├── .gitignore
├── .idea
├── Java-Interview-Tutorial.iml
└── codeStyles
│ └── codeStyleConfig.xml
├── .vscode
├── .server-controller-port.log
└── settings.json
├── LICENSE
├── README.md
├── build.sh
├── docs
├── .DS_Store
├── .vuepress
│ ├── components
│ │ ├── HideArticle.vue
│ │ ├── LockArticle.vue
│ │ ├── PayArticle.vue
│ │ └── RoadMap.vue
│ ├── config.js
│ ├── enhanceApp.js
│ ├── public
│ │ ├── CNAME
│ │ ├── LICENSE
│ │ ├── bcloud_nginx_user.conf
│ │ ├── favicon.ico
│ │ ├── images
│ │ │ ├── 12306
│ │ │ │ └── 12306项目文档.png
│ │ │ ├── personal
│ │ │ │ ├── javaedge.png
│ │ │ │ ├── qrcode.png
│ │ │ │ └── xingqiu.png
│ │ │ └── system
│ │ │ │ ├── banner.jpg
│ │ │ │ ├── blog-02.png
│ │ │ │ ├── download-2.png
│ │ │ │ ├── logo.jpg
│ │ │ │ ├── toc.png
│ │ │ │ ├── toggle.png
│ │ │ │ ├── wexin4.png
│ │ │ │ ├── xingqiu.png
│ │ │ │ └── 合作单位-04.svg
│ │ ├── js
│ │ │ ├── btwplugin.js
│ │ │ ├── fingerprint2.min.js
│ │ │ ├── global.js
│ │ │ └── jquery.min.js
│ │ └── robots.txt
│ ├── styles
│ │ ├── index.styl
│ │ └── palette.styl
│ └── theme
│ │ ├── components
│ │ ├── AlgoliaSearchBox.vue
│ │ ├── DropdownLink.vue
│ │ ├── DropdownTransition.vue
│ │ ├── FullScreenBtn.vue
│ │ ├── Home.vue
│ │ ├── NavLinks.vue
│ │ ├── Navbar.vue
│ │ ├── Page.vue
│ │ ├── PageSidebar.vue
│ │ ├── PageSidebarBackToTop.vue
│ │ ├── PageSidebarToc.vue
│ │ ├── PageSidebarTocLink.vue
│ │ └── SiteMap.vue
│ │ ├── index.js
│ │ ├── layouts
│ │ └── Layout.vue
│ │ ├── styles
│ │ └── wrapper.styl
│ │ └── util
│ │ └── index.js
├── README.md
└── md
│ ├── 12306
│ ├── 12306-basic-info.md
│ ├── 12306架构设计难点.md
│ ├── Builder模式在项目设计中的应用.md
│ ├── ES深分页问题解决方案.md
│ ├── MySQL深分页调优实战.md
│ ├── Redis缓存雪崩、缓存穿透、缓存击穿解决方案详解.md
│ ├── SpringBoot统一异常处理流程.md
│ ├── redis-cache-expiry-strategy.md
│ ├── redisson分布式锁使用.md
│ ├── 使用JUC中的核心组件来优化业务功能性能.md
│ ├── 分布式锁在项目设计中的应用.md
│ ├── 单例+简单工厂模式在项目设计中的应用.md
│ ├── 如何处理消息丢失问题?.md
│ ├── 如何生成分布式ID.md
│ ├── 死磕设计模式之抽象策略模式.md
│ ├── 死磕设计模式之抽象责任链模式.md
│ ├── 环境搭建.md
│ ├── 策略模式在项目设计中的应用.md
│ ├── 详解雪花算法.md
│ ├── 责任链模式重构复杂业务场景.md
│ └── 选择合适的缓存过期策略.md
│ ├── .DS_Store
│ ├── AI
│ ├── 00-introduce-to-LangGraph.md
│ ├── 00-introduction-to-langchain.md
│ ├── 00-为什么要学习大模型.md
│ ├── 01-RAG应用框架和解析器.md
│ ├── 01-langchain-hello-world-project.md
│ ├── 01-three-minute-fastapi-ai-agent-setup.md
│ ├── 01-what-are-agents.md
│ ├── 01-大语言模型发展.md
│ ├── 02-Agent应用对话情感优化.md
│ ├── 02-LangChain实战:用prompts模板调教LLM的输入出.md
│ ├── 02-domestic-and-international-llm-multi-model-strong-applications.md
│ ├── 02-how-langchain-agents-are-implemented.md
│ ├── 02-相似性检索的关键 - Embedding.md
│ ├── 03-core-of-rag-result-retrieval-and-reordering.md
│ ├── 03-large-language-model-flaws.md
│ ├── 03-use-tts-to-make-your-ai-agent-speak.md
│ ├── 03-what-is-zero-shot-one-shot-few-shot-learning.md
│ ├── 03-示例选择器.md
│ ├── 04-LLMs和Chat Models.md
│ ├── 04-ai-ecosystem-industry-analysis.md
│ ├── 04-how-to-add-memory-in-langchain-agents.md
│ ├── 04-prompt-helping-llm-understand-knowledge.md
│ ├── 05-Loader机制.md
│ ├── 05-ai-era-turning-point-for-app-developers.md
│ ├── 05-how-to-enable-memory-sharing-between-agent-and-tool.md
│ ├── 06-how-to-use-langchain-built-in-tools.md
│ ├── 06-文档转换实战.md
│ ├── 06-智能体项目案例.md
│ ├── 07-lcel-langchain-expression-language.md
│ ├── 08-ali-tongyi-qianwen-openai-compatible-solution.md
│ ├── 09-lcel-chain-and-prompt-implementation.md
│ ├── 10-ali-tongyi-qianwen-status-codes-explanation.md
│ ├── 11-lcel-memory-addition-method.md
│ ├── 12-lcel-agent-core-components.md
│ ├── 13-best-development-practices.md
│ ├── 2025-future-rag-trends-four-technologies.md
│ ├── AI Agent应用出路到底在哪?.md
│ ├── AI大模型企业应用实战.md
│ ├── Complex-SQL-Joins-with-LangGraph-and-Waii.md
│ ├── a2a
│ │ └── a2a-a-new-era-of-agent-interoperability.md
│ ├── agent
│ │ ├── Build-App-with-Dify.md
│ │ ├── Junie.md
│ │ ├── ai-agents-dont-security-nightmare.md
│ │ ├── boost-ai-workflow-resilience-with-error-handling.md
│ │ ├── changelog-cursor.md
│ │ ├── configuring-models-in-dify.md
│ │ ├── dify-agent-and-zapier-mcp-unlock-ai-automation.md
│ │ ├── dify-deep-research-workflow-farewell-to-fragmented-search-unlock-ai-driven-insights.md
│ │ ├── dify-v1-0-building-a-vibrant-plugin-ecosystem.md
│ │ ├── dify-v1-1-0-filtering-knowledge-retrieval-with-customized-metadata.md
│ │ ├── goodbye-cursor-hello-windsurf.md
│ │ ├── improve-quality-gen-ai.md
│ │ ├── introducing-codex.md
│ │ ├── perplexity-labs.md
│ │ ├── what-is-llmops.md
│ │ └── windsurf-update.md
│ ├── ai-agent-is-coming.md
│ ├── ai-trends-disrupting-software-teams.md
│ ├── aigc-app-in-e-commerce-review.md
│ ├── amazon-strands-agents-sdk.md
│ ├── building-effective-agents.md
│ ├── customizing-a-tool-for-your-ai-agent.md
│ ├── document-parsing-and-chunking-in-open-source-tools.md
│ ├── effective-datasets-fine-tuning.md
│ ├── langchain4j
│ │ ├── 01-intro.md
│ │ ├── 04-0-最新发布功能.md
│ │ ├── 04-1-最新发布功能.md
│ │ ├── 04-2-最新发布功能.md
│ │ ├── 04-3-最新发布功能.md
│ │ ├── ai-services.md
│ │ ├── chat-and-language-models.md
│ │ ├── chat-memory.md
│ │ ├── customizable-http-client.md
│ │ ├── get-started.md
│ │ ├── mcp.md
│ │ ├── observability.md
│ │ ├── rag.md
│ │ ├── response-streaming.md
│ │ ├── spring-boot-integration.md
│ │ ├── structured-outputs.md
│ │ └── tools.md
│ ├── langgraph-studio.md
│ ├── langserve-revolutionizes-llm-app-deployment.md
│ ├── llm
│ │ ├── ChatGPT为啥不用Websocket而是EventSource.md
│ │ ├── Claude3到底多强.md
│ │ ├── GPTs.md
│ │ ├── accelerating-workflow-processing-with-parallel-branch.md
│ │ ├── chatgpt-canva.md
│ │ ├── claude-3-7-sonnet.md
│ │ ├── claude-4.md
│ │ ├── contextual-retrieval.md
│ │ ├── cuda.md
│ │ ├── deepseek-r1-detail.md
│ │ ├── enhancing-llm-memory-with-conversation-variables-and-variable-assigners.md
│ │ ├── gpullama3-java-gpu-llm.md
│ │ ├── inference-engine.md
│ │ ├── integrate-dify-and-aws-services-to-enable-more-flexible-translation-workflows.md
│ │ ├── introducing-parent-child-retrieval-for-enhanced-knowledge.md
│ │ ├── llama-4-multimodal-intelligence.md
│ │ ├── llm-api-platform.md
│ │ ├── llm-knowledge-base-segmentation-data-cleaning.md
│ │ ├── llm-reasoning-limitations.md
│ │ ├── lm-studio-transform-mac-into-ai-tool.md
│ │ ├── lmstudio-local-llm-call.md
│ │ ├── making-an-llm-that-sees-and-reasons.md
│ │ ├── memory-faq.md
│ │ ├── navigating-llm-deployment-tips-tricks-and-techniques.md
│ │ ├── only-ai-flow-can-do.md
│ │ ├── qwen-QwQ.md
│ │ ├── qwen3-embedding.md
│ │ ├── qwen3.md
│ │ ├── 中国大陆用户如何使用Jetbrains内置的AI插件AI Assistant.md
│ │ ├── 携手阿里云:JetBrains AI Assistant 正式发布!.md
│ │ └── 计算机使用功能.md
│ ├── local-large-model-deployment.md
│ ├── mcp
│ │ ├── mcp-and-the-future-of-ai-tooling.md
│ │ ├── mcp-fad-or-fixture.md
│ │ ├── mcp-java-sdk.md
│ │ └── resources.md
│ ├── methods-adapting-large-language-models.md
│ ├── ml
│ │ ├── 01-人工智能概要.md
│ │ ├── 02-MR 算法分类.md
│ │ ├── 05-开发环境安装.md
│ │ ├── MapReduce分治思想.md
│ │ ├── basic-of-nlp.md
│ │ ├── building-neural-networks-with-pytorch.md
│ │ ├── gated-recurrent-unit-model.md
│ │ ├── key-path-from-feature-enhancement-to-dimensional-norm.md
│ │ ├── long-short-term-memory.md
│ │ ├── mask-tensor.md
│ │ ├── neural-memory-engine-for-sequence-modeling.md
│ │ ├── pytorch-cifar10-image-classifier-tutorial.md
│ │ ├── text-data-analysis-practical-guide.md
│ │ ├── text-data-augmentation-back-translation-guide.md
│ │ ├── text-preprocessing-overview.md
│ │ ├── text-vectorization-guide.md
│ │ ├── what-is-neural-network.md
│ │ ├── what-is-rnn.md
│ │ ├── what-is-tensor.md
│ │ ├── 一文看懂AI的Transformer架构.md
│ │ └── 软件工程师转型AI的全攻略.md
│ ├── multi_agent.md
│ ├── overcoming-fear-uncertainty-and-doubt-in-the-era-of-ai-transformation.md
│ ├── prompt
│ │ ├── 01-Prompt网站.md
│ │ └── 02-常用Prompt.md
│ ├── rag-introduction-tool-to-eliminate-llm-hallucinations.md
│ ├── software-development-in-AI2.md
│ ├── spring-ai-alibaba
│ │ └── why-choose-spring-ai-alibaba-for-smart-customer-service.md
│ └── to-fine-tune-or-not-to-fine-tune-llm.md
│ ├── DDD
│ ├── 00-DDD专栏规划.md
│ ├── 02-领域驱动设计DDD在B端营销系统的实践.md
│ ├── 04-DDD设计流程,以业务案例解读.md
│ ├── 09-DDD在大厂交易系统演进的应用.md
│ ├── 11-上下文映射.md
│ ├── 13-DDD分层架构及代码目录结构.md
│ ├── 23-理解领域事件(Domain Event).md
│ ├── decouple-event-retrieval-from-processing.md
│ ├── domain-service.md
│ ├── event-versioning.md
│ ├── integrating-event-driven-microservices-with-request-response-APIs.md
│ ├── rate-limit-event-processing.md
│ ├── use-circuit-breaker-to-pause-event-retrieval.md
│ └── 基于电商履约场景的DDD实战.md
│ ├── Dubbo
│ ├── 01-互联网架构的发展历程.md
│ ├── 02-Dubbo特性及工作原理.md
│ ├── 03-Dubbo的负载均衡及高性能RPC调用.md
│ ├── 04-Dubbo的通信协议.md
│ ├── 05-Dubbo的应用及注册和SPI机制.md
│ ├── 06-Dubbo相关面试题和源码使用技巧.md
│ └── 07-Dubbo真实生产环境思考.md
│ ├── MQTT
│ ├── avoid-bare-parsefrom-mqtt-protobuf-consumption.md
│ ├── mqtt-kafka-iot-message-streaming-integration.md
│ └── mqtt-publish-subscribe-intro.md
│ ├── RocketMQ
│ ├── 01-RocketMQ核心内容.md
│ ├── 01-基本概念.md
│ ├── 02-下载安装.md
│ ├── 02-基于电商场景的高并发RocketMQ实战.md
│ ├── 03-消息的有序性.md
│ ├── 04 - 订阅机制.md
│ ├── 05 - 批量消息和事务消息.md
│ ├── RocketMQ 5.x任意时间延时消息原理.md
│ ├── RocketMQ各版本新特性.md
│ ├── RocketMQ在基金大厂的分布式事务实践.md
│ ├── RocketMQ如何实现事务?.md
│ ├── RocketMQ的延时消息.md
│ ├── message-queues-more-than-app-communication.md
│ ├── 核心概念.md
│ ├── 消息恰好被消费一次.md
│ ├── 消息队列的事务消息.md
│ ├── 消息队列面试必问解析.md
│ └── 避免无法克服的队列积压.md
│ ├── ShardingSphere
│ ├── 10-顶级企业如何用数据脱敏保护用户隐私!.md
│ ├── 11-动态配置管理背后的编排治理真相!.md
│ ├── 14-ShardingSphere的分布式主键实现.md
│ ├── 19-路由引擎:如何在路由过程中集成多种路由策略和路由算法?.md
│ ├── ShardingSphere 如何完美驾驭分布式事务与 XA 协议?.md
│ └── ShardingSphere 如何轻松驾驭 Seata 柔性分布式事务?.md
│ ├── activiti
│ └── activiti7-introduction.md
│ ├── algorithm
│ ├── .DS_Store
│ ├── basic
│ │ ├── 00-数据结构与算法专栏大纲.md
│ │ ├── dag-directed-acyclic-graph.md
│ │ ├── 【图解数据结构】外行人也能看懂的哈希表.md
│ │ └── 【图解数据结构与算法】LRU缓存淘汰算法面试时到底该怎么写.md
│ ├── leetcode
│ │ ├── .DS_Store
│ │ ├── 00-阿里秋招高频算法题汇总-基础篇.md
│ │ ├── 01-阿里秋招高频算法题汇总-中级篇.md
│ │ ├── 02-阿里秋招高频算法题汇总-进阶篇.md
│ │ ├── 03-字节秋招高频算法题汇总-基础篇.md
│ │ ├── 04-字节秋招高频算法题汇总-中级篇.md
│ │ └── 05-字节秋招高频算法题汇总-进阶篇.md
│ └── practise
│ │ └── 哈希算法原来有这么多应用场景!.md
│ ├── arthas
│ └── Arthas使用.md
│ ├── assembly
│ ├── api-gateway
│ │ └── todo.md
│ ├── idea-plugin
│ │ └── todo.md
│ └── middleware
│ │ └── todo.md
│ ├── bigdata
│ ├── 00-新一代数据栈将逐步替代国内单一“数据中台”.md
│ ├── 01-Hadoop.md
│ ├── 01-大数据的尽头是数据中台吗?.md
│ ├── 02-分布式对象存储设计原理.md
│ ├── 03-HDFS伪分布式环境搭建.md
│ ├── 03-构建数据中台的三要素:方法论、组织和技术.md
│ ├── 04-hdfs dfs命令详解.md
│ ├── 05-如何统一管理纷繁杂乱的数据指标?.md
│ ├── AB测试与灰度发布.md
│ ├── DolphinScheduler参数.md
│ ├── DolphinScheduler告警通知.md
│ ├── DolphinScheduler简介.md
│ ├── DolphinScheduler资源中心.md
│ ├── DolphinScheduler部署.md
│ ├── HDFS.md
│ ├── Hive 2.x 的安装与配置.md
│ ├── Hive专栏概述.md
│ ├── Hive修复分区.md
│ ├── Hive分区和分桶.md
│ ├── Hive执行原理.md
│ ├── OLAP平台架构演化历程.md
│ ├── Spark+ClickHouse实战企业级数据仓库专栏.md
│ ├── hiveserver2.md
│ ├── hive的严格模式.md
│ ├── 中小企业参考的商业大数据平台.md
│ ├── 作业帮基于 DolphinScheduler 的数据开发平台实践.md
│ ├── 大数据基准测试.md
│ ├── 大数据平台架构.md
│ ├── 安装下载Hadoop.md
│ ├── 对象存储.md
│ ├── 当大数据遇上物联网.md
│ ├── 数仓业务调研.md
│ ├── 数仓分层和数仓建模.md
│ ├── 数仓开发之ADS层.md
│ ├── 数仓开发之DIM层.md
│ ├── 数仓开发之DWD层.md
│ ├── 数仓开发之DWS层.md
│ ├── 数仓开发之ODS层.md
│ ├── 数仓数据导出.md
│ ├── 数仓逻辑模型.md
│ ├── 移动计算.md
│ ├── 维度建模理论之事实表.md
│ ├── 维度建模理论之维度表.md
│ ├── 轻松驾驭Hive数仓.md
│ └── 阿里云开源离线同步工具DataX3.0介绍.md
│ ├── biz-arch
│ ├── 00-优惠券系统设计 Coupon System.md
│ ├── 00-聚合支付架构从零到一.md
│ ├── 01-DMP系统简介.md
│ ├── 01-供应链域数据中台设计.md
│ ├── 02-供应链采购视角的业务系统架构.md
│ ├── 03-客服平台架构实践.md
│ ├── 04-数据质量中心系统设计.md
│ ├── 05-大厂CRM系统架构优化实战.md
│ ├── 05-用户画像是什么?.md
│ ├── 06-构建高质量的用户画像.md
│ ├── 06-运营后台系统设计.md
│ ├── 07-大厂报价查询系统性能优化之道.md
│ ├── 07-用户画像和特征工程.md
│ ├── 08-视频推荐索引构建.md
│ ├── System design: Uber.md
│ ├── cloud-efficiency-at-netflix.md
│ ├── data-gateway-a-platform-for-growing-and-protecting-the-data-tier.md
│ ├── enhancing-netflix-reliability-with-service-level-prioritized-load-shedding.md
│ ├── how-meta-improved-their-cache-consistency-to-99-99999999.md
│ ├── linkedin-architecture-which-enables-searching-a-message-within-150ms.md
│ ├── netflixs-distributed-counter-abstraction.md
│ ├── title-launch-observability-at-netflix-scale.md
│ ├── 事件中心架构概述.md
│ ├── 小游戏的大促实践.md
│ ├── 打造一个高并发的十万用户 IM 聊天系统,你需要了解这些架构设计技巧!.md
│ ├── 短链系统设计(design tiny url).md
│ ├── 设计消息通知系统(Notification System).md
│ └── 高性能排名系统的核心架构原理,架构师必看!.md
│ ├── career
│ ├── 03-新人程序员入行忠告.md
│ ├── 04-外企也半夜发布上线吗?.md
│ ├── 05-中外程序员到底有啥区别?.md
│ ├── 06-全球顶级架构师推荐的书单.md
│ ├── 08-程序员为何一直被唱衰?.md
│ ├── 09-程序员的“三步走”发展战略.md
│ ├── 10-为何我建议你学会抄代码.md
│ ├── 11-计师能去哪些央国企?.md
│ ├── Java-reading-list.md
│ ├── big-company-work-style.md
│ ├── efficient-professional-reading-list.md
│ ├── how-i-tricked-my-brain-to-be-addicted-to-coding.md
│ ├── life-beyond-career-growth.md
│ ├── mastering-architecture-diagrams.md
│ ├── moat-of-rd.md
│ ├── must-have-soft-skills-for-rd.md
│ ├── no-tech-no-future-for-rd.md
│ ├── p6-promotion-guide.md
│ ├── performance-review-guideline.md
│ ├── why-hard-work-didnt-get-you-promoted-the-overlooked-truth.md
│ ├── workplace-jargon.md
│ ├── workplace-rule.md
│ ├── 为什么中国的程序员有35岁危机.md
│ ├── 研发的立足之本到底是啥?.md
│ ├── 经常被压缩开发时间,延期还要背锅,如何破局?.md
│ └── 转型传统行业避坑指南.md
│ ├── chain
│ ├── 00-区块链专栏概述.md
│ ├── 01-以太坊智能合约与高级语言.md
│ ├── 01-联盟链入门.md
│ ├── 02-DAPP.md
│ ├── 02-认识Flow Cadence.md
│ ├── 03-Cadence基础语法.md
│ ├── 03-以太坊的EVM.md
│ ├── 03-百度联盟链Xuperchain核心概念.md
│ ├── 04-Solidity基础语法.md
│ ├── 04-XuperChain核心流程.md
│ ├── 05-Solidity开发智能合约.md
│ ├── 05-账本模型.md
│ ├── 06-智能合约.md
│ ├── 06-通过web3.js与以太坊客户端进行交互.md
│ ├── 07-Truffle.md
│ ├── 07-网络与共识.md
│ ├── 08-工作量证明.md
│ ├── 09-一文看懂以太坊智能合约!.md
│ ├── blockchain-smart-contract-helloworld-project.md
│ ├── 三分钟,快速了解区块链技术.md
│ └── 隐私计算技术原理.md
│ ├── ck
│ ├── clickhouse-jdbc.md
│ ├── clickhouse概述.md
│ ├── 为啥要学习ClickHouse.md
│ ├── 为啥适合OLAP?.md
│ ├── 单机安装部署.md
│ └── 客户端基本操作.md
│ ├── data-analysis
│ └── basic
│ │ ├── correct-data-analysis-learning-methods.md
│ │ ├── how-to-use-octoparse-for-data-scraping.md
│ │ ├── learning-path-data-mining.md
│ │ ├── 为啥要学习数据分析?.md
│ │ ├── 企业如何利用数据打造精准用户画像?.md
│ │ └── 如何自动化采集数据.md
│ ├── ddd-mall
│ ├── 04-BFF 架构简介.md
│ ├── 05-dddmall-database-spring-boot-starter.md
│ ├── 05-亿级用户如何分库分表.md
│ ├── 06-dddmall-ddd-framework-core.md
│ ├── 06-商品秒杀库存超卖问题.md
│ ├── 07-dddmall-designpattern-spring-boot-starter.md
│ ├── 07-亿级商品数据同步至ES的高效方案.md
│ ├── 07-建造者模式.md
│ ├── 07-责任链模式.md
│ ├── 08-订单超时未支付自动取消和库存回滚.md
│ ├── 09-【防止重复下单】分布式系统接口幂等性实现方案.md
│ ├── 10-百万数据量快速导入、导出MySQL.md
│ ├── 11-分库分表平滑上线&快速回滚.md
│ ├── DDD-Mall商城的公共组件设计.md
│ ├── building-product-information-caching-system.md
│ ├── dddmall-base-spring-boot-starter.md
│ ├── dddmall-cache-spring-boot-starter.md
│ ├── dddmall-common-spring-boot-starter.md
│ ├── dddmall-convention-spring-boot-starter.md
│ ├── dddmall-idempotent-spring-boot-starter.md
│ ├── 什么是DDD商城.md
│ └── 天天说架构,那CDN到底是什么?.md
│ ├── design
│ ├── 00-软件架构权衡-我们为什么以及如何进行权衡?.md
│ ├── 01-单一职责原则.md
│ ├── 01-软件架构权衡-无意识决策的问题.md
│ ├── 02-软件架构权衡-架构特性.md
│ ├── cell-based-architecture-adoption-guidelines.md
│ ├── cell-based-architecture-distributed-systems.md
│ ├── cell-based-architecture-resilient-fault-tolerant-systems.md
│ ├── evolution-software-architecture-mainframes-to-distributed-computing.md
│ ├── flyweight-pattern.md
│ ├── iterator-pattern.md
│ ├── measuring-technical-debt.md
│ ├── open-close-principle.md
│ ├── proxy-pattern.md
│ ├── rest-api-design-resource-modeling.md
│ ├── strategy-pattern.md
│ ├── template-pattern.md
│ ├── 【Java设计模式实战】单例模式.md
│ ├── 业务代码如何才能不再写出大串的if else?.md
│ ├── 代码的坏味道.md
│ ├── 分离关注点的意义.md
│ ├── 如何了解一个软件的设计?.md
│ ├── 建造者模式.md
│ ├── 架构之美:教你如何分析一个接口?.md
│ ├── 架构师教你kill祖传石山代码重复&大量ifelse.md
│ ├── 适配器模式.md
│ ├── 门面模式.md
│ └── 阿里P8架构师都是怎么分析软件模型的?.md
│ ├── develop
│ ├── design-pattern
│ │ └── todo.md
│ ├── framework
│ │ └── todo.md
│ ├── images
│ │ └── 责任链模式.png
│ └── standard
│ │ └── todo.md
│ ├── distdb
│ ├── 01-爆火的分布式数据库到底是个啥?.md
│ ├── 03-BASE 还能撑多久?强一致性才是事务处理的终极奥义!.md
│ ├── 18-分布式数据库的HTAP能统一OLTP和 OLAP吗?.md
│ ├── 21-查询执行引擎:加速聚合计算加速.md
│ └── bank-distributed-database-selection.md
│ ├── docker
│ ├── 00-Docker基础命令大全.md
│ ├── 01-标准化打包技术.md
│ ├── Docker环境搭建.md
│ └── 通俗易懂的图文解密Docker容器网络.md
│ ├── es
│ ├── 02-MacOS下载安装启动ES和Kibana.md
│ ├── 03-核心概念之NRT Document Index 分片 副本.md
│ ├── 04-Kibana常见RESTful API操作.md
│ ├── 05-倒排索引与分词.md
│ ├── 07-整合进 SpringBoot 项目.md
│ ├── ES专栏大纲.md
│ ├── ES基本概念.md
│ └── building-product-search-system-with-es.md
│ ├── ffmpeg
│ ├── audio-video-roadmap.md
│ └── video-basic.md
│ ├── flink
│ ├── 01-Flink实战-概述.md
│ ├── 05-Flink实战DataStream API编程.md
│ ├── Flink部署及任务提交.md
│ ├── flink-architecture.md
│ ├── flink-beginner-case-study.md
│ ├── flink-broadcast-state.md
│ ├── flink-cep.md
│ ├── flink-checkpoint.md
│ ├── flink-data-latency-solution.md
│ ├── flink-programming-paradigms-core-concepts.md
│ ├── flink-state-backend.md
│ ├── flink-state-management.md
│ └── streaming-connectors-programming.md
│ ├── go-gateway
│ ├── 00-Go微服务网关专栏概述.md
│ └── open-systems-interconnection-model.md
│ ├── go
│ ├── 00-Go概述.md
│ ├── 01-macOS 安装go配置GOROOT GOPATH.md
│ ├── 02-Go基本语法.md
│ └── 03-Go的数组array和切片slice语法详解.md
│ ├── hbase
│ └── hbase-scan.md
│ ├── java
│ ├── 00-Java并发编程.md
│ ├── 01-synchronized原理.md
│ ├── 02-volatile原理.md
│ ├── 03-ReentrantLock与AQS.md
│ ├── 04-线程池以及生产环境使用.md
│ ├── 05-京东并行框架asyncTool如何针对高并发场景进行优化?.md
│ ├── IntelliJ IDEA 2024.1 最新变化.md
│ ├── Java16-new-features.md
│ ├── Java21-new-features.md
│ ├── Java22-new-features.md
│ ├── Java23-new-features.md
│ ├── Java9-new-features.md
│ ├── What’s-New-in-IntelliJ-IDEA-2024.2.md
│ ├── What’s-New-in-IntelliJ-IDEA-2024.3.md
│ ├── java-news-roundup-jun02-2025.md
│ ├── java-se-support-roadmap.md
│ ├── java2024.md
│ ├── java21-virtual-threads-where-did-my-lock-go.md
│ ├── java24-new-features.md
│ ├── jdk14-new-features-complete-guide.md
│ ├── understanding-java17-new-features-sealed-classes.md
│ └── 并发编程专栏概述.md
│ ├── jvm
│ ├── 00-G1垃圾收集器的日志格式.md
│ ├── 00-JDK为何自己首先破坏双亲委派模型.md
│ ├── 01-JVM虚拟机-上篇.md
│ ├── 01-JVM虚拟机.md
│ ├── 02-JVM虚拟机-下篇.md
│ ├── JDK性能调优神器.md
│ ├── JVM专栏概述.md
│ ├── Java NIO为何导致堆外内存OOM了?.md
│ ├── Java 性能调优:优化 GC 线程设置.md
│ ├── Metadata GC Threshold in Java.md
│ ├── deep-dive-into-jvm-runtime-data-areas-from-pc-to-metaspace.md
│ ├── 一次由热部署导致的OOM排查经历.md
│ ├── 对象内存分配及Minor GC和Full GC全过程.md
│ ├── 线上频繁Full GC,原来是外包同学不合理设置JVM参数!.md
│ ├── 队列积压了百万条消息,线上直接OOM了!.md
│ └── 高并发BI系统避免频繁Y-GC.md
│ ├── k8s
│ ├── 00-Kubernetes的基本架构.md
│ ├── 00-为啥选择 kubesphere.md
│ ├── 01-一键部署神器kubeadm.md
│ ├── 02-Kubernetes核心组件之kube-proxy实现原理.md
│ ├── 23-0-声明式API.md
│ ├── 23-1-Envoy.md
│ ├── Kubernetes容器日志处理方案.md
│ ├── kubectl命令.md
│ ├── kubernetes-workloads-controllers-deployment.md
│ ├── nature-of-kubernetes.md
│ ├── pod-in-kubernetes.md
│ ├── 使用 Kubernetes 部署 Nginx 应用.md
│ └── 快速搭建Kubernetes集群.md
│ ├── kafka
│ ├── 00-Kafka专栏大纲.md
│ ├── 01-为何大厂都选择Kafka作为消息队列.md
│ ├── 08-全网最全图解Kafka适用场景.md
│ ├── 09-消息队列的消息大量积压怎么办?.md
│ ├── 15-基于kafka实现延迟队列.md
│ ├── Kafka门派知多少.md
│ ├── kafka-operations-tool-exploring-adminclient-principles-and-practices.md
│ ├── kafka-transaction-implementation.md
│ └── kafka-versions.md
│ ├── linux
│ ├── 00-操作系统专栏大纲.md
│ ├── 01-Linux命令.md
│ ├── 02-进程管理.md
│ ├── 04-还记得纸带编程吗?.md
│ └── 超线程(Hyper-Threading),单指令多数据流(SIMD)技术.md
│ ├── low-code
│ ├── 01-低代码平台到底是什么样的?.md
│ └── 为什么“低代码”是未来趋势?.md
│ ├── mgr
│ ├── 00-咋带领团队做成事?.md
│ ├── 00-如何学习项目管理专栏.md
│ └── 01-避免新手常犯的项目管理错误.md
│ ├── monitor
│ ├── 00-你居然还去服务器上捞日志,搭个日志收集系统难道不香么!.md
│ ├── 01-性能分析思路.md
│ ├── 03-Loki 日志监控.md
│ ├── performance-optimization-guide.md
│ └── 并发用户、RPS、TPS的解读.md
│ ├── mysql
│ ├── 00-MySQL专栏大纲.md
│ ├── InnoDB架构设计.md
│ ├── Java业务系统是怎么和MySQL交互的?.md
│ ├── Java生态中性能最强数据库连接池HikariCP.md
│ ├── MySQL新特性.md
│ ├── MySQL查询优化.md
│ ├── MySQL深分页调优实战.md
│ ├── how-to-use-indexes-when-grouping-in-sql.md
│ ├── mysql-architecture-design.md
│ ├── mysql-read-write-splitting.md
│ ├── mysql-transaction-isolation-mechanism.md
│ ├── online-sql-deadlock-incident-how-to-prevent-deadlocks.md
│ ├── optimize-slow-queries-massive-row-deletions.md
│ ├── what-is-new-in-mysql9.md
│ ├── 一文看懂这篇MySQL的锁机制.md
│ ├── 为什么临时表可以重名?.md
│ ├── 为什么阿里不推荐使用MySQL分区表?.md
│ └── 亿级数据量商品系统的SQL调优实战.md
│ ├── nacos
│ └── 00-Nacos 版本.md
│ ├── neo4j
│ └── neo4j-revolutionary-power-of-graph-databases.md
│ ├── netty
│ ├── (06-1)-ChannelHandler 家族.md
│ ├── (08)-学习Netty BootStrap的核心知识,成为网络编程高手!.md
│ ├── 01-Netty源码面试实战+原理(一)-鸿蒙篇.md
│ ├── 11-4-解码基于分隔符的协议和基于长度的协议.md
│ ├── 18-检测新连接.md
│ ├── ChannelPipeline接口.md
│ ├── java-lock-optimization-practice-netty-examples_boost-concurrency-performance.md
│ ├── netty-basic-components.md
│ ├── netty-off-heap-memory-leak-detection.md
│ └── use-netty-to-handle-large-data-efficiently.md
│ ├── network
│ ├── TCP协议详解.md
│ ├── TCP连接的建立和断开受哪些系统配置影响?.md
│ ├── 天天说架构,那CDN到底是什么?.md
│ └── 计算机网络-网络层原理.md
│ ├── opensearch
│ └── opensearch-3-0-enhances-vector-database-performance.md
│ ├── other
│ └── guide-to-reading.md
│ ├── product-center
│ ├── 00-商品中心的spu、sku设计.md
│ ├── 01-电商商品中心解密:仅凭SKU真的足够吗?.md
│ └── 02-大厂电商设计解析之商品管理系统.md
│ ├── product
│ ├── book
│ │ └── todo.md
│ └── pdf
│ │ └── todo.md
│ ├── python
│ ├── 00-macOS和Linux安装和管理多个Python版本.md
│ └── Installing packages into 'Python 3.9' requires administrator privileges.md
│ ├── rabbitmq
│ ├── 00-RabbitMQ实战下载与安装.md
│ ├── 04-RabbitMQ & Spring整合开发.md
│ ├── 08-RabbitMQ的七种队列模式.md
│ ├── 12-RabbitMQ实战-消费端ACK、NACK及重回队列机制.md
│ ├── RabbitMQ消费端幂等性概念及解决方案.md
│ ├── RabbitMQ的 RPC 消息模式你会了吗?.md
│ └── 用了这么久的RabbitMQ异步编程竟然都是错的.md
│ ├── reactive
│ ├── 00-Spring响应式编程.md
│ ├── 01-想让系统更具有弹性?了解背压机制和响应式流的秘密!.md
│ ├── 04-Spring为何偏爱Reactor响应式编程框架.md
│ ├── 05-流式操作:如何使用 Flux 和 Mono 高效构建响应式数据流?.md
│ ├── applicable-scenarios-for-reactive-programming.md
│ └── spring-5-reactive-programming-high-performance-full-stack-apps.md
│ ├── redis
│ ├── 00-数据结构的最佳实践.md
│ ├── 01-Redis和ZK分布式锁优缺点对比以及生产环境使用建议.md
│ ├── 02-Redisson可重入锁加锁源码分析.md
│ ├── 03-Redisson公平锁加锁源码分析.md
│ ├── 04-Redisson读写锁加锁机制分析.md
│ ├── 05-缓存读写策略模式详解.md
│ ├── 06-如何快速定位 Redis 热 key.md
│ ├── 12-Redis 闭源?.md
│ ├── Redis Quicklist.md
│ ├── Redis异步子线程原理详解.md
│ ├── Redis的RDB源码解析.md
│ ├── Redis的整数数组和压缩列表.md
│ ├── Sorted sets、zset数据结构详解.md
│ └── redis-agpl-license.md
│ ├── risk-control
│ ├── coupon-distribution-risk-control-challenges.md
│ ├── coupon-fraud-grey-market-chain.md
│ ├── flink-real-time-risk-control-system-overview.md
│ ├── reasons-for-choosing-groovy-for-risk-control-engine.md
│ ├── risk-control-engine-architecture-design.md
│ └── risk-control-rules-thresholds-for-coupon-scenarios.md
│ ├── road-map
│ └── todo.md
│ ├── rpc
│ ├── 04-RPC框架在网络通信的网络IO模型选型.md
│ ├── 11-RPC的负载均衡.md
│ ├── RPC-Traffic-Replay.md
│ ├── rpc-retry-mechanism.md
│ └── 熔断限流.md
│ ├── rules-engine
│ └── drools
│ │ └── drools-core-guide-configuration-to-drl-and-decision-tables.md
│ ├── seata
│ ├── 01-Seata客户端依赖坐标引入与踩坑排雷.md
│ ├── 02-Seata客户端全局事务配置与实现.md
│ ├── 03-Seata柔性事务.md
│ ├── 04-Seata是什么?.md
│ ├── 05-开始.md
│ └── docker-install-configure-seata-server.md
│ ├── security
│ ├── 03-OAuth2.0实战-轻松学会使用JWT,让你的OAuth2.0实现更加安全高效!.md
│ ├── 07-你确定懂OAuth 2.0的三方软件和受保护资源服务?.md
│ └── OAuth 2.0实战-为什么要先获取授权码code.md
│ ├── sentinel
│ ├── basic-api-resource-rule.md
│ ├── origin-authority-control.md
│ └── spring-boot-integration-with-sentinel-practical-tutorial-from-dependency-to-custom-flow-control-and-monitoring.md
│ ├── serverless
│ └── serverless-is-a-scam.md
│ ├── sideline
│ ├── 16-精益独立开发实践.md
│ ├── 17-用户画像都是怎么产生的?.md
│ ├── 20-个人支付解决方案.md
│ ├── 21-处理用户反馈和增长优化.md
│ └── 22-大纲的注意点.md
│ ├── spark
│ ├── 00-Spark安装及启动.md
│ ├── 00-为啥要学习Spark Streaming.md
│ ├── 01-Spark Streaming专栏概述.md
│ ├── 01-Spark的Local模式与应用开发入门.md
│ ├── 02-Spark Streaming小试流式处理.md
│ ├── 03-SparkSQL入门.md
│ ├── 04-SparkSQL的API编程之DataFrame.md
│ ├── 05-快速理解SparkSQL的DataSet.md
│ ├── 06-RDD与DataFrame的互操作.md
│ ├── 07-Spark的Data Sources.md
│ ├── 07-回归算法.md
│ ├── 08-Spark SQL整合Hive.md
│ ├── Spark架构.md
│ ├── spark-ml-basic-statistics.md
│ └── 为啥要学习Spark?.md
│ ├── spider
│ └── 00-爬虫基础.md
│ ├── spring
│ ├── 00-可能是全网最全的SpringBoot启动流程源码分析.md
│ ├── 01-HelloSpringBoot应用程序.md
│ ├── 02-实现http请求的异步长轮询.md
│ ├── SpringBoot3.4-release.md
│ ├── SpringBoot默认线程池.md
│ ├── SpringMVC-AsyncHandlerInterceptor.md
│ ├── SpringMVC-DispatcherServlet-doDispatch.md
│ ├── SpringMVC-HandlerInterceptor.md
│ ├── SpringMVC-service-doDispatch.md
│ ├── Spring之BeanNameAware和BeanFactoryAware接口.md
│ ├── Spring框架使用了哪些设计模式.md
│ ├── farewell-bean-not-found-easily-solve-spring-boot-package-scanning-issues.md
│ ├── mastering-multi-tenancy-with-spring-multi-tenancy-library.md
│ ├── spring-cloud
│ │ ├── Spring Cloud Alibaba大纲.xmind
│ │ ├── SpringCloudAlibaba介绍.md
│ │ ├── SpringCloudGateway之Filter多过程介绍.md
│ │ ├── SpringCloudGateway之灰度发布篇.md
│ │ ├── SpringCloudGateway之熔断集成篇.md
│ │ ├── SpringCloudGateway之统一鉴权篇.md
│ │ ├── SpringCloudGateway之限流集成篇.md
│ │ ├── SpringCloudGateway之高性能篇.md
│ │ ├── SpringCloudGateway工作原理与链路图.md
│ │ ├── SpringCloudGateway核心之Predicate.md
│ │ ├── practise
│ │ │ └── 01-Segment为何永别微服务了?.md
│ │ └── todo.md
│ ├── why-spring-bean-difficult-birth-overcome-constructor-injection-dependencies-and-ambiguity.md
│ ├── 别小看Spring过滤器,这些知识点你必须得掌握.md
│ ├── 这次彻底搞懂IoC容器依赖注入的源码.md
│ └── 阿里四面:你知道Spring AOP创建Proxy的过程吗?.md
│ ├── tomcat
│ ├── 00-不知道这些Servlet规范、容器,还敢说自己是Java程序员.md
│ ├── 01-Jetty架构设计之Connector、Handler组件.md
│ ├── 03-Tomcat的生命周期管理.md
│ ├── 04-Tomcat实现热部署、热加载原理解析.md
│ ├── 05-Tomcat如何打破双亲委派机制实现隔离Web应用的?.md
│ └── how-to-solve-high-cpu-usage-in-tomcat-process.md
│ ├── trade
│ ├── 00-如何防止订单二次重复支付?.md
│ ├── 01-扫码支付后都发生了啥?.md
│ ├── 02-大厂的第三方支付业务架构设计.md
│ ├── high-avail-payments.md
│ └── wechat-pay-development-guide-avoid-pitfalls.md
│ ├── vue
│ ├── 01-Vue开发实战.md
│ ├── 05-教你快速搭建Vue3工程化项目.md
│ ├── Vuex设计Vue3项目的数据流.md
│ ├── goodbye-jquery-thinking-create-checklist-apps-with-vue-js-experience-the-charm-of-data-driven.md
│ ├── router.md
│ ├── table.md
│ ├── vue-js-vs-axios-practical-guide-from-ajax-requests-to-api-proxy-configuration.md
│ └── vue2-to-vue3.md
│ ├── zqy
│ ├── JVM
│ │ └── JVM虚拟机基础.md
│ ├── MySQL
│ │ └── MySQL高手实战.md
│ ├── Redis
│ │ └── 基于电商场景的高并发Redis实战.md
│ ├── RocketMQ
│ │ ├── RocketMQ基础.md
│ │ └── 基于电商场景的高并发RocketMQ实战.md
│ ├── ZooKeeper
│ │ └── ZooKeeper高手实战.md
│ └── 面试题
│ │ ├── 01-分布式技术面试实战.md
│ │ ├── 02-注册中心和网关面试实战.md
│ │ ├── 03-生产部署面试实战.md
│ │ ├── 04-分布式锁、幂等性问题实战.md
│ │ ├── 05-Java基础面试实战.md
│ │ ├── 06-Spring面试实战.md
│ │ ├── 07-计算机网络面试实战.md
│ │ ├── 08-数据库面试实战.md
│ │ ├── 09-网络通信及可见性面试实战.md
│ │ ├── 10-Java 系统架构安全面试实战.md
│ │ ├── 11-深挖网络 IO 面试实战.md
│ │ ├── 12-分布式架构、性能优化、场景设计面试实战.md
│ │ ├── gaopin
│ │ ├── 00-RocketMQ可靠性、重复消费解决方案.md
│ │ ├── 01-RocketMQ有序性、消息积压解决方案.md
│ │ ├── 02-Redis的IO多路复用.md
│ │ └── 03-ZooKeeper运行原理.md
│ │ ├── jiagou
│ │ ├── 01-B站评论系统架构设计.md
│ │ └── 02-该从哪些方面提升系统的吞吐量?.md
│ │ ├── mianjing
│ │ ├── 00-淘天提前批面试.md
│ │ ├── 01-饿了么一面.md
│ │ ├── 02-美团优选后端一面.md
│ │ ├── 03.腾讯后端一面.md
│ │ ├── 04.美团优选后端一面.md
│ │ ├── 05.携程暑期实习一面.md
│ │ └── 06.携程暑期实习二面.md
│ │ ├── 面试突击.md
│ │ ├── 面试题-Java基础.md
│ │ ├── 面试题-MySQL.md
│ │ ├── 面试题-Netty.md
│ │ ├── 面试题-Redis.md
│ │ └── 面试题-场景题.md
│ └── zsxq
│ ├── about
│ └── todo.md
│ ├── booklet
│ └── todo.md
│ ├── material
│ └── todo.md
│ ├── memorabilia
│ └── todo.md
│ ├── other
│ └── todo.md
│ ├── project
│ └── todo.md
│ └── source-code
│ └── todo.md
├── package-lock.png
├── package.json
└── security
├── oauth2_and_encryption.drawio
└── oauth2_and_encryption_diagram.drawio
/.gitignore:
--------------------------------------------------------------------------------
1 | /.idea/
2 |
3 | /package-lock.json
4 |
5 | /node_modules/
6 |
7 | /.site/
8 |
9 | /.temp/
10 |
--------------------------------------------------------------------------------
/.idea/Java-Interview-Tutorial.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
--------------------------------------------------------------------------------
/.idea/codeStyles/codeStyleConfig.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
--------------------------------------------------------------------------------
/.vscode/.server-controller-port.log:
--------------------------------------------------------------------------------
1 | {
2 | "port": 9145,
3 | "time": 1744085260411,
4 | "version": "0.0.3"
5 | }
--------------------------------------------------------------------------------
/.vscode/settings.json:
--------------------------------------------------------------------------------
1 | {
2 | "cSpell.words": [
3 | "clickhouse",
4 | "dddmall",
5 | "distdb",
6 | "OLAP",
7 | "println",
8 | "rabbitmq",
9 | "Servlet",
10 | "springframework"
11 | ],
12 | "Codegeex.RepoIndex": true,
13 | "files.autoSave": "afterDelay"
14 | }
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 编程严选网
2 |
3 | ## 0 本地启动项目
4 | 1. 安装Node.js
5 | 2. 下载依赖:npm install
6 | 3. 启动服务: npm run dev -- --port 8081
7 |
8 | https://www.bilibili.com/video/BV1vb411m7NY
9 |
10 | 视频前两节即可学会本地启动 Vuepress项目,还可学到其他相关配置。
11 |
12 | ## 1 图片调整路径
13 | docs/.vuepress/public/images 存储网站本身展示所需宣传营销图片。
14 |
15 | 文章中的绘图不建议存储源文件,请直接使用阿里云 oos 对象存储来存储图片或者白嫖使用 CSDN 的博客图床
16 |
17 | ## 2 提交文章
18 |
19 | ### 2.1 新增 md 文件(必须)
20 |
21 | 在 md 目录新建 concurrency 目录,新建00-Java并发编程.md文件,将文章内容放进去
22 |
23 | ### 2.2 修改 config.js
24 |
25 | #### 2.2.1 配置
26 |
27 | - 专栏名称(新增专栏时必须)
28 | - 文章路径(新增文章非必须)
29 | ```js
30 | {
31 | text: '并发编程',
32 | items: [
33 | {text: '00-Java并发编程', link: '/md/concurrency/00-Java并发编程.md'},
34 | ]
35 | },
36 | ```
37 | #### 2.2.2 配置专栏侧边导航栏(必须)
38 | 如
39 | ```js
40 | "/md/concurrency/": [
41 | {
42 | title: "并发编程",
43 | collapsable: false,
44 | sidebarDepth: 0,
45 | children: [
46 | "00-Java并发编程.md"
47 | ]
48 | }
49 | ],
50 | ```
51 |
52 | 注意,该步骤不要带有()、【】、空格等特殊字符!!!
53 | 文章标题是可以有空格的,不然也就没法正常断句了!
54 | ### 2.3 本地调试
55 | 浏览器前端能正常看到文章,即可提交代码
56 |
57 | ## 3 Git GUI 工具
58 | 建议下载 Github Desktop,可视化提交文章相关数据。
59 | 注意本仓库分为 master、main两个分支,只在 main 分支操作文章,勿碰 master 分支!
60 |
61 | ## FAQ
62 | 文章名称不要带有括号、#等特色字符
63 |
64 | 文章内容不要带有尖括号、#等特殊字符,如
65 | ```
66 | - Java API中,用户需要使用Dataset表示DataFrame
67 | ```
68 | 会导致整篇文章不显示!
69 |
70 | 对此,需将其包进一个代码块里,如:
71 | `Dataset`
72 | 这样就能正常显示了。
73 |
74 | 文章内容不要使用 html 标签渲染,也会导致空白页!
--------------------------------------------------------------------------------
/build.sh:
--------------------------------------------------------------------------------
1 | NODE_OPTIONS=--max-old-space-size=14096 npm run build
--------------------------------------------------------------------------------
/docs/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.DS_Store
--------------------------------------------------------------------------------
/docs/.vuepress/components/HideArticle.vue:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
25 |
26 |
--------------------------------------------------------------------------------
/docs/.vuepress/enhanceApp.js:
--------------------------------------------------------------------------------
1 | export default ({router}) => {
2 | /**
3 | * 路由切换事件处理
4 | */
5 | router.beforeEach((to, from, next) => {
6 | //触发百度的pv统计
7 | if (typeof _hmt != "undefined") {
8 | if (to.path) {
9 | _hmt.push(["_trackPageview", to.fullPath]);
10 | }
11 | }
12 | // continue
13 | next();
14 | });
15 | };
--------------------------------------------------------------------------------
/docs/.vuepress/public/CNAME:
--------------------------------------------------------------------------------
1 | javaedge.cn
2 |
--------------------------------------------------------------------------------
/docs/.vuepress/public/bcloud_nginx_user.conf:
--------------------------------------------------------------------------------
1 | error_page 404 http://www.javaedge.cn/#/index;
2 | location ~ .*\.(html|js)$ {
3 | #禁止缓存,每次都从服务器请求
4 | // add_header Cache-Control no-store;
5 | }
--------------------------------------------------------------------------------
/docs/.vuepress/public/favicon.ico:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/favicon.ico
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/12306/12306项目文档.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/12306/12306项目文档.png
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/personal/javaedge.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/personal/javaedge.png
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/personal/qrcode.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/personal/qrcode.png
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/personal/xingqiu.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/personal/xingqiu.png
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/system/banner.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/system/banner.jpg
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/system/blog-02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/system/blog-02.png
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/system/download-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/system/download-2.png
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/system/logo.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/system/logo.jpg
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/system/toc.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/system/toc.png
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/system/toggle.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/system/toggle.png
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/system/wexin4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/system/wexin4.png
--------------------------------------------------------------------------------
/docs/.vuepress/public/images/system/xingqiu.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/.vuepress/public/images/system/xingqiu.png
--------------------------------------------------------------------------------
/docs/.vuepress/public/js/btwplugin.js:
--------------------------------------------------------------------------------
1 | window.onload = function() {
2 | themeDefaultContent = $(
3 | '#app > .theme-container>.page > .theme-default-content'
4 | );
5 |
6 | themeDefaultContent.attr('id', 'container');
7 | btw = new BTWPlugin(); // 注意btw需要是个全局变量,把const去掉
8 | btw.init({
9 | id: 'container',
10 | blogId: '31809-1711934972129-598',
11 | name: 'JavaEdge',
12 | qrcode: 'https://javaedge-1256172393.cos.ap-shanghai.myqcloud.com/qrcode_for_gh_ab5f6d46c1ff_258.jpg',
13 | keyword: '编程严选网',
14 | });
15 | };
--------------------------------------------------------------------------------
/docs/.vuepress/public/js/global.js:
--------------------------------------------------------------------------------
1 | window.onload = function () {
2 | let $article = $('.theme-default-content > h1');
3 | if ($article.length <= 0) return null;
4 |
5 | let clientWidth = $article[0].clientWidth;
6 |
7 | // 根据ID获取iframe对象
8 | var ifr = document.getElementById('B-Video');
9 |
10 | if (ifr) {
11 | ifr.style.width = clientWidth + 'px';
12 | if (clientWidth < 450) {
13 | ifr.style.height = (523 * clientWidth) / 700 + 'px'
14 | } else {
15 | ifr.style.height = '450px'
16 | }
17 | }
18 |
19 | };
--------------------------------------------------------------------------------
/docs/.vuepress/public/robots.txt:
--------------------------------------------------------------------------------
1 | Sitemap: https://javaedge.cn/sitemap.xml
2 | User-agent: *
3 |
--------------------------------------------------------------------------------
/docs/.vuepress/styles/index.styl:
--------------------------------------------------------------------------------
1 | body
2 | font-size 0.95rem
3 |
4 | // markdown blockquote
5 | blockquote
6 | font-size 0.95rem
7 | color #2c3e50;
8 | border-left .5rem solid #42b983
9 | background-color #f3f5f7
10 | margin 1rem 0
11 | padding 1rem 1rem 1rem 1rem
12 | & > p
13 | margin 0
14 |
15 | // markdown h1
16 | h1
17 | font-size 1.8rem
18 | padding-bottom 1rem
19 | border-bottom 1px solid $borderColor
20 |
21 | // markdown h2
22 | h2
23 | font-size 1.55rem
24 | border-bottom 0px solid $borderColor
25 |
26 | .theme-default-content h4
27 | font-size 1.1rem
28 | text-decoration underline
29 |
30 | // sidebar
31 | .sidebar
32 | width: 18rem
33 | font-size: 15px
--------------------------------------------------------------------------------
/docs/.vuepress/styles/palette.styl:
--------------------------------------------------------------------------------
1 | // 内容的宽度
2 | $contentWidth = 100%
3 |
4 | // 首页的宽度
5 | $homePageWidth = 1200px
6 |
7 | $MQNarrow ?= 1280px
8 |
9 | // 颜色
10 | $accentColor = #3eaf7c
11 | $textColor = #2c3e50
12 | $borderColor = #eaecef
13 | $codeBgColor = #282c34
--------------------------------------------------------------------------------
/docs/.vuepress/theme/components/DropdownTransition.vue:
--------------------------------------------------------------------------------
1 |
2 |
8 |
9 |
10 |
11 |
12 |
28 |
29 |
34 |
--------------------------------------------------------------------------------
/docs/.vuepress/theme/components/FullScreenBtn.vue:
--------------------------------------------------------------------------------
1 |
2 |
3 |  4 | 全屏看
5 |
6 |
7 |
8 |
9 |
32 |
--------------------------------------------------------------------------------
/docs/.vuepress/theme/components/PageSidebarBackToTop.vue:
--------------------------------------------------------------------------------
1 |
2 |
3 |
27 |
28 |
29 |
30 |
69 |
70 |
--------------------------------------------------------------------------------
/docs/.vuepress/theme/components/PageSidebarToc.vue:
--------------------------------------------------------------------------------
1 |
2 |
3 |
9 |
10 |
11 |
12 |
88 |
--------------------------------------------------------------------------------
/docs/.vuepress/theme/index.js:
--------------------------------------------------------------------------------
1 | module.exports = {
2 | extend: '@vuepress/theme-default'
3 | };
4 |
--------------------------------------------------------------------------------
/docs/.vuepress/theme/styles/wrapper.styl:
--------------------------------------------------------------------------------
1 | $wrapper
2 | max-width $contentWidth
3 | margin 0 auto
4 | padding 2rem 2.5rem
5 | @media (max-width: $MQNarrow)
6 | padding 1.2rem
7 | @media (max-width: $MQMobileNarrow)
8 | padding 1rem
9 |
--------------------------------------------------------------------------------
/docs/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | home: true
3 | heroImage: /images/system/logo.jpg
4 | actionLinks:
5 | - link: /md/other/guide-to-reading.md
6 | text: 开始阅读 →
7 | class: primary
8 | - link: https://wx.zsxq.com/dweb2/index/group/51112182212124
9 | text: 知识星球
10 | class: secondary
11 | - link: http://www.javaedge.cn:3000/#/article/76
12 | text: 后端技术专家学习路线 👣
13 | class: secondary
14 | - link: http://www.javaedge.cn:3000/#/index
15 | text: 网站 💐
16 | class: secondary
17 | footer:
18 |
4 | 全屏看
5 |
6 |
7 |
8 |
9 |
32 |
--------------------------------------------------------------------------------
/docs/.vuepress/theme/components/PageSidebarBackToTop.vue:
--------------------------------------------------------------------------------
1 |
2 |
3 |
27 |
28 |
29 |
30 |
69 |
70 |
--------------------------------------------------------------------------------
/docs/.vuepress/theme/components/PageSidebarToc.vue:
--------------------------------------------------------------------------------
1 |
2 |
3 |
9 |
10 |
11 |
12 |
88 |
--------------------------------------------------------------------------------
/docs/.vuepress/theme/index.js:
--------------------------------------------------------------------------------
1 | module.exports = {
2 | extend: '@vuepress/theme-default'
3 | };
4 |
--------------------------------------------------------------------------------
/docs/.vuepress/theme/styles/wrapper.styl:
--------------------------------------------------------------------------------
1 | $wrapper
2 | max-width $contentWidth
3 | margin 0 auto
4 | padding 2rem 2.5rem
5 | @media (max-width: $MQNarrow)
6 | padding 1.2rem
7 | @media (max-width: $MQMobileNarrow)
8 | padding 1rem
9 |
--------------------------------------------------------------------------------
/docs/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | home: true
3 | heroImage: /images/system/logo.jpg
4 | actionLinks:
5 | - link: /md/other/guide-to-reading.md
6 | text: 开始阅读 →
7 | class: primary
8 | - link: https://wx.zsxq.com/dweb2/index/group/51112182212124
9 | text: 知识星球
10 | class: secondary
11 | - link: http://www.javaedge.cn:3000/#/article/76
12 | text: 后端技术专家学习路线 👣
13 | class: secondary
14 | - link: http://www.javaedge.cn:3000/#/index
15 | text: 网站 💐
16 | class: secondary
17 | footer:
18 |  19 | 皖ICP备2024059525号 | Copyright © JavaEdge
20 | footerHtml: true
21 | ---
22 |
23 | ---
24 |
--------------------------------------------------------------------------------
/docs/md/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/.DS_Store
--------------------------------------------------------------------------------
/docs/md/12306/Builder模式在项目设计中的应用.md:
--------------------------------------------------------------------------------
1 | # **Builder模式在项目设计中的应用**
2 |
3 | ## Builder模式简介:
4 | 构建者模式(Builder Pattern)是一种对象创建型设计模式,它提供了一种灵活的解决方案,用于在创建复杂对象时将构造过程与其表示分离,以便相同的构建过程可以创建不同的表示。这种模式通常用于那些具有多个组成部分且这些部分经常变化的场景中,例如创建一个复杂的用户界面或一个多步骤的复杂算法。
5 |
6 | ### 构建者模式的应用场景
7 |
8 | 构建者模式适用于以下几种情况:
9 |
10 | - 1. **对象构造复杂**:当一个对象的构建比较复杂时,可以使用构建者模式将复杂对象的构建过程抽象出来,是的这个抽象过程和具体的产品类分离,使得客户端不需要知道其具体的构建细节。
11 | - 2. **对象内部构建有多个步骤**:如果一个对象有多个构建步骤,并且希望允许用户以任意顺序提供这些步骤的信息,那么可以使用构建者模式来提供更灵活的构建过程。
12 | - 3. **对象构建需要多个简单对象组合**:如果一个对象是由多个简单的对象组合而成,而这些简单的对象又有不同的组合方式和可选的组合项,构建者模式可以帮助简化这种组合逻辑。
13 | - 4. **构建与表示分离**:当需要将一个复杂对象的构建过程与其最终表示分离时,构建者模式可以将这两个方面解耦,使得同样的构建过程可以创建出不同的表示。
14 |
15 | ### 构建者模式的实现
16 |
17 | 构建者模式通常包括以下几个角色:
18 |
19 | - 1. **Builder**:为创建一个Product对象的各个部件指定抽象接口,具体构建者实现该接口以构造和装配该产品的各个部件。
20 | - 2. **ConcreteBuilder**:实现Builder接口,构建和装配各个部分,最终返回一个构造完毕的Product对象。
21 | - 3. **Director**:负责按照特定顺序组装各个部件,并返回一个构建好的实例或者使用构建者实例来构建最终的对象。
22 | - 4. **Product**:是最终被构建出来的复杂对象。
23 |
24 | #### 示例代码
25 |
26 | 下面是12306项目中展示使用构建者模式的案例。
27 |
28 | ```java
29 | //产品
30 |
31 | // 构建者角色
32 | /**
33 | * Builder 模式抽象接口
34 | *
35 | */
36 | public interface Builder extends Serializable {
37 |
38 | /**
39 | * 构建方法
40 | *
41 | * @return 构建后的对象
42 | */
43 | T build();
44 | }
45 |
46 | // 具体构建者
47 | // todo
48 |
49 | // 指导者角色
50 | // todo
51 |
52 | // 实际业务场景使用
53 | //todo
54 |
55 | ```
56 |
57 | ### 构建者模式的优点与缺点
58 |
59 | **优点:**
60 | - **封装性良好**:客户端无需了解产品内部的组成细节,只需要知道如何通过构建者来构造它即可。
61 | - **易于扩展**:可以通过增加新的具体构建者来轻松扩展系统,而不影响其他代码。
62 | - **分步构建,链式调用**:可以在构建过程中逐步完成,也可以采用链式调用的方式,提高易用性和可读性。
63 |
64 | **缺点:**
65 | - **设计相对复杂**:相比直接使用构造函数或工厂方法创建对象,构建者模式的设计更为复杂。
66 | - **违反单一职责原则**:构建者除了构建产品的职责外,还需要知道如何一步步构建,这增加了其职责。
67 | - **对象创建成本高**:因为构建者的设计和实现较为复杂,所以相比于直接创建对象,构建者模式可能会增加额外的时间和空间成本。
68 |
69 | ### 结论
70 |
71 | 构建者模式在创建复杂对象时非常有用,尤其是当对象的构建过程需要多个步骤,并且这些步骤可以灵活配置时。它提供了一个清晰的方式来组织和封装一个复杂对象的构建过程,同时保持了系统的灵活性和可扩展性。然而,它的复杂性可能不适合所有的场景,所以在决定使用构建者模式之前,应该仔细评估它带来的额外复杂度是否值得。
--------------------------------------------------------------------------------
/docs/md/12306/使用JUC中的核心组件来优化业务功能性能.md:
--------------------------------------------------------------------------------
1 | # **使用JUC中的核心组件来优化业务功能性能**
2 |
3 | ## JUC简介:
4 | 在Java并发编程中,`java.util.concurrent`(简称JUC)工具类库提供了强大的线程管理和任务执行的工具,它允许开发者能够更加容易地写出高效且线程安全的代码。使用JUC进行优化可以显著提升系统的性能和响应能力,同时降低开发复杂性。本文将介绍如何使用JUC中的一些核心组件来优化业务功能性能。
5 |
6 | ### JUC的核心组件
7 |
8 | JUC包含了许多用于处理并发的实用工具,其中一些关键的组件包括:
9 |
10 | 1. **ExecutorService 和 ThreadPoolExecutor**:提供线程池管理,可以有效地重用线程,减少创建和销毁线程的开销。
11 | 2. **CountDownLatch 和 CyclicBarrier**:用于协调多个线程之间的同步操作。
12 | 3. **Semaphore**:限流器,用于控制同时访问资源的线程数量。
13 | 4. **Future 和 CompletableFuture**:代表异步计算的结果,允许应用程序在计算完成之前继续执行其他任务。
14 | 5. **ConcurrentHashMap** 和其他并发集合:提供高并发的数据结构,支持高效的并发访问。
15 |
16 | ### 使用JUC优化业务功能
17 |
18 | #### 线程池优化
19 |
20 | 线程池是管理线程的强大工具,它可以极大地减少在执行大量异步任务时因频繁创建和销毁线程而产生的性能开销。使用`Executors`类可以方便地创建一个线程池:
21 |
22 | ```java
23 | ExecutorService executor = Executors.newFixedThreadPool(10);
24 | ```
25 |
26 | 在需要执行任务时,只需将`Runnable`或`Callable`任务提交给线程池:
27 |
28 | ```java
29 | executor.submit(() -> {
30 | // 业务逻辑代码
31 | });
32 | ```
33 |
34 | 当所有任务完成后,记得关闭线程池以释放资源:
35 |
36 | ```java
37 | executor.shutdown();
38 | ```
39 |
40 | #### 同步工具类优化
41 |
42 | 在多线程环境下对数据进行操作时,可以使用`CountDownLatch`、`CyclicBarrier`和`Semaphore`等同步辅助类来控制线程的执行顺序和数量。例如,使用`CountDownLatch`确保所有线程都准备好之后再开始执行:
43 |
44 | ```java
45 | CountDownLatch latch = new CountDownLatch(N);
46 | for (int i = 0; i < N; i++) {
47 | new Thread(() -> {
48 | // 准备工作...
49 | latch.countDown();
50 | try {
51 | latch.await(); // 等待所有线程准备完毕
52 | } catch (InterruptedException e) {
53 | Thread.currentThread().interrupt();
54 | }
55 | // 执行任务...
56 | }).start();
57 | }
58 | ```
59 |
60 | #### 异步编程优化
61 |
62 | 利用`CompletableFuture`可以实现异步编程,避免阻塞主线程,提高系统吞吐量。下面的例子展示了如何使用`CompletableFuture`异步执行任务并在结果可用时进行处理:
63 |
64 | ```java
65 | CompletableFuture.supplyAsync(() -> {
66 | // 耗时操作...
67 | return result;
68 | }).thenAccept(result -> {
69 | // 处理结果...
70 | });
71 | ```
72 |
73 | #### 并发集合的使用
74 |
75 | 使用并发集合如`ConcurrentHashMap`可以在多线程环境下安全地进行数据操作,而无需外部同步:
76 |
77 | ```java
78 | ConcurrentHashMap map = new ConcurrentHashMap<>();
79 | map.put("key", "value");
80 | ```
81 |
82 | ### 结论
83 |
84 | 通过合理运用JUC提供的工具,我们可以显著提升业务功能的并发处理能力,减少资源消耗,并简化多线程编程的复杂性。无论是线程池管理、线程同步控制,还是异步编程和并发数据结构,JUC为我们提供了一套全面的解决方案。然而,值得注意的是,虽然JUC提供了很多便捷的工具,但正确使用它们要求开发者理解并发编程的原理和细节。错误的使用方法可能会导致难以发现的并发问题。因此,在使用JUC进行系统性能优化时,建议仔细测试和审查代码。
--------------------------------------------------------------------------------
/docs/md/12306/分布式锁在项目设计中的应用.md:
--------------------------------------------------------------------------------
1 | # **分布式锁在项目设计中的应用**
2 |
3 | ## 分布式锁简介
4 | 分布式锁是一种在分布式系统中用于协调多个进程或服务之间共享资源访问的同步机制。在项目设计中,分布式锁的应用非常关键,尤其是在需要确保多个节点上的操作的原子性、一致性和排他性时。
5 |
6 | ### 分布式锁在项目设计中的几种典型应用场景:
7 |
8 | - 1. 数据库操作的同步
9 | 在分布式系统中,多个服务可能需要访问和修改同一份数据库资源。为了防止数据不一致和并发问题,可以使用分布式锁来确保同一时间只有一个服务能够执行特定的数据库操作。
10 | - 2. 缓存更新的同步
11 | 分布式系统中的缓存更新操作需要保证原子性,以防止缓存数据不一致。例如,当一个服务更新缓存时,可以使用分布式锁来阻止其他服务同时对相同的缓存键进行操作。
12 | - 3. 任务的串行执行
13 | 在处理一些需要串行执行的任务时,分布式锁可以确保任务在分布式环境下按照预定的顺序执行。例如,定时任务、批处理作业等,可以通过分布式锁来控制任务的启动和执行。
14 | - 4. 资源的独占访问
15 | 在分布式系统中,某些资源(如文件、网络连接等)可能需要独占访问。分布式锁可以用来确保在任何给定时间,只有一个服务能够访问这些资源。
16 | - 5. 限流和节流
17 | 分布式锁可以用于实现分布式环境下的限流和节流策略。例如,通过限制同时访问某个服务的请求数量,可以防止系统过载。
18 | - 6. 领导选举
19 | 在分布式系统中,领导选举算法(如Raft或ZooKeeper的Leader Election)通常会用到分布式锁来确保集群中的一个节点成为领导者,并对系统状态进行协调。
20 |
21 | ### 实现分布式锁的技术
22 | 实现分布式锁的技术有多种,包括但不限于:
23 |
24 | - 基于数据库:使用数据库事务和唯一索引来实现锁。
25 | - 基于缓存系统:使用Redis的SETNX(SET if Not eXists)命令或Redisson等库来实现锁。
26 | - 基于分布式协调服务:使用ZooKeeper、etcd等分布式协调服务来实现锁。
27 | - 基于消息队列:使用消息队列的顺序消息特性来实现分布式锁。
28 |
29 | ## 设计考虑
30 | 在使用分布式锁时,需要考虑以下几个设计要点:
31 |
32 | - 性能:锁的获取和释放需要高效,以免成为系统瓶颈。
33 | - 可靠性:锁的实现必须可靠,确保在分布式环境下的一致性和可用性。
34 | - 死锁处理:需要有机制来处理死锁情况,例如通过设置锁的超时时间。
35 | - 容错性:在分布式锁的实现中,需要考虑节点故障和网络分区的情况。
36 | - 可扩展性:随着系统规模的扩大,分布式锁的实现应当能够适应更多的并发访问。、
37 |
38 | ## 分布式锁在项目中的实现和应用
39 | // todo
40 |
41 | ## 总结
42 |
43 | 综上所述,分布式锁在项目设计中扮演着关键角色,它有助于确保分布式环境下的数据一致性和操作的原子性。在设计和实现分布式锁时,需要权衡多种因素,选择最适合项目需求的技术方案。
--------------------------------------------------------------------------------
/docs/md/12306/如何生成分布式ID.md:
--------------------------------------------------------------------------------
1 | # **如何生成分布式ID**
2 | 随着12306开源项目的不断发展,后端服务需要处理来自全国乃至全球的海量请求。在这样的分布式系统中,生成全局唯一且高效的ID是保障数据一致性和服务可靠性的关键。以下是针对12306开源项目的分布式ID选型分析与实践。
3 |
4 | ## **项目需求分析**
5 |
6 | 首先,我们需要明确12306项目对分布式ID的基本要求:
7 | - **全局唯一性**:确保每个交易、订单或记录都有一个独一无二的标识符。
8 | - **高并发支持**:系统需能够支撑极高的并发请求,特别是在购票高峰期。
9 | - **可排序性**:ID最好能反映时间信息,便于数据库索引和数据分片。
10 | - **易扩展性**:随着业务的增长,ID生成系统应易于水平扩展。
11 | - **兼容性**:ID生成方案不应依赖于特定的技术栈或存储系统。
12 |
13 | ## **可选方案对比**
14 |
15 | 基于以上需求,我们评估了几种常见的分布式ID生成策略:
16 |
17 | - **UUID**:虽然UUID可以保证全局唯一性和高并发性能,但其长度过长且无法排序,不适合作为数据库主键,因此被排除。
18 |
19 | - **数据库自增ID**:这种方法实现简单,但显然不适合分布式环境,因为多个节点间难以协调,容易产生冲突。
20 |
21 | - **雪花算法(Snowflake)**:Twitter的雪花算法在分布式系统中得到了广泛应用。它生成的ID有序且高效,但依赖于系统时钟,并且当单个数据中心内的节点数量超过最大序列号时,需要进行微调。
22 |
23 | - **Leaf**:美团点评开源的Leaf提供了高度的灵活性和可扩展性,支持自定义比特位分配,适合大型分布式系统。
24 |
25 | ## **选型决策**
26 |
27 | 综合考虑项目的具体需求和各方案的优缺点,我们决定在12306开源项目中采用改进型的雪花算法或Leaf作为分布式ID的生成策略。
28 |
29 | ### **实施细节**
30 |
31 | - **时间戳精度**:考虑到票务系统的特点,我们可以将时间戳的精度从毫秒级调整到秒级,以减少ID冲突的可能性。
32 |
33 | - **数据中心和机器ID分配**:根据12306的服务器部署情况,合理规划数据中心和机器ID的分配,确保ID的唯一性和高效生成。
34 |
35 | - **序列号设计**:为了避免同一毫秒内生成的ID冲突,序列号的范围应该足够大,同时考虑未来可能的水平扩展需求。
36 |
37 | - **容错机制**:建立监控和报警机制,确保在系统时钟不同步或其他异常情况下,ID生成服务仍能正常工作。
38 |
39 | - **测试验证**:在实际投入使用前,进行充分的性能测试和压力测试,确保在不同的负载条件下ID生成系统的稳定性和可靠性。
40 |
41 | ## **结语**
42 |
43 | 通过精心的设计和选型,12306开源项目的分布式ID生成方案将为整个系统的稳定运行提供坚实的基础。无论是日常运营还是高峰时段的压力,一个可靠的ID生成策略都是保障数据完整性和服务可用性的关键。随着项目的不断进化,我们也将持续优化ID生成方案,以满足业务的持续发展需求。
44 |
45 |
--------------------------------------------------------------------------------
/docs/md/12306/死磕设计模式之抽象策略模式.md:
--------------------------------------------------------------------------------
1 | # **死磕设计模式之抽象策略模式**
--------------------------------------------------------------------------------
/docs/md/12306/环境搭建.md:
--------------------------------------------------------------------------------
1 | # **运行环境搭建指南**
2 |
3 | 随着12306项目的开源,越来越多的开发者和企业有机会研究、使用乃至改进这一国民级应用。
4 | 本文旨在提供一份详细的运行环境搭建指南,帮助开发者快速搭建起12306开源项目的本地开发和测试环境。
5 |
6 | ## **一、系统要求**
7 |
8 | 在开始之前,请确保你的系统满足以下要求:
9 | - 操作系统:推荐使用Linux(如Ubuntu 18.04 LTS或更高版本),也可以使用Windows 10或更高版本,macOS Catalina或更高版本。
10 | - 内存:至少4GB RAM,推荐8GB或以上。
11 | - 存储空间:至少20GB的可用硬盘空间。
12 | - 网络:稳定的网络连接以便下载必要的软件包和依赖。
13 |
14 | ## **二、开发环境准备**
15 |
16 | 以下是搭建开发环境的基本步骤:
17 |
18 | 1. **安装Docker**
19 | - Docker是用于自动部署应用程序的开源平台,可以方便地创建和管理容器。
20 | - 根据你使用的操作系统,从Docker官网下载并安装适合的Docker版本。
21 |
22 | 2. **安装Docker Compose**
23 | - Docker Compose是一个用于定义和运行多容器Docker应用程序的工具。
24 | - 使用以下命令安装Docker Compose:
25 | ```
26 | sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
27 | sudo chmod +x /usr/local/bin/docker-compose
28 | ```
29 |
30 | 3. **安装Git**
31 | - Git是一个分布式版本控制系统,用于源代码管理。
32 | - 根据操作系统的指令完成Git的安装。
33 |
34 | 4. **克隆12306项目代码仓库**
35 | - 使用以下命令将12306项目的代码仓库克隆到本地:
36 | ```
37 | git https://gitee.com/Ken2024888/12306.git
38 | cd 12306
39 | ```
40 |
41 | 5. **配置环境变量**
42 | - 根据项目文档,设置必要的环境变量,这些变量可能包括数据库地址、端口号、API密钥等。
43 |
44 | ## **三、启动项目**
45 |
46 | 在确保所有依赖和环境变量配置正确后,可以使用以下命令启动项目:
47 |
48 | 1. **构建Docker镜像**
49 | ```
50 | docker-compose build
51 | ```
52 |
53 | 2. **启动Docker容器**
54 | ```
55 | docker-compose up -d
56 | ```
57 |
58 | 此时,所有的服务将以容器的形式在后台运行。如果需要停止服务,可以使用`docker-compose down`命令。
59 |
60 | ## **四、验证安装**
61 |
62 | 要验证项目是否成功运行,可以在浏览器中访问项目的Web界面(通常是`http://localhost:端口号`),或通过API接口发送请求并检查响应。
63 |
64 | ## **五、常见错误处理**
65 |
66 | 在环境搭建过程中可能会遇到一些常见问题,如端口冲突、权限不足等。这时应检查日志文件和系统消息,根据具体错误信息进行调整和修复。
67 |
68 | ## **结语**
69 |
70 | 以上步骤为12306开源项目运行环境的搭建提供了基本指导。请注意,实际项目中可能需要根据具体情况调整配置和步骤。搭建完成后,你可以自由地进行代码开发、功能测试和性能优化等工作。祝你在12306开源项目的探索和学习之旅中收获满满!
71 |
--------------------------------------------------------------------------------
/docs/md/12306/详解雪花算法.md:
--------------------------------------------------------------------------------
1 | # 详解雪花算法
2 |
3 | ### 外置Snowflake
4 |
5 | 雪花算法Snowflake,Twitter公司分布式项目采用的ID生成算法。
6 |
7 | 
8 |
9 | 这个算法生成的ID是一个64位的长整型long:
10 |
11 | - 1位符号位,值为 0,没有实际意义,主要为兼容长整型的格式
12 | - 41位时间戳,记录本地的毫秒时间。41 位的时间戳可以容纳的毫秒数是 2 的 41 次幂,一年所使用的毫秒数是365 * 24 * 60 * 60 * 1000,即 69.73 年。即ShardingSphere 的 SnowFlake 算法的时间纪元从 2016 年 11 月 1 日零点开始,可以使用到 2086 年
13 | - 10 bit工作进程位,机器ID,机器就是生成ID的节点,用10位长度给机器做编码,那意味着最大规模可以达到1024个节点(2^10)。前 5 个 bit 代表机房 id,后 5 个 bit 代表机器i
14 | - 12位序列号,某个机房某台机器上在一毫秒内同时生成的 ID 序号。如果在这个毫秒内生成的数量超过 4096(即 2 的 12 次幂),那么生成器会等待下个毫秒继续生成。序列的长度直接决定了一个节点1毫秒能够产生的ID数量,12位就是4096(2^12)
15 |
16 | 据数据结构推算:
17 |
18 | - 每秒可以产生 26 万个自增可排序的 ID
19 | - 支持TPS可达(2^22*1000,419万左右),够绝大多数系统。
20 |
21 | 但实现雪花算法时,注意时间回拨影响。机器时钟若回拨,产生的ID就可能重复,需在算法中特殊处理。
22 |
23 | SnowFlake 算法依赖时间戳,需考虑时钟回拨,即服务器因时间同步,导致某部分机器的时钟回到了过去的时间点。时间戳的回滚肯定会导致生成一个已使用过的ID,因此默认分布式主键生成器提供一个最大容忍的时钟回拨ms数:
24 |
25 | - 若时钟回拨时间超过最大容忍的毫秒数阈值,则程序报错
26 | - 在可容忍范围内,默认分布式主键生成器会等待时钟同步到最后一次主键生成的时间后,再继续工作
--------------------------------------------------------------------------------
/docs/md/AI/01-RAG应用框架和解析器.md:
--------------------------------------------------------------------------------
1 | # 01-RAG应用框架和解析器
2 |
3 | ## 1 开源解析和拆分文档
4 |
5 | 第三方工具去对文件解析拆分,将文件内容给提取出来,并将我们的文档内容去拆分成一个小的chunk。
6 |
7 | 常见的PDF、word、markdown、JSON、HTML,都有很好的模块去把这些文件去进行一个东西去提取。
8 |
9 | ### 1.1 优势
10 |
11 | - 支持丰富的文档类型
12 | - 每种文档多样化选择
13 | - 与开源框架无缝集成
14 |
15 |
16 |
17 | 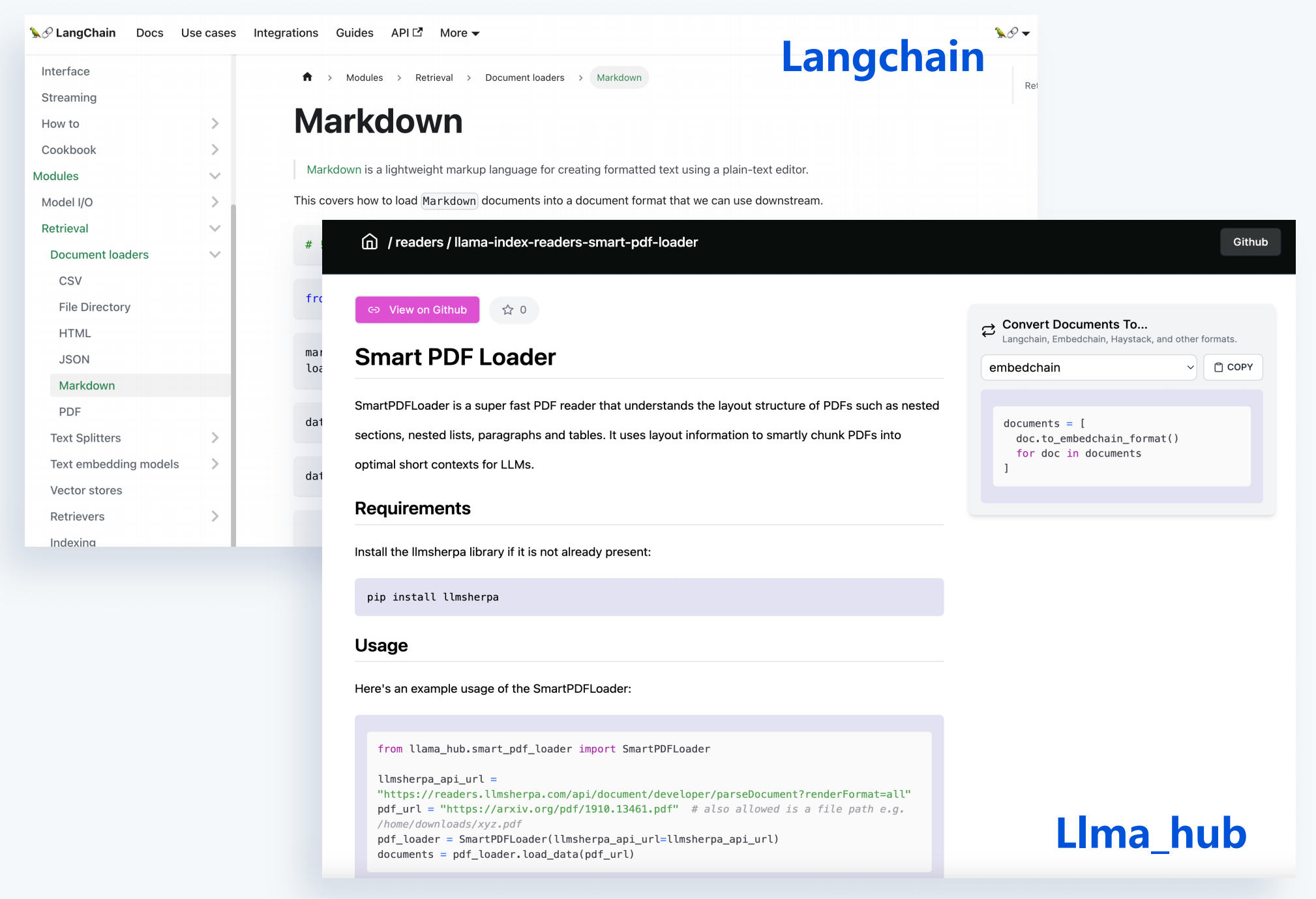
18 |
19 | 但有时效果很差,内容跟原始文件内容差别大。
20 |
21 | ## 2 PDF格式多样性
22 |
23 |
24 |
25 | 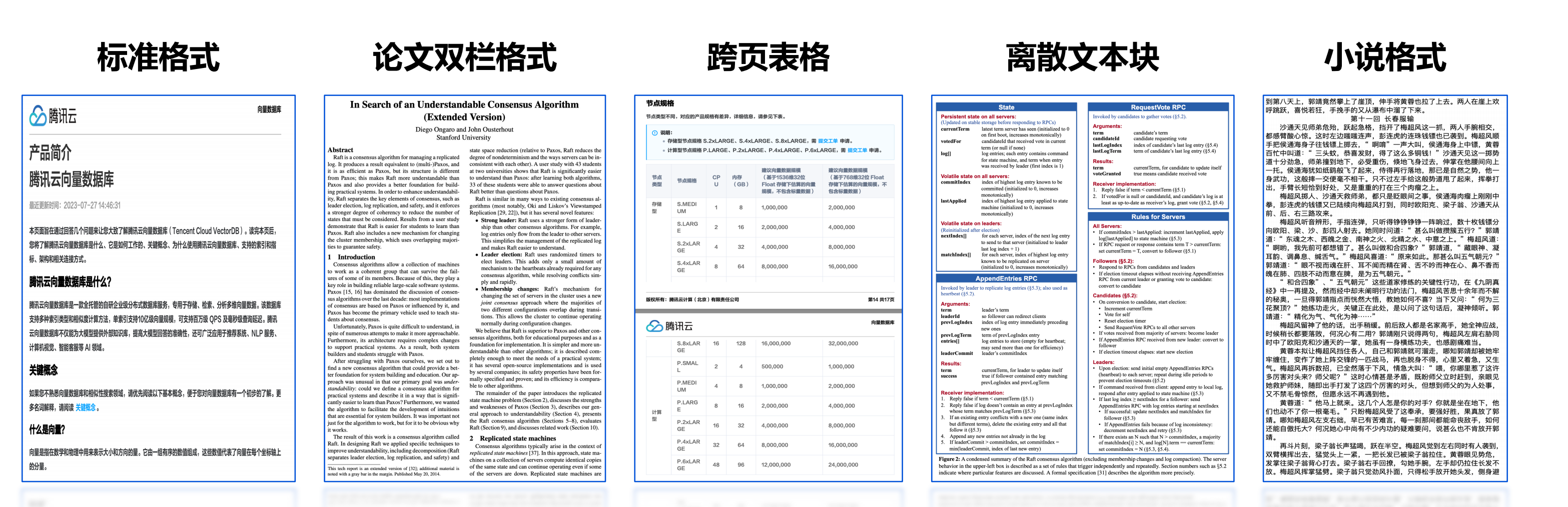
26 |
27 | **复杂多变的文档格式,提高解析效果十分困难**。
28 |
29 | ## 3 复杂文档格式解析问题
30 |
31 | 文档内容质量将很大程度影响最终效果,文档处理过程涉及问题:
32 |
33 | ### 3.1 内容不完整
34 |
35 | 对文档的内容提取时,可能发现提取出的文档内容会被截断。跨页形式,提取出来它的上下页,两部分内容就会被截断,导致文档内部分内容丢失,去解析图片或双栏复杂的这种格式,它会有一部分内容丢失。
36 |
37 | ### 3.2 内容错误
38 |
39 | 同一页PDF文件可能存在文本、表格、图片等混合。
40 |
41 | PDF解析过程中,同一页它不同段落其实会也会有不同标准的一些格式。按通用格式去提取解析就遇到同页不同段落格式不标准情况。
42 |
43 | ### 3.3 文档格式
44 |
45 | 像常见PDF md文件,需要去支持把这些各类型的文档格式的文件都给提取。
46 |
47 | ### 3,4 边界场景
48 |
49 | 代码块还有单元格这些,都是我们去解析一个复杂文档格式中会遇到的一些问题。
50 |
51 | ## 4 PDF内容提取流程
52 |
53 |
54 |
55 | 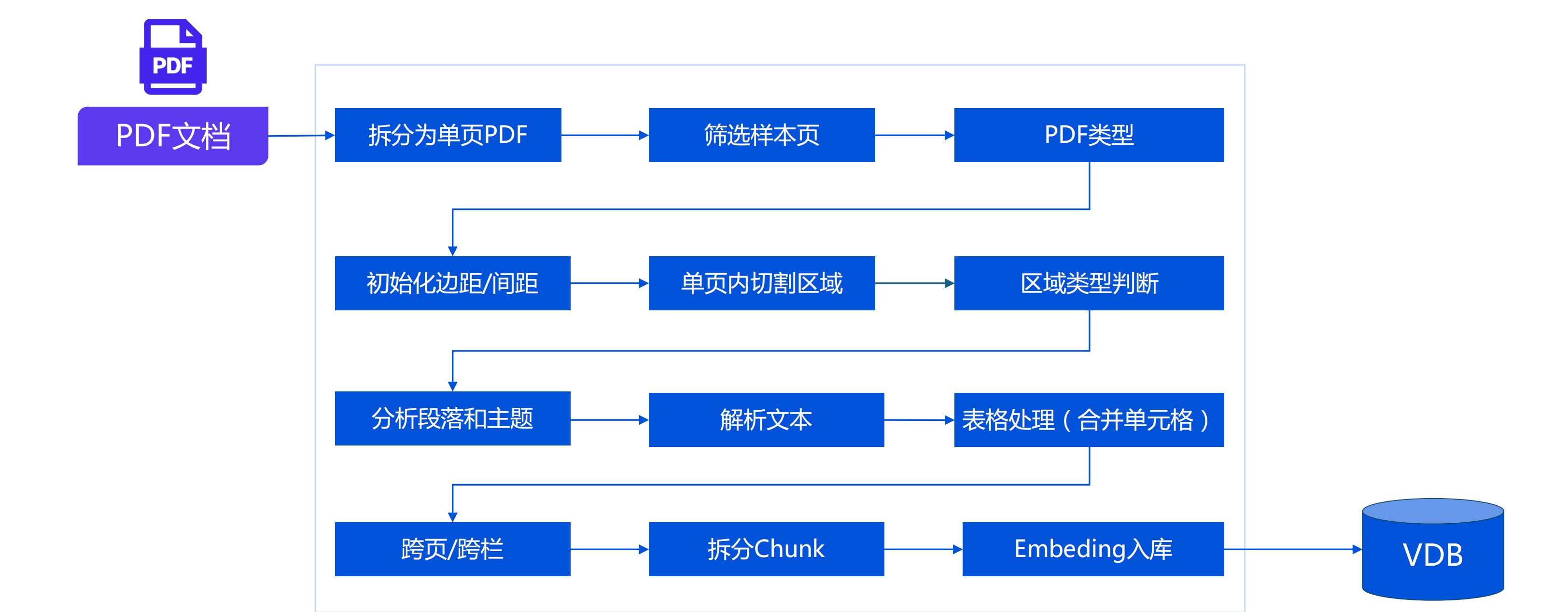
56 |
57 | ## 5 为啥解析文档后,要做知识片段拆分?
58 |
59 | ### 5.1 Token限制
60 |
61 | - 绝大部分开源限制 <= 512 Tokens
62 | - bge_base、e5_large、m3e_base、text2vector_large_chinese、multilingnal-e5-base..
63 |
64 | ### 5.2 效果影响
65 |
66 | - 召回效果:有限向量维度下表达较多的文档信息易产生失真
67 | - 回答效果:召回内容中包含与问题无关信息对LLM增加干扰
68 |
69 | ### 5.3 成本控制
70 |
71 | - LLM费用:按Token计费
72 | - 网络费用:按流量计费
73 |
74 | ## 6 Chunk(块)拆分对最终效果的影响
75 |
76 | ### 6.1 Chunk太长
77 |
78 | 信息压缩失真。
79 |
80 | ### 6.2 Chunk太短
81 |
82 | 表达缺失上下文;匹配分数容易变高。
83 |
84 | ### 6.3 Chunk跨主题
85 |
86 | 内容关系脱节。
87 |
88 | ### 原文连续内容(含表格)被截断
89 |
90 | 单个Chunk信息表达不完整,或含义相反
91 |
92 | ### 干扰信息
93 |
94 | 如空白、HTML、XML等格式,同等长度下减少有效信息、增加干扰信息
95 |
96 | ### 主题和关系丢失
97 |
98 | 缺失了主题和知识点之间的关系
99 |
100 | ## 7 改进知识的拆分方案
101 |
102 |
103 |
104 | 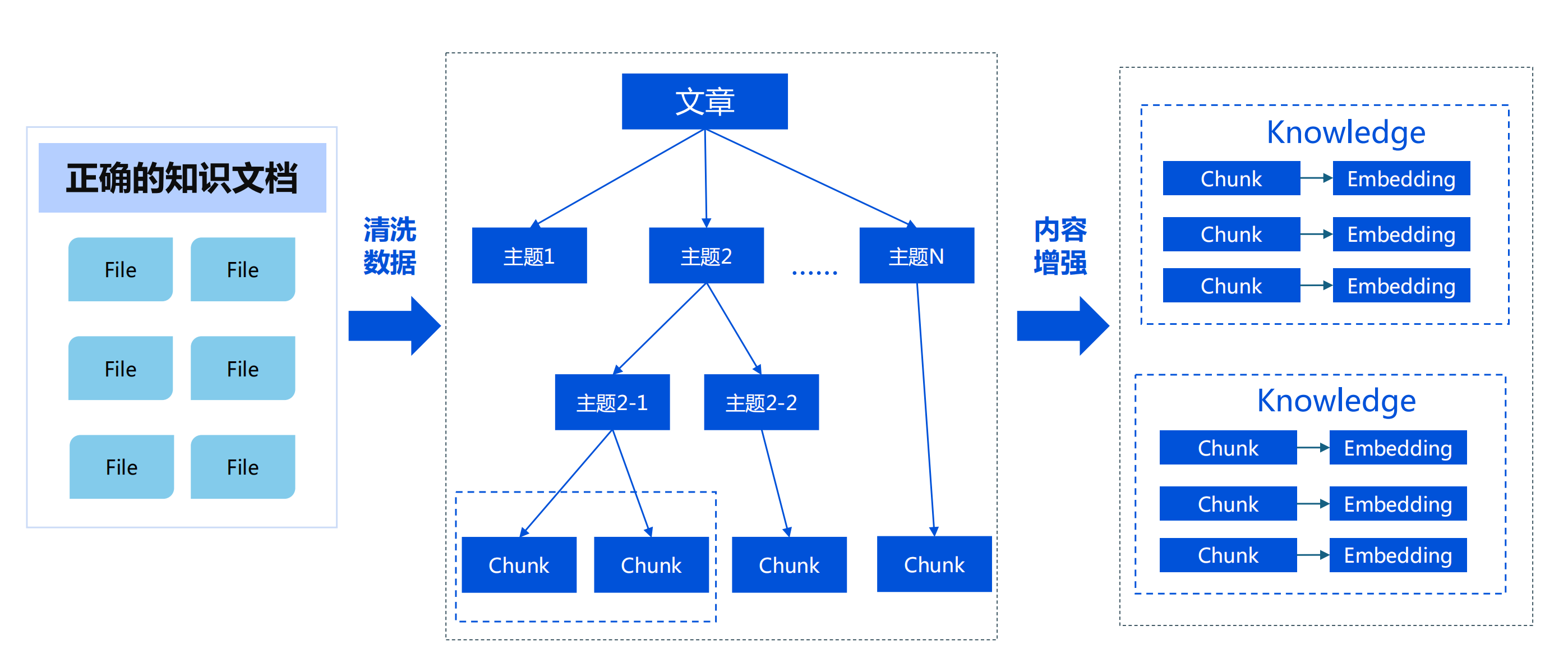
105 |
106 | ## 8 商用向量数据库AI套件
107 |
108 | 云厂商:
109 |
110 | 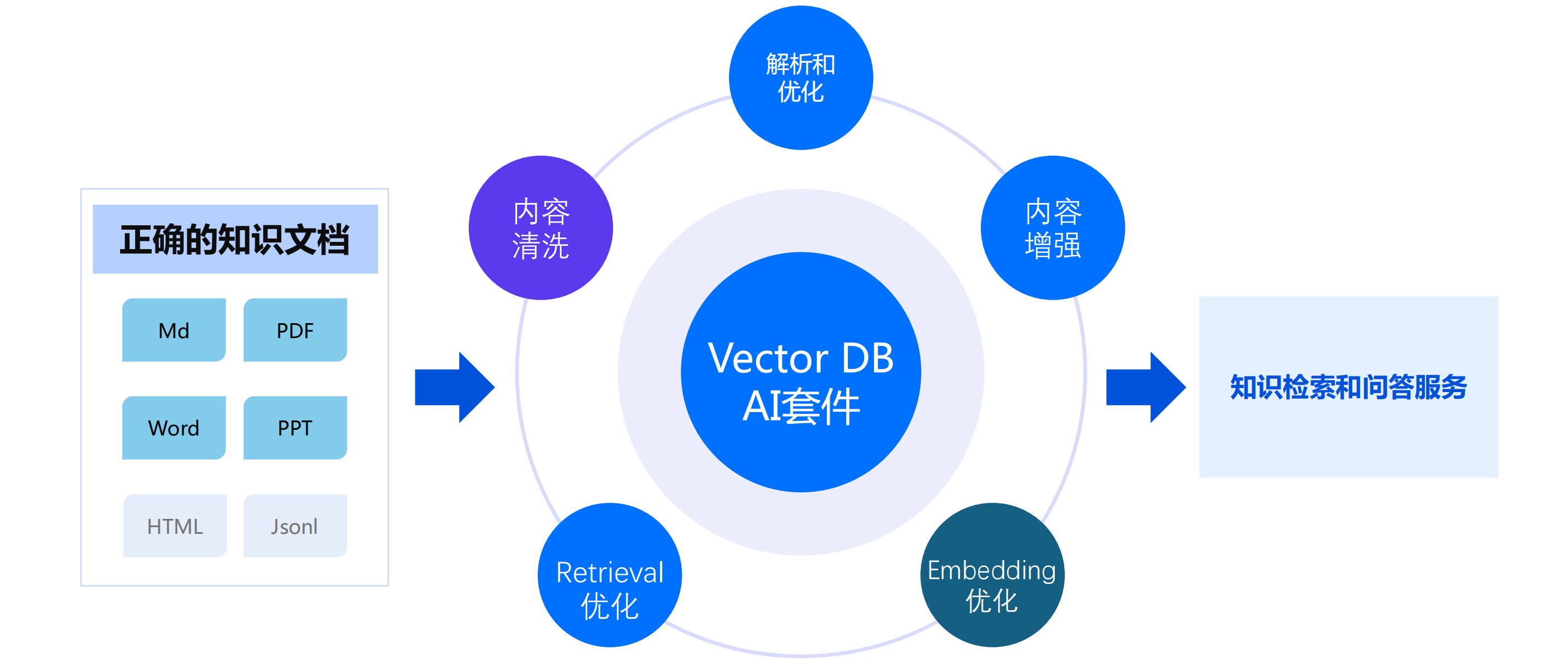
--------------------------------------------------------------------------------
/docs/md/AI/04-prompt-helping-llm-understand-knowledge.md:
--------------------------------------------------------------------------------
1 | # 04-prompt-helping-llm-understand-knowledge
2 |
3 | ## 1 Prompt
4 |
5 | Prompt 可理解为指导AI模型生成特定类型、主题或格式内容的文本。
6 |
7 | NLP中,Prompt 通常由一个问题或任务描述组成,如“给我写一篇有关RAG的文章”,这句话就是Prompt。
8 |
9 | Prompt赋予LLM小样本甚至零样本学习的能力:
10 |
11 | 
12 |
13 | LLM能力本质上说是续写,通过编写更好的prompt来指导模型,并因此获得更好的结果:
14 |
15 | 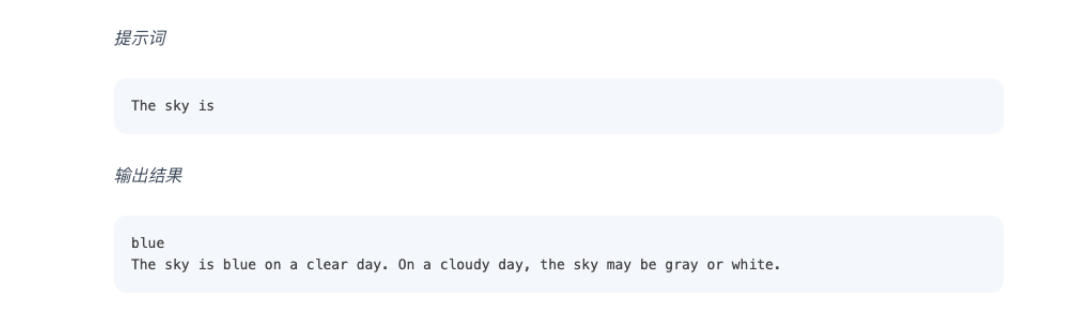
16 |
17 | 无具体指令,模型只会续写。输出结果可能出人意料或远高于任务要求:
18 |
19 | 
20 |
21 | 告知模型去完善句子,因此输出结果和最初输入完全符合。Prompt Engineering就是探讨如何设计最佳Prompt,用于指导LLM高效完成某项任务。
22 |
23 | ## 2 Prompt的进阶技巧CoT
24 |
25 | Chain of Thought,让模型输出更多的上下文与思考过程,提升模型输出下一个token的准确率。
26 |
27 | 
28 |
29 | ## 3 优化Prompt,提升模型推理能力和问答准确率
30 |
31 | ### 3.1 分布式引导提问
32 |
33 | 把解决问题的思路分成多步,引导模型分步执行
34 |
35 | 
36 |
37 | ### 3.2 Prompt代码化
38 |
39 | LLM通常都会有代码数据,prompt代码化进一步提升模型的推理能力。
40 |
41 | 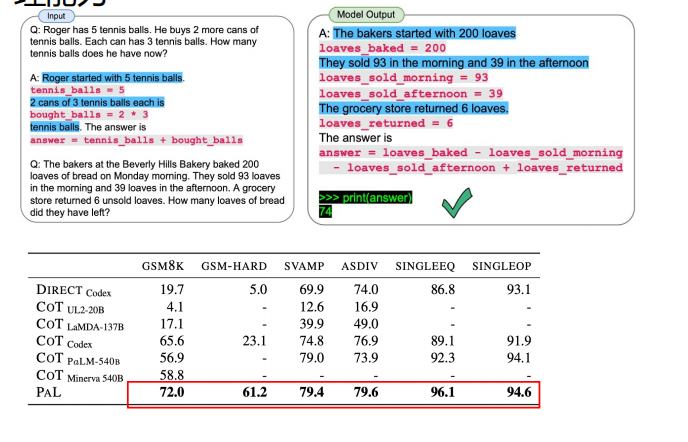
42 |
43 | 
--------------------------------------------------------------------------------
/docs/md/AI/13-best-development-practices.md:
--------------------------------------------------------------------------------
1 | # 13-最佳开发实践
2 |
3 | ## 1 LangChain 的定位
4 |
5 |
6 |
7 | 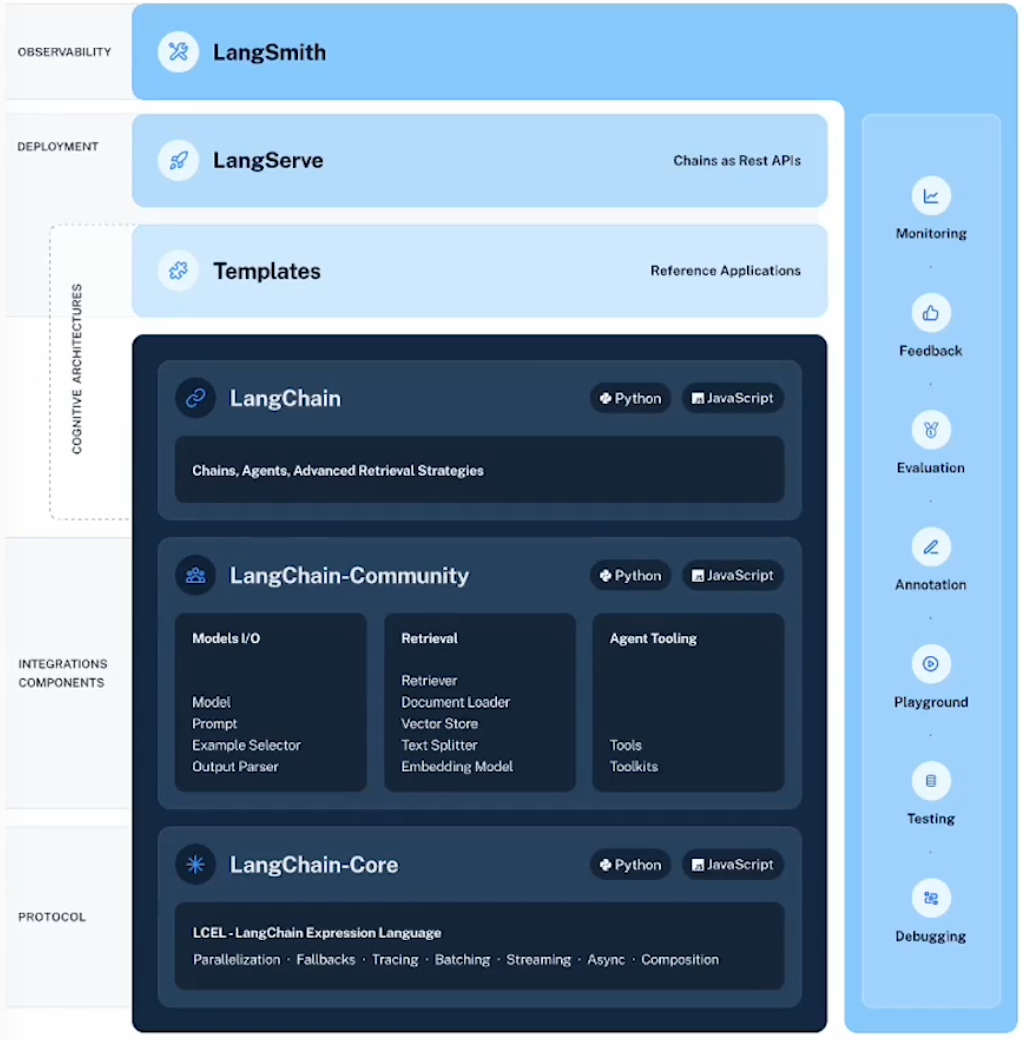
8 |
9 | - 【代码层】LangChain-Core: LCEL
10 | - 【代码层】LangChain-Community 社区贡献
11 | - 【代码层】LangChain 封装组件
12 | - 一站式开发平台 LangSmith
13 | - 便捷AI应用服务器部署套件LangServe
14 |
15 | ## 2 大模型选型
16 |
17 | 考虑模型、agent、prompt、chain评估:
18 |
19 | 
20 |
21 | ### 2.1 闭源大模型+API
22 |
23 | - 优点:省事、强大
24 | - 缺点:成本、限速、数据隐私
25 |
26 | ### 2.2 开源大模型+自托管
27 |
28 | 优点:数据私有、更灵活、成本低
29 |
30 | 缺点:算力设施、技术支撑
--------------------------------------------------------------------------------
/docs/md/AI/AI大模型企业应用实战.md:
--------------------------------------------------------------------------------
1 | # AI 大模型企业应用实战
2 |
3 | ## 你将获得
4 |
5 | - gpt/qwen API 编程要点 + LangChain 使用技巧
6 | - 基于 LLM 的代码生成与调试实践
7 | - LLM 在研发全过程的应用案例
8 | - LLM 的云原生部署任务实践
9 | - 企业应用引入 LLM 的排坑指南
10 |
11 | ## 专栏介绍
12 |
13 | 现在以 GPT/qwen 为代表的大语言模型广受关注,许多企业都在积极探索在自身领域落地 AIGC 技术。
14 |
15 | 虽然大模型在辅助文档编写、问题回答、内容总结等特定的日常任务上表现良好,但想要把 GPT 这类自然语言模型真正应用到企业应用开发,提高系统的智能化和自动化,我们仍然面临着许多挑战。
16 |
17 | - LLM 基于历史数据训练,处理最新信息相关查询的能力有限。
18 | - 与环境的交互问题处理难度大,比如通过 LLM 执行 shell 命令或调用 API 等任务,都涉及到对系统外部环境的联动。
19 | - LLM 需要结合企业内部数据训练调优,才能保障生成内容的准确性。
20 | - LLM 的代码生成能力虽然很强大,但往往针对通用功能,无法处理企业里更复杂的需求。
21 |
22 | 为了帮你解决这些问题,根据我在云原生平台中集成大模型的实操经验,带你沉浸式体验如何把 LLM 应用到企业应用开发的整体流程中。
23 |
24 | 实践是检验真理的唯一标准,而可以执行的代码是掌握理论的最佳路径。因此专栏以具体场景的代码实战演练与调试为主,使用 Python 作为编程语言。
25 |
26 | 配套代码你可以从这里获取:https://github.com/Java-Edge/AIAgent
27 |
28 | **专栏设计**
29 |
30 | 基础篇、企业应用篇和研发效率篇三个章节,带你循序渐进掌握 LLM 的应用落地。
31 |
32 | 
33 |
34 | **基础篇**
35 | 带你快速熟悉 LLM 的基本用法与应用技巧。我们会一起构建开发环境和运行环境,运行第一个大语言模型程序,学习相关提示词技巧,认识 LangChain,并给聊天机器人注入记忆。
36 |
37 | **企业应用篇**
38 | 结合大量例子,带你应对企业应用融入 LLM 时面临的诸多挑战,包括与现有企业内部数据的整合、与其他程序的整合、LLM 生成部分与外部环境交互等问题。学完这一章,你就能综合应用大模型和其他工具解决实际工程问题,并结合具体需求场景定制自己的 AutoGPT。
39 |
40 | **研发效率篇**
41 | 结合之前所学,探索如何将 LLM 应用到整个研发生命周期里,有效提升我们的工作效率和质量。这一章不但会为你演示 LLM 在系统设计、代码生成、测试生成、云原生部署等方面的应用方法与调优思路,还会与你探讨如何调整现有的架构思维和研发方式,更充分地发掘大模型价值。
42 |
43 | ## 适合人群
44 |
45 | 1. 希望在企业应用中落地大语言模型,并借此提升团队研发效率的软件工程师和架构师。
46 | 2. 初中级开发者可以学到如何通过编程方式使用大模型,提高自身开发效率。
47 | 3. 高级软件开发者和架构师,可以获得对未来软件的新思考,了解大模型带来的软件架构变革和基于大语言模型的全新开发范式。
48 | 4. 需要了解一门编程语言,后续专栏里会使用 Python 语言做演示。
49 |
50 | ## 专栏目录
51 |
52 | 
--------------------------------------------------------------------------------
/docs/md/AI/agent/boost-ai-workflow-resilience-with-error-handling.md:
--------------------------------------------------------------------------------
1 | # v0.14.0:告别 AI 应用崩溃,构建更可靠的智能工作流!
2 |
3 | ## 0 前言
4 |
5 | 使用 Dify 构建AI应用程序,需要处理复杂的工作流程,其中单个组件(节点)可能会遇到 API 超时或 LLM 输出异常等问题。以前,单个节点故障就可能扰乱整个工作流程。
6 |
7 | Dify引入强大的[错误处理功能 ](https://docs.dify.ai/guides/workflow/error-handling),以防级联故障:
8 |
9 | - 不仅可捕获异常以维护工作流的执行
10 | - 还允许开发人员为四种关键节点类型定义自定义错误处理
11 |
12 | 实现详细的调试并确保弹性
13 |
14 | ## 1 为啥错误处理很重要?
15 |
16 | 考虑文档处理工作流:
17 |
18 | 1. 文本从PDF提取
19 | 2. LLM分析该文本并生成结构化数据
20 | 3. 代码处理这些数据,完善文本
21 | 4. 输出精炼文本
22 |
23 | 若无错误处理,LLM生成格式错误的数据或代码节点遇到错误都导致工作流程停止。Dify现提供以下解决方案:
24 |
25 | - **默认值:** 预定义输出值,允许下游节点即使在输入缺失、不正确或格式错误的情况下也能继续运行
26 | - **工作流重定向:** 异常时,工作流重定向到备用分支,用 `error_type` 、 `error_message` 变量捕获错误详细信息并启用后续操作,如通知或备份工具激活
27 |
28 | 并行工作流中,单个分支故障以往导致整个流程停止。现在,这些错误处理策略允许其他分支继续运行,显著提高可靠性:
29 |
30 | 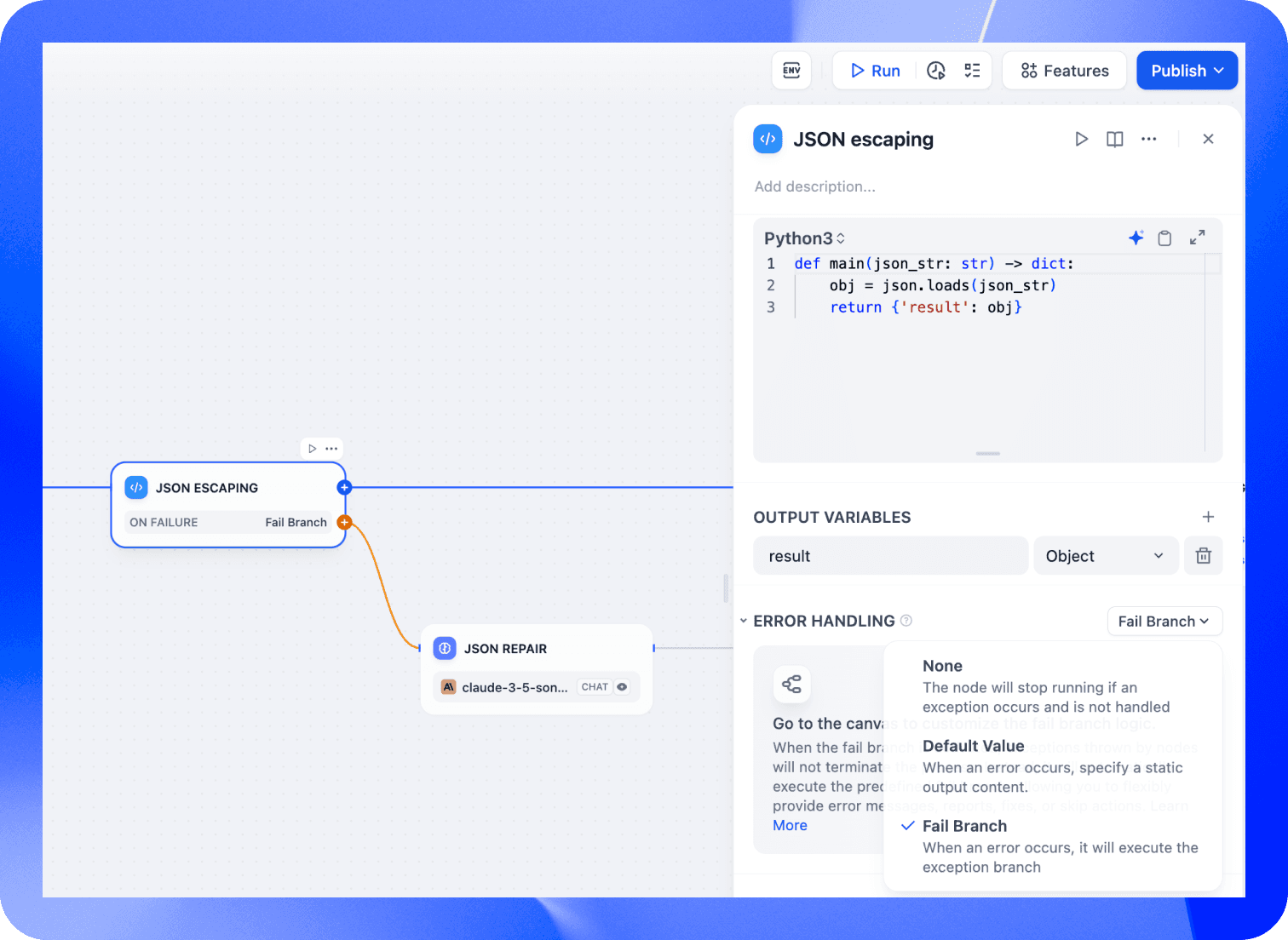
31 |
32 | ## 2 具有错误处理的关键节点
33 |
34 | Dify高级错误处理针对四种易出错的节点类型:
35 |
36 | 1. **LLM 节点:** 处理无效响应、API 问题和速率限制。开发者可设置默认输出或使用条件分支来获取替代解决方案
37 | 2. **HTTP 节点:** 在保持工作流执行的同时,通过重试间隔和详细的错误消息解决 HTTP 错误(404、500、超时)
38 | 3. **工具节点:** 如果主工具出现故障,可以快速切换到备用工具
39 | 4. **代码节点:** 使用预定义值或替代逻辑分支管理运行时错误,记录错误详细信息以防止中断
40 |
41 | ## 3 错误处理实例
42 |
43 | 与外部 API 交互的工作流。为模拟各种 HTTP 状态代码,用 [httpstat.us](http://httpstat.us/) 服务:
44 |
45 | 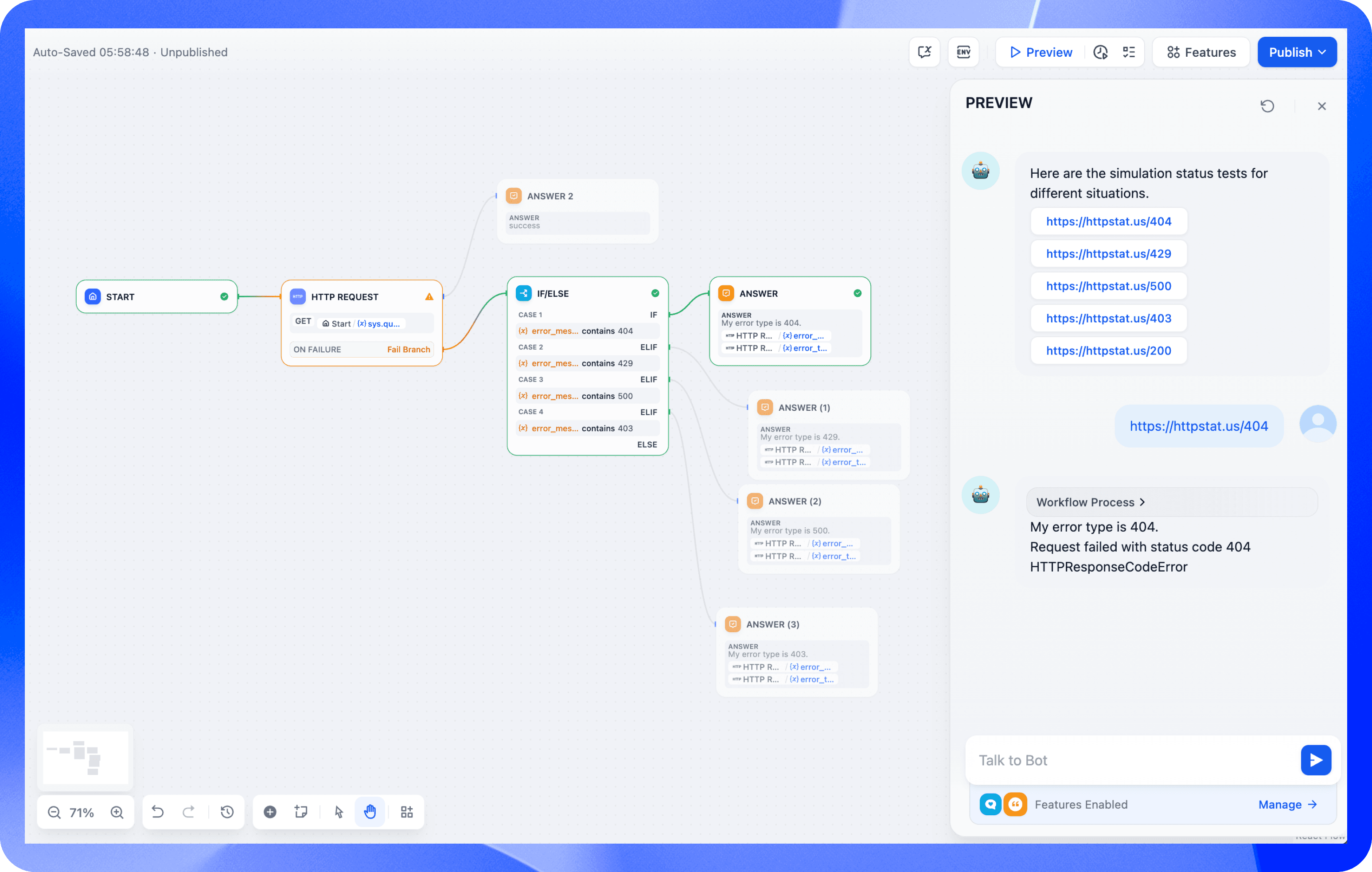
46 |
47 | 1. 起始节点启动工作流
48 | 2. HTTP请求节点调用 [httpstat.us](http://httpstat.us/)
49 | 3. 失败分支处理错误
50 | 4. 条件逻辑(Conditional logic)响应特定错误码:
51 | - 403(禁止):显示权限消息
52 | - 404(未找到):记录“未找到资源”消息
53 | - 429(请求过多):建议稍后重试
54 | - 500(服务器错误):切换到备份服务或触发警报
55 | 5. 输出节点,生成适当的响应
56 |
57 | 通过确保工作流程的稳定性并提供有价值的错误反馈,这种设计增强了业务运营的可靠性。
58 |
59 | ## 4 使用Dify构建更可靠AI工作流
60 |
61 | Dify v0.14.0 增强的错误管理功能,提供更强大的控制力和灵活性,实现稳健工作流,妥善处理异常并防止中断,确保 AI 应用程序的可靠性。
--------------------------------------------------------------------------------
/docs/md/AI/agent/dify-v1-1-0-filtering-knowledge-retrieval-with-customized-metadata.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/AI/agent/dify-v1-1-0-filtering-knowledge-retrieval-with-customized-metadata.md
--------------------------------------------------------------------------------
/docs/md/AI/agent/perplexity-labs.md:
--------------------------------------------------------------------------------
1 | # 不止于搜索!Perplexity Labs深度解析:以项目为核心的 AI 工作流!
2 |
3 | ## 0 前言
4 |
5 | Perplexity推出全新功能 [Labs](https://www.perplexity.ai/pl/hub/blog/introducing-perplexity-labs),专为 Pro 订阅用户设计,旨在支持更复杂的任务,功能超越了传统的问答服务。这一重大更新标志着 Perplexity 从以搜索为核心的交互模式,转向由生成式 AI 驱动的结构化、多步骤工作流。
6 |
7 | ## 1 交互模式
8 |
9 | Perplexity Labs 让用户可在一个统一界面完成多种任务,包括生成报告、分析数据、编写和执行代码、构建轻量级网页应用等。用户可以通网页和移动端的新模式切换器进入 Labs,桌面端支持也即将上线。
10 |
11 | ## 2 适用场景
12 |
13 | 与专注于简洁回答的 Perplexity Search 和提供深入信息整合的 Research(原名 Deep Research)不同,Labs 更适合需要完整成果输出的用户。这些成果可能包括格式化的电子表格、可视化图表、交互式仪表盘和基础网页工具等。
14 |
15 | 每个 Lab 项目都包含一个“Assets”标签页,用户可在此查看或下载所有生成的素材,如图表、图片、CSV 文件和代码文件。有些 Labs 还支持“App”标签页,可以直接在项目环境中渲染基本网页应用。
16 |
17 | ## 3 使用反馈
18 |
19 | Perplexity 的 CEO 和联合创始人 Aravind Srinivas 表示:
20 |
21 | > 推出 Perplexity Labs,是我们在 Perplexity 上进行搜索的一种全新方式,支持更复杂的任务,如构建交易策略、仪表盘、用于房地产研究的无头浏览任务、迷你网页应用、故事板,以及生成素材的目录等。
22 |
23 | 实际使用看,Labs 实现了多个软件工具功能的整合与自动化,大大减少了手动操作,尤其适用于结构化研究、数据处理或原型开发等场景。
24 |
25 | 用户反馈也显示出平台在速度和语境理解方面的优势。Sundararajan Anandan 就曾[分享](https://www.linkedin.com/feed/update/urn:li:ugcPost:7333908730314399752?commentUrn=urn%3Ali%3Acomment%3A(ugcPost%3A7333908730314399752%2C7334912579871326209)&dashCommentUrn=urn%3Ali%3Afsd_comment%3A(7334912579871326209%2Curn%3Ali%3AugcPost%3A7333908730314399752)):
26 |
27 | > 我最近尝试了 Perplexity Labs,它真的改变了游戏规则。以前需要花几个小时才能完成的手动研究和格式整理,现在在 10 分钟内就能输出清晰、可执行的见解。虽然目前还处于早期阶段,平台也有待进一步完善,但初次体验已经相当令人惊艳。
28 |
29 | 不过,一些早期用户也指出了可改进的地方,特别是在初次生成后进行跟进操作或修改代码方面功能有限。正如一位 Reddit 用户[评论](https://www.reddit.com/r/perplexity_ai/comments/1kza7vo/comment/mv6koy5/?utm_source=share&utm_medium=web3x&utm_name=web3xcss&utm_term=1&utm_content=share_button)所说:
30 |
31 | > Labs 最大的问题在于它对后续操作的支持不够,基本要求用户一击命中,非常考验技巧。
32 |
33 | ## 4 总结
34 |
35 | Perplexity 还宣布将统一产品术语,将“Deep Research”简化为“Research”,以便更清晰地区分三种模式:Search、Research 和 Labs。
36 |
37 | 目前,Perplexity Labs 已正式上线,向所有 Pro 用户开放。平台还提供了 [Projects Gallery](https://www.perplexity.ai/labs),展示了各种示例和使用案例,帮助用户快速上手完成实际任务。
--------------------------------------------------------------------------------
/docs/md/AI/document-parsing-and-chunking-in-open-source-tools.md:
--------------------------------------------------------------------------------
1 | # 01-RAG应用框架和解析器
2 |
3 | ## 1 开源解析和拆分文档
4 |
5 | 第三方工具去对文件解析拆分,提取文件内容,并将文档内容拆分成一个小chunk。
6 |
7 | PDF、word、markdown、JSON、HTML等都有很好的模块执行提取。
8 |
9 | ### 1.1 优势
10 |
11 | - 支持丰富的文档类型
12 | - 每种文档多样化选择
13 | - 与开源框架无缝集成
14 |
15 | 
16 |
17 | 但有时效果很差,内容跟原文件差别大。
18 |
19 | ## 2 PDF格式多样性
20 |
21 | 
22 |
23 | 复杂多变的文档格式,提高解析效果困难。
24 |
25 | ## 3 复杂文档格式解析问题
26 |
27 | 文档内容质量很大程度影响最终效果,文档处理涉及问题:
28 |
29 | ### 3.1 内容不完整
30 |
31 | 对文档的内容提取时,可能发现提取出的文档内容会被截断。跨页形式,提取出来它的上下页,两部分内容就会被截断,导致文档内部分内容丢失,去解析图片或双栏复杂的这种格式,它会有一部分内容丢失。
32 |
33 | ### 3.2 内容错误
34 |
35 | 同一页PDF文件可能存在文本、表格、图片等混合。
36 |
37 | PDF解析过程中,同一页它不同段落其实会也会有不同标准的一些格式。按通用格式去提取解析就遇到同页不同段落格式不标准情况。
38 |
39 | ### 3.3 文档格式
40 |
41 | 像常见PDF md文件,需要去支持把这些各类型的文档格式的文件都给提取。
42 |
43 | ### 3,4 边界场景
44 |
45 | 代码块还有单元格这些,都是我们去解析一个复杂文档格式中会遇到的一些问题。
46 |
47 | ## 4 PDF内容提取流程
48 |
49 | 
50 |
51 | ## 5 为啥解析文档后,要做知识片段拆分?
52 |
53 | ### 5.1 Token限制
54 |
55 | - 绝大部分开源限制 <= 512 Tokens
56 | - bge_base、e5_large、m3e_base、text2vector_large_chinese、multilingnal-e5-base..
57 |
58 | ### 5.2 效果影响
59 |
60 | - 召回效果:有限向量维度下表达较多的文档信息易产生失真
61 | - 回答效果:召回内容中包含与问题无关信息对LLM增加干扰
62 |
63 | ### 5.3 成本控制
64 |
65 | - LLM费用:按Token计费
66 | - 网络费用:按流量计费
67 |
68 | ## 6 Chunk拆分对最终效果的影响
69 |
70 | ### 6.1 Chunk太长
71 |
72 | 信息压缩失真。
73 |
74 | ### 6.2 Chunk太短
75 |
76 | 表达缺失上下文;匹配分数容易变高。
77 |
78 | ### 6.3 Chunk跨主题
79 |
80 | 内容关系脱节。
81 |
82 | ### 原文连续内容(含表格)被截断
83 |
84 | 单个Chunk信息表达不完整,或含义相反
85 |
86 | ### 干扰信息
87 |
88 | 如空白、HTML、XML等格式,同等长度下减少有效信息、增加干扰信息
89 |
90 | ### 主题和关系丢失
91 |
92 | 缺失了主题和知识点之间的关系
93 |
94 | ## 7 改进知识的拆分方案
95 |
96 | 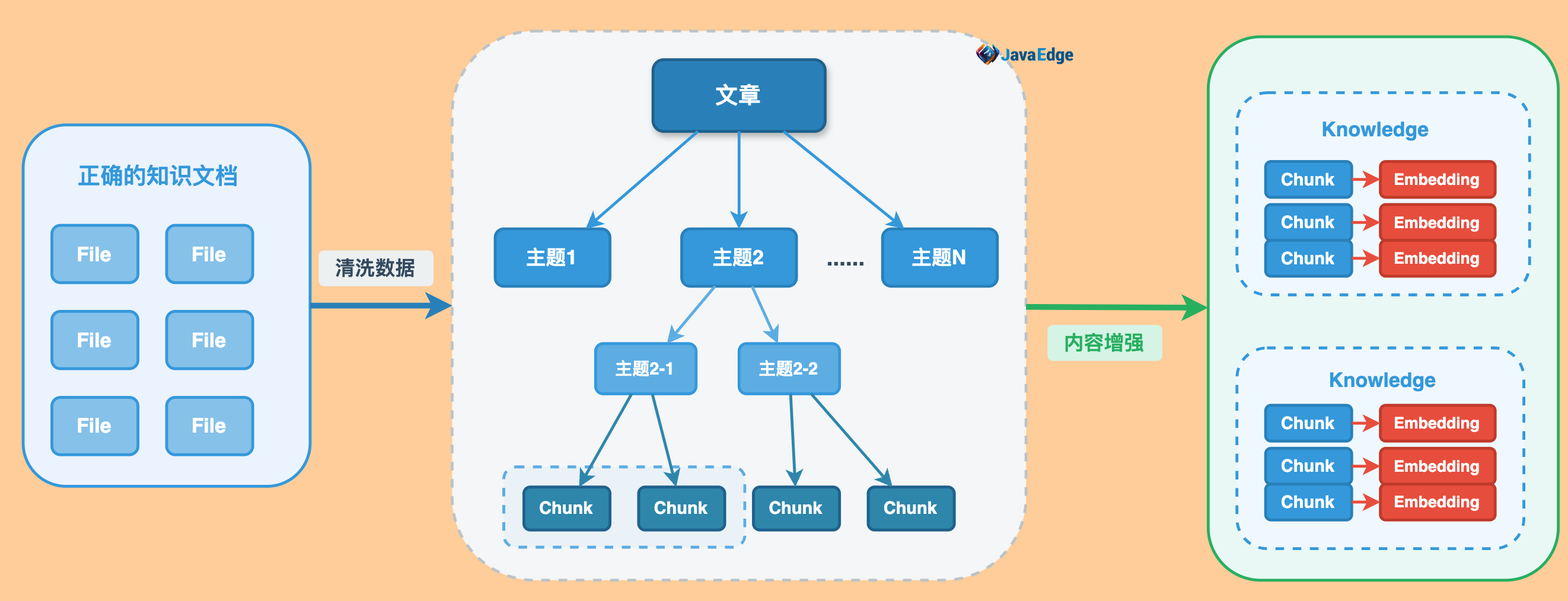
97 |
98 | ## 8 商用向量数据库AI套件
99 |
100 | Vector DB AI套件:
101 |
102 | 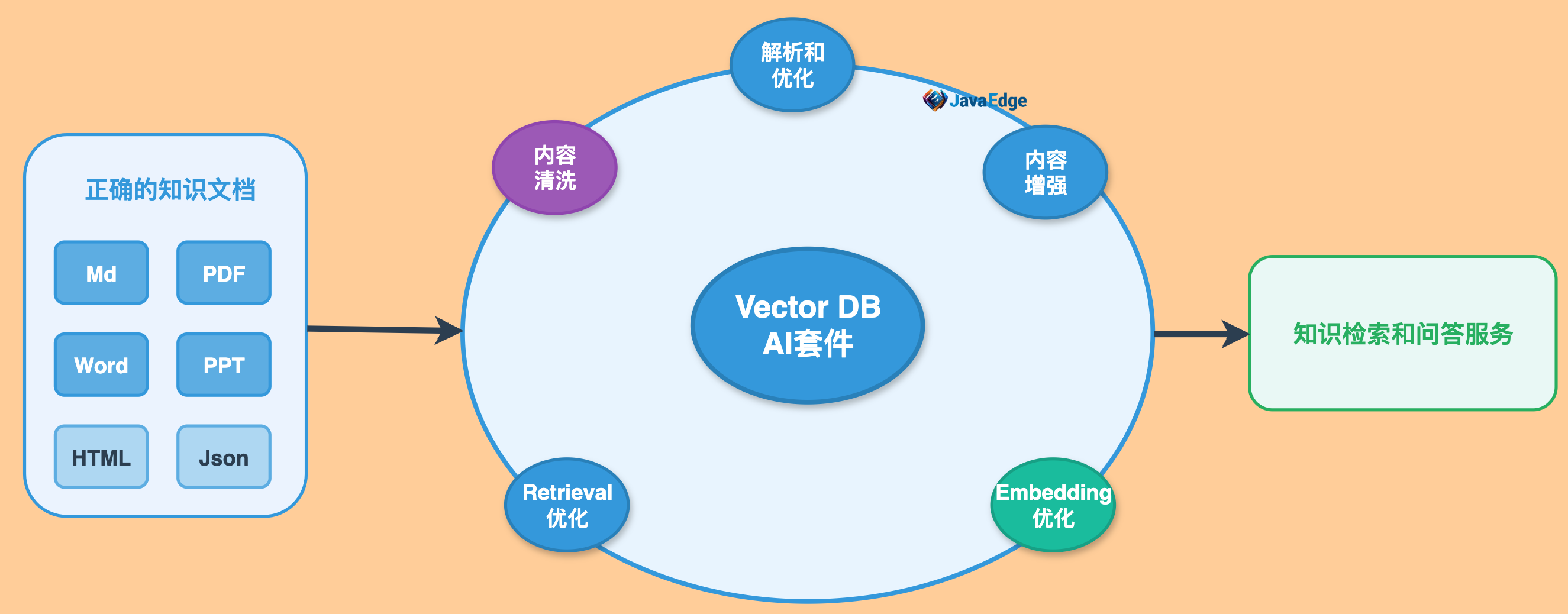
--------------------------------------------------------------------------------
/docs/md/AI/langchain4j/customizable-http-client.md:
--------------------------------------------------------------------------------
1 | # HTTP 客户端
2 |
3 | >LangChain4j HTTP 客户端定制:解锁 LLM API 交互的更多可能性
4 |
5 | ## 0 前言
6 |
7 | 一些 LangChain4j 模块(目前是 OpenAI 和 Ollama)支持自定义用于调用 LLM 提供程序 API 的 HTTP 客户端。
8 |
9 | `langchain4j-http-client` 模块实现了一个 `HttpClient` SPI,这些模块用它来调用 LLM 提供程序的 REST API。即底层 HTTP 客户端可自定义,并通过实现 `HttpClient` SPI 来集成任何其他 HTTP 客户端。
10 |
11 | ## 1 实现方案
12 |
13 | 目前,有两种开箱即用的实现:
14 |
15 | ### 1.1 JdkHttpClient
16 |
17 | `langchain4j-http-client-jdk` 模块中的 `JdkHttpClient` 。当使用受支持的模块(如 `langchain4j-open-ai` )时,默认使用它。
18 |
19 | ### 1.2 SpringRestClient
20 |
21 | `langchain4j-http-client-spring-restclient` 中的 `SpringRestClient` 。当使用受支持的模块的 Spring Boot 启动器(例如 `langchain4j-open-ai-spring-boot-starter` )时,默认使用它。
22 |
23 | ## 2 自定义JDK的HttpClient
24 |
25 | ```java
26 | HttpClient.Builder httpClientBuilder = HttpClient.newBuilder()
27 | .sslContext(...);
28 |
29 | JdkHttpClientBuilder jdkHttpClientBuilder = JdkHttpClient.builder()
30 | .httpClientBuilder(httpClientBuilder);
31 |
32 | OpenAiChatModel model = OpenAiChatModel.builder()
33 | .httpClientBuilder(jdkHttpClientBuilder)
34 | .apiKey(System.getenv("OPENAI_API_KEY"))
35 | .modelName("gpt-4o-mini")
36 | .build();
37 | ```
38 |
39 | ## 3 定制 Spring 的RestClient
40 |
41 | ```java
42 | RestClient.Builder restClientBuilder = RestClient.builder()
43 | .requestFactory(new HttpComponentsClientHttpRequestFactory());
44 |
45 | SpringRestClientBuilder springRestClientBuilder = SpringRestClient.builder()
46 | .restClientBuilder(restClientBuilder)
47 | .streamingRequestExecutor(new VirtualThreadTaskExecutor());
48 |
49 | OpenAiChatModel model = OpenAiChatModel.builder()
50 | .httpClientBuilder(springRestClientBuilder)
51 | .apiKey(System.getenv("OPENAI_API_KEY"))
52 | .modelName("gpt-4o-mini")
53 | .build();
54 | ```
--------------------------------------------------------------------------------
/docs/md/AI/langchain4j/observability.md:
--------------------------------------------------------------------------------
1 | # 10-可观测性
2 |
3 | ## LLM 可观测性
4 |
5 | [特定](/integrations/language-models) 的 `ChatLanguageModel` 和 `StreamingChatLanguageModel` 实现(请参见“可观测性”列)允许配置 `ChatModelListener`,用于监听以下事件:
6 |
7 | - 对 LLM 的请求
8 | - LLM 的响应
9 | - 错误
10 |
11 | 这些事件包含的属性包括[OpenTelemetry 生成 AI 语义约定](https://opentelemetry.io/docs/specs/semconv/gen-ai/)中的描述,例如:
12 |
13 | - 请求:
14 | - 模型
15 | - 温度(Temperature)
16 | - Top P
17 | - 最大 Tokens
18 | - 消息
19 | - 工具
20 | - 响应:
21 | - ID
22 | - 模型
23 | - Token 使用情况
24 | - 结束原因
25 | - AI 助手消息
26 |
27 | 以下是使用 `ChatModelListener` 的示例:
28 |
29 | ```java
30 | ChatModelListener listener = new ChatModelListener() {
31 |
32 | @Override
33 | public void onRequest(ChatModelRequestContext requestContext) {
34 | ChatModelRequest request = requestContext.request();
35 | Map attributes = requestContext.attributes();
36 | // 在此处理请求事件
37 | ...
38 | }
39 |
40 | @Override
41 | public void onResponse(ChatModelResponseContext responseContext) {
42 | ChatModelResponse response = responseContext.response();
43 | ChatModelRequest request = responseContext.request();
44 | Map attributes = responseContext.attributes();
45 | // 在此处理响应事件
46 | ...
47 | }
48 |
49 | @Override
50 | public void onError(ChatModelErrorContext errorContext) {
51 | Throwable error = errorContext.error();
52 | ChatModelRequest request = errorContext.request();
53 | ChatModelResponse partialResponse = errorContext.partialResponse();
54 | Map attributes = errorContext.attributes();
55 | // 在此处理错误事件
56 | ...
57 | }
58 | };
59 |
60 | ChatLanguageModel model = OpenAiChatModel.builder()
61 | .apiKey(System.getenv("OPENAI_API_KEY"))
62 | .modelName(GPT_4_O_MINI)
63 | .listeners(List.of(listener))
64 | .build();
65 |
66 | model.generate("讲一个关于 Java 的笑话");
67 | ```
68 |
69 | `attributes` 映射允许在 `onRequest`、`onResponse` 和 `onError` 方法之间传递信息。
--------------------------------------------------------------------------------
/docs/md/AI/langchain4j/response-streaming.md:
--------------------------------------------------------------------------------
1 | # 06-响应流
2 |
3 | 本文描述了使用低级别大语言模型(LLM)API的响应流处理。有关高级 LLM API,请参见[AI 服务](/tutorials/ai-services#streaming)。
4 |
5 | LLM 是逐个 token 生成文本的,因此许多 LLM 提供商提供了一种逐个 token 流式传输响应的方式,而不是等待整个文本生成完成。这显著改善了用户体验,因为用户无需等待未知的时间,可以几乎立即开始阅读响应内容。
6 |
7 | 对于 `ChatLanguageModel` 和 `LanguageModel` 接口,存在相应的 `StreamingChatLanguageModel` 和 `StreamingLanguageModel` 接口。它们的 API 类似,但可以流式传输响应。它们接受一个实现 `StreamingResponseHandler` 接口的参数。
8 |
9 | ```java
10 | public interface StreamingResponseHandler {
11 |
12 | void onNext(String token);
13 |
14 | default void onComplete(Response response) {}
15 |
16 | void onError(Throwable error);
17 | }
18 | ```
19 |
20 | 通过实现 `StreamingResponseHandler`,可为以下事件定义操作:
21 |
22 | - 当下一个 token 被生成时:会调用 `onNext(String token)`。 如可在 token 可用时将其直接发送到 UI
23 | - 当 LLM 完成生成时:会调用 `onComplete(Response response)`。在 `StreamingChatLanguageModel` 中,`T` 代表 `AiMessage`,在 `StreamingLanguageModel` 中,`T` 代表 `String`。`Response` 对象包含完整的响应
24 | - 当发生错误时:会调用 `onError(Throwable error)`
25 |
26 | 使用 `StreamingChatLanguageModel` 实现流式传输示例
27 |
28 | ```java
29 | StreamingChatLanguageModel model = OpenAiStreamingChatModel.builder()
30 | .apiKey(System.getenv("OPENAI_API_KEY"))
31 | .modelName(GPT_4_O_MINI)
32 | .build();
33 |
34 | String userMessage = "给我讲个笑话";
35 |
36 | model.generate(userMessage, new StreamingResponseHandler() {
37 |
38 | @Override
39 | public void onNext(String token) {
40 | System.out.println("onNext: " + token);
41 | }
42 |
43 | @Override
44 | public void onComplete(Response response) {
45 | System.out.println("onComplete: " + response);
46 | }
47 |
48 | @Override
49 | public void onError(Throwable error) {
50 | error.printStackTrace();
51 | }
52 | });
53 | ```
--------------------------------------------------------------------------------
/docs/md/AI/llm/GPTs.md:
--------------------------------------------------------------------------------
1 | # GPTs推荐
2 |
3 | ## 1 OpenAI GPTs
4 |
5 | ### 1.1 [科技文章翻译](https://chatgpt.com/g/g-uBhKUJJTl-ke-ji-wen-zhang-fan-yi)
6 |
7 | 请直接输入要翻译的内容或者网页url即可开始翻译。如果需要复制翻译后的Markdown,请点击翻译结果下的剪贴板📋图标。
8 |
9 | ### 1.2 [Code Tutor](https://chatgpt.com/g/g-HxPrv1p8v-code-tutor)
10 |
11 |
12 |
13 | 
14 |
15 | 不同于普通的编程助手,它不会简单给出答案,而是引导你思考,一步步地帮助你深入理解问题的本质。
16 |
17 | 这不仅能帮助你解决眼前的问题,更能提升你的编程思维和解决问题的能力。
18 |
19 | 
20 |
21 | 比如,在理解Python中的lists和dictionaries的区别时,“代码导师”并没有在立马给出答案,反而在鼓励我说出我所知道的关于它们的一切。
22 |
23 | 
24 |
25 | 这种引导式学习方法,让我们在解决问题的过程中,不断地思考和总结,从而更深入地理解编程的本质。
26 |
27 | 它不仅仅是一个问题解答者,更是一个激发我们思考的良师益友!
28 |
29 | ## 2 Coze
30 |
31 | coze bot对标 GPTs,还能举一反三,帮你全面学习一个新知识点,常用推荐:
32 |
33 | ### 2.1 [编程问题解答](https://www.coze.com/store/bot/7333256624091496453?bid=MDQEEBD2-JiIy8RDOfgQPFnfEskEHtV0pHay8ZG6U9-MVOy6u3LLGWV023s6uEsAEXRtnQQA&from=bots_card)
--------------------------------------------------------------------------------
/docs/md/AI/llm/enhancing-llm-memory-with-conversation-variables-and-variable-assigners.md:
--------------------------------------------------------------------------------
1 | # Dify v0.7.0利用对话变量与变量赋值节点增强 LLM 记忆能力
2 |
3 | ## 0 前言
4 |
5 | Dify一直致力于优化大语言模型(LLM)在应用中的记忆管理,以更好地应对各种具体场景需求。虽 LLM 能通过上下文窗口存储对话历史,但因为注意力机制的限制,在复杂场景中往往会出现记忆断层或聚焦不精准的问题。
6 |
7 | Dify 最新版本为此引入了两个新功能:
8 |
9 | - **对话变量(Conversation Variables)**
10 | - **变量赋值节点(Variable Assigner nodes)**
11 |
12 | 结合使用,可让基于 Chatflow 构建的 LLM 应用拥有更加灵活的记忆控制能力,支持读取与写入关键用户输入,从而提升 LLM 在生产环境中的实用性。
13 |
14 | ## 1 对话变量:精准存储上下文信息
15 |
16 | 允许 LLM 应用存储并引用上下文信息。开发者可在 Chatflow 会话中临时保存特定数据,如上下文内容、用户偏好,未来还将支持上传文件等内容。通过 **变量赋值节点**,可以在对话流程中的任意位置写入或更新这些变量。
17 |
18 | 
19 |
20 | ### 优势
21 |
22 | - **精准的上下文管理:** 以变量为单位管理信息,而不仅仅是整个对话历史
23 | - **支持结构化数据:** 能处理字符串、数字、对象、数组等复杂数据类型
24 | - **便于流程集成:** 可在 Chatflow 的任何节点中写入或更新变量,供后续的 LLM 节点使用
25 |
26 | 相比默认的对话历史机制,对话变量提供了更精细的信息管理方式。它让应用能够准确记住并调用特定信息,实现更加个性化的多轮对话体验。
27 |
28 | ## 2 变量赋值节点:设置并写入对话变量
29 |
30 | 要用于为可写变量(如对话变量)设置值。这类节点允许开发者将用户输入暂存,以供后续对话中引用。
31 |
32 | 
33 |
34 | 如在需要记录用户初始偏好的应用中,可结合使用对话变量和变量赋值节点来:
35 |
36 | - 存储用户的语言偏好
37 | - 在后续回复中持续使用该语言
38 |
39 | 举例来说,若用户在对话开始时选择中文,变量赋值节点会将该偏好写入 `language` 对话变量。随后,LLM 就会依据该变量,在整个对话过程中持续使用中文。
40 |
41 | 
42 |
43 | 这种做法简化了偏好的捕捉与应用流程,提升了对话的连贯性与用户体验。
44 |
45 | ## 3 更多应用场景
46 |
47 | 远不止于偏好存储,还可用于:
48 |
49 | - **患者接待助手:** 将用户输入的性别、年龄、症状等存入变量,用于推荐合适的就诊科室
50 |
51 | - **对话摘要生成器:** 通过变量赋值节点提取摘要,避免加载完整对话历史造成记忆超载
52 |
53 | - **数据分析助手:** 在对话中调取外部系统数据,并用于后续交互中
54 |
55 | - **创意写作工具:** 以对象数组形式动态存储和修改故事元素:
56 |
57 | ```json
58 | [
59 | { "name": "Alice", "role": "主角", "trait": "勇敢" },
60 | { "name": "神秘森林", "type": "场景", "atmosphere": "诡异" }
61 | ]
62 | ```
63 |
64 | 这些示例展示了对话变量与变量赋值节点如何满足复杂应用对个性化记忆的需求,进一步提升 LLM 应用在实际场景中的能力与表现。
--------------------------------------------------------------------------------
/docs/md/AI/llm/lm-studio-transform-mac-into-ai-tool.md:
--------------------------------------------------------------------------------
1 | # LM Studio让你的Mac秒变AI神器!
2 |
3 | ## 0 前言
4 |
5 | M芯片Mac想跑大模型,强烈推荐LM Studio。因为它支持专门为M系列芯片优化过的模型文件,运行速度快了不止亿点点!intel mac 不支持哦!
6 |
7 | 本地运行大模型的工具中,LM Studio和Ollama是最受欢迎的两款。最近LM Studio新增了对MLX的支持。
8 |
9 | ## 1 MLX是啥?
10 |
11 | 苹果公司开源的一个机器学习框架,专门为M系列芯片做了优化,如采用了统一内存模型、对应统一内存架构。所以,使用这个框架就可以非常高效地部署和运行模型。
12 |
13 | 
14 |
15 | MLX去年12月才开源,还很新,但是在社区支持下发展很快,主流模型都有对应的版本。在最新版本的LM Studio中也特意做了标注和筛选,方便苹果用户下载。
16 |
17 | ## 2 下载和使用LM Studio
18 |
19 | 
20 |
21 | 打开软件,左边栏是它的主要功能页面,包括聊天模式、服务器模式、查看已有模型等等:
22 |
23 | 
24 |
25 | 进入发现页面,就可以搜索和下载模型了:
26 |
27 | 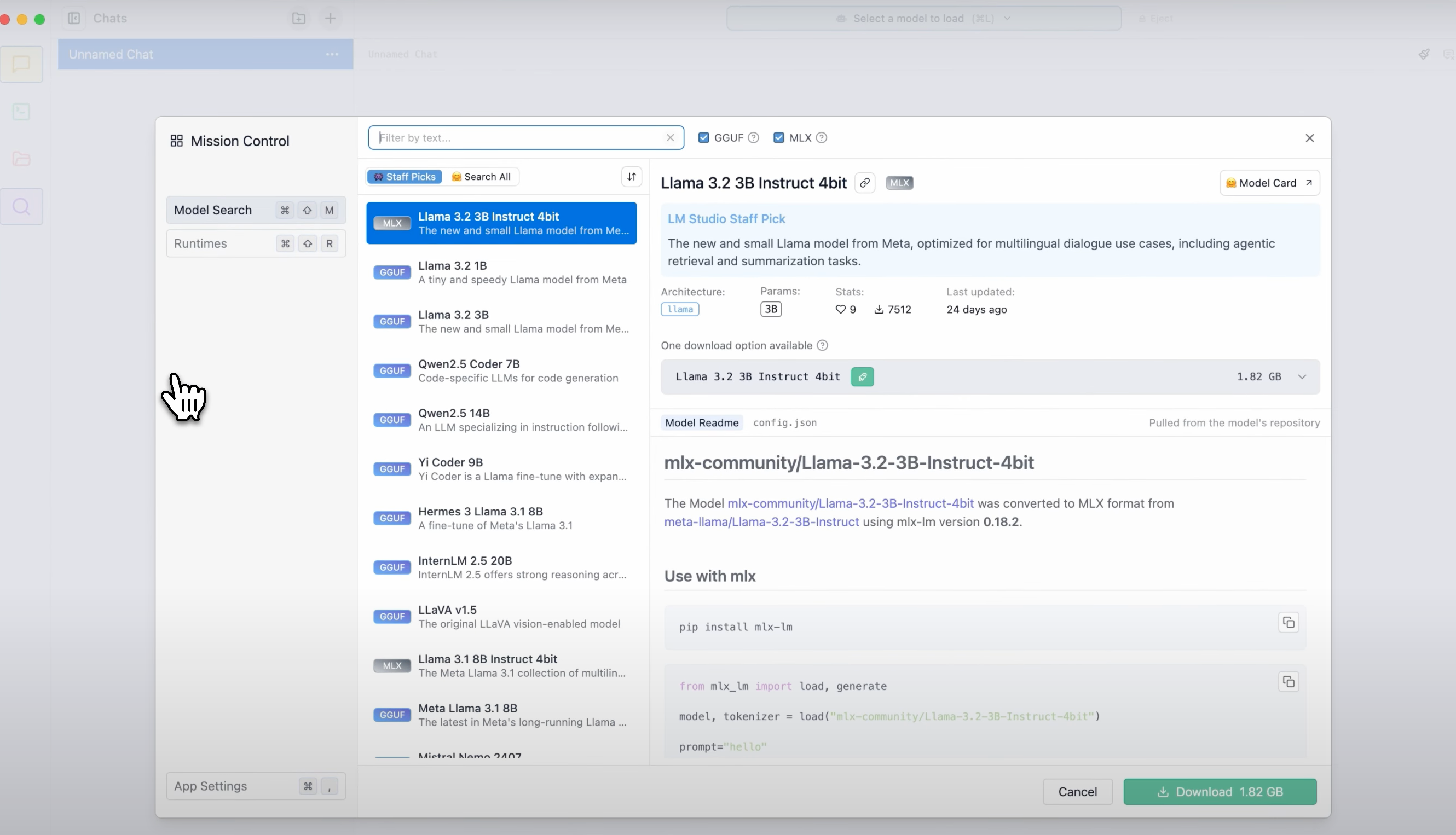
28 |
29 | LM Studio把MLX版的模型专门标注,列表里很容易找到。它默认是推荐Staff Pick也就是官方推荐的模型,如果你想要更多,那就选择Hugging Face(Search All)。
30 |
31 | 模型文件下载好:
32 |
33 | 
34 |
35 | 指定一个:
36 |
37 | 
38 |
39 | 就在聊天模式里加载它:
40 |
41 | 
42 |
43 | ## 3 苹果AI落后?
44 |
45 | 苹果硬件积累远超那些PC厂商,看到最近发布的 M4 系列芯片你也就懂了。在内存带宽上,M4 Pro也比上一代大增75%,支持高达64GB的高速统一内存和273GB/s的内存带宽,直接达到任意AI PC芯片的两倍。
46 |
47 | 桌面端有MLX框架,发挥统一内存架构最大优势:
48 |
49 | - CPU和GPU可以直接访问共享内存中的数据,不需要进行数据传输
50 | - 小规模操作用CPU搞定。遇到计算密集型的需求再上GPU
51 |
52 | 到时明年我去香港买个港版,M4 urtra Mac Studio到手后我就开始测评!
53 |
54 | ## 4 总结
55 |
56 | 如今在 AI 软件领域,各家都在扩张自己的势力范围。如LM Studio,以前只是偏后端软件,帮你在本地跑大模型。现在,它把聊天模式往前提,添加RAG功能。主动从后端走向前端的打法会逐渐成为各家的共同选择。AI应用大混战时代来了。
--------------------------------------------------------------------------------
/docs/md/AI/llm/lmstudio-local-llm-call.md:
--------------------------------------------------------------------------------
1 | # Ollama平替!LM Studio本地大模型调用实战
2 |
3 | ## 0 前言
4 |
5 | 可像 Ollama 通过暴露本地端口,实现本地客户端调用。
6 |
7 | ## 1 选择模型
8 |
9 | 在 LM Studio 的 “开发者” 选项卡中选择模型:
10 |
11 | 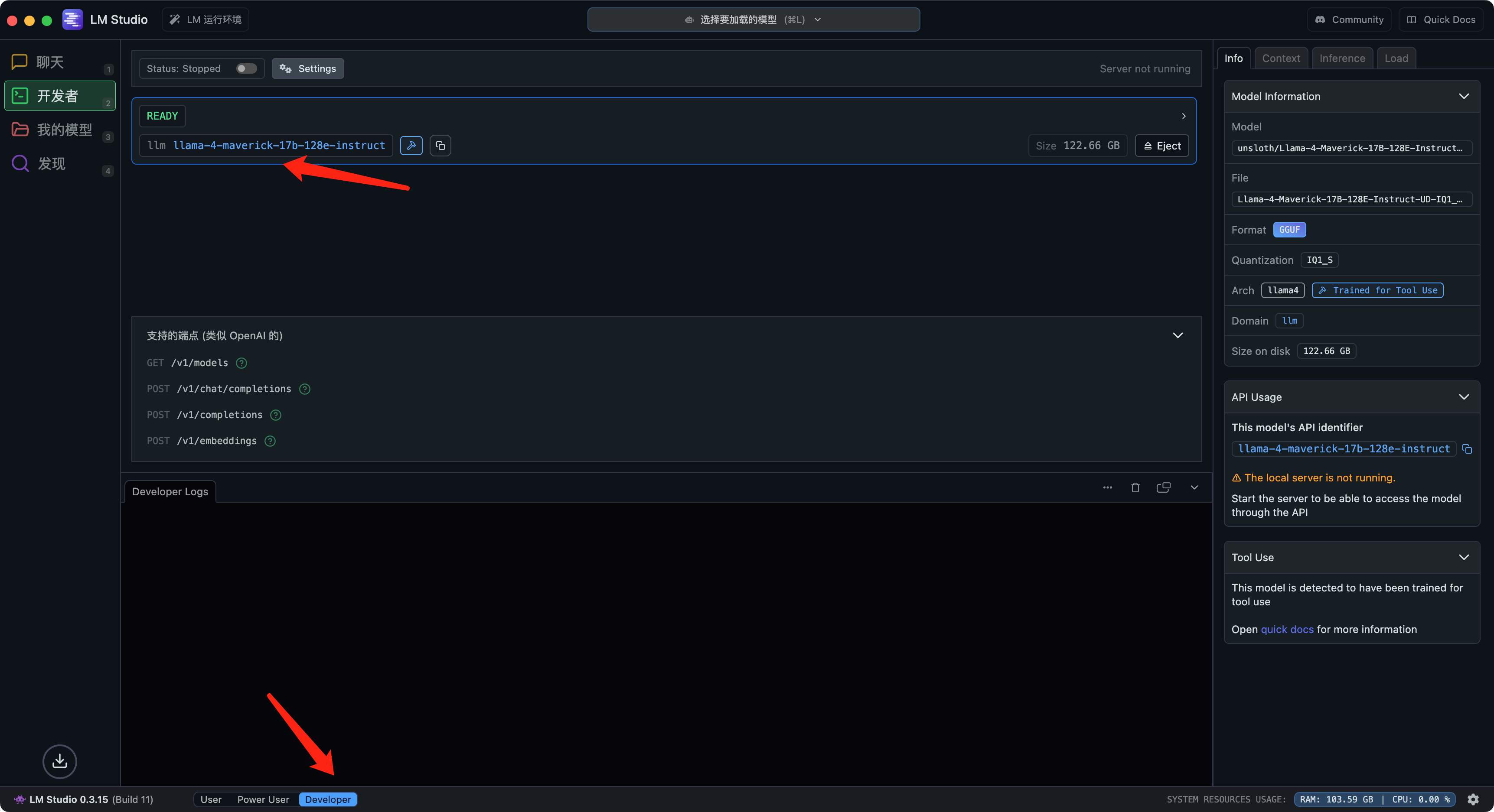
12 |
13 |
14 |
15 | ## 2 端口暴露
16 |
17 | 设置暴露的端口(默认1234):
18 |
19 | 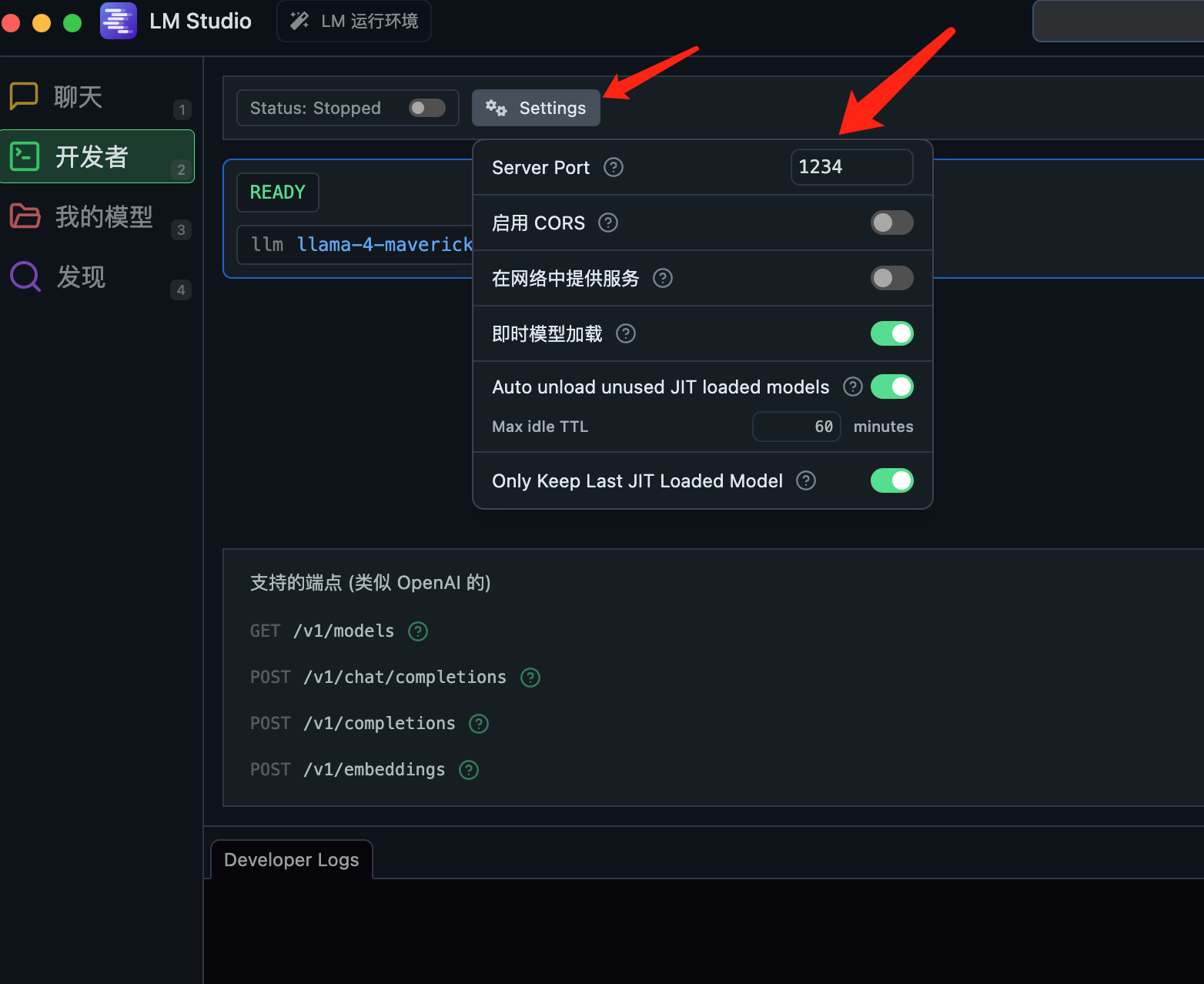
20 |
21 | 启用 CORS 后,可对接网页应用或其他客户端工具。
22 |
23 | ## 3 启动服务
24 |
25 | 点击状态选项卡:
26 |
27 | 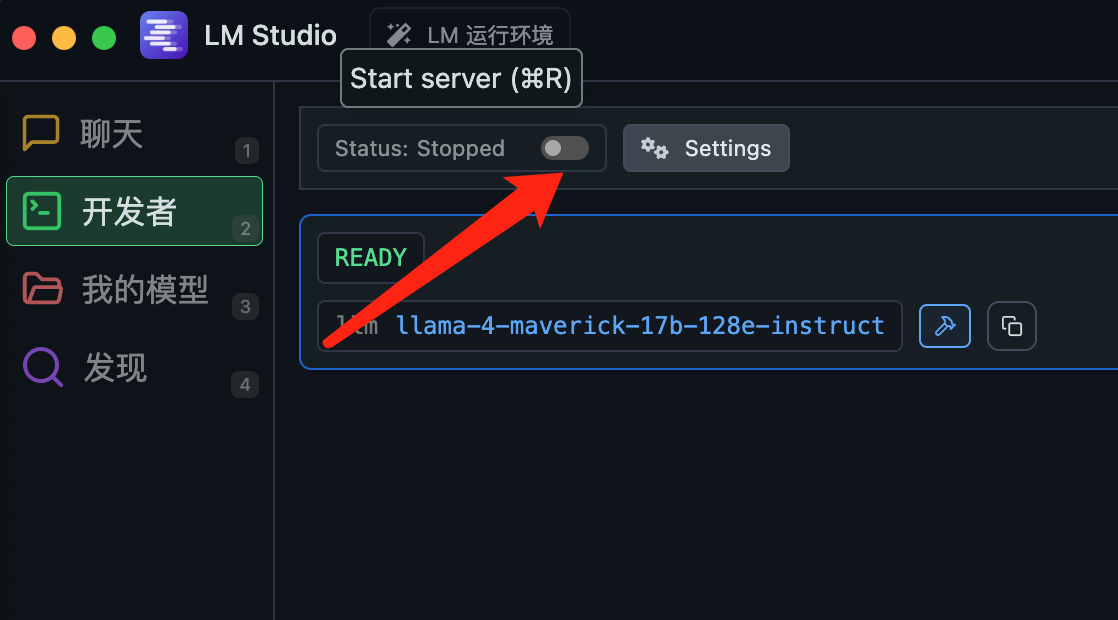
28 |
29 | 控制台会显示运行日志和访问地址:
30 |
31 | 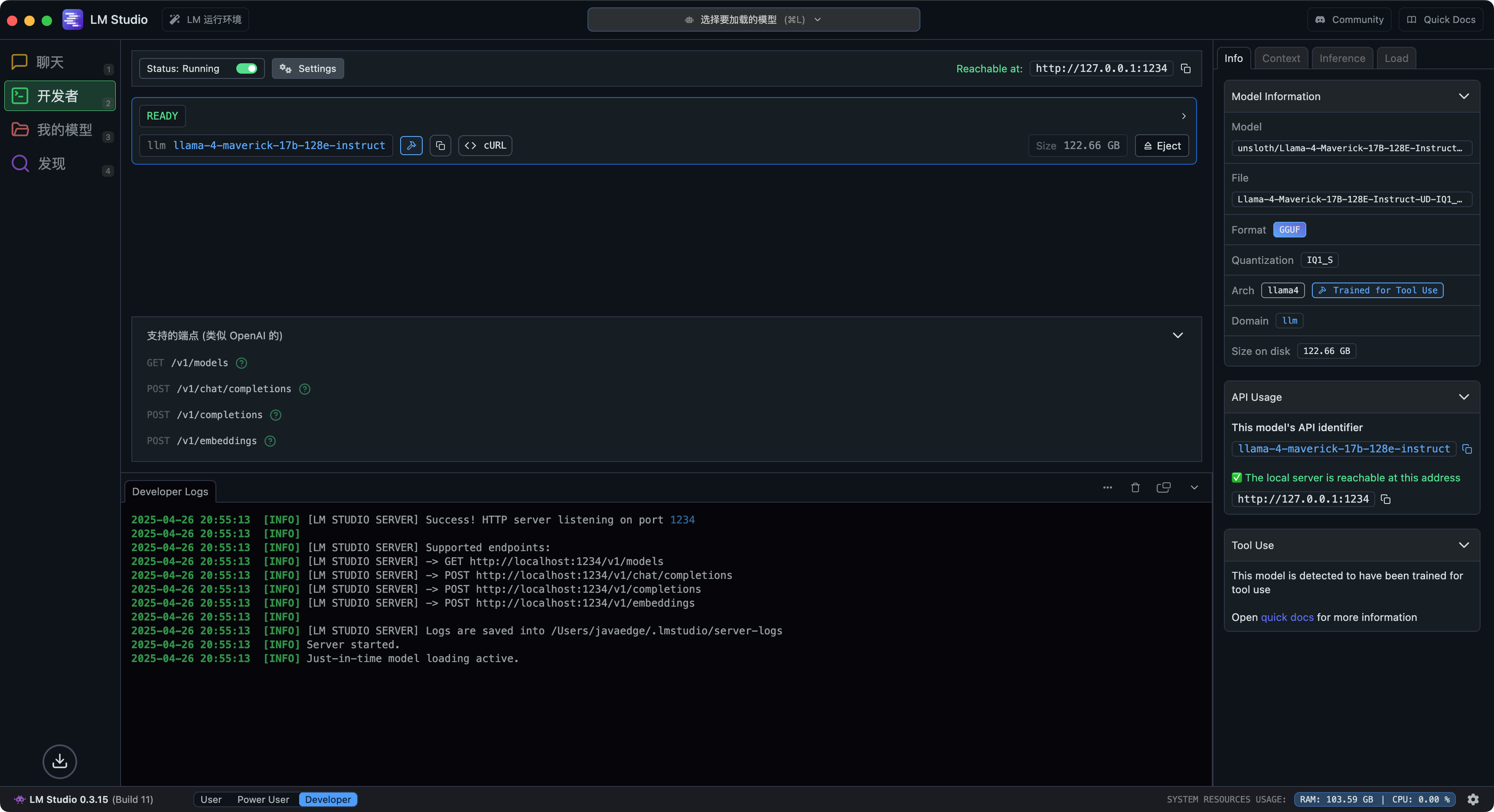
32 |
33 | ## 4 快速上手
34 |
35 | ### 4.1 快速ping
36 |
37 | 列出已加载并就绪的模型:
38 |
39 | ```bash
40 | curl http://127.0.0.1:1234/v1/models/
41 | ```
42 |
43 | 
44 |
45 | 这也是验证服务器是否可访问的一种有效方法!
46 |
47 | ### 4.2 聊天
48 |
49 | 这是一个类似调用OpenAI的操作,通过`curl`工具访问`/v1/chat/completion`端点:
50 |
51 | - 在Mac或Linux系统,可用任意终端运行
52 | - Windows系统用Git Bash
53 |
54 | ```bash
55 | curl http://127.0.0.1:1234/v1/chat/completions \
56 | -H "Content-Type: application/json" \
57 | -d '{
58 | "model": "llama-4-maverick-17b-128e-instruct",
59 | "messages": [
60 | { "role": "system", "content": "Always answer in rhymes." },
61 | { "role": "user", "content": "Introduce yourself." }
62 | ],
63 | "temperature": 0.7,
64 | "max_tokens": -1,
65 | "stream": true
66 | }'
67 | ```
68 |
69 | 该调用是“无状态的”,即服务器不会保留对话历史记录。调用方有责任在每次调用时提供完整的对话历史记录。
70 |
71 | #### 流式传输 V.S 累积完整响应
72 |
73 | 注意`"stream": true`(流式传输:开启)参数:
74 |
75 | - `true`(开启)时,LM Studio会在预测出标记(token)的同时将其逐一流式返回
76 | - 如将此参数设置为`false`(关闭),在调用返回之前,完整的预测结果会被先累积起来。对于较长的内容生成或者运行速度较慢的模型,这可能需要花费一些时间!
--------------------------------------------------------------------------------
/docs/md/AI/llm/携手阿里云:JetBrains AI Assistant 正式发布!.md:
--------------------------------------------------------------------------------
1 | # 携手阿里云:JetBrains AI Assistant 正式发布!
2 |
3 | 在 2024 年[云栖大会](https://yunqi.aliyun.com/)上,JetBrains 与阿里云宣布了一项令人瞩目的战略合作——**推出基于阿里云通义大模型的智能开发工具 AI Assistant。**这是我们完善开发工具产品生态上的重要一环,期待能够为国内开发者带来全新的开发体验。
4 |
5 | 
6 |
7 | ## **专为中国市场量身定制的智能助手**
8 |
9 | 我们与阿里云的合作,推出了基于阿里云通义大模型的 AI Assistant,这不仅是技术上的融合,更是我们对国内市场承诺。通过深度融合中文自然语言处理技术,AI Assistant 能够以更加贴近中国开发者的方式,提供智能化服务。
10 |
11 | ## **无缝集成,智能提升**
12 |
13 | 得益于我们超过 20 在开发领域的经验积累,AI Assistant 与我们的 IDE 的深度集成,它能更好地理解您的代码及其上下文,从而提供更加精准和高效的辅助。无论是代码补全、错误诊断还是重构建议,AI Assistant 都能以您的方式,按照您的风格,提供个性化的支持。
14 |
15 | ## **专注于创新,让 AI 处理繁琐**
16 |
17 | 开发者的时间是宝贵的,应该被用于创新和解决复杂问题。通过 AI Assistant,那些重复性高、技术含量低的任务将不再是您的负担。您可以将这些工作交给 AI Assistant,而您则可以专注于那些真正需要您专业知识和创造力的工作。
18 |
19 | [立即体验](https://www.jetbrains.com.cn/ai/)
20 |
21 |
22 |
23 | ### **如何启动您的 AI Assistant?**
24 |
25 | 1. 首先确保您**没有使用**任何 VPN,并且您在 JetBrains **个人资料**中的地区也是中国大陆
26 | 2. 打开设置 | 插件 (Settings | Plugins) 对话框,搜索 “AI Assistant” 插件并安装。
27 | 3. 打开集成开发环境,进入 设置 | 外观和行为 | 地区和语言设置 (Settings | Appearance & Behavior | Region and Language)
28 | 4. 将地区更改为 “中国大陆”
29 | 5. 打开帮助 | 注册菜单 (Help | Register)
30 | 6. 从左下角注销,然后**重新**使用您的 JetBrains Account **登录**
31 | 7. 激活 IDE 和 AI Assistant 插件
32 |
33 | 如果您想在 ReSharper 中使用 AI Assistant,请按照[说明](https://www.jetbrains.com/help/resharper/AI_Assistant.html?_gl=1*1xj8zzt*_gcl_au*OTIwMjMwMDgxLjE3MjI0OTA4NDE.*_ga*MTM0Mjg2NjMxNS4xNjk4Njc1ODA0*_ga_9J976DJZ68*MTcyNjE0NDkwMS42NS4xLjE3MjYxNDU5MjIuNTkuMC4w)操作。
34 |
35 | 您还可以参考[**此视频**](https://www.bilibili.com/video/BV19RpTeZE7D/?vd_source=d5bff3f058fda83df56c79cfb7e8209e)完成启动流程。
36 |
37 |
38 |
39 | 希望 JetBrains AI Assistant 能够为您带来不一样的开发体验,如果您在探索 AI Assistant 功能时有任何问题或需要进一步支持,我们鼓励您随时访问 [YouTrack 平台](https://youtrack.jetbrains.com/issues/LLM)提交问题或联系我们的中文销售支持([sales.cn@jetbrains.com](mailto:sales.cn@jetbrains.com))和中文技术支持([support.cn@jetbrains.com](mailto:support.cn@jetbrains.com))。我们很乐意帮助您。
40 |
41 |
42 |
43 | 祝您开发愉快!
--------------------------------------------------------------------------------
/docs/md/AI/ml/mask-tensor.md:
--------------------------------------------------------------------------------
1 | # 编码器-掩码张量实现
2 |
3 | ## 0 目标
4 |
5 | - 什么是掩码张量及其作用
6 | - 生成掩码张量的实现过程
7 |
8 | ## 1 啥是掩码张量
9 |
10 | - 掩代表遮掩
11 | - 码就是张量中的数值
12 |
13 | 尺寸不定,里面一般只有1和0的元素,代表位置被遮掩或不被遮掩,至于是0 or 1位置被遮掩可自定义,因此它的作用就是让另外一个张量中的一些数值被遮掩,也可以说被替换,其表现形式是一个张量。
14 |
15 | ## 2 掩码张量的作用
16 |
17 | transformer中,掩码张量的主要作用在应用attention时,有些生成的attention张量中的值计算有可能已知了未来信息而得,未来信息被看到是因为训练时会把整个输出结果都一次性Embedding,但理论上解码器的输出却非一次就能产生最终结果,而是一次次通过上一次结果综合得出。因此,未来的信息可能被提前利用, 所以要遮掩。
18 |
19 | ## 3 生成掩码张量
20 |
21 | ```python
22 | # 生成一个用于遮掩后续位置的掩码张量
23 | def subsequent_mask(size):
24 | """生成向后遮掩的掩码张量, 参数size是掩码张量最后两个维度的大小, 它的最后两维形成一个方阵"""
25 | # 初始化掩码张量的形状
26 | attn_shape = (1, size, size)
27 | # 上三角矩阵
28 | print('====', np.triu(np.ones(attn_shape), k=1))
29 | # 再用np.ones向这形状中添加1元素,形成上三角阵
30 | subsequent_mask = (np.triu(np.ones(attn_shape), k=1)
31 | # 最后为节约空间,再使其中的数据类型转变
32 | .astype('uint8'))
33 | # 最后将numpy类型转化为torch中的tensor, 内部做一个1 - 操作,
34 | # 就是做一个三角阵的反转, 上三角变下三角,即subsequent_mask中的每个元素都被1减,如:
35 | # 原是0, subsequent_mask中的该位置由0变成1
36 | # 原是1, subsequent_mask中的该位置由1变成0
37 | return torch.from_numpy(1 - subsequent_mask)
38 | ```
39 |
40 | 输入:
41 |
42 | ```python
43 | size = 5
44 | ```
45 |
46 | 调用:
47 |
48 | ```python
49 | sm = subsequent_mask(size)
50 | print("sm:", sm)
51 | ```
52 |
53 | 输出:
54 |
55 | ```python
56 | # 最后两维形成一个下三角阵
57 | sm: (0 ,.,.) =
58 | 1 0 0 0 0
59 | 1 1 0 0 0
60 | 1 1 1 0 0
61 | 1 1 1 1 0
62 | 1 1 1 1 1
63 | [torch.ByteTensor of size 1x5x5]
64 | ```
65 |
66 | ### 掩码张量的可视化
67 |
68 | ```python
69 | plt.figure(figsize=(5,5))
70 | plt.imshow(subsequent_mask(20)[0])
71 | ```
72 |
73 | 
74 |
75 | 观察可视化方阵:
76 |
77 | - 黄色是1的部分,代表被遮掩
78 | - 紫色代表未被遮掩的信息
79 | - 横坐标代表目标词汇的位置,0的位置一眼望去都是黄色,都被遮住,1的位置一眼望去还是黄色,说明第一次词还没产生,从第二个位置看过去,就能看到位置1的词,其他位置看不到,以此类推
80 | - 纵坐标代表可查看的位置
--------------------------------------------------------------------------------
/docs/md/AI/overcoming-fear-uncertainty-and-doubt-in-the-era-of-ai-transformation.md:
--------------------------------------------------------------------------------
1 | # 克服 AI 时代的恐惧、不确定性和疑虑
2 |
3 | ## 1 学习咋通过培养 AI 技能,提高职场对 AI 的积极性
4 |
5 | 职场中抵触 AI 的现象确实存在。很多人并非不愿意接受变化,而是因为对 AI 存在“FUD”——即*恐惧(Fear)、不确定性(Uncertainty)和疑虑(Doubt)*。
6 |
7 | 要在 AI 转型时代取得成功,必须积极应对这些 FUD,并**营造一种支持学习的文化,让员工能够适应和成长**,最终推动整个组织共同进步。
8 |
9 | 大厂们都始终在内部率先使用和测试自家的 AI 技术,然后才推向客户。因此他们深知理解 FUD 的根源、找到积极的解决方案,并提供实用的应对措施的重要性。通过学习 AI 技能,了解 AI 如何优化工作流程、提升决策能力和提高生产力,可有效减少担忧,让人们对这项前沿技术更加充满信心。
10 |
11 | ## 2 化恐惧为机遇
12 |
13 | 职场中最常见的 AI 相关恐惧,莫过于“AI 会导致失业”。但事实上,许多专家对此持乐观态度。根据 [联合国国际劳工组织(ILO)的研究](https://www.ilo.org/resource/news/generative-ai-likely-augment-rather-destroy-jobs),AI **更可能增强而非取代工作岗位**,它主要通过自动化某些任务来辅助人类,而非完全取代某个职位。因此,未来许多工作角色可能会演变成“AI + 人工”混合模式,让 AI 成为工作得力副手。
14 |
15 | 在这种工作模式转变的背景下,**AI 技能的需求持续增长**,这对于各行各业的员工而言都是一个发展机遇。主动学习 AI 技能,可帮助员工适应新的工作环境,并增强他们对 AI 技术的信心。对于企业而言,提供 AI 技能培训不仅能帮助员工成长,也能提升组织整体的竞争力。
16 |
17 | ## 3 通过学习文化消除 AI 带来的不确定性
18 |
19 | AI 技术的发展速度之快,让人们对其感到不确定甚至迷茫。但事实上,我们都处在一个“边学边用”的阶段。其实我们在测试 AI 应用和服务的过程中,也不断探索 AI 的潜力。同样地,职场中的每个人都需要尝试使用 AI,才能真正理解它的能力。一个良好的组织学习文化,可以帮助团队克服不确定性,快速适应 AI 变革。
20 |
21 | 沃顿商学院管理学教授、AI 与创业领域的知名专家 Ethan Mollick 认为,**最大的收益来自那些鼓励协作学习的组织**。在 [*Beyond the Prompt* 播客](https://podcast.beyondtheprompt.ai/episodes/practical-strategies-for-leveraging-ai-in-your-business-wharton-professor-ethan-mollick)的一期节目《企业如何正确使用 AI》中,他强调:“一切都始于文化。”
22 |
23 | 该节目还提出了一条重要建议:“尽可能多地使用 AI,真正理解它的能力,最好的方式就是让它参与尽可能多的任务。”
24 |
25 | ## 4 为团队提供 AI 培训
26 |
27 | 想要克服 AI 相关的恐惧、不确定性和疑虑,**关键在于技能培训和学习文化**,而团队培训环境可以有效支持这一成长过程。提高员工信心:
28 |
29 | - 完整的 AI 技能培养手册,帮助企业制定 AI 培训计划,最大化个人、团队和组织层面的学习成效
30 | - 提供 AI 技能培训资源、课程及建立学习型文化的策略和见解
31 | - Copilot 学习中心、AI 学习中心和安全学习中心
32 | - 提供最新的 AI 技术培训计划,如“使用 GitHub 构建、测试和部署应用程序”,“在AI Studio中实施数据集成和模型优化”,“利用 GitHub Copilot 加速应用开发”等
33 | - 增强 AI 和云计算领域的专业技能,适应关键岗位和项目需求
34 |
35 | 技能认证:
36 |
37 | - 验证特定岗位所需的全面技能,需通过考试获得。例如数据科学家认证。
38 | - 应用技能认证:侧重于实际技术场景,通过互动实验评估技能。超过一半的应用技能认证与 AI 相关,例如“使用AI Language 构建自然语言处理解决方案”和“使用 AI 文档智能创建智能文档处理解决方案”等
39 |
40 | ## 5 总结
41 |
42 | 培养 AI 技能不仅能帮助个人和团队适应 AI 时代的变革,还能增强组织的竞争力。通过持续学习和实践,我们可以克服恐惧、不确定性和疑虑,让 AI 成为提升工作效率和创新能力的强大工具。
--------------------------------------------------------------------------------
/docs/md/AI/prompt/01-Prompt网站.md:
--------------------------------------------------------------------------------
1 | # 01-Prompt网站
2 |
3 | https://gpt890.com/prompt/28
--------------------------------------------------------------------------------
/docs/md/AI/prompt/02-常用Prompt.md:
--------------------------------------------------------------------------------
1 | # 02-常用Prompt
2 |
3 | ## 1 写作
4 |
5 | ### 1.1 标题党生成器
6 |
7 | 根据常见的标题党套路,快速写出5个震撼标题,只需填写文章主题
8 |
9 | ```
10 | 从现在开始,你就是标题党头条的制造者。你的任务是根据以下标题党写作策略制作5个标题:
11 |
12 | - 夸张用词:使用夸张的形容词或副词来增加标题的吸引力,例如“史上最…”,“绝对震撼”,“惊人的发现”等。
13 |
14 | - 引发好奇心:在标题中提出悬念或问题,引发读者的好奇心,例如“你绝对不知道的…”,“这个秘密让人惊讶”等。
15 |
16 | - 制造争议:使用具有争议性的观点或论断,挑起读者的兴趣和热议,例如“为什么…是错误的”,“这个观点引发争议”等。
17 |
18 | - 利用名人效应:在标题中提到名人或知名人物,以吸引读者的关注,例如“名人X震惊评论了…”,“X名人的独家秘闻”等。
19 |
20 | - 采用排行榜形式:使用数字和排名,列举一系列有吸引力的事物或观点,例如“十大最惊人的…”,“你必须尝试的五种…”等。
21 |
22 | 请确保标题与主题“#文章主题#”保持一致,并采用指定的标题党技术,使其引人入胜。
23 | ```
24 |
25 | ### 1.2 翻译
26 |
27 |
28 | ```bash
29 |
30 | 你是一位精通简体中文的专业翻译,尤其擅长将专业学术论文翻译成浅显易懂的科普文章。请你帮我将以下英文段落翻译成中文,风格与中文科普读物相似。
31 |
32 | 规则:
33 | - 翻译时要准确传达原文的事实和背景。
34 | - 即使上意译也要保留原始段落格式,以及保留术语,例如 FLAC,JPEG 等。保留公司缩写,例如 Microsoft, Amazon, OpenAI 等。
35 | - 人名不翻译
36 | - 同时要保留引用的论文,例如 [20] 这样的引用。
37 | - 对于 Figure 和 Table,翻译的同时保留原有格式,例如:“Figure 1: ”翻译为“图 1: ”,“Table 1: ”翻译为:“表 1: ”。
38 | - 全角括号换成半角括号,并在左括号前面加半角空格,右括号后面加半角空格。
39 | - 输入格式为 Markdown 格式,输出格式也必须保留原始 Markdown 格式
40 | - 在翻译专业术语时,第一次出现时要在括号里面写上英文原文,例如:“生成式 AI (Generative AI)”,之后就可以只写中文了。
41 | - 以下是常见的 AI 相关术语词汇对应表(English -> 中文):
42 | * Transformer -> Transformer
43 | * Token -> Token
44 | * LLM/Large Language Model -> 大语言模型
45 | * Zero-shot -> 零样本
46 | * Few-shot -> 少样本
47 | * AI Agent -> AI 智能体
48 | * AGI -> 通用人工智能
49 |
50 | 策略:
51 |
52 | 分三步进行翻译工作,并打印每步的结果:
53 | 1. 根据英文内容直译,保持原有格式,不要遗漏任何信息
54 | 2. 根据第一步直译的结果,指出其中存在的具体问题,要准确描述,不宜笼统的表示,也不需要增加原文不存在的内容或格式,包括不仅限于:
55 | - 不符合中文表达习惯,明确指出不符合的地方
56 | - 语句不通顺,指出位置,不需要给出修改意见,意译时修复
57 | - 晦涩难懂,不易理解,可以尝试给出解释
58 | 3. 根据第一步直译的结果和第二步指出的问题,重新进行意译,保证内容的原意的基础上,使其更易于理解,更符合中文的表达习惯,同时保持原有的格式不变
59 |
60 | 返回格式如下,"{xxx}"表示占位符:
61 |
62 | ### 直译
63 | {直译结果}
64 |
65 | ***
66 |
67 | ### 问题
68 | {直译的具体问题列表}
69 |
70 | ***
71 |
72 | ### 意译
73 | 【意译结果】
74 |
75 | 现在请按照上面的要求从第一行开始翻译以下内容为简体中文【】
76 | ```
77 |
78 | ### 1.3 SEO-slug
79 |
80 | ```bash
81 | Prompt:
82 | This GPT will convert input titles or content into SEO-friendly English URL slugs. The slugs will clearly convey the original meaning while being concise and not exceeding 60 characters. If the input content is too long, the GPT will first condense it into an English phrase within 60 characters before generating the slug. If the title is too short, the GPT will prompt the user to input a longer title. Special characters in the input will be directly removed.
83 | ```
--------------------------------------------------------------------------------
/docs/md/DDD/decouple-event-retrieval-from-processing.md:
--------------------------------------------------------------------------------
1 | # 将事件检索与事件处理解耦
2 |
3 | ## 0 前言
4 |
5 | part1讨论了集成过程中遇到的挑战以及幂等事件处理的作用。解决集成问题之后,我们需要反思事件检索的问题。我们的经验教训表明,将事件检索与事件处理解耦至关重要。
6 |
7 | ## 1 事件处理与请求/响应 API 紧耦合
8 |
9 | part1讨论了将请求/响应 API 集成到事件驱动微服务中时,由于基于请求/响应的通信,导致紧耦合。单个事件的处理速度取决于请求/响应 API 及其响应时间,因为事件处理会阻塞直到收到响应。
10 |
11 | 像我们在part1中使用的简单事件循环实现或 [AWS SQS Java Messaging Library](https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-jms-code-examples.html#example-synchronous-message-receiver) 中的工作示例,会顺序处理事件。
12 |
13 | 不推荐这种方法,因为整体处理时间是所有单个处理时间的总和。
14 |
15 | ## 2 并发处理事件
16 |
17 | 幸运的是,像 [Spring Cloud AWS](https://awspring.io/) 这种库提供支持并发处理事件的更高效实现。属性 [ALWAYS_POLL_MAX_MESSAGES](https://docs.awspring.io/spring-cloud-aws/docs/3.0.2/reference/html/index.html#message-processing-throughput) 的行为在下图概述:并发事件处理
18 |
19 | 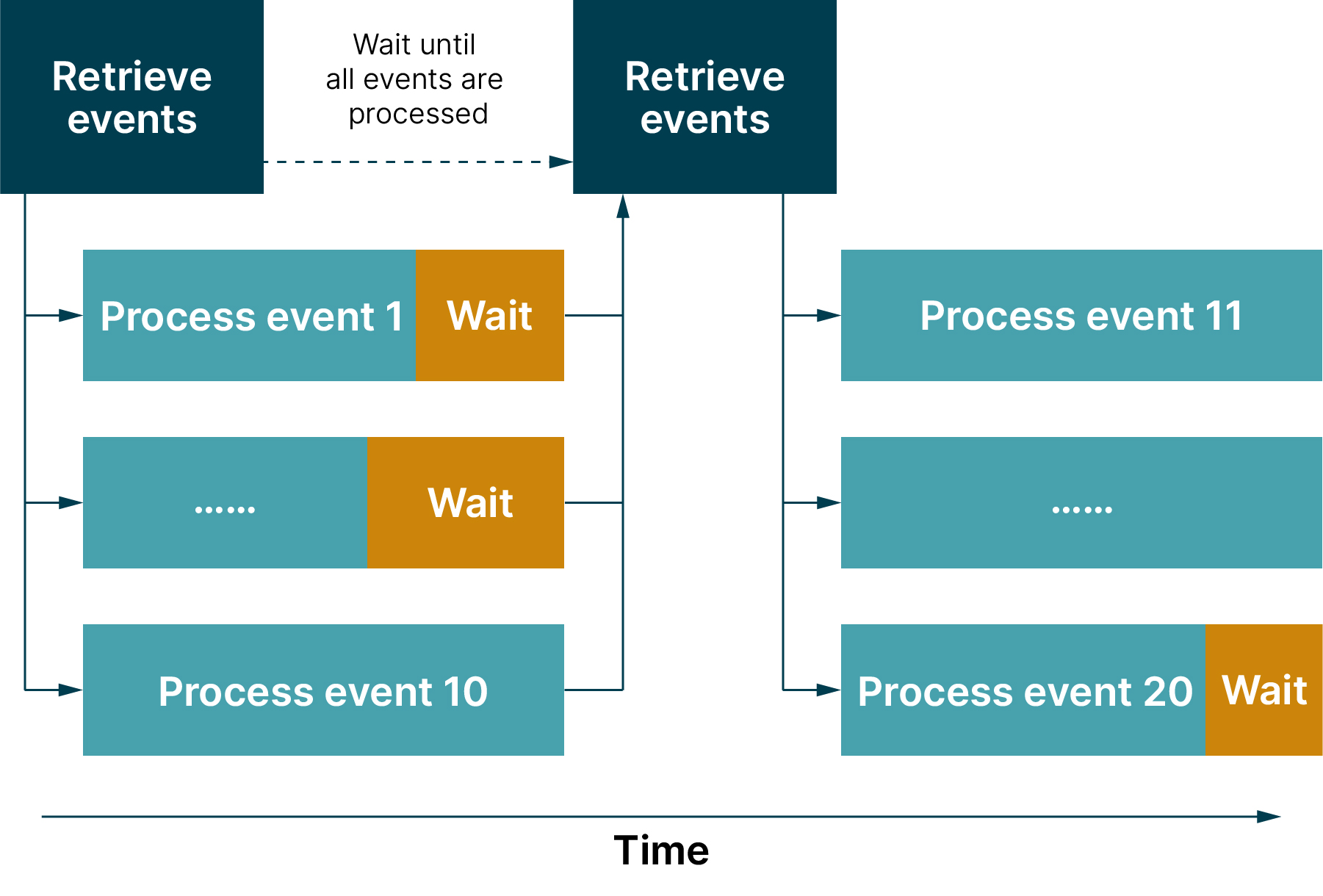
20 |
21 | 检索到一批事件后,每个事件在一个单独的线程中并发处理。当所有线程完成处理后,将检索下一批事件。由于基于请求/响应的通信导致的紧耦合,可能使事件处理速度不同。较快的线程会在较慢的线程处理事件时处于等待状态。因此,一批事件的处理时间对应于处理最慢的事件的时间。
22 |
23 | 当事件顺序不重要时,并发处理可以是一个合理的默认设置。但根据经验,某些情况下,事件处理可进一步优化。当单个事件的处理时间差异较大时,线程可能长时间处于等待状态。
24 |
25 | 如集成了一个性能波动较大的请求/响应 API。平均而言,该 API 在 0.5s 后响应。但第 95 百分位和第 99 百分位值经常分别为 1.5s 和超过 10s。在这种并发事件处理方式中,由于响应缓慢的 API,线程经常会等待几s,然后才能处理新事件。
26 |
27 | ## 3 将事件检索与事件处理解耦
28 |
29 | 即可进一步优化事件处理。这样,处理时间较长的单个事件不会减慢其他事件的处理速度。Spring Cloud AWS 提供了 [FIXED_HIGH_THROUGHPUT](https://docs.awspring.io/spring-cloud-aws/docs/3.0.2/reference/html/index.html#message-processing-throughput) 属性,展示了这种解耦可能的实现方式。
30 |
31 | 具体描述如下。详细信息可在[文档](https://docs.awspring.io/spring-cloud-aws/docs/3.0.2/reference/html/index.html#message-processing-throughput)中找到。
32 |
33 | 解耦的事件处理策略:
34 |
35 | 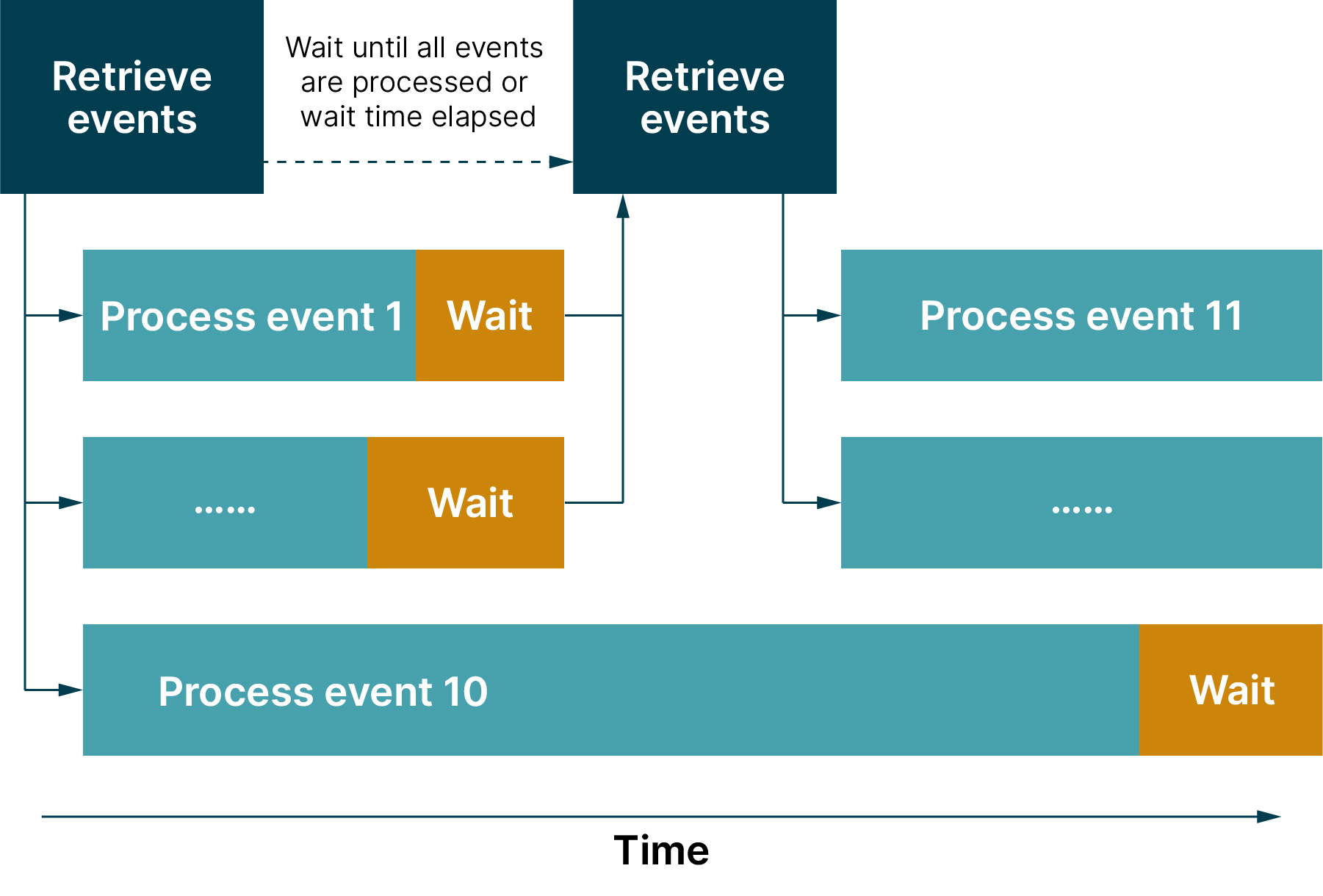
36 |
37 | 为此,定义一个额外属性,用于在两次事件检索之间的最大等待时间。当所有事件已处理完毕或等待时间已过期时,将检索新事件。若在等待时间过期后,如一个事件仍未处理完毕,则会提前接收九个新事件,并可以开始处理。这意味着这九个线程不会等到最后一个事件处理完毕后才开始工作。
38 |
39 | 根据经验,如果等待时间和其他参数配置得当,解耦可提高单个线程的利用率。一个可能缺点,由于事件往往以更频繁但较小批次的方式被检索,因此可能增加成本。因此,了解 API 性能特征,对于在并发和解耦事件处理之间做出选择至关重要。
40 |
41 | ## 4 结论
42 |
43 | 当你将事件驱动微服务与请求/响应 API 集成时,会引入紧耦合。请求/响应 API 的性能特征很重要,因为它们有助于你在并发和解耦事件处理之间做出选择。
44 |
45 | 本文重点讨论了请求/响应 API 的请求时间性能及其如何影响事件驱动微服务的性能。
--------------------------------------------------------------------------------
/docs/md/DDD/event-versioning.md:
--------------------------------------------------------------------------------
1 | # 事件版本管理
2 |
3 | 有一种办法:发送会议邀请给所有团队,经过101次会议后,发布维护横幅,所有人同时点击发布按钮。或...
4 |
5 | 可用**适配器**,但微调。没错!就像软件开发中90%问题一样,有种**模式**帮助你找到聪明解决方案。
6 |
7 | ## 1 问题
8 |
9 | 你已经有了一个模式,消费者已知咋处理它,所以他们依赖你保持兼容性,但实际上,你要打破这种兼容性。
10 |
11 | 一个生产者和三个消费者例来探讨这问题:
12 |
13 | 
14 |
15 | ## 2 解决方案
16 |
17 | 与其陷入协调部署的陷阱,不如利用适配器模式并加以战略性调整。五步操作:
18 |
19 | 
20 |
21 | ### 2.1 创建新主题
22 |
23 | 当你引入一个新模式时,不要强迫所有消费者立即适应,而是创建一个新topic。这个topic将成为使用新模式生成的事件的归宿。
24 |
25 | ### 2.2 引入适配器
26 |
27 | 部署一个监听新topic的适配器,该适配器将事件翻译回旧模式格式,并重新发布到原始主题。这样,现有消费者可继续接收他们期望格式的事件,而无需立即进行任何更改。
28 |
29 | ### 2.3 更新生产者
30 |
31 | 修改生产者,使其使用新模式生成事件,并将这些事件发布到新创建的topic中。
32 |
33 | 
34 |
35 | ### 2.4 逐步迁移消费者
36 |
37 | 现在,旧格式和新格式并存,可按自己节奏开始迁移消费者。当你更新每个消费者以处理新模式时,只需将其指向新topic。
38 |
39 | 
40 |
41 | ### 2.5 停用适配器
42 |
43 | 一旦所有消费者成功迁移到新模式,你可以安全地退役适配器和旧topic。
44 |
45 | 
46 |
47 |
48 |
49 | ## 3 优势:减少压力,增加灵活性
50 |
51 | ### 3.1 向后兼容
52 |
53 | 适配器确保现有消费者在过渡期间继续正常运行,无需立即更新,维护系统稳定性。
54 |
55 | ### 3.2 无需协调部署
56 |
57 | 通过解耦生产者和消费者的升级过程,消除了同步部署的需求。每个团队可以独立工作,降低出错的风险。
58 |
59 | ### 3.3 集中测试
60 |
61 | 随着每个消费者的迁移,测试可以更集中和可控。你可以逐一验证每个过渡,使问题更容易识别和解决。
62 |
63 | ### 3.4 减少会议
64 |
65 | 由于协调需求减少,你可以告别无数的会议。迁移过程变得更简单、更可预测,压力也更小。
66 |
67 | ## 4 总结
68 |
69 | 目标是找到一种最简单、最有效的解决方案来打破兼容性。
70 |
71 | 适配器模式为在 EDA 中处理事件版本管理提供了务实的方法。
--------------------------------------------------------------------------------
/docs/md/DDD/rate-limit-event-processing.md:
--------------------------------------------------------------------------------
1 | # 限流事件处理
2 |
3 | ## 0 引言
4 |
5 | part3讨论了使用断路器来处理请求/响应API不可用的情况。现在,我们将讨论如何通过限流来遵守请求/响应API的流量限制。
6 |
7 | ## 1 限流事件处理
8 |
9 | 由外部服务提供的请求/响应API通常有流量限制,如100次请求/s,上游微服务须遵守这些限制。与这些请求/响应API集成的事件驱动微服务可能会在没有额外措施的情况下超出其使用限制。
10 |
11 | 限流是一种确保不超出流量限制的有效方法。通常,下游微服务会使用限流来防止过多请求。实现这一目标的一种方法是安装一个Web应用防火墙(WAF),当上游微服务超过流量限制时,该防火墙会阻止请求。然后,WAF会返回一个错误,如429 TOO_MANY_REQUESTS。
12 |
13 | 从发送请求到请求/响应API的事件驱动微服务的角度,这种类型的错误响应会导致重试机制启动。与之前博文中的示例一样,事件最终进入死信队列。
14 |
15 | 如part3讨论那样,集成一个断路器只能在一定程度帮助解决问题。一旦事件驱动微服务超出使用限制并接收到429错误,断路器将暂停事件处理;它将在一段时间后恢复处理。如果断路器恢复处理前的等待时间足够长,WAF和请求/响应API将再次接受请求。然而,由于断路器并不影响事件处理的速度,流量限制很可能再次被超出。断路器会不断地停止和恢复事件处理。
16 |
17 | 在向事件驱动微服务添加限流器以防止其超出API的流量限制方面有过积极的经验。根据具体的限流实现,可提供不同的算法。如[resilience4j](https://github.com/resilience4j/resilience4j)库提供[令牌桶](https://en.wikipedia.org/wiki/Token_bucket)算法实现,使用该算法可以实现每秒最多100次请求的场景。你可配置一个max为100个令牌的桶,并将限流器配置为每秒将桶填满至100个令牌。
18 |
19 | 在事件处理期间,在你向具有流量限制的API发送请求前,可用限流器从桶中获取一个令牌:
20 |
21 | - 如桶中有足够令牌,可用令牌的数量减一,并且事件处理可继续
22 | - 如果没有令牌可用,事件处理只能稍后继续
23 |
24 | 限流器可以阻止事件处理,直到桶被重新填满并且令牌再次可用。
25 |
26 | ## 2 将限流器集成到事件处理
27 |
28 | blockAndAcquireToken()方法对应之前描述的行为。该方法尝试从桶中获取一个令牌;如果有令牌可用,令牌会从桶中移除,事件处理继续,通过创建并发送请求到API。如果没有令牌可用,该方法会等待直到新令牌可用。它会阻止事件处理,以避免超出API的流量限制。
29 |
30 | ```java
31 | // 使用限流器的事件处理
32 | void processEvent(Event event) {
33 |
34 | /* ... */
35 |
36 | rateLimiter.blockAndAcquireToken();
37 |
38 | Request request = createRequest(event);
39 |
40 | Response response = sendRequestAndWaitForResponse(request);
41 |
42 | moreBusinessLogic(event, response);
43 |
44 | /* ... */
45 |
46 | }
47 | ```
48 |
49 | 在像resilience4j这样的实现中,`blockAndAcquireToken()`方法只会在指定时间内阻止处理,然后返回一个错误并使事件处理失败。配置的等待时间和中间件的可见性超时应保持一致。如果`blockAndAcquireToken()`方法因为没有令牌可用而阻止事件处理,它应该在可见性超时到期之前返回一个错误并使事件处理失败。此外,如果它获得了一个令牌并恢复了事件处理,那么在可见性超时到期之前应该有足够的时间来完成事件处理。
50 |
51 | 如果无法做到这一点,就会导致事件的重复处理。尽管part1讨论了如何处理重复事件,但通过适当地配置可见性超时和限流器的等待时间应该尽量避免这种情况。
52 |
53 | ## 3 结论
54 |
55 | 外部服务提供商通常会定义并强制执行其提供的请求/响应API的流量限制。在本文中,我们已经看到限流是遵守事件驱动微服务中流量限制的有效解决方案。
56 |
57 | 本文是关于我们将事件驱动微服务与请求/响应API集成经验的系列文章的最后一篇。正如我们所见,集成涉及到一些相当大的挑战。然而,许多情况下集成是必须的——如依赖第三方服务提供商或系统尚未在遗留现代化过程中迁移到事件驱动架构,这是你将需要做的事情。
--------------------------------------------------------------------------------
/docs/md/Dubbo/01-互联网架构的发展历程.md:
--------------------------------------------------------------------------------
1 | # 01-互联网架构的发展历程
2 |
3 | # 最新 Dubbo3 深入理解原理系列
4 |
5 | 
6 |
7 | ## 互联网的发展
8 |
9 | 随着互联网的发展,用户规模、数据规模、请求规模逐渐扩大,常规的单体架构、垂直应用架构已经无法满足网站需要,因此需要通过 `分布式架构` 、 `流动计算架构` 来对系统进行优化升级,提升性能来应对大规模的用户请求!
10 |
11 | 
12 |
13 | ### 单一应用架构
14 |
15 | 将所有功能都揉进一个应用中,核心就是面向数据库的 CRUD 操作,该架构中的关键就是 ORM,通过 ORM 思想来操作数据库!
16 |
17 | ### 垂直应用架构
18 |
19 | 由单一应用架构进一步升级,按照子系统进行拆分,每个 `子系统独立部署` 、 `共享数据库资源`
20 |
21 | 解决了单体架构中子系统耦合程度高、扩展性差、不好维护的问题
22 |
23 | 像现在许多小公司,使用的还都是垂直应用架构,因为访问量、数据量都不大,垂直应用架构部署、开发简单,完全可以满足需求!
24 |
25 | 对于电商系统来说,垂直应用架构就是 `Web 端` 部署为一个 `jar 包` ,Web 端应用是用户进行购物、结算等操作的,而 `后台管理端` 部署为另一个 `jar 包` ,用于工作人员管理商品、库存的,他们是 `两个不同的 JVM 进程` :
26 |
27 | 
28 |
29 | ### RPC 架构
30 |
31 | RPC 架构由垂直应用架构进一步演变,就是为了解决不同模块之间调用的问题
32 |
33 | 
34 |
35 | 但是 RPC 架构也存在问题:比如库存管理模块压力比较大,我们 `想要对库存管理模块进行扩容` ,部署多份,那么我们必须要 `将后台管理端部署多份` 才可以达到这个效果,这显然资源比较浪费,因为后台管理端还包括了商品管理模块和订单模块
36 |
37 |
38 |
39 | ### 分布式架构
40 |
41 | 由 RPC 架构进一步升级,将应用的不同模块进行进一步的拆分,使得单个模块职责更加单一,相比于 RPC 架构,可以进行负载均衡、服务注册、服务监控等功能
42 |
43 | 
44 |
45 |
46 |
47 | ### 微服务架构
48 |
49 | 微服务架构是 SOA 架构的升级,其实现在微服务架构和 SOA 架构指的基本上就是一个东西了,只不过微服务架构是 SOA 架构做到极致的架构
50 |
51 | 通过微服务架构对多个应用进行编排、服务治理、服务注册、服务发现、负载均衡、限流、配置中心等操作
52 |
53 | 
54 |
55 |
--------------------------------------------------------------------------------
/docs/md/Dubbo/02-Dubbo特性及工作原理.md:
--------------------------------------------------------------------------------
1 | # 02-Dubbo特性及工作原理
2 |
3 |
4 | ## Dubbo 的特性
5 |
6 | 这里说一下 Dubbo 最主要的特性,从这些特性中,就可以看出来我们为什么要选用 Dubbo,也可以将 Dubbo 和 Spring Cloud 进行对比,比如我们搭建一套微服务系统,出于什么考虑选用 Dubbo,又是出于什么考虑而选用 Spring Cloud 呢?
7 |
8 | ### Dubbo 主要的特性
9 |
10 | - **负载均衡**
11 | - **服务注册、服务发现**
12 | - **高性能 RPC 调用**
13 |
14 |
15 |
16 | 接下来针对 Dubbo 的讲解主要从这 3 个特性出发
17 |
18 | ### Dubbo、SpringCloud 技术选型
19 |
20 | 不过在说 Dubbo 特性之前,要先说一下面试相关的东西,因为我们在面试中,Dubbo 毕竟是分布式相关的东西,那么面试官可能问我们公司是如何进行技术选型的呢?为什么选择使用了 Dubbo 而不是 Spring Cloud 呢?
21 |
22 | 其实技术选型的东西,就是比较考察你对这两个框架特性的了解,那么像你如果选用了 Dubbo,那么就说一下 Spring Cloud 存在的缺点即可:
23 |
24 | - 落地成本以及后期维护成本大
25 | - 欠缺服务治理功能,尤其负载均衡、流量路由方面较弱
26 | - 基于 HTTP 进行通信,性能不如 RPC 框架
27 |
28 | 而这些缺点,也正是 Dubbo 的优势所在,Dubbo 使用 RPC 进行通信,追求极致的性能,并且可以进行服务治理、负载均衡!
29 |
30 | 答出来他们各自的优势,那么再说一下由于公司开发人员对于 Dubbo 比较熟悉,因此最终选用 Dubbo 作为分布式框架
31 |
32 |
33 |
34 | ## Dubbo 工作原理
35 |
36 | 首先,在讲解 Dubbo 特性之前,先把 Dubbo 的工作原理给梳理一下,了解 Dubbo 底层是如何进行工作的
37 |
38 | 从整体上先把握,之后再深入到具体特性进行学习
39 |
40 | Dubbo 主要分为 3 个部分:注册中心、服务消费者、服务提供者,**Dubbo 工作的流程如下**:
41 |
42 | 1、每个服务提供者都会去注册中心注册自己,包括自己的地址(ip+port)
43 |
44 | 2、服务消费者去消费时,从注册中心(Dubbo 使用 ZooKeeper 作为注册中心)中拉取服务列表
45 |
46 | 3、消费者会去为远程代理对象创建一个动态代理对象,通过动态代理来拦截方法的执行
47 |
48 | 4、在代理对象的拦截中,会去执行一系列的操作
49 |
50 | 4.1、负载均衡,选择一台机器进行通信
51 |
52 | 4.2、选择一种通信协议:Dubbo 提供了自定义的高性能 rpc 通信协议
53 |
54 | 4.3、将请求进行封装,并且序列化
55 |
56 | 4.4、通过网络通信框架,将远程调用请求传给 Dubbo 服务提供者
57 |
58 | 5、Dubbo 服务提供者收到后,也会进行一系列操作解析请求,最后调用本地服务,将执行结果返回给服务消费者
59 |
60 | 
61 |
62 |
63 |
64 |
--------------------------------------------------------------------------------
/docs/md/algorithm/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/algorithm/.DS_Store
--------------------------------------------------------------------------------
/docs/md/algorithm/basic/00-数据结构与算法专栏大纲.md:
--------------------------------------------------------------------------------
1 | # 00-数据结构与算法专栏大纲
2 |
3 | ## 你将获得
4 |
5 | - 20 个经典数据结构与算法
6 | - 100 个真实项目场景案例
7 | - 文科生都能懂的算法手绘图解
8 | - 轻松搞定 BAT 的面试通关秘籍
9 |
10 | ## 专栏介绍
11 |
12 | 踏上编程路,也就选择了终身学习的生活。每个程序员都要练就十八般武艺,而掌握数据结构与算法就像修炼九阳神功,你的内功修炼速度就会有质的飞跃。
13 |
14 | 无论:
15 |
16 | - 业务开发,想评估代码性能和资源消耗
17 | - 还是架构设计,想优化设计模式
18 | - 或想快速玩转热门技术,如人工智能、区块链
19 |
20 | 都要先搞定数据结构与算法。因为,任凭新技术如何变化,只要掌握了这些计算机科学的核心“招式”,就可见招拆招,始终立“不败之地”。
21 |
22 | 咋才能真正掌握数据结构与算法?把常用数据结构与算法背熟?即便如此,面对现实千变万化,你也不太可能照搬某算法解决即将遇到的下一问题。因此,就像学习设计模式、架构模式一样,**学习数据结构与算法的关键,在于掌握其中的思想和精髓,学会解决实际问题的方法**。
23 |
24 | ## 专栏模块
25 |
26 | ### 入门篇
27 |
28 | 为什么要学习数据结构与算法?数据结构与算法该怎么学?学习的重点又是什么?这一模块将为你指明数据结构与算法的学习路径;并着重介绍贯穿整个专栏学习的重要概念:时间复杂度和空间复杂度,为后面的学习打好基础。
29 |
30 | ### 基础篇
31 |
32 | 将介绍最常见、最重要的数据结构与算法。每种都从“来历”“特点”“适合解决的问题”“实际的应用场景”出发,进行详细介绍;并配有清晰易懂的手绘图解,由浅入深进行讲述;还适时总结一些实用“宝典”,教你解决真实开发问题的思路和方法。
33 |
34 | ### 高级篇
35 |
36 | 将从概念和应用的角度,深入剖析一些稍复杂的数据结构与算法,推演海量数据下的算法问题解决过程;帮你更加深入理解算法精髓,开拓视野,训练逻辑;真正带你升级算法思维,修炼深厚的编程内功。
37 |
38 | ### 实战篇
39 |
40 | 将通过实战案例串讲前面讲到的数据结构和算法;并拿一些开源项目和框架,剖析它们背后的数据结构和算法;并带你用学过的内容实现一个短网址系统;深化对概念和应用的理解,灵活使用数据结构和算法。
41 |
42 | ## 目录
43 |
44 | 
--------------------------------------------------------------------------------
/docs/md/algorithm/basic/dag-directed-acyclic-graph.md:
--------------------------------------------------------------------------------
1 | # DAG有向无环图
2 |
3 | 有向无环图(Directed Acyclic Graph,DAG),与分布式计算和大数据处理结合在许多现代数据处理框架和系统中,如Spark、Flink。
4 |
5 | DAGs在这些系统发挥作用的关键方面:
6 |
7 | ## 1 任务调度
8 |
9 | 分布式计算中,作业被划分成多个任务,这些任务根据他们的依赖关系被组织成DAG。DAG确保在满足所有依赖条件前,不执行任何任务。
10 |
11 | 这样可并行执行多个不相互依赖的任务,优化资源使用并加快处理速度。
12 |
13 | ## 2 容错和状态恢复
14 |
15 | 大数据处理中,任务可能因各种原因(如机器故障或网络问题)失败。由于DAG提供清晰的任务依赖图,系统可通过重新执行失败任务的部分DAG来进行恢复,而无需从头开始整个作业。
16 |
17 | ## 3 执行计划优化
18 |
19 | 分布式数据处理框架使用DAG优化执行计划。如可重组DAG的节点(任务)来减少数据的跨节点移动,或者合并多个操作以减少I/O操作次数。
20 |
21 | ## 4 流式处理
22 |
23 | 流式数据处理领域,DAGs描述了数据从一组操作到另一组操作流动的过程。这允许框架在保持高吞吐量和低延迟的同时,对连续的数据流进行实时分析。
24 |
25 | 以Apache Spark为例,Spark的核心是一个叫做RDD(弹性分布式数据集)的抽象概念,用户对这些RDD执行的转换和动作操作被建模为DAG。Spark引擎会将这些DAG转换成物理执行计划,进行数据分区、任务调度和执行,利用集群中的多台机器并行处理数据。
26 |
27 | 而在Apache Flink中,数据流程使用DAG进行表示,其中节点(顶点)表示数据处理操作,边表示数据流动的方向。
28 |
29 | ## 总结
30 |
31 | DAG在分布式计算和大数据处理中充当了任务的组织和执行路线图的角色,其目的是通过优化任务执行、保证作业的容错性和流式处理的连贯性来提高性能和可靠性。
--------------------------------------------------------------------------------
/docs/md/algorithm/leetcode/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/algorithm/leetcode/.DS_Store
--------------------------------------------------------------------------------
/docs/md/arthas/Arthas使用.md:
--------------------------------------------------------------------------------
1 | # Arthas使用
2 |
3 | ## 0 下载
4 |
5 | [github release](https://github.com/alibaba/arthas/releases):
6 |
7 | 
8 |
9 | ## 1 启动
10 |
11 | 解压后,在文件夹里有`as.sh`,直接用`./as.sh`的方式启动:
12 |
13 | ```bash
14 | ./as.sh
15 | ```
16 |
17 | 或者命令行执行(使用和目标进程一致的用户启动,否则可能attach失败):
18 |
19 | ```shell
20 | java -jar arthas-boot.jar
21 | ```
22 |
23 | 
24 |
25 | 执行该程序的用户需要和目标进程具有相同的权限。
26 |
27 | ```bash
28 | java -jar arthas-boot.jar -h 打印更多参数信息。
29 | ```
30 |
31 | 选择应用的Java进程即可。
32 | 输入6,再`enter`。Arthas会attach到目标进程上,并输出日志:
33 | 
34 |
35 | ## 2 dashboard
36 |
37 | 输入dashboard,enter,展示当前进程信息,按ctrl+c可中断执行:
38 |
39 | 
40 |
41 | ## 3 thread
42 |
43 | 获取到进程的Main Class:
44 | 
45 |
46 | 参考
47 |
48 | - https://arthas.aliyun.com/doc/advanced-use.html
49 |
50 |
--------------------------------------------------------------------------------
/docs/md/assembly/api-gateway/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/assembly/api-gateway/todo.md
--------------------------------------------------------------------------------
/docs/md/assembly/idea-plugin/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/assembly/idea-plugin/todo.md
--------------------------------------------------------------------------------
/docs/md/assembly/middleware/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/assembly/middleware/todo.md
--------------------------------------------------------------------------------
/docs/md/bigdata/00-新一代数据栈将逐步替代国内单一“数据中台”.md:
--------------------------------------------------------------------------------
1 | # 00-新一代数据栈将逐步替代国内单一“数据中台”
2 |
3 | 2021年,硅谷最火爆词汇就是现代数据栈(Modern Data Stack,MDS),以云原生、开源为背景的一系列全新数据技术引擎。相比传统的闭源、私有化的数据技术,现代数据栈凭借其开放性及公有云的 SaaS 服务快速得到了大量企业用户的认可。
4 |
5 | 现代数据栈分为若干层次,每个层次相互支持,相互协助,形成有机整体。企业使用的时候,易利用 SaaS 模式将其整合到一起解决企业数据问题。而开源又给 MDS 生态加入新活力,快速发展社区的同时让上下游快速出现新的合作。
6 |
7 | 
8 |
9 | ## 国内数据技术
10 |
11 | 近年,国内出现大量开源数据技术。2022 年,这些技术形成具有上下游的有机集合体,从新一代数据源体系到数据处理体系,再到数分、AI 算法体系,逐步相互融合、相互支持形成有机整体。可以看到,国内新一代的数据栈在支持云原生技术基础上,还支持私有云/公有云部署,用新一代的计算引擎、算法、调度、同步机制来支持新一代的数据基础建设。
12 |
13 | 
14 |
15 | 这些新一代技术栈的流行和商业工具生态的整合,将逐步替代国内单一“数据中台”服务四五个领域的局面。这变得跟美国类似——若干家各自领域的专业企业相互集成,最终给用户提供高效且灵活的专业解决方案。
16 |
17 | 这些开源现代数据栈中很多的商业公司,正在美国、欧洲快速建立社区、SaaS 和相关的商业服务,也有一些公司已经和全球的开源现代技术栈公司进行竞争。整体上,来自国内的新一代的开源现代数据栈(Open-source MDS)现在刚刚兴起。
18 |
19 | 国内具有大量优秀的开发者、丰富的场景和大量的数据基础,一定会有若干家卓越的开源商业公司出现,最终在全球开源现代数据栈中有一席之地!
--------------------------------------------------------------------------------
/docs/md/bigdata/04-hdfs dfs命令详解.md:
--------------------------------------------------------------------------------
1 | # 04-hdfs dfs命令详解
2 |
3 | Hadoop 分布式文件系统 (HDFS) 的命令行工具,用于在 HDFS 上执行文件系统操作。以下是 `hdfs dfs` 命令的一些常见用法和解释:
4 |
5 | 1. **查看文件或目录内容:**
6 | - `hdfs dfs -ls `:列出指定路径下的文件和目录信息。
7 | - `hdfs dfs -ls -h `:以人类可读的格式列出文件和目录信息。
8 | 2. **创建目录或文件:**
9 | - `hdfs dfs -mkdir `:创建一个新目录。
10 | - `hdfs dfs -touchz `:创建一个空文件。
11 | - `hdfs dfs -copyFromLocal `:将本地文件复制到 HDFS。
12 | 3. **删除目录或文件:**
13 | - `hdfs dfs -rm `:删除指定的文件。
14 | - `hdfs dfs -rmdir `:删除指定的目录。
15 | 4. **移动或重命名文件或目录:**
16 | - `hdfs dfs -mv `:将文件或目录从一个路径移动到另一个路径,也可用于重命名。
17 | - `hdfs dfs -cp `:复制文件或目录到另一个路径。
18 | 5. **上传和下载文件:**
19 | - `hdfs dfs -put `:上传本地文件到 HDFS。
20 | - `hdfs dfs -get `:从 HDFS 下载文件到本地。
21 | 6. **查看文件内容:**
22 | - `hdfs dfs -cat `:显示文件内容。
23 | - `hdfs dfs -tail `:显示文件末尾内容。
24 | 7. **权限管理:**
25 | - `hdfs dfs -chmod `:设置文件或目录的权限。
26 | - `hdfs dfs -chown : `:设置文件或目录的所有者和组。
27 | 8. **其他常用命令:**
28 | - `hdfs dfs -du `:显示指定路径的磁盘使用情况。
29 | - `hdfs dfs -count `:统计文件或目录的大小和数量。
30 | - `hdfs dfs -expunge`:永久删除回收站中的文件。
31 |
32 | 这些命令可以帮助您在 HDFS 上执行各种文件系统操作,管理数据和资源,确保数据的安全和可靠性。
--------------------------------------------------------------------------------
/docs/md/bigdata/DolphinScheduler告警通知.md:
--------------------------------------------------------------------------------
1 | # DolphinScheduler告警通知
2 |
3 | Dolphinscheduler支持多种告警媒介,此处以电子邮件为例进行演示。
4 |
5 | ## 1 准备邮箱
6 |
7 | 如需使用DolphinScheduler的电子邮件告警通知功能,需要准备一个电子邮箱账号,并启用SMTP服务。此处以 QQ 邮箱为例。
8 |
9 | ### 1.1 开启 SMTP 服务
10 |
11 | 
12 |
13 | 拖动进度条在页面下方找到下图所示内容,开启 POP3/SMTP | IMAP/SMTP 任一。
14 |
15 | 
16 |
17 | ### 1.2 获得授权码
18 |
19 | 
20 |
21 | ## 2 DolphinScheduler配置
22 |
23 | (1)切换管理员用户
24 |
25 | (2)创建告警实例
26 |
27 | ### 2.1 点击创建告警实例
28 |
29 | 
30 |
31 | ### 2.2 编辑告警实例
32 |
33 |
34 |
35 | 
36 |
37 | ### 2.3 创建告警组
38 |
39 | 第一步:点击创建告警组
40 |
41 | 
42 |
43 | 第二步:编辑告警组
44 |
45 | 
46 |
47 | 3)测试告警通知
48 |
49 | (1)切换普通用户
50 |
51 | (2)执行工作流测试
52 |
53 | 
54 |
55 | (3)等待接受邮件
--------------------------------------------------------------------------------
/docs/md/bigdata/Hive专栏概述.md:
--------------------------------------------------------------------------------
1 | # Hive专栏概述
2 |
3 | Hive“出身名门”,是最初由Facebook公司开发的数据仓库工具。它简单且容易上手,是深入学习Hadoop技术的一个很好的切入点。专栏内容包括:Hive的安装和配置,其核心组件和架构,Hive数据操作语言,如何加载、查询和分析数据,Hive的性能调优以及安全性,等等。本书旨在为读者打牢基础,从而踏上专业的大数据处理之旅。
--------------------------------------------------------------------------------
/docs/md/bigdata/Hive修复分区.md:
--------------------------------------------------------------------------------
1 | # Hive修复分区
2 |
3 | ## 简介
4 |
5 | Hive的`MSCK REPAIR TABLE`命令用于修复(即添加丢失的)表分区。通常用于那些已在HDFS中存在,但尚未在Hive元数据中注册的分区。
6 |
7 | 当你在HDFS文件系统中手动添加或删除分区目录,Hive并不会自动识别这些更改。为同步元数据与实际文件系统之间的状态,可用命令:
8 |
9 | ```sql
10 | MSCK REPAIR TABLE table_name;
11 | ```
12 |
13 | 较老Hive版本,用旧命令:
14 |
15 | ```sql
16 | ALTER TABLE table_name RECOVER PARTITIONS;
17 | ```
18 |
19 | 执行后,Hive会检查表的分区列在HDFS中的路径,并将在HDFS中找到但Hive元数据中缺失的分区添加到元数据中。这样,当你查询那些分区时,Hive就能够正确地检索到数据。
20 |
21 | 这个命令并不会修复损坏的分区文件;如果分区文件损坏或丢失,你需要从备份中恢复或重新计算分区数据。`MSCK REPAIR TABLE`只是同步元数据与文件系统的状态,不会更改实际的文件。
22 |
23 | ## 手动删除分区目录,会恢复吗?
24 |
25 | 若你在HDFS中手动删除了一个分区目录,执行`MSCK REPAIR TABLE`命令并不会恢复已被删除的分区目录或数据。`MSCK REPAIR TABLE`命令的作用是同步Hive元数据与HDFS上当前的实际文件系统状态,它会添加那些存在于HDFS上但尚未在Hive元数据中注册的分区。
26 |
27 | 在你手动删除HDFS上的一个分区目录的情况下,执行`MSCK REPAIR TABLE`命令将会从Hive元数据中移除对应这个已删除目录的分区信息,因为该命令会发现HDFS上不再有这个分区的目录,并更新Hive元数据以反映这个变化。
28 |
29 | 若希望恢复被删除的分区数据,你要从备份中恢复数据或者重新计算并重新写入这些分区数据到HDFS中。一旦数据在HDFS中被恢复或重新放置,你可再运行`MSCK REPAIR TABLE`更新Hive元数据,使其包含新恢复的分区信息。
30 |
31 | ## 总结
32 |
33 | `MSCK REPAIR TABLE`用于同步Hive元数据,不能用来恢复在HDFS中被删除的数据。
--------------------------------------------------------------------------------
/docs/md/bigdata/Hive分区和分桶.md:
--------------------------------------------------------------------------------
1 | # Hive分区和分桶
2 |
3 | 两种用于优化查询性能的数据组织策略,数仓设计的关键概念,可提升Hive在读取大量数据时的性能。
4 |
5 | ## 1 分区(Partitioning)
6 |
7 | 根据表的某列的值来组织数据。每个分区对应一个特定值,并映射到HDFS的不同目录。为大幅减少数据量,基本必须要做!
8 |
9 | 常用于经常查询的列,如日期、区域等。这样可以在查询时仅扫描相关的分区,而不是整个数据集,从而减少查询所需要处理的数据量,提高查询效率。
10 |
11 | 物理上将数据按照指定的列(分区键)值分散存放于不同的目录中,每个分区都作为表的一个子目录。
12 |
13 | ### 创建分区表
14 |
15 | 在新能源汽车数仓项目中,如希望对整车日志表按照统计日期字段进行分区,建表语句:
16 |
17 | ```sql
18 | # 车辆标识`vehicle_id`、事件发生的时间戳`timestamp`、日志级别`log_level`、日志消息`message`、引擎温度`engine_temperature`、电池电量`battery_level`以及车辆位置`location`等
19 | CREATE EXTERNAL TABLE ev_vehicle_logs (
20 | vehicle_id STRING,
21 | timestamp BIGINT,
22 | log_level STRING,
23 | message STRING,
24 | engine_temperature DOUBLE,
25 | battery_level INT,
26 | location STRING
27 | )
28 | PARTITIONED BY (log_date DATE)
29 | ROW FORMAT DELIMITED
30 | FIELDS TERMINATED BY '\t'
31 | STORED AS TEXTFILE
32 | LOCATION '/path/to/hdfs/new_energy_vehicle/logs';
33 | ```
34 |
35 | `PARTITIONED BY (log_date DATE)`子句定义`log_date`作为表的分区键,即按照统计日期对数据进行分区存储。
36 |
37 | 分区键`log_date`通常是日志数据中的一个字段,该字段存储每条日志记录的日期。按日期分区日志数据可以极大地提高查询性能,特别是对于那些限定在特定日期范围内的查询。例如,如果用户只想看昨天的日志,Hive只需要扫描昨天日期分区对应的数据,而不必扫描整个数据表。
38 |
39 | 创建分区表之后,可以根据实际需要将数据加载到对应的分区目录中。例如,如果有一份新的日志数据,其日期为2023年10月1日,你可以这样导入数据:
40 |
41 | ```sql
42 | LOAD DATA INPATH '/path/to/local/file/2023-10-01.log' INTO TABLE ev_vehicle_logs PARTITION (log_date='2023-10-01');
43 | ```
44 |
45 | 或也可用Hive的动态分区特性让Hive在数据加载时自动根据数据内容创建分区。
46 |
47 | ## 2 分桶(Bucketing)
48 |
49 | 使用哈希函数将数据行分配到固定数量的存储桶(即文件)中。这在表内部进一步组织数据。
50 |
51 | - 对提高具有大量重复值的列(如用户ID)上JOIN操作的效率特别有用,因为它可以更有效地处理数据倾斜
52 | - 要求在创建表时指定分桶的列和分桶的数目
53 |
54 | ### 创建分桶表
55 |
56 | ```sql
57 | CREATE TABLE user_activities (
58 | user_id INT,
59 | activity_date DATE,
60 | page_views INT
61 | )
62 | CLUSTERED BY (user_id) INTO 256 BUCKETS;
63 | ```
64 |
65 | `user_id`是用于分桶的列,数据会根据用户ID的哈希值分配到256个存储桶中。
66 |
67 | ## 3 对比
68 |
69 | - 分区是基于列的值,将数据分散到不同的HDFS目录;分桶则基于哈希值,将数据均匀地分散到固定数量的文件中。
70 | - 分区通常用于减少扫描数据的量,特别适用于有高度选择性查询的场景;而分桶有助于优化数据的读写性能,特别是JOIN操作。
71 | - 分区可以动态添加新的分区,只需要导入具有新分区键值的数据;分桶的数量则在创建表时定义且不能更改。
72 |
73 | 使用分区时要注意避免过多分区会导致元数据膨胀,合理选择分区键,确保分布均匀;而分桶则通常针对具有高度重复值的列。两者结合使用时,可以进一步优化表的读写性能和查询效率。
--------------------------------------------------------------------------------
/docs/md/bigdata/Spark+ClickHouse实战企业级数据仓库专栏.md:
--------------------------------------------------------------------------------
1 | # Spark+ClickHouse实战企业级数据仓库专栏
2 |
3 | ## 1 就业前景广
4 |
5 | 数据仓库被广泛应用于互联网业务中,就业前景极为广阔
6 |
7 | 
8 |
9 | ## 2 热门技术
10 |
11 | 结合热门技术,实战企业级数仓项目
12 |
13 | 轻松掌握高薪数据工程师必备技能。全方位提升项目开发经验,上手 ClickHouse+Spark,实现个人的成长蜕变
14 |
15 | ### 2.1 深度实战 数据仓库 模型设计与调优
16 |
17 | - 数仓整体分层设计方案
18 | - 维度表模型设计
19 | - 面向业务过程的事实表建模
20 | - 面向分析主题的事实表建模
21 | - 千万级数据分析与调优
22 | - 维度表存储选型
23 | - BI工具 Superset/Granfana的数据展示
24 |
25 | ### 2.2 系统掌握 ClickHouse 核心技能与生产实践
26 |
27 | - 表引擎的使用和优化
28 | - ClickHouse 的 SQL优化
29 | - 搭建分布式集群
30 | - ClickHouse 监控
31 | - Clickhouse 字典优化
32 | - 负载均衡与高可用
33 | - 生产实践优化
34 |
35 | ### 2.3 充分提升 Spark/ClickHouse 项目开发与实用操作
36 |
37 | - Spark 自定义 ClickHouse 外部数据源
38 | - Spark 的数据处理与调优
39 | - Spark 自定义本地分片写入策略
40 | - Spark 源码、开源组件源码二次开发
41 | - Spark 参数调优
42 |
43 | ## 3 生产实践案例
44 |
45 | 通过更贴近生产实践的案例,掌握多种实用方案,满足复杂业务需求
46 |
47 | 
48 |
49 | ## 4 遵照数仓分层模型
50 |
51 | 实战数据处理的各个环节,构建实用技术体系
52 |
53 | 
54 |
55 | ## FAQ
56 |
57 | Q:是CDH项目吗?
58 |
59 | A:Hadoop生态相关的环境是以Apache Hadoop + Apache Spark构建, 专栏源码兼容CDH版本的Hadoop和Spark。
60 |
61 | Q:项目的环境是自己进行搭建吗?还是网站提供
62 |
63 | A:手把手带领大家,从0开始搭建环境。 同时提供了开箱即用的虚拟机文件,可直接导入虚拟机用于开发。
64 |
65 | Q:是实时数仓吗?
66 |
67 | A:如果同学指的是,基于流处理和批处理的维度区分,专栏属离线数仓;如果基于响应实时性维度,可以做到在几分钟之内, 算准实时。
--------------------------------------------------------------------------------
/docs/md/bigdata/hiveserver2.md:
--------------------------------------------------------------------------------
1 | # hiveserver2
2 |
3 | ## 1 简介
4 |
5 | Apache Hive的一部分,是一个服务接口,允许客户端使用JDBC或Thrift协议来执行查询、获取结果及管理Hive的服务。即它提供了一个机制,使得外部客户端程序可以与Hive进行交互。
6 |
7 | ## 2 主要特性
8 |
9 | - **多客户端并发**:HiveServer2支持多客户端同时并发访问和执行查询
10 | - **会话管理**:HiveServer2可维护和管理用户会话,每个客户端连接都在自己的会话中执行
11 | - **安全访问**:集成安全功能,可配置基于LDAP的身份验证、Kerberos等安全机制
12 | - **JDBC和ODBC接口**:提供标准JDBC和ODBC接口,这让它能与各种企业级应用以及BI(商业智能)工具兼容
13 | - **Thrift服务**:除JDBC和ODBC,还提供Thrift服务接口,允许各种编程语言创建客户端以访问Hive
14 |
15 | HiveServer2是Hive的核心组件之一,是HiveServer升级版,提供更好性能、稳定性与可伸缩性。在大数据生态系统中,HiveServer2是执行SQL风格查询、数据挖掘和管理大规模数据集的重要工具。正是通过如HiveServer2这样的服务,Hive才能在整个Hadoop生态系统中发挥其强大的数据仓库功能。
--------------------------------------------------------------------------------
/docs/md/bigdata/hive的严格模式.md:
--------------------------------------------------------------------------------
1 | # hive的严格模式
2 |
3 | ## 1 参数控制
4 |
5 | 一项配置,旨在阻止执行某些可能导致效率低下的查询操作。主要是通过以下几个配置参数控制的:
6 |
7 | ### 1.1 hive.mapred.mode
8 |
9 | - 默认值:
10 | - Hive 0.x: `nonstrict`
11 | - Hive 1.x: `nonstrict`
12 | - Hive 2.x: `strict` ([HIVE-12413](https://issues.apache.org/jira/browse/HIVE-12413))
13 | - 添加于:Hive 0.3.0
14 |
15 | Hive 操作执行的模式。在 `strict` 模式下,一些风险较高的查询不允许运行。如阻止:
16 |
17 | - 全表扫描(参见 [HIVE-10454](https://issues.apache.org/jira/browse/HIVE-10454))
18 | - [ORDER BY](https://cwiki.apache.org/confluence/display/Hive/LanguageManual+SortBy#LanguageManualSortBy-SyntaxofOrderBy) 需 LIMIT 子句
19 |
20 | - 没有WHERE子句的查询(可能会扫描整个表)
21 | - 无分区键的查询(对分区表而言,如果不使用分区键进行查询,也可能会扫描整个表)
22 |
23 | ### 1.2 hive.strict.checks.large.query
24 |
25 | 若置true,Hive会对大查询大数据做析假以限制(如,防止笛卡尔积)
26 |
27 | ### 1.3 hive.strict.checks.no.partition.filter
28 |
29 | 若设置为true,Hive会要求分区表的查询须含有分区列的过滤条件,为防止查询无意中扫描全表。
30 |
31 | ### 1.4 hive.strict.checks.bucketing
32 |
33 | 置true时,Hive会检查对于bucketed表的查询是否使用了正确的数据集合方法。
34 |
35 | ## 2 开启
36 |
37 | ```sql
38 | SET hive.mapred.mode=STRICT;
39 | ```
40 |
41 | ## 3 关闭
42 |
43 | ```sql
44 | SET hive.mapred.mode=nonstrict;
45 | ```
46 |
47 | 严格模式下,如果你必须执行全表扫描或者不指定分区键的查询,你需要明确告知Hive你知晓这些潜在的效率问题并且接受后果。这可以通过在查询时添加相关的LIMIT子句,或者在查询中使用分区过滤条件来实现。
48 |
49 | 例如,在严格模式下,下面的查询会被阻止:
50 |
51 | ```sql
52 | SELECT * FROM sales; -- 无WHERE子句,可能扫描全表
53 | ```
54 |
55 | 你需要这样修改查询以避免被阻止:
56 |
57 | ```sql
58 | SELECT * FROM sales WHERE sale_date = '2023-04-15'; -- 使用WHERE子句限制扫描
59 | ```
60 |
61 | 者:
62 |
63 | ```sql
64 | SELECT * FROM sales LIMIT 100; -- 使用LIMIT子句限制返回结果的数量
65 | ```
66 |
67 | ## 4 总结
68 |
69 | 开启严格模式是一种好的实践,因为它可以帮助我们避免执行一些可能导致计算资源浪费的低效查询。这在处理大型数据集和维护生产环境时尤其重要。但是,在某些情况下,如果我们知道所执行的操作是确定的,并且我们需要执行全表扫描这样的操作,可临时关闭严格模式。
--------------------------------------------------------------------------------
/docs/md/bigdata/数仓逻辑模型.md:
--------------------------------------------------------------------------------
1 | # 数仓逻辑模型
2 |
3 | ## 0 前言
4 |
5 | 数据仓库的逻辑模型指的是描述数据仓库中数据如何组织、存储和相互关联的高层次抽象模型。它不涉及数据在物理层面上的实现细节(例如具体的数据库表结构),而是关注于数据模型的设计与规划,以便于支持业务决策和数据分析工作。
6 |
7 | 以下是数据仓库逻辑模型的两种常见设计方法:
8 |
9 | ## 1 星型模式(Star Schema)
10 |
11 | 星型模式是一种数据模型,其中包含一个或多个事实表和多个维度表。事实表存储量化的业务数据(事实),例如销售总额、交易次数等,并且通常包含大量记录。维度表用于存储描述性数据来提供上下文信息,例如时间、地点、产品信息等。这种模式的名称来源于其看上去像一个星星的形状——中心的事实表被各个维度表围绕。
12 |
13 | 当表关系可视化时,事实表在中间,被一系列维度表包围;与这些表的连接就像星星光芒。
14 |
15 | ```plaintext
16 | [时间维度表]
17 | |
18 | [产品维度表] - [事实表] - [店铺维度表]
19 | |
20 | [顾客维度表]
21 | ```
22 |
23 | 该模板的变体为
24 |
25 | ## 2 雪花模式(Snowflake Schema)
26 |
27 | 雪花模式是星型模式的变体,其中维度表可以有它们自己的维度表(被称为子维度表或归一化维度表)。在雪花模式中,数据库的结构更复杂,维度数据经过了进一步的归一化,它可以减少数据冗余,但可能会使得查询变得复杂,因为需要多个连接操作。
28 |
29 | ```plaintext
30 | [时间维度表]
31 | |
32 | [产品类型] - [产品维度表]
33 | | - [事实表] - [店铺类型] - [店铺维度表]
34 | |
35 | [顾客国家] - [顾客维度表]
36 | ```
37 |
38 | 其中维度被进一步分解为子维度。如品牌和产品类别可能有单独表格,且`dim_product` 表格中的每行都能再次将品牌和类别作为外键,而不是将它们作为字符串直接存储在 `dim_product` 表。雪花模式比星形模式更规范化,但星形模式是首选,因为对于分析师,它更简单。
39 |
40 | 典型数仓中,表格很宽:
41 |
42 | - 事实表通常超100列,甚至数百列
43 | - 维度表也可能宽,因为它们包括可能与分析相关的所有元数据。如`dim_store` 表可能包括在每个商店提供哪些服务的细节,是否具有店内面包房,店面面积,商店开张日期,最后一次装修时间,距离最近的高速公路有多远
44 |
45 | ## 3 核心原则
46 |
47 | - **支持业务需求**:
48 | 逻辑模型应确保可以满足所有当前和预期的业务分析需求。
49 | - **可扩展性**:
50 | 数据模型应方便未来的调整和扩展,以容纳新的数据源和新的业务需求。
51 | - **性能优化**:
52 | 模型应经优化以支持高效的数00-数仓逻辑模型据访问和查询性能。
53 | - **易用性**:
54 | 数据模型应容易理解和使用,尤其对于业务用户而言应显得直观。
55 | - **数据质量与一致性**:
56 | 逻辑模型应保证数据的准确性、完整性和一致性。
57 |
58 | 在构建数据仓库的逻辑模型时,将考虑如何将不同的数据源整合到一致的框架中,以及如何结构化这些数据以便于报告和数据分析。逻辑模型是数据仓库概念和物理实现之间的桥梁。
--------------------------------------------------------------------------------
/docs/md/bigdata/维度建模理论之维度表.md:
--------------------------------------------------------------------------------
1 | # 维度建模理论之维度表
2 |
3 | 维度建模是数据仓库设计中的一种方法,用于组织和管理数据以支持分析和报告需求。在维度建模中,维度表是非常重要的一部分,它包含描述业务过程的维度属性,可以帮助用户对数据进行多维分析。描述属性的表通常被设计为维度表。
4 |
5 | ## 1 维度表概述
6 |
7 | 维度表是数据仓库中描述业务实体的表,例如时间、产品、地区等。包含描述维度属性的列,如维度键、层级、描述性属性等。
8 |
9 | 维度表通常具有较少的记录,但有多个属性描述每个记录。
10 |
11 | ## 2 维度表的特点
12 |
13 | - 维度表的记录通常是静态的,不会频繁更新,因为它们描述的是静态业务实体。
14 | - 维度表的主键是维度键,用于与事实表进行关联。
15 | - 维度表通常包含层级结构,例如时间维度可以包含年、季度、月等层级。
16 |
17 | ## 3 维度表的设计原则
18 |
19 | - 清晰定义维度表的业务含义,确保每个维度表只描述一个业务实体。
20 | - 使用稳定的、不频繁变化的属性作为维度表的描述性属性。
21 | - 为维度表的层级设计合适的字段,支持多层次的分析。
22 | - 使用适当的维度键进行唯一标识,通常采用自然键或人工主键。
23 |
24 | 维度表可与任意表组中的任意表进行关联,且创建时无需配置分区信息,但是对单表个数有所限制。通常要求维度表的单表量不超过1000万个。
25 |
26 | - 维度表的数据不应被大量更新。
27 | - 可用MAPJOIN语句进行维度表和其它表的JOIN操作。
28 |
29 | ## 4 维度表与事实表的关系
30 |
31 | - 维度表与事实表之间通过维度键建立关联,形成维度模型。
32 | - 事实表包含业务过程的度量或指标,而维度表描述了这些度量的上下文和属性。
33 |
34 | ## 5 维度表的分类
35 |
36 | - 时间维度表:描述时间属性,如年、月、日、周等。
37 | - 产品维度表:描述产品属性,如产品ID、名称、类别等。
38 | - 地区维度表:描述地区属性,如国家、省份、城市等。
39 |
40 | ## 6 维度表的优势
41 |
42 | - 支持多维分析:通过维度表可以对数据进行多维度的分析,提供更全面的业务视角。
43 | - 提高查询性能:合理设计的维度表结构可以提高查询效率,加快数据检索和报表生成的速度。
44 | - 方便理解和使用:维度表的设计符合业务逻辑,使用户更容易理解和使用数据仓库中的数据。
45 |
46 | 维度表在数据仓库设计中扮演着重要的角色,合理设计和使用维度表可以提高数据仓库的效率和灵活性,为用户提供更好的数据分析和报告支持。
--------------------------------------------------------------------------------
/docs/md/biz-arch/01-DMP系统简介.md:
--------------------------------------------------------------------------------
1 | # 01-DMP系统简介
2 |
3 | ## 1 是什么?
4 |
5 | 数据管理平台(Data Management Platform),广泛应用在互联网的广告定向(Ad Targeting)、个性化推荐(Recommendation)领域。
6 |
7 | 可以把DMP简单理解成一个**数据池子**,接受来自各方的数据,然后融合,处理和优化,最后使用这些数据。
8 |
9 | DMP = 数据+管理 +平台
10 |
11 | DMP是集数据采集,存储,处理,分析,输出应用于一体。数据应用是搭建DMP的目标!
12 |
13 | ## 2 数据来源
14 |
15 | 第一方数据:
16 |
17 | - 企业供应商数据
18 | - 企业会员数据
19 | - 企业销售数据
20 |
21 | 第三方数据:
22 |
23 | - 用户隐私信息
24 | - 运营商数据
25 | - 行业数据
26 |
27 | 第二方数据:
28 |
29 | - 用户行为数据
30 | - 用户消费数据
31 |
32 | ## 3 应用场景
33 |
34 | - 人群画像
35 | - 精准营销
36 | - 营销活动优化
37 | - 程序化广告投放
38 |
39 | DMP系统会通过处理海量互联网访问数据及机器学习算法,给用户标注各种标签。然后,在个性化推荐和广告投放时,再利用这些这些标签做实际广告排序、推荐等工作。无论是搜索广告、千人千面商品信息,还是信息流推荐,背后都有DMP系统。
40 |
41 | 
42 |
43 | ## 4 DMP 行业图谱
44 |
45 | 第一方DMP:单体企业,以企业CRM系统为主。最终表现是BI平台,挖掘销售线索,打造营销闭环
46 |
47 | 第二方DMP:广告公司,广告投放为主
48 |
49 | - 阿里的达摩盘
50 | - 腾讯的广点通
51 | - 头条的巨量千川
52 | - 京东的京准通
53 | - 百度的智选
54 |
55 | 第三方DMP:大数据服务商,以数据交易为主
56 |
57 | TalkingData,如个推数据、神策数据
58 |
59 | ## 5 前景
60 |
61 |
62 |
63 | 
64 |
65 | ## 6 DMP帮助用户达到啥效果?
66 |
67 | ### 用户分析与定向投放
68 |
69 | - 广告精准投放
70 | - 提供丰富标签服务
71 |
72 | ### 广告效果分析
73 |
74 | - 各渠道的获客数量
75 | - 各渠道的转化率
76 | - 订单成本分析
77 |
78 | ### 广告效果优化
79 |
80 | - 个性化广告信息
81 | - 各渠道消费者的复购
82 |
83 | ## 7 DMP平台必须具备的能力
84 |
85 | - 海量多源数据采集能力
86 | - 多元信息挖掘能力
87 | - 数据建模能力
88 | - 丰富的标签体系
89 | - 海量数据存储,处理,分析能力
90 | - 敏捷强大的数据分析
91 |
92 | ## 8 愿景
93 |
94 | - 数字化决策支持,让数据能够运用到企业营销策略之中
95 | - 让数字资产成为企业的大脑,参与到商业场景的每个细节中
96 | - 在人工智能的加持下,实现数据智能化洞察、决策和运用
97 |
98 | ## 9 DMP系统怎么搭建?
99 |
100 | 对于外部使用DMP的系统或者用户来说,可以简单地把DMP看成是一个键-值对(Key-Value)数据库。广告系统或推荐系统,可以通过一个客户端输入用户的唯一标识(ID),然后拿到这个用户的各种信息:
101 |
102 | 用户的人口属性信息(Demographic),如性别、年龄
103 | 有些是非常具体行为(Behavior),如用户最近浏览商品,用户的手机型号
104 | 有些是通过算法系统计算出来的兴趣(Interests),如用户喜欢健身、听音乐
105 | 有些则是完全通过机器学习算法得出的用户向量,给后面的推荐算法或者广告算法作为数据输入。
--------------------------------------------------------------------------------
/docs/md/biz-arch/05-用户画像是什么?.md:
--------------------------------------------------------------------------------
1 | # 05-用户画像是什么?
2 |
3 | ## 1 什么是用户画像
4 |
5 | 用户画像是指根据用户的个人信息、行为数据、兴趣爱好等多方面数据构建出的用户的特征模型或描述。用户画像旨在更好地理解和洞察用户,从而为用户提供个性化的服务和体验。
6 |
7 | 通过数据建立描绘用户的标签,个性化推荐、广告系统、活动营销、都是基于用户画像的应用。
8 |
9 | ## 2 特点和作用
10 |
11 | 1. **多维数据:** 用户画像通常包括多种维度的数据,例如用户的基本信息(年龄、性别、地域)、行为数据(浏览记录、购买记录)、兴趣爱好(关注的话题、喜欢的产品类别)等。
12 |
13 | 2. **个性化服务:** 基于用户画像,企业可以针对不同用户群体提供个性化的服务和推荐,例如个性化推荐商品、定制化的营销活动等,提升用户满意度和忠诚度。
14 |
15 | 3. **精准营销:** 用户画像可以帮助企业更准确地了解用户的需求和偏好,从而进行精准的营销活动,提高营销效果和转化率。
16 |
17 | 4. **产品优化:** 通过分析用户画像,企业可以发现用户的使用习惯和痛点,从而优化产品设计和功能,提升产品的用户体验和市场竞争力。
18 |
19 | 5. **决策支持:** 用户画像还可以为企业提供数据支持,辅助决策制定和业务发展方向,帮助企业更好地了解市场和用户需求。
20 |
21 | 6. **跨平台应用:** 用户画像不仅可以应用于电子商务和在线服务领域,还可以在金融、医疗、教育等多个领域进行应用,为不同行业提供个性化服务和解决方案。
22 |
23 | 总的来说,用户画像是通过对用户数据进行分析和建模,形成对用户特征和行为的描述,从而为企业提供个性化服务、精准营销、产品优化等方面的支持,是数字化时代企业数据驱动和个性化服务的重要工具之一。
24 |
25 | ## 3 正确理解用户画像
26 |
27 | - 不能把典型用户当作用户画像
28 |
29 | 典型用户是虚构的,每个真实用户都有自己的用户画像
30 |
31 | - 用户画像不是用户标签的简单组合
32 | 用户画像的标签要和业务相结合
33 |
34 | - 用户画像的有效性
35 | 用户的行为,偏好会随时间而变化
36 |
37 | 标签是用户画像的核心,只有真正有效的用户画像标签,才能提升运营效果。
38 |
39 | ## 4 用户画像如何生成
40 |
41 | ### 4.1 统一用户唯一标识
42 |
43 | 如手机号
44 |
45 | ### 4.2 给用户打标签
46 |
47 | 属性标签、消费标签、行为标签、内容分析
48 |
49 | ### 4.3 将用户画像与业务关联
50 |
51 | 获客、粘客、留客
52 |
53 | ## 5 用户画像的标签维度
54 |
55 | ### 5.1 标签类型,从标签主题的角度
56 |
57 | - 用户属性
58 | - 用户行为
59 | - 用户消费
60 | - 风险控制
61 | - 内容分析
62 |
63 | ### 5.2 标签类型一从标签生成的角度
64 |
65 | #### 5.2.1 统计类型
66 |
67 | 需要使用聚合函数计算后得到的标签。如总消费金额
68 |
69 | #### 5.2.2 规则匹配类型
70 |
71 | - 人口属性
72 | - 用户生命周期
73 |
74 | #### 5.2.3 挖掘类型
75 |
76 | 用户偏好
77 |
78 | ### 5.3 标签类型一从数据提取的角度
79 |
80 | #### 5.3.1 事实标签
81 |
82 | 从生产系统获取数据
83 |
84 | #### 5.3.2 模型标签
85 |
86 | 对用户属性和行为进行聚类
87 |
88 | #### 5.3.3 预测标签
89 |
90 | 基于用户属性和行为,挖掘用户潜在需求。
91 |
92 | ### 5.4 标签类型一从数据时效的角度
93 |
94 | 静态属性标签:长期甚至永久都不会发生变化,如性别
95 | 动态属性标签:存在有效期,需要定期的更新,如用户活跃度
96 |
97 | ### 5.5 人群的标签组合
98 |
99 | 性别:有2个标签 男、女
100 |
101 | 年龄段维度:有7个标签,18-,20-30,30-40,40-50,50-60,60-70
102 |
103 | 月均消费维度:有7个标签 100-,100-500,500-1000 ...
104 |
105 | ```bash
106 | 人群标签数量=2*7*7=98
107 | ```
--------------------------------------------------------------------------------
/docs/md/biz-arch/06-构建高质量的用户画像.md:
--------------------------------------------------------------------------------
1 | # 06-构建高质量的用户画像
2 |
3 | ## 1 构建准则
4 |
5 | - 人口属性 != 用户画像
6 | - 用户的行为是构成用户与用户之间差异化的核心
7 | - 观察用户行为不是观察他做了什么事情,而是观察他做这件事情的动机
8 |
9 | ## 2 案例
10 |
11 | 看一用户画像:
12 |
13 | 
14 |
15 | 看起来很全面了是吗?好像各种交友软件都这么明摆给你看到这个画像了对吗?但对于购车业务,这就是一份无用的用户画像。
16 |
17 | 应该推荐价格低的(白领)?还是外观好的(女性)?还是实用性的车(租房)?所以看不出买车的决定性因素。
18 |
19 | ## 3 咋确定用户购物的决策动机
20 |
21 | 考量度:用户在做一个决策之前,所需要思考的程度。
22 |
23 | ### 高考量度的产品
24 |
25 | 用户经过了深入的自我剖析,60%的决策都在见到真正的产品之前,可以明确的说出自己决策的依据是什么。如房、车。
26 |
27 | ### 低考量度的产品
28 |
29 | 是一种用户在无意识的情况下作出的决策,用户可能很难说出来明确的决策依据,例如点外卖、刷新闻,所以对这种产品,用户偏好会随时会变
30 |
31 | 适合通过大数据标签统计来进行建模分析,分析用户偏好,确定用户的画像。
32 |
33 | ### 中考量度产品
34 |
35 | 用户在看到产品之前可能并不知道自己具体想要什么,但看到产品后,就会有那么一个产品特性触动用户,让用户做出购买决策,且在事后用户也可以说出是什么因素导致了购买的行为。
36 |
37 | 适合使用访谈的方式确定用户的画像。
38 |
39 |
40 |
41 | 有些产品,用户与用户之间考量度会有很大差异。即使同一个用户群,也会因为价格,用途等因素使得考量度出现很大的差异。
42 |
43 | ## 4 高质量的用户群体画像
44 |
45 | 用户群体应该根据考量度来归类,用户的考量度不同,应该归入不同的用户群。
46 |
47 | 如果用户的考量要素绝大多数相同,只有小部分考量要素不同,则可以合并为同一个的用户群。
--------------------------------------------------------------------------------
/docs/md/biz-arch/07-用户画像和特征工程.md:
--------------------------------------------------------------------------------
1 | # 07-用户画像和特征工程
2 |
3 | ## 1 什么是特征工程
4 |
5 | 单纯的身高和体重,并不能确定人是否胖或瘦。而
6 | ```
7 | BMI=体重/(身高^2)
8 | ```
9 |
10 | 就能确定人是否胖或瘦。
11 |
12 | 特征工程是打开数据密码的钥匙,特征工程就是将数据转换为特征的过程。
13 |
14 | 高质量的特征能提高模型的准确性
15 |
16 | ## 2 什么是特征
17 |
18 | 
19 |
20 | 一个二维数据集,每行表示一个样本,每个特征由一列表示,由观察到的全部的特征集形成一个二维特征矩阵,因此又称这数据集为特征集。
21 |
22 | 特征集还有一类表示类别,如该数据集里职业就是类别,即标签列。而基于数据集的特征可分为:
23 |
24 | - 原始特征
25 |
26 | 原始特征是直接从数据集里面获得的,没有额外的数据操作。
27 |
28 | - 派生特征
29 |
30 | 通常是从特征工程中获得的,即从现有的数据属性中提取出来的特征。
31 |
32 | ## 3 用户画像和特征工程的关系
33 |
34 | ### 3.1 明确问题
35 |
36 | 以及了解数据
37 |
38 | ### 3.2 数据预处理
39 |
40 | 包括数据集成、数据冗余、数据冲突、数据采样、数据清洗、缺失值的处理以及噪声数据的处理
41 |
42 | ### 3.3 特征工程
43 |
44 | **提取对所需要解决问题的有用的特征**,然后针对所解决的问题选择最有用的特征集合。我们可以通过人工或者算法来筛选出重要的特征
45 |
46 | ### 3.4 模型算法
47 |
48 | 我们可以根据应用场景选择多种模型来尝试比较我们所考虑的因素,可以有数据集的大小,特征的维度的大小,所解决的问题是线性的还是非线性的,需不需要考虑过拟合,对性能有哪些要求等。
--------------------------------------------------------------------------------
/docs/md/career/03-新人程序员入行忠告.md:
--------------------------------------------------------------------------------
1 | # 03-新人程序员入行忠告
2 |
3 | ## 1 主动解决【技术】问题
4 |
5 | 不仅要学会做基于增删改查的业务代码,更要主动去解决技术问题。在面试中能证明自己能力的,除了之前的大公司背景外,一般得说解决过哪些技术问题,如何在项目里用(值钱)技术。
6 |
7 | ## 2 涨薪只能靠跳槽
8 |
9 | 程序员薪资倒挂是常有的事,干一样的活,你入职时,你的薪资大概率会比在其中干了3年的员工高,同时,2,3年后入职的员工,哪怕比你年轻,薪资大概率比你高,所以程序员涨薪得靠跳槽。不过现在,有工作就不错了!
10 |
11 | ## 3 竞争力
12 |
13 | 不要在小公司待久,更不要在外包公司呆久。除非是大公司,否则在一家公司呆的时间别超过3年,外包公司的话,除非是刚入行或者当下实在找不到其它工作,否则别去,去了顶多呆2年。否则就不说薪资倒挂,你出去面试时,竞争力会大打折扣。
14 |
15 | ## 4 如何判断公司值得长呆吗?
16 |
17 | 判断一家公司是否值得长呆,就去看比你大3,5岁的程序员在干嘛,除非是大公司,如果比你大的程序员干的活和你差不多,这就是你3,5年后的样子。如果有些公司看不到大龄程序员,这就意味着到时候老板会让你走。
18 |
19 | ## 5 业界知名度
20 |
21 | 大专程序员或低学历程序员,争取尽快升本。程序员最好去出本书,在面试过程中,有一本书的收益会超出你的想象。
22 |
23 | ## 6 最佳学习途径
24 |
25 | 程序员得不断学习,学习的最好途径是,多去解决项目里的问题,多去参与项目上线,或多去解决运维相关问题。同时记住,学习的目的不是让你在当前职位干更好,因为当前职位的薪资已经固定,学习的目的是让你在之后的面试中,能说出自己能干薪资更高的活。
26 |
27 | ## 7 项目证明
28 |
29 | 比如Python深度学习或大模型,看再多资料跑通再多代码,顶多只能让你熟悉API和基本用法,在面试中,你最好能结合你之前公司和项目背景,证明你用过相关技术,解决过实际问题,这是你的学习方向。但如果一味上视频课,跑通学习项目,是无法达到这个效果的。
30 |
31 | ## 8 对的年纪找找对的平台
32 |
33 | 程序员过大龄这个关卡,不是靠掌握多少技术,也不是靠做过多少项目,更不是靠所谓的管理经验,而是得靠“平台”。国企或大公司,对大龄程序员更加友好。
34 |
35 | ## 9 别兼职
36 |
37 | 在进好公司前,不建议做兼职。当下做兼职,一个月挣5,6千,这得耗费很多经历,用这样的经历想办法进好公司,一个月多挣个1,2w,效率更高。同样说做兼职,如果真要做,别单靠技术,首先得去多和不同的人打交道,多去体会些人性。接活挣钱时,更要维护稳定的挣钱渠道。
38 |
39 | ## 10 不轻易转管理
40 |
41 | 不要轻易转管理,更别轻易转中小公司的管理。
42 |
43 | ## X 最后的忠告
44 |
45 | 时代变化太快了,不要把前辈的忠告太当回事。要形成自己的判断力。
--------------------------------------------------------------------------------
/docs/md/career/04-外企也半夜发布上线吗?.md:
--------------------------------------------------------------------------------
1 | # 04-外企也半夜发布上线吗?
2 |
3 | ## 0 别把问题想得太复杂
4 |
5 | - 如果有灰度发布的能力,最好白天发布;
6 | - 如果没有灰度发布,只能在半夜发布。
7 |
8 | 即使有灰度发布能力,也不要沾沾自喜,好好反思一下你们的灰度发布是否真的经得起考验,还是仅仅是装装样子。
9 |
10 | 回滚方案最好在上级环境中使用生产数据演练,避免在0.1%的情况下需要回滚时,发现无法简单地通过发布上一版本服务来回滚,届时会非常尴尬。
11 |
12 | 同时,服务类型也需要考虑,比如大型网络游戏(如《王者荣耀》),都是在午夜时间停服维护,这其实说明了问题。
13 |
14 | ## 1 形式上,必须凌晨!
15 |
16 | 必须得在凌晨上线。程序员的工作有一个“原罪”,就是别人很难看出来你有多努力,尤其是管理层。如果你不上班搞凌晨发布,管理层看不到你的努力,尤其是部门的整体表现。既然能选择凌晨上线,那就凌晨上线!
17 |
18 | 如果有加班费或者调休补偿,凌晨上线大家嗑着瓜子儿,吃着零食,公司提供的外卖和饮料,像开派对一样,和乐融融地等待凌晨。如果有领导或者HR路过,大家一个个愁眉苦脸,盯着屏幕苦苦思索,心里想,怎么还不结束呢。
19 |
20 | 即使上线跟你没关系,也要来,大家要在一起,部门派对。技术上早就不需要这么干了,但我们这里就是喜欢看苦情戏,必须得凌晨,只是这种凌晨非彼凌晨,一起开party~
21 |
22 | 
23 |
24 | ## 2 说点实际的
25 |
26 | ### 外企的发布流程
27 |
28 | 对于外企来说,发布流程相对规范:
29 |
30 | 1. **项目规模小,客户不多:**
31 | 这种情况下,随时可以上线,比如一些管理系统或新项目的上线。
32 |
33 | 2. **项目规模大,用户量大:**
34 | 这种情况下,通常选择访问量较少的时间上线,一般是凌晨,有时甚至是周末的凌晨。
35 |
36 | - 年底会确定下一年的上线日期(release day),每个上线日之间会间隔一个半月,这个周期相当于敏捷开发中的迭代周期。如果业务组有需要,可以通过流程,在规定的上线日之外进行发布。
37 | - 每年都有代码冻结期(code freeze period),通常是12月冻结一个月,因为圣诞假期维护人员放假,处理问题不方便,所以这个月不允许发布。如果需要发布,需要高级别领导批准。
38 | - 发布环境分为测试、集成测试和生产环境。测试环境每个组可以自由发布,集成测试环境需要邮件通知支持组进行发布,生产环境只能在发布日发布。发布通常是一键部署(one click deployment),开发组提前在Jenkins或Udeploy等部署工具中写好脚本,经过支持组审核后,由支持组在发布日进行实际操作。
39 | - 发布日前一周的周五会封闭集成测试环境,各开发组应该提前一周将代码部署到集成测试环境并通过测试,确保发布时风险最小。如果在发布周内发现问题,需要重新部署测试,需要部门领导审批。
40 | - 发布日一般在美国时间周五下午9点(中国时间周六上午9点),各组提前填写发布申请报告,通过审批后通知支持组进行发布。发布完成后,各组需要在生产环境上确认,没有问题则表示发布成功。
41 |
42 | ### 小公司的发布流程
43 |
44 | 一些小公司的发布流程类似于上述流程,都是敏捷开发流程,发布前在测试环境上测试代码,发布前代码会封版,确保代码质量。
45 |
46 | ### 互联网公司发布流程
47 |
48 | 对于包含高并发组件(如Redis集群、Kafka等)的互联网公司,发布过程更加复杂,不仅需要管理代码,还需要重启中间件,或使用中间件清洗或导入数据。如果能在面试中证明自己参与过发布,并解决过发布中的问题,那么一定能有效证明自己的商业项目经验。
49 |
50 | ### 结论
51 |
52 | 无论是大公司还是小公司,凌晨发布都是为了确保用户影响最小化,同时也是为了在特殊情况下能快速响应并回滚。理解并掌握发布流程,能够帮助开发人员更好地应对上线过程中的各种问题。
--------------------------------------------------------------------------------
/docs/md/career/05-中外程序员到底有啥区别?.md:
--------------------------------------------------------------------------------
1 | # 05-中外程序员到底有啥区别?
2 |
3 | ### 中国程序员的特点
4 |
5 | 中国程序员的最大优点是非常勤奋。中国互联网行业有句话叫:**“they earn a lot of money but die early”(赚得多死得早)**。由于工作强度大,经常有程序员突然去世的新闻报道。
6 |
7 | - **996 工作制度**:中国程序员通常实行“996”工作制度(即每天工作从早9点到晚9点,每周工作6天)。这已经成为程序员的潜规则。中国程序员一天的工作量通常与欧洲或美国程序员一周的工作量相同,而他们的平均工资只有欧美程序员的80%左右。
8 | - **工作压力**:这种加班文化并不是老板要你加班,而是你的工作量只有加班才能完成。由于整个中国的互联网行业都是如此,所以你无法通过更换工作来改变这一点。
9 | - **高薪诱惑**:尽管这种生活方式很辛苦,但如果你大学毕业后选择了程序员行当,你的工资将是其它同学的2-3倍,所以仍然有很多人心甘情愿。
10 | - **35岁的门槛**:中国程序员有35岁的门槛,这意味着35岁以上的程序员要么自己当老板,要么成为自由职业者,要么就必须转行,这是因为老程序员无法适应如此紧张的工作。因此,中国的程序员通过十几年的紧张工作,赚到其他专业人员30年的工资,然后选择退出,比如他们会去开店、做自媒体,甚至还有出家的。
11 |
12 | ### 程序员国别特点
13 |
14 | 以下是某大佬与不同国家程序员合作的经历总结:
15 |
16 | #### 1. 中国程序员
17 |
18 | - **工作态度**:只是按照吩咐去做,很少跳出框框思考。
19 | - **费用影响**:当你支付的费用超出他们的正常预期时,他们会认为是好的;当你支付的费用比他们的预期少一点时,他们会认为是坏的。
20 | - **工作效率**:总的来说,对中国程序员的尊重是他们工作很努力,但这也是他们不能跳出框框思考的原因(因为没有时间思考,因长时间工作而感到沮丧)。
21 |
22 | #### 2. 日本和美国程序员
23 |
24 | - **工作质量**:工资很高,通常工作很好,成绩也很好。
25 | - **思维方式**:解决方案并没有经过深思熟虑,多是临时解决方案。日本的解决方案大多数时候都是过时的解决方案。
26 | - **沟通方式**:美国人更加友好,善于倾听真正的需求。日本人非常善于倾听和满足需求,会举行大量会议直到要点明确,这就是他们需要时间来实施的原因。
27 |
28 | #### 3. 印度程序员
29 |
30 | - **工作态度**:通常很好,但有时花了钱却没有好结果,这取决于与你一起工作的人。
31 | - **沟通习惯**:他们从不说“不”,而只说“是,先生”,即使有时不明白某些要点。
32 | - **责任感**:大多数时候,不会在任务完成后进行检查,但在被告知时会进行调试。升级或更新时,可能会出现问题,他们不承担任何责任,只是尝试解决问题。
33 |
34 | #### 4. 伊朗、俄罗斯、乌克兰程序员
35 |
36 | - **工作质量**:便宜、智能、大量开箱即用的解决方案,高薪的解决方案非常精确,并在非常短的时间内提供解决方案。
37 | - **开发方法**:以现代方式开发,而不是使用传统编程。
38 | - **沟通问题**:大多数时候缺乏回应。如果他们手头有一些更有利可图的任务,可能会立即忘记你,不做任何回复。这是最大且最常发生的案例。
39 |
40 | #### 5. 德国和奥地利程序员
41 |
42 | - **工作质量**:精确而昂贵,可能是见过最贵的。
43 | - **解决方案**:有时不是用现代方法,但任务至少是按要求完成的。
--------------------------------------------------------------------------------
/docs/md/career/08-程序员为何一直被唱衰?.md:
--------------------------------------------------------------------------------
1 | # 08-程序员为何一直被唱衰?
2 |
3 | ## 0 的确悲哀!
4 |
5 | 悲哀的就是,想吃技术饭,那就要走专家路线,但国内软件开发绝大多是应用,能给得起钱的也是应用,对专家需求根本没多少,除了那几个超有钱的大公司。
6 |
7 | 这条路确是独木桥,走到后来,你会发现,你潜心研究的技术都是狗屁,不赚钱那就是shit。
8 |
9 | 例如某个回答里提到的,什么悲观锁[乐观锁]。我曾经也天天喜欢研究这类问题,但后来发现,一个框架就搞定了呀,现在做饭的厨子难道还得精通每种调料具体是啥成分???
10 |
11 | 我们的业务量根本做不到需要所谓技术专家的量级,等我们做起来了,系统推倒重来再说。
12 |
13 | ## 1 那国内最缺的到底是啥?
14 |
15 | 懂管理、懂技术、懂业务的人!
16 |
17 | 这类人太少了,B乎上你来看,有几个程序员能给你讲清楚他们公司业务的?有几个能说清楚老板天天咋想问题的?有几个人有企业发展战略性思维的?
18 |
19 | - [CTO]这个群体,要说技术能力,一群人跑出来七嘴八舌给你出主意
20 | - 一说业务,好多人就只是粗糙的背背宣传材料,公司到底怎么赚钱,行业趋势什么样,商业模式怎么创新,两眼一抹黑。对业务的理解就是“代码中的业务逻辑”
21 | - 一说管理,全抓瞎,连沟通都费劲,别说激发员工潜力,打造[技术COE]这种话题了
22 |
23 | 就这个水平,这个能力,35岁还不淘汰,难道把中层领导都裁了?
24 |
25 | 还有脸说内卷……可不是内卷吗?光会技术,那不就是个高级开发,大头兵!老板直聘上的 3~5 年,本科毕业后25~28岁的不就能用,还便宜!我养你个38的,我 tmd 有钱没处花?
26 |
27 | ## 2 国家、企业战略视角
28 |
29 | 这些都是格局上的大角度,所以有些人感觉不舒服,说我是爹味哈哈哈,很正常,基层如果格局跟高层一样了,早就平步青云了,何至于在破帖子下讽刺我。
30 |
31 |
32 |
33 | 很多人不懂,作为一个技术人
34 |
35 | ## 3 为什么要懂业务,懂管理?
36 |
37 | 其实我并没有要求你懂,我只是告诉你,你若只是钻研技术,**天花板就是脚踏板**。
38 |
39 | 至于你到底想咋突破,是不是想突破,是不是要走业务和管理的路,**随你**!
40 |
41 | ## 4 技术人在行业面前的无力感
42 |
43 | 国内软件技术让大家能亲身感受的,莫过电商和支付业务。
44 |
45 | 阿里是这行业里世界级翘楚,三高那是真的高!敢在双十一玩真秒杀!
46 |
47 | 有个网友朋友,2012年进入支付行业,一直走技术路线。那么支付行业什么时候最赚钱?2015年跟着[P2P]赚了一笔钱。
48 |
49 | 2015年,公司明面利润N个亿,销售冠军奖励900万,[首席产品官]奖励400万,CTO你猜多少?100万都不到。他在技术团队跟着喝汤,下了一场毛毛雨而已。那时候你看他们晒什么?晒全世界到处旅游,晒品味,晒格调。
50 |
51 | 2016年开始走下坡路了,随着**备付金统一存管,网联启动,通道同质化,[第四方支付]崛起,监管步步收紧**,第三方支付的颓势在2016年开始盛极转衰。
52 |
53 | ## 5 这叫[行业趋势分析]
54 |
55 | 啥叫业务?business,商业,就是公司咋赚钱!
56 |
57 | 绝大多数技术人不懂这个,甚至就是故意不想关心这个,所以在2016年,他还是很兴奋,觉得钱可以继续赚下去,好日子还在继续。
58 |
59 | 大家都在拼谁技术强,谁职级高,谁能涨薪,你三万,我就四万,你四万,我就五万。
60 |
61 | 各大P2P公司搅乱市场,只要你有金融背景,就直接待遇翻倍。
62 |
63 | 到了2017年,有先知先觉的就已经退出支付行业了。那时候他还懵懵懂懂,因为一直在中台做产品,他不太了解前端的行业趋势,但是很羡慕有人赚了钱。所以2018年,他去内部创业,去研究监管,研究市场,研究客户,研究业务模式,跟公司签了对赌。
64 |
65 | 这一年研究的结果,他跟我聊的是:第三方支付死定了。
66 |
67 | 这哥们后来急流勇退,不管哪家支付公司让他去,甚至[许下CTO]的职位,他都抵死不从,坚决不碰支付了。
68 |
69 | 2016年能看出支付完蛋的,是神人。2017年能看出支付完蛋的,是牛人。2018年看出支付不行了的,是普通人。2019年,甚至2020年还在往第三方支付圈子里钻的,不敢说没有牛人,但大多数都是废人。
70 |
71 | ## 6 总结
72 |
73 | 技术人,你可以选择两耳不闻窗外事,一心只读圣贤书。但这条路是独木桥,天花板低,竞争压力极大。
74 |
75 | 甚至一个行业的兴衰,决定了你最黄金的十年到底能有多大成就。
76 |
77 | 人生几十年,错过了就是错过了,愿意在技术领域呆着,没人反对,自己的路自己走就完了。
--------------------------------------------------------------------------------
/docs/md/career/09-程序员的“三步走”发展战略.md:
--------------------------------------------------------------------------------
1 | # 09-程序员的“三步走”发展战略
2 |
3 | 三步走战略。
4 |
5 |
6 |
7 | ## 1 第一种:还在入门阶段的嫩头青
8 |
9 | 这个阶段你要做的事情就是把代码功底练到位。
10 |
11 | 什么是[代码功底]?用你习惯的编程语言,前端后端无所谓,都能写逻辑,去反复练把常见的一些逻辑操作用代码实现出来。
12 |
13 | ### 例子
14 |
15 | 语法方面:两个变量的值交换;数组中插入取出或者查找某个元素;数组合并去重或者找出共同元素;字符串搜索匹配替换等等
16 |
17 | 语言方面:
18 |
19 | - 各种封装好的[api]要能在需要用的时候随时想得起来
20 | - 怎么给指定接口发一个请求
21 | - 数据库怎么连接怎么操作
22 | - 代码异常了怎么捕获处理抛出错误
23 | - [json格式]文本内容怎么解析取值
24 | - 怎么读写文件内容等等诸如此类
25 |
26 | 至少达到能够保证有能力正常去完成常见的业务需求,最差也至少要有能写[CRUD]水平吧。
27 |
28 | ## 2 第二种:已经过了入门阶段的小青年
29 |
30 | 在这个阶段你应该就已经天天写CRUD写到厌倦了,给你一个熟悉的业务需求,闭着眼睛也能把代码给写出来。而这时往往就会被自己的技术面宽度所限制。
31 |
32 | 什么是技术面的宽度呢?就是你见过的世面技术栈够不够多。
33 |
34 | ### 例子
35 |
36 | 某天突然接了一个新需求,需要识别用户上传的图片文字,这时候对于你这种写惯了数据库操作的人来说一下子就懵了,因为这里开始涉及到了需要对图像进行操作,而这部分恰好是你平时几乎没有用到过也几乎没有去看过相关实现方案,让你凭借目前现有的技术储备去硬写,肯定是两眼一抹黑,写不出来的。
37 |
38 | 这个时候往往就会遇到很多类似于上述情况的实际应用场景下的问题,需要去找各种对应的解决方案
39 |
40 | - 图片上传你会写,但是里面的内容识别怎么做呢?
41 | - 二维码怎么生成解析呢?
42 | - 别人的扫码登录是怎么实现的呢?
43 |
44 | 遇到这种情况,就只能硬着头皮把问题扔搜索引擎里面各种搜相关的链接,看别人的实现方案,用别人封装好的第三方包,以此来一点一点提升自己的技术知识面。
45 |
46 | 这时候写代码就已经不再枯燥了,而是会涉及到很多自己从来没有解决过的需求,不停地去接触新东西,去多看别人大佬提供的方案,翻阅别人的[博客],逛各种论坛,找别人开源的项目来逐个体验,看云厂商的组件服务,这时你才会发现,自己原来的技术知识面是多么地狭窄。原来代码可以用来干这么多事儿。
47 |
48 | ## 3 第三种:做好产品
49 |
50 | 对绝大多数别人的项目都基本上能一眼看出内部的实现逻辑,自己感觉空有一身码艺,想要去做点啥却有没有一个明确的目标。
51 |
52 | 这个阶段也是绝大多数入行两三年之后的技术人会碰到的瓶颈。每天看着别人那些层出不穷的项目,总是觉得心里痒痒,自己难道就比别人弱吗?既然别人都能做点项目,那为什么自己不行。
53 |
54 | 这种时候就应该尽量多去关注一些远离代码以外的事情,例如生活中自己每天都在接触的事物,或者自己平时的各类兴趣爱好。
55 |
56 | ### 例子
57 |
58 | 我每天都会在公司中午点外卖吃,但是经常不知道该吃点什么好,陷入了选择困难当中。那我能不能做一个极简的应用,来解决这个问题呢?也就是通过这个应用,解决了自己每天中午不知道吃什么外卖的问题。那么既然自己会碰到这个问题,当然同样也会有其他人被类似的问题所困扰。能够通过一个小应用解决这个问题,就可以尝试着把它推荐给别人去使用。
59 |
60 | ***也就是从生活当中去发现问题->由问题产生需求->再通过代码能力去尝试满足需求解决问题***
61 |
62 | 很多伟大的项目,都是从生活中可能没人注意的很小的一个需求点而不断发展迭代出来的。
63 |
64 | 所以说,再好的编程水平和代码能力,最终还是要回归到现实生活当中,才可以真正发挥它的作用。
65 |
66 | 毕竟,技术人所写的每一行代码,都是To make the world [a better place]
--------------------------------------------------------------------------------
/docs/md/career/efficient-professional-reading-list.md:
--------------------------------------------------------------------------------
1 | # 高效职场人书单
2 |
3 | ## 《高效人士的七个习惯》
4 |
5 | 
6 |
7 | 帮助人们提高效率和个人影响力的七个习惯。这些习惯涵盖了从个人成长到与他人协作的核心原则:
8 |
9 | ### **1:个人成功(从依赖到独立)**
10 | 1. **积极主动(Be Proactive)**
11 | - 主动掌控自己的生活,而非被外界环境左右。
12 | - 关注“影响圈”(可控的事情)而非“关注圈”(不可控的事情)。
13 | - 你有权选择自己的态度、行为和反应。
14 |
15 | 2. **以终为始(Begin with the End in Mind)**
16 | - 明确自己的目标和核心价值观,设定人生方向。
17 | - 通过制定个人使命宣言,确保所有行动与目标一致。
18 | - 把每一天当作实现长期目标的步骤。
19 |
20 | 3. **要事第一(Put First Things First)**
21 | - 确定优先事项,专注于重要但不紧急的事情(如规划、学习、健康)。
22 | - 学会说“不”,避免被琐事或紧急但不重要的事情牵绊。
23 | - 将时间和精力用在对长期成功最有意义的地方。
24 |
25 | ### **2:公众成功(从独立到互赖)**
26 | 4. **双赢思维(Think Win-Win)**
27 | - 在人际关系中寻求互利互惠,合作共赢,而不是竞争或损人利己。
28 | - 建立信任,关注双方的利益和长期关系。
29 | - 追求“丰盈心态”(相信资源充足,人人都能成功)。
30 |
31 | 5. **知彼解己(Seek First to Understand, Then to Be Understood)**
32 | - 学会倾听,真正理解他人的观点、需求和感受,而不是急于表达自己。
33 | - 运用同理心沟通,避免只从自己的角度出发。
34 | - 在理解对方后,再清晰表达自己的意见。
35 |
36 | 6. **协作增效(Synergize)**
37 | - 尊重并运用多样性,通过团队合作产生“1+1>2”的效果。
38 | - 接受不同观点,寻找创新解决方案。
39 | - 利用集体智慧和资源,实现个人无法单独完成的目标。
40 |
41 | ### **3:持续改进**
42 | 7. **不断更新(Sharpen the Saw)**
43 | - 持续提升身体、心智、情感和精神四个方面的能力。
44 | - 定期锻炼、学习新知识、发展人际关系、实践反思。
45 | - 保持精力充沛,避免倦怠,通过更新自己实现长期成长。
46 |
47 | ---
--------------------------------------------------------------------------------
/docs/md/career/为什么中国的程序员有35岁危机.md:
--------------------------------------------------------------------------------
1 | # 02-为什么中国的程序员有35岁危机
2 |
3 | 我的八年编程生涯,几乎都是在大中厂之间游走,有一些经验跟大家分享:
4 |
5 | ## 1 大厂入职培训体系更完善
6 |
7 | 对毕业生,除了专业知识,对于未来的一切未知。这个时候需要有人来帮忙引路。
8 |
9 | 大公司通常都会有一套完善的培训体系和新人成长计划,这些可以帮助新员工快速适应工作环境,走好人生角色转变的第一步。
10 |
11 | 相对于小厂,入职后大厂后一般会有公司层面的一个全体新员工培训,这一阶段的培训主要是针对公司架构、企业文化、规章制度等方面。有助于新同学快速了解公司,融入公司文化。这期间由于是公司层面的新员工培训,你能认识各个不同领域的人,结交各种志同道合的朋友。
12 |
13 | 公司层面的培训结束后还会有部门培训,这一阶段除了部门架构、规章制度的介绍外主要会对部门所涉业务进行培训,从理论、技术、框架等层面让你更清楚的了解以后的具体工作。这期间团队还会为你安排导师,业务和生活上的问题都可以向他请教。
14 |
15 | 无论是部门层面还是公司层面,都会定期举办技术分享、技术沙龙、前沿讲座等活动,让员工不断更新知识,提高技能,进而让你始终保持对新技术的关注和热情。
16 |
17 | 总之,大厂规范完善的系列培训和指导能够让你无障碍入职并融入公司,快速成长,助力你职业发展的全过程。
18 |
19 | ## 2 大厂生产管理更规范
20 |
21 | 软件项目开发是一个系统性工程,如果没有良好的项目管理规范和足够的人员配备,就会导致所有的压力转嫁到最底层的程序员身上。
22 |
23 | 规范的流程管理和项目管理,清晰的责任划分和职责分配能够大概率避免需求的反复修改、无休止的加班和查不完的BUG。
24 |
25 | 大厂的资源优势能够保证系统开发过程中充足的人员配备,同时引入规范化的项目流程管理。专业的人做专业的事,让个人价值得到充分体现,提高了每个环节的工作效率,避免了很多上述的无用功。
26 |
27 | ## 3 大厂稳定福利待遇更棒
28 |
29 | 大树底下好乘凉,大厂不管是在薪资福利还是人性化管理等方面都要比所谓的小厂更加规范。
30 |
31 | 除了基本的福利待遇,大厂的办公条件、员工关怀等方面也是强于小厂。即使要裁你,我会给你充足的补偿。都是干活,大厂能让你舒舒服服的干活,高高兴兴的加班。
32 |
33 | 对于小厂来说,由于资源和规模限制,福利待遇和人性化管理肯定是远不如大厂。很多小厂甚至还处在努力活下去的阶段,今天吃饱了,明天还存不存在都说不定。因此,对于职场新人来讲,小厂的风险太大。
34 |
35 | ## 4 大厂晋升渠道多样化
36 |
37 | 对于程序员而言,职业发展要经历很多阶段,但大都是沿着技术或者管理等方向发展。无论是走技术路线还是管理路线,大厂都提供了方便灵活的晋升机制和考核评价体系。只要你能力满足要求,都能顺利发展。
38 |
39 | 此外,大厂的转岗渠道也更佳通畅,不仅能提供本地的内部转岗。如果大厂的分公司比较多,你还可以选择异地转岗,事儿少钱多离家近不是梦,当然前提是你要有一定的工作年限。
40 |
41 | ## 5 大厂背景为你跳槽镀金
42 |
43 | 大厂的经验积累能够让你的职业素养得到快速提升,即使你在离职后,头顶着大厂工作经历的光环也更有利于找工作。
44 |
45 | 很多小厂也更青睐于有过大厂工作经验的程序员,他们除了过硬的技术,也能把一些好的管理模式带入小厂,助力小厂的持续发展。
46 |
47 | ## 6 能够交到更多志同道合的朋友
48 |
49 | 大厂突出特点就是大!校招时会招入很多应届生,大家在一个起跑线上前进会有更多的共同话题。因而能结交到更多志同道合的朋友。这些朋友将是你今后人生过程中的一笔重要财富。
50 |
51 | 相比小厂,即使都是新人,应届生可能也只占很少一部分,大多都是通过社招过来,技能水平和生活阅历都不在一条线上,共同话题自然不多,最后能成为朋友的机率自然也不大。
52 |
53 | ## X 总结
54 |
55 | 总之,毕业能进大厂尽量选择大厂,绝对有助于你职业生涯的发展。
56 |
57 | 大公司整体会相对规范,无论是工作、培训还是个人成长,都有相对清晰的通道和方向,适合应届生快速成长。
58 |
59 | 最现实的,大公司简历好看点,以后跳槽选择多。国企社招都要大厂背景的!除非你校招就进国企底薪躺平!
60 |
61 | 程序员大多出身不是贵族,刚毕业的人如果家里没有钱,最好的选择就是大公司,如果家里有矿,就不一定了。
--------------------------------------------------------------------------------
/docs/md/chain/00-区块链专栏概述.md:
--------------------------------------------------------------------------------
1 | # 00-区块链专栏概述
2 |
3 | Web3.0入门与实战 一站式掌握4大主流区块链开发。从0到1全面掌握Web3.0核心技术,快速切换新赛道。
4 |
5 | ## 你将学到
6 |
7 |
8 |
9 | - 从0到1快速全面入行Web3.0
10 | - 掌握Solidty/Motoko/Cadence
11 | - 掌握四大主流链开发全流程
12 | - 掌握Web3.0主流开发框架
13 | - 能够独立开发Web3.0 Dapp
14 | - 基于Web3.0拓展副业收入
15 |
16 | Web3.0迎来爆发式增长,技术人才紧缺,薪资涨幅可观。但Web3.0体系庞杂,很难系统掌握。打造适合初学者从0到1系统学习的课程。从编程语言,到四大主流链项目开发,带大家系统全面掌握Web3.0开发技术,帮助大家顺利入行,开拓新的职业机会,增长职业竞争力及副业收入。
--------------------------------------------------------------------------------
/docs/md/chain/02-DAPP.md:
--------------------------------------------------------------------------------
1 | # 02-DAPP
2 |
3 | ## 1 啥是 DApp?
4 |
5 | DApp,部署在链上的去中心化的应用。
6 |
7 | DApp 是开放源代码,能运行在分布式网络上,通过网络中不同对等节点相互通信进行去中心化操作的应用。
8 |
9 | DAPP 开放源代码,才能获得人的信任。如比特币,尽管很多人没读过比特币源码,但仍不影响这些人相信并持有比特币,就是因为比特币是开源的,如有问题肯定会被发现。
10 |
11 | 去中心化应用肯定是分布式的应用,因为无中心节点,须能在节点之间进行通信,每一个去中心化应用都有自己的通信协议,使用相同协议的节点共同组成一个去中心化应用的网络。
12 |
13 | ## 优点
14 |
15 | DApp是分布式的应用,所以不存在单点故障,一个节点或几个节点坏了完全不影响DApp的正常运行。
16 |
17 | 因为数据是分布式的,所以数据很难完全删除,数据不会像中心化应用那样因为中心节点故障或其他原因而造成数据丢失。
18 |
19 | DApp也比中心化应用更值得信任,因为 DApp 使用共识算法保证数据不可篡改,而中心化服务的数据不可篡改依赖于对中心节点的信任,也就是对服务提供者的信任,如使用网银转账,是建立在对银行信任的基础。
20 |
21 | ## 2 DApp的存在的问题
22 |
23 | DApp节点分布在网络中,因此DApp的数据不会被轻易修改,辩证地看,也就让DApp升级困难。
24 |
25 | DApp 保证了用户的匿名性,那么通常带来问题就是用户身份的验证困难,同样,因为DApp的安全性高,就存在DApp系统更加复杂的问题。
26 |
27 | DApp的去中心化,导致DApp不能依赖已中心化的服务,那么生态的建立是非常缓慢的。
28 |
29 | ## 3 DAPP网络组建过程
30 |
31 | 万维网(WWW)就是指通过HTTP协议连接的网络。HTTP协议应用是一个典型的中心化应用,必须要有服务提供者,服务提供者就是一个中心节点,所有其他的用户通过服务提供者交互。
32 |
33 | DAPP不是中心化的应用,仅用HTTP协议显然不够。以二手交易中的买家和卖家为例,在DApp中一个卖家如何找到一个买家呢?使用 HTTP 的 Web 应用,买家和卖家都可通过域名服务找到中心节点的二手交易平台,但去中心化应用咋解决发现其他的节点?
34 |
35 | DAPP需实现一个新的协议来发现运行 DApp客户端的节点,假设我们已有相互发现节点的协议,那DAPP组网的过程就清晰了。
36 |
37 | 首先开发DAPP,运行DAPP成为一个DAPP的节点,DAPP通过协议发现其他节点,这些节点共同组成一个DAPP网络,例如比特币主网、比特币测试网络、以太坊主网和以太坊测试网等。
38 |
39 | ## 4 DAPP 与智能合约
40 |
41 | 以太坊中一般认为智能合约就是DAPP,更准确的可认为智能合约相当于服务器后台,另外要实现用户体
42 | 验,还需要UI交互界面。
43 |
44 | 那DAPP就是包含完整的智能合约+用户UI交互界面。
45 |
46 | 区块链相对于DAPP来说是应用运行的底层环境。简单的可类比IOS,Android等手机操作系统于运行与之上的各种App。
47 |
48 | 一个完全的DAPP是需要满足完全开源并且是自治的应用程序。DAPP一经部署完毕,便不可更改,应用的升级必须由大部分用户达成共识后,才可进行升级。
49 |
50 | 所有的数据必须进行加密存储在去中心化的区块链应用平台上。其次DAPP必须要有token机制。区块链DAPP能够进行容错。它们没有中心化的机构能够进行干扰,不会出现某些数据的删除或者修改。甚至不能被关闭。
--------------------------------------------------------------------------------
/docs/md/chain/03-以太坊的EVM.md:
--------------------------------------------------------------------------------
1 | # 03-以太坊的EVM
2 |
3 | ## 1 啥是以太坊虚拟机 EVM
4 |
5 | EVM,ETHereum Virtual Machine,以太坊虚拟机。就像所有区块链,以太坊会使用在自己计算机上运行的节点,来保证安全性同时也保持信任。每个参与到以太坊协议中的节点都会在各自电脑上运行软件,这就被称为以太坊虚拟机(EVM)。
6 |
7 | 首先,EVM会通过防止DOS(拒绝服务攻击)攻击来保证安全性,这个攻击是加密货币领域的挑战。
8 |
9 | 其次,EVM会解释并执行以太坊编程语言,并确保可在没有任何干扰的情况下实现通信。
10 |
11 | 可简单把EVM理解为一个系统,其存在是为让我们用Solidity编写的合约代码,运行在以太坊的环境。以太坊相当于计算机环境,EVM把合约代码编译成以太坊能识别的机器码运行。
12 |
13 | ## 2 EVM有什么作用?
14 |
15 | 当以太坊区块链上有转账时,EVM按如下步骤执行:
16 |
17 | 1. 确认转账是否有正确的数值,确认签名的有效性以及是否转账nonce符合特定转账数量的nonce。如有误差,转账会被作为错误返回
18 | 2. 计算转账需要的费用,并且收取燃料费用
19 | 3. 执行数字资产转账到特定地址
20 |
21 | 如EVM检测转出者无足够的手续费用,转账将被回滚。且转账费用不会退回,这会支付给矿工。
22 |
23 | 如转账失败是因为接受者地址有问题,EVM会把发出的资金数量及相关手续费,退还给出发出者(没有矿工收到费用)。
--------------------------------------------------------------------------------
/docs/md/chain/03-百度联盟链Xuperchain核心概念.md:
--------------------------------------------------------------------------------
1 | # 03-百度联盟链Xuperchain核心概念
2 |
3 | ## 1 高性能一计算能力突破单核、单机的边界
4 |
5 | ### 1.1 性能提升的核心技术
6 |
7 | - 链内并行技术(基于自研XVM虚拟机构建DAG)
8 | - 大规模共识技术
9 | - 分叉状态机技术
10 |
11 | 系统峰值TPS达8.7w,支撑业务高效运行:
12 |
13 | 
14 |
15 | ## 2 易开发且可扩展的智能合约开发架构
16 |
17 | ### 2.1 百度区块链共识机制优势
18 |
19 | #### 1 热插拔共识
20 |
21 | 支持适用多种业务场景的共识类型链上无缝切换,以适应不同的业务需求,如: XPOSPoW、PBFT、Chained-BFT、Raft。可满足不同业务场景使用需求,并根据业务需求拓展。
22 |
23 | 支持热插拔多共识机制,并可根据业务需求拓展:
24 |
25 | 
26 |
27 | #### 2 安全、可扩展
28 |
29 | 独特的共识模型,底层Chained-BFT提供安全模型、中间层提供扩展性,做到去中心化、安全性、效率的多层保障。
30 |
31 | #### 3 高性能
32 |
33 | 链式BFT技术和自研XVM虚拟机引警技术相结合,单链可达8.7万TPS,性能业内领先。
34 |
35 | ### 2.2 智能合约开发架构
36 |
37 |
38 |
39 | 
40 |
41 | ### 2.3 百度区块链智能合约特色
42 |
43 | #### 丰富的智能合约模板,保证场景简单应用
44 |
45 | 提供基于功能和基于业务场景的智能合约模板,包括:存证、溯源、积分管理等,满足政务、金融等多领域,支持多种应用场景快速接入。
46 |
47 | #### 完善的智能合约开发者工具集,保证便捷性
48 |
49 | 在线IDE、编译器集成、静态分析工具、测试框架,合约基础库,使业务开发更便捷。
50 |
51 | #### 多语言支持,降低研发门槛
52 |
53 | 支持业务方使用Java/Python/NodeJS等语言SDK访问区块链网络,支持使用Java/GO/C++等语言编写智能合约,并支持根据业务需求便捷拓展降低研发和使用门槛
54 |
55 | #### 精准资源度量,保证安全性
56 |
57 | 支持按照Wasm指令,内存和磁盘计费,形成有效激励和防止DDOS攻击Wasm最小化外部依赖,线性内存减少内存缺陷: 基于llvm的静态分析保证智能合约的安全可控。
58 |
59 | #### 合约预行性高,保证业务运行效果
60 |
61 | 合约AOT执行,对象代码缓存;合约实例独立上下文,并行执行;读写集缓存,保证智能合约高性能执行,满足业务需求。
62 |
63 | ## 3 强安全-全方位、多层次的区块链安全保障
64 |
65 | ### 百度区块链安全体系
66 |
67 | #### 密钥安全
68 |
69 | 通过本地密码加密技术对密钥加密存储,并支持助记词密钥恢复也具备密钥备份的能力。权限账户体系,实现密钥丢失保护,基于可信计算环境实现秘钥托管和分发,保障隐私数据的安全性。
70 |
71 | #### 数据安全
72 |
73 | 数据安全方面主要通过密码学技术保证数据第三方不可破解,以及通过账号权限系统细粒度区分数据访问权限,保证数据访问安全
74 |
75 | #### 网络安全
76 |
77 | 通过TLS加密保证了数据传输安全,并通过CA限制了节点加入网络的权限:超级链也关注核心节点的DDoS防范力,针对KAD网络的路由毒害攻击设计了节点身份认证机制和分层网络路由保护机制,并限制来源IP的身份数量,能有效的解决女巫攻击和日食攻击。
78 |
79 | #### 支持多种密码学算法
80 |
81 | 支持国密算法,支持NIST系列算法,并支持加密算法一键自动切换。支持多种圆曲线和签名算法的混合使用。支持ECDSA、史诺签名、环签名、多重签名、Xuper签名等多种签名算法。
82 |
83 | #### 数据隐私保护
84 |
85 | 支持环签名、零知识证明
86 |
87 | 
--------------------------------------------------------------------------------
/docs/md/chain/07-网络与共识.md:
--------------------------------------------------------------------------------
1 | # 07-网络与共识
2 |
3 | ## 1 共识架构
4 |
5 |
6 |
7 | 
8 |
9 | ## 2 支持的共识列表
10 |
11 |
12 |
13 | 
14 |
15 | ## 3 提案治理机制
16 |
17 |
18 |
19 | 
20 |
21 | Step1:提案者(proposer)通过发起一个事务声明一个可调用的合约,并约定提案的投票截止高度,生效高度
22 |
23 | Step2:投票者(voter)通过发起一个事务来对提案投票,当达到系统约定的投票率并且账本达到合约的生效高度后合约就会自动被调用
24 |
25 | Step3:为了防止机制被滥用,被投票的事务的需要冻结参与者的一笔燃料,直到合约生效高度以后解冻。(防止一笔钱投多个提案)
26 |
27 | ### TDPOS 共识角色转换
28 |
29 | 选民:所有节点拥有选民的角色,可以对候选节点进行投票
30 |
31 | 候选人:需要参与验证人竞选的节点通过注册机制成为候选人,通过注销机制退出验证人竞选
32 |
33 | 验证人:每轮第一个节点进行检票,检票最高的topK候选人集合成为该轮的验证人,被选举出的每一轮区块生产周期的验证者集合,负责该轮区块的生产和验证,某个时间片内会有一个矿工进行区块打包,其余的节点会对该区块进行验证
34 |
35 | 
36 |
37 | ### TDPOS 创世块配置
38 |
39 |
40 |
41 | 
42 |
43 | ### TDPOS 共识关键参数
44 |
45 |
46 |
47 | 
48 |
49 | ## 4 合约账户
50 |
51 | ### 4.1 更灵活的资产管理方式
52 |
53 | - 支持多私钥持有账户
54 | - 灵活的权限管理模型
55 |
56 | ### 4.2 更安全的智能合约管理
57 |
58 | - 智能合约需要部署到一个具体的账户内部
59 | - 设置合约Method的权限管理模型
60 |
61 | 
62 |
63 | ### 4.3 合约账户的权重阈值模型
64 |
65 | - 账户A权限闽值 >=0.4
66 | - 账户B权限阈值 >= 0.6
67 |
68 | 
69 |
70 |
71 |
72 | 
--------------------------------------------------------------------------------
/docs/md/ck/单机安装部署.md:
--------------------------------------------------------------------------------
1 | # 单机安装部署
2 |
3 |
4 |
5 | ## 1 安装
6 |
7 | 进入[官网](https://clickhouse.com/)点击:
8 |
9 | 
10 |
11 | ## 2 .repo文件
12 |
13 | 通常指Linux中用于存储软件源配置信息的文件。这些文件位于CentOS和其他基于Red Hat的Linux发行版中,用于管理系统中可用的软件包源。
14 |
15 | .repo文件包含软件包管理器(如yum或dnf)所需的配置信息,包括软件源的名称、URL、GPG密钥验证等。这些信息告诉系统在哪里可以找到软件包并进行安装、更新或卸载操作。比如:https://packages.clickhouse.com/rpm/clickhouse.repo 文件内容
16 |
17 | ```toml
18 | [clickhouse-stable]
19 | name=ClickHouse - Stable Repository
20 | baseurl=https://packages.clickhouse.com/rpm/stable/
21 | gpgkey=https://packages.clickhouse.com/rpm/stable/repodata/repomd.xml.key
22 | gpgcheck=0
23 | repo_gpgcheck=1
24 | enabled=1
25 |
26 | [clickhouse-lts]
27 | name=ClickHouse - LTS Repository
28 | baseurl=https://packages.clickhouse.com/rpm/lts/
29 | gpgkey=https://packages.clickhouse.com/rpm/lts/repodata/repomd.xml.key
30 | gpgcheck=0
31 | repo_gpgcheck=1
32 | enabled=0
33 | ```
34 |
35 | 在这个示例中,.repo文件包含了两个软件源配置:base和updates。它们分别指定了基础软件包和更新软件包的URL地址、GPG密钥验证方式等信息。
36 |
37 | 在使用Linux系统时,可编辑.repo文件来管理软件源,添加新的软件源、启用或禁用特定的软件源,或者修改软件源的配置信息。这样可以灵活地控制系统中软件包的来源和管理。那就按 repo 文件指引,来到[软件包下载地址](https://packages.clickhouse.com/rpm/lts/):
38 |
39 | 
40 |
41 | 时间戳格式:ISO 8601,它是一种国际标准的日期和时间表示方法。该时间戳表示的日期和时间:
42 |
43 | - 年份:2022年
44 | - 月份:9月
45 | - 日期:21日
46 | - 时间:12点08分59秒
47 | - 毫秒:544毫秒
48 | - 时区:Z表示UTC时间(协调世界时)
49 |
50 |
51 |
52 | 注意需要下载四种文件:
53 |
54 | - clickhouse-client-21.3.20.1-2.noarch.rpm
55 | - clickhouse-common-static-21.3.20.1-2.x86_64.rpm
56 | - clickhouse-common-static-dbg-21.3.20.1-2.x86_64.rpm
57 | - clickhouse-server-21.3.20.1-2.noarch.rpm
58 |
59 | ## 3 开始安装
60 |
61 | 在 linux 服务器的 clickhouse 目录下准备好这四个文件,然后开始安装:
62 |
63 | ```bash
64 | rpm -ivh *rpm
65 | ```
66 |
67 | 安装后检查状态:
68 |
69 | ```bash
70 | [root@~]# systemctl status clickhouse-server
71 | ● clickhouse-server.service - ClickHouse Server (analytic DBMS for big data)
72 | Loaded: loaded (/usr/lib/systemd/system/clickhouse-server.service; enabled; vendor preset: disabled)
73 | Active: inactive (dead)
74 | ```
--------------------------------------------------------------------------------
/docs/md/ddd-mall/04-BFF 架构简介.md:
--------------------------------------------------------------------------------
1 | # 04-BFF 架构简介
2 |
3 | ## 1 概念
4 |
5 | BFF,Backends For Frontends(服务于前端的后端),Sam Newman曾在他的博客中写了一篇相关文章Pattern: Backends For Frontends,在文章中Sam Newman详细地说明了BFF。
6 |
7 | BFF就是服务器设计API时会考虑到不同设备需求,即为不同设备提供不同API接口,虽然它们可能实现相同功能,但因不同设备的特殊性,它们对服务端的API访问也各有其特点,需区别处理。因此出现了类似下图的
8 |
9 | ## 2 设计方式
10 |
11 | ### 2.1 图一
12 |
13 | 
14 |
15 | ### 2.2 图二
16 |
17 | 
18 |
19 | 客户端都不是直接访问服务器的公共接口,而是调用BFF层提供的接口,BFF层再调用基层的公共服务,不同的客户端拥有不同BFF层,它们定制客户端需要的API。图一、图二不同在于是否需要为相似的设备人,如IOS和android分别提供一个BFF,这需根据现实情况决定。
20 |
21 | ## 3 BFF V.S 多端公用、单一的API
22 |
23 | ### 3.1 满足不同客户端特殊交互引起的对新接口的要求
24 |
25 | 所以一开始就会针对相应设备设计好对应接口。若使用单一、通用API,而一开始并没有考虑到特殊需求,则有新请求需要出现时,可能出现:
26 |
27 | - 若添加新接口,易造成接口不稳定
28 | - 若考虑在原有接口上修改,可能产生一些耦合,破坏单一职责
29 |
30 | #### 案例
31 |
32 | 因为移动APP的屏幕限制,在某个列表页,我们只需展示一些关键信息,但由于调用的是服务端提供统一的API,服务端在设计时只考虑到web端,就返回了所有字段,但这些对移动端都无用。
33 |
34 | 优化性能时处理这样的问题,服务器端就需新增接口或通过引入相关耦合来解决。而使用BFF,很大程度能避免这类问题。
35 |
36 | ### 3.2 当由于某客户端需调用多个不同服务端接口,来实现某功能
37 |
38 | 可直接在对应BFF层编写相应API,而不影响基层公共服务,且客户端不用直接向多个后台发起调用,可优化性能。
39 |
40 | BFF带来便利好处同时,也会引起一些问题:代码重复,加大开发工作量等。
41 |
42 | 所以在使用时需要结合现实情况仔细斟酌,符合项目的应用开发背景。例如蚂蚁财富使用BFF的场景如下:
43 |
44 | 
45 |
46 | 参考
47 |
48 | - https://samnewman.io/patterns/architectural/bff/
--------------------------------------------------------------------------------
/docs/md/ddd-mall/05-dddmall-database-spring-boot-starter.md:
--------------------------------------------------------------------------------
1 | # 05-dddmall-database-spring-boot-starter
2 |
3 | ## 1 MybatisPlus配置
4 |
5 | ### 1.1 分页插件集成
6 |
7 | 通过`mybatisPlusInterceptor`方法集成`MybatisPlus`的分页插件,使得分页查询能够自动适应不同数据库方言,提高开发效率,减少重复代码。
8 |
9 | ```java
10 | @Bean
11 | public MybatisPlusInterceptor mybatisPlusInterceptor() {
12 | MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
13 | interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
14 | return interceptor;
15 | }
16 | ```
17 |
18 | ### 1.2 自动填充功能
19 |
20 | `myMetaObjectHandler`方法提供元数据填充的能力,允许在插入或更新数据时自动填充某些字段(如创建时间、更新时间等),减少了手动设置这些字段的需要。
21 |
22 | ```java
23 | @Bean
24 | public MyMetaObjectHandler myMetaObjectHandler() {
25 | return new MyMetaObjectHandler();
26 | }
27 | ```
28 |
29 | ### 1.3 自定义ID生成策略
30 |
31 | 通过`idGenerator`方法引入自定义的ID生成器,这里使用雪花算法,保证分布式系统中ID的唯一性和顺序性,对于业务的扩展性和数据的一致性至关重要。
32 |
33 | ```java
34 | @Bean
35 | @Primary
36 | public IdentifierGenerator idGenerator() {
37 | return new CustomIdGenerator();
38 | }
39 | ```
40 |
41 | ### 1.4 好处
42 |
43 | 1. **统一配置管理**:将Mybatis Plus的关键配置集中管理,提高项目的可维护性和可读性。开发者可以在一个地方快速查看和修改与Mybatis Plus相关的配置,而不需要在多个地方进行搜索和修改
44 |
45 | 2. **业务扩展性**:通过自定义ID生成器和自动填充功能,为业务数据的一致性和完整性提供了保障。特别是在处理大量数据和高并发场景时,这些配置确保了数据处理的效率和准确性
46 |
47 | 3. **提高开发效率**:自动配置分页插件和元数据填充功能,减少了开发者在进行数据操作时的重复工作,使得开发者可以将更多的精力集中在业务逻辑的实现上,加快了开发周期
--------------------------------------------------------------------------------
/docs/md/ddd-mall/06-dddmall-ddd-framework-core.md:
--------------------------------------------------------------------------------
1 | # 06-dddmall-ddd-framework-core
2 |
3 |
4 |
5 | ## 1 CommandHandler接口设计
6 |
7 | ### 1.1 泛型支持
8 |
9 | 通过泛型 ``,`CommandHandler` 接口支持不同类型的命令请求和响应,增加了代码的复用性和灵活性。这种设计允许开发者定义多种处理逻辑,而不必为每种命令实现单独的接口。
10 |
11 | ```java
12 | public interface CommandHandler {
13 | R handler(T requestParam);
14 | }
15 | ```
16 |
17 | ### 1.2 解耦合
18 |
19 | `CommandHandler` 接口作为命令处理的统一入口,有助于解耦命令的发送者和接收者。命令发送者只需知道有一个能处理该命令的接口即可,无需关心具体的处理逻辑,从而降低系统各部分之间的耦合度。
20 |
21 | ### 1.3 易于扩展
22 |
23 | 随业务发展,可能会增加更多的命令类型。`CommandHandler` 接口使得添加新的命令处理器变得简单,只需实现该接口即可。这种设计支持开闭原则,对扩展开放,对修改封闭。
24 |
25 | ### 1.4 业务考量
26 |
27 |
28 |
29 | 1. **业务流程抽象**:`CommandHandler` 接口抽象了业务操作的执行流程,每个实现类代表一个具体的业务操作。这种设计使得业务逻辑更加清晰,每个业务操作都有明确的界定,便于理解和维护。
30 |
31 | 2. **事务控制**:在实现 `CommandHandler` 接口的类中,可以很方便地添加事务控制逻辑。这意味着业务操作的执行可以保证数据的一致性和完整性,对于保障系统的稳定性和可靠性至关重要。
32 |
33 | 3. **权限验证**:`CommandHandler` 接口的实现类也可以用于进行权限验证。在处理命令之前,可以检查用户是否有执行该命令的权限,从而确保系统的安全性。
--------------------------------------------------------------------------------
/docs/md/ddd-mall/06-商品秒杀库存超卖问题.md:
--------------------------------------------------------------------------------
1 | # 06-商品秒杀库存超卖问题
2 |
3 | ## 超卖问题
4 |
5 | 1个商品卖给多个人:1商品多订单。
6 |
7 | 多人抢购同一商品时,多人同时判断是否有库存,若只剩一个,则都会判断有库存,此时会导致超卖,即一个商品被下了多个订单。
8 |
9 | ### 常见库存扣减方式
10 |
11 | - 下单减库存:买家下单后,在商品总库存-买家购买数量。这是最简单的减库存方式,也是控制最精确的,下单时直接通过DB事务控制商品库存,一定不会出现超卖的情况。但有些人下完单可能不会付款。
12 | - 付款减库存:买家下单后,不立即减库存,而等到用户付款后才真正减库存,否则库存一直保留给其他买家。但因付款时才减库存,若并发较高,可能导致买家下单后付不了款,因为商品可能已被其他人先付款买走。
13 | - 预扣库存:买家下单后,库存为其保留一定时间(如 30 min),超时候,库存自动释放,其他买家就能继续购买了。买家付款前,系统会校验该订单的库存是否还有保留:若无保留,则再次尝试预扣;若库存不足(即预扣失败)则不允许继续付款;若预扣成功,则完成付款并实际地减去库存。
14 |
15 | 采用哪种需要基于业务考虑,减库存最核心的是大并发请求时保证DB中的库存字段值不能为负。
16 |
17 | 方案一:
18 |
19 | 扣减库存场景,使用行级锁,通过DB引擎本身对记录加锁的控制,保证DB更新的安全性,且通过`where`语句,保证库存不会被减到负数,也就是能够有效的控制超卖的场景。
20 |
21 | ```sql
22 | update ... set amount = amount - 1 where id = $id and amount - 1 >=0
23 | ```
24 |
25 | 方案二
26 |
27 | 设置数据库的字段数据为无符号整数,这样减后库存字段值小于零时 SQL 语句会报错。
28 |
29 | ### 2.1 思路分析
30 |
31 | 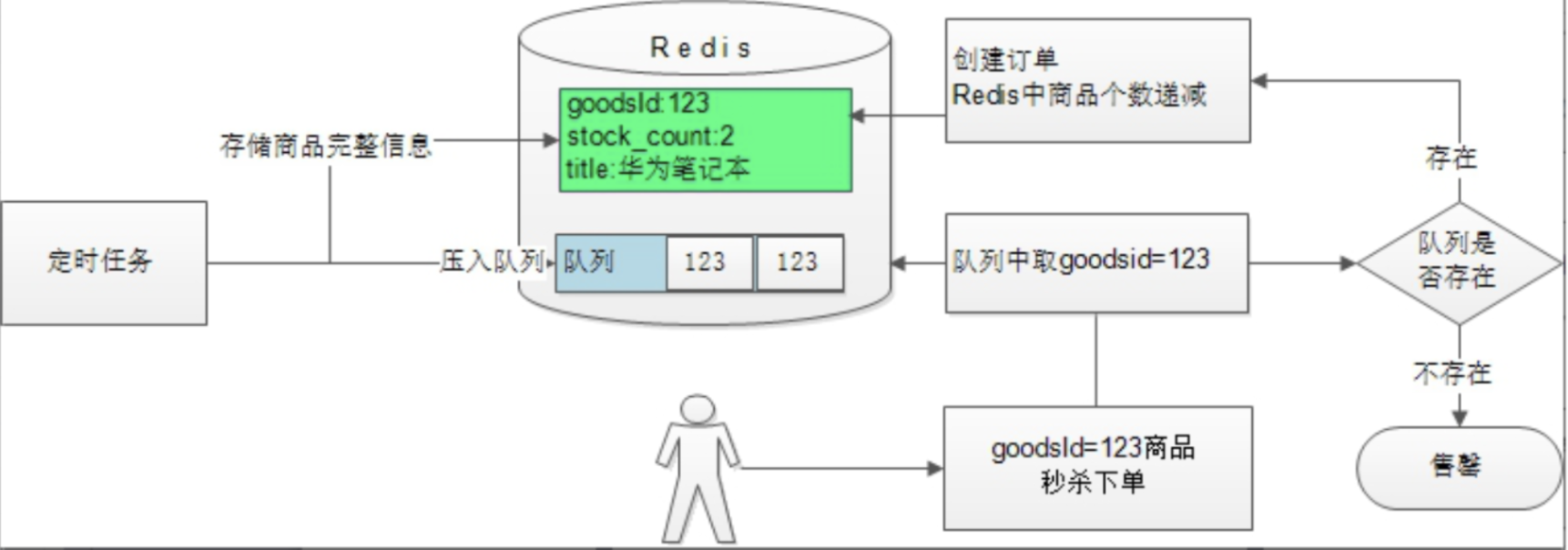利用Redis list队列,给每件商品创建一个独立的商品个数队列,如:A商品有2个,A商品的ID为1001,则创建一个list,key=SeckillGoodsCountList_1001,往该队列中塞2次该商品ID。
32 |
33 | 每次给用户下单时,先从队列取数据:
34 |
35 | - 能取到数据
36 |
37 | 有库存
38 |
39 | - 取不到
40 |
41 | 无库存
42 |
43 | 这就防止了超卖。
44 |
45 | 操作Redis大部分都是先查出数据查,在内存中修改,然后存入Redis。高并发下就有数据错乱问题,为控制数量准确,单独将商品数量整个自增键,自增键是线程安全的,无需担心并发问题。
46 |
47 | 
48 |
49 | 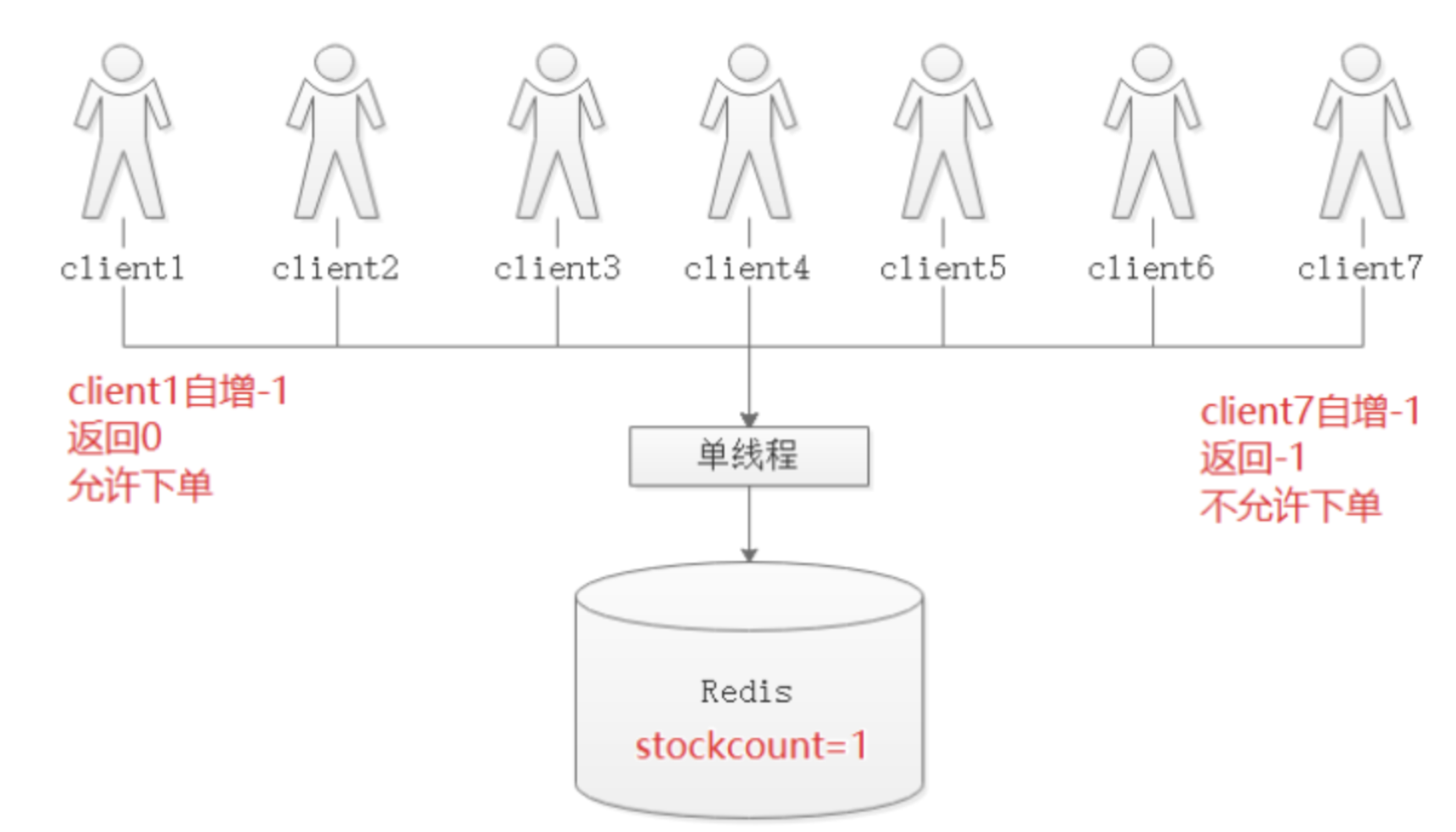
50 |
51 | ### 2.2 代码
52 |
53 | 每次将商品压入Redis时,创建一个商品队列。
54 |
55 | 修改SeckillGoodsPushTask,添加一个pushIds方法,用于将指定商品ID放入到指定数字:
56 |
57 | ```java
58 | /***
59 | * 将商品ID存入到数组中
60 | * @param len:长度
61 | * @param id :值
62 | * @return
63 | */
64 | public Long[] pushIds(int len,Long id){
65 | Long[] ids = new Long[len];
66 | for (int i = 0; i dump_file.sql
28 | ```
29 |
30 | 导入:
31 |
32 | ```sql
33 | mysql -u username -p database_name < dump_file.sql
34 | ```
35 |
36 |
37 |
38 | ## 3 多线程并行导入
39 |
40 |
41 |
42 |
43 |
44 | ## 4 使用中间临时表导入数据
45 |
46 | 先在MySQL中建立临时表无索引,批量导入数据到临时表,最后再用 insert into...select 从临时表导入到正式表。
47 |
48 | ```sql
49 | -- 创建临时表
50 | CREATE TEMPORARY TABLE temp_table LIKE your_table;
51 |
52 | -- 禁用索引
53 | ALTER TABLE temp_table DISABLE KEYS;
54 |
55 | -- 导入数据到临时表
56 | LOAD DATA INFILE '/path/to/your/file.csv'
57 | INTO TABLE temp_table
58 | FIELDS TERMINATED BY ','
59 | ENCLOSED BY '"'
60 | LINES TERMINATED BY '\n'
61 | IGNORE 1 ROWS;
62 |
63 | -- 从临时表导入到正式表
64 | INSERT INTO your_table SELECT * FROM temp_table;
65 |
66 | -- 启用索引
67 | ALTER TABLE your_table ENABLE KEYS;
68 |
69 | -- 删除临时表
70 | DROP TEMPORARY TABLE temp_table;
71 | ```
72 |
73 |
74 |
75 | ## 5 MyISAM 引擎表
76 |
77 | 先导入到对应的 .txt 文件,然后使用 REPAIR TABLE 命令修复并重建索引。
78 |
79 | ## 6 调整 MySQL 的配置参数
80 |
81 | 增大 bulk_insert_buffer_size、max_allowed_packet 等,以优化导入性能。
82 |
83 |
84 |
85 | ## 7 总结
86 |
87 | - 如果是自主开发的系统,建议在应用层对数据进行分批插入,可以充分利用多线程,实现更高的导入效率
88 | - 第三方工具如 mysqldump、mydumper、MyData 等,这些工具提供了多线程导入、断点续传等高级功能
89 | - 检查磁盘I/O、CPU等系统资源是否够用,是否有瓶颈。如果资源不足,可以考虑分库分表的策略
--------------------------------------------------------------------------------
/docs/md/ddd-mall/DDD-Mall商城的公共组件设计.md:
--------------------------------------------------------------------------------
1 | # DDD-Mall商城的公共组件设计
2 |
3 | ## 0 前言
4 |
5 |
6 |
7 | 
8 |
9 |
10 |
11 | ## 1 整体架构
12 |
13 |
14 |
15 | 
16 |
17 |
--------------------------------------------------------------------------------
/docs/md/ddd-mall/building-product-information-caching-system.md:
--------------------------------------------------------------------------------
1 | # 商品信息缓存体系构建
2 |
3 | ## 0 前言
4 |
5 | 在电商系统中,商品信息的快速获取对用户体验至关重要。本文将详细讲解一个多层级的商品信息缓存体系,旨在提高系统性能和可靠性。
6 |
7 | 开局一张图,剩下全靠编!
8 |
9 | 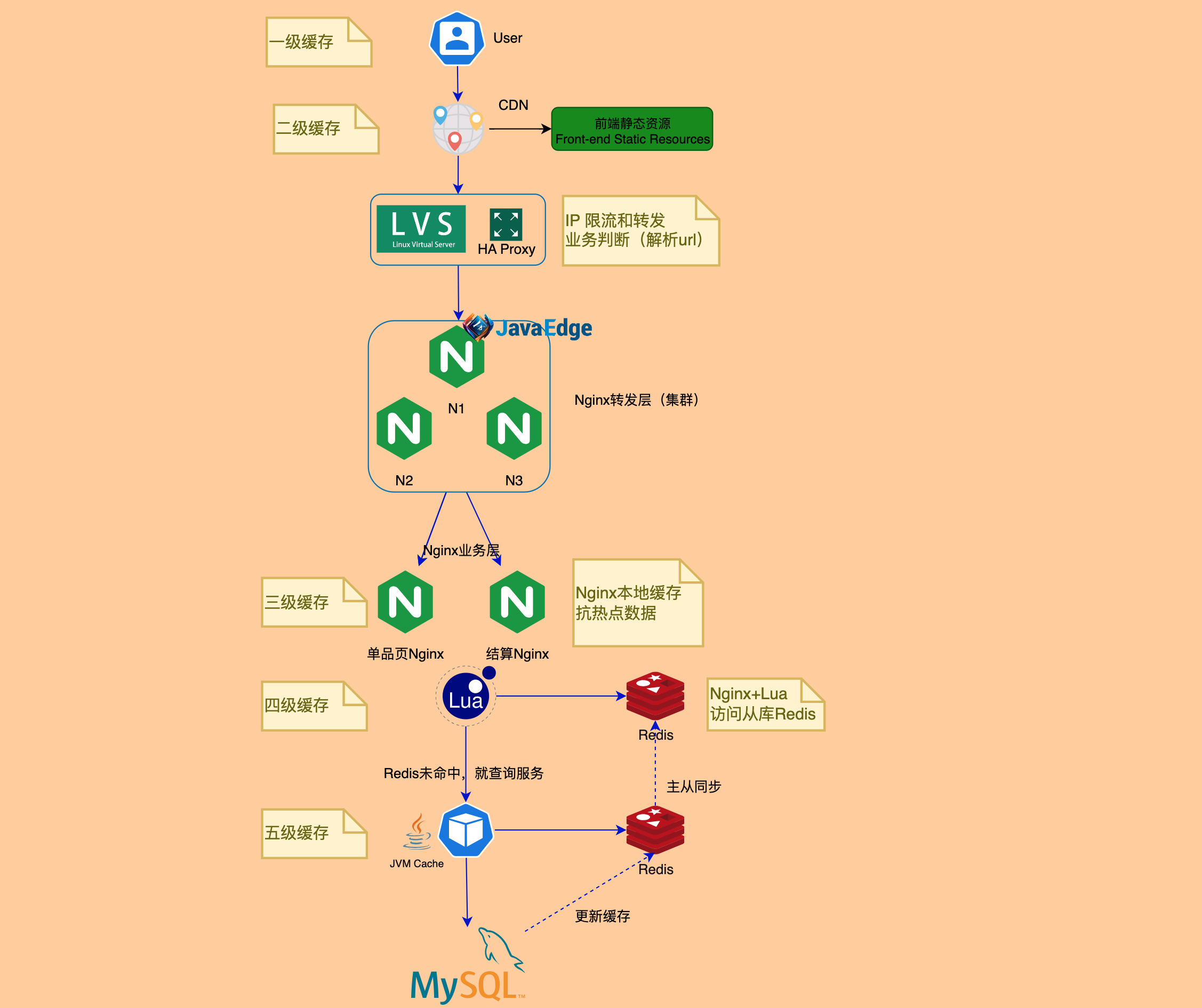
10 |
11 | ## 1 整体架构
12 |
13 | 该缓存体系采用了多级缓存策略,从前端到后端,逐层深入:
14 |
15 | 1. CDN缓存
16 | 2. Nginx缓存集群
17 | 3. Redis缓存
18 | 4. JVM本地缓存
19 | 5. MySQL持久化存储
20 |
21 | ## 2 详细解析
22 |
23 | ### 1. 用户请求入口
24 |
25 | 用户的请求首先通过CDN(内容分发网络):
26 |
27 | ```markdown
28 | User -> CDN -> 前端静态资源 (Front-end Static Resources)
29 | ```
30 |
31 | CDN负责分发静态资源,减轻主服务器负载。
32 |
33 | ### 2. 负载均衡
34 |
35 | 请求经过CDN后,进入负载均衡层:
36 |
37 | ```markdown
38 | CDN -> LVS (Linux Virtual Server) + HA Proxy
39 | ```
40 |
41 | - LVS: 实现高性能、高可用的负载均衡
42 | - HA Proxy: 提供更细粒度的流量控制和健康检查
43 |
44 | ### 3. Nginx边缘节点
45 |
46 | ```markdown
47 | LVS + HA Proxy -> JavaEdge (Nginx转发层)
48 | ```
49 |
50 | JavaEdge是一个Nginx集群,负责请求的初步处理和转发。这里可能进行:
51 |
52 | - IP限流和转发
53 | - 业务判断(解析URL)
54 |
55 | ### 4. Nginx业务层
56 |
57 | JavaEdge将请求转发到Nginx业务层:
58 |
59 | ```markdown
60 | JavaEdge -> 单品页Nginx / 结算Nginx
61 | ```
62 |
63 | 这一层的Nginx服务器针对不同的业务场景(如单品页、结算页)进行了优化。
64 |
65 | ### 5. Lua脚本和Redis缓存
66 |
67 | 在Nginx业务层,使用Lua脚本实现了与Redis的交互:
68 |
69 | ```markdown
70 | Nginx业务层 -> Lua -> Redis
71 | ```
72 |
73 | Lua脚本在Nginx中执行,直接从Redis读取缓存数据,实现高效的数据获取。
74 |
75 | ### 6. JVM缓存
76 |
77 | 如果Redis中没有所需数据,请求会转发到Java应用服务器:
78 |
79 | ```markdown
80 | Redis (未命中) -> JVM Cache
81 | ```
82 |
83 | JVM缓存作为本地缓存,可以进一步提高数据访问速度。
84 |
85 | ### 7. MySQL持久化
86 |
87 | 作为最后的数据源,MySQL存储所有的商品信息:
88 |
89 | ```markdown
90 | JVM Cache (未命中) -> MySQL
91 | ```
92 |
93 | 当缓存未命中时,系统会查询MySQL,并更新各级缓存。
94 |
95 | ## 3 缓存层级
96 |
97 | 图中展示了五个缓存层级:
98 |
99 | 1. 一级缓存:可能指CDN或浏览器缓存
100 | 2. 二级缓存:Nginx层的缓存
101 | 3. 三级缓存:Redis缓存
102 | 4. 四级缓存:JVM本地缓存
103 | 5. 五级缓存:MySQL(作为最终数据源)
104 |
105 | ## 4 特殊说明
106 |
107 | 1. **Nginx本地缓存**:用于存储热点数据,提高访问速度。
108 | 2. **Redis主从同步**:确保Redis数据的高可用性。
109 | 3. **JVM Cache到Redis的更新**:保证数据一致性。
110 |
111 | ## 5 总结
112 |
113 | 这个多层级的缓存体系通过合理利用各种缓存技术,实现了高效的商品信息获取。从前端到后端,逐层深入,每一层都在努力提供最快的响应。这种架构不仅提高了系统性能,还增强了系统的可靠性和扩展性。
114 |
115 | 在实际应用中,还需要考虑缓存一致性、过期策略、热点数据处理等问题,以构建一个完善的商品信息缓存体系。
--------------------------------------------------------------------------------
/docs/md/ddd-mall/dddmall-cache-spring-boot-starter.md:
--------------------------------------------------------------------------------
1 | # dddmall-cache-spring-boot-starter
2 |
3 |
4 |
5 | #### 缓存穿透布隆过滤器
6 |
7 | ```java
8 | /**
9 | * 防止缓存穿透的布隆过滤器
10 | */
11 | @Bean
12 | @ConditionalOnProperty(prefix = BloomFilterPenetrateProperties.PREFIX, name = "enabled", havingValue = "true", matchIfMissing = true)
13 | public RBloomFilter cachePenetrationBloomFilter(RedissonClient redissonClient, BloomFilterPenetrateProperties bloomFilterPenetrateProperties) {
14 | RBloomFilter cachePenetrationBloomFilter = redissonClient.getBloomFilter(bloomFilterPenetrateProperties.getName());
15 | cachePenetrationBloomFilter.tryInit(bloomFilterPenetrateProperties.getExpectedInsertions(), bloomFilterPenetrateProperties.getFalseProbability());
16 | return cachePenetrationBloomFilter;
17 | }
18 | ```
19 |
20 | #### 静态代理模式
21 |
22 | 静态代理模式:Redis 客户端代理类增强
23 |
24 | ```java
25 | @Bean
26 | public StringRedisTemplateProxy stringRedisTemplateProxy(RedisKeySerializer redisKeySerializer,
27 | StringRedisTemplate stringRedisTemplate,
28 | RedissonClient redissonClient) {
29 | stringRedisTemplate.setKeySerializer(redisKeySerializer);
30 | return new StringRedisTemplateProxy(stringRedisTemplate, redisDistributedProperties, redissonClient);
31 | }
32 | ```
33 |
34 | 使用静态代理模式自己实现一个StringRedisTemplateProxy类,而非直接通过Spring的@Bean注解引入框架自带的StringRedisTemplate实例,主要有以下几个好处:
35 |
36 | 定制化:通过静态代理类,可不修改原StringRedisTemplate类基础,增加额外功能。如在代理类中添加日志记录、性能监控、安全检查等功能
37 |
38 | 解耦:静态代理类作为中间层,减少业务代码与第三方库的直接依赖。这样,如果未来需要替换底层的Redis客户端,只需修改代理类而不影响业务代码
39 |
40 | 增强控制:代理类可控制对被代理类的访问,实现懒加载、权限控制等高级功能
41 |
42 | 统一管理:若项目中多处使用到StringRedisTemplate,通过代理类可以统一管理这些使用点,便于维护和更新
43 |
44 | 扩展性:静态代理类可以根据需要实现多个接口,提供更丰富的功能,而直接使用Spring的@Bean注解引入的实例则受限于原有类的功能。
45 |
46 | 总之,使用静态代理模式自定义StringRedisTemplateProxy类,提供了更大的灵活性和控制力,有助于构建更加健壮和可维护的应用。
--------------------------------------------------------------------------------
/docs/md/develop/design-pattern/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/develop/design-pattern/todo.md
--------------------------------------------------------------------------------
/docs/md/develop/framework/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/develop/framework/todo.md
--------------------------------------------------------------------------------
/docs/md/develop/images/责任链模式.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/develop/images/责任链模式.png
--------------------------------------------------------------------------------
/docs/md/develop/standard/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/develop/standard/todo.md
--------------------------------------------------------------------------------
/docs/md/es/ES专栏大纲.md:
--------------------------------------------------------------------------------
1 | # ES专栏大纲
2 |
3 | ## 1 你将获得
4 |
5 | 1. 掌握 Elasticsearch 核心技能
6 | 2. 熟练进行生产环境中的部署与优化
7 | 3. 灵活运用 ELK 进行搜索与大数据分析
8 | 4. 具备通过 Elastic 官方认证的能力
9 |
10 | ## 2 专栏介绍
11 |
12 | Elasticsearch 是一款非常强大的开源搜索及分析引擎。
13 |
14 | 在 DB-Engines Ranking 的数据库评测中,Elasticsearch 在 [Search Engine 分类](https://db-engines.com/en/ranking/search+engine)中长期位列第一。
15 |
16 | 除了搜索,结合 Kibana、Logstash 和 Beats,Elasticsearch 还被广泛运用在大数据近实时分析,包括日志分析、指标监控、信息安全等多个领域。
17 |
18 | 在国内,阿里巴巴、腾讯、滴滴、今日头条、饿了么、360 安全、小米、vivo 等诸多知名公司都在使用 Elasticsearch。
19 |
20 | 带你全面掌握 Elasticsearch 在生产环境中的核心实战技能。学完后,你可以在工作中快速构建出符合自身业务的分布式搜索和数据分析系统。
21 |
22 | - 由浅入深:从基础概念到进阶用法,再到集群管理和大数据分析,学完即可应用到实际生产环境中;
23 | - 实战演练:通过两个 Elasticsearch 实战项目,手把手带你进行实战服务搭建,巩固所学知识点;
24 | - 认证备考:课程内容涵盖 Elastic 认证的全部考点,有助于你顺利通过认证考试。
25 |
26 | ## 3 目录
27 |
28 | 
--------------------------------------------------------------------------------
/docs/md/ffmpeg/audio-video-roadmap.md:
--------------------------------------------------------------------------------
1 | # 00-音视频小白秒变大神?看完这条学习路线就够了!
2 |
3 | ## 0 前言
4 |
5 | 虽前些年音视频技术都在持续发展,但近年影响导致音视频需求快速上涨,5G技术又给音视频提供很好硬件支持,很多活动转入线上,在线教育、视频会议、电商的直播带货等都迫切需要音视频技术,音视频开发行业充满无限可能。
6 |
7 | ## 1 快速进场
8 |
9 | 音视频领域需要知识储备庞大,涉及各种音视频基础知识、常用技术框架、不同应用场景。先要了解音视频领域基础概念知识,如:
10 |
11 | - 啥是PCM?
12 | - 咋计算音频码率?
13 | - 帧率是啥?有啥分类?
14 | - 为啥会出现视频播放不了?
15 | - FFmpeg有啥功能?具体咋用?
16 | - …
17 |
18 | 这些音视频技术基础,是所有音视频开发都要掌握的。这些在专栏都能找到答案。除了这些基础知识,如想快速入门音视频技术,要先找到突破口。音视频领域突破口非FFmpeg莫属,音视频平台及音视频系统开发必不可少的组件库,也是掌握音视频编解码基础知识与流程的抓手。掌握FFmpeg用法,音视频方面的一些基操都不再难。
19 |
20 | 但掌握FFmpeg有难度,一千多页官方文档,咋攻克FFmpeg?刚接触FFmpeg,国内资料少,需查官方文档,难啃,为一周内解决领导的任务,硬着头皮看,看完帮助文档最开始一部分后,发现窍门,即根据需求,按文档索引线索查看就能快速找到对应信息。这样“锻炼”不但学到技术知识,还学会咋用好帮助文档。
21 |
22 | ## 2 社区交流
23 |
24 | 频繁在社区用代码交流,自己也很大提升。
25 |
26 | 参与FFmpeg开源社区交流能解决很多问题。因为有时我们自己改的代码不一定最合理,社区能人较多,思考问题较全,比一个人做review,质量也更有保证。所以本专栏也教你咋参与社区交流,创建自己专属模块,乃至成为社区开发。与世界开发者交流,探索更多功能,获得最前沿信息。
27 |
28 | 熟悉FFmpeg后,你会发现音视频处理,学习音视频各方面的知识都事半功倍。因为大多知识相通,如能了解并熟练用FFmpeg,其他工具也不是难事。
29 |
30 | ## 3 学习路径
31 |
32 | - 了解音视频相关基础知识与概念
33 | - 找到突破点,学会使用FFmpeg
34 | - 知识迁移,做到举一反三
35 |
36 | 就能快速入门音视频。
37 |
38 | 
39 |
40 | ### 音视频基础概念
41 |
42 | 讲解音视频相关参数、视频转码相关知识、直播行业技术迭代,扫清认知障碍,对音视频基础有整体了解。
43 |
44 | ### 流媒体技术速成
45 |
46 | 实际操作应用,几个工具如直播推流工具OBS、MP4专业工具,咋通过FFmpeg的基本用法深度挖掘FFmpeg更多能力。
47 |
48 | 对音视频处理的常用工具有整体认识,并掌握咋自助查找FFmpeg帮助信息,获得相关音视频处理能力。
49 |
50 | ### FFmpeg API应用
51 |
52 | 解读FFmpeg 基础模块、关键结构体和常见应用场景。对FFmpeg的API接口有基本认识,对FFmpeg常用的音视频处理上下文结构体有一个整体的了解,并且能够结合前面两部分内容做一些基本的音视频工具开发。
53 |
54 | ### FFmpeg社区“玩法”
55 |
56 | 介绍FFmpeg开发工具,FFmpeg开发者平时参与社区交流的规则,如何为FFmpeg添加一个新的模块。之后遇到问题,你就可以参与FFmpeg官方社区的交流与讨论,甚至给社区回馈代码。
57 |
58 | 音视频技术相关的工具咋用,有啥技巧,都倾囊相授,让你少走弯路,减轻畏难情绪。按这学习实践,不但会获得独立处理音视频相关操作能力,还能借鉴专栏各种方法做更多探索。扎实技术基础和解决问题的方法!
59 |
60 | 音视频行业在持续发展中,各种生活场景逐渐线上化,如VR/AR技术、线上会议、远程看诊等都需要强大的音视频能力的加持;受流感、元宇宙、5G影响,迭代速度很快,就需我们有自己独立处理开发需求、独立思考探索的能力,主动地去追逐新技术。
--------------------------------------------------------------------------------
/docs/md/flink/flink-data-latency-solution.md:
--------------------------------------------------------------------------------
1 | # Flink对数据延迟的解决方案!
2 |
3 | ## 1 前言
4 |
5 | 
6 |
7 | 一系列数据(Data-5, Data-4, Data-1, Data-3, Data-2)按一定顺序排列。
8 |
9 | 异常:数据到达顺序与它们实际发生时间顺序不一致。按照时间戳来看,Data-1最先发生,但却排在Data-4和Data-5之后。
10 |
11 | Data-1即为延迟数据,因为它比Data-4和Data-5更早发生,但更晚到达。
12 |
13 | 注意 data-1 只是延迟,不是丢失了!
14 |
15 | ## 2 数据延迟的影响
16 |
17 | ### 2.1 影响计算结果
18 |
19 | 在Flink的窗口计算中,乱序数据会导致窗口的关闭时机不准确,从而影响计算结果。如若按照窗口大小来划分,Data-1可能会被分配到一个错误的窗口中。
20 |
21 | ### 2.2 实时性降低
22 |
23 | 延迟数据的存在会降低Flink处理数据的实时性。如果Data-1承载着重要的实时信息,那么延迟到达会影响决策的时效性。
24 |
25 | ### 2.3 数据丢失风险
26 |
27 | 某些情况下,严重的延迟数据甚至可能导致数据丢失。例如,如果窗口已经关闭,而迟到的数据又无法被重新处理,那么这些数据就会丢失。
28 |
29 | ## 3 导致数据延迟的原因
30 |
31 | - **网络传输延迟:** 数据在网络传输过程中可能遇到拥塞、丢包等问题,导致延迟。
32 | - **数据源产生延迟:** 数据源本身可能存在延迟,例如数据库查询缓慢、传感器数据采集不及时。
33 | - **Flink任务处理瓶颈:** Flink任务的并行度、资源配置等因素可能导致处理速度跟不上数据到达的速度。
34 | - **Watermark设置不合理:** Watermark是Flink用来处理乱序数据的重要机制,如果Watermark设置不合理,也会导致数据延迟问题。
35 |
36 | ## 4 解决思路
37 |
38 | - 使用事件时间作为标准
39 |
40 | - 设置水位线:根据数据特性和业务需求,合理设置Watermark生成策略。
41 |
42 | - 设置允许延迟的时间:对于允许一定程度的延迟,可以在窗口定义时设置允许迟到的时间。在窗口关闭后,仍然会等待一段时间,以接收迟到的数据
43 |
44 | ## 5 步骤
45 |
46 | 1. 定义窗口时间
47 | 2. 设置:水位线 为最大事件时间 - 允许延迟的时间
48 |
49 | ### 5.1 触发窗口计算
50 |
51 | 1. 水位线 > 窗口时间:当水位线超过窗口的结束时间,保证了窗口内的数据基本都到达了,避免过早触发计算导致结果不准确。
52 | 2. 窗口内有数据:这个条件保证了窗口计算是有意义的,避免对空的窗口进行计算。仅当窗口内存在数据时,才会触发计算,即使水位线已超过窗口时间
53 |
54 | ### 5.2 案例
55 |
56 | 假设现在:
57 |
58 | - 窗口时间=10s
59 | - 允许延迟的时间 =3.5s
60 | - 水位线=最大EventTime -允许延迟的时间
61 |
62 | 触发窗口计算条件:
63 |
64 | - 水位线>窗口时间
65 | - 窗口内有数据
66 |
67 | 
68 |
69 | **事件1:** 表示一个到达Flink系统的事件,其事件时间为8。
70 |
71 | **窗口时间:** 设置为10s,即每10s生成一个新窗口。
72 |
73 | **允许延迟时间:** 设置3.5s,表示系统允许事件到达的时间延迟最多为3.5s。
74 |
75 | **水位线:** 水位线是Flink用于跟踪事件时间的一个特殊标记,它的计算方式为:最大事件时间 - 允许延迟时间。在当前示例中,水位线为max(8) - 3.5 = 4.5<10,所以不触发计算。
76 |
77 | 事件二来了,看起来它是个延迟事件了。但依旧不能触发计算:
78 |
79 | 
80 |
81 | 事件三来了,开始触发计算了:
82 |
83 | 
84 |
85 | 但即便如此,对那些超长延迟的数据还是无法计算。处理方案:
86 |
87 | - 单独搜集,稍后处理
88 | - 完全不处理,直接丢弃
--------------------------------------------------------------------------------
/docs/md/flink/flink-state-backend.md:
--------------------------------------------------------------------------------
1 | # 状态的存储StateBackend
2 |
3 | 状态后端是Flink用于管理和存储状态信息的组件,不同的后端有不同的特性和适用场景。
4 |
5 | Checkpoint机制开启之后,State会随着Checkpoint作持久化的存储。State的存储地方是通过 StateBackend 决定。
6 |
7 | StateBackend定义状态咋存储的,支持三种状态后端
8 |
9 | ## 1 Memory State Backend
10 |
11 | 将工作状态(Task State)存储在 TaskManager 的内存中,将检查点(Job State)存储在 JobManager 的内存中。
12 |
13 | - **特点:** 将状态直接存储在JVM的堆内存
14 | - **优点:** 访问速度快,性能高
15 | - **缺点:** 容错能力较弱,一旦任务失败,状态数据可能会丢失。适用于状态数据量较小、对性能要求较高的场景,如小型实验或测试环境
16 |
17 | ## 2 FS State Backend
18 |
19 | 将工作状态(Task State)存储在 TaskManager 的内存中,将检查点(Job State)存储在文件系统中(通常是分布式文件系统)
20 |
21 | - **特点:** 将状态数据定期持久化到分布式文件系统(如HDFS、S3)中。
22 | - **优点:** 容错能力强,支持高可用。
23 | - **缺点:** 性能相对Memory State Backend较低,频繁的读写操作会影响性能。适用于状态数据量较大、对容错要求较高的场景。
24 |
25 | ## 3 RocksDB State Backend
26 |
27 | 把工作状态(Task State)存储在 RocksDB,将检查点存储在文件系统(类似FsStateBackend)。
28 |
29 | - **特点:** 基于RocksDB嵌入式数据库,将状态数据存储在本地磁盘上。
30 | - **优点:** 性能优异,支持快速随机读写,同时具备良好的容错能力。
31 | - **缺点:** 配置相对复杂。适用于对性能和容错性都有较高要求的场景,例如大规模的实时计算任务。
32 |
33 | ## 4 Flink 内置实现
34 |
35 | ### 4.1 HashMapStateBackend
36 |
37 | 默认,MemoryStateBackend、FsStateBackend的实现。
38 |
39 | 此StateBackend根据配置 CheckpointStorage 的 TaskManager 和检查点的内存(JVM 堆)中保存工作状态。
40 |
41 | #### 大小考虑
42 |
43 | 工作状态保持在 TaskManager 堆。如果 TaskManager 同时执行多个任务(如果 TaskManager 有多个slot,或者使用slot共享),则所有任务的聚合状态需要适合该 TaskManager 的内存。
44 |
45 | #### 配置
46 |
47 | 对于所有的StateBackend,这个后端可以在应用程序中配置(通过使用相应的构造函数参数创建后端并在执行环境中设置它),或在 Flink 配置中指定它。
48 |
49 | 如果在应用程序中指定StateBackend,它可能会从 Flink 配置中获取额外的配置参数。例如,如果在应用程序中配置了后端,而没有默认的保存点目录,它将选择正在运行的作业/ 集群的 Flink 配置中指定的默认保存点目录。该行为是通过该 configure(ReadableConfig, ClassLoader) 方法实现的。
50 |
51 | ```java
52 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
53 | env.setStateBackend(new HashMapStateBackend());
54 | ```
55 |
56 | ### 4.2 EmbeddedRocksDBStateBackend
57 |
58 | RocksDBStateBackend的实现。
59 |
60 | ## 5 选型权衡
61 |
62 | - **状态数据量:** 对于小规模状态数据,Memory State Backend是一个不错的选择;对于大规模状态数据,RocksDB State Backend或FS State Backend更合适。
63 | - **容错要求:** 如果对数据容错性要求较高,建议选择FS State Backend或RocksDB State Backend。
64 | - **性能要求:** 如果对性能要求较高,且状态数据量不大,可以选择Memory State Backend;如果需要兼顾性能和容错性,RocksDB State Backend是一个不错的选择。
65 | - **成本:** 不同的后端存储的成本也不同,需要根据实际情况进行选择。
66 |
67 | ## 6 总结
68 |
69 | Flink提供了多种状态后端供用户选择,每种后端都有其自身的特点和适用场景。在选择状态后端时,需要综合考虑状态数据量、容错要求、性能要求和成本等因素,选择最适合的方案。
--------------------------------------------------------------------------------
/docs/md/flink/streaming-connectors-programming.md:
--------------------------------------------------------------------------------
1 | # Streaming Connectors 编程
2 |
3 | Flink已内置很多Source、Sink。
4 |
5 | ## 2 附带的连接器(Flink Project Connectors)
6 |
7 | 连接器可和第三方系统交互,目前支持:
8 |
9 | - 文件
10 | - 目录
11 | - socket
12 | - 从集合和迭代器摄取数据
13 |
14 | 预定义的数据接收器支持写入:
15 |
16 | - 文件
17 | - 标准输入输出
18 | - socket
19 |
20 | ### 1.2 绑定连接器
21 |
22 | 连接器提供用于与各种第三方系统连接的代码。目前支持:
23 |
24 | - [Apache Kafka](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/connectors/datastream/kafka/) (source/sink)
25 | - [Elasticsearch](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/connectors/datastream/elasticsearch/) (sink)
26 | - [Apache Pulsar](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/connectors/datastream/pulsar/) (source)
27 | - [JDBC](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/connectors/datastream/jdbc/) (sink)
28 |
29 | 使用一种连接器时,通常需额外的第三方组件,如数据存储服务器或MQ。 这些列举的连接器是 Flink 工程的一部分,包含在发布的源码中,但不包含在二进制发行版中。
30 |
31 | ## 3 Apache Bahir中的连接器
32 |
33 | Flink额外的连接器,通过 [Apache Bahir](https://bahir.apache.org/) 发布,:
34 |
35 | - [Redis](https://bahir.apache.org/docs/flink/current/flink-streaming-redis/) (sink)
36 | - [Akka](https://bahir.apache.org/docs/flink/current/flink-streaming-akka/) (sink)
37 | - [Netty](https://bahir.apache.org/docs/flink/current/flink-streaming-netty/) (source)
38 |
39 | ## 4 连接Flink的其它方法
40 |
41 | ### 4.1 异步I / O
42 |
43 | 使用connector不是将数据输入和输出Flink的唯一方法。一种常见的模式:从外部DB或 Web 服务查询数据得到初始数据流,然后 `Map` 或 `FlatMap` 对初始数据流进行丰富和增强。
44 |
45 | Flink 提供[异步 I/O](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/datastream/operators/asyncio/) API 让这过程更简单、高效和稳定。
46 |
47 | ### 4.2 可查询状态
48 |
49 | 当 Flink 应用程序需向外部存储推送大量数据时会导致 I/O 瓶颈问题出现。此时,若对数据的读操作<<写操作,则让外部应用从 Flink 拉取所需的数据更好。 [可查询状态](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/datastream/fault-tolerance/queryable_state/) 接口可以实现这个功能,该接口允许被 Flink 托管的状态可以被按需查询。
50 |
51 | 看几个具体的连接器。
52 |
53 | 参考
54 |
55 | - [Streaming Connectors](https://ci.apache.org/projects/flink/flink-docs-master/dev/connectors/kafka.html)
56 | - [Kafka官方文档](
--------------------------------------------------------------------------------
/docs/md/go/00-Go概述.md:
--------------------------------------------------------------------------------
1 | # 00-Go概述
2 |
3 | ## 1 为何使用 Go
4 |
5 | - 开发效率高(完整的开发工程链tools, test, benchmark, builtin .etc)
6 | - 部署简单(Compile once, run everywhere)
7 | - 良好的native http库及模版引擎(无需任何第三方框架)
8 | - 并发模型
9 |
10 | ## 2 热点项目
11 |
12 | - Docker
13 | - Caddy
14 | - Kubernetes
15 | - CockroachDB
16 |
17 | ## 3 设计初衷
18 |
19 | - 针对其他语言的痛点进行设计。
20 | - 并发编程
21 | - 为大数据、微服务、并发而生的通用语言
22 | - 项目转型首选
23 |
24 | 
25 |
26 |
27 |
28 | 
29 |
30 |
31 |
32 | 
33 |
34 |
35 |
36 | 
37 |
38 |
39 |
40 |
41 |
42 | 
43 |
44 |
45 |
46 |
47 |
48 | 
49 |
50 |
51 |
52 | 
--------------------------------------------------------------------------------
/docs/md/go/01-macOS 安装go配置GOROOT GOPATH.md:
--------------------------------------------------------------------------------
1 | # 01-macOS 安装go配置GOROOT GOPATH
2 |
3 | ## 1 获取go相关信息
4 |
5 |
6 |
7 | ```bash
8 | javaedge@JavaEdgedeMac-mini src % brew info go
9 | ==> Downloading https://mirrors.ustc.edu.cn/homebrew-bottles/api/cask.jws.json
10 | ######################################################################### 100.0%
11 | ==> go: stable 1.21.0 (bottled), HEAD
12 | Open source programming language to build simple/reliable/efficient software
13 | https://go.dev/
14 | Not installed
15 | From: https://github.com/Homebrew/homebrew-core/blob/HEAD/Formula/go.rb
16 | License: BSD-3-Clause
17 | ==> Options
18 | --HEAD
19 | Install HEAD version
20 | javaedge@JavaEdgedeMac-mini src %
21 | ```
22 |
23 | ## 2 安装
24 |
25 | 安装包地址:
26 |
27 | - https://golang.org/dl/
28 | - https://golang.google.cn/dl/
29 | - https://studygolang.com/dl
30 |
31 | ```bash
32 | brew install go
33 | ```
34 |
35 | 此处我下载的是最新版本1.15
36 | brew安装go是在目录
37 |
38 | ```bash
39 | /usr/local/Cellar
40 | ```
41 |
42 | 
43 |
44 | ## 3 配置GOROOT、GOPATH、PATH
45 |
46 | 编辑文件
47 |
48 | ```bash
49 | export GOROOT="/usr/local/Cellar/go/1.15.3/libexec"
50 | export GOPATH="/Users/apple/doc/GoProjects"
51 | export PATH="/Users/apple/doc/GoProjects/bin:$PATH"
52 | export GO111MODULE=on
53 | export GOPROXY=https://mirrors.aliyun.com/goproxy/
54 | ```
55 |
56 | 
57 |
58 | ### GOROOT
59 |
60 | go 安装目录:
61 |
62 | - brew安装,进入go目录之后可看到bin目录在libexec下
63 | - 源码安装,可按习惯直接复制到/usr/local/go,此时GOROOT 为/usr/local/go
64 |
65 | ### GOPATH
66 |
67 | go的工作目录,即写代码位置。也可配置`$HOME`来配置。
68 |
69 | 安装上述编辑好.bash_profile文件好保存退出,执行命令
--------------------------------------------------------------------------------
/docs/md/java/02-volatile原理.md:
--------------------------------------------------------------------------------
1 | # 02-volatile原理
2 | ## volatile
3 |
4 | synchronized 在多线程场景下存在性能问题
5 |
6 | 而 `volatile` 关键字是一个更轻量级的线程安全解决方案
7 |
8 | volatile 关键字的作用:保证多线程场景下变量的可见性和有序性
9 |
10 | - 可见性:保证此变量的修改对所有线程的可见性。
11 | - 有序性:禁止指令重排序优化,编译器和处理器在进行指令优化时,不能把在 volatile 变量操作(读/写)后面的语句放到其前面执行,也不能将volatile变量操作前面的语句放在其后执行。遵循了JMM 的 happens-before 规则
12 |
13 | 线程写 volatile 变量的过程:
14 |
15 | 1. 改变线程本地内存中volatile变量副本的值;
16 | 2. 将改变后的副本的值从本地内存刷新到主内存
17 |
18 | 线程读 volatile 变量的过程:
19 |
20 | 1. 从主内存中读取volatile变量的最新值到线程的本地内存中
21 | 2. 从本地内存中读取volatile变量的副本
22 |
23 |
24 |
25 | ### volatile 实现原理
26 |
27 | 如果面试中问到了 volatile 关键字,应该从 Java 内存模型开始讲解,再说到原子性、可见性、有序性是什么
28 |
29 | 之后说 volatile 解决了`有序性`和`可见性`,但是并不解决`原子性`
30 |
31 | volatile 可以说是 Java 虚拟机提供的最轻量级的同步机制,在很多开源框架中,都会大量使用 volatile 保证并发下的有序性和可见性
32 |
33 | > volatile 实现 `可见性`和 `有序性` 就是基于 `内存屏障` 的:
34 |
35 | 内存屏障是一种 `CPU 指令`,用于控制特定条件下的重排序和内存可见性问题
36 |
37 | - 写操作时,在写指令后边加上 store 屏障指令,让线程本地内存的变量能立即刷到主内存中
38 | - 读操作时,在读指令前边加上 load 屏障指令,可以及时读取到主内存中的值
39 |
40 | JMM 中有 4 类`内存屏障`:(Load 操作是从主内存加载数据,Store 操作是将数据刷新到主内存)
41 |
42 | - LoadLoad:确保该内存屏障前的 Load 操作先于屏障后的所有 Load 操作。对于屏障前后的 Store 操作并无影响屏障类型
43 |
44 |
45 | - StoreStore:确保该内存屏障前的 Store 操作先于屏障后的所有 Store 操作。对于屏障前后的Load操作并无影响
46 | - LoadStore:确保屏障指令之前的所有Load操作,先于屏障之后所有 Store 操作
47 | - StoreLoad:确保屏障之前的所有内存访问操作(包括Store和Load)完成之后,才执行屏障之后的内存访问操作。全能型屏障,会屏蔽屏障前后所有指令的重排
48 |
49 |
50 |
51 | 在字节码层面上,变量添加 volatile 之后,读取和写入该变量都会加入内存屏障:
52 |
53 | **读取 volatile 变量时,在后边添加内存屏障,不允许之后的操作重排序到读操作之前**
54 |
55 | ```java
56 | volatile变量读操作
57 | LoadLoad
58 | LoadStore
59 | ```
60 |
61 | **写入 volatile 变量时,前后加入内存屏障,不允许写操作的前后操作重排序**
62 |
63 | ```java
64 | LoadStore
65 | StoreStore
66 | volatile变量写操作
67 | StoreLoad
68 | ```
69 |
70 |
71 |
72 |
73 | **volatile 的缺陷就是不能保证变量的原子性**
74 |
75 | 解决方案:可以通过加锁或者 `AtomicInteger`原子操作类来保证该变量操作时的原子性
76 |
77 | ```java
78 | public static AtomicInteger count = new AtomicInteger(0);
79 | ```
80 |
81 |
--------------------------------------------------------------------------------
/docs/md/java/并发编程专栏概述.md:
--------------------------------------------------------------------------------
1 | # 并发编程实战专栏概述
2 |
3 | ## 1 你将获得
4 |
5 | - 全面了解并发编程核心原理;
6 | - 深入掌握 12 个 Java 并发工具类;
7 | - 搞懂 9 种最常见的并发设计模式;
8 | - 4 大经典并发编程实战案例。
9 |
10 | ## 2 专栏介绍
11 |
12 | 对于一个 Java 程序员而言,**能否熟练掌握并发编程是判断他优秀与否的重要标准之一**。因为并发编程是 Java 语言中最为晦涩的知识点,它涉及操作系统、内存、CPU、编程语言等多方面的基础能力,更为考验一个程序员的内功。
13 |
14 | 那到底应该怎么学习并发编程呢?Java SDK 的并发工具包有很多,是要死记硬背每一个工具的优缺点和使用场景吗?当然不是,想要学好并发编程,你需要从一个个单一的知识和技术中“跳出来”,高屋建瓴地看问题,并逐步建立自己的知识体系。
15 |
16 | 本专栏希望能够帮助你建立起一张处理并发问题的全景图,让你能够彻底理解并发问题的本质所在。同时,专栏还会深入介绍 Java 并发编程技术背后的逻辑关系以及应用场景,助你能够游刃有余地游走在这些技术之中。
17 |
18 | 5 大模块。
19 |
20 | **1. 并发理论基础**
21 | 这个模块主要介绍并发编程相关的概念和理论。但不会死板地堆叠结论,而是关注具体概念和理论的产生背景,挖掘它们背后的逻辑关系,发现核心矛盾并寻找解决方案。比如,深度认识 Java 内存模型、死锁产生的原因和解决方案、线程间的协作机制,等等。
22 |
23 | **2. 并发工具类**
24 | 这个模块主要探讨 Java SDK 里的并发工具类。这些工具类大部分都是基于管程实现的,所以这里会首先介绍隐藏在并发包中的管程及其使用。紧接着还会为你详细解读信号量、读写锁、CountDownLatch 和 CyclicBarrier,以及并发编程的三个核心问题“分工”“同步”“互斥”相关的技术内容。
25 |
26 | **3. 并发设计模式**
27 | 并发设计模式是解决并发问题的最佳实践。这个模块将会介绍 9 种常见的设计模式。其中,前 3 种设计模式的核心思想是避免共享变量,从而避免并发问题;后面 6 种设计模式则都属于典型的分工模式。
28 |
29 | **4. 案例分析**
30 | 这个模块着重分析 4 个经典的开源框架是如何处理并发问题的,包括高性能限流器 Guava RateLimiter、高性能网络应用框架 Netty、高性能队列 Disruptor、高性能数据库连接池 HiKariCP,希望能够帮你融会贯通相关知识点,并从实战场景中思考问题的最优解。
31 |
32 | **5. 其他并发模型**
33 |
34 | 并发问题是一个通用问题,Java 语言解决并发问题采用的是共享内存模型,但这个模型并不是解决并发问题唯一的模型。这个模块将会介绍共享内存模型之外的模型,主要有 Actor 模型、软件事务内存、协程和 CSP 模型。
35 |
36 | ## 3 专栏大纲
37 |
38 | 
--------------------------------------------------------------------------------
/docs/md/jvm/JVM专栏概述.md:
--------------------------------------------------------------------------------
1 | # JVM专栏概述
2 |
3 | ## 0 为啥要学习JVM专栏?
4 |
5 | ### 每个Java程序都离不开JVM
6 |
7 | 你玩得转么?学JVM不需要理由,不学JVM才需要理由!
8 |
9 | 
10 |
11 | ### 打通JVM理论与实践,构建完整JVM知识体系
12 |
13 | JVM是中高级Java开发工程师深入理解Java代码的关键,也是Java面试的重要考核部分
14 |
15 | 
16 |
17 | ### 基础-进阶-实战
18 |
19 | 迅速提升Java开发经验,掌握JVM调优高效操作技术
20 |
21 | 
22 |
23 | ### JVM实战项目
24 |
25 | 实际工作中怎么调优,做一遍你就懂了。结合专栏中的JVM技术点,在项目中实现性能监控与优化的企业级调优
26 |
27 | - Java 工程师进阶加薪必修课
28 | - 4 大模块全方位拆解 JVM
29 | - 帮助你编写高效 Java 代码
30 | - 揭秘 Oracle 最新 Java 黑科技
31 |
32 | ## 2 专栏介绍
33 |
34 | 作为开发工程师,你也许会在日常编程中被 Java 的启动性能和内存耗费所震惊,继而对 Java 语言产生怀疑;或许在使用虚拟机遇见内存溢出等一系列异常时头疼万分,困扰于为什么会出现各种问题。
35 |
36 | 和语言朝夕相处的开发者们,提及代码的详细运行过程也难免会一时语塞。这都是由于 Java 虚拟机封装得太好,让使用者几乎感觉不到它的存在。虽然这种“一次编写,到处运行”优势颇多,但是却也让我们忽略了学习 Java 虚拟机的必要。
37 |
38 | 熟知 Java 虚拟机的工作原理可以大幅提升日常编程的效率,对寻常 Bug 的修复更是轻而易举。同时,这也是 Java 技术的重要组成成分之一,是实现技术进阶必不可缺的知识。
39 |
40 | 本专栏通过揭秘 Java 虚拟机的工作原理,详细阐述 Java 程序是如何被执行并且被优化的。介绍的内容并不限于某一个版本,从 8 到 21 都会涉及。通过学习此专栏,你将了解如何编写高效的代码,如何对 Bug 达到最优处理,以及如何针对自己的应用调整虚拟机的运行参数。
41 |
42 | 本课程从源码到运行、类加载,再到内存分配和垃圾回收,以及JVM调优的技巧与实战。理论-实战-面试三结合,带你剖析整个JVM知识体系,一次性学习,解决JVM问题。
43 |
44 | 专栏分四大模块。
45 |
46 | ### 模块一 Java 虚拟机基本原理
47 |
48 | 剖析 Java 虚拟机的运行机制,逐次介绍 Java 虚拟机的设计决策以及工程实现。
49 |
50 | ### 模块二 高效编译
51 |
52 | 在本模块中,作者将带你探索 Java 编译器,以及内嵌于 Java 虚拟机中的即时编译器,帮助你更好地理解 Java 语言特性,继而写出简洁高效的代码。
53 |
54 | ### 模块三 代码优化
55 |
56 | 在实践过程中我们经常会遇到形形色色的性能问题,解决方法不外乎加机器加内存。本模块将介绍上述方法失效后的 Plan B,即如何利用工具定位并解决代码中的潜在问题,以及在已有工具不适用的情况下,如何打造专属轮子。此外,本模块还将介绍对 JVM 内存管理失去信心的开发者所选取的解决方案,以备不时之需。
57 |
58 | ### 模块四 虚拟机黑科技
59 |
60 | 当一门程序语言成熟稳定后,技术大神们便热衷于用这种语言开发实现编译器或虚拟机。在 Java 10 中,Graal 已作为试验性即时编译器一同发布。本模块将详细科普 GraalVM 的各个组成部分,其中包括编译器 Graal,语言实现框架 Truffle,以及支持 Ahead-of-Time(AOT)编译的 SubstrateVM。
61 |
62 | ## 3 专栏大纲
63 |
64 |
65 |
66 | 
67 |
68 | ## 4 适合人群
69 |
70 | - 希望了解底层 Java 虚拟机实现的开发者
71 | - 有一定 Java 基础,希望达成技术进阶的 Java 工程师
72 | - 希望在面试中对答如流的 Java 语言应聘者,以及希望考倒应聘者的面试官们
73 | - 想要了解 Oracle GraalVM 黑科技,或考虑借此技术转型的开发人员
--------------------------------------------------------------------------------
/docs/md/jvm/Metadata GC Threshold in Java.md:
--------------------------------------------------------------------------------
1 | # Metadata GC Threshold in Java
2 |
3 | ## 1 概述
4 |
5 | 本文探讨Metaspace和元数据GC阈值(Metadata GC Threshold)及如何调整它们这些参数。
6 |
7 | ## 2 元数据(Metadata)
8 |
9 | Metadata包含有关堆中对象的信息,包括类定义、方法表等相关信息。根据Java的版本,JVM将这些数据存储在永久代(Permanent Generation)或Metaspace。
10 |
11 | JVM依靠这些信息来执行类加载、字节码验证和动态绑定等任务。
12 |
13 | ## 3 PermGen和Metaspace
14 |
15 | Java 8开始,JVM用一个叫做Metaspace的新内存区域替代了永久代(PermGen)来存储元数据。
16 |
17 | - 永久代是一个固定大小的内存区域,独立于主堆,用于存储JVM加载的类和方法的元数据。它有一个固定的最大大小,一旦满了,JVM就会抛出OOM
18 | - 而Metaspace的大小不固定,可以根据应用中的元数据量动态增长。Metaspace存在于独立于主堆的本地内存(进程内存)段中。它的大小仅受主机os的限制
19 |
20 | ## 4 元数据GC阈值
21 |
22 | Java中,当我们创建一个带有元数据的对象时,它会像其他对象一样占用内存空间。JVM需要这些元数据来执行各种任务。与普通对象不同,元数据在达到某阈值之前不会进行垃圾回收。
23 |
24 | 随着Java程序执行过程中动态加载的类越来越多,Metaspace会逐渐填满。
25 |
26 | JVM为Metaspace内容大小设置了一个阈值,当某个分配不符合此阈值时,会触发一次元数据GC阈值的垃圾回收周期。
27 |
28 | ## 5 用于元数据的JVM参数
29 |
30 | 可用类似`-XX:+PrintClassHistogram`和`-XX:+PrintMetaspaceStatistics`的JVM标志来收集有关使用大量元数据内存的类的信息,并打印有关Metaspace的统计信息,如用于类元数据的空间量。
31 |
32 | 使用这些信息,可优化代码以改善Metaspace和垃圾回收周期的使用情况。此外,我们还可以调整与Metaspace相关的JVM参数。
33 |
34 | 下面是一些用于调整元数据和Metaspace的JVM参数。
35 |
36 | ### 5.1 `-XX:MetaspaceSize=`
37 |
38 | 用于设置分配给类元数据的初始空间量(初始高水位线,以字节为单位),该空间量可能会导致垃圾回收以卸载类。这个数值是近似的,这意味着JVM也可以决定增加或减少Metaspace的大小。
39 |
40 | 较大的参数值可以确保垃圾回收发生的频率较低。此参数的默认值取决于平台,范围从12 MB到约20 MB。
41 |
42 | 如设为128 MB:
43 |
44 | ```
45 | -XX:MetaspaceSize=128m
46 | ```
47 |
48 | ### 5.2. `-XX:MaxMetaspaceSize=`
49 |
50 | 设置Metaspace的最大大小,超过此大小后会抛出OutOfMemory错误。此标志限制了分配给类元数据的空间量,分配给此参数的值是近似的。
51 |
52 | 默认情况下,没有设置限制,这意味着Metaspace可能增长到可用本地内存的大小。
53 |
54 | 如置100 MB:
55 |
56 | ```
57 | ‑XX:MaxMetaSpaceSize=100m
58 | ```
59 |
60 | ### 5.3. `-XX:+UseCompressedClassPointers`
61 |
62 | 通过压缩对象引用来减少64位Java应用程序的内存占用。当此参数设置为true时,JVM将使用压缩指针来处理类元数据,这使得JVM可以使用32位寻址来处理类相关数据,而不是完整的64位指针。
63 |
64 | 在64位架构上,此优化尤其有价值,因为它减少了类元数据的内存使用,以及对象引用所需的内存,从而可能提高应用程序的整体性能。
65 |
66 | 压缩类指针将类空间分配与非类空间分配分开。因此,我们有两个全局Metaspace上下文:一个用于保存Klass结构的分配(压缩类空间),一个用于保存其他所有内容(非类Metaspace)。
67 |
68 | 最近JVM版本中,通常在运行64位Java应用程序时,默认启用此标志,因此我们通常不需要显式设置此标志。
69 |
70 | ### 5.4. `-XX:+UseCompressedOops`
71 |
72 | 标志启用或禁用在64位JVM中使用压缩指针处理Java对象。当参数设置为true时,JVM将使用压缩指针,这意味着对象引用将使用32位指针,而不是完整的64位指针。
73 |
74 | 使用压缩指针,只能寻址较小范围的内存。这迫使JVM使用较小的指针并节省内存。
75 |
76 | ## 6 结论
77 |
78 | 本文中,我们探讨了元数据和Metaspace的概念。
79 |
80 | 我们探讨了触发元数据GC阈值的原因。我们还了解了元数据GC阈值以及用于调整Metaspace和优化垃圾回收周期的不同JVM参数。
81 |
82 | 下一讲,我们讨论Metaspace导致的一个 OOM 生产排查案例!
--------------------------------------------------------------------------------
/docs/md/jvm/队列积压了百万条消息,线上直接OOM了!.md:
--------------------------------------------------------------------------------
1 | # 队列积压了百万条消息,线上直接OOM了!
2 |
3 | ## 0 前言
4 |
5 | 某系统不停发布数据到Kafka,数据同步系统专门从Kafka消费数据,再保存到自己数据库,可类比物联网数据网关系统:
6 |
7 | 
8 |
9 | 这么简单的系统,居然时不时报OOM,得重启,过段时间又OOM。而且这系统处理数据量越来越大,OOM频率也越来越高。
10 |
11 | ## 1 从现象看本质
12 |
13 | 既然每次重启后,都会在一段时间后OOM,说明肯定是每次重启后,内存都不断上涨。一般要高到OOM,通常就是因为:
14 |
15 | - 并发太高,瞬间大量并发创建过多的对象,导致系统宕机
16 | - 内存泄漏之类,即很多对象都赖在内存不死,无论怎么GC都回收不了
17 |
18 | 而该系统负载并不高,虽数据量不少,但绝非瞬时高并发。
19 |
20 | 看来可能就是随时间推移,某种对象越来越多,赖在内存。然后不断触发GC,结果每次GC都回收不掉这些对象。一直到最后,内存实在不足,造成 OOM:
21 |
22 | 
23 |
24 | ## 2 jstat验证
25 |
26 | 直接在一次重启系统后,jstat观察JVM运行情况:
27 |
28 | 发现,Old对象一直不停增长。每次YGC后,老年代对象就增长不少。且当老年代使用率达100%后,正常触发Full GC,但Full GC回收不掉任何对象,导致老年代使用率还是100%!
29 |
30 | 然后老年代使用率维持100%一段时间后,就OOM了,因为再有新对象进入老年代,实在没空间放了!
31 |
32 | 这就验证了判断,每次系统启动,有啥对象,会一直进堆内存,且随YGC执行,对象会一直进入老年代,最后触发Full GC都无法回收老年代的对象,导致OOM。
33 |
34 | ## 3 MAT/JProfile找到占用内存最大对象!
35 |
36 | 内存快照中发现有个队列数据结构,直接引用大量数据,就是这队列数据结构占满内存!
37 |
38 | ### 3.1 这队列做啥的?
39 |
40 | 从Kafka消费出的数据会先入队,再从队列慢慢写入DB,主要是要额外做中间数据处理和转换,所以自己在中间又加个队列:
41 |
42 | 
43 |
44 | ### 3.2 这队列咋用的?咋随便用就出问题!
45 |
46 | 从Kafka批量消费,可能一次消费几百条数据。因此,coder直接每次消费几百条数据出来给做成一个List,然后把这List入队!
47 |
48 | 最后就搞成:若一个队列有1000个元素,每个元素都是个List,每个List里都有几百条数据!
49 |
50 | 这就导致内存队列积压几十万甚至百万条数据!最终一定OOM! 而且只要你数据还停留在队列中,就无法被回收!
51 |
52 | 
53 |
54 | 这是典型的对生产和消费的速率没控制好:
55 |
56 | - 从Kafka消费出来的数据,入队速度很快(生产者速率很快)
57 | - 但从队列里消费数据进行处理,然后写DB速度较慢(消费者速度很慢)
58 |
59 | 最终导致内存队列快速积压数据,导致OOM。而且这种队列每个元素都是个List或者大对象,就会导致内存队列能容纳的数据量极速增长,提前OOM。
60 |
61 | ## 4 解决方案
62 |
63 | 修改内存队列的使用,做成定长的阻塞队列。
64 |
65 | 如最多1024个元素,每次从Kafka消费出来数据,一条条写入队列,而不是做成一个List入队作为一个元素。
66 |
67 | 这样内存中最多1024个数据,一旦内存队列满,此时Kafka消费线程就会停止工作,因为被队列给阻塞住了。不会让内存队列中的数据过多:
68 |
69 | 
--------------------------------------------------------------------------------
/docs/md/k8s/23-1-Envoy.md:
--------------------------------------------------------------------------------
1 | # 23-1-Envoy
2 |
3 | 你觉得为什么它能击败Nginx以及HAProxy等竞品,成为Service Mesh体系核心?
4 |
5 | Envoy 是由 Lyft 开发并开源的一款高性能开源代理,近年来迅速成为 Service Mesh 体系的核心组件之一。它之所以能够击败 Nginx 和 HAProxy 等竞品,成为众多微服务架构中的首选,有以下几个主要原因:
6 |
7 | ### 1. **设计现代化**
8 |
9 | - **初始设计即为云原生和微服务**:Envoy 从一开始就设计为服务代理,专注于服务间通信的复杂性,而不是像 Nginx 和 HAProxy 那样起源于传统的 L7 代理和负载均衡。
10 | - **面向分布式系统**:Envoy 的设计考虑了现代分布式系统的需求,例如动态配置、服务发现、健康检查等。
11 |
12 | ### 2. **可观察性**
13 |
14 | - **高级监控和追踪**:Envoy 提供丰富的指标、日志和分布式追踪功能,能够与 Prometheus、Grafana、Jaeger 等工具无缝集成,使得服务之间的调用和性能问题能够被详细地监控和追踪。
15 | - **丰富的可视化数据**:支持详细的统计数据和可视化,帮助运维人员了解系统内部的工作情况。
16 |
17 | ### 3. **动态配置和管理**
18 |
19 | - **xDS API**:Envoy 使用 xDS API 进行动态配置,允许管理者通过中心化的控制平面动态调整路由、限流、熔断等配置,而无需重新启动代理。这在频繁变化的微服务环境中尤为重要。
20 | - **热重载配置**:配置变更不需要重启服务,这一点在生产环境中尤其关键,能够保证服务的连续性。
21 |
22 | ### 4. **丰富的功能**
23 |
24 | - **全面的 L7 代理功能**:除了基本的 L4 负载均衡,Envoy 还提供 L7 代理功能,如 HTTP/2 和 gRPC 支持、流量劫持、路由控制、流量镜像等,适用于复杂的微服务通信需求。
25 | - **服务发现和负载均衡**:Envoy 支持多种服务发现机制和负载均衡策略,能够适应不同的微服务架构和部署环境。
26 |
27 | ### 5. **扩展性和插件化**
28 |
29 | - **可扩展架构**:Envoy 的架构设计允许开发者通过插件扩展其功能,使其能够适应特定的业务需求。
30 | - **WebAssembly(Wasm)支持**:Envoy 支持通过 Wasm 插件进行扩展,提供了一种灵活、安全且高效的扩展机制。
31 |
32 | ### 6. **社区和生态系统**
33 |
34 | - **活跃的社区**:Envoy 由一个活跃且不断壮大的开源社区支持,Lyft、Google 等大型科技公司积极参与,确保了项目的持续发展和创新。
35 | - **广泛的集成**:Envoy 已被集成到许多开源项目和商业产品中,特别是在 Service Mesh 领域,如 Istio 和 Consul Connect,这些项目将 Envoy 作为数据平面代理,进一步扩大了其影响力和应用范围。
36 |
37 | ### 7. **安全性**
38 |
39 | - **先进的安全特性**:Envoy 提供全面的安全功能,包括 TLS 终结和起源验证、mTLS(双向 TLS)、RBAC(基于角色的访问控制)等,确保服务间通信的安全性。
40 |
41 | ### 对比 Nginx 和 HAProxy
42 |
43 | 虽然 Nginx 和 HAProxy 也在不断发展并引入了许多现代功能,但 Envoy 的设计初衷和功能集更贴合微服务架构的需求。具体对比:
44 |
45 | - **动态配置**:Envoy 的 xDS API 和热重载配置比 Nginx 和 HAProxy 的静态配置文件和较为复杂的动态配置管理更为先进。
46 | - **L7 代理功能**:Envoy 的 L7 代理功能和对 HTTP/2、gRPC 的支持更为全面,而 Nginx 和 HAProxy 主要还是在 L4 和基础的 L7 代理功能上。
47 | - **可观察性**:Envoy 原生支持高级监控和分布式追踪,而 Nginx 和 HAProxy 需要依赖额外的插件或外部工具。
48 | - **扩展性**:Envoy 通过 Wasm 插件提供了高效的扩展机制,而 Nginx 和 HAProxy 在插件化和扩展性上较为有限。
49 |
50 | 综上所述,Envoy 的现代化设计、高度的可观察性、动态配置能力、丰富的功能集、强大的扩展性和活跃的社区,使得它在微服务架构中更具优势,从而在与 Nginx 和 HAProxy 的竞争中脱颖而出,成为 Service Mesh 体系的核心组件。
--------------------------------------------------------------------------------
/docs/md/linux/00-操作系统专栏大纲.md:
--------------------------------------------------------------------------------
1 | # 00-操作系统专栏大纲
2 |
3 | ## 1 你将获得
4 |
5 | - 快速掌握 Linux 常用命令及配置
6 | - 熟练进行系统管理和故障排查
7 | - 熟悉 Vim 基本操作及 Shell 编程
8 | - 搭建并维护基于 Linux 的常用服务
9 | - Linux 常用的性能分析工具合集
10 | - 30 个 Linux 性能问题诊断思路
11 | - 读懂 CPU、内存、I/O 等指标
12 | - 5 个真实的线上环境分析案例
13 |
14 | ## 2 专栏介绍
15 |
16 | 本专栏基于 CentOS 7 进行讲解。入门级的 Linux 学习教材,内容由浅入深,案例丰富,通俗易懂!分两部分:前面为基础知识,涉及安装、登录、文件和目录管理、磁盘管理、Vim、压缩和解压缩等;后面为进阶知识,包括 LAMP、LNMP、NFS、FTP、Linux 集群和 Zabbix 监控等。与上一版相比,这版不仅将虚拟机软件由 VMware 10 改为 VMware 14,删掉了 LAMP 环境搭建与配置,还增加 Docker 等内容。
17 |
18 | Linux实操过程中,你是否疑问:
19 |
20 | - 如何提取日志中含有关键字的指定行,上一行或上几行?
21 | - ln 做了符号链接,对符号链接进行权限修改,原文件是否会受到影响?
22 | - Shell 脚本里有很多特殊符号,到底该怎么用?网上流传的 .(){.|.&};. 脚本能不能执行?
23 | - Linux 里的编辑器繁多,比如 vim、sed、awk, 它们各自有哪些特点?如何在不同的场景下做出合适的选择?
24 |
25 | 这些虽然不是什么刁钻的问题,你在网上也能搜到一堆参考资料,但是看完之后还是会觉得似懂非懂,无法举一反三,从网上复制粘贴了事,则极有可能不起作用。
26 |
27 | 如果侥幸解决了特定的问题,也意识到自己需要系统学习一下 Linux ,以便今后能更高效地解决其他 Linux 相关问题,但又发现 Linux 涉及到的常用命令实在是太多了,更别提每个命令又有一大堆相关参数,导致学起来毫无头绪。
28 |
29 | 而且,对于习惯了 Windows、macOS 等图形界面的用户来说,Linux 以命令行为主的操作方式导致它刚开始的学习曲线还是很陡峭的。因此,希望能帮你构建起系统化的 Linux 实战技能,逐步成长为一名 Linux 实战高手。
30 |
31 | 1. 实战导向:学完即可轻松应对工作中 85% 以上的 Linux 使用场景;
32 | 2. 内容全面:不仅包括基本的系统操作指令和常见服务搭建,还包含 Vim 的使用、Shell 编程等内容;
33 | 3. 结业项目:专栏最后会通过搭建一个家用 NAS 系统将专栏知识点全部贯穿起来,让你牢牢掌握所学知识。
34 |
35 |
36 |
37 | Linux 性能问题一直是程序员头上的“紧箍咒”,哪怕很多工作多年的资深工程师也不例外。日常工作中我们总是会遇到这样或那样的问题:
38 |
39 | - 应用程序响应太慢,从哪儿入手找原因?
40 | - 服务器总是时不时丢包,到底要怎么办?
41 | - 一个 SQL 查询要 30 秒,究竟是怎么回事?
42 | - 内存泄漏了,该怎么定位和处理?
43 |
44 | 面对这些问题,很多人都会发怵,似乎性能问题总是不那么简单。那如何才能搞定性能优化呢?
45 |
46 | 啃下所有的大块头原理书籍?多数人都会望而却步,不能坚持,即便是学了很多底层原理,碰到问题时依然会不知所措、无从下手。向牛人请教有效的方法?但管得了一时管不了永远,你很难形成系统的知识体系。实际上,找到正确的学习方法,你完全可以更轻松、更高效地掌握性能问题的解决之道。
47 |
48 | 以**案例驱动**的思路,从实际问题出发,带你由浅入深学习一些基本底层原理,掌握常见的性能指标和工具,学习实际工作中的优化技巧,让你可以准确分析和优化大多数的性能问题。另外,专栏中会有大量的案例分析,带你实战演练,更好地消化和巩固所学。
49 |
50 | 专栏共 5 个模块。
51 |
52 | 前 4 个模块从资源使用的视角出发,带你分析各种 Linux 资源可能会碰到的性能问题,包括**CPU 性能**、**磁盘 I/O 性能**、**内存性能**以及**网络性能**,让你掌握必备的基础知识,会用常见的性能工具和解决方法。
53 |
54 | 第 5 个综合实战模块,将为你还原真实的工作场景,介绍一些开源项目、框架或者系统设计的案例的观测、剖析和调优方法,让你在“高级战场”中学习演练。
55 |
56 | 
57 |
58 | 
--------------------------------------------------------------------------------
/docs/md/mgr/00-如何学习项目管理专栏.md:
--------------------------------------------------------------------------------
1 | # 00-如何学习项目管理专栏
2 |
3 | ## 1 为啥迭代?
4 |
5 | 核心用户就是程序员、项目经理,或者是想要从程序员转行/转岗到项目经理的人。
6 |
7 | 近两年随着超级个体时代的到来,我们也越来越深刻地体会到,项目管理这项技能,不仅仅是项目经理的专属技能,而是每一个想要独当一面之人的必备技能。说得直白一点,项目管理技能就是帮助你“使众人行”,帮助你成事儿的。
8 |
9 | **项目管理的核心是借事修人。其中“事”是项目,但终点是提升人的领导力。**
10 |
11 | 摘掉“程序员”帽子,给所有想习得项目管理技能的人:
12 |
13 | - 梳理、搭建起来的项目管理知识框架,依托的是《项目管理知识体系指南》,核心没变
14 | - 原有课程中的实战案例,取材实际经历,所选择的案例既切中用户的痛点,同时也极具代表性,时至今日仍有非常大的价值
15 |
16 | ## 迭代了啥?
17 |
18 | 增加Edge虚拟人物。通过Edge学习项目管理的经历,你也可以看到一个项目管理小白的成长历程与路径。相应地,这也可能会是你所需要的学习路径。
19 |
20 | 这里我也对Edge这个形象做一些背景说明。Edge作为跨行转过来的项目管理小白,对这份工作有着非常大的热情,也想要在项目管理这一赛道上深耕。
21 |
22 | 更注重实战性。
23 |
24 | 模块:
25 |
26 | - 常识篇
27 |
28 | - 硬技能篇
29 |
30 | - 软技能篇
31 |
32 | - 故事案例实战篇
33 |
34 | 在真实生动的故事案例中,呈现如何综合运用项目管理的底层思维——对焦。相比繁杂的理论知识,把握好底层思维,你就拥有了以不变应万变的能力
35 |
36 | 原范式按金字塔式的写作方式(背景-问题-冲突-解决方法)呈现。迭代后,着重在场景这一部分做优化,主要是将简单的场景变换成更具有真实感的故事,让你有更强的代入感,更好地入门。
37 |
38 | ## 小结
39 |
40 | - 整体设计增加Edge的虚拟人物形象,并将原来的琐碎的案例通过Edge这个人物,统一串联起来,增强实战性。
41 | - 故事案例实战篇助你掌握项目管理的底层思维。
42 | - 将简单的场景变换成更具有真实感的故事,让你有更强的代入感;所有图片重新绘制,并增加思维导图
43 |
44 | 开启项目管理之旅!
--------------------------------------------------------------------------------
/docs/md/monitor/并发用户、RPS、TPS的解读.md:
--------------------------------------------------------------------------------
1 | # 并发用户、RPS、TPS的解读
2 |
3 | ## 1 术语
4 |
5 | - 并发用户:在性能测试工具中,一般称为虚拟用户(Virtual User,简称VU),指的是现实系统中操作业务的用户。
6 |
7 | **说明** 并发用户与注册用户、在线用户不同。注册用户一般指的是数据库中存在的用户。在线用户只是“挂”在系统上,对服务器不产生压力。但并发用户一定会对服务器产生压力。
8 |
9 | - TPS:Transaction Per Second,每秒事务数,是衡量系统性能的一个非常重要的指标。
10 |
11 | - RPS:Request Per Second,每秒请求数。RPS模式适合用于容量规划和作为限流管控的参考依据。
12 |
13 | - RT:Response Time,响应时间,指的是业务从客户端发起到客户端接受的时间。
14 |
15 | 在性能测试中,通常有两种施压模式:并发模式和RPS模式。统方式是使用并发用户数来衡量系统的性能(站在客户端视角)。此方法一般适用于一些网页站点的压测(例如H5页面);而RPS(Requests per second)模式主要是为了方便直接衡量系统的吞吐能力TPS(Transaction Per Second,每秒事务数)而设计的(站在服务端视角),按照被压测端需要达到TPS等量设置相应的RPS,应用场景主要是一些动态的接口API,例如登录、提交订单等等。
16 |
17 | ## VU和TPS换算
18 |
19 | - 简单例子:在术语中解释了TPS是每秒事务数,但是事务是要靠虚拟用户做出来的,假如1个虚拟用户在1秒内完成1笔事务,那么TPS明显就是1;如果某笔业务响应时间是1 ms,那么1个用户在1s内能完成1000笔事务,TPS就是1000了;如果某笔业务响应时间是1s,那么1个用户在1s内只能完成1笔事务,要想达到1000 TPS,至少需要1000个用户;因此可以说1个用户可以产生1000 TPS,1000个用户也可以产生1000 TPS,无非是看响应时间快慢。
20 |
21 | - 复杂公式: 试想一下复杂场景,多个脚本,每个脚本里面定义了多个事务(例如一个脚本里面有100个请求,我们把这100个连续请求叫做Action,只有第10个请求,第20个请求分别定义了事务10和事务20)具体公式如下。
22 |
23 | 符号代表意义:
24 |
25 | - Vui表示的是第i个脚本使用的并发用户数。
26 | - Rtj表示的是第i个脚本第j个事务花费的时间,此时间会影响整个Action时间。
27 | - Rti表示的是第i个脚本一次完成所有操作的时间,即Action时间。
28 | - n表示的是第n个脚本。
29 | - m表示的是每个脚本中m个事务。
30 | - 那么第j个事务的TPS = Vui/Rti。
31 |
32 | 总的TPS=。
33 |
34 | ## 如何获取VU和TPS
35 |
36 | - VU获取方式:
37 |
38 | 已有系统:可选取高峰时刻,在一定时间内使用系统的人数,这些人数可认为是在线用户数,并发用户数可以取10%,例如在半个小时内,使用系统的用户数为10万,那么取10%(即1万)作为并发用户数基本就够了。
39 |
40 | 新系统:没有历史数据作参考,建议通过业务部门进行评估。
41 |
42 | - TPS获取方式:
43 |
44 | 已有系统:可选取高峰时刻,在一定时间内(如3分钟~10分钟),获取系统总业务量,计算单位时间(秒)内完成的笔数,乘以2~5倍作为峰值的TPS,例如峰值3分钟内处理订单18万笔,平均TPS是1000,峰值TPS可以是2000~5000。
45 |
46 | 新系统:没有历史数据作参考,建议通过业务部门进行评估。
47 |
48 | ## 如何评价系统的性能
49 |
50 | 针对服务器端的性能,以TPS为主来衡量系统的性能,并发用户数为辅来衡量系统的性能,如果必须要用并发用户数来衡量的话,需要一个前提,那就是交易在多长时间内完成,因为在系统负载不高的情况下,将思考时间(思考时间的值等于交易响应时间)加到串联链路中,并发用户数基本可以增加一倍,因此用并发用户数来衡量系统的性能没太大的意义。同样的,如果系统间的吞吐能力差别很大,那么同样的并发下TPS差距也会很大。
51 |
52 | ## 性能测试策略
53 |
54 | 做性能测试需要一套标准化流程及测试策略。做负载测试时,传统方式一般按梯度施压的方式去加用户数,避免在没预估情况下,一次加几万个用户,导致交易失败率非常高,响应时间非常长,已超过使用者忍受范围内;较为适合互联网分布式架构的方式,也是阿里最佳实践是用TPS模式(吞吐量模式)+设置起始和目标最大量级,然后根据系统表现灵活的手工实时调速,效率更高,服务端吞吐能力的衡量一步到位。
55 |
56 | ## 总结
57 |
58 | - 系统的性能由TPS决定,跟并发用户数没有多大关系。
59 | - 系统的最大TPS是一定的(在一个范围内),但并发用户数不一定,可以调整。
60 | - 建议性能测试的时候,不要设置过长的思考时间,以最坏的情况下对服务器施压。
61 | - 一般情况下,大型系统(业务量大、机器多)做压力测试,10000~50000个用户并发,中小型系统做压力测试,5000个用户并发比较常见。
--------------------------------------------------------------------------------
/docs/md/mysql/00-MySQL专栏大纲.md:
--------------------------------------------------------------------------------
1 | # 00-MySQL专栏大纲
2 |
3 | ## 你将获得
4 |
5 | - MySQL 核心技术详解与原理说明
6 | - MySQL 常见痛点问题解析
7 | - 完整的 MySQL 学习路径
8 |
9 | ## 介绍
10 |
11 | MySQL 使用和面试中遇到的问题,很多人会通过搜索别人的经验来解决 ,零散不成体系。实际上只要理解了 MySQL 的底层工作原理,就能很快地直戳问题的本质。
12 |
13 | 通过探讨 MySQL 实战中最常见的痛点问题,串起各个零散的知识点,配合大量详解图,由线到面带你构建 MySQL 系统的学习路径。
14 |
15 | 专栏梳理了 **MySQL 的主线知识**,如**事务、索引、锁**等;并基于这条主线,带你缕清**概念、机制、原理、案例分析**以及本质,让你真正能掌握 **MySQL 核心技术与底层原理。**
16 |
17 | 每篇文章中都附有**实践案例**,给你从理论到实战的系统性指导,让你少走弯路,彻底搞懂 MySQL。
18 |
19 | ## 模块
20 |
21 | **模块一,基础篇**。为你深入浅出地讲述 MySQL 核心知识,涵盖 MySQL 基础架构、日志系统、事务隔离、锁等内容。
22 |
23 | **模块二,实践篇**。将从一个个关键的数据库问题出发,分析数据库原理,并给出实践指导。每个问题,都不只是简单地给出答案,而是从为什么要这么想、到底该怎样做出发,让你能够知其所以然,都将能够解决你平时工作中的一个疑惑点。
--------------------------------------------------------------------------------
/docs/md/mysql/MySQL新特性.md:
--------------------------------------------------------------------------------
1 | # MySQL历史版本特性
2 |
3 | MySQL 是一个广泛使用的开源关系型数据库管理系统,由 Oracle 公司维护和开发。自 1995 年首次发布以来,MySQL 经历了多个版本的迭代,每个版本都引入了新功能和优化。以下是 MySQL 各大版本的主要新功能和优化:
4 |
5 | ### MySQL 3.23
6 |
7 | - **发布时间**: 2001年
8 | - **主要新功能**:
9 | - 引入了 `InnoDB` 存储引擎。
10 | - 支持 `UNION` 和子查询。
11 | - 引入了 `LOAD DATA INFILE` 语句。
12 |
13 | ### MySQL 4.0
14 |
15 | - **发布时间**: 2003年
16 | - **主要新功能**:
17 | - 支持多表删除 (`DELETE` with `JOIN`)。
18 | - 引入了 `FULLTEXT` 索引。
19 | - 支持 `BLOB` 和 `TEXT` 列的索引。
20 |
21 | ### MySQL 4.1
22 |
23 | - **发布时间**: 2004年
24 | - **主要新功能**:
25 | - 引入了子查询和视图。
26 | - 支持 Unicode 字符集。
27 | - 改进了 `InnoDB` 存储引擎的性能。
28 |
29 | ### MySQL 5.0
30 |
31 | - **发布时间**: 2005年
32 | - **主要新功能**:
33 | - 引入了存储过程和触发器。
34 | - 支持游标。
35 | - 引入了 ` INFORMATION_SCHEMA` 数据库。
36 |
37 | ### MySQL 5.1
38 |
39 | - **发布时间**: 2008年
40 | - **主要新功能**:
41 | - 支持分区表。
42 | - 引入了事件调度器。
43 | - 改进了插件架构。
44 |
45 | ### MySQL 5.5
46 |
47 | - **发布时间**: 2010年
48 | - **主要新功能**:
49 | - 默认存储引擎改为 `InnoDB`。
50 | - 支持半同步复制。
51 | - 改进了性能和可扩展性。
52 |
53 | ### MySQL 5.6
54 |
55 | - **发布时间**: 2013年
56 | - **主要新功能**:
57 | - 支持全文索引的改进。
58 | - 引入了多线程复制。
59 | - 改进了 `InnoDB` 的性能和可靠性。
60 |
61 | ### MySQL 5.7
62 |
63 | - **发布时间**: 2015年
64 | - **主要新功能**:
65 | - 引入了 JSON 支持。
66 | - 改进了 GIS 功能。
67 | - 支持多源复制。
68 | - 改进了性能和安全性。
69 |
70 | ### MySQL 6.x
71 |
72 | 多年前,在 Sun 收购 MySQL AB 之前,MySQL 曾有过一个编号为 6 的版本。 遗憾的是,它有点雄心勃勃,所有权的变更让它枯萎了。
73 |
74 | ### MySQL7.x
75 |
76 | 多年来,MySQL Cluster 产品一直使用 7 系列。 随着 MySQL 8 的新变化,开发人员认为他们已经对其进行了足够的修改,以提升这个大版本。
77 |
78 | ### MySQL 8.0
79 |
80 | - **发布时间**: 2018年
81 | - **主要新功能**:
82 | - 引入了窗口函数。
83 | - 支持公用表表达式 (CTE)。
84 | - 改进了 JSON 支持。
85 | - 引入了原子数据定义语句 (DDL)。
86 | - 改进了安全和性能。
87 |
88 | ### MySQL 8.1
89 |
90 | - **发布时间**: 2023年
91 | - **主要新功能**:
92 | - 引入了 InnoDB 表空间加密。
93 | - 支持在线添加列。
94 | - 改进了 GIS 功能。
95 | - 引入了新的优化器功能。
96 |
97 | ### MySQL 8.2
98 |
99 | - **发布时间**: 2023年
100 | - **主要新功能**:
101 | - 引入了 InnoDB 表空间加密。
102 | - 支持在线添加列。
103 | - 改进了 GIS 功能。
104 | - 引入了新的优化器功能。
105 |
106 | 每个版本的 MySQL 都在前一版本的基础上进行了改进和优化,增加了新的功能以满足不断变化的需求和技术发展。MySQL 的持续发展使其成为世界上最受欢迎的数据库管理系统之一。
--------------------------------------------------------------------------------
/docs/md/mysql/how-to-use-indexes-when-grouping-in-sql.md:
--------------------------------------------------------------------------------
1 | # SQL执行Grouping by时如何才能使用索引?
2 |
3 | group by是否能用索引?有时需要group by把数据分组,再用count、sum等聚合函数做聚合统计。
4 |
5 | 假设有 SQL:
6 |
7 | ```sql
8 | select count(*) from table group by xx
9 | ```
10 |
11 | 看起来必须把所有数据放到一个临时磁盘文件里还有加上部分内存,去搞一个分组,按指定字段值分组,接着对每组执行一个聚合函数,这性能也是极差,涉及大量磁盘交互。
12 |
13 | 因为索引树默认按指定的一些字段都排序好的,字段值相同的数据都在一起,若走索引去执行分组后再聚合,性能就比临时磁盘文件好多了。
14 |
15 | 所以一般对group by后的字段,最好也按联合索引最左侧字段开始,按序排列,就能完美利用索引直接提取一组组数据,然后针对每组数据,执行聚合函数。
16 |
17 | group by和order by利用索引原理和条件差不多,本质都是在group by和order by之后的字段顺序和联合索引中的从最左侧开始字段顺序一致,然后就能利用索引树,快速根据排序好的数据执行后续操作。
18 |
19 | 就无需针对杂乱数据利用临时磁盘文件+部分内存数据结构,进行耗时耗力的现场排序和分组,真是速度慢,性能差。
20 |
21 | ## 平时设计表里的索引
22 |
23 | 必须充分考虑后续SQL要咋写:
24 |
25 | - 会根据啥字段进行where语句里筛选和过滤?
26 | - 根据哪些字段进行排序和分组?
27 |
28 | 考虑好后,就能为表设计两三个常用索引,覆盖常见的where筛选、order by排序和group by分组的需求,保证常见SQL语句都能用上索引。只要所有查询语句都可利用索引执行,速度和性能通常都不会太慢。如查询还是有问题,就要基于执行计划进行深度SQL调优。
29 |
30 | 然后对更新语句,最核心问题:
31 |
32 | - 索引别太多,否则更新时维护太多索引树
33 | - 可能涉及锁等待和死锁
34 | - 可能涉及MySQL连接池、写redo log文件等
--------------------------------------------------------------------------------
/docs/md/netty/01-Netty源码面试实战+原理(一)-鸿蒙篇.md:
--------------------------------------------------------------------------------
1 | # 01-Netty源码面试实战+原理(一)-鸿蒙篇
2 |
3 | ## 1 简介
4 |
5 | Trustin Lee,韩国大佬发明:
6 |
7 | 
8 |
9 | 在 2008 年提交第一个commit至今,转眼间已经走过15年:
10 |
11 | 
12 |
13 | Netty封装JDK的NIO接口而成的框架。所以 JDK NIO 是基础。
14 |
15 | ## 2 啥是Netty?
16 |
17 | - 异步事件驱动框架,可快速开发高性能的服务端和客户端
18 | - 封装了JDK底层BIO和NIO模型,提供更加简单易用安全的 API
19 | - 自带编解码器解决拆包粘包问题,无需用户困扰
20 | - Reactor线程模型支持高并发海量连接
21 | - 自带各种协议栈
22 |
23 | ## 3 Netty 的特点
24 |
25 | - 设计
26 | 针对多种传输类型的统一接口 - 阻塞和非阻塞
27 | 简单但更强大的线程模型
28 | 真正的无连接的数据报套接字支持
29 | 链接逻辑支持复用
30 | - 易用性
31 | 大量的 Javadoc 和 代码实例
32 | 除了在 JDK 1.6 + 额外的限制。(一些特征是只支持在Java 1.7 +。可选的功能可能有额外的限制。)
33 | - 性能
34 | 比核心 Java API 更好的吞吐量,较低的延时
35 | 资源消耗更少,这个得益于共享池和重用
36 | 减少内存拷贝
37 | - 健壮性
38 | 消除由于慢,快,或重载连接产生的 OutOfMemoryError
39 | 消除经常发现在 NIO 在高速网络中的应用中的不公平的读/写比
40 | - 安全
41 | 完整的 SSL / TLS 和 StartTLS 的支持
42 | 运行在受限的环境例如 Applet 或 OSGI
43 | - 社区
44 | 发布的更早和更频繁
45 | 社区驱动
46 |
47 | ## 4 为什么要研究 Netty
48 |
49 | - 开发任何网络编程。实现自己的rpc框架
50 | - 能够作为一-些公有协议的broker组件。如mqtt, http
51 | - 不少的开源软件及大数据领域间的通信也会使用到netty
52 | - 为了面试跳槽涨薪
53 |
54 | ## 5 本地调试
55 |
56 | 使用“网络调试助手”小软件发送客户端请求。
--------------------------------------------------------------------------------
/docs/md/other/guide-to-reading.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 目录
3 | ---
4 |
5 | # 程序员的编码指南 🔥
6 |
7 | ## 作者团简介
8 |
9 | ### JavaEdge
10 | - 🚀 魔都架构师 | 全网30W技术追随者
11 | - 🔧 大厂分布式系统/数据中台实战专家
12 | - 🏆 主导交易系统百万级流量调优 & 车联网平台架构
13 | - 🧠 AIGC应用开发先行者 | 区块链落地实践者
14 | - 🌍 以技术驱动创新,我们的征途是改变世界!
15 |
16 | ### 11来了
17 |
18 | 在读研究生,秋招备战中,编程严选星球合伙人,Java 领域新星创作者(CSDN)
19 |
20 | > 个人技术公众号:【 **11来了** 】 ,专攻底层源码原理
21 |
22 | > 个人专栏:
23 | > - [并发专栏](/md/concurrency/01-synchronized原理.html) | [Redisson分布式锁源码解析](/md/redis/01-Redis和ZK分布式锁优缺点对比以及生产环境使用建议.md)
24 | > - [面试突击专栏](/md/zqy/面试题/01-分布式技术面试实战.html) | [MySQL面试专栏](/md/zqy/面试题/面试题-MySQL.html) | [Redis面试专栏](/md/zqy/面试题/面试题-Redis.html) | [JVM专栏](/md/jvm/01-JVM虚拟机-上篇.html)
25 |
26 | ### Ken
27 |
28 | 深圳某知名科技公司的Java后端开发,编程严选星球合伙人,有丰富的后端开发经验。
29 |
30 | > 个人专栏:
31 | > - [12306专栏](/md/12306/项目介绍.html)
32 | >
33 |
34 | ### 知青先生
35 |
36 | 现任泛微ecology产品开发经理;曾任国企南方电网深圳数字研究院一线业务开发;编程严选星球合伙人;有丰富的web端全栈开发经验;CSDN技术博主。
37 |
38 | > 个人专栏:
39 | > - [spring-cloud专栏](/md/spring/spring-cloud/SpringCloudAlibaba介绍.md)
40 |
41 | 参考:
42 |
43 | - [编程严选网](http://www.javaedge.cn/#/index)
44 | 备用域名:http://www.javaedge.com.cn/
45 |
--------------------------------------------------------------------------------
/docs/md/product-center/00-商品中心的spu、sku设计.md:
--------------------------------------------------------------------------------
1 | # 00-商品中心的spu、sku设计
2 |
3 |
4 |
5 | ## 1 商品管理系统数据结构
6 |
7 | ### 1.1 Spu (Standard Product Unit,标准产品单位)
8 |
9 | 标准的商品单元,通常指一个商品系列。
10 |
11 | 商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。
12 |
13 | 通俗点讲,属性值、特性相同的商品就可以称为一个SPU。如:华为P20 pro就是一个SPU,与商家,与颜色、款式、套餐都无关。
14 |
15 | ### 1.2 Sku (Stock Keeping Unit,库存量单位)
16 |
17 | 库存存储单元,通常指具体的库存商品。
18 |
19 | SKU即库存进出计量的单位, 可以是以件、盒、托盘等为单位。
20 |
21 | SKU是物理上不可分割的最小存货单元。在使用时要根据不同业态,不同管理模式来处理。在服装、鞋类商品中使用最多最普遍。如:
22 |
23 | - 华为P20 pro 宝石蓝 64G
24 | - 华为P20 pro 亮黑色 64G
25 | - 华为P20 pro 宝石蓝 128G
26 | - 华为P20 pro 亮黑色 128G
27 |
28 | Spu包含Sku,Spu表和Sku表是一对多。
29 |
30 | ## 2 spu的功能
31 |
32 |
33 |
34 | 
35 |
36 | 1. 根据spu和sku的电商设计模型
37 | 2. 根据电商网站用户检索和过滤的需求
38 |
39 | ### spu的功能
40 |
41 | - 查询spu数据列表
42 | - spu的添加功能
43 |
44 | ## 3 spu的添加
45 |
46 | ### spu信息
47 |
48 | Spu名称,spu的描述
49 |
50 | ### spu图片信息
51 |
52 | - 图片对象数据保存在分布式文件存储服务器。
53 | - 图片元数据信息保存在数据库
54 |
55 | 用户在选择完图片后:
56 |
57 | - 我们把图片在用户提交时候和其他的商品spu信息一起提交到后台
58 | - 我们在用户选择图片是,就将图片上传至服务器
59 |
60 | ### spu的销售属性信息
61 |
62 | 商品的平台属性属于电商网站后台管理(整个商品平台的维度下的)
63 |
64 | 商品的销售属性属于在电商网站上卖商品的商家管理(属于某一件商品的维度下的)
65 |
66 | ### 销售属性
67 |
68 | - 商品的平台属性属于电商网站后台管理
69 | - 商品的销售属性属于商家管理
--------------------------------------------------------------------------------
/docs/md/product-center/01-电商商品中心解密:仅凭SKU真的足够吗?.md:
--------------------------------------------------------------------------------
1 | # 01-电商商品中心解密:仅凭SKU真的足够吗?
2 |
3 | 在电子商务系统中,SKU(Stock Keeping Unit,库存单位)和SPU(Standard Product Unit,标准产品单位)是两种不同的概念,它们共同用于商品管理和库存控制。虽然理论上可以只使用SKU来管理商品,但在实际应用中,同时使用SPU和SKU有其明显的优势和必要性。
4 |
5 | ### SKU(库存单位)
6 |
7 | - SKU是商品的具体型号或款式,每个SKU都有唯一的标识符。
8 | - 它通常关联到商品的一个具体的销售属性,如尺寸、颜色等。
9 | - SKU用于库存管理,每个SKU都对应一定数量的库存。
10 |
11 | ### SPU(标准产品单位)
12 |
13 | - 商品的一种抽象,代表一个商品系列或分类
14 | - 包含一组具有相同特征,但在某些属性(如颜色、尺寸)上可能有所不同的商品
15 | - 有助简化商品分类和搜索,便于消费者理解和选择
16 |
17 | ### 使用SPU和SKU的理由
18 |
19 | 1. **分类管理**:SPU可以帮助商家对商品进行更高层次的分类,而SKU则用于区分同一SPU下的不同规格或型号。
20 |
21 | 2. **库存管理**:每个SKU对应一定数量库存,使库存管理更精确高效
22 |
23 | 3. **搜索和过滤**:消费者可基于SPU进行商品搜索,然后通过不同SKU筛选想要的具体商品
24 |
25 | 4. **销售分析**:SPU可帮助商家分析整个商品系列的表现,而SKU则可以提供每个具体商品的销售数据
26 |
27 | 5. **简化操作**:商品上架、促销和维护时,使用SPU可减少重复工作,因为同一SPU下的不同SKU可共享基础信息
28 |
29 | 6. **扩展性**:添加新的规格或型号时,只需添加新SKU,无需重新创建整个商品系列
30 |
31 | ### 只使用SKU的局限性
32 |
33 | - 如果只使用SKU,可能会使得商品分类变得复杂和混乱,特别是当商品种类繁多时。
34 | - 缺少了SPU的抽象层,消费者可能会在搜索和选择商品时遇到困难。
35 | - 库存管理和商品分析可能会变得繁琐,因为没有一个统一的层级来组织和理解商品数据。
36 |
37 | ### 结论
38 |
39 | 虽然在理论上可以只使用SKU来管理商品,但在实践中,结合使用SPU和SKU能够提供更为高效、清晰和灵活的商品管理方式。这种方式有助于提高运营效率,改善消费者体验,并支持更精准的数据分析和决策。
40 |
41 |
42 |
43 | 在项目初期,确实可以主要依赖SKU来管理商品。尤其是在以下情况下,使用SKU作为主要的商品管理单位可能是足够的:
44 |
45 | 1. **商品种类有限**:如果项目初期商品种类不多,使用SKU进行管理可以简化流程。
46 |
47 | 2. **标准化商品**:如果销售的商品具有较少的变体,例如尺寸或颜色选择不多,那么SKU可能足以区分所有商品。
48 |
49 | 3. **运营团队较小**:在项目初期,如果运营团队规模较小,SKU管理可能更加直观和易于操作。
50 |
51 | 4. **快速迭代**:项目初期可能需要快速迭代和调整,使用SKU可以更快地响应市场变化和测试不同的商品。
52 |
53 | 5. **简化库存管理**:在SKU足够区分所有商品的情况下,可以简化库存管理和减少运营复杂性。
54 |
55 | 6. **减少系统复杂性**:避免在项目初期引入过多的概念和系统复杂性,可以集中精力在核心功能的开发上。
56 |
57 | 然而,即使在项目初期主要使用SKU,也应考虑以下几点:
58 |
59 | - **扩展性**:随着项目的发展,商品种类和变体可能会增加。需要确保系统设计有足够的灵活性来引入SPU的概念。
60 |
61 | - **数据结构**:即使主要使用SKU,也应该设计良好的数据结构,以便未来可以轻松地添加SPU层。
62 |
63 | - **用户体验**:考虑用户如何搜索和选择商品。如果SKU足以提供良好的用户体验,那么可以暂时不引入SPU。
64 |
65 | - **长期规划**:即使在项目初期不使用SPU,也应该有长远的规划,考虑未来可能的需求变化。
66 |
67 | - **性能考虑**:评估使用SKU进行管理对系统性能的影响,确保系统能够处理预期的数据量。
68 |
69 | - **市场调研**:了解目标市场和竞争对手的做法,看看他们是如何管理商品的,这可能会影响你的决策。
70 |
71 | 总之,项目初期使用SKU作为主要的商品管理单位是可行的,但需要考虑到未来的发展和可能的需求变化。随着项目的成长,可能需要逐步引入SPU来优化商品管理和用户体验。
--------------------------------------------------------------------------------
/docs/md/product/book/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/product/book/todo.md
--------------------------------------------------------------------------------
/docs/md/product/pdf/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/product/pdf/todo.md
--------------------------------------------------------------------------------
/docs/md/rabbitmq/08-RabbitMQ的七种队列模式.md:
--------------------------------------------------------------------------------
1 | # 08-RabbitMQ的七种队列模式
2 |
3 |
--------------------------------------------------------------------------------
/docs/md/rabbitmq/RabbitMQ消费端幂等性概念及解决方案.md:
--------------------------------------------------------------------------------
1 | # RabbitMQ消费端幂等性概念及解决方案
2 |
3 | ## 1 什么是幂等性
4 |
5 | 用户对于同一操作发起的一次请求或者多次请求的结果是一致的。
6 |
7 | 如数据库乐观锁,执行更新操作前:
8 |
9 | - 先去数据库查询version
10 | - 然后执行更新语句
11 | - 以version作为条件,如果执行更新时有其他人先更新了这张表的数据,那么这个条件就不生效了,也就不会执行操作了
12 |
13 | 通过这种乐观锁的机制来保障幂等性。
14 |
15 | ## 2 Con幂等性
16 |
17 | ### 2.1 什么是Con幂等性
18 |
19 | 消费端实现幂等性,即消息永远不会消费多次,即使收到多条一样消息。
20 |
21 | 在业务高峰期最容易产生消息重复消费问题:当Con消费完消息后给Pro返回ack时,由于网络中断,导致Pro未收到确认信息,该条消息就会重新发送并被Con消费,但实际上该消费者已成功消费,就导致重复消费。
22 |
23 | ### 2.2 主流幂等性实现方案
24 |
25 | #### ① 唯一ID+指纹码
26 |
27 | 利用DB主键去重:
28 |
29 | ```sql
30 | SELECT COUNT(1) FROM T_ORDER
31 | WHERE ID = 唯一ID
32 | AND IS_CONSUM = 指纹码
33 | ```
34 |
35 | 唯一ID:业务表的主键
36 |
37 | 指纹码:为区别每次正常操作的码,每次操作时生成指纹码。可用时间戳+业务编号或标志位(视业务场景而定)
38 |
39 | 优势:实现简单
40 |
41 | 弊端:高并发下有数据库写入的性能瓶颈
42 |
43 | 解决方案:根据ID进行分库分表算法路由
44 |
45 | ##### 小结
46 |
47 | 先根据消息生成一个全局唯一ID,然后加上一个指纹码。指纹码不一定是系统生成,而是一些外部规则或内部业务规则去拼接,就是为保障这次操作的绝对唯一性。
48 |
49 | ID + 指纹码拼接好的值作为数据库主键,即可去重。消费消息前,先去数据库查询这条消息的指纹码标识:
50 |
51 | - 不存在,就执行insert
52 | - 存在,代表已被消费,就不需要管了
53 |
54 | #### ② 利用Redis的原子性
55 |
56 | 需考虑:
57 |
58 | - 是否要数据落库。若落库,数据库和缓存如何做到原子性
59 | - 若不落库,都存储到缓存,如何设置定时同步策略
60 |
61 | 这里只提Redis原子性去解决MQ幂等性重复消费问题
62 |
63 | > MQ的幂等性问题,根本在于Pro未正常接收ACK,可能是网络抖动、网络中断导致
64 |
65 | ##### 实现
66 |
67 | Con消费开始时,将ID放入Redis BitMap。Pro每次生产数据时,从Redis的BitMap对应位置若不能取出ID,则生产消息发送,否则不进行消息发送。
68 |
69 | 有人说,万一Con、Pro的Redis命令执行失败咋办,虽然又出现重复消费又出现Redis非正常执行命令可能性极低,万一呢?可在Redis命令执行失败时,将消息落库,每日用定时器,对这种极特殊的消息进行处理。
--------------------------------------------------------------------------------
/docs/md/reactive/00-Spring响应式编程.md:
--------------------------------------------------------------------------------
1 | # 00-Spring响应式编程
2 |
3 | ## 1 为啥学习响应式编程
4 |
5 | - 随着微服务架构的不断发展
6 | - 以及各种中间件技术的日益成熟
7 | - 响应式编程所提供的异步非阻塞式编程模型
8 | - 非常适合用来构建技术驱动的服务化架构体系
9 |
10 | 对于开发人员而言,需要熟练使用这些基于响应式编程技术所构建的开源框架,来应对业务发展的需求。
11 |
12 | 网关工具 Spring cloud Gateway相比 Netflix 中提供的基于同步阻塞式模型的 Zuul 网关,其性能显著提升原因就是采用了异步非阻塞式的实现机制。
13 |
14 | 对于架构师而言:需要熟练掌握这些开源框架和中间件的核心原理以便更好地对框架进行维护、优化,甚至二次开发。
15 |
16 | Spring Cloud Netflix Hystrix组件HealthCountsStream类提供滑动窗口机制,完成对运行时请求数据的动态收集和处理。Hystrix实现这机制大量采用数据流处理方面技术及 RxJava 响应式编程框架。它代表一种新型编程模型,代表一种技术发展和演进的趋势,紧跟这趋势,对提升职业门槛是加分项。
17 |
18 | ## 2 教程设计
19 |
20 | 弥补此前基于 Spring5的响应式编程系统化学习的空白,系统化、由浅入深的学习路径。
21 |
22 | 不仅掌握响应式编程的全局,而且实战角度出发高效掌握基于 Spring 框架的响应式编程使用方法和开发技巧
23 |
24 | 
25 |
26 | ## 3 大纲
27 |
28 | 
29 |
30 | 
31 |
32 | 
33 |
34 | 
35 |
36 | 
37 |
38 | 
39 |
40 | 各个响应式编程核心组件以及基于 Spring 框架的实现方式我都会按照完整的案例分析,给出详细的代码实现方案方便你进行学习和改造。
41 |
42 |
43 | 在现代互联网应用系统开发过程中,即时响应是可用性和实用性的基石。需要引入新的架构模式和编程技术以满足不断增长的对便捷高效服务的需求,而响应式编程代表的就是这样一种全新的编程模型。
44 |
45 |
--------------------------------------------------------------------------------
/docs/md/redis/Redis的整数数组和压缩列表.md:
--------------------------------------------------------------------------------
1 | # Redis的整数数组和压缩列表
2 |
3 | ## 0 前言
4 |
5 | 整数数组、压缩列表的查找时间复杂度无很大优势,为啥Redis把它们作底层数据结构?
6 |
7 | ## 1 内存利用率
8 |
9 | 紧凑型数据结构,比链表占用内存少。毕竟大量数据存到内存,需尽可能优化提高内存利用率。
10 |
11 | 整数数组和压缩列表的entry都是实际的集合元素,一个挨一个保存,很节省内存空间:
12 |
13 | 
14 |
15 | ## 2 数组对CPU高速缓存支持更友好
16 |
17 | - 数组是连续内存空间
18 | - 局部性原理
19 |
20 | 所以集合数据元素较少时,默认采用内存紧凑排列方式存储,同时利用CPU高速缓存不会降低访问速度。
21 |
22 | 当数据元素超过设定阈值,为避免查询时间复杂度太高,转为哈希和跳表数据结构存储。
23 |
24 | CPU预读一个cache line大小数据,数组数据排列紧凑、相同大小空间保存的元素更多,访问下一个元素时,恰已在cpu缓存。若随机访问,就不能充分利用cpu缓存。如int元素,一个4byte,CacheLine默认64byte,可预读16个挨着的元素,若下次随机访问的元素不在这16个元素,就需重新从内存读取。
25 |
26 | Redis底层使用数组和压缩链表对数据大小限制在64个字节以下,当大于64个字节会改变存储数据的数据结构,所以随机访问对CPU高速缓存没啥影响。
27 |
28 | Redis List底层使用压缩列表,本质是将所有元素紧凑存储,所以分配的是一块连续内存空间,虽然数据结构本身没有时间复杂度优势,但:
29 |
30 | - 节省空间
31 | - 也避免一些内存碎片
32 |
33 | 因为按照一个cache line加载进cpu cache 按照当代cpu指令周期来看随机遍历的花销可忽略不计。
34 |
35 | 当一个缓存行无法加载完ziplist时,因为redis内部hash存储的是指针,也就是逻辑成环, 所以CPU加载开销无法忽视。此时只能转别的数据结构来解决,如skiplist。
36 |
37 | 参考:
38 |
39 | - https://www.bigocheatsheet.com/
--------------------------------------------------------------------------------
/docs/md/risk-control/coupon-distribution-risk-control-challenges.md:
--------------------------------------------------------------------------------
1 | # 02-发券风控难题
2 |
3 | 其实风控并不遥远,防止超卖就是一种。传统风控不行了。
4 |
5 | 代码不严谨,无门槛优惠券场景下引发的业务逻辑漏洞
6 |
7 | ## 1 发券漏洞
8 |
9 | 无门槛优惠券场景下发券漏洞:
10 |
11 | - 无门槛优惠券没有限制总数
12 | - 无门槛优惠券没有严格限制领取资格
13 | - 无门槛优惠券不知道哪些用户(身份核实)领取了券
14 |
15 | ## 2 用券漏洞
16 |
17 | 1.使用券时,没有核验用户的异常行为特征
18 | 2.使用券时,没有横向比较用户的历史下单信息
19 | 3.使用券时,没有核验异常用户的共同特征
20 |
21 | ## 3 库存漏洞
22 |
23 | - 没有在库存机制设定一个上限
24 | - 订单进入待发货状态时,没有再做一次订单核验
25 |
26 | ## 4 监控漏洞
27 |
28 | 订单实时数据指标监控和警报没有做好
29 |
30 | ## 5 运营漏洞
31 |
32 | 优惠券人工设置,没有控制权限
33 | 优惠券人工设置,没有大于1次的审核机制
--------------------------------------------------------------------------------
/docs/md/risk-control/coupon-fraud-grey-market-chain.md:
--------------------------------------------------------------------------------
1 | # 01-羊毛党灰产链路
2 |
3 | 能产生利益的地方,就离不开黑灰产。
4 |
5 | 即使利润很低,黑灰产依然会想办法通过机器,批量操作来规模获利。
6 |
7 | 假设我是羊毛党,去刷无门槛优惠券获利,需要经过哪些步骤?
8 |
9 | 1. 搜集优惠信息:新手福利,优惠券,红包...
10 | 2. 数量庞大的账号:通过这些账号去批量拿优惠券
11 | 3. 自动的拿优惠券:一个账号拿一张优惠券,不可能手动
12 | 4. 销赃渠道:批量获取优惠券就是为了获利
13 |
14 | 
15 |
16 |
17 |
18 | 
19 |
20 |
21 |
22 | 
--------------------------------------------------------------------------------
/docs/md/risk-control/flink-real-time-risk-control-system-overview.md:
--------------------------------------------------------------------------------
1 | # 00-Flink实战实时风控系统专栏概述
2 |
3 | Flink 核心技能实操 + 亿级数据性能调优 + Groovy 动态规则引擎实践
4 |
5 | 大数据开发进阶必备,从0到1搭建基于Flink + Groovy 实现动态规则的优惠券场景风控系统。
6 |
7 | ## 你将学到
8 |
9 | - 提升架构设计思维与能力
10 | - 构建 Flink 核心技能体系
11 | - 积累亿级数据实时处理经验
12 | - 实践 Flink 动态规则引擎
13 | - 具备生产环境故障处理能力
14 | - 解锁Flink 生态框架整合技巧
15 |
16 | ## 专栏简介
17 |
18 | 黑灰产问题日益突出,“风控”已成大多数公司基础业务之一。能设计并架构风控体系,是大数据工程师重要竞争力。
19 |
20 | 本专栏基于 Flink+ Groovy 构建风控系统,以生产视角带你掌握风控体系设计的核心要素、Flink 实用技能、优化技巧、故障处理策略等高阶技能,并融合贯通运用到实际工作中,助力提升你的架构设计思维和代码实践能力,少走弯路,加速职业发展。
21 |
22 | ## FAQ
23 |
24 | Q:没有大数据的基础能学吗,目前的话只要做的是java开发
25 |
26 | A:能,专栏重点flink ,是完全基础开始学习,使用Java ,不涉及其他大数据组件,所以只掌握 java 是完全能够学习!
27 |
28 | 
29 |
30 |
31 |
32 |
33 |
34 | 
35 |
36 |
37 |
38 | 
39 |
40 |
41 |
42 | 
43 |
44 |
45 |
46 | 
47 |
48 |
49 |
50 | 
51 |
52 |
53 |
54 | 
55 |
56 | ## 分析问题比解决问题重要
57 |
58 | 明确需要解决的问题 ->解决方案 ->架构设计 ->技术实现
59 |
60 |
--------------------------------------------------------------------------------
/docs/md/risk-control/reasons-for-choosing-groovy-for-risk-control-engine.md:
--------------------------------------------------------------------------------
1 | # 06-风控规则引擎选用Groovy的原因
2 |
3 | ## 0 前言
4 |
5 | 在当今的电商行业中,风控系统是保障平台安全、防范欺诈行为的关键组成部分。随着大数据和实时计算技术的发展,Flink 作为一种高效的流处理框架,被广泛应用于电商大厂的风控系统中。而在 Flink 的风控规则引擎中,Groovy 作为一种动态脚本语言,被选为主要规则定义和执行的语言。本文将探讨为何电商大厂在 Flink 风控规则引擎中选用 Groovy,并分析其优势。
6 |
7 | 
8 |
9 | ```groovy
10 | if (规则1 && 规则2 || 规则3) {
11 | // 列入可疑名单
12 | } else {
13 | // TO DO
14 | }
15 | ```
16 |
17 | 若又来需求了呢?
18 |
19 | ```groovy
20 | if (规则1 && 规则2 || 规则3)
21 | // 列入可疑名单
22 | if (规则4 || 规则5)
23 | // 列入可疑名单
24 | else
25 | // TO DO
26 | ```
27 |
28 | ### 缺点
29 |
30 | - 臃肿难维护
31 | - 可读性差
32 | - 无法实时修改,重新打包部署
33 |
34 |
35 |
36 | 抛弃 if-else,拥抱规则引擎
37 | 风控规则本质上是通过AND、OR等逻辑运算组成的规则集,风控规则往往是一个复杂且不断变化的规则组合。
38 |
39 | ## 1 引入规则引擎
40 |
41 |
42 |
43 | 
44 |
45 | ### 1.1 风险规则编写痛点
46 |
47 | - 风险规则变动频率高,组合复杂,数量多
48 | - If-else 越写越长
49 | - 因为是硬编码,即使很小的改动,也要经常重启系统
50 |
51 | ### 1.2 规则引擎如何解决痛点
52 |
53 | - 不再是 If-else 流程分支,而是交给规则引擎执行
54 | - 规则文件可预加载
55 | - 规则变更,直接修改规则文件,动态加载,无需重启系统
56 | - 规则的变更,可直接给运营修改
57 |
58 | ## 2 规则引擎技术选型
59 |
60 | - Groovy,学习门槛低
61 | - Drools
62 |
63 | ## 3 为啥选择Groovy
64 |
65 | ### 3.1 动态语言特性
66 |
67 | Groovy 是一种基于 JVM 的动态语言,它结合了 Java 的语法和动态语言的特性。在风控规则引擎中,规则的更新和调整是频繁且必要的,而 Groovy 的动态特性使得规则的修改和部署变得更加灵活和便捷。Java 程序员可以利用 Groovy 的动态特性,在运行时修改和加载规则,而无需重启整个应用,大大提高了系统的响应速度和灵活性。
68 |
69 | ### 3.2 无缝集成 Java
70 |
71 | Groovy 与 Java 有着天然的兼容性,Groovy 代码可以无缝集成到 Java 应用中。对于电商大厂而言,其技术栈大多以 Java 为主,选用 Groovy 作为规则引擎的语言,可以充分利用现有的 Java 生态系统和开发资源,减少学习成本和开发成本。Java 程序员可以轻松地将 Groovy 脚本嵌入到现有的 Flink 作业中,实现规则的动态执行。
72 |
73 | ### 3.3 强大的元编程能力
74 |
75 | Groovy 提供了强大的元编程能力,包括元对象协议(MOP)和运行时元编程。这使得开发者可以在运行时动态地创建类、方法和属性,极大地增强了规则引擎的灵活性和扩展性。在风控系统中,新的欺诈模式和风险行为不断出现,Groovy 的元编程能力可以帮助快速响应这些变化,实现规则的快速迭代和更新。
76 |
77 | ### 3.4 简洁的语法
78 |
79 | Groovy 的语法比 Java 更加简洁和易读,减少样板代码,提高开发效率。对于复杂的规则逻辑,Groovy 的简洁语法可以使得规则的编写和维护变得更加容易。此外,Groovy 支持闭包、集合字面量等现代编程语言特性,使得规则的表达更加直观和高效。
80 |
81 | ### 3.5 成熟的生态系统
82 |
83 | Groovy 拥有一个成熟的生态系统,包括大量的第三方库和工具支持。在风控规则引擎的开发和维护过程中,可以利用这些现成的库和工具,加速开发进程,提高系统的稳定性和可靠性。例如,Groovy 可以与 Spring 框架无缝集成,利用 Spring 的依赖注入和 AOP 功能,进一步增强规则引擎的功能和性能。
84 |
85 | ## 4 总结
86 |
87 | 对于 Java 程序员而言,掌握 Groovy 不仅可以提升个人的技术能力,还能在实际项目中发挥更大的价值。
--------------------------------------------------------------------------------
/docs/md/road-map/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/road-map/todo.md
--------------------------------------------------------------------------------
/docs/md/seata/01-Seata客户端依赖坐标引入与踩坑排雷.md:
--------------------------------------------------------------------------------
1 | # 01-Seata客户端依赖坐标引入与踩坑排雷
2 |
3 | ## 1 官方推荐配置
4 |
5 | spring-cloud-starter-alibaba-seata推荐依赖配置方式
6 |
7 | ```xml
8 |
9 | io.seata
10 | seata-spring-boot-starter
11 | 1.5.2
12 |
13 |
14 |
15 | com.alibaba.cloud
16 | spring-cloud-starter-alibaba-seata
17 | 最新版本
18 |
19 |
20 | io.seata
21 | seata-spring-boot-starter
22 |
23 |
24 |
25 | ```
26 |
27 | 为啥这样呢?先看
28 |
29 | ## 2 逆官网配置
30 |
31 |
32 |
33 | ```xml
34 |
35 | com.alibaba.cloud
36 | spring-cloud-starter-alibaba-seata
37 |
38 | ```
39 |
40 | 刷新 maven,可见依赖的 1.4.2 版本:
41 |
42 | 
43 |
44 | ## 3 调整路线
45 |
46 | 但我们要用最新 1.5.2 版本,就要调整,先排除原有依赖:
47 |
48 | ```xml
49 |
50 | com.alibaba.cloud
51 | spring-cloud-starter-alibaba-seata
52 |
53 |
54 | io.seata
55 | seata-spring-boot-starter
56 |
57 |
58 |
59 | ```
60 |
61 | 再加段配置:
62 |
63 | ```xml
64 |
65 | io.seata
66 | seata-spring-boot-starter
67 | 1.5.2
68 |
69 | ```
70 |
71 | 完成:
72 |
73 | 
74 |
75 |
--------------------------------------------------------------------------------
/docs/md/seata/02-Seata客户端全局事务配置与实现.md:
--------------------------------------------------------------------------------
1 | # 02-Seata客户端全局事务配置与实现
2 |
3 | 根据 [官方文档](https://seata.io/zh-cn/docs/ops/deploy-guide-beginner.html):
4 |
5 | 
6 |
7 | 这也是 1.4 和 1.5 的区别。
8 |
9 | https://github.com/seata/seata/tree/master/script/client/conf:
10 |
11 | 
12 |
13 | ## yml 配置
14 |
15 | ```yml
16 | seata:
17 | enabled: true
18 | ```
19 |
20 | 注意如下默认配置,我们需要定制化修改:
21 |
22 | 
23 |
24 | ```yml
25 | seata:
26 | enabled: true
27 | tx-service-group: javaedge_tx_group
28 | service:
29 | vgroup-mapping:
30 | javaedge_tx_group: SEATA_GROUP
31 | grouplist:
32 | SEATA_GROUP: localhost:8091
33 | config:
34 | nacos:
35 | server-addr: localhost:8848
36 | username: nacos
37 | password: nacos
38 | registry:
39 | nacos:
40 | server-addr: localhost:8848
41 | username: nacos
42 | password: nacos
43 | ```
44 |
45 | 还没完:
46 |
47 | ```
48 | config:
49 | nacos:
50 | server-addr: localhost:8848
51 | username: nacos
52 | password: nacos
53 | registry:
54 | nacos:
55 | server-addr: localhost:8848
56 | username: nacos
57 | password: nacos
58 | ```
59 |
60 |
--------------------------------------------------------------------------------
/docs/md/seata/03-Seata柔性事务.md:
--------------------------------------------------------------------------------
1 | # 03-Seata柔性事务
2 |
3 | ## 1 核心概念
4 |
5 | AT 事务的目标是在微服务架构下,提供增量的事务 ACID 语意,让开发者像使用本地事务一样,使用分布式事务,核心理念同ShardingSphere。
6 |
7 | Seata AT 事务模型包含:
8 |
9 | - TM事务管理器:全局事务的发起方,负责全局事务开启,提交和回滚
10 |
11 | - RM资源管理器:全局事务的参与者,负责分支事务的执行结果上报,并通过 TC 的协调进行分支事务的提交和回滚
12 |
13 | - TC事务协调器
14 |
15 | TC是独立部署的服务,TM、RM 以 jar 包同业务应用一同部署,它们同 TC 建立长连接,整个事务生命周期内,保持远程通信。
16 |
17 | Seata 管理的分布式事务的典型生命周期:
18 |
19 | 1. TM 要求 TC 开始一个全新的全局事务。TC 生成一个代表该全局事务的 XID。
20 | 2. XID 贯穿于微服务的整个调用链。
21 | 3. 作为该 XID 对应到的 TC 下的全局事务的一部分,RM 注册本地事务。
22 | 4. TM 要求 TC 提交或回滚 XID 对应的全局事务。
23 | 5. TC 驱动 XID 对应的全局事务下的所有分支事务完成提交或回滚。
24 |
25 | Seata AT事务模型:
26 |
27 | 
28 |
29 | ## 2 实现原理
30 |
31 | 整合 Seata AT 事务时,需将 TM,RM 和 TC 的模型融入ShardingSphere的分布式事务生态。
32 |
33 | 在数据库资源上,Seata 通过对接 `DataSource` 接口,让 JDBC 操作可以同 TC 进行远程通信。 ShardingSphere 也面向 `DataSource` 接口,对用户配置的数据源进行聚合。 因此,将 `DataSource` 封装为 基于Seata 的 `DataSource` 后,就可将 Seata AT 事务融入到ShardingSphere的分片生态中。
34 |
35 | 
36 |
37 | ### 引擎初始化
38 |
39 | 包含 Seata 柔性事务的应用启动时,用户配置的数据源会根据 `seata.conf` 的配置,适配为 Seata 事务所需的 `DataSourceProxy`,并且注册至 RM。
40 |
41 | ### 开启全局事务
42 |
43 | - TM 控制全局事务的边界,TM 通过向 TC 发送 Begin 指令,获取全局事务 ID
44 | - 所有分支事务通过此全局事务 ID,参与到全局事务中
45 | - 全局事务 ID 的上下文存放在当前线程变量
46 |
47 | ### 执行真实分片SQL
48 |
49 | 处于 Seata 全局事务中的分片 SQL 通过 RM 生成 undo 快照,并发送 `participate` 指令至 TC,加入全局事务。
50 |
51 | 由于 ShardingSphere 的分片物理 SQL 采取多线程,因此整合 Seata AT 事务时,需要在主线程、子线程间进行全局事务 ID 的上下文传递。
52 |
53 | ### 提交或回滚事务
54 |
55 | 提交 Seata 事务时,TM 会向 TC 发送全局事务的提交或回滚指令,TC 根据全局事务 ID 协调所有分支事务进行提交或回滚。
56 |
57 | ## 3 使用规范
58 |
59 | ### 支持项
60 |
61 | - 支持数据分片后的跨库事务;
62 | - 支持RC隔离级别;
63 | - 通过undo快照进行事务回滚;
64 | - 支持服务宕机后的,自动恢复提交中的事务。
65 |
66 | ### 不支持项
67 |
68 | - 不支持除RC之外的隔离级别。
69 |
70 | ### 待优化项
71 |
72 | - Apache ShardingSphere 和 Seata 重复 SQL 解析。
--------------------------------------------------------------------------------
/docs/md/sideline/20-个人支付解决方案.md:
--------------------------------------------------------------------------------
1 | # 20-个人支付解决方案
2 |
3 | AI 时代,先忽略繁琐的开发环节,先谈谈变现。绝大部分支付方案都面向企业,面向个人的正规支付方案很少。对没注册公司的个人,咋才能安全收款?
4 |
5 | ## 1 常见的几种个人收款方式
6 |
7 | ### 1.1 个人收款码
8 |
9 | 市面上最简单粗暴的个人收款方案:利用微信或支付宝的个人收款码来做。
10 |
11 | 就是生成一张二维码,在这二维码上面添加一个付款备注,让用户备注中补充上特定的消息后(如订单号)支付。完成支付,就通过APP或网站,得到备注里填的消息,通过识别,就能定位到订单,自动发货。也有不用备注,用支付金额来识别的。
12 |
13 | 这个方式淘宝店家很熟练了,它的问题在于:
14 |
15 | - 用户端体验,需填写额外消息或发送不确定的金额
16 | - 商家端体验,它要有一个常驻服务,时刻监测收款的相关消息,这就有相当的不稳定因素
17 |
18 | ### 1.2 二次封装接口
19 |
20 | 由那些有资质的企业申请到接口权限后,二次封装后提供给个人来用。
21 |
22 | 问题在于,钱是支付给提供接口的企业的,我们只能定期找他们结算提款。万一对方跑路,我们的钱也没了。这种方式风险非常高,不推荐。
23 |
24 | ### 1.3 小微商户
25 |
26 | 支付平台针对个人、也就是大量没有企业资质的用户推出的一个解决方案。最开始推出是为帮助一些线下店面,快捷地接入支付而存在的一个服务,然后又扩展到了网上网店和商家。
27 |
28 | 一些银行和微信都有这服务。但是微信并没有给它做专门的后台页面,所以我们在支付平台的后台里是看不见它的,它只有API。
29 |
30 | 微信把这一部分业务,交给了微信开放平台上的服务商。由服务商去调用这些接口来帮助个人接入到微信的支付服务里面来,同时服务商会提供后台的页面帮个人用户进行管理、也是服务商封装API供个人使用。
31 |
32 | 好处在于完全合规,而且这个钱是从微信直接打到小微商户的银行卡里边,不经中间服务商,非常安全。
33 |
34 | 有命的如 xorpay.com 和 payjs.cn 。都是收费服务,前者的费用似乎更为便宜一些。使用之前请自行判断其靠谱系数。
35 |
36 | ## 2 数字内容销售平台
37 |
38 | 如我们就是写个软件,想简单进行销售获得收入的话,还可用一些现成的数字内容销售平台:
39 |
40 | - 面向国外市场,可用Gumroad.com
41 | - 面向国内市场,可用mianbaoduo.com
42 |
43 |
44 |
45 | 逻辑上,所有网店都能解决卖软件的需求,但相对而言,面包多这类专门面向数字商品的平台提供了更低的手续费和更为全面的 API 接口。
46 |
47 | 
--------------------------------------------------------------------------------
/docs/md/sideline/21-处理用户反馈和增长优化.md:
--------------------------------------------------------------------------------
1 | # 21-处理用户反馈和增长优化
2 |
3 | # 1 使用「兔小巢」处理用户反馈
4 |
5 | 管理用户反馈的产品很多,但大部分收费;介绍个腾讯出品的免费工具「兔小巢」。
6 |
7 | 
8 |
9 | 该产品最大用户就是腾讯自己,原叫「吐个槽」,后来升级并更名为「兔小巢」:
10 |
11 | - 用户端,支持微信和QQ登入,能及时推送回复通知
12 | - 运营端,明显感受到这是一款看似简单,功能却相当强大的产品。如可设置移动端的展示方式;可适配大型产品和通用产品;默认发帖可隐藏,也就可以当做工单使用;甚至还配备团队博客和知识库
13 | - 不足在于,提供的 API 较少,但也够在自己产品中展示用户反馈了
14 |
15 | 有了它,我觉得大部分情况下,就不用再去购买同类的付费产品。
16 |
17 | 分享一些整合细节供参考。
18 |
19 | ## 链接跳转
20 |
21 | 提供非常浅的整合,不管 Web 还是 APP 中,都是通过网页转向方式进行。通过设置,在反馈区上方可以显示一个链接,供用户返回到产品。
22 |
23 | ## 状态登入
24 |
25 | 通过链接跳转会遇到问题:我们的产品和兔小巢之间,用户的登录状态会丢失,我们就不知道那个反馈是哪一个用户提交的。
26 |
27 | 为此,兔小巢提供[tucao.js](https://txc.qq.com/helper/configLogonState),让我们可以在跳转时传递用户的登录态,从而实现用户统一。
28 |
29 | ## 反馈数据整合
30 |
31 | 默认,我们只能点击链接后,在单独的页面上才能看到反馈信息。但通过兔小巢提供的 [API](https://txc.qq.com/helper/usrFetchAPIGuide),可直接在产品中显示反馈内容。
32 |
33 | # 2A3R漏斗和增长优化
34 |
35 | ## 啥是 2A3R 漏斗?
36 |
37 | 又叫 AARRR 漏斗,描述用户转化的结构。
38 |
39 | 
40 |
41 | 一个五层结构,分别是:
42 |
43 | 1. 获客层
44 | 2. 激活层
45 | 3. 留存层
46 | 4. 推荐层
47 | 5. 付费层
48 |
49 | 用户由上至下逐步转化,直至完成付费。其中,留存层、推荐层和付费层可以是并列的,因为用户激活以后,立刻就可以付费、推荐好友。
50 |
51 | ## 使用 2A3R 漏斗进行业务优化
52 |
53 | 2A3R 漏斗的现实意义在于,它促使我们从结果出发,去反向优化前边各个环节的转化率。
54 |
55 | 如福利单词项目的销售额定为 1000 套,那么就是说最终到达付费层的用户有 1000 人。而在付费层上至少还有获客层、激活层。
56 |
57 | 把获客指标定义为「访问网站」;把激活指标定义为「用户登入」。假设每一层的转化率是 10%,那么访问我们产品的用户数需要达到:
58 | $$
59 | 1000 * 100 = 10 万人
60 | $$
61 | 优化方向包括:
62 |
63 | 1. 加大推广力度,让访问人数从十万变成一百万,这样就能卖掉一万套软件了。
64 | 2. 优化「用户登入」环节,在微信里边做成自动登录,这样把原来 10% 的激活转化提高为 30%,这样即使依然是 10 万访客,销售额也会变为 3000 套。
65 | 3. 强化「付费转化」环节,给第一次访问的用户一个限时折扣,比如 1 个小时内购买,买一送一。如果能拉升 10% 的支付转化,我们的销售也会上升。
66 |
67 | ## 留存层优化
68 |
69 | 主要用于一些基于高粘度增长引擎的业务,或者免费+付费模式的产品。在这些模式下,用户需要经过很长时间的使用,才会付费。如果留存做不好,用户熬不到付费那天。
70 |
71 | 对于福利单词而言,留存层优化可以通过推送通知、定时提醒等功能来做。因为背单词本来就是一个周期性行为,所以我们有足够的理由去召回用户。
72 |
73 | ## 推荐层优化
74 |
75 | 现在的流量已经是非常贵的了,所以我们必须珍惜每一滴流量。通过旧用户带来新用户,可以为我们提供免费流量;如果做得足够好,流量甚至能像滚雪球一样不断变大。这就是推荐层优化要做的事情。
76 |
77 | 在我们的应用中,我们可以选择几个用户情绪高涨的点来做分享触发:
78 |
79 | 1. 完成当天的背单词目标,比如背了 100 个单词
80 | 2. 完成有挑战的任务,比如连续 30 个单词不出错
81 | 3. 看到赏心悦目的图片,比如看到超级呆萌的猫
82 |
83 | 在这些时刻,我们都可以引导用户通过海报来分享他们的激动心情,同时为我们带来新的用户。
84 |
85 | ## 推荐阅读
86 |
87 | 增长优化推荐两本书:
88 |
89 | - 肖恩·埃利斯的《增长黑客》,系统化地讲述了如果建立增长实验机制并从中受益
90 | - 《病毒循环》,记录了众多流量传奇
91 |
92 | 它们中很多细节和技巧,都可以用到我们的副业当中。
--------------------------------------------------------------------------------
/docs/md/sideline/22-大纲的注意点.md:
--------------------------------------------------------------------------------
1 | # 22-大纲的注意点
2 |
3 | 这一节我们来讲大纲。大纲大家都会做,所以我们不全面的展开,只挑其中一些需要注意的点和大家交流。
4 |
5 | ## 1 条理性
6 |
7 | 最重要的一点,就是大纲一定要有条理性。如果在条例性上做得不够好,其他细节做得再好,这个课做出来在逻辑上也是乱的,最后学起来就会很别扭。
8 |
9 | 具体来说,我们要保证大纲的层次足够清楚,逻辑足够严密。有一个比较常用的结构推荐给大家,尤其适合知识性为课程。
10 |
11 | ### 1.1 三段式
12 |
13 | 这个结构分成三段,是一个总、分、总的结构。
14 |
15 | #### 总
16 |
17 | 在课程的最开始,我们会简明扼要地讲明白整个课程包含哪些内容;课程中的一些基础、原理也会放到这里。
18 |
19 | #### 分
20 |
21 | 之后呢,我们就可以按照章节进行展开,对每一个部分进行详细地讲解。
22 |
23 | #### 总
24 |
25 | 在最后我们会进行一个总结,同时放入一个大的实践章节。这样不但可以复习内容,还可以学以致用。当然在每一章结尾也可以安排小实践内容。
26 |
27 | 绝大部分以知识讲授为主的课程都可以采用这种总分总的结构,非常好用。
28 |
29 | ### 1.2 提问式
30 |
31 | 我们也可以用问问题的方式来引出我们的每一部分结构。比如「是什么」——「为什么」——「怎么做」。这种结构可以是全局的,也可以是针对每一部分的。它会让我们的逻辑和层次更清晰。
32 |
33 | ## 2 覆盖面
34 |
35 | 第二个需要注意的点是覆盖面。因为我们的课程往往是出于自己的实践经验,有时候会局限于我们所在的公司和所在的行业节点,它的覆盖不一定特别的全。所以我们的视角不一定能覆盖到所有的需求方。
36 |
37 | 有时候我们的课程是为了一类人做的,但另外一类人,实际上也可以学习我们的课程,就差一点点的周边知识。在这种情况下,如果我们可以注意到大纲的覆盖面,把缺少的那点知识补上,就可以扩大受众,让我们的销售变得更为容易。
38 |
39 | 那具体怎么保证大纲的覆盖面呢?
40 |
41 | 那首先大纲应该覆盖该领域的主要内容,这些内容通常来源于以下几个地方:
42 |
43 | 1. 官方文档:官方会处理几乎所有来自社区和其他客户的需求,即使一些边缘的需求,因为囤积的时间比较长,也会慢慢地累积起来,所以一般来讲官方资料的覆盖度是最为全面的
44 | 2. 行业的权威文档:虽然不是官方出品的,但因为日积月累它最后可能变成了事实标准,也是我们作为参考的一个主要来源
45 | 3. 图书:这也是大参考源,对于经典知识来讲,一些销量比较好的图书,会经过多次的再版,并会加入一些之前没有覆盖的内容。使用微信读书的无限卡,无需购买就可以直接搜索大量计算机图书,对查资料来讲非常好用
46 | 4. 同类课程:国外的同类课程往往也是非常好的参考,尤其是面向新技术的课程
47 |
48 | 然后呢,我们的大纲应该覆盖该领域最频繁出现的问题,那我们到什么地方找问题呢?
49 |
50 | 1. 搜索关键词
51 | 2. 专业问答网站,比如 stackoverflow.com
52 | 3. GitHub 的 issue 区
53 | 4. 课程平台的答疑区
54 |
55 | ## 3 粒度
56 |
57 | 除了条例性和覆盖面,那我们最后,而且其实也是非常想强调的一个问题,就是大家一定要注意我们大纲的粒度。
58 |
59 | 大纲这名字听起来就像一个目录,很具备误导性。很多同学做大纲的时候,通常做两个层次就算是做得细的了。事实上,大纲的粒度越细,课程的品质就越可控,后期制作起来速度就越快。而且我们要拿大纲去做预售来验证需求,它越细,验证的效果就越好。
60 |
61 | 所以呢,建议大家把大纲至少细化到段落这个级别,同时把段落以下的一些知识点所涉及到的素材和资料,全部都整理到这个节点上去。
62 |
63 | 这里推荐大家使用 Dynalist 这种无限分级的树状笔记软件来做大纲,会特别方便。
--------------------------------------------------------------------------------
/docs/md/spark/00-为啥要学习Spark Streaming.md:
--------------------------------------------------------------------------------
1 | # 00-为啥要学习Spark Streaming
2 |
3 | 本专栏从实时数据产生和流向的各个环节出发,通过集成主流的:
4 |
5 | - 分布式日志收集框架Flume
6 | - 分布式消息队列Kafka
7 | - 分布式列式数据库HBase
8 | - 当前非常火爆的Spark Streaming
9 |
10 | 打造实时流处理项目实战,让你掌握实时处理的整套处理流程,达到大数据中级研发工程师的水平!
11 |
12 | ## 前提
13 |
14 | 适合有编程基础,想转行投身大数据行业的工程师,对你的学习能力及基础要求如下:
15 |
16 | 1、熟悉常用Linux命令的使用
17 |
18 | 2、掌握Hadoop、Spark的基本使用
19 |
20 | 3、至少熟悉一门编程语言Java/Scala/Python
21 |
22 | #### 基于Flume+Kafka+Spark Streaming打造企业大数据流处理平台
23 |
24 | 流行框架打造通用平台,直接应用于企业项目:
25 |
26 | - 处理流程剖析
27 | - 日志产生器
28 | - 使用Flume采集日志
29 | - 将Flume收集到的数据输出到Kafka
30 | - Spark Streaming消费Kafka的数据进行统计
31 | - Spark Streaming如何高效的读写数据到Hbase
32 | - 本地测试和生产环境使用的拓展
33 | - Java开发Spark要点拓展
34 |
35 | ## 原理+场景,彻底搞懂Spark Streaming
36 |
37 | 全面了解Spark Streaming的特性及场景应用,完成各个不同维度的统计分析。
38 |
39 | #### 日志收集框架Flume
40 |
41 | Flume架构及核心组件
42 |
43 | Flume&JDK环境部署
44 |
45 | Flume实战案例
46 |
47 | #### 分布式消息队列Kafka
48 |
49 | Kafka架构及核心概念 / Zookeeper安装
50 |
51 | Kafka单、多broker部署及使用
52 |
53 | Kafka Producer Java API编程
54 |
55 | Kafka Consumer Java API编程
56 |
57 | #### 1.入门
58 |
59 | Spark Streaming概述及应用场景
60 |
61 | Spark Streaming集成Spark生态系统使用
62 |
63 | 从词频统计功能着手入门Spark Streaming
64 |
65 | Spark Streaming工作原理(粗/细粒度)
66 |
67 | #### 2.核心
68 |
69 | StreamingContext/Dstream
70 |
71 | Input DStreams和Receivers
72 |
73 | Transformation和Output Operations
74 |
75 | Spark Streaming处理socket/文件系统数据
76 |
77 | #### 3.进阶
78 |
79 | updateStateByKey算子的使用
80 |
81 | 统计结果写入到MySQL数据库
82 |
83 | 窗口函数的使用、黑名单过滤
84 |
85 | Spark Streaming整合Spark SQL操作
86 |
87 | #### Streaming整合Flume
88 |
89 | Push和Pull两种方式介绍
90 |
91 | 与Flume Agent配置
92 |
93 | 本地、服务器环境联调
94 |
95 | 整合Spark Streaming应用开发
96 |
97 | #### Streaming整合Kafka
98 |
99 | 版本选择详解
100 |
101 | Receiver和Direct两种方式
102 |
103 | 本地、服务器环境联调
104 |
105 | 整合Spark Streaming应用开发及测试
106 |
107 | ## 总结
108 |
109 | 渐进式学习让你彻底学会整套流程的开发
110 |
111 | 需求分析 → 数据清洗 → 数据统计分析 → 统计结果入库 → 数据可视化
--------------------------------------------------------------------------------
/docs/md/spark/01-Spark Streaming专栏概述.md:
--------------------------------------------------------------------------------
1 | # 01-Spark Streaming专栏概述
2 |
3 | ## 1 实战目标
4 |
5 | - 至今专栏的访问量
6 | - 至今从搜索引擎引流过来的专栏的访问量
7 |
8 | ## 2 实战流程
9 |
10 | 
11 |
12 | ## 3 可视化显示
13 |
14 | - 使用Spring Boot整合Echarts
15 | - 阿里云DataV数据可视化框架
16 |
17 | ## 4 教程概要
18 |
19 | - 初识实时流处理
20 | - 日志收集框架Flume
21 | - 消息队列Kafka
22 | - 实战环境搭建
23 | - Spark Streaming入门
24 | - Spark Streaming进阶
25 | - Spark Streaming集成Kafka
26 | - Spark Streaming集成Flume
27 |
28 | ## 5 计划
29 |
30 | - 整合Flume、Kafka、 Spark Streaming打造通用的流处理平台基础
31 | - Spark Streaming项目实战
32 | - 数据处理结果可视化
33 | - 拓展
34 |
35 | ## 6 前提
36 |
37 | - 熟悉Linux基本命令
38 | - 熟悉Scala/Python/Java
39 | - 有Hadoop和Spark基础
40 |
41 | ## 7 环境
42 |
43 | - JDK : 1.8
44 | - Hadoop: CDH ( 5.7 )
45 | - Scala : 2.12
46 | - Spark: 2.4.1
--------------------------------------------------------------------------------
/docs/md/spark/02-Spark Streaming小试流式处理.md:
--------------------------------------------------------------------------------
1 | # 02-Spark Streaming小试流式处理
2 |
3 | ## 1 业务分析
4 |
5 | ### 1.1 需求
6 |
7 | 统计主站每个(指定)教程访问的客户端、地域信息分布
8 |
9 | 地域: ip转换 Spark SQL项目实战
10 | 客户端:useragent获取 Hadoop基础教程
11 |
12 | =》如上两个操作:采用离线(Spark/MapReduce )的方式进行统计
13 |
14 | ### 1.2 实现步骤
15 |
16 | 课程编号、ip信息、useragent
17 | 进行相应的统计分析操作: MapReduce/Spark
18 |
19 | ### 1.3 项目架构
20 |
21 | 日志收集: Flume
22 | 离线分析: MapReduce/Spark
23 | 统计结果图形化展示
24 |
25 | 看起来很简单,没什么高深的,但是现在需求改了嘛,很正常的骚操作对不对!
26 | 现在要求实时的精度大幅度提高!那么现在的架构已经无法满足需求了!
27 |
28 | #### 1.3.1 问题
29 |
30 | 小时级别
31 | 10分钟
32 | 5分钟
33 | 1分钟
34 | 秒级别
35 | 根本达不到精度要求!
36 |
37 | 实时流处理,应运而生!
38 |
39 | ## 2 实时流处理产生背景
40 |
41 | ◆ 时效性高
42 | ◆ 数据量大
43 |
44 | ◆ 实时流处理架构与技术选型
45 |
46 | ## 3 实时流处理概述
47 |
48 | - 实时计算:响应时间比较短。
49 | - 流式计算:数据不断的进入,不停顿。
50 | - 实时流式计算:在不断产生的数据流上,进行实时计算
51 |
52 | ## 4 离线计算与实时计算对比
53 |
54 | ### 4.1 数据来源
55 |
56 | 离线:HDFS历史数据,数据量较大。
57 | 实时:消息队列(Kafka),实时新增/修改记录实时过来的某一笔数据。
58 |
59 | ### 4.2 处理过程
60 |
61 | 离线:Map + Reduce
62 | 实时:Spark(DStream/SS)
63 |
64 | ### 4.3 处理速度
65 |
66 | 离线:速度慢
67 | 实时:快速拿到结果
68 |
69 | ### 4.4 进程角度
70 |
71 | 离线:启动 + 销毁进程
72 | 实时: 7 * 24小时进行统计,线程不停止
73 |
74 | ## 5 实时流处理架构与技术选型
75 |
76 |
77 |
78 | 
79 |
80 | - Flume实时收集WebServer产生的日志
81 | - 添加Kafka,进行流量消峰,防止Spark/Storm崩掉
82 | - 处理完数据,持久化到RDBMS/NoSQL
83 | - 最后进行可视化展示
84 |
85 | Kafka、Flume一起搭配更舒服哦~
86 |
87 | ## 6 实时流处理应用
88 |
89 | - 电信行业:推荐流量包
90 | - 电商行业:推荐系统算法
--------------------------------------------------------------------------------
/docs/md/spark/06-RDD与DataFrame的互操作.md:
--------------------------------------------------------------------------------
1 | # 06-RDD与DataFrame的互操作
2 |
3 | ```scala
4 | val spark = SparkSession.builder()
5 | .master("local").appName("DatasetApp")
6 | .getOrCreate()
7 | ```
8 |
9 | Spark SQL支持两种不同方法将现有RDD转换为DataFrame:
10 |
11 | ## 1 反射推断
12 |
13 | 包含特定对象类型的 RDD 的schema。
14 | 这种基于反射的方法可使代码更简洁,在编写 Spark 应用程序时已知schema时效果很好
15 |
16 | ```scala
17 | // 读取文件内容为RDD,每行内容为一个String元素
18 | val peopleRDD: RDD[String] = spark.sparkContext.textFile(projectRootPath + "/data/people.txt")
19 |
20 | // RDD转换为DataFrame的过程
21 | val peopleDF: DataFrame = peopleRDD
22 | // 1. 使用map方法将每行字符串按逗号分割为数组
23 | .map(_.split(","))
24 | // 2. 再次使用map方法,将数组转换为People对象
25 | .map(x => People(x(0), x(1).trim.toInt))
26 | // 3. 最后调用toDF将RDD转换为DataFrame
27 | .toDF()
28 | ```
29 |
30 | ## 2 通过编程接口
31 |
32 | 构造一个schema,然后将其应用到现有的 RDD。
33 |
34 | ### 2.0 适用场景
35 |
36 | 虽该法更冗长,但它允许运行时构造 Dataset,当列及其类型直到运行时才知道时很有用。
37 |
38 | ### 2.1 step1
39 |
40 | ```scala
41 | // 定义一个RDD[Row]类型的变量peopleRowRDD,用于存储处理后的每行数据
42 | val peopleRowRDD: RDD[Row] = peopleRDD
43 | // 使用map方法将每行字符串按逗号分割为数组,得到一个RDD[Array[String]]
44 | .map(_.split(","))
45 | // 再次使用map方法,将数组转换为Row对象,Row对象的参数类型需要和schema中定义的一致
46 | // 这里假设schema中的第一个字段为String类型,第二个字段为Int类型
47 | .map(x => Row(x(0), x(1).trim.toInt))
48 | ```
49 |
50 | ### 2.2 step2
51 |
52 | ```scala
53 | // 描述DataFrame的schema结构
54 | val struct = StructType(
55 | // 使用StructField定义每个字段
56 | StructField("name", StringType, nullable = true) ::
57 | StructField("age", IntegerType, nullable = false) :: Nil)
58 | ```
59 |
60 | ### 2.3 step3
61 |
62 | 使用SparkSession的createDataFrame方法将RDD转换为DataFrame
63 |
64 | ```scala
65 | val peopleDF: DataFrame = spark.createDataFrame(peopleRowRDD, struct)
66 |
67 | peopleDF.show()
68 | ```
--------------------------------------------------------------------------------
/docs/md/spider/00-爬虫基础.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/spider/00-爬虫基础.md
--------------------------------------------------------------------------------
/docs/md/spring/01-HelloSpringBoot应用程序.md:
--------------------------------------------------------------------------------
1 | # 01-HelloSpringBoot应用程序
2 |
3 | ## 1 前言
4 |
5 | Spring Boot对Spring平台和第三方库整合,可创建`可运行的、独立的、生产级的`基于Spring的应用程序,大多Spring Boot应用程序只需很少的Spring配置。
6 |
7 | Spring Boot可用java -jar或更传统war部署启动的Java应用程序创建,可内嵌Tomcat 、Jetty 、Undertow容器,快速启动web程序。
8 |
9 | ## 2 目录结构
10 |
11 |
12 |
13 | 
14 |
15 | ## 3 代码
16 |
17 | ```java
18 | import org.springframework.web.bind.annotation.RequestMapping;
19 | import org.springframework.web.bind.annotation.RequestMethod;
20 | import org.springframework.web.bind.annotation.RestController;
21 |
22 | @RestController
23 | public class HelloController {
24 |
25 | @RequestMapping(value = "/hello",method = RequestMethod.GET)
26 | public String say() {
27 | return "Hello Spring Boot!";
28 | }
29 | }
30 | ```
31 |
32 | ### @RequestMapping
33 |
34 | 将请求URL,如 /hello,映射到整个类或某特定的处理器方法。
35 |
36 | 一般类级别的注解负责将一个特定(或符合某种模式)的请求路径映射到一个控制器上,同时通过方法级别的注解来细化映射,即根据特定的HTTP请求方法("GET""POST"方法等)、HTTP请求中是否携带特定参数等条件,将请求映射到匹配的方法上。
37 |
38 | ### @RestController
39 |
40 | 当今让控制器实现一个REST API,控制器只需提供JSON、XML或其他自定义的媒体类型内容即可,无需在每个 @RequestMapping 方法上都增加一个 @ResponseBody 注解,更简明的做法,是给你的控制器加上一个 @RestController 的注解。
41 |
42 | @RestController是一个原生内置注解,结合了 @ResponseBody 与 @Controller 功能。不仅如此,也让你的控制器更表义,且在框架未来的发布版本中,它也可能承载更多意义。
43 |
44 | 与普通的 @Controller 本质无异。
45 |
46 | ```java
47 | import org.springframework.boot.SpringApplication;
48 | import org.springframework.boot.autoconfigure.SpringBootApplication;
49 |
50 | @SpringBootApplication
51 | public class GirlApplication {
52 |
53 | public static void main(String[] args) {
54 | SpringApplication.run(GirlApplication.class, args);
55 | }
56 | }
57 |
58 | ```
59 |
60 | ### @SpringBootApplication
61 |
62 | 开启Spring的组件扫描和Spring Boot的自动配置功能。底层将3个有用的注解组合:
63 |
64 | - import org.springframework.boot.autoconfigure.EnableAutoConfiguration:开启Spring Boot自动配置。
65 | - import org.springframework.context.annotation.ComponentScan:启用组件扫描,如此所写的web控制器类和其他组件才能被自动发现并注册为Spring应用上下文里的bean(即启用Spring Boot的自动bean加载机制)
66 | - import org.springframework.context.annotation.Configuration:标明该类使用Spring基于Java的配置
67 |
68 | 自动配置侧重于根据项目依赖和配置来自动配置应用程序,而自动Bean加载机制侧重于扫描和加载标注了Spring注解的类。
69 |
70 | ## 4 效果
71 |
72 |
73 |
74 | 
--------------------------------------------------------------------------------
/docs/md/spring/SpringMVC-AsyncHandlerInterceptor.md:
--------------------------------------------------------------------------------
1 | # 01-SpringMVC的AsyncHandlerInterceptor异步的处理器拦截器
2 |
3 | HandlerInterceptor 类扩展了一个回调方法,该方法在异步请求处理开始后被调用。当处理器启动一个异步请求时,DispatcherServlet 退出而不会像处理同步请求那样调用 postHandle 和 afterCompletion,因为请求处理的结果(例如 ModelAndView)可能尚未准备好,并将由另一个线程并发生成。在这种情况下,会调用 afterConcurrentHandlingStarted,允许实现类在释放线程到 Servlet 容器之前执行清理线程绑定属性等任务。
4 |
5 | 当异步处理完成时,请求会被调度到容器进行进一步处理。在这个阶段,DispatcherServlet 会调用 preHandle、postHandle 和 afterCompletion。为了区分初始请求和异步处理完成后的后续调度,拦截器可以检查 jakarta.servlet.ServletRequest 的 jakarta.servlet.DispatcherType 是 "REQUEST" 还是 "ASYNC"。
6 |
7 | HandlerInterceptor 实现可能需要在异步请求超时或由于网络错误而完成时进行处理。对这种case,Servlet 容器不会调度,因此不会调用 postHandle 和 afterCompletion。相反地,拦截器可通过 WebAsyncManager#registerCallbackInterceptor、registerDeferredResultInterceptor 注册来跟踪异步请求。这可以在每个请求的 preHandle 中主动完成,而不管是否会启动异步请求处理。
8 |
9 | 自版本 3.2 起提供。
10 |
11 | 另请参见:
12 |
13 | - org.springframework.web.context.request.async.WebAsyncManager
14 | - org.springframework.web.context.request.async.CallableProcessingInterceptor
15 | - org.springframework.web.context.request.async.DeferredResultProcessingInterceptor
--------------------------------------------------------------------------------
/docs/md/spring/spring-cloud/Spring Cloud Alibaba大纲.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/spring/spring-cloud/Spring Cloud Alibaba大纲.xmind
--------------------------------------------------------------------------------
/docs/md/spring/spring-cloud/SpringCloudGateway之灰度发布篇.md:
--------------------------------------------------------------------------------
1 | # Spring Cloud Gateway之灰度发布篇
2 | >Spring Cloud Gateway 实现灰度发布通常依赖于服务治理和路由规则的动态配置。
3 |
4 | ## 灰度发布
5 | >灰度发布(又名金丝雀发布)是指在黑与白之间,能够平滑过渡的一种发布方式。是一种软件发布策略,它允许开发者在一部分用户或者部分服务器上先部署新版本的应用程序,同时保持其他用户或服务器继续使用旧版本。通过这种方式,开发团队可以在真实环境中逐步验证新版本的性能、兼容性和功能,减少潜在问题对整体用户群体造成的影响,并根据灰度期间的反馈和数据指标决定是否将新版本全面上线。
6 |
7 | ### 灰度发布的服务治理与路由机制
8 | >服务注册与发现:每个服务实例在启动时向服务中心注册自身的元信息,包括版本号、环境标签等,用于标识其为稳定版还是灰度版。
9 |
10 | >动态路由规则:网关组件如Spring Cloud Gateway、Zuul等,可以通过配置动态路由规则,根据请求头、Cookie或其他上下文信息将特定流量导向灰度版本的服务实例。
11 |
12 | >监控与评估:在灰度发布阶段,持续监控灰度版本的服务运行状态,收集性能指标、错误日志等数据,对比分析新版本与旧版本之间的差异。
13 |
14 | >逐步扩大范围:根据灰度测试结果,如果新版本表现良好,则可以逐渐增加灰度流量的比例,直至全量覆盖所有用户。
15 |
16 | >回滚策略:若灰度阶段发现问题,应立即停止进一步扩大灰度范围,并及时进行版本回滚,以保证整体系统的稳定性。
17 |
18 | ## Spring Cloud Gateway实现灰度发布配置
19 | > 在Spring Cloud Gateway的应用中配置服务注册与发现,这里以使用Nacos作为服务注册中心。
20 |
21 | ```yaml
22 | spring:
23 | cloud:
24 | gateway:
25 | discovery:
26 | locator:
27 | enabled: true # 启用服务发现功能
28 | path-mapping:
29 | /your-service-name: /your-service-path # 将服务名映射到指定的路径
30 | routes:
31 | - id: gray-route # 路由ID
32 | uri: lb://your-service-name # 指向的服务名
33 | predicates:
34 | - Header=X-User-Type, gray # 根据请求头X-User-Type的值为gray进行灰度路由
35 | ```
36 | >在服务提供方的应用中,添加灰度版本的标签
37 |
38 | ```yaml
39 | spring:
40 | cloud:
41 | nacos:
42 | discovery:
43 | metadata:
44 | version: gray # 设置灰度版本的标签为gray
45 | ```
46 | >灰度路由规则配置在Nacos中,创建一个配置文件,例如gray-route.yml
47 |
48 | ```yaml
49 | spring:
50 | cloud:
51 | gateway:
52 | routes:
53 | - id: gray-route # 路由ID
54 | uri: lb://your-service-name # 指向的服务名
55 | predicates:
56 | - Header=X-User-Type, gray # 根据请求头X-User-Type的值为gray进行灰度路由
57 | ```
58 | >在Spring Cloud Gateway应用中,通过引入spring-cloud-starter-alibaba-nacos-config依赖,配置Nacos的地址和命名空间,以实现动态加载路由规则
59 |
60 | ```yaml
61 | spring:
62 | cloud:
63 | nacos:
64 | config:
65 | server-addr: nacos-address:port # Nacos配置中心地址
66 | namespace: your-namespace # 命名空间ID
67 | group: your-group # 配置分组
68 | ```
69 | >启动Spring Cloud Gateway应用和带有灰度版本标签的服务提供方应用,当请求头X-User-Type的值为gray时,请求将被路由到灰度版本的服务实例上。
70 |
--------------------------------------------------------------------------------
/docs/md/spring/spring-cloud/SpringCloudGateway之限流集成篇.md:
--------------------------------------------------------------------------------
1 | # SpringCloudGateway之限流集成篇
2 | >在Spring Cloud Gateway中实现限流(Rate Limiting)可以通过集成Spring Cloud Gateway的熔断和限流功能以及第三方限流组件如Sentinel或Resilience4j。
3 |
4 | ## SpringCloudGateway与Sentinel组件集成
5 | ### 添加依赖
6 |
7 | ```xml
8 | 首先确保项目包含Spring Cloud Gateway和Sentinel相关依赖。
9 |
10 |
11 | org.springframework.cloud
12 | spring-cloud-starter-gateway
13 |
14 |
15 |
16 | com.alibaba.csp
17 | sentinel-adapter-spring-cloud-gateway-2.x
18 | {sentinel-version}
19 |
20 |
21 |
22 | com.alibaba.csp
23 | sentinel-core
24 | {sentinel-version}
25 |
26 |
27 | ```
28 | ### 配置Sentinel
29 | > 在application.yml或application.properties文件中配置Sentinel的相关参数
30 |
31 | ```yaml
32 | spring:
33 | cloud:
34 | sentinel:
35 | transport:
36 | dashboard: localhost:8080 # Sentinel控制台地址
37 | port: 8719 # Sentinel与控制台之间的通讯端口
38 | filter:
39 | url-patterns: "/api/**" # 需要进行限流处理的路由路径
40 | ```
41 |
42 | ### 启用Sentinel Gateway适配器
43 | >创建一个配置类以启用Sentinel适配器,并注册到Spring容器中
44 |
45 | ```java
46 | import com.alibaba.csp.sentinel.adapter.gateway.sc.SentinelGatewayFilter;
47 | import com.alibaba.csp.sentinel.adapter.gateway.sc.config.SentinelGatewayConfig;
48 | import org.springframework.cloud.gateway.filter.GlobalFilter;
49 | import org.springframework.context.annotation.Bean;
50 | import org.springframework.context.annotation.Configuration;
51 |
52 | @Configuration
53 | public class SentinelGatewayConfiguration {
54 |
55 | @Bean
56 | public GlobalFilter sentinelGatewayFilter() {
57 | return new SentinelGatewayFilter();
58 | }
59 |
60 | @Bean
61 | public SentinelGatewayConfig sentinelGatewayConfig() {
62 | return new SentinelGatewayConfig();
63 | }
64 | }
65 | ```
66 | ### 配置限流规则
67 | >通过Sentinel控制台或API动态添加限流规则,包括QPS限制、热点限流等策略
68 | >为/api/user路由设置QPS限流
69 | 为/api/user路由设置QPS限流
70 | 在Sentinel控制台上新建一个限流规则,资源名可以是/api/user,然后设置每秒允许的请求次数。
--------------------------------------------------------------------------------
/docs/md/spring/spring-cloud/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/spring/spring-cloud/todo.md
--------------------------------------------------------------------------------
/docs/md/spring/阿里四面:你知道Spring AOP创建Proxy的过程吗?.md:
--------------------------------------------------------------------------------
1 | # 阿里四面:你知道Spring AOP创建Proxy的过程吗?
2 |
3 |
--------------------------------------------------------------------------------
/docs/md/trade/wechat-pay-development-guide-avoid-pitfalls.md:
--------------------------------------------------------------------------------
1 | # 微信支付开发避坑指南
2 |
3 | ## 1 微信支付的坑
4 |
5 | ### 1.1 不能用前端传递过来的金额
6 |
7 | 订单的商品金额要从数据库获取,前端只传商品 id。
8 |
9 | ### 1.2 交易类型trade type字段不要传错
10 |
11 | v2版API,不同交易类型,要调用的支付方式也不同。
12 |
13 | ### 1.3 二次签名
14 |
15 | 下单时,在拿到预支付交易会话标识时,要进行二次签名操作。二次签名后的值,才能返回给前端使用。
16 |
17 | ### 1.4 小程序可绑定到其它公司的商户下
18 |
19 | 可同时关联到多个商户号:
20 |
21 | 
22 |
23 | ### 1.5 微信支付的单位是分,最小金额是0.01元
24 |
25 | 支付宝是元。
26 |
27 | ### 1.6 做避免重复消费的处理
28 |
29 |
30 |
31 | 
32 |
33 | 处理成功之后不要再进行二次处理了,那首先是有事务操作。
34 |
35 | 第一次处理成功后,需要更新对应订单的状态。更新完成后,下次再处理时,直接返回成功,不再进行实际业务处理。
36 |
37 | 也可以拿这个订单号加分布式锁,保证对同一个用户,同时只能处理一个订单。
38 |
39 | ### 1.7 支付结果验签
40 |
41 | 对支付结果通知,一定要拿配置的私钥进行验签处理。
42 |
43 | ```java
44 | // 处理内部业务逻辑
45 | try {
46 | // 支付结果验签
47 | boolean valid = WXPayUtil.isSignatureValid(map1, weixinpaypartner);
48 | if (valid == false) {
49 | log.info("签名不一致" + outTradeNo);
50 | return "ERROR";
51 | } else {
52 | //1、更新订单状态
53 | dealAfterSuccess(basOrder, time_end, transaction_id, result_code);
54 | log.info("验签成功" + outTradeNo);
55 | result = CommUtils.setXml("SUCCESS", "OK");
56 | log.info("收到异步通知返回微信的内容--" + result);
57 | return result;
58 | }
59 | } catch (Exception e) {
60 | e.printStackTrace();
61 | return "ERROR";
62 | }
63 | ```
64 |
65 | 不验签也可以继续执行,但支付结果页容易被伪造哦!
66 |
67 | ### 1.8 对支付结果通知处理逻辑中的非事务性操作做操作记录
68 |
69 | 可能在支付通知后,通过小程序给用户发送模板消息通知或公众号消息通知触达。若这时事务处理失败,但结果发送成功了,会造成啥结果?那你下次是否要重新处理这个订单流程,在重新处理订单时难道再发一次推送吗?肯定不可以。
70 |
71 | 所以最好拿订单号作为标识,判断记录这个订单是否已经有过啥事务性、非事务性操作,下次或者是订单补偿时,就只处理事务性操作,不再处理非事务性操作。
72 |
73 | ### 1.9 v2的统一下单的接口
74 |
75 | 服务号、H5下单和小程序下单都可调用,甚至app下单都可以调用。
--------------------------------------------------------------------------------
/docs/md/zqy/面试题/03-生产部署面试实战.md:
--------------------------------------------------------------------------------
1 | # 03-生产部署面试实战
2 |
3 | ## 生产部署面试实战
4 |
5 | 接下来说一下,对于 `生产部署` 方面会从哪些方面来问?
6 |
7 |
8 |
9 | ### 服务如何部署?
10 |
11 | 比如,你们生产环境中,各个服务是如何进行部署的呢?
12 |
13 | 其实也就是问:
14 |
15 | - `网关`、`注册中心`以及各个 `服务` 是如何部署的?
16 | - 部署的 `机器配置` 是怎样的?
17 | - 每天 `访问量` 是多少?
18 | - `高峰期接口访问量` 是多少?
19 |
20 |
21 |
22 | 回答的话,也不用回答细节,将整个流程给回答一下:
23 |
24 | `网关部署` 的话,就根据系统的访问量,如果不大,部署 2-3 个网关系统即可
25 |
26 | `注册中心` 一般都是集群部署,比如 zk 集群部署(1 主 2 从)
27 |
28 | `服务` 部署一般看每个服务的负载情况了,负载高的服务,就多部署几个,分散一下请求
29 |
30 |
31 |
32 | 而对于 `系统访问量` 来说,可能很多人都没有什么概念,并且对于机器可以抗多少数量的并发请求也都不太清楚
33 |
34 | 这些都是属于更细节一些的东西了,属于 `进阶部分`,可以了解一下,但是深入学习这些内容之前,一定要先将基础把握住,不要本末倒置了
35 |
36 | 其实想要看系统访问量的话,很简单的一个方式就是,在代码中加入一些统计的接口,比如统计每个接口请求数量、接口请求延时、系统访问量,可以直接在代码中记录,再向外暴露出一个接口,可以查询到这些 `统计值`
37 |
38 | 就比如说,一个接口请求一次之后,在代码中,对这个接口请求次数加 1,用 AtomicLong 来统计每天的接口请求数量,接口平均请求延时的话,将接口请求延时加起来除以接口请求次数也能算出来
39 |
40 |
41 |
42 | 这里还要了解一下 `性能监控` 中的一些指标,T99、T95
43 |
44 | 如 `T99 = 50ms`,表示 99% 的请求耗费时长都在 50ms 以内
45 |
46 | `T95 = 50ms`,表示 95% 的请求耗费时长都在 50ms 以内
47 |
48 |
49 |
50 | **怎么看系统可以承载的最大负荷呢?**
51 |
52 | 使用开源的 `压测工具`,例如 Jmeter,去模拟用户向系统发送请求
53 |
54 | 通过控制发送请求数量,查看系统的负载情况,以及系统最多可以处理的并发请求数量
55 |
56 | 比如发送 1000 个请求,系统只可以处理 800 个,那么就说明系统最大处理并发请求数量为 800
57 |
58 |
59 |
60 | ### 数据库如何部署
61 |
62 | 对于数据库来说的话,一般也会使用 `比较好的机器配置` 来部署,16C32G 的机器比较适合,32C64G 的机器可以根据数据库的负载来选择,负载较高的话,可以升级一下机器的配置
63 |
64 | 那么一般来说 16C32G 的机器,每秒抗 `小几千的并发请求` 还是问题不大的,只要 `不存在一个 SQL 执行 2-3 秒的情况` 就可以!
65 |
66 | 但是对于数据库来说,如果平均每秒都是三四千请求,此时 MySQL 机器虽然不会崩掉,但是它的负载是很高的,包括 CPU 使用率、磁盘 IO、网络负载都是处于比较高的水平
67 |
68 | 大部分的系统,其实每秒钟也就几十个请求,高峰期几百个请求,系统都是可以抗住的
69 |
70 | 
71 |
72 |
73 |
74 |
75 |
76 | ### 如果访问量扩大 10 倍,如何应对?
77 |
78 | 访问量扩大 10 倍的话
79 |
80 | - 对于 `网关系统` 来说,部署 10 倍的网关机器即可,再通过 nginx 将请求分发到不同的网关中去,就可以分散大量请求压力
81 |
82 | 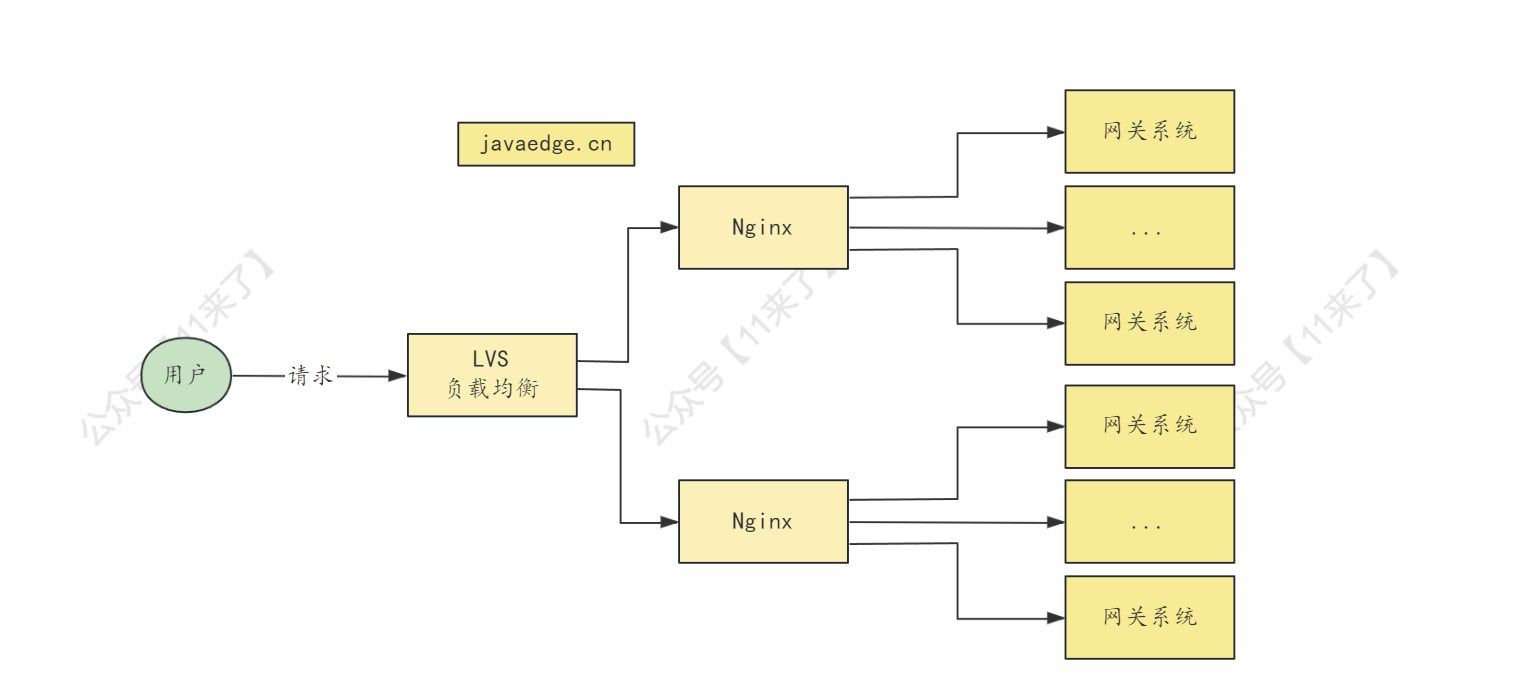
83 |
84 | - 对于 `服务实例` 来说,也是比较简单,通过增加服务实例的数量,并且注册到 `注册中心` 去,这样通过 `负载均衡` 将一个服务的压力也给分散到多个服务实例中去了
85 |
86 | - 对于 `数据库` 来说,如果原本高峰期每秒三四百请求,扩大 10 倍后,每秒三四千的访问量,如果对数据库横向扩容比较麻烦,因此可以考虑给部署数据库的服务器提升配置,比如从 16C32G 提升到 32C64G 的配置,抗 3-4000 的请求还是没有问题的
87 |
88 |
89 |
90 |
91 |
92 | 在生产部署面试方面,主要就是问一些系统 QPS 、部署以及应对并发量上来之后的措施,这其实就考察有没有生产经验,或者说你有没有对系统进行过 `压测` 并进行性能优化
93 |
94 | > 压测方面的内容,可以关注我,发送 `"压测"` 领取一份压测视频教程!
95 |
96 |
--------------------------------------------------------------------------------
/docs/md/zqy/面试题/jiagou/02-该从哪些方面提升系统的吞吐量?.md:
--------------------------------------------------------------------------------
1 | # 02-该从哪些方面提升系统的吞吐量?
2 |
3 | 我们平时自己做的项目一般没有用户量,都是练手项目,所以并不会在吞吐量上做出很多的优化,但是这样的话,又会导致项目和其他人相比并没有什么亮点,因此可以借鉴一些高吞吐量的架构设计,来为自己的项目添加一些亮点功能,这里总结一下 **B 站千万长连消息系统** 如何提升系统吞吐量!
4 |
5 | B 站千万长连消息系统原文链接:https://mp.weixin.qq.com/s/Thw_mkb-aUepzcjd9RCDzw
6 |
7 | ## 1、负载均衡
8 |
9 | 负载均衡是比较常用的了,通过负载均衡将请求分发到不同的服务器上处理,分散单个节点上的压力,可以提高系统的扩展性和稳定性。
10 |
11 | 可以根据实际需求设计负载均衡策略,选择合适的节点进行请求的转发。
12 |
13 | 负载均衡中比较重要的就是 **节点的动态扩缩容** ,也就是可以实现节点实时增加、减少,这样在高峰期可以增加部分节点来抗下更高的吞吐量,低峰期可以减少部分节点,避免资源浪费。
14 |
15 | ## 2、消息队列
16 |
17 | 消息队列也是很常用的一个手段,高并发系统的三把利器:**分流、缓存、异步**
18 |
19 | 其中分流指的就是将流量分开,对应负载均衡,异步即对应消息队列
20 |
21 | **为什么要用消息队列呢?**
22 |
23 | 一方面是进行业务之间的解耦,另一方面是为了提升系统的性能,通过消息队列可以提升主干流程的响应速度,将一些比较耗时的操作从主干流程中剥离出去。
24 |
25 | 这里 B 站在设计上增加了 **消息队列和消息分发层** ,如果服务层在执行业务逻辑时,还要去推送大量的消息到各个节点上,比较影响消息的吞吐量,因此通过增加 **消息分发层** 来推送和维护消息,提高了系统的并发处理能力,避免了因消息推送阻塞而导致的性能问题。
26 |
27 | ## 3、消息聚合
28 |
29 | 消息聚合也是比较常用的一个手段,我看了 B 站分享出来的技术文章,多次提到了消息聚合。
30 |
31 | 如果不使用消息聚合,就拿弹幕消息来说,如果一个用户发送一条弹幕消息,那么这条消息需要扩散到同时在线的所有用户,假如说有 1kw 人在线,那么发送的消息数量就是 1kw * 1kw,消息量巨大!
32 |
33 | 因此,可以根据一定的规则进行消息聚合,批量推送,比如说达到一定时间内推送一次,或者消息数量达到多少就进行推送一次,如下图:
34 |
35 | 
36 |
37 | 根据 B 站统计结果,加入消息聚合后,发送消息的 QPS 下降了 60% 左右,大大减少了发送消息所带来的压力!
38 |
39 |
40 |
41 | ## 4、压缩算法
42 |
43 | 在消息聚合后,降低了消息的数量,减少了发送次数,但是同时发送消息的体积会增加,影响了写入 IO,因此采用 **压缩算法** 来对消息进行压缩。
44 |
45 | 市面上常用的两个压缩算法:zlib 和 brotli。
46 |
47 | 原文对两个压缩算法进行了比较,发现 brotli 算法比较具有优势,因此选择了该算法。
48 |
49 | 比较结果如下(来自于原文)
50 |
51 | 
--------------------------------------------------------------------------------
/docs/md/zsxq/about/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/about/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/booklet/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/booklet/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/material/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/material/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/memorabilia/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/memorabilia/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/other/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/other/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/project/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/project/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/source-code/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/source-code/todo.md
--------------------------------------------------------------------------------
/package-lock.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/package-lock.png
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "Code-Select",
3 | "version": "2.0.1",
4 | "private": true,
5 | "scripts": {
6 | "dev": "vuepress dev docs --temp .temp",
7 | "build": "vuepress build docs"
8 | },
9 | "devDependencies": {
10 | "@vuepress/plugin-back-to-top": "^1.8.2",
11 | "@vuepress/plugin-google-analytics": "^1.8.2",
12 | "@vuepress/plugin-medium-zoom": "^1.8.2",
13 | "mermaid": "^7.1.2",
14 | "vuepress": "^1.9.10",
15 | "vuepress-plugin-seo": "^0.1.4",
16 | "vuepress-plugin-sitemap": "^2.3.1",
17 | "vuepress-plugin-tags": "^1.0.2",
18 | "vuepress-plugin-thirdparty-search": "^1.0.2",
19 | "watchpack": "^1.7.5",
20 | "webpack-dev-server": "^3.11.2"
21 | },
22 | "dependencies": {
23 | "@vssue/api-github-v3": "^1.4.7",
24 | "@vssue/vuepress-plugin-vssue": "^1.4.8",
25 | "@vuepress/core": "^1.8.2",
26 | "browserslist": "^4.16.3",
27 | "caniuse-lite": "^1.0.30001196",
28 | "screenfull": "^5.1.0",
29 | "vuepress-plugin-baidu-autopush": "^1.0.1",
30 | "vuepress-plugin-code-copy": "^1.0.6",
31 | "vuepress-plugin-copyright": "^1.0.2",
32 | "vuepress-plugin-img-lazy": "^1.0.4",
33 | "vuepress-plugin-mermaidjs": "^2.0.0-beta.2",
34 | "vuepress-plugin-table-of-contents": "^1.1.7"
35 | }
36 | }
37 |
--------------------------------------------------------------------------------
19 | 皖ICP备2024059525号 | Copyright © JavaEdge
20 | footerHtml: true
21 | ---
22 |
23 | ---
24 |
--------------------------------------------------------------------------------
/docs/md/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/.DS_Store
--------------------------------------------------------------------------------
/docs/md/12306/Builder模式在项目设计中的应用.md:
--------------------------------------------------------------------------------
1 | # **Builder模式在项目设计中的应用**
2 |
3 | ## Builder模式简介:
4 | 构建者模式(Builder Pattern)是一种对象创建型设计模式,它提供了一种灵活的解决方案,用于在创建复杂对象时将构造过程与其表示分离,以便相同的构建过程可以创建不同的表示。这种模式通常用于那些具有多个组成部分且这些部分经常变化的场景中,例如创建一个复杂的用户界面或一个多步骤的复杂算法。
5 |
6 | ### 构建者模式的应用场景
7 |
8 | 构建者模式适用于以下几种情况:
9 |
10 | - 1. **对象构造复杂**:当一个对象的构建比较复杂时,可以使用构建者模式将复杂对象的构建过程抽象出来,是的这个抽象过程和具体的产品类分离,使得客户端不需要知道其具体的构建细节。
11 | - 2. **对象内部构建有多个步骤**:如果一个对象有多个构建步骤,并且希望允许用户以任意顺序提供这些步骤的信息,那么可以使用构建者模式来提供更灵活的构建过程。
12 | - 3. **对象构建需要多个简单对象组合**:如果一个对象是由多个简单的对象组合而成,而这些简单的对象又有不同的组合方式和可选的组合项,构建者模式可以帮助简化这种组合逻辑。
13 | - 4. **构建与表示分离**:当需要将一个复杂对象的构建过程与其最终表示分离时,构建者模式可以将这两个方面解耦,使得同样的构建过程可以创建出不同的表示。
14 |
15 | ### 构建者模式的实现
16 |
17 | 构建者模式通常包括以下几个角色:
18 |
19 | - 1. **Builder**:为创建一个Product对象的各个部件指定抽象接口,具体构建者实现该接口以构造和装配该产品的各个部件。
20 | - 2. **ConcreteBuilder**:实现Builder接口,构建和装配各个部分,最终返回一个构造完毕的Product对象。
21 | - 3. **Director**:负责按照特定顺序组装各个部件,并返回一个构建好的实例或者使用构建者实例来构建最终的对象。
22 | - 4. **Product**:是最终被构建出来的复杂对象。
23 |
24 | #### 示例代码
25 |
26 | 下面是12306项目中展示使用构建者模式的案例。
27 |
28 | ```java
29 | //产品
30 |
31 | // 构建者角色
32 | /**
33 | * Builder 模式抽象接口
34 | *
35 | */
36 | public interface Builder extends Serializable {
37 |
38 | /**
39 | * 构建方法
40 | *
41 | * @return 构建后的对象
42 | */
43 | T build();
44 | }
45 |
46 | // 具体构建者
47 | // todo
48 |
49 | // 指导者角色
50 | // todo
51 |
52 | // 实际业务场景使用
53 | //todo
54 |
55 | ```
56 |
57 | ### 构建者模式的优点与缺点
58 |
59 | **优点:**
60 | - **封装性良好**:客户端无需了解产品内部的组成细节,只需要知道如何通过构建者来构造它即可。
61 | - **易于扩展**:可以通过增加新的具体构建者来轻松扩展系统,而不影响其他代码。
62 | - **分步构建,链式调用**:可以在构建过程中逐步完成,也可以采用链式调用的方式,提高易用性和可读性。
63 |
64 | **缺点:**
65 | - **设计相对复杂**:相比直接使用构造函数或工厂方法创建对象,构建者模式的设计更为复杂。
66 | - **违反单一职责原则**:构建者除了构建产品的职责外,还需要知道如何一步步构建,这增加了其职责。
67 | - **对象创建成本高**:因为构建者的设计和实现较为复杂,所以相比于直接创建对象,构建者模式可能会增加额外的时间和空间成本。
68 |
69 | ### 结论
70 |
71 | 构建者模式在创建复杂对象时非常有用,尤其是当对象的构建过程需要多个步骤,并且这些步骤可以灵活配置时。它提供了一个清晰的方式来组织和封装一个复杂对象的构建过程,同时保持了系统的灵活性和可扩展性。然而,它的复杂性可能不适合所有的场景,所以在决定使用构建者模式之前,应该仔细评估它带来的额外复杂度是否值得。
--------------------------------------------------------------------------------
/docs/md/12306/使用JUC中的核心组件来优化业务功能性能.md:
--------------------------------------------------------------------------------
1 | # **使用JUC中的核心组件来优化业务功能性能**
2 |
3 | ## JUC简介:
4 | 在Java并发编程中,`java.util.concurrent`(简称JUC)工具类库提供了强大的线程管理和任务执行的工具,它允许开发者能够更加容易地写出高效且线程安全的代码。使用JUC进行优化可以显著提升系统的性能和响应能力,同时降低开发复杂性。本文将介绍如何使用JUC中的一些核心组件来优化业务功能性能。
5 |
6 | ### JUC的核心组件
7 |
8 | JUC包含了许多用于处理并发的实用工具,其中一些关键的组件包括:
9 |
10 | 1. **ExecutorService 和 ThreadPoolExecutor**:提供线程池管理,可以有效地重用线程,减少创建和销毁线程的开销。
11 | 2. **CountDownLatch 和 CyclicBarrier**:用于协调多个线程之间的同步操作。
12 | 3. **Semaphore**:限流器,用于控制同时访问资源的线程数量。
13 | 4. **Future 和 CompletableFuture**:代表异步计算的结果,允许应用程序在计算完成之前继续执行其他任务。
14 | 5. **ConcurrentHashMap** 和其他并发集合:提供高并发的数据结构,支持高效的并发访问。
15 |
16 | ### 使用JUC优化业务功能
17 |
18 | #### 线程池优化
19 |
20 | 线程池是管理线程的强大工具,它可以极大地减少在执行大量异步任务时因频繁创建和销毁线程而产生的性能开销。使用`Executors`类可以方便地创建一个线程池:
21 |
22 | ```java
23 | ExecutorService executor = Executors.newFixedThreadPool(10);
24 | ```
25 |
26 | 在需要执行任务时,只需将`Runnable`或`Callable`任务提交给线程池:
27 |
28 | ```java
29 | executor.submit(() -> {
30 | // 业务逻辑代码
31 | });
32 | ```
33 |
34 | 当所有任务完成后,记得关闭线程池以释放资源:
35 |
36 | ```java
37 | executor.shutdown();
38 | ```
39 |
40 | #### 同步工具类优化
41 |
42 | 在多线程环境下对数据进行操作时,可以使用`CountDownLatch`、`CyclicBarrier`和`Semaphore`等同步辅助类来控制线程的执行顺序和数量。例如,使用`CountDownLatch`确保所有线程都准备好之后再开始执行:
43 |
44 | ```java
45 | CountDownLatch latch = new CountDownLatch(N);
46 | for (int i = 0; i < N; i++) {
47 | new Thread(() -> {
48 | // 准备工作...
49 | latch.countDown();
50 | try {
51 | latch.await(); // 等待所有线程准备完毕
52 | } catch (InterruptedException e) {
53 | Thread.currentThread().interrupt();
54 | }
55 | // 执行任务...
56 | }).start();
57 | }
58 | ```
59 |
60 | #### 异步编程优化
61 |
62 | 利用`CompletableFuture`可以实现异步编程,避免阻塞主线程,提高系统吞吐量。下面的例子展示了如何使用`CompletableFuture`异步执行任务并在结果可用时进行处理:
63 |
64 | ```java
65 | CompletableFuture.supplyAsync(() -> {
66 | // 耗时操作...
67 | return result;
68 | }).thenAccept(result -> {
69 | // 处理结果...
70 | });
71 | ```
72 |
73 | #### 并发集合的使用
74 |
75 | 使用并发集合如`ConcurrentHashMap`可以在多线程环境下安全地进行数据操作,而无需外部同步:
76 |
77 | ```java
78 | ConcurrentHashMap map = new ConcurrentHashMap<>();
79 | map.put("key", "value");
80 | ```
81 |
82 | ### 结论
83 |
84 | 通过合理运用JUC提供的工具,我们可以显著提升业务功能的并发处理能力,减少资源消耗,并简化多线程编程的复杂性。无论是线程池管理、线程同步控制,还是异步编程和并发数据结构,JUC为我们提供了一套全面的解决方案。然而,值得注意的是,虽然JUC提供了很多便捷的工具,但正确使用它们要求开发者理解并发编程的原理和细节。错误的使用方法可能会导致难以发现的并发问题。因此,在使用JUC进行系统性能优化时,建议仔细测试和审查代码。
--------------------------------------------------------------------------------
/docs/md/12306/分布式锁在项目设计中的应用.md:
--------------------------------------------------------------------------------
1 | # **分布式锁在项目设计中的应用**
2 |
3 | ## 分布式锁简介
4 | 分布式锁是一种在分布式系统中用于协调多个进程或服务之间共享资源访问的同步机制。在项目设计中,分布式锁的应用非常关键,尤其是在需要确保多个节点上的操作的原子性、一致性和排他性时。
5 |
6 | ### 分布式锁在项目设计中的几种典型应用场景:
7 |
8 | - 1. 数据库操作的同步
9 | 在分布式系统中,多个服务可能需要访问和修改同一份数据库资源。为了防止数据不一致和并发问题,可以使用分布式锁来确保同一时间只有一个服务能够执行特定的数据库操作。
10 | - 2. 缓存更新的同步
11 | 分布式系统中的缓存更新操作需要保证原子性,以防止缓存数据不一致。例如,当一个服务更新缓存时,可以使用分布式锁来阻止其他服务同时对相同的缓存键进行操作。
12 | - 3. 任务的串行执行
13 | 在处理一些需要串行执行的任务时,分布式锁可以确保任务在分布式环境下按照预定的顺序执行。例如,定时任务、批处理作业等,可以通过分布式锁来控制任务的启动和执行。
14 | - 4. 资源的独占访问
15 | 在分布式系统中,某些资源(如文件、网络连接等)可能需要独占访问。分布式锁可以用来确保在任何给定时间,只有一个服务能够访问这些资源。
16 | - 5. 限流和节流
17 | 分布式锁可以用于实现分布式环境下的限流和节流策略。例如,通过限制同时访问某个服务的请求数量,可以防止系统过载。
18 | - 6. 领导选举
19 | 在分布式系统中,领导选举算法(如Raft或ZooKeeper的Leader Election)通常会用到分布式锁来确保集群中的一个节点成为领导者,并对系统状态进行协调。
20 |
21 | ### 实现分布式锁的技术
22 | 实现分布式锁的技术有多种,包括但不限于:
23 |
24 | - 基于数据库:使用数据库事务和唯一索引来实现锁。
25 | - 基于缓存系统:使用Redis的SETNX(SET if Not eXists)命令或Redisson等库来实现锁。
26 | - 基于分布式协调服务:使用ZooKeeper、etcd等分布式协调服务来实现锁。
27 | - 基于消息队列:使用消息队列的顺序消息特性来实现分布式锁。
28 |
29 | ## 设计考虑
30 | 在使用分布式锁时,需要考虑以下几个设计要点:
31 |
32 | - 性能:锁的获取和释放需要高效,以免成为系统瓶颈。
33 | - 可靠性:锁的实现必须可靠,确保在分布式环境下的一致性和可用性。
34 | - 死锁处理:需要有机制来处理死锁情况,例如通过设置锁的超时时间。
35 | - 容错性:在分布式锁的实现中,需要考虑节点故障和网络分区的情况。
36 | - 可扩展性:随着系统规模的扩大,分布式锁的实现应当能够适应更多的并发访问。、
37 |
38 | ## 分布式锁在项目中的实现和应用
39 | // todo
40 |
41 | ## 总结
42 |
43 | 综上所述,分布式锁在项目设计中扮演着关键角色,它有助于确保分布式环境下的数据一致性和操作的原子性。在设计和实现分布式锁时,需要权衡多种因素,选择最适合项目需求的技术方案。
--------------------------------------------------------------------------------
/docs/md/12306/如何生成分布式ID.md:
--------------------------------------------------------------------------------
1 | # **如何生成分布式ID**
2 | 随着12306开源项目的不断发展,后端服务需要处理来自全国乃至全球的海量请求。在这样的分布式系统中,生成全局唯一且高效的ID是保障数据一致性和服务可靠性的关键。以下是针对12306开源项目的分布式ID选型分析与实践。
3 |
4 | ## **项目需求分析**
5 |
6 | 首先,我们需要明确12306项目对分布式ID的基本要求:
7 | - **全局唯一性**:确保每个交易、订单或记录都有一个独一无二的标识符。
8 | - **高并发支持**:系统需能够支撑极高的并发请求,特别是在购票高峰期。
9 | - **可排序性**:ID最好能反映时间信息,便于数据库索引和数据分片。
10 | - **易扩展性**:随着业务的增长,ID生成系统应易于水平扩展。
11 | - **兼容性**:ID生成方案不应依赖于特定的技术栈或存储系统。
12 |
13 | ## **可选方案对比**
14 |
15 | 基于以上需求,我们评估了几种常见的分布式ID生成策略:
16 |
17 | - **UUID**:虽然UUID可以保证全局唯一性和高并发性能,但其长度过长且无法排序,不适合作为数据库主键,因此被排除。
18 |
19 | - **数据库自增ID**:这种方法实现简单,但显然不适合分布式环境,因为多个节点间难以协调,容易产生冲突。
20 |
21 | - **雪花算法(Snowflake)**:Twitter的雪花算法在分布式系统中得到了广泛应用。它生成的ID有序且高效,但依赖于系统时钟,并且当单个数据中心内的节点数量超过最大序列号时,需要进行微调。
22 |
23 | - **Leaf**:美团点评开源的Leaf提供了高度的灵活性和可扩展性,支持自定义比特位分配,适合大型分布式系统。
24 |
25 | ## **选型决策**
26 |
27 | 综合考虑项目的具体需求和各方案的优缺点,我们决定在12306开源项目中采用改进型的雪花算法或Leaf作为分布式ID的生成策略。
28 |
29 | ### **实施细节**
30 |
31 | - **时间戳精度**:考虑到票务系统的特点,我们可以将时间戳的精度从毫秒级调整到秒级,以减少ID冲突的可能性。
32 |
33 | - **数据中心和机器ID分配**:根据12306的服务器部署情况,合理规划数据中心和机器ID的分配,确保ID的唯一性和高效生成。
34 |
35 | - **序列号设计**:为了避免同一毫秒内生成的ID冲突,序列号的范围应该足够大,同时考虑未来可能的水平扩展需求。
36 |
37 | - **容错机制**:建立监控和报警机制,确保在系统时钟不同步或其他异常情况下,ID生成服务仍能正常工作。
38 |
39 | - **测试验证**:在实际投入使用前,进行充分的性能测试和压力测试,确保在不同的负载条件下ID生成系统的稳定性和可靠性。
40 |
41 | ## **结语**
42 |
43 | 通过精心的设计和选型,12306开源项目的分布式ID生成方案将为整个系统的稳定运行提供坚实的基础。无论是日常运营还是高峰时段的压力,一个可靠的ID生成策略都是保障数据完整性和服务可用性的关键。随着项目的不断进化,我们也将持续优化ID生成方案,以满足业务的持续发展需求。
44 |
45 |
--------------------------------------------------------------------------------
/docs/md/12306/死磕设计模式之抽象策略模式.md:
--------------------------------------------------------------------------------
1 | # **死磕设计模式之抽象策略模式**
--------------------------------------------------------------------------------
/docs/md/12306/环境搭建.md:
--------------------------------------------------------------------------------
1 | # **运行环境搭建指南**
2 |
3 | 随着12306项目的开源,越来越多的开发者和企业有机会研究、使用乃至改进这一国民级应用。
4 | 本文旨在提供一份详细的运行环境搭建指南,帮助开发者快速搭建起12306开源项目的本地开发和测试环境。
5 |
6 | ## **一、系统要求**
7 |
8 | 在开始之前,请确保你的系统满足以下要求:
9 | - 操作系统:推荐使用Linux(如Ubuntu 18.04 LTS或更高版本),也可以使用Windows 10或更高版本,macOS Catalina或更高版本。
10 | - 内存:至少4GB RAM,推荐8GB或以上。
11 | - 存储空间:至少20GB的可用硬盘空间。
12 | - 网络:稳定的网络连接以便下载必要的软件包和依赖。
13 |
14 | ## **二、开发环境准备**
15 |
16 | 以下是搭建开发环境的基本步骤:
17 |
18 | 1. **安装Docker**
19 | - Docker是用于自动部署应用程序的开源平台,可以方便地创建和管理容器。
20 | - 根据你使用的操作系统,从Docker官网下载并安装适合的Docker版本。
21 |
22 | 2. **安装Docker Compose**
23 | - Docker Compose是一个用于定义和运行多容器Docker应用程序的工具。
24 | - 使用以下命令安装Docker Compose:
25 | ```
26 | sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
27 | sudo chmod +x /usr/local/bin/docker-compose
28 | ```
29 |
30 | 3. **安装Git**
31 | - Git是一个分布式版本控制系统,用于源代码管理。
32 | - 根据操作系统的指令完成Git的安装。
33 |
34 | 4. **克隆12306项目代码仓库**
35 | - 使用以下命令将12306项目的代码仓库克隆到本地:
36 | ```
37 | git https://gitee.com/Ken2024888/12306.git
38 | cd 12306
39 | ```
40 |
41 | 5. **配置环境变量**
42 | - 根据项目文档,设置必要的环境变量,这些变量可能包括数据库地址、端口号、API密钥等。
43 |
44 | ## **三、启动项目**
45 |
46 | 在确保所有依赖和环境变量配置正确后,可以使用以下命令启动项目:
47 |
48 | 1. **构建Docker镜像**
49 | ```
50 | docker-compose build
51 | ```
52 |
53 | 2. **启动Docker容器**
54 | ```
55 | docker-compose up -d
56 | ```
57 |
58 | 此时,所有的服务将以容器的形式在后台运行。如果需要停止服务,可以使用`docker-compose down`命令。
59 |
60 | ## **四、验证安装**
61 |
62 | 要验证项目是否成功运行,可以在浏览器中访问项目的Web界面(通常是`http://localhost:端口号`),或通过API接口发送请求并检查响应。
63 |
64 | ## **五、常见错误处理**
65 |
66 | 在环境搭建过程中可能会遇到一些常见问题,如端口冲突、权限不足等。这时应检查日志文件和系统消息,根据具体错误信息进行调整和修复。
67 |
68 | ## **结语**
69 |
70 | 以上步骤为12306开源项目运行环境的搭建提供了基本指导。请注意,实际项目中可能需要根据具体情况调整配置和步骤。搭建完成后,你可以自由地进行代码开发、功能测试和性能优化等工作。祝你在12306开源项目的探索和学习之旅中收获满满!
71 |
--------------------------------------------------------------------------------
/docs/md/12306/详解雪花算法.md:
--------------------------------------------------------------------------------
1 | # 详解雪花算法
2 |
3 | ### 外置Snowflake
4 |
5 | 雪花算法Snowflake,Twitter公司分布式项目采用的ID生成算法。
6 |
7 | 
8 |
9 | 这个算法生成的ID是一个64位的长整型long:
10 |
11 | - 1位符号位,值为 0,没有实际意义,主要为兼容长整型的格式
12 | - 41位时间戳,记录本地的毫秒时间。41 位的时间戳可以容纳的毫秒数是 2 的 41 次幂,一年所使用的毫秒数是365 * 24 * 60 * 60 * 1000,即 69.73 年。即ShardingSphere 的 SnowFlake 算法的时间纪元从 2016 年 11 月 1 日零点开始,可以使用到 2086 年
13 | - 10 bit工作进程位,机器ID,机器就是生成ID的节点,用10位长度给机器做编码,那意味着最大规模可以达到1024个节点(2^10)。前 5 个 bit 代表机房 id,后 5 个 bit 代表机器i
14 | - 12位序列号,某个机房某台机器上在一毫秒内同时生成的 ID 序号。如果在这个毫秒内生成的数量超过 4096(即 2 的 12 次幂),那么生成器会等待下个毫秒继续生成。序列的长度直接决定了一个节点1毫秒能够产生的ID数量,12位就是4096(2^12)
15 |
16 | 据数据结构推算:
17 |
18 | - 每秒可以产生 26 万个自增可排序的 ID
19 | - 支持TPS可达(2^22*1000,419万左右),够绝大多数系统。
20 |
21 | 但实现雪花算法时,注意时间回拨影响。机器时钟若回拨,产生的ID就可能重复,需在算法中特殊处理。
22 |
23 | SnowFlake 算法依赖时间戳,需考虑时钟回拨,即服务器因时间同步,导致某部分机器的时钟回到了过去的时间点。时间戳的回滚肯定会导致生成一个已使用过的ID,因此默认分布式主键生成器提供一个最大容忍的时钟回拨ms数:
24 |
25 | - 若时钟回拨时间超过最大容忍的毫秒数阈值,则程序报错
26 | - 在可容忍范围内,默认分布式主键生成器会等待时钟同步到最后一次主键生成的时间后,再继续工作
--------------------------------------------------------------------------------
/docs/md/AI/01-RAG应用框架和解析器.md:
--------------------------------------------------------------------------------
1 | # 01-RAG应用框架和解析器
2 |
3 | ## 1 开源解析和拆分文档
4 |
5 | 第三方工具去对文件解析拆分,将文件内容给提取出来,并将我们的文档内容去拆分成一个小的chunk。
6 |
7 | 常见的PDF、word、markdown、JSON、HTML,都有很好的模块去把这些文件去进行一个东西去提取。
8 |
9 | ### 1.1 优势
10 |
11 | - 支持丰富的文档类型
12 | - 每种文档多样化选择
13 | - 与开源框架无缝集成
14 |
15 |
16 |
17 | 
18 |
19 | 但有时效果很差,内容跟原始文件内容差别大。
20 |
21 | ## 2 PDF格式多样性
22 |
23 |
24 |
25 | 
26 |
27 | **复杂多变的文档格式,提高解析效果十分困难**。
28 |
29 | ## 3 复杂文档格式解析问题
30 |
31 | 文档内容质量将很大程度影响最终效果,文档处理过程涉及问题:
32 |
33 | ### 3.1 内容不完整
34 |
35 | 对文档的内容提取时,可能发现提取出的文档内容会被截断。跨页形式,提取出来它的上下页,两部分内容就会被截断,导致文档内部分内容丢失,去解析图片或双栏复杂的这种格式,它会有一部分内容丢失。
36 |
37 | ### 3.2 内容错误
38 |
39 | 同一页PDF文件可能存在文本、表格、图片等混合。
40 |
41 | PDF解析过程中,同一页它不同段落其实会也会有不同标准的一些格式。按通用格式去提取解析就遇到同页不同段落格式不标准情况。
42 |
43 | ### 3.3 文档格式
44 |
45 | 像常见PDF md文件,需要去支持把这些各类型的文档格式的文件都给提取。
46 |
47 | ### 3,4 边界场景
48 |
49 | 代码块还有单元格这些,都是我们去解析一个复杂文档格式中会遇到的一些问题。
50 |
51 | ## 4 PDF内容提取流程
52 |
53 |
54 |
55 | 
56 |
57 | ## 5 为啥解析文档后,要做知识片段拆分?
58 |
59 | ### 5.1 Token限制
60 |
61 | - 绝大部分开源限制 <= 512 Tokens
62 | - bge_base、e5_large、m3e_base、text2vector_large_chinese、multilingnal-e5-base..
63 |
64 | ### 5.2 效果影响
65 |
66 | - 召回效果:有限向量维度下表达较多的文档信息易产生失真
67 | - 回答效果:召回内容中包含与问题无关信息对LLM增加干扰
68 |
69 | ### 5.3 成本控制
70 |
71 | - LLM费用:按Token计费
72 | - 网络费用:按流量计费
73 |
74 | ## 6 Chunk(块)拆分对最终效果的影响
75 |
76 | ### 6.1 Chunk太长
77 |
78 | 信息压缩失真。
79 |
80 | ### 6.2 Chunk太短
81 |
82 | 表达缺失上下文;匹配分数容易变高。
83 |
84 | ### 6.3 Chunk跨主题
85 |
86 | 内容关系脱节。
87 |
88 | ### 原文连续内容(含表格)被截断
89 |
90 | 单个Chunk信息表达不完整,或含义相反
91 |
92 | ### 干扰信息
93 |
94 | 如空白、HTML、XML等格式,同等长度下减少有效信息、增加干扰信息
95 |
96 | ### 主题和关系丢失
97 |
98 | 缺失了主题和知识点之间的关系
99 |
100 | ## 7 改进知识的拆分方案
101 |
102 |
103 |
104 | 
105 |
106 | ## 8 商用向量数据库AI套件
107 |
108 | 云厂商:
109 |
110 | 
--------------------------------------------------------------------------------
/docs/md/AI/04-prompt-helping-llm-understand-knowledge.md:
--------------------------------------------------------------------------------
1 | # 04-prompt-helping-llm-understand-knowledge
2 |
3 | ## 1 Prompt
4 |
5 | Prompt 可理解为指导AI模型生成特定类型、主题或格式内容的文本。
6 |
7 | NLP中,Prompt 通常由一个问题或任务描述组成,如“给我写一篇有关RAG的文章”,这句话就是Prompt。
8 |
9 | Prompt赋予LLM小样本甚至零样本学习的能力:
10 |
11 | 
12 |
13 | LLM能力本质上说是续写,通过编写更好的prompt来指导模型,并因此获得更好的结果:
14 |
15 | 
16 |
17 | 无具体指令,模型只会续写。输出结果可能出人意料或远高于任务要求:
18 |
19 | 
20 |
21 | 告知模型去完善句子,因此输出结果和最初输入完全符合。Prompt Engineering就是探讨如何设计最佳Prompt,用于指导LLM高效完成某项任务。
22 |
23 | ## 2 Prompt的进阶技巧CoT
24 |
25 | Chain of Thought,让模型输出更多的上下文与思考过程,提升模型输出下一个token的准确率。
26 |
27 | 
28 |
29 | ## 3 优化Prompt,提升模型推理能力和问答准确率
30 |
31 | ### 3.1 分布式引导提问
32 |
33 | 把解决问题的思路分成多步,引导模型分步执行
34 |
35 | 
36 |
37 | ### 3.2 Prompt代码化
38 |
39 | LLM通常都会有代码数据,prompt代码化进一步提升模型的推理能力。
40 |
41 | 
42 |
43 | 
--------------------------------------------------------------------------------
/docs/md/AI/13-best-development-practices.md:
--------------------------------------------------------------------------------
1 | # 13-最佳开发实践
2 |
3 | ## 1 LangChain 的定位
4 |
5 |
6 |
7 | 
8 |
9 | - 【代码层】LangChain-Core: LCEL
10 | - 【代码层】LangChain-Community 社区贡献
11 | - 【代码层】LangChain 封装组件
12 | - 一站式开发平台 LangSmith
13 | - 便捷AI应用服务器部署套件LangServe
14 |
15 | ## 2 大模型选型
16 |
17 | 考虑模型、agent、prompt、chain评估:
18 |
19 | 
20 |
21 | ### 2.1 闭源大模型+API
22 |
23 | - 优点:省事、强大
24 | - 缺点:成本、限速、数据隐私
25 |
26 | ### 2.2 开源大模型+自托管
27 |
28 | 优点:数据私有、更灵活、成本低
29 |
30 | 缺点:算力设施、技术支撑
--------------------------------------------------------------------------------
/docs/md/AI/AI大模型企业应用实战.md:
--------------------------------------------------------------------------------
1 | # AI 大模型企业应用实战
2 |
3 | ## 你将获得
4 |
5 | - gpt/qwen API 编程要点 + LangChain 使用技巧
6 | - 基于 LLM 的代码生成与调试实践
7 | - LLM 在研发全过程的应用案例
8 | - LLM 的云原生部署任务实践
9 | - 企业应用引入 LLM 的排坑指南
10 |
11 | ## 专栏介绍
12 |
13 | 现在以 GPT/qwen 为代表的大语言模型广受关注,许多企业都在积极探索在自身领域落地 AIGC 技术。
14 |
15 | 虽然大模型在辅助文档编写、问题回答、内容总结等特定的日常任务上表现良好,但想要把 GPT 这类自然语言模型真正应用到企业应用开发,提高系统的智能化和自动化,我们仍然面临着许多挑战。
16 |
17 | - LLM 基于历史数据训练,处理最新信息相关查询的能力有限。
18 | - 与环境的交互问题处理难度大,比如通过 LLM 执行 shell 命令或调用 API 等任务,都涉及到对系统外部环境的联动。
19 | - LLM 需要结合企业内部数据训练调优,才能保障生成内容的准确性。
20 | - LLM 的代码生成能力虽然很强大,但往往针对通用功能,无法处理企业里更复杂的需求。
21 |
22 | 为了帮你解决这些问题,根据我在云原生平台中集成大模型的实操经验,带你沉浸式体验如何把 LLM 应用到企业应用开发的整体流程中。
23 |
24 | 实践是检验真理的唯一标准,而可以执行的代码是掌握理论的最佳路径。因此专栏以具体场景的代码实战演练与调试为主,使用 Python 作为编程语言。
25 |
26 | 配套代码你可以从这里获取:https://github.com/Java-Edge/AIAgent
27 |
28 | **专栏设计**
29 |
30 | 基础篇、企业应用篇和研发效率篇三个章节,带你循序渐进掌握 LLM 的应用落地。
31 |
32 | 
33 |
34 | **基础篇**
35 | 带你快速熟悉 LLM 的基本用法与应用技巧。我们会一起构建开发环境和运行环境,运行第一个大语言模型程序,学习相关提示词技巧,认识 LangChain,并给聊天机器人注入记忆。
36 |
37 | **企业应用篇**
38 | 结合大量例子,带你应对企业应用融入 LLM 时面临的诸多挑战,包括与现有企业内部数据的整合、与其他程序的整合、LLM 生成部分与外部环境交互等问题。学完这一章,你就能综合应用大模型和其他工具解决实际工程问题,并结合具体需求场景定制自己的 AutoGPT。
39 |
40 | **研发效率篇**
41 | 结合之前所学,探索如何将 LLM 应用到整个研发生命周期里,有效提升我们的工作效率和质量。这一章不但会为你演示 LLM 在系统设计、代码生成、测试生成、云原生部署等方面的应用方法与调优思路,还会与你探讨如何调整现有的架构思维和研发方式,更充分地发掘大模型价值。
42 |
43 | ## 适合人群
44 |
45 | 1. 希望在企业应用中落地大语言模型,并借此提升团队研发效率的软件工程师和架构师。
46 | 2. 初中级开发者可以学到如何通过编程方式使用大模型,提高自身开发效率。
47 | 3. 高级软件开发者和架构师,可以获得对未来软件的新思考,了解大模型带来的软件架构变革和基于大语言模型的全新开发范式。
48 | 4. 需要了解一门编程语言,后续专栏里会使用 Python 语言做演示。
49 |
50 | ## 专栏目录
51 |
52 | 
--------------------------------------------------------------------------------
/docs/md/AI/agent/boost-ai-workflow-resilience-with-error-handling.md:
--------------------------------------------------------------------------------
1 | # v0.14.0:告别 AI 应用崩溃,构建更可靠的智能工作流!
2 |
3 | ## 0 前言
4 |
5 | 使用 Dify 构建AI应用程序,需要处理复杂的工作流程,其中单个组件(节点)可能会遇到 API 超时或 LLM 输出异常等问题。以前,单个节点故障就可能扰乱整个工作流程。
6 |
7 | Dify引入强大的[错误处理功能 ](https://docs.dify.ai/guides/workflow/error-handling),以防级联故障:
8 |
9 | - 不仅可捕获异常以维护工作流的执行
10 | - 还允许开发人员为四种关键节点类型定义自定义错误处理
11 |
12 | 实现详细的调试并确保弹性
13 |
14 | ## 1 为啥错误处理很重要?
15 |
16 | 考虑文档处理工作流:
17 |
18 | 1. 文本从PDF提取
19 | 2. LLM分析该文本并生成结构化数据
20 | 3. 代码处理这些数据,完善文本
21 | 4. 输出精炼文本
22 |
23 | 若无错误处理,LLM生成格式错误的数据或代码节点遇到错误都导致工作流程停止。Dify现提供以下解决方案:
24 |
25 | - **默认值:** 预定义输出值,允许下游节点即使在输入缺失、不正确或格式错误的情况下也能继续运行
26 | - **工作流重定向:** 异常时,工作流重定向到备用分支,用 `error_type` 、 `error_message` 变量捕获错误详细信息并启用后续操作,如通知或备份工具激活
27 |
28 | 并行工作流中,单个分支故障以往导致整个流程停止。现在,这些错误处理策略允许其他分支继续运行,显著提高可靠性:
29 |
30 | 
31 |
32 | ## 2 具有错误处理的关键节点
33 |
34 | Dify高级错误处理针对四种易出错的节点类型:
35 |
36 | 1. **LLM 节点:** 处理无效响应、API 问题和速率限制。开发者可设置默认输出或使用条件分支来获取替代解决方案
37 | 2. **HTTP 节点:** 在保持工作流执行的同时,通过重试间隔和详细的错误消息解决 HTTP 错误(404、500、超时)
38 | 3. **工具节点:** 如果主工具出现故障,可以快速切换到备用工具
39 | 4. **代码节点:** 使用预定义值或替代逻辑分支管理运行时错误,记录错误详细信息以防止中断
40 |
41 | ## 3 错误处理实例
42 |
43 | 与外部 API 交互的工作流。为模拟各种 HTTP 状态代码,用 [httpstat.us](http://httpstat.us/) 服务:
44 |
45 | 
46 |
47 | 1. 起始节点启动工作流
48 | 2. HTTP请求节点调用 [httpstat.us](http://httpstat.us/)
49 | 3. 失败分支处理错误
50 | 4. 条件逻辑(Conditional logic)响应特定错误码:
51 | - 403(禁止):显示权限消息
52 | - 404(未找到):记录“未找到资源”消息
53 | - 429(请求过多):建议稍后重试
54 | - 500(服务器错误):切换到备份服务或触发警报
55 | 5. 输出节点,生成适当的响应
56 |
57 | 通过确保工作流程的稳定性并提供有价值的错误反馈,这种设计增强了业务运营的可靠性。
58 |
59 | ## 4 使用Dify构建更可靠AI工作流
60 |
61 | Dify v0.14.0 增强的错误管理功能,提供更强大的控制力和灵活性,实现稳健工作流,妥善处理异常并防止中断,确保 AI 应用程序的可靠性。
--------------------------------------------------------------------------------
/docs/md/AI/agent/dify-v1-1-0-filtering-knowledge-retrieval-with-customized-metadata.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/AI/agent/dify-v1-1-0-filtering-knowledge-retrieval-with-customized-metadata.md
--------------------------------------------------------------------------------
/docs/md/AI/agent/perplexity-labs.md:
--------------------------------------------------------------------------------
1 | # 不止于搜索!Perplexity Labs深度解析:以项目为核心的 AI 工作流!
2 |
3 | ## 0 前言
4 |
5 | Perplexity推出全新功能 [Labs](https://www.perplexity.ai/pl/hub/blog/introducing-perplexity-labs),专为 Pro 订阅用户设计,旨在支持更复杂的任务,功能超越了传统的问答服务。这一重大更新标志着 Perplexity 从以搜索为核心的交互模式,转向由生成式 AI 驱动的结构化、多步骤工作流。
6 |
7 | ## 1 交互模式
8 |
9 | Perplexity Labs 让用户可在一个统一界面完成多种任务,包括生成报告、分析数据、编写和执行代码、构建轻量级网页应用等。用户可以通网页和移动端的新模式切换器进入 Labs,桌面端支持也即将上线。
10 |
11 | ## 2 适用场景
12 |
13 | 与专注于简洁回答的 Perplexity Search 和提供深入信息整合的 Research(原名 Deep Research)不同,Labs 更适合需要完整成果输出的用户。这些成果可能包括格式化的电子表格、可视化图表、交互式仪表盘和基础网页工具等。
14 |
15 | 每个 Lab 项目都包含一个“Assets”标签页,用户可在此查看或下载所有生成的素材,如图表、图片、CSV 文件和代码文件。有些 Labs 还支持“App”标签页,可以直接在项目环境中渲染基本网页应用。
16 |
17 | ## 3 使用反馈
18 |
19 | Perplexity 的 CEO 和联合创始人 Aravind Srinivas 表示:
20 |
21 | > 推出 Perplexity Labs,是我们在 Perplexity 上进行搜索的一种全新方式,支持更复杂的任务,如构建交易策略、仪表盘、用于房地产研究的无头浏览任务、迷你网页应用、故事板,以及生成素材的目录等。
22 |
23 | 实际使用看,Labs 实现了多个软件工具功能的整合与自动化,大大减少了手动操作,尤其适用于结构化研究、数据处理或原型开发等场景。
24 |
25 | 用户反馈也显示出平台在速度和语境理解方面的优势。Sundararajan Anandan 就曾[分享](https://www.linkedin.com/feed/update/urn:li:ugcPost:7333908730314399752?commentUrn=urn%3Ali%3Acomment%3A(ugcPost%3A7333908730314399752%2C7334912579871326209)&dashCommentUrn=urn%3Ali%3Afsd_comment%3A(7334912579871326209%2Curn%3Ali%3AugcPost%3A7333908730314399752)):
26 |
27 | > 我最近尝试了 Perplexity Labs,它真的改变了游戏规则。以前需要花几个小时才能完成的手动研究和格式整理,现在在 10 分钟内就能输出清晰、可执行的见解。虽然目前还处于早期阶段,平台也有待进一步完善,但初次体验已经相当令人惊艳。
28 |
29 | 不过,一些早期用户也指出了可改进的地方,特别是在初次生成后进行跟进操作或修改代码方面功能有限。正如一位 Reddit 用户[评论](https://www.reddit.com/r/perplexity_ai/comments/1kza7vo/comment/mv6koy5/?utm_source=share&utm_medium=web3x&utm_name=web3xcss&utm_term=1&utm_content=share_button)所说:
30 |
31 | > Labs 最大的问题在于它对后续操作的支持不够,基本要求用户一击命中,非常考验技巧。
32 |
33 | ## 4 总结
34 |
35 | Perplexity 还宣布将统一产品术语,将“Deep Research”简化为“Research”,以便更清晰地区分三种模式:Search、Research 和 Labs。
36 |
37 | 目前,Perplexity Labs 已正式上线,向所有 Pro 用户开放。平台还提供了 [Projects Gallery](https://www.perplexity.ai/labs),展示了各种示例和使用案例,帮助用户快速上手完成实际任务。
--------------------------------------------------------------------------------
/docs/md/AI/document-parsing-and-chunking-in-open-source-tools.md:
--------------------------------------------------------------------------------
1 | # 01-RAG应用框架和解析器
2 |
3 | ## 1 开源解析和拆分文档
4 |
5 | 第三方工具去对文件解析拆分,提取文件内容,并将文档内容拆分成一个小chunk。
6 |
7 | PDF、word、markdown、JSON、HTML等都有很好的模块执行提取。
8 |
9 | ### 1.1 优势
10 |
11 | - 支持丰富的文档类型
12 | - 每种文档多样化选择
13 | - 与开源框架无缝集成
14 |
15 | 
16 |
17 | 但有时效果很差,内容跟原文件差别大。
18 |
19 | ## 2 PDF格式多样性
20 |
21 | 
22 |
23 | 复杂多变的文档格式,提高解析效果困难。
24 |
25 | ## 3 复杂文档格式解析问题
26 |
27 | 文档内容质量很大程度影响最终效果,文档处理涉及问题:
28 |
29 | ### 3.1 内容不完整
30 |
31 | 对文档的内容提取时,可能发现提取出的文档内容会被截断。跨页形式,提取出来它的上下页,两部分内容就会被截断,导致文档内部分内容丢失,去解析图片或双栏复杂的这种格式,它会有一部分内容丢失。
32 |
33 | ### 3.2 内容错误
34 |
35 | 同一页PDF文件可能存在文本、表格、图片等混合。
36 |
37 | PDF解析过程中,同一页它不同段落其实会也会有不同标准的一些格式。按通用格式去提取解析就遇到同页不同段落格式不标准情况。
38 |
39 | ### 3.3 文档格式
40 |
41 | 像常见PDF md文件,需要去支持把这些各类型的文档格式的文件都给提取。
42 |
43 | ### 3,4 边界场景
44 |
45 | 代码块还有单元格这些,都是我们去解析一个复杂文档格式中会遇到的一些问题。
46 |
47 | ## 4 PDF内容提取流程
48 |
49 | 
50 |
51 | ## 5 为啥解析文档后,要做知识片段拆分?
52 |
53 | ### 5.1 Token限制
54 |
55 | - 绝大部分开源限制 <= 512 Tokens
56 | - bge_base、e5_large、m3e_base、text2vector_large_chinese、multilingnal-e5-base..
57 |
58 | ### 5.2 效果影响
59 |
60 | - 召回效果:有限向量维度下表达较多的文档信息易产生失真
61 | - 回答效果:召回内容中包含与问题无关信息对LLM增加干扰
62 |
63 | ### 5.3 成本控制
64 |
65 | - LLM费用:按Token计费
66 | - 网络费用:按流量计费
67 |
68 | ## 6 Chunk拆分对最终效果的影响
69 |
70 | ### 6.1 Chunk太长
71 |
72 | 信息压缩失真。
73 |
74 | ### 6.2 Chunk太短
75 |
76 | 表达缺失上下文;匹配分数容易变高。
77 |
78 | ### 6.3 Chunk跨主题
79 |
80 | 内容关系脱节。
81 |
82 | ### 原文连续内容(含表格)被截断
83 |
84 | 单个Chunk信息表达不完整,或含义相反
85 |
86 | ### 干扰信息
87 |
88 | 如空白、HTML、XML等格式,同等长度下减少有效信息、增加干扰信息
89 |
90 | ### 主题和关系丢失
91 |
92 | 缺失了主题和知识点之间的关系
93 |
94 | ## 7 改进知识的拆分方案
95 |
96 | 
97 |
98 | ## 8 商用向量数据库AI套件
99 |
100 | Vector DB AI套件:
101 |
102 | 
--------------------------------------------------------------------------------
/docs/md/AI/langchain4j/customizable-http-client.md:
--------------------------------------------------------------------------------
1 | # HTTP 客户端
2 |
3 | >LangChain4j HTTP 客户端定制:解锁 LLM API 交互的更多可能性
4 |
5 | ## 0 前言
6 |
7 | 一些 LangChain4j 模块(目前是 OpenAI 和 Ollama)支持自定义用于调用 LLM 提供程序 API 的 HTTP 客户端。
8 |
9 | `langchain4j-http-client` 模块实现了一个 `HttpClient` SPI,这些模块用它来调用 LLM 提供程序的 REST API。即底层 HTTP 客户端可自定义,并通过实现 `HttpClient` SPI 来集成任何其他 HTTP 客户端。
10 |
11 | ## 1 实现方案
12 |
13 | 目前,有两种开箱即用的实现:
14 |
15 | ### 1.1 JdkHttpClient
16 |
17 | `langchain4j-http-client-jdk` 模块中的 `JdkHttpClient` 。当使用受支持的模块(如 `langchain4j-open-ai` )时,默认使用它。
18 |
19 | ### 1.2 SpringRestClient
20 |
21 | `langchain4j-http-client-spring-restclient` 中的 `SpringRestClient` 。当使用受支持的模块的 Spring Boot 启动器(例如 `langchain4j-open-ai-spring-boot-starter` )时,默认使用它。
22 |
23 | ## 2 自定义JDK的HttpClient
24 |
25 | ```java
26 | HttpClient.Builder httpClientBuilder = HttpClient.newBuilder()
27 | .sslContext(...);
28 |
29 | JdkHttpClientBuilder jdkHttpClientBuilder = JdkHttpClient.builder()
30 | .httpClientBuilder(httpClientBuilder);
31 |
32 | OpenAiChatModel model = OpenAiChatModel.builder()
33 | .httpClientBuilder(jdkHttpClientBuilder)
34 | .apiKey(System.getenv("OPENAI_API_KEY"))
35 | .modelName("gpt-4o-mini")
36 | .build();
37 | ```
38 |
39 | ## 3 定制 Spring 的RestClient
40 |
41 | ```java
42 | RestClient.Builder restClientBuilder = RestClient.builder()
43 | .requestFactory(new HttpComponentsClientHttpRequestFactory());
44 |
45 | SpringRestClientBuilder springRestClientBuilder = SpringRestClient.builder()
46 | .restClientBuilder(restClientBuilder)
47 | .streamingRequestExecutor(new VirtualThreadTaskExecutor());
48 |
49 | OpenAiChatModel model = OpenAiChatModel.builder()
50 | .httpClientBuilder(springRestClientBuilder)
51 | .apiKey(System.getenv("OPENAI_API_KEY"))
52 | .modelName("gpt-4o-mini")
53 | .build();
54 | ```
--------------------------------------------------------------------------------
/docs/md/AI/langchain4j/observability.md:
--------------------------------------------------------------------------------
1 | # 10-可观测性
2 |
3 | ## LLM 可观测性
4 |
5 | [特定](/integrations/language-models) 的 `ChatLanguageModel` 和 `StreamingChatLanguageModel` 实现(请参见“可观测性”列)允许配置 `ChatModelListener`,用于监听以下事件:
6 |
7 | - 对 LLM 的请求
8 | - LLM 的响应
9 | - 错误
10 |
11 | 这些事件包含的属性包括[OpenTelemetry 生成 AI 语义约定](https://opentelemetry.io/docs/specs/semconv/gen-ai/)中的描述,例如:
12 |
13 | - 请求:
14 | - 模型
15 | - 温度(Temperature)
16 | - Top P
17 | - 最大 Tokens
18 | - 消息
19 | - 工具
20 | - 响应:
21 | - ID
22 | - 模型
23 | - Token 使用情况
24 | - 结束原因
25 | - AI 助手消息
26 |
27 | 以下是使用 `ChatModelListener` 的示例:
28 |
29 | ```java
30 | ChatModelListener listener = new ChatModelListener() {
31 |
32 | @Override
33 | public void onRequest(ChatModelRequestContext requestContext) {
34 | ChatModelRequest request = requestContext.request();
35 | Map attributes = requestContext.attributes();
36 | // 在此处理请求事件
37 | ...
38 | }
39 |
40 | @Override
41 | public void onResponse(ChatModelResponseContext responseContext) {
42 | ChatModelResponse response = responseContext.response();
43 | ChatModelRequest request = responseContext.request();
44 | Map attributes = responseContext.attributes();
45 | // 在此处理响应事件
46 | ...
47 | }
48 |
49 | @Override
50 | public void onError(ChatModelErrorContext errorContext) {
51 | Throwable error = errorContext.error();
52 | ChatModelRequest request = errorContext.request();
53 | ChatModelResponse partialResponse = errorContext.partialResponse();
54 | Map attributes = errorContext.attributes();
55 | // 在此处理错误事件
56 | ...
57 | }
58 | };
59 |
60 | ChatLanguageModel model = OpenAiChatModel.builder()
61 | .apiKey(System.getenv("OPENAI_API_KEY"))
62 | .modelName(GPT_4_O_MINI)
63 | .listeners(List.of(listener))
64 | .build();
65 |
66 | model.generate("讲一个关于 Java 的笑话");
67 | ```
68 |
69 | `attributes` 映射允许在 `onRequest`、`onResponse` 和 `onError` 方法之间传递信息。
--------------------------------------------------------------------------------
/docs/md/AI/langchain4j/response-streaming.md:
--------------------------------------------------------------------------------
1 | # 06-响应流
2 |
3 | 本文描述了使用低级别大语言模型(LLM)API的响应流处理。有关高级 LLM API,请参见[AI 服务](/tutorials/ai-services#streaming)。
4 |
5 | LLM 是逐个 token 生成文本的,因此许多 LLM 提供商提供了一种逐个 token 流式传输响应的方式,而不是等待整个文本生成完成。这显著改善了用户体验,因为用户无需等待未知的时间,可以几乎立即开始阅读响应内容。
6 |
7 | 对于 `ChatLanguageModel` 和 `LanguageModel` 接口,存在相应的 `StreamingChatLanguageModel` 和 `StreamingLanguageModel` 接口。它们的 API 类似,但可以流式传输响应。它们接受一个实现 `StreamingResponseHandler` 接口的参数。
8 |
9 | ```java
10 | public interface StreamingResponseHandler {
11 |
12 | void onNext(String token);
13 |
14 | default void onComplete(Response response) {}
15 |
16 | void onError(Throwable error);
17 | }
18 | ```
19 |
20 | 通过实现 `StreamingResponseHandler`,可为以下事件定义操作:
21 |
22 | - 当下一个 token 被生成时:会调用 `onNext(String token)`。 如可在 token 可用时将其直接发送到 UI
23 | - 当 LLM 完成生成时:会调用 `onComplete(Response response)`。在 `StreamingChatLanguageModel` 中,`T` 代表 `AiMessage`,在 `StreamingLanguageModel` 中,`T` 代表 `String`。`Response` 对象包含完整的响应
24 | - 当发生错误时:会调用 `onError(Throwable error)`
25 |
26 | 使用 `StreamingChatLanguageModel` 实现流式传输示例
27 |
28 | ```java
29 | StreamingChatLanguageModel model = OpenAiStreamingChatModel.builder()
30 | .apiKey(System.getenv("OPENAI_API_KEY"))
31 | .modelName(GPT_4_O_MINI)
32 | .build();
33 |
34 | String userMessage = "给我讲个笑话";
35 |
36 | model.generate(userMessage, new StreamingResponseHandler() {
37 |
38 | @Override
39 | public void onNext(String token) {
40 | System.out.println("onNext: " + token);
41 | }
42 |
43 | @Override
44 | public void onComplete(Response response) {
45 | System.out.println("onComplete: " + response);
46 | }
47 |
48 | @Override
49 | public void onError(Throwable error) {
50 | error.printStackTrace();
51 | }
52 | });
53 | ```
--------------------------------------------------------------------------------
/docs/md/AI/llm/GPTs.md:
--------------------------------------------------------------------------------
1 | # GPTs推荐
2 |
3 | ## 1 OpenAI GPTs
4 |
5 | ### 1.1 [科技文章翻译](https://chatgpt.com/g/g-uBhKUJJTl-ke-ji-wen-zhang-fan-yi)
6 |
7 | 请直接输入要翻译的内容或者网页url即可开始翻译。如果需要复制翻译后的Markdown,请点击翻译结果下的剪贴板📋图标。
8 |
9 | ### 1.2 [Code Tutor](https://chatgpt.com/g/g-HxPrv1p8v-code-tutor)
10 |
11 |
12 |
13 | 
14 |
15 | 不同于普通的编程助手,它不会简单给出答案,而是引导你思考,一步步地帮助你深入理解问题的本质。
16 |
17 | 这不仅能帮助你解决眼前的问题,更能提升你的编程思维和解决问题的能力。
18 |
19 | 
20 |
21 | 比如,在理解Python中的lists和dictionaries的区别时,“代码导师”并没有在立马给出答案,反而在鼓励我说出我所知道的关于它们的一切。
22 |
23 | 
24 |
25 | 这种引导式学习方法,让我们在解决问题的过程中,不断地思考和总结,从而更深入地理解编程的本质。
26 |
27 | 它不仅仅是一个问题解答者,更是一个激发我们思考的良师益友!
28 |
29 | ## 2 Coze
30 |
31 | coze bot对标 GPTs,还能举一反三,帮你全面学习一个新知识点,常用推荐:
32 |
33 | ### 2.1 [编程问题解答](https://www.coze.com/store/bot/7333256624091496453?bid=MDQEEBD2-JiIy8RDOfgQPFnfEskEHtV0pHay8ZG6U9-MVOy6u3LLGWV023s6uEsAEXRtnQQA&from=bots_card)
--------------------------------------------------------------------------------
/docs/md/AI/llm/enhancing-llm-memory-with-conversation-variables-and-variable-assigners.md:
--------------------------------------------------------------------------------
1 | # Dify v0.7.0利用对话变量与变量赋值节点增强 LLM 记忆能力
2 |
3 | ## 0 前言
4 |
5 | Dify一直致力于优化大语言模型(LLM)在应用中的记忆管理,以更好地应对各种具体场景需求。虽 LLM 能通过上下文窗口存储对话历史,但因为注意力机制的限制,在复杂场景中往往会出现记忆断层或聚焦不精准的问题。
6 |
7 | Dify 最新版本为此引入了两个新功能:
8 |
9 | - **对话变量(Conversation Variables)**
10 | - **变量赋值节点(Variable Assigner nodes)**
11 |
12 | 结合使用,可让基于 Chatflow 构建的 LLM 应用拥有更加灵活的记忆控制能力,支持读取与写入关键用户输入,从而提升 LLM 在生产环境中的实用性。
13 |
14 | ## 1 对话变量:精准存储上下文信息
15 |
16 | 允许 LLM 应用存储并引用上下文信息。开发者可在 Chatflow 会话中临时保存特定数据,如上下文内容、用户偏好,未来还将支持上传文件等内容。通过 **变量赋值节点**,可以在对话流程中的任意位置写入或更新这些变量。
17 |
18 | 
19 |
20 | ### 优势
21 |
22 | - **精准的上下文管理:** 以变量为单位管理信息,而不仅仅是整个对话历史
23 | - **支持结构化数据:** 能处理字符串、数字、对象、数组等复杂数据类型
24 | - **便于流程集成:** 可在 Chatflow 的任何节点中写入或更新变量,供后续的 LLM 节点使用
25 |
26 | 相比默认的对话历史机制,对话变量提供了更精细的信息管理方式。它让应用能够准确记住并调用特定信息,实现更加个性化的多轮对话体验。
27 |
28 | ## 2 变量赋值节点:设置并写入对话变量
29 |
30 | 要用于为可写变量(如对话变量)设置值。这类节点允许开发者将用户输入暂存,以供后续对话中引用。
31 |
32 | 
33 |
34 | 如在需要记录用户初始偏好的应用中,可结合使用对话变量和变量赋值节点来:
35 |
36 | - 存储用户的语言偏好
37 | - 在后续回复中持续使用该语言
38 |
39 | 举例来说,若用户在对话开始时选择中文,变量赋值节点会将该偏好写入 `language` 对话变量。随后,LLM 就会依据该变量,在整个对话过程中持续使用中文。
40 |
41 | 
42 |
43 | 这种做法简化了偏好的捕捉与应用流程,提升了对话的连贯性与用户体验。
44 |
45 | ## 3 更多应用场景
46 |
47 | 远不止于偏好存储,还可用于:
48 |
49 | - **患者接待助手:** 将用户输入的性别、年龄、症状等存入变量,用于推荐合适的就诊科室
50 |
51 | - **对话摘要生成器:** 通过变量赋值节点提取摘要,避免加载完整对话历史造成记忆超载
52 |
53 | - **数据分析助手:** 在对话中调取外部系统数据,并用于后续交互中
54 |
55 | - **创意写作工具:** 以对象数组形式动态存储和修改故事元素:
56 |
57 | ```json
58 | [
59 | { "name": "Alice", "role": "主角", "trait": "勇敢" },
60 | { "name": "神秘森林", "type": "场景", "atmosphere": "诡异" }
61 | ]
62 | ```
63 |
64 | 这些示例展示了对话变量与变量赋值节点如何满足复杂应用对个性化记忆的需求,进一步提升 LLM 应用在实际场景中的能力与表现。
--------------------------------------------------------------------------------
/docs/md/AI/llm/lm-studio-transform-mac-into-ai-tool.md:
--------------------------------------------------------------------------------
1 | # LM Studio让你的Mac秒变AI神器!
2 |
3 | ## 0 前言
4 |
5 | M芯片Mac想跑大模型,强烈推荐LM Studio。因为它支持专门为M系列芯片优化过的模型文件,运行速度快了不止亿点点!intel mac 不支持哦!
6 |
7 | 本地运行大模型的工具中,LM Studio和Ollama是最受欢迎的两款。最近LM Studio新增了对MLX的支持。
8 |
9 | ## 1 MLX是啥?
10 |
11 | 苹果公司开源的一个机器学习框架,专门为M系列芯片做了优化,如采用了统一内存模型、对应统一内存架构。所以,使用这个框架就可以非常高效地部署和运行模型。
12 |
13 | 
14 |
15 | MLX去年12月才开源,还很新,但是在社区支持下发展很快,主流模型都有对应的版本。在最新版本的LM Studio中也特意做了标注和筛选,方便苹果用户下载。
16 |
17 | ## 2 下载和使用LM Studio
18 |
19 | 
20 |
21 | 打开软件,左边栏是它的主要功能页面,包括聊天模式、服务器模式、查看已有模型等等:
22 |
23 | 
24 |
25 | 进入发现页面,就可以搜索和下载模型了:
26 |
27 | 
28 |
29 | LM Studio把MLX版的模型专门标注,列表里很容易找到。它默认是推荐Staff Pick也就是官方推荐的模型,如果你想要更多,那就选择Hugging Face(Search All)。
30 |
31 | 模型文件下载好:
32 |
33 | 
34 |
35 | 指定一个:
36 |
37 | 
38 |
39 | 就在聊天模式里加载它:
40 |
41 | 
42 |
43 | ## 3 苹果AI落后?
44 |
45 | 苹果硬件积累远超那些PC厂商,看到最近发布的 M4 系列芯片你也就懂了。在内存带宽上,M4 Pro也比上一代大增75%,支持高达64GB的高速统一内存和273GB/s的内存带宽,直接达到任意AI PC芯片的两倍。
46 |
47 | 桌面端有MLX框架,发挥统一内存架构最大优势:
48 |
49 | - CPU和GPU可以直接访问共享内存中的数据,不需要进行数据传输
50 | - 小规模操作用CPU搞定。遇到计算密集型的需求再上GPU
51 |
52 | 到时明年我去香港买个港版,M4 urtra Mac Studio到手后我就开始测评!
53 |
54 | ## 4 总结
55 |
56 | 如今在 AI 软件领域,各家都在扩张自己的势力范围。如LM Studio,以前只是偏后端软件,帮你在本地跑大模型。现在,它把聊天模式往前提,添加RAG功能。主动从后端走向前端的打法会逐渐成为各家的共同选择。AI应用大混战时代来了。
--------------------------------------------------------------------------------
/docs/md/AI/llm/lmstudio-local-llm-call.md:
--------------------------------------------------------------------------------
1 | # Ollama平替!LM Studio本地大模型调用实战
2 |
3 | ## 0 前言
4 |
5 | 可像 Ollama 通过暴露本地端口,实现本地客户端调用。
6 |
7 | ## 1 选择模型
8 |
9 | 在 LM Studio 的 “开发者” 选项卡中选择模型:
10 |
11 | 
12 |
13 |
14 |
15 | ## 2 端口暴露
16 |
17 | 设置暴露的端口(默认1234):
18 |
19 | 
20 |
21 | 启用 CORS 后,可对接网页应用或其他客户端工具。
22 |
23 | ## 3 启动服务
24 |
25 | 点击状态选项卡:
26 |
27 | 
28 |
29 | 控制台会显示运行日志和访问地址:
30 |
31 | 
32 |
33 | ## 4 快速上手
34 |
35 | ### 4.1 快速ping
36 |
37 | 列出已加载并就绪的模型:
38 |
39 | ```bash
40 | curl http://127.0.0.1:1234/v1/models/
41 | ```
42 |
43 | 
44 |
45 | 这也是验证服务器是否可访问的一种有效方法!
46 |
47 | ### 4.2 聊天
48 |
49 | 这是一个类似调用OpenAI的操作,通过`curl`工具访问`/v1/chat/completion`端点:
50 |
51 | - 在Mac或Linux系统,可用任意终端运行
52 | - Windows系统用Git Bash
53 |
54 | ```bash
55 | curl http://127.0.0.1:1234/v1/chat/completions \
56 | -H "Content-Type: application/json" \
57 | -d '{
58 | "model": "llama-4-maverick-17b-128e-instruct",
59 | "messages": [
60 | { "role": "system", "content": "Always answer in rhymes." },
61 | { "role": "user", "content": "Introduce yourself." }
62 | ],
63 | "temperature": 0.7,
64 | "max_tokens": -1,
65 | "stream": true
66 | }'
67 | ```
68 |
69 | 该调用是“无状态的”,即服务器不会保留对话历史记录。调用方有责任在每次调用时提供完整的对话历史记录。
70 |
71 | #### 流式传输 V.S 累积完整响应
72 |
73 | 注意`"stream": true`(流式传输:开启)参数:
74 |
75 | - `true`(开启)时,LM Studio会在预测出标记(token)的同时将其逐一流式返回
76 | - 如将此参数设置为`false`(关闭),在调用返回之前,完整的预测结果会被先累积起来。对于较长的内容生成或者运行速度较慢的模型,这可能需要花费一些时间!
--------------------------------------------------------------------------------
/docs/md/AI/llm/携手阿里云:JetBrains AI Assistant 正式发布!.md:
--------------------------------------------------------------------------------
1 | # 携手阿里云:JetBrains AI Assistant 正式发布!
2 |
3 | 在 2024 年[云栖大会](https://yunqi.aliyun.com/)上,JetBrains 与阿里云宣布了一项令人瞩目的战略合作——**推出基于阿里云通义大模型的智能开发工具 AI Assistant。**这是我们完善开发工具产品生态上的重要一环,期待能够为国内开发者带来全新的开发体验。
4 |
5 | 
6 |
7 | ## **专为中国市场量身定制的智能助手**
8 |
9 | 我们与阿里云的合作,推出了基于阿里云通义大模型的 AI Assistant,这不仅是技术上的融合,更是我们对国内市场承诺。通过深度融合中文自然语言处理技术,AI Assistant 能够以更加贴近中国开发者的方式,提供智能化服务。
10 |
11 | ## **无缝集成,智能提升**
12 |
13 | 得益于我们超过 20 在开发领域的经验积累,AI Assistant 与我们的 IDE 的深度集成,它能更好地理解您的代码及其上下文,从而提供更加精准和高效的辅助。无论是代码补全、错误诊断还是重构建议,AI Assistant 都能以您的方式,按照您的风格,提供个性化的支持。
14 |
15 | ## **专注于创新,让 AI 处理繁琐**
16 |
17 | 开发者的时间是宝贵的,应该被用于创新和解决复杂问题。通过 AI Assistant,那些重复性高、技术含量低的任务将不再是您的负担。您可以将这些工作交给 AI Assistant,而您则可以专注于那些真正需要您专业知识和创造力的工作。
18 |
19 | [立即体验](https://www.jetbrains.com.cn/ai/)
20 |
21 |
22 |
23 | ### **如何启动您的 AI Assistant?**
24 |
25 | 1. 首先确保您**没有使用**任何 VPN,并且您在 JetBrains **个人资料**中的地区也是中国大陆
26 | 2. 打开设置 | 插件 (Settings | Plugins) 对话框,搜索 “AI Assistant” 插件并安装。
27 | 3. 打开集成开发环境,进入 设置 | 外观和行为 | 地区和语言设置 (Settings | Appearance & Behavior | Region and Language)
28 | 4. 将地区更改为 “中国大陆”
29 | 5. 打开帮助 | 注册菜单 (Help | Register)
30 | 6. 从左下角注销,然后**重新**使用您的 JetBrains Account **登录**
31 | 7. 激活 IDE 和 AI Assistant 插件
32 |
33 | 如果您想在 ReSharper 中使用 AI Assistant,请按照[说明](https://www.jetbrains.com/help/resharper/AI_Assistant.html?_gl=1*1xj8zzt*_gcl_au*OTIwMjMwMDgxLjE3MjI0OTA4NDE.*_ga*MTM0Mjg2NjMxNS4xNjk4Njc1ODA0*_ga_9J976DJZ68*MTcyNjE0NDkwMS42NS4xLjE3MjYxNDU5MjIuNTkuMC4w)操作。
34 |
35 | 您还可以参考[**此视频**](https://www.bilibili.com/video/BV19RpTeZE7D/?vd_source=d5bff3f058fda83df56c79cfb7e8209e)完成启动流程。
36 |
37 |
38 |
39 | 希望 JetBrains AI Assistant 能够为您带来不一样的开发体验,如果您在探索 AI Assistant 功能时有任何问题或需要进一步支持,我们鼓励您随时访问 [YouTrack 平台](https://youtrack.jetbrains.com/issues/LLM)提交问题或联系我们的中文销售支持([sales.cn@jetbrains.com](mailto:sales.cn@jetbrains.com))和中文技术支持([support.cn@jetbrains.com](mailto:support.cn@jetbrains.com))。我们很乐意帮助您。
40 |
41 |
42 |
43 | 祝您开发愉快!
--------------------------------------------------------------------------------
/docs/md/AI/ml/mask-tensor.md:
--------------------------------------------------------------------------------
1 | # 编码器-掩码张量实现
2 |
3 | ## 0 目标
4 |
5 | - 什么是掩码张量及其作用
6 | - 生成掩码张量的实现过程
7 |
8 | ## 1 啥是掩码张量
9 |
10 | - 掩代表遮掩
11 | - 码就是张量中的数值
12 |
13 | 尺寸不定,里面一般只有1和0的元素,代表位置被遮掩或不被遮掩,至于是0 or 1位置被遮掩可自定义,因此它的作用就是让另外一个张量中的一些数值被遮掩,也可以说被替换,其表现形式是一个张量。
14 |
15 | ## 2 掩码张量的作用
16 |
17 | transformer中,掩码张量的主要作用在应用attention时,有些生成的attention张量中的值计算有可能已知了未来信息而得,未来信息被看到是因为训练时会把整个输出结果都一次性Embedding,但理论上解码器的输出却非一次就能产生最终结果,而是一次次通过上一次结果综合得出。因此,未来的信息可能被提前利用, 所以要遮掩。
18 |
19 | ## 3 生成掩码张量
20 |
21 | ```python
22 | # 生成一个用于遮掩后续位置的掩码张量
23 | def subsequent_mask(size):
24 | """生成向后遮掩的掩码张量, 参数size是掩码张量最后两个维度的大小, 它的最后两维形成一个方阵"""
25 | # 初始化掩码张量的形状
26 | attn_shape = (1, size, size)
27 | # 上三角矩阵
28 | print('====', np.triu(np.ones(attn_shape), k=1))
29 | # 再用np.ones向这形状中添加1元素,形成上三角阵
30 | subsequent_mask = (np.triu(np.ones(attn_shape), k=1)
31 | # 最后为节约空间,再使其中的数据类型转变
32 | .astype('uint8'))
33 | # 最后将numpy类型转化为torch中的tensor, 内部做一个1 - 操作,
34 | # 就是做一个三角阵的反转, 上三角变下三角,即subsequent_mask中的每个元素都被1减,如:
35 | # 原是0, subsequent_mask中的该位置由0变成1
36 | # 原是1, subsequent_mask中的该位置由1变成0
37 | return torch.from_numpy(1 - subsequent_mask)
38 | ```
39 |
40 | 输入:
41 |
42 | ```python
43 | size = 5
44 | ```
45 |
46 | 调用:
47 |
48 | ```python
49 | sm = subsequent_mask(size)
50 | print("sm:", sm)
51 | ```
52 |
53 | 输出:
54 |
55 | ```python
56 | # 最后两维形成一个下三角阵
57 | sm: (0 ,.,.) =
58 | 1 0 0 0 0
59 | 1 1 0 0 0
60 | 1 1 1 0 0
61 | 1 1 1 1 0
62 | 1 1 1 1 1
63 | [torch.ByteTensor of size 1x5x5]
64 | ```
65 |
66 | ### 掩码张量的可视化
67 |
68 | ```python
69 | plt.figure(figsize=(5,5))
70 | plt.imshow(subsequent_mask(20)[0])
71 | ```
72 |
73 | 
74 |
75 | 观察可视化方阵:
76 |
77 | - 黄色是1的部分,代表被遮掩
78 | - 紫色代表未被遮掩的信息
79 | - 横坐标代表目标词汇的位置,0的位置一眼望去都是黄色,都被遮住,1的位置一眼望去还是黄色,说明第一次词还没产生,从第二个位置看过去,就能看到位置1的词,其他位置看不到,以此类推
80 | - 纵坐标代表可查看的位置
--------------------------------------------------------------------------------
/docs/md/AI/overcoming-fear-uncertainty-and-doubt-in-the-era-of-ai-transformation.md:
--------------------------------------------------------------------------------
1 | # 克服 AI 时代的恐惧、不确定性和疑虑
2 |
3 | ## 1 学习咋通过培养 AI 技能,提高职场对 AI 的积极性
4 |
5 | 职场中抵触 AI 的现象确实存在。很多人并非不愿意接受变化,而是因为对 AI 存在“FUD”——即*恐惧(Fear)、不确定性(Uncertainty)和疑虑(Doubt)*。
6 |
7 | 要在 AI 转型时代取得成功,必须积极应对这些 FUD,并**营造一种支持学习的文化,让员工能够适应和成长**,最终推动整个组织共同进步。
8 |
9 | 大厂们都始终在内部率先使用和测试自家的 AI 技术,然后才推向客户。因此他们深知理解 FUD 的根源、找到积极的解决方案,并提供实用的应对措施的重要性。通过学习 AI 技能,了解 AI 如何优化工作流程、提升决策能力和提高生产力,可有效减少担忧,让人们对这项前沿技术更加充满信心。
10 |
11 | ## 2 化恐惧为机遇
12 |
13 | 职场中最常见的 AI 相关恐惧,莫过于“AI 会导致失业”。但事实上,许多专家对此持乐观态度。根据 [联合国国际劳工组织(ILO)的研究](https://www.ilo.org/resource/news/generative-ai-likely-augment-rather-destroy-jobs),AI **更可能增强而非取代工作岗位**,它主要通过自动化某些任务来辅助人类,而非完全取代某个职位。因此,未来许多工作角色可能会演变成“AI + 人工”混合模式,让 AI 成为工作得力副手。
14 |
15 | 在这种工作模式转变的背景下,**AI 技能的需求持续增长**,这对于各行各业的员工而言都是一个发展机遇。主动学习 AI 技能,可帮助员工适应新的工作环境,并增强他们对 AI 技术的信心。对于企业而言,提供 AI 技能培训不仅能帮助员工成长,也能提升组织整体的竞争力。
16 |
17 | ## 3 通过学习文化消除 AI 带来的不确定性
18 |
19 | AI 技术的发展速度之快,让人们对其感到不确定甚至迷茫。但事实上,我们都处在一个“边学边用”的阶段。其实我们在测试 AI 应用和服务的过程中,也不断探索 AI 的潜力。同样地,职场中的每个人都需要尝试使用 AI,才能真正理解它的能力。一个良好的组织学习文化,可以帮助团队克服不确定性,快速适应 AI 变革。
20 |
21 | 沃顿商学院管理学教授、AI 与创业领域的知名专家 Ethan Mollick 认为,**最大的收益来自那些鼓励协作学习的组织**。在 [*Beyond the Prompt* 播客](https://podcast.beyondtheprompt.ai/episodes/practical-strategies-for-leveraging-ai-in-your-business-wharton-professor-ethan-mollick)的一期节目《企业如何正确使用 AI》中,他强调:“一切都始于文化。”
22 |
23 | 该节目还提出了一条重要建议:“尽可能多地使用 AI,真正理解它的能力,最好的方式就是让它参与尽可能多的任务。”
24 |
25 | ## 4 为团队提供 AI 培训
26 |
27 | 想要克服 AI 相关的恐惧、不确定性和疑虑,**关键在于技能培训和学习文化**,而团队培训环境可以有效支持这一成长过程。提高员工信心:
28 |
29 | - 完整的 AI 技能培养手册,帮助企业制定 AI 培训计划,最大化个人、团队和组织层面的学习成效
30 | - 提供 AI 技能培训资源、课程及建立学习型文化的策略和见解
31 | - Copilot 学习中心、AI 学习中心和安全学习中心
32 | - 提供最新的 AI 技术培训计划,如“使用 GitHub 构建、测试和部署应用程序”,“在AI Studio中实施数据集成和模型优化”,“利用 GitHub Copilot 加速应用开发”等
33 | - 增强 AI 和云计算领域的专业技能,适应关键岗位和项目需求
34 |
35 | 技能认证:
36 |
37 | - 验证特定岗位所需的全面技能,需通过考试获得。例如数据科学家认证。
38 | - 应用技能认证:侧重于实际技术场景,通过互动实验评估技能。超过一半的应用技能认证与 AI 相关,例如“使用AI Language 构建自然语言处理解决方案”和“使用 AI 文档智能创建智能文档处理解决方案”等
39 |
40 | ## 5 总结
41 |
42 | 培养 AI 技能不仅能帮助个人和团队适应 AI 时代的变革,还能增强组织的竞争力。通过持续学习和实践,我们可以克服恐惧、不确定性和疑虑,让 AI 成为提升工作效率和创新能力的强大工具。
--------------------------------------------------------------------------------
/docs/md/AI/prompt/01-Prompt网站.md:
--------------------------------------------------------------------------------
1 | # 01-Prompt网站
2 |
3 | https://gpt890.com/prompt/28
--------------------------------------------------------------------------------
/docs/md/AI/prompt/02-常用Prompt.md:
--------------------------------------------------------------------------------
1 | # 02-常用Prompt
2 |
3 | ## 1 写作
4 |
5 | ### 1.1 标题党生成器
6 |
7 | 根据常见的标题党套路,快速写出5个震撼标题,只需填写文章主题
8 |
9 | ```
10 | 从现在开始,你就是标题党头条的制造者。你的任务是根据以下标题党写作策略制作5个标题:
11 |
12 | - 夸张用词:使用夸张的形容词或副词来增加标题的吸引力,例如“史上最…”,“绝对震撼”,“惊人的发现”等。
13 |
14 | - 引发好奇心:在标题中提出悬念或问题,引发读者的好奇心,例如“你绝对不知道的…”,“这个秘密让人惊讶”等。
15 |
16 | - 制造争议:使用具有争议性的观点或论断,挑起读者的兴趣和热议,例如“为什么…是错误的”,“这个观点引发争议”等。
17 |
18 | - 利用名人效应:在标题中提到名人或知名人物,以吸引读者的关注,例如“名人X震惊评论了…”,“X名人的独家秘闻”等。
19 |
20 | - 采用排行榜形式:使用数字和排名,列举一系列有吸引力的事物或观点,例如“十大最惊人的…”,“你必须尝试的五种…”等。
21 |
22 | 请确保标题与主题“#文章主题#”保持一致,并采用指定的标题党技术,使其引人入胜。
23 | ```
24 |
25 | ### 1.2 翻译
26 |
27 |
28 | ```bash
29 |
30 | 你是一位精通简体中文的专业翻译,尤其擅长将专业学术论文翻译成浅显易懂的科普文章。请你帮我将以下英文段落翻译成中文,风格与中文科普读物相似。
31 |
32 | 规则:
33 | - 翻译时要准确传达原文的事实和背景。
34 | - 即使上意译也要保留原始段落格式,以及保留术语,例如 FLAC,JPEG 等。保留公司缩写,例如 Microsoft, Amazon, OpenAI 等。
35 | - 人名不翻译
36 | - 同时要保留引用的论文,例如 [20] 这样的引用。
37 | - 对于 Figure 和 Table,翻译的同时保留原有格式,例如:“Figure 1: ”翻译为“图 1: ”,“Table 1: ”翻译为:“表 1: ”。
38 | - 全角括号换成半角括号,并在左括号前面加半角空格,右括号后面加半角空格。
39 | - 输入格式为 Markdown 格式,输出格式也必须保留原始 Markdown 格式
40 | - 在翻译专业术语时,第一次出现时要在括号里面写上英文原文,例如:“生成式 AI (Generative AI)”,之后就可以只写中文了。
41 | - 以下是常见的 AI 相关术语词汇对应表(English -> 中文):
42 | * Transformer -> Transformer
43 | * Token -> Token
44 | * LLM/Large Language Model -> 大语言模型
45 | * Zero-shot -> 零样本
46 | * Few-shot -> 少样本
47 | * AI Agent -> AI 智能体
48 | * AGI -> 通用人工智能
49 |
50 | 策略:
51 |
52 | 分三步进行翻译工作,并打印每步的结果:
53 | 1. 根据英文内容直译,保持原有格式,不要遗漏任何信息
54 | 2. 根据第一步直译的结果,指出其中存在的具体问题,要准确描述,不宜笼统的表示,也不需要增加原文不存在的内容或格式,包括不仅限于:
55 | - 不符合中文表达习惯,明确指出不符合的地方
56 | - 语句不通顺,指出位置,不需要给出修改意见,意译时修复
57 | - 晦涩难懂,不易理解,可以尝试给出解释
58 | 3. 根据第一步直译的结果和第二步指出的问题,重新进行意译,保证内容的原意的基础上,使其更易于理解,更符合中文的表达习惯,同时保持原有的格式不变
59 |
60 | 返回格式如下,"{xxx}"表示占位符:
61 |
62 | ### 直译
63 | {直译结果}
64 |
65 | ***
66 |
67 | ### 问题
68 | {直译的具体问题列表}
69 |
70 | ***
71 |
72 | ### 意译
73 | 【意译结果】
74 |
75 | 现在请按照上面的要求从第一行开始翻译以下内容为简体中文【】
76 | ```
77 |
78 | ### 1.3 SEO-slug
79 |
80 | ```bash
81 | Prompt:
82 | This GPT will convert input titles or content into SEO-friendly English URL slugs. The slugs will clearly convey the original meaning while being concise and not exceeding 60 characters. If the input content is too long, the GPT will first condense it into an English phrase within 60 characters before generating the slug. If the title is too short, the GPT will prompt the user to input a longer title. Special characters in the input will be directly removed.
83 | ```
--------------------------------------------------------------------------------
/docs/md/DDD/decouple-event-retrieval-from-processing.md:
--------------------------------------------------------------------------------
1 | # 将事件检索与事件处理解耦
2 |
3 | ## 0 前言
4 |
5 | part1讨论了集成过程中遇到的挑战以及幂等事件处理的作用。解决集成问题之后,我们需要反思事件检索的问题。我们的经验教训表明,将事件检索与事件处理解耦至关重要。
6 |
7 | ## 1 事件处理与请求/响应 API 紧耦合
8 |
9 | part1讨论了将请求/响应 API 集成到事件驱动微服务中时,由于基于请求/响应的通信,导致紧耦合。单个事件的处理速度取决于请求/响应 API 及其响应时间,因为事件处理会阻塞直到收到响应。
10 |
11 | 像我们在part1中使用的简单事件循环实现或 [AWS SQS Java Messaging Library](https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-jms-code-examples.html#example-synchronous-message-receiver) 中的工作示例,会顺序处理事件。
12 |
13 | 不推荐这种方法,因为整体处理时间是所有单个处理时间的总和。
14 |
15 | ## 2 并发处理事件
16 |
17 | 幸运的是,像 [Spring Cloud AWS](https://awspring.io/) 这种库提供支持并发处理事件的更高效实现。属性 [ALWAYS_POLL_MAX_MESSAGES](https://docs.awspring.io/spring-cloud-aws/docs/3.0.2/reference/html/index.html#message-processing-throughput) 的行为在下图概述:并发事件处理
18 |
19 | 
20 |
21 | 检索到一批事件后,每个事件在一个单独的线程中并发处理。当所有线程完成处理后,将检索下一批事件。由于基于请求/响应的通信导致的紧耦合,可能使事件处理速度不同。较快的线程会在较慢的线程处理事件时处于等待状态。因此,一批事件的处理时间对应于处理最慢的事件的时间。
22 |
23 | 当事件顺序不重要时,并发处理可以是一个合理的默认设置。但根据经验,某些情况下,事件处理可进一步优化。当单个事件的处理时间差异较大时,线程可能长时间处于等待状态。
24 |
25 | 如集成了一个性能波动较大的请求/响应 API。平均而言,该 API 在 0.5s 后响应。但第 95 百分位和第 99 百分位值经常分别为 1.5s 和超过 10s。在这种并发事件处理方式中,由于响应缓慢的 API,线程经常会等待几s,然后才能处理新事件。
26 |
27 | ## 3 将事件检索与事件处理解耦
28 |
29 | 即可进一步优化事件处理。这样,处理时间较长的单个事件不会减慢其他事件的处理速度。Spring Cloud AWS 提供了 [FIXED_HIGH_THROUGHPUT](https://docs.awspring.io/spring-cloud-aws/docs/3.0.2/reference/html/index.html#message-processing-throughput) 属性,展示了这种解耦可能的实现方式。
30 |
31 | 具体描述如下。详细信息可在[文档](https://docs.awspring.io/spring-cloud-aws/docs/3.0.2/reference/html/index.html#message-processing-throughput)中找到。
32 |
33 | 解耦的事件处理策略:
34 |
35 | 
36 |
37 | 为此,定义一个额外属性,用于在两次事件检索之间的最大等待时间。当所有事件已处理完毕或等待时间已过期时,将检索新事件。若在等待时间过期后,如一个事件仍未处理完毕,则会提前接收九个新事件,并可以开始处理。这意味着这九个线程不会等到最后一个事件处理完毕后才开始工作。
38 |
39 | 根据经验,如果等待时间和其他参数配置得当,解耦可提高单个线程的利用率。一个可能缺点,由于事件往往以更频繁但较小批次的方式被检索,因此可能增加成本。因此,了解 API 性能特征,对于在并发和解耦事件处理之间做出选择至关重要。
40 |
41 | ## 4 结论
42 |
43 | 当你将事件驱动微服务与请求/响应 API 集成时,会引入紧耦合。请求/响应 API 的性能特征很重要,因为它们有助于你在并发和解耦事件处理之间做出选择。
44 |
45 | 本文重点讨论了请求/响应 API 的请求时间性能及其如何影响事件驱动微服务的性能。
--------------------------------------------------------------------------------
/docs/md/DDD/event-versioning.md:
--------------------------------------------------------------------------------
1 | # 事件版本管理
2 |
3 | 有一种办法:发送会议邀请给所有团队,经过101次会议后,发布维护横幅,所有人同时点击发布按钮。或...
4 |
5 | 可用**适配器**,但微调。没错!就像软件开发中90%问题一样,有种**模式**帮助你找到聪明解决方案。
6 |
7 | ## 1 问题
8 |
9 | 你已经有了一个模式,消费者已知咋处理它,所以他们依赖你保持兼容性,但实际上,你要打破这种兼容性。
10 |
11 | 一个生产者和三个消费者例来探讨这问题:
12 |
13 | 
14 |
15 | ## 2 解决方案
16 |
17 | 与其陷入协调部署的陷阱,不如利用适配器模式并加以战略性调整。五步操作:
18 |
19 | 
20 |
21 | ### 2.1 创建新主题
22 |
23 | 当你引入一个新模式时,不要强迫所有消费者立即适应,而是创建一个新topic。这个topic将成为使用新模式生成的事件的归宿。
24 |
25 | ### 2.2 引入适配器
26 |
27 | 部署一个监听新topic的适配器,该适配器将事件翻译回旧模式格式,并重新发布到原始主题。这样,现有消费者可继续接收他们期望格式的事件,而无需立即进行任何更改。
28 |
29 | ### 2.3 更新生产者
30 |
31 | 修改生产者,使其使用新模式生成事件,并将这些事件发布到新创建的topic中。
32 |
33 | 
34 |
35 | ### 2.4 逐步迁移消费者
36 |
37 | 现在,旧格式和新格式并存,可按自己节奏开始迁移消费者。当你更新每个消费者以处理新模式时,只需将其指向新topic。
38 |
39 | 
40 |
41 | ### 2.5 停用适配器
42 |
43 | 一旦所有消费者成功迁移到新模式,你可以安全地退役适配器和旧topic。
44 |
45 | 
46 |
47 |
48 |
49 | ## 3 优势:减少压力,增加灵活性
50 |
51 | ### 3.1 向后兼容
52 |
53 | 适配器确保现有消费者在过渡期间继续正常运行,无需立即更新,维护系统稳定性。
54 |
55 | ### 3.2 无需协调部署
56 |
57 | 通过解耦生产者和消费者的升级过程,消除了同步部署的需求。每个团队可以独立工作,降低出错的风险。
58 |
59 | ### 3.3 集中测试
60 |
61 | 随着每个消费者的迁移,测试可以更集中和可控。你可以逐一验证每个过渡,使问题更容易识别和解决。
62 |
63 | ### 3.4 减少会议
64 |
65 | 由于协调需求减少,你可以告别无数的会议。迁移过程变得更简单、更可预测,压力也更小。
66 |
67 | ## 4 总结
68 |
69 | 目标是找到一种最简单、最有效的解决方案来打破兼容性。
70 |
71 | 适配器模式为在 EDA 中处理事件版本管理提供了务实的方法。
--------------------------------------------------------------------------------
/docs/md/DDD/rate-limit-event-processing.md:
--------------------------------------------------------------------------------
1 | # 限流事件处理
2 |
3 | ## 0 引言
4 |
5 | part3讨论了使用断路器来处理请求/响应API不可用的情况。现在,我们将讨论如何通过限流来遵守请求/响应API的流量限制。
6 |
7 | ## 1 限流事件处理
8 |
9 | 由外部服务提供的请求/响应API通常有流量限制,如100次请求/s,上游微服务须遵守这些限制。与这些请求/响应API集成的事件驱动微服务可能会在没有额外措施的情况下超出其使用限制。
10 |
11 | 限流是一种确保不超出流量限制的有效方法。通常,下游微服务会使用限流来防止过多请求。实现这一目标的一种方法是安装一个Web应用防火墙(WAF),当上游微服务超过流量限制时,该防火墙会阻止请求。然后,WAF会返回一个错误,如429 TOO_MANY_REQUESTS。
12 |
13 | 从发送请求到请求/响应API的事件驱动微服务的角度,这种类型的错误响应会导致重试机制启动。与之前博文中的示例一样,事件最终进入死信队列。
14 |
15 | 如part3讨论那样,集成一个断路器只能在一定程度帮助解决问题。一旦事件驱动微服务超出使用限制并接收到429错误,断路器将暂停事件处理;它将在一段时间后恢复处理。如果断路器恢复处理前的等待时间足够长,WAF和请求/响应API将再次接受请求。然而,由于断路器并不影响事件处理的速度,流量限制很可能再次被超出。断路器会不断地停止和恢复事件处理。
16 |
17 | 在向事件驱动微服务添加限流器以防止其超出API的流量限制方面有过积极的经验。根据具体的限流实现,可提供不同的算法。如[resilience4j](https://github.com/resilience4j/resilience4j)库提供[令牌桶](https://en.wikipedia.org/wiki/Token_bucket)算法实现,使用该算法可以实现每秒最多100次请求的场景。你可配置一个max为100个令牌的桶,并将限流器配置为每秒将桶填满至100个令牌。
18 |
19 | 在事件处理期间,在你向具有流量限制的API发送请求前,可用限流器从桶中获取一个令牌:
20 |
21 | - 如桶中有足够令牌,可用令牌的数量减一,并且事件处理可继续
22 | - 如果没有令牌可用,事件处理只能稍后继续
23 |
24 | 限流器可以阻止事件处理,直到桶被重新填满并且令牌再次可用。
25 |
26 | ## 2 将限流器集成到事件处理
27 |
28 | blockAndAcquireToken()方法对应之前描述的行为。该方法尝试从桶中获取一个令牌;如果有令牌可用,令牌会从桶中移除,事件处理继续,通过创建并发送请求到API。如果没有令牌可用,该方法会等待直到新令牌可用。它会阻止事件处理,以避免超出API的流量限制。
29 |
30 | ```java
31 | // 使用限流器的事件处理
32 | void processEvent(Event event) {
33 |
34 | /* ... */
35 |
36 | rateLimiter.blockAndAcquireToken();
37 |
38 | Request request = createRequest(event);
39 |
40 | Response response = sendRequestAndWaitForResponse(request);
41 |
42 | moreBusinessLogic(event, response);
43 |
44 | /* ... */
45 |
46 | }
47 | ```
48 |
49 | 在像resilience4j这样的实现中,`blockAndAcquireToken()`方法只会在指定时间内阻止处理,然后返回一个错误并使事件处理失败。配置的等待时间和中间件的可见性超时应保持一致。如果`blockAndAcquireToken()`方法因为没有令牌可用而阻止事件处理,它应该在可见性超时到期之前返回一个错误并使事件处理失败。此外,如果它获得了一个令牌并恢复了事件处理,那么在可见性超时到期之前应该有足够的时间来完成事件处理。
50 |
51 | 如果无法做到这一点,就会导致事件的重复处理。尽管part1讨论了如何处理重复事件,但通过适当地配置可见性超时和限流器的等待时间应该尽量避免这种情况。
52 |
53 | ## 3 结论
54 |
55 | 外部服务提供商通常会定义并强制执行其提供的请求/响应API的流量限制。在本文中,我们已经看到限流是遵守事件驱动微服务中流量限制的有效解决方案。
56 |
57 | 本文是关于我们将事件驱动微服务与请求/响应API集成经验的系列文章的最后一篇。正如我们所见,集成涉及到一些相当大的挑战。然而,许多情况下集成是必须的——如依赖第三方服务提供商或系统尚未在遗留现代化过程中迁移到事件驱动架构,这是你将需要做的事情。
--------------------------------------------------------------------------------
/docs/md/Dubbo/01-互联网架构的发展历程.md:
--------------------------------------------------------------------------------
1 | # 01-互联网架构的发展历程
2 |
3 | # 最新 Dubbo3 深入理解原理系列
4 |
5 | 
6 |
7 | ## 互联网的发展
8 |
9 | 随着互联网的发展,用户规模、数据规模、请求规模逐渐扩大,常规的单体架构、垂直应用架构已经无法满足网站需要,因此需要通过 `分布式架构` 、 `流动计算架构` 来对系统进行优化升级,提升性能来应对大规模的用户请求!
10 |
11 | 
12 |
13 | ### 单一应用架构
14 |
15 | 将所有功能都揉进一个应用中,核心就是面向数据库的 CRUD 操作,该架构中的关键就是 ORM,通过 ORM 思想来操作数据库!
16 |
17 | ### 垂直应用架构
18 |
19 | 由单一应用架构进一步升级,按照子系统进行拆分,每个 `子系统独立部署` 、 `共享数据库资源`
20 |
21 | 解决了单体架构中子系统耦合程度高、扩展性差、不好维护的问题
22 |
23 | 像现在许多小公司,使用的还都是垂直应用架构,因为访问量、数据量都不大,垂直应用架构部署、开发简单,完全可以满足需求!
24 |
25 | 对于电商系统来说,垂直应用架构就是 `Web 端` 部署为一个 `jar 包` ,Web 端应用是用户进行购物、结算等操作的,而 `后台管理端` 部署为另一个 `jar 包` ,用于工作人员管理商品、库存的,他们是 `两个不同的 JVM 进程` :
26 |
27 | 
28 |
29 | ### RPC 架构
30 |
31 | RPC 架构由垂直应用架构进一步演变,就是为了解决不同模块之间调用的问题
32 |
33 | 
34 |
35 | 但是 RPC 架构也存在问题:比如库存管理模块压力比较大,我们 `想要对库存管理模块进行扩容` ,部署多份,那么我们必须要 `将后台管理端部署多份` 才可以达到这个效果,这显然资源比较浪费,因为后台管理端还包括了商品管理模块和订单模块
36 |
37 |
38 |
39 | ### 分布式架构
40 |
41 | 由 RPC 架构进一步升级,将应用的不同模块进行进一步的拆分,使得单个模块职责更加单一,相比于 RPC 架构,可以进行负载均衡、服务注册、服务监控等功能
42 |
43 | 
44 |
45 |
46 |
47 | ### 微服务架构
48 |
49 | 微服务架构是 SOA 架构的升级,其实现在微服务架构和 SOA 架构指的基本上就是一个东西了,只不过微服务架构是 SOA 架构做到极致的架构
50 |
51 | 通过微服务架构对多个应用进行编排、服务治理、服务注册、服务发现、负载均衡、限流、配置中心等操作
52 |
53 | 
54 |
55 |
--------------------------------------------------------------------------------
/docs/md/Dubbo/02-Dubbo特性及工作原理.md:
--------------------------------------------------------------------------------
1 | # 02-Dubbo特性及工作原理
2 |
3 |
4 | ## Dubbo 的特性
5 |
6 | 这里说一下 Dubbo 最主要的特性,从这些特性中,就可以看出来我们为什么要选用 Dubbo,也可以将 Dubbo 和 Spring Cloud 进行对比,比如我们搭建一套微服务系统,出于什么考虑选用 Dubbo,又是出于什么考虑而选用 Spring Cloud 呢?
7 |
8 | ### Dubbo 主要的特性
9 |
10 | - **负载均衡**
11 | - **服务注册、服务发现**
12 | - **高性能 RPC 调用**
13 |
14 |
15 |
16 | 接下来针对 Dubbo 的讲解主要从这 3 个特性出发
17 |
18 | ### Dubbo、SpringCloud 技术选型
19 |
20 | 不过在说 Dubbo 特性之前,要先说一下面试相关的东西,因为我们在面试中,Dubbo 毕竟是分布式相关的东西,那么面试官可能问我们公司是如何进行技术选型的呢?为什么选择使用了 Dubbo 而不是 Spring Cloud 呢?
21 |
22 | 其实技术选型的东西,就是比较考察你对这两个框架特性的了解,那么像你如果选用了 Dubbo,那么就说一下 Spring Cloud 存在的缺点即可:
23 |
24 | - 落地成本以及后期维护成本大
25 | - 欠缺服务治理功能,尤其负载均衡、流量路由方面较弱
26 | - 基于 HTTP 进行通信,性能不如 RPC 框架
27 |
28 | 而这些缺点,也正是 Dubbo 的优势所在,Dubbo 使用 RPC 进行通信,追求极致的性能,并且可以进行服务治理、负载均衡!
29 |
30 | 答出来他们各自的优势,那么再说一下由于公司开发人员对于 Dubbo 比较熟悉,因此最终选用 Dubbo 作为分布式框架
31 |
32 |
33 |
34 | ## Dubbo 工作原理
35 |
36 | 首先,在讲解 Dubbo 特性之前,先把 Dubbo 的工作原理给梳理一下,了解 Dubbo 底层是如何进行工作的
37 |
38 | 从整体上先把握,之后再深入到具体特性进行学习
39 |
40 | Dubbo 主要分为 3 个部分:注册中心、服务消费者、服务提供者,**Dubbo 工作的流程如下**:
41 |
42 | 1、每个服务提供者都会去注册中心注册自己,包括自己的地址(ip+port)
43 |
44 | 2、服务消费者去消费时,从注册中心(Dubbo 使用 ZooKeeper 作为注册中心)中拉取服务列表
45 |
46 | 3、消费者会去为远程代理对象创建一个动态代理对象,通过动态代理来拦截方法的执行
47 |
48 | 4、在代理对象的拦截中,会去执行一系列的操作
49 |
50 | 4.1、负载均衡,选择一台机器进行通信
51 |
52 | 4.2、选择一种通信协议:Dubbo 提供了自定义的高性能 rpc 通信协议
53 |
54 | 4.3、将请求进行封装,并且序列化
55 |
56 | 4.4、通过网络通信框架,将远程调用请求传给 Dubbo 服务提供者
57 |
58 | 5、Dubbo 服务提供者收到后,也会进行一系列操作解析请求,最后调用本地服务,将执行结果返回给服务消费者
59 |
60 | 
61 |
62 |
63 |
64 |
--------------------------------------------------------------------------------
/docs/md/algorithm/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/algorithm/.DS_Store
--------------------------------------------------------------------------------
/docs/md/algorithm/basic/00-数据结构与算法专栏大纲.md:
--------------------------------------------------------------------------------
1 | # 00-数据结构与算法专栏大纲
2 |
3 | ## 你将获得
4 |
5 | - 20 个经典数据结构与算法
6 | - 100 个真实项目场景案例
7 | - 文科生都能懂的算法手绘图解
8 | - 轻松搞定 BAT 的面试通关秘籍
9 |
10 | ## 专栏介绍
11 |
12 | 踏上编程路,也就选择了终身学习的生活。每个程序员都要练就十八般武艺,而掌握数据结构与算法就像修炼九阳神功,你的内功修炼速度就会有质的飞跃。
13 |
14 | 无论:
15 |
16 | - 业务开发,想评估代码性能和资源消耗
17 | - 还是架构设计,想优化设计模式
18 | - 或想快速玩转热门技术,如人工智能、区块链
19 |
20 | 都要先搞定数据结构与算法。因为,任凭新技术如何变化,只要掌握了这些计算机科学的核心“招式”,就可见招拆招,始终立“不败之地”。
21 |
22 | 咋才能真正掌握数据结构与算法?把常用数据结构与算法背熟?即便如此,面对现实千变万化,你也不太可能照搬某算法解决即将遇到的下一问题。因此,就像学习设计模式、架构模式一样,**学习数据结构与算法的关键,在于掌握其中的思想和精髓,学会解决实际问题的方法**。
23 |
24 | ## 专栏模块
25 |
26 | ### 入门篇
27 |
28 | 为什么要学习数据结构与算法?数据结构与算法该怎么学?学习的重点又是什么?这一模块将为你指明数据结构与算法的学习路径;并着重介绍贯穿整个专栏学习的重要概念:时间复杂度和空间复杂度,为后面的学习打好基础。
29 |
30 | ### 基础篇
31 |
32 | 将介绍最常见、最重要的数据结构与算法。每种都从“来历”“特点”“适合解决的问题”“实际的应用场景”出发,进行详细介绍;并配有清晰易懂的手绘图解,由浅入深进行讲述;还适时总结一些实用“宝典”,教你解决真实开发问题的思路和方法。
33 |
34 | ### 高级篇
35 |
36 | 将从概念和应用的角度,深入剖析一些稍复杂的数据结构与算法,推演海量数据下的算法问题解决过程;帮你更加深入理解算法精髓,开拓视野,训练逻辑;真正带你升级算法思维,修炼深厚的编程内功。
37 |
38 | ### 实战篇
39 |
40 | 将通过实战案例串讲前面讲到的数据结构和算法;并拿一些开源项目和框架,剖析它们背后的数据结构和算法;并带你用学过的内容实现一个短网址系统;深化对概念和应用的理解,灵活使用数据结构和算法。
41 |
42 | ## 目录
43 |
44 | 
--------------------------------------------------------------------------------
/docs/md/algorithm/basic/dag-directed-acyclic-graph.md:
--------------------------------------------------------------------------------
1 | # DAG有向无环图
2 |
3 | 有向无环图(Directed Acyclic Graph,DAG),与分布式计算和大数据处理结合在许多现代数据处理框架和系统中,如Spark、Flink。
4 |
5 | DAGs在这些系统发挥作用的关键方面:
6 |
7 | ## 1 任务调度
8 |
9 | 分布式计算中,作业被划分成多个任务,这些任务根据他们的依赖关系被组织成DAG。DAG确保在满足所有依赖条件前,不执行任何任务。
10 |
11 | 这样可并行执行多个不相互依赖的任务,优化资源使用并加快处理速度。
12 |
13 | ## 2 容错和状态恢复
14 |
15 | 大数据处理中,任务可能因各种原因(如机器故障或网络问题)失败。由于DAG提供清晰的任务依赖图,系统可通过重新执行失败任务的部分DAG来进行恢复,而无需从头开始整个作业。
16 |
17 | ## 3 执行计划优化
18 |
19 | 分布式数据处理框架使用DAG优化执行计划。如可重组DAG的节点(任务)来减少数据的跨节点移动,或者合并多个操作以减少I/O操作次数。
20 |
21 | ## 4 流式处理
22 |
23 | 流式数据处理领域,DAGs描述了数据从一组操作到另一组操作流动的过程。这允许框架在保持高吞吐量和低延迟的同时,对连续的数据流进行实时分析。
24 |
25 | 以Apache Spark为例,Spark的核心是一个叫做RDD(弹性分布式数据集)的抽象概念,用户对这些RDD执行的转换和动作操作被建模为DAG。Spark引擎会将这些DAG转换成物理执行计划,进行数据分区、任务调度和执行,利用集群中的多台机器并行处理数据。
26 |
27 | 而在Apache Flink中,数据流程使用DAG进行表示,其中节点(顶点)表示数据处理操作,边表示数据流动的方向。
28 |
29 | ## 总结
30 |
31 | DAG在分布式计算和大数据处理中充当了任务的组织和执行路线图的角色,其目的是通过优化任务执行、保证作业的容错性和流式处理的连贯性来提高性能和可靠性。
--------------------------------------------------------------------------------
/docs/md/algorithm/leetcode/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/algorithm/leetcode/.DS_Store
--------------------------------------------------------------------------------
/docs/md/arthas/Arthas使用.md:
--------------------------------------------------------------------------------
1 | # Arthas使用
2 |
3 | ## 0 下载
4 |
5 | [github release](https://github.com/alibaba/arthas/releases):
6 |
7 | 
8 |
9 | ## 1 启动
10 |
11 | 解压后,在文件夹里有`as.sh`,直接用`./as.sh`的方式启动:
12 |
13 | ```bash
14 | ./as.sh
15 | ```
16 |
17 | 或者命令行执行(使用和目标进程一致的用户启动,否则可能attach失败):
18 |
19 | ```shell
20 | java -jar arthas-boot.jar
21 | ```
22 |
23 | 
24 |
25 | 执行该程序的用户需要和目标进程具有相同的权限。
26 |
27 | ```bash
28 | java -jar arthas-boot.jar -h 打印更多参数信息。
29 | ```
30 |
31 | 选择应用的Java进程即可。
32 | 输入6,再`enter`。Arthas会attach到目标进程上,并输出日志:
33 | 
34 |
35 | ## 2 dashboard
36 |
37 | 输入dashboard,enter,展示当前进程信息,按ctrl+c可中断执行:
38 |
39 | 
40 |
41 | ## 3 thread
42 |
43 | 获取到进程的Main Class:
44 | 
45 |
46 | 参考
47 |
48 | - https://arthas.aliyun.com/doc/advanced-use.html
49 |
50 |
--------------------------------------------------------------------------------
/docs/md/assembly/api-gateway/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/assembly/api-gateway/todo.md
--------------------------------------------------------------------------------
/docs/md/assembly/idea-plugin/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/assembly/idea-plugin/todo.md
--------------------------------------------------------------------------------
/docs/md/assembly/middleware/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/assembly/middleware/todo.md
--------------------------------------------------------------------------------
/docs/md/bigdata/00-新一代数据栈将逐步替代国内单一“数据中台”.md:
--------------------------------------------------------------------------------
1 | # 00-新一代数据栈将逐步替代国内单一“数据中台”
2 |
3 | 2021年,硅谷最火爆词汇就是现代数据栈(Modern Data Stack,MDS),以云原生、开源为背景的一系列全新数据技术引擎。相比传统的闭源、私有化的数据技术,现代数据栈凭借其开放性及公有云的 SaaS 服务快速得到了大量企业用户的认可。
4 |
5 | 现代数据栈分为若干层次,每个层次相互支持,相互协助,形成有机整体。企业使用的时候,易利用 SaaS 模式将其整合到一起解决企业数据问题。而开源又给 MDS 生态加入新活力,快速发展社区的同时让上下游快速出现新的合作。
6 |
7 | 
8 |
9 | ## 国内数据技术
10 |
11 | 近年,国内出现大量开源数据技术。2022 年,这些技术形成具有上下游的有机集合体,从新一代数据源体系到数据处理体系,再到数分、AI 算法体系,逐步相互融合、相互支持形成有机整体。可以看到,国内新一代的数据栈在支持云原生技术基础上,还支持私有云/公有云部署,用新一代的计算引擎、算法、调度、同步机制来支持新一代的数据基础建设。
12 |
13 | 
14 |
15 | 这些新一代技术栈的流行和商业工具生态的整合,将逐步替代国内单一“数据中台”服务四五个领域的局面。这变得跟美国类似——若干家各自领域的专业企业相互集成,最终给用户提供高效且灵活的专业解决方案。
16 |
17 | 这些开源现代数据栈中很多的商业公司,正在美国、欧洲快速建立社区、SaaS 和相关的商业服务,也有一些公司已经和全球的开源现代技术栈公司进行竞争。整体上,来自国内的新一代的开源现代数据栈(Open-source MDS)现在刚刚兴起。
18 |
19 | 国内具有大量优秀的开发者、丰富的场景和大量的数据基础,一定会有若干家卓越的开源商业公司出现,最终在全球开源现代数据栈中有一席之地!
--------------------------------------------------------------------------------
/docs/md/bigdata/04-hdfs dfs命令详解.md:
--------------------------------------------------------------------------------
1 | # 04-hdfs dfs命令详解
2 |
3 | Hadoop 分布式文件系统 (HDFS) 的命令行工具,用于在 HDFS 上执行文件系统操作。以下是 `hdfs dfs` 命令的一些常见用法和解释:
4 |
5 | 1. **查看文件或目录内容:**
6 | - `hdfs dfs -ls `:列出指定路径下的文件和目录信息。
7 | - `hdfs dfs -ls -h `:以人类可读的格式列出文件和目录信息。
8 | 2. **创建目录或文件:**
9 | - `hdfs dfs -mkdir `:创建一个新目录。
10 | - `hdfs dfs -touchz `:创建一个空文件。
11 | - `hdfs dfs -copyFromLocal `:将本地文件复制到 HDFS。
12 | 3. **删除目录或文件:**
13 | - `hdfs dfs -rm `:删除指定的文件。
14 | - `hdfs dfs -rmdir `:删除指定的目录。
15 | 4. **移动或重命名文件或目录:**
16 | - `hdfs dfs -mv `:将文件或目录从一个路径移动到另一个路径,也可用于重命名。
17 | - `hdfs dfs -cp `:复制文件或目录到另一个路径。
18 | 5. **上传和下载文件:**
19 | - `hdfs dfs -put `:上传本地文件到 HDFS。
20 | - `hdfs dfs -get `:从 HDFS 下载文件到本地。
21 | 6. **查看文件内容:**
22 | - `hdfs dfs -cat `:显示文件内容。
23 | - `hdfs dfs -tail `:显示文件末尾内容。
24 | 7. **权限管理:**
25 | - `hdfs dfs -chmod `:设置文件或目录的权限。
26 | - `hdfs dfs -chown : `:设置文件或目录的所有者和组。
27 | 8. **其他常用命令:**
28 | - `hdfs dfs -du `:显示指定路径的磁盘使用情况。
29 | - `hdfs dfs -count `:统计文件或目录的大小和数量。
30 | - `hdfs dfs -expunge`:永久删除回收站中的文件。
31 |
32 | 这些命令可以帮助您在 HDFS 上执行各种文件系统操作,管理数据和资源,确保数据的安全和可靠性。
--------------------------------------------------------------------------------
/docs/md/bigdata/DolphinScheduler告警通知.md:
--------------------------------------------------------------------------------
1 | # DolphinScheduler告警通知
2 |
3 | Dolphinscheduler支持多种告警媒介,此处以电子邮件为例进行演示。
4 |
5 | ## 1 准备邮箱
6 |
7 | 如需使用DolphinScheduler的电子邮件告警通知功能,需要准备一个电子邮箱账号,并启用SMTP服务。此处以 QQ 邮箱为例。
8 |
9 | ### 1.1 开启 SMTP 服务
10 |
11 | 
12 |
13 | 拖动进度条在页面下方找到下图所示内容,开启 POP3/SMTP | IMAP/SMTP 任一。
14 |
15 | 
16 |
17 | ### 1.2 获得授权码
18 |
19 | 
20 |
21 | ## 2 DolphinScheduler配置
22 |
23 | (1)切换管理员用户
24 |
25 | (2)创建告警实例
26 |
27 | ### 2.1 点击创建告警实例
28 |
29 | 
30 |
31 | ### 2.2 编辑告警实例
32 |
33 |
34 |
35 | 
36 |
37 | ### 2.3 创建告警组
38 |
39 | 第一步:点击创建告警组
40 |
41 | 
42 |
43 | 第二步:编辑告警组
44 |
45 | 
46 |
47 | 3)测试告警通知
48 |
49 | (1)切换普通用户
50 |
51 | (2)执行工作流测试
52 |
53 | 
54 |
55 | (3)等待接受邮件
--------------------------------------------------------------------------------
/docs/md/bigdata/Hive专栏概述.md:
--------------------------------------------------------------------------------
1 | # Hive专栏概述
2 |
3 | Hive“出身名门”,是最初由Facebook公司开发的数据仓库工具。它简单且容易上手,是深入学习Hadoop技术的一个很好的切入点。专栏内容包括:Hive的安装和配置,其核心组件和架构,Hive数据操作语言,如何加载、查询和分析数据,Hive的性能调优以及安全性,等等。本书旨在为读者打牢基础,从而踏上专业的大数据处理之旅。
--------------------------------------------------------------------------------
/docs/md/bigdata/Hive修复分区.md:
--------------------------------------------------------------------------------
1 | # Hive修复分区
2 |
3 | ## 简介
4 |
5 | Hive的`MSCK REPAIR TABLE`命令用于修复(即添加丢失的)表分区。通常用于那些已在HDFS中存在,但尚未在Hive元数据中注册的分区。
6 |
7 | 当你在HDFS文件系统中手动添加或删除分区目录,Hive并不会自动识别这些更改。为同步元数据与实际文件系统之间的状态,可用命令:
8 |
9 | ```sql
10 | MSCK REPAIR TABLE table_name;
11 | ```
12 |
13 | 较老Hive版本,用旧命令:
14 |
15 | ```sql
16 | ALTER TABLE table_name RECOVER PARTITIONS;
17 | ```
18 |
19 | 执行后,Hive会检查表的分区列在HDFS中的路径,并将在HDFS中找到但Hive元数据中缺失的分区添加到元数据中。这样,当你查询那些分区时,Hive就能够正确地检索到数据。
20 |
21 | 这个命令并不会修复损坏的分区文件;如果分区文件损坏或丢失,你需要从备份中恢复或重新计算分区数据。`MSCK REPAIR TABLE`只是同步元数据与文件系统的状态,不会更改实际的文件。
22 |
23 | ## 手动删除分区目录,会恢复吗?
24 |
25 | 若你在HDFS中手动删除了一个分区目录,执行`MSCK REPAIR TABLE`命令并不会恢复已被删除的分区目录或数据。`MSCK REPAIR TABLE`命令的作用是同步Hive元数据与HDFS上当前的实际文件系统状态,它会添加那些存在于HDFS上但尚未在Hive元数据中注册的分区。
26 |
27 | 在你手动删除HDFS上的一个分区目录的情况下,执行`MSCK REPAIR TABLE`命令将会从Hive元数据中移除对应这个已删除目录的分区信息,因为该命令会发现HDFS上不再有这个分区的目录,并更新Hive元数据以反映这个变化。
28 |
29 | 若希望恢复被删除的分区数据,你要从备份中恢复数据或者重新计算并重新写入这些分区数据到HDFS中。一旦数据在HDFS中被恢复或重新放置,你可再运行`MSCK REPAIR TABLE`更新Hive元数据,使其包含新恢复的分区信息。
30 |
31 | ## 总结
32 |
33 | `MSCK REPAIR TABLE`用于同步Hive元数据,不能用来恢复在HDFS中被删除的数据。
--------------------------------------------------------------------------------
/docs/md/bigdata/Hive分区和分桶.md:
--------------------------------------------------------------------------------
1 | # Hive分区和分桶
2 |
3 | 两种用于优化查询性能的数据组织策略,数仓设计的关键概念,可提升Hive在读取大量数据时的性能。
4 |
5 | ## 1 分区(Partitioning)
6 |
7 | 根据表的某列的值来组织数据。每个分区对应一个特定值,并映射到HDFS的不同目录。为大幅减少数据量,基本必须要做!
8 |
9 | 常用于经常查询的列,如日期、区域等。这样可以在查询时仅扫描相关的分区,而不是整个数据集,从而减少查询所需要处理的数据量,提高查询效率。
10 |
11 | 物理上将数据按照指定的列(分区键)值分散存放于不同的目录中,每个分区都作为表的一个子目录。
12 |
13 | ### 创建分区表
14 |
15 | 在新能源汽车数仓项目中,如希望对整车日志表按照统计日期字段进行分区,建表语句:
16 |
17 | ```sql
18 | # 车辆标识`vehicle_id`、事件发生的时间戳`timestamp`、日志级别`log_level`、日志消息`message`、引擎温度`engine_temperature`、电池电量`battery_level`以及车辆位置`location`等
19 | CREATE EXTERNAL TABLE ev_vehicle_logs (
20 | vehicle_id STRING,
21 | timestamp BIGINT,
22 | log_level STRING,
23 | message STRING,
24 | engine_temperature DOUBLE,
25 | battery_level INT,
26 | location STRING
27 | )
28 | PARTITIONED BY (log_date DATE)
29 | ROW FORMAT DELIMITED
30 | FIELDS TERMINATED BY '\t'
31 | STORED AS TEXTFILE
32 | LOCATION '/path/to/hdfs/new_energy_vehicle/logs';
33 | ```
34 |
35 | `PARTITIONED BY (log_date DATE)`子句定义`log_date`作为表的分区键,即按照统计日期对数据进行分区存储。
36 |
37 | 分区键`log_date`通常是日志数据中的一个字段,该字段存储每条日志记录的日期。按日期分区日志数据可以极大地提高查询性能,特别是对于那些限定在特定日期范围内的查询。例如,如果用户只想看昨天的日志,Hive只需要扫描昨天日期分区对应的数据,而不必扫描整个数据表。
38 |
39 | 创建分区表之后,可以根据实际需要将数据加载到对应的分区目录中。例如,如果有一份新的日志数据,其日期为2023年10月1日,你可以这样导入数据:
40 |
41 | ```sql
42 | LOAD DATA INPATH '/path/to/local/file/2023-10-01.log' INTO TABLE ev_vehicle_logs PARTITION (log_date='2023-10-01');
43 | ```
44 |
45 | 或也可用Hive的动态分区特性让Hive在数据加载时自动根据数据内容创建分区。
46 |
47 | ## 2 分桶(Bucketing)
48 |
49 | 使用哈希函数将数据行分配到固定数量的存储桶(即文件)中。这在表内部进一步组织数据。
50 |
51 | - 对提高具有大量重复值的列(如用户ID)上JOIN操作的效率特别有用,因为它可以更有效地处理数据倾斜
52 | - 要求在创建表时指定分桶的列和分桶的数目
53 |
54 | ### 创建分桶表
55 |
56 | ```sql
57 | CREATE TABLE user_activities (
58 | user_id INT,
59 | activity_date DATE,
60 | page_views INT
61 | )
62 | CLUSTERED BY (user_id) INTO 256 BUCKETS;
63 | ```
64 |
65 | `user_id`是用于分桶的列,数据会根据用户ID的哈希值分配到256个存储桶中。
66 |
67 | ## 3 对比
68 |
69 | - 分区是基于列的值,将数据分散到不同的HDFS目录;分桶则基于哈希值,将数据均匀地分散到固定数量的文件中。
70 | - 分区通常用于减少扫描数据的量,特别适用于有高度选择性查询的场景;而分桶有助于优化数据的读写性能,特别是JOIN操作。
71 | - 分区可以动态添加新的分区,只需要导入具有新分区键值的数据;分桶的数量则在创建表时定义且不能更改。
72 |
73 | 使用分区时要注意避免过多分区会导致元数据膨胀,合理选择分区键,确保分布均匀;而分桶则通常针对具有高度重复值的列。两者结合使用时,可以进一步优化表的读写性能和查询效率。
--------------------------------------------------------------------------------
/docs/md/bigdata/Spark+ClickHouse实战企业级数据仓库专栏.md:
--------------------------------------------------------------------------------
1 | # Spark+ClickHouse实战企业级数据仓库专栏
2 |
3 | ## 1 就业前景广
4 |
5 | 数据仓库被广泛应用于互联网业务中,就业前景极为广阔
6 |
7 | 
8 |
9 | ## 2 热门技术
10 |
11 | 结合热门技术,实战企业级数仓项目
12 |
13 | 轻松掌握高薪数据工程师必备技能。全方位提升项目开发经验,上手 ClickHouse+Spark,实现个人的成长蜕变
14 |
15 | ### 2.1 深度实战 数据仓库 模型设计与调优
16 |
17 | - 数仓整体分层设计方案
18 | - 维度表模型设计
19 | - 面向业务过程的事实表建模
20 | - 面向分析主题的事实表建模
21 | - 千万级数据分析与调优
22 | - 维度表存储选型
23 | - BI工具 Superset/Granfana的数据展示
24 |
25 | ### 2.2 系统掌握 ClickHouse 核心技能与生产实践
26 |
27 | - 表引擎的使用和优化
28 | - ClickHouse 的 SQL优化
29 | - 搭建分布式集群
30 | - ClickHouse 监控
31 | - Clickhouse 字典优化
32 | - 负载均衡与高可用
33 | - 生产实践优化
34 |
35 | ### 2.3 充分提升 Spark/ClickHouse 项目开发与实用操作
36 |
37 | - Spark 自定义 ClickHouse 外部数据源
38 | - Spark 的数据处理与调优
39 | - Spark 自定义本地分片写入策略
40 | - Spark 源码、开源组件源码二次开发
41 | - Spark 参数调优
42 |
43 | ## 3 生产实践案例
44 |
45 | 通过更贴近生产实践的案例,掌握多种实用方案,满足复杂业务需求
46 |
47 | 
48 |
49 | ## 4 遵照数仓分层模型
50 |
51 | 实战数据处理的各个环节,构建实用技术体系
52 |
53 | 
54 |
55 | ## FAQ
56 |
57 | Q:是CDH项目吗?
58 |
59 | A:Hadoop生态相关的环境是以Apache Hadoop + Apache Spark构建, 专栏源码兼容CDH版本的Hadoop和Spark。
60 |
61 | Q:项目的环境是自己进行搭建吗?还是网站提供
62 |
63 | A:手把手带领大家,从0开始搭建环境。 同时提供了开箱即用的虚拟机文件,可直接导入虚拟机用于开发。
64 |
65 | Q:是实时数仓吗?
66 |
67 | A:如果同学指的是,基于流处理和批处理的维度区分,专栏属离线数仓;如果基于响应实时性维度,可以做到在几分钟之内, 算准实时。
--------------------------------------------------------------------------------
/docs/md/bigdata/hiveserver2.md:
--------------------------------------------------------------------------------
1 | # hiveserver2
2 |
3 | ## 1 简介
4 |
5 | Apache Hive的一部分,是一个服务接口,允许客户端使用JDBC或Thrift协议来执行查询、获取结果及管理Hive的服务。即它提供了一个机制,使得外部客户端程序可以与Hive进行交互。
6 |
7 | ## 2 主要特性
8 |
9 | - **多客户端并发**:HiveServer2支持多客户端同时并发访问和执行查询
10 | - **会话管理**:HiveServer2可维护和管理用户会话,每个客户端连接都在自己的会话中执行
11 | - **安全访问**:集成安全功能,可配置基于LDAP的身份验证、Kerberos等安全机制
12 | - **JDBC和ODBC接口**:提供标准JDBC和ODBC接口,这让它能与各种企业级应用以及BI(商业智能)工具兼容
13 | - **Thrift服务**:除JDBC和ODBC,还提供Thrift服务接口,允许各种编程语言创建客户端以访问Hive
14 |
15 | HiveServer2是Hive的核心组件之一,是HiveServer升级版,提供更好性能、稳定性与可伸缩性。在大数据生态系统中,HiveServer2是执行SQL风格查询、数据挖掘和管理大规模数据集的重要工具。正是通过如HiveServer2这样的服务,Hive才能在整个Hadoop生态系统中发挥其强大的数据仓库功能。
--------------------------------------------------------------------------------
/docs/md/bigdata/hive的严格模式.md:
--------------------------------------------------------------------------------
1 | # hive的严格模式
2 |
3 | ## 1 参数控制
4 |
5 | 一项配置,旨在阻止执行某些可能导致效率低下的查询操作。主要是通过以下几个配置参数控制的:
6 |
7 | ### 1.1 hive.mapred.mode
8 |
9 | - 默认值:
10 | - Hive 0.x: `nonstrict`
11 | - Hive 1.x: `nonstrict`
12 | - Hive 2.x: `strict` ([HIVE-12413](https://issues.apache.org/jira/browse/HIVE-12413))
13 | - 添加于:Hive 0.3.0
14 |
15 | Hive 操作执行的模式。在 `strict` 模式下,一些风险较高的查询不允许运行。如阻止:
16 |
17 | - 全表扫描(参见 [HIVE-10454](https://issues.apache.org/jira/browse/HIVE-10454))
18 | - [ORDER BY](https://cwiki.apache.org/confluence/display/Hive/LanguageManual+SortBy#LanguageManualSortBy-SyntaxofOrderBy) 需 LIMIT 子句
19 |
20 | - 没有WHERE子句的查询(可能会扫描整个表)
21 | - 无分区键的查询(对分区表而言,如果不使用分区键进行查询,也可能会扫描整个表)
22 |
23 | ### 1.2 hive.strict.checks.large.query
24 |
25 | 若置true,Hive会对大查询大数据做析假以限制(如,防止笛卡尔积)
26 |
27 | ### 1.3 hive.strict.checks.no.partition.filter
28 |
29 | 若设置为true,Hive会要求分区表的查询须含有分区列的过滤条件,为防止查询无意中扫描全表。
30 |
31 | ### 1.4 hive.strict.checks.bucketing
32 |
33 | 置true时,Hive会检查对于bucketed表的查询是否使用了正确的数据集合方法。
34 |
35 | ## 2 开启
36 |
37 | ```sql
38 | SET hive.mapred.mode=STRICT;
39 | ```
40 |
41 | ## 3 关闭
42 |
43 | ```sql
44 | SET hive.mapred.mode=nonstrict;
45 | ```
46 |
47 | 严格模式下,如果你必须执行全表扫描或者不指定分区键的查询,你需要明确告知Hive你知晓这些潜在的效率问题并且接受后果。这可以通过在查询时添加相关的LIMIT子句,或者在查询中使用分区过滤条件来实现。
48 |
49 | 例如,在严格模式下,下面的查询会被阻止:
50 |
51 | ```sql
52 | SELECT * FROM sales; -- 无WHERE子句,可能扫描全表
53 | ```
54 |
55 | 你需要这样修改查询以避免被阻止:
56 |
57 | ```sql
58 | SELECT * FROM sales WHERE sale_date = '2023-04-15'; -- 使用WHERE子句限制扫描
59 | ```
60 |
61 | 者:
62 |
63 | ```sql
64 | SELECT * FROM sales LIMIT 100; -- 使用LIMIT子句限制返回结果的数量
65 | ```
66 |
67 | ## 4 总结
68 |
69 | 开启严格模式是一种好的实践,因为它可以帮助我们避免执行一些可能导致计算资源浪费的低效查询。这在处理大型数据集和维护生产环境时尤其重要。但是,在某些情况下,如果我们知道所执行的操作是确定的,并且我们需要执行全表扫描这样的操作,可临时关闭严格模式。
--------------------------------------------------------------------------------
/docs/md/bigdata/数仓逻辑模型.md:
--------------------------------------------------------------------------------
1 | # 数仓逻辑模型
2 |
3 | ## 0 前言
4 |
5 | 数据仓库的逻辑模型指的是描述数据仓库中数据如何组织、存储和相互关联的高层次抽象模型。它不涉及数据在物理层面上的实现细节(例如具体的数据库表结构),而是关注于数据模型的设计与规划,以便于支持业务决策和数据分析工作。
6 |
7 | 以下是数据仓库逻辑模型的两种常见设计方法:
8 |
9 | ## 1 星型模式(Star Schema)
10 |
11 | 星型模式是一种数据模型,其中包含一个或多个事实表和多个维度表。事实表存储量化的业务数据(事实),例如销售总额、交易次数等,并且通常包含大量记录。维度表用于存储描述性数据来提供上下文信息,例如时间、地点、产品信息等。这种模式的名称来源于其看上去像一个星星的形状——中心的事实表被各个维度表围绕。
12 |
13 | 当表关系可视化时,事实表在中间,被一系列维度表包围;与这些表的连接就像星星光芒。
14 |
15 | ```plaintext
16 | [时间维度表]
17 | |
18 | [产品维度表] - [事实表] - [店铺维度表]
19 | |
20 | [顾客维度表]
21 | ```
22 |
23 | 该模板的变体为
24 |
25 | ## 2 雪花模式(Snowflake Schema)
26 |
27 | 雪花模式是星型模式的变体,其中维度表可以有它们自己的维度表(被称为子维度表或归一化维度表)。在雪花模式中,数据库的结构更复杂,维度数据经过了进一步的归一化,它可以减少数据冗余,但可能会使得查询变得复杂,因为需要多个连接操作。
28 |
29 | ```plaintext
30 | [时间维度表]
31 | |
32 | [产品类型] - [产品维度表]
33 | | - [事实表] - [店铺类型] - [店铺维度表]
34 | |
35 | [顾客国家] - [顾客维度表]
36 | ```
37 |
38 | 其中维度被进一步分解为子维度。如品牌和产品类别可能有单独表格,且`dim_product` 表格中的每行都能再次将品牌和类别作为外键,而不是将它们作为字符串直接存储在 `dim_product` 表。雪花模式比星形模式更规范化,但星形模式是首选,因为对于分析师,它更简单。
39 |
40 | 典型数仓中,表格很宽:
41 |
42 | - 事实表通常超100列,甚至数百列
43 | - 维度表也可能宽,因为它们包括可能与分析相关的所有元数据。如`dim_store` 表可能包括在每个商店提供哪些服务的细节,是否具有店内面包房,店面面积,商店开张日期,最后一次装修时间,距离最近的高速公路有多远
44 |
45 | ## 3 核心原则
46 |
47 | - **支持业务需求**:
48 | 逻辑模型应确保可以满足所有当前和预期的业务分析需求。
49 | - **可扩展性**:
50 | 数据模型应方便未来的调整和扩展,以容纳新的数据源和新的业务需求。
51 | - **性能优化**:
52 | 模型应经优化以支持高效的数00-数仓逻辑模型据访问和查询性能。
53 | - **易用性**:
54 | 数据模型应容易理解和使用,尤其对于业务用户而言应显得直观。
55 | - **数据质量与一致性**:
56 | 逻辑模型应保证数据的准确性、完整性和一致性。
57 |
58 | 在构建数据仓库的逻辑模型时,将考虑如何将不同的数据源整合到一致的框架中,以及如何结构化这些数据以便于报告和数据分析。逻辑模型是数据仓库概念和物理实现之间的桥梁。
--------------------------------------------------------------------------------
/docs/md/bigdata/维度建模理论之维度表.md:
--------------------------------------------------------------------------------
1 | # 维度建模理论之维度表
2 |
3 | 维度建模是数据仓库设计中的一种方法,用于组织和管理数据以支持分析和报告需求。在维度建模中,维度表是非常重要的一部分,它包含描述业务过程的维度属性,可以帮助用户对数据进行多维分析。描述属性的表通常被设计为维度表。
4 |
5 | ## 1 维度表概述
6 |
7 | 维度表是数据仓库中描述业务实体的表,例如时间、产品、地区等。包含描述维度属性的列,如维度键、层级、描述性属性等。
8 |
9 | 维度表通常具有较少的记录,但有多个属性描述每个记录。
10 |
11 | ## 2 维度表的特点
12 |
13 | - 维度表的记录通常是静态的,不会频繁更新,因为它们描述的是静态业务实体。
14 | - 维度表的主键是维度键,用于与事实表进行关联。
15 | - 维度表通常包含层级结构,例如时间维度可以包含年、季度、月等层级。
16 |
17 | ## 3 维度表的设计原则
18 |
19 | - 清晰定义维度表的业务含义,确保每个维度表只描述一个业务实体。
20 | - 使用稳定的、不频繁变化的属性作为维度表的描述性属性。
21 | - 为维度表的层级设计合适的字段,支持多层次的分析。
22 | - 使用适当的维度键进行唯一标识,通常采用自然键或人工主键。
23 |
24 | 维度表可与任意表组中的任意表进行关联,且创建时无需配置分区信息,但是对单表个数有所限制。通常要求维度表的单表量不超过1000万个。
25 |
26 | - 维度表的数据不应被大量更新。
27 | - 可用MAPJOIN语句进行维度表和其它表的JOIN操作。
28 |
29 | ## 4 维度表与事实表的关系
30 |
31 | - 维度表与事实表之间通过维度键建立关联,形成维度模型。
32 | - 事实表包含业务过程的度量或指标,而维度表描述了这些度量的上下文和属性。
33 |
34 | ## 5 维度表的分类
35 |
36 | - 时间维度表:描述时间属性,如年、月、日、周等。
37 | - 产品维度表:描述产品属性,如产品ID、名称、类别等。
38 | - 地区维度表:描述地区属性,如国家、省份、城市等。
39 |
40 | ## 6 维度表的优势
41 |
42 | - 支持多维分析:通过维度表可以对数据进行多维度的分析,提供更全面的业务视角。
43 | - 提高查询性能:合理设计的维度表结构可以提高查询效率,加快数据检索和报表生成的速度。
44 | - 方便理解和使用:维度表的设计符合业务逻辑,使用户更容易理解和使用数据仓库中的数据。
45 |
46 | 维度表在数据仓库设计中扮演着重要的角色,合理设计和使用维度表可以提高数据仓库的效率和灵活性,为用户提供更好的数据分析和报告支持。
--------------------------------------------------------------------------------
/docs/md/biz-arch/01-DMP系统简介.md:
--------------------------------------------------------------------------------
1 | # 01-DMP系统简介
2 |
3 | ## 1 是什么?
4 |
5 | 数据管理平台(Data Management Platform),广泛应用在互联网的广告定向(Ad Targeting)、个性化推荐(Recommendation)领域。
6 |
7 | 可以把DMP简单理解成一个**数据池子**,接受来自各方的数据,然后融合,处理和优化,最后使用这些数据。
8 |
9 | DMP = 数据+管理 +平台
10 |
11 | DMP是集数据采集,存储,处理,分析,输出应用于一体。数据应用是搭建DMP的目标!
12 |
13 | ## 2 数据来源
14 |
15 | 第一方数据:
16 |
17 | - 企业供应商数据
18 | - 企业会员数据
19 | - 企业销售数据
20 |
21 | 第三方数据:
22 |
23 | - 用户隐私信息
24 | - 运营商数据
25 | - 行业数据
26 |
27 | 第二方数据:
28 |
29 | - 用户行为数据
30 | - 用户消费数据
31 |
32 | ## 3 应用场景
33 |
34 | - 人群画像
35 | - 精准营销
36 | - 营销活动优化
37 | - 程序化广告投放
38 |
39 | DMP系统会通过处理海量互联网访问数据及机器学习算法,给用户标注各种标签。然后,在个性化推荐和广告投放时,再利用这些这些标签做实际广告排序、推荐等工作。无论是搜索广告、千人千面商品信息,还是信息流推荐,背后都有DMP系统。
40 |
41 | 
42 |
43 | ## 4 DMP 行业图谱
44 |
45 | 第一方DMP:单体企业,以企业CRM系统为主。最终表现是BI平台,挖掘销售线索,打造营销闭环
46 |
47 | 第二方DMP:广告公司,广告投放为主
48 |
49 | - 阿里的达摩盘
50 | - 腾讯的广点通
51 | - 头条的巨量千川
52 | - 京东的京准通
53 | - 百度的智选
54 |
55 | 第三方DMP:大数据服务商,以数据交易为主
56 |
57 | TalkingData,如个推数据、神策数据
58 |
59 | ## 5 前景
60 |
61 |
62 |
63 | 
64 |
65 | ## 6 DMP帮助用户达到啥效果?
66 |
67 | ### 用户分析与定向投放
68 |
69 | - 广告精准投放
70 | - 提供丰富标签服务
71 |
72 | ### 广告效果分析
73 |
74 | - 各渠道的获客数量
75 | - 各渠道的转化率
76 | - 订单成本分析
77 |
78 | ### 广告效果优化
79 |
80 | - 个性化广告信息
81 | - 各渠道消费者的复购
82 |
83 | ## 7 DMP平台必须具备的能力
84 |
85 | - 海量多源数据采集能力
86 | - 多元信息挖掘能力
87 | - 数据建模能力
88 | - 丰富的标签体系
89 | - 海量数据存储,处理,分析能力
90 | - 敏捷强大的数据分析
91 |
92 | ## 8 愿景
93 |
94 | - 数字化决策支持,让数据能够运用到企业营销策略之中
95 | - 让数字资产成为企业的大脑,参与到商业场景的每个细节中
96 | - 在人工智能的加持下,实现数据智能化洞察、决策和运用
97 |
98 | ## 9 DMP系统怎么搭建?
99 |
100 | 对于外部使用DMP的系统或者用户来说,可以简单地把DMP看成是一个键-值对(Key-Value)数据库。广告系统或推荐系统,可以通过一个客户端输入用户的唯一标识(ID),然后拿到这个用户的各种信息:
101 |
102 | 用户的人口属性信息(Demographic),如性别、年龄
103 | 有些是非常具体行为(Behavior),如用户最近浏览商品,用户的手机型号
104 | 有些是通过算法系统计算出来的兴趣(Interests),如用户喜欢健身、听音乐
105 | 有些则是完全通过机器学习算法得出的用户向量,给后面的推荐算法或者广告算法作为数据输入。
--------------------------------------------------------------------------------
/docs/md/biz-arch/05-用户画像是什么?.md:
--------------------------------------------------------------------------------
1 | # 05-用户画像是什么?
2 |
3 | ## 1 什么是用户画像
4 |
5 | 用户画像是指根据用户的个人信息、行为数据、兴趣爱好等多方面数据构建出的用户的特征模型或描述。用户画像旨在更好地理解和洞察用户,从而为用户提供个性化的服务和体验。
6 |
7 | 通过数据建立描绘用户的标签,个性化推荐、广告系统、活动营销、都是基于用户画像的应用。
8 |
9 | ## 2 特点和作用
10 |
11 | 1. **多维数据:** 用户画像通常包括多种维度的数据,例如用户的基本信息(年龄、性别、地域)、行为数据(浏览记录、购买记录)、兴趣爱好(关注的话题、喜欢的产品类别)等。
12 |
13 | 2. **个性化服务:** 基于用户画像,企业可以针对不同用户群体提供个性化的服务和推荐,例如个性化推荐商品、定制化的营销活动等,提升用户满意度和忠诚度。
14 |
15 | 3. **精准营销:** 用户画像可以帮助企业更准确地了解用户的需求和偏好,从而进行精准的营销活动,提高营销效果和转化率。
16 |
17 | 4. **产品优化:** 通过分析用户画像,企业可以发现用户的使用习惯和痛点,从而优化产品设计和功能,提升产品的用户体验和市场竞争力。
18 |
19 | 5. **决策支持:** 用户画像还可以为企业提供数据支持,辅助决策制定和业务发展方向,帮助企业更好地了解市场和用户需求。
20 |
21 | 6. **跨平台应用:** 用户画像不仅可以应用于电子商务和在线服务领域,还可以在金融、医疗、教育等多个领域进行应用,为不同行业提供个性化服务和解决方案。
22 |
23 | 总的来说,用户画像是通过对用户数据进行分析和建模,形成对用户特征和行为的描述,从而为企业提供个性化服务、精准营销、产品优化等方面的支持,是数字化时代企业数据驱动和个性化服务的重要工具之一。
24 |
25 | ## 3 正确理解用户画像
26 |
27 | - 不能把典型用户当作用户画像
28 |
29 | 典型用户是虚构的,每个真实用户都有自己的用户画像
30 |
31 | - 用户画像不是用户标签的简单组合
32 | 用户画像的标签要和业务相结合
33 |
34 | - 用户画像的有效性
35 | 用户的行为,偏好会随时间而变化
36 |
37 | 标签是用户画像的核心,只有真正有效的用户画像标签,才能提升运营效果。
38 |
39 | ## 4 用户画像如何生成
40 |
41 | ### 4.1 统一用户唯一标识
42 |
43 | 如手机号
44 |
45 | ### 4.2 给用户打标签
46 |
47 | 属性标签、消费标签、行为标签、内容分析
48 |
49 | ### 4.3 将用户画像与业务关联
50 |
51 | 获客、粘客、留客
52 |
53 | ## 5 用户画像的标签维度
54 |
55 | ### 5.1 标签类型,从标签主题的角度
56 |
57 | - 用户属性
58 | - 用户行为
59 | - 用户消费
60 | - 风险控制
61 | - 内容分析
62 |
63 | ### 5.2 标签类型一从标签生成的角度
64 |
65 | #### 5.2.1 统计类型
66 |
67 | 需要使用聚合函数计算后得到的标签。如总消费金额
68 |
69 | #### 5.2.2 规则匹配类型
70 |
71 | - 人口属性
72 | - 用户生命周期
73 |
74 | #### 5.2.3 挖掘类型
75 |
76 | 用户偏好
77 |
78 | ### 5.3 标签类型一从数据提取的角度
79 |
80 | #### 5.3.1 事实标签
81 |
82 | 从生产系统获取数据
83 |
84 | #### 5.3.2 模型标签
85 |
86 | 对用户属性和行为进行聚类
87 |
88 | #### 5.3.3 预测标签
89 |
90 | 基于用户属性和行为,挖掘用户潜在需求。
91 |
92 | ### 5.4 标签类型一从数据时效的角度
93 |
94 | 静态属性标签:长期甚至永久都不会发生变化,如性别
95 | 动态属性标签:存在有效期,需要定期的更新,如用户活跃度
96 |
97 | ### 5.5 人群的标签组合
98 |
99 | 性别:有2个标签 男、女
100 |
101 | 年龄段维度:有7个标签,18-,20-30,30-40,40-50,50-60,60-70
102 |
103 | 月均消费维度:有7个标签 100-,100-500,500-1000 ...
104 |
105 | ```bash
106 | 人群标签数量=2*7*7=98
107 | ```
--------------------------------------------------------------------------------
/docs/md/biz-arch/06-构建高质量的用户画像.md:
--------------------------------------------------------------------------------
1 | # 06-构建高质量的用户画像
2 |
3 | ## 1 构建准则
4 |
5 | - 人口属性 != 用户画像
6 | - 用户的行为是构成用户与用户之间差异化的核心
7 | - 观察用户行为不是观察他做了什么事情,而是观察他做这件事情的动机
8 |
9 | ## 2 案例
10 |
11 | 看一用户画像:
12 |
13 | 
14 |
15 | 看起来很全面了是吗?好像各种交友软件都这么明摆给你看到这个画像了对吗?但对于购车业务,这就是一份无用的用户画像。
16 |
17 | 应该推荐价格低的(白领)?还是外观好的(女性)?还是实用性的车(租房)?所以看不出买车的决定性因素。
18 |
19 | ## 3 咋确定用户购物的决策动机
20 |
21 | 考量度:用户在做一个决策之前,所需要思考的程度。
22 |
23 | ### 高考量度的产品
24 |
25 | 用户经过了深入的自我剖析,60%的决策都在见到真正的产品之前,可以明确的说出自己决策的依据是什么。如房、车。
26 |
27 | ### 低考量度的产品
28 |
29 | 是一种用户在无意识的情况下作出的决策,用户可能很难说出来明确的决策依据,例如点外卖、刷新闻,所以对这种产品,用户偏好会随时会变
30 |
31 | 适合通过大数据标签统计来进行建模分析,分析用户偏好,确定用户的画像。
32 |
33 | ### 中考量度产品
34 |
35 | 用户在看到产品之前可能并不知道自己具体想要什么,但看到产品后,就会有那么一个产品特性触动用户,让用户做出购买决策,且在事后用户也可以说出是什么因素导致了购买的行为。
36 |
37 | 适合使用访谈的方式确定用户的画像。
38 |
39 |
40 |
41 | 有些产品,用户与用户之间考量度会有很大差异。即使同一个用户群,也会因为价格,用途等因素使得考量度出现很大的差异。
42 |
43 | ## 4 高质量的用户群体画像
44 |
45 | 用户群体应该根据考量度来归类,用户的考量度不同,应该归入不同的用户群。
46 |
47 | 如果用户的考量要素绝大多数相同,只有小部分考量要素不同,则可以合并为同一个的用户群。
--------------------------------------------------------------------------------
/docs/md/biz-arch/07-用户画像和特征工程.md:
--------------------------------------------------------------------------------
1 | # 07-用户画像和特征工程
2 |
3 | ## 1 什么是特征工程
4 |
5 | 单纯的身高和体重,并不能确定人是否胖或瘦。而
6 | ```
7 | BMI=体重/(身高^2)
8 | ```
9 |
10 | 就能确定人是否胖或瘦。
11 |
12 | 特征工程是打开数据密码的钥匙,特征工程就是将数据转换为特征的过程。
13 |
14 | 高质量的特征能提高模型的准确性
15 |
16 | ## 2 什么是特征
17 |
18 | 
19 |
20 | 一个二维数据集,每行表示一个样本,每个特征由一列表示,由观察到的全部的特征集形成一个二维特征矩阵,因此又称这数据集为特征集。
21 |
22 | 特征集还有一类表示类别,如该数据集里职业就是类别,即标签列。而基于数据集的特征可分为:
23 |
24 | - 原始特征
25 |
26 | 原始特征是直接从数据集里面获得的,没有额外的数据操作。
27 |
28 | - 派生特征
29 |
30 | 通常是从特征工程中获得的,即从现有的数据属性中提取出来的特征。
31 |
32 | ## 3 用户画像和特征工程的关系
33 |
34 | ### 3.1 明确问题
35 |
36 | 以及了解数据
37 |
38 | ### 3.2 数据预处理
39 |
40 | 包括数据集成、数据冗余、数据冲突、数据采样、数据清洗、缺失值的处理以及噪声数据的处理
41 |
42 | ### 3.3 特征工程
43 |
44 | **提取对所需要解决问题的有用的特征**,然后针对所解决的问题选择最有用的特征集合。我们可以通过人工或者算法来筛选出重要的特征
45 |
46 | ### 3.4 模型算法
47 |
48 | 我们可以根据应用场景选择多种模型来尝试比较我们所考虑的因素,可以有数据集的大小,特征的维度的大小,所解决的问题是线性的还是非线性的,需不需要考虑过拟合,对性能有哪些要求等。
--------------------------------------------------------------------------------
/docs/md/career/03-新人程序员入行忠告.md:
--------------------------------------------------------------------------------
1 | # 03-新人程序员入行忠告
2 |
3 | ## 1 主动解决【技术】问题
4 |
5 | 不仅要学会做基于增删改查的业务代码,更要主动去解决技术问题。在面试中能证明自己能力的,除了之前的大公司背景外,一般得说解决过哪些技术问题,如何在项目里用(值钱)技术。
6 |
7 | ## 2 涨薪只能靠跳槽
8 |
9 | 程序员薪资倒挂是常有的事,干一样的活,你入职时,你的薪资大概率会比在其中干了3年的员工高,同时,2,3年后入职的员工,哪怕比你年轻,薪资大概率比你高,所以程序员涨薪得靠跳槽。不过现在,有工作就不错了!
10 |
11 | ## 3 竞争力
12 |
13 | 不要在小公司待久,更不要在外包公司呆久。除非是大公司,否则在一家公司呆的时间别超过3年,外包公司的话,除非是刚入行或者当下实在找不到其它工作,否则别去,去了顶多呆2年。否则就不说薪资倒挂,你出去面试时,竞争力会大打折扣。
14 |
15 | ## 4 如何判断公司值得长呆吗?
16 |
17 | 判断一家公司是否值得长呆,就去看比你大3,5岁的程序员在干嘛,除非是大公司,如果比你大的程序员干的活和你差不多,这就是你3,5年后的样子。如果有些公司看不到大龄程序员,这就意味着到时候老板会让你走。
18 |
19 | ## 5 业界知名度
20 |
21 | 大专程序员或低学历程序员,争取尽快升本。程序员最好去出本书,在面试过程中,有一本书的收益会超出你的想象。
22 |
23 | ## 6 最佳学习途径
24 |
25 | 程序员得不断学习,学习的最好途径是,多去解决项目里的问题,多去参与项目上线,或多去解决运维相关问题。同时记住,学习的目的不是让你在当前职位干更好,因为当前职位的薪资已经固定,学习的目的是让你在之后的面试中,能说出自己能干薪资更高的活。
26 |
27 | ## 7 项目证明
28 |
29 | 比如Python深度学习或大模型,看再多资料跑通再多代码,顶多只能让你熟悉API和基本用法,在面试中,你最好能结合你之前公司和项目背景,证明你用过相关技术,解决过实际问题,这是你的学习方向。但如果一味上视频课,跑通学习项目,是无法达到这个效果的。
30 |
31 | ## 8 对的年纪找找对的平台
32 |
33 | 程序员过大龄这个关卡,不是靠掌握多少技术,也不是靠做过多少项目,更不是靠所谓的管理经验,而是得靠“平台”。国企或大公司,对大龄程序员更加友好。
34 |
35 | ## 9 别兼职
36 |
37 | 在进好公司前,不建议做兼职。当下做兼职,一个月挣5,6千,这得耗费很多经历,用这样的经历想办法进好公司,一个月多挣个1,2w,效率更高。同样说做兼职,如果真要做,别单靠技术,首先得去多和不同的人打交道,多去体会些人性。接活挣钱时,更要维护稳定的挣钱渠道。
38 |
39 | ## 10 不轻易转管理
40 |
41 | 不要轻易转管理,更别轻易转中小公司的管理。
42 |
43 | ## X 最后的忠告
44 |
45 | 时代变化太快了,不要把前辈的忠告太当回事。要形成自己的判断力。
--------------------------------------------------------------------------------
/docs/md/career/04-外企也半夜发布上线吗?.md:
--------------------------------------------------------------------------------
1 | # 04-外企也半夜发布上线吗?
2 |
3 | ## 0 别把问题想得太复杂
4 |
5 | - 如果有灰度发布的能力,最好白天发布;
6 | - 如果没有灰度发布,只能在半夜发布。
7 |
8 | 即使有灰度发布能力,也不要沾沾自喜,好好反思一下你们的灰度发布是否真的经得起考验,还是仅仅是装装样子。
9 |
10 | 回滚方案最好在上级环境中使用生产数据演练,避免在0.1%的情况下需要回滚时,发现无法简单地通过发布上一版本服务来回滚,届时会非常尴尬。
11 |
12 | 同时,服务类型也需要考虑,比如大型网络游戏(如《王者荣耀》),都是在午夜时间停服维护,这其实说明了问题。
13 |
14 | ## 1 形式上,必须凌晨!
15 |
16 | 必须得在凌晨上线。程序员的工作有一个“原罪”,就是别人很难看出来你有多努力,尤其是管理层。如果你不上班搞凌晨发布,管理层看不到你的努力,尤其是部门的整体表现。既然能选择凌晨上线,那就凌晨上线!
17 |
18 | 如果有加班费或者调休补偿,凌晨上线大家嗑着瓜子儿,吃着零食,公司提供的外卖和饮料,像开派对一样,和乐融融地等待凌晨。如果有领导或者HR路过,大家一个个愁眉苦脸,盯着屏幕苦苦思索,心里想,怎么还不结束呢。
19 |
20 | 即使上线跟你没关系,也要来,大家要在一起,部门派对。技术上早就不需要这么干了,但我们这里就是喜欢看苦情戏,必须得凌晨,只是这种凌晨非彼凌晨,一起开party~
21 |
22 | 
23 |
24 | ## 2 说点实际的
25 |
26 | ### 外企的发布流程
27 |
28 | 对于外企来说,发布流程相对规范:
29 |
30 | 1. **项目规模小,客户不多:**
31 | 这种情况下,随时可以上线,比如一些管理系统或新项目的上线。
32 |
33 | 2. **项目规模大,用户量大:**
34 | 这种情况下,通常选择访问量较少的时间上线,一般是凌晨,有时甚至是周末的凌晨。
35 |
36 | - 年底会确定下一年的上线日期(release day),每个上线日之间会间隔一个半月,这个周期相当于敏捷开发中的迭代周期。如果业务组有需要,可以通过流程,在规定的上线日之外进行发布。
37 | - 每年都有代码冻结期(code freeze period),通常是12月冻结一个月,因为圣诞假期维护人员放假,处理问题不方便,所以这个月不允许发布。如果需要发布,需要高级别领导批准。
38 | - 发布环境分为测试、集成测试和生产环境。测试环境每个组可以自由发布,集成测试环境需要邮件通知支持组进行发布,生产环境只能在发布日发布。发布通常是一键部署(one click deployment),开发组提前在Jenkins或Udeploy等部署工具中写好脚本,经过支持组审核后,由支持组在发布日进行实际操作。
39 | - 发布日前一周的周五会封闭集成测试环境,各开发组应该提前一周将代码部署到集成测试环境并通过测试,确保发布时风险最小。如果在发布周内发现问题,需要重新部署测试,需要部门领导审批。
40 | - 发布日一般在美国时间周五下午9点(中国时间周六上午9点),各组提前填写发布申请报告,通过审批后通知支持组进行发布。发布完成后,各组需要在生产环境上确认,没有问题则表示发布成功。
41 |
42 | ### 小公司的发布流程
43 |
44 | 一些小公司的发布流程类似于上述流程,都是敏捷开发流程,发布前在测试环境上测试代码,发布前代码会封版,确保代码质量。
45 |
46 | ### 互联网公司发布流程
47 |
48 | 对于包含高并发组件(如Redis集群、Kafka等)的互联网公司,发布过程更加复杂,不仅需要管理代码,还需要重启中间件,或使用中间件清洗或导入数据。如果能在面试中证明自己参与过发布,并解决过发布中的问题,那么一定能有效证明自己的商业项目经验。
49 |
50 | ### 结论
51 |
52 | 无论是大公司还是小公司,凌晨发布都是为了确保用户影响最小化,同时也是为了在特殊情况下能快速响应并回滚。理解并掌握发布流程,能够帮助开发人员更好地应对上线过程中的各种问题。
--------------------------------------------------------------------------------
/docs/md/career/05-中外程序员到底有啥区别?.md:
--------------------------------------------------------------------------------
1 | # 05-中外程序员到底有啥区别?
2 |
3 | ### 中国程序员的特点
4 |
5 | 中国程序员的最大优点是非常勤奋。中国互联网行业有句话叫:**“they earn a lot of money but die early”(赚得多死得早)**。由于工作强度大,经常有程序员突然去世的新闻报道。
6 |
7 | - **996 工作制度**:中国程序员通常实行“996”工作制度(即每天工作从早9点到晚9点,每周工作6天)。这已经成为程序员的潜规则。中国程序员一天的工作量通常与欧洲或美国程序员一周的工作量相同,而他们的平均工资只有欧美程序员的80%左右。
8 | - **工作压力**:这种加班文化并不是老板要你加班,而是你的工作量只有加班才能完成。由于整个中国的互联网行业都是如此,所以你无法通过更换工作来改变这一点。
9 | - **高薪诱惑**:尽管这种生活方式很辛苦,但如果你大学毕业后选择了程序员行当,你的工资将是其它同学的2-3倍,所以仍然有很多人心甘情愿。
10 | - **35岁的门槛**:中国程序员有35岁的门槛,这意味着35岁以上的程序员要么自己当老板,要么成为自由职业者,要么就必须转行,这是因为老程序员无法适应如此紧张的工作。因此,中国的程序员通过十几年的紧张工作,赚到其他专业人员30年的工资,然后选择退出,比如他们会去开店、做自媒体,甚至还有出家的。
11 |
12 | ### 程序员国别特点
13 |
14 | 以下是某大佬与不同国家程序员合作的经历总结:
15 |
16 | #### 1. 中国程序员
17 |
18 | - **工作态度**:只是按照吩咐去做,很少跳出框框思考。
19 | - **费用影响**:当你支付的费用超出他们的正常预期时,他们会认为是好的;当你支付的费用比他们的预期少一点时,他们会认为是坏的。
20 | - **工作效率**:总的来说,对中国程序员的尊重是他们工作很努力,但这也是他们不能跳出框框思考的原因(因为没有时间思考,因长时间工作而感到沮丧)。
21 |
22 | #### 2. 日本和美国程序员
23 |
24 | - **工作质量**:工资很高,通常工作很好,成绩也很好。
25 | - **思维方式**:解决方案并没有经过深思熟虑,多是临时解决方案。日本的解决方案大多数时候都是过时的解决方案。
26 | - **沟通方式**:美国人更加友好,善于倾听真正的需求。日本人非常善于倾听和满足需求,会举行大量会议直到要点明确,这就是他们需要时间来实施的原因。
27 |
28 | #### 3. 印度程序员
29 |
30 | - **工作态度**:通常很好,但有时花了钱却没有好结果,这取决于与你一起工作的人。
31 | - **沟通习惯**:他们从不说“不”,而只说“是,先生”,即使有时不明白某些要点。
32 | - **责任感**:大多数时候,不会在任务完成后进行检查,但在被告知时会进行调试。升级或更新时,可能会出现问题,他们不承担任何责任,只是尝试解决问题。
33 |
34 | #### 4. 伊朗、俄罗斯、乌克兰程序员
35 |
36 | - **工作质量**:便宜、智能、大量开箱即用的解决方案,高薪的解决方案非常精确,并在非常短的时间内提供解决方案。
37 | - **开发方法**:以现代方式开发,而不是使用传统编程。
38 | - **沟通问题**:大多数时候缺乏回应。如果他们手头有一些更有利可图的任务,可能会立即忘记你,不做任何回复。这是最大且最常发生的案例。
39 |
40 | #### 5. 德国和奥地利程序员
41 |
42 | - **工作质量**:精确而昂贵,可能是见过最贵的。
43 | - **解决方案**:有时不是用现代方法,但任务至少是按要求完成的。
--------------------------------------------------------------------------------
/docs/md/career/08-程序员为何一直被唱衰?.md:
--------------------------------------------------------------------------------
1 | # 08-程序员为何一直被唱衰?
2 |
3 | ## 0 的确悲哀!
4 |
5 | 悲哀的就是,想吃技术饭,那就要走专家路线,但国内软件开发绝大多是应用,能给得起钱的也是应用,对专家需求根本没多少,除了那几个超有钱的大公司。
6 |
7 | 这条路确是独木桥,走到后来,你会发现,你潜心研究的技术都是狗屁,不赚钱那就是shit。
8 |
9 | 例如某个回答里提到的,什么悲观锁[乐观锁]。我曾经也天天喜欢研究这类问题,但后来发现,一个框架就搞定了呀,现在做饭的厨子难道还得精通每种调料具体是啥成分???
10 |
11 | 我们的业务量根本做不到需要所谓技术专家的量级,等我们做起来了,系统推倒重来再说。
12 |
13 | ## 1 那国内最缺的到底是啥?
14 |
15 | 懂管理、懂技术、懂业务的人!
16 |
17 | 这类人太少了,B乎上你来看,有几个程序员能给你讲清楚他们公司业务的?有几个能说清楚老板天天咋想问题的?有几个人有企业发展战略性思维的?
18 |
19 | - [CTO]这个群体,要说技术能力,一群人跑出来七嘴八舌给你出主意
20 | - 一说业务,好多人就只是粗糙的背背宣传材料,公司到底怎么赚钱,行业趋势什么样,商业模式怎么创新,两眼一抹黑。对业务的理解就是“代码中的业务逻辑”
21 | - 一说管理,全抓瞎,连沟通都费劲,别说激发员工潜力,打造[技术COE]这种话题了
22 |
23 | 就这个水平,这个能力,35岁还不淘汰,难道把中层领导都裁了?
24 |
25 | 还有脸说内卷……可不是内卷吗?光会技术,那不就是个高级开发,大头兵!老板直聘上的 3~5 年,本科毕业后25~28岁的不就能用,还便宜!我养你个38的,我 tmd 有钱没处花?
26 |
27 | ## 2 国家、企业战略视角
28 |
29 | 这些都是格局上的大角度,所以有些人感觉不舒服,说我是爹味哈哈哈,很正常,基层如果格局跟高层一样了,早就平步青云了,何至于在破帖子下讽刺我。
30 |
31 |
32 |
33 | 很多人不懂,作为一个技术人
34 |
35 | ## 3 为什么要懂业务,懂管理?
36 |
37 | 其实我并没有要求你懂,我只是告诉你,你若只是钻研技术,**天花板就是脚踏板**。
38 |
39 | 至于你到底想咋突破,是不是想突破,是不是要走业务和管理的路,**随你**!
40 |
41 | ## 4 技术人在行业面前的无力感
42 |
43 | 国内软件技术让大家能亲身感受的,莫过电商和支付业务。
44 |
45 | 阿里是这行业里世界级翘楚,三高那是真的高!敢在双十一玩真秒杀!
46 |
47 | 有个网友朋友,2012年进入支付行业,一直走技术路线。那么支付行业什么时候最赚钱?2015年跟着[P2P]赚了一笔钱。
48 |
49 | 2015年,公司明面利润N个亿,销售冠军奖励900万,[首席产品官]奖励400万,CTO你猜多少?100万都不到。他在技术团队跟着喝汤,下了一场毛毛雨而已。那时候你看他们晒什么?晒全世界到处旅游,晒品味,晒格调。
50 |
51 | 2016年开始走下坡路了,随着**备付金统一存管,网联启动,通道同质化,[第四方支付]崛起,监管步步收紧**,第三方支付的颓势在2016年开始盛极转衰。
52 |
53 | ## 5 这叫[行业趋势分析]
54 |
55 | 啥叫业务?business,商业,就是公司咋赚钱!
56 |
57 | 绝大多数技术人不懂这个,甚至就是故意不想关心这个,所以在2016年,他还是很兴奋,觉得钱可以继续赚下去,好日子还在继续。
58 |
59 | 大家都在拼谁技术强,谁职级高,谁能涨薪,你三万,我就四万,你四万,我就五万。
60 |
61 | 各大P2P公司搅乱市场,只要你有金融背景,就直接待遇翻倍。
62 |
63 | 到了2017年,有先知先觉的就已经退出支付行业了。那时候他还懵懵懂懂,因为一直在中台做产品,他不太了解前端的行业趋势,但是很羡慕有人赚了钱。所以2018年,他去内部创业,去研究监管,研究市场,研究客户,研究业务模式,跟公司签了对赌。
64 |
65 | 这一年研究的结果,他跟我聊的是:第三方支付死定了。
66 |
67 | 这哥们后来急流勇退,不管哪家支付公司让他去,甚至[许下CTO]的职位,他都抵死不从,坚决不碰支付了。
68 |
69 | 2016年能看出支付完蛋的,是神人。2017年能看出支付完蛋的,是牛人。2018年看出支付不行了的,是普通人。2019年,甚至2020年还在往第三方支付圈子里钻的,不敢说没有牛人,但大多数都是废人。
70 |
71 | ## 6 总结
72 |
73 | 技术人,你可以选择两耳不闻窗外事,一心只读圣贤书。但这条路是独木桥,天花板低,竞争压力极大。
74 |
75 | 甚至一个行业的兴衰,决定了你最黄金的十年到底能有多大成就。
76 |
77 | 人生几十年,错过了就是错过了,愿意在技术领域呆着,没人反对,自己的路自己走就完了。
--------------------------------------------------------------------------------
/docs/md/career/09-程序员的“三步走”发展战略.md:
--------------------------------------------------------------------------------
1 | # 09-程序员的“三步走”发展战略
2 |
3 | 三步走战略。
4 |
5 |
6 |
7 | ## 1 第一种:还在入门阶段的嫩头青
8 |
9 | 这个阶段你要做的事情就是把代码功底练到位。
10 |
11 | 什么是[代码功底]?用你习惯的编程语言,前端后端无所谓,都能写逻辑,去反复练把常见的一些逻辑操作用代码实现出来。
12 |
13 | ### 例子
14 |
15 | 语法方面:两个变量的值交换;数组中插入取出或者查找某个元素;数组合并去重或者找出共同元素;字符串搜索匹配替换等等
16 |
17 | 语言方面:
18 |
19 | - 各种封装好的[api]要能在需要用的时候随时想得起来
20 | - 怎么给指定接口发一个请求
21 | - 数据库怎么连接怎么操作
22 | - 代码异常了怎么捕获处理抛出错误
23 | - [json格式]文本内容怎么解析取值
24 | - 怎么读写文件内容等等诸如此类
25 |
26 | 至少达到能够保证有能力正常去完成常见的业务需求,最差也至少要有能写[CRUD]水平吧。
27 |
28 | ## 2 第二种:已经过了入门阶段的小青年
29 |
30 | 在这个阶段你应该就已经天天写CRUD写到厌倦了,给你一个熟悉的业务需求,闭着眼睛也能把代码给写出来。而这时往往就会被自己的技术面宽度所限制。
31 |
32 | 什么是技术面的宽度呢?就是你见过的世面技术栈够不够多。
33 |
34 | ### 例子
35 |
36 | 某天突然接了一个新需求,需要识别用户上传的图片文字,这时候对于你这种写惯了数据库操作的人来说一下子就懵了,因为这里开始涉及到了需要对图像进行操作,而这部分恰好是你平时几乎没有用到过也几乎没有去看过相关实现方案,让你凭借目前现有的技术储备去硬写,肯定是两眼一抹黑,写不出来的。
37 |
38 | 这个时候往往就会遇到很多类似于上述情况的实际应用场景下的问题,需要去找各种对应的解决方案
39 |
40 | - 图片上传你会写,但是里面的内容识别怎么做呢?
41 | - 二维码怎么生成解析呢?
42 | - 别人的扫码登录是怎么实现的呢?
43 |
44 | 遇到这种情况,就只能硬着头皮把问题扔搜索引擎里面各种搜相关的链接,看别人的实现方案,用别人封装好的第三方包,以此来一点一点提升自己的技术知识面。
45 |
46 | 这时候写代码就已经不再枯燥了,而是会涉及到很多自己从来没有解决过的需求,不停地去接触新东西,去多看别人大佬提供的方案,翻阅别人的[博客],逛各种论坛,找别人开源的项目来逐个体验,看云厂商的组件服务,这时你才会发现,自己原来的技术知识面是多么地狭窄。原来代码可以用来干这么多事儿。
47 |
48 | ## 3 第三种:做好产品
49 |
50 | 对绝大多数别人的项目都基本上能一眼看出内部的实现逻辑,自己感觉空有一身码艺,想要去做点啥却有没有一个明确的目标。
51 |
52 | 这个阶段也是绝大多数入行两三年之后的技术人会碰到的瓶颈。每天看着别人那些层出不穷的项目,总是觉得心里痒痒,自己难道就比别人弱吗?既然别人都能做点项目,那为什么自己不行。
53 |
54 | 这种时候就应该尽量多去关注一些远离代码以外的事情,例如生活中自己每天都在接触的事物,或者自己平时的各类兴趣爱好。
55 |
56 | ### 例子
57 |
58 | 我每天都会在公司中午点外卖吃,但是经常不知道该吃点什么好,陷入了选择困难当中。那我能不能做一个极简的应用,来解决这个问题呢?也就是通过这个应用,解决了自己每天中午不知道吃什么外卖的问题。那么既然自己会碰到这个问题,当然同样也会有其他人被类似的问题所困扰。能够通过一个小应用解决这个问题,就可以尝试着把它推荐给别人去使用。
59 |
60 | ***也就是从生活当中去发现问题->由问题产生需求->再通过代码能力去尝试满足需求解决问题***
61 |
62 | 很多伟大的项目,都是从生活中可能没人注意的很小的一个需求点而不断发展迭代出来的。
63 |
64 | 所以说,再好的编程水平和代码能力,最终还是要回归到现实生活当中,才可以真正发挥它的作用。
65 |
66 | 毕竟,技术人所写的每一行代码,都是To make the world [a better place]
--------------------------------------------------------------------------------
/docs/md/career/efficient-professional-reading-list.md:
--------------------------------------------------------------------------------
1 | # 高效职场人书单
2 |
3 | ## 《高效人士的七个习惯》
4 |
5 | 
6 |
7 | 帮助人们提高效率和个人影响力的七个习惯。这些习惯涵盖了从个人成长到与他人协作的核心原则:
8 |
9 | ### **1:个人成功(从依赖到独立)**
10 | 1. **积极主动(Be Proactive)**
11 | - 主动掌控自己的生活,而非被外界环境左右。
12 | - 关注“影响圈”(可控的事情)而非“关注圈”(不可控的事情)。
13 | - 你有权选择自己的态度、行为和反应。
14 |
15 | 2. **以终为始(Begin with the End in Mind)**
16 | - 明确自己的目标和核心价值观,设定人生方向。
17 | - 通过制定个人使命宣言,确保所有行动与目标一致。
18 | - 把每一天当作实现长期目标的步骤。
19 |
20 | 3. **要事第一(Put First Things First)**
21 | - 确定优先事项,专注于重要但不紧急的事情(如规划、学习、健康)。
22 | - 学会说“不”,避免被琐事或紧急但不重要的事情牵绊。
23 | - 将时间和精力用在对长期成功最有意义的地方。
24 |
25 | ### **2:公众成功(从独立到互赖)**
26 | 4. **双赢思维(Think Win-Win)**
27 | - 在人际关系中寻求互利互惠,合作共赢,而不是竞争或损人利己。
28 | - 建立信任,关注双方的利益和长期关系。
29 | - 追求“丰盈心态”(相信资源充足,人人都能成功)。
30 |
31 | 5. **知彼解己(Seek First to Understand, Then to Be Understood)**
32 | - 学会倾听,真正理解他人的观点、需求和感受,而不是急于表达自己。
33 | - 运用同理心沟通,避免只从自己的角度出发。
34 | - 在理解对方后,再清晰表达自己的意见。
35 |
36 | 6. **协作增效(Synergize)**
37 | - 尊重并运用多样性,通过团队合作产生“1+1>2”的效果。
38 | - 接受不同观点,寻找创新解决方案。
39 | - 利用集体智慧和资源,实现个人无法单独完成的目标。
40 |
41 | ### **3:持续改进**
42 | 7. **不断更新(Sharpen the Saw)**
43 | - 持续提升身体、心智、情感和精神四个方面的能力。
44 | - 定期锻炼、学习新知识、发展人际关系、实践反思。
45 | - 保持精力充沛,避免倦怠,通过更新自己实现长期成长。
46 |
47 | ---
--------------------------------------------------------------------------------
/docs/md/career/为什么中国的程序员有35岁危机.md:
--------------------------------------------------------------------------------
1 | # 02-为什么中国的程序员有35岁危机
2 |
3 | 我的八年编程生涯,几乎都是在大中厂之间游走,有一些经验跟大家分享:
4 |
5 | ## 1 大厂入职培训体系更完善
6 |
7 | 对毕业生,除了专业知识,对于未来的一切未知。这个时候需要有人来帮忙引路。
8 |
9 | 大公司通常都会有一套完善的培训体系和新人成长计划,这些可以帮助新员工快速适应工作环境,走好人生角色转变的第一步。
10 |
11 | 相对于小厂,入职后大厂后一般会有公司层面的一个全体新员工培训,这一阶段的培训主要是针对公司架构、企业文化、规章制度等方面。有助于新同学快速了解公司,融入公司文化。这期间由于是公司层面的新员工培训,你能认识各个不同领域的人,结交各种志同道合的朋友。
12 |
13 | 公司层面的培训结束后还会有部门培训,这一阶段除了部门架构、规章制度的介绍外主要会对部门所涉业务进行培训,从理论、技术、框架等层面让你更清楚的了解以后的具体工作。这期间团队还会为你安排导师,业务和生活上的问题都可以向他请教。
14 |
15 | 无论是部门层面还是公司层面,都会定期举办技术分享、技术沙龙、前沿讲座等活动,让员工不断更新知识,提高技能,进而让你始终保持对新技术的关注和热情。
16 |
17 | 总之,大厂规范完善的系列培训和指导能够让你无障碍入职并融入公司,快速成长,助力你职业发展的全过程。
18 |
19 | ## 2 大厂生产管理更规范
20 |
21 | 软件项目开发是一个系统性工程,如果没有良好的项目管理规范和足够的人员配备,就会导致所有的压力转嫁到最底层的程序员身上。
22 |
23 | 规范的流程管理和项目管理,清晰的责任划分和职责分配能够大概率避免需求的反复修改、无休止的加班和查不完的BUG。
24 |
25 | 大厂的资源优势能够保证系统开发过程中充足的人员配备,同时引入规范化的项目流程管理。专业的人做专业的事,让个人价值得到充分体现,提高了每个环节的工作效率,避免了很多上述的无用功。
26 |
27 | ## 3 大厂稳定福利待遇更棒
28 |
29 | 大树底下好乘凉,大厂不管是在薪资福利还是人性化管理等方面都要比所谓的小厂更加规范。
30 |
31 | 除了基本的福利待遇,大厂的办公条件、员工关怀等方面也是强于小厂。即使要裁你,我会给你充足的补偿。都是干活,大厂能让你舒舒服服的干活,高高兴兴的加班。
32 |
33 | 对于小厂来说,由于资源和规模限制,福利待遇和人性化管理肯定是远不如大厂。很多小厂甚至还处在努力活下去的阶段,今天吃饱了,明天还存不存在都说不定。因此,对于职场新人来讲,小厂的风险太大。
34 |
35 | ## 4 大厂晋升渠道多样化
36 |
37 | 对于程序员而言,职业发展要经历很多阶段,但大都是沿着技术或者管理等方向发展。无论是走技术路线还是管理路线,大厂都提供了方便灵活的晋升机制和考核评价体系。只要你能力满足要求,都能顺利发展。
38 |
39 | 此外,大厂的转岗渠道也更佳通畅,不仅能提供本地的内部转岗。如果大厂的分公司比较多,你还可以选择异地转岗,事儿少钱多离家近不是梦,当然前提是你要有一定的工作年限。
40 |
41 | ## 5 大厂背景为你跳槽镀金
42 |
43 | 大厂的经验积累能够让你的职业素养得到快速提升,即使你在离职后,头顶着大厂工作经历的光环也更有利于找工作。
44 |
45 | 很多小厂也更青睐于有过大厂工作经验的程序员,他们除了过硬的技术,也能把一些好的管理模式带入小厂,助力小厂的持续发展。
46 |
47 | ## 6 能够交到更多志同道合的朋友
48 |
49 | 大厂突出特点就是大!校招时会招入很多应届生,大家在一个起跑线上前进会有更多的共同话题。因而能结交到更多志同道合的朋友。这些朋友将是你今后人生过程中的一笔重要财富。
50 |
51 | 相比小厂,即使都是新人,应届生可能也只占很少一部分,大多都是通过社招过来,技能水平和生活阅历都不在一条线上,共同话题自然不多,最后能成为朋友的机率自然也不大。
52 |
53 | ## X 总结
54 |
55 | 总之,毕业能进大厂尽量选择大厂,绝对有助于你职业生涯的发展。
56 |
57 | 大公司整体会相对规范,无论是工作、培训还是个人成长,都有相对清晰的通道和方向,适合应届生快速成长。
58 |
59 | 最现实的,大公司简历好看点,以后跳槽选择多。国企社招都要大厂背景的!除非你校招就进国企底薪躺平!
60 |
61 | 程序员大多出身不是贵族,刚毕业的人如果家里没有钱,最好的选择就是大公司,如果家里有矿,就不一定了。
--------------------------------------------------------------------------------
/docs/md/chain/00-区块链专栏概述.md:
--------------------------------------------------------------------------------
1 | # 00-区块链专栏概述
2 |
3 | Web3.0入门与实战 一站式掌握4大主流区块链开发。从0到1全面掌握Web3.0核心技术,快速切换新赛道。
4 |
5 | ## 你将学到
6 |
7 |
8 |
9 | - 从0到1快速全面入行Web3.0
10 | - 掌握Solidty/Motoko/Cadence
11 | - 掌握四大主流链开发全流程
12 | - 掌握Web3.0主流开发框架
13 | - 能够独立开发Web3.0 Dapp
14 | - 基于Web3.0拓展副业收入
15 |
16 | Web3.0迎来爆发式增长,技术人才紧缺,薪资涨幅可观。但Web3.0体系庞杂,很难系统掌握。打造适合初学者从0到1系统学习的课程。从编程语言,到四大主流链项目开发,带大家系统全面掌握Web3.0开发技术,帮助大家顺利入行,开拓新的职业机会,增长职业竞争力及副业收入。
--------------------------------------------------------------------------------
/docs/md/chain/02-DAPP.md:
--------------------------------------------------------------------------------
1 | # 02-DAPP
2 |
3 | ## 1 啥是 DApp?
4 |
5 | DApp,部署在链上的去中心化的应用。
6 |
7 | DApp 是开放源代码,能运行在分布式网络上,通过网络中不同对等节点相互通信进行去中心化操作的应用。
8 |
9 | DAPP 开放源代码,才能获得人的信任。如比特币,尽管很多人没读过比特币源码,但仍不影响这些人相信并持有比特币,就是因为比特币是开源的,如有问题肯定会被发现。
10 |
11 | 去中心化应用肯定是分布式的应用,因为无中心节点,须能在节点之间进行通信,每一个去中心化应用都有自己的通信协议,使用相同协议的节点共同组成一个去中心化应用的网络。
12 |
13 | ## 优点
14 |
15 | DApp是分布式的应用,所以不存在单点故障,一个节点或几个节点坏了完全不影响DApp的正常运行。
16 |
17 | 因为数据是分布式的,所以数据很难完全删除,数据不会像中心化应用那样因为中心节点故障或其他原因而造成数据丢失。
18 |
19 | DApp也比中心化应用更值得信任,因为 DApp 使用共识算法保证数据不可篡改,而中心化服务的数据不可篡改依赖于对中心节点的信任,也就是对服务提供者的信任,如使用网银转账,是建立在对银行信任的基础。
20 |
21 | ## 2 DApp的存在的问题
22 |
23 | DApp节点分布在网络中,因此DApp的数据不会被轻易修改,辩证地看,也就让DApp升级困难。
24 |
25 | DApp 保证了用户的匿名性,那么通常带来问题就是用户身份的验证困难,同样,因为DApp的安全性高,就存在DApp系统更加复杂的问题。
26 |
27 | DApp的去中心化,导致DApp不能依赖已中心化的服务,那么生态的建立是非常缓慢的。
28 |
29 | ## 3 DAPP网络组建过程
30 |
31 | 万维网(WWW)就是指通过HTTP协议连接的网络。HTTP协议应用是一个典型的中心化应用,必须要有服务提供者,服务提供者就是一个中心节点,所有其他的用户通过服务提供者交互。
32 |
33 | DAPP不是中心化的应用,仅用HTTP协议显然不够。以二手交易中的买家和卖家为例,在DApp中一个卖家如何找到一个买家呢?使用 HTTP 的 Web 应用,买家和卖家都可通过域名服务找到中心节点的二手交易平台,但去中心化应用咋解决发现其他的节点?
34 |
35 | DAPP需实现一个新的协议来发现运行 DApp客户端的节点,假设我们已有相互发现节点的协议,那DAPP组网的过程就清晰了。
36 |
37 | 首先开发DAPP,运行DAPP成为一个DAPP的节点,DAPP通过协议发现其他节点,这些节点共同组成一个DAPP网络,例如比特币主网、比特币测试网络、以太坊主网和以太坊测试网等。
38 |
39 | ## 4 DAPP 与智能合约
40 |
41 | 以太坊中一般认为智能合约就是DAPP,更准确的可认为智能合约相当于服务器后台,另外要实现用户体
42 | 验,还需要UI交互界面。
43 |
44 | 那DAPP就是包含完整的智能合约+用户UI交互界面。
45 |
46 | 区块链相对于DAPP来说是应用运行的底层环境。简单的可类比IOS,Android等手机操作系统于运行与之上的各种App。
47 |
48 | 一个完全的DAPP是需要满足完全开源并且是自治的应用程序。DAPP一经部署完毕,便不可更改,应用的升级必须由大部分用户达成共识后,才可进行升级。
49 |
50 | 所有的数据必须进行加密存储在去中心化的区块链应用平台上。其次DAPP必须要有token机制。区块链DAPP能够进行容错。它们没有中心化的机构能够进行干扰,不会出现某些数据的删除或者修改。甚至不能被关闭。
--------------------------------------------------------------------------------
/docs/md/chain/03-以太坊的EVM.md:
--------------------------------------------------------------------------------
1 | # 03-以太坊的EVM
2 |
3 | ## 1 啥是以太坊虚拟机 EVM
4 |
5 | EVM,ETHereum Virtual Machine,以太坊虚拟机。就像所有区块链,以太坊会使用在自己计算机上运行的节点,来保证安全性同时也保持信任。每个参与到以太坊协议中的节点都会在各自电脑上运行软件,这就被称为以太坊虚拟机(EVM)。
6 |
7 | 首先,EVM会通过防止DOS(拒绝服务攻击)攻击来保证安全性,这个攻击是加密货币领域的挑战。
8 |
9 | 其次,EVM会解释并执行以太坊编程语言,并确保可在没有任何干扰的情况下实现通信。
10 |
11 | 可简单把EVM理解为一个系统,其存在是为让我们用Solidity编写的合约代码,运行在以太坊的环境。以太坊相当于计算机环境,EVM把合约代码编译成以太坊能识别的机器码运行。
12 |
13 | ## 2 EVM有什么作用?
14 |
15 | 当以太坊区块链上有转账时,EVM按如下步骤执行:
16 |
17 | 1. 确认转账是否有正确的数值,确认签名的有效性以及是否转账nonce符合特定转账数量的nonce。如有误差,转账会被作为错误返回
18 | 2. 计算转账需要的费用,并且收取燃料费用
19 | 3. 执行数字资产转账到特定地址
20 |
21 | 如EVM检测转出者无足够的手续费用,转账将被回滚。且转账费用不会退回,这会支付给矿工。
22 |
23 | 如转账失败是因为接受者地址有问题,EVM会把发出的资金数量及相关手续费,退还给出发出者(没有矿工收到费用)。
--------------------------------------------------------------------------------
/docs/md/chain/03-百度联盟链Xuperchain核心概念.md:
--------------------------------------------------------------------------------
1 | # 03-百度联盟链Xuperchain核心概念
2 |
3 | ## 1 高性能一计算能力突破单核、单机的边界
4 |
5 | ### 1.1 性能提升的核心技术
6 |
7 | - 链内并行技术(基于自研XVM虚拟机构建DAG)
8 | - 大规模共识技术
9 | - 分叉状态机技术
10 |
11 | 系统峰值TPS达8.7w,支撑业务高效运行:
12 |
13 | 
14 |
15 | ## 2 易开发且可扩展的智能合约开发架构
16 |
17 | ### 2.1 百度区块链共识机制优势
18 |
19 | #### 1 热插拔共识
20 |
21 | 支持适用多种业务场景的共识类型链上无缝切换,以适应不同的业务需求,如: XPOSPoW、PBFT、Chained-BFT、Raft。可满足不同业务场景使用需求,并根据业务需求拓展。
22 |
23 | 支持热插拔多共识机制,并可根据业务需求拓展:
24 |
25 | 
26 |
27 | #### 2 安全、可扩展
28 |
29 | 独特的共识模型,底层Chained-BFT提供安全模型、中间层提供扩展性,做到去中心化、安全性、效率的多层保障。
30 |
31 | #### 3 高性能
32 |
33 | 链式BFT技术和自研XVM虚拟机引警技术相结合,单链可达8.7万TPS,性能业内领先。
34 |
35 | ### 2.2 智能合约开发架构
36 |
37 |
38 |
39 | 
40 |
41 | ### 2.3 百度区块链智能合约特色
42 |
43 | #### 丰富的智能合约模板,保证场景简单应用
44 |
45 | 提供基于功能和基于业务场景的智能合约模板,包括:存证、溯源、积分管理等,满足政务、金融等多领域,支持多种应用场景快速接入。
46 |
47 | #### 完善的智能合约开发者工具集,保证便捷性
48 |
49 | 在线IDE、编译器集成、静态分析工具、测试框架,合约基础库,使业务开发更便捷。
50 |
51 | #### 多语言支持,降低研发门槛
52 |
53 | 支持业务方使用Java/Python/NodeJS等语言SDK访问区块链网络,支持使用Java/GO/C++等语言编写智能合约,并支持根据业务需求便捷拓展降低研发和使用门槛
54 |
55 | #### 精准资源度量,保证安全性
56 |
57 | 支持按照Wasm指令,内存和磁盘计费,形成有效激励和防止DDOS攻击Wasm最小化外部依赖,线性内存减少内存缺陷: 基于llvm的静态分析保证智能合约的安全可控。
58 |
59 | #### 合约预行性高,保证业务运行效果
60 |
61 | 合约AOT执行,对象代码缓存;合约实例独立上下文,并行执行;读写集缓存,保证智能合约高性能执行,满足业务需求。
62 |
63 | ## 3 强安全-全方位、多层次的区块链安全保障
64 |
65 | ### 百度区块链安全体系
66 |
67 | #### 密钥安全
68 |
69 | 通过本地密码加密技术对密钥加密存储,并支持助记词密钥恢复也具备密钥备份的能力。权限账户体系,实现密钥丢失保护,基于可信计算环境实现秘钥托管和分发,保障隐私数据的安全性。
70 |
71 | #### 数据安全
72 |
73 | 数据安全方面主要通过密码学技术保证数据第三方不可破解,以及通过账号权限系统细粒度区分数据访问权限,保证数据访问安全
74 |
75 | #### 网络安全
76 |
77 | 通过TLS加密保证了数据传输安全,并通过CA限制了节点加入网络的权限:超级链也关注核心节点的DDoS防范力,针对KAD网络的路由毒害攻击设计了节点身份认证机制和分层网络路由保护机制,并限制来源IP的身份数量,能有效的解决女巫攻击和日食攻击。
78 |
79 | #### 支持多种密码学算法
80 |
81 | 支持国密算法,支持NIST系列算法,并支持加密算法一键自动切换。支持多种圆曲线和签名算法的混合使用。支持ECDSA、史诺签名、环签名、多重签名、Xuper签名等多种签名算法。
82 |
83 | #### 数据隐私保护
84 |
85 | 支持环签名、零知识证明
86 |
87 | 
--------------------------------------------------------------------------------
/docs/md/chain/07-网络与共识.md:
--------------------------------------------------------------------------------
1 | # 07-网络与共识
2 |
3 | ## 1 共识架构
4 |
5 |
6 |
7 | 
8 |
9 | ## 2 支持的共识列表
10 |
11 |
12 |
13 | 
14 |
15 | ## 3 提案治理机制
16 |
17 |
18 |
19 | 
20 |
21 | Step1:提案者(proposer)通过发起一个事务声明一个可调用的合约,并约定提案的投票截止高度,生效高度
22 |
23 | Step2:投票者(voter)通过发起一个事务来对提案投票,当达到系统约定的投票率并且账本达到合约的生效高度后合约就会自动被调用
24 |
25 | Step3:为了防止机制被滥用,被投票的事务的需要冻结参与者的一笔燃料,直到合约生效高度以后解冻。(防止一笔钱投多个提案)
26 |
27 | ### TDPOS 共识角色转换
28 |
29 | 选民:所有节点拥有选民的角色,可以对候选节点进行投票
30 |
31 | 候选人:需要参与验证人竞选的节点通过注册机制成为候选人,通过注销机制退出验证人竞选
32 |
33 | 验证人:每轮第一个节点进行检票,检票最高的topK候选人集合成为该轮的验证人,被选举出的每一轮区块生产周期的验证者集合,负责该轮区块的生产和验证,某个时间片内会有一个矿工进行区块打包,其余的节点会对该区块进行验证
34 |
35 | 
36 |
37 | ### TDPOS 创世块配置
38 |
39 |
40 |
41 | 
42 |
43 | ### TDPOS 共识关键参数
44 |
45 |
46 |
47 | 
48 |
49 | ## 4 合约账户
50 |
51 | ### 4.1 更灵活的资产管理方式
52 |
53 | - 支持多私钥持有账户
54 | - 灵活的权限管理模型
55 |
56 | ### 4.2 更安全的智能合约管理
57 |
58 | - 智能合约需要部署到一个具体的账户内部
59 | - 设置合约Method的权限管理模型
60 |
61 | 
62 |
63 | ### 4.3 合约账户的权重阈值模型
64 |
65 | - 账户A权限闽值 >=0.4
66 | - 账户B权限阈值 >= 0.6
67 |
68 | 
69 |
70 |
71 |
72 | 
--------------------------------------------------------------------------------
/docs/md/ck/单机安装部署.md:
--------------------------------------------------------------------------------
1 | # 单机安装部署
2 |
3 |
4 |
5 | ## 1 安装
6 |
7 | 进入[官网](https://clickhouse.com/)点击:
8 |
9 | 
10 |
11 | ## 2 .repo文件
12 |
13 | 通常指Linux中用于存储软件源配置信息的文件。这些文件位于CentOS和其他基于Red Hat的Linux发行版中,用于管理系统中可用的软件包源。
14 |
15 | .repo文件包含软件包管理器(如yum或dnf)所需的配置信息,包括软件源的名称、URL、GPG密钥验证等。这些信息告诉系统在哪里可以找到软件包并进行安装、更新或卸载操作。比如:https://packages.clickhouse.com/rpm/clickhouse.repo 文件内容
16 |
17 | ```toml
18 | [clickhouse-stable]
19 | name=ClickHouse - Stable Repository
20 | baseurl=https://packages.clickhouse.com/rpm/stable/
21 | gpgkey=https://packages.clickhouse.com/rpm/stable/repodata/repomd.xml.key
22 | gpgcheck=0
23 | repo_gpgcheck=1
24 | enabled=1
25 |
26 | [clickhouse-lts]
27 | name=ClickHouse - LTS Repository
28 | baseurl=https://packages.clickhouse.com/rpm/lts/
29 | gpgkey=https://packages.clickhouse.com/rpm/lts/repodata/repomd.xml.key
30 | gpgcheck=0
31 | repo_gpgcheck=1
32 | enabled=0
33 | ```
34 |
35 | 在这个示例中,.repo文件包含了两个软件源配置:base和updates。它们分别指定了基础软件包和更新软件包的URL地址、GPG密钥验证方式等信息。
36 |
37 | 在使用Linux系统时,可编辑.repo文件来管理软件源,添加新的软件源、启用或禁用特定的软件源,或者修改软件源的配置信息。这样可以灵活地控制系统中软件包的来源和管理。那就按 repo 文件指引,来到[软件包下载地址](https://packages.clickhouse.com/rpm/lts/):
38 |
39 | 
40 |
41 | 时间戳格式:ISO 8601,它是一种国际标准的日期和时间表示方法。该时间戳表示的日期和时间:
42 |
43 | - 年份:2022年
44 | - 月份:9月
45 | - 日期:21日
46 | - 时间:12点08分59秒
47 | - 毫秒:544毫秒
48 | - 时区:Z表示UTC时间(协调世界时)
49 |
50 |
51 |
52 | 注意需要下载四种文件:
53 |
54 | - clickhouse-client-21.3.20.1-2.noarch.rpm
55 | - clickhouse-common-static-21.3.20.1-2.x86_64.rpm
56 | - clickhouse-common-static-dbg-21.3.20.1-2.x86_64.rpm
57 | - clickhouse-server-21.3.20.1-2.noarch.rpm
58 |
59 | ## 3 开始安装
60 |
61 | 在 linux 服务器的 clickhouse 目录下准备好这四个文件,然后开始安装:
62 |
63 | ```bash
64 | rpm -ivh *rpm
65 | ```
66 |
67 | 安装后检查状态:
68 |
69 | ```bash
70 | [root@~]# systemctl status clickhouse-server
71 | ● clickhouse-server.service - ClickHouse Server (analytic DBMS for big data)
72 | Loaded: loaded (/usr/lib/systemd/system/clickhouse-server.service; enabled; vendor preset: disabled)
73 | Active: inactive (dead)
74 | ```
--------------------------------------------------------------------------------
/docs/md/ddd-mall/04-BFF 架构简介.md:
--------------------------------------------------------------------------------
1 | # 04-BFF 架构简介
2 |
3 | ## 1 概念
4 |
5 | BFF,Backends For Frontends(服务于前端的后端),Sam Newman曾在他的博客中写了一篇相关文章Pattern: Backends For Frontends,在文章中Sam Newman详细地说明了BFF。
6 |
7 | BFF就是服务器设计API时会考虑到不同设备需求,即为不同设备提供不同API接口,虽然它们可能实现相同功能,但因不同设备的特殊性,它们对服务端的API访问也各有其特点,需区别处理。因此出现了类似下图的
8 |
9 | ## 2 设计方式
10 |
11 | ### 2.1 图一
12 |
13 | 
14 |
15 | ### 2.2 图二
16 |
17 | 
18 |
19 | 客户端都不是直接访问服务器的公共接口,而是调用BFF层提供的接口,BFF层再调用基层的公共服务,不同的客户端拥有不同BFF层,它们定制客户端需要的API。图一、图二不同在于是否需要为相似的设备人,如IOS和android分别提供一个BFF,这需根据现实情况决定。
20 |
21 | ## 3 BFF V.S 多端公用、单一的API
22 |
23 | ### 3.1 满足不同客户端特殊交互引起的对新接口的要求
24 |
25 | 所以一开始就会针对相应设备设计好对应接口。若使用单一、通用API,而一开始并没有考虑到特殊需求,则有新请求需要出现时,可能出现:
26 |
27 | - 若添加新接口,易造成接口不稳定
28 | - 若考虑在原有接口上修改,可能产生一些耦合,破坏单一职责
29 |
30 | #### 案例
31 |
32 | 因为移动APP的屏幕限制,在某个列表页,我们只需展示一些关键信息,但由于调用的是服务端提供统一的API,服务端在设计时只考虑到web端,就返回了所有字段,但这些对移动端都无用。
33 |
34 | 优化性能时处理这样的问题,服务器端就需新增接口或通过引入相关耦合来解决。而使用BFF,很大程度能避免这类问题。
35 |
36 | ### 3.2 当由于某客户端需调用多个不同服务端接口,来实现某功能
37 |
38 | 可直接在对应BFF层编写相应API,而不影响基层公共服务,且客户端不用直接向多个后台发起调用,可优化性能。
39 |
40 | BFF带来便利好处同时,也会引起一些问题:代码重复,加大开发工作量等。
41 |
42 | 所以在使用时需要结合现实情况仔细斟酌,符合项目的应用开发背景。例如蚂蚁财富使用BFF的场景如下:
43 |
44 | 
45 |
46 | 参考
47 |
48 | - https://samnewman.io/patterns/architectural/bff/
--------------------------------------------------------------------------------
/docs/md/ddd-mall/05-dddmall-database-spring-boot-starter.md:
--------------------------------------------------------------------------------
1 | # 05-dddmall-database-spring-boot-starter
2 |
3 | ## 1 MybatisPlus配置
4 |
5 | ### 1.1 分页插件集成
6 |
7 | 通过`mybatisPlusInterceptor`方法集成`MybatisPlus`的分页插件,使得分页查询能够自动适应不同数据库方言,提高开发效率,减少重复代码。
8 |
9 | ```java
10 | @Bean
11 | public MybatisPlusInterceptor mybatisPlusInterceptor() {
12 | MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
13 | interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
14 | return interceptor;
15 | }
16 | ```
17 |
18 | ### 1.2 自动填充功能
19 |
20 | `myMetaObjectHandler`方法提供元数据填充的能力,允许在插入或更新数据时自动填充某些字段(如创建时间、更新时间等),减少了手动设置这些字段的需要。
21 |
22 | ```java
23 | @Bean
24 | public MyMetaObjectHandler myMetaObjectHandler() {
25 | return new MyMetaObjectHandler();
26 | }
27 | ```
28 |
29 | ### 1.3 自定义ID生成策略
30 |
31 | 通过`idGenerator`方法引入自定义的ID生成器,这里使用雪花算法,保证分布式系统中ID的唯一性和顺序性,对于业务的扩展性和数据的一致性至关重要。
32 |
33 | ```java
34 | @Bean
35 | @Primary
36 | public IdentifierGenerator idGenerator() {
37 | return new CustomIdGenerator();
38 | }
39 | ```
40 |
41 | ### 1.4 好处
42 |
43 | 1. **统一配置管理**:将Mybatis Plus的关键配置集中管理,提高项目的可维护性和可读性。开发者可以在一个地方快速查看和修改与Mybatis Plus相关的配置,而不需要在多个地方进行搜索和修改
44 |
45 | 2. **业务扩展性**:通过自定义ID生成器和自动填充功能,为业务数据的一致性和完整性提供了保障。特别是在处理大量数据和高并发场景时,这些配置确保了数据处理的效率和准确性
46 |
47 | 3. **提高开发效率**:自动配置分页插件和元数据填充功能,减少了开发者在进行数据操作时的重复工作,使得开发者可以将更多的精力集中在业务逻辑的实现上,加快了开发周期
--------------------------------------------------------------------------------
/docs/md/ddd-mall/06-dddmall-ddd-framework-core.md:
--------------------------------------------------------------------------------
1 | # 06-dddmall-ddd-framework-core
2 |
3 |
4 |
5 | ## 1 CommandHandler接口设计
6 |
7 | ### 1.1 泛型支持
8 |
9 | 通过泛型 ``,`CommandHandler` 接口支持不同类型的命令请求和响应,增加了代码的复用性和灵活性。这种设计允许开发者定义多种处理逻辑,而不必为每种命令实现单独的接口。
10 |
11 | ```java
12 | public interface CommandHandler {
13 | R handler(T requestParam);
14 | }
15 | ```
16 |
17 | ### 1.2 解耦合
18 |
19 | `CommandHandler` 接口作为命令处理的统一入口,有助于解耦命令的发送者和接收者。命令发送者只需知道有一个能处理该命令的接口即可,无需关心具体的处理逻辑,从而降低系统各部分之间的耦合度。
20 |
21 | ### 1.3 易于扩展
22 |
23 | 随业务发展,可能会增加更多的命令类型。`CommandHandler` 接口使得添加新的命令处理器变得简单,只需实现该接口即可。这种设计支持开闭原则,对扩展开放,对修改封闭。
24 |
25 | ### 1.4 业务考量
26 |
27 |
28 |
29 | 1. **业务流程抽象**:`CommandHandler` 接口抽象了业务操作的执行流程,每个实现类代表一个具体的业务操作。这种设计使得业务逻辑更加清晰,每个业务操作都有明确的界定,便于理解和维护。
30 |
31 | 2. **事务控制**:在实现 `CommandHandler` 接口的类中,可以很方便地添加事务控制逻辑。这意味着业务操作的执行可以保证数据的一致性和完整性,对于保障系统的稳定性和可靠性至关重要。
32 |
33 | 3. **权限验证**:`CommandHandler` 接口的实现类也可以用于进行权限验证。在处理命令之前,可以检查用户是否有执行该命令的权限,从而确保系统的安全性。
--------------------------------------------------------------------------------
/docs/md/ddd-mall/06-商品秒杀库存超卖问题.md:
--------------------------------------------------------------------------------
1 | # 06-商品秒杀库存超卖问题
2 |
3 | ## 超卖问题
4 |
5 | 1个商品卖给多个人:1商品多订单。
6 |
7 | 多人抢购同一商品时,多人同时判断是否有库存,若只剩一个,则都会判断有库存,此时会导致超卖,即一个商品被下了多个订单。
8 |
9 | ### 常见库存扣减方式
10 |
11 | - 下单减库存:买家下单后,在商品总库存-买家购买数量。这是最简单的减库存方式,也是控制最精确的,下单时直接通过DB事务控制商品库存,一定不会出现超卖的情况。但有些人下完单可能不会付款。
12 | - 付款减库存:买家下单后,不立即减库存,而等到用户付款后才真正减库存,否则库存一直保留给其他买家。但因付款时才减库存,若并发较高,可能导致买家下单后付不了款,因为商品可能已被其他人先付款买走。
13 | - 预扣库存:买家下单后,库存为其保留一定时间(如 30 min),超时候,库存自动释放,其他买家就能继续购买了。买家付款前,系统会校验该订单的库存是否还有保留:若无保留,则再次尝试预扣;若库存不足(即预扣失败)则不允许继续付款;若预扣成功,则完成付款并实际地减去库存。
14 |
15 | 采用哪种需要基于业务考虑,减库存最核心的是大并发请求时保证DB中的库存字段值不能为负。
16 |
17 | 方案一:
18 |
19 | 扣减库存场景,使用行级锁,通过DB引擎本身对记录加锁的控制,保证DB更新的安全性,且通过`where`语句,保证库存不会被减到负数,也就是能够有效的控制超卖的场景。
20 |
21 | ```sql
22 | update ... set amount = amount - 1 where id = $id and amount - 1 >=0
23 | ```
24 |
25 | 方案二
26 |
27 | 设置数据库的字段数据为无符号整数,这样减后库存字段值小于零时 SQL 语句会报错。
28 |
29 | ### 2.1 思路分析
30 |
31 | 利用Redis list队列,给每件商品创建一个独立的商品个数队列,如:A商品有2个,A商品的ID为1001,则创建一个list,key=SeckillGoodsCountList_1001,往该队列中塞2次该商品ID。
32 |
33 | 每次给用户下单时,先从队列取数据:
34 |
35 | - 能取到数据
36 |
37 | 有库存
38 |
39 | - 取不到
40 |
41 | 无库存
42 |
43 | 这就防止了超卖。
44 |
45 | 操作Redis大部分都是先查出数据查,在内存中修改,然后存入Redis。高并发下就有数据错乱问题,为控制数量准确,单独将商品数量整个自增键,自增键是线程安全的,无需担心并发问题。
46 |
47 | 
48 |
49 | 
50 |
51 | ### 2.2 代码
52 |
53 | 每次将商品压入Redis时,创建一个商品队列。
54 |
55 | 修改SeckillGoodsPushTask,添加一个pushIds方法,用于将指定商品ID放入到指定数字:
56 |
57 | ```java
58 | /***
59 | * 将商品ID存入到数组中
60 | * @param len:长度
61 | * @param id :值
62 | * @return
63 | */
64 | public Long[] pushIds(int len,Long id){
65 | Long[] ids = new Long[len];
66 | for (int i = 0; i dump_file.sql
28 | ```
29 |
30 | 导入:
31 |
32 | ```sql
33 | mysql -u username -p database_name < dump_file.sql
34 | ```
35 |
36 |
37 |
38 | ## 3 多线程并行导入
39 |
40 |
41 |
42 |
43 |
44 | ## 4 使用中间临时表导入数据
45 |
46 | 先在MySQL中建立临时表无索引,批量导入数据到临时表,最后再用 insert into...select 从临时表导入到正式表。
47 |
48 | ```sql
49 | -- 创建临时表
50 | CREATE TEMPORARY TABLE temp_table LIKE your_table;
51 |
52 | -- 禁用索引
53 | ALTER TABLE temp_table DISABLE KEYS;
54 |
55 | -- 导入数据到临时表
56 | LOAD DATA INFILE '/path/to/your/file.csv'
57 | INTO TABLE temp_table
58 | FIELDS TERMINATED BY ','
59 | ENCLOSED BY '"'
60 | LINES TERMINATED BY '\n'
61 | IGNORE 1 ROWS;
62 |
63 | -- 从临时表导入到正式表
64 | INSERT INTO your_table SELECT * FROM temp_table;
65 |
66 | -- 启用索引
67 | ALTER TABLE your_table ENABLE KEYS;
68 |
69 | -- 删除临时表
70 | DROP TEMPORARY TABLE temp_table;
71 | ```
72 |
73 |
74 |
75 | ## 5 MyISAM 引擎表
76 |
77 | 先导入到对应的 .txt 文件,然后使用 REPAIR TABLE 命令修复并重建索引。
78 |
79 | ## 6 调整 MySQL 的配置参数
80 |
81 | 增大 bulk_insert_buffer_size、max_allowed_packet 等,以优化导入性能。
82 |
83 |
84 |
85 | ## 7 总结
86 |
87 | - 如果是自主开发的系统,建议在应用层对数据进行分批插入,可以充分利用多线程,实现更高的导入效率
88 | - 第三方工具如 mysqldump、mydumper、MyData 等,这些工具提供了多线程导入、断点续传等高级功能
89 | - 检查磁盘I/O、CPU等系统资源是否够用,是否有瓶颈。如果资源不足,可以考虑分库分表的策略
--------------------------------------------------------------------------------
/docs/md/ddd-mall/DDD-Mall商城的公共组件设计.md:
--------------------------------------------------------------------------------
1 | # DDD-Mall商城的公共组件设计
2 |
3 | ## 0 前言
4 |
5 |
6 |
7 | 
8 |
9 |
10 |
11 | ## 1 整体架构
12 |
13 |
14 |
15 | 
16 |
17 |
--------------------------------------------------------------------------------
/docs/md/ddd-mall/building-product-information-caching-system.md:
--------------------------------------------------------------------------------
1 | # 商品信息缓存体系构建
2 |
3 | ## 0 前言
4 |
5 | 在电商系统中,商品信息的快速获取对用户体验至关重要。本文将详细讲解一个多层级的商品信息缓存体系,旨在提高系统性能和可靠性。
6 |
7 | 开局一张图,剩下全靠编!
8 |
9 | 
10 |
11 | ## 1 整体架构
12 |
13 | 该缓存体系采用了多级缓存策略,从前端到后端,逐层深入:
14 |
15 | 1. CDN缓存
16 | 2. Nginx缓存集群
17 | 3. Redis缓存
18 | 4. JVM本地缓存
19 | 5. MySQL持久化存储
20 |
21 | ## 2 详细解析
22 |
23 | ### 1. 用户请求入口
24 |
25 | 用户的请求首先通过CDN(内容分发网络):
26 |
27 | ```markdown
28 | User -> CDN -> 前端静态资源 (Front-end Static Resources)
29 | ```
30 |
31 | CDN负责分发静态资源,减轻主服务器负载。
32 |
33 | ### 2. 负载均衡
34 |
35 | 请求经过CDN后,进入负载均衡层:
36 |
37 | ```markdown
38 | CDN -> LVS (Linux Virtual Server) + HA Proxy
39 | ```
40 |
41 | - LVS: 实现高性能、高可用的负载均衡
42 | - HA Proxy: 提供更细粒度的流量控制和健康检查
43 |
44 | ### 3. Nginx边缘节点
45 |
46 | ```markdown
47 | LVS + HA Proxy -> JavaEdge (Nginx转发层)
48 | ```
49 |
50 | JavaEdge是一个Nginx集群,负责请求的初步处理和转发。这里可能进行:
51 |
52 | - IP限流和转发
53 | - 业务判断(解析URL)
54 |
55 | ### 4. Nginx业务层
56 |
57 | JavaEdge将请求转发到Nginx业务层:
58 |
59 | ```markdown
60 | JavaEdge -> 单品页Nginx / 结算Nginx
61 | ```
62 |
63 | 这一层的Nginx服务器针对不同的业务场景(如单品页、结算页)进行了优化。
64 |
65 | ### 5. Lua脚本和Redis缓存
66 |
67 | 在Nginx业务层,使用Lua脚本实现了与Redis的交互:
68 |
69 | ```markdown
70 | Nginx业务层 -> Lua -> Redis
71 | ```
72 |
73 | Lua脚本在Nginx中执行,直接从Redis读取缓存数据,实现高效的数据获取。
74 |
75 | ### 6. JVM缓存
76 |
77 | 如果Redis中没有所需数据,请求会转发到Java应用服务器:
78 |
79 | ```markdown
80 | Redis (未命中) -> JVM Cache
81 | ```
82 |
83 | JVM缓存作为本地缓存,可以进一步提高数据访问速度。
84 |
85 | ### 7. MySQL持久化
86 |
87 | 作为最后的数据源,MySQL存储所有的商品信息:
88 |
89 | ```markdown
90 | JVM Cache (未命中) -> MySQL
91 | ```
92 |
93 | 当缓存未命中时,系统会查询MySQL,并更新各级缓存。
94 |
95 | ## 3 缓存层级
96 |
97 | 图中展示了五个缓存层级:
98 |
99 | 1. 一级缓存:可能指CDN或浏览器缓存
100 | 2. 二级缓存:Nginx层的缓存
101 | 3. 三级缓存:Redis缓存
102 | 4. 四级缓存:JVM本地缓存
103 | 5. 五级缓存:MySQL(作为最终数据源)
104 |
105 | ## 4 特殊说明
106 |
107 | 1. **Nginx本地缓存**:用于存储热点数据,提高访问速度。
108 | 2. **Redis主从同步**:确保Redis数据的高可用性。
109 | 3. **JVM Cache到Redis的更新**:保证数据一致性。
110 |
111 | ## 5 总结
112 |
113 | 这个多层级的缓存体系通过合理利用各种缓存技术,实现了高效的商品信息获取。从前端到后端,逐层深入,每一层都在努力提供最快的响应。这种架构不仅提高了系统性能,还增强了系统的可靠性和扩展性。
114 |
115 | 在实际应用中,还需要考虑缓存一致性、过期策略、热点数据处理等问题,以构建一个完善的商品信息缓存体系。
--------------------------------------------------------------------------------
/docs/md/ddd-mall/dddmall-cache-spring-boot-starter.md:
--------------------------------------------------------------------------------
1 | # dddmall-cache-spring-boot-starter
2 |
3 |
4 |
5 | #### 缓存穿透布隆过滤器
6 |
7 | ```java
8 | /**
9 | * 防止缓存穿透的布隆过滤器
10 | */
11 | @Bean
12 | @ConditionalOnProperty(prefix = BloomFilterPenetrateProperties.PREFIX, name = "enabled", havingValue = "true", matchIfMissing = true)
13 | public RBloomFilter cachePenetrationBloomFilter(RedissonClient redissonClient, BloomFilterPenetrateProperties bloomFilterPenetrateProperties) {
14 | RBloomFilter cachePenetrationBloomFilter = redissonClient.getBloomFilter(bloomFilterPenetrateProperties.getName());
15 | cachePenetrationBloomFilter.tryInit(bloomFilterPenetrateProperties.getExpectedInsertions(), bloomFilterPenetrateProperties.getFalseProbability());
16 | return cachePenetrationBloomFilter;
17 | }
18 | ```
19 |
20 | #### 静态代理模式
21 |
22 | 静态代理模式:Redis 客户端代理类增强
23 |
24 | ```java
25 | @Bean
26 | public StringRedisTemplateProxy stringRedisTemplateProxy(RedisKeySerializer redisKeySerializer,
27 | StringRedisTemplate stringRedisTemplate,
28 | RedissonClient redissonClient) {
29 | stringRedisTemplate.setKeySerializer(redisKeySerializer);
30 | return new StringRedisTemplateProxy(stringRedisTemplate, redisDistributedProperties, redissonClient);
31 | }
32 | ```
33 |
34 | 使用静态代理模式自己实现一个StringRedisTemplateProxy类,而非直接通过Spring的@Bean注解引入框架自带的StringRedisTemplate实例,主要有以下几个好处:
35 |
36 | 定制化:通过静态代理类,可不修改原StringRedisTemplate类基础,增加额外功能。如在代理类中添加日志记录、性能监控、安全检查等功能
37 |
38 | 解耦:静态代理类作为中间层,减少业务代码与第三方库的直接依赖。这样,如果未来需要替换底层的Redis客户端,只需修改代理类而不影响业务代码
39 |
40 | 增强控制:代理类可控制对被代理类的访问,实现懒加载、权限控制等高级功能
41 |
42 | 统一管理:若项目中多处使用到StringRedisTemplate,通过代理类可以统一管理这些使用点,便于维护和更新
43 |
44 | 扩展性:静态代理类可以根据需要实现多个接口,提供更丰富的功能,而直接使用Spring的@Bean注解引入的实例则受限于原有类的功能。
45 |
46 | 总之,使用静态代理模式自定义StringRedisTemplateProxy类,提供了更大的灵活性和控制力,有助于构建更加健壮和可维护的应用。
--------------------------------------------------------------------------------
/docs/md/develop/design-pattern/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/develop/design-pattern/todo.md
--------------------------------------------------------------------------------
/docs/md/develop/framework/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/develop/framework/todo.md
--------------------------------------------------------------------------------
/docs/md/develop/images/责任链模式.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/develop/images/责任链模式.png
--------------------------------------------------------------------------------
/docs/md/develop/standard/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/develop/standard/todo.md
--------------------------------------------------------------------------------
/docs/md/es/ES专栏大纲.md:
--------------------------------------------------------------------------------
1 | # ES专栏大纲
2 |
3 | ## 1 你将获得
4 |
5 | 1. 掌握 Elasticsearch 核心技能
6 | 2. 熟练进行生产环境中的部署与优化
7 | 3. 灵活运用 ELK 进行搜索与大数据分析
8 | 4. 具备通过 Elastic 官方认证的能力
9 |
10 | ## 2 专栏介绍
11 |
12 | Elasticsearch 是一款非常强大的开源搜索及分析引擎。
13 |
14 | 在 DB-Engines Ranking 的数据库评测中,Elasticsearch 在 [Search Engine 分类](https://db-engines.com/en/ranking/search+engine)中长期位列第一。
15 |
16 | 除了搜索,结合 Kibana、Logstash 和 Beats,Elasticsearch 还被广泛运用在大数据近实时分析,包括日志分析、指标监控、信息安全等多个领域。
17 |
18 | 在国内,阿里巴巴、腾讯、滴滴、今日头条、饿了么、360 安全、小米、vivo 等诸多知名公司都在使用 Elasticsearch。
19 |
20 | 带你全面掌握 Elasticsearch 在生产环境中的核心实战技能。学完后,你可以在工作中快速构建出符合自身业务的分布式搜索和数据分析系统。
21 |
22 | - 由浅入深:从基础概念到进阶用法,再到集群管理和大数据分析,学完即可应用到实际生产环境中;
23 | - 实战演练:通过两个 Elasticsearch 实战项目,手把手带你进行实战服务搭建,巩固所学知识点;
24 | - 认证备考:课程内容涵盖 Elastic 认证的全部考点,有助于你顺利通过认证考试。
25 |
26 | ## 3 目录
27 |
28 | 
--------------------------------------------------------------------------------
/docs/md/ffmpeg/audio-video-roadmap.md:
--------------------------------------------------------------------------------
1 | # 00-音视频小白秒变大神?看完这条学习路线就够了!
2 |
3 | ## 0 前言
4 |
5 | 虽前些年音视频技术都在持续发展,但近年影响导致音视频需求快速上涨,5G技术又给音视频提供很好硬件支持,很多活动转入线上,在线教育、视频会议、电商的直播带货等都迫切需要音视频技术,音视频开发行业充满无限可能。
6 |
7 | ## 1 快速进场
8 |
9 | 音视频领域需要知识储备庞大,涉及各种音视频基础知识、常用技术框架、不同应用场景。先要了解音视频领域基础概念知识,如:
10 |
11 | - 啥是PCM?
12 | - 咋计算音频码率?
13 | - 帧率是啥?有啥分类?
14 | - 为啥会出现视频播放不了?
15 | - FFmpeg有啥功能?具体咋用?
16 | - …
17 |
18 | 这些音视频技术基础,是所有音视频开发都要掌握的。这些在专栏都能找到答案。除了这些基础知识,如想快速入门音视频技术,要先找到突破口。音视频领域突破口非FFmpeg莫属,音视频平台及音视频系统开发必不可少的组件库,也是掌握音视频编解码基础知识与流程的抓手。掌握FFmpeg用法,音视频方面的一些基操都不再难。
19 |
20 | 但掌握FFmpeg有难度,一千多页官方文档,咋攻克FFmpeg?刚接触FFmpeg,国内资料少,需查官方文档,难啃,为一周内解决领导的任务,硬着头皮看,看完帮助文档最开始一部分后,发现窍门,即根据需求,按文档索引线索查看就能快速找到对应信息。这样“锻炼”不但学到技术知识,还学会咋用好帮助文档。
21 |
22 | ## 2 社区交流
23 |
24 | 频繁在社区用代码交流,自己也很大提升。
25 |
26 | 参与FFmpeg开源社区交流能解决很多问题。因为有时我们自己改的代码不一定最合理,社区能人较多,思考问题较全,比一个人做review,质量也更有保证。所以本专栏也教你咋参与社区交流,创建自己专属模块,乃至成为社区开发。与世界开发者交流,探索更多功能,获得最前沿信息。
27 |
28 | 熟悉FFmpeg后,你会发现音视频处理,学习音视频各方面的知识都事半功倍。因为大多知识相通,如能了解并熟练用FFmpeg,其他工具也不是难事。
29 |
30 | ## 3 学习路径
31 |
32 | - 了解音视频相关基础知识与概念
33 | - 找到突破点,学会使用FFmpeg
34 | - 知识迁移,做到举一反三
35 |
36 | 就能快速入门音视频。
37 |
38 | 
39 |
40 | ### 音视频基础概念
41 |
42 | 讲解音视频相关参数、视频转码相关知识、直播行业技术迭代,扫清认知障碍,对音视频基础有整体了解。
43 |
44 | ### 流媒体技术速成
45 |
46 | 实际操作应用,几个工具如直播推流工具OBS、MP4专业工具,咋通过FFmpeg的基本用法深度挖掘FFmpeg更多能力。
47 |
48 | 对音视频处理的常用工具有整体认识,并掌握咋自助查找FFmpeg帮助信息,获得相关音视频处理能力。
49 |
50 | ### FFmpeg API应用
51 |
52 | 解读FFmpeg 基础模块、关键结构体和常见应用场景。对FFmpeg的API接口有基本认识,对FFmpeg常用的音视频处理上下文结构体有一个整体的了解,并且能够结合前面两部分内容做一些基本的音视频工具开发。
53 |
54 | ### FFmpeg社区“玩法”
55 |
56 | 介绍FFmpeg开发工具,FFmpeg开发者平时参与社区交流的规则,如何为FFmpeg添加一个新的模块。之后遇到问题,你就可以参与FFmpeg官方社区的交流与讨论,甚至给社区回馈代码。
57 |
58 | 音视频技术相关的工具咋用,有啥技巧,都倾囊相授,让你少走弯路,减轻畏难情绪。按这学习实践,不但会获得独立处理音视频相关操作能力,还能借鉴专栏各种方法做更多探索。扎实技术基础和解决问题的方法!
59 |
60 | 音视频行业在持续发展中,各种生活场景逐渐线上化,如VR/AR技术、线上会议、远程看诊等都需要强大的音视频能力的加持;受流感、元宇宙、5G影响,迭代速度很快,就需我们有自己独立处理开发需求、独立思考探索的能力,主动地去追逐新技术。
--------------------------------------------------------------------------------
/docs/md/flink/flink-data-latency-solution.md:
--------------------------------------------------------------------------------
1 | # Flink对数据延迟的解决方案!
2 |
3 | ## 1 前言
4 |
5 | 
6 |
7 | 一系列数据(Data-5, Data-4, Data-1, Data-3, Data-2)按一定顺序排列。
8 |
9 | 异常:数据到达顺序与它们实际发生时间顺序不一致。按照时间戳来看,Data-1最先发生,但却排在Data-4和Data-5之后。
10 |
11 | Data-1即为延迟数据,因为它比Data-4和Data-5更早发生,但更晚到达。
12 |
13 | 注意 data-1 只是延迟,不是丢失了!
14 |
15 | ## 2 数据延迟的影响
16 |
17 | ### 2.1 影响计算结果
18 |
19 | 在Flink的窗口计算中,乱序数据会导致窗口的关闭时机不准确,从而影响计算结果。如若按照窗口大小来划分,Data-1可能会被分配到一个错误的窗口中。
20 |
21 | ### 2.2 实时性降低
22 |
23 | 延迟数据的存在会降低Flink处理数据的实时性。如果Data-1承载着重要的实时信息,那么延迟到达会影响决策的时效性。
24 |
25 | ### 2.3 数据丢失风险
26 |
27 | 某些情况下,严重的延迟数据甚至可能导致数据丢失。例如,如果窗口已经关闭,而迟到的数据又无法被重新处理,那么这些数据就会丢失。
28 |
29 | ## 3 导致数据延迟的原因
30 |
31 | - **网络传输延迟:** 数据在网络传输过程中可能遇到拥塞、丢包等问题,导致延迟。
32 | - **数据源产生延迟:** 数据源本身可能存在延迟,例如数据库查询缓慢、传感器数据采集不及时。
33 | - **Flink任务处理瓶颈:** Flink任务的并行度、资源配置等因素可能导致处理速度跟不上数据到达的速度。
34 | - **Watermark设置不合理:** Watermark是Flink用来处理乱序数据的重要机制,如果Watermark设置不合理,也会导致数据延迟问题。
35 |
36 | ## 4 解决思路
37 |
38 | - 使用事件时间作为标准
39 |
40 | - 设置水位线:根据数据特性和业务需求,合理设置Watermark生成策略。
41 |
42 | - 设置允许延迟的时间:对于允许一定程度的延迟,可以在窗口定义时设置允许迟到的时间。在窗口关闭后,仍然会等待一段时间,以接收迟到的数据
43 |
44 | ## 5 步骤
45 |
46 | 1. 定义窗口时间
47 | 2. 设置:水位线 为最大事件时间 - 允许延迟的时间
48 |
49 | ### 5.1 触发窗口计算
50 |
51 | 1. 水位线 > 窗口时间:当水位线超过窗口的结束时间,保证了窗口内的数据基本都到达了,避免过早触发计算导致结果不准确。
52 | 2. 窗口内有数据:这个条件保证了窗口计算是有意义的,避免对空的窗口进行计算。仅当窗口内存在数据时,才会触发计算,即使水位线已超过窗口时间
53 |
54 | ### 5.2 案例
55 |
56 | 假设现在:
57 |
58 | - 窗口时间=10s
59 | - 允许延迟的时间 =3.5s
60 | - 水位线=最大EventTime -允许延迟的时间
61 |
62 | 触发窗口计算条件:
63 |
64 | - 水位线>窗口时间
65 | - 窗口内有数据
66 |
67 | 
68 |
69 | **事件1:** 表示一个到达Flink系统的事件,其事件时间为8。
70 |
71 | **窗口时间:** 设置为10s,即每10s生成一个新窗口。
72 |
73 | **允许延迟时间:** 设置3.5s,表示系统允许事件到达的时间延迟最多为3.5s。
74 |
75 | **水位线:** 水位线是Flink用于跟踪事件时间的一个特殊标记,它的计算方式为:最大事件时间 - 允许延迟时间。在当前示例中,水位线为max(8) - 3.5 = 4.5<10,所以不触发计算。
76 |
77 | 事件二来了,看起来它是个延迟事件了。但依旧不能触发计算:
78 |
79 | 
80 |
81 | 事件三来了,开始触发计算了:
82 |
83 | 
84 |
85 | 但即便如此,对那些超长延迟的数据还是无法计算。处理方案:
86 |
87 | - 单独搜集,稍后处理
88 | - 完全不处理,直接丢弃
--------------------------------------------------------------------------------
/docs/md/flink/flink-state-backend.md:
--------------------------------------------------------------------------------
1 | # 状态的存储StateBackend
2 |
3 | 状态后端是Flink用于管理和存储状态信息的组件,不同的后端有不同的特性和适用场景。
4 |
5 | Checkpoint机制开启之后,State会随着Checkpoint作持久化的存储。State的存储地方是通过 StateBackend 决定。
6 |
7 | StateBackend定义状态咋存储的,支持三种状态后端
8 |
9 | ## 1 Memory State Backend
10 |
11 | 将工作状态(Task State)存储在 TaskManager 的内存中,将检查点(Job State)存储在 JobManager 的内存中。
12 |
13 | - **特点:** 将状态直接存储在JVM的堆内存
14 | - **优点:** 访问速度快,性能高
15 | - **缺点:** 容错能力较弱,一旦任务失败,状态数据可能会丢失。适用于状态数据量较小、对性能要求较高的场景,如小型实验或测试环境
16 |
17 | ## 2 FS State Backend
18 |
19 | 将工作状态(Task State)存储在 TaskManager 的内存中,将检查点(Job State)存储在文件系统中(通常是分布式文件系统)
20 |
21 | - **特点:** 将状态数据定期持久化到分布式文件系统(如HDFS、S3)中。
22 | - **优点:** 容错能力强,支持高可用。
23 | - **缺点:** 性能相对Memory State Backend较低,频繁的读写操作会影响性能。适用于状态数据量较大、对容错要求较高的场景。
24 |
25 | ## 3 RocksDB State Backend
26 |
27 | 把工作状态(Task State)存储在 RocksDB,将检查点存储在文件系统(类似FsStateBackend)。
28 |
29 | - **特点:** 基于RocksDB嵌入式数据库,将状态数据存储在本地磁盘上。
30 | - **优点:** 性能优异,支持快速随机读写,同时具备良好的容错能力。
31 | - **缺点:** 配置相对复杂。适用于对性能和容错性都有较高要求的场景,例如大规模的实时计算任务。
32 |
33 | ## 4 Flink 内置实现
34 |
35 | ### 4.1 HashMapStateBackend
36 |
37 | 默认,MemoryStateBackend、FsStateBackend的实现。
38 |
39 | 此StateBackend根据配置 CheckpointStorage 的 TaskManager 和检查点的内存(JVM 堆)中保存工作状态。
40 |
41 | #### 大小考虑
42 |
43 | 工作状态保持在 TaskManager 堆。如果 TaskManager 同时执行多个任务(如果 TaskManager 有多个slot,或者使用slot共享),则所有任务的聚合状态需要适合该 TaskManager 的内存。
44 |
45 | #### 配置
46 |
47 | 对于所有的StateBackend,这个后端可以在应用程序中配置(通过使用相应的构造函数参数创建后端并在执行环境中设置它),或在 Flink 配置中指定它。
48 |
49 | 如果在应用程序中指定StateBackend,它可能会从 Flink 配置中获取额外的配置参数。例如,如果在应用程序中配置了后端,而没有默认的保存点目录,它将选择正在运行的作业/ 集群的 Flink 配置中指定的默认保存点目录。该行为是通过该 configure(ReadableConfig, ClassLoader) 方法实现的。
50 |
51 | ```java
52 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
53 | env.setStateBackend(new HashMapStateBackend());
54 | ```
55 |
56 | ### 4.2 EmbeddedRocksDBStateBackend
57 |
58 | RocksDBStateBackend的实现。
59 |
60 | ## 5 选型权衡
61 |
62 | - **状态数据量:** 对于小规模状态数据,Memory State Backend是一个不错的选择;对于大规模状态数据,RocksDB State Backend或FS State Backend更合适。
63 | - **容错要求:** 如果对数据容错性要求较高,建议选择FS State Backend或RocksDB State Backend。
64 | - **性能要求:** 如果对性能要求较高,且状态数据量不大,可以选择Memory State Backend;如果需要兼顾性能和容错性,RocksDB State Backend是一个不错的选择。
65 | - **成本:** 不同的后端存储的成本也不同,需要根据实际情况进行选择。
66 |
67 | ## 6 总结
68 |
69 | Flink提供了多种状态后端供用户选择,每种后端都有其自身的特点和适用场景。在选择状态后端时,需要综合考虑状态数据量、容错要求、性能要求和成本等因素,选择最适合的方案。
--------------------------------------------------------------------------------
/docs/md/flink/streaming-connectors-programming.md:
--------------------------------------------------------------------------------
1 | # Streaming Connectors 编程
2 |
3 | Flink已内置很多Source、Sink。
4 |
5 | ## 2 附带的连接器(Flink Project Connectors)
6 |
7 | 连接器可和第三方系统交互,目前支持:
8 |
9 | - 文件
10 | - 目录
11 | - socket
12 | - 从集合和迭代器摄取数据
13 |
14 | 预定义的数据接收器支持写入:
15 |
16 | - 文件
17 | - 标准输入输出
18 | - socket
19 |
20 | ### 1.2 绑定连接器
21 |
22 | 连接器提供用于与各种第三方系统连接的代码。目前支持:
23 |
24 | - [Apache Kafka](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/connectors/datastream/kafka/) (source/sink)
25 | - [Elasticsearch](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/connectors/datastream/elasticsearch/) (sink)
26 | - [Apache Pulsar](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/connectors/datastream/pulsar/) (source)
27 | - [JDBC](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/connectors/datastream/jdbc/) (sink)
28 |
29 | 使用一种连接器时,通常需额外的第三方组件,如数据存储服务器或MQ。 这些列举的连接器是 Flink 工程的一部分,包含在发布的源码中,但不包含在二进制发行版中。
30 |
31 | ## 3 Apache Bahir中的连接器
32 |
33 | Flink额外的连接器,通过 [Apache Bahir](https://bahir.apache.org/) 发布,:
34 |
35 | - [Redis](https://bahir.apache.org/docs/flink/current/flink-streaming-redis/) (sink)
36 | - [Akka](https://bahir.apache.org/docs/flink/current/flink-streaming-akka/) (sink)
37 | - [Netty](https://bahir.apache.org/docs/flink/current/flink-streaming-netty/) (source)
38 |
39 | ## 4 连接Flink的其它方法
40 |
41 | ### 4.1 异步I / O
42 |
43 | 使用connector不是将数据输入和输出Flink的唯一方法。一种常见的模式:从外部DB或 Web 服务查询数据得到初始数据流,然后 `Map` 或 `FlatMap` 对初始数据流进行丰富和增强。
44 |
45 | Flink 提供[异步 I/O](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/datastream/operators/asyncio/) API 让这过程更简单、高效和稳定。
46 |
47 | ### 4.2 可查询状态
48 |
49 | 当 Flink 应用程序需向外部存储推送大量数据时会导致 I/O 瓶颈问题出现。此时,若对数据的读操作<<写操作,则让外部应用从 Flink 拉取所需的数据更好。 [可查询状态](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/datastream/fault-tolerance/queryable_state/) 接口可以实现这个功能,该接口允许被 Flink 托管的状态可以被按需查询。
50 |
51 | 看几个具体的连接器。
52 |
53 | 参考
54 |
55 | - [Streaming Connectors](https://ci.apache.org/projects/flink/flink-docs-master/dev/connectors/kafka.html)
56 | - [Kafka官方文档](
--------------------------------------------------------------------------------
/docs/md/go/00-Go概述.md:
--------------------------------------------------------------------------------
1 | # 00-Go概述
2 |
3 | ## 1 为何使用 Go
4 |
5 | - 开发效率高(完整的开发工程链tools, test, benchmark, builtin .etc)
6 | - 部署简单(Compile once, run everywhere)
7 | - 良好的native http库及模版引擎(无需任何第三方框架)
8 | - 并发模型
9 |
10 | ## 2 热点项目
11 |
12 | - Docker
13 | - Caddy
14 | - Kubernetes
15 | - CockroachDB
16 |
17 | ## 3 设计初衷
18 |
19 | - 针对其他语言的痛点进行设计。
20 | - 并发编程
21 | - 为大数据、微服务、并发而生的通用语言
22 | - 项目转型首选
23 |
24 | 
25 |
26 |
27 |
28 | 
29 |
30 |
31 |
32 | 
33 |
34 |
35 |
36 | 
37 |
38 |
39 |
40 |
41 |
42 | 
43 |
44 |
45 |
46 |
47 |
48 | 
49 |
50 |
51 |
52 | 
--------------------------------------------------------------------------------
/docs/md/go/01-macOS 安装go配置GOROOT GOPATH.md:
--------------------------------------------------------------------------------
1 | # 01-macOS 安装go配置GOROOT GOPATH
2 |
3 | ## 1 获取go相关信息
4 |
5 |
6 |
7 | ```bash
8 | javaedge@JavaEdgedeMac-mini src % brew info go
9 | ==> Downloading https://mirrors.ustc.edu.cn/homebrew-bottles/api/cask.jws.json
10 | ######################################################################### 100.0%
11 | ==> go: stable 1.21.0 (bottled), HEAD
12 | Open source programming language to build simple/reliable/efficient software
13 | https://go.dev/
14 | Not installed
15 | From: https://github.com/Homebrew/homebrew-core/blob/HEAD/Formula/go.rb
16 | License: BSD-3-Clause
17 | ==> Options
18 | --HEAD
19 | Install HEAD version
20 | javaedge@JavaEdgedeMac-mini src %
21 | ```
22 |
23 | ## 2 安装
24 |
25 | 安装包地址:
26 |
27 | - https://golang.org/dl/
28 | - https://golang.google.cn/dl/
29 | - https://studygolang.com/dl
30 |
31 | ```bash
32 | brew install go
33 | ```
34 |
35 | 此处我下载的是最新版本1.15
36 | brew安装go是在目录
37 |
38 | ```bash
39 | /usr/local/Cellar
40 | ```
41 |
42 | 
43 |
44 | ## 3 配置GOROOT、GOPATH、PATH
45 |
46 | 编辑文件
47 |
48 | ```bash
49 | export GOROOT="/usr/local/Cellar/go/1.15.3/libexec"
50 | export GOPATH="/Users/apple/doc/GoProjects"
51 | export PATH="/Users/apple/doc/GoProjects/bin:$PATH"
52 | export GO111MODULE=on
53 | export GOPROXY=https://mirrors.aliyun.com/goproxy/
54 | ```
55 |
56 | 
57 |
58 | ### GOROOT
59 |
60 | go 安装目录:
61 |
62 | - brew安装,进入go目录之后可看到bin目录在libexec下
63 | - 源码安装,可按习惯直接复制到/usr/local/go,此时GOROOT 为/usr/local/go
64 |
65 | ### GOPATH
66 |
67 | go的工作目录,即写代码位置。也可配置`$HOME`来配置。
68 |
69 | 安装上述编辑好.bash_profile文件好保存退出,执行命令
--------------------------------------------------------------------------------
/docs/md/java/02-volatile原理.md:
--------------------------------------------------------------------------------
1 | # 02-volatile原理
2 | ## volatile
3 |
4 | synchronized 在多线程场景下存在性能问题
5 |
6 | 而 `volatile` 关键字是一个更轻量级的线程安全解决方案
7 |
8 | volatile 关键字的作用:保证多线程场景下变量的可见性和有序性
9 |
10 | - 可见性:保证此变量的修改对所有线程的可见性。
11 | - 有序性:禁止指令重排序优化,编译器和处理器在进行指令优化时,不能把在 volatile 变量操作(读/写)后面的语句放到其前面执行,也不能将volatile变量操作前面的语句放在其后执行。遵循了JMM 的 happens-before 规则
12 |
13 | 线程写 volatile 变量的过程:
14 |
15 | 1. 改变线程本地内存中volatile变量副本的值;
16 | 2. 将改变后的副本的值从本地内存刷新到主内存
17 |
18 | 线程读 volatile 变量的过程:
19 |
20 | 1. 从主内存中读取volatile变量的最新值到线程的本地内存中
21 | 2. 从本地内存中读取volatile变量的副本
22 |
23 |
24 |
25 | ### volatile 实现原理
26 |
27 | 如果面试中问到了 volatile 关键字,应该从 Java 内存模型开始讲解,再说到原子性、可见性、有序性是什么
28 |
29 | 之后说 volatile 解决了`有序性`和`可见性`,但是并不解决`原子性`
30 |
31 | volatile 可以说是 Java 虚拟机提供的最轻量级的同步机制,在很多开源框架中,都会大量使用 volatile 保证并发下的有序性和可见性
32 |
33 | > volatile 实现 `可见性`和 `有序性` 就是基于 `内存屏障` 的:
34 |
35 | 内存屏障是一种 `CPU 指令`,用于控制特定条件下的重排序和内存可见性问题
36 |
37 | - 写操作时,在写指令后边加上 store 屏障指令,让线程本地内存的变量能立即刷到主内存中
38 | - 读操作时,在读指令前边加上 load 屏障指令,可以及时读取到主内存中的值
39 |
40 | JMM 中有 4 类`内存屏障`:(Load 操作是从主内存加载数据,Store 操作是将数据刷新到主内存)
41 |
42 | - LoadLoad:确保该内存屏障前的 Load 操作先于屏障后的所有 Load 操作。对于屏障前后的 Store 操作并无影响屏障类型
43 |
44 |
45 | - StoreStore:确保该内存屏障前的 Store 操作先于屏障后的所有 Store 操作。对于屏障前后的Load操作并无影响
46 | - LoadStore:确保屏障指令之前的所有Load操作,先于屏障之后所有 Store 操作
47 | - StoreLoad:确保屏障之前的所有内存访问操作(包括Store和Load)完成之后,才执行屏障之后的内存访问操作。全能型屏障,会屏蔽屏障前后所有指令的重排
48 |
49 |
50 |
51 | 在字节码层面上,变量添加 volatile 之后,读取和写入该变量都会加入内存屏障:
52 |
53 | **读取 volatile 变量时,在后边添加内存屏障,不允许之后的操作重排序到读操作之前**
54 |
55 | ```java
56 | volatile变量读操作
57 | LoadLoad
58 | LoadStore
59 | ```
60 |
61 | **写入 volatile 变量时,前后加入内存屏障,不允许写操作的前后操作重排序**
62 |
63 | ```java
64 | LoadStore
65 | StoreStore
66 | volatile变量写操作
67 | StoreLoad
68 | ```
69 |
70 |
71 |
72 |
73 | **volatile 的缺陷就是不能保证变量的原子性**
74 |
75 | 解决方案:可以通过加锁或者 `AtomicInteger`原子操作类来保证该变量操作时的原子性
76 |
77 | ```java
78 | public static AtomicInteger count = new AtomicInteger(0);
79 | ```
80 |
81 |
--------------------------------------------------------------------------------
/docs/md/java/并发编程专栏概述.md:
--------------------------------------------------------------------------------
1 | # 并发编程实战专栏概述
2 |
3 | ## 1 你将获得
4 |
5 | - 全面了解并发编程核心原理;
6 | - 深入掌握 12 个 Java 并发工具类;
7 | - 搞懂 9 种最常见的并发设计模式;
8 | - 4 大经典并发编程实战案例。
9 |
10 | ## 2 专栏介绍
11 |
12 | 对于一个 Java 程序员而言,**能否熟练掌握并发编程是判断他优秀与否的重要标准之一**。因为并发编程是 Java 语言中最为晦涩的知识点,它涉及操作系统、内存、CPU、编程语言等多方面的基础能力,更为考验一个程序员的内功。
13 |
14 | 那到底应该怎么学习并发编程呢?Java SDK 的并发工具包有很多,是要死记硬背每一个工具的优缺点和使用场景吗?当然不是,想要学好并发编程,你需要从一个个单一的知识和技术中“跳出来”,高屋建瓴地看问题,并逐步建立自己的知识体系。
15 |
16 | 本专栏希望能够帮助你建立起一张处理并发问题的全景图,让你能够彻底理解并发问题的本质所在。同时,专栏还会深入介绍 Java 并发编程技术背后的逻辑关系以及应用场景,助你能够游刃有余地游走在这些技术之中。
17 |
18 | 5 大模块。
19 |
20 | **1. 并发理论基础**
21 | 这个模块主要介绍并发编程相关的概念和理论。但不会死板地堆叠结论,而是关注具体概念和理论的产生背景,挖掘它们背后的逻辑关系,发现核心矛盾并寻找解决方案。比如,深度认识 Java 内存模型、死锁产生的原因和解决方案、线程间的协作机制,等等。
22 |
23 | **2. 并发工具类**
24 | 这个模块主要探讨 Java SDK 里的并发工具类。这些工具类大部分都是基于管程实现的,所以这里会首先介绍隐藏在并发包中的管程及其使用。紧接着还会为你详细解读信号量、读写锁、CountDownLatch 和 CyclicBarrier,以及并发编程的三个核心问题“分工”“同步”“互斥”相关的技术内容。
25 |
26 | **3. 并发设计模式**
27 | 并发设计模式是解决并发问题的最佳实践。这个模块将会介绍 9 种常见的设计模式。其中,前 3 种设计模式的核心思想是避免共享变量,从而避免并发问题;后面 6 种设计模式则都属于典型的分工模式。
28 |
29 | **4. 案例分析**
30 | 这个模块着重分析 4 个经典的开源框架是如何处理并发问题的,包括高性能限流器 Guava RateLimiter、高性能网络应用框架 Netty、高性能队列 Disruptor、高性能数据库连接池 HiKariCP,希望能够帮你融会贯通相关知识点,并从实战场景中思考问题的最优解。
31 |
32 | **5. 其他并发模型**
33 |
34 | 并发问题是一个通用问题,Java 语言解决并发问题采用的是共享内存模型,但这个模型并不是解决并发问题唯一的模型。这个模块将会介绍共享内存模型之外的模型,主要有 Actor 模型、软件事务内存、协程和 CSP 模型。
35 |
36 | ## 3 专栏大纲
37 |
38 | 
--------------------------------------------------------------------------------
/docs/md/jvm/JVM专栏概述.md:
--------------------------------------------------------------------------------
1 | # JVM专栏概述
2 |
3 | ## 0 为啥要学习JVM专栏?
4 |
5 | ### 每个Java程序都离不开JVM
6 |
7 | 你玩得转么?学JVM不需要理由,不学JVM才需要理由!
8 |
9 | 
10 |
11 | ### 打通JVM理论与实践,构建完整JVM知识体系
12 |
13 | JVM是中高级Java开发工程师深入理解Java代码的关键,也是Java面试的重要考核部分
14 |
15 | 
16 |
17 | ### 基础-进阶-实战
18 |
19 | 迅速提升Java开发经验,掌握JVM调优高效操作技术
20 |
21 | 
22 |
23 | ### JVM实战项目
24 |
25 | 实际工作中怎么调优,做一遍你就懂了。结合专栏中的JVM技术点,在项目中实现性能监控与优化的企业级调优
26 |
27 | - Java 工程师进阶加薪必修课
28 | - 4 大模块全方位拆解 JVM
29 | - 帮助你编写高效 Java 代码
30 | - 揭秘 Oracle 最新 Java 黑科技
31 |
32 | ## 2 专栏介绍
33 |
34 | 作为开发工程师,你也许会在日常编程中被 Java 的启动性能和内存耗费所震惊,继而对 Java 语言产生怀疑;或许在使用虚拟机遇见内存溢出等一系列异常时头疼万分,困扰于为什么会出现各种问题。
35 |
36 | 和语言朝夕相处的开发者们,提及代码的详细运行过程也难免会一时语塞。这都是由于 Java 虚拟机封装得太好,让使用者几乎感觉不到它的存在。虽然这种“一次编写,到处运行”优势颇多,但是却也让我们忽略了学习 Java 虚拟机的必要。
37 |
38 | 熟知 Java 虚拟机的工作原理可以大幅提升日常编程的效率,对寻常 Bug 的修复更是轻而易举。同时,这也是 Java 技术的重要组成成分之一,是实现技术进阶必不可缺的知识。
39 |
40 | 本专栏通过揭秘 Java 虚拟机的工作原理,详细阐述 Java 程序是如何被执行并且被优化的。介绍的内容并不限于某一个版本,从 8 到 21 都会涉及。通过学习此专栏,你将了解如何编写高效的代码,如何对 Bug 达到最优处理,以及如何针对自己的应用调整虚拟机的运行参数。
41 |
42 | 本课程从源码到运行、类加载,再到内存分配和垃圾回收,以及JVM调优的技巧与实战。理论-实战-面试三结合,带你剖析整个JVM知识体系,一次性学习,解决JVM问题。
43 |
44 | 专栏分四大模块。
45 |
46 | ### 模块一 Java 虚拟机基本原理
47 |
48 | 剖析 Java 虚拟机的运行机制,逐次介绍 Java 虚拟机的设计决策以及工程实现。
49 |
50 | ### 模块二 高效编译
51 |
52 | 在本模块中,作者将带你探索 Java 编译器,以及内嵌于 Java 虚拟机中的即时编译器,帮助你更好地理解 Java 语言特性,继而写出简洁高效的代码。
53 |
54 | ### 模块三 代码优化
55 |
56 | 在实践过程中我们经常会遇到形形色色的性能问题,解决方法不外乎加机器加内存。本模块将介绍上述方法失效后的 Plan B,即如何利用工具定位并解决代码中的潜在问题,以及在已有工具不适用的情况下,如何打造专属轮子。此外,本模块还将介绍对 JVM 内存管理失去信心的开发者所选取的解决方案,以备不时之需。
57 |
58 | ### 模块四 虚拟机黑科技
59 |
60 | 当一门程序语言成熟稳定后,技术大神们便热衷于用这种语言开发实现编译器或虚拟机。在 Java 10 中,Graal 已作为试验性即时编译器一同发布。本模块将详细科普 GraalVM 的各个组成部分,其中包括编译器 Graal,语言实现框架 Truffle,以及支持 Ahead-of-Time(AOT)编译的 SubstrateVM。
61 |
62 | ## 3 专栏大纲
63 |
64 |
65 |
66 | 
67 |
68 | ## 4 适合人群
69 |
70 | - 希望了解底层 Java 虚拟机实现的开发者
71 | - 有一定 Java 基础,希望达成技术进阶的 Java 工程师
72 | - 希望在面试中对答如流的 Java 语言应聘者,以及希望考倒应聘者的面试官们
73 | - 想要了解 Oracle GraalVM 黑科技,或考虑借此技术转型的开发人员
--------------------------------------------------------------------------------
/docs/md/jvm/Metadata GC Threshold in Java.md:
--------------------------------------------------------------------------------
1 | # Metadata GC Threshold in Java
2 |
3 | ## 1 概述
4 |
5 | 本文探讨Metaspace和元数据GC阈值(Metadata GC Threshold)及如何调整它们这些参数。
6 |
7 | ## 2 元数据(Metadata)
8 |
9 | Metadata包含有关堆中对象的信息,包括类定义、方法表等相关信息。根据Java的版本,JVM将这些数据存储在永久代(Permanent Generation)或Metaspace。
10 |
11 | JVM依靠这些信息来执行类加载、字节码验证和动态绑定等任务。
12 |
13 | ## 3 PermGen和Metaspace
14 |
15 | Java 8开始,JVM用一个叫做Metaspace的新内存区域替代了永久代(PermGen)来存储元数据。
16 |
17 | - 永久代是一个固定大小的内存区域,独立于主堆,用于存储JVM加载的类和方法的元数据。它有一个固定的最大大小,一旦满了,JVM就会抛出OOM
18 | - 而Metaspace的大小不固定,可以根据应用中的元数据量动态增长。Metaspace存在于独立于主堆的本地内存(进程内存)段中。它的大小仅受主机os的限制
19 |
20 | ## 4 元数据GC阈值
21 |
22 | Java中,当我们创建一个带有元数据的对象时,它会像其他对象一样占用内存空间。JVM需要这些元数据来执行各种任务。与普通对象不同,元数据在达到某阈值之前不会进行垃圾回收。
23 |
24 | 随着Java程序执行过程中动态加载的类越来越多,Metaspace会逐渐填满。
25 |
26 | JVM为Metaspace内容大小设置了一个阈值,当某个分配不符合此阈值时,会触发一次元数据GC阈值的垃圾回收周期。
27 |
28 | ## 5 用于元数据的JVM参数
29 |
30 | 可用类似`-XX:+PrintClassHistogram`和`-XX:+PrintMetaspaceStatistics`的JVM标志来收集有关使用大量元数据内存的类的信息,并打印有关Metaspace的统计信息,如用于类元数据的空间量。
31 |
32 | 使用这些信息,可优化代码以改善Metaspace和垃圾回收周期的使用情况。此外,我们还可以调整与Metaspace相关的JVM参数。
33 |
34 | 下面是一些用于调整元数据和Metaspace的JVM参数。
35 |
36 | ### 5.1 `-XX:MetaspaceSize=`
37 |
38 | 用于设置分配给类元数据的初始空间量(初始高水位线,以字节为单位),该空间量可能会导致垃圾回收以卸载类。这个数值是近似的,这意味着JVM也可以决定增加或减少Metaspace的大小。
39 |
40 | 较大的参数值可以确保垃圾回收发生的频率较低。此参数的默认值取决于平台,范围从12 MB到约20 MB。
41 |
42 | 如设为128 MB:
43 |
44 | ```
45 | -XX:MetaspaceSize=128m
46 | ```
47 |
48 | ### 5.2. `-XX:MaxMetaspaceSize=`
49 |
50 | 设置Metaspace的最大大小,超过此大小后会抛出OutOfMemory错误。此标志限制了分配给类元数据的空间量,分配给此参数的值是近似的。
51 |
52 | 默认情况下,没有设置限制,这意味着Metaspace可能增长到可用本地内存的大小。
53 |
54 | 如置100 MB:
55 |
56 | ```
57 | ‑XX:MaxMetaSpaceSize=100m
58 | ```
59 |
60 | ### 5.3. `-XX:+UseCompressedClassPointers`
61 |
62 | 通过压缩对象引用来减少64位Java应用程序的内存占用。当此参数设置为true时,JVM将使用压缩指针来处理类元数据,这使得JVM可以使用32位寻址来处理类相关数据,而不是完整的64位指针。
63 |
64 | 在64位架构上,此优化尤其有价值,因为它减少了类元数据的内存使用,以及对象引用所需的内存,从而可能提高应用程序的整体性能。
65 |
66 | 压缩类指针将类空间分配与非类空间分配分开。因此,我们有两个全局Metaspace上下文:一个用于保存Klass结构的分配(压缩类空间),一个用于保存其他所有内容(非类Metaspace)。
67 |
68 | 最近JVM版本中,通常在运行64位Java应用程序时,默认启用此标志,因此我们通常不需要显式设置此标志。
69 |
70 | ### 5.4. `-XX:+UseCompressedOops`
71 |
72 | 标志启用或禁用在64位JVM中使用压缩指针处理Java对象。当参数设置为true时,JVM将使用压缩指针,这意味着对象引用将使用32位指针,而不是完整的64位指针。
73 |
74 | 使用压缩指针,只能寻址较小范围的内存。这迫使JVM使用较小的指针并节省内存。
75 |
76 | ## 6 结论
77 |
78 | 本文中,我们探讨了元数据和Metaspace的概念。
79 |
80 | 我们探讨了触发元数据GC阈值的原因。我们还了解了元数据GC阈值以及用于调整Metaspace和优化垃圾回收周期的不同JVM参数。
81 |
82 | 下一讲,我们讨论Metaspace导致的一个 OOM 生产排查案例!
--------------------------------------------------------------------------------
/docs/md/jvm/队列积压了百万条消息,线上直接OOM了!.md:
--------------------------------------------------------------------------------
1 | # 队列积压了百万条消息,线上直接OOM了!
2 |
3 | ## 0 前言
4 |
5 | 某系统不停发布数据到Kafka,数据同步系统专门从Kafka消费数据,再保存到自己数据库,可类比物联网数据网关系统:
6 |
7 | 
8 |
9 | 这么简单的系统,居然时不时报OOM,得重启,过段时间又OOM。而且这系统处理数据量越来越大,OOM频率也越来越高。
10 |
11 | ## 1 从现象看本质
12 |
13 | 既然每次重启后,都会在一段时间后OOM,说明肯定是每次重启后,内存都不断上涨。一般要高到OOM,通常就是因为:
14 |
15 | - 并发太高,瞬间大量并发创建过多的对象,导致系统宕机
16 | - 内存泄漏之类,即很多对象都赖在内存不死,无论怎么GC都回收不了
17 |
18 | 而该系统负载并不高,虽数据量不少,但绝非瞬时高并发。
19 |
20 | 看来可能就是随时间推移,某种对象越来越多,赖在内存。然后不断触发GC,结果每次GC都回收不掉这些对象。一直到最后,内存实在不足,造成 OOM:
21 |
22 | 
23 |
24 | ## 2 jstat验证
25 |
26 | 直接在一次重启系统后,jstat观察JVM运行情况:
27 |
28 | 发现,Old对象一直不停增长。每次YGC后,老年代对象就增长不少。且当老年代使用率达100%后,正常触发Full GC,但Full GC回收不掉任何对象,导致老年代使用率还是100%!
29 |
30 | 然后老年代使用率维持100%一段时间后,就OOM了,因为再有新对象进入老年代,实在没空间放了!
31 |
32 | 这就验证了判断,每次系统启动,有啥对象,会一直进堆内存,且随YGC执行,对象会一直进入老年代,最后触发Full GC都无法回收老年代的对象,导致OOM。
33 |
34 | ## 3 MAT/JProfile找到占用内存最大对象!
35 |
36 | 内存快照中发现有个队列数据结构,直接引用大量数据,就是这队列数据结构占满内存!
37 |
38 | ### 3.1 这队列做啥的?
39 |
40 | 从Kafka消费出的数据会先入队,再从队列慢慢写入DB,主要是要额外做中间数据处理和转换,所以自己在中间又加个队列:
41 |
42 | 
43 |
44 | ### 3.2 这队列咋用的?咋随便用就出问题!
45 |
46 | 从Kafka批量消费,可能一次消费几百条数据。因此,coder直接每次消费几百条数据出来给做成一个List,然后把这List入队!
47 |
48 | 最后就搞成:若一个队列有1000个元素,每个元素都是个List,每个List里都有几百条数据!
49 |
50 | 这就导致内存队列积压几十万甚至百万条数据!最终一定OOM! 而且只要你数据还停留在队列中,就无法被回收!
51 |
52 | 
53 |
54 | 这是典型的对生产和消费的速率没控制好:
55 |
56 | - 从Kafka消费出来的数据,入队速度很快(生产者速率很快)
57 | - 但从队列里消费数据进行处理,然后写DB速度较慢(消费者速度很慢)
58 |
59 | 最终导致内存队列快速积压数据,导致OOM。而且这种队列每个元素都是个List或者大对象,就会导致内存队列能容纳的数据量极速增长,提前OOM。
60 |
61 | ## 4 解决方案
62 |
63 | 修改内存队列的使用,做成定长的阻塞队列。
64 |
65 | 如最多1024个元素,每次从Kafka消费出来数据,一条条写入队列,而不是做成一个List入队作为一个元素。
66 |
67 | 这样内存中最多1024个数据,一旦内存队列满,此时Kafka消费线程就会停止工作,因为被队列给阻塞住了。不会让内存队列中的数据过多:
68 |
69 | 
--------------------------------------------------------------------------------
/docs/md/k8s/23-1-Envoy.md:
--------------------------------------------------------------------------------
1 | # 23-1-Envoy
2 |
3 | 你觉得为什么它能击败Nginx以及HAProxy等竞品,成为Service Mesh体系核心?
4 |
5 | Envoy 是由 Lyft 开发并开源的一款高性能开源代理,近年来迅速成为 Service Mesh 体系的核心组件之一。它之所以能够击败 Nginx 和 HAProxy 等竞品,成为众多微服务架构中的首选,有以下几个主要原因:
6 |
7 | ### 1. **设计现代化**
8 |
9 | - **初始设计即为云原生和微服务**:Envoy 从一开始就设计为服务代理,专注于服务间通信的复杂性,而不是像 Nginx 和 HAProxy 那样起源于传统的 L7 代理和负载均衡。
10 | - **面向分布式系统**:Envoy 的设计考虑了现代分布式系统的需求,例如动态配置、服务发现、健康检查等。
11 |
12 | ### 2. **可观察性**
13 |
14 | - **高级监控和追踪**:Envoy 提供丰富的指标、日志和分布式追踪功能,能够与 Prometheus、Grafana、Jaeger 等工具无缝集成,使得服务之间的调用和性能问题能够被详细地监控和追踪。
15 | - **丰富的可视化数据**:支持详细的统计数据和可视化,帮助运维人员了解系统内部的工作情况。
16 |
17 | ### 3. **动态配置和管理**
18 |
19 | - **xDS API**:Envoy 使用 xDS API 进行动态配置,允许管理者通过中心化的控制平面动态调整路由、限流、熔断等配置,而无需重新启动代理。这在频繁变化的微服务环境中尤为重要。
20 | - **热重载配置**:配置变更不需要重启服务,这一点在生产环境中尤其关键,能够保证服务的连续性。
21 |
22 | ### 4. **丰富的功能**
23 |
24 | - **全面的 L7 代理功能**:除了基本的 L4 负载均衡,Envoy 还提供 L7 代理功能,如 HTTP/2 和 gRPC 支持、流量劫持、路由控制、流量镜像等,适用于复杂的微服务通信需求。
25 | - **服务发现和负载均衡**:Envoy 支持多种服务发现机制和负载均衡策略,能够适应不同的微服务架构和部署环境。
26 |
27 | ### 5. **扩展性和插件化**
28 |
29 | - **可扩展架构**:Envoy 的架构设计允许开发者通过插件扩展其功能,使其能够适应特定的业务需求。
30 | - **WebAssembly(Wasm)支持**:Envoy 支持通过 Wasm 插件进行扩展,提供了一种灵活、安全且高效的扩展机制。
31 |
32 | ### 6. **社区和生态系统**
33 |
34 | - **活跃的社区**:Envoy 由一个活跃且不断壮大的开源社区支持,Lyft、Google 等大型科技公司积极参与,确保了项目的持续发展和创新。
35 | - **广泛的集成**:Envoy 已被集成到许多开源项目和商业产品中,特别是在 Service Mesh 领域,如 Istio 和 Consul Connect,这些项目将 Envoy 作为数据平面代理,进一步扩大了其影响力和应用范围。
36 |
37 | ### 7. **安全性**
38 |
39 | - **先进的安全特性**:Envoy 提供全面的安全功能,包括 TLS 终结和起源验证、mTLS(双向 TLS)、RBAC(基于角色的访问控制)等,确保服务间通信的安全性。
40 |
41 | ### 对比 Nginx 和 HAProxy
42 |
43 | 虽然 Nginx 和 HAProxy 也在不断发展并引入了许多现代功能,但 Envoy 的设计初衷和功能集更贴合微服务架构的需求。具体对比:
44 |
45 | - **动态配置**:Envoy 的 xDS API 和热重载配置比 Nginx 和 HAProxy 的静态配置文件和较为复杂的动态配置管理更为先进。
46 | - **L7 代理功能**:Envoy 的 L7 代理功能和对 HTTP/2、gRPC 的支持更为全面,而 Nginx 和 HAProxy 主要还是在 L4 和基础的 L7 代理功能上。
47 | - **可观察性**:Envoy 原生支持高级监控和分布式追踪,而 Nginx 和 HAProxy 需要依赖额外的插件或外部工具。
48 | - **扩展性**:Envoy 通过 Wasm 插件提供了高效的扩展机制,而 Nginx 和 HAProxy 在插件化和扩展性上较为有限。
49 |
50 | 综上所述,Envoy 的现代化设计、高度的可观察性、动态配置能力、丰富的功能集、强大的扩展性和活跃的社区,使得它在微服务架构中更具优势,从而在与 Nginx 和 HAProxy 的竞争中脱颖而出,成为 Service Mesh 体系的核心组件。
--------------------------------------------------------------------------------
/docs/md/linux/00-操作系统专栏大纲.md:
--------------------------------------------------------------------------------
1 | # 00-操作系统专栏大纲
2 |
3 | ## 1 你将获得
4 |
5 | - 快速掌握 Linux 常用命令及配置
6 | - 熟练进行系统管理和故障排查
7 | - 熟悉 Vim 基本操作及 Shell 编程
8 | - 搭建并维护基于 Linux 的常用服务
9 | - Linux 常用的性能分析工具合集
10 | - 30 个 Linux 性能问题诊断思路
11 | - 读懂 CPU、内存、I/O 等指标
12 | - 5 个真实的线上环境分析案例
13 |
14 | ## 2 专栏介绍
15 |
16 | 本专栏基于 CentOS 7 进行讲解。入门级的 Linux 学习教材,内容由浅入深,案例丰富,通俗易懂!分两部分:前面为基础知识,涉及安装、登录、文件和目录管理、磁盘管理、Vim、压缩和解压缩等;后面为进阶知识,包括 LAMP、LNMP、NFS、FTP、Linux 集群和 Zabbix 监控等。与上一版相比,这版不仅将虚拟机软件由 VMware 10 改为 VMware 14,删掉了 LAMP 环境搭建与配置,还增加 Docker 等内容。
17 |
18 | Linux实操过程中,你是否疑问:
19 |
20 | - 如何提取日志中含有关键字的指定行,上一行或上几行?
21 | - ln 做了符号链接,对符号链接进行权限修改,原文件是否会受到影响?
22 | - Shell 脚本里有很多特殊符号,到底该怎么用?网上流传的 .(){.|.&};. 脚本能不能执行?
23 | - Linux 里的编辑器繁多,比如 vim、sed、awk, 它们各自有哪些特点?如何在不同的场景下做出合适的选择?
24 |
25 | 这些虽然不是什么刁钻的问题,你在网上也能搜到一堆参考资料,但是看完之后还是会觉得似懂非懂,无法举一反三,从网上复制粘贴了事,则极有可能不起作用。
26 |
27 | 如果侥幸解决了特定的问题,也意识到自己需要系统学习一下 Linux ,以便今后能更高效地解决其他 Linux 相关问题,但又发现 Linux 涉及到的常用命令实在是太多了,更别提每个命令又有一大堆相关参数,导致学起来毫无头绪。
28 |
29 | 而且,对于习惯了 Windows、macOS 等图形界面的用户来说,Linux 以命令行为主的操作方式导致它刚开始的学习曲线还是很陡峭的。因此,希望能帮你构建起系统化的 Linux 实战技能,逐步成长为一名 Linux 实战高手。
30 |
31 | 1. 实战导向:学完即可轻松应对工作中 85% 以上的 Linux 使用场景;
32 | 2. 内容全面:不仅包括基本的系统操作指令和常见服务搭建,还包含 Vim 的使用、Shell 编程等内容;
33 | 3. 结业项目:专栏最后会通过搭建一个家用 NAS 系统将专栏知识点全部贯穿起来,让你牢牢掌握所学知识。
34 |
35 |
36 |
37 | Linux 性能问题一直是程序员头上的“紧箍咒”,哪怕很多工作多年的资深工程师也不例外。日常工作中我们总是会遇到这样或那样的问题:
38 |
39 | - 应用程序响应太慢,从哪儿入手找原因?
40 | - 服务器总是时不时丢包,到底要怎么办?
41 | - 一个 SQL 查询要 30 秒,究竟是怎么回事?
42 | - 内存泄漏了,该怎么定位和处理?
43 |
44 | 面对这些问题,很多人都会发怵,似乎性能问题总是不那么简单。那如何才能搞定性能优化呢?
45 |
46 | 啃下所有的大块头原理书籍?多数人都会望而却步,不能坚持,即便是学了很多底层原理,碰到问题时依然会不知所措、无从下手。向牛人请教有效的方法?但管得了一时管不了永远,你很难形成系统的知识体系。实际上,找到正确的学习方法,你完全可以更轻松、更高效地掌握性能问题的解决之道。
47 |
48 | 以**案例驱动**的思路,从实际问题出发,带你由浅入深学习一些基本底层原理,掌握常见的性能指标和工具,学习实际工作中的优化技巧,让你可以准确分析和优化大多数的性能问题。另外,专栏中会有大量的案例分析,带你实战演练,更好地消化和巩固所学。
49 |
50 | 专栏共 5 个模块。
51 |
52 | 前 4 个模块从资源使用的视角出发,带你分析各种 Linux 资源可能会碰到的性能问题,包括**CPU 性能**、**磁盘 I/O 性能**、**内存性能**以及**网络性能**,让你掌握必备的基础知识,会用常见的性能工具和解决方法。
53 |
54 | 第 5 个综合实战模块,将为你还原真实的工作场景,介绍一些开源项目、框架或者系统设计的案例的观测、剖析和调优方法,让你在“高级战场”中学习演练。
55 |
56 | 
57 |
58 | 
--------------------------------------------------------------------------------
/docs/md/mgr/00-如何学习项目管理专栏.md:
--------------------------------------------------------------------------------
1 | # 00-如何学习项目管理专栏
2 |
3 | ## 1 为啥迭代?
4 |
5 | 核心用户就是程序员、项目经理,或者是想要从程序员转行/转岗到项目经理的人。
6 |
7 | 近两年随着超级个体时代的到来,我们也越来越深刻地体会到,项目管理这项技能,不仅仅是项目经理的专属技能,而是每一个想要独当一面之人的必备技能。说得直白一点,项目管理技能就是帮助你“使众人行”,帮助你成事儿的。
8 |
9 | **项目管理的核心是借事修人。其中“事”是项目,但终点是提升人的领导力。**
10 |
11 | 摘掉“程序员”帽子,给所有想习得项目管理技能的人:
12 |
13 | - 梳理、搭建起来的项目管理知识框架,依托的是《项目管理知识体系指南》,核心没变
14 | - 原有课程中的实战案例,取材实际经历,所选择的案例既切中用户的痛点,同时也极具代表性,时至今日仍有非常大的价值
15 |
16 | ## 迭代了啥?
17 |
18 | 增加Edge虚拟人物。通过Edge学习项目管理的经历,你也可以看到一个项目管理小白的成长历程与路径。相应地,这也可能会是你所需要的学习路径。
19 |
20 | 这里我也对Edge这个形象做一些背景说明。Edge作为跨行转过来的项目管理小白,对这份工作有着非常大的热情,也想要在项目管理这一赛道上深耕。
21 |
22 | 更注重实战性。
23 |
24 | 模块:
25 |
26 | - 常识篇
27 |
28 | - 硬技能篇
29 |
30 | - 软技能篇
31 |
32 | - 故事案例实战篇
33 |
34 | 在真实生动的故事案例中,呈现如何综合运用项目管理的底层思维——对焦。相比繁杂的理论知识,把握好底层思维,你就拥有了以不变应万变的能力
35 |
36 | 原范式按金字塔式的写作方式(背景-问题-冲突-解决方法)呈现。迭代后,着重在场景这一部分做优化,主要是将简单的场景变换成更具有真实感的故事,让你有更强的代入感,更好地入门。
37 |
38 | ## 小结
39 |
40 | - 整体设计增加Edge的虚拟人物形象,并将原来的琐碎的案例通过Edge这个人物,统一串联起来,增强实战性。
41 | - 故事案例实战篇助你掌握项目管理的底层思维。
42 | - 将简单的场景变换成更具有真实感的故事,让你有更强的代入感;所有图片重新绘制,并增加思维导图
43 |
44 | 开启项目管理之旅!
--------------------------------------------------------------------------------
/docs/md/monitor/并发用户、RPS、TPS的解读.md:
--------------------------------------------------------------------------------
1 | # 并发用户、RPS、TPS的解读
2 |
3 | ## 1 术语
4 |
5 | - 并发用户:在性能测试工具中,一般称为虚拟用户(Virtual User,简称VU),指的是现实系统中操作业务的用户。
6 |
7 | **说明** 并发用户与注册用户、在线用户不同。注册用户一般指的是数据库中存在的用户。在线用户只是“挂”在系统上,对服务器不产生压力。但并发用户一定会对服务器产生压力。
8 |
9 | - TPS:Transaction Per Second,每秒事务数,是衡量系统性能的一个非常重要的指标。
10 |
11 | - RPS:Request Per Second,每秒请求数。RPS模式适合用于容量规划和作为限流管控的参考依据。
12 |
13 | - RT:Response Time,响应时间,指的是业务从客户端发起到客户端接受的时间。
14 |
15 | 在性能测试中,通常有两种施压模式:并发模式和RPS模式。统方式是使用并发用户数来衡量系统的性能(站在客户端视角)。此方法一般适用于一些网页站点的压测(例如H5页面);而RPS(Requests per second)模式主要是为了方便直接衡量系统的吞吐能力TPS(Transaction Per Second,每秒事务数)而设计的(站在服务端视角),按照被压测端需要达到TPS等量设置相应的RPS,应用场景主要是一些动态的接口API,例如登录、提交订单等等。
16 |
17 | ## VU和TPS换算
18 |
19 | - 简单例子:在术语中解释了TPS是每秒事务数,但是事务是要靠虚拟用户做出来的,假如1个虚拟用户在1秒内完成1笔事务,那么TPS明显就是1;如果某笔业务响应时间是1 ms,那么1个用户在1s内能完成1000笔事务,TPS就是1000了;如果某笔业务响应时间是1s,那么1个用户在1s内只能完成1笔事务,要想达到1000 TPS,至少需要1000个用户;因此可以说1个用户可以产生1000 TPS,1000个用户也可以产生1000 TPS,无非是看响应时间快慢。
20 |
21 | - 复杂公式: 试想一下复杂场景,多个脚本,每个脚本里面定义了多个事务(例如一个脚本里面有100个请求,我们把这100个连续请求叫做Action,只有第10个请求,第20个请求分别定义了事务10和事务20)具体公式如下。
22 |
23 | 符号代表意义:
24 |
25 | - Vui表示的是第i个脚本使用的并发用户数。
26 | - Rtj表示的是第i个脚本第j个事务花费的时间,此时间会影响整个Action时间。
27 | - Rti表示的是第i个脚本一次完成所有操作的时间,即Action时间。
28 | - n表示的是第n个脚本。
29 | - m表示的是每个脚本中m个事务。
30 | - 那么第j个事务的TPS = Vui/Rti。
31 |
32 | 总的TPS=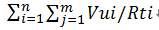。
33 |
34 | ## 如何获取VU和TPS
35 |
36 | - VU获取方式:
37 |
38 | 已有系统:可选取高峰时刻,在一定时间内使用系统的人数,这些人数可认为是在线用户数,并发用户数可以取10%,例如在半个小时内,使用系统的用户数为10万,那么取10%(即1万)作为并发用户数基本就够了。
39 |
40 | 新系统:没有历史数据作参考,建议通过业务部门进行评估。
41 |
42 | - TPS获取方式:
43 |
44 | 已有系统:可选取高峰时刻,在一定时间内(如3分钟~10分钟),获取系统总业务量,计算单位时间(秒)内完成的笔数,乘以2~5倍作为峰值的TPS,例如峰值3分钟内处理订单18万笔,平均TPS是1000,峰值TPS可以是2000~5000。
45 |
46 | 新系统:没有历史数据作参考,建议通过业务部门进行评估。
47 |
48 | ## 如何评价系统的性能
49 |
50 | 针对服务器端的性能,以TPS为主来衡量系统的性能,并发用户数为辅来衡量系统的性能,如果必须要用并发用户数来衡量的话,需要一个前提,那就是交易在多长时间内完成,因为在系统负载不高的情况下,将思考时间(思考时间的值等于交易响应时间)加到串联链路中,并发用户数基本可以增加一倍,因此用并发用户数来衡量系统的性能没太大的意义。同样的,如果系统间的吞吐能力差别很大,那么同样的并发下TPS差距也会很大。
51 |
52 | ## 性能测试策略
53 |
54 | 做性能测试需要一套标准化流程及测试策略。做负载测试时,传统方式一般按梯度施压的方式去加用户数,避免在没预估情况下,一次加几万个用户,导致交易失败率非常高,响应时间非常长,已超过使用者忍受范围内;较为适合互联网分布式架构的方式,也是阿里最佳实践是用TPS模式(吞吐量模式)+设置起始和目标最大量级,然后根据系统表现灵活的手工实时调速,效率更高,服务端吞吐能力的衡量一步到位。
55 |
56 | ## 总结
57 |
58 | - 系统的性能由TPS决定,跟并发用户数没有多大关系。
59 | - 系统的最大TPS是一定的(在一个范围内),但并发用户数不一定,可以调整。
60 | - 建议性能测试的时候,不要设置过长的思考时间,以最坏的情况下对服务器施压。
61 | - 一般情况下,大型系统(业务量大、机器多)做压力测试,10000~50000个用户并发,中小型系统做压力测试,5000个用户并发比较常见。
--------------------------------------------------------------------------------
/docs/md/mysql/00-MySQL专栏大纲.md:
--------------------------------------------------------------------------------
1 | # 00-MySQL专栏大纲
2 |
3 | ## 你将获得
4 |
5 | - MySQL 核心技术详解与原理说明
6 | - MySQL 常见痛点问题解析
7 | - 完整的 MySQL 学习路径
8 |
9 | ## 介绍
10 |
11 | MySQL 使用和面试中遇到的问题,很多人会通过搜索别人的经验来解决 ,零散不成体系。实际上只要理解了 MySQL 的底层工作原理,就能很快地直戳问题的本质。
12 |
13 | 通过探讨 MySQL 实战中最常见的痛点问题,串起各个零散的知识点,配合大量详解图,由线到面带你构建 MySQL 系统的学习路径。
14 |
15 | 专栏梳理了 **MySQL 的主线知识**,如**事务、索引、锁**等;并基于这条主线,带你缕清**概念、机制、原理、案例分析**以及本质,让你真正能掌握 **MySQL 核心技术与底层原理。**
16 |
17 | 每篇文章中都附有**实践案例**,给你从理论到实战的系统性指导,让你少走弯路,彻底搞懂 MySQL。
18 |
19 | ## 模块
20 |
21 | **模块一,基础篇**。为你深入浅出地讲述 MySQL 核心知识,涵盖 MySQL 基础架构、日志系统、事务隔离、锁等内容。
22 |
23 | **模块二,实践篇**。将从一个个关键的数据库问题出发,分析数据库原理,并给出实践指导。每个问题,都不只是简单地给出答案,而是从为什么要这么想、到底该怎样做出发,让你能够知其所以然,都将能够解决你平时工作中的一个疑惑点。
--------------------------------------------------------------------------------
/docs/md/mysql/MySQL新特性.md:
--------------------------------------------------------------------------------
1 | # MySQL历史版本特性
2 |
3 | MySQL 是一个广泛使用的开源关系型数据库管理系统,由 Oracle 公司维护和开发。自 1995 年首次发布以来,MySQL 经历了多个版本的迭代,每个版本都引入了新功能和优化。以下是 MySQL 各大版本的主要新功能和优化:
4 |
5 | ### MySQL 3.23
6 |
7 | - **发布时间**: 2001年
8 | - **主要新功能**:
9 | - 引入了 `InnoDB` 存储引擎。
10 | - 支持 `UNION` 和子查询。
11 | - 引入了 `LOAD DATA INFILE` 语句。
12 |
13 | ### MySQL 4.0
14 |
15 | - **发布时间**: 2003年
16 | - **主要新功能**:
17 | - 支持多表删除 (`DELETE` with `JOIN`)。
18 | - 引入了 `FULLTEXT` 索引。
19 | - 支持 `BLOB` 和 `TEXT` 列的索引。
20 |
21 | ### MySQL 4.1
22 |
23 | - **发布时间**: 2004年
24 | - **主要新功能**:
25 | - 引入了子查询和视图。
26 | - 支持 Unicode 字符集。
27 | - 改进了 `InnoDB` 存储引擎的性能。
28 |
29 | ### MySQL 5.0
30 |
31 | - **发布时间**: 2005年
32 | - **主要新功能**:
33 | - 引入了存储过程和触发器。
34 | - 支持游标。
35 | - 引入了 ` INFORMATION_SCHEMA` 数据库。
36 |
37 | ### MySQL 5.1
38 |
39 | - **发布时间**: 2008年
40 | - **主要新功能**:
41 | - 支持分区表。
42 | - 引入了事件调度器。
43 | - 改进了插件架构。
44 |
45 | ### MySQL 5.5
46 |
47 | - **发布时间**: 2010年
48 | - **主要新功能**:
49 | - 默认存储引擎改为 `InnoDB`。
50 | - 支持半同步复制。
51 | - 改进了性能和可扩展性。
52 |
53 | ### MySQL 5.6
54 |
55 | - **发布时间**: 2013年
56 | - **主要新功能**:
57 | - 支持全文索引的改进。
58 | - 引入了多线程复制。
59 | - 改进了 `InnoDB` 的性能和可靠性。
60 |
61 | ### MySQL 5.7
62 |
63 | - **发布时间**: 2015年
64 | - **主要新功能**:
65 | - 引入了 JSON 支持。
66 | - 改进了 GIS 功能。
67 | - 支持多源复制。
68 | - 改进了性能和安全性。
69 |
70 | ### MySQL 6.x
71 |
72 | 多年前,在 Sun 收购 MySQL AB 之前,MySQL 曾有过一个编号为 6 的版本。 遗憾的是,它有点雄心勃勃,所有权的变更让它枯萎了。
73 |
74 | ### MySQL7.x
75 |
76 | 多年来,MySQL Cluster 产品一直使用 7 系列。 随着 MySQL 8 的新变化,开发人员认为他们已经对其进行了足够的修改,以提升这个大版本。
77 |
78 | ### MySQL 8.0
79 |
80 | - **发布时间**: 2018年
81 | - **主要新功能**:
82 | - 引入了窗口函数。
83 | - 支持公用表表达式 (CTE)。
84 | - 改进了 JSON 支持。
85 | - 引入了原子数据定义语句 (DDL)。
86 | - 改进了安全和性能。
87 |
88 | ### MySQL 8.1
89 |
90 | - **发布时间**: 2023年
91 | - **主要新功能**:
92 | - 引入了 InnoDB 表空间加密。
93 | - 支持在线添加列。
94 | - 改进了 GIS 功能。
95 | - 引入了新的优化器功能。
96 |
97 | ### MySQL 8.2
98 |
99 | - **发布时间**: 2023年
100 | - **主要新功能**:
101 | - 引入了 InnoDB 表空间加密。
102 | - 支持在线添加列。
103 | - 改进了 GIS 功能。
104 | - 引入了新的优化器功能。
105 |
106 | 每个版本的 MySQL 都在前一版本的基础上进行了改进和优化,增加了新的功能以满足不断变化的需求和技术发展。MySQL 的持续发展使其成为世界上最受欢迎的数据库管理系统之一。
--------------------------------------------------------------------------------
/docs/md/mysql/how-to-use-indexes-when-grouping-in-sql.md:
--------------------------------------------------------------------------------
1 | # SQL执行Grouping by时如何才能使用索引?
2 |
3 | group by是否能用索引?有时需要group by把数据分组,再用count、sum等聚合函数做聚合统计。
4 |
5 | 假设有 SQL:
6 |
7 | ```sql
8 | select count(*) from table group by xx
9 | ```
10 |
11 | 看起来必须把所有数据放到一个临时磁盘文件里还有加上部分内存,去搞一个分组,按指定字段值分组,接着对每组执行一个聚合函数,这性能也是极差,涉及大量磁盘交互。
12 |
13 | 因为索引树默认按指定的一些字段都排序好的,字段值相同的数据都在一起,若走索引去执行分组后再聚合,性能就比临时磁盘文件好多了。
14 |
15 | 所以一般对group by后的字段,最好也按联合索引最左侧字段开始,按序排列,就能完美利用索引直接提取一组组数据,然后针对每组数据,执行聚合函数。
16 |
17 | group by和order by利用索引原理和条件差不多,本质都是在group by和order by之后的字段顺序和联合索引中的从最左侧开始字段顺序一致,然后就能利用索引树,快速根据排序好的数据执行后续操作。
18 |
19 | 就无需针对杂乱数据利用临时磁盘文件+部分内存数据结构,进行耗时耗力的现场排序和分组,真是速度慢,性能差。
20 |
21 | ## 平时设计表里的索引
22 |
23 | 必须充分考虑后续SQL要咋写:
24 |
25 | - 会根据啥字段进行where语句里筛选和过滤?
26 | - 根据哪些字段进行排序和分组?
27 |
28 | 考虑好后,就能为表设计两三个常用索引,覆盖常见的where筛选、order by排序和group by分组的需求,保证常见SQL语句都能用上索引。只要所有查询语句都可利用索引执行,速度和性能通常都不会太慢。如查询还是有问题,就要基于执行计划进行深度SQL调优。
29 |
30 | 然后对更新语句,最核心问题:
31 |
32 | - 索引别太多,否则更新时维护太多索引树
33 | - 可能涉及锁等待和死锁
34 | - 可能涉及MySQL连接池、写redo log文件等
--------------------------------------------------------------------------------
/docs/md/netty/01-Netty源码面试实战+原理(一)-鸿蒙篇.md:
--------------------------------------------------------------------------------
1 | # 01-Netty源码面试实战+原理(一)-鸿蒙篇
2 |
3 | ## 1 简介
4 |
5 | Trustin Lee,韩国大佬发明:
6 |
7 | 
8 |
9 | 在 2008 年提交第一个commit至今,转眼间已经走过15年:
10 |
11 | 
12 |
13 | Netty封装JDK的NIO接口而成的框架。所以 JDK NIO 是基础。
14 |
15 | ## 2 啥是Netty?
16 |
17 | - 异步事件驱动框架,可快速开发高性能的服务端和客户端
18 | - 封装了JDK底层BIO和NIO模型,提供更加简单易用安全的 API
19 | - 自带编解码器解决拆包粘包问题,无需用户困扰
20 | - Reactor线程模型支持高并发海量连接
21 | - 自带各种协议栈
22 |
23 | ## 3 Netty 的特点
24 |
25 | - 设计
26 | 针对多种传输类型的统一接口 - 阻塞和非阻塞
27 | 简单但更强大的线程模型
28 | 真正的无连接的数据报套接字支持
29 | 链接逻辑支持复用
30 | - 易用性
31 | 大量的 Javadoc 和 代码实例
32 | 除了在 JDK 1.6 + 额外的限制。(一些特征是只支持在Java 1.7 +。可选的功能可能有额外的限制。)
33 | - 性能
34 | 比核心 Java API 更好的吞吐量,较低的延时
35 | 资源消耗更少,这个得益于共享池和重用
36 | 减少内存拷贝
37 | - 健壮性
38 | 消除由于慢,快,或重载连接产生的 OutOfMemoryError
39 | 消除经常发现在 NIO 在高速网络中的应用中的不公平的读/写比
40 | - 安全
41 | 完整的 SSL / TLS 和 StartTLS 的支持
42 | 运行在受限的环境例如 Applet 或 OSGI
43 | - 社区
44 | 发布的更早和更频繁
45 | 社区驱动
46 |
47 | ## 4 为什么要研究 Netty
48 |
49 | - 开发任何网络编程。实现自己的rpc框架
50 | - 能够作为一-些公有协议的broker组件。如mqtt, http
51 | - 不少的开源软件及大数据领域间的通信也会使用到netty
52 | - 为了面试跳槽涨薪
53 |
54 | ## 5 本地调试
55 |
56 | 使用“网络调试助手”小软件发送客户端请求。
--------------------------------------------------------------------------------
/docs/md/other/guide-to-reading.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 目录
3 | ---
4 |
5 | # 程序员的编码指南 🔥
6 |
7 | ## 作者团简介
8 |
9 | ### JavaEdge
10 | - 🚀 魔都架构师 | 全网30W技术追随者
11 | - 🔧 大厂分布式系统/数据中台实战专家
12 | - 🏆 主导交易系统百万级流量调优 & 车联网平台架构
13 | - 🧠 AIGC应用开发先行者 | 区块链落地实践者
14 | - 🌍 以技术驱动创新,我们的征途是改变世界!
15 |
16 | ### 11来了
17 |
18 | 在读研究生,秋招备战中,编程严选星球合伙人,Java 领域新星创作者(CSDN)
19 |
20 | > 个人技术公众号:【 **11来了** 】 ,专攻底层源码原理
21 |
22 | > 个人专栏:
23 | > - [并发专栏](/md/concurrency/01-synchronized原理.html) | [Redisson分布式锁源码解析](/md/redis/01-Redis和ZK分布式锁优缺点对比以及生产环境使用建议.md)
24 | > - [面试突击专栏](/md/zqy/面试题/01-分布式技术面试实战.html) | [MySQL面试专栏](/md/zqy/面试题/面试题-MySQL.html) | [Redis面试专栏](/md/zqy/面试题/面试题-Redis.html) | [JVM专栏](/md/jvm/01-JVM虚拟机-上篇.html)
25 |
26 | ### Ken
27 |
28 | 深圳某知名科技公司的Java后端开发,编程严选星球合伙人,有丰富的后端开发经验。
29 |
30 | > 个人专栏:
31 | > - [12306专栏](/md/12306/项目介绍.html)
32 | >
33 |
34 | ### 知青先生
35 |
36 | 现任泛微ecology产品开发经理;曾任国企南方电网深圳数字研究院一线业务开发;编程严选星球合伙人;有丰富的web端全栈开发经验;CSDN技术博主。
37 |
38 | > 个人专栏:
39 | > - [spring-cloud专栏](/md/spring/spring-cloud/SpringCloudAlibaba介绍.md)
40 |
41 | 参考:
42 |
43 | - [编程严选网](http://www.javaedge.cn/#/index)
44 | 备用域名:http://www.javaedge.com.cn/
45 |
--------------------------------------------------------------------------------
/docs/md/product-center/00-商品中心的spu、sku设计.md:
--------------------------------------------------------------------------------
1 | # 00-商品中心的spu、sku设计
2 |
3 |
4 |
5 | ## 1 商品管理系统数据结构
6 |
7 | ### 1.1 Spu (Standard Product Unit,标准产品单位)
8 |
9 | 标准的商品单元,通常指一个商品系列。
10 |
11 | 商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。
12 |
13 | 通俗点讲,属性值、特性相同的商品就可以称为一个SPU。如:华为P20 pro就是一个SPU,与商家,与颜色、款式、套餐都无关。
14 |
15 | ### 1.2 Sku (Stock Keeping Unit,库存量单位)
16 |
17 | 库存存储单元,通常指具体的库存商品。
18 |
19 | SKU即库存进出计量的单位, 可以是以件、盒、托盘等为单位。
20 |
21 | SKU是物理上不可分割的最小存货单元。在使用时要根据不同业态,不同管理模式来处理。在服装、鞋类商品中使用最多最普遍。如:
22 |
23 | - 华为P20 pro 宝石蓝 64G
24 | - 华为P20 pro 亮黑色 64G
25 | - 华为P20 pro 宝石蓝 128G
26 | - 华为P20 pro 亮黑色 128G
27 |
28 | Spu包含Sku,Spu表和Sku表是一对多。
29 |
30 | ## 2 spu的功能
31 |
32 |
33 |
34 | 
35 |
36 | 1. 根据spu和sku的电商设计模型
37 | 2. 根据电商网站用户检索和过滤的需求
38 |
39 | ### spu的功能
40 |
41 | - 查询spu数据列表
42 | - spu的添加功能
43 |
44 | ## 3 spu的添加
45 |
46 | ### spu信息
47 |
48 | Spu名称,spu的描述
49 |
50 | ### spu图片信息
51 |
52 | - 图片对象数据保存在分布式文件存储服务器。
53 | - 图片元数据信息保存在数据库
54 |
55 | 用户在选择完图片后:
56 |
57 | - 我们把图片在用户提交时候和其他的商品spu信息一起提交到后台
58 | - 我们在用户选择图片是,就将图片上传至服务器
59 |
60 | ### spu的销售属性信息
61 |
62 | 商品的平台属性属于电商网站后台管理(整个商品平台的维度下的)
63 |
64 | 商品的销售属性属于在电商网站上卖商品的商家管理(属于某一件商品的维度下的)
65 |
66 | ### 销售属性
67 |
68 | - 商品的平台属性属于电商网站后台管理
69 | - 商品的销售属性属于商家管理
--------------------------------------------------------------------------------
/docs/md/product-center/01-电商商品中心解密:仅凭SKU真的足够吗?.md:
--------------------------------------------------------------------------------
1 | # 01-电商商品中心解密:仅凭SKU真的足够吗?
2 |
3 | 在电子商务系统中,SKU(Stock Keeping Unit,库存单位)和SPU(Standard Product Unit,标准产品单位)是两种不同的概念,它们共同用于商品管理和库存控制。虽然理论上可以只使用SKU来管理商品,但在实际应用中,同时使用SPU和SKU有其明显的优势和必要性。
4 |
5 | ### SKU(库存单位)
6 |
7 | - SKU是商品的具体型号或款式,每个SKU都有唯一的标识符。
8 | - 它通常关联到商品的一个具体的销售属性,如尺寸、颜色等。
9 | - SKU用于库存管理,每个SKU都对应一定数量的库存。
10 |
11 | ### SPU(标准产品单位)
12 |
13 | - 商品的一种抽象,代表一个商品系列或分类
14 | - 包含一组具有相同特征,但在某些属性(如颜色、尺寸)上可能有所不同的商品
15 | - 有助简化商品分类和搜索,便于消费者理解和选择
16 |
17 | ### 使用SPU和SKU的理由
18 |
19 | 1. **分类管理**:SPU可以帮助商家对商品进行更高层次的分类,而SKU则用于区分同一SPU下的不同规格或型号。
20 |
21 | 2. **库存管理**:每个SKU对应一定数量库存,使库存管理更精确高效
22 |
23 | 3. **搜索和过滤**:消费者可基于SPU进行商品搜索,然后通过不同SKU筛选想要的具体商品
24 |
25 | 4. **销售分析**:SPU可帮助商家分析整个商品系列的表现,而SKU则可以提供每个具体商品的销售数据
26 |
27 | 5. **简化操作**:商品上架、促销和维护时,使用SPU可减少重复工作,因为同一SPU下的不同SKU可共享基础信息
28 |
29 | 6. **扩展性**:添加新的规格或型号时,只需添加新SKU,无需重新创建整个商品系列
30 |
31 | ### 只使用SKU的局限性
32 |
33 | - 如果只使用SKU,可能会使得商品分类变得复杂和混乱,特别是当商品种类繁多时。
34 | - 缺少了SPU的抽象层,消费者可能会在搜索和选择商品时遇到困难。
35 | - 库存管理和商品分析可能会变得繁琐,因为没有一个统一的层级来组织和理解商品数据。
36 |
37 | ### 结论
38 |
39 | 虽然在理论上可以只使用SKU来管理商品,但在实践中,结合使用SPU和SKU能够提供更为高效、清晰和灵活的商品管理方式。这种方式有助于提高运营效率,改善消费者体验,并支持更精准的数据分析和决策。
40 |
41 |
42 |
43 | 在项目初期,确实可以主要依赖SKU来管理商品。尤其是在以下情况下,使用SKU作为主要的商品管理单位可能是足够的:
44 |
45 | 1. **商品种类有限**:如果项目初期商品种类不多,使用SKU进行管理可以简化流程。
46 |
47 | 2. **标准化商品**:如果销售的商品具有较少的变体,例如尺寸或颜色选择不多,那么SKU可能足以区分所有商品。
48 |
49 | 3. **运营团队较小**:在项目初期,如果运营团队规模较小,SKU管理可能更加直观和易于操作。
50 |
51 | 4. **快速迭代**:项目初期可能需要快速迭代和调整,使用SKU可以更快地响应市场变化和测试不同的商品。
52 |
53 | 5. **简化库存管理**:在SKU足够区分所有商品的情况下,可以简化库存管理和减少运营复杂性。
54 |
55 | 6. **减少系统复杂性**:避免在项目初期引入过多的概念和系统复杂性,可以集中精力在核心功能的开发上。
56 |
57 | 然而,即使在项目初期主要使用SKU,也应考虑以下几点:
58 |
59 | - **扩展性**:随着项目的发展,商品种类和变体可能会增加。需要确保系统设计有足够的灵活性来引入SPU的概念。
60 |
61 | - **数据结构**:即使主要使用SKU,也应该设计良好的数据结构,以便未来可以轻松地添加SPU层。
62 |
63 | - **用户体验**:考虑用户如何搜索和选择商品。如果SKU足以提供良好的用户体验,那么可以暂时不引入SPU。
64 |
65 | - **长期规划**:即使在项目初期不使用SPU,也应该有长远的规划,考虑未来可能的需求变化。
66 |
67 | - **性能考虑**:评估使用SKU进行管理对系统性能的影响,确保系统能够处理预期的数据量。
68 |
69 | - **市场调研**:了解目标市场和竞争对手的做法,看看他们是如何管理商品的,这可能会影响你的决策。
70 |
71 | 总之,项目初期使用SKU作为主要的商品管理单位是可行的,但需要考虑到未来的发展和可能的需求变化。随着项目的成长,可能需要逐步引入SPU来优化商品管理和用户体验。
--------------------------------------------------------------------------------
/docs/md/product/book/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/product/book/todo.md
--------------------------------------------------------------------------------
/docs/md/product/pdf/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/product/pdf/todo.md
--------------------------------------------------------------------------------
/docs/md/rabbitmq/08-RabbitMQ的七种队列模式.md:
--------------------------------------------------------------------------------
1 | # 08-RabbitMQ的七种队列模式
2 |
3 |
--------------------------------------------------------------------------------
/docs/md/rabbitmq/RabbitMQ消费端幂等性概念及解决方案.md:
--------------------------------------------------------------------------------
1 | # RabbitMQ消费端幂等性概念及解决方案
2 |
3 | ## 1 什么是幂等性
4 |
5 | 用户对于同一操作发起的一次请求或者多次请求的结果是一致的。
6 |
7 | 如数据库乐观锁,执行更新操作前:
8 |
9 | - 先去数据库查询version
10 | - 然后执行更新语句
11 | - 以version作为条件,如果执行更新时有其他人先更新了这张表的数据,那么这个条件就不生效了,也就不会执行操作了
12 |
13 | 通过这种乐观锁的机制来保障幂等性。
14 |
15 | ## 2 Con幂等性
16 |
17 | ### 2.1 什么是Con幂等性
18 |
19 | 消费端实现幂等性,即消息永远不会消费多次,即使收到多条一样消息。
20 |
21 | 在业务高峰期最容易产生消息重复消费问题:当Con消费完消息后给Pro返回ack时,由于网络中断,导致Pro未收到确认信息,该条消息就会重新发送并被Con消费,但实际上该消费者已成功消费,就导致重复消费。
22 |
23 | ### 2.2 主流幂等性实现方案
24 |
25 | #### ① 唯一ID+指纹码
26 |
27 | 利用DB主键去重:
28 |
29 | ```sql
30 | SELECT COUNT(1) FROM T_ORDER
31 | WHERE ID = 唯一ID
32 | AND IS_CONSUM = 指纹码
33 | ```
34 |
35 | 唯一ID:业务表的主键
36 |
37 | 指纹码:为区别每次正常操作的码,每次操作时生成指纹码。可用时间戳+业务编号或标志位(视业务场景而定)
38 |
39 | 优势:实现简单
40 |
41 | 弊端:高并发下有数据库写入的性能瓶颈
42 |
43 | 解决方案:根据ID进行分库分表算法路由
44 |
45 | ##### 小结
46 |
47 | 先根据消息生成一个全局唯一ID,然后加上一个指纹码。指纹码不一定是系统生成,而是一些外部规则或内部业务规则去拼接,就是为保障这次操作的绝对唯一性。
48 |
49 | ID + 指纹码拼接好的值作为数据库主键,即可去重。消费消息前,先去数据库查询这条消息的指纹码标识:
50 |
51 | - 不存在,就执行insert
52 | - 存在,代表已被消费,就不需要管了
53 |
54 | #### ② 利用Redis的原子性
55 |
56 | 需考虑:
57 |
58 | - 是否要数据落库。若落库,数据库和缓存如何做到原子性
59 | - 若不落库,都存储到缓存,如何设置定时同步策略
60 |
61 | 这里只提Redis原子性去解决MQ幂等性重复消费问题
62 |
63 | > MQ的幂等性问题,根本在于Pro未正常接收ACK,可能是网络抖动、网络中断导致
64 |
65 | ##### 实现
66 |
67 | Con消费开始时,将ID放入Redis BitMap。Pro每次生产数据时,从Redis的BitMap对应位置若不能取出ID,则生产消息发送,否则不进行消息发送。
68 |
69 | 有人说,万一Con、Pro的Redis命令执行失败咋办,虽然又出现重复消费又出现Redis非正常执行命令可能性极低,万一呢?可在Redis命令执行失败时,将消息落库,每日用定时器,对这种极特殊的消息进行处理。
--------------------------------------------------------------------------------
/docs/md/reactive/00-Spring响应式编程.md:
--------------------------------------------------------------------------------
1 | # 00-Spring响应式编程
2 |
3 | ## 1 为啥学习响应式编程
4 |
5 | - 随着微服务架构的不断发展
6 | - 以及各种中间件技术的日益成熟
7 | - 响应式编程所提供的异步非阻塞式编程模型
8 | - 非常适合用来构建技术驱动的服务化架构体系
9 |
10 | 对于开发人员而言,需要熟练使用这些基于响应式编程技术所构建的开源框架,来应对业务发展的需求。
11 |
12 | 网关工具 Spring cloud Gateway相比 Netflix 中提供的基于同步阻塞式模型的 Zuul 网关,其性能显著提升原因就是采用了异步非阻塞式的实现机制。
13 |
14 | 对于架构师而言:需要熟练掌握这些开源框架和中间件的核心原理以便更好地对框架进行维护、优化,甚至二次开发。
15 |
16 | Spring Cloud Netflix Hystrix组件HealthCountsStream类提供滑动窗口机制,完成对运行时请求数据的动态收集和处理。Hystrix实现这机制大量采用数据流处理方面技术及 RxJava 响应式编程框架。它代表一种新型编程模型,代表一种技术发展和演进的趋势,紧跟这趋势,对提升职业门槛是加分项。
17 |
18 | ## 2 教程设计
19 |
20 | 弥补此前基于 Spring5的响应式编程系统化学习的空白,系统化、由浅入深的学习路径。
21 |
22 | 不仅掌握响应式编程的全局,而且实战角度出发高效掌握基于 Spring 框架的响应式编程使用方法和开发技巧
23 |
24 | 
25 |
26 | ## 3 大纲
27 |
28 | 
29 |
30 | 
31 |
32 | 
33 |
34 | 
35 |
36 | 
37 |
38 | 
39 |
40 | 各个响应式编程核心组件以及基于 Spring 框架的实现方式我都会按照完整的案例分析,给出详细的代码实现方案方便你进行学习和改造。
41 |
42 |
43 | 在现代互联网应用系统开发过程中,即时响应是可用性和实用性的基石。需要引入新的架构模式和编程技术以满足不断增长的对便捷高效服务的需求,而响应式编程代表的就是这样一种全新的编程模型。
44 |
45 |
--------------------------------------------------------------------------------
/docs/md/redis/Redis的整数数组和压缩列表.md:
--------------------------------------------------------------------------------
1 | # Redis的整数数组和压缩列表
2 |
3 | ## 0 前言
4 |
5 | 整数数组、压缩列表的查找时间复杂度无很大优势,为啥Redis把它们作底层数据结构?
6 |
7 | ## 1 内存利用率
8 |
9 | 紧凑型数据结构,比链表占用内存少。毕竟大量数据存到内存,需尽可能优化提高内存利用率。
10 |
11 | 整数数组和压缩列表的entry都是实际的集合元素,一个挨一个保存,很节省内存空间:
12 |
13 | 
14 |
15 | ## 2 数组对CPU高速缓存支持更友好
16 |
17 | - 数组是连续内存空间
18 | - 局部性原理
19 |
20 | 所以集合数据元素较少时,默认采用内存紧凑排列方式存储,同时利用CPU高速缓存不会降低访问速度。
21 |
22 | 当数据元素超过设定阈值,为避免查询时间复杂度太高,转为哈希和跳表数据结构存储。
23 |
24 | CPU预读一个cache line大小数据,数组数据排列紧凑、相同大小空间保存的元素更多,访问下一个元素时,恰已在cpu缓存。若随机访问,就不能充分利用cpu缓存。如int元素,一个4byte,CacheLine默认64byte,可预读16个挨着的元素,若下次随机访问的元素不在这16个元素,就需重新从内存读取。
25 |
26 | Redis底层使用数组和压缩链表对数据大小限制在64个字节以下,当大于64个字节会改变存储数据的数据结构,所以随机访问对CPU高速缓存没啥影响。
27 |
28 | Redis List底层使用压缩列表,本质是将所有元素紧凑存储,所以分配的是一块连续内存空间,虽然数据结构本身没有时间复杂度优势,但:
29 |
30 | - 节省空间
31 | - 也避免一些内存碎片
32 |
33 | 因为按照一个cache line加载进cpu cache 按照当代cpu指令周期来看随机遍历的花销可忽略不计。
34 |
35 | 当一个缓存行无法加载完ziplist时,因为redis内部hash存储的是指针,也就是逻辑成环, 所以CPU加载开销无法忽视。此时只能转别的数据结构来解决,如skiplist。
36 |
37 | 参考:
38 |
39 | - https://www.bigocheatsheet.com/
--------------------------------------------------------------------------------
/docs/md/risk-control/coupon-distribution-risk-control-challenges.md:
--------------------------------------------------------------------------------
1 | # 02-发券风控难题
2 |
3 | 其实风控并不遥远,防止超卖就是一种。传统风控不行了。
4 |
5 | 代码不严谨,无门槛优惠券场景下引发的业务逻辑漏洞
6 |
7 | ## 1 发券漏洞
8 |
9 | 无门槛优惠券场景下发券漏洞:
10 |
11 | - 无门槛优惠券没有限制总数
12 | - 无门槛优惠券没有严格限制领取资格
13 | - 无门槛优惠券不知道哪些用户(身份核实)领取了券
14 |
15 | ## 2 用券漏洞
16 |
17 | 1.使用券时,没有核验用户的异常行为特征
18 | 2.使用券时,没有横向比较用户的历史下单信息
19 | 3.使用券时,没有核验异常用户的共同特征
20 |
21 | ## 3 库存漏洞
22 |
23 | - 没有在库存机制设定一个上限
24 | - 订单进入待发货状态时,没有再做一次订单核验
25 |
26 | ## 4 监控漏洞
27 |
28 | 订单实时数据指标监控和警报没有做好
29 |
30 | ## 5 运营漏洞
31 |
32 | 优惠券人工设置,没有控制权限
33 | 优惠券人工设置,没有大于1次的审核机制
--------------------------------------------------------------------------------
/docs/md/risk-control/coupon-fraud-grey-market-chain.md:
--------------------------------------------------------------------------------
1 | # 01-羊毛党灰产链路
2 |
3 | 能产生利益的地方,就离不开黑灰产。
4 |
5 | 即使利润很低,黑灰产依然会想办法通过机器,批量操作来规模获利。
6 |
7 | 假设我是羊毛党,去刷无门槛优惠券获利,需要经过哪些步骤?
8 |
9 | 1. 搜集优惠信息:新手福利,优惠券,红包...
10 | 2. 数量庞大的账号:通过这些账号去批量拿优惠券
11 | 3. 自动的拿优惠券:一个账号拿一张优惠券,不可能手动
12 | 4. 销赃渠道:批量获取优惠券就是为了获利
13 |
14 | 
15 |
16 |
17 |
18 | 
19 |
20 |
21 |
22 | 
--------------------------------------------------------------------------------
/docs/md/risk-control/flink-real-time-risk-control-system-overview.md:
--------------------------------------------------------------------------------
1 | # 00-Flink实战实时风控系统专栏概述
2 |
3 | Flink 核心技能实操 + 亿级数据性能调优 + Groovy 动态规则引擎实践
4 |
5 | 大数据开发进阶必备,从0到1搭建基于Flink + Groovy 实现动态规则的优惠券场景风控系统。
6 |
7 | ## 你将学到
8 |
9 | - 提升架构设计思维与能力
10 | - 构建 Flink 核心技能体系
11 | - 积累亿级数据实时处理经验
12 | - 实践 Flink 动态规则引擎
13 | - 具备生产环境故障处理能力
14 | - 解锁Flink 生态框架整合技巧
15 |
16 | ## 专栏简介
17 |
18 | 黑灰产问题日益突出,“风控”已成大多数公司基础业务之一。能设计并架构风控体系,是大数据工程师重要竞争力。
19 |
20 | 本专栏基于 Flink+ Groovy 构建风控系统,以生产视角带你掌握风控体系设计的核心要素、Flink 实用技能、优化技巧、故障处理策略等高阶技能,并融合贯通运用到实际工作中,助力提升你的架构设计思维和代码实践能力,少走弯路,加速职业发展。
21 |
22 | ## FAQ
23 |
24 | Q:没有大数据的基础能学吗,目前的话只要做的是java开发
25 |
26 | A:能,专栏重点flink ,是完全基础开始学习,使用Java ,不涉及其他大数据组件,所以只掌握 java 是完全能够学习!
27 |
28 | 
29 |
30 |
31 |
32 |
33 |
34 | 
35 |
36 |
37 |
38 | 
39 |
40 |
41 |
42 | 
43 |
44 |
45 |
46 | 
47 |
48 |
49 |
50 | 
51 |
52 |
53 |
54 | 
55 |
56 | ## 分析问题比解决问题重要
57 |
58 | 明确需要解决的问题 ->解决方案 ->架构设计 ->技术实现
59 |
60 |
--------------------------------------------------------------------------------
/docs/md/risk-control/reasons-for-choosing-groovy-for-risk-control-engine.md:
--------------------------------------------------------------------------------
1 | # 06-风控规则引擎选用Groovy的原因
2 |
3 | ## 0 前言
4 |
5 | 在当今的电商行业中,风控系统是保障平台安全、防范欺诈行为的关键组成部分。随着大数据和实时计算技术的发展,Flink 作为一种高效的流处理框架,被广泛应用于电商大厂的风控系统中。而在 Flink 的风控规则引擎中,Groovy 作为一种动态脚本语言,被选为主要规则定义和执行的语言。本文将探讨为何电商大厂在 Flink 风控规则引擎中选用 Groovy,并分析其优势。
6 |
7 | 
8 |
9 | ```groovy
10 | if (规则1 && 规则2 || 规则3) {
11 | // 列入可疑名单
12 | } else {
13 | // TO DO
14 | }
15 | ```
16 |
17 | 若又来需求了呢?
18 |
19 | ```groovy
20 | if (规则1 && 规则2 || 规则3)
21 | // 列入可疑名单
22 | if (规则4 || 规则5)
23 | // 列入可疑名单
24 | else
25 | // TO DO
26 | ```
27 |
28 | ### 缺点
29 |
30 | - 臃肿难维护
31 | - 可读性差
32 | - 无法实时修改,重新打包部署
33 |
34 |
35 |
36 | 抛弃 if-else,拥抱规则引擎
37 | 风控规则本质上是通过AND、OR等逻辑运算组成的规则集,风控规则往往是一个复杂且不断变化的规则组合。
38 |
39 | ## 1 引入规则引擎
40 |
41 |
42 |
43 | 
44 |
45 | ### 1.1 风险规则编写痛点
46 |
47 | - 风险规则变动频率高,组合复杂,数量多
48 | - If-else 越写越长
49 | - 因为是硬编码,即使很小的改动,也要经常重启系统
50 |
51 | ### 1.2 规则引擎如何解决痛点
52 |
53 | - 不再是 If-else 流程分支,而是交给规则引擎执行
54 | - 规则文件可预加载
55 | - 规则变更,直接修改规则文件,动态加载,无需重启系统
56 | - 规则的变更,可直接给运营修改
57 |
58 | ## 2 规则引擎技术选型
59 |
60 | - Groovy,学习门槛低
61 | - Drools
62 |
63 | ## 3 为啥选择Groovy
64 |
65 | ### 3.1 动态语言特性
66 |
67 | Groovy 是一种基于 JVM 的动态语言,它结合了 Java 的语法和动态语言的特性。在风控规则引擎中,规则的更新和调整是频繁且必要的,而 Groovy 的动态特性使得规则的修改和部署变得更加灵活和便捷。Java 程序员可以利用 Groovy 的动态特性,在运行时修改和加载规则,而无需重启整个应用,大大提高了系统的响应速度和灵活性。
68 |
69 | ### 3.2 无缝集成 Java
70 |
71 | Groovy 与 Java 有着天然的兼容性,Groovy 代码可以无缝集成到 Java 应用中。对于电商大厂而言,其技术栈大多以 Java 为主,选用 Groovy 作为规则引擎的语言,可以充分利用现有的 Java 生态系统和开发资源,减少学习成本和开发成本。Java 程序员可以轻松地将 Groovy 脚本嵌入到现有的 Flink 作业中,实现规则的动态执行。
72 |
73 | ### 3.3 强大的元编程能力
74 |
75 | Groovy 提供了强大的元编程能力,包括元对象协议(MOP)和运行时元编程。这使得开发者可以在运行时动态地创建类、方法和属性,极大地增强了规则引擎的灵活性和扩展性。在风控系统中,新的欺诈模式和风险行为不断出现,Groovy 的元编程能力可以帮助快速响应这些变化,实现规则的快速迭代和更新。
76 |
77 | ### 3.4 简洁的语法
78 |
79 | Groovy 的语法比 Java 更加简洁和易读,减少样板代码,提高开发效率。对于复杂的规则逻辑,Groovy 的简洁语法可以使得规则的编写和维护变得更加容易。此外,Groovy 支持闭包、集合字面量等现代编程语言特性,使得规则的表达更加直观和高效。
80 |
81 | ### 3.5 成熟的生态系统
82 |
83 | Groovy 拥有一个成熟的生态系统,包括大量的第三方库和工具支持。在风控规则引擎的开发和维护过程中,可以利用这些现成的库和工具,加速开发进程,提高系统的稳定性和可靠性。例如,Groovy 可以与 Spring 框架无缝集成,利用 Spring 的依赖注入和 AOP 功能,进一步增强规则引擎的功能和性能。
84 |
85 | ## 4 总结
86 |
87 | 对于 Java 程序员而言,掌握 Groovy 不仅可以提升个人的技术能力,还能在实际项目中发挥更大的价值。
--------------------------------------------------------------------------------
/docs/md/road-map/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/road-map/todo.md
--------------------------------------------------------------------------------
/docs/md/seata/01-Seata客户端依赖坐标引入与踩坑排雷.md:
--------------------------------------------------------------------------------
1 | # 01-Seata客户端依赖坐标引入与踩坑排雷
2 |
3 | ## 1 官方推荐配置
4 |
5 | spring-cloud-starter-alibaba-seata推荐依赖配置方式
6 |
7 | ```xml
8 |
9 | io.seata
10 | seata-spring-boot-starter
11 | 1.5.2
12 |
13 |
14 |
15 | com.alibaba.cloud
16 | spring-cloud-starter-alibaba-seata
17 | 最新版本
18 |
19 |
20 | io.seata
21 | seata-spring-boot-starter
22 |
23 |
24 |
25 | ```
26 |
27 | 为啥这样呢?先看
28 |
29 | ## 2 逆官网配置
30 |
31 |
32 |
33 | ```xml
34 |
35 | com.alibaba.cloud
36 | spring-cloud-starter-alibaba-seata
37 |
38 | ```
39 |
40 | 刷新 maven,可见依赖的 1.4.2 版本:
41 |
42 | 
43 |
44 | ## 3 调整路线
45 |
46 | 但我们要用最新 1.5.2 版本,就要调整,先排除原有依赖:
47 |
48 | ```xml
49 |
50 | com.alibaba.cloud
51 | spring-cloud-starter-alibaba-seata
52 |
53 |
54 | io.seata
55 | seata-spring-boot-starter
56 |
57 |
58 |
59 | ```
60 |
61 | 再加段配置:
62 |
63 | ```xml
64 |
65 | io.seata
66 | seata-spring-boot-starter
67 | 1.5.2
68 |
69 | ```
70 |
71 | 完成:
72 |
73 | 
74 |
75 |
--------------------------------------------------------------------------------
/docs/md/seata/02-Seata客户端全局事务配置与实现.md:
--------------------------------------------------------------------------------
1 | # 02-Seata客户端全局事务配置与实现
2 |
3 | 根据 [官方文档](https://seata.io/zh-cn/docs/ops/deploy-guide-beginner.html):
4 |
5 | 
6 |
7 | 这也是 1.4 和 1.5 的区别。
8 |
9 | https://github.com/seata/seata/tree/master/script/client/conf:
10 |
11 | 
12 |
13 | ## yml 配置
14 |
15 | ```yml
16 | seata:
17 | enabled: true
18 | ```
19 |
20 | 注意如下默认配置,我们需要定制化修改:
21 |
22 | 
23 |
24 | ```yml
25 | seata:
26 | enabled: true
27 | tx-service-group: javaedge_tx_group
28 | service:
29 | vgroup-mapping:
30 | javaedge_tx_group: SEATA_GROUP
31 | grouplist:
32 | SEATA_GROUP: localhost:8091
33 | config:
34 | nacos:
35 | server-addr: localhost:8848
36 | username: nacos
37 | password: nacos
38 | registry:
39 | nacos:
40 | server-addr: localhost:8848
41 | username: nacos
42 | password: nacos
43 | ```
44 |
45 | 还没完:
46 |
47 | ```
48 | config:
49 | nacos:
50 | server-addr: localhost:8848
51 | username: nacos
52 | password: nacos
53 | registry:
54 | nacos:
55 | server-addr: localhost:8848
56 | username: nacos
57 | password: nacos
58 | ```
59 |
60 |
--------------------------------------------------------------------------------
/docs/md/seata/03-Seata柔性事务.md:
--------------------------------------------------------------------------------
1 | # 03-Seata柔性事务
2 |
3 | ## 1 核心概念
4 |
5 | AT 事务的目标是在微服务架构下,提供增量的事务 ACID 语意,让开发者像使用本地事务一样,使用分布式事务,核心理念同ShardingSphere。
6 |
7 | Seata AT 事务模型包含:
8 |
9 | - TM事务管理器:全局事务的发起方,负责全局事务开启,提交和回滚
10 |
11 | - RM资源管理器:全局事务的参与者,负责分支事务的执行结果上报,并通过 TC 的协调进行分支事务的提交和回滚
12 |
13 | - TC事务协调器
14 |
15 | TC是独立部署的服务,TM、RM 以 jar 包同业务应用一同部署,它们同 TC 建立长连接,整个事务生命周期内,保持远程通信。
16 |
17 | Seata 管理的分布式事务的典型生命周期:
18 |
19 | 1. TM 要求 TC 开始一个全新的全局事务。TC 生成一个代表该全局事务的 XID。
20 | 2. XID 贯穿于微服务的整个调用链。
21 | 3. 作为该 XID 对应到的 TC 下的全局事务的一部分,RM 注册本地事务。
22 | 4. TM 要求 TC 提交或回滚 XID 对应的全局事务。
23 | 5. TC 驱动 XID 对应的全局事务下的所有分支事务完成提交或回滚。
24 |
25 | Seata AT事务模型:
26 |
27 | 
28 |
29 | ## 2 实现原理
30 |
31 | 整合 Seata AT 事务时,需将 TM,RM 和 TC 的模型融入ShardingSphere的分布式事务生态。
32 |
33 | 在数据库资源上,Seata 通过对接 `DataSource` 接口,让 JDBC 操作可以同 TC 进行远程通信。 ShardingSphere 也面向 `DataSource` 接口,对用户配置的数据源进行聚合。 因此,将 `DataSource` 封装为 基于Seata 的 `DataSource` 后,就可将 Seata AT 事务融入到ShardingSphere的分片生态中。
34 |
35 | 
36 |
37 | ### 引擎初始化
38 |
39 | 包含 Seata 柔性事务的应用启动时,用户配置的数据源会根据 `seata.conf` 的配置,适配为 Seata 事务所需的 `DataSourceProxy`,并且注册至 RM。
40 |
41 | ### 开启全局事务
42 |
43 | - TM 控制全局事务的边界,TM 通过向 TC 发送 Begin 指令,获取全局事务 ID
44 | - 所有分支事务通过此全局事务 ID,参与到全局事务中
45 | - 全局事务 ID 的上下文存放在当前线程变量
46 |
47 | ### 执行真实分片SQL
48 |
49 | 处于 Seata 全局事务中的分片 SQL 通过 RM 生成 undo 快照,并发送 `participate` 指令至 TC,加入全局事务。
50 |
51 | 由于 ShardingSphere 的分片物理 SQL 采取多线程,因此整合 Seata AT 事务时,需要在主线程、子线程间进行全局事务 ID 的上下文传递。
52 |
53 | ### 提交或回滚事务
54 |
55 | 提交 Seata 事务时,TM 会向 TC 发送全局事务的提交或回滚指令,TC 根据全局事务 ID 协调所有分支事务进行提交或回滚。
56 |
57 | ## 3 使用规范
58 |
59 | ### 支持项
60 |
61 | - 支持数据分片后的跨库事务;
62 | - 支持RC隔离级别;
63 | - 通过undo快照进行事务回滚;
64 | - 支持服务宕机后的,自动恢复提交中的事务。
65 |
66 | ### 不支持项
67 |
68 | - 不支持除RC之外的隔离级别。
69 |
70 | ### 待优化项
71 |
72 | - Apache ShardingSphere 和 Seata 重复 SQL 解析。
--------------------------------------------------------------------------------
/docs/md/sideline/20-个人支付解决方案.md:
--------------------------------------------------------------------------------
1 | # 20-个人支付解决方案
2 |
3 | AI 时代,先忽略繁琐的开发环节,先谈谈变现。绝大部分支付方案都面向企业,面向个人的正规支付方案很少。对没注册公司的个人,咋才能安全收款?
4 |
5 | ## 1 常见的几种个人收款方式
6 |
7 | ### 1.1 个人收款码
8 |
9 | 市面上最简单粗暴的个人收款方案:利用微信或支付宝的个人收款码来做。
10 |
11 | 就是生成一张二维码,在这二维码上面添加一个付款备注,让用户备注中补充上特定的消息后(如订单号)支付。完成支付,就通过APP或网站,得到备注里填的消息,通过识别,就能定位到订单,自动发货。也有不用备注,用支付金额来识别的。
12 |
13 | 这个方式淘宝店家很熟练了,它的问题在于:
14 |
15 | - 用户端体验,需填写额外消息或发送不确定的金额
16 | - 商家端体验,它要有一个常驻服务,时刻监测收款的相关消息,这就有相当的不稳定因素
17 |
18 | ### 1.2 二次封装接口
19 |
20 | 由那些有资质的企业申请到接口权限后,二次封装后提供给个人来用。
21 |
22 | 问题在于,钱是支付给提供接口的企业的,我们只能定期找他们结算提款。万一对方跑路,我们的钱也没了。这种方式风险非常高,不推荐。
23 |
24 | ### 1.3 小微商户
25 |
26 | 支付平台针对个人、也就是大量没有企业资质的用户推出的一个解决方案。最开始推出是为帮助一些线下店面,快捷地接入支付而存在的一个服务,然后又扩展到了网上网店和商家。
27 |
28 | 一些银行和微信都有这服务。但是微信并没有给它做专门的后台页面,所以我们在支付平台的后台里是看不见它的,它只有API。
29 |
30 | 微信把这一部分业务,交给了微信开放平台上的服务商。由服务商去调用这些接口来帮助个人接入到微信的支付服务里面来,同时服务商会提供后台的页面帮个人用户进行管理、也是服务商封装API供个人使用。
31 |
32 | 好处在于完全合规,而且这个钱是从微信直接打到小微商户的银行卡里边,不经中间服务商,非常安全。
33 |
34 | 有命的如 xorpay.com 和 payjs.cn 。都是收费服务,前者的费用似乎更为便宜一些。使用之前请自行判断其靠谱系数。
35 |
36 | ## 2 数字内容销售平台
37 |
38 | 如我们就是写个软件,想简单进行销售获得收入的话,还可用一些现成的数字内容销售平台:
39 |
40 | - 面向国外市场,可用Gumroad.com
41 | - 面向国内市场,可用mianbaoduo.com
42 |
43 |
44 |
45 | 逻辑上,所有网店都能解决卖软件的需求,但相对而言,面包多这类专门面向数字商品的平台提供了更低的手续费和更为全面的 API 接口。
46 |
47 | 
--------------------------------------------------------------------------------
/docs/md/sideline/21-处理用户反馈和增长优化.md:
--------------------------------------------------------------------------------
1 | # 21-处理用户反馈和增长优化
2 |
3 | # 1 使用「兔小巢」处理用户反馈
4 |
5 | 管理用户反馈的产品很多,但大部分收费;介绍个腾讯出品的免费工具「兔小巢」。
6 |
7 | 
8 |
9 | 该产品最大用户就是腾讯自己,原叫「吐个槽」,后来升级并更名为「兔小巢」:
10 |
11 | - 用户端,支持微信和QQ登入,能及时推送回复通知
12 | - 运营端,明显感受到这是一款看似简单,功能却相当强大的产品。如可设置移动端的展示方式;可适配大型产品和通用产品;默认发帖可隐藏,也就可以当做工单使用;甚至还配备团队博客和知识库
13 | - 不足在于,提供的 API 较少,但也够在自己产品中展示用户反馈了
14 |
15 | 有了它,我觉得大部分情况下,就不用再去购买同类的付费产品。
16 |
17 | 分享一些整合细节供参考。
18 |
19 | ## 链接跳转
20 |
21 | 提供非常浅的整合,不管 Web 还是 APP 中,都是通过网页转向方式进行。通过设置,在反馈区上方可以显示一个链接,供用户返回到产品。
22 |
23 | ## 状态登入
24 |
25 | 通过链接跳转会遇到问题:我们的产品和兔小巢之间,用户的登录状态会丢失,我们就不知道那个反馈是哪一个用户提交的。
26 |
27 | 为此,兔小巢提供[tucao.js](https://txc.qq.com/helper/configLogonState),让我们可以在跳转时传递用户的登录态,从而实现用户统一。
28 |
29 | ## 反馈数据整合
30 |
31 | 默认,我们只能点击链接后,在单独的页面上才能看到反馈信息。但通过兔小巢提供的 [API](https://txc.qq.com/helper/usrFetchAPIGuide),可直接在产品中显示反馈内容。
32 |
33 | # 2A3R漏斗和增长优化
34 |
35 | ## 啥是 2A3R 漏斗?
36 |
37 | 又叫 AARRR 漏斗,描述用户转化的结构。
38 |
39 | 
40 |
41 | 一个五层结构,分别是:
42 |
43 | 1. 获客层
44 | 2. 激活层
45 | 3. 留存层
46 | 4. 推荐层
47 | 5. 付费层
48 |
49 | 用户由上至下逐步转化,直至完成付费。其中,留存层、推荐层和付费层可以是并列的,因为用户激活以后,立刻就可以付费、推荐好友。
50 |
51 | ## 使用 2A3R 漏斗进行业务优化
52 |
53 | 2A3R 漏斗的现实意义在于,它促使我们从结果出发,去反向优化前边各个环节的转化率。
54 |
55 | 如福利单词项目的销售额定为 1000 套,那么就是说最终到达付费层的用户有 1000 人。而在付费层上至少还有获客层、激活层。
56 |
57 | 把获客指标定义为「访问网站」;把激活指标定义为「用户登入」。假设每一层的转化率是 10%,那么访问我们产品的用户数需要达到:
58 | $$
59 | 1000 * 100 = 10 万人
60 | $$
61 | 优化方向包括:
62 |
63 | 1. 加大推广力度,让访问人数从十万变成一百万,这样就能卖掉一万套软件了。
64 | 2. 优化「用户登入」环节,在微信里边做成自动登录,这样把原来 10% 的激活转化提高为 30%,这样即使依然是 10 万访客,销售额也会变为 3000 套。
65 | 3. 强化「付费转化」环节,给第一次访问的用户一个限时折扣,比如 1 个小时内购买,买一送一。如果能拉升 10% 的支付转化,我们的销售也会上升。
66 |
67 | ## 留存层优化
68 |
69 | 主要用于一些基于高粘度增长引擎的业务,或者免费+付费模式的产品。在这些模式下,用户需要经过很长时间的使用,才会付费。如果留存做不好,用户熬不到付费那天。
70 |
71 | 对于福利单词而言,留存层优化可以通过推送通知、定时提醒等功能来做。因为背单词本来就是一个周期性行为,所以我们有足够的理由去召回用户。
72 |
73 | ## 推荐层优化
74 |
75 | 现在的流量已经是非常贵的了,所以我们必须珍惜每一滴流量。通过旧用户带来新用户,可以为我们提供免费流量;如果做得足够好,流量甚至能像滚雪球一样不断变大。这就是推荐层优化要做的事情。
76 |
77 | 在我们的应用中,我们可以选择几个用户情绪高涨的点来做分享触发:
78 |
79 | 1. 完成当天的背单词目标,比如背了 100 个单词
80 | 2. 完成有挑战的任务,比如连续 30 个单词不出错
81 | 3. 看到赏心悦目的图片,比如看到超级呆萌的猫
82 |
83 | 在这些时刻,我们都可以引导用户通过海报来分享他们的激动心情,同时为我们带来新的用户。
84 |
85 | ## 推荐阅读
86 |
87 | 增长优化推荐两本书:
88 |
89 | - 肖恩·埃利斯的《增长黑客》,系统化地讲述了如果建立增长实验机制并从中受益
90 | - 《病毒循环》,记录了众多流量传奇
91 |
92 | 它们中很多细节和技巧,都可以用到我们的副业当中。
--------------------------------------------------------------------------------
/docs/md/sideline/22-大纲的注意点.md:
--------------------------------------------------------------------------------
1 | # 22-大纲的注意点
2 |
3 | 这一节我们来讲大纲。大纲大家都会做,所以我们不全面的展开,只挑其中一些需要注意的点和大家交流。
4 |
5 | ## 1 条理性
6 |
7 | 最重要的一点,就是大纲一定要有条理性。如果在条例性上做得不够好,其他细节做得再好,这个课做出来在逻辑上也是乱的,最后学起来就会很别扭。
8 |
9 | 具体来说,我们要保证大纲的层次足够清楚,逻辑足够严密。有一个比较常用的结构推荐给大家,尤其适合知识性为课程。
10 |
11 | ### 1.1 三段式
12 |
13 | 这个结构分成三段,是一个总、分、总的结构。
14 |
15 | #### 总
16 |
17 | 在课程的最开始,我们会简明扼要地讲明白整个课程包含哪些内容;课程中的一些基础、原理也会放到这里。
18 |
19 | #### 分
20 |
21 | 之后呢,我们就可以按照章节进行展开,对每一个部分进行详细地讲解。
22 |
23 | #### 总
24 |
25 | 在最后我们会进行一个总结,同时放入一个大的实践章节。这样不但可以复习内容,还可以学以致用。当然在每一章结尾也可以安排小实践内容。
26 |
27 | 绝大部分以知识讲授为主的课程都可以采用这种总分总的结构,非常好用。
28 |
29 | ### 1.2 提问式
30 |
31 | 我们也可以用问问题的方式来引出我们的每一部分结构。比如「是什么」——「为什么」——「怎么做」。这种结构可以是全局的,也可以是针对每一部分的。它会让我们的逻辑和层次更清晰。
32 |
33 | ## 2 覆盖面
34 |
35 | 第二个需要注意的点是覆盖面。因为我们的课程往往是出于自己的实践经验,有时候会局限于我们所在的公司和所在的行业节点,它的覆盖不一定特别的全。所以我们的视角不一定能覆盖到所有的需求方。
36 |
37 | 有时候我们的课程是为了一类人做的,但另外一类人,实际上也可以学习我们的课程,就差一点点的周边知识。在这种情况下,如果我们可以注意到大纲的覆盖面,把缺少的那点知识补上,就可以扩大受众,让我们的销售变得更为容易。
38 |
39 | 那具体怎么保证大纲的覆盖面呢?
40 |
41 | 那首先大纲应该覆盖该领域的主要内容,这些内容通常来源于以下几个地方:
42 |
43 | 1. 官方文档:官方会处理几乎所有来自社区和其他客户的需求,即使一些边缘的需求,因为囤积的时间比较长,也会慢慢地累积起来,所以一般来讲官方资料的覆盖度是最为全面的
44 | 2. 行业的权威文档:虽然不是官方出品的,但因为日积月累它最后可能变成了事实标准,也是我们作为参考的一个主要来源
45 | 3. 图书:这也是大参考源,对于经典知识来讲,一些销量比较好的图书,会经过多次的再版,并会加入一些之前没有覆盖的内容。使用微信读书的无限卡,无需购买就可以直接搜索大量计算机图书,对查资料来讲非常好用
46 | 4. 同类课程:国外的同类课程往往也是非常好的参考,尤其是面向新技术的课程
47 |
48 | 然后呢,我们的大纲应该覆盖该领域最频繁出现的问题,那我们到什么地方找问题呢?
49 |
50 | 1. 搜索关键词
51 | 2. 专业问答网站,比如 stackoverflow.com
52 | 3. GitHub 的 issue 区
53 | 4. 课程平台的答疑区
54 |
55 | ## 3 粒度
56 |
57 | 除了条例性和覆盖面,那我们最后,而且其实也是非常想强调的一个问题,就是大家一定要注意我们大纲的粒度。
58 |
59 | 大纲这名字听起来就像一个目录,很具备误导性。很多同学做大纲的时候,通常做两个层次就算是做得细的了。事实上,大纲的粒度越细,课程的品质就越可控,后期制作起来速度就越快。而且我们要拿大纲去做预售来验证需求,它越细,验证的效果就越好。
60 |
61 | 所以呢,建议大家把大纲至少细化到段落这个级别,同时把段落以下的一些知识点所涉及到的素材和资料,全部都整理到这个节点上去。
62 |
63 | 这里推荐大家使用 Dynalist 这种无限分级的树状笔记软件来做大纲,会特别方便。
--------------------------------------------------------------------------------
/docs/md/spark/00-为啥要学习Spark Streaming.md:
--------------------------------------------------------------------------------
1 | # 00-为啥要学习Spark Streaming
2 |
3 | 本专栏从实时数据产生和流向的各个环节出发,通过集成主流的:
4 |
5 | - 分布式日志收集框架Flume
6 | - 分布式消息队列Kafka
7 | - 分布式列式数据库HBase
8 | - 当前非常火爆的Spark Streaming
9 |
10 | 打造实时流处理项目实战,让你掌握实时处理的整套处理流程,达到大数据中级研发工程师的水平!
11 |
12 | ## 前提
13 |
14 | 适合有编程基础,想转行投身大数据行业的工程师,对你的学习能力及基础要求如下:
15 |
16 | 1、熟悉常用Linux命令的使用
17 |
18 | 2、掌握Hadoop、Spark的基本使用
19 |
20 | 3、至少熟悉一门编程语言Java/Scala/Python
21 |
22 | #### 基于Flume+Kafka+Spark Streaming打造企业大数据流处理平台
23 |
24 | 流行框架打造通用平台,直接应用于企业项目:
25 |
26 | - 处理流程剖析
27 | - 日志产生器
28 | - 使用Flume采集日志
29 | - 将Flume收集到的数据输出到Kafka
30 | - Spark Streaming消费Kafka的数据进行统计
31 | - Spark Streaming如何高效的读写数据到Hbase
32 | - 本地测试和生产环境使用的拓展
33 | - Java开发Spark要点拓展
34 |
35 | ## 原理+场景,彻底搞懂Spark Streaming
36 |
37 | 全面了解Spark Streaming的特性及场景应用,完成各个不同维度的统计分析。
38 |
39 | #### 日志收集框架Flume
40 |
41 | Flume架构及核心组件
42 |
43 | Flume&JDK环境部署
44 |
45 | Flume实战案例
46 |
47 | #### 分布式消息队列Kafka
48 |
49 | Kafka架构及核心概念 / Zookeeper安装
50 |
51 | Kafka单、多broker部署及使用
52 |
53 | Kafka Producer Java API编程
54 |
55 | Kafka Consumer Java API编程
56 |
57 | #### 1.入门
58 |
59 | Spark Streaming概述及应用场景
60 |
61 | Spark Streaming集成Spark生态系统使用
62 |
63 | 从词频统计功能着手入门Spark Streaming
64 |
65 | Spark Streaming工作原理(粗/细粒度)
66 |
67 | #### 2.核心
68 |
69 | StreamingContext/Dstream
70 |
71 | Input DStreams和Receivers
72 |
73 | Transformation和Output Operations
74 |
75 | Spark Streaming处理socket/文件系统数据
76 |
77 | #### 3.进阶
78 |
79 | updateStateByKey算子的使用
80 |
81 | 统计结果写入到MySQL数据库
82 |
83 | 窗口函数的使用、黑名单过滤
84 |
85 | Spark Streaming整合Spark SQL操作
86 |
87 | #### Streaming整合Flume
88 |
89 | Push和Pull两种方式介绍
90 |
91 | 与Flume Agent配置
92 |
93 | 本地、服务器环境联调
94 |
95 | 整合Spark Streaming应用开发
96 |
97 | #### Streaming整合Kafka
98 |
99 | 版本选择详解
100 |
101 | Receiver和Direct两种方式
102 |
103 | 本地、服务器环境联调
104 |
105 | 整合Spark Streaming应用开发及测试
106 |
107 | ## 总结
108 |
109 | 渐进式学习让你彻底学会整套流程的开发
110 |
111 | 需求分析 → 数据清洗 → 数据统计分析 → 统计结果入库 → 数据可视化
--------------------------------------------------------------------------------
/docs/md/spark/01-Spark Streaming专栏概述.md:
--------------------------------------------------------------------------------
1 | # 01-Spark Streaming专栏概述
2 |
3 | ## 1 实战目标
4 |
5 | - 至今专栏的访问量
6 | - 至今从搜索引擎引流过来的专栏的访问量
7 |
8 | ## 2 实战流程
9 |
10 | 
11 |
12 | ## 3 可视化显示
13 |
14 | - 使用Spring Boot整合Echarts
15 | - 阿里云DataV数据可视化框架
16 |
17 | ## 4 教程概要
18 |
19 | - 初识实时流处理
20 | - 日志收集框架Flume
21 | - 消息队列Kafka
22 | - 实战环境搭建
23 | - Spark Streaming入门
24 | - Spark Streaming进阶
25 | - Spark Streaming集成Kafka
26 | - Spark Streaming集成Flume
27 |
28 | ## 5 计划
29 |
30 | - 整合Flume、Kafka、 Spark Streaming打造通用的流处理平台基础
31 | - Spark Streaming项目实战
32 | - 数据处理结果可视化
33 | - 拓展
34 |
35 | ## 6 前提
36 |
37 | - 熟悉Linux基本命令
38 | - 熟悉Scala/Python/Java
39 | - 有Hadoop和Spark基础
40 |
41 | ## 7 环境
42 |
43 | - JDK : 1.8
44 | - Hadoop: CDH ( 5.7 )
45 | - Scala : 2.12
46 | - Spark: 2.4.1
--------------------------------------------------------------------------------
/docs/md/spark/02-Spark Streaming小试流式处理.md:
--------------------------------------------------------------------------------
1 | # 02-Spark Streaming小试流式处理
2 |
3 | ## 1 业务分析
4 |
5 | ### 1.1 需求
6 |
7 | 统计主站每个(指定)教程访问的客户端、地域信息分布
8 |
9 | 地域: ip转换 Spark SQL项目实战
10 | 客户端:useragent获取 Hadoop基础教程
11 |
12 | =》如上两个操作:采用离线(Spark/MapReduce )的方式进行统计
13 |
14 | ### 1.2 实现步骤
15 |
16 | 课程编号、ip信息、useragent
17 | 进行相应的统计分析操作: MapReduce/Spark
18 |
19 | ### 1.3 项目架构
20 |
21 | 日志收集: Flume
22 | 离线分析: MapReduce/Spark
23 | 统计结果图形化展示
24 |
25 | 看起来很简单,没什么高深的,但是现在需求改了嘛,很正常的骚操作对不对!
26 | 现在要求实时的精度大幅度提高!那么现在的架构已经无法满足需求了!
27 |
28 | #### 1.3.1 问题
29 |
30 | 小时级别
31 | 10分钟
32 | 5分钟
33 | 1分钟
34 | 秒级别
35 | 根本达不到精度要求!
36 |
37 | 实时流处理,应运而生!
38 |
39 | ## 2 实时流处理产生背景
40 |
41 | ◆ 时效性高
42 | ◆ 数据量大
43 |
44 | ◆ 实时流处理架构与技术选型
45 |
46 | ## 3 实时流处理概述
47 |
48 | - 实时计算:响应时间比较短。
49 | - 流式计算:数据不断的进入,不停顿。
50 | - 实时流式计算:在不断产生的数据流上,进行实时计算
51 |
52 | ## 4 离线计算与实时计算对比
53 |
54 | ### 4.1 数据来源
55 |
56 | 离线:HDFS历史数据,数据量较大。
57 | 实时:消息队列(Kafka),实时新增/修改记录实时过来的某一笔数据。
58 |
59 | ### 4.2 处理过程
60 |
61 | 离线:Map + Reduce
62 | 实时:Spark(DStream/SS)
63 |
64 | ### 4.3 处理速度
65 |
66 | 离线:速度慢
67 | 实时:快速拿到结果
68 |
69 | ### 4.4 进程角度
70 |
71 | 离线:启动 + 销毁进程
72 | 实时: 7 * 24小时进行统计,线程不停止
73 |
74 | ## 5 实时流处理架构与技术选型
75 |
76 |
77 |
78 | 
79 |
80 | - Flume实时收集WebServer产生的日志
81 | - 添加Kafka,进行流量消峰,防止Spark/Storm崩掉
82 | - 处理完数据,持久化到RDBMS/NoSQL
83 | - 最后进行可视化展示
84 |
85 | Kafka、Flume一起搭配更舒服哦~
86 |
87 | ## 6 实时流处理应用
88 |
89 | - 电信行业:推荐流量包
90 | - 电商行业:推荐系统算法
--------------------------------------------------------------------------------
/docs/md/spark/06-RDD与DataFrame的互操作.md:
--------------------------------------------------------------------------------
1 | # 06-RDD与DataFrame的互操作
2 |
3 | ```scala
4 | val spark = SparkSession.builder()
5 | .master("local").appName("DatasetApp")
6 | .getOrCreate()
7 | ```
8 |
9 | Spark SQL支持两种不同方法将现有RDD转换为DataFrame:
10 |
11 | ## 1 反射推断
12 |
13 | 包含特定对象类型的 RDD 的schema。
14 | 这种基于反射的方法可使代码更简洁,在编写 Spark 应用程序时已知schema时效果很好
15 |
16 | ```scala
17 | // 读取文件内容为RDD,每行内容为一个String元素
18 | val peopleRDD: RDD[String] = spark.sparkContext.textFile(projectRootPath + "/data/people.txt")
19 |
20 | // RDD转换为DataFrame的过程
21 | val peopleDF: DataFrame = peopleRDD
22 | // 1. 使用map方法将每行字符串按逗号分割为数组
23 | .map(_.split(","))
24 | // 2. 再次使用map方法,将数组转换为People对象
25 | .map(x => People(x(0), x(1).trim.toInt))
26 | // 3. 最后调用toDF将RDD转换为DataFrame
27 | .toDF()
28 | ```
29 |
30 | ## 2 通过编程接口
31 |
32 | 构造一个schema,然后将其应用到现有的 RDD。
33 |
34 | ### 2.0 适用场景
35 |
36 | 虽该法更冗长,但它允许运行时构造 Dataset,当列及其类型直到运行时才知道时很有用。
37 |
38 | ### 2.1 step1
39 |
40 | ```scala
41 | // 定义一个RDD[Row]类型的变量peopleRowRDD,用于存储处理后的每行数据
42 | val peopleRowRDD: RDD[Row] = peopleRDD
43 | // 使用map方法将每行字符串按逗号分割为数组,得到一个RDD[Array[String]]
44 | .map(_.split(","))
45 | // 再次使用map方法,将数组转换为Row对象,Row对象的参数类型需要和schema中定义的一致
46 | // 这里假设schema中的第一个字段为String类型,第二个字段为Int类型
47 | .map(x => Row(x(0), x(1).trim.toInt))
48 | ```
49 |
50 | ### 2.2 step2
51 |
52 | ```scala
53 | // 描述DataFrame的schema结构
54 | val struct = StructType(
55 | // 使用StructField定义每个字段
56 | StructField("name", StringType, nullable = true) ::
57 | StructField("age", IntegerType, nullable = false) :: Nil)
58 | ```
59 |
60 | ### 2.3 step3
61 |
62 | 使用SparkSession的createDataFrame方法将RDD转换为DataFrame
63 |
64 | ```scala
65 | val peopleDF: DataFrame = spark.createDataFrame(peopleRowRDD, struct)
66 |
67 | peopleDF.show()
68 | ```
--------------------------------------------------------------------------------
/docs/md/spider/00-爬虫基础.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/spider/00-爬虫基础.md
--------------------------------------------------------------------------------
/docs/md/spring/01-HelloSpringBoot应用程序.md:
--------------------------------------------------------------------------------
1 | # 01-HelloSpringBoot应用程序
2 |
3 | ## 1 前言
4 |
5 | Spring Boot对Spring平台和第三方库整合,可创建`可运行的、独立的、生产级的`基于Spring的应用程序,大多Spring Boot应用程序只需很少的Spring配置。
6 |
7 | Spring Boot可用java -jar或更传统war部署启动的Java应用程序创建,可内嵌Tomcat 、Jetty 、Undertow容器,快速启动web程序。
8 |
9 | ## 2 目录结构
10 |
11 |
12 |
13 | 
14 |
15 | ## 3 代码
16 |
17 | ```java
18 | import org.springframework.web.bind.annotation.RequestMapping;
19 | import org.springframework.web.bind.annotation.RequestMethod;
20 | import org.springframework.web.bind.annotation.RestController;
21 |
22 | @RestController
23 | public class HelloController {
24 |
25 | @RequestMapping(value = "/hello",method = RequestMethod.GET)
26 | public String say() {
27 | return "Hello Spring Boot!";
28 | }
29 | }
30 | ```
31 |
32 | ### @RequestMapping
33 |
34 | 将请求URL,如 /hello,映射到整个类或某特定的处理器方法。
35 |
36 | 一般类级别的注解负责将一个特定(或符合某种模式)的请求路径映射到一个控制器上,同时通过方法级别的注解来细化映射,即根据特定的HTTP请求方法("GET""POST"方法等)、HTTP请求中是否携带特定参数等条件,将请求映射到匹配的方法上。
37 |
38 | ### @RestController
39 |
40 | 当今让控制器实现一个REST API,控制器只需提供JSON、XML或其他自定义的媒体类型内容即可,无需在每个 @RequestMapping 方法上都增加一个 @ResponseBody 注解,更简明的做法,是给你的控制器加上一个 @RestController 的注解。
41 |
42 | @RestController是一个原生内置注解,结合了 @ResponseBody 与 @Controller 功能。不仅如此,也让你的控制器更表义,且在框架未来的发布版本中,它也可能承载更多意义。
43 |
44 | 与普通的 @Controller 本质无异。
45 |
46 | ```java
47 | import org.springframework.boot.SpringApplication;
48 | import org.springframework.boot.autoconfigure.SpringBootApplication;
49 |
50 | @SpringBootApplication
51 | public class GirlApplication {
52 |
53 | public static void main(String[] args) {
54 | SpringApplication.run(GirlApplication.class, args);
55 | }
56 | }
57 |
58 | ```
59 |
60 | ### @SpringBootApplication
61 |
62 | 开启Spring的组件扫描和Spring Boot的自动配置功能。底层将3个有用的注解组合:
63 |
64 | - import org.springframework.boot.autoconfigure.EnableAutoConfiguration:开启Spring Boot自动配置。
65 | - import org.springframework.context.annotation.ComponentScan:启用组件扫描,如此所写的web控制器类和其他组件才能被自动发现并注册为Spring应用上下文里的bean(即启用Spring Boot的自动bean加载机制)
66 | - import org.springframework.context.annotation.Configuration:标明该类使用Spring基于Java的配置
67 |
68 | 自动配置侧重于根据项目依赖和配置来自动配置应用程序,而自动Bean加载机制侧重于扫描和加载标注了Spring注解的类。
69 |
70 | ## 4 效果
71 |
72 |
73 |
74 | 
--------------------------------------------------------------------------------
/docs/md/spring/SpringMVC-AsyncHandlerInterceptor.md:
--------------------------------------------------------------------------------
1 | # 01-SpringMVC的AsyncHandlerInterceptor异步的处理器拦截器
2 |
3 | HandlerInterceptor 类扩展了一个回调方法,该方法在异步请求处理开始后被调用。当处理器启动一个异步请求时,DispatcherServlet 退出而不会像处理同步请求那样调用 postHandle 和 afterCompletion,因为请求处理的结果(例如 ModelAndView)可能尚未准备好,并将由另一个线程并发生成。在这种情况下,会调用 afterConcurrentHandlingStarted,允许实现类在释放线程到 Servlet 容器之前执行清理线程绑定属性等任务。
4 |
5 | 当异步处理完成时,请求会被调度到容器进行进一步处理。在这个阶段,DispatcherServlet 会调用 preHandle、postHandle 和 afterCompletion。为了区分初始请求和异步处理完成后的后续调度,拦截器可以检查 jakarta.servlet.ServletRequest 的 jakarta.servlet.DispatcherType 是 "REQUEST" 还是 "ASYNC"。
6 |
7 | HandlerInterceptor 实现可能需要在异步请求超时或由于网络错误而完成时进行处理。对这种case,Servlet 容器不会调度,因此不会调用 postHandle 和 afterCompletion。相反地,拦截器可通过 WebAsyncManager#registerCallbackInterceptor、registerDeferredResultInterceptor 注册来跟踪异步请求。这可以在每个请求的 preHandle 中主动完成,而不管是否会启动异步请求处理。
8 |
9 | 自版本 3.2 起提供。
10 |
11 | 另请参见:
12 |
13 | - org.springframework.web.context.request.async.WebAsyncManager
14 | - org.springframework.web.context.request.async.CallableProcessingInterceptor
15 | - org.springframework.web.context.request.async.DeferredResultProcessingInterceptor
--------------------------------------------------------------------------------
/docs/md/spring/spring-cloud/Spring Cloud Alibaba大纲.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/spring/spring-cloud/Spring Cloud Alibaba大纲.xmind
--------------------------------------------------------------------------------
/docs/md/spring/spring-cloud/SpringCloudGateway之灰度发布篇.md:
--------------------------------------------------------------------------------
1 | # Spring Cloud Gateway之灰度发布篇
2 | >Spring Cloud Gateway 实现灰度发布通常依赖于服务治理和路由规则的动态配置。
3 |
4 | ## 灰度发布
5 | >灰度发布(又名金丝雀发布)是指在黑与白之间,能够平滑过渡的一种发布方式。是一种软件发布策略,它允许开发者在一部分用户或者部分服务器上先部署新版本的应用程序,同时保持其他用户或服务器继续使用旧版本。通过这种方式,开发团队可以在真实环境中逐步验证新版本的性能、兼容性和功能,减少潜在问题对整体用户群体造成的影响,并根据灰度期间的反馈和数据指标决定是否将新版本全面上线。
6 |
7 | ### 灰度发布的服务治理与路由机制
8 | >服务注册与发现:每个服务实例在启动时向服务中心注册自身的元信息,包括版本号、环境标签等,用于标识其为稳定版还是灰度版。
9 |
10 | >动态路由规则:网关组件如Spring Cloud Gateway、Zuul等,可以通过配置动态路由规则,根据请求头、Cookie或其他上下文信息将特定流量导向灰度版本的服务实例。
11 |
12 | >监控与评估:在灰度发布阶段,持续监控灰度版本的服务运行状态,收集性能指标、错误日志等数据,对比分析新版本与旧版本之间的差异。
13 |
14 | >逐步扩大范围:根据灰度测试结果,如果新版本表现良好,则可以逐渐增加灰度流量的比例,直至全量覆盖所有用户。
15 |
16 | >回滚策略:若灰度阶段发现问题,应立即停止进一步扩大灰度范围,并及时进行版本回滚,以保证整体系统的稳定性。
17 |
18 | ## Spring Cloud Gateway实现灰度发布配置
19 | > 在Spring Cloud Gateway的应用中配置服务注册与发现,这里以使用Nacos作为服务注册中心。
20 |
21 | ```yaml
22 | spring:
23 | cloud:
24 | gateway:
25 | discovery:
26 | locator:
27 | enabled: true # 启用服务发现功能
28 | path-mapping:
29 | /your-service-name: /your-service-path # 将服务名映射到指定的路径
30 | routes:
31 | - id: gray-route # 路由ID
32 | uri: lb://your-service-name # 指向的服务名
33 | predicates:
34 | - Header=X-User-Type, gray # 根据请求头X-User-Type的值为gray进行灰度路由
35 | ```
36 | >在服务提供方的应用中,添加灰度版本的标签
37 |
38 | ```yaml
39 | spring:
40 | cloud:
41 | nacos:
42 | discovery:
43 | metadata:
44 | version: gray # 设置灰度版本的标签为gray
45 | ```
46 | >灰度路由规则配置在Nacos中,创建一个配置文件,例如gray-route.yml
47 |
48 | ```yaml
49 | spring:
50 | cloud:
51 | gateway:
52 | routes:
53 | - id: gray-route # 路由ID
54 | uri: lb://your-service-name # 指向的服务名
55 | predicates:
56 | - Header=X-User-Type, gray # 根据请求头X-User-Type的值为gray进行灰度路由
57 | ```
58 | >在Spring Cloud Gateway应用中,通过引入spring-cloud-starter-alibaba-nacos-config依赖,配置Nacos的地址和命名空间,以实现动态加载路由规则
59 |
60 | ```yaml
61 | spring:
62 | cloud:
63 | nacos:
64 | config:
65 | server-addr: nacos-address:port # Nacos配置中心地址
66 | namespace: your-namespace # 命名空间ID
67 | group: your-group # 配置分组
68 | ```
69 | >启动Spring Cloud Gateway应用和带有灰度版本标签的服务提供方应用,当请求头X-User-Type的值为gray时,请求将被路由到灰度版本的服务实例上。
70 |
--------------------------------------------------------------------------------
/docs/md/spring/spring-cloud/SpringCloudGateway之限流集成篇.md:
--------------------------------------------------------------------------------
1 | # SpringCloudGateway之限流集成篇
2 | >在Spring Cloud Gateway中实现限流(Rate Limiting)可以通过集成Spring Cloud Gateway的熔断和限流功能以及第三方限流组件如Sentinel或Resilience4j。
3 |
4 | ## SpringCloudGateway与Sentinel组件集成
5 | ### 添加依赖
6 |
7 | ```xml
8 | 首先确保项目包含Spring Cloud Gateway和Sentinel相关依赖。
9 |
10 |
11 | org.springframework.cloud
12 | spring-cloud-starter-gateway
13 |
14 |
15 |
16 | com.alibaba.csp
17 | sentinel-adapter-spring-cloud-gateway-2.x
18 | {sentinel-version}
19 |
20 |
21 |
22 | com.alibaba.csp
23 | sentinel-core
24 | {sentinel-version}
25 |
26 |
27 | ```
28 | ### 配置Sentinel
29 | > 在application.yml或application.properties文件中配置Sentinel的相关参数
30 |
31 | ```yaml
32 | spring:
33 | cloud:
34 | sentinel:
35 | transport:
36 | dashboard: localhost:8080 # Sentinel控制台地址
37 | port: 8719 # Sentinel与控制台之间的通讯端口
38 | filter:
39 | url-patterns: "/api/**" # 需要进行限流处理的路由路径
40 | ```
41 |
42 | ### 启用Sentinel Gateway适配器
43 | >创建一个配置类以启用Sentinel适配器,并注册到Spring容器中
44 |
45 | ```java
46 | import com.alibaba.csp.sentinel.adapter.gateway.sc.SentinelGatewayFilter;
47 | import com.alibaba.csp.sentinel.adapter.gateway.sc.config.SentinelGatewayConfig;
48 | import org.springframework.cloud.gateway.filter.GlobalFilter;
49 | import org.springframework.context.annotation.Bean;
50 | import org.springframework.context.annotation.Configuration;
51 |
52 | @Configuration
53 | public class SentinelGatewayConfiguration {
54 |
55 | @Bean
56 | public GlobalFilter sentinelGatewayFilter() {
57 | return new SentinelGatewayFilter();
58 | }
59 |
60 | @Bean
61 | public SentinelGatewayConfig sentinelGatewayConfig() {
62 | return new SentinelGatewayConfig();
63 | }
64 | }
65 | ```
66 | ### 配置限流规则
67 | >通过Sentinel控制台或API动态添加限流规则,包括QPS限制、热点限流等策略
68 | >为/api/user路由设置QPS限流
69 | 为/api/user路由设置QPS限流
70 | 在Sentinel控制台上新建一个限流规则,资源名可以是/api/user,然后设置每秒允许的请求次数。
--------------------------------------------------------------------------------
/docs/md/spring/spring-cloud/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/spring/spring-cloud/todo.md
--------------------------------------------------------------------------------
/docs/md/spring/阿里四面:你知道Spring AOP创建Proxy的过程吗?.md:
--------------------------------------------------------------------------------
1 | # 阿里四面:你知道Spring AOP创建Proxy的过程吗?
2 |
3 |
--------------------------------------------------------------------------------
/docs/md/trade/wechat-pay-development-guide-avoid-pitfalls.md:
--------------------------------------------------------------------------------
1 | # 微信支付开发避坑指南
2 |
3 | ## 1 微信支付的坑
4 |
5 | ### 1.1 不能用前端传递过来的金额
6 |
7 | 订单的商品金额要从数据库获取,前端只传商品 id。
8 |
9 | ### 1.2 交易类型trade type字段不要传错
10 |
11 | v2版API,不同交易类型,要调用的支付方式也不同。
12 |
13 | ### 1.3 二次签名
14 |
15 | 下单时,在拿到预支付交易会话标识时,要进行二次签名操作。二次签名后的值,才能返回给前端使用。
16 |
17 | ### 1.4 小程序可绑定到其它公司的商户下
18 |
19 | 可同时关联到多个商户号:
20 |
21 | 
22 |
23 | ### 1.5 微信支付的单位是分,最小金额是0.01元
24 |
25 | 支付宝是元。
26 |
27 | ### 1.6 做避免重复消费的处理
28 |
29 |
30 |
31 | 
32 |
33 | 处理成功之后不要再进行二次处理了,那首先是有事务操作。
34 |
35 | 第一次处理成功后,需要更新对应订单的状态。更新完成后,下次再处理时,直接返回成功,不再进行实际业务处理。
36 |
37 | 也可以拿这个订单号加分布式锁,保证对同一个用户,同时只能处理一个订单。
38 |
39 | ### 1.7 支付结果验签
40 |
41 | 对支付结果通知,一定要拿配置的私钥进行验签处理。
42 |
43 | ```java
44 | // 处理内部业务逻辑
45 | try {
46 | // 支付结果验签
47 | boolean valid = WXPayUtil.isSignatureValid(map1, weixinpaypartner);
48 | if (valid == false) {
49 | log.info("签名不一致" + outTradeNo);
50 | return "ERROR";
51 | } else {
52 | //1、更新订单状态
53 | dealAfterSuccess(basOrder, time_end, transaction_id, result_code);
54 | log.info("验签成功" + outTradeNo);
55 | result = CommUtils.setXml("SUCCESS", "OK");
56 | log.info("收到异步通知返回微信的内容--" + result);
57 | return result;
58 | }
59 | } catch (Exception e) {
60 | e.printStackTrace();
61 | return "ERROR";
62 | }
63 | ```
64 |
65 | 不验签也可以继续执行,但支付结果页容易被伪造哦!
66 |
67 | ### 1.8 对支付结果通知处理逻辑中的非事务性操作做操作记录
68 |
69 | 可能在支付通知后,通过小程序给用户发送模板消息通知或公众号消息通知触达。若这时事务处理失败,但结果发送成功了,会造成啥结果?那你下次是否要重新处理这个订单流程,在重新处理订单时难道再发一次推送吗?肯定不可以。
70 |
71 | 所以最好拿订单号作为标识,判断记录这个订单是否已经有过啥事务性、非事务性操作,下次或者是订单补偿时,就只处理事务性操作,不再处理非事务性操作。
72 |
73 | ### 1.9 v2的统一下单的接口
74 |
75 | 服务号、H5下单和小程序下单都可调用,甚至app下单都可以调用。
--------------------------------------------------------------------------------
/docs/md/zqy/面试题/03-生产部署面试实战.md:
--------------------------------------------------------------------------------
1 | # 03-生产部署面试实战
2 |
3 | ## 生产部署面试实战
4 |
5 | 接下来说一下,对于 `生产部署` 方面会从哪些方面来问?
6 |
7 |
8 |
9 | ### 服务如何部署?
10 |
11 | 比如,你们生产环境中,各个服务是如何进行部署的呢?
12 |
13 | 其实也就是问:
14 |
15 | - `网关`、`注册中心`以及各个 `服务` 是如何部署的?
16 | - 部署的 `机器配置` 是怎样的?
17 | - 每天 `访问量` 是多少?
18 | - `高峰期接口访问量` 是多少?
19 |
20 |
21 |
22 | 回答的话,也不用回答细节,将整个流程给回答一下:
23 |
24 | `网关部署` 的话,就根据系统的访问量,如果不大,部署 2-3 个网关系统即可
25 |
26 | `注册中心` 一般都是集群部署,比如 zk 集群部署(1 主 2 从)
27 |
28 | `服务` 部署一般看每个服务的负载情况了,负载高的服务,就多部署几个,分散一下请求
29 |
30 |
31 |
32 | 而对于 `系统访问量` 来说,可能很多人都没有什么概念,并且对于机器可以抗多少数量的并发请求也都不太清楚
33 |
34 | 这些都是属于更细节一些的东西了,属于 `进阶部分`,可以了解一下,但是深入学习这些内容之前,一定要先将基础把握住,不要本末倒置了
35 |
36 | 其实想要看系统访问量的话,很简单的一个方式就是,在代码中加入一些统计的接口,比如统计每个接口请求数量、接口请求延时、系统访问量,可以直接在代码中记录,再向外暴露出一个接口,可以查询到这些 `统计值`
37 |
38 | 就比如说,一个接口请求一次之后,在代码中,对这个接口请求次数加 1,用 AtomicLong 来统计每天的接口请求数量,接口平均请求延时的话,将接口请求延时加起来除以接口请求次数也能算出来
39 |
40 |
41 |
42 | 这里还要了解一下 `性能监控` 中的一些指标,T99、T95
43 |
44 | 如 `T99 = 50ms`,表示 99% 的请求耗费时长都在 50ms 以内
45 |
46 | `T95 = 50ms`,表示 95% 的请求耗费时长都在 50ms 以内
47 |
48 |
49 |
50 | **怎么看系统可以承载的最大负荷呢?**
51 |
52 | 使用开源的 `压测工具`,例如 Jmeter,去模拟用户向系统发送请求
53 |
54 | 通过控制发送请求数量,查看系统的负载情况,以及系统最多可以处理的并发请求数量
55 |
56 | 比如发送 1000 个请求,系统只可以处理 800 个,那么就说明系统最大处理并发请求数量为 800
57 |
58 |
59 |
60 | ### 数据库如何部署
61 |
62 | 对于数据库来说的话,一般也会使用 `比较好的机器配置` 来部署,16C32G 的机器比较适合,32C64G 的机器可以根据数据库的负载来选择,负载较高的话,可以升级一下机器的配置
63 |
64 | 那么一般来说 16C32G 的机器,每秒抗 `小几千的并发请求` 还是问题不大的,只要 `不存在一个 SQL 执行 2-3 秒的情况` 就可以!
65 |
66 | 但是对于数据库来说,如果平均每秒都是三四千请求,此时 MySQL 机器虽然不会崩掉,但是它的负载是很高的,包括 CPU 使用率、磁盘 IO、网络负载都是处于比较高的水平
67 |
68 | 大部分的系统,其实每秒钟也就几十个请求,高峰期几百个请求,系统都是可以抗住的
69 |
70 | 
71 |
72 |
73 |
74 |
75 |
76 | ### 如果访问量扩大 10 倍,如何应对?
77 |
78 | 访问量扩大 10 倍的话
79 |
80 | - 对于 `网关系统` 来说,部署 10 倍的网关机器即可,再通过 nginx 将请求分发到不同的网关中去,就可以分散大量请求压力
81 |
82 | 
83 |
84 | - 对于 `服务实例` 来说,也是比较简单,通过增加服务实例的数量,并且注册到 `注册中心` 去,这样通过 `负载均衡` 将一个服务的压力也给分散到多个服务实例中去了
85 |
86 | - 对于 `数据库` 来说,如果原本高峰期每秒三四百请求,扩大 10 倍后,每秒三四千的访问量,如果对数据库横向扩容比较麻烦,因此可以考虑给部署数据库的服务器提升配置,比如从 16C32G 提升到 32C64G 的配置,抗 3-4000 的请求还是没有问题的
87 |
88 |
89 |
90 |
91 |
92 | 在生产部署面试方面,主要就是问一些系统 QPS 、部署以及应对并发量上来之后的措施,这其实就考察有没有生产经验,或者说你有没有对系统进行过 `压测` 并进行性能优化
93 |
94 | > 压测方面的内容,可以关注我,发送 `"压测"` 领取一份压测视频教程!
95 |
96 |
--------------------------------------------------------------------------------
/docs/md/zqy/面试题/jiagou/02-该从哪些方面提升系统的吞吐量?.md:
--------------------------------------------------------------------------------
1 | # 02-该从哪些方面提升系统的吞吐量?
2 |
3 | 我们平时自己做的项目一般没有用户量,都是练手项目,所以并不会在吞吐量上做出很多的优化,但是这样的话,又会导致项目和其他人相比并没有什么亮点,因此可以借鉴一些高吞吐量的架构设计,来为自己的项目添加一些亮点功能,这里总结一下 **B 站千万长连消息系统** 如何提升系统吞吐量!
4 |
5 | B 站千万长连消息系统原文链接:https://mp.weixin.qq.com/s/Thw_mkb-aUepzcjd9RCDzw
6 |
7 | ## 1、负载均衡
8 |
9 | 负载均衡是比较常用的了,通过负载均衡将请求分发到不同的服务器上处理,分散单个节点上的压力,可以提高系统的扩展性和稳定性。
10 |
11 | 可以根据实际需求设计负载均衡策略,选择合适的节点进行请求的转发。
12 |
13 | 负载均衡中比较重要的就是 **节点的动态扩缩容** ,也就是可以实现节点实时增加、减少,这样在高峰期可以增加部分节点来抗下更高的吞吐量,低峰期可以减少部分节点,避免资源浪费。
14 |
15 | ## 2、消息队列
16 |
17 | 消息队列也是很常用的一个手段,高并发系统的三把利器:**分流、缓存、异步**
18 |
19 | 其中分流指的就是将流量分开,对应负载均衡,异步即对应消息队列
20 |
21 | **为什么要用消息队列呢?**
22 |
23 | 一方面是进行业务之间的解耦,另一方面是为了提升系统的性能,通过消息队列可以提升主干流程的响应速度,将一些比较耗时的操作从主干流程中剥离出去。
24 |
25 | 这里 B 站在设计上增加了 **消息队列和消息分发层** ,如果服务层在执行业务逻辑时,还要去推送大量的消息到各个节点上,比较影响消息的吞吐量,因此通过增加 **消息分发层** 来推送和维护消息,提高了系统的并发处理能力,避免了因消息推送阻塞而导致的性能问题。
26 |
27 | ## 3、消息聚合
28 |
29 | 消息聚合也是比较常用的一个手段,我看了 B 站分享出来的技术文章,多次提到了消息聚合。
30 |
31 | 如果不使用消息聚合,就拿弹幕消息来说,如果一个用户发送一条弹幕消息,那么这条消息需要扩散到同时在线的所有用户,假如说有 1kw 人在线,那么发送的消息数量就是 1kw * 1kw,消息量巨大!
32 |
33 | 因此,可以根据一定的规则进行消息聚合,批量推送,比如说达到一定时间内推送一次,或者消息数量达到多少就进行推送一次,如下图:
34 |
35 | 
36 |
37 | 根据 B 站统计结果,加入消息聚合后,发送消息的 QPS 下降了 60% 左右,大大减少了发送消息所带来的压力!
38 |
39 |
40 |
41 | ## 4、压缩算法
42 |
43 | 在消息聚合后,降低了消息的数量,减少了发送次数,但是同时发送消息的体积会增加,影响了写入 IO,因此采用 **压缩算法** 来对消息进行压缩。
44 |
45 | 市面上常用的两个压缩算法:zlib 和 brotli。
46 |
47 | 原文对两个压缩算法进行了比较,发现 brotli 算法比较具有优势,因此选择了该算法。
48 |
49 | 比较结果如下(来自于原文)
50 |
51 | 
--------------------------------------------------------------------------------
/docs/md/zsxq/about/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/about/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/booklet/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/booklet/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/material/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/material/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/memorabilia/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/memorabilia/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/other/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/other/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/project/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/project/todo.md
--------------------------------------------------------------------------------
/docs/md/zsxq/source-code/todo.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/docs/md/zsxq/source-code/todo.md
--------------------------------------------------------------------------------
/package-lock.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Java-Edge/Java-Interview-Tutorial/7ff45781c88c1074a97b1351c8da8afc98b3bcfb/package-lock.png
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "Code-Select",
3 | "version": "2.0.1",
4 | "private": true,
5 | "scripts": {
6 | "dev": "vuepress dev docs --temp .temp",
7 | "build": "vuepress build docs"
8 | },
9 | "devDependencies": {
10 | "@vuepress/plugin-back-to-top": "^1.8.2",
11 | "@vuepress/plugin-google-analytics": "^1.8.2",
12 | "@vuepress/plugin-medium-zoom": "^1.8.2",
13 | "mermaid": "^7.1.2",
14 | "vuepress": "^1.9.10",
15 | "vuepress-plugin-seo": "^0.1.4",
16 | "vuepress-plugin-sitemap": "^2.3.1",
17 | "vuepress-plugin-tags": "^1.0.2",
18 | "vuepress-plugin-thirdparty-search": "^1.0.2",
19 | "watchpack": "^1.7.5",
20 | "webpack-dev-server": "^3.11.2"
21 | },
22 | "dependencies": {
23 | "@vssue/api-github-v3": "^1.4.7",
24 | "@vssue/vuepress-plugin-vssue": "^1.4.8",
25 | "@vuepress/core": "^1.8.2",
26 | "browserslist": "^4.16.3",
27 | "caniuse-lite": "^1.0.30001196",
28 | "screenfull": "^5.1.0",
29 | "vuepress-plugin-baidu-autopush": "^1.0.1",
30 | "vuepress-plugin-code-copy": "^1.0.6",
31 | "vuepress-plugin-copyright": "^1.0.2",
32 | "vuepress-plugin-img-lazy": "^1.0.4",
33 | "vuepress-plugin-mermaidjs": "^2.0.0-beta.2",
34 | "vuepress-plugin-table-of-contents": "^1.1.7"
35 | }
36 | }
37 |
--------------------------------------------------------------------------------