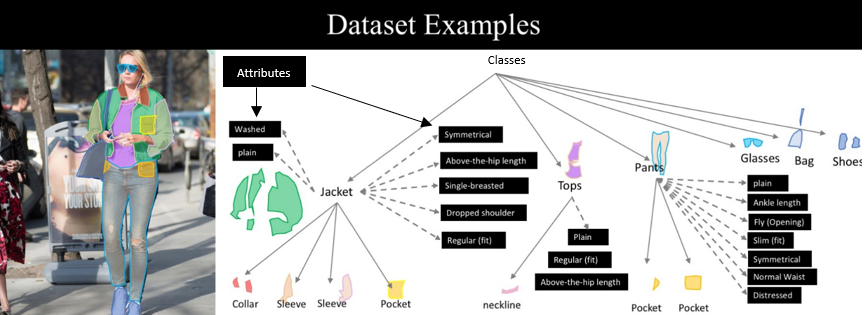
\n",
157 | " \n",
158 | " | 322 | \n",
159 | " /home/julien/data-science/kaggle/imaterialist/... | \n",
160 | " 1131858 13 1131917 36 1133630 42 1133718 40 11... | \n",
161 | " 1800 | \n",
162 | " 1200 | \n",
163 | " 23 | \n",
164 | " [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | \n",
165 | " 628 | \n",
166 | " 1418 | \n",
167 | " 692 | \n",
168 | " 1583 | \n",
169 | "
\n",
170 | " \n",
171 | " | 307 | \n",
172 | " /home/julien/data-science/kaggle/imaterialist/... | \n",
173 | " 212864 7 213881 21 214899 31 215920 35 216943 ... | \n",
174 | " 1024 | \n",
175 | " 683 | \n",
176 | " 23 | \n",
177 | " [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | \n",
178 | " 207 | \n",
179 | " 878 | \n",
180 | " 257 | \n",
181 | " 961 | \n",
182 | "
\n",
183 | " \n",
184 | " | 136 | \n",
185 | " /home/julien/data-science/kaggle/imaterialist/... | \n",
186 | " 179500 6 180515 16 181534 22 182557 25 183579 ... | \n",
187 | " 1024 | \n",
188 | " 680 | \n",
189 | " 10 | \n",
190 | " [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | \n",
191 | " 175 | \n",
192 | " 163 | \n",
193 | " 530 | \n",
194 | " 956 | \n",
195 | "
\n",
196 | " \n",
197 | " | 370 | \n",
198 | " /home/julien/data-science/kaggle/imaterialist/... | \n",
199 | " 5669654 1 5673613 1 5677571 3 5681530 4 568548... | \n",
200 | " 3960 | \n",
201 | " 2640 | \n",
202 | " 31 | \n",
203 | " [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | \n",
204 | " 1431 | \n",
205 | " 1546 | \n",
206 | " 2057 | \n",
207 | " 2923 | \n",
208 | "
\n",
209 | " \n",
210 | " | 288 | \n",
211 | " /home/julien/data-science/kaggle/imaterialist/... | \n",
212 | " 896338 1 897937 4 899537 7 901137 9 902736 13 ... | \n",
213 | " 1600 | \n",
214 | " 1067 | \n",
215 | " 33 | \n",
216 | " [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | \n",
217 | " 560 | \n",
218 | " 282 | \n",
219 | " 631 | \n",
220 | " 349 | \n",
221 | "
\n",
222 | " \n",
223 | " | 167 | \n",
224 | " /home/julien/data-science/kaggle/imaterialist/... | \n",
225 | " 247017 4 248399 11 249780 16 251162 18 252543 ... | \n",
226 | " 1383 | \n",
227 | " 900 | \n",
228 | " 4 | \n",
229 | " [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | \n",
230 | " 178 | \n",
231 | " 337 | \n",
232 | " 682 | \n",
233 | " 984 | \n",
234 | "
\n",
235 | " \n",
236 | " | 53 | \n",
237 | " /home/julien/data-science/kaggle/imaterialist/... | \n",
238 | " 701292 5 703597 15 705903 25 708209 34 710515 ... | \n",
239 | " 2310 | \n",
240 | " 1536 | \n",
241 | " 6 | \n",
242 | " [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | \n",
243 | " 303 | \n",
244 | " 1181 | \n",
245 | " 824 | \n",
246 | " 2136 | \n",
247 | "
\n",
248 | " \n",
249 | " | 75 | \n",
250 | " /home/julien/data-science/kaggle/imaterialist/... | \n",
251 | " 1590945 1 1593942 4 1596939 7 1599938 8 160293... | \n",
252 | " 3000 | \n",
253 | " 2000 | \n",
254 | " 37 | \n",
255 | " [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | \n",
256 | " 530 | \n",
257 | " 929 | \n",
258 | " 741 | \n",
259 | " 1003 | \n",
260 | "
\n",
261 | " \n",
262 | " | 350 | \n",
263 | " /home/julien/data-science/kaggle/imaterialist/... | \n",
264 | " 243646 2 244218 6 244714 16 244743 3 244760 5 ... | \n",
265 | " 576 | \n",
266 | " 1024 | \n",
267 | " 24 | \n",
268 | " [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | \n",
269 | " 422 | \n",
270 | " 217 | \n",
271 | " 456 | \n",
272 | " 575 | \n",
273 | "
\n",
274 | " \n",
275 | " | 265 | \n",
276 | " /home/julien/data-science/kaggle/imaterialist/... | \n",
277 | " 1660869 5 1663151 15 1665436 21 1667723 22 167... | \n",
278 | " 2287 | \n",
279 | " 1522 | \n",
280 | " 33 | \n",
281 | " [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | \n",
282 | " 726 | \n",
283 | " 499 | \n",
284 | " 887 | \n",
285 | " 571 | \n",
286 | "
\n",
287 | " \n",
288 | "