├── Roam_DB
├── August 15th, 2022.md
├── Zettelkasten.md
├── TODO
│ └── DONE.md
├── roam
│ └── templates.md
└── White Paper.md
├── docs.index
├── .idea
├── .gitignore
├── vcs.xml
├── misc.xml
├── inspectionProfiles
│ └── profiles_settings.xml
├── modules.xml
└── notion-qa.iml
├── faiss_store.pkl
├── images
├── export_roam.png
├── export_format.png
├── roam-qa-example.png
└── roam-qa-example-cn.png
├── Roam-Export-1675782732639.zip
├── requirements.txt
├── qa.py
├── LICENSE
├── ingest.py
├── main.py
├── .gitignore
└── README.md
/Roam_DB/August 15th, 2022.md:
--------------------------------------------------------------------------------
1 | {{embed-path: ((rdJcOMHVE))}}
2 |
3 |
--------------------------------------------------------------------------------
/docs.index:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JimmyLv/roam-qa/HEAD/docs.index
--------------------------------------------------------------------------------
/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # Default ignored files
2 | /shelf/
3 | /workspace.xml
4 |
--------------------------------------------------------------------------------
/faiss_store.pkl:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JimmyLv/roam-qa/HEAD/faiss_store.pkl
--------------------------------------------------------------------------------
/images/export_roam.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JimmyLv/roam-qa/HEAD/images/export_roam.png
--------------------------------------------------------------------------------
/images/export_format.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JimmyLv/roam-qa/HEAD/images/export_format.png
--------------------------------------------------------------------------------
/images/roam-qa-example.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JimmyLv/roam-qa/HEAD/images/roam-qa-example.png
--------------------------------------------------------------------------------
/Roam-Export-1675782732639.zip:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JimmyLv/roam-qa/HEAD/Roam-Export-1675782732639.zip
--------------------------------------------------------------------------------
/images/roam-qa-example-cn.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/JimmyLv/roam-qa/HEAD/images/roam-qa-example-cn.png
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | langchain==0.0.58
2 | openai
3 | tiktoken
4 | faiss-cpu
5 | streamlit
6 | streamlit-chat
7 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/.idea/inspectionProfiles/profiles_settings.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/notion-qa.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
--------------------------------------------------------------------------------
/qa.py:
--------------------------------------------------------------------------------
1 | """Ask a question to the Roam Research graph."""
2 | import faiss
3 | from langchain import OpenAI
4 | from langchain.chains import VectorDBQAWithSourcesChain
5 | import pickle
6 | import argparse
7 |
8 | parser = argparse.ArgumentParser(description='Ask a question to the Roam DB.')
9 | parser.add_argument('question', type=str, help='The question to ask the Roam DB')
10 | args = parser.parse_args()
11 |
12 | # Load the LangChain.
13 | index = faiss.read_index("docs.index")
14 |
15 | with open("faiss_store.pkl", "rb") as f:
16 | store = pickle.load(f)
17 |
18 | store.index = index
19 | chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
20 | result = chain({"question": args.question})
21 | print(f"Answer: {result['answer']}")
22 | print(f"Sources: {result['sources']}")
23 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2022 Harrison Chase
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/ingest.py:
--------------------------------------------------------------------------------
1 | """This is the logic for ingesting Roam data into LangChain."""
2 | from pathlib import Path
3 | from langchain.text_splitter import CharacterTextSplitter
4 | import faiss
5 | from langchain.vectorstores import FAISS
6 | from langchain.embeddings import OpenAIEmbeddings
7 | import pickle
8 |
9 |
10 | # Here we load in the data in the format that Roam exports it in.
11 | ps = list(Path("Roam_DB/").glob("**/*.md"))
12 |
13 | data = []
14 | sources = []
15 | for p in ps:
16 | with open(p) as f:
17 | data.append(f.read())
18 | sources.append(p)
19 |
20 | # Here we split the documents, as needed, into smaller chunks.
21 | # We do this due to the context limits of the LLMs.
22 | text_splitter = CharacterTextSplitter(chunk_size=1500, separator="\n")
23 | docs = []
24 | metadatas = []
25 | for i, d in enumerate(data):
26 | splits = text_splitter.split_text(d)
27 | docs.extend(splits)
28 | metadatas.extend([{"source": sources[i]}] * len(splits))
29 |
30 | filtered_docs = list(filter(None, docs))
31 | print(f"Filter Docs: {filtered_docs}")
32 |
33 | # Here we create a vector store from the documents and save it to disk.
34 | store = FAISS.from_texts(filtered_docs, OpenAIEmbeddings(), metadatas=metadatas)
35 | faiss.write_index(store.index, "docs.index")
36 | store.index = None
37 | with open("faiss_store.pkl", "wb") as f:
38 | pickle.dump(store, f)
39 |
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | """Python file to serve as the frontend"""
2 | import streamlit as st
3 | from streamlit_chat import message
4 | import faiss
5 | from langchain import OpenAI
6 | from langchain.chains import VectorDBQAWithSourcesChain
7 | import pickle
8 |
9 | # Load the LangChain.
10 | index = faiss.read_index("docs.index")
11 |
12 | with open("faiss_store.pkl", "rb") as f:
13 | store = pickle.load(f)
14 |
15 | store.index = index
16 | chain = VectorDBQAWithSourcesChain.from_llm(llm=OpenAI(temperature=0), vectorstore=store)
17 |
18 |
19 | # From here down is all the StreamLit UI.
20 | st.set_page_config(page_title="Roam Research QA Bot", page_icon=":robot:")
21 | st.header("Roam Research QA Bot")
22 |
23 | if "generated" not in st.session_state:
24 | st.session_state["generated"] = []
25 |
26 | if "past" not in st.session_state:
27 | st.session_state["past"] = []
28 |
29 |
30 | def get_text():
31 | input_text = st.text_input("You: ", "What's the content of Roam Research's white paper?", key="input")
32 | return input_text
33 |
34 |
35 | user_input = get_text()
36 |
37 | if user_input:
38 | result = chain({"question": user_input})
39 | output = f"Answer: {result['answer']}\nSources: {result['sources']}"
40 |
41 | st.session_state.past.append(user_input)
42 | st.session_state.generated.append(output)
43 |
44 | if st.session_state["generated"]:
45 |
46 | for i in range(len(st.session_state["generated"]) - 1, -1, -1):
47 | message(st.session_state["generated"][i], key=str(i))
48 | message(st.session_state["past"][i], is_user=True, key=str(i) + "_user")
49 |
--------------------------------------------------------------------------------
/Roam_DB/Zettelkasten.md:
--------------------------------------------------------------------------------
1 | ## Roam Team Videos::
2 |
3 | ### Live Zettling on Roam by [[Conor White-Sullivan]]
4 |
5 | {{[[video]]:https://www.youtube.com/watch?v=ScRrcL__SSI&t=2029s&ab_channel=ConorWhite-Sullivan}}
6 | #[[Current time]] | #[[Page References]] | #[[Block References]] | #[[Indentation]] | #[[Daily Notes]] | #[[Right Sidebar]] | #[[Block Embed]] | #[[Alias]] | #[[TODO/DONE]] | #[[Indentation]] | #[[Query]] | #[[Table]]
7 |
8 | Articles::
9 |
10 | ### [Active Reading in Roam Research Featuring the Zettelkasten Method](https://padminipyapali.medium.com/zettelkasten-method-roam-research-f7b341f14fbd) by [[Padmini Pyapali]]
11 |
12 | #[[Block References]] | #[[Page References]]
13 |
14 | ### [Implementing Zettelkasten in Roam: A Practical Guide](https://www.roambrain.com/implementing-zettelkasten-in-roam/) by [[RoamBrain]]
15 |
16 | #[[Page References]] | #[[Block References]]
17 |
18 | ### [Roamkasten - a practical how to guide to optimize Zettelkasten in Roam Research](https://www.thrivinghenry.com/writings/roamkasten-a-practical-how-to-guide-to-optimize-zettelkasten-in-roam-research) by [[Thriving Henry]]
19 |
20 |
21 | #[[Page References]] | #[[Linked References]] | #[[Unlinked References]] | #[[Indentation]] |
22 |
23 | ### [Roamkasten - a practical how to guide to optimize Zettelkasten in Roam Research](https://www.thrivinghenry.com/writings/roamkasten-a-practical-how-to-guide-to-optimize-zettelkasten-in-roam-research) by [[Thriving Henry]]
24 |
25 | #[[Page References]] | #[[Linked References]] | #[[Unlinked References]] | #[[Indentation]] | #[[Block References]] | #[[Right Sidebar]]
26 |
27 |
28 |
29 | ## Community Videos::
30 |
31 | ### How to Take Smart Notes | Zettelkasten Method in Roam Research by [[Shu Omi]]
32 |
33 | {{[[video]]: https://www.youtube.com/watch?v=ljyo_WAJevQ&t=188s&ab_channel=ShuOmi}}
34 | #[[Page References]] | #[[Right Sidebar]] | #[[Block References]] | #[[Linked References]] | #[[Filter]]
35 |
36 | ### How Taking Smart, Simple Notes Will Make You a Better Writer
37 | by [[Drew Coffman]]
38 |
39 | {{[[video]]: https://www.youtube.com/watch?v=wMOACjJzfgM}}
40 |
41 | ### Roam Tour: Professor [[Joel Chan]]- Zettelkasten and Evergreen Notes for Generative Thought by [[Robert Haisfield]]
42 |
43 | {{[[video]]: https://www.youtube.com/watch?v=A6PIrVZoZAk&ab_channel=RobertHaisfield}}
44 | #[[Page References]] | #[[Right Sidebar]] | #[[Query]] | #[[Linked References]] | #[[Indentation]]
45 |
46 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea/
2 |
3 | # Byte-compiled / optimized / DLL files
4 | __pycache__/
5 | *.py[cod]
6 | *$py.class
7 |
8 | # C extensions
9 | *.so
10 |
11 | # Distribution / packaging
12 | .Python
13 | build/
14 | develop-eggs/
15 | dist/
16 | downloads/
17 | eggs/
18 | .eggs/
19 | lib/
20 | lib64/
21 | parts/
22 | sdist/
23 | var/
24 | wheels/
25 | pip-wheel-metadata/
26 | share/python-wheels/
27 | *.egg-info/
28 | .installed.cfg
29 | *.egg
30 | MANIFEST
31 |
32 | # PyInstaller
33 | # Usually these files are written by a python script from a template
34 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
35 | *.manifest
36 | *.spec
37 |
38 | # Installer logs
39 | pip-log.txt
40 | pip-delete-this-directory.txt
41 |
42 | # Unit test / coverage reports
43 | htmlcov/
44 | .tox/
45 | .nox/
46 | .coverage
47 | .coverage.*
48 | .cache
49 | nosetests.xml
50 | coverage.xml
51 | *.cover
52 | *.py,cover
53 | .hypothesis/
54 | .pytest_cache/
55 |
56 | # Translations
57 | *.mo
58 | *.pot
59 |
60 | # Django stuff:
61 | *.log
62 | local_settings.py
63 | db.sqlite3
64 | db.sqlite3-journal
65 |
66 | # Flask stuff:
67 | instance/
68 | .webassets-cache
69 |
70 | # Scrapy stuff:
71 | .scrapy
72 |
73 | # Sphinx documentation
74 | docs/_build/
75 |
76 | # PyBuilder
77 | target/
78 |
79 | # Jupyter Notebook
80 | .ipynb_checkpoints
81 |
82 | # IPython
83 | profile_default/
84 | ipython_config.py
85 |
86 | # pyenv
87 | .python-version
88 |
89 | # pipenv
90 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
91 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
92 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
93 | # install all needed dependencies.
94 | #Pipfile.lock
95 |
96 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
97 | __pypackages__/
98 |
99 | # Celery stuff
100 | celerybeat-schedule
101 | celerybeat.pid
102 |
103 | # SageMath parsed files
104 | *.sage.py
105 |
106 | # Environments
107 | .env
108 | .venv
109 | env/
110 | venv/
111 | ENV/
112 | env.bak/
113 | venv.bak/
114 |
115 | # Spyder project settings
116 | .spyderproject
117 | .spyproject
118 |
119 | # Rope project settings
120 | .ropeproject
121 |
122 | # mkdocs documentation
123 | /site
124 |
125 | # mypy
126 | .mypy_cache/
127 | .dmypy.json
128 | dmypy.json
129 |
130 | # Pyre type checker
131 | .pyre/
132 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Roam Research Question-Answering
2 |
3 | 🤖Ask questions to your Roam Research graph in natural language🤖
4 |
5 | 💪 Built with [LangChain](https://github.com/hwchase17/langchain)
6 |
7 | 🤯 Inspired by [hwchase17/notion-qa](https://github.com/hwchase17/notion-qa)
8 |
9 | # 🌲 Environment Setup
10 |
11 | In order to set your environment up to run the code here, first install all requirements:
12 |
13 | ```shell
14 | pip install -r requirements.txt
15 | ```
16 |
17 | Then set your OpenAI API key (if you don't have one, get one [here](https://beta.openai.com/playground))
18 |
19 | ```shell
20 | export OPENAI_API_KEY=....
21 | ```
22 |
23 | # 📄 What is in here?
24 | - Example data from Blendle
25 | - Python script to query Roam Graph with a question
26 | - Code to deploy on StreamLit
27 | - Instructions for ingesting your own dataset
28 |
29 | ## 📊 Example Data
30 | This repo uses the [Roam Help Graph](https://roamresearch.com/#/app/help) as an example.
31 | It was downloaded at [[February 7, 2023]] so may have changed slightly since then!
32 |
33 | ## 💬 Ask a question
34 | In order to ask a question, run a command like:
35 |
36 | ```shell
37 | python qa.py "What's the content of Roam Research's white paper?"
38 | ```
39 |
40 |
41 |
42 | You can switch out `What's the content of Roam Research's white paper?` for any question of your liking!
43 |
44 | Of course, OpenAI also supports other languages, such as Chinese:
45 |
46 |
47 |
48 | This exposes a chat interface for interacting with a Roam Research graph.
49 | IMO, this is a more natural and convenient interface for getting information.
50 |
51 | ## 🚀 Code to deploy on StreamLit
52 |
53 | The code to run the StreamLit app is in `main.py`.
54 | Note that when setting up your StreamLit app you should make sure to add `OPENAI_API_KEY` as a secret environment variable.
55 |
56 | ## 🧑 Instructions for ingesting your own dataset
57 |
58 | Export your dataset from Roam Research. You can do this by clicking on the three dots in the upper right hand corner and then clicking `Export`.
59 |
60 |
61 |
62 | When exporting, make sure to select the `Flat Markdown` format option.
63 |
64 |
65 |
66 | This will produce a `.zip` file in your Downloads folder. Move the `.zip` file into this repository.
67 |
68 | Run the following command to unzip the zip file (replace the `Export...` with your own file name as needed).
69 |
70 | ```shell
71 | unzip Roam-Export-1675782732639.zip -d Roam_DB
72 | ```
73 |
74 | Run the following command to ingest the data.
75 |
76 | ```shell
77 | python ingest.py
78 | ```
79 |
80 | Boom! Now you're done, and you can ask it questions like:
81 |
82 | ```shell
83 | python qa.py "What's the content of Roam Research's white paper?"
84 | ```
85 |
86 | ## Trouble Shooting
87 |
88 | ```shell
89 | openai.error.RateLimitError: Rate limit reached for default-global-with-image-limits in organization org-xxxxxxxxxxxxxxxxxxxx on requests per min. Limit: 60.000000 / min. Current: 70.000000 / min. Contact support@openai.com if you continue to have issues. Please add a payment method to your account to increase your rate limit. Visit https://platform.openai.com/account/billing to add a payment method.
90 | ```
91 |
92 | Maybe you can try to upgrade the account access.
93 |
--------------------------------------------------------------------------------
/Roam_DB/TODO/DONE.md:
--------------------------------------------------------------------------------
1 | TODOs are the core of [task management]([[Task Management]]). We have been using them in our bullet journals, task apps, and now... Roam.
2 |
3 | Creating TODOs in Roam is incredibly easy! Below are different ways to do that:
4 |
5 | **Right clicking on the bullet**
6 |
7 | 1. `Right-click` on the bullet you want to transform into a todo.
8 | 2. Click on `Make TODO`
9 |
10 | **Using the keyboard shortcut**
11 |
12 | 1. While you're editing the block you want to transform into a TODO, press:
13 |
14 | `cmd+return` (macOS)
15 |
16 | `ctrl+enter` (PC)
17 |
18 | **Using the** [[/ Commands]] **Menu**
19 |
20 | 1. Type `/`
21 | 2. Hit `enter`
22 |
23 | ## Roam Team Videos::
24 |
25 | {{[[video]]: https://www.youtube.com/watch?v=3aCl7dCYVqA&t=6s&ab_channel=ConorWhite-Sullivan}}
26 | #[[TODO/DONE]] | #[[Daily Notes]] | #[[Filter]] | #[[Linked References]] | #[[Block Embed]] | #[[Current time]] | #[[Block References]]
27 |
28 | {{[[video]]: https://www.youtube.com/watch?v=asQ4RSjjCu4&ab_channel=ConorWhite-Sullivan}}
29 | #[[TODO/DONE]] | #[[Linked References]]
30 |
31 | ## Team GIFs::
32 |
33 | ### Cycling state in one block
34 |
35 | 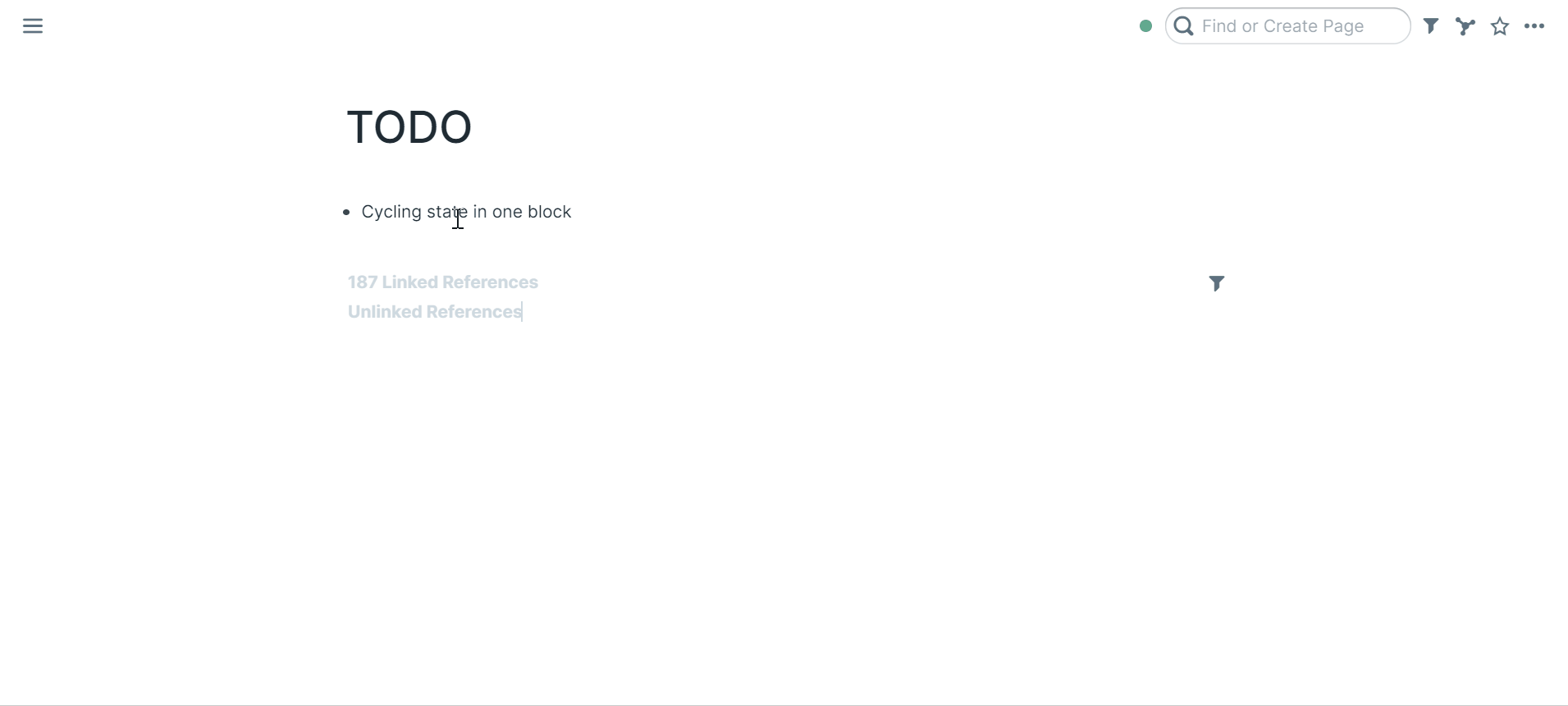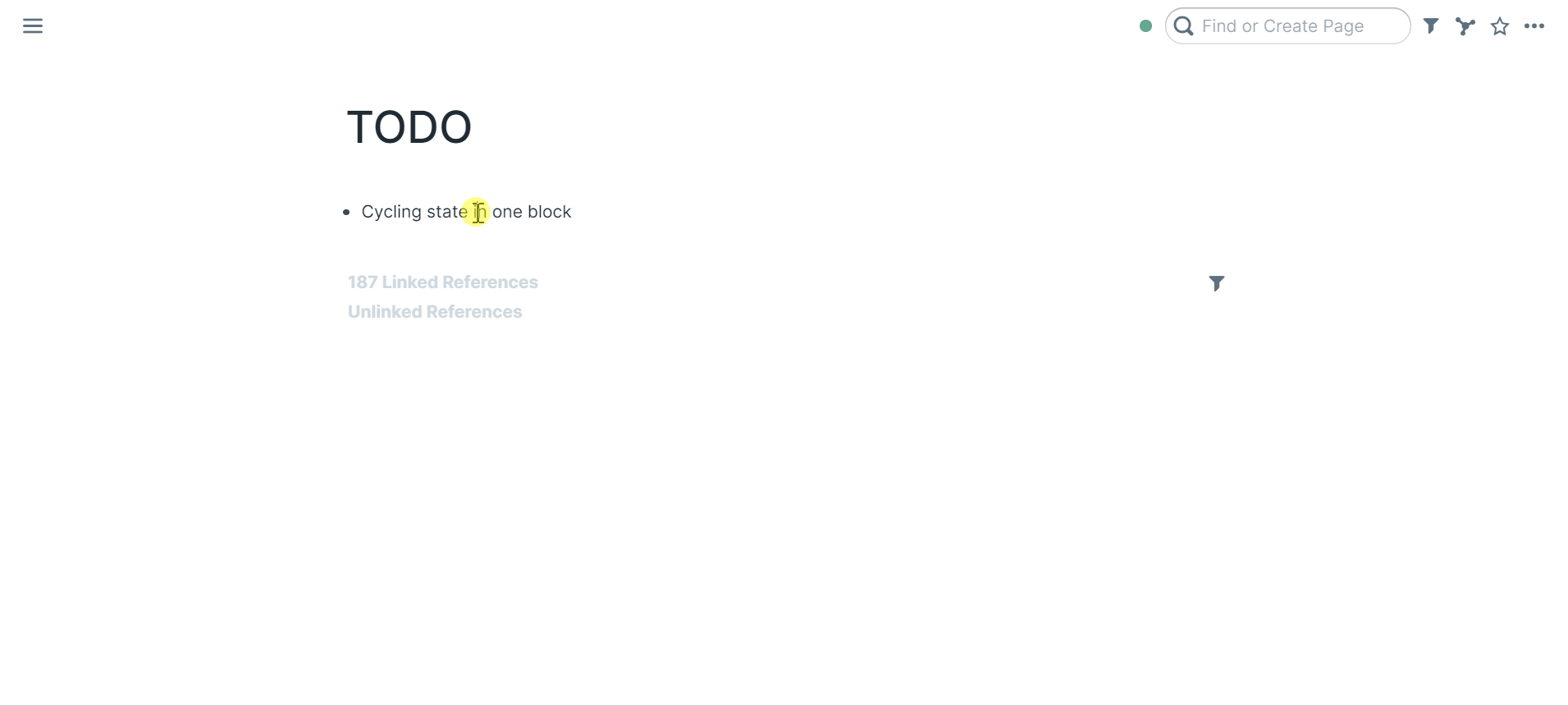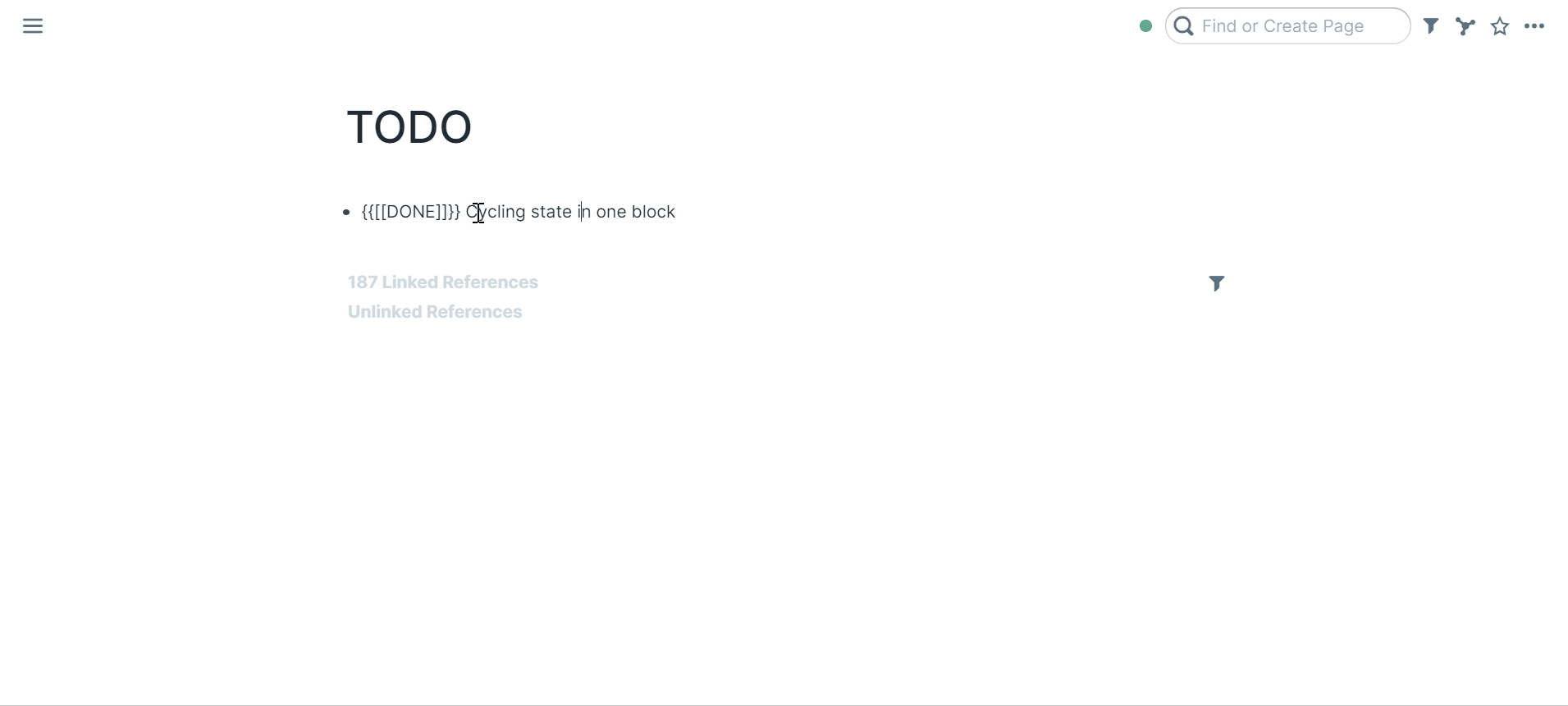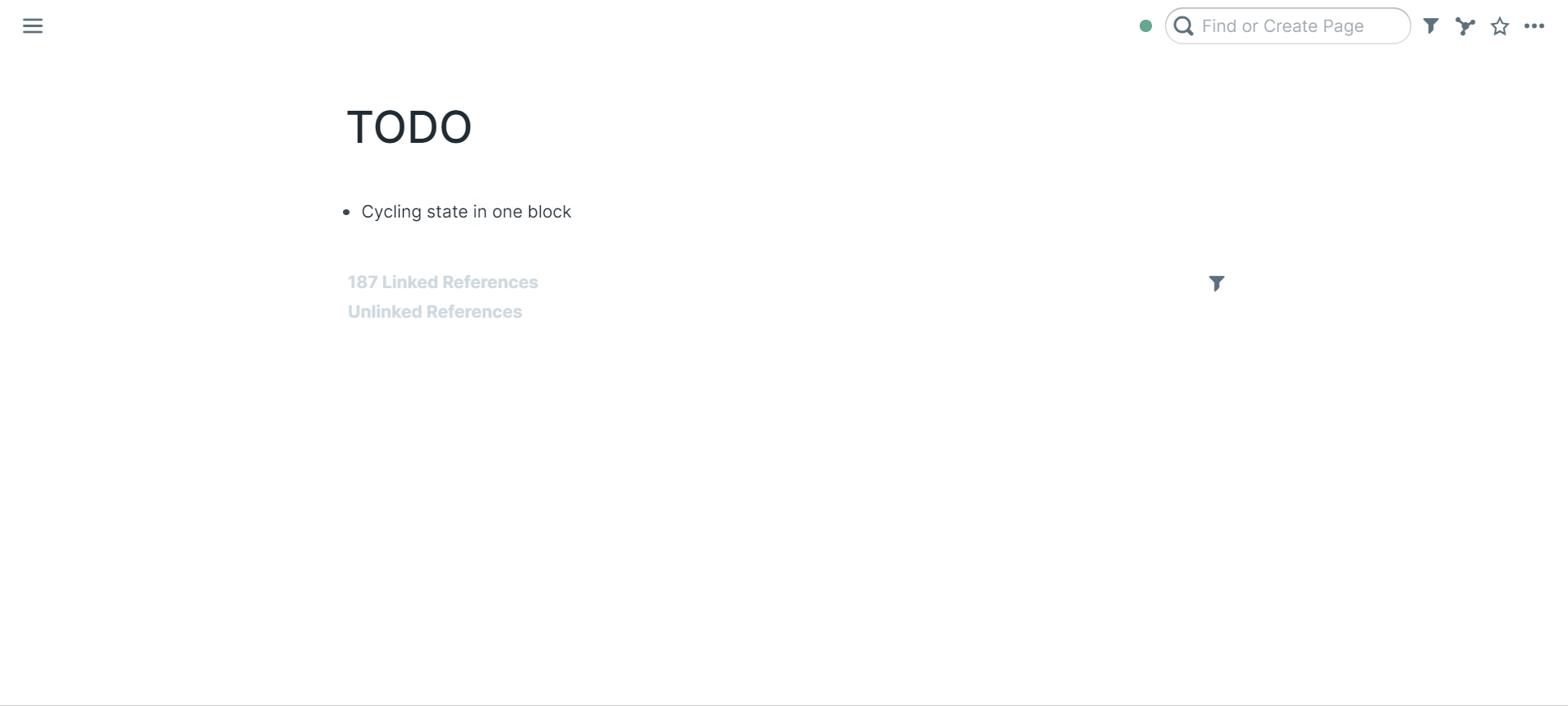
36 |
37 | Select a block
38 |
39 | Press `ctrl+enter` (PC) / `cmd+return` (macOS)
40 |
41 | ### Cycling state in multiple blocks
42 |
43 | 
44 |
45 | Select multiple blocks
46 |
47 | Press Ctrl+enter (PC) / Cmd+enter (macOS)
48 |
49 | ### Checking todo box and unchecking it
50 |
51 | 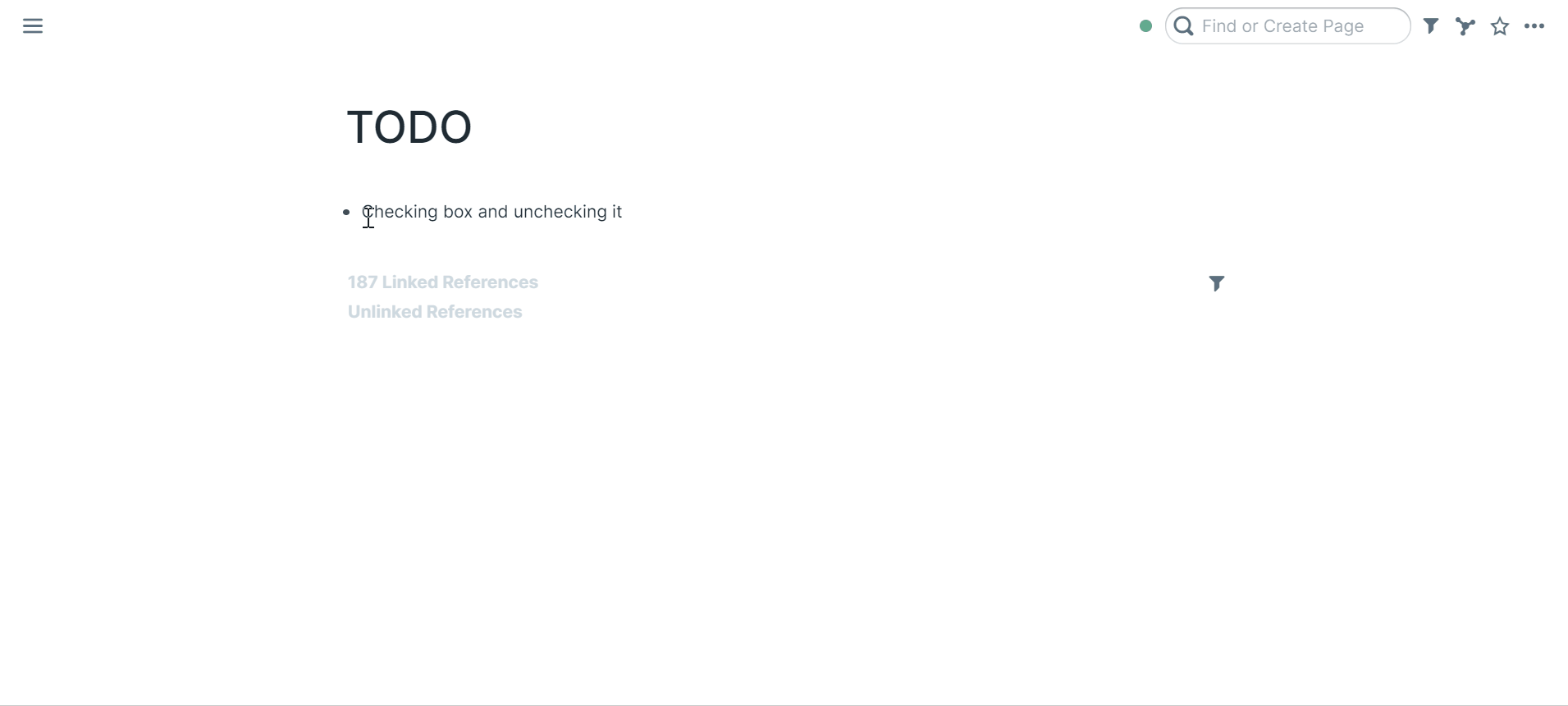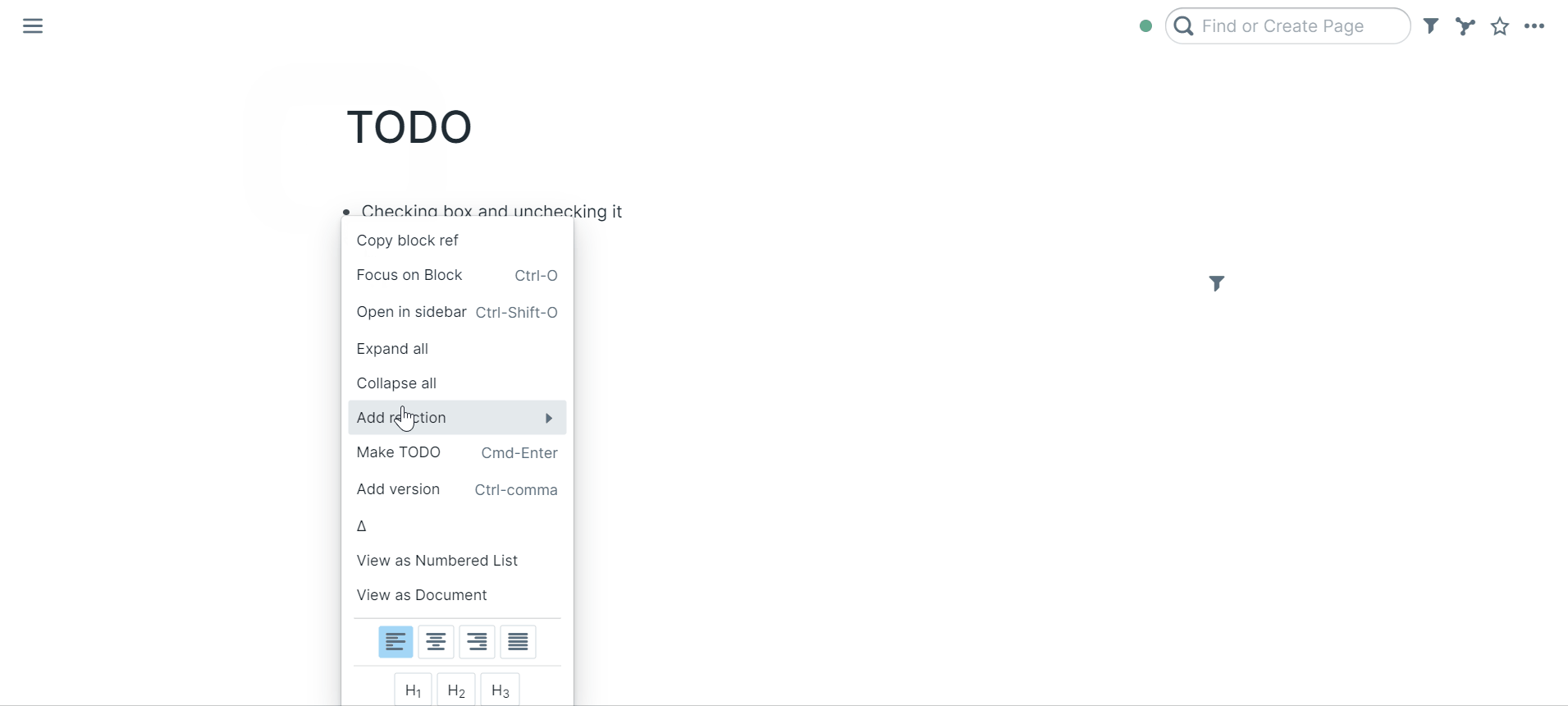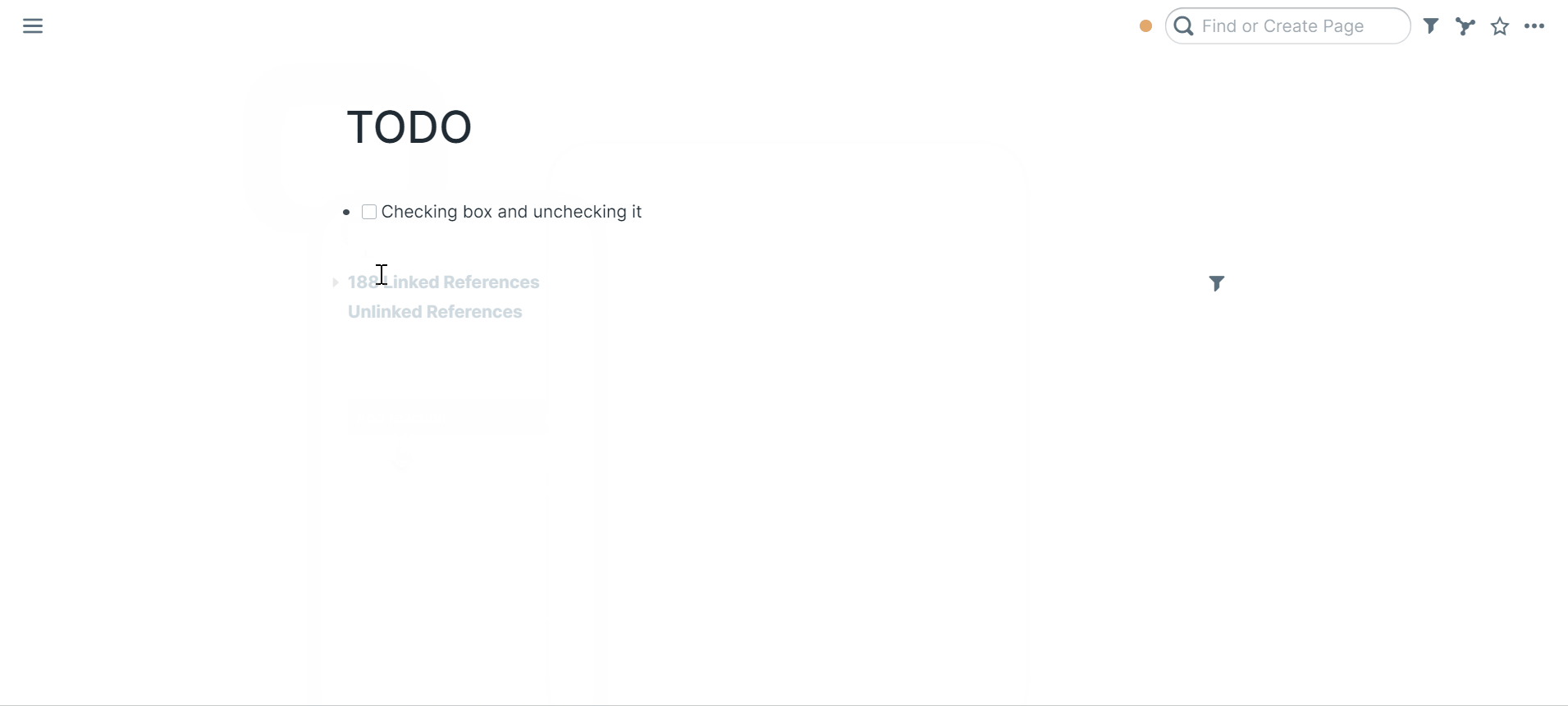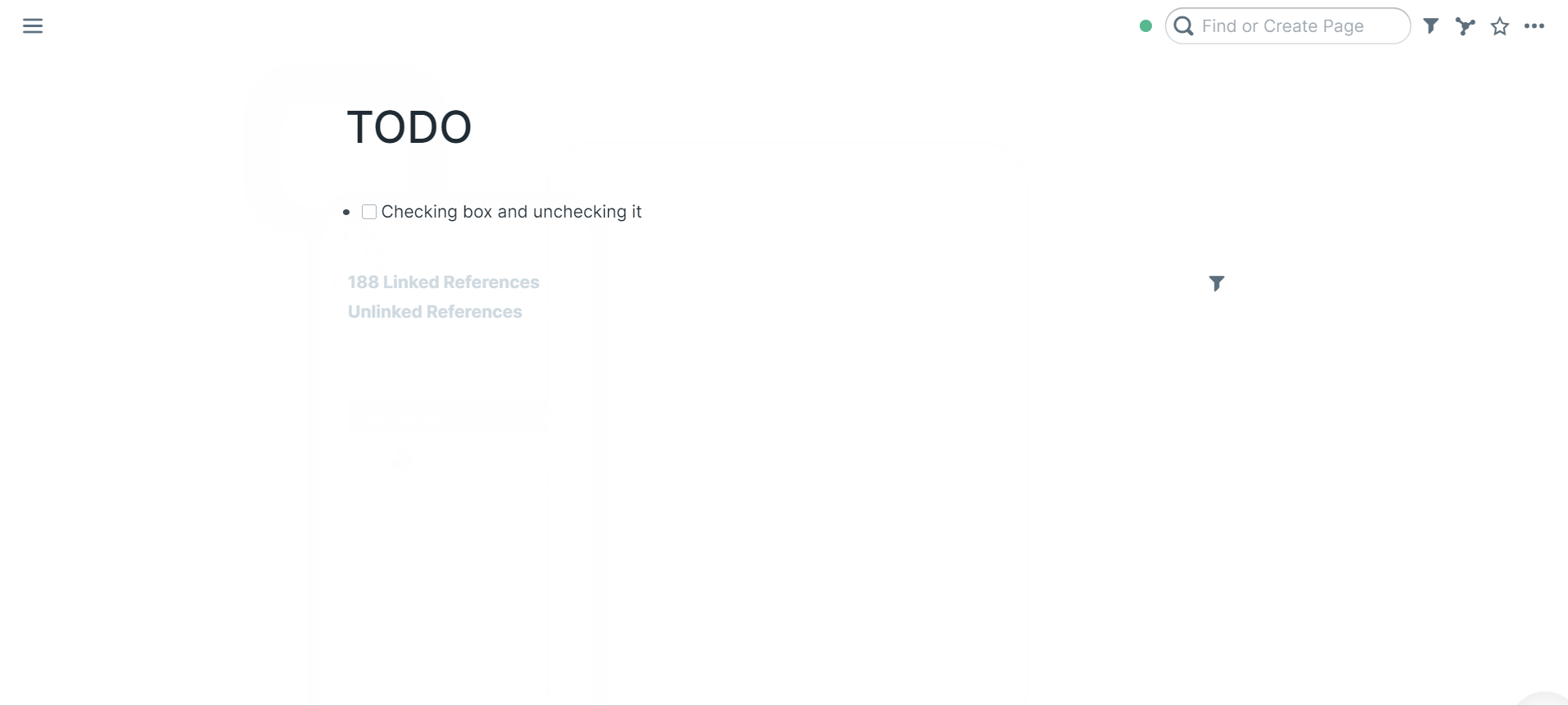
52 |
53 | You can also right click the bullet to "Make TODO"
54 |
55 | Click the todo box to mark it TODO or DONE
56 |
57 | ## Community Videos::
58 |
59 | ### Roam Research: TODOs by [[Les Kristofs]]
60 |
61 | {{[[video]]: https://www.youtube.com/watch?v=3taL1v-IKXg}}
62 | #[[TODO/DONE]] | #[[Linked References]] | #[[/ Commands]]
63 |
64 | ### Roam: How to Make a Master Task List on Roam by [[Shu Omi]]
65 |
66 | {{[[video]]: https://www.youtube.com/watch?v=mIEgS0JkJBo&t=5s&ab_channel=ShuOmi}}
67 | #[[TODO/DONE]] | #[[Page References]] | #[[Filter]] | #[[Daily Notes]]
68 |
69 | ### Plan Your Day With The Magic List (Roam Research Task Management) by [[Daniel Wirtz]]
70 |
71 | {{[[video]]: https://www.youtube.com/watch?v=5U62cEE7QsM&t=6s&ab_channel=DanielWirtz}}
72 | #[[TODO/DONE]] | #[[Query]] | #[[Page References]] | #[[Daily Notes]] | #[[Block References]]
73 |
74 | ### Todoist to Roam Research - Advanced Task Management in Roam by [[Matt Goldenberg]]
75 |
76 | {{[[video]]: https://www.youtube.com/watch?v=xOTTyLtgqpM}}
77 | #[[roam/css]] | #[[Extensions]] | #[[roam/js]] | #[[Sidebar]] | #[[TODO/DONE]] | #[[Query]]
78 |
79 | ## Articles::
80 |
81 | ### [Using Roam Research for GTD-Style Task Management – The Sweet Setup](https://thesweetsetup.com/using-roam-research-for-gtd-style-task-management/)
82 |
83 | #[[Daily Notes]] | #[[TODO/DONE]] | #[[Page References]] | #[[Query]] | #[[Linked References]]
84 |
85 | ### [Using TODO to Get Things Done with Roam Research (GTD) — Roam Tips & Hacks](https://www.roamtips.com/home/use-todo-get-things-done-roam-research-gtd)
86 |
87 | #[[TODO/DONE]] | #[[Page References]] | #[[Date picker]] | #[[Filter]]
88 |
89 | ## Key Commands::
90 |
91 | Cycle through TODO/DONE state:
92 |
93 | `cmd+return` for macOS
94 |
95 | `ctrl+enter` for Windows
96 |
97 |
--------------------------------------------------------------------------------
/Roam_DB/roam/templates.md:
--------------------------------------------------------------------------------
1 | Dev docs #.h
2 |
3 | Tutorials::
4 |
5 | How-to guides::
6 |
7 | [[Reference]]
8 |
9 | [[Examples]]
10 |
11 | [[Community]]
12 |
13 | Roam Daily Template
14 |
15 | Designer:: [[Jonathan Borichevskiy]]
16 |
17 | Special Features::
18 |
19 | #Slider | #Tags | #TODO/DONE
20 |
21 | Templates::
22 |
23 | Last updated:: [[February 27th, 2021]]
24 |
25 | Weekly Agenda (created on a different day, and embedded with /Block Reference)
26 |
27 | [[Morning Questions]]
28 |
29 | {{[[slider]]}} How many hours of sleep did I get?
30 |
31 | What's one thing top of mind today?
32 |
33 | What's the one thing I need to get done today to make progress?
34 |
35 | Review #[[Index: Questions]] #values
36 |
37 | Agenda
38 |
39 | {{[[TODO]]}} Morning walk #goal-health #habit
40 |
41 | {{[[TODO]]}} Check calendar for scheduled events
42 |
43 | {{[[TODO]]}} Morning focus hour
44 |
45 | {{[[TODO]]}} Read 30 minutes #goal-learning #habit
46 |
47 | {{[[TODO]]}} Review Readwise.io
48 |
49 | {{[[TODO]]}} 10 minutes meditation #goal-health #habit
50 |
51 | {{[[TODO]]}} Workout or run #goal-health #habit
52 |
53 | {{[[TODO]]}} Evening focus hour
54 |
55 | {{[[TODO]]}} Do 7 - 30 - 90 review
56 |
57 | {{[[TODO]]}} read for pleasure, watch something, go for a walk
58 |
59 | [[Evening Questions]]
60 |
61 | List three things I'm grateful for #habit #gratitude
62 |
63 | What made me happy today?
64 |
65 | What made me sad?
66 |
67 | Where there any signs of my day going to shit that I could recognize?
68 |
69 | What prevented me from reaching my goals today?
70 |
71 | What am I looking forward to?
72 |
73 | Skeletons/Methods/Tags/Tools
74 |
75 | Designer:: [[Samuel Orion]]
76 |
77 | Special Features::
78 |
79 | #[[Attributes]] | #[[Kanban]]
80 |
81 | Templates::
82 |
83 | Last updated:: [[July 1st, 2020]]
84 |
85 | ### Article::
86 |
87 | **Topic:**
88 |
89 | **Tags: **
90 |
91 | **URL**:
92 |
93 | **Quotes / Summary:**
94 |
95 | **Comments / Questions:**
96 |
97 | ### Book::
98 |
99 | **Quotes / Summary:**
100 |
101 | **Comments / Questions:**
102 |
103 | **Topic**:
104 |
105 | **Tags**:
106 |
107 | **URL**:
108 |
109 | Podcast
110 |
111 | Show:
112 |
113 | Speaker(s):
114 |
115 | Topic:
116 |
117 | Tags:
118 |
119 | URL:
120 |
121 | Summary:
122 |
123 | Videos
124 |
125 | Speaker:
126 |
127 | Tags:
128 |
129 | Summary:
130 |
131 | Link or Embed:
132 |
133 | Projects
134 |
135 | Due Date:
136 |
137 | Completed Date:
138 |
139 | Status:
140 |
141 | Related Goals:
142 |
143 | Success Criteria:
144 |
145 | Tags:
146 |
147 | Quarterly Preview
148 |
149 | Review [[Yearly Planning]]
150 |
151 | My biggest wins
152 |
153 | Process on annual goals for this quarter (% successful)
154 |
155 | Overall, what worked and what didn’t?
156 |
157 | What will you keep doing?
158 |
159 | What will you start doing?
160 |
161 | What will you improve?
162 |
163 | What will you stop doing?
164 |
165 | [[tools]]
166 |
167 | [[Find and replace]]
168 |
169 | [[KANBAN BOX]]
170 |
171 | {{kanban}}
172 |
173 | indent once for column title
174 |
175 | and another item
176 |
177 | this could be a great way to write an articles / thesis - very easy to read
178 |
179 | clock on the block to open the side bar - and see furtherinfo
180 |
181 | I was in column 2, now I am in column 1
182 |
183 | This is a second collum
184 |
185 | I was in column 1, now I am in column 2 - just click and drag
186 |
187 | indent again for items to put in list (ps look at the next level)
188 |
189 | stuff inside
190 |
191 | A third column
192 |
193 | more stuff
194 |
195 | Daily Log
196 |
197 | Designer:: [[Mark Robertson]]
198 |
199 | Twitter:: [@calhistorian](https://twitter.com/calhistorian)
200 |
201 | Special Features::
202 |
203 | #[[Attributes]] | #[[Query]] | #[[TODO/DONE]]
204 |
205 | 
206 |
207 | Code::
208 |
209 | Last updated:: [[July 1st, 2020]]
210 |
211 | #[[Morning Review]]
212 |
213 | #[[Weather Report]]
214 |
215 | Location:: #Home
216 |
217 | Weather Summary:: Weather Data (Summary)
218 |
219 | Conditions:: Weather Data (Condition) with Weather Data (Precipitation Chance)
220 |
221 | H/L Temp:: High - Weather Data (High), Low - Weather Data (Low)
222 |
223 | #[[Sleep Log]]
224 |
225 | Sleep Time::
226 |
227 | Sleep Quality::
228 |
229 | #[[Morning Pages]]
230 |
231 | #[[Morning Reflection]]
232 |
233 | {{[[query]]: {and: [[-1 Day]] [[Evening Pages]] {not: [[query]]}}}}
234 |
235 | [[Who benefits from your work?]]
236 |
237 | [[What am I grateful for?]]
238 |
239 | [[What do I want the day’s highlight to be?]]
240 |
241 | [[Daily Affirmations]]
242 |
243 | [[What am I think of?]]
244 |
245 | #[[Open Questions]]
246 |
247 | {{[[query]]: {and: [[Question]] [[TODO]] {not: {or:[[query]] [[DONE]] [[Templates]]}}}}}
248 |
249 | #[[Calendar]]
250 |
251 | #Family
252 |
253 | Family Events
254 |
255 | #Professional
256 |
257 | #[[Pedagogical Reflections]]
258 |
259 | #[[Daily Notes]]
260 |
261 | #[[Action List]]
262 |
263 | {{[[TODO]]}} Process Linked and Unlinked Mentions
264 |
265 | {{[[query]]: {and: [[TODO]] [[Action]] {not: {or: [[query]] [[Subtask:]]}}}}}
266 | #[[Upcoming]]
267 |
268 | {{[[query]]: {and: [[TODO]] [[Scheduled]] {not: {or: [[query]] [[Action]]}} {between: [[Today's Date]] [[+2 Weeks]]}}}}
269 |
270 | #[[Evening Review]]
271 |
272 | {{[[TODO]]}} #[[Evening Pages]]
273 |
274 | [[Amazing things that happened]]
275 |
276 | [[What I have learned]]
277 |
278 | [[What could I have done better?]]
279 |
280 | #[[Capture Inbox]]
281 |
282 | The Roam Team
283 |
284 | Contact
285 |
286 | Name::
287 |
288 | Email::
289 |
290 | Company::
291 |
292 | Phone::
293 |
294 | Choice
295 |
296 | {{[[TODO]]}} [[Choice]]
297 |
298 | Context::
299 |
300 | Options::
301 |
302 | Decision::
303 |
304 | Daily agenda Updated
305 |
306 | [[Daily agenda]]
307 |
308 | {{[[kanban]]}}
309 |
310 | All day
311 |
312 | 00:00
313 |
314 | 01:00
315 |
316 | 02:00
317 |
318 | 03:00
319 |
320 | 04:00
321 |
322 | 05:00
323 |
324 | 06:00
325 |
326 | 07:00
327 |
328 | 08:00
329 |
330 | 09:00
331 |
332 | 10:00
333 |
334 | 11:00
335 |
336 | 12:00
337 |
338 | 13:00
339 |
340 | 14:00
341 |
342 | 15:00
343 |
344 | 16:00
345 |
346 | 17:00
347 |
348 | 18:00
349 |
350 | 19:00
351 |
352 | 20:00
353 |
354 | 21:00
355 |
356 | 22:00
357 |
358 | 23:00
359 |
360 | [[Need to plan]]
361 |
362 | An Engineering Problem Solving Process
363 |
364 | ^^An engineered, systematic approach to problem solving can be invaluable in solving problems, capturing knowledge, and discovering solutions.^^ An approach that I suggest involves starting with a simple outline consisting of the following sections (as appropriate - sometimes it makes sense to combine or eliminate certain sections). Feel free to delete this paragraph as you fill out the template.
365 |
366 | Problem Statement:: This should be a simple 1-2 sentence (no more!) statement of the problem. Do not describe symptoms. To the best of your ability, reduce the problem to its bare essence here. Over time this statement may be refined. A key principle is that ^^if you cannot state your problem concisely, you probably don't know what it is and you almost certainly cannot communicate it effectively to others^^.
367 |
368 | Description:: Here you provide a detailed description of the problem.
369 |
370 | Describe why you want to solve this problem (if you do) and what, if anything, makes this problem particularly hard. This can be particularly valuable if you are considering writing new code. Sometimes after further evaluation you will realize it is better to use an alternative or take no action at present.
371 |
372 | Sometimes it is worth capturing the ideas but saving the solution for another time.
373 |
374 | Given:: List all things that have been provided to you, including facts, stories, etc.
375 |
376 | Required:: State all of the requirements to be met to provide a solution to the problem.
377 |
378 | Functional/User (Required): These are the things that a user must be able to do to solve the problem. They may be stated as user stories such as "As a user, I can do X so that Y." If you do not state who can do what and why, then the requirement is suspect.
379 |
380 | Nonfunctional/Technical: Technical requirements often revolve around criteria such as scaling, cost, operations, etc. I often recommend a different page for technical requirements as it is easy for problem solvers (especially developers) to move towards a technical solution (a form) prior to actually understanding the problem to be solved (the function).[1](((https://en.wikipedia.org/wiki/Form_follows_function)))
381 |
382 | Knowns:: State all the things you know about the problem. Provide links, references, citations, etc. as needed to trace the lineage of each known item.
383 |
384 | Unknowns:: What don't you know about the problem. Here you will try to anticipate the questions that you need to answer to better understand the problem.
385 |
386 | Alternative presentations of knowns and unknowns could include a Johari Window[2](((https://en.wikipedia.org/wiki/Johari_window))) or a "Rumsfeld-esque"[3](((https://en.wikipedia.org/wiki/There_are_known_knowns))) categorization.
387 |
388 | {{[[table]]}}
389 |
390 |
391 |
392 | Known to Self
393 |
394 | Not Known to Self
395 |
396 | Known to Others
397 |
398 | Arena
399 |
400 | Blind Spot
401 |
402 | Not Known to Others
403 |
404 | Facade
405 |
406 | Unknown
407 |
408 | Assumptions:: What do you believe to be true regarding this problem?
409 |
410 | Alternatives:: What alternatives already exist to this problem? What do you do now to solve the problem? What happens if you do nothing? If this is a technical solution, can an existing solution be used?
411 |
412 | Solution:: Based on all of the previous information, provide the solution to the problem. This could be a technical solution, process, new product, etc. Note that if multiple solutions are provided (suppose you provide multiple product offerings to solve the same problem) it is perfectly appropriate to have subpages for each solution.
413 |
414 | Recommendations:: An alternative to (or something to be used in conjunction with) a solution is one or more recommendations. Again, if appropriate recommendations can merit their own subpages.
415 |
416 | Hickey Design Process
417 |
418 | [[Problems]]
419 |
420 | Take wants/needs and translate them into problems
421 |
422 | [[Symptoms]]
423 |
424 | Symptoms of the problems
425 |
426 | [[Requirements]]
427 |
428 | [[Knowns]]
429 |
430 | What I know how to do
431 |
432 | [[Unknowns]]
433 |
434 | What I don't know how to do
435 |
436 | [[Domain-side]]
437 |
438 | Business requirement
439 |
440 | [[Solution-side]]
441 |
442 | Technical constraints (it has to compile to JS, for example)
443 |
444 | [[Unstated]]
445 |
446 | Things that everyone wants the system to avoid
447 |
448 | Doesn't crash, use too much memory, require too much energy, are examples of unstated requirements
449 |
450 | [[Solutions]]
451 |
452 | Solution A
453 |
454 | Benefits::
455 |
456 |
457 |
458 | Tradeoffs::
459 |
460 |
461 |
462 | Costs::
463 |
464 |
465 |
466 | Problem fit::
467 |
468 |
469 |
470 | Solution B
471 |
472 | Benefits::
473 |
474 |
475 |
476 | Tradeoffs::
477 |
478 |
479 |
480 | Costs::
481 |
482 |
483 |
484 | Problem fit::
485 |
486 |
487 |
488 | Course
489 |
490 | ### [Course name](course link) by `[[Author Name]]` __price__
491 |
492 | 2-3 sentence blurb describing the course
493 |
494 | Theme
495 |
496 | `theme name`
497 |
498 | Screenshots::
499 |
500 | Last updated::
501 |
502 | Designer:: name
503 |
504 | Twitter:: [link to bio]()
505 |
506 | Love this theme? Say thanks via [PayPal]() (and/or other payment service)
507 |
508 | Special Features::
509 |
510 | Code::
511 |
512 | {{[[roam/css]]}}
513 |
514 | ```css
515 | ```
516 |
517 | Plugin
518 |
519 | `plugin_name`
520 |
521 | Info::
522 |
523 | Must include GIF and/or video of usage
524 |
525 | Link::
526 |
527 | Getting started::
528 |
529 | Installation, activation and configuration
530 |
531 | Tutorials::
532 |
533 |
534 |
535 | Reference::
536 |
537 | Developer::
538 |
539 | Twitter::
540 |
541 | Love this plugin? Say thanks via [Paypal]()
542 |
543 | Code::
544 |
545 | Browser Extension
546 |
547 | `browser_extension_name`
548 |
549 | Info::
550 |
551 | Must include GIF and/or video of usage
552 |
553 | Link::
554 |
555 | Getting started::
556 |
557 | Installation, activation and configuration
558 |
559 | Tutorials::
560 |
561 |
562 |
563 | Reference::
564 |
565 | Developer::
566 |
567 | Twitter::
568 |
569 | Love this plugin? Say thanks via [Paypal]()
570 |
571 | Coaching
572 |
573 | `Course Author Name`
574 |
575 | Info::
576 |
577 | Website::
578 |
579 | Areas of specialty::
580 |
581 | Contact::
582 |
583 | Price::
584 |
585 | Docs #.h
586 |
587 | {{[[TODO]]}} Introduction (few bullets) and some GIFs
588 |
589 | Roam Team Videos::
590 |
591 | {{[[TODO]]}}
592 |
593 | Articles::
594 |
595 | {{[[TODO]]}}
596 |
597 | Community Videos::
598 |
599 | {{[[TODO]]}}
600 |
601 | Key Commands::
602 |
603 | Video/article #.h
604 |
605 | {{[[TODO]]}} [Article link]() or {{[[video]]: }}
606 |
607 | Features mentioned::
608 |
609 | Page refs to features
610 |
611 |
--------------------------------------------------------------------------------
/Roam_DB/White Paper.md:
--------------------------------------------------------------------------------
1 | **Abstract**. Roam is an online workspace for organizing and evaluating knowledge. The system is built on a directed graph, which frees it from the constraints of the classic file tree. Users can remix and connect ideas in multiple overlapping hierarchies, with each unit of information becoming a node in a dynamic network. Any given node can occupy multiple positions simultaneously, convey information through defined relationships, and populate changes throughout the graph. With weightings assigned to the strength of relationships between nodes, Roam also becomes a tool for Bayesian inference and decision making. The ultimate goal is to extend the system to collaborative reasoning, allowing groups to build shared mental maps and make faster and better-informed decisions.
2 |
3 | **1. Introduction**
4 |
5 | We are experiencing an unprecedented explosion of knowledge. Every day, 2700 books are published in the United States alone, 6850 scientific papers are authored, more than 2 million blog posts go live, and 294 billion emails fly back and forth. The amount of total data produced with every rotation of the Earth would fill a stack of books stretching to the moon and back. [1](((u-XvVlybt))) While this exponential growth presents enormous opportunities for individuals and society at large, neither the human brain nor current technologies are equipped to harness it to its full potential.
6 |
7 | **2. Current approaches to knowledge management**
8 |
9 | Humans are poorly adapted to the Information Age, which has arisen only in the last ~0.02% of our evolutionary history. While the brain does have a remarkable capacity for raw storage, probably in the range of several petabytes,[2](((PWlZyEjRU))) it is infamously fallible in processing information. Memory retrieval is lossy and unreliable, while many of our hardwired cognitive biases and heuristics misfire in the modern world, distorting our perception, judgement and decision-making ability. The plasticity of the brain enables it to rewire itself with new connections, but even this is a ‘use it or lose it’ feature, causing neglected neural pathways to atrophy.
10 |
11 | Many technologies for organizing knowledge outside of the brain have arisen in response to these limitations. Physical books and journals proliferated after the invention of the Gutenberg Press, and have since been partially supplanted by word processors, websites, blogs, forums, wikis, and software applications.
12 |
13 | While we are presented with a plethora of choices for organizing knowledge, almost every technology follows the same basic ‘file cabinet’ format: A unit of knowledge is saved to a certain file path, which places it within a taxonomy of folders, chapters or categories. Tags may be applied when an item relates to many things, but each file is generally only stored within one nested hierarchy. To access the information, the user must remember where they stored the file, what they tagged it with, or use a search function to locate it.
14 |
15 | Related Twitter Thread
16 |
17 | https://twitter.com/Conaw/status/1099181050045952006
18 |
19 | **3. Problems with the file cabinet approach**
20 |
21 | In some regards, current technologies remain vastly inferior to the human brain. If each neuron only held a single ‘unit’ of memory in this manner, our brains would quickly fill to overflowing. Instead, information is conveyed in the connections between neurons and neural networks, so a common idea can be made available across the entire brain; the concept of a blue sky might be used in countless seemingly discrete memories of time spent outdoors. This efficiency helps to explain why a computer requires several million times more energy to perform the same tasks as a human brain (which runs on about as much power as a dim light bulb).[3](((j6_rKU-PG)))
22 |
23 | Unlike the brain, the file cabinet approach makes it difficult or impossible to remix or reuse the same piece of information. Each time a change is made to any given file, it has to be tracked down and updated in every location in which it exists. This leads to redundancy, with a cluttering of near-identical ideas, and significant work any time a system-wide change is required.
24 |
25 | Current solutions also lack interconnectivity. Many files are divorced from context; cast into a drawer, rather than methodically fitted into a broader framework of knowledge. Knowledge trees can create pseudo-relationships between files nested within a given hierarchy, but these are not explicit, and can only describe a vertical ‘parent and child’ taxonomy. Some tools, such as web pages and wikis, also allow for orthogonal linking between related files, but this takes place in an ad hoc fashion, and again, there is no ability to explicitly define relationships.
26 |
27 | **4. Knowledge graphs as nodal networks **
28 |
29 | Large-scale collaboration requires a more flexible data structure than the classic file tree. Roam is built on a knowledge graph that maps all possible relationships, with ‘smart’ links between defined concepts. Users can connect similar ideas in multiple overlapping hierarchies, remix them without overwriting the original context, and selectively share parts of the graph with others to collaborate on specific sub-questions.
30 |
31 | If current tools resemble filing cabinets, Roam is more akin to the nodal networks in telecommunications, or the neurons in the human brain. Rather than existing in a vacuum, each note or file becomes a node in an interconnected graph of ideas. A single node may simultaneously hold positions in several different sequences, hierarchies or file paths, and can ‘talk’ to other nodes, communicating information back and forth about the nature of each relationship. The network is dynamic, so updates and revisions are populated across the entire graph simultaneously. Individual nodes or branches within the network can be forked as required, allowing a new pathway to deviate without changing the original meaning.
32 |
33 | At the simplest level, Roam’s structure makes it inherently easier to store, recall, and cross-reference ideas. This is the primary proposition for students, writers, self-directed learners, and users of existing note-taking apps.
34 |
35 | For power users, the knowledge graph also unlocks applications in logic and reasoning, Bayesian inference and decision-making, modelling complex problems, and collaborative research.
36 |
37 | These features are explored in Chapters 5 - 8, along with potential use cases for the technology.
38 |
39 | **5. Dependency graphs and logical reasoning**
40 |
41 | Everything from peer-reviewed research papers to the opinion pages of a newspaper are based on formulating arguments that support a certain premise, along the lines of the following:
42 |
43 | If A is true, then B is true.
44 |
45 | If C and D are both true, then A is true.
46 |
47 | C and D are true.
48 |
49 | Therefore, B is true.
50 |
51 | Example:: [[Precise Links]]
52 |
53 | {{embed:((PWRiHAsEv)) }}
54 |
55 |
56 |
57 | Often, C and D will be supported by links to external articles, where they are conclusions reached by larger arguments based on combining other premises. Unfortunately, the structure of the argument is only implied by the prose. Rarely are the relationships between arguments and pieces of evidence explicitly laid out, except perhaps in the notes of the author investigating the claims.
58 |
59 | Roam allows individual researchers or writers to organize all the claims they wish to make across a number of different projects. It also creates opportunities for large-scale interdisciplinary research projects. When teams of interested collaborators have an agreed-upon structure for formatting arguments and counterarguments, it is possible to create expandable user interfaces which “bubble up” insight from claims which require expertise, to ones that are more easily understood by laypersons.
60 |
61 | The ambiguity of natural language derails many discussions. Unless [[terms]] are clearly defined from the outset, any form of argument is futile, and will often end up entrenching the initial positions of the interlocutors.
62 |
63 | Example A
64 |
65 | Alice: "A tree falling in a deserted forest makes a sound."
66 |
67 | Bob: "A tree falling in a deserted forest does not make a sound."
68 |
69 | Example B
70 |
71 | Alice: "A tree falling in a deserted forest [generates acoustic vibrations]."
72 |
73 | Bob: "A tree falling in a deserted forest does not [generate auditory experiences]." [4](((T8k78DDAe)))
74 |
75 | While these positions are contradictory as expressed in Example A, simply defining the term ‘sound’ reveals the underlying beliefs are entirely compatible.
76 |
77 | The ability to use clearly defined sets within a dependency graph helps to resolve ambiguity, reducing the chances of participants talking at cross-purposes, or deliberate “motte-and-bailey” style strategic equivocation. [5](((MtGChSUvh)))
78 |
79 | Besides reasoning and argument, dependency graphs have applications in education, self-directed learning, and general decision-making. Even a very complicated project can be traced backwards to a number of smaller [[task]]s. The user can see the tradeoffs involved in each pathway, map out which route is the fastest, and which path might bring them closer to other interesting goals. As the student marks their progress, they can discover new projects and pathways which make use of the skills they have acquired.
80 |
81 | The problems of prose apply even in the domain of mathematical proofs, see Lamport’s [[How to write a 21st Century Proof]]”
82 |
83 | **6. Untangling complexity**
84 |
85 | **6.1 Nonlinear causality**
86 |
87 | Simple problems often follow a straightforward causal path. When a patient has a range of symptoms strongly associated with the flu, the doctor might conclude from the observable variables that there is one invisible variable - the influenza virus. Treat that latent variable, and the symptoms disappear.
88 |
89 | Scott Alexander observes that his peers in psychiatry similarly try to attribute a collection of linked symptoms to a latent variable; for example, depression. [6](((36qeTMgmO))) However, the symptoms ‘caused’ by depression - e.g. sleep disturbance, fatigue, guilt - can also have a causal effect on one another, and on the disorder itself. This complex web of relationships, which may include feedback loops, does not follow a path of linear causality. For complicated problems of this nature, nodal networks are a much more accurate model:
90 |
91 | A model of major depression (MD) and generalised anxiety disorder (GAD) by Nuijten, Deserno, Cramer, and Borsboom.[7](((rC_nGuzjf))) The disorders roughly map onto clusters of symptoms that are often found together and reinforce one another, but there is no clear ‘bright line’ between the conditions.
92 |
93 | Even at face value, a nodal network provides a visual aid to problem-solving - a bird’s eye view of the connections between various elements. This may help to identify patterns or clusters which may be counterintuitive or entirely invisible when each piece of the puzzle is examined at the object level.
94 |
95 | **6.2 Bayesian reasoning**
96 |
97 | Applying Bayesian reasoning to the knowledge graph makes it a powerful tool for estimating probabilities, testing hypotheses, and making decisions. Bayes’ Theorem is a law of probability that tells us how much we should change our minds about something when we learn a new fact or acquire new evidence. The theorem is stated in the following equation:
98 |
99 | $$P(A|B) = {P(B|A) P(A) \over P(B)}$$
100 |
101 |
102 | where A is the proposition of interest, B is the observed evidence, P(A) and P(B) are prior probabilities, and P(A|B) is the posterior probability of A.
103 |
104 | Suppose a doctor has a patient who is worried about carrying a latent disease, because he belongs to an at-risk group. This is the ‘proposition of interest’ on the left side of the equation. Prior data suggests 4% of the general population are carriers, so $$P(A) = 0.04$$. B is the observed evidence, which is that 32% of the general population are members of the at-risk group. $$P(B) = 0.32$$. The doctor knows that among patients who do carry the disease, 80% belong to the at-risk group: $$B|A = 0.8$$.
105 |
106 | The doctor applies Bayes’ theorem:
107 |
108 | $$P(A|B) = (0.8 * 0.04)/0.32$$
109 |
110 | $$P(A|B) = 0.1$$
111 |
112 | Her patient only has a one in 10 chance of being a carrier - which might be less than expected, given that almost all carriers are members of the at-risk group.
113 |
114 | While this is a simple calculation, the strength of Bayesian reasoning is that it breaks down seemingly insurmountable problems into small pieces. Even where no data are available, successive layers of estimates can still provide useful refinements to the confidence levels of various outcomes. By incorporating this framework into the defined relationships between nodes, revisions to the weightings at any point in the network will automatically populate throughout the knowledge graph.
115 |
116 | Bayesian probability also provides a framework for decision-making. By estimating the costs and tradeoffs of various options, users can calculate which pathway provides the highest expected value. Again, the quality of the decisions can be refined by successive layers of evidence for and against, even when the weightings are simple estimates of personal preference. An evaluation matrix allows someone to integrate a great deal of information into the final decision, rather than defaulting to simple heuristics.
117 |
118 | {{[[TODO]]}} [Example [[Diagrams]] of decision tree/matrix]
119 |
120 | **7. Optimising for **[[Serendipity]]
121 |
122 | Just as humans are incapable of generating random numbers, we struggle to consciously generate random ideas - to the point where actively trying to ‘think differently’ often seems to only further calcify existing patterns. Instead of attempting to brute-force creativity, the brain must be confronted with novel stimuli in order to reorganize its perception. Exposure to a certain amount of random ‘noise’ - drugs, dreams, meditation, Tarot readings, mistakes - can jolt thoughts out of well-tracked grooves and into entirely new areas of idea-space. Typically these insights occur at the juncture of two or more seemingly unrelated fields, concepts, or images.
123 |
124 | The interconnectivity of the Roam knowledge graph constantly creates opportunities for [[Serendipity]] to blossom. Each node in the network can be viewed in several graphical displays, allowing users to see related ideas, scan up and down the vertical hierarchy, examine nearby clusters of nodes, and observe patterns.
125 |
126 | The Roam search function can be calibrated to include as much or as little ‘noise’ as the user desires. While looking for a specific passage or note, search is narrow enough to find exactly what the user has in mind. However, it can also be broadened out for ‘fishing trips’ aimed at surfacing categories of ideas. Some search results will consist of notes that the user might otherwise have forgotten about, some will be noise, and others will spark ideas the user didn’t even know they were looking for.
127 |
128 | The synthesis and cross-pollination of ideas from diverse fields presents low-hanging fruit for both individuals and society. The investment of time and effort required to become a specialist quickly runs into a point of diminishing returns. By contrast, accumulating a ‘talent stack’ of dilettante-level knowledge or skills can unlock insights and opportunities that have not been capitalised on by experts with a narrower focus.
129 |
130 | Highly specialised knowledge remains essential for opening new frontiers. However, an interdisciplinary approach is often required to solve the increasingly complex problems faced by scientists, technologists, and policymakers.
131 |
132 | **8. Collaborative problem-solving**
133 |
134 | While the individual use case for Roam stands on its own merits, the ultimate goal is to create a platform for collaborative research and learning. Current protocols are bound by the assumption of necessary consensus. The flexibility of a curated knowledge graph allows for a more pluralistic approach, with the ability to weight conflicting opinions and separate signal from noise without resorting to either autocracy or democracy.
135 |
136 | 8.1 **Finding signal in the noise**
137 |
138 | As the frequency of information increases, the world becomes noisier and noisier. Deliberate exposure to noise is a useful strategy in specific contexts, as described in Chapter 7, but otherwise obscures meaning. [8](((urKnXjnSR))) Given we have a propensity for imposing stories and explanations onto randomness - the narrative fallacy - it is becoming increasingly difficult to separate out genuine signal from noise.
139 |
140 | Assume a trend has a signal-to-noise ratio of 1:1 on an annual basis (50% of the data are meaningful, 50% are random). Observing the same data on a daily basis, the composition changes to 95% noise, 5% signal. Observing the data hourly (as news hounds and market junkies do), and it becomes 99.5% random - which is to say, two hundred times more noise than signal.[9](((_eOgBulZd)))
141 |
142 | Institutions entrusted with interpreting the data include the media, academia, and legislature. Some agents within these institutions deliberately obscure the truth, as demonstrated by ‘fake news’, p-hacking, and politicking. While actively malicious behaviour is the exception, even the best-intentioned reporters, researchers and analysts are not immune to being fooled by randomness.
143 |
144 | For most people, the problem of sorting signal from noise therefore involves finding trustworthy and accurate secondary sources of information. This difficult [[task]] is often frustrated by gated scientific journals, as well as search engine algorithms increasingly gamed by SEO-savvy content marketers.
145 |
146 | 8.2 **Redundancy**
147 |
148 | Navigating a vast sea of information creates massive redundancy. Most people labour away at problems that have already been solved a million times over. Those who tackle unsolved problems often do so in silos, unaware of each other’s existence. All the pieces of any given puzzle may be present, but no one individual or group holds them all. The wheel is reinvented over and over again, in endless forums and comments sections and web pages and books that burst into existence and fade just as quickly to obscurity.
149 |
150 | The goal of Roam is to enable systematic curation and collaboration on a large scale. Users will be able to selectively share parts of their graphs publicly, or with circles of peers and colleagues. In turn, they will be able to follow the work of persons they trust, whether they be domain experts or enthusiastic amateurs. Those looking to acquire specific knowledge can turn immediately to trusted sources, and set alerts to receive updates about new pieces of information pertaining to an area of interest.
151 |
152 | 8.3 **Dispensing with necessary consensus**
153 |
154 | Almost every medium today presents knowledge as though it were the last word; assuming both a necessary consensus and an uncomposable page. Wikipedia is one of the great wonders of the Internet age, but it makes both of these mistakes. There can only be one article on any subject for any given language, and the only connection between pages is through links, with no article "built" off another.
155 |
156 | By way of contrast, consider Github: Libraries are built on other libraries, and functions are built from other functions. Developers build tools that others can build upon to build ever more impressive tools. Most of the modern web is built on open-source technologies, which would not have been possible if programmers followed the old protocols for intellectual collaboration.
157 |
158 | Many problems can be solved by writing code, but natural language is still the way we determine which problems are worth solving. Natural language is how we explain the world to one another, and communicate our models of reality. It is the language of education. It is the language of decision-making. That language needs a toolchain for collaboration that is just as good as the one for managing code.
159 |
160 | 8.4 **Against autocracy; against democracy**
161 |
162 | The problem of necessary consensus is resolved by individuals or groups assembling their own graph of inferences, based on premises or data curated from their trusted networks. However, collaboration still requires a mechanism for evaluating which ideas are best. In the same way that individuals assign weightings to their personal predictions and decisions, groups must be able to ‘vote’ on the merits of any given idea, premise, or piece of evidence. There are various options for how these collective weightings might be calibrated, some of which are briefly described below.
163 |
164 | a) **Wisdom of crowds**
165 |
166 | A diverse collection of people can make certain decisions and predictions much better than any given individual: The great statistician Francis Galton was stunned to find that 800 people guessing the weight of an ox at a country fair returned an average that was just one pound shy of the correct figure of 1198 pounds.
167 |
168 | In other situations, the opinion of the crowd bears little relationship to objective reality. By definition, the tyranny of the majority will quash any position that is unpopular, regardless of whether it is true. Often, domain-specific knowledge may be required; for example, someone who has not studied free will would only be adding noise by ‘voting’ a preference for compatibilism, hard determinism, or libertarianism.
169 |
170 | Simple popularity contests do not always move us closer to the truth, but they are useful in that they tell us what we believe. This data could potentially be broken down by demographic to demonstrate how different groups perceive reality, and possibly alert users to biases amongst their own in-groups.
171 |
172 | b) **Believability scores**
173 |
174 | Hedge fund manager Ray Dalio pioneered a decision-making system at Bridgewater Associates that is much closer to epistocracy than democracy: The opinions of more “believable” people, who have repeatedly proven their grasp of a given topic or trait, hold more weight than those with lower believability scores. There is nothing to stop Dalio being overruled by his most junior employees, as long are they are consistently more right than he is. Implementing a similar system in Roam would necessitate the ability to track performance, perhaps by how much original content a user has contributed to the graph with broad support, or how well-calibrated their predictions are.
175 |
176 | c) **Prediction markets**
177 |
178 | When people succumb to peer pressure and other biases, do not have enough specialist knowledge, or deliberately make false predictions, the ‘wisdom of the crowd’ can end up being very wrong.
179 |
180 | The insight behind prediction markets is that participants can be incentivised to profit from any such mistakes. Wherever someone believes the consensus is wrong, they can stake money on it, and move the probability back to a better informed position. Insider information is not only permitted, but welcomed. In this way, vast amounts of information can be synthesised into one constantly updated data point, which is often remarkably accurate.
181 |
182 | The uptake and growth of prediction markets has been dampened by regulatory issues, but possible workarounds include a non-fiat token, or reputation-linked points system.
183 |
184 | **9. Conclusion**
185 |
186 | The project of human knowledge, as it stands today, is a vast ocean of ephemeral and fragmented information and ideas, much of it inaccurate, some of it malicious, with the best sources either restricted by gatekeepers, or near-impossible to locate. The volume of information is growing exponentially, which promises enormous opportunities if the underlying coordination problems can be resolved.
187 |
188 | Clearly a fundamentally different approach is required. The Roam vision for human knowledge is a collective, open-source intelligence, constantly rearranging, iterating and evolving in the pursuit of truth. Each of us would become a node within this collective intelligence, forging links and creating networks, sharing the very best each has to offer, improving ourselves even as we improve others, and advancing the interests of humanity as a whole.
189 |
190 | About Roam
191 |
192 | Roam was founded by Conor White-Sullivan and Joshua Brown. Conor has been working on tools for collective intelligence for more than nine years, founding the online town common Localocracy (acquired by AOL in 2011) then leading R&D for Huffington Post following the acquisition. Conor and Josh met at 42.us.org, a tuition-free coding university, where Josh placed in the top five of the first 1000 cadets to enter the US program during the month-long application exam. This white paper was co-authored by business journalist Richard Meadows, whose trial of early prototypes led him to become the first investor in Roam.
193 |
194 | The Roam stack:
195 |
196 | React
197 |
198 | Clojure and Clojurescript
199 |
200 | Datalog
201 |
202 | Contact Conor at cwhitesullivan@gmail.com with any enquiries.
203 |
204 | Notes and references
205 |
206 | [1] At least 2.5 quintillion bytes of information are produced every day, which is about the same amount as was produced during the entire year of 2002.
207 |
208 | [2] Scientific American: New Estimate Boosts the Human Brain's Memory Capacity 10-Fold.
209 |
210 | [3] Microelectronics pioneer Carver Mead, who coined the term Moore’s Law, correctly predicted in 1990 that present-day computers would use ten million times more energy for a single instruction than the brain uses for a synaptic activation.
211 |
212 | [4] This example is adapted from the Less Wrong sequence 37 Ways Words Can be Wrong.
213 |
214 | [5] Motte-and-bailey refers to arguing an easy-to-defend and often common-sense statement (the motte), in order to ward off critics from a hard-to-defend and more controversial statement (the bailey). The term was popularised by Scott Alexander, and explained in All in All, Another Brick in the Motte.
215 |
216 | [6] Slate Star Codex: Mental disorders as networks.
217 |
218 | [7] Michèle B. Nuijten, Marie K. Deserno, Angélique O. J. Cramer, Denny Borsboom: An introduction and overview of a network approach to psychopathology.
219 |
220 | [8] As Carl Sagan observed, while more data is broadcast in TV programs every day than the combined written works of all of history, "not all bits have equal value".
221 |
222 | [9] This example comes from Nassim Taleb’s Antifragile.
223 |
224 | Further Reading
225 |
226 | Daniel Kahneman, Thinking, Fast and Slow
227 |
228 | Robin Hanson, Could Gambling Save Science?
229 |
230 | [[Ray Dalio]], [[Principles]]
231 |
232 | H Van Dyke Paranuk, Don’t Link Me In: Set Based Hypermedia for Taxonomic Reasoning
233 |
234 | [[Michael Nielsen]], Reinventing Discovery: The New Era of Networked Science
235 |
236 | Richards J Heuer The Psychology of Intelligence Analysis
237 |
238 | Leslie Lamport: [[How to write a 21st Century Proof]]
239 |
240 | Douglas Engelbart, [[Augmenting the Human Intellect: A Conceptual Framework]]
241 |
242 | About this Paper
243 |
244 | We wrote this White Paper in Winter of 2017/2018, and while it still reflects much of our vision for the tool, some of the features -- particularly related to [[Bayesian Reasoning]], [[Argument Analysis]], and [[Prediction Markets]] we found to be in-fact much lower priority for the researchers and decision makers whose thinking we aim to assist -- and risked making the tool too complex for the more significant use cases. If you are interested in using Roam for more formal Quantitative Reasoning or building out formal models of belief networks, or if you are excited about ideas in this paper which you do not see a way to do currently within Roam, please contact us.
245 |
246 |
--------------------------------------------------------------------------------
 41 |
42 | You can switch out `What's the content of Roam Research's white paper?` for any question of your liking!
43 |
44 | Of course, OpenAI also supports other languages, such as Chinese:
45 |
46 |
41 |
42 | You can switch out `What's the content of Roam Research's white paper?` for any question of your liking!
43 |
44 | Of course, OpenAI also supports other languages, such as Chinese:
45 |
46 |  47 |
48 | This exposes a chat interface for interacting with a Roam Research graph.
49 | IMO, this is a more natural and convenient interface for getting information.
50 |
51 | ## 🚀 Code to deploy on StreamLit
52 |
53 | The code to run the StreamLit app is in `main.py`.
54 | Note that when setting up your StreamLit app you should make sure to add `OPENAI_API_KEY` as a secret environment variable.
55 |
56 | ## 🧑 Instructions for ingesting your own dataset
57 |
58 | Export your dataset from Roam Research. You can do this by clicking on the three dots in the upper right hand corner and then clicking `Export`.
59 |
60 |
47 |
48 | This exposes a chat interface for interacting with a Roam Research graph.
49 | IMO, this is a more natural and convenient interface for getting information.
50 |
51 | ## 🚀 Code to deploy on StreamLit
52 |
53 | The code to run the StreamLit app is in `main.py`.
54 | Note that when setting up your StreamLit app you should make sure to add `OPENAI_API_KEY` as a secret environment variable.
55 |
56 | ## 🧑 Instructions for ingesting your own dataset
57 |
58 | Export your dataset from Roam Research. You can do this by clicking on the three dots in the upper right hand corner and then clicking `Export`.
59 |
60 |  61 |
62 | When exporting, make sure to select the `Flat Markdown` format option.
63 |
64 |
61 |
62 | When exporting, make sure to select the `Flat Markdown` format option.
63 |
64 |  65 |
66 | This will produce a `.zip` file in your Downloads folder. Move the `.zip` file into this repository.
67 |
68 | Run the following command to unzip the zip file (replace the `Export...` with your own file name as needed).
69 |
70 | ```shell
71 | unzip Roam-Export-1675782732639.zip -d Roam_DB
72 | ```
73 |
74 | Run the following command to ingest the data.
75 |
76 | ```shell
77 | python ingest.py
78 | ```
79 |
80 | Boom! Now you're done, and you can ask it questions like:
81 |
82 | ```shell
83 | python qa.py "What's the content of Roam Research's white paper?"
84 | ```
85 |
86 | ## Trouble Shooting
87 |
88 | ```shell
89 | openai.error.RateLimitError: Rate limit reached for default-global-with-image-limits in organization org-xxxxxxxxxxxxxxxxxxxx on requests per min. Limit: 60.000000 / min. Current: 70.000000 / min. Contact support@openai.com if you continue to have issues. Please add a payment method to your account to increase your rate limit. Visit https://platform.openai.com/account/billing to add a payment method.
90 | ```
91 |
92 | Maybe you can try to upgrade the account access.
93 |
--------------------------------------------------------------------------------
/Roam_DB/TODO/DONE.md:
--------------------------------------------------------------------------------
1 | TODOs are the core of [task management]([[Task Management]]). We have been using them in our bullet journals, task apps, and now... Roam.
2 |
3 | Creating TODOs in Roam is incredibly easy! Below are different ways to do that:
4 |
5 | **Right clicking on the bullet**
6 |
7 | 1. `Right-click` on the bullet you want to transform into a todo.
8 | 2. Click on `Make TODO`
9 |
10 | **Using the keyboard shortcut**
11 |
12 | 1. While you're editing the block you want to transform into a TODO, press:
13 |
14 | `cmd+return` (macOS)
15 |
16 | `ctrl+enter` (PC)
17 |
18 | **Using the** [[/ Commands]] **Menu**
19 |
20 | 1. Type `/`
21 | 2. Hit `enter`
22 |
23 | ## Roam Team Videos::
24 |
25 | {{[[video]]: https://www.youtube.com/watch?v=3aCl7dCYVqA&t=6s&ab_channel=ConorWhite-Sullivan}}
26 | #[[TODO/DONE]] | #[[Daily Notes]] | #[[Filter]] | #[[Linked References]] | #[[Block Embed]] | #[[Current time]] | #[[Block References]]
27 |
28 | {{[[video]]: https://www.youtube.com/watch?v=asQ4RSjjCu4&ab_channel=ConorWhite-Sullivan}}
29 | #[[TODO/DONE]] | #[[Linked References]]
30 |
31 | ## Team GIFs::
32 |
33 | ### Cycling state in one block
34 |
35 | 
36 |
37 | Select a block
38 |
39 | Press `ctrl+enter` (PC) / `cmd+return` (macOS)
40 |
41 | ### Cycling state in multiple blocks
42 |
43 | 
44 |
45 | Select multiple blocks
46 |
47 | Press Ctrl+enter (PC) / Cmd+enter (macOS)
48 |
49 | ### Checking todo box and unchecking it
50 |
51 | 
52 |
53 | You can also right click the bullet to "Make TODO"
54 |
55 | Click the todo box to mark it TODO or DONE
56 |
57 | ## Community Videos::
58 |
59 | ### Roam Research: TODOs by [[Les Kristofs]]
60 |
61 | {{[[video]]: https://www.youtube.com/watch?v=3taL1v-IKXg}}
62 | #[[TODO/DONE]] | #[[Linked References]] | #[[/ Commands]]
63 |
64 | ### Roam: How to Make a Master Task List on Roam by [[Shu Omi]]
65 |
66 | {{[[video]]: https://www.youtube.com/watch?v=mIEgS0JkJBo&t=5s&ab_channel=ShuOmi}}
67 | #[[TODO/DONE]] | #[[Page References]] | #[[Filter]] | #[[Daily Notes]]
68 |
69 | ### Plan Your Day With The Magic List (Roam Research Task Management) by [[Daniel Wirtz]]
70 |
71 | {{[[video]]: https://www.youtube.com/watch?v=5U62cEE7QsM&t=6s&ab_channel=DanielWirtz}}
72 | #[[TODO/DONE]] | #[[Query]] | #[[Page References]] | #[[Daily Notes]] | #[[Block References]]
73 |
74 | ### Todoist to Roam Research - Advanced Task Management in Roam by [[Matt Goldenberg]]
75 |
76 | {{[[video]]: https://www.youtube.com/watch?v=xOTTyLtgqpM}}
77 | #[[roam/css]] | #[[Extensions]] | #[[roam/js]] | #[[Sidebar]] | #[[TODO/DONE]] | #[[Query]]
78 |
79 | ## Articles::
80 |
81 | ### [Using Roam Research for GTD-Style Task Management – The Sweet Setup](https://thesweetsetup.com/using-roam-research-for-gtd-style-task-management/)
82 |
83 | #[[Daily Notes]] | #[[TODO/DONE]] | #[[Page References]] | #[[Query]] | #[[Linked References]]
84 |
85 | ### [Using TODO to Get Things Done with Roam Research (GTD) — Roam Tips & Hacks](https://www.roamtips.com/home/use-todo-get-things-done-roam-research-gtd)
86 |
87 | #[[TODO/DONE]] | #[[Page References]] | #[[Date picker]] | #[[Filter]]
88 |
89 | ## Key Commands::
90 |
91 | Cycle through TODO/DONE state:
92 |
93 | `cmd+return` for macOS
94 |
95 | `ctrl+enter` for Windows
96 |
97 |
--------------------------------------------------------------------------------
/Roam_DB/roam/templates.md:
--------------------------------------------------------------------------------
1 | Dev docs #.h
2 |
3 | Tutorials::
4 |
5 | How-to guides::
6 |
7 | [[Reference]]
8 |
9 | [[Examples]]
10 |
11 | [[Community]]
12 |
13 | Roam Daily Template
14 |
15 | Designer:: [[Jonathan Borichevskiy]]
16 |
17 | Special Features::
18 |
19 | #Slider | #Tags | #TODO/DONE
20 |
21 | Templates::
22 |
23 | Last updated:: [[February 27th, 2021]]
24 |
25 | Weekly Agenda (created on a different day, and embedded with /Block Reference)
26 |
27 | [[Morning Questions]]
28 |
29 | {{[[slider]]}} How many hours of sleep did I get?
30 |
31 | What's one thing top of mind today?
32 |
33 | What's the one thing I need to get done today to make progress?
34 |
35 | Review #[[Index: Questions]] #values
36 |
37 | Agenda
38 |
39 | {{[[TODO]]}} Morning walk #goal-health #habit
40 |
41 | {{[[TODO]]}} Check calendar for scheduled events
42 |
43 | {{[[TODO]]}} Morning focus hour
44 |
45 | {{[[TODO]]}} Read 30 minutes #goal-learning #habit
46 |
47 | {{[[TODO]]}} Review Readwise.io
48 |
49 | {{[[TODO]]}} 10 minutes meditation #goal-health #habit
50 |
51 | {{[[TODO]]}} Workout or run #goal-health #habit
52 |
53 | {{[[TODO]]}} Evening focus hour
54 |
55 | {{[[TODO]]}} Do 7 - 30 - 90 review
56 |
57 | {{[[TODO]]}} read for pleasure, watch something, go for a walk
58 |
59 | [[Evening Questions]]
60 |
61 | List three things I'm grateful for #habit #gratitude
62 |
63 | What made me happy today?
64 |
65 | What made me sad?
66 |
67 | Where there any signs of my day going to shit that I could recognize?
68 |
69 | What prevented me from reaching my goals today?
70 |
71 | What am I looking forward to?
72 |
73 | Skeletons/Methods/Tags/Tools
74 |
75 | Designer:: [[Samuel Orion]]
76 |
77 | Special Features::
78 |
79 | #[[Attributes]] | #[[Kanban]]
80 |
81 | Templates::
82 |
83 | Last updated:: [[July 1st, 2020]]
84 |
85 | ### Article::
86 |
87 | **Topic:**
88 |
89 | **Tags: **
90 |
91 | **URL**:
92 |
93 | **Quotes / Summary:**
94 |
95 | **Comments / Questions:**
96 |
97 | ### Book::
98 |
99 | **Quotes / Summary:**
100 |
101 | **Comments / Questions:**
102 |
103 | **Topic**:
104 |
105 | **Tags**:
106 |
107 | **URL**:
108 |
109 | Podcast
110 |
111 | Show:
112 |
113 | Speaker(s):
114 |
115 | Topic:
116 |
117 | Tags:
118 |
119 | URL:
120 |
121 | Summary:
122 |
123 | Videos
124 |
125 | Speaker:
126 |
127 | Tags:
128 |
129 | Summary:
130 |
131 | Link or Embed:
132 |
133 | Projects
134 |
135 | Due Date:
136 |
137 | Completed Date:
138 |
139 | Status:
140 |
141 | Related Goals:
142 |
143 | Success Criteria:
144 |
145 | Tags:
146 |
147 | Quarterly Preview
148 |
149 | Review [[Yearly Planning]]
150 |
151 | My biggest wins
152 |
153 | Process on annual goals for this quarter (% successful)
154 |
155 | Overall, what worked and what didn’t?
156 |
157 | What will you keep doing?
158 |
159 | What will you start doing?
160 |
161 | What will you improve?
162 |
163 | What will you stop doing?
164 |
165 | [[tools]]
166 |
167 | [[Find and replace]]
168 |
169 | [[KANBAN BOX]]
170 |
171 | {{kanban}}
172 |
173 | indent once for column title
174 |
175 | and another item
176 |
177 | this could be a great way to write an articles / thesis - very easy to read
178 |
179 | clock on the block to open the side bar - and see furtherinfo
180 |
181 | I was in column 2, now I am in column 1
182 |
183 | This is a second collum
184 |
185 | I was in column 1, now I am in column 2 - just click and drag
186 |
187 | indent again for items to put in list (ps look at the next level)
188 |
189 | stuff inside
190 |
191 | A third column
192 |
193 | more stuff
194 |
195 | Daily Log
196 |
197 | Designer:: [[Mark Robertson]]
198 |
199 | Twitter:: [@calhistorian](https://twitter.com/calhistorian)
200 |
201 | Special Features::
202 |
203 | #[[Attributes]] | #[[Query]] | #[[TODO/DONE]]
204 |
205 | 
206 |
207 | Code::
208 |
209 | Last updated:: [[July 1st, 2020]]
210 |
211 | #[[Morning Review]]
212 |
213 | #[[Weather Report]]
214 |
215 | Location:: #Home
216 |
217 | Weather Summary:: Weather Data (Summary)
218 |
219 | Conditions:: Weather Data (Condition) with Weather Data (Precipitation Chance)
220 |
221 | H/L Temp:: High - Weather Data (High), Low - Weather Data (Low)
222 |
223 | #[[Sleep Log]]
224 |
225 | Sleep Time::
226 |
227 | Sleep Quality::
228 |
229 | #[[Morning Pages]]
230 |
231 | #[[Morning Reflection]]
232 |
233 | {{[[query]]: {and: [[-1 Day]] [[Evening Pages]] {not: [[query]]}}}}
234 |
235 | [[Who benefits from your work?]]
236 |
237 | [[What am I grateful for?]]
238 |
239 | [[What do I want the day’s highlight to be?]]
240 |
241 | [[Daily Affirmations]]
242 |
243 | [[What am I think of?]]
244 |
245 | #[[Open Questions]]
246 |
247 | {{[[query]]: {and: [[Question]] [[TODO]] {not: {or:[[query]] [[DONE]] [[Templates]]}}}}}
248 |
249 | #[[Calendar]]
250 |
251 | #Family
252 |
253 | Family Events
254 |
255 | #Professional
256 |
257 | #[[Pedagogical Reflections]]
258 |
259 | #[[Daily Notes]]
260 |
261 | #[[Action List]]
262 |
263 | {{[[TODO]]}} Process Linked and Unlinked Mentions
264 |
265 | {{[[query]]: {and: [[TODO]] [[Action]] {not: {or: [[query]] [[Subtask:]]}}}}}
266 | #[[Upcoming]]
267 |
268 | {{[[query]]: {and: [[TODO]] [[Scheduled]] {not: {or: [[query]] [[Action]]}} {between: [[Today's Date]] [[+2 Weeks]]}}}}
269 |
270 | #[[Evening Review]]
271 |
272 | {{[[TODO]]}} #[[Evening Pages]]
273 |
274 | [[Amazing things that happened]]
275 |
276 | [[What I have learned]]
277 |
278 | [[What could I have done better?]]
279 |
280 | #[[Capture Inbox]]
281 |
282 | The Roam Team
283 |
284 | Contact
285 |
286 | Name::
287 |
288 | Email::
289 |
290 | Company::
291 |
292 | Phone::
293 |
294 | Choice
295 |
296 | {{[[TODO]]}} [[Choice]]
297 |
298 | Context::
299 |
300 | Options::
301 |
302 | Decision::
303 |
304 | Daily agenda Updated
305 |
306 | [[Daily agenda]]
307 |
308 | {{[[kanban]]}}
309 |
310 | All day
311 |
312 | 00:00
313 |
314 | 01:00
315 |
316 | 02:00
317 |
318 | 03:00
319 |
320 | 04:00
321 |
322 | 05:00
323 |
324 | 06:00
325 |
326 | 07:00
327 |
328 | 08:00
329 |
330 | 09:00
331 |
332 | 10:00
333 |
334 | 11:00
335 |
336 | 12:00
337 |
338 | 13:00
339 |
340 | 14:00
341 |
342 | 15:00
343 |
344 | 16:00
345 |
346 | 17:00
347 |
348 | 18:00
349 |
350 | 19:00
351 |
352 | 20:00
353 |
354 | 21:00
355 |
356 | 22:00
357 |
358 | 23:00
359 |
360 | [[Need to plan]]
361 |
362 | An Engineering Problem Solving Process
363 |
364 | ^^An engineered, systematic approach to problem solving can be invaluable in solving problems, capturing knowledge, and discovering solutions.^^ An approach that I suggest involves starting with a simple outline consisting of the following sections (as appropriate - sometimes it makes sense to combine or eliminate certain sections). Feel free to delete this paragraph as you fill out the template.
365 |
366 | Problem Statement:: This should be a simple 1-2 sentence (no more!) statement of the problem. Do not describe symptoms. To the best of your ability, reduce the problem to its bare essence here. Over time this statement may be refined. A key principle is that ^^if you cannot state your problem concisely, you probably don't know what it is and you almost certainly cannot communicate it effectively to others^^.
367 |
368 | Description:: Here you provide a detailed description of the problem.
369 |
370 | Describe why you want to solve this problem (if you do) and what, if anything, makes this problem particularly hard. This can be particularly valuable if you are considering writing new code. Sometimes after further evaluation you will realize it is better to use an alternative or take no action at present.
371 |
372 | Sometimes it is worth capturing the ideas but saving the solution for another time.
373 |
374 | Given:: List all things that have been provided to you, including facts, stories, etc.
375 |
376 | Required:: State all of the requirements to be met to provide a solution to the problem.
377 |
378 | Functional/User (Required): These are the things that a user must be able to do to solve the problem. They may be stated as user stories such as "As a user, I can do X so that Y." If you do not state who can do what and why, then the requirement is suspect.
379 |
380 | Nonfunctional/Technical: Technical requirements often revolve around criteria such as scaling, cost, operations, etc. I often recommend a different page for technical requirements as it is easy for problem solvers (especially developers) to move towards a technical solution (a form) prior to actually understanding the problem to be solved (the function).[1](((https://en.wikipedia.org/wiki/Form_follows_function)))
381 |
382 | Knowns:: State all the things you know about the problem. Provide links, references, citations, etc. as needed to trace the lineage of each known item.
383 |
384 | Unknowns:: What don't you know about the problem. Here you will try to anticipate the questions that you need to answer to better understand the problem.
385 |
386 | Alternative presentations of knowns and unknowns could include a Johari Window[2](((https://en.wikipedia.org/wiki/Johari_window))) or a "Rumsfeld-esque"[3](((https://en.wikipedia.org/wiki/There_are_known_knowns))) categorization.
387 |
388 | {{[[table]]}}
389 |
390 |
391 |
392 | Known to Self
393 |
394 | Not Known to Self
395 |
396 | Known to Others
397 |
398 | Arena
399 |
400 | Blind Spot
401 |
402 | Not Known to Others
403 |
404 | Facade
405 |
406 | Unknown
407 |
408 | Assumptions:: What do you believe to be true regarding this problem?
409 |
410 | Alternatives:: What alternatives already exist to this problem? What do you do now to solve the problem? What happens if you do nothing? If this is a technical solution, can an existing solution be used?
411 |
412 | Solution:: Based on all of the previous information, provide the solution to the problem. This could be a technical solution, process, new product, etc. Note that if multiple solutions are provided (suppose you provide multiple product offerings to solve the same problem) it is perfectly appropriate to have subpages for each solution.
413 |
414 | Recommendations:: An alternative to (or something to be used in conjunction with) a solution is one or more recommendations. Again, if appropriate recommendations can merit their own subpages.
415 |
416 | Hickey Design Process
417 |
418 | [[Problems]]
419 |
420 | Take wants/needs and translate them into problems
421 |
422 | [[Symptoms]]
423 |
424 | Symptoms of the problems
425 |
426 | [[Requirements]]
427 |
428 | [[Knowns]]
429 |
430 | What I know how to do
431 |
432 | [[Unknowns]]
433 |
434 | What I don't know how to do
435 |
436 | [[Domain-side]]
437 |
438 | Business requirement
439 |
440 | [[Solution-side]]
441 |
442 | Technical constraints (it has to compile to JS, for example)
443 |
444 | [[Unstated]]
445 |
446 | Things that everyone wants the system to avoid
447 |
448 | Doesn't crash, use too much memory, require too much energy, are examples of unstated requirements
449 |
450 | [[Solutions]]
451 |
452 | Solution A
453 |
454 | Benefits::
455 |
456 |
457 |
458 | Tradeoffs::
459 |
460 |
461 |
462 | Costs::
463 |
464 |
465 |
466 | Problem fit::
467 |
468 |
469 |
470 | Solution B
471 |
472 | Benefits::
473 |
474 |
475 |
476 | Tradeoffs::
477 |
478 |
479 |
480 | Costs::
481 |
482 |
483 |
484 | Problem fit::
485 |
486 |
487 |
488 | Course
489 |
490 | ### [Course name](course link) by `[[Author Name]]` __price__
491 |
492 | 2-3 sentence blurb describing the course
493 |
494 | Theme
495 |
496 | `theme name`
497 |
498 | Screenshots::
499 |
500 | Last updated::
501 |
502 | Designer:: name
503 |
504 | Twitter:: [link to bio]()
505 |
506 | Love this theme? Say thanks via [PayPal]() (and/or other payment service)
507 |
508 | Special Features::
509 |
510 | Code::
511 |
512 | {{[[roam/css]]}}
513 |
514 | ```css
515 | ```
516 |
517 | Plugin
518 |
519 | `plugin_name`
520 |
521 | Info::
522 |
523 | Must include GIF and/or video of usage
524 |
525 | Link::
526 |
527 | Getting started::
528 |
529 | Installation, activation and configuration
530 |
531 | Tutorials::
532 |
533 |
534 |
535 | Reference::
536 |
537 | Developer::
538 |
539 | Twitter::
540 |
541 | Love this plugin? Say thanks via [Paypal]()
542 |
543 | Code::
544 |
545 | Browser Extension
546 |
547 | `browser_extension_name`
548 |
549 | Info::
550 |
551 | Must include GIF and/or video of usage
552 |
553 | Link::
554 |
555 | Getting started::
556 |
557 | Installation, activation and configuration
558 |
559 | Tutorials::
560 |
561 |
562 |
563 | Reference::
564 |
565 | Developer::
566 |
567 | Twitter::
568 |
569 | Love this plugin? Say thanks via [Paypal]()
570 |
571 | Coaching
572 |
573 | `Course Author Name`
574 |
575 | Info::
576 |
577 | Website::
578 |
579 | Areas of specialty::
580 |
581 | Contact::
582 |
583 | Price::
584 |
585 | Docs #.h
586 |
587 | {{[[TODO]]}} Introduction (few bullets) and some GIFs
588 |
589 | Roam Team Videos::
590 |
591 | {{[[TODO]]}}
592 |
593 | Articles::
594 |
595 | {{[[TODO]]}}
596 |
597 | Community Videos::
598 |
599 | {{[[TODO]]}}
600 |
601 | Key Commands::
602 |
603 | Video/article #.h
604 |
605 | {{[[TODO]]}} [Article link]() or {{[[video]]: }}
606 |
607 | Features mentioned::
608 |
609 | Page refs to features
610 |
611 |
--------------------------------------------------------------------------------
/Roam_DB/White Paper.md:
--------------------------------------------------------------------------------
1 | **Abstract**. Roam is an online workspace for organizing and evaluating knowledge. The system is built on a directed graph, which frees it from the constraints of the classic file tree. Users can remix and connect ideas in multiple overlapping hierarchies, with each unit of information becoming a node in a dynamic network. Any given node can occupy multiple positions simultaneously, convey information through defined relationships, and populate changes throughout the graph. With weightings assigned to the strength of relationships between nodes, Roam also becomes a tool for Bayesian inference and decision making. The ultimate goal is to extend the system to collaborative reasoning, allowing groups to build shared mental maps and make faster and better-informed decisions.
2 |
3 | **1. Introduction**
4 |
5 | We are experiencing an unprecedented explosion of knowledge. Every day, 2700 books are published in the United States alone, 6850 scientific papers are authored, more than 2 million blog posts go live, and 294 billion emails fly back and forth. The amount of total data produced with every rotation of the Earth would fill a stack of books stretching to the moon and back. [1](((u-XvVlybt))) While this exponential growth presents enormous opportunities for individuals and society at large, neither the human brain nor current technologies are equipped to harness it to its full potential.
6 |
7 | **2. Current approaches to knowledge management**
8 |
9 | Humans are poorly adapted to the Information Age, which has arisen only in the last ~0.02% of our evolutionary history. While the brain does have a remarkable capacity for raw storage, probably in the range of several petabytes,[2](((PWlZyEjRU))) it is infamously fallible in processing information. Memory retrieval is lossy and unreliable, while many of our hardwired cognitive biases and heuristics misfire in the modern world, distorting our perception, judgement and decision-making ability. The plasticity of the brain enables it to rewire itself with new connections, but even this is a ‘use it or lose it’ feature, causing neglected neural pathways to atrophy.
10 |
11 | Many technologies for organizing knowledge outside of the brain have arisen in response to these limitations. Physical books and journals proliferated after the invention of the Gutenberg Press, and have since been partially supplanted by word processors, websites, blogs, forums, wikis, and software applications.
12 |
13 | While we are presented with a plethora of choices for organizing knowledge, almost every technology follows the same basic ‘file cabinet’ format: A unit of knowledge is saved to a certain file path, which places it within a taxonomy of folders, chapters or categories. Tags may be applied when an item relates to many things, but each file is generally only stored within one nested hierarchy. To access the information, the user must remember where they stored the file, what they tagged it with, or use a search function to locate it.
14 |
15 | Related Twitter Thread
16 |
17 | https://twitter.com/Conaw/status/1099181050045952006
18 |
19 | **3. Problems with the file cabinet approach**
20 |
21 | In some regards, current technologies remain vastly inferior to the human brain. If each neuron only held a single ‘unit’ of memory in this manner, our brains would quickly fill to overflowing. Instead, information is conveyed in the connections between neurons and neural networks, so a common idea can be made available across the entire brain; the concept of a blue sky might be used in countless seemingly discrete memories of time spent outdoors. This efficiency helps to explain why a computer requires several million times more energy to perform the same tasks as a human brain (which runs on about as much power as a dim light bulb).[3](((j6_rKU-PG)))
22 |
23 | Unlike the brain, the file cabinet approach makes it difficult or impossible to remix or reuse the same piece of information. Each time a change is made to any given file, it has to be tracked down and updated in every location in which it exists. This leads to redundancy, with a cluttering of near-identical ideas, and significant work any time a system-wide change is required.
24 |
25 | Current solutions also lack interconnectivity. Many files are divorced from context; cast into a drawer, rather than methodically fitted into a broader framework of knowledge. Knowledge trees can create pseudo-relationships between files nested within a given hierarchy, but these are not explicit, and can only describe a vertical ‘parent and child’ taxonomy. Some tools, such as web pages and wikis, also allow for orthogonal linking between related files, but this takes place in an ad hoc fashion, and again, there is no ability to explicitly define relationships.
26 |
27 | **4. Knowledge graphs as nodal networks **
28 |
29 | Large-scale collaboration requires a more flexible data structure than the classic file tree. Roam is built on a knowledge graph that maps all possible relationships, with ‘smart’ links between defined concepts. Users can connect similar ideas in multiple overlapping hierarchies, remix them without overwriting the original context, and selectively share parts of the graph with others to collaborate on specific sub-questions.
30 |
31 | If current tools resemble filing cabinets, Roam is more akin to the nodal networks in telecommunications, or the neurons in the human brain. Rather than existing in a vacuum, each note or file becomes a node in an interconnected graph of ideas. A single node may simultaneously hold positions in several different sequences, hierarchies or file paths, and can ‘talk’ to other nodes, communicating information back and forth about the nature of each relationship. The network is dynamic, so updates and revisions are populated across the entire graph simultaneously. Individual nodes or branches within the network can be forked as required, allowing a new pathway to deviate without changing the original meaning.
32 |
33 | At the simplest level, Roam’s structure makes it inherently easier to store, recall, and cross-reference ideas. This is the primary proposition for students, writers, self-directed learners, and users of existing note-taking apps.
34 |
35 | For power users, the knowledge graph also unlocks applications in logic and reasoning, Bayesian inference and decision-making, modelling complex problems, and collaborative research.
36 |
37 | These features are explored in Chapters 5 - 8, along with potential use cases for the technology.
38 |
39 | **5. Dependency graphs and logical reasoning**
40 |
41 | Everything from peer-reviewed research papers to the opinion pages of a newspaper are based on formulating arguments that support a certain premise, along the lines of the following:
42 |
43 | If A is true, then B is true.
44 |
45 | If C and D are both true, then A is true.
46 |
47 | C and D are true.
48 |
49 | Therefore, B is true.
50 |
51 | Example:: [[Precise Links]]
52 |
53 | {{embed:((PWRiHAsEv)) }}
54 |
55 |
56 |
57 | Often, C and D will be supported by links to external articles, where they are conclusions reached by larger arguments based on combining other premises. Unfortunately, the structure of the argument is only implied by the prose. Rarely are the relationships between arguments and pieces of evidence explicitly laid out, except perhaps in the notes of the author investigating the claims.
58 |
59 | Roam allows individual researchers or writers to organize all the claims they wish to make across a number of different projects. It also creates opportunities for large-scale interdisciplinary research projects. When teams of interested collaborators have an agreed-upon structure for formatting arguments and counterarguments, it is possible to create expandable user interfaces which “bubble up” insight from claims which require expertise, to ones that are more easily understood by laypersons.
60 |
61 | The ambiguity of natural language derails many discussions. Unless [[terms]] are clearly defined from the outset, any form of argument is futile, and will often end up entrenching the initial positions of the interlocutors.
62 |
63 | Example A
64 |
65 | Alice: "A tree falling in a deserted forest makes a sound."
66 |
67 | Bob: "A tree falling in a deserted forest does not make a sound."
68 |
69 | Example B
70 |
71 | Alice: "A tree falling in a deserted forest [generates acoustic vibrations]."
72 |
73 | Bob: "A tree falling in a deserted forest does not [generate auditory experiences]." [4](((T8k78DDAe)))
74 |
75 | While these positions are contradictory as expressed in Example A, simply defining the term ‘sound’ reveals the underlying beliefs are entirely compatible.
76 |
77 | The ability to use clearly defined sets within a dependency graph helps to resolve ambiguity, reducing the chances of participants talking at cross-purposes, or deliberate “motte-and-bailey” style strategic equivocation. [5](((MtGChSUvh)))
78 |
79 | Besides reasoning and argument, dependency graphs have applications in education, self-directed learning, and general decision-making. Even a very complicated project can be traced backwards to a number of smaller [[task]]s. The user can see the tradeoffs involved in each pathway, map out which route is the fastest, and which path might bring them closer to other interesting goals. As the student marks their progress, they can discover new projects and pathways which make use of the skills they have acquired.
80 |
81 | The problems of prose apply even in the domain of mathematical proofs, see Lamport’s [[How to write a 21st Century Proof]]”
82 |
83 | **6. Untangling complexity**
84 |
85 | **6.1 Nonlinear causality**
86 |
87 | Simple problems often follow a straightforward causal path. When a patient has a range of symptoms strongly associated with the flu, the doctor might conclude from the observable variables that there is one invisible variable - the influenza virus. Treat that latent variable, and the symptoms disappear.
88 |
89 | Scott Alexander observes that his peers in psychiatry similarly try to attribute a collection of linked symptoms to a latent variable; for example, depression. [6](((36qeTMgmO))) However, the symptoms ‘caused’ by depression - e.g. sleep disturbance, fatigue, guilt - can also have a causal effect on one another, and on the disorder itself. This complex web of relationships, which may include feedback loops, does not follow a path of linear causality. For complicated problems of this nature, nodal networks are a much more accurate model:
90 |
91 | A model of major depression (MD) and generalised anxiety disorder (GAD) by Nuijten, Deserno, Cramer, and Borsboom.[7](((rC_nGuzjf))) The disorders roughly map onto clusters of symptoms that are often found together and reinforce one another, but there is no clear ‘bright line’ between the conditions.
92 |
93 | Even at face value, a nodal network provides a visual aid to problem-solving - a bird’s eye view of the connections between various elements. This may help to identify patterns or clusters which may be counterintuitive or entirely invisible when each piece of the puzzle is examined at the object level.
94 |
95 | **6.2 Bayesian reasoning**
96 |
97 | Applying Bayesian reasoning to the knowledge graph makes it a powerful tool for estimating probabilities, testing hypotheses, and making decisions. Bayes’ Theorem is a law of probability that tells us how much we should change our minds about something when we learn a new fact or acquire new evidence. The theorem is stated in the following equation:
98 |
99 | $$P(A|B) = {P(B|A) P(A) \over P(B)}$$
100 |
101 |
102 | where A is the proposition of interest, B is the observed evidence, P(A) and P(B) are prior probabilities, and P(A|B) is the posterior probability of A.
103 |
104 | Suppose a doctor has a patient who is worried about carrying a latent disease, because he belongs to an at-risk group. This is the ‘proposition of interest’ on the left side of the equation. Prior data suggests 4% of the general population are carriers, so $$P(A) = 0.04$$. B is the observed evidence, which is that 32% of the general population are members of the at-risk group. $$P(B) = 0.32$$. The doctor knows that among patients who do carry the disease, 80% belong to the at-risk group: $$B|A = 0.8$$.
105 |
106 | The doctor applies Bayes’ theorem:
107 |
108 | $$P(A|B) = (0.8 * 0.04)/0.32$$
109 |
110 | $$P(A|B) = 0.1$$
111 |
112 | Her patient only has a one in 10 chance of being a carrier - which might be less than expected, given that almost all carriers are members of the at-risk group.
113 |
114 | While this is a simple calculation, the strength of Bayesian reasoning is that it breaks down seemingly insurmountable problems into small pieces. Even where no data are available, successive layers of estimates can still provide useful refinements to the confidence levels of various outcomes. By incorporating this framework into the defined relationships between nodes, revisions to the weightings at any point in the network will automatically populate throughout the knowledge graph.
115 |
116 | Bayesian probability also provides a framework for decision-making. By estimating the costs and tradeoffs of various options, users can calculate which pathway provides the highest expected value. Again, the quality of the decisions can be refined by successive layers of evidence for and against, even when the weightings are simple estimates of personal preference. An evaluation matrix allows someone to integrate a great deal of information into the final decision, rather than defaulting to simple heuristics.
117 |
118 | {{[[TODO]]}} [Example [[Diagrams]] of decision tree/matrix]
119 |
120 | **7. Optimising for **[[Serendipity]]
121 |
122 | Just as humans are incapable of generating random numbers, we struggle to consciously generate random ideas - to the point where actively trying to ‘think differently’ often seems to only further calcify existing patterns. Instead of attempting to brute-force creativity, the brain must be confronted with novel stimuli in order to reorganize its perception. Exposure to a certain amount of random ‘noise’ - drugs, dreams, meditation, Tarot readings, mistakes - can jolt thoughts out of well-tracked grooves and into entirely new areas of idea-space. Typically these insights occur at the juncture of two or more seemingly unrelated fields, concepts, or images.
123 |
124 | The interconnectivity of the Roam knowledge graph constantly creates opportunities for [[Serendipity]] to blossom. Each node in the network can be viewed in several graphical displays, allowing users to see related ideas, scan up and down the vertical hierarchy, examine nearby clusters of nodes, and observe patterns.
125 |
126 | The Roam search function can be calibrated to include as much or as little ‘noise’ as the user desires. While looking for a specific passage or note, search is narrow enough to find exactly what the user has in mind. However, it can also be broadened out for ‘fishing trips’ aimed at surfacing categories of ideas. Some search results will consist of notes that the user might otherwise have forgotten about, some will be noise, and others will spark ideas the user didn’t even know they were looking for.
127 |
128 | The synthesis and cross-pollination of ideas from diverse fields presents low-hanging fruit for both individuals and society. The investment of time and effort required to become a specialist quickly runs into a point of diminishing returns. By contrast, accumulating a ‘talent stack’ of dilettante-level knowledge or skills can unlock insights and opportunities that have not been capitalised on by experts with a narrower focus.
129 |
130 | Highly specialised knowledge remains essential for opening new frontiers. However, an interdisciplinary approach is often required to solve the increasingly complex problems faced by scientists, technologists, and policymakers.
131 |
132 | **8. Collaborative problem-solving**
133 |
134 | While the individual use case for Roam stands on its own merits, the ultimate goal is to create a platform for collaborative research and learning. Current protocols are bound by the assumption of necessary consensus. The flexibility of a curated knowledge graph allows for a more pluralistic approach, with the ability to weight conflicting opinions and separate signal from noise without resorting to either autocracy or democracy.
135 |
136 | 8.1 **Finding signal in the noise**
137 |
138 | As the frequency of information increases, the world becomes noisier and noisier. Deliberate exposure to noise is a useful strategy in specific contexts, as described in Chapter 7, but otherwise obscures meaning. [8](((urKnXjnSR))) Given we have a propensity for imposing stories and explanations onto randomness - the narrative fallacy - it is becoming increasingly difficult to separate out genuine signal from noise.
139 |
140 | Assume a trend has a signal-to-noise ratio of 1:1 on an annual basis (50% of the data are meaningful, 50% are random). Observing the same data on a daily basis, the composition changes to 95% noise, 5% signal. Observing the data hourly (as news hounds and market junkies do), and it becomes 99.5% random - which is to say, two hundred times more noise than signal.[9](((_eOgBulZd)))
141 |
142 | Institutions entrusted with interpreting the data include the media, academia, and legislature. Some agents within these institutions deliberately obscure the truth, as demonstrated by ‘fake news’, p-hacking, and politicking. While actively malicious behaviour is the exception, even the best-intentioned reporters, researchers and analysts are not immune to being fooled by randomness.
143 |
144 | For most people, the problem of sorting signal from noise therefore involves finding trustworthy and accurate secondary sources of information. This difficult [[task]] is often frustrated by gated scientific journals, as well as search engine algorithms increasingly gamed by SEO-savvy content marketers.
145 |
146 | 8.2 **Redundancy**
147 |
148 | Navigating a vast sea of information creates massive redundancy. Most people labour away at problems that have already been solved a million times over. Those who tackle unsolved problems often do so in silos, unaware of each other’s existence. All the pieces of any given puzzle may be present, but no one individual or group holds them all. The wheel is reinvented over and over again, in endless forums and comments sections and web pages and books that burst into existence and fade just as quickly to obscurity.
149 |
150 | The goal of Roam is to enable systematic curation and collaboration on a large scale. Users will be able to selectively share parts of their graphs publicly, or with circles of peers and colleagues. In turn, they will be able to follow the work of persons they trust, whether they be domain experts or enthusiastic amateurs. Those looking to acquire specific knowledge can turn immediately to trusted sources, and set alerts to receive updates about new pieces of information pertaining to an area of interest.
151 |
152 | 8.3 **Dispensing with necessary consensus**
153 |
154 | Almost every medium today presents knowledge as though it were the last word; assuming both a necessary consensus and an uncomposable page. Wikipedia is one of the great wonders of the Internet age, but it makes both of these mistakes. There can only be one article on any subject for any given language, and the only connection between pages is through links, with no article "built" off another.
155 |
156 | By way of contrast, consider Github: Libraries are built on other libraries, and functions are built from other functions. Developers build tools that others can build upon to build ever more impressive tools. Most of the modern web is built on open-source technologies, which would not have been possible if programmers followed the old protocols for intellectual collaboration.
157 |
158 | Many problems can be solved by writing code, but natural language is still the way we determine which problems are worth solving. Natural language is how we explain the world to one another, and communicate our models of reality. It is the language of education. It is the language of decision-making. That language needs a toolchain for collaboration that is just as good as the one for managing code.
159 |
160 | 8.4 **Against autocracy; against democracy**
161 |
162 | The problem of necessary consensus is resolved by individuals or groups assembling their own graph of inferences, based on premises or data curated from their trusted networks. However, collaboration still requires a mechanism for evaluating which ideas are best. In the same way that individuals assign weightings to their personal predictions and decisions, groups must be able to ‘vote’ on the merits of any given idea, premise, or piece of evidence. There are various options for how these collective weightings might be calibrated, some of which are briefly described below.
163 |
164 | a) **Wisdom of crowds**
165 |
166 | A diverse collection of people can make certain decisions and predictions much better than any given individual: The great statistician Francis Galton was stunned to find that 800 people guessing the weight of an ox at a country fair returned an average that was just one pound shy of the correct figure of 1198 pounds.
167 |
168 | In other situations, the opinion of the crowd bears little relationship to objective reality. By definition, the tyranny of the majority will quash any position that is unpopular, regardless of whether it is true. Often, domain-specific knowledge may be required; for example, someone who has not studied free will would only be adding noise by ‘voting’ a preference for compatibilism, hard determinism, or libertarianism.
169 |
170 | Simple popularity contests do not always move us closer to the truth, but they are useful in that they tell us what we believe. This data could potentially be broken down by demographic to demonstrate how different groups perceive reality, and possibly alert users to biases amongst their own in-groups.
171 |
172 | b) **Believability scores**
173 |
174 | Hedge fund manager Ray Dalio pioneered a decision-making system at Bridgewater Associates that is much closer to epistocracy than democracy: The opinions of more “believable” people, who have repeatedly proven their grasp of a given topic or trait, hold more weight than those with lower believability scores. There is nothing to stop Dalio being overruled by his most junior employees, as long are they are consistently more right than he is. Implementing a similar system in Roam would necessitate the ability to track performance, perhaps by how much original content a user has contributed to the graph with broad support, or how well-calibrated their predictions are.
175 |
176 | c) **Prediction markets**
177 |
178 | When people succumb to peer pressure and other biases, do not have enough specialist knowledge, or deliberately make false predictions, the ‘wisdom of the crowd’ can end up being very wrong.
179 |
180 | The insight behind prediction markets is that participants can be incentivised to profit from any such mistakes. Wherever someone believes the consensus is wrong, they can stake money on it, and move the probability back to a better informed position. Insider information is not only permitted, but welcomed. In this way, vast amounts of information can be synthesised into one constantly updated data point, which is often remarkably accurate.
181 |
182 | The uptake and growth of prediction markets has been dampened by regulatory issues, but possible workarounds include a non-fiat token, or reputation-linked points system.
183 |
184 | **9. Conclusion**
185 |
186 | The project of human knowledge, as it stands today, is a vast ocean of ephemeral and fragmented information and ideas, much of it inaccurate, some of it malicious, with the best sources either restricted by gatekeepers, or near-impossible to locate. The volume of information is growing exponentially, which promises enormous opportunities if the underlying coordination problems can be resolved.
187 |
188 | Clearly a fundamentally different approach is required. The Roam vision for human knowledge is a collective, open-source intelligence, constantly rearranging, iterating and evolving in the pursuit of truth. Each of us would become a node within this collective intelligence, forging links and creating networks, sharing the very best each has to offer, improving ourselves even as we improve others, and advancing the interests of humanity as a whole.
189 |
190 | About Roam
191 |
192 | Roam was founded by Conor White-Sullivan and Joshua Brown. Conor has been working on tools for collective intelligence for more than nine years, founding the online town common Localocracy (acquired by AOL in 2011) then leading R&D for Huffington Post following the acquisition. Conor and Josh met at 42.us.org, a tuition-free coding university, where Josh placed in the top five of the first 1000 cadets to enter the US program during the month-long application exam. This white paper was co-authored by business journalist Richard Meadows, whose trial of early prototypes led him to become the first investor in Roam.
193 |
194 | The Roam stack:
195 |
196 | React
197 |
198 | Clojure and Clojurescript
199 |
200 | Datalog
201 |
202 | Contact Conor at cwhitesullivan@gmail.com with any enquiries.
203 |
204 | Notes and references
205 |
206 | [1] At least 2.5 quintillion bytes of information are produced every day, which is about the same amount as was produced during the entire year of 2002.
207 |
208 | [2] Scientific American: New Estimate Boosts the Human Brain's Memory Capacity 10-Fold.
209 |
210 | [3] Microelectronics pioneer Carver Mead, who coined the term Moore’s Law, correctly predicted in 1990 that present-day computers would use ten million times more energy for a single instruction than the brain uses for a synaptic activation.
211 |
212 | [4] This example is adapted from the Less Wrong sequence 37 Ways Words Can be Wrong.
213 |
214 | [5] Motte-and-bailey refers to arguing an easy-to-defend and often common-sense statement (the motte), in order to ward off critics from a hard-to-defend and more controversial statement (the bailey). The term was popularised by Scott Alexander, and explained in All in All, Another Brick in the Motte.
215 |
216 | [6] Slate Star Codex: Mental disorders as networks.
217 |
218 | [7] Michèle B. Nuijten, Marie K. Deserno, Angélique O. J. Cramer, Denny Borsboom: An introduction and overview of a network approach to psychopathology.
219 |
220 | [8] As Carl Sagan observed, while more data is broadcast in TV programs every day than the combined written works of all of history, "not all bits have equal value".
221 |
222 | [9] This example comes from Nassim Taleb’s Antifragile.
223 |
224 | Further Reading
225 |
226 | Daniel Kahneman, Thinking, Fast and Slow
227 |
228 | Robin Hanson, Could Gambling Save Science?
229 |
230 | [[Ray Dalio]], [[Principles]]
231 |
232 | H Van Dyke Paranuk, Don’t Link Me In: Set Based Hypermedia for Taxonomic Reasoning
233 |
234 | [[Michael Nielsen]], Reinventing Discovery: The New Era of Networked Science
235 |
236 | Richards J Heuer The Psychology of Intelligence Analysis
237 |
238 | Leslie Lamport: [[How to write a 21st Century Proof]]
239 |
240 | Douglas Engelbart, [[Augmenting the Human Intellect: A Conceptual Framework]]
241 |
242 | About this Paper
243 |
244 | We wrote this White Paper in Winter of 2017/2018, and while it still reflects much of our vision for the tool, some of the features -- particularly related to [[Bayesian Reasoning]], [[Argument Analysis]], and [[Prediction Markets]] we found to be in-fact much lower priority for the researchers and decision makers whose thinking we aim to assist -- and risked making the tool too complex for the more significant use cases. If you are interested in using Roam for more formal Quantitative Reasoning or building out formal models of belief networks, or if you are excited about ideas in this paper which you do not see a way to do currently within Roam, please contact us.
245 |
246 |
--------------------------------------------------------------------------------
65 |
66 | This will produce a `.zip` file in your Downloads folder. Move the `.zip` file into this repository.
67 |
68 | Run the following command to unzip the zip file (replace the `Export...` with your own file name as needed).
69 |
70 | ```shell
71 | unzip Roam-Export-1675782732639.zip -d Roam_DB
72 | ```
73 |
74 | Run the following command to ingest the data.
75 |
76 | ```shell
77 | python ingest.py
78 | ```
79 |
80 | Boom! Now you're done, and you can ask it questions like:
81 |
82 | ```shell
83 | python qa.py "What's the content of Roam Research's white paper?"
84 | ```
85 |
86 | ## Trouble Shooting
87 |
88 | ```shell
89 | openai.error.RateLimitError: Rate limit reached for default-global-with-image-limits in organization org-xxxxxxxxxxxxxxxxxxxx on requests per min. Limit: 60.000000 / min. Current: 70.000000 / min. Contact support@openai.com if you continue to have issues. Please add a payment method to your account to increase your rate limit. Visit https://platform.openai.com/account/billing to add a payment method.
90 | ```
91 |
92 | Maybe you can try to upgrade the account access.
93 |
--------------------------------------------------------------------------------
/Roam_DB/TODO/DONE.md:
--------------------------------------------------------------------------------
1 | TODOs are the core of [task management]([[Task Management]]). We have been using them in our bullet journals, task apps, and now... Roam.
2 |
3 | Creating TODOs in Roam is incredibly easy! Below are different ways to do that:
4 |
5 | **Right clicking on the bullet**
6 |
7 | 1. `Right-click` on the bullet you want to transform into a todo.
8 | 2. Click on `Make TODO`
9 |
10 | **Using the keyboard shortcut**
11 |
12 | 1. While you're editing the block you want to transform into a TODO, press:
13 |
14 | `cmd+return` (macOS)
15 |
16 | `ctrl+enter` (PC)
17 |
18 | **Using the** [[/ Commands]] **Menu**
19 |
20 | 1. Type `/`
21 | 2. Hit `enter`
22 |
23 | ## Roam Team Videos::
24 |
25 | {{[[video]]: https://www.youtube.com/watch?v=3aCl7dCYVqA&t=6s&ab_channel=ConorWhite-Sullivan}}
26 | #[[TODO/DONE]] | #[[Daily Notes]] | #[[Filter]] | #[[Linked References]] | #[[Block Embed]] | #[[Current time]] | #[[Block References]]
27 |
28 | {{[[video]]: https://www.youtube.com/watch?v=asQ4RSjjCu4&ab_channel=ConorWhite-Sullivan}}
29 | #[[TODO/DONE]] | #[[Linked References]]
30 |
31 | ## Team GIFs::
32 |
33 | ### Cycling state in one block
34 |
35 | 
36 |
37 | Select a block
38 |
39 | Press `ctrl+enter` (PC) / `cmd+return` (macOS)
40 |
41 | ### Cycling state in multiple blocks
42 |
43 | 
44 |
45 | Select multiple blocks
46 |
47 | Press Ctrl+enter (PC) / Cmd+enter (macOS)
48 |
49 | ### Checking todo box and unchecking it
50 |
51 | 
52 |
53 | You can also right click the bullet to "Make TODO"
54 |
55 | Click the todo box to mark it TODO or DONE
56 |
57 | ## Community Videos::
58 |
59 | ### Roam Research: TODOs by [[Les Kristofs]]
60 |
61 | {{[[video]]: https://www.youtube.com/watch?v=3taL1v-IKXg}}
62 | #[[TODO/DONE]] | #[[Linked References]] | #[[/ Commands]]
63 |
64 | ### Roam: How to Make a Master Task List on Roam by [[Shu Omi]]
65 |
66 | {{[[video]]: https://www.youtube.com/watch?v=mIEgS0JkJBo&t=5s&ab_channel=ShuOmi}}
67 | #[[TODO/DONE]] | #[[Page References]] | #[[Filter]] | #[[Daily Notes]]
68 |
69 | ### Plan Your Day With The Magic List (Roam Research Task Management) by [[Daniel Wirtz]]
70 |
71 | {{[[video]]: https://www.youtube.com/watch?v=5U62cEE7QsM&t=6s&ab_channel=DanielWirtz}}
72 | #[[TODO/DONE]] | #[[Query]] | #[[Page References]] | #[[Daily Notes]] | #[[Block References]]
73 |
74 | ### Todoist to Roam Research - Advanced Task Management in Roam by [[Matt Goldenberg]]
75 |
76 | {{[[video]]: https://www.youtube.com/watch?v=xOTTyLtgqpM}}
77 | #[[roam/css]] | #[[Extensions]] | #[[roam/js]] | #[[Sidebar]] | #[[TODO/DONE]] | #[[Query]]
78 |
79 | ## Articles::
80 |
81 | ### [Using Roam Research for GTD-Style Task Management – The Sweet Setup](https://thesweetsetup.com/using-roam-research-for-gtd-style-task-management/)
82 |
83 | #[[Daily Notes]] | #[[TODO/DONE]] | #[[Page References]] | #[[Query]] | #[[Linked References]]
84 |
85 | ### [Using TODO to Get Things Done with Roam Research (GTD) — Roam Tips & Hacks](https://www.roamtips.com/home/use-todo-get-things-done-roam-research-gtd)
86 |
87 | #[[TODO/DONE]] | #[[Page References]] | #[[Date picker]] | #[[Filter]]
88 |
89 | ## Key Commands::
90 |
91 | Cycle through TODO/DONE state:
92 |
93 | `cmd+return` for macOS
94 |
95 | `ctrl+enter` for Windows
96 |
97 |
--------------------------------------------------------------------------------
/Roam_DB/roam/templates.md:
--------------------------------------------------------------------------------
1 | Dev docs #.h
2 |
3 | Tutorials::
4 |
5 | How-to guides::
6 |
7 | [[Reference]]
8 |
9 | [[Examples]]
10 |
11 | [[Community]]
12 |
13 | Roam Daily Template
14 |
15 | Designer:: [[Jonathan Borichevskiy]]
16 |
17 | Special Features::
18 |
19 | #Slider | #Tags | #TODO/DONE
20 |
21 | Templates::
22 |
23 | Last updated:: [[February 27th, 2021]]
24 |
25 | Weekly Agenda (created on a different day, and embedded with /Block Reference)
26 |
27 | [[Morning Questions]]
28 |
29 | {{[[slider]]}} How many hours of sleep did I get?
30 |
31 | What's one thing top of mind today?
32 |
33 | What's the one thing I need to get done today to make progress?
34 |
35 | Review #[[Index: Questions]] #values
36 |
37 | Agenda
38 |
39 | {{[[TODO]]}} Morning walk #goal-health #habit
40 |
41 | {{[[TODO]]}} Check calendar for scheduled events
42 |
43 | {{[[TODO]]}} Morning focus hour
44 |
45 | {{[[TODO]]}} Read 30 minutes #goal-learning #habit
46 |
47 | {{[[TODO]]}} Review Readwise.io
48 |
49 | {{[[TODO]]}} 10 minutes meditation #goal-health #habit
50 |
51 | {{[[TODO]]}} Workout or run #goal-health #habit
52 |
53 | {{[[TODO]]}} Evening focus hour
54 |
55 | {{[[TODO]]}} Do 7 - 30 - 90 review
56 |
57 | {{[[TODO]]}} read for pleasure, watch something, go for a walk
58 |
59 | [[Evening Questions]]
60 |
61 | List three things I'm grateful for #habit #gratitude
62 |
63 | What made me happy today?
64 |
65 | What made me sad?
66 |
67 | Where there any signs of my day going to shit that I could recognize?
68 |
69 | What prevented me from reaching my goals today?
70 |
71 | What am I looking forward to?
72 |
73 | Skeletons/Methods/Tags/Tools
74 |
75 | Designer:: [[Samuel Orion]]
76 |
77 | Special Features::
78 |
79 | #[[Attributes]] | #[[Kanban]]
80 |
81 | Templates::
82 |
83 | Last updated:: [[July 1st, 2020]]
84 |
85 | ### Article::
86 |
87 | **Topic:**
88 |
89 | **Tags: **
90 |
91 | **URL**:
92 |
93 | **Quotes / Summary:**
94 |
95 | **Comments / Questions:**
96 |
97 | ### Book::
98 |
99 | **Quotes / Summary:**
100 |
101 | **Comments / Questions:**
102 |
103 | **Topic**:
104 |
105 | **Tags**:
106 |
107 | **URL**:
108 |
109 | Podcast
110 |
111 | Show:
112 |
113 | Speaker(s):
114 |
115 | Topic:
116 |
117 | Tags:
118 |
119 | URL:
120 |
121 | Summary:
122 |
123 | Videos
124 |
125 | Speaker:
126 |
127 | Tags:
128 |
129 | Summary:
130 |
131 | Link or Embed:
132 |
133 | Projects
134 |
135 | Due Date:
136 |
137 | Completed Date:
138 |
139 | Status:
140 |
141 | Related Goals:
142 |
143 | Success Criteria:
144 |
145 | Tags:
146 |
147 | Quarterly Preview
148 |
149 | Review [[Yearly Planning]]
150 |
151 | My biggest wins
152 |
153 | Process on annual goals for this quarter (% successful)
154 |
155 | Overall, what worked and what didn’t?
156 |
157 | What will you keep doing?
158 |
159 | What will you start doing?
160 |
161 | What will you improve?
162 |
163 | What will you stop doing?
164 |
165 | [[tools]]
166 |
167 | [[Find and replace]]
168 |
169 | [[KANBAN BOX]]
170 |
171 | {{kanban}}
172 |
173 | indent once for column title
174 |
175 | and another item
176 |
177 | this could be a great way to write an articles / thesis - very easy to read
178 |
179 | clock on the block to open the side bar - and see furtherinfo
180 |
181 | I was in column 2, now I am in column 1
182 |
183 | This is a second collum
184 |
185 | I was in column 1, now I am in column 2 - just click and drag
186 |
187 | indent again for items to put in list (ps look at the next level)
188 |
189 | stuff inside
190 |
191 | A third column
192 |
193 | more stuff
194 |
195 | Daily Log
196 |
197 | Designer:: [[Mark Robertson]]
198 |
199 | Twitter:: [@calhistorian](https://twitter.com/calhistorian)
200 |
201 | Special Features::
202 |
203 | #[[Attributes]] | #[[Query]] | #[[TODO/DONE]]
204 |
205 | 
206 |
207 | Code::
208 |
209 | Last updated:: [[July 1st, 2020]]
210 |
211 | #[[Morning Review]]
212 |
213 | #[[Weather Report]]
214 |
215 | Location:: #Home
216 |
217 | Weather Summary:: Weather Data (Summary)
218 |
219 | Conditions:: Weather Data (Condition) with Weather Data (Precipitation Chance)
220 |
221 | H/L Temp:: High - Weather Data (High), Low - Weather Data (Low)
222 |
223 | #[[Sleep Log]]
224 |
225 | Sleep Time::
226 |
227 | Sleep Quality::
228 |
229 | #[[Morning Pages]]
230 |
231 | #[[Morning Reflection]]
232 |
233 | {{[[query]]: {and: [[-1 Day]] [[Evening Pages]] {not: [[query]]}}}}
234 |
235 | [[Who benefits from your work?]]
236 |
237 | [[What am I grateful for?]]
238 |
239 | [[What do I want the day’s highlight to be?]]
240 |
241 | [[Daily Affirmations]]
242 |
243 | [[What am I think of?]]
244 |
245 | #[[Open Questions]]
246 |
247 | {{[[query]]: {and: [[Question]] [[TODO]] {not: {or:[[query]] [[DONE]] [[Templates]]}}}}}
248 |
249 | #[[Calendar]]
250 |
251 | #Family
252 |
253 | Family Events
254 |
255 | #Professional
256 |
257 | #[[Pedagogical Reflections]]
258 |
259 | #[[Daily Notes]]
260 |
261 | #[[Action List]]
262 |
263 | {{[[TODO]]}} Process Linked and Unlinked Mentions
264 |
265 | {{[[query]]: {and: [[TODO]] [[Action]] {not: {or: [[query]] [[Subtask:]]}}}}}
266 | #[[Upcoming]]
267 |
268 | {{[[query]]: {and: [[TODO]] [[Scheduled]] {not: {or: [[query]] [[Action]]}} {between: [[Today's Date]] [[+2 Weeks]]}}}}
269 |
270 | #[[Evening Review]]
271 |
272 | {{[[TODO]]}} #[[Evening Pages]]
273 |
274 | [[Amazing things that happened]]
275 |
276 | [[What I have learned]]
277 |
278 | [[What could I have done better?]]
279 |
280 | #[[Capture Inbox]]
281 |
282 | The Roam Team
283 |
284 | Contact
285 |
286 | Name::
287 |
288 | Email::
289 |
290 | Company::
291 |
292 | Phone::
293 |
294 | Choice
295 |
296 | {{[[TODO]]}} [[Choice]]
297 |
298 | Context::
299 |
300 | Options::
301 |
302 | Decision::
303 |
304 | Daily agenda Updated
305 |
306 | [[Daily agenda]]
307 |
308 | {{[[kanban]]}}
309 |
310 | All day
311 |
312 | 00:00
313 |
314 | 01:00
315 |
316 | 02:00
317 |
318 | 03:00
319 |
320 | 04:00
321 |
322 | 05:00
323 |
324 | 06:00
325 |
326 | 07:00
327 |
328 | 08:00
329 |
330 | 09:00
331 |
332 | 10:00
333 |
334 | 11:00
335 |
336 | 12:00
337 |
338 | 13:00
339 |
340 | 14:00
341 |
342 | 15:00
343 |
344 | 16:00
345 |
346 | 17:00
347 |
348 | 18:00
349 |
350 | 19:00
351 |
352 | 20:00
353 |
354 | 21:00
355 |
356 | 22:00
357 |
358 | 23:00
359 |
360 | [[Need to plan]]
361 |
362 | An Engineering Problem Solving Process
363 |
364 | ^^An engineered, systematic approach to problem solving can be invaluable in solving problems, capturing knowledge, and discovering solutions.^^ An approach that I suggest involves starting with a simple outline consisting of the following sections (as appropriate - sometimes it makes sense to combine or eliminate certain sections). Feel free to delete this paragraph as you fill out the template.
365 |
366 | Problem Statement:: This should be a simple 1-2 sentence (no more!) statement of the problem. Do not describe symptoms. To the best of your ability, reduce the problem to its bare essence here. Over time this statement may be refined. A key principle is that ^^if you cannot state your problem concisely, you probably don't know what it is and you almost certainly cannot communicate it effectively to others^^.
367 |
368 | Description:: Here you provide a detailed description of the problem.
369 |
370 | Describe why you want to solve this problem (if you do) and what, if anything, makes this problem particularly hard. This can be particularly valuable if you are considering writing new code. Sometimes after further evaluation you will realize it is better to use an alternative or take no action at present.
371 |
372 | Sometimes it is worth capturing the ideas but saving the solution for another time.
373 |
374 | Given:: List all things that have been provided to you, including facts, stories, etc.
375 |
376 | Required:: State all of the requirements to be met to provide a solution to the problem.
377 |
378 | Functional/User (Required): These are the things that a user must be able to do to solve the problem. They may be stated as user stories such as "As a user, I can do X so that Y." If you do not state who can do what and why, then the requirement is suspect.
379 |
380 | Nonfunctional/Technical: Technical requirements often revolve around criteria such as scaling, cost, operations, etc. I often recommend a different page for technical requirements as it is easy for problem solvers (especially developers) to move towards a technical solution (a form) prior to actually understanding the problem to be solved (the function).[1](((https://en.wikipedia.org/wiki/Form_follows_function)))
381 |
382 | Knowns:: State all the things you know about the problem. Provide links, references, citations, etc. as needed to trace the lineage of each known item.
383 |
384 | Unknowns:: What don't you know about the problem. Here you will try to anticipate the questions that you need to answer to better understand the problem.
385 |
386 | Alternative presentations of knowns and unknowns could include a Johari Window[2](((https://en.wikipedia.org/wiki/Johari_window))) or a "Rumsfeld-esque"[3](((https://en.wikipedia.org/wiki/There_are_known_knowns))) categorization.
387 |
388 | {{[[table]]}}
389 |
390 |
391 |
392 | Known to Self
393 |
394 | Not Known to Self
395 |
396 | Known to Others
397 |
398 | Arena
399 |
400 | Blind Spot
401 |
402 | Not Known to Others
403 |
404 | Facade
405 |
406 | Unknown
407 |
408 | Assumptions:: What do you believe to be true regarding this problem?
409 |
410 | Alternatives:: What alternatives already exist to this problem? What do you do now to solve the problem? What happens if you do nothing? If this is a technical solution, can an existing solution be used?
411 |
412 | Solution:: Based on all of the previous information, provide the solution to the problem. This could be a technical solution, process, new product, etc. Note that if multiple solutions are provided (suppose you provide multiple product offerings to solve the same problem) it is perfectly appropriate to have subpages for each solution.
413 |
414 | Recommendations:: An alternative to (or something to be used in conjunction with) a solution is one or more recommendations. Again, if appropriate recommendations can merit their own subpages.
415 |
416 | Hickey Design Process
417 |
418 | [[Problems]]
419 |
420 | Take wants/needs and translate them into problems
421 |
422 | [[Symptoms]]
423 |
424 | Symptoms of the problems
425 |
426 | [[Requirements]]
427 |
428 | [[Knowns]]
429 |
430 | What I know how to do
431 |
432 | [[Unknowns]]
433 |
434 | What I don't know how to do
435 |
436 | [[Domain-side]]
437 |
438 | Business requirement
439 |
440 | [[Solution-side]]
441 |
442 | Technical constraints (it has to compile to JS, for example)
443 |
444 | [[Unstated]]
445 |
446 | Things that everyone wants the system to avoid
447 |
448 | Doesn't crash, use too much memory, require too much energy, are examples of unstated requirements
449 |
450 | [[Solutions]]
451 |
452 | Solution A
453 |
454 | Benefits::
455 |
456 |
457 |
458 | Tradeoffs::
459 |
460 |
461 |
462 | Costs::
463 |
464 |
465 |
466 | Problem fit::
467 |
468 |
469 |
470 | Solution B
471 |
472 | Benefits::
473 |
474 |
475 |
476 | Tradeoffs::
477 |
478 |
479 |
480 | Costs::
481 |
482 |
483 |
484 | Problem fit::
485 |
486 |
487 |
488 | Course
489 |
490 | ### [Course name](course link) by `[[Author Name]]` __price__
491 |
492 | 2-3 sentence blurb describing the course
493 |
494 | Theme
495 |
496 | `theme name`
497 |
498 | Screenshots::
499 |
500 | Last updated::
501 |
502 | Designer:: name
503 |
504 | Twitter:: [link to bio]()
505 |
506 | Love this theme? Say thanks via [PayPal]() (and/or other payment service)
507 |
508 | Special Features::
509 |
510 | Code::
511 |
512 | {{[[roam/css]]}}
513 |
514 | ```css
515 | ```
516 |
517 | Plugin
518 |
519 | `plugin_name`
520 |
521 | Info::
522 |
523 | Must include GIF and/or video of usage
524 |
525 | Link::
526 |
527 | Getting started::
528 |
529 | Installation, activation and configuration
530 |
531 | Tutorials::
532 |
533 |
534 |
535 | Reference::
536 |
537 | Developer::
538 |
539 | Twitter::
540 |
541 | Love this plugin? Say thanks via [Paypal]()
542 |
543 | Code::
544 |
545 | Browser Extension
546 |
547 | `browser_extension_name`
548 |
549 | Info::
550 |
551 | Must include GIF and/or video of usage
552 |
553 | Link::
554 |
555 | Getting started::
556 |
557 | Installation, activation and configuration
558 |
559 | Tutorials::
560 |
561 |
562 |
563 | Reference::
564 |
565 | Developer::
566 |
567 | Twitter::
568 |
569 | Love this plugin? Say thanks via [Paypal]()
570 |
571 | Coaching
572 |
573 | `Course Author Name`
574 |
575 | Info::
576 |
577 | Website::
578 |
579 | Areas of specialty::
580 |
581 | Contact::
582 |
583 | Price::
584 |
585 | Docs #.h
586 |
587 | {{[[TODO]]}} Introduction (few bullets) and some GIFs
588 |
589 | Roam Team Videos::
590 |
591 | {{[[TODO]]}}
592 |
593 | Articles::
594 |
595 | {{[[TODO]]}}
596 |
597 | Community Videos::
598 |
599 | {{[[TODO]]}}
600 |
601 | Key Commands::
602 |
603 | Video/article #.h
604 |
605 | {{[[TODO]]}} [Article link]() or {{[[video]]: }}
606 |
607 | Features mentioned::
608 |
609 | Page refs to features
610 |
611 |
--------------------------------------------------------------------------------
/Roam_DB/White Paper.md:
--------------------------------------------------------------------------------
1 | **Abstract**. Roam is an online workspace for organizing and evaluating knowledge. The system is built on a directed graph, which frees it from the constraints of the classic file tree. Users can remix and connect ideas in multiple overlapping hierarchies, with each unit of information becoming a node in a dynamic network. Any given node can occupy multiple positions simultaneously, convey information through defined relationships, and populate changes throughout the graph. With weightings assigned to the strength of relationships between nodes, Roam also becomes a tool for Bayesian inference and decision making. The ultimate goal is to extend the system to collaborative reasoning, allowing groups to build shared mental maps and make faster and better-informed decisions.
2 |
3 | **1. Introduction**
4 |
5 | We are experiencing an unprecedented explosion of knowledge. Every day, 2700 books are published in the United States alone, 6850 scientific papers are authored, more than 2 million blog posts go live, and 294 billion emails fly back and forth. The amount of total data produced with every rotation of the Earth would fill a stack of books stretching to the moon and back. [1](((u-XvVlybt))) While this exponential growth presents enormous opportunities for individuals and society at large, neither the human brain nor current technologies are equipped to harness it to its full potential.
6 |
7 | **2. Current approaches to knowledge management**
8 |
9 | Humans are poorly adapted to the Information Age, which has arisen only in the last ~0.02% of our evolutionary history. While the brain does have a remarkable capacity for raw storage, probably in the range of several petabytes,[2](((PWlZyEjRU))) it is infamously fallible in processing information. Memory retrieval is lossy and unreliable, while many of our hardwired cognitive biases and heuristics misfire in the modern world, distorting our perception, judgement and decision-making ability. The plasticity of the brain enables it to rewire itself with new connections, but even this is a ‘use it or lose it’ feature, causing neglected neural pathways to atrophy.
10 |
11 | Many technologies for organizing knowledge outside of the brain have arisen in response to these limitations. Physical books and journals proliferated after the invention of the Gutenberg Press, and have since been partially supplanted by word processors, websites, blogs, forums, wikis, and software applications.
12 |
13 | While we are presented with a plethora of choices for organizing knowledge, almost every technology follows the same basic ‘file cabinet’ format: A unit of knowledge is saved to a certain file path, which places it within a taxonomy of folders, chapters or categories. Tags may be applied when an item relates to many things, but each file is generally only stored within one nested hierarchy. To access the information, the user must remember where they stored the file, what they tagged it with, or use a search function to locate it.
14 |
15 | Related Twitter Thread
16 |
17 | https://twitter.com/Conaw/status/1099181050045952006
18 |
19 | **3. Problems with the file cabinet approach**
20 |
21 | In some regards, current technologies remain vastly inferior to the human brain. If each neuron only held a single ‘unit’ of memory in this manner, our brains would quickly fill to overflowing. Instead, information is conveyed in the connections between neurons and neural networks, so a common idea can be made available across the entire brain; the concept of a blue sky might be used in countless seemingly discrete memories of time spent outdoors. This efficiency helps to explain why a computer requires several million times more energy to perform the same tasks as a human brain (which runs on about as much power as a dim light bulb).[3](((j6_rKU-PG)))
22 |
23 | Unlike the brain, the file cabinet approach makes it difficult or impossible to remix or reuse the same piece of information. Each time a change is made to any given file, it has to be tracked down and updated in every location in which it exists. This leads to redundancy, with a cluttering of near-identical ideas, and significant work any time a system-wide change is required.
24 |
25 | Current solutions also lack interconnectivity. Many files are divorced from context; cast into a drawer, rather than methodically fitted into a broader framework of knowledge. Knowledge trees can create pseudo-relationships between files nested within a given hierarchy, but these are not explicit, and can only describe a vertical ‘parent and child’ taxonomy. Some tools, such as web pages and wikis, also allow for orthogonal linking between related files, but this takes place in an ad hoc fashion, and again, there is no ability to explicitly define relationships.
26 |
27 | **4. Knowledge graphs as nodal networks **
28 |
29 | Large-scale collaboration requires a more flexible data structure than the classic file tree. Roam is built on a knowledge graph that maps all possible relationships, with ‘smart’ links between defined concepts. Users can connect similar ideas in multiple overlapping hierarchies, remix them without overwriting the original context, and selectively share parts of the graph with others to collaborate on specific sub-questions.
30 |
31 | If current tools resemble filing cabinets, Roam is more akin to the nodal networks in telecommunications, or the neurons in the human brain. Rather than existing in a vacuum, each note or file becomes a node in an interconnected graph of ideas. A single node may simultaneously hold positions in several different sequences, hierarchies or file paths, and can ‘talk’ to other nodes, communicating information back and forth about the nature of each relationship. The network is dynamic, so updates and revisions are populated across the entire graph simultaneously. Individual nodes or branches within the network can be forked as required, allowing a new pathway to deviate without changing the original meaning.
32 |
33 | At the simplest level, Roam’s structure makes it inherently easier to store, recall, and cross-reference ideas. This is the primary proposition for students, writers, self-directed learners, and users of existing note-taking apps.
34 |
35 | For power users, the knowledge graph also unlocks applications in logic and reasoning, Bayesian inference and decision-making, modelling complex problems, and collaborative research.
36 |
37 | These features are explored in Chapters 5 - 8, along with potential use cases for the technology.
38 |
39 | **5. Dependency graphs and logical reasoning**
40 |
41 | Everything from peer-reviewed research papers to the opinion pages of a newspaper are based on formulating arguments that support a certain premise, along the lines of the following:
42 |
43 | If A is true, then B is true.
44 |
45 | If C and D are both true, then A is true.
46 |
47 | C and D are true.
48 |
49 | Therefore, B is true.
50 |
51 | Example:: [[Precise Links]]
52 |
53 | {{embed:((PWRiHAsEv)) }}
54 |
55 |
56 |
57 | Often, C and D will be supported by links to external articles, where they are conclusions reached by larger arguments based on combining other premises. Unfortunately, the structure of the argument is only implied by the prose. Rarely are the relationships between arguments and pieces of evidence explicitly laid out, except perhaps in the notes of the author investigating the claims.
58 |
59 | Roam allows individual researchers or writers to organize all the claims they wish to make across a number of different projects. It also creates opportunities for large-scale interdisciplinary research projects. When teams of interested collaborators have an agreed-upon structure for formatting arguments and counterarguments, it is possible to create expandable user interfaces which “bubble up” insight from claims which require expertise, to ones that are more easily understood by laypersons.
60 |
61 | The ambiguity of natural language derails many discussions. Unless [[terms]] are clearly defined from the outset, any form of argument is futile, and will often end up entrenching the initial positions of the interlocutors.
62 |
63 | Example A
64 |
65 | Alice: "A tree falling in a deserted forest makes a sound."
66 |
67 | Bob: "A tree falling in a deserted forest does not make a sound."
68 |
69 | Example B
70 |
71 | Alice: "A tree falling in a deserted forest [generates acoustic vibrations]."
72 |
73 | Bob: "A tree falling in a deserted forest does not [generate auditory experiences]." [4](((T8k78DDAe)))
74 |
75 | While these positions are contradictory as expressed in Example A, simply defining the term ‘sound’ reveals the underlying beliefs are entirely compatible.
76 |
77 | The ability to use clearly defined sets within a dependency graph helps to resolve ambiguity, reducing the chances of participants talking at cross-purposes, or deliberate “motte-and-bailey” style strategic equivocation. [5](((MtGChSUvh)))
78 |
79 | Besides reasoning and argument, dependency graphs have applications in education, self-directed learning, and general decision-making. Even a very complicated project can be traced backwards to a number of smaller [[task]]s. The user can see the tradeoffs involved in each pathway, map out which route is the fastest, and which path might bring them closer to other interesting goals. As the student marks their progress, they can discover new projects and pathways which make use of the skills they have acquired.
80 |
81 | The problems of prose apply even in the domain of mathematical proofs, see Lamport’s [[How to write a 21st Century Proof]]”
82 |
83 | **6. Untangling complexity**
84 |
85 | **6.1 Nonlinear causality**
86 |
87 | Simple problems often follow a straightforward causal path. When a patient has a range of symptoms strongly associated with the flu, the doctor might conclude from the observable variables that there is one invisible variable - the influenza virus. Treat that latent variable, and the symptoms disappear.
88 |
89 | Scott Alexander observes that his peers in psychiatry similarly try to attribute a collection of linked symptoms to a latent variable; for example, depression. [6](((36qeTMgmO))) However, the symptoms ‘caused’ by depression - e.g. sleep disturbance, fatigue, guilt - can also have a causal effect on one another, and on the disorder itself. This complex web of relationships, which may include feedback loops, does not follow a path of linear causality. For complicated problems of this nature, nodal networks are a much more accurate model:
90 |
91 | A model of major depression (MD) and generalised anxiety disorder (GAD) by Nuijten, Deserno, Cramer, and Borsboom.[7](((rC_nGuzjf))) The disorders roughly map onto clusters of symptoms that are often found together and reinforce one another, but there is no clear ‘bright line’ between the conditions.
92 |
93 | Even at face value, a nodal network provides a visual aid to problem-solving - a bird’s eye view of the connections between various elements. This may help to identify patterns or clusters which may be counterintuitive or entirely invisible when each piece of the puzzle is examined at the object level.
94 |
95 | **6.2 Bayesian reasoning**
96 |
97 | Applying Bayesian reasoning to the knowledge graph makes it a powerful tool for estimating probabilities, testing hypotheses, and making decisions. Bayes’ Theorem is a law of probability that tells us how much we should change our minds about something when we learn a new fact or acquire new evidence. The theorem is stated in the following equation:
98 |
99 | $$P(A|B) = {P(B|A) P(A) \over P(B)}$$
100 |
101 |
102 | where A is the proposition of interest, B is the observed evidence, P(A) and P(B) are prior probabilities, and P(A|B) is the posterior probability of A.
103 |
104 | Suppose a doctor has a patient who is worried about carrying a latent disease, because he belongs to an at-risk group. This is the ‘proposition of interest’ on the left side of the equation. Prior data suggests 4% of the general population are carriers, so $$P(A) = 0.04$$. B is the observed evidence, which is that 32% of the general population are members of the at-risk group. $$P(B) = 0.32$$. The doctor knows that among patients who do carry the disease, 80% belong to the at-risk group: $$B|A = 0.8$$.
105 |
106 | The doctor applies Bayes’ theorem:
107 |
108 | $$P(A|B) = (0.8 * 0.04)/0.32$$
109 |
110 | $$P(A|B) = 0.1$$
111 |
112 | Her patient only has a one in 10 chance of being a carrier - which might be less than expected, given that almost all carriers are members of the at-risk group.
113 |
114 | While this is a simple calculation, the strength of Bayesian reasoning is that it breaks down seemingly insurmountable problems into small pieces. Even where no data are available, successive layers of estimates can still provide useful refinements to the confidence levels of various outcomes. By incorporating this framework into the defined relationships between nodes, revisions to the weightings at any point in the network will automatically populate throughout the knowledge graph.
115 |
116 | Bayesian probability also provides a framework for decision-making. By estimating the costs and tradeoffs of various options, users can calculate which pathway provides the highest expected value. Again, the quality of the decisions can be refined by successive layers of evidence for and against, even when the weightings are simple estimates of personal preference. An evaluation matrix allows someone to integrate a great deal of information into the final decision, rather than defaulting to simple heuristics.
117 |
118 | {{[[TODO]]}} [Example [[Diagrams]] of decision tree/matrix]
119 |
120 | **7. Optimising for **[[Serendipity]]
121 |
122 | Just as humans are incapable of generating random numbers, we struggle to consciously generate random ideas - to the point where actively trying to ‘think differently’ often seems to only further calcify existing patterns. Instead of attempting to brute-force creativity, the brain must be confronted with novel stimuli in order to reorganize its perception. Exposure to a certain amount of random ‘noise’ - drugs, dreams, meditation, Tarot readings, mistakes - can jolt thoughts out of well-tracked grooves and into entirely new areas of idea-space. Typically these insights occur at the juncture of two or more seemingly unrelated fields, concepts, or images.
123 |
124 | The interconnectivity of the Roam knowledge graph constantly creates opportunities for [[Serendipity]] to blossom. Each node in the network can be viewed in several graphical displays, allowing users to see related ideas, scan up and down the vertical hierarchy, examine nearby clusters of nodes, and observe patterns.
125 |
126 | The Roam search function can be calibrated to include as much or as little ‘noise’ as the user desires. While looking for a specific passage or note, search is narrow enough to find exactly what the user has in mind. However, it can also be broadened out for ‘fishing trips’ aimed at surfacing categories of ideas. Some search results will consist of notes that the user might otherwise have forgotten about, some will be noise, and others will spark ideas the user didn’t even know they were looking for.
127 |
128 | The synthesis and cross-pollination of ideas from diverse fields presents low-hanging fruit for both individuals and society. The investment of time and effort required to become a specialist quickly runs into a point of diminishing returns. By contrast, accumulating a ‘talent stack’ of dilettante-level knowledge or skills can unlock insights and opportunities that have not been capitalised on by experts with a narrower focus.
129 |
130 | Highly specialised knowledge remains essential for opening new frontiers. However, an interdisciplinary approach is often required to solve the increasingly complex problems faced by scientists, technologists, and policymakers.
131 |
132 | **8. Collaborative problem-solving**
133 |
134 | While the individual use case for Roam stands on its own merits, the ultimate goal is to create a platform for collaborative research and learning. Current protocols are bound by the assumption of necessary consensus. The flexibility of a curated knowledge graph allows for a more pluralistic approach, with the ability to weight conflicting opinions and separate signal from noise without resorting to either autocracy or democracy.
135 |
136 | 8.1 **Finding signal in the noise**
137 |
138 | As the frequency of information increases, the world becomes noisier and noisier. Deliberate exposure to noise is a useful strategy in specific contexts, as described in Chapter 7, but otherwise obscures meaning. [8](((urKnXjnSR))) Given we have a propensity for imposing stories and explanations onto randomness - the narrative fallacy - it is becoming increasingly difficult to separate out genuine signal from noise.
139 |
140 | Assume a trend has a signal-to-noise ratio of 1:1 on an annual basis (50% of the data are meaningful, 50% are random). Observing the same data on a daily basis, the composition changes to 95% noise, 5% signal. Observing the data hourly (as news hounds and market junkies do), and it becomes 99.5% random - which is to say, two hundred times more noise than signal.[9](((_eOgBulZd)))
141 |
142 | Institutions entrusted with interpreting the data include the media, academia, and legislature. Some agents within these institutions deliberately obscure the truth, as demonstrated by ‘fake news’, p-hacking, and politicking. While actively malicious behaviour is the exception, even the best-intentioned reporters, researchers and analysts are not immune to being fooled by randomness.
143 |
144 | For most people, the problem of sorting signal from noise therefore involves finding trustworthy and accurate secondary sources of information. This difficult [[task]] is often frustrated by gated scientific journals, as well as search engine algorithms increasingly gamed by SEO-savvy content marketers.
145 |
146 | 8.2 **Redundancy**
147 |
148 | Navigating a vast sea of information creates massive redundancy. Most people labour away at problems that have already been solved a million times over. Those who tackle unsolved problems often do so in silos, unaware of each other’s existence. All the pieces of any given puzzle may be present, but no one individual or group holds them all. The wheel is reinvented over and over again, in endless forums and comments sections and web pages and books that burst into existence and fade just as quickly to obscurity.
149 |
150 | The goal of Roam is to enable systematic curation and collaboration on a large scale. Users will be able to selectively share parts of their graphs publicly, or with circles of peers and colleagues. In turn, they will be able to follow the work of persons they trust, whether they be domain experts or enthusiastic amateurs. Those looking to acquire specific knowledge can turn immediately to trusted sources, and set alerts to receive updates about new pieces of information pertaining to an area of interest.
151 |
152 | 8.3 **Dispensing with necessary consensus**
153 |
154 | Almost every medium today presents knowledge as though it were the last word; assuming both a necessary consensus and an uncomposable page. Wikipedia is one of the great wonders of the Internet age, but it makes both of these mistakes. There can only be one article on any subject for any given language, and the only connection between pages is through links, with no article "built" off another.
155 |
156 | By way of contrast, consider Github: Libraries are built on other libraries, and functions are built from other functions. Developers build tools that others can build upon to build ever more impressive tools. Most of the modern web is built on open-source technologies, which would not have been possible if programmers followed the old protocols for intellectual collaboration.
157 |
158 | Many problems can be solved by writing code, but natural language is still the way we determine which problems are worth solving. Natural language is how we explain the world to one another, and communicate our models of reality. It is the language of education. It is the language of decision-making. That language needs a toolchain for collaboration that is just as good as the one for managing code.
159 |
160 | 8.4 **Against autocracy; against democracy**
161 |
162 | The problem of necessary consensus is resolved by individuals or groups assembling their own graph of inferences, based on premises or data curated from their trusted networks. However, collaboration still requires a mechanism for evaluating which ideas are best. In the same way that individuals assign weightings to their personal predictions and decisions, groups must be able to ‘vote’ on the merits of any given idea, premise, or piece of evidence. There are various options for how these collective weightings might be calibrated, some of which are briefly described below.
163 |
164 | a) **Wisdom of crowds**
165 |
166 | A diverse collection of people can make certain decisions and predictions much better than any given individual: The great statistician Francis Galton was stunned to find that 800 people guessing the weight of an ox at a country fair returned an average that was just one pound shy of the correct figure of 1198 pounds.
167 |
168 | In other situations, the opinion of the crowd bears little relationship to objective reality. By definition, the tyranny of the majority will quash any position that is unpopular, regardless of whether it is true. Often, domain-specific knowledge may be required; for example, someone who has not studied free will would only be adding noise by ‘voting’ a preference for compatibilism, hard determinism, or libertarianism.
169 |
170 | Simple popularity contests do not always move us closer to the truth, but they are useful in that they tell us what we believe. This data could potentially be broken down by demographic to demonstrate how different groups perceive reality, and possibly alert users to biases amongst their own in-groups.
171 |
172 | b) **Believability scores**
173 |
174 | Hedge fund manager Ray Dalio pioneered a decision-making system at Bridgewater Associates that is much closer to epistocracy than democracy: The opinions of more “believable” people, who have repeatedly proven their grasp of a given topic or trait, hold more weight than those with lower believability scores. There is nothing to stop Dalio being overruled by his most junior employees, as long are they are consistently more right than he is. Implementing a similar system in Roam would necessitate the ability to track performance, perhaps by how much original content a user has contributed to the graph with broad support, or how well-calibrated their predictions are.
175 |
176 | c) **Prediction markets**
177 |
178 | When people succumb to peer pressure and other biases, do not have enough specialist knowledge, or deliberately make false predictions, the ‘wisdom of the crowd’ can end up being very wrong.
179 |
180 | The insight behind prediction markets is that participants can be incentivised to profit from any such mistakes. Wherever someone believes the consensus is wrong, they can stake money on it, and move the probability back to a better informed position. Insider information is not only permitted, but welcomed. In this way, vast amounts of information can be synthesised into one constantly updated data point, which is often remarkably accurate.
181 |
182 | The uptake and growth of prediction markets has been dampened by regulatory issues, but possible workarounds include a non-fiat token, or reputation-linked points system.
183 |
184 | **9. Conclusion**
185 |
186 | The project of human knowledge, as it stands today, is a vast ocean of ephemeral and fragmented information and ideas, much of it inaccurate, some of it malicious, with the best sources either restricted by gatekeepers, or near-impossible to locate. The volume of information is growing exponentially, which promises enormous opportunities if the underlying coordination problems can be resolved.
187 |
188 | Clearly a fundamentally different approach is required. The Roam vision for human knowledge is a collective, open-source intelligence, constantly rearranging, iterating and evolving in the pursuit of truth. Each of us would become a node within this collective intelligence, forging links and creating networks, sharing the very best each has to offer, improving ourselves even as we improve others, and advancing the interests of humanity as a whole.
189 |
190 | About Roam
191 |
192 | Roam was founded by Conor White-Sullivan and Joshua Brown. Conor has been working on tools for collective intelligence for more than nine years, founding the online town common Localocracy (acquired by AOL in 2011) then leading R&D for Huffington Post following the acquisition. Conor and Josh met at 42.us.org, a tuition-free coding university, where Josh placed in the top five of the first 1000 cadets to enter the US program during the month-long application exam. This white paper was co-authored by business journalist Richard Meadows, whose trial of early prototypes led him to become the first investor in Roam.
193 |
194 | The Roam stack:
195 |
196 | React
197 |
198 | Clojure and Clojurescript
199 |
200 | Datalog
201 |
202 | Contact Conor at cwhitesullivan@gmail.com with any enquiries.
203 |
204 | Notes and references
205 |
206 | [1] At least 2.5 quintillion bytes of information are produced every day, which is about the same amount as was produced during the entire year of 2002.
207 |
208 | [2] Scientific American: New Estimate Boosts the Human Brain's Memory Capacity 10-Fold.
209 |
210 | [3] Microelectronics pioneer Carver Mead, who coined the term Moore’s Law, correctly predicted in 1990 that present-day computers would use ten million times more energy for a single instruction than the brain uses for a synaptic activation.
211 |
212 | [4] This example is adapted from the Less Wrong sequence 37 Ways Words Can be Wrong.
213 |
214 | [5] Motte-and-bailey refers to arguing an easy-to-defend and often common-sense statement (the motte), in order to ward off critics from a hard-to-defend and more controversial statement (the bailey). The term was popularised by Scott Alexander, and explained in All in All, Another Brick in the Motte.
215 |
216 | [6] Slate Star Codex: Mental disorders as networks.
217 |
218 | [7] Michèle B. Nuijten, Marie K. Deserno, Angélique O. J. Cramer, Denny Borsboom: An introduction and overview of a network approach to psychopathology.
219 |
220 | [8] As Carl Sagan observed, while more data is broadcast in TV programs every day than the combined written works of all of history, "not all bits have equal value".
221 |
222 | [9] This example comes from Nassim Taleb’s Antifragile.
223 |
224 | Further Reading
225 |
226 | Daniel Kahneman, Thinking, Fast and Slow
227 |
228 | Robin Hanson, Could Gambling Save Science?
229 |
230 | [[Ray Dalio]], [[Principles]]
231 |
232 | H Van Dyke Paranuk, Don’t Link Me In: Set Based Hypermedia for Taxonomic Reasoning
233 |
234 | [[Michael Nielsen]], Reinventing Discovery: The New Era of Networked Science
235 |
236 | Richards J Heuer The Psychology of Intelligence Analysis
237 |
238 | Leslie Lamport: [[How to write a 21st Century Proof]]
239 |
240 | Douglas Engelbart, [[Augmenting the Human Intellect: A Conceptual Framework]]
241 |
242 | About this Paper
243 |
244 | We wrote this White Paper in Winter of 2017/2018, and while it still reflects much of our vision for the tool, some of the features -- particularly related to [[Bayesian Reasoning]], [[Argument Analysis]], and [[Prediction Markets]] we found to be in-fact much lower priority for the researchers and decision makers whose thinking we aim to assist -- and risked making the tool too complex for the more significant use cases. If you are interested in using Roam for more formal Quantitative Reasoning or building out formal models of belief networks, or if you are excited about ideas in this paper which you do not see a way to do currently within Roam, please contact us.
245 |
246 |
--------------------------------------------------------------------------------