├── Markdown笔记
├── Redis设计与实现1-数据结构.md
├── Redis设计与实现10-发布与订阅.md
├── Redis设计与实现11-事务.md
├── Redis设计与实现12-Lua脚本.md
├── Redis设计与实现2-对象.md
├── Redis设计与实现3-数据库基本结构.md
├── Redis设计与实现4-RDB持久化和AOF持久化.md
├── Redis设计与实现5-事件.md
├── Redis设计与实现6-客户端与服务器.md
├── Redis设计与实现7-复制.md
├── Redis设计与实现8-Sentinel.md
└── Redis设计与实现9-集群.md
├── README.md
├── 思维导图
├── Pic
│ ├── 单机数据库.png
│ ├── 多机数据库.png
│ ├── 数据结构与对象.png
│ └── 独立功能的实现.png
└── Xmind
│ ├── 单机数据库.xmind
│ ├── 多机数据库.xmind
│ ├── 数据结构与对象.xmind
│ └── 独立功能的实现.xmind
└── 面试相关
├── Redis的简单应用场景总结.md
└── Redis面试常见基本问题.md
/Markdown笔记/Redis设计与实现1-数据结构.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现1-数据结构
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | - 数据结构
11 | mathjax: true
12 | date: 2020-01-02 10:30:29
13 | ---
14 |
15 | 由于C语言的缺陷,Redis自身创建了许多有用的数据结构,包括:简单动态字符串、链表、字典、跳跃表、整数集合、压缩列表。
16 |
17 | # 1. 简单动态字符串
18 |
19 | 传统C语言的字符串以空字符结尾,而Redis自己重新构建了一种新的字符串结构,命名为简单动态字符串(simple dynamic string, SDS)。
20 |
21 | 在Redis中,**C字符串只会用在一些无须修改的地方**,比如打印常量:
22 |
23 | ```C
24 | redisLog(REDIS_WARNING,"Redis is now ready to exit, bye bye...");
25 | ```
26 |
27 | 如果是需要修改的地方,会使用SDS来表示:
28 |
29 | ```SHELL
30 | redis> RPUSH fruits "apple" "banana" "cherry"
31 | (integer) 3
32 | ```
33 |
34 | Redis 将在数据库中创建一个**新的键值对**,其中:
35 |
36 | - key是一个**字符串对象**,底层保存了一个字符串fruits的SDS。
37 | - value是一个**列表对象**,**列表包含了三个字符串对象**,由SDS实现。
38 |
39 | ## 1.1 SDS的定义
40 |
41 | SDS是一个结构体,定义在`sds.h/sdshdr`中
42 |
43 | ```C
44 | struct sdshdr {
45 | // 记录 buf 数组中已使用字节的数量
46 | // 等于 SDS 所保存字符串的长度
47 | int len;
48 | // 记录 buf 数组中未使用字节的数量
49 | int free;
50 | // 字节数组,用于保存字符串
51 | char buf[];
52 | };
53 | ```
54 |
55 | 下面给出了一个示例,free为0代表所有空间都被使用,len长度为5,表示SDS保存的字符串长度为5,buf就是字符串实体。
56 |
57 | 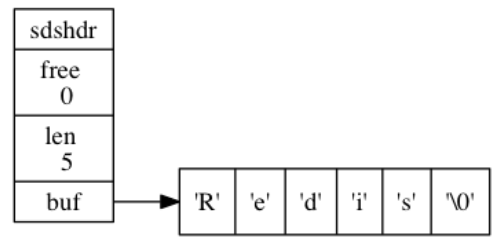 58 |
59 | 保存空字符的1字节空间**不计算在len属性内**。遵循空字符结尾这一惯例的好处是, **SDS 可以直接重用一部分 C 字符串函数库里面的函数。**
60 |
61 | 比如我们不需要对SDS专门设置打印函数。
62 |
63 | ```C
64 | printf("%s",s->buf);
65 | ```
66 |
67 | ## 1.2 SDS 与 C 字符串的区别
68 |
69 | C 语言使用的简单的字符串表示方式, 并不能满足 Redis 对字符串在安全性、效率、以及功能方面的要求。主要有以下几个弊端。
70 |
71 | **(1)C字符串获取长度的能力有限**
72 |
73 | C字符串需要依靠遍历获取长度,时间复杂度$O(N)$,而SDS本身记录了len,所以时间复杂度$O (1)$,**常数时间**。
74 |
75 | **(2)杜绝缓冲区溢出**
76 |
77 | 由于C字符串不记录长度,当我们拼接两个字符串的时候,容器可能**因为空间不足发生溢出**。redis中的`sdscat`将在执行拼接操作前**检查长度是否充足**,若不足则先拓展空间,再拼接。
78 |
79 | **(3)减少修改字符串时带来的内存重分配次数**
80 |
81 | C字符串类似于数组,每次修改大小都会重新分配以此内存。Redis的分配原理类似于`std::vector`,通过**空间预分配**的办法**优化字符串增加**,分配规则如下:
82 |
83 | - 若len比较小(小于1MB),则free是len一样大。如果修改后len为13字节,则free也为13字节,buf实际长度为13+13+1=27字节。
84 | - 若len比较大(大于1MB),则每次free只会有1MB,比如修改后len为30MB,则free为1MB,总长度为30MB+1MB+1byte。
85 |
86 | 此外,使用**惰性空间释放**来**优化字符串缩短**。当缩短时,将释放的空间放入free中保存起来,等待使用。
87 |
88 | **(4)二进制安全**
89 |
90 | C字符串以空字符`\0`结尾,使得 C 字符串只能保存文本数据, 而不能保存像图片、音频、视频、压缩文件这样的二进制数据。我们希望**有一种使用空字符来分割多个单词的特殊数据格式**。换句话说,**数据写入时什么样,读取时就是什么样**。
91 |
92 | SDS利用len来判断是否结束,而不是空字符`\0`
93 |
94 |
58 |
59 | 保存空字符的1字节空间**不计算在len属性内**。遵循空字符结尾这一惯例的好处是, **SDS 可以直接重用一部分 C 字符串函数库里面的函数。**
60 |
61 | 比如我们不需要对SDS专门设置打印函数。
62 |
63 | ```C
64 | printf("%s",s->buf);
65 | ```
66 |
67 | ## 1.2 SDS 与 C 字符串的区别
68 |
69 | C 语言使用的简单的字符串表示方式, 并不能满足 Redis 对字符串在安全性、效率、以及功能方面的要求。主要有以下几个弊端。
70 |
71 | **(1)C字符串获取长度的能力有限**
72 |
73 | C字符串需要依靠遍历获取长度,时间复杂度$O(N)$,而SDS本身记录了len,所以时间复杂度$O (1)$,**常数时间**。
74 |
75 | **(2)杜绝缓冲区溢出**
76 |
77 | 由于C字符串不记录长度,当我们拼接两个字符串的时候,容器可能**因为空间不足发生溢出**。redis中的`sdscat`将在执行拼接操作前**检查长度是否充足**,若不足则先拓展空间,再拼接。
78 |
79 | **(3)减少修改字符串时带来的内存重分配次数**
80 |
81 | C字符串类似于数组,每次修改大小都会重新分配以此内存。Redis的分配原理类似于`std::vector`,通过**空间预分配**的办法**优化字符串增加**,分配规则如下:
82 |
83 | - 若len比较小(小于1MB),则free是len一样大。如果修改后len为13字节,则free也为13字节,buf实际长度为13+13+1=27字节。
84 | - 若len比较大(大于1MB),则每次free只会有1MB,比如修改后len为30MB,则free为1MB,总长度为30MB+1MB+1byte。
85 |
86 | 此外,使用**惰性空间释放**来**优化字符串缩短**。当缩短时,将释放的空间放入free中保存起来,等待使用。
87 |
88 | **(4)二进制安全**
89 |
90 | C字符串以空字符`\0`结尾,使得 C 字符串只能保存文本数据, 而不能保存像图片、音频、视频、压缩文件这样的二进制数据。我们希望**有一种使用空字符来分割多个单词的特殊数据格式**。换句话说,**数据写入时什么样,读取时就是什么样**。
91 |
92 | SDS利用len来判断是否结束,而不是空字符`\0`
93 |
94 | 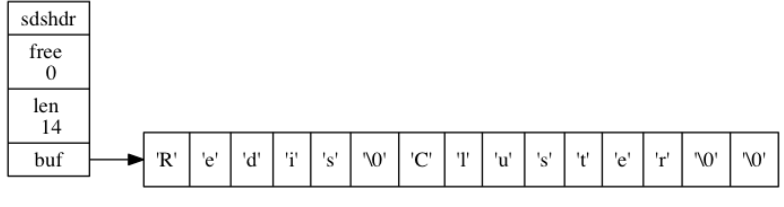 95 |
96 | # 2. 链表
97 |
98 | 链表随机读写能力差,但增删和重排能力较强。C语言没有链表结构,所以Redis自制了一个。
99 |
100 | **链表节点**定义在`adlist.h/listNode`,如下:
101 |
102 | ```C
103 | typedef struct listNode {
104 | // 前置节点
105 | struct listNode *prev;
106 | // 后置节点
107 | struct listNode *next;
108 | // 节点的值
109 | void *value;
110 | } listNode;
111 | ```
112 |
113 | 这是一个**双端链表**。
114 |
115 | 
116 |
117 | 虽然可以多个Node组成链表,但是为了方便,Redis设计了`adlist.h/list` 来持有链表。
118 |
119 | ```C
120 | typedef struct list {
121 | // 表头节点
122 | listNode *head;
123 | // 表尾节点
124 | listNode *tail;
125 | // 链表所包含的节点数量
126 | unsigned long len;
127 | // 节点值复制函数
128 | void *(*dup)(void *ptr);
129 | // 节点值释放函数
130 | void (*free)(void *ptr);
131 | // 节点值对比函数
132 | int (*match)(void *ptr, void *key);
133 | } list;
134 | ```
135 |
136 | Redis 的链表实现的特性可以总结如下:
137 |
138 | - 双端
139 | - 无环,表头和结尾都指向`NULL`
140 | - 带有表头表位指针,访问$ O (1)$
141 | - 自带链表长度计数器
142 | - **多态**:使用`void*`来保存节点值,有泛型编程内味了。
143 |
144 | # 3. 字典
145 |
146 | 在字典中, 一个键(key)可以和一个值(value)进行关联(或者说将键映射为值), 这些**关联的键和值就被称为键值对**。字典中的每个键必须保证都是独一无二的。C并没有这样的结构,所以Redis自己实现了。
147 |
148 | ## 3.1 字典的实现
149 |
150 | Redis 字典所使用的**哈希表**由 `dict.h/dictht` 结构定义:
151 |
152 | ```C
153 | typedef struct dictht {
154 | // 哈希表数组
155 | dictEntry **table;
156 | // 哈希表大小
157 | unsigned long size;
158 | // 哈希表大小掩码,用于计算索引值
159 | // 总是等于 size - 1
160 | unsigned long sizemask
161 | // 该哈希表已有节点的数量
162 | unsigned long used;
163 | } dictht;
164 | ```
165 |
166 | `table` 是一个数组, 数组中的每个元素都是一个指向 `dict.h/dictEntry` 结构的指针。
167 |
168 |
95 |
96 | # 2. 链表
97 |
98 | 链表随机读写能力差,但增删和重排能力较强。C语言没有链表结构,所以Redis自制了一个。
99 |
100 | **链表节点**定义在`adlist.h/listNode`,如下:
101 |
102 | ```C
103 | typedef struct listNode {
104 | // 前置节点
105 | struct listNode *prev;
106 | // 后置节点
107 | struct listNode *next;
108 | // 节点的值
109 | void *value;
110 | } listNode;
111 | ```
112 |
113 | 这是一个**双端链表**。
114 |
115 | 
116 |
117 | 虽然可以多个Node组成链表,但是为了方便,Redis设计了`adlist.h/list` 来持有链表。
118 |
119 | ```C
120 | typedef struct list {
121 | // 表头节点
122 | listNode *head;
123 | // 表尾节点
124 | listNode *tail;
125 | // 链表所包含的节点数量
126 | unsigned long len;
127 | // 节点值复制函数
128 | void *(*dup)(void *ptr);
129 | // 节点值释放函数
130 | void (*free)(void *ptr);
131 | // 节点值对比函数
132 | int (*match)(void *ptr, void *key);
133 | } list;
134 | ```
135 |
136 | Redis 的链表实现的特性可以总结如下:
137 |
138 | - 双端
139 | - 无环,表头和结尾都指向`NULL`
140 | - 带有表头表位指针,访问$ O (1)$
141 | - 自带链表长度计数器
142 | - **多态**:使用`void*`来保存节点值,有泛型编程内味了。
143 |
144 | # 3. 字典
145 |
146 | 在字典中, 一个键(key)可以和一个值(value)进行关联(或者说将键映射为值), 这些**关联的键和值就被称为键值对**。字典中的每个键必须保证都是独一无二的。C并没有这样的结构,所以Redis自己实现了。
147 |
148 | ## 3.1 字典的实现
149 |
150 | Redis 字典所使用的**哈希表**由 `dict.h/dictht` 结构定义:
151 |
152 | ```C
153 | typedef struct dictht {
154 | // 哈希表数组
155 | dictEntry **table;
156 | // 哈希表大小
157 | unsigned long size;
158 | // 哈希表大小掩码,用于计算索引值
159 | // 总是等于 size - 1
160 | unsigned long sizemask
161 | // 该哈希表已有节点的数量
162 | unsigned long used;
163 | } dictht;
164 | ```
165 |
166 | `table` 是一个数组, 数组中的每个元素都是一个指向 `dict.h/dictEntry` 结构的指针。
167 |
168 | 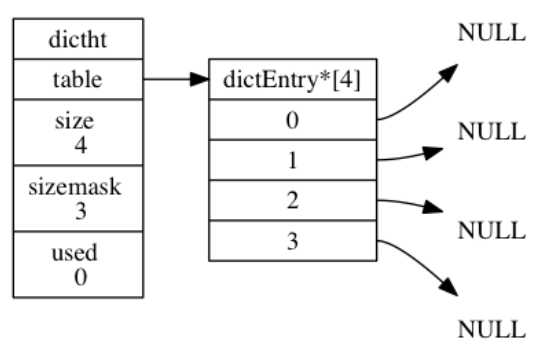 169 |
170 | **哈希表节点**使用 `dictEntry` 结构表示, 每个 `dictEntry` 结构都保存着一个键值对:
171 |
172 | ```C
173 | typedef struct dictEntry {
174 | // 键
175 | void *key;
176 | // 值
177 | union {
178 | void *val;
179 | uint64_t u64;
180 | int64_t s64;
181 | } v;
182 | // 指向下个哈希表节点,形成链表
183 | struct dictEntry *next;
184 | } dictEntry;
185 | ```
186 |
187 | `v` 属性则保存着键值对中的值, 值可以是一个指针, 或者是一个 `uint64_t` 整数, 又或者是一个 `int64_t` 整数。
188 |
189 | `next` 属性是指向另一个哈希表节点的指针, 这个指针可以将多个哈希值相同的键值对连接在一次, 以此来**解决键冲突(collision)的问题**。
190 |
191 | 下图中,键的索引值都是2,通过链表的形式完成了冲突的规避。
192 |
193 |
169 |
170 | **哈希表节点**使用 `dictEntry` 结构表示, 每个 `dictEntry` 结构都保存着一个键值对:
171 |
172 | ```C
173 | typedef struct dictEntry {
174 | // 键
175 | void *key;
176 | // 值
177 | union {
178 | void *val;
179 | uint64_t u64;
180 | int64_t s64;
181 | } v;
182 | // 指向下个哈希表节点,形成链表
183 | struct dictEntry *next;
184 | } dictEntry;
185 | ```
186 |
187 | `v` 属性则保存着键值对中的值, 值可以是一个指针, 或者是一个 `uint64_t` 整数, 又或者是一个 `int64_t` 整数。
188 |
189 | `next` 属性是指向另一个哈希表节点的指针, 这个指针可以将多个哈希值相同的键值对连接在一次, 以此来**解决键冲突(collision)的问题**。
190 |
191 | 下图中,键的索引值都是2,通过链表的形式完成了冲突的规避。
192 |
193 | 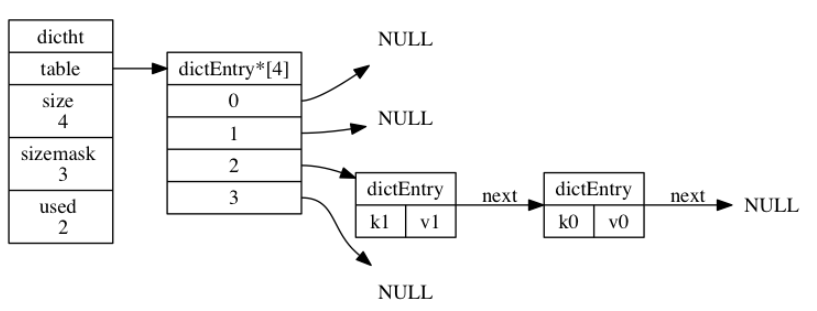 194 |
195 | ---
196 |
197 | 上面提到的是哈希表和哈希表节点的实现,现在来说真正的**字典结构**。Redis 中的字典由 `dict.h/dict` 结构表示:
198 |
199 | ```C
200 | typedef struct dict {
201 | // 类型特定函数
202 | dictType *type;
203 | // 私有数据
204 | void *privdata;
205 | // 哈希表
206 | dictht ht[2];
207 | // rehash 索引
208 | // 当 rehash 不在进行时,值为 -1
209 | int rehashidx; /* rehashing not in progress if rehashidx == -1 */
210 | } dict;
211 | ```
212 |
213 | 其中`type` 属性和 `privdata` 属性是**针对不同类型的键值对, 为创建多态字典而设置的**。
214 |
215 | - `type` 属性是一个指向 `dictType` 结构的指针, 每个 `dictType` 结构保存了一簇用于操作特定类型键值对的函数。
216 | - `privdata` 属性则保存了需要传给那些类型特定函数的可选参数。
217 |
218 | ```C
219 | typedef struct dictType {
220 | // 计算哈希值的函数
221 | unsigned int (*hashFunction)(const void *key);
222 | // 复制键的函数
223 | void *(*keyDup)(void *privdata, const void *key);
224 | // 复制值的函数
225 | void *(*valDup)(void *privdata, const void *obj);
226 | // 对比键的函数
227 | int (*keyCompare)(void *privdata, const void *key1, const void *key2);
228 | // 销毁键的函数
229 | void (*keyDestructor)(void *privdata, void *key);
230 | // 销毁值的函数
231 | void (*valDestructor)(void *privdata, void *obj);
232 | } dictType;
233 | ```
234 |
235 | 哈希表数组ht包含了两个元素, 一般情况下, 字典只使用 `ht[0]` 哈希表, `ht[1]` 哈希表只会在对 `ht[0]` 哈希表进行 rehash 时使用。
236 |
237 | 除了 `ht[1]` 之外, 另一个和 rehash 有关的属性就是 `rehashidx` : 它记录了 rehash 目前的进度, 如果目前没有在进行 rehash , 那么它的值为 `-1` 。
238 |
239 | 下图展示了一个普通状态下(没有rehash)的字典
240 |
241 |
194 |
195 | ---
196 |
197 | 上面提到的是哈希表和哈希表节点的实现,现在来说真正的**字典结构**。Redis 中的字典由 `dict.h/dict` 结构表示:
198 |
199 | ```C
200 | typedef struct dict {
201 | // 类型特定函数
202 | dictType *type;
203 | // 私有数据
204 | void *privdata;
205 | // 哈希表
206 | dictht ht[2];
207 | // rehash 索引
208 | // 当 rehash 不在进行时,值为 -1
209 | int rehashidx; /* rehashing not in progress if rehashidx == -1 */
210 | } dict;
211 | ```
212 |
213 | 其中`type` 属性和 `privdata` 属性是**针对不同类型的键值对, 为创建多态字典而设置的**。
214 |
215 | - `type` 属性是一个指向 `dictType` 结构的指针, 每个 `dictType` 结构保存了一簇用于操作特定类型键值对的函数。
216 | - `privdata` 属性则保存了需要传给那些类型特定函数的可选参数。
217 |
218 | ```C
219 | typedef struct dictType {
220 | // 计算哈希值的函数
221 | unsigned int (*hashFunction)(const void *key);
222 | // 复制键的函数
223 | void *(*keyDup)(void *privdata, const void *key);
224 | // 复制值的函数
225 | void *(*valDup)(void *privdata, const void *obj);
226 | // 对比键的函数
227 | int (*keyCompare)(void *privdata, const void *key1, const void *key2);
228 | // 销毁键的函数
229 | void (*keyDestructor)(void *privdata, void *key);
230 | // 销毁值的函数
231 | void (*valDestructor)(void *privdata, void *obj);
232 | } dictType;
233 | ```
234 |
235 | 哈希表数组ht包含了两个元素, 一般情况下, 字典只使用 `ht[0]` 哈希表, `ht[1]` 哈希表只会在对 `ht[0]` 哈希表进行 rehash 时使用。
236 |
237 | 除了 `ht[1]` 之外, 另一个和 rehash 有关的属性就是 `rehashidx` : 它记录了 rehash 目前的进度, 如果目前没有在进行 rehash , 那么它的值为 `-1` 。
238 |
239 | 下图展示了一个普通状态下(没有rehash)的字典
240 |
241 | 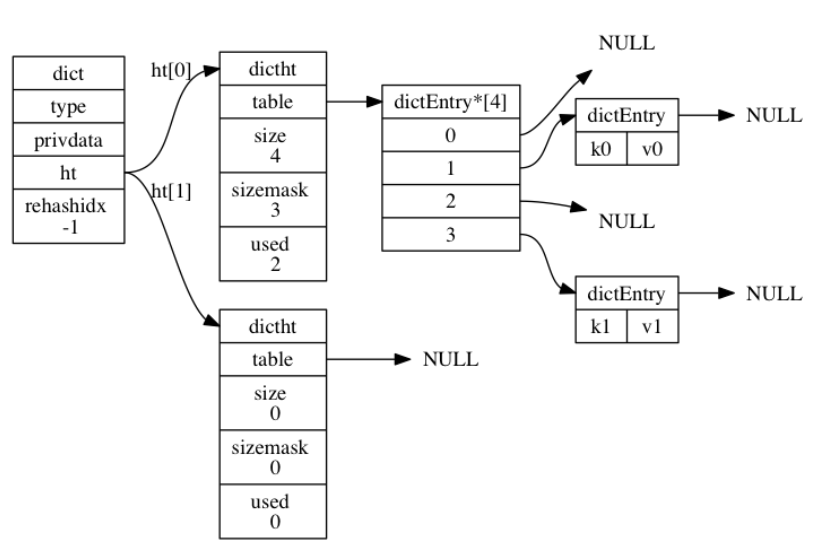 242 |
243 | ## 3.2 哈希算法
244 |
245 | 程序需要先根据键值对的键计算出**哈希值和索引值**, 然后再根据索引值, 将包含新键值对的哈希表节点放到哈希表数组的指定索引上面。
246 |
247 | Redis 计算哈希值和索引值的方法如下:
248 |
249 | ```C
250 | // 使用字典设置的哈希函数,计算键 key 的哈希值
251 | hash = dict->type->hashFunction(key);
252 |
253 | // 使用哈希表的 sizemask 属性和哈希值,计算出索引值
254 | // 根据情况不同, ht[x] 可以是 ht[0] 或者 ht[1]
255 | index = hash & dict->ht[x].sizemask;
256 | ```
257 |
258 | 举个例子,假如想要将键值对`k0` 和 `v0` 添加到下面的字典中。
259 |
260 |
242 |
243 | ## 3.2 哈希算法
244 |
245 | 程序需要先根据键值对的键计算出**哈希值和索引值**, 然后再根据索引值, 将包含新键值对的哈希表节点放到哈希表数组的指定索引上面。
246 |
247 | Redis 计算哈希值和索引值的方法如下:
248 |
249 | ```C
250 | // 使用字典设置的哈希函数,计算键 key 的哈希值
251 | hash = dict->type->hashFunction(key);
252 |
253 | // 使用哈希表的 sizemask 属性和哈希值,计算出索引值
254 | // 根据情况不同, ht[x] 可以是 ht[0] 或者 ht[1]
255 | index = hash & dict->ht[x].sizemask;
256 | ```
257 |
258 | 举个例子,假如想要将键值对`k0` 和 `v0` 添加到下面的字典中。
259 |
260 | 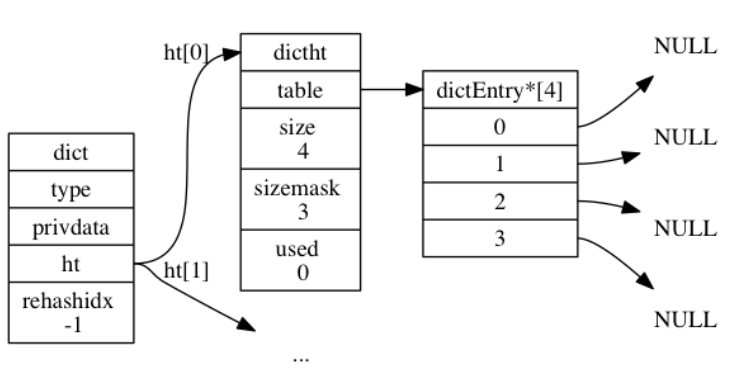 261 |
262 | 假设计算出的hash值是8,则index为
263 |
264 | ```c
265 | index = hash & dict->ht[0].sizemask = 8 & 3 = 0;
266 | ```
267 |
268 |
261 |
262 | 假设计算出的hash值是8,则index为
263 |
264 | ```c
265 | index = hash & dict->ht[0].sizemask = 8 & 3 = 0;
266 | ```
267 |
268 | 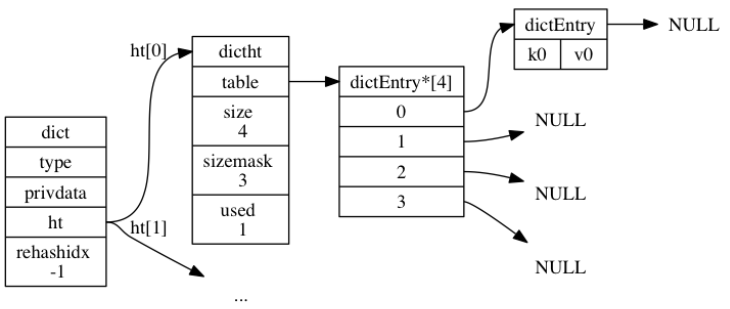 269 |
270 | 至于Redis的哈希值计算方法,使用的是 MurmurHash2。这种算法的优点在于, 即使输入的键是有规律的, 算法仍能给出一个很好的随机分布性, 并且算法的计算速度也非常快。
271 |
272 | ## 3.3 Rehash
273 |
274 | 随着操作的不断执行, 哈希表保存的键值对会逐渐地增多或者减少, 为了让哈希表的**负载因子(load factor)**维持在一个合理的范围之内, **当哈希表保存的键值对数量太多或者太少时, 程序需要对哈希表的大小进行相应的扩展或者收缩。**
275 |
276 | 再哈希的关键在于**重新分配哈希表的大小**,分配的原则如下:
277 |
278 | - 如果执行拓展操作`ht[1]` 的大小为第一个大于等于 `ht[0].used * 2` 的 $2^n$,比如原表大小为4,则 `ht[0].used * 2`结果为8,而8刚好是$2^3$,所以新的大小是8。
279 | - 如果执行的是收缩操作, 那么 `ht[1]` 的大小为第一个大于等于 `ht[0].used` 的$2^ n$
280 |
281 | 完成分配后,将保存在 `ht[0]` 中的所有键值对 **rehash** 到 `ht[1]` 上面,然后 将 `ht[1]` 设置为 `ht[0]` , 并在 `ht[1]` 新创建一个空白哈希表, 为下一次 rehash 做准备。
282 |
283 | 决定是否再Hash的要素来自于负载因子,计算方法如下:
284 |
285 | ```C
286 | //负载因子 = 哈希表已保存节点数量 / 哈希表大小
287 | load_factor = ht[0].used / ht[0].size
288 | ```
289 |
290 | ## 3.4 渐进式Rehash
291 |
292 | 如果键值对很多,则将`ht[0]`重新hash到`ht[1]`上,则会导致服务器在一段时间内停止服务。为了避免这种问题,需要分多次渐进式的慢慢映射。
293 |
294 | 关键点在于维持一个**索引计数器变量** `rehashidx` , 并将它的值设置为 `0` , 表示 rehash 工作正式开始。
295 |
296 | 在 rehash 进行期间, 每次对字典执行增删改查, 程序除了执行指定的操作以外, **还会顺带将 `ht[0]` 哈希表在 `rehashidx` 索引上的所有键值对 rehash 到 `ht[1]`** , 当 rehash 工作完成之后, 程序将 `rehashidx` **属性的值增一**。
297 |
298 | 完成后程序将 `rehashidx` 属性的值设为 `-1` , 表示 rehash 操作已完成。
299 |
300 | 渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个增删改查上, 从而避免了集中式 rehash 而带来的庞大计算量。
301 |
302 | # 4. 跳跃表
303 |
304 | ## 4.1 什么是跳跃表
305 |
306 | 我们知道链表随机读写的能力很差,当增删改查的时候,如果要找到目标元素就需要遍历链表。假设某个数据结构是有序的,我们就会想到用二分法来快速查找,但**链表是没有索引的**,所以我们需要添加。
307 |
308 | 
309 |
310 | 可以继续向上拓展层数:
311 |
312 | 
313 |
314 | 但是我们的链表不是静态的,增加和删除会破坏二分结构,所以我们就不强制要求 `1:2` 了,一个节点要不要被索引,建几层的索引,都在节点插入时由**随机决定**。
315 |
316 | 现在假设节点 `17` 是最后插入的,在插入之前,我们需要搜索得到插入的位置:
317 |
318 | 
319 |
320 | ## 4.2 跳跃表的实现
321 |
322 | Redis 的跳跃表由 `redis.h/zskiplistNode` 和 `redis.h/zskiplist` 两个结构定义, 其中 `zskiplistNode` 结构用于表示跳跃表**节点**, 而 `zskiplist`结构则用于保存跳跃表节点的相关信息, 比如**节点的数量, 以及指向表头节点和表尾节点的指针**, 等等。
323 |
324 | 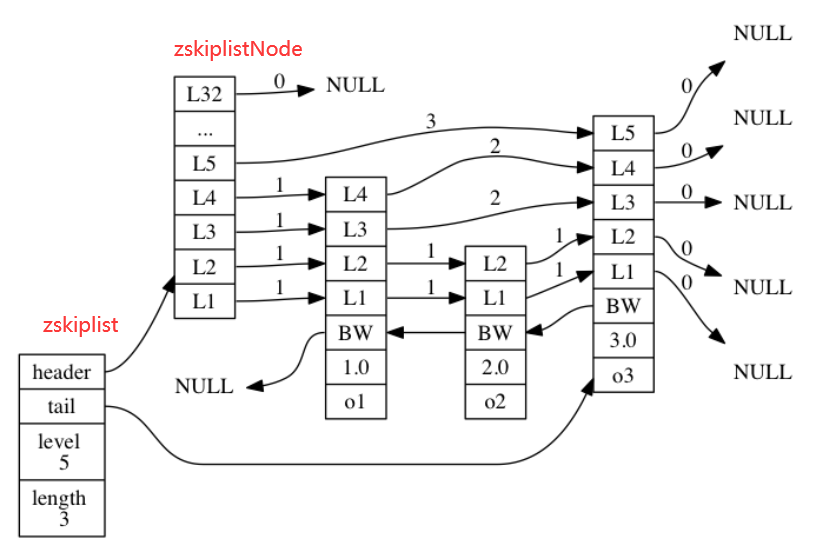
325 |
326 | 在`zskiplist`中`level` 记录目前跳跃表内最大层数(表头不算),`length`记录包含的节点数量(表头不算)。
327 |
328 | `zskiplistNode` 结构包含以下属性:
329 |
330 | - 层:每一层有两个属性
331 | - 前进指针用于访问位于表尾方向的其他节点
332 | - 跨度则记录了前进指针所指向节点和当前节点的距离。
333 | - 后退指针(bw):指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
334 | - 分值(score):各个节点中的 `1.0` 、 `2.0` 和 `3.0` 是节点所保存的分值。用于从小到大排列。**如果分值相同,则成员对象小的排在前面。**
335 | - 成员对象(obj):各个节点中的 `o1` 、 `o2` 和 `o3` 是节点所保存的成员对象。
336 |
337 | ```C
338 | typedef struct zskiplistNode {
339 | // 后退指针
340 | struct zskiplistNode *backward;
341 | // 分值
342 | double score;
343 | // 成员对象
344 | robj *obj;
345 | // 层
346 | struct zskiplistLevel {
347 | // 前进指针
348 | struct zskiplistNode *forward;
349 | // 跨度
350 | unsigned int span;
351 | } level[];
352 | } zskiplistNode;
353 | ```
354 |
355 | **(1)层**
356 |
357 | 每次创建一个新跳跃表节点的时候, 程序都根据幂次定律 ([power law](http://en.wikipedia.org/wiki/Power_law),**越大的数出现的概率越小**) **随机**生成一个介于 `1` 和 `32` 之间的值作为 `level` 数组的大小, 这个大小就是层的“高度”。
358 |
359 | 下图展示了三个高度为 `1` 层、 `3` 层和 `5` 层的节点
360 |
361 | 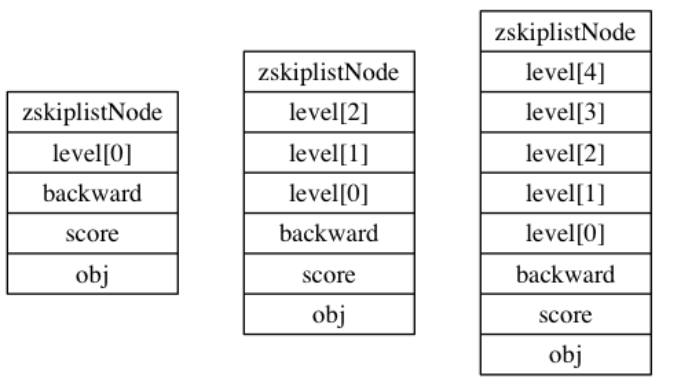
362 |
363 | **(2)前进指针**
364 |
365 | 前进指针分属于不同的层,`level[i].forward`,用于从表头向表尾方向访问节点。
366 |
367 | **(3)跨度**
368 |
369 | 跨度也分属不同的层,指向 `NULL` 的所有前进指针的跨度都为 `0`, 因为它们没有连向任何节点。
370 |
371 | 跨度实际上是用来计算**位次**(rank)的: **将沿途访问过的所有层的跨度累计起来, 得到的结果就是目标节点在跳跃表中的排位。**
372 |
373 | 下图的例子中,查找分值为3.0的节点,由于只经过了一个层,跨度为3,所以跳跃表中的排位为3。
374 |
375 |
269 |
270 | 至于Redis的哈希值计算方法,使用的是 MurmurHash2。这种算法的优点在于, 即使输入的键是有规律的, 算法仍能给出一个很好的随机分布性, 并且算法的计算速度也非常快。
271 |
272 | ## 3.3 Rehash
273 |
274 | 随着操作的不断执行, 哈希表保存的键值对会逐渐地增多或者减少, 为了让哈希表的**负载因子(load factor)**维持在一个合理的范围之内, **当哈希表保存的键值对数量太多或者太少时, 程序需要对哈希表的大小进行相应的扩展或者收缩。**
275 |
276 | 再哈希的关键在于**重新分配哈希表的大小**,分配的原则如下:
277 |
278 | - 如果执行拓展操作`ht[1]` 的大小为第一个大于等于 `ht[0].used * 2` 的 $2^n$,比如原表大小为4,则 `ht[0].used * 2`结果为8,而8刚好是$2^3$,所以新的大小是8。
279 | - 如果执行的是收缩操作, 那么 `ht[1]` 的大小为第一个大于等于 `ht[0].used` 的$2^ n$
280 |
281 | 完成分配后,将保存在 `ht[0]` 中的所有键值对 **rehash** 到 `ht[1]` 上面,然后 将 `ht[1]` 设置为 `ht[0]` , 并在 `ht[1]` 新创建一个空白哈希表, 为下一次 rehash 做准备。
282 |
283 | 决定是否再Hash的要素来自于负载因子,计算方法如下:
284 |
285 | ```C
286 | //负载因子 = 哈希表已保存节点数量 / 哈希表大小
287 | load_factor = ht[0].used / ht[0].size
288 | ```
289 |
290 | ## 3.4 渐进式Rehash
291 |
292 | 如果键值对很多,则将`ht[0]`重新hash到`ht[1]`上,则会导致服务器在一段时间内停止服务。为了避免这种问题,需要分多次渐进式的慢慢映射。
293 |
294 | 关键点在于维持一个**索引计数器变量** `rehashidx` , 并将它的值设置为 `0` , 表示 rehash 工作正式开始。
295 |
296 | 在 rehash 进行期间, 每次对字典执行增删改查, 程序除了执行指定的操作以外, **还会顺带将 `ht[0]` 哈希表在 `rehashidx` 索引上的所有键值对 rehash 到 `ht[1]`** , 当 rehash 工作完成之后, 程序将 `rehashidx` **属性的值增一**。
297 |
298 | 完成后程序将 `rehashidx` 属性的值设为 `-1` , 表示 rehash 操作已完成。
299 |
300 | 渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个增删改查上, 从而避免了集中式 rehash 而带来的庞大计算量。
301 |
302 | # 4. 跳跃表
303 |
304 | ## 4.1 什么是跳跃表
305 |
306 | 我们知道链表随机读写的能力很差,当增删改查的时候,如果要找到目标元素就需要遍历链表。假设某个数据结构是有序的,我们就会想到用二分法来快速查找,但**链表是没有索引的**,所以我们需要添加。
307 |
308 | 
309 |
310 | 可以继续向上拓展层数:
311 |
312 | 
313 |
314 | 但是我们的链表不是静态的,增加和删除会破坏二分结构,所以我们就不强制要求 `1:2` 了,一个节点要不要被索引,建几层的索引,都在节点插入时由**随机决定**。
315 |
316 | 现在假设节点 `17` 是最后插入的,在插入之前,我们需要搜索得到插入的位置:
317 |
318 | 
319 |
320 | ## 4.2 跳跃表的实现
321 |
322 | Redis 的跳跃表由 `redis.h/zskiplistNode` 和 `redis.h/zskiplist` 两个结构定义, 其中 `zskiplistNode` 结构用于表示跳跃表**节点**, 而 `zskiplist`结构则用于保存跳跃表节点的相关信息, 比如**节点的数量, 以及指向表头节点和表尾节点的指针**, 等等。
323 |
324 | 
325 |
326 | 在`zskiplist`中`level` 记录目前跳跃表内最大层数(表头不算),`length`记录包含的节点数量(表头不算)。
327 |
328 | `zskiplistNode` 结构包含以下属性:
329 |
330 | - 层:每一层有两个属性
331 | - 前进指针用于访问位于表尾方向的其他节点
332 | - 跨度则记录了前进指针所指向节点和当前节点的距离。
333 | - 后退指针(bw):指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
334 | - 分值(score):各个节点中的 `1.0` 、 `2.0` 和 `3.0` 是节点所保存的分值。用于从小到大排列。**如果分值相同,则成员对象小的排在前面。**
335 | - 成员对象(obj):各个节点中的 `o1` 、 `o2` 和 `o3` 是节点所保存的成员对象。
336 |
337 | ```C
338 | typedef struct zskiplistNode {
339 | // 后退指针
340 | struct zskiplistNode *backward;
341 | // 分值
342 | double score;
343 | // 成员对象
344 | robj *obj;
345 | // 层
346 | struct zskiplistLevel {
347 | // 前进指针
348 | struct zskiplistNode *forward;
349 | // 跨度
350 | unsigned int span;
351 | } level[];
352 | } zskiplistNode;
353 | ```
354 |
355 | **(1)层**
356 |
357 | 每次创建一个新跳跃表节点的时候, 程序都根据幂次定律 ([power law](http://en.wikipedia.org/wiki/Power_law),**越大的数出现的概率越小**) **随机**生成一个介于 `1` 和 `32` 之间的值作为 `level` 数组的大小, 这个大小就是层的“高度”。
358 |
359 | 下图展示了三个高度为 `1` 层、 `3` 层和 `5` 层的节点
360 |
361 | 
362 |
363 | **(2)前进指针**
364 |
365 | 前进指针分属于不同的层,`level[i].forward`,用于从表头向表尾方向访问节点。
366 |
367 | **(3)跨度**
368 |
369 | 跨度也分属不同的层,指向 `NULL` 的所有前进指针的跨度都为 `0`, 因为它们没有连向任何节点。
370 |
371 | 跨度实际上是用来计算**位次**(rank)的: **将沿途访问过的所有层的跨度累计起来, 得到的结果就是目标节点在跳跃表中的排位。**
372 |
373 | 下图的例子中,查找分值为3.0的节点,由于只经过了一个层,跨度为3,所以跳跃表中的排位为3。
374 |
375 | 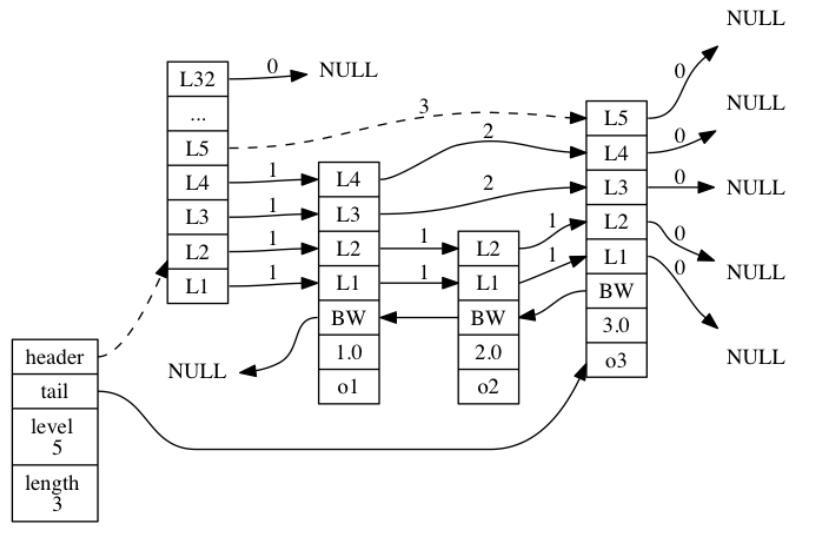 376 |
377 | ---
378 |
379 | 使用一个 `zskiplist` 结构来持有这些节点, 程序可以更方便地对整个跳跃表进行处理。
380 |
381 | ```C
382 | typedef struct zskiplist {
383 | // 表头节点和表尾节点
384 | struct zskiplistNode *header, *tail;
385 | // 表中节点的数量
386 | unsigned long length;
387 | // 表中层数最大的节点的层数
388 | int level;
389 | } zskiplist;
390 | ```
391 |
392 | # 5. 整数集合
393 |
394 | 当一个集合中**只包含整数**,并且**元素的个数不是很多**的话,redis 会用**整数集合**作为底层存储,它可以节省很多内存。
395 |
396 | ## 5.1 整数集合的实现
397 |
398 | 整数集合(intset)是 Redis 用于保存整数值的集合抽象数据结构, 它可以保存类型为 `int16_t` 、 `int32_t` 或者 `int64_t` 的整数值, 并且保证集合中不会出现重复元素。
399 |
400 | 每个 `intset.h/intset` 结构表示一个整数集合:
401 |
402 | ```C
403 | typedef struct intset {
404 | // 编码方式
405 | uint32_t encoding;
406 | // 集合包含的元素数量
407 | uint32_t length;
408 | // 保存元素的数组
409 | int8_t contents[];
410 | } intset;
411 | ```
412 |
413 | `contents` 数组是整数集合的底层实现: 整数集合的每个元素都是 `contents` 数组的一个数组项(item), 从小到大有序地排列,不包含任何重复项。
414 |
415 | 虽然 `intset` 结构将 `contents` 属性声明为 `int8_t` 类型的数组, 但实际上 `contents` 数组并不保存任何 `int8_t` 类型的值 —— **`contents` 数组的真正类型取决于 `encoding` 属性的值**:
416 |
417 | - `encoding` 为 `INTSET_ENC_INT16`,`int16_t` 类型的数组,范围$[-2^{16},2^{16}-1]$
418 | - `encoding` `INTSET_ENC_INT32` , 是一个 `int32_t` 类型的数组。
419 | - `encoding` 为 `INTSET_ENC_INT64` , 是一个 `int64_t` 类型的数组
420 |
421 | 下图展示了一个示例:
422 |
423 |
376 |
377 | ---
378 |
379 | 使用一个 `zskiplist` 结构来持有这些节点, 程序可以更方便地对整个跳跃表进行处理。
380 |
381 | ```C
382 | typedef struct zskiplist {
383 | // 表头节点和表尾节点
384 | struct zskiplistNode *header, *tail;
385 | // 表中节点的数量
386 | unsigned long length;
387 | // 表中层数最大的节点的层数
388 | int level;
389 | } zskiplist;
390 | ```
391 |
392 | # 5. 整数集合
393 |
394 | 当一个集合中**只包含整数**,并且**元素的个数不是很多**的话,redis 会用**整数集合**作为底层存储,它可以节省很多内存。
395 |
396 | ## 5.1 整数集合的实现
397 |
398 | 整数集合(intset)是 Redis 用于保存整数值的集合抽象数据结构, 它可以保存类型为 `int16_t` 、 `int32_t` 或者 `int64_t` 的整数值, 并且保证集合中不会出现重复元素。
399 |
400 | 每个 `intset.h/intset` 结构表示一个整数集合:
401 |
402 | ```C
403 | typedef struct intset {
404 | // 编码方式
405 | uint32_t encoding;
406 | // 集合包含的元素数量
407 | uint32_t length;
408 | // 保存元素的数组
409 | int8_t contents[];
410 | } intset;
411 | ```
412 |
413 | `contents` 数组是整数集合的底层实现: 整数集合的每个元素都是 `contents` 数组的一个数组项(item), 从小到大有序地排列,不包含任何重复项。
414 |
415 | 虽然 `intset` 结构将 `contents` 属性声明为 `int8_t` 类型的数组, 但实际上 `contents` 数组并不保存任何 `int8_t` 类型的值 —— **`contents` 数组的真正类型取决于 `encoding` 属性的值**:
416 |
417 | - `encoding` 为 `INTSET_ENC_INT16`,`int16_t` 类型的数组,范围$[-2^{16},2^{16}-1]$
418 | - `encoding` `INTSET_ENC_INT32` , 是一个 `int32_t` 类型的数组。
419 | - `encoding` 为 `INTSET_ENC_INT64` , 是一个 `int64_t` 类型的数组
420 |
421 | 下图展示了一个示例:
422 |
423 | 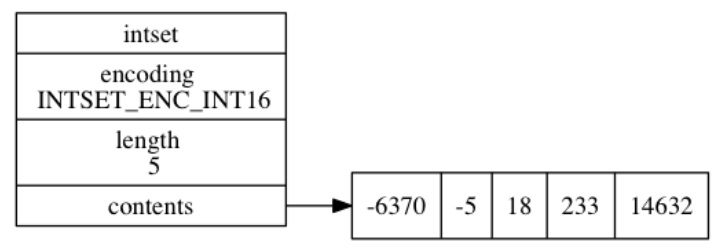 424 |
425 | ## 5.2 升级
426 |
427 | 每当我们要将一个新元素添加到整数集合里面, 并且**新元素的类型比整数集合元素的类型长时**, 整数集合需要先进行**升级(upgrade)**, 然后才能将新元素添加到整数集合里面。
428 |
429 | 过程如下:
430 |
431 | 1. 根据新类型,扩展整数集合底层数组的空间大小, 并为新元素分配空间
432 | 2. 将底层数组现有的所有元素都转换成与新元素相同的类型, 并将类型转换后的元素有序放置。
433 | 3. 将新元素添加到底层数组里面。
434 |
435 | 假设想要在16位编码的intset中插入32位的65535数据,原来的集合是这样的:
436 |
437 |
424 |
425 | ## 5.2 升级
426 |
427 | 每当我们要将一个新元素添加到整数集合里面, 并且**新元素的类型比整数集合元素的类型长时**, 整数集合需要先进行**升级(upgrade)**, 然后才能将新元素添加到整数集合里面。
428 |
429 | 过程如下:
430 |
431 | 1. 根据新类型,扩展整数集合底层数组的空间大小, 并为新元素分配空间
432 | 2. 将底层数组现有的所有元素都转换成与新元素相同的类型, 并将类型转换后的元素有序放置。
433 | 3. 将新元素添加到底层数组里面。
434 |
435 | 假设想要在16位编码的intset中插入32位的65535数据,原来的集合是这样的:
436 |
437 | 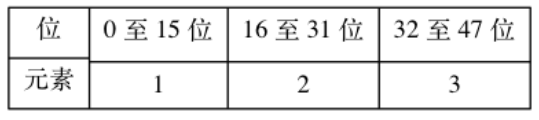 438 |
439 | 需要扩容为$32\times4=128$位,新intset结构会扩容成这样:
440 |
441 |
438 |
439 | 需要扩容为$32\times4=128$位,新intset结构会扩容成这样:
440 |
441 |  442 |
443 | 剩下就需要对元素重排。
444 |
445 | 先将3移动到新intset结构的索引2的位置上,然后将2移动到索引1的位置,然后将1移动到索引0的位置。最后再讲65535移动到索引3的位置。
446 |
447 | ## 5.3 降级
448 |
449 | 整数集合不支持降级操作, 一旦对数组进行了升级, 编码就会一直保持升级后的状态。
450 |
451 | 即使我们将集合里唯一一个真正需要使用 `int64_t` 类型来保存的元素 `4294967295` 删除了, 整数集合的编码仍然会维持 `INTSET_ENC_INT64`。
452 |
453 | # 6. 压缩列表
454 |
455 | 压缩列表(ziplist)**是列表键和哈希键的底层实现之一。**当一个列表键只包含少量列表项, 并且每个列表项要么就是**小整数值或长度比较短的字符串**, 那么 Redis 就会使用压缩列表来做列表键的底层实现。
456 |
457 | ## 6.1 压缩列表的构成
458 |
459 | 压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的**连续内存块组成的顺序型(sequential)数据结构。**
460 |
461 |
442 |
443 | 剩下就需要对元素重排。
444 |
445 | 先将3移动到新intset结构的索引2的位置上,然后将2移动到索引1的位置,然后将1移动到索引0的位置。最后再讲65535移动到索引3的位置。
446 |
447 | ## 5.3 降级
448 |
449 | 整数集合不支持降级操作, 一旦对数组进行了升级, 编码就会一直保持升级后的状态。
450 |
451 | 即使我们将集合里唯一一个真正需要使用 `int64_t` 类型来保存的元素 `4294967295` 删除了, 整数集合的编码仍然会维持 `INTSET_ENC_INT64`。
452 |
453 | # 6. 压缩列表
454 |
455 | 压缩列表(ziplist)**是列表键和哈希键的底层实现之一。**当一个列表键只包含少量列表项, 并且每个列表项要么就是**小整数值或长度比较短的字符串**, 那么 Redis 就会使用压缩列表来做列表键的底层实现。
456 |
457 | ## 6.1 压缩列表的构成
458 |
459 | 压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的**连续内存块组成的顺序型(sequential)数据结构。**
460 |
461 |  462 |
463 | | 属性 | 类型 | 长度 | 作用 |
464 | | :-----: | :------: | :---: | :------------------------------------: |
465 | | zlbytes | uint32_t | 4字节 | 整个压缩列表占用内存字节数 |
466 | | zltail | uint32_t | 4字节 | 记录表尾节点距离表起始地址有多少个字节 |
467 | | zllen | uint16_t | 2字节 | 记录节点数量 |
468 | | entryX | | 不定 | 节点 |
469 | | zlend | uint8_t | 1字节 | 用于标记末端 |
470 |
471 | 下面展示了一个例子:
472 |
473 |
462 |
463 | | 属性 | 类型 | 长度 | 作用 |
464 | | :-----: | :------: | :---: | :------------------------------------: |
465 | | zlbytes | uint32_t | 4字节 | 整个压缩列表占用内存字节数 |
466 | | zltail | uint32_t | 4字节 | 记录表尾节点距离表起始地址有多少个字节 |
467 | | zllen | uint16_t | 2字节 | 记录节点数量 |
468 | | entryX | | 不定 | 节点 |
469 | | zlend | uint8_t | 1字节 | 用于标记末端 |
470 |
471 | 下面展示了一个例子:
472 |
473 | 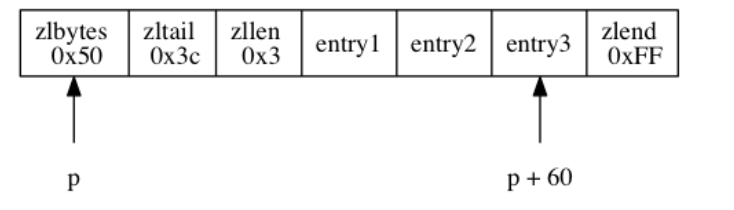 474 |
475 | - `zlbytes` 属性的值为 `0x50` (十进制 `80`), 表示压缩列表的总长为 `80` 字节。
476 | - `zltail` 属性的值为 `0x3c` (十进制 `60`),如果一个指向压缩列表起始地址的指针 `p` , 那么只要用指针 `p` 加上偏移量 `60` , 就可以计算出表尾节点 `entry3` 的地址。
477 | - `zllen` 属性的值为 `0x3` (十进制 `3`), 表示压缩列表包含三个节点。
478 |
479 | ## 6.2 压缩列表的节点构成
480 |
481 | 每个压缩列表节点可以保存一个字节数组或者一个整数值, 其中, 字节数组可以是以下三种长度的其中一种:
482 |
483 | 1. 长度小于等于`63`($2^6-1$)字节的字节数组;
484 | 2. 长度小于等于 `16383` ($2^{14}-1$)字节的字节数组;
485 | 3. 长度小于等于 `4294967295` ($2^{32}-1$)字节的字节数组;
486 |
487 | 而整数值则可以是以下六种长度的其中一种:
488 |
489 | 1. `4` 位长,介于 `0` 至 `12` 之间的无符号整数;
490 | 2. `1` 字节长的有符号整数;
491 | 3. `3` 字节长的有符号整数;
492 | 4. `int16_t` 类型整数;
493 | 5. `int32_t` 类型整数;
494 | 6. `int64_t` 类型整数。
495 |
496 | 每个压缩列表节点都由 `previous_entry_length` 、 `encoding` 、 `content` 三个部分组成。
497 |
498 | ---
499 |
500 | **(1)previous_entry_length**
501 |
502 | 以字节为单位, 记录了压缩列表中**前一个节点的长度。**这个属性的长度可以是1字节或5字节,如果前一个小于254则使用1字节,反之使用5字节( 其中属性的**第一字节会被设置为 `0xFE`(十进制值 `254`)**, 而之后的四个字节则用于保存前一节点的长度)
503 |
504 |
474 |
475 | - `zlbytes` 属性的值为 `0x50` (十进制 `80`), 表示压缩列表的总长为 `80` 字节。
476 | - `zltail` 属性的值为 `0x3c` (十进制 `60`),如果一个指向压缩列表起始地址的指针 `p` , 那么只要用指针 `p` 加上偏移量 `60` , 就可以计算出表尾节点 `entry3` 的地址。
477 | - `zllen` 属性的值为 `0x3` (十进制 `3`), 表示压缩列表包含三个节点。
478 |
479 | ## 6.2 压缩列表的节点构成
480 |
481 | 每个压缩列表节点可以保存一个字节数组或者一个整数值, 其中, 字节数组可以是以下三种长度的其中一种:
482 |
483 | 1. 长度小于等于`63`($2^6-1$)字节的字节数组;
484 | 2. 长度小于等于 `16383` ($2^{14}-1$)字节的字节数组;
485 | 3. 长度小于等于 `4294967295` ($2^{32}-1$)字节的字节数组;
486 |
487 | 而整数值则可以是以下六种长度的其中一种:
488 |
489 | 1. `4` 位长,介于 `0` 至 `12` 之间的无符号整数;
490 | 2. `1` 字节长的有符号整数;
491 | 3. `3` 字节长的有符号整数;
492 | 4. `int16_t` 类型整数;
493 | 5. `int32_t` 类型整数;
494 | 6. `int64_t` 类型整数。
495 |
496 | 每个压缩列表节点都由 `previous_entry_length` 、 `encoding` 、 `content` 三个部分组成。
497 |
498 | ---
499 |
500 | **(1)previous_entry_length**
501 |
502 | 以字节为单位, 记录了压缩列表中**前一个节点的长度。**这个属性的长度可以是1字节或5字节,如果前一个小于254则使用1字节,反之使用5字节( 其中属性的**第一字节会被设置为 `0xFE`(十进制值 `254`)**, 而之后的四个字节则用于保存前一节点的长度)
503 |
504 |  505 |
506 | 程序可以通过指针运算, 根据当前节点的起始地址来**计算出前一个节点的起始地址**。进而可以回溯到表头。
507 |
508 | **(2)encoding**
509 |
510 | 节点的 `encoding` 属性记录了节点的 `content` 属性所保存数据的类型以及长度。编码由8位组成。
511 |
512 | **如果是字符类型**,则开头两位`00`,`01`,`10`分别表示1字节,2字节,5字节,后6位表示字符串长度。
513 |
514 | 保存每个元素是1个字节的数组,长度11。
515 |
516 |
505 |
506 | 程序可以通过指针运算, 根据当前节点的起始地址来**计算出前一个节点的起始地址**。进而可以回溯到表头。
507 |
508 | **(2)encoding**
509 |
510 | 节点的 `encoding` 属性记录了节点的 `content` 属性所保存数据的类型以及长度。编码由8位组成。
511 |
512 | **如果是字符类型**,则开头两位`00`,`01`,`10`分别表示1字节,2字节,5字节,后6位表示字符串长度。
513 |
514 | 保存每个元素是1个字节的数组,长度11。
515 |
516 |  517 |
518 | 如果是整数类型,则开头必是11,然后从第6位开始往低位开始计数:
519 |
520 |
517 |
518 | 如果是整数类型,则开头必是11,然后从第6位开始往低位开始计数:
519 |
520 | 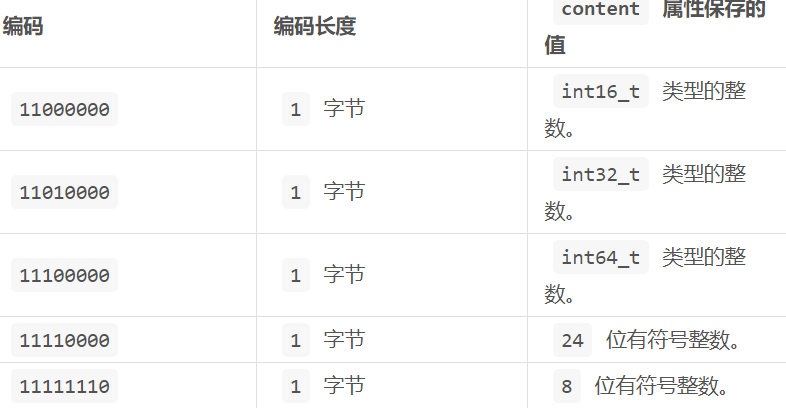 521 |
522 | 每个元素`int16_t`,值为10086
523 |
524 |
521 |
522 | 每个元素`int16_t`,值为10086
523 |
524 |  525 |
526 | ## 6.3 连锁更新
527 |
528 | 每个节点的 `previous_entry_length` 属性都记录了前一个节点的长度:
529 |
530 | - 如果前一节点的长度小于 `254` 字节, 那么 `previous_entry_length` 属性需要用 `1` 字节长的空间来保存这个长度值。
531 | - 如果前一节点的长度大于等于 `254` 字节, 那么 `previous_entry_length` 属性需要用 `5` 字节长的空间来保存这个长度值。
532 |
533 | 假设现在有一些长度为252字节的节点,他们在`previous_entry_length`中保存为1字节。现在插入了一个260字节的新节点,`new` 将成为 `e1` 的前置节点。
534 |
535 |
525 |
526 | ## 6.3 连锁更新
527 |
528 | 每个节点的 `previous_entry_length` 属性都记录了前一个节点的长度:
529 |
530 | - 如果前一节点的长度小于 `254` 字节, 那么 `previous_entry_length` 属性需要用 `1` 字节长的空间来保存这个长度值。
531 | - 如果前一节点的长度大于等于 `254` 字节, 那么 `previous_entry_length` 属性需要用 `5` 字节长的空间来保存这个长度值。
532 |
533 | 假设现在有一些长度为252字节的节点,他们在`previous_entry_length`中保存为1字节。现在插入了一个260字节的新节点,`new` 将成为 `e1` 的前置节点。
534 |
535 | 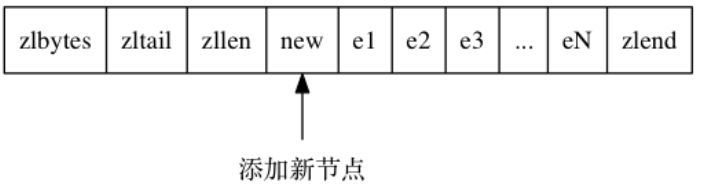 536 |
537 | 因为 `e1` 的 `previous_entry_length` 属性仅长 `1` 字节, 它没办法保存新节点 `new` 的长度, 所以程序将对压缩列表执行空间重分配操作, **并将`e1` 节点的 `previous_entry_length` 属性从原来的 `1` 字节长扩展为 `5` 字节长。**
538 |
539 | 由于`previous_entry_length` 的变化,导致`e1`的长度也发生了变化$252+4=256>254$,所以导致`e2`也必须更新它的`previous_entry_length` 。这就是连锁更新。
540 |
541 | 除了添加节点外,删除节点也会导致连锁更新,若删除一个260字节的节点,则后一个节点长度也会变化。如果很不凑巧,小于254,则又会引起后序效应。
542 |
543 | 连锁更新在最坏情况下需要对压缩列表执行 `N` 次空间重分配操作, 而每次空间重分配的最坏复杂度为$O(N)$ , 所以连锁更新的最坏复杂度为 $O(N^2)$ 。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现10-发布与订阅.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现10-发布与订阅
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-07 12:46:10
12 | ---
13 |
14 | Redis的发布与订阅功能由PUBLISH、SUBSCRIBE、PSUB-SCRIBE等命令组成。本章主要介绍这些命令的实现原理。
15 |
16 | 通过执行SUBSCRIBE命令,客户端可以订阅一个或多个频道,从而成为这些频道的**订阅者**(subscriber):**每当有其他客户端向被订阅的频道发送消息(message)时,频道的所有订阅者都会收到这条消息**。
17 |
18 | 假如ABC三个客户端都执行了:
19 |
20 | ```C
21 | SUBSCRIBE "news.it"
22 | ```
23 |
24 | 那么这三个客户端都成了"news.it"频道的订阅者,
25 |
26 |
536 |
537 | 因为 `e1` 的 `previous_entry_length` 属性仅长 `1` 字节, 它没办法保存新节点 `new` 的长度, 所以程序将对压缩列表执行空间重分配操作, **并将`e1` 节点的 `previous_entry_length` 属性从原来的 `1` 字节长扩展为 `5` 字节长。**
538 |
539 | 由于`previous_entry_length` 的变化,导致`e1`的长度也发生了变化$252+4=256>254$,所以导致`e2`也必须更新它的`previous_entry_length` 。这就是连锁更新。
540 |
541 | 除了添加节点外,删除节点也会导致连锁更新,若删除一个260字节的节点,则后一个节点长度也会变化。如果很不凑巧,小于254,则又会引起后序效应。
542 |
543 | 连锁更新在最坏情况下需要对压缩列表执行 `N` 次空间重分配操作, 而每次空间重分配的最坏复杂度为$O(N)$ , 所以连锁更新的最坏复杂度为 $O(N^2)$ 。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现10-发布与订阅.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现10-发布与订阅
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-07 12:46:10
12 | ---
13 |
14 | Redis的发布与订阅功能由PUBLISH、SUBSCRIBE、PSUB-SCRIBE等命令组成。本章主要介绍这些命令的实现原理。
15 |
16 | 通过执行SUBSCRIBE命令,客户端可以订阅一个或多个频道,从而成为这些频道的**订阅者**(subscriber):**每当有其他客户端向被订阅的频道发送消息(message)时,频道的所有订阅者都会收到这条消息**。
17 |
18 | 假如ABC三个客户端都执行了:
19 |
20 | ```C
21 | SUBSCRIBE "news.it"
22 | ```
23 |
24 | 那么这三个客户端都成了"news.it"频道的订阅者,
25 |
26 | 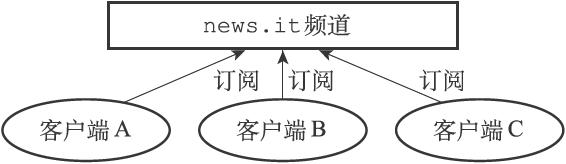 27 |
28 | 向"news.it"频道发送消息"hello",那么"news.it"的三个订阅者都将收到这条消息。
29 |
30 |
27 |
28 | 向"news.it"频道发送消息"hello",那么"news.it"的三个订阅者都将收到这条消息。
29 |
30 | 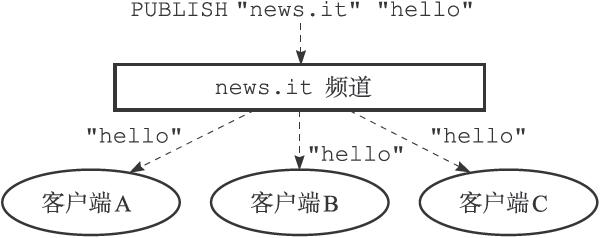 31 |
32 | 除了订阅频道之外,客户端还可以通过执行**PSUBSCRIBE**命令订阅一个或多个**模式**,从而成为这些模式的订阅者:每当有其他客户端向某个频道发送消息时,消息不仅会被发送给这个频道的所有订阅者,**它还会被发送给所有与这个频道相匹配的模式的订阅者。**
33 |
34 |
31 |
32 | 除了订阅频道之外,客户端还可以通过执行**PSUBSCRIBE**命令订阅一个或多个**模式**,从而成为这些模式的订阅者:每当有其他客户端向某个频道发送消息时,消息不仅会被发送给这个频道的所有订阅者,**它还会被发送给所有与这个频道相匹配的模式的订阅者。**
33 |
34 |  35 |
36 | # 1. 订阅与退订
37 |
38 | ## 1.1 频道的订阅与退订
39 |
40 | Redis将所有频道的订阅关系都保存在服务器状态的`pubsub_channels`**字典**里面,这个字典的**键是某个被订阅的频道**,而键的**值则是一个链表**,链表里面记录了所有订阅这个频道的客户端。
41 |
42 | 看下图,不同客户端订阅了不同频道:
43 |
44 |
35 |
36 | # 1. 订阅与退订
37 |
38 | ## 1.1 频道的订阅与退订
39 |
40 | Redis将所有频道的订阅关系都保存在服务器状态的`pubsub_channels`**字典**里面,这个字典的**键是某个被订阅的频道**,而键的**值则是一个链表**,链表里面记录了所有订阅这个频道的客户端。
41 |
42 | 看下图,不同客户端订阅了不同频道:
43 |
44 | 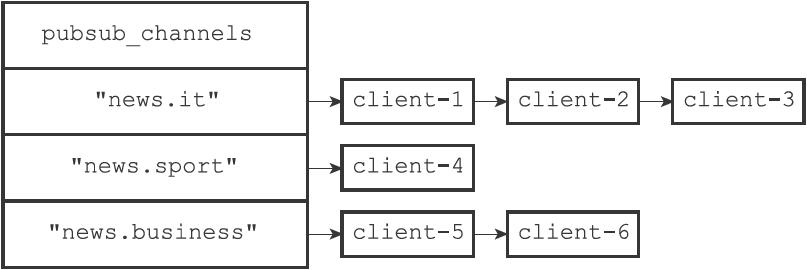 45 |
46 | ---
47 |
48 | 订阅的原理是:**服务器将客户端与被订阅频道在`pubsub_channels`字典中进行关联。**
49 |
50 | 假如客户端10086执行命令:
51 |
52 | ```C
53 | SUBSCRIBE "news.sport" "news.movie"
54 | ```
55 |
56 | 服务器完成两件事:
57 |
58 | - 将10086添加到sport链表后面
59 | - 新增一个键"news.movie"
60 |
61 |
45 |
46 | ---
47 |
48 | 订阅的原理是:**服务器将客户端与被订阅频道在`pubsub_channels`字典中进行关联。**
49 |
50 | 假如客户端10086执行命令:
51 |
52 | ```C
53 | SUBSCRIBE "news.sport" "news.movie"
54 | ```
55 |
56 | 服务器完成两件事:
57 |
58 | - 将10086添加到sport链表后面
59 | - 新增一个键"news.movie"
60 |
61 | 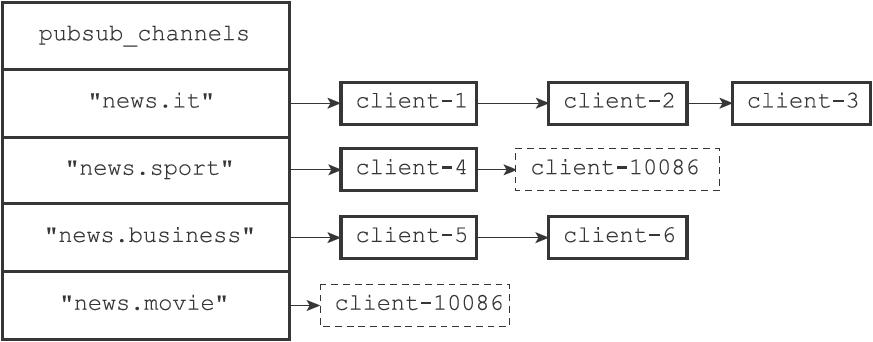 62 |
63 | ---
64 |
65 | 退订就是在链表中删除客户端信息,如果退订后某个键没有任何客户端,则**程序将从pubsub_channels字典中删除频道对应的键。**
66 |
67 | ## 1.2 模式的订阅与退订
68 |
69 | 类似地,服务器也将所有模式的订阅关系都保存在服务器状态的`pubsub_patterns`属性。
70 |
71 | 与频道不同的是,这是一个**链表**,链表中的每个节点都包含着一个`pubsubPattern`结构,这个结构的`pattern`属性记录了被订阅的模式,而`client`属性则记录了订阅模式的客户端:
72 |
73 | ```C
74 | typedef struct pubsub_Pattern
75 | {
76 | // 订阅模式的客户端
77 | redisClient *client;
78 | // 被订阅的模式
79 | robj *pattern;
80 | } pubsubPattern;
81 | ```
82 |
83 | 下面举一个例子:
84 |
85 | - 客户端7正在订阅模式"music.*"
86 | - 客户端8正在订阅模式"book.*"
87 | - 客户端9正在订阅模式"news.*"
88 |
89 |
62 |
63 | ---
64 |
65 | 退订就是在链表中删除客户端信息,如果退订后某个键没有任何客户端,则**程序将从pubsub_channels字典中删除频道对应的键。**
66 |
67 | ## 1.2 模式的订阅与退订
68 |
69 | 类似地,服务器也将所有模式的订阅关系都保存在服务器状态的`pubsub_patterns`属性。
70 |
71 | 与频道不同的是,这是一个**链表**,链表中的每个节点都包含着一个`pubsubPattern`结构,这个结构的`pattern`属性记录了被订阅的模式,而`client`属性则记录了订阅模式的客户端:
72 |
73 | ```C
74 | typedef struct pubsub_Pattern
75 | {
76 | // 订阅模式的客户端
77 | redisClient *client;
78 | // 被订阅的模式
79 | robj *pattern;
80 | } pubsubPattern;
81 | ```
82 |
83 | 下面举一个例子:
84 |
85 | - 客户端7正在订阅模式"music.*"
86 | - 客户端8正在订阅模式"book.*"
87 | - 客户端9正在订阅模式"news.*"
88 |
89 |  90 |
91 | ---
92 |
93 | 订阅模式时,服务器会对每个被订阅的模式执行以下两个操作:
94 |
95 | 1. 新建一个`pubsubPattern`结构,将结构的`pattern`属性设置为被订阅的模式,`client`属性设置为订阅模式的客户端。
96 | 2. 将`pubsubPattern`结构添加到`pubsub_patterns`链表的表尾。
97 |
98 |
90 |
91 | ---
92 |
93 | 订阅模式时,服务器会对每个被订阅的模式执行以下两个操作:
94 |
95 | 1. 新建一个`pubsubPattern`结构,将结构的`pattern`属性设置为被订阅的模式,`client`属性设置为订阅模式的客户端。
96 | 2. 将`pubsubPattern`结构添加到`pubsub_patterns`链表的表尾。
97 |
98 |  99 |
100 | 退订时,在`pubsub_patterns`链表中查找并删除。
101 |
102 | # 2. 发布消息
103 |
104 | 发布消息有两个动作:
105 |
106 | 1. 将消息发送给所有channel的订阅者。
107 | 2. 如果有一个或多个模式与频道channel匹配,则同时将消息发送给模式的订阅者。
108 |
109 | **对于频道订阅者**,首先服务器要在`pubsub_channels`中找到相对应的channel(一个链表),然后顺着这个链表,将消息发送给所有客户端。
110 |
111 | **对于模式订阅者**,服务器会在`pubsub_patterns`链表中找到**与channel频道相匹配的模式**,然后将消息发送给订阅了这些模式的所有客户端。
112 |
113 | # 3. 查看订阅消息
114 |
115 | **PUBSUB**命令是Redis 2.8新增加的命令之一,**客户端可以通过这个命令来查看频道或者模式的相关信息**,比如某个频道目前有多少订阅者,又或者某个模式目前有多少订阅者。本节介绍这个命令的实现方法。
116 |
117 | ## 3.1 PUBSUB CHANNELS
118 |
119 | `PUBSUB CHANNELS[pattern]`子命令用于返回服务器**当前被订阅的频道**,其中`pattern`参数是可选的:
120 |
121 | - 不给定,则返回所有被订阅的所有频道。
122 | - 给定,与pattern模式相匹配的频道。
123 |
124 | 比如:
125 |
126 | ```C
127 | redis> PUBSUB CHANNELS
128 | 1) "news.it"
129 | 2) "news.sport"
130 | 3) "news.business"
131 | 4) "news.movie"
132 |
133 | redis> PUBSUB CHANNELS "news.[is]*"
134 | 1) "news.it"
135 | 2) "news.sport"
136 | ```
137 |
138 | ## 3.2 PUBSUB NUMSUB
139 |
140 | `PUBSUB NUMSUB[channel-1 channel-2...channel-n]`子命令接受任意多个频道作为输入参数,并返回这些**频道的订阅者数量**。
141 |
142 | 这个子命令是通过在`pubsub_channels`字典中找到频道对应的订阅者链表,然后**返回订阅者链表的长度**。
143 |
144 | ## 3.3 PUBSUB NUMPAT
145 |
146 | `PUBSUB NUMPAT`子命令用于返回服务器当前被**订阅模式的数量**。
147 |
148 | 通过返回`pubsub_patterns`链表的长度来实现的。注意一下频道数量的查找逻辑是:**频道字典->频道订阅者链表->数量**;而模式数量的查找逻辑是:**模式链表->数量**。
149 |
150 |
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现11-事务.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现11-事务
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-07 13:54:21
12 | ---
13 |
14 | Redis通过MULTI、EXEC、WATCH等命令来实现事务(transaction)功能。事务将**一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制**,并且在事务执行期间,**服务器不会中断事务**而改去执行其他客户端的命令请求。
15 |
16 | ```C
17 | redis->MULTI
18 | OK
19 |
20 | redis->SET "name" "hellp"
21 | QUEUED
22 |
23 | redis->GET "name"
24 | QUEUED
25 |
26 | redis->EXEC
27 | 1)OK
28 | 2)"hellp"
29 | ```
30 |
31 | # 1. 事务的实现
32 |
33 | 一个事务从开始到结束会经历三个阶段:
34 |
35 | - 事务开始
36 | - 命令入队
37 | - 事务执行
38 |
39 | **(1)事务开始**
40 |
41 | 通过MULTI命令可以将执行该命令的客户端**从非事务状态切换至事务状态**,这一切换是通过在客户端状态的flags属性中打开REDIS_MULTI标识来完成的。
42 |
43 | 当一个客户端已经处于非事务状态时,这个客户端发送的**命令会被服务器执行**。然而当切换到事务状态后,服务器会根据这个客户端发来的不同命令执行不同的操作:
44 |
45 | - 如果客户端发送EXEC,DISCARD,WATCH,MULTI这四个命令,则立即执行。
46 | - 如果发送的是其他命令,则放到事务队列里面,向客户端返回QUEUED回复。
47 |
48 |
99 |
100 | 退订时,在`pubsub_patterns`链表中查找并删除。
101 |
102 | # 2. 发布消息
103 |
104 | 发布消息有两个动作:
105 |
106 | 1. 将消息发送给所有channel的订阅者。
107 | 2. 如果有一个或多个模式与频道channel匹配,则同时将消息发送给模式的订阅者。
108 |
109 | **对于频道订阅者**,首先服务器要在`pubsub_channels`中找到相对应的channel(一个链表),然后顺着这个链表,将消息发送给所有客户端。
110 |
111 | **对于模式订阅者**,服务器会在`pubsub_patterns`链表中找到**与channel频道相匹配的模式**,然后将消息发送给订阅了这些模式的所有客户端。
112 |
113 | # 3. 查看订阅消息
114 |
115 | **PUBSUB**命令是Redis 2.8新增加的命令之一,**客户端可以通过这个命令来查看频道或者模式的相关信息**,比如某个频道目前有多少订阅者,又或者某个模式目前有多少订阅者。本节介绍这个命令的实现方法。
116 |
117 | ## 3.1 PUBSUB CHANNELS
118 |
119 | `PUBSUB CHANNELS[pattern]`子命令用于返回服务器**当前被订阅的频道**,其中`pattern`参数是可选的:
120 |
121 | - 不给定,则返回所有被订阅的所有频道。
122 | - 给定,与pattern模式相匹配的频道。
123 |
124 | 比如:
125 |
126 | ```C
127 | redis> PUBSUB CHANNELS
128 | 1) "news.it"
129 | 2) "news.sport"
130 | 3) "news.business"
131 | 4) "news.movie"
132 |
133 | redis> PUBSUB CHANNELS "news.[is]*"
134 | 1) "news.it"
135 | 2) "news.sport"
136 | ```
137 |
138 | ## 3.2 PUBSUB NUMSUB
139 |
140 | `PUBSUB NUMSUB[channel-1 channel-2...channel-n]`子命令接受任意多个频道作为输入参数,并返回这些**频道的订阅者数量**。
141 |
142 | 这个子命令是通过在`pubsub_channels`字典中找到频道对应的订阅者链表,然后**返回订阅者链表的长度**。
143 |
144 | ## 3.3 PUBSUB NUMPAT
145 |
146 | `PUBSUB NUMPAT`子命令用于返回服务器当前被**订阅模式的数量**。
147 |
148 | 通过返回`pubsub_patterns`链表的长度来实现的。注意一下频道数量的查找逻辑是:**频道字典->频道订阅者链表->数量**;而模式数量的查找逻辑是:**模式链表->数量**。
149 |
150 |
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现11-事务.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现11-事务
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-07 13:54:21
12 | ---
13 |
14 | Redis通过MULTI、EXEC、WATCH等命令来实现事务(transaction)功能。事务将**一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制**,并且在事务执行期间,**服务器不会中断事务**而改去执行其他客户端的命令请求。
15 |
16 | ```C
17 | redis->MULTI
18 | OK
19 |
20 | redis->SET "name" "hellp"
21 | QUEUED
22 |
23 | redis->GET "name"
24 | QUEUED
25 |
26 | redis->EXEC
27 | 1)OK
28 | 2)"hellp"
29 | ```
30 |
31 | # 1. 事务的实现
32 |
33 | 一个事务从开始到结束会经历三个阶段:
34 |
35 | - 事务开始
36 | - 命令入队
37 | - 事务执行
38 |
39 | **(1)事务开始**
40 |
41 | 通过MULTI命令可以将执行该命令的客户端**从非事务状态切换至事务状态**,这一切换是通过在客户端状态的flags属性中打开REDIS_MULTI标识来完成的。
42 |
43 | 当一个客户端已经处于非事务状态时,这个客户端发送的**命令会被服务器执行**。然而当切换到事务状态后,服务器会根据这个客户端发来的不同命令执行不同的操作:
44 |
45 | - 如果客户端发送EXEC,DISCARD,WATCH,MULTI这四个命令,则立即执行。
46 | - 如果发送的是其他命令,则放到事务队列里面,向客户端返回QUEUED回复。
47 |
48 |  49 |
50 | **(2)命令入队**
51 |
52 | 事务的关键实现在于**命令入队**,每个Redis客户端都有自己的**事务状态**,这个事务状态保存在客户端状态的mstate属性里面:
53 |
54 | ```C
55 | typedef struct redisClient
56 | {
57 | //...
58 | multiState mstate;
59 | //...
60 | }
61 | ```
62 |
63 | 而**事务状态结构体**又包含了一个**事务队列**,以及一个**已入队命令的计数器**。
64 |
65 | ```C
66 | typedef struct multiState
67 | {
68 | // 事务队列,FIFO顺序
69 | multiCmd *commands;
70 | // 已入队命令计数
71 | int count;
72 | } multiState;
73 | ```
74 |
75 | **事务队列**是一个结构体,实现了队列数据结构,执行FIFO先进先出的策略。真实结构是一个数组。
76 |
77 | ```c
78 | typedef struct multiCmd
79 | {
80 | // 参数
81 | robj **argv;
82 | // 参数数量
83 | int argc;
84 | // 命令指针
85 | struct redisCommand *cmd;
86 | } multiCmd;
87 | ```
88 |
89 | 事务结构具体的包含逻辑是:**客户端->事务状态multiState->事务队列multiCmd->具体命令cmd**
90 |
91 |
49 |
50 | **(2)命令入队**
51 |
52 | 事务的关键实现在于**命令入队**,每个Redis客户端都有自己的**事务状态**,这个事务状态保存在客户端状态的mstate属性里面:
53 |
54 | ```C
55 | typedef struct redisClient
56 | {
57 | //...
58 | multiState mstate;
59 | //...
60 | }
61 | ```
62 |
63 | 而**事务状态结构体**又包含了一个**事务队列**,以及一个**已入队命令的计数器**。
64 |
65 | ```C
66 | typedef struct multiState
67 | {
68 | // 事务队列,FIFO顺序
69 | multiCmd *commands;
70 | // 已入队命令计数
71 | int count;
72 | } multiState;
73 | ```
74 |
75 | **事务队列**是一个结构体,实现了队列数据结构,执行FIFO先进先出的策略。真实结构是一个数组。
76 |
77 | ```c
78 | typedef struct multiCmd
79 | {
80 | // 参数
81 | robj **argv;
82 | // 参数数量
83 | int argc;
84 | // 命令指针
85 | struct redisCommand *cmd;
86 | } multiCmd;
87 | ```
88 |
89 | 事务结构具体的包含逻辑是:**客户端->事务状态multiState->事务队列multiCmd->具体命令cmd**
90 |
91 |  92 |
93 | **(3)执行事务**
94 |
95 | 当一个处于事务状态的客户端向服务器发送EXEC命令时,这个EXEC命令将立即被服务器执行。**服务器会遍历这个客户端的事务队列,执行队列中保存的所有命令,最后将执行命令所得的结果全部返回给客户端。**
96 |
97 | 1. 创建空白回复队列
98 | 2. 抽取一条命令,读取参数、参数个数以及要执行的函数
99 | 3. 执行命令,取得返回值
100 | 4. 将返回值追加到1中的队列末尾,重复步骤2
101 |
102 | 完成所有命令后,将**清除REDIS_MULTI标志**,让客户端变为非事务状态,同时清**零入队命令计数器,并释放事务队列。**
103 |
104 | # 2. WATCH命令的实现
105 |
106 | WATCH可以别翻译为**监视器**。WATCH命令是一个**乐观锁(optimistic locking)**。
107 |
108 | > 悲观锁:有罪推定原则,每次有人操作数据时都会假定他要修改,每次都会上互斥锁。
109 | >
110 | > 乐观锁:无罪推定原则,每次别人拿数据都假定他不修改,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。
111 |
112 | 它可以**在EXEC命令执行之前**,**监视任意数量的数据库键**,并在EXEC命令执行时,**检查被监视的键是否至少有一个已经被修改过了**,**如果是的话,服务器将拒绝执行事务**,并向客户端返回代表事务执行失败的空回复。
113 |
114 | ```C
115 | redis-> WATCH "name"
116 | OK
117 |
118 | redis-> MULTI
119 | OK
120 |
121 | redis-> SET "name" "peter"
122 | QUEUED
123 |
124 | redis-> EXEC
125 | (nil)
126 | ```
127 |
128 | 上面的例子中,WATCH监视器发现了事务修改了name的值,因此拒绝执行该事务,返回空回复。
129 |
130 | ## 2.1 监视原理
131 |
132 | 每个Redis数据库都保存着一个`watched_keys`字典,这个字典的**键是某个被WATCH命令监视的数据库键**,而**字典的值则是一个链表,链表中记录了所有监视相应数据库键的客户端:**
133 |
134 | ```C
135 | typedef struct redisDb
136 | {
137 | // ...
138 | // 正在被WATCH命令监视的键
139 | dict *watched_keys;
140 | // ...
141 | } redisDb;
142 | ```
143 |
144 | 下图说明:c1和c2客户端正在监视键"name",c3客户端正在监视"age"....
145 |
146 |
92 |
93 | **(3)执行事务**
94 |
95 | 当一个处于事务状态的客户端向服务器发送EXEC命令时,这个EXEC命令将立即被服务器执行。**服务器会遍历这个客户端的事务队列,执行队列中保存的所有命令,最后将执行命令所得的结果全部返回给客户端。**
96 |
97 | 1. 创建空白回复队列
98 | 2. 抽取一条命令,读取参数、参数个数以及要执行的函数
99 | 3. 执行命令,取得返回值
100 | 4. 将返回值追加到1中的队列末尾,重复步骤2
101 |
102 | 完成所有命令后,将**清除REDIS_MULTI标志**,让客户端变为非事务状态,同时清**零入队命令计数器,并释放事务队列。**
103 |
104 | # 2. WATCH命令的实现
105 |
106 | WATCH可以别翻译为**监视器**。WATCH命令是一个**乐观锁(optimistic locking)**。
107 |
108 | > 悲观锁:有罪推定原则,每次有人操作数据时都会假定他要修改,每次都会上互斥锁。
109 | >
110 | > 乐观锁:无罪推定原则,每次别人拿数据都假定他不修改,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。
111 |
112 | 它可以**在EXEC命令执行之前**,**监视任意数量的数据库键**,并在EXEC命令执行时,**检查被监视的键是否至少有一个已经被修改过了**,**如果是的话,服务器将拒绝执行事务**,并向客户端返回代表事务执行失败的空回复。
113 |
114 | ```C
115 | redis-> WATCH "name"
116 | OK
117 |
118 | redis-> MULTI
119 | OK
120 |
121 | redis-> SET "name" "peter"
122 | QUEUED
123 |
124 | redis-> EXEC
125 | (nil)
126 | ```
127 |
128 | 上面的例子中,WATCH监视器发现了事务修改了name的值,因此拒绝执行该事务,返回空回复。
129 |
130 | ## 2.1 监视原理
131 |
132 | 每个Redis数据库都保存着一个`watched_keys`字典,这个字典的**键是某个被WATCH命令监视的数据库键**,而**字典的值则是一个链表,链表中记录了所有监视相应数据库键的客户端:**
133 |
134 | ```C
135 | typedef struct redisDb
136 | {
137 | // ...
138 | // 正在被WATCH命令监视的键
139 | dict *watched_keys;
140 | // ...
141 | } redisDb;
142 | ```
143 |
144 | 下图说明:c1和c2客户端正在监视键"name",c3客户端正在监视"age"....
145 |
146 |  147 |
148 | ## 2.2 监视触发
149 |
150 | 对数据库**执行修改命令**时,比如SET、LPUSH、SADD、ZREM、DEL、FLUSHDB等等,在执行之后都会调用`multi.c/touchWatchKey`函数对`watched_keys`字典进行检查。**查看当前命令修改的键是否在`watched_keys`字典中**,如果有,则客户端的`REDIS_DIRTY_CAS`标识打开**,表示该客户端的事务安全性已经被破坏**。
151 |
152 | ## 2.3 判断事务是否安全
153 |
154 | 当服务器接收到一个客户端发来的EXEC命令时,服务器会根据这个客户端是否打开了`REDIS_DIRTY_CAS`标识来决定是否执行事务。
155 |
156 | - 如果标志被打开,则说明哨兵监视的键中被修改过了,所以当前提交的事务不再安全,拒绝执行客户端提交的事务。
157 | - 反之,是安全的,继续执行。
158 |
159 | # 3. 事务的ACID性质
160 |
161 | 所谓ACID性质是指:**有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、耐久性(Durability)。**
162 |
163 | **(1)原子性**
164 |
165 | 所谓原子性就是某个操作不可再分,比如汇编语言里面的`MOV DST,SRC`。事务的定义就是:将多个命令打包成一个实现,**要么全部执行,要么都不执行**。**在命令入队的时候,用WATCH进行检查**,不符合要求就直接返回。
166 |
167 | Redis的事务和传统的关系型数据库事务的最大区别在于,**Redis不支持事务回滚机制(rollback)**。作者认为Redis追求简单高效,回滚机制太复杂。
168 |
169 | > 回滚(rollback)是指当事务中某一条命令执行出错时,意味着前面的命令可能也不安全,这时候就会释放掉前面的操作,恢复到执行事务之前的状态。MySQL数据库支持回滚操作。
170 |
171 | **(2)一致性**
172 |
173 | “**一致”指的是数据符合数据库本身的定义和要求,没有包含非法或者无效的错误数据。**如果数据库在执行事务之前是一致的,那么在事务执行之后,无论事务是否执行成功,数据库也应该仍然是一致的。Redis保证一致性的方法如下:
174 |
175 | - **入队错误**:事务入队时命令格式不正确,则Redis拒绝执行
176 | - **执行错误**:执行时操作不正确,会被服务器识别,并做错误处理,所以这些出错命令不会对数据库做任何修改
177 | - **服务器停机**:停机分三种情况,
178 | - 无持久化:重启后清空,数据总是一致的
179 | - RDB模式:根据RDB恢复数据,还原为一致状态
180 | - AOF模式:根据AOF恢复数据,还原为一致状态
181 |
182 | **(3)隔离性**
183 |
184 | 隔离性也可被理解为**不存在竞争**。即使数据库中有多个事务并发地执行,各个事务之间也不会互相影响。
185 |
186 | 因为Redis使用**单线程**的方式来执行事务(以及事务队列中的命令),并且服务器保证,在执行事务期间**不会对事务进行中断**。这种**串行**的方式保证了事务也总是具有隔离性的。
187 |
188 | **(4)耐久性**
189 |
190 | 事务的耐久性指的是,当一个事务执行完毕时,执行这个事务所得的结果已经**被保存到永久性存储介质**(比如硬盘)里面了,即使服务器在事务执行完毕之后停机,执行事务所得的结果也不会丢失。
191 |
192 | Redis事务只是简答包裹了一组Redis命令,耐久性由持久化实现。前面提到持久化分不同的情况
193 |
194 | - RDB模式下,只有特定条件被满足时才会执行BGSAVE,具有耐久性。
195 | - AOF模式根据appendfsync选项来决定
196 | - always,每次执行命令后都会调用同步函数,具有耐久性。
197 | - everysec,每一秒才会同步到硬盘,不具有耐久性。
198 | - no,程序会交由操作系统来决定何时将命令数据同步到硬盘。不具有耐久性。
199 |
200 | ---
201 |
202 | 总的来说,Redis事务**一定**具有原子性,一致性和隔离性,但**只有在特定条件**下才具有耐久性。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现12-Lua脚本.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现12-Lua脚本
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-08 11:27:51
12 | ---
13 |
14 | Redis提供了非常丰富的指令集,官网上提供了200多个命令。但是某些特定领域,需要扩充若干指令原子性执行时,仅使用原生命令便无法完成,所以需要Lua脚本进行补充。Redis客户端可以使用Lua脚本,**直接在服务器端原子地执行多个Redis命令。**
15 |
16 | 比如,使用EVAL命令可以对脚本进行求值
17 |
18 | ```C
19 | redis> EVAL "return 1+1" 0
20 | (integer) 2
21 | ```
22 |
23 | 使用Lua的原因主要有:
24 |
25 | - **拓展原生指令集功能**。
26 | - **减少网络开销**。多个指令集同时发出,作为整体执行。
27 | - **原子操作**。对事务功能的一个替代,避免竞争。
28 | - **复用**。发送的脚本会以函数形式保存在Redis中,其他客户端也能使用。
29 |
30 | # 1. Lua环境
31 |
32 | Redis在服务器内嵌了一个Lua环境(environ-ment),并**对这个Lua环境进行了一系列修改**,从而确保这个Lua环境可以满足Redis服务器的需要。
33 |
34 | 步骤如下:
35 |
36 | 1. 创建一个基础的Lua环境
37 | 2. 载入多个函数库到Lua环境里面,让Lua脚本可以使用这些函数库来进行数据操作
38 | 3. 创建**全局表格**redis,这个表格包含了对Redis进行操作的函数。
39 | 4. 使用Redis自制的随机函数来替换Lua原有的带有副作用的随机函数,从而**避免在脚本中引入副作用。**
40 | 5. 创建排序辅助函数,Lua环境使用这个辅佐函数来对一部分Redis命令的结果进行排序,从而**消除这些命令的不确定性**。
41 | 6. 创建redis.pcall函数的错误报告辅助函数,这个函数可以提供更详细的出错信息。
42 | 7. **对Lua环境中的全局环境进行保护**,防止用户在执行Lua脚本的过程中,将额外的全局变量添加到Lua环境中。
43 | 8. 将完成修改的Lua环境保存到服务器状态的lua属性中,等待执行服务器传来的Lua脚本。
44 |
45 | **(1)创建Lua环境**
46 |
47 | 在最开始的这一步,服务器首先调用Lua的C API函数`lua_open`,创建一个新的Lua环境。因为`lua_open`函数创建的**只是一个基本的Lua环境**,为了让这个Lua环境可以满足Redis的操作要求,接下来服务器将对这个Lua环境进行一系列修改。
48 |
49 | **(2)载入函数库**
50 |
51 | Redis修改Lua环境的第一步,就是将以下函数库载入到Lua环境里面:
52 |
53 | - 基础库:包含了Lua核心函数
54 | - 表格库:用于处理表格的通用函数
55 | - 字符串库
56 | - 数学库:标准C语言数学库的接口
57 | - 调试库:钩子函数和取得钩子函数,还包括元数据相关函数
58 | - Lua CJSON库:用于处理UTF-8编码的JSON格式
59 | - Lua cmsgpack库:用于处理MessagePack格式的数据
60 |
61 | **(3)创建redis表格**
62 |
63 | 服务器将在Lua环境中创建一个redis表格(table),**并将它设为全局变量**。这个redis表格包含以下函数:
64 |
65 | - 用于执行Redis命令的`redis.call`和`redis.pcall`函数。
66 | - 用于记录Redis日志(log)的`redis.log`函数
67 | - 用于计算SHA1校验和的`redis.sha1hex`函数。
68 | - 用于返回错误信息的`redis.error_reply`函数和`redis.status_reply`函数。
69 |
70 | **(4)自制随机函数替代Lua原有的随机函数**
71 |
72 | 为了保证相同的脚本可以在不同的机器上产生相同的结果,**Redis要求所有传入服务器的Lua脚本,以及Lua环境中的所有函数,都必须是无副作用(side effect)的纯函数(pure func-tion)。**
73 |
74 | > 副作用是指:函数使用时除了返回值以外还破坏了系统环境,比如全局变量。
75 |
76 | Redis使用自制的函数替换了math库中原有的`math.random`函数和`math.randomseed`函数,替换之后的两个函数有以下特征:
77 |
78 | - 对于相同的seed来说,`math.random`总产生相同的随机数序列
79 | - 除非在脚本中使用`math.randomseed`显式地修改seed,否则每次运行脚本时,Lua环境都使用固定的`math.random-seed(0)`语句来初始化seed。
80 |
81 | **(5)创建排序辅助函数**
82 |
83 | 另一个可能产生不一致数据的地方是**那些带有不确定性质的命令**。比如对于一个集合键来说,因为集合元素的排列是无序的,所以即使两个集合的元素完全相同,它们的输出结果也可能并不相同。
84 |
85 | 为了消除这些命令带来的不确定性,服务器会为Lua环境创建一个排序辅助函数`__redis__compare_helper`,当Lua脚本执行完一个带有不确定性的命令之后,程序会使用`__redis__compare_helper`**作为对比函数自动调用`table.sort`函数对命令的返回值做一次排序,以此来保证相同的数据集总是产生相同的输出。**
86 |
87 | 如果我们在Lua脚本中对fruit集合和anotherfruit集合执行`SMEMBERS`命令,那么两个脚本将得出相同的结果:
88 |
89 | ```C
90 | redis> EVAL "return redis.call('SMEMBERS', KEYS[1])" 1 anotherfruit
91 | 1) "apple"
92 | 2) "banana"
93 | 3) "cherry"
94 |
95 | redis> EVAL "return redis.call('SMEMBERS', KEYS[1])" 1 fruit
96 | 1) "apple"
97 | 2) "banana"
98 | 3) "cherry"
99 | ```
100 |
101 | **(6)创建redis.pcall函数的错误报告辅助函数**
102 |
103 | 服务器将为Lua环境创建一个名为`__redis__err__handler`的错误处理函数,当脚本调用`redis.pcall`函数执行Redis命令,并且被执行的命令出现错误时,`__re-dis__err__handler`就会打印出错代码的来源和发生错误的行数,为程序的调试提供方便。
104 |
105 | **(7)保护Lua的全局环境**
106 |
107 | **确保传入服务器的脚本不会因为忘记使用local关键字而将额外的全局变量添加到Lua环境里面**。
108 |
109 | 如果误操作,程序会报错:
110 |
111 | ```
112 | redis> EVAL "x = 10" 0
113 | (error) ERR Error running script
114 | (call to f_df1ad3745c2d2f078f0f41377a92bb6f8ac79af0):
115 | @enable_strict_lua:7: user_script:1:
116 | Script attempted to create global variable 'x'
117 | ```
118 |
119 | 试图获取一个不存在的全局变量也会引发一个错误
120 |
121 | 不过**Redis并未禁止用户修改已存在的全局变量**,所以在执行Lua脚本的时候,必须非常小心,以免错误地修改了已存在的全局变量。
122 |
123 | ```C
124 | redis> EVAL "redis = 10086; return redis" 0
125 | (integer) 10086
126 | ```
127 |
128 | **(8)将Lua环境保存到服务器状态的lua属性里面**
129 |
130 | 最后的这一步,服务器会将Lua环境和服务器状态的lua属性关联起来
131 |
132 |
147 |
148 | ## 2.2 监视触发
149 |
150 | 对数据库**执行修改命令**时,比如SET、LPUSH、SADD、ZREM、DEL、FLUSHDB等等,在执行之后都会调用`multi.c/touchWatchKey`函数对`watched_keys`字典进行检查。**查看当前命令修改的键是否在`watched_keys`字典中**,如果有,则客户端的`REDIS_DIRTY_CAS`标识打开**,表示该客户端的事务安全性已经被破坏**。
151 |
152 | ## 2.3 判断事务是否安全
153 |
154 | 当服务器接收到一个客户端发来的EXEC命令时,服务器会根据这个客户端是否打开了`REDIS_DIRTY_CAS`标识来决定是否执行事务。
155 |
156 | - 如果标志被打开,则说明哨兵监视的键中被修改过了,所以当前提交的事务不再安全,拒绝执行客户端提交的事务。
157 | - 反之,是安全的,继续执行。
158 |
159 | # 3. 事务的ACID性质
160 |
161 | 所谓ACID性质是指:**有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、耐久性(Durability)。**
162 |
163 | **(1)原子性**
164 |
165 | 所谓原子性就是某个操作不可再分,比如汇编语言里面的`MOV DST,SRC`。事务的定义就是:将多个命令打包成一个实现,**要么全部执行,要么都不执行**。**在命令入队的时候,用WATCH进行检查**,不符合要求就直接返回。
166 |
167 | Redis的事务和传统的关系型数据库事务的最大区别在于,**Redis不支持事务回滚机制(rollback)**。作者认为Redis追求简单高效,回滚机制太复杂。
168 |
169 | > 回滚(rollback)是指当事务中某一条命令执行出错时,意味着前面的命令可能也不安全,这时候就会释放掉前面的操作,恢复到执行事务之前的状态。MySQL数据库支持回滚操作。
170 |
171 | **(2)一致性**
172 |
173 | “**一致”指的是数据符合数据库本身的定义和要求,没有包含非法或者无效的错误数据。**如果数据库在执行事务之前是一致的,那么在事务执行之后,无论事务是否执行成功,数据库也应该仍然是一致的。Redis保证一致性的方法如下:
174 |
175 | - **入队错误**:事务入队时命令格式不正确,则Redis拒绝执行
176 | - **执行错误**:执行时操作不正确,会被服务器识别,并做错误处理,所以这些出错命令不会对数据库做任何修改
177 | - **服务器停机**:停机分三种情况,
178 | - 无持久化:重启后清空,数据总是一致的
179 | - RDB模式:根据RDB恢复数据,还原为一致状态
180 | - AOF模式:根据AOF恢复数据,还原为一致状态
181 |
182 | **(3)隔离性**
183 |
184 | 隔离性也可被理解为**不存在竞争**。即使数据库中有多个事务并发地执行,各个事务之间也不会互相影响。
185 |
186 | 因为Redis使用**单线程**的方式来执行事务(以及事务队列中的命令),并且服务器保证,在执行事务期间**不会对事务进行中断**。这种**串行**的方式保证了事务也总是具有隔离性的。
187 |
188 | **(4)耐久性**
189 |
190 | 事务的耐久性指的是,当一个事务执行完毕时,执行这个事务所得的结果已经**被保存到永久性存储介质**(比如硬盘)里面了,即使服务器在事务执行完毕之后停机,执行事务所得的结果也不会丢失。
191 |
192 | Redis事务只是简答包裹了一组Redis命令,耐久性由持久化实现。前面提到持久化分不同的情况
193 |
194 | - RDB模式下,只有特定条件被满足时才会执行BGSAVE,具有耐久性。
195 | - AOF模式根据appendfsync选项来决定
196 | - always,每次执行命令后都会调用同步函数,具有耐久性。
197 | - everysec,每一秒才会同步到硬盘,不具有耐久性。
198 | - no,程序会交由操作系统来决定何时将命令数据同步到硬盘。不具有耐久性。
199 |
200 | ---
201 |
202 | 总的来说,Redis事务**一定**具有原子性,一致性和隔离性,但**只有在特定条件**下才具有耐久性。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现12-Lua脚本.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现12-Lua脚本
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-08 11:27:51
12 | ---
13 |
14 | Redis提供了非常丰富的指令集,官网上提供了200多个命令。但是某些特定领域,需要扩充若干指令原子性执行时,仅使用原生命令便无法完成,所以需要Lua脚本进行补充。Redis客户端可以使用Lua脚本,**直接在服务器端原子地执行多个Redis命令。**
15 |
16 | 比如,使用EVAL命令可以对脚本进行求值
17 |
18 | ```C
19 | redis> EVAL "return 1+1" 0
20 | (integer) 2
21 | ```
22 |
23 | 使用Lua的原因主要有:
24 |
25 | - **拓展原生指令集功能**。
26 | - **减少网络开销**。多个指令集同时发出,作为整体执行。
27 | - **原子操作**。对事务功能的一个替代,避免竞争。
28 | - **复用**。发送的脚本会以函数形式保存在Redis中,其他客户端也能使用。
29 |
30 | # 1. Lua环境
31 |
32 | Redis在服务器内嵌了一个Lua环境(environ-ment),并**对这个Lua环境进行了一系列修改**,从而确保这个Lua环境可以满足Redis服务器的需要。
33 |
34 | 步骤如下:
35 |
36 | 1. 创建一个基础的Lua环境
37 | 2. 载入多个函数库到Lua环境里面,让Lua脚本可以使用这些函数库来进行数据操作
38 | 3. 创建**全局表格**redis,这个表格包含了对Redis进行操作的函数。
39 | 4. 使用Redis自制的随机函数来替换Lua原有的带有副作用的随机函数,从而**避免在脚本中引入副作用。**
40 | 5. 创建排序辅助函数,Lua环境使用这个辅佐函数来对一部分Redis命令的结果进行排序,从而**消除这些命令的不确定性**。
41 | 6. 创建redis.pcall函数的错误报告辅助函数,这个函数可以提供更详细的出错信息。
42 | 7. **对Lua环境中的全局环境进行保护**,防止用户在执行Lua脚本的过程中,将额外的全局变量添加到Lua环境中。
43 | 8. 将完成修改的Lua环境保存到服务器状态的lua属性中,等待执行服务器传来的Lua脚本。
44 |
45 | **(1)创建Lua环境**
46 |
47 | 在最开始的这一步,服务器首先调用Lua的C API函数`lua_open`,创建一个新的Lua环境。因为`lua_open`函数创建的**只是一个基本的Lua环境**,为了让这个Lua环境可以满足Redis的操作要求,接下来服务器将对这个Lua环境进行一系列修改。
48 |
49 | **(2)载入函数库**
50 |
51 | Redis修改Lua环境的第一步,就是将以下函数库载入到Lua环境里面:
52 |
53 | - 基础库:包含了Lua核心函数
54 | - 表格库:用于处理表格的通用函数
55 | - 字符串库
56 | - 数学库:标准C语言数学库的接口
57 | - 调试库:钩子函数和取得钩子函数,还包括元数据相关函数
58 | - Lua CJSON库:用于处理UTF-8编码的JSON格式
59 | - Lua cmsgpack库:用于处理MessagePack格式的数据
60 |
61 | **(3)创建redis表格**
62 |
63 | 服务器将在Lua环境中创建一个redis表格(table),**并将它设为全局变量**。这个redis表格包含以下函数:
64 |
65 | - 用于执行Redis命令的`redis.call`和`redis.pcall`函数。
66 | - 用于记录Redis日志(log)的`redis.log`函数
67 | - 用于计算SHA1校验和的`redis.sha1hex`函数。
68 | - 用于返回错误信息的`redis.error_reply`函数和`redis.status_reply`函数。
69 |
70 | **(4)自制随机函数替代Lua原有的随机函数**
71 |
72 | 为了保证相同的脚本可以在不同的机器上产生相同的结果,**Redis要求所有传入服务器的Lua脚本,以及Lua环境中的所有函数,都必须是无副作用(side effect)的纯函数(pure func-tion)。**
73 |
74 | > 副作用是指:函数使用时除了返回值以外还破坏了系统环境,比如全局变量。
75 |
76 | Redis使用自制的函数替换了math库中原有的`math.random`函数和`math.randomseed`函数,替换之后的两个函数有以下特征:
77 |
78 | - 对于相同的seed来说,`math.random`总产生相同的随机数序列
79 | - 除非在脚本中使用`math.randomseed`显式地修改seed,否则每次运行脚本时,Lua环境都使用固定的`math.random-seed(0)`语句来初始化seed。
80 |
81 | **(5)创建排序辅助函数**
82 |
83 | 另一个可能产生不一致数据的地方是**那些带有不确定性质的命令**。比如对于一个集合键来说,因为集合元素的排列是无序的,所以即使两个集合的元素完全相同,它们的输出结果也可能并不相同。
84 |
85 | 为了消除这些命令带来的不确定性,服务器会为Lua环境创建一个排序辅助函数`__redis__compare_helper`,当Lua脚本执行完一个带有不确定性的命令之后,程序会使用`__redis__compare_helper`**作为对比函数自动调用`table.sort`函数对命令的返回值做一次排序,以此来保证相同的数据集总是产生相同的输出。**
86 |
87 | 如果我们在Lua脚本中对fruit集合和anotherfruit集合执行`SMEMBERS`命令,那么两个脚本将得出相同的结果:
88 |
89 | ```C
90 | redis> EVAL "return redis.call('SMEMBERS', KEYS[1])" 1 anotherfruit
91 | 1) "apple"
92 | 2) "banana"
93 | 3) "cherry"
94 |
95 | redis> EVAL "return redis.call('SMEMBERS', KEYS[1])" 1 fruit
96 | 1) "apple"
97 | 2) "banana"
98 | 3) "cherry"
99 | ```
100 |
101 | **(6)创建redis.pcall函数的错误报告辅助函数**
102 |
103 | 服务器将为Lua环境创建一个名为`__redis__err__handler`的错误处理函数,当脚本调用`redis.pcall`函数执行Redis命令,并且被执行的命令出现错误时,`__re-dis__err__handler`就会打印出错代码的来源和发生错误的行数,为程序的调试提供方便。
104 |
105 | **(7)保护Lua的全局环境**
106 |
107 | **确保传入服务器的脚本不会因为忘记使用local关键字而将额外的全局变量添加到Lua环境里面**。
108 |
109 | 如果误操作,程序会报错:
110 |
111 | ```
112 | redis> EVAL "x = 10" 0
113 | (error) ERR Error running script
114 | (call to f_df1ad3745c2d2f078f0f41377a92bb6f8ac79af0):
115 | @enable_strict_lua:7: user_script:1:
116 | Script attempted to create global variable 'x'
117 | ```
118 |
119 | 试图获取一个不存在的全局变量也会引发一个错误
120 |
121 | 不过**Redis并未禁止用户修改已存在的全局变量**,所以在执行Lua脚本的时候,必须非常小心,以免错误地修改了已存在的全局变量。
122 |
123 | ```C
124 | redis> EVAL "redis = 10086; return redis" 0
125 | (integer) 10086
126 | ```
127 |
128 | **(8)将Lua环境保存到服务器状态的lua属性里面**
129 |
130 | 最后的这一步,服务器会将Lua环境和服务器状态的lua属性关联起来
131 |
132 |  133 |
134 | # 2. Lua环境协作组件
135 |
136 | ## 2.1 伪客户端
137 |
138 | 伪客户端负责处理Lua脚本中包含的所有Redis命令。Lua脚本使用`redis.call`函数或者`redis.pcall`函数执行一个Redis命令,需要完成以下步骤:
139 |
140 | 1. `redis.call`函数或者`redis.pcall`函数想要执行的命令传给伪客户端。
141 | 2. 伪客户端将命令传递给命令执行器
142 | 3. 命令执行器执行,将结果返回给伪客户端
143 | 4. 伪客户端接受结果,返回给Lua环境
144 | 5. Lua环境在接收到命令结果之后,将该结果返回给`redis.call`函数或者`redis.pcall`函数。
145 | 6. 接收到结果的`redis.call`函数或者`redis.pcall`函数会将命令结果作为函数返回值返回给脚本中的调用者。
146 |
147 |
133 |
134 | # 2. Lua环境协作组件
135 |
136 | ## 2.1 伪客户端
137 |
138 | 伪客户端负责处理Lua脚本中包含的所有Redis命令。Lua脚本使用`redis.call`函数或者`redis.pcall`函数执行一个Redis命令,需要完成以下步骤:
139 |
140 | 1. `redis.call`函数或者`redis.pcall`函数想要执行的命令传给伪客户端。
141 | 2. 伪客户端将命令传递给命令执行器
142 | 3. 命令执行器执行,将结果返回给伪客户端
143 | 4. 伪客户端接受结果,返回给Lua环境
144 | 5. Lua环境在接收到命令结果之后,将该结果返回给`redis.call`函数或者`redis.pcall`函数。
145 | 6. 接收到结果的`redis.call`函数或者`redis.pcall`函数会将命令结果作为函数返回值返回给脚本中的调用者。
146 |
147 | 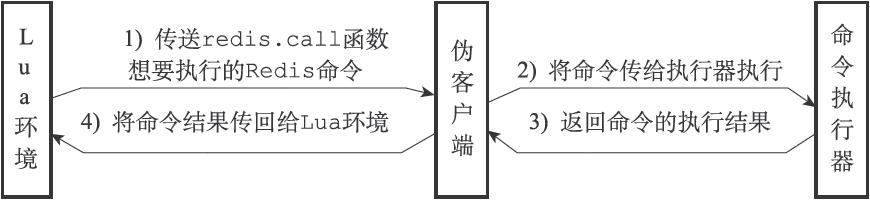 148 |
149 | ## 2.2 lua_script字典
150 |
151 | 这个字典的**键**为某个Lua脚本的SHA1校验和(checksum),而字典的**值**则是SHA1校验和对应的Lua脚本:
152 |
153 | ```C
154 | struct redisServer
155 | {
156 | // ...
157 | dict *lua_scripts;
158 | // ...
159 | };
160 | ```
161 |
162 | Redis服务器会**将所有被EVAL命令执行过的Lua脚本,以及所有被`SCRIPT LOAD`命令载入过的Lua脚本都保存到`lua_scripts`字典里面。**
163 |
164 | 如果客户端给服务器发送以下命令:
165 |
166 | ```C
167 | redis> SCRIPT LOAD "return 'hi'"
168 | "2f31ba2bb6d6a0f42cc159d2e2dad55440778de3"
169 |
170 | redis> SCRIPT LOAD "return 1+1"
171 | "a27e7e8a43702b7046d4f6a7ccf5b60cef6b9bd9"
172 |
173 | redis> SCRIPT LOAD "return 2*2"
174 | "4475bfb5919b5ad16424cb50f74d4724ae833e72"
175 | ```
176 |
177 |
148 |
149 | ## 2.2 lua_script字典
150 |
151 | 这个字典的**键**为某个Lua脚本的SHA1校验和(checksum),而字典的**值**则是SHA1校验和对应的Lua脚本:
152 |
153 | ```C
154 | struct redisServer
155 | {
156 | // ...
157 | dict *lua_scripts;
158 | // ...
159 | };
160 | ```
161 |
162 | Redis服务器会**将所有被EVAL命令执行过的Lua脚本,以及所有被`SCRIPT LOAD`命令载入过的Lua脚本都保存到`lua_scripts`字典里面。**
163 |
164 | 如果客户端给服务器发送以下命令:
165 |
166 | ```C
167 | redis> SCRIPT LOAD "return 'hi'"
168 | "2f31ba2bb6d6a0f42cc159d2e2dad55440778de3"
169 |
170 | redis> SCRIPT LOAD "return 1+1"
171 | "a27e7e8a43702b7046d4f6a7ccf5b60cef6b9bd9"
172 |
173 | redis> SCRIPT LOAD "return 2*2"
174 | "4475bfb5919b5ad16424cb50f74d4724ae833e72"
175 | ```
176 |
177 |  178 |
179 | # 3. Lua相关命令的实现
180 |
181 | ## 3.1 EVAL命令
182 |
183 | EVAL命令有三个参数:
184 |
185 | - Lua脚本
186 | - 脚本中使用键的个数
187 | - 键参数和脚本参数
188 |
189 | 比如,下面的例子中,2表示有两个键,名字为Key1和key2,first和second为脚本参数。
190 |
191 | ```lua
192 | -> EVAL "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
193 | 1) "key1"
194 | 2) "key2"
195 | 3) "first"
196 | 4) "second"
197 | ```
198 |
199 | 下面的例子中,比较了两种不同的用法:
200 |
201 | ```lua
202 | -> EVAL "return redis.call('set','foo','bar')" 0
203 | OK
204 |
205 | -> EVAL "return redis.call('set',KEYS[1],'bar')" 1 foo
206 | OK
207 | ```
208 |
209 | EVAL命令实现的过程分三步:
210 |
211 | 1. 根据客户端给定的Lua脚本,在Lua环境中定义一个Lua函数。
212 | 2. 将客户端给定的脚本保存到`lua_scripts`字典
213 | 3. 执行刚刚在Lua环境中定义的函数,以此来执行客户端给定的Lua脚本
214 |
215 | **(1)定义脚本函数**
216 |
217 | 服务器首先要做的就是在Lua环境中,为传入的脚本**定义一个与这个脚本相对应的Lua函数**。Lua函数的名字为`"_f"+SHA1校验和`,而函数的体(body)则是脚本本身。
218 |
219 | ```lua
220 | function f_5332031c6b470dc5a0dd9b4bf2030dea6d65de91()
221 | return 'hello world'
222 | end
223 | ```
224 |
225 | 使用函数来保存客户端传入的脚本可以**让Lua环境保持清洁**:减少了垃圾回收的工作量,并且避免了使用全局变量。
226 |
227 | **(2)脚本保存到lua_scripts字典**
228 |
229 | 首先服务器向lua_stripts字典中添加一个键值对,键为Lua脚本的SHA1校验和,值为Lua脚本本身(一个字符串)
230 |
231 |
178 |
179 | # 3. Lua相关命令的实现
180 |
181 | ## 3.1 EVAL命令
182 |
183 | EVAL命令有三个参数:
184 |
185 | - Lua脚本
186 | - 脚本中使用键的个数
187 | - 键参数和脚本参数
188 |
189 | 比如,下面的例子中,2表示有两个键,名字为Key1和key2,first和second为脚本参数。
190 |
191 | ```lua
192 | -> EVAL "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
193 | 1) "key1"
194 | 2) "key2"
195 | 3) "first"
196 | 4) "second"
197 | ```
198 |
199 | 下面的例子中,比较了两种不同的用法:
200 |
201 | ```lua
202 | -> EVAL "return redis.call('set','foo','bar')" 0
203 | OK
204 |
205 | -> EVAL "return redis.call('set',KEYS[1],'bar')" 1 foo
206 | OK
207 | ```
208 |
209 | EVAL命令实现的过程分三步:
210 |
211 | 1. 根据客户端给定的Lua脚本,在Lua环境中定义一个Lua函数。
212 | 2. 将客户端给定的脚本保存到`lua_scripts`字典
213 | 3. 执行刚刚在Lua环境中定义的函数,以此来执行客户端给定的Lua脚本
214 |
215 | **(1)定义脚本函数**
216 |
217 | 服务器首先要做的就是在Lua环境中,为传入的脚本**定义一个与这个脚本相对应的Lua函数**。Lua函数的名字为`"_f"+SHA1校验和`,而函数的体(body)则是脚本本身。
218 |
219 | ```lua
220 | function f_5332031c6b470dc5a0dd9b4bf2030dea6d65de91()
221 | return 'hello world'
222 | end
223 | ```
224 |
225 | 使用函数来保存客户端传入的脚本可以**让Lua环境保持清洁**:减少了垃圾回收的工作量,并且避免了使用全局变量。
226 |
227 | **(2)脚本保存到lua_scripts字典**
228 |
229 | 首先服务器向lua_stripts字典中添加一个键值对,键为Lua脚本的SHA1校验和,值为Lua脚本本身(一个字符串)
230 |
231 |  232 |
233 | **(3)执行脚本函数**
234 |
235 | 执行过程如下:
236 |
237 | 1. 将EVAL命令中传入的**键名(key name)参数和脚本参数分别保存到KEYS数组和ARGV数组**,然后将这两个数组作为全局变量传入到Lua环境里面。
238 | 2. 为Lua环境装载**超时处理钩子(hook)**,这个钩子可以在脚本出现超时运行情况时,让客户端通过SCRIPT KILL命令停止脚本,或者通过SHUTDOWN命令直接关闭服务器。
239 | 3. 执行脚本函数
240 | 4. 卸载钩子
241 | 5. 结果保存到客户端状态的输出缓冲区里面,等待服务器将结果返回给客户端。
242 | 6. 对Lua环境执行垃圾回收操作。
243 |
244 | ## 3.2 EVALSHA命令的实现
245 |
246 | 只要脚本对应的函数曾经在Lua环境里面定义过,那么**即使不知道脚本的内容本身,客户端也可以根据脚本的SHA1校验和来调用脚本对应的函数**,从而达到执行脚本的目的,这就是EVALSHA命令的实现原理。
247 |
248 |
232 |
233 | **(3)执行脚本函数**
234 |
235 | 执行过程如下:
236 |
237 | 1. 将EVAL命令中传入的**键名(key name)参数和脚本参数分别保存到KEYS数组和ARGV数组**,然后将这两个数组作为全局变量传入到Lua环境里面。
238 | 2. 为Lua环境装载**超时处理钩子(hook)**,这个钩子可以在脚本出现超时运行情况时,让客户端通过SCRIPT KILL命令停止脚本,或者通过SHUTDOWN命令直接关闭服务器。
239 | 3. 执行脚本函数
240 | 4. 卸载钩子
241 | 5. 结果保存到客户端状态的输出缓冲区里面,等待服务器将结果返回给客户端。
242 | 6. 对Lua环境执行垃圾回收操作。
243 |
244 | ## 3.2 EVALSHA命令的实现
245 |
246 | 只要脚本对应的函数曾经在Lua环境里面定义过,那么**即使不知道脚本的内容本身,客户端也可以根据脚本的SHA1校验和来调用脚本对应的函数**,从而达到执行脚本的目的,这就是EVALSHA命令的实现原理。
247 |
248 |  249 |
250 | 举个例子,当服务器执行完以下EVAL命令之后:
251 |
252 | ```lua
253 | redis> EVAL "return 'hello world'" 0
254 | "hello world"
255 | ```
256 |
257 | 当客户端执行以下EVALSHA命令时:
258 |
259 | ```lua
260 | redis> EVALSHA "5332031c6b470dc5a0dd9b4bf2030dea6d65de91" 0
261 | "hello world"
262 | ```
263 |
264 | ## 3.3 脚本管理命令的实现
265 |
266 | 除了EVAL命令和EVALSHA命令之外,Redis中与Lua脚本有关的命令还有四个,它们分别是**SCRIPT FLUSH命令、SCRIPT EXISTS命令、SCRIPT LOAD命令、以及SCRIPT KILL命令**。
267 |
268 | **(1)SCRIPT FLUSH**
269 |
270 | 释放并重建lua_scripts字典,关闭现有的Lua环境并重新创建一个新的Lua环境。
271 |
272 | **(2)SCRIPT EXISTS**
273 |
274 | 检查校验和对应的脚本是否存在于服务器中
275 |
276 | **(3)SCRIPT LOAD**
277 |
278 | Load和EVAL比较相似,区别在于Load装载后并不执行。
279 |
280 | ```lua
281 | redis> SCRIPT LOAD "return 'hi'"
282 | "2f31ba2bb6d6a0f42cc159d2e2dad55440778de3"
283 | ```
284 |
285 | 执行后,服务器创建此函数,于是我们可以:
286 |
287 | ```lua
288 | redis> EVALSHA "2f31ba2bb6d6a0f42cc159d2e2dad55440778de3" 0
289 | "hi"
290 | ```
291 |
292 | **(4)SCRIPT KILL**
293 |
294 | 如果服务器设置了`lua-time-limit`配置选项,那么在每次执行Lua脚本之前,服务器都会在Lua环境里面设置一个超时处理钩子(hook)。
295 |
296 | 一旦钩子发现脚本的运行时间已经超过了lua-time-limit选项设置的时长,**钩子将定期在脚本运行的间隙中,查看是否有SCRIPT KILL命令或者SHUTDOWN命令到达服务器。**达到类似于**中断**的效果。
297 |
298 |
249 |
250 | 举个例子,当服务器执行完以下EVAL命令之后:
251 |
252 | ```lua
253 | redis> EVAL "return 'hello world'" 0
254 | "hello world"
255 | ```
256 |
257 | 当客户端执行以下EVALSHA命令时:
258 |
259 | ```lua
260 | redis> EVALSHA "5332031c6b470dc5a0dd9b4bf2030dea6d65de91" 0
261 | "hello world"
262 | ```
263 |
264 | ## 3.3 脚本管理命令的实现
265 |
266 | 除了EVAL命令和EVALSHA命令之外,Redis中与Lua脚本有关的命令还有四个,它们分别是**SCRIPT FLUSH命令、SCRIPT EXISTS命令、SCRIPT LOAD命令、以及SCRIPT KILL命令**。
267 |
268 | **(1)SCRIPT FLUSH**
269 |
270 | 释放并重建lua_scripts字典,关闭现有的Lua环境并重新创建一个新的Lua环境。
271 |
272 | **(2)SCRIPT EXISTS**
273 |
274 | 检查校验和对应的脚本是否存在于服务器中
275 |
276 | **(3)SCRIPT LOAD**
277 |
278 | Load和EVAL比较相似,区别在于Load装载后并不执行。
279 |
280 | ```lua
281 | redis> SCRIPT LOAD "return 'hi'"
282 | "2f31ba2bb6d6a0f42cc159d2e2dad55440778de3"
283 | ```
284 |
285 | 执行后,服务器创建此函数,于是我们可以:
286 |
287 | ```lua
288 | redis> EVALSHA "2f31ba2bb6d6a0f42cc159d2e2dad55440778de3" 0
289 | "hi"
290 | ```
291 |
292 | **(4)SCRIPT KILL**
293 |
294 | 如果服务器设置了`lua-time-limit`配置选项,那么在每次执行Lua脚本之前,服务器都会在Lua环境里面设置一个超时处理钩子(hook)。
295 |
296 | 一旦钩子发现脚本的运行时间已经超过了lua-time-limit选项设置的时长,**钩子将定期在脚本运行的间隙中,查看是否有SCRIPT KILL命令或者SHUTDOWN命令到达服务器。**达到类似于**中断**的效果。
297 |
298 | 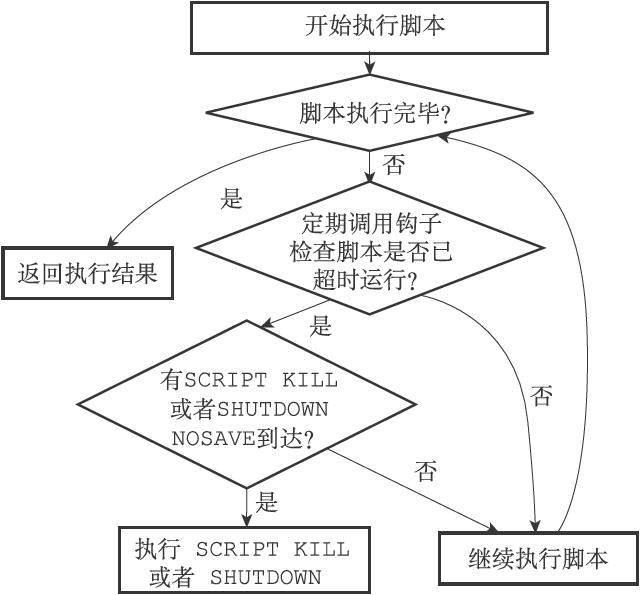 --------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现2-对象.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现2-对象
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-03 11:01:39
12 |
13 | ---
14 |
15 | 前一章介绍了Redis的主要数据结构,但Redis并没有直接使用这些数据结构来实现键值对数据库, 而是基于这些数据结构创建了一个对象系统 ,**这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象**这五种类型的对象。
16 |
17 | 使用对象有两个好处:
18 |
19 | - 执行命令前,根据对象类型来**判断是否可以执行此命令**。
20 | - 针对不同使用场景,为对象**设置多种不同的数据结构实现**,达到优化的目的。
21 |
22 | 此外,对象系统还引入了**引用计数实现内存回收机制**,以及**对象共享**。
23 |
24 | # 1. 对象的类型与编码
25 |
26 | Redis 中的**每个键值对的键和值都是一个对象,每个对象都由一个 `redisObject` 结构表示**, 该结构中和保存数据有关的三个属性分别是 `type` 属性、 `encoding` 属性和 `ptr` 属性:
27 |
28 | ```C
29 | typedef struct redisObject {
30 | // 类型
31 | unsigned type:4;
32 | // 编码
33 | unsigned encoding:4;
34 | // 指向底层实现数据结构的指针
35 | void *ptr;
36 | ...
37 |
38 | } robj;
39 | ```
40 |
41 | > 结构体的冒号表示位域,表示该变量占用的二进制位数
42 |
43 | ---
44 |
45 | 对象的 `type` 属性记录了**对象的类型**,属性的值如下表所示:
46 |
47 | | 类型常量 | 对象的名称 |
48 | | :------------: | :----------: |
49 | | `REDIS_STRING` | 字符串对象 |
50 | | `REDIS_LIST` | 列表对象 |
51 | | `REDIS_HASH` | 哈希对象 |
52 | | `REDIS_SET` | 集合对象 |
53 | | `REDIS_ZSET` | 有序集合对象 |
54 |
55 | 对于 Redis 数据库保存的键值对来说, **键总是一个字符串对象**, 而值则可以是上表中的其中一个。
56 |
57 | 所以,当我们称呼一个数据库键为“字符串键”时, 我们指的是“这个数据库键所对应的**值**为字符串对象”;同理,当我们称呼一个键为“列表键”时, 我们指的是“这个数据库键所对应的**值**为列表对象”。
58 |
59 | ---
60 |
61 | 对象的 `ptr` 指针指向对象的底层实现数据结构, 而这些数据结构由对象的 `encoding` 属性决定。`encoding` 属性如下表所示:
62 |
63 | | 编码常量 | 编码所对应的底层数据结构 |
64 | | :-------------------------: | :---------------------------: |
65 | | `REDIS_ENCODING_INT` | `long` 类型的整数 |
66 | | `REDIS_ENCODING_EMBSTR` | `embstr` 编码的简单动态字符串 |
67 | | `REDIS_ENCODING_RAW` | 简单动态字符串 |
68 | | `REDIS_ENCODING_HT` | 字典 |
69 | | `REDIS_ENCODING_LINKEDLIST` | 双端链表 |
70 | | `REDIS_ENCODING_ZIPLIST` | 压缩列表 |
71 | | `REDIS_ENCODING_INTSET` | 整数集合 |
72 | | `REDIS_ENCODING_SKIPLIST` | 跳跃表和字典 |
73 |
74 | # 2. 字符串对象
75 |
76 | ## 2.1 编码方式
77 |
78 | 字符串对象的编码可以是 `int` 、 `raw` 或者 `embstr` 。
79 |
80 | (1)如果一个字符串对象保存的是**整数值**, 并且这个整数值可以用 `long` 类型来表示, 那么字符串对象会**将整数值保存在字符串对象结构的 `ptr`属性里面**(将 `void*` 转换成 `long` ), 并将字符串对象的编码设置为 `int` 。
81 |
82 |
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现2-对象.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现2-对象
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-03 11:01:39
12 |
13 | ---
14 |
15 | 前一章介绍了Redis的主要数据结构,但Redis并没有直接使用这些数据结构来实现键值对数据库, 而是基于这些数据结构创建了一个对象系统 ,**这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象**这五种类型的对象。
16 |
17 | 使用对象有两个好处:
18 |
19 | - 执行命令前,根据对象类型来**判断是否可以执行此命令**。
20 | - 针对不同使用场景,为对象**设置多种不同的数据结构实现**,达到优化的目的。
21 |
22 | 此外,对象系统还引入了**引用计数实现内存回收机制**,以及**对象共享**。
23 |
24 | # 1. 对象的类型与编码
25 |
26 | Redis 中的**每个键值对的键和值都是一个对象,每个对象都由一个 `redisObject` 结构表示**, 该结构中和保存数据有关的三个属性分别是 `type` 属性、 `encoding` 属性和 `ptr` 属性:
27 |
28 | ```C
29 | typedef struct redisObject {
30 | // 类型
31 | unsigned type:4;
32 | // 编码
33 | unsigned encoding:4;
34 | // 指向底层实现数据结构的指针
35 | void *ptr;
36 | ...
37 |
38 | } robj;
39 | ```
40 |
41 | > 结构体的冒号表示位域,表示该变量占用的二进制位数
42 |
43 | ---
44 |
45 | 对象的 `type` 属性记录了**对象的类型**,属性的值如下表所示:
46 |
47 | | 类型常量 | 对象的名称 |
48 | | :------------: | :----------: |
49 | | `REDIS_STRING` | 字符串对象 |
50 | | `REDIS_LIST` | 列表对象 |
51 | | `REDIS_HASH` | 哈希对象 |
52 | | `REDIS_SET` | 集合对象 |
53 | | `REDIS_ZSET` | 有序集合对象 |
54 |
55 | 对于 Redis 数据库保存的键值对来说, **键总是一个字符串对象**, 而值则可以是上表中的其中一个。
56 |
57 | 所以,当我们称呼一个数据库键为“字符串键”时, 我们指的是“这个数据库键所对应的**值**为字符串对象”;同理,当我们称呼一个键为“列表键”时, 我们指的是“这个数据库键所对应的**值**为列表对象”。
58 |
59 | ---
60 |
61 | 对象的 `ptr` 指针指向对象的底层实现数据结构, 而这些数据结构由对象的 `encoding` 属性决定。`encoding` 属性如下表所示:
62 |
63 | | 编码常量 | 编码所对应的底层数据结构 |
64 | | :-------------------------: | :---------------------------: |
65 | | `REDIS_ENCODING_INT` | `long` 类型的整数 |
66 | | `REDIS_ENCODING_EMBSTR` | `embstr` 编码的简单动态字符串 |
67 | | `REDIS_ENCODING_RAW` | 简单动态字符串 |
68 | | `REDIS_ENCODING_HT` | 字典 |
69 | | `REDIS_ENCODING_LINKEDLIST` | 双端链表 |
70 | | `REDIS_ENCODING_ZIPLIST` | 压缩列表 |
71 | | `REDIS_ENCODING_INTSET` | 整数集合 |
72 | | `REDIS_ENCODING_SKIPLIST` | 跳跃表和字典 |
73 |
74 | # 2. 字符串对象
75 |
76 | ## 2.1 编码方式
77 |
78 | 字符串对象的编码可以是 `int` 、 `raw` 或者 `embstr` 。
79 |
80 | (1)如果一个字符串对象保存的是**整数值**, 并且这个整数值可以用 `long` 类型来表示, 那么字符串对象会**将整数值保存在字符串对象结构的 `ptr`属性里面**(将 `void*` 转换成 `long` ), 并将字符串对象的编码设置为 `int` 。
81 |
82 | 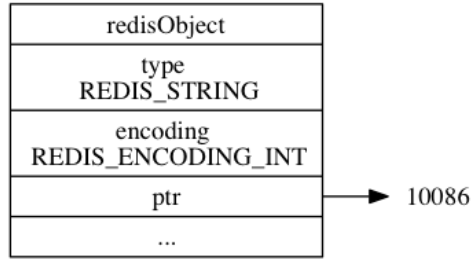 83 |
84 | (2)如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度**大于** `39` 字节, 那么字符串对象将**使用一个简单动态字符串(SDS)来保存这个字符串值**, 并将对象的编码设置为 `raw` 。
85 |
86 |
83 |
84 | (2)如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度**大于** `39` 字节, 那么字符串对象将**使用一个简单动态字符串(SDS)来保存这个字符串值**, 并将对象的编码设置为 `raw` 。
85 |
86 | 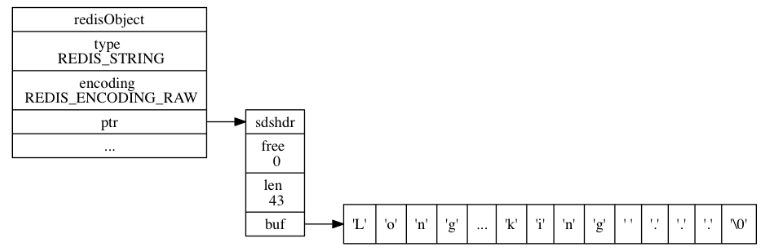 87 |
88 | (3)如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度**小于等于** `39` 字节, 那么字符串对象将使用 `embstr` 编码的方式来保存这个字符串值。
89 |
90 | `embstr` 编码是**专门用于保存短字符串**的一种优化编码方式。这种编码和 `raw` 编码一样, 都使用 `redisObject` 结构和 `sdshdr` 结构来表示字符串对象,区别在于:
91 |
92 | - `raw` 编码会**调用两次内存分配**函数来**分别**创建 `redisObject` 结构和 `sdshdr` 结构。
93 | - `embstr` 编码则通过**调用一次**内存分配函数来分配一块**连续的空间**。
94 |
95 |
87 |
88 | (3)如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度**小于等于** `39` 字节, 那么字符串对象将使用 `embstr` 编码的方式来保存这个字符串值。
89 |
90 | `embstr` 编码是**专门用于保存短字符串**的一种优化编码方式。这种编码和 `raw` 编码一样, 都使用 `redisObject` 结构和 `sdshdr` 结构来表示字符串对象,区别在于:
91 |
92 | - `raw` 编码会**调用两次内存分配**函数来**分别**创建 `redisObject` 结构和 `sdshdr` 结构。
93 | - `embstr` 编码则通过**调用一次**内存分配函数来分配一块**连续的空间**。
94 |
95 |  96 |
97 | 由于减少了内存分配的次数,以及将零散的内存整合到一起,这种编码的字符串对象比起 `raw` 编码能够**更好地利用缓存带来的优势**。
98 |
99 | 如果保存浮点数,则会先转化为字符串类型保存。比如保存3.14就会先转化为`"3.14"`。下表是值和对应的编码类型
100 |
101 | | 值 | 编码 |
102 | | :------------------------------------------------: | :-----------------: |
103 | | 可以用 `long` 类型保存的整数。 | `int` |
104 | | 可以用 `long double` 类型保存的浮点数。 | `embstr` 或者 `raw` |
105 | | 字符串值,长度太大没办法用 `long` 类型表示的整数。 | `embstr` 或者 `raw` |
106 |
107 | ## 2.2 编码转换
108 |
109 | 编码之间也会有**互相转换**的情况。对于 `int` 编码的字符串对象来说,如果因为命令导致这个对象保存的不再是整数值, 而是一个字符串值, 那么字符串对象的编码将从 `int` 变为 `raw` 。
110 |
111 | ```C
112 | redis> SET number 10086
113 | OK
114 |
115 | redis> OBJECT ENCODING number
116 | "int"
117 |
118 | redis> APPEND number " is a good number!"
119 | (integer) 23
120 |
121 | redis> GET number
122 | "10086 is a good number!"
123 |
124 | redis> OBJECT ENCODING number
125 | "raw"
126 | ```
127 |
128 | 因为 Redis 没有为 `embstr` 编码的字符串对象编写任何相应的修改程序 , 所以 `embstr` 编码的字符串对象**实际上是只读的**。当修改`embstr` 编码的字符串对象, 程序会**先将对象的编码从 `embstr` 转换成 `raw` , 然后再执行修改命令**。
129 |
130 | ```C
131 | redis> SET msg "hello world"
132 | OK
133 |
134 | redis> OBJECT ENCODING msg
135 | "embstr"
136 |
137 | redis> APPEND msg " again!"
138 | (integer) 18
139 |
140 | redis> OBJECT ENCODING msg
141 | "raw"
142 | ```
143 |
144 | # 3. 列表对象
145 |
146 | ## 3.1 编码方式
147 |
148 | 列表对象的编码可以是 `ziplist` 或者 `linkedlist`。
149 |
150 | 如同前面提到的,**压缩列表每个节点(entry)只保存一个列表元素**。下面例子中,我们输入数字1,字符"three"和数字5,
151 |
152 | ```C
153 | redis> RPUSH numbers 1 "three" 5
154 | (integer) 3
155 | ```
156 |
157 |
96 |
97 | 由于减少了内存分配的次数,以及将零散的内存整合到一起,这种编码的字符串对象比起 `raw` 编码能够**更好地利用缓存带来的优势**。
98 |
99 | 如果保存浮点数,则会先转化为字符串类型保存。比如保存3.14就会先转化为`"3.14"`。下表是值和对应的编码类型
100 |
101 | | 值 | 编码 |
102 | | :------------------------------------------------: | :-----------------: |
103 | | 可以用 `long` 类型保存的整数。 | `int` |
104 | | 可以用 `long double` 类型保存的浮点数。 | `embstr` 或者 `raw` |
105 | | 字符串值,长度太大没办法用 `long` 类型表示的整数。 | `embstr` 或者 `raw` |
106 |
107 | ## 2.2 编码转换
108 |
109 | 编码之间也会有**互相转换**的情况。对于 `int` 编码的字符串对象来说,如果因为命令导致这个对象保存的不再是整数值, 而是一个字符串值, 那么字符串对象的编码将从 `int` 变为 `raw` 。
110 |
111 | ```C
112 | redis> SET number 10086
113 | OK
114 |
115 | redis> OBJECT ENCODING number
116 | "int"
117 |
118 | redis> APPEND number " is a good number!"
119 | (integer) 23
120 |
121 | redis> GET number
122 | "10086 is a good number!"
123 |
124 | redis> OBJECT ENCODING number
125 | "raw"
126 | ```
127 |
128 | 因为 Redis 没有为 `embstr` 编码的字符串对象编写任何相应的修改程序 , 所以 `embstr` 编码的字符串对象**实际上是只读的**。当修改`embstr` 编码的字符串对象, 程序会**先将对象的编码从 `embstr` 转换成 `raw` , 然后再执行修改命令**。
129 |
130 | ```C
131 | redis> SET msg "hello world"
132 | OK
133 |
134 | redis> OBJECT ENCODING msg
135 | "embstr"
136 |
137 | redis> APPEND msg " again!"
138 | (integer) 18
139 |
140 | redis> OBJECT ENCODING msg
141 | "raw"
142 | ```
143 |
144 | # 3. 列表对象
145 |
146 | ## 3.1 编码方式
147 |
148 | 列表对象的编码可以是 `ziplist` 或者 `linkedlist`。
149 |
150 | 如同前面提到的,**压缩列表每个节点(entry)只保存一个列表元素**。下面例子中,我们输入数字1,字符"three"和数字5,
151 |
152 | ```C
153 | redis> RPUSH numbers 1 "three" 5
154 | (integer) 3
155 | ```
156 |
157 | 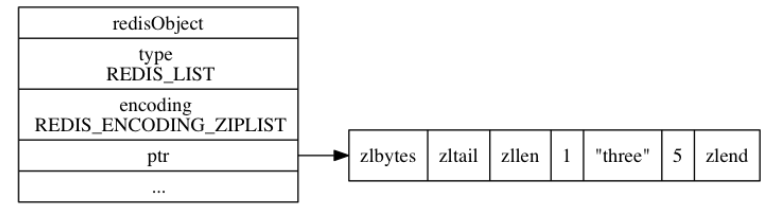 158 |
159 | ---
160 |
161 | 如果使用的不是 `ziplist` 编码, 而是 `linkedlist`双端链表 编码, 那么
162 |
163 |
158 |
159 | ---
160 |
161 | 如果使用的不是 `ziplist` 编码, 而是 `linkedlist`双端链表 编码, 那么
162 |
163 | 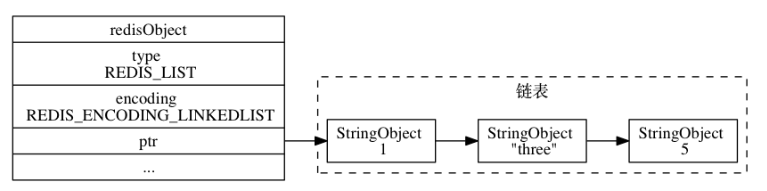 164 |
165 | 这其实是一个**嵌套编码**,Redis使用了一个带有 `StringObject` 来表示一个字符串对象,编码方式如同上面提到的那三种。**如果编码对象时字符串值**,展开后就是:
166 |
167 |
164 |
165 | 这其实是一个**嵌套编码**,Redis使用了一个带有 `StringObject` 来表示一个字符串对象,编码方式如同上面提到的那三种。**如果编码对象时字符串值**,展开后就是:
166 |
167 |  168 |
169 | ## 3.2 编码转换
170 |
171 | 当列表对象可以同时满足以下两个条件时, 列表对象使用 `ziplist` 编码:
172 |
173 | 1. 列表对象保存的**所有**字符串元素的长度都小于 `64` 字节;
174 | 2. 列表对象保存的元素数量小于 `512` 个;
175 |
176 | 当上述条件任意一个不满足时,就会执行**转换操作**: 原本保存在压缩列表里的所有列表元素都会被转移并保存到双端链表里面, 对象的编码也会从 `ziplist` 变为 `linkedlist` 。
177 |
178 | # 4. 哈希对象
179 |
180 | ## 4.1 编码方式
181 |
182 | 哈希对象的编码可以是 `ziplist` 或者 `hashtable` 。
183 |
184 | `ziplist` 编码时,每当有新的键值对要加入到哈希对象时, 程序会**先将保存了键**的压缩列表节点推入到压缩列表表尾, 然后**再将保存了值**的压缩列表节点推入到压缩列表表尾, 因此:
185 |
186 | - 保存了同一键值对的两个节点总是**紧挨在一起, 键前值后。**
187 | - **先添加**到哈希对象中的键值对会被放在压缩列表的**表头方向**, 而**后来添加**到哈希对象中的键值对会被放在压缩列表的**表尾方向**。
188 |
189 | 比如:
190 |
191 | ```C
192 | redis> HSET profile name "Tom"
193 | (integer) 1
194 |
195 | redis> HSET profile age 25
196 | (integer) 1
197 |
198 | redis> HSET profile career "Programmer"
199 | (integer) 1
200 | ```
201 |
202 |
168 |
169 | ## 3.2 编码转换
170 |
171 | 当列表对象可以同时满足以下两个条件时, 列表对象使用 `ziplist` 编码:
172 |
173 | 1. 列表对象保存的**所有**字符串元素的长度都小于 `64` 字节;
174 | 2. 列表对象保存的元素数量小于 `512` 个;
175 |
176 | 当上述条件任意一个不满足时,就会执行**转换操作**: 原本保存在压缩列表里的所有列表元素都会被转移并保存到双端链表里面, 对象的编码也会从 `ziplist` 变为 `linkedlist` 。
177 |
178 | # 4. 哈希对象
179 |
180 | ## 4.1 编码方式
181 |
182 | 哈希对象的编码可以是 `ziplist` 或者 `hashtable` 。
183 |
184 | `ziplist` 编码时,每当有新的键值对要加入到哈希对象时, 程序会**先将保存了键**的压缩列表节点推入到压缩列表表尾, 然后**再将保存了值**的压缩列表节点推入到压缩列表表尾, 因此:
185 |
186 | - 保存了同一键值对的两个节点总是**紧挨在一起, 键前值后。**
187 | - **先添加**到哈希对象中的键值对会被放在压缩列表的**表头方向**, 而**后来添加**到哈希对象中的键值对会被放在压缩列表的**表尾方向**。
188 |
189 | 比如:
190 |
191 | ```C
192 | redis> HSET profile name "Tom"
193 | (integer) 1
194 |
195 | redis> HSET profile age 25
196 | (integer) 1
197 |
198 | redis> HSET profile career "Programmer"
199 | (integer) 1
200 | ```
201 |
202 |  203 |
204 | ---
205 |
206 | `hashtable` 编码时, 哈希对象中的每个键值对都使用一个字典键值对来保存:
207 |
208 | - 字典的每个键都是一个**字符串对象**, 对象中保存了键值对的键;
209 | - 字典的每个值都是一个**字符串对象**, 对象中保存了键值对的值。
210 |
211 | 比如,上面的例子改为`hashtable` 编码
212 |
213 |
203 |
204 | ---
205 |
206 | `hashtable` 编码时, 哈希对象中的每个键值对都使用一个字典键值对来保存:
207 |
208 | - 字典的每个键都是一个**字符串对象**, 对象中保存了键值对的键;
209 | - 字典的每个值都是一个**字符串对象**, 对象中保存了键值对的值。
210 |
211 | 比如,上面的例子改为`hashtable` 编码
212 |
213 | 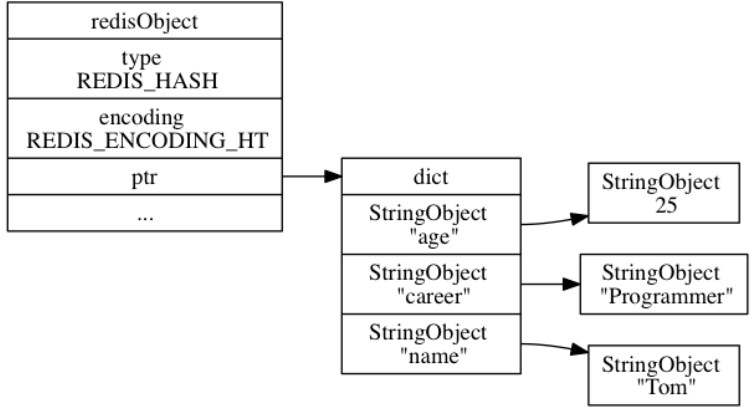 214 |
215 | ## 4.2 编码转换
216 |
217 | 当哈希对象可以同时满足以下两个条件时, 哈希对象使用 `ziplist` 编码:
218 |
219 | 1. 哈希对象保存的所有键值对的键和值的字符串长度都小于 `64` 字节;
220 | 2. 哈希对象保存的键值对数量小于 `512` 个;
221 |
222 | 和列表对象一样,不满足条件时原本保存在压缩列表里的所有键值对都会被转移并保存到字典里面, 对象的编码也会从 `ziplist` 变为 `hashtable` 。
223 |
224 | # 5. 集合对象
225 |
226 | Redis中集合和列表结构相似,但**集合具有唯一性,列表不具有**。
227 |
228 | ## 5.1 编码方式
229 |
230 | 集合对象的编码可以是 `intset` 或者 `hashtable` 。
231 |
232 | `intset` 编码时,元素将被密集得堆叠在位上,比如
233 |
234 | ```C
235 | redis> SADD numbers 1 3 5
236 | (integer) 3
237 | ```
238 |
239 |
214 |
215 | ## 4.2 编码转换
216 |
217 | 当哈希对象可以同时满足以下两个条件时, 哈希对象使用 `ziplist` 编码:
218 |
219 | 1. 哈希对象保存的所有键值对的键和值的字符串长度都小于 `64` 字节;
220 | 2. 哈希对象保存的键值对数量小于 `512` 个;
221 |
222 | 和列表对象一样,不满足条件时原本保存在压缩列表里的所有键值对都会被转移并保存到字典里面, 对象的编码也会从 `ziplist` 变为 `hashtable` 。
223 |
224 | # 5. 集合对象
225 |
226 | Redis中集合和列表结构相似,但**集合具有唯一性,列表不具有**。
227 |
228 | ## 5.1 编码方式
229 |
230 | 集合对象的编码可以是 `intset` 或者 `hashtable` 。
231 |
232 | `intset` 编码时,元素将被密集得堆叠在位上,比如
233 |
234 | ```C
235 | redis> SADD numbers 1 3 5
236 | (integer) 3
237 | ```
238 |
239 | 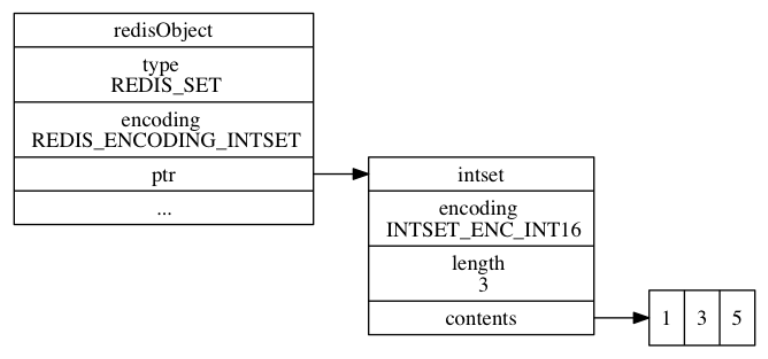 240 |
241 | ---
242 |
243 | 另一方面, `hashtable` 编码的集合对象使用字典作为底层实现, 字典的**每个键都是一个字符串对象**, 每个字符串对象包含了一个集合元素, 而**字典的值则全部被设置为 `NULL` 。**
244 |
245 |
240 |
241 | ---
242 |
243 | 另一方面, `hashtable` 编码的集合对象使用字典作为底层实现, 字典的**每个键都是一个字符串对象**, 每个字符串对象包含了一个集合元素, 而**字典的值则全部被设置为 `NULL` 。**
244 |
245 |  246 |
247 | ## 5.2 编码的转换
248 |
249 | 当集合对象可以同时满足以下两个条件时, 对象使用 `intset` 编码:
250 |
251 | 1. 集合对象保存的所有元素**都是整数值**;
252 | 2. 集合对象保存的元素数量不超过 `512` 个;
253 |
254 | 当使用 `intset` 编码所需的两个条件的任意一个不能被满足时, 对象的编码转换操作就会被执行: 原本保存在整数集合中的所有元素都会被转移并保存到字典里面, 并且对象的编码也会从 `intset` 变为 `hashtable` 。
255 |
256 | # 6. 有序集合对象
257 |
258 | ## 6.1 编码方式
259 |
260 | 有序集合的编码可以是 `ziplist` 或者 `skiplist` 。
261 |
262 | `ziplist` 编码的有序集合对象使用压缩列表作为底层实现, 每个集合元素使用两个紧挨在一起的压缩列表节点来保存, 第一个节点保存元素的成员(member), 而第二个元素则保存元素的分值(score)。
263 |
264 | ```C
265 | redis> ZADD price 8.5 apple 5.0 banana 6.0 cherry
266 | (integer) 3
267 | ```
268 |
269 |
246 |
247 | ## 5.2 编码的转换
248 |
249 | 当集合对象可以同时满足以下两个条件时, 对象使用 `intset` 编码:
250 |
251 | 1. 集合对象保存的所有元素**都是整数值**;
252 | 2. 集合对象保存的元素数量不超过 `512` 个;
253 |
254 | 当使用 `intset` 编码所需的两个条件的任意一个不能被满足时, 对象的编码转换操作就会被执行: 原本保存在整数集合中的所有元素都会被转移并保存到字典里面, 并且对象的编码也会从 `intset` 变为 `hashtable` 。
255 |
256 | # 6. 有序集合对象
257 |
258 | ## 6.1 编码方式
259 |
260 | 有序集合的编码可以是 `ziplist` 或者 `skiplist` 。
261 |
262 | `ziplist` 编码的有序集合对象使用压缩列表作为底层实现, 每个集合元素使用两个紧挨在一起的压缩列表节点来保存, 第一个节点保存元素的成员(member), 而第二个元素则保存元素的分值(score)。
263 |
264 | ```C
265 | redis> ZADD price 8.5 apple 5.0 banana 6.0 cherry
266 | (integer) 3
267 | ```
268 |
269 | 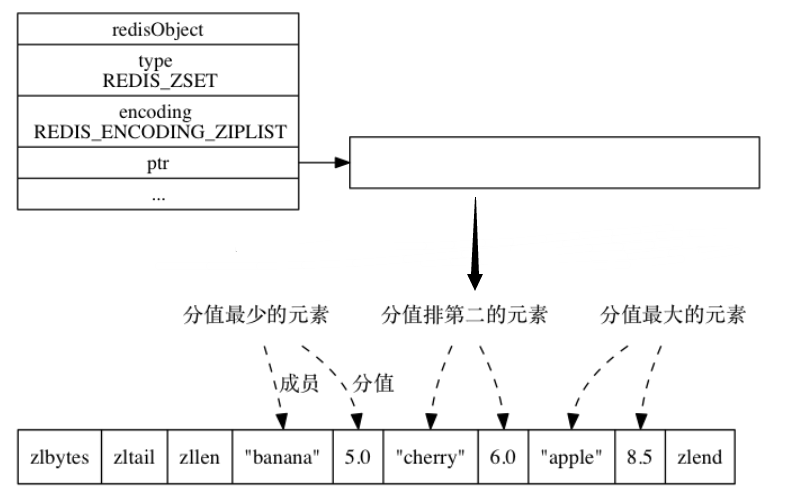 270 |
271 | ---
272 |
273 | `skiplist` 编码的有序集合对象使用 `zset` 结构作为底层实现, 一个 `zset` 结构同时**包含一个字典和一个跳跃表**:
274 |
275 | ```C
276 | typedef struct zset {
277 | zskiplist *zsl;
278 | dict *dict;
279 | } zset;
280 | ```
281 |
282 | 起作用主要是跳跃表,字典是辅助加速用。**字典的键记录了元素的成员,而值则保存了元素的分值**。通过字典,能实现$O(1)$复杂度的查找给定成员分值。
283 |
284 |
270 |
271 | ---
272 |
273 | `skiplist` 编码的有序集合对象使用 `zset` 结构作为底层实现, 一个 `zset` 结构同时**包含一个字典和一个跳跃表**:
274 |
275 | ```C
276 | typedef struct zset {
277 | zskiplist *zsl;
278 | dict *dict;
279 | } zset;
280 | ```
281 |
282 | 起作用主要是跳跃表,字典是辅助加速用。**字典的键记录了元素的成员,而值则保存了元素的分值**。通过字典,能实现$O(1)$复杂度的查找给定成员分值。
283 |
284 |  285 |
286 | ---
287 |
288 | 有序集合**每个元素的成员都是一个字符串对象**, 而每个元素的**分值都是一个 `double` 类型的浮点数**。
289 |
290 | 虽然 `zset` 结构同时使用跳跃表和字典来保存有序集合元素, 但这两种数据结构都会**通过指针来共享相同元素的成员和分值**, 所以同时使用跳跃表和字典来保存集合元素不会产生任何重复成员或者分值, 也不会因此而浪费额外的内存。
291 |
292 | ## 6.2 编码转换
293 |
294 | 当有序集合对象可以同时满足以下两个条件时, 对象使用 `ziplist` 编码:
295 |
296 | 1. 有序集合保存的元素数量小于 `128` 个;
297 | 2. 有序集合保存的所有元素成员的长度都小于 `64` 字节;
298 |
299 | 不能满足以上两个条件的有序集合对象将使用 `skiplist` 编码。
300 |
301 | # 7. 内存回收、对象共享和空转时长
302 |
303 | 对象中包括了一个引用计数器:
304 |
305 | ```C
306 | typedef struct redisObject {
307 | // ...
308 | // 引用计数
309 | int refcount;
310 | // ...
311 | } robj;
312 | ```
313 |
314 | 对象的引用计数信息会随着对象的使用状态而不断变化:
315 |
316 | - 在创建一个新对象时, 引用计数的值会被初始化为 `1` ;
317 | - 当对象被引用时,计数值+1;
318 | - 当对象不再被引用时,计数值-1;
319 | - 当对象的引用计数值变为 `0` 时, 对象所占用的内存会被释放。
320 |
321 | | 函数 | 作用 |
322 | | :-------------: | :----------------------------------------------------------: |
323 | | `incrRefCount` | 将对象的引用计数值增一。 |
324 | | `decrRefCount` | 将对象的引用计数值减一, 当对象的引用计数值等于 `0` 时, 释放对象。 |
325 | | `resetRefCount` | 将对象的引用计数值设置为 `0` , 但并不释放对象, 这个函数通常在需要重新设置对象的引用计数值时使用。 |
326 |
327 | ---
328 |
329 | 通过引用机制,还能实现对象共享。共享**只针对整数值对象,不针对包含字符串的对象。**
330 |
331 | 假设键 A 创建了一个包含整数值 `100` 的字符串对象作为值对象,
332 |
333 |
285 |
286 | ---
287 |
288 | 有序集合**每个元素的成员都是一个字符串对象**, 而每个元素的**分值都是一个 `double` 类型的浮点数**。
289 |
290 | 虽然 `zset` 结构同时使用跳跃表和字典来保存有序集合元素, 但这两种数据结构都会**通过指针来共享相同元素的成员和分值**, 所以同时使用跳跃表和字典来保存集合元素不会产生任何重复成员或者分值, 也不会因此而浪费额外的内存。
291 |
292 | ## 6.2 编码转换
293 |
294 | 当有序集合对象可以同时满足以下两个条件时, 对象使用 `ziplist` 编码:
295 |
296 | 1. 有序集合保存的元素数量小于 `128` 个;
297 | 2. 有序集合保存的所有元素成员的长度都小于 `64` 字节;
298 |
299 | 不能满足以上两个条件的有序集合对象将使用 `skiplist` 编码。
300 |
301 | # 7. 内存回收、对象共享和空转时长
302 |
303 | 对象中包括了一个引用计数器:
304 |
305 | ```C
306 | typedef struct redisObject {
307 | // ...
308 | // 引用计数
309 | int refcount;
310 | // ...
311 | } robj;
312 | ```
313 |
314 | 对象的引用计数信息会随着对象的使用状态而不断变化:
315 |
316 | - 在创建一个新对象时, 引用计数的值会被初始化为 `1` ;
317 | - 当对象被引用时,计数值+1;
318 | - 当对象不再被引用时,计数值-1;
319 | - 当对象的引用计数值变为 `0` 时, 对象所占用的内存会被释放。
320 |
321 | | 函数 | 作用 |
322 | | :-------------: | :----------------------------------------------------------: |
323 | | `incrRefCount` | 将对象的引用计数值增一。 |
324 | | `decrRefCount` | 将对象的引用计数值减一, 当对象的引用计数值等于 `0` 时, 释放对象。 |
325 | | `resetRefCount` | 将对象的引用计数值设置为 `0` , 但并不释放对象, 这个函数通常在需要重新设置对象的引用计数值时使用。 |
326 |
327 | ---
328 |
329 | 通过引用机制,还能实现对象共享。共享**只针对整数值对象,不针对包含字符串的对象。**
330 |
331 | 假设键 A 创建了一个包含整数值 `100` 的字符串对象作为值对象,
332 |
333 | 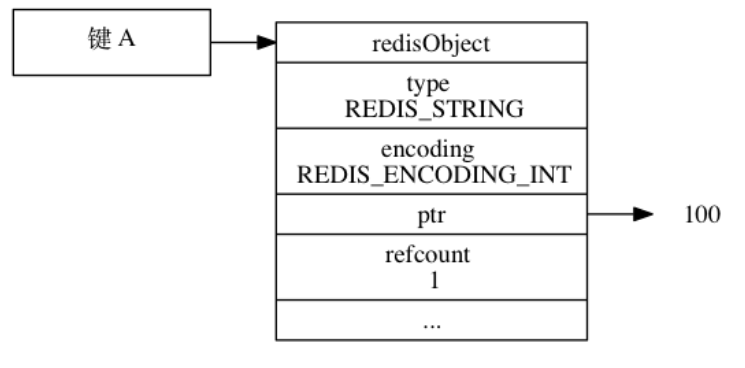 334 |
335 | 如果这时键 B 也要创建一个同样保存了整数值 `100` 的字符串对象作为值对象, 那么服务器有以下两种做法:
336 |
337 | 1. 为键 B 新创建一个包含整数值 `100` 的字符串对象;
338 | 2. 让键 A 和键 B 共享同一个字符串对象;
339 |
340 | 以上两种方法很明显是第二种方法更节约内存。在 Redis 中, 让多个键共享同一个值对象需要执行以下两个步骤:
341 |
342 | 1. 将数据库键的值指针指向一个现有的值对象;
343 | 2. 将被共享的值对象的引用计数增一。
344 |
345 | Redis 会在初始化服务器时, 创建一万个**字符串对象**, 这些对象包含了从 `0` 到 `9999` 的所有整数值, 当服务器需要用到值为 `0`到 `9999` 的字符串对象时, 服务器就会使用这些共享对象, 而不是新创建对象。
346 |
347 | 为什么 Redis 不共享包含字符串的对象?
348 |
349 | 判断是否共享时要检验**共享对象和目标对象是否相同**。复杂度如下,
350 |
351 | | 共享对象 | 复杂度 |
352 | | :------------------------------: | :------: |
353 | | 保存整数值字符串对象 | $O( 1)$ |
354 | | 保存字符串值的字符串对象 | $O(N)$ |
355 | | 包含了多个值的对象(列表或哈希) | $O(N^2)$ |
356 |
357 | ---
358 |
359 | `redisObject` 结构包含的最后一个属性为 `lru` 属性, 该属性记录了对象最后一次被命令程序访问的时间:
360 |
361 | ```C
362 | typedef struct redisObject {
363 | // ...
364 | unsigned lru:22;
365 | // ...
366 |
367 | } robj;
368 | ```
369 |
370 | `OBJECT IDLETIME` 命令可以打印出给定键的空转时长, 这一空转时长就是通过将当前时间减去键的值对象的 `lru` 时间计算得出的:
371 |
372 | ```C
373 | redis> SET msg "hello world"
374 | OK
375 |
376 | # 等待一小段时间
377 | redis> OBJECT IDLETIME msg
378 | (integer) 20
379 | ```
380 |
381 | 注意`OBJECT IDLETIME` 命令的实现是特殊的, 这个命令在访问键的值对象时, **不会修改值对象的 `lru` 属性**。这类似于`std::weak_ptr`的作用。
382 |
383 | 当内存满时,空转时长较长的键会被优先释放。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现3-数据库基本结构.md:
--------------------------------------------------------------------------------
1 | ---
2 | Rtitle: Redis设计与实现3-数据库基本结构
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-04 09:59:28
12 | ---
13 |
14 | 本章将对Redis服务器的数据库实现进行介绍,介绍键空间、过期键,数据库通知的实现方法。
15 |
16 | # 1. 数据库的切换
17 |
18 | Redis服务器将所有数据库都保存在**服务器状态**`redis.h/redisServer`结构的db数组中,db数组的每个项都是一个`redis.h/redisDb`结构,**每个redisDb结构代表一个数据库**:
19 |
20 | ```C
21 | struct redisServer
22 | {
23 | // ...
24 | redisDb *db;
25 | int dbnum;
26 | // ...
27 | };
28 | ```
29 |
30 | 初始化时,程序会根据当前服务器的`dbnum`属性来**决定建立数据库的个数**,默认创建16个。
31 |
32 |
334 |
335 | 如果这时键 B 也要创建一个同样保存了整数值 `100` 的字符串对象作为值对象, 那么服务器有以下两种做法:
336 |
337 | 1. 为键 B 新创建一个包含整数值 `100` 的字符串对象;
338 | 2. 让键 A 和键 B 共享同一个字符串对象;
339 |
340 | 以上两种方法很明显是第二种方法更节约内存。在 Redis 中, 让多个键共享同一个值对象需要执行以下两个步骤:
341 |
342 | 1. 将数据库键的值指针指向一个现有的值对象;
343 | 2. 将被共享的值对象的引用计数增一。
344 |
345 | Redis 会在初始化服务器时, 创建一万个**字符串对象**, 这些对象包含了从 `0` 到 `9999` 的所有整数值, 当服务器需要用到值为 `0`到 `9999` 的字符串对象时, 服务器就会使用这些共享对象, 而不是新创建对象。
346 |
347 | 为什么 Redis 不共享包含字符串的对象?
348 |
349 | 判断是否共享时要检验**共享对象和目标对象是否相同**。复杂度如下,
350 |
351 | | 共享对象 | 复杂度 |
352 | | :------------------------------: | :------: |
353 | | 保存整数值字符串对象 | $O( 1)$ |
354 | | 保存字符串值的字符串对象 | $O(N)$ |
355 | | 包含了多个值的对象(列表或哈希) | $O(N^2)$ |
356 |
357 | ---
358 |
359 | `redisObject` 结构包含的最后一个属性为 `lru` 属性, 该属性记录了对象最后一次被命令程序访问的时间:
360 |
361 | ```C
362 | typedef struct redisObject {
363 | // ...
364 | unsigned lru:22;
365 | // ...
366 |
367 | } robj;
368 | ```
369 |
370 | `OBJECT IDLETIME` 命令可以打印出给定键的空转时长, 这一空转时长就是通过将当前时间减去键的值对象的 `lru` 时间计算得出的:
371 |
372 | ```C
373 | redis> SET msg "hello world"
374 | OK
375 |
376 | # 等待一小段时间
377 | redis> OBJECT IDLETIME msg
378 | (integer) 20
379 | ```
380 |
381 | 注意`OBJECT IDLETIME` 命令的实现是特殊的, 这个命令在访问键的值对象时, **不会修改值对象的 `lru` 属性**。这类似于`std::weak_ptr`的作用。
382 |
383 | 当内存满时,空转时长较长的键会被优先释放。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现3-数据库基本结构.md:
--------------------------------------------------------------------------------
1 | ---
2 | Rtitle: Redis设计与实现3-数据库基本结构
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-04 09:59:28
12 | ---
13 |
14 | 本章将对Redis服务器的数据库实现进行介绍,介绍键空间、过期键,数据库通知的实现方法。
15 |
16 | # 1. 数据库的切换
17 |
18 | Redis服务器将所有数据库都保存在**服务器状态**`redis.h/redisServer`结构的db数组中,db数组的每个项都是一个`redis.h/redisDb`结构,**每个redisDb结构代表一个数据库**:
19 |
20 | ```C
21 | struct redisServer
22 | {
23 | // ...
24 | redisDb *db;
25 | int dbnum;
26 | // ...
27 | };
28 | ```
29 |
30 | 初始化时,程序会根据当前服务器的`dbnum`属性来**决定建立数据库的个数**,默认创建16个。
31 |
32 |  33 |
34 | ---
35 |
36 | 每个Redis客户端都有自己的目标数据库,当客户端执行读写命令时,就需要**切换数据库**。
37 |
38 | 默认情况下,Redis客户端的目标数据库为0号数据库,但客户端可以通过执行**SELECT命令**来切换目标数据库。
39 |
40 | ```c
41 | redis> SET msg "hello world"
42 | OK
43 |
44 | redis> GET msg
45 | "hello world"
46 |
47 | redis> SELECT 2
48 | OK
49 |
50 | redis[2]> GET msg
51 | (nil)
52 | ```
53 |
54 | 在服务器内部,**客户端状态**redisClient结构的db属性记录了**客户端当前的目标数据库**,这个属性是一个指向redisDb结构的指针:
55 |
56 | ```C
57 | typedef struct redisClient
58 | {
59 | // ...
60 | //记录客户端当前正在使用的数据库
61 | redisDb *db;
62 | // ...
63 | } redisClient;
64 | ```
65 |
66 | 如果某个**客户端的目标数据库**为1号数据库,那么这个客户端所对应的客户端状态和**服务器状态**之间的关系如图:
67 |
68 |
33 |
34 | ---
35 |
36 | 每个Redis客户端都有自己的目标数据库,当客户端执行读写命令时,就需要**切换数据库**。
37 |
38 | 默认情况下,Redis客户端的目标数据库为0号数据库,但客户端可以通过执行**SELECT命令**来切换目标数据库。
39 |
40 | ```c
41 | redis> SET msg "hello world"
42 | OK
43 |
44 | redis> GET msg
45 | "hello world"
46 |
47 | redis> SELECT 2
48 | OK
49 |
50 | redis[2]> GET msg
51 | (nil)
52 | ```
53 |
54 | 在服务器内部,**客户端状态**redisClient结构的db属性记录了**客户端当前的目标数据库**,这个属性是一个指向redisDb结构的指针:
55 |
56 | ```C
57 | typedef struct redisClient
58 | {
59 | // ...
60 | //记录客户端当前正在使用的数据库
61 | redisDb *db;
62 | // ...
63 | } redisClient;
64 | ```
65 |
66 | 如果某个**客户端的目标数据库**为1号数据库,那么这个客户端所对应的客户端状态和**服务器状态**之间的关系如图:
67 |
68 |  69 |
70 | 通过修改指针,使他指向服务器中不同的数据库,从而达到切换的目的。
71 |
72 | # 2. 数据库键空间
73 |
74 | ## 2.1 键空间结构
75 |
76 | Redis是一个**键值对数据库服务器**,每个数据库都是一个redis.h/redisDb结构。**其中`dict`字典保存了数据库中所有的键值对**,我们将这个字典称为**键空间(key space)**。
77 |
78 | ```C
79 | typedef struct redisDb
80 | { // ...
81 | // 数据库键空间,保存着数据库中的所有键值对
82 | dict *dict;
83 | // ...
84 | } redisDb;
85 | ```
86 |
87 | 键空间的键就是数据库的键,每个键是一个**字符串对象**。键空间的值就是数据库的值,可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象中的一种。
88 |
89 | 当我们输入以下命令时:
90 |
91 | ```C
92 | redis> SET message "hello world"
93 | OK
94 |
95 | redis> RPUSH alphabet "a" "b" "c"
96 | (integer)3
97 |
98 | redis> HSET book name "Redis in Action"
99 | (integer) 1
100 |
101 | redis> HSET book author "Josiah L. Carlson"
102 | (integer) 1
103 |
104 | redis> HSET book publisher "Manning"
105 | (integer) 1
106 | ```
107 |
108 | 数据库的键空间结构如下:
109 |
110 |
69 |
70 | 通过修改指针,使他指向服务器中不同的数据库,从而达到切换的目的。
71 |
72 | # 2. 数据库键空间
73 |
74 | ## 2.1 键空间结构
75 |
76 | Redis是一个**键值对数据库服务器**,每个数据库都是一个redis.h/redisDb结构。**其中`dict`字典保存了数据库中所有的键值对**,我们将这个字典称为**键空间(key space)**。
77 |
78 | ```C
79 | typedef struct redisDb
80 | { // ...
81 | // 数据库键空间,保存着数据库中的所有键值对
82 | dict *dict;
83 | // ...
84 | } redisDb;
85 | ```
86 |
87 | 键空间的键就是数据库的键,每个键是一个**字符串对象**。键空间的值就是数据库的值,可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象中的一种。
88 |
89 | 当我们输入以下命令时:
90 |
91 | ```C
92 | redis> SET message "hello world"
93 | OK
94 |
95 | redis> RPUSH alphabet "a" "b" "c"
96 | (integer)3
97 |
98 | redis> HSET book name "Redis in Action"
99 | (integer) 1
100 |
101 | redis> HSET book author "Josiah L. Carlson"
102 | (integer) 1
103 |
104 | redis> HSET book publisher "Manning"
105 | (integer) 1
106 | ```
107 |
108 | 数据库的键空间结构如下:
109 |
110 |  111 |
112 | ## 2.2 键空间的增删改查
113 |
114 | **(1)添加和修改键**
115 |
116 | 添加新键值对和修改键值的操作是一样的,**区别在于键是新的是旧的**。
117 |
118 | | 对象 | 命令 |
119 | | :--------: | :----------------------------------------------------------- |
120 | | 字符串对象 | **SET** date 2020/1/1
111 |
112 | ## 2.2 键空间的增删改查
113 |
114 | **(1)添加和修改键**
115 |
116 | 添加新键值对和修改键值的操作是一样的,**区别在于键是新的是旧的**。
117 |
118 | | 对象 | 命令 |
119 | | :--------: | :----------------------------------------------------------- |
120 | | 字符串对象 | **SET** date 2020/1/1
**MSET** date1 19 date2 20 |
121 | | 哈希对象 | **HSET** book name C++primer
**HMSET** fruit name apple size large |
122 | | 列表对象 | **LSET** cloth 0 shirt
**LPUSH** food potato
**RPUSH** brand apple
**LRANGE** level 0 5 |
123 | | 集合对象 | **SADD** occupation firefighter |
124 | | 有序集合 | **ZADD** grade 87 Tom 65 Terry
|
125 |
126 | **(2)删除键**
127 |
128 | | 对象 | 命令 |
129 | | :--------: | :----------------------------------------------------------- |
130 | | 字符串对象 | **DEL** date |
131 | | 哈希对象 | **HDEL** myhash field1 myhash field2 |
132 | | 列表对象 | **BLPOP** list1 100
**BRPOP** list1 150
**LPOP** list2
**LREM** list3 -2 "hello" |
133 | | 集合对象 | **SPOP** food "rice"
**SREM** food "noodle" |
134 | | 有序集合 | **ZREM** website google.com
**ZREMRANGEBYLEX** drink [sprit (coco
**ZREMRANGEBYRANK** salary 0 2
**ZREMRANGEBYSCORE** salary 1500 3500 |
135 |
136 | POP在删除的同时,会返回结果,打印到控制台,而REM则是单纯的删除。BLPOP在移除元素时,如果列表没有元素则会等待至超时或发现元素为止。
137 |
138 | 有序集合范围删除中,LEX表示键, [ ( 表示区间开闭。而`ZREMRANGEBYRANK salary 0 2`表示删除salary最高的三个。
139 |
140 | **(3)查询键**
141 |
142 | | 对象 | 命令 |
143 | | :--------: | :----------------------------------------------------------- |
144 | | 字符串对象 | **GET** time
**MGET** time1 time2 |
145 | | 哈希对象 | **HGET** site baidu
**HMGET** site baidu google
**HGETALL** site
**HKEYS** site |
146 | | 列表对象 | **LINDEX** mylist 2
**LRANGE** mylist 0 2 |
147 | | 集合对象 | **SISMEMBER** myset1 "hello" |
148 | | 有序集合 | ... |
149 |
150 | HGET是根据键返回值,HGETALL则返回所有键值对,HKEYS返回所有键。列表对象根据主要根据下标返回结果。
151 |
152 | # 3. 过期键
153 |
154 | ## 3.1 设置过期时间
155 |
156 | 通过**EXPIRE命令**或者**PEXPIRE命令**,**客户端**可以以**秒**或者**毫秒**精度某个键设置**生存时间(Time To Live,TTL)**,在经过指定的秒数或者毫秒数之后,服务器就会**自动删除生存时间为0的键**:
157 |
158 | ```C
159 | redis> SET key value
160 | OK
161 |
162 | redis> EXPIRE key 5
163 | (integer) 1
164 |
165 | redis> GET key // 5秒之内
166 | "value"
167 | redis> GET key // 5秒之后
168 | (nil)
169 | ```
170 |
171 | 与前面相似,客户端可以通过**EXPIREAT命令**或**PEXPIREAT命令**,以秒或者毫秒精度给数据库中的某个键设置**过期时间(expire time)**。过期时间由UNIX时间戳表示。
172 |
173 | 而**TTL命令**和**PTTL命令**则返回**一个键的剩余生存时间。**
174 |
175 | 所有的命令在Redis中**最终都会转化为PEXPIREAT**执行。
176 |
177 |  178 |
179 | ---
180 |
181 | 在RedisDb结构中,**在键空间之外**,有一个expires字典专门保存所有键的过期时间,我们称之为**过期字典**。过期字典保存的值是long long 类型整数,**保存一个毫秒精度的UNIX时间戳**。
182 |
183 | ```C
184 | typedef struct redisDb
185 | { // ...
186 | // 过期字典,保存着键的过期时间
187 | dict *expires;
188 | // ...
189 | } redisDb;
190 | ```
191 |
192 | 虽然键空间和过期时间都有相同的键,但他们以指针形式指向同一个键,不会造成空间浪费。
193 |
194 |
178 |
179 | ---
180 |
181 | 在RedisDb结构中,**在键空间之外**,有一个expires字典专门保存所有键的过期时间,我们称之为**过期字典**。过期字典保存的值是long long 类型整数,**保存一个毫秒精度的UNIX时间戳**。
182 |
183 | ```C
184 | typedef struct redisDb
185 | { // ...
186 | // 过期字典,保存着键的过期时间
187 | dict *expires;
188 | // ...
189 | } redisDb;
190 | ```
191 |
192 | 虽然键空间和过期时间都有相同的键,但他们以指针形式指向同一个键,不会造成空间浪费。
193 |
194 |  195 |
196 | ## 3.2 过期键的删除策略
197 |
198 | 通过过期字典知道了哪些键已经过期,那么**过期的键什么时候会被删除呢?**删除策略有三种:
199 |
200 | - 定时删除:在设置键的过期时间的同时,创建一个定时器(timer),定时结束后删除。
201 | - 惰性删除:放着不管,每次从键空间获取时检查是否过期,过期就删除。
202 | - 定期删除:每隔一段时间,程序检查一次数据库,删除过期键。
203 |
204 | **(1)定时删除**
205 |
206 | 定时删除**有利于内存管理**,但**对CPU不友好**。如果过期键太多,删除会占用相当一部分CPU。
207 |
208 | 所以策略应该是:当有大量命令请求服务器处理时,并且服务器内存充足,就应该优先将CPU资源安排在处理客户端请求上,而不是删除过期键。
209 |
210 | 创建一个定时器需要用到Redis服务器中的**时间事件**,而当前时间事件的实现方式——无序链表,查找一个事件的时间复杂度为$O(N)$,并**不能高效地处理大量时间事件**。
211 |
212 | **(2)惰性删除**
213 |
214 | **对CPU最友好**,**但浪费内存**。如果数据库中有很多过期键,而这些过期键永远也不会被访问的话,他们就会永远占据空间,可视为**内存泄漏**。
215 |
216 | 一些和时间有关的数据,比如日志,在某个时间点后,他们的访问就会很少。如果这类过期数据大量积压,会造成严重的内存浪费。
217 |
218 | **(3)定期删除**
219 |
220 | 定期删除是一种折中,通过选择较为空闲的时间点来处理过期键,减少CPU压力。同时也能及时释放内存,避免内存泄漏。
221 |
222 | ---
223 |
224 | 在Redis中,**实际使用的是惰性删除和定期删除这两种**。
225 |
226 | **(1)Redis中的惰性删除**
227 |
228 | 存在于`db.c/expireIfNeeded`函数。**所有读写数据库的Redis命令在执行之前都会调用`expireIfNeeded`函数对输入键进行检查**:
229 |
230 | - 过期,函数将输入键删除
231 | - 不过期,函数不动作
232 |
233 | **(2)Redis中的定期删除**
234 |
235 | 过期键的定期删除策略由`redis.c/activeExpireCycle`函数实现,**每当Redis的服务器周期性操作`redis.c/serverCron`函数执行时**,`activeExpireCycle`函数就会被调用,它在规定的时间内,**分多次遍历服务器中的各个数据库**,从数据库的expires字典中**随机检查一部分键的过期时间**,并删除其中的过期键。
236 |
237 | 全局变量`current_db`会**记录当前`activeExpireCycle`函数检查的进度**,并在**下一次检查时接着上一次的进度进行处理**。比如说,如果当前`activeExpireCycle`函数在遍历10号数据库时返回了,那么下次就会从11号数据库开始工作。
238 |
239 | 如果所有数据库都被检查了一遍,则`current_db`将会被置0,然后开始新一轮检查。
240 |
241 | # 4. 数据库通知
242 |
243 | 通知是Redis2.8新增的功能,可以**让客户端通过订阅给定的频道或者模式,来获知数据库中键的变化,以及数据库中命令的执行情况。**
244 |
245 | ## 4.1 订阅通知
246 |
247 | 订阅有两种模式:
248 |
249 | - 订阅某一个键,返回键的所有操作
250 | - 订阅某一个操作,返回执行这个操作的键
251 |
252 | 情况1,从0号数据库订阅了键message的消息。如果此时有其他客户端操作了message,则会将消息通知到此处。
253 |
254 | ```C
255 | 127.0.0.1:6379> SUBSCRIBE _ _keyspace@0_ _:message
256 | Reading messages... (press Ctrl-C to quit)
257 |
258 | 1) "subscribe" // 订阅信息
259 | 2) "__keyspace@0__:message"
260 | 3) (integer) 1
261 |
262 | 1) "message" //执行SET命令
263 | 2) "_ _keyspace@0_ _:message"
264 | 3) "set"
265 |
266 | 1) "message" //执行EXPIRE命令
267 | 2) "_ _keyspace@0_ _:message"
268 | 3) "expire"
269 | ```
270 |
271 | 情况2,客户端订阅了0号数据库中的DEL命令。
272 |
273 | ```C
274 | 127.0.0.1:6379> SUBSCRIBE _ _keyevent@0_ _:del
275 | Reading messages... (press Ctrl-C to quit)
276 | 1) "subscribe" // 订阅信息
277 | 2) "_ _keyevent@0_ _:del"
278 | 3) (integer) 1
279 |
280 | 1) "message" //键key执行了DEL命令
281 | 2) "_ _keyevent@0_ _:del"
282 | 3) "key"
283 |
284 | 1) "message" //键number执行了DEL命令
285 | 2) "_ _keyevent@0_ _:del"
286 | 3) "number"
287 | ```
288 |
289 | ## 4.2 发送通知
290 |
291 | 发送数据库通知的功能是由`notify.c/notifyKeyspaceEvent`函数实现,函数声明如下:
292 |
293 | ```C
294 | void notifyKeyspaceEvent(int type,char *event,robj *key,int dbid);
295 | ```
296 |
297 | **type参数是发送的通知的类型,event、keys和dbid分别是事件的名称、产生事件的键,以及产生事件的数据库编号**,函数会根据type参数以及这三个参数来构建事件通知的内容,以及接收通知的频道名。
298 |
299 | 比如SADD命令的实现函数中,通知的发送方式是
300 |
301 | ```C
302 | void saddCommand(redisClient* c)
303 | {
304 | //...
305 | if(added)
306 | {
307 | //...添加成功,发送通知
308 | notifyKeyspaceEvent(REDIS_NOTIFY_SET,"add",c->argv[1],c->db->id);
309 | //...
310 | }
311 | }
312 | ```
313 |
314 | 当SADD命令成功地向集合添加了一个集合元素之后,命令就会发送通知,**该通知的类型为REDIS_NOTIFY_SET(表示这是一个集合键通知)**,名称为sadd(表示这是执行SADD命令所产生的通知)。
315 |
316 | 发布时调用的`notifyKeyspaceEvent`函数逻辑是:
317 |
318 | 1. 检查服务器是否允许发送此类通知,如果不允许就返回
319 | 2. 是否允许发送**键空间通知**(4.1提到的情况1),允许就发送
320 | 3. 是否允许发送**键事件通知**(4.2提到的情况2),允许就发送
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现4-RDB持久化和AOF持久化.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现4-RDB和AOF持久化
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-04 14:10:19
12 | ---
13 |
14 | 持久化的意思是将数据永久保存在磁盘中。Redis采用RDB和AOF两种策略。
15 |
16 | # 1. RDB持久化
17 |
18 | 将服务器中的非空数据库以及它们的键值对统称为**数据库状态**。下图三个非空数据库,以及其中的键值对就是该服务器的数据库状态。
19 |
20 |
195 |
196 | ## 3.2 过期键的删除策略
197 |
198 | 通过过期字典知道了哪些键已经过期,那么**过期的键什么时候会被删除呢?**删除策略有三种:
199 |
200 | - 定时删除:在设置键的过期时间的同时,创建一个定时器(timer),定时结束后删除。
201 | - 惰性删除:放着不管,每次从键空间获取时检查是否过期,过期就删除。
202 | - 定期删除:每隔一段时间,程序检查一次数据库,删除过期键。
203 |
204 | **(1)定时删除**
205 |
206 | 定时删除**有利于内存管理**,但**对CPU不友好**。如果过期键太多,删除会占用相当一部分CPU。
207 |
208 | 所以策略应该是:当有大量命令请求服务器处理时,并且服务器内存充足,就应该优先将CPU资源安排在处理客户端请求上,而不是删除过期键。
209 |
210 | 创建一个定时器需要用到Redis服务器中的**时间事件**,而当前时间事件的实现方式——无序链表,查找一个事件的时间复杂度为$O(N)$,并**不能高效地处理大量时间事件**。
211 |
212 | **(2)惰性删除**
213 |
214 | **对CPU最友好**,**但浪费内存**。如果数据库中有很多过期键,而这些过期键永远也不会被访问的话,他们就会永远占据空间,可视为**内存泄漏**。
215 |
216 | 一些和时间有关的数据,比如日志,在某个时间点后,他们的访问就会很少。如果这类过期数据大量积压,会造成严重的内存浪费。
217 |
218 | **(3)定期删除**
219 |
220 | 定期删除是一种折中,通过选择较为空闲的时间点来处理过期键,减少CPU压力。同时也能及时释放内存,避免内存泄漏。
221 |
222 | ---
223 |
224 | 在Redis中,**实际使用的是惰性删除和定期删除这两种**。
225 |
226 | **(1)Redis中的惰性删除**
227 |
228 | 存在于`db.c/expireIfNeeded`函数。**所有读写数据库的Redis命令在执行之前都会调用`expireIfNeeded`函数对输入键进行检查**:
229 |
230 | - 过期,函数将输入键删除
231 | - 不过期,函数不动作
232 |
233 | **(2)Redis中的定期删除**
234 |
235 | 过期键的定期删除策略由`redis.c/activeExpireCycle`函数实现,**每当Redis的服务器周期性操作`redis.c/serverCron`函数执行时**,`activeExpireCycle`函数就会被调用,它在规定的时间内,**分多次遍历服务器中的各个数据库**,从数据库的expires字典中**随机检查一部分键的过期时间**,并删除其中的过期键。
236 |
237 | 全局变量`current_db`会**记录当前`activeExpireCycle`函数检查的进度**,并在**下一次检查时接着上一次的进度进行处理**。比如说,如果当前`activeExpireCycle`函数在遍历10号数据库时返回了,那么下次就会从11号数据库开始工作。
238 |
239 | 如果所有数据库都被检查了一遍,则`current_db`将会被置0,然后开始新一轮检查。
240 |
241 | # 4. 数据库通知
242 |
243 | 通知是Redis2.8新增的功能,可以**让客户端通过订阅给定的频道或者模式,来获知数据库中键的变化,以及数据库中命令的执行情况。**
244 |
245 | ## 4.1 订阅通知
246 |
247 | 订阅有两种模式:
248 |
249 | - 订阅某一个键,返回键的所有操作
250 | - 订阅某一个操作,返回执行这个操作的键
251 |
252 | 情况1,从0号数据库订阅了键message的消息。如果此时有其他客户端操作了message,则会将消息通知到此处。
253 |
254 | ```C
255 | 127.0.0.1:6379> SUBSCRIBE _ _keyspace@0_ _:message
256 | Reading messages... (press Ctrl-C to quit)
257 |
258 | 1) "subscribe" // 订阅信息
259 | 2) "__keyspace@0__:message"
260 | 3) (integer) 1
261 |
262 | 1) "message" //执行SET命令
263 | 2) "_ _keyspace@0_ _:message"
264 | 3) "set"
265 |
266 | 1) "message" //执行EXPIRE命令
267 | 2) "_ _keyspace@0_ _:message"
268 | 3) "expire"
269 | ```
270 |
271 | 情况2,客户端订阅了0号数据库中的DEL命令。
272 |
273 | ```C
274 | 127.0.0.1:6379> SUBSCRIBE _ _keyevent@0_ _:del
275 | Reading messages... (press Ctrl-C to quit)
276 | 1) "subscribe" // 订阅信息
277 | 2) "_ _keyevent@0_ _:del"
278 | 3) (integer) 1
279 |
280 | 1) "message" //键key执行了DEL命令
281 | 2) "_ _keyevent@0_ _:del"
282 | 3) "key"
283 |
284 | 1) "message" //键number执行了DEL命令
285 | 2) "_ _keyevent@0_ _:del"
286 | 3) "number"
287 | ```
288 |
289 | ## 4.2 发送通知
290 |
291 | 发送数据库通知的功能是由`notify.c/notifyKeyspaceEvent`函数实现,函数声明如下:
292 |
293 | ```C
294 | void notifyKeyspaceEvent(int type,char *event,robj *key,int dbid);
295 | ```
296 |
297 | **type参数是发送的通知的类型,event、keys和dbid分别是事件的名称、产生事件的键,以及产生事件的数据库编号**,函数会根据type参数以及这三个参数来构建事件通知的内容,以及接收通知的频道名。
298 |
299 | 比如SADD命令的实现函数中,通知的发送方式是
300 |
301 | ```C
302 | void saddCommand(redisClient* c)
303 | {
304 | //...
305 | if(added)
306 | {
307 | //...添加成功,发送通知
308 | notifyKeyspaceEvent(REDIS_NOTIFY_SET,"add",c->argv[1],c->db->id);
309 | //...
310 | }
311 | }
312 | ```
313 |
314 | 当SADD命令成功地向集合添加了一个集合元素之后,命令就会发送通知,**该通知的类型为REDIS_NOTIFY_SET(表示这是一个集合键通知)**,名称为sadd(表示这是执行SADD命令所产生的通知)。
315 |
316 | 发布时调用的`notifyKeyspaceEvent`函数逻辑是:
317 |
318 | 1. 检查服务器是否允许发送此类通知,如果不允许就返回
319 | 2. 是否允许发送**键空间通知**(4.1提到的情况1),允许就发送
320 | 3. 是否允许发送**键事件通知**(4.2提到的情况2),允许就发送
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现4-RDB持久化和AOF持久化.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现4-RDB和AOF持久化
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-04 14:10:19
12 | ---
13 |
14 | 持久化的意思是将数据永久保存在磁盘中。Redis采用RDB和AOF两种策略。
15 |
16 | # 1. RDB持久化
17 |
18 | 将服务器中的非空数据库以及它们的键值对统称为**数据库状态**。下图三个非空数据库,以及其中的键值对就是该服务器的数据库状态。
19 |
20 | 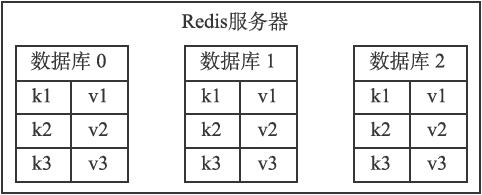 21 |
22 | 在Redis中,只有将数据保存在内存磁盘里才会永久保存,**如果服务器进程退出,服务器中的数据库状态就会消失。**为了解决这个问题,Redis提供了RDB持久化功能,这个功能可以将Redis在内存中的数据库状态保存到磁盘里面。
23 |
24 | RDB持久化产生的RDB文件(Redis Database)是一个**经过压缩的二进制文件,该文件可以被还原为数据库状态**,所以即使服务器停机,服务器的数据还是被安全保存在硬盘中。
25 |
26 | ## 1.1 RDB文件的创建与载入
27 |
28 | 有两个Redis命令可以用于生成RDB文件,一个是**SAVE**,另一个是**BGSAVE **(BackGround SAVE)。SAVE命令会**阻塞Redis服务器进程**,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求:
29 |
30 | ```C
31 | redis> SAVE //等待直到RDB文件创建完毕
32 | OK
33 | ```
34 |
35 | 而BGSAVE命令会**增加一个子进程**,负责创建RDB文件。
36 |
37 | ```C
38 | redis> BGSAVE //派生子进程,并由子进程创建RDB文件
39 | Background saving started
40 | ```
41 |
42 | BGSAVE执行时,会阻止SAVE、其他BGSAVE和BGREWRITEAOF这三个命令执行,防止竞争。
43 |
44 | 创建RDB文件的实际工作由`rdb.c/rdbSave`函数完成,SAVE命令和BGSAVE命令会以不同的方式调用这个函数。
45 |
46 | ---
47 |
48 | Redis并没有载入RDB文件的命令,只要服务器启动时**检测到RDB文件存在,他就会自动载入。**比如下面日志的第二条:
49 |
50 |
21 |
22 | 在Redis中,只有将数据保存在内存磁盘里才会永久保存,**如果服务器进程退出,服务器中的数据库状态就会消失。**为了解决这个问题,Redis提供了RDB持久化功能,这个功能可以将Redis在内存中的数据库状态保存到磁盘里面。
23 |
24 | RDB持久化产生的RDB文件(Redis Database)是一个**经过压缩的二进制文件,该文件可以被还原为数据库状态**,所以即使服务器停机,服务器的数据还是被安全保存在硬盘中。
25 |
26 | ## 1.1 RDB文件的创建与载入
27 |
28 | 有两个Redis命令可以用于生成RDB文件,一个是**SAVE**,另一个是**BGSAVE **(BackGround SAVE)。SAVE命令会**阻塞Redis服务器进程**,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求:
29 |
30 | ```C
31 | redis> SAVE //等待直到RDB文件创建完毕
32 | OK
33 | ```
34 |
35 | 而BGSAVE命令会**增加一个子进程**,负责创建RDB文件。
36 |
37 | ```C
38 | redis> BGSAVE //派生子进程,并由子进程创建RDB文件
39 | Background saving started
40 | ```
41 |
42 | BGSAVE执行时,会阻止SAVE、其他BGSAVE和BGREWRITEAOF这三个命令执行,防止竞争。
43 |
44 | 创建RDB文件的实际工作由`rdb.c/rdbSave`函数完成,SAVE命令和BGSAVE命令会以不同的方式调用这个函数。
45 |
46 | ---
47 |
48 | Redis并没有载入RDB文件的命令,只要服务器启动时**检测到RDB文件存在,他就会自动载入。**比如下面日志的第二条:
49 |
50 |  51 |
52 | ## 1.2 自动间隔性保存
53 |
54 | 由于BGSAVE可以不阻塞服务器执行,所以我们可以**设置条件**,让服务器每隔一段时间自动保存。举个例子:
55 |
56 | ```C
57 | save 900 1
58 | save 300 10
59 | save 60 10000
60 | ```
61 |
62 | 这些条件的意思是:900秒内对数据库至少进行了1次修改,300秒内对数据库进行了10次修改....
63 |
64 | 服务器程序会根据save选项所设置的保存条件,设置服务器状态`redisServer`结构的`saveparams`属性:
65 |
66 | ```C
67 | struct redisServer
68 | {
69 | // ...
70 | // 记录了保存条件的数组
71 | struct saveparam *saveparams;
72 | // ...
73 | };
74 | ```
75 |
76 | `saveparams`属性是一个数组,数组中的每个元素都是一个`saveparam`结构,每个`saveparam`结构都保存了一个save选项设置的保存条件:
77 |
78 | ```c
79 | struct saveparam
80 | {
81 | // 秒数
82 | time_t seconds;
83 | // 修改数
84 | int changes;
85 | };
86 | ```
87 |
88 |
51 |
52 | ## 1.2 自动间隔性保存
53 |
54 | 由于BGSAVE可以不阻塞服务器执行,所以我们可以**设置条件**,让服务器每隔一段时间自动保存。举个例子:
55 |
56 | ```C
57 | save 900 1
58 | save 300 10
59 | save 60 10000
60 | ```
61 |
62 | 这些条件的意思是:900秒内对数据库至少进行了1次修改,300秒内对数据库进行了10次修改....
63 |
64 | 服务器程序会根据save选项所设置的保存条件,设置服务器状态`redisServer`结构的`saveparams`属性:
65 |
66 | ```C
67 | struct redisServer
68 | {
69 | // ...
70 | // 记录了保存条件的数组
71 | struct saveparam *saveparams;
72 | // ...
73 | };
74 | ```
75 |
76 | `saveparams`属性是一个数组,数组中的每个元素都是一个`saveparam`结构,每个`saveparam`结构都保存了一个save选项设置的保存条件:
77 |
78 | ```c
79 | struct saveparam
80 | {
81 | // 秒数
82 | time_t seconds;
83 | // 修改数
84 | int changes;
85 | };
86 | ```
87 |
88 |  89 |
90 | ---
91 |
92 | 除了设置保存条件的saveparams数组外,服务器状态还维持着一个**dirty计数器**,以及一个**lastsave属性**:
93 |
94 | - dirty计数器记录自上一次SAVE和BGSAVE以后,服务器对数据库状态进行了多少次修改(包括增删改)
95 | - lastsave则是一个时间戳,记录了上一次执行保存的时间。
96 |
97 | 当服务器执行修改命令一次以后,dirty计数器就加一。如果是一次性修改多个元素,计数器此时加N
98 |
99 | ```C
100 | redis->SADD database0 apple orange watermelon
101 | ```
102 |
103 | ---
104 |
105 | Redis的服务器**周期性操作函数serverCron默认每隔100毫秒就会执行一次**,该函数用于对正在运行的服务器进行维护,它的其中一项工作就是检查save选项所设置的保存条件是否已经满足,如果满足的话,就执行BGSAVE命令。
106 |
107 | 执行完以后,dirty清0,lastsave更新。
108 |
109 | ## 1.3 RDB文件结构
110 |
111 | 完整的RDB文件如下,
112 |
113 |
89 |
90 | ---
91 |
92 | 除了设置保存条件的saveparams数组外,服务器状态还维持着一个**dirty计数器**,以及一个**lastsave属性**:
93 |
94 | - dirty计数器记录自上一次SAVE和BGSAVE以后,服务器对数据库状态进行了多少次修改(包括增删改)
95 | - lastsave则是一个时间戳,记录了上一次执行保存的时间。
96 |
97 | 当服务器执行修改命令一次以后,dirty计数器就加一。如果是一次性修改多个元素,计数器此时加N
98 |
99 | ```C
100 | redis->SADD database0 apple orange watermelon
101 | ```
102 |
103 | ---
104 |
105 | Redis的服务器**周期性操作函数serverCron默认每隔100毫秒就会执行一次**,该函数用于对正在运行的服务器进行维护,它的其中一项工作就是检查save选项所设置的保存条件是否已经满足,如果满足的话,就执行BGSAVE命令。
106 |
107 | 执行完以后,dirty清0,lastsave更新。
108 |
109 | ## 1.3 RDB文件结构
110 |
111 | 完整的RDB文件如下,
112 |
113 |  114 |
115 | RDB是一个二进制文件而不是文本文件。
116 |
117 | > 广义来说,所有文件都是二进制文件。狭义来说,文本文件是基于字符编码的文件,常见的编码有**ASCII编码,UNICODE编码**等等;二进制文件是基于值编码的文件,也可以理解为**自定义编码。**
118 |
119 | - 开头的REDIS占5个字节,这5个字符**用于检查是不是RDB文件。**
120 | - db_version长度为4字节,值被解析为**RDB版本**,比如"0006"就代表第6版。
121 | - database部分包含着**多个数据库的键值对数据**,根据大小不同,长度有所不同。
122 | - EOF占1个字节,结束位标志。
123 | - check_sum是占8字节,保存**校验和**。服务器在载入时会根据读入的实际数据计算出一个数来和校验值比较,以此来检查是否有损坏。
124 |
125 | ### 1.3.1 database部分
126 |
127 | 每个非空数据库在RDB文件中都可以保存为`SELECTDB`、`db_number`、`key_value_pairs`三个部分,如图所示。
128 |
129 |
114 |
115 | RDB是一个二进制文件而不是文本文件。
116 |
117 | > 广义来说,所有文件都是二进制文件。狭义来说,文本文件是基于字符编码的文件,常见的编码有**ASCII编码,UNICODE编码**等等;二进制文件是基于值编码的文件,也可以理解为**自定义编码。**
118 |
119 | - 开头的REDIS占5个字节,这5个字符**用于检查是不是RDB文件。**
120 | - db_version长度为4字节,值被解析为**RDB版本**,比如"0006"就代表第6版。
121 | - database部分包含着**多个数据库的键值对数据**,根据大小不同,长度有所不同。
122 | - EOF占1个字节,结束位标志。
123 | - check_sum是占8字节,保存**校验和**。服务器在载入时会根据读入的实际数据计算出一个数来和校验值比较,以此来检查是否有损坏。
124 |
125 | ### 1.3.1 database部分
126 |
127 | 每个非空数据库在RDB文件中都可以保存为`SELECTDB`、`db_number`、`key_value_pairs`三个部分,如图所示。
128 |
129 |  130 |
131 | - `SELECTDB`,1字节,当读取到此值时,程序知道接下来要读入一个数据库号码。
132 | - `db_number`,1、2、5字节,保存数据库号码。
133 | - `key_value_pairs`,保存键值对,包括过期时间。
134 |
135 | ### 1.3.2 key_value_pairs部分
136 |
137 | 不带过期时间的键值对在RDB文件中由TYPE、key、value三部分组成,
138 |
139 |
130 |
131 | - `SELECTDB`,1字节,当读取到此值时,程序知道接下来要读入一个数据库号码。
132 | - `db_number`,1、2、5字节,保存数据库号码。
133 | - `key_value_pairs`,保存键值对,包括过期时间。
134 |
135 | ### 1.3.2 key_value_pairs部分
136 |
137 | 不带过期时间的键值对在RDB文件中由TYPE、key、value三部分组成,
138 |
139 |  140 |
141 | 带有过期时间的键值对在RDB中的结构如下
142 |
143 |
140 |
141 | 带有过期时间的键值对在RDB中的结构如下
142 |
143 |  144 |
145 | - EPIRETIME_MS,1字节,告诉程序接下来读取一个以毫秒为单位的过期时间。
146 | - ms,8字节带符号整数,记录一个以毫秒为单位的UNIX时间戳。
147 |
148 | ### 1.3.3 value部分
149 |
150 | **(1)字符串对象**
151 |
152 | 如果TYPE的值为`REDIS_RDB_TYPE_STRING`,那么value保存的就是一个字符串对象,字符串对象的编码可以是`REDIS_ENCODING_INT`或者`REDIS_ENCODING_RAW`。
153 |
154 | 如果是INT,则表示对象是一个**长度不超过32位的整数**,保存方式如下:
155 |
156 |
144 |
145 | - EPIRETIME_MS,1字节,告诉程序接下来读取一个以毫秒为单位的过期时间。
146 | - ms,8字节带符号整数,记录一个以毫秒为单位的UNIX时间戳。
147 |
148 | ### 1.3.3 value部分
149 |
150 | **(1)字符串对象**
151 |
152 | 如果TYPE的值为`REDIS_RDB_TYPE_STRING`,那么value保存的就是一个字符串对象,字符串对象的编码可以是`REDIS_ENCODING_INT`或者`REDIS_ENCODING_RAW`。
153 |
154 | 如果是INT,则表示对象是一个**长度不超过32位的整数**,保存方式如下:
155 |
156 |  157 |
158 | 其中,`ENCODING`的值可以是`REDIS_RDB_ENC_INT8`、`REDIS_RDB_ENC_INT16`或者`REDIS_RDB_ENC_INT32`三个常量的其中一个,它们分别代表RDB文件使用8位、16位或者32位来保存整数值integer。
159 |
160 | 如果是RAW格式,则说明对象是一个**字符串值**,有压缩和不压缩两种方法来保存。对于没有压缩的字符串,保存格式如下:
161 |
162 |
157 |
158 | 其中,`ENCODING`的值可以是`REDIS_RDB_ENC_INT8`、`REDIS_RDB_ENC_INT16`或者`REDIS_RDB_ENC_INT32`三个常量的其中一个,它们分别代表RDB文件使用8位、16位或者32位来保存整数值integer。
159 |
160 | 如果是RAW格式,则说明对象是一个**字符串值**,有压缩和不压缩两种方法来保存。对于没有压缩的字符串,保存格式如下:
161 |
162 |  163 |
164 | 压缩后的字符串,保存格式如下:
165 |
166 |
163 |
164 | 压缩后的字符串,保存格式如下:
165 |
166 |  167 |
168 | - REDIS_RDB_ENC_LZF,表明已被LZF算法压缩
169 | - compressed_len,被压缩后的字符串长度
170 | - origin_len,原来的长度
171 | - compressed_string,被压缩后的字符串
172 |
173 | **(2)列表对象**
174 |
175 | 如果TYPE的值为`REDIS_RDB_TYPE_LIST`,那么value保存的就是一个`REDIS_ENCODING_LINKEDLIST`编码的列表对象,RDB文件保存这种对象的结构如图所示。
176 |
177 |
167 |
168 | - REDIS_RDB_ENC_LZF,表明已被LZF算法压缩
169 | - compressed_len,被压缩后的字符串长度
170 | - origin_len,原来的长度
171 | - compressed_string,被压缩后的字符串
172 |
173 | **(2)列表对象**
174 |
175 | 如果TYPE的值为`REDIS_RDB_TYPE_LIST`,那么value保存的就是一个`REDIS_ENCODING_LINKEDLIST`编码的列表对象,RDB文件保存这种对象的结构如图所示。
176 |
177 |  178 |
179 | **每一个列表项都是一个字符串对象**,所以程序会以字符串对象的方式来保存。
180 |
181 |
178 |
179 | **每一个列表项都是一个字符串对象**,所以程序会以字符串对象的方式来保存。
180 |
181 |  182 |
183 | 结构中,3表示列表长度,5表示第一个列表项长度为5,内容为"hello"。
184 |
185 | **(3)集合对象**
186 |
187 | 如果TYPE的值为`REDIS_RDB_TYPE_SET`,那么value保存的就是一个`REDIS_ENCODING_HT`编码的集合对象,RDB文件保存这种对象的结构如图所示。
188 |
189 |
182 |
183 | 结构中,3表示列表长度,5表示第一个列表项长度为5,内容为"hello"。
184 |
185 | **(3)集合对象**
186 |
187 | 如果TYPE的值为`REDIS_RDB_TYPE_SET`,那么value保存的就是一个`REDIS_ENCODING_HT`编码的集合对象,RDB文件保存这种对象的结构如图所示。
188 |
189 |  190 |
191 | 图中elem代表集合的元素,**每个集合元素都是一个字符串对象。**
192 |
193 |
190 |
191 | 图中elem代表集合的元素,**每个集合元素都是一个字符串对象。**
192 |
193 |  194 |
195 | 和列表一样,4代表集合大小,5代表元素长度,值为"apple"。
196 |
197 | **(4)哈希表对象**
198 |
199 | 如果TYPE的值为`REDIS_RDB_TYPE_HASH`,那么value保存的就是一个`REDIS_ENCODING_HT`编码的集合对象,RDB文件保存这种对象的结构如图所示。
200 |
201 |
194 |
195 | 和列表一样,4代表集合大小,5代表元素长度,值为"apple"。
196 |
197 | **(4)哈希表对象**
198 |
199 | 如果TYPE的值为`REDIS_RDB_TYPE_HASH`,那么value保存的就是一个`REDIS_ENCODING_HT`编码的集合对象,RDB文件保存这种对象的结构如图所示。
200 |
201 |  202 |
203 | 例子如下,
204 |
205 |
202 |
203 | 例子如下,
204 |
205 |  206 |
207 | 哈希表长度为2,第一个键值对,键长度为1的字符串"a",值为5的字符串"apple"。
208 |
209 | **(5)有序集合对象**
210 |
211 | 如果TYPE的值为`REDIS_RDB_TYPE_ZSET`,那么value保存的就是一个`REDIS_ENCODING_SKIPLIST`编码的有序集合对象,RDB文件保存这种对象的结构如图所示。
212 |
213 |
206 |
207 | 哈希表长度为2,第一个键值对,键长度为1的字符串"a",值为5的字符串"apple"。
208 |
209 | **(5)有序集合对象**
210 |
211 | 如果TYPE的值为`REDIS_RDB_TYPE_ZSET`,那么value保存的就是一个`REDIS_ENCODING_SKIPLIST`编码的有序集合对象,RDB文件保存这种对象的结构如图所示。
212 |
213 |  214 |
215 | 比如:
216 |
217 |
214 |
215 | 比如:
216 |
217 |  218 |
219 | 大小为2,第一个元素是长度为2的字符串"pi",分值被转换为长度为4的字符串"3.14"。
220 |
221 | **(6)INTSET编码的集合**
222 |
223 | 如果TYPE的值为`REDIS_RDB_TYPE_SET_INTSET`,那么value保存的就是一个**整数集合对象**,RDB文件保存这种对象的方法是,**先将整数集合转换为字符串对象**,然后将这个字符串对象保存到RDB文件里面。
224 |
225 | **(7)ZIPLIST编码的列表、哈希表和有序集合**
226 |
227 | 如果TYPE的值为`REDIS_RDB_TYPE_LIST_ZIPLIST`、`REDIS_RDB_TYPE_HASH_ZIPLIST`或者`REDIS_RDB_TYPE_ZSET_ZIPLIST`,那么value保存的就是一个**压缩列表对象**,保存策略和上面一一样:先转化为字符串对象。
228 |
229 | # 2. AOF持久化
230 |
231 | RDB持久化记录的是数据库本身,而AOF(Append Only File)则**记录Redis服务器所执行的写命令**。
232 |
233 |
218 |
219 | 大小为2,第一个元素是长度为2的字符串"pi",分值被转换为长度为4的字符串"3.14"。
220 |
221 | **(6)INTSET编码的集合**
222 |
223 | 如果TYPE的值为`REDIS_RDB_TYPE_SET_INTSET`,那么value保存的就是一个**整数集合对象**,RDB文件保存这种对象的方法是,**先将整数集合转换为字符串对象**,然后将这个字符串对象保存到RDB文件里面。
224 |
225 | **(7)ZIPLIST编码的列表、哈希表和有序集合**
226 |
227 | 如果TYPE的值为`REDIS_RDB_TYPE_LIST_ZIPLIST`、`REDIS_RDB_TYPE_HASH_ZIPLIST`或者`REDIS_RDB_TYPE_ZSET_ZIPLIST`,那么value保存的就是一个**压缩列表对象**,保存策略和上面一一样:先转化为字符串对象。
228 |
229 | # 2. AOF持久化
230 |
231 | RDB持久化记录的是数据库本身,而AOF(Append Only File)则**记录Redis服务器所执行的写命令**。
232 |
233 | 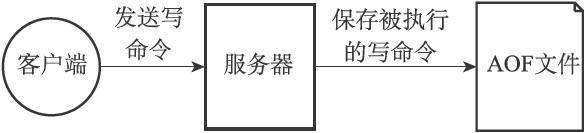 234 |
235 | 假如使用如下命令:
236 |
237 | ```C
238 | redis> SET msg "hello"
239 | OK
240 | ```
241 |
242 | 则AOF记录形式如下:
243 |
244 | ```
245 | *2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n
246 | *3\r\n$3\r\nSET\r\n$3\r\nmsg\r\n$5\r\nhello\r\n
247 | ```
248 |
249 | ## 2.1 AOF实现原理
250 |
251 | AOF如其名所示,Append Only File,AOF持久化功能的实现可以分为**命令追加(append)、文件写入与同步(sync)**
252 |
253 | **(1)命令追加**
254 |
255 | 如果AOF被打开,则服务器执行完一个命令后,会以协议格式将命令**追加到服务器状态aof_buf缓冲区的结尾**:
256 |
257 | ```C
258 | struct redisServer
259 | {
260 | // ...
261 | sds aof_buf; // AOF缓冲区
262 | // ...
263 | };
264 | ```
265 |
266 | 比如执行了`SET KEY VALUE`后,会将以下协议内容加载到aof_buf缓冲区:
267 |
268 | ```
269 | *3\r\n$3\r\nSET\r\n$3\r\nKEY\r\n$5\r\nVALUE\r\n
270 | ```
271 |
272 | **(2)AOF文件的写入与同步**
273 |
274 | Redis的服务器进程就是一个**事件循环(loop)**,这个循环中的**文件事件负责接收客户端的命令请求**,**以及向客户端发送命令回复**,而**时间事件则负责执行像`serverCron`函数这样需要定时运行的函数**。
275 |
276 | 服务器每次结束一个事件循环之前,它都会调用`flushAppendOnlyFile`函数,**考虑是否需要将`aof_buf`缓冲区中的内容写入和保存到AOF文件里面**。
277 |
278 |
234 |
235 | 假如使用如下命令:
236 |
237 | ```C
238 | redis> SET msg "hello"
239 | OK
240 | ```
241 |
242 | 则AOF记录形式如下:
243 |
244 | ```
245 | *2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n
246 | *3\r\n$3\r\nSET\r\n$3\r\nmsg\r\n$5\r\nhello\r\n
247 | ```
248 |
249 | ## 2.1 AOF实现原理
250 |
251 | AOF如其名所示,Append Only File,AOF持久化功能的实现可以分为**命令追加(append)、文件写入与同步(sync)**
252 |
253 | **(1)命令追加**
254 |
255 | 如果AOF被打开,则服务器执行完一个命令后,会以协议格式将命令**追加到服务器状态aof_buf缓冲区的结尾**:
256 |
257 | ```C
258 | struct redisServer
259 | {
260 | // ...
261 | sds aof_buf; // AOF缓冲区
262 | // ...
263 | };
264 | ```
265 |
266 | 比如执行了`SET KEY VALUE`后,会将以下协议内容加载到aof_buf缓冲区:
267 |
268 | ```
269 | *3\r\n$3\r\nSET\r\n$3\r\nKEY\r\n$5\r\nVALUE\r\n
270 | ```
271 |
272 | **(2)AOF文件的写入与同步**
273 |
274 | Redis的服务器进程就是一个**事件循环(loop)**,这个循环中的**文件事件负责接收客户端的命令请求**,**以及向客户端发送命令回复**,而**时间事件则负责执行像`serverCron`函数这样需要定时运行的函数**。
275 |
276 | 服务器每次结束一个事件循环之前,它都会调用`flushAppendOnlyFile`函数,**考虑是否需要将`aof_buf`缓冲区中的内容写入和保存到AOF文件里面**。
277 |
278 | 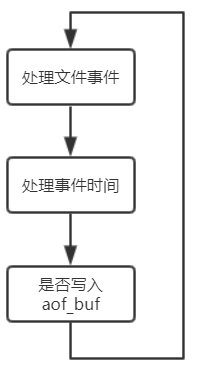 279 |
280 | 这个函数的行为有服务器配置的`appendfsync`选项来设置,默认为`everysec`:
281 |
282 |
279 |
280 | 这个函数的行为有服务器配置的`appendfsync`选项来设置,默认为`everysec`:
281 |
282 |  283 |
284 | 默认情况下,距离上次同步过了一秒钟,则服务器会将aof_buf内容写入AOF文件中。
285 |
286 | ## 2.2 AOF文件的载入与数据还原
287 |
288 | 因为AOF文件里面包含了重建数据库状态所需的所有写命令,所以服务器只要**读入并重新执行一遍AOF文件里面保存的写命令**,就可以还原服务器关闭之前的数据库状态。
289 |
290 | AOF还原数据库的步骤如下:
291 |
292 | 1. 创建一个不带网络连接的**伪客户端(fake client)**:因为Redis的命令只能在客户端上下文中执行。
293 | 2. 从AOF中读出一条命令。
294 | 3. 使用伪客户端执行被读出的写命令。
295 | 4. 重复23步
296 |
297 | ## 2.3 AOF重写
298 |
299 | 随着时间的增长,AOF文件的大小将会越来越大。为了解决这个问题,Redis提供了**AOF重写**功能。
300 |
301 | 重写后,Redis服务器可以创建一个新的AOF文件来替代现有的AOF文件,新旧两个**AOF文件保存的数据库状态完全相同**。
302 |
303 | 如果要保存一个键值对,我们其实只关心它当前的状态。所以重写策略是:首先**从数据库中读取键现在的值,然后用一条命令去记录键值对**,用到了`aof_rewrite`函数。
304 |
305 | 比如,对list进行`RPUSH`操作填入"A"、"B"、"C",然后再`LPOP`一次,我们操作了4次,但其实用`RPUSH list A B`这一条指令就可以代替。
306 |
307 | `aof_rewrite`函数包含了大量写入操作,调用时会导致线程被长时间阻塞,所以Redis**将AOF重写放入子进程里**。
308 |
309 | ----
310 |
311 | 还有一个问题:子进程AOF重写时,主进程也在写命令,导致两者状态不一致。因此,**Redis服务器设置了一个AOF重写缓冲区**,这个缓冲区在服务器创建子进程之后开始使用,当Redis服务器执行完一个写命令之后,它会**同时**将这个写命令发送给**AOF缓冲区**和**AOF重写缓冲区**。
312 |
313 | 换句话说,子进程执行AOF期间,服务器进程需要:
314 |
315 | - 执行客户端指令
316 | - 将执行后的命令追加到AOF缓冲区
317 | - 将执行后的命令追加到AOF重写缓冲区
318 |
319 | ---
320 |
321 | 子进程执行完AOF后,向父进程发送一个信号。父进程接收后:
322 |
323 | 1. 将AOF重写缓冲区的内容写入AOF文件中,保证一致性。
324 | 2. 对新AOF文件改名,原子的(atomic)覆盖现有AOF文件。
325 |
326 | 在整个AOF后台重写过程中,**只有信号处理函数执行时会对服务器进程(父进程)造成阻塞**,在其他时候,AOF后台重写都不会阻塞父进程,这将AOF重写对服务器性能造成的影响降到了最低。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现5-事件.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现5-事件
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-05 13:17:25
12 | ---
13 |
14 | Redis是一个**事件驱动程序**,前面提到,服务器需要处理文件事件和时间事件。
15 |
16 | - **文件事件**:Redis服务器通过套接字与客户端(或者其他Redis服务器)进行连接,而**文件事件就是服务器对套接字操作的抽象**。
17 | - **时间事件**:些操作会在给定的时间点进行,对这类**定时操作的抽象就是时间事件。**
18 |
19 | # 1. 文件事件
20 |
21 | Redis基于Reactor模式开发了自己的网络事件处理器:这个处理器被称为**文件事件处理器(file event handler)**
22 |
23 | > Reactor模式用于高并发,依靠事件驱动。传统的线程连接中,IO连接后需要等待客户的请求。而事件驱动中,IO可以干别的事情,等客户发来请求后再处理。
24 |
25 | 在Redis中,
26 |
27 | - 文件事件处理器使用I/O多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
28 | - 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
29 |
30 | 虽然文件事件处理器**以单线程方式运**行,但通过使用**I/O多路复用**程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与Redis服务器中其他**同样以单线程方式运行的模块进行对接**,这保持了**Redis内部单线程设计的简单性。**
31 |
32 | ## 1.1 构成
33 |
34 | 文件事件处理器的四个组成部分,它们分别是**套接字**、**I/O多路复用程序**、**文件事件分派器(dispatcher)**,以及**事件处理器**。
35 |
36 |
283 |
284 | 默认情况下,距离上次同步过了一秒钟,则服务器会将aof_buf内容写入AOF文件中。
285 |
286 | ## 2.2 AOF文件的载入与数据还原
287 |
288 | 因为AOF文件里面包含了重建数据库状态所需的所有写命令,所以服务器只要**读入并重新执行一遍AOF文件里面保存的写命令**,就可以还原服务器关闭之前的数据库状态。
289 |
290 | AOF还原数据库的步骤如下:
291 |
292 | 1. 创建一个不带网络连接的**伪客户端(fake client)**:因为Redis的命令只能在客户端上下文中执行。
293 | 2. 从AOF中读出一条命令。
294 | 3. 使用伪客户端执行被读出的写命令。
295 | 4. 重复23步
296 |
297 | ## 2.3 AOF重写
298 |
299 | 随着时间的增长,AOF文件的大小将会越来越大。为了解决这个问题,Redis提供了**AOF重写**功能。
300 |
301 | 重写后,Redis服务器可以创建一个新的AOF文件来替代现有的AOF文件,新旧两个**AOF文件保存的数据库状态完全相同**。
302 |
303 | 如果要保存一个键值对,我们其实只关心它当前的状态。所以重写策略是:首先**从数据库中读取键现在的值,然后用一条命令去记录键值对**,用到了`aof_rewrite`函数。
304 |
305 | 比如,对list进行`RPUSH`操作填入"A"、"B"、"C",然后再`LPOP`一次,我们操作了4次,但其实用`RPUSH list A B`这一条指令就可以代替。
306 |
307 | `aof_rewrite`函数包含了大量写入操作,调用时会导致线程被长时间阻塞,所以Redis**将AOF重写放入子进程里**。
308 |
309 | ----
310 |
311 | 还有一个问题:子进程AOF重写时,主进程也在写命令,导致两者状态不一致。因此,**Redis服务器设置了一个AOF重写缓冲区**,这个缓冲区在服务器创建子进程之后开始使用,当Redis服务器执行完一个写命令之后,它会**同时**将这个写命令发送给**AOF缓冲区**和**AOF重写缓冲区**。
312 |
313 | 换句话说,子进程执行AOF期间,服务器进程需要:
314 |
315 | - 执行客户端指令
316 | - 将执行后的命令追加到AOF缓冲区
317 | - 将执行后的命令追加到AOF重写缓冲区
318 |
319 | ---
320 |
321 | 子进程执行完AOF后,向父进程发送一个信号。父进程接收后:
322 |
323 | 1. 将AOF重写缓冲区的内容写入AOF文件中,保证一致性。
324 | 2. 对新AOF文件改名,原子的(atomic)覆盖现有AOF文件。
325 |
326 | 在整个AOF后台重写过程中,**只有信号处理函数执行时会对服务器进程(父进程)造成阻塞**,在其他时候,AOF后台重写都不会阻塞父进程,这将AOF重写对服务器性能造成的影响降到了最低。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现5-事件.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现5-事件
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-05 13:17:25
12 | ---
13 |
14 | Redis是一个**事件驱动程序**,前面提到,服务器需要处理文件事件和时间事件。
15 |
16 | - **文件事件**:Redis服务器通过套接字与客户端(或者其他Redis服务器)进行连接,而**文件事件就是服务器对套接字操作的抽象**。
17 | - **时间事件**:些操作会在给定的时间点进行,对这类**定时操作的抽象就是时间事件。**
18 |
19 | # 1. 文件事件
20 |
21 | Redis基于Reactor模式开发了自己的网络事件处理器:这个处理器被称为**文件事件处理器(file event handler)**
22 |
23 | > Reactor模式用于高并发,依靠事件驱动。传统的线程连接中,IO连接后需要等待客户的请求。而事件驱动中,IO可以干别的事情,等客户发来请求后再处理。
24 |
25 | 在Redis中,
26 |
27 | - 文件事件处理器使用I/O多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
28 | - 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
29 |
30 | 虽然文件事件处理器**以单线程方式运**行,但通过使用**I/O多路复用**程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与Redis服务器中其他**同样以单线程方式运行的模块进行对接**,这保持了**Redis内部单线程设计的简单性。**
31 |
32 | ## 1.1 构成
33 |
34 | 文件事件处理器的四个组成部分,它们分别是**套接字**、**I/O多路复用程序**、**文件事件分派器(dispatcher)**,以及**事件处理器**。
35 |
36 | 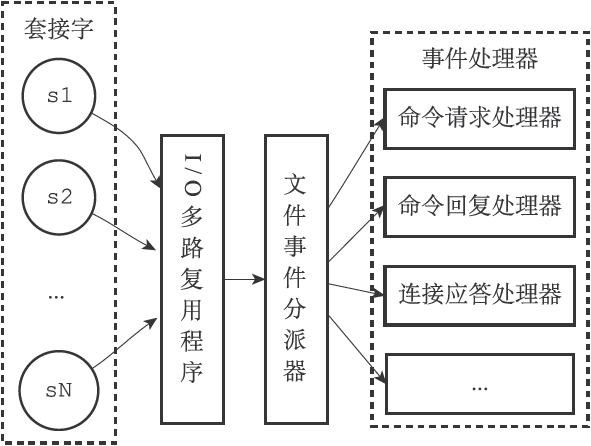 37 |
38 | 前面提到,文件事件是对套接字操作的抽象,**当一个套接字准备好后,就会产生一个文件事件。**
39 |
40 | 尽管多个文件事件可能会并发地出现,但I/O多路复用程序总是会**将所有产生事件的套接字都放到一个队列里面**,然后通过这个队列,以**有序(sequentially)**、**同步(synchronously)**、**每次一个套接字**的方式向文件事件分派器传送套接字。**只有当上一个套接字处理完毕后,复用程序才会向分派器传送下一个套接字。**
41 |
42 |
37 |
38 | 前面提到,文件事件是对套接字操作的抽象,**当一个套接字准备好后,就会产生一个文件事件。**
39 |
40 | 尽管多个文件事件可能会并发地出现,但I/O多路复用程序总是会**将所有产生事件的套接字都放到一个队列里面**,然后通过这个队列,以**有序(sequentially)**、**同步(synchronously)**、**每次一个套接字**的方式向文件事件分派器传送套接字。**只有当上一个套接字处理完毕后,复用程序才会向分派器传送下一个套接字。**
41 |
42 |  43 |
44 | ## 1.2 IO多路复用程序的实现
45 |
46 | Redis的I/O多路复用程序的所有功能都是**通过包装常见的select、epoll、evport和kqueue这些I/O多路复用函数库来实现的**,每个I/O多路复用函数库在Redis源码中都对应一个单独的文件,比如ae_select.c、ae_epoll.c、ae_kqueue.c。
47 |
48 | > ae表示A simple event-driven programming library,一个简单的事件驱动程序库
49 |
50 | 由于IO复用程序提供了统一的接口,所以**底层实现方法可以互换。**
51 |
52 |
43 |
44 | ## 1.2 IO多路复用程序的实现
45 |
46 | Redis的I/O多路复用程序的所有功能都是**通过包装常见的select、epoll、evport和kqueue这些I/O多路复用函数库来实现的**,每个I/O多路复用函数库在Redis源码中都对应一个单独的文件,比如ae_select.c、ae_epoll.c、ae_kqueue.c。
47 |
48 | > ae表示A simple event-driven programming library,一个简单的事件驱动程序库
49 |
50 | 由于IO复用程序提供了统一的接口,所以**底层实现方法可以互换。**
51 |
52 | 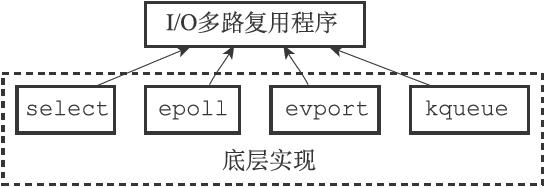 53 |
54 | ## 1.3 事件类型
55 |
56 | I/O多路复用程序可以**同时**监听多个套接字的`ae.h/AE_READABLE`和`ae.h/AE_WRITABLE`这两种事件,这两类事件和套接字操作之间的对应关系如下:
57 |
58 | - 客户端对套接字执行write操作,客户端对服务器的监听套接字执行connect操作。此时套接字对服务器**变为可读状态**,就会产生`AE_READABLE`事件。
59 | - 客户端对套接字执行read操作。此时套接字对服务器变为**可写状态**,就会产生`AR_WRITABLE`事件。
60 |
61 | 虽然是可以同时处理这两种事件,但**优先处理可写事件。**
62 |
63 | ## 1.4 事件处理器
64 |
65 | 事件处理器有很多,最常用的是**通信的连接应答处理器**、**命令请求处理器**和**命令回复处理器**。
66 |
67 | **(1)连接应答处理器**
68 |
69 | `networking.c/acceptTcpHandler`函数是Redis的连接应答处理器,具体实现为`sys/socket.h/accept`函数的包装。
70 |
71 | 当Redis服务器进行**初始化**的时候,程序会将**连接应答处理器**和**服务器监听套接字的`AE_READABLE`事件**关联起来,当有客户端用`sys/socket.h/connec`t函数连接服务器监听套接字的时候,**套接字就会产生`AE_READABLE`事件,引发连接应答处理器执行**。
72 |
73 |
53 |
54 | ## 1.3 事件类型
55 |
56 | I/O多路复用程序可以**同时**监听多个套接字的`ae.h/AE_READABLE`和`ae.h/AE_WRITABLE`这两种事件,这两类事件和套接字操作之间的对应关系如下:
57 |
58 | - 客户端对套接字执行write操作,客户端对服务器的监听套接字执行connect操作。此时套接字对服务器**变为可读状态**,就会产生`AE_READABLE`事件。
59 | - 客户端对套接字执行read操作。此时套接字对服务器变为**可写状态**,就会产生`AR_WRITABLE`事件。
60 |
61 | 虽然是可以同时处理这两种事件,但**优先处理可写事件。**
62 |
63 | ## 1.4 事件处理器
64 |
65 | 事件处理器有很多,最常用的是**通信的连接应答处理器**、**命令请求处理器**和**命令回复处理器**。
66 |
67 | **(1)连接应答处理器**
68 |
69 | `networking.c/acceptTcpHandler`函数是Redis的连接应答处理器,具体实现为`sys/socket.h/accept`函数的包装。
70 |
71 | 当Redis服务器进行**初始化**的时候,程序会将**连接应答处理器**和**服务器监听套接字的`AE_READABLE`事件**关联起来,当有客户端用`sys/socket.h/connec`t函数连接服务器监听套接字的时候,**套接字就会产生`AE_READABLE`事件,引发连接应答处理器执行**。
72 |
73 | 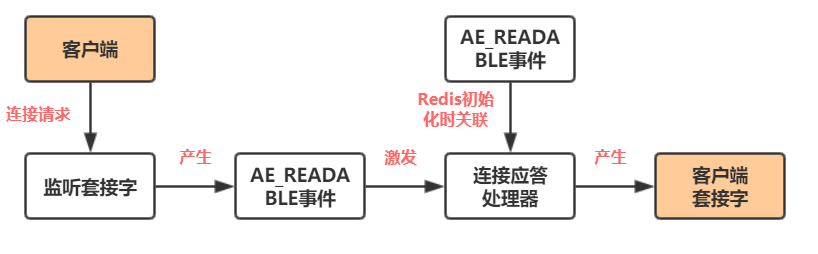 74 |
75 | **(2)命令请求处理器**
76 |
77 | `networking.c/readQueryFromClient`函数是Redis的命令请求处理器,这个处理器负责从套接字中读入客户端发送的命令请求内容,具体实现为`unistd.h/read`函数的包装。
78 |
79 | 和上面一样,当客户端**通过连接应答处理器成功连接到服务器后**,服务器会将**客户端套接字的AE_READABLE事件**和**命令请求处理器**关联起来,当客户端向服务器发送命令请求的时候,**套接字就会产生AE_READABLE事件**,**引发命令请求处理器执行**。
80 |
81 |
74 |
75 | **(2)命令请求处理器**
76 |
77 | `networking.c/readQueryFromClient`函数是Redis的命令请求处理器,这个处理器负责从套接字中读入客户端发送的命令请求内容,具体实现为`unistd.h/read`函数的包装。
78 |
79 | 和上面一样,当客户端**通过连接应答处理器成功连接到服务器后**,服务器会将**客户端套接字的AE_READABLE事件**和**命令请求处理器**关联起来,当客户端向服务器发送命令请求的时候,**套接字就会产生AE_READABLE事件**,**引发命令请求处理器执行**。
80 |
81 | 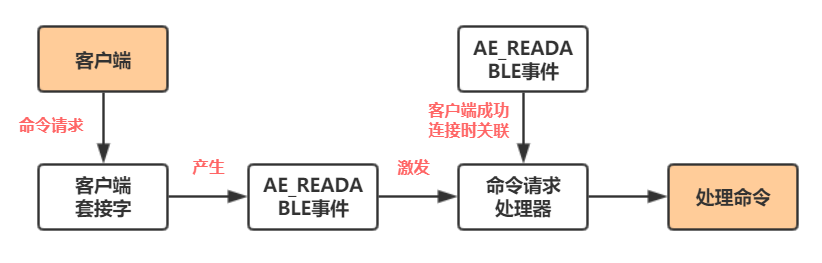 82 |
83 | **(3)命令回复处理器**
84 |
85 | `networking.c/sendReplyToClient`函数是Redis的命令回复处理器,这个处理器**负责将服务器执行命令后得到的命令通过套接字返回给客户端**,具体实现为`unistd.h/write`函数的包装。
86 |
87 | 当服务器有命令回复需要传送给客户端的时候,服务器会将**客户端套接字的AE_WRITABLE事件**和**命令回复处理器**关联起来,当客户端准备好接收服务器传回的命令回复时,就会**产生AE_WRITABLE事件,引发命令回复处理器执行**。
88 |
89 |
82 |
83 | **(3)命令回复处理器**
84 |
85 | `networking.c/sendReplyToClient`函数是Redis的命令回复处理器,这个处理器**负责将服务器执行命令后得到的命令通过套接字返回给客户端**,具体实现为`unistd.h/write`函数的包装。
86 |
87 | 当服务器有命令回复需要传送给客户端的时候,服务器会将**客户端套接字的AE_WRITABLE事件**和**命令回复处理器**关联起来,当客户端准备好接收服务器传回的命令回复时,就会**产生AE_WRITABLE事件,引发命令回复处理器执行**。
88 |
89 | 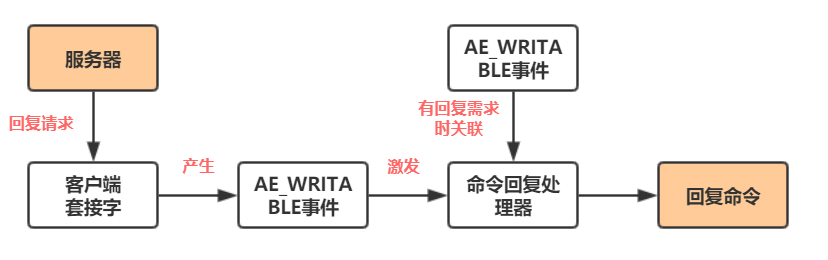 90 |
91 | # 2. 时间事件
92 |
93 | Redis时间事件分为两类:
94 |
95 | - **定时事件**:程序在指定时间后执行一次。
96 | - **周期性事件**:每隔一段时间就执行,循环往复。
97 |
98 | 一个时间事件主要由以下三个属性组成:
99 |
100 | - **id**:服务器为时间事件创造全局唯一ID作为识别,新事件比旧事件号码要大。
101 | - **when**:毫秒级UNIX时间戳,记录时间事件到达时间。
102 | - **timeProc**:时间事件处理器,到时间后处理事件。
103 |
104 | ## 2.1 构成
105 |
106 | 服务器将所有时间事件都放在一个**无序链表**中,每当时间事件执行器运行时,它就**遍历整个链表**,**查找所有已到达的时间事件**,并调用相应的事件处理器。
107 |
108 | 因为新的事件总是放在表头,所以三个时间事件分别按逆序ID排列:
109 |
110 |
90 |
91 | # 2. 时间事件
92 |
93 | Redis时间事件分为两类:
94 |
95 | - **定时事件**:程序在指定时间后执行一次。
96 | - **周期性事件**:每隔一段时间就执行,循环往复。
97 |
98 | 一个时间事件主要由以下三个属性组成:
99 |
100 | - **id**:服务器为时间事件创造全局唯一ID作为识别,新事件比旧事件号码要大。
101 | - **when**:毫秒级UNIX时间戳,记录时间事件到达时间。
102 | - **timeProc**:时间事件处理器,到时间后处理事件。
103 |
104 | ## 2.1 构成
105 |
106 | 服务器将所有时间事件都放在一个**无序链表**中,每当时间事件执行器运行时,它就**遍历整个链表**,**查找所有已到达的时间事件**,并调用相应的事件处理器。
107 |
108 | 因为新的事件总是放在表头,所以三个时间事件分别按逆序ID排列:
109 |
110 | 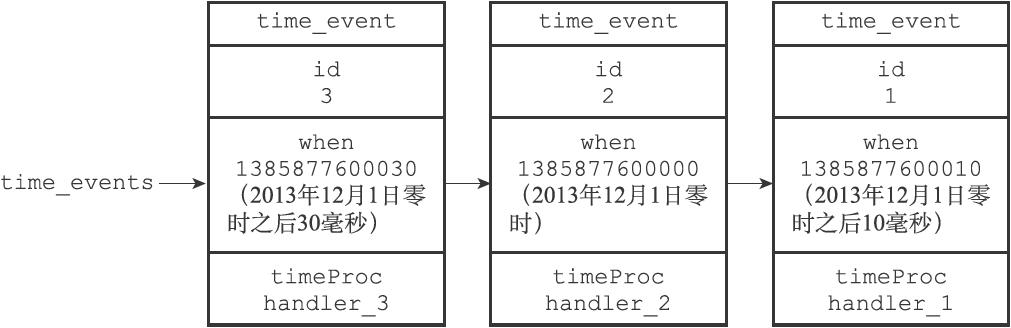 111 |
112 | 注意,我们说保存时间事件的链表为无序链表,指的不是链表不按ID排序,而是说,**该链表不按when属性的大小排序**。
113 |
114 | ## 2.2 API
115 |
116 | `ae.c/aeCreateTimeEvent`函数接受一个毫秒数milliseconds和一个时间事件处理器proc作为参数,**将一个新的时间事件添加到服务器**。
117 |
118 | `ae.c/aeDeleteFileEvent`函数接受一个时间事件ID作为参数,然后从服务器中**删除**该ID所对应的时间事件。
119 |
120 | `ae.c/aeSearchNearestTimer`函数返回到达时间距离当前时间最接近的那个时间事件。
121 |
122 | `ae.c/processTimeEvents`函数是时间事件的执行器,这个函数会**遍历所有已到达的时间事件**,并调**用这些事件的处理器**。已到达指的是,时间事件的when属性记录的UNIX时间戳等于或小于当前时间的UNIX时间戳。
123 |
124 | ## 2.3 severCron函数
125 |
126 | 持续运行的Redis服务器需要**定期**对自身的资源和状态进行检查和调整,这些定期操作由`redis.c/serverCron`函数负责执行,它的主要工作包括:
127 |
128 | - 更新服务器统计信息,包括事件、内存占用等情况
129 | - 清理过期键值对
130 | - 关闭和清理失效的客户端连接
131 | - AOF和RDB持久化操作
132 | - 如果sever是主服务器,则对从服务器进行定期同步
133 | - 如果是集群模式,对集群进行定期同步和连接测试
134 |
135 | > cron在unix中表示计划任务,计时程序
136 |
137 | 默认频率是100毫秒一次,用户可以在redis.conf中修改hz选项来改变。
138 |
139 | ## 2.3 事件的调度与执行
140 |
141 | 因为服务器中同时存在文件事件和时间事件两种事件类型,所以服务器必须对这两种事件进行调度,**决定何时应该处理什么文件,以及花多少时间来处理它们等等。**事件的调度和执行由`ae.c/aeProcessEvents`函数负责。
142 |
143 |
111 |
112 | 注意,我们说保存时间事件的链表为无序链表,指的不是链表不按ID排序,而是说,**该链表不按when属性的大小排序**。
113 |
114 | ## 2.2 API
115 |
116 | `ae.c/aeCreateTimeEvent`函数接受一个毫秒数milliseconds和一个时间事件处理器proc作为参数,**将一个新的时间事件添加到服务器**。
117 |
118 | `ae.c/aeDeleteFileEvent`函数接受一个时间事件ID作为参数,然后从服务器中**删除**该ID所对应的时间事件。
119 |
120 | `ae.c/aeSearchNearestTimer`函数返回到达时间距离当前时间最接近的那个时间事件。
121 |
122 | `ae.c/processTimeEvents`函数是时间事件的执行器,这个函数会**遍历所有已到达的时间事件**,并调**用这些事件的处理器**。已到达指的是,时间事件的when属性记录的UNIX时间戳等于或小于当前时间的UNIX时间戳。
123 |
124 | ## 2.3 severCron函数
125 |
126 | 持续运行的Redis服务器需要**定期**对自身的资源和状态进行检查和调整,这些定期操作由`redis.c/serverCron`函数负责执行,它的主要工作包括:
127 |
128 | - 更新服务器统计信息,包括事件、内存占用等情况
129 | - 清理过期键值对
130 | - 关闭和清理失效的客户端连接
131 | - AOF和RDB持久化操作
132 | - 如果sever是主服务器,则对从服务器进行定期同步
133 | - 如果是集群模式,对集群进行定期同步和连接测试
134 |
135 | > cron在unix中表示计划任务,计时程序
136 |
137 | 默认频率是100毫秒一次,用户可以在redis.conf中修改hz选项来改变。
138 |
139 | ## 2.3 事件的调度与执行
140 |
141 | 因为服务器中同时存在文件事件和时间事件两种事件类型,所以服务器必须对这两种事件进行调度,**决定何时应该处理什么文件,以及花多少时间来处理它们等等。**事件的调度和执行由`ae.c/aeProcessEvents`函数负责。
142 |
143 | 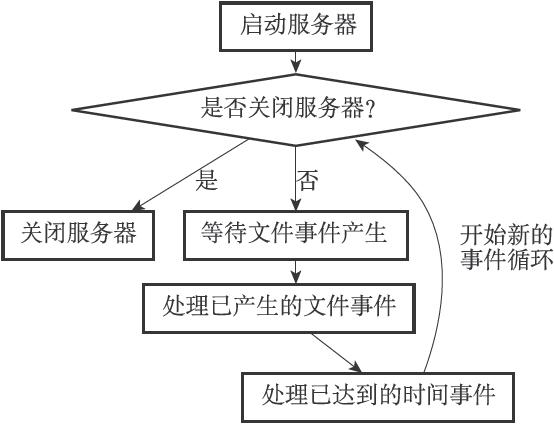 144 |
145 | 对事件处理的原则是:
146 |
147 | - 如果等待并处理完一次文件事件之后,仍未有任何时间事件到达,那么服务器将**再次等待并处理文件事件。**
148 | - 对两种事件处理都是**同步、有序、原子**地执行的,服务器**不会中途中断事件处理,也不会对事件进行抢占**,因此需要尽可能地减少程序的阻塞时间,并在有需要时主动让出执行权。(比如写入字节太长,命令回复处理器就会break跳出,将余下的数据留到下次)
149 | - 由于不能抢占,时间事件到达后需要等待文件事件处理完成,所以**一般会稍晚于到达时间。**
150 |
151 |
144 |
145 | 对事件处理的原则是:
146 |
147 | - 如果等待并处理完一次文件事件之后,仍未有任何时间事件到达,那么服务器将**再次等待并处理文件事件。**
148 | - 对两种事件处理都是**同步、有序、原子**地执行的,服务器**不会中途中断事件处理,也不会对事件进行抢占**,因此需要尽可能地减少程序的阻塞时间,并在有需要时主动让出执行权。(比如写入字节太长,命令回复处理器就会break跳出,将余下的数据留到下次)
149 | - 由于不能抢占,时间事件到达后需要等待文件事件处理完成,所以**一般会稍晚于到达时间。**
150 |
151 | 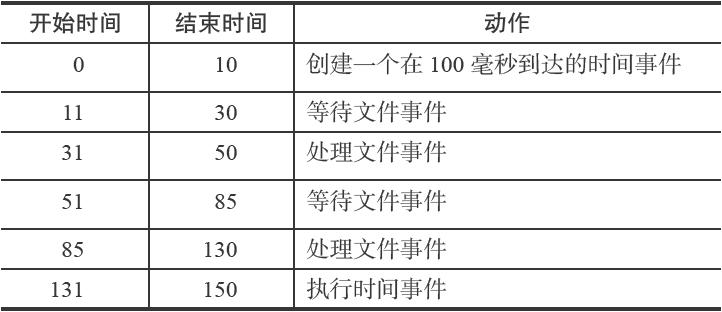 --------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现6-客户端与服务器.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现6-客户端与服务器
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-06 10:09:16
12 | ---
13 |
14 | 介绍Redis服务器与客户端。
15 |
16 | # 1. 客户端
17 |
18 | Redis服务器是典型的一对多服务器程序:一个服务器可以与多个客户端建立网络连接,处理他们的请求。
19 |
20 | 通过使用**由I/O多路复用技术实现的文件事件处理器**,Redis服务器使用**单线程单进程的方式**来处理命令请求,并与多个客户端进行网络通信。
21 |
22 | 对于每个与服务器进行连接的客户端,服务器都为这些客户端建立了相应的`redis.h/redisClient`结构(**客户端状态**),这个结构保存了客户端**当前的状态信息**。
23 |
24 | 在服务器中,用一个**链表**保存客户端的所有状态
25 |
26 | ```C
27 | struct redisServer
28 | {
29 | // ...
30 | // 一个链表,保存了所有客户端状态
31 | list *clients;
32 | // ...
33 | };
34 | ```
35 |
36 |
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现6-客户端与服务器.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现6-客户端与服务器
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-06 10:09:16
12 | ---
13 |
14 | 介绍Redis服务器与客户端。
15 |
16 | # 1. 客户端
17 |
18 | Redis服务器是典型的一对多服务器程序:一个服务器可以与多个客户端建立网络连接,处理他们的请求。
19 |
20 | 通过使用**由I/O多路复用技术实现的文件事件处理器**,Redis服务器使用**单线程单进程的方式**来处理命令请求,并与多个客户端进行网络通信。
21 |
22 | 对于每个与服务器进行连接的客户端,服务器都为这些客户端建立了相应的`redis.h/redisClient`结构(**客户端状态**),这个结构保存了客户端**当前的状态信息**。
23 |
24 | 在服务器中,用一个**链表**保存客户端的所有状态
25 |
26 | ```C
27 | struct redisServer
28 | {
29 | // ...
30 | // 一个链表,保存了所有客户端状态
31 | list *clients;
32 | // ...
33 | };
34 | ```
35 |
36 |  37 |
38 | ## 1.1 客户端属性
39 |
40 | **(1)套接字描述符**
41 |
42 | 客户端状态的fd属性记录了客户端**正在使用的套接字描述符**。根据客户端类型不同,fd的值可以是**-1或大于-1的整数**:
43 |
44 | - 伪客户端为-1:伪客户端用于处理的AOF文件或Lua脚本,**而不是网络**。
45 | - 普通客户端为大于-1的整数。
46 |
47 | 执行CLIENT list命令会列出所有连接到服务器的普通客户端。
48 |
49 | ```c
50 | redis> CLIENT list
51 | addr=127.0.0.1:53428 fd=6 name= age=1242 idle=0 ...
52 | addr=127.0.0.1:53469 fd=7 name= age=4 idle=4 ...
53 | ```
54 |
55 | **(2)名字**
56 |
57 | 默认情况下客户端是没有名字的,比如上面的例子中name处就是空白。使用**CLIENT setname**命令可以为客户端设置一个名字,让客户端的身份变得更清晰。
58 |
59 | ```C
60 | typedef struct redisClient
61 | {
62 | //...
63 | robj *name;
64 | //...
65 | }redisClient;
66 | ```
67 |
68 | 如果客户端没有名字,那么相应客户端状态的name属性指向NULL指针;相反,如果有名字,那么name属性将指向一个字符串对象。
69 |
70 | **(3)标志**
71 |
72 | 客户端的标志属性flags记录了客户端的角色(role),以及客户端目前所处的状态:
73 |
74 | ```C
75 | typedef struct redisClient
76 | {
77 | // ...
78 | int flags;
79 | // ...
80 | } redisClient;
81 | ```
82 |
83 | 比如`REDIS_BLOCKED`标志表示客户端正在被BRPOP、BLPOP等命令阻塞。flag可以是单个标志,也可以是多个标志的组合。比如:
84 |
85 | ```C
86 | flags=REDIS_SLAVE | REDIS_PRE_PSYNC;
87 | ```
88 |
89 | **(4)输入缓冲区**
90 |
91 | 客户端状态的输入缓冲区用于**保存客户端发送的命令请求**:
92 |
93 | ```C
94 | typedef struct redisClient
95 | {
96 | // ...
97 | sds querybuf;
98 | // ...
99 | } redisClient;
100 | ```
101 |
102 | 保存方式和AOF类似,比如`SET key value`被转化为如下的SDS值:
103 |
104 | ```
105 | *3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n
106 | ```
107 |
108 |
37 |
38 | ## 1.1 客户端属性
39 |
40 | **(1)套接字描述符**
41 |
42 | 客户端状态的fd属性记录了客户端**正在使用的套接字描述符**。根据客户端类型不同,fd的值可以是**-1或大于-1的整数**:
43 |
44 | - 伪客户端为-1:伪客户端用于处理的AOF文件或Lua脚本,**而不是网络**。
45 | - 普通客户端为大于-1的整数。
46 |
47 | 执行CLIENT list命令会列出所有连接到服务器的普通客户端。
48 |
49 | ```c
50 | redis> CLIENT list
51 | addr=127.0.0.1:53428 fd=6 name= age=1242 idle=0 ...
52 | addr=127.0.0.1:53469 fd=7 name= age=4 idle=4 ...
53 | ```
54 |
55 | **(2)名字**
56 |
57 | 默认情况下客户端是没有名字的,比如上面的例子中name处就是空白。使用**CLIENT setname**命令可以为客户端设置一个名字,让客户端的身份变得更清晰。
58 |
59 | ```C
60 | typedef struct redisClient
61 | {
62 | //...
63 | robj *name;
64 | //...
65 | }redisClient;
66 | ```
67 |
68 | 如果客户端没有名字,那么相应客户端状态的name属性指向NULL指针;相反,如果有名字,那么name属性将指向一个字符串对象。
69 |
70 | **(3)标志**
71 |
72 | 客户端的标志属性flags记录了客户端的角色(role),以及客户端目前所处的状态:
73 |
74 | ```C
75 | typedef struct redisClient
76 | {
77 | // ...
78 | int flags;
79 | // ...
80 | } redisClient;
81 | ```
82 |
83 | 比如`REDIS_BLOCKED`标志表示客户端正在被BRPOP、BLPOP等命令阻塞。flag可以是单个标志,也可以是多个标志的组合。比如:
84 |
85 | ```C
86 | flags=REDIS_SLAVE | REDIS_PRE_PSYNC;
87 | ```
88 |
89 | **(4)输入缓冲区**
90 |
91 | 客户端状态的输入缓冲区用于**保存客户端发送的命令请求**:
92 |
93 | ```C
94 | typedef struct redisClient
95 | {
96 | // ...
97 | sds querybuf;
98 | // ...
99 | } redisClient;
100 | ```
101 |
102 | 保存方式和AOF类似,比如`SET key value`被转化为如下的SDS值:
103 |
104 | ```
105 | *3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n
106 | ```
107 |
108 | 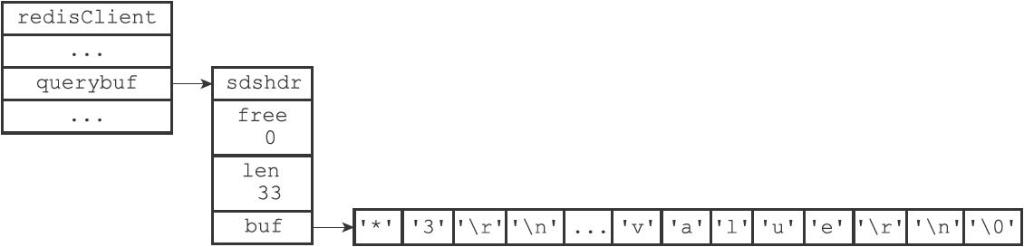 109 |
110 | **(5)命令与命令参数**
111 |
112 | 在服务器将客户端发送的命令请求保存到客户端状态的querybuf属性之后,服务器将对命令请求的内容进行**分析**,并将得出的**命令参数**以及**命令参数的个数**分别保存到客户端状态的**argv属性**和**argc属性**:
113 |
114 | ```C
115 | typedef struct redisClient
116 | {
117 | // ...
118 | robj **argv;
119 | int argc;
120 | // ...
121 | } redisClient;
122 | ```
123 |
124 | argv属性是一个数组,**数组中的每个项都是一个字符串对象**,其中`argv[0]`是**要执行的命令**,而之后的其他项则是**传给命令的参数**。
125 |
126 |
109 |
110 | **(5)命令与命令参数**
111 |
112 | 在服务器将客户端发送的命令请求保存到客户端状态的querybuf属性之后,服务器将对命令请求的内容进行**分析**,并将得出的**命令参数**以及**命令参数的个数**分别保存到客户端状态的**argv属性**和**argc属性**:
113 |
114 | ```C
115 | typedef struct redisClient
116 | {
117 | // ...
118 | robj **argv;
119 | int argc;
120 | // ...
121 | } redisClient;
122 | ```
123 |
124 | argv属性是一个数组,**数组中的每个项都是一个字符串对象**,其中`argv[0]`是**要执行的命令**,而之后的其他项则是**传给命令的参数**。
125 |
126 |  127 |
128 | **(6)命令的实现函数**
129 |
130 | 当服务器从协议内容中分析并得出argv属性和argc属性的值之后,服务器**将根据项argv[0]的值,在命令表中查找命令所对应的命令实现函数。**
131 |
132 | 命令表是一个字典结构,键是SDS结构,保存了命令的名字,**值是redisCommand结构**,保存了:
133 |
134 | - 实现函数
135 | - 命令标志
136 | - 命令的参数个数
137 | - 命令的总执行次数
138 | - 总消耗时长
139 |
140 |
127 |
128 | **(6)命令的实现函数**
129 |
130 | 当服务器从协议内容中分析并得出argv属性和argc属性的值之后,服务器**将根据项argv[0]的值,在命令表中查找命令所对应的命令实现函数。**
131 |
132 | 命令表是一个字典结构,键是SDS结构,保存了命令的名字,**值是redisCommand结构**,保存了:
133 |
134 | - 实现函数
135 | - 命令标志
136 | - 命令的参数个数
137 | - 命令的总执行次数
138 | - 总消耗时长
139 |
140 | 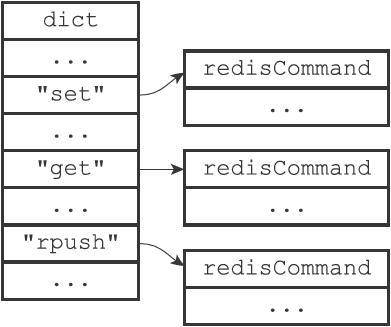 141 |
142 | 当程序在命令表中成功找到argv[0]所对应的redisCommand结构时,**客户端状态的cmd指针指向这个结构**:
143 |
144 | ```C
145 | typedef struct redisClient
146 | {
147 | // ...
148 | struct redisCommand *cmd;
149 | // ...
150 | } redisClient;
151 | ```
152 |
153 | 服务器就可以使用cmd属性所指向的redisCommand结构,以及argv、argc属性中保存的命令参数信息,调用命令实现函数,执行客户端指定的命令。
154 |
155 |
141 |
142 | 当程序在命令表中成功找到argv[0]所对应的redisCommand结构时,**客户端状态的cmd指针指向这个结构**:
143 |
144 | ```C
145 | typedef struct redisClient
146 | {
147 | // ...
148 | struct redisCommand *cmd;
149 | // ...
150 | } redisClient;
151 | ```
152 |
153 | 服务器就可以使用cmd属性所指向的redisCommand结构,以及argv、argc属性中保存的命令参数信息,调用命令实现函数,执行客户端指定的命令。
154 |
155 | 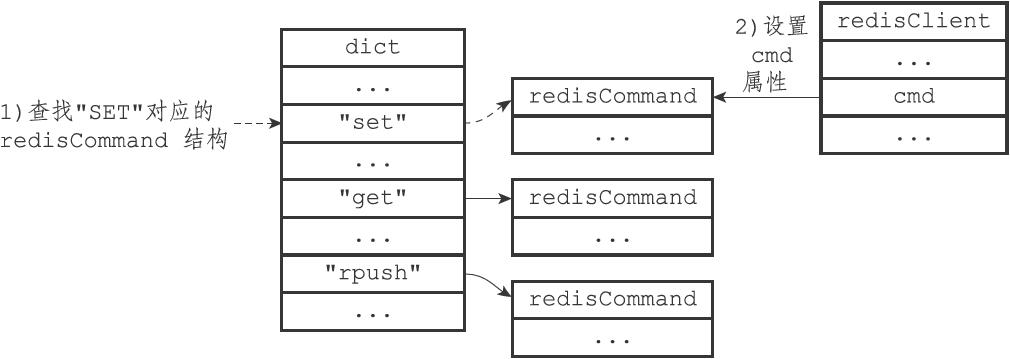 156 |
157 | **(7)输出缓冲区**
158 |
159 | **命令回复**会被保存在客户端状态的输出缓冲区里面,每个客户端都有两个输出缓冲区可用,**一个缓冲区的大小是固定的,另一个缓冲区的大小是可变的**:
160 |
161 | - 固定大小的缓冲区用于**保存那些长度比较小的回复**,比如OK、简短的字符串值、整数值、错误回复等等。
162 | - 可变大小的缓冲区用于保存那些长度比较大的回复,比如一个非常长的字符串值,一个由很多项组成的列表,一个包含了很多元素的集合等等。
163 |
164 | **(8)身份验证**
165 |
166 | 客户端状态的**authenticated**属性用于记录客户端是否通过了身份验证:
167 |
168 | ```C
169 | typedef struct redisClient
170 | {
171 | // ...
172 | int authenticated;
173 | // ...
174 | } redisClient;
175 | ```
176 |
177 | 为0表示没有通过验证,为1表示通过。如果没有通过,**除了AUTH命令之外,客户端发送的所有其他命令都会被服务器拒绝执行**。
178 |
179 | ```C
180 | redis> SET msg "hello world"
181 | (error) NOAUTH Authentication required.
182 | ```
183 |
184 | 当客户端通过AUTH命令成功进行身份验证之后,客户端状态authenticated属性的值就会从0变为1.
185 |
186 | **(9)时间**
187 |
188 | 客户端还有几个和时间有关的属性:
189 |
190 | ```C
191 | typedef struct redisClient
192 | { // ...
193 | time_t ctime;
194 | time_t lastinteraction;
195 | time_t obuf_soft_limit_reached_time; // ...
196 | } redisClient;
197 | ```
198 |
199 | - ctime属性记录了创建客户端的时间,这个时间可以用来计算客户端与服务器已经连接了多少秒。
200 | - lastinteraction属性记录了客户端与服务器最后一次进行互动(interaction)的时间。(收或者发命令)
201 | - obuf_soft_limit_reached_time属性记录了输出缓冲区第一次到达软性限制(soft limit)的时间
202 |
203 | ## 1.2 创建与关闭客户端
204 |
205 | **(1)普通客户端**
206 |
207 | 所谓普通客户端是**指客户端通过网络与服务器连接**,客户端使用connect函数连接到服务器时就会**调用连接事件处理器**。
208 |
209 | 之后,会将新客户端的状态添加到clients链表的末尾。
210 |
211 |
156 |
157 | **(7)输出缓冲区**
158 |
159 | **命令回复**会被保存在客户端状态的输出缓冲区里面,每个客户端都有两个输出缓冲区可用,**一个缓冲区的大小是固定的,另一个缓冲区的大小是可变的**:
160 |
161 | - 固定大小的缓冲区用于**保存那些长度比较小的回复**,比如OK、简短的字符串值、整数值、错误回复等等。
162 | - 可变大小的缓冲区用于保存那些长度比较大的回复,比如一个非常长的字符串值,一个由很多项组成的列表,一个包含了很多元素的集合等等。
163 |
164 | **(8)身份验证**
165 |
166 | 客户端状态的**authenticated**属性用于记录客户端是否通过了身份验证:
167 |
168 | ```C
169 | typedef struct redisClient
170 | {
171 | // ...
172 | int authenticated;
173 | // ...
174 | } redisClient;
175 | ```
176 |
177 | 为0表示没有通过验证,为1表示通过。如果没有通过,**除了AUTH命令之外,客户端发送的所有其他命令都会被服务器拒绝执行**。
178 |
179 | ```C
180 | redis> SET msg "hello world"
181 | (error) NOAUTH Authentication required.
182 | ```
183 |
184 | 当客户端通过AUTH命令成功进行身份验证之后,客户端状态authenticated属性的值就会从0变为1.
185 |
186 | **(9)时间**
187 |
188 | 客户端还有几个和时间有关的属性:
189 |
190 | ```C
191 | typedef struct redisClient
192 | { // ...
193 | time_t ctime;
194 | time_t lastinteraction;
195 | time_t obuf_soft_limit_reached_time; // ...
196 | } redisClient;
197 | ```
198 |
199 | - ctime属性记录了创建客户端的时间,这个时间可以用来计算客户端与服务器已经连接了多少秒。
200 | - lastinteraction属性记录了客户端与服务器最后一次进行互动(interaction)的时间。(收或者发命令)
201 | - obuf_soft_limit_reached_time属性记录了输出缓冲区第一次到达软性限制(soft limit)的时间
202 |
203 | ## 1.2 创建与关闭客户端
204 |
205 | **(1)普通客户端**
206 |
207 | 所谓普通客户端是**指客户端通过网络与服务器连接**,客户端使用connect函数连接到服务器时就会**调用连接事件处理器**。
208 |
209 | 之后,会将新客户端的状态添加到clients链表的末尾。
210 |
211 |  212 |
213 | 关闭的原因可能有很多种
214 |
215 | - 客户端进程退出或被杀死
216 | - 客户端向服务器发送了带有不符合协议格式的命令请求
217 | - 如果客户端成为了CLIENT KILL命令的目标
218 | - 客户端空转超时
219 | - 客户端发送的命令请求的大小超过了输入缓冲区的限制大小(默认为1 GB)
220 | - 如果要发送给客户端的命令回复的大小超过了输出缓冲区的限制大小
221 |
222 | 除了超过1GB大小的**硬性限制**外,还有**软性限制**,用到了之前提到的`obuf_soft_limit_reached_time`属性。
223 |
224 | 如果输出缓冲区的大小超过了软性限制所设置的大小,但还没超过硬性限制,那么服务器将使用客户端状态结构的`obuf_soft_limit_reached_time`属性记录下客户端到达软性限制的起始时间。之后服务器会继续监视客户端,**如果输出缓冲区的大小一直超出软性限制,并且持续时间超过服务器设定的时长,那么服务器将关闭客户端**
225 |
226 | **(2)Lua脚本的伪客户端**
227 |
228 | 服务器会在**初始化时**创建负责执行Lua脚本中包含的Redis命令的伪客户端,并将这个伪客户端关联在服务器状态结构的lua_client属性中:
229 |
230 | ```C
231 | struct redisServer
232 | {
233 | // ...
234 | redisClient *lua_client;
235 | // ...
236 | };
237 | ```
238 |
239 | Lua脚本会一直存在于服务器生命周期,只有服务器被关闭时他才会停止。
240 |
241 | 服务器在载入AOF文件时,会创建用于执行AOF文件包含的Redis命令的伪客户端,并在载入完成之后,关闭这个伪客户端。
242 |
243 | # 2. 服务器
244 |
245 | ## 2.1 命令请求的执行过程
246 |
247 | 在处理`SET KEY VALUE`的过程中,客户端和服务器共需要执行以下操作:
248 |
249 | 1. 客户端向服务器发送命令请求`SET KEY VALUE`
250 | 2. 服务器接收并处理,产生回复命令OK
251 | 3. 服务器发送OK给客户端
252 | 4. 客户端接收到命令,并打印给用户
253 |
254 | **(1)发送命令请求**
255 |
256 | 用户在客户端键入一个请求时,客户端会**将命令请求转换为协议格式**,然后通过套接字发送给服务器。
257 |
258 |
212 |
213 | 关闭的原因可能有很多种
214 |
215 | - 客户端进程退出或被杀死
216 | - 客户端向服务器发送了带有不符合协议格式的命令请求
217 | - 如果客户端成为了CLIENT KILL命令的目标
218 | - 客户端空转超时
219 | - 客户端发送的命令请求的大小超过了输入缓冲区的限制大小(默认为1 GB)
220 | - 如果要发送给客户端的命令回复的大小超过了输出缓冲区的限制大小
221 |
222 | 除了超过1GB大小的**硬性限制**外,还有**软性限制**,用到了之前提到的`obuf_soft_limit_reached_time`属性。
223 |
224 | 如果输出缓冲区的大小超过了软性限制所设置的大小,但还没超过硬性限制,那么服务器将使用客户端状态结构的`obuf_soft_limit_reached_time`属性记录下客户端到达软性限制的起始时间。之后服务器会继续监视客户端,**如果输出缓冲区的大小一直超出软性限制,并且持续时间超过服务器设定的时长,那么服务器将关闭客户端**
225 |
226 | **(2)Lua脚本的伪客户端**
227 |
228 | 服务器会在**初始化时**创建负责执行Lua脚本中包含的Redis命令的伪客户端,并将这个伪客户端关联在服务器状态结构的lua_client属性中:
229 |
230 | ```C
231 | struct redisServer
232 | {
233 | // ...
234 | redisClient *lua_client;
235 | // ...
236 | };
237 | ```
238 |
239 | Lua脚本会一直存在于服务器生命周期,只有服务器被关闭时他才会停止。
240 |
241 | 服务器在载入AOF文件时,会创建用于执行AOF文件包含的Redis命令的伪客户端,并在载入完成之后,关闭这个伪客户端。
242 |
243 | # 2. 服务器
244 |
245 | ## 2.1 命令请求的执行过程
246 |
247 | 在处理`SET KEY VALUE`的过程中,客户端和服务器共需要执行以下操作:
248 |
249 | 1. 客户端向服务器发送命令请求`SET KEY VALUE`
250 | 2. 服务器接收并处理,产生回复命令OK
251 | 3. 服务器发送OK给客户端
252 | 4. 客户端接收到命令,并打印给用户
253 |
254 | **(1)发送命令请求**
255 |
256 | 用户在客户端键入一个请求时,客户端会**将命令请求转换为协议格式**,然后通过套接字发送给服务器。
257 |
258 |  259 |
260 | **(2)读取命令请求**
261 |
262 | 当客户端与服务器之间的连接套接字因为客户端的写入而**变得可读**时,服务器将调用命令请求处理器来执行以下操作:
263 |
264 | 1. 读取套接字中的协议请求,并保存在客户端状态的输入缓冲区内
265 | 2. 分析命令,提取命令参数和个数,存在argv和argc属性中
266 | 3. 调用命令执行器
267 |
268 | **(3)命令执行器**
269 |
270 | 前面提到过,命令执行器会在命令表中查找命令,并将找到的结果保存在客户端状态cmd中。
271 |
272 | 字典的键是一个命令的字符串格式,值则是一个redisCommand结构:
273 |
274 |
259 |
260 | **(2)读取命令请求**
261 |
262 | 当客户端与服务器之间的连接套接字因为客户端的写入而**变得可读**时,服务器将调用命令请求处理器来执行以下操作:
263 |
264 | 1. 读取套接字中的协议请求,并保存在客户端状态的输入缓冲区内
265 | 2. 分析命令,提取命令参数和个数,存在argv和argc属性中
266 | 3. 调用命令执行器
267 |
268 | **(3)命令执行器**
269 |
270 | 前面提到过,命令执行器会在命令表中查找命令,并将找到的结果保存在客户端状态cmd中。
271 |
272 | 字典的键是一个命令的字符串格式,值则是一个redisCommand结构:
273 |
274 | 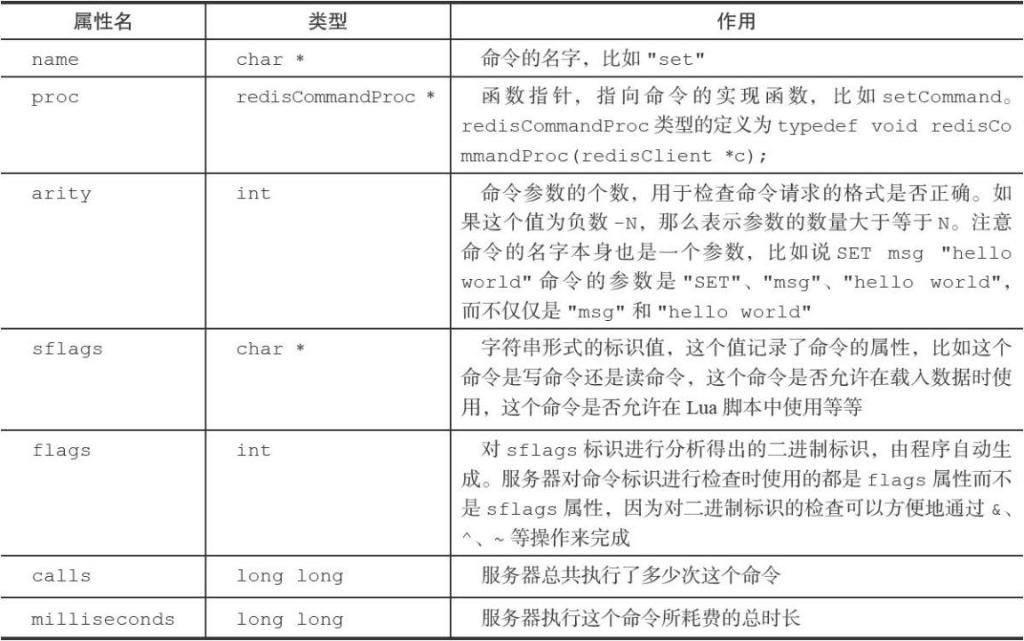 275 |
276 | 下表展示了slags属性可以使用的标识和意义:
277 |
278 |
275 |
276 | 下表展示了slags属性可以使用的标识和意义:
277 |
278 | 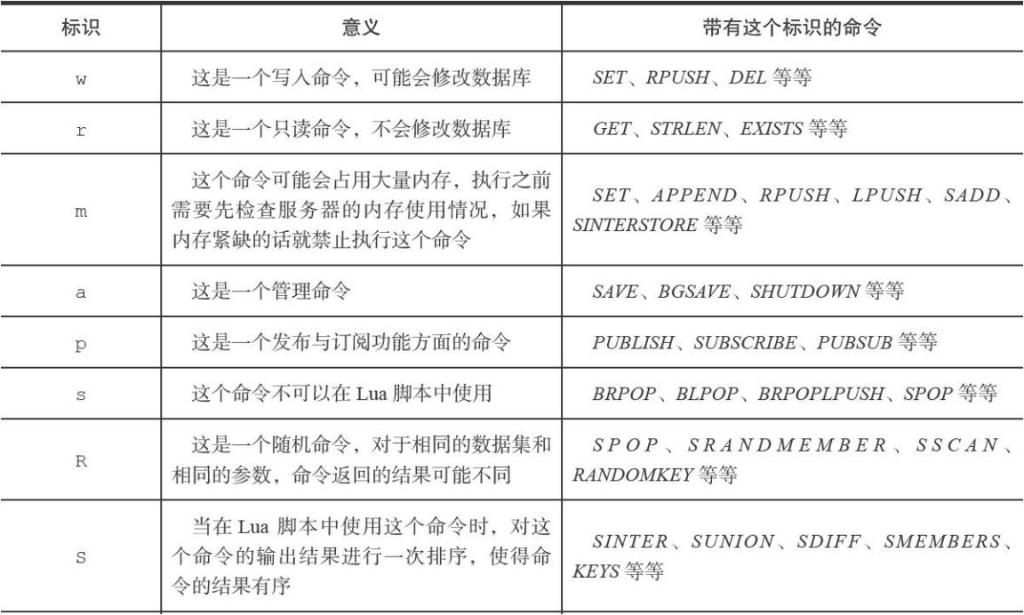 279 |
280 | 比如set执行时,就会:
281 |
282 |
279 |
280 | 比如set执行时,就会:
281 |
282 |  283 |
284 | ---
285 |
286 | 现在已经成功完成了:连接所需函数,参数,参数个数。但在真正执行之前还需要进行检查:
287 |
288 | - 检查客户端状态cmd是否指向NULL
289 | - 根据redisCommand结构的arity属性,检查参数个数是否正确
290 | - 检查身份验证
291 | - 检查内存占用
292 | - 如果当前客户端正在SUBSCRIBE命令订阅频道,则只接受订阅命令,其他命令会被拒绝。
293 | - 服务器因Lua脚本超时并阻塞,服务器只会执行关闭命令,其他会被拒绝。
294 | - 如果客户端正在执行事务,则服务器只会执行客户端发来的EXEC、DISCARD、MULTI、WATCH四个命令,其他命令都会被放进事务队列中。
295 | - 如果打开了监视器功能,服务器会把将要执行的命令发送给监视器。
296 |
297 | ---
298 |
299 | 在执行命令时,先找到客户端状态指针client,然后找到命令字典cmd,然后查找命令的函数指针proc
300 |
301 | ```C
302 | client->cmd->proc(client);
303 | ```
304 |
305 |
283 |
284 | ---
285 |
286 | 现在已经成功完成了:连接所需函数,参数,参数个数。但在真正执行之前还需要进行检查:
287 |
288 | - 检查客户端状态cmd是否指向NULL
289 | - 根据redisCommand结构的arity属性,检查参数个数是否正确
290 | - 检查身份验证
291 | - 检查内存占用
292 | - 如果当前客户端正在SUBSCRIBE命令订阅频道,则只接受订阅命令,其他命令会被拒绝。
293 | - 服务器因Lua脚本超时并阻塞,服务器只会执行关闭命令,其他会被拒绝。
294 | - 如果客户端正在执行事务,则服务器只会执行客户端发来的EXEC、DISCARD、MULTI、WATCH四个命令,其他命令都会被放进事务队列中。
295 | - 如果打开了监视器功能,服务器会把将要执行的命令发送给监视器。
296 |
297 | ---
298 |
299 | 在执行命令时,先找到客户端状态指针client,然后找到命令字典cmd,然后查找命令的函数指针proc
300 |
301 | ```C
302 | client->cmd->proc(client);
303 | ```
304 |
305 | 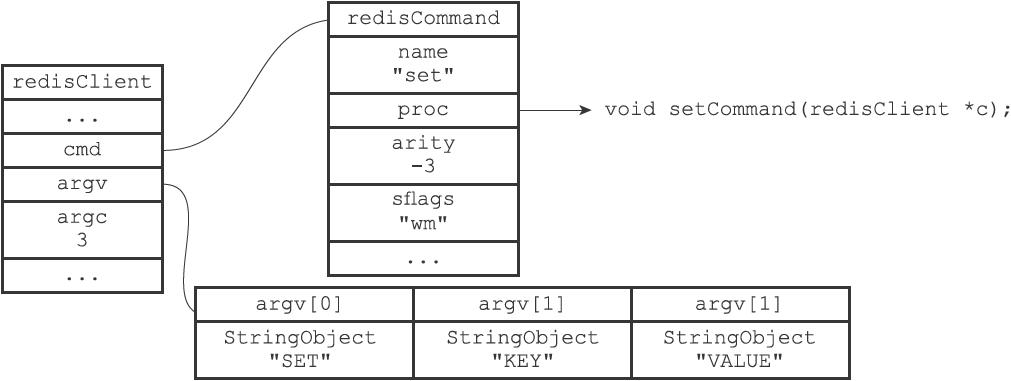 306 |
307 | 处理完毕后,产生回复,**保存在输出缓冲区里面**,之后实现函数还会为客户端的套接字**关联命令回复处理器**,这个处理器负责将命令回复返回给客户端。
308 |
309 |
306 |
307 | 处理完毕后,产生回复,**保存在输出缓冲区里面**,之后实现函数还会为客户端的套接字**关联命令回复处理器**,这个处理器负责将命令回复返回给客户端。
308 |
309 | 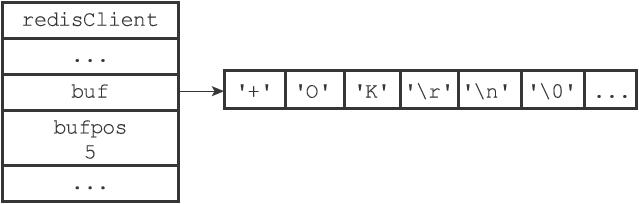 310 |
311 | ## 2.2 severCron函数
312 |
313 | Redis服务器中的serverCron函数默认每隔100毫秒执行一次,这个函数负责管理服务器的资源,并保持服务器自身的良好运转。severCorn函数的常见功能如下:
314 |
315 | **(1)更新服务器时间缓存**
316 |
317 | Redis服务器中有不少功能需要**获取系统的当前时间**,而每次获取系统的当前时间都需要执行一次系统调用,**为了减少系统调用的执行次数**,服务器状态中的unixtime属性和mstime属性被用作当前时间的缓存:
318 |
319 | ```C
320 | struct redisServer
321 | {
322 | // ...
323 | // 保存了秒级精度的系统当前UNIX时间戳
324 | time_t unixtime;
325 | // 保存了毫秒级精度的系统当前UNIX时间戳
326 | long long mstime;
327 | };
328 | ```
329 |
330 | 因为serverCron函数默认会以每100毫秒一次的频率更新unixtime属性和mstime属性,所以**这两个属性记录的时间的精确度并不高**。
331 |
332 | **(2)更新LRU时钟**
333 |
334 | LRU是Least Recent Used,原理如下:
335 |
336 |
310 |
311 | ## 2.2 severCron函数
312 |
313 | Redis服务器中的serverCron函数默认每隔100毫秒执行一次,这个函数负责管理服务器的资源,并保持服务器自身的良好运转。severCorn函数的常见功能如下:
314 |
315 | **(1)更新服务器时间缓存**
316 |
317 | Redis服务器中有不少功能需要**获取系统的当前时间**,而每次获取系统的当前时间都需要执行一次系统调用,**为了减少系统调用的执行次数**,服务器状态中的unixtime属性和mstime属性被用作当前时间的缓存:
318 |
319 | ```C
320 | struct redisServer
321 | {
322 | // ...
323 | // 保存了秒级精度的系统当前UNIX时间戳
324 | time_t unixtime;
325 | // 保存了毫秒级精度的系统当前UNIX时间戳
326 | long long mstime;
327 | };
328 | ```
329 |
330 | 因为serverCron函数默认会以每100毫秒一次的频率更新unixtime属性和mstime属性,所以**这两个属性记录的时间的精确度并不高**。
331 |
332 | **(2)更新LRU时钟**
333 |
334 | LRU是Least Recent Used,原理如下:
335 |
336 |  337 |
338 | 服务器状态中的lruclock属性保存了服务器的LRU时钟,这个属性和上面介绍的unixtime属性、mstime属性一样,都是**服务器时间缓存的一种**。
339 |
340 | ```C
341 | struct redisServer
342 | {
343 | // ...
344 | // 默认每10秒更新一次的时钟缓存,
345 | // 用于计算键的空转(idle)时长。
346 | unsigned lruclock:22;
347 | //...
348 | };
349 | ```
350 |
351 | 每个Redis对象都会有一个lru属性,这个lru属性保存了对象最后一次被命令访问的时间:
352 |
353 | ```C
354 | typedef struct redisObject
355 | {
356 | // ...
357 | unsigned lru:22;
358 | // ...
359 | } robj;
360 | ```
361 |
362 | 当服务器要**计算一个数据库键的空转时间**(也即是数据库键对应的值对象的空转时间),程序会用服务器的lruclock属性记录的时间减去对象的lru属性记录的时间。
363 |
364 | 由于是10秒更新一次,所以时钟并不是实时的,这个LRU时间只是一个模糊的估算值。
365 |
366 | **(3)更新服务器每秒执行命令次数**
367 |
368 | `serverCron`函数中的`trackOperationsPerSecond`函数会以每100毫秒一次的频率执行,这个函数的功能是以**抽样**计算的方式,**估算并记录服务器在最近一秒钟处理的命令请求数量**。
369 |
370 | `trackOperationsPerSecond`函数每次运行,都会根据`ops_sec_last_sample_time`记录的上一次抽样时间和服务器的当前时间,以及`ops_sec_last_sample_ops`**记录的上一次抽样的已执行命令数量和服务器当前的已执行命令数量**,计算出两次`trackOperationsPerSecond`调用之间,服务器**平均每一毫秒处理了多少个命令请求,然后将这个平均值乘以1000,这就得到了服务器在一秒钟内能处理多少个命令请求的估计值**,这个估计值会被作为一个新的数组项被放进`ops_sec_samples`环形数组里面。
371 |
372 | **(4)更新内存峰值记录**
373 |
374 | 服务器状态中的`stat_peak_memory`属性记录了服务器的内存峰值大小:
375 |
376 | ```C
377 | struct redisServer
378 | {
379 | // ...
380 | // 已使用内存峰值
381 | size_t stat_peak_memory;
382 | // ...
383 | };
384 | ```
385 |
386 | 每次serverCron函数执行时,**程序都会查看服务器当前使用的内存数量,并与stat_peak_memory保存的数值进行比较**,如果当前使用的内存数量比stat_peak_memory属性记录的值要大,那么就替换峰值。
387 |
388 | **(5)处理SIGTERM信号**
389 |
390 | 在启动服务器时,Redis会为服务器进程的SIGTERM信号关联处理器`sigtermHandler`函数,这个信号处理器负责在服务器**接到SIGTERM信号时,打开服务器状态的shutdown_asap标识**。
391 |
392 | 每次serverCron函数运行时,程序都会对服务器状态的shutdown_asap属性进行检查,并**根据属性的值决定是否关闭服务器**。
393 |
394 | **(6)管理客户端资源**
395 |
396 | serverCron函数每次执行都会调用clientsCron函数,检查:
397 |
398 | - 客户端服务器连接超时(长时间没有互动),程序将释放这个客户端。
399 | - 客户端在上一次执行命令后,输入缓冲区大小超过一定长度,程序会释放客户端当前的输入缓冲区。
400 |
401 | **(7)管理数据库资源**
402 |
403 | serverCron函数每次执行都会调用databasesCron函数,这个函数会对服务器中的一部分数据库进行检查,删除其中的过期键,并在有需要时,对字典进行收缩操作。参见[Redis中的定期检查]([https://jiangren.work/2020/01/04/Redis%E8%A7%A3%E6%9E%903-%E6%95%B0%E6%8D%AE%E5%BA%93/#2-%E6%95%B0%E6%8D%AE%E5%BA%93%E9%94%AE%E7%A9%BA%E9%97%B4](https://jiangren.work/2020/01/04/Redis解析3-数据库/#2-数据库键空间))
404 |
405 | **(8)执行被延迟的BGREWRITEAOF**
406 |
407 | 在服务器执行BGSAVE命令的期间,如果客户端向服务器发来BGREWRITEAOF命令,那么服务器会将BGREWRITEAOF命令的执行时间延迟到BGSAVE命令执行完毕之后。
408 |
409 | 每次serverCron函数执行时,函数都会检查BGSAVE命令或者BGREWRITEAOF命令是否正在执行,如果这两个命令都没在执行,且有被延迟的BGREWRITEAOF,则执行。
410 |
411 |
337 |
338 | 服务器状态中的lruclock属性保存了服务器的LRU时钟,这个属性和上面介绍的unixtime属性、mstime属性一样,都是**服务器时间缓存的一种**。
339 |
340 | ```C
341 | struct redisServer
342 | {
343 | // ...
344 | // 默认每10秒更新一次的时钟缓存,
345 | // 用于计算键的空转(idle)时长。
346 | unsigned lruclock:22;
347 | //...
348 | };
349 | ```
350 |
351 | 每个Redis对象都会有一个lru属性,这个lru属性保存了对象最后一次被命令访问的时间:
352 |
353 | ```C
354 | typedef struct redisObject
355 | {
356 | // ...
357 | unsigned lru:22;
358 | // ...
359 | } robj;
360 | ```
361 |
362 | 当服务器要**计算一个数据库键的空转时间**(也即是数据库键对应的值对象的空转时间),程序会用服务器的lruclock属性记录的时间减去对象的lru属性记录的时间。
363 |
364 | 由于是10秒更新一次,所以时钟并不是实时的,这个LRU时间只是一个模糊的估算值。
365 |
366 | **(3)更新服务器每秒执行命令次数**
367 |
368 | `serverCron`函数中的`trackOperationsPerSecond`函数会以每100毫秒一次的频率执行,这个函数的功能是以**抽样**计算的方式,**估算并记录服务器在最近一秒钟处理的命令请求数量**。
369 |
370 | `trackOperationsPerSecond`函数每次运行,都会根据`ops_sec_last_sample_time`记录的上一次抽样时间和服务器的当前时间,以及`ops_sec_last_sample_ops`**记录的上一次抽样的已执行命令数量和服务器当前的已执行命令数量**,计算出两次`trackOperationsPerSecond`调用之间,服务器**平均每一毫秒处理了多少个命令请求,然后将这个平均值乘以1000,这就得到了服务器在一秒钟内能处理多少个命令请求的估计值**,这个估计值会被作为一个新的数组项被放进`ops_sec_samples`环形数组里面。
371 |
372 | **(4)更新内存峰值记录**
373 |
374 | 服务器状态中的`stat_peak_memory`属性记录了服务器的内存峰值大小:
375 |
376 | ```C
377 | struct redisServer
378 | {
379 | // ...
380 | // 已使用内存峰值
381 | size_t stat_peak_memory;
382 | // ...
383 | };
384 | ```
385 |
386 | 每次serverCron函数执行时,**程序都会查看服务器当前使用的内存数量,并与stat_peak_memory保存的数值进行比较**,如果当前使用的内存数量比stat_peak_memory属性记录的值要大,那么就替换峰值。
387 |
388 | **(5)处理SIGTERM信号**
389 |
390 | 在启动服务器时,Redis会为服务器进程的SIGTERM信号关联处理器`sigtermHandler`函数,这个信号处理器负责在服务器**接到SIGTERM信号时,打开服务器状态的shutdown_asap标识**。
391 |
392 | 每次serverCron函数运行时,程序都会对服务器状态的shutdown_asap属性进行检查,并**根据属性的值决定是否关闭服务器**。
393 |
394 | **(6)管理客户端资源**
395 |
396 | serverCron函数每次执行都会调用clientsCron函数,检查:
397 |
398 | - 客户端服务器连接超时(长时间没有互动),程序将释放这个客户端。
399 | - 客户端在上一次执行命令后,输入缓冲区大小超过一定长度,程序会释放客户端当前的输入缓冲区。
400 |
401 | **(7)管理数据库资源**
402 |
403 | serverCron函数每次执行都会调用databasesCron函数,这个函数会对服务器中的一部分数据库进行检查,删除其中的过期键,并在有需要时,对字典进行收缩操作。参见[Redis中的定期检查]([https://jiangren.work/2020/01/04/Redis%E8%A7%A3%E6%9E%903-%E6%95%B0%E6%8D%AE%E5%BA%93/#2-%E6%95%B0%E6%8D%AE%E5%BA%93%E9%94%AE%E7%A9%BA%E9%97%B4](https://jiangren.work/2020/01/04/Redis解析3-数据库/#2-数据库键空间))
404 |
405 | **(8)执行被延迟的BGREWRITEAOF**
406 |
407 | 在服务器执行BGSAVE命令的期间,如果客户端向服务器发来BGREWRITEAOF命令,那么服务器会将BGREWRITEAOF命令的执行时间延迟到BGSAVE命令执行完毕之后。
408 |
409 | 每次serverCron函数执行时,函数都会检查BGSAVE命令或者BGREWRITEAOF命令是否正在执行,如果这两个命令都没在执行,且有被延迟的BGREWRITEAOF,则执行。
410 |
411 | 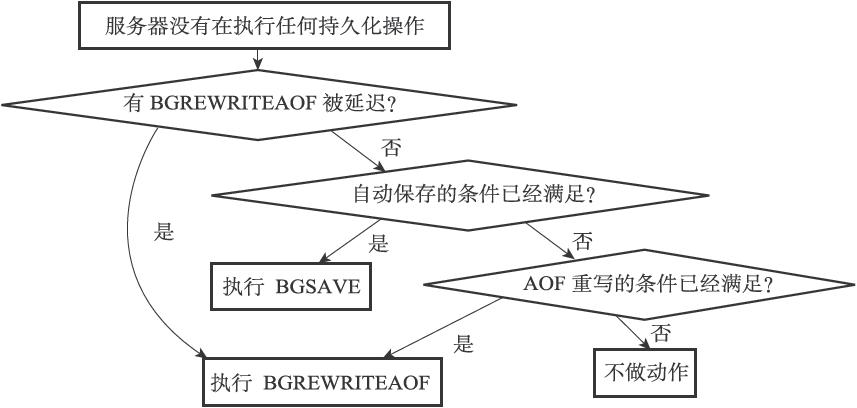 412 |
413 | **(9)将AOF缓冲区内容写入AOF文件**
414 |
415 | **(10)关闭输出缓冲区超限的客户端**
416 |
417 | **(11)增加cronloops计数**
418 |
419 | 服务器状态的cronloops属性记录了serverCron函数执行的次数,每执行一次就增加计数。作用是:在**复制模块**中实现“**每执行serverCron函数N次就执行一次指定代码**”的功能。
420 |
421 | ## 2.3 服务器初始化
422 |
423 | 服务器初始化要完成以下几个任务:
424 |
425 | - 初始化服务器状态结构
426 | - 载入配置选项
427 | - 初始化服务器数据结构
428 | - 还原数据库状态
429 | - 执行时间循环
430 |
431 | ---
432 |
433 | **(1)初始化服务器状态结构**
434 |
435 | 创建一个`struct redisServer`类型的实例变量`server`作为服务器的状态,并为结构中的各个属性设置默认值。
436 |
437 | 初始化server变量的工作由`redis.c/initServerConfig`函数完成,主要工作:
438 |
439 | - 设置服务器ID
440 | - 设置服务器运行默认频率
441 | - 设置配置文件路径
442 | - 设置运行架构
443 | - 设置默认端口号
444 | - 设置RDB持久化和AOF持久化条件
445 | - 初始化LRU时钟
446 | - 创建命令表
447 |
448 | **(2)载入配置选项**
449 |
450 | 完成初始化服务器状态结构后**,所有变量会被附上默认的值**,但是实际上用户可能修改了某些参数。此时,载入用户的配置选项,**替换掉那些被修改后的默认值**。
451 |
452 | **(3)初始化服务器数据结构**
453 |
454 | 除了在之前执行`initServerConfig`函数初始化server状态时,程序只创建了命令表一个数据结构,在这个阶段还需要创建其他数据结构:
455 |
456 | - `server.client`链表,记录了所有与服务器相连的客户端状态结构。
457 | - `server.db`数组,数组中包含了所有数据库。
458 | - `server.pubsub_channels`字典,保存模式订阅信息的`server.pubsub_patterns`链表。
459 | - `server.lua`,用于执行Lua脚本的Lua环境
460 | - `server.slowlog`,用于保存慢查询日志。
461 |
462 | 服务器到现在才初始化数据结构的原因在于,服务器**必须先载入用户指定的配置选项,然后才能正确地对数据结构进行初始化**。
463 |
464 | **(4)还原数据库状态**
465 |
466 | 在完成了对服务器状态server变量的初始化之后,服务器需要载入RDB文件或者AOF文件,并根据文件记录的内容来还原服务器的数据库状态。
467 |
468 | 如果启用了AOF持久化功能,则会使用AOF来还原,否则用RDB文件还原。
469 |
470 | **(5)执行事件循环**
471 |
472 | 在初始化的最后一步,服务器将打印出以下日志:
473 |
474 | ```
475 | [5244] 21 Nov 22:43:49.084 * The server is now ready to accept connections on port 6379
476 | ```
477 |
478 | 开始执行事件循环,意味着服务器现在开始可以接受客户端的连接请求了。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现7-复制.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现7-复制
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-06 11:03:18
12 |
13 | ---
14 |
15 | 本章将介绍2.8以前的老版复制功能和2.8以后的新版复制功能,讲解机制和优劣势。
16 |
17 | 在Redis中,用户可以通过执行SLAVEOF命令或者设置slaveof选项,让一个服务器去复制另一个服务器,我们称呼被复制的服务器为**主服务器(master)**,而对主服务器进行复制的服务器则被称为**从服务器(slave)**。搞清楚关系,如果服务器A输入指令SLAVEOF,则A变成B的从服务器。
18 |
19 | 进行复制中的主从服务器双方的数据库将保存相同的数据,概念上将这种现象称作“**数据库状态一致**”,或者简称“一致”。比如,在**主**服务器上执行命令,
20 |
21 | ```c
22 | 127.0.0.1:6379> SET msg "hello world"
23 | OK
24 | ```
25 |
26 | 则同时可以在**从**服务器上获取msg键的值,
27 |
28 | ```C
29 | 127.0.0.1:12345> GET msg
30 | "hello world"
31 | ```
32 |
33 | # 1. 旧版复制
34 |
35 | ## 1.1 旧版复制的实现
36 |
37 | Redis的复制功能分为**同步(sync)**和**命令传播(commandpropagate)**两个操作:
38 |
39 | - 同步操作用于将从服务器的数据库状态更新至主服务器当前所处的数据库状态。
40 | - 命令传播操作则用于在**主服务器的数据库状态被修改**,导致主从服务器的数据库状态出现不一致时,让主从服务器的数据库重新回到一致状态。
41 |
42 | **(1)同步**
43 |
44 | 从服务器对主服务器的同步操作需要通过**向主服务器**发送**SYNC命令**来完成,以下是SYNC命令的执行步骤:
45 |
46 | 1. 从服务器向主服务器发送SYNC命令
47 | 2. 主服务器收到后,执行BGSAVE命令,生成RDB文件,并使用缓冲区记录现在开始执行的所有写命令。
48 | 3. 将RDB文件发送给从服务器,从服务器收到后更新
49 | 4. 主服务器将缓冲区的内容发送给从服务器,从服务器收到后更新。
50 |
51 | > BGSAVE命令会**增加一个子进程**,负责创建RDB文件。
52 |
53 |
412 |
413 | **(9)将AOF缓冲区内容写入AOF文件**
414 |
415 | **(10)关闭输出缓冲区超限的客户端**
416 |
417 | **(11)增加cronloops计数**
418 |
419 | 服务器状态的cronloops属性记录了serverCron函数执行的次数,每执行一次就增加计数。作用是:在**复制模块**中实现“**每执行serverCron函数N次就执行一次指定代码**”的功能。
420 |
421 | ## 2.3 服务器初始化
422 |
423 | 服务器初始化要完成以下几个任务:
424 |
425 | - 初始化服务器状态结构
426 | - 载入配置选项
427 | - 初始化服务器数据结构
428 | - 还原数据库状态
429 | - 执行时间循环
430 |
431 | ---
432 |
433 | **(1)初始化服务器状态结构**
434 |
435 | 创建一个`struct redisServer`类型的实例变量`server`作为服务器的状态,并为结构中的各个属性设置默认值。
436 |
437 | 初始化server变量的工作由`redis.c/initServerConfig`函数完成,主要工作:
438 |
439 | - 设置服务器ID
440 | - 设置服务器运行默认频率
441 | - 设置配置文件路径
442 | - 设置运行架构
443 | - 设置默认端口号
444 | - 设置RDB持久化和AOF持久化条件
445 | - 初始化LRU时钟
446 | - 创建命令表
447 |
448 | **(2)载入配置选项**
449 |
450 | 完成初始化服务器状态结构后**,所有变量会被附上默认的值**,但是实际上用户可能修改了某些参数。此时,载入用户的配置选项,**替换掉那些被修改后的默认值**。
451 |
452 | **(3)初始化服务器数据结构**
453 |
454 | 除了在之前执行`initServerConfig`函数初始化server状态时,程序只创建了命令表一个数据结构,在这个阶段还需要创建其他数据结构:
455 |
456 | - `server.client`链表,记录了所有与服务器相连的客户端状态结构。
457 | - `server.db`数组,数组中包含了所有数据库。
458 | - `server.pubsub_channels`字典,保存模式订阅信息的`server.pubsub_patterns`链表。
459 | - `server.lua`,用于执行Lua脚本的Lua环境
460 | - `server.slowlog`,用于保存慢查询日志。
461 |
462 | 服务器到现在才初始化数据结构的原因在于,服务器**必须先载入用户指定的配置选项,然后才能正确地对数据结构进行初始化**。
463 |
464 | **(4)还原数据库状态**
465 |
466 | 在完成了对服务器状态server变量的初始化之后,服务器需要载入RDB文件或者AOF文件,并根据文件记录的内容来还原服务器的数据库状态。
467 |
468 | 如果启用了AOF持久化功能,则会使用AOF来还原,否则用RDB文件还原。
469 |
470 | **(5)执行事件循环**
471 |
472 | 在初始化的最后一步,服务器将打印出以下日志:
473 |
474 | ```
475 | [5244] 21 Nov 22:43:49.084 * The server is now ready to accept connections on port 6379
476 | ```
477 |
478 | 开始执行事件循环,意味着服务器现在开始可以接受客户端的连接请求了。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现7-复制.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现7-复制
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-06 11:03:18
12 |
13 | ---
14 |
15 | 本章将介绍2.8以前的老版复制功能和2.8以后的新版复制功能,讲解机制和优劣势。
16 |
17 | 在Redis中,用户可以通过执行SLAVEOF命令或者设置slaveof选项,让一个服务器去复制另一个服务器,我们称呼被复制的服务器为**主服务器(master)**,而对主服务器进行复制的服务器则被称为**从服务器(slave)**。搞清楚关系,如果服务器A输入指令SLAVEOF,则A变成B的从服务器。
18 |
19 | 进行复制中的主从服务器双方的数据库将保存相同的数据,概念上将这种现象称作“**数据库状态一致**”,或者简称“一致”。比如,在**主**服务器上执行命令,
20 |
21 | ```c
22 | 127.0.0.1:6379> SET msg "hello world"
23 | OK
24 | ```
25 |
26 | 则同时可以在**从**服务器上获取msg键的值,
27 |
28 | ```C
29 | 127.0.0.1:12345> GET msg
30 | "hello world"
31 | ```
32 |
33 | # 1. 旧版复制
34 |
35 | ## 1.1 旧版复制的实现
36 |
37 | Redis的复制功能分为**同步(sync)**和**命令传播(commandpropagate)**两个操作:
38 |
39 | - 同步操作用于将从服务器的数据库状态更新至主服务器当前所处的数据库状态。
40 | - 命令传播操作则用于在**主服务器的数据库状态被修改**,导致主从服务器的数据库状态出现不一致时,让主从服务器的数据库重新回到一致状态。
41 |
42 | **(1)同步**
43 |
44 | 从服务器对主服务器的同步操作需要通过**向主服务器**发送**SYNC命令**来完成,以下是SYNC命令的执行步骤:
45 |
46 | 1. 从服务器向主服务器发送SYNC命令
47 | 2. 主服务器收到后,执行BGSAVE命令,生成RDB文件,并使用缓冲区记录现在开始执行的所有写命令。
48 | 3. 将RDB文件发送给从服务器,从服务器收到后更新
49 | 4. 主服务器将缓冲区的内容发送给从服务器,从服务器收到后更新。
50 |
51 | > BGSAVE命令会**增加一个子进程**,负责创建RDB文件。
52 |
53 |  54 |
55 | **(2)命令传播**
56 |
57 | 主服务器会将自己执行的**写命令**,也即是造成主从服务器不一致的那条写命令,发送给从服务器执行,当从服务器执行了相同的写命令之后,主从服务器将再次回到一致状态。
58 |
59 |
54 |
55 | **(2)命令传播**
56 |
57 | 主服务器会将自己执行的**写命令**,也即是造成主从服务器不一致的那条写命令,发送给从服务器执行,当从服务器执行了相同的写命令之后,主从服务器将再次回到一致状态。
58 |
59 | 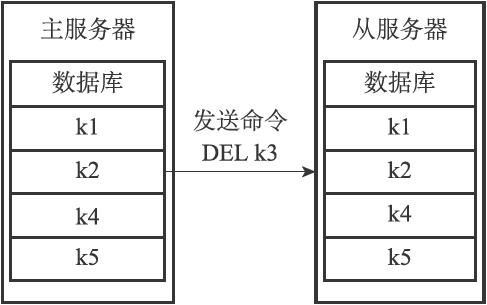 60 |
61 | ## 1.2 旧版复制的缺陷
62 |
63 | 在Redis中,从服务器对主服务器的复制可以分为以下两种情况:
64 |
65 | - **初次复制**:从服务器以前没有复制过任何主服务器,或者要复制的主服务器和上一次复制的主服务器不同。
66 | - **断线后重复制**:处于命令传播阶段的主从服务器因为网络原因而中断了复制,但从服务器通过自动重连接重新连上了主服务器,并继续复制主服务器。
67 |
68 | 初次复制效果挺好的,但断线后重新复制效率就很低。因为执行SYNC命令是非常消耗资源的行为。
69 |
70 | # 2. 新版复制
71 |
72 | ## 2.1 新版复制功能的实现
73 |
74 | Redis从2.8版本开始,使用**PSYNC命令**代替SYNC命令来执行复制时的同步操作。
75 |
76 | PSYNC命令具有**完整重同步(full resynchronization)**和**部分重同步(partial resynchronization)**两种模式:
77 |
78 | - 完整重同步用于初次复制,和SYNC命令完全一致
79 | - 部分重同步,将断线后的命令发送给从服务器。
80 |
81 | ---
82 |
83 | 要实现部分重同步,需要完成三个部分:
84 |
85 | - 主服务器的**复制偏移量**(replication offset)和从服务器的复制偏移量。
86 | - 主服务器的**复制积压缓冲区**(replication backlog)。
87 | - 服务器的**运行ID**(run ID)。
88 |
89 | **(1)复制偏移量**
90 |
91 | 主服务器和从服务器会分别维护一个复制偏移量:
92 |
93 | - 主服务器每次向从服务器传播N个字节的数据时,就将自己的复制偏移量的值加上N。
94 | - 从服务器每次收到主服务器传播来的N个字节的数据时,就将自己的复制偏移量的值加上N。
95 |
96 |
60 |
61 | ## 1.2 旧版复制的缺陷
62 |
63 | 在Redis中,从服务器对主服务器的复制可以分为以下两种情况:
64 |
65 | - **初次复制**:从服务器以前没有复制过任何主服务器,或者要复制的主服务器和上一次复制的主服务器不同。
66 | - **断线后重复制**:处于命令传播阶段的主从服务器因为网络原因而中断了复制,但从服务器通过自动重连接重新连上了主服务器,并继续复制主服务器。
67 |
68 | 初次复制效果挺好的,但断线后重新复制效率就很低。因为执行SYNC命令是非常消耗资源的行为。
69 |
70 | # 2. 新版复制
71 |
72 | ## 2.1 新版复制功能的实现
73 |
74 | Redis从2.8版本开始,使用**PSYNC命令**代替SYNC命令来执行复制时的同步操作。
75 |
76 | PSYNC命令具有**完整重同步(full resynchronization)**和**部分重同步(partial resynchronization)**两种模式:
77 |
78 | - 完整重同步用于初次复制,和SYNC命令完全一致
79 | - 部分重同步,将断线后的命令发送给从服务器。
80 |
81 | ---
82 |
83 | 要实现部分重同步,需要完成三个部分:
84 |
85 | - 主服务器的**复制偏移量**(replication offset)和从服务器的复制偏移量。
86 | - 主服务器的**复制积压缓冲区**(replication backlog)。
87 | - 服务器的**运行ID**(run ID)。
88 |
89 | **(1)复制偏移量**
90 |
91 | 主服务器和从服务器会分别维护一个复制偏移量:
92 |
93 | - 主服务器每次向从服务器传播N个字节的数据时,就将自己的复制偏移量的值加上N。
94 | - 从服务器每次收到主服务器传播来的N个字节的数据时,就将自己的复制偏移量的值加上N。
95 |
96 | 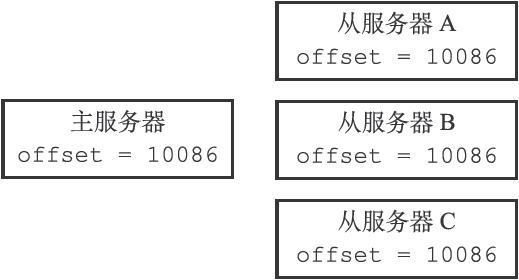 97 |
98 |
97 |
98 | 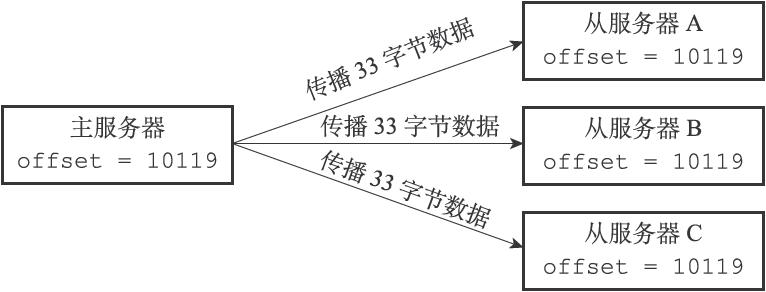 99 |
100 | **通过对比主从服务器的复制偏移量,程序可以很容易地知道主从服务器是否处于一致状态**:
101 |
102 | - 如果主从服务器处于一致状态,那么主从服务器两者的偏移量总是相同的。
103 | - 相反,如果主从服务器两者的偏移量并不相同,那么说明主从服务器并未处于一致状态。
104 |
105 | **(2)复制积压缓冲区**
106 |
107 | 复制积压缓冲区是由主服务器维护的一个**固定长度**(fixed-size)先进先出(FIFO)队列,默认大小为1MB。当主服务器进行命令传播时,它不仅会将写命令发送给所有从服务器,还会**将写命令入队到复制积压缓冲区里面**。
108 |
109 |
99 |
100 | **通过对比主从服务器的复制偏移量,程序可以很容易地知道主从服务器是否处于一致状态**:
101 |
102 | - 如果主从服务器处于一致状态,那么主从服务器两者的偏移量总是相同的。
103 | - 相反,如果主从服务器两者的偏移量并不相同,那么说明主从服务器并未处于一致状态。
104 |
105 | **(2)复制积压缓冲区**
106 |
107 | 复制积压缓冲区是由主服务器维护的一个**固定长度**(fixed-size)先进先出(FIFO)队列,默认大小为1MB。当主服务器进行命令传播时,它不仅会将写命令发送给所有从服务器,还会**将写命令入队到复制积压缓冲区里面**。
108 |
109 | 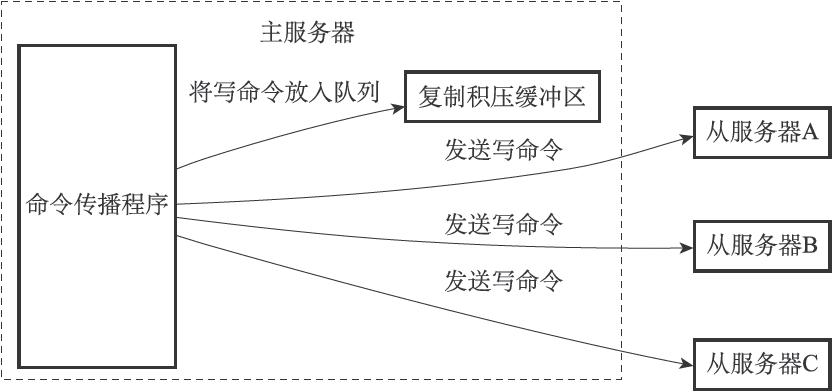 110 |
111 | 与此同时,主服务器也会向积压缓冲区添加偏移量,
112 |
113 |
110 |
111 | 与此同时,主服务器也会向积压缓冲区添加偏移量,
112 |
113 | 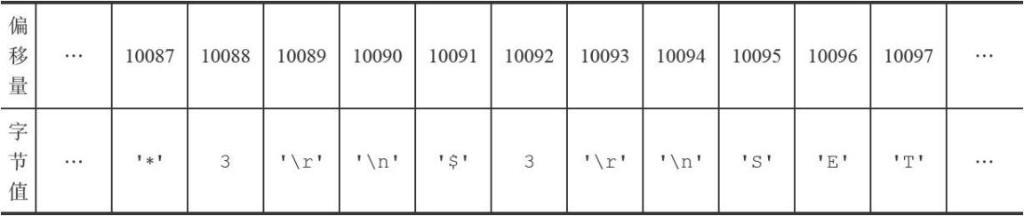 114 |
115 | 当服务器重新连接上主服务器时,从服务器会通过PSYNC命令将自己的复制偏移量offset发送给主服务器,**主服务器会根据这个复制偏移量来决定对从服务器执行何种同步操作**:
116 |
117 | - offset偏移量之后的数据仍然存在于复制积压缓冲区中,主服务器执行部分重同步操作
118 | - 反之,偏移量之后的数据已不存在于复制积压缓冲区,则执行完整重同步。
119 |
120 | 复制积压缓冲区作为一个**限制性容器**保证了复制的高效性:
121 |
122 | - 如果断线时间短,错过的命令少,则直接调用偏移量为从服务器补上命令
123 | - 反之,则直接完全重同步。
124 |
125 | **(3)服务器运行ID**
126 |
127 | 每个Redis服务器,不论主服务器还是从服务,都会有自己的运行ID,运行ID在服务器启动时自动生成,由40个随机的十六进制字符组成。
128 |
129 | 当从服务器对主服务器进行初次复制时,主服务器会将自己的运行ID传送给从服务器,而从服务器则会将这个运行ID保存起来。
130 |
131 | 当从服务器断线并重新连上一个主服务器时,从服务器将向当前连接的主服务器发送之前保存的运行ID:
132 |
133 | - 如果ID相同,则表示**之前同步的主服务器就是这个**,执行部分重同步。
134 | - 如果ID不同,则表明从**服务器断线之前复制的主服务器并不是当前连接的这个主服务器**,执行完整重同步操作。
135 |
136 | ## 2.2 PSYNC命令的实现
137 |
138 | PSYNC命令的调用方法有两种:
139 |
140 | - 如果是初次复制,则从服务器发送`PSYNC?-1`命令,主动请求主服务器进行完整重同步。
141 | - 如果已经复制过,则从服务器发送`PSYNC`命令。即:上一次复制的主服务器ID+当前的复制偏移量。
142 |
143 | 根据情况,接收到PSYNC命令的主服务器会向从服务器返回以下三种回复的其中一种:
144 |
145 | **(1)**如果主服务器返回`+FULLRESYNC `回复,那么表示主服务器将与从服务器执行完整重同步操作。从服务器将ID保存起来,在下一次PSYNC命令时使用,同时将offset的值当做自己的初始化偏移量。
146 |
147 | **(2)**如果主服务器返回+CONTINUE回复,那么表示主服务器将与从服务器执行部分重同步操作,从服务器只要等着主服务器将自己缺少的那部分数据发送过来就可以了。
148 |
149 | **(3)**如果主服务器返回-ERR回复,那么表示主服务器的版本低于Redis2.8,它识别不了PSYNC命令,从服务器将向主服务器发送SYNC命令,并与主服务器执行完整同步操作。
150 |
151 |
114 |
115 | 当服务器重新连接上主服务器时,从服务器会通过PSYNC命令将自己的复制偏移量offset发送给主服务器,**主服务器会根据这个复制偏移量来决定对从服务器执行何种同步操作**:
116 |
117 | - offset偏移量之后的数据仍然存在于复制积压缓冲区中,主服务器执行部分重同步操作
118 | - 反之,偏移量之后的数据已不存在于复制积压缓冲区,则执行完整重同步。
119 |
120 | 复制积压缓冲区作为一个**限制性容器**保证了复制的高效性:
121 |
122 | - 如果断线时间短,错过的命令少,则直接调用偏移量为从服务器补上命令
123 | - 反之,则直接完全重同步。
124 |
125 | **(3)服务器运行ID**
126 |
127 | 每个Redis服务器,不论主服务器还是从服务,都会有自己的运行ID,运行ID在服务器启动时自动生成,由40个随机的十六进制字符组成。
128 |
129 | 当从服务器对主服务器进行初次复制时,主服务器会将自己的运行ID传送给从服务器,而从服务器则会将这个运行ID保存起来。
130 |
131 | 当从服务器断线并重新连上一个主服务器时,从服务器将向当前连接的主服务器发送之前保存的运行ID:
132 |
133 | - 如果ID相同,则表示**之前同步的主服务器就是这个**,执行部分重同步。
134 | - 如果ID不同,则表明从**服务器断线之前复制的主服务器并不是当前连接的这个主服务器**,执行完整重同步操作。
135 |
136 | ## 2.2 PSYNC命令的实现
137 |
138 | PSYNC命令的调用方法有两种:
139 |
140 | - 如果是初次复制,则从服务器发送`PSYNC?-1`命令,主动请求主服务器进行完整重同步。
141 | - 如果已经复制过,则从服务器发送`PSYNC`命令。即:上一次复制的主服务器ID+当前的复制偏移量。
142 |
143 | 根据情况,接收到PSYNC命令的主服务器会向从服务器返回以下三种回复的其中一种:
144 |
145 | **(1)**如果主服务器返回`+FULLRESYNC `回复,那么表示主服务器将与从服务器执行完整重同步操作。从服务器将ID保存起来,在下一次PSYNC命令时使用,同时将offset的值当做自己的初始化偏移量。
146 |
147 | **(2)**如果主服务器返回+CONTINUE回复,那么表示主服务器将与从服务器执行部分重同步操作,从服务器只要等着主服务器将自己缺少的那部分数据发送过来就可以了。
148 |
149 | **(3)**如果主服务器返回-ERR回复,那么表示主服务器的版本低于Redis2.8,它识别不了PSYNC命令,从服务器将向主服务器发送SYNC命令,并与主服务器执行完整同步操作。
150 |
151 |  152 |
153 | ## 2.3 新版复制的完整流程
154 |
155 | 本节主要展示新版复制操作的全过程,假设主服务器IP地址为127.0.0.1端口号为6379,从服务器IP为127.0.0.1端口号12345.
156 |
157 | **(1)设置主服务器地址和端口**
158 |
159 | 当**客户端**向**从服务器**发送以下命令时:
160 |
161 | ```C
162 | 127.0.0.1:12345> SLAVEOF 127.0.0.1 6379
163 | OK
164 | ```
165 |
166 | 从服务器首先要做的就是将客户端给定的主服务器IP地址127.0.0.1以及端口6379保存到服务器状态的masterhost属性和masterport属性里面:
167 |
168 | ```C
169 | struct redisServer{
170 | //...
171 | char *masterhost;
172 | int masterport;
173 | //...
174 | };
175 | ```
176 |
177 |
152 |
153 | ## 2.3 新版复制的完整流程
154 |
155 | 本节主要展示新版复制操作的全过程,假设主服务器IP地址为127.0.0.1端口号为6379,从服务器IP为127.0.0.1端口号12345.
156 |
157 | **(1)设置主服务器地址和端口**
158 |
159 | 当**客户端**向**从服务器**发送以下命令时:
160 |
161 | ```C
162 | 127.0.0.1:12345> SLAVEOF 127.0.0.1 6379
163 | OK
164 | ```
165 |
166 | 从服务器首先要做的就是将客户端给定的主服务器IP地址127.0.0.1以及端口6379保存到服务器状态的masterhost属性和masterport属性里面:
167 |
168 | ```C
169 | struct redisServer{
170 | //...
171 | char *masterhost;
172 | int masterport;
173 | //...
174 | };
175 | ```
176 |
177 |  178 |
179 | **(2)建立套接字连接**
180 |
181 | **从服务器**将根据命令所设置的IP地址和端口,创建**连向主服务器的**套接字连接
182 |
183 |
178 |
179 | **(2)建立套接字连接**
180 |
181 | **从服务器**将根据命令所设置的IP地址和端口,创建**连向主服务器的**套接字连接
182 |
183 |  184 |
185 | 此时,**从服务器变为了主服务器的客户端。**从服务器**同时具备**服务器和客户端的两个身份。
186 |
187 | **(3)发送PING命令**
188 |
189 | 连接成功后,从服务器立马发送一个PING命令,主要作用是:
190 |
191 | - 检查套接字读写是否正常
192 | - 检查主服务器能否正常处理命令
193 |
194 | 回复有三种可能:
195 |
196 | - 主服务器**返回了命令回复**,但**从服务器不能再规定的时间内读出**,表明主从之间**网络连接不佳**。从服务器**断开并重新创建**连向主服务器的套接字。
197 | - 主服务器**返回一个错误**,表示主服务器暂时无法处理请求(比如正在处理一个超时运行脚本),从服务器**断开并重新创建**连向主服务器的套接字。
198 | - 从服务器收到PONG回复,表示主从之间连接正常。
199 |
200 |
184 |
185 | 此时,**从服务器变为了主服务器的客户端。**从服务器**同时具备**服务器和客户端的两个身份。
186 |
187 | **(3)发送PING命令**
188 |
189 | 连接成功后,从服务器立马发送一个PING命令,主要作用是:
190 |
191 | - 检查套接字读写是否正常
192 | - 检查主服务器能否正常处理命令
193 |
194 | 回复有三种可能:
195 |
196 | - 主服务器**返回了命令回复**,但**从服务器不能再规定的时间内读出**,表明主从之间**网络连接不佳**。从服务器**断开并重新创建**连向主服务器的套接字。
197 | - 主服务器**返回一个错误**,表示主服务器暂时无法处理请求(比如正在处理一个超时运行脚本),从服务器**断开并重新创建**连向主服务器的套接字。
198 | - 从服务器收到PONG回复,表示主从之间连接正常。
199 |
200 | 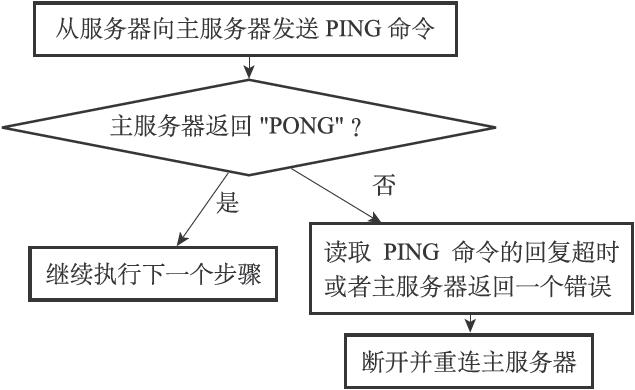 201 |
202 | **(4)身份验证**
203 |
204 | 收到pong的回复后,下一步是确定是否进行身份验证:如果从服务器设置了masterauth选项,那么进行身份验证;反之则不进行。
205 |
206 |
201 |
202 | **(4)身份验证**
203 |
204 | 收到pong的回复后,下一步是确定是否进行身份验证:如果从服务器设置了masterauth选项,那么进行身份验证;反之则不进行。
205 |
206 | 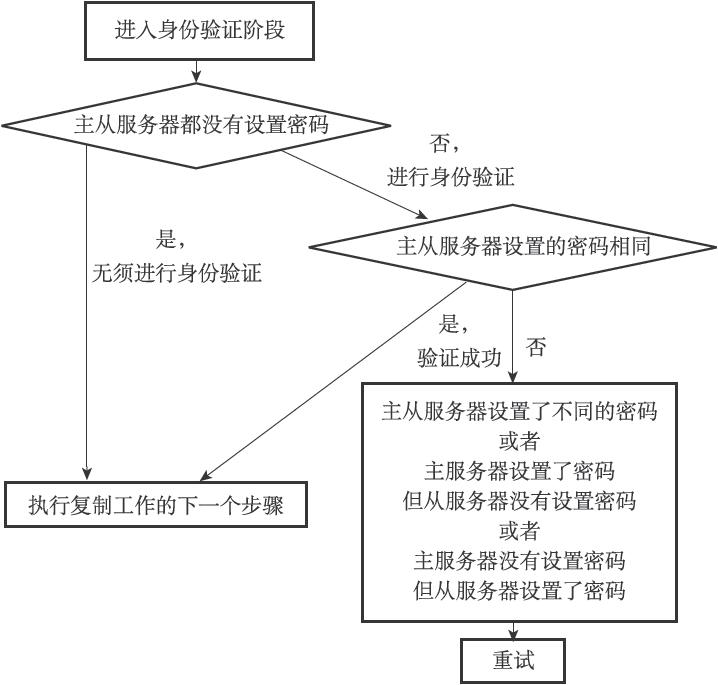 207 |
208 | **(5)发送端口信息**
209 |
210 | 从服务器向主服务器发送从服务器的监听端口号。主服务器在接收到这个命令之后,会将端口号记录在从服务器所对应的客户端状态的`slave_listening_port`属性中:
211 |
212 | ```C
213 | typedef struct redisClient
214 | {
215 | // ...
216 | // 从服务器的监听端口号
217 | int slave_listening_port;
218 | // ...
219 | } redisClient;
220 | ```
221 |
222 | **(6)同步**
223 |
224 | 在这一步,从服务器将向主服务器发送PSYNC命令,执行同步操作,并将自己的数据库更新至主服务器数据库当前所处的状态。
225 |
226 | 在同步操作执行之前,只有从服务器是主服务器的客户端,但是**在执行同步操作之后,主服务器也会成为从服务器的客户端**。
227 |
228 | **(7)命令传播**
229 |
230 | 主服务器只要一直将自己执行的写命令发送给从服务器,而从服务器只要一直接收并执行主服务器发来的写命令,就可以保证主从服务器一直保持一致了。
231 |
232 | # 4. 心跳检测
233 |
234 | 在**命令传播阶段**,从服务器默认会以每秒一次的频率,向主服务器发送命令:
235 |
236 | ```C
237 | REPLCONF ACK
238 | ```
239 |
240 | 其中`replication_offset`是从服务器当前的复制偏移量。发送`REPLCONF ACK`命令对于主从服务器有三个作用:
241 |
242 | - 检测主从服务器的网络连接状态。
243 | - 辅助实现min-slaves选项。
244 | - 检测命令丢失。
245 |
246 | **(1)检测连接状态**
247 |
248 | 如果主服务器超过一秒钟没有收到从服务器发来的REPLCONF ACK命令,那么主服务器就知道主从服务器之间的连接出现问题了。
249 |
250 | **(2)辅助实现min-slaves选项**
251 |
252 | Redis的`min-slaves-to-write`和`min-slaves-max-lag`两个选项可以防止主服务器在不安全的情况下执行写命令。
253 |
254 | 举个例子,如果我们向主服务器提供以下设置:
255 |
256 | ```C
257 | min-slaves-to-write 3
258 | min-slaves-max-lag 10
259 | ```
260 |
261 | 那么在从服务器的数量少于3个,或者三个从服务器的延迟(lag)值都大于或等于10秒时,主服务器将拒绝执行写命令。
262 |
263 | **(3)检测命令丢失**
264 |
265 | 假如主服务器的向从服务器发送的传播命令因为网络问题丢失,会导致二者偏移量不一致。这是心跳检测命令会侦察到这种情况,于是主服务器会补发。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现8-Sentinel.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现8-Sentinel
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-06 13:27:28
12 | ---
13 |
14 | Sentinel(哨岗、哨兵)是Redis的高可用性(high avail-ability)解决方案:由一个或多个Sentinel实例(instance)组成的Sentinel系统(system)对主从服务器进行监视。
15 |
16 | 所谓Sentinel['sentɪnl]的高可用性指**系统无中断地执行其功能的能力**。Sentinel的主要功能是:
17 |
18 | 1. 监控Redis整体是否正常运行。
19 | 2. 某个节点出问题时,**通知给其他进程**(比如他的客户端)。
20 | 3. 主服务器下线时,在从服务器中**选举**出一个新的主服务器。
21 |
22 |
207 |
208 | **(5)发送端口信息**
209 |
210 | 从服务器向主服务器发送从服务器的监听端口号。主服务器在接收到这个命令之后,会将端口号记录在从服务器所对应的客户端状态的`slave_listening_port`属性中:
211 |
212 | ```C
213 | typedef struct redisClient
214 | {
215 | // ...
216 | // 从服务器的监听端口号
217 | int slave_listening_port;
218 | // ...
219 | } redisClient;
220 | ```
221 |
222 | **(6)同步**
223 |
224 | 在这一步,从服务器将向主服务器发送PSYNC命令,执行同步操作,并将自己的数据库更新至主服务器数据库当前所处的状态。
225 |
226 | 在同步操作执行之前,只有从服务器是主服务器的客户端,但是**在执行同步操作之后,主服务器也会成为从服务器的客户端**。
227 |
228 | **(7)命令传播**
229 |
230 | 主服务器只要一直将自己执行的写命令发送给从服务器,而从服务器只要一直接收并执行主服务器发来的写命令,就可以保证主从服务器一直保持一致了。
231 |
232 | # 4. 心跳检测
233 |
234 | 在**命令传播阶段**,从服务器默认会以每秒一次的频率,向主服务器发送命令:
235 |
236 | ```C
237 | REPLCONF ACK
238 | ```
239 |
240 | 其中`replication_offset`是从服务器当前的复制偏移量。发送`REPLCONF ACK`命令对于主从服务器有三个作用:
241 |
242 | - 检测主从服务器的网络连接状态。
243 | - 辅助实现min-slaves选项。
244 | - 检测命令丢失。
245 |
246 | **(1)检测连接状态**
247 |
248 | 如果主服务器超过一秒钟没有收到从服务器发来的REPLCONF ACK命令,那么主服务器就知道主从服务器之间的连接出现问题了。
249 |
250 | **(2)辅助实现min-slaves选项**
251 |
252 | Redis的`min-slaves-to-write`和`min-slaves-max-lag`两个选项可以防止主服务器在不安全的情况下执行写命令。
253 |
254 | 举个例子,如果我们向主服务器提供以下设置:
255 |
256 | ```C
257 | min-slaves-to-write 3
258 | min-slaves-max-lag 10
259 | ```
260 |
261 | 那么在从服务器的数量少于3个,或者三个从服务器的延迟(lag)值都大于或等于10秒时,主服务器将拒绝执行写命令。
262 |
263 | **(3)检测命令丢失**
264 |
265 | 假如主服务器的向从服务器发送的传播命令因为网络问题丢失,会导致二者偏移量不一致。这是心跳检测命令会侦察到这种情况,于是主服务器会补发。
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现8-Sentinel.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现8-Sentinel
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-06 13:27:28
12 | ---
13 |
14 | Sentinel(哨岗、哨兵)是Redis的高可用性(high avail-ability)解决方案:由一个或多个Sentinel实例(instance)组成的Sentinel系统(system)对主从服务器进行监视。
15 |
16 | 所谓Sentinel['sentɪnl]的高可用性指**系统无中断地执行其功能的能力**。Sentinel的主要功能是:
17 |
18 | 1. 监控Redis整体是否正常运行。
19 | 2. 某个节点出问题时,**通知给其他进程**(比如他的客户端)。
20 | 3. 主服务器下线时,在从服务器中**选举**出一个新的主服务器。
21 |
22 | 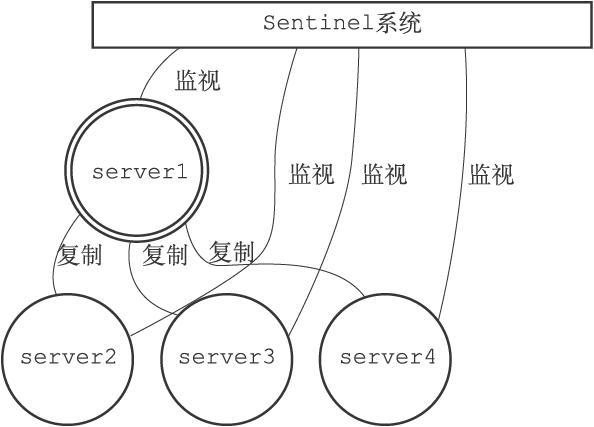 23 |
24 | # 1. 启动与初始化
25 |
26 | 启动命令:
27 |
28 | ```
29 | $ redis-sentinel /path/to/your/sentinel.conf
30 | $ redis-server /path/to/your/sentinel.conf --sentinel
31 | ```
32 |
33 | 一个Sentinel启动时,需要执行以下步骤:
34 |
35 | 1. 初始化服务器
36 | 2. 将普通Redis服务器使用的代码替换成Sentinel专用代码。
37 | 3. 初始化Sentinel状态
38 | 4. 根据给定的配置文件,初始化Sentinel的监视主服务器列表
39 | 5. 创建连向主服务器的网络连接
40 |
41 | **(1)初始化服务器**
42 |
43 | Sentinel**本质上只是一个运行在特殊模式下的Redis服务器**,所以启动Sentinel的第一步,就是初始化一个普通的Redis服务器。
44 |
45 | 由于Sentinel执行的工作和普通的Redis服务器执行的工作不同,所以初始化也不相同。首先先来回忆一下普通服务器的初始化过程:
46 |
47 | 1. 初始化服务器状态结构
48 | 2. 载入配置选项
49 | 3. 初始化服务器数据结构
50 | 4. 还原数据库状态
51 | 5. 执行事件循环
52 |
53 | 而Sentinel初始化时,并不会使用AOF和RDB来还原数据库,此外很多命令比如WATCH,EVAL等都不会使用。
54 |
55 | **(2)使用Sentinel专用代码**
56 |
57 | 主要分两部分:**端口**和**命令集**
58 |
59 | 普通Redis服务器使用`redis.h/REDIS_SERVERPORT`常量的值作为服务器端口:
60 |
61 | ```C
62 | #define REDIS_SERVERPORT 6379
63 | ```
64 |
65 | 而Sentinel则使用`sentinel.c/REDIS_SENTINEL_POR`T常量的值作为服务器端口:
66 |
67 | ```C
68 | #define REDIS_SENTINEL_PORT 26379
69 | ```
70 |
71 | ---
72 |
73 | 普通Redis服务器使用`redis.c/redisCom-mandTable`作为服务器的命令表。而Sentinel则使用`sentinel.c/sentinelcmds`作为服务器的命令表。
74 |
75 | `sentinelcmds`命令表也解释了为什么在Sentinel模式下,Redis服务器不能执行诸如SET、DBSIZE、EVAL等等这些命令,因为服务器**根本没有在命令表中载入这些命令**。PING、SEN-TINEL、INFO、SUBSCRIBE、UNSUBSCRIBE、PSUBSCRIBE和PUNSUBSCRIBE这七个命令就是客户端可以对Sentinel执行的全部命令了。
76 |
77 | **(3)初始化Sentinel状态**
78 |
79 | 在应用了Sentinel的专用代码之后,接下来,服务器会初始化一个`sentinel.c/sentinelState`结构,也就是Sentinel状态。服务器的一般状态仍然由`redis.h/redisServer`结构保存。
80 |
81 | **(4)初始化Sentinel状态的masters属性**
82 |
83 | Sentinel状态中的masters字典记录了所有被Sentinel监视的主服务器的相关信息,其中:
84 |
85 | - 字典的**键**是**被监视主服务器**的名字。
86 | - 而字典的**值**则是**被监视主服务器**对应的`sentinel.c/sentinelRedisInstance`结构。
87 |
88 | 每个`sentinelRedisInstance`结构(后面简称“实例结构”)**代表一个被Sentinel监视的Redis服务器实例(instance)**,这个实例可以是主服务器、从服务器,或者另外一个Sentinel。
89 |
90 | 对Sentinel状态的初始化将引发对masters字典的初始化,而masters字典的初始化是根据被载入的Sentinel配置文件来进行的。
91 |
92 | **(5)创建连向主服务器的网络连接**
93 |
94 | Sentinel会创建两个连向主服务器的异步网络连接:
95 |
96 | - 一个是命令连接,这个连接专门用于向主服务器发送命令,并接收命令回复。
97 | - 另一个是订阅连接,这个连接专门用于订阅主服务器的`__sentinel__:hello`频道。
98 |
99 | Redis目前的发布与订阅功能中,被发送的信息都不会保存在Redis服务器里面,如果在信息发送时,想要接收信息的客户端不在线或者断线,那么这个客户端就会丢失这条信息。因此,为了不丢失`__sentinel__:hello`频道的任何信息,Sentinel必须专门用一个订阅连接来接收该频道的信息。
100 |
101 | 因为Sentinel需要与多个实例创建多个网络连接,所以Sentinel使用的是异步连接。
102 |
103 | # 2. 获取服务器信息
104 |
105 | ## 2.1 获取主服务器信息
106 |
107 | Sentinel默认会以每十秒一次的频率,通过命令连接向被监视的**主服务器发送INFO命令**,并通过分析INFO命令的回复来获取主服务器的当前信息。
108 |
109 |
23 |
24 | # 1. 启动与初始化
25 |
26 | 启动命令:
27 |
28 | ```
29 | $ redis-sentinel /path/to/your/sentinel.conf
30 | $ redis-server /path/to/your/sentinel.conf --sentinel
31 | ```
32 |
33 | 一个Sentinel启动时,需要执行以下步骤:
34 |
35 | 1. 初始化服务器
36 | 2. 将普通Redis服务器使用的代码替换成Sentinel专用代码。
37 | 3. 初始化Sentinel状态
38 | 4. 根据给定的配置文件,初始化Sentinel的监视主服务器列表
39 | 5. 创建连向主服务器的网络连接
40 |
41 | **(1)初始化服务器**
42 |
43 | Sentinel**本质上只是一个运行在特殊模式下的Redis服务器**,所以启动Sentinel的第一步,就是初始化一个普通的Redis服务器。
44 |
45 | 由于Sentinel执行的工作和普通的Redis服务器执行的工作不同,所以初始化也不相同。首先先来回忆一下普通服务器的初始化过程:
46 |
47 | 1. 初始化服务器状态结构
48 | 2. 载入配置选项
49 | 3. 初始化服务器数据结构
50 | 4. 还原数据库状态
51 | 5. 执行事件循环
52 |
53 | 而Sentinel初始化时,并不会使用AOF和RDB来还原数据库,此外很多命令比如WATCH,EVAL等都不会使用。
54 |
55 | **(2)使用Sentinel专用代码**
56 |
57 | 主要分两部分:**端口**和**命令集**
58 |
59 | 普通Redis服务器使用`redis.h/REDIS_SERVERPORT`常量的值作为服务器端口:
60 |
61 | ```C
62 | #define REDIS_SERVERPORT 6379
63 | ```
64 |
65 | 而Sentinel则使用`sentinel.c/REDIS_SENTINEL_POR`T常量的值作为服务器端口:
66 |
67 | ```C
68 | #define REDIS_SENTINEL_PORT 26379
69 | ```
70 |
71 | ---
72 |
73 | 普通Redis服务器使用`redis.c/redisCom-mandTable`作为服务器的命令表。而Sentinel则使用`sentinel.c/sentinelcmds`作为服务器的命令表。
74 |
75 | `sentinelcmds`命令表也解释了为什么在Sentinel模式下,Redis服务器不能执行诸如SET、DBSIZE、EVAL等等这些命令,因为服务器**根本没有在命令表中载入这些命令**。PING、SEN-TINEL、INFO、SUBSCRIBE、UNSUBSCRIBE、PSUBSCRIBE和PUNSUBSCRIBE这七个命令就是客户端可以对Sentinel执行的全部命令了。
76 |
77 | **(3)初始化Sentinel状态**
78 |
79 | 在应用了Sentinel的专用代码之后,接下来,服务器会初始化一个`sentinel.c/sentinelState`结构,也就是Sentinel状态。服务器的一般状态仍然由`redis.h/redisServer`结构保存。
80 |
81 | **(4)初始化Sentinel状态的masters属性**
82 |
83 | Sentinel状态中的masters字典记录了所有被Sentinel监视的主服务器的相关信息,其中:
84 |
85 | - 字典的**键**是**被监视主服务器**的名字。
86 | - 而字典的**值**则是**被监视主服务器**对应的`sentinel.c/sentinelRedisInstance`结构。
87 |
88 | 每个`sentinelRedisInstance`结构(后面简称“实例结构”)**代表一个被Sentinel监视的Redis服务器实例(instance)**,这个实例可以是主服务器、从服务器,或者另外一个Sentinel。
89 |
90 | 对Sentinel状态的初始化将引发对masters字典的初始化,而masters字典的初始化是根据被载入的Sentinel配置文件来进行的。
91 |
92 | **(5)创建连向主服务器的网络连接**
93 |
94 | Sentinel会创建两个连向主服务器的异步网络连接:
95 |
96 | - 一个是命令连接,这个连接专门用于向主服务器发送命令,并接收命令回复。
97 | - 另一个是订阅连接,这个连接专门用于订阅主服务器的`__sentinel__:hello`频道。
98 |
99 | Redis目前的发布与订阅功能中,被发送的信息都不会保存在Redis服务器里面,如果在信息发送时,想要接收信息的客户端不在线或者断线,那么这个客户端就会丢失这条信息。因此,为了不丢失`__sentinel__:hello`频道的任何信息,Sentinel必须专门用一个订阅连接来接收该频道的信息。
100 |
101 | 因为Sentinel需要与多个实例创建多个网络连接,所以Sentinel使用的是异步连接。
102 |
103 | # 2. 获取服务器信息
104 |
105 | ## 2.1 获取主服务器信息
106 |
107 | Sentinel默认会以每十秒一次的频率,通过命令连接向被监视的**主服务器发送INFO命令**,并通过分析INFO命令的回复来获取主服务器的当前信息。
108 |
109 |  110 |
111 | 会收到类似以下内容的回复:
112 |
113 | ```C
114 | #Server
115 | ...
116 | run_id:7611c59dc3a29aa6fa0609f841bb6a1019008a9c
117 | ...
118 | # Replication
119 | role:master...
120 | slave0:ip=127.0.0.1,port=11111,state=online,offset=43,lag=0
121 | slave1:ip=127.0.0.1,port=22222,state=online,offset=43,lag=0
122 | slave2:ip=127.0.0.1,port=33333,state=online,offset=43,lag=0
123 | ...
124 | # Other sections
125 | ```
126 |
127 | 通过分析主服务器返回的INFO命令回复,Sentinel可以明确:主服务器本身的信息,从服务器的信息。之后进行更新:
128 |
129 | - 根据run_id域和role域记录的信息,**更新Sentinel主服务器的实例结构**。
130 | - 返回的从服务器信息,则会被用于**更新主服务器实例结构的slaves字典**,这个字典记录了主服务器属下从服务器的名单。
131 |
132 |
110 |
111 | 会收到类似以下内容的回复:
112 |
113 | ```C
114 | #Server
115 | ...
116 | run_id:7611c59dc3a29aa6fa0609f841bb6a1019008a9c
117 | ...
118 | # Replication
119 | role:master...
120 | slave0:ip=127.0.0.1,port=11111,state=online,offset=43,lag=0
121 | slave1:ip=127.0.0.1,port=22222,state=online,offset=43,lag=0
122 | slave2:ip=127.0.0.1,port=33333,state=online,offset=43,lag=0
123 | ...
124 | # Other sections
125 | ```
126 |
127 | 通过分析主服务器返回的INFO命令回复,Sentinel可以明确:主服务器本身的信息,从服务器的信息。之后进行更新:
128 |
129 | - 根据run_id域和role域记录的信息,**更新Sentinel主服务器的实例结构**。
130 | - 返回的从服务器信息,则会被用于**更新主服务器实例结构的slaves字典**,这个字典记录了主服务器属下从服务器的名单。
131 |
132 | 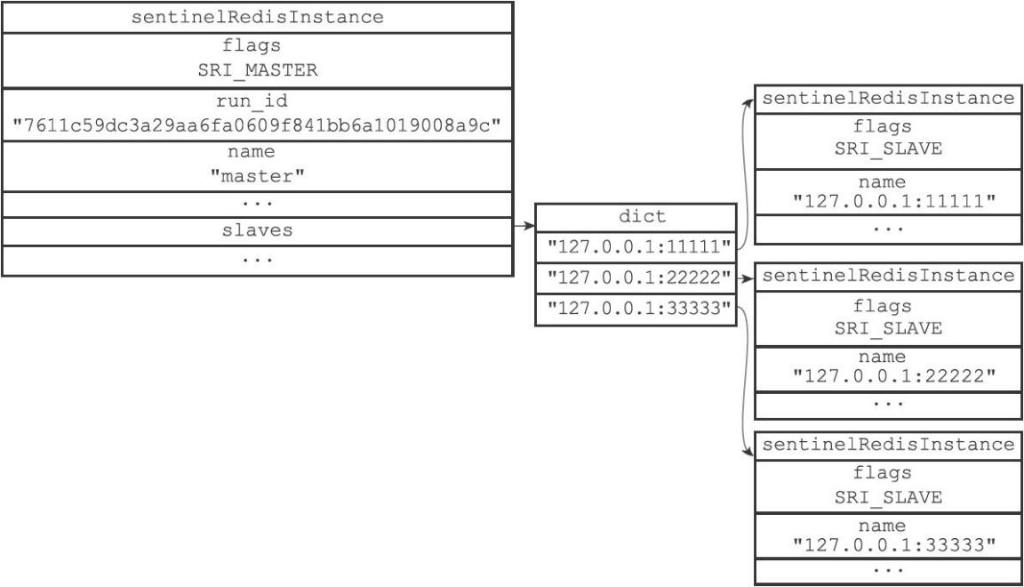 133 |
134 | ## 2.2 获取从服务器信息
135 |
136 | 当Sentinel发现主服务器有新的从服务器出现时,Sentinel除了会为这个新的从服务器创建相应的实例结构之外,Sentinel还会创建连接到从服务器的命令连接和订阅连接。
137 |
138 |
133 |
134 | ## 2.2 获取从服务器信息
135 |
136 | 当Sentinel发现主服务器有新的从服务器出现时,Sentinel除了会为这个新的从服务器创建相应的实例结构之外,Sentinel还会创建连接到从服务器的命令连接和订阅连接。
137 |
138 | 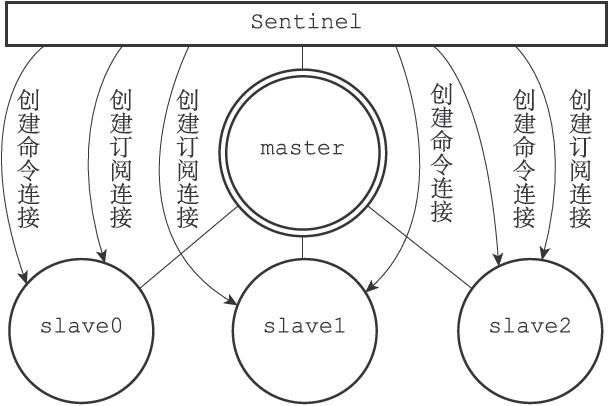 139 |
140 | 在创建命令连接之后,Sentinel在默认情况下,会以每十秒一次的频率通过命令连接向**从服务器发送INFO命令**,并获得类似于以下内容的回复:
141 |
142 | ```C
143 | # Server
144 | ...
145 | run_id:32be0699dd27b410f7c90dada3a6fab17f97899f
146 | ...
147 | # Replication
148 | role:slave
149 | master_host:127.0.0.1
150 | master_port:6379
151 | master_link_status:up
152 | slave_repl_offset:11887
153 | slave_priority:100
154 | #
155 | Other sections
156 | ...
157 | ```
158 |
159 | 利用这些信息更新从服务器的实例结构:
160 |
161 |
139 |
140 | 在创建命令连接之后,Sentinel在默认情况下,会以每十秒一次的频率通过命令连接向**从服务器发送INFO命令**,并获得类似于以下内容的回复:
141 |
142 | ```C
143 | # Server
144 | ...
145 | run_id:32be0699dd27b410f7c90dada3a6fab17f97899f
146 | ...
147 | # Replication
148 | role:slave
149 | master_host:127.0.0.1
150 | master_port:6379
151 | master_link_status:up
152 | slave_repl_offset:11887
153 | slave_priority:100
154 | #
155 | Other sections
156 | ...
157 | ```
158 |
159 | 利用这些信息更新从服务器的实例结构:
160 |
161 | 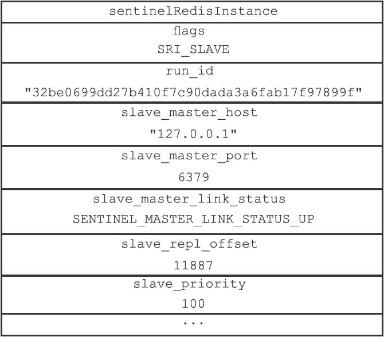 162 |
163 | ## 2.3 接收主从服务器的频道
164 |
165 | 当Sentinel与一个主服务器或者从服务器建立起订阅连接之后,Sentinel就会通过订阅连接,向服务器发送以下命令:
166 |
167 | ```C
168 | SUBSCRIBE __sentinel__:hello
169 | ```
170 |
171 | Sentinel对`__sentinel__:hello`频道的订阅会一直持续到Sentinel与服务器的连接断开为止。
172 |
173 | 对于每个与Sentinel连接的服务器,Sentinel既通过命令连接向服务器的`__sentinel__:hello`频道发送信息,又通过订阅连接从服务器的`__sentinel__:hello`频道接收信息
174 |
175 |
162 |
163 | ## 2.3 接收主从服务器的频道
164 |
165 | 当Sentinel与一个主服务器或者从服务器建立起订阅连接之后,Sentinel就会通过订阅连接,向服务器发送以下命令:
166 |
167 | ```C
168 | SUBSCRIBE __sentinel__:hello
169 | ```
170 |
171 | Sentinel对`__sentinel__:hello`频道的订阅会一直持续到Sentinel与服务器的连接断开为止。
172 |
173 | 对于每个与Sentinel连接的服务器,Sentinel既通过命令连接向服务器的`__sentinel__:hello`频道发送信息,又通过订阅连接从服务器的`__sentinel__:hello`频道接收信息
174 |
175 |  176 |
177 | 假设现在有sentinel1、sentinel2、sentinel3三个Sentinel在监视同一个服务器,那么当sentinel1向服务器的`__sentinel__:hello`频道发送一条信息时,所有订阅了`__sen-tinel__:hello`频道的Sentinel都会收到这条信息。
178 |
179 |
176 |
177 | 假设现在有sentinel1、sentinel2、sentinel3三个Sentinel在监视同一个服务器,那么当sentinel1向服务器的`__sentinel__:hello`频道发送一条信息时,所有订阅了`__sen-tinel__:hello`频道的Sentinel都会收到这条信息。
178 |
179 |  180 |
181 | # 3. Sentinel互相监督
182 |
183 | ## 3.1 Sentinel字典
184 |
185 | Sentinel为主服务器创建的实例结构中的**sentinels字典**保存了除Sentinel本身之外,所有同样**监视这个主服务器的其他Sentinel的资料。**
186 |
187 | 当一个Sentinel接收到其他Sentinel发来的信息时,会提取出两方面信息:
188 |
189 | - **与Sentinel有关的参数**:源Sentinel的IP,port,ID和配置参数
190 | - **与主服务器有关的参数**:源Sentinel正在监视的主服务器的名字,IP,端口号和配置参数。
191 |
192 | 提取以后,Sentinel会在自己的Sentinel状态的masters字典中查找相应的主服务器实例结构,**检查源Sentinel的实例结构是否存在:**
193 |
194 | - 存在,则更新
195 | - 不存在,则创建
196 |
197 | Sentinel可以通过分析接收到的频道信息来获知其他Sentinel的存在,并通过发送频道信息来让其他Sentinel知道自己的存在**,监视同一个主服务器的多个Sentinel可以自动发现对方**。
198 |
199 | ## 3.2 连接其他Sentinel
200 |
201 | 当Sentinel通过频道信息发现一个新的Sentinel时,它不仅会为新Sentinel在sentinels字典中创建相应的实例结构**,还会创建一个连向新Sentinel的命令连接**,而**新Sentinel也同样会创建连向这个Sentinel的命令连接**,最终监视同一主服务器的多个Sentinel将形成相互连接的**环形网络**。
202 |
203 |
180 |
181 | # 3. Sentinel互相监督
182 |
183 | ## 3.1 Sentinel字典
184 |
185 | Sentinel为主服务器创建的实例结构中的**sentinels字典**保存了除Sentinel本身之外,所有同样**监视这个主服务器的其他Sentinel的资料。**
186 |
187 | 当一个Sentinel接收到其他Sentinel发来的信息时,会提取出两方面信息:
188 |
189 | - **与Sentinel有关的参数**:源Sentinel的IP,port,ID和配置参数
190 | - **与主服务器有关的参数**:源Sentinel正在监视的主服务器的名字,IP,端口号和配置参数。
191 |
192 | 提取以后,Sentinel会在自己的Sentinel状态的masters字典中查找相应的主服务器实例结构,**检查源Sentinel的实例结构是否存在:**
193 |
194 | - 存在,则更新
195 | - 不存在,则创建
196 |
197 | Sentinel可以通过分析接收到的频道信息来获知其他Sentinel的存在,并通过发送频道信息来让其他Sentinel知道自己的存在**,监视同一个主服务器的多个Sentinel可以自动发现对方**。
198 |
199 | ## 3.2 连接其他Sentinel
200 |
201 | 当Sentinel通过频道信息发现一个新的Sentinel时,它不仅会为新Sentinel在sentinels字典中创建相应的实例结构**,还会创建一个连向新Sentinel的命令连接**,而**新Sentinel也同样会创建连向这个Sentinel的命令连接**,最终监视同一主服务器的多个Sentinel将形成相互连接的**环形网络**。
202 |
203 | 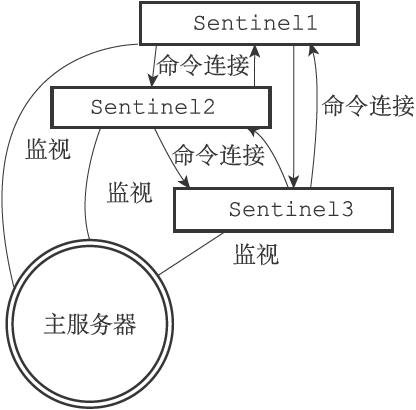 204 |
205 | 注意:Sentinel之间**只会创建命令连接,但不会创建订阅**。Sentinel需要通过接收主服务器或者从服务器发来的频道信息来发现未知的新Sentinel,所以才需要建立订阅连接。相互已知的Sentinel只要使用命令连接来进行通信就足够了。
206 |
207 | # 4. 检测下线状态
208 |
209 | ## 4.1 检测主观下线状态
210 |
211 | Sentinel会以每秒一次的频率向所有与它创建了命令连接的实例(包括**主服务器、从服务器、其他Sentinel在内**)发送PING命令,并通过实例返回的PING命令回复来**判断对方是否在线。**
212 |
213 |
204 |
205 | 注意:Sentinel之间**只会创建命令连接,但不会创建订阅**。Sentinel需要通过接收主服务器或者从服务器发来的频道信息来发现未知的新Sentinel,所以才需要建立订阅连接。相互已知的Sentinel只要使用命令连接来进行通信就足够了。
206 |
207 | # 4. 检测下线状态
208 |
209 | ## 4.1 检测主观下线状态
210 |
211 | Sentinel会以每秒一次的频率向所有与它创建了命令连接的实例(包括**主服务器、从服务器、其他Sentinel在内**)发送PING命令,并通过实例返回的PING命令回复来**判断对方是否在线。**
212 |
213 | 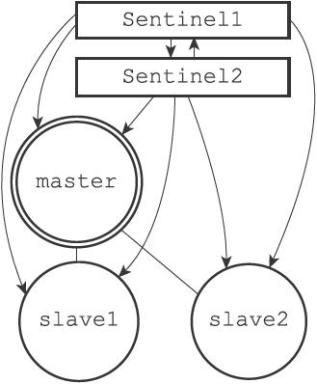 214 |
215 | 当对方超过一段时间不向Sentinel回复时(比如超时5000毫秒)则Sentinel1就会**将对方标记为主观下线**。
216 |
217 | ## 4.2 检查客观下线状态
218 |
219 | 当Sentinel将一个主服务器判断为主观下线之后,为了确认这个主服务器是否真的下线了,它会**向同样监视这一主服务器的其他Sentinel进行询问,看它们是否也认为主服务器已经进入了下线状态**。当Sentinel从其他Sentinel那里接收到足够数量的已下线判断之后,Sentinel就会将从服务器**判定为客观下线**,并对主服务器执行故障转移操作。
220 |
221 | # 5. 下线后的补救
222 |
223 | ## 5.1 选举Sentinel领袖
224 |
225 | 一个主服务器被判断为客观下线时,监视这个下线主服务器的各个Sentinel会进行协商,**选举出一个领头Sentinel,并由领头Sentinel对下线主服务器执行故障转移操作。**
226 |
227 | 选举策略:
228 |
229 | - **候选人**:所有在线的Sentinel
230 | - **选举过程**:一个Sentinel向另一个Sentinel发送设置请求`SENTINEL is-master-down-by-addr`命令
231 | - **胜选条件**:
232 | - **局部领头Sentinel:先到先得**,最先向目标Sentinel发送设置要求的源Sentinel将成为目标Sen-tinel的局部领头Sentinel,而之后接收到的所有设置要求都会被目标Sentinel拒绝。
233 | - **领头Sentinel:**如果有某个Sentinel**被半数**以上的Sentinel设置成了局部领头Sentinel,那么这个Sentinel成为领头Sentinel。
234 | - **重选条件:**如果没有过半,则再次投票,知道选出过半的为止。
235 |
236 |
214 |
215 | 当对方超过一段时间不向Sentinel回复时(比如超时5000毫秒)则Sentinel1就会**将对方标记为主观下线**。
216 |
217 | ## 4.2 检查客观下线状态
218 |
219 | 当Sentinel将一个主服务器判断为主观下线之后,为了确认这个主服务器是否真的下线了,它会**向同样监视这一主服务器的其他Sentinel进行询问,看它们是否也认为主服务器已经进入了下线状态**。当Sentinel从其他Sentinel那里接收到足够数量的已下线判断之后,Sentinel就会将从服务器**判定为客观下线**,并对主服务器执行故障转移操作。
220 |
221 | # 5. 下线后的补救
222 |
223 | ## 5.1 选举Sentinel领袖
224 |
225 | 一个主服务器被判断为客观下线时,监视这个下线主服务器的各个Sentinel会进行协商,**选举出一个领头Sentinel,并由领头Sentinel对下线主服务器执行故障转移操作。**
226 |
227 | 选举策略:
228 |
229 | - **候选人**:所有在线的Sentinel
230 | - **选举过程**:一个Sentinel向另一个Sentinel发送设置请求`SENTINEL is-master-down-by-addr`命令
231 | - **胜选条件**:
232 | - **局部领头Sentinel:先到先得**,最先向目标Sentinel发送设置要求的源Sentinel将成为目标Sen-tinel的局部领头Sentinel,而之后接收到的所有设置要求都会被目标Sentinel拒绝。
233 | - **领头Sentinel:**如果有某个Sentinel**被半数**以上的Sentinel设置成了局部领头Sentinel,那么这个Sentinel成为领头Sentinel。
234 | - **重选条件:**如果没有过半,则再次投票,知道选出过半的为止。
235 |
236 | 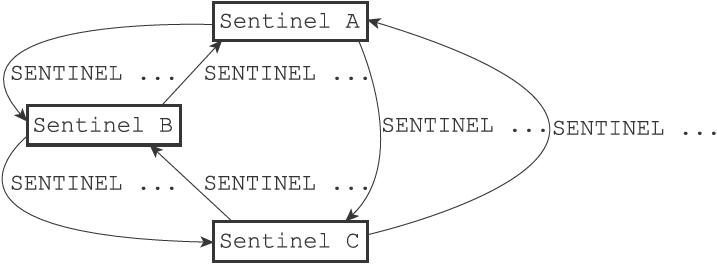 237 |
238 | ## 5.1 故障转移
239 |
240 | 在选举产生出领头Sentinel之后,领头Sentinel将对已下线的主服务器执行故障转移操作,该操作包含以下三个步骤:
241 |
242 | 1. 从已下线的主服务器的从服务器中**拔举**一个作为主服务器。
243 | 2. 让已下线主服务器属下的所有从服务器改为复制新的主服务器
244 | 3. 将已下线主服务器设置为新的主服务器的从服务器,当这个旧的主服务器重新上线时,它就会成为新的主服务器的从服务器。
245 |
246 | **(1)选出新的主服务器**
247 |
248 | 选择的标准是:状态良好、数据完整的从服务器。在满足基本连接需求后,判断偏移量,**选出偏移量最大(保存最新数据)的从服务器作为新的主服务器。**然后向这个从服务器发送**SLAVEOF no one**命令,将这个从服务器转换为主服务器。
249 |
250 | 在发送**SLAVEOF no one**命令之后,领头Sentinel会以每秒一次的频率(平时是每十秒一次),**向被升级的从服务器发送INFO命令**,并观察命令回复中的角色(role)信息,当被升级服务器的role从原来的slave变为master时,领头Sentinel就知道被选中的从服务器已经顺利升级为主服务器了。
251 |
252 | **(2)修改复制目标**
253 |
254 | 之后需要让已下线主服务器属下的所有从服务器去复制新的主服务器,这一动作可以通过向从服务器发送SLAVEOF命令来实现。
255 |
256 |
237 |
238 | ## 5.1 故障转移
239 |
240 | 在选举产生出领头Sentinel之后,领头Sentinel将对已下线的主服务器执行故障转移操作,该操作包含以下三个步骤:
241 |
242 | 1. 从已下线的主服务器的从服务器中**拔举**一个作为主服务器。
243 | 2. 让已下线主服务器属下的所有从服务器改为复制新的主服务器
244 | 3. 将已下线主服务器设置为新的主服务器的从服务器,当这个旧的主服务器重新上线时,它就会成为新的主服务器的从服务器。
245 |
246 | **(1)选出新的主服务器**
247 |
248 | 选择的标准是:状态良好、数据完整的从服务器。在满足基本连接需求后,判断偏移量,**选出偏移量最大(保存最新数据)的从服务器作为新的主服务器。**然后向这个从服务器发送**SLAVEOF no one**命令,将这个从服务器转换为主服务器。
249 |
250 | 在发送**SLAVEOF no one**命令之后,领头Sentinel会以每秒一次的频率(平时是每十秒一次),**向被升级的从服务器发送INFO命令**,并观察命令回复中的角色(role)信息,当被升级服务器的role从原来的slave变为master时,领头Sentinel就知道被选中的从服务器已经顺利升级为主服务器了。
251 |
252 | **(2)修改复制目标**
253 |
254 | 之后需要让已下线主服务器属下的所有从服务器去复制新的主服务器,这一动作可以通过向从服务器发送SLAVEOF命令来实现。
255 |
256 | 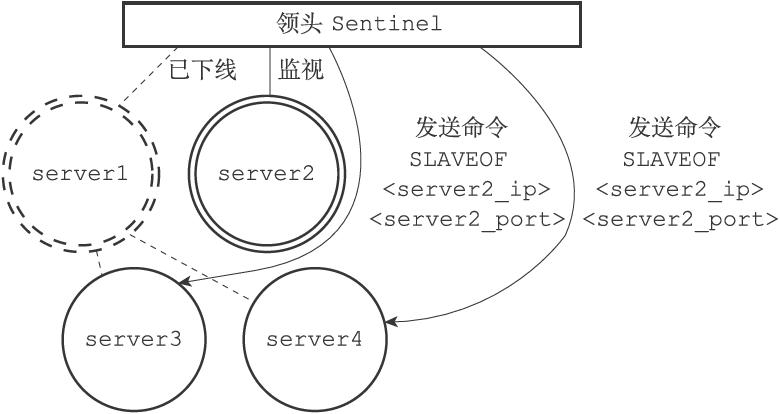 257 |
258 | **(3)将旧的主服务器变为从服务器**
259 |
260 | 当原来的主服务器重新上线时,Sentinel就会向它发送SLAVEOF命令,让它成为新主服务器的从服务器。
261 |
262 |
257 |
258 | **(3)将旧的主服务器变为从服务器**
259 |
260 | 当原来的主服务器重新上线时,Sentinel就会向它发送SLAVEOF命令,让它成为新主服务器的从服务器。
261 |
262 | 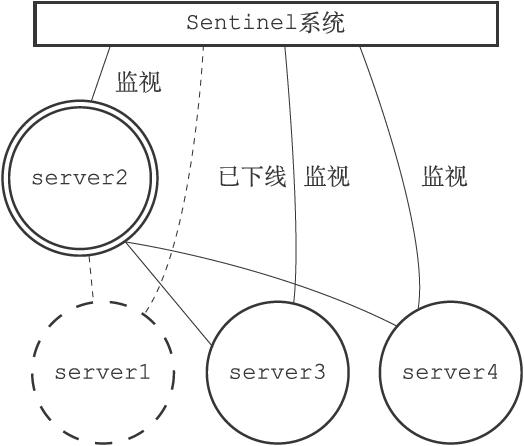 263 |
264 |
263 |
264 | 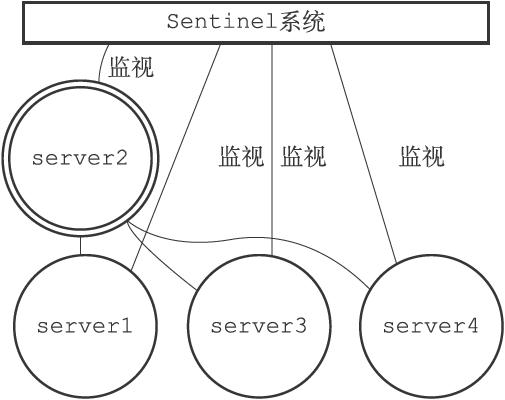 --------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现9-集群.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现9-集群
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-06 18:17:06
12 |
13 | ---
14 |
15 | Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)来进行数据共享,并提供复制和故障转移功能。
16 |
17 | # 1. 节点
18 |
19 | ## 1.1 节点是什么
20 |
21 | 节点时Redis中数据存储的单位。一个Redis集群通常由多个节点(node)组成,**在刚开始的时候,每个节点都是相互独立的**,它们都处于一个只包含自己的集群当中,要组建一个真正可工作的集群,我们必须**将各个独立的节点连接起来,构成一个包含多个节点的集群。**
22 |
23 | 使用`CLUSTER MEET`命令来完成,该命令的格式如下:
24 |
25 | ```C
26 | CLUSTER MEET
27 | ```
28 |
29 | 当前节点发送`CLUSTER MEET`命令,可以与**ip和port所指定的节点进行握手(handshake)**,当握手成功时,node节点就会将ip和port所指定的节点添加到node节点当前所在的集群中。
30 |
31 |
--------------------------------------------------------------------------------
/Markdown笔记/Redis设计与实现9-集群.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis设计与实现9-集群
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-06 18:17:06
12 |
13 | ---
14 |
15 | Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)来进行数据共享,并提供复制和故障转移功能。
16 |
17 | # 1. 节点
18 |
19 | ## 1.1 节点是什么
20 |
21 | 节点时Redis中数据存储的单位。一个Redis集群通常由多个节点(node)组成,**在刚开始的时候,每个节点都是相互独立的**,它们都处于一个只包含自己的集群当中,要组建一个真正可工作的集群,我们必须**将各个独立的节点连接起来,构成一个包含多个节点的集群。**
22 |
23 | 使用`CLUSTER MEET`命令来完成,该命令的格式如下:
24 |
25 | ```C
26 | CLUSTER MEET
27 | ```
28 |
29 | 当前节点发送`CLUSTER MEET`命令,可以与**ip和port所指定的节点进行握手(handshake)**,当握手成功时,node节点就会将ip和port所指定的节点添加到node节点当前所在的集群中。
30 |
31 | 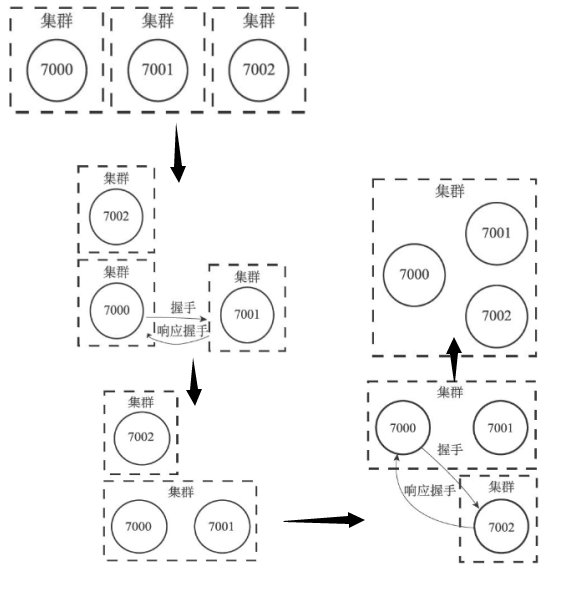 32 |
33 | ## 1.2 启动节点
34 |
35 | **一个节点就是一个运行在集群模式下的Redis服务器**,Redis服务器在启动时会根据`cluster-enabled`配置选项是否为yes来决定是否开启服务器的集群模式:
36 |
37 |
32 |
33 | ## 1.2 启动节点
34 |
35 | **一个节点就是一个运行在集群模式下的Redis服务器**,Redis服务器在启动时会根据`cluster-enabled`配置选项是否为yes来决定是否开启服务器的集群模式:
36 |
37 |  38 |
39 | ## 1.3 集群数据结构
40 |
41 | `clusterNode`结构保存了一个节点的当前状态,比如节点的创建时间、节点的名字、节点当前的配置纪元、节点的IP地址和端口号等等。**每个节点都会使用一个`clusterNode`结构来记录自己的状态,并为集群中的所有其他节点(包括主节点和从节点)都创建一个相应的clusterNode结构,以此来记录其他节点的状态:**
42 |
43 | ```C
44 | struct clusterNode {
45 |
46 | // 创建节点的时间
47 | mstime_t ctime;
48 |
49 | // 节点的名字,由 40 个十六进制字符组成
50 | // 例如 68eef66df23420a5862208ef5b1a7005b806f2ff
51 | char name[REDIS_CLUSTER_NAMELEN];
52 |
53 | // 节点标识
54 | // 使用各种不同的标识值记录节点的角色(比如主节点或者从节点),
55 | // 以及节点目前所处的状态(比如在线或者下线)。
56 | int flags;
57 |
58 | // 节点当前的配置纪元,用于实现故障转移
59 | uint64_t configEpoch;
60 |
61 | // 节点的 IP 地址
62 | char ip[REDIS_IP_STR_LEN];
63 |
64 | // 节点的端口号
65 | int port;
66 |
67 | // 保存连接节点所需的有关信息
68 | clusterLink *link;
69 | // ...
70 | };
71 | ```
72 |
73 | `clusterNode` 结构的 `link` 属性是一个 `clusterLink` 结构, 该结构保存了**连接节点所需的有关信息**, 比如套接字描述符, 输入缓冲区和输出缓冲区:
74 |
75 | ```C
76 | typedef struct clusterLink {
77 |
78 | // 连接的创建时间
79 | mstime_t ctime;
80 |
81 | // TCP 套接字描述符
82 | int fd;
83 |
84 | // 输出缓冲区,保存着等待发送给其他节点的消息(message)。
85 | sds sndbuf;
86 |
87 | // 输入缓冲区,保存着从其他节点接收到的消息。
88 | sds rcvbuf;
89 |
90 | // 与这个连接相关联的节点,如果没有的话就为 NULL
91 | struct clusterNode *node;
92 |
93 | } clusterLink;
94 | ```
95 |
96 | 假设现在有三个独立的节点127.0.0.1:7000、127.0.0.1:7001、127.0.0.1:7002,将他们创立为集群后,数据结构如下:
97 |
98 |
38 |
39 | ## 1.3 集群数据结构
40 |
41 | `clusterNode`结构保存了一个节点的当前状态,比如节点的创建时间、节点的名字、节点当前的配置纪元、节点的IP地址和端口号等等。**每个节点都会使用一个`clusterNode`结构来记录自己的状态,并为集群中的所有其他节点(包括主节点和从节点)都创建一个相应的clusterNode结构,以此来记录其他节点的状态:**
42 |
43 | ```C
44 | struct clusterNode {
45 |
46 | // 创建节点的时间
47 | mstime_t ctime;
48 |
49 | // 节点的名字,由 40 个十六进制字符组成
50 | // 例如 68eef66df23420a5862208ef5b1a7005b806f2ff
51 | char name[REDIS_CLUSTER_NAMELEN];
52 |
53 | // 节点标识
54 | // 使用各种不同的标识值记录节点的角色(比如主节点或者从节点),
55 | // 以及节点目前所处的状态(比如在线或者下线)。
56 | int flags;
57 |
58 | // 节点当前的配置纪元,用于实现故障转移
59 | uint64_t configEpoch;
60 |
61 | // 节点的 IP 地址
62 | char ip[REDIS_IP_STR_LEN];
63 |
64 | // 节点的端口号
65 | int port;
66 |
67 | // 保存连接节点所需的有关信息
68 | clusterLink *link;
69 | // ...
70 | };
71 | ```
72 |
73 | `clusterNode` 结构的 `link` 属性是一个 `clusterLink` 结构, 该结构保存了**连接节点所需的有关信息**, 比如套接字描述符, 输入缓冲区和输出缓冲区:
74 |
75 | ```C
76 | typedef struct clusterLink {
77 |
78 | // 连接的创建时间
79 | mstime_t ctime;
80 |
81 | // TCP 套接字描述符
82 | int fd;
83 |
84 | // 输出缓冲区,保存着等待发送给其他节点的消息(message)。
85 | sds sndbuf;
86 |
87 | // 输入缓冲区,保存着从其他节点接收到的消息。
88 | sds rcvbuf;
89 |
90 | // 与这个连接相关联的节点,如果没有的话就为 NULL
91 | struct clusterNode *node;
92 |
93 | } clusterLink;
94 | ```
95 |
96 | 假设现在有三个独立的节点127.0.0.1:7000、127.0.0.1:7001、127.0.0.1:7002,将他们创立为集群后,数据结构如下:
97 |
98 | 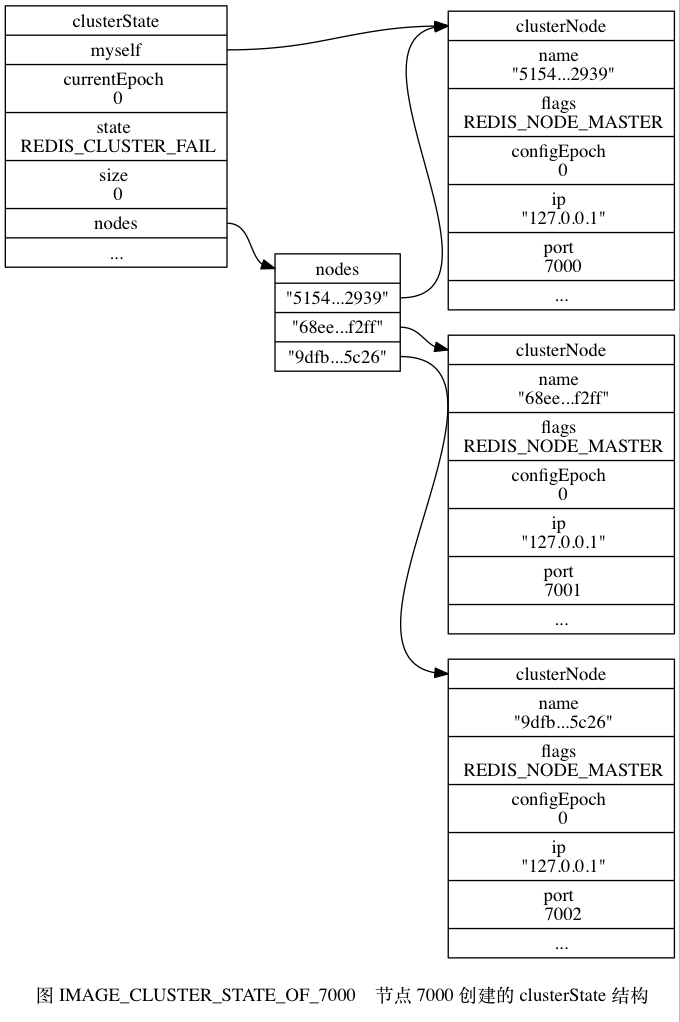 99 |
100 | 总的来说:
101 |
102 | - clusterState保存**集群状态**,**每个节点都保存着一个这样的状态**,记录了它们眼中的集群的样子。
103 | - clusterNode保存了**某个节点的状态**,同时通过指针指向其他节点,达到关联的目的
104 | - clusterLink保存了**和其他节点通信的信息**。
105 |
106 | ## 1.4 实现CLUSTER MEET命令
107 |
108 | **向A**发送命令,**希望A和B形成集群**,则:
109 |
110 | 1. 节点A会为节点B创建一个clusterNode结构,并将该结构添加到自己的`clusterState.nodes`字典里面。
111 | 2. 根据命令给定的IP和端口,节点A向B发送一条MEET消息
112 | 3. B收到以后,为节点A创建一个clusterNode结构,并将该结构添加到自己的clusterState.nodes字典里面。
113 | 4. B向A返回一条PONG消息
114 | 5. A收到PONG后向B返回一条PING
115 | 6. B收到PING后,握手完成。
116 |
117 |
99 |
100 | 总的来说:
101 |
102 | - clusterState保存**集群状态**,**每个节点都保存着一个这样的状态**,记录了它们眼中的集群的样子。
103 | - clusterNode保存了**某个节点的状态**,同时通过指针指向其他节点,达到关联的目的
104 | - clusterLink保存了**和其他节点通信的信息**。
105 |
106 | ## 1.4 实现CLUSTER MEET命令
107 |
108 | **向A**发送命令,**希望A和B形成集群**,则:
109 |
110 | 1. 节点A会为节点B创建一个clusterNode结构,并将该结构添加到自己的`clusterState.nodes`字典里面。
111 | 2. 根据命令给定的IP和端口,节点A向B发送一条MEET消息
112 | 3. B收到以后,为节点A创建一个clusterNode结构,并将该结构添加到自己的clusterState.nodes字典里面。
113 | 4. B向A返回一条PONG消息
114 | 5. A收到PONG后向B返回一条PING
115 | 6. B收到PING后,握手完成。
116 |
117 | 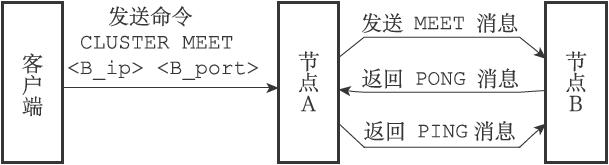 118 |
119 | # 2. 槽指派
120 |
121 | Redis集群通过分片的方式来保存数据库中的键值对:**集群的整个数据库被分为16384个槽(slot)**,**数据库中的每个键都属于这16384个槽的其中一个**,集群中的每个节点可以处理0个或最多16384个槽。
122 |
123 | 当数据库中的16384个槽**都有**节点在处理时,**集群处于上线状态(ok)**;相反地,如果数据库中有任何一个槽没有得到处理,那么集群处于下线状态(fail)。
124 |
125 | 换句话说,只有完全分配了16384个槽才会进入上线状态。
126 |
127 | ## 2.1 当前节点的槽指派信息
128 |
129 | clusterNode结构的`slots`属性和`numslot`属性记录了节点负责处理哪些槽:
130 |
131 | ```C
132 | struct clusterNode
133 | {
134 | // ...
135 | unsigned char slots[16384/8];
136 | int numslots;
137 | // ...
138 | };
139 | ```
140 |
141 | `slots`属性是一个二进制位数组(bit array),这个数组的长度为16384/8=2048个字节,共包含16384个二进制位。通过判断二进制的01状态来判断,此槽是否属于。
142 |
143 | 下图表示这个节点负责处理槽0至7,
144 |
145 |
118 |
119 | # 2. 槽指派
120 |
121 | Redis集群通过分片的方式来保存数据库中的键值对:**集群的整个数据库被分为16384个槽(slot)**,**数据库中的每个键都属于这16384个槽的其中一个**,集群中的每个节点可以处理0个或最多16384个槽。
122 |
123 | 当数据库中的16384个槽**都有**节点在处理时,**集群处于上线状态(ok)**;相反地,如果数据库中有任何一个槽没有得到处理,那么集群处于下线状态(fail)。
124 |
125 | 换句话说,只有完全分配了16384个槽才会进入上线状态。
126 |
127 | ## 2.1 当前节点的槽指派信息
128 |
129 | clusterNode结构的`slots`属性和`numslot`属性记录了节点负责处理哪些槽:
130 |
131 | ```C
132 | struct clusterNode
133 | {
134 | // ...
135 | unsigned char slots[16384/8];
136 | int numslots;
137 | // ...
138 | };
139 | ```
140 |
141 | `slots`属性是一个二进制位数组(bit array),这个数组的长度为16384/8=2048个字节,共包含16384个二进制位。通过判断二进制的01状态来判断,此槽是否属于。
142 |
143 | 下图表示这个节点负责处理槽0至7,
144 |
145 |  146 |
147 | 因为数组自带索引,所以取出某个槽是否使用的时间复杂的为$O(1)$。
148 |
149 | ## 2.2 传播节点的槽指派信息
150 |
151 | 一个节点除了会将自己负责处理的槽记录在clusterNode结构的slots属性和numslots属性之外,它**还会将自己的slots数组通过消息发送给集群中的其他节点,以此来告知其他节点自己目前负责处理哪些槽。**
152 |
153 | 当节点A通过消息从节点B那里接收到节点B的`slots`数组时,节点A会在自己的`clusterState.nodes`字典中**查找节点B对应的clusterNode结构,并对结构中的`slots`数组进行保存或者更新。**
154 |
155 | 因此,集群中的**每个节点**都会知道数据库中的16384个槽分别被指派给了集群中的哪些节点。
156 |
157 | 在clusterState中有一个myself指针,指向当前节点clusterNode,这个结构中包含了一个二进制数组,记录当前节点的槽指派情况。而clusterState中还有一个`clusterNode *slots[REDIS_CLUSTER_SLOTS];`,记录了其他节点的槽指派情况。例如 `slots[i] = clusterNode_A` 表示槽 i 由节点 A 处理
158 |
159 | ## 2.3 集群所有槽的指派信息
160 |
161 | clusterState结构中的`slots`数组记录了集群中所有16384个槽的指派信息:
162 |
163 | ```C
164 | typedef struct clusterState
165 | {
166 | // ...
167 | clusterNode *slots[16384];
168 | // ...
169 | } clusterState;
170 | ```
171 |
172 | 每个数组都是指向`clusterNode`结构的指针:
173 |
174 | - 如果指向NULL,表示尚未指派给任何节点。
175 | - 如果指向某一个clusterNode,则表示槽i指派给了某一个节点。
176 |
177 | 如果只将槽指派信息保存在各个节点的`clusterNode.slots`数组里,会出现一些无法高效地解决的问题,而`clusterState.slots`数组的存在解决了这些问题:
178 |
179 | - 如果想知道某个槽是否被指派以及被指派给了谁,需要遍历所有clusterNode结构。
180 | - 通过`clusterState`保存的数组,可以以$O(1)$的时间取得结果。
181 |
182 | ## 2.4 槽的保存方式
183 |
184 | 节点还会用`clusterState`结构中的`slots_to_keys`**跳跃表**来保存槽和键之间的关系:
185 |
186 | ```C
187 | typedef struct clusterState
188 | {
189 | // ...
190 | zskiplist *slots_to_keys;
191 | // ...
192 | } clusterState;
193 | ```
194 |
195 | `slots_to_keys`跳跃表每个节点的分值(score)都是一个槽号,而每个节点的成员(member)都是一个数据库键:
196 |
197 |
146 |
147 | 因为数组自带索引,所以取出某个槽是否使用的时间复杂的为$O(1)$。
148 |
149 | ## 2.2 传播节点的槽指派信息
150 |
151 | 一个节点除了会将自己负责处理的槽记录在clusterNode结构的slots属性和numslots属性之外,它**还会将自己的slots数组通过消息发送给集群中的其他节点,以此来告知其他节点自己目前负责处理哪些槽。**
152 |
153 | 当节点A通过消息从节点B那里接收到节点B的`slots`数组时,节点A会在自己的`clusterState.nodes`字典中**查找节点B对应的clusterNode结构,并对结构中的`slots`数组进行保存或者更新。**
154 |
155 | 因此,集群中的**每个节点**都会知道数据库中的16384个槽分别被指派给了集群中的哪些节点。
156 |
157 | 在clusterState中有一个myself指针,指向当前节点clusterNode,这个结构中包含了一个二进制数组,记录当前节点的槽指派情况。而clusterState中还有一个`clusterNode *slots[REDIS_CLUSTER_SLOTS];`,记录了其他节点的槽指派情况。例如 `slots[i] = clusterNode_A` 表示槽 i 由节点 A 处理
158 |
159 | ## 2.3 集群所有槽的指派信息
160 |
161 | clusterState结构中的`slots`数组记录了集群中所有16384个槽的指派信息:
162 |
163 | ```C
164 | typedef struct clusterState
165 | {
166 | // ...
167 | clusterNode *slots[16384];
168 | // ...
169 | } clusterState;
170 | ```
171 |
172 | 每个数组都是指向`clusterNode`结构的指针:
173 |
174 | - 如果指向NULL,表示尚未指派给任何节点。
175 | - 如果指向某一个clusterNode,则表示槽i指派给了某一个节点。
176 |
177 | 如果只将槽指派信息保存在各个节点的`clusterNode.slots`数组里,会出现一些无法高效地解决的问题,而`clusterState.slots`数组的存在解决了这些问题:
178 |
179 | - 如果想知道某个槽是否被指派以及被指派给了谁,需要遍历所有clusterNode结构。
180 | - 通过`clusterState`保存的数组,可以以$O(1)$的时间取得结果。
181 |
182 | ## 2.4 槽的保存方式
183 |
184 | 节点还会用`clusterState`结构中的`slots_to_keys`**跳跃表**来保存槽和键之间的关系:
185 |
186 | ```C
187 | typedef struct clusterState
188 | {
189 | // ...
190 | zskiplist *slots_to_keys;
191 | // ...
192 | } clusterState;
193 | ```
194 |
195 | `slots_to_keys`跳跃表每个节点的分值(score)都是一个槽号,而每个节点的成员(member)都是一个数据库键:
196 |
197 | 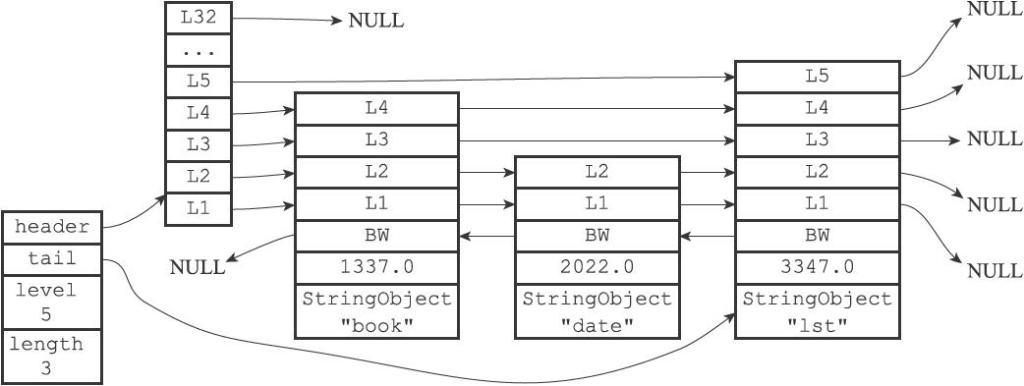 198 |
199 | # 3. MOVED错误
200 |
201 | 前面提到,指派完槽以后,集群会进入上线状态,此时客户端可以向集群中的节点发送数据命令。
202 |
203 | 当客户端向节点发送与数据库键有关的命令时,**接收命令的节点会计算出命令要处理的数据库键属于哪个槽,并检查这个槽是否指派给了自己:**
204 |
205 | - 如果指派给自己,执行
206 | - 否则,返回MOVED错误,并**将客户端指向正确的节点**。
207 |
208 |
198 |
199 | # 3. MOVED错误
200 |
201 | 前面提到,指派完槽以后,集群会进入上线状态,此时客户端可以向集群中的节点发送数据命令。
202 |
203 | 当客户端向节点发送与数据库键有关的命令时,**接收命令的节点会计算出命令要处理的数据库键属于哪个槽,并检查这个槽是否指派给了自己:**
204 |
205 | - 如果指派给自己,执行
206 | - 否则,返回MOVED错误,并**将客户端指向正确的节点**。
207 |
208 | 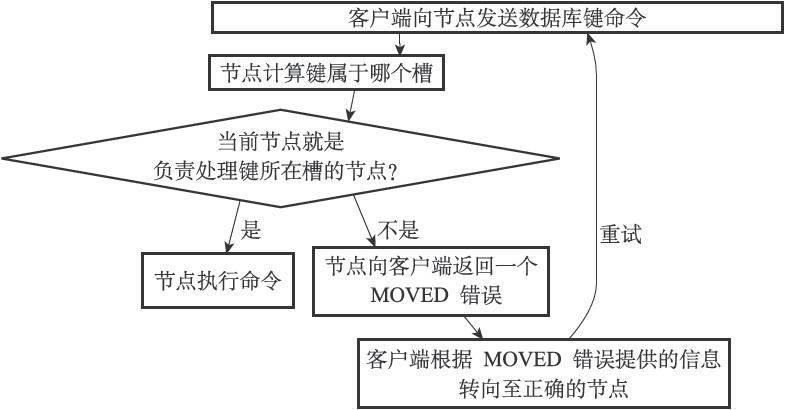 209 |
210 | 比如,date键所在的槽正好是节点7000负责,正常执行。
211 |
212 | ```C
213 | 127.0.0.1:7000> SET date "2013-12-31"
214 | OK
215 | ```
216 |
217 | 如果是如下的情况,客户端会被自动转到正确的节点。
218 |
219 | ```c
220 | 127.0.0.1:7000> SET msg "happy new year!"
221 | -> Redirected to slot [6257] located at 127.0.0.1:7001
222 | OK
223 |
224 | 127.0.0.1:7001> GET msg
225 | "happy new year!"
226 | ```
227 |
228 | 要完成上面的操作,需要至少两步:
229 |
230 | - 判断槽是否自己负责
231 | - MOVED错误的实现方法
232 |
233 | ## 3.1 判断槽是否自己负责
234 |
235 | 键属于哪个槽需要用到CRC-16校验的办法:
236 |
237 | ```C
238 | slot_number = CRC16(key)&16383
239 | ```
240 |
241 | 这样就可以计算出一个介于0至16383之间的整数作为键key的槽号。
242 |
243 | 当节点计算出键所属的槽i之后,节点就会检查自己在`clusterState.slots`数组中的项i,判断键所在的槽是否由自己负责:
244 |
245 | - 如果`clusterState.slots[i]`等于`clusterState.myself`,那么说明槽i由当前节点负责,节点可以执行客户端发送的命令。
246 | - 反之,则记下指向clusterNode结构所记录的IP和端口号
247 |
248 |
209 |
210 | 比如,date键所在的槽正好是节点7000负责,正常执行。
211 |
212 | ```C
213 | 127.0.0.1:7000> SET date "2013-12-31"
214 | OK
215 | ```
216 |
217 | 如果是如下的情况,客户端会被自动转到正确的节点。
218 |
219 | ```c
220 | 127.0.0.1:7000> SET msg "happy new year!"
221 | -> Redirected to slot [6257] located at 127.0.0.1:7001
222 | OK
223 |
224 | 127.0.0.1:7001> GET msg
225 | "happy new year!"
226 | ```
227 |
228 | 要完成上面的操作,需要至少两步:
229 |
230 | - 判断槽是否自己负责
231 | - MOVED错误的实现方法
232 |
233 | ## 3.1 判断槽是否自己负责
234 |
235 | 键属于哪个槽需要用到CRC-16校验的办法:
236 |
237 | ```C
238 | slot_number = CRC16(key)&16383
239 | ```
240 |
241 | 这样就可以计算出一个介于0至16383之间的整数作为键key的槽号。
242 |
243 | 当节点计算出键所属的槽i之后,节点就会检查自己在`clusterState.slots`数组中的项i,判断键所在的槽是否由自己负责:
244 |
245 | - 如果`clusterState.slots[i]`等于`clusterState.myself`,那么说明槽i由当前节点负责,节点可以执行客户端发送的命令。
246 | - 反之,则记下指向clusterNode结构所记录的IP和端口号
247 |
248 | 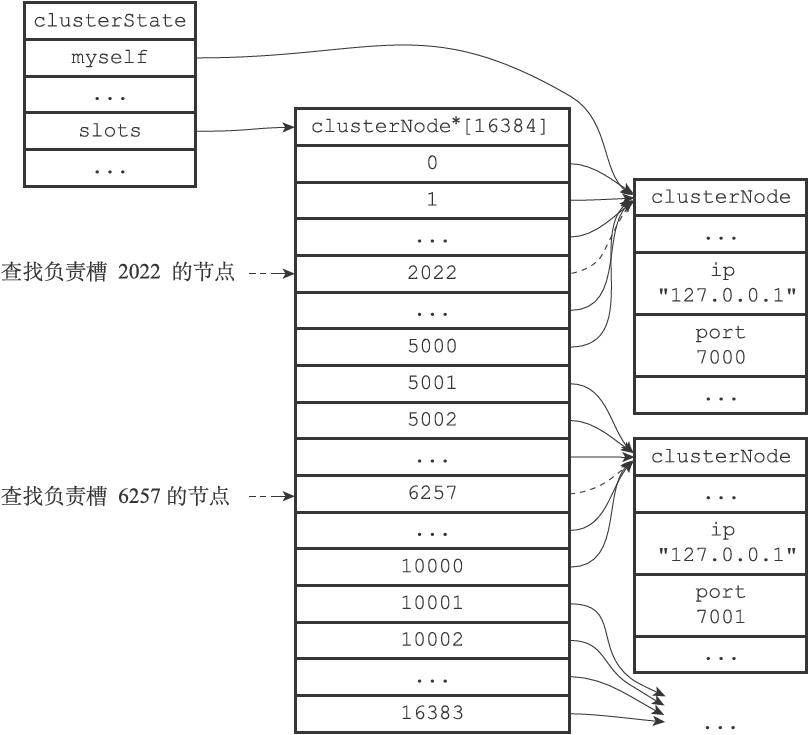 249 |
250 | ## 3.2 MOVED错误实现
251 |
252 | MOVED错误的格式为:
253 |
254 | ```
255 | MOVED :
256 | ```
257 |
258 | 其中slot为键所在的槽,而ip和port则是负责处理槽slot的节点的IP地址和端口号。
259 |
260 | 当客户端接收到节点返回的MOVED错误时,客户端会根据MOVED错误中提供的IP地址和端口号,转向至负责处理槽slot的节点,并向该节点重新发送之前想要执行的命令。
261 |
262 | ```C
263 | 127.0.0.1:7000> SET msg "happy new year!"
264 | -> Redirected to slot [6257] located at 127.0.0.1:7001
265 | OK
266 | ```
267 |
268 |
249 |
250 | ## 3.2 MOVED错误实现
251 |
252 | MOVED错误的格式为:
253 |
254 | ```
255 | MOVED :
256 | ```
257 |
258 | 其中slot为键所在的槽,而ip和port则是负责处理槽slot的节点的IP地址和端口号。
259 |
260 | 当客户端接收到节点返回的MOVED错误时,客户端会根据MOVED错误中提供的IP地址和端口号,转向至负责处理槽slot的节点,并向该节点重新发送之前想要执行的命令。
261 |
262 | ```C
263 | 127.0.0.1:7000> SET msg "happy new year!"
264 | -> Redirected to slot [6257] located at 127.0.0.1:7001
265 | OK
266 | ```
267 |
268 |  269 |
270 |
269 |
270 |  271 |
272 | # 4. 重新分片
273 |
274 | Redis集群的重新分片操作可以将**任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点)**,并且相关槽所属的键值对也会从源节点被移动到目标节点。
275 |
276 | 重新分片操作可以**在线(online)进行**,在重新分片的过程中,集群不需要下线,并且**源节点和目标节点都可以继续处理命令请求**。
277 |
278 | Redis集群的重新分片操作是由Redis的集群管理软件**redis-trib**负责执行的,**Redis提供了进行重新分片所需的所有命令**,而redis-trib则**通过向源节点和目标节点发送命令来进行重新分片操作。**
279 |
280 | 重新分配步骤如下:
281 |
282 |
271 |
272 | # 4. 重新分片
273 |
274 | Redis集群的重新分片操作可以将**任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点)**,并且相关槽所属的键值对也会从源节点被移动到目标节点。
275 |
276 | 重新分片操作可以**在线(online)进行**,在重新分片的过程中,集群不需要下线,并且**源节点和目标节点都可以继续处理命令请求**。
277 |
278 | Redis集群的重新分片操作是由Redis的集群管理软件**redis-trib**负责执行的,**Redis提供了进行重新分片所需的所有命令**,而redis-trib则**通过向源节点和目标节点发送命令来进行重新分片操作。**
279 |
280 | 重新分配步骤如下:
281 |
282 | 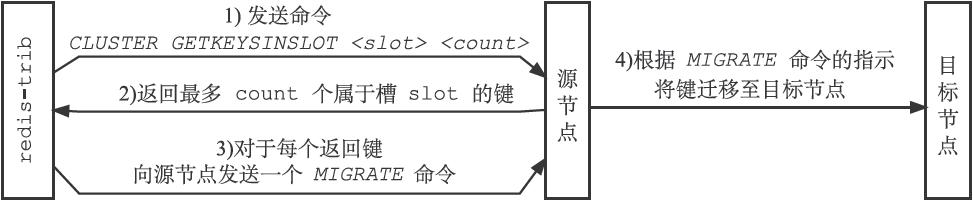 283 |
284 | 如果重新分片涉及多个槽,那么redis-trib将对每个给定的槽分别执行上面给出的步骤。
285 |
286 |
283 |
284 | 如果重新分片涉及多个槽,那么redis-trib将对每个给定的槽分别执行上面给出的步骤。
285 |
286 | 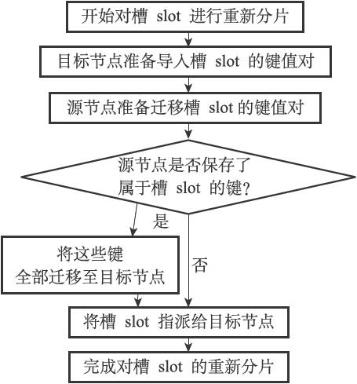 287 |
288 | # 5. ASK错误
289 |
290 | **正在重新分片时**,属于被迁移槽的一部分键值对保存在源节点里面,而另一部分键值对则保存在目标节点里面。
291 |
292 | 当客户端向源节点发送一个与数据库键有关的命令,并且命令要处理的数据库键恰好就属于正在被迁移的槽时:
293 |
294 | - 槽在自己这里,执行客户端命令。
295 | - 槽不在,返回ASK错误,指引客户端转向正在导入槽的目标节点。
296 |
297 | 下面讲解ASK错误的实现原理:
298 |
299 | ## 5.1 关键命令
300 |
301 | **(1)CLUSTER SETSLOT IMPORTING命令的实现**
302 |
303 | `clusterState`结构的`importing_slots_from`数组记录了当前节点正在从其他节点导入的槽:
304 |
305 | ```c
306 | typedef struct clusterState
307 | {
308 | // ...
309 | clusterNode *importing_slots_from[16384];
310 | // ...
311 | } clusterState;
312 | ```
313 |
314 | 如果`importing_slots_from[i]`的值不为NULL,而是指向一个clusterNode结构,那么表示**当前节点正在从clusterNode所代表的节点导入槽i。**
315 |
316 | 在对集群进行重新分片的时候,向目标节点发送命令:
317 |
318 | ```C
319 | CLUSTER SETSLOT IMPORTING
320 | ```
321 |
322 | 假如,客户端向节点7003发送命令:
323 |
324 | ```C
325 | # 9dfb... 是节点7002 的ID
326 | 127.0.0.1:7003> CLUSTER SETSLOT 16198 IMPORTING
327 | 9dfb4c4e016e627d9769e4c9bb0d4fa208e65c26OK
328 | ```
329 |
330 |
287 |
288 | # 5. ASK错误
289 |
290 | **正在重新分片时**,属于被迁移槽的一部分键值对保存在源节点里面,而另一部分键值对则保存在目标节点里面。
291 |
292 | 当客户端向源节点发送一个与数据库键有关的命令,并且命令要处理的数据库键恰好就属于正在被迁移的槽时:
293 |
294 | - 槽在自己这里,执行客户端命令。
295 | - 槽不在,返回ASK错误,指引客户端转向正在导入槽的目标节点。
296 |
297 | 下面讲解ASK错误的实现原理:
298 |
299 | ## 5.1 关键命令
300 |
301 | **(1)CLUSTER SETSLOT IMPORTING命令的实现**
302 |
303 | `clusterState`结构的`importing_slots_from`数组记录了当前节点正在从其他节点导入的槽:
304 |
305 | ```c
306 | typedef struct clusterState
307 | {
308 | // ...
309 | clusterNode *importing_slots_from[16384];
310 | // ...
311 | } clusterState;
312 | ```
313 |
314 | 如果`importing_slots_from[i]`的值不为NULL,而是指向一个clusterNode结构,那么表示**当前节点正在从clusterNode所代表的节点导入槽i。**
315 |
316 | 在对集群进行重新分片的时候,向目标节点发送命令:
317 |
318 | ```C
319 | CLUSTER SETSLOT IMPORTING
320 | ```
321 |
322 | 假如,客户端向节点7003发送命令:
323 |
324 | ```C
325 | # 9dfb... 是节点7002 的ID
326 | 127.0.0.1:7003> CLUSTER SETSLOT 16198 IMPORTING
327 | 9dfb4c4e016e627d9769e4c9bb0d4fa208e65c26OK
328 | ```
329 |
330 | 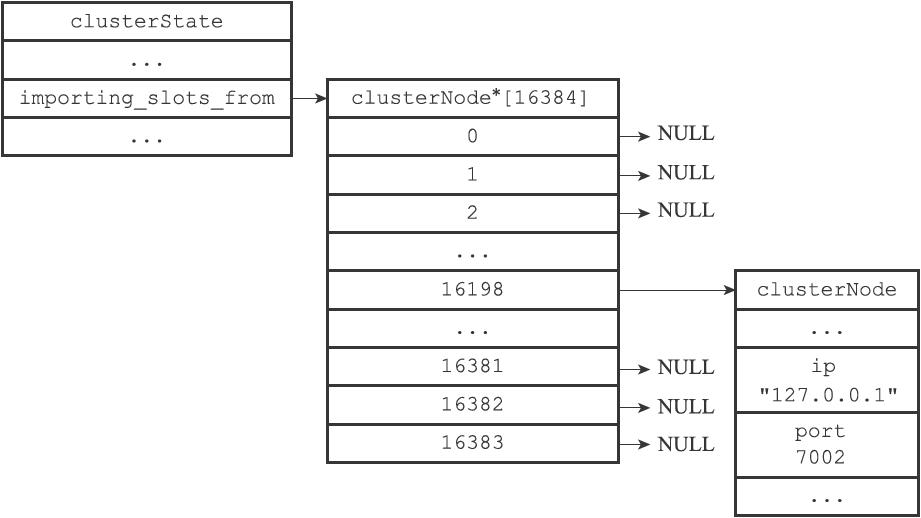 331 |
332 | **(2)CLUSTER SETSLOT MIGRATING命令的实现**
333 |
334 | `clusterState`结构的`migrating_slots_to`数组记录了当前节点正在迁移至其他节点的槽:
335 |
336 | ```C
337 | typedef struct clusterState
338 | {
339 | // ...
340 | clusterNode *migrating_slots_to[16384];
341 | // ...
342 | } clusterState;
343 | ```
344 |
345 | 同理,如果索引i不为NULL,则表示当前节点正在将槽i迁移至目标节点。
346 |
347 | 在对集群进行重新分片的时候,向源节点发送命令:
348 |
349 | ```C
350 | CLUSTER SETSLOT MIGRATING
351 | ```
352 |
353 | 可以将源节点`clusterState.migrating_slots_to[i]`的值设置为target_id所代表节点的clusterNode结构。
354 |
355 | ## 5.2 ASKING命令
356 |
357 | 通过`migrating_slots_to`这个数组,我们知道当前节点的某个键是否正在迁移。如果是则返回ASK错误。
358 |
359 | ```C
360 | ASK 16198 127.0.0.1:7003
361 | ```
362 |
363 |
331 |
332 | **(2)CLUSTER SETSLOT MIGRATING命令的实现**
333 |
334 | `clusterState`结构的`migrating_slots_to`数组记录了当前节点正在迁移至其他节点的槽:
335 |
336 | ```C
337 | typedef struct clusterState
338 | {
339 | // ...
340 | clusterNode *migrating_slots_to[16384];
341 | // ...
342 | } clusterState;
343 | ```
344 |
345 | 同理,如果索引i不为NULL,则表示当前节点正在将槽i迁移至目标节点。
346 |
347 | 在对集群进行重新分片的时候,向源节点发送命令:
348 |
349 | ```C
350 | CLUSTER SETSLOT MIGRATING
351 | ```
352 |
353 | 可以将源节点`clusterState.migrating_slots_to[i]`的值设置为target_id所代表节点的clusterNode结构。
354 |
355 | ## 5.2 ASKING命令
356 |
357 | 通过`migrating_slots_to`这个数组,我们知道当前节点的某个键是否正在迁移。如果是则返回ASK错误。
358 |
359 | ```C
360 | ASK 16198 127.0.0.1:7003
361 | ```
362 |
363 |  364 |
365 | 接到ASK错误的客户端会根据错误提供的IP地址和端口号,**转向至正在导入槽的目标节点,然后首先向目标节点发送一个ASKING命令**,之后再重新发送原本想要执行的命令。
366 |
367 |
364 |
365 | 接到ASK错误的客户端会根据错误提供的IP地址和端口号,**转向至正在导入槽的目标节点,然后首先向目标节点发送一个ASKING命令**,之后再重新发送原本想要执行的命令。
366 |
367 | 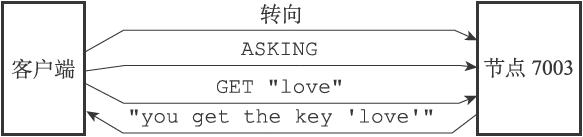 368 |
369 | ---
370 |
371 | ASKING命令的目的就是打开REDIS_ASKING标识,而且**是一次性的打开**,意味着使用完后会被关闭。
372 |
373 |
368 |
369 | ---
370 |
371 | ASKING命令的目的就是打开REDIS_ASKING标识,而且**是一次性的打开**,意味着使用完后会被关闭。
372 |
373 | 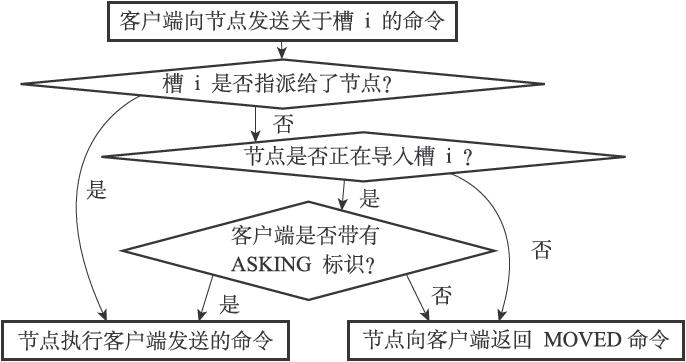 374 |
375 | ---
376 |
377 | ASK错误和MOVED错误的区别:
378 |
379 | - **相同点**:都会导致客户端转向
380 | - **不同点:**
381 | - MOVED错误代表槽的**负责权已经从一个节点转移到了另一个节点**:在客户端收到关于槽i的MOVED错误之后,客户端**每次遇到**关于槽i的命令请求时,都可以直接将命令请求发送至MOVED错误所指向的节点。
382 | - ASK错误只是两个节点在迁移槽的**过程中使用的一种临时措施**:在客户端收到关于槽i的ASK错误之后,客户端只会在**接下来的一次命令请求中将关于槽i的命令请求发送至ASK错误所指示的节点**,但这种转向不会对客户端今后发送关于槽i的命令请求产生任何影响,**客户端仍然会将关于槽i的命令请求发送至目前负责处理槽i的节点**,除非ASK错误再次出现。
383 |
384 | # 6. 节点的复制与故障转移
385 |
386 | 和主从服务器的关系非常相似,不过**在集群模式下服务器被替换为节点。**Redis集群中的节点分为主节点(master)和从节点(slave),其中主节点用于处理槽,而从节点则用于复制某个主节点,并在被复制的主节点下线时,代替下线主节点继续处理命令请求。
387 |
388 | ## 6.1 设置从节点
389 |
390 | 向一个节点发送命令:
391 |
392 | ```C
393 | CLUSTER REPLICATE
394 | ```
395 |
396 | 可以让接收命令的节点成为node_id所指定节点的从节点,并开始对主节点进行复制,步骤如下:
397 |
398 | **(1)修改指针指向**
399 |
400 | 接收到该命令的节点首先会在自己的`clusterState.nodes`字典中找到node_id所对应节点的clusterNode结构,**并将自己的`clusterState.myself.slaveof`指针指向这个结构**,以此来记录这个节点正在复制的主节点:
401 |
402 | ```C
403 | struct clusterNode
404 | {
405 | // ...
406 | // 如果这是一个从节点,那么指向主节点
407 | struct clusterNode *slaveof;
408 | };
409 | ```
410 |
411 | **(2)修改标识**
412 |
413 | 然后节点会修改自己在`clusterState.myself.flags`中的属性,关闭原本的`REDIS_NODE_MASTER`标识,打开`REDIS_NODE_SLAVE`标识。
414 |
415 | **(3)调用复制代码**
416 |
417 | 根据`clusterState.my-self.slaveof`指向的clusterNode结构所保存的IP地址和端口号,对主节点进行复制。因为**节点的复制功能和单机Redis服务器的复制功能使用了相同的代码**,所以让从节点复制主节点相当于向从节点发送命令SLAVEOF。
418 |
419 |
374 |
375 | ---
376 |
377 | ASK错误和MOVED错误的区别:
378 |
379 | - **相同点**:都会导致客户端转向
380 | - **不同点:**
381 | - MOVED错误代表槽的**负责权已经从一个节点转移到了另一个节点**:在客户端收到关于槽i的MOVED错误之后,客户端**每次遇到**关于槽i的命令请求时,都可以直接将命令请求发送至MOVED错误所指向的节点。
382 | - ASK错误只是两个节点在迁移槽的**过程中使用的一种临时措施**:在客户端收到关于槽i的ASK错误之后,客户端只会在**接下来的一次命令请求中将关于槽i的命令请求发送至ASK错误所指示的节点**,但这种转向不会对客户端今后发送关于槽i的命令请求产生任何影响,**客户端仍然会将关于槽i的命令请求发送至目前负责处理槽i的节点**,除非ASK错误再次出现。
383 |
384 | # 6. 节点的复制与故障转移
385 |
386 | 和主从服务器的关系非常相似,不过**在集群模式下服务器被替换为节点。**Redis集群中的节点分为主节点(master)和从节点(slave),其中主节点用于处理槽,而从节点则用于复制某个主节点,并在被复制的主节点下线时,代替下线主节点继续处理命令请求。
387 |
388 | ## 6.1 设置从节点
389 |
390 | 向一个节点发送命令:
391 |
392 | ```C
393 | CLUSTER REPLICATE
394 | ```
395 |
396 | 可以让接收命令的节点成为node_id所指定节点的从节点,并开始对主节点进行复制,步骤如下:
397 |
398 | **(1)修改指针指向**
399 |
400 | 接收到该命令的节点首先会在自己的`clusterState.nodes`字典中找到node_id所对应节点的clusterNode结构,**并将自己的`clusterState.myself.slaveof`指针指向这个结构**,以此来记录这个节点正在复制的主节点:
401 |
402 | ```C
403 | struct clusterNode
404 | {
405 | // ...
406 | // 如果这是一个从节点,那么指向主节点
407 | struct clusterNode *slaveof;
408 | };
409 | ```
410 |
411 | **(2)修改标识**
412 |
413 | 然后节点会修改自己在`clusterState.myself.flags`中的属性,关闭原本的`REDIS_NODE_MASTER`标识,打开`REDIS_NODE_SLAVE`标识。
414 |
415 | **(3)调用复制代码**
416 |
417 | 根据`clusterState.my-self.slaveof`指向的clusterNode结构所保存的IP地址和端口号,对主节点进行复制。因为**节点的复制功能和单机Redis服务器的复制功能使用了相同的代码**,所以让从节点复制主节点相当于向从节点发送命令SLAVEOF。
418 |
419 | 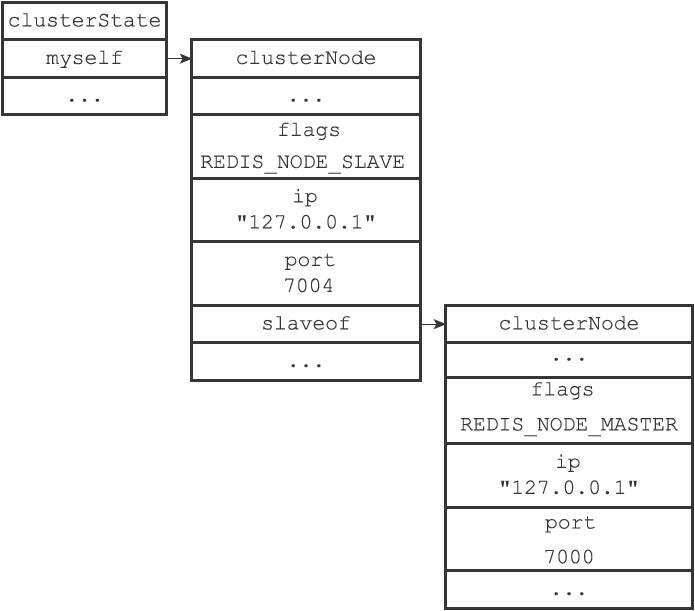 420 |
421 | 一个节点成为从节点,并开始复制某个主节点这一信息**会通过消息发送给集群中的其他节点,最终集群中的所有节点都会知道某个从节点正在复制某个主节点。**
422 |
423 | 集群中的所有节点都会在代表主节点的clusterNode结构的`slaves`属性和`numslaves`属性中记录正在复制这个主节点的从节点名单:
424 |
425 | ```C
426 | struct clusterNode
427 | {
428 | // ...
429 | // 正在复制这个主节点的从节点数量
430 | int numslaves;
431 | // 一个数组
432 | // 每个数组项指向一个正在复制这个主节点的从节点的clusterNode结构
433 | struct clusterNode **slaves;
434 | //....
435 | }
436 | ```
437 |
438 | ## 6.2 故障检测
439 |
440 | 集群中的每个节点都会定期地向集群中的其他节点发送PING消息,如果接收PING消息的节点没有在规定的时间内返回PONG,那么发送PING消息的节点就会将接收PING消息的节点**标记为疑似下线(probable fail,PFAIL)**
441 |
442 | 集群中的各个节点会通过**互相发送消息**的方式来交换集群中各个节点的状态信息,例如某个节点是处于**在线状态、疑似下线状态(PFAIL),还是已下线状态(FAIL)。**
443 |
444 | 当一个主节点A通过消息得知主节点B认为主节点C进入了疑似下线状态时,主节点A会在自己的`clusterState.nodes`字典中找到主节点C所对应的clusterNode结构,**并将主节点B的下线报告(failure report)添加到clusterNode结构的`fail_reports`链表里面:**
445 |
446 | ```C
447 | struct clusterNode
448 | {
449 | // ...
450 | // 一个链表,记录了所有其他节点对该节点的下线报告
451 | list *fail_reports;
452 | // ...
453 | };
454 | ```
455 |
456 | 如果在一个集群里面,**半数以上负责处理槽的主节点都将某个主节点x报告为疑似下线,那么这个主节点x将被标记为已下线(FAIL**),将主节点x标记为已下线的节点**会向集群广播一条关于主节点x的FAIL消息,所有收到这条FAIL消息的节点都会立即将主节点x标记为已下线。**
457 |
458 | ## 6.3 故障转移
459 |
460 | 当一个从节点发现自己正在复制的主节点进入了已下线状态时,从节点将开始对下线主节点进行故障转移,以下是故障转移的执行步骤:
461 |
462 | 1. 从已下线主节点中选出一个从节点
463 | 2. 从节点执行SLAVEOF no one命令,成为新的主节点
464 | 3. 新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己。
465 | 4. 新的主节点向集群广播一条PONG消息,这条PONG消息可以让集群中的其他节点立即知道这个节点已经由从节点变成了主节点。
466 | 5. 新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
467 |
468 | # 7. 消息
469 |
470 | 集群中的各个节点通过发送和接收消息(message)来进行通信,节点发送的消息主要有以下五种:
471 |
472 | - **MEET消息:**当发送者接到客户端发送的CLUSTER MEET命令时,发送者会**向接收者**发送MEET消息,请求接收者加入到发送者当前所处的集群里面。
473 | - **PING消息:**集群里的每个节点默认每隔一秒钟就会从**已知节点列表中随机选出五个节点**,然后对这五个节点中最长时间没有发送过PING消息的节点发送PING消息,以此来检测被选中的节点是否在线。
474 | - **PONG消息:**当接收者收到发送者发来的MEET消息或者PING消息时,为了向发送者确认这条MEET消息或者PING消息已到达,接收者**会向发送者**返回一条PONG消息。另外,一个节点也可以通过向**集群广播**自己的PONG消息来让集群中的其他节点立即刷新关于这个节点的认识。
475 | - **FAIL消息:**当一个主节点A判断另一个主节点B已经进入FAIL状态时,节点A会**向集群广播**一条关于节点B的FAIL消息,所有收到这条消息的节点都会立即将节点B标记为已下线。
476 | - **PUBLISH消息**:当节点接收到一个PUBLISH命令时,节点会执行这个命令,并**向集群广播**一条PUBLISH消息,所有接收到这条PUBLISH消息的节点都会执行相同的PUBLISH命令。
477 |
478 | ## 7.1 消息的结构
479 |
480 | 一条消息由消息头(header)和消息正文(data)组成
481 |
482 | 每个消息头都由一个`cluster.h/clusterMsg`结构表示:
483 |
484 | ```C
485 | // 用来表示集群消息的结构(消息头,header)
486 | typedef struct {
487 | //...
488 | // 消息的长度(包括这个消息头的长度和消息正文的长度)
489 | uint32_t totlen;
490 |
491 | // 消息的类型
492 | uint16_t type;
493 |
494 | // 消息正文包含的节点信息数量
495 | // 只在发送 MEET 、 PING 和 PONG 这三种 Gossip 协议消息时使用
496 | uint16_t count;
497 |
498 | // 消息发送者的配置纪元
499 | uint64_t currentEpoch;
500 |
501 | // 如果消息发送者是一个主节点,那么这里记录的是消息发送者的配置纪元
502 | // 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的配置纪元
503 | uint64_t configEpoch;
504 |
505 | // 节点的复制偏移量
506 | uint64_t offset;
507 |
508 | // 消息发送者的名字(ID)
509 | char sender[REDIS_CLUSTER_NAMELEN]; /
510 |
511 | // 消息发送者目前的槽指派信息
512 | unsigned char myslots[REDIS_CLUSTER_SLOTS/8];
513 |
514 | // 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的名字
515 | // 如果消息发送者是一个主节点,那么这里记录的是 REDIS_NODE_NULL_NAME
516 | // (一个 40 字节长,值全为 0 的字节数组)
517 | char slaveof[REDIS_CLUSTER_NAMELEN];
518 |
519 | // 消息发送者的端口号
520 | uint16_t port; /* Sender TCP base port */
521 |
522 | // 消息发送者的标识值
523 | uint16_t flags; /* Sender node flags */
524 |
525 | // 消息发送者所处集群的状态
526 | unsigned char state; /* Cluster state from the POV of the sender */
527 |
528 | // 消息标志
529 | unsigned char mflags[3];
530 |
531 | // 消息的正文(或者说,内容)
532 | union clusterMsgData data;
533 |
534 | } clusterMsg;
535 | ```
536 |
537 | datas属性指向联合`cluster.h/clusterMsgData`,也就是消息的正文
538 |
539 | ```C
540 | nion clusterMsgData {
541 |
542 | /* PING, MEET and PONG */
543 | struct {
544 | // 每条消息都包含两个 clusterMsgDataGossip 结构
545 | clusterMsgDataGossip gossip[1]; //gossip八卦,小道消息,闲话的意思
546 | } ping;
547 |
548 | /* FAIL */
549 | struct {
550 | clusterMsgDataFail about;
551 | } fail;
552 |
553 | /* PUBLISH */
554 | struct {
555 | clusterMsgDataPublish msg;
556 | } publish;
557 | //...
558 |
559 | };
560 | ```
561 |
562 | ## 7.2 消息的实现
563 |
564 | **(1)Gossip消息的实现**
565 |
566 | gossip是八卦,小道消息,闲话的意思,专指MEET、PING、PONG这几个消息。这三种消息的正文都由**两个**`cluster.h/clusterMsgDataGossip`结构组成。
567 |
568 | 因为MEET、PING、PONG三种消息都使用相同的消息正文,所以节点通过消息头的type属性来判断一条消息是MEET消息、PING消息还是PONG消息。
569 |
570 | 每次发送MEET、PING、PONG消息时,发送者都从自己的已知节点列表中**随机选出两个节点**(可以是主节点或者从节点),并将这两个被选中节点的信息分别保存到两个clusterMsg-DataGossip结构里面。
571 |
572 | 接受者接收到MEET、PING、PONG消息时,根据保存的两个节点是否认识来选择进行哪种操作:
573 |
574 | - 不认识,说明接收者**第一次接触被选中节点**,则接收者与被选中节点握手
575 | - 认识,根据结构信息进行更新。
576 |
577 | 比如A节点发送的PING给B,携带了CD两个节点,然后B回复PONG携带了EF两个节点,这样就完成了ABCDEF六个节点的信息交换。**每个节点按照周期向不同节点传播PING-PONG信息,就能完成整个集群的状态更新。**
578 |
579 | **(2)FAIL消息的实现**
580 |
581 | Gossip协议传播速度很慢,而主节点下线的消息需要立即通知给所有人。
582 |
583 | FAIL消息的正文由`cluster.h/clusterMsgDataFail`结构表示,这个结构只包含一个nodename属性,该属性记录了已下线节点的名字:
584 |
585 | ```C
586 | typedef struct
587 | {
588 | char nodename[REDIS_CLUSTER_NAMELEN];
589 | } clusterMsgDataFail;
590 | ```
591 |
592 | 因为集群里的所有节点都有一个独一无二的名字,所以FAIL消息里面只需要保存下线节点的名字,接收到消息的节点就可以根据这个名字来判断是哪个节点下线了。
593 |
594 | **(3)PUBLISH消息的实现**
595 |
596 | 当客户端向集群中的某个节点发送命令:
597 |
598 | ```C
599 | PUBLISH
600 | ```
601 |
602 | 接收到PUBLISH命令的节点**不仅会向channel频道发送消息message,它还会向集群广播一条PUBLISH消息,所有接收到这条PUBLISH消息的节点都会向channel频道发送message消息**。
603 |
604 | 也就是说,向集群发送`PUBLISH `,会导致集群所有节点都向channel发送message消息。
605 |
606 |
420 |
421 | 一个节点成为从节点,并开始复制某个主节点这一信息**会通过消息发送给集群中的其他节点,最终集群中的所有节点都会知道某个从节点正在复制某个主节点。**
422 |
423 | 集群中的所有节点都会在代表主节点的clusterNode结构的`slaves`属性和`numslaves`属性中记录正在复制这个主节点的从节点名单:
424 |
425 | ```C
426 | struct clusterNode
427 | {
428 | // ...
429 | // 正在复制这个主节点的从节点数量
430 | int numslaves;
431 | // 一个数组
432 | // 每个数组项指向一个正在复制这个主节点的从节点的clusterNode结构
433 | struct clusterNode **slaves;
434 | //....
435 | }
436 | ```
437 |
438 | ## 6.2 故障检测
439 |
440 | 集群中的每个节点都会定期地向集群中的其他节点发送PING消息,如果接收PING消息的节点没有在规定的时间内返回PONG,那么发送PING消息的节点就会将接收PING消息的节点**标记为疑似下线(probable fail,PFAIL)**
441 |
442 | 集群中的各个节点会通过**互相发送消息**的方式来交换集群中各个节点的状态信息,例如某个节点是处于**在线状态、疑似下线状态(PFAIL),还是已下线状态(FAIL)。**
443 |
444 | 当一个主节点A通过消息得知主节点B认为主节点C进入了疑似下线状态时,主节点A会在自己的`clusterState.nodes`字典中找到主节点C所对应的clusterNode结构,**并将主节点B的下线报告(failure report)添加到clusterNode结构的`fail_reports`链表里面:**
445 |
446 | ```C
447 | struct clusterNode
448 | {
449 | // ...
450 | // 一个链表,记录了所有其他节点对该节点的下线报告
451 | list *fail_reports;
452 | // ...
453 | };
454 | ```
455 |
456 | 如果在一个集群里面,**半数以上负责处理槽的主节点都将某个主节点x报告为疑似下线,那么这个主节点x将被标记为已下线(FAIL**),将主节点x标记为已下线的节点**会向集群广播一条关于主节点x的FAIL消息,所有收到这条FAIL消息的节点都会立即将主节点x标记为已下线。**
457 |
458 | ## 6.3 故障转移
459 |
460 | 当一个从节点发现自己正在复制的主节点进入了已下线状态时,从节点将开始对下线主节点进行故障转移,以下是故障转移的执行步骤:
461 |
462 | 1. 从已下线主节点中选出一个从节点
463 | 2. 从节点执行SLAVEOF no one命令,成为新的主节点
464 | 3. 新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己。
465 | 4. 新的主节点向集群广播一条PONG消息,这条PONG消息可以让集群中的其他节点立即知道这个节点已经由从节点变成了主节点。
466 | 5. 新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
467 |
468 | # 7. 消息
469 |
470 | 集群中的各个节点通过发送和接收消息(message)来进行通信,节点发送的消息主要有以下五种:
471 |
472 | - **MEET消息:**当发送者接到客户端发送的CLUSTER MEET命令时,发送者会**向接收者**发送MEET消息,请求接收者加入到发送者当前所处的集群里面。
473 | - **PING消息:**集群里的每个节点默认每隔一秒钟就会从**已知节点列表中随机选出五个节点**,然后对这五个节点中最长时间没有发送过PING消息的节点发送PING消息,以此来检测被选中的节点是否在线。
474 | - **PONG消息:**当接收者收到发送者发来的MEET消息或者PING消息时,为了向发送者确认这条MEET消息或者PING消息已到达,接收者**会向发送者**返回一条PONG消息。另外,一个节点也可以通过向**集群广播**自己的PONG消息来让集群中的其他节点立即刷新关于这个节点的认识。
475 | - **FAIL消息:**当一个主节点A判断另一个主节点B已经进入FAIL状态时,节点A会**向集群广播**一条关于节点B的FAIL消息,所有收到这条消息的节点都会立即将节点B标记为已下线。
476 | - **PUBLISH消息**:当节点接收到一个PUBLISH命令时,节点会执行这个命令,并**向集群广播**一条PUBLISH消息,所有接收到这条PUBLISH消息的节点都会执行相同的PUBLISH命令。
477 |
478 | ## 7.1 消息的结构
479 |
480 | 一条消息由消息头(header)和消息正文(data)组成
481 |
482 | 每个消息头都由一个`cluster.h/clusterMsg`结构表示:
483 |
484 | ```C
485 | // 用来表示集群消息的结构(消息头,header)
486 | typedef struct {
487 | //...
488 | // 消息的长度(包括这个消息头的长度和消息正文的长度)
489 | uint32_t totlen;
490 |
491 | // 消息的类型
492 | uint16_t type;
493 |
494 | // 消息正文包含的节点信息数量
495 | // 只在发送 MEET 、 PING 和 PONG 这三种 Gossip 协议消息时使用
496 | uint16_t count;
497 |
498 | // 消息发送者的配置纪元
499 | uint64_t currentEpoch;
500 |
501 | // 如果消息发送者是一个主节点,那么这里记录的是消息发送者的配置纪元
502 | // 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的配置纪元
503 | uint64_t configEpoch;
504 |
505 | // 节点的复制偏移量
506 | uint64_t offset;
507 |
508 | // 消息发送者的名字(ID)
509 | char sender[REDIS_CLUSTER_NAMELEN]; /
510 |
511 | // 消息发送者目前的槽指派信息
512 | unsigned char myslots[REDIS_CLUSTER_SLOTS/8];
513 |
514 | // 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的名字
515 | // 如果消息发送者是一个主节点,那么这里记录的是 REDIS_NODE_NULL_NAME
516 | // (一个 40 字节长,值全为 0 的字节数组)
517 | char slaveof[REDIS_CLUSTER_NAMELEN];
518 |
519 | // 消息发送者的端口号
520 | uint16_t port; /* Sender TCP base port */
521 |
522 | // 消息发送者的标识值
523 | uint16_t flags; /* Sender node flags */
524 |
525 | // 消息发送者所处集群的状态
526 | unsigned char state; /* Cluster state from the POV of the sender */
527 |
528 | // 消息标志
529 | unsigned char mflags[3];
530 |
531 | // 消息的正文(或者说,内容)
532 | union clusterMsgData data;
533 |
534 | } clusterMsg;
535 | ```
536 |
537 | datas属性指向联合`cluster.h/clusterMsgData`,也就是消息的正文
538 |
539 | ```C
540 | nion clusterMsgData {
541 |
542 | /* PING, MEET and PONG */
543 | struct {
544 | // 每条消息都包含两个 clusterMsgDataGossip 结构
545 | clusterMsgDataGossip gossip[1]; //gossip八卦,小道消息,闲话的意思
546 | } ping;
547 |
548 | /* FAIL */
549 | struct {
550 | clusterMsgDataFail about;
551 | } fail;
552 |
553 | /* PUBLISH */
554 | struct {
555 | clusterMsgDataPublish msg;
556 | } publish;
557 | //...
558 |
559 | };
560 | ```
561 |
562 | ## 7.2 消息的实现
563 |
564 | **(1)Gossip消息的实现**
565 |
566 | gossip是八卦,小道消息,闲话的意思,专指MEET、PING、PONG这几个消息。这三种消息的正文都由**两个**`cluster.h/clusterMsgDataGossip`结构组成。
567 |
568 | 因为MEET、PING、PONG三种消息都使用相同的消息正文,所以节点通过消息头的type属性来判断一条消息是MEET消息、PING消息还是PONG消息。
569 |
570 | 每次发送MEET、PING、PONG消息时,发送者都从自己的已知节点列表中**随机选出两个节点**(可以是主节点或者从节点),并将这两个被选中节点的信息分别保存到两个clusterMsg-DataGossip结构里面。
571 |
572 | 接受者接收到MEET、PING、PONG消息时,根据保存的两个节点是否认识来选择进行哪种操作:
573 |
574 | - 不认识,说明接收者**第一次接触被选中节点**,则接收者与被选中节点握手
575 | - 认识,根据结构信息进行更新。
576 |
577 | 比如A节点发送的PING给B,携带了CD两个节点,然后B回复PONG携带了EF两个节点,这样就完成了ABCDEF六个节点的信息交换。**每个节点按照周期向不同节点传播PING-PONG信息,就能完成整个集群的状态更新。**
578 |
579 | **(2)FAIL消息的实现**
580 |
581 | Gossip协议传播速度很慢,而主节点下线的消息需要立即通知给所有人。
582 |
583 | FAIL消息的正文由`cluster.h/clusterMsgDataFail`结构表示,这个结构只包含一个nodename属性,该属性记录了已下线节点的名字:
584 |
585 | ```C
586 | typedef struct
587 | {
588 | char nodename[REDIS_CLUSTER_NAMELEN];
589 | } clusterMsgDataFail;
590 | ```
591 |
592 | 因为集群里的所有节点都有一个独一无二的名字,所以FAIL消息里面只需要保存下线节点的名字,接收到消息的节点就可以根据这个名字来判断是哪个节点下线了。
593 |
594 | **(3)PUBLISH消息的实现**
595 |
596 | 当客户端向集群中的某个节点发送命令:
597 |
598 | ```C
599 | PUBLISH
600 | ```
601 |
602 | 接收到PUBLISH命令的节点**不仅会向channel频道发送消息message,它还会向集群广播一条PUBLISH消息,所有接收到这条PUBLISH消息的节点都会向channel频道发送message消息**。
603 |
604 | 也就是说,向集群发送`PUBLISH `,会导致集群所有节点都向channel发送message消息。
605 |
606 | 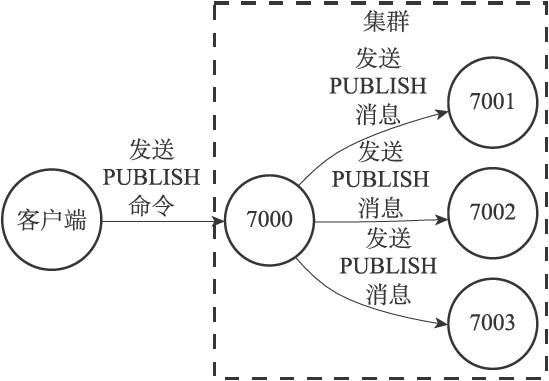 --------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | # Redis-study
4 |
5 | 基于《Redis设计与实现》的内容,对Redis的基础知识进行总结。
6 |
7 | 整个项目分为三部分:
8 |
9 | :red_circle:**Part1:《Redis设计与实现》读书笔记**
10 |
11 | **:red_circle:Part2:Redis基础知识思维导图**
12 |
13 | **:red_circle:Part3:Redis常见面试题汇总**
14 |
15 | # Part1:《Redis设计与实现》读书笔记
16 |
17 | 这一部分是对《Redis设计与实现》内容的总结。学完后,能够对Redis的基本内容和实现原理有一个较好的理解,有一些部分对原书进行了重新编排。
18 |
19 | 内容已经放在了我的个人博客上[Jr's Blog](https://jiangren.work/categories/数据库/),欢迎大家预览。
20 |
21 | :zap:**第一部分:数据结构与对象**
22 |
23 | :cloud:[P1.数据结构](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现1-数据结构.md)
24 |
25 | :cloud:[P2.对象](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现2-对象.md)
26 |
27 | **:zap:第二部分:单机数据库**
28 |
29 | :cloud_with_lightning:[P3.数据库的基本结构](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现3-数据库.md)
30 |
31 | :cloud_with_lightning:[P4.RDB和AOF持久化](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现4-RDB持久化和AOF持久化.md)
32 |
33 | :cloud_with_lightning:[P5.事件](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现5-事件.md)
34 |
35 | :cloud_with_lightning:[P6.客户端与服务器](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现6-客户端与服务器.md)
36 |
37 | :zap:**第三部分:多机数据库**
38 |
39 | :cloud_with_lightning_and_rain:[P7.复制](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现7-复制.md)
40 |
41 | :cloud_with_lightning_and_rain:[P8.Sentinel](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现8-Sentinel.md)
42 |
43 | :cloud_with_lightning_and_rain:[P9.集群](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现9-集群.md)
44 |
45 | :zap:**第四部分:独立功能的实现**
46 |
47 | :cloud_with_rain:[P10.发布与订阅](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现10-发布与订阅.md)
48 |
49 | :cloud_with_rain:[P11.事务](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现11-事务.md)
50 |
51 | :cloud_with_rain:[P12.Lua脚本](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现12-Lua脚本.md)
52 |
53 | # Part2:思维导图
54 |
55 | 
56 |
57 | 
58 |
59 | 
60 |
61 | 
62 |
63 | # Part3: 面试常见问题
64 |
65 | 分为两部分:Redis原理相关和Redis应用相关,主要从网上搜集整理而来,并做了许多原创性的改编。
66 |
67 | :hourglass_flowing_sand: [面试常问的原理性问题](https://github.com/JiangRRRen/Redis-study/blob/master/面试相关/Redis面试常见基本问题.md)
68 |
69 | :hourglass_flowing_sand: [Redis的简单应用场景](https://github.com/JiangRRRen/Redis-study/blob/master/面试相关/Redis的简单应用场景总结.md)
--------------------------------------------------------------------------------
/思维导图/Pic/单机数据库.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Pic/单机数据库.png
--------------------------------------------------------------------------------
/思维导图/Pic/多机数据库.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Pic/多机数据库.png
--------------------------------------------------------------------------------
/思维导图/Pic/数据结构与对象.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Pic/数据结构与对象.png
--------------------------------------------------------------------------------
/思维导图/Pic/独立功能的实现.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Pic/独立功能的实现.png
--------------------------------------------------------------------------------
/思维导图/Xmind/单机数据库.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Xmind/单机数据库.xmind
--------------------------------------------------------------------------------
/思维导图/Xmind/多机数据库.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Xmind/多机数据库.xmind
--------------------------------------------------------------------------------
/思维导图/Xmind/数据结构与对象.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Xmind/数据结构与对象.xmind
--------------------------------------------------------------------------------
/思维导图/Xmind/独立功能的实现.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Xmind/独立功能的实现.xmind
--------------------------------------------------------------------------------
/面试相关/Redis的简单应用场景总结.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis的简单应用场景总结
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-16 16:15:22
12 | ---
13 |
14 | # 1. 缓存
15 |
16 | 比如我要从数据库查看最新的5000条评论:
17 |
18 | ```sql
19 | SELECT comments FROM user
20 | ORDER BY time DESC LIMIT 5000
21 | ```
22 |
23 | 这样的操作随着数据的增加会变得越来越慢,因为要进行排序操作。而且这种排序本身不应该发生:因为我们存的时候是按时间存进去的。
24 |
25 | 我们可以使用redis的列表对象来实现,此时列表由Linkedlist数据结构实现。
26 |
27 | 每次新评论发表时,我们会将它的ID添加到一个Redis列表`LPUSH latest.comments`,然后将列表裁剪到5000,`LTRIM latest.comments 0 5000`
28 |
29 | 每次我们需要获取最新评论的项目范围时,我们调用一个函数来完成(使用伪代码):
30 |
31 | ```pseudocode
32 | FUNCTION get_latest_comment(num_items):
33 | id_list=redis.lrange("latest.comments",0,num_items-1)
34 | IF id_list ZINCRBY vote_activity 1 Bob
64 | "1"
65 |
66 | redis> ZINCRBY vote_activity 1 Tim
67 | "1"
68 |
69 | redis> ZINCRBY vote_activity 1 Bob
70 | "2"
71 | ```
72 |
73 | 有序列表入队时,按分值排好序了,我们可以方便的用`ZSCORE key member`查询分数。
74 |
75 | ```
76 | redis> zscore vote_activity Bob
77 | "2"
78 | ```
79 |
80 | 以及获取某人的排名,获取前10名,获取前10名分数等等,
81 |
82 | ```
83 | #获取Alice排名(从高到低,zero-based)
84 | redis> zrevrank vote_activity Alice
85 | (integer) 0
86 |
87 | #获取前10名(从高到低)
88 | redis> zrevrange vote_activity 0 9
89 | 1) "Alice"
90 | 2) "Bob"
91 |
92 | #获取前10名及对应的分数(从高到低)
93 | redis> zrevrange vote_activity 0 9 withscores
94 | 1) "Alice"
95 | 2) "2"
96 | 3) "Bob"
97 | 4) "1"
98 | ```
99 |
100 | # 3. 消息队列
101 |
102 | 一般来说,消息队列有两种场景:一种是**发布者订阅者模式**;一种是生**产者消费者模式**。利用redis这两种场景的消息队列都能够实现。定义:
103 |
104 | - 生产者消费者模式:生产者生产消息放到队列里,多个消费者同时监听队列,谁先抢到消息谁就会从队列中取走消息;即对于**每个消息只能被最多一个消费者拥有**。(常用于处理高并发写操作)
105 | - 发布者订阅者模式:发布者生产消息放到队列里,多个监听队列的消费者都会收到同一份消息;即正常情况下**每个消费者收到的消息应该都是一样的**。(常用来作为日志收集中一份原始数据对多个应用场景)
106 |
107 | ---
108 |
109 | 发布者订阅者模式可以直接使用pub/sub指令实现。
110 |
111 | ---
112 |
113 | 生产者消费者模式分两种:
114 |
115 | - 普通的
116 | - 带有优先级的
117 |
118 | 普通模式下使用`brpop`指令,可以以阻塞的形式返回数据列表中新添加的参数:
119 |
120 | ```C++
121 | while(true)
122 | {
123 | List msgs = redis.brpop(BLOCK_TIMEOUT,listKey);
124 | Handle(msgs);
125 | }
126 | ```
127 |
128 | 如果是优先级模式,当优先级不是很多是,可以分为两组:
129 |
130 | ```C
131 | while(true)
132 | {
133 | List msgs = redis.brpop(['high_task_queue', 'low_task_queue'],0);
134 | Handle(msgs);
135 | }
136 | ```
137 |
138 | `brpop`命令可以输入多个键,如果同时都有元素可读,读先输入的那个键。
139 |
140 | 如果优先级划分很多,就需要再用列表排序的办法了(有序集合不好,因为没有阻塞模式)。假如有1000个优先级,我们可以先分组,分为10组,每组按优先级顺序排列,查找时二分查找。
141 |
142 | # 4. 时间轴
143 |
144 | 所谓时间轴系统就是典型的微博模式:用户在自己的主页可以看到其关注的博主发表的信息列表(按时间排序);而其它用户可以一个用户的个人主页看到这个人发布的信息列表(按时间排序)。
145 |
146 | 解决方案主要有两种:
147 |
148 | - 推模式:某人发布内容之后推送给所有粉丝,空间换时间,瓶颈在写入;
149 | - 拉模式:粉丝从自己的关注列表中读取内容,时间换空间,瓶颈在读取;
150 |
151 | 以推模式为例:
152 |
153 | **(1)博主发布博文**
154 |
155 | 我们创建一个哈希对象post,键为博文ID,值为博文内容字符串。存储博文。
156 |
157 | ```
158 | redis> HSET post 4396 "hahahahah"
159 | ```
160 |
161 | 再使用一个列表,按先后顺序存储该博主的博文:
162 |
163 | ```
164 | redis>LPUSH Dasima 4396
165 | ```
166 |
167 | 然后使用一个集合,存储该博主的所有粉丝,利用`SMEMBERS`获取这些粉丝的名单。
168 |
169 | ```
170 | redis> SMEMBERS Dasima
171 | ```
172 |
173 | 每一个粉丝拥有一个timeline列表,存取所有推送博文的ID。之后对所有粉丝的推送列表进行写入。
174 |
175 | **(2)用户读取博文推送**
176 |
177 | 利用`LRANGE`从推送中拉取一定数量的博文,根据拉到的博文ID,读取哈希表的内容。
178 |
179 | ```
180 | redis>LRANGE timeline 0 30
181 |
182 | redis>HGETALL(4396)
183 | ```
184 |
185 | # 5. 实现分布式锁
186 |
187 | **(1)什么是分布式锁?**
188 |
189 | 对于单进程的程序,采用普通锁即可防止竞争,而对于多进程分布式系统来说需要采用分布式锁来保证一致性。
190 |
191 | **(2)redis如何实现分布式锁**
192 |
193 | 在 Redis 2.6.12 版本开始,`set`命令增加了三个参数,替换以前的`setnx`命令:
194 |
195 | - `EX`:设置键的过期时间(单位为秒)
196 | - `PX`:设置键的过期时间(单位为毫秒)
197 | - `NX` | `XX`:当设置为`NX`时,仅当 key 存在时才进行操作,设置为`XX`时,仅当 key 不存在才会进行操作
198 |
199 | 我们可以以此实现简单的分布式锁:
200 |
201 | ```
202 | set key "lock" EX 1 XX
203 | ```
204 |
205 | 如果这个操作返回`false`,说明 key 的添加不成功,也就是当前有人在占用这把锁。而如果返回`true`,则说明得了锁,便可以继续进行操作,并且在操作后通过`del`命令释放掉锁。并且即使程序因为某些原因并没有释放锁,**由于设置了过期时间,该锁也会在 1 秒后自动释放**,不会影响到其他程序的运行。
206 |
207 | ```
208 | del "lock"
209 | ```
210 |
211 |
--------------------------------------------------------------------------------
/面试相关/Redis面试常见基本问题.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis面试常见基本问题
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | - 面试经验
11 | mathjax: true
12 | date: 2020-01-16 16:11:46
13 | ---
14 |
15 | # 1.基础
16 |
17 | ## 1.1 什么是Redis?
18 |
19 | Redis的全称是:Remote Dictionary Server,本质上是一个 Key-Value 类型的内存数据库。
20 |
21 | 整个数据库统统**加载在内存**当中进行操作,定期通过异步操作把数据库数据保存在硬盘。因为是纯内存操作,Redis 的性能非常出色。
22 |
23 | ## 1.2 Redis的优劣势?
24 |
25 | 优势:
26 |
27 | - 纯内存读写操作,性能好。
28 | - 支持多种数据结构。
29 | - 单线程,不用担心竞争
30 | - 特性丰富,支持发布订阅、过期、sentinel等功能。
31 |
32 | 劣势:
33 |
34 | - 容量受物理内存限制,不能用作海量数据的高性能读写。
35 |
36 | ## 1.3 Redis和Memcached比较
37 |
38 | Memcached早年被很多公司使用,现在内存越来越便宜,基本都是用Redis。Redis被认为是Memcached的替代者,优势有:
39 |
40 | - memcached值均为简单字符串,redis支持更丰富的类型
41 | - redis性能更好(速度快,内存大)Memcached内存限制为1MB,而Redis可以达到1GB
42 | - redis可以持久化
43 | - Memcached集群功能不好,没有原生集群模式
44 |
45 | 劣势有:
46 |
47 | - redis只是用一个核,而memcached使用多核,在大数据处理上,memecached效率要好一些。
48 |
49 | ## 1.4 Redis支持哪些数据类型
50 |
51 | 对象:
52 |
53 | - 字符串对象,支持int、raw、embstr编码
54 | - 列表对象,支持ziplist和linkedlist编码
55 | - 哈希对象,支持ziplist和hashtable
56 | - 集合对象,支持intset和hashtable
57 | - 有序集合对象,支持ziplist和skiplist
58 |
59 | # 2. 缓存相关
60 |
61 | ## 2.1 什么是缓存雪崩?
62 |
63 | 首先,为什么要使用缓存?
64 |
65 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | # Redis-study
4 |
5 | 基于《Redis设计与实现》的内容,对Redis的基础知识进行总结。
6 |
7 | 整个项目分为三部分:
8 |
9 | :red_circle:**Part1:《Redis设计与实现》读书笔记**
10 |
11 | **:red_circle:Part2:Redis基础知识思维导图**
12 |
13 | **:red_circle:Part3:Redis常见面试题汇总**
14 |
15 | # Part1:《Redis设计与实现》读书笔记
16 |
17 | 这一部分是对《Redis设计与实现》内容的总结。学完后,能够对Redis的基本内容和实现原理有一个较好的理解,有一些部分对原书进行了重新编排。
18 |
19 | 内容已经放在了我的个人博客上[Jr's Blog](https://jiangren.work/categories/数据库/),欢迎大家预览。
20 |
21 | :zap:**第一部分:数据结构与对象**
22 |
23 | :cloud:[P1.数据结构](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现1-数据结构.md)
24 |
25 | :cloud:[P2.对象](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现2-对象.md)
26 |
27 | **:zap:第二部分:单机数据库**
28 |
29 | :cloud_with_lightning:[P3.数据库的基本结构](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现3-数据库.md)
30 |
31 | :cloud_with_lightning:[P4.RDB和AOF持久化](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现4-RDB持久化和AOF持久化.md)
32 |
33 | :cloud_with_lightning:[P5.事件](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现5-事件.md)
34 |
35 | :cloud_with_lightning:[P6.客户端与服务器](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现6-客户端与服务器.md)
36 |
37 | :zap:**第三部分:多机数据库**
38 |
39 | :cloud_with_lightning_and_rain:[P7.复制](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现7-复制.md)
40 |
41 | :cloud_with_lightning_and_rain:[P8.Sentinel](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现8-Sentinel.md)
42 |
43 | :cloud_with_lightning_and_rain:[P9.集群](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现9-集群.md)
44 |
45 | :zap:**第四部分:独立功能的实现**
46 |
47 | :cloud_with_rain:[P10.发布与订阅](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现10-发布与订阅.md)
48 |
49 | :cloud_with_rain:[P11.事务](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现11-事务.md)
50 |
51 | :cloud_with_rain:[P12.Lua脚本](https://github.com/JiangRRRen/Redis-study/blob/master/Markdown笔记/Redis设计与实现12-Lua脚本.md)
52 |
53 | # Part2:思维导图
54 |
55 | 
56 |
57 | 
58 |
59 | 
60 |
61 | 
62 |
63 | # Part3: 面试常见问题
64 |
65 | 分为两部分:Redis原理相关和Redis应用相关,主要从网上搜集整理而来,并做了许多原创性的改编。
66 |
67 | :hourglass_flowing_sand: [面试常问的原理性问题](https://github.com/JiangRRRen/Redis-study/blob/master/面试相关/Redis面试常见基本问题.md)
68 |
69 | :hourglass_flowing_sand: [Redis的简单应用场景](https://github.com/JiangRRRen/Redis-study/blob/master/面试相关/Redis的简单应用场景总结.md)
--------------------------------------------------------------------------------
/思维导图/Pic/单机数据库.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Pic/单机数据库.png
--------------------------------------------------------------------------------
/思维导图/Pic/多机数据库.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Pic/多机数据库.png
--------------------------------------------------------------------------------
/思维导图/Pic/数据结构与对象.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Pic/数据结构与对象.png
--------------------------------------------------------------------------------
/思维导图/Pic/独立功能的实现.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Pic/独立功能的实现.png
--------------------------------------------------------------------------------
/思维导图/Xmind/单机数据库.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Xmind/单机数据库.xmind
--------------------------------------------------------------------------------
/思维导图/Xmind/多机数据库.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Xmind/多机数据库.xmind
--------------------------------------------------------------------------------
/思维导图/Xmind/数据结构与对象.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Xmind/数据结构与对象.xmind
--------------------------------------------------------------------------------
/思维导图/Xmind/独立功能的实现.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JiangRRRen/Redis-study/9a7c2fbee39c985e3d273139a80b0b4f5f602eca/思维导图/Xmind/独立功能的实现.xmind
--------------------------------------------------------------------------------
/面试相关/Redis的简单应用场景总结.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis的简单应用场景总结
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | mathjax: true
11 | date: 2020-01-16 16:15:22
12 | ---
13 |
14 | # 1. 缓存
15 |
16 | 比如我要从数据库查看最新的5000条评论:
17 |
18 | ```sql
19 | SELECT comments FROM user
20 | ORDER BY time DESC LIMIT 5000
21 | ```
22 |
23 | 这样的操作随着数据的增加会变得越来越慢,因为要进行排序操作。而且这种排序本身不应该发生:因为我们存的时候是按时间存进去的。
24 |
25 | 我们可以使用redis的列表对象来实现,此时列表由Linkedlist数据结构实现。
26 |
27 | 每次新评论发表时,我们会将它的ID添加到一个Redis列表`LPUSH latest.comments`,然后将列表裁剪到5000,`LTRIM latest.comments 0 5000`
28 |
29 | 每次我们需要获取最新评论的项目范围时,我们调用一个函数来完成(使用伪代码):
30 |
31 | ```pseudocode
32 | FUNCTION get_latest_comment(num_items):
33 | id_list=redis.lrange("latest.comments",0,num_items-1)
34 | IF id_list ZINCRBY vote_activity 1 Bob
64 | "1"
65 |
66 | redis> ZINCRBY vote_activity 1 Tim
67 | "1"
68 |
69 | redis> ZINCRBY vote_activity 1 Bob
70 | "2"
71 | ```
72 |
73 | 有序列表入队时,按分值排好序了,我们可以方便的用`ZSCORE key member`查询分数。
74 |
75 | ```
76 | redis> zscore vote_activity Bob
77 | "2"
78 | ```
79 |
80 | 以及获取某人的排名,获取前10名,获取前10名分数等等,
81 |
82 | ```
83 | #获取Alice排名(从高到低,zero-based)
84 | redis> zrevrank vote_activity Alice
85 | (integer) 0
86 |
87 | #获取前10名(从高到低)
88 | redis> zrevrange vote_activity 0 9
89 | 1) "Alice"
90 | 2) "Bob"
91 |
92 | #获取前10名及对应的分数(从高到低)
93 | redis> zrevrange vote_activity 0 9 withscores
94 | 1) "Alice"
95 | 2) "2"
96 | 3) "Bob"
97 | 4) "1"
98 | ```
99 |
100 | # 3. 消息队列
101 |
102 | 一般来说,消息队列有两种场景:一种是**发布者订阅者模式**;一种是生**产者消费者模式**。利用redis这两种场景的消息队列都能够实现。定义:
103 |
104 | - 生产者消费者模式:生产者生产消息放到队列里,多个消费者同时监听队列,谁先抢到消息谁就会从队列中取走消息;即对于**每个消息只能被最多一个消费者拥有**。(常用于处理高并发写操作)
105 | - 发布者订阅者模式:发布者生产消息放到队列里,多个监听队列的消费者都会收到同一份消息;即正常情况下**每个消费者收到的消息应该都是一样的**。(常用来作为日志收集中一份原始数据对多个应用场景)
106 |
107 | ---
108 |
109 | 发布者订阅者模式可以直接使用pub/sub指令实现。
110 |
111 | ---
112 |
113 | 生产者消费者模式分两种:
114 |
115 | - 普通的
116 | - 带有优先级的
117 |
118 | 普通模式下使用`brpop`指令,可以以阻塞的形式返回数据列表中新添加的参数:
119 |
120 | ```C++
121 | while(true)
122 | {
123 | List msgs = redis.brpop(BLOCK_TIMEOUT,listKey);
124 | Handle(msgs);
125 | }
126 | ```
127 |
128 | 如果是优先级模式,当优先级不是很多是,可以分为两组:
129 |
130 | ```C
131 | while(true)
132 | {
133 | List msgs = redis.brpop(['high_task_queue', 'low_task_queue'],0);
134 | Handle(msgs);
135 | }
136 | ```
137 |
138 | `brpop`命令可以输入多个键,如果同时都有元素可读,读先输入的那个键。
139 |
140 | 如果优先级划分很多,就需要再用列表排序的办法了(有序集合不好,因为没有阻塞模式)。假如有1000个优先级,我们可以先分组,分为10组,每组按优先级顺序排列,查找时二分查找。
141 |
142 | # 4. 时间轴
143 |
144 | 所谓时间轴系统就是典型的微博模式:用户在自己的主页可以看到其关注的博主发表的信息列表(按时间排序);而其它用户可以一个用户的个人主页看到这个人发布的信息列表(按时间排序)。
145 |
146 | 解决方案主要有两种:
147 |
148 | - 推模式:某人发布内容之后推送给所有粉丝,空间换时间,瓶颈在写入;
149 | - 拉模式:粉丝从自己的关注列表中读取内容,时间换空间,瓶颈在读取;
150 |
151 | 以推模式为例:
152 |
153 | **(1)博主发布博文**
154 |
155 | 我们创建一个哈希对象post,键为博文ID,值为博文内容字符串。存储博文。
156 |
157 | ```
158 | redis> HSET post 4396 "hahahahah"
159 | ```
160 |
161 | 再使用一个列表,按先后顺序存储该博主的博文:
162 |
163 | ```
164 | redis>LPUSH Dasima 4396
165 | ```
166 |
167 | 然后使用一个集合,存储该博主的所有粉丝,利用`SMEMBERS`获取这些粉丝的名单。
168 |
169 | ```
170 | redis> SMEMBERS Dasima
171 | ```
172 |
173 | 每一个粉丝拥有一个timeline列表,存取所有推送博文的ID。之后对所有粉丝的推送列表进行写入。
174 |
175 | **(2)用户读取博文推送**
176 |
177 | 利用`LRANGE`从推送中拉取一定数量的博文,根据拉到的博文ID,读取哈希表的内容。
178 |
179 | ```
180 | redis>LRANGE timeline 0 30
181 |
182 | redis>HGETALL(4396)
183 | ```
184 |
185 | # 5. 实现分布式锁
186 |
187 | **(1)什么是分布式锁?**
188 |
189 | 对于单进程的程序,采用普通锁即可防止竞争,而对于多进程分布式系统来说需要采用分布式锁来保证一致性。
190 |
191 | **(2)redis如何实现分布式锁**
192 |
193 | 在 Redis 2.6.12 版本开始,`set`命令增加了三个参数,替换以前的`setnx`命令:
194 |
195 | - `EX`:设置键的过期时间(单位为秒)
196 | - `PX`:设置键的过期时间(单位为毫秒)
197 | - `NX` | `XX`:当设置为`NX`时,仅当 key 存在时才进行操作,设置为`XX`时,仅当 key 不存在才会进行操作
198 |
199 | 我们可以以此实现简单的分布式锁:
200 |
201 | ```
202 | set key "lock" EX 1 XX
203 | ```
204 |
205 | 如果这个操作返回`false`,说明 key 的添加不成功,也就是当前有人在占用这把锁。而如果返回`true`,则说明得了锁,便可以继续进行操作,并且在操作后通过`del`命令释放掉锁。并且即使程序因为某些原因并没有释放锁,**由于设置了过期时间,该锁也会在 1 秒后自动释放**,不会影响到其他程序的运行。
206 |
207 | ```
208 | del "lock"
209 | ```
210 |
211 |
--------------------------------------------------------------------------------
/面试相关/Redis面试常见基本问题.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Redis面试常见基本问题
3 | category:
4 | - 数据库
5 | tags:
6 | - 计算机网络
7 | - 数据库
8 | - Redis
9 | - 读书笔记
10 | - 面试经验
11 | mathjax: true
12 | date: 2020-01-16 16:11:46
13 | ---
14 |
15 | # 1.基础
16 |
17 | ## 1.1 什么是Redis?
18 |
19 | Redis的全称是:Remote Dictionary Server,本质上是一个 Key-Value 类型的内存数据库。
20 |
21 | 整个数据库统统**加载在内存**当中进行操作,定期通过异步操作把数据库数据保存在硬盘。因为是纯内存操作,Redis 的性能非常出色。
22 |
23 | ## 1.2 Redis的优劣势?
24 |
25 | 优势:
26 |
27 | - 纯内存读写操作,性能好。
28 | - 支持多种数据结构。
29 | - 单线程,不用担心竞争
30 | - 特性丰富,支持发布订阅、过期、sentinel等功能。
31 |
32 | 劣势:
33 |
34 | - 容量受物理内存限制,不能用作海量数据的高性能读写。
35 |
36 | ## 1.3 Redis和Memcached比较
37 |
38 | Memcached早年被很多公司使用,现在内存越来越便宜,基本都是用Redis。Redis被认为是Memcached的替代者,优势有:
39 |
40 | - memcached值均为简单字符串,redis支持更丰富的类型
41 | - redis性能更好(速度快,内存大)Memcached内存限制为1MB,而Redis可以达到1GB
42 | - redis可以持久化
43 | - Memcached集群功能不好,没有原生集群模式
44 |
45 | 劣势有:
46 |
47 | - redis只是用一个核,而memcached使用多核,在大数据处理上,memecached效率要好一些。
48 |
49 | ## 1.4 Redis支持哪些数据类型
50 |
51 | 对象:
52 |
53 | - 字符串对象,支持int、raw、embstr编码
54 | - 列表对象,支持ziplist和linkedlist编码
55 | - 哈希对象,支持ziplist和hashtable
56 | - 集合对象,支持intset和hashtable
57 | - 有序集合对象,支持ziplist和skiplist
58 |
59 | # 2. 缓存相关
60 |
61 | ## 2.1 什么是缓存雪崩?
62 |
63 | 首先,为什么要使用缓存?
64 |
65 | 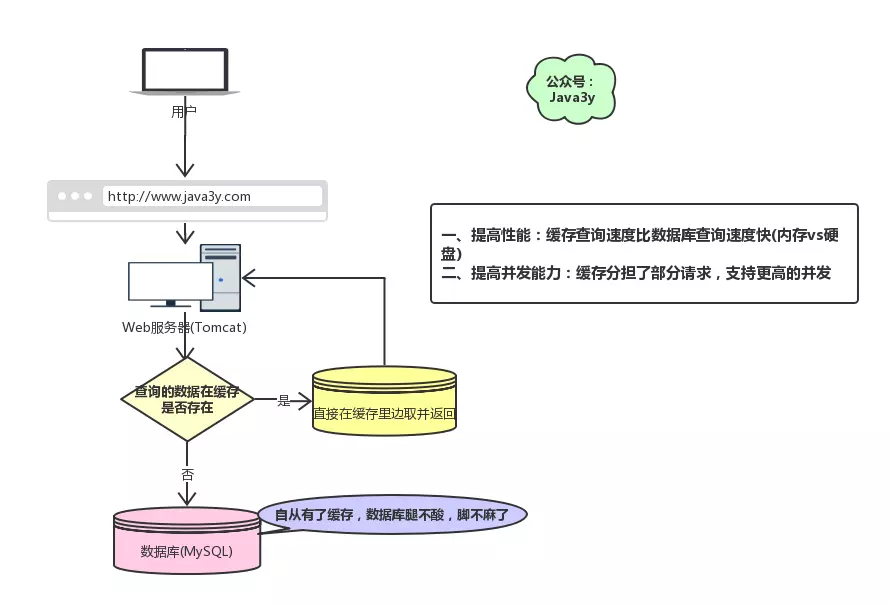 66 |
67 | 缓存区域的大小是有限的,为了避免数量膨胀,redis采取了[过期删除策略](https://jiangren.work/2020/01/04/Redis设计与实现3-数据库/#3-过期键)。但是如果缓存数据设置的过期时间是相同的,会导致这些缓存**同时失效**,所有请求全部跑向数据库,造成巨大冲击。这就是**缓存雪崩**。
68 |
69 | 发生的原因可能是:
70 |
71 | - Redis挂掉。
72 | - 由于过期键时间问题,导致同时失效。
73 |
74 | ## 2.2 如何解决缓存雪崩?
75 |
76 | 对于过期键失效问题:
77 |
78 | - 在缓存的时候给过期时间加上一个**随机值**,这样就会大幅度的**减少缓存在同一时间过期**。
79 |
80 | 对于redis挂掉的问题:
81 |
82 | - 主从服务器+sentinel+集群模式,保证有继承人存在,及时推举。
83 | - 如果redis真的挂了,可以设置**本地缓存+限流**
84 | - 事发后,利用持久化特性,尽快从磁盘上加载数据,恢复缓存。
85 |
86 | ## 2.3 什么是缓存穿透?
87 |
88 | 缓存穿透是指查询一个一定**不存在的数据**。由于缓存不命中,并且出于容错考虑,如果从**数据库查不到数据则不写入缓存**,这将导致这个不存在的数据**每次请求都要到数据库去查询**,失去了缓存的意义。
89 |
90 |
66 |
67 | 缓存区域的大小是有限的,为了避免数量膨胀,redis采取了[过期删除策略](https://jiangren.work/2020/01/04/Redis设计与实现3-数据库/#3-过期键)。但是如果缓存数据设置的过期时间是相同的,会导致这些缓存**同时失效**,所有请求全部跑向数据库,造成巨大冲击。这就是**缓存雪崩**。
68 |
69 | 发生的原因可能是:
70 |
71 | - Redis挂掉。
72 | - 由于过期键时间问题,导致同时失效。
73 |
74 | ## 2.2 如何解决缓存雪崩?
75 |
76 | 对于过期键失效问题:
77 |
78 | - 在缓存的时候给过期时间加上一个**随机值**,这样就会大幅度的**减少缓存在同一时间过期**。
79 |
80 | 对于redis挂掉的问题:
81 |
82 | - 主从服务器+sentinel+集群模式,保证有继承人存在,及时推举。
83 | - 如果redis真的挂了,可以设置**本地缓存+限流**
84 | - 事发后,利用持久化特性,尽快从磁盘上加载数据,恢复缓存。
85 |
86 | ## 2.3 什么是缓存穿透?
87 |
88 | 缓存穿透是指查询一个一定**不存在的数据**。由于缓存不命中,并且出于容错考虑,如果从**数据库查不到数据则不写入缓存**,这将导致这个不存在的数据**每次请求都要到数据库去查询**,失去了缓存的意义。
89 |
90 | 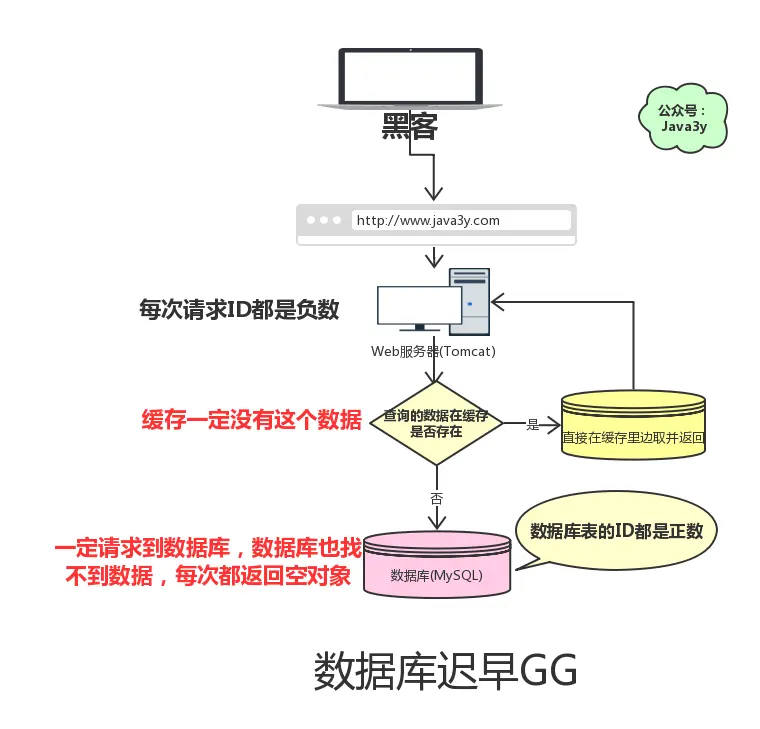 91 |
92 | ## 2.4 如何解决缓存穿透?
93 |
94 | - 使用**布隆过滤器**
95 | - 当我们从数据库找不到的时候,我们也将这个**空对象设置到缓存里边去**。下次再请求的时候,就可以从缓存里边获取了。这种情况我们一般会将空对象设置一个**较短的过期时间**
96 |
97 | 布隆过滤器的原理解释https://zhuanlan.zhihu.com/p/43263751。
98 |
99 | ## 2.5 如何解决缓存与数据库双写不一致?
100 |
101 | 在写更新数据时,我们要进行两步操作:**删除缓存**和**更新数据库**(一般不使用更新缓存,都是直接删除),现在的问题就是:这两步先做哪一个?
102 |
103 | 1. 先更新数据库,再删除缓存
104 | 2. 先删除缓存,再更新数据库
105 |
106 | **如果是1**,则
107 |
108 | - 当原子性破坏时(更新了库,没删缓存),**导致数据不一致**
109 | - 并发场景**出现问题的概率较低**,仅发生在**缓存失效时**
110 | 1. 线程A查询数据库,得到旧值
111 | 2. 线程B将新值写入数据库
112 | 3. 线程B删除缓存
113 | 4. 线程A将查到的旧值写入缓存
114 |
115 | 为什么说发生概率低呢?
116 |
117 | - 仅发生在缓存失效时
118 | - 写操作一般比较慢,很难出现c在d前面的情况。
119 |
120 | **如果是2**,则:
121 |
122 | - 原子性被破坏时,不影响一致性
123 | - 并发时,问题很大
124 | 1. 线程A删除缓存
125 | 2. 线程B查询时缓存不存在,于是到数据库取了一个旧值
126 | 3. 线程B将旧值写入缓存
127 | 4. 线程A将新值写入数据库
128 |
129 | 如何保证并发下的一致呢?
130 |
131 | 将删除缓存、修改数据库、读取缓存等的操作积压到**队列**里边,实现**串行化**。
132 |
133 |
91 |
92 | ## 2.4 如何解决缓存穿透?
93 |
94 | - 使用**布隆过滤器**
95 | - 当我们从数据库找不到的时候,我们也将这个**空对象设置到缓存里边去**。下次再请求的时候,就可以从缓存里边获取了。这种情况我们一般会将空对象设置一个**较短的过期时间**
96 |
97 | 布隆过滤器的原理解释https://zhuanlan.zhihu.com/p/43263751。
98 |
99 | ## 2.5 如何解决缓存与数据库双写不一致?
100 |
101 | 在写更新数据时,我们要进行两步操作:**删除缓存**和**更新数据库**(一般不使用更新缓存,都是直接删除),现在的问题就是:这两步先做哪一个?
102 |
103 | 1. 先更新数据库,再删除缓存
104 | 2. 先删除缓存,再更新数据库
105 |
106 | **如果是1**,则
107 |
108 | - 当原子性破坏时(更新了库,没删缓存),**导致数据不一致**
109 | - 并发场景**出现问题的概率较低**,仅发生在**缓存失效时**
110 | 1. 线程A查询数据库,得到旧值
111 | 2. 线程B将新值写入数据库
112 | 3. 线程B删除缓存
113 | 4. 线程A将查到的旧值写入缓存
114 |
115 | 为什么说发生概率低呢?
116 |
117 | - 仅发生在缓存失效时
118 | - 写操作一般比较慢,很难出现c在d前面的情况。
119 |
120 | **如果是2**,则:
121 |
122 | - 原子性被破坏时,不影响一致性
123 | - 并发时,问题很大
124 | 1. 线程A删除缓存
125 | 2. 线程B查询时缓存不存在,于是到数据库取了一个旧值
126 | 3. 线程B将旧值写入缓存
127 | 4. 线程A将新值写入数据库
128 |
129 | 如何保证并发下的一致呢?
130 |
131 | 将删除缓存、修改数据库、读取缓存等的操作积压到**队列**里边,实现**串行化**。
132 |
133 | 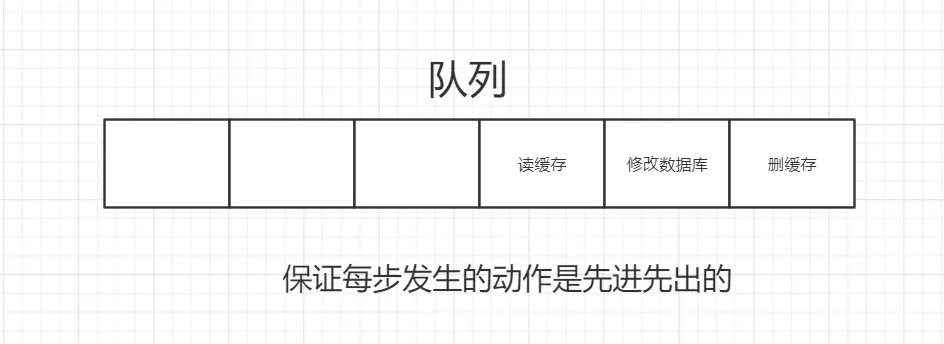 134 |
135 | # 3. 线程模型
136 |
137 | ## 3.1 为什么Redis是单线程?
138 |
139 | 首先CPU的性能并不是瓶颈,主要考虑本地内存和网络带宽。其次,单线程可以避免线程切换的资源消耗和竞争问题,有利于性能提升。
140 |
141 | ## 3.2 介绍一下IO多路复用
142 |
143 |
144 |
145 | IO多路复用的原理是:存在一个接线员,当有客户连接时,接线员接收连接,分派到制定执行函数,然后接着监听。这样就可以避免处理某一个连接而阻塞其他用户的情况。
146 |
147 |
134 |
135 | # 3. 线程模型
136 |
137 | ## 3.1 为什么Redis是单线程?
138 |
139 | 首先CPU的性能并不是瓶颈,主要考虑本地内存和网络带宽。其次,单线程可以避免线程切换的资源消耗和竞争问题,有利于性能提升。
140 |
141 | ## 3.2 介绍一下IO多路复用
142 |
143 |
144 |
145 | IO多路复用的原理是:存在一个接线员,当有客户连接时,接线员接收连接,分派到制定执行函数,然后接着监听。这样就可以避免处理某一个连接而阻塞其他用户的情况。
146 |
147 |  148 |
149 | ---
150 |
151 | Redis的I/O多路复用程序的所有功能都是**通过包装常见的select、epoll这些I/O多路复用函数库来实现的**。由于IO复用程序提供了统一的接口,所以**底层实现方法可以互换。**
152 |
153 | ## 3.3 介绍一下redis线程模型的处理流程
154 |
155 | Redis基于Reactor模式开发了自己的网络事件处理器:这个处理器被称为**文件事件处理器(file event handler)**。
156 |
157 | 文件事件处理器包括:
158 |
159 | - 套接字
160 | - IO复用程序
161 | - 文件事件分派器
162 | - 事件处理器
163 |
164 | 事件处理器包括:
165 |
166 | - 连接应答处理器
167 | - 命令请求处理器
168 | - 命令回复处理器
169 |
170 | 详情参见[事件处理器讲解](https://jiangren.work/2020/01/05/Redis设计与实现5-事件/#1-2-IO多路复用程序的实现)
171 |
172 |
173 |
174 | # 4. 数据删除与淘汰机制
175 |
176 | ## 4.1 介绍一下redis的过期删除策略
177 |
178 | **(1)惰性删除**
179 |
180 | 放着不管,每次从键空间获取时检查是否过期,过期就删除。
181 |
182 | **对CPU最友好**,**但浪费内存**。如果数据库中有很多过期键,而这些过期键永远也不会被访问的话,他们就会永远占据空间,可视为**内存泄漏**。比如一些和时间有关的数据(日志)。
183 |
184 | **(2)定期删除**
185 |
186 | 每隔一段时间,程序检查一次数据库,删除过期键。
187 |
188 | **对CPU和内存是一种折中**。通过选择较为空闲的时间点来处理过期键,减少CPU压力。同时也能及时释放内存,避免内存泄漏。
189 |
190 | 在redis中由周期函数severCron负责,它在规定的时间内,**分多次遍历服务器中的各个数据库**,从数据库的expires字典中**随机检查一部分键的过期时间**,并删除其中的过期键。他会记录检查进度,在**下一次检查时接着上一次的进度进行处理**。比如说,如果当前函数在遍历10号数据库时返回了,那么下次就会从11号数据库开始工作。
191 |
192 | ## 4.2 介绍一下Redis的内存淘汰机制
193 |
194 | 惰性删除和定期删除依然可能保留大量过期键,这时候需要用到内存淘汰机制。内存淘汰机制有6个:
195 |
196 | - **noeviction**:eviction是驱逐的意思,当内存不足以容纳新写入数据时,新写入操作会报错。
197 | - **allkeys-lru**:当内存不足以容纳新写入数据时,在**键空间**中,移除最近最少使用的 key :ok_hand::ok_hand:
198 | - **allkeys-random**:当内存不足以容纳新写入数据时,在**键空间**中,随机移除某个 key。
199 | - **volatile-lru**:[ˈvɒlətaɪl]易挥发的,易丢失的。当内存不足以容纳新写入数据时,在**设置了过期时间的键空间**中,移除最近最少使用的 key。
200 | - **volatile-random**:当内存不足以容纳新写入数据时,在**设置了过期时间的键空间**中,**随机移除**某个 key。:ok_hand:
201 | - **volatile-ttl**:当内存不足以容纳新写入数据时,在**设置了过期时间的键空间**中,有**更早过期时间**的 key 优先移除。:ok_hand:
202 |
203 | ## 4.3 写一个LRU算法
204 |
205 | 我的博客有总结,是一道Leetcode题目,C++版本:
206 |
207 | [Leetcode146-LRU缓存机制](https://jiangren.work/2019/09/05/Leetcode题目总结7-容器的应用/)
208 |
209 | # 5. Redis高并发和高可用
210 |
211 | ## 5.1 Redis的高并发是如何实现的?
212 |
213 | 首先**从程序编写的角度上**来说,
214 |
215 | - Redis是纯内存数据库,读写速度快,
216 | - 采用了非阻塞IO复用,
217 | - 采用了单线程减少切换,
218 | - 采用了优秀的数据结构设计,
219 | - 设计了分离的文件事件处理器和文件事件分派器。
220 |
221 | 然后,**从布局架构上**来说,实现**高并发**主要依靠**主从架构**(**单线程多进程**),比如**单机写数据,多机查数据**。单机能达到几万QPS(queries per sec),多个从实例能达到10W的QPS。
222 |
223 | 更进一步,可以采用集群,不仅能实现高并发,还能容纳大量数据。
224 |
225 | ## 5.2 Redis的高可用是如何实现的?
226 |
227 | 高可用性指**系统无中断地执行其功能的能力**。Redis实现高可用依靠的是Sentinel哨兵机制。Sentinel**本质上只是一个运行在特殊模式下的Redis服务器**,是一个进程。
228 |
229 | **Sentinel作用:**
230 |
231 | - 监控Redis整体是否正常运行。
232 | - 某个节点出问题时,**通知给其他进程**(比如他的客户端)。
233 | - 主服务器下线时,在从服务器中**选举**出一个新的主服务器。
234 |
235 | **Sentinel监督服务器:**
236 |
237 | 1. 与主服务器构建连接,每10秒向主服务器发送INFO命令,分析回复消息分析主服务器状态。
238 | 2. 从主服务器状态中获取从服务器信息,并与他们建立连接。达到全覆盖的目的。
239 |
240 | **Sentinel互相监督:**
241 |
242 | 1. Sentinel和服务器之间建立hello频道连接
243 | 2. Sentinel在hello频道发送信息时会被其他Sentinel发现,达到握手的目的。
244 | 3. 发现后,Sentinel之间建立连接,形成环形网络。
245 |
246 | **Sentinel监督下线:**
247 |
248 | - 按频率向所有创建连接的实例发送PING,查看是否回复PONG来判断是否在线,不回复则**标记为主观下线状态**。
249 | - 向其他Sentinel询问,如果足够数量的Sentinel也标记为下线状态,则改为**客观下线**。
250 |
251 | **Sentinel下线补救措施:**
252 |
253 | **(1)选举领头的Sentinel**
254 |
255 | 过程:一个Sentinel向另一个Sentinel发送设置请求命令。**最先向目标Sentinel**发送设置要求的源Sentinel将成为目标Sentinel的局部领头Sentinel,而之后接收到的所有设置要求都会被目标Sentinel拒绝。
256 |
257 | 如果有某个Sentinel**被半数**以上的Sentinel设置成了局部领头Sentinel,那么这个Sentinel成为领头Sentinel。
258 |
259 | **(2)故障转移**
260 |
261 | 1. 从已下线的主服务器的从服务器中**拔举**一个作为主服务器。标准:**偏移量最大**
262 | 2. 让已下线主服务器属下的所有从服务器改为复制新的主服务器
263 | 3. 将已下线主服务器设置为新的主服务器的从服务器,当这个旧的主服务器重新上线时,它就会成为新的主服务器的从服务器。
264 |
265 | # 6. 多机架构
266 |
267 | ## 6.1 Redis有哪些多机架构?
268 |
269 | 不考虑中间件,原生的架构有**主从复制架构**和**集群架构**。
270 |
271 | ## 6.2 介绍一下复制过程
272 |
273 | Redis中复制有新老两版。
274 |
275 | 老版:分为同步和命令传播两个阶段。
276 |
277 | ---
278 |
279 | **老版:**
280 |
281 | **在同步阶段:**
282 |
283 | 1. 从机向主机发送SYNC命令
284 | 2. 主机收到后,执行BGSAVE生成RDB文件,并使用缓冲区记录现在开始执行的所有写操作。
285 | 3. 将RDB文件发给从服务器
286 | 4. 将缓冲区内容发送给从服务器
287 |
288 | **在命令传播阶段:**
289 |
290 | 主服务器将自己执行的写命令发送给从服务器,让他执行相同的命令
291 |
292 | **缺陷:**
293 |
294 | 初次复制效果较好,但断线后重连复制效率很低,需要全部重录RDB文件。
295 |
296 | ---
297 |
298 | **新版:**
299 |
300 | 分为完整重同步和部分重同步,前者和旧版一样。部分重同步有三个部分:
301 |
302 | - 主从服务器的复制偏移量
303 | - 主服务器的复制积压缓冲区
304 | - 服务器的运行ID
305 |
306 | 主服务器和从服务器会分别维护一个复制偏移量,通过对比偏移量来知道主从服务器是否处于一致状态:
307 |
308 | - 主服务器每次向从服务器传播N个字节的数据时,就将自己的复制偏移量的值加上N。
309 | - 从服务器每次收到主服务器传播来的N个字节的数据时,就将自己的复制偏移量的值加上N。
310 |
311 | 复制积压缓冲区是由主服务器维护的一个**固定长度**(fixed-size)先进先出(FIFO)队列。当主服务器进行命令传播时,它不仅会将写命令发送给所有从服务器,还会**将写命令入队到复制积压缓冲区里面**。同时,主服务器也会向积压缓冲区添加偏移量。重新上线时根据偏移量决定如何重同步:
312 |
313 | - 下线后,数据长度超过了缓冲区,导致溢出,说明下线时间太长,执行完全重同步。
314 | - 否则,部分重同步。
315 |
316 | 而主服务器ID则帮助重新上线的从服务器识别,
317 |
318 | - 如果ID和从服务器记录的相同,则表示**之前同步的主服务器就是这个**,执行部分重同步。
319 | - 如果ID不同,则表明从**服务器断线之前复制的主服务器并不是当前连接的这个主服务器**,执行完整重同步操作。
320 |
321 | ## 6.3 介绍一下集群
322 |
323 | 集群通过分片(sharding)来进行数据共享,并提供复制和故障转移功能,保证高可用性。
324 |
325 | **集群的结构**是:多个节点(node)组成一个集群,节点是Redis中数据存储的单位,在刚开始的时候,每个节点都是相互独立的。通过`CLUSTER MEET`命令相互握手,组成集群。
326 |
327 | **集群数据的存储方式**是:集群的整个数据库被分一万多个槽(slot)**,**数据库中的每个键都属于槽的其中一个。当所有槽都有节点在处理时,集群处于上线状态。
328 |
329 | ## 6.4 集群的通信方式是怎样的?
330 |
331 | 集群依靠消息通信,消息有5种:MEET, PING, PONG, FAIL, PUBLISH。
332 |
333 | Redis集群中的各个节点通过**Gossip协议**来交换各自关于不同节点的状态信息,其中Gossip协议由MEET、PING、PONG三种消息实现。
334 |
335 | ---
336 |
337 | 所谓Gossip是八卦消息的意思,在Redis中,发送每次发送MEET、PING、PONG消息时,发送者都从自己的已知节点列表中**随机选出两个节点**(可以是主节点或者从节点),保存到一个特殊结构体中。
338 |
339 | 接受者接收到MEET、PING、PONG消息时,根据保存的两个节点是否认识来选择进行哪种操作:
340 |
341 | - 不认识,说明接收者**第一次接触被选中节点**,则接收者与被选中节点握手
342 | - 认识,根据结构信息进行更新。
343 |
344 | 比如A节点发送的PING给B,携带了CD两个节点,然后B回复PONG携带了EF两个节点,这样就完成了ABCDEF六个节点的信息交换。**每个节点按照周期向不同节点传播PING-PONG信息,就能完成整个集群的状态更新。**
345 |
346 | ---
347 |
348 | 如果节点很多,则Gossip消息比较慢,而主节点下线的消息需要立即通知给所有人。FAIL消息的正文只包含已下线的节点名称,直接通知给所有已知节点。
349 |
350 | 
351 |
352 | 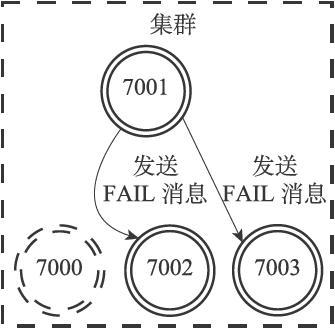
353 |
354 | ---
355 |
356 | 接收到PUBLISH命令的节点**不仅会向channel频道发送消息message,它还会向集群广播一条PUBLISH消息,所有接收到这条PUBLISH消息的节点都会向channel频道发送message消息**。
357 |
358 | 也就是说,向集群发送`PUBLISH `,会导致集群所有节点都向channel发送message消息。
359 |
360 | 
361 |
362 | ## 6.5 集群分片的原理是什么?
363 |
364 | Redis引入了哈希槽的概念,通过槽指派的方式存储数据。
365 |
366 | Redis集群有$2^{14}=16384$个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽`slot = CRC16(key) & 16383`,集群的每个节点负责一部分hash槽。
367 |
368 | **使用哈希槽的好处就在于可以方便的添加或移除节点。**
369 |
370 | 1. 当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;
371 | 2. 当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了。
372 |
373 | CRC16算法能分配65535个槽位,但作为包发送太臃肿,一般情况下一个redis集群不会有超过1000个master节点,所以采用$1/4$
374 |
375 | ## 6.6 集群扩容和收缩是怎么实现的?
376 |
377 | 集群的伸缩是通过重新分片的方式实现的,重新分片操作可以将**任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点)**,并且相关槽所属的键值对也会从源节点被移动到目标节点。
378 |
379 | 重新分片操作可以**在线(online)进行**,在重新分片的过程中,集群不需要下线,并且**源节点和目标节点都可以继续处理命令请求**。
380 |
381 | 重新分片由redis-trib负责,步骤如下:
382 |
383 | 1. trib向源节点发送命令,包含了执行迁移的槽slot,要迁移键的数量count。
384 | 2. 源节点返回属于槽slot的count个键。
385 | 3. 对于每个返回键,trib向源节点发送一个MIGRATE命令
386 | 4. 源节点根据MIGRATE命令将键迁移到目标节点,
387 |
388 | 
389 |
390 | 如果多槽,则分别对不同槽执行多次。
391 |
392 | # 7. 持久化
393 |
394 | ## 7.1 为什么采用持久化?
395 |
396 | 持久化有两个作用:方便主从复制和灾难恢复。
397 |
398 | 由于Redis的数据全都放在内存而不是磁盘里面,如果Redis挂了,没有配置持久化的话,重启的时候数据会全部丢失。所以需要将数据写入磁盘,本地化保存。
399 |
400 | ## 7.2 持久化的方式有哪些?
401 |
402 | 有RDB持久化和AOF持久化。
403 |
404 | ---
405 |
406 | RDB持久化:
407 |
408 | 将数据库状态以RDB文件格式保存。可以采用SAVE命令阻塞服务器进程,也可以用BGSAVE命令fork一个子进程。
409 |
410 | 通过周期性函数serverCron不断的判断保存条件,如果条件满足就保存。
411 |
412 | ---
413 |
414 | AOF持久化:
415 |
416 | AOF(Append Only File)**记录Redis服务器所执行的写命令**。AOF实现原理是**命令追加**和**文件写入同步**,
417 |
418 | - 命令追加:服务器执行完一个命令后,会以协议格式将命令**追加到服务器状态aof_buf缓冲区的结尾**
419 | - 文件写入同步:服务器每次结束一个事件循环之前都**考虑是否需要将`aof_buf`缓冲区中的内容写入和保存到AOF文件里面**。
420 |
421 | AOF还原时需要建立一个不带网络连接的伪客户端,因为Redis的命令只能在客户端上下文中执行。
422 |
423 | ## 7.3 AOF的重写是什么意思?
424 |
425 | 随着时间的增长,AOF文件的大小将会越来越大。通过重写,Redis服务器可以创建一个新的AOF文件来替代现有的AOF文件,新旧两个**AOF文件保存的数据库状态完全相同**,但新的文件体积更小。
426 |
427 | 重写的策略是:**从数据库中读取键现在的值,然后用一条命令去记录键值对**。相当于折叠命令,只求最终结果。
428 |
429 | 此外,子进程AOF重写时,主进程也在写命令,导致两者状态不一致。因此,**Redis服务器设置了一个AOF重写缓冲区**,当Redis服务器执行完一个写命令之后,它会**同时**将这个写命令发送给**AOF缓冲区**和**AOF重写缓冲区**。
430 |
431 | ## 7.4 AOF和RDB优劣势比较
432 |
433 | RDB
434 |
435 | 优势:完整,恢复迅速
436 |
437 | 劣势:消耗资源大,每次保存的间隔周期长,丢失数据多
438 |
439 | ---
440 |
441 | AOF
442 |
443 | 优势:保存间隔短,丢失数据少,系统资源消耗少。保存格式清晰,适合误操作的恢复。
444 |
445 | 劣势:恢复速度较慢,需要建立伪客户端,如果发生崩溃的情况需要尽快恢复,最好采用RDB。重写后数据保存不一定完整,可能有BUG。
446 |
447 | # 8. 事务
448 |
449 | ## 8.1 什么是事务?
450 |
451 | Redis通过MULTI、EXEC、WATCH等命令来实现事务(transaction)功能。事务将**一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制**,并且在事务执行期间,**服务器不会中断事务**而改去执行其他客户端的命令请求。
452 |
453 | ## 8.2 Redis中事务是如何实现的?
454 |
455 | 事务从开始到结束经历三个阶段:
456 |
457 | 1. 事务开始
458 | 2. 事务入队
459 | 3. 事务执行
460 |
461 | ---
462 |
463 | 通过MULTI命令可以将执行该命令的客户端**从非事务状态切换至事务状态**,在是事务状态下,
464 |
465 | - 如果客户端发送EXEC,DISCARD,WATCH,MULTI这四个命令,则立即执行。
466 | - 如果发送的是其他命令,则放到事务队列里面,向客户端返回QUEUED回复。
467 |
468 | ---
469 |
470 | 每个Redis客户端都有自己的**事务状态结构体**,每个结构体中又包含了一个**事务队列**和**已入队命令计数器。**在事务队列中包含了**具体的命令cmd**。
471 |
472 | ---
473 |
474 | 当一个处于事务状态的客户端向服务器发送EXEC命令时,这个EXEC命令将立即被服务器执行。**服务器会遍历这个客户端的事务队列,执行队列中保存的所有命令,最后将执行命令所得的结果全部返回给客户端。**过程是:
475 |
476 | 1. 创建空白回复队列
477 | 2. 抽取一条命令,读取参数、参数个数以及要执行的函数
478 | 3. 行命令,取得返回值
479 | 4. 将返回值追加到1中的队列末尾,重复步骤2
480 | 5. 完成后,清除事务标志,回到非事务状态,同时清空计数器和释放事务队列。
481 |
482 | ## 8.3 事务中的乐观锁是什么?
483 |
484 | 乐观锁,也称CAS(check and set),属于无罪推定原则,每次别人拿数据都假定他不修改,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。
485 |
486 | Redis中通过WATCH来实现,它可以**在EXEC命令执行之前**,**监视任意数量的数据库键**,并在EXEC命令执行时,**检查被监视的键是否被其他客户修改过,**如果是的话,**服务器将拒绝执行事务**,并向客户端返回代表事务执行失败的空回复。
487 |
488 | ## 8.4 WATCH命令的原理是什么?
489 |
490 | 每个Redis数据库都保存着一个`watched_keys`字典,这个字典的**键是某个被WATCH命令监视的数据库键**,而**字典的值则是一个链表,链表中记录了所有监视相应数据库键的客户端**。
491 |
492 | 对数据库**执行修改命令**时,会对字典进行检查。**查看当前命令修改的键是否在`watched_keys`字典中**,如果有,且事务标志被打开**,表示该客户端的事务安全性已经被破坏**。将`REDIS_DIRTY_CAS`标识打开。
493 |
494 | 在EXEC命令执行时,检查`REDIS_DIRTY_CAS`标志是否打开判断是否应该执行。
495 |
496 | ## 8.5 解释一下事务的ACID性质
497 |
498 | 所谓ACID性质是指:**有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、耐久性(Durability)。**
499 |
500 | **原子性**:事务在执行前用WATCH检查,命令有没有被插入执行过。
501 |
502 | **一致性**:**入队错误**:事务入队时命令格式不正确,则Redis拒绝执行;**执行错误**:执行时操作不正确,会被服务器识别,并做错误处理,所以这些出错命令不会对数据库做任何修改;**停机后**根据持久化,也能还原为一致状态。
503 |
504 | **隔离性**:单线程,且事务不会被打断,串行的方式保证不同事务的隔离性(不保证键不会冲突)
505 |
506 | **耐久性**:不一定,得看哪种持久化,只有always模式下的AOF才有。(每次执行命令都会调用同步函数)
--------------------------------------------------------------------------------
148 |
149 | ---
150 |
151 | Redis的I/O多路复用程序的所有功能都是**通过包装常见的select、epoll这些I/O多路复用函数库来实现的**。由于IO复用程序提供了统一的接口,所以**底层实现方法可以互换。**
152 |
153 | ## 3.3 介绍一下redis线程模型的处理流程
154 |
155 | Redis基于Reactor模式开发了自己的网络事件处理器:这个处理器被称为**文件事件处理器(file event handler)**。
156 |
157 | 文件事件处理器包括:
158 |
159 | - 套接字
160 | - IO复用程序
161 | - 文件事件分派器
162 | - 事件处理器
163 |
164 | 事件处理器包括:
165 |
166 | - 连接应答处理器
167 | - 命令请求处理器
168 | - 命令回复处理器
169 |
170 | 详情参见[事件处理器讲解](https://jiangren.work/2020/01/05/Redis设计与实现5-事件/#1-2-IO多路复用程序的实现)
171 |
172 |
173 |
174 | # 4. 数据删除与淘汰机制
175 |
176 | ## 4.1 介绍一下redis的过期删除策略
177 |
178 | **(1)惰性删除**
179 |
180 | 放着不管,每次从键空间获取时检查是否过期,过期就删除。
181 |
182 | **对CPU最友好**,**但浪费内存**。如果数据库中有很多过期键,而这些过期键永远也不会被访问的话,他们就会永远占据空间,可视为**内存泄漏**。比如一些和时间有关的数据(日志)。
183 |
184 | **(2)定期删除**
185 |
186 | 每隔一段时间,程序检查一次数据库,删除过期键。
187 |
188 | **对CPU和内存是一种折中**。通过选择较为空闲的时间点来处理过期键,减少CPU压力。同时也能及时释放内存,避免内存泄漏。
189 |
190 | 在redis中由周期函数severCron负责,它在规定的时间内,**分多次遍历服务器中的各个数据库**,从数据库的expires字典中**随机检查一部分键的过期时间**,并删除其中的过期键。他会记录检查进度,在**下一次检查时接着上一次的进度进行处理**。比如说,如果当前函数在遍历10号数据库时返回了,那么下次就会从11号数据库开始工作。
191 |
192 | ## 4.2 介绍一下Redis的内存淘汰机制
193 |
194 | 惰性删除和定期删除依然可能保留大量过期键,这时候需要用到内存淘汰机制。内存淘汰机制有6个:
195 |
196 | - **noeviction**:eviction是驱逐的意思,当内存不足以容纳新写入数据时,新写入操作会报错。
197 | - **allkeys-lru**:当内存不足以容纳新写入数据时,在**键空间**中,移除最近最少使用的 key :ok_hand::ok_hand:
198 | - **allkeys-random**:当内存不足以容纳新写入数据时,在**键空间**中,随机移除某个 key。
199 | - **volatile-lru**:[ˈvɒlətaɪl]易挥发的,易丢失的。当内存不足以容纳新写入数据时,在**设置了过期时间的键空间**中,移除最近最少使用的 key。
200 | - **volatile-random**:当内存不足以容纳新写入数据时,在**设置了过期时间的键空间**中,**随机移除**某个 key。:ok_hand:
201 | - **volatile-ttl**:当内存不足以容纳新写入数据时,在**设置了过期时间的键空间**中,有**更早过期时间**的 key 优先移除。:ok_hand:
202 |
203 | ## 4.3 写一个LRU算法
204 |
205 | 我的博客有总结,是一道Leetcode题目,C++版本:
206 |
207 | [Leetcode146-LRU缓存机制](https://jiangren.work/2019/09/05/Leetcode题目总结7-容器的应用/)
208 |
209 | # 5. Redis高并发和高可用
210 |
211 | ## 5.1 Redis的高并发是如何实现的?
212 |
213 | 首先**从程序编写的角度上**来说,
214 |
215 | - Redis是纯内存数据库,读写速度快,
216 | - 采用了非阻塞IO复用,
217 | - 采用了单线程减少切换,
218 | - 采用了优秀的数据结构设计,
219 | - 设计了分离的文件事件处理器和文件事件分派器。
220 |
221 | 然后,**从布局架构上**来说,实现**高并发**主要依靠**主从架构**(**单线程多进程**),比如**单机写数据,多机查数据**。单机能达到几万QPS(queries per sec),多个从实例能达到10W的QPS。
222 |
223 | 更进一步,可以采用集群,不仅能实现高并发,还能容纳大量数据。
224 |
225 | ## 5.2 Redis的高可用是如何实现的?
226 |
227 | 高可用性指**系统无中断地执行其功能的能力**。Redis实现高可用依靠的是Sentinel哨兵机制。Sentinel**本质上只是一个运行在特殊模式下的Redis服务器**,是一个进程。
228 |
229 | **Sentinel作用:**
230 |
231 | - 监控Redis整体是否正常运行。
232 | - 某个节点出问题时,**通知给其他进程**(比如他的客户端)。
233 | - 主服务器下线时,在从服务器中**选举**出一个新的主服务器。
234 |
235 | **Sentinel监督服务器:**
236 |
237 | 1. 与主服务器构建连接,每10秒向主服务器发送INFO命令,分析回复消息分析主服务器状态。
238 | 2. 从主服务器状态中获取从服务器信息,并与他们建立连接。达到全覆盖的目的。
239 |
240 | **Sentinel互相监督:**
241 |
242 | 1. Sentinel和服务器之间建立hello频道连接
243 | 2. Sentinel在hello频道发送信息时会被其他Sentinel发现,达到握手的目的。
244 | 3. 发现后,Sentinel之间建立连接,形成环形网络。
245 |
246 | **Sentinel监督下线:**
247 |
248 | - 按频率向所有创建连接的实例发送PING,查看是否回复PONG来判断是否在线,不回复则**标记为主观下线状态**。
249 | - 向其他Sentinel询问,如果足够数量的Sentinel也标记为下线状态,则改为**客观下线**。
250 |
251 | **Sentinel下线补救措施:**
252 |
253 | **(1)选举领头的Sentinel**
254 |
255 | 过程:一个Sentinel向另一个Sentinel发送设置请求命令。**最先向目标Sentinel**发送设置要求的源Sentinel将成为目标Sentinel的局部领头Sentinel,而之后接收到的所有设置要求都会被目标Sentinel拒绝。
256 |
257 | 如果有某个Sentinel**被半数**以上的Sentinel设置成了局部领头Sentinel,那么这个Sentinel成为领头Sentinel。
258 |
259 | **(2)故障转移**
260 |
261 | 1. 从已下线的主服务器的从服务器中**拔举**一个作为主服务器。标准:**偏移量最大**
262 | 2. 让已下线主服务器属下的所有从服务器改为复制新的主服务器
263 | 3. 将已下线主服务器设置为新的主服务器的从服务器,当这个旧的主服务器重新上线时,它就会成为新的主服务器的从服务器。
264 |
265 | # 6. 多机架构
266 |
267 | ## 6.1 Redis有哪些多机架构?
268 |
269 | 不考虑中间件,原生的架构有**主从复制架构**和**集群架构**。
270 |
271 | ## 6.2 介绍一下复制过程
272 |
273 | Redis中复制有新老两版。
274 |
275 | 老版:分为同步和命令传播两个阶段。
276 |
277 | ---
278 |
279 | **老版:**
280 |
281 | **在同步阶段:**
282 |
283 | 1. 从机向主机发送SYNC命令
284 | 2. 主机收到后,执行BGSAVE生成RDB文件,并使用缓冲区记录现在开始执行的所有写操作。
285 | 3. 将RDB文件发给从服务器
286 | 4. 将缓冲区内容发送给从服务器
287 |
288 | **在命令传播阶段:**
289 |
290 | 主服务器将自己执行的写命令发送给从服务器,让他执行相同的命令
291 |
292 | **缺陷:**
293 |
294 | 初次复制效果较好,但断线后重连复制效率很低,需要全部重录RDB文件。
295 |
296 | ---
297 |
298 | **新版:**
299 |
300 | 分为完整重同步和部分重同步,前者和旧版一样。部分重同步有三个部分:
301 |
302 | - 主从服务器的复制偏移量
303 | - 主服务器的复制积压缓冲区
304 | - 服务器的运行ID
305 |
306 | 主服务器和从服务器会分别维护一个复制偏移量,通过对比偏移量来知道主从服务器是否处于一致状态:
307 |
308 | - 主服务器每次向从服务器传播N个字节的数据时,就将自己的复制偏移量的值加上N。
309 | - 从服务器每次收到主服务器传播来的N个字节的数据时,就将自己的复制偏移量的值加上N。
310 |
311 | 复制积压缓冲区是由主服务器维护的一个**固定长度**(fixed-size)先进先出(FIFO)队列。当主服务器进行命令传播时,它不仅会将写命令发送给所有从服务器,还会**将写命令入队到复制积压缓冲区里面**。同时,主服务器也会向积压缓冲区添加偏移量。重新上线时根据偏移量决定如何重同步:
312 |
313 | - 下线后,数据长度超过了缓冲区,导致溢出,说明下线时间太长,执行完全重同步。
314 | - 否则,部分重同步。
315 |
316 | 而主服务器ID则帮助重新上线的从服务器识别,
317 |
318 | - 如果ID和从服务器记录的相同,则表示**之前同步的主服务器就是这个**,执行部分重同步。
319 | - 如果ID不同,则表明从**服务器断线之前复制的主服务器并不是当前连接的这个主服务器**,执行完整重同步操作。
320 |
321 | ## 6.3 介绍一下集群
322 |
323 | 集群通过分片(sharding)来进行数据共享,并提供复制和故障转移功能,保证高可用性。
324 |
325 | **集群的结构**是:多个节点(node)组成一个集群,节点是Redis中数据存储的单位,在刚开始的时候,每个节点都是相互独立的。通过`CLUSTER MEET`命令相互握手,组成集群。
326 |
327 | **集群数据的存储方式**是:集群的整个数据库被分一万多个槽(slot)**,**数据库中的每个键都属于槽的其中一个。当所有槽都有节点在处理时,集群处于上线状态。
328 |
329 | ## 6.4 集群的通信方式是怎样的?
330 |
331 | 集群依靠消息通信,消息有5种:MEET, PING, PONG, FAIL, PUBLISH。
332 |
333 | Redis集群中的各个节点通过**Gossip协议**来交换各自关于不同节点的状态信息,其中Gossip协议由MEET、PING、PONG三种消息实现。
334 |
335 | ---
336 |
337 | 所谓Gossip是八卦消息的意思,在Redis中,发送每次发送MEET、PING、PONG消息时,发送者都从自己的已知节点列表中**随机选出两个节点**(可以是主节点或者从节点),保存到一个特殊结构体中。
338 |
339 | 接受者接收到MEET、PING、PONG消息时,根据保存的两个节点是否认识来选择进行哪种操作:
340 |
341 | - 不认识,说明接收者**第一次接触被选中节点**,则接收者与被选中节点握手
342 | - 认识,根据结构信息进行更新。
343 |
344 | 比如A节点发送的PING给B,携带了CD两个节点,然后B回复PONG携带了EF两个节点,这样就完成了ABCDEF六个节点的信息交换。**每个节点按照周期向不同节点传播PING-PONG信息,就能完成整个集群的状态更新。**
345 |
346 | ---
347 |
348 | 如果节点很多,则Gossip消息比较慢,而主节点下线的消息需要立即通知给所有人。FAIL消息的正文只包含已下线的节点名称,直接通知给所有已知节点。
349 |
350 | 
351 |
352 | 
353 |
354 | ---
355 |
356 | 接收到PUBLISH命令的节点**不仅会向channel频道发送消息message,它还会向集群广播一条PUBLISH消息,所有接收到这条PUBLISH消息的节点都会向channel频道发送message消息**。
357 |
358 | 也就是说,向集群发送`PUBLISH `,会导致集群所有节点都向channel发送message消息。
359 |
360 | 
361 |
362 | ## 6.5 集群分片的原理是什么?
363 |
364 | Redis引入了哈希槽的概念,通过槽指派的方式存储数据。
365 |
366 | Redis集群有$2^{14}=16384$个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽`slot = CRC16(key) & 16383`,集群的每个节点负责一部分hash槽。
367 |
368 | **使用哈希槽的好处就在于可以方便的添加或移除节点。**
369 |
370 | 1. 当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;
371 | 2. 当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了。
372 |
373 | CRC16算法能分配65535个槽位,但作为包发送太臃肿,一般情况下一个redis集群不会有超过1000个master节点,所以采用$1/4$
374 |
375 | ## 6.6 集群扩容和收缩是怎么实现的?
376 |
377 | 集群的伸缩是通过重新分片的方式实现的,重新分片操作可以将**任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点)**,并且相关槽所属的键值对也会从源节点被移动到目标节点。
378 |
379 | 重新分片操作可以**在线(online)进行**,在重新分片的过程中,集群不需要下线,并且**源节点和目标节点都可以继续处理命令请求**。
380 |
381 | 重新分片由redis-trib负责,步骤如下:
382 |
383 | 1. trib向源节点发送命令,包含了执行迁移的槽slot,要迁移键的数量count。
384 | 2. 源节点返回属于槽slot的count个键。
385 | 3. 对于每个返回键,trib向源节点发送一个MIGRATE命令
386 | 4. 源节点根据MIGRATE命令将键迁移到目标节点,
387 |
388 | 
389 |
390 | 如果多槽,则分别对不同槽执行多次。
391 |
392 | # 7. 持久化
393 |
394 | ## 7.1 为什么采用持久化?
395 |
396 | 持久化有两个作用:方便主从复制和灾难恢复。
397 |
398 | 由于Redis的数据全都放在内存而不是磁盘里面,如果Redis挂了,没有配置持久化的话,重启的时候数据会全部丢失。所以需要将数据写入磁盘,本地化保存。
399 |
400 | ## 7.2 持久化的方式有哪些?
401 |
402 | 有RDB持久化和AOF持久化。
403 |
404 | ---
405 |
406 | RDB持久化:
407 |
408 | 将数据库状态以RDB文件格式保存。可以采用SAVE命令阻塞服务器进程,也可以用BGSAVE命令fork一个子进程。
409 |
410 | 通过周期性函数serverCron不断的判断保存条件,如果条件满足就保存。
411 |
412 | ---
413 |
414 | AOF持久化:
415 |
416 | AOF(Append Only File)**记录Redis服务器所执行的写命令**。AOF实现原理是**命令追加**和**文件写入同步**,
417 |
418 | - 命令追加:服务器执行完一个命令后,会以协议格式将命令**追加到服务器状态aof_buf缓冲区的结尾**
419 | - 文件写入同步:服务器每次结束一个事件循环之前都**考虑是否需要将`aof_buf`缓冲区中的内容写入和保存到AOF文件里面**。
420 |
421 | AOF还原时需要建立一个不带网络连接的伪客户端,因为Redis的命令只能在客户端上下文中执行。
422 |
423 | ## 7.3 AOF的重写是什么意思?
424 |
425 | 随着时间的增长,AOF文件的大小将会越来越大。通过重写,Redis服务器可以创建一个新的AOF文件来替代现有的AOF文件,新旧两个**AOF文件保存的数据库状态完全相同**,但新的文件体积更小。
426 |
427 | 重写的策略是:**从数据库中读取键现在的值,然后用一条命令去记录键值对**。相当于折叠命令,只求最终结果。
428 |
429 | 此外,子进程AOF重写时,主进程也在写命令,导致两者状态不一致。因此,**Redis服务器设置了一个AOF重写缓冲区**,当Redis服务器执行完一个写命令之后,它会**同时**将这个写命令发送给**AOF缓冲区**和**AOF重写缓冲区**。
430 |
431 | ## 7.4 AOF和RDB优劣势比较
432 |
433 | RDB
434 |
435 | 优势:完整,恢复迅速
436 |
437 | 劣势:消耗资源大,每次保存的间隔周期长,丢失数据多
438 |
439 | ---
440 |
441 | AOF
442 |
443 | 优势:保存间隔短,丢失数据少,系统资源消耗少。保存格式清晰,适合误操作的恢复。
444 |
445 | 劣势:恢复速度较慢,需要建立伪客户端,如果发生崩溃的情况需要尽快恢复,最好采用RDB。重写后数据保存不一定完整,可能有BUG。
446 |
447 | # 8. 事务
448 |
449 | ## 8.1 什么是事务?
450 |
451 | Redis通过MULTI、EXEC、WATCH等命令来实现事务(transaction)功能。事务将**一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制**,并且在事务执行期间,**服务器不会中断事务**而改去执行其他客户端的命令请求。
452 |
453 | ## 8.2 Redis中事务是如何实现的?
454 |
455 | 事务从开始到结束经历三个阶段:
456 |
457 | 1. 事务开始
458 | 2. 事务入队
459 | 3. 事务执行
460 |
461 | ---
462 |
463 | 通过MULTI命令可以将执行该命令的客户端**从非事务状态切换至事务状态**,在是事务状态下,
464 |
465 | - 如果客户端发送EXEC,DISCARD,WATCH,MULTI这四个命令,则立即执行。
466 | - 如果发送的是其他命令,则放到事务队列里面,向客户端返回QUEUED回复。
467 |
468 | ---
469 |
470 | 每个Redis客户端都有自己的**事务状态结构体**,每个结构体中又包含了一个**事务队列**和**已入队命令计数器。**在事务队列中包含了**具体的命令cmd**。
471 |
472 | ---
473 |
474 | 当一个处于事务状态的客户端向服务器发送EXEC命令时,这个EXEC命令将立即被服务器执行。**服务器会遍历这个客户端的事务队列,执行队列中保存的所有命令,最后将执行命令所得的结果全部返回给客户端。**过程是:
475 |
476 | 1. 创建空白回复队列
477 | 2. 抽取一条命令,读取参数、参数个数以及要执行的函数
478 | 3. 行命令,取得返回值
479 | 4. 将返回值追加到1中的队列末尾,重复步骤2
480 | 5. 完成后,清除事务标志,回到非事务状态,同时清空计数器和释放事务队列。
481 |
482 | ## 8.3 事务中的乐观锁是什么?
483 |
484 | 乐观锁,也称CAS(check and set),属于无罪推定原则,每次别人拿数据都假定他不修改,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。
485 |
486 | Redis中通过WATCH来实现,它可以**在EXEC命令执行之前**,**监视任意数量的数据库键**,并在EXEC命令执行时,**检查被监视的键是否被其他客户修改过,**如果是的话,**服务器将拒绝执行事务**,并向客户端返回代表事务执行失败的空回复。
487 |
488 | ## 8.4 WATCH命令的原理是什么?
489 |
490 | 每个Redis数据库都保存着一个`watched_keys`字典,这个字典的**键是某个被WATCH命令监视的数据库键**,而**字典的值则是一个链表,链表中记录了所有监视相应数据库键的客户端**。
491 |
492 | 对数据库**执行修改命令**时,会对字典进行检查。**查看当前命令修改的键是否在`watched_keys`字典中**,如果有,且事务标志被打开**,表示该客户端的事务安全性已经被破坏**。将`REDIS_DIRTY_CAS`标识打开。
493 |
494 | 在EXEC命令执行时,检查`REDIS_DIRTY_CAS`标志是否打开判断是否应该执行。
495 |
496 | ## 8.5 解释一下事务的ACID性质
497 |
498 | 所谓ACID性质是指:**有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、耐久性(Durability)。**
499 |
500 | **原子性**:事务在执行前用WATCH检查,命令有没有被插入执行过。
501 |
502 | **一致性**:**入队错误**:事务入队时命令格式不正确,则Redis拒绝执行;**执行错误**:执行时操作不正确,会被服务器识别,并做错误处理,所以这些出错命令不会对数据库做任何修改;**停机后**根据持久化,也能还原为一致状态。
503 |
504 | **隔离性**:单线程,且事务不会被打断,串行的方式保证不同事务的隔离性(不保证键不会冲突)
505 |
506 | **耐久性**:不一定,得看哪种持久化,只有always模式下的AOF才有。(每次执行命令都会调用同步函数)
--------------------------------------------------------------------------------