float64(input_matrix.transpose(0,1))\n",
112 | " u, s, v = np.linalg.svd(input_matrix)\n",
113 | " output_matrix = torch.tensor(np.dot(u, v))\n",
114 | " return output_matrix \n",
115 | " \n",
116 | "################ Weiwen on 12-30-2020 ################\n",
117 | "# Function: fire_ibmq from Listing 6\n",
118 | "# Note: used for execute quantum circuit using \n",
119 | "# simulation or ibm quantum processor\n",
120 | "# Parameters: (1) quantum circuit; \n",
121 | "# (2) number of shots;\n",
122 | "# (3) simulation or quantum processor;\n",
123 | "# (4) backend name if quantum processor.\n",
124 | "######################################################\n",
125 | "def fire_ibmq(circuit,shots,Simulation = False,backend_name='ibmq_essex'): \n",
126 | " count_set = []\n",
127 | " if not Simulation:\n",
128 | " provider = IBMQ.get_provider('ibm-q-academic')\n",
129 | " backend = provider.get_backend(backend_name)\n",
130 | " else:\n",
131 | " backend = Aer.get_backend('qasm_simulator')\n",
132 | " job_ibm_q = execute(circuit, backend, shots=shots)\n",
133 | " job_monitor(job_ibm_q)\n",
134 | " result_ibm_q = job_ibm_q.result()\n",
135 | " counts = result_ibm_q.get_counts()\n",
136 | " return counts\n",
137 | "\n",
138 | "################ Weiwen on 12-30-2020 ################\n",
139 | "# Function: analyze from Listing 6\n",
140 | "# Note: used for analyze the count on states to \n",
141 | "# formulate the probability for each qubit\n",
142 | "# Parameters: (1) counts returned by fire_ibmq; \n",
143 | "######################################################\n",
144 | "def analyze(counts):\n",
145 | " mycount = {}\n",
146 | " for i in range(2):\n",
147 | " mycount[i] = 0\n",
148 | " for k,v in counts.items():\n",
149 | " bits = len(k) \n",
150 | " for i in range(bits): \n",
151 | " if k[bits-1-i] == \"1\":\n",
152 | " if i in mycount.keys():\n",
153 | " mycount[i] += v\n",
154 | " else:\n",
155 | " mycount[i] = v\n",
156 | " return mycount,bits\n",
157 | "\n",
158 | "################ Weiwen on 12-30-2020 ################\n",
159 | "# Function: cccz from Listing 3\n",
160 | "# Note: using the basic Toffoli gates and CZ gate\n",
161 | "# to implement cccz gate, which will flip the\n",
162 | "# sign of state |1111>\n",
163 | "# Parameters: (1) quantum circuit; \n",
164 | "# (2-4) control qubits;\n",
165 | "# (5) target qubits;\n",
166 | "# (6-7) auxiliary qubits.\n",
167 | "######################################################\n",
168 | "def cccz(circ, q1, q2, q3, q4, aux1, aux2):\n",
169 | " # Apply Z-gate to a state controlled by 4 qubits\n",
170 | " circ.ccx(q1, q2, aux1)\n",
171 | " circ.ccx(q3, aux1, aux2)\n",
172 | " circ.cz(aux2, q4)\n",
173 | " # cleaning the aux bits\n",
174 | " circ.ccx(q3, aux1, aux2)\n",
175 | " circ.ccx(q1, q2, aux1)\n",
176 | " return circ\n",
177 | "\n",
178 | "################ Weiwen on 12-30-2020 ################\n",
179 | "# Function: cccz from Listing 4\n",
180 | "# Note: using the basic Toffoli gate to implement ccccx\n",
181 | "# gate. It is used to switch the quantum states\n",
182 | "# of |11110> and |11111>.\n",
183 | "# Parameters: (1) quantum circuit; \n",
184 | "# (2-5) control qubits;\n",
185 | "# (6) target qubits;\n",
186 | "# (7-8) auxiliary qubits.\n",
187 | "######################################################\n",
188 | "def ccccx(circ, q1, q2, q3, q4, q5, aux1, aux2):\n",
189 | " circ.ccx(q1, q2, aux1)\n",
190 | " circ.ccx(q3, q4, aux2)\n",
191 | " circ.ccx(aux2, aux1, q5)\n",
192 | " # cleaning the aux bits\n",
193 | " circ.ccx(q3, q4, aux2)\n",
194 | " circ.ccx(q1, q2, aux1)\n",
195 | " return circ\n",
196 | "\n",
197 | "################ Weiwen on 12-30-2020 ################\n",
198 | "# Function: neg_weight_gate from Listing 3\n",
199 | "# Note: adding NOT(X) gate before the qubits associated\n",
200 | "# with 0 state. For example, if we want to flip \n",
201 | "# the sign of |1101>, we add X gate for q2 before\n",
202 | "# the cccz gate, as follows.\n",
203 | "# --q3-----|---\n",
204 | "# --q2----X|X--\n",
205 | "# --q1-----|---\n",
206 | "# --q0-----z---\n",
207 | "# Parameters: (1) quantum circuit; \n",
208 | "# (2) all qubits, say q0-q3;\n",
209 | "# (3) the auxiliary qubits used for cccz\n",
210 | "# (4) states, say 1101\n",
211 | "######################################################\n",
212 | "def neg_weight_gate(circ,qubits,aux,state):\n",
213 | " idx = 0\n",
214 | " # The index of qubits are reversed in terms of states.\n",
215 | " # As shown in the above example: we put X at q2 not the third position.\n",
216 | " state = state[::-1]\n",
217 | " for idx in range(len(state)):\n",
218 | " if state[idx]=='0':\n",
219 | " circ.x(qubits[idx])\n",
220 | " cccz(circ,qubits[0],qubits[1],qubits[2],qubits[3],aux[0],aux[1])\n",
221 | " for idx in range(len(state)):\n",
222 | " if state[idx]=='0':\n",
223 | " circ.x(qubits[idx])\n"
224 | ],
225 | "outputs": [],
226 | "metadata": {
227 | "pycharm": {
228 | "is_executing": false
229 | },
230 | "id": "J0zY8bo9k_xE"
231 | }
232 | },
233 | {
234 | "cell_type": "code",
235 | "execution_count": null,
236 | "source": [
237 | "################ Weiwen on 12-30-2020 ################\n",
238 | "# Using torch to load MNIST data\n",
239 | "######################################################\n",
240 | "\n",
241 | "# convert data to torch.FloatTensor\n",
242 | "transform = transforms.Compose([transforms.Resize((ori_img_size,ori_img_size)),\n",
243 | " transforms.ToTensor()])\n",
244 | "# Path to MNIST Dataset\n",
245 | "train_data = datasets.MNIST(root='./data', train=True,\n",
246 | " download=True, transform=transform)\n",
247 | "test_data = datasets.MNIST(root='./data', train=False,\n",
248 | " download=True, transform=transform)\n",
249 | "\n",
250 | "train_data = select_num(train_data,interest_num)\n",
251 | "test_data = select_num(test_data,interest_num)\n",
252 | "\n",
253 | "# prepare data loaders\n",
254 | "train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,\n",
255 | " num_workers=num_workers, shuffle=True, drop_last=True)\n",
256 | "test_loader = torch.utils.data.DataLoader(test_data, batch_size=inference_batch_size, \n",
257 | " num_workers=num_workers, shuffle=True, drop_last=True)\n"
258 | ],
259 | "outputs": [],
260 | "metadata": {
261 | "pycharm": {
262 | "is_executing": false
263 | },
264 | "id": "asUyEv0Nk_xJ"
265 | }
266 | },
267 | {
268 | "cell_type": "code",
269 | "execution_count": null,
270 | "source": [
271 | "################ Weiwen on 12-30-2020 ################\n",
272 | "# T1: Downsample the image from 28*28 to 4*4\n",
273 | "# T2: Convert classical data to quantum data which \n",
274 | "# can be encoded to the quantum states (amplitude)\n",
275 | "######################################################\n",
276 | "\n",
277 | "# Process data by hand, we can also integrate ToQuantumData into transform\n",
278 | "def data_pre_pro(img):\n",
279 | " # Print original figure\n",
280 | " img = img\n",
281 | " npimg = img.numpy()\n",
282 | " plt.imshow(np.transpose(npimg, (1, 2, 0))) \n",
283 | " plt.show()\n",
284 | " # Print resized figure\n",
285 | " image = np.asarray(npimg[0] * 255, np.uint8) \n",
286 | " im = Image.fromarray(image,mode=\"L\")\n",
287 | " im = im.resize((4,4),Image.BILINEAR) \n",
288 | " plt.imshow(im,cmap='gray',)\n",
289 | " plt.show()\n",
290 | " # Converting classical data to quantum data\n",
291 | " trans_to_tensor = transforms.ToTensor()\n",
292 | " trans_to_vector = ToQuantumData()\n",
293 | " trans_to_matrix = ToQuantumMatrix() \n",
294 | " print(\"Classical Data: {}\".format(trans_to_tensor(im).flatten()))\n",
295 | " print(\"Quantum Data: {}\".format(trans_to_vector(trans_to_tensor(im)).flatten()))\n",
296 | " return trans_to_matrix(trans_to_tensor(im)),trans_to_vector(trans_to_tensor(im))\n",
297 | "\n",
298 | "# Use the first image from test loader as example\n",
299 | "for batch_idx, (data, target) in enumerate(test_loader):\n",
300 | " torch.set_printoptions(threshold=sys.maxsize)\n",
301 | " print(\"Batch Id: {}, Target: {}\".format(batch_idx,target))\n",
302 | " quantum_matrix,qantum_data = data_pre_pro(torchvision.utils.make_grid(data))\n",
303 | " break"
304 | ],
305 | "outputs": [],
306 | "metadata": {
307 | "scrolled": true,
308 | "pycharm": {
309 | "is_executing": false
310 | },
311 | "id": "hvMOUIRXk_xJ"
312 | }
313 | },
314 | {
315 | "cell_type": "code",
316 | "execution_count": null,
317 | "source": [
318 | "print(torch.__version__)\n",
319 | "################ Weiwen on 12-30-2020 ################\n",
320 | "# Parameters of the trained model\n",
321 | "# The training procedure will be found in another repo\n",
322 | "# https://github.com/weiwenjiang/QuantumFlow\n",
323 | "######################################################\n",
324 | "\n",
325 | "# Model initialization\n",
326 | "weight_1_1 = torch.tensor([1., 1., 1., 1., 1., 1., 1., -1., 1., -1., 1., -1., 1., 1., 1., 1.])\n",
327 | "weight_1_2 = torch.tensor([-1., -1., -1., -1., -1., -1., -1., -1., -1., 1., -1., 1., -1., -1.,-1., -1.])\n",
328 | "\n",
329 | "weight_2_1 = torch.tensor([1., -1.])\n",
330 | "norm_flag_1 = True\n",
331 | "norm_para_1 = torch.tensor(0.3060)\n",
332 | "\n",
333 | "weight_2_2 = torch.tensor([-1., -1.])\n",
334 | "norm_flag_2 = False\n",
335 | "norm_para_2 = torch.tensor(0.6940)"
336 | ],
337 | "outputs": [],
338 | "metadata": {
339 | "pycharm": {
340 | "is_executing": false
341 | },
342 | "id": "29EbhzNsk_xK"
343 | }
344 | },
345 | {
346 | "cell_type": "code",
347 | "execution_count": null,
348 | "source": [
349 | "################ Weiwen on 12-30-2020 ################\n",
350 | "# Quantum circuit implementation\n",
351 | "######################################################\n",
352 | "\n",
353 | "# From Listing 2: creat the qubits to hold data\n",
354 | "inp_1 = QuantumRegister(4,\"in1_qbit\")\n",
355 | "inp_2 = QuantumRegister(4,\"in2_qbit\")\n",
356 | "circ = QuantumCircuit(inp_1,inp_2)\n",
357 | "data_matrix = quantum_matrix\n",
358 | "circ.append(UnitaryGate(data_matrix, label=\"Input\"), inp_1[0:4])\n",
359 | "circ.append(UnitaryGate(data_matrix, label=\"Input\"), inp_2[0:4])\n",
360 | "\n",
361 | "# From Listing 3: create auxiliary qubits\n",
362 | "aux = QuantumRegister(2,\"aux_qbit\")\n",
363 | "circ.add_register(aux)\n",
364 | "\n",
365 | "# From Listing 4: create output qubits for the first layer (hidden neurons)\n",
366 | "hidden_neurons = QuantumRegister(2,\"hidden_qbits\")\n",
367 | "circ.add_register(hidden_neurons)\n",
368 | "\n",
369 | "\n",
370 | "# From Listing 3: to multiply inputs and weights on quantum circuit\n",
371 | "if weight_1_1.sum()<0:\n",
372 | " weight_1_1 = weight_1_1*-1\n",
373 | "idx = 0\n",
374 | "for idx in range(weight_1_1.flatten().size()[0]):\n",
375 | " if weight_1_1[idx]==-1:\n",
376 | " state = \"{0:b}\".format(idx).zfill(4)\n",
377 | " neg_weight_gate(circ,inp_1,aux,state)\n",
378 | " circ.barrier()\n",
379 | "\n",
380 | "if weight_1_2.sum()<0:\n",
381 | " weight_1_2 = weight_1_2*-1\n",
382 | "idx = 0\n",
383 | "for idx in range(weight_1_2.flatten().size()[0]):\n",
384 | " if weight_1_2[idx]==-1:\n",
385 | " state = \"{0:b}\".format(idx).zfill(4)\n",
386 | " neg_weight_gate(circ,inp_2,aux,state)\n",
387 | " circ.barrier()\n",
388 | " \n",
389 | "# From Listing 4: applying the quadratic function on the weighted sum\n",
390 | "circ.h(inp_1)\n",
391 | "circ.x(inp_1)\n",
392 | "ccccx(circ,inp_1[0],inp_1[1],inp_1[2],inp_1[3],hidden_neurons[0],aux[0],aux[1])\n",
393 | "\n",
394 | "circ.h(inp_2)\n",
395 | "circ.x(inp_2)\n",
396 | "ccccx(circ,inp_2[0],inp_2[1],inp_2[2],inp_2[3],hidden_neurons[1],aux[0],aux[1])\n",
397 | "\n",
398 | "\n",
399 | "print(\"Hidden layer created!\")"
400 | ],
401 | "outputs": [],
402 | "metadata": {
403 | "scrolled": true,
404 | "pycharm": {
405 | "is_executing": false
406 | },
407 | "id": "5m_uJYdXk_xK"
408 | }
409 | },
410 | {
411 | "cell_type": "code",
412 | "execution_count": null,
413 | "source": [
414 | "################ Weiwen on 12-30-2020 ################\n",
415 | "# Quantum circuit implementation of the output layer\n",
416 | "# fundamentals, please see our Nature Communication\n",
417 | "# paper (P-LYR) https://arxiv.org/pdf/2006.14815.pdf\n",
418 | "######################################################\n",
419 | "\n",
420 | "inter_q_1 = QuantumRegister(1,\"inter_q_1_qbits\")\n",
421 | "norm_q_1 = QuantumRegister(1,\"norm_q_1_qbits\")\n",
422 | "out_q_1 = QuantumRegister(1,\"out_q_1_qbits\")\n",
423 | "circ.add_register(inter_q_1,norm_q_1,out_q_1)\n",
424 | "\n",
425 | "circ.barrier()\n",
426 | "\n",
427 | "if weight_2_1.sum()<0:\n",
428 | " weight_2_1 = weight_2_1*-1\n",
429 | "idx = 0\n",
430 | "for idx in range(weight_2_1.flatten().size()[0]):\n",
431 | " if weight_2_1[idx]==-1:\n",
432 | " circ.x(hidden_neurons[idx])\n",
433 | "circ.h(inter_q_1)\n",
434 | "circ.cz(hidden_neurons[0],inter_q_1)\n",
435 | "circ.x(inter_q_1)\n",
436 | "circ.cz(hidden_neurons[1],inter_q_1)\n",
437 | "circ.x(inter_q_1)\n",
438 | "circ.h(inter_q_1)\n",
439 | "circ.x(inter_q_1)\n",
440 | "\n",
441 | "circ.barrier()\n",
442 | "\n",
443 | "norm_init_rad = float(norm_para_1.sqrt().asin()*2)\n",
444 | "circ.ry(norm_init_rad,norm_q_1)\n",
445 | "if norm_flag_1:\n",
446 | " circ.cx(inter_q_1,out_q_1)\n",
447 | " circ.x(inter_q_1)\n",
448 | " circ.ccx(inter_q_1,norm_q_1,out_q_1)\n",
449 | "else:\n",
450 | " circ.ccx(inter_q_1,norm_q_1,out_q_1)\n",
451 | "\n",
452 | "for idx in range(weight_2_1.flatten().size()[0]):\n",
453 | " if weight_2_1[idx]==-1:\n",
454 | " circ.x(hidden_neurons[idx])\n",
455 | "\n",
456 | "circ.barrier()\n",
457 | "\n",
458 | "\n",
459 | "\n",
460 | "\n",
461 | "inter_q_2 = QuantumRegister(1,\"inter_q_2_qbits\")\n",
462 | "norm_q_2 = QuantumRegister(1,\"norm_q_2_qbits\")\n",
463 | "out_q_2 = QuantumRegister(1,\"out_q_2_qbits\")\n",
464 | "circ.add_register(inter_q_2,norm_q_2,out_q_2)\n",
465 | "\n",
466 | "circ.barrier()\n",
467 | "\n",
468 | "if weight_2_2.sum()<0:\n",
469 | " weight_2_2 = weight_2_2*-1\n",
470 | "idx = 0\n",
471 | "for idx in range(weight_2_2.flatten().size()[0]):\n",
472 | " if weight_2_2[idx]==-1:\n",
473 | " circ.x(hidden_neurons[idx])\n",
474 | "circ.h(inter_q_2)\n",
475 | "circ.cz(hidden_neurons[0],inter_q_2)\n",
476 | "circ.x(inter_q_2)\n",
477 | "circ.cz(hidden_neurons[1],inter_q_2)\n",
478 | "circ.x(inter_q_2)\n",
479 | "circ.h(inter_q_2)\n",
480 | "circ.x(inter_q_2)\n",
481 | "\n",
482 | "circ.barrier()\n",
483 | "\n",
484 | "norm_init_rad = float(norm_para_2.sqrt().asin()*2)\n",
485 | "circ.ry(norm_init_rad,norm_q_2)\n",
486 | "if norm_flag_2:\n",
487 | " circ.cx(inter_q_2,out_q_2)\n",
488 | " circ.x(inter_q_2)\n",
489 | " circ.ccx(inter_q_2,norm_q_2,out_q_2)\n",
490 | "else:\n",
491 | " circ.ccx(inter_q_2,norm_q_2,out_q_2)\n",
492 | "\n",
493 | "for idx in range(weight_2_2.flatten().size()[0]):\n",
494 | " if weight_2_2[idx]==-1:\n",
495 | " circ.x(hidden_neurons[idx])\n",
496 | "\n",
497 | "circ.barrier()\n",
498 | "\n",
499 | "c_reg = ClassicalRegister(2,\"reg\")\n",
500 | "circ.add_register(c_reg)\n",
501 | "circ.measure(out_q_1,c_reg[0])\n",
502 | "circ.measure(out_q_2,c_reg[1])\n",
503 | "\n",
504 | "print(\"Output layer created!\")"
505 | ],
506 | "outputs": [],
507 | "metadata": {
508 | "pycharm": {
509 | "is_executing": false
510 | },
511 | "id": "xApLPzJGk_xL"
512 | }
513 | },
514 | {
515 | "cell_type": "code",
516 | "execution_count": null,
517 | "source": [
518 | "################ Weiwen on 12-30-2020 ################\n",
519 | "# Quantum simulation\n",
520 | "######################################################\n",
521 | "\n",
522 | "# From Listing 6: execute the quantum circuit to obtain the results\n",
523 | "qc_shots=8192\n",
524 | "counts = fire_ibmq(circ,qc_shots,True)\n",
525 | "(mycount,bits) = analyze(counts)\n",
526 | "class_prob=[]\n",
527 | "for b in range(bits):\n",
528 | " class_prob.append(float(mycount[b])/qc_shots)\n"
529 | ],
530 | "outputs": [],
531 | "metadata": {
532 | "pycharm": {
533 | "is_executing": false
534 | },
535 | "id": "_aJ1C3dDk_xL"
536 | }
537 | },
538 | {
539 | "cell_type": "code",
540 | "execution_count": null,
541 | "source": [
542 | "print(class_prob)\n",
543 | "print(\"Prediction class: {}\".format(class_prob.index(max(class_prob))))\n",
544 | "print(\"Target class: {}\".format(target[0]))\n",
545 | "if class_prob.index(max(class_prob))==target[0]:\n",
546 | " print(\"Correct prediction\")\n",
547 | "else:\n",
548 | " print(\"Incorrect prediction\")"
549 | ],
550 | "outputs": [],
551 | "metadata": {
552 | "pycharm": {
553 | "is_executing": false
554 | },
555 | "id": "mW3wt56wk_xM"
556 | }
557 | }
558 | ],
559 | "metadata": {
560 | "kernelspec": {
561 | "name": "python3",
562 | "language": "python",
563 | "display_name": "Python 3"
564 | },
565 | "language_info": {
566 | "codemirror_mode": {
567 | "name": "ipython",
568 | "version": 3
569 | },
570 | "file_extension": ".py",
571 | "mimetype": "text/x-python",
572 | "name": "python",
573 | "nbconvert_exporter": "python",
574 | "pygments_lexer": "ipython3",
575 | "version": "3.8.5"
576 | },
577 | "pycharm": {
578 | "stem_cell": {
579 | "cell_type": "raw",
580 | "source": [],
581 | "metadata": {
582 | "collapsed": false
583 | }
584 | }
585 | },
586 | "colab": {
587 | "provenance": []
588 | }
589 | },
590 | "nbformat": 4,
591 | "nbformat_minor": 0
592 | }
--------------------------------------------------------------------------------
/session_2/Tutorial_5_QF-Map-Eval.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "source": [
7 | "!pip install -q torch==1.8.1\n",
8 | "\n",
9 | "import warnings\n",
10 | "warnings.filterwarnings(\"ignore\", category=DeprecationWarning) \n",
11 | "\n",
12 | "import torch\n",
13 | "import functools\n",
14 | "print = functools.partial(print, flush=True)\n",
15 | "import numpy as np \n",
16 | "import math\n",
17 | "import functools\n",
18 | "from torch.autograd import Function"
19 | ],
20 | "outputs": [],
21 | "metadata": {
22 | "collapsed": true,
23 | "pycharm": {
24 | "is_executing": false
25 | },
26 | "id": "Gh5OgZzFrqpH"
27 | }
28 | },
29 | {
30 | "cell_type": "code",
31 | "execution_count": null,
32 | "source": [
33 | "\n",
34 | "import math\n",
35 | "import copy\n",
36 | "\n",
37 | "################ Zhirui on 12-30-2020 ################\n",
38 | "# U-layer \n",
39 | "######################################################\n",
40 | "def get_index_list(input,target):\n",
41 | " index_list = []\n",
42 | " try:\n",
43 | " beg_pos = 0\n",
44 | " while True:\n",
45 | " find_pos = input.index(target,beg_pos)\n",
46 | " index_list.append(find_pos)\n",
47 | " beg_pos = find_pos+1\n",
48 | " except Exception as exception: \n",
49 | " pass \n",
50 | " return index_list\n",
51 | "\n",
52 | "def change_sign(sign,bin):\n",
53 | " affect_num = [bin]\n",
54 | " one_positions = []\n",
55 | " \n",
56 | " try:\n",
57 | " beg_pos = 0\n",
58 | " while True:\n",
59 | " find_pos = bin.index(\"1\",beg_pos)\n",
60 | " one_positions.append(find_pos)\n",
61 | " beg_pos = find_pos+1\n",
62 | " except Exception as exception:\n",
63 | " # print(\"Not Found\")\n",
64 | " pass\n",
65 | " \n",
66 | " for k,v in sign.items():\n",
67 | " change = True\n",
68 | " for pos in one_positions:\n",
69 | " if k[pos]==\"0\": \n",
70 | " change = False\n",
71 | " break\n",
72 | " if change:\n",
73 | " sign[k] = -1*v\n",
74 | " \n",
75 | "\n",
76 | "def find_start(affect_count_table,target_num):\n",
77 | " for k in list(affect_count_table.keys())[::-1]:\n",
78 | " if target_num<=k:\n",
79 | " return k\n",
80 | "\n",
81 | "\n",
82 | "def recursive_change(direction,start_point,target_num,sign,affect_count_table,quantum_gates):\n",
83 | " \n",
84 | " if start_point == target_num:\n",
85 | " # print(\"recursive_change: STOP\")\n",
86 | " return\n",
87 | " \n",
88 | " gap = int(math.fabs(start_point-target_num)) \n",
89 | " step = find_start(affect_count_table,gap)\n",
90 | " change_sign(sign,affect_count_table[step])\n",
91 | " quantum_gates.append(affect_count_table[step])\n",
92 | " \n",
93 | " if direction==\"r\": \n",
94 | " # print(\"recursive_change: From\",start_point,\"Right(-):\",step)\n",
95 | " start_point = start_point - step\n",
96 | " direction = \"l\"\n",
97 | " recursive_change(direction,start_point,target_num,sign,affect_count_table,quantum_gates)\n",
98 | " \n",
99 | " else: \n",
100 | " # print(\"recursive_change: From\",start_point,\"Left(+):\",step)\n",
101 | " start_point = start_point + step\n",
102 | " direction = \"r\"\n",
103 | " recursive_change(direction,start_point,target_num,sign,affect_count_table,quantum_gates)\n",
104 | " \n",
105 | " \n",
106 | "\n",
107 | "def guarntee_upper_bound_algorithm(sign,target_num,total_len,digits): \n",
108 | " flag = \"0\"+str(digits)+\"b\"\n",
109 | " pre_num = 0\n",
110 | " affect_count_table = {}\n",
111 | " quantum_gates = []\n",
112 | " for i in range(digits):\n",
113 | " cur_num = pre_num + pow(2,i)\n",
114 | " pre_num = cur_num\n",
115 | " binstr_cur_num = format(cur_num,flag) \n",
116 | " affect_count_table[int(pow(2,binstr_cur_num.count(\"0\")))] = binstr_cur_num \n",
117 | " \n",
118 | " if target_num in affect_count_table.keys():\n",
119 | " quantum_gates.append(affect_count_table[target_num])\n",
120 | " change_sign(sign,affect_count_table[target_num]) \n",
121 | " else:\n",
122 | " direction = \"r\"\n",
123 | " start_point = find_start(affect_count_table,target_num)\n",
124 | " quantum_gates.append(affect_count_table[start_point])\n",
125 | " change_sign(sign,affect_count_table[start_point])\n",
126 | " recursive_change(direction,start_point,target_num,sign,affect_count_table,quantum_gates)\n",
127 | " \n",
128 | " return quantum_gates\n",
129 | "\n",
130 | "def qf_map_extract_from_weight(weights): \n",
131 | " # Find Z control gates according to weights\n",
132 | " w = (weights.detach().cpu().numpy())\n",
133 | " total_len = len(w)\n",
134 | " target_num = np.count_nonzero(w == -1)\n",
135 | " if target_num > total_len/2:\n",
136 | " w = w*-1\n",
137 | " target_num = np.count_nonzero(w == -1) \n",
138 | " digits = int(math.log(total_len,2))\n",
139 | " flag = \"0\"+str(digits)+\"b\"\n",
140 | " max_num = int(math.pow(2,digits))\n",
141 | " sign = {}\n",
142 | " for i in range(max_num): \n",
143 | " sign[format(i,flag)] = +1\n",
144 | " quantum_gates = guarntee_upper_bound_algorithm(sign,target_num,total_len,digits)\n",
145 | " \n",
146 | " \n",
147 | " # Build the mapping from weight to final negative num \n",
148 | " fin_sign = list(sign.values())\n",
149 | " fin_weig = [int(x) for x in list(w)]\n",
150 | " \n",
151 | " # print(fin_sign)\n",
152 | " # print(fin_weig)\n",
153 | " sign_neg_index = [] \n",
154 | " try:\n",
155 | " beg_pos = 0\n",
156 | " while True:\n",
157 | " find_pos = fin_sign.index(-1,beg_pos) \n",
158 | " # qiskit_position = int(format(find_pos,flag)[::-1],2) \n",
159 | " sign_neg_index.append(find_pos)\n",
160 | " beg_pos = find_pos+1\n",
161 | " except Exception as exception: \n",
162 | " pass \n",
163 | " \n",
164 | "\n",
165 | " weight_neg_index = []\n",
166 | " try:\n",
167 | " beg_pos = 0\n",
168 | " while True:\n",
169 | " find_pos = fin_weig.index(-1,beg_pos)\n",
170 | " weight_neg_index.append(find_pos)\n",
171 | " beg_pos = find_pos+1\n",
172 | " except Exception as exception: \n",
173 | " pass \n",
174 | " map = {}\n",
175 | " for i in range(len(sign_neg_index)):\n",
176 | " map[sign_neg_index[i]] = weight_neg_index[i]\n",
177 | " ret_index = list([-1 for i in range(len(fin_weig))])\n",
178 | "\n",
179 | " for k,v in map.items():\n",
180 | " ret_index[k]=v\n",
181 | "\n",
182 | " for i in range(len(fin_weig)):\n",
183 | " if ret_index[i]!=-1:\n",
184 | " continue\n",
185 | " for j in range(len(fin_weig)):\n",
186 | " if j not in ret_index:\n",
187 | " ret_index[i]=j\n",
188 | " break\n",
189 | " return quantum_gates,ret_index\n",
190 | "\n",
191 | "################ Zhirui on 12-30-2020 ################\n",
192 | "# ffnn-layer \n",
193 | "######################################################\n",
194 | "def AinB(A,B):\n",
195 | " idx_a = []\n",
196 | " for i in range(len(A)):\n",
197 | " if A[i]==\"1\":\n",
198 | " idx_a.append(i) \n",
199 | " flag = True\n",
200 | " for j in idx_a:\n",
201 | " if B[j]==\"0\":\n",
202 | " flag=False\n",
203 | " break\n",
204 | " return flag\n",
205 | " \n",
206 | " \n",
207 | "def FFNN_Create_Weight(weights): \n",
208 | " # Find Z control gates according to weights\n",
209 | " w = (weights.detach().cpu().numpy())\n",
210 | " total_len = len(w) \n",
211 | " digits = int(math.log(total_len,2))\n",
212 | " flag = \"0\"+str(digits)+\"b\"\n",
213 | " max_num = int(math.pow(2,digits))\n",
214 | " sign = {}\n",
215 | " for i in range(max_num): \n",
216 | " sign[format(i,flag)] = +1 \n",
217 | " sign_expect = {}\n",
218 | " for i in range(max_num):\n",
219 | " sign_expect[format(i,flag)] = int(w[i]) \n",
220 | " \n",
221 | " order_list = []\n",
222 | " for i in range(digits+1):\n",
223 | " for key in sign.keys():\n",
224 | " if key.count(\"1\") == i:\n",
225 | " order_list.append(key) \n",
226 | " \n",
227 | " gates = [] \n",
228 | " sign_cur = copy.deepcopy(sign_expect)\n",
229 | " for idx in range(len(order_list)):\n",
230 | " key = order_list[idx]\n",
231 | " if sign_cur[key] == -1:\n",
232 | " gates.append(key)\n",
233 | " for cor_idx in range(idx,len((order_list))):\n",
234 | " if AinB(key,order_list[cor_idx]):\n",
235 | " sign_cur[order_list[cor_idx]] = (-1)*sign_cur[order_list[cor_idx]] \n",
236 | " return gates\n",
237 | "\n",
238 | "################ Zhirui on 12-30-2020 ################\n",
239 | "# commons\n",
240 | "######################################################\n",
241 | "\n",
242 | "def gates_to_cost(gates):\n",
243 | " cost = 0\n",
244 | " for gate in gates:\n",
245 | " num_one = gate.count(\"1\")\n",
246 | " if num_one==1:\n",
247 | " cost += 1\n",
248 | " else:\n",
249 | " cost += (num_one-1)*2-1\n",
250 | " return cost\n",
251 | " \n",
252 | "\n",
253 | "class BinarizeF(Function):\n",
254 | "\n",
255 | " @staticmethod\n",
256 | " def forward(cxt, input):\n",
257 | " output = input.new(input.size())\n",
258 | " output[input >= 0] = 1\n",
259 | " output[input < 0] = -1\n",
260 | "\n",
261 | " return output\n",
262 | "\n",
263 | " @staticmethod\n",
264 | " def backward(cxt, grad_output):\n",
265 | " grad_input = grad_output.clone()\n",
266 | " return grad_input\n",
267 | "\n",
268 | "\n",
269 | "# aliases\n",
270 | "binarize = BinarizeF.apply\n",
271 | "\n",
272 | "\n"
273 | ],
274 | "outputs": [],
275 | "metadata": {
276 | "pycharm": {
277 | "name": "#%% QF-Map\n",
278 | "is_executing": false
279 | },
280 | "id": "WVBZUH7ArqpN"
281 | }
282 | },
283 | {
284 | "cell_type": "code",
285 | "execution_count": null,
286 | "source": [
287 | "\n",
288 | "################ Zhirui on 12-30-2020 ################\n",
289 | "# caculate the cost of FFNN and U-Layer for a set number of qubits (4-12)\n",
290 | "######################################################\n",
291 | "\n",
292 | "QF_Cost={}\n",
293 | "FFNN_Cost={}\n",
294 | "MLP_Cost={}\n",
295 | "\n",
296 | "range_end = 9\n",
297 | "\n",
298 | "qf_net_cost = 0\n",
299 | "ffnn_cost = 0\n",
300 | "for e in range(4,range_end):\n",
301 | " QF_Cost[e]=[]\n",
302 | " FFNN_Cost[e]=[]\n",
303 | " MLP_Cost[e]=[]\n",
304 | " for r in range(50):\n",
305 | " MLP_Cost[e].append(2**e*2+e)\n",
306 | " \n",
307 | " x=torch.rand(2**e)-0.5 \n",
308 | " x = binarize(x)\n",
309 | " \n",
310 | " sq_cost = e+e*2-1\n",
311 | " \n",
312 | " quantum_gates,ret_index = qf_map_extract_from_weight(x)\n",
313 | " qf_net_cost = gates_to_cost(quantum_gates)+sq_cost\n",
314 | " \n",
315 | " gates = FFNN_Create_Weight(x)\n",
316 | " ffnn_cost = gates_to_cost(gates)+sq_cost\n",
317 | " \n",
318 | " QF_Cost[e].append(qf_net_cost)\n",
319 | " FFNN_Cost[e].append(ffnn_cost)\n",
320 | " \n",
321 | " # print(e,2**e*2+e,qf_net_cost,ffnn_cost)"
322 | ],
323 | "outputs": [],
324 | "metadata": {
325 | "pycharm": {
326 | "name": "#%%\n",
327 | "is_executing": false
328 | },
329 | "id": "d_e3pX-SrqpR"
330 | }
331 | },
332 | {
333 | "cell_type": "code",
334 | "execution_count": null,
335 | "source": [
336 | "################ Zhirui on 12-30-2020 ################\n",
337 | "# caculate how many times is the cost of FFNN and U-Layer for a set number of qubits (4-12)\n",
338 | "######################################################\n",
339 | "\n",
340 | "for e in range(4,range_end):\n",
341 | " print(e,end=\" \")\n",
342 | "\n",
343 | "mean_mlp_cost = []\n",
344 | "mean_ffnn_cost = []\n",
345 | "mean_qf_cost = []\n",
346 | "mean_mlp_div_qf = []\n",
347 | "x_axis = []\n",
348 | "print()\n",
349 | "for e in range(4,range_end):\n",
350 | " print(float(sum(MLP_Cost[e])/len(MLP_Cost[e])),end=\" \")\n",
351 | " mean_mlp_cost.append(float(sum(MLP_Cost[e])/len(MLP_Cost[e])))\n",
352 | " \n",
353 | "print()\n",
354 | "print()\n",
355 | "\n",
356 | "\n",
357 | "for e in range(4,range_end):\n",
358 | " print(e,end=\" \")\n",
359 | "print()\n",
360 | "for e in range(4,range_end):\n",
361 | " print(float(sum(FFNN_Cost[e])/len(FFNN_Cost[e])),end=\" \")\n",
362 | " mean_ffnn_cost.append(float(sum(FFNN_Cost[e])/len(FFNN_Cost[e])))\n",
363 | " \n",
364 | "print()\n",
365 | "print()\n",
366 | "\n",
367 | "\n",
368 | "for e in range(4,range_end):\n",
369 | " print(e,end=\" \")\n",
370 | " x_axis.append(e)\n",
371 | " \n",
372 | "print()\n",
373 | "for e in range(4,range_end):\n",
374 | " print(float(sum(QF_Cost[e])/len(QF_Cost[e])),end=\" \")\n",
375 | " mean_qf_cost.append(float(sum(QF_Cost[e])/len(QF_Cost[e])))\n",
376 | "\n",
377 | "for i in range(0,len(mean_qf_cost)):\n",
378 | " times = int(float(mean_mlp_cost[i])/ float(mean_qf_cost[i]))\n",
379 | " mean_mlp_div_qf.append(times)"
380 | ],
381 | "outputs": [],
382 | "metadata": {
383 | "pycharm": {
384 | "name": "#%%\n",
385 | "is_executing": false
386 | },
387 | "id": "FDCu0L0jrqpS"
388 | }
389 | },
390 | {
391 | "cell_type": "code",
392 | "execution_count": null,
393 | "source": [
394 | "import matplotlib.pyplot as plt\n",
395 | "\n",
396 | "# x_data = ['2011','2012','2013','2014','2015','2016','2017']\n",
397 | "# y_data = [58000,60200,63000,71000,84000,90500,107000]\n",
398 | "# y_data2 = [52000,54200,51500,58300,56800,59500,62700]\n",
399 | "\n",
400 | "ln1, = plt.plot(x_axis,mean_mlp_cost,color='burlywood',linewidth=2.0,linestyle='--')\n",
401 | "ln2, = plt.plot(x_axis,mean_ffnn_cost,color='plum',linewidth=3.0,linestyle='-.')\n",
402 | "ln3, = plt.plot(x_axis,mean_qf_cost,color='paleturquoise',linewidth=3.0,linestyle=':')\n",
403 | "\n",
404 | "plt.title(\"Quantum Advantage achieved by U-LYR in QuantumFlow\")\n",
405 | "plt.legend(handles=[ln1,ln2,ln3],labels=['mlp','ffnn','qf'])\n",
406 | "plt.yscale('log')\n",
407 | "ax = plt.gca()\n",
408 | "\n",
409 | "for i in range(0,len(mean_mlp_div_qf)):\n",
410 | " ax.text((i+4),mean_ffnn_cost[i] ,'x'+ str(mean_mlp_div_qf[i]),style='italic',bbox={'facecolor':'white','alpha':0.5,'pad':10})\n",
411 | "ax.spines['right'].set_color('none')\n",
412 | "ax.spines['top'].set_color('none')\n",
413 | "\n",
414 | "plt.show()"
415 | ],
416 | "outputs": [],
417 | "metadata": {
418 | "id": "5UQDiGXzrqpT"
419 | }
420 | }
421 | ],
422 | "metadata": {
423 | "kernelspec": {
424 | "name": "python3",
425 | "display_name": "Python 3.8.10 64-bit ('qf': conda)"
426 | },
427 | "language_info": {
428 | "name": "python",
429 | "version": "3.8.10",
430 | "mimetype": "text/x-python",
431 | "codemirror_mode": {
432 | "name": "ipython",
433 | "version": 3
434 | },
435 | "pygments_lexer": "ipython3",
436 | "nbconvert_exporter": "python",
437 | "file_extension": ".py"
438 | },
439 | "interpreter": {
440 | "hash": "f24048f0d5bdb0ff49c5e7c8a9899a65bc3ab13b0f32660a2227453ca6b95fd8"
441 | },
442 | "colab": {
443 | "provenance": []
444 | }
445 | },
446 | "nbformat": 4,
447 | "nbformat_minor": 0
448 | }
--------------------------------------------------------------------------------
/session_3/EX_1_QF_pNet.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "source": [
6 | "# How to build p-net\n",
7 | "## Prepare environment and define parameters"
8 | ],
9 | "metadata": {
10 | "collapsed": false
11 | }
12 | },
13 | {
14 | "cell_type": "code",
15 | "execution_count": null,
16 | "outputs": [],
17 | "source": [
18 | "is_colab = True\n",
19 | "import sys\n",
20 | "\n",
21 | "if is_colab:\n",
22 | " !pip install -q torch==1.9.0\n",
23 | " !pip install -q torchvision==0.10.0\n",
24 | " !pip install -q qiskit==0.20.0\n",
25 | " !pip install qfnn\n",
26 | " !wget --no-check-certificate 'https://docs.google.com/uc?export=download&id=1w9VRv0iVfsH20Kb_MkF3yFhFeiYDVy5n' -O model.tar.gz\n",
27 | " !tar zxvf /content/model.tar.gz\n",
28 | "\n",
29 | "import torch\n",
30 | "\n",
31 | "from qiskit import QuantumCircuit, ClassicalRegister\n",
32 | "import functools\n",
33 | "\n",
34 | "\n",
35 | "from qfnn.qf_fb.q_output import fire_ibmq,analyze,add_measure\n",
36 | "from qfnn.qf_circ.p_lyr_circ import P_LYR_Circ,P_Neuron_Circ\n",
37 | "from qfnn.qf_fb.c_input import load_data,to_quantum_matrix\n",
38 | "\n",
39 | "from qfnn.qf_net.p_lyr import P_LYR\n",
40 | "import torch.nn as nn\n",
41 | "print = functools.partial(print, flush=True)\n"
42 | ],
43 | "metadata": {
44 | "collapsed": false,
45 | "pycharm": {
46 | "name": "#%%\n"
47 | }
48 | }
49 | },
50 | {
51 | "cell_type": "markdown",
52 | "source": [
53 | "## Inference\n",
54 | "### Get parameters\n",
55 | "\n",
56 | "At beginning, we need to extract the weights and related parameters\n",
57 | "from the model. These parameters will be used to build the quantum circuit."
58 | ],
59 | "metadata": {
60 | "collapsed": false
61 | }
62 | },
63 | {
64 | "cell_type": "code",
65 | "execution_count": null,
66 | "outputs": [],
67 | "source": [
68 | "# Model initialization\n",
69 | "weight_1 = torch.tensor([[1., -1., 1., 1.],[-1., 1., 1., 1.]]) # weights of layer 2\n",
70 | "weight_2 = torch.tensor([[1., -1.],[-1., -1.]]) # weights of layer 1\n",
71 | "input = [0,0,0,0] # input"
72 | ],
73 | "metadata": {
74 | "collapsed": false,
75 | "pycharm": {
76 | "name": "#%%\n"
77 | }
78 | }
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "source": [
83 | "### An example to implement a P-LYR based quantum neuron\n",
84 | "\n",
85 | "In the following cell, we will use *P_Neuron_Circ* to create the circuit for the\n",
86 | "quantum neuron designed based on P-LYR in [QuantumFlow](https://www.nature.com/articles/s41467-020-20729-5).\n",
87 | "\n",
88 | "**Note**: we will use the weight *weight_1* for embedding the weights to the circuit.\n"
89 | ],
90 | "metadata": {
91 | "collapsed": false
92 | }
93 | },
94 | {
95 | "cell_type": "code",
96 | "execution_count": null,
97 | "outputs": [],
98 | "source": [
99 | "#create circuit\n",
100 | "circuit_demo = QuantumCircuit()\n",
101 | "\n",
102 | "#init circuit\n",
103 | "p_layer_example = P_Neuron_Circ(4)\n",
104 | "\n",
105 | "#create qubits to be invovled and store them\n",
106 | "inps = p_layer_example.add_input_qubits(circuit_demo,'p_input')\n",
107 | "aux =p_layer_example.add_aux(circuit_demo,'aux_qubit')\n",
108 | "output = p_layer_example.add_out_qubits(circuit_demo,'p_out_qubit')\n",
109 | "\n",
110 | "#add p-neuron to the circuit\n",
111 | "p_layer_example.forward(circuit_demo,[weight_1[0]],inps[0],output,aux,input)\n",
112 | "\n",
113 | "#show your circuit\n",
114 | "circuit_demo.draw('text',fold=300)"
115 | ],
116 | "metadata": {
117 | "collapsed": false,
118 | "pycharm": {
119 | "name": "#%%\n"
120 | }
121 | }
122 | },
123 | {
124 | "cell_type": "markdown",
125 | "source": [
126 | "### Build the QF-pNet network\n",
127 | "\n",
128 | "In the following cell, we build the first layer of the QF-pNet using the qfnn library."
129 | ],
130 | "metadata": {
131 | "collapsed": false
132 | }
133 | },
134 | {
135 | "cell_type": "code",
136 | "execution_count": null,
137 | "outputs": [],
138 | "source": [
139 | "input_list = []\n",
140 | "aux_list = []\n",
141 | "output_list = []\n",
142 | "circuit = QuantumCircuit()\n",
143 | "for i in range(2):\n",
144 | " #init circuit\n",
145 | " p_layer = P_Neuron_Circ(4)\n",
146 | "\n",
147 | " #create and store qubits\n",
148 | " inps = p_layer.add_input_qubits(circuit,'p'+str(i)+\"_input\")\n",
149 | " aux =p_layer.add_aux(circuit,'aux'+str(i)+\"_qubit\")\n",
150 | " output = p_layer.add_out_qubits(circuit,'p_out_'+str(i)+\"_qubit\")\n",
151 | "\n",
152 | " input_list.append(inps)\n",
153 | " aux_list.append(aux)\n",
154 | " output_list.append(output)\n",
155 | "\n",
156 | " #add p-neuron to your circuit\n",
157 | " p_layer.forward(circuit,[weight_1[i]],input_list[i][0],output_list[i],aux_list[i],input)\n",
158 | "\n",
159 | "circuit.barrier()\n",
160 | "circuit.draw('text',fold=300)\n"
161 | ],
162 | "metadata": {
163 | "collapsed": false,
164 | "pycharm": {
165 | "name": "#%%\n"
166 | }
167 | }
168 | },
169 | {
170 | "cell_type": "markdown",
171 | "source": [
172 | "Now, we have a one-layer neural network. In the next step, we will on top\n",
173 | "of this layer to add an output layer to the built quantum circuit.\n",
174 | "\n",
175 | "As pointed by [QuantumFlow](https://www.nature.com/articles/s41467-020-20729-5),\n",
176 | "the last layer can share the inputs. We will use *P_LYR_Circ* for the implementation,\n",
177 | "where the first parameter shows how many neurons for the input, and the second\n",
178 | "parameter shows how many neurons for the output.\n",
179 | "\n",
180 | "**Note:** since the input of this layer is the output of the previous layer,\n",
181 | "we do not need new input qubits. But, we will need an addition output qubits, which\n",
182 | "can be obtained by using the *add_out_qubits* method."
183 | ],
184 | "metadata": {
185 | "collapsed": false
186 | }
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": null,
191 | "outputs": [],
192 | "source": [
193 | "p_layer = P_LYR_Circ(2,2)\n",
194 | "\n",
195 | "# Create output qubits\n",
196 | "p_layer_output = p_layer.add_out_qubits(circuit)\n",
197 | "\n",
198 | "# Build the second layer\n",
199 | "p_layer.forward(circuit,weight_2,output_list,p_layer_output)\n",
200 | "\n",
201 | "# Extract the results at the end of the quantum circuit\n",
202 | "add_measure(circuit,p_layer_output,'reg')\n",
203 | "print(\"Output layer created!\")\n",
204 | "\n",
205 | "circuit.draw('text',fold=300)"
206 | ],
207 | "metadata": {
208 | "collapsed": false,
209 | "pycharm": {
210 | "name": "#%%\n"
211 | }
212 | }
213 | },
214 | {
215 | "cell_type": "markdown",
216 | "source": [
217 | "### simulation"
218 | ],
219 | "metadata": {
220 | "collapsed": false
221 | }
222 | },
223 | {
224 | "cell_type": "code",
225 | "execution_count": null,
226 | "outputs": [],
227 | "source": [
228 | "# result\n",
229 | "qc_shots=8192\n",
230 | "opt_counts = fire_ibmq(circuit,qc_shots,True)\n",
231 | "(opt_mycount,bits) = analyze(opt_counts)\n",
232 | "opt_class_prob=[]\n",
233 | "for b in range(bits):\n",
234 | " opt_class_prob.append(float(opt_mycount[b])/qc_shots)\n",
235 | "print(\"Simukation Result :\",opt_class_prob)"
236 | ],
237 | "metadata": {
238 | "collapsed": false,
239 | "pycharm": {
240 | "name": "#%%\n"
241 | }
242 | }
243 | },
244 | {
245 | "cell_type": "markdown",
246 | "source": [
247 | "### classical inference"
248 | ],
249 | "metadata": {
250 | "collapsed": false
251 | }
252 | },
253 | {
254 | "cell_type": "code",
255 | "execution_count": null,
256 | "outputs": [],
257 | "source": [
258 | "class Net(nn.Module):\n",
259 | " def __init__(self):\n",
260 | " super(Net, self).__init__()\n",
261 | " self.fc1 =P_LYR(4, 2, bias=False)\n",
262 | " self.fc2 =P_LYR(2, 2, bias=False)\n",
263 | " def forward(self,x):\n",
264 | " x = self.fc1(x)\n",
265 | " x = self.fc2(x)\n",
266 | " return x\n",
267 | "\n",
268 | "model = Net()\n",
269 | "\n",
270 | "state_dict= model.state_dict()\n",
271 | "state_dict[\"fc1.weight\"] = weight_1\n",
272 | "state_dict[\"fc2.weight\"] = weight_2\n",
273 | "model.load_state_dict(state_dict)\n",
274 | "\n",
275 | "state = torch.tensor([[0,0,0,0]],dtype= torch.float)\n",
276 | "output = model.forward(state)\n",
277 | "print(\"classical inference Result :\",output)"
278 | ],
279 | "metadata": {
280 | "collapsed": false,
281 | "pycharm": {
282 | "name": "#%%\n"
283 | }
284 | }
285 | }
286 | ],
287 | "metadata": {
288 | "kernelspec": {
289 | "display_name": "Python 3",
290 | "language": "python",
291 | "name": "python3"
292 | },
293 | "language_info": {
294 | "codemirror_mode": {
295 | "name": "ipython",
296 | "version": 2
297 | },
298 | "file_extension": ".py",
299 | "mimetype": "text/x-python",
300 | "name": "python",
301 | "nbconvert_exporter": "python",
302 | "pygments_lexer": "ipython2",
303 | "version": "2.7.6"
304 | }
305 | },
306 | "nbformat": 4,
307 | "nbformat_minor": 0
308 | }
--------------------------------------------------------------------------------
/session_3/EX_2_QF_hNet.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "source": [
6 | "# How to build the h-net\n",
7 | "## Prepare environment and define parameters"
8 | ],
9 | "metadata": {
10 | "collapsed": false
11 | }
12 | },
13 | {
14 | "cell_type": "code",
15 | "execution_count": null,
16 | "outputs": [],
17 | "source": [
18 | "is_colab = True\n",
19 | "import sys\n",
20 | "if is_colab:\n",
21 | " !pip install -q torch==1.9.0\n",
22 | " !pip install -q torchvision==0.10.0\n",
23 | " !pip install -q qiskit==0.20.0\n",
24 | " !pip install qfnn\n",
25 | " !wget --no-check-certificate 'https://docs.google.com/uc?export=download&id=1w9VRv0iVfsH20Kb_MkF3yFhFeiYDVy5n' -O model.tar.gz\n",
26 | " !tar zxvf /content/model.tar.gz\n",
27 | "\n",
28 | "import torch\n",
29 | "import torchvision\n",
30 | "\n",
31 | "import qiskit\n",
32 | "from qiskit import QuantumCircuit, ClassicalRegister\n",
33 | "import numpy as np\n",
34 | "import functools\n",
35 | "\n",
36 | "\n",
37 | "from qfnn.qf_fb.q_output import fire_ibmq,analyze,add_measure\n",
38 | "from qfnn.qf_circ.n_lyr_circ import N_LYR_Circ\n",
39 | "from qfnn.qf_circ.u_lyr_circ import U_LYR_Circ\n",
40 | "from qfnn.qf_circ.p_lyr_circ import P_LYR_Circ\n",
41 | "from qfnn.qf_fb.c_input import load_data,to_quantum_matrix\n",
42 | "from qfnn.qf_net.utils import binarize\n",
43 | "from qfnn.qf_fb.c_qf_mixer import Net\n",
44 | "from qfnn.qf_fb.c_input import ToQuantumData\n",
45 | "print = functools.partial(print, flush=True)"
46 | ],
47 | "metadata": {
48 | "collapsed": false,
49 | "pycharm": {
50 | "name": "#%%\n"
51 | }
52 | }
53 | },
54 | {
55 | "cell_type": "markdown",
56 | "source": [
57 | "## Inference\n",
58 | "### Input data preparation\n",
59 | "\n",
60 | "In this example, we will use MNIST dataset for demonstrating how the neural network\n",
61 | "runs on a quantum circuit.\n",
62 | "\n",
63 | "So, the first step is to load data from the MNIST. There are serveral points to be\n",
64 | " noted.\n",
65 | "\n",
66 | "* The model trained for demonstration is based on the subset of MNSIT with digits 3 and 6.\n",
67 | "* The input is down sampled to 4 by 4 to be executed on 4 qubits (which has 2^4=16 states)."
68 | ],
69 | "metadata": {
70 | "collapsed": false
71 | }
72 | },
73 | {
74 | "cell_type": "code",
75 | "execution_count": null,
76 | "outputs": [],
77 | "source": [
78 | "interest_num = [3,6]\n",
79 | "img_size = 4\n",
80 | "batch_size = 32\n",
81 | "inference_batch_size = 1\n",
82 | "\n",
83 | "if is_colab:\n",
84 | " data_path = '/content/data' #mnist path\n",
85 | "else:\n",
86 | " data_path = 'Your path for data' #mnist path\n",
87 | "\n",
88 | "train_loader, test_loader = load_data(interest_num,data_path,False,img_size,batch_size,inference_batch_size,False)\n",
89 | "for batch_idx, (data, target) in enumerate(test_loader):\n",
90 | " torch.set_printoptions(threshold=sys.maxsize)\n",
91 | " print(\"Batch Id: {}, Target: {}\".format(batch_idx,target))\n",
92 | " quantum_matrix = to_quantum_matrix(data)\n",
93 | " break"
94 | ],
95 | "metadata": {
96 | "collapsed": false,
97 | "pycharm": {
98 | "name": "#%%\n"
99 | }
100 | }
101 | },
102 | {
103 | "cell_type": "markdown",
104 | "source": [
105 | "### load model\n",
106 | "\n",
107 | "We have trained the neural network model. Here, we need to extract the data from the\n",
108 | "model to the local variables, which will be used for building the quantum circuit."
109 | ],
110 | "metadata": {
111 | "collapsed": false
112 | }
113 | },
114 | {
115 | "cell_type": "code",
116 | "execution_count": null,
117 | "outputs": [],
118 | "source": [
119 | "if is_colab:\n",
120 | " resume_path = '/content/model/u2_p2/model_best.tar' #model path\n",
121 | "else:\n",
122 | " resume_path = 'Your path for model' #model path\n",
123 | "\n",
124 | "checkpoint = torch.load(resume_path, map_location='cpu')\n",
125 | "print(checkpoint['state_dict']['fc0.weight'])\n",
126 | "print(checkpoint['state_dict']['fc1.weight'])\n",
127 | "# print(checkpoint['state_dict']['fc2.batch.x_l_0_5'])\n",
128 | "# print(checkpoint['state_dict']['fc2.batch.x_g_0_5'])\n",
129 | "\n",
130 | "weight_1 = checkpoint['state_dict']['fc0.weight']\n",
131 | "weight_2 = checkpoint['state_dict']['fc1.weight']\n",
132 | "# norm_flag = checkpoint['state_dict']['fc2.batch.x_l_0_5']\n",
133 | "# norm_para = checkpoint['state_dict']['fc2.batch.x_running_rot']\n",
134 | "# print(norm_para)"
135 | ],
136 | "metadata": {
137 | "collapsed": false,
138 | "pycharm": {
139 | "name": "#%%\n"
140 | }
141 | }
142 | },
143 | {
144 | "cell_type": "markdown",
145 | "source": [
146 | "## Build the QF-pNet network\n",
147 | "\n",
148 | "In the following cell, we build the first layer of the QF-hNet using the qfnn library.\n"
149 | ],
150 | "metadata": {
151 | "collapsed": false
152 | }
153 | },
154 | {
155 | "cell_type": "code",
156 | "execution_count": null,
157 | "outputs": [],
158 | "source": [
159 | "################ Weiwen on 12-30-2020 ################\n",
160 | "# Generate the circuit of u-layer\n",
161 | "######################################################\n",
162 | "#create circuit\n",
163 | "circuit = QuantumCircuit()\n",
164 | "\n",
165 | "#init circuit, which is corresponding to a neuron with 4 qubits and 2 outputs\n",
166 | "u_layer = U_LYR_Circ(4,2)\n",
167 | "\n",
168 | "#create qubits to be invovled\n",
169 | "inps = u_layer.add_input_qubits(circuit)\n",
170 | "aux =u_layer.add_aux(circuit)\n",
171 | "u_layer_out_qubits = u_layer.add_out_qubits(circuit)\n",
172 | "\n",
173 | "#add u-layer to your circuit\n",
174 | "u_layer.forward(circuit,binarize(weight_1) ,inps,u_layer_out_qubits,quantum_matrix,aux)\n",
175 | "\n",
176 | "#show your circuit\n",
177 | "circuit.barrier()\n",
178 | "circuit.draw('text',fold=300)"
179 | ],
180 | "metadata": {
181 | "collapsed": false,
182 | "pycharm": {
183 | "name": "#%%\n"
184 | }
185 | }
186 | },
187 | {
188 | "cell_type": "markdown",
189 | "source": [
190 | "Now, we have a one-layer neural network with U-LYR. In the next step, we will on top\n",
191 | "of this layer to add an output layer, which is based on P-LYR, to the built\n",
192 | "quantum circuit of QF-hN."
193 | ],
194 | "metadata": {
195 | "collapsed": false
196 | }
197 | },
198 | {
199 | "cell_type": "code",
200 | "execution_count": null,
201 | "outputs": [],
202 | "source": [
203 | "#add p-layer to your circuit\n",
204 | "p_layer = P_LYR_Circ(2,2)\n",
205 | "p_aux = p_layer.add_aux(circuit,\"p_aux\")\n",
206 | "p_layer_output = p_layer.add_out_qubits(circuit)\n",
207 | "p_layer.forward(circuit,binarize(weight_2),u_layer_out_qubits,p_layer_output,p_aux)\n",
208 | "\n",
209 | "# #add n-layer to your circuit\n",
210 | "# norm = N_LYR_Circ(2)\n",
211 | "# norm_qubit = norm.add_norm_qubits(circuit)\n",
212 | "# norm_output_qubit = norm.add_out_qubits(circuit)\n",
213 | "# norm.forward(circuit,p_layer_output,norm_qubit,norm_output_qubit,norm_flag,norm_para)\n",
214 | "\n",
215 | "#add measurement to your circuit\n",
216 | "add_measure(circuit,p_layer_output,'reg')\n",
217 | "\n",
218 | "print(\"Output layer created!\")\n",
219 | "\n",
220 | "circuit.draw('text',fold =300)"
221 | ],
222 | "metadata": {
223 | "collapsed": false,
224 | "pycharm": {
225 | "name": "#%%\n"
226 | }
227 | }
228 | },
229 | {
230 | "cell_type": "markdown",
231 | "source": [
232 | "### Quantum simulation"
233 | ],
234 | "metadata": {
235 | "collapsed": false
236 | }
237 | },
238 | {
239 | "cell_type": "code",
240 | "execution_count": null,
241 | "outputs": [],
242 | "source": [
243 | "################ Weiwen on 12-30-2020 ################\n",
244 | "# Quantum simulation\n",
245 | "######################################################\n",
246 | "\n",
247 | "qc_shots=8192\n",
248 | "opt_counts = fire_ibmq(circuit,qc_shots,True)\n",
249 | "(opt_mycount,bits) = analyze(opt_counts)\n",
250 | "opt_class_prob=[]\n",
251 | "for b in range(bits):\n",
252 | " opt_class_prob.append(float(opt_mycount[b])/qc_shots)\n",
253 | "\n",
254 | "\n",
255 | "print(\"Simulation Result :\",opt_class_prob)\n",
256 | "print(\"Prediction class: {}\".format(opt_class_prob.index(max(opt_class_prob))))\n",
257 | "print(\"Target class: {}\".format(target[0]))\n",
258 | "if opt_class_prob.index(max(opt_class_prob))==target[0]:\n",
259 | " print(\"Correct prediction\")\n",
260 | "else:\n",
261 | " print(\"Incorrect prediction\")\n",
262 | "print(\"=\"*30)"
263 | ],
264 | "metadata": {
265 | "collapsed": false,
266 | "pycharm": {
267 | "name": "#%%\n"
268 | }
269 | }
270 | },
271 | {
272 | "cell_type": "markdown",
273 | "source": [
274 | "### classical inference"
275 | ],
276 | "metadata": {
277 | "collapsed": false
278 | }
279 | },
280 | {
281 | "cell_type": "code",
282 | "execution_count": null,
283 | "outputs": [],
284 | "source": [
285 | "\n",
286 | "neural_in_layers = 'u:2,p:2'\n",
287 | "layers = []\n",
288 | "for item1 in neural_in_layers.split(\",\"):\n",
289 | " x= item1.split(\":\")\n",
290 | " layer =[]\n",
291 | " layer.append(x[0].strip())\n",
292 | " layer.append(int(x[1].strip()))\n",
293 | " layers.append(layer)\n",
294 | "given_ang =[]\n",
295 | "given_ang.append([])\n",
296 | "given_ang.append([])\n",
297 | "# given_ang.append(norm_para)\n",
298 | "model = Net(img_size,layers,False,False,given_ang,False)\n",
299 | "model.load_state_dict(checkpoint[\"state_dict\"])\n",
300 | "# print(quantum_matrix)\n",
301 | "to_quantum_data = ToQuantumData(img_size)\n",
302 | "output_data = to_quantum_data(data)\n",
303 | "output = model.forward(output_data,False)\n",
304 | "print(\"classical inference:\",output)"
305 | ],
306 | "metadata": {
307 | "collapsed": false,
308 | "pycharm": {
309 | "name": "#%%\n"
310 | }
311 | }
312 | }
313 | ],
314 | "metadata": {
315 | "kernelspec": {
316 | "display_name": "Python 3",
317 | "language": "python",
318 | "name": "python3"
319 | },
320 | "language_info": {
321 | "codemirror_mode": {
322 | "name": "ipython",
323 | "version": 2
324 | },
325 | "file_extension": ".py",
326 | "mimetype": "text/x-python",
327 | "name": "python",
328 | "nbconvert_exporter": "python",
329 | "pygments_lexer": "ipython2",
330 | "version": "2.7.6"
331 | }
332 | },
333 | "nbformat": 4,
334 | "nbformat_minor": 0
335 | }
--------------------------------------------------------------------------------
/session_3/EX_3_QF_FB.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import time
3 | import torch
4 | import torch.nn as nn
5 | import os
6 | import sys
7 | from collections import Counter
8 | from pathlib import Path
9 | import qfnn
10 |
11 |
12 | from qfnn.qf_fb.c_input import load_data,modify_target
13 | from qfnn.qf_net.utils import binarize,save_checkpoint
14 | from qfnn.qf_fb.c_qf_mixer import Net
15 |
16 |
17 | # from qiskit_simulator_wbn import run_simulator
18 |
19 | import logging
20 | logging.basicConfig(stream=sys.stdout,
21 | level=logging.WARNING,
22 | format='%(asctime)s %(name)-12s %(levelname)-8s %(message)s')
23 | logger = logging.getLogger(__name__)
24 |
25 |
26 | def parse_args():
27 | parser = argparse.ArgumentParser(description='QuantumFlow Classification Training')
28 |
29 | # ML related
30 | parser.add_argument('--device', default='cpu', help='device')
31 | parser.add_argument('-c','--interest_class',default="3,6",help="investigate classes",)
32 | parser.add_argument('-s','--img_size', default="4", help="image size 4: 4*4", )
33 | parser.add_argument('-dp', '--datapath', default='data', help='dataset')
34 | parser.add_argument('-ppd', "--preprocessdata", help="Using the preprocessed data", action="store_true", )
35 | parser.add_argument('-j','--num_workers', default="0", help="worker to load data", )
36 | parser.add_argument('-tb','--batch_size', default="32", help="training batch size", )
37 | parser.add_argument('-ib','--inference_batch_size', default="1", help="inference batch size", )
38 | parser.add_argument('-nn','--neural_in_layers', default="u:4,p:2", help="QNN structrue :", )
39 |
40 | parser.add_argument('-l','--init_lr', default="0.01", help="PNN learning rate", )
41 | parser.add_argument('-m','--milestones', default=" 5, 7, 9", help="Training milestone", )
42 | parser.add_argument('-e','--max_epoch', default="2", help="Training epoch", )
43 | parser.add_argument('-r','--resume_path', default='', help='resume from checkpoint')
44 | parser.add_argument('-t',"--test_only", help="Only Test without Training", action="store_true", )
45 | parser.add_argument('-bin', "--binary",default=False , help="binary activation", action="store_true", )
46 |
47 | # QC related
48 | parser.add_argument('-qa',"--given_ang", default=" 1, 1, 1 1", help="ang amplify, the same size with --neural_in_layers",)
49 | parser.add_argument('-qt',"--train_ang",default=True , help="train anglee", action="store_true", )
50 |
51 |
52 | # File
53 | parser.add_argument('-chk',"--save_chkp",default=True , help="Save checkpoints", action="store_true", )
54 | parser.add_argument('-chkname', '--chk_name', default='u4_p2', help='folder name for chkpoint')
55 | parser.add_argument('-chkpath', '--chk_path', default='.', help='Root folder for chkpoint')
56 |
57 | args = parser.parse_args()
58 | return args
59 |
60 |
61 | def train(epoch,interest_num,criterion,train_loader):
62 | model.train()
63 | correct = 0
64 | epoch_loss = []
65 | for batch_idx, (data, target) in enumerate(train_loader):
66 | # data = ToQuantumData_Batch()(data)
67 | target, new_target = modify_target(target,interest_num)
68 |
69 | data, target = data.to(device), target.to(device)
70 | optimizer.zero_grad()
71 | output = model(data, True)
72 | # print("output",output)
73 |
74 | pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
75 | correct += pred.eq(target.data.view_as(pred)).cpu().sum()
76 |
77 | loss = criterion(output, target)
78 | epoch_loss.append(loss.item())
79 | loss.backward()
80 |
81 | optimizer.step()
82 |
83 | if batch_idx % 25 == 0:
84 | logger.info('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tAccuracy: {}/{} ({:.2f}%)'.format(
85 | epoch, batch_idx * len(data), len(train_loader.dataset),
86 | 100. * batch_idx / len(train_loader), loss, correct, (batch_idx + 1) * len(data),
87 | 100. * float(correct) / float(((batch_idx + 1) * len(data)))))
88 | print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tAccuracy: {}/{} ({:.2f}%)'.format(
89 | epoch, batch_idx * len(data), len(train_loader.dataset),
90 | 100. * batch_idx / len(train_loader), loss, correct, (batch_idx + 1) * len(data),
91 | 100. * float(correct) / float(((batch_idx + 1) * len(data)))))
92 | print("-" * 20, "training done, loss", "-" * 20)
93 | logger.info("Training Set: Average loss: {}".format(round(sum(epoch_loss) / len(epoch_loss), 6)))
94 |
95 |
96 | accur = []
97 |
98 | def test(interest_num,criterion,test_loader):
99 | model.eval()
100 | test_loss = 0
101 | correct = 0
102 | for data, target in test_loader:
103 | # data = ToQuantumData_Batch()(data)
104 | target, new_target = modify_target(target,interest_num)
105 | data, target = data.to(device), target.to(device)
106 | output = model(data, False)
107 | test_loss += criterion(output, target) # sum up batch loss
108 | pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
109 | correct += pred.eq(target.data.view_as(pred)).cpu().sum() # get the right number
110 |
111 | a = 100. * correct / len(test_loader.dataset)
112 | accur.append(a)
113 | test_loss /= len(test_loader.dataset)
114 | print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)'.format(
115 | test_loss, correct, len(test_loader.dataset),
116 | 100. * float(correct) / float(len(test_loader.dataset))))
117 |
118 | return float(correct) / len(test_loader.dataset)
119 |
120 |
121 |
122 |
123 |
124 | if __name__ == "__main__":
125 |
126 | print("=" * 100)
127 | print("Training procedure for Quantum Computer:")
128 | print("\tStart at:", time.strftime("%m/%d/%Y %H:%M:%S"))
129 | print("\tProblems and issues, please contact Dr. Weiwen Jiang (wjiang2@nd.edu)")
130 | print("\tEnjoy and Good Luck!")
131 | print("=" * 100)
132 | print()
133 |
134 | args = parse_args()
135 |
136 | datapath = args.datapath
137 | chkpath = args.chk_path
138 | isppd = args.preprocessdata
139 | device = args.device
140 | interest_class = [int(x.strip()) for x in args.interest_class.split(",")]
141 | img_size = int(args.img_size)
142 | num_workers = int(args.num_workers)
143 | batch_size = int(args.batch_size)
144 | inference_batch_size = int(args.inference_batch_size)
145 | given_ang = [[int(y) for y in x.strip().split(" ")] for x in args.given_ang.split(",")]
146 | train_ang = args.train_ang
147 | layers =[]
148 |
149 | for item1 in args.neural_in_layers.split(","):
150 | x= item1.split(":")
151 | layer =[]
152 | layer.append(x[0].strip())
153 | layer.append(int(x[1].strip()))
154 | layers.append(layer)
155 |
156 | print("layers:",layers)
157 |
158 | init_lr = float(args.init_lr)
159 | milestones = [int(x.strip()) for x in args.milestones.split(",")]
160 | max_epoch = int(args.max_epoch)
161 | resume_path = args.resume_path
162 | training = not(args.test_only)
163 | binary = args.binary
164 | # with_norm = args.with_norm
165 |
166 | save_chkp = args.save_chkp
167 | if save_chkp:
168 | if args.chk_name!="":
169 | save_path = chkpath + "/model/" + args.chk_name
170 | else:
171 | save_path = chkpath + "/model/" + os.path.basename(sys.argv[0]) + "_" + time.strftime("%Y_%m_%d-%H_%M_%S")
172 | Path(save_path).mkdir(parents=True, exist_ok=True)
173 |
174 | logger.info("Checkpoint path: {}".format(save_path))
175 | print(("Checkpoint path: {}".format(save_path)))
176 |
177 | if save_chkp:
178 | fh = open(save_path+"/config","w")
179 | print("=" * 21, "Your setting is listed as follows", "=" * 22, file=fh)
180 | print("\t{:<25} {:<15}".format('Attribute', 'Input'), file=fh)
181 | for k, v in vars(args).items():
182 | print("\t{:<25} {:<15}".format(k, v), file=fh)
183 | print("=" * 22, "Exploration will start, have fun", "=" * 22, file=fh)
184 | print("=" * 78, file=fh)
185 |
186 | print("=" * 21, "Your setting is listed as follows", "=" * 22)
187 | print("\t{:<25} {:<15}".format('Attribute', 'Input'))
188 | for k,v in vars(args).items():
189 | print("\t{:<25} {:<15}".format(k, v))
190 | print("=" * 22, "Exploration will start, have fun", "=" * 22)
191 | print("=" * 78)
192 |
193 |
194 | # Schedule train and test
195 |
196 | train_loader, test_loader = load_data(interest_class,datapath,isppd,img_size,batch_size,inference_batch_size,True,num_workers)
197 | criterion = nn.CrossEntropyLoss()
198 | model = Net(img_size,layers,training,binary,given_ang,train_ang)
199 | model = model.to(device)
200 |
201 | print(device)
202 | optimizer = torch.optim.Adam(model.parameters(),lr=init_lr)
203 |
204 | for item in model.parameters():
205 | print("model.parameter:",item)
206 |
207 | scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1)
208 | # print(resume_path,os.path.isfile(resume_path))
209 |
210 | if os.path.isfile(resume_path):
211 | print("=> loading checkpoint from '{}'<=".format(resume_path))
212 | checkpoint = torch.load(resume_path, map_location=device)
213 | epoch_init, acc = checkpoint["epoch"], checkpoint["acc"]
214 | model.load_state_dict(checkpoint["state_dict"])
215 |
216 |
217 | scheduler.load_state_dict(checkpoint["scheduler"])
218 | scheduler.milestones = Counter(milestones)
219 | optimizer.load_state_dict(checkpoint["optimizer"])
220 | else:
221 | epoch_init, acc = 0, 0
222 |
223 |
224 |
225 | if training:
226 | for epoch in range(epoch_init, max_epoch + 1):
227 | print("=" * 20, epoch, "epoch", "=" * 20)
228 | print("Epoch Start at:", time.strftime("%m/%d/%Y %H:%M:%S"))
229 |
230 | print("-" * 20, "learning rates", "-" * 20)
231 | for param_group in optimizer.param_groups:
232 | print(param_group['lr'], end=",")
233 | print()
234 |
235 | print("-" * 20, "training", "-" * 20)
236 | print("Trainign Start at:", time.strftime("%m/%d/%Y %H:%M:%S"))
237 | train(epoch,interest_class,criterion,train_loader)
238 | print("Trainign End at:", time.strftime("%m/%d/%Y %H:%M:%S"))
239 | print("-" * 60)
240 |
241 |
242 | print()
243 |
244 | print("-" * 20, "testing", "-" * 20)
245 | print("Testing Start at:", time.strftime("%m/%d/%Y %H:%M:%S"))
246 | cur_acc = test(interest_class,criterion,test_loader)
247 | print("Testing End at:", time.strftime("%m/%d/%Y %H:%M:%S"))
248 | print("-" * 60)
249 | print()
250 |
251 |
252 |
253 |
254 | scheduler.step()
255 |
256 | is_best = False
257 | if cur_acc > acc:
258 | is_best = True
259 | acc = cur_acc
260 |
261 | print("Best accuracy: {}; Current accuracy {}. Checkpointing".format(acc, cur_acc))
262 |
263 |
264 | if save_chkp:
265 | save_checkpoint({
266 | 'epoch': epoch + 1,
267 | 'acc': acc,
268 | 'state_dict': model.state_dict(),
269 | 'optimizer': optimizer.state_dict(),
270 | 'scheduler': scheduler.state_dict(),
271 | }, is_best, save_path, 'checkpoint_{}_{}.pth.tar'.format(epoch, round(cur_acc, 4)))
272 | print("Epoch End at:", time.strftime("%m/%d/%Y %H:%M:%S"))
273 | print("=" * 60)
274 | print()
275 | else:
276 | print("=" * 20, max_epoch, "Testing", "=" * 20)
277 | print("=" * 100)
278 | for name, para in model.named_parameters():
279 | if "fc" in name:
280 | print(name,binarize(para))
281 | else:
282 | print(name, para)
283 | print("="*100)
284 |
285 | q_start = time.time()
286 | test(interest_class, criterion, test_loader)
287 | q_end = time.time()
288 |
289 | print(q_start-q_end)
290 |
291 |
292 |
293 |
294 |
--------------------------------------------------------------------------------
/session_3/EX_4_FFNN.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "source": [
6 | "# How to build FFNN (f-lyr + p-lyr)"
7 | ],
8 | "metadata": {
9 | "collapsed": false,
10 | "pycharm": {
11 | "name": "#%% md\n"
12 | }
13 | }
14 | },
15 | {
16 | "cell_type": "markdown",
17 | "source": [
18 | "## Prepare environment and define parameters "
19 | ],
20 | "metadata": {}
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": null,
25 | "source": [
26 | "is_colab = True\n",
27 | "import sys\n",
28 | "if is_colab:\n",
29 | " !pip install -q torch==1.9.0\n",
30 | " !pip install -q torchvision==0.10.0\n",
31 | " !pip install -q qiskit==0.20.0\n",
32 | " !pip install qfnn\n",
33 | " !wget --no-check-certificate 'https://docs.google.com/uc?export=download&id=1w9VRv0iVfsH20Kb_MkF3yFhFeiYDVy5n' -O model.tar.gz\n",
34 | " !tar zxvf /content/model.tar.gz\n",
35 | "\n",
36 | "import torch\n",
37 | "from qiskit import QuantumCircuit\n",
38 | "import functools\n",
39 | "import qfnn\n",
40 | "from qfnn.qf_fb.q_output import fire_ibmq,analyze,add_measure\n",
41 | "from qfnn.qf_circ.f_lyr_circ import F_LYR_Circ\n",
42 | "from qfnn.qf_circ.p_lyr_circ import P_LYR_Circ\n",
43 | "from qfnn.qf_net.utils import binarize\n",
44 | "from qfnn.qf_fb.q_input import UMatrixCircuit\n",
45 | "from qfnn.qf_fb.c_input import load_data,to_quantum_matrix\n",
46 | "\n",
47 | "print = functools.partial(print, flush=True)\n",
48 | "\n",
49 | "################ Zhirui on 12-30-2020 ################\n",
50 | "# path \n",
51 | "# remember to change the path on your computer\n",
52 | "######################################################\n",
53 | "if is_colab:\n",
54 | " data_path = '/content/data' #mnist path\n",
55 | " resume_path = '/content/model/u2_p2/model_best.tar' #model path\n",
56 | "else:\n",
57 | " data_path = 'your local path' #mnist path\n",
58 | " resume_path = 'your local path' #model path\n"
59 | ],
60 | "outputs": [],
61 | "metadata": {
62 | "collapsed": false,
63 | "pycharm": {
64 | "name": "#%%\n",
65 | "is_executing": true
66 | }
67 | }
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": null,
72 | "source": [
73 | "\n",
74 | "################ Zhirui on 12-30-2020 ################\n",
75 | "# Parameters of settings\n",
76 | "######################################################\n",
77 | "interest_num = [3,6]\n",
78 | "img_size = 4\n",
79 | "batch_size = 1# how many samples per batch to load\n",
80 | "inference_batch_size = 1\n",
81 | "isppd = False #is prepared data\n"
82 | ],
83 | "outputs": [],
84 | "metadata": {}
85 | },
86 | {
87 | "cell_type": "markdown",
88 | "source": [
89 | "## Load data"
90 | ],
91 | "metadata": {}
92 | },
93 | {
94 | "cell_type": "code",
95 | "execution_count": null,
96 | "source": [
97 | "train_loader, test_loader = load_data(interest_num,data_path,isppd,img_size,batch_size,inference_batch_size,False)\n",
98 | "\n",
99 | "\n",
100 | "for batch_idx, (data, target) in enumerate(test_loader):\n",
101 | " torch.set_printoptions(threshold=sys.maxsize)\n",
102 | " print(\"Batch Id: {}, Target: {}\".format(batch_idx,target))\n",
103 | " quantum_matrix = to_quantum_matrix(data)\n",
104 | " break"
105 | ],
106 | "outputs": [],
107 | "metadata": {}
108 | },
109 | {
110 | "cell_type": "markdown",
111 | "source": [
112 | "## Inference"
113 | ],
114 | "metadata": {}
115 | },
116 | {
117 | "cell_type": "code",
118 | "execution_count": null,
119 | "source": [
120 | "################ hzr on 12-30-2020 ################\n",
121 | "# Get the parameters of the trained model\n",
122 | "######################################################\n",
123 | "\n",
124 | "# Model initialization\n",
125 | "checkpoint = torch.load(resume_path, map_location='cpu')\n",
126 | "print(checkpoint['state_dict']['fc0.weight'])\n",
127 | "print(checkpoint['state_dict']['fc1.weight'])\n",
128 | "weight_1 = checkpoint['state_dict']['fc0.weight']\n",
129 | "weight_2 = checkpoint['state_dict']['fc1.weight']\n"
130 | ],
131 | "outputs": [],
132 | "metadata": {
133 | "collapsed": false,
134 | "pycharm": {
135 | "name": "#%%\n",
136 | "is_executing": true
137 | }
138 | }
139 | },
140 | {
141 | "cell_type": "markdown",
142 | "source": [
143 | "### data encoding"
144 | ],
145 | "metadata": {}
146 | },
147 | {
148 | "cell_type": "code",
149 | "execution_count": null,
150 | "source": [
151 | "################ hzr on 12-30-2020 ################\n",
152 | "# Generate the circuit of u-Matrix()\n",
153 | "######################################################\n",
154 | "\n",
155 | "#init circuit\n",
156 | "circuit = QuantumCircuit()\n",
157 | "#define your input and repeat number\n",
158 | "u_mat = UMatrixCircuit(4,4)\n",
159 | "#add input qubit to your circuit if needed\n",
160 | "inputs = u_mat.add_input_qubits(circuit)\n",
161 | "#add u-matrix to your circuit\n",
162 | "u_mat.forward(circuit,inputs,quantum_matrix)"
163 | ],
164 | "outputs": [],
165 | "metadata": {}
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "source": [
170 | "### the first layer"
171 | ],
172 | "metadata": {}
173 | },
174 | {
175 | "cell_type": "code",
176 | "execution_count": null,
177 | "source": [
178 | "################ hzr on 12-30-2020 ################\n",
179 | "# Generate the circuit of f-layer\n",
180 | "######################################################\n",
181 | "\n",
182 | "#define your input and repeat number\n",
183 | "f_layer = F_LYR_Circ(4,2)\n",
184 | "\n",
185 | "#add qubits to your circuit if needed\n",
186 | "aux = f_layer.add_aux(circuit)\n",
187 | "f_layer_out_qubits = f_layer.add_out_qubits(circuit)\n",
188 | "\n",
189 | "#add f-layer to your circuit\n",
190 | "f_layer.forward(circuit,binarize(weight_1),inputs,f_layer_out_qubits,None,aux)\n",
191 | "\n",
192 | "circuit.barrier()\n",
193 | "\n",
194 | "circuit.draw('text',fold=300)"
195 | ],
196 | "outputs": [],
197 | "metadata": {
198 | "collapsed": false,
199 | "pycharm": {
200 | "name": "#%%\n",
201 | "is_executing": true
202 | }
203 | }
204 | },
205 | {
206 | "cell_type": "markdown",
207 | "source": [
208 | "### the second layer"
209 | ],
210 | "metadata": {}
211 | },
212 | {
213 | "cell_type": "code",
214 | "execution_count": null,
215 | "source": [
216 | "################ Weiwen on 12-30-2020 ################\n",
217 | "# Generate the circuit of p-layer\n",
218 | "######################################################\n",
219 | "\n",
220 | "#define your input and repeat number\n",
221 | "p_layer = P_LYR_Circ(2,2)\n",
222 | "\n",
223 | "#add output qubit to your circuit if needed\n",
224 | "p_layer_output = p_layer.add_out_qubits(circuit)\n",
225 | "\n",
226 | "#add p-layer to your circuit\n",
227 | "p_layer.forward(circuit,binarize(weight_2),f_layer_out_qubits,p_layer_output)\n",
228 | "\n",
229 | "#add measurement to your circuit if needed\n",
230 | "add_measure(circuit,p_layer_output,'reg')\n",
231 | "\n",
232 | "circuit.draw('text',fold=300)\n",
233 | "\n"
234 | ],
235 | "outputs": [],
236 | "metadata": {}
237 | },
238 | {
239 | "cell_type": "markdown",
240 | "source": [
241 | "### simulation\n",
242 | "\n"
243 | ],
244 | "metadata": {
245 | "collapsed": false
246 | }
247 | },
248 | {
249 | "cell_type": "code",
250 | "execution_count": null,
251 | "source": [
252 | "################ Weiwen on 12-30-2020 ################\n",
253 | "# Quantum simulation\n",
254 | "######################################################\n",
255 | "\n",
256 | "\n",
257 | "qc_shots=8192\n",
258 | "opt_counts = fire_ibmq(circuit,qc_shots,True)\n",
259 | "(opt_mycount,bits) = analyze(opt_counts)\n",
260 | "opt_class_prob=[]\n",
261 | "for b in range(bits):\n",
262 | " opt_class_prob.append(float(opt_mycount[b])/qc_shots)\n",
263 | "\n",
264 | "\n",
265 | "print(\"Simulation Result :\",opt_class_prob)\n",
266 | "print(\"Prediction class: {}\".format(opt_class_prob.index(max(opt_class_prob))))\n",
267 | "print(\"Target class: {}\".format(target[0]))\n",
268 | "if opt_class_prob.index(max(opt_class_prob))==target[0]:\n",
269 | " print(\"Correct prediction\")\n",
270 | "else:\n",
271 | " print(\"Incorrect prediction\")\n",
272 | "print(\"=\"*30)"
273 | ],
274 | "outputs": [],
275 | "metadata": {
276 | "collapsed": false,
277 | "pycharm": {
278 | "name": "#%%\n",
279 | "is_executing": true
280 | }
281 | }
282 | },
283 | {
284 | "cell_type": "markdown",
285 | "source": [
286 | "### classical inference"
287 | ],
288 | "metadata": {}
289 | },
290 | {
291 | "cell_type": "code",
292 | "execution_count": null,
293 | "source": [
294 | "\n",
295 | "from qfnn.qf_fb.c_qf_mixer import Net\n",
296 | "from qfnn.qf_fb.c_input import ToQuantumData\n",
297 | "neural_in_layers = 'u:2,p:2'\n",
298 | "layers = []\n",
299 | "for item1 in neural_in_layers.split(\",\"):\n",
300 | " x= item1.split(\":\")\n",
301 | " layer =[]\n",
302 | " layer.append(x[0].strip())\n",
303 | " layer.append(int(x[1].strip()))\n",
304 | " layers.append(layer)\n",
305 | "\n",
306 | "print(\"layers:\",layers)\n",
307 | "model = Net(img_size,layers,False,False)\n",
308 | "model.load_state_dict(checkpoint[\"state_dict\"])\n",
309 | "\n",
310 | "to_quantum_data = ToQuantumData(img_size)\n",
311 | "output_data = to_quantum_data(data)\n",
312 | "output = model.forward(output_data,False)\n",
313 | "print(\"Simulation Result:\",output)"
314 | ],
315 | "outputs": [],
316 | "metadata": {}
317 | }
318 | ],
319 | "metadata": {
320 | "kernelspec": {
321 | "name": "python3",
322 | "display_name": "Python 3.8.10 64-bit ('qf': conda)"
323 | },
324 | "language_info": {
325 | "name": "python",
326 | "version": "3.8.10",
327 | "mimetype": "text/x-python",
328 | "codemirror_mode": {
329 | "name": "ipython",
330 | "version": 3
331 | },
332 | "pygments_lexer": "ipython3",
333 | "nbconvert_exporter": "python",
334 | "file_extension": ".py"
335 | },
336 | "interpreter": {
337 | "hash": "f24048f0d5bdb0ff49c5e7c8a9899a65bc3ab13b0f32660a2227453ca6b95fd8"
338 | }
339 | },
340 | "nbformat": 4,
341 | "nbformat_minor": 2
342 | }
--------------------------------------------------------------------------------
/session_3/EX_5_VQC.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "source": [
6 | "# How to build the variance quantum circuit"
7 | ],
8 | "metadata": {
9 | "collapsed": false,
10 | "pycharm": {
11 | "name": "#%% md\n"
12 | }
13 | }
14 | },
15 | {
16 | "cell_type": "markdown",
17 | "source": [
18 | "## Prepare environment and define parameters "
19 | ],
20 | "metadata": {}
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": null,
25 | "source": [
26 | "is_colab = True\n",
27 | "import sys\n",
28 | "if is_colab:\n",
29 | " !pip install -q torch==1.9.0\n",
30 | " !pip install -q torchvision==0.10.0\n",
31 | " !pip install -q qiskit==0.20.0\n",
32 | " !pip install qfnn\n",
33 | " !wget --no-check-certificate 'https://docs.google.com/uc?export=download&id=1w9VRv0iVfsH20Kb_MkF3yFhFeiYDVy5n' -O model.tar.gz\n",
34 | " !tar zxvf /content/model.tar.gz\n",
35 | "\n",
36 | "\n",
37 | "import torch\n",
38 | "import torchvision\n",
39 | "\n",
40 | "import qiskit\n",
41 | "from qiskit import QuantumCircuit, ClassicalRegister\n",
42 | "import numpy as np\n",
43 | "import functools\n",
44 | "\n",
45 | "################ Zhirui on 12-30-2020 ################\n",
46 | "# path\n",
47 | "######################################################\n",
48 | "if is_colab:\n",
49 | " data_path = '/content/data' #mnist path\n",
50 | " resume_path = '/content/model/v16_v2/model_best.tar' #model path\n",
51 | "else:\n",
52 | " data_path = 'your local path' #mnist path\n",
53 | " resume_path = 'your local path' #model path\n"
54 | ],
55 | "outputs": [],
56 | "metadata": {
57 | "collapsed": false,
58 | "pycharm": {
59 | "name": "#%%\n",
60 | "is_executing": true
61 | }
62 | }
63 | },
64 | {
65 | "cell_type": "code",
66 | "execution_count": null,
67 | "source": [
68 | "from qfnn.qf_fb.q_output import fire_ibmq,analyze,add_measure\n",
69 | "from qfnn.qf_circ.v_lyr_circ import V_LYR_Circ\n",
70 | "from qfnn.qf_net.utils import binarize\n",
71 | "from qfnn.qf_fb.q_input import UMatrixCircuit\n",
72 | "from qfnn.qf_fb.c_input import load_data,to_quantum_matrix\n",
73 | "from qfnn.qf_fb.c_qf_mixer import Net\n",
74 | "from qfnn.qf_fb.c_input import ToQuantumData\n",
75 | "print = functools.partial(print, flush=True)\n",
76 | "\n",
77 | "\n",
78 | "\n",
79 | "################ Zhirui on 12-30-2020 ################\n",
80 | "# Parameters of settings\n",
81 | "######################################################\n",
82 | "interest_num = [3,6]\n",
83 | "ori_img_size = 28\n",
84 | "img_size = 4\n",
85 | "num_workers = 0 # number of subprocesses to use for data loading\n",
86 | "batch_size = 1# how many samples per batch to load\n",
87 | "inference_batch_size = 1\n",
88 | "isppd = False #is prepared data\n",
89 | "\n"
90 | ],
91 | "outputs": [],
92 | "metadata": {}
93 | },
94 | {
95 | "cell_type": "markdown",
96 | "source": [
97 | "## Load data"
98 | ],
99 | "metadata": {}
100 | },
101 | {
102 | "cell_type": "code",
103 | "execution_count": null,
104 | "source": [
105 | "train_loader, test_loader = load_data(interest_num,data_path,isppd,img_size,batch_size,inference_batch_size,False)\n",
106 | "\n",
107 | "\n",
108 | "for batch_idx, (data, target) in enumerate(test_loader):\n",
109 | " torch.set_printoptions(threshold=sys.maxsize)\n",
110 | " print(\"Batch Id: {}, Target: {}\".format(batch_idx,target))\n",
111 | " quantum_matrix = to_quantum_matrix(data)\n",
112 | " break"
113 | ],
114 | "outputs": [],
115 | "metadata": {}
116 | },
117 | {
118 | "cell_type": "markdown",
119 | "source": [
120 | "## Inference"
121 | ],
122 | "metadata": {}
123 | },
124 | {
125 | "cell_type": "code",
126 | "execution_count": null,
127 | "source": [
128 | "################ hzr on 12-30-2020 ################\n",
129 | "# Get the parameters of the trained model\n",
130 | "######################################################\n",
131 | "\n",
132 | "# Model initialization\n",
133 | "checkpoint = torch.load(resume_path, map_location='cpu')\n",
134 | "\n",
135 | "theta1 = checkpoint['state_dict']['fc0.theta']\n",
136 | "theta2 = checkpoint['state_dict']['fc1.theta']\n"
137 | ],
138 | "outputs": [],
139 | "metadata": {
140 | "collapsed": false,
141 | "pycharm": {
142 | "name": "#%%\n",
143 | "is_executing": true
144 | }
145 | }
146 | },
147 | {
148 | "cell_type": "markdown",
149 | "source": [
150 | "### data encoding"
151 | ],
152 | "metadata": {}
153 | },
154 | {
155 | "cell_type": "code",
156 | "execution_count": null,
157 | "source": [
158 | "################ hzr on 12-30-2020 ################\n",
159 | "# Generate the circuit of u-Matrix\n",
160 | "######################################################\n",
161 | "\n",
162 | "#init circuit\n",
163 | "circuit = QuantumCircuit()\n",
164 | "#define your input and repeat number\n",
165 | "u_mat = UMatrixCircuit(4,1)\n",
166 | "#add input qubit to your circuit if needed\n",
167 | "inputs = u_mat.add_input_qubits(circuit)\n",
168 | "#add u-matrix to your circuit\n",
169 | "u_mat.forward(circuit,inputs,quantum_matrix)"
170 | ],
171 | "outputs": [],
172 | "metadata": {}
173 | },
174 | {
175 | "cell_type": "markdown",
176 | "source": [
177 | "### build network"
178 | ],
179 | "metadata": {}
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": null,
184 | "source": [
185 | "################ hzr on 12-30-2020 ################\n",
186 | "# Generate the circuit of v-layer\n",
187 | "######################################################\n",
188 | "\n",
189 | "#define your input qubits\n",
190 | "vqc = V_LYR_Circ(4)\n",
191 | "#add the first v-layer to your circuit; We currently provide V10 and V5 only\n",
192 | "vqc.forward(circuit,inputs,'v10',np.array(theta1,dtype=np.double))\n",
193 | "#add the second v-layer to your circuit\n",
194 | "vqc.forward(circuit,inputs,'v10',np.array(theta2,dtype=np.double))\n",
195 | "\n",
196 | "circuit.barrier()\n",
197 | "#add measurement to your circuit if needed\n",
198 | "add_measure(circuit,[inputs[0][3],inputs[0][2]],'reg')\n",
199 | "\n",
200 | "circuit.draw('text',fold=300)"
201 | ],
202 | "outputs": [],
203 | "metadata": {}
204 | },
205 | {
206 | "cell_type": "markdown",
207 | "source": [
208 | "### Simulation"
209 | ],
210 | "metadata": {
211 | "collapsed": false
212 | }
213 | },
214 | {
215 | "cell_type": "code",
216 | "execution_count": null,
217 | "source": [
218 | "################ Weiwen on 12-30-2020 ################\n",
219 | "# Quantum simulation\n",
220 | "######################################################\n",
221 | "\n",
222 | "\n",
223 | "qc_shots=8192\n",
224 | "opt_counts = fire_ibmq(circuit,qc_shots,True)\n",
225 | "(opt_mycount,bits) = analyze(opt_counts)\n",
226 | "opt_class_prob=[]\n",
227 | "for b in range(bits):\n",
228 | " opt_class_prob.append(float(opt_mycount[b])/qc_shots)\n",
229 | "\n",
230 | "\n",
231 | "print(\"Simulation Result :\",opt_class_prob)\n",
232 | "print(\"Prediction class: {}\".format(opt_class_prob.index(max(opt_class_prob))))\n",
233 | "print(\"Target class: {}\".format(target[0]))\n",
234 | "if opt_class_prob.index(max(opt_class_prob))==target[0]:\n",
235 | " print(\"Correct prediction\")\n",
236 | "else:\n",
237 | " print(\"Incorrect prediction\")\n",
238 | "print(\"=\"*30)"
239 | ],
240 | "outputs": [],
241 | "metadata": {
242 | "collapsed": false,
243 | "pycharm": {
244 | "name": "#%%\n",
245 | "is_executing": true
246 | }
247 | }
248 | },
249 | {
250 | "cell_type": "markdown",
251 | "source": [
252 | "### classical inference"
253 | ],
254 | "metadata": {}
255 | },
256 | {
257 | "cell_type": "code",
258 | "execution_count": null,
259 | "source": [
260 | "\n",
261 | "neural_in_layers = 'v:16,v:2'\n",
262 | "layers = []\n",
263 | "for item1 in neural_in_layers.split(\",\"):\n",
264 | " x= item1.split(\":\")\n",
265 | " layer =[]\n",
266 | " layer.append(x[0].strip())\n",
267 | " layer.append(int(x[1].strip()))\n",
268 | " layers.append(layer)\n",
269 | "\n",
270 | "model = Net(img_size,layers,False,False)\n",
271 | "model.load_state_dict(checkpoint[\"state_dict\"])\n",
272 | "\n",
273 | "to_quantum_data = ToQuantumData(img_size)\n",
274 | "output_data = to_quantum_data(data)\n",
275 | "output = model.forward(output_data,False)\n",
276 | "print(\"classical inference:\",output)"
277 | ],
278 | "outputs": [],
279 | "metadata": {}
280 | }
281 | ],
282 | "metadata": {
283 | "kernelspec": {
284 | "name": "python3",
285 | "display_name": "Python 3.8.10 64-bit ('qf': conda)"
286 | },
287 | "language_info": {
288 | "name": "python",
289 | "version": "3.8.10",
290 | "mimetype": "text/x-python",
291 | "codemirror_mode": {
292 | "name": "ipython",
293 | "version": 3
294 | },
295 | "pygments_lexer": "ipython3",
296 | "nbconvert_exporter": "python",
297 | "file_extension": ".py"
298 | },
299 | "interpreter": {
300 | "hash": "f24048f0d5bdb0ff49c5e7c8a9899a65bc3ab13b0f32660a2227453ca6b95fd8"
301 | }
302 | },
303 | "nbformat": 4,
304 | "nbformat_minor": 2
305 | }
--------------------------------------------------------------------------------
/session_4/EX_6_QF_MixNN_V_U.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "source": [
6 | "# How to build the circuit of V-layer + U-layer "
7 | ],
8 | "metadata": {
9 | "collapsed": false,
10 | "pycharm": {
11 | "name": "#%% md\n"
12 | }
13 | }
14 | },
15 | {
16 | "cell_type": "markdown",
17 | "source": [
18 | "## Prepare environment and define parameters "
19 | ],
20 | "metadata": {}
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": null,
25 | "source": [
26 | "is_colab = True\n",
27 | "import sys\n",
28 | "if is_colab:\n",
29 | " !pip install -q torch==1.9.0\n",
30 | " !pip install -q torchvision==0.10.0\n",
31 | " !pip install -q qiskit==0.20.0\n",
32 | " !pip install qfnn\n",
33 | " !wget --no-check-certificate 'https://docs.google.com/uc?export=download&id=1w9VRv0iVfsH20Kb_MkF3yFhFeiYDVy5n' -O model.tar.gz\n",
34 | " !tar zxvf /content/model.tar.gz\n",
35 | "\n",
36 | "\n",
37 | "import torch\n",
38 | "from qiskit import QuantumCircuit, ClassicalRegister\n",
39 | "import numpy as np\n",
40 | "import functools\n",
41 | "from qfnn.qf_fb.q_output import fire_ibmq, analyze, add_measure\n",
42 | "from qfnn.qf_circ.f_lyr_circ import F_LYR_Circ\n",
43 | "from qfnn.qf_circ.v_lyr_circ import V_LYR_Circ\n",
44 | "from qfnn.qf_net.utils import binarize\n",
45 | "from qfnn.qf_fb.q_input import UMatrixCircuit\n",
46 | "from qfnn.qf_fb.c_input import load_data,to_quantum_matrix\n",
47 | "\n",
48 | "from qfnn.qf_fb.c_qf_mixer import Net\n",
49 | "from qfnn.qf_fb.c_input import ToQuantumData\n",
50 | "print = functools.partial(print, flush=True)\n",
51 | "################ Zhirui on 12-30-2020 ################\n",
52 | "# path\n",
53 | "# remember to change the path on your computer\n",
54 | "######################################################\n",
55 | "if is_colab:\n",
56 | " data_path = '/content/data' # mnist path\n",
57 | " resume_path = '/content/model/v16_u2/model_best.tar' # model path\n",
58 | "else:\n",
59 | " data_path = '/home/hzr/Software/quantum/qc_mnist/pytorch/data' # mnist path\n",
60 | " resume_path = '/home/hzr/Software/quantum/QuantumFlow_Tutorial/model/v16_u2/model_best.tar' # model path"
61 | ],
62 | "outputs": [],
63 | "metadata": {
64 | "collapsed": false,
65 | "pycharm": {
66 | "name": "#%%\n"
67 | }
68 | }
69 | },
70 | {
71 | "cell_type": "code",
72 | "execution_count": null,
73 | "source": [
74 | "################ Zhirui on 12-30-2020 ################\n",
75 | "# Parameters of settings\n",
76 | "######################################################\n",
77 | "interest_num = [3,6]\n",
78 | "img_size = 4\n",
79 | "batch_size = 1 # how many samples per batch to load\n",
80 | "inference_batch_size = 1\n",
81 | "isppd = False #is prepared data\n",
82 | "\n"
83 | ],
84 | "outputs": [],
85 | "metadata": {}
86 | },
87 | {
88 | "cell_type": "markdown",
89 | "source": [
90 | "## Load data"
91 | ],
92 | "metadata": {}
93 | },
94 | {
95 | "cell_type": "code",
96 | "execution_count": null,
97 | "source": [
98 | "train_loader, test_loader = load_data(interest_num, data_path, isppd, img_size, batch_size,inference_batch_size,False)\n",
99 | "\n",
100 | "\n",
101 | "for batch_idx, (data, target) in enumerate(test_loader):\n",
102 | " torch.set_printoptions(threshold=sys.maxsize)\n",
103 | " print(\"Batch Id: {}, Target: {}\".format(batch_idx,target))\n",
104 | " quantum_matrix = to_quantum_matrix(data)\n",
105 | " break"
106 | ],
107 | "outputs": [],
108 | "metadata": {}
109 | },
110 | {
111 | "cell_type": "markdown",
112 | "source": [
113 | "## Inference"
114 | ],
115 | "metadata": {}
116 | },
117 | {
118 | "cell_type": "markdown",
119 | "source": [
120 | "### load model parameter"
121 | ],
122 | "metadata": {}
123 | },
124 | {
125 | "cell_type": "code",
126 | "execution_count": null,
127 | "source": [
128 | "################ hzr on 12-30-2020 ################\n",
129 | "# Get the parameters of the trained model\n",
130 | "######################################################\n",
131 | "\n",
132 | "# Model initialization\n",
133 | "checkpoint = torch.load(resume_path, map_location='cpu')\n",
134 | "print(checkpoint['state_dict']['fc0.theta'])\n",
135 | "print(checkpoint['state_dict']['fc1.weight'])\n",
136 | "theta = checkpoint['state_dict']['fc0.theta']\n",
137 | "weight = checkpoint['state_dict']['fc1.weight']\n"
138 | ],
139 | "outputs": [],
140 | "metadata": {
141 | "collapsed": false,
142 | "pycharm": {
143 | "name": "#%%\n"
144 | }
145 | }
146 | },
147 | {
148 | "cell_type": "markdown",
149 | "source": [
150 | "### classical inference"
151 | ],
152 | "metadata": {}
153 | },
154 | {
155 | "cell_type": "code",
156 | "execution_count": null,
157 | "source": [
158 | "neural_in_layers = 'v:16,u:2'\n",
159 | "layers = []\n",
160 | "for item1 in neural_in_layers.split(\",\"):\n",
161 | " x= item1.split(\":\")\n",
162 | " layer =[]\n",
163 | " layer.append(x[0].strip())\n",
164 | " layer.append(int(x[1].strip()))\n",
165 | " layers.append(layer)\n",
166 | "print(layers)\n",
167 | "\n",
168 | "img_size = 4\n",
169 | "model = Net(img_size,layers,False,False)\n",
170 | "model.load_state_dict(checkpoint[\"state_dict\"])\n",
171 | "to_quantum_data = ToQuantumData(img_size)\n",
172 | "output_data = to_quantum_data(data)\n",
173 | "# output = model.forward(output_data,False)\n",
174 | "output = model(output_data, False)\n",
175 | "print(\"classical inference result:\",output)"
176 | ],
177 | "outputs": [],
178 | "metadata": {}
179 | },
180 | {
181 | "cell_type": "markdown",
182 | "source": [
183 | "### data encoding"
184 | ],
185 | "metadata": {}
186 | },
187 | {
188 | "cell_type": "code",
189 | "execution_count": null,
190 | "source": [
191 | "################ hzr on 12-30-2020 ################\n",
192 | "# Generate the circuit of u-Matrix\n",
193 | "######################################################\n",
194 | "\n",
195 | "#init circuit\n",
196 | "circuit = QuantumCircuit()\n",
197 | "#define your input and repeat number\n",
198 | "u_mat = UMatrixCircuit(4,2)\n",
199 | "#add input qubit to your circuit if needed\n",
200 | "inputs = u_mat.add_input_qubits(circuit)\n",
201 | "#add u-matrix to your circuit\n",
202 | "u_mat.forward(circuit,inputs,quantum_matrix)\n",
203 | "circuit.draw('text',fold=300)"
204 | ],
205 | "outputs": [],
206 | "metadata": {}
207 | },
208 | {
209 | "cell_type": "markdown",
210 | "source": [
211 | "### build the network on Quantum Circuit"
212 | ],
213 | "metadata": {
214 | "collapsed": false,
215 | "pycharm": {
216 | "name": "#%% md\n"
217 | }
218 | }
219 | },
220 | {
221 | "cell_type": "code",
222 | "source": [
223 | "################ hzr on 12-30-2020 ################\n",
224 | "# Generate the circuit of v-layer\n",
225 | "######################################################\n",
226 | "\n",
227 | "# define your input and repeat number\n",
228 | "vqc = V_LYR_Circ(4,2)\n",
229 | "# add v-layer to your circuit\n",
230 | "vqc.forward(circuit, inputs, 'v10', np.array(theta, dtype=np.double))\n",
231 | "\n",
232 | "circuit.draw('text',fold=300)"
233 | ],
234 | "metadata": {
235 | "collapsed": false,
236 | "pycharm": {
237 | "name": "#%%\n"
238 | }
239 | },
240 | "execution_count": null,
241 | "outputs": []
242 | },
243 | {
244 | "cell_type": "code",
245 | "execution_count": null,
246 | "source": [
247 | "################ hzr on 12-30-2020 ################\n",
248 | "# Generate the circuit of f-layer\n",
249 | "######################################################\n",
250 | "\n",
251 | "#define your input and repeat number\n",
252 | "f_layer = F_LYR_Circ(4,2)\n",
253 | "\n",
254 | "#add auxiliary qubit to your circuit if needed\n",
255 | "aux =f_layer.add_aux(circuit)\n",
256 | "\n",
257 | "#add output qubit to your circuit if needed\n",
258 | "f_layer_out_qubits = f_layer.add_out_qubits(circuit)\n",
259 | "\n",
260 | "#add f-layer to your circuit\n",
261 | "f_layer.forward(circuit,binarize(weight),inputs,f_layer_out_qubits,None,aux)\n",
262 | "\n",
263 | "#add measurement to your circuit if needed\n",
264 | "add_measure(circuit,f_layer_out_qubits,'reg')\n",
265 | "circuit.barrier()\n",
266 | "\n",
267 | "circuit.draw('text',fold=300)\n",
268 | "\n"
269 | ],
270 | "outputs": [],
271 | "metadata": {
272 | "collapsed": false,
273 | "pycharm": {
274 | "name": "#%%\n"
275 | }
276 | }
277 | },
278 | {
279 | "cell_type": "markdown",
280 | "source": [
281 | "### simulation\n"
282 | ],
283 | "metadata": {}
284 | },
285 | {
286 | "cell_type": "code",
287 | "execution_count": null,
288 | "source": [
289 | "################ Weiwen on 12-30-2020 ################\n",
290 | "# Quantum simulation\n",
291 | "######################################################\n",
292 | "\n",
293 | "\n",
294 | "qc_shots= 10000 # 8192\n",
295 | "opt_counts = fire_ibmq(circuit, qc_shots, True)\n",
296 | "(opt_mycount, bits) = analyze(opt_counts)\n",
297 | "opt_class_prob=[]\n",
298 | "for b in range(bits):\n",
299 | " opt_class_prob.append(float(opt_mycount[b])/qc_shots)\n",
300 | "\n",
301 | "\n",
302 | "print(\"Simulation Result :\",opt_class_prob)\n",
303 | "print(\"Prediction class: {}\".format(opt_class_prob.index(max(opt_class_prob))))\n",
304 | "print(\"Target class: {}\".format(target[0]))\n",
305 | "if opt_class_prob.index(max(opt_class_prob))==target[0]:\n",
306 | " print(\"Correct prediction\")\n",
307 | "else:\n",
308 | " print(\"Incorrect prediction\")\n",
309 | "print(\"=\"*30)"
310 | ],
311 | "outputs": [],
312 | "metadata": {}
313 | }
314 | ],
315 | "metadata": {
316 | "kernelspec": {
317 | "name": "python3",
318 | "display_name": "Python 3.8.10 64-bit ('qf': conda)"
319 | },
320 | "language_info": {
321 | "name": "python",
322 | "version": "3.8.10",
323 | "mimetype": "text/x-python",
324 | "codemirror_mode": {
325 | "name": "ipython",
326 | "version": 3
327 | },
328 | "pygments_lexer": "ipython3",
329 | "nbconvert_exporter": "python",
330 | "file_extension": ".py"
331 | },
332 | "interpreter": {
333 | "hash": "f24048f0d5bdb0ff49c5e7c8a9899a65bc3ab13b0f32660a2227453ca6b95fd8"
334 | }
335 | },
336 | "nbformat": 4,
337 | "nbformat_minor": 2
338 | }
--------------------------------------------------------------------------------
/session_4/EX_7_QF_MixNN_U_V.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "source": [
6 | "# How to build the circuit of U-layer + v-layer "
7 | ],
8 | "metadata": {
9 | "collapsed": false,
10 | "pycharm": {
11 | "name": "#%% md\n"
12 | }
13 | }
14 | },
15 | {
16 | "cell_type": "markdown",
17 | "source": [
18 | "## Prepare environment and define parameters "
19 | ],
20 | "metadata": {}
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": null,
25 | "source": [
26 | "is_colab = True\n",
27 | "import sys\n",
28 | "if is_colab:\n",
29 | " !pip install -q torch==1.9.0\n",
30 | " !pip install -q torchvision==0.10.0\n",
31 | " !pip install -q qiskit==0.20.0\n",
32 | " !pip install qfnn\n",
33 | " !wget --no-check-certificate 'https://docs.google.com/uc?export=download&id=1w9VRv0iVfsH20Kb_MkF3yFhFeiYDVy5n' -O model.tar.gz\n",
34 | " !tar zxvf /content/model.tar.gz\n",
35 | "\n",
36 | "import torch\n",
37 | "from qiskit import QuantumCircuit, ClassicalRegister\n",
38 | "import numpy as np\n",
39 | "import functools\n",
40 | "from qfnn.qf_fb.q_output import fire_ibmq,analyze,add_measure\n",
41 | "from qfnn.qf_circ.u_lyr_circ import U_LYR_Circ\n",
42 | "from qfnn.qf_circ.v_lyr_circ import V_LYR_Circ\n",
43 | "from qfnn.qf_net.utils import binarize\n",
44 | "from qfnn.qf_fb.c_input import load_data,to_quantum_matrix\n",
45 | "from qfnn.qf_fb.c_qf_mixer import Net\n",
46 | "from qfnn.qf_fb.c_input import ToQuantumData\n",
47 | "print = functools.partial(print, flush=True)\n",
48 | "\n",
49 | "################ Zhirui on 12-30-2020 ################\n",
50 | "# path\n",
51 | "# remember to change the path on your computer\n",
52 | "######################################################\n",
53 | "if is_colab:\n",
54 | " data_path = '/content/data' #mnist path\n",
55 | " resume_path = '/content/model/u4_v2/model_best.tar' #model path\n",
56 | "else:\n",
57 | " data_path = '/home/hzr/Software/quantum/qc_mnist/pytorch/data' #mnist path\n",
58 | " resume_path = '/home/hzr/Software/quantum/QuantumFlow_Tutorial/model/u4_v2/model_best.tar' #model path"
59 | ],
60 | "outputs": [],
61 | "metadata": {
62 | "collapsed": false,
63 | "pycharm": {
64 | "name": "#%%\n",
65 | "is_executing": true
66 | }
67 | }
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": null,
72 | "source": [
73 | "\n",
74 | "################ Zhirui on 12-30-2020 ################\n",
75 | "# Parameters of data settings\n",
76 | "######################################################\n",
77 | "interest_num = [3,6]\n",
78 | "img_size = 4\n",
79 | "batch_size = 32# how many samples per batch to load\n",
80 | "inference_batch_size = 1\n",
81 | "isppd = False #is prepared data\n"
82 | ],
83 | "outputs": [],
84 | "metadata": {}
85 | },
86 | {
87 | "cell_type": "markdown",
88 | "source": [
89 | "## Load data"
90 | ],
91 | "metadata": {}
92 | },
93 | {
94 | "cell_type": "code",
95 | "execution_count": null,
96 | "source": [
97 | "################ Zhirui on 12-30-2020 ################\n",
98 | "# load data.\n",
99 | "######################################################\n",
100 | "\n",
101 | "train_loader, test_loader = load_data(interest_num,data_path,isppd,img_size,batch_size,inference_batch_size,False)\n",
102 | "for batch_idx, (data, target) in enumerate(test_loader):\n",
103 | " torch.set_printoptions(threshold=sys.maxsize)\n",
104 | " print(\"Batch Id: {}, Target: {}\".format(batch_idx,target))\n",
105 | " quantum_matrix = to_quantum_matrix(data)\n",
106 | " break"
107 | ],
108 | "outputs": [],
109 | "metadata": {}
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "source": [
114 | "## Inference"
115 | ],
116 | "metadata": {}
117 | },
118 | {
119 | "cell_type": "markdown",
120 | "source": [
121 | "### load model parameter"
122 | ],
123 | "metadata": {}
124 | },
125 | {
126 | "cell_type": "code",
127 | "execution_count": null,
128 | "source": [
129 | "\n",
130 | "\n",
131 | "# Model initialization\n",
132 | "\n",
133 | "checkpoint = torch.load(resume_path, map_location='cpu')\n",
134 | "weight = checkpoint['state_dict']['fc0.weight']\n",
135 | "theta = checkpoint['state_dict']['fc2.theta']\n"
136 | ],
137 | "outputs": [],
138 | "metadata": {
139 | "collapsed": false,
140 | "pycharm": {
141 | "name": "#%%\n",
142 | "is_executing": true
143 | }
144 | }
145 | },
146 | {
147 | "cell_type": "markdown",
148 | "source": [
149 | "### Classical inference"
150 | ],
151 | "metadata": {}
152 | },
153 | {
154 | "cell_type": "code",
155 | "execution_count": null,
156 | "source": [
157 | "neural_in_layers = 'u:4,p2a:16,v:2'\n",
158 | "layers = []\n",
159 | "for item1 in neural_in_layers.split(\",\"):\n",
160 | " x= item1.split(\":\")\n",
161 | " layer =[]\n",
162 | " layer.append(x[0].strip())\n",
163 | " layer.append(int(x[1].strip()))\n",
164 | " layers.append(layer)\n",
165 | "print(layers)\n",
166 | "\n",
167 | "img_size = 4\n",
168 | "\n",
169 | "model = Net(img_size, layers, False, False)\n",
170 | "model.load_state_dict(checkpoint[\"state_dict\"])\n",
171 | "to_quantum_data = ToQuantumData(img_size)\n",
172 | "output_data = to_quantum_data(data)\n",
173 | "output = model(output_data,False)\n",
174 | "print(\"classical inference result :\",output)"
175 | ],
176 | "outputs": [],
177 | "metadata": {
178 | "collapsed": false,
179 | "pycharm": {
180 | "name": "#%%\n",
181 | "is_executing": true
182 | }
183 | }
184 | },
185 | {
186 | "cell_type": "markdown",
187 | "source": [
188 | "### build the network : the first layer :u-layer"
189 | ],
190 | "metadata": {}
191 | },
192 | {
193 | "cell_type": "code",
194 | "execution_count": null,
195 | "source": [
196 | "################ Weiwen on 12-30-2020 ################\n",
197 | "# Generate the circuit of u-layer\n",
198 | "######################################################\n",
199 | "\n",
200 | "#init circuit\n",
201 | "circuit = QuantumCircuit()\n",
202 | "\n",
203 | "#define your input and output number\n",
204 | "u_layer = U_LYR_Circ(4,4)\n",
205 | "\n",
206 | "#add input qubit to your circuit\n",
207 | "inps = u_layer.add_input_qubits(circuit)\n",
208 | "\n",
209 | "#add auxiliary qubit to your circuit\n",
210 | "aux =u_layer.add_aux(circuit)\n",
211 | "\n",
212 | "#add output qubit to your circuit\n",
213 | "u_layer_out_qubits = u_layer.add_out_qubits(circuit)\n",
214 | "\n",
215 | "#add u-layer to your circuit\n",
216 | "u_layer.forward(circuit,binarize(weight),inps,u_layer_out_qubits,quantum_matrix,aux)\n",
217 | "\n",
218 | "#add measurement\n",
219 | "circuit.barrier()\n",
220 | "add_measure(circuit,u_layer_out_qubits,'reg')\n",
221 | "\n",
222 | "#show your circuit\n",
223 | "circuit.draw('text',fold=300)\n",
224 | "\n"
225 | ],
226 | "outputs": [],
227 | "metadata": {
228 | "collapsed": false,
229 | "pycharm": {
230 | "name": "#%%\n",
231 | "is_executing": true
232 | }
233 | }
234 | },
235 | {
236 | "cell_type": "markdown",
237 | "source": [
238 | "### u-layer simulation"
239 | ],
240 | "metadata": {}
241 | },
242 | {
243 | "cell_type": "code",
244 | "execution_count": null,
245 | "source": [
246 | "################ hzr on 12-30-2020 ################\n",
247 | "# u-layer simulation\n",
248 | "######################################################\n",
249 | "\n",
250 | "qc_shots= 10000\n",
251 | "u_layer_counts = fire_ibmq(circuit,qc_shots,True)\n",
252 | "print(u_layer_counts)\n",
253 | "(u_layer_counts,u_layer_bits) = analyze(u_layer_counts)\n",
254 | "\n"
255 | ],
256 | "outputs": [],
257 | "metadata": {}
258 | },
259 | {
260 | "cell_type": "markdown",
261 | "source": [
262 | "### build the network : the second layer :v-layer"
263 | ],
264 | "metadata": {}
265 | },
266 | {
267 | "cell_type": "code",
268 | "execution_count": null,
269 | "source": [
270 | "\n",
271 | "import math\n",
272 | "#init new circuit\n",
273 | "circuit2 = QuantumCircuit()\n",
274 | "vqc = V_LYR_Circ(4,1)\n",
275 | "v_inputs = vqc.add_input_qubits(circuit2)\n",
276 | "\n",
277 | "#init state by u-layer-measurement (angle encoding)\n",
278 | "for b in range(u_layer_bits):\n",
279 | " prob =float(u_layer_counts[b])/qc_shots\n",
280 | " circuit2.ry(2*math.asin(math.sqrt(prob)),b)\n",
281 | "\n",
282 | "#add vqc to the circuit\n",
283 | "vqc.forward(circuit2,v_inputs,'v10',np.array(theta,dtype=np.double))\n",
284 | "\n",
285 | "\n",
286 | "#add measurement to the circuit2\n",
287 | "circuit2.barrier()\n",
288 | "add_measure(circuit2,[v_inputs[0][3],v_inputs[0][2]],'reg_v')\n",
289 | "circuit2.draw('text',300)"
290 | ],
291 | "outputs": [],
292 | "metadata": {}
293 | },
294 | {
295 | "cell_type": "markdown",
296 | "source": [
297 | "### v-layer simulation"
298 | ],
299 | "metadata": {}
300 | },
301 | {
302 | "cell_type": "code",
303 | "execution_count": null,
304 | "source": [
305 | "opt_counts = fire_ibmq(circuit2,qc_shots,True)\n",
306 | "print(opt_counts)\n",
307 | "(opt_mycount,bits) = analyze(opt_counts)\n",
308 | "opt_class_prob=[]\n",
309 | "\n",
310 | "for b in range(2):\n",
311 | " opt_class_prob.append(float(opt_mycount[b])/qc_shots)\n",
312 | "\n",
313 | "print(\"Result of u+v:\",opt_class_prob)\n",
314 | "print(\"Prediction class: {}\".format(opt_class_prob.index(max(opt_class_prob))))\n",
315 | "print(\"Target class: {}\".format(target[0]))\n",
316 | "if opt_class_prob.index(max(opt_class_prob))==target[0]:\n",
317 | " print(\"Correct prediction\")\n",
318 | "else:\n",
319 | " print(\"Incorrect prediction\")\n",
320 | "print(\"=\"*30)\n"
321 | ],
322 | "outputs": [],
323 | "metadata": {}
324 | }
325 | ],
326 | "metadata": {
327 | "kernelspec": {
328 | "name": "python3",
329 | "display_name": "Python 3.8.10 64-bit ('qf': conda)"
330 | },
331 | "language_info": {
332 | "name": "python",
333 | "version": "3.8.10",
334 | "mimetype": "text/x-python",
335 | "codemirror_mode": {
336 | "name": "ipython",
337 | "version": 3
338 | },
339 | "pygments_lexer": "ipython3",
340 | "nbconvert_exporter": "python",
341 | "file_extension": ".py"
342 | },
343 | "interpreter": {
344 | "hash": "f24048f0d5bdb0ff49c5e7c8a9899a65bc3ab13b0f32660a2227453ca6b95fd8"
345 | }
346 | },
347 | "nbformat": 4,
348 | "nbformat_minor": 2
349 | }
--------------------------------------------------------------------------------